
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
codydroster/drone-comp | https://github.com/codydroster/drone-comp | 64bf86360a014702dc4d32f0772e546a1c8b0ee3 | 75a8b80e4726d2d1438e298b55553dd1abdc36ba | ceea504ea61e263070ddf7f1c2c4299c5f2cb47c | refs/heads/master | 2023-05-24T18:42:17.687511 | 2020-03-31T01:27:40 | 2020-03-31T01:27:40 | 251,469,884 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6285008192062378,
"alphanum_fraction": 0.657331109046936,
"avg_line_length": 19.931034088134766,
"blob_id": "c4abb6a4a7d59ffc7f5937cdb2dc6bbca37759f7",
"content_id": "82abf18c01717fb6644bdd8a2412bffc65a6ed83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1214,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 58,
"path": "/main.py",
"repo_name": "codydroster/drone-comp",
"src_encoding": "UTF-8",
"text": "import serial\nimport serial.tools.list_ports\n\n\n\n#available_ports = serial.tools.list_ports.comports()\n\n\n#for port in available_ports:\n#\tprint(port.device)\n\n\n\nser1 = serial.Serial('/dev/ttyUSB0')\n\nser1.baudrate = 115200\nser1.bytesize = serial.EIGHTBITS\nser1.parity = serial.PARITY_NONE\nser1.stopbits = serial.STOPBITS_ONE\nser1.close()\nser1.open()\n\nroll = 0\n\nwhile(True):\n\n#\tprint(byteread)\n\tif(ser1.read() == b'B'):\n#\t\tprint(ser1.read())\n\t\tif(ser1.read() == b'C'):\n\t\t#read next 8 bytes\n\t\t\tpitchLSB = ser1.read()\n\t\t\tpitchMSB = ser1.read()\n\t\t\trollLSB = ser1.read()\n\t\t\trollMSB = ser1.read()\n\t\t\tyawLSB = ser1.read()\n\t\t\tyawMSB = ser1.read()\n\n\t\t#\troll |= rollMSB << 0x8\n\t\t#\troll |= rollLSB & 0xff\n\n\t\t\tpitch = int.from_bytes(pitchLSB + pitchMSB, \"big\", signed=True)\n\t\t\troll = int.from_bytes(rollLSB + rollMSB, \"big\", signed=True)\n\t\t\tyaw = int.from_bytes(yawLSB + yawMSB, \"big\", signed=True)\n\n\t\t\n\t\t\tprint(yaw)\n\t\t\t\n#\t\tprint(ser1.read())\n#\tprint(ser1.in_waiting)\n\n#\t\t\tport = self.serialportbox.useport\n#\t\t\tport.__init__()\n#\t\t\tport.port = self.serialportbox.edit.get_text()\n#\t\t\tport.baudrate = int(serialinfo[0])\n#\t\t\tport.bytesize = int(serialinfo[1])\n#\t\t\tport.parity = serialinfo[2][0]\n#\t\t\tport.stopbits = int(serialinfo[3])\n"
}
] | 1 |
D0PP3L64N63R/SHORTCUT | https://github.com/D0PP3L64N63R/SHORTCUT | 48794a007cbbc026c8934c455d7b09465f85acf8 | 59ccf858e9526a27103009ddb93e069aade37e8b | 192c57ebe1f4d0aed2facc6ef7d53268a1c913f4 | refs/heads/master | 2020-08-25T08:06:09.325476 | 2019-10-23T06:51:10 | 2019-10-23T06:51:10 | 216,986,837 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7190082669258118,
"alphanum_fraction": 0.7685950398445129,
"avg_line_length": 29.5,
"blob_id": "0dc4c7eb95294e0691567de903440e0c45041eab",
"content_id": "a27344a5b8e2dcc888173f4748781f038cb69328",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 4,
"path": "/shortcut.py",
"repo_name": "D0PP3L64N63R/SHORTCUT",
"src_encoding": "UTF-8",
"text": "#apa lo liat liat\n#gk sor main\nimport marshal,zlib,base64\nexec(marshal.loads(zlib.decompress(base64.b16decode(\"789C9554EB53DA4010DFE32546AD52ADD8F6CBF9096A854055AA4EDBD18AD5CE203240C70E0CCEC4DC29918430B9CB289FFDC3DBBD0BF8987E6A927DDC3E7E77BBB7131B264F1CE900491C1000861F0117A013E93170097831E8C480B03874E2C012D049004B4227091CE036052C050F040847DF0C644F4E39BAD34A61B3802B341BC0E6604559E69525066C214AC1C8573AE5D134CE68D419608B7A7D319C0142C890C06F85B4F4325A01645E9AD86BE8A481CF025B06B6020F787603B801B773C0D351122EE6E101507B0242EC37FF62AF4E4DD9C814D5BBF698F216B23C0959F64E974BA0957F8F9D74FEE053CF633B412655675DCE474269EFBB7B9FBCA956F644426B254F87D92EB70291456D96D256DF0FEC50D26B3FA07DEE8EE8D80F4526F2515A2D351A5BB5CA76BDB2D5141BDADA977224F64DF3C691FDF0AA68FB9EF93CCA1408281151AA637D74F2EA5CCBC88C1667D6F086561DDA087CC145B1E8A810F14139BBEB3DEA59030703240FBCF09E8E027FC403E970419913705BFAC1B858140ACF6496B42286DB17A304F3DA71B930FBBEC7CD8949CC633022B742DBE642D075B136DDEB2CDA4B70198EA8CA4468079DFC5E065661C0C7827EA5DD6EEEB87594DBCC994805A4D3F3B36314BF1AC88EEB55E48D135CF436BBB9F6E1775C1EB59B351487B536F2DAF10F25AAE7177514CD9F27A76D9D51ADE77A3DB1FF1F859891283EF54477F74E2C4405D2A70A33D30A5B5C4A556238C246C754A357D59C68A042C05DDF620511C508ED7A86731DBAEE98AEAFD3CB4B515280065E7538BC716869776FA7B4532A97F73EEF986A512997B7CBBB7BA58AD1EE5BC381A0FB1B869157E7926A535F48357BD2F17853FD04F4B92DCDAF34B7654A9D6D2C248FA6D31BE0754BF5B3C05BD0C958F350470DFCA1F45D1D751738924FA61987494D053C31A1B66637328DE28BE7B3D0E5DFF4ACA9FFCF3C598AA7887A17C82CBE49944962A0669038C92025B48E144B9145F41A13AFA205F217FA58099B\"))))"
}
] | 1 |
timseed/fatrow | https://github.com/timseed/fatrow | e81451eb095fa7c4bd8dc6aeff73975b3a96a07c | 673a3cd13a9720fd5e3cc2378ee7224d27f78105 | 3645d1bd1c101f7a98394485a667162bd1cc23da | refs/heads/master | 2021-04-15T04:30:45.187686 | 2016-06-08T14:18:35 | 2016-06-08T14:18:35 | 60,703,409 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6528258323669434,
"alphanum_fraction": 0.6678200960159302,
"avg_line_length": 21.842105865478516,
"blob_id": "a9c4798c372633aefc80f625ad7acd1c08956937",
"content_id": "bdab99b79ef0259b0216adc2d8d18d1675215853",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 867,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 38,
"path": "/README.md",
"repo_name": "timseed/fatrow",
"src_encoding": "UTF-8",
"text": "#FATROW\n\nA fatrow is a name I use in the office to refer to an hbase row which possesses many values for 1 key. \n\nExample:\n\nCarReg: A21BC , Seen1: Doctors, Seen2: Hospital, Seen3: Trainstation\n\n1 Key - can have many results.\n\n#Boiling down the CSV\n\nThe CSV data needs to be extracted and placed into a dictionary. For that purpose there is the process command.\n\nit is formatted like this.\n\n##process\n\nProcess a line of data. Adding the unique values to a dictionary. Please note: Duplicate values are removed.\n\n\n#Example\nfrom fatrow import fatrow\n\n fr = fatrow()\n fr.process('1,this')\n fr.process('1,test')\n fr.process('1,record')\n fr.process('2,junk')\n fr.process('1,a')\n fr.process('3,still')\n \n #See the output\n \n for k, v in fr:\n logger.debug('' + k + '--->' + str(v))\n \nSee the file **test.py** to check the output."
},
{
"alpha_fraction": 0.5021459460258484,
"alphanum_fraction": 0.5040534138679504,
"avg_line_length": 33.93333435058594,
"blob_id": "3eebb9d964c9102cd85d647ff788906fd9d0048a",
"content_id": "e0ecbfc64a407d5ca1ad8f6868d73e11dbe16935",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2097,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 60,
"path": "/fatrow.py",
"repo_name": "timseed/fatrow",
"src_encoding": "UTF-8",
"text": "from collections import OrderedDict\nimport logging.config\nimport logging\nimport yaml\n\n\nclass fatrow(object):\n def __init__(self):\n self.ds = {}\n self.logger = logging.getLogger(__name__)\n self.logger.debug(str.format('{} initialized',__name__))\n\n\n def process(self, line_of_data, delim=',', key=0):\n '''\n Process a line of data. Adding the unique values to a dictionary.\n\n Please note: Duplicate values are removed.\n\n :param line_of_data:\n :param delim: the delimiter of the data\n :param key: key to be extracted, starting at 0. This is removed from the data passed\n :return: Nothing\n '''\n\n try:\n parts = line_of_data.split(delim)\n try:\n keyvalue = parts[key]\n new_parts = parts[:key] + parts[key + 1:]\n self.logger.debug(str.format('{} {}',keyvalue,str(new_parts)))\n if keyvalue not in self.ds:\n self.ds[keyvalue] = []\n for np in new_parts:\n self.ds[keyvalue].append(np)\n else:\n try:\n to_add = list(set(new_parts)-set(self.ds[keyvalue]))\n self.logger.debug(str.format('Dict{} May_Add{} Diff{}',str(self.ds[keyvalue]),str(new_parts),str(to_add)))\n if len(to_add)>0:\n for ta in to_add:\n self.ds[keyvalue].append(ta)\n except:\n self.logger.debug(\"Finding additions error\")\n except IndexError:\n self.logger.debug(str.format(\"Error getting key {} from {}\", key, line_of_data))\n pass\n except:\n self.logger.debug(\"Split Line Error\")\n pass\n\n def __iter__(self):\n '''\n Simple iterator to allow access to the key Ordered data\n\n :return: a Tuple (key, list of values)\n '''\n od = OrderedDict(self.ds.items())\n for i in od:\n yield (i, self.ds[i])\n\n"
},
{
"alpha_fraction": 0.5429864525794983,
"alphanum_fraction": 0.5683258175849915,
"avg_line_length": 24.697673797607422,
"blob_id": "fb078db72a957ba0ccc342db7befbb237892bf19",
"content_id": "6ee7e7881cfb82ad7f232ab1aa01fcef08a4da77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1105,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 43,
"path": "/test.py",
"repo_name": "timseed/fatrow",
"src_encoding": "UTF-8",
"text": "import logging.config\nimport logging\nimport yaml\nfrom fatrow import fatrow\n\nif __name__ == \"__main__\":\n with open('logging.yaml','rt') as f:\n config=yaml.safe_load(f.read())\n f.close()\n logging.config.dictConfig(config)\n logger=logging.getLogger(__name__)\n logger.debug(\"main is starting\")\n fr = fatrow()\n fr.process('1,this')\n fr.process('1,test')\n fr.process('1,record')\n fr.process('2,junk')\n fr.process('1,a')\n fr.process('3,still')\n fr.process('2,record')\n fr.process('5,end')\n fr.process('1,is')\n fr.process('1,this')\n fr.process('1,test')\n fr.process('1,record')\n fr.process('2,junk')\n fr.process('1,a')\n fr.process('1,this')\n fr.process('1,test')\n fr.process('1,record')\n fr.process('2,junk')\n fr.process('1,a')\n fr.process('3,still')\n fr.process('2,record')\n fr.process('5,end')\n fr.process('1,is')\n fr.process('1,this')\n fr.process('1,test')\n fr.process('1,record')\n fr.process('2,junk')\n fr.process('1,a')\n for k, v in fr:\n logger.debug('' + k + '--->' + str(v))\n"
}
] | 3 |
rodolfosgarcia/MazeSolverPY | https://github.com/rodolfosgarcia/MazeSolverPY | d36da6f13f67c2f8575df995da6d7b128b2b24d6 | ad5895de747012cd5d07af8753ee8a1cefcc5a7f | f5d7451d8de7d235f854baf63ddd1d6c6280e58b | refs/heads/main | 2023-03-25T13:59:28.048853 | 2021-03-27T02:36:04 | 2021-03-27T02:36:04 | 351,964,541 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5266813635826111,
"alphanum_fraction": 0.5354904532432556,
"avg_line_length": 30.97765350341797,
"blob_id": "aee0be6f6dfc3f62311e19b64bc02de7ca22f2f5",
"content_id": "c4fb14ebe8b0c5e22fadb61b9f980d063e9c8a0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5903,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 179,
"path": "/DestPuzzSolution.py",
"repo_name": "rodolfosgarcia/MazeSolverPY",
"src_encoding": "UTF-8",
"text": "import csv\r\n\r\nclass Rooms(object):\r\n def __init__(self, id, center, doors, link1, link2, link3, link4, link5, link6, parent=None):\r\n self.id = id.strip()\r\n self.center = center.strip()\r\n self.doors = []\r\n #self.doors = doors.split(',').strip()\r\n for door in doors.split(','):\r\n self.doors.append(door.strip())\r\n self.links = ['0', link1.strip(), link2.strip(), link3.strip(), link4.strip(), link5.strip(), link6.strip()]\r\n\r\n self.g = 0\r\n self.h = 0\r\n self.f = 0\r\n\r\n #store the Parent Room Object\r\n self.parent = parent\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\ndef AStar(maze, links, start, end):\r\n #maze is a dict of Rooms objects\r\n #start is the Room object\r\n #end is the Room object\r\n\r\n \"\"\"Returns a list of Rooms IDs (str) as a path from the given start to the given end in the given maze\"\"\"\r\n\r\n start.g = 2000\r\n start.h = 2000\r\n start.f = start.g + start.h\r\n end.g = end.h = end.f = 0\r\n\r\n print(start.g)\r\n\r\n # Initialize both open and closed list\r\n openSet = []\r\n closedSet = []\r\n openSet.append(start)\r\n\r\n\r\n while len(openSet) > 0:\r\n # Get the current node\r\n currentRoom = openSet[0]\r\n currentIndex = 0\r\n print(\"********** \" + currentRoom.center + \" \" + currentRoom.id + \" **********\")\r\n\r\n #update the curentRoom to the lowest f score\r\n for index, item in enumerate(openSet):\r\n #print(\"openSet \" + item.center + \"|f\" + str(item.f))\r\n #print(\"Current \" + currentRoom.center + \"|f\" + str(currentRoom.f))\r\n if item.f < currentRoom.f:\r\n currentRoom = item\r\n currentIndex = index\r\n\r\n\r\n if (currentRoom == end):\r\n #FINISHED! it found a path\r\n print (\"FOUND IT\")\r\n #checksum the parent links\r\n #for keyRoom in maze:\r\n #if maze[keyRoom].parent is not None:\r\n #print (\"center: \" + maze[keyRoom].center + \" | parent: \" + maze[keyRoom].parent.center)\r\n CompleteReversePath = []\r\n blipsRoom = currentRoom\r\n print(\"currentRoom: \" + blipsRoom.id)\r\n while blipsRoom is not None:\r\n if blipsRoom.center != 'Blank':\r\n CompleteReversePath.append(blipsRoom.center)\r\n blipsRoom = blipsRoom.parent\r\n if blipsRoom is not None:\r\n print(\"currentRoom: \" + blipsRoom.id)\r\n else:\r\n print(\"currentRoom: None\")\r\n #CompleteReversePath.reverse()\r\n print (\"Total Rooms passed:\" + str(len(CompleteReversePath)))\r\n return CompleteReversePath\r\n\r\n\r\n # Pop current off open list, add to closed list\r\n openSet.pop(currentIndex)\r\n closedSet.append(currentRoom)\r\n\r\n\r\n\r\n\r\n #search for the link between current room and next room with open doors\r\n neighborsOfCurrent = []\r\n for door in currentRoom.doors:\r\n print(links[currentRoom.links[int(door)]])\r\n for NeighborId in links[currentRoom.links[int(door)]]:\r\n if currentRoom.id != NeighborId and links[currentRoom.links[int(door)]] != \"UUUUUUU\":\r\n if maze[NeighborId] not in closedSet:\r\n neighborsOfCurrent.append(maze[NeighborId])\r\n maze[NeighborId].parent = currentRoom\r\n print(\"neighbors \" + maze[NeighborId].center + \"|f\" + str(maze[NeighborId].f) + \"|pai \" + str(maze[NeighborId].parent.center))\r\n\r\n\r\n\r\n\r\n\r\n\r\n for neighbor in neighborsOfCurrent:\r\n print(neighbor.center)\r\n #if Room already in closed set just ignore\r\n if neighbor in closedSet:\r\n #print(\"continue closedSet\")\r\n continue\r\n\r\n #create f, g and h values\r\n temp_g = currentRoom.g + 1\r\n #print(\"temp_g: \" + str(temp_g))\r\n #print(\"neighbor.g: \" + str(neighbor.g))\r\n\r\n\r\n for openNeighbor in openSet:\r\n if neighbor == openNeighbor and neighbor.g > openNeighbor.g:\r\n continue\r\n neighbor.g = temp_g\r\n neighbor.h = 25 - int(currentRoom.id[(len(currentRoom.id)-3)*-1:])\r\n print(str(currentRoom.id[(len(currentRoom.id)-3)*-1:]))\r\n neighbor.f = neighbor.g + neighbor.h\r\n print(\"adding to openSet\")\r\n openSet.append(neighbor)\r\n\r\n\r\n\r\n\r\n #checksum the parent links\r\n #for keyRoom in maze:\r\n #if maze[keyRoom].parent is not None:\r\n #print (\"center: \" + maze[keyRoom].center + \" | parent: \" + maze[keyRoom].parent.center)\r\n\r\n\r\n\r\n\r\n return (\"path not found\")\r\n\r\n\r\n\r\n\r\ndef populateMazeLinks(dict, link, id):\r\n if link != \"BBBBBBB\":\r\n if link in dict:\r\n dict[link].append(id)\r\n else:\r\n dict[link] = [id]\r\n\r\n\r\n\r\ndef main():\r\n\r\n mazeMap = {}\r\n mazeLinks = {}\r\n\r\n with open('MazeInput.csv', mode='r', newline='') as infile:\r\n csv_reader = csv.DictReader(infile)\r\n for row in csv_reader:\r\n room = Rooms(row['ID'], row['CENTER'], row['DOORS'], row['LINK1'], row['LINK2'], row['LINK3'], row['LINK4'], row['LINK5'], row['LINK6'])\r\n mazeMap[row['ID']] = room\r\n populateMazeLinks(mazeLinks, row['LINK1'], row['ID'])\r\n populateMazeLinks(mazeLinks, row['LINK2'], row['ID'])\r\n populateMazeLinks(mazeLinks, row['LINK3'], row['ID'])\r\n populateMazeLinks(mazeLinks, row['LINK4'], row['ID'])\r\n populateMazeLinks(mazeLinks, row['LINK5'], row['ID'])\r\n populateMazeLinks(mazeLinks, row['LINK6'], row['ID'])\r\n startRoom = mazeMap['ROW23']\r\n endRoom = mazeMap['ROW907']\r\n\r\n path = AStar(mazeMap, mazeLinks, startRoom, endRoom)\r\n print(path)\r\n\r\n\r\nif __name__ == '__main__':\r\n main()\r\n"
}
] | 1 |
nopunkintended/dmsh | https://github.com/nopunkintended/dmsh | fc5bcbab716d0017eb6f8dddada8e8466fae95ed | cdd25c87a4c63255d33f8d9f4ab682944349755e | 8349bb577f525746999d490f15c50dc8ff7da9ba | refs/heads/master | 2020-04-22T21:39:40.242351 | 2019-03-23T12:59:52 | 2019-03-23T12:59:52 | 170,680,054 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.7354260087013245,
"alphanum_fraction": 0.7488788962364197,
"avg_line_length": 21.299999237060547,
"blob_id": "2927c899ac5c92cf896206566ba9165351bf1991",
"content_id": "75b4ccb83de2ddac8999fd5bc060cf4ae7b7f96c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 446,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 20,
"path": "/Dockerfile",
"repo_name": "nopunkintended/dmsh",
"src_encoding": "UTF-8",
"text": "FROM bitnami/minideb:stretch\nLABEL maintainer=\"nopunkindented\"\n\nWORKDIR /tmp\n\nRUN install_packages python3 \\\n\t\tpython3-pip \\\n\t\tpython3-setuptools \\\n\t\tpython3-dev \\\n\t\tbuild-essential \\\n\t\tsupervisor\n\nCOPY requirements.txt /tmp/requirements.txt\nRUN pip3 install -U pip\nRUN pip3 install -r /tmp/requirements.txt\n\nADD api /dmsh/api/\nADD supervisor /etc/supervisor/\n\nCMD [\"/usr/bin/supervisord\", \"-c\", \"/etc/supervisor/supervisord.conf\", \"--nodaemon\"]\n"
},
{
"alpha_fraction": 0.6133333444595337,
"alphanum_fraction": 0.6133333444595337,
"avg_line_length": 8.375,
"blob_id": "c318e5828a7f3cba0dfc9af6626c49656cdea9bd",
"content_id": "5588c9993f5c5f043c585cf5d990d55e0a6ad4a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 8,
"path": "/api/api.py",
"repo_name": "nopunkintended/dmsh",
"src_encoding": "UTF-8",
"text": "import hug\n\n\[email protected]()\[email protected]()\[email protected]()\ndef ping():\n\treturn 'pong'\n"
},
{
"alpha_fraction": 0.7941681146621704,
"alphanum_fraction": 0.7941681146621704,
"avg_line_length": 92.03225708007812,
"blob_id": "68176d752262215fe1682e9fc20bd298fd6bd6cf",
"content_id": "e103ee1872f3b949394b581df98e62430e48ab7d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2915,
"license_type": "no_license",
"max_line_length": 450,
"num_lines": 31,
"path": "/README.md",
"repo_name": "nopunkintended/dmsh",
"src_encoding": "UTF-8",
"text": "# The Docker-Minideb-Supervisor-Hug (DMSH) stack\r\n\r\nIn order to provide a working environment for an interconnected tool, and such turning it into an available microservice piece for a more complex structure, a segregated daemon is required. Applying this principle to current technologies provides us with the _API-in-a-Container template_. The **Docker-Minideb-Supervisor-Hug stack** is an application of this template.\r\n\r\n## API-in-a-Container\r\n- Container: [docker](https://github.com/docker) - \"*platform built for developers to build and run applications*\".\r\n- System: [minideb](https://github.com/bitnami/minideb) - \"*small image based on Debian by bitnami*\".\r\n- Manager: [supervisor](https://github.com/Supervisor/supervisor) - \"*process control system for UNIX*\".\r\n- API: [hug](https://github.com/timothycrosley/hug) - \"*APIs, as simple as possible, but no simpler*\".\r\n- *your code here*\r\n\r\n## The Container level\r\nBuilding the microservice inside an isolated and portable environment allows for:\r\n- easier **integration** (isolating constraints and requirements)\r\n- easier **delivery** (regarding distribution and transportability issues)\r\n\r\nNote that any internal or intermediate infrastructure (e.g.: development environments, CI/CD toolchains) benefits from the same advantages as the final complex structure.\r\n\r\nAside from [Docker](https://github.com/docker), options for the Container level could go from fully-virtualized machines to segregated environment variables. Docker provides a good compromise between the learning curve and the features versus limitations ratio. Distribution infrastructure already exists through the Docker hub system. Same goes for containers management system, providing an eventual basis for the complex structure.\r\n\r\n## The System level\r\nBenefeting from the Container segregation for the microservice System allows for:\r\n- easier **optimisation** (focusing on a smaller set of limitations)\r\n- easier **design** (building upon the minimalist microservice infosystem)\r\n\r\nNote that templating easier optimisation and easier design in the same level provides a common playfield between low- and high-level requirements.\r\n\r\nAside from [minideb](https://github.com/bitnami/minideb), options for the System level could go from fully-fledged corporate system to Linux From Scratch. Minideb provides a good compromise between access to open-source software and the user-friendly versus weight ratio. Minideb is shipped with a self-cleaning variant of a package installer in a common server-oriented open-source system, already providing support for both optimisation and design.\r\n\r\n## Side-benefits\r\nIncluding a Container level in the template decouples the underlying structure and the microservice constraints. Providing a more virgin environnment to crafters is a huge plus regarding democratic access to innovation and thus the overall capabilities of complex structures.\r\n"
}
] | 3 |
Louis991/CS50-Showcase | https://github.com/Louis991/CS50-Showcase | a83262ac1d9a304d857f4002e15eb2b36acc7d9f | 1e3bdec9c68f4d3e570281a5b7e6c93e4e289f1b | 86d46f56b1ccec61820ede2391c4d7d59cd9fc4e | refs/heads/main | 2023-02-19T19:14:14.916791 | 2021-01-16T18:33:42 | 2021-01-16T18:33:42 | 330,226,983 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4701184928417206,
"alphanum_fraction": 0.5363214612007141,
"avg_line_length": 39.42708206176758,
"blob_id": "24c2868db4ac1679dfdf1c8da572921b4a8180cd",
"content_id": "e33bcfa3f5130a6476b8a4bd694ab0fd1736b561",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3888,
"license_type": "no_license",
"max_line_length": 248,
"num_lines": 96,
"path": "/Louis991-cs50-problems-2020-x-credit/credit.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <cs50.h>\n\nint main(void)\n{\n // Get input\n long num = get_long(\"Insert your credit card number (no hyphens): \");\n\n // Checksum logic and initializing some variables used.\n int num2; // Used to store the expression that's used to cycle through each digit of the card number.\n long n = 10; // n is used in both the expression to cycle through each digit and to control the condition that sustains the main do-while loop. Long data type was used to circumvent floating point errors in the while condition of the main loop.\n int k = 1; // k is used to keep track of our current digit position in the card number, to determine parity when counting and to determine the total number of digits in the card number.\n int num3; // Stores each number multiplied by 2.\n int num4; // Same expression as in num2, but used in an inner loop when one of the digits multiplied by 2 is equal to or larger than 10 and we need to sum its digits.\n int sum = 0; // Used to store the sum of the products’ (by 2) digits.\n int sum2 = 0; // Used to store the sum of every other number that wasn't multiplied by 2, as per Luhn’s algorithm.\n do\n {\n // Cycling through each digit of the card number, from last to first (right to left), via the expression assigned to num2.\n num2 = (num % n) / (n / 10);\n n *= 10;\n // if conditional to separate every other digit of the card number, in order to apply Luhn’s algorithm. These are considered when (k % 2) == 0 is true.\n if ((k % 2) == 0)\n {\n num3 = num2 * 2;\n // If conditional for when one of the digits multiplied by 2 is equal to or larger than 10 and we need to sum its digits. For example: if num = 11 -> 1+1 = 2.\n\n if (num3 >= 10)\n {\n int m = 1;\n do\n {\n m *= 10;\n num4 = (num3 % m) / (m / 10);\n sum += num4;\n }\n while ((num3 % m) != num3);\n }\n\n else\n {\n // This is the same sum variable as above, for the case of numbers with a single digit after being multiplied by 2. In this case: 0 through 4.\n sum += num3;\n }\n }\n\n else\n {\n sum2 += num2;\n }\n\n k++;\n }\n // Condition to get out of the main loop, after cycling through every digit of the card number.\n while ((num % (n / 10)) != num);\n\n // Actual checksum and determining the card company, based on the length of the number and the number(s) with which it starts.\n int check = sum + sum2;\n\n // Check condition.\n if ((check % 10) == 0)\n {\n // k-1 is used in the check instead of k, due to it being initialized with a value of 1 above.\n if (((k - 1) == 15) && (((num / 10000000000000) == 34) || ((num / 10000000000000) == 37)))\n {\n string result = \"AMEX\\n\";\n printf(\"%s\", result);\n }\n\n else if (((k - 1) == 16) && (((num / 100000000000000) == 51) || ((num / 100000000000000) == 52) || ((num / 100000000000000) == 53)\n || ((num / 100000000000000) == 54) || ((num / 100000000000000) == 55)))\n {\n string result = \"MASTERCARD\\n\";\n printf(\"%s\", result);\n }\n\n else if (((k - 1) >= 13 && (k - 1) <= 16) && (((num / 1000000000000) == 4) || ((num / 10000000000000) == 4)\n || ((num / 100000000000000) == 4) || ((num / 1000000000000000) == 4)))\n {\n string result = \"VISA\\n\";\n printf(\"%s\", result);\n }\n\n else\n {\n string result = \"INVALID\\n\";\n printf(\"%s\", result);\n }\n }\n\n else\n {\n string result = \"INVALID\\n\";\n printf(\"%s\", result);\n }\n}\n\n"
},
{
"alpha_fraction": 0.40785497426986694,
"alphanum_fraction": 0.4199395775794983,
"avg_line_length": 18.5,
"blob_id": "7beae39eb9dc96b52c921cb532975b27b9ae845d",
"content_id": "e297f03091ccb8d063cac1a5bb1030bf247e7834",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 662,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 34,
"path": "/Louis991-cs50-problems-2020-x-mario-less/mario.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <cs50.h>\n\nint main(void)\n{\n //Get pyramid height.\n int height;\n do\n {\n height = get_int(\"Enter the pyramid's height: \");\n }\n while (height > 8 || height < 1);\n\n //Draw the pyramid.\n //Outer loop. Starts a new line.\n for (int i = 0; i < height; i++)\n {\n //Inner loop, to align the pyramid to the right.\n for (int k = 0; k < (height - i - 1); k++)\n {\n printf(\" \");\n }\n \n //Inner loop, to draw hashes.\n int j = 0;\n do\n {\n printf(\"#\");\n j++;\n }\n while (j <= i);\n printf(\"\\n\");\n }\n}"
},
{
"alpha_fraction": 0.45848026871681213,
"alphanum_fraction": 0.4773063361644745,
"avg_line_length": 30.73826789855957,
"blob_id": "f3c1d25c18e572f48ebf98f88b47673649bc94f1",
"content_id": "9069a2f12632509f8a5a3ac47fad284917bbb6d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 17582,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 554,
"path": "/Louis991-cs50-problems-2020-x-filter-more/helpers.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include \"helpers.h\"\n#include <math.h>\n\n// Auxiliary function declarations\nvoid average(int height, int width, int row, int column, RGBTRIPLE image[height][width], RGBTRIPLE imagecopy[height][width]);\nvoid edge(int height, int width, int i, int j, RGBTRIPLE image[height][width], RGBTRIPLE imagecopy[height][width], int Gx[3][3], int Gy[3][3]);\n\n// Convert image to grayscale\nvoid grayscale(int height, int width, RGBTRIPLE image[height][width])\n{\n int averageColor = 0;\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n averageColor = round((image[i][j].rgbtBlue + image[i][j].rgbtGreen + image[i][j].rgbtRed) / 3.0);\n image[i][j].rgbtBlue = averageColor;\n image[i][j].rgbtGreen = averageColor;\n image[i][j].rgbtRed = averageColor;\n }\n }\n return;\n}\n\n// Convert image to sepia\nvoid sepia(int height, int width, RGBTRIPLE image[height][width])\n{\n float sepiaBlue = 0, sepiaGreen = 0, sepiaRed = 0;\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n sepiaBlue = round(0.272 * image[i][j].rgbtRed + 0.534 * image[i][j].rgbtGreen + 0.131 * image[i][j].rgbtBlue);\n if (sepiaBlue > 255)\n {\n sepiaBlue = 255;\n }\n\n sepiaGreen = round(0.349 * image[i][j].rgbtRed + 0.686 * image[i][j].rgbtGreen + 0.168 * image[i][j].rgbtBlue);\n if (sepiaGreen > 255)\n {\n sepiaGreen = 255;\n }\n\n sepiaRed = round(0.393 * image[i][j].rgbtRed + 0.769 * image[i][j].rgbtGreen + 0.189 * image[i][j].rgbtBlue);\n if (sepiaRed > 255)\n {\n sepiaRed = 255;\n }\n\n image[i][j].rgbtBlue = sepiaBlue;\n image[i][j].rgbtGreen = sepiaGreen;\n image[i][j].rgbtRed = sepiaRed;\n }\n }\n return;\n}\n\n// Reflect image horizontally\nvoid reflect(int height, int width, RGBTRIPLE image[height][width])\n{\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < round(width / 2); j++)\n {\n int storage1 = image[i][width - 1 - j].rgbtBlue;\n image[i][width - 1 - j].rgbtBlue = image[i][j].rgbtBlue;\n image[i][j].rgbtBlue = storage1;\n\n int storage2 = image[i][width - 1 - j].rgbtGreen;\n image[i][width - 1 - j].rgbtGreen = image[i][j].rgbtGreen;\n image[i][j].rgbtGreen = storage2;\n\n int storage3 = image[i][width - 1 - j].rgbtRed;\n image[i][width - 1 - j].rgbtRed = image[i][j].rgbtRed;\n image[i][j].rgbtRed = storage3;\n }\n }\n return;\n}\n\n// Blur image\nvoid blur(int height, int width, RGBTRIPLE image[height][width])\n{\n // Copying the image. The copy will be used to calculate the blurred value without altering the original image's information.\n RGBTRIPLE imagecopy[height][width];\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n imagecopy[i][j] = image[i][j];\n }\n }\n\n // Goes through the original image, average() reads through its data and overwrites data in the copy.\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n average(height, width, i, j, image, imagecopy);\n }\n }\n\n // Substituting data in the original image with data from the copy.\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n image[i][j] = imagecopy[i][j];\n }\n }\n\n return;\n}\n\nvoid average(int height, int width, int row, int column, RGBTRIPLE image[height][width], RGBTRIPLE imagecopy[height][width])\n{\n float sumGreen = 0, sumBlue = 0, sumRed = 0;\n float avgCounter = 0;\n\n // Top-left pixel\n if (row == 0 && column == 0)\n {\n for (int i = row; i <= row + 1; i++)\n {\n for (int j = column; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // Top-right pixel\n else if (row == 0 && column == width - 1)\n {\n for (int i = row; i <= row + 1; i++)\n {\n for (int j = column; j >= column - 1; j--)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // Bottom-left pixel\n else if (row == height - 1 && column == 0)\n {\n for (int i = row; i >= row - 1; i--)\n {\n for (int j = column; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // Bottom-right pixel\n else if (row == height - 1 && column == width - 1)\n {\n for (int i = row; i >= row - 1; i--)\n {\n for (int j = column; j >= column - 1; j--)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For pixels along the top edge of the image\n else if (row == 0)\n {\n for (int i = row; i <= row + 1; i++)\n {\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For pixels along the bottom edge of the image\n else if (row == height - 1)\n {\n for (int i = row; i >= row - 1; i--)\n {\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For pixels along the left edge of the image\n else if (column == 0)\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n for (int j = column; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For pixels along the right edge of the image\n else if (column == width - 1)\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n for (int j = column; j >= column - 1; j--)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For any pixel in the center area\n else if ((row > 0 && row < height) && (column > 0 && column < width))\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // Storing blurred values in the copy.\n imagecopy[row][column].rgbtGreen = round(sumGreen / avgCounter);\n if (imagecopy[row][column].rgbtGreen > 255)\n {\n imagecopy[row][column].rgbtGreen = 255;\n }\n\n imagecopy[row][column].rgbtBlue = round(sumBlue / avgCounter);\n if (imagecopy[row][column].rgbtBlue > 255)\n {\n imagecopy[row][column].rgbtBlue = 255;\n }\n\n imagecopy[row][column].rgbtRed = round(sumRed / avgCounter);\n if (imagecopy[row][column].rgbtRed > 255)\n {\n imagecopy[row][column].rgbtRed = 255;\n }\n\n return;\n}\n\n// Detect edges\nvoid edges(int height, int width, RGBTRIPLE image[height][width])\n{\n // Copying the image. The copy will be used to calculate the blurred value without altering the original image's information\n RGBTRIPLE imagecopy[height][width];\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n imagecopy[i][j] = image[i][j];\n }\n }\n\n // Declares and initializes Gx and Gy\n int Gx[3][3] = {{-1, 0, 1}, {-2, 0, 2}, {-1, 0, 1}};\n int Gy[3][3] = {{-1, -2, 1}, {0, 0, 0}, {1, 2, 1}};\n\n // Goes through the original image, edge() computes the filtered pixels and updates the filtered copy.\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n edge(height, width, i, j, image, imagecopy, Gx, Gy);\n }\n }\n\n // Substituting data in the original image with data from the copy.\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n image[i][j] = imagecopy[i][j];\n }\n }\n\n return;\n}\n\nvoid edge(int height, int width, int row, int column, RGBTRIPLE image[height][width], RGBTRIPLE imagecopy[height][width], int Gx[3][3], int Gy[3][3])\n{\n float sumXBlue = 0, sumYBlue = 0, sumXGreen = 0, sumYGreen = 0, sumXRed = 0, sumYRed = 0;\n int sobelBlue = 0, sobelGreen = 0, sobelRed = 0;\n int rowCount = 0, columnCount = 0;\n\n // For any pixel in the center area\n if((row > 0 && row < height - 1) && (column > 0 && column < width - 1))\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n columnCount = 0;\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumXBlue += Gx[rowCount][columnCount] * image[i][j].rgbtBlue;\n sumYBlue += Gy[rowCount][columnCount] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[rowCount][columnCount] * image[i][j].rgbtGreen;\n sumYGreen += Gy[rowCount][columnCount] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[rowCount][columnCount] * image[i][j].rgbtRed;\n sumYRed += Gy[rowCount][columnCount] * image[i][j].rgbtRed;\n\n columnCount++;\n }\n rowCount++;\n }\n }\n\n // For pixels along the edges\n\n // Top-left pixel\n else if (row == 0 && column == 0)\n {\n for (int i = row; i <= row + 1; i++)\n {\n columnCount = 0;\n for (int j = column; j <= column + 1; j++)\n {\n sumXBlue += Gx[i + 1][j + 1] * image[i][j].rgbtBlue;\n sumYBlue += Gy[i + 1][j + 1] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[i + 1][j + 1] * image[i][j].rgbtGreen;\n sumYGreen += Gy[i + 1][j + 1] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[i + 1][j + 1] * image[i][j].rgbtRed;\n sumYRed += Gy[i + 1][j + 1] * image[i][j].rgbtRed;\n\n columnCount++;\n }\n rowCount++;\n }\n }\n\n // Top-right pixel\n else if (row == 0 && column == width - 1)\n {\n for (int i = row; i <= row + 1; i++)\n {\n columnCount = 0;\n for (int j = column; j >= column - 1; j--)\n {\n sumXBlue += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n sumYBlue += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n sumYGreen += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtRed;\n sumYRed += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtRed;\n\n columnCount--;\n }\n rowCount++;\n }\n }\n\n // Bottom-left pixel\n else if (row == height - 1 && column == 0)\n {\n for (int i = row; i >= row - 1; i--)\n {\n columnCount = 0;\n for (int j = column; j <= column + 1; j++)\n {\n sumXBlue += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n sumYBlue += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n sumYGreen += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtRed;\n sumYRed += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtRed;\n\n columnCount++;\n }\n rowCount--;\n }\n }\n\n // Bottom-right pixel\n else if (row == height - 1 && column == width - 1)\n {\n for (int i = row; i >= row - 1; i--)\n {\n columnCount = 0;\n for (int j = column; j >= column - 1; j--)\n {\n sumXBlue += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n sumYBlue += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n sumYGreen += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[1 + rowCount][1 + columnCount] * image[i][j].rgbtRed;\n sumYRed += Gy[1 + rowCount][1 + columnCount] * image[i][j].rgbtRed;\n\n columnCount--;\n }\n rowCount--;\n }\n }\n\n // For pixels along the top edge of the image\n else if (row == 0)\n {\n for (int i = row; i <= row + 1; i++)\n {\n columnCount = 0;\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumXBlue += Gx[1 + rowCount][columnCount] * image[i][j].rgbtBlue;\n sumYBlue += Gy[1 + rowCount][columnCount] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[1 + rowCount][columnCount] * image[i][j].rgbtGreen;\n sumYGreen += Gy[1 + rowCount][columnCount] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[1 + rowCount][columnCount] * image[i][j].rgbtRed;\n sumYRed += Gy[1 + rowCount][columnCount] * image[i][j].rgbtRed;\n\n columnCount++;\n }\n rowCount++;\n }\n }\n\n // For pixels along the bottom edge of the image\n else if (row == height - 1)\n {\n for (int i = row; i >= row - 1; i--)\n {\n columnCount = 0;\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumXBlue += Gx[1 + rowCount][columnCount] * image[i][j].rgbtBlue;\n sumYBlue += Gy[1 + rowCount][columnCount] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[1 + rowCount][columnCount] * image[i][j].rgbtGreen;\n sumYGreen += Gy[1 + rowCount][columnCount] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[1 + rowCount][columnCount] * image[i][j].rgbtRed;\n sumYRed += Gy[1 + rowCount][columnCount] * image[i][j].rgbtRed;\n\n columnCount++;\n }\n rowCount--;\n }\n }\n\n // For pixels along the left edge of the image\n else if (column == 0)\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n columnCount = 0;\n for (int j = column; j <= column + 1; j++)\n {\n sumXBlue += Gx[rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n sumYBlue += Gy[rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n sumYGreen += Gy[rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[rowCount][1 + columnCount] * image[i][j].rgbtRed;\n sumYRed += Gy[rowCount][1 + columnCount] * image[i][j].rgbtRed;\n\n columnCount++;\n }\n rowCount++;\n }\n }\n\n // For pixels along the right edge of the image\n else if (column == width - 1)\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n columnCount = 0;\n for (int j = column; j >= column - 1; j--)\n {\n sumXBlue += Gx[rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n sumYBlue += Gy[rowCount][1 + columnCount] * image[i][j].rgbtBlue;\n\n sumXGreen += Gx[rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n sumYGreen += Gy[rowCount][1 + columnCount] * image[i][j].rgbtGreen;\n\n sumXRed += Gx[rowCount][1 + columnCount] * image[i][j].rgbtRed;\n sumYRed += Gy[rowCount][1 + columnCount] * image[i][j].rgbtRed;\n\n columnCount--;\n }\n rowCount++;\n }\n }\n\n\n // Updates the filtered copy.\n sobelBlue = round(sqrt(sumXBlue * sumXBlue + sumYBlue * sumYBlue));\n if (sobelBlue > 255)\n {\n sobelBlue = 255;\n }\n\n sobelGreen = round(sqrt(sumXGreen * sumXGreen + sumYGreen * sumYGreen));\n if (sobelGreen > 255)\n {\n sobelGreen = 255;\n }\n\n sobelRed = round(sqrt(sumXRed * sumXRed + sumYRed * sumYRed));\n if (sobelRed > 255)\n {\n sobelRed = 255;\n }\n\n imagecopy[row][column].rgbtBlue = sobelBlue;\n imagecopy[row][column].rgbtGreen = sobelGreen;\n imagecopy[row][column].rgbtRed = sobelRed;\n}"
},
{
"alpha_fraction": 0.6482792496681213,
"alphanum_fraction": 0.656512439250946,
"avg_line_length": 38.05787658691406,
"blob_id": "f6e4c058dd44ad384cc8844b86cd138d2a7d159d",
"content_id": "2eb789647163ef238f509a14b4034ffda7458425",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12146,
"license_type": "no_license",
"max_line_length": 320,
"num_lines": 311,
"path": "/Louis991-cs50-problems-2020-x-tracks-web-finance/application.py",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom cs50 import SQL\nfrom flask import Flask, flash, jsonify, redirect, render_template, request, session\nfrom flask_session import Session\nfrom tempfile import mkdtemp\nfrom werkzeug.exceptions import default_exceptions, HTTPException, InternalServerError\nfrom werkzeug.security import check_password_hash, generate_password_hash\nfrom helpers import apology, login_required, lookup, usd\nimport re\n\n# Configure application\napp = Flask(__name__)\n\n# Ensure templates are auto-reloaded\napp.config[\"TEMPLATES_AUTO_RELOAD\"] = True\n\n# Ensure responses aren't cached\[email protected]_request\ndef after_request(response):\n response.headers[\"Cache-Control\"] = \"no-cache, no-store, must-revalidate\"\n response.headers[\"Expires\"] = 0\n response.headers[\"Pragma\"] = \"no-cache\"\n return response\n\n# Custom filter\napp.jinja_env.filters[\"usd\"] = usd\n\n# Configure session to use filesystem (instead of signed cookies)\napp.config[\"SESSION_FILE_DIR\"] = mkdtemp()\napp.config[\"SESSION_PERMANENT\"] = False\napp.config[\"SESSION_TYPE\"] = \"filesystem\"\nSession(app)\n\n# Configure CS50 Library to use SQLite database\ndb = SQL(\"sqlite:///finance.db\")\n\n# Make sure API key is set\nif not os.environ.get(\"API_KEY\"):\n raise RuntimeError(\"API_KEY not set\")\n\n\[email protected](\"/\")\n@login_required\ndef index():\n # Query database for symbol and cumulative \"bought\" (+ for purchases, - for sales) for the current user stored in sessions.\n rows = db.execute(\"SELECT symbol, SUM(bought) FROM transactions WHERE id = :id GROUP BY symbol\", id=session[\"user_id\"])\n\n # Lists to store company names, their current stock prices and the user's holdings. All monetary values are treated and manipulated as integers and expressed as cents\n companyNames = []\n stockPrices = []\n holdingValues = []\n holdingValuesString = []\n\n for row in rows:\n # Obtains name, price and symbol.\n currentInfo = lookup(row[\"symbol\"])\n currentInfo[\"price\"] = int(currentInfo[\"price\"] * 100)\n\n # Adds info to the lists.\n companyNames.append(currentInfo[\"name\"])\n stockPrices.append(usd(currentInfo[\"price\"] / 100))\n holdingValues.append(currentInfo[\"price\"] * row[\"SUM(bought)\"])\n holdingValuesString.append(usd((currentInfo[\"price\"] * row[\"SUM(bought)\"]) / 100))\n\n # Obtain the current user's balance.\n currentCashDict = db.execute(\"SELECT cash FROM users WHERE users.id = :id\", id=session[\"user_id\"])[0]\n currentCashString = usd(currentCashDict[\"cash\"]/100)\n\n # User's grand total.\n grandSum = 0\n for holding in holdingValues:\n grandSum += holding\n grandTotal = usd((grandSum + currentCashDict[\"cash\"])/100)\n\n # Length of the rows list.\n rowsLength = len(rows)\n\n # Render the index table\n return render_template(\"index.html\", rows=rows, companyNames=companyNames, stockPrices=stockPrices, holdingValuesString=holdingValuesString, currentCashString=currentCashString, grandTotal=grandTotal, rowsLength=rowsLength)\n\n\[email protected](\"/buy\", methods=[\"GET\", \"POST\"])\n@login_required\ndef buy():\n if request.method == \"POST\":\n\n # Input check - empty symbol input.\n if not request.form.get(\"symbol\"):\n return apology(\"Enter a stock's symbol.\")\n\n # Input check - no number of shares.\n if not request.form.get(\"shares\"):\n return apology(\"Enter a number of shares to buy.\")\n\n # Input check - Negative share number.\n if int(request.form.get(\"shares\")) <= 0:\n return apology(\"Only positive integer numbers are allowed when buying shares.\", 403)\n else:\n shareNumber = int(request.form.get(\"shares\"))\n\n # Obtain symbol object (contains name, price and symbol of the stock to be bought), call apology if it's not returned.\n if lookup(request.form.get(\"symbol\")) != None:\n sym = lookup(request.form.get(\"symbol\"))\n # Convert stock's price from float to integer type (cents)\n sym[\"price\"] = int(sym[\"price\"] * 100)\n else:\n return apology(\"The stock symbol doesn't exist.\", 403)\n\n # Current amount of cash for the user\n currentCashDict = db.execute(\"SELECT cash FROM users WHERE users.id = :id\", id=session[\"user_id\"])[0]\n currentCash = currentCashDict[\"cash\"]\n\n # If cash is insufficient to make the purchase.\n if currentCash < shareNumber * (sym[\"price\"]):\n return apology(\"You don't have enough cash to make this transaction.\", 403)\n\n # Else, make the purchase.\n else:\n transactionCost = shareNumber * sym[\"price\"]\n\n # Deduct purchase amount from cash in the users table.\n db.execute(\"UPDATE users SET cash = cash - :amount WHERE users.id = :id\", amount=transactionCost, id=session[\"user_id\"])\n\n # Register the operation into the transactions table.\n db.execute(\"INSERT INTO transactions (id, symbol, bought, stockPrice, balance) values (:idTr, :symbol, :bought, :stockPrice, :balance)\", idTr=session[\"user_id\"], symbol=sym[\"symbol\"], bought=shareNumber, stockPrice=usd(sym[\"price\"]/100), balance=usd((currentCash-transactionCost)/100))\n\n #Notify the user that the purchase was successful.\n flash(\"Your purchase was successful.\")\n return render_template(\"buy.html\")\n\n # If GET method.\n else:\n return render_template(\"buy.html\")\n\n\[email protected](\"/history\")\n@login_required\ndef history():\n \"\"\"Show history of transactions\"\"\"\n\n # Extract transaction history of the user.\n rows = db.execute(\"SELECT symbol, bought, stockPrice, date FROM transactions WHERE transactions.id = :idTr\", idTr=session[\"user_id\"])\n\n # rowsLength -> number of dictionaries returned by db.execute(). Each dictionary represents the data for each row.\n rowsLength = len(rows)\n\n # List with the names of every company the user has bought stock from.\n companyNames = []\n for row in rows:\n companyInfo = lookup(row[\"symbol\"])\n companyNames.append(companyInfo[\"name\"])\n\n # Send information to the history template and render it.\n return render_template(\"history.html\", rows=rows, rowsLength=rowsLength, companyNames=companyNames)\n\[email protected](\"/login\", methods=[\"GET\", \"POST\"])\ndef login():\n \"\"\"Log user in\"\"\"\n\n # Forget any user_id\n session.clear()\n\n # User reached route via POST (as by submitting a form via POST)\n if request.method == \"POST\":\n\n # Ensure username was submitted\n if not request.form.get(\"username\"):\n return apology(\"You must provide an username.\", 403)\n\n # Ensure password was submitted\n elif not request.form.get(\"password\"):\n return apology(\"You must provide a password.\", 403)\n\n # Query database for username\n rows = db.execute(\"SELECT * FROM users WHERE username = :username\",\n username=request.form.get(\"username\"))\n\n # Ensure username exists and password is correct\n if len(rows) != 1 or not check_password_hash(rows[0][\"hash\"], request.form.get(\"password\")):\n return apology(\"Invalid username and/or password.\", 403)\n\n # Remember which user has logged in\n session[\"user_id\"] = rows[0][\"id\"]\n\n # Redirect user to home page\n return redirect(\"/\")\n\n # User reached route via GET (as by clicking a link or via redirect)\n else:\n return render_template(\"login.html\")\n\n\[email protected](\"/logout\")\ndef logout():\n \"\"\"Log user out\"\"\"\n\n # Forget any user_id\n session.clear()\n\n # Redirect user to login form\n return redirect(\"/\")\n\n\[email protected](\"/quote\", methods=[\"GET\", \"POST\"])\n@login_required\ndef quote():\n if request.method == \"POST\":\n sym = lookup(request.form.get(\"symbol\"))\n price = usd(sym[\"price\"])\n return render_template(\"quoted.html\", sym = sym, price=price)\n\n else:\n return render_template(\"quote.html\")\n\n\[email protected](\"/register\", methods=[\"GET\", \"POST\"])\ndef register():\n if request.method == \"POST\":\n\n # No username.\n if not request.form.get(\"username\"):\n return apology(\"Insert an username.\", 403)\n\n # If username already exists.\n rows = db.execute(\"SELECT * FROM users WHERE username = :username\",\n username=request.form.get(\"username\"))\n if len(rows) == 1:\n return apology(\"This username already exists.\", 403)\n\n # Missing password or confirmation.\n if not request.form.get(\"password\") or not request.form.get(\"confirmation\"):\n return apology(\"Insert a password and its confirmation.\", 403)\n\n # Password and its confirmation don't match.\n if not request.form.get(\"password\") == request.form.get(\"confirmation\"):\n return apology(\"Password and its confirmation don't match.\", 403)\n\n # If all previous checks fail, register the new user and the corresponding hash.\n db.execute(\"INSERT INTO users (username, hash) VALUES (:username, :hash)\", username=request.form.get(\"username\"), hash=generate_password_hash(request.form.get(\"password\"), method='pbkdf2:sha256', salt_length=8))\n\n # Redirect to the login route.\n return redirect(\"/login\")\n\n else:\n return render_template(\"register.html\")\n\n\[email protected](\"/sell\", methods=[\"GET\", \"POST\"])\n@login_required\ndef sell():\n # Extract the user's investments in a dictionary -> investments = {\"symbol\":numberOfShares, ...}\n # {\"AAPL\":10, \"CSCO\":5, ...}\n investments = {}\n rows = db.execute(\"SELECT symbol, SUM(bought) FROM transactions WHERE id = :id GROUP BY symbol\", id=session[\"user_id\"])\n for row in rows:\n investments[row[\"symbol\"]] = row[\"SUM(bought)\"]\n\n if request.method == \"POST\":\n\n # Input checking - User doesn't select a stock.\n if not request.form.get(\"symbol\"):\n return apology(\"Please select a stock's symbol.\", 403)\n\n # Input checking - User doesn't own any shares from the stock selected or number of shares isn't greater than 0.\n if not investments[request.form.get(\"symbol\")] or not investments[request.form.get(\"symbol\")] > 0:\n return apology(\"You don't own any shares from the selected stock.\", 403)\n\n # Input checking - User doesn't input a number of shares to sell.\n if not request.form.get(\"shares\"):\n return apology(\"Please enter a number of shares to sell.\", 403)\n\n # If user attempts to sell more shares than he owns.\n if investments[request.form.get(\"symbol\")] < int(request.form.get(\"shares\")):\n return apology(\"You don't own enough shares to make this sale.\", 403)\n\n # Price of the stock to be sold, in cents, as an integer.\n stockInfo = lookup(request.form.get(\"symbol\"))\n stockPrice = int(stockInfo[\"price\"] * 100)\n\n # Cash gained from the sale, in cents, as an integer.\n cashGained = int(request.form.get(\"shares\")) * stockPrice\n\n # Add cash gained to the user's balance.\n db.execute(\"UPDATE users SET cash = cash + :cashGained WHERE users.id = :idTr\", cashGained=cashGained, idTr=session[\"user_id\"])\n\n # Extract the user's cash balance\n currentCashDict = db.execute(\"SELECT cash FROM users WHERE users.id = :idTr\", idTr=session[\"user_id\"])[0]\n currentCash = currentCashDict[\"cash\"]\n\n # Register the transaction.\n db.execute(\"INSERT INTO transactions (id, symbol, bought, stockPrice, balance) values (:id, :symbol, :bought, :stockPrice, :balance)\", id=session[\"user_id\"], symbol=request.form.get(\"symbol\"), bought=int(request.form.get(\"shares\"))*(-1), stockPrice=usd(stockPrice/100), balance=usd((currentCash+cashGained)/100))\n\n #Notify the user that the sale was successful.\n flash(\"Your sale was successful.\")\n return redirect(\"/\")\n\n else:\n return render_template(\"sell.html\", investments=investments)\n\n\ndef errorhandler(e):\n \"\"\"Handle error\"\"\"\n if not isinstance(e, HTTPException):\n e = InternalServerError()\n return apology(e.name, e.code)\n\n\n# Listen for errors\nfor code in default_exceptions:\n app.errorhandler(code)(errorhandler)"
},
{
"alpha_fraction": 0.44991257786750793,
"alphanum_fraction": 0.46802398562431335,
"avg_line_length": 28.318681716918945,
"blob_id": "173ca4419dbfb6a4782823c7eecf7531263eafa6",
"content_id": "a4c0fb786fdc6b10503086da8cb993f660b9bdbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8006,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 273,
"path": "/Louis991-cs50-problems-2020-x-filter-less/helpers.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include \"helpers.h\"\n#include <math.h>\n\n// Auxiliary function declaration\nvoid average(int height, int width, int row, int column, RGBTRIPLE image[height][width], RGBTRIPLE imagecopy[height][width]);\n\n// Convert image to grayscale\nvoid grayscale(int height, int width, RGBTRIPLE image[height][width])\n{\n int averageColor = 0;\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n averageColor = round((image[i][j].rgbtBlue + image[i][j].rgbtGreen + image[i][j].rgbtRed) / 3.0);\n image[i][j].rgbtBlue = averageColor;\n image[i][j].rgbtGreen = averageColor;\n image[i][j].rgbtRed = averageColor;\n }\n }\n return;\n}\n\n// Convert image to sepia\nvoid sepia(int height, int width, RGBTRIPLE image[height][width])\n{\n float sepiaBlue = 0, sepiaGreen = 0, sepiaRed = 0;\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n sepiaBlue = round(0.272 * image[i][j].rgbtRed + 0.534 * image[i][j].rgbtGreen + 0.131 * image[i][j].rgbtBlue);\n if (sepiaBlue > 255)\n {\n sepiaBlue = 255;\n }\n\n sepiaGreen = round(0.349 * image[i][j].rgbtRed + 0.686 * image[i][j].rgbtGreen + 0.168 * image[i][j].rgbtBlue);\n if (sepiaGreen > 255)\n {\n sepiaGreen = 255;\n }\n\n sepiaRed = round(0.393 * image[i][j].rgbtRed + 0.769 * image[i][j].rgbtGreen + 0.189 * image[i][j].rgbtBlue);\n if (sepiaRed > 255)\n {\n sepiaRed = 255;\n }\n\n image[i][j].rgbtBlue = sepiaBlue;\n image[i][j].rgbtGreen = sepiaGreen;\n image[i][j].rgbtRed = sepiaRed;\n }\n }\n return;\n}\n\n// Reflect image horizontally\nvoid reflect(int height, int width, RGBTRIPLE image[height][width])\n{\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < round(width / 2); j++)\n {\n int storage1 = image[i][width - 1 - j].rgbtBlue;\n image[i][width - 1 - j].rgbtBlue = image[i][j].rgbtBlue;\n image[i][j].rgbtBlue = storage1;\n\n int storage2 = image[i][width - 1 - j].rgbtGreen;\n image[i][width - 1 - j].rgbtGreen = image[i][j].rgbtGreen;\n image[i][j].rgbtGreen = storage2;\n\n int storage3 = image[i][width - 1 - j].rgbtRed;\n image[i][width - 1 - j].rgbtRed = image[i][j].rgbtRed;\n image[i][j].rgbtRed = storage3;\n }\n }\n return;\n}\n\n// Blur image\nvoid blur(int height, int width, RGBTRIPLE image[height][width])\n{\n // Copying the image. The copy will be used to calculate the blurred value without altering the original image's information.\n RGBTRIPLE imagecopy[height][width];\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n imagecopy[i][j] = image[i][j];\n }\n }\n\n // Goes through the original image, average() reads through its data and overwrites data in the copy.\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n average(height, width, i, j, image, imagecopy);\n }\n }\n\n // Substituting data in the original image with data from the copy.\n for (int i = 0; i < height; i++)\n {\n for (int j = 0; j < width; j++)\n {\n image[i][j] = imagecopy[i][j];\n }\n }\n\n return;\n}\n\nvoid average(int height, int width, int row, int column, RGBTRIPLE image[height][width], RGBTRIPLE imagecopy[height][width])\n{\n float sumGreen = 0, sumBlue = 0, sumRed = 0;\n float avgCounter = 0;\n\n // Top-left pixel\n if (row == 0 && column == 0)\n {\n for (int i = row; i <= row + 1; i++)\n {\n for (int j = column; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // Top-right pixel\n else if (row == 0 && column == width - 1)\n {\n for (int i = row; i <= row + 1; i++)\n {\n for (int j = column; j >= column - 1; j--)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // Bottom-left pixel\n else if (row == height - 1 && column == 0)\n {\n for (int i = row; i >= row - 1; i--)\n {\n for (int j = column; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // Bottom-right pixel\n else if (row == height - 1 && column == width - 1)\n {\n for (int i = row; i >= row - 1; i--)\n {\n for (int j = column; j >= column - 1; j--)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For pixels along the top edge of the image\n else if (row == 0)\n {\n for (int i = row; i <= row + 1; i++)\n {\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For pixels along the bottom edge of the image\n else if (row == height - 1)\n {\n for (int i = row; i >= row - 1; i--)\n {\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For pixels along the left edge of the image\n else if (column == 0)\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n for (int j = column; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For pixels along the right edge of the image\n else if (column == width - 1)\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n for (int j = column; j >= column - 1; j--)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // For any pixel in the center area\n else if ((row > 0 && row < height) && (column > 0 && column < width))\n {\n for (int i = row - 1; i <= row + 1; i++)\n {\n for (int j = column - 1; j <= column + 1; j++)\n {\n sumGreen += image[i][j].rgbtGreen;\n sumBlue += image[i][j].rgbtBlue;\n sumRed += image[i][j].rgbtRed;\n avgCounter++;\n }\n }\n }\n\n // Storing blurred values in the copy.\n imagecopy[row][column].rgbtGreen = round(sumGreen / avgCounter);\n if (imagecopy[row][column].rgbtGreen > 255)\n {\n imagecopy[row][column].rgbtGreen = 255;\n }\n\n imagecopy[row][column].rgbtBlue = round(sumBlue / avgCounter);\n if (imagecopy[row][column].rgbtBlue > 255)\n {\n imagecopy[row][column].rgbtBlue = 255;\n }\n\n imagecopy[row][column].rgbtRed = round(sumRed / avgCounter);\n if (imagecopy[row][column].rgbtRed > 255)\n {\n imagecopy[row][column].rgbtRed = 255;\n }\n}\n\n\n"
},
{
"alpha_fraction": 0.6879659295082092,
"alphanum_fraction": 0.6964856386184692,
"avg_line_length": 36.599998474121094,
"blob_id": "6bf362a2e4a128efd0a58768e82dc3089a008f65",
"content_id": "71c8a9cececa52c46b41db3aafa98db0782d481f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 939,
"license_type": "no_license",
"max_line_length": 180,
"num_lines": 25,
"path": "/Louis991-cs50-problems-2020-x-tracks-web-homepage/index.js",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "/* Code for toggling a darkmode class (in styles.css) for the body. Based on: https://harlemsquirrel.github.io/css/javascript/2017/12/08/dark-light-mode-persistent-switcher.html */\n\n/* Returns a boolean for the theme being requested, true if dark, false if light. */\nfunction whichTheme()\n{\n return document.cookie.match(/theme=dark/i) != null;\n}\n\n/* Sets the theme based on the cookie's data */\nfunction setTheme()\n{\n document.querySelector('body').className = whichTheme() ? 'darkmode' : 'lightmode';\n}\n\n/* Creates cookie that stores data about which theme is being requested. */\nfunction setCookie()\n{\n var body = document.querySelector('body');\n var currentClass = body.className;\n var newClass = (currentClass == 'darkmode' ? 'lightmode' : 'darkmode');\n body.className = newClass;\n\n document.cookie = 'theme=' + (newClass == 'darkmode' ? 'dark' : 'light');\n console.log('Current cookie: ' + document.cookie);\n}"
},
{
"alpha_fraction": 0.5731170773506165,
"alphanum_fraction": 0.5799890160560608,
"avg_line_length": 22.771242141723633,
"blob_id": "079e4c7ceaa35f3359bff4554952c9e8280eeca3",
"content_id": "4a9e7e7bad0578a4869715f114a0518cd09d6df5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3638,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 153,
"path": "/Louis991-cs50-problems-2020-x-challenges-speller/dictionary.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "// Implements a dictionary's functionality\n\n#include <stdbool.h>\n#include \"dictionary.h\"\n#include <string.h>\n#include <strings.h>\n#include <stdio.h>\n#include <ctype.h>\n#include <stdlib.h>\n\n// Represents a node in a hash table\ntypedef struct node\n{\n char word[LENGTH + 1];\n struct node *next;\n}\nnode;\n\n// Number of buckets in hash table\nconst unsigned int N = 65536;\n\n// Hash table\nnode *table[N];\n\n// Variable to count the number of words loaded.\nunsigned int wordCount = 0;\n\n// State of the dictionary, loaded = true, unloaded = false.\nbool state = false;\n\n// Returns true if word is in dictionary else false\nbool check(const char *word)\n{\n // Gets the key corresponding to the word.\n unsigned int key = hash(word);\n\n // Traverse through the linked list.\n for (node *traverse = table[key]; traverse != NULL; traverse = traverse->next)\n {\n // If there's a match.\n if (strcasecmp(traverse->word, word) == 0)\n {\n return true;\n }\n }\n\n // If the word wasn't found in the dictionary.\n return false;\n}\n\n// Hashes word to a number.\n// djb2 hash, written by Daniel J. Bernstein. Edited to work within the limitations of an unsigned int return value and a strictly lowercase word.\nunsigned int hash(const char *word)\n{\n unsigned long hash = 5381;\n int c;\n\n while ((c = *word++))\n {\n hash = ((hash << 5) + hash) + tolower(c); /* hash * 33 + c */\n }\n unsigned int key = hash % 65535;\n return key;\n}\n\n// Loads dictionary into memory, returning true if successful else false\nbool load(const char *dictionary)\n{\n // Open dictionary stream\n FILE *dict = fopen(dictionary, \"r\");\n\n // If it can't be opened successfully, end.\n if (dict == NULL)\n {\n return false;\n }\n\n // Temporary buffer overwritten for each word.\n char buffer[LENGTH + 1];\n\n // Scan through the whole dictionary, until the end of file.\n while (fscanf(dict, \"%s\", buffer) != EOF)\n {\n // Create a new node.\n node *n = malloc(sizeof(node));\n // If memory for the pointer couldn't be allocated, quit.\n if (n == NULL)\n {\n return false;\n }\n\n // Fill node information.\n strcpy(n->word, buffer);\n n->next = NULL;\n\n // Get the key corresponding to the current word.\n unsigned int key = hash(buffer);\n\n // Increment the dictionary word count.\n wordCount++;\n\n // If there's no previous entry, append by editing the linked list's head.\n if (table[key] == NULL)\n {\n table[key] = n;\n }\n // If there's a previous entry, append the node after the linked list's head\n else\n {\n n->next = table[key]->next;\n table[key]->next = n;\n }\n }\n\n // Close dictionary stream, free dynamically allocated memory and quit, returning true.\n fclose(dict);\n state = true;\n return true;\n}\n\n// Returns number of words in dictionary if loaded else 0 if not yet loaded\nunsigned int size(void)\n{\n if (state == true)\n {\n return wordCount;\n }\n else\n {\n return 0;\n }\n}\n\n// Unloads dictionary from memory, returning true if successful else false\nbool unload(void)\n{\n // Go through each linked list in table[N].\n for (int i = 0; i < N; i++)\n {\n if (table[i] != NULL)\n {\n node *traverse = table[i];\n while (traverse != NULL)\n {\n node *temporal = traverse;\n traverse = traverse->next;\n free(temporal);\n }\n }\n }\n state = false;\n return true;\n}\n\n"
},
{
"alpha_fraction": 0.46666666865348816,
"alphanum_fraction": 0.49275362491607666,
"avg_line_length": 15.428571701049805,
"blob_id": "0c6a67cae1e29b4a62ef7ca6e12b2b66432bb283",
"content_id": "f549a0a8f8e8dd1cf765ea899509ab0d090f871e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 345,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 21,
"path": "/Louis991-cs50-problems-2020-x-sentimental-mario-more/mario.py",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "from sys import exit\nfrom cs50 import get_int\n\n\ndef main():\n h = 0\n while h < 1 or h > 8:\n h = get_int(\"Height: \")\n pyramid(h)\n exit(0)\n \n\ndef pyramid(height):\n space = \" \"\n hash = \"#\"\n for n in range(height):\n print(f\"{space * (height - 1 - n)}{hash * (n + 1)} {hash * (n + 1)}\")\n return True\n\n\nmain()\n"
},
{
"alpha_fraction": 0.4170258641242981,
"alphanum_fraction": 0.43211206793785095,
"avg_line_length": 19.64444351196289,
"blob_id": "175db2df268ab0956c88ac1095930f127a82de97",
"content_id": "1762a38fa5445bfd14d55d7dc5b11e0cbb70be4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 928,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 45,
"path": "/Louis991-cs50-problems-2020-x-mario-more/mario.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <cs50.h>\n\nint main(void)\n{\n //Get pyramid height, between 1 and 8.\n int height;\n do\n {\n height = get_int(\"Enter the pyramid's height: \");\n }\n while (height > 8 || height < 1);\n\n //Draw the pyramid.\n //Outer loop. Starts a new line.\n for (int i = 0; i < height; i++)\n {\n //Inner loop, to align the 1st pyramid to the right.\n for (int k = 0; k < (height - i - 1); k++)\n {\n printf(\" \");\n }\n\n //Inner loop, to draw hashes of the 1st pyramid.\n int j = 0;\n do\n {\n printf(\"#\");\n j++;\n }\n while (j <= i);\n\n //Draws the two spaces between pyramids.\n int l = 0;\n printf(\" \");\n\n //Inner loop, to draw hashes of the 2nd pyramid.\n while (l <= i)\n {\n printf(\"#\");\n l++;\n }\n printf(\"\\n\");\n }\n}"
},
{
"alpha_fraction": 0.6116071343421936,
"alphanum_fraction": 0.632440447807312,
"avg_line_length": 32.650001525878906,
"blob_id": "7d433575b27d19872cfe2658fad856598f26ee20",
"content_id": "7269fed82ef427ab82108f7b09f19b2db3c1152b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 20,
"path": "/Louis991-cs50-problems-2020-x-houses/roster.py",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "from sys import argv, exit\nimport cs50\n\n# Command-line-check\nif len(argv) != 2:\n print(\"Correct usage: python import.py 'name of house'\")\n exit(1)\n\n# Setup the database connection\ndb = cs50.SQL(\"sqlite:///students.db\")\n\n# db.execute returns a list of dict objects, each one corresponds to a student.\nrows = db.execute(\"SELECT * FROM students WHERE (house == ?) ORDER BY last ASC, first ASC\", argv[1])\n\n# Prints student data.\nfor row in rows:\n if row[\"middle\"] != None:\n print(\"{0} {1} {2}, born {3}\".format(row[\"first\"], row[\"middle\"], row[\"last\"], row[\"birth\"]))\n else:\n print(\"{0} {1}, born {2}\".format(row[\"first\"], row[\"last\"], row[\"birth\"]))"
},
{
"alpha_fraction": 0.5951859951019287,
"alphanum_fraction": 0.6110503077507019,
"avg_line_length": 32.254547119140625,
"blob_id": "8d0b5cf80d440ec017b5411c56148b747ef85969",
"content_id": "d0f8a6e836ea5581208711f9975b68a6e57de3f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1828,
"license_type": "no_license",
"max_line_length": 233,
"num_lines": 55,
"path": "/Louis991-cs50-problems-2020-x-dna/dna.py",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "from sys import argv, exit\nimport csv\n\n# Command-line argument check.\nif len(argv) != 3:\n print(\"Correct usage: python dna.py 'path of .csv database' 'path of DNA sequence .txt'\")\n exit(1)\n\n# Header = [\"name\", \"AGATC\", \"TTTTTTCT\", ...]\nheader = []\n\n# data = [[\"Albus\", \"15\", \"49\", ...], [\"Cedric\", \"31\", \"21\", ...] ... ]\ndata = []\n\n# Open CSV file and extract its data into the previous lists.\nwith open(argv[1], 'r') as csv_file:\n csv_reader = csv.reader(csv_file)\n lineCount = 0\n # Each row is a list of string elements.\n for row in csv_reader:\n # Extract data from the header.\n if lineCount == 0:\n header.extend(row)\n lineCount += 1\n # Extract other data, row by row, each row corresponding to each person.\n else:\n data.append(row)\n lineCount += 1\n\n# Open sequence text file and store it into memory.\nwith open(argv[2], 'r') as text:\n sequence = text.read()\n\n# Convert numbers in data from strings to integers.\nfor person in data:\n for x in range(1, len(header), 1):\n person[x] = int(person[x])\n\n# Length of the header minus \"name\".\nSTRnum = len(header) - 1\n\n# Loops through each person's data to determine if there is a match.\nfor person in data:\n count = 0\n for head in range(1, len(header), 1):\n # If, for example, AGATCAGATCAGATC (header[head] * 3) exists in the sequence and is the highest consecutive count for that STR, AGATC (header[head] * 1) and AGATCAGATC (header[head] * 2) are excluded when determining a match.\n if (header[head] * person[head] in sequence) and (header[head] * (person[head] + 1) not in sequence):\n count += 1\n # If there's a match.\n if count == STRnum:\n print(person[0])\n exit(0)\n\n# If there's not a match.\nprint(\"No match\")"
},
{
"alpha_fraction": 0.5676004886627197,
"alphanum_fraction": 0.6041412949562073,
"avg_line_length": 23.878787994384766,
"blob_id": "f2d6356ba4dfffa3b018b60e54b1a9b659b20e5c",
"content_id": "f534e90ef31782a59761f0e532ef4e97e2543503",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 821,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 33,
"path": "/Louis991-cs50-problems-2020-x-sentimental-readability/readability.py",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "# Getting the text input.\ntext = input(\"Text: \")\n\n# Variables used when extracting information from the text.\nletterCount = 0\nspaceCount = 1\nsentenceCount = 0\n\n\n# Extracting information from the text.\nfor letter in text:\n # The number of letters\n if (letter >= 'A' and letter <= 'Z') or (letter >= 'a' and letter <= 'z'):\n letterCount += 1\n # The number of spaces\n if (letter == ' '):\n spaceCount += 1\n # The number of sentences\n if (letter == '.' or letter == '!' or letter == '?'):\n sentenceCount += 1\n\n# Calculating the index.\nl = (letterCount / spaceCount) * 100\ns = (sentenceCount / spaceCount) * 100\nindex = round(0.0588 * l - 0.296 * s - 15.8)\n\n# Output\nif (index < 1):\n print(\"Before Grade 1\")\nelif (index >= 16):\n print(\"Grade 16+\")\nelse:\n print(f\"Grade {index}\")\n"
},
{
"alpha_fraction": 0.40510639548301697,
"alphanum_fraction": 0.4297872483730316,
"avg_line_length": 17.66666603088379,
"blob_id": "23c66548edf6cfbac34fcd9a31d8b1620045182b",
"content_id": "65918e98a2b5351f14ae5c8d8b5855a03a1455b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1175,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 63,
"path": "/Louis991-cs50-problems-2020-x-cash/cash.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <cs50.h>\n#include <math.h>\n\nint main(void)\n{\n //Setting global variables: amount owed and count, the min. number of coins.\n float owed;\n int count = 0;\n \n //Get user input, in $.\n do\n {\n owed = get_float(\"Enter the amount owed: \");\n }\n while (owed <= 0);\n \n //Convert amount owed to cents, which implies changing the data type of the input from float to int.\n int cents = round(owed * 100);\n \n //Calculate the minimum amount of change necessary.\n if (cents >= 25)\n {\n do\n {\n cents -= 25;\n count += 1;\n }\n while (cents >= 25);\n }\n \n if (cents >= 10)\n {\n do\n {\n cents -= 10;\n count += 1;\n }\n while (cents >= 10);\n }\n \n if (cents >= 5)\n {\n do\n {\n cents -= 5;\n count += 1;\n }\n while (cents >= 5);\n }\n \n if (cents >= 1)\n {\n do\n {\n cents -= 1;\n count += 1;\n }\n while (cents >= 1);\n }\n //Print the min. number of coins required.\n printf(\"%i\\n\", count);\n}"
},
{
"alpha_fraction": 0.5844780206680298,
"alphanum_fraction": 0.5975274443626404,
"avg_line_length": 38.378379821777344,
"blob_id": "f74d3d03ca07d17aba9b1319e16cddda4d84d816",
"content_id": "4442546e20b0361300eb8592380f1ad9af9778c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1456,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 37,
"path": "/Louis991-cs50-problems-2020-x-houses/import.py",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "from sys import argv, exit\nimport csv\nimport cs50\nimport re\n\n# Command-line argument check.\nif len(argv) != 2:\n print(\"Correct usage: python import.py 'path of .csv file' \")\n exit(1)\n\n# Setup the database connection\ndb = cs50.SQL(\"sqlite:///students.db\")\n\n# Create a regex object. This stores the pattern of each student's possible name.\nnamePattern = re.compile(r'(\\w{1,})\\s(\\w{1,}-\\w{1,}|\\w{1,})\\s?(\\w{1,})?')\n\n# Open CSV file.\nwith open(argv[1], 'r') as file:\n reader = csv.DictReader(file)\n for row in reader:\n\n # Pass the current name into the regex object's search() method. This returns a match object.\n runRe = namePattern.search(row[\"name\"])\n \n # Use the match object's groups() method to determine the type of name and to grab each part of it.\n\n # If name -> first name + last name.\n if runRe.group(3) == None:\n # Write the current row to the DB.\n db.execute(\"INSERT INTO students (first, middle, last, house, birth) VALUES(?, ?, ?, ?, ?)\", \n runRe.group(1), None, runRe.group(2), row[\"house\"], row[\"birth\"])\n\n # If name -> first name + middle name + last name.\n if runRe.group(3) != None:\n # Write the current row to the DB.\n db.execute(\"INSERT INTO students (first, middle, last, house, birth) VALUES(?, ?, ?, ?, ?)\", \n runRe.group(1), runRe.group(2), runRe.group(3), row[\"house\"], row[\"birth\"])"
},
{
"alpha_fraction": 0.5878052711486816,
"alphanum_fraction": 0.5974414348602295,
"avg_line_length": 66.64044952392578,
"blob_id": "e9ed250ddb109a6c164b75db2c89b9e30736d5eb",
"content_id": "81c3ed60e376ed5b48a8825e372e3f7514393932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 6019,
"license_type": "no_license",
"max_line_length": 473,
"num_lines": 89,
"path": "/Louis991-cs50-problems-2020-x-tracks-web-homepage/ee.html",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\n<html lang=\"en\">\n <head>\n <link href=\"https://stackpath.bootstrapcdn.com/bootstrap/4.5.0/css/bootstrap.min.css\" rel=\"stylesheet\">\n <link href=\"styles.css\" rel=\"stylesheet\">\n <link href=\"ee.css\" rel=\"stylesheet\">\n <script src=\"index.js\"></script>\n <meta charset=\"UTF-8\">\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1\">\n <title>My Homepage - EE</title>\n </head>\n <body>\n <div id=\"container\">\n <!-- Navigation bar-->\n <nav class=\"navbar sticky-top navbar-expand-lg navbar-dark bg-dark\" id=\"navbar\">\n <a class=\"navbar-brand\" href=\"#\">LF</a>\n <div class=\"collapse navbar-collapse\" id=\"navbarNav\">\n <ul class=\"nav navbar-nav\">\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"index.html\">About <span class=\"sr-only\">(current)</span></a>\n </li>\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"ee.html\">E.E. Info</a>\n </li>\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"books.html\">Favorite books</a>\n </li>\n <li class=\"nav-item\">\n <a class=\"nav-link\" href=\"music.html\">Music</a>\n </li>\n </ul>\n </div>\n <a class=\"navbar-brand ml-auto\" onclick=\"setCookie()\" href=\"#\"><div class=\"moon\"></div></a>\n <button class=\"navbar-toggler\" type=\"button\" data-toggle=\"collapse\" data-target=\"#navbarNav\" aria-controls=\"navbarNav\" aria-expanded=\"false\" aria-label=\"Toggle navigation\"><span class=\"navbar-toggler-icon\"></span>\n </button>\n </nav>\n <!-- About EE-->\n <section id=\"aboutEE-section\">\n <h1>Some neat things in the realm of Electrical Engineering.</h1>\n <p>That I would like to show you.</p>\n </section>\n <section id=\"pv\">\n <h2>Renewable generation.</h2>\n <p>Renewable energy is energy that is collected from renewable resources, which are naturally replenished on a human timescale, including carbon neutral sources like sunlight, wind, rain, tides, waves, and geothermal heat. The term often also encompasses biomass as well, whose carbon neutral status is under debate.</p>\n <p>Renewable energy often provides energy in four important areas: electricity generation, air and water heating/cooling, transportation, and rural (off-grid) energy services.</p>\n </section>\n <!-- EE images-->\n <div id=\"pvimg\">\n <img id=\"pv1\" src=\"images/pv1.png\" alt=\"Thin-film non-silicon photovoltaic power plant.\">\n <img id=\"pv2\" src=\"images/pv2.png\" alt=\"Thin film dye-sensitized module\">\n <img id=\"pv3\" src=\"images/pv3.png\" alt=\"Nanoantenna structure captures IR spectrum radiation\">\n <img id=\"wind1\" src=\"images/wind1.png\" alt=\"Compact wind acceleration turbine\">\n <img id=\"wind2\" src=\"images/wind2.png\" alt=\"Bladed tip wind turbines installed on a roof\">\n <img id=\"hawt\" src=\"images/HAWT.png\" alt=\"Horizontal axis wind turbine off-shore\">\n <img id=\"hoover\" src=\"images/hooverdam.png\" alt=\"Hoover Dam\">\n <img id=\"vawt\" src=\"images/VAWT.png\" alt=\"Vertical axis wind turbine\">\n <img id=\"kinetic\" src=\"images/kinetic.png\" alt=\"Kinetic energy conversion pad\">\n <img id=\"oyster\" src=\"images/OWEC.png\" alt=\"Oyster wave energy converter\">\n <img id=\"picohydro\" src=\"images/picohydro.png\" alt=\"Pico hydro generator\">\n <img id=\"buoy\" src=\"images/buoy.png\" alt=\"Buoy for ocean wave hydrokinetic generation\">\n </div>\n <!-- Automation and robotics-->\n <section id=\"robo\">\n <h2>Automation and robotics.</h2>\n <p>Automation is the technology by which a process or procedure is performed with minimal human assistance. Automation, or automatic control, is the use of various control systems for operating equipment such as machinery, processes in factories, boilers, and heat-treating ovens, switching on telephone networks, steering, and stabilization of ships, aircraft, and other applications and vehicles with minimal or reduced human intervention.</p>\n <p>Robotics is an interdisciplinary research area at the interface of computer science and engineering. Robotics involves design, construction, operation, and use of robots. The goal of robotics is to design intelligent machines that can help and assist humans in their day-to-day lives and keep everyone safe. Robotics draws on the achievement of information engineering, computer engineering, mechanical engineering, electronic engineering and others.</p>\n </section>\n <!-- Robo images-->\n <div id=\"roboimg\">\n <img id=\"robo1\" src=\"images/robo1.png\" alt=\"Robot arm used in manufacturing\">\n <img id=\"robo2\" src=\"images/robo2.png\" alt=\"Lunar exploration robot\">\n </div>\n <!-- Footer-->\n <div id=\"footer\" class=\"footer\">\n <p>Made for the CS50x web track. Luis Fuenmayor, 2020</p>\n </div>\n </div>\n\n <!-- Bootstrap scripts-->\n <script src=\"https://code.jquery.com/jquery-3.5.1.slim.min.js\" integrity=\"sha384-DfXdz2htPH0lsSSs5nCTpuj/zy4C+OGpamoFVy38MVBnE+IbbVYUew+OrCXaRkfj\" crossorigin=\"anonymous\"></script>\n <script src=\"https://cdn.jsdelivr.net/npm/[email protected]/dist/js/bootstrap.bundle.min.js\" integrity=\"sha384-ho+j7jyWK8fNQe+A12Hb8AhRq26LrZ/JpcUGGOn+Y7RsweNrtN/tE3MoK7ZeZDyx\" crossorigin=\"anonymous\"></script>\n <!-- Load theme. Method from: https://stackoverflow.com/questions/9899372/pure-javascript-equivalent-of-jquerys-ready-how-to-call-a-function-when-t/9899701#9899701-->\n <script>\n (function() {\n setTheme();\n })();\n </script>\n </body>\n</html>"
},
{
"alpha_fraction": 0.6836734414100647,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 94,
"blob_id": "a0bfde0b1072173e401d21ed47d13f3585aeb7ca",
"content_id": "20048f6a2c241a39b55f06fc14d3655997c1ff78",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 1,
"path": "/Louis991-cs50-problems-2020-x-movies/4.sql",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "SELECT COUNT(*) FROM (movies JOIN ratings ON movies.id = ratings.movie_id) WHERE rating = 10.0\n\n\n\n"
},
{
"alpha_fraction": 0.5058962106704712,
"alphanum_fraction": 0.5294811129570007,
"avg_line_length": 20.705127716064453,
"blob_id": "eecd6986275d3c5f422f6919d8a74cf5293bfcb7",
"content_id": "241350df02a836530c538698d82146f06edc0bbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1696,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 78,
"path": "/Louis991-cs50-problems-2020-x-readability/readability.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <cs50.h>\n#include <math.h>\n#include <string.h>\n\n// Function declarations.\nfloat textInfo(string text, float infoArray[]);\n\n// Main.\nint main(void)\n{\n // Getting text input.\n string text = get_string(\"Text: \");\n\n // Text data is passed by the textInfo function (passed by reference) into the array infoArray.\n float infoArray[3];\n textInfo(text, infoArray);\n\n // Variables required to calculate the Coleman-Liau index.\n float l = (infoArray[0] / infoArray[1]) * 100;\n float s = (infoArray[2] / infoArray[1]) * 100;\n\n // Index calculation and rounding.\n float index = 0.0588 * l - 0.296 * s - 15.8;\n int rounded = round(index);\n\n // Index branches.\n if (index < 1)\n {\n printf(\"Before Grade 1\\n\");\n }\n\n else if (index >= 16)\n {\n printf(\"Grade 16+\\n\");\n }\n\n else\n {\n printf(\"Grade %i\\n\", rounded);\n }\n}\n\n//Function that extracts the number of letters, words and sentences in the text.\nfloat textInfo(string text, float infoArray[])\n{\n // # of letters.\n float lettercount = 0; \n\n //# of words.\n float spacecount = 0; \n\n //# of sentences.\n float sentencecount = 0; \n\n for (int i = 0, h = strlen(text); i < h; i++)\n {\n if ((text[i] >= 'A' && text[i] <= 'Z') || (text[i] >= 'a' && text[i] <= 'z'))\n {\n lettercount++;\n }\n\n if (text[i] == ' ')\n {\n spacecount++;\n }\n\n if (text[i] == '.' || text[i] == '!' || text[i] == '?')\n {\n sentencecount++;\n }\n }\n\n infoArray[0] = lettercount;\n infoArray[1] = spacecount + 1;\n infoArray[2] = sentencecount;\n return 0;\n}\n\n\n\n"
},
{
"alpha_fraction": 0.4482142925262451,
"alphanum_fraction": 0.4744047522544861,
"avg_line_length": 21.648649215698242,
"blob_id": "cadccc16d513dd8a74fed815f72468afbfc0baab",
"content_id": "f33baff3019d89d242ab3abe0ace25d3e8f2728c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1680,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 74,
"path": "/Louis991-cs50-problems-2020-x-substitution/substitution.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <cs50.h>\n#include <string.h>\n#include <ctype.h>\n\nint main(int argc, string argv[])\n{\n //Checking that we have only one command-line argument.\n if (argc != 2)\n {\n printf(\"Use only 1 argument (key).\");\n return 1;\n }\n\n //Checking the validity of the key.\n int l = strlen(argv[1]);\n if (l != 26)\n {\n printf(\"The key needs to be 26 characters long.\");\n return 1;\n }\n\n for (int i = 0; i < l; i++)\n {\n if (isalpha(argv[1][i]) == 0)\n {\n printf(\"The key needs to be strictly alphabetical.\");\n return 1;\n }\n }\n\n for (int j = 0; j < l; j++)\n {\n for (int k = j + 1; k < l; k++)\n {\n if (argv[1][k] == argv[1][j])\n {\n printf(\"Each key letter must be unique.\");\n return 1;\n }\n }\n }\n\n //Input.\n string plain = get_string(\"plaintext: \");\n\n //Converting the key string into an array of characters, each character being uppercase for purposes of the substitution.\n char upperKey[27];\n for (int q = 0; q < l; q++)\n {\n upperKey[q] = toupper(argv[1][q]);\n }\n upperKey[26] = '\\0';\n\n //Substituting the message.\n int l3 = strlen(plain);\n for (int m = 0; m < l3; m++)\n {\n if (plain[m] >= 65 && plain[m] <= 90)\n {\n plain[m] = upperKey[plain[m] - 65];\n }\n\n if (plain[m] >= 97 && plain[m] <= 122)\n {\n plain[m] = tolower(upperKey[plain[m] - 97]);\n }\n }\n\n //Outputting the substituted message.\n printf(\"ciphertext: %s\", plain);\n printf(\"\\n\");\n return 0;\n}\n\n\n\n\n"
},
{
"alpha_fraction": 0.5147745013237,
"alphanum_fraction": 0.561430811882019,
"avg_line_length": 16.88888931274414,
"blob_id": "62ae6865f90df69ff524b700fbd72917726e429b",
"content_id": "422135e82ae9178a776a6143ea2203ae1701df7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 643,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 36,
"path": "/Louis991-cs50-problems-2020-x-sentimental-cash/cash.py",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "from cs50 import get_float\n\n# Amount owed and counter for the minimum number of coins required.\nowed = 0\ncount = 0\n\n# Getting user input.\nwhile owed <= 0:\n owed = get_float(\"Enter the amount owed: \")\n\n# Converting the amount to cents\nowed = round(owed * 100)\n\n# Determining the min. amount of coins\nif owed >= 25:\n while owed >= 25:\n owed -= 25\n count += 1\n\nif owed >= 10:\n while owed >= 10:\n owed -= 10\n count += 1\n\nif owed >= 5:\n while (owed >= 5):\n owed -= 5\n count += 1\n\nif owed >= 1:\n while (owed >= 1):\n owed -= 1\n count += 1\n\n# Printing the output\nprint(f\"{count}\")"
},
{
"alpha_fraction": 0.41380396485328674,
"alphanum_fraction": 0.4314528703689575,
"avg_line_length": 26.36206817626953,
"blob_id": "3abd140f1424e15567329000a71b2d71bf6f963b",
"content_id": "fc1bd2102129cb53e6e0352cac0e0110f23481fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 3173,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 116,
"path": "/Louis991-cs50-problems-2020-x-caesar/caesar.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <cs50.h>\n#include <string.h>\n#include <stdlib.h> \n#include <math.h> \n\n// Function declarations.\nvoid caesar(int key, string message);\nint isnumeric(string parameter);\n\n\nint main(int argc, string argv[])\n{\n\n // Condition for correct input. Program execution + 1 single argument.\n if (argc == 2)\n {\n // Non-numeric string check\n if (isnumeric(argv[1]) == true)\n {\n printf(\"Argument is not numeric. Usage: ./caesar key\\n\");\n return 1;\n }\n\n else\n {\n int z = atoi(argv[1]);\n if (z > 0)\n {\n // Getting the plaintext input.\n string plain = get_string(\"plaintext: \");\n int k = atoi(argv[1]);\n if (k > 26)\n {\n // Adapting k for k > 26 so the displacement always starts from the a/A letter.\n printf(\"k = %i\\n\", k);\n float division = (float) k / 26;\n printf(\"division = %f\\n\", division);\n int intpart = (int) division;\n printf(\"intpart = %i\\n\", intpart);\n float decimal = division - intpart;\n printf(\"decimal = %f\\n\", decimal);\n int displacement = (int) round(26 * decimal);\n printf(\"displacement = %i\\n\", displacement);\n\n // Output cipher for k > 26.\n caesar(displacement, plain);\n printf(\"ciphertext: %s\\n\", plain);\n return 0;\n }\n \n // Output cipher for k <= 26.\n caesar(k, plain);\n printf(\"ciphertext: %s\\n\", plain);\n return 0;\n }\n else\n {\n printf(\"Enter a positive k parameter only.\\n\");\n return 1;\n }\n }\n }\n else\n {\n printf(\"Usage: ./caesar key\\n\");\n return 1;\n }\n}\n\n// Cipher function\nvoid caesar(int key, string message)\n{\n // Goes through the plain text.\n for (int n = 0, l = strlen(message); n < l; n++)\n {\n // Discriminates for letters, A through Z and applies Caesar's encription.\n if (message[n] >= 65 && message[n] <= 90)\n {\n if (message[n] + key > 90)\n {\n message[n] = 65 - 1 + (message[n] + key - 90);\n }\n else\n {\n message[n] += key;\n }\n }\n \n // Discriminates for letters, a through z and applies Caesar's encription.\n if (message[n] >= 97 && message[n] <= 122)\n {\n if (message[n] + key > 122)\n {\n message[n] = 97 - 1 + (message[n] + key - 122);\n }\n else\n {\n message[n] += key;\n }\n }\n }\n}\n\n// Function isnumeric\nint isnumeric(string parameter)\n{\n for (int i = 0, l = strlen(parameter); i < l; i++)\n {\n if (parameter[i] < 48 || parameter[i] > 57)\n {\n return true;\n }\n }\n return false;\n}"
},
{
"alpha_fraction": 0.6763753890991211,
"alphanum_fraction": 0.6893203854560852,
"avg_line_length": 17.117647171020508,
"blob_id": "5fc59d85b57f75eec005277586aa1f6ecc203d83",
"content_id": "0b7dcca9ed7e1d9164b849cf436aa0e92f08a91c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 309,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 17,
"path": "/Louis991-cs50-problems-2020-x-movies/13.sql",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "SELECT people.name\nFROM people\nWHERE people.id IN\n(\n\tSELECT stars.person_id\n\tFROM stars\n\tWHERE stars.movie_id IN\n\t(\n\t\tSELECT stars.movie_id\n\t\tFROM stars\n\t\tWHERE stars.person_id IN\n\t\t(\n\t\t\tSELECT people.id\n\t\t\tFROM people\n\t\t\tWHERE people.name = 'Kevin Bacon' AND people.birth = 1958))\n)\nAND people.name != 'Kevin Bacon';\n\n"
},
{
"alpha_fraction": 0.45928069949150085,
"alphanum_fraction": 0.4820173680782318,
"avg_line_length": 29.25,
"blob_id": "33f9f81dbcbea11612e4f0c538a9c2f7c8fbedbd",
"content_id": "ee4967a3ef2e0ae44a5e0687e380d728183d770c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2419,
"license_type": "no_license",
"max_line_length": 165,
"num_lines": 80,
"path": "/Louis991-cs50-problems-2020-x-recover/recover.c",
"repo_name": "Louis991/CS50-Showcase",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <stdint.h>\n\nint main(int argc, char *argv[])\n{\n // Checks for a correct number of input arguments.\n if (argc == 2)\n {\n // Opens reading stream.\n FILE *rawImage = fopen(argv[1], \"r\");\n if (rawImage == NULL)\n {\n printf(\"The image data could not be read.\");\n return 1;\n }\n\n // Initializes pointer to output (NULL for now)\n FILE *outputImage;\n\n // Counts the number of images recovered thus far.\n int imageNumber = 0;\n\n // Defines the BYTE type.\n typedef uint8_t BYTE;\n\n // Declares an array used as a buffer for each 512-byte data block.\n BYTE buffer[512];\n\n // Declares an 8-bit array used to store the image file name, following the format \"###.jpg\" specified. 7 chars + \\0. It will be used as a buffer by sprintf.\n char imageName[8];\n\n // Reads through image data.\n while (fread(buffer, 512, 1, rawImage) == 1)\n {\n // Checks for a .jpg header.\n if (buffer[0] == 0xff && buffer[1] == 0xd8 && buffer[2] == 0xff && ((buffer[3] & 0xf0) == 0xe0))\n {\n // Operations for the 1st block of each of the rest of the images.\n if (imageNumber > 0)\n {\n fclose(outputImage);\n sprintf(imageName, \"%03i.jpg\", imageNumber);\n outputImage = fopen(imageName, \"a\");\n fwrite(buffer, 512, 1, outputImage);\n imageNumber++;\n }\n\n // Operations for the 1st block of the first image.\n if (imageNumber == 0)\n {\n sprintf(imageName, \"%03i.jpg\", imageNumber);\n outputImage = fopen(imageName, \"a\");\n fwrite(buffer, 512, 1, outputImage);\n imageNumber++;\n }\n }\n\n // Writes the rest of the blocks of the current image that's being operated on.\n else\n {\n if (imageNumber > 0)\n {\n fwrite(buffer, 512, 1, outputImage);\n }\n }\n }\n fclose(outputImage);\n fclose(rawImage);\n }\n\n else\n {\n printf(\"Usage: ./recover image.raw\");\n return 1;\n }\n\n // Done.\n return 0;\n}"
}
] | 22 |
ARjUN-ZORO/NewsHub | https://github.com/ARjUN-ZORO/NewsHub | 83342c910dc305d226da5b835e15b01152c7369c | 1d9803cff8da3d1fa91d5c011a327f1242e57cd9 | 577d904270507f68f7dd816b2f92ba47c418f7dc | refs/heads/master | 2021-02-04T01:25:47.577231 | 2020-06-30T15:40:47 | 2020-06-30T15:40:47 | 243,595,608 | 1 | 0 | null | 2020-02-27T19:08:07 | 2020-04-29T13:38:08 | 2020-05-03T20:58:25 | Python | [
{
"alpha_fraction": 0.7131147384643555,
"alphanum_fraction": 0.7131147384643555,
"avg_line_length": 30.20930290222168,
"blob_id": "5a38c12788aeed7c27b72bcea444da0c0d0d279d",
"content_id": "ca2adefdaf5758d503b579a32ec300ae6c6014c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1342,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 43,
"path": "/newshub/__init__.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_login import LoginManager\nfrom flask_bcrypt import Bcrypt\nfrom newshub.settings import Config\nfrom flask_admin import Admin\n\npos_db = SQLAlchemy()\nbcrypt = Bcrypt()\nlogin_manager = LoginManager()\nadmin = Admin()\n\n\nlogin_manager.login_view = \"site_bp.login\"\n# login_manager.login_message_category = \"info\"\n\ndef create_app():\n print('app_name = {}'.format(\"app\"))\n app = Flask(__name__)\n app.config.from_object(Config)\n bcrypt.init_app(app)\n pos_db.init_app(app)\n from newshub.data.scrape_data import scrape\n login_manager.init_app(app)\n from newshub.site.site_routes import site_bp\n app.register_blueprint(site_bp)\n\n from newshub.api.db import mon_db, db\n from newshub.api.settings import SECRET, MONGO_URI, MONGO_DBNAME, DEBUG\n app.debug = DEBUG\n app.config['SECRET_KEY'] = SECRET\n app.config['MONGO_DBNAME'] = MONGO_DBNAME\n app.config['MONGO_URI'] = MONGO_URI\n mon_db.init_app(app)\n from newshub.api.main import api\n api.init_app(app)\n admin.init_app(app)\n from flask_admin.contrib.sqla import ModelView\n from newshub.api.models import pagesView\n from newshub.site.models import User\n # admin.add_view(pagesView(db.pages),'Feeds')\n admin.add_view(ModelView(User,pos_db.session))\n return app\n"
},
{
"alpha_fraction": 0.5613451600074768,
"alphanum_fraction": 0.5718773007392883,
"avg_line_length": 31.214284896850586,
"blob_id": "7c1e196d5659373fa4f65a72e14c12c104ee282b",
"content_id": "2201c453af38d53970d1cbbaee935fbca7c32809",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5412,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 168,
"path": "/newshub/data/scrape_data.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from newshub.data.settings import *\nfrom bs4 import BeautifulSoup\nimport requests\nimport re\nimport datetime\nimport pytz\nfrom flask import jsonify\nfrom pymongo import MongoClient\nimport pymongo\n\n\ndef scrape():\n\terrors = {}\n\terrors[\"link_errors\"] = {}\n\tlink_errors = errors[\"link_errors\"]\n\tlink_errors[\"link_error\"] = []\n\tlink_error = link_errors[\"link_error\"]\n\terrors[\"page_errors\"] = {}\n\tpage_errors = errors[\"page_errors\"]\n\tpage_errors[\"page_error\"] = []\n\tpage_error = page_errors[\"page_error\"]\n\tlink_data = {}\n\tpage_d = {}\n\tdate = datetime.datetime.now(pytz.timezone('Asia/Calcutta')).strftime('%x')\n\ttry:\n\t\tclient1 = MongoClient(DB_CON)\n\t\tdb1 = client1.newshub\n\t\tdoc1 = db1[\"links\"]\n\texcept Exception as e:\n\t\tlink_error.append({'error': e, 'time': datetime.datetime.now(pytz.timezone('Asia/Calcutta'))})\n\n\ttry:\n\t\tclient2 = MongoClient(DB_CON)\n\t\tdb2 = client2.newshub\n\t\tdoc2 = db2[\"page_data\"]\n\texcept Exception as e:\n\t\tpage_error.append({'error': e, 'time': datetime.datetime.now(pytz.timezone('Asia/Calcutta'))})\n\n\trequest_page = requests.get(\n\t\turl=SCRAPE)\n\traw_content = request_page.content\n\thtml_page = BeautifulSoup(raw_content, \"html.parser\")\n\tlatest_news_ul = html_page.find_all(\"ul\", {\"class\": \"latest-news\"})\n\tlatest_news_ul = latest_news_ul[0]\n\tli = latest_news_ul.find_all(\"li\")\n\tli = li[::-1]\n\tlinks = []\n\tfor all in li:\n\t\tlink = all.find(\"a\")['href']\n\t\tif doc1.find_one(link.split('/')[-1][:-4]):\n\t\t\tprint('skip')\n\t\t\tpass\n\t\telse:\n\t\t\ttry:\n\t\t\t\tlink_data = {\n\t\t\t\t\t\"_id\": link.split('/')[-1][:-4],\n\t\t\t\t\t\"link\": link,\n\t\t\t\t\t\"title\": all.find(\"a\").text,\n\t\t\t\t\t\"time\": all.find(\"span\", {\"class\": \"l-datetime\"}).text,\n\t\t\t\t\t\"type\": all.find(\"span\", {\"class\": \"homeSection-name\"}).text,\n\t\t\t\t\t\"date\": datetime.datetime.now(pytz.timezone('Asia/Calcutta')).strftime('%x')\n\t\t\t\t}\n\t\t\t\tres = doc1.insert_one(link_data)\n\t\t\t\tprint(res.acknowledged)\n\t\t\t\tif (res.acknowledged):\n\t\t\t\t\tsource = {'name': 'thehindu.com'}\n\t\t\t\t\tdescription = ''\n\t\t\t\t\tsection_name = ''\n\t\t\t\t\ttitle = ''\n\t\t\t\t\tauthor_name = ''\n\t\t\t\t\tplace = ''\n\t\t\t\t\tpost_time = ''\n\t\t\t\t\tupdated_time = ''\n\t\t\t\t\timg_name = ''\n\t\t\t\t\timg = ''\n\t\t\t\t\tcontent = ''\n\t\t\t\t\turl = ''\n\t\t\t\t\ttry:\n\t\t\t\t\t\t_id = link.split('/')[-1][:-4]\n\t\t\t\t\t\tpage = requests.get(url=link)\n\t\t\t\t\t\tcontents = page.content\n\t\t\t\t\t\tsoup = BeautifulSoup(contents, \"html.parser\")\n\t\t\t\t\t\tarticle_full = soup.find_all(\n\t\t\t\t\t\t\t\"div\", {\"class\": \"article\", \"role\": \"main\"})\n\t\t\t\t\t\tsection_name = article_full[0].find(\n\t\t\t\t\t\t\t\"a\", {\"class\": 'section-name'}).text\n\t\t\t\t\t\tif (article_full[0].find(\"h1\").text):\n\t\t\t\t\t\t\ttitle = article_full[0].find(\"h1\").text\n\t\t\t\t\t\tif (article_full[0].find(\"a\", {\"class\": 'auth-nm'})):\n\t\t\t\t\t\t\tauthor_name = article_full[0].find(\n\t\t\t\t\t\t\t\t\"a\", {\"class\": 'auth-nm'}).text\n\t\t\t\t\t\tplace_time_uptime = article_full[0].find(\n\t\t\t\t\t\t\t\"div\", {\"class\": 'ut-container'})\n\t\t\t\t\t\tplace = place_time_uptime.find_all(\n\t\t\t\t\t\t\t\"span\")[0].text.replace(\"\\n\", \"\")[:-2]\n\t\t\t\t\t\tpost_time = place_time_uptime.find_all(\n\t\t\t\t\t\t\t\"span\")[1].text.replace(\"\\n\", \"\")\n\t\t\t\t\t\t# if (place_time_uptime.find_all(\"span\")[2] is not None):\n\t\t\t\t\t\t# updated_time=place_time_uptime.find_all(\"span\")[2].text.replace(\"\\n\",\"\")\n\t\t\t\t\t\tif (article_full[0].find_all(\"img\", {\"class\": 'lead-img'})):\n\t\t\t\t\t\t\timg = article_full[0].find_all(\n\t\t\t\t\t\t\t\t\"img\", {\"class\": 'lead-img'})\n\t\t\t\t\t\t\tif (article_full[0].find_all(\"picture\")):\n\t\t\t\t\t\t\t\timg = article_full[0].find_all(\"picture\")\n\t\t\t\t\t\t\t\tif (img[0].find_all(\"source\")[0]['srcset']):\n\t\t\t\t\t\t\t\t\timg = img[0].find_all(\"source\")[\n\t\t\t\t\t\t\t\t\t\t0]['srcset']\n\t\t\t\t\t\t\t\t\timg_name = img.split('/')[-1]+\".jpg\"\n\t\t\t\t\t\t\t\t\t# if ('newshub/img/'+img_name):\n\t\t\t\t\t\t\t\t\t# \tpass\n\t\t\t\t\t\t\t\t\t# else:\n\t\t\t\t\t\t\t\t\t# \twith open('newshub/img/'+img_name ,'wb') as w:\n\t\t\t\t\t\t\t\t\t# \t\timg_res = requests.get(img,stream=True)\n\t\t\t\t\t\t\t\t\t# \t\tif not img_res.ok:\n\t\t\t\t\t\t\t\t\t# \t\t\tprint(img_res)\n\t\t\t\t\t\t\t\t\t# \t\tfor b in img_res.iter_content(1024):\n\t\t\t\t\t\t\t\t\t# \t\t\tif not b:\n\t\t\t\t\t\t\t\t\t# \t\t\t\tbreak\n\t\t\t\t\t\t\t\t\t# \t\t\tw.write(b)\n\t\t\t\t\t\tif (article_full[0].find(\"h2\", {\"class\": 'intro'})):\n\t\t\t\t\t\t\tdescription = article_full[0].find(\n\t\t\t\t\t\t\t\t\"h2\", {\"class\": 'intro'}).text\n\t\t\t\t\t\tid_ = re.compile('^content-body-')\n\t\t\t\t\t\tcontent = article_full[0].find_all(\n\t\t\t\t\t\t\t\"div\", {\"id\": id_})[0].text\n\t\t\t\t\texcept Exception as e:\n\t\t\t\t\t\ttraceback.print_exc()\n\t\t\t\t\t\tprint(e)\n\t\t\t\t\t\tpage_error.append({'error': e, 'time': datetime.datetime.now(pytz.timezone('Asia/Calcutta'))})\n\t\t\t\t\ttry:\n\t\t\t\t\t\tpage_d = {\n\t\t\t\t\t\t\t'article_id': _id,\n\t\t\t\t\t\t\t'source': source,\n\t\t\t\t\t\t\t'section_name': section_name,\n\t\t\t\t\t\t\t'title': title,\n\t\t\t\t\t\t\t'author_name': author_name,\n\t\t\t\t\t\t\t'place': place,\n\t\t\t\t\t\t\t'post_time': post_time,\n\t\t\t\t\t\t\t# 'Updated':updated_time,\n\t\t\t\t\t\t\t'img_name': img_name,\n\t\t\t\t\t\t\t'img_url': img,\n\t\t\t\t\t\t\t'description': description,\n\t\t\t\t\t\t\t'content': content,\n\t\t\t\t\t\t\t'url': link,\n\t\t\t\t\t\t\t'Comments': {}\n\t\t\t\t\t\t}\n\t\t\t\t\t\tdoc2.insert_one(page_d)\n\t\t\t\t\texcept Exception as e:\n\t\t\t\t\t\tpage_error.append({'error': e, 'time': datetime.datetime.now(pytz.timezone('Asia/Calcutta'))})\n\t\t\t\t\t\t# time.sleep(34)\n\n\n\t\t\texcept pymongo.errors.DuplicateKeyError:\n\t\t\t\tpass\n\t\t\texcept Exception as er:\n\t\t\t\tlink_error.append({'error': er, 'time': datetime.datetime.now(pytz.timezone('Asia/Calcutta'))})\n\t\t\tlinks.append(link)\n\n\t# last = doc.find({'date': datetime.datetime.now().strftime(\"%x\")}).sort(\n\t\t# \"time\", pymongo.DESCENDING)[0]\n\tfinal = {'data': {'link_data': link_data, 'page_data': page_d}}\n\tall_data = {'errors': errors, 'final': final}\n\t# print(all_data)\n\tprint(all_data)\n\treturn all_data\n\n\n# print(scrape())\n"
},
{
"alpha_fraction": 0.6416666507720947,
"alphanum_fraction": 0.6518518328666687,
"avg_line_length": 33.83871078491211,
"blob_id": "9897b65f952d9192a7e0e116fd8435958fb3ce90",
"content_id": "202f02cf5f0b07e3ed76086cbf4ea614a9fc931a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1080,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 31,
"path": "/newshub/site/models.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from newshub import pos_db, login_manager\nfrom datetime import datetime\nfrom flask_login import UserMixin\nfrom .settings import SECRET\nfrom flask import current_app\nfrom newshub.api.db import mon_db\n\n@login_manager.user_loader\ndef load_user(user_id):\n return User.query.get(int(user_id))\n\nclass User(pos_db.Model, UserMixin):\n __tablename__ = \"user\"\n id = pos_db.Column(pos_db.Integer, primary_key=True)\n email = pos_db.Column(pos_db.String(50), unique=True)\n username = pos_db.Column(pos_db.String(20))\n password = pos_db.Column(pos_db.String(255))\n dob = pos_db.Column(pos_db.Date())\n # phone = pos_db.Column(pos_db.Integer)\n address = pos_db.Column(pos_db.String(200))\n #j_date = pos_db.Column(pos_db.Date())\n # active = pos_db.Column(pos_db.Boolean(),nullable=False,server_default='0')\n\n # def __init__(self, email, username):\n # self.email = email\n # self.username = username\n\n # def serialize(self):\n # return {\"id\": self.id,\n # \"email\": self.email,\n # \"username\": self.username}\n"
},
{
"alpha_fraction": 0.6439560651779175,
"alphanum_fraction": 0.6456654667854309,
"avg_line_length": 38,
"blob_id": "c8b45faace99a4079073f852b36ec51ddcdf2ed9",
"content_id": "3805c1c887faa217c157213f1a18ead24c9d19e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4095,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 105,
"path": "/newshub/site/site_routes.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, render_template, flash, request, redirect, url_for\nfrom flask_login import login_user, current_user, logout_user, login_required\nfrom newshub import pos_db, bcrypt, admin\nfrom newshub.site.models import User\nfrom newshub.site.forms import LoginForm, RegisterForm, UpdateAccountForm\nimport requests\n\nsite_bp = Blueprint('site_bp',__name__)\n\n@site_bp.route('/')\n@site_bp.route('/index')\n@site_bp.route('/home')\ndef index():\n # if request.headers.getlist(\"X-Forwarded-For\"):\n # ip = request.headers.getlist(\"X-Forwarded-For\")[0]\n # else:\n # ip = request.remote_addr\n # url = 'https://ipinfo.io/'+str(ip)+'/json?token=b579f4931aac3b'\n # loc = requests.get(url)\n page = request.args.get('page',type=int,default=1)\n print(request.remote_addr)\n news_data = requests.get('http://localhost:5000/api/latest_news?page='+str(page))\n return render_template('home.html',news_data=news_data.json())\n\n@site_bp.route('/about')\ndef about():\n return render_template('lazy.html',title=\"lazy\",error=\"eeerr\")\n\n@site_bp.route('/login',methods=['GET','POST'])\ndef login():\n if current_user.is_authenticated:\n return redirect(\"login\")\n form = LoginForm()\n if form.validate_on_submit():\n # Get user in db by email\n user = User.query.filter_by(email=form.email.data).first()\n # Check users hashed password matches typed password\n if user and bcrypt.check_password_hash(user.password, form.password.data):\n login_user(user, remember=form.remember.data)\n # Check for any next parameter arguments\n next_page = request.args.get(\"next\")\n # Ternary to send user to next page if it exists, otherwise send user to home page\n return redirect(next_page) if next_page else redirect(url_for(\"site_bp.about\"))\n else:\n flash(\"Login unsuccessful. Check email or password\", \"danger\")\n\n return render_template(\"login.html\", title=\"Login\", form=form)\n\n@site_bp.route('/logout')\n@login_required\ndef logout():\n logout_user()\n return redirect(url_for(\"site_bp.index\"))\n\n@site_bp.route('/register',methods=['GET','POST'])\ndef register():\n if current_user.is_authenticated:\n return redirect(\"login\")\n form = RegisterForm()\n if form.validate_on_submit():\n # Hash password\n hashed_password = bcrypt.generate_password_hash(form.password.data).decode(\n \"utf-8\"\n )\n\n # Construct new user\n user = User(\n username=form.name.data,\n email=form.email.data,\n password=hashed_password,\n # dob=form.dob.data,\n address=form.address.data,\n )\n # Save user to db\n pos_db.session.add(user)\n pos_db.session.commit()\n flash(\"Your account has been created. Please log in\", \"success\")\n return redirect(url_for(\"site_bp.login\"))\n return render_template(\"register.html\", title=\"Register\", form=form)\n\n@site_bp.route(\"/account\", methods=[\"GET\", \"POST\"])\n@login_required\ndef account():\n form = UpdateAccountForm()\n # Check if form data is valid, update user account info in database, redirect to account page\n if form.validate_on_submit():\n # Check for picture data\n # if form.picture.data:\n # picture_file = save_picture(form.picture.data)\n # current_user.image_file = picture_file\n current_user.username = form.name.data\n current_user.email = form.email.data\n # current_user.profile_type = form.profile_type.data\n pos_db.session.commit()\n flash(\"Your account has been updated!\", \"success\")\n return redirect(url_for(\"site_bp.account\"))\n elif request.method == \"GET\":\n form.name.data = current_user.username\n form.email.data = current_user.email\n # form.profile_type.data = current_user.profile_type\n # Set profile picture image file\n # image_file = url_for(\"static\", filename=\"profile_pics/\" + current_user.image_file)\n return render_template(\n \"account.html\", title=\"Account\", form=form\n )\n"
},
{
"alpha_fraction": 0.6959064602851868,
"alphanum_fraction": 0.707602322101593,
"avg_line_length": 23.428571701049805,
"blob_id": "3a7b6e3cb44445c86eca57a9e46c3833ce8b8daf",
"content_id": "d8e25cbe8e5e8aaf1af8e0fdf86a449d881dd2ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 14,
"path": "/newshub/api/models.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from .db import mon_db\nfrom wtforms import form, fields\nfrom flask_admin.contrib.sqla import ModelView\n\nclass pages(form.Form):\n article_id = fields.StringField(50)\n title = fields.StringField(50)\n\n\nclass pagesView(ModelView):\n column_list = ('article_id','title')\n column_sortable_list = ('article_id','title')\n\n form = pages\n"
},
{
"alpha_fraction": 0.49467775225639343,
"alphanum_fraction": 0.5029997825622559,
"avg_line_length": 36.715328216552734,
"blob_id": "afc026dc4fa858420dad8f26a6423f07b4603cff",
"content_id": "24f4ac0ccca6a00ec458a9e244a135ef55fbc7ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5167,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 137,
"path": "/newshub/api/resources.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from flask_restful import Resource, reqparse\nfrom flask import jsonify, request\nimport re, datetime, pytz, urllib, math\n# from .models import PageModel\nfrom .db import mon_db\npage_con = mon_db.db.pages\n# page_con = mon_db.db.page_data\ndef jj(obj):\n ret = {}\n ret[\"_id\"] = str(obj['_id'])\n ret['article_id'] = obj['article_id']\n ret['section_name'] = obj['section_name']\n ret['title'] = obj['title']\n ret['author_name'] = obj['author_name']\n ret['place'] = obj['place']\n ret['post_time'] = obj['post_time']\n ret['img_name'] = obj['img_name']\n ret['img_url'] = obj['img_url']\n ret['description'] = obj['description']\n ret['content'] = obj['content']\n # ret[''] = obj['']\n return ret\n\ndef page_args(page):\n if page < 1:\n page = 1\n return page\ndef cat_arg(page,cat):\n return {'page':page,'cat':cat}\n\ndef find_arg(page,find):\n return {'page':page,'find':find}\n\nclass Page(Resource):\n\n def get(self):\n parser = reqparse.RequestParser()\n parser.add_argument('page',\n type=int,\n required=False,\n help=\"Page Num\",\n default=1\n )\n data = parser.parse_args()\n page = page_args(**data)\n date = datetime.datetime.now(pytz.timezone('Asia/Calcutta')) + datetime.timedelta(days = 0)\n date = date.strftime('%B %d, %Y')\n filter={'post_time': re.compile(date)}\n sort=list({'_id': -1}.items())\n skip = (page-1)*20\n limit=20\n ps = []\n # page_con = mon_db.db.pages\n if page_con:\n tot = page_con.count(filter=None)\n for i in page_con.find(skip=skip,limit=limit,sort=sort,filter=None):\n # print(i)\n ps.append(jj(i))\n prv_link = '/api/latest_news?page=' + str(page - 1)\n nxt_link = '/api/latest_news?page=' + str(page + 1)\n pages = math.ceil(tot/20)\n return {'tot':tot,'pagenum':page,'tot_pages':pages,'prv_link':prv_link,'nxt_link':nxt_link,'out':ps}\n return {'message': \"Something's wrong i can feel it\" }, 666\n\nclass Page_by_cat(Resource):\n\n def get(self):\n parser = reqparse.RequestParser()\n parser.add_argument('cat',\n type=str,\n required=True,\n help=\"Page Num\"\n )\n parser.add_argument('page',\n type=int,\n required=False,\n help=\"Page Num\",\n default=1\n )\n data = parser.parse_args()\n cat_args = cat_arg(**data)\n page = cat_args['page']\n cat = cat_args['cat']\n date = datetime.datetime.now(pytz.timezone('Asia/Calcutta')) + datetime.timedelta(days = 0)\n date = date.strftime('%B %d, %Y')\n filter={'section_name':'\\n'+cat+'\\n'}\n sort=list({'_id': -1}.items())\n skip = (page-1)*20\n limit=20\n ps = []\n # page_con = mon_db.db.pages\n if page_con:\n tot = page_con.count(filter=filter)\n for i in page_con.find(skip=skip,limit=limit,sort=sort,filter=filter):\n # print(i)\n ps.append(jj(i))\n prv_link = '/api/news?cat='+urllib.parse.quote(cat)+'&page=' + str(page - 1)\n nxt_link = '/api/news?cat='+urllib.parse.quote(cat)+'&page=' + str(page + 1)\n return {'tot':tot,'pagenum':page,'prv_link':prv_link,'nxt_link':nxt_link,'out':ps}\n return {'message': \"Something's wrong i can feel it\" }, 404\n\nclass Page_search(Resource):\n\n def get(self):\n parser = reqparse.RequestParser()\n parser.add_argument('find',\n type=str,\n required=True,\n help=\"Page Num\"\n )\n parser.add_argument('page',\n type=int,\n required=False,\n help=\"Page Num\",\n default=1\n )\n data = parser.parse_args()\n find_args = find_arg(**data)\n page = find_args['page']\n find = find_args['find']\n date = datetime.datetime.now(pytz.timezone('Asia/Calcutta')) + datetime.timedelta(days = 0)\n date = date.strftime('%B %d, %Y')\n filter={'title':re.compile(find,re.IGNORECASE)}\n sort=list({'_id': -1}.items())\n skip = (page-1)*20\n limit=20\n ps = []\n # page_con = db.db.pages\n if page_con:\n tot = page_con.count(filter=filter)\n for i in page_con.find(skip=skip,limit=limit,sort=sort,filter=filter):\n # print(i)\n ps.append(jj(i))\n prv_link = '/api/news?find='+urllib.parse.quote(find)+'&page=' + str(page - 1)\n nxt_link = '/api/news?find='+urllib.parse.quote(find)+'&page=' + str(page + 1)\n return {'tot':tot,'pagenum':page,'search_key':find,'prv_link':prv_link,'nxt_link':nxt_link,'out':ps}\n return {'message': \"Something's wrong i can feel it\" }, 404\n"
},
{
"alpha_fraction": 0.7265625,
"alphanum_fraction": 0.7265625,
"avg_line_length": 24.600000381469727,
"blob_id": "a643818c4df7d8b9436780aedb9ee1612e8a1721",
"content_id": "cca5670be2e100c4bc48e7baa26aa7511a3c60de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 256,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/newshub/api/main.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from flask_restful import Api\n\nfrom .db import mon_db\nfrom .resources import Page, Page_by_cat, Page_search\n\napi = Api()\n\napi.add_resource(Page, '/api/latest_news')\napi.add_resource(Page_by_cat, '/api/news')\napi.add_resource(Page_search, '/api/news_find')\n"
},
{
"alpha_fraction": 0.7177792191505432,
"alphanum_fraction": 0.7323198914527893,
"avg_line_length": 57.19230651855469,
"blob_id": "f5a1671719bb331f2eb8e32a96f690dee7a0739a",
"content_id": "536403a4e157e3fd78ffd4a30f524d6124383cf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1513,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 26,
"path": "/newshub/site/forms.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField, PasswordField, BooleanField, TextAreaField, RadioField, SubmitField\nfrom wtforms.fields.html5 import DateField\nfrom wtforms.validators import InputRequired,Email,Length, NumberRange, EqualTo\n\nclass LoginForm(FlaskForm):\n email = StringField('Enter your Email',validators=[InputRequired(),Email(),Length(min=5,max=25)])\n password = PasswordField('Enter your Password',validators=[InputRequired(),Length(min=6,max=80)])\n remember = BooleanField('Remember me')\n submit = SubmitField(\"Login\")\n\nclass RegisterForm(FlaskForm):\n name = StringField('Full Name',validators=[InputRequired(),Length(min=2,max=20)])\n # dob = DateField('Date of Birth',format=\"%Y-%m-%d\",validators=[InputRequired()])\n email = StringField('Enter your Email',validators=[InputRequired(),Email(),Length(min=5,max=25)])\n password = PasswordField('Password',validators=[InputRequired(),Length(min=6,max=80)])\n repassword = PasswordField('Conform Password',validators=[InputRequired(),EqualTo('password')])\n address = TextAreaField('Address')\n submit = SubmitField(\"Register\")\n\nclass UpdateAccountForm(FlaskForm):\n name = StringField('Full Name',validators=[InputRequired(),Length(min=2,max=20)])\n # dob = DateField('Date of Birth',format=\"%Y-%m-%d\",validators=[InputRequired()])\n email = StringField('Enter your Email',validators=[InputRequired(),Email(),Length(min=5,max=25)])\n address = TextAreaField('Address')\n submit = SubmitField(\"Update\")\n"
},
{
"alpha_fraction": 0.588652491569519,
"alphanum_fraction": 0.6453900933265686,
"avg_line_length": 22.5,
"blob_id": "cb41c44c60ae174965e1330946495e63a1adca0d",
"content_id": "c5a0de79f8ec3468c20920ee551f11c23a407eb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 141,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 6,
"path": "/app.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from newshub import create_app\n\napp = create_app()\n\nif __name__ == '__main__':\n\tapp.run(debug=True, port=5000, threaded=True,host=\"0.0.0.0\")\n"
},
{
"alpha_fraction": 0.7973856329917908,
"alphanum_fraction": 0.7973856329917908,
"avg_line_length": 26.81818199157715,
"blob_id": "bcb290a9349e3d8815e735d0e6794bd20459a009",
"content_id": "bb617f0033591198bf6cae6e2484a5845d98edca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 11,
"path": "/newshub/api/db.py",
"repo_name": "ARjUN-ZORO/NewsHub",
"src_encoding": "UTF-8",
"text": "from flask_pymongo import PyMongo\nimport pymongo\n# from flask_mongoengine import MongoEngine, MongoEngineSessionInterface\n# from flask import current_app as app\n\n# mdb = MongoEngine(app)\nmon_db = PyMongo()\n# app.session_interface=MongoEngineSessionInterface(mdb)\n\nconn = pymongo.MongoClient()\ndb = conn.nh\n"
}
] | 10 |
lsjdn/Projet-Nao-Luis-CG | https://github.com/lsjdn/Projet-Nao-Luis-CG | 3dc77be6915693380aeafcf201050f51d28f080c | 55a8270f94c4c5ab45f3d38bdecb06535bdfe5c3 | e958d70b7a2cb1af1b2069a2e04ac67f15764202 | refs/heads/master | 2021-09-04T12:54:27.134725 | 2018-01-18T22:37:04 | 2018-01-18T22:37:04 | 112,584,391 | 2 | 2 | null | 2017-11-30T08:16:40 | 2017-12-07T12:45:40 | 2018-01-18T22:37:05 | Python | [
{
"alpha_fraction": 0.6541095972061157,
"alphanum_fraction": 0.6969178318977356,
"avg_line_length": 28.200000762939453,
"blob_id": "4d9249875f4649fabe1e490520234cc78ceb3e5b",
"content_id": "2dc6a7ba3386097d311df73f60639abae3fafcd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1168,
"license_type": "no_license",
"max_line_length": 203,
"num_lines": 40,
"path": "/py_luis_sql_answer.py",
"repo_name": "lsjdn/Projet-Nao-Luis-CG",
"src_encoding": "UTF-8",
"text": "import mysql.connector\nimport requests\n#from luis_sdk import LUISClient\n\n#mysql connector\ncnn = mysql.connector.connect(user='root', password='root',\n host='127.0.0.1', port=8889,\n database='sakila')\n\ncursor = cnn.cursor(dictionary=True)\n\n#query when voice translates into speech text\nvar = raw_input(u'Please input the text to predict:\\n')\n\n#luis api\nr= requests.get('https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/48bb4ab4-82ee-4b67-9b5a-e618a8aecc8b?subscription-key=309fa2d4b3d74d999cce7eb84b2f97a6&verbose=true&timezoneOffset=0&q=%s'% var)\n\n#get json\nres = r.json()\n\n#recoginize entities\nlastname = res[\"entities\"][0]['entity']\n#print lastname\n\ne_mail = res[\"entities\"][1]['entity']\n\nfirstname = res[\"entities\"][2]['entity']\n#print firstname\n\n#search answers in mysql database\nquery = (\"\"\"SELECT * FROM customer WHERE LOWER(first_name) LIKE '%s' AND LOWER(last_name) LIKE '%s' \"\"\" % (firstname, lastname))\ncursor.execute(query)\nrows = cursor.fetchall()\n\n#print answer as text (prepare for translating into voice)\nfor row in rows:\n print \"%s\" % (row[\"email\"])\n\ncursor.close()\ncnn.close()\n"
},
{
"alpha_fraction": 0.5951613187789917,
"alphanum_fraction": 0.6290322542190552,
"avg_line_length": 15.942028999328613,
"blob_id": "b33f438be77152a7ce3841f72e1d0e6c1ce7ccbb",
"content_id": "ef9a09138c67bea16a9775eaa6c6a0b0efc9e7e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1240,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 69,
"path": "/entityIdentifier.py",
"repo_name": "lsjdn/Projet-Nao-Luis-CG",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\r\n\r\n\r\nimport types\r\n\r\nimport urllib\r\n\r\nimport json\r\n\r\n\r\n# Get the dataflow from URL\r\n\r\ndef URL_GetData(url):\r\n\r\n try:\r\n\r\n ReplyData = urllib.urlopen(url).read()\r\n\r\n\r\n\r\n return ReplyData\r\n\r\n \r\n\r\n except Exception, e:\r\n\r\n print e\r\n\r\n\r\n# Put what we get from the LUIS app in a JSON file\r\n\r\ndef JSON_Write(data):\r\n\r\n file = open(\"reply.json\", \"w\")\r\n\r\n file.write(data)\r\n\r\n file.close\r\n\r\n\r\n# Find out the top scoring intent and entity, and print out\r\n\r\ndef JSON_Parse(data):\r\n\r\n dataflow = json.loads(data)\r\n \r\n # Attention: if any of needed datas cannot be found, the program will return an error\r\n\r\n print \"Main Intent: \" + dataflow['topScoringIntent']['intent']\r\n print \"Main Entity: \" + dataflow['entities'][0]['entity']\r\n\r\n\r\n# Main method\r\n\r\nif __name__ == \"__main__\":\r\n\r\n URLbase = 'https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/e53cdca5-4c82-4d0c-b671-913314c95fe4?subscription-key=309fa2d4b3d74d999cce7eb84b2f97a6&verbose=true&timezoneOffset=0&q='\r\n\r\n QuoteText = raw_input() # Please give the query via keyboard\r\n\r\n URLcomplete = URLbase + QuoteText\r\n\r\n\r\n\r\n data = URL_GetData(URLcomplete)\r\n\r\n JSON_Write(data)\r\n\r\n JSON_Parse(data)\r\n\r\n"
},
{
"alpha_fraction": 0.779411792755127,
"alphanum_fraction": 0.779411792755127,
"avg_line_length": 33,
"blob_id": "06f3f20d05e681cdc62fc63ea343e049ff1131e8",
"content_id": "68b037091a660f0c23d72787c04b6491f2d6bf3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 68,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 2,
"path": "/README.md",
"repo_name": "lsjdn/Projet-Nao-Luis-CG",
"src_encoding": "UTF-8",
"text": "# Projet-Nao-Luis-CG\nImplementing a bot inside a Nao for Cap Gemini\n"
},
{
"alpha_fraction": 0.6642066240310669,
"alphanum_fraction": 0.676506757736206,
"avg_line_length": 28.11111068725586,
"blob_id": "7022f9b92be38d2d1371e7795375e88f515720ad",
"content_id": "234d00331506cad19e54ded84a6817aa5ac807c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 813,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 27,
"path": "/Testprojet.py",
"repo_name": "lsjdn/Projet-Nao-Luis-CG",
"src_encoding": "UTF-8",
"text": "#NAO sound recording avec ALAudioRecorder\r\n\r\nimport argparse\r\nfrom naoqi import ALProxy\r\nimport time\r\nimport os\r\n\r\nrobot_IP = \"XXX.XXX.X.XXX\"\r\ntts = audio = record = aup = None\r\n\r\ndef record_NAO(robot_IP, robot_PORT= XXXX):\r\n global tts, audio, record, aup\r\n #connexion au robot\r\n tts = ALProxy(\"ALTextToSpeech\", robot_IP, robot_PORT)\r\n record = ALProxy(\"ALAudioRecorder\", robot_IP, robot_PORT)\r\n #enregistrement\r\n record.stopMicrophonrdRecording()\r\n print 'start recordng...'\r\n tts.say(\"start recording...\")\r\n record_path = '/home/nao/record.wav'\r\n record.startMicrophonesRecording(record_path, 'wav', 16000, (0,0,1,0))\r\n time.sleep(4)\r\n record.stopMicrophonesRecording()\r\n print.stopMicrophonesRecording()\r\n print 'record over'\r\n tts.say(\"record over\")\r\n return\r\n"
},
{
"alpha_fraction": 0.6871508359909058,
"alphanum_fraction": 0.707402229309082,
"avg_line_length": 26.600000381469727,
"blob_id": "c7146e011240757183f171cca9d44a40f404c792",
"content_id": "cd30969572bf586615ea7c955371c844c58b7035",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1433,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 50,
"path": "/Testprojet_v2.py",
"repo_name": "lsjdn/Projet-Nao-Luis-CG",
"src_encoding": "UTF-8",
"text": "#!/usr/include/python2.7\r\n#coding=utf-8\r\n\r\n\r\nimport argparse\r\nfrom naoqi import *\r\nimport time\r\nimport os\r\nfrom ftplib import FTP\r\nimport string\r\n#import speech_recognition as sr\r\n\r\nrobot_IP = \"172.30.185.103\" #ip du nao a mettre avant\r\nrobot_PORT= 9559\r\n\r\n\r\n#def record_NAO(robot_IP, robot_PORT):\r\n#connexion au robot\r\ntts = ALProxy(\"ALTextToSpeech\", robot_IP, robot_PORT)\r\nrecord = ALProxy(\"ALAudioRecorder\", robot_IP, robot_PORT)\r\nchannels = [1,0,0,0] #ne prend que le micro avant\r\nftp = FTP(robot_IP)\r\nftp.login('nao', 'stark') \r\nftp.delete('record.wav') \t\r\n#enregistrement\r\n#TODO allumage des leds quand il lance l'enregistrement\r\ntts.say(\"What do you want\") \r\nrecord.startMicrophonesRecording(\"/home/nao/record.wav\",\"wav\",16000, channels)\r\nrecord_path = '/home/nao/record.wav'\r\ntime.sleep(10)\r\nrecord.stopMicrophonesRecording()\r\n#print.stopMicrophonesRecording()\r\nprint 'record over'\r\ntts.say(\"record over\")\r\n\r\n\r\n# transfert de document .wav a l'ordi\r\n \t\r\n#ftp.retrlines('LIST') pour voir la liste des fichiers \r\nftp.retrbinary('RETR record.wav', open('record.wav', 'wb').write)\r\nftp.close()\r\nr + sr.Recognizer()\r\n#os.system(\"aplay record.wav\") #joue l'enregistrement (programmer un oui/non et voir la qualité)\r\n#speech to text\r\n#with sr.WavFile(\"record.wav\") as source:\r\n#\taudio = r.record(source)\r\n#try:\r\n#\tprint(\"Transcription: \" +r.recognize(audio))\r\n#except LookupError:\r\n#\tprint(\"Could not understand audio\")\r\n\r\n"
},
{
"alpha_fraction": 0.6636977791786194,
"alphanum_fraction": 0.6885749101638794,
"avg_line_length": 25.361345291137695,
"blob_id": "2626eaa9070c6b393d3dde637f13498e6aa3bc09",
"content_id": "578f8984c6c4bda196a95e2b15563104316fd6ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3256,
"license_type": "no_license",
"max_line_length": 206,
"num_lines": 119,
"path": "/projet.py",
"repo_name": "lsjdn/Projet-Nao-Luis-CG",
"src_encoding": "UTF-8",
"text": "#!/usr/include/python2.7\r\n#coding=utf-8\r\n\r\nimport mysql.connector\r\nimport requests\r\n#from luis_sdk import LUISClient\r\n\r\n\r\nimport argparse\r\nfrom naoqi import *\r\nimport time\r\nimport os\r\nfrom ftplib import FTP\r\nimport string\r\nimport speech_recognition as sr\r\n\r\nimport types\r\nimport urllib\r\nimport json\r\n\r\nrobot_IP = \"172.30.185.102\" #ip du nao a mettre avant\r\nrobot_PORT= 9559\r\n\r\n\r\n#connexion au robot\r\ntts = ALProxy(\"ALTextToSpeech\", robot_IP, robot_PORT)\r\nrecord = ALProxy(\"ALAudioRecorder\", robot_IP, robot_PORT)\r\nchannels = [1,0,0,0] #ne prend que le micro avant\r\nftp = FTP(robot_IP)\r\nftp.login('nao', 'lannister') \r\nftp.delete('record.wav') \t\r\n#enregistrement\r\n#TODO allumage des leds quand il lance l'enregistrement\r\ntts.say(\"What do you want\") \r\nrecord.startMicrophonesRecording(\"/home/nao/record.wav\",\"wav\",16000, channels)\r\nrecord_path = '/home/nao/record.wav'\r\ntime.sleep(6)\r\nrecord.stopMicrophonesRecording()\r\nprint 'record over'\r\ntts.say(\"record over\")\r\n\r\n\r\n# transfert de document .wav a l'ordi\r\n \t\r\n#ftp.retrlines('LIST') pour voir la liste des fichiers \r\nftp.retrbinary('RETR record.wav', open('record.wav', 'wb').write)\r\nftp.close()\r\n#speech to text\r\nr = sr.Recognizer()\r\nwith sr.AudioFile(\"record.wav\") as source:\r\n\taudio = r.record(source)\r\n\tsptote = r.recognize_google(audio)\r\ntry:\r\n\tprint(\"I think you said \" + sptote)\r\nexcept sr.UnknownValueError:\r\n\tprint(\"I could not understand audio\")\r\nexcept sr.RequestError as e:\r\n\tprint(\"I Could not request results from Google Speech Recognition service; {0}\".format(e))\r\n#TODO joue ce que sors le speech to text\r\nverif = str(sptote)\r\n\r\n#verif oui/non\r\nftp = FTP(robot_IP)\r\nftp.login('nao', 'lannister') \r\nftp.delete('verif.wav')\r\ntts.say(\"Did you say \" + verif)\r\nrecord.startMicrophonesRecording(\"/home/nao/verif.wav\",\"wav\",16000, channels)\r\nrecord_path = '/home/nao/verif.wav'\r\ntime.sleep(3)\r\nrecord.stopMicrophonesRecording()\r\nftp.retrbinary('RETR verif.wav', open('verif.wav', 'wb').write)\r\nftp.close()\r\nwith sr.AudioFile(\"verif.wav\") as source:\r\n\taudio = r.record(source)\r\n\tyeno = str(r.recognize_google(audio))\r\nif yeno == \"yes\":\r\n\t#send a Luis\r\n\ttts.say(\"Sending to Luis\")\r\n\t\r\n\tcnn = mysql.connector.connect(user='root', password='root',\r\n\t\t\t host='127.0.0.1',\r\n\t\t\t database='sakila')\r\n\r\n\tcursor = cnn.cursor(dictionary=True)\r\n\r\n\r\n\t#luis api\r\n\tr= requests.get('https://westus.api.cognitive.microsoft.com/luis/v2.0/apps/48bb4ab4-82ee-4b67-9b5a-e618a8aecc8b?subscription-key=309fa2d4b3d74d999cce7eb84b2f97a6&verbose=true&timezoneOffset=0&q=%s'% verif)\r\n\r\n\t#get json\r\n\tres = r.json()\r\n\r\n\t#recoginize entities\r\n\tlastname = res[\"entities\"][0]['entity']\r\n\t#print lastname\r\n\r\n\te_mail = res[\"entities\"][1]['entity']\r\n\r\n\tfirstname = res[\"entities\"][2]['entity']\r\n\t#print firstname\r\n\r\n\t#search answers in mysql database\r\n\tquery = (\"\"\"SELECT * FROM customer WHERE LOWER(first_name) LIKE '%s' AND LOWER(last_name) LIKE '%s' \"\"\" % (firstname, lastname))\r\n\tcursor.execute(query)\r\n\trows = cursor.fetchall()\r\n\r\n\t#print answer as text (prepare for translating into voice)\r\n\tfor row in rows:\r\n\t\tresult = str(row[\"email\"])\r\n\t\tprint \"%s\" % (result)\r\n\r\n\t\tcursor.close()\r\n\t\tcnn.close()\r\n\t\r\n\ttts.say(result)\r\n\r\n\t\t\r\nelse : \r\n\ttts.say(\"I didn't understant please try again\")\r\n"
},
{
"alpha_fraction": 0.6365921497344971,
"alphanum_fraction": 0.6603351831436157,
"avg_line_length": 22.689655303955078,
"blob_id": "eb6b6abdb63566697e7cf20b2270cc27443a5438",
"content_id": "9039d8487fc075ac63f96776affebe9099358da7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3580,
"license_type": "no_license",
"max_line_length": 185,
"num_lines": 145,
"path": "/Testprojetok.py",
"repo_name": "lsjdn/Projet-Nao-Luis-CG",
"src_encoding": "UTF-8",
"text": "#!/usr/include/python2.7\r\n#coding=utf-8\r\n\r\n\r\nimport argparse\r\nfrom naoqi import *\r\nimport time\r\nimport os\r\nfrom ftplib import FTP\r\nimport string\r\nimport speech_recognition as sr\r\n\r\nimport types\r\nimport urllib\r\nimport json\r\n\r\nrobot_IP = \"172.30.185.102\" #ip du nao a mettre avant\r\nrobot_PORT= 9559\r\n\r\n\r\n#connexion au robot\r\ntts = ALProxy(\"ALTextToSpeech\", robot_IP, robot_PORT)\r\nrecord = ALProxy(\"ALAudioRecorder\", robot_IP, robot_PORT)\r\nchannels = [1,0,0,0] #ne prend que le micro avant\r\nftp = FTP(robot_IP)\r\nftp.login('nao', 'lannister') \r\nftp.delete('record.wav') \t\r\n#enregistrement\r\n#TODO allumage des leds quand il lance l'enregistrement\r\ntts.say(\"What do you want\") \r\nrecord.startMicrophonesRecording(\"/home/nao/record.wav\",\"wav\",16000, channels)\r\nrecord_path = '/home/nao/record.wav'\r\ntime.sleep(6)\r\nrecord.stopMicrophonesRecording()\r\nprint 'record over'\r\ntts.say(\"record over\")\r\n\r\n\r\n# transfert de document .wav a l'ordi\r\n \t\r\n#ftp.retrlines('LIST') pour voir la liste des fichiers \r\nftp.retrbinary('RETR record.wav', open('record.wav', 'wb').write)\r\nftp.close()\r\n#speech to text\r\nr = sr.Recognizer()\r\nwith sr.AudioFile(\"record.wav\") as source:\r\n\taudio = r.record(source)\r\n\tsptote = r.recognize_google(audio)\r\ntry:\r\n\tprint(\"I think you said \" + sptote)\r\nexcept sr.UnknownValueError:\r\n\tprint(\"I could not understand audio\")\r\nexcept sr.RequestError as e:\r\n\tprint(\"I Could not request results from Google Speech Recognition service; {0}\".format(e))\r\n#TODO joue ce que sors le speech to text\r\nverif = str(sptote)\r\n\r\n#verif oui/non\r\nftp = FTP(robot_IP)\r\nftp.login('nao', 'lannister') \r\nftp.delete('verif.wav')\r\ntts.say(\"Did you say \" + verif)\r\nrecord.startMicrophonesRecording(\"/home/nao/verif.wav\",\"wav\",16000, channels)\r\nrecord_path = '/home/nao/verif.wav'\r\ntime.sleep(3)\r\nrecord.stopMicrophonesRecording()\r\nftp.retrbinary('RETR verif.wav', open('verif.wav', 'wb').write)\r\nftp.close()\r\nwith sr.AudioFile(\"verif.wav\") as source:\r\n\taudio = r.record(source)\r\n\tyeno = str(r.recognize_google(audio))\r\nif yeno == \"yes\":\r\n\t#send a Luis\r\n\ttts.say(\"Sending to Luis\")\r\n\r\n\t# Get the dataflow from URL\r\n\r\n\tdef URL_GetData(url):\r\n\r\n\t try:\r\n\r\n\t\tReplyData = urllib.urlopen(url).read()\r\n\r\n\r\n\r\n\t\treturn ReplyData\r\n\r\n\t \r\n\r\n\t except Exception, e:\r\n\r\n\t\tprint e\r\n\r\n\r\n\t# Put what we get from the LUIS app in a JSON file\r\n\r\n\tdef JSON_Write(data):\r\n\r\n\t file = open(\"reply.json\", \"w\")\r\n\r\n\t file.write(data)\r\n\r\n\t file.close\r\n\r\n\r\n\t# Find out the top scoring intent and entity, and print out\r\n\r\n\tdef JSON_Parse(data):\r\n\r\n\t dataflow = json.loads(data)\r\n\t \r\n\t # Attention: if any of needed datas cannot be found, the program will return an error\r\n\t try : \r\n\t\tprint \"Intent: \" + dataflow['topScoringIntent']['intent']\r\n\t\tprint \"Entities :\"\r\n\t \tprint dataflow['entities'][0]['type'] + \" : \" + dataflow['entities'][0]['entity']\r\n\t \tprint dataflow['entities'][1]['type'] + \" : \" + dataflow['entities'][1]['entity']\r\n\t \tprint dataflow['entities'][2]['type'] + \" : \" + dataflow['entities'][2]['entity']\r\n\t\tprint dataflow['entities'][3]['type'] + \" : \" + dataflow['entities'][3]['entity']\r\n\t except : \r\n\t\tIndexError\r\n\t\r\n\r\n\r\n\r\n\t# Main method\r\n\r\n\tif __name__ == \"__main__\":\r\n\r\n\t URLbase = 'https://westeurope.api.cognitive.microsoft.com/luis/v2.0/apps/237713c3-796d-4417-bfc1-cada7e8f8b1d?subscription-key=e494c64d42754eb88cea0c029d1d4f93&timezoneOffset=0&q='\r\n\r\n\t \r\n\r\n\t URLcomplete = URLbase + sptote\r\n\r\n\r\n\r\n\t data = URL_GetData(URLcomplete)\r\n\r\n\t JSON_Write(data)\r\n\r\n\t JSON_Parse(data)\r\n\r\nelse : \r\n\ttts.say(\"I didn't understant please try again\")\r\n"
}
] | 7 |
slowbull/rl_a3c_pytorch | https://github.com/slowbull/rl_a3c_pytorch | 7080ed0c516135b9d690e26b1d3663b26a73af79 | 7f3a397d34398a3ad169c5e8065843055b73ff15 | 1c84400b694960322dcd91cf8148e61ea39fa888 | refs/heads/master | 2021-01-25T10:56:34.565588 | 2017-06-18T02:48:50 | 2017-06-18T02:48:50 | 93,897,716 | 0 | 0 | null | 2017-06-09T21:21:32 | 2017-06-09T20:50:07 | 2017-06-09T16:29:34 | null | [
{
"alpha_fraction": 0.6262760758399963,
"alphanum_fraction": 0.6466932892799377,
"avg_line_length": 30.29166603088379,
"blob_id": "90172e7820f60dfdb9a869a7a1456ca5e501cfa3",
"content_id": "4dc218d0beb434ecef9ebadcc1e72e257b17728f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2253,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 72,
"path": "/envs.py",
"repo_name": "slowbull/rl_a3c_pytorch",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nimport json\nimport cv2\nimport logging\nimport numpy as np\n\nfrom gym.spaces.box import Box\nimport gym\n\n\ndef setup_logger(logger_name, log_file, level=logging.INFO):\n l = logging.getLogger(logger_name)\n formatter = logging.Formatter('%(asctime)s : %(message)s')\n\n fileHandler = logging.FileHandler(log_file, mode='w')\n fileHandler.setFormatter(formatter)\n\n streamHandler = logging.StreamHandler()\n streamHandler.setFormatter(formatter)\n\n l.setLevel(level)\n l.addHandler(fileHandler)\n l.addHandler(streamHandler)\n\ndef read_config(file_path):\n \"\"\"Read JSON config.\"\"\"\n json_object = json.load(open(file_path, 'r'))\n return json_object\n\ndef atari_env(env_id, env_conf):\n env = gym.make(env_id)\n env = AtariRescale(env, env_conf)\n env = NormalizedEnv(env)\n return env\n\ndef _process_frame(frame, conf):\n frame = frame[conf[\"crop1\"]:conf[\"crop2\"] + 160, :160]\n frame = cv2.cvtColor(frame, cv2.COLOR_RGB2GRAY)\n frame = cv2.resize(frame, (80, conf[\"dimension2\"])) #maybe we can remove this part.\n frame = cv2.resize(frame, (80, 80))\n return frame\n\nclass AtariRescale(gym.ObservationWrapper):\n\n def __init__(self, env, env_conf):\n super(AtariRescale, self).__init__(env)\n self.observation_space = Box(0.0, 1.0, [1, 80, 80])\n self.conf = env_conf\n\n def _observation(self, observation):\n return _process_frame(observation, self.conf)\n\n# moving average and std. \nclass NormalizedEnv(gym.ObservationWrapper):\n def __init__(self, env=None):\n super(NormalizedEnv, self).__init__(env)\n self.state_mean = 0\n self.state_std = 0\n self.alpha = 0.9999\n self.num_steps = 0\n\n def _observation(self, observation):\n self.num_steps += 1\n self.state_mean = self.state_mean * self.alpha + \\\n observation.mean() * (1 - self.alpha)\n self.state_std = self.state_std * self.alpha + \\\n observation.std() * (1 - self.alpha)\n\n unbiased_mean = self.state_mean / (1 - pow(self.alpha, self.num_steps))\n unbiased_std = self.state_std / (1 - pow(self.alpha, self.num_steps))\n\n return np.expand_dims((observation - unbiased_mean) / (unbiased_std + 1e-8), axis=0)\n"
},
{
"alpha_fraction": 0.7549595832824707,
"alphanum_fraction": 0.7869213819503784,
"avg_line_length": 47.55356979370117,
"blob_id": "3ade74f203dba1172b594684c1224332dae063b6",
"content_id": "90c786cac98ae47a5939a7eff661fe54c9d1c0b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2722,
"license_type": "no_license",
"max_line_length": 574,
"num_lines": 56,
"path": "/README.MD",
"repo_name": "slowbull/rl_a3c_pytorch",
"src_encoding": "UTF-8",
"text": "\n# RL A3C Pytorch\n\n \n\nThis repository includes my implementation with reinforcement learning using Asynchronous Advantage Actor-Critic (A3C) in Pytorch an algorithm from Google Deep Mind's paper \"Asynchronous Methods for Deep Reinforcement Learning.\"\n\n### A3C LSTM\n\nI implemented an A3C LSTM model and trained it in the atari 2600 environments provided in the Openai Gym. Included in repo are trained models for Pong-v0, MsPacman-v0, Breakout-v0, BeamRider-v0, and Asteroids-v0 which have had very good performance and currently hold the top scores on openai gym leaderboard for each of those games. Saved models in trained_models folder. Added a pre-trained SpaceInvadersDeterministic-v3 model which you can see in gif getting a score of 30,330! and scores often higher and as high as 50,000! Can see link for gym evaluation for it below..\n\nHave optimizers using shared statistics for RMSProp and Adam available for use in training as well option to use non shared optimizer.\n\nGym atari settings are more difficult to train than traditional ALE atari settings as Gym uses stochastic frame skipping and has higher number of discrete actions. Such as Breakout-v0 has 6 discrete actions in Gym but ALE is set to only 4 discrete actions. Also in GYM atari they randomly repeat the previous action with probability 0.25 and there is time/step limit that limits performance.\n\nlink to the Gym environment evaluations below\n\n[SpaceInvadersDeterministic-v3](https://gym.openai.com/evaluations/eval_ZaX8BbF5Rl6Hi6CViyMuoQ#reproducibility)\n\n[Breakout-v0](https://gym.openai.com/envs/Breakout-v0)\n\n[BeamRider-v0](https://gym.openai.com/envs/BeamRider-v0)\n\n[MsPacman-v0](https://gym.openai.com/envs/MsPacman-v0)\n\n\n\n  \n\n\n## Requirements\n\n- Python 2.7+\n- Openai Gym and Universe\n- Pytorch\n\n## Training\nTo train agent in Pong-v0 environment with 32 different worker threads:\n\n```\npython main.py --env-name Pong-v0 --num-processes 32\n```\n\nHit Ctrl C to end training session properly\n\n\n\n## Evaluation\nTo run a 100 episode gym evaluation with trained model\n```\npython gym_eval.py --env-name Pong-v0 --num-episodes 100\n```\n\n## Project Reference\n\n- https://github.com/ikostrikov/pytorch-a3c\n\n\n"
}
] | 2 |
dmitriz/satellizer | https://github.com/dmitriz/satellizer | ccf8540cc16e3a728c2c8a13a233bf1a6431c623 | 18535f351fc4ab2753c62c70109a2d60ca094fb4 | 550c0e902a6d498a3f6a2493d60f4fc5c0314fb3 | refs/heads/master | 2021-04-09T14:44:09.396044 | 2020-07-10T03:35:03 | 2020-07-10T03:35:03 | 23,114,207 | 0 | 0 | MIT | 2014-08-19T14:56:20 | 2020-07-10T03:35:07 | 2020-07-10T03:35:05 | JavaScript | [
{
"alpha_fraction": 0.6315789222717285,
"alphanum_fraction": 0.6315789222717285,
"avg_line_length": 23,
"blob_id": "0525c50e03cd77f71bfba6c39e3513c0fb5d31a4",
"content_id": "a5f6fc607808ca4f6615f24027b9ea0b09064c3c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 95,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 4,
"path": "/examples/client/controllers/logout.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "angular.module('MyApp')\n .controller('LogoutCtrl', function($auth) {\n $auth.logout();\n });"
},
{
"alpha_fraction": 0.620669424533844,
"alphanum_fraction": 0.6241925954818726,
"avg_line_length": 24.787878036499023,
"blob_id": "84075971fcb3dfb4184e51232a276ec339b675fb",
"content_id": "a20950bc9505a35286b523cd2015220dad3235a8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1703,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 66,
"path": "/test/$authSpec.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "describe('$auth provider', function() {\n beforeEach(module('Satellizer'));\n\n it('shouldbe able to call login', inject(function($auth, $httpBackend) {\n var token = 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyIjp7Il9pZCI6IjUzZTU3ZDZiY2MzNmMxNTgwNzU4NDJkZCIsImVtYWlsIjoiZm9vQGJhci5jb20iLCJfX3YiOjB9LCJpYXQiOjE0MDc1NDg3ODI5NzMsImV4cCI6MTQwODE1MzU4Mjk3M30.1Ak6mij5kfkSi6d_wtPOx4yK7pS7ZFSiwbkL7AJbnYs';\n var user = {\n email: '[email protected]',\n password: '1234'\n };\n\n $httpBackend.expectPOST('/auth/login').respond({ token: token });\n\n $auth.login(user);\n\n $httpBackend.flush();\n\n expect(angular.isFunction($auth.login)).toBe(true);\n }));\n\n it('should be able to call signup', inject(function($auth, $httpBackend, $location) {\n var user = {\n email: '[email protected]',\n password: '1234'\n };\n\n $httpBackend.expectPOST('/auth/signup').respond(200);\n\n $auth.signup(user);\n\n $httpBackend.flush();\n\n expect(angular.isFunction($auth.signup)).toBe(true);\n expect($location.path()).toEqual('/login');\n }));\n\n it('should log out a user', inject(function($window, $location, $auth) {\n $auth.logout();\n expect($window.localStorage.jwtToken).toBeUndefined();\n expect($location.path()).toEqual('/');\n }));\n\n it('should have a signup function', inject(function($window, Local) {\n expect(Local.signup).toBeDefined();\n expect(angular.isFunction(Local.signup)).toBe(true);\n }));\n\n it('should create a new user', inject(function($httpBackend, $location, Local) {\n var user = {\n email: '[email protected]',\n password: '1234'\n };\n\n $httpBackend.expectPOST('/auth/signup').respond(200);\n\n Local.signup(user);\n\n $httpBackend.flush();\n\n expect($location.path()).toEqual('/login');\n }));\n\n it('should have a isAuthenticated function', inject(function($auth) {\n $auth.isAuthenticated();\n expect($auth.isAuthenticated).toBeDefined();\n }));\n});\n\n"
},
{
"alpha_fraction": 0.6507618427276611,
"alphanum_fraction": 0.6539695262908936,
"avg_line_length": 25.80645179748535,
"blob_id": "713f6a39bdf6e3f21f6fac736a7eeb97c4048d6b",
"content_id": "8fbda220d210891f348d60bbe924ad0900d7a698",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2494,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 93,
"path": "/test/configSpec.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "describe('Configuration', function() {\n\n var auth;\n var authProvider;\n\n beforeEach(module('Satellizer'));\n\n beforeEach(inject(function($auth) {\n auth = $auth;\n }));\n\n beforeEach(function() {\n angular.module('Satellizer').config(function($authProvider) {\n authProvider = $authProvider;\n });\n });\n\n it('should have a config object', function() {\n expect(auth).toBeDefined();\n });\n\n it('should have facebook method', function() {\n expect(authProvider.facebook).toBeDefined();\n });\n\n it('should have google method', function() {\n expect(authProvider.google).toBeDefined();\n });\n\n it('should have linkedin method', function() {\n expect(authProvider.linkedin).toBeDefined();\n });\n\n it('should have twitter method', function() {\n expect(authProvider.twitter).toBeDefined();\n });\n\n it('should have oauth1', function() {\n expect(authProvider.oauth1).toBeDefined();\n });\n\n it('should have oauth2 method', function() {\n expect(authProvider.oauth2).toBeDefined();\n });\n\n it('should update a facebook provider with new params', function() {\n authProvider.facebook({\n scope: 'profile'\n });\n expect(authProvider.providers.facebook.scope).toBe('profile');\n });\n\n it('should update a google provider with new params', function() {\n authProvider.google({\n state: 'secret'\n });\n expect(authProvider.providers.google.state).toBe('secret');\n });\n\n it('should update a linkedin provider with new params', function() {\n authProvider.linkedin({\n state: 'secret'\n });\n expect(authProvider.providers.linkedin.state).toBe('secret');\n });\n\n it('should update a twitter provider with new params', function() {\n authProvider.twitter({\n url: '/oauth/twitter'\n });\n expect(authProvider.providers.twitter.url).toBe('/oauth/twitter');\n });\n\n it('should add a new oauth2 provider', function() {\n authProvider.oauth2({\n name: 'github',\n url: '/auth/github',\n authorizationEndpoint: 'https://github.com/login/oauth/authorize'\n });\n expect(angular.isObject(authProvider.providers['github'])).toBe(true);\n expect(authProvider.providers['github'].name).toBe('github');\n });\n\n it('should add a new oauth1 provider', function() {\n authProvider.oauth1({\n name: 'goodreads',\n url: '/auth/goodreads',\n });\n expect(angular.isObject(authProvider.providers['goodreads'])).toBe(true);\n expect(authProvider.providers['goodreads'].url).toBe('/auth/goodreads');\n });\n\n});\n\n"
},
{
"alpha_fraction": 0.5546875,
"alphanum_fraction": 0.5546875,
"avg_line_length": 18.25,
"blob_id": "cd762a06d818399c0487fe676d5127804e10431b",
"content_id": "906eec87b4bfba2a9d60d9678a3ad6925de530a1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "C#",
"length_bytes": 386,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 20,
"path": "/examples/server/c#/Satellizer/Controllers/AuthController.cs",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "using Microsoft.AspNet.Mvc;\n\nnamespace Satellizer.Controllers\n{\n public class AuthController : Controller\n {\n public void PostFacebook(string code)\n {\n }\n public void PostGoogle(string code)\n {\n }\n public void PostLinkedin(string code)\n {\n }\n public void GetTwitter(string oauth)\n {\n }\n }\n}"
},
{
"alpha_fraction": 0.6281890273094177,
"alphanum_fraction": 0.6378084421157837,
"avg_line_length": 26.159090042114258,
"blob_id": "f467f9eff00ff257cfef77a91ef2a3063be98bd0",
"content_id": "a7da21e8709850350382eeb72da39af164d410f9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2391,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 88,
"path": "/test/localSpec.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "describe('Email and password flow', function() {\n beforeEach(module('Satellizer'));\n\n it('should have a login function', inject(function(Local) {\n expect(angular.isFunction(Local.login)).toBe(true);\n }));\n\n it('should return a user object on successful login', inject(function($httpBackend, Local) {\n var result = null;\n var token = 'eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJ1c2VyIjp7Il9pZCI6IjUzZTU3ZDZiY2MzNmMxNTgwNzU4NDJkZCIsImVtYWlsIjoiZm9vQGJhci5jb20iLCJfX3YiOjB9LCJpYXQiOjE0MDc1NDg3ODI5NzMsImV4cCI6MTQwODE1MzU4Mjk3M30.1Ak6mij5kfkSi6d_wtPOx4yK7pS7ZFSiwbkL7AJbnYs';\n var user = {\n email: '[email protected]',\n password: '1234'\n };\n\n $httpBackend.expectPOST('/auth/login').respond({ token: token });\n\n Local.login(user).then(function(response) {\n result = response;\n });\n\n $httpBackend.flush();\n\n expect(result).toEqual({\n _id: '53e57d6bcc36c158075842dd',\n email: '[email protected]',\n __v: 0\n });\n }));\n\n it('should fail login with incorrect credentials', inject(function($httpBackend, Local) {\n var result = null;\n var user = {\n email: '[email protected]',\n password: 'invalid'\n };\n\n $httpBackend.expectPOST('/auth/login').respond(401, 'Wrong email or password');\n\n Local.login(user).catch(function(response) {\n result = response;\n });\n\n $httpBackend.flush();\n\n expect(result).toEqual('Wrong email or password');\n }));\n\n it('should have a logout function', inject(function(Local) {\n expect(Local.logout).toBeDefined();\n expect(angular.isFunction(Local.logout)).toBe(true);\n }));\n\n it('should log out a user', inject(function($window, $location, Local) {\n Local.logout();\n expect($window.localStorage.jwtToken).toBeUndefined();\n expect($location.path()).toEqual('/');\n }));\n\n it('should have a signup function', inject(function($window, Local) {\n expect(Local.signup).toBeDefined();\n expect(angular.isFunction(Local.signup)).toBe(true);\n }));\n\n it('should create a new user', inject(function($httpBackend, $location, Local) {\n var user = {\n email: '[email protected]',\n password: '1234'\n };\n\n $httpBackend.expectPOST('/auth/signup').respond(200);\n\n Local.signup(user);\n\n $httpBackend.flush();\n\n expect($location.path()).toEqual('/login');\n }));\n\n it('should have a isAuthenticated function', inject(function(Local) {\n expect(Local.isAuthenticated).toBeDefined();\n expect(angular.isFunction(Local.isAuthenticated)).toBe(true);\n }));\n\n it('should have a isAuthenticated function', inject(function(Local) {\n expect(Local.isAuthenticated()).toBe(false);\n }));\n});\n\n"
},
{
"alpha_fraction": 0.6648044586181641,
"alphanum_fraction": 0.6648044586181641,
"avg_line_length": 5.666666507720947,
"blob_id": "8dbb65251d5f9e44c1ce328ee8bfa21b31614938",
"content_id": "0515078340a9c5d10678055e45f6150808f36afa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 179,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 27,
"path": "/examples/server/ruby/app/controllers/auth_controller.rb",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "class AuthController < ApplicationController\n\n def login\n\n end\n\n def signup\n\n end\n\n def facebook\n\n end\n\n def google\n\n end\n\n def linkedin\n\n end\n\n def twitter\n\n end\n\nend"
},
{
"alpha_fraction": 0.6245614290237427,
"alphanum_fraction": 0.6502923965454102,
"avg_line_length": 26.158729553222656,
"blob_id": "468f3086c3c39cd57a63486fadec6be21a11d363",
"content_id": "0eddf9648aa3e9a93bc07bd2bc44aa4533decedc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1710,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 63,
"path": "/examples/server/php/app/models/Nonce.php",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "<?php\n\n/*\n * Based on:\n * https://core.trac.wordpress.org/browser/tags/3.8/src/wp-includes/pluggable.php#L0\n * http://fullthrottledevelopment.com/php-nonce-library\n */\n\nclass Nonce {\n\t\n\tprotected static $NONCE_KEY = '_nonce';\n\n\tprotected static $SALT = 'gu6Wd3m$)bAg6[j9gZb4d8g[cn{hnNjg6d9A';\n\n\t/* nonce life is in a range of 5 minutes (for duration set to 300), as 2 windows of 2m30s\n\t * actual life expectancy between 4m59s and 2m31s\n\t */\n\tprotected static $DURATION = 300;\n\n\tprivate $unique_key;\n\tprivate $value;\n\n\tpublic function __construct( $user_id='', $action='' ){\n\t\t$this->duration = $duration;\n\t\t$this->unique_key = uniqid();\n\t\t$this->value = self::generateHash($user_id, $action, self::$DURATION);\n\t}\n\n\tpublic function getValue() {\n\t\treturn $this->value;\n\t}\n\n\tpublic function getKey() {\n\t\treturn $this->unique_key;\n\t}\n\n\tpublic function getQueryArgument() {\n\t\treturn self::$NONCE_KEY . '=' . $this->value;\n\t}\n\n\tpublic static function isValid($nonce, $user_id, $action){\n\t\t// Nonce generated between 0 to ($DURATION/2) seconds ago \n\t\tif ( self::generateHash( $user_id . $action ) == $nonce )\n\t\t\treturn true;\n\n\t\t// Nonce generated between $DURATION to ($DURATION/2) seconds ago \n\t\tif ( self::generateHashPreviousWindow( $user_id . $action ) == $nonce )\n\t\t\treturn true;\n\n\t\treturn false;\n\t}\n\n\tprotected static function generateHash( $user_id='', $action='' ) {\n\t\t$nb = ceil( time() / ( self::$DURATION / 2 ) );\n\t\treturn substr( md5( $nb . $action . $user_id . self::$SALT ), -12, 10);\n\t}\n\n\tprotected static function generateHashPreviousWindow( $user_id='', $action='' ) {\n\t\t$nb = ceil( time() / ( self::$DURATION / 2 ) );\n\t\treturn substr( md5( $nb-1 . $action . $user_id . self::$SALT ), -12, 10);\n\t}\n\n}"
},
{
"alpha_fraction": 0.6888889074325562,
"alphanum_fraction": 0.6888889074325562,
"avg_line_length": 24.11111068725586,
"blob_id": "e1c069738369bdd345abd07187cb95d9d359eee3",
"content_id": "a7b8ff679444711694bdd8f6508324008357ae9f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 225,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 9,
"path": "/examples/server/php/app/database/seeds/remove_admin.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "/* run from mongo shell with:\n\nload(\"/Users/jeremy/Sites/baolabs/app/database/seeds/seed_admin.js\")\n\n*/\n\ndb = db.getSiblingDB('test_api'); \t// or from shell: use test_api\n\ndb.system.users.remove({\"_id\":\"test_api.test_user\"});"
},
{
"alpha_fraction": 0.6188481450080872,
"alphanum_fraction": 0.6345549821853638,
"avg_line_length": 24.105262756347656,
"blob_id": "ad4c9a5932bd3e9207e1ad42c5c8d91b37077b57",
"content_id": "4da8e0653454b51c1a15f0dde96581ffc7419adf",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 955,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 38,
"path": "/test/oauth1Spec.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "describe('OAuth 1.0 Login', function() {\n\n var $auth, Oauth1, $httpBackend, $interval;\n\n beforeEach(module('Satellizer'));\n\n beforeEach(inject(function(_$auth_, _Oauth1_, _$httpBackend_, _$interval_) {\n $auth = _$auth_;\n Oauth1 = _Oauth1_;\n $httpBackend = _$httpBackend_;\n $interval = _$interval_;\n }));\n\n it('should have open function', function() {\n expect(Oauth1.open).toBeDefined();\n expect(angular.isFunction(Oauth1.open)).toBe(true);\n });\n\n it('should start the oauth1 flow', function() {\n Oauth1.open();\n expect(Oauth1.open).toBeDefined();\n });\n\n it('should exchange oauth for token', function() {\n var oauthData = 'oauth_token=hNDG4EmuJWPhqwJPrb0296aQaRKxInJ655Sop391BQ&oauth_verifier=SXkKIEPedLTGFwtDnU5kq1rhBPryIetlHSXcaQYLPc';\n\n\n Oauth1.open({\n url: '/auth/twitter',\n authorizationEndpoint: 'https://api.twitter.com/oauth/authenticate',\n type: 'oauth1'\n });\n\n Oauth1.exchangeForToken(oauthData);\n\n expect(Oauth1.exchangeForToken).toBeDefined()\n });\n});\n\n"
},
{
"alpha_fraction": 0.6201171875,
"alphanum_fraction": 0.6279296875,
"avg_line_length": 30.060606002807617,
"blob_id": "8c82201914794768460b210ef5c5f3e8f372129a",
"content_id": "336121eb5da986edb4f91d6ad248172be79c0878",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1024,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 33,
"path": "/test/runSpec.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "describe('Run block', function() {\n beforeEach(module('Satellizer'));\n\n it('should have a run function', inject(function(RunBlock) {\n expect(angular.isFunction(RunBlock.run)).toBe(true);\n }));\n\n it('should postMessage on oauth_verifier and oauth_token', inject(function($window, $location, RunBlock) {\n $window.opener = {\n location: { origin: $window.location.origin },\n postMessage: function() {\n return this;\n }\n };\n $location.search({ oauth_token: 1234, oauth_verifier: 5678 });\n RunBlock.run();\n expect($location.search()).toEqual({ oauth_token: 1234, oauth_verifier: 5678 });\n }));\n\n it('should postMessage on authorization code', inject(function($window, $location, RunBlock) {\n $window.opener = {\n location: { origin: $window.location.origin },\n postMessage: function() {\n return this;\n }\n };\n $location.search({ code: 2014 });\n RunBlock.run();\n expect($location.search()).toEqual({ code: 2014 });\n }));\n\n\n});"
},
{
"alpha_fraction": 0.5535168051719666,
"alphanum_fraction": 0.5535168051719666,
"avg_line_length": 28.772727966308594,
"blob_id": "68e232b633f3f5118ba9f94ae2f93257192f0e39",
"content_id": "a242f0238beae870dc01d9eb89595a965fc50407",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 654,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 22,
"path": "/examples/client/directives/repeatPassword.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "angular.module('MyApp')\n .directive('repeatPassword', function() {\n return {\n require: 'ngModel',\n link: function(scope, elem, attrs, ctrl) {\n var otherInput = elem.inheritedData(\"$formController\")[attrs.repeatPassword];\n\n ctrl.$parsers.push(function(value) {\n if (value === otherInput.$viewValue) {\n ctrl.$setValidity('repeat', true);\n return value;\n }\n ctrl.$setValidity('repeat', false);\n });\n\n otherInput.$parsers.push(function(value) {\n ctrl.$setValidity('repeat', value === ctrl.$viewValue);\n return value;\n });\n }\n };\n });"
},
{
"alpha_fraction": 0.5380116701126099,
"alphanum_fraction": 0.719298243522644,
"avg_line_length": 16.100000381469727,
"blob_id": "d03a3bae397f2056f1e01b8f80c1a50acc30649c",
"content_id": "27d3c26610d0d441ebf643cc4d11dde1c073c738",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 171,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 10,
"path": "/examples/server/python/requirements.txt",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "Flask==0.10.1\nFlask-SQLAlchemy==1.0\nJinja2==2.7.3\nMarkupSafe==0.23\nSQLAlchemy==0.9.7\nWerkzeug==0.12\nitsdangerous==0.24\njwt==0.3.1\nrequests==2.3.0\nrequests-oauthlib==0.4.1\n"
},
{
"alpha_fraction": 0.6170583367347717,
"alphanum_fraction": 0.6353350877761841,
"avg_line_length": 26.33333396911621,
"blob_id": "53b5506238c337a949d1778afd768e855bf71e10",
"content_id": "a4ae92d9a9686c366a38814f76ef0cadbf54a709",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1149,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 42,
"path": "/test/popupSpec.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "describe('Configuration', function() {\n\n var Popup, $q, $interval, $window;\n\n beforeEach(module('Satellizer'));\n\n beforeEach(inject(function(_Popup_, _$interval_, _$q_) {\n Popup = _Popup_;\n $interval = _$interval_;\n $q = _$q_;\n }));\n\n\n it('Popup should be defined', function() {\n expect(Popup).toBeDefined();\n });\n\n it('should add left and top offset options', function() {\n var options = { width: 481, height: 269 };\n var preparedOptions = Popup.prepareOptions(options);\n expect(preparedOptions.left).toBeDefined();\n expect(preparedOptions.top).toBeDefined();\n });\n\n it('should stringify popup options', function() {\n var options = { width: 481, height: 269 };\n var stringOptions = Popup.stringifyOptions(options);\n expect(stringOptions).toBe('width=481,height=269');\n });\n\n it('should open a new popup', function() {\n var open = Popup.open();\n $interval.flush(300);\n window.postMessage('testing', '*');\n expect(angular.isObject(open)).toBe(true);\n });\n\n it('should postMessage to window', function() {\n var open = Popup.open();\n expect(angular.isObject(open)).toBe(true);\n });\n});\n\n"
},
{
"alpha_fraction": 0.6036961078643799,
"alphanum_fraction": 0.6078028678894043,
"avg_line_length": 19.25,
"blob_id": "a7ad4e7ebd88ad0cbb1f422056038c8c6ee7c825",
"content_id": "1759b46f6fe67d1a5fcd7157b5679c5b34490b1f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 487,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 24,
"path": "/test/utilsSpec.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "describe('OAuth 1.0 Login', function() {\n\n var Utils;\n\n beforeEach(module('Satellizer'));\n\n beforeEach(inject(function(_Utils_) {\n Utils = _Utils_;\n }));\n\n it('should have parseQueryString method', function() {\n expect(Utils.parseQueryString).toBeDefined();\n });\n\n it('should parse a querystring', function() {\n var qs = 'hello=world&foo=bar';\n var obj = Utils.parseQueryString(qs);\n expect(obj).toEqual({\n hello: 'world',\n foo: 'bar'\n });\n });\n\n});\n\n"
},
{
"alpha_fraction": 0.6173518896102905,
"alphanum_fraction": 0.6236106753349304,
"avg_line_length": 32.454872131347656,
"blob_id": "3785c6b463ab137a5e9c2a22e4d03e51fa9d2c3b",
"content_id": "9b35158240e8591e1dcb7d273b0703894c70c713",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9267,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 277,
"path": "/examples/server/python/app.py",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "# Satellizer Python Example\n# (c) 2014 Sahat Yalkabov\n# License: MIT\n\nfrom datetime import datetime, timedelta\nimport os\nimport jwt\nimport json\nimport requests\nfrom functools import wraps\nfrom urlparse import parse_qsl\nfrom urllib import urlencode\nfrom flask import Flask, g, send_file, request, redirect, url_for, jsonify\nfrom flask.ext.sqlalchemy import SQLAlchemy\nfrom werkzeug.security import generate_password_hash, check_password_hash\nfrom requests_oauthlib import OAuth1\n\n# Configuration\n\ncurrent_path = os.path.dirname(__file__)\nclient_path = os.path.abspath(os.path.join(current_path, '..', '..', 'client'))\n\napp = Flask(__name__, static_url_path='', static_folder=client_path)\napp.config.from_object('config')\n\n# Database and User Model\n\ndb = SQLAlchemy(app)\n\n\nclass User(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n email = db.Column(db.String(120), unique=True)\n password = db.Column(db.String(120))\n first_name = db.Column(db.String(120))\n last_name = db.Column(db.String(120))\n facebook = db.Column(db.String(120))\n google = db.Column(db.String(120))\n linkedin = db.Column(db.String(120))\n twitter = db.Column(db.String(120))\n\n def __init__(self, email=None, password=None, first_name=None,\n last_name=None, facebook=None, google=None,\n linkedin=None, twitter=None):\n if email:\n self.email = email.lower()\n if password:\n self.set_password(password)\n if first_name:\n self.first_name = first_name\n if last_name:\n self.last_name = last_name\n if facebook:\n self.facebook = facebook\n if google:\n self.google = google\n if linkedin:\n self.linkedin = linkedin\n if twitter:\n self.twitter = twitter\n\n def set_password(self, password):\n self.password = generate_password_hash(password)\n\n def check_password(self, password):\n return check_password_hash(self.password, password)\n\n\ndb.create_all()\n\n# Helper Functions\n\ndef create_jwt_token(user):\n payload = dict(\n iat=datetime.now(),\n exp=datetime.now() + timedelta(days=7),\n user=dict(\n id=user.id,\n email=user.email,\n first_name=user.first_name,\n last_name=user.last_name,\n facebook=user.facebook,\n google=user.google,\n linkedin=user.linkedin,\n twitter=user.twitter))\n token = jwt.encode(payload, app.config['TOKEN_SECRET'])\n return token\n\n\ndef login_required(f):\n @wraps(f)\n def decorated_function(*args, **kwargs):\n if not request.headers.get('Authorization'):\n response = jsonify(message='Missing authorization header')\n response.status_code = 401\n return response\n auth = request.headers.get('Authorization')\n token = auth.split()[1]\n payload = jwt.decode(token, app.config['TOKEN_SECRET'])\n if datetime.fromtimestamp(payload['exp']) < datetime.now():\n response = jsonify(message='Token has expired')\n response.status_code = 401\n return response\n\n g.user = payload['user']\n return f(*args, **kwargs)\n\n return decorated_function\n\n\n# Routes\n\[email protected]('/')\ndef index():\n return send_file('../../client/index.html')\n\n\[email protected]('/api/me')\n@login_required\ndef me():\n return jsonify(g.user)\n\n\[email protected]('/auth/login', methods=['POST'])\ndef login():\n user = User.query.filter_by(email=request.json['email']).first()\n if not user or not user.check_password(request.json['password']):\n response = jsonify(message='Wrong Email or Password')\n response.status_code = 401\n return response\n token = create_jwt_token(user)\n return jsonify(token=token)\n\n\[email protected]('/auth/signup', methods=['POST'])\ndef signup():\n u = User(email=request.json['email'],\n password=request.json['password'])\n db.session.add(u)\n db.session.commit()\n return 'OK'\n\n\[email protected]('/auth/facebook', methods=['POST'])\ndef facebook():\n access_token_url = 'https://graph.facebook.com/oauth/access_token'\n graph_api_url = 'https://graph.facebook.com/me'\n\n params = dict(client_id=request.json['clientId'],\n redirect_uri=request.json['redirectUri'],\n client_secret=app.config['FACEBOOK_SECRET'],\n code=request.json['code'])\n\n # Step 1. Exchange authorization code for access token.\n r = requests.get(access_token_url, params=params)\n access_token = dict(parse_qsl(r.text))\n\n # Step 2. Retrieve information about the current user.\n r = requests.get(graph_api_url, params=access_token)\n profile = json.loads(r.text)\n\n user = User.query.filter_by(facebook=profile['id']).first()\n if user:\n token = create_jwt_token(user)\n return jsonify(token=token)\n u = User(facebook=profile['id'],\n first_name=profile['first_name'],\n last_name=profile['last_name'])\n db.session.add(u)\n db.session.commit()\n token = create_jwt_token(u)\n return jsonify(token=token)\n\n\[email protected]('/auth/google', methods=['POST'])\ndef google():\n access_token_url = 'https://accounts.google.com/o/oauth2/token'\n people_api_url = 'https://www.googleapis.com/plus/v1/people/me/openIdConnect'\n\n payload = dict(client_id=request.json['clientId'],\n redirect_uri=request.json['redirectUri'],\n client_secret=app.config['GOOGLE_SECRET'],\n code=request.json['code'],\n grant_type='authorization_code')\n\n # Step 1. Exchange authorization code for access token.\n r = requests.post(access_token_url, data=payload)\n token = json.loads(r.text)\n headers = {'Authorization': 'Bearer {0}'.format(token['access_token'])}\n\n # Step 2. Retrieve information about the current user.\n r = requests.get(people_api_url, headers=headers)\n profile = json.loads(r.text)\n\n user = User.query.filter_by(google=profile['sub']).first()\n if user:\n token = create_jwt_token(user)\n return jsonify(token=token)\n u = User(google=profile['sub'],\n first_name=profile['given_name'],\n last_name=profile['family_name'])\n db.session.add(u)\n db.session.commit()\n token = create_jwt_token(u)\n return jsonify(token=token)\n\n\[email protected]('/auth/linkedin', methods=['POST'])\ndef linkedin():\n access_token_url = 'https://www.linkedin.com/uas/oauth2/accessToken'\n people_api_url = 'https://api.linkedin.com/v1/people/~:(id,first-name,last-name)'\n\n payload = dict(client_id=request.json['clientId'],\n redirect_uri=request.json['redirectUri'],\n client_secret=app.config['LINKEDIN_SECRET'],\n code=request.json['code'],\n grant_type='authorization_code')\n\n # Step 1. Exchange authorization code for access token.\n r = requests.post(access_token_url, data=payload)\n access_token = json.loads(r.text)\n params = dict(oauth2_access_token=access_token['access_token'],\n format='json')\n\n # Step 2. Retrieve information about the current user.\n r = requests.get(people_api_url, params=params)\n profile = json.loads(r.text)\n\n user = User.query.filter_by(linkedin=profile['id']).first()\n if user:\n token = create_jwt_token(user)\n return jsonify(token=token)\n u = User(linkedin=profile['id'],\n first_name=profile['firstName'],\n last_name=profile['lastName'])\n db.session.add(u)\n db.session.commit()\n token = create_jwt_token(u)\n return jsonify(token=token)\n\n\[email protected]('/auth/twitter')\ndef twitter():\n request_token_url = 'https://api.twitter.com/oauth/request_token'\n access_token_url = 'https://api.twitter.com/oauth/access_token'\n authenticate_url = 'https://api.twitter.com/oauth/authenticate'\n\n if request.args.get('oauth_token') and request.args.get('oauth_verifier'):\n auth = OAuth1(app.config['TWITTER_CONSUMER_KEY'],\n client_secret=app.config['TWITTER_CONSUMER_SECRET'],\n resource_owner_key=request.args.get('oauth_token'),\n verifier=request.args.get('oauth_verifier'))\n r = requests.post(access_token_url, auth=auth)\n profile = dict(parse_qsl(r.text))\n\n user = User.query.filter_by(twitter=profile['user_id']).first()\n if user:\n token = create_jwt_token(user)\n return jsonify(token=token)\n u = User(twitter=profile['user_id'],\n first_name=profile['screen_name'])\n db.session.add(u)\n db.session.commit()\n token = create_jwt_token(u)\n return jsonify(token=token)\n else:\n oauth = OAuth1(app.config['TWITTER_CONSUMER_KEY'],\n client_secret=app.config['TWITTER_CONSUMER_SECRET'],\n callback_uri=app.config['TWITTER_CALLBACK_URL'])\n r = requests.post(request_token_url, auth=oauth)\n oauth_token = dict(parse_qsl(r.text))\n qs = urlencode(dict(oauth_token=oauth_token['oauth_token']))\n return redirect(authenticate_url + '?' + qs)\n\n\nif __name__ == '__main__':\n app.run(port=3000)\n"
},
{
"alpha_fraction": 0.6492281556129456,
"alphanum_fraction": 0.6496569514274597,
"avg_line_length": 26.7738094329834,
"blob_id": "a69973107120e777a75974c878f47dec572efc6c",
"content_id": "fddf7e78279cfc23a9d340343c47e01e57470971",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 2332,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 84,
"path": "/examples/server/php/app/models/TwitterWrapper.php",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "<?php\n\nrequire_once( \"../vendor/abraham/twitteroauth/twitteroauth/twitteroauth.php\" );\n\nclass TwitterWrapper extends TwitterOAuth {\n\n\n\tpublic function __construct($oauth_token = NULL, $oauth_token_secret = NULL){\n\n\t\t// Set the Consumer Key\n\t\t$key = Config::get('social.twitter.app_id');\n\n\t\t// Set the Consumer Secret\n\t\t$secret = Config::get('social.twitter.app_secret');\n\n\t\t$oauth_token = Config::get('social.twitter.access_token');\n\t\t$oauth_token_secret = Config::get('social.twitter.access_token_secret');\n\n\t\t// Log::info('app key '.$key);\n\t\t// Log::info('app secret '.$secret);\n\t\t// Log::info('client token '.$oauth_token);\n\t\t// Log::info('client token secret '.$oauth_token_secret);\n\t\t\n\t\tparent::__construct($key, $secret, $oauth_token, $oauth_token_secret);\n\t}\n\n\n\tpublic function getConsumer() {\n\t\treturn $this->consumer;\n\t}\n\n\tpublic function getToken() {\n\t\treturn $this->token;\n\t}\n\n\tpublic function getProfileURL( $screen_name ) {\n\t\treturn 'https://twitter.com/' . $screen_name;\n\t}\n\n\tpublic function showUserById( $user_id, $include_entities = false ) {\n\t\t$params['user_id'] = $user_id;\n\t\t$params['include_entities'] = $include_entities;\n\t\treturn $this->get('users/show', $params);\n\t}\n\n\tpublic function showUserByName( $screen_name, $include_entities = false ) {\n\t\t$params['screen_name'] = $screen_name;\n\t\t$params['include_entities'] = $include_entities;\n\t\treturn $this->get('users/show', $params);\n\t}\n\n\tpublic function getSettings($params = array()) {\n\t\treturn $this->get('account/settings', $params);\n\t}\n\n\tpublic function verifyCredentials( $skip_status = true, $include_entities = false ) {\n\t\t$params['skip_status'] = $skip_status;\n\t\t$params['include_entities'] = $include_entities;\n\t\t$response = $this->get('account/verify_credentials', $params);\n\n\t\tif ( isset($response->errors) && is_array($response->errors) ){\n\t\t\t$errors = $response->errors[0]->message;\n\t \treturn array('error' => $errors );\n\t\t}\n\n\t if ( empty($response) )\n\t \treturn array('error' => 'User profile was not found');\n\n\t if ( isset($response->error) )\n\t \treturn array('error' => $response->error);\n\n\t return $response;\n\t}\n\n\tpublic function testURL( $url, $params = array() ) {\n\t\t$array = array(\n\t\t\t'url'\t\t\t=>\t$url,\n\t\t\t'response'\t\t=>\t$this->get($url, $params),\n\t\t\t'http_code'\t\t=>\t$this->http_code,\n\t\t);\n\t\treturn json_encode($array);\n\t}\n\n}"
},
{
"alpha_fraction": 0.764127790927887,
"alphanum_fraction": 0.773955762386322,
"avg_line_length": 39.79999923706055,
"blob_id": "e225f9ee62d94d6657e8e82373e964871713a0ad",
"content_id": "df54474a99a1e9656175a2fda929a98c252ad638",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 407,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 10,
"path": "/examples/server/python/config.py",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "DEBUG = True\nTOKEN_SECRET = 'keyboard cat'\nFACEBOOK_SECRET = 'Facebook Client Secret'\nFOURSQUARE_SECRET = 'Foursquare Client Secret'\nGOOGLE_SECRET = 'Google Client Secret'\nLINKEDIN_SECRET = 'LinkedIn Client Secret'\nTWITTER_CONSUMER_KEY = 'Twitter Consumer Secret'\nTWITTER_CONSUMER_SECRET = 'Twitter Consumer Secret'\nTWITTER_CALLBACK_URL = 'http://localhost:3000'\nSQLALCHEMY_DATABASE_URI = 'sqlite:///app.db'"
},
{
"alpha_fraction": 0.6497175097465515,
"alphanum_fraction": 0.6497175097465515,
"avg_line_length": 28.66666603088379,
"blob_id": "9738023832d19138488425771cc2fa7dad1c076d",
"content_id": "2276975b371f0311b5826ca45781da37352a3b17",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 177,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 6,
"path": "/examples/client/controllers/protected.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "angular.module('MyApp')\n .controller('ProtectedCtrl', function($scope, Account) {\n Account.getUserInfo().success(function(data) {\n $scope.userInfo = data;\n });\n });"
},
{
"alpha_fraction": 0.5633423328399658,
"alphanum_fraction": 0.5633423328399658,
"avg_line_length": 22.25,
"blob_id": "dd84debb99b08a7c6d527e7dac048cc058b669e2",
"content_id": "461c56274ba54f9965c9030d8d94ce9ab33cc259",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 371,
"license_type": "permissive",
"max_line_length": 52,
"num_lines": 16,
"path": "/examples/client/controllers/login.js",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "angular.module('MyApp')\n .controller('LoginCtrl', function($scope, $auth) {\n\n\n $scope.login = function() {\n $auth.login({\n email: $scope.email,\n password: $scope.password\n });\n };\n $scope.authenticate = function(provider) {\n $auth.authenticate(provider).then(function() {\n console.log('authenticated!');\n });\n }\n });"
},
{
"alpha_fraction": 0.5050774812698364,
"alphanum_fraction": 0.5093532800674438,
"avg_line_length": 35,
"blob_id": "38bf16da3ac925d4a7707526545f7015b11f4284",
"content_id": "203c703932068329a6d435d82db233d6a9ce93e7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 1871,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 52,
"path": "/examples/server/php/app/routes.php",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "<?php\n\n\n/** ------------------------------------------\n * Route model binding\n * ------------------------------------------\n *\tModels are bson encoded objects (mongoDB)\n */\nRoute::model('users', 'User');\n\n/*\n|--------------------------------------------------------------------------\n| Application Routes\n|--------------------------------------------------------------------------\n|\n| Here is where you can register all of the routes for an application.\n| It's a breeze. Simply tell Laravel the URIs it should respond to\n| and give it the Closure to execute when that URI is requested.\n|\n*/\n\nRoute::get('/', function()\n{\n\treturn View::make('hello');\n});\n\nRoute::group(array('prefix' => 'v1'), function(){\n \n\n Route::post('users/auth', array('as' => 'v1.users.auth', 'uses' => 'UserController@authenticate') );\n Route::post('users/auth/facebook', array('as' => 'v1.users.auth.facebook', 'uses' => 'UserController@authenticateFacebook') );\n // Route::post('users/forgot', array('as' => 'v1.users.forgot', 'uses' => 'UserController@forgot') );\n // Route::post('users/reset', array('as' => 'v1.users.reset', 'uses' => 'UserController@resetPassword') );\n\n Route::resource('users', 'UserController', array('only' => array('index', 'store')) );\n\n //\tuser needs to have a registered and active token\n Route::group(array('before' => 'logged_in'), function() {\n\n Route::get('users/sessions', array('as' => 'v1.users.sessions', 'uses' => 'UserController@sessions') );\n\n Route::group(array('prefix' => 'users/{users}'), function() {\n\n Route::get('show', array('as' => 'v1.users.show', 'uses' => 'UserController@show') );\n Route::post('logout', array('as' => 'v1.users.logout', 'uses' => 'UserController@logout') );\n\n });\n\n });\n \n\n});"
},
{
"alpha_fraction": 0.6372247338294983,
"alphanum_fraction": 0.6374615430831909,
"avg_line_length": 31.492307662963867,
"blob_id": "fda874f37fdaa173a282cb2362bc2650e83fcd50",
"content_id": "d1d4960b60455b90159f6a4a16e660dfc45f9c0d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 4223,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 130,
"path": "/examples/server/php/app/models/FacebookWrapper.php",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "<?php\n\n/**\n *\t@see https://github.com/facebook/facebook/php-sdk-v4\n */\n\nuse Facebook\\FacebookRequest;\nuse Facebook\\FacebookSession;\nuse Facebook\\GraphUser;\n\nclass FacebookWrapper {\n\n\t/**\n\t *\tThe current facebook session\n\t *\t@var FacebookSession\n\t */\n\tpublic $session = NULL;\n\n\tpublic function __construct() {\n\t\tFacebookSession::setDefaultApplication(\n\t\t\t\tConfig::get('social.facebook.app_id'), \n\t\t\t\tConfig::get('social.facebook.app_secret')\n\t\t\t);\n\t\tFacebookSession::enableAppSecretProof( Config::get('social.facebook.app_secret_proof') );\n\t}\n\n\tpublic function loginAsUser( $access_token ) {\n\t\t$this->session = new FacebookSession( $access_token );\n\t\treturn $this;\n\t}\n\n\tpublic function loginAsApp() {\n\t\t$this->session = FacebookSession::newAppSession();\n\t\treturn $this;\n\t}\n\n\tpublic function loginAsSignedRequest( $signed_request ) {\n\t\t$this->session = FacebookSession::newSessionFromSignedRequest( $signed_request );\n\t\treturn $this;\n\t}\n\n\tpublic function isLoggedIn() {\n\t\t$logged = false;\n\t\tif ( !empty( $this->session ) ){\n\t\t\ttry {\n\t\t\t\t$this->session->validate();\n\t\t\t\t$logged = true;\n\t\t\t}\n\t\t\tcatch (FacebookRequestException $ex) {\n\t\t\t \t// Session not valid, Graph API returned an exception with the reason.\n\t\t\t \tLog::warning( $ex->getMessage() );\n\t\t\t} catch (Exception $ex) {\n\t\t\t \t// Graph API returned info, but it may mismatch the current app or have expired.\n\t\t\t \tLog::warning( $ex->getMessage() );\n\t\t\t}\n\t\t\treturn $logged;\n\t\t}\n\t\telse return $logged;\n\t}\n\n\tpublic function makeRequest( $http_method , $path, $params = NULL, $version = NULL ) {\n\t\treturn new FacebookRequest( $this->session , $http_method, $path, $params, $version );\n\t}\n\n\tpublic function post($path, $classname, $params=NULL, $version = NULL) {\n\t\t$profile = null;\n\t\ttry {\n\t\t\t$profile = $this->makeRequest('POST', $path, $params, $version )->execute()->getGraphObject( $classname );\n\t\t}\n\t\tcatch(FacebookRequestException $ex) {\n\t\t\tLog::warning( \"Facebook Request Exception occured, code: \" . $ex->getCode() . \" with message: \" . $ex->getMessage() );\n\t\t\t$profile = array('error' => $ex->getMessage() );\n\t\t}\n\t\tcatch (Exception $ex) {\n\t\t\tLog::warning( \"Exception occured, code: \" . $ex->getCode() . \" with message: \" . $ex->getMessage() );\n\t\t\t$profile = array('error' => $ex->getMessage() );\n\t\t}\n\t\treturn $profile;\n\t}\n\n\tpublic function get($path, $classname, $params=NULL, $version = NULL) {\n\t\t$profile = null;\n\t\ttry {\n\t\t\t$profile = $this->makeRequest('GET', $path, $params, $version)->execute()->getGraphObject( $classname );\n\t\t}\n\t\tcatch(FacebookRequestException $ex) {\n\t\t\tLog::warning( \"Facebook Request Exception occured, code: \" . $ex->getCode() . \" with message: \" . $ex->getMessage() );\n\t\t\t$profile = array('error' => $ex->getMessage() );\n\t\t}\n\t\tcatch (Exception $ex) {\n\t\t\tLog::warning( \"Exception occured, code: \" . $ex->getCode() . \" with message: \" . $ex->getMessage() );\n\t\t\t$profile = array('error' => $ex->getMessage() );\n\t\t}\n\t\treturn $profile;\n\t}\n\n\tpublic function getMe( $params=NULL, $version = NULL ) {\n\t\t$profile = null;\n\t\ttry {\n\t\t\t$profile = $this->makeRequest('GET', '/me', $params, $version)->execute()->getGraphObject( GraphUser::className() );\n\t\t}\n\t\tcatch(FacebookRequestException $ex) {\n\t\t\tLog::warning( \"Facebook Request Exception occured, code: \" . $ex->getCode() . \" with message: \" . $ex->getMessage() );\n\t\t\t$profile = array('error' => $ex->getMessage() );\n\t\t}\n\t\tcatch (Exception $ex) {\n\t\t\tLog::warning( \"Exception occured, code: \" . $ex->getCode() . \" with message: \" . $ex->getMessage() );\n\t\t\t$profile = array('error' => $ex->getMessage() );\n\t\t}\n\t\treturn $profile;\n\t}\n\n\tpublic function getUserById( $uid, $params=NULL, $version = NULL ) {\n\t\t$profile = null;\n\t\ttry {\n\t\t\t$profile = $this->makeRequest('GET', '/'.$uid, $params, $version)->execute()->getGraphObject( GraphUser::className() );\n\t\t}\n\t\tcatch(FacebookRequestException $ex) {\n\t\t\tLog::warning( \"Facebook Request Exception occured, code: \" . $ex->getCode() . \" with message: \" . $ex->getMessage() );\n\t\t\t$profile = array('error' => $ex->getMessage() );\n\t\t}\n\t\tcatch (Exception $ex) {\n\t\t\tLog::warning( \"Exception occured, code: \" . $ex->getCode() . \" with message: \" . $ex->getMessage() );\n\t\t\t$profile = array('error' => $ex->getMessage() );\n\t\t}\n\t\treturn $profile;\n\t}\n\n\n}"
},
{
"alpha_fraction": 0.7607816457748413,
"alphanum_fraction": 0.763477087020874,
"avg_line_length": 38,
"blob_id": "70e4042d4934cb3e6f4b61dd6815ccb50d67dee6",
"content_id": "b23d582907ec1f1473de039e5481455a9cbdce45",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1484,
"license_type": "permissive",
"max_line_length": 204,
"num_lines": 38,
"path": "/examples/server/php/README.md",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "#Laravel Restful API Starter\n\n> Check out the [WIKI] now!\n\n## What is it about?\n\nThis starter is based on:\n - [Laravel] 4.2 : Use the power a lightweight trendy Framework\n\nUse MongoDB for storage, and still Eloquent for ORM:\n - Eloquent for MongoDB : ([Laravel MongoDB]) You can easily use MongoDB (NoSQL) as well as the basic SQL database managed by Laravel (MySQL, PGSQL, SQLite, SQL server). Everything is already configured!\n - Seeder files (js) to set up MongoDB users\n\nSend custom response messages:\n - ApiResponse (extends Illuminate\\Support\\Facades\\Response) to quickly send json encoded response message, with adapted Http status codes, and even failed validation rules\n\nMulti-device session:\n - Token : allow a user to login from multiple devices and track all his active sessions.\n\nSocial media login:\n - single config file: *app/config/social.php*\n - [Facebook] Authentication (sdk v4): Wrapper class to easily connect and retrieve info\n\n## About it\n\n### Feedback appreciated \nContact me on [GitHub]\n\n### License\nMIT\n\n[Facebook]:https://github.com/facebook/facebook-php-sdk-v4\n[WIKI]:https://github.com/merlosy/laravel-restful-api-starter/wiki\n[Laravel MongoDB]:https://github.com/jenssegers/laravel-mongodb\n[Laravel]:http://laravel.com/docs/quick\n[GitHub]:https://github.com/merlosy\n[Starter API]:https://github.com/merlosy/laravel-restful-api-starter\n[Postman]:https://chrome.google.com/webstore/detail/postman-rest-client/fdmmgilgnpjigdojojpjoooidkmcomcm\n\n\n"
},
{
"alpha_fraction": 0.599967360496521,
"alphanum_fraction": 0.6014350652694702,
"avg_line_length": 27.262672424316406,
"blob_id": "0e915d666a4d5a963b488f95c98f708ecfda557a",
"content_id": "92d15d75ec6c046faca81cd21e2923cab145c85d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "PHP",
"length_bytes": 6132,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 217,
"path": "/examples/server/php/app/controllers/UserController.php",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "<?php\n\nclass UserController extends BaseController {\n\n\tpublic $restful = true;\n\n\tpublic function index() {\n\t\treturn User::all();\n\t}\n\t\n\tpublic function store() {\n\n\t\t$input = Input::all();\n\t\t$user = '';\n\n\t\t$validator = Validator::make( $input, User::getCreateRules() );\n\n\t\tif ( $validator->passes() ) {\n\n\t\t\t$user = new User();\n\t\t\t$user->email \t\t\t\t= Input::has('email')? $input['email'] : '';\n\t\t\t$user->firstname \t\t\t= Input::has('firstname')? $input['firstname'] : '';\n\t\t\t$user->lastname \t\t\t= Input::has('lastname')? $input['lastname'] : '';\n\t\t\t$user->password \t\t\t= Hash::make( $input['password'] );\n\n\t\t\tif ( !$user->save() )\n\t\t\t\t$user = ApiResponse::errorInternal('An error occured. Please, try again.');\n\n\t\t}\n\t\telse {\n\t\t\treturn ApiResponse::validation($validator);\n\t\t}\n\t\tLog::info('<!> Created : '.$user);\n\n\t\treturn ApiResponse::json($user);\n\t}\n\n\tpublic function authenticate() {\n\n\t\t$input = Input::all();\n\t\t$validator = Validator::make( $input, User::getAuthRules() );\n\n\t\tif ( $validator->passes() ){\n\n\t\t\t$user = User::where('email', '=', $input['email'])->first();\n\t\t\tif ( !($user instanceof User) ) {\n\t\t\t\treturn ApiResponse::json(\"User is not registered.\");\n\t\t\t}\n\t\t\t\n\t\t\tif ( Hash::check( $input['password'] , $user->password) ) {\n\n\t\t\t\t$device_id = Input::has('device_id')? $input['device_id'] : '';\n\t\t\t\t$device_type = Input::has('device_type')? $input['device_type'] : '';\n\t\t\t\t$device_token = Input::has('device_token')? $input['device_token'] : '';\n\n\t\t\t\t$token = $user->login( $device_id, $device_type, $device_token );\n\n\t\t\t\tLog::info('<!> Device Token Received : '. $device_token .' - Device ID Received : '. $device_id .' for user id: '.$token->user_id);\n\t\t\t\tLog::info('<!> Logged : '.$token->user_id.' on '.$token->device_os.'['.$token->device_id.'] with token '.$token->key);\n\t\t\t\t\n\t\t\t\t$token->user = $user->toArray();\n\t\t\t\t$token = ApiResponse::json($token, '202');\n\t\t\t}\n\t\t\telse $token = ApiResponse::json(\"Incorrect password.\", '412');\n\t\t\t\n\t\t\treturn $token;\n\t\t}\n\t\telse {\n\t\t\treturn ApiResponse::validation($validator);\n\t\t}\n\t}\n\n\tpublic function authenticateFacebook() {\n\n\t\t$input = Input::all();\n\t\t$validator = Validator::make( $input, User::getAuthFBRules() );\n\n\t\tif ( $validator->passes() ){\n\n\t\t\t$facebook = new FacebookWrapper();\n\t\t\t$facebook->loginAsUser( $input['access_token'] );\n\n\t\t\t$profile = $facebook->getMe();\n\n\t\t\tif ( is_array($profile) && isset($profile['error']) )\n\t\t\t\treturn json_encode($profile);\n\n\t\t\tLog::info( json_encode( $profile->asArray() ) );\n\n\t\t\t$user = User::where('facebook.id', '=', $profile->getId() )->first();\n\t\t\t\n\t\t\tif ( !($user instanceof User) )\n\t\t\t\t$user = User::where('email', '=', $profile->getProperty('email') )->first();\n\n\t\t\tif ( !($user instanceof User) ){\n\t\t\t\t// Create an account if none is found\n\t\t\t\t$user = new User();\n\t\t\t\t$user->firstname = $profile->getFirstName();\n\t\t\t\t$user->lastname = $profile->getLastName();\n\t\t\t\t$user->email = $profile->getProperty('email');\n\t\t\t\t$user->password = Hash::make( uniqid() );\n\t\t\t}\n\t\t\t\t\n\t\t\t$user->facebook = array('id'\t=>\t$profile->getId() );\n\t\t\t$user->save();\n\n\t\t\t$device_id = Input::has('device_id')? $input['device_id'] : '';\n\t\t\t$device_type = Input::has('device_type')? $input['device_type'] : '';\n\t\t\t$device_token = Input::has('device_token')? $input['device_token'] : '';\n\n\t\t\t$token = $user->login( $device_id, $device_type, $device_token );\n\t\t\t\n\t\t\tLog::info('<!> Device Token Received : '. $device_token .' - Device ID Received : '. $device_id .' for user id: '.$token->user_id);\n\t\t\tLog::info('<!> FACEBOOK Logged : '.$token->user_id.' on '.$token->device_os.'['.$token->device_id.'] with token '.$token->token);\n\n\t\t\t$token = $token->toArray();\n\t\t\t$token['user'] = $user->toArray();\n\n\t\t\tLog::info( json_encode($token) );\n\t\t\t\n\t\t\treturn ApiResponse::json($token);\n\t\t}\n\t\telse {\n\t\t\treturn ApiResponse::validation($validator);\n\t\t}\n\t}\n\n\tpublic function logout( $user ) {\n\n\t\tif ( !Input::has('token') ) return ApiResponse::json('No token given.');\n\n\t\t$input_token = Input::get('token');\n\t\t$token = Token::where('key', '=', $input_token)->first();\n\n\t\tif ( empty($token) ) return ApiResponse::json('No active session found.');\n\n\t\tif ( $token->user_id !== $user->id ) return ApiResponse::errorForbidden('You do not own this token.');\n\n\t\tif ( $token->delete() ){\n\t\t\tLog::info('<!> Logged out from : '.$input_token );\n\t\t\treturn ApiResponse::json('User logged out successfully.', '202');\n\t\t}\t\n\t\telse\n\t\t\treturn ApiResponse::errorInternal('User could not log out. Please try again.');\n\n\t}\n\n\tpublic function sessions() {\n\n\t\tif ( !Input::has('token') ) return ApiResponse::json('No token given.');\n\n\t\t$user = Token::userFor ( Input::get('token') );\n\n\t\tif ( empty($user) ) return ApiResponse::json('User not found.');\n\n\t\t$user->sessions;\n\n\t\treturn ApiResponse::json( $user );\n\t}\n\n\tpublic function forgot() {\n\t\t$input = Input::all();\n\t\t$validator = Validator::make( $input, User::getForgotRules() );\n\n\t\tif ( $validator->passes() ) {\n\n\t\t\t$user = User::where('email', '=', $input['email'])->first();\n\t\t\t// $reset = $user->generatePassResetKey();\n\n\t\t\t// $sent = TriggerEmail::send( 'lost_password', $user, $reset );\n\t\t\t$sent = false;\n\n\t\t\tif ( $sent )\n\t\t\t\treturn ApiResponse::json('Email sent successfully.');\n\t\t\telse\n\t\t\t\treturn ApiResponse::json('An error has occured, the Email was not sent.');\n\t\t}\n\t\telse {\n\t\t\treturn ApiResponse::validation($validator);\n\t\t}\n\t}\n\n\tpublic function resetPassword() {\n\t\t$input = Input::all();\n\t\t$validator = Validator::make( $input, User::getResetPassRules() );\n\n\t\tif ( $validator->passes() ) {\n\t\t\t$reset = ResetKeys::where('key', $input['key'])->first();\n\t\t\tif ( !($reset instanceof ResetKeys) )\n\t\t\t\treturn ApiResponse::errorUnauthorized(\"Invalid reset key.\");\n\n\t\t\t$user = $reset->user;\n\n\t\t\t$user->password = Hash::make($input['password']);\n\t\t\t$user->save();\n\n\t\t\t$reset->delete();\n\n\t\t\treturn ApiResponse::json($user);\n\t\t}\n\t\telse {\n\t\t\treturn ApiResponse::validation($validator);\n\t\t}\n\t}\n\n\tpublic function show($user) {\n\t\t$user->sessions;\n\t\t// Log::info('<!> Showing : '.$user );\n\t\treturn $user;\n\t}\n\n\tpublic function missingMethod( $parameters = array() )\n\t{\n\t return ApiResponse::errorNotFound('Sorry, no method found');\n\t}\n\n}"
},
{
"alpha_fraction": 0.6498422622680664,
"alphanum_fraction": 0.6498422622680664,
"avg_line_length": 34.22222137451172,
"blob_id": "bb6eec676e63e70ec0f4af486b7f0320693ed463",
"content_id": "897d46fec8518a0c4739fd71c6b184316ca4a2ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 317,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 9,
"path": "/examples/server/ruby/config/routes.rb",
"repo_name": "dmitriz/satellizer",
"src_encoding": "UTF-8",
"text": "Rails.application.routes.draw do\n get '/api/me', to: 'users:me'\n get '/auth/login', to: 'auth#login'\n get '/auth/signup', to: 'auth#signup'\n get '/auth/facebook', to: 'auth#facebook'\n get '/auth/google', to: 'auth#google'\n get '/auth/linkedin', to: 'auth#linkedin'\n get '/auth/twitter', to: 'auth#twitter'\nend\n"
}
] | 24 |
svioletg/organization-scripts | https://github.com/svioletg/organization-scripts | 1f28297bc39d7975cf955559a03d9c89313dcc8d | b0825d64a282eada457c28d639b664b1475ae068 | bb59188f4abac0891e3dd00d3c309c1e22511a57 | refs/heads/master | 2022-01-07T05:14:01.709793 | 2019-05-08T12:08:00 | 2019-05-08T12:08:00 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6352201104164124,
"alphanum_fraction": 0.6467505097389221,
"avg_line_length": 24.27814483642578,
"blob_id": "b90479e012c49c34fd21f7ad01e260b4983ffa92",
"content_id": "e7c3e47da488add9ecbb08e3f41181f708ddff2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3816,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 151,
"path": "/sortbydate.py",
"repo_name": "svioletg/organization-scripts",
"src_encoding": "UTF-8",
"text": "# Organizes all files within a specified directory into folders corresponding to creation date.\n# e.g If a file's creation date is 2019-05-03, a \"2019\" folder will be created in the directory. \n# That folder will contain a \"05 May\" folder, and the file will be stored there.\n\n# Only tested on Windows 10 with Python 3.7 so far.\n# Can be run from anywhere.\n\nimport os\nimport tkinter as tk\nimport sys\nfrom tkinter import filedialog\nfrom datetime import datetime\n\nroot = tk.Tk()\nroot.withdraw()\n\ndirectory = filedialog.askdirectory()+'/'\n\nfiles = os.listdir(directory)\ntry:\n\tfiles.remove(__file__)\n\tfiles.remove('__pycache__')\nexcept ValueError:\n\tpass\n\nprint('Found {} items in \"{}\".'.format(len(files),directory))\n\n# Set to 'n' by default\nchoice = 'n'\nchoice = input('[y/n] Sort folders? ').lower().strip()\nif choice == 'y':\n\tsort_folders = True\nelse:\n\tsort_folders = False\n\nchoice = 'n'\nchoice = input('[y/n] Sort files? ').lower().strip()\nif choice == 'y':\n\tsort_files = True\nelse:\n\tsort_files = False\n\nif sort_folders == False:\n\tfor i in files:\n\t\tif os.path.isdir(directory+i):\n\t\t\tfiles.remove(i)\n\nif sort_files == False:\n\tfor i in files:\n\t\tif os.path.isfile(directory+i):\n\t\t\tfiles.remove(i)\n\nwhile True:\n\ttry:\n\t\tmonth_type = int(input(\"\"\"\n1 - Number only; e.g 09\n2 - Number and abbreviation; e.g 09 Sep\n3 - Number and full name; e.g 09 September\n4 - Abbreviation; e.g Sep\n5 - Full name; e.g September\n\nChoose the month naming format: \"\"\"))\n\texcept ValueError:\n\t\tprint('Option must be an integer.')\n\t\tcontinue\n\n\tif month_type not in [1, 2, 3, 4, 5]:\n\t\tprint('Invalid option.')\n\telse:\n\t\tbreak\n\ndef get_date(file):\n\tif month_type == 1:\n\t\treturn datetime.utcfromtimestamp(os.path.getctime(file)).strftime('%Y/%m')\n\tif month_type == 2:\n\t\treturn datetime.utcfromtimestamp(os.path.getctime(file)).strftime('%Y/%m %b')\n\tif month_type == 3:\n\t\treturn datetime.utcfromtimestamp(os.path.getctime(file)).strftime('%Y/%m %B')\n\tif month_type == 4:\n\t\treturn datetime.utcfromtimestamp(os.path.getctime(file)).strftime('%Y/%b')\n\tif month_type == 5:\n\t\treturn datetime.utcfromtimestamp(os.path.getctime(file)).strftime('%Y/%B')\n\nchoice = ''\n\nwhile True:\n\tchoice = input(\"\"\"\ns - Start moving items.\nl - List items to be moved.\nx - Exclude a certain item from the list (will open another input prompt).\ne - Exit script.\n> \"\"\").lower().strip()\n\tif choice in ['e', 's', 'l', 'x']:\n\t\tif choice == 'e':\n\t\t\traise SystemExit\n\t\telif choice == 'l':\n\t\t\tprint('Listing...')\n\t\t\tfor i in files:\n\t\t\t\titemtype = ''\n\t\t\t\tif os.path.isdir(directory+i):\n\t\t\t\t\titemtype = 'DIRECTORY'\n\t\t\t\telif os.path.isfile(directory+i):\n\t\t\t\t\titemtype = 'FILE'\n\t\t\t\tprint('({current}/{total}) [{itemtype}] {name}'.format(\n\t\t\t\t\tcurrent=str(files.index(i)+1),\n\t\t\t\t\ttotal=len(files),\n\t\t\t\t\titemtype=itemtype,\n\t\t\t\t\tname=i))\n\t\telif choice == 'x':\n\t\t\ttry:\n\t\t\t\texclusion = input('Exact name of item to exclude (you can also use \"#\" followed by a number): ')\n\t\t\t\tif exclusion.startswith('#'):\n\t\t\t\t\texclusion = files[int(exclusion.replace('#',''))-1]\n\n\t\t\t\tchoice = input('[y/n] Confirm the exclusion of \"{}\": '.format(exclusion))\n\n\t\t\t\tif choice == 'y':\n\t\t\t\t\tfiles.remove(exclusion)\n\t\t\t\t\tprint('\"{}\" will not be moved.'.format(exclusion))\n\t\t\t\telse:\n\t\t\t\t\tcontinue\n\t\t\texcept ValueError:\n\t\t\t\tprint('\"{}\" is not in the list.'.format(exclusion))\n\t\telif choice == 's':\n\t\t\tbreak\n\telse:\n\t\tprint('Invalid response.')\n\t\tcontinue\n\nprint('\\nRenaming...')\n\nos.chdir(directory)\n\nfor file in files:\n\tdate = get_date(file)\n\ty = date.split('/')[0]\n\tm = date.split('/')[1]\n\tif not os.path.exists(y):\n\t\tos.mkdir(y)\n\t\tos.mkdir(y+'/'+m)\n\n\tnewdir = '{directory}/{name}'.format(directory=date,name=file)\n\tos.rename(file,newdir)\n\tprint('({}/{}) {} -> {}'.format(\n\t\tstr(files.index(file)+1),\n\t\tlen(files),\n\t\tfile,\n\t\tnewdir)\n\t)\n\ninput('\\nFinished, press enter to exit.')"
},
{
"alpha_fraction": 0.6374956965446472,
"alphanum_fraction": 0.6451054811477661,
"avg_line_length": 24.787036895751953,
"blob_id": "e33019064f8fb072208c1b179aada66ccab0c659",
"content_id": "25a558780c2b0f07ecde79eda3ef196bc7c6ee23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2891,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 108,
"path": "/namebydate.py",
"repo_name": "svioletg/organization-scripts",
"src_encoding": "UTF-8",
"text": "# Adds the creation date of a file (formatted to YYYY-MM-DD) to the beginning of all files within a specified directory.\r\n# Only tested on Windows 10 with Python 3.7 so far.\r\n\r\n# Can be run from anywhere.\r\n\r\nimport os\r\nimport tkinter as tk\r\nfrom tkinter import filedialog\r\nfrom datetime import datetime\r\n\r\ndef get_date(file):\r\n\treturn datetime.utcfromtimestamp(os.path.getctime(file)).strftime('%Y-%m-%d')\r\n\r\nroot = tk.Tk()\r\nroot.withdraw()\r\n\r\ndirectory = filedialog.askdirectory()+'/'\r\n\r\nrename_folders = False\r\njoinwith = '-'\r\n\r\n# Set choice to no by default\r\nchoice = 'n'\r\nchoice = input('[y/n] Rename folders? ').lower()\r\n\r\nif choice == 'y':\r\n\tprint('The script will rename folders.')\r\n\trename_folders = True\r\nelse:\r\n\tprint('The script will not rename folders.')\r\n\trename_folders = False\r\n\r\nfiles = os.listdir(directory)\r\ntry:\r\n\tfiles.remove(__file__)\r\n\tfiles.remove('__pycache__')\r\nexcept ValueError:\r\n\tpass\r\n\r\nif rename_folders == False:\r\n\tfor i in files:\r\n\t\tif os.path.isdir(i):\r\n\t\t\tfiles.remove(i)\r\n\r\nprint('\\nFound {} items in directory.'.format(len(files)))\r\n\r\nchoice = ''\r\n\r\nwhile True:\r\n\tchoice = input(\"\"\"\r\ns - Start renaming items.\r\nl - List items to be renamed.\r\nx - Exclude a certain item from the list. Will open another input prompt.\r\nj - Choose character/string to be inserted between the date and the original filename. This is a hyphen by default\r\n\te.g if the joining character is a hyphen: \"2018-07-15-filename.txt\"\r\n\tif the joining character is \".\": \"2018-07-15.filename.txt\"\r\ne - Exit script.\r\n> \"\"\").lower().strip()\r\n\tif choice in ['e', 's', 'l', 'x', 'j']:\r\n\t\tif choice == 'e':\r\n\t\t\traise SystemExit\r\n\t\telif choice == 'l':\r\n\t\t\tprint('Listing...')\r\n\t\t\tfor i in files:\r\n\t\t\t\titemtype = ''\r\n\t\t\t\tif os.path.isdir(directory+i):\r\n\t\t\t\t\titemtype = 'DIRECTORY'\r\n\t\t\t\telif os.path.isfile(directory+i):\r\n\t\t\t\t\titemtype = 'FILE'\r\n\t\t\t\tprint('({current}/{total}) [{itemtype}] {name}'.format(\r\n\t\t\t\t\tcurrent=str(files.index(i)+1),\r\n\t\t\t\t\ttotal=len(files),\r\n\t\t\t\t\titemtype=itemtype,\r\n\t\t\t\t\tname=i))\r\n\t\telif choice == 'x':\r\n\t\t\ttry:\r\n\t\t\t\texclusion = input('Exact name of item to exclude: ')\r\n\t\t\t\tfiles.remove(exclusion)\r\n\t\t\t\tprint('{} will not be renamed.'.format(exclusion))\r\n\t\t\texcept ValueError:\r\n\t\t\t\tprint('{} is not in the list.'.format(exclusion))\r\n\t\telif choice == 'j':\r\n\t\t\tjoinwith = input('Joining character/string: ')\r\n\t\telif choice == 's':\r\n\t\t\tbreak\r\n\telse:\r\n\t\tprint('Invalid response.')\r\n\r\nprint('\\nRenaming...')\r\n\r\nos.chdir(directory)\r\n\r\nfor file in files:\r\n\t# Skip any files with dates already added\r\n\tif get_date(file) in file:\r\n\t\tprint('Item \"{}\" already has a date added to it.'.format(file))\r\n\t\tcontinue\r\n\r\n\tnewname = '{date}{joinwith}{name}'.format(date=get_date(file),joinwith=joinwith,name=file)\r\n\tos.rename(file,newname)\r\n\tprint('({}/{}) {} -> {}'.format(\r\n\t\tstr(files.index(file)+1),\r\n\t\tlen(files),\r\n\t\tfile,\r\n\t\tnewname)\r\n\t)\r\n\r\ninput('\\nFinished, press enter to exit.')"
}
] | 2 |
Jerrykim91/Daily | https://github.com/Jerrykim91/Daily | 0533afe1956ca5cc88f7d69f7810b489240e70e6 | 30f738fc9728b7501bf5601e17189f47c13aaec9 | f54fdbb8301f54dda8551bb811e864d3a81da6de | refs/heads/master | 2021-07-24T23:18:09.686269 | 2020-10-17T12:07:57 | 2020-10-17T12:07:57 | 226,638,343 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6010743379592896,
"alphanum_fraction": 0.6358495950698853,
"avg_line_length": 15.229357719421387,
"blob_id": "1ab002ce46b0f4611d30c7fc52b6361c68b98d40",
"content_id": "30f9469cda20e565427743a6c29d66aeade0cb3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4713,
"license_type": "no_license",
"max_line_length": 161,
"num_lines": 218,
"path": "/Virtual_Environment/Setup_SparkEnv.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# SetUp : 스파크 사용환경 구축\n\n혹시 Visual C++ 런타임 라이브러리여부를 확인하고 없다면 설치하는 것이 좋다.\n\n---\n설치: <https://knowledge.autodesk.com/ko/search-result/caas/sfdcarticles/sfdcarticles/KOR/How-to-remove-and-reinstall-Microsoft-Visual-C-Runtime-Libraries.html> \n\n---\n\n<br>\n<br>\n\n## 1. 자바(java) 설치 \n\n커맨드(cmd)창에 다음과 같이 입력했을때 출력이 있어야 한다.\n\n\n```cmd\n$ java -version\n\n출력 >>> java version \"1.8.0_144\"\n Java(TM) SE Runtime Environment (build 1.8.0_144-b01)\n Java HotSpot(TM) Client VM (build 25.144-b01, mixed mode, sharing)\n\n```\n\n만약 위와 같이 나오지 않는다면 자바가 설치가 안 된 것이므로 아래 링크에서 설치한다.\n\n---\n설치경로 1 : <https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html>\n\n설치경로 2 : <https://www.apache.org/dyn/closer.lua/spark/spark-2.4.5/spark-2.4.5-bin-hadoop2.7.tgz>\n\n---\n\n<!-- --- -->\n<br>\n\n### 1.1 자바 환경변수 설정 \n\n시스템 환경변수에서 아래와같이 설정 해주어야한다.\n\n```cmd\n\n# JAVA_HOME 변수를 설정\nJAVA_HOME = C:\\Program Files\\Java\\jdk1.8.0_201\n\n# 경로를 환경변수에 추가 \nC:\\Program Files\\Java\\jdk1.8.0_201\\bin \n\n```\n<!-- --- -->\n\n<br>\n\n### 1.2 자바 환경변수 설정 확인\n\n커맨드(cmd) 창 재시작 후 \n- `$where yarn`\n\nWinutils 확인 \n- `$ where winutils.exe`\n\n\n\n<br>\n\n## 2. SPARK Install\n\n스파크 설치를 진행하기위해 아래의 링크에서 데이터를 다운받는다. \n\n---\n설치 경로 : <http://spark.apache.org/downloads.html>\n\n---\n\n<br>\n\n### 2.1 스파크 환경변수 설정 \n\n시스템 환경변수에서 아래와 같이 설정이 필요하다.\n\n추가) \n복붙시 파일이름은 본인들 파일이름 일 것 \n본인들이 다운받은 파일과 동일한 파일 이름일 것 - 아래는 예시 \n\n```cmd\n\n# SPARK_HOME, HADOOP_HOME변수를 설정\nSPARK_HOME = C:\\spark\\spark-2.3.2-bin-hadoop2.7\nHADOOP_HOME = C:\\spark\\hadoop2.7 \n\n# PATH에 아래와 같이 선언 \nC:\\spark\\spark-2.3.2-bin-hadoop2.7\\bin \n\n```\n\n<br>\n<br>\n\n## 3. winutils.exe 설치\n\n---\n설치 경로: <https://github.com/steveloughran/winutils> \n\n---\n\n하둡버전과 동일하게 설치를 진행해준다. \n다운받은 winutils.exe를 스파크를 설치해준 bin폴더에 저장한다. \n\n예) 현재 나의 경로 -> C:\\spark\\spark-2.3.2-bin-hadoop2.7\n\n<br>\n\n### 3.1 폴더생성 \n\n`C:\\tmp\\hive` 와 동일한 경로에 폴더를 생성한다.\n\n<br>\n\n### 3.2 관리자 권한으로 cmd를 실행시키고 두개의 명령어를 실행\n\n\n```cmd\n$ winutils.exe chmod -R 777 C:\\tmp\\hive\n$ winutils.exe ls -F C:\\tmp\\hive\n\n# 이렇게 실행하면 다음과 유사하게 출력됨\n출력 >>> drwxrwxrwx|1|LAPTOP-.....\n\n```\n\n\n<br>\n<br>\n\n## 4. Pyspark 설치 확인 \n\n\nPyspark 설치 : `conda install -c conda-forge pyspark`\n\ncmd창에 들어가서 pyspark명령어를 치면 \n아래와 같이 뜨면 성공 \n\n```cmd\n\n(base) C:\\>pyspark\nPython 3.6.5 |Anaconda, Inc.| (default, Mar 29 2018, 13:32:41) [MSC v.1900 64 bit (AMD64)] on win32\nType \"help\", \"copyright\", \"credits\" or \"license\" for more information.\nUsing Spark's default log4j profile: org/apache/spark/log4j-defaults.properties\nSetting default log level to \"WARN\".\nTo adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).\nWelcome to\n ____ __\n / __/__ ___ _____/ /__\n _\\ \\/ _ \\/ _ `/ __/ '_/\n /__ / .__/\\_,_/_/ /_/\\_\\ version 2.4.5\n /_/\n\n\n```\n\n<br>\n\n### 4.1 Pyspark 설치 확인 - 체크 \n\n추가 확인으로 pyspark 실행후 다음과 같은 명령어가 동작하는지 확인 \n\n```cmd\n\nnums = sc.parallelize([1,2,3,4])\nnums.map(lambda x:x*x).collect()\n\n```\n\n<br>\n<br>\n\n## 5. Pyspark를 쥬피터 노트북에 연결 \n\nanaconda prompt가 설치되어있다는 가정하에 진행한다.\n\n<br>\n\n아래의 명령어를 실행한다. \n\n```cmd\n# findspark 설치 \n$ conda install -c conda-forge findspark\n```\n\n이후 jupyter notebook을 실행시키고 다음과 같이 컴파일\n\n```py\nimport findspark \nfindspark.init()\nfindspark.find() \n\nimport pyspark \nfindspark.find()\n\n# spark 세션을 생성해주기위해서 다음과 같이 컴파일을 진행해준다.\n\nfrom pyspark import SparkContext, SparkConf \nfrom pyspark.sql import SparkSession \n\nconf = pyspark.SparkConf().setAppName('appName').setMaster('local’) \nsc = pyspark.SparkContext(conf=conf) # sc에 스파크 콘텍스트를 담는다.\nspark = SparkSession(sc) # sc를 세션을 할당한다.\n\n# 만약 세션이 끝난다면 다음과같은 코드를 실행한다\nsc.stop() # 세션 종료\n```\n<br>\n---\n<br>"
},
{
"alpha_fraction": 0.5093708038330078,
"alphanum_fraction": 0.5384872555732727,
"avg_line_length": 19.97058868408203,
"blob_id": "5504adff0ab7b541a0c83050482cce61cd1e36c8",
"content_id": "148aafe741054f38a9ffd4ad8c54cd8b2bc1dd10",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4090,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 136,
"path": "/Data Structure and algorithm/DSAA_basic01_Array.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 자료구조와 알고리즘 강의 \r\n# 6~7강_ 배열과 파이썬 \r\n\r\n# 꼭 알아둬야 할 자료구조 : 배열(Arrawy)\r\n# - 데이터를 나열하고, 각 데이터를 인덱스에 대응하도록 구성한 데이터 구조\r\n# - 파이썬에서는 리스트 타입이 배열 기능을 제공\r\n\r\n## 1. 배열이 왜 필요할까?\r\n# - 같은 종류의 데이터를 효율적으로 관리하게 하기 위해 사용 \r\n# - 같은 종류의 데이터를 순차적으로 저장\r\n\r\n# 연관된 공간에 저장가능하고 데이터에 맞게 인덱스를 부여 \r\n# => 연결된 데이터의 일부분에 바로 접근 \r\n\r\n # 장점\r\n # - 배열은 빠른 접근이 가능 \r\n\r\n # 단점 \r\n # - 연관된 데이터의 추가가 힘들다 \r\n # - 데이터가 가변적이라 삭제를 하게 되면 데이터가 손상된다. \r\n # 그래서 데이터 삭제가 어렵다. \r\n\r\n## 2. 배열 with 파이썬 \r\n\r\n# > c언어로 배열을 표현 \r\n# ``` C\r\n# #include<stdio.h>\r\n\r\n# int main(int argc, char*argv[])\r\n# {\r\n# # 3개의 공간을 지정 \r\n# char country[3] =\"US\";\r\n# printf(\"%c%c\\n\", country[0],country[1]);\r\n# printf(\"%s\\n\", country);\r\n# return 0;\r\n# }\r\n# ```\r\n# - C언어는 배열의 사이즈를 미리 정한다. \r\n\r\ncountry = \"US\"\r\nprint(country)\r\n\r\n# 내부정으로 배열을 쓰는데 c언어처럼 배열의 길이를 지정하지 않는다. \r\ncountry = country + 'A'\r\nprint(country)\r\n\r\ndata = [1, 2, 3, 4, 5]\r\n# list(range(1,6))\r\nprint(data)\r\n#>>>[1, 2, 3, 4, 5]\r\n\r\n# 2차원 배열 : 리스트로 구현시 \r\ndata = [[1,2,3],[4,5,6],[7,8,9]]\r\nprint(data)\r\n# >>> [[1, 2, 3], [4, 5, 6], [7, 8, 9]]\r\n\r\n#1차원 데이터의 접근 \r\nprint(data[0])\r\n#>>> [1, 2, 3]\r\n\r\nprint(data[0][0])\r\nprint(data[0][1])\r\nprint(data[0][2])\r\nprint(data[1][0])\r\n#>>> 1\r\n#>>> 2\r\n#>>> 3\r\n#>>> 4\r\n\r\n## 3. 프로그래밍 연습 \r\n#### 연습 01 : 위의 2차원 배열에서 9,8,7 순서로 출력해보기 \r\nprint(data[2][2],data[2][1],data[2][0])\r\n# >>> 9 8 7\r\n\r\n\r\n#### 연습 02 : 다음 dataset에서 전체 이름안에 M이 몇번 나왔는지 빈도수 출력하기\r\n\r\ndataset = ['Braund, Mr. Owen Harris',\r\n'Cumings, Mrs. John Bradley (Florence Briggs Thayer)',\r\n'Heikkinen, Miss. Laina',\r\n'Futrelle, Mrs. Jacques Heath (Lily May Peel)',\r\n'Allen, Mr. William Henry',\r\n'Moran, Mr. James',\r\n'McCarthy, Mr. Timothy J',\r\n'Palsson, Master. Gosta Leonard',\r\n'Johnson, Mrs. Oscar W (Elisabeth Vilhelmina Berg)',\r\n'Nasser, Mrs. Nicholas (Adele Achem)',\r\n'Sandstrom, Miss. Marguerite Rut',\r\n'Bonnell, Miss. Elizabeth',\r\n'Saundercock, Mr. William Henry',\r\n'Andersson, Mr. Anders Johan',\r\n'Vestrom, Miss. Hulda Amanda Adolfina',\r\n'Hewlett, Mrs. (Mary D Kingcome) ',\r\n'Rice, Master. Eugene',\r\n'Williams, Mr. Charles Eugene',\r\n'Vander Planke, Mrs. Julius (Emelia Maria Vandemoortele)',\r\n'Masselmani, Mrs. Fatima',\r\n'Fynney, Mr. Joseph J',\r\n'Beesley, Mr. Lawrence',\r\n'McGowan, Miss. Anna \"Annie\"',\r\n'Sloper, Mr. William Thompson',\r\n'Palsson, Miss. Torborg Danira',\r\n'Asplund, Mrs. Carl Oscar (Selma Augusta Emilia Johansson)',\r\n'Emir, Mr. Farred Chehab',\r\n'Fortune, Mr. Charles Alexander',\r\n'Dwyer, Miss. Ellen \"Nellie\"',\r\n'Todoroff, Mr. Lalio']\r\n\r\n# 어떻게 다음 dataset의 전체 이름안에서 M이 몇번 나왔는지 빈도수를 출력할것인가 \r\n# 5분 고민 해보기 \r\n\r\n# for문이 돌때마다 이름을 확인해서 M의 여부를 확인 \r\n# 좋다 근데 어떻게 ''묶여있는 이름안에 M이있는지 확인할것인가 ? \r\n# 여기까지는 접근했어 근데 M인지아닌지는 어떻게 ?\r\nprint('dataset[0]자리 =',dataset[0], '\\ndataset[0][1]자리 =',dataset[0][1])\r\n# >>> dataset[0]자리 = Braund, Mr. Owen Harris \r\n# >>> dataset[0][1]자리 = r\r\n\r\nfor index in range(len(data)):\r\n print(index)\r\ndata[index]\r\n\r\n\r\n# 데이터셋 안의 데이터를 포문을 돌려 나열한다 \r\n# 그리고 또 포문을 돌리는데 데이터 길이의 인덱스를 나열하는데 \r\n# 출력은 포문을 돌려 만든 인덱스의 숫자와 데이터의 인덱스와 매치되는 글자를 보여준다. \r\nfor data in dataset:\r\n for index in range(len(data)):\r\n print(data[index])\r\n\r\nm_count= 0\r\nfor data in dataset:\r\n for index in range(len(data)):\r\n if data[index] == 'M':\r\n m_count+=1\r\nprint(m_count)\r\n"
},
{
"alpha_fraction": 0.6103895902633667,
"alphanum_fraction": 0.6450216174125671,
"avg_line_length": 27.875,
"blob_id": "0e809cfc60049fcb5c13fb8a16d6203d2dc66d9d",
"content_id": "ed7ae4138e33c2ffc95ffa85661e537afe2bd737",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 339,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 8,
"path": "/Artificial_Intelligence/Deep_Learning/DL_basic00.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 인공지능( 머신러닝, 딥러닝, 텐서플로우 )강좌 \n# python 3.6 (64bit)\n# - IDE : jupyter notebook( 모듈 단위의 작업)\n# - scipy, matplotlib, tensorflow\n# 교육과정 교과서 [https://www.kyohak.co.kr/2014textbooks/index.asp]\n# 필요 수학 ( 함수, 삼각함수, 행렬, 복소수, 방정식, 미분, 확통)\n\n# "
},
{
"alpha_fraction": 0.3771592974662781,
"alphanum_fraction": 0.42418426275253296,
"avg_line_length": 17.1130428314209,
"blob_id": "f27e3c72d204c8be85c5827fccb535339cf654da",
"content_id": "aea7ad725208396ff244aedf35d2445bfcaac324",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2258,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 115,
"path": "/Project/Mini Project/Src_NoComment/ExamGradeProgram_ver00.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# ExamGradeProgram.py\n# ver_00\n\n# 변수 \nscore_case1 = {\n 'A+' : '4.5',\n 'A' : '4.0',\n 'A-' : 'X' ,\n 'B+' : '3.5',\n 'B' : '3.0',\n 'B-' : 'X' , \n 'C+' : '2.5', \n 'C' : '2.0',\n 'C-' : 'X',\n 'F' : '0' }\n\nscore_case2 = {\n 'A+' : '4.3',\n 'A' : '4.0',\n 'A-' : '3.7',\n 'B+' : '3.5',\n 'B' : '3.0',\n 'B-' : '2.7', \n 'C+' : '2.5',\n 'C' : '2.0',\n 'C-' : '1.7',\n 'F' : '0' }\n\n\n# Step00\nUser_input_name = input('과 목 명 :')\nUser_input_score = input('점 수 :')\nUser_input_grader = input('취득학점 :')\n\nlog_txt = {\n 'calculating_way':'몇점 만점인가요? \\n 1. 4.5점 \\n 2. 4.3점 \\n 입력하시오 :',\n } \n\nGrader_calculate = input(log_txt['calculating_way'])\n# print(type(Grader_calculate)) # str\n\n\n\n# # func_loof\n# def func_loof(case):\n# f_loop = [gdr for gdr in case ]\n# for num in range(len(f_loop)):\n# if User_input_score == f_loop[num]:\n\n# print(f_loop[num], case[f_loop[num]])\n\n# return f_loop[num], case[f_loop[num]]\n\n# # func_loof(score_case1)\n\n\n# 다중 조건문\nif Grader_calculate == '1':\n print('='*50,'\\n',str(4.5)+'점')\n f_loop = [gdr for gdr in score_case1 ]\n for i in range(len(f_loop)):\n if User_input_score == f_loop[i]:\n # 학점 , score\n print(f_loop[i], score_case1[f_loop[i]])\n\n # return 0\n\nelif Grader_calculate == '2':\n print('='*50,'\\n',str(4.3)+'점')\n f_loop = [gdr for gdr in score_case2 ]\n for j in range(len(f_loop)):\n if User_input_score == f_loop[j]:\n # 학점 , score\n print(f_loop[j], score_case1[f_loop[j]])\n\n \n\n# print(score_case1) \n# 점수 - 소수\n# 4.5 만점\n # A+ - 4.5점\n # A - 4.0점\n # A- - 없음\n # B+ - 3.5점\n # B - 3.0\n # B- - 없음\n # C+ - 2.5점\n # C - 2.0점\n # C- - 없음\n # F - 0\n\n# print(score_case2)\n\n# 4.3 만점\n# A+ - 4.3점\n# A - 4.0점\n# A- - 3.7\n# B+ - 3.5점\n# B - 3.0\n# B- - 2.7\n# C+ - 2.5점\n# C - 2.0점\n# C- - 1.7\n# F - 0 \n\n# ======\n# 본문\n\ndef main():pass\n\nif __name__ == '__main__':\n main()\n\n# 수정 해야 할것 \n# 취득 학점을 입력한 경우 => get 한 학점 / 총학점 아닌가 ? \n"
},
{
"alpha_fraction": 0.5721830725669861,
"alphanum_fraction": 0.5862675905227661,
"avg_line_length": 19.285715103149414,
"blob_id": "0e81b89d00eb3f179e98b0b1a9f1b813760e3b46",
"content_id": "68ec6c2ab1267d23fd7a6df0ab87df9913329b95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 888,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 28,
"path": "/Python/python_one_of_class.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "class Man:\n def __init__(self, name):\n self.name = name \n print(\"Initialized!\")\n \n def hello(self):\n print(\"HELLO\" + self.name + \"!\")\n\n def goodbye(self):\n print(\"Good-bye\" + self.name + \"!\")\n\nm = Man(\"David\") # Man(자기자신, name)\nm.hello()\nm.goodbye()\n# conda activate project\n\n\n\n# 2020.02.28 \n# 클래스는 또 다른 함수인가 ? \n# 클래스와 생성자가 한 몸이고 \n# 생성자가 받아들인 것(파라메터)을 자기 자신이라고 생성자에서 선포하고 \n# 그 생성자를 클래스안의 모든 메소드에 인자 값으로 집어 넣는것인가 \n\n# 결국 클래스에서 받아들인 파라메터들은 뿔뿔이 흩어져 \n# 각각 사용하고자 하는 함수에 들어가는것인가 ? \n# 틀은 같지만 재료에따라 다르듯 \n# 그값을 가졌을대 각기다른 아웃풋이 나오는거고 ?\n"
},
{
"alpha_fraction": 0.5726714134216309,
"alphanum_fraction": 0.5900716185569763,
"avg_line_length": 15.140496253967285,
"blob_id": "5e6328f970f01cc3252da1f39a7ecd85d27d7a3f",
"content_id": "60200e1bfd96c2b16152690d267fc3ab0b461b33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3846,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 121,
"path": "/Project/Solution_Base/Problem_1.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# Problem : 1차시\n\n진행중인 프로젝트에 관한 여러가지 이슈 그리고 해결방안을 포스팅하고자 한다. \n\n<BR>\n\n간략하게 프로젝트에 대해 설명하겠다. \n\n<br>\n\n#### 기술 \n- 웹 크롤링\n\t- 텍스트 크롤링 \n<br>\n\n- 머신러닝 \n\t- 텍스트 분석\n\t- 감성분석\n\t- Emotional dictionary\n\t- Flavor dictionary\n<br>\n\n - 딥러닝\n\t- 이미지 분석\n\t- Image Preprocessing\n\t- Various categories Image classification\n\t\t- 약 150종 \n\t- Model based in CNN\n\n\t\n<br>\n<br>\n\n#### 사용환경 \n\n - Ubuntu 18.04\n - Window 10\n<br>\n<br>\n\n\n#### 기간 \n\n- 프로젝트 총 기간은 5주이다. \n\t- 현재 3주정도 남았다. \n<br>\n<br>\n\n#### 업무 분장 \n\n- 이미지 분석 : 2 인\n- 텍스트 분석 : 2 인 \n<br>\n<br>\n\n#### 진행 상황\n\n현재 전체적인 진행상황은 아래와 같다. \n- 이미지 분석 : 45 % \n- 텍스트 분석 : 89 %\n- 시스템 구현 : 10% \n\n<br>\n<br>\n\n## 전체적인 상황 및 이슈들\n<br>\n \n\n### 이슈 1 : 생각보다 전체적으로 더딘 진행속도 \n\n각 팀원간의 의사 결정 방향이 다 달랐다. \n여러 의사 소통적인 부분에서 여러가지 문제들이 발생했다. \n그래서 그것을 해결하기 위해 회의시간을 많이 늘렸고 수시로 각 파트에 업무를 체크하는데 많은 시간을 들였다. \n데일리 리포트를 꾸준히 받으려 노력하고 작성한 리포트를 읽었다.\n\n또한 서로가 공부가 부족했고 여러가지 의견충돌이 있었다. \n이를 해결하기 위해 각자의 의견을 검증하는 시간들이 많이 걸렸다. \n<br>\n\n### 이슈 2 : 처음부터 끝까지 다 가능하다는 욕심\n\n모든 카테고리를 다 가지고 가자라는 욕심이 과했다. \n전처리 필요하다는 것을 이미 우리는 직감하고 있었지만 ... \n너무나 방대한 양이고 전처리를 하게되면 그 전처리가 번거롭고 힘들기 때문에 우리는 외면했다. \n이러한 선택이 스케줄을 딜레이되게 하는데 크게 작용했다. \n<br>\n\n### 이슈 3 : 나오지않는 정확도 \n\n모델을 만들고 학습을 진행하였지만 나오지 않는 정확도 때문에 \n아니.. 그냥 모델이 학습자체를 못했다고 보는게 맞는것 같다. \n<br>\n\n초반에는 전처리 작업이 문제인가라는 생각이 들었고 \n이를 해결하기위해 카테고리 샘플링을 시행해서 \n임의의 색깔을 선정해 색깔당 5개씩 카테고리를 추출하였다. \n총 10의 카테고리 이미지를 전처리하고 작업을 진행하였다. \n<br>\n다행이도 전처리를 하니 조금은 변화가 있었다. \n<br>\n데이터 카테고리가 작아서(10/150)인지 \n전처리를 했기 때문인지는 모르겠지만 데이터가 조금은 학습 되는 것을 확인했다. \n그러다 혹시 모델에 문제가 있을 수 있겠다라는 합리적인 의심을 가지게 되었다. \n<br>\n다양한 분류모델을 조사하고 공부하여 분류모델을 만들어 돌렸더니 \n정확도가 60%까지 오른것을 확인 할 수 있었다. \n<br>\n\n### 이슈 4 : 너무 많은 카테고리 \n이미지 전처리 같은 경우 워낙 많고 시간적인 때문에 이미지 카테고리를 줄이는 방안을 모색해야했다. \n<br>\n\n### 지금까지 느낌점 \n<br>\n조금 돌아왔지만 전처리의 필요성도 확인하고 모델의 중요성 역시도 확인하게 되었다. \n\n우리는 처음에 외면했던 절차를 다시 돌아서 밟게 되었다. \n현재 전처리 작업 중에 있다. 고생은 했는데 경험으로 체감하니 더욱 필요성을 알게되어서 보람있었다. \n다음부터는 착착 전처리부터 잘 밟아서 진행할것 같다. \n<br>\n"
},
{
"alpha_fraction": 0.5783475637435913,
"alphanum_fraction": 0.6196581125259399,
"avg_line_length": 12.77450942993164,
"blob_id": "f9e0c7b3741d7a84e9dbff6410057e9d2c758e89",
"content_id": "297fe9bfa1906468277af66cc364a85feb05b729",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1907,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 102,
"path": "/Python/자료구조/number_fraction.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# number_fraction.py\n\n## 복소수 \n\n# 파이썬에서 복소수는 z= 3+4j 같이 생긴 복소수점 한쌍을 갖는 불변형이다. \n\n# z.real() -> 실수부 \n# z.imag() -> 허수부\n# z.conjugate() -> 컬레 복수부\n\n# 복수수를 사용하기위해서는 cmath 모듈을 임포트 해야야한다. \n# cmath 는 math 모듈에 들어 있는 대부분의 삼각 함수, 로그함수의 복소수 버전을 제공한다. \n\n\n\nfrom fractions import Fraction # 분수모듈\n\n\ndef rounding_floats(num1,plc):\n return round(num1,plc) # 까운 짝수값으로 올림 연산\n\ndef float_to_fractions(num):\n return Fraction(*num.as_integer_ratio())\n\ndef get_denominator(num1,num2):\n \"\"\"\n 분모를 반환한다.\n \"\"\"\n a = Fraction(num1,num2)\n return a.denominator\n\ndef get_numerator(num1,num2):\n \"\"\"\n 분자를 반환한다.\n \"\"\"\n a = Fraction(num1,num2)\n return a.numerator\n\ndef test_testing_floats():\n \"\"\"\n 동작함수\n\n \"\"\"\n num1 = 1.25\n num2 = 1\n num3 = -1\n num4 = 5/4\n num6 = 6\n\n #\n assert()\n print('mas')\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n## Fraction\n\n## Fractions는 분수 모듈이다.\n# - 유리수를 나타내는 Fraction클래스와 최대공약수(GCD:Greatest Common Divisor)를 구하는 모듈 함수\n# 유리수 -> 두 정수의 분수 형태로 나타낼 수 있는 실수 두 정수의 분수 형태로 나타낼수 없는 실수를 무리수라고 한다. π(파이_, √2 는 대표적인 무리수\n\n## assert : 가정 설정문\n# assert 는 뒤의 조건이 true가 아니면 AssertError가 발생 \n# assert 가 필요한 이유\n# [가정 설정문(assert)](https://wikidocs.net/21050)\n# [참조1](https://iissgnoheci.tistory.com/7)\n# [참조2](https://brownbears.tistory.com/135)\n\n# 참조 \n# https://m.blog.naver.com/PostView.nhn?blogId=dudwo567890&logNo=130165177493&proxyReferer=https:%2F%2Fwww.google.com%2F"
},
{
"alpha_fraction": 0.3718550205230713,
"alphanum_fraction": 0.431130051612854,
"avg_line_length": 18.073171615600586,
"blob_id": "b98b429561dd49dd304c7931d5689306ff2438e3",
"content_id": "c8324f70326107058102c222410113ad49dd0057",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2811,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 123,
"path": "/Project/Mini Project/ExamGradeProgram.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# ExamGradeProgram.py\n# ver_01\n\n\n\n# class_code = {\n# 103 : ['문학',float(3)],\n\n# }\n\n# 과목명을 수치화해서 입력 => class_code \nclass_code = {\n # 과목 코드 : ['과목명', 학점] \n 100 : ['문학' , float(3)],\n 101 : ['비문학' , float(3)],\n 102 : ['선형대수' , float(3)],\n 103 : ['확률과통계', float(3)],\n 104 : ['논리학' , float(3)],\n 105 : ['가정의학' , float(2)], \n 106 : ['언어의이해', float(2)], \n 107 : ['토익실전' , float(2)],\n 108 : ['정역학' , float(3)],\n 109 : ['공업수학' , float(3)]\n}\n\n\n# print(class_code[103])\n\n# 변수 \nscore_case1 = {\n 'A+' : '4.5',\n 'A' : '4.0',\n 'A-' : 'X' ,\n 'B+' : '3.5',\n 'B' : '3.0',\n 'B-' : 'X' , \n 'C+' : '2.5', \n 'C' : '2.0',\n 'C-' : 'X',\n 'F' : '0' }\n\n# print(score_case1['X'])\nscore_case2 = {\n 'A+' : '4.3',\n 'A' : '4.0',\n 'A-' : '3.7',\n 'B+' : '3.5',\n 'B' : '3.0',\n 'B-' : '2.7', \n 'C+' : '2.5',\n 'C' : '2.0',\n 'C-' : '1.7',\n 'F' : '0' }\n\n# func_loof\ndef func_loof(case):\n f_loop = [gdr for gdr in case ]\n for num in range(len(f_loop)):\n if User_input_score == f_loop[num]:\n if score_case1.values() == 'X':\n print('False') \n else:\n continue\n print(f_loop[num], case[f_loop[num]])\n\n return f_loop[num], case[f_loop[num]]\n\n# func_loof(score_case1)\n\n# Step00. 사용자에게 값을 입력 받아야 한다 -> input() 사용\n# 과목, 점수, 취득학점\n# User_input_name = input('과 목 명 :')\nUser_input_score = input('점 수 :')\nUser_input_grader = input('취득학점 :')\n\n\n# 만점이 몇점인지 묻는다\nlog_txt = {\n 'calculating_way':'몇점 만점인가요? \\n 1. 4.5점 \\n 2. 4.3점 \\n 입력하시오 :',\n } \nGrader_calculate = input(log_txt['calculating_way'])\n# print(type(Grader_calculate)) # str\n\n\n# 다중 조건문\nif Grader_calculate == '1':\n print('='*50,'\\n',str(4.5)+'점')\n func_loof(score_case1 )\n\nelif Grader_calculate == '2':\n print('='*50,'\\n',str(4.3)+'점')\n func_loof(score_case2 )\n\n# 1개짜리 계산함수 생성 \ndef test():pass\n # 사용자로 부터 값을 받아온다 \n # 교과코드(과목 코드 : ['과목명', 학점] )\n # 계산 방식을 정한다 \n # 방식에 따라 연산한다. \n # 사용자에게 연산 내용을 돌려준다 \n # 받아야 하는것\n\n # 1. \n # 2. \n\n# return \n\n\n\n\n\n# class_code = {\n# '100' : '문학',\n# '101' : '비문학',\n# '102' : '선형대수' ,\n# '103' : '확률과통계',\n# '104' : '논리학',\n# '105' : '가정의학' , \n# '106' : '언어의이해', \n# '107' : '토익실전',\n# '108' : '정역학',\n# '109' : '공업수학'\n# }"
},
{
"alpha_fraction": 0.5128316879272461,
"alphanum_fraction": 0.5232709646224976,
"avg_line_length": 8.737288475036621,
"blob_id": "86dc9d0c84811e66046c02eb60f5866148ccc05f",
"content_id": "33a34c09b1640e46addecb6761a44ff317661d4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4231,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 236,
"path": "/데이터 분석(Data Analytics)/이론_데이터의 이해(추가).md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 1. 데이터 분석(Data Analytics) - 데이터의 이해\n\n<br>\n\n# 데이터의 이해와 정형데이터 다루기\n\n<br>\n\n## 1. 데이터의 이해 \n\n- 데이터 > 정보 > 지식 > 지혜 \n\n<br>\n\n### 1) 데이터 \n\n- 특정의 목적에 대하여 평가 되지 않은 상태의 단순한 여러사실\n- 지역별, 기후 반복 주기, 최대치들을 고려한 관계 \n\n<br>\n\n### 2) 정보 \n\n- 데이터를 일정한 프로그램(양식) 처리.가공하여, 특정목적을 달성하는 데 필요한 정보가 생산\n- 특정 마을의 강수량, 지형조건 , 배수시설 등의 정보를 고려한 관계 \n\n<br>\n\n### 3) 지식 \n\n- 동종의 정보가 집적되어 일반화 된 형태로 정리된것 \n- 정보가 의사결정이나 창출에 이용되어 부가가치가 발생 \n- 수해 대책이 몸에 밴 특정 주민의 삶의 노하우 \n\n<br>\n\n### 4) 지혜 \n\n- 지식을 얻고 이해하고 응용하고 발전해나가는 정신적인 능력 \n- 마을 주민의 생활 노하우 \n\n<br>\n\n|내용|내용|\n|:--:|:--:|\n|데이터| 사실적 자료|\n|정보|처리, 가공|\n|지식|일반화 , 의사결정-> 부가가치 양성|\n|지혜|내재화된 능력|\n\n<br><br>\n\n## 2. 데이터 특징 이해 \n\n<br>\n\n### 1) 존재적 특징 - 정성적\n\n데이터 하나하나가 함축적인 의미를 가지고 있다.\n\n<br>\n\n|구분|내용|\n|:--:|:--:|\n|형태| 비정형 데이터 |\n|특징| 객체 하나에 함의된 정보를 갖고 있음 |\n|구성| 언어, 문자 등으로 이루어짐 |\n|저장형태| 파일 , 웹 |\n\n<br>\n\n### 2) 존재적 특징 - 정량적\n\n측정이나 설명이 가능하도록 구성되어 있다. \n- 이름, 나이, 성별, 주소\n\n<br>\n\n|구분|내용|\n|:--:|:--:|\n|형태| 정형, 반정형 데이터 |\n|특징| 속성이 모여 객체를 이룸 |\n|구성| 수치, 도형, 기호 등으로 이루어짐 |\n|저장형태| 데이터베이스, 스프레드시트|\n\n<br>\n\n### 3) 형태적 특징 - 정형 데이터\n\n\n- 저장하는 데이터의 구조(스키마)가 미리 정의된 데이터 \n- 타입과 길이가 미리 정의됨 \n- 관계형 데이터 베이스에 스키마를 관리하는 데이터 베이스가 별도로 존재 db저장소와 구분됨 \n\n<br>\n\n### 4) 형태적 특징 - 반정형 데이터 \n\n- 내부에 정형데이터의 스키마에 해당되는 메타 데이터를 가지고 있으며 일반적인 파일형태로 저장\n- 정형데이터에 가깝지만 정형이라고 보기에는 아쉬움 \n\n<br>\n\n| 형태 |내용|\n|:--:|:--:|\n|JSON, XML| 오픈 API 형태로 제공|\n|HTML|URL 형태|\n|로그형태|웹로그 , IOT 에서 제공하는 센서 데이터|\n\n<br>\n\n### 5) 형태적 특징 - 비정형 데이터 \n\n```py\n# ;추가 \n```\n\n<br><br>\n\n## 3. 데이터베이스\n\n<br>\n\n### 데이터베이스의 정의 \n\n한 조직의 여러 응용시스템이 공용하기 위해 최소의 중복으로 통합, 저장된 운영 데이터의 집합 \n\n- **통합된 데이터, 저장된 데이터, 운영 데이터, 공용 데이터**\n\n<br>\n\n### 데이터베이스 장점 \n\n```py\n# ;추가 \n```\n\n### 데이터베이스의 특징 \n\n```py\n# ;추가 \n```\n\n### DBMS(Database Management System)\n\n응용 프로그램과 데이터 베이스 사이의 중재자로 모든 응용 프로그램들이 Data를 공유 할 수 있게 관리해주는 시스템 \n\n- 종속성과 중복성의 문제를 해결하기 위한 시스템 \n\n```py\n# ;추가 \n```\n\n<br><br>\n\n\n## 4. 데이터 독립성의 이해 \n\n<br>\n\n### 3단계 구조의 이해 \n\n1. 외부 스키마 \n- 사용자 관점\n\n2. 개념 스키마 \n- 통합 관점\n\n3. 내부 스키마 \n- 물리적 저장구조 \n\n<br>\n\n### 3단계 구조의 데이터 독립성의 이해 \n\n```py\n# ;추가 \n```\n\n### 데이터 독립성의 개념 \n\n```py\n# ;추가 \n```\n\n### 데이터 독립성의 목적 \n\n```py\n# ;추가 \n```\n\n### 데이터 독립성의 종류 \n\n```py\n# ;추가 \n```\n\n### 3단계 구조의 스키마와 인스턴스 \n\n```py\n# ;추가 \n```\n\n<br><br>\n\n## 5. 트랜젝션의 이해 \n\n<br>\n\n### 트랜젝션의 정의 \n\n```py\n# ;추가 \n```\n\n<!-- https://coding-factory.tistory.com/226 # 참고 -->\n\n<br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n\n\n<!-- - 파이썬 코딩도장 : <https://dojang.io/> <br> -->\n\n"
},
{
"alpha_fraction": 0.5121602416038513,
"alphanum_fraction": 0.5278970003128052,
"avg_line_length": 6.865168571472168,
"blob_id": "6070e1acd5b3250905806329bab776900b7211c8",
"content_id": "58fc2dd8404a2cab29b83b901bce0f271888afc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 919,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 89,
"path": "/데이터 분석(Data Analytics)/이론_SQL.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 1. 데이터 분석(Data Analytics) - SQL\n\n<br>\n\n# SQL\n\n<br>\n\nSQL은 Structured Query Language의 약자\n\n관게형 데이터 베이스 관리 시스템(RDBMS)의 데이터를 관리하기 위해 설계된 특수 목적의 프로그래밍 언어 \n\n<br>\n\n## 기본적인 구조\n\n```SQL\nSELECT 컬럼이름\nFROM 테이블 이름 \nWHERE 조건\nGROUP BY 그룹화할 컬럼\nHAVING 그룹화한 후의 조건\nLIMIT 제한 할 개수\n```\n\n---\n\n<br>\n\n\n\n## 2.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 비전공자를 위한 SQL : <https://coding-factory.tistory.com/226> <br>\n- SQL 전문가 되어보기 : <https://wikidocs.net/1205> <br>\n\n\n<!-- - 파이썬 코딩도장 : <https://dojang.io/> <br> -->\n\n<!-- <br>\n<br>\n\n## Practice makes perfect! <br> -->\n\n<!-- - [내용](주소) -->"
},
{
"alpha_fraction": 0.498395711183548,
"alphanum_fraction": 0.5213903784751892,
"avg_line_length": 9.218579292297363,
"blob_id": "cb0f6c9aece85923d91daa8b3ae9908124537cf7",
"content_id": "f2f420e0fcf29a26cd7543fe7e628c5f7cb5746b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3196,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 183,
"path": "/데이터 분석(Data Analytics)/이론_데이터 모델링.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 02. 데이터 분석(Data Analytics) - 데이터 모델링\n\n전체적인 수정 필요 \n<br>\n\n# 데이터 모델링 이해\n\n<br>\n\n## 1. 관계형 데이터 모델\n\n지금까지 제안된 데이터 모델들중에서 가장 개념이 단순한 데이터 모델의 하나 \n\n<br>\n\n### 1) 데이터베이스 관계 \n\n<!-- 이미지 참조 -->\n\n```sql\n개념적 모델링\n논리적 모델링\n물리적 모델링\n```\n<br>\n\n### 2) 성공요인 \n\n- 간단한 테이블을 사용 \n- **중첩된 복잡한 구조가 없다.** \n- **집합 위주로 데이터를 처리한다.**\n- 숙련되지 않은 사용자도 쉽게 이해할 수 있음 \n- 잘 정비된 이론과 **표준데이터에 좋은 응용력**을 보여준다. \n- 관계형 데이터베이스 **설계와 효율적인 질의 처리면에서 뛰어난 장점**을 가진다. \n\n<br>\n\n### 3) 관계형 데이터 모델 \n\n\n57p\n<br>\n\n\n### 4) 기본적인 용어 \n\n|이름|내용|\n|:--:|:--|\n|릴레이션| 2차원 테이블 |\n|레코드| 릴레이션의 각 행 |\n|튜플| 레코드를 좀 더 공식적으로 부르는 용어 |\n|애트리뷰트| 릴레이션에서 이름을 가진 하나의 열 |\n\n<!-- 이미지 참조 -->\n\n#### 용어들의 대응 관계 \n\n|공식|자주사용|파일시스템|\n|:--:|:--|:--|\n|릴레이션| 테이블 |파일|\n|튜플| 레코드 & 행 |레코드|\n|애트리뷰트| 열 |필드|\n\n<br><br>\n\n### 도메인 \n\n<!-- 내용 -->\n<!-- 이미지 참조 -->\n\n<br>\n\n\n### 차수와 카디날리티\n\n<!-- 내용 -->\n\n<br>\n\n### **널값(null Value)**\n\n'알려지지 않음' 또는 '적용할 수 없음' -> 널값을 사용하며 주의해야 할 점은 널값은 숫자 도메인의 0이나 문자열 도메인의 공백 문자 또는 공백 문자열과 다르는것이다. \n\n또한 DBMS들 마다 널 값을 나타내기 위해 서로 다른 기호를 사용한다. \n\n\n<br>\n\n### 릴레이션 스키마(Relation Schema)\n\n<!-- 교재가 이해미흡 / 추가 정보 수집이 필요 -->\n\n```py\n# 추가\n```\n<br>\n\n\n### 릴레이션 인스턴스(Relation Insrance)\n\n릴레이션에 어느 시점에 들어 있는 튜플들의 집합을 말한다. \n시계열성을 띄며 일반적으로 릴레이션에는 현재의 인스턴스만 저장된다. \n\n<!-- 추가적으로 내포와 외연을 공부하자 -> 먼소리인지 모르게뜨아 -->\n\n```py\n# 추가\n```\n<br>\n\n### 관계형 데이터 베이스 - 스키마 \n\n하나 이상의 릴레이션 스키마들로 이루어진다. \n\n<!-- 스키마의 정의 -->\n```py\n# 추가\n```\n<br>\n\n### 관계형 데이터 베이스 - 인스턴스 \n\n릴레이션 인스턴스들의 모임으로 구성된다.\n\n<!-- 이미지 필요할듯 -->\n\n```py\n# 추가\n```\n\n<br><br>\n\n## 2. ERD의 이해\n\n<br>\n\n```py\n# 추가\n```\n\n<br>\n\n\n\n## 3. 키에 대한 이해 \n\n<br>\n\n```py\n# 추가\n```\n\n<br><br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br><br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n- 참고 : <https://velog.io/@rosewwross/Django-%EA%B4%80%EA%B3%84%ED%98%95-%EB%8D%B0%EC%9D%B4%ED%84%B0%EB%B2%A0%EC%9D%B4%EC%8A%A4%EC%99%80-ORM> <br>\n<!-- - 파이썬 코딩도장 : <https://dojang.io/> <br> -->\n\n- 참고자료 : https://bamdule.tistory.com/46\n"
},
{
"alpha_fraction": 0.5459973812103271,
"alphanum_fraction": 0.5540212988853455,
"avg_line_length": 11.154194831848145,
"blob_id": "c60c3ee409d0ede616565233fdf97d7534ba31d2",
"content_id": "44165629808a6e240173c971b869211bd56c002f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8113,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 441,
"path": "/Python/6.심화_클래스상속.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 6. 파이썬 심화 - 클래스 상속(inheritance)\n\n<br>\n\n# 클래스 상속(inheritance)\n\n<br>\n\n\n## 1. 상속(inheritance)\n\n상속은 물려받은 기능을 유지한채로 다른 기능을 추가할 때 사용하는 기능이라고 보면된다.\n\n상속에는 두가지 클래스가 있다. 부모클래스(기반클래스)와 자식클래스(파생클래스)! <br>\n\n부모클래스틑 우리가 클래스를 만들었을때 가장 기본이 되는 클래스이며 <br>\n\n자식클래스는 부모 클래스에서 가지고 온 클래스를 기반으로 만든것을 자식클래스라고 한다. \n\n<br>\n\n<br>\n\n사람을 예로 설명하자면 <br>\n\n가장 기본적 구성요소들로 이루어진 `Person` 라는 클래스를 하나 만들었다. <br>\n\n여기서 모든 값은 기본값으로 설정한다. <br>\n\n그런 후 `Person` 클래스를 활용해 `Doctor` 클래스를 만든다. <br>\n\n\n<br>\n\n\n자 여기서 ! <br>\n\n부모클래스는 자동차 클래스이다. <br>\n\n이것을 베이스로 해서 만들어진 `Doctor` 클래스는 자식클래스라고 보면 된다. <br>\n\n부모클래스를 통해서 나올 수 있는 자식클래스는 `Doctor` 클래스 뿐만아니라 학생, 선생님, 요리사등등 될 수 있다.\n\n<br>\n<br>\n\n### 상속 - 기본 구조 \n\n<br>\n\n\n상속은 새로운 기능을 만들때마다 계속 클래스를 만든다면 중복되는 부분은 계속 중복되기 때문에<br>\n\n이런부분들을 보완하기위해서 상속을 사용하고 중복되는 기능을 반복해서 만들지 않게 하기 위함이다. <br>\n\n기존 기능들을 재사용 가능하게하여 효율성과 코드의 간결함을 극대화 시킬 수 있다. \n\n<br>\n\n```py\n\nclass 부모클래스:\n code\n \nclass 자식클래스(부모클래스): # ()내부에 부모클래스의 이름을 넣는다.\n code\n\n```\n\n<br>\n\n### 상속 - 이해하기\n\n<br>\n\n```py\n\nclass Person:\n\n def greeting(self):\n print('안녕하세요!')\n \nclass Doctor(Person):\n \"\"\"\n Person을 상속 받음\n \"\"\"\n def checkUp(self):\n print('어디가 아프신가요?')\n\n\nJoy = Doctor()\nJoy.greeting() # 부모클래스에서 호출 -> 상속 \nJoy.checkUp() # 자식클래스의 checkUp 메소드 \n\n# outPut\n\n# >>> 안녕하세요! \n# >>> 어디가 아프신가요?\n\n```\n<br>\n\n상속은 클래스의 기능을 유지하면서 새로운 기능을 추가 할수있다. <br>\n\n상속에도 범위가 존재한다. 여기저기 다 쓸수는없다. 어디까지를 상속으로 사용하는 것이 좋을까?<br>\n\n음 ... 상속은 명확하게 같은 종류이며 동등한 관계일 경우...? <br>\n\n즉, 연관성 + 동등한 기능을 사용할 때 그냥 쉽게 확장의 개념일때 사용한다. <br>\n\n<br>\n<br>\n\n\n## 2. 상속 & 포함 관계 \n\n<br>\n\n포함관계라는 것이 있다. 상속처럼 한번에 이해하고, 활용하기는 어려울 수 있다. \n\n이부분은 리뷰하기에는 조금 부족한 느낌이있어 추후 다시 업데이트 하도록 하겠다. \n\n<br>\n\n<!-- <br>\n\n```py\n\nclass Person:\n\n def greeting(self):\n print('안녕하세요!')\n \nclass PatientChart(Person):\n \"\"\"\n Person을 상속 받음\n \"\"\"\n def __init__(self):\n\n self.patient_chart = [] # Person 인스턴스를 담을 그릇\n\n def appendPatient(self, preson):\n self.patient_chart.append(preson)\n\n\n```\n\n<br> -->\n\n\n\n\n## 3. 포함 관계(심화)\n\n추후 \n\n<!--<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n -->\n\n<br>\n<br>\n\n## 4. 메소드 오버라이딩\\*\\* \n\n<br>\n\n메소드 오버라이딩은 같은이름의 메소드를 덮어쓴다.\n\n상속의 개념중 하나로 같은 이름으로 기능을 다양하게 사용 해야할때 사용한다. \n\n중복을 줄일수있는 아주 좋은 문법이다. \n\n- 재정의 ->> 부모 클래스의 메소드를 무시하고 새로운 메소드를 생성 \n\n<br>\n\n### 메소드 오버라이딩 - 이해하기 \n\n```py\n\nclass Person:\n\n def greeting(self):\n print('안녕하세요!')\n \nclass Doctor(Person):\n\n def greeting(self):\n print('어디가 아프신가요?')\n\n\nJoy = Doctor()\nJoy.greeting() \n \n\n```\n\n이해가 잘 안될것 같아 \n\n다른 예를 들어 설명 하겠다. \n\n\n<br>\n\n```py\n\nclass father(): # 부모 클래스\n\n def handsome(self):\n print('잘생겼다.')\n\nclass Brother(father):\n \"\"\"\n 아들\n \"\"\"\n\nclass Sister(father):\n \"\"\"\n 딸 : 예쁘다 라는 걸 가지고 있기 때문에 \n 잘생겼다에서 오버라이딩 됨\n\n 딸에게만 영향을 미치며 아빠와는 무광 \n \"\"\"\n def pretty(self):\n print('예쁘다')\n\n def handsome(self):\n self.pretty()\n\n\nChild_b = Brother()\nChild_b.handsome()\n \nChild_g = Sister()\nChild_g.handsome()\n\n```\n\n<br>\n<br>\n\n\n## 5. `super()` 개념\n\n<br>\n\n자식 클래스에서 부모클래스의 내용을 사용하고 싶을경우 사용한다. \n\n`super().메소드()`\n\n<br>\n\n### `super()` - 이해하기 \n\n```py\n\nclass Person:\n\n def __init__(self):\n print('부모 - 생성자')\n self.hello = '안녕하세요!'\n \nclass Doctor(Person):\n\n def __init__(self):\n print('자식 - 생성자')\n super().__init__() # super()로 부모 __init__ 호출 \n # 부모클래스 초기화 \n self.hospital = 'Severance!'\n\n\nJoy = Doctor()\nprint(Joy.hello) \nprint(Joy.hospital) \n\n```\n\n<br>\n\n만약 자식클래스에 생성자가 없다면 `super()` 을 사용해서 부모클래스를 초기화할 필요 없다.\n\n<br>\n\n\n```py\nclass Person:\n\n def greeting(self):\n print('안녕하세요!')\n \nclass Doctor(Person):\n\n def greeting(self):\n super().greeting() # 만약 없으면 '안녕하세요'는 누락 -> 오버라이딩 때문\n print('어디가 아프신가요?')\n\n\nJoy = Doctor()\nJoy.greeting() \n\n```\n\n<br>\n\n추가 실습은 -> Practice makes perfect!의 링크를 참조 \n\n<br>\n<br>\n\n## 6. 다중 상속 \n\n<br>\n\n다중상속은 두개 이상의 부모클래스로부터 상속 받아 자식클래스를 생성하는 것을 의미한다. \n \n\n- 장점 \n\n - 여러 개의 부모 클래스로부터 멤버(메소드) 모두 상속 받을 수 있다는 점에서 매우 강력한 상속 방법\n\n\n- 단점 \n\n - 상속 받은 부모클래스에 같은 이름의 멤버(메소드)가 존재 \n - 하나의 클래스를 간접적으로 두번 이상 상속 받을 가능성 존재\n\n\n다 떠나서 다중 상속은 프로그래밍을 복잡하게 만들 수 있다. \n\n그렇기 때문에 될수로 사용을 자제하는것이 좋다. \n\n\n<br>\n\n### 다중 상속 - 기본 구조 \n\n<br>\n\n\n```py\n\nclass 부모클래스1:\n code\n\nclass 부모클래스2:\n code\n \nclass 자식클래스(부모클래스1, 부모클래스2): \n code\n\n```\n\n<br>\n\n### 다중 상속 - 이해하기\n\n\n```py\n\nclass Father:\n \n def __init__(self):\n self.fname = '김우빈'\n\n def fatherName(self):\n print(f'아빠는 {self.fname} ,')\n\nclass Mather:\n\n def __init__(self):\n self.mname = '신민아'\n\n def matherName(self):\n print(f'엄마는 {self.mname} ,')\n\nclass Child(Father,Mather):\n\n def __init__(self):\n # super().__init__()\n Father.__init__(self)\n Mather.__init__(self)\n self.name = '김빈아'\n\n def greeting(self):\n super().__init__()\n print(f'저는 {self.name}입니다.')\n\n\nchild = Child()\nprint(child.__dict__)\n\nchild.fatherName()\nchild.matherName()\nchild.greeting()\n\n# outPut\n\n# >>> {'fname': '김우빈', 'mname': '신민아', 'name': '김빈아'}\n# >>> 아빠는 김우빈 ,\n# >>> 엄마는 신민아 ,\n# >>> 저는 김빈아입니다.\n\n```\n\n<br>\n<br>\n\n\n\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n\n- 개발자의 취미 생활 : <https://rednooby.tistory.com/55?category=633023>\n\n- : <https://uzooin.tistory.com/137>\n\n## Practice makes perfect! <br>\n\n- [심화_클래스활용](https://github.com/Jerrykim91/KISS/tree/master/Python/%EC%8B%AC%ED%99%94_%ED%81%B4%EB%9E%98%EC%8A%A4%ED%99%9C%EC%9A%A9)"
},
{
"alpha_fraction": 0.5076872706413269,
"alphanum_fraction": 0.5286228060722351,
"avg_line_length": 13.0829496383667,
"blob_id": "d6f7e03053c796c4c5466434871e3199d456cc14",
"content_id": "8d5e99a8ae3f5d4ec6f3efac07bbe3f42a8d20fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4677,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 217,
"path": "/Python/1.심화_재귀호출.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n#### 1. 파이썬 심화 - 재귀호출(Recursive call)\n\n<br>\n\n# 재귀호출(Recursive call)\n\n재귀호출 혹은 재귀함수(Recursive call)라고 불린다. \n\n- 함수 안에서 함수 자기자신을 호출하는 방식이다. \n- 다양한 수학문제를 해결하는데 매우유용하고 자주 쓰인다. \n - 팩토리얼\n - 피보나치 수열\n - 그외...\n\n- 일반적인 상황에서 잘 사용하지 않는다.\n- 알고리즘을 만들때 유용하다.\n - 보통 알고리즘은 반복문으로 구현한 코드보다 \n 재귀호출로 구현한 코드가 좀 더 직관적이고 이해하기 쉬운 경우가 많다.\n\n- 코드는 간단하지만 머리속으로 많은 생각을 필요로 한다. \n\n \n<br>\n<br>\n\n\n## 재귀호출 사용하기 \n\n<br>\n\n아래처럼 구현하게 되면 무한루프에 빠지듯이 끊임없이 계속 함수를 호출한다. \n\n<br>\n\n```py\n\ndef Func():\n\n print('Hello, world!')\n Func() # 재귀호출\n \nFunc() # 호출\n\n```\n\n<br>\n\n이렇게 반복된다. \n이런 경우 `Ctrl+C` 를 통해 `KeyboardInterrupt` 를 발생시켜서 함수를 빠져 나올 수 있다. \n\n<br>\n\n```bash\n# OutPut\n# >>> Hello, world!\n# >>> Hello, world!\n# >>> Hello, world!\n# >>> ... 에러날때까지 반복 \n\n# => 파이썬은 최대 재귀 깊이(maximum recursion depth) -> 1,000으로 정해져 있음\n# => 최대 재귀 깊이를 초과하면 RecursionError가 발생 -> 스택 오버플로를 발생을 제어하기 위함 \n\n\nFunc\n ㄴFunc\n ㄴFunc\n ㄴFunc\n ㄴFunc\n ㄴ 반복...\n```\n\n<br>\n\n\n## 재귀호출 - 종료 조건 \n\n<br>\n\n재귀 호출을 빠져 나오기 위해서는 while문에서 사용한것처럼 if문을 이용해서 빠져 나올 수 있다.\n\n```py\n\ndef Func(cnt):\n\n if cnt == 0: # 종료 조건을 만족하는 cnt==0이되면 함수를 호출하지 않음 \n # cnt가 0이 아니면 다시 Func 함수를 호출\n return\n \n print('Hello, world!', cnt)\n \n cnt -= 1 # cnt를 1 감소시킨 뒤\n Func(cnt) # 다시 Func에 넣음\n \nFunc(5) # Func 함수 호출\n\n```\n\n<br>\n\n\n## 재귀호출 - 팩토리얼\n\n실습겸 팩토리얼을 재귀호출을 이용해서 만들어 보겠다.\n\n팩토리얼은 1부터 n까지 양의 정수를 차례대로 곱한 값 => `!`로 표기 \n\n<br>\n\n```py\n\ndef Factorial(n):\n\n if n == 1: \n return 1 # 1을 리턴하고 재귀호출을 종료\n return n * Factorial(n - 1) # n과 Factorial 함수에 n - 1을 넣어서\n # 리턴된 값을 곱함 -> 이게 핵심 \n \nprint(Factorial(5))\n# Output\n# >>> 120 \n```\n\n계산값이 즉시 구해지는 것이 아니라 재귀호출로 `n-1`을 계속 전달하다가 `n == 1` 때 `1`을 리턴하면서 n과 곱하고 다시 결과값을 리턴하는 구조가 반복된다. \n\n```cmd\n\nFactorial(5)\n5 * Factorial(4) \n5 * 4 * Factorial(3)\n5 * 4 * 3 * Factorial(2)\n5 * 4 * 3 * 2 * Factorial(1)\n5 * 4 * 3 * 2 * 1\n\n120\n\n```\n\n<br>\n\n**여기서 왜 `n ==1`을 한건지 궁금해서 여러가지 방식으로 실행을 해보았다.** \n\n<br>\n\n```py\n\n# n == 0 이고 리턴 값이 없을때 \ndef Factorial(n):\n\n if n == 0: \n return \n return n * Factorial(n - 1) \n \nprint(Factorial(5))\n\n# Output\n# >>> TypeError: unsupported operand type(s) for *: 'int' and 'NoneType'\n\n# n == 0 이고 리턴 값이 0 일때 \n\ndef Factorial(n):\n\n if n == 0: \n return 0 \n return n * Factorial(n - 1) \n \nprint(Factorial(5))\n\n# Output\n# >>> 0\n\n```\n\n<br>\n\n납득납득 ...\n\n\n재귀호출은 코드를 간단하게 만들어 주는 장점이있다. \n반대로 디버그 하기가 어렵고 메모리를 많이 잡아 먹는것과 동시에 시간도 소비한다. \n그래서 사용할때 잘 생각하고 사용하는것을 권장한다. \n\n조금 어려워서 재귀호출을 생략 할까라는 생각도 했지만 \n한번쯤은 코드를 보고 경험하는것이 좋다고 판단해서 정리하고 넘어간다. \n\n<br>\n\n### 참고 - isinstance \n\n\n팩토리얼 함수는 실수와 음의 정수는 계산할 수 없다.\n이 경우에 `isinstanc ` 를 사용하여 숫자(객체)가 **정수일 때만 계산하도록** 만들 수 있다.\n\n```py\n\ndef Factorial(n):\n\n if not isinstance(n, int) or n < 0: # n이 정수가 아니거나 음수이면 함수를 끝냄\n return None\n if n == 1:\n return 1\n return n * Factorial(n - 1)\n\nprint(Factorial(3))\n\n```\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n"
},
{
"alpha_fraction": 0.29812735319137573,
"alphanum_fraction": 0.3955056071281433,
"avg_line_length": 19.538461685180664,
"blob_id": "c3936465b851e52d307b38ea6ceb954cf1e6033b",
"content_id": "b0eb3916e1753dc323399c5ed28b4092eec39b0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1469,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 65,
"path": "/Project/Mini Project/WhileLoop.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 2019.12.18 <ver_1>\n\n# base ------------------------------\nprint('2019.12.18 <ver_1>')\nprint('-'*40)\na = [1,2,3,4,5]\nwhile len(a) > 0:\n print(a.pop())\n print('반복작업')\nprint('-'*40)\n#------------------------------------\n\n# 2019.12.18 <ver_2>\n\n# tuning ----------------------------\nprint('2019.12.18 <ver_2>')\nprint('-'*40)\na = [1,2,3,4,5]\nwhile len(a) > 0 :\n print('조건을 확인하고 참이면 내려온다.')\n print('[0] 현재 멤버수', len(a))\n print(a.pop())\n print('[1] 현재 멤버수 ', len(a))\n # print('-'*20)\n#------------------------------------\nprint('-'*40)\nprint('2019.12.18 <ver_2_test>')\nprint('-'*40)\na = [1,2,3,4,5]\nwhile a: \n print('조건을 확인하고 참이면 내려온다.')\n print('[0] 현재 멤버수', len(a))\n print(a.pop())\n print('[1] 현재 멤버수 ', len(a))\n #print('-'*20)\n#------------------------------------\nprint('-'*40)\nprint('2019.12.18 <ver_2_test_2>')\nprint('-'*40)\na = [1,2,3,4,5]\nwhile a :\n print(a.pop())\nelse:\n print('잘돌았다. 중단없이 종료')\n#------------------------------------\n\n# 2019.12.18 <ver_3>\n\n# tuning ----------------------------\nprint('-'*40)\nprint('2019.12.18 <ver_3>')\nprint('-'*40)\nDone = False \na = [1,2,3,4,5]\nwhile not Done:\n if len(a)> 0 :\n #print(a.pop())\n print(a.pop(),'반복작업')\n else:\n len(a) == 0\n print('끝')\n break\n Done\nprint('-'*40)\n#------------------------------------"
},
{
"alpha_fraction": 0.5057034492492676,
"alphanum_fraction": 0.5589353442192078,
"avg_line_length": 13,
"blob_id": "93c8cd2e4c0e94ad9f3d2cb5fb56e6f0aa60fb0e",
"content_id": "e7f36a4a2eaea0f6a1677d6380f874e25fbd5ec0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 778,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 37,
"path": "/Project/Mini Project/Payment.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 급여 계산기 \n\n'''\n<< 급여계산 프로그램 >>\n 시급을 입력해주세요\n 일일 근무 시간 : \n 한달 근무 시간 : \n\n수습을 적용하나요?\n1. 적용 \n2. 미적용 \n\n예상 월급 : 입니다. \n\n예상월급으로 할 수 있는일\n\nPC방 (시간당 1200원 기준 ) :\n점심 (한끼당 7000원 기준 ) :\n영화 (한편당 11000원 기준) :\n노래방( 20000원 기준 ) :\n\n'''\n\n# 1. 인풋 \nPractice = input(\" \\n 1. 수습 적용 \\n 2. 수습 미적용 \")\n\nPerHour = input('시급을 입력해주세요')\nDayTime = input('일일 근무 시간 :')\nMonthTime = input('한달 근무 일 수 :')\n\npayment = PerHour * DayTime * MonthTime\nif Practice == 1 : \n # 90 %\n Practice_pay = payment // 10\n print(Practice_pay)\nelse:\n payment\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5152386426925659,
"alphanum_fraction": 0.5347900986671448,
"avg_line_length": 21.888158798217773,
"blob_id": "a03f5b5cc369cc1c509747da78237334a2d660a9",
"content_id": "4f5710c5b46cec68bf19d2ace7b8c43068ecc865",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4712,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 152,
"path": "/Artificial_Intelligence/Reinforcement_Learning/Slot_Machine_ver2.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport random\nimport math\n\nimport matplotlib.pyplot as plt\n\nclass Machine():\n # 속성 - 확률\n def __init__(self,p):\n # 확률이라는 속성을 부여 \n self.percentage = p\n # 외부에서 입력된 p로 인해 값이 초기화\n \n # 보상\n def reward(self):\n # 머신 선택시 보상 지급 \n # 세팅된 확률보다 랜덤 값이 적으면 1 아니면 0 \n if self.percentage > random.random():\n return 1.0\n else:\n return 0.0\n\n# 랜덤 값의 범위 확인\n# print([ random.random() for n in range(10)])\n\n# Machines = [ Machine(0.3), Machine(0.5), Machine(0.9) ]\n# print(Machines) # 확인용\n\nclass Engine():\n # 초기화 함수 -> 알고리즘에 필요한 값을 초기화\n def initialize(self):\n # 값을 초기화\n pass\n\n def select_machin(self):\n # 기계를 선택\n pass\n\n # 폴리시 업데이트 -> 각 액션마다\n def policyUpdate(self):\n # 파라미터를 핸들링\n pass\n \n # 알고리즘 이름 출력\n def Algo_Naming(self):\n pass\n \n\n\"\"\"\n# Engine Class\n- 표준 인터페이스\n- 알고리즘 2개를 사용 예정 \n\"\"\"\n\n\nclass UCB1_Engine(Engine):\n \n \"\"\"\n # UCB1 알고리즘\n\n - 1. 선택한 팔의 시행 횟수 +1\n - 2. 성공시(보상을 받으면), 선택한 팔의 성공 횟수 +1\n - 3. 시행 횟수가 0인 팔이 존재하는 경우, 가치를 갱신하지 않는다 => 0으로 나눌 수가 없어서\n - 4. 시행 횟수가 모두 0이상이면, 팔의 가치에 대해서 탐색과 이용에 대한 균형을 잡는다는 대전에 하에, 모든 팔의 가치를 갱신한다.\n\n - 모든 팔을 한번 이상 사용할때까지는 가치 갱신을 하지 않는다 => 탐색\n - 모든 팔을 최소 1회 이상 사용해 봤다면, 전체 arm에대 가치 갱신을 시도한다.\n\n \"\"\" \n\n def initialize(self):\n # 값을 초기화\n # 시행 횟수\n # 팔의 가치 \n # 성공 횟수\n pass\n\n def select_machin(self):\n # 기계를 선택\n # 모든 머신을 한번씩 선택 \n # 그중에 값이 큰 머신을 선택 -> argmax()\n pass\n\n # 폴리시 업데이트 -> 각 액션마다\n def policyUpdate(self):\n # 파라미터를 핸들링\n # 선택한 암의 시행 횟수(행동)+1 -> 시도에 대한 횟수 증가 \n # 만약 보상을 받았다면, 성공 횟수를 증가 -> 총 보상 + 1 \n # 시행 횟수가 0인 머신이 존재할 경우 -> 갱신하지 않는다. \n # \n # UCB1의 수식에 의해 모든 머신에 대한 가치 갱신\n # 성공률 = (개별 머신의 성공 수)/(개별 머신의 시행횟수)\n # 바이어스 = ( (2*math.log(모든 시행 횟수))/(개별 머신의 시행횟수) )**0.5\n # 개별팔의가치 = 성공률 + 편향(바이어스)\n # \n pass\n \n # 알고리즘 이름 출력\n def Algo_Naming(self):\n return 'UCB1 알고리즘'\n\n\n\ndef simulator(algo, Machines, simulator_cnt, episode_cnt):\n\n times = np.zeros(simulator_cnt * episode_cnt) #'횟수'\n rewards = np.zeros_like(times)#'보상'\n\n # 시뮬 동작\n for action in range(simulator_cnt):\n # 주어진 팔의 개수만큼 자료구조를 생성 -> 0으로 초기화 \n algo.initialize(len(Machines))\n\n for time in range(episode_cnt):\n offset = episode_cnt * action\n index = offset + time\n times[index] = time + 1 \n choice_machine = algo.select_machin()\n new_reward = Machines[choice_machine].reward()\n rewards[index] = new_reward\n # 경험을 업데이트 \n algo.policyUpdate(choice_machine, new_reward)\n\n return times, rewards\n\n\n\n# 시뮬레이터 \n# 머신을 준비 -> 각 확률을 부여 \nMachines = [ Machine(0.3), Machine(0.5), Machine(0.9) ] # 30%, 50%, 90%\n# print(Machines) \n# 1개의 알고리즘 \nalgos = [UCB1_Engine()]\n# 알고리즘 별로 시뮬레이션을 1000번\nSIMULATION_COUNT = 1000\n# 1번의 시뮬레이션에서는 250의 에피소드가 존재\nEPISODE_COUNT = 250\n\nfor algo in algos:\n result = simulator(algo, Machines, SIMULATION_COUNT , EPISODE_COUNT )\n # print(result)\n df = pd.DataFrame( {'times':result[0], 'rewards':result[1]} )\n tmp = df.groupby( 'times' ).mean()\n # 시각화(선형 차트)\n plt.plot( tmp, label=algo.Algo_Naming() )\n\n# 그래프 표시\nplt.xlabel('Episode')\nplt.ylabel('Reward Average')\nplt.legend(loc='best')\nplt.show()"
},
{
"alpha_fraction": 0.5409226417541504,
"alphanum_fraction": 0.5461309552192688,
"avg_line_length": 9.295019149780273,
"blob_id": "57982b139e850e258431ad4199198743dea9b49c",
"content_id": "410e6ba9b89b0acf39604b26ecc736bed267846d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5162,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 261,
"path": "/데이터 분석(Data Analytics)/이론_BigData.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 1. 데이터 분석(Data Analytics) - BigData 개요\n\n<br>\n\n# BigData\n\n<br>\n\n## 1. **빅데이터(BigData)**의 개념 \n\n<br>\n\n### 1) 빅데이터(BigData)는\n\n- 가치 창출의 연료이다. => 현재의 ict 주도권 -> 데이터 \n- 정보 수집뿐만 아니라 활용의 여부가 미래 경ㅁ쟁력을 좌우한다.\n- 많은 양의 데이터를 수집,저장,분석 그리고 관리를 말한다. \n\n<br>\n\n### 2) 개념\n\n- 복잡하고 다양한 데이터 형식을 포함하는 형식을 가진다. \n- 데이터 형식이 다양하고 유통속도가 빠르다 그래서 관리, 분석이 어렵다. \n- 정형, 반정형, 비정형 데이터 모두를 일컬어 말한다.\n- 스마트기기와 소셜미디어의 발전으로 빅데이터가 급증하고 있다. \n\n\n- 마케팅 측면에서 소비자의 심리나 행태를 파악하고 전략을 짜기 용이 하기 때문에 중요하다. \n\n### 3) 데이터의 종류 \n\n**정형**\n\n- 고정된 필드에 정의된 데이터 \n- RDBMS\n\n**반정형**\n\n- 고정된 필드는 아니지만 스키마를 포함하는 데이터\n- 스키마란 ? \n- 로그, 엑셀, html\n\n**비정형**\n\n- 고정된 필드에 저장되어 있지 않은 데이터 \n- 텍스트, 이미지, 동영상 \n\n#### 유형(구조) \n\n내부 \n- 고객과 접족하는 데이터 \n\n외부 \n- 공급자(관계사)가 제공하는 데이터 \n- 기업이 제공하는 데이터 이외의 공공데이터 \n\n<br>\n\n### 4) 빅데이터에 대한 지적 -> 양면성 \n\n- 비인간성\n- 빅브라더로 돌변 가능성 크다. \n - 집단젇인 이익위해 사용 -> 사람의 사생활? 감시가 될수도 있다. \n - 곧 사람이 문제가 될 것 그렇기 때문에 \n- 사람의 중심 운영에 초점을 둬야함 \n\n<br>\n\n### 5) 빅데이터 특성 -> 3V\n\n<br>\n\n**규모(Volume)**\n- 기술적인 발전과 it의 일상화가 진행되면서 정보량이 기하급수적으로 증가 \n\n- 복잡성 증가 (4번째 특성) \n - 구조화 되지 않은 데이터, 데이터 저장 방식의 차이, 중복성 문제등 \n - 데이터 종류의 확대, 외부데이터의 활용으로 관리대상의 증가 \n - 외부데이터 활용, 중복성 \n\n<br>\n\n**다양성(variety)**\n- 로그기록, 소셜, 위치, 현실데이터등 데이터 종류의 증가 \n텍스트 이외의 멀티미디어 등의 비정형화된 데이터 유형의 다양화 \n\n<br>\n\n**속도(Velocity)**-> 실시간성 정보\n- 사물 정보(센서, 모니터링), 스트리밍 정보등의 실시간성 정보 증가 \n- 실시간성으로 인한 데이터 생성, 이동(유통), 속도의 증가 \n- 대규모의 데이터 처리 및 가치있는 현재정보(실시간) 활용을 위해 데이터 처리 및 분석 속도가 중요 \n \n<br><br>\n\n\n\n## 2. 빅데이터시대의 등장 배경 \n\n```py\n# ;추가 \n```\n\n### 생활속 빅데이터 등장\n\n```py\n# ;추가 \n```\n\n### 데이터 폭팔과 빅데이터 분석 \n\n```py\n# ;추가 \n```\n\n### 빅데이터 기술적 요건 \n\n```py\n# ;추가 \n```\n\n### 빅데이터 분석 발전 추동원인 \n\n```py\n# ;추가 \n```\n\n\n## dummy \n\n```txt\n\n\n## 1. 4차 산업 혁명과 공공빅데이터\n\n<br>\n\n도메인 + ICT기술(클라우드, AI, IoT 등등) \n\n<br>\n\n\n### 4차 산업 혁명\n\n\n기계화 -> 산업화 -> 정보화 -> 지능화\n\n<br>\n\n### 배경\n\nICT 기술의 발달 (빅데이터 Bigdata, IoT, 인공지능 AI )\n신 성장 동력이 필요 \n\n<br>\n\n### 지능화 된 사회 \n\n초연결성(IoT) , 초지능화(Ai, 빅데이터), 초융합(산업영역과 경계의 융합)\n\n<br>\n\n### ICT 융합 확산 \n\n개인 \n- 스마트 헬스 케어 \n- 로보어드바이저 ??? (내용조사)\n\n기업 \n- 스마트 팩토리 \n- 자율주행차\n\n정부 \n- 무인경계로봇\n- 지구 제난 드론 \n\n<br>\n\n### 산업 구조와 고용변화 \n\n생산품에서 서비스로 변화되는 산업구조 \n\n<br>\n\n### 기업의 변화 \n\n\nICT 의 성장 -> 소프트파워 -> 혁신적인 서비스 \n\n아이디어, 데이터를 기반으로 하는 회사들의 대거 성장 \n \n크고 강한것보다 현재는 빠른것이 더 중요하다. \n\n플렛폼 확보 경쟁 -> 기술주기가 짧아서 판이 계속 바뀐다. \n\n<br>\n\n\n### 핵심기술 \n\n#### IoT(내용조사)\n\n\n<br>\n\n#### 빅데이터 \n\n정형 데이터 , 비정형 데이터 => 정보 추출 <!-- 데이터 조사 -->\n\n3V : 데이터 품짓, 속도, 타입 그리고 가치 \n\n제품개선 , 피드백 분석, 동향예측, 소비자 패턴 분석 \n\n예측분석, 실시간 분석, 통찰력 제공, 민첩한 실행 -> 빅데이터를 할용가능 \n\n\n새로운 패턴\n\n단일 포괄 분석\n다양한 형태 분석 \n새로운 타입 분석 \n\n<br>\n\n\n#### AI : 인공지능(지능화 기숳)\n\n사람처럼 생각하고 사람처럼 행동하는 기계\n\n목표 -> 똑똑한 컴퓨터와 기계를 만드는것 \n- 기계가 학습하는 분야 -> 머신러닝 \n- 패턴을 발견해 분석하는 분야 -> 딥러닝 \n\n예시 \n- 자율 주행차(법규 미비)\n- 인공지능 여러가지 로봇\n- 드론 \n- 챗봇(행정분야에 접목)\n\n\n\n\n\n\n```\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n<!-- - 파이썬 코딩도장 : <https://dojang.io/> <br> -->\n\n"
},
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8369565010070801,
"avg_line_length": 92,
"blob_id": "7ba1fb7b66b4b9bae0fafb0b7641a46c17e7b71b",
"content_id": "158e9d45c934df3f059f5637dbc567ec6b6965d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 1,
"path": "/Artificial_Intelligence/Deep_Learning/Tensorflow/tf_mnist.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# https://tensorflowkorea.gitbooks.io/tensorflow-kr/content/g3doc/tutorials/mnist/beginners/"
},
{
"alpha_fraction": 0.5359001159667969,
"alphanum_fraction": 0.556711733341217,
"avg_line_length": 14.015625,
"blob_id": "183e27519667b1c5f46537f726cc0f587a24a14b",
"content_id": "66ea19947308d540b82da924e1cd720f4f967be1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1299,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 64,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_1.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n\"\"\"\n클래스 메소드의 사용법\n\"\"\"\n\nclass Employee(object):\n\n raiseAmount = 1.1 # 연봉 인상률 클래스 변수 \n\n def __init__(self, fst, lst, pay):\n\n self.first = fst\n self.last = lst\n self.pay = pay\n \n\n def applyRaise(self):\n\n \"\"\"\n 직원의 연봉을 인상할때 모든 직원 인스턴스에게 같은 인상율이 적용\n \"\"\"\n self.pay = int(self.pay * self.raiseAmount)\n\n\n def fullName(self):\n\n return '{}{}'.format(self.first, self.last)\n \n\n def getPay(self):\n \n return '현재 \"{}\"의 연봉은 \"{}\" 입니다.'.format(self.fullName(), self.pay)\n\n\n\nemp_1 = Employee('Jerry', 'Kim', 60000)\nemp_2 = Employee('Joy', 'Kim', 45000)\n\n\n# 연봉 인상 전 \n\nprint(emp_1.getPay())\nprint(emp_2.getPay())\n\n\n# 연봉 인상\n\nemp_1.applyRaise()\nemp_2.applyRaise()\n\n\n# 연봉 인상 후 \n\nprint(emp_1.getPay())\nprint(emp_2.getPay())\n\n\n# 만약 다음 해에 연봉 인상율을 변경해야 한다면 \n# 클래스 메소드를 사용하여 변경하는 것이 좋다.\n\n# 직접 클래스 변수를 변경하는 방법도 있지만 \n# 데이터 검사나 다른 부가 기능등의 추가가 필요할때 \n# 클래스 메소드를 사용하면 아주 편리하다."
},
{
"alpha_fraction": 0.48846277594566345,
"alphanum_fraction": 0.51251220703125,
"avg_line_length": 11.457489967346191,
"blob_id": "b0538a4ba422f9dc35434f760b769a75a853b324",
"content_id": "8e874db690755903198894e982e99ef9e935c29c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4507,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 247,
"path": "/Python/2.심화_변수.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n#### 2. 파이썬 심화 - 변수\n\n<br>\n\n# 변수 \n\n뒤부분에 나올 클로저를 알기위해서는 반드시 개념을 숙지하고 지나가야하는 부분이다. \n\n<br>\n\n## 전역변수(Global variable) \n\n- 함수 밖에서 만들어진 변수 \n\n- 프로그램 전체에서 동작\n\n- 프로그램이 복잡해질수록 골치 아파지는 변수 \n\n<br>\n\n### 전역변수 예제 \n\n```py\n\n# 전역변수 예제 \n\nx = 100 \ndef val():\n print(x) # 전역변수 \n\nval()\nprint(x)\n\n# Output\n# >>> 100\n# >>> 100\n\n``` \n\n<br>\n\n## 지역변수(Local variable)\n\n- 함수 안에서 만들어 진 변수 그래서 함수 내부에서 동작\n- 함수의 외부에서는 지역변수를 호출 x\n\n<br>\n\n### 지역변수 예제 \n\n\n```py\n\n## 지역변수 예제 \n\nx = 100 \ndef val():\n x = 10 # 지역변수 -> 함수 외부에서 호출 x \n print(x) \n\nval()\nprint(x)\n\n# Output\n# >>> 10\n# >>> 100\n\n```\n\n<br>\n\n## 함수안에서 전역변수의 값을 변경 - Global 사용 \n\n- 함수안에서 전역변수의 값을 변경하려면 `global` \n - 함수의 단계 상관없이 `global` 키워드를 사용하면 무조건 전역 변수를 사용하게 된다. \n\n<br>\n\n```py\n\nx = 100 \ndef val():\n\n global x # 전역변수로 선언 \n x = 10 # 지역변수 x -> 전역변수로 변경 \n print(x) \n\nval()\nprint(x)\n\n# Output\n# >>> 100\n# >>> 100\n\n```\n\n<br>\n<br>\n\n## 다중 함수 - `global` 사용 \n\n```py\n## global 사용 \nx = 1 # 1번\ndef fstPhase():\n x = 50 # 2번\n def fstPart():\n x = 70 # 3번\n def fstStep():\n global x # 1번 변수를 호출해서 사용 \n\n x = x + 80 # 1 + 80 = 81\n print(x)\n\n fstStep()\n\n fstPart()\n\nfstPhase()\n\n# Output\n# >>> 81 \n\n```\n\n<br>\n\n 함수에서 값을 주고 받을 경우에는 매개 변수와 변환 값을 사용하는 것이 좋다. <br>\n\n 왜냐하면 전역 변수는 코드가 복잡할때 변수의 값을 어디서 바꾸는지 알기가 힘들기 때문이다. <br>\n 그래서 전역변수는 가급적이면 사용하지 않는 것을 권한다. <br>\n\n<br>\n<br>\n\n## 상위 함수의 지역변수 호출 - `nonlocal` 사용 \n\n\n파이썬에서는 함수에서 변수를 만들면 항상 현재 함수의 지역변수가 된다.\n\n\n```py\n\n## 지역변수 변경\ndef Outer():\n x = 35 # Outer의 지역변수 x\n\n def Inner():\n x = 25 # Inner의 지역변수 x\n Inner()\n print(x) # 지역변수 출력 \n\nOuter()\n\n# Output\n# >>> 35 -> 당연한 결과 -> Outer함수의 지역변수를 호출\n\n```\n\n<br>\n\n이중 함수 안의 지역변수를 이중함수 밖(Outer에서)에서 \n\n즉, Inner의 지역변수 x를 외부에서 호출하려면 `nonlocal` 을 사용하면 된다.\n\n<br>\n\n\n```py\n\n# Inner의 x를 출력하려면\ndef Outer():\n x = 35 \n # 지역변수 x\n def Inner():\n nonlocal x # 현재 함수의 외부에서 이 지역변수를 사용 가능 \n # -> 잘 사용 할 일은 없을것 \n x = 25 \n Inner()\n print(x) # 지역변수 출력 \n\nOuter() \n# Output\n# >>> 25 # Outer함수의 지역변수가 아니라 Inner함수의 지역변수를 호출 \n\n```\n\n<br>\n\n`nonlocal`을 어디서, 왜 써야하는지 감이안와서 이해를 위해 조금 더 알아봤다. \n\n<br>\n\n```py\n\ndef Outer():\n x = 10\n\n def Inner():\n x += 10\n print('x:', x)\n Inner()\nOuter()\n\n# Output\n# >>> UnboundLocalError: local variable 'a' referenced before assignment\n\n```\n\n<br>\n\n이 경우 `UnboundLocalError: local variable 'a' referenced before assignment` 라는 에러가 발생하는데, \n이 에러는 해당 범위 내에서 변수를 할당을 할 때 \n 할당되는 변수가 파이썬에 의해서 자동적으로 로컬 변수로 간주 되어서 발생한 에러이다. \n그래서 변수에 용도에 맞도록 `nonlocal` 혹은 `global` 이름표를 달아 주어야한다. \n\n아래 예제의 경우에 `nonlocal`을 사용한다. \n\n<br>\n\n```py\n# nonlocal을 추가 \ndef Outer():\n x = 10\n\n def Inner():\n nonlocal x # 추가된 항목\n x += 10\n print('a:', x)\n Inner()\nOuter()\n\n# Output\n# >>> a: 20\n```\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n- SchoolOfWeb : <http://schoolofweb.net/> <br>\n- 끝나지 않는 프로그래밍 일기 : <https://blog.hexabrain.net/347>"
},
{
"alpha_fraction": 0.4978967607021332,
"alphanum_fraction": 0.5131931304931641,
"avg_line_length": 19.45081901550293,
"blob_id": "82f5e0fe8db2373eb6990a33db8fc8b7fb367f2a",
"content_id": "0635ccb9c9a8641a27c4e91ce3517e1abb7a5055",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4245,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 122,
"path": "/Data Structure and algorithm/DSAA_basic03_Stack.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 꼭 알아둬야 할 자료구조 \r\n\r\n# ## 스택 (Stack)\r\n# - 데이터를 제한적으로 접근할 수 있는 구조 \r\n# - 한쪽 끝에서만 자료를 넣거나 뺄 수 있는 구조 = 큐와 같음\r\n# - 가장 나중에 쌓은 데이터를 가장 먼저 빼낼 수 있는 데이터 구조 \r\n# => **큐와 다른 부분**\r\n# - 큐 : FIFO 정책**\r\n# - 스택 : LIFO 정책**\r\n\r\n\r\n# ### 1. 스택의 구조\r\n# - 스택은 IFO 정책(Last-In, Last-Out) 또는 FIFO(First-In, First-Out) 데이터 관리 방식을 따름 \r\n# - LIFO: 마지막에 넣은 데이터를 가장 먼저 추출하는 데이터 관리 정책\r\n# - FILO: 처음에 넣은 데이터를 가장 마지막에 추출하는 데이터 관리 정책\r\n\r\n# - 대표적인 스택의 활용 \r\n# - 컴퓨터 내부의 프로세스 구조의 함수 동작 방식 \r\n\r\n# - 주요기능 \r\n# - push(): 데이터를 스택에 **넣기**\r\n# - 아래에서부터 차례차례 넣는다.\r\n# - pop() : 데이터를 스택에서 **꺼내기**\r\n# - 꺼낼때는 마지막에 넣은 데이터부터 꺼낸다. \r\n\r\n# # Visualgo 사이트에서 시연해보며 이해하기 (push/pop 만 클릭해보며): \r\n# # https://visualgo.net/en/list\r\n\r\n\r\n# ### 2. 스택의 구조와 프로세스 스택 \r\n# - 스택의 구조는 프로세스 실행구조의 가장 기본 \r\n# - 함수 호출시 프로세스 실행구조를 스택과 비교해서 이해 필요 \r\n\r\n\r\n# 가볍게 이해를 돕기 위한 실습 \r\n# 재귀함수 \r\n# >> 리커시브라는 함수를 만드는데 \r\n# -> 만약에 데이터가 0보다 작으면 \r\n# -> 엔드를 출력하고 \r\n# -> 그게 아니라면 데이터를 출력한다 \r\n# -> 그리고 함수안에서 리커시브함수( 자기함수 )를 호출한다. \r\n# -> 가지고있는데이터에서 -1을 하고 출력\r\n# -> 그리고 데이터를 출력 \r\ndef recursive(data) :\r\n if data < 0 :\r\n print(\"ended\")\r\n else:\r\n print(data)\r\n recursive(data-1)\r\n print(\"returned\", data)\r\n\r\n# 재귀함수에서 자기함수를 출력해서 출력물이 많다. \r\nrecursive(4)\r\n\r\n\r\n\r\n\"\"\"### Process Stack \r\n \r\n -1 | recursive(-1) -out-> 1 \r\n 0 | recursive(0) -out-> 2 \r\n 1 | recursive(1) -out-> 3 \r\n 2 | recursive(2) -out-> 4 \r\n 3 | recursive(3) ... \r\n 4 | recursive(4) ... \r\n \r\n \r\n **recursive(data-1)**\r\n\"\"\"\r\n\r\n# ### 3. 자료구조 스택의 장단점\r\n# - 장점** \r\n# - 구조가 단순 => 구현하기 쉽다. \r\n# - 데이터 저장 /읽기 속도가 빠르다. \r\n\r\n# - 단점(일반적인 스택구현시)\r\n# - 데이터 최대 갯수를 미리 정해야한다. \r\n# - 파이썬의 경우 재귀 함수는 1000번까지만 호출이 가능 \r\n# - 저장공간의 낭비가 발생할수 있음 \r\n# - 미리 최대 갯수만큼 저장공간을 확보해야 함 \r\n \r\n# > 스택은 단순하고 빠른 성능을 위해 사용되므로, \r\n# 보통 배열 구조를 활용해서 구현하는 것이 일반적. \r\n# 위에서 열거한 단점이 있을 수 있음 \r\n\r\n# ### 4. 파이썬 리스트 기능에서 제공하는 메서드로 스택 사용해보기\r\n# - append(push), pop메서드 제공 \r\n# \r\ndata_stack = list()\r\ndata_stack.append(1)\r\ndata_stack.append(2)\r\n\r\ndata_stack\r\n\r\n\r\n# 가장 마지막에 들어 간 데이터를 뽑아낸다. \r\ndata_stack.pop()\r\n\r\n\r\n### 5. 프로그래밍 연습 \r\n\r\n#### 연습1 : 리스트 변수로 스택을 다루는 pop, push 기능을 구현해보기 (pop , push 함수 사용하지 않고 직접 구현해보기)\r\n\r\nstack_list = list()\r\n\r\n# 조건이 들어가니까 인자에 데이터를 넣고 \r\ndef push(data) : \r\n stack_list.append(data) # 맨 앞에서부터 데이터가 들어간다. \r\n #pass \r\n\r\n# pop 굳이 필요없기때문에 인자에 값을 넣지 않는다. \r\ndef pop() : \r\n data = stack_list[-1] # 맨끝을 가지고 와야해서 -1 \r\n del stack_list[-1] # 꺼낸 데이터는 없애야 해서 del 을이용해 삭제 \r\n return data # 데이터 값을 리턴한다. \r\n\r\n\r\n# 데이터 확인 \r\nfor index in range(10):\r\n push(index)\r\n\r\n# 그대로 마지막에 들어간 값인 9가 출력 \r\npop()"
},
{
"alpha_fraction": 0.35809019207954407,
"alphanum_fraction": 0.3687002658843994,
"avg_line_length": 3.5542168617248535,
"blob_id": "2045e48d229e31e1fcccd8fd5356037a26fcab28",
"content_id": "7247d0fde27ffdb26296bf7ff02f4554a8fd3ab0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 83,
"path": "/CodingTest/BigO.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### num. CodingTest - BigO\n\n<br>\n\n# BigO\n\n<br>\n \n## 1.\n\n### 소제목\n\n#### 소소제목 \n\n내용\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n## 2.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n<!-- - 파이썬 코딩도장 : <https://dojang.io/> <br> -->\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n<!-- - [내용](주소) -->"
},
{
"alpha_fraction": 0.4161261320114136,
"alphanum_fraction": 0.5895393490791321,
"avg_line_length": 23.959016799926758,
"blob_id": "a6bfb5523d497df9dcc3c2d9a30e751a83d5d457",
"content_id": "889a1b749ebc2a4ac45faad4de65a4d59f2475c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 17892,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 488,
"path": "/R/src/R_src_02.R",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "### 통계기초 \n\n# 평균, 중앙값, 분산, 표준편차\nscore <- c(85,90,93,86,82)\nmean(score) #평균값\nmedian(score) # 중앙값\nvar(score) # 분산\nsd(score) # 표준편차\n\n\n#### 편차 확인해 보기 \n평균 <- mean(score) ;평균\nresult <- 0 \n\nfor(i in score){\n cat( i ,\"점의 편차는\", result = i - 평균,\"입니다. /n\")\n}\n\n\n\n\n\n#### 실습 \n\n\"\"\"\n문제 1. \n4가지의 교육 방법의 효과를 비교분석 하기위해 \n학생 40명을 무작위로 10명씩 4개의 집단으로 나누고\n한 학기 동안 각 교육방법으로 교육을 실시한 후에 \n치른 기말 시험이 다음자료와 같다.\n\"\"\"\n\n# 각 교육방법에 따른 성적 \nA <- c(65,87,73,79,81,69,80,77,68,74)\nB <- c(75,69,83,81,72,79,90,88,76,82)\nC <- c(59,78,67,62,83,76,55,75,49,68)\nD <- c(94,89,80,88,90,85,79,93,88,85)\n\n# 간단하게 정리 및 1차 분석 \n\n # Min. 1st Qu. Median Mean 3rd Qu. Max \nsummary(A) # 65.00 70.00 75.50 75.30 79.75 87.00\nsummary(B) # 69.00 75.25 80.00 79.50 82.75 90.00 \nsummary(C) # 49.00 59.75 67.50 67.20 75.75 83.00\nsummary(D) # 79.00 85.00 88.00 87.10 89.75 94.00 \n\n# 각각의 집단은 서로 다른 값을 보여주고 있다. \n# D 의 경우 전체적으로 값이 가장 높다는 것을 알 수 있다. \n# 추정 : 대립가설 -> 교육방법을 달리하면 성적에 영향이 있을것이다. \n# 1차로 평균, 표준편차를 통해 각 교육의 효과성을 검정가능 하지만 \n# 타당성을 확보하기위해 정규분포를 진행하고자 한다. \n\n\n# 정규분포를 한번 확인해 보자 \nshapiro.test(A) # W = 0.97691, p-value = 0.9465\nshapiro.test(B) # W = 0.97827, p-value = 0.9553\nshapiro.test(C) # W = 0.96954, p-value = 0.8865\nshapiro.test(D) # W = 0.94461, p-value = 0.6054\n\n\n## 정규분포 결과해석\n# 각각의 p-value를 전체적으로 확인했을때 0.05보다 높다는것을 확인할 수있다. \n\n## 가설 설정 \n# 귀무가설 : 교육방법을 달리하면 성적에 영향이 없을 것이다. \n# 귀무가설 -> 차이가 없거나 의미있는 차이가 없는 경우의 가설이며 이것이 맞거나 맞지 않다는 통계학적 증거를 통해 증명하려는 가설 \n# 대립가설 : 교육방법을 달리하면 성적에 영향이 있을 것이다. \n\n\n## 검정방법 및 이유\n# 3개 이상의 집단이 있기 때문에 t-검정이 아닌 One-way analysis을 진행\noneway_data <- c(A,B,C,D); oneway_data\ngrp <- c(rep(1,10),rep(2,10),rep(3,10),rep(4,10));grp\n# One-way analysis of means\noneway.test(oneway_data~grp,var=T) # F = 11.727, num df = 3, denom df = 36, p-value = 1.653e-05\n\n## 결과 해석 \n# 유의확률이 p-value = 1.653e-05 < 0.05 이기 때문에 귀무가설의 기각하고 대립가설을 채택한다. \n# 그렇기 때문에 교육방법을 달리하면 성적에 영향이 있을 것이다. \n\n\n\n\n\"\"\"\n문제 2. 국어 성적을 올리기 위해 교육을 8명의 타자수에게 실시하여\n교육 전과 후의 국어 성적을 조사하였더니 아래와 같다.\n교육의 효과를 설명 할 수있는가?\n\"\"\"\n\n# 교육 전과 후의 국어 성적\n\nBefore_class <-c(52,60,63,43,46,56,62,50) # 교육전\nAfter_class <-c(58,62,62,48,50,55,68,57) # 교육후\n\n\n# 간단하게 정리 및 1차 분석 \n\n # Min. 1st Qu. Median Mean 3rd Qu. Max \nsummary(Before_class) # 43.0 49.0 54.0 54.0 60.5 63.0\nsummary(After_class) # 48.00 53.75 57.50 57.50 62.00 68.00\n\n# 교육전과 후를 비교해보았을때 전체적으로 성적이 향산된 것을 확인할 수 있다. \n# 추정 : 대립가설 -> 교육하면 성적에 영향이 있을것이다. \n\n# 평균, 표준편차를 통해 각 교육의 효과성을 검정가능하다. \n# 하지만 타당성을 확보하기위해 추가로 정규분포를 진행하고자 한다. \n\n\n## 정규성 검증\nshapiro.test(Before_class) # W = 0.93924, p-value = 0.6037\nshapiro.test(After_class) # W = 0.97079, p-value = 0.9042\n\n\n## 정규분포 결과해석 \n# 두 p-value를 확인했을때 0.05보다 높다는것을 확인할 수있다. \n\n\n## 가설설정\n# 귀무가설 : 교육하면 성적에 영향이 없을 것이다. \n# 대립가설 : 교육하면 성적에 영향이 있을 것이다. \n\n\n## 검정방법 및 이유\n# 두 집단 간의 평균을 비교해야하기 때문에 -> t-검정을 사용하여 검증을 진행한다. \n# 대응 표본이기 때문에 전후를 비교하기위해 paired = T 설정해줘야 한다. \n# t.test(Before_class,After_class) # t = -0.99422, df = 13.788, p-value = 0.3372\nt.test(Before_class, After_class, paired = T) # t = -3.1305, df = 7, p-value = 0.0166\n\n\n## 결과 해석 \n# 유의확률이 p-value = 0.0166 < 0.05 이기 때문에 귀무가설의 기각하고 대립가설을 채택한다. \n# 그렇기 때문에 국어 성적을 올리기위해 교육하면 성적에 영향이 있을것이다. \n\n\n\n\"\"\"\n문제 3. \n적용 사례로 보면, 환자 10명을 상대로 성형전과 성형후 만족도를 측정하고 \n이 두자료의 평균이 다르다고 할수있는지를 검증하고자 한다. \n\"\"\"\n\n# 환자 10명의 성형전과 성형후 만족도\nBefore_patient <-c(13.2, 8.2, 10.9, 14.3, 10.7, 6.6, 9.5, 10.8, 8.8, 13.3) \nAfter_patient <-c(14.0, 8.8, 11.2, 14.2, 11.8, 6.4, 9.8, 11.3, 9.3, 13.6) \n\n\n# 간단하게 정리 및 1차 분석 \n # Min. 1st Qu. Median Mean 3rd Qu. Max \nsummary(Before_patient) # 6.600 8.975 10.750 10.630 12.625 14.300\nsummary(After_patient) # 6.400 9.425 11.250 11.040 13.150 14.200\n\n# 추정 : 대립가설 -> 성형이후 환자의 만족도가 차이가 있다. \n\n\n## 정규성 검증\nshapiro.test(Before_patient) # W = 0.9624, p-value = 0.8129\nshapiro.test(After_patient) # W = 0.94815, p-value = 0.6467\n\n\n## 정규분포 결과해석 \n# 두 p-value를 확인했을때 0.05보다 높다는것을 확인할 수있다. \n\n\n## 가설설정\n# 귀무가설 : 성형이후 환자의 만족도의 차이가 없다. \n# 대립가설 : 성형이후 환자의 만족도가 차이가 있다. \n\n\n## 검정방법 및 이유\n# t-검정을 사용하여 두 집단 간의 평균을 비교한다.\n# 대응 표본이기 때문에 전후를 비교하기위해 paired = T 설정해줘야 한다. \nt.test(Before_patient, After_patient, paired = T) # t = -3.3489, df = 9, p-value = 0.008539\n\n\n## 결과 해석 \n# 유의확률이 p-value = 0.008539 < 0.05 이기 때문에 귀무가설의 기각하고 대립가설을 채택한다. \n# 그렇기 때문에 성형전후 환자의 만족도가 차이가 있다는 것을 알 수 있다. \n# 또한 평균과 중앙값을 통해 성형후가 만족도가 좋다는것을 알수있다. \n\n\n\n\n\"\"\"\n문제 4.\n\n개발된 신약의 효과를 측정하기 위해 환자집단을 두 집단으로 나누어\n한 집단은 신약을 조제하여 치료하고, 나머지 한 집단은 위약을 제공한 후 \n환자들의 치료효과가 나타나는 시간을 측정하였다. \n결과는 다음과 같다. \n\"\"\"\n\n# 두 환자집단의 치료효과가 나타나는 시간\nnew_medicine <-c(15,10,13,7,9,8,21,9,14,8) \nold_medicine <-c(15,14,12,8,14,7,16,10,15,12) \n\n# 간단하게 정리 및 1차 분석 \n # Min. 1st Qu. Median Mean 3rd Qu. Max \nsummary(new_medicine) # 7.00 8.25 9.50 11.40 13.75 21.00\nsummary(old_medicine) # 7.00 10.50 13.00 12.30 14.75 16.00\n\n# 추정 : 대립가설 -> 치료효과가 나타나는 시간이 신약이 빠르다.\n\n\n## 정규성 검증\nshapiro.test(new_medicine) # W = 0.86663, p-value = 0.09131\nshapiro.test(old_medicine) # W = 0.91249, p-value = 0.2986\n\n\n## 가설설정\n# 귀무가설 : 치료시간이 차이가 안난다. \n# 대립가설 : 치료시간이 차이가 난다. \n\n\n## 정규분포 결과해석 \n# 두 p-value를 확인했을때 0.05보다 높다는것을 확인할 수있다. \nt.test(new_medicine, old_medicine) #t = -0.53311, df = 16.245, p-value = 0.6012\n\n\n## 결과 해석 \n# 유의확률이 p-value = 0.6012 > 0.05 이기 때문에 귀무가설을 채택한다. \n# 평균과 중앙값을 통해 신약이 빠를것이라고 추정하였으나 치료시간이 차이가 안난다는것을 t-검증을 알 수 있다.\n# 그렇기 때문에 신약과 위약의 치료속도 차이가 안난다는것을 알수있다. \n\n\n\n\"\"\"\n문제 5.\n\n어느 공장에서 제품을 생산하는데 열처리 온도에 따라서 \n제품의 강도가 차이를 보이는지를 조사하기 위하여 \n열처리 온도를 다음 자료와 같이 변화시키고 \n각 열처리 온도에서 7개의 제품을 표본으로 추월하고 강도를 측정한다. \n\n분산분석표를 작성하고 온도에 따른 제품의 강도가 \n동일한가에 대한 대하여 유의수준 0.05에서 R을 사용하여 검증하라.\n\"\"\"\n\n## 열처리 온도에서 7개의 제품을 표본\nC_125 <-c(23,27,24,25,29,30,26) \nC_150 <-c(35,32,38,36,32,33,34) \nC_175 <-c(36,41,38,39,40,38,39) \nC_200 <-c(32,30,37,34,35,34,32)\n\n\n# 간단하게 정리 및 1차 분석 \n # Min. 1st Qu. Median Mean 3rd Qu. Max \nsummary(C_125) # 23.00 24.50 26.00 26.29 28.00 30.00\nsummary(C_150) # 32.00 32.50 34.00 34.29 35.50 38.00\nsummary(C_175) # 36.00 38.00 39.00 38.71 39.50 41.00\nsummary(C_200) # 30.00 32.00 34.00 33.43 34.50 37.00\n\n# 1차 분석 - 중앙값과 평균을 기반으로 보았을때 C_175가장 강도가 좋을것으로 보이며\n# 1차분석을 기반으로 온도에 따른 제품의 강도가 강도가 차이를 보이는 것으로 추축한다.\n\n\n## 정규성 검증\nshapiro.test(C_125) # W = 0.96211, p-value = 0.8366\nshapiro.test(C_150) # W = 0.93053, p-value = 0.5554\nshapiro.test(C_175) # W = 0.96707, p-value = 0.8766\nshapiro.test(C_200) # W = 0.97232, p-value = 0.9147\n\n## 정규분포 결과해석 \n# 정규성검증을 진행하였고 p-value 가 0.05 이상으로 모두 정규성띄는것을 알수있다. \n\n# 가설설정 \n# 귀무가설 : 온도에 따른 제품의 강도가 차이를 보이지 않는다.\n# 대립가설 : 온도에 따른 제품의 강도가 차이를 보인다.\n \n# t 검증 \n\nall_data <- c(C_125,C_150, C_175, C_200)\ngrp <-c(rep(1,length(C_125)),rep(2,length(C_150)),rep(3,length(C_175)),rep(4,length(C_200)))\noneway.test(all_data~grp,var=T) # F = 38.352, num df = 3, denom df = 24, p-value = 2.581e-09\n\n## 결과 해석 \n# 1차분석을 기반으로 온도에 따른 제품의 강도가 강도가 차이를 보이는 것으로 추측하였고 이추측이 타당했음을 \n# oneway 검증을 통해 알수있다. \n# p-value = 2.581e-09 < 0.05 으로 차이를 보이지 않는다라는 귀무가설을 기각하고 강도가 차이를보인다라는 대립가설을 채택한다.\n\n\n\"\"\"\n문제 6.\n병원 직원들의 친절도가 병원 만족도에 \n영향을 미치는지 연구하고자 한다.\n\"\"\"\n\n## 병원 직원들의 친절도가 병원 만족도\nkindness <-c(15,10,13,7,9,8,21,9,14,8) # 친절도\nsatisfaction <-c(15,14,12,8,14,7,16,10,15,12) # 만족도\n\n# 간단하게 정리 및 1차 분석 \n # Min. 1st Qu. Median Mean 3rd Qu. Max \nsummary(kindness) # 7.00 8.25 9.50 11.40 13.75 21.00\nsummary(satisfaction) # 7.00 10.50 13.00 12.30 14.75 16.00\n\n# 1차 분석 \n# 서머리를 보았을때 전체적으로 친절도가 높으면 만족도가 높은것으로 보인다.\n# 그래서 친절도가 높으면 만족도가 높을 것이라는 추측을 해본다. \n# 타당성을 보기위해 추가적인 검증과정을 진행 하고자한다. \n\n## 가설\n# 귀무가설 : 병원 직원들의 친절도가 병원 만족도에 영향을 안미친다.\n# 대립가설 : 병원 직원들의 친절도가 병원 만족도에 영향을 미친다.\n\n\n# 과거의 친절도를 기준으로 미래의 만족도를 예측하는 것이므로 회귀분석를 사용하고자한다. \n# 그리고 종속변수에 영향을 주는 변수는 1개 이기때문에 단순 회귀분석을 사용하여 진행하고자 한다. \n\n\nout = lm(kindness~satisfaction);out # 회귀식 Y = -1.286 + 1.031x \nsummary(out)\n\n\"\"\"\nResiduals:\n Min 1Q Median 3Q Max\n-4.1533 -2.3641 0.0035 1.6359 5.7840\n\nCoefficients:\n Estimate Std. Error t value Pr(>|t|)\n(Intercept) -1.2857 4.2774 -0.301 0.7714 \nsatisfaction 1.0314 0.3383 3.049 0.0158 *\n---\nSignif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1\n\nResidual standard error: 3.139 on 8 degrees of freedom\nMultiple R-squared: 0.5375, Adjusted R-squared: 0.4797\nF-statistic: 9.296 on 1 and 8 DF, p-value: 0.01585\n\"\"\"\n\n\n## 결과 \n# 유의확률이 유의수준 미만(p-value = 0.01585 < 0.05 )이기 때문에 귀무가설을 기각하고 대립가설을 채택한다.\n# 이로 병원 직원들의 친절도가 병원 만족도에 영향을 미친다는것을 알수있다. \n# Adjusted R-squared: 0.4797 을 통해 위 추정 회귀식의 관측 값은 48%(0.4797)로 설명이 가능하다.\n# 이가설은 비신뢰적이라고 판단된다. α>0.6이면... 신뢰할만한데\n\n\n\n\"\"\"\n문제 7.\n개인요인[인성, 얼굴, 성격]은 인맥 관리에 유의한 영향을 미친다.\n라는것을 연구하고자 한다. \n\"\"\"\n\n# 10명의 개인요인[인성, 얼굴, 성격]\n인맥관리 <-c(100,90,98,79,81,69,80,77,68,54)\n인성 <-c(5,4,5,3,4,3,2,3,2,1)\n얼굴 <-c(5,3,4,3,4,3,2,3,2,1) \n성격 <-c(5,3,3,2,3,3,4,3,2,1) \n\n\n# 데이터 프레이미 생성 \npeople <- data.frame(y=인맥관리, s1 = 인성, s2 = 얼굴, s3 = 성격);people\n\n\n## 가설\n# 귀무가설 : 개인요인[인성, 얼굴, 성격]은 인맥 관리에 유의한 영향을 안미친다.\n# 대립가설 : 개인요인[인성, 얼굴, 성격]은 인맥 관리에 유의한 영향을 미친다.\n\n\n# 종속변수에 영향을 주는 변수는 3개 이기때문에 다중 회귀분석을 사용하여 진행하고자 한다. \nmodel <- lm( y~., data=people );model # Y = 4.84 + 13.84x_1 + (-8.22)x_2 + 5.22x_3 \nsummary(model)\n\n\"\"\"\nCall:\nlm(formula = y ~ ., data = people)\n\nResiduals:\n Min 1Q Median 3Q Max\n-8.3546 -1.5585 0.3085 1.4096 6.8652\n\nCoefficients:\n Estimate Std. Error t value Pr(>|t|)\n(Intercept) 44.844 4.804 9.336 8.56e-05 ***\ns1 13.837 3.960 3.494 0.0129 *\ns2 -8.220 4.912 -1.673 0.1453 \ns3 5.220 2.067 2.525 0.0450 *\n---\nSignif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1\n\nResidual standard error: 4.813 on 6 degrees of freedom\nMultiple R-squared: 0.9217, Adjusted R-squared: 0.8825 \nF-statistic: 23.53 on 3 and 6 DF, p-value: 0.00102\n\"\"\"\n\n## 결과 \n\n# 전체 유의확률이 유의수준 미만(p-value = 0.00102 < 0.05 )이기 때문에 귀무가설을 기각하고 대립가설을 채택한다.\n# 이로 개인요인[인성, 얼굴, 성격]은 인맥 관리에 유의한 영향을 미친다는 것을 알수있다. \n# Adjusted R-squared: 0.8825을 통해 위 추정 회귀식의 관측 값은 88%(0.8825)로 설명이 가능하다.\n\n# 세부 유의확률은 s1(인성), s3(성격이) 유의한 영향을 미친다는 것을 알수있다.\n# 그래서 인성과 성격중 어느것이 더 큰 영향이 미칠것인가가 라는 의문이 들었고\n# 추가적으로 분석을 진행하였다. \n \n\n# 10명의 개인요인[인성, 얼굴, 성격]\n인맥관리 <-c(100,90,98,79,81,69,80,77,68,54)\n인성 <-c(5,4,5,3,4,3,2,3,2,1)\n성격 <-c(5,3,3,2,3,3,4,3,2,1) \n\n# 데이터 프레이미 생성 \n(people_snd <- data.frame(y=인맥관리, s1 = 인성, s2 = 성격))\n\n\n# 가설검증 - 위와 동일 \n\n# 종속변수에 영향을 주는 변수는 2개 \n(model_snd <- lm( y~., data=people_snd ))\nsummary(model_snd)\n\n\n\"\"\"\nResiduals:\n Min 1Q Median 3Q Max\n-9.4261 -1.4509 -0.1513 4.0080 5.5613\n\nCoefficients:\n Estimate Std. Error t value Pr(>|t|)\n(Intercept) 43.876 5.347 8.206 7.74e-05 ***\ns1 7.752 1.757 4.411 0.00311 **\ns2 3.765 2.102 1.791 0.11646 \n---\nSignif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1\n\nResidual standard error: 5.397 on 7 degrees of freedom\nMultiple R-squared: 0.8851, Adjusted R-squared: 0.8523\nF-statistic: 26.96 on 2 and 7 DF, p-value: 0.0005142\n\n\"\"\"\n\n\n### 결과를 보니\n# 전체 유의확률이 유의수준 미만(p-value = 0.0005142 < 0.05 )이기 때문에 귀무가설을 기각하고 대립가설을 채택한다.\n# 이전 검증(3개의 독립변수)보다 눈에 띄는 p-value수치를 확인할 수 있었다.\n# 여기서부터\n# 개인요인 중에 인성이 성격보다 더! 중요한것을 알수있었다.\n# 또한 Adjusted R-squared 통해 본 신뢰도는 85%(0.8523)를 가진다. \n\n\n\"\"\"\n문제 8.\n\n\"\"\"\n\n#문제1. \nx1<-c(65,87,73,79,81,69,80,77,68,74) \nx2<-c(75,69,83,81,72,79,90,88,76,82) \nx3<-c(59,78,67,62,83,76,55,75,49,68) \nx4<-c(94,89,80,88,90,85,79,93,88,85) \n\n#문제2\nx<-c(52,60,63,43,46,56,62,50) \ny<-c(58,62,62,48,50,55,68,57)\n\n#문제 3.\npre<-c(13.2, 8.2, 10.9, 14.3, 10.7, 6.6, 9.5, 10.8, 8.8, 13.3) \npost <-c(14.0,8.8,11.2,14.2,11.8,6.4,9.8,11.3,9.3,13.6) \n\n#문제 4.\nx<-c(15,10,13,7,9,8,21,9,14,8) \ny<-c(15,14,12,8,14,7,16,10,15,12) \n\n#문제 5.\nx1<-c(23,27,24,25,29,30,26) \nx2<-c(35,32,38,36,32,33,34) \nx3<-c(36,41,38,39,40,38,39) \nx4<-c(32,30,37,34,35,34,32)\n\n#문제 6.\nx<-c(15,10,13,7,9,8,21,9,14,8) \ny<-c(15,14,12,8,14,7,16,10,15,12) \n\n#문제 7.\nx1<-c(100,90,98,79,81,69,80,77,68,54)\nx2<-c(5,4,5,3,4,3,2,3,2,1)\nx3<-c(5,3,4,3,4,3,2,3,2,1) \nx4<-c(5,3,3,2,3,3,4,3,2,1) \n\n#문제 8.\nx1<-c(100,90,98,79,81,69,80,77,68,74) \nx2<-c(5,4,4,3,4,3,4,3,2,3) \nx3<-c(4,3,3,2,3,2,3,3,2,3) \nx4<-c(5,3,3,2,3,3,4,3,2,3)\n\n#문제 9.\na <- c(58, 49, 39, 99, 32, 88, 62, 30, 55, 65, 44, 55, 57, 53, 88, 42, 39)"
},
{
"alpha_fraction": 0.5081967115402222,
"alphanum_fraction": 0.5409836173057556,
"avg_line_length": 10.181818008422852,
"blob_id": "9275c257748e70a936100f548a50c3c528c30f99",
"content_id": "26cf5cd85dd423c945fe1544d4caf6087267df26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 11,
"path": "/CodingTest/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 코딩테스트 준비 \n\n## 그냥 공부용 \n\n## 참고 자료 \n\n\n\n<!-- ## 1. Jump_to_python\n- Coding Source Study Olny Use\n- 점프투 파이썬 (100% - Done) -->"
},
{
"alpha_fraction": 0.5813191533088684,
"alphanum_fraction": 0.6050798892974854,
"avg_line_length": 12.49171257019043,
"blob_id": "1f0690ab96d11c65070cb72fce86b0d9e3640318",
"content_id": "99f6168d6aba8fdb7a904062fdf009977a200e31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3749,
"license_type": "no_license",
"max_line_length": 201,
"num_lines": 181,
"path": "/Python/7.심화_추상클래스.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 7. 파이썬 심화 - 추상 클래스\n\n\n<br>\n\n# 추상 클래스\n\n<br>\n\n## 1. 추상화\n\n<br>\n\n함수의 이름을 통해 구체적으로 하는 일의 전체적인 특징(특성)을 추상적으로 보여주는것이 추상화이다. \n\n쉽게 말하자면 하고자하는 것의 전체적인 특징을 보여주는것이다.\n\n예를들면 단기간 많은 것을 기억해야 할 때 전부를 기억하는것 보다\n\n일정한 패턴이나 글의 맥락을 외우면 기억해야 할 양을 줄이고 \n\n전체적인 그림을 그릴 수 있는 것처럼 하고자하는것을 전달하기쉽게 특징만으로 뽑아서 보여주는것이다.\n\n\n<br>\n\n### 추상화의 장점 \n\n- 코드의 재사용성, 가독성 향상 => 결국 생산성, 에러의 감소와 같은 요소에 영향\n\n<br>\n<br>\n\n## 2. 추상 클래스\n\n<br>\n\n메소드 목록**만** 가진 클래스이며 상속받는 클래스에서 메소드 구현을 **강요하기** 위해 사용한다. \n- 자식 클래스가 **반드시 구현**해야 하는 메소드를 정해줄 수 있다.\n\n<br>\n\n### 추상 클래스 - 기본 구조 \n\n<br>\n\n```py\n\nfrom abc import *\n#import abc # 일때 abc.ABCMeta, @abc.abstractmethod로 사용\n \nclass 추상클래스이름(metaclass=ABCMeta):\n\n @abstractmethod\n def 메소드이름(self):\n 코드\n\n```\n\n<br>\n\n### 추상 클래스 - 이해하기 1\n\n<br>\n\n```py\n\n# ABC를 정의하기 위한 메타 클래스 ABCMeta\nfrom abc import ABC\n\n# ABCMeta를 메타 클래스로 가지는 도우미 클래스\n\nclass MyABC(ABC):\n \"\"\"\n 메타클래스 없이 ABC에서 파생 \n \"\"\"\n pass\n\n# ABC => 여전히 ABCMeta\n\n```\n\n#### 다중 상속이 메타 클래스 충돌을 일으킬 수 있기 때문에 메타 클래스사용할때 주의가 필요하다. \n\n```py\n\nfrom abc import ABCMeta\n\nclass MyABC(metaclass=ABCMeta):\n \"\"\"\n metaclass 키워드를 전달하고 \n ABCMeta를 직접 사용해서 추상 베이스 클래스를 정의\n \"\"\"\n\n @abstractmethod\n def 메소드이름(self):\n 코드\n\n```\n\n<br>\n\n### 추상 클래스 - 이해하기 2\n\n<br>\n\n```py\n\nfrom abc import *\n \nclass CookBase(metaclass=ABCMeta):\n\n \"\"\"\n 반드시 해야 하는 일을 추상메소드로 구현 \n\n 추상 클래스는 인스턴스로 만들 수 없음 -> 빈메소드를 만들어야하는 이유\n ㄴ 인스턴스를 만들 수 없다! = 호출할 일이 없다!\n \"\"\"\n\n @abstractmethod\n def FindRecipe(self):\n pass\n \n @abstractmethod\n def Ingredients(self):\n pass\n \n \nclass Cook(CookBase):\n\n \"\"\"\n 구현할때 Base에서 구현한 item(@abstractmethod 추상메소드)은\n 자식클래스에서 모두 구현 해야한다 - 아니면 에러발생 \n \"\"\"\n\n def FindRecipe(self):\n print('요리 레시피 준비')\n \n def Ingredients(self):\n print('요리재료 준비')\n \n\njoy = Cook()\njoy.FindRecipe()\njoy.Ingredients()\n\n# output\n\n# >>> 요리 레시피 준비\n# >>> 요리재료 준비\n\n```\n\n<br>\n\n추상 클래스는 인스턴스로 만들 때는 사용하지 않으며 오로지 상속에만 사용하며\n \n자식 클래스에서 반드시 구현해야 할 메소드를 정해 줄 때 사용한다.\n\n<br>\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n\n- 프로페셔널 프로그래머 : <https://m.blog.naver.com/PostView.nhn?blogId=knix008&logNo=220700047637&proxyReferer=https:%2F%2Fwww.google.com%2F>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [Advanced_OOP_추상클래스](https://github.com/Jerrykim91/KISS/tree/master/Python/%EC%8B%AC%ED%99%94_%ED%81%B4%EB%9E%98%EC%8A%A4%ED%99%9C%EC%9A%A9/Advanced_OOP_%EC%B6%94%EC%83%81%ED%81%B4%EB%9E%98%EC%8A%A4)"
},
{
"alpha_fraction": 0.5783730149269104,
"alphanum_fraction": 0.6259920597076416,
"avg_line_length": 10.732558250427246,
"blob_id": "fa028f46ed51e8ad098a94853ef0372a356f1cea",
"content_id": "15acb0fff921a178556f71bd1ba969318c782466",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1418,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 86,
"path": "/Virtual_Environment/리눅스/howto_requirements.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# 가상환경 구축 후 버전통일\n\n## 환경구성\n\n### 폴더 생성 \n\nFinalProject \n\nEmotion (감정분석) \n\n- README.md\n\nFood_Img (이미지)\n\n- README.md\n\nFood_rec(추천)\n\n- README.md\n\nREADME.md\n\nrequirements.txt\n\n<br>\n<br>\n\n## 가상환경 생성\n\n텐서는 두가지 버전으로 진행 해야 할 수 있어서 가상환경을 둘로 나눌께요\n\n추가로 사용하는 페키지 생기면 알려주세요 다같이 추가하거나 버전 바꿀겁니다 \n\n- 가상환경 이름\n\n - fmfa_m\n\n - 텐서 1.5\n\n - fmfa_t\n\n - 텐서 2\n\nrequirements.txt => 기본 + 알파\n\n### 절차\n\n1. 콘다네비게이터에서 가상환경 fmfa_m(기본), fmfa_t생성 <br>\n \n 1-1) 가상환경 fmfa_m기반 주피터 설치\n\n2. fmfa_m가상환경에서 open terminal 구동\n\n3. requirements.txt 작업 환경으로 이동 \n\n4. requirements.txt 파일이 존재하는 곳까지 현재 디렉토리 이동\n\n5. terminal에서 `$ conda install --file requirements.txt` \n\n6. 텐서 플로우는 따로 설치\n\n ```bash\n $ conda install tensorflow==1.15.0\n $ conda install tensorflow==2.0\n ```\n\n7. conda에 없는 패키지는 제거후 따로 설치\n예 )$ pip install pymysql \n $ pip install folium==0.10.0\n\n산출물 : requirement.txt\n\n\n```bash\n\npandas == 1.0.3\nrequests==2.18.4\nbeautifulsoup4==4.8.2\nnumpy==1.18.1\nscikit-learn==0.22.1\nmatplotlib==2.2.2\nseaborn==0.10.0\n\n```"
},
{
"alpha_fraction": 0.5192307829856873,
"alphanum_fraction": 0.5192307829856873,
"avg_line_length": 7.166666507720947,
"blob_id": "3c3d3ee618c006e5331bf4c7647786310aa8b0ba",
"content_id": "c466cb310d9f4a03f53ecb78add60536c2b52272",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 6,
"path": "/Project/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# Project\n\n##### JUST DO IT RIGHT NOW\n\n<br>\n<br>\n\n\n\n"
},
{
"alpha_fraction": 0.4941037595272064,
"alphanum_fraction": 0.5,
"avg_line_length": 6.580357074737549,
"blob_id": "d6b4dba6667cdfa3049015669f0fe82b96e90aea",
"content_id": "48d47fe8cf7beaab116e4be01d4760fdf416b3a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1116,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 112,
"path": "/Python/아직/9.심화_데코레이터.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 9. 파이썬 심화 - 데코레이터 \n\n<br>\n\n# 데코레이터 \n\n<br>\n\n## 1. 데코레이터란\n\n메서드를 꾸며준다해서 데코레이터라고 하며 장식자라고 불린다. \n\n@staticmethod, @classmethod, @abstractmethod 와 함께 사용하였는데 @ 가 붙는 item들은 전부 데코레이터라고 한다. \n\n주로 메소드를 수정하지 않은 상태에서 추가기능을 구현할때 사용한다. \n\n<br>\n\n```py\n\nclass Calc:\n @staticmethod # 데코레이터!\n def add(a, b):\n print(a + b)\n\n```\n\n<br>\n\n\n\n## 2. 데코레이터 - 이해하기 \n\n<br>\n\n```py\n\ndef point():\n print('start')\n print('point')\n print('end')\n \ndef check():\n print('start')\n print('check')\n print('end')\n \npoint()\ncheck()\n\n# output\n\n# >>> start\n# >>> point\n# >>> end\n# >>> start\n# >>> check\n# >>> end\n\n# 데코레이터 사용 \n\n\n```\n\n<br>\n\n\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [내용](주소)"
},
{
"alpha_fraction": 0.52944016456604,
"alphanum_fraction": 0.5516409277915955,
"avg_line_length": 9.112195014953613,
"blob_id": "43ed9ed0e51cfc9e47ae87145c14127905f8fc06",
"content_id": "f98d3313f0d1191f776ea1428a15145ee37d39aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3614,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 205,
"path": "/R/R_ 통계기초_01.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 01. R 통계 기초 - R로 배우는 통계 기초\n\n<br>\n\n# R로 배우는 통계 기초\n\n<br>\n\n## 1. 용어정리\n\n<br>\n\n### 1) 평균(mean)\n\n<br>\n\n- 데이터 전체를 더한 후 데이터 개수로 나눈 값을 의미한다.\n- `데이터의 총합 / 데이터의 길이 or 개수(n)` \n- `mean()`\n\n<br>\n\n### 2) 중앙값(median) \n\n<br>\n\n- 데이터가 가진 값을 크기순으로 정렬시킨 후 중앙에 있는 값을 의미한다.\n- `median()`\n\n#### 집단의 특성을 잘 나타내는 수치 - 평균값, 중앙값\n\n<br>\n\n### 3) 편차 \n\n<br>\n\n- 원래의 값에서 평균을 뺀 값으로 편차는 `+`, `-` 될 수 있다. \n- 쉽게 말해서 평균과 해당 값의 차이로 `관측치-평균값`을 말한다. \n- 0 : 편차가 없다. \n\n<br>\n\n### 4) 제곱평균\n\n<br>\n\n- 편차값을 제곱해서 평균을 구하는 원리 \n- 마이너스의 값을 플러스의 값으로 바꾼 후 평균을 구하는것 \n\n\n<br>\n\n### 5) 분산(Variance)\n\n<br>\n\n- 편차의 제곱의 합을 의미한다. \n- 편차의 값을 제곱해서 나온 값으로 **분산의 정도를 알려준다.** `var()`\n\n<br>\n\n### 6) 표준편차\n\n<br>\n\n- 평균 값이 실제 값에서부터 얼마나의 오류가 있는가? 이 말인 즉, 평균에 대한 오차를 말한다.\n- 실제 데이터의 값이 평균을 기준으로 할때 얼마나 들쭉 날쭉하냐를 보여준다. \n- 평균으로부터 원래 데이터에 대한 오차범위의 근사값이다.\n\n<br>\n\n- 분산값에 루트를 적용한 값 `sd()`\n - 분산은 실제값에서 너무 멀어지기 때문에 실제값과 가까워지기 위해 제곱근을 씌워준다.\n - 분산에서 제곱했으니, 반대로 제곱근(루트)을 씌운다. \n\n<br>\n\n### 7) 모집단\n\n<br>\n\n- 계산에 사용한 원본 대상\n\n<br>\n\n### 8) 표본\n\n<br>\n\n- 일부 대표성을 가진 데이터 \n\n<br>\n\n### 9)자유도\n\n<br>\n\n- 자유롭게 뽑을 수 있는 경우의 수 \n\n표본의 분산과 표준편차를 계산할 때 나누는 분모의 수 : 모집단 - 1 \n주어진 데이터에서 표본을 자유롭게 뽑을수 있는 경우의 수를 의미 \n표본을 추출해서 표본의 분산과 편차를 계산할 때는 항상 자유도를 분모로 사용한다. \n\n<br>\n\n\n### 표준값과 표준화의 차이 \n\n표준값은 공통된 기준을 적용해서 수치화한것 이라면 표준화는 모든값들의 표준값을 정하고 그 기준으로 차이를 구해서 비교하는것 이다. \n\n<br>\n\n```r\n\n```\n\n<br><br>\n\n\n\n\n## 2. 탐색적 데이터 분석 \n\n<br>\n\n### 1) \n\n<br>\n\n### 2) t-검정\n\n\nt-검정을 할 때는 두 가지 가정이 만족되는지 먼저 확인해야 한다.\n\n1. 정규성 가정 (normality assumption)\n \n: 두 집단의 분포가 정규분포를 따른다고 할 수 있는지\n\n *정규성 검정에 대한 내용은 아래 포스팅 참조\n\n http://mansoostat.tistory.com/22\n\nt-검정\n\n2. 등분산성 가정 (homogeneity of variance)\n\n: 두 집단의 분산이 같다고 할 수 있는지\n\n (귀무가설을 기각하지 않으면 등분산성 가정을 할 수 있다.)\n \n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n<!-- - 조대협의 블로그 : <https://bcho.tistory.com/972/> <br> -->\n<br>\n\n### 책은 판매 사이트를 올립니다. \n\n- [책] Do it! 쉽게 배우는 R 데이터 분석 : <http://www.yes24.com/Product/Goods/44015086> <br>\n- [책] 데이터 과학을 위한 통계 : <https://www.hanbit.co.kr/store/books/look.php?p_code=B2845507407> <br>"
},
{
"alpha_fraction": 0.6053639650344849,
"alphanum_fraction": 0.611494243144989,
"avg_line_length": 10.06779670715332,
"blob_id": "2d47cf1319d789aad27755c98959cedae7398fd8",
"content_id": "f19042f7330a5a6061c2ec5d27ffd9da3e3a83c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1981,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 118,
"path": "/Virtual_Environment/리눅스/리눅스_VScode 설치 .md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 2. Ubuntu 18.04 - VScode 설치 \n\n<br>\n\n# VScode 설치 \n\n아직까지는 이명령어로 에러난적은 없기 때문에 혹시라도 에러사항이 생긴다면 업데이트 하도록 하겠다.\n\n<br>\n\n## 1. VScode 설치 \n\n<br>\n\n필자는 VScode를 굉장히 선호하는편이라 컴퓨터를 세팅할때 가장 VScode 먼저 설치한다. \n\n<br>\n\n일단은 `curl`을 설치해 준다. \n\n```bash\n# 설치 \n$ sudo apt-get install curl\n```\n\n<br>\n\n그리고 이후 아래 코드를 입력한다. \n\n<br>\n\n```bash\n\n# 경로를 복사\n$ sudo sh -c 'curl https://packages.microsoft.com/keys/microsoft.asc | gpg --dearmor > /etc/apt/trusted.gpg.d/microsoft.gpg'\n\n# 경로를 추가 \n$ sudo sh -c 'echo \"deb [arch=amd64] https://packages.microsoft.com/repos/vscode stable main\" > /etc/apt/sources.list.d/vscode.list'\n\n```\n\n<br>\n\n이제 패키지 목록을 불러온 다음 vscode를 설치하면 설치가 완료된다. \n\n<br>\n\n```bash\n\n# 패키지 목록 불러오기 \n$ sudo apt-get update\n\n# vscode 설치\n$ sudo apt-get install code\n\n```\n\n이렇게 설치가 완료되었다. \n\n만약 비쥬얼 코드를 실행하고자 한다면 \n커맨드 창에서 `code`치면 실행된다.\n\n<br>\n\n## Git 설치 \n\n만약 VScode에서 깃허브를 이용해야한다면 `git`을 설치해야한다. \n그러기위해서는 아래와 같이 진행하자 ! \n\n<br>\n\n```bash\n\n# Git 설치 방법\n\n$ sudo apt-get install git # git 설치 명령어\n\n```\n\n<br>\n\n### 레지스트리를 다운로드 할 경우\n\n주의 할점 : 다운 받고자 하는 경로를 잘 입력해서 올바른 경로에 설치하자 ! \n생각없이 설치하다가는 어디있는지 못찾게 된다. \n\n<br>\n\n```bash\n\n# 레지스트리 다운로드 \n$ git clone 레지스트리 경로.git\n\n# 레지스트리 삭제 \n$rm -rf ~/레지스트리 이름 \n\n```\n\n<br>\n<br>\n\n\n---\n\n<br>\n\n## Reference <br>\n\n- 내용 : <주소> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [내용](주소)"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 12.823529243469238,
"blob_id": "21b8a260d62742910337268cb7ef5750380d9fc9",
"content_id": "f8feb960f466fd75d03244f58ff4f96ec256beeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 17,
"path": "/Python/자료구조/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# Python \n##### JUST DO IT RIGHT NOW\n\n<br>\n\n## 파이썬 자료구조 \n\n### 뭘 해야할지 솔직히 어떻게 해야할지 모르겠다.\n스스로랑 약속한대로 매일 커밋은 해야하고 공부는 하기 싫고 그래서 그냥 \n뭐라도 해보기 위해서 카피 코딩이라도 진행해 보고자 한다. \n\n\n## Reference <br>\n\n- [도서] 파이썬 알고리즘과 자료구조 : <> <br>\n"
},
{
"alpha_fraction": 0.3219616115093231,
"alphanum_fraction": 0.48827293515205383,
"avg_line_length": 12.05555534362793,
"blob_id": "bf9e664d734659f2c4d459b1fdbf90be02de58fd",
"content_id": "00fa24a730fd82d8cbd8a20458c0c4fc8dacc736",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 36,
"path": "/Python/Boost-Course/Enumerate & Zip.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# Enumerate & Zip\n\n\n## list comprehension + zip\n\na, b, c = zip((1, 2, 3), (10, 20, 30), (100, 200, 300))\nprint(a, b, c)\n\n\n# outut\n# (1, 10, 100) (2, 20, 200) (3, 30, 300)\n\nprint([sum(x) for x in zip((1, 2, 3), (10, 20, 30), (100, 200, 300))])\n\n\n# outut\n# [111, 222, 333]\n\n\n\n\n## enumerate + zip\n\na_list = ['a1', 'a2', 'a3']\nb_list = ['b1', 'b2', 'b3']\n\n\nfor i,(a,b) in enumerate(zip(a_list,b_list)):\n print(i,\":\" , a, b)\n\n\n\n# outut\n# 0 : a1 b1\n# 1 : a2 b2\n# 2 : a3 b3"
},
{
"alpha_fraction": 0.5397489666938782,
"alphanum_fraction": 0.5578800439834595,
"avg_line_length": 22.139785766601562,
"blob_id": "5dff8a329bb6a395752086aa24f97fd3ca5ae068",
"content_id": "ceb2ac174c5504f29a7d18a03e9947fce73ed77a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3267,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 93,
"path": "/Python/기본_Regular Expression.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 정규 표현식 - 패캠\n\n## 정리해야함 \n---\n\n### 정규표현식을 숙지하고 커스텀 해보자 \n\n---\n\n## 정규표현식 Regular Expression\n\n- **특정 패턴과 일치하는 문자열을 검색, 치환, 제거 하는 기능** \n = > 특정 패턴을 찾는것 \n 예를 들면 => 이메일 형식 판별, 전화번호 형식 판별, 숫자로만 이루어진 문자열 등\n\n- raw string => 그대로 문자열로인식 \n\n**문자열 앞에 r이 붙으면 해당 문자열이 구성된 그대로 문자열에 반환한다.** \n\n```py\n# Raw string의 예\na = 'abcd\\n hi' # escapce 문자열\nprint(a)\n# Raw string 이용 => 문자열 앞에 r이 붙임\nb = r'abcd\\n hi' \nprint(b)\n```\n---\n\n# 기본 패턴 \n- 문자하나하나의 캐릭터(character)들은 정확히 해당 문자와 일치 \n - 패턴 test는 test 문자열과 일치\n - 대소문자의 경우 기본적으로 구별하나, 구별하지 않도록 설정 가능 \n- 몇몇 문자들에 대해서 예외 존재 => 특별한의미로 사용 \n - . ^ $ * + ? { } [ ] \\ | ( )\n- .(마침표) - 어떤 한개의 캐릭터(character)와 일치 \n - \\w - 문자 character와 일치 [a-zA-Z0-9_]\n - \\s - 공백문자와 일치\n - \\t, \\n, \\r - tab, newline, return\n - \\d - 숫자 character와 일치 [0-9]\n - ^ = 시작, $ = 끝 각각 문자열의 시작과 끝을 의미\n - \\가 붙으면 스페셜한 의미가 없어짐. 예를들어 \\\\.는 .자체를 의미 \\\\\\는 \\를 의미\n - 자세한 내용은 [링크](https://docs.python.org/3/library/re.html) 참조\n---\n\n# search method\n - 첫번째로 패턴을 찾으면 match 객체를 반환\n - 패턴을 찾지 못하면 None 반환\n\n\n \n```py\nimport re # 정규식 패키지 \n\n# search method\n# - 첫번째로 패턴을 찾으면 match 객체를 반환\n# - 패턴을 찾지 못하면 None 반환\n\n# 패턴찾기 - 1\nsrc_search = re.search(r'abc','abcdef')\nprint(src_search.start()) # 인덱스 번호 시작 0 \nprint(src_search.end()) # 인덱스 끝은 3 => 3은 포함하지 않는다. \nidx = 'abcdef'\nprint(idx[3]) # d \nprint(src_search.group()) # '그룹('abc')를 불러온다\nprint('='*50)\n\n# 패턴 찾기 - 2 \nsrc_search = re.search(r'abc','123abcdef')\nprint(src_search.start()) # 인덱스 번호 시작 3\nprint(src_search.end()) # 인덱스 끝은 6 => 6은 포함하지 않는다. \nprint(src_search.group()) # '그룹('abc')를 불러온다\n\n# \\d - 숫자 character와 일치 [0-9]\nsrc_search = re.search(r'\\d\\d\\d\\w', '112abedwf119')\nprint(src_search) # match='112a'\n\n# \\w - 문자 character와 일치 [a-zA-Z0-9_]\n# .. 은 어떠한 문자든지 2개가 앞에오고 문자를 출력하라 \nsrc_search = re.search(r'..\\w\\w', '@#$%ABCDabcd')\nprint(src_search) # match='$%AB'\n\n# Meta-characters (메타 캐릭터)\n# [ ] 문자들의 범위를 나타내기 위해서 사용함\n# - [abck] : a or b or c or k\n# - [abc.^] : a or b or c or . or ^\n# - [a-d] : -와 함께 사용되면 해당 문자 사이의 범위에 속하는 문자 중 하나\n# - [0-9] : 모든 숫자\n# - [a-z] : 모든 소문자\n# - [A-Z] : 모든 대문자\n# - [a-zA-Z0-9] : 모든 알파벳 문자 및 숫자\n# - [^0-9] : ^가 맨 앞에 사용 되는 경우 해당 문자 패턴이 아닌 것과 매\n```"
},
{
"alpha_fraction": 0.5263158082962036,
"alphanum_fraction": 0.5449660420417786,
"avg_line_length": 12.694805145263672,
"blob_id": "3098cdd9c44796712c2376d108f7b9328b8ba695",
"content_id": "6d905c1e9be479574a1b4dfb99936cc521b82715",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8969,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 462,
"path": "/Python/8.심화_예외처리.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 8. 파이썬 심화 - 예외처리_01\n\n<br>\n\n# 예외처리\n\n<br>\n\n예외(exception) 상황 = 코드 실행중 에러가 발생한 상황\n\n<br>\n\n## 1. Try & Except\n\n<br>\n\n예외가 발생했을 때도 스크립트 실행을 중단하지 않고 계속 실행한다. try안에 에러가 발생할것같은 코드를 넣고 except 예외가 발생했을 때 처리하는 코드를 추가하면 에러발생시 잘 대처할수 있다. \n\n<br>\n\n### Try & Except - 기본 구조 \n\n<br>\n\n```py\n\ntry:\n 실행할 코드\n \nexcept:\n 예외가 발생했을 때 처리하는 코드\n\n```\n\n<br>\n\n### Try & Except - 이해하기\n\n<br>\n\n```py\n\ntry:\n num = int(input('숫자만!:')) # 예외가 발생하면 코드 실행을 중단 \n print(f'{num}는 숫자입니다.') # except로 가서 코드 실행 \n\n# try의 코드에서 에러가 발생했을 때 실행됨\nexcept: \n print('숫자가 아닙니다.예외가 발생했습니다.')\n\n```\n\n<br>\n<br>\n\n\n## 2. 특정 예외 처리\n\n<br>\n\nexcept 부분에 예외 이름을 지정 후 특정한 예외상황이 발생했을 경우 코드가 실행된다. \n\n<br>\n\n### 특정 예외 처리 - 기본 구조 \n\n<br>\n\n```py\n\ntry:\n 실행할 코드\n \nexcept 예외이름:\n 예외가 발생했을 때 처리하는 코드\n\n```\n\n<br>\n\n### 특정 예외 처리 - 이해하기\n\n<br>\n\n```py\n\ny = [10, 20, 30]\n \ntry:\n index, x = map(int, input('인덱스와 나눌 숫자를 입력하세요 : ').split())\n print(y[index] / x)\n\n\n# 2개의 except문을 사용 \n## 숫자를 0으로 나눠서 에러가 발생했을 때 실행됨\nexcept ZeroDivisionError: \n print('숫자를 0으로 나눌 수 없습니다.')\n\n## 범위를 벗어난 인덱스에 접근하여 에러가 발생했을 때 실행됨\nexcept IndexError: \n print('잘못된 인덱스입니다.')\n \nexcept ValueError: \n print('벗어난 범위 입니다.')\n\n```\n\n<br>\n\n아래처럼 `except 에러 as e(혹은 err)` e 변수를 지정해 발생한 예외의 메시지를 함께 출력가능하다. \n\n예외상황이 여러개 발생 할 경우 먼저 발생한 예외의 처리 코드만 실행 우선적을 실행 \n\n<br>\n\n```py\n\ny = [10, 20, 30]\n \ntry:\n index, x = map(int, input('인덱스와 나눌 숫자를 입력하세요 : ').split())\n print(y[index] / x)\n\n\nexcept ZeroDivisionError as err : \n print('숫자를 0으로 나눌 수 없습니다.', err)\n\nexcept IndexError as err: \n print('잘못된 인덱스입니다.', err)\n\nexcept ValueError as err: \n print('벗어난 범위 입니다.', err)\n\n```\n\n<br>\n<br>\n\n## 3. 모든 예외의 에러 메시지를 출력\n\n<br>\n\n만약 에러 이름을 모를 때 except에 `Exception` 을 지정한다.\n\n<br>\n\n### 모든 예외 처리 - 기본 구조\n\n\n<br>\n\n```py\n\nexcept Exception as err: \n print('예외가 발생했습니다.', err)\n\n```\n\n<br>\n<br>\n\n## 4. 사용자 유도( Raise ) 에러 \n\n<br>\n\n사용자가 **직접 에러**를 만들어 발생시킬때 주로 사용하며 \n\n많이 사용하면 코드의 가독성이 떨어지기 때문에 정말 필요할 경우 사용하는 것을 추천한다. \n\n<br>\n\n### Raise 에러 - 이해하기 1\n\n<br>\n\n\n```py\n\n# 올바른 값을 넣지 않으면 에러를 발생시키고 적당한 문구를 표시\ndef rsp(mine, yours):\n allowed = ['가위','바위', '보']\n if mine not in allowed:\n raise ValueError # 함수 외부에서 예외를 발생\n if yours not in allowed: # except이 나올때까지 상위로 올라감 \n raise ValueError\n\ntry:\n rsp('가위', '바') # 함수를 try문 안에 집어 넣음 \nexcept ValueError:\n print('잘못된 값을 넣었습니다!') \n\n```\n\n<br>\n\n### Raise 에러 - 이해하기 2 \\*\\*\n\n<br>\n\n```py\n\n# 190이 넘는 학생을 발견하면 반복을 종료\nclassRoom = {\n '1반' : [150, 156, 179, 191, 199],\n '2반' : [150, 195, 179, 191, 199] }\n\ntry:\n for class_number, students in classRoom.items():\n for student in students:\n if student > 190:\n print(class_number, '190을 넘는 학생이 있습니다.')\n # break # 바로 상위 for문은 종료되지만 최고 상위 for문은 종료 X\n raise StopIteration\n # 예외가 try 문 안에 있지 않으면 에러 발생시 프로그램이 멈춤\n\nexcept StopIteration:\n print('정상종료') \n\n```\n\n<br>\n\n### Re-Raise 에러 - 이해하기 \n\n<br>\n\nTry & Except 에서 처리한 예외를 다시 발생시키는 방법으로 \n\nexcept 안에서 raise를 사용하면 현재 예외를 다시 발생시킨다.(Re-Raise)\n\n<br>\n\n```py\n\n# 올바른 값을 넣지 않으면 에러를 발생시키고 적당한 문구를 표시\ndef rsp(mine, yours):\n\n allowed = ['가위','바위', '보']\n\n if mine not in allowed:\n raise Exception('잘못된 값을 넣었습니다!') \n print(mine)\n\n if yours not in allowed: \n raise Exception('잘못된 값을 넣었습니다!') \n print(yours)\n\ntry:\n rsp('가위', '바') # 함수를 try문 안에 집어 넣음 \n\nexcept Exception as e: # 하위 코드 블록에서 예외가 발생해도 실행됨\n print('스크립트 파일에서 예외가 발생했습니다.', e)\n\n```\n\n\n<br>\n\n### Re-Raise 에러 - 활용하기(LottoChecker System)\n\n<br>\n\n#### LottoChecker System\n\n```py\n\ndef LottoNumber(x, maxNum=46):\n \"\"\"\n LottoNumber : 1-45까지 랜덤으로 x개의 번호 부여 \n \"\"\"\n import random \n tmp = list(range(1,maxNum))\n random.shuffle(tmp)\n x = int(x)\n cnt = 0\n number = []\n \n for num in tmp:\n cnt += 1 \n if cnt <= x : \n number.append(num)\n pass\n\n return number\n\n\ndef LottoChecker( rang=6 ):\n \n \"\"\"\n LottoNumber 에서 생성한 정답과 내가 입력한 정답 비교 \n\n \"\"\"\n\n myLotto = [ i for i in map(int, input('1-45까지 6개의 숫자를 입력하세요 : ').split())]\n \n if len(myLotto) != rang:\n raise Exception(f'{len(myLotto)} 는 6 개') \n\n elif len(set(myLotto))!= rang:\n raise Exception(' 값이 중복 됩니다.')\n \n c = 0\n dum = []\n LottoWinningNumber = sorted(LottoNumber(int(rang)))\n\n for i in myLotto :\n if i in LottoWinningNumber:\n c += 1\n print(f\"{c}개 맞았습니다.\")\n\n if c == 6:\n print('다 맞았습니다. 잊지말고 로또 사세요!')\n \n else:\n dum.append(i)\n \n print(f'{c}개 맞았습니다. {sorted(dum)} not in {LottoWinningNumber}') \n\n \ntry:\n LottoChecker()\n\nexcept Exception as e: # 하위 코드 블록에서 예외가 발생해도 실행됨\n\n print('스크립트 파일에서 예외가 발생했습니다.', e) \n\n```\n\n<br>\n\n## 5. if else 사용\n\n<br>\n\n상황에 따라 예외처리 대신 if else를 사용하여 작업이 가능하다. \n\n<br>\n\n### Try & Except 과 if else 비교 \n\n<br>\n\n\n```py\n\n# Try & Except\n\ndef idx_print(list, index):\n\t\"\"\"\n\tlist 와 index를 입력받아야함 \n\t\"\"\"\n\ttry:\n\t\tprint(list.pop(index))\n\texcept IndexError:\n\t\tprint(f'{index} : index의 값을 가져올 수 없습니다.')\n\nidx_print([1,2,3], 1 )\nidx_print([1,2,3], 10 )\t # index 길이 초과 \n\t\t\t\t\t\t# -> 10 : index의 값을 가져올 수 없습니다.\n\n# if 문\ndef idx_print(list, index):\n\t\"\"\"\n\tlist 와 index를 입력받아야함 \n\t\"\"\"\n if index < len(list):\n print(list.pop(index))\n else:\n print('{} index의 값을 가져올 수 없습니다.'.format(index))\n\nidx_print([1,2,3], 0 )\nidx_print([1,2,3], 5 )\t # index 길이 초과 \n\t\t\t\t\t\t# -> 5 : index의 값을 가져올 수 없습니다.\n\n```\n\n<br>\n\n### 예외처리를 사용해야 할 경우\n\n<br>\n\n\n```py\n\ntry:\n import 모듈이름\nexcept ImportError:\n print('모듈이 없습니다.')\n\n```\n\n<br>\n<br>\n\n## 6. 예외가 발생하지 않았을 때 Else \n\n<br>\n\n### Try & Except & Else - 기본 구조 \n\n\n예외가 발생하지 않았을 때 코드를 실행하는 else 를 Try & Except 아래에 추가한다. \nexcept은 생략할 수 없다. \n\n<br>\n\n```py\n\ntry:\n 실행할 코드\nexcept:\n 예외가 발생했을 때 처리하는 코드\nelse:\n 예외가 발생하지 않았을 때 실행할 코드\n\n```\n\n<br>\n<br>\n\n\n## 7. 항상 코드를 실행하는 Finally\n\n<br>\n\n### Try & Except & Else & Finally - 기본 구조 \n\n\nFinally는 항상 코드를 실행하며 except와 else를 생략가능하다. \n\n<br>\n\n```py\n\ntry:\n 실행할 코드\nexcept:\n 예외가 발생했을 때 처리하는 코드\nelse:\n 예외가 발생하지 않았을 때 실행할 코드\nfinally:\n 예외 발생 여부와 상관없이 항상 실행할 코드\n\n```\n\n<br>\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n- 초보몽키의 개발공부로그 : <https://wayhome25.github.io/python/2017/02/26/py-12-exception/> <br>\n\n<br>\n<br>\n"
},
{
"alpha_fraction": 0.5971564054489136,
"alphanum_fraction": 0.6571879982948303,
"avg_line_length": 15.230769157409668,
"blob_id": "0a77d920b211c2dc840a5e195f460d2e9db265d8",
"content_id": "b057de1a770c24e1ac5bf1b69bca3dc5dc1ee55d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 825,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 39,
"path": "/Python/심화_클래스활용_실습코드/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# Python 심화 연습 \n\n<br><br>\n\n## Advanced_OOP \\- Advanced_OOP_06 \n\n내용 : 클래스 메소드와 스태틱 메소드\n\n - 출처 : [SchoolOfWeb LINK](http://schoolofweb.net/blog/posts/파이썬-oop-part-4-클래스-메소드와-스태틱-메소드-class-method-and-static-method/)\n\n<br>\n\n## Advanced_OOP_객체합성\n\n - 출처 : [초보몽키의 개발공부로그 LINK](https://wayhome25.github.io/cs/2017/04/09/cs-09/)\n\n\n<br>\n\n\n## Advanced_OOP_Super\n\n - 출처 : [개발자의 취미 생활 LINK](https://rednooby.tistory.com/56?category=633023)\n\n\n<br>\n\n## Advanced_OOP_다중상속\n\n - 출처 : [뚱땡이 우주인 LINK](https://uzooin.tistory.com/137)\n\n\n<br>\n\n## [폴더] Advanced_OOP_추상클래스\n\n - 출처 : [초보몽키의 개발공부로그 LINK](https://wayhome25.github.io/cs/2017/04/10/cs-11/)\n"
},
{
"alpha_fraction": 0.6343001127243042,
"alphanum_fraction": 0.6702395677566528,
"avg_line_length": 24.54838752746582,
"blob_id": "9387c639ea4f20b00b4a7fa346c19505e84bec3d",
"content_id": "8982ac32d98de2640b1ad58e2d9a78d1929830e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3252,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 62,
"path": "/Artificial_Intelligence/Machine_Learning/머신러닝 이론.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 머신러닝 \n데이터가 잘 정제되고 많다는 가정하에 말하자면\n\n내가 생각하는 머신러닝은 어떠한 데이터의 일정한 패턴을 학습해서 그 경험을 보여주는것이 머신러닝이라고 생각한다.\n머신러닝의 발전이 어려운 이유는 사람은 다양한 경험을 가지고있고 그것을 무언가를 배울때 활용한다. \n하지만 인공지능은 백지 상태에서 한가지만 학습을 하는 경우이니 당연히 경험적으로 부족하기 때문에 발전이 어렵다고 생각한다.\n\n만약에 모델들이 원활히 소통하는 기술력을 가지게되고 그것을 뒷받침하는 하드웨어가 개발된다면 우리는 조금 많이 아주 많이 두려워 해야할것이다. \n\n이제 생각은 접어두고 머신러닝을 정리해보자 \n\n<br>\n\n\n# 데이터 전처리\n\n사이킷런 머신러닝 알고리즘은 문자열 값을 입력 값으로 받아들이지를 못한다. 그렇기 때문에 모든 문자열 값들을 숫자형으로 인코딩하는 전처리 작업후에 머신러닝 모델에 학습을 시켜야한다. \n\n\n## 원핫 인코딩을 하는 이유 \n\n텍스트를 유위미한 숫자(벡터)로 바꾸는 가장 손쉬운 방법론은 이기 때문이다.\n이는 N개의 단어를 각각 N차원의 벡터로 표현하는 방식이다. 단어가 포함되는 자리에는 1을 넣고 나머지에는 0을 넣는다. 단어 하나에 인덱스 정수를 할당한다는 점에서 '단어 주머니'라고 부르기도 한다. \n\n단점은 컴퓨터가 단어의 의미 또는 개념의 차이를 담지 못한다 \n관련어와 유의어이 관계를 담지 못한다. \n\n\n## 레이블 인코딩 \n\n## 상관계수 \n\n\n# 인공신경망 : 컴퓨터가 사람처럼 생각하는 방법이다.\n<br>\n\n## 인공 신경망 구축의 시작 퍼셉트론(preceptron)\n\n단일 퍼셉트론은 다수의 신호 즉,input을 받아서 하나의 output를 출력한다. \n그래서 동작은 뉴런과 굉장히 유사하다.\n퍼셉트론은 각 입력 신호의 세기에 따라 가중치를 부여한다.\n\n\n입력 신호의 세기 -> 이것을 조절하는 것만으로 결과가 달라진다.\n이런식으로 특정 입력값에 대해 활성/비활성을 결정하는 함수를 활성함수라고 한다. \n퍼셉트론의 동작 과정 4번째에 속하는 단계로 \n활성화 함수의 출력값이 미리 설정한 임계점보다 클 경우 다음 뉴런으로 결과를 전달한다. \n\n<퍼셉트로 동작과정>\n\n1. 다수의 input일때 -> X\n2. 퍼셉트론은 각 입력의 신호 세기에 따라 다른 가중치를 부여한다. -> X\\* Weight\n3. 그 결과르 고유한 방식 bias으로 처리한다. -> X \\* \\+ Bias\n4. 입력의 신호의 합($sum$)이 일정한 값(임계점)을 초과한다면 -> if{ sum(X \\* Weight \\+ Bias)> 일정값 } \n5. 그 결과를 다른 뉴런으로 전달한다. -> if{ sum(X \\* W \\+ B)> 일정값} \n\n\n\n\n< 참고 >\n딥러닝을 이용한 자연어 처리 : <https://wikidocs.net/24958>\n인공신경망 이해하기 : <https://de-novo.org/2018/04/17/%EC%9D%B8%EA%B3%B5%EC%8B%A0%EA%B2%BD%EB%A7%9D-%EC%9D%B4%ED%95%B4%ED%95%98%EA%B8%B0-2-%ED%8D%BC%EC%85%89%ED%8A%B8%EB%A1%A0%EA%B3%BC-%EC%8B%A0%EA%B2%BD%EB%A7%9D/>\n\n"
},
{
"alpha_fraction": 0.5938316583633423,
"alphanum_fraction": 0.6147412657737732,
"avg_line_length": 18.92708396911621,
"blob_id": "fc9b09ee61329d01700aacd2ff17af946105330b",
"content_id": "42f9c23eb7a388bf396e9ade3d6e2166e9a3e48d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4113,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 96,
"path": "/Project/Solution_Base/Problem_2.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# Problem : 2차시 \n\n진행중인 프로젝트에 관한 여러가지 이슈 그리고 해결방안을 포스팅하고자 한다. \n\n<br>\n\n## 진행 상황\n\n현재 전체적인 진행상황은 아래와 같다. \n\n- 이미지 분석 : 45 % \n- 텍스트 분석 : 89 %\n- 시스템 구현 : 10% \n\n<br>\n<br>\n\n## 이슈 \n\n### 이슈 1 : 모델 설계 \n\n아이디어를 구체화 시키면서 쭉 생각하고 있던 아이디어였는데 \n일단 우리 데이터는 학습 시킬 카테고리가 많다. \n즉, 이말은 한 모델이 이미지를 여러가지를 한번에 학습을 해야한다는 말이다. \n그러면 150개의 카테고리가 150/100이 된다는 말이 된다. \n\n나는 과연 이 작업이 얼마나 효율적일까라는 의구심을 가졌고 \n이러한 생각이 들었다. 굳이 왜 한 모델에 무조건 다 넣어야만 하지? \n꼭 그렇게 해야할 필요가 있나? 라는 생각. \n\n그래서 나는 디렉토리를 레이블링을 하고 모델을 파이프라인으로 구축하거나 \n트리화 시켜서 작업 하는것도 효율적일 것이라고 생각했다. \n마치 여과지를 통해 불순물을 걸러내는것처럼 \n이미지도 각각이 가진 유사한 특징 별로 묶어서 큰 특징을 걸러내고 \n그것을 토대로 잔잔한 특징들을 잡아내는 모델로 세세하게 잡아낸다면 \n괜찮을 것이라고 생각했다. \n\n단점으로는 좀 많이 느리다는 점... 이부분은 좀더 공부를 한다면 보완이 가능하다고 나는 생각했다.\n\n이아이디어는 누구도 나에게 도전해봐라, 시도해봐라, 가능은 하다라는 언급이 없어 배제하고 있었다. \n당연히 안될것같다라는 생각도 가지고 있었다. \n그런데 이번에 가능하다는 답을 얻었고 이를 진행 해보고자한다. \n\n<br>\n\n```bash\n\n# 상위 카테고리 \n# ㄴ 각각 카테고리를 모아서(file), 합쳐서 나열한다. \n# => 모델을 만든다.\n#\n# 이렇게 만든 상위 모델에서 나온 값을 받아 \n# 하위 카테고리\n# ㄴ 각 카테고리를 학습시킨다(dir), 합쳐서 나열한다. \n#\n# 그 값을 if문을 이용해 탐색하요 하위 카테고리 모델로 전달하여 재학습 시킨다. \n# 현재까지 아이디어는 여기까지인데 \n\n# 여기서 문제점이 있다. \n\n# 1. 상위모델은 하위 모델 보다 정확도가 높아야 한다. \n# 2. 하위모델은 적어도 정확도가 90은 나와야 한다. \n# 3. 입력으로 들어오는 이미지는 최대한 음식에 집중되어야 한다. \n\n```\n\n<br>\n<br>\n\n\n### 이슈 2 : 이미지 전처리 \n\n이전글에서 언급 했다시피 전처리와 모델을 잘 만드는것이 중요하다는것을 확인하게 되었고 전처리 작업부터 진행하기로 하였다. \n<br>\n전처리 작업을 진행을 하면서 이미지들을 전체적으로 확인해보았다. \n아니나 다를까 이질적인 이미지 데이터가 포함이 되어있었다. \n이뿐만아니라 보유하고있는 이미지 데이터가 일정한 패턴을 보여야하는데 전혀 패턴을 확인 할 수 없었다. \n모델은 일정한 패턴을 기반으로 분류 모델을 통해 학습이 되어야하는데 전혀 없었다. \n오히려 전체적인 잡음이 너무 많았다. 이는 학습에 방해가 되기 때문에 최대한 데이터를 다듬어 줘야한다. \n\n그래서 전체적으로 고른것을 분류하고 \n일정한 패턴을 수작업으로 살려 데이터를 전처리하였고 \n각 카테고리 가 1,000장이라는 가정하에 70~80% 정도 살릴 수 있었다. \n\n<br>\n\n### 이슈 3 : 모델 튜닝 - 상위 모델 \n\n\n전처리를 하였지만 아직도 새로 만든 모델은 조금 과적합이 보였다. \n- 모델 튜닝을 통해서 이미지 인식률을 90~95% 사이까지 진행을 목표로 하고있다. \n\n1. 과적합 문제 해결 필요\n2. 전처리 이미지 균등화 -> 품질확인 필요 \n3. 이미지 인식률 최대한 향상 \n4. 같은 모델일 필요 없다."
},
{
"alpha_fraction": 0.3769111931324005,
"alphanum_fraction": 0.39809882640838623,
"avg_line_length": 17.550477981567383,
"blob_id": "d121141b16c26396fbf3710d3b7738f19df34a2e",
"content_id": "06665570cf97a181f4e6c1c3f879c27661008610",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 19619,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 941,
"path": "/Python/TestDummy.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n\n\n\n\n\n\n\n############################################################\n\n# 39\n\n\n# def hello():\n# print('start')\n# print('hello')\n# print('end')\n \n# def world():\n# print('start')\n# print('world')\n# print('end')\n \n# hello()\n# world()\n\n\n\n\n############################################################\n\n# 38\n\n# def RandomNum(x):\n \n# import random \n# tmp = list(range(1,46))\n# random.shuffle(tmp)\n# # print('log1')\n# x = int(x)\n# cnt = 0\n# number = []\n \n# for num in tmp:\n# cnt += 1 \n# # print('log2')\n# if cnt <= x : \n# # print(num)\n# number.append(num)\n# pass\n\n# number = [num for num in tmp (cnt += 1 if cnt <= x)]\n# # print('Count : %s' % len(number), number)\n# # print('Count : %s' % len(number))\n# return number\n\n# # rang = 1\n# print(rang < 100)\n\n############################################################\n\n# 37\n# def RandomNum(x):\n \n# import random \n# tmp = list(range(1,46))\n# # try:\n \n# # except Exception as e :\n# # print('범위를 벗어났습니다 1 - 45 까지만 가능합니다.', e)\n\n# random.shuffle(tmp)\n# # print('log1')\n# x = int(x)\n# cnt = 0\n# number = list()\n \n# for num in tmp:\n# cnt += 1 \n# # print('log2')\n# if cnt <= x : \n# # print(num)\n# number.append(num)\n# pass\n\n# # print('Count : %s' % len(number), number)\n# # print('Count : %s' % len(number))\n# return number\n\n\n# # print(findnum)\n\n# def Checker( rang=6 ):\n\n# myLotto = [ i for i in map(int, input('1-45까지 6개의 숫자를 입력하세요 : ').split())]\n# # print(myLotto)\n# if len(myLotto) != rang:\n# raise Exception(f'{len(myLotto)} 는 6 개') \n\n# elif len(set(myLotto))!= rang:\n# raise Exception(f' 값이 중복 됩니다.')\n\n# LottoWinningNumber = sorted(RandomNum(int(rang)))\n# # print(findnum)\n# c = 0\n# dum = []\n# for i in myLotto :\n\n# if i in LottoWinningNumber:\n# c += 1\n# print(f\"{c}개 맞았습니다.\")\n\n# else:\n# dum.append(i)\n \n# print(f'{c}개 맞았습니다. {sorted(dum)} not in {LottoWinningNumber}') \n \n# try:\n# Checker()\n\n# except Exception as e: # 하위 코드 블록에서 예외가 발생해도 실행됨\n# print('스크립트 파일에서 예외가 발생했습니다.', e)\n\n############################################################\n\n# 36\n\n# # 올바른 값을 넣지 않으면 에러를 발생시키고 적당한 문구를 표시\n# def checker( list , index):\n\n# if mine not in allowed:\n# raise Exception('잘못된 값을 넣었습니다!') \n# print(mine)\n\n# if yours not in allowed: \n# raise Exception('잘못된 값을 넣었습니다!') \n# print(yours)\n\n# try:\n# rsp('가위', '바') # 함수를 try문 안에 집어 넣음 \n\n# except Exception as e: # 하위 코드 블록에서 예외가 발생해도 실행됨\n# print('스크립트 파일에서 예외가 발생했습니다.', e)\n\n\n\n# def idx_print(list, index):\n# \t\"\"\"\n# \tlist 와 index를 입력받아야함 \n# \t\"\"\"\n# \ttry:\n# \t\tprint(list.pop(index))\n# \texcept IndexError:\n# \t\tprint(f'{index} : index의 값을 가져올 수 없습니다.')\n\n# idx_print([1,2,3], 1 )\n# idx_print([1,2,3], 10 )\t # index 길이 초과 \n# \t\t\t\t\t\t# -> 10 : index의 값을 가져올 수 없습니다.\n\n\n############################################################\n\n# 38\n\n# # 190이 넘는 학생을 발견하면 반복을 종료\n# classRoom = {'1반' : [150, 156, 179, 191, 199], '2반' : [150, 195, 179, 191, 199]}\n\n# try:\n# for class_number, students in classRoom.items():\n# for student in students:\n# if student > 190:\n# print(class_number, '190을 넘는 학생이 있습니다.')\n# # break # 바로 상위 for문은 종료되지만 최고 상위 for문은 종료되지 않는다.\n# raise StopIteration\n# # 예외가 try 문 안에 있지 않으면 에러 발생시 프로그램이 멈춘다.\n# except StopIteration:\n# print('정상종료') \n\n############################################################\n\n# 37\n\n# # Try & Except\n# def index_print(list, index):\n\n# try:\n# print(list.pop(index))\n# except IndexError:\n# print('{} index의 값을 가져올 수 없습니다.'.format(index))\n\n# index_print([1,2,3], 5) # 5 index의 값을 가져올 수 없습니다.\n\n# # if 문\n# def index_print(list, index):\n# if index < len(list):\n# print(list.pop(index))\n# else:\n# print('{} index의 값을 가져올 수 없습니다.'.format(index))\n\n# index_print([1,2,3], 5) # 5 index의 값을 가져올 수 없습니다.\n\n\n############################################################\n\n# 36\n\n# y = [10, 20, 30]\n \n# try:\n# index, x = map(int, input('인덱스와 나눌 숫자를 입력하세요 : ').split())\n# print(y[index] / x)\n\n# # 숫자를 0으로 나눠서 에러가 발생했을 때 실행됨\n# except ZeroDivisionError as err : \n# print('숫자를 0으로 나눌 수 없습니다.', err)\n\n# # 범위를 벗어난 인덱스에 접근하여 에러가 발생했을 때 실행됨\n# except IndexError as err: \n# print('잘못된 인덱스입니다.', err)\n\n# except ValueError as err: \n# print('벗어난 범위 입니다.', err)\n\n############################################################\n\n# 35\n\n# y = [10, 20, 30]\n \n# try:\n# index, x = map(int, input('인덱스와 나눌 숫자를 입력하세요 : ').split())\n# print(y[index] / x)\n\n# # 숫자를 0으로 나눠서 에러가 발생했을 때 실행됨\n# except ZeroDivisionError: \n# print('숫자를 0으로 나눌 수 없습니다.')\n\n# # 범위를 벗어난 인덱스에 접근하여 에러가 발생했을 때 실행됨\n# except IndexError: \n# print('잘못된 인덱스입니다.')\n\n# except ValueError: \n# print('벗어난 범위 입니다.')\n\n############################################################\n\n# 34\n\n\n# try:\n# num = int(input('숫자만!:'))\n# print(f'{num}는 숫자입니다.')\n\n\n# except: # 예외가 발생했을 때 실행됨\n# print('숫자가 아닙니다.예외가 발생했습니다.')\n\n############################################################\n\n# 33\n\n# from abc import *\n \n# class CookBase(metaclass=ABCMeta):\n# \"\"\"\n# 반드시 해야 하는 일을 추상메소드로 구현 \n# \"\"\"\n# @abstractmethod\n# def FindRecipe(self):\n# pass\n \n# @abstractmethod\n# def Ingredients(self):\n# pass\n \n# class Cook(CookBase):\n# \"\"\"\n# 구현할때 Base에서 구현한 item(@abstractmethod 추상메소드)은\n# 자식클래스에서 모두 구현 해야한다 - 아니면 에러발생 \n# \"\"\"\n# def FindRecipe(self):\n# print('요리 레시피 준비')\n \n# def Ingredients(self):\n# print('요리재료 준비')\n \n# james = Cook()\n# james.FindRecipe()\n# james.Ingredients()\n\n\n\n############################################################\n\n# 32\n\n# class Father:\n \n# def __init__(self):\n# self.fname = '김우빈'\n\n# def fatherName(self):\n# print(f'아빠는 {self.fname} ,')\n\n# class Mather:\n\n# def __init__(self):\n# self.mname = '신민아'\n\n# def matherName(self):\n# print(f'엄마는 {self.mname} ,')\n\n# class Child(Father,Mather):\n\n# def __init__(self):\n# # super().__init__()\n# Father.__init__(self)\n# Mather.__init__(self)\n# self.name = '김빈아'\n\n# def greeting(self):\n# super().__init__()\n# print(f'저는 {self.name}입니다.')\n\n# child = Child()\n# print(child.__dict__)\n\n# child.fatherName()\n# child.matherName()\n# child.greeting()\n\n############################################################\n\n# 31\n\n# class Person:\n\n# def __init__(self):\n# print('부모 - 생성자')\n# self.hello = '안녕하세요!'\n \n# class Doctor(Person):\n\n# def __init__(self):\n# print('자식 - 생성자')\n# super().__init__() # super()로 부모 __init__ 호출\n# self.hospital = 'Severance!'\n\n\n# Joy = Doctor()\n# print(Joy.hello) \n# print(Joy.hospital) \n\n############################################################\n\n# 30 - 미완\n\n# class Person:\n\n# def greeting(self):\n# print('안녕하세요!')\n \n# class PatientChart(Person):\n# \"\"\"\n# Person을 상속 받음\n# \"\"\"\n# def __init__(self):\n\n# self.patient_chart = [] # Person 인스턴스를 담을 그릇\n\n# def appendPatient(self, preson):\n\n# self.patient_chart.append(preson)\n# return self.patient_chart\n \n\n\n# Joy = PatientChart()\n# Joy.greeting() \n# Joy.appendPatient('k')\n# # print(Joy())\n# print(Joy) \n\n############################################################\n\n# 29\n\n# class Person:\n\n# def greeting(self):\n# print('안녕하세요!')\n \n# class Doctor(Person):\n# \"\"\"\n# Person을 상속 받음\n# \"\"\"\n# def checkUp(self):\n# print('어디가 아프신가요?')\n\n\n# Joy = Doctor()\n# Joy.greeting() \n# Joy.checkUp() \n\n############################################################\n\n# 28\n\n# class Mall:\n# \"\"\"\n# wMart와 eMart 중 어디가 더 저렴할까 ?\n# \"\"\"\n\n# @staticmethod\n# def wMart(a, b):\n# print(f'$ {int((a + b)*0.8)}')\n \n# @staticmethod\n# def eMart(a, b):\n# print(f'$ {a + b}')\n\n# apple = 10 \n# soup = 20\n\n# Mall.wMart(apple, soup) \n# Mall.eMart(apple, soup) # 클래스 -> 바로 메서드 호출\n\n############################################################\n\n# 27\n\n# class creditCard:\n# \"\"\"\n# 1만불 한도의 신용카드 \n# \"\"\"\n# __money_limit = 10000 # 비공개 클래스 속성\n \n# def show_money_limit(self):\n# print(creditCard.__money_limit) # 내부 접근\n \n \n# amax = creditCard()\n# amax.show_money_limit() # 1만불\n \n# print(creditCard.__money_limit) # 외부 접근 불가\n\n############################################################\n\n# 26\n# class Person :\n# # bag = [] \n# def __init__(self):\n# self.bag = []\n\n# def putBag(self, stuff):\n# self.bag.append(stuff)\n\n# Jerry = Person()\n# Jerry.putBag('Books')\n\n# Joy = Person()\n# Joy.putBag('wallet')\n\n# print(Jerry.bag) # 제리의 가방\n# print(Joy.bag) # 조이의 가방 \n\n############################################################\n\n# 25\n\n# class Person :\n# bag = [] \n\n# def putBag(self, stuff):\n# self.bag.append(stuff)\n\n# Jerry = Person()\n# Jerry.putBag('Books')\n\n# Joy = Person()\n# Joy.putBag('wallet')\n\n# print(Jerry.bag) # 제리의 가방\n# print(Joy.bag) # 조이의 가방 \n\n############################################################\n\n# 24\n\n# class Person:\n\n# \"\"\"\n# 매개변수 : self, 이름, 나이, 주소 \n# + 지갑\n# \"\"\"\n\n# def __init__(self, name, age, address, wallet):\n\n# self.hello = '안녕!'\n# self.name = name # self에 넣어서 속성으로 만듦\n# self.age = age\n# self.address = address\n# self.__wallet = wallet # __를 붙여서 비공개 속성\n\n# def Greeting(self):\n# # print('{0} 나는 {1}야!'.format(self.hello, self.name))\n# print(f'{self.hello} 나는 {self.name}야!')\n\n# def pay(self, amount):\n\n# self.__wallet -= amount # 비공개 속성은 클래스 안의 메서드에서만 접근할 수 있음\n# print('잔여 금액 : {0}원'.format(self.__wallet))\n\n# Joy = Person('조이', 30, '인천', 500000 ) # 인스턴스 생성 \n# # Joy.__wallet # 비공개 속성이라 외부에서 접근 불가능 -> 에러발생 \n# Joy.pay(3900) \n# # Joy.Greeting()\n\n############################################################\n\n# 23\n\n# class Person:\n# \"\"\"\n# 매개변수 : self, 이름, 나이, 주소 \n# \"\"\"\n\n# def __init__(self, name, age, address):\n# self.hello = '안녕!'\n# self.name = name\n# self.age = age\n# self.address = address\n\n# def Greeting(self):\n# # print('{0} 나는 {1}야!'.format(self.hello, self.name))\n# print(f'{self.hello} 나는 {self.name}야!')\n\n# Joy = Person('조이', 30, '인천' )\n# Joy.Greeting()\n\n# print('이름:', Joy.name) \n# print('나이:', Joy.age) \n# print('주소:', Joy.address) \n\n############################################################\n\n# 22\n\n# class Person:\n# def greeting(self): # 메소드(Method)\n# print('Hello')\n\n# Jerry = Person() # 인스턴스(instance)\n# Jerry.greeting()\n\n############################################################\n\n# 클래스\n\n############################################################\n\n# 21\n\n# def Factorial(n):\n# if not isinstance(n, int) or n < 0: # n이 정수가 아니거나 음수이면 함수를 끝냄\n# return None\n# if n == 1:\n# return 1\n# return n * Factorial(n - 1)\n\n# print(Factorial(3))\n\n############################################################\n\n# 20\n\n# def factorial(n):\n# if n == 0: \n# return 0 \n# return n * factorial(n - 1) \n \n# print(factorial(5))\n\n\n############################################################\n\n# 19\n\n# def Func(cnt):\n# if cnt == 0: # 종료 조건을 만듦. \n# # cnt가 0이면 다시 Func 함수를 호출하지 않고 끝냄\n# return\n \n# print('Hello, world!', cnt)\n \n# cnt -= 1 # cnt를 1 감소시킨 뒤\n# Func(cnt) # 다시 Func에 넣음\n \n# Func(5) # Func 함수 호출\n\n\n############################################################\n\n# 18\n\n# def Closr(tag): \n# tag = tag \n\n# def Func(input): \n# txt = input \n# print(f'<{tag}>{txt}<{tag}>')\n\n# return Func \n\n# h1Func = Closr('h1') \n# pFunc = Closr('p') \n\n# h1Func('h1태그의 내부') \n# pFunc('p태그의 내부') \n\n############################################################\n\n# 17\n\n# def Closr(tag): \n# txt = '안녕하세요' \n# tag = tag \n\n# def Func(): \n# print(f'<{tag}>{txt}<{tag}>')\n\n# return Func \n\n# h1Func = Closr('h1') \n# pFunc = Closr('p') \n\n# h1Func() \n# pFunc() \n\n############################################################\n\n# 16\n\n# def Func():\n# Code = 'Func의 test'\n\n# def FuncInFunc():\n# print(Code)\n \n# return FuncInFunc\n\n# MyFunc = Func()\n\n# d = [dir(MyFunc),\n# type(MyFunc.__closure__),\n# MyFunc.__closure__, \n# MyFunc.__closure__[0],\n# dir(MyFunc.__closure__[0]),\n# MyFunc.__closure__[0].cell_contents\n# ]\n\n# for i in d :\n# print(i)\n# print('='*50)\n\n############################################################\n\n# 15\n\n# def outer_func(): #1\n# message = 'Hi' #3\n\n# def inner_func(): #4\n# print(message) #6\n\n# return inner_func #5\n\n# my_func = outer_func() #2\n\n# print(my_func)\n\n############################################################\n\n# 14\n\n# 연습 문제 \n\n# def cnt():\n# i = 0 \n# def count(x):\n# nonlocal i\n# i = i + 1\n# print(i)\n# return count\n\n# c = cnt()\n# for i in range(10):\n# c(i)\n\n# print('='*50)\n\n# def cnt_an():\n# i = 0 \n# def count_an(x):\n# nonlocal i\n# i += 1\n# return i \n# return count_an\n\n# my_fnc = cnt_an()\n# for k in range(10):\n# print(my_fnc(k), end= ' ')\n\n############################################################\n\n# 13\n\n# def calc():\n# a = 3\n# b = 5\n# total = 0\n# def mul_add(x):\n# nonlocal total\n# total = total + a * x + b\n# print(total)\n# return mul_add\n \n# c = calc()\n# c(1)\n# c(2)\n# c(3)\n\n############################################################\n\n# 12\n\n# def closr(): \n# i = 10\n# j = 10\n# tal = 0\n\n# def mul(x): \n# nonlocal tal\n# tal = tal + i * x + j \n# print(tal) \n# return mul\n\n# y = closr() \n# # print(y(1))\n# # print(y(1),y(2),y(3))\n# y(1)\n# y(2)\n# y(3)\n\n# # Output\n# # >>> 20\n# # >>> 50\n# # >>> 90\n# # >>> None None None\n\n############################################################\n\n# 11\n\n# # lambda 사용 \n\n# def closr(): \n# i = 10\n# j = 10\n\n# return lambda x: i * x + j # 람다 표현식을 반환 \n\n# y = closr() \n# print(y(1),y(2),y(3),y(4),y(5))\n\n# # Output\n# # >>> [20, 30, 40, 50, 60]\n\n############################################################\n\n# 10\n\n# nonlocal를 사용하는 이유 \n# def outer():\n# a = 10\n# def inner():\n# a += 10\n# print('a:', a)\n# inner()\n# outer()\n\n# Output\n# >>> UnboundLocalError: local variable 'a' referenced before assignment\n\n\n# def outer():\n# a = 10\n# def inner():\n# nonlocal a\n# a += 10\n# print('a:', a)\n# inner()\n# outer()\n\n############################################################\n\n# 9\n\n# ## 클로저 형태의 함수 \n\n# def closr(): # 1. 선언 \n# i = 10\n# j = 10\n\n# def mul(x): # 4. 호출\n# return i * x + j # 5. 함수 밖의 변수 호출해서 연산 후 리턴 \n\n# return mul # 3. mul 함수자체를 반환 -> ()는 사용하면 x \n\n# y = closr() # 2. 호출 \n# print(y(1),y(2),y(3),y(4),y(5))\n\n# # Output\n# # >>> 20 30 40 50 60 \n\n# dum = [ y(i) for i in range(1,6)]\n# print(dum) \n\n# # Output\n# # >>> [20, 30, 40, 50, 60]\n\n############################################################\n\n# 8\n\n# # global a\n# a = 1\n \n# def test():\n# # global a\n# a = 3\n# b = 2\n \n# return a + b\n \n \n# print('>>> test\\n',test())\n# print('>>> a\\n',a)\n\n############################################################\n\n# 7\n\n## global변수 사용 \n\n# x = 1 \n# def Fst_Phase():\n# x = 50 # Fst_Phase의 지역변수 x\n# def Fst_Part():\n# x = 70 # Fst_Part의 지역변수 x\n# def Fst_Step():\n# global x\n# x = x + 80\n# print(x)\n\n# Fst_Step()\n\n# Fst_Part()\n\n# Fst_Phase()\n\n\n# # Output\n\n############################################################\n\n# 6\n# def Outer():\n# x = 35 # 지역변수 x\n# def Inner():\n# nonlocal x\n# x = 25 \n# Inner()\n# print(x) # 지역변수 출력 \n\n# Outer() \n\n############################################################\n\n# 5\n# def Outer():\n# x = 35 # 지역변수 x\n# def Inner():\n# x = 25 \n# Inner()\n# print(x) # 지역변수 출력 \n\n# Outer()\n\n############################################################\n\n# 4\n# def Func():\n# Code = 'Func의 test'\n\n# def FuncInFunc():\n# print(Code)\n \n# FuncInFunc()\n\n# Func()\n\n############################################################\n\n# # 3\n# def Func():\n# Code = 'Func의 test'\n\n# def FuncInFunc():\n# print(Code)\n \n# return FuncInFunc()\n\n# Func()\n\n############################################################\n\n# 2\n\n# x = 100 \n# def val():\n# x = 10\n# print(x) # 전역변수 \n\n# val()\n# print(x)\n\n############################################################\n\n# 1 \n\n# x = 100 # 전역 변수 \n# def val():\n# print(x) # 전역변수 \n\n# val()\n# print(x)\n\n############################################################"
},
{
"alpha_fraction": 0.577497124671936,
"alphanum_fraction": 0.611940324306488,
"avg_line_length": 23.85714340209961,
"blob_id": "cfd928747ae29b9159c7dcba293420a852a10aff",
"content_id": "4d4e3193867eaf9e924195d8102a9324525c7612",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 893,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 35,
"path": "/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# Daily\n\n##### JUST DO IT RIGHT NOW\n\n<br>\n\n\n## Rule\n---\n\n- **Commit Rule** (2020.10.06~)\n\n - First \n - When you add anything, Please write down date format like this. \n ex :\n add.Title_YYYY.MM.DD \n chg.Filename_Reason_YYYY.MM.DD or Please write down reason at sub msg box\n\n - Second\n - When you are made file name or any kind of commit title. Please write down like this. \n ex : \n coffeeprice.py => CoffeePrice.py, MUDgame.py => MUDGame.py\n - Use file name style Camel case\n \n <!-- - Third\n - -->\n---\n<br><br>\n\n### History\n\n0. Rule creation date : 2019.12.18\n1. Coding_Library move - Private Repository\n2. 자주 사용하는 코드 - 정리본 dir move -> [MySourceCode](https://github.com/Jerrykim91/MySourceCode)\n3. Have kept the rules until now but change Commit Rule -> Rule creation date : 2020.10.06\n\n"
},
{
"alpha_fraction": 0.5218508839607239,
"alphanum_fraction": 0.5372750759124756,
"avg_line_length": 16.68181800842285,
"blob_id": "c14168e9b8d765949504fe9240daf9586fc70bc7",
"content_id": "d9fa3676cb6b30e164c92136374a5b1d053abe0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 22,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_3.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n\"\"\"\n인스턴스 생성자(constructor)와 같은 용도로 사용\n\"\"\"\n\nclass Person(object):\n\n def __init__(self, year, month, day, sex):\n\n self.year = year\n self.month = month\n self.day = day\n self.sex = sex\n\n def __str__(self):\n\n return '{}년 {}월 {}일생 {}'.format(self.year, self.month, self.day, self.sex)\n\n\nJun = Person(1988, 7, 4, '남성')\nprint(Jun)"
},
{
"alpha_fraction": 0.5142857432365417,
"alphanum_fraction": 0.5324675440788269,
"avg_line_length": 19.3157901763916,
"blob_id": "317556e0cf5fd28ac879bccafe58334209adcc88",
"content_id": "56386ebf2ad019b8f77b8f94fbaac9ea1a6b7429",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 495,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 19,
"path": "/Project/Mini Project/test.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# test.py\n\n# 기본 틀\nclass Enermy:\n '''\n - SPEED, HP, EXP, LEVEL, COLOR, x, y 등 속성이 있다 \n - move, attack, demeage등의 행동을 가지고 있다\n - 이런 클레스를 구현하시오\n - 전제하지 않는 것들은 가정하시오\n '''\n # 맴버 변수\n SPEED, HP, EXP, LEVEL, COLOR, x, y = (0,0,0,0,0,0,0)\n \n # 맴버 함수 \n def move(self):pass\n def attack(self):pass\n def demeage(self):pass\n # 생성자\n def __init__(self):pass"
},
{
"alpha_fraction": 0.3672182857990265,
"alphanum_fraction": 0.39558708667755127,
"avg_line_length": 21.678571701049805,
"blob_id": "1468570e8cc962194e9a58e1f541f357ff8da01f",
"content_id": "c06fb107a7f6469ba2e90f15d6f1008a24d90a77",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1281,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 56,
"path": "/Project/Mini Project/Src_NoComment/t.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "score_case1 = {\n 'A+' : '4.5',\n 'A' : '4.0',\n 'A-' : 'X' ,\n 'B+' : '3.5',\n 'B' : '3.0',\n 'B-' : 'X' , \n 'C+' : '2.5', \n 'C' : '2.0',\n 'C-' : 'X',\n 'F' : '0' }\n\n# print(score_case1['X'])\nscore_case2 = {\n 'A+' : '4.3',\n 'A' : '4.0',\n 'A-' : '3.7',\n 'B+' : '3.5',\n 'B' : '3.0',\n 'B-' : '2.7', \n 'C+' : '2.5',\n 'C' : '2.0',\n 'C-' : '1.7',\n 'F' : '0' }\n\n# User_input_score = input('점 수 :')\n# User_input_grader = input('취득학점 :')\n\nUser_input_score = 'A-'\n# func_loof\ndef func_loof(User_input_score ,case = score_case1): \n f_loop = [gdr for gdr in case ]\n # print(f_loop)\n # Run = True\n # while Run :\n for num in range(len(f_loop)):\n # print(num)\n # print(User_input_score)\n # print('get num')\n if User_input_score == f_loop[num]:\n # print( case[f_loop[num]])\n # print('match')\n if case[f_loop[num]] == 'X':\n print('False')\n else:\n continue\n # Run = False\n \n return f_loop[num], case[f_loop[num]] \n \n # break\n # print(f_loop[num], case[f_loop[num]])\n \n # return f_loop[num], case[f_loop[num]]\n\nfunc_loof(User_input_score)"
},
{
"alpha_fraction": 0.6600000262260437,
"alphanum_fraction": 0.6600000262260437,
"avg_line_length": 15.333333015441895,
"blob_id": "4d7c86a3d685693a345db37085c106c866e920c8",
"content_id": "59e8d0a4ee1aa75e5aba036715881984e342aeed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 3,
"path": "/OR/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 오퍼레이션 리서치 (OR, Operations Research)\n\n## 그냥 공부용 \n"
},
{
"alpha_fraction": 0.6735537052154541,
"alphanum_fraction": 0.6735537052154541,
"avg_line_length": 12.5,
"blob_id": "de7a7e133f60257e7d8f07dd56bb155d212dfb16",
"content_id": "158403d7d8eb9824a81fe316f52a1ddd2e662aa9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 444,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 18,
"path": "/R/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# R\n##### JUST DO IT RIGHT NOW\n\n<br><br>\n\n## Main Reference\n\n<br>\n\nMain Reference는 공공데이터 인턴쉽 수업 내용을 복습한 것으로 데이터는 공개하지 않겠습니다. 또한 공부하고 이해한 내용만 작성한 것입니다.\n\n각 페이지에서 제공하는 Reference는 그 페이지를 공부할 때 참고한 내용입니다.\n\n문제 될 시에는 메일을 통해 알려주시면 감사합니다. \n\n<br>"
},
{
"alpha_fraction": 0.35384616255760193,
"alphanum_fraction": 0.372307687997818,
"avg_line_length": 3.2337663173675537,
"blob_id": "20c55433be4e2d3c9202a6a798a700192f3a9ed8",
"content_id": "ec26446eb4703b3154139f01275514ea94db4f7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 77,
"path": "/Python/아직/14.심화_코루틴.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 14. 파이썬 심화 - 코루틴\n\n<br>\n\n# 주제\n\n<br>\n\n## 1.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n## 2.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [내용](주소)"
},
{
"alpha_fraction": 0.45717018842697144,
"alphanum_fraction": 0.4877971112728119,
"avg_line_length": 12.592190742492676,
"blob_id": "04c0e5d4ddcf8172864d67aec8afacd7a8ae37ae",
"content_id": "e0499732f43aefe324ad017d36270459b2bc7755",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8043,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 461,
"path": "/Python/3.심화_클로저.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n#### 3. 파이썬 심화 - 클로저(Closure)\n\n<br>\n\n# 클로저(Closure) \n\n<br>\n\n```py\n\n# 함수안에 함수를 만들어서 지역변수 호출 \n\ndef Func(): # 1. 선언 \n Code = 'Func의 test' # 3. 변수 선언\n\n def FuncInFunc():\n print(Code) # 4. Code변수를 참고하여 출력 \n # 6. 이 함수에서 정의 되지 않았지만 사용됨 -> Func안에 들어있는 모든 코드에 접근가능함\n \n return FuncInFunc() # 5. 호출과 동시에 리턴 -> return 생략가능\n\nFunc() # 2. 실행\n\n# Output\n# >>>> Func의 test\n\n```\n\n<br>\n\n일반 함수와는 다르게 자신의 영역 밖에서 호출된 함수의 변수 값과 레퍼런스를 복사하고 저장한뒤 값들을 엑세스 가능하게 해주는 역활을 한다. \n\n- 어떤 함수를 함수 자신이 가지고 있는 환경과 함께 저장한 레코드 이며 \n - 코드안에 정의 되지 않은 변수를 클로저가 만들어지는 당시의 값과 레퍼런스에 맵핑하여 주는 역할을 한다. \n\n\n- 함수를 둘러싼 환경을 유지하다가, 함수를 호출 할때 다시 꺼내서 사용하는 함수를 클로저라고 한다. \n\n<br>\n<br>\n\n## 클로저(Closure) 사용하기 \n\n<br>\n\n- 함수 내부에서 정의된 함수는 클로저\n- 바깥 함수로부터 생성된 변수값을 변경 또는 저장할 수 있는 함수\n\n<br>\n<br>\n\n### 함수를 클로저 형태로 만드는 방법\n\n<br>\n함수 바깥쪽에 있는 지역변수를 사용해서 연산을 진행 \n\n글로저를 사용하면 프로그램의 흐름을 변수에 **저장가능** \n클로저 = 지역변수 + 코드 묶어서 사용\n\n클로저에 속한 지역변수는 바깥에서 **직접** 접근 할 수 없으므로 데이터를 숨기고 싶을때 사용 \n\n<br>\n\n```py\n\n## 클로저 형태의 함수 \n\ndef Closr(): # 1. 선언 \n i = 10\n j = 10\n\n def mul(x): # 4. 호출\n return i * x + j # 5. 함수 밖의 변수 호출해서 연산 후 리턴 \n\n return mul # 3. mul 함수를 리턴 \n # 함수를 리턴 할때는 함수 이름만 반환 -> ()는 사용하면 x \n\n\ny = Closr() # 2. 호출 \n # y에 저장된 함수 => 클로저\n\nprint(y(1),y(2),y(3),y(4),y(5))\n\n# Output\n# >>> 20 30 40 50 60 \n\ndum = [ y(i) for i in range(1,6)]\nprint(dum) \n\n# Output\n# >>> [20, 30, 40, 50, 60]\n\n```\n\n<br>\n\n### 클로저 만들기 - lambda 사용\n\n<br>\n\n람다 표현식을 이용하면 클로저를 쉽게 만들 수 있다. \n클로저와 람다표현식은 주로 같이 사용하는 경우가 많아서 혼동하기가 쉬운데\n\n- 람다\n - 이름 없는 익명함수\n- 클로저\n - 함수를 둘러싼 환경을 유지하고 이후에 다시 사용하는 함수\n\n두 함수는 다르다. 그렇기 때문에 혼동하지 말자. \n\n<br>\n\n```py\n\n# lambda 사용 \n\ndef Closr(): \n\n i = 10\n j = 10\n\n return lambda x: i * x + j # 람다 표현식을 반환 \n\ny = Closr() \nprint(y(1),y(2),y(3),y(4),y(5))\n\n# Output\n# >>> [20, 30, 40, 50, 60]\n\n```\n\n<br>\n\n## 클로저 심화 \n\n<br>\n\n```py\n\ndef Func():\n Code = 'Func의 test'\n\n def FuncInFunc():\n print(Code)\n \n FuncInFunc()\n\nMyFunc = Func()\n\n```\n\n<br>\n\nMyFunc에 함수가 들어있는지 확인 해보자 \n\n<br>\n\n```py\n\ndef Func():\n Code = 'Func의 test'\n\n def FuncInFunc():\n print(Code)\n \n return FuncInFunc\n\nMyFunc = Func()\nprint(MyFunc)\n\n# Output\n# >>> <function Func.<locals>.FuncInFunc at 0x0000021C2FDEEF78>\n\n```\n\n<br>\n\nFuncInFunc 함수가 할당된 것을 확인 -> MyFunc을 이용해서 FuncInFunc 호출 해보자 !! \n\n**FuncInFunc = MyFunc** \n\n<br>\n\n```py\n\ndef Func():\n Code = 'Func의 test'\n\n def FuncInFunc():\n print(Code)\n \n return FuncInFunc\n\nMyFunc = Func()\nprint(MyFunc)\n\n# Output\n# >>> <function Func.<locals>.FuncInFunc at 0x0000021C2FDEEF78>\n\n```\n\n<br>\n\n이 함수의 상세 내부 구조에 대해서 확인해보자 \n\n<br>\n\n```py\ndef Func():\n Code = 'Func의 test'\n\n def FuncInFunc():\n print(Code)\n \n return FuncInFunc\n\nMyFunc = Func()\n\nd = [dir(MyFunc),\n type(MyFunc.__closure__),\n MyFunc.__closure__, \n MyFunc.__closure__[0],\n dir(MyFunc.__closure__[0]),\n MyFunc.__closure__[0].cell_contents\n ]\n\nfor i in d :\n print(i)\n print('='*50)\n\n```\n\n<br>\n\n### dir(MyFunc) => __closure\\_\\_ 라는 속성을 확인 \n\n```py\n\n>>> ['__annotations__', '__call__', '__class__', '__closure__', '__code__', \n'__defaults__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', \n'__format__', '__ge__', '__get__', '__getattribute__', '__globals__', \n'__gt__', '__hash__', '__init__', '__init_subclass__', '__kwdefaults__',\n'__le__', '__lt__', '__module__', '__name__', '__ne__', '__new__',\n'__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__',\n'__sizeof__', '__str__', '__subclasshook__']\n\n```\n\n<br>\n\n### type(MyFunc.__closure\\_\\_) => __closure__의 타입 - 튜플\n\n```py\n\n>>> <class 'tuple'>\n\n```\n\n<br>\n\n### MyFunc.__closure\\_\\_ => 튜플안을 확인 - 1개의 객체 확인 \n\n```py\n\n>>> (<cell at 0x000001CA797BB6A8: str object at 0x000001CA797D77A0>,)\n\n```\n\n<br>\n\n### MyFunc.__closure\\_\\_[0] => \"cell\" 문자열 객체\n\n```py\n\n>>> <cell at 0x000001CA797BB6A8: str object at 0x000001CA797D77A0>\n\n```\n\n<br>\n\n### dir(MyFunc.__closure\\_\\_[0]) => cell의 속성 - cell_contents 확인 \n\n```py\n\n>>> ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__',\n'__format__', '__ge__', '__getattribute__', '__gt__', '__hash__',\n'__init__', '__init_subclass__', '__le__', '__lt__', '__ne__',\n'__new__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__',\n'__sizeof__', '__str__', '__subclasshook__', 'cell_contents']\n\n```\n\n<br>\n\n### MyFunc.__closure\\_\\_[0].cell_contents => 확인 => Func의 test\n\n```py\n\n>>> Func의 test\n\n```\n\n<br>\n\n언제나 느꼈지만 ... 함수의 내부구조는 복잡하구나를 또 다시 느끼고 ....\n\n<br>\n<br>\n\n## 클로저 응용 및 실습 \n\n<br>\n\n앞에서 배운 변수들을 이용해서 클로저의 지역 변수를 변경해보자.\n\n```py\n\ndef Closr(): \n\n i = 10\n j = 10\n tal = 0\n\n def mul(x): \n nonlocal tal # \n tal = tal + i * x + j # 값이 누적 \n print(tal) \n return mul\n\ny = Closr() \n\nprint(y(1),y(2),y(3))\n\n# Output\n# >>> 20\n# >>> 50\n# >>> 90\n# >>> None None None # print()문 때문에 생성 \n\ny(1)\ny(2)\ny(3)\n\n# Output\n# >>> 20\n# >>> 50\n# >>> 90\n```\n\n<br>\n\n### schoolofweb를 통해 알게 된 건데 이렇게도 활용이 가능하다. \n---\n\n<br>\n\n#### h1태그와 p태그로 문자열을 감싸는 함수\n\n```py\n\ndef Closr(tag): \n\n txt = '안녕하세요' \n tag = tag \n\n def Func(): \n print(f'<{tag}>{txt}<{tag}>')\n\n return Func \n\nh1Func = Closr('h1') \npFunc = Closr('p') \n\nh1Func() \npFunc() \n\n# Output\n# >>> <h1>안녕하세요<h1>\n# >>> <p>안녕하세요<p>\n\n```\n\n<br>\n\n#### 태그안의 문자열을 컨트롤\n\n```py \n\ndef Closr(tag): \n\n tag = tag \n\n def Func(input): \n txt = input \n print(f'<{tag}>{txt}<{tag}>')\n\n return Func \n\nh1Func = Closr('h1') \npFunc = Closr('p') \n\nh1Func('여긴 h1태그의 내부') \npFunc('여긴 p태그의 내부') \n\n# Output\n# >>> <h1>여긴 h1태그의 내부<h1>\n# >>> <p>여긴 p태그의 내부<p>\n\n```\n\n<br>\n\n#### 1~10까지 출력 하는 연습문제 \n\n```py\n\n# MyFunc\ndef cnt():\n i = 0 \n \n def count(x):\n nonlocal i\n i = i + 1\n print(i)\n return count\n\nc = cnt()\n\nfor i in range(10):\n c(i)\n\nprint('='*50)\n\n# 정답 \n\ndef cnt_an():\n i = 0 \n\n def count_an(x):\n nonlocal i\n i += 1\n return i \n return count_an\n\nmy_fnc = cnt_an()\n\nfor k in range(10):\n print(my_fnc(k), end= ' ')\n\n```\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n- SchoolOfWeb : <http://schoolofweb.net/> <br>\n\n\n"
},
{
"alpha_fraction": 0.38309550285339355,
"alphanum_fraction": 0.4665203094482422,
"avg_line_length": 21.75,
"blob_id": "cc6cea3f96403ddf6a5b538da11c6f2670e2544b",
"content_id": "f8fd3afb0eacfa57ec1d224df3ef0090aa641742",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1087,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 40,
"path": "/CodingTest/Recursive.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# Recursive\n\n# 100명이 테이블에 착석해야함 \n# 1명은 안됨 2명이상만 착석이 가능 \n\n# 박스 \n# 가로 : 테이블수 상한 => 10\n# 세로 : 테이블에 앉을 사람 상한 => 100\n\n# 10*100 => 1000\n\n#m , n = 10, 100\nm= 10\nn = 100\ntab_cnt = [0] * (m+1)\n# print(tab_cnt, len(tab_cnt)) # [[1,0*100], 0, 0, 0, 0, 0, 0, 0, 0, 0, 0] , 11\nfor i in range(0, m+1):\n # print(i) \n tab_cnt[i] = [0]*(n+1)\n # print(tab_cnt[i],len(tab_cnt[i])) # i번수 만큼 한번씩 [0]*101을 출력\n tab_cnt[i][0] = 1\n # print(tab_cnt[i],len(tab_cnt[i])) # i번수 만큼 한번씩 리스트의 인텍스 0자리에 1을 할당\n# print(type(tab_cnt))\n\nfor i in range(1, m+1):\n # print(i) # 1 ~ 10 \n i = int(i)\n for j in range(2, n+1):\n j = int(j)\n # print(j) #2~ 100까지 순서대로 한번씩 i번 출력 \n if((i >=2)and(j>=i)): # ??\n tab_cnt[i][j] = tab_cnt[i][j-1]\n # print(tab_cnt[i][j])\n if i > 2 : # ???\n tab_cnt[i][j] += tab_cnt[i-1][j]\n\n# print(tab_cnt[8][:])\n\n\nprint(tab_cnt[m][n])\n\n"
},
{
"alpha_fraction": 0.617125391960144,
"alphanum_fraction": 0.6382262706756592,
"avg_line_length": 17.480226516723633,
"blob_id": "0c948bbbf74335d552805adec1359d2b8ec6af60",
"content_id": "d3f6df105c4474e7aca7ff15618838449790271c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4644,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 177,
"path": "/Virtual_Environment/SparkEnv_func.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# SparkEnv_func\n\n\n## 패키지 불러오기 \n```py\nimport pyspark # pyspark\n\nimport findspark # findspark\n# findspark 패키지를 통해서 스파크를 찾아내고 \n# pyspark.SparkContext 명령어로 스파크 접속지 점을 특정\n```\n\n\n\n<br>\n\n# RDD\n\nRDD는 외부데이터를 읽어서 처리하거나 자체적으로 컬렉션 데이터를 생성하여 처리할 수 있다. \n\n또한 데이터 처리는 파티션 단위로 분리해서 작업을 처리한다. \n\n\nRDD 타입 \n- 트랜스포메이션(transformation)\n - 필터링 같은 작업으로 RDD에서 새로운 RDD를 반환 \n- 액션(action) \n - RDD로 작업을 처리하여 결과를 반환\n - 실행될 때마다 새로운 연산을 처리 \n - 만약 작업의 처리 결과를 재사용하고 싶으면 persist() 메소드를 사용하여 결과를 메모리에 유지할 수 있다. \n \n \nRDD는 SparkContext객체를 이용하여 생성이 가능하다. \n- SparkContext\n - SparkConf 객체를 이용해서 파라메터값을 설정 혹은 생성한다. \n - 초기화도 가능하다. \n\n<br>\n\n## RDD 데이터 이용\n\n1. 내부 데이터를 이용하는 방법(Parallelized Collections)\n - parallelize() 메소드를 이용\n - 연산 : map(), reduce(), filter() 등의 RDD 연산을 이용해서 처리한다. \n\n\n2. 외부데이터 이용 \n - textFile() 메소드를 이용\n\n<br>\n\n## spark 세션을 생성해주기위해서 다음과 같이 컴파일을 진행해준다. \n\n```py\nfrom pyspark import SparkContext, SparkConf\nfrom pyspark.sql import SparkSession\n\nconf = pyspark.SparkConf().setAppName('appName').setMaster('local[2]')\n# sc = SparkContext(master='local[2]', appName='appName')\nsc = pyspark.SparkContext(conf=conf)\nspark = SparkSession(sc)\n# sc.stop()\n\n```\n### 만약 세션이 끝나면 코드를 실행한다. \n\n```py\n\n# 리스트에서 RDD 생성 \ndata = list(range(1,6))\n\n# inputdata의 새로운 집합을 생성하기위함 \nrdd = sc.parallelize(data, 4) # data를 메모리에 저장될때 4조각으로 쪼개서 메모리에 저장 \n\nsc.defaultParallelism\nrdd1 = rdd.map(lambda x: x * 2)\n# map() : 데이터를 가공한다. 반환타입이 같지 않아도 된다.\n\n# collect()는 액션이며 실제로 collect()가 호출되면 RDD가 메모리에 올려져 계산이 이루어진다. \n# 각 테스크의 엔트리들을 수집한후 그결과를 다시 SparkContext전송한다.\nrdd1.collect()\n\nrdd2 = rdd.filter(lambda x: x % 2 == 0)\n# filter() : 함수의 결과가 참인경우에만 요소들을 통과시키는 함수이다. 결과로 새로운 RDD를 생성한다 \n# 액션은 아니다. \n\nrdd2.collect()\n\n```\n<br>\n\n## Test_1 - code( filter를 테스트 해보자 ) \n\n``` py\ndef ten(val):\n if(val<10):\n return True\n else:\n return False\n \n\nFilter_test = rdd1.filter(ten)\nFilter_test.collect()\n\n# 주어진 조건에 해당하는 데이터만 선별해 오는 것을 알 수 있다.\n```\n\n<br>\n\n### Action\n\n- reduce(func) \n- take(n) \n- collect() \n- takeOrdered(n, key=func) \n\n<br>\n\n```py\nrdd3 = sc.parallelize([1, 4, 2, 2, 3])\nrdd3.distinct().collect()\n# distinct() : 중복을 제거한 RDD를 반환한다. \n\nrdd4 = sc.parallelize([1, 2, 3])\nrdd4.map(lambda x: [x, x+5]).collect()\n\nrdd4.flatMap(lambda x: [x, x+5]).collect()\n# 차원 변경 ?\n# iterator 안에 포함된 값으로 RDD를 구성하기 원할 경우에 flatmap()을 사용\n\nrdd = sc.parallelize([1,2,3])\nrdd.reduce(lambda a, b : a * b)\n\n# reduce(func): 계산된 값을 하나로 합쳐준다. \n# reduce은 파티션 레벨 단위로 적용된다.\n\nrdd.take(2)\n# take(): RDD에서 해당 개수만큼 데이터를 가져온다. \n\nrdd5 = sc.parallelize([5, 3, 1, 2])\nrdd5.takeOrdered(3, lambda s: -1 * s)\n# takeOrdered() : 해당 개수만큼 데이터를 가져오는데 정렬해서 가져온다.(오름차순, 내림차순)\n\n```\n\n\n## Test_2 - code( 데이터 세트를 넘겨주고 RDD를 생성 ) \n\n``` py\n\n# 리스트를 생성\ntmp_data = range(1,10001)\n\n# 담자 \nplc_RDD = sc.parallelize(data,10) # 파티션은 제한이 없는것인가? \nprint('type of plc_RDD: {0}'.format(type(plc_RDD)))\n\n# 해당 RDD의 파티션 숫자를 확인\nplc_RDD.getNumPartitions() \n\nprint(plc_RDD.toDebugString()) \n >> b'(10) ParallelCollectionRDD[2] at parallelize at PythonRDD.scala:195 []'\n\nprint('plc_RDD id: {0}'.format(plc_RDD.id())) # RDD id 확인 \n >>> plc_RDD id: 2\n\n```\n\n<br>\n\n<참조><br>\n빅데이터 - 스칼라(scala), 스파크(spark)로 시작하기: <https://wikidocs.net/28387> \n\\[SPARK\\]Tutorial(pyspark) : <https://yujuwon.tistory.com/entry/spark-tutorial>\n\n<br>"
},
{
"alpha_fraction": 0.5566820502281189,
"alphanum_fraction": 0.5806451439857483,
"avg_line_length": 11.904762268066406,
"blob_id": "b1d2d18293a97fadbfac53ee21dfd3a634fdace7",
"content_id": "83d150938ebe031a58f24567173ce5a4a6c33b6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2153,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 84,
"path": "/Project/Solution_Base/Problem_3.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# Problem : 3차시 \n<br>\n\n진행중인 프로젝트에 관한 여러가지 이슈 그리고 해결방안을 포스팅하고자 한다. \n\n<br>\n\n## 일자 \n- 2020년 06월 01일 월요일 \n\n<br>\n\n## 진행 상황\n\n현재 전체적인 진행상황은 아래와 같다. \n\n- 이미지 분석 : 45 % \n- 텍스트 분석 : 85 % (감소)\n- 시스템 구현 : 10% \n\n<br>\n<br>\n\n## 이슈 \n\n### 이슈 1 : 모델 설계 \n<br>\n\n시간상 전체적인 모델 룰을 정하고 진행하기로 했다. \n\n1. 모델의 손실 값이 아직까지는 줄어 드는 것을 봐서는 에포크 값을 늘려도 될것\n2. 모델이 단순해서 튜닝할 여지가 많아 튜닝해서 모델을 안정화 시키는 것 \n3. 모델을 튜닝할때는 에포크를 줄이고 진행할것 \n\n<br>\n<br>\n\n```bash\n\n# 상위 카테고리 \n# ㄴ 각각 카테고리를 모아서(file), 합쳐서 나열한다. \n# => 모델을 만든다.\n#\n# 이렇게 만든 상위 모델에서 나온 값을 받아 \n# 하위 카테고리\n# ㄴ 각 카테고리를 학습시킨다(dir), 합쳐서 나열한다. \n#\n# 그 값을 if문을 이용해 탐색하요 하위 카테고리 모델로 전달하여 재학습 시킨다. \n# 현재까지 아이디어는 여기까지인데 \n\n# 여기서 문제점이 있다. \n\n# 1. 상위모델은 하위 모델 보다 정확도가 높아야 한다. \n# 2. 하위모델은 적어도 정확도가 90은 나와야 한다. \n# 3. 입력으로 들어오는 이미지는 최대한 음식에 집중되어야 한다. \n\n```\n\n\n<br>\n<br>\n\n\n### 이슈 2 : 모델 튜닝 - 상위 모델 \n\n<br>\n\n우리가 가진 cnn 모델은 일단 튜닝할 여지가 많다. \n그래서 튜닝을 조금 시작할것이다. \n\n추가로 Transfer Learnning 공부해서 모델의 성능을 높이는 방향도 모색 할 것 \n\n<br>\n<br>\n\n### 이슈 3 : 이미지 전처리 \n\n<br>\n\n멘토링을 했는데 우리의 데이터가 조금 이상했던것같다. \n그래서 서브멘토가 확인을 해주겠다고 했다. \n그래서 오늘 로이미지 데이터와 코드를 넘겼고 전처리 과정이 어떤 문제가 있는지 피드백을 받기로했다. \n\n<br>\n"
},
{
"alpha_fraction": 0.502043604850769,
"alphanum_fraction": 0.5091961622238159,
"avg_line_length": 12.651163101196289,
"blob_id": "52d0c7b782e4ecbd3165671677c1776d032bbf8c",
"content_id": "6fe8ea74bbb92723cd58a3df13412a2e72e272b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4270,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 215,
"path": "/Python/4.심화_클래스_02.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n#### 4. 파이썬 심화 - 클래스_02\n\n<br>\n\n## 0. 비공개 속성 & 비공개 메소드\n\n<br>\n\n### 비공개 속성\n\n<br>\n\n앞에서 설명했지만 익숙해지기 위해서 다시 언급하고 넘어간다.\n\n- 공개 속성(public attribute) : 클래스 외부에서 접근\n\n- 비공개 속성(private attribute) : 클래스 내부에서만 접근 가능 \n\n<br>\n\n### 비공개 매서드\n\n<br>\n\n- 비공개 속성과 유사한 형태로 사용가능하다.\n - 비공개 메소드도 메소드를 클래스 바깥으로 드러내고 싶지 않을 때 사용한다.\n\n- 내부에서만 호출되어야 하는 메소드를 비공개 메소드로 생성 \n\n<br>\n\n```py\n# 비공개 메소드 \n\nclass Bank:\n\n def __Account(self):\n print('money')\n \n def Payment(self):\n self.__Account() # 호출가능 \n \nBoA = Bank()\nBoA.__wallet() # 에러\n\n```\n\n<br>\n\n## 1. 위치인수 & 키워드인수\n\n<br>\n\n클래스로 인스턴스를 만들 때 위치인수와 키워드인수를 사용가능하다.\n\n규칙 : **위치 인수**와 리스트 언패킹을 사용하려면 `*args` 를 사용하면 가능 <br>\n\n매개변수에서 값을 가지고 오려면 `args[0]` 이렇게 사용 !!!\n\n\n<br>\n\n```py\n\nclass Person():\n \n def __init__(self, *args): # 위치인수 : *args\n \n self.name = args[0]\n self.age = args[1]\n self.adress = args[2]\n\nJerry = Person(*['제리', 30, '부산'])\n\n```\n\n<br>\n\n만약에 **키워드인수**와 딕셔너리 언패킹을 사용하려면 <br>\n\n다음과 같이 `**kwargs` 를 사용하면 된다.\n\n매개변수에서 가져오는 값은 kwargs['키값'] 이렇게 하면 된다. \n\n<br>\n\n```py\n\nclass Person():\n \n def __init__(self, **kwargs): # 키워드인수 : **kwargs\n \n self.name = kwargs['name']\n self.age = kwargs['age']\n self.adress = kwargs['address']\n\nJerry_frt = Person( name = '제리', age = 30, address = '부산'] )\nJerry_snd = Person( **{ 'name' : '제리', 'age' : 30, 'adress' : '부산'} )\n\n```\n\n<br>\n<br>\n\n## 2. 인스턴스 생성후 속성 추가 + 특정속성만 \n\n<br>\n\n`__init__` 메소드 뿐아니라 <br>\n\n클래스로 인스턴스를 만든 뒤 `인스턴스.속성 = 값` 형식으로 속성을 계속 추가 가능하다.\n\n<br>\n\n```py\n\n# 예제 \n\nclass Person: # 빈클래스 생성 \n pass\n\nJoy = Person() # 인스턴스 생성\nJoy.name = '조이' # 인스턴스를 만든 뒤 속성 추가 -> 해당 인스턴스에만 생성 \nJoy.name # 다른 인스턴스에서는 추가한 속성이 생성안됨 \n\n# outPut\n# >>> '조이'\n\n### 다른 인스턴스에서는 추가한 속성이 생성안됨 -> 예시 \n\nJun = Person() # Jun 인스턴스 생성 \nJun.name # Joy 인스턴스에만 name 속성을 추가 -> Jun 인스턴스에는 name X\n\n```\n\n<br>\n\n에러가 발생 하였다. \n\n<br>\n\n```bsh\n\n# outPut\n# >>> Traceback (most recent call last):\n# File \"<pyshell#11>\", line 1, in <module>\n# Jun.name\n# AttributeError: 'Person' object has no attribute 'name'\n\n```\n\n<br>\n\n메소드를 호출하고 속성을 부여하면 동작한다. \n\n<br>\n\n```py\n\n# 예제 \n\nclass Person: # 빈클래스 생성 \n\n def greeting(self):\n self.hello = '안냥'\n\nJoy = Person() # 인스턴스 생성\nJoy.hello # 아직은 속성 x \n\n# 그럼 다시 \nJoy.greeting() # greeting 메소드를 호출\nJoy.hello # hello 속성 o\n\n# outPut\n# >>> '조이'\n\n```\n\n<br>\n\n인스턴스는 자유롭게 속성을 추가 가능 하지만 특정 속성만 허용, 다른속성은 제한하고자 할 때 \n\n\n클래스에서 `__slots__` 에 허용할 속성 이름을 리스트 -> 속성의 이름은 반드시 문자열 !\n\n<br>\n\n```py\n\n# 예제\n\nclass Person: \n __slots__ = ['name', 'age'] # name, age만 허용(다른 속성은 생성 제한)\n\n\nJoy = Person() \nJoy.name = '조이' # 속성 허용 \nJoy.age = 30 # 속성 허용 \nJoy.adress = '인천' # 허용안됨 -> 추가할 때 에러가 발생함\n\n```\n\n<br>\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n"
},
{
"alpha_fraction": 0.3741496503353119,
"alphanum_fraction": 0.4274376332759857,
"avg_line_length": 5.041095733642578,
"blob_id": "0fa1d12fe09badd8dd60c0618862d9794fb312dc",
"content_id": "57d2b5cd0ba31ab5ca4a8707f652bb55f574eb0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1208,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 146,
"path": "/Python/2.기본_기본요소.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 3. 파이썬 기본 - 기본요소\n\n<br>\n\n# 기본요소 \n\n<br>\n\n## 1. 수치형 \n\n파이썬은 모든것이 객체이다. \n10은 수치값이 아닌 객체이다 => 주소값이 변수에 세팅된거라서 \n\n- 정수(...,-1,0,1,...) \n- 실수\n- 십진수(`10`, `11`), 이진수(`0` or `1`), 8진수, 16진수(`0xFF`)\n- 부동소수(`-3.14`,0,0,1,2..)\n\n```py\n\n# 정수\na = 10\nprint( a )\n\n# 소수 \na = 1.1\nprint( a )\n\n\n# 일반적인 연산자는 대동소이하다.\n\n# 연산자도 우선순위가 있다\n# *, / 가 +, - 우선한다 => 연산자 우선순위를 다 알면 좋으나,\n# 괄호를 이용하여 () 우선순위 연산을 그룹으로 묶어준다\n(1+2+3+4) * 2 , 1+2+3+4 * 2\n\n```\n\n\n<br>\n\n## 2. 변수 \n\n<br>\n\n\n<br>\n\n```py\n\n\n\n```\n\n<br>\n<br>\n\n## 3.\n\n\n\n```py\n\n```\n\n<br>\n\n\n<br>\n\n## 4. 데이터 출력 \n\n```py\n\n```\n<br>\n\n\n<br>\n\n```py\n\n\n```\n\n<br>\n\n\n\n```py\n\n\n```\n<br>\n\n\n\n<br>\n\n```py\n\n\n```\n<br>\n\n```py\n\n\n\n```\n\n<br>\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n\n\n<br>\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n- 핵심만 간단히, 파이썬 : <https://wikidocs.net/13876> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n"
},
{
"alpha_fraction": 0.5322580933570862,
"alphanum_fraction": 0.5322580933570862,
"avg_line_length": 6.875,
"blob_id": "602f27c26db5a5ae5628609df89d74f6b90a4232",
"content_id": "9cc86985cede77b282e62779335b4c687a85a8dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 8,
"path": "/Python/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# Python 심화 \n##### JUST DO IT RIGHT NOW\n\n<br>\n\n## 파이썬 문법"
},
{
"alpha_fraction": 0.49460533261299133,
"alphanum_fraction": 0.5877342224121094,
"avg_line_length": 17.691490173339844,
"blob_id": "d136040ea92c8a6ecb5be3ab8174f122145db47a",
"content_id": "5b6d1a3e2a3d54ff6c78e92024f772b614bbe82a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3149,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 94,
"path": "/Python/자료구조/number.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# numbe.py\n\n## 숫자는 정수, 부동소수점, 복소수로 나타낸다. \n## 사람은 열손가락을 이용할수있는 십진법을 사용한다. \n## 하지만 컴퓨터는 전자 상태의 신호인 0과 1을 사용한다. # 이진법\n## 컴퓨터는 정보를 비트로 표현한다. \n\n\n### 정수 \n\n# 파이썬에서 정수는 불변형이다. \n# 파이썬의 정수의 크기는 메모리에의해 제한되며 정수의 크기는 적어도 32비트이다. \n# 정수를 나타내는데 사용하는 바이트 수를 확인 하려면 (정수).bit_length() 를 이용하여 확인하면 된다. \n\n\n# 불변형 객체는 변수와 객체 간에 차이가 없다. \n\n\n# 확인해보기 \n(999).bit_length() \n## >>> 10\n\n\n# 어떤 문자열을 정수로 변환하거나 , 다른 진법으로 변경하려면 int(문자열, 밑)사용한다. \n\ns = '11' \nd = int(s)\nprint(d)\n## >>> 11\n\nb = int(s, 2) # 2-36 사이의 선택적인 인수다. \nprint(b) # s의 해당 숫자의 밑을 벗어 나는 값을 입력(12 같은)하면 벨류에러가 발생한다. \n## >>> 3\n\n\n### 부동소수점\n\n# 이진수 분수로 표현되기 때문에 함부로 비교하거나 빼면 안된다. \n# float를 이용해 부동소수점을 나타내며 불변형이다. \n# [무시] 단정도(single precision)방식에서 32 비트 부동소수점을 나타낼 때 1비트는 부호(sign) 0,1, 23비트는 유효숫자 자릿수, 8비트는 지수다.\n# \n# 단정도 \n# 1. 숫자의 절대값을 이진수로 변환 -> 1110110.101\n# 2. 이진수를 정규화() -> 1110110.101(2) = 1.110110101(2)*2^6 \n# 3. 가수부(23비트)에 넣고 부족한자리는 0으로 채운다. -> 11011010100000000000000\n# 4. 지수는 6이므로 바이어스를 더한다. -> 지수 6에 127(0111 1111(2))를 더함 \n# => 6(10) + 127(10) = 133(10) = 10000101(2) \n\n\n# 부동소수점의 숫자는 메모리에서 비트 패턴으로 비교할 수 있다. \n# 두 숫자가 음수이면, 부호를 뒤집고, 숫자를 반전하여 비교한다. 지수패턴이 같으면 가수를 비교한다. \n\n\n### 정수와 부동소수점 \n\n# 파이썬에서 나누기 연산자(/)는 항상 부동소수점을 반환한다.\n# 연산자(//) 정수로 반환도 가능은 하다., 연산자(%)는 나머지를 구한다.\n\n# divmod(x,y) => 몫과 나머지를 반환\n\nx = 45\ny = 6\ndivmod(x,y) # x를 y로 나눌 때\n## >>> (7, 3)\n\n# round(x,n)\n# n 이 음수인 경우 x 를 n 만큼 반올림한 값을 반환 \n# n 이 양수인 경우 x 를 소수점 이하 n자리로 반올림한 값을 반환 \n\n## 1\nx = 100.96\nn = -2\nround(x,n) \n## >>> 100.0\n\n## 2\nx = 100.96\nn = 2\nround(x,n) \n## >>> 100.96\n\n\n## 부동 소수점을 분수로 표현하기\n2.75.as_integer_ratio()\n## >>> (11,4)\n\n## 복소수 \n# 파이썬에서 복소수는 z= 3+4j 같이 생긴 복소수점 한쌍을 갖는 불변형이다. \n# z.real() -> 실수부 \n# z.imag() -> 허수부\n# z.conjugate() -> 컬레 복수부\n\n# 복수수를 사용하기위해서는 cmath 모듈을 임포트 해야야한다. \n# cmath 는 math 모듈에 들어 있는 대부분의 삼각 함수, 로그함수의 복소수 버전을 제공한다. \n\n\n\n"
},
{
"alpha_fraction": 0.5698560476303101,
"alphanum_fraction": 0.5863674879074097,
"avg_line_length": 17.85714340209961,
"blob_id": "5ea0fe955d577dcb03323fe33c2f7f8dcdd14135",
"content_id": "9cfa8baee716793a882279e72ab464de92ab4ba5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3626,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 119,
"path": "/Data Structure and algorithm/DSAA_basic02_Quene.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 8강__큐01\r\n\r\n## 대표적인 데이터 구조 : 큐(Quene)\r\n\r\n### 1. 큐 구조\r\n# * 줄을 서는 행위와 유사\r\n# * 가장 먼저 넣은 데이터를 가장 먼저 꺼낼 수 있는 구조 => 선입선출\r\n# - 음식점에서 가장 먼저 줄을 선 사람이 제일 먼저 음식점에 입장하는 것과 동일\r\n# - **FIFO(First-In, First-Out)** 또는 **LILO(Last-In, Last-Out)** 방식으로 스택과 꺼내는 순서가 반대\r\n\r\n\r\n### 2. 알아둘 용어\r\n# - Enqueue: 큐에 데이터를 **넣는** 기능 \r\n# - Dequeue : 큐에 데이터를 **꺼내는** 기능 \r\n\r\n\r\n### 3. 파이썬 queue 라이브러리 활용해서 큐 자료구조 사용해보기 \r\n# - queue 라이브러리에는 다양한 큐 구조로 Queue(),LifoQueue(),PriorityQueue()제공\r\n# - <font color='#BF360C'>프로그램을 작성할 때 프로그램에 따라 적합한 자료구조를 사용</font> \r\n# - Queue() : 가장 일반적인 큐 자료구조 \r\n# - LifoQueue(): 나중에 입력된 데이터가 먼저 출력되는 구조(스택 구조라고 보면 됨)\r\n# - PriorityQueue(): 데이터마다 우선순위를 넣어서, 우선순위가 높은 순으로 데이터를 출력 \r\n# > 일반적인 큐 외에 다양한 정책이 적용된 큐들이 있음 \r\n\r\n\r\n\r\n### 3.1 Queue()로 큐 만들기(가장 일반적인 큐, FIFO(first-in,First-Out))\r\nimport queue\r\n\r\ndata_queue = queue.Queue()\r\n\r\n\r\ndata_queue.put(\"datacoding\")\r\ndata_queue.put(1)\r\n# data_queue 안에 두개가 들어 있다. \r\ndata_queue.qsize()\r\n# 가장 먼저 들어간데이터가 빠져 나온다. \r\n# 1회\r\ndata_queue.get()\r\n# 2회\r\ndata_queue.get()\r\n# check\r\ndata_queue.qsize()\r\n\r\n\r\n\r\n# 9강__ 큐02\r\n### 3.2 LifoQueue()큐 만들기 LILO(Last-In, Last-Out)\r\nimport queue\r\n\r\ndata_queue = queue.LifoQueue()\r\n\r\n\r\ndata_queue.put(\"datacoding\")\r\ndata_queue.put(1)\r\n# 두개가 들어있다 ! => 데이터를 뽑으면 \r\ndata_queue.qsize()\r\n# 마지막에 넣은 것이 출력된다. \r\ndata_queue.get()\r\n\r\n\r\n\r\n### 3.3 Priority(우선순위)Queue()큐 만들기** \r\n# - **중요**\r\n# - 데이터를 넣을때마다 우선순위를 매긴다. \r\n# - 꺼낼때는 우선순위대로 데이터를 꺼내온다.\r\nimport queue\r\n\r\ndata_queue = queue.PriorityQueue()\r\n\r\n\r\n# 데이터는 하나인데 튜플로 들어감 \r\ndata_queue.put((10,\"korea\"))\r\ndata_queue.put((5,1))\r\ndata_queue.put((15,\"china\"))\r\n# 들어있는데 이터가 3개라서 윗라인과 비교 \r\ndata_queue.qsize()\r\n\r\n# 1st\r\n# 우선순위가 높은거를 출력 \r\n# (앞,뒤) => 앞이 우선순위 \r\ndata_queue.get()\r\n# 2nd\r\ndata_queue.get()\r\n\r\n\r\n### 어디에 큐가 많이 쓰이는가 ?\r\n# - 멀티 테스킹을 위한 프로세스 스케쥴링 방식을 구현하기 위해 많이 사용된다. => 운영체제 참조 \r\n# - 큐의 경우 장단점 보다는 특별히 언급되는 장점은 없다\r\n# - 큐의 활용의 예 => 프로세스 스케쥴링방식을 함께 이해해 두는 것이 좋다.\r\n\r\n\r\n### 4. 프로그래밍 연습 \r\n#### 연습 01 : 리스트 변수로 큐를 다루는 equeue, dequeue 기능 구현 \r\nqueue_list = list()\r\n\r\ndef enqueue(data):\r\n queue_list.append(data)\r\n\r\ndef dequeue():\r\n data = queue_list[0]\r\n del queue_list[0]\r\n return data \r\n\r\n# for문으로 enqueue를 확인 \r\nfor i in range(10):\r\n enqueue(i)\r\n\r\nlen(queue_list)\r\n\r\n# dequeue 확인 => 0번부터 순차적으로 출력된다. \r\ndequeue()\r\ndequeue()\r\n\r\n\r\n# 큐의 구조는 데이터 선입선출 \r\n# 하지만 큐의 종류 중에서 \r\n# 마지막의 것부터 출력하는 큐와\r\n# 우선순위 먼저 출력하는 큐가 있다. "
},
{
"alpha_fraction": 0.6333333253860474,
"alphanum_fraction": 0.6333333253860474,
"avg_line_length": 29,
"blob_id": "a3c5ab1d020a9943c4af1db075847e14ff7d2775",
"content_id": "c16b2144d4e2cf22e9cb75e50723dc13e740f13f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 58,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 1,
"path": "/Virtual_Environment/Setup_hadoopEnv.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# SetUp : 빅데이터 분산 저장 처리 환경 구축 "
},
{
"alpha_fraction": 0.546460747718811,
"alphanum_fraction": 0.5621621608734131,
"avg_line_length": 28.21804428100586,
"blob_id": "721d475545eb19fa2b14b676bc40a5b98bec8abc",
"content_id": "8d52f12a5bf3e353669199c3d6a3c8b330ddfe1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 4957,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 133,
"path": "/R/src/R_src_데이터.R",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "## 실습 - 데이터\n\n#########################################################\n\n## 파일 읽고 쓰기 -> 데이터는 미공개\n# 파일 마지막 행에서 [Enter]를 누르지 않은 경우\nstudents <- read.table(\"C:/r/students1.txt\", header = T) \n\n# 파일 마지막 행에서 [Enter]를 누른 경우\nstudents <- read.table(\"C:/r/students.txt\", header = T) \nstudents\n\n# 읽은 파일의 구조 확인\nstr(students) \n\n# 파일을 있는 형태 그대로 읽음\nstudents <- read.table(\"C:/r/students.txt\", header = T, as.is = T) \nstr(students)\n\n# 파일을 읽을 때 문장을 요인으로 인식하지 않도록 설정\nstudents <- read.table(\"C:/r/students.txt\", header = T, stringsAsFactors = F) \nstr(students)\n\n# read.csv 함수: CSV(Comma-Separated Values) 파일을 읽을 때 사용\n# 첫 행이 header이므로 header 옵션을 지정할 필요가 없음\nstudents <- read.csv(\"C:/r/students.csv\") \nstudents\n\n# 읽은 파일의 구조 확인\nstr(students) \n\n# name 속성을 요인에서 문장으로 변경\nstudents$name <- as.character(students$name) \nstr(students)\n\n# stringsAsFactors -> 파일을 읽을 때 문장을 요인으로 인식하지 않도록 설정함\nstudents <- read.csv(\"C:/r/students.csv\", stringsAsFactors = FALSE) \nstr(students)\n\n\n# write.table 큰따옴표 여부 \n# 1. 문장에 큰따옴표가 표시됨.\nwrite.table(students, file = \"C:/r/output1.txt\") \n\n# 2. 문장에 큰따옴표되지 않음.\nwrite.table(students, file = \"C:/r/output1.txt\", quote = F) \n\n#########################################################\n\n## 결측값 처리 \n# is.na 함수를 이용해 결측값 처리하기\nstr(airquality)\t# airquality 데이터의 구조를 살펴봄.\n\n# airquality 데이터에서 NA는 TRUE, 아니면 FALSE. \nhead(is.na(airquality))\t\ntable(is.na(airquality))\t# NA가 총 44개 있음.\n\n\ntable(is.na(airquality$Temp))\t# Temp에는 NA가 없음을 확인함.\ntable(is.na(airquality$Ozone))\t# Ozone에는 NA가 37개 발견됨.\n\nmean(airquality$Temp)\t\t# NA가 없는 Temp는 평균이 구해짐.\nmean(airquality$Ozone)\t\t# NA가 있는 Ozone은 평균이 NA로 나옴.\n\n# Ozone 속성에서 NA가 없는 값만 추출함.\nair_narm <- airquality[!is.na(airquality$Ozone), ] \nair_narm\nmean(air_narm$Ozone)\t# 결측값 제거후 mean 함수 동작\n\n# na.omit 함수를 이용해 결측값 처리하기\nair_narm1 <- na.omit(airquality)\nmean(air_narm1$Ozone)\n\n# 함수 속성인 na.rm을 이용해 결측값 처리하기\nmean(airquality$Ozone, na.rm = T)\n\n#########################################################\n\n## 이상값 처리\n# 이상값이 포함된 환자 데이터\npatients <- data.frame(name = c(\"하나\", \"두나\", \"세나\", \"네나\", \"다나\"), \n age = c(22, 20, 25, 30, 27), \n gender = factor(c(\"M\", \"F\", \"M\", \"K\", \"F\")), \n blood = factor(c(\"A\", \"O\", \"B\", \"AB\", \"C\")))\n\n# 성별에서 이상값 제거\npatients_outrm <- patients[patients$gender==\"M\"|patients$gender==\"F\", ]\npatients_outrm\t\n\n# 성별과 혈액형에서 이상값 제거\npatients_outrm1 <- patients[(patients$gender == \"M\"|patients$gender == \"F\") \n & (patients$blood == \"A\"\n |patients$blood == \"B\"\n |patients$blood == \"O\"\n |patients$blood == \"AB\"), ]\npatients_outrm1\t \n\n# 성별은 남자는 1, 여자는 2로 표시, 혈액형은 A, B, O, AB형을 각각 1, 2, 3, 4로 표현\n# 이상값이 포함된 환자 데이터\npatients <- data.frame(name = c(\"하나\", \"두나\", \"세나\", \"네나\", \"다나\"), \n age = c(22, 20, 25, 30, 27), \n gender = c(1, 2, 1, 3, 2), \n blood = c(1, 3, 2, 4, 5))\t\n\n# 성별에 있는 이상값을 결측값으로 변경\npatients$gender <- ifelse((patients$gender<1|patients$gender>2), \n NA, patients$gender)\npatients\t\n\n# 혈액형에 있는 이상값도 결측값으로 변경\npatients$blood <- ifelse((patients$blood<1|patients$blood>4), \n NA, patients$blood)\n# 결측값을 모두 제거\npatients[!is.na(patients$gender)&!is.na(patients$blood), ]\n\n\n# boxplot을 활용하여 정상값과 이상값을 구분\nboxplot(airquality[, c(1:4)]) # Ozone, Solar.R, Wind, Temp에 대한 boxplot\nboxplot(airquality[, 1])$stats # Ozone의 boxplot 통계값 계산\n\nair <- airquality # 임시 저장 변수로 airquality 데이터 복사\ntable(is.na(air$Ozone)) # Ozone의 현재 NA 개수 확인\n\n# 이상값을 NA로 변경\nair$Ozone <- ifelse(air$Ozone<1|air$Ozone>122, NA, air$Ozone) \ntable(is.na(air$Ozone)) # 이상값 처리 후 NA 개수 확인(2개 증가)\n\n# NA 제거\nair_narm <- air[!is.na(air$Ozone), ] \nmean(air_narm$Ozone) # 이상값 두 개 제거로 is.na 결과보다 값이 줄어듦\nboxplot(air_narm$Ozone)$stats\n\n#########################################################"
},
{
"alpha_fraction": 0.604434072971344,
"alphanum_fraction": 0.6079346537590027,
"avg_line_length": 15.075471878051758,
"blob_id": "314585b14b09861e35b1c645239d2c606b379ea7",
"content_id": "905483ec342c675b14a205f866d4e1f863727fbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1681,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 53,
"path": "/Artificial_Intelligence/Deep_Learning/딥러닝_정리전.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n\n# 딥러닝 \n\n\n\n## learing Rate \ntoo low -> 속도가 느리다? 보다는 이상값에 민감하다 \njust right \ntoo high -> 너무 높으면 값이 튀어버린다. \n\n## 배치 사이즈 \n- 모든 데이터를 한번에 넣을 수 없다.\n - 6만개 -> 한모델에 다 넣을 수 없다. \n - 모델에 데이터를 나누어 넣는데 그때 몇장을 넣는 지정하는 것이 배치 사이즈 \n - 에폭/스텝 : 모델이 데이터를 회독한 횟수 \n\n## 데이터 셋 \n\n데이터 셋 안에 트레인 셋 테스트 셋으로 나뉜다. (6:4 이상으로 나눌것)\n여기서 또 한번 나누어지는데 트레인 셋이 트레인과 벨이데이션(Eval)으로 나누어 진다. \n\n## 레이블 / 그라운드 트루\n\n정답 데이터 , \n\n\n## CNN 모델 구조 \n\nfeature Extraction / Classification\n\n레이어 -> 컨볼루션 , 렐루, 맥스풀링 층층이 쌓여잇음 -> 특징을 추출하는 곳 \n예측 -> fully connected layer(플리커넥티드 레이어) -> 결정을 내림 \n\n특징 -> 어떠한 패턴 \n\n### 특징을 뽑는 과정\n특징들을 잡아 내서 합성하면 강조\n필터에 따라 결정을 내린다 -> 그만큼 특징은 중요하다. \n\n### 풀링 레이어 (맥스풀링)\n특징중 수치가 높은 것들만 뽑아서 반으로 줄여 다시 반으로 줄은 특징을 만드는 것 -> 쉬게 이미지를 압축 \n\n### 렐루\n특징들중 불필요한것들은 삭제\n\n**반복되고**\n\n### 마지막에 fully connrcted \n계산해서 예측한다. 선 하나하나가 수식을 가진다 \nw,b로 층하나하나 정답이 나올수 있도록 유도한다\n\n특징들을 쭉 나열해서 예측한다.\n\n# 모델들 \n\n\n"
},
{
"alpha_fraction": 0.4481939971446991,
"alphanum_fraction": 0.6042055487632751,
"avg_line_length": 20.21582794189453,
"blob_id": "643e1bab9626994ac385e5742b86a2717904517e",
"content_id": "dcf06037951cd0785dc0fd6f0e8eec8ff94f18b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 7541,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 278,
"path": "/R/src/R_src_03.R",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "#### 회귀 모델 \n\n\"\"\"\n대학생 90명의 키와 몸무게 데이터를 이용\n\n## 실습순서\n\n1. 데이터셋 읽어오기\n2. 회귀모델 생성\n3. 회귀계수 구하기\n4. 회귀계수 값 검증하기\n5. 잔차구하기\n6. 잔차 제곱 합 구하기\n7. 회귀 계수 신뢰구간 구하기\n8. 새로운 학생 키로 몸무게 예측하기 \n9. 모델 평가하기\n\"\"\"\n\n### 데이터 셋 로딩하기 \ndata_PATH <- file.path('C:\\\\', \"data\") # 경로 설정\n\n## 대학생 92명의 키와 몸무게 데이터 \nstd_cnt_92 <- read.table(file.path(data_PATH, \"student90.csv\"),sep = \",\",stringsAsFactors = FALSE,header = TRUE,na.strings = \"\")\n\n# 데이터 확인\nlength(std_cnt_92$weight_kg) # 90개의 데이터 존재 -> 데이터 누락 데이터가 있는것 같음 \nnrow(std_cnt_92)\n\n# 데이터의 머리와 꼬리 확인 \nhead(std_cnt_92)\ntail(std_cnt_92) # 2개의 데이터가 없는것 같음 \n\n### 회귀 모델 생성 \n## 대학생 90명의 키와 몸무게 데이터 셋을 이용한 회귀모델 생성하기 -> 몸무게 = 절편+ 개수 * 학생의 키\nmodel <- lm(weight_kg~height_cm, data=std_cnt_92); model # 32.6604 0.2247 \n\n\"\"\"\n# model\nCall:\nlm(formula = weight_kg ~ height_cm, data = std_cnt_92)\n\nCoefficients:\n(Intercept) height_cm\n 32.6604 0.2247 \n\"\"\"\n\n### 회계 계수 구하기 \n## 대학생 90명의 키와 몸무게 데이터에서 몸무게와 키 생성된 회귀 모델에서 회귀계수 구하기 \ncoef(model) # 32.6604144 0.2246605\n\n### 예측값 구하기 \n## 대학생 90명의 키와 몸무게 데이터에서 몸무게와 키 생성된 회귀모델로 예측값 찾기 \n\nfitted(model)[1:4]\n\n\"\"\"\n 1 2 3 4\n77.14319 70.85270 70.85270 77.14319\n\"\"\"\n\n## 직접 구하면 \n# Y(학생몸무게) = 32.66 + 0.225 * x(학생의키)\ntest <- ((32.6604144) + (0.2246605) * (std90$height_cm[1:4]))\ntest # [1] 77.14319 70.85270 70.85270 77.14319\n\n# 이상값 테스트 -> 'which' must be in 1:6\n# 박스 플롯보고싶다\nplot(model, which=2)\nplot(model, which=4)\nplot(model, which=5)\nplot(model, which=6)\n\n# 그래프를 보면 3개값이 이상값으로 추측되지만 수치적인 탐색이 수반되어야 할것같다\n# 그이후 이상값을 결정할수있을것같다. \n\n### 이상값 진단\ncooks_dist<- cooks.distance(model) ### ** 검색 \ncooks_dist[1:4] # 5.992961e-02 1.202838e-03 2.314356e-05 2.277257e-02\n\n\nNROW(cooks_dist) ### ** 검색 \n\n\ncooks_dist[which(cooks_dist>qf(0.5, df1 = 2, df2 = 88))] # named numeric(0)\n\n# 본페로니 검정 – 설치 및 불러오기\n# install.packages(\"car\")\nlibrary(car)\noutlierTest(model)\n\"\"\"\nNo Studentized residuals with Bonferroni p < 0.05\nLargest |rstudent|:\n rstudent unadjusted p-value Bonferroni p\n90 2.709609 0.0081125 0.73013\n\n# 본페로니 p(=0.73) > 0.05 이상치가 검출 되지 않았다. \n\"\"\"\n\n\"\"\"\n추측과는 다르게 Bonferroni p가 0.05보다 큰 값이 나와 이상치로 검출되지 않았고 \n시각화로 찾아낸 이상치 데이터들은\n수치가 높을 뿐 이상치라고는 할 수 없다고 본다. \n그렇기 때문때 따로 이상치를 제거하거하는 작업은 \n진행하지 않고 다음작업으로 넘어가도록한다\n\"\"\"\n##################################################################################3\n\n## 잔차 구하기 -> 잔차를 구하는 이유는 정규성을 보기 이함이다. \n# 추가 ) 잔차를 구하는이유 : \n# 조건에 따라 편향되지 않고 분산이 일정해야한다. \n# 특정조건에서 잔차가 튀는 것이 없어야 한다. \n\n\n\n# 1~4번째 잔차 : residuals(model)\nresiduals(model)[1:4] # 20.8568064 6.1473004 -0.8526996 12.8568064\n\nstd90$weight_kg[1:4] # 98 77 70 90\n\n# 실제 데이터 값 = 적합 된 값 + 잔차\nfitted(model)[1:4] + residuals(model)[1:4] # 98 77 70 90\n\n\n\n### 잔차분석 \n# Q-Q plot으로 잔차의 정규성 확인 \n\n## Q-Q plot\nqqnorm(residuals(model))\nqqline(residuals(model))\n\n## 샤피로 월크 검정을 이용해서 잔차의 정규성확인 \n# 샤피로 월크 검정 - 일변수 자료에 대해 수치적으로 정규성을 검정하는 기법 \nshapiro.test(residuals(model)) # W = 0.98121, p-value = 0.2189\n\n# 귀무가설 \n# 대립가설 \n\n### 회귀 계수의 신뢰구간 구하기 \nconfint(model, level = 0.95)\n\n\"\"\"\n 2.5 % 97.5 %\n(Intercept) 4.68512548 60.6357032\nheight_cm 0.05911794 0.3902031\n\n\"\"\"\n\n### 신뢰구간 -> 옵션설정 interval = \"confidence\"\nmodel_conf <- predict(model, level = 0.95, interval = \"confidence\")\nhead(model_conf)\n\n\"\"\"\n fit lwr upr\n1 77.14319 71.45341 82.83298\n2 70.85270 68.02003 73.68536\n3 70.85270 68.02003 73.68536\n4 77.14319 71.45341 82.83298\n5 70.85270 68.02003 73.68536\n6 69.72940 66.86626 72.59253\n\"\"\"\n\n\n## 주어진 키에 대한 평균 몸무게의 95% 신뢰구간 과 산포도\n## 추정된 평균 몸무게를 그린 예시\n\n### 키와 몸무게 산포도, 추정된 평균 몸무게, 신뢰구간\nplot(weight_kg~height_cm, data = std_cnt_92)\nlwr <- model_conf[,2]\nupr <- model_conf[,3]\n\nsx <- sort(std_cnt_92$height_cm, index.return=TRUE)\nabline(coef(model), lwd=2)\nlines(sx$x, lwr[sx$ix],col=\"blue\" , lty=2)\nlines(sx$x, upr[sx$ix],col=\"blue\" , lty=2)\n\n\n### 예측하기 \n\nmodel_pred <- predict(model, level=0.95, interval=\"predict\")\nhead(model_pred)\n\n\"\"\"\n fit lwr upr\n1 77.14319 49.83131 104.45507\n2 70.85270 43.99029 97.71511\n3 70.85270 43.99029 97.71511\n4 77.14319 49.83131 104.45507\n5 70.85270 43.99029 97.71511\n6 69.72940 42.86376 96.59504\n\n\"\"\"\n\n# 예측구간 \n## 키와 몸무게 산포도, 예측구간 \n\np_lwr <- model_pred[,2]\np_upr <- model_pred[,3]\n\n# abline(coef(model), lwd=2)\nlines(std_cnt_92$height_cm, p_lwr, col=\"red\", lty=2)\nlines(std_cnt_92$height_cm, p_upr, col=\"red\", lty=2)\n\n######################################################################\n\n\n## 잔차 제곱의 합 \ndeviance(model) # 15899.88\n\n## 예측 - 2 \n## 새로운 학생의 키가 175 cm 이 학생의 예상되는 몸무게 구하기 \n\npredict(model, newdata = data.frame(height_cm=175), interval=\"confidence\")\n\"\"\"\n fit lwr upr\n1 71.976 68.93945 75.01255\n\"\"\"\n\n# 모델평가 \nsummary(model)\n\n\"\"\"\nResiduals:\n Min 1Q Median 3Q Max\n-30.020 -8.460 -1.066 6.918 34.654\n\nCoefficients:\n Estimate Std. Error t value Pr(>|t|)\n(Intercept) 32.6604 14.0771 2.320 0.02265 *\nheight_cm 0.2247 0.0833 2.697 0.00838 **\n---\nSignif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1\n\nResidual standard error: 13.44 on 88 degrees of freedom\nMultiple R-squared: 0.07635, Adjusted R-squared: 0.06585 \nF-statistic: 7.274 on 1 and 88 DF, p-value: 0.008385\n\n\"\"\"\n\n### 예측 3\n(model_a_pre <- lm(weight_kg ~ height_cm, data = std_cnt_92))\n\n\"\"\"\nCoefficients:\n(Intercept) height_cm\n 32.6604 0.2247\n\"\"\"\n(model_b_pre <- lm(weight_kg ~ 1, data = std_cnt_92))\n\n\"\"\"\nCoefficients:\n(Intercept)\n 70.43\n\"\"\"\n\n### 분산 분석 및 모델간의 비교\nanova(model_a_pre, model_b_pre)\n\n\"\"\"\nAnalysis of Variance Table\n\nModel 1: weight_kg ~ height_cm\nModel 2: weight_kg ~ 1\n Res.Df RSS Df Sum of Sq F Pr(>F)\n1 88 15900\n2 89 17214 -1 -1314.2 7.2737 0.008385 **\n---\nSignif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1\n\"\"\"\n\n### RMSE, MAE를 이용한 모델 비교 \n# install.packages(\"modelr\")\nlibrary(modelr)\n\nrmse(model_a_pre, std_cnt_92) # 13.29155\nmse(model_a_pre, std_cnt_92) # 176.6653\nrmse(model_b_pre, std_cnt_92) # 13.82996\nmse(model_b_pre, std_cnt_92) # 191.2678"
},
{
"alpha_fraction": 0.5319982767105103,
"alphanum_fraction": 0.5528950691223145,
"avg_line_length": 16.263158798217773,
"blob_id": "87bed0545197b7e5d7f143cb43a268743e91832f",
"content_id": "a7436593cadc04f417cb48a6e87c80b05ceba275",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3371,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 133,
"path": "/Python/10.심화_정규표현식.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 10. 파이썬 심화 - 정규표현식\n\n<br>\n\n# 정규표현식\n\n<br>\n\n## 1. 정규표현식 Regular Expression\n\n<br>\n\n**특정 패턴과 일치하는 문자열을 검색, 치환, 제거 하는 기능** = > 특정 패턴을 찾는것 \n- 예를 들면 => 이메일 형식 판별, 전화번호 형식 판별, 숫자로만 이루어진 문자열 등\n- raw string => 그대로 문자열로인식 \n\n**문자열 앞에 r이 붙으면 해당 문자열이 구성된 그대로 문자열에 반환한다.** \n\n```py\n# Raw string의 예\na = 'abcd\\n hi' # escapce 문자열\nprint(a)\n# Raw string 이용 => 문자열 앞에 r이 붙임\nb = r'abcd\\n hi' \nprint(b)\n```\n\n<br>\n<br>\n\n\n## 2.기본 패턴 \n\n<br>\n\n1. 문자하나하나의 캐릭터(character)들은 정확히 해당 문자와 일치 \n- 패턴 test는 test 문자열과 일치 하며 \n 대소문자의 경우 기본적으로 구별하나, 구별하지 않도록 설정 가능 \n\n2. 몇몇 문자들에 대해서 예외 존재 => 특별한의미로 사용 \n - . ^ $ * + ? { } [ ] \\ | ( )\n3. .(마침표) - 어떤 한개의 캐릭터(character)와 일치 \n - \\w - 문자 character와 일치 [a-zA-Z0-9_]\n - \\s - 공백문자와 일치\n - \\t, \\n, \\r - tab, newline, return\n - \\d - 숫자 character와 일치 [0-9]\n - ^ = 시작, $ = 끝 각각 문자열의 시작과 끝을 의미\n - \\가 붙으면 스페셜한 의미가 없어짐. 예를들어 \\\\.는 .자체를 의미 \\\\\\는 \\를 의미\n - 자세한 내용은 [링크](https://docs.python.org/3/library/re.html) 참조\n\n<br>\n<br>\n\n## 3. search method\n\n<br>\n\n첫번째로 패턴을 찾으면 match 객체를 반환, 패턴을 찾지 못하면 None 반환\n\n<br>\n\n```py\nimport re # 정규식 패키지 \n\n# 패턴찾기 - 1\nsrc_search = re.search(r'abc','abcdef')\nprint(src_search.start()) # 인덱스 번호 시작 0 \nprint(src_search.end()) # 인덱스 끝은 3 => 3은 포함하지 않는다. \nidx = 'abcdef'\nprint(idx[3]) # d \nprint(src_search.group()) # '그룹('abc')를 불러온다\nprint('='*50)\n\n\n# 패턴 찾기 - 2 \nsrc_search = re.search(r'abc','123abcdef')\nprint(src_search.start()) # 인덱스 번호 시작 3\nprint(src_search.end()) # 인덱스 끝은 6 => 6은 포함하지 않는다. \nprint(src_search.group()) # '그룹('abc')를 불러온다\n\n# \\d - 숫자 character와 일치 [0-9]\nsrc_search = re.search(r'\\d\\d\\d\\w', '112abedwf119')\nprint(src_search) # match='112a'\n\n# \\w - 문자 character와 일치 [a-zA-Z0-9_]\n# .. 은 어떠한 문자든지 2개가 앞에오고 문자를 출력하라 \nsrc_search = re.search(r'..\\w\\w', '@#$%ABCDabcd')\nprint(src_search) # match='$%AB'\n\n\n```\n\n<br>\n<br>\n\n## 4. Meta-characters (메타 캐릭터)\n\n<br>\n\n```py\n# 메타 캐릭터\n[ ] 문자들의 범위를 나타내기 위해서 사용함\n- [abck] : a or b or c or k\n- [abc.^] : a or b or c or . or ^\n- [a-d] : -와 함께 사용되면 해당 문자 사이의 범위에 속하는 문자 중 하나\n- [0-9] : 모든 숫자\n- [a-z] : 모든 소문자\n- [A-Z] : 모든 대문자\n- [a-zA-Z0-9] : 모든 알파벳 문자 및 숫자\n- [^0-9] : ^가 맨 앞에 사용 되는 경우 해당 문자 패턴이 아닌 것과 매\n\n```\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 패스트 캠퍼스 : <https://www.fastcampus.co.kr/> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n<!-- - [내용](주소) -->\n\n"
},
{
"alpha_fraction": 0.4658356308937073,
"alphanum_fraction": 0.4972299039363861,
"avg_line_length": 21.824174880981445,
"blob_id": "f88cd415f23382090a4eaa0dd0e8dd2961a1a5de",
"content_id": "c22e6f0eade1c19c89fe78d31096ff01e8e07239",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3250,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 91,
"path": "/Data Structure and algorithm/Temporary/DSAA_basic04_LinkedList_01.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 대표적인 데이터 구조 \r\n## 링크드 리스트 (Linked list) 구조\r\n\r\n### 링크드 리스트 (Linked list) 구조\r\n\r\n - 연결리스트 \r\n - 배열 : 순차적 연결된 공간에서 데이터를 나열하는 데이터구조 \r\n - 링크드 리스트 : 떨어진 곳에 존재하는 데이터를 화살표로 연결해서 관리하는 데이터 구조\r\n - 원래는 C언어에서 주요한 데이터 구조 \r\n - 파이썬은 리스트 타입이 링크드 리스트기능을 모두 지원 \r\n\r\n- 링크드 리스트 기본 구조와 용어\r\n - 노드(Node) : 데이터의 저장단위 (데이터값, 포인터)로 구성\r\n - 포인터(Pointer) : 각 노드 안에서, 다음이나 이전의 노드와의 연결정보를 가지고 있는 공간 \r\n\r\n# why Array? : STR을 저장하려면 ? => 미리 예약을 해야해 \r\n```\r\n내부주소 : | 0000h | 0001h | 0002h | 0003h | 0004h | 0005h |\r\n데이터 : | S | T | R | I | N | G |\r\n인덱스 : | 0 | 1 | 2 | 3 | 4 | 5 |\r\n```\r\n\r\n# 배열은 미리 특정 공간을 예약을 해놓고 거기에 데이터를 쓰고 읽지만 \r\n# 링크드 리스트는 예약이 필요없이 사용가능하다.-> 자유롭다.\r\n\r\n# 일반적인 링크드 리스트 형태 -> 데이터가 주소를 가지고 있다\r\n# a가 50(b) 주소값 -> B(50)가 60(c)-> C\r\n```\r\n- : | 12 | 포인터 | 99 | 포인터 | 37 | 포인터 | |\r\n- : | | -> | | -> | | -> | |\r\n```\r\n\r\n### 간단한 링크드 리스트 예\r\n- 노드 구현\r\n - 보통 파이썬에서 링크드 리스트 구현시, 파이썬 클래스를 활용함\r\n - 파이썬 객체지향 문법 이해 필요 \r\n - 참고 :https://www.fun-coding.org/PL&OOP1-3.html\r\n\r\nclass Node1:\r\n def __init__(self,data):\r\n self.data = data\r\n self.next = None\r\n\r\nclass Node:\r\n def __init__(self, data, next=None):\r\n self.data = data\r\n self.next = next\r\n\r\n#### Node와 Node 연결하기 (포인터 활용)\r\n\r\n# 인자 하나에 디폴트 None \r\n# 별도로 객체를 두개를만듬 -> 하지만 연결은 안됨 \r\nnode1 = Node(1)\r\nnode2 = Node(2)\r\n# 포인더 \r\n# node1(head) -> node2\r\nnode1.next = node2\r\nhead = node1\r\n\r\n#### 링크드 리스트로 데이터 추가하기\r\nclass Node: #next=None**\r\n def __init__(self, data, next=None)\r\n self.data = data\r\n self.next = next\r\n\r\n# 별도 함수 => 마지막 노드를 찾기 위한 코드\r\ndef add(data):\r\n node = head #헤드의 값을 저장 \r\n # 링크드리스트가 저장하는 데이터 위치는 맨 뒤 \r\n \r\n # 노드가 가르치는 주소로 노드를 따라가는 구조 \r\n # node1 -> node2 -> node3 ->\r\n while node.next:\r\n # 다음 노드로 가는 주소 저장되어 있다 그러므로 \r\n # 다시 노드 = 경로 저장 \r\n # 다시 while 노드가 가진 경로를 반복하면서 노드 위치값을 추적 반복\r\n node = node.next\r\n #마지막 노드를 찾기 위한 코드 \r\n node.next = Node(data)\r\n\r\n#\r\nnode1 = Node(1)\r\n#node2 = Node(2)\r\n#node1.next = node2\r\nhead = node1\r\nfor index in range(10):\r\n add(index)\r\n\r\n#\r\nfor i in range(10):\r\n add(i)"
},
{
"alpha_fraction": 0.48905110359191895,
"alphanum_fraction": 0.525547444820404,
"avg_line_length": 16.25,
"blob_id": "09a7be622fabb1ed586c64d5f434659bd0c416bb",
"content_id": "e9dd8f724267332a58020af6b63bcb6c160570f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 8,
"path": "/Python/.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "Box = ['사과','포도','자몽','사과','배']\n# print(Box['사과'])\n# Box = '사과'\n# print(Box[0])\nprint(Box[2:4])\n\n# print(Box[0].next)\nprint(next(Box[0]))"
},
{
"alpha_fraction": 0.5727440118789673,
"alphanum_fraction": 0.5849447250366211,
"avg_line_length": 14.948529243469238,
"blob_id": "a2041ce7b74d16920d7bde80ac0c6f87bef88f89",
"content_id": "9647415b39758499fc38f398b433b60b00d8d826",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7512,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 272,
"path": "/Python/3.기본_타입과변수.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 2. 파이썬 기본 - 타입 & 변수\n\n<br>\n\n# 기본타입 & 변수 \n\n<br>\n\n## 1. 기본데이터 \n\n기본 데이터 타입 선언 => `int`, `float`, `str`, `bool`\n- 타입을 확인하기 위해서는 `type()`함수를 사용하면 된다. \n\n### 기본 데이터 타입 \n\n- `int`: 정수(`1,2,3,...`)\n- `float`: 실수(`0.2,0.6,0.8,....`)\n- `str`: 문자열(`'hello','bye',...`)\n- `bool` : `True`,`False`\n\n### 타입의 변환 \n\n타입을 변환할 수 있는 함수가 내재되어 있기에 간단반 방법으로 타입을 변환가능하다.\n변환시키고 싶은 타입의 형식으로 감싸 주면 타입이 바뀌게 된다.\n\n```py\ni = 60\ntype( i ) # int 타입\nf = float( i ) # float 타입으로 변환\nprint( f ) # 42.0으로 출력\ntype( f ) # float 타입\n\n\ns = '123'\ntype(s) # str 타입\nprint(s + 1) # 문자열 + int -> 오류 => 타입이 다른 변수에 대해 연산\n\niv = int(s)\ntype(iv) # int 타입\nprint(iv + 1) # int 타입 간 연산이기 때문에 오류 발생안함 -> 124로 출력됨\n```\n\n### None\n\n타 언어와 동일한 의미로 아무런 값을 가지고 있지 않을 경우 사용한다. \n\n변수가 초기 값을 갖고 있지 않게 하기 위해서 `box`라는 변수를 사용하기전 `box = None`으롤 선언한다. (선택사항)\n\n<br>\n\n```py\nbox = None \nprint(box)\n```\n\n\n<br>\n\n## 2. 변수 \n\n- 데이터를 저장하는 공간\n- 사전에 정의된 키워드, 내장 함수등의 이름을 변수로 사용 X\n- 메모리에 값을 생성하고 이름을 지정 \n\n\n각 언어마다 변수 이름 규칙이 존재하는데 기본적으로 파이썬의 변수이름 규칙은 아래와 같다. \n\n\n### 변수 이름 생성 규칙(variable naming)\n\n0. 변수 명은 타언어와 동일하게 사용 \n1. 영문 문자와 숫자를 함께 사용할수 있다. \n2. 숫자로 시작하는 이름을 제외하고 영문 대소문자, 숫자로 구성가능하다.\n3. 일반적으로 해당 변수를 표현하고자 하는 정확하고 간결한 이름을 사용하는 것이 원칙이다. \n4. \\_(밑줄문자: 언더 스코어) 시작 가능하다. \n5. 특수문자(+,-,\\*,\\/,$,@,&,%등)는 사용할수 없다.\n6. 파이썬 키워드(if , for , while, and , or) 등은 사용할수 없다.(예약어) \n7. 코드를 읽은 것을 더 쉽게 할 수 있다.-> 코드의 이해도가 증가 -> 수정 \n- 예를 들면 a = 10 보다 **apple_count = 10**로 표현한것이 변수에 대한 이해가 쉽고 빠르다.\n\n\n#### 예약어( reserved keywords )\n예약어는 파이썬에서 미리 선점하여 사용중인 키워드이며 선점해서 가지고 있기 때문에 변수, 함수, 클래스 등등의 사용자 정의 이름으로 사용할 수 없다. \n\n<br>\n\n\n### 대입연산자(=)\n\n'='은 변수에 값을 할당한다라는 의미\n\n- `변수명 = 'hello'`\n\n<br>\n\n### 비교연산자(==)\n\n프로그래밍에서는 수학등호 같은 연산자는 `==` \n비교를 할 경우, `=` 대신 `==`를 사용\n \n\n- `만약에 a == b 같다면 `\n- 대입연산자와 다르게 사용되므로 주의 해야 한다. \n- `<` , `>` (작다, 크다)\n- `<=` , `>=` (작거나 같다, 크거나 같다)\n- `==` 같다\n- `!=` 같지 않다\n- 비교 연산자의 결과는 불린타입으로 출력\n\n<br>\n\n```py\n\nOne = 1\nTen = 10\n\nprint(One < Ten) # True\nprint(One > Ten) # False\nprint(One <= Ten) # True\nprint(One >= Ten) # False\nprint(One == Ten) # False\nprint(One != Ten) # True \n\n```\n\n<br>\n<br>\n\n## 3. comment(주석)\n\n코드 이외의 것을 작성할 때 유용하며 개발자가 보기 위한 용도로 사용된다. \n- 코드나 문자앞에 `#` 붙여서 사용된다.\n- 프로그램이 코드를 실행하면서 `#`를 만나면 무시, 코드만 실행한다.\n\n\n```py\n# 코드가 실행할때 # 이 있는 라인은 소스코드가 실행 되지 않는다. \n```\n\n<br>\n<br>\n\n## 4. 데이터 입출력 \n\n보통 뭔가를 설명할때 순차적으로 (입력 -> 출력) 알려주는 편이 받아들이는 사람의 기억에 잘 남지만 프로그래밍언어는 코드 하나 하나가 입력이기 때문에 출력부터 알려줘야 입력을 알려줄수있다. 우선은 출력에 핵심인 `print` 함수에 대해서 설명하겠다. \n\n### `print` 함수 \n\n먼저 함수란 특정 기능을 반복적으로 호출하여 사용가능한 코드블럭이다. \n\n그중 `print` 함수는 변수의 값을 (`'여기'`)안에 입력하여 괄호안에 입력한 메세지나 값을 출력해준다. \n\n\n\n- `sep` : 구분자 , 각 출력할 변수 사이에서 구별하는 역할을 함\n- `end` : 마지막에 출력할 문자열\n\n```py\nfor i in range(10):\n print(i, end='')\n```\n<br>\n\n한줄에 결과 값을 계속 이어어 출력하려면 매개변수 `end` 를 사용해 끝문자를 지정할수 있다. \n\n<br>\n\n```py\n# 변수에 든 값이나 연산을 통해 전달된 값을 담아서 print() 출력 \nHow = '값'\nprint(How) # '값' 이 출력 된다. \n\n```\n\n<br>\n\n쉽표 `,` 로 여러 변수를 나열하면 한줄에 출력가능하다. \n\n<br>\n\n```py\n\nfst = 'first'\nsnd = 'second'\ntrd = 'third'\n\nprint(fst,snd,trd) # 기본적으로는 한칸 띄워쓰기 후 출력 \n\n```\n\n<br>\n\n파이썬은 한 문장의 끝(statement)에 아무것도 붙이지 않는다.\n\n<br>\n\n```py\n#단, 한줄에 여러 수행문의 넣고 싶다면 구분을 위해 ;을 붙인다\nHow = 1;print(How)\n```\n\n<br>\n\n출력시 에러가 발생할 경우가 있는데 오타이거나 변수를 찾을수 없을 때 발생한다. \n\n항상 에러를 잘 읽어 보는 습관을 가지는 것이 좋다.\n\n<br>\n\n```py\nTraceback (most recent call last):\n File \"c:/바탕화면/Python/공부/base.py\", line 9, in <module>\n prirnt(One != Ten) \nNameError: name 'prirnt' is not defined\n\n# prirnt 오타이기 때문에 함수를 제대로 추척하지못해서 발생하는 에러이다. \n# ' name '****' is not defined' 라는 에러 문장이 뜨면 오타가 없는지 확인 해보자 \n```\n\n<br>\n\n### `input` 함수 \n\n위에서 출력을 먼저 설명해줬는데 기본적으로 코드 자체가 컴퓨터에 전달되는 입력이지만\n\n사용자로부터 받는 데이터값을 컴퓨터로 전달해야하는 경우가 생긴다. \n\n이때 컴퓨터가 사용자로부터 입력값을 받아야할때 사용하는 코드가 바로 `input`함수이다. \n\n<br>\n\n```py\nmsg = \" 한박스에 사과 24개씩 들어있습니다. 몇개가 필요하신가요? \\n\"\nbox = input(msg)\nprint(box)\n\n```\n\n출력문인 `print`가 없으면 `input`을 실행 할 수가 없다라고 생각했으나 `print(box)` 가 없어도 잘 실행된다. \n\n하지만 변수에 잘 담겼는지 확인하는 출력문이 없기 때문에 사용자가 입력한 값만 출력문을 통해서 확인가능하다. \n\n\n<br>\n\n\n이렇게 파이썬의 기본 타입과 변수 선언 방법 더나아가 데이터 입출력까지 확인하였는데 아직 파이썬의 매력은 시작도 안했으니 더 기대해도 좋다. \n빠지면 빠질수록 매력적인게 파이썬이니까...! \n\n\n\n<br>\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n- 핵심만 간단히, 파이썬 : <https://wikidocs.net/13876> <br>\n- 부스트코스 - 모두를 위한 프로그래밍 : 파이썬 : <https://www.edwith.org/pythonforeverybody/> <br>\n\n- List of Keywords in Python : <https://www.programiz.com/python-programming/keyword-list> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.529644250869751,
"alphanum_fraction": 0.5533596873283386,
"avg_line_length": 15.681318283081055,
"blob_id": "4b897d8c2aab8207eb272274f5d164048e357615",
"content_id": "f036fd3f3fe0bf351fae1ebdace776f90c42b3e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1886,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 91,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_2.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n\"\"\"\n클래스 메소드의 사용법\n\"\"\"\n\nclass Employee(object):\n\n raiseAmount = 1.1 # 연봉인상률 클래스 변수 \n numOfEmps = 0 #1 클래스 변수 정의\n\n def __init__(self, fst, lst, pay):\n\n self.first = fst\n self.last = lst\n self.pay = pay\n\n Employee.numOfEmps += 1\n\n def applyRaise(self):\n\n self.pay = int(self.pay * self.raiseAmount)\n\n def fullName(self):\n\n return '{}{}'.format(self.first, self.last)\n \n def getPay(self):\n\n return '현재 \"{}\"의 연봉은 \"{}\" 입니다.'.format(self.fullName(), self.pay)\n\n def __del__(self):\n\n Employee.numOfEmps -= 1 # 퇴사자\n \n\n @classmethod\n def changeRaiseAmount(cls,amount):\n\n \"\"\"\n 클래스 메소드 데코레이터를 사용하여 클래스 메소드를 정의 \n\n 인상률이 1보다 작으면 재입력을 요청하는 코드 \n \"\"\"\n # 데이터 무결성 검사를 실시\n while amount < 1:\n\n print('[경고] 인상률은 1보다 작을 수 없습니다.')\n amount = input('[입력] 인상률을 다시 입력해 주세요.\\n')\n amount = float(amount)\n\n cls.raiseAmount = amount\n print('\"{}\" 인상율이 적용 되었습니다.'.format(amount))\n\n\n\nemp_1 = Employee('Jerry', 'Kim', 60000)\nemp_2 = Employee('Joy', 'Kim', 45000)\nemp_3 = Employee('Jain', 'Li', 90000)\n\n\n# 직원수 \n\nprint(f'현재 직원수 : {Employee.numOfEmps}')\n\n\n\n# 연봉 인상 전 \n\nprint(emp_1.getPay())\nprint(emp_2.getPay())\n\n# 연봉 인상율 변경\nEmployee.changeRaiseAmount(0.9) # 재입력 코드 동작 \n\n# 퇴사자 \ndel emp_3\nprint('퇴사')\n\n# 연봉 인상\n\nemp_1.applyRaise()\nemp_2.applyRaise()\n\n\n# 연봉 인상 후 \n\nprint(emp_1.getPay())\nprint(emp_2.getPay())\n\nprint(f'현재 직원수 : {Employee.numOfEmps}')"
},
{
"alpha_fraction": 0.4201031029224396,
"alphanum_fraction": 0.4355670213699341,
"avg_line_length": 3.9240505695343018,
"blob_id": "ccc6224524566df76d0c7c9bcacb2572b7a33746",
"content_id": "1819ddf962bdcde6c66249805d01ad69c5c2d804",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 498,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 79,
"path": "/Python/아직/12.심화_이터레이터.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 12. 파이썬 심화 - 이터레이터\n\n<br>\n\n# 이터레이터\n\n<br>\n\n## 1. 이터레이터란\n\n값을 차례대로 꺼낼 수 있는 객체(object)를 이터레이터(iterator)라고 한다.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n## 2.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [내용](주소)"
},
{
"alpha_fraction": 0.44928911328315735,
"alphanum_fraction": 0.5071089863777161,
"avg_line_length": 16.016128540039062,
"blob_id": "6575b1db36862eb1fd312481afa58a89132f19b0",
"content_id": "c57ce90a74fe4a4cbeda545a6529f75464822761",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1151,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 62,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_5.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n\"\"\"\n클래스 메소드의 사용법\n# 함수가 클래스 안에 메소드로 정의\n\"\"\"\n\nclass Person(object):\n\n \"\"\"\n Advanced_OOP_4 코드보다 조금 더 세련된 코드\n \"\"\"\n\n def __init__(self, year, month, day, sex):\n\n self.year = year\n self.month = month\n self.day = day\n self.sex = sex\n\n def __str__(self):\n\n return '{}년 {}월 {}일생 {}'.format(self.year, self.month, self.day, self.sex)\n\n\n @classmethod\n def ssnConstructor(cls, ssn):\n\n front, back = ssn.split('-')\n sex = back[0]\n\n if sex == '1' or sex == '2':\n year = '19' + front[:2]\n\n else :\n year = '20' + front[:2]\n\n if (int(sex)%2) == 0 :\n sex = '여성'\n\n else :\n sex = '남성'\n\n month = front[2:4]\n day = front[4:6] \n\n return cls(year, month, day, sex)\n\n\nssn_1 = '900829-1000006'\nssn_2 = '951224-2000069'\nssn_3 = '201214-4000069'\n\n\nJun = Person.ssnConstructor(ssn_1)\nJain = Person.ssnConstructor(ssn_2)\nRose = Person.ssnConstructor(ssn_3)\n\n\nprint(Jun)\nprint(Jain)\nprint(Rose)"
},
{
"alpha_fraction": 0.6062864661216736,
"alphanum_fraction": 0.6305897831916809,
"avg_line_length": 14.4350004196167,
"blob_id": "1022006b2597137e6eec64bad86cec86ea95d7c5",
"content_id": "ddd24cb7ac7eab83ad56f03cc8fc307dc5f6e0a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4574,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 200,
"path": "/Virtual_Environment/리눅스/리눅스_아나콘다 설치.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 3. Ubuntu 18.04 - 아나콘다 설치 (아직 안됨 )\n\n<br>\n\n# 아나콘다 설치\n\n<br>\n\n## 1. 아나콘다 설치\n\n<br>\n\n프로젝트를 하다 보면 같은 팩이라도 버전을 달리 사용하는 경우가 있다. \n그런 경우 충돌이 일어나거나 버전 에러가 발생한다. \n그것을 미리 방지하고자 아나콘다 같은 가상환경을 사용한다.\n\n필자는 주로 아나콘다를 이용한다 미니도 있고 여러가지 툴들이 많지만 아나콘다가 편하기때문에 ... ㅎㅎㅎ \n\n<br>\n\n### 아나콘다 다운로드 및 설치 \n\n보통 설치 경로는 `/home/[userid]/anaconda3`로 지정하는것이 좋다. \n`.bashrc`에 패스 등록를 등록해주자 \n\n<br>\n\n```bash\n\n# 아나콘다 파일을 다운로드\n$ wget https://repo.anaconda.com/archive/Anaconda3-2020.02-Linux-x86_64.sh\n\n# 아나콘다 설치 \n$ bash Anaconda3-2020.02-Linux-x86_64.sh\n\n\n# 위에 나오는 설명은 전부 엔터 !!! \n# 그리고 나오는 거는 전부 yes \nDo you accept the license terms? [yes|no] # 사용자 라이센스 \n[no] >>>\nPlease answer 'yes' or 'no':'\n>>> yes\n\nAnaconda3 will now be installed into this location:\n/home/user1/anaconda3\n\n - Press ENTER to confirm the location\n - Press CTRL-C to abort the installation\n - Or specify a different location below\n\n[/home/user1/anaconda3] >>> ENTER입력 \n'\n# 여기서도 yes 입력 \ninstallation finished.\nDo you wish the installer to initialize Anaconda3\nby running conda init? [yes|no] # 아나콘다 설치 위치 \n[no] >>> yes \n\n\n>>> 보통 설치 경로는 /home/[userid]/anaconda3로 디폴트로 지정\n\n```\n<br>\n\n터미널을 재실행한후 `.bashrc`에 패스 등록한다.\n\n- `source ` : 스크립트 파일을 수정한 후에 수정된 값을 바로 적용\n- `.bashrc` : 부팅 전 미리 적용하여 구동할때 적용되도록 설정하는 파일\n\n<br>\n\n```bash\n# 적용 \n$ source ~/.bashrc \n\n# 확인 하면 잡혀있다. \n$ export PATH=\"~/anaconda/bin:$PATH\n```\n\n<br>\n\n### 아나콘다 삭제 \n\n<br>\n\n커맨드 창에서 `conda list` 치고 리스트 혹은 리스트 창이 뜨면 성공적이다. \n만약에 패스설정이나 여러부분에 실수를 했다면 \n아나콘다를 삭제하고 다시 설치하는것을 추천한다. 우븐투는 꼬이면 골치아프다.\n\n<br>\n\n```bash\n# 잘못 설치한 경우 \n$ rm -rf ~/anaconda3 # 아나콘다 삭제하기\n```\n<br>\n<br>\n\n\n\n## 2. 주피터 노트북 환경설정\n\n<br>\n\n만약 주피터 노트북의 실행경로라던지 환경적인 부분을 설정하려면 \n편집기를 설치하여 환경 설정 파일에서 원하는 부분만 부분적으로 수정하면 된다.\n\n<br>\n \n편집기가 있으신분은 pass!! \n없으시다면 stop ! 들렸다가 가세욤 ~\n\n```bash\n\n# 편집기 설치 (vim or nano)\n\n$ sudo apt install vim -y \n$ sudo apt install nano -y \n\n```\n<br>\n\n```bash\n\n# 쥬피터 노트북 환결설정 실행하기 \n$ jupyter notebook --generate-config # 주피터 환경설정파일 생성\n\n\n# 환결설정 수정하기 \n\n$ vim ~/.jupyter/jupyter_notebook_config.py\n# OR\n$ nano ~/.jupyter/jupyter_notebook_config.py\n\n 048라인 : c.NotebookApp.allow_origin = '*' # 외부 접속 허용하기\n 204라인 : c.NotebookApp.ip = '*' # 아이피 설정\n 266라인 : c.NotebookApp.notebook_dir = u'/home/user1/jupyter-workspace' # 작업경로 설정\n 272라인 : c.NotebookApp.open_browser = False # 시작 시 서버PC에서 주피터 노트북 창이 열릴 필요 없음\n \n\n$ sudo ufw allow 8888 # 방화벽 열기\n\n$ mkdir ~/jupyter-workspace # 폴더생성\n\n$ jupyter notebook --config ~/.jupyter/jupyter_notebook_config.py\n\n# 주어진 주소로 접속하면 주피터노트북으로 이동\n\n```\n\n## 2. 가상 환경 설정\n\n<br>\n\n### 가상환경 생성 \n\n```bash\n$ conda create -n 환경이름 # 원하는 가상환경 이름을 입력 -> env라는 명칭은 자제 바란다.\n>>> conda create -n py37 # py37 생성\n\n# 가상환경 활성화 \n$ source activate 환경이름\n>>> source activate py37 # py37 생성 실행 \n\n# 가상환경 비활성화 \n$ source deactivate 환경이름\n>>> source deactivate py37 # py37 비활성화 \n\n# 가상환경 종료 \n$ conda deactivate\n>>> conda deactivate py37 # py37 비활성화 \n\n# 가상환경 목록 \n$ conda env list \n\n\n# 터미널에서 \n>>> (py37)user1@호스트네임: ~$ # 가상환경이 실행중 \n```\n\n\n<br>\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 내용 : <주소> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [내용](주소)"
},
{
"alpha_fraction": 0.4552238881587982,
"alphanum_fraction": 0.4808102250099182,
"avg_line_length": 16.876190185546875,
"blob_id": "863d7d3a12236274ca4de7ea5d45fa6f571ac096",
"content_id": "78a3cd1462f06dd75ae878c5cb5f5e5f6048e1a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2496,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 105,
"path": "/Python/Unit_11-test.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 사용자 함수 \nfrom fun_pkg.random_num import random_num # 랜덤 숫자 생성\n\n# Unit_11-test.py\n# 시퀸즈 자료형 활용하기 - 응용 연습 \n\ntxt = \"\"\"\n# 시퀸즈 자료형 활용하기 \n- 리스트 , 튜플 , range, 문자열 => 연속성(sequence)을 가짐 \n- 시퀸즈 자료형 => ( 리스트 , 튜플 , range, 문자열)\n- 시퀸즈 자료형의 공통기능 사용 \n - 시퀸스 자료형의 큰 특징을 공통동작과 기능을 제공 \n - 시퀸즈 자료형으로 만든 객체를 시퀴즈 객체라고 함 => 각 값을 요소라고 칭 함 \n - 특정 값을 확인 \n => 값 in 시퀸즈 객체\n => 값 not in 시퀸즈 객체\n => 값 in range(값)\n - 시퀸즈 객채 연결하기 \n - 시퀸즈 객체 1 + 시퀸즈 객체 2 \n - **range는 + , \\* 연산자로 객체를 연결 할 수 없다.** \n - 근데! 리스트, 튜플로 묶어서 연결하면 가능 => 아래 예시 참조\n - 시퀸즈 객체 반복 \n - 시퀸즈 객체 * 정수\n - 정수 * 시퀸즈 객체 \n - 시퀸즈 요소 개수 구하기 \n - len(시퀸즈 객체)\n -> 리스트, 튜플, 문자열도 마찬가지로 길이를 구할 수 있다. \n - range의 숫자 생성 개수 구하기 =>len(range( 값 ))\n\"\"\"\nprint(txt)\nprint('-'*40)\n\n\n# 시퀸즈 객체 반복 \na = [[1,2,3]] * 5 \nb = [1,2,3] * 5\n\nprint(b)\nprint('-'*40)\n\ntest = [1] * 5\ntest_1 = [[0]] * 10 \nprint(test)\nprint(test_1)\n\nprint('-'*40)\n\ntmp = list()\nfor i in range(1,10):\n # print(i)\n # tmp.append(i)\n tmp.append([i])\n\nprint(tmp)\nprint('-'*40)\n\n\n# 리스트 내포 \ntmp1 = [[i] for i in range(1,10)]\nprint(tmp1)\n\nprint('-'*40)\n\n\n\n# 요소에 값 할당하기 \n\"\"\"\n- 시퀸즈 객체[인텍스] = 값\n\n\"\"\"\na = [0]*5 \nprint(a)\nfor i in range(len(a)) : \n print('a[%d] = ' % i, a[i])\n # print(i)\n\n# 변경 \na = [0]*5 \nb = random_num(5)\n# print(b)\nfor i in range(len(b)) : \n print('b[%d] = ' % i, b[i])\n\ntmp = []\nzro = [0] * 5 \nrdm_num = random_num(5)\nprint('rdm_num :',rdm_num)\n# print(zro)\nfor i in range(len(zro)) : \n # print('zro[%d] = ' % i, zro[i])\n print(i)\n\n for j in range(len(rdm_num)):\n # print(rdm_num)\n # dum = 0\n pass\n # print('test : rdm_num[%d] = ' % i, rdm_num[i])\n # print('정상작동')\n zro[i] = rdm_num[i]\n print('rdm_num[%d] = ' % i, rdm_num[i])\n tmp.append(zro[i])\n\nprint('zro[i]만 추출',tmp)\nprint(tmp[0])\nprint(tmp[4])"
},
{
"alpha_fraction": 0.4746059477329254,
"alphanum_fraction": 0.4798598885536194,
"avg_line_length": 29.70270347595215,
"blob_id": "1c4a419e250d41bc4c1812cf8c1fff47ada2e588",
"content_id": "5c69198c7a9b85f773a40ca4d16615ba1c966a01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2166,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 37,
"path": "/Data Structure and algorithm/data structure.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# **자료구조** \n- 일단 원리를 파악하고 나서, 원리를 적용해가면서 이해 \n- 최소 스스로 10줄의 코드는 작성 할 수 있어야한다. \n => 구구단 문제는 혼자 풀 수 있어야 한다. \n---\n\n## 1 강 \n**- 자료구조란?** \n - 자료구조, 데이터 구조, Data Structure \n - 대량의 데이터를 효율적으로 관리할 수 있는 데이터의 구조를 의미 \n - 코드상 효율적으로 처리하기 위해, 데이터의 특성에 따라, 체계적으로 데이터를 구조화하는것 \n - 어떤 데이터 구조를 사용하느냐에 따라, 코드의 효율이 달라진다. \n\n\\# 효율적인 데이터 관리 예 \n - 우편번호 5 자리 \n - 앞 3자리 : 시군구 \n - 뒤 2자리 : 일련번호 \n - 학생관리 \n - 학년/반/학번 \n => 많은 학생을 손쉽게 관리할 수 있게 만듬 \n \n### 대표적인 자료구조 (중요\\**)\n- 배열, 스택, 큐, 링크드 리스트, 해쉬 테이블, 힙 etc...\n\n**- 알고리즘이란?** \n - 알고리즘 , algorithom \n - 주요 요소 : 얼마나 시간이 걸리느냐 \n - 어떤 문제를 풀기 위한 절차 혹은 방법 \n - 어떤 문제에 대해, 특정한 '입력'을 넣으면, 원하는 '출력'을 얻을 수 있도록 만드는 프로그래밍 \n - ex) 요리 레시피(백종원 레시피) : 맛있고 간단하다.\n\n**- 자료구조와 알고리즘이 중요한 이유!!** \n - 어떤 자료 구조를 사용하고 알고리즘을 쓰느냐에 따라 성능이 천지차이 \n -> 즉, 프로그램을 잘 할수있는 기술과 역량을 익히고 검증 가능하다. \n\n**- 자료구조와 알고리즘 그리고 파이썬!!** \n - 어떤 언어로 자료구조와 알고리즘을 익힐 수 있다. 과거의 경우 주로 C/C++을 이용해 작성된 경우가 많았다. 최근 언어의 제약과 평가가 없어지고, 가장 쉽고 빠르게 자료구조와 알고리즘을 익힐 수 있는 파이썬을 많이 사용한다. \n"
},
{
"alpha_fraction": 0.5794872045516968,
"alphanum_fraction": 0.5794872045516968,
"avg_line_length": 10.171428680419922,
"blob_id": "63d214f2b853c0ebb05b8e7b02fc83216b9cf748",
"content_id": "4f8413da2e3bbc2a0cb7f8b1dd977f59c19ae6b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 652,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 35,
"path": "/Artificial_Intelligence/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# Bigdata_Analytics_Review\n\n<br>\n\n## Artificial_Intelligence\n\n- 인공지능 수업 과정을 다시 정리하고 보기 편하게 올린다.\n - 머신러닝\n - 딥러닝\n - 강화학습\n\n<br>\n<br>\n\n## Data_Visualization\n\n- 데이터 시각화를 하는 방법들을 정리해서 올린다. \n - 데이터 시각화 \n - 데이터 분석 방법론 \n - 머신러닝 실전\n\n<br>\n<br>\n\n## Virtual_Environment\n\n- 빅데이터를 분산하는 방법을 정리 할 것이다. \n - 이 부분은 조금 많이 불안정 할 것이지만 진행하도록 한다 \n - 대부분 셋업 방법 위주로 진행될 수 있다.\n\n\n<br>\n<br>"
},
{
"alpha_fraction": 0.5324802994728088,
"alphanum_fraction": 0.5354330539703369,
"avg_line_length": 14.393939018249512,
"blob_id": "90cacd834f3d69a64be4605e8130d0edd57f86a5",
"content_id": "d38890bca7f8e8a23104bad93085c41aa0a1b64f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1134,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 66,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_다중상속.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n# 다중 상속 실습 \n# https://uzooin.tistory.com/137\n\n\nclass Father:\n \n def __init__(self):\n self.fname = '김우빈'\n\n def fatherName(self):\n print(f'아빠는 {self.fname} ,')\n\n def func(self):\n print('call Father.func')\n\n\nclass Mather:\n\n def __init__(self):\n self.mname = '신민아'\n\n def matherName(self):\n print(f'엄마는 {self.mname} ,')\n\n def func(self):\n \"\"\"\n 다중 상속 - need\n \"\"\"\n print('call Mather.func')\n\n\nclass Child(Father, Mather):\n\n def __init__(self):\n # super().__init__()\n Father.__init__(self)\n Mather.__init__(self)\n self.name = '김빈아'\n\n def greeting(self):\n super().__init__()\n print(f'저는 {self.name}입니다.')\n\n def oneFunc(self):\n Father.func(self)\n\n\n def twoFunc(self):\n Mather.func(self)\n\n\n\nchild = Child()\n\nprint(child.__dict__)\n\nchild.fatherName()\nchild.matherName()\nchild.greeting()\n\n# 메소드가 사용되어 질때 첫번째 메소드부터 순차적으로 검색\n\nchild.oneFunc()\nchild.twoFunc()"
},
{
"alpha_fraction": 0.3218451738357544,
"alphanum_fraction": 0.37168610095977783,
"avg_line_length": 26.75,
"blob_id": "897fd6b19ac16fcfa811a49a60be2760a9977f9d",
"content_id": "41d6b02be3b473694410d0765cbc2e6c8d0e94e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2130,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 68,
"path": "/Project/Mini Project/ForLoop.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 2019.12.18 <ver_1>\n# [실습]\n# 3-7단까지만 구구단을 출력하시오 \n# 출력 형식은 3x1 = 3 ... 한줄에 하나씩 \nprint('2019.12.18 <ver_2>')\nprint('-'*40)\n# 배열이용 \n# used array ----------------------------\na = [3,4,5,6,7]\nfor i in a:\n print('%d단'%i)\n for j in range(9):\n j=j+1\n print(i ,'x', j ,'=',i*j)\n#----------------------------------------\n### 문제점 : range() 잘 못다룬다 \nprint('-'*40)\n# tuning --------------------------------\na = [3,4,5,6,7]\nfor i in range(3,8):\n print('%d단'%i,'\\n','='*30 )\n for j in range(1,10):\n print(i ,'x', j ,'=',i*j)\n#----------------------------------------\nprint('-'*40)\n# tuning --------------------------------\nfor i in range( 3, 8 ):\n print( '%d단'%i,'\\n','='*30 )\n for j in range( 1, 10 ):\n print( '%s x %s = %2s'% (i,j,i*j))\n#----------------------------------------\nprint('-'*40)\n# tuning --------------------------------\n# 결과를 먼저 쓰고 내용을 확인하는 ?\n['%s x %s = %2s' % (i,j,i*j) for i in range(3,8) for j in range(1,10)]\n#----------------------------------------\nprint('-'*40)\nprint('5단만 제외하고 작업 (긍정)')\n# 5단만 제외하고 작업 (긍정)\n# tuning --------------------------------\nresults = []\nfor i in range( 3, 8 ): \n if i == 5:\n #print(int(i.pop())\n continue\n #print( '%d단'%i,'\\n','='*30 )\n for j in range( 1, 10 ):\n results.append(i*j)\nprint(results)# 프린트로 찍으면 옆으로 \nprint('총 개수:', len(results))\n\n#----------------------------------------\nprint('-'*40)\nprint('5단만 제외하고 작업 (부정)')\n# 5단만 제외하고 작업 (부정)\n# tuning --------------------------------\nresults = list()\nfor i in range( 3, 8 ): \n if i != 5:\n for j in range( 1, 10 ):\n results.append(i*j)\nprint(results,'\\n총 개수:', len(results))\n# tuning --------------------------------\nprint('== python 방식_ 리스트 내포 ==')\na = [(i*j) for i in range( 3, 8 ) if i != 5 for j in range( 1, 10 )]\nprint(a,'\\n총 개수:',len(a))\n#----------------------------------------\nprint('-'*40)"
},
{
"alpha_fraction": 0.47986191511154175,
"alphanum_fraction": 0.5005753636360168,
"avg_line_length": 14.535714149475098,
"blob_id": "9d809b41ef8707e2d4d80bc68d49e538ce2e7ebd",
"content_id": "f6213bce1d861141e136518608b5c02e8d062526",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 881,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 56,
"path": "/Python/fun_pkg/random_num.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# random_num 함수 \nhistory_log = \"\"\"\n# 진행과정 \n\n# tmp = list()\n# print(tmp)\n\ntmp = list(range(1,100))\n# print(random.shuffle( tmp ))\nrandom.shuffle( tmp )\n# print(tmp)\n\n\nnumber = [] \nx = 50\ncnt = 0\nfor num in tmp:\n cnt += 1 \n if cnt <= x : \n # print(num)\n number.append(num)\n pass \nprint('Count : %s' % len(number), number)\n\"\"\"\n# print(history_log)\n\n\n\ndef step_num():\n pass\n\ndef random_num(x):\n \n import random \n tmp = list(range(1,100))\n random.shuffle( tmp )\n # print('log1')\n x = int(x)\n cnt = 0\n number = list()\n \n for num in tmp:\n cnt += 1 \n # print('log2')\n if cnt <= x : \n # print(num)\n number.append(num)\n pass\n\n # print('Count : %s' % len(number), number)\n print('Count : %s' % len(number))\n return number\n\n# a = random_num(20)\n\n# print( a )"
},
{
"alpha_fraction": 0.453125,
"alphanum_fraction": 0.47265625,
"avg_line_length": 4.829545497894287,
"blob_id": "44bda3387fdbbc58ec30c9b07ab79763d4d57c43",
"content_id": "710d0df851dc7b560a0014813af4e8571e1f1e4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 630,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 88,
"path": "/Python/Boost-Course/Asterisk.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### ?. 파이썬 심화 - Asterisk\n\n<br>\n\n# Asterisk\n\n<br>\n\n## 1. Asterisk\n\n<br>\n\n단순 곱셈, 제곱연산, 가변 인자활용 등 여러 의미를 갖는 연산들을 가능하게 만든다. \n\n\n흔히 알고있는 \\* 을 의미\n\n```py\n\ndef asterisk_test(a, *args):\n print(a, args)\n print(type(args))ㄴ\n\nasterisk_test(1,2,3,4,5,6)\n\n```\n\n<br>\n\n\n\n\n## 2.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [내용](주소)"
},
{
"alpha_fraction": 0.4889217019081116,
"alphanum_fraction": 0.4889217019081116,
"avg_line_length": 13.69565200805664,
"blob_id": "166231ec6e5e80a14a0ac4083866dd0a18527f4d",
"content_id": "95499b68c9c676210468517a757f160f66c28f86",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 823,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 46,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_Super.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n# super() 실습 \nclass father(): \n \"\"\"\n 부모 클래스\n \"\"\"\n\n def __init__(self, who):\n\n self.who = who\n\n def handsome(self):\n\n print(f'{self.who}를 닮아 잘생겼다')\n\n\n\nclass Brother(father):\n \"\"\"\n 자식 클래스 - 아들\n \"\"\"\n pass\n\n\n\nclass Sister(father):\n \"\"\"\n 자식 클래스 - 딸\n 자식클래스(부모클래스) 아빠 메소드를 상속\n \"\"\"\n def __init__(self, who, where):\n\n super().__init__(who) # super 사용 - 부모(기반)에게 상속\n self.where = where\n\n def choice(self):\n print(f\"{self.where} !!\")\n\n def handsome(self):\n super().handsome() # super 사용 - 부모(기반)에게 상속\n self.choice()\n\n\nGirl = Sister(\"아빠\", \"얼굴\")\nGirl.handsome()\n"
},
{
"alpha_fraction": 0.41625088453292847,
"alphanum_fraction": 0.456878125667572,
"avg_line_length": 16.30864143371582,
"blob_id": "0fd6592128d09749755c1bd3781803448833cfc6",
"content_id": "5acbbf92be8ced65d4af64f0c549da4bb4353960",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1591,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 81,
"path": "/Project/Mini Project/Src_NoComment/ExamGradeProgram_ver01.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# ExamGradeProgram_ver_01.py\n\n\n# 변수 \nscore_case1 = {\n 'A+' : '4.5',\n 'A' : '4.0',\n 'A-' : 'X' ,\n 'B+' : '3.5',\n 'B' : '3.0',\n 'B-' : 'X' , \n 'C+' : '2.5', \n 'C' : '2.0',\n 'C-' : 'X',\n 'F' : '0' }\n\nscore_case2 = {\n 'A+' : '4.3',\n 'A' : '4.0',\n 'A-' : '3.7',\n 'B+' : '3.5',\n 'B' : '3.0',\n 'B-' : '2.7', \n 'C+' : '2.5',\n 'C' : '2.0',\n 'C-' : '1.7',\n 'F' : '0' }\n\n\n# Step00. 사용자에게 값을 입력 받아야 한다 -> input() 사용\n# # 과목, 점수, 취득학점\nUser_input_name = input('과 목 명 :')\nUser_input_score = input('점 수 :')\nUser_input_grader = input('취득학점 :')\n\n\n# 만점이 몇점인지 묻는다\nlog_txt = {\n 'calculating_way':'몇점 만점인가요? \\n 1. 4.5점 \\n 2. 4.3점 \\n 입력하시오 :',\n } \n\n\nGrader_calculate = input(log_txt['calculating_way'])\n# print(type(Grader_calculate)) # str\n\n\n# func_loof\ndef func_loof(case):\n f_loop = [gdr for gdr in case ]\n for num in range(len(f_loop)):\n if User_input_score == f_loop[num]:\n print(f_loop[num], case[f_loop[num]])\n\n return f_loop[num], case[f_loop[num]]\n\n# func_loof(score_case1)\n\n\n\n# 다중 조건문\nif Grader_calculate == '1':\n print('='*50,'\\n',str(4.5)+'점')\n func_loof(score_case1 )\n\nelif Grader_calculate == '2':\n print('='*50,'\\n',str(4.3)+'점')\n func_loof(score_case2 )\n\n\n\n# ======\n# 본문\n\ndef main():pass\n\nif __name__ == '__main__':\n main()\n\n# 수정 해야하는거 \n# 취득 학점을 입력한 경우 => get 한 학점 / 총학점 아닌가 ? \n# "
},
{
"alpha_fraction": 0.5422453880310059,
"alphanum_fraction": 0.5766782164573669,
"avg_line_length": 24.798507690429688,
"blob_id": "ea3e0b4f16ab3f1b8aab68c10e48e70fe3bb823b",
"content_id": "c3851c785a653661a157cc9014eefe60bf902b92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4400,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 134,
"path": "/Artificial_Intelligence/Deep_Learning/Tensorflow/Keras_mnist.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nfrom tensorflow import keras\nfrom tensorflow.keras import models, layers, backend\nfrom tensorflow.keras.datasets import mnist # datasets\n\n# 데이터 셋 준비 \n(X_train, y_train), (X_test, y_test) = mnist.load_data()\nimg_rows, img_cols = X_train.shape[1:] # 이미지 크기 \n# print(img_rows, img_cols) # 28, 28\n\n# 데이터의 포멧에 따라, 채널의 위치를 조정\nbackend.image_data_format()\n\n# 데이터를 이런 형식으로 맟춰서 준비 \n\n# 채널 => 흑백이미지(1), 칼라(3) => (60000, 28, 28, 3)\ninput_channel = 1 \n\nif backend.image_data_format == 'channels_last':\n # (1, rows, cols) => (1, H, W)\n # X_train.reshape(빈자리알아서(-1),채널,img_rows, img_cols)\n X_train = X_train.reshape( -1, 1, img_rows, img_cols ) # (60000, 1, 28, 28)\n X_test = X_test.reshape( -1, 1, img_rows, img_cols ) # (10000, 1, 28, 28)\n input_shape = ( input_channel, img_rows, img_cols )\n \nelse : # 'channels_last'\n X_train = X_train.reshape( -1, img_rows, img_cols, 1 )\n X_test = X_test.reshape( -1, img_rows, img_cols, 1 )\n input_shape = ( img_rows, img_cols ,input_channel )\n\n# print(X_train.shape, X_test.shape)\n# print(X_train.dtype)# 데이터 성분, 범위, 타입\n\n# 타입 변경 \nX_train = X_train.astype('float32')\nX_test = X_test.astype('float32')\nprint(X_train.dtype)# 데이터 성분, 범위, 타입\n\n\n# 정규화\n# float32로 변화 처리하지만, 의미는 다르다.\nprint(y_train[:10])\n\n# 텐서플로우에서 사용한 방식으로 사용해 본다면 \n# 원-핫 인코딩 스타일로 작성해 본다면 케라스의 유틸리티를 사용 \n# 답을 구성하는 클래스의 총수( 가짓수, 답안의 케이스 수)\nnum_classes = 10\ny_train = keras.utils.to_categorical(y_train, num_classes)\nprint(y_train[:10])\n\n# 동일하게 테스트셋에도 \ny_test = keras.utils.to_categorical(y_test, num_classes)\n\n\"\"\"\n# 정규화 표준화 \n\n- 기본적인 튜토리얼은 각 픽셀값이 0과 1로 정규화 되어있다. \n- 정규화 과정을 거치지 않은 상태로\n 이파일은 픽셀이 0과 255사이의 값을 가진다.\n 그렇기 때문에 전체 픽셀값을 255로 나누어서 정규화를 진행 -> 더욱 빠르게 연산이 가능하다.\n\"\"\"\n\n# 정규화 처리(최대값 기준) \n# -> 이부분 잘모르겠다. 텐서 문법인가...? \nX_train /= 255\nX_test /= 255\n\n\n# print(X_train.shape, y_train.shape, X_test.shape, y_test.shape)\n\n# 신경망 구성하기 \n# 인공신경망을 만든다고 선언적 표현, 모델 생성\nmodel = models.Sequential()\n\n# 합성곱층 생성 추가\n# filters : 출력 채널수 -> 1을 넣어서 32가 출력\n# kernal_size : 3x3\nmodel.add( layers.Conv2D(32, \n kernel_size=(3,3),\n strides=(1, 1),\n padding='valid',\n activation='relu',\n input_shape=input_shape\n ) )\n\n# 풀링층 생성 추가 \nmodel.add(layers.MaxPool2D(pool_size=(2,2),))\n# 과적합 방지 추가 \nmodel.add(layers.Dropout(0.25))\n\n# 합성곱층 생성 추가 : 기본값들이 있는 부분들은 생략해서 표현\nmodel.add(layers.Conv2D(64, \n kernel_size=(3,3),\n #strides=(1, 1),\n #padding='valid',\n activation='relu',\n #input_shape=input_shape,\n ))\n\n\n# 풀링층 생성 추가\nmodel.add( layers.MaxPool2D( pool_size=(2,2) ) )\n\n# 과적합 방지 추가\nmodel.add( layers.Dropout(0.25) )\n# 전결합층 추가 \nmodel.add(layers.Dense(0.5))\n\n# 출력층 추가 => y\n# num_classes => 10\nmodel.add( layers.Dense( num_classes, activation='softmax' ) )\n# 손실함수, 최적화, 정확도 추가 혹은 컴파일\nmodel.compile( loss=keras.losses.categorical_crossentropy,\n optimizer='rmsprop',\n metrics=['accuracy']\n )\n\n# 훈련 및 테스트 \n\n# 실험값, 임계값\n# 실험 횟수, 세대수, 훈련 횟수\nepochs = 10 # 설정값\n# 1회 학습시 사용되는 데이터양\nbatch_size = 128 # 설정값\n\nmodel.fit( X_train, y_train, \n epochs = epochs,\n batch_size = batch_size,\n validation_split=0.2 \n )\n\n# 테스트 데이터로 확인\nscore = model.evaluate(X_test, y_test)\nprint(score)"
},
{
"alpha_fraction": 0.442176878452301,
"alphanum_fraction": 0.4897959232330322,
"avg_line_length": 17.375,
"blob_id": "60e8e850a080e7b542f0e188df90484f0e073e56",
"content_id": "befeb3f74d6f0635bfec822af561b2d43e42eac0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 147,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 8,
"path": "/CodingTest/permutation.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "def nCr(n,r):\n result = 1 \n for i in range(1, r+1):\n result = result * ( n-i +1)/ i\n return result\n\nm , n = 10,3\nprint(nCr(m , n))\n"
},
{
"alpha_fraction": 0.29071536660194397,
"alphanum_fraction": 0.3394216001033783,
"avg_line_length": 21.620689392089844,
"blob_id": "6e2cc498de8412f25c0c20a70b6b5eefac699e54",
"content_id": "0e14a2402db86ef590f8d90b68457b60b279b180",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 753,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 29,
"path": "/Project/Mini Project/Multipcation.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 구구단 혼자 만드니까 자료구조 듣습니다아아아이조아\n# 2019.12.16 <ver_1>\n#----------------------------------------\n# 일단 구구단 get 0\nfor i in range(10):\n k = i+1\n print('--',k,\"단\",'--')\n for j in range(10):\n print(k,'x',j,'=',k*j)\n # print('---')\n # print(k*j)\n # print('-'*10)\nprint('--DONE--')\n#----------------------------------------\n# 일단 구구단 get 1\nfor i in range(10):\n k = i+1\n print('--',k,\"단\",'--')\n for j in range(10):\n l = j+1\n print(k,'x',l,'=',k*l)\n # print('---')\n # print(k*j)\n # print('--------')\nprint('--DONE--')\n#----------------------------------------\n\n# 2019.12.18 => \n# 사용자로 부터 입력값을 받을것 \n"
},
{
"alpha_fraction": 0.473300963640213,
"alphanum_fraction": 0.4939320385456085,
"avg_line_length": 5.25,
"blob_id": "d880ad2a796921526a5b0906881a09e3764caafb",
"content_id": "1b5c4059472118d6829c0fbbb74ee9029e9d841e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1232,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 132,
"path": "/R/R_ 통계기초_02.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 02. R 통계 기초 - R로 배우는 통계 이해\n\n<br>\n\n# R로 배우는 통계 이해\n\n<br>\n\n## 1. 통계적 실험과 유의성 검증 \n\n<br>\n\n### 가설 검정\n\n가설 설정 및 검정의 단계 \n\n<br>\n\n1. 귀무가설 \n2. 대립가설\n\n\n1. 일원 가설 검정 \n2. 이원 가설 검정\n\n가설 검정 개요 \n\n### 통계적 유의성과 p-value\n\n<br>\n\n### \n\n<br>\n\n\n\n### \n<br>\n\n### \n\n<br>\n\n\n<br>\n\n```r\n\n```\n\n<br>\n\n\n\n\n## 2.\n\nt-검정\n\n\nt-검정을 할 때는 두 가지 가정이 만족되는지 먼저 확인해야 한다.\n\n1. 정규성 가정 (normality assumption)\n \n: 두 집단의 분포가 정규분포를 따른다고 할 수 있는지\n\n *정규성 검정에 대한 내용은 아래 포스팅 참조\n\n http://mansoostat.tistory.com/22\n\n2. 등분산성 가정 (homogeneity of variance)\n\n: 두 집단의 분산이 같다고 할 수 있는지\n\n (귀무가설을 기각하지 않으면 등분산성 가정을 할 수 있다.)\n \n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 3.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n## 4.\n\n<br>\n\n```py\n\n```\n\n<br>\n\n\n\n\n\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n<!-- - 조대협의 블로그 : <https://bcho.tistory.com/972/> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [내용](주소) -->"
},
{
"alpha_fraction": 0.6849315166473389,
"alphanum_fraction": 0.6849315166473389,
"avg_line_length": 17.16666603088379,
"blob_id": "ce7592277c2af377697615ff1315c0c88b2f918b",
"content_id": "9ab0d427a249eddbc16ff4375ec40c23f407b02f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 271,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 12,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_추상클래스/Player.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n# 추상 클래스 실습 - 플레이어 \n# Player.py\n\nfrom Character import Character\n\n# 추상클래스의 자식 클래스(player)\nclass Player(Character):\n\n def getDamage(self, attackPower, attackKind):\n self.hp -= attackPower\n"
},
{
"alpha_fraction": 0.7083333134651184,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 11.25,
"blob_id": "6b751e24df3d9a96c02455d18ef3ac37c7ed32b6",
"content_id": "e3fda18bff16781c6b24494a6eff3685f10b0c6c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 4,
"path": "/Artificial_Intelligence/Machine_Learning/README.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# Machine Learning(ML)\n---\n\nMachine Learning(ML)"
},
{
"alpha_fraction": 0.5345959663391113,
"alphanum_fraction": 0.5487373471260071,
"avg_line_length": 11.113149642944336,
"blob_id": "81a5f5fcbd3264a1cfebf9fe523480ee754cf030",
"content_id": "2f4f5eabc2e97ea68f884484eb8fea4b462baaac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5756,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 327,
"path": "/Python/5.심화_클래스활용.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 5. 파이썬 심화 - 클래스 활용 \n\n<br>\n\n# 클래스 활용 \n\n<br>\n\n## 1. 클래스의 속성 \n\n클래스 속성은 클래스에 속해 있다. <br>\n\n그렇기 때문에 클래스의 속성은 모든 인스턴스에서 공유된다. \n\n<br>\n\n### 클래스의 속성 기본 구조 \n\n어렵게 생각할것 없이 클래스에 바로 속성을 만들면 된다. <br>\n\n```py\n\nclass 클래스 이름 :\n\n 속성 = 값 \n\n# 주의) __init__ => 인스턴스 속성 ! \n\n```\n\n<br>\n\n인스턴스 속성 같은 경우는 클래스의 속성과 다르게 인스턴스 별로 독립되어 있고 그렇기 때문에 서로 영향을 주지 않는다.\n\n그럼 확인 해보자! \n\n\n<br>\n\n### 클래스의 속성일때 \n\n```py\n\nclass Person :\n\n bag = [] \n\n def putBag(self, stuff):\n self.bag.append(stuff)\n # Person.bag.append(stuff) # 클래스로 클래스 속성에 접근\n\nJerry = Person()\nJerry.putBag('Books')\n# Person.putBag('pen')\n\nJoy = Person()\nJoy.putBag('Wallet')\n\nprint(Jerry.bag) # 제리의 가방\nprint(Joy.bag) # 조이의 가방 \n\n# outPut\n# >>> ['Books', 'Wallet']\n# >>> ['Books', 'Wallet']\n\n```\n\n<br>\n\n### 인스턴스가 존재 할때 \n\n```py\n\nclass Person :\n\n # bag = [] \n def __init__(self):\n self.bag = [] # 인스턴스 속성 \n\n def putBag(self, stuff):\n self.bag.append(stuff)\n\nJerry = Person()\nJerry.putBag('Books')\n\nJoy = Person()\nJoy.putBag('Wallet')\n\nprint(Jerry.bag) # 제리의 가방\nprint(Joy.bag) # 조이의 가방 \n\n# outPut\n# >>> ['Books']\n# >>> ['Wallet']\n\n```\n\n<br>\n\n정리 하자면 <br>\n\n- 클래스 속성\n\n - 모든 인스턴스가 공유 \n - 인스턴스 전체가 사용해야 하는 값을 저장할 때 사용\n\n- 인스턴스 속성\n\n - 인스턴스별로 독립되어 있음\n - 각 인스턴스가 값을 따로 저장해야 할 때 사용\n\n<br>\n<br>\n\n## 2. 비공개 클래스 속성\n\n<br>\n\n비공개 속성은 `__속성` \n\n<br>\n\n### 비공개 클래스의 속성 기본 구조 \n\n어렵게 생각할것 없이 비공개 클래스에 바로 속성을 만들면 된다. <br>\n\n```py\n\nclass 클래스 이름 :\n\n __속성 = 값 # 비공개 클래스의 속성 -> 외부에서 접근 x \n\n```\n\n<br>\n\n만약 클래스에서 공개하고 싶지 않은 특정 속성이 있다면 <br>\n\n비공개 클래스를 사용하는것이 좋다고 한다. \n\n<br>\n\n```py\n\nclass creditCard:\n \"\"\"\n 1만불 한도의 신용카드 \n \"\"\"\n __money_limit = 10000 # 비공개 클래스 속성\n \n def show_money_limit(self):\n print(creditCard.__money_limit) # 내부 접근\n \n \namax = creditCard()\namax.show_money_limit() # 1만불\n \nprint(creditCard.__money_limit) # 외부 접근 불가\n\n# outPut\n\n# >>> 10000\n# >>> Traceback (most recent call last):\n# File \"c:/KISS/Python/TestDummy.py\", line 19, in <module>\n# print(creditCard.__money_limit) # 외부 접근 불가\n# AttributeError: type object 'creditCard' has no attribute '__money_limit'\n\n```\n\n<br>\n<br>\n\n## 3. 정적 메소드 \\*\\*\n\n<br>\n\n정적 메소드는 인스턴스를 통하지 않고 클래스에서 **바로 호출**이 가능하다.\n\n메소드 위에 `@staticmethod` 를 붙이면 정적 메소드로 사용가능하다. \n\n그리고 `@staticmethod` 을 붙인 정적 메소드는 매개변수에 self를 지정하지 않는다. \n\n`@` 은 메소드(함수)에 추가 기능을 구현할때 쓰는 데코레이터이다.\n\n<br>\n\n### 정적 메소드 기본 구조 \n\n\n```py\n\nclass 클래스이름: \n\n @staticmethod\n def 메소드(매개변수1, 매개변수2):\n 코드\n\n```\n\n<br>\n\n심플하게 정적 메소드를 활용 해 보자 !\n\n<br>\n\n```py\n\nclass Mall:\n \"\"\"\n wMart와 eMart 중 어디가 더 저렴할까 ?\n \"\"\"\n\n @staticmethod\n def wMart(a, b):\n print(f'$ {int((a + b)*0.8)}')\n \n @staticmethod\n def eMart(a, b):\n print(f'$ {a + b}')\n\napple = 10 \nsoup = 20\n\nMall.wMart(apple, soup) \nMall.eMart(apple, soup) # 클래스 -> 바로 메소드 호출\n\n# outPut\n\n# >>> $ 24\n# >>> $ 30\n\n```\n<br>\n\n정적 메소드는 인스턴스 속성에는 접근할 수 없다.\n\n그래서 인스턴스(속성, 메소드)가 필요없을 경우 사용하는데 \n\n인스턴스의 상태를 변화시키지 않는 메소드 \n\n즉, 메소드의 실행이 외부 상태에 영향을 끼치지 않는 순수 함수(Pure function)를 만들 때 사용한다. \n\n\n<br>\n<br>\n\n## 4. 클래스 메소드 \\*\\*\n\n<br>\n\n정적 메소드와 유사하지만 다른 메소드에 대해 알아보자 !\n\n클래스 메소드 = `@classmethod`\n\n정적 메소드처럼 메소드 위에 `@classmethod` 을 붙인다. \n\n<br>\n\n### 클래스 메소드 기본 구조 \n\n\n```py\n\nclass 클래스이름:\n\n @classmethod\n def 메소드(cls, 매개변수1, 매개변수2):\n 코드\n\n```\n\n<br>\n\n### 클래스 메소드 출력\n\n<br>\n\n클래스 메소드는 메소드 안에서 클래스 속성, 클래스 메소드에 접근 할때 사용하며 \n\n정적 메소드처럼 인스턴스 없이 호출할 수 있다.\n\n`cls()` = `Person()`\n\n```py\n\nclass Person:\n\n cnt = 0 \n \n def __init__(self):\n Person.cnt += 1 # 명확하게 클래스 속성에 접근을 확인하기 위함\n\n \n @classmethod\n def printCnt(cls):\n print(f'생성 : {cls.cnt}') # cls로 클래스 속성에 접근\n \n\nJerry = Person()\nJoy = Person()\n \nPerson.printCnt() \n\n#outPut\n# >>> 생성 : 2 \n\n```\n\n<br>\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [심화_클래스활용](https://github.com/Jerrykim91/KISS/tree/master/Python/%EC%8B%AC%ED%99%94_%ED%81%B4%EB%9E%98%EC%8A%A4%ED%99%9C%EC%9A%A9)"
},
{
"alpha_fraction": 0.5571847558021545,
"alphanum_fraction": 0.5571847558021545,
"avg_line_length": 16.487178802490234,
"blob_id": "18e9de73915324260782f5222b8e2a6edecfe4ed",
"content_id": "464e49da4fd10597513d94235f05ff2cac57c508",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 732,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 39,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_추상클래스/Monster.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n# 추상 클래스 실습 - 몬스터 \n# Monster.py\n\nfrom Character import Character\n\n\n\n# 추상클래스의 자식 클래스(Monster)\n\nclass IceMonster(Character):\n\n def getDamage(self, attackPower, attackKind):\n\n if attackKind == 'ICE':\n self.hp += attackPower # +\n\n else :\n self.hp -= attackPower # -\n\n def __str__(self):\n\n return f\"Ice Monster's HP : {self.hp}\"\n\n\nclass FireMonster(Character):\n\n def getDamage(self, attackPower, attackKind):\n\n if attackKind == 'FIRE':\n self.hp += attackPower # +\n\n else :\n self.hp -= attackPower # -\n\n def __str__(self):\n\n return f\"Fire Monster's HP : {self.hp}\""
},
{
"alpha_fraction": 0.5603715181350708,
"alphanum_fraction": 0.5665634870529175,
"avg_line_length": 18,
"blob_id": "04550269e940a27e604a38a6d1c25c1feed031ca",
"content_id": "60b4007a84d66ab57a6064bc55494db1c74a37cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 678,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 34,
"path": "/Python/Boost-Course/ListComprehensions.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# List Comprehension\n\n## Nested For loop + if 문\n\n\ncase_1 = [\"A\", \"B\", \"C\"]\ncase_2 = [\"D\", \"E\", \"A\"]\n\nresult = [i+j for i in case_1 for j in case_2 if not (i==j)]\n\n# print(result)\n\n# >>> ['AD', 'AE', 'BD', 'BE', 'BA', 'CD', 'CE', 'CA']\n\nresult.sort()\nprint(result)\n\n# >>> ['AD', 'AE', 'BA', 'BD', 'BE', 'CA', 'CD', 'CE']\n\n\n## split + list Comprehension\n\n# words = 'The quick brown fox jumps over the lazy dog'.split() # 이렇게 쓰는게 코드 길이가 짧아지네 \nwords = 'The quick brown fox jumps over the lazy dog'\n# print(words)\n\nwords = words.split()\nprint(words)\n\nstuff = [[w.upper(), w.lower(), len(w)] for w in words]\nprint(stuff)\n\nfor i in stuff:\n print(i)"
},
{
"alpha_fraction": 0.40466392040252686,
"alphanum_fraction": 0.42455416917800903,
"avg_line_length": 19.680850982666016,
"blob_id": "8e5a58ae5470d120382db51620634e8a6e97bf0e",
"content_id": "a829eca72e274a9171c80d84f96d97c533891bd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3814,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 141,
"path": "/Artificial_Intelligence/Machine_Learning/algo/pererceptron/Perceptron.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 퍼셉트론을 직접 구현해보자 \n\n\n```py\n\nimport pickle\nimport numpy as np\nfrom time import time\n# from perceptron import perceptron\n\n```\n\n## 1단계 퍼셉트론 생성 \n\n```py\n\n# perceptron 알고리즘 구현\n\nimport numpy as np\n\n\nclass Preceptron:\n \"\"\"\n 클래스 멤버 : 주요 알고리즘 \n \"\"\"\n \n # 생성자 함수 생성 \n def __init__(self, thresholds =0.0, eta=0.01, n_iter=10 ):\n\n \"\"\"\n # 생성자의 기본 인자들 \n - thresholds: 임계값(default =0.0)\n - eta = 학습률(default =0.01)\n - n_iter = 학습의 횟수(default =10) \n\n \"\"\"\n self.thresholds = thresholds\n self.eta = eta\n self.n_iter = n_iter\n\n\n # 학습함수\n def fit(self, X, y):\n\n \"\"\"\n X : 독립변수 - 입력 데이터 (대문자)\n y : 종속 변수 - 결과 데이터 \n \"\"\"\n self.w_ = np.zeros(1 + X.shape[1]) # 가중치를 넘파이 배열로 정의 \n # X.shape[1] 트레이닝 데이터의 입력값 개수를 의미 \n # X 가 5 x 2인 경우 -> x.shape = (5,2)\n \n \n # 예측값과 실제값을 비교 \n self.errors_ = [] # 예측값과 실제 결과값이 다른 오류 회수하고 저장하기 위한 에러박스 \n \n # 지정된 학습 횟수만큼 반복 -> 왜 버려 ?\n \"\"\"\n self.n_iter 지정한 숫자만큼 반복 \n _ 값은 아무런 ㅡ이미없는 변수 \n -> 단순하게 for문을 특정 횟수 만큼만 반복 하자고 할 때 \n 관습적으로 반복하는 변수 \n\n \"\"\"\n for _ in range(self.n_iter):\n # 예측값과 실제 값을 담을 변수 \n errors = 0 \n tmp = zip( X, y ) # 입력값과 결과값을 묶어줌\n \n for xi, target in tmp : # 입력받은 입력값을 묶음을 가지고 반복\n #입력값을 가지고 예측값을 계산\n a1 = self.predict(xi)\n \n if target != a1 : # 입력값과 예측값이 다르면 가중치를 계산 \n update = self.eta * (target - a1)\n self.w_[1:] += update * xi \n self.w_[0] += update\n\n # 값이 다른 횟수를 누적\n errors += int(update != 0.0)\n\n # 값이 다른 횟수값을 배열에 담음\n self.errors_.append(errors)\n print(self.w_)\n\n\n def net_input(self, X):\n\n \"\"\"\n - 각 자리의 값과 가중치를 곱한 총합을 구함 \n - 가중치 * 입력값의 총합을 계산 \n - X : 입력값\n \"\"\"\n a1 = np.dot(X, self.w_[1:]) + self.w_[0] # al = sum(w_ * X) + b \n return a1\n\n\n # 예측\n def predict(self, X): \n \"\"\"\n - 예측된 결과를 가지고 판단\n - X : 입력값 배열 \n \"\"\"\n # 0 > 1\n # 0 <= -1 \n a2 = np.where(self.net_input(X) > self.thresholds, 1, -1 )\n return a2 \n\n\n\n```\nfit 부분인 조금 아리송송하다 \n\n## 2 단계 학습 \n\n```py\n\ndef step1_learning():\n # 학습과 테스트를 위해 사용할 데이터를 정의한다. \n X = np.array([0,0],[0,1],[1,0],[1,1])\n y = np.array([-1,-1,-1,1])\n \n # 퍼셉트론 객체를 생성\n ppn = perceptron(eta=0.1)\n\n # 학습 \n stime = time()\n ppn.fit( X, y )\n etime = time()\n print(\"학습에 걸린 시간 : \", (etime - stime))\n print(\"학습중 오차가 난 개수 : \", ppn.errors_)\n\n\n # 학습이 완료된 객체 파일로 저장\n\n with open('./data/perceptron.dat', 'wb') as fp :\n pickle.dump(ppn, fp)\n\n print(\" 머신러닝 학습 완료 \")\n\n```"
},
{
"alpha_fraction": 0.6293103694915771,
"alphanum_fraction": 0.6396551728248596,
"avg_line_length": 19.714284896850586,
"blob_id": "a82082e263b171016385d0870eb8a49f49ee5ac8",
"content_id": "edd4d6b4ab52cd690b13c14608ef13066a828d7e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 716,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 28,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_추상클래스/Character.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n# 추상 클래스 실습 - 캐릭터 \n# Character.py\n\nfrom abc import * # Abstrace Base Class\n\nclass Character(metaclass = ABCMeta):\n\n def __init__(self):\n self.hp = 100\n self.attackPower = 20 \n\n def attack(self, other, attackKind):\n other.getDamage(self.attackPower, attackKind)\n\n @abstractclassmethod # Character 클래스를 상속받는 모든 클래스는 함수를 오버라이딩으로 구현해야 인스턴스 생성이 가능\n def getDamage(self, attackPower, attackKind):\n pass\n\n\n# dev_mode \n\nif __name__ == '__main__':\n \n ch1 = Character()\n\n# Character 클래스를 상속 받아서 Player, Monster 클래스를 각각 정의"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 22.33333396911621,
"blob_id": "e5cab6e9af242801aa23b2bd8424df0a388d22c2",
"content_id": "5ed4f9701af423efed6d2bbe72881813e49f7dbe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 3,
"path": "/Python/index.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "print(\"Hello Python\")\nprint(\" 오~ 신기하당 !!! \")\nprint(\" 저장을 해야하는구나 ?! \")\n"
},
{
"alpha_fraction": 0.6929716467857361,
"alphanum_fraction": 0.7046855688095093,
"avg_line_length": 23.223880767822266,
"blob_id": "f6dd48cee8dee24af4b5c5924c738d1798b91156",
"content_id": "33363979b35bd849c34cf18ce1ab43825136f1ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3056,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 67,
"path": "/Virtual_Environment/SparkEnv_Outline.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n# SparkEnv_Outline\n\n우리는 pyspark를 이용해 스파크를 간접적(?)으로 다루게 된다. \n그러기 위해서는 간단하게라도 pyspark가 무엇인지 spark란 무엇인지를 알아야한다. \n\n<br>\n\n# 1. Spark란 ?\n\n\n아파치 스파크(**Spark**)는Apache에서 관리되고 있는 오픈소스 프로젝트이며 \n빅데이터 처리를 위한 분산 클러스터컴퓨터 프레임워크이다. \n스파크는 복수의 컴포넌트로 구성되며, 스파크 코어는 데이터소스로 HDFS(Hadoop Distributed File System) 뿐만 아니라 Hive, HBase, PostgreSQL, MySQL, CSV 파일 등도 처리가 가능하다. \n \n\n인메모리를 기반으로 한 대용량 데이터를 처리할 수 있는 데이터 고속 처리 엔진을 가지고있다.\n그렇기때문에 대량의 데이터를 고속 병렬분산처리한다. \n스파크는 하둡보다 100배정도 빠른속도를 가지고 있다. \n\n\n스파크는 데이터셋으로부터 데이터를 읽어 들인 뒤 스토리지 I/O와 네트워크 I/O를 최소화하도록 처리한다. 따라서 스파크는 동일한 데이터에 대한 변환처리가 연속으로 이루어지는 경우와 머신러닝처럼 결과셋을 여러 번 반복해 처리하는 경우에 적합하다. 지연이 작게 동작하는 특성을 이용해 스트림처리를 할 수도 있다. \n\n\n스파크에서 가장 기본적인 개념은 데이터셋이라고 불리는 분산 컬렉션이다. \nDataset은 Hadoop InputFormat(HDFS파일)으로 부터 만들어지거나 다른 데이터셋을 변경하여 만들어진다. \n동적으로 타입 검사를 수행하는 파이썬의 특성 때문에 파이썬에서는 데이터셋의 타입의 체크는 필요하지 않다. \nPython에서 사용하는 모든 Dataset은 DataSet[Row]의 형태인데 이것은 우리가 주로 사용하는 DataFrame의 DataFrame과 동일한 개념이다. \n\n\n<br>\n\n# 2. pyspark란 ? \n\n병렬 및 분산엔진인 스파크를 이용하기 위한 파이썬 api이다. \n\nRDD(Resilient Distributed Dataset)을 지원하는 아키텍쳐 \nRDD는 read-only를 목적으로 다양한 머신에 데이터셋으 멀티셋(중복을 허용)을 분산해두고 특정한 머신에 문제가 생기더라도 문제없이 읽을 수 있도록 지원한다. \n\n설치 관련은 SparkSetup.md 을 참조! \n\nSpark를 많이 쓰는 이유는 속도가 빨라서 \n실제로 디비나, 리스트 처럼 데이터가 묶음으로 있을때 이를 병렬로 처리해서 속도를 빨리처리 \n매트릭스 연산과 비슷하다고 해도 무방할정도로 \n\n\n**-ing** \n\n<br>\n\n---\n\n< 참조 >\n\n\n1. 스파크 공식홈페이지 -> [이동](https://spark-korea.github.io/docs/index.html)\n\n2. 아파치 스파크란? ->\n[이동](https://12bme.tistory.com/433)\n\n3. 스파크 이해하기 -> [이동](https://12bme.tistory.com/305) \n\n4. 클러스터 리소스 최적화를 위한 Spark 아키텍처 -> [이동](https://www.samsungsds.com/global/ko/support/insights/Spark-Cluster-job-server.html)\n\n---\n<br>"
},
{
"alpha_fraction": 0.550000011920929,
"alphanum_fraction": 0.550000011920929,
"avg_line_length": 20,
"blob_id": "5411b56ee99509141f4b7934931ce9569610170f",
"content_id": "f19edbf9e5d213131c7c015eb67565f49c14a665",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/Python/fun_pkg/__init__.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# __init__.py 내용은 비움"
},
{
"alpha_fraction": 0.5464216470718384,
"alphanum_fraction": 0.5609284043312073,
"avg_line_length": 12.701986312866211,
"blob_id": "2b24dc23fb1bb92bbc517c2aafef7d293c6645d1",
"content_id": "bf9959899cc053c10826afd7268d480d74c612d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3052,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 151,
"path": "/Virtual_Environment/리눅스/리눅스.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 1. Ubuntu 18.04 - 리눅스 기본 세팅\n\n<br>\n\n# 리눅스 기본 세팅\n\n<br>\n\n## 1. 설치 직후 버벅 거릴 때\n\n<br>\n\n버벅거릴 때는 주로 드라이버가 제대로 안 잡혀있는 경우 발생한다. \n이럴때 아래의 코드를 설치하면 버벅거림은 줄어들고 가끔 멈추는 현상이 사라진다. \n\n\n**`apt-get update` 설치 되어있는 패키지들의 새로운 버전이 있는지 확인할 때 사용하는 명령어다.**\n\n<br>\n\n```bash\n\n# apt 업데이트\n$ sudo apt-get update \n# 혹은 \n$ sudo apt-get update -y\n\n```\n<br>\n\n**`sudo ubuntu-drivers autoinstall`는 Nvidia 드라이버 설치하는 명령어이다.**\n\n<br>\n\n\n```bash\n\n# 드라이버 설치 \n$ sudo ubuntu-drivers autoinstall\n\n```\n\n<br>\n<br>\n\n\n## 2. 편집기 설치\n\n<br>\n\n편집기는 주로 vim 아니면 nano를 이용하기 때문에 둘 다 설치를 진행하였다.\nvim을 많이 사용하지만 처음 시작하는 사람들에게는 vim이 조금 어렵게 느껴질 수 있어서 \n초심자인 나는 nano를 주로 사용한다.\n\nnano 같은 경우 검색, 자동 들여쓰기 등의 기능이 있지만 사용하는 주 이유는 단축키가 창의 맨 아래에 나열되어 있어 사용하기가 수월하기 때문이다.\n\n<br>\n\n```bash\n\n# 편집기 설치 (vim or nano) \n$ sudo apt install vim -y \n$ sudo apt install nano -y \n\n# 단축키 : 나노 ctrl + - # 번호 검색 \n# alt + shift + 3 # 라인 넘버 리스트화\n\n```\n\n<br>\n<br>\n\n\n\n## 3. 주로 사용하는 단축키\n\n<br>\n\n```bash\n\n# Ubuntu에서 terminal 열기 \nctrl + alt + t # 터미널 오픈 단축기 \n\n$ sudo apt update -y # 업데이트 실행 \n$ ifconfig # 서버 ip 주소 -> ubunt ip 주소 확인한다. \n$ hostname # 호스트네임 확인 \n$ sudo reboot # 리부팅 \n$ df -h # 용량확인\n\n```\n\n<br>\n<br>\n\n\n## 4. 방화벽\n\n<br>\n\n```py\n$ sudo ufw enable # 방화벽 활성화 \n$ sudo ufw allow 22 # 방화벽 열기 22 \n$ sudo ufw status # 방화벽 확인 \n\n## 디테일한 방화벽 설정 \n\n# UFW 활성화/비활성화 \n$ sudo ufw enable # 활성화 \n$ sudo ufw disable # 비활성화 \n$ sudo ufw status verbose # UFW 상태 확인 \n\n# 기본 툴 \n# - 들어오는 패킷에 대해서는 전부 거부(deny) \n# - 나가는 패킷에 대해서는 전부 허가(allow) \n \n# 기본룰 확인 \n$ sudo ufw show raw \n$ sudo ufw default deny # 기본 정책 차단 \n$ sudo ufw default allow # 기본 정책 허용 \n\n# 포트 허용 \n$ sudo ufw allow 22 # ssh 포트 22번 거부(tcp/udp 22번 포트를 모두 거부) \n$ sudo ufw allow 22/tcp # tcp 22번 포트만을 거부 \n$ sudo ufw allow 22/udp # udp 22번 포트만을 거부 \n$ sudo ufw delete deny 22/tcp # UFW 룰의 삭제 \n\n# 로그기록 \n$ sudo ufw logging on \n$ sudo ufw logging off\n\n```\n\n<br>\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 내용 : <주소> <br>\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n- [내용](주소)"
},
{
"alpha_fraction": 0.6229773759841919,
"alphanum_fraction": 0.6278316974639893,
"avg_line_length": 13.891566276550293,
"blob_id": "f511dcb9c400db1afa284a1012b76822b67d3980",
"content_id": "320c43f90abcbb59d15b9844bcf4e26a36562e05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2378,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 83,
"path": "/Python/0.기본_PythonUnderScore.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 1. 파이썬 기본 - 언더 스코어\n\n<br>\n\n# 파이썬 - 언더 스코어\n\n<br>\n\n타언어의 언더스코어는 단지 스네이크 표기법\\*의 변수나 함수명을 위해서만 사용한다. \n\n하지만 파이썬에서는 언더스코어는 특별한 용도로 사용되는데 언제 어떤 의미로 쓰이는지 알아보자.\n\n파이썬을 공부한다면 알아 두고 차근차근 익혀나가는것을 추천한다. \n\n<br>\n\n## 파이썬 사용되는 상황 \n\n1. 인터프리터에서 마지막 값을 저장할때 \n - 마지막으로 실행된 결과값이 `_` 라는 변수에 저장된다.\n2. 값을 무시하고 싶을때 \n - 특정한 값을 무시하거나 값을 버릴때 사용\n3. 변수나 함수 명에 특별한 의미 또는 기능을 부여하고 싶을때 \n4. 국제화 / 지역화 함수로 사용할때 \n5. 숫자 리터럴값의 자릿수 구분을 위한 구분자로써 사용할 때 \n\n<br>\n<br>\n\n\n## \\* 표기법이란 ? \n\n<br>\n\n알아두면 좋은표기법 중 카멜 표기법( camelCase ), 파스칼표기법( PascalCase ) 스네이크 표기법( snake_case )이 있다. <br>\n그중 스네이크 표기법에 대해 설명하고자 한다. <br>\n\n<br><br>\n\n### 카멜 표기법( thisIsCamel )\n\n<br>\n\n변수나 함수에 많이 사용되며<br>\n첫 문자를 소문자로 표기하고 그 다음 문자부터는 대문자로 표기한다.<br>\n자바 문법에 권장되는 표기법으로 단봉 낙타 표기법이라고 한다. <br>\n\n<br><br>\n\n### 파스칼 표기법( ThisIsPascal )\n\n<br>\n\n카멜표기법과는다르게 첫 문자부터 대문자로 표기하고 그다음문자 역시 대문자료 표기하는 방법이다. <br>\n\n주로 클래스 명을 만들때는 이 표기법 사용하며 가끔 함수에서도 사용하는것을 볼수 있다. <br>\n\n<br><br>\n\n### 스네이크 표기법( this_is_snake ) \n\n<br>\n\n주로 소문자를 사용하며 한문자가 끝날때 마다 언더스코어`_`를 붙여 문자를 연결하는 방식이다. <br>\n주로 변수명, 함수명, 데이터 타입 네임스페이스 등등에 많이 사용된다. \n개인적으로 파이썬에서 많이 사용하게 되는것 같다.<br>\n\n\n<br><br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 언더스코어(_)에 대하여 : <https://mingrammer.com/underscore-in-python/> <br>\n\n<br>\n\n## Practice makes perfect! <br>\n"
},
{
"alpha_fraction": 0.5963455438613892,
"alphanum_fraction": 0.6179401874542236,
"avg_line_length": 15.722222328186035,
"blob_id": "368f973087a98209412f82f4f38adbf792d91c0c",
"content_id": "6e1e6067a676694b22b44ef36c1b4f0012fe125f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 698,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 36,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_추상클래스/main.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n# 추상 클래스 실습 - 실행 파일 \n# main.py\n\nfrom Player import Player # 특정 \nfrom Monster import * # 전부다 \n\n\nplay = Player()\nice = IceMonster()\nfire = FireMonster()\n\nprint(ice) # Ice MOnster's HP : 100\nprint(fire) # Fire MOnster's HP : 100\n\n# # 검증 1 \n\n# play.attack(ice, 'ICE') # 동일한 속성일 경우 HP 증가 \n# play.attack(fire, 'ICE') # 반대 속성일 경우 HP 감소 \n\n\n# print(ice) # Ice MOnster's HP : 120\n# print(fire) # Fire MOnster's HP : 80\n\n\n# 검증 2 \n\nmonsters = [] # 리스트 생성 \nmonsters.append(ice)\nmonsters.append(fire)\n\n\nfor monster in monsters:\n play.attack(monster, 'ICE')\n print(monster)"
},
{
"alpha_fraction": 0.5645471811294556,
"alphanum_fraction": 0.5703275799751282,
"avg_line_length": 19.65999984741211,
"blob_id": "de897db2a061bb8074a2b5f8e45d75ca12cc3f64",
"content_id": "3f973c1e27c0e2da9399adeeefa52a387f16cd7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1598,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 50,
"path": "/Python/python_basic.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n---\n### 이터레이터 \n 반복 가능한 객체를 말한다 \n 객체에 .next가 가능하다면 이터레이터가 맞음 \n list는 반복 가능하지만 이터레이터는 아니다 \n 명시적으로 반복가능란 객체로 만들어서 사용해야한다.\n\n- **이터러블** \n 반복 가능하다는 뜻 => 반복(loop)연산이 가능하여 \n 해당 위치를 이동해가면서 값을 사용할수 있는지를 말함\n\n a라는 dict를 생성하여 class 확인을 하면 a는 dict일뿐 이터레이터는 아니다. \n\n- 이터레이션 \n반복가능한 객체에사 해당 값을 가져오는 행위 \n\n- 이터 함수 \n list나 dict를 이터레이터로 만들어 주는 함수\n dict를 생성하여 iter함수를 통하여 b라는 이터레이터를 만듬\n 이터러블 하기때문에 for문과 짝을 이루어 사용한다. \n\n\n### 제너레이터 \n 이터레이터를 만들어주는것을 말함 \n = 반복 가능한 객체를 만들어 주는 행위 \n\n- yield\n function에서 return과 동일한 역할을 수행 = 반환값\n\n```py\n# def generator(n):\n# print \"get_START\"\n# i = 0\n# while i < n:\n# yield i\n# print \"yield 이후 %d\" % i\n# i += 1\n# print \"get_END\"\n\n# for i in generator(4):\n# print \"for_START %d\" % i\n# print i\n# print \"for_END %d\" % i\n\n``` \n<hr />\n< 참고 자료 > \n 1. [fastcampus](www.fastcampus.co.kr) \n 2. [A Byte of Python](http://byteofpython-korean.sourceforge.net/byte_of_python.html) \n 3. [codecademy](https://www.codecademy.com/) \n"
},
{
"alpha_fraction": 0.5943601131439209,
"alphanum_fraction": 0.6117136478424072,
"avg_line_length": 13.568421363830566,
"blob_id": "e84cf1671c91b2627166776a76b3d6d203189566",
"content_id": "dbcd1813da96bd7207977ae9420e16bbadfa6986",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2887,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 95,
"path": "/Project/Solution_Base/Problem_5.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# Problem : 5차시 \n<br>\n\n진행중인 프로젝트에 관한 여러가지 이슈 그리고 해결방안\n\n<br>\n\n## 일자 \n\n- 2020년 06월 10일 화요일 \n\n<br>\n\n## 진행 상황\n\n현재 전체적인 진행상황은 아래와 같다. \n\n- 이미지 분석 : 89 % \n- 텍스트 분석 : 89 % \n- 시스템 구현 : 50 % \n\n<br>\n<br>\n\n\n## 이슈 1 : 모델 \n---\n\n<br>\n분류기를 어셈블해서 테스트를 해보았다 그런데 모델의 정확도에 비해 분류가 제대로 이루어지지 않았다. \n\n정황상으로 봤을때 큰분류기가 제대로 이미지를 분류 하지 못하는것 같다. \n\n정확도는 좋은데 왜 그런걸까? \n\n손실값도 괜찮은 편이고 ...이 의미는 입력데이터를 전달할때 이미지 전처리에서 문제가 있을 수 있겠다라는 생각이 든다. \n\n\n또다른 개인적인 생각으로는 이미지를 분류할떄 분류기가 특징을 잡아야하는데 \n\n이미지의 색상에 큰 비중을 잡고 그것을 기준으로 특징을 잡아 학습하는것 같다. \n\n일부 작은 분류기 같은 경우는 제법 성능이 괜찮은것 같다. \n\n<br>\n<br>\n\n### << 예상되는 문제점 >>\n<br>\n\n1. 전처리 -> 이미지크기, 고르지 못한 이미지( 기준이 없음 )\n<br>\n\n2. 모델이 어떤 특징을 잡아야 할지 모른다는거 \n - 색상, 형태\n<br>\n\n3. 그래서 진행한다면 잘 분류 못하는 아이들을 모아 레이어 별로 특징을 가지고 오는 부분을 확인하고 그것에 알맞게 진행 하는것이 좋을것 같다.\n<br>\n\n4. 특징을 잘 잡지 못하는 것이나 여러가지 부분들을 해결가능한게 오터인코더 혹은 간인데 \n 그 부분들을 추가로 공부해서 보완을 한다면 부족한 부분을 보충 할 수 있을것 같다.\n\n<br>\n<br>\n\n## 이슈 2 : 시스템 서버\n---\n\n모델 웹 배포시에 발견한 문제 \n\n<br>\n\n1. 이미지를 촬영하고 별다른 크롭 없이 사진의 크기만 변경해서 분류기에 넣는다는 점 \n<br>\n\n2. 모니터 화면에 나온 사진을 찍으면 정확도가 많이 떨어진다. \n - 그것을 통해 추측 할수있는 부분이 이전에 사진 분류를 하는 인공지능 어플로 동일한 액션을 했지만 잘 인식했다는 것이다. \n -> 그말은 그사람들은 이미지의 음식의 아웃라인을 따서 학습시켰을 수도 있겠다라는 생각을 했다. \n <br>\n\n3. 모델 버전에 맞게 케라스를 호출 해야한다는 점 \n<br>\n<br>\n\n### 데이터 베이스 \n\n- mongoDB 사용 -> 추후 오라클 혹은 마리아 디비\n\n - 지금은 사용하긴하는데 mongoDB가 정적인 데이터를 넣기에는 부적절하다고 판단\n - 오라클로 변경 혹은 마리아 디비로 변경하는것이 좋을것\n - 디장고는 객체지향적인 웹이기때문에 mongoDB와는 잘 맞지 않다는 점 \n\n<br>\n<br>"
},
{
"alpha_fraction": 0.5405774712562561,
"alphanum_fraction": 0.5481857061386108,
"avg_line_length": 11.783041954040527,
"blob_id": "6e4ac42108f22bd053a8e89ecdab4e91542a031f",
"content_id": "c53c862d2823bb3de4793313ecc3bcb471cf81fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8046,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 401,
"path": "/Python/4.심화_클래스_01.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n#### 4. 파이썬 심화 - 클래스_01\n\n<br>\n\n# 클래스\n\n<br>\n\n\n클래스는 객체(Object)를 표현하기 위한 문법이다.<br>\n \n프로그래밍으로 객체를 만들 때 사용하는 것이 클래스이다. \n\n<br>\n\n\n예를 들어<br>\n\n게임을 만든다고 하면 전사, 법사, 궁수, 암살자 등 직업별로 클래스를 만들어서 표현가능하다.\n\n기본적으로 게임 캐릭터는 체력(피), 마나, 물리공격력, 마법공격력, 방어력 등등이 필요하다.<br>\n\n그리고 전사는 무기를 이용해서 베기, 찌르기 등등의 스킬이 있어야 한다. \n\n<br>\n\n자 ! <br>\n\n클래스의 속성(Attribute) -> 체력(피), 마나, 물리공격력, 마법공격력, 방어력 <br>\n\n클래스의 메소드(Method) -> 무기를 이용해서 베기, 찌르기 등등의 액션 <br>\n\n클래스의 속성과 메소드는 아주 중요하기 때문에 만약 모르겠다면 혹은 감이 안잡힌다면 다른 예제를 찾아보고 개념을 잘 숙지 하는것을 추천한다. \n\n<br>\n\n만약 Car 로 예를 들어보면 아래와 같다.\n\n클래스의 속성(Attribute) -> 색상, 연식, 속도, 기어 <br>\n\n클래스의 메소드(Method) -> 가속, 감속, 정지, 시동, 기어변경 (동작)<br>\n\n\n\n<br>\n\n객체지향 프로그래밍은 복잡한 문제를 잘게 나누어(분해) 객체로 만들고, 객체를 조합(조립)해서 문제를 해결한다. <br>\n\n따라서 복잡한 문제를 해결하는데 유용하며<br>\n\n기능을 개선하고 발전시킬 때도 해당 클래스만 수정하면 되기 때문에 유지보수에도 효율적이다. <br>\n\n\n※ 참고로 파이썬은 모든것이 객체이다.\n\n<br>\n<br>\n\n## 1. 클래스 & 메소드\n\n<br>\n\n### 클래스의 기본 구조 \n\n<br>\n\n```py\n\nclass 클래스이름:\n\n def 메소드(self):\n code\n\n# 동일 \n\nclass 클래스이름(object):\n\n def 메소드(self):\n code\n\n\n```\n\n<br>\n\n#### 사람 클래스 예시 \n\n<br>\n\n클래스는 특정 개념을 표현, 인스턴스를 생성해야한다. \n\n<br>\n\n```py\n\nclass Person:\n\n def Greeting(self): # 메소드(Method)\n\n print('Hello')\n\nJerry = Person() # 인스턴스(instance)\n\n```\n\n<br>\n\n메소드를 호출은 위의 내용에 `Jerry.Greeting()` 를 추가하여 실행하면 된다. <br>\n\n메소드는 클래스가 아니라 인스턴스를 통해 호출 해야한다. <br>\n\n`인스턴스.메소드()` (인스턴스 메소드)를 하면 호출가능하다. <br>\n\n<br>\n\n```py\n\nclass Person:\n\n def Greeting(self): # 메소드(Method)\n\n print('Hello')\n\nJerry = Person() # 인스턴스(instance)\nJerry.Greeting()\n\n# 인스턴스 인지 아닌지 확인 \nisinstance(Jerry, Person) # 객체의 자료형을 판단할때 사용 \n\n# OutPut\n# >>> 'Hello'\n# >>> True\n\n```\n\n<br>\n\n인스턴스와 객체의 차이는 유사하하다.\n\n인스턴스를 클래스와 연관을 지어서 말을 할 경우 객체를 인스턴스라고 말한다. <br>\n\n그외의 보통 객체라면 그냥 객체라고 보면 될것 같다. \n\n나도 아직은 많이 어려운 개념이라 조금 더 자세하게 알아보고 이부분만 상세하게 리뷰 하도록 하겠다. <br>\n\n<br>\n\n메소드 안에서 메소드를 호출도 가능하다.<br>\n\n\n```py\n\nclass Person:\n\n def greeting(self):\n\n print('hello')\n\n def Hello(self):\n\n self.greeting() # self.메소드() -> 클래스 안의 메소드를 호출 \n\nJerry = Person() \nJerry.Hello()\n\n# OutPut\n# >>> 'Hello'\n\n```\n\n<br>\n<br>\n\n\n## 2. 속성(Attribute)\n\n<br>\n\n속성(attribute)을 만들때에는 `__init__` 메소드 안에서 `self.속성` 에 값을 담는다. \n\n<br>\n\n```py\n\n# 이렇게 \n\nclass 클래스이름:\n\n def __init__(self): \n\n self.속성 = 값\n\n# 생성자 : 객체를 생성, 초기화(옵션)\n\n```\n\n<br>\n\n`__init__` (Initialize) 는 인스턴스를 만들 때 호출되는 특별한 메소드이다. <br>\n\n그리고 인스턴스를 초기화한다. <br>\n\n`self` 는 인스턴스 자기 자신을 의미하며 인스턴스가 생성될때 자기자신에 속성을 부여한다. <br>\n\n<br>\n\n```py\n\nclass Person:\n\n def __init__(self):\n\n self.hello = '안녕!' # 속성 생성 \n\n def Greeting(self):\n\n print(self.hello) # 속성 사용 \n\nJerry = Person()\nJerry.Greeting()\n\n# Output\n# >>> '안녕!'\n\n```\n\n<br>\n\n클래스로 인스턴스를 만들때 값을 받는 방법은<br>\n\n`__init__` 메소드를 이용해서 `self` 에 매개변수를 지정한 후 <br>\n\n속성을 부여하면 값을 받을 수 있다. <br>\n\n<br>\n\n```py\n\nclass 클래스이름:\n\n def __init__(self, 매개변수1, 매개변수2):\n\n self.속성1 = 매개변수1\n self.속성2 = 매개변수2\n\n```\n\n<br>\n\n요로케 !! \n\n<br>\n\n위의 예제를 활용해서 매개변수를 추가해보면 아래와 같다.\n\n\n```py\n\nclass Person:\n\n \"\"\"\n 매개변수 : self, 이름, 나이, 주소 \n \"\"\"\n\n def __init__(self, name, age, address):\n\n self.hello = '안녕!'\n self.name = name # self에 넣어서 속성으로 만듦\n self.age = age\n self.address = address\n\n def Greeting(self):\n # print('{0} 나는 {1}야!'.format(self.hello, self.name))\n print(f'{self.hello} 나는 {self.name}야!')\n\nJoy = Person('조이', 30, '인천' ) # 인스턴스 생성 \nJoy.Greeting()\n\nprint('이름:', Joy.name) # 외부에서 인스턴스에 접근 할 경우 \nprint('나이:', Joy.age) # 인스턴스.속성 형식으로 접근 -> 인스턴스 속성\nprint('주소:', Joy.address) \n\n# Output\n# >>> 안녕! 나는 조이야!\n# >>> 이름: 조이\n# >>> 나이: 30\n# >>> 주소: 인천\n\n```\n\n<br>\n\n매개변수는 말그대로 변수이지만 <br>\n\n어떠한 매개체를 이용해서 변수로서 역활을 한다고 보면 될것같다. <br>\n\n그 매개체가 클래스 자기자신인거고 <br>\n\n<br>\n\n\n\n## 3. 비공개 속성 (Private attribute )\n\n<br>\n\nPerson 클래스에는 hello, name, age, address 속성을 활용해서<br>\n\n클래스 외부에서는 접근이 불가하고 내부에서만 사용가능한 비공개 속성에 대해서 알아보자 <br>\n\n비공개 속성은 `__속성` 과 같이 (`__`)로 만들어져야한다. <br>\n\n**`__속성` 과 `__속성__` 은 다르다.** <br>\n\n비공개 속성은 클래스 외부에 드러내고 싶지않은 값을 다룰때 사용한다. <br>\n\n중요한값일경울 더더욱 외부에 공개되서는 안될때 비공개 속성을 사용한다. <br>\n\n<br>\n\n기본 구조는 아래와 같다.\n\n<br>\n\n```py\n\nclass 클래스이름:\n\n def __init__(self, 매개변수)\n self.__속성 = 값 \n\n```\n<br>\n\n이전에 했던 실습에 활용 해보면 \n\n<br>\n\n```py\n\nclass Person:\n\n \"\"\"\n 매개변수 : self, 이름, 나이, 주소 \n 비공개속성 : 지갑\n \"\"\"\n\n def __init__(self, name, age, address, wallet):\n\n self.hello = '안녕!'\n self.name = name # self에 넣어서 속성으로 만듦\n self.age = age\n self.address = address\n self.__wallet = wallet # __를 붙여서 비공개 속성\n\n def Greeting(self):\n\n # print('{0} 나는 {1}야!'.format(self.hello, self.name))\n print(f'{self.hello} 나는 {self.name}야!')\n\n def pay(self, amount):\n\n if amount > self.__wallet:\n print('금액 부족')\n return\n\n self.__wallet -= amount # 1. 비공개 속성은 클래스 안의 메소드에서만 접근가능\n print(f'잔여 금액 : {self.__wallet}원')\n\n\nJoy = Person('조이', 30, '인천', 500000 ) # 인스턴스 생성 \n# Joy.__wallet # 비공개 속성이라 외부에서 접근 불가능 -> 에러발생 \nJoy.pay(3900) \n\n# Output\n# >>> 잔여 금액 : 496100원\n\n```\n\n<br>\n\n아직은 언제 어느때에 써야할지 잘 모르겠지만 꽤나 유용해보인다. \n\n\n\n<br>\n<br>\n\n---\n\n<br>\n\n## Reference <br>\n\n- 파이썬 코딩도장 : <https://dojang.io/> <br>\n\n<br>\n\n ※ 혹시 수정사항 있으면 알려주세요 !! \n\n<br>"
},
{
"alpha_fraction": 0.49266862869262695,
"alphanum_fraction": 0.5161290168762207,
"avg_line_length": 19.9375,
"blob_id": "e653baa40b019cdbb7d1d81409bb9f0cab103160",
"content_id": "9d512992b2645064d720b93b0cc4bdcbdb21a18f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 16,
"path": "/Project/Mini Project/readme.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# Daily MiniProjct\n\n<File> \n\n- CoffeePrice.py \n - 커피값을 입력받아서 잔돈 출력 \n- Multipcation \n - 구구단 \n- WhileLoop.py \n - while문 파악 \n- ForLoop.py \n - for문 파악 \n- MUDGame.py \n - 배운 문법 정리 차원으로 진행하는 머드게임(2019.12.18~) \n - 먼저 코드과정을 이해하고 스스로 짠것 \n - 추후 복습계념으로 다시 작성 예정(_ 스스로 짰어도 뭔가 보고 짜는 느낌을 받음 )\n\n\n "
},
{
"alpha_fraction": 0.5312600135803223,
"alphanum_fraction": 0.5460083484649658,
"avg_line_length": 13.712264060974121,
"blob_id": "2bce86c6e1a64bfc9e327538cf3377da02af52c6",
"content_id": "f15018282fd12d4a2ff5c32b009030840a914828",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5273,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 212,
"path": "/R/R_기초_03.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 03. R 기초 - 데이터 핸들링\n\n<br>\n\n# 데이터 핸들링\n\n데이터 핸들링 파트에서는 데이터를 불러오고 불러온 데이터를 올바르게 정제하는 법에 대해 정리하겠다. \n\n\n<br>\n\n## 1. 데이터 정제를 위한 문법 \n\n\n<br>\n\n### 1) 조건문(if) \n\n<br>\n\n조건문은 주어진 값에 조건을 지정하고 조건의 여부에 따라 액션을 취한다. \n\n조건문에는 3가지 종류가 있다. \n\n<br>\n\n1. 한가지 조건일떄 : `if else`\n\n ```R\n if(조건){\n 조건이 참일때 실행 # 표현식\n } else {\n 조건이 거짓일때 실행 # 표현식\n }\n ```\n\n<br>\n\n2. 두개 이상의 조건일떄 : `else if`\n\n 여러가지 조건을 지정 할 수 있다.\n\n ```R\n if(조건1){\n 조건1이 참일때 실행 # 표현식\n } else if {\n 조건2이 참일때 실행 # 표현식\n }else{\n 모든 조건이 거짓일때 실행 # 표현식\n }\n ```\n\n<br>\n\n3. 조건을 한 문장으로 표현하고자 할 때 : `ifelse`\n\n 조건문을 한줄로 구현가능하다. \n 위 두가지의 조건문과 달리 `ifelse`의 장점은 유일하게 벡터연산이 가능하다. \n 단점은 리턴값만 반환하기 때문에 출력만 가능하다는 점이다. \n\n ```R\n ifelse(조건, 참일때, 거짓일때)\n ```\n [참조-ifelse](https://data-make.tistory.com/43)\n\n<br>\n\n### 2) 반복문\n\n\n1. for문 \n\n ```R\n for(반복변수 in 횟수){\n 반복을 수행할 표현식\n }\n ```\n<br>\n\n2. while문 \n\n while문 같은 경우 특정시작값과 특정시작값을 증가시키는 증가식이 필요하다.\n\n for문과는 다르게 특정조건을 만족하지 못하면 무한루프에 빠질 수 있다. \n\n ```R\n var <- 특정시각값\n while(조건){\n 조건이 참일 때 수행할 표현식\n 증가식\n }\n ```\n<br>\n\n3. repeat문 \n\n repeat문 while문과 유사하다. 다만 repeat안에 조건문이 들어간다는 점이 다르며 break문을 만날때까지 계속 실행된다.\n\n ```R\n var <- 특정시각값\n repeat{\n 반복을 수행할 표현식 \n 조건문-> 참-> break문\n }\n ```\n\n\n<br><br>\n\n## 2. 핸들링\n\n<br>\n\n### 1) 파일 읽고 쓰기 \n\n<br>\n\n대부분의 데이터는 파일 형태로 존재한다. \n\n1. `read.table()` \n\n - 일반 텍스트 파일을 읽을 때 사용한다. \n - sep 옵션 : 구분자 지정 (`sep=\"\\t\"`, `sep=\",\"`,`sep=\";\"`)\n - header 옵션 : 첫줄 열 인식 여부(`header=T`)\n\n2. `data.table()` \n\n - 큰 데이터를 정제할때 아주 유용하다.\n - 빠른속도를 자랑한다.\n - data.table의 형식 : [행, 표현식, 옵션]\n\n3. `read.csv()` \n - csv 파일을 읽을 때 사용한다.\n\n<br>\n\n\n### 2) 결측값 처리 \n\n<br>\n\n수집한 데이터들은 대부분 결측값이 존재한다. \n**결측값**이란 실수에 의한 값 혹은 누락된 값을 말하며 결측값이 존재하는 상태로 데이터 가공을 하면 잘못된 데이터를 가공하게 된다. \n그렇기 때문에 정제하는 과정에서 적절한 데이터 처리가 필요하다. \n\n<br>\n\n#### 결측값 처리 \n\n1. `is.na()` : NA인 데이터 존재 시 T, 없으면 F \n2. `na.omit()` : NA인 데이터를 제거한다. -> NA가 포함된 행을 모두 지운다. \n3. 함수의 속성 `na.rm=T` 를 이용하여 결측값을 제거한다. \n\n ```R\n # 함수 속성인 na.rm을 이용해 결측값 처리\n mean(airquality$Ozone, na.rm = T)\n ```\n\n<br>\n\n### 3) 이상치(Outlier) 처리 \n\n<br>\n\n이상치란 **'패턴에서 벗어난 값 혹은 동떨어진 값'** 이다. \n이상치를 처리하지 않은 상태로 분석을 진행하면 분석 결과가 왜곡된다. 그렇기 때문에 이상치를 처리하는 것은 정말 중요하며 데이터분석 과정 중 가장 많은 시간이 들어간다. \n\n<br>\n\n1. 논리적으로 존재 할 수 없는 값 \n - 예를들면 >>> 혈액형은 A, B, O, AB 형만 존재하는데 F형이 데이터 상에 존재 할 경우인데 <br> \n 이런 경우는 형을 결측치로 변경한 후 진행하면 된다. \n\n2. 값들 중 극단적인 값 \n - 논리적으로 존재는 하지만 극단적으로 값이 무리의 값들과 차이가 날때 극단적인 값 극단치라고 한다.\n - 평균뿐 아니라 표준편차에 큰 영향을 주기 때문에 데이터의 신뢰도를 떨어트린다. \n\n<br>\n\n보통은 빈도 수를 보고 이상치를 확인한다. \n시각적으로 이상치를 탐색하는것은 `boxplot`을 활용하여 정상과 이상치을 구분한다. \n\n<br>\n\n#### `Boxplot` \n\n중앙값, 사분위수등 기술통계량을 상자로 요약한것으로 특정 수치 값을 기반으로 그려진 그래프이다.\n\n<br>\n\n```r\n# boxplot\nboxplot(data)\n```\n<br>\n\n\n\n\n<br><br>\n\n---\n\n<br>\n\n## Reference <br>\n\n<!-- - 파이썬 코딩도장 : <https://dojang.io/> <br> -->\n- 황군'story_`data.table()` : <https://using.tistory.com/81> <br>\n- Understanding Boxplots_파이썬기반 : <https://towardsdatascience.com/understanding-boxplots-5e2df7bcbd51> <br>\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6698113083839417,
"avg_line_length": 17.705883026123047,
"blob_id": "30c271193bd755da7ef35ffd3b2c215c4f4e863f",
"content_id": "1ec3055d24699be61588a5fe135beac05f1009c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 798,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 34,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\nclass SuperClass(object):\n super_var = '수퍼 네임스페이스에 있는 변수'\n\nclass MyClass(SuperClass):\n class_var = '클래스 네임스페이스에 있는 변수'\n \n def __init__(self):\n self.instance_var = '인스턴스 네임스페이스에 있는 변수'\n \n\nmy_instance = MyClass()\n\n# 엑세스 가능한 경우\nprint(my_instance.instance_var)\nprint(my_instance.class_var)\nprint(my_instance.super_var)\nprint(MyClass.class_var)\nprint(MyClass.super_var)\nprint(SuperClass.super_var)\nprint('-'*30)\n\n\n# 엑세스 불가능한 경우\ntry:\n print(SuperClass.class_var)\nexcept:\n print('class_var를 찾을 수가 없습니다.')\n \ntry:\n print(MyClass.instance_var)\nexcept:\n print('instance_var를 찾을 수가 없습니다.')"
},
{
"alpha_fraction": 0.584822952747345,
"alphanum_fraction": 0.5986509323120117,
"avg_line_length": 11.205760955810547,
"blob_id": "67b48a40e7604a1e01d1265b820817dede8cbc20",
"content_id": "d9fac9b033c5b8e3c83fc7d0bfca2153913dcb52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5603,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 243,
"path": "/Python/dum/프로그램이란.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 0. 파이썬 기본 - 프로그램이란 ?\n\n<br><br>\n\n# 프로그램이란 ?\n\n<br>\n\n## 컴퓨터\n<br>\n\n사람을 위해 일하기 위한 목적으로 만들어진 것이다. <br> \n컴퓨터에게 원하는 일을 시키려면 컴퓨터 언어를 알아야 한다.\n\n<br>\n\n### CPU\n\n<br>\n\n프로그램을 실행한다. 그리고 다음에 무엇을 해야하는지 끊임없이 질문한다. <br>\n매우 빠르다.\n그런데? 똑똑하지는 않다. -> 컴퓨터의 뇌는 아니다. 그냥 처리능력이 빠를 뿐 \n\n<br>\n<br>\n\n### 입력장치\n<br>\n\n사람에 의해 정보를 입력 받는 기기이다.\n- 키보드, 마우스, 터치화면\n\n<br>\n<br>\n\n### 출력 장치\n<br>\n\n처리된 정보의 결과를 보여주는 기계이다.\n- 모니터에 출력되는 화면, 스피커, 프린트\n\n<br><br>\n\n### 메인 메모리(램)\n<br>\n적은 양의 정보를 저장하는 장치 <br>\n속도는 매우 빠르지만 컴퓨터를 종료하면 메모리가 사라지는 휘발성 메모리 <br>\n<br>\n단순하게 보면 작고 빠르고 일시적 저장소 - 재부팅하면 지워진다.\n\n<br><br>\n\n### 보조 저장소\n<br>\n\n지우지 않는 이상 정보를 계속해서 가지고 있다. <br>\n메인메모리와 다르게 휘발성은 아니다. 느리고 큰 영구적 저장소 -> 지워질 때까지 보존된다. \n- 외장하드, usb , CD 등등 ...\n\n<br><br>\n\n## 프로그래밍 언어 \n<br>\n\n### 컴퓨터 언어 ? 프로그래밍 언어 ?\n<br>\n컴퓨터 언어는 컴퓨터가 이해가능한 언어로 0 과 1 로 이루어진 기계어이다. \n\n그래서 컴퓨터와 소통하기 위해서는 이언어를 알아야 한다. \n\n하지만 기계가 수많은 나라의 언어를 배우기 힘들기 때문에 \n\n프로그래밍언어가 생겼고 사람이 쓰기 편한 프로그래밍 언어로 코드를 작성하는것이 효율적이다. \n\n인간이 이해 할수 있는 프로그래밍언어는 정말 많다. \n\n그중 대표적인 언어로 C, Java, Python, Swift, Python 등등이 있다.\n\n<br><br>\n\n프로그래밍을 하면서 여러가지 에러를 보게 될것이다. \n\n에러 같은 경우는 프로그래밍 실력보다는 \n\n컴퓨터가 언어의 해당 코드 블록을 이해하지 못하였고 자세한 설명을 해달라는 hlep 같은것이다. \n\n그렇기 때문에 에러가 발생했다고 겁먹지 말고 차근차근 에러를 읽어 보는것을 추천한다. \n\n<br><br>\n\n### 상호대화식, 스크립트식 \n<br>\n\n커맨드라인에서 코드를 한줄씩 실행하는 방법은 상호대화식(Interactive) 이라고 한다. <br>\n상호 대화식은 즉각적인 결과를 확인하는데 유리하며 코드가 길어질 경우에는 스크립트 방식이 효과적이다. \n\n<br>\n\n### 변수 \n\n메모리에 사람이 이해할 수 있는 변수명으로 원하는 데이터를 넣을 수 있는 공간을 말한다. \n\n```py\nx = 10\nprint(x) # 10이 출력\ny = 14\nx = 20 \nprint(x) # 20이 출력\n```\n\n`=` 은 할당자이며 그 뒤에 위치한 숫자는 변수에 넣을수 있는 값이다.\n\n### 할당문 \n\n대입문은 오른쪽 표현의 결과를 왼쪽의 변수에 저장하는 것이다. \n\n<br>\n\n### 예약어 \n\n<br>\n\n파이썬에서 약속되어진 단어로만 사용이 가능하다. \n그래서 변수의 이름이나 식별자로 사용할 수 없다. \n\n<br><br>\n\n## 프로그래밍의 흐름 \n<br>\n\n### 순차문 \n<br>\n\n코드가 첫줄 부터 차례대로 실행되는 경우 \n- 단조롭고 짧은 경우만 해당 \n\n<br><br>\n\n### 조건문 \n<br>\n\n어떤 조건이 참일 경우 실행 <br>\n예약어 if를 이용하여 참인 경우 들여쓰기가 되어 있는 코드 부분이 실행\n\n<br>\n\n```py\nx = 5\nif x < 10: \n print('Smaller') # Smaller가 출력\nif x > 20: \n print('Bigger')\nprint('Finis') # Finis가 출력\n```\n<br>\n\n### 반복문 \n\n<br>\n\n주어진 조건(n>0)이 참인 경우에는 들여쓰기 되어 있는 부분이 계속 실행,\n그렇지 않은 경우 실행을 종료된다. \n\n<br>\n\n```py\nn = 5\nwhile n > 0:\n print(n) # 5,4,3,2,1을 출력\n n = n - 1\nprint('Blastoff!') # Blastoff를 출력\n```\n\n<br>\n<br>\n\n## 프로그래머\n\n<br>\n\n컴퓨터의 작동 방식과 언어를 학습 도구를 사용해 새로운 도구를 만든다.\n\n<br><br>\n\n\n## 의사코드 \n\n<br>\n\n프로그램을 작성할때 각 모듈이 작동하는 논리를 표현하기 위한 언어이다. \n특정 프로그래밍 언어가 아닌 일반적인 언어를 흉내내어 만든 코들로 컴퓨터가 인지할 수 없는 가짜코드이다. \n주로 알고리즘 모델링을 할때 주고 사용한다. \n\n<br>\n\n### 작성하는 방법\n\n<br>\n\n기준은 없으며 자연스럽게 자신의 생각을 모국어로 표현하면 된다. \n그러면서 짜고자 하는 언어의 형식에 맞게 하다보면 감이온다. \n\n의사코드는 형식이 자유롭지만 그래도 나름대로의 원칙은 세워두고 일관성 있게 코드를 작성하는것이 좋다. \n\n그래도 막막하고 어떻게 해야하는지 모르겠다면 \n그냥 단순하게 단어 혹은 키워드 -> 문장 -> 스토리 \n\n<br>\n\n```의사코드\nx를 2에서 9까지 반복 :\n 프린트(x)\n\ty를 1에서 9까지 반복:\n\t\t프린트(x * y = 결과) \n\t반복 끝\n반복 끝\n```\n\n<br><br>\n\n\n---\n\n<br>\n\n## Reference <br>\n\n- 부스트코스 - 모두를 위한 프로그래밍( 파이썬 ) : <https://www.edwith.org/pythonforeverybody/> <br>\n\n- 위키백과( 의사코드 ) : <https://ko.wikipedia.org/wiki/%EC%9D%98%EC%82%AC%EC%BD%94%EB%93%9C> <br>\n\n\n\n\n<br>\n<br>\n\n## Practice makes perfect! <br>\n\n<!-- - [내용](주소) -->"
},
{
"alpha_fraction": 0.49416667222976685,
"alphanum_fraction": 0.5083333253860474,
"avg_line_length": 15.63888931274414,
"blob_id": "42b4b0734248283b35ada470afed2c800bd93add",
"content_id": "3d077183f719e5d744b2bd5ec368da86a95579a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1550,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 72,
"path": "/Python/심화_클래스활용_실습코드/Advanced_OOP_객체합성.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "\n# 출처 : README.md 참조\n\n# 객체 합성 \n# has - a \n\nclass Gun:\n\n def __init__(self, kind):\n self.kind = kind\n\n def bang(self):\n print('bang!bang!')\n \n\n\n# 객체 합성 \n\nclass Police():\n\n def __init__(self, gunKind=''):\n if gunKind:\n self.gun = Gun(gunKind) # Gun클래스의 인스턴스객체 생성\n # Police의 인스턴스 멤버로 할당한다. \n else:\n self.gun = None # gun이라는 인스턴스 멤버는 존재 but 값은 없음 \n \n def getGun(self, gunKind):\n self.gun = Gun(gunKind)\n\n def shoot(self):\n if self.gun:\n self.gun.bang()\n else:\n print('당신에게는 총이 없습니다.')\n\n\n\nNA_cab = Police('리볼버')\nprint(NA_cab.gun.kind) # 리볼버 \nNA_cab.shoot() # shoot it\n\nLA_cab = Police() \nLA_cab.shoot() # 당신에게는 총이 없습니다. \n\nLA_cab.getGun('기관총')\nLA_cab.shoot() # shoot it\n\n\n\n# 추가 \n\n\"\"\"\n\n__name__ = '__main__'\n\n테스트를 위해 넣은 코드가 모듈 import 시에 실행되지 않도록 하는 코드 \npython test.py 처럼 직접 파일을 실행시키면 if 문이 참이되어 if 다음 문장들이 수행\n모듈을 개발할 때 확인을 위한 테스트 코드 작성시에 활용\n\n\n# 구조\n\nif __name__ == \"__main__\":\n ....\n 테스트 실행문\n\n\n# 참조 -> 추후에 리뷰 \n\nhttps://hashcode.co.kr/questions/3/if-__name__-__main__%EC%9D%80-%EC%99%9C%EC%93%B0%EB%82%98%EC%9A%94\n\n\"\"\"\n\n"
},
{
"alpha_fraction": 0.43150684237480164,
"alphanum_fraction": 0.49608609080314636,
"avg_line_length": 25.894737243652344,
"blob_id": "026837833a4de387cf825f41eaadff5d5a0b83cb",
"content_id": "5b5bb824e4e617f3caba54324ba242007d3d1bb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1278,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 38,
"path": "/Project/Mini Project/CoffeePrice.py",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 2019.12.17 <ver_1>\n# **<문제>** \n# 커피값을 입력받아서 1500원이상이면 거스럼돈을 줘라 \n# 내용은 \"거스름돈(받은금액-1500)은 XX원 입니다.\"\n\n# base ------------------------------\ncoffee_price =int(input('커피값을 주세요'))\nif coffee_price >= 1500 :\n tmp = '잔돈은 %d원 입니다.'% (coffee_price - 1500)\n print(tmp)\n pass\n\n# ----------------------------------\n\n# 2019.12.18 <ver_2>\n# base 튜닝-------------------------\ncoffee_price = int(input('커피값을 주세요'))\nif coffee_price > 1500 :\n tmp = '잔돈은 %d원 입니다.'% (coffee_price - 1500)\n print(tmp)\nelif coffee_price < 1500: \n tmp = '금액이 부족합니다. %d원 더 주세요.'% (1500 - coffee_price)\n print(tmp) \nelif coffee_price == 1500: \n tmp = '\\n%d원 받았습니다.\\n감사합니다.'% (coffee_price)\n print(tmp)\nelse :\n print('감사합니다.')\n pass\n# ----------------------------------\ncoffee_price = int(input('커피값을 주세요'))\nif coffee_price > 1500:\n print('잔돈은 %d원 입니다.'% (coffee_price - 1500))\nelif coffee_price == 1500:\n print('\\n%d원 받았습니다.\\n감사합니다.'% (coffee_price))\nelse:\n print('감사합니다.')\n# ----------------------------------\n"
},
{
"alpha_fraction": 0.5178645849227905,
"alphanum_fraction": 0.535521388053894,
"avg_line_length": 12.332409858703613,
"blob_id": "5e8263bc4839b2be788edb4e4ad0158862930571",
"content_id": "c57c5669598a27ceaa896611278575a3c1f0cdda",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8134,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 361,
"path": "/Python/1.기본_파이썬 개요.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "<br>\n\n#### 1. 파이썬 기본 - 파이썬 개요\n\n<br>\n<br>\n\n# 파이썬이 뭐냐면?\n\n<br>\n\n## 1. 파이썬 \n\n<br>\n\n**파이썬 = 쉽다.** 라고 표현해도 무방한것 같다.\n\n`Python` 은 **배우기 쉽고 확장하기 쉽고** 뭐 그렇다고 다 쉬운것은 아니지만\n\n효율적인 자료 구조들과 객체 지향 프로그래밍에 대해 **간단하고 효과적인** 사용방법을 제공한다.\n\n`C` 보다 훨씬 많은 에러 검사를 제공하며 유연한 배열과 딕셔너리같은 고수준의 자료형들을 가지고 있다. \n`Java` , `C` 에 비해서는 툴을 습득하기 쉬운 융통성있는 프로그래밍 언어이다.\n\n<br>\n\n프로그래밍언어는 컴퓨터가 알아듣는 언어로 아래의 두가지로 나누어진다.\n\n<br>\n\n### 컴파일링 언어\n\n- 한 번에 컴파일링 하기 때문에 \"구조\"가 중요 -> 객체 지향 발전\n\n### 인터프리터 언어( 함수 언어 )\n\n- 명령어 한 줄씩 대화형태로 컴파일링 되기 때문에 명령어 한줄 한줄이 중요하다.\n- 문제 풀듯 빠른 피드백을 받을수 있다. \n\n#### 인터프리터적 특징\n\n- `C` 나 `C++`로 구현된 함수나 자료 구조를 쉽게 추가가능하다.\n\n- 동적 타이핑, 우아한 문법을 가진다.\n\n- 컴파일과 링크 단계가 필요 없으며 대화형으로 사용할수있어 개발 시간을 상당히 단축할수 있다.\n\n<br>\n\n여러가지 속도면에서 **파이썬은 빠르다.**\n\n1. 빠른 개발이 가능하다.\n2. 빨리 배울 수 있다. -> 배우는 시간이 적게드는편이다.\n3. 빠르게 라이브러리를 가져와 사용할수있다. -> 검증된 라이브러리들이 많아서 바로바로 가져다가 사용가능하다. \n\n또한, 파이썬은 **간결**하고 **읽기 쉽게** 프로그램을 작성 가능하며 파이썬은 같은 기능(변수선언, if, for, ...)의 `C`, `C++`, `Java` 프로그램들에 비교해보면 확실히 간결하다.\n\n<br>\n\n자료형때문에 복잡한 연산을 짧은 문장으로 표현가능하다.\n\n<br>\n\n```의사 코드 \n# 의사코드 \n반복 시작 -> x를 2에서 9까지 반복\n\t반복 시작 -> y를 1에서 9까지 반복\n\t\t출력 -> x * y = 결과 \n\t반복 끝\n반복 끝\n```\n<br>\n\njava로 표현하면 아래와 같다.\n\n<br>\n\n```java\n// java\npublic class Loop {\n\tpublic static void main(String[] args) {\n\t\tfor( int x = 2; x < 10; x ++ ) {\n\t\t\tfor ( int y = 1; y < 10; y++ ) {\n\t\t\t\tSystem.out.println( x +\" * \" + y + \" = \" + x*y );\n\t\t\t}\n\t\t}\n\t}\n}\n```\n<br>\n\nC++ 로 표현하면 아래와 같다.\n\n```C++\n// C++\n\n#include <iostream>\n\nusing namespace std;\n\nint main(void)\n{\n for( int X = 2; X < 10; X++ )\n {\n for( int Y = 1; Y < 10; Y++ )\n {\n cout << X << \" * \" << Y << \" = \" << X*Y << endl;\n }\n }\n return 0;\n}\n```\n<br>\n\n같은 코드를 `Python`로 표현하면\n\n```py\n# Python\nfor x in range(2,10):\n\tfor y in range(1,10):\n\t\tprint(str(x) + \" * \" + str(y) + \" = \" + str(x * y))\n```\n<br>\n\n\n비해서 훨씬 간결한것을 알 수 있다.\n\n문장의 묶음은 `{ }`가 아닌 들여쓰기로 이루어지며 **변수와 인자의 선언이 필요없다.**\n\n<br>\n\n### 파이썬을 실행시키는 3가지\n\n1.\t명령 프롬프트 -> `python.exe` 실행\n2.\tIDLE -> 파이썬 자체 에디터 -> 파이썬 쉘을 실행 후 사용\n3.\t에디터로 코드작성 후 실행\n\n<br>\n<br>\n\n## 2.\t파이썬 시작전 기본 문법 목록 \n\n<br>\n\n### 자료구조 - 기본형\n\n#### 수치 자료형\n\n-\t정수(...,-1,0,1,...)\n-\t십진수(`10`, `11`), 이진수(`0` or `1`), 8진수, 16진수(`0xFF`\\)\n-\t부동소수(`-3.14`,0,0,1,2..)\n\n<br>\n\n#### 문자형(단일형으로 분류하지만, 실체는 연속형) -> string\n\n-\t`str()`, string\n-\t`\"helloworld\"`,`'helloworld'`,`\"\"\"..\"\"\"`,`'''..'''`\n\n<br>\n\n#### 논리 / 불린 자료형( 첫 글자는 대문자 T/F )\n\n-\tBoolean : `Ture`\\(`1`) , `False`\\(`0`) ( `data = True` )\n-\t이진데이터\n\n<br>\n\n#### 연산자 그리고 피연산자\n\n-\t`+`, `-`, `*`, `/` 같은 기호 연산자\n-\t**연산자에 의해 계산 되는 문자나 숫자**를 피연산자\n-\t`3+2` 는 `3` 과 `2` 는 *피연산자* , + 는 *연산자*\n-\t수식에서 연산자의 역활과 순서는 수학에서 연산자와 동일 문자간 연산도 가능하다.\n\n<br>\n\n### 자료구조 - 연속형\n\n값을 여러개를 들고 있다.\n\n<br>\n\n#### 리스트\n\n-\t`list()` , `[]`\n-\t순서(인덱스)가 있다.\n-\t값이 중복되도 OK\n\n<br>\n\n#### 딕셔너리\n\n-\t`dict()` , `{}`\n-\t순서 없다.\n-\t키와 값의 세트로 구성\n-\t키는 중복X\n\n<br>\n\n##### 튜플\n\n-\t`tuple()` , `()`\n-\t순서(인덱스)가 있다.\n-\t갑이 중복되도 OK\n-\t단순 묶음\n-\t수정 불가\n-\t추가 불가 (읽기전용)\n\n<br>\n\n#### 집합\n\n- `{}`\n- 중복 없음(불가, 제거) = 중복된 값을 제거함\n\n<br>\n\n\n### 조건문, 반복문, 제어문, 식 -> 절차적 프로그램\n\n- 조건식 결론 => 참이냐 거짓이냐?\n- 조건식을 가지고 상황따라 움직이는 방식 : 조건문(`if`\\)\n- 반목문 : 반복작업(`for`, `while`\\)\n\n\n<br>\n\n### 함수 -> 함수 지향적 프로그램\n\n- 내장함수, 외장함수, 람다함수, 커스텀함수(사용자정의함수)\n\n<br>\n\n### 클래스 -> 객체 지향적 프로그램\n<br>\n\n\n### 모듈화, 모듈가져오기\n\n<br>\n\n\n### 패키지\n\n<br>\n\n### 예외처리\n\n<br><br>\n\n---\n\n<br>\n\n## 3. 눈에 익히기 \n\n<br>\n\n파이썬을 시작하기전에 눈에 익힐것 몇가지를 언급하고 넘어 갈까 한다. 유심히 보지않아도 된다 지금은 눈에 익혀두는것이 더 중요하다.\n\n<br>\n\n### 1. Slicing & Indexing (문자열 index 추출)\n\n#### `Indexing`\n\n<br>\n\n슬라이싱을 설명하기 앞서 인덱싱부터 알아야 슬라이싱을 이해할수있다. 그렇기때문에 인덱싱부터 설명하고자 한다.\n\n문자열의 각각 문자는 `index` 라는 순서가 있다. 앞에서부터 순차적으로 나열되어 있다. 인덱스 번호로 해당위치에 데이터를 호출 할 수 있다.\n\n<br>\n\n아래 예시를 보면서 설명하겠다.\n\n<br>\n\n```py\nBox = ['사과','포도','자몽','사과','배']\n\nprint(Box[0])\n# >>> '사과'\nprint(Box[2])\n# >>> '자몽'\n```\n\n<br>\n\n`Box[0]`을 보면 `0` 이라는 숫자는 인텍스 넘버를 말한다.\n\n쉽게말하면 변수에 데이터가 메모리에 저장될때 데이터가 가지는 데이터의 위치주소라고 보면 될것같다.\n\n비울수 있고 채울수있고 지울수있고 생성할수도 있다.\n\nBox 안에 `'사과','포도','자몽','사과','배'` 가 담겨있고\n\n각각 `Box[0]` , `Box[1]` , `Box[2]` , `Box[3]` , `Box[4]` 로 순차적인 인덱스를 가지고 있다.\n\n주의할점은 인텍스 넘버는 0부터 시작한다.!! `1` 부터가 아니기 때문에 주의해야한다.\n\n<br>\n\n이렇게 순차적인 인덱스에서 사용자가 명시한 부분만 콕 찝어서 출력하는것을 **인덱싱**이라고한다.\n\n- **박스 1번 출력해! = `Box[1]`**\n\n<br><br>\n\n만약 리스트에 담겨있지 않은 문자열이라면 요소를 각각을 출력한다.\n\n<br>\n\n```py\nBox = '사과'\n\nprint(Box[0])\n# >>> 사\n```\n\n<br>\n\n#### `Slicing`\n\n`Slicing` 은 연속적인 데이터를 범위를 지정, 선택해서 가지고 오는 기법이다.\n\n이말은 인덱싱에서 언급했다싶이 인덱스 번호는 위치정보이고 이를 이용해서 슬라이싱 기법으로 사용자가 원하는 특정 부분을 잘라 올 수 있다.\n\n시작과 끝을 명시해서 그사이의 값을 가지고 올 수 있다.\n\n```py\nBox = ['사과','포도','자몽','사과','배']\n\nprint(Box[0:2])\n# >>> '사과','포도','자몽'\n\nprint(Box[2:4])\n# >>> '자몽','사과'\n```\n\n<br><br>\n\n---\n\n<br>\n\nReference <br>\n---\n\n- 파이썬 : https://docs.python.org/ko/3/tutorial/introduction.html <br>\n\n- 핵심만 간단히, 파이썬 : https://wikidocs.net/13876 <br>\n\n- 부스트코스 - 모두를 위한 프로그래밍 : 파이썬 : <https://www.edwith.org/pythonforeverybody/> <br>\n\n- List of Keywords in Python : <https://www.programiz.com/python-programming/keyword-list> <br>\n\n<br>\n\nPractice makes perfect! <br>\n\n"
},
{
"alpha_fraction": 0.44748711585998535,
"alphanum_fraction": 0.4890463948249817,
"avg_line_length": 16.060440063476562,
"blob_id": "46b7d2fce008796156c300e0ebaa258460a211b1",
"content_id": "629db6af0c5685463f20e69a6eb7a69f90ea10cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3538,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 182,
"path": "/CodingTest/백준_1463_풀이.md",
"repo_name": "Jerrykim91/Daily",
"src_encoding": "UTF-8",
"text": "# 백준_1463_풀이\n\n\n## 1번 : https://doorbw.tistory.com/57\n\n```py\n\n# 1번\na = int(input())\ncount = 0\nminimum=[a]\n# 함수 \ndef cal(a):\n list = []\n for i in a:\n list.append(i-1)\n if i%3 == 0:\n list.append(i/3)\n if i%2 == 0:\n list.append(i/2)\n return list\n \n# 본식 \n \n \nwhile True:\n if a == 1:\n print(count)\n break\n temp = minimum[:]\n minimum = []\n minimum = cal(temp)\n count +=1\n if min(minimum) == 1:\n print(count)\n break\n\n```\n\n<br>\n<br>\n\n## 2번 : https://hwiyong.tistory.com/252\n\n```py\n# 함수\ndef min(x, y):\n return x if x <= y else y\n \nx = int(input())\n \nminimum_count = [0 for _ in range(x+1)]\n \nindex = 0\n\nwhile(True):\n if index > x:\n break\n \n if index <= 1:\n minimum_count[index] = 0\n else:\n temp_min = x + 1\n if index % 3 == 0:\n temp_index = int(index/3)\n temp_min = min(temp_min, minimum_count[temp_index])\n \n if index % 2 == 0:\n temp_index = int(index/2)\n temp_min = min(temp_min, minimum_count[temp_index])\n \n temp_min = min(temp_min, minimum_count[index-1])\n minimum_count[index] = int(temp_min + 1)\n index = index + 1\n \nprint(minimum_count[x])\n\n```\n<br>\n<br>\n\n## 3번 :https://claude-u.tistory.com/174\n\n```py\nN = int(input())\n\nresult = [0 for _ in range(N + 1)]\n\nfor i in range(1, N + 1):\n if i == 1:\n result[i] = 0\n continue\n result[i] = result[i-1] + 1\n if i % 3 == 0 and result[i//3] + 1 < result[i]:\n result[i] = result[i//3] + 1\n if i % 2 == 0 and result[i//2] + 1< result[i]:\n result[i] = result[i//2] + 1\n \nprint(result[N])\n\n```\n<br>\n<br>\n\n## 4번 : https://parkssiss.tistory.com/64\n\n```py\nn = int(input())\n\ndp = []\n\ndp.append(0)\ndp.append(0)\ndp.append(1)\ndp.append(1)\n\nfor i in range(4, n + 1):\ndp.append(dp[i - 1] + 1);\nif(i % 2 == 0):\ndp[i] = min(dp[i], dp[i // 2] + 1)\nif(i % 3 == 0):\ndp[i] = min(dp[i], dp[i // 3] + 1)\n\n\n```\n<br>\n<br>\n\n## 5번 : https://statssy.github.io/pro/2019/10/14/baekjoon_1463/ 왈\n<br>\n\n### 문제풀이\n- 최고 중요한 다이나믹 프로그래밍 문제\n- 재귀함수로 푸는것보다 Bottom-Up으로 푸는것이 좋음\n- 결국 Bottom-Up은 for문으로 문제를 처음부터 훑으면서 d[n]에 최소(min)수를 집어 넣는 방법\n<br>\n \n### 다이나믹 프로그래밍\n- 큰 문제를 작은 문제로 나눠서 푸는 알고리즘(예:피보나치 수)\n- Overlapping Subproblem(큰 문제와 작은 문제를 같은 방법으로 풀 수 있음), Optimal Substructure(문제의 정답을 작은 문제에서 풀 수 있음) 이 두가지를 만족해야함\n\n```py\n\n# Top-Down(재귀 이용) : 재귀를 이용하게 되면 메모리 제한 때문에 메모리 초과가 되므로 Bottom-Up으로 푸는 것이 좋다.\n\ndef go(n):\n if n == 1:\n return 0\n if d[n] > 0:\n return d[n]\n d[n] = go(n-1) + 1\n if n%2 == 0:\n temp = go(n//2) + 1 # 나누기(/)로 하면 소수 나와서 오류생김\n if d[n] > temp:\n d[n] = temp\n if n%3 == 0:\n temp = go(n//3) + 1\n if d[n] > temp:\n d[n] = temp\n return d[n]\n\n\nn = int(input())\nd = [0]*(n+1)\nprint(go(n))\n\n\n# Bottom-Up(For문 이용)\nn = int(input())\nd = [0]*(n+1)\nd[1] = 0\nfor i in range(2, n+1):\n d[i] = d[i-1] + 1\n if i%2 == 0 and d[i] > d[i//2] + 1:\n d[i] = d[i//2] + 1\n if i%3 == 0 and d[i] > d[i//3] + 1:\n d[i] = d[i//3] + 1\nprint(d[n])\n\n```\n<br>\n<br>"
}
] | 103 |
Erzyl/MPquest | https://github.com/Erzyl/MPquest | d912228ab16207cc2019eeede4ae5b1ff7c0be59 | d9a3bfc36920eb39387f31244f18b367fefdd0e7 | d5c8863e639f6b45f03312ea0deea8df30ea5ef4 | refs/heads/master | 2022-04-25T13:23:06.832859 | 2020-04-28T06:10:25 | 2020-04-28T06:10:25 | 259,547,418 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5676567554473877,
"alphanum_fraction": 0.5676567554473877,
"avg_line_length": 22.153846740722656,
"blob_id": "b70926ff9eaae48702e20bf411ac865351800dc0",
"content_id": "5966e77bd1959b3bf87b85839ab1e83dc1d60b49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 303,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 13,
"path": "/Entity.py",
"repo_name": "Erzyl/MPquest",
"src_encoding": "UTF-8",
"text": "import threading\n\n\nclass Entity(threading.Thread):\n def __init__(self, entityMaster, eid, name, x, y):\n threading.Thread.__init__(self)\n\n self.entityMaster = entityMaster\n self.eid = eid\n self.name = name\n self.x = x\n self.y = y\n self.active = True\n\n\n"
},
{
"alpha_fraction": 0.5756579041481018,
"alphanum_fraction": 0.6085526347160339,
"avg_line_length": 17.91666603088379,
"blob_id": "993f67fb7a167816b33b9bdc5fb7796a744a3563",
"content_id": "a1f237c927e8b55b2104edf4f80e47b1af461ebc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 912,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 48,
"path": "/User.py",
"repo_name": "Erzyl/MPquest",
"src_encoding": "UTF-8",
"text": "import time,threading\n\n\nclass User(threading.Thread):\n\n\tdef __init__(self, x, y, hp, username,client):\n\t\tthreading.Thread.__init__(self)\n\t\tself.client = client\n\t\tself.x = x\n\t\tself.y = y\n\t\tself.username = username\n\t\tself.step = 0\n\t\tself.Running=True\n\t\tself.inputs = [0, 0, 0, 0] # left,right,up,down\n\t\tself.hp = hp\n\t\tself.hsp = 0\n\t\tself.vsp = 0\n\t\tself.lastPing = 0\n\t\tself.curWeapon = 0\n\t\tself.w1unlock = 1\n\t\tself.w2unlock = 0\n\t\tself.recordKills = 0\n\n\tdef run(self):\n\t\twhile self.Running:\n\t\t\tself.lastPing += 0.01\n\n\n\n\t\t\tstart_time = time.time()\n\t\t\tself.move()\n\n\t\t\tself.step += 1\n\t\t\tend_time = time.time()\n\n\t\t\ttime.sleep(max(.01666-(end_time-start_time), 0)) # Go at 60 steps/second\n\n\tdef move(self):\n\t\tself.x += self.hsp\n\t\tself.y += self.vsp\n\t\t#if self.inputs[0]:\n\t\t\t#self.x -= hsp;\n\t\t#if self.inputs[1]:\n\t\t\t#self.x += speed\n\t\t#if self.inputs[2]:\n\t\t#\tself.y -= speed\n\t\t#if self.inputs[3]:\n\t\t\t#self.y += speed\n\n\n\n\n"
},
{
"alpha_fraction": 0.4305555522441864,
"alphanum_fraction": 0.4969135820865631,
"avg_line_length": 13.065217018127441,
"blob_id": "3b2b4355899bcbfda5f5c2733bd29b252f9a4f0f",
"content_id": "bc0cadf7ac6ec309b5df90cbc22f6bd3bdb17619",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 648,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 46,
"path": "/NetworkConstants.py",
"repo_name": "Erzyl/MPquest",
"src_encoding": "UTF-8",
"text": "from enum import Enum\n\n\n\n\nreceive_codes = {\n \"PING\": 0,\n \"HANDSHAKE\": 1,\n \"DISCONNECT\": 2,\n \"REGISTER\":3,\n \"LOGIN\":4,\n \"MOVE\":5,\n \"CHAT\":6,\n \"HP\":7,\n \"SHOOT\":8,\n \"AIM\":9,\n \"ENT_DELETE\":10,\n \"PLAYER_WEAPON_SWITCH\":11,\n \"UNLOCK_WEAPON\":12,\n \"RECORD_KILLS\":13,\n}\n\nsend_codes = {\n\t\"PING\":0,\n \"REGISTER\":3,\n\t\"LOGIN\":4,\n\t\"MOVE\":5,\n\t\"JOIN\":6,\n\t\"LEAVE\":7,\n \"CHAT\":8,\n \"CLOSE\":9,\n \"HP\": 10,\n \"SHOOT\":11,\n \"AIM\":12,\n \"ENT_CREATE\":13,\n \"ENT_DELETE\":14,\n \"PLAYER_WEAPON_SWITCH\":15,\n \"RECORD_KILLS\":16,\n}\n\n\nhandshake_codes = {\n \"UNKNOWN\": 0,\n \"WAITING_ACK\": 1,\n \"COMPLETED\": 2\n}\n\n"
},
{
"alpha_fraction": 0.5224473476409912,
"alphanum_fraction": 0.5389352440834045,
"avg_line_length": 24.3015079498291,
"blob_id": "202e4fe4502787a447c57b26fb093762679dad7d",
"content_id": "aa46fcb8dc1faea1f9d7b9fbc884938bb1680817",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5034,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 199,
"path": "/EntityMaster.py",
"repo_name": "Erzyl/MPquest",
"src_encoding": "UTF-8",
"text": "import random\n\nfrom NetworkConstants import receive_codes, send_codes, handshake_codes\nimport struct,threading,socket,time\nfrom Network import *\nimport Network\nfrom Entity import Entity\n\n\nclass EntityMaster(threading.Thread):\n def __init__(self, server):\n threading.Thread.__init__(self)\n\n self.buffer = Network.Buff()\n self.entities = []\n self.running = True\n self.server = server\n\n self.eCurId = 1\n\n self.wep_doSpawn = 1\n self.wep_timer = 0\n self.wep_timeToRespawn = 5\n self.wep_spawnLocations = []\n self.wep_spawnLocations.append((3000, 950))\n\n self.hp_doSpawn = 1\n self.hp_timer = 0\n self.hp_timeToRespawn = 5\n self.hp_spawnLocations = []\n self.hp_spawnLocations.append((2200, 900))\n self.hp_spawnLocations.append((1300, 2200))\n self.hp_spawnLocations.append((2900, 3300))\n\n def run(self):\n\n while self.running:\n time.sleep(1 / 1000)\n\n # HANDLE WEP SPAWN\n name = \"o_w2pickup\"\n if self.wep_doSpawn == 1:\n self.wep_doSpawn = 0\n spot = 0\n xx = self.wep_spawnLocations[spot][0]\n yy = self.wep_spawnLocations[spot][1]\n self.spawnNew(self.eCurId, name, xx, yy)\n\n exists = 0\n if len(self.entities) != 0:\n for e in self.entities:\n if e.name == name:\n exists = 1\n if exists == 0:\n self.wep_timer += 1 / 1000\n\n if self.wep_timer >= self.wep_timeToRespawn:\n self.wep_doSpawn = 1\n self.wep_timer = 0\n else:\n self.wep_timer = 0\n\n #HANDLE HP SPAWN\n name = \"o_healthPacket\"\n if self.hp_doSpawn == 1:\n self.hp_doSpawn = 0\n spot = round(random.randrange(0, 3))\n xx = self.hp_spawnLocations[spot][0]\n yy = self.hp_spawnLocations[spot][1]\n self.spawnNew(self.eCurId,name, xx, yy)\n\n exists = 0\n if len(self.entities) != 0:\n for e in self.entities:\n if e.name == name:\n exists = 1\n if exists == 0:\n self.hp_timer += 1 / 1000\n\n if self.hp_timer >= self.hp_timeToRespawn:\n self.hp_doSpawn = 1\n self.hp_timer = 0\n else:\n self.hp_timer = 0\n\n\n\n\n def spawnNew(self, id, name, x, y):\n print(\"Spawning entity: {0} ({1},{2})\".format(name, x, y))\n entity = Entity(self, id, name, x, y)\n entity.start()\n self.send_entity_create(id, name, x, y)\n self.entities.append(entity)\n self.eCurId += 1\n\n def send_entity_create(self, id, name, x, y):\n self.clearbuffer()\n self.writebyte(send_codes[\"ENT_CREATE\"])\n self.writebyte(id)\n self.writestring(name)\n self.writedouble(x)\n self.writedouble(y)\n self.sendmessage_other()\n\n\n\n\n ## MAKE INTO OWN SCRIPT\n def sendmessage(self, buff=None, debug=False):\n if buff == None:\n buff = self.buffer\n types = ''.join(buff.BufferWriteT)\n length = struct.calcsize(\"=\" + types)\n buff.BufferWrite[0] = length # set the header length\n\n self.connection.send(struct.pack(\"=\" + types, *buff.BufferWrite))\n if debug == True:\n print(*buff.BufferWrite, ''.join(buff.BufferWriteT), struct.pack(\"=\" + types, *buff.BufferWrite))\n\n\n def sendmessage_other(self):\n for c in self.server.clients:\n if id(c) != id(self) and c.user != None:\n c.sendmessage(self.buffer)\n\n\n def sendmessage_all(self):\n for c in self.server.clients:\n if c.user != None:\n c.sendmessage(self.buffer)\n\n\n def clearbuffer(self):\n self.buffer.clearbuffer()\n\n\n def writebit(self, b):\n self.buffer.writebit(b)\n\n\n def writebyte(self, b):\n self.buffer.writebyte(b)\n\n\n def writestring(self, b):\n self.buffer.writestring(b)\n\n\n def writeint(self, b):\n self.buffer.writeint(b)\n\n\n def writedouble(self, b):\n self.buffer.writedouble(b)\n\n\n def writefloat(self, b):\n self.buffer.writefloat(b)\n\n\n def writeshort(self, b):\n self.buffer.writeshort(b)\n\n\n def writeushort(self, b):\n self.buffer.writeushort(b)\n\n\n def readstring(self):\n return self.buffer.readstring()\n\n\n def readbyte(self):\n return self.buffer.readbyte()\n\n\n def readbit(self):\n return self.buffer.readbit()\n\n\n def readint(self):\n return self.buffer.readint()\n\n\n def readdouble(self):\n return self.buffer.readdouble()\n\n\n def readfloat(self):\n return self.buffer.readfloat()\n\n\n def readshort(self):\n return self.buffer.readshort()\n\n\n def readushort(self):\n return self.buffer.readushort()"
},
{
"alpha_fraction": 0.6845261454582214,
"alphanum_fraction": 0.6891986727714539,
"avg_line_length": 27.4722843170166,
"blob_id": "7c6352f7e5bfbbcbcd6cf27deb1bac2b9fb03301",
"content_id": "3a866c1c3458e9803b3de1d79d45e3064e2598de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12841,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 451,
"path": "/Client.py",
"repo_name": "Erzyl/MPquest",
"src_encoding": "UTF-8",
"text": "import struct, threading, socket, bcrypt, time\n\nfrom NetworkConstants import receive_codes, send_codes, handshake_codes\nfrom Network import *\nimport Network\nimport User\n\n\nclass Client(threading.Thread):\n\tdef __init__(self, connection, address, server, pid):\n\t\tthreading.Thread.__init__(self)\n\n\t\tself.connection = connection # Connection Information\n\t\tself.address = address # Client Address Properties\n\t\tself.server = server # Reference to main server\n\t\tself.connected = True # Connection status\n\t\tself.handshake = handshake_codes['UNKNOWN'] # Handshake status defaulted to unknown\n\t\tself.user = None # Clients each have a user for the game\n\t\tself.pid = pid\n\t\tself.id = -1\n\t\tself.username = \"\"\n\t\tself.buffer = Network.Buff()\n\n\tdef sendmessage(self, buff=None, debug=False):\n\t\tif buff == None:\n\t\t\tbuff = self.buffer\n\t\ttypes = ''.join(buff.BufferWriteT)\n\t\tlength = struct.calcsize(\"=\" + types)\n\t\tbuff.BufferWrite[0] = length # set the header length\n\n\t\tself.connection.send(struct.pack(\"=\" + types, *buff.BufferWrite))\n\t\tif debug == True:\n\t\t\tprint(*buff.BufferWrite, ''.join(buff.BufferWriteT), struct.pack(\"=\" + types, *buff.BufferWrite))\n\n\tdef sendmessage_other(self):\n\t\tfor c in self.server.clients:\n\t\t\tif id(c) != id(self) and c.user != None:\n\t\t\t\tc.sendmessage(self.buffer)\n\n\tdef sendmessage_all(self):\n\t\tfor c in self.server.clients:\n\t\t\tif c.user != None:\n\t\t\t\tc.sendmessage(self.buffer)\n\n\tdef run(self):\n\t\t# Wait for handshake to complete before reading any data\n\t\tself.wait_for_handshake()\n\t\t# Handshake complete so execute main data read loop\n\t\twhile self.connected:\n\t\t\tif self.user != None:\n\t\t\t\tif self.user.lastPing >= 1:\n\t\t\t\t\tself.disconnect_user()\n\n\t\t\ttry:\n\t\t\t\t# Receive data from clients\n\t\t\t\tself.buffer.Buffer = self.connection.recv(1024)\n\t\t\t\tself.buffer.BufferO = self.buffer.Buffer\n\n\t\t\t\twhile (len(self.buffer.Buffer)) > 0:\n\t\t\t\t\tpacket_size = len(self.buffer.Buffer)\n\n\t\t\t\t\tmsg_size = self.readushort() # read the header\n\n\t\t\t\t\t# If we have not gotten enough data, keep receiving until we have\n\t\t\t\t\twhile (len(self.buffer.Buffer) + 2 < msg_size):\n\t\t\t\t\t\tself.buffer.Buffer += self.connection.recv(1024)\n\t\t\t\t\t\tpacket_size = len(self.buffer.Buffer) + 2\n\t\t\t\t\tself.handlepacket()\n\n\t\t\t\t\t# pop the remaining data in the packet\n\t\t\t\t\twhile ((packet_size - len(self.buffer.Buffer)) < msg_size):\n\t\t\t\t\t\tself.readbyte()\n\n\n\n\t\t\texcept ConnectionError:\n\t\t\t\tself.disconnect_user()\n\n\tdef handlepacket(self):\n\t\tevent_id = self.readbyte()\n\n\t\tif event_id == receive_codes['PING']:\n\t\t\tself.case_message_ping()\n\t\telif event_id == receive_codes['DISCONNECT']:\n\t\t\tself.case_message_player_leave()\n\t\telif event_id == receive_codes[\"REGISTER\"]:\n\t\t\tself.case_message_player_register()\n\t\telif event_id == receive_codes[\"LOGIN\"]:\n\t\t\tself.case_messasge_player_login()\n\t\telif event_id == receive_codes[\"MOVE\"]:\n\t\t\tself.case_message_player_move()\n\t\telif event_id == receive_codes[\"CHAT\"]:\n\t\t\tself.case_message_player_chat()\n\t\telif event_id == receive_codes[\"HP\"]:\n\t\t\tself.case_message_player_hp()\n\t\telif event_id == receive_codes[\"SHOOT\"]:\n\t\t\tself.case_message_player_shoot()\n\t\telif event_id == receive_codes[\"AIM\"]:\n\t\t\tself.case_message_player_aim()\n\t\telif event_id == receive_codes[\"ENT_DELETE\"]:\n\t\t\tself.case_message_ent_delete()\n\t\telif event_id == receive_codes[\"PLAYER_WEAPON_SWITCH\"]:\n\t\t\tself.case_message_player_weapon_switch()\n\t\telif event_id == receive_codes[\"UNLOCK_WEAPON\"]:\n\t\t\tself.case_message_unlock_weapon()\n\t\telif event_id == receive_codes[\"RECORD_KILLS\"]:\n\t\t\tself.case_message_record_kills()\n\n\t# EVENTS ###############################################\n\n\tdef case_message_ent_delete(self):\n\t\teid = self.readbyte()\n\n\t\t# check if index exists first!\n\t\tlist = self.server.entityMaster.entities\n\n\t\tfor e in list:\n\t\t\tif e.eid == eid:\n\t\t\t\tself.server.entityMaster.entities.remove(e)\n\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"ENT_DELETE\"])\n\t\tself.writebyte(eid)\n\t\tself.sendmessage_other()\n\n\tdef case_message_player_chat(self):\n\t\tchat = self.readstring()\n\t\t# send to everyone\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"CHAT\"])\n\t\tself.writebyte(self.pid)\n\t\tself.writestring(chat)\n\t\tself.sendmessage_all()\n\n\tdef case_message_ping(self):\n\n\t\t# Move to separate, PLAYER JUST ENTERETED NEW ROOM event\n\t\teMaster = self.server.entityMaster\n\t\tfor e in eMaster.entities:\n\t\t\teMaster.send_entity_create(e.eid, e.name, e.x, e.y)\n\n\t\ttime = self.readint()\n\n\t\tif self.user != None:\n\t\t\tself.user.lastPing = 0\n\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"PING\"])\n\t\tself.writeint(time)\n\t\tself.sendmessage()\n\n\tdef case_messasge_player_login(self):\n\t\tusername = self.readstring()\n\t\tpassword = self.readstring()\n\n\t\tlogin = True\n\t\tlogin_msg = \"\"\n\n\t\t# Check if correct username+password\n\t\tresult = self.server.sql(\"SELECT * FROM users_creds WHERE username=?\", (username,))\n\t\tif result == None:\n\t\t\tlogin = False\n\t\t\tlogin_msg = \"Invalid username or password\"\n\t\tif login:\n\t\t\tpwd = result[\"password\"]\n\t\t\tif not bcrypt.checkpw(password.encode('utf8'), pwd):\n\t\t\t\tlogin = False\n\t\t\t\tlogin_msg = \"Invalid username or password\"\n\n\t\t# Check if they are already logged in\n\t\tfor c in self.server.clients:\n\t\t\tif c.user != None and c.user.username == username:\n\t\t\t\tlogin = False\n\t\t\t\tlogin_msg = \"You are already logged in!\"\n\n\t\t# x = 0\n\t\t# y = 0\n\t\t# hp = 75\n\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"LOGIN\"])\n\t\tself.writebit(login)\n\n\t\t# ini current client\n\t\tif login:\n\t\t\tuser_data = self.server.sql(\"SELECT * FROM users_stats WHERE id=?\", (result[\"id\"],))\n\n\t\t\tself.writestring(username)\n\t\t\tself.writebyte(self.pid)\n\t\t\tself.id = user_data[\"id\"]\n\t\t\tx = user_data[\"x\"]\n\t\t\ty = user_data[\"y\"]\n\t\t\trecordKills = user_data[\"recordKills\"]\n\t\t\thp = user_data[\"hp\"]\n\t\t\tcurWeapon = user_data[\"curWeapon\"]\n\t\t\tw1unlock = user_data[\"w1unlock\"]\n\t\t\tw2unlock = user_data[\"w2unlock\"]\n\t\t\tself.writedouble(x)\n\t\t\tself.writedouble(y)\n\t\t\tself.writeint(recordKills)\n\t\t\tself.writeint(hp)\n\t\t\tself.writebyte(curWeapon)\n\t\t\tself.writebyte(w1unlock)\n\t\t\tself.writebyte(w2unlock)\n\t\t\tprint(\"{0} logged in from {1}:{2}\".format(username, self.address[0], self.address[1]))\n\t\t\tself.username = username\n\t\telse:\n\t\t\tself.writestring(login_msg)\n\t\tself.sendmessage()\n\n\t\tif login:\n\t\t\tself.user = User.User(x, y, hp, username, self)\n\t\t\tself.user.start()\n\n\t\t\t# Send new client info to other clients\n\t\t\tself.clearbuffer()\n\t\t\tself.writebyte(send_codes[\"JOIN\"])\n\t\t\tself.writebyte(self.pid)\n\t\t\tself.writestring(self.username)\n\t\t\tself.writedouble(x)\n\t\t\tself.writedouble(y)\n\t\t\tself.writeint(recordKills)\n\t\t\tself.writeint(hp)\n\t\t\tself.writebyte(curWeapon)\n\t\t\tself.writebit(True)\n\t\t\tself.sendmessage_other()\n\n\t\t\t# time.sleep(1)\n\t\t\t# Get data from all other clients\n\t\t\tfor c in self.server.clients:\n\t\t\t\tif id(c) != id(self) and c.user != None:\n\t\t\t\t\tself.clearbuffer()\n\t\t\t\t\tself.writebyte(send_codes[\"JOIN\"])\n\t\t\t\t\tself.writebyte(c.pid)\n\t\t\t\t\tself.writestring(c.username)\n\t\t\t\t\tself.writedouble(c.user.x)\n\t\t\t\t\tself.writedouble(c.user.y)\n\t\t\t\t\tself.writeint(c.user.recordKills)\n\t\t\t\t\tself.writeint(c.user.hp)\n\t\t\t\t\tself.writebyte(c.user.curWeapon)\n\t\t\t\t\tself.writebit(False)\n\t\t\t\t\tself.sendmessage(buff=self.buffer)\n\n\tdef case_message_player_register(self):\n\t\tusername = self.readstring()\n\t\tpassword = self.readstring()\n\t\tresult = self.server.sql(\"SELECT * FROM users_creds WHERE username=?;\", (username,))\n\t\tif result == None:\n\t\t\tpassword = bcrypt.hashpw(password.encode('utf8'), bcrypt.gensalt())\n\t\t\tself.server.sql(\"INSERT INTO users_creds (username,password) VALUES(?,?)\", (username, password))\n\t\t\tresult = self.server.sql(\"SELECT * FROM users_creds WHERE username=?;\", (username,))\n\t\t\tself.server.sql(\"INSERT INTO users_stats(id) VALUES(?)\", (result[\"id\"],))\n\t\t\tself.clearbuffer()\n\t\t\tself.writebyte(send_codes[\"REGISTER\"])\n\t\t\tself.writebit(True)\n\t\t\tself.writestring(username)\n\t\t\tself.sendmessage()\n\t\t\tprint(\"{0} registered from {1}:{2}\".format(username, self.address[0], self.address[1]))\n\t\telse:\n\t\t\tself.clearbuffer()\n\t\t\tself.writebyte(send_codes[\"REGISTER\"])\n\t\t\tself.writebit(False)\n\t\t\tself.writestring(\"There is already an account by that name\")\n\t\t\tself.sendmessage()\n\n\tdef case_message_player_move(self):\n\t\t# self.user.inputs=[self.readbit(),self.readbit(),self.readbit(),self.readbit()]\n\t\tself.user.x = self.readdouble()\n\t\tself.user.y = self.readdouble()\n\t\tself.user.hsp = self.readfloat()\n\t\tself.user.vsp = self.readfloat()\n\n\t\t# forward to other clients\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"MOVE\"])\n\t\tself.writebyte(self.pid)\n\t\tself.writefloat(self.user.hsp)\n\t\tself.writefloat(self.user.vsp)\n\t\t# self.writebit(self.user.inputs[0])\n\t\t# self.writebit(self.user.inputs[1])\n\t\t# self.writebit(self.user.inputs[2])\n\t\t# self.writebit(self.user.inputs[3])\n\t\tself.writedouble(self.user.x)\n\t\tself.writedouble(self.user.y)\n\t\tself.sendmessage_other()\n\n\tdef case_message_player_hp(self):\n\t\tself.user.hp = self.readint()\n\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"HP\"])\n\t\tself.writebyte(self.pid)\n\t\tself.writeint(self.user.hp)\n\t\tself.sendmessage_other()\n\n\tdef case_message_player_shoot(self):\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"SHOOT\"])\n\t\tself.writebyte(self.pid)\n\t\tself.sendmessage_other()\n\n\tdef case_message_unlock_weapon(self):\n\t\twhatWeapon = self.readbyte()\n\t\twhatStatus = self.readbyte()\n\n\t\tif whatWeapon == 2:\n\t\t\tself.user.w2unlock = whatStatus\n\n\tdef case_message_record_kills(self):\n\t\trecord = self.readint()\n\t\tself.user.recordKills = record\n\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"RECORD_KILLS\"])\n\t\tself.writebyte(self.pid)\n\t\tself.writeint(record)\n\t\tself.sendmessage_other()\n\n\tdef case_message_player_weapon_switch(self):\n\t\tself.user.curWeapon = self.readbyte()\n\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"PLAYER_WEAPON_SWITCH\"])\n\t\tself.writebyte(self.pid)\n\t\tself.writebyte(self.user.curWeapon)\n\t\tself.sendmessage_other()\n\n\tdef case_message_player_aim(self):\n\t\taim = self.readint()\n\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"AIM\"])\n\t\tself.writebyte(self.pid)\n\t\tself.writeint(aim)\n\t\tself.sendmessage_other()\n\n\tdef case_message_player_leave(self):\n\t\tself.disconnect_user()\n\n\t# OTHER\n\n\tdef wait_for_handshake(self):\n\t\t\"\"\"\n\t\t\tWait for the handshake to complete before reading any other information\n\t\t\tTODO: Add better implementation for handshake\n\t\t\"\"\"\n\n\t\twhile self.connected and self.handshake != handshake_codes[\"COMPLETED\"]:\n\n\t\t\tif self.handshake == handshake_codes['UNKNOWN']:\n\t\t\t\t# First send message to client letting them know we are engaging in a handshake\n\t\t\t\tself.clearbuffer()\n\t\t\t\tself.writebyte(receive_codes['HANDSHAKE'])\n\t\t\t\tself.sendmessage()\n\n\t\t\t\tself.handshake = handshake_codes['WAITING_ACK']\n\n\t\t\telse:\n\t\t\t\t# Wait for handshake ack\n\t\t\t\tself.buffer.Buffer = self.connection.recv(1024)\n\t\t\t\tself.readushort() # packet header\n\t\t\t\tevent_id = self.readbyte()\n\t\t\t\t# event_id = struct.unpack('B', data[:2])[0]\n\n\t\t\t\tif event_id == receive_codes['HANDSHAKE']:\n\t\t\t\t\t# Received handshake successfully from client\n\t\t\t\t\tself.handshake = handshake_codes['COMPLETED']\n\t\t\t\t\tprint(\"Handshake with {0} complete...\".format(self.address[0]))\n\n\tdef disconnect_user(self):\n\t\t\"\"\"\n\t\t\tRemoves the user from the server after disconnection\n\t\t\"\"\"\n\t\tprint(\"Disconnected from {0}:{1}\".format(self.address[0], self.address[1]))\n\n\t\t# save into db\n\t\tif self.user != None:\n\t\t\tself.server.sql(\"UPDATE users_stats SET x=?, y=?, hp=?, curWeapon=?, w1unlock=?, w2unlock=?, recordKills=? WHERE id=?\",\n\t\t\t\t\t\t\t(self.user.x, self.user.y, self.user.hp, self.user.curWeapon, self.user.w1unlock,\n\t\t\t\t\t\t\t self.user.w2unlock, self.user.recordKills,self.id))\n\t\t\tself.server.sql(\"COMMIT\")\n\n\t\tself.connected = False\n\n\t\tif self in self.server.clients:\n\t\t\tself.server.clients.remove(self)\n\t\t\tif self.user != None:\n\t\t\t\tself.user.Running = False\n\t\t\t\t# forward to other clients\n\t\t\t\tself.clearbuffer()\n\t\t\t\tself.writebyte(send_codes[\"LEAVE\"])\n\t\t\t\tself.writebyte(self.pid)\n\t\t\t\tself.sendmessage_other()\n\n\tdef kick_user(self):\n\t\tself.clearbuffer()\n\t\tself.writebyte(send_codes[\"CLOSE\"])\n\t\tself.writestring(\"You have been kicked\")\n\t\tself.sendmessage()\n\t\tself.disconnect_user()\n\n\tdef clearbuffer(self):\n\t\tself.buffer.clearbuffer()\n\n\tdef writebit(self, b):\n\t\tself.buffer.writebit(b)\n\n\tdef writebyte(self, b):\n\t\tself.buffer.writebyte(b)\n\n\tdef writestring(self, b):\n\t\tself.buffer.writestring(b)\n\n\tdef writeint(self, b):\n\t\tself.buffer.writeint(b)\n\n\tdef writedouble(self, b):\n\t\tself.buffer.writedouble(b)\n\n\tdef writefloat(self, b):\n\t\tself.buffer.writefloat(b)\n\n\tdef writeshort(self, b):\n\t\tself.buffer.writeshort(b)\n\n\tdef writeushort(self, b):\n\t\tself.buffer.writeushort(b)\n\n\tdef readstring(self):\n\t\treturn self.buffer.readstring()\n\n\tdef readbyte(self):\n\t\treturn self.buffer.readbyte()\n\n\tdef readbit(self):\n\t\treturn self.buffer.readbit()\n\n\tdef readint(self):\n\t\treturn self.buffer.readint()\n\n\tdef readdouble(self):\n\t\treturn self.buffer.readdouble()\n\n\tdef readfloat(self):\n\t\treturn self.buffer.readfloat()\n\n\tdef readshort(self):\n\t\treturn self.buffer.readshort()\n\n\tdef readushort(self):\n\t\treturn self.buffer.readushort()\n"
}
] | 5 |
PedroMateusCunha/TRP | https://github.com/PedroMateusCunha/TRP | d7bcd00f2878b8defd2f2e7ebebd11b36ca3ec75 | 497c8cc19a8b4521427257c46db3bc15aba9875f | ba2db39f5caf0ab21de3ab6423aa87e35238c63b | refs/heads/master | 2020-07-27T21:18:25.433408 | 2019-09-18T04:55:26 | 2019-09-18T04:55:26 | 209,218,803 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4057731032371521,
"alphanum_fraction": 0.5516384840011597,
"avg_line_length": 21.905149459838867,
"blob_id": "ff0f4e586c329888d5e96b4173c416716a4a3f95",
"content_id": "822643730fde86e4d540a75ac90c03f271cd2eb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8453,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 369,
"path": "/torre.c",
"repo_name": "PedroMateusCunha/TRP",
"src_encoding": "UTF-8",
"text": "#include <stdlib.h>\n#include <stdio.h>\n\nint torre();\nint fibra();\n\nint fibra_centro();\nint fibra_floresta();\nint fibra_paciencia();\nint fibra_prado();\n\nint torre_anajas();\nint torre_araca();\nint torre_barrerinha();\nint torre_caretinha();\nint torre_conjuntoBarcelona();\nint torre_criuli();\nint torre_lan();\nint torre_floresta();\nint torre_furnas();\nint torre_germano();\nint torre_lagoaDaCruz();\nint torre_macambira();\nint torre_paciencia();\nint torre_recreio();\nint torre_peDoMorro();\nint torre_prado();\nint torre_salomao();\nint torre_vertente();\nint torre_village();\n\n\nint main()\n{\n int tipo;\n system(\"cls\");\n printf(\"[ * ] ESCOLHA O TIPO DE TESTE: \\n\\n\");\n printf(\"[ 1 ] Fibra\\n[ 2 ] Torre\\n\");\n scanf(\"%d\", &tipo);\n\n switch (tipo)\n {\n case 1:\n fibra();\n break;\n\n case 2:\n torre();\n break;\n\n default:\n printf(\"Valor invalido!\\n\");\n }\n return 0;\n}\n\nint fibra()\n{\n switch (lugar)\n {\n case 1:\n fibra_centro();\n break;\n case 2:\n fibra_floresta();\n break;\n case 3:\n fibra_paciencia();\n break;\n case 4:\n fibra_prado();\n break;\n default:\n printf (\"OPCAO INVALIDA\\n\");\n }\n return 0;\n}\n\nint torre()\n{\n switch (lugar)\n {\n case 1:\n torre_anajas();\n break;\n case 2:\n torre_araca();\n break;\n case 3:\n torre_barrerinha();\n break;\n case 4:\n torre_caretinha();\n break;\n case 5:\n torre_conjuntoBarcelona();\n break;\n case 6:\n torre_criuli();\n break;\n case 7:\n torre_floresta();\n break;\n case 8:\n torre_furnas();\n break;\n case 9:\n torre_germano();\n break;\n case 10:\n torre_lagoaDaCruz();\n break;\n case 11:\n torre_lan();\n break;\n case 12:\n torre_macambira();\n break;\n case 13:\n torre_paciencia();\n break;\n case 14:\n torre_peDoMorro(;)\n break;\n case 15:\n torre_prado();\n break;\n case 16:\n torre_recreio();\n break;\n case 17:\n torre_salomao();\n break;\n case 18:\n torre_vertente();\n break;\n case 19:\n torre_village();\n break;\n \n default:\n printf (\"OPCAO INVALIDA\\n\");\n break;\n }\n}\n\nint fibra_centro()\n{\n system(\"start ping -t 172.16.254.245\");\n system(\"start ping -t 172.16.254.246\");\n system(\"start ping -t 172.16.254.247\");\n system(\"start ping -t 172.16.254.248\");\n system(\"start ping -t 172.16.254.249\");\n return 0;\n}\nint fibra_floresta()\n{\n system(\"start ping -t 172.16.254.240\");\n system(\"start ping -t 172.16.254.241\");\n system(\"start ping -t 172.16.254.242\");\n system(\"start ping -t 172.16.254.243\");\n system(\"start ping -t 172.16.254.244\");\n return 0;\n}\nint fibra_paciencia()\n{\n system(\"start ping -t 172.16.254.140\");\n system(\"start ping -t 172.16.254.141\");\n return 0;\n}\nint fibra_prado()\n{\n system(\"start ping -t 172.16.254.142\");\n system(\"start ping -t 172.16.254.143\");\n system(\"start ping -t 172.16.254.144\");\n system(\"start ping -t 172.16.254.145\");\n system(\"start ping -t 172.16.254.146\");\n return 0;\n}\n\nint torre_anajas()\n{\n system(\"start ping -t 172.16.254.100\");\n system(\"start ping -t 172.16.254.101\");\n system(\"start ping -t 172.16.254.102\");\n return 0;\n\n}\n\nint torre_araca()\n{\n system(\"start ping -t 172.16.254.70\");\n system(\"start ping -t 172.16.254.71\");\n system(\"start ping -t 172.16.254.72\");\n system(\"start ping -t 172.16.254.73\");\n system(\"start ping -t 172.16.254.74\");\n return 0;\n}\n\nint torre_barrerinha()\n{\n system(\"start ping -t 172.16.254.80\");\n system(\"start ping -t 172.16.254.81\");\n return 0;\n}\n\nint torre_caretinha()\n{\n system(\"start ping -t 172.16.254.60\");\n system(\"start ping -t 172.16.254.61\");\n system(\"start ping -t 172.16.254.62\");\n system(\"start ping -t 172.16.254.63\");\n system(\"start ping -t 172.16.254.64\");\n system(\"start ping -t 172.16.254.65\");\n return 0;\n}\n\nint torre_conjuntoBarcelona()\n{\n system(\"start ping -t 172.16.254.200\");\n system(\"start ping -t 172.16.254.201\");\n system(\"start ping -t 172.16.254.202\");\n return 0;\n}\n\nint torre_criuli()\n{\n system(\"start ping -t 172.16.254.160\");\n system(\"start ping -t 172.16.254.161\");\n system(\"start ping -t 172.16.254.162\");\n system(\"start ping -t 172.16.254.163\");\n return 0;\n}\n\nint torre_lan()\n{\n system(\"start ping -t 172.16.254.120\");\n system(\"start ping -t 172.16.254.121\");\n system(\"start ping -t 172.16.254.122\");\n system(\"start ping -t 172.16.254.123\");\n system(\"start ping -t 172.16.254.124\");\n system(\"start ping -t 172.16.254.125\");\n system(\"start ping -t 172.16.254.126\");\n system(\"start ping -t 172.16.254.127\");\n system(\"start ping -t 172.16.254.128\");\n return 0;\n}\n\nint torre_floresta()\n{\n system(\"start ping -t 172.16.254.90\");\n system(\"start ping -t 172.16.254.91\");\n system(\"start ping -t 172.16.254.92\");\n system(\"start ping -t 172.16.254.93\");\n system(\"start ping -t 172.16.254.94\");\n system(\"start ping -t 172.16.254.95\");\n system(\"start ping -t 172.16.254.96\");\n return 0;\n}\n\nint torre_furnas()\n{\n system(\"start ping -t 172.16.254.230\");\n system(\"start ping -t 172.16.254.231\");\n return 0;\n}\n\nint torre_germano()\n{\n system(\"start ping -t 172.16.254.210\");\n system(\"start ping -t 172.16.254.211\");\n return 0;\n}\n\nint torre_lagoaDaCruz()\n{\n system(\"start ping -t 172.16.254.50\");\n system(\"start ping -t 172.16.254.51\");\n system(\"start ping -t 172.16.254.52\");\n system(\"start ping -t 172.16.254.53\");\n system(\"start ping -t 172.16.254.54\");\n return 0;\n}\n\nint torre_macambira()\n{\n system(\"start ping -t 172.16.254.220\");\n system(\"start ping -t 172.16.254.221\");\n return 0;\n}\n\nint torre_paciencia()\n{\n system(\"start ping -t 172.16.254.170\");\n system(\"start ping -t 172.16.254.171\");\n system(\"start ping -t 172.16.254.172\");\n system(\"start ping -t 172.16.254.173\");\n return 0;\n}\n\nint torre_recreio()\n{\n system(\"start ping -t 172.16.254.110\");\n system(\"start ping -t 172.16.254.111\");\n system(\"start ping -t 172.16.254.112\");\n system(\"start ping -t 172.16.254.113\");\n system(\"start ping -t 172.16.254.114\");\n system(\"start ping -t 172.16.254.115\");\n return 0;\n}\n\nint torre_peDoMorro()\n{\n system(\"start ping -t 172.16.254.40\");\n system(\"start ping -t 172.16.254.41\");\n system(\"start ping -t 172.16.254.42\");\n system(\"start ping -t 172.16.254.43\");\n system(\"start ping -t 172.16.254.44\");\n system(\"start ping -t 172.16.254.45\");\n return 0;\n}\n\nint torre_prado()\n{\n system(\"start ping -t 172.16.254.180\");\n system(\"start ping -t 172.16.254.181\");\n system(\"start ping -t 172.16.254.183\");\n system(\"start ping -t 172.16.254.184\");\n system(\"start ping -t 172.16.254.185\");\n system(\"start ping -t 172.16.254.186\");\n system(\"start ping -t 172.16.254.187\");\n return 0;\n}\n\nint torre_salomao()\n{\n system(\"start ping -t 172.16.254.150\");\n system(\"start ping -t 172.16.254.151\");\n system(\"start ping -t 172.16.254.152\");\n system(\"start ping -t 172.16.254.153\");\n system(\"start ping -t 172.16.254.154\");\n system(\"start ping -t 172.16.254.155\");\n system(\"start ping -t 172.16.254.156\");\n return 0;\n}\n\nint torre_vertente()\n{\n system(\"start ping -t 172.16.254.20\");\n system(\"start ping -t 172.16.254.21\");\n system(\"start ping -t 172.16.254.22\");\n system(\"start ping -t 172.16.254.23\");\n system(\"start ping -t 172.16.254.24\");\n system(\"start ping -t 172.16.254.25\");\n system(\"start ping -t 172.16.254.25\");\n system(\"start ping -t 172.16.254.26\");\n system(\"start ping -t 172.16.254.27\");\n return 0;\n}\n\nint torre_village()\n{\n system(\"start ping -t 172.16.254.2\");\n system(\"start ping -t 172.16.254.3\");\n system(\"start ping -t 172.16.254.4\");\n system(\"start ping -t 172.16.254.5\");\n system(\"start ping -t 172.16.254.6\");\n return 0;\n}\n\n"
},
{
"alpha_fraction": 0.5760822892189026,
"alphanum_fraction": 0.681954562664032,
"avg_line_length": 53.25581359863281,
"blob_id": "038640e10ccf67eaceeeaf3e8e65ae55b5def16e",
"content_id": "9c410ae8fbf16b20452c7b441b8f5a0cb7291933",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2337,
"license_type": "no_license",
"max_line_length": 324,
"num_lines": 43,
"path": "/torre.py",
"repo_name": "PedroMateusCunha/TRP",
"src_encoding": "UTF-8",
"text": "import sys #importar a biblioteca de sistema de argumento\nfrom scapy.all import * #importar todas as bibliotecas do scapy\nconf.verb = False #desabilita as informações desnecessarias\naraca = {'192.168.200.91':'AP_STORM_ARACA_VERTENTE','192.168.200.72':'STORM_ARACA_VERTENTE','192.168.200.33':'STORM_CENTRO','192.168.200.93':'STORM_ARACA_2.4'}\nlagoadacruz = {'192.168.200.176':'WOG_STORM_LAGOA_DA_CRUZ','192.168.200.73':'STORM_PONTE_LAGOA_DA_CRUZ','192.168.200.68':'STORM_ALEGRE'}\npedomorro = {'192.168.200.74':'POWER_BEAM_RECEBE_PE_DO_MORRO_vertente','192.168.200.213':'AP_MK-RB_METAL_2.4','192.168.200.79':'NETWORK_T','192.168.200.92':'STORM_nano2.4','192.168.200.94':'STORM_PE_DO_MORRO_BAUNEARIO'}\nvertente = {'192.168.200.24':'STORM_VERTENTE_2.4','192.168.200.31':'AP_VAI_PE_DO_MORRO','192.168.200.44':'STORM_PROVEDOR_ARACA','192.168.200.39':'AP_OMINTIK_5.8_VERTENTE','192.168.200.20':'STORM_ALGCOM-VERTENTE_AP','192.168.200.110':'STORM','192.168.200.211':'STORM_LG_DENTRO','192.168.200.113':'STORM_PONTE_ARACA_VERTENTE'}\nif len(sys.argv) != 2: #Bloco de repiteção para dar o exemplo\n print(\"Use: {} <interior>\\n\".format(sys.argv[0]))#Exemplo\n print(\"Escreva tudo minusculo e sem espaco\")\n sys.exit(1)\n\ndef check(interior):#funcao de checker\n\tfor ip in interior:#para cada ip dentro de interior\n\t\tprint(\"Esperando resposta de {}\".format(ip))\n\t\ttry:\n\t\t pkt=IP(dst=ip)/ICMP() #executa a funcao ip(dentro de scapy)/ destination = ip\n\t\t er=sr1(pkt,retry=4,timeout=4) #echo reply = sr1== enviador de pacotes e recebe a primeira resposta\n\t\texcept PermissionError:#sudo su\n\t\t\tprint(\"[*] Use root.\\n\")\n\t\t\tsys.exit(1)\n\t\texcept Exception as erro: #erros a parte do sudo\n\t\t\tprint(\"[*] {}\".format(erro))\n\t\t\tsys.exit(1)\n\t\tif er: #Se tiver resposta\n\t\t\tprint(ip,\"- ONLINE\")\n\t\telse:#se tiver vazia \n\t\t\tprint(ip,\"- OFFLINE\")\ndef main(interior_passado):#funcao principal\n if interior_passado == 'araca':\n check(araca)\n elif interior_passado == 'lagoadacruz':\n check(lagoadacruz)\n elif interior_passado == 'pedomorro':\n \tcheck(pedomorro)\n elif interior_passado == 'vertente':\n \tcheck(vertente)\n else:#Tratamento de erros\n print(\"[!] INTERIOR INVALIDO.\\n\")\n sys.exit(1)\n\nif __name__ == '__main__': #Poder ser importada e executada\n main(sys.argv[1]) #Chama main e passa o argumento 1\n"
},
{
"alpha_fraction": 0.7527472376823425,
"alphanum_fraction": 0.7527472376823425,
"avg_line_length": 44.5,
"blob_id": "67183f67a5658ddc338253d9554d04670779d874",
"content_id": "f04644baca1e190e11e0b7d67c170469ea0f7e2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 4,
"path": "/README.md",
"repo_name": "PedroMateusCunha/TRP",
"src_encoding": "UTF-8",
"text": "# TRP - Teste Rápido de Ping\n\nPython - Realiza o teste rápido de ping por bloco de Torre.\nC - Abre uma série de terminais com o processo de ping, em cada rádio da torre selecionada.\n"
}
] | 3 |
StanfordSocialNeuroscienceLab/communities-ema-feedback | https://github.com/StanfordSocialNeuroscienceLab/communities-ema-feedback | 0d01d1eac151158b20c3a505ffe13231144f5775 | 5408848e11956a11ba0aa03bffb258c9f3092e2c | fbd0d0bd05c1709cd698cc98b58e9347132bed7c | refs/heads/master | 2022-05-01T06:13:20.182496 | 2019-12-07T22:25:11 | 2019-12-07T22:25:11 | 223,049,350 | 0 | 0 | null | 2019-11-20T23:50:57 | 2019-12-07T22:26:01 | 2022-04-22T22:45:13 | HTML | [
{
"alpha_fraction": 0.49275362491607666,
"alphanum_fraction": 0.693581759929657,
"avg_line_length": 15.655172348022461,
"blob_id": "f2024009e3ca2aaa96aa08dd99d043878311ef90",
"content_id": "4be37ee41f59e7d6d0a1e3e1c3b084f33562502a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 483,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 29,
"path": "/requirements.txt",
"repo_name": "StanfordSocialNeuroscienceLab/communities-ema-feedback",
"src_encoding": "UTF-8",
"text": "attrs==19.3.0\nClick==7.0\ncoverage==4.5.4\ndj-database-url==0.5.0\nDjango==2.2.7\ndjango-heroku==0.3.1\nFlask==1.1.1\nflask-heroku==0.1.9\nFlask-SQLAlchemy==2.4.1\ngunicorn==20.0.0\nimportlib-metadata==0.23\nitsdangerous==1.1.0\nJinja2==2.10.3\nMarkupSafe==1.1.1\nmore-itertools==7.2.0\npackaging==19.2\npluggy==0.13.0\npsycopg2==2.8.4\npy==1.8.0\npyparsing==2.4.5\npytest==5.3.0\npytz==2019.3\nsix==1.13.0\nSQLAlchemy==1.3.11\nsqlparse==0.3.0\nwcwidth==0.1.7\nWerkzeug==0.16.0\nwhitenoise==4.1.4\nzipp==0.6.0\n"
},
{
"alpha_fraction": 0.6924493312835693,
"alphanum_fraction": 0.7108655571937561,
"avg_line_length": 27.578947067260742,
"blob_id": "8524fba44d8458149257831bcee21bd5abde5493",
"content_id": "1bbd49c2937623715801b70a1ec9244e89d77ada",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 19,
"path": "/feedback/schema.sql",
"repo_name": "StanfordSocialNeuroscienceLab/communities-ema-feedback",
"src_encoding": "UTF-8",
"text": "DROP TABLE IF EXISTS participant;\n\nCREATE TABLE participant (\n id SERIAL PRIMARY KEY,\n username TEXT UNIQUE NOT NULL,\n password TEXT NOT NULL,\n fullname TEXT NOT NULL,\n pct_pings_completed FLOAT(24) NOT NULL,\n amount_earned FLOAT(24) NOT NULL,\n completion_streak INTEGER NOT NULL,\n activity_low_stress TEXT,\n activity_happiness TEXT,\n common_activity_1 TEXT,\n common_activity_2 TEXT,\n common_activity_3 TEXT,\n interaction_partner_1 TEXT,\n interaction_partner_2 TEXT,\n interaction_partner_3 TEXT\n);\n"
},
{
"alpha_fraction": 0.5554569363594055,
"alphanum_fraction": 0.5569358468055725,
"avg_line_length": 27.897436141967773,
"blob_id": "cb830e9f7ea84264e9732317ecbcca7d3e796577",
"content_id": "0ff6158b30c72379224bd20d20ff3e543dbca755",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3381,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 117,
"path": "/feedback/auth.py",
"repo_name": "StanfordSocialNeuroscienceLab/communities-ema-feedback",
"src_encoding": "UTF-8",
"text": "import functools\n\nfrom flask import (\n Blueprint, flash, g, redirect, render_template, request, session, url_for\n)\nfrom psycopg2.extras import RealDictCursor\nfrom werkzeug.security import check_password_hash, generate_password_hash\n\nfrom feedback.db import get_db\n\nbp = Blueprint('auth', __name__, url_prefix='/auth')\n\[email protected]('/register', methods=('GET', 'POST'))\ndef register():\n if request.method == 'POST':\n username = request.form['username']\n password = request.form['password']\n db = get_db()\n cursor = db.cursor(cursor_factory = RealDictCursor)\n error = None\n\n\n\n if not username:\n error = 'Username is required.'\n elif not password:\n error = 'Password is required.'\n else:\n cursor.execute(\n 'SELECT id FROM participant WHERE username = %s', (username,))\n if cursor.rowcount != 0:\n error = f'Participant {username} is already registered.'\n\n if error is None:\n form = request.form\n insert_command = 'INSERT INTO participant (%s) VALUES (%s)' % (\n \", \".join(form.keys()),\n ', '.join(['%s'] * len(form)))\n print(insert_command)\n values = []\n for k, v in form.items():\n if k == 'password':\n values.append(generate_password_hash(v))\n else:\n values.append(v)\n cursor.execute(\n insert_command,\n values\n )\n db.commit()\n return redirect(url_for('auth.login'))\n\n flash(error)\n\n return render_template('auth/register.html')\n\n\[email protected]('/login', methods=('GET', 'POST'))\ndef login():\n if request.method == 'POST':\n username = request.form['username']\n password = request.form['password']\n db = get_db()\n cursor = db.cursor(cursor_factory = RealDictCursor)\n error = None\n cursor.execute(\n 'SELECT * FROM participant WHERE username = %s', (username,)\n )\n\n if cursor.rowcount == 0:\n error = 'Unknown participant.'\n else:\n participant = cursor.fetchall()[0]\n if not check_password_hash(participant['password'], password):\n error = 'Incorrect password.'\n\n if error is None:\n session.clear()\n session['participant_id'] = participant['id']\n return redirect(url_for('index'))\n\n flash(error)\n\n return render_template('auth/login.html')\n\[email protected]_app_request\ndef load_logged_in_user():\n participant_id = session.get('participant_id')\n g.participant = None\n\n if participant_id is not None:\n cursor = get_db().cursor(cursor_factory = RealDictCursor)\n cursor.execute(\n 'SELECT * FROM participant WHERE id = %s', (participant_id,)\n )\n if cursor.rowcount > 0:\n g.participant = cursor.fetchone()\n else:\n session.clear()\n\n\n\[email protected]('/logout')\ndef logout():\n session.clear()\n return redirect(url_for('auth.login'))\n\n\ndef login_required(view):\n @functools.wraps(view)\n def wrapped_view(**kwargs):\n if g.participant is None:\n return redirect(url_for('auth.login'))\n\n return view(**kwargs)\n\n return wrapped_view\n"
},
{
"alpha_fraction": 0.6158574223518372,
"alphanum_fraction": 0.6183159351348877,
"avg_line_length": 28.071428298950195,
"blob_id": "e157c618ab47596eb69a21574af5d6738ce2394e",
"content_id": "ba5d390c38275f5f101a2d290cf78d3be6b042ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1627,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 56,
"path": "/feedback/__init__.py",
"repo_name": "StanfordSocialNeuroscienceLab/communities-ema-feedback",
"src_encoding": "UTF-8",
"text": "import os\n\nfrom flask import Flask, render_template, g\n\nfrom feedback.auth import login_required\n\n\ndef create_app(test_config=None):\n # create and configure the app\n app = Flask(__name__, instance_relative_config=True)\n app.config.from_mapping(\n SECRET_KEY=os.environ['SECRET_KEY'],\n # DATABASE=os.path.join(app.instance_path, 'feeedback.sqlite'),\n # SQLALCHEMY_DATABASE_URI=os.environ['DATABASE_URL']\n DATABASE_URL=os.environ['DATABASE_URL']\n )\n\n if test_config is None:\n # load the instance config, if it exists, when not testing\n app.config.from_pyfile('config.py', silent=True)\n else:\n # load the test config if passed in\n app.config.from_mapping(test_config)\n\n # ensure the instance folder exists\n try:\n os.makedirs(app.instance_path)\n except OSError:\n pass\n\n @app.route('/')\n @login_required\n def index():\n common_activities = []\n for i in range(1, 4):\n col = 'common_activity_%d' % i\n if g.participant[col]:\n common_activities.append(g.participant[col])\n interaction_partners = []\n for i in range(1, 4):\n col = 'interaction_partner_%d' % i\n if g.participant[col]:\n interaction_partners.append(g.participant[col])\n return render_template('feedback.html',\n common_activities=common_activities,\n interaction_partners=interaction_partners)\n\n from . import db\n db.init_app(app)\n\n from . import auth\n app.register_blueprint(auth.bp)\n\n return app\n\nfeedback_app = create_app()"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 54,
"blob_id": "a25abae56acd28feb93deca91b364fea261cc86b",
"content_id": "9327cc13895382c5a4b40483fcf4af797ee9a23a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 55,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 1,
"path": "/README.md",
"repo_name": "StanfordSocialNeuroscienceLab/communities-ema-feedback",
"src_encoding": "UTF-8",
"text": "# https://stanford-communities-feedback.herokuapp.com/\n"
}
] | 5 |
rafaelcaricio/hackkrk_painters | https://github.com/rafaelcaricio/hackkrk_painters | dc081384542352352b704256a0e4a68fb7256d8c | 403f9b3541c9ffeb4c5168eef7cabb07edf0c20e | dec95e3f02a30cf5ba807b8f3a184a1463a30e03 | refs/heads/master | 2021-01-10T22:10:54.133887 | 2013-04-24T21:24:17 | 2013-04-24T21:24:17 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6241458058357239,
"alphanum_fraction": 0.6419893503189087,
"avg_line_length": 33.20779037475586,
"blob_id": "58e3cb822c85481d8536847d261bafcdb802e5bb",
"content_id": "8db800f245586a9889e2b3dd7c54a282f1da3ed5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2634,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 77,
"path": "/painter.py",
"repo_name": "rafaelcaricio/hackkrk_painters",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport os\nimport base64\nfrom json import dumps, loads\nfrom StringIO import StringIO\n\nfrom PIL import Image\nimport requests\n\n\nclass ChallengeService(object):\n NEW_URL = 'http://canvas.hackkrk.com/api/new_challenge.json'\n SOLUTION_URL = 'http://canvas.hackkrk.com/api/challenge/{challenge_id}.json'\n\n def __init__(self, token):\n self.token = token\n self.basic_auth = {\n 'api_token': self.token\n }\n\n def get_new_challenge(self):\n return self.call(ChallengeService.NEW_URL)\n\n def call(self, url, data={}):\n data.update(self.basic_auth)\n headers = {'Content-Type': 'application/json'}\n print data\n print url\n response = requests.post(url, data=dumps(data), headers=headers)\n if response.status_code == 200:\n return loads(response.text)\n else:\n print response.text\n raise Exception(\"Non 200 code returned by the server.\")\n\n def solve(self, challenge, base64_image):\n url = ChallengeService.SOLUTION_URL.format(challenge_id=challenge['id'])\n return self.call(url, data={'image': base64_image})\n\nclass ImageFinder(object):\n def get_image_with_color(self, r, g, b):\n raise NotImplementedError\n\n def convert_to_base64(self, image):\n byte_array = StringIO()\n image.save(byte_array, format='PNG')\n result = byte_array.getvalue()\n byte_array.close()\n return base64.b64encode(result)\n\nclass PILImageGenerator(ImageFinder):\n def get_image_with_color(self, r, g, b):\n image_object = Image.new('RGB', (64, 64), (r, g, b))\n return self.convert_to_base64(image_object)\n\n\nclass FromPictureAlphaGenerator(ImageFinder):\n def __init__(self, file_name):\n im = Image.open(file_name)\n self.image = im.convert('RGB')\n self.image.thumbnail((64,64), Image.ANTIALIAS)\n\n def get_image_with_color(self, r, g, b):\n background = Image.new('RGB', (64, 64), (r, g, b))\n output = Image.blend(self.image, background, 0.75)\n output.thumbnail((64,64), Image.ANTIALIAS)\n output.save('result.png', format='PNG')\n return self.convert_to_base64(output)\n\nif __name__ == '__main__':\n chlgs = ChallengeService(token=os.environ.get('HACKKRK_TOKEN', ''))\n current_challenge = chlgs.get_new_challenge()\n print 'Got the challenge: %s' % dumps(current_challenge)\n base64_image = FromPictureAlphaGenerator('rafael.jpg').get_image_with_color(*current_challenge['color'])\n print 'Image generated: %s' % base64_image\n print chlgs.solve(current_challenge, base64_image)\n"
}
] | 1 |
mfarmer11/Stock_Dashboard | https://github.com/mfarmer11/Stock_Dashboard | a62e387e2a694eaeb7be410633dae8178073b5da | f85f3004fb091870dc8f29eab9e08d7c3878327d | 41486d7aae76dc24eb689d9397f47e01a99ff4a9 | refs/heads/master | 2023-01-03T17:44:00.829857 | 2020-10-30T23:07:15 | 2020-10-30T23:07:15 | 286,331,367 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6138790249824524,
"alphanum_fraction": 0.6423487663269043,
"avg_line_length": 25.761905670166016,
"blob_id": "713a4c1649ec3f3a5b01a0fab6beea58a10de1b1",
"content_id": "e56744c4014fa436be77615fc768504b8b6e743e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 562,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 21,
"path": "/data/mystocks.py",
"repo_name": "mfarmer11/Stock_Dashboard",
"src_encoding": "UTF-8",
"text": "from pandas_datareader import data\nimport pandas as pd\n\n#Define List of Stock Tickers\ntickers = [\"TWTR\",\"INO\",\"GPS\",\"TSLA\",\"AZN\",\"TLRY\",\"JMIA\",\"NVAX\",\"CGC\"]\n#Define Function to Collect Data\ndef get_data(tickers):\n start_date = '2018-08-27'\n end_date = '2020-08-01'\n datum = dict()\n df_ = dict()\n \n for ticker in tickers:\n datum = data.DataReader(ticker,'yahoo',start_date,end_date)\n df_[ticker] = datum \n df_[ticker].to_csv(f\"~/Desktop/mystockdashboard/data/{ticker}.csv\")\n\n return df_\n\n#Call function\nget_data(tickers)\n"
},
{
"alpha_fraction": 0.7265306115150452,
"alphanum_fraction": 0.7918367385864258,
"avg_line_length": 34,
"blob_id": "3be4caae6ab11a676fb00aae0b88afa91732bea7",
"content_id": "013c86a011274e0bad8a038ce8cb27373679b9bc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 245,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 7,
"path": "/README.md",
"repo_name": "mfarmer11/Stock_Dashboard",
"src_encoding": "UTF-8",
"text": "# Stock_Dashboard\n\nA vizualization of miscellaneous stocks' highs, lows, and volume from 08-27-2018 to 08-01-2020.\n\nData folder contains python file used to collect csv files for each stock.\n\n*visualization can be found in attached website link\n"
},
{
"alpha_fraction": 0.47975707054138184,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 16.034482955932617,
"blob_id": "df97695837ad7b3df1e8b7b94e2e0c7877afff2d",
"content_id": "4374d021b9b8772dbd79338ff8237cbe9af1ccb4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 494,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 29,
"path": "/requirements.txt",
"repo_name": "mfarmer11/Stock_Dashboard",
"src_encoding": "UTF-8",
"text": "Brotli==1.0.7\ncertifi==2020.6.20\nchardet==3.0.4\nclick==7.1.2\ndash==1.12.0\ndash-core-components==1.10.0\ndash-html-components==1.0.3\ndash-renderer==1.4.1\ndash-table==4.7.0\nFlask==1.1.2\nFlask-Compress==1.5.0\nfuture==0.18.2\ngunicorn==20.0.4\nidna==2.10\nitsdangerous==1.1.0\nJinja2==2.11.2\nlxml==4.5.2\nMarkupSafe==1.1.1\nnumpy==1.18.1\npandas==1.0.0\npandas-datareader==0.9.0\nplotly==4.8.0\npython-dateutil==2.8.1\npytz==2020.1\nrequests==2.24.0\nretrying==1.3.3\nsix==1.15.0\nurllib3==1.25.10\nWerkzeug==1.0.1\n"
},
{
"alpha_fraction": 0.4196906089782715,
"alphanum_fraction": 0.4315454661846161,
"avg_line_length": 52.627906799316406,
"blob_id": "3d8335a727f8d466d73bcedf33f0e330e25fe4ae",
"content_id": "4776598318762f237ab8b01be361c67d39513cf2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6917,
"license_type": "permissive",
"max_line_length": 163,
"num_lines": 129,
"path": "/mystockapp.py",
"repo_name": "mfarmer11/Stock_Dashboard",
"src_encoding": "UTF-8",
"text": "import dash\nimport dash_core_components as dcc\nimport dash_html_components as html\nimport pandas as pd\nimport plotly.graph_objs as go\nfrom dash.dependencies import Input, Output\n\n\napp = dash.Dash()\nserver = app.server\n\nall_data=dict()\nall_data['twtr'] = pd.read_csv(\"data/TWTR.csv\")\nall_data['ino'] = pd.read_csv(\"data/INO.csv\")\nall_data['gps'] = pd.read_csv(\"data/GPS.csv\")\nall_data['tsla'] = pd.read_csv(\"data/TSLA.csv\")\nall_data['azn'] = pd.read_csv(\"data/AZN.csv\")\nall_data['tlry'] = pd.read_csv(\"data/TLRY.csv\")\nall_data['jmia'] = pd.read_csv(\"data/JMIA.csv\")\nall_data['nvax'] = pd.read_csv(\"data/NVAX.csv\")\nall_data['cgc'] = pd.read_csv(\"data/CGC.csv\")\n\napp.layout = html.Div(children=[\n # Main title of dashboard\n html.H1(children=\"Twitter Stock\",style={\"textAlign\": \"center\"}),\n # Create Dashboard Tab Layout\n dcc.Tab(id=\"Stock Prices\", children=[\n html.Div([\n html.H1(\"Stock Highs vs Lows\",\n style={'textAlign':'center'}),\n #Add dropdown menu\n dcc.Dropdown(id='my-dropdown', options=[{'label':'Twitter','value':'TWTR'},\n {'label':'Inovio','value':'INO'},\n {'label':'Gap','value':'GPS'},\n {'label':'AstraZeneca','value':'AZN'},\n {'label':'Tilray','value':'TLRY'},\n {'label':'Jumia Technologies','value':'JMIA'},\n {'label':'Novavax','value':'NVAX'},\n {'label':'Canopy Growth','value':'CGC'}],\n multi=True, value=['TWTR'],\n style={\"display\":\"block\",\"margin-left\":\"auto\",\"margin-right\":\"auto\",\"width\":\"60%\"}),\n dcc.Graph(id='highlow',figure={}),\n html.H1('Market Volume', style={'textAlign':'center'}),\n #Adding the second dropdown menu and graph\n dcc.Dropdown(id='my-dropdown2',\n options=[{'label':'Twitter','value':'TWTR'},\n {'label':'Inovio','value':'INO'},\n {'label':'Gap','value':'GPS'},\n {'label':'AstraZeneca','value':'AZN'},\n {'label':'Tilray','value':'TLRY'},\n {'label':'Jumia Technologies','value':'JMIA'},\n {'label':'Novavax','value':'NVAX'},\n {'label':'Canopy Growth','value':'CGC'}],\n multi=True, value=['TWTR'],\n style={'display':'block','margin-left':'auto',\n 'margin-right':'auto','width':'60%'}),\n dcc.Graph(id='volume')\n ], className='container'),\n ])\n ])\n\n\[email protected](Output(\"highlow\",\"figure\"),\n [Input('my-dropdown','value')])\ndef update_graph(selected_dropdown):\n dropdown={\"TWTR\":\"Twitter\",\"INO\":\"Inovio\",\"GPS\":\"Gap\",\"AZN\":\"AstraZeneca\",\"TLRY\":\"Tilray\",\"JMIA\":\"Jumia Technologies\",\"NVAX\":\"Novavax\",\"CGC\":\"Canopy Growth\"}\n trace1 = []\n trace2 = []\n for stock in selected_dropdown:\n trace1.append(\n go.Scatter(x=all_data[stock.lower()]['Date'],y=all_data[stock.lower()]['High'],\n mode='lines',opacity=0.7,\n name=f'High {stock}', textposition='bottom center'))\n trace2.append(\n go.Scatter(x=all_data[stock.lower()]['Date'],y=all_data[stock.lower()]['Low'],\n mode='lines',opacity=0.6,\n name=f'Low {stock}',textposition='bottom center'))\n traces = [trace1, trace2]\n data1 = [val for sublist in traces for val in sublist]\n figure = {'data':data1,\n 'layout':go.Layout(colorway=['#5E0DAC', '#FF4F00','#375CB1',\n '#FF7400', '#FFF400', '#FF0056'],\n height=600,\n title=f\"High and Low Prices for {', '.join(str(dropdown[i]) for i in selected_dropdown)} Over Time\",\n xaxis={\"title\":\"Date\",\n 'rangeselector': {'buttons': list([{'count': 1, 'label':'1M',\n 'step':'month',\n 'stepmode':'backward'},\n {'count': 6, 'label': '6M',\n 'step':'month',\n 'stepmode':'backward'},\n {'step': 'all'}])},\n 'rangeslider':{'visible':True}, 'type':'date'},\n yaxis={\"title\":\"Price (USD)\"})}\n\n return figure\n\[email protected](Output('volume','figure'),\n [Input('my-dropdown2','value')])\ndef update_graph(selected_dropdown_value):\n dropdown = {\"TWTR\":\"Twitter\",\"INO\":\"Inovio\",\"GPS\":\"Gap\",\"AZN\":\"AstraZeneca\",\"TLRY\":\"Tilray\",\"JMIA\":\"Jumia Technologies\",\"NVAX\":\"Novavax\",\"CGC\":\"Canopy Growth\"}\n trace1 = []\n for stock in selected_dropdown_value:\n trace1.append(\n go.Scatter(x=all_data[stock.lower()]['Date'],\n y=all_data[stock.lower()]['Volume'],\n mode='lines', opacity=0.7,\n name=f'Volume {stock}', textposition='bottom center'))\n traces = [trace1]\n data1 = [val for sublist in traces for val in sublist]\n figure = {'data': data1,\n 'layout': go.Layout(colorway=['#5E0DAC', '#FF4F00', '#375CB1', \n '#FF7400', '#FFF400', '#FF0056'],\n height=600,\n title= f\"Market Volume for {', '.join(str(dropdown[i]) for i in selected_dropdown_value)} Over Time\",\n xaxis={\"title\":\"Date\",\n 'rangeselector': {'buttons': list([{'count': 1, 'label': '1M', \n 'step': 'month', \n 'stepmode': 'backward'},\n {'count': 6, 'label': '6M',\n 'step': 'month', \n 'stepmode': 'backward'},\n {'step': 'all'}])},\n 'rangeslider': {'visible': True}, 'type': 'date'},\n yaxis={\"title\":\"Transactions Volume\"})}\n return figure\n\nif __name__=='__main__':\n app.run_server(debug=False)"
}
] | 4 |
pxltech/SmartSystems | https://github.com/pxltech/SmartSystems | fec0af8dedd96583a153e1b36d71880a96a7a684 | 79f5a6ad9fed76eeffdc2dac5caf370fb507dabd | 05a99e231ae26a35b6b79eb4a316c97f64cd79d6 | refs/heads/master | 2018-12-05T21:34:42.856317 | 2018-10-02T11:29:49 | 2018-10-02T11:29:49 | 108,404,673 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.584369421005249,
"alphanum_fraction": 0.6447601914405823,
"avg_line_length": 19.071428298950195,
"blob_id": "b5542b798a43db0799633e0542514a84e62b5a3a",
"content_id": "83c5c39bbf336cbb5469bc136a6d71ca7dfd2710",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 563,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 28,
"path": "/gh-pages/Example02.Rmd",
"repo_name": "pxltech/SmartSystems",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Example02\"\nauthor: \"Vincent Claes\"\ndate: \"26 oktober 2017\"\noutput: html_document\n---\n\n```{r setup, include=FALSE}\nknitr::opts_chunk$set(echo = TRUE)\n```\n\n# Our Location\n\n```{r echo = TRUE, warning=FALSE}\nlibrary(leaflet)\n\nEAIcon <- makeIcon(\n iconUrl = \"http://pxl-ea-ict.be/trinity/images/2.png\",\n iconWidth = 160, iconHeight = 100,\n iconAnchorX = 22, iconAnchorY = 94\n)\n\n\nEA_map <- leaflet() %>% \n addTiles() %>%\n addMarkers(lng=5.384984, lat=50.927781, icon = EAIcon, popup='<a href=\"https://www.facebook.com/pbaeaict/\">PBA EA-ICT!</a>')\nEA_map\n```\n\n"
},
{
"alpha_fraction": 0.6924095153808594,
"alphanum_fraction": 0.6946160793304443,
"avg_line_length": 24.177778244018555,
"blob_id": "a1fe63eb774f9278d950c8ed13dd7c34337e9529",
"content_id": "5a3963d20c6dcd96dad539660ff9ca8a86200731",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2266,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 90,
"path": "/FlaskPythonHerokuDB/dbApp.py",
"repo_name": "pxltech/SmartSystems",
"src_encoding": "UTF-8",
"text": "import os\nfrom flask import Flask, jsonify\nfrom flask import render_template, request\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_marshmallow import Marshmallow\nfrom flask_restful import Resource, Api, reqparse\nfrom marshmallow_sqlalchemy import ModelSchema\nfrom datetime import datetime\n\n# made by Vincent Claes\n# www.cteq.eu\n\napp = Flask(__name__)\napp.config.update({\n 'SQLALCHEMY_DATABASE_URI': os.environ['DATABASE_URL'],\n 'SQLALCHEMY_TRACK_MODIFICATIONS': True\n})\ndb = SQLAlchemy(app)\nma = Marshmallow(app)\n\nclass Temperature(db.Model):\n id = db.Column(db.Integer, primary_key=True)\n value = db.Column(db.String(80))\n place = db.Column(db.String(120))\n creation_date = db.Column(db.DateTime, default=datetime.utcnow)\n\nclass TemperatureSchema(ma.ModelSchema):\n class Meta:\n model = Temperature\n\ntemperature_schema = TemperatureSchema()\ntemperatures_schema = TemperatureSchema(many=True)\t\t\n\n# MAIN ROUTE\[email protected]('/')\ndef home():\n return \"Hello World!\"\n\n# ALL TEMP VALUES\t\[email protected]('/api/temps/')\ndef temps():\n all_temps = Temperature.query.all()\n result = temperatures_schema.dump(all_temps)\n return jsonify(result.data)\n\n# TEMP VALUE BY ID\t\[email protected]('/api/temps/<id>')\ndef user_detail(id):\n temp = Temperature.query.get(id)\n return temperature_schema.jsonify(temp)\t\n\n# NEW VALUE >POST METHOD\t\[email protected](\"/api/temp\", methods=[\"POST\"])\ndef add_temp():\n value = request.json['value']\n place = request.json['place']\n\n new_temp = Temperature(value=value, place=place)\n\n db.session.add(new_temp)\n db.session.commit()\n\n tempe = Temperature.query.get(new_temp.id)\n\n return temperature_schema.jsonify(tempe)\n\n# UPDATE TEMP VALUE\t\[email protected](\"/api/temp/<id>\", methods=[\"PUT\"])\ndef user_update(id):\n tempe = Temperature.query.get(id)\n value = request.json['value']\n place = request.json['place']\n\n tempe.value = value\n tempe.place = place\n\n db.session.commit()\n return temperature_schema.jsonify(tempe)\n\t\n# DELETE TEMP VALUE \[email protected](\"/api/temp/<id>\", methods=[\"DELETE\"])\ndef user_delete(id):\n tempe = Temperature.query.get(id)\n db.session.delete(tempe)\n db.session.commit()\n\n return temperature_schema.jsonify(tempe)\t\n\t\nif __name__ == '__main__':\n app.run()\n"
},
{
"alpha_fraction": 0.5766128897666931,
"alphanum_fraction": 0.5887096524238586,
"avg_line_length": 20.434782028198242,
"blob_id": "f45cc0dafee3e6dba655339b84c487540b482520",
"content_id": "ff10cb74fa9dfa81158b454488b3ee5a8b92943d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 496,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 23,
"path": "/FlaskPythonHeroku/PXLApp.py",
"repo_name": "pxltech/SmartSystems",
"src_encoding": "UTF-8",
"text": "from flask import Flask, url_for, request, json, Response, jsonify\nfrom functools import wraps\n\napp = Flask(__name__)\n\n# test with curl -i https://xxxxx.herokuapps.com/hi\[email protected]('/hi', methods = ['GET'])\ndef api_hi():\n data = {\n 'hello': 'world',\n 'number': 456\n }\n js = json.dumps(data)\n \n resp = Response(js, status=200, mimetype='application/json')\n resp.headers['Link']= 'http://www.cteq.eu'\n return resp\n\n\n\n\nif __name__ == '__main__':\n app.run()\n "
},
{
"alpha_fraction": 0.6662507653236389,
"alphanum_fraction": 0.6687461137771606,
"avg_line_length": 25.616666793823242,
"blob_id": "14cdbb3620019e79ef5e140a21c619cc7d2390de",
"content_id": "d41e97cc74ef07251b84e1e9ae6a89e46836f10f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1603,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 60,
"path": "/test/app.R",
"repo_name": "pxltech/SmartSystems",
"src_encoding": "UTF-8",
"text": "#\n# This is a Shiny web application. You can run the application by clicking\n# the 'Run App' button above.\n#\n# Find out more about building applications with Shiny here:\n#\n# http://shiny.rstudio.com/\n#\n\nlibrary(shiny)\nlibrary(quantmod)\n\n# Define UI for application that draws a histogram\nui <- fluidPage(\n \n # Application title\n titlePanel(\"Stock Charting by Vincent Claes\"),\n \n # Sidebar with a slider input for number of bins \n sidebarLayout(\n sidebarPanel(\n selectInput(\"stock\", \"Choose a stock:\",\n list(`StockList` = c(\"AAPL\", \"IBM\", \"ORCL\"))\n ),\n textOutput(\"string1\"),\n textOutput(\"string2\")\n \n ),\n \n # Show a plot of the stock\n mainPanel(\n plotOutput(\"stockPlot\"),\n textOutput(\"MeanStockValue\")\n )\n )\n\n)\n\n# Define server logic required to draw a histogram\nserver <- function(input, output) {\n \n output$stockPlot <- renderPlot({\n stockdata<-getSymbols(input$stock, src=\"google\", auto.assign=FALSE)\n chartSeries(stockdata, theme=\"white\")\n addBBands()\n \n })\n output$MeanStockValue <-renderText({\n stockdata<-getSymbols(input$stock, src=\"google\", auto.assign=FALSE)\n count <-mean(Cl(stockdata),na.rm=TRUE)\n paste(\"Mean value over time of stock:\",count)\n }\n )\n output$string1<-renderText(\"Please select a stock in the dropdown menu, on the right side you can see the stock price over time with bollingerbands\")\n output$string2<-renderText(\"Below the chart you can see the mean closing price of the stock for this time period\")\n \n}\n\n# Run the application \nshinyApp(ui = ui, server = server)\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.5286195278167725,
"alphanum_fraction": 0.7306397557258606,
"avg_line_length": 16.47058868408203,
"blob_id": "c75649ca0612ebdc5e2acf7ac16a7a9a73b685d2",
"content_id": "fbca60b636e259a6e04ac2504531d137b0a3672e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 297,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 17,
"path": "/FlaskPythonHerokuDB/requirements.txt",
"repo_name": "pxltech/SmartSystems",
"src_encoding": "UTF-8",
"text": "aniso8601==3.0.0\nclick==6.7\nFlask==0.12.2\nFlask-RESTful==0.3.6\nFlask-SQLAlchemy==2.3.2\ngunicorn==19.7.1\nitsdangerous==0.24\nJinja2==2.10\nMarkupSafe==1.0\nmarshmallow==2.15.0\nflask-marshmallow\nmarshmallow-sqlalchemy==0.13.2\npsycopg2==2.7.4\npytz==2018.3\nsix==1.11.0\nSQLAlchemy==1.2.5\nWerkzeug==0.14.1\n"
},
{
"alpha_fraction": 0.7857142686843872,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 27,
"blob_id": "453e01c6a8387ae1b93593747ac2731f11aaa0da",
"content_id": "a2034f6ba1c988b8796bb712227317f2ecf1d049",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 2,
"path": "/gh-pages/README.md",
"repo_name": "pxltech/SmartSystems",
"src_encoding": "UTF-8",
"text": "# SmartSystems\nExample dump for Smart Systems by Vincent Claes\n"
}
] | 6 |
samj1912/cookiecutter-advanced-demo | https://github.com/samj1912/cookiecutter-advanced-demo | 1bf8d86e762b2e09d045ccfa0e0939a5f15805d7 | 44bd2a6d2062a97c272e9606070158345730d459 | 5da1619ab33bc1a7f0fcc3ae0a9e6e9466a71c65 | refs/heads/master | 2022-12-23T04:44:49.980963 | 2020-08-22T20:22:49 | 2020-08-22T20:22:49 | 289,543,801 | 18 | 3 | null | null | null | null | null | [
{
"alpha_fraction": 0.75251704454422,
"alphanum_fraction": 0.7612861394882202,
"avg_line_length": 38.47435760498047,
"blob_id": "323f42f2ab251d2999cc770603d4ff7ac5408561",
"content_id": "502ac0c068d0c850ecf3f0eeeb4b0e746722f4a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3079,
"license_type": "no_license",
"max_line_length": 199,
"num_lines": 78,
"path": "/README.md",
"repo_name": "samj1912/cookiecutter-advanced-demo",
"src_encoding": "UTF-8",
"text": "## Advanced context modification for cookiecutter.\n\n[](https://github.com/samj1912/cookiecutter-advanced-demo/stargazers)\n\nThis repo is an advanced example of a cookiecutter that can modify cookiecutter's\ncontext values from hooks. Read the [pre_gen_project.py](https://github.com/samj1912/cookiecutter-advanced-demo/blob/master/hooks/pre_gen_project.py) for examples and a demo on how to modify context.\n\n<details>\n<summary>Contents - pre_gen_hook.py</summary>\n \n```python\n\"\"\"\nYou can update the cookiecutter context though Jinja.\nIn order to do so - you can use Jinja inside the pre gen hook\nto update the cookiecutter context.\n\nI use the docstring of the pre gen hook since it is an easy way to update things\nwithout causing any syntax errors.\n\nExample -\n\n1. You can add values to the context -\n\n{{ cookiecutter.update({\"updated_value\": cookiecutter.value * 2 }) }}\n\nThe above is useful for a bunch of cases -\n* Being able to add values to the context independent of the user input -\n for eg. creating a valid project slug from a project name by escaping\n the values.\n* When you are sharing files between different cookiecutter\n directories and you want to define defaults in order to avoid\n Jinja from complaining the certain values are not defined.\n\n2. You can also modify existing values -\n\n{{ cookiecutter.update({\"modify_value\": \"modified_value\" }) }}\n\n3. It is also possible to use Jinja tags to modify values conditionally.\nYou can also do this to change the name of the generated project directory.\nSee the example below. This is useful when handling inputs from the user\nthat you want to escape.\n\nEg -\n\n{% if cookiecutter.project_name != \"advanced_test\" %}\n{{ cookiecutter.update({ \"project_name_modified\": True }) }}\n{% else %}\n{{ cookiecutter.update({ \"project_name_modified\": False }) }}\n{% endif %}\n\"\"\"\n```\n</details>\n\nTo run this demo cookiecutter do -\n\n cookiecutter https://github.com/samj1912/cookiecutter-advanced-demo\n\nThis demo shows how to do the following -\n\n1. Add values to the cookiecutter context.\n\nThe above is useful for a bunch of cases -\n* Being able to add values to the context independent of the user input -\n for eg. creating a valid project slug from a project name by escaping\n the values.\n* When you are sharing files between different cookiecutter\n directories and you want to define defaults in order to avoid\n Jinja from complaining the certain values are not defined.\n\n2. Modify existing values cookiecutter context values even after user input-\n\nThis is useful when you want to handle bad user input and instead of raising an\nerror, set the cookiecutter context values correct. For eg modifying the project_slug\nfrom the user to be valid.\n\n3. Conditionally modify the above based on user input.\n\nNote - You can also do this to change the name of the variable that is used to define the generated project directory. This is useful when handling inputs from the user that you want to escape.\n"
},
{
"alpha_fraction": 0.7347089052200317,
"alphanum_fraction": 0.7376565933227539,
"avg_line_length": 33.79487228393555,
"blob_id": "3f07cb71bcf9c7831a827f71fe565bedd2aee6ef",
"content_id": "d1cc048cad9e9988d6dad5af640d500d9914f585",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1357,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 39,
"path": "/hooks/pre_gen_project.py",
"repo_name": "samj1912/cookiecutter-advanced-demo",
"src_encoding": "UTF-8",
"text": "\"\"\"\nYou can update the cookiecutter context though Jinja.\nIn order to do so - you can use Jinja inside the pre gen hook\nto update the cookiecutter context.\n\nI use the docstring of the pre gen hook since it is an easy way to update things\nwithout causing any syntax errors.\n\nExample -\n\n1. You can add values to the context -\n\n{{ cookiecutter.update({\"updated_value\": cookiecutter.value * 2 }) }}\n\nThe above is useful for a bunch of cases -\n* Being able to add values to the context independent of the user input -\n for eg. creating a valid project slug from a project name by escaping\n the values.\n* When you are sharing files between different cookiecutter\n directories and you want to define defaults in order to avoid\n Jinja from complaining the certain values are not defined.\n\n2. You can also modify existing values -\n\n{{ cookiecutter.update({\"modify_value\": \"modified_value\" }) }}\n\n3. It is also possible to use Jinja tags to modify values conditionally.\nYou can also do this to change the name of the generated project directory.\nSee the example below. This is useful when handling inputs from the user\nthat you want to escape.\n\nEg -\n\n{% if cookiecutter.project_name != \"advanced_test\" %}\n{{ cookiecutter.update({ \"project_name_modified\": True }) }}\n{% else %}\n{{ cookiecutter.update({ \"project_name_modified\": False }) }}\n{% endif %}\n\"\"\"\n"
},
{
"alpha_fraction": 0.7108843326568604,
"alphanum_fraction": 0.7108843326568604,
"avg_line_length": 23.5,
"blob_id": "6b5ad3eccb8c25995374958a6ef804eb6cfcfec4",
"content_id": "a4e114c311e897aeb99e04af5f6d23fe5e89ac34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 294,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 12,
"path": "/{{ cookiecutter.project_name }}/README.md",
"repo_name": "samj1912/cookiecutter-advanced-demo",
"src_encoding": "UTF-8",
"text": "Values is : {{ cookiecutter.value }}\nUpdated value is : {{ cookiecutter.updated_value }}\n\nCookiecutter context looks like -\n\n```json\n{{ cookiecutter | jsonify }}\n```\n\n{% if cookiecutter.project_name_modified %}\nYou modified the project name to something other than \"advanced_test\".\n{% endif %}\n"
}
] | 3 |
poojaranawade/Recommendation-System | https://github.com/poojaranawade/Recommendation-System | fba92819ed5021d58b2e6dd83eeb39fd3fb71fd7 | 408a59ea4ad8d2d8dd2881a5488e2ed430f065c7 | e643534b223707766b40b5b234008c04eaa67a37 | refs/heads/master | 2020-03-06T21:47:16.051811 | 2018-03-28T05:09:51 | 2018-03-28T05:09:51 | 127,086,533 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49341824650764465,
"alphanum_fraction": 0.5116772651672363,
"avg_line_length": 33.691917419433594,
"blob_id": "77dc34934a92431a42bbdadbda43f90cdbf9a5c7",
"content_id": "ae3884f30583c49cae90da96c86689a79f8acfa6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7065,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 198,
"path": "/recommendation.py",
"repo_name": "poojaranawade/Recommendation-System",
"src_encoding": "UTF-8",
"text": "import math\r\nimport numpy as np\r\n# =============================================================================\r\n# common functionalities\r\n# =============================================================================\r\ndef avg_current(test_list):\r\n sum_r = 0\r\n for u in test_list:\r\n sum_r += u\r\n return sum_r / 5\r\n\r\n\r\ndef clean_up(rating):\r\n if rating < 1:\r\n return 1\r\n if rating > 5:\r\n return 5\r\n return rating\r\n\r\n# =============================================================================\r\n# item based similarity functions\r\n# =============================================================================\r\ndef find_cosine_sim_movies(movie1_list,movie2_list):\r\n numerator=0\r\n denominator,d1,d2=0,0,0\r\n for i in range(200):\r\n numerator+=movie1_list[i]*movie2_list[i]\r\n d1+=(movie1_list[i])**2\r\n d2+=(movie2_list[i])**2\r\n denominator=(d1**0.5)*(d2**0.5)\r\n return numerator/denominator\r\n\r\ndef sort_index(current_movie,similarity_list):\r\n# k=20\r\n similar_movies,movies=[],[]\r\n for index,val in enumerate(similarity_list):\r\n if index!=current_movie and val!=0:\r\n similar_movies.append((val,index))\r\n similar_movies.sort(reverse=True)\r\n \r\n for m in similar_movies:\r\n movies.append(m[1])\r\n return movies\r\n\r\ndef get_similar_movies(train_mat):\r\n cosine_movies=np.zeros(shape=(1000,1000))\r\n for i in range(1000):\r\n for j in range(1000):\r\n val=find_cosine_sim_movies(train_mat[:,i],train_mat[:,j])\r\n if not np.isnan(val):\r\n cosine_movies[i][j]=val\r\n \r\n similar_movies={k:[] for k in range(1000)}\r\n for index,row in enumerate(cosine_movies):\r\n similar_movies[index]=sort_index(index,row)\r\n return similar_movies,cosine_movies\r\n\r\n\r\ndef get_k_nearest(similar_movies,movie_index,cosine_movies,test_list):\r\n k=50\r\n nearest,newList=[],[]\r\n for m in similar_movies[movie_index]:\r\n newList.append((cosine_movies[movie_index][m],m))\r\n \r\n newList.sort(reverse=True)\r\n for m in newList:\r\n if len(nearest)<=k:\r\n nearest.append(m[1])\r\n return nearest\r\n \r\n \r\ndef item_based(movie_index,test_list,similar_movies,cosine_movies,train_mat):\r\n sim_m=get_k_nearest(similar_movies,movie_index,cosine_movies,test_list)\r\n rating_pred=0\r\n denomimnator,numerator=0,0\r\n for m in sim_m:\r\n if test_list[m]!=0:\r\n numerator+=cosine_movies[movie_index][m]*test_list[m]\r\n denomimnator+=cosine_movies[movie_index][m]\r\n if denomimnator!=0:\r\n rating_pred=math.ceil(numerator/denomimnator)\r\n else:\r\n rating_pred=math.ceil(avg_current(test_list))\r\n return clean_up(rating_pred)\r\n\r\n# =============================================================================\r\n# cosine similarity functions\r\n# =============================================================================\r\ndef find_cosine_sim(curr_u, movie_index, test_list, train_mat):\r\n cosine, users, similarity = [], [], []\r\n k = 50\r\n for index, row in enumerate(train_mat):\r\n if row[movie_index] != 0:\r\n numerator, d1, d2 = 0, 0, 0\r\n for j, col in enumerate(row):\r\n if col != 0 and test_list[j] != 0:\r\n numerator += col * test_list[j]\r\n d1 += col ** 2\r\n d2 += test_list[j] ** 2\r\n denominator = (d1 ** 0.5) * (d2 ** 0.5)\r\n if denominator != 0:\r\n cosine.append(((numerator / denominator), index))\r\n\r\n cosine.sort(reverse=True)\r\n if len(cosine) >= k:\r\n for i in range(k):\r\n users.append(cosine[i][1])\r\n similarity.append(cosine[i][0])\r\n else:\r\n for u in cosine:\r\n users.append(u[1])\r\n similarity.append(u[0])\r\n return similarity, users\r\n\r\n\r\ndef cosine_sim(curr_u, movie_index, test_list, train_mat):\r\n similarity, users = find_cosine_sim(curr_u, movie_index, test_list, train_mat)\r\n rating_pred = 0\r\n if len(users) == 0:\r\n rating_pred = math.ceil(avg_current(test_list))\r\n else:\r\n weight = 0\r\n for index, u in enumerate(users):\r\n weight += similarity[index] * train_mat[u][movie_index]\r\n rating_pred = math.ceil(weight / sum(similarity))\r\n return clean_up(rating_pred)\r\n\r\n# =============================================================================\r\n# pearson correkation functions\r\n# =============================================================================\r\ndef find_avg_test(movie_index, test_list):\r\n avg_test, count = 0, 0\r\n for index, rating in enumerate(test_list):\r\n if index != movie_index:\r\n avg_test += rating\r\n count += 1\r\n avg_test /= count\r\n return avg_test\r\n\r\n\r\ndef avg_train_user(movie_index, train_mat):\r\n avg_user = {}\r\n for index, row in enumerate(train_mat):\r\n if row[movie_index] != 0:\r\n count, avg_u = 0, 0\r\n for movie, rating in enumerate(row):\r\n if movie != movie_index:\r\n avg_u += rating\r\n count += 1\r\n avg_user[index] = avg_u / count\r\n return avg_user\r\n\r\n\r\ndef find_weights(avg_user, train_mat, test_list, avg_test):\r\n weights = {}\r\n users = list(avg_user.keys())\r\n for user_index, user in enumerate(train_mat):\r\n if user_index in users:\r\n numerator, denominator = 0, 0\r\n d1, d2, n1, n2 = 0, 0, 0, 0\r\n for movie, rate in enumerate(user):\r\n n1 = rate - avg_user[user_index]\r\n n2 = test_list[movie] - avg_test\r\n numerator += n1 * n2\r\n d1 += n1 ** 2\r\n d2 += n2 ** 2\r\n denominator = (d1 ** 0.5) * (d2 ** 0.5)\r\n if denominator != 0:\r\n weights[user_index] = numerator / denominator\r\n return weights\r\n\r\n\r\ndef pearson_corelation(curr_u, movie_index, test_list, train_mat):\r\n # find avg_test for test user excluding movie_index\r\n avg_test = find_avg_test(movie_index, test_list)\r\n\r\n # find avgerage of each train user excluding and remember relevant users\r\n avg_user = avg_train_user(movie_index, train_mat)\r\n sim_users = list(avg_user.keys())\r\n\r\n # find weights for each relevant users(= users who have rated movie_index)\r\n weights = find_weights(avg_user, train_mat, test_list, avg_test)\r\n \r\n rating_pred = 0\r\n if len(weights) == 0:\r\n rating_pred = math.ceil(avg_current(test_list))\r\n else:\r\n # find test users rating for movie_index\r\n numerator = 0\r\n for user_index, user in enumerate(train_mat):\r\n if user_index in sim_users:\r\n numerator += (user[movie_index] - avg_user[user_index]) * weights[user_index]\r\n denominator = 0\r\n for u in sim_users:\r\n denominator += abs(weights[u]) \r\n rating_pred = math.ceil(avg_test + (numerator / denominator))\r\n \r\n return clean_up(rating_pred)"
},
{
"alpha_fraction": 0.4432092010974884,
"alphanum_fraction": 0.4711877107620239,
"avg_line_length": 48.457942962646484,
"blob_id": "4cc2db69fd22edb3f491bc7df4bb8b9825983eff",
"content_id": "9ece46745800f0c34dc2e6e3d28fe9afd0b346f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5397,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 107,
"path": "/main.py",
"repo_name": "poojaranawade/Recommendation-System",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\nimport numpy\r\nimport csv\r\nfrom recommendation import cosine_sim, pearson_corelation,get_similar_movies,item_based\r\n\r\nif __name__ == '__main__':\r\n # =============================================================================\r\n # reading data from files\r\n # =============================================================================\r\n with open('train.txt', 'r') as in_file:\r\n stripped = (line.strip() for line in in_file)\r\n lines = (line.split(\"\\t\") for line in stripped if line)\r\n with open('train.csv', 'w') as out_file:\r\n writer = csv.writer(out_file)\r\n writer.writerows(lines)\r\n\r\n train_data = pd.read_csv('train.csv', header=None)\r\n train_mat = train_data.as_matrix()\r\n similar_movies,cosine_movies=get_similar_movies(train_mat)\r\n \r\n # =============================================================================\r\n # test5.text\r\n # =============================================================================\r\n with open('test5.txt', 'r') as in_file:\r\n stripped = (line.strip() for line in in_file)\r\n lines = (line.split(\" \") for line in stripped if line)\r\n with open('test5.csv', 'w') as out_file:\r\n writer = csv.writer(out_file)\r\n writer.writerows(lines)\r\n\r\n test_data = pd.read_csv('test5.csv', header=None)\r\n test_mat = numpy.zeros(shape=(100, 1000))\r\n predict = {k: [] for k in range(100)}\r\n for row in test_data.iterrows():\r\n test_mat[row[1][0] - 201][row[1][1] - 1] = row[1][2]\r\n if row[1][2] == 0:\r\n predict[row[1][0] - 201].append(row[1][1] - 1)\r\n\r\n with open('testResC5.txt', 'w') as res_file:\r\n for i, row in enumerate(test_mat):\r\n print(\"\\ni\", i+201, end=\" \")\r\n for index, col in enumerate(row):\r\n cosine_sim_rating,pearson_rating=0,0\r\n if col == 0 and index in predict[i]:\r\n cosine_sim_rating = cosine_sim(i, index, row, train_mat)\r\n pearson_rating = pearson_corelation(i, index, row, train_mat)\r\n row[index]=(cosine_sim_rating+pearson_rating)/2\r\n# rating=item_based(index,row,similar_movies,cosine_movies,train_mat)\r\n res_file.write(\"%d %d %d\\n\" % ((i + 201), index + 1, row[index]))\r\n # =============================================================================\r\n # test10.text\r\n # =============================================================================\r\n with open('test10.txt', 'r') as in_file:\r\n stripped = (line.strip() for line in in_file)\r\n lines = (line.split(\" \") for line in stripped if line)\r\n with open('test10.csv', 'w') as out_file:\r\n writer = csv.writer(out_file)\r\n writer.writerows(lines)\r\n\r\n test_data = pd.read_csv('test10.csv', header=None)\r\n test_mat = numpy.zeros(shape=(100, 1000))\r\n predict = {k: [] for k in range(100)}\r\n for row in test_data.iterrows():\r\n test_mat[row[1][0] - 301][row[1][1] - 1] = row[1][2]\r\n if row[1][2] == 0:\r\n predict[row[1][0] - 301].append(row[1][1] - 1)\r\n\r\n with open('testResC10.txt', 'w') as res_file:\r\n for i, row in enumerate(test_mat):\r\n print(\"\\ni\", i+301, end=\" \")\r\n for index, col in enumerate(row):\r\n cosine_sim_rating,pearson_rating=0,0\r\n if col == 0 and index in predict[i]:\r\n cosine_sim_rating = cosine_sim(i, index, row, train_mat)\r\n pearson_rating = pearson_corelation(i, index, row, train_mat)\r\n row[index]=(cosine_sim_rating+pearson_rating)/2\r\n# row[index]=item_based(index,row,similar_movies,cosine_movies,train_mat)\r\n res_file.write(\"%d %d %d\\n\" % ((i + 301), index + 1, row[index]))\r\n # =============================================================================\r\n # test20.text\r\n # =============================================================================\r\n with open('test20.txt', 'r') as in_file:\r\n stripped = (line.strip() for line in in_file)\r\n lines = (line.split(\" \") for line in stripped if line)\r\n with open('test20.csv', 'w') as out_file:\r\n writer = csv.writer(out_file)\r\n writer.writerows(lines)\r\n\r\n test_data = pd.read_csv('test20.csv', header=None)\r\n test_mat = numpy.zeros(shape=(100, 1000))\r\n predict = {k: [] for k in range(100)}\r\n for row in test_data.iterrows():\r\n test_mat[row[1][0] - 401][row[1][1] - 1] = row[1][2]\r\n if row[1][2] == 0:\r\n predict[row[1][0] - 401].append(row[1][1] - 1)\r\n\r\n with open('testResC20.txt', 'w') as res_file:\r\n for i, row in enumerate(test_mat):\r\n print(\"\\ni\", i+401, end=\" \")\r\n for index, col in enumerate(row):\r\n cosine_sim_rating,pearson_rating=0,0\r\n if col == 0 and index in predict[i]:\r\n cosine_sim_rating = cosine_sim(i, index, row, train_mat)\r\n pearson_rating = pearson_corelation(i, index, row, train_mat)\r\n row[index]=(cosine_sim_rating+pearson_rating)/2\r\n# row[index]=item_based(index,row,similar_movies,cosine_movies,train_mat)\r\n res_file.write(\"%d %d %d\\n\" % ((i + 401), index + 1, row[index]))"
},
{
"alpha_fraction": 0.8167701959609985,
"alphanum_fraction": 0.8260869383811951,
"avg_line_length": 79.5,
"blob_id": "c119c724764340e5a0d01ba6680726d5f70d3912",
"content_id": "fd9ca4688aaa6acb8d8556c3a61500fd4046468c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 322,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 4,
"path": "/README.md",
"repo_name": "poojaranawade/Recommendation-System",
"src_encoding": "UTF-8",
"text": "# Movie Recommendation System\no Built web-based recommendation system using collaborative filtering in Python (sci-kitlearn) and trained the algorithm using Netflix dataset. \no Developed an ensemble algorithm with cosine similarity, Pearson correlation and item-based similarity.\no Gives root mean squared error of 0.72.\n"
}
] | 3 |
oneminimax/AsciiDataFile | https://github.com/oneminimax/AsciiDataFile | 224795794109e833bd98d3ddb6e802eb9dd94e0b | aea729c3f07113a58ab2002bc1b72ba0c865662c | baffc4edac0f0ae4c272574bc307edb1ca2c8348 | refs/heads/master | 2022-02-23T09:37:06.972764 | 2022-02-14T19:55:12 | 2022-02-14T19:55:12 | 142,199,312 | 0 | 0 | null | 2018-07-24T18:43:03 | 2018-08-22T18:47:57 | 2018-08-22T18:50:15 | Python | [
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.75,
"avg_line_length": 11.899999618530273,
"blob_id": "87b44ce3d758008d1163384f62edfd9c4739a046",
"content_id": "b9fb94c9aa114ce6d3ae16e03ebd2001f862b024",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 128,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 10,
"path": "/__init__.py",
"repo_name": "oneminimax/AsciiDataFile",
"src_encoding": "UTF-8",
"text": "\"\"\"\nAsciiDataFile\nPython Package\[email protected]\n2018/07/24\n\"\"\"\n\nfrom . import Readers\nfrom . import Writers\nfrom . import DataContainer"
},
{
"alpha_fraction": 0.6039038300514221,
"alphanum_fraction": 0.6063529849052429,
"avg_line_length": 30.302326202392578,
"blob_id": "4304ab58b06a4ee1d9482caf7d1cc768e2cd489b",
"content_id": "9854f0df81ca939a8c131b4ddba253a5065a0572",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13474,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 430,
"path": "/DataContainer.py",
"repo_name": "oneminimax/AsciiDataFile",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom scipy.interpolate import interp1d\n\nclass Column(object):\n\n def __init__(self,name,units,data = list()):\n\n self.name = name\n self.set_units(units)\n self.set_data(data)\n\n self.update_length()\n\n def __len__(self):\n\n return len(self.data)\n\n def __str__(self):\n\n return f'{self.name} ({self.units}) : {self.data_length} points'\n\n def __repr__(self):\n\n return f'{self.name} ({self.units}) : {self.data_length} points'\n\n def set_units(self,units):\n\n self.units = units\n\n def set_data(self,data):\n\n self.data = np.array(data)\n\n def get_data(self):\n\n return self.data[:self.data_length]\n\n def get_units(self):\n\n return self.units\n\n def rename(self,name):\n\n self.name = name\n\n def add_data_point(self,value):\n\n self.data[self.data_length] = value\n \n self.data_length += 1\n\n def filter(self,mask):\n\n self.set_data(self.data[mask])\n self.update_length()\n\n def update_length(self):\n\n self.data_length = len(self.data)\n self.extend_data_length = len(self.data)\n\n def _extend_chunk(self,chunk_size):\n\n larger_data = np.zeros((self.data_length + chunk_size,))\n larger_data[:self.data_length] = self.data\n self.data = larger_data\n self.extend_data_length = self.data_length + chunk_size\n\n def _crop(self):\n\n self.data = self.data[:self.data_length]\n self.extend_data_length = self.data_length+0\n\n def _copy(self):\n\n return self.__class__(self.name,self.units,self.get_data())\n\n def equals_within_tolerance(self,value,tolerance):\n\n return np.abs((self.get_data() - value)) < tolerance\n\n def in_range(self,limits):\n\n data = self.get_data()\n return np.logical_and(data > limits[0], data < limits[1])\n\nclass DataCurve(object):\n\n def __init__(self,*vargs,**kwargs):\n\n self.chunk_size = 100\n\n self.parameter_dict = dict()\n self.column_dict = dict()\n\n self.data_length = 0\n self.extend_data_length = 0\n self.name = 'DataCurve'\n\n for arg in vargs:\n if isinstance(arg,DataCurve):\n self.set_column_dict(arg.column_dict)\n self.set_parameter_dict(arg.parameter_dict)\n self.data_length = arg.data_length\n self.extend_data_length = self.extend_data_length\n\n if 'column_names' in kwargs and 'column_units_labels' in kwargs:\n self.init_columns(kwargs['column_names'],kwargs['column_units_labels'])\n elif 'column_dict' in kwargs:\n self.set_column_dict(kwargs['column_dict'])\n\n def __getattr__(self,name):\n\n if name in self.column_dict:\n return self.column_dict[name].get_data()\n \n var_name = name.replace('_',' ')\n if var_name in self.column_dict:\n return self.column_dict[var_name].get_data()\n\n def __str__(self):\n\n info_str = f'{self.name:s} ({self.data_length:d} data points)\\n'\n if self.parameter_dict:\n for parameter_name in self.parameter_dict:\n info_str += parameter_name + ' : ' + str(self.parameter_dict[parameter_name]) + ', '\n if self.column_dict:\n for column_name, column in self.column_dict.items():\n info_str += ' ' + column_name + ' (' + str(column.units) + ')\\n'\n\n return info_str[:-1]\n\n def _copy_column_dict(self):\n\n new_column_dict = dict()\n for column_name, column in self.column_dict.items():\n new_column_dict[column_name] = column._copy()\n\n return new_column_dict\n\n def convert(self,new_class):\n\n return new_class(self)\n\n def init_columns(self,column_names,column_units_labels = []):\n \n if len(column_names) == len(column_units_labels):\n for i, (column_name,column_units_label) in enumerate(zip(column_names,column_units_labels)):\n self.add_column(column_name,column_units_label)\n else:\n for i, column_name in enumerate(column_names):\n self.add_column(column_name,'')\n\n def add_column(self,column_name,column_units_label,column_data = None):\n\n if column_data is None:\n column_data = np.empty([0,])\n\n if self.data_length:\n if not len(column_data) == self.data_length:\n raise Exception('Data length must be the same')\n else:\n self.data_length = len(column_data)\n\n self.column_dict[column_name] = Column(column_name,column_units_label,column_data)\n\n def add_parameter(self,parameter_name,parameter_value):\n\n self.parameter_dict[parameter_name] = parameter_value\n\n def update_column(self,column_name,column_data,units = None):\n\n if not len(column_data) == self.data_length:\n raise Exception('Data length must be the same')\n\n self.column_dict[column_name].set_data(column_data)\n if units is not None:\n self.column_dict[column_name].set_units(units)\n\n def rename_column(self,old_name,new_name):\n\n if old_name in self.get_column_names():\n self.column_dict[old_name].rename(new_name)\n self.column_dict[new_name] = self.column_dict.pop(old_name)\n\n def add_data_point(self,values):\n\n if not len(values) == self.column_number():\n raise ValueError('New Data dimension ({0:d}) is not conform to the number of data columns ({1:d}).'.format(len(values),self.column_number()))\n\n if self.extend_data_length == self.data_length:\n self._extend_chunk()\n\n if isinstance(values,dict):\n new_data = values\n if not new_data.keys() == self.column_dict.keys():\n ValueError('Column name should already be present in DataCurve')\n\n elif isinstance(values,list) or isinstance(values,np.ndarray):\n new_data = dict(zip(self.get_column_names(),values))\n\n for column_name in self.column_dict:\n self.column_dict[column_name].add_data_point(new_data[column_name])\n \n self.data_length += 1\n\n def column_number(self):\n\n return len(self.column_dict)\n\n def _extend_chunk(self):\n\n for column_name in self.column_dict:\n self.column_dict[column_name]._extend_chunk(self.chunk_size)\n self.extend_data_length = self.data_length+self.chunk_size\n\n def _crop(self):\n\n for column_name in self.column_dict:\n self.column_dict[column_name]._crop()\n\n self.extend_data_length = self.data_length+0\n\n\n def _check_column_name(self):\n\n for column_name, column in self.column_dict.items():\n column.rename(column_name)\n\n ''' Sets '''\n\n def set_column_dict(self,column_dict):\n\n data_lengths = list()\n for column_name in column_dict:\n data_lengths.append(len(column_dict[column_name]))\n\n data_length = np.unique(data_lengths)\n if len(data_length) == 1:\n self.column_dict = column_dict\n self.data_length = data_length[0]\n self.extend_data_length = data_length[0]\n else:\n raise Exception('Data length must be the same')\n\n self._check_column_name()\n\n def set_parameter_dict(self,parameter_dict):\n\n self.parameter_dict = parameter_dict\n\n ''' Gets '''\n\n def get_column_names(self):\n\n return list(self.column_dict.keys())\n\n def get_column_unitss(self):\n\n column_unitss = list()\n\n for column_name, column in self.column_dict.items():\n column_unitss.append(self.column_dict[column_name].get_units())\n\n return column_unitss\n\n def get_column_data(self,column_name):\n\n return self.column_dict[column_name].get_data()\n\n def get_column(self,column_name):\n\n return self.column_dict[column_name].get_data()\n\n def get_columns(self,column_names):\n\n columns = list()\n for column_name in column_names:\n columns.append(self.get_column_data(column_name))\n\n return columns\n\n def get_column_units(self,column_name):\n\n return self.column_dict[column_name].get_units()\n\n # Manipulation methods\n\n def filter(self,mask,new_curve = False):\n\n if new_curve:\n column_dict = self._copy_column_dict()\n else:\n column_dict = self.column_dict\n\n for column_name, column in column_dict.items():\n column.filter(mask)\n\n if new_curve:\n return self.__class__(column_dict = column_dict,parameter_dict = self.parameter_dict)\n\n def filter_column(self,column_names):\n\n new_column_dict = dict()\n for column_name in column_names:\n column = self.column_dict[column_name]\n new_column_dict[column_name] = Column(column_name,column.units,column.data)\n #getattr(self,column_name)\n\n self.set_column_dict(new_column_dict)\n\n return self\n\n def sort_by(self,column_name):\n\n sort_i = np.argsort(self.column_dict[column_name].get_data())\n new_column_dict = dict()\n for column_name, column in self.column_dict.items():\n column.set_data(column.get_data()[sort_i])\n\n def select_value(self,column_name,value,tolerance,new_curve = False):\n \n mask = self.column_dict[column_name].equals_within_tolerance(value,tolerance)\n return self.filter(mask,new_curve)\n\n def select_range(self,column_name,limits,new_curve = False):\n\n mask = self.column_dict[column_name].in_range(limits)\n return self.filter(mask,new_curve)\n\n def select_direction(self,column_name,direction,new_curve = False):\n\n mask = np.gradient(self.get_column_data(column_name))*direction > 0\n return self.filter(mask,new_curve)\n\n def average_multiple_measurement(self,select_column_name,value_step):\n\n unique_values = np.unique(np.round(self.get_column_data(select_column_name)/value_step))*value_step\n \n select_column_data = self.get_column_data(select_column_name)\n for column_name, column in self.column_dict.items():\n new_data = np.zeros(unique_values.shape)\n for i_value, value in enumerate(unique_values):\n ind = (select_column_data - value)**2 < value_step**2/2\n new_data[i_value] = np.average(column.get_data()[ind])\n\n column.set_data(new_data)\n self.data_length = len(unique_values)\n self.extend_data_length = len(unique_values)\n\n def interpolate(self,x_column_name,x_values):\n\n x_column_data = self.get_column_data(x_column_name)\n new_column_dict = dict()\n for column_name, column in self.column_dict.items():\n if column_name == x_column_name:\n new_column = Column(column_name,column.units,x_values)\n else:\n new_column = Column(column_name,column.units,self.y_at_x(x_column_name,column_name,x_values))\n\n new_column_dict[column_name] = new_column\n\n return self.__class__(column_dict = new_column_dict,parameter_dict = self.parameter_dict)\n\n def y_at_x(self,x_column_name,y_column_name,x_values):\n\n f = interp1d(self.get_column_data(x_column_name),self.get_column_data(y_column_name),fill_value='extrapolate')\n\n return f(x_values)\n\n def symetrize(self,x_column_name,sym_y_column_names = list(),antisym_y_column_names = list(),x_values = None,x_step = None):\n\n if x_values is None and not x_step is None:\n x_values = self.auto_sym_x_values(x_column_name,x_step)\n elif not x_values is None and x_step is None:\n pass\n else:\n raise(ValueError('Most provide x_values or x_step'))\n\n sym_column_dict = dict()\n for column_name, column in self.column_dict.items():\n f = interp1d(self.get_column_data(x_column_name),column.data,fill_value='extrapolate')\n if column_name in sym_y_column_names:\n sym_data = (f(x_values) + f(-x_values))/2\n elif column_name in antisym_y_column_names:\n sym_data = (f(x_values) - f(-x_values))/2\n else:\n continue\n\n sym_column_dict[column_name] = Column(column_name,column.units,sym_data)\n \n return self.set_column_dict(sym_column_dict)\n\n def auto_sym_x_values(self,x_column_name,x_step):\n\n max_x_value = np.max(np.round(self.get_column_data(x_column_name)/x_step))*x_step\n\n return np.linspace(0,max_x_value,int(max_x_value/x_step)+1)\n\n def get_values_array(self):\n\n self._crop()\n values_array = np.zeros((self.data_length,self.column_number()))\n for i, column_name in enumerate(self.column_dict):\n values_array[:,i] = self.column_dict[column_name].get_data()\n\n return values_array\n\n def append(self,other):\n\n new_column_dict = dict()\n for column_name, column in self.column_dict.items():\n X1 = self.column_dict[column_name].get_data()\n X2 = other.column_dict[column_name].get_data()\n new_data = np.concatenate((X1,X2))\n\n new_column_dict[column_name] = Column(column_name,column.units,new_data)\n\n self.set_column_dict(new_column_dict)\n\nclass DataCurveSequence(object):\n\n def __init__(self,data_curves = list()):\n\n self.data_curves = data_curves\n\n def add_data_curve(self,data_curve):\n\n self.data_curves.append(data_curve)\n\n\n\n\n\n \n"
},
{
"alpha_fraction": 0.527439296245575,
"alphanum_fraction": 0.5380326509475708,
"avg_line_length": 30.0717830657959,
"blob_id": "d22685ac03351e717c7af44a365f7dc9288ab4b9",
"content_id": "02b630f333f0d28fe47f84e6e613860425af95fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12555,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 404,
"path": "/Readers.py",
"repo_name": "oneminimax/AsciiDataFile",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport re\nfrom .DataContainer import DataCurve\n\nclass Reader(object):\n\n codec = 'utf-8'\n\n def __init__(self):\n\n pass\n\n def __str__(self):\n\n return str(self.get_column_names())\n\n def read(self,file_path):\n \"\"\" Read a file \n\n file_path : full path to the data file\n\n Return the data formated into a DataContainer\n \"\"\"\n\n self._open_file(file_path)\n self._read_header()\n\n self.column_names, self.column_units, self.column_numbers = self.define_column_names_units_numbers()\n self._init_data_mapper()\n \n data_curve = self._read_data()\n\n return data_curve \n\n def _open_file(self,file_path):\n \"\"\" Open a file. Set the file as the active file. \n \n file_path : full path to the data file\n\n Store the file ID in the Reader\n \"\"\"\n\n try:\n self.f_id = open(file_path,'r',encoding = self.codec)\n\n except IOError:\n print(\"Cannot open {0:s}\".format(file_path))\n raise\n\n def _new_data_curve(self):\n \"\"\" Create the DataContainer with the field names and units \"\"\"\n \n data_curve = DataCurve(column_names = self.column_names,column_units_labels = self.column_units)\n\n return data_curve\n\n def define_column_names_units_numbers(self):\n \"\"\" Define three list : column_names, column_units and column_numbers. \n This is Reader dependant. \n Can be user defined for GenericDataReader\n \"\"\"\n\n pass\n\n def _init_data_mapper(self):\n \"\"\" Initialise the data_mapper \n\n The data_mapper is a dict where keys are data field name and values are data column number\n \"\"\"\n\n data_mapper = dict()\n for i, column_name in enumerate(self.column_names):\n data_mapper[column_name] = self.column_numbers[i]\n\n self.data_mapper = data_mapper\n\n def _read_data_line(self):\n \"\"\" Read a data line\n\n Return a bool (True if line succesfully read) \n and an array with the data in the same order as column_names\n \"\"\"\n\n line = self.f_id.readline()\n splited_line = re.split(self.separator,line)\n if len(splited_line) >= len(self.column_names):\n new_data = self.map_data_line(splited_line)\n else:\n new_data = None\n \n return bool(line), new_data\n\n def _read_header(self):\n \"\"\" Read the header of the active data file. This is Reader dependant.\n Should fill self._column_names and self._units with relevant strings\n \"\"\"\n\n pass\n\n def _read_data(self):\n \"\"\" Read the data part of the file \n\n Return the data formated into a DataContainer\n \"\"\"\n\n data_curve = self._new_data_curve()\n while True:\n # try:\n keep_reading, new_data = self._read_data_line()\n if keep_reading:\n if isinstance(new_data,np.ndarray):\n data_curve.add_data_point(new_data)\n else:\n break\n # except:\n # break\n\n data_curve._crop()\n\n return data_curve\n\n def map_data_line(self,splited_line):\n \"\"\" Map a splited data line and map selected column in the same order as column_names \"\"\"\n\n new_data = np.zeros((len(self.column_names),))\n for i_column, channel in enumerate(self.column_names):\n column_numbers = self.data_mapper[channel]\n try:\n new_data[i_column] = float(splited_line[column_numbers])\n except:\n pass\n\n return new_data\n\n def get_column_names(self):\n\n return self.column_names\n\n def get_column_units(self):\n\n return self.column_units\n\n def get_column_index(self,column_name):\n\n return self.column_names.index(column_name)\n\nclass GenericDataReader(Reader):\n \"\"\" GenericDataReader can be customized to read any ASCII character separated data file \"\"\"\n def __init__(self,separator,column_names,column_units = list(),nb_head_lines = 0):\n \"\"\" Initialize a GenericDataReader\n\n separator : Character(s) separating the data (ex : ',' or '\\t')\n column_names : List of data columns\n column_units : List of units string in the same order as column_names (optional)\n nb_head_lines : Number of lines to skip at the begining of the file (default = 0)\n \"\"\"\n \n self.separator = separator\n self._column_names = column_names\n self._units = column_units\n self._nb_head_lines = nb_head_lines\n\n super().__init__()\n\n def define_column_names_units_numbers(self):\n\n return self._column_names, self._units, list(range(len(self._column_names)))\n\n def _read_header(self):\n \"\"\" Read the header of the active data file.\"\"\"\n\n header_lines = list()\n\n for n in range(self._nb_head_lines):\n header_lines.append(self.f_id.readline())\n\nclass DataColumnReader(Reader): # todo\n def __init__(self,separator = ','):\n\n super().__init__()\n\n self.separator = separator\n\n def _read_header(self):\n header_line = self.f_id.readline()\n column_heads = re.split(self.separator,header_line)\n\n column_names = list()\n column_units = list()\n\n for column_head in column_heads:\n column_head = column_head.strip()\n m_wu = re.match(r\"(.+)\\((.+)\\)\",column_head)\n if m_wu:\n column_name = m_wu.group(1).strip()\n column_unit = m_wu.group(2).strip()\n else:\n column_name = column_head\n column_unit = None\n\n column_names.append(column_name)\n column_units.append(column_unit)\n\n self._column_names = column_names\n self._units = column_units\n\n def define_column_names_units_numbers(self):\n\n return self._column_names, self._units, list(range(len(self._column_names)))\n\nclass MDDataFileReader(Reader):\n \"\"\" MDDataFileReader read in house data file where the header contains the information\n about the column names and units.\"\"\"\n \n def __init__(self):\n\n super().__init__()\n self.separator = ','\n\n def _read_header(self):\n \"\"\" Read the header lines. Store the column names and units. \"\"\"\n\n header_lines = list()\n\n while True:\n line = self.f_id.readline()\n if not line:\n break\n m1 = re.match(r\"\\[Header\\]\",line)\n m2 = re.match(r\"\\[Instrument List\\]\",line)\n if m1 or m2:\n break\n\n while True:\n line = self.f_id.readline()\n if not line:\n break\n m1 = re.match(r\"\\[Header end\\]\",line)\n m2 = re.match(r\"\\[Instrument List end\\]\",line)\n if m1 or m2:\n break\n else:\n header_lines.append(line.strip())\n\n column_names = list()\n column_units = list()\n for line in header_lines:\n m = re.match(\"Column .. : (.+)\",line)\n if m:\n subLine = m.group(1)\n m1 = re.match(r\"([\\w -]+)\\t(.+)$\",subLine)\n m2 = re.match(r\"([\\w -]+) in (\\w+)\",subLine)\n if m2:\n m22 = re.match(r\"(.+)\\s+(\\w+)\\s+(\\w+)$\",m2.group(1).strip())\n column_names.append(m22.group(2).strip())\n column_units.append(m2.group(2).strip())\n elif m1:\n column_names.append(m1.group(1).strip())\n column_units.append(m1.group(2).strip())\n else:\n column_names.append(subLine.strip())\n column_units.append('u.a.')\n\n self._column_names = column_names\n self._units = column_units\n\n def define_column_names_units_numbers(self):\n\n return self._column_names, self._units, list(range(len(self._column_names)))\n\nclass QDReader(Reader):\n\n def _read_header(self):\n \"\"\" Not implemented yet. Just skip to the data part. \"\"\"\n\n while True:\n line = self.f_id.readline()\n if bool(re.match(r\"\\[Data\\]\",line)):\n break\n line = self.f_id.readline()\n\n def define_column_names_units_numbers(self):\n\n column_names = list()\n column_units = list()\n column_numbers = list()\n for column_tuple in self.column_tuples:\n column_names.append(column_tuple[1])\n column_units.append(column_tuple[2])\n column_numbers.append(column_tuple[0])\n\n return column_names, column_units, column_numbers\n\nclass SQUIDDataReader(QDReader):\n \"\"\" SQUIDDataReader read Quantum Design SQUID data file format.\"\"\"\n\n def __init__(self):\n \n super().__init__()\n\n self.separator = ','\n self.column_tuples = [\n (0,'time','s'),\n (2,'magnetic field','Oe'),\n (3,'temperature','K'),\n (4,'long moment','mA/m**2'), #ureg.milliampere*ureg.meter**2\n (5,'long scan std dev','mA/m**2'),\n (6,'long algorithm',None),\n (7,'long reg fit',None),\n (8,'long percent error','%')\n ]\n\nclass PPMSResistivityDataReader(QDReader):\n \"\"\" SQUIDDataReader read Quantum Design PPMS resistivity data file format.\"\"\"\n\n def __init__(self):\n \n super().__init__()\n\n self.separator = ','\n self.column_tuples = [\n (1,'time','s'),\n (3,'temperature','K'),\n (4,'magnetic field','Oe'),\n (5,'sample position','deg')\n ]\n\n def read(self,file_path,sample_number = 0,*vargs,**kwargs):\n\n self.add_channel_column_tuples(sample_number)\n\n return Reader.read(self,file_path,*vargs,**kwargs)\n\n def add_channel_column_tuples(self,sample_number):\n if sample_number == 0:\n for i in range(1,4):\n self.column_tuples.append((4 + 2*i,'resistance{0:d}'.format(i),'ohm'))\n self.column_tuples.append((5 + 2*i,'current{0:d}'.format(i),'uA'))\n\n elif sample_number in [1,2,3]:\n self.column_tuples.append((4 + 2*sample_number,'resistance','ohm'))\n self.column_tuples.append((5 + 2*sample_number,'current','uA'))\n\nclass PPMSACMSDataReader(QDReader):\n \"\"\" SQUIDDataReader read Quantum Design PPMS ACMS data file format.\"\"\"\n\n def __init__(self,number_of_harmonics = 1):\n\n super().__init__()\n\n self.number_of_harmonics = number_of_harmonics\n self.separator = ','\n self.column_tuples = [\n (1,'time','s'),\n (2,'temperature','K'),\n (3,'magnetic field','Oe'),\n (4,'frequency','Hz'),\n (5,'amplitude','Oe'),\n (6,'magnetization dc','mA/m**2'),\n (7,'magnetization std','mA/m**2')\n ]\n\n \n\n def add_harmonics_column_tuples(self,number_of_harmonics):\n for har in range(self.number_of_harmonics):\n self.column_tuples.append((8 + 4 * har,'magnetizationReal[{0:d}]'.format(har+1),''))\n self.column_tuples.append((9 + 4 * har,'magnetizationImag[{0:d}]'.format(har+1),''))\n self.column_tuples.append((10 + 4 * har,'magnetizationAbs[{0:d}]'.format(har+1),''))\n self.column_tuples.append((11 + 4 * har,'magnetizationPhase[{0:d}]'.format(har+1),''))\n\nclass PPMSHeatCapacityDataReader(QDReader):\n \"\"\" SQUIDDataReader read Quantum Design PPMS ACMS data file format.\"\"\"\n\n codec = 'cp1252'\n\n def __init__(self):\n\n super().__init__()\n \n self.separator = ','\n self.column_tuples = [\n (0,'time','s'),\n (1,'PPMS status',None),\n (2,'puck temperature','K'),\n (3,'system temperature','K'),\n (4,'magnetic field','Oe'),\n (5,'pressure','torr'),\n (6,'sample temperature','K'),\n (7,'temperature rise','K'),\n (8,'sample HC','uJ/K'),\n (9,'sample HC err','uJ/K'),\n (10,'addenda HC','uJ/K'),\n (11,'addenda HC err','uJ/K'),\n (12,'total HC','uJ/K'),\n (13,'total HC err','uJ/K'),\n (14,'fit deviation',None),\n (15,'tau1','s'),\n (16,'tau2','s'),\n (17,'sample coupling','%'),\n (18,'debye temperature','K'),\n (19,'debye temperature err','K'),\n (20,'cal correction',None)\n ]\n\n\n"
},
{
"alpha_fraction": 0.661389946937561,
"alphanum_fraction": 0.6783784031867981,
"avg_line_length": 25.428571701049805,
"blob_id": "7c69f15aea6f2056182b505605ae5c439a78614b",
"content_id": "acbfdb247f8b2a1fc2b0d5f09f46e4f63d59641f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5180,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 196,
"path": "/Examples/Examples.py",
"repo_name": "oneminimax/AsciiDataFile",
"src_encoding": "UTF-8",
"text": "from os import path\n\nfrom pint import UnitRegistry, set_application_registry\nureg = UnitRegistry(system = 'mks')\n\nimport time\n\ndef read_PPMS_Resistivity_data_file():\n\n from AsciiDataFile.Readers import PPMSResistivityDataReader as Reader\n\n data_path = 'data/'\n data_file = '20181108_RvsT_3CH_Side1.dat'\n\n reader = Reader()\n data_curve = reader.read(path.join(data_path,data_file),1,apply_units = True)\n print(data_curve)\n\n X = data_curve.temperature\n Y = data_curve.resistance\n\n # print(X)\n\ndef read_SQUID_data_file():\n\n from AsciiDataFile.Readers import SQUIDDataReader as Reader\n\n data_path = 'data/'\n data_file = '20171003_NiFe_ech1_MvsH_500eO_001.dc.dat'\n\n reader = Reader()\n data_curve = reader.read(path.join(data_path,data_file),apply_units = True)\n print(data_curve)\n\n # X = data_container.get_column_by_name('magnetic field')\n # Y = data_container.get_column_by_name('long moment')\n\ndef read_PPMS_ACMS_data_file():\n\n from AsciiDataFile.Readers import PPMSACMSDataReader as Reader\n\n data_path = 'data/'\n data_file = 'PPMS_ACMS_dataFile.dat'\n\n reader = Reader()\n data_curve = reader.read(path.join(data_path,data_file),apply_units = True)\n\n print(data_curve)\n\n\ndef read_PPMS_Heat_Capacity_data_file():\n\n from AsciiDataFile.Readers import PPMSHeatCapacityDataReader as Reader\n\n data_path = 'data/'\n data_file = 'Add-135-15Feb2019-1.dat'\n\n reader = Reader()\n data_curve = reader.read(path.join(data_path,data_file),apply_units = True)\n print(data_curve)\n\n # X = data_container.get_column_by_name('sample temperature')\n # Y = data_container.get_column_by_name('sample HC')\n\ndef read_MD_data_file():\n\n from AsciiDataFile.Readers import MDDataFileReader as Reader\n\n data_path = 'data/'\n data_file = '20180711_44.0K.txt'\n\n reader = Reader()\n\n data_curve = reader.read(path.join(data_path,data_file),apply_units = True)\n print(data_curve)\n\n # X = data_container.get_column_by_name('magneticField')\n # Y = data_container.get_column_by_name('VH')\n\ndef read_XRD_generic_data_file():\n\n from AsciiDataFile.Readers import GenericDataReader as Reader\n\n data_path = 'data/'\n data_file = 'XRD_T2T_dataFile.dat'\n\n reader = Reader(' ',['angle','signal'],['deg','count'])\n\n data_curve = reader.read(path.join(data_path,data_file),apply_units = True)\n print(data_curve)\n\ndef read_AcquisXD():\n\n from AsciiDataFile.Readers import GenericDataReader as Reader\n\n data_path = '/Users/oneminimax/Documents/Projets Physique/PCCO 17 Hall and Lin Res/Transport Data/FAB Samples/20180703B/Acquis'\n data_file = 'VrhoVH-vs-H-42K-HR.txt'\n\n reader = Reader('\\t',['temperature','champ','V1','V2','I'])\n\n data_container = reader.read(path.join(data_path,data_file))\n\ndef write_column_data_file():\n\n from AsciiDataFile.Writers import DataColumnWriter as Writer\n from AsciiDataFile.DataContainer import DataCurve\n import numpy as np\n\n data_path = 'data/'\n data_file = 'test_column.txt'\n\n writer = Writer(path.join(data_path,data_file),auto_numbering = False,separator = ', ',column_width = 15)\n \n X = np.linspace(0,100,500)*ureg.second\n Y = np.sin(X*1*ureg.hertz)*ureg.meter\n\n data_curve = DataCurve()\n data_curve.add_column('X',X)\n data_curve.add_column('Y',Y)\n\n writer.write_data_curve(data_curve)\n\ndef write_column_data_file_2():\n\n from AsciiDataFile.Writers import DataColumnWriter as Writer\n import numpy as np\n\n data_path = 'data/'\n data_file = 'test_column_continous.txt'\n\n writer = Writer(path.join(data_path,data_file),auto_numbering = False,separator = '\\t',column_width = 15)\n\n X = np.linspace(0,100,500)*ureg.second\n Y = np.sin(X*1*ureg.hertz)*ureg.meter\n \n writer.write_header(column_names = ['X','Y'],column_units = ['s','m'])\n\n for i in range(len(X)):\n writer.add_data_point([X[i],Y[i]])\n\n\ndef read_column_data_file():\n\n t0 = time.time()\n\n from AsciiDataFile.Readers import DataColumnReader as Reader\n\n data_path = 'data/'\n data_file = 'test_column.txt'\n\n reader = Reader(separator = '\\t')\n data_curve = reader.read(path.join(data_path,data_file))\n\n print(data_curve)\n print(time.time()- t0)\n\n\ndef modify_column_data_file():\n\n t0 = time.time()\n\n from AsciiDataFile.Readers import DataColumnReader as Reader\n from AsciiDataFile.Writers import DataColumnWriterWithUnits as Writer\n\n data_path = 'data/'\n data_file = 'test_column.txt'\n\n reader = Reader(separator = '\\t')\n data_curve = reader.read(path.join(data_path,data_file))\n\n print(data_curve.X)\n\n data_curve.update_column('X',-data_curve.X)\n # data_curve.X = -data_curve.X\n print(data_curve.X)\n\n writer = Writer(path.join(data_path,'test_column_mod.txt'),auto_numbering = False)\n writer.write_data_curve(data_curve)\n\n print(time.time()- t0)\n\n\n\n# read_PPMS_Resistivity_data_file()\n# read_PPMS_Heat_Capacity_data_file()\n# read_SQUID_data_file()\n# read_PPMS_ACMS_data_file()\n# read_MD_data_file()\n# read_XRD_generic_data_file()\n# write_column_data_file()\nwrite_column_data_file_2()\n\n# modify_column_data_file()\n\n# read_column_data_file()\n# read_AcquisXD()\n"
},
{
"alpha_fraction": 0.629447877407074,
"alphanum_fraction": 0.629447877407074,
"avg_line_length": 22.314285278320312,
"blob_id": "0659057d49203a39bd9518fb509b5dcd0a93df7a",
"content_id": "3474e16b656020ad531b9baba8e20690020aa0cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 35,
"path": "/HotReader.py",
"repo_name": "oneminimax/AsciiDataFile",
"src_encoding": "UTF-8",
"text": "class HotReader():\n def __init__(self,reader,file_path):\n\n self.reader = reader\n self.file_path = file_path\n\n self.data_curve = self.reader.read(file_path)\n\n def read_data_line(self):\n\n good_line, new_data = self.reader._read_data_line()\n if good_line:\n self.data_curve.add_data_point(new_data)\n\n return good_line\n\n def get_file_path(self):\n\n return self.file_path\n\n def get_column_names(self):\n\n return self.data_curve.get_column_names()\n\n def get_column_units(self):\n\n return self.data_curve.get_column_units()\n\n def get_column_index(self,column_name):\n\n return self.reader.get_column_index(column_name)\n\n def get_column_by_name(self,column_name):\n\n return self.data_curve.get_column_by_name(column_name)"
},
{
"alpha_fraction": 0.6073059439659119,
"alphanum_fraction": 0.6590563058853149,
"avg_line_length": 22.5,
"blob_id": "32b98cbc1f13113cf77c23821b13b0b3e702a2fc",
"content_id": "79536e6bb79794a92e3ee799ceae3bf4bda34197",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 657,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 28,
"path": "/Tests/test_DataContainer.py",
"repo_name": "oneminimax/AsciiDataFile",
"src_encoding": "UTF-8",
"text": "from AsciiDataFile import DataContainer\nfrom AsciiDataFile.Readers import DataColumnReader as Reader\n\nimport os\n\n\nreader = Reader()\n\nDC1 = reader.read('../Examples/Data/test_column.txt')\nDC2 = reader.read('../Examples/Data/test_column.txt')\nprint(DC1)\n# DC1.rename_column('X','Z')\n# print(DC1)\n# DC1.add_data_point([0,1])\n# \n# DC1.filter(DC1.get_column('Y')>0)\n# DC1.select_value('Y',0.9,0.1)\n# DC1.select_direction('Y',1)\n# DC1.average_multiple_measurement('Y',0.1)\n# y = DC1.y_at_x('X','Y',[0.2])\n# print(y)\n\n# DC1.symetrize('Y',[],['X','Y'],x_step = 0.1)\n# sym_y = DC1.auto_sym_x_values('Y',0.1)\n# print(sym_y)\nDC1.append(DC2)\nDC1.sort_by('X')\nprint(DC1)"
},
{
"alpha_fraction": 0.5388517379760742,
"alphanum_fraction": 0.5473830103874207,
"avg_line_length": 30.165468215942383,
"blob_id": "e5ccdede37df2059e228e53d82fd79b70a0ca127",
"content_id": "11b89d8668aed6bd3757a35af67a838ea1e86774",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4337,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 139,
"path": "/Writers.py",
"repo_name": "oneminimax/AsciiDataFile",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom os import path\nimport time\nimport re\n\nclass Writer(object):\n def __init__(self,file_name,auto_numbering = True,separator = ', ',column_width = 15,decimal = '.'):\n self.file_name = file_name\n self.auto_numbering = auto_numbering\n self.separator = separator\n self.column_width = column_width\n self.decimal = decimal\n\n self.column_number = 0\n self.column_length = 0\n\n self._open_file()\n\n def _open_file(self):\n\n if self.auto_numbering:\n self.check_existing_file()\n\n self.f_id = open(self.file_name,'w')\n\n def close(self):\n\n self.f_id.close()\n\n def check_existing_file(self):\n\n new_file_name = self.file_name\n while path.isfile(new_file_name):\n m = re.match(r\"(.+)_(\\d{3}).([^.]+)\\Z\",new_file_name)\n if m:\n base_name = m.group(1)\n dig = int(m.group(2))\n ext = m.group(3)\n new_file_name = '{0:s}_{1:03d}.{2:s}'.format(base_name,dig+1,ext)\n else:\n root, ext = path.splitext(new_file_name)\n new_file_name = root + '_002' + ext\n\n print(self.file_name,'-->',new_file_name)\n\n self.file_name = new_file_name\n\n def write_header(self,column_names,column_units = None):\n\n self.column_number = len(column_names)\n self._write_header(column_names,column_units)\n\n def _write_header(self,column_names,column_units = None):\n pass # to be defined by writer type\n\n def write_values(self,values):\n\n if self.column_number == 0:\n self._write_datas(values)\n else:\n values_shape = values.shape\n if values_shape[0] == self.column_number:\n self._write_values(values)\n elif values_shape[1] == self.column_number:\n self._write_values(np.transpose(values))\n else:\n raise()\n\n def _write_values(self,values):\n\n for i in range(values.shape[0]):\n self.add_data_point(values[i,:])\n\n def write(self,column_names,values,column_units = None):\n\n self.write_header(column_names,column_units)\n self.write_datas(column_datas)\n self.f_id.flush()\n\n def add_data_point(self,data_point):\n\n line = ''\n for value in data_point:\n if hasattr(value,'units'):\n value = value.magnitude\n \n line += \"{value:+{width}.8e}{sep:s}\".format(\n value = value,\n width = self.column_width,\n sep = self.separator\n )\n\n if self.decimal is ',':\n line = line.replace('.',',')\n\n\n if line:\n self.f_id.write(line[:-len(self.separator)] + \"\\n\")\n self.f_id.flush()\n\n def write_data_curve(self,data_curve):\n\n column_names = data_curve.get_column_names()\n column_units = data_curve.get_column_unitss()\n\n self._write_header(column_names,column_units)\n self._write_values(data_curve.get_values_array())\n\nclass MDDataFileWriter(Writer):\n \n def write_header(self,column_names,column_units = None):\n\n self.f_id.write(\"{0:s}\\n\".format(time.strftime(\"%c\")))\n self.f_id.write(\"[Header]\\n\")\n if column_units is None:\n for i, column_name in enumerate(column_names):\n self.f_id.write(\"Column {0:2d} : {1:20s}\\n\".format(i, column_name))\n else:\n for i, column_name in enumerate(column_names):\n self.f_id.write(\"Column {0:2d} : {1:20s}\\t{2:s}\\n\".format(i, column_name, column_units[i]))\n\n self.f_id.write(\"[Header end]\\n\\n\")\n self.f_id.flush()\n\nclass DataColumnWriter(Writer):\n\n def _write_header(self,column_names,column_units = None):\n\n head_line = ''\n for i, column_name in enumerate(column_names):\n if column_units[i] is None:\n column_str = \"{0:s}\".format(column_name)\n else:\n column_str = \"{0:s}({1:s})\".format(column_name,column_units[i])\n head_line += \"{col:>{width}s}{sep:s}\".format(col = column_str,width = self.column_width,sep = self.separator)\n\n if head_line:\n self.f_id.write(head_line[:-len(self.separator)] + \"\\n\")\n self.f_id.flush()\n \n"
}
] | 7 |
Jeremy37/src | https://github.com/Jeremy37/src | 80415bfcc4ba32233a4d90ce779131ad408fdc2d | 25172af310efecb33f0100d6414704d072ab5d4d | 097940f495b116823a5e75ff76b73026ee6da8df | refs/heads/master | 2021-07-06T08:06:51.389962 | 2021-05-18T15:05:41 | 2021-05-18T15:05:41 | 31,013,336 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6267560124397278,
"alphanum_fraction": 0.6409879922866821,
"avg_line_length": 30.836257934570312,
"blob_id": "549208ab3dde1287abdb94b415b5c42ad878bc77",
"content_id": "5f1450663969b52e51e604df67f34f58fef45c15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 10891,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 342,
"path": "/useful.commands.sh",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n##########################################################################################\n## Bash\n\n# To use local/path version of python/R/etc at top of script\n#!/usr/bin/env python\n#!/usr/bin/env Rscript\n\nfilename=$(basename \"$fullfile\")\nextension=\"${filename##*.}\"\nfilename_no_ext=\"${filename%.*}\"\n\n# Pass a tab on the command line\npython test.py $'\\t'\n\n# Make a directory; -p makes parent dirs as needed\nif [ ! -d \"path/dir\" ]; then\n mkdir -p path/dir\nfi\n\n# translate characters uppercase lowercase\necho -e \"A\\nB\\nC\" | tr '[:upper:]' '[:lower:]'\necho -e \"A\\nB\\nC\" | perl -pe 'chomp if eof' | tr '\\n' ','\necho -ne \"test\\tX\" > test.txt # no newline at end\n\n# iterate through array in bash\narr=( one two three )\nfor i in \"${arr[@]}\"\ndo\n echo \"$i\" # or do whatever with individual element of the array\ndone\n\nfor i in `seq 1 10`;\ndo\n echo $i\ndone\n\nfor i in {8..20..2};\ndo\n echo $i\ndone\n\n# For each line in a file\nwhile read p; do\n echo $p\ndone < file.txt\n\n# Splitting into variables\nwhile IFS=\" \" read -r value1 value2 remainder; do\n ...\ndone < \"input.txt\"\n\n# print the header (the first line of input)\n# and then run the specified command on the body (the rest of the input)\n# use it in a pipeline, e.g. ps | body grep somepattern\nbody() {\n IFS= read -r header\n printf '%s\\n' \"$header\"\n \"$@\"\n}\n# Example:\nps -o pid,comm | body sort -k2\n\n\n# count unique values - note that sort is critical for uniq to work\ncat file.txt | cut -f 2 | sort | uniq | wc -l\n\ntar -zcvf newarchive.tar.gz dirToArchive\ntar -ztf archive.tar.gz [file to list]\n\nln -s targetfile linkname\n\n# arithmetic in bash: runs bjobs and counts lines, and does subtraction using $((A-B))\nalias bjc='echo $((`bjobs | wc -l` - 1))'\nz=`expr $z + 3` # The 'expr' command performs the expansion.\nz=$((z+3)) # The use of backticks (backquotes) in arithmetic expansion has been superseded by double parentheses -- ((...)) and $((...)) -- and also by the very convenient let construction.\n\n# Get file lines starting at number 123\ntail -n +123 file.txt\n\n# <(cmd) is bash process substitution, where the output of the command can be treated\n# as a file descriptor input for standard unix commands\npaste <(cut -f 1 --complement file1.txt) <(cut -f 5 file2.txt)\n\nsed '1d' file.txt | awk 'BEGIN {OFS=\"\\t\"}{if ($1 ~ /NA/) $1=0.5; print $1,$2,\"chr9\",$2\"_\"$3}'\n\n# Sum fields in a file\ncat file.txt | awk '{ if (NR>1){ sum+=$2 }} END {print sum}'\n\nawk 'BEGIN {OFS=\"\\t\"} function abs(x){return ((x < 0.0) ? -x : x)} {print abs($2-$1)}'\n\n# Pass a variable to awk\nvariable=\"line one\\nline two\"\nawk -v var=\"$variable\" 'BEGIN {print var}'\n\n# Get non-header rows of VCF\nzcat file.vcf.gz | grep -v \"#\"\n\n# Rename a set of files\nfor f in DIR/VORX.*; do\n NAME=`echo $f | perl -ne '@fparts=split(/\\./); print join(\".\", @fparts[1..$#fparts]);'`\n mv VORX.$NAME ZUTA.$NAME\ndone\n\n# Get VCF samples\nzcat file.vcf.gz | head -n 1000 | grep \"#CHROM\" | cut -f 10- | tr '\\t' '\\n' > vcfheader.samples.txt\n\n# Get autosome VCF coords\nzcat file.vcf.gz | grep -v \"#\" | perl -ne '@l=split();($l[0] =~ /^[\\d]+$/) and print;' | cut -f 1,2,3 > file.snp_coords.txt\n\n# Find files and delete them\nfind . -name '*.txt' -delete\n# Find files and get their total size\nfind . -name \"*.bg\" -print0 | du --files0-from=- -hc | tail -n1\n\n# Find files and grep them for 'Assigned'\nfind . -name '*.sh' -print0 | xargs -r0 grep -H 'Assigned'\n# Find in files matching multiple patterns\nfind . \\( -iname \\*.sh -o -iname \\*.py -o -iname \\*.R -o -iname \\*.Rmd \\) -print0 | xargs -r0 grep -H 'tofind'\n\n# Find files and send them to tail\nfind . -name \"*.ASEcounts\" | xargs -I {} sh -c \"echo {}; tail -n2 {}\"\n# Find files and send them to gzip\nfind . -name '*.txt' -print0 | xargs -r0 gzip\n# Find files changed in the last day\nfind . -name '*.txt' -mtime -1\n# Find files changed in the last hour\nfind . -name '*.txt' -mmin -60\n\n# Get file sizes sorted by size\ndu . -h -- * | sort -rh | less\n\n\nbcftools view --samples-file list.txt vcf.gz | bcftools filter -O z -i 'MAF[0] >= 0.05' > maf0.05.vcf.gz\n\n# Efficient way to extract specific SNPs from a VCF\ngrep -wFf rsid.list <(gunzip -c vcf.gz)\n\n# Regular expression matching a line that does NOT contain a string\n^((?!mystring).)*$\\n\n\n# Compare gzipped files to see if they are identical\ncmp -i 8 file1.gz file2.gz # fastest, see http://unix.stackexchange.com/questions/64200/how-can-i-check-if-two-gzipped-files-are-equal\nzdiff file1.gz file2.gz # uncompresses to compare actual contents\n\n# Check if file exists (and is a regular file, not a device file)\nif [ -f $FILE ]; then\nfi\n\n# -a archive (recurse dirs, copy symlinks as links, preserve permissions, file times, groups)\n# -u update (do not replace if file newer at dest)\nrsync -a -u src dest\n\n# Change group ownership for files recursively\nchown -R js29:newgroup * .\n\n# Set file access control list to allow a user not in your group to access files\n# May need to set access for directories *above* the one you want to give access to\nsetfacl -R -m u:nk5:rx /lustre/scratch115/realdata/mdt3/projects/otcoregen/jeremys/ipsneurons/\nsetfacl -R -m g:team170:rx /lustre/scratch115/realdata/mdt3/projects/otcoregen/jeremys/ipsneurons/\n\n##########################################################################################\n## Perl\n\n# -ne runs per line; -a autosplits $_ into @F; -s allows variable passing with -- after script\ncat file.txt | perl -sane 'chomp; print join(\"\\t\", @F, $locus).\"\\n\"' -- -locus=BMI_2\n\n# extract field from regex\nif ($str =~ /(regex)/) {\n my $match = $1;\n} else {die \"match failed\";}\n\nmy ($a, $b) = split /:/, $str;\n\n##########################################################################################\n## Python\n\nhttp://mediawiki.internal.sanger.ac.uk/index.php/Python_virtualenv\n# Set up a virtual environment for python (e.g. in a directory called python 2.7)\nvirtualenv $HOME/python2.7\n# Use that copy of python\nsource $HOME/python2.7/bin/activate\n# Stop using this python virtualenv\ndeactivate\n\n\n##########################################################################################\n## R \n\n# Get the size of all objects in memory\nsort( sapply(ls(),function(x){object.size(get(x))}))\n\n# Limit numbers to certain precision in output\nrpkm[,1:ncol] <- sprintf(\"%.4f\", rpkm[,1:ncol])\nrpkm[as.numeric(rpkm) == 0] <- \"0\"\n\n# ggplot rotated axis text\nggplot()... + theme(axis.text.x = element_text(angle = 45, hjust = 1))\n# ggplot remove legend\nscale_colour_discrete(guide=F)\nscale_color_manual(guide=F, values=colorScale)\nscale_shape_discrete(guide=F)\n# legend top right\nd <- ggplot(mtcars, aes(x=wt, y=mpg, colour=cyl)) + geom_point(aes(colour=cyl)) + labs(title = \"Legend is top right\") +\ntheme(legend.justification = c(1, 1), legend.position = c(1, 1))\n\n\n# Install old version of a package\nrequire(devtools)\ninstall_version(\"ggplot2\", version = \"0.9.1\", repos = \"http://cran.us.r-project.org\")\n\nViewDups = function(df, col) {\n df = as.data.frame(df)\n dupVals = df[duplicated(df[,col]), col]\n dups = df[df[,col] %in% dupVals,]\n View(dups[order(dups[,col]),])\n}\n\n\n##########################################################################################\n## git \n# https://git-scm.com/book/en/v2/Git-Branching-Basic-Branching-and-Merging\n\ngit add <filename> # stage files for commit\ngit status # see staged files\ngit commit -m <message>\ngit push origin master\ngit diff origin/master [local-path]\n\ngit branch hotfix # make a branch\ngit checkout hotfix # switch HEAD to point to latest branch\ngit checkout -b hotfix # Make hotfix branch and switch to it\n# Do commits to hotfix\n\ngit checkout master\ngit merge hotfix # Master and hotfix now point to the same place\ngit mergetool # Useful if there are conflicts to merge\ngit branch -d hotfix # Delete branch no longer needed (i.e. after it's merged into master)\n\n\n\ngit log --oneline --decorate # see commits and branches\n\n\n\n##########################################################################################\n## Farm\n\n# Check your priority on a queue\nbqueues -r queuename\n\n# What's occupying the yesterday queue\nbjobs -u all -q yesterday\n\n\n# Example of getting CPU runtime from many farm output files\ngrep CPU FarmOut/*.txt > runRasqual.CPUtimes.txt\ncat runRasqual.CPUtimes.txt | perl -ne '@l=split(/\\.|_|(\\s)+/);print join(\"\\t\", @l)' | cut -f 3,17 | sort -nk1,1 > runRasqual.CPUtimes.sorted.txt\n\nkinit\nimeta qu -z seq -d study = 'Mapping regulatory variation in sensory neurons using IPS lines from the HIPSCI project' and target = 1 and manual_qc = 1 > irods.study.meta.txt\n\nlfs quota /lustre/scratch109\n\n#Use lfs quota for yourself and groups you are in:\nlfs quota -h (-g GROUP | -u USER) FILESYSTEM\n\nlfs quota -g otcoregen /lustre/scratch115\n\n\n#HGI's LustreTree webapp also shows this (and more)\n#information for all directories on Lustre:\n https://hgi.dev.sanger.ac.uk/lustretree/\n\n\n# Use bash process substitution with bsub\n#1. Workaround, e.g. using a pipe into grep:\nbsub -o getSNPs.txt -J getSNPs \"gunzip -c my.vcf.gz | grep -wFf SNPids.txt > my.snps.vcf\"\n\n#2. using bash -c, e.g.:\nbsub -o getSNPs.txt -J getSNPs \"/bin/bash -c 'grep -wFf SNPids.txt <(gunzip -c my.vcf.gz) > my.snps.vcf'\"\n\n# Waiting for a job to finish\nsubmitJobs.py --MEM 200 -j jobname -o farmOut --blocking -c \"sleep 5\"\nbsub -K -o out.1 sleep 10 &\nbsub -K -o out.2 sleep 5 &\nwait\n\n\n##########################################################################################\n## tmux\nhttps://www.hamvocke.com/blog/a-quick-and-easy-guide-to-tmux/\n\n\ntmux\t\t# start session\ntmux ls\t\t# list existing sessions\ntmux attach -t 0\t#\n\n# Type Ctrl-b and release, then next key\n# Ctrl-b %\t\t\tsplit pane\n# Ctrl-b arrow\t\tswitch panes\n# Ctrl-d or exit\tclose pane\n# Ctrl-b c\t\t\tcreate window\n# Ctrl-b p/n\t\tprevious/next window\n# Ctrl-b <number>\tgo to window number\n# Ctrl-b d\t\t\tdetach\n\n\n##########################################################################################\n## Google cloud\n\ngcloud auth application-default login\n\n# specify gsutil project, e.g. for copy\ngsutil -u \"bill-this-project\" cp src dest\n\n# docs\nhttps://cloud.google.com/storage/docs/gsutil/commands/cp\n\n# Useful options\n# -n no-clobber (don't replace existing items at destination)\n# -r recursive\n# -c continue if one file has an error\n# -z compress for upload (but actual files are left uncompressed)\n# -P preserve attributes (e.g. mod time, owner, group, etc)\n\n# copy without over-writing (-n)\ngsutil -m cp -r -n -L manifest_log_file dir gs://my-bucket\n\n# When using -m, I got this error:\n# Reauthentication challenge could not be answered because you are not in an interactive session.\n# I couldn't figure it out, until I removed the -m option... then I was able to\n# enter my password, and then all subsequent commands with -m worked.\n\n# Get file sizes\n# -c to include total size, -h for human readable, \ngsutil -m du -ch gs://bucket\n\n\n# ssh to a cloud VM instance\nssh -i /Users/jeremys/.ssh/gcloud-ssh [email protected]\n\n\n\n"
},
{
"alpha_fraction": 0.6039475202560425,
"alphanum_fraction": 0.6261671185493469,
"avg_line_length": 48.764705657958984,
"blob_id": "4d090f083f2667d39d7e0524ef7312cc9e1e2b37",
"content_id": "d70167f122f0cce99b8f5948dea7b784c86343c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 8461,
"license_type": "no_license",
"max_line_length": 202,
"num_lines": 170,
"path": "/gene_network/rank_locus_genes.R",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env Rscript\nlibrary(GenomicRanges)\nlibrary(pheatmap)\nlibrary(annotables)\nlibrary(liftOver)\nlibrary(tidyverse)\n\n###############################################################################\n# Get clear locus definition from merging OT locus2gene score from two\n# IBD GWAS - Jimmy Liu's and Katrina de Lange's.\ndir = \"/Users/jeremys/work/opentargets/gene_network/ibd\"\nl2g.katie.df = read_tsv(file.path(dir, \"l2g.IBD.deLange.tsv\")) %>% rename(chr = chrom)\nl2g.jimmy.df = read_tsv(file.path(dir, \"l2g.IBD.Liu.tsv\")) %>% rename(chr = chrom)\n\nl2g.df = bind_rows(l2g.katie.df, l2g.jimmy.df) %>%\n arrange(chr, pos) %>%\n mutate(id = paste(study_id, chr, pos, ref, alt)) %>%\n dplyr::select(id, gene_id, y_proba_full_model)\n\nl2g.df.spread = l2g.df %>%\n spread(key = \"id\", value = y_proba_full_model)\nl2g.df.spread[is.na(l2g.df.spread)] = 0\n\n# Look at a heatmap that shows the correlation between loci, based on the \n# overlap between their nearby genes. Some loci are unique to one study,\n# and some are shared.\nl2g.df.cor = cor(l2g.df.spread %>% dplyr::select(-gene_id))\npheatmap(l2g.df.cor, treeheight_row = 0, treeheight_col = 0, show_colnames = F, fontsize = 5)\n\n# Make a table with all genes at each locus in a single line\ngrch38_nodup = grch38 %>% filter(!duplicated(ensgene))\nl2g.df = bind_rows(l2g.katie.df, l2g.jimmy.df) %>%\n arrange(chr, pos) %>%\n mutate(id = paste(study_id, chr, pos, ref, alt, sep = \"_\")) %>%\n dplyr::select(study_id, id, chr, l2g_pos = pos, ref, alt, gene_id, l2g_score = y_proba_full_model) %>%\n left_join(grch38_nodup %>% dplyr::select(ensgene, symbol), by=c(\"gene_id\" = \"ensgene\"))\n\nl2g.locus.df = l2g.df %>%\n arrange(id, desc(l2g_score)) %>%\n group_by(id) %>%\n summarise(chr = dplyr::first(chr),\n l2g_pos = dplyr::first(l2g_pos),\n ref = dplyr::first(ref), \n alt = dplyr::first(alt),\n top_gene = dplyr::first(symbol),\n top_gene_score = dplyr::first(l2g_score),\n locus_genes = paste(sprintf(\"%s_%g\", symbol, l2g_score), collapse=(\", \")),\n locus_genes_ens = paste(sprintf(\"%s_%g\", gene_id, l2g_score), collapse=(\", \"))) %>%\n arrange(chr, l2g_pos)\n\n# Save this file, which has all the l2g scores for each locus **for each study** (Jimmy's, Katie's)\nwrite_tsv(l2g.locus.df, path = file.path(dir, \"l2g.IBD_loci.by_study.tsv\"))\n\n\n# Merge together nearby loci (within 200 kb)\n# To do this we first make a column with a \"locus ID\" that is the\n# chr:pos of the first signal in a region\nl2g.locus.mapping.df = l2g.locus.df %>%\n arrange(chr, l2g_pos) %>%\n mutate(l2g_locus = paste(chr, l2g_pos, sep = \"_\")) %>%\n ungroup() %>%\n mutate(prev_row_dist = l2g_pos - lag(l2g_pos)) %>%\n rowwise() %>%\n mutate(prev_row_dist = max(0, prev_row_dist)) %>%\n mutate(l2g_locus_merged = l2g_locus)\nfor (i in 2:nrow(l2g.locus.mapping.df)) {\n if (l2g.locus.mapping.df$prev_row_dist[i] < 2e5 & l2g.locus.mapping.df$chr[i] == l2g.locus.mapping.df$chr[i-1]) {\n l2g.locus.mapping.df$l2g_locus_merged[i] = l2g.locus.mapping.df$l2g_locus_merged[i-1]\n }\n}\nl2g.locus.mapping.df = l2g.locus.mapping.df %>%\n ungroup() %>%\n filter(!duplicated(l2g_locus))\n\n# The unique loci remaining\nnrow(l2g.locus.mapping.df %>% filter(!duplicated(l2g_locus_merged)))\n\n# Now group by the new locus_id and get summary values for all genes at each locus.\n# E.g. mean score, max score\nl2g.df = l2g.df %>%\n mutate(l2g_locus = paste(chr, l2g_pos, sep = \"_\")) %>%\n left_join(l2g.locus.mapping.df %>% select(l2g_locus, l2g_locus_merged), by=\"l2g_locus\")\n\nl2g.merged.df = l2g.df %>%\n arrange(desc(l2g_score)) %>%\n group_by(l2g_locus_merged, gene_id) %>%\n summarise(symbol = first(symbol),\n id = first(id),\n chr = first(chr),\n l2g_pos = first(l2g_pos),\n ref = first(ref),\n alt = first(alt),\n l2g_score_mean = mean(l2g_score),\n l2g_score_max = max(l2g_score))\n# This table has the genes associated with the merged loci. This is useful later so let's save it.\nl2g.merged.df = l2g.merged.df %>%\n select(l2g_locus_merged, chr, l2g_pos, ref, alt, gene_id, symbol, l2g_score_mean, l2g_score_max)\nwrite_tsv(l2g.merged.df, path = file.path(dir, \"l2g.IBD_genes.merged.tsv\"))\n\n# This table now has the average (and max) L2G score for each gene at each of our\n# merged loci.\nl2g.locus.merged.df = l2g.merged.df %>%\n arrange(desc(l2g_score_mean)) %>%\n group_by(l2g_locus_merged) %>%\n summarise(chr = dplyr::first(chr),\n l2g_mean_pos = mean(l2g_pos),\n l2g_pos = dplyr::first(l2g_pos),\n ref = dplyr::first(ref), \n alt = dplyr::first(alt),\n top_gene_mean = dplyr::first(symbol),\n top_gene_score_mean = dplyr::first(l2g_score_mean),\n locus_genes_mean = paste(sprintf(\"%s_%g\", symbol, l2g_score_mean), collapse=(\", \")),\n locus_genes_ens_mean = paste(sprintf(\"%s_%g\", gene_id, l2g_score_mean), collapse=(\", \")),\n locus_genes_max = paste(sprintf(\"%s_%g\", symbol, l2g_score_max), collapse=(\", \")),\n locus_genes_ens_max = paste(sprintf(\"%s_%g\", gene_id, l2g_score_max), collapse=(\", \")))\n\n\nl2g.gr = makeGRangesFromDataFrame(l2g.locus.merged.df %>% dplyr::select(chr, pos = l2g_pos, l2g_locus_merged), keep.extra.columns = T, ignore.strand = T,\n seqinfo = NULL, seqnames.field = \"chr\", start.field = \"pos\", end.field = \"pos\")\n\n\n###############################################################################\n# Annotated loci from de Lange Supp Table 2\nlocus.df = read_tsv(file.path(dir, \"deLange.locus_table.tsv\"))\n# ibd.locus.df = locus.df %>%\n# filter(grepl(\"IBD\", Trait))\n# Rethinking this - don't filter at all, so that we retain as many annotated loci as possible\nibd.locus.df = locus.df\nibd.locus.gr.hg19 = makeGRangesFromDataFrame(ibd.locus.df, keep.extra.columns = T, ignore.strand = T,\n seqinfo = NULL, seqnames.field = \"chr\", start.field = \"pos\", end.field = \"pos\")\n\n# Liftover the SNP positions to hg38\nlibrary(rtracklayer)\npath = system.file(package=\"liftOver\", \"extdata\", \"hg19ToHg38.over.chain\")\nchain = import.chain(path)\nseqlevelsStyle(ibd.locus.gr.hg19) = \"UCSC\"\nibd.locus.gr.hg38 = liftOver(ibd.locus.gr.hg19, chain)\nibd.locus.gr.hg38 = unlist(ibd.locus.gr.hg38)\n#as_tibble(ibd.locus.gr.hg38)\nibd.locus.df = ibd.locus.df %>%\n dplyr::rename(pos_hg19 = pos, deLange_locus_genes = locus_genes) %>%\n left_join(as_tibble(ibd.locus.gr.hg38) %>% dplyr::select(rsid, pos_hg38 = start), by=\"rsid\")\nibd.locus.gr.hg38 = makeGRangesFromDataFrame(ibd.locus.df %>% select(chr, pos = pos_hg38, rsid), keep.extra.columns = T, ignore.strand = T,\n seqinfo = NULL, seqnames.field = \"chr\", start.field = \"pos\", end.field = \"pos\")\n\n\n###############################################################################\n# Get the nearest IBD locus from the Supp Table to each Locus2Gene region\nhits.df = as_tibble( distanceToNearest(l2g.gr, ibd.locus.gr.hg38, ignore.strand = T) )\n# This gives us the indices of hits in the l2g table and in the ibd.locus table (GRanges)\n# Since the order is the same in the data.frames we've made, we just index into those.\n\nnearest.df = bind_cols(l2g.locus.merged.df[hits.df$queryHits,],\n ibd.locus.df[hits.df$subjectHits,] %>% dplyr::select(-chr),\n distance = hits.df$distance)\n\nmerged.locus.df = nearest.df %>%\n mutate(rsid_group = rsid)\nmerged.locus.df$rsid_group[merged.locus.df$distance > 500000] = paste0(\"indep\", 1:(sum(merged.locus.df$distance > 500000)))\n\n# merged.locus.df = merged.locus.df %>%\n# group_by(rsid_group) %>%\n# mutate(consensus_gene0.5 = if_else(all(top_gene == first(top_gene)) & max(top_gene_score) > 0.5, first(top_gene), \"\"),\n# consensus_gene0.8 = if_else(all(top_gene == first(top_gene)) & max(top_gene_score) > 0.8, first(top_gene), \"\")) %>%\n# dplyr::select(id, chr, l2g_pos, pos_hg19, consensus_gene0.5, consensus_gene0.8, top_gene, top_gene_score, implicated_gene, rsid, distance, locus_genes, locus_genes_ens, everything()) %>%\n# arrange(chr, l2g_pos)\n\nmerged.locus.df = merged.locus.df %>%\n select(l2g_locus_merged, chr, l2g_pos, l2g_mean_pos, ref, alt, top_gene_mean, top_gene_score_mean, locus_genes_mean, locus_genes_max, lead_p, implicated_gene, rsid, rsid_group, distance, everything())\nwrite_tsv(merged.locus.df, path = file.path(dir, \"l2g.IBD_loci.merged.annotated.tsv\"))\n\n"
},
{
"alpha_fraction": 0.5452386736869812,
"alphanum_fraction": 0.5502256155014038,
"avg_line_length": 39.49038314819336,
"blob_id": "f05f88dc0beadabdcabdf27f8aec4b8777d46a0c",
"content_id": "fa6d02d41ce6c917b57102e3844c646c6129340a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4211,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 104,
"path": "/python/gcs_parquet_to_text.py",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n#\n# Jeremy Schwartzentruber\n#\n# Gets the first few lines of a parquet file from Google cloud, and saves it\n# in text format.\n#\nimport sys\nimport os\nimport pandas as pd\nimport subprocess as sp\nimport argparse\nimport re\nimport gzip\n\n#args.file = \"gs://genetics-portal-staging/v2d/200207/toploci.parquet\"\n# Example:\n# gcs_parquet_to_text.py -f gs://genetics-portal-staging/v2d/200207/toploci.parquet\ndef main():\n args = parse_args()\n if args.mirror_path and args.out_file is not None:\n print(\"Arguments --out_file and --mirror_path are mutually exclusive\")\n exit(1)\n\n fname = args.file\n downloaded_file = None\n if re.match('^gs://', args.file):\n # First download the file with gsutil\n fname = \"tmp.\" + os.path.basename(args.file)\n if not os.path.isfile(fname) or args.overwrite:\n cmd = \"gsutil cp {} {}\".format(args.file, fname)\n result = sp.call(cmd, shell=True)\n if result != 0:\n print(\"gsutil call failed\", file=sys.stderr)\n exit(1)\n downloaded_file = fname\n \n try:\n df = pd.read_parquet(fname, engine='pyarrow')\n shape_msg = ''\n if args.nlines is not None:\n nlines = min(args.nlines, df.shape[0])\n if nlines < df.shape[0]:\n shape_msg = '...{} total rows\\n'.format(df.shape[0])\n df = df[:nlines]\n \n out_file = args.out_file\n if args.mirror_path:\n out_file = args.file.replace(\"gs://\", \"\")\n out_file = os.path.splitext(out_file)[0] + '.tsv'\n if out_file is not None:\n # If out_file is empty, we create a relative path that is equivalent to\n # that in the input file\n dir = os.path.dirname(out_file)\n if dir and not os.path.exists(dir):\n os.makedirs(dir)\n if args.pretty:\n if re.search('.gz$', out_file):\n with gzip.open(out_file, \"wt\") as f:\n f.write(df.to_string(index=None, na_rep='NA') + \"\\n\" + shape_msg)\n else:\n with open(out_file, \"wt\") as f:\n f.write(df.to_string(index=None, na_rep='NA') + \"\\n\" + shape_msg)\n else:\n df.to_csv(out_file, sep='\\t', index=None, na_rep='NA')\n if not re.search('.gz$', out_file):\n with open(out_file, \"at\") as f:\n f.write(shape_msg)\n else:\n if args.pretty:\n print(df.to_string(index=None, na_rep='NA') + shape_msg)\n else:\n df.to_csv(sys.stdout, sep='\\t', index=None, na_rep='NA')\n print(shape_msg)\n finally:\n if downloaded_file is not None and not args.keep:\n os.remove(downloaded_file)\n \n\n\ndef parse_args():\n \"\"\" Load command line args \"\"\"\n parser = argparse.ArgumentParser()\n parser.add_argument('-f', '--file', metavar=\"<file>\", type=str, required=True,\n help=('A parquet file (may be on Google Cloud Storage)'))\n parser.add_argument('-n', '--nlines', metavar=\"<int>\", type=int, required=False,\n help=('Number of lines to get'))\n parser.add_argument('-o', '--out_file', metavar=\"<file>\", type=str, required=False,\n help=(\"Output file path (created if not present)\"))\n parser.add_argument('-m', '--mirror_path', action='store_true',\n help=(\"Save the output to a file with a relative filepath equivalent to the downloaded file.\"))\n parser.add_argument('--pretty', action='store_true',\n help=(\"If True, then for a Google storage file the file will be re-downloaded even if the local copy exists\"))\n parser.add_argument('--keep', action='store_true',\n help=(\"If True, then keep the downloaded parquet file\"))\n parser.add_argument('--overwrite', action='store_true',\n help=(\"If True, then for a Google storage file the file will be re-downloaded even if the local copy exists\"))\n args = parser.parse_args()\n return args\n\n\nif __name__ == '__main__':\n\n main()\n"
},
{
"alpha_fraction": 0.6613032817840576,
"alphanum_fraction": 0.6790024042129517,
"avg_line_length": 44.181819915771484,
"blob_id": "d6d2b6908422d570ec0343d8d9e7108b5bc15289",
"content_id": "b670f7352be8fad6099043366fce8891636e5474",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 4972,
"license_type": "no_license",
"max_line_length": 327,
"num_lines": 110,
"path": "/misc/saige_mr_vs_coloc.Rmd",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Exploring quality of pQTL-MR associations\"\noutput: html_document\n---\n\n## Introduction\n\nMohd has run MR between the Sun et al. pQTL dataset and SAIGE binary trait GWAS of UK Biobank.\n\nAn important question is: how informative is it to have an MR association at a given p-value level? Because we are doing many MR tests, some associations below a given p-value threshold will be false positives (FPs). We would like to use additional evidence to understand what the FP rate is at different MR p-value thresholds.\n\n```{r, warning=FALSE, message=FALSE}\nlibrary(tidyverse)\noptions(stringsAsFactors = F)\ntheme_set(theme_bw())\n```\n\nLet's first look at the distributions of p values across all tests (of QTL-trait MR), for:\n\n- QTL associations\n- trait associations\n- MR (QTL-trait) associations\n\nNote that these will be the p value distributions across all TESTS, not necessarily across all QTLs or trait loci, since QTLs / loci may be tested multiple times.\n\n```{r, warning=FALSE, message=FALSE}\nsaige_mr = read_tsv(\"/Users/jeremys/work/otgenetics/misc/mohd/gsmr_cis_sun_SAIGE_Sep2020_coloc_ncases.tsv.gz\") %>%\n rename(mr_p = bxy_pval, mr_beta = bxy, mr_se = bxy_se,\n qtl_p = bzx_pval, qtl_beta = bzx, qtl_se = bzx_se,\n trait_p = bzy_pval, trait_beta = bzy, trait_se = bzy_se)\n\nsaige_mr = saige_mr %>%\n group_by(prot, out) %>%\n summarise(nsnp = first(nsnp),\n snp = first(snp),\n trait_beta = first(trait_beta),\n trait_se = first(trait_se),\n trait_p = min(trait_p),\n qtl_beta = first(qtl_beta),\n qtl_se = first(qtl_se),\n qtl_p = min(qtl_p),\n mr_beta = first(mr_beta),\n mr_se = first(mr_se),\n mr_p = min(mr_p),\n candidate_coloc_snp = first(candidate_coloc_snp),\n n_cases = first(n_cases),\n coloc_prob = first(posterior_prob) )\n```\n\nBecause we have selected only significant QTLs to test, the average QTL is quite strong (median p about 1e-11).\n\n```{r, warning=FALSE, message=FALSE}\nggplot(saige_mr, aes(x=-log10(qtl_p))) + geom_histogram(bins = 100) + ggtitle(\"QTL P values\")\n```\n\nThe opposite is true for the trait loci. The majority have minimum p > 0.01 (trait p values across the selected QTL SNP instruments).\n\n```{r, warning=FALSE, message=FALSE}\nggplot(saige_mr, aes(x=-log10(trait_p))) + geom_histogram(bins = 100) + ggtitle(\"Trait P values\")\nggplot(saige_mr %>% filter(-log10(trait_p) < 5), aes(x=-log10(trait_p))) +\n geom_histogram(bins = 100) + ggtitle(\"Trait P values - zoomed in\")\n```\n\nThe large majority of the MR p values are also > 0.01. This isn't surprising, since we are underpowered for most of the MR tests, due to the traits not having a genetic association at the locus. Note that the table I have is already thresholded for MR p < 0.05.\n\n```{r, warning=FALSE, message=FALSE}\nggplot(saige_mr, aes(x=-log10(mr_p))) + geom_histogram(bins = 100) + ggtitle(\"MR P values\")\nggplot(saige_mr %>% filter(-log10(mr_p) < 5), aes(x=-log10(mr_p))) +\n geom_histogram(bins = 100) + ggtitle(\"MR P values - zoomed in\")\n```\n\nLet's see what fraction of the time we have a colocalising signal, in addition to MR p < 0.05, in different bins of trait minimum p value.\n\n```{r, warning=FALSE, message=FALSE}\n# A function to split a continuous annotation into categories\ncategorize = function(vals, thresholds) {\n threshold = sort(thresholds)\n if (length(thresholds) < 1) {\n return(NULL)\n }\n catLevels = c(paste0(\"<= \", threshold[1]))\n cats = rep(catLevels[1], length(vals))\n for (i in 1:length(thresholds)) {\n if (i == length(thresholds)) {\n catLevels[i+1] = paste0(\"> \", threshold[i])\n cats[vals > threshold[i]] = catLevels[i+1]\n } else {\n catLevels[i+1] = paste0(threshold[i], \"-\", threshold[i+1])\n cats[vals > threshold[i]] = catLevels[i+1]\n }\n }\n cats = factor(cats, levels = catLevels)\n return(cats)\n}\n\nsaige_mr$trait_p_bin = categorize(saige_mr$trait_p, c(0.05, 0.01, 0.001, 1e-4, 1e-5))\n\nggplot(saige_mr, aes(x=trait_p_bin, y=coloc_prob, fill=trait_p_bin)) +\n geom_boxplot(outlier.shape = NA) +\n geom_jitter(width = 0.2, alpha = 0.1) +\n xlab(\"Trait minimum P (for SNP instruments)\") + ylab(\"Coloc probability\")\n```\n\n### Interpretation\n\nWe rarely get a colocalisation signal (with coloc prob > 0.8) when minimum p value for the trait is > 1e-4, and never do if it's > 1e-3. This doesn't mean that there definitely isn't a shared genetic association, just that we're not powered to detect one.\n\nOne thing we could do is to plot the H4/H3 ratio from tests done using the standard coloc package. I still don't think this tells us what we want to know, however.\n\nWe want to know the probability that an MR association is real, given the MR p value, and possibly also the QTL SNP and trait P values. I think that the only way to do that would be to compare MR tests done on simulated data (from UK Biobank), generated under the null or alternative hypotheses.\n\n\n"
},
{
"alpha_fraction": 0.6918535828590393,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 35.78260803222656,
"blob_id": "c5c0d334ba152e407a1797f6a3eff0c4e36bf4ca",
"content_id": "498b25f2b43359540ad1e4cc9cdb825f33b05c27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 847,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 23,
"path": "/gene_network/get_locus2gene.py",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "# This script reads data from OT Genetics datasets with locus2gene scores,\n# and saves a subset with the relevant studies.\nfrom pyspark.sql import SparkSession\nimport pandas as pd\n\nspark = SparkSession.builder.getOrCreate()\ndf = spark.read.load(\"/Users/jeremys/Downloads/l2g\")\n#df.head(2)\n\n# The below is inefficient\n#df = pd.read_parquet('/Users/jeremys/Downloads/l2g/')\n\n# Katie de Lange's IBD study\ndfs = df.filter(df[\"study_id\"] == \"GCST004131\")\n\n#print((df.count(), len(df.columns)))\n#dfs.write.csv('/Users/jeremys/Downloads/l2g.IBD.deLange.tsv', sep='\\t')\ndfs.toPandas().to_csv('/Users/jeremys/Downloads/l2g.IBD.deLange.tsv', sep='\\t', index=False)\n\n# Jimmy Liu's IBD study\ndfs = df.filter(df[\"study_id\"] == \"GCST003043\")\n#print((dfs.count(), len(dfs.columns)))\ndfs.toPandas().to_csv('/Users/jeremys/Downloads/l2g.IBD.Liu.tsv', sep='\\t', index=False)\n\n"
},
{
"alpha_fraction": 0.6023481488227844,
"alphanum_fraction": 0.6321252584457397,
"avg_line_length": 29.44559669494629,
"blob_id": "86498dd85a4fa033869cedba194d29dcd58870ee",
"content_id": "567653aae9fdc7488a525801cdac5c2aa8c69abd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 5877,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 193,
"path": "/misc/L2G_distribution.Rmd",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Number of L2G-prioritized genes\"\noutput: html_document\n---\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nlibrary(tidyverse)\nlibrary(annotables)\noptions(stringsAsFactors = F)\ntheme_set(theme_bw())\n\nlibrary(tidyverse)\ntheme_set(theme_bw())\n\notgdir = \"/Users/jeremys/work/otgenetics\"\ndf = read_tsv(\"/Users/jeremys/work/otgenetics/otg/l2g.full.tsv.gz\", col_types = cols_only(study_id = \"c\", gene_id = \"c\", y_proba = \"d\")) %>%\n rename(l2g = y_proba)\nstudies = read_tsv(\"/Users/jeremys/work/otgenetics/otg/studies.tsv.gz\")\n\ndf = df %>%\n left_join(studies %>% select(study_id, trait_reported, trait_category, has_sumstats)) %>%\n left_join(grch38 %>% select(gene_id = ensgene, symbol) %>% filter(!duplicated(gene_id)))\n\ntrait_category_counts = studies %>%\n group_by(trait_category) %>%\n summarise(n = n())\n```\n\nTotal number of unique genes with high L2G score in any study.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nnum = df %>% filter(l2g > 0.5) %>% .$gene_id %>% unique() %>% length()\nprint(sprintf(\"L2G > 0.5: %d\", num))\n\nnum = df %>% filter(has_sumstats, l2g > 0.5) %>% .$gene_id %>% unique() %>% length()\nprint(sprintf(\"L2G > 0.5 (has sumstats): %d\", num))\n\nnum = df %>% filter(l2g > 0.8) %>% .$gene_id %>% unique() %>% length()\nprint(sprintf(\"L2G > 0.8: %d\", num))\n\nnum = df %>% filter(has_sumstats, l2g > 0.8) %>% .$gene_id %>% unique() %>% length()\nprint(sprintf(\"L2G > 0.8 (has sumstats): %d\", num))\n\n```\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n# Save a list of all genes with the max L2G score per gene\nmax_l2g = df %>%\n arrange(desc(l2g)) %>%\n filter(!duplicated(gene_id)) %>%\n select(study_id, gene_id, symbol, l2g, trait_reported, trait_category)\nwrite_tsv(max_l2g, path = file.path(otgdir, \"misc/l2g_summary/max_l2g_per_gene.tsv\"), na = \"\")\n```\n\n## Number of studies in which a given gene has high L2G score\nNotice log-scaled axis.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\ndf %>%\n filter(l2g > 0.5) %>%\n group_by(gene_id) %>%\n filter(!duplicated(study_id)) %>%\n summarise(num_studies = n()) %>%\n ggplot(aes(x=num_studies)) +\n geom_histogram(bins=50) +\n scale_y_log10() +\n ggtitle(\"L2G > 0.5\") +\n xlab(\"Number of genes prioritised in study\") + ylab(\"Number of studies\")\n```\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\ndf %>%\n filter(l2g > 0.8) %>%\n group_by(gene_id) %>%\n filter(!duplicated(study_id)) %>%\n summarise(num_studies = n()) %>%\n ggplot(aes(x=num_studies)) +\n geom_histogram(bins=50) +\n scale_y_log10() +\n ggtitle(\"L2G > 0.8\") +\n xlab(\"Number of genes prioritised in study\") + ylab(\"Number of studies\")\n```\n\n## Genes with L2G > 0.5 in the most studies\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\ndf %>%\n filter(l2g > 0.5) %>%\n group_by(gene_id) %>%\n filter(!duplicated(study_id)) %>%\n summarise(num_studies = n(),\n symbol = first(symbol)) %>%\n arrange(desc(num_studies)) %>%\n select(symbol, num_studies)\n```\n\nAC002094.3 overlaps gene VTN, and seems to be a trans-pQTL for a large number of proteins in the Emilsson study.\n\nWithout the Emilsson study:\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nstudy_counts = df %>%\n filter(l2g > 0.5) %>%\n filter(!grepl(\"GCST006585_\", study_id)) %>%\n group_by(gene_id) %>%\n filter(!duplicated(study_id)) %>%\n summarise(symbol = first(symbol),\n num_studies = n())\n\nstudy_counts %>%\n arrange(desc(num_studies)) %>%\n write_tsv(path = file.path(otgdir, \"misc/l2g_summary/num_studies_per_gene_l2g_gt_0.5.tsv\"), na = \"\")\n\nstudy_counts %>%\n arrange(desc(num_studies)) %>%\n select(symbol, num_studies)\n```\n\n## Studies prioritising the most genes\n(excluding Emilsson)\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\ngt_0.5 = df %>%\n filter(l2g > 0.5) %>%\n filter(!grepl(\"GCST006585_\", study_id)) %>%\n filter(!duplicated(gene_id)) %>%\n group_by(study_id) %>%\n summarise(num_genes = n()) %>%\n arrange(desc(num_genes))\n\ngt_0.8 = df %>%\n filter(l2g > 0.8) %>%\n filter(!grepl(\"GCST006585_\", study_id)) %>%\n filter(!duplicated(gene_id)) %>%\n group_by(study_id) %>%\n summarise(num_genes = n()) %>%\n arrange(desc(num_genes))\n\ngene_counts = studies %>%\n left_join(gt_0.5 %>% rename('L2G>0.5' = num_genes), by=\"study_id\") %>%\n left_join(gt_0.8 %>% rename('L2G>0.8' = num_genes), by=\"study_id\")\ngene_counts$`L2G>0.5`[is.na(gene_counts$`L2G>0.5`)] = 0\ngene_counts$`L2G>0.8`[is.na(gene_counts$`L2G>0.8`)] = 0\n\ngene_counts %>%\n arrange(desc(`L2G>0.5`)) %>%\n select(study_id, trait_reported, `L2G>0.5`, `L2G>0.8`, pub_title) %>%\n head(10)\n```\n\nStudies prioritising the most genes, also excluding anthropometric measurements:\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\ngene_counts %>%\n arrange(desc(`L2G>0.5`)) %>%\n filter(!grepl(\"Anthropometric\", trait_category, ignore.case = T)) %>%\n filter(!grepl(\"Measurement\", trait_category, ignore.case = T)) %>%\n filter(!grepl(\"UKB\", pub_author, ignore.case = T)) %>%\n select(study_id, trait_reported, `L2G>0.5`, `L2G>0.8`, pub_title) %>%\n head(10)\n\n```\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n\n# Number of unique genes with L2G score per study\n# df %>%\n# group_by(study_id) %>%\n# filter(!duplicated(gene_id)) %>%\n# summarise(num_genes = n()) %>%\n# ggplot(aes(x=num_genes)) +\n# geom_histogram() +\n# scale_y_log10()\n\n# Number of unique genes with L2G > 0.5 per study\nnum_unique_genes = df %>%\n group_by(study_id) %>%\n filter(l2g > 0.5, !duplicated(gene_id)) %>%\n summarise(num_genes_prioritised = n())\n\nnum_unique_genes %>%\n ggplot(aes(x=num_genes_prioritised)) +\n geom_histogram() +\n scale_y_log10() + scale_x_log10() +\n ggtitle(\"Number of studies prioritising (L2G > 0.5) a given number of genes\") +\n ylab(\"Number of studies\") + xlab(\"Number of genes prioritised\")\n\ngene_counts %>%\n arrange(desc(`L2G>0.5`)) %>%\n write_tsv(path = file.path(otgdir, \"misc/l2g_summary/num_genes_per_study_l2g_gt_0.5.tsv\"), na = \"\")\n```\n\n"
},
{
"alpha_fraction": 0.774193525314331,
"alphanum_fraction": 0.774193525314331,
"avg_line_length": 61,
"blob_id": "f04f53853e8a5ec2281b59a2e640d0dad32a9fbc",
"content_id": "b405555d7ec840236b31d1d4798466a0e04ebfe4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 1,
"path": "/README.md",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "A place for my source code that doesn't fit in anywhere else.\n"
},
{
"alpha_fraction": 0.6378542184829712,
"alphanum_fraction": 0.6744081377983093,
"avg_line_length": 49.528926849365234,
"blob_id": "1da5e7f4668d370a7730856235dbeb44a9d46f15",
"content_id": "c654766858a5f877980f6c40fbdf2ab86e63f245",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 48914,
"license_type": "no_license",
"max_line_length": 503,
"num_lines": 968,
"path": "/gene_network/analyze_ibd_network.Rmd",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Network analysis of IBD GWAS\"\noutput: html_document\n---\n\n## Introduction\nTo explore the value of network propagation from GWAS of specific traits, we have defined 2 sets of seed genes for inflammatory bowel disease (IBD).\n\n1. Curated: 37 selected high-confidence causal genes, from expert curation\n2. L2G: 110 curated genes with L2G score > 0.5\n\nWe have run network propagation with these seed genes, and for each set we compare against 1,000 runs of network propagation with the same number of randomly selected genes as seed genes. From these runs we can define the Pagerank percentile of each gene relative to randomised inputs.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nlibrary(GenomicRanges)\nlibrary(tidyverse)\nlibrary(ggExtra)\nlibrary(annotables)\nlibrary(cowplot)\noptions(stringsAsFactors = F)\nknitr::opts_chunk$set(fig.width=8, fig.height=5)\ntheme_set(theme_bw())\nsaveFiles = T\n\nroot_dir = \"/Users/jeremys/work/opentargets/gene_network/ibd\"\nanalysis_dir = \"/Users/jeremys/work/opentargets/gene_network/ibd/2021_05_06\"\n\nl2g.loci.df = read_tsv(file.path(analysis_dir, \"l2g.IBD_loci.merged.annotated.tsv\"))\nl2g.genes.df = read_tsv(file.path(analysis_dir, \"l2g.IBD_genes.merged.tsv\"))\n\nnetwork1.df = read_csv(file.path(analysis_dir, \"input/zsco_set1.csv.gz\")) %>%\n mutate(pagerank_pctile = rankingIte1000.node / 10,\n seed_gene = padj > 0) %>%\n rename(gene_id = ENSG, geneSymbol = gene)\n\nnetwork2.df = read_csv(file.path(analysis_dir, \"input/zsco_set2.csv.gz\")) %>%\n mutate(pagerank_pctile = rankingIte1000.node / 10,\n seed_gene = padj > 0) %>%\n rename(gene_id = ENSG, geneSymbol = gene)\n\nseed_genes_curated = network1.df %>% filter(seed_gene) %>% .$geneSymbol %>% unique()\n\nseed_genes_l2g = network2.df %>% filter(seed_gene) %>% .$geneSymbol %>% unique()\nseed_genes_l2g = seed_genes_l2g[!seed_genes_l2g %in% seed_genes_curated]\n```\n\nThe number of unique genes in the network should be the same for each of the seed gene selection sets:\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nnetwork1.summary.df = network1.df %>%\n filter(!seed_gene) %>%\n group_by(gene_id) %>%\n summarise(numRuns = n(),\n Trait = if_else(numRuns == 1, first(Trait), \"\"),\n geneSymbol = dplyr::first(geneSymbol),\n pagerank.mean = mean(page.rank),\n pagerank = median(page.rank),\n degree = dplyr::first(degree),\n Zsco.pagerank.node.mean = mean(Zsco.page.rank.node),\n Zsco.pagerank.node = median(Zsco.page.rank.node),\n pagerank_pctile.mean = mean(pagerank_pctile),\n pagerank_pctile = median(pagerank_pctile),\n seed_gene = (numRuns == 1))\n\nnetwork2.summary.df = network2.df %>%\n filter(!seed_gene) %>%\n group_by(gene_id) %>%\n summarise(numRuns = n(),\n Trait = if_else(numRuns == 1, first(Trait), \"\"),\n geneSymbol = dplyr::first(geneSymbol),\n pagerank.mean = mean(page.rank),\n pagerank = median(page.rank),\n degree = dplyr::first(degree),\n Zsco.pagerank.node.mean = mean(Zsco.page.rank.node),\n Zsco.pagerank.node = median(Zsco.page.rank.node),\n pagerank_pctile.mean = mean(pagerank_pctile),\n pagerank_pctile = median(pagerank_pctile),\n seed_gene = (numRuns == 1))\n\nif (saveFiles) {\n write_tsv(network1.summary.df %>% arrange(desc(pagerank_pctile)), file.path(analysis_dir, \"network.curated.summary.tsv\"), na = \"\")\n write_tsv(network2.summary.df %>% arrange(desc(pagerank_pctile)), file.path(analysis_dir, \"network.l2g.summary.tsv\"), na = \"\")\n}\n```\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n#length(unique(network1.df$gene_id))\nnrow(network1.summary.df)\nnrow(network2.summary.df)\n\n# idx = which(!network1.summary.df$gene_id %in% network2.summary.df$gene_id)\n# View(network1.summary.df[idx,])\n# \"ENSG00000075426\" %in% network2.df$gene_id\n# \"FOSL2\" %in% network2.df$geneSymbol\n# \"ENSG00000075426\" %in% network2.df$gene_id\n# \"FOSL2\" %in% network2.summary.df$geneSymbol\n\n#length(unique(network1.df %>% filter(padj > 0) %>% .$gene_id))\n#length(unique(network2.df %>% filter(padj > 0) %>% .$gene_id))\n#length(unique(network3.df %>% filter(padj > 0) %>% .$gene_id))\n```\n\n\n## Distributions\n\nWe first consider the network scores based on the stringent set of 33 curated IBD genes.\n\n### Distribution of Pagerank percentile\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n#ggplot(network1.df, aes(x=pagerank_pctile)) + geom_histogram(bins = 100)\nggplot(network1.summary.df, aes(x=pagerank_pctile)) + geom_histogram(bins = 100) + ggtitle(\"Pagerank pctile distribution (curated seed gene network)\")\nggplot(network2.summary.df, aes(x=pagerank_pctile)) + geom_histogram(bins = 100) + ggtitle(\"Pagerank pctile distribution (L2G seed gene network)\")\n```\n\nEach of the network sets has a peak of occurrence at a particular (fairly low) pagerank percentile, which differs between the networks. There is also some depletion of very low pagerank percentiles for the stringent seed gene networks, but apart from that, the distribution of pagerank percentile is fairly uniform.\n\nLet's look at a QQ plot to see how the quantiles of this distribution relate to the uniform distribution.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nggplot(network1.summary.df, aes(x=pagerank_pctile)) + stat_ecdf(geom = \"step\") +\n geom_abline(slope = 0.01, intercept = 0, col = \"blue\") +\n ylab(\"Distribution quantile\") + ggtitle(\"Pagerank pctile QQ plot (curated seed gene network)\")\n\nggplot(network2.summary.df, aes(x=pagerank_pctile)) + stat_ecdf(geom = \"step\") +\n geom_abline(slope = 0.01, intercept = 0, col = \"blue\") +\n ylab(\"Distribution quantile\") + ggtitle(\"Pagerank pctile QQ plot (L2G seed gene network)\")\n```\n\nThese are close enough to uniform (better than for AD) that we can use the Pagerank percentiles as-is. (Especially since we're not concerned about the very low range of Pagerank anyway.) So in general, a pagerank percentile of 80% means (to a close approximation) that the gene has a network score greater than 80% of genes.\n\n### Distribution of node degree\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nggplot(network1.summary.df, aes(x=degree, col=seed_gene, fill=seed_gene)) +\n geom_density(alpha = 0.3, size = 1) +\n scale_x_log10() +\n ggtitle(\"Gene degree by gene category (curated seed gene network)\")\n\nggplot(network2.summary.df, aes(x=degree, col=seed_gene, fill=seed_gene)) +\n geom_density(alpha = 0.3, size = 1) +\n scale_x_log10() +\n ggtitle(\"Gene degree by gene category (L2G seed gene network)\")\n```\n\nSummary for seed genes (for the 3 networks):\n\n```{r, warning=FALSE, message=FALSE}\nnetwork1.summary.df %>% filter(seed_gene) %>% .$degree %>% summary()\nnetwork2.summary.df %>% filter(seed_gene) %>% .$degree %>% summary()\n```\n\nSummary for non-seed genes:\n\n```{r, warning=FALSE, message=FALSE}\nnetwork1.summary.df %>% filter(!seed_gene) %>% .$degree %>% summary()\n```\n\nOur seed genes have a higher node degree on average than remaining genes. The L2G-based seed genes tend to have lower degree than the curated genes, but still higher than the average gene.\n\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n# A function to split a continuous annotation into categories\ncategorize = function(vals, thresholds) {\n threshold = sort(thresholds)\n if (length(thresholds) < 1) {\n return(NULL)\n }\n catLevels = c(paste0(\"<= \", threshold[1]))\n cats = rep(catLevels[1], length(vals))\n for (i in 1:length(thresholds)) {\n if (i == length(thresholds)) {\n catLevels[i+1] = paste0(\"> \", threshold[i])\n cats[vals > threshold[i]] = catLevels[i+1]\n } else {\n catLevels[i+1] = paste0(threshold[i], \"-\", threshold[i+1])\n cats[vals > threshold[i]] = catLevels[i+1]\n }\n }\n cats = factor(cats, levels = catLevels)\n return(cats)\n}\n\nstratifiedOddsRatios = function(df, cat1, cat2, vsBaseCategory = T) {\n df = df[, c(cat1, cat2)]\n if (any(is.na(df))) {\n warning(\"stratifiedOddsRatios: Note - input table has NA values. These will be omitted.\")\n df = na.omit(df)\n }\n cat1levels = levels(pull(df,cat1))\n cat2levels = levels(pull(df,cat2))\n cat1base = levels(pull(df,cat1))[1]\n cat2base = levels(pull(df,cat2))[1]\n oddsRatio.df = data.frame(comparisonStr = character(), cat1 = character(), cat2 = character(),\n estimate = numeric(), confint_lo = numeric(), confint_hi = numeric())\n cat1higherLevels = cat1levels[cat1levels != cat1base]\n cat2higherLevels = cat2levels[cat2levels != cat2base]\n \n for (cat1level in cat1higherLevels) {\n for (cat2level in cat2higherLevels) {\n if (vsBaseCategory) {\n mat = matrix(c(sum(df[,cat1] == cat1level & df[,cat2] == cat2level),\n sum(df[,cat1] == cat1base & df[,cat2] == cat2level),\n sum(df[,cat1] == cat1level & df[,cat2] == cat2base),\n sum(df[,cat1] == cat1base & df[,cat2] == cat2base)), nrow=2)\n comparisonStr = sprintf(\"%s vs. %s to %s vs. %s\", cat1level, cat1base, cat2level, cat2base)\n } else {\n mat = matrix(c(sum(df[,cat1] == cat1level & df[,cat2] == cat2level),\n sum(df[,cat1] != cat1level & df[,cat2] == cat2level),\n sum(df[,cat1] == cat1level & df[,cat2] != cat2level),\n sum(df[,cat1] != cat1level & df[,cat2] != cat2level)), nrow=2)\n comparisonStr = sprintf(\"%s to %s\", cat1level, cat2level)\n }\n res = fisher.test(mat)\n oddsRatio.df = bind_rows(oddsRatio.df,\n data.frame(comparisonStr, cat1 = cat1level, cat2 = cat2level,\n estimate = res$estimate, confint_lo = res$conf.int[1], confint_hi = res$conf.int[2]))\n }\n }\n oddsRatio.df\n}\n\nstratifiedOddsRatioPlot = function(or.df, cat1name, cat2name, cat1levels = NULL, cat2levels = NULL) {\n if (!is.null(cat1levels)) {\n or.df$cat1 = factor(or.df$cat1, levels = cat1levels)\n }\n if (!is.null(cat2levels)) {\n or.df$cat2 = factor(or.df$cat2, levels = cat2levels)\n }\n ggplot(or.df, aes(x=cat1, y=estimate, fill=cat2)) +\n geom_bar(stat = \"identity\", position = \"dodge\") +\n geom_errorbar(aes(ymin = confint_lo, ymax = confint_hi), position = position_dodge2(width = 0.4, padding = 0.6), color = \"grey40\") +\n scale_y_log10() + ylab(\"Odds ratio\") +\n xlab(cat1name) +\n scale_fill_discrete(name = cat2name)\n}\n```\n\n\n## Network scores of seed genes\n\nWe assess the extent to which our seed genes have higher Pagerank percentiles than average.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n#, fig.width=5, fig.height=4\nl2g.net.df = l2g.genes.df %>% left_join(network1.df, by=\"gene_id\")\n\nl2g.net.uniq.df = l2g.net.df %>%\n filter(!duplicated(gene_id), !is.na(pagerank_pctile))\n\nnetwork1.summary.df = network1.summary.df %>%\n mutate(locus_gene = gene_id %in% l2g.genes.df$gene_id,\n gene_type = if_else(geneSymbol %in% seed_genes_curated,\n \"curated gene\",\n if_else(geneSymbol %in% seed_genes_l2g,\n \"L2G gene\",\n if_else(locus_gene, \"locus gene\", \"other gene\")))) %>%\n mutate(gene_type = factor(as.character(gene_type), levels = c(\"other gene\", \"locus gene\", \"L2G gene\", \"curated gene\")))\n\n\np = ggplot(network1.summary.df, aes(x = gene_type, y = pagerank_pctile, fill = gene_type)) +\n geom_jitter(width = 0.1, alpha = 0.2) +\n geom_violin(alpha = 0.3) +\n geom_boxplot(outlier.shape = NA, width = 0.07, alpha = 0.8, fill=\"white\") +\n theme_bw(12) +\n ggtitle(\"Pagerank pctile by gene group (curated seed gene network)\") +\n scale_fill_discrete(guide=F) +\n ylab(\"Pagerank percentile\") +\n theme(axis.text.x = element_text(angle = 25, hjust = 1), axis.title.x = element_blank())\nprint(p)\n\nif (saveFiles) {\n pdf(file.path(analysis_dir, \"pagerank_pctile_violin.pdf\"), width=4.7, height=3.5)\n print(p + theme(plot.title = element_blank()))\n dev.off()\n}\nsummary(network1.summary.df %>% filter(seed_gene) %>% .$pagerank_pctile)\n#network1.summary.df %>% filter(gene_type == \"curated gene\") %>% nrow()\n\nwilcox.test(network1.summary.df %>% filter(seed_gene) %>% .$pagerank_pctile,\n network1.summary.df %>% filter(gene_type == \"locus gene\") %>% .$pagerank_pctile,\n alternative = \"greater\")\n# ks.test(network1.summary.df %>% filter(seed_gene) %>% .$pagerank_pctile,\n# network1.summary.df %>% filter(gene_type == \"locus gene\") %>% .$pagerank_pctile,\n# alternative = \"less\")\n# t.test(network1.summary.df %>% filter(seed_gene) %>% .$pagerank_pctile,\n# network1.summary.df %>% filter(gene_type == \"locus gene\") %>% .$pagerank_pctile,\n# alternative = \"greater\")\n\n```\n\nThey are much higher on average, with a few outliers.\n\nLet's also look at this for the L2G network.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nnetwork2.summary.df = network2.summary.df %>%\n mutate(locus_gene = gene_id %in% l2g.genes.df$gene_id,\n gene_type = if_else(geneSymbol %in% seed_genes_curated,\n \"curated gene\",\n if_else(geneSymbol %in% seed_genes_l2g,\n \"L2G gene\",\n if_else(locus_gene, \"locus gene\", \"other gene\")))) %>%\n mutate(gene_type = factor(as.character(gene_type), levels = c(\"other gene\", \"locus gene\", \"L2G gene\", \"curated gene\")))\n\nggplot(network2.summary.df, aes(x = gene_type, y = pagerank_pctile, fill = gene_type)) +\n geom_jitter(width = 0.1, alpha = 0.2) +\n geom_violin(alpha = 0.3) +\n geom_boxplot(outlier.shape = NA, width = 0.07, alpha = 0.8, fill=\"white\") +\n ggtitle(\"Pagerank pctile QQ plot (L2G seed gene network)\")\n\nsummary(network2.summary.df %>% filter(seed_gene) %>% .$pagerank_pctile)\n#network2.summary.df %>% filter(gene_type == \"L2G gene\") %>% nrow()\n\nwilcox.test(network2.summary.df %>% filter(gene_type == \"L2G gene\") %>% .$pagerank_pctile,\n network2.summary.df %>% filter(gene_type == \"locus gene\") %>% .$pagerank_pctile,\n alternative = \"greater\")\n\n\n```\n\nIn the network based on 110 L2G > 0.5 genes, the curated genes have slightly lower network scores than before, whereas the L2G genes are slightly higher. I'm not sure what this indicates - it could be interesting? Perhaps the curated genes are more biased towards specific coherent (known) pathways, and hence being selected as a curated gene means you are likely to be in those (high-network scoring) pathways... whereas L2G genes are less biased, as so do better on average in the less biased network?\n\nLet's see the correlation between scores for the 2 networks.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nmerged_network = network1.summary.df %>%\n rename(curated_PRpctile = pagerank_pctile) %>%\n left_join(network2.summary.df %>% rename(L2G_PRpctile = pagerank_pctile) %>% select(gene_id, L2G_PRpctile), by=\"gene_id\") %>%\n left_join(l2g.genes.df %>% select(gene_id, geneSymbol = symbol, l2g_score_mean), by=\"geneSymbol\")\n\nggplot(merged_network, aes(x=curated_PRpctile, y=L2G_PRpctile)) +\n geom_point(alpha = 0.1)\ncor.test(merged_network$curated_PRpctile, merged_network$L2G_PRpctile, method = \"spearman\")\n```\n\n\n## Network scores vs. locus2gene\n\nLet's look at the correlation (scatterplot) of locus2gene score and network score with each as the x-axis variable in turn.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nggplot(l2g.net.uniq.df, aes(x=l2g_score_mean, y=pagerank_pctile)) +\n geom_point(alpha=0.4) +\n geom_smooth() + ylab(\"Curated network PRpctile\")\n\nggplot(l2g.net.uniq.df, aes(y=l2g_score_mean, x=pagerank_pctile)) +\n geom_point(alpha=0.4) +\n geom_smooth() + xlab(\"Curated network PRpctile\")\n```\n\nA violin plot might give a clearer view of what network score to expect for highly confident genes (based on high l2g score). This is similar to just looking at the curated, strict, or lenient gene sets as we did above.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nl2g.net.uniq.df$pagerank_pctile.cat = categorize(l2g.net.uniq.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90, 95, 98))\nl2g.net.uniq.df$l2g_score_mean.cat = categorize(l2g.net.uniq.df$l2g_score_mean, thresholds = c(0.2, 0.4, 0.6, 0.8))\nggplot(l2g.net.uniq.df, aes(x=l2g_score_mean.cat, y=pagerank_pctile)) +\n geom_violin(alpha = 0.9) +\n geom_jitter(width = 0.25, alpha = 0.2) +\n geom_boxplot(width = 0.05, outlier.shape = NA, fill=\"white\") +\n ylab(\"Curated network PRpctile\")\n```\n\nAnd similarly, but with axes reversed.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nggplot(l2g.net.uniq.df, aes(x=pagerank_pctile.cat, y=l2g_score_mean)) +\n geom_violin(alpha = 0.9) +\n geom_boxplot(width = 0.05, outlier.shape = NA, fill=\"white\") +\n xlab(\"Curated network PRpctile\")\n```\n\n\n## Network scores per locus\n\nWe can look at these loci in more detail.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=8, fig.height=4.2}\nnetwork1_seedgenes = network1.summary.df %>% filter(seed_gene) %>% .$gene_id %>% unique()\nnetwork1_seedgene_loci = l2g.genes.df %>% filter(gene_id %in% network1_seedgenes) %>% .$l2g_locus_merged %>% unique()\n\nl2g.seed_locus.df = l2g.genes.df %>% filter(l2g_locus_merged %in% network1_seedgene_loci)\n#ViewDups(l2g.seed_locus.df, 6)\nl2g.seed_locus.df = l2g.seed_locus.df %>%\n left_join(network1.summary.df, by = \"gene_id\") %>%\n group_by(l2g_locus_merged) %>%\n arrange(desc(seed_gene)) %>%\n mutate(locus_name = first(geneSymbol),\n has_seed_gene = any(seed_gene)) %>%\n select(l2g_locus_merged, seed_gene, geneSymbol, locus_name, everything()) %>% na.omit()\n\np = ggplot(l2g.seed_locus.df %>% filter(!seed_gene), aes(x=locus_name, y=pagerank_pctile, col=seed_gene, size=seed_gene)) +\n geom_point(alpha=0.5) +\n geom_point(data = l2g.seed_locus.df %>% filter(seed_gene), alpha=0.7) +\n theme(axis.text.x = element_text(angle = 45, hjust = 1)) +\n ggtitle(\"PageRank percentile per locus\") +\n ylab(\"Pagerank percentile\") + xlab(\"Seed gene\") +\n scale_color_manual(name = \"Seed gene\", values = c(\"FALSE\"=\"grey20\", \"TRUE\"=\"blue\")) +\n scale_size_manual(name = \"Seed gene\", values=c(\"TRUE\"=2.5, \"FALSE\"=1.5))\nprint(p)\n\nif (saveFiles) {\n pdf(file.path(analysis_dir, \"pagerank_pct_per_locus.pdf\"), width=8, height=4.2)\n print(p)\n dev.off()\n}\n```\n\n(Caveat: this focuses on genes identified by Locus2Gene as being near Katie's GWAS loci. It's not a good definition of \"locus\" yet, which is why you have some loci here with no seed genes. Selection of locus genes should be made more robust in future.)\n\nDig into loci where our seed gene isn't among the top few.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=8, fig.height=6}\nl2g.seed_locus.df = l2g.seed_locus.df %>%\n filter(has_seed_gene) %>%\n group_by(locus_name) %>%\n mutate(locus_rank = rank(-pagerank_pctile))\n\n#View(l2g.seed_locus.df %>% arrange(desc(seed_gene), locus_rank) %>% select(locus_name, seed_gene, locus_rank, pagerank_pctile, everything()))\n\nplot.df = l2g.seed_locus.df %>%\n filter(locus_name %in% (l2g.seed_locus.df %>% filter(seed_gene, locus_rank >= 3, pagerank_pctile < 90) %>% .$locus_name)) %>%\n group_by(locus_name) %>%\n mutate(locus_seed_gene_rank = max(if_else(seed_gene, locus_rank, 0)),\n label = if_else(locus_rank <= locus_seed_gene_rank, geneSymbol, \"\"))\n#View(plot.df %>% select(locus_name, seed_gene, locus_rank, pagerank_pctile, geneSymbol, label, y_proba_full_model, everything()) %>% arrange(desc(locus_name), desc(y_proba_full_model)))\n\nggplot(plot.df %>% filter(!seed_gene),\n aes(x=locus_name, y=pagerank_pctile, col=seed_gene, size=seed_gene)) +\n geom_point(alpha=0.5) +\n geom_point(data = plot.df %>% filter(seed_gene), alpha=0.7) +\n geom_text(data = plot.df, aes(label = label), hjust = 0, nudge_x = 0.1, size = 2) +\n theme(axis.text.x = element_text(angle = 45, hjust = 1)) +\n ggtitle(\"Loci with genes having higher network score than seed genes\") +\n ylab(\"Pagerank percentile\") + xlab(\"Seed gene\") +\n scale_color_manual(name = \"Seed gene\", values = c(\"FALSE\"=\"grey20\", \"TRUE\"=\"blue\")) +\n scale_size_manual(name = \"Seed gene\", values=c(\"TRUE\"=2.5, \"FALSE\"=1.5))\n\n\n```\n\nWe can look at a scatterplot of individual loci to help determine which loci might have better candidates (based on network score and/or locus2gene) than the ones that were picked. Two examples are below, and plots for all loci are saved in a PDF.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=6, fig.height=4}\nl2g_scatterplot = function(l2g.seed_locus.df, cur_locus_name) {\n p.df = l2g.seed_locus.df %>% filter(locus_name == cur_locus_name)\n ggplot(p.df, aes(x=l2g_score_mean, y=pagerank_pctile, col=seed_gene, size=seed_gene)) +\n geom_point(data = p.df %>% filter(!seed_gene), alpha=0.5) +\n geom_text(data = p.df %>% filter(!seed_gene), aes(label = geneSymbol), hjust = 0, nudge_x = 0.01, size = 2.0) +\n geom_point(data = p.df %>% filter(seed_gene), alpha=0.8) +\n geom_text(data = p.df %>% filter(seed_gene), aes(label = geneSymbol), hjust = 0, nudge_x = 0.01, size = 2.3) +\n ggtitle(cur_locus_name) +\n ylab(\"Pagerank percentile\") + xlab(\"L2G score\") +\n scale_color_manual(name = \"Seed gene\", values = c(\"FALSE\"=\"grey20\", \"TRUE\"=\"blue\"), guide=F) +\n scale_size_manual(name = \"Seed gene\", values=c(\"TRUE\"=2.5, \"FALSE\"=1.5), guide=F) +\n xlim(0, max(p.df$l2g_score_mean) + 0.1)\n# ggtitle(sprintf(\"Locus scatterplot: %s\", cur_locus_name)) +\n}\n\nif (saveFiles) {\n locus_names = unique(l2g.seed_locus.df$locus_name)\n pdf(file = file.path(analysis_dir, \"curated_network.locus_scatterplots.pdf\"), width=7, height=5)\n for (cur_locus in locus_names) {\n print( l2g_scatterplot(l2g.seed_locus.df, cur_locus) )\n }\n dev.off()\n}\nprint( l2g_scatterplot(l2g.seed_locus.df, \"INAVA\") )\nprint( l2g_scatterplot(l2g.seed_locus.df, \"LRRK2\") )\nprint( l2g_scatterplot(l2g.seed_locus.df, \"BANK1\") )\n\n```\n\nIn most cases, for the loci where the curated gene has a low network score, it has a very high L2G, and no other genes do. This suggests to me that at these loci the network is missing something relevant.\nOne outlier is BANK1, which has high network score and L2G score, whereas SLC39A8 is selected, and is relatively low for both scores.\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, eval=FALSE}\n# Get genes in the lenient network which are in the same module as LACC1\nlacc1_module = network2.df %>% filter(Trait == \"AL512506.3\", gene_id == \"ENSG00000179630\") %>% .$cluster.walktrap\nlacc1_module_genes = network2.df %>% filter(Trait == \"LACC1\", cluster.walktrap == lacc1_module) %>% .$geneSymbol\n# Get the intersection of genes in this module with our lenient seed genes\nlacc1_module_seed_genes = lacc1_module_genes[lacc1_module_genes %in% seed_genes_lenient]\nnetwork3.df %>% filter(Trait == \"SOX4\", geneSymbol == \"SOX4\")\nnetwork3.df %>% filter(Trait == \"ZEB2\", geneSymbol == \"ZEB2\")\nnetwork3.df %>% filter(Trait == \"SATB1\", geneSymbol == \"SATB1\")\n\n```\n\n\nNotes:\n\n* For most of these loci the seed gene is still near the top.\n* SIRPG could be interesting at the FKBP1A locus (high L2G + network score)\n* Both MST1 and APEH could be interesting at the MST1 locus\n* For TNFSF8, I would put money on TNFSF15 being the gene, since it has a high L2G score (nearest gene), stronger coloc evidence (in the genetics portal at least), and higher network score.\n* For ERAP2/ERAP1, I would be cautious in making any conclusions, since these have fairly low degree (number of connections), so the difference could be down to one connection - e.g. if one is missing for ERAP2 due to incompleteness in the network.\n\nLet's look at this for all loci, based on the curated seed gene network.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=15, fig.height=6}\nl2g.genes.net.df = l2g.genes.df %>%\n left_join(network1.summary.df, by = \"gene_id\") %>%\n group_by(l2g_locus_merged) %>%\n arrange(desc(seed_gene)) %>%\n mutate(locus_name = first(geneSymbol),\n has_seed_gene = any(seed_gene)) %>%\n select(l2g_locus_merged, seed_gene, geneSymbol, locus_name, gene_type, everything()) %>% na.omit()\n\n#length(unique(l2g.genes.net.df %>% filter(chr <= 4) %>% .$l2g_locus_merged))\n\nggplot(l2g.genes.net.df %>% filter(gene_type == \"locus gene\"), aes(x=l2g_locus_merged, y=pagerank_pctile, col=gene_type, size=gene_type)) +\n geom_point(alpha=0.5) +\n geom_point(data = l2g.genes.net.df %>% filter(gene_type != \"locus gene\"), alpha=0.7) +\n theme(axis.text.x = element_text(angle = 45, hjust = 1)) +\n ggtitle(\"PageRank percentile per locus\") +\n ylab(\"Pagerank percentile\") + xlab(\"Locus\") +\n scale_color_manual(name = \"Gene group\", values = c(\"locus gene\"=\"grey20\", \"curated gene\"=\"blue\", \"L2G gene\"=\"red\")) +\n scale_size_manual(name = \"Gene group\", values=c(\"locus gene\"=1.5, \"curated gene\"=2.5, \"L2G gene\"=2.5))\n\n```\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=6, fig.height=4}\n# Let's also save some l2g scatterplots for all loci based on the L2G >0.5 seed gene networks\nnetwork2_seedgenes = network2.summary.df %>% filter(seed_gene) %>% .$gene_id %>% unique()\nnetwork2_seedgene_loci = l2g.genes.df %>% filter(gene_id %in% network2_seedgenes) %>% .$l2g_locus_merged %>% unique()\nl2g.locus.df = l2g.genes.df %>% filter(l2g_locus_merged %in% network2_seedgene_loci)\n#ViewDups(l2g.seed_locus.df, 6)\nl2g.locus.df = l2g.locus.df %>%\n left_join(network2.summary.df, by = \"gene_id\") %>%\n group_by(l2g_locus_merged) %>%\n arrange(desc(seed_gene), desc(l2g_score_mean)) %>%\n mutate(locus_name = first(geneSymbol),\n has_seed_gene = any(seed_gene)) %>%\n select(l2g_locus_merged, seed_gene, geneSymbol, locus_name, everything()) %>% na.omit()\n\nif (saveFiles) {\n locus_names = unique(l2g.locus.df$locus_name)\n pdf(file = file.path(analysis_dir, \"l2g_network.locus_scatterplots.pdf\"), width=7, height=5)\n for (cur_locus in locus_names) {\n print( l2g_scatterplot(l2g.locus.df, cur_locus) )\n }\n dev.off()\n}\n#print( l2g_scatterplot(l2g.locus.df, \"ICAM1\") )\n#print( l2g_scatterplot(l2g.locus.df, \"LACC1\") )\n\n```\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=10, fig.height=4}\n# Save a file that has 3 locus scatter plots side by side for each locus,\n# one for each of the networks\nif (saveFiles) {\n l2g.network.df = l2g.genes.df %>%\n left_join(network2.summary.df %>% select(gene_id, seed_gene2 = seed_gene, prpct2 = pagerank_pctile, geneSymbol), by = \"gene_id\") %>%\n left_join(network1.summary.df %>% select(gene_id, seed_gene1 = seed_gene, prpct1 = pagerank_pctile), by = \"gene_id\") %>%\n group_by(l2g_locus_merged) %>%\n arrange(desc(seed_gene2), desc(l2g_score_mean)) %>%\n mutate(locus_name = first(geneSymbol),\n has_seed_gene = any(seed_gene2 | seed_gene1)) %>%\n select(l2g_locus_merged, locus_name, gene_id, geneSymbol, seed_gene2, seed_gene1, starts_with(\"l2g\"), everything()) %>%\n filter(!is.na(prpct2))\n \n locus_names = unique(l2g.network.df$locus_name)\n l2g.network1.df = l2g.genes.df %>%\n left_join(network1.summary.df %>% select(gene_id, geneSymbol, seed_gene, pagerank_pctile), by = \"gene_id\") %>% mutate(network=\"curated\")\n l2g.network2.df = l2g.genes.df %>%\n left_join(network2.summary.df %>% select(gene_id, geneSymbol, seed_gene, pagerank_pctile), by = \"gene_id\") %>% mutate(network=\"l2g\")\n l2g.network.df = bind_rows(l2g.network1.df, l2g.network2.df) %>%\n group_by(l2g_locus_merged) %>%\n arrange(desc(seed_gene), desc(l2g_score_mean)) %>%\n mutate(locus_name = first(geneSymbol)) %>%\n ungroup() %>%\n mutate(network = factor(as.character(network), levels=c(\"curated\", \"l2g\")))\n locus_names = unique(l2g.network.df$locus_name)\n\n pdf(file = file.path(analysis_dir, \"locus_scatterplots.2networks.pdf\"), width=10, height=4)\n for (cur_locus in locus_names) {\n p = l2g_scatterplot(l2g.network.df, cur_locus) + facet_wrap(~network, nrow = 1) + theme_bw(10)\n print(p)\n }\n dev.off()\n}\n```\n\n\n## Pathway enrichments\n\nLook at pathway enrichments for the top 100 or 1000 genes in the curated seed gene network. These are visualised below using GOSummaries, and the gProfiler outputs are saved as .tsv files.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=9, eval=FALSE}\nlibrary(GOsummaries)\nlibrary(gProfileR)\n\ntop100Genes_PRpctile = network1.summary.df %>% arrange(desc(pagerank_pctile)) %>% .$gene_id %>% .[1:100]\ntop1000Genes_PRpctile = network1.summary.df %>% arrange(desc(pagerank_pctile)) %>% .$gene_id %>% .[1:1000]\n\ngs = gosummaries(list(top100PRpctile = top100Genes_PRpctile), custom_bg = network1.summary.df$gene_id)\nplot(gs, fontsize = 11)\n\ngs = gosummaries(list(top1000PRpctile = top1000Genes_PRpctile), custom_bg = network1.summary.df$gene_id)\nplot(gs, fontsize = 11)\n\ngp.top100 = gprofiler(query = top100Genes_PRpctile, custom_bg = network1.summary.df$gene_id, organism = \"hsapiens\")\ngp.top1000 = gprofiler(query = top1000Genes_PRpctile, custom_bg = network1.summary.df$gene_id, organism = \"hsapiens\")\ngp.top100 %>% arrange(p.value) %>% write_tsv(file.path(analysis_dir, \"curated.top100.gprofiler.tsv\"))\ngp.top1000 %>% arrange(p.value) %>% write_tsv(file.path(analysis_dir, \"curated.top1000.gprofiler.tsv\"))\n\n```\n\n\n## IBD p-value network enrichment (10 kb window)\n\nFirst look at the distribution of minp values across genes. (For Katie's IBD GWAS.)\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=6, fig.height=4}\nvecQuantiles = function(x) {\n sapply(x, function(val) if (is.na(val)) { NA } else { (sum(x <= val, na.rm = T) - 1) / (sum(!is.na(x)) - 1) })\n}\n\ngene_minp_file = file.path(root_dir, \"genes.pc.10kb_window.katie_ibd.minp.tsv.gz\")\n\nif (!file.exists(gene_minp_file)) {\n genes.minp.df = readr::read_tsv(file.path(root_dir, \"genes.pc.10kb_window.katie_ibd.snp_overlaps.tsv.gz\")) %>%\n filter(pvalue != -1) %>%\n na.omit() %>%\n group_by(gene_id) %>%\n summarise(chr = first(chr),\n gene_window_start = first(gene_window_start),\n gene_window_end = first(gene_window_end),\n snp_pos = first(snp_pos),\n snp_id = first(snp_id),\n minp = min(pvalue)) %>%\n filter(minp > -1) %>%\n ungroup() %>%\n mutate(minp.quantile = vecQuantiles(-minp))\n write_tsv(genes.minp.df, gene_minp_file)\n} \ngenes.minp.df = readr::read_tsv(gene_minp_file)\n\nnetwork1.minp.df = network1.summary.df %>%\n inner_join(genes.minp.df, by=\"gene_id\")\n\nggplot(network1.minp.df %>% filter(minp > 1e-8), aes(x=-log10(minp))) +\n geom_histogram(bins=100) + ggtitle(\"Distribution of minp values (Katie IBD GWAS)\")\n#sum(is.na(network1.minp.df$minp))\n#sum(network1.minp.df$minp < 5e-8, na.rm=T)\n#quantile(network1.minp.df$minp, probs=seq(0, 1, 0.01), na.rm=T)\n\n```\n\nDo similarly for Jimmy's IBD GWAS.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=6, fig.height=4}\njimmy_gene_minp_file = file.path(root_dir, \"genes.pc.10kb_window.jimmy_ibd.minp.tsv.gz\")\n\nif (!file.exists(jimmy_gene_minp_file)) {\n genes.jimmy.minp.df = readr::read_tsv(file.path(root_dir, \"genes.pc.10kb_window.jimmy_ibd.snp_overlaps.tsv.gz\")) %>%\n filter(pvalue != -1) %>%\n na.omit() %>%\n group_by(gene_id) %>%\n summarise(chr = first(chr),\n gene_window_start = first(gene_window_start),\n gene_window_end = first(gene_window_end),\n snp_pos = first(snp_pos),\n snp_id = first(snp_id),\n minp = min(pvalue)) %>%\n filter(minp > -1) %>%\n ungroup() %>%\n mutate(minp.quantile = vecQuantiles(-minp))\n write_tsv(genes.jimmy.minp.df, jimmy_gene_minp_file)\n} \ngenes.jimmy.minp.df = readr::read_tsv(jimmy_gene_minp_file)\n\nnetwork1.jimmy.minp.df = network1.summary.df %>%\n inner_join(genes.jimmy.minp.df, by=\"gene_id\")\n\nggplot(network1.jimmy.minp.df %>% filter(minp > 1e-8), aes(x=-log10(minp))) +\n geom_histogram(bins=100) + ggtitle(\"Distribution of minp values (Jimmy IBD GWAS)\")\n#sum(is.na(network1.minp.df$minp))\n#sum(network1.minp.df$minp < 5e-8, na.rm=T)\n#quantile(network1.minp.df$minp, probs=seq(0, 1, 0.01), na.rm=T)\n\n```\n\nJimmy's GWAS had only 157k variants. As you might expect, minp values are higher on average, since we're taking the minimum across fewer variants.\n\nNow we look at the odds ratio for genes at a given network percentile to have low p-values (within specific ranges, relative to p > 0.01 and pagerank pctile < 50).\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n#, fig.width=5.5, fig.height=4\n# network1.minp.df$pagerank_pctile.cat = categorize(network1.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90, 95))\n# network1.minp.df$pagerank_pctile.cat = factor(network1.minp.df$pagerank_pctile.cat, levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"90-95\", \"> 95\"))\n# \n# ggplot(network1.minp.df, aes(x=pagerank_pctile.cat, y=minp.quantile)) +\n# geom_boxplot() + geom_jitter(width=0.25, alpha=0.2)\n\nnetwork1.minp.df$minp_cat = categorize(network1.minp.df$minp, thresholds = c(0.01, 1e-4, 1e-6, 1e-8))\nminp_cat_levels = c(\"> 0.01\", \"1e-04-0.01\", \"1e-06-1e-04\", \"1e-08-1e-06\", \"<= 1e-08\")\nnetwork1.minp.df$minp_cat = factor(network1.minp.df$minp_cat, levels = minp_cat_levels)\n\nnetwork1.minp.df$pagerank_pctile.cat = categorize(network1.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"> 90\")\nnetwork1.minp.df$pagerank_pctile.cat = categorize(network1.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90, 95, 98))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"90-95\", \"95-98\", \"> 98\")\nnetwork1.minp.df$pagerank_pctile.cat = factor(network1.minp.df$pagerank_pctile.cat, levels = pagerank_pct_cat_levels)\n#xtabs(~ minp_cat + pagerank_pctile.cat, data = network1.minp.df)\nor.df = stratifiedOddsRatios(network1.minp.df, \"minp_cat\", \"pagerank_pctile.cat\")\nor.df$cat1 = factor(or.df$cat1, levels = minp_cat_levels)\n#or.df$cat1[or.df$cat1 == \"1e-06-1e-04\"] = parse(text=\"10^-6 - 10^-4\")\nor.df$cat2 = factor(or.df$cat2, levels = pagerank_pct_cat_levels)\n\nminp_cat_display_levels = c(\"> 0.01\", parse(text=\"10^-2 - 10^-4\"), parse(text=\"10^-4 - 10^-6\"), parse(text=\"10^-6 - 10^-8\"), paste(\"< \", parse(text=\"10^-8\")))\n\np = stratifiedOddsRatioPlot(or.df, \"Minimum p value (Katie IBD GWAS)\", \"Pagerank\\npercentile\") +\n ggtitle(\"Curated seed gene network - Katie's GWAS minp\") +\n theme_bw(12) +\n theme(axis.text.x = element_text(angle = 25, hjust = 1), axis.title.x = element_blank()) +\n scale_x_discrete(breaks = minp_cat_levels, labels = minp_cat_display_levels)\nprint(p)\n\nif (saveFiles) {\n pdf(file.path(analysis_dir, \"minp_enrichment.curated_network.pdf\"), width=5.5, height=4)\n print(p + theme(plot.title = element_blank()) + xlab(\"Minimum p value\"))\n dev.off()\n}\n```\n\nWe can look at the same thing for gene minp values for Jimmy's GWAS.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nnetwork1.jimmy.minp.df$minp_cat = categorize(network1.jimmy.minp.df$minp, thresholds = c(0.01, 1e-4, 1e-6, 1e-8))\nminp_cat_levels = c(\"> 0.01\", \"1e-04-0.01\", \"1e-06-1e-04\", \"1e-08-1e-06\", \"<= 1e-08\")\nnetwork1.jimmy.minp.df$minp_cat = factor(network1.jimmy.minp.df$minp_cat, levels = minp_cat_levels)\n\nnetwork1.jimmy.minp.df$pagerank_pctile.cat = categorize(network1.jimmy.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"> 90\")\nnetwork1.jimmy.minp.df$pagerank_pctile.cat = categorize(network1.jimmy.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90, 95, 98))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"90-95\", \"95-98\", \"> 98\")\nnetwork1.jimmy.minp.df$pagerank_pctile.cat = factor(network1.jimmy.minp.df$pagerank_pctile.cat, levels = pagerank_pct_cat_levels)\n#xtabs(~ minp_cat + pagerank_pctile.cat, data = network1.jimmy.minp.df)\nor.df = stratifiedOddsRatios(network1.jimmy.minp.df, \"minp_cat\", \"pagerank_pctile.cat\")\nor.df$cat1 = factor(or.df$cat1, levels = minp_cat_levels)\nor.df$cat2 = factor(or.df$cat2, levels = pagerank_pct_cat_levels)\nstratifiedOddsRatioPlot(or.df, \"Minimum p value (Jimmy IBD GWAS)\", \"Pagerank\\npercentile\") + ggtitle(\"Curated seed gene network - Jimmy's GWAS minp\")\n\n```\n\nThe results are very similar, so we only use Katie's GWAS in future plots.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nnetwork2.minp.df = network2.summary.df %>%\n inner_join(genes.minp.df, by=\"gene_id\")\n\nnetwork2.minp.df$minp_cat = categorize(network2.minp.df$minp, thresholds = c(0.01, 1e-4, 1e-6, 1e-8))\nminp_cat_levels = c(\"> 0.01\", \"1e-04-0.01\", \"1e-06-1e-04\", \"1e-08-1e-06\", \"<= 1e-08\")\nnetwork2.minp.df$minp_cat = factor(network2.minp.df$minp_cat, levels = minp_cat_levels)\n\nnetwork2.minp.df$pagerank_pctile.cat = categorize(network2.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"> 90\")\nnetwork2.minp.df$pagerank_pctile.cat = categorize(network2.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90, 95, 98))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"90-95\", \"95-98\", \"> 98\")\nnetwork2.minp.df$pagerank_pctile.cat = factor(network2.minp.df$pagerank_pctile.cat, levels = pagerank_pct_cat_levels)\n#xtabs(~ minp_cat + pagerank_pctile.cat, data = network2.minp.df)\nor.df = stratifiedOddsRatios(network2.minp.df, \"minp_cat\", \"pagerank_pctile.cat\")\nor.df$cat1 = factor(or.df$cat1, levels = minp_cat_levels)\nor.df$cat2 = factor(or.df$cat2, levels = pagerank_pct_cat_levels)\nstratifiedOddsRatioPlot(or.df, \"Minimum p value\", \"Pagerank\\npercentile\") + ggtitle(\"L2G seed gene network - Katie's GWAS minp\")\n\n```\n\n\n\n## IBD p-value network enrichment (gene-overlapping)\n\nWe can do the same odds ratio analyses considering only variants that overlap genes, without a 10 kb window. This avoids the problem that +/-10 kb will include the same SNPs multiple times in gene-dense regions.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.width=6, fig.height=4}\ngene_minp_file = file.path(root_dir, \"genes.pc.overlapping.katie_ibd.minp.tsv.gz\")\n\nif (!file.exists(gene_minp_file)) {\n gene_pvalues_file = file.path(root_dir, \"genes.pc.katie_ibd.snp_overlaps.tsv.gz\")\n genes.minp.df = readr::read_tsv(gene_pvalues_file) %>%\n filter(pvalue != -1) %>%\n na.omit() %>%\n group_by(gene_id) %>%\n summarise(chr = first(chr),\n gene_window_start = first(gene_window_start),\n gene_window_end = first(gene_window_end),\n snp_pos = first(snp_pos),\n snp_id = first(snp_id),\n minp = min(pvalue)) %>%\n filter(minp > -1) %>%\n ungroup() %>%\n mutate(minp.quantile = vecQuantiles(-minp))\n write_tsv(genes.minp.df, gene_minp_file)\n} \ngenes.minp.df = readr::read_tsv(gene_minp_file)\n\nnetwork1.minp.df = network1.summary.df %>%\n inner_join(genes.minp.df, by=\"gene_id\")\n\nggplot(network1.minp.df %>% filter(minp > 1e-8), aes(x=-log10(minp))) +\n geom_histogram(bins=100) + ggtitle(\"Distribution of minp values (Katie IBD GWAS, gene-overlapping)\")\n#sum(is.na(network1.minp.df$minp))\n#sum(network1.minp.df$minp < 5e-8, na.rm=T)\n#quantile(network1.minp.df$minp, probs=seq(0, 1, 0.01), na.rm=T)\n\n```\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n# network1.minp.df$pagerank_pctile.cat = categorize(network1.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90, 95))\n# network1.minp.df$pagerank_pctile.cat = factor(network1.minp.df$pagerank_pctile.cat, levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"90-95\", \"> 95\"))\n# \n# ggplot(network1.minp.df, aes(x=pagerank_pctile.cat, y=minp.quantile)) +\n# geom_boxplot() + geom_jitter(width=0.25, alpha=0.2)\n\nnetwork1.minp.df$minp_cat = categorize(network1.minp.df$minp, thresholds = c(0.01, 1e-4, 1e-6, 1e-8))\nminp_cat_levels = c(\"> 0.01\", \"1e-04-0.01\", \"1e-06-1e-04\", \"1e-08-1e-06\", \"<= 1e-08\")\nnetwork1.minp.df$minp_cat = factor(network1.minp.df$minp_cat, levels = minp_cat_levels)\n\nnetwork1.minp.df$pagerank_pctile.cat = categorize(network1.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"> 90\")\nnetwork1.minp.df$pagerank_pctile.cat = categorize(network1.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90, 95, 98))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"90-95\", \"95-98\", \"> 98\")\nnetwork1.minp.df$pagerank_pctile.cat = factor(network1.minp.df$pagerank_pctile.cat, levels = pagerank_pct_cat_levels)\n#xtabs(~ minp_cat + pagerank_pctile.cat, data = network1.minp.df)\nor.df = stratifiedOddsRatios(network1.minp.df, \"minp_cat\", \"pagerank_pctile.cat\")\nor.df$cat1 = factor(or.df$cat1, levels = minp_cat_levels)\nor.df$cat2 = factor(or.df$cat2, levels = pagerank_pct_cat_levels)\nstratifiedOddsRatioPlot(or.df, \"Minimum p value\", \"Pagerank\\npercentile\") + ggtitle(\"Curated seed gene network\")\n\n```\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nnetwork2.minp.df = network2.summary.df %>%\n inner_join(genes.minp.df, by=\"gene_id\")\n\nnetwork2.minp.df$minp_cat = categorize(network2.minp.df$minp, thresholds = c(0.01, 1e-4, 1e-6, 1e-8))\nminp_cat_levels = c(\"> 0.01\", \"1e-04-0.01\", \"1e-06-1e-04\", \"1e-08-1e-06\", \"<= 1e-08\")\nnetwork2.minp.df$minp_cat = factor(network2.minp.df$minp_cat, levels = minp_cat_levels)\n\nnetwork2.minp.df$pagerank_pctile.cat = categorize(network2.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"> 90\")\nnetwork2.minp.df$pagerank_pctile.cat = categorize(network2.minp.df$pagerank_pctile, thresholds = c(50, 60, 70, 80, 90, 95, 98))\npagerank_pct_cat_levels = c(\"<= 50\", \"50-60\", \"60-70\", \"70-80\", \"80-90\", \"90-95\", \"95-98\", \"> 98\")\nnetwork2.minp.df$pagerank_pctile.cat = factor(network2.minp.df$pagerank_pctile.cat, levels = pagerank_pct_cat_levels)\n#xtabs(~ minp_cat + pagerank_pctile.cat, data = network2.minp.df)\nor.df = stratifiedOddsRatios(network2.minp.df, \"minp_cat\", \"pagerank_pctile.cat\")\nor.df$cat1 = factor(or.df$cat1, levels = minp_cat_levels)\nor.df$cat2 = factor(or.df$cat2, levels = pagerank_pct_cat_levels)\nstratifiedOddsRatioPlot(or.df, \"Minimum p value\", \"Pagerank\\npercentile\") + ggtitle(\"Strict seed gene network\")\n\n```\n\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n# PRIORITIZING GENES\n# Here we write out a table with genes prioritised both by L2G and network\n# First we need to find all genes within a window at each locus\nwindowSize = 5e5\nl2g.loci.df2 = l2g.loci.df %>%\n dplyr::select(chr, l2g_mean_pos, l2g_locus_merged) %>%\n mutate(l2g_start = l2g_mean_pos - windowSize, l2g_end = l2g_mean_pos + windowSize)\nl2g.gr = makeGRangesFromDataFrame(l2g.loci.df2, keep.extra.columns = T, ignore.strand = T,\n seqinfo = NULL, seqnames.field = \"chr\", start.field = \"l2g_start\", end.field = \"l2g_end\")\n\ngrch38.nodup = grch38 %>% filter(!duplicated(ensgene))\ngrch38.df = grch38.nodup %>%\n select(chr, gene_start = start, gene_end = end, ensgene, symbol)\ngrch38.gr = makeGRangesFromDataFrame(grch38.df, keep.extra.columns = T, ignore.strand = T,\n seqinfo = NULL, seqnames.field = \"chr\", start.field = \"gene_start\", end.field = \"gene_end\")\n\nhits.df = as_tibble( findOverlaps(l2g.gr, grch38.gr, ignore.strand = T) )\n\n# Get all genes within the window around or L2G loci, and then merge in\n# each of the network pageranks\nlocus_genes.df = bind_cols(l2g.loci.df[hits.df$queryHits,] %>%\n select(l2g_locus_merged, chr, l2g_mean_pos, top_gene_mean, top_gene_score_mean, lead_p),\n grch38.df[hits.df$subjectHits,] %>% dplyr::select(-chr) %>% dplyr::rename(gene_id = ensgene)) %>%\n left_join(l2g.genes.df %>% select(l2g_locus_merged, gene_id, l2g_score_mean), by=c(\"gene_id\", \"l2g_locus_merged\")) %>%\n left_join(network1.summary.df %>% select(gene_id, geneSymbol, network1_pagerank_pctile = pagerank_pctile, network1_seed_gene = seed_gene)) %>%\n left_join(network2.summary.df %>% select(gene_id, network2_pagerank_pctile = pagerank_pctile, network2_seed_gene = seed_gene))\n\n# Create a network score that rewards being above the 50th pctile and is the\n# average across the 3 networks\n# Then get ranks of genes at each locus based on their network scores\nlocus_genes.df = locus_genes.df %>%\n group_by(l2g_locus_merged) %>%\n mutate(network1_rank = rank(-network1_pagerank_pctile, ties.method = \"average\"),\n network2_rank = rank(-network2_pagerank_pctile, ties.method = \"average\")) %>%\n rowwise() %>%\n mutate(network_avg = mean(c(network1_pagerank_pctile, network2_pagerank_pctile)),\n network_max = max(c(network1_pagerank_pctile, network2_pagerank_pctile)),\n network_score = max(0, (network_max - 50) * 2),\n l2g_network_score = sqrt(l2g_score_mean) * network_score) %>%\n group_by(l2g_locus_merged) %>%\n mutate(l2g_network_score_rank = rank(-l2g_network_score, ties.method = \"average\")) %>%\n arrange(chr, l2g_mean_pos, l2g_locus_merged, desc(l2g_network_score))\nwrite_tsv(locus_genes.df, file.path(analysis_dir, \"locus_genes.network.tsv\"), na = \"\")\n\n#ViewDups(locus_genes.df, \"gene_id\")\n```\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n# Flag genes where the gene has a higher network score than the top L2G gene\n# and also has a L2G score of at least 0.1\nlocus_top_l2gene_network_score = locus_genes.df %>%\n group_by(l2g_locus_merged) %>%\n arrange(desc(l2g_score_mean)) %>%\n mutate(locus_has_curated_gene = any(network1_seed_gene, na.rm = T)) %>%\n filter(row_number() == 1) %>%\n select(l2g_locus_merged, top_gene_network_score = network_score, locus_has_curated_gene) %>%\n mutate(top_gene_network_score = if_else(is.na(top_gene_network_score), 0, top_gene_network_score))\nlocus_second_best_network_candidate = locus_genes.df %>%\n filter(network_avg > 80, l2g_score_mean > 0.1) %>%\n group_by(l2g_locus_merged) %>%\n arrange(desc(network_score)) %>%\n filter(row_number() == 2) %>%\n select(l2g_locus_merged, second_best_network_score = network_score)\nlocus_second_best_l2g_net_candidate = locus_genes.df %>%\n group_by(l2g_locus_merged) %>%\n arrange(desc(l2g_network_score)) %>%\n filter(row_number() == 2) %>%\n select(l2g_locus_merged, second_best_l2g_network_score = l2g_network_score)\nlocus_genes.df2 = locus_genes.df %>%\n group_by(gene_id) %>%\n left_join(locus_top_l2gene_network_score, by=\"l2g_locus_merged\") %>%\n left_join(locus_second_best_network_candidate, by=\"l2g_locus_merged\") %>%\n left_join(locus_second_best_l2g_net_candidate, by=\"l2g_locus_merged\") %>%\n mutate(second_best_network_score = if_else(is.na(second_best_network_score), 0, second_best_network_score)) %>%\n mutate(network_revised_candidate = (!locus_has_curated_gene & network_score > top_gene_network_score & network_score > 60 & top_gene_network_score < 60 & l2g_score_mean > 0.1 & l2g_network_score_rank == 1),\n network_top_new_candidate = (!locus_has_curated_gene & network_score > 90 & l2g_score_mean > 0.1 & l2g_network_score_rank == 1 & second_best_network_score < 60),\n network_l2g_top_new_candidate = (!locus_has_curated_gene & l2g_network_score_rank == 1 & (l2g_network_score - second_best_l2g_network_score) > 20)) %>%\n left_join(grch38.nodup %>% select(ensgene, description), by=c(\"gene_id\" = \"ensgene\")) %>%\n arrange(chr, l2g_mean_pos, l2g_locus_merged, desc(l2g_score_mean)) %>%\n select(l2g_locus_merged:gene_id, network_top_new_candidate, network_l2g_top_new_candidate, symbol, l2g_network_score, l2g_score_mean, network1_pagerank_pctile, network2_pagerank_pctile, network1_seed_gene, network2_seed_gene, second_best_l2g_network_score, second_best_network_score, l2g_network_score_rank, everything())\n#sum(locus_genes.df2$network_revised_candidate, na.rm=T)\nsum(locus_genes.df2$network_revised_candidate, na.rm=T)\nsum(locus_genes.df2$network_top_new_candidate, na.rm=T)\nsum(locus_genes.df2$network_l2g_top_new_candidate, na.rm=T)\nwrite_tsv(locus_genes.df2, file.path(analysis_dir, \"locus_genes.network.revised_candidates.tsv\"), na = \"\")\n```\n\n\n## Sub-threshold genes\n\nLet's look for genes with high network scores that have sub-genome-wide significant p values. This is the distribution of network scores after excluding genome-wide significant loci. (But actually I need a better way to do this, because I've only removed genes with a \"locus2gene\" score - and some genes remain at the GWAS loci, which suggests that we're missing some L2G scores. This could be due to LD and the window size used for L2G.)\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nnetwork1.subthreshold.df = network1.minp.df %>%\n filter(!gene_id %in% l2g.genes.df$gene_id)\n\nView(network1.subthreshold.df %>% filter(minp > 5e-8) %>% arrange(minp) %>% select(geneSymbol, degree, pagerank_pctile, minp, chr, gene_window_start, gene_window_end, everything()))\n\nggplot(network1.minp.df, aes(x=minp_cat, y=pagerank_pctile)) +\n geom_violin(alpha = 0.9) + geom_jitter(width = 0.25, alpha = 0.2) + geom_boxplot(width = 0.05, outlier.shape = NA, fill=\"white\")\n\n\n```\n\n\n"
},
{
"alpha_fraction": 0.6610599756240845,
"alphanum_fraction": 0.6925030946731567,
"avg_line_length": 43.1363639831543,
"blob_id": "430325ccba05ff9778d0ef6294045e4b78c57ae0",
"content_id": "6bad9d37a2506a82ff97737a23770fc9c06a7dbc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "RMarkdown",
"length_bytes": 14566,
"license_type": "no_license",
"max_line_length": 616,
"num_lines": 330,
"path": "/misc/check_covid_qtl_alleles.Rmd",
"repo_name": "Jeremy37/src",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Check covid-19 GWAS SNPs for QTL effects\"\noutput: html_document\n---\n\n## Introduction\n\nThe first covid-19 GWAS to find a genome-wide significant effect, <a href=\"https://www.nejm.org/doi/full/10.1056/NEJMoa2020283\">Ellinghaus et al.</a>, defined a credible set with 22 SNPs at chromosome 3p21.31 (lead SNP rs11385942). Here we analyse the overlap between COVID-19 SNPs and various eQTL datasets.\n\nFirst off, here are the COVID-associated SNPs we're using.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\nlibrary(tidyverse)\nlibrary(coloc)\nlibrary(GenomicRanges)\nlibrary(Rsamtools)\nlibrary(annotables)\n\nverbose = T\ndir = \"/Users/jeremys/work/opentargets/covid\"\ntabix_paths = read.delim(\"https://raw.githubusercontent.com/eQTL-Catalogue/eQTL-Catalogue-resources/master/tabix/tabix_ftp_paths.tsv\", sep = \"\\t\", header = TRUE, stringsAsFactors = FALSE) %>% dplyr::as_tibble()\nimported_tabix_paths = read.delim(\"https://raw.githubusercontent.com/eQTL-Catalogue/eQTL-Catalogue-resources/master/tabix/tabix_ftp_paths_imported.tsv\", sep = \"\\t\", header = TRUE, stringsAsFactors = FALSE) %>% dplyr::as_tibble()\ntheme_set(theme_bw(10))\n\ngrch38_nodup = grch38 %>%\n filter(!duplicated(ensgene))\n\n# Define the COVID SNPs as chr_pos_ref_alt to match eQTL catalogue\ncovid_snps = c(\n\"3_45805277_A_G\",\n\"3_45801750_G_A\",\n\"3_45807268_G_C\",\n\"3_45801823_C_T\",\n\"3_45801947_G_T\",\n\"3_45859142_G_C\",\n\"3_45867532_A_G\",\n\"3_45866624_A_T\",\n\"3_45818159_G_A\",\n\"3_45858159_A_G\",\n\"3_45825948_A_G\",\n\"3_45847198_A_G\",\n\"3_45820440_G_A\",\n\"3_45821460_T_C\",\n\"3_45859597_C_T\",\n\"3_45823240_T_C\",\n\"3_45830416_G_A\",\n\"3_45867022_C_G\",\n\"3_45848429_A_T\",\n\"3_45838989_T_C\",\n\"3_45848457_C_T\",\n\"3_45834967_G_GA\")\ncovid_snps_chr = paste0(\"chr\", covid_snps)\n\nprint(covid_snps)\n```\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE}\n#' A general function to quickly import tabix indexed tab-separated files into data_frame\n#'\n#' @param tabix_file Path to tabix-indexed text file\n#' @param param An instance of GRanges, RangedData, or RangesList\n#' provide the sequence names and regions to be parsed. Passed onto Rsamtools::scanTabix()\n#' @param ... Additional parameters to be passed on to readr::read_delim()\n#'\n#' @return List of data_frames, one for each entry in the param GRanges object.\n#' @export\nscanTabixDataFrame <- function(tabix_file, param, ...){\n tabix_list = Rsamtools::scanTabix(tabix_file, param = param)\n df_list = lapply(tabix_list, function(x,...){\n if(length(x) > 0){\n if(length(x) == 1){\n #Hack to make sure that it also works for data frames with only one row\n #Adds an empty row and then removes it\n result = paste(paste(x, collapse = \"\\n\"),\"\\n\",sep = \"\")\n result = readr::read_delim(result, delim = \"\\t\", ...)[1,]\n }else{\n result = paste(x, collapse = \"\\n\")\n result = readr::read_delim(result, delim = \"\\t\", ...)\n }\n } else{\n #Return NULL if the nothing is returned from tabix file\n result = NULL\n }\n return(result)\n }, ...)\n return(df_list)\n}\n\n# In eQTL Catalogue, variants with multiple rsids are split over multiple rows in the summary statistics files.\n# Thus, we first want to retain only one unique record per variant. To simplify colocalisation analysis, we\n# also want to exclude multi-allelic variants. The following function imports summary statistics from a\n# tabix-index TSV file and performs necessary filtering.\nimport_eQTLCatalogue <- function(ftp_path, region, column_names, verbose = TRUE) {\n if(verbose){\n print(ftp_path)\n }\n \n #Fetch summary statistics with Rsamtools\n summary_stats = scanTabixDataFrame(ftp_path, region, col_names = column_names)[[1]]\n \n #Remove rsid duplicates and multi-allelic variant\n summary_stats = dplyr::select(summary_stats, -rsid) %>% \n dplyr::distinct() %>% #rsid duplicates\n dplyr::mutate(id = paste(chromosome, position, sep = \":\")) %>% \n dplyr::group_by(id, gene_id) %>% \n dplyr::mutate(row_count = n()) %>% dplyr::ungroup() %>% \n dplyr::filter(row_count == 1) #Multiallelics\n \n return(summary_stats)\n}\n\nimport_multiTissue_eQTL = function(paths.df, region, column_names, verbose = TRUE) {\n sumstat_list = lapply(1:nrow(paths.df), FUN = function(i) {\n tryCatch( {\n df = import_eQTLCatalogue(paths.df$ftp_path[i], region, column_names, verbose)\n bind_cols(paths.df[rep(i, nrow(df)),] %>% select(-tissue_ontology_id, -ftp_path, -qtl_group), df)\n }, error = function(err) { NULL })\n } )\n return( bind_rows(sumstat_list) )\n}\n```\n\nFor comparing with eQTLs in the region, we will look at all SNPs within 200 kb of these SNPs, to determine whether any of these are credibly causal SNPs for the eQTL effect.\n\nLet's first look at the minimum p value for Covid credible set SNPs for any gene (within 100 kb) for each QTL dataset. We'll do this first for eQTL catalogue datasets.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.height=6, fig.width=8}\n# Get sumstats from eQTL catalogue and filter for our SNPs of interest\nqtl_catalogue_column_names = colnames(readr::read_tsv(tabix_paths$ftp_path[1], n_max = 1))\n\n# Range from first to last credset SNP, plus window of 100 kb\nregion_granges = GenomicRanges::GRanges(\n seqnames = \"3\", \n ranges = IRanges::IRanges(start = 45601750, end = 46067532), \n strand = \"*\")\n\nnearby_genes = grch38_nodup %>%\n filter(chr == \"3\") %>%\n rowwise() %>%\n mutate(geneDist = min(abs(45801750 - start), abs(45801750 - end), abs(45867532 - start), abs(45867532 - end))) %>%\n filter(geneDist < 100000)\n\n# First try a subset of studies\n#sel_studies = seq(1, nrow(tabix_paths), 20)\nsel_studies = seq(1, nrow(tabix_paths), 1)\n\nif (!file.exists(\"qtl.catalogue.covid.chr3.tsv.gz\")) {\n qtl.catalogue.df = import_multiTissue_eQTL(tabix_paths[sel_studies,] %>% filter(quant_method == \"ge\"), region_granges, qtl_catalogue_column_names, verbose=verbose) %>%\n filter(gene_id %in% nearby_genes$ensgene) %>%\n mutate(qtl_dataset = paste(study, tissue_label, condition_label, quant_method))\n write_tsv(qtl.catalogue.df, path = \"qtl.catalogue.covid.chr3.tsv.gz\")\n} else {\n qtl.catalogue.df = read_tsv(\"qtl.catalogue.covid.chr3.tsv.gz\")\n}\n\nqtl.catalogue.covid.df = qtl.catalogue.df %>% filter(variant %in% covid_snps_chr)\n\nqtl.catalogue.covid.study.minp.df = qtl.catalogue.covid.df %>%\n group_by(qtl_dataset) %>%\n summarise(minp = min(pvalue))\n\nggplot(qtl.catalogue.covid.study.minp.df, aes(y=fct_reorder(qtl_dataset, -log10(minp)), x=-log10(minp))) +\n geom_point() +\n ylab(\"QTL dataset\") +\n ggtitle(\"eQTL catalogue: MinP per QTL study for Covid credset SNPs\")\n```\n\nNext do the same thing for GTEx.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.height=6, fig.width=8}\ngtex_column_names = colnames(readr::read_tsv(imported_tabix_paths$ftp_path[1], n_max = 1))\n\nif (!file.exists(\"qtl.gtex.covid.chr3.tsv.gz\")) {\n qtl.gtex.df = import_multiTissue_eQTL(imported_tabix_paths %>% filter(quant_method == \"ge\"), region_granges, gtex_column_names, verbose=verbose) %>%\n filter(gene_id %in% nearby_genes$ensgene) %>%\n mutate(qtl_dataset = tissue_label)\n write_tsv(qtl.gtex.df, path = \"qtl.gtex.covid.chr3.tsv.gz\")\n} else {\n qtl.gtex.df = read_tsv(\"qtl.gtex.covid.chr3.tsv.gz\")\n}\n\nqtl.gtex.covid.df = qtl.gtex.df %>% filter(variant %in% covid_snps_chr)\n\nqtl.gtex.covid.study.minp.df = qtl.gtex.covid.df %>%\n group_by(qtl_dataset) %>%\n summarise(minp = min(pvalue))\n\nggplot(qtl.gtex.covid.study.minp.df, aes(y=fct_reorder(qtl_dataset, -log10(minp)), x=-log10(minp))) +\n geom_point() +\n ylab(\"QTL dataset\") +\n ggtitle(\"GTEx: MinP per QTL study for Covid credset SNPs\")\n```\n\nWe can also look at the minimum p value across QTL datasets for each gene, for both COVID SNPs and other SNPs. First for eQTL catalogue.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.height=3, fig.width=7}\nqtl.catalogue.gene.minp.df = qtl.catalogue.df %>%\n group_by(gene_id) %>%\n summarise(minp = min(pvalue)) %>%\n left_join(grch38_nodup, by=c(\"gene_id\" = \"ensgene\")) %>%\n filter(!is.na(symbol)) %>%\n mutate(type = \"All SNPs\")\nqtl.catalogue.covid.gene.minp.df = qtl.catalogue.covid.df %>%\n group_by(gene_id) %>%\n summarise(minp = min(pvalue)) %>%\n left_join(grch38_nodup, by=c(\"gene_id\" = \"ensgene\")) %>%\n filter(!is.na(symbol)) %>%\n mutate(type = \"Covid SNPs\")\n\ngene.summary.df = bind_rows(qtl.catalogue.gene.minp.df, qtl.catalogue.covid.gene.minp.df)\nggplot(gene.summary.df, aes(y=fct_reorder(symbol, -log10(minp)), x=-log10(minp), col=type)) +\n geom_point(alpha=0.7) +\n theme(axis.text.x = element_text(angle = 90, hjust = 1)) +\n ylab(\"Gene ID\") +\n ggtitle(\"eQTL catalogue: MinP per gene (across QTL datasets)\")\n```\nAnd also for GTEx.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.height=4, fig.width=7}\ngrch38_nodup = grch38 %>%\n filter(!duplicated(ensgene))\nqtl.gtex.gene.minp.df = qtl.gtex.df %>%\n group_by(gene_id) %>%\n summarise(minp = min(pvalue)) %>%\n left_join(grch38_nodup, by=c(\"gene_id\" = \"ensgene\")) %>%\n filter(!is.na(symbol)) %>%\n mutate(type = \"All SNPs\")\nqtl.gtex.covid.gene.minp.df = qtl.gtex.covid.df %>%\n group_by(gene_id) %>%\n summarise(minp = min(pvalue)) %>%\n left_join(grch38_nodup, by=c(\"gene_id\" = \"ensgene\")) %>%\n filter(!is.na(symbol)) %>%\n mutate(type = \"Covid SNPs\")\n\ngene.summary.df = bind_rows(qtl.gtex.gene.minp.df, qtl.gtex.covid.gene.minp.df)\nggplot(gene.summary.df, aes(y=fct_reorder(symbol, -log10(minp)), x=-log10(minp), col=type)) +\n geom_point(alpha=0.7) +\n theme(axis.text.x = element_text(angle = 90, hjust = 1)) +\n ylab(\"Gene ID\") +\n ggtitle(\"GTEx: MinP per gene (across QTL datasets)\")\n```\n\nSLC6A20 is the only gene for which a COVID SNP is also the top QTL SNP across datasets.\nOther genes where the top COVID SNP is near the top SNP overall include LZTFL1 and CCR9.\n\n\n### Per Gene - genes of interest\n\nWe would like to know if any of the COVID SNPs are credibly causal for the eQTL. This is not a proper colocalisation analysis, but we can get some of the way there by checking whether any COVID SNP has a QTL p value within a couple orders of magnitude of the minimum QTL p value for the same gene.\n\nWe will only do this for genes where at least one COVID SNP has a QTL p value smaller than 1e-3. For this, let's merge the eQTL catalogue and GTEx results in each plot.\n\nThe direction of the arrow indicates whether the SNP is associated with increased (upwards arrow) or decreased (downwards arrow) **gene expression**. Note that this for COVID SNPs, this also indicates the direction of effect on COVID risk, since the ALT allele is the effect allele. For non-COVID SNPs, we can't know for sure the direction of effect on COVID risk. (Where the p values are close for the top SNP and top COVID SNP, it's more likely that these are in LD, and so the arrow then reflects the direction of COVID risk. But we would have to check the LD, or check in the GWAS summary statistics to be sure.)\n\nWe are hoping to find cases where the p value of the top COVID SNP (blue) is similar to the p value of the top SNP overall (red), and in the same direction. In general it makes sense to ignore most QTL datasets where the top SNP has a p value worse than about 1e-3 or 1e-4, since these are just noise. I would only pay attention to datasets where there is a clear QTL effect.\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.height=9, fig.width=8}\n# Do the same, but now getting minp for QTL study / gene combinations\nqtl.gene.minp.df = bind_rows(qtl.catalogue.df, qtl.gtex.df) %>%\n group_by(qtl_dataset, gene_id) %>%\n filter(pvalue == min(pvalue)) %>%\n mutate(type = \"All SNPs\",\n qtl_risk = if_else(beta > 0, \"positive\", \"negative\")) %>%\n left_join(grch38_nodup, by=c(\"gene_id\" = \"ensgene\")) %>%\n filter(!is.na(symbol))\nqtl.covid.gene.minp.df = bind_rows(qtl.catalogue.covid.df, qtl.gtex.covid.df) %>%\n group_by(qtl_dataset, gene_id) %>%\n filter(pvalue == min(pvalue)) %>%\n mutate(type = \"Covid SNPs\",\n qtl_risk = if_else(beta > 0, \"positive\", \"negative\")) %>%\n left_join(grch38_nodup, by=c(\"gene_id\" = \"ensgene\")) %>%\n filter(!is.na(symbol))\n\nqtl.combined.df = bind_rows(qtl.gene.minp.df, qtl.covid.gene.minp.df)\n\n#View(qtl.gtex.df %>% filter(grepl(\"Muscle\", tissue_label), gene_id == \"ENSG00000163817\"))\n \nsymbols = unique(qtl.covid.gene.minp.df %>% filter(pvalue < 1e-3) %>% arrange(pvalue) %>% .$symbol)\n#pdf(\"covid_gwas_qtls.filtered.pdf\", width=7, height=4)\nfor (geneSymbol in symbols) {\n df = qtl.combined.df %>%\n filter(symbol == geneSymbol) %>%\n group_by(qtl_dataset) %>%\n mutate(covid_snp_p = min(pvalue[type == \"Covid SNPs\"]))\n p1 = ggplot(df, aes(y=fct_reorder(qtl_dataset, -log10(covid_snp_p)), x=-log10(pvalue), col=type, fill=type, shape=qtl_risk)) +\n geom_point(alpha = 0.8, size=2) +\n scale_shape_manual(values = c(\"positive\" = 24, \"negative\" = 25)) +\n ylab(\"QTL dataset\") +\n ggtitle(sprintf(\"%s: MinP per QTL dataset\", geneSymbol))\n print(p1)\n}\n#dev.off()\n```\n\n## Interpretation\n\nGenes of interest based on this:\n\n* CXCR6 has a COVID SNP as the top for the Schmiedel Tfh cell naive dataset. The SNP is also highly ranked and directionally concordance in Artery-Tibial and Adipose. Muscle has a strong eQTL in the opposite direction as the COVID SNP.\n* SLC6A20 has a COVID SNP near the top in a few GTEx datasets (muscle, esophagus, breast, tibial nerve).\n* A transcript AC098476.1 (TEC - to be experimentally confirmed) has COVID SNPs among the top in the tibial nerve, muscle, breast. This transcript is between SLC6A20 and SACM1L.\n\nOther genes, such as FYCO1, LZTFL1, and CCR9, in general don't show COVID SNPs as candidates for being causal.\n\nOverall I don't feel this is great support for any gene, since we don't have a case where many (independent) datasets point to the same gene with a COVID SNP near the top in most cases.\n\n\n\n```{r, warning=FALSE, message=FALSE, echo=FALSE, fig.height=6, fig.width=8, eval=FALSE}\n#Next, include all genes.\n\n#pdf(\"covid_gwas_qtls.pdf\", width=7, height=4)\nsymbols = unique(qtl.combined.df$symbol)\nfor (geneSymbol in symbols) {\n df = qtl.combined.df %>%\n filter(symbol == geneSymbol) %>%\n group_by(qtl_dataset) %>%\n mutate(covid_snp_p = min(pvalue[type == \"Covid SNPs\"]))\n p1 = ggplot(df, aes(x=fct_reorder(qtl_dataset, log10(pvalue)), y=-log10(pvalue), col=type, fill=type, shape=qtl_risk)) +\n geom_point(alpha = 0.8, size=2) +\n theme(axis.text.x = element_text(angle = 90, hjust = 1)) +\n scale_shape_manual(values = c(\"positive\" = 24, \"negative\" = 25)) +\n xlab(\"QTL dataset\") +\n ggtitle(sprintf(\"%s: MinP per QTL dataset\", geneSymbol))\n print(p1)\n}\n#dev.off()\n\n```\n\n"
}
] | 9 |
picklelo/zerofs | https://github.com/picklelo/zerofs | 5a849bfaefdd280c95dc4a7b9114726650f47c5a | b3d450267ce647a7726c55334d0be82a06d2ef37 | bacfd614d9edf402ed431c22b95046eec0965d59 | refs/heads/master | 2021-08-15T00:31:41.837548 | 2020-08-23T00:29:04 | 2020-08-23T00:29:04 | 183,403,475 | 1 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6106420159339905,
"alphanum_fraction": 0.6158311367034912,
"avg_line_length": 27.639799118041992,
"blob_id": "ab979ab073da4d8926c262c8810b2a9999ab3d3c",
"content_id": "6c9e35d3dcaa6a6338a082aca443b20739fe1271",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11370,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 397,
"path": "/zerofs/fs.py",
"repo_name": "picklelo/zerofs",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\nfrom errno import ENOENT, ENOTEMPTY, EINVAL\nfrom logging import getLogger\nfrom stat import S_IFDIR, S_IFLNK\nfrom threading import Lock\nfrom time import time\nfrom typing import Dict, List, Tuple, Union\n\nfrom b2py import B2, utils as b2_utils\nfrom fuse import FuseOSError, Operations, LoggingMixIn\nfrom zerofs.cache import Cache\nfrom zerofs.file import Directory, File\nfrom zerofs.task_queue import TaskQueue\n\nlogger = getLogger('zerofs')\n\n\nclass ZeroFS(LoggingMixIn, Operations):\n \"\"\"Virtual filesystem backed by the B2 object store.\"\"\"\n\n def __init__(self,\n bucket_name: str,\n cache_dir: str = '~/.zerofs',\n cache_size: int = 1000,\n upload_delay: float = 5.0,\n update_period: float = 0.0,\n num_workers: int = 10):\n \"\"\"Initialize the FUSE filesystem.\n\n Args:\n bucket_name: The name of the remote bucket to mount.\n cache_dir: The directory to cache files to.\n cache_size: The cache size in MB for saving files on local disk.\n upload_delay: Delay in seconds after writing before uploading to cloud.\n update_period: The period (s) at which to update directory contents.\n num_workers: Number of background thread workers.\n \"\"\"\n self.bucket_name = bucket_name\n self.cache = Cache(cache_dir, cache_size)\n self.b2 = B2()\n self.file_locks = defaultdict(Lock)\n self.upload_delay = upload_delay\n\n # Initialize the root directory\n buckets = self.b2.list_buckets()\n bucket = [b for b in buckets if b['bucketName'] == self.bucket_name]\n if not len(bucket):\n raise ValueError('Create a bucket named {} to enable zerofs.'.format(\n self.bucket_name))\n self.bucket_id = bucket[0]['bucketId']\n self.root = Directory(\n self.b2, self.bucket_id, '', update_period=update_period)\n self.fd = 0\n\n # Initialize the task queue\n self.task_queue = TaskQueue(num_workers)\n\n def init(self, _):\n \"\"\"Start the background task queue.\"\"\"\n self.task_queue.start()\n\n @staticmethod\n def _to_bytes(s: Union[str, bytes]):\n if type(s) == bytes:\n return s\n return s.encode('utf-8')\n\n def chmod(self, path: str, mode: int):\n \"\"\"Change the file permissions.\n\n Args:\n path: The path to the file.\n mode: The new file mode permissions\n \"\"\"\n logger.info('chmod %s %s', path, mode)\n file = self.root.file_at_path(path)\n file.chmod(mode)\n\n def chown(self, path: str, uid: str, gid: str):\n \"\"\"Change the file owner.\n\n Args:\n path: The path to the file.\n uid: The user owner id.\n gid: The group owner id.\n \"\"\"\n logger.info('chown %s %s %s', path, uid, gid)\n file = self.root.file_at_path(path)\n file.chown(uid, gid)\n\n def create(self, path: str, mode: int) -> int:\n \"\"\"Create an empty file.\n\n Args:\n path: The path to the file to create.\n mode: The permissions on the file.\n\n Returns:\n The file descriptor.\n \"\"\"\n logger.info('create %s %s', path, mode)\n file = self.root.touch(path, mode)\n self.cache.add(file.file_id, self._to_bytes(''))\n self.task_queue.submit_task(file.file_id, self.upload_delay,\n self._upload_file, path)\n return self.open()\n\n def open(self, _=None, __=None) -> int:\n \"\"\"Increment the file descriptor.\n\n Returns:\n A new file descriptor.\n \"\"\"\n self.fd += 1\n return self.fd\n\n def getattr(self, path: str, _) -> Dict:\n \"\"\"\n Args:\n path: The path to the file.\n\n Returns:\n The file metadata.\n \"\"\"\n if not self.root.file_exists(path):\n raise FuseOSError(ENOENT)\n return self.root.file_at_path(path).metadata\n\n def getxattr(self, path: str, name: str, _=None) -> str:\n \"\"\"Read a file attribute.\n\n Args:\n path: The path to the file.\n name: The name of the attribute to read.\n \n Returns:\n The value of the attribute for the file.\n \"\"\"\n file = self.root.file_at_path(path)\n if name in file.attrs:\n return file.attrs[name]\n return ''.encode('utf-8')\n\n def listxattr(self, path: str) -> List[str]:\n \"\"\"\n Args:\n path: The path to the file.\n\n Returns:\n The file's extra attributes.\n \"\"\"\n file = self.root.file_at_path(path)\n return file.attrs.keys()\n\n def mkdir(self, path: str, mode: int):\n \"\"\"Create a new directory.\n\n Args:\n path: The path to create.\n mode: The directory permissions.\n \"\"\"\n logger.info('mkdir %s %s', path, mode)\n self.root.mkdir(path, mode)\n\n def read(self, path: str, size: int, offset: int, _=None) -> str:\n \"\"\"Read the file's contents.\n\n Args:\n path: Theh path to the file to read.\n size: The number of bytes to read.\n offset: The offset to read from.\n\n Returns:\n The queried bytes of the file.\n \"\"\"\n logger.info('read %s %s %s', path, offset, size)\n file = self.root.file_at_path(path)\n logger.info('Found file %s', file.file_id)\n\n if file.st_size == 0:\n # Special case for empty files\n logger.info('File size %s', 0)\n return self._to_bytes('')\n\n with self.file_locks[file.file_id]:\n # Download from the object store if the file is not cached\n if not self.cache.has(file.file_id):\n logger.info('File not in cache, downloading from store')\n contents = self._to_bytes(self.b2.download_file(file.file_id))\n logger.info('File downloaded %s', len(contents))\n self.cache.add(file.file_id, contents)\n\n content = self.cache.get(file.file_id, offset, size)\n logger.info('Reading bytes %s', len(content))\n return content\n\n def readdir(self, path: str, _) -> List[str]:\n \"\"\"Read the entries in the directory.\n\n Args:\n path: The path to the directory.\n \n Returns:\n The names of the entries (files and subdirectories).\n \"\"\"\n logger.info('readdir %s', path)\n dir = self.root.file_at_path(path)\n return ['.', '..'] + list(dir.files.keys())\n\n def readlink(self, path: str) -> str:\n \"\"\"Read the entire contents of the file.\n\n Args:\n path: The file to read.\n\n Returns:\n The file's contents.\n \"\"\"\n logger.info('readlink %s', path)\n return self.read(path, None, 0)\n\n def removexattr(self, path: str, name: str):\n \"\"\"Remove an attribute from a file.\n\n Args:\n path: Path to the file.\n name: Name of the attribute to remove.\n \"\"\"\n file = self.root.file_at_path(path)\n if name in file.attrs:\n del file.attrs[name]\n\n def rename(self, old: str, new: str):\n \"\"\"Rename a file by deleting and recreating it.\n\n Args:\n old: The old path of the file.\n new: The new path of the file.\n \"\"\"\n logger.info('rename %s %s', old, new)\n file = self.root.file_at_path(old)\n if type(file) == Directory:\n if len(file.files) > 0:\n logger.info('Directory not empty')\n return ENOTEMPTY\n self.rmdir(old)\n self.mkdir(new, file.st_mode)\n else:\n contents = self.readlink(old)\n self.unlink(old)\n self.create(new, file.st_mode)\n self.write(new, contents, 0)\n\n def rmdir(self, path):\n \"\"\"Remove a directory, if it is not empty.\n\n Args:\n path: The path to the directory.\n \"\"\"\n logger.info('rmdir %s', path)\n directory = self.root.file_at_path(path)\n if len(directory.files) > 0:\n return ENOTEMPTY\n self.root.rm(path)\n\n def setxattr(self, path: str, name: str, value: str, _=None, __=None):\n \"\"\"Set an attribute for the file.\n\n Args:\n path: Path to the file.\n name: Name of the attribute to set.\n value: Value of the attribute.\n \"\"\"\n file = self.root.file_at_path(path)\n file.attrs[name] = value\n\n def statfs(self, _):\n \"\"\"Get file system stats.\"\"\"\n return dict(f_bsize=4096, f_blocks=4294967296, f_bavail=4294967296)\n\n def symlink(self, target, source):\n \"\"\"Symlink from a target to a source.\n\n Args:\n target: The symlinked file.\n source: The original file.\n \"\"\"\n # No support for symlinking\n return FuseOSError(EINVAL)\n\n def truncate(self, path: str, length: int, _):\n \"\"\"Truncate or pad the file to the specified length.\n\n Args:\n path: The file to truncate.\n length: The desired lenght.\n \"\"\"\n file = self.root.file_at_path(path)\n content = self.readlink(path)\n content = content.ljust(length, '\\x00'.encode('utf-8'))\n file.st_size = length\n\n def _delete_file(self, path: str):\n \"\"\"Delete a file from both the local cache and the object store.\n\n Args:\n path: The path to the file.\n \"\"\"\n file = self.root.file_at_path(path)\n with self.file_locks[file.file_id]:\n if self.cache.has(file.file_id):\n logger.info('Deleting from cache %s', file.file_id)\n self.cache.delete(file.file_id)\n if not file.is_local_file:\n logger.info('Deleting from object store %s', file.file_id)\n self.b2.delete_file(file.file_id, path.strip('/'))\n\n def unlink(self, path: str):\n \"\"\"Delete a file.\n\n Args:\n path: The path to the file.\n \"\"\"\n logger.info('unlink %s', path)\n file = self.root.file_at_path(path)\n if type(file) == Directory:\n self.rmdir(path)\n else:\n self._delete_file(path)\n self.root.rm(path)\n\n def utimens(self, path: str, times: Tuple[int, int] = None):\n \"\"\"Update the touch time for the file.\n\n Args:\n path: The file to update.\n times: The modify times to apply.\n \"\"\"\n file = self.root.file_at_path(path)\n now = time()\n mtime, atime = times if times else (now, now)\n file.update(modify_time=mtime, access_time=atime)\n\n def _upload_file(self, path: str) -> str:\n \"\"\"Upload a file to the object store.\n\n Args:\n path: The path of the file to upload.\n\n \"\"\"\n logger.info('upload %s', path)\n file = self.root.file_at_path(path)\n\n # Delete the exisiting version of the file if it exists\n content = self.cache.get(file.file_id)\n\n with self.file_locks[file.file_id]:\n logger.info('Uploading file %s', len(content))\n response = self.b2.upload_file(self.bucket_id, path.strip('/'), content)\n logger.info('Upload complete, updating cache')\n\n self._delete_file(path)\n\n with self.file_locks[file.file_id]:\n file.update(file_id=response['fileId'], file_size=len(content))\n logger.info('Saving to cache %s', file.file_id)\n self.cache.add(file.file_id, content)\n\n def write(self, path: str, data: str, offset: str, _=None) -> int:\n \"\"\"Write data to a file.\n\n Args:\n path: The file to write to.\n data: The bytes to write.\n offset: The offset in the file to begin writing at.\n \n Returns:\n The number of bytes written.\n \"\"\"\n logger.info('write %s %s %s', path, offset, len(data))\n file = self.root.file_at_path(path)\n\n with self.file_locks[file.file_id]:\n # Write the new bytes\n data = self._to_bytes(data)\n\n # Immediately save locally\n logger.info('Writing to cache %s %s', file.file_id, len(data))\n num_bytes = self.cache.update(file.file_id, data, offset)\n file_size = self.cache.file_size(file.file_id)\n file.update(file_size=file_size)\n\n # Submit task to upload to object store\n self.task_queue.submit_task(file.file_id, self.upload_delay,\n self._upload_file, path)\n\n return num_bytes\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8500000238418579,
"avg_line_length": 59,
"blob_id": "7f5c544d6930acbf970c0873aa3a27094202cb0d",
"content_id": "f834209c8724f5598e4c4bbb052e7224313a4324",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 60,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 1,
"path": "/README.md",
"repo_name": "picklelo/zerofs",
"src_encoding": "UTF-8",
"text": "Transparant filesystem backed by Backblaze B2 object store.\n"
},
{
"alpha_fraction": 0.782608687877655,
"alphanum_fraction": 0.782608687877655,
"avg_line_length": 22,
"blob_id": "c8f6a5e77ac73a73f59617dd66598a26cdbfe115",
"content_id": "281916f9bf9e57b7e1dd51ee844de80c3c660780",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23,
"license_type": "permissive",
"max_line_length": 22,
"num_lines": 1,
"path": "/zerofs/__init__.py",
"repo_name": "picklelo/zerofs",
"src_encoding": "UTF-8",
"text": "from .fs import ZeroFS\n"
},
{
"alpha_fraction": 0.6254871487617493,
"alphanum_fraction": 0.6272408366203308,
"avg_line_length": 28.66473960876465,
"blob_id": "94b595ebb08db0769b23756f9ba1c41eb497d527",
"content_id": "5bfacb9ce12cb9b1debb03e6f79d1b22baf89ee9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5132,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 173,
"path": "/zerofs/task_queue.py",
"repo_name": "picklelo/zerofs",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\nfrom enum import Enum\nfrom logging import getLogger\nfrom queue import PriorityQueue\nfrom time import sleep, time\nfrom threading import Thread, Lock\nfrom typing import Callable\n\nlogger = getLogger('task_queue')\n\n\nclass Signal(Enum):\n \"\"\"A special signal to send to a worker queue.\"\"\"\n STOP = 'stop'\n\n\nclass RunState(Enum):\n \"\"\"Enum to specify the running state of the task queue.\"\"\"\n STOPPED = 'stopped'\n RUNNING = 'running'\n\n\nclass TaskQueue:\n \"\"\"Class to asynchronously handle tasks in the background.\"\"\"\n\n def __init__(self, num_workers: int = 1):\n \"\"\"Initialize the task queue.\n\n Args;\n num_workers: How many worker threads to launch to process tasks.\n \"\"\"\n self.num_workers = num_workers\n self.queue = PriorityQueue()\n # Map from task id to latest version number for that task\n self.tasks = defaultdict(int)\n self.task_locks = defaultdict(Lock)\n self.run_state = RunState.STOPPED\n self.threads = []\n\n def run_worker(self, i, num_retries=5):\n \"\"\"Function each worker will run.\n\n Args:\n i: The thread index.\n num_retries; How many times to retry the task.\n \"\"\"\n logger.info('Initialized task worker %s', i)\n while True:\n # Get the next task.\n task = self.queue.get()\n\n # Check any special signals.\n if task[1] == Signal.STOP:\n break\n\n # Otherwise it is a real task to run.\n time_to_run, task_args = task\n task_id, task_version, fn, args, kwargs = task_args\n logger.info('Worker received task %s', task_id)\n logger.info('Task queue size %s', self.queue.qsize())\n\n # If there is a newer version of the task, skip this one\n with self.task_locks[task_id]:\n if self.tasks[task_id] > task_version:\n logger.info('Task cancelled')\n self.queue.task_done()\n continue\n\n # Sleep until we are ready to run the code\n time_to_sleep = max(1, time_to_run - time())\n logger.info('Time to sleep %s', time_to_sleep)\n if time_to_sleep > 0:\n sleep(time_to_sleep)\n\n # Make this check again\n with self.task_locks[task_id]:\n if self.tasks[task_id] > task_version:\n logger.info('Task cancelled')\n self.queue.task_done()\n continue\n\n # Run the function, retry on failures\n finished = False\n for backoff in [2**i for i in range(num_retries + 1)]:\n try:\n fn(*args, **kwargs)\n finished = True\n break\n except Exception as e:\n logger.info('An error occurred: %s', str(e))\n logger.info('Sleeping %s', backoff)\n sleep(backoff)\n\n # Put the task back in the queue if we still failed\n if not finished:\n logger.info('Task failed, reinserting into queue %s', task_id)\n self.queue.put(task)\n\n self.queue.task_done()\n\n logger.info('Worker %s exiting', i)\n\n def start(self):\n \"\"\"Start the background worker threads.\"\"\"\n if self.run_state == RunState.RUNNING:\n raise ValueError('Task queue already started.')\n\n for i in range(self.num_workers):\n thread = Thread(target=self.run_worker, args=(i,))\n thread.start()\n self.threads.append(thread)\n self.run_state = RunState.RUNNING\n\n def stop(self, finish_ongoing_tasks: bool = True):\n \"\"\"Send signals to stop all worker threads.\n\n Args:\n finish_ongoing_tasks: If true, finishes all current tasks and then stops\n the worker threads, otherwise stops the threads immediately.\n \"\"\"\n if self.run_state == RunState.STOPPED:\n raise ValueError('Task queue already stopped.')\n\n # Gather the queue mutex to clear it and send stop signals.\n if not finish_ongoing_tasks:\n with self.queue.mutex:\n self.queue.clear()\n\n for i in range(self.num_workers):\n self.queue.put((float('inf'), Signal.STOP))\n\n logger.info('Waiting for workers to stop.')\n for thread in self.threads:\n thread.join()\n\n logger.info('Task queue stopped.')\n self.run_state = RunState.STOPPED\n\n def submit_task(self, task_id: str, delay: float, fn: Callable, *args,\n **kwargs):\n \"\"\"Add a task to run.\n\n Args:\n task_id: An id to specify the task.\n delay: How much time to wait before running the task.\n fn: The function to run.\n args: The args to pass to fn.\n kwargs: The kwargs to pass to fn.\n \"\"\"\n if self.run_state == RunState.STOPPED:\n raise ValueError('Start the task queue before submitting tasks.')\n\n logger.info('Received task %s %s', task_id, delay)\n time_to_run = time() + delay\n args = args or ()\n kwargs = kwargs or {}\n\n with self.task_locks[task_id]:\n self.tasks[task_id] += 1\n task_version = self.tasks[task_id]\n\n self.queue.put((time_to_run, (task_id, task_version, fn, args, kwargs)))\n logger.info('Task queue size %s', self.queue.qsize())\n\n def cancel_task(self, task_id: str):\n \"\"\"Cancel a submitted task.\n\n Args:\n task_id: The task to cancel.\n \"\"\"\n logger.info('Cancel task %s', task_id)\n with self.task_locks[task_id]:\n self.tasks[task_id] += 1\n"
},
{
"alpha_fraction": 0.632808268070221,
"alphanum_fraction": 0.6393264532089233,
"avg_line_length": 28.22222137451172,
"blob_id": "3e8592491bb49dd7e75cae755dc33d16ff825a10",
"content_id": "7815a11b12a9e57c9505437e73c20170f871c6a9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1841,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 63,
"path": "/bin/zerofs",
"repo_name": "picklelo/zerofs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\"\"\"Main script to launch the ZeroFS file system.\"\"\"\n\nimport argparse\nimport logging\nimport os\n\nfrom fuse import FUSE\n\nfrom zerofs import ZeroFS\n\nif __name__ == '__main__':\n parser = argparse.ArgumentParser()\n parser.add_argument('mount')\n parser.add_argument(\n '--bucket', type=str, required=True, help='The B2 bucket to mount')\n parser.add_argument(\n '--background', action='store_true', help='Run in the background')\n parser.add_argument(\n '--cache-dir',\n type=str,\n help='Cache directory to use',\n default='~/.zerofs')\n parser.add_argument(\n '--cache-size', type=int, help='Disk cache size in MB', default=5000)\n parser.add_argument('--log-file', type=str, help='File to log to', default='')\n parser.add_argument(\n '--num_workers',\n type=int,\n help='Num thread workers for uploads',\n default=10)\n parser.add_argument(\n '--upload_delay',\n type=float,\n help='Delay in seconds before writing to object store',\n default=5.0)\n parser.add_argument(\n '--update_period',\n type=float,\n help='Period (s) at which to update directory contents',\n default=0.0)\n parser.add_argument('--verbose', action='store_true', help='Log debug info')\n args = parser.parse_args()\n\n if args.verbose:\n logging.basicConfig(level=logging.INFO)\n\n if args.log_file:\n logging.basicConfig(\n filename=args.log_file, filemode='w', level=logging.INFO)\n\n cache_dir = os.path.expanduser(args.cache_dir)\n fuse = FUSE(\n ZeroFS(\n args.bucket,\n cache_dir=cache_dir,\n cache_size=args.cache_size,\n upload_delay=args.upload_delay,\n update_period=args.update_period,\n num_workers=args.num_workers),\n args.mount,\n foreground=not args.background,\n allow_other=True)\n"
},
{
"alpha_fraction": 0.61834317445755,
"alphanum_fraction": 0.6301774978637695,
"avg_line_length": 26.040000915527344,
"blob_id": "fa7ac762cfad2786e254434d2c97db45bb4b061b",
"content_id": "8d55bf4bd9f757379073fcd93fb3f1a7d983de1b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 676,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 25,
"path": "/setup.py",
"repo_name": "picklelo/zerofs",
"src_encoding": "UTF-8",
"text": "from setuptools import setup\n\n\ndef read(file_name):\n with open(file_name) as f:\n return f.read()\n\n\nsetup(\n name='zerofs',\n version='0.2.0',\n description='Transparant filesystem backed by Backblaze B2 object store',\n long_description=read('README.md'),\n url='https://github.com/picklelo/zerofs',\n author='Nikhil Rao',\n author_email='[email protected]',\n classifiers=[\n 'Development Status :: 3 - Alpha',\n 'License :: OSI Approved :: MIT License',\n 'Programming Language :: Python :: 3'\n ],\n keywords='backblaze b2 zero fs filesystem',\n packages=['zerofs'],\n scripts=['bin/zerofs'],\n install_requires=['backblazeb2', 'fusepy'])\n"
},
{
"alpha_fraction": 0.5806796550750732,
"alphanum_fraction": 0.5892347693443298,
"avg_line_length": 25.632911682128906,
"blob_id": "5ef5f1b8240185f9325805dff4971111fc264237",
"content_id": "2838799fa03668079c2061469f2385d8aa97429e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8416,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 316,
"path": "/zerofs/file.py",
"repo_name": "picklelo/zerofs",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\nfrom collections import defaultdict\nfrom stat import S_IFDIR, S_IFREG\nfrom time import time\nfrom typing import Dict, List, Union\nfrom uuid import UUID, uuid4\n\nfrom b2py import B2\n\n\nclass FileBase(ABC):\n \"\"\"Abstract base class for file-like objects.\"\"\"\n\n def __init__(self, name: str):\n self.name = name\n self.st_mode = None\n self.st_uid = None\n self.st_gid = None\n self.attrs = {}\n\n def chmod(self, mode):\n self.st_mode &= 0o770000\n self.st_mode |= mode\n\n def chown(self, uid, gid):\n self.st_uid = uid\n self.st_gid = gid\n\n\nclass File(FileBase):\n \"\"\"Represents a file backed by the object store.\"\"\"\n\n def __init__(self, file: Dict):\n \"\"\"Create a file object.\n\n Args:\n file: A dictionary of file metadata from B2.\n \"\"\"\n super().__init__(file.get('fileName', ''))\n self.file_id = file.get('fileId', str(uuid4()))\n self.st_size = file.get('contentLength', 0)\n self.st_mtime = file.get('uploadTimestamp', time() * 1e3) * 1e-3\n self.st_ctime = self.st_mtime\n self.st_atime = self.st_mtime\n self.st_mode = S_IFREG | 0o755\n self.st_nlink = 1\n\n def __repr__(self):\n return '<File {}>'.format(self.name)\n\n @property\n def is_local_file(self) -> bool:\n \"\"\"Whether this file is local only, and not on the server.\"\"\"\n try:\n UUID(self.file_id)\n return True\n except:\n return False\n\n @property\n def metadata(self) -> Dict:\n return {\n 'st_mode': self.st_mode,\n 'st_ctime': self.st_ctime,\n 'st_mtime': self.st_mtime,\n 'st_atime': self.st_atime,\n 'st_nlink': self.st_nlink,\n 'st_size': self.st_size\n }\n\n def update(self,\n file_id: str = None,\n file_size: int = None,\n modify_time: str = None,\n access_time: int = None):\n \"\"\"Update the file metadata.\n Automatically updates the last modified time.\n\n Args:\n file_id: The new file id.\n file_size: The new file size.\n \"\"\"\n if file_id:\n self.file_id = file_id\n if file_size:\n self.st_size = file_size\n if modify_time:\n self.st_mtime = modify_time\n if access_time:\n self.st_atime = access_time\n\n\nclass Directory(FileBase):\n \"\"\"A virtual directory containing subfiles and directories.\"\"\"\n\n def __init__(self,\n b2: B2,\n bucket_id: str,\n name: str,\n mode=0o755,\n update_period: float = 600.0):\n \"\"\"Initialize with a list of files in this directory.\n\n Args:\n b2: The B2 instance to get data from.\n bucket_id: The bucket the directory lives in.\n name: The name of the directory.\n mode: The permissions to set.\n update_period: Reload the directory contents after this amount of time (s).\n \"\"\"\n super().__init__(name)\n self.mode = mode\n self.st_mode = S_IFDIR | self.mode\n self.st_atime = time()\n\n # Lazily load the files in the directory when needed\n self.b2 = b2\n self.bucket_id = bucket_id\n self.files = {}\n self.last_update_time = None\n self.update_period = update_period\n\n def _should_update(self) -> bool:\n # If we have never updated yet, we should\n if self.last_update_time is None:\n return True\n\n # If we have updated and the update_period is 0, don't update again\n if self.update_period == 0.0:\n return False\n\n # Update if the update period has passed\n return (time() - self.last_update_time) > self.update_period\n\n def _update(self, chunk_size: int = 10000):\n \"\"\"Load the files in the directory from B2.\n\n Args:\n chunk_size: How many files to load in each request.\n \"\"\"\n # Iterate to get all the direct children\n self.files = {}\n start_file_name = None\n\n while True:\n file_info = self.b2.list_files(\n self.bucket_id,\n start_file_name=start_file_name,\n prefix=self.name,\n list_directory=True,\n limit=chunk_size)\n for info in file_info:\n key = info['fileName'].strip('/').split('/')[-1]\n if info['action'] == 'folder':\n # This is a directory\n self.files[key] = Directory(\n self.b2,\n self.bucket_id,\n info['fileName'],\n mode=self.mode,\n update_period=self.update_period)\n else:\n # This is a file\n self.files[key] = File(info)\n\n if len(file_info) < chunk_size:\n break\n start_file_name = file_info[-1]['fileName']\n\n self.last_update_time = time()\n\n @property\n def st_mtime(self) -> float:\n \"\"\"The last modified time of the directory.\"\"\"\n if len(self.files) == 0:\n return self.st_atime\n return max([f.st_mtime for f in self.files.values()])\n\n @property\n def st_nlink(self) -> int:\n \"\"\"Number of hard links pointing to the directory.\"\"\"\n return 2 + len([f for f in self.files.values() if type(f) == Directory])\n\n @property\n def metadata(self) -> Dict:\n return {\n 'st_mode': self.st_mode,\n 'st_ctime': self.st_mtime,\n 'st_mtime': self.st_mtime,\n 'st_atime': self.st_mtime,\n 'st_nlink': self.st_nlink\n }\n\n @staticmethod\n def _to_path_list(path: Union[str, List[str]]) -> List[str]:\n \"\"\"Combine a path to a path list.\n\n Args:\n path: The path to convert (can be a string or a list)\n\n Returns:\n A list that can be used to find the node in the tree.\n \"\"\"\n if type(path) == str:\n path = path.strip('/').split('/')\n return path\n\n def file_nesting(self, path: Union[str, List[str]]) -> List['Directory']:\n \"\"\"Get the nesting directories of a file or directory.\n\n Args:\n path: The path to get the nesting in.\n\n Returns:\n A list of directories indicating the nested structure of the path.\n \"\"\"\n # Update the directory contents if needed\n if self._should_update():\n self._update()\n\n path = self._to_path_list(path)\n if path[0] == '':\n return [self]\n file = self.files[path[0]]\n if len(path) == 1:\n # The file is in the root directory\n return [self, file]\n return [self] + file.file_nesting(path[1:])\n\n def file_at_path(self, path: Union[str, List[str]]) -> File:\n \"\"\"Get the file given a path relative to this directory.\n\n Args:\n path: The path of the file to query.\n\n Returns:\n The file object at the path if it exists.\n \"\"\"\n return self.file_nesting(path)[-1]\n\n def file_exists(self, path: str) -> bool:\n \"\"\"\n Args:\n path: The path to the file to check.\n\n Returns:\n Whether the file exists.\n \"\"\"\n try:\n self.file_at_path(path)\n return True\n except KeyError:\n return False\n\n def _find_node(self, path: Union[str, List[str]]) -> FileBase:\n \"\"\"Find the node in the directory tree.\n\n Args:\n path: The path to the node to find.\n\n Returns:\n The found node.\n \"\"\"\n path = self._to_path_list(path)\n if len(path) == 0:\n return self\n\n if (path[0] not in self.files or type(self.files[path[0]]) != Directory):\n raise KeyError('Cannot find node, directory {} does not exist'.format(\n path[0]))\n\n return self.files[path[0]]._find_node(path[1:])\n\n def mkdir(self, path: Union[str, List[str]], mode: int):\n \"\"\"Create a subdirectory.\n\n Args:\n path: The path to the directory to create.\n mode: The directory permissions.\n \"\"\"\n path = self._to_path_list(path)\n node = self._find_node(path[:-1])\n if path[-1] in node.files:\n raise KeyError('Directory {} already exists'.format(path))\n node.files[path[-1]] = Directory(\n self.b2,\n self.bucket_id,\n path[-1],\n mode=mode,\n update_period=self.update_period)\n\n def rm(self, path: Union[str, List[str]]):\n \"\"\"Remove a file or directory.\n\n Args:\n name: The path to the file.\n \"\"\"\n nesting = self.file_nesting(path)\n if len(nesting) < 2:\n raise ValueError('Cannot rm the root directory')\n parent_dir, file = nesting[-2:]\n del parent_dir.files[file.name]\n\n def touch(self, path: Union[str, List[str]], mode: int) -> File:\n \"\"\"Create an empty file.\n\n Args:\n path: The path to the file to create.\n mode: The file permissions.\n \"\"\"\n path = self._to_path_list(path)\n node = self._find_node(path[:-1])\n file = File({'fileName': path[-1]})\n node.files[path[-1]] = file\n return file\n"
},
{
"alpha_fraction": 0.6104992032051086,
"alphanum_fraction": 0.6123740077018738,
"avg_line_length": 25.018293380737305,
"blob_id": "83aa584e3c406a6011c3cc535ac0cf3d8b724382",
"content_id": "49249dcb837bfae5e4a260a1f4b5b36210779fc4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4267,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 164,
"path": "/zerofs/cache.py",
"repo_name": "picklelo/zerofs",
"src_encoding": "UTF-8",
"text": "import os\nfrom glob import glob\nfrom logging import getLogger\n\nfrom b2py import utils as b2_utils\n\nlogger = getLogger('cache')\n\n\nclass Cache:\n \"\"\"Cache files to the local disk to save bandwidth.\"\"\"\n\n def __init__(self, cache_dir: str, cache_size: int):\n \"\"\"Initialize a local object cache.\n\n Args:\n cache_dir: The directory to save cached files to.\n cache_size: The size, in MB, to limit the cache dir to.\n \"\"\"\n self.cache_dir = cache_dir\n self.cache_size = int(cache_size * 1e6)\n self.index = {}\n self.touch_list = []\n self._populate_index()\n\n def _populate_index(self):\n \"\"\"Read the cache dir and set a local index of records.\"\"\"\n os.makedirs(self.cache_dir, exist_ok=True)\n local_files = glob('{}/*'.format(self.cache_dir))\n for file in local_files:\n self._add_to_index(os.path.basename(file), os.path.getsize(file))\n\n def _touch_file(self, file_id):\n \"\"\"Move the file to the end of the queue by touching it.\n\n Args:\n file_id: The file to touch.\n \"\"\"\n if file_id in self.touch_list:\n self.touch_list.remove(file_id)\n self.touch_list.append(file_id)\n\n def _recover_disk_space(self):\n \"\"\"Make sure we stay under our disk space quota.\"\"\"\n while self.used_disk_space > self.cache_size:\n space_to_recover = self.used_disk_space - self.cache_size\n logger.info('Recovering disk space %s', space_to_recover)\n lru_file = self.touch_list.pop(0)\n file_path = self._path_to_file(lru_file)\n logger.info('Deleting %s', file_path)\n os.remove(file_path)\n del self.index[lru_file]\n\n def _path_to_file(self, file_id: str):\n \"\"\"\n Args:\n file_id: The B2 file id to query.\n\n Returns:\n The local path to the cached file.\n \"\"\"\n return os.path.join(self.cache_dir, file_id)\n\n @property\n def used_disk_space(self) -> int:\n \"\"\"\n Returns:\n The used disk space in bytes.\n \"\"\"\n return sum(self.index.values())\n\n def _add_to_index(self, file_id: str, content_size: int):\n \"\"\"\n Args:\n file_id: The file key.\n content_size: The size of the file's contents.\n \"\"\"\n self._touch_file(file_id)\n self.index[file_id] = content_size\n self._recover_disk_space()\n\n def has(self, file_id):\n \"\"\"\n Args:\n file_id: The file to check.\n\n Returns:\n Whether the cache contains the file.\n \"\"\"\n return file_id in self.index\n\n def add(self, file_id: str, contents: bytes):\n \"\"\"Add a file to the cache.\n\n Args:\n file_id: The unique key to look the file up by.\n contents: The file contents.\n \"\"\"\n file_path = self._path_to_file(file_id)\n b2_utils.write_file(file_path, contents)\n self._add_to_index(file_id, len(contents))\n\n def update(self, file_id: str, data: bytes, offset: int) -> int:\n \"\"\"Update an existing file in the cache.\n\n Args:\n file_id: The file to update.\n data: The data to write to the file.\n offset: The start offset to write the data at.\n\n Returns:\n The number of bytes written.\n \"\"\"\n if not self.has(file_id):\n raise KeyError('No file {}'.format(file_id))\n\n self._touch_file(file_id)\n file_path = self._path_to_file(file_id)\n\n with open(file_path, 'r+b') as f:\n f.seek(offset)\n return f.write(data)\n\n def get(self, file_id: str, offset: int = 0, size: int = None) -> bytes:\n \"\"\"\n Args:\n file_id: The file to read.\n offset: The offset to read from.\n size: The number of bytes to read.\n \n Returns:\n The file's contents.\n \"\"\"\n if not self.has(file_id):\n raise KeyError('No file {}'.format(file_id))\n\n self._touch_file(file_id)\n file_path = self._path_to_file(file_id)\n\n with open(file_path, 'rb') as f:\n f.seek(offset)\n return f.read(size)\n\n def delete(self, file_id: str):\n \"\"\"Delete the file from the cache.\n\n Args:\n file_id: The file to delete.\n \"\"\"\n file_path = self._path_to_file(file_id)\n os.remove(file_path)\n del self.index[file_id]\n\n def file_size(self, file_id: int):\n \"\"\"Get the size of the file in bytes.\n\n Args:\n file_id: The id of the file in the cache.\n \n Returns:\n The file size.\n \"\"\"\n file_path = self._path_to_file(file_id)\n return os.path.getsize(file_path)\n"
}
] | 8 |
forestdussault/SnapperDB_Automator | https://github.com/forestdussault/SnapperDB_Automator | 5d2737b02239ceceeb13c6cb833cf525a0e58e03 | 410efd4b64dc27dd62233a8d2b2aa7a3fea7894a | b4f908cf9c860c397bd7847a63701a28d6329f34 | refs/heads/master | 2021-09-05T11:01:33.176226 | 2018-01-26T18:27:56 | 2018-01-26T18:27:56 | 119,087,181 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6436576247215271,
"alphanum_fraction": 0.6493422389030457,
"avg_line_length": 34.182857513427734,
"blob_id": "0698f146d5e4e81c2f2ebbdbd65f978466e241a0",
"content_id": "be1c5fb3ea83001bea967a7664ba9482cb2be14d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6157,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 175,
"path": "/helpers.py",
"repo_name": "forestdussault/SnapperDB_Automator",
"src_encoding": "UTF-8",
"text": "import os\nimport glob\nimport logging\n\n\ndef retrieve_fastqgz(directory):\n \"\"\"\n :param directory: Path to folder containing output from MiSeq run\n :return: list of all .fastq.gz files in directory\n \"\"\"\n fastq_file_list = glob.glob(os.path.join(directory, '*.fastq.gz'))\n return fastq_file_list\n\n\ndef retrieve_unique_sampleids(fastq_file_list):\n \"\"\"\n :param fastq_file_list: List of fastq.gz filepaths generated by retrieve_fastqgz()\n :return: List of valid OLC Sample IDs\n \"\"\"\n # Iterate through all of the fastq files and grab the sampleID, append to list\n sample_id_list = list()\n for file in fastq_file_list:\n if valid_olc_id(file):\n sample_id = os.path.basename(file)[:13] # WARNING: This is specific to the OLC naming scheme\n sample_id_list.append(sample_id)\n\n # Get unique sample IDs\n sample_id_list = list(set(sample_id_list))\n\n return sample_id_list\n\n\ndef get_readpair(sample_id, fastq_file_list):\n \"\"\"\n :param sample_id: String of a valid OLC ID\n :param fastq_file_list: List of fastq.gz file paths generated by retrieve_fastqgz()\n :return: the absolute filepaths of R1 and R2 for a given sample ID\n \"\"\"\n\n r1, r2 = None, None\n for file in fastq_file_list:\n if sample_id in os.path.basename(file):\n if 'R1' in os.path.basename(file):\n r1 = file\n elif 'R2' in os.path.basename(file):\n r2 = file\n if r1 is not None:\n return [os.path.abspath(r1), os.path.abspath(r2)]\n else:\n pass\n\n\ndef populate_sample_dictionary(sample_id_list, fastq_file_list):\n \"\"\"\n :param sample_id_list: List of unique Sample IDs generated by retrieve_unique_sampleids()\n :param fastq_file_list: List of fastq.gz file paths generated by retrieve_fastqgz()\n :return: dictionary with each Sample ID as a key and the read pairs as values\n \"\"\"\n\n # Find file pairs for each unique sample ID\n sample_dictionary = {}\n for sample_id in sample_id_list:\n read_pair = get_readpair(sample_id, fastq_file_list)\n sample_dictionary[sample_id] = read_pair\n return sample_dictionary\n\n\ndef get_sample_dictionary(directory):\n \"\"\"\n Chains several functions together to create a sample dictionary with unique/valid sample IDs as keys\n and paths to forward and reverse reads as values\n :param directory: Path to a directory containing .fastq.gz files\n :return: Validated sample dictionary with sample_ID:R1,R2 structure\n \"\"\"\n fastq_file_list = retrieve_fastqgz(directory)\n sample_id_list = retrieve_unique_sampleids(fastq_file_list)\n sample_dictionary = populate_sample_dictionary(sample_id_list, fastq_file_list)\n return sample_dictionary\n\n\ndef valid_olc_id(filename):\n \"\"\"\n Validate that a fastq.gz file contains a valid OLC sample ID\n :param filename: Path to file\n :return: boolean of valid status\n \"\"\"\n sample_id = os.path.basename(filename).split('_')[0]\n id_components = sample_id.split(b'-')\n valid_status = False\n if id_components[0].isdigit() and id_components[1].isalpha() and id_components[2].isdigit():\n valid_status = True\n else:\n logging.warning('ID for {} is not a valid OLC ID'.format(sample_id))\n return valid_status\n\n\ndef make_executable(path):\n \"\"\"\n Takes a shell script and makes it executable\n :param path: path to shell script\n \"\"\"\n mode = os.stat(path).st_mode\n mode |= (mode & 0o444) >> 2\n os.chmod(path, mode)\n\n\ndef prepare_db_update_script(config_file, work_dir, sample_dictionary):\n \"\"\"\n Create an executable shell script in fastq_links for every file in the dictionary\n :param config_file:\n :param work_dir:\n :param sample_dictionary:\n :returns: path to the executable script (needs to be run within the SnapperDB venv)\n \"\"\"\n script_path = os.path.join(work_dir, 'db_update_script.sh')\n with open(script_path, 'w+') as file:\n for key, value in sample_dictionary.items():\n file.write('# {}'.format(key))\n file.write('\\n')\n snapperdb = 'run_snapperdb.py '\n snappercmd = 'fastq_to_db '\n config = '-c '\n r1 = ' ' + value[0] + ' '\n r2 = value[1]\n cmd = ''.join([snapperdb, snappercmd, config, config_file, r1, r2])\n file.write(cmd)\n file.write('\\n\\n')\n file.write('# Updating distance matrix and clusters\\n')\n file.write('run_snapperdb.py update_distance_matrix -c {}\\n'.format(config_file))\n file.write('run_snapperdb.py update_clusters -c {}'.format(config_file))\n # chmod +x\n make_executable(script_path)\n return script_path\n\n\ndef link_files(id_file, work_dir):\n \"\"\"\n :param id_file: file with list of OLC IDs to link\n :param work_dir: destination directory to link files\n :returns fastq_path: path to fastq folder\n :returns filtered_id_list: list of the links that were made that did not already exist in the folder\n \"\"\"\n fastq_path = os.path.join(work_dir, 'fastq_links')\n try:\n os.mkdir(fastq_path)\n except OSError:\n pass\n\n # Do a check first with retrieve_sample_dict to avoid redundant link-making effort\n existing_samples = get_sample_dictionary(fastq_path)\n\n # Read file into a list\n with open(id_file) as f1:\n content = f1.readlines()\n content = [x.strip() for x in content]\n\n # Create new filtered list\n filtered_id_list = []\n for sampleid in content:\n if sampleid not in existing_samples:\n filtered_id_list.append(sampleid)\n\n # Write filtered list to text file\n filtered_id_file = id_file.replace('.txt', '_filtered.txt')\n with open(filtered_id_file, 'w') as f2:\n for seqid in filtered_id_list:\n f2.write(seqid + '\\n')\n\n # Do file linking based off of filtered file\n logging.info('Preparing FASTQ links at {}'.format(fastq_path))\n cmd = 'python2 /mnt/nas/MiSeq_Backup/file_linker.py {seqidlist} {output_folder}'.format(\n seqidlist=filtered_id_file,\n output_folder=fastq_path)\n os.system(cmd)\n return fastq_path, filtered_id_list\n"
},
{
"alpha_fraction": 0.6370038390159607,
"alphanum_fraction": 0.6466069221496582,
"avg_line_length": 39.0512809753418,
"blob_id": "b246bbe2573e81f747bdfb6b816fb8f92be59e5d",
"content_id": "67b551e221bc36812a20f823da1a49afaf591e9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1562,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 39,
"path": "/cli.py",
"repo_name": "forestdussault/SnapperDB_Automator",
"src_encoding": "UTF-8",
"text": "import click\nimport logging\nimport helpers\n\n\[email protected]()\[email protected]('--config_file', help='Path to SnapperDB instance configuration file')\[email protected]('--id_file', help='Path to text file containing all samples to add to SnapperDB instance')\[email protected]('--work_dir', help='Path to SnapperDB database working directory')\ndef cli(config_file, id_file, work_dir):\n logging.basicConfig(\n format='\\033[92m \\033[1m %(asctime)s \\033[0m %(message)s ',\n level=logging.INFO,\n datefmt='%Y-%m-%d %H:%M:%S')\n\n # Gather and link files from text file (id_file) to {work_dir}/fastq_links\n fastq_folder_path, filtered_id_list = helpers.link_files(id_file, work_dir)\n\n # Prepare dictionary with {sample_id:[R1,R2],} format\n sample_dictionary = helpers.get_sample_dictionary(fastq_folder_path)\n\n # Filter dictionary so only new stuff is added to the shell script\n filtered_sample_dictionary = {}\n for key, value in sample_dictionary.items():\n if key in filtered_id_list:\n logging.info('Detected new sample: {}'.format(key))\n filtered_sample_dictionary[key] = value\n else:\n logging.info('{} already in SnapperDB --- skipped'.format(key))\n\n # Make shell script\n helpers.prepare_db_update_script(config_file=config_file,\n work_dir=work_dir,\n sample_dictionary=filtered_sample_dictionary)\n\n logging.info('Created SnapperDB shell script at {}'.format(work_dir))\n\nif __name__ == '__main__':\n cli()\n"
}
] | 2 |
bt-nguyen/metis-projects | https://github.com/bt-nguyen/metis-projects | 8de77e492c16a01c901f0a72193f8660f4f95769 | 0e2e7b1df31ef7f67a5f00ad69768a11f6a5463f | b4b258f7a14e6143b9d50c076a2a92425c851d21 | refs/heads/main | 2023-02-16T12:10:07.075897 | 2021-01-08T00:17:57 | 2021-01-08T00:17:57 | 327,747,777 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7709125280380249,
"alphanum_fraction": 0.7737642526626587,
"avg_line_length": 41.08000183105469,
"blob_id": "8c3f270dc55d0df3fc9a7be26714b4c47eb33672",
"content_id": "22bfb9604397d711a123ea8565c67c41a3de0dc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1052,
"license_type": "no_license",
"max_line_length": 292,
"num_lines": 25,
"path": "/project-5/README.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "# Project 5 Proposal\n\n\n\n### By: Brian Nguyen\n\n\n\n### Project/Goal:\n\nFor my passion project, I'll be creating a movie recommendation system. I will be using a mix of supervised and unsupervised learning to generate the recommender. The end-goal is a tunable recommender based on what the user is interested in (something different, similar, director/cast, etc).\n\n\n\n### Background:\n\nI've been an avid movie-goer for a long time. Watching a movie is an avenue to escape to a different reality, where a new world is built and you can follow characters that you connect with (or don't connect with and learn their perspective).\n\nI hope that this provides an effective, but different method, of looking for movie recommenders. A lot of recommendations have felt the same during the COVID-19 pandemic and I hope that this can expand the discovery of movies.\n\n\n\n### Data:\n\nI will use a master dataset containing the MovieLensm, TMDB, and GroupLens dataset available on Kaggle. The dataset includes an overview of the plot synopsis, directors, user reviews, and more.\n"
},
{
"alpha_fraction": 0.7618364691734314,
"alphanum_fraction": 0.7704447507858276,
"avg_line_length": 28.04166603088379,
"blob_id": "2565893be10f1bee3dc51fc0c5dab19dad993065",
"content_id": "44db5888719cae5599de1feed703a8a38507dea6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 697,
"license_type": "no_license",
"max_line_length": 190,
"num_lines": 24,
"path": "/README.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "## Metis Projects\n\nAll these projects were individually produced (with the exception of project 1) by Brian Nguyen. Each project is intended to cover a specific domain of data science:\n\n\n\n* Project 1 - Navigating through Jupyter Notebook, Pandas, and NumPy\n\n* Project 2 - Regression\n\n* Project 3 - Classification\n\n* Project 4 - Natural Language Processing (NLP)\n\n* Project 5 - Passion Project\n\n\n\n\nThe specific project topic (outside the above mentioned) were determined by myself, primarily chosen due to interest in the topic or machine learning techniques learned by handling the data.\n\nIf you have any questions, please feel free to reach out to me:\n\nLinkedIn: https://www.linkedin.com/in/bt-nguyen/\n"
},
{
"alpha_fraction": 0.739130437374115,
"alphanum_fraction": 0.7479186058044434,
"avg_line_length": 32.78125,
"blob_id": "0f5407841d829c413f6bd59c80c5e7d880b375c8",
"content_id": "86e06f791a812eba34f10cb32cda7974b5b59502",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2162,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 64,
"path": "/project-5/3_Recommender_Surprise_All.py",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\n\nfrom surprise import accuracy\nfrom surprise import SVD, NMF\nfrom surprise import Dataset\nfrom surprise import Reader\nfrom surprise import NormalPredictor\nfrom surprise.model_selection import cross_validate\nfrom surprise.model_selection import KFold\nfrom surprise.model_selection import GridSearchCV\n\n# Read in the ratings_small (user-item) dataframe\ndf_ratings = pd.read_csv('data/ratings.csv')\n\ndf_all = pd.read_csv('data/dataframe_merged.csv', usecols=['id', 'title'])\n\ndf_ratings = df_ratings[df_ratings['movieId'].isin(df_all['id'])]\n\n# Set the reader to have a rating_scale from 1-5 (default)\nreader = Reader(rating_scale=(1, 5))\n\n# The data only consists of userId, movieId, and rating\ndata = Dataset.load_from_df(df_ratings[['userId', 'movieId', 'rating']], reader)\n\n# Use surprise package for a train-test split of 80-20\n# Note that the train-test split will split by general rows, not specific users\nfrom surprise.model_selection import train_test_split\ntrainset, testset = train_test_split(data, test_size=0.20)\n\ntrainset_iids = list(trainset.all_items())\niid_converter = lambda x: trainset.to_raw_iid(x)\ntrainset_raw_iids = list(map(iid_converter, trainset_iids))\n\nfrom surprise import KNNWithMeans\nmy_k = 15\nmy_min_k = 5\nmy_sim_option = {\n 'name':'cosine', 'user_based':False, 'verbose': False\n }\nalgo = KNNWithMeans(sim_options = my_sim_option)\nalgo.fit(trainset)\n\n# Same dataframe as algo.sim but the indices/columns are now movieId\ndf_cos_surprise = pd.DataFrame(algo.sim, index=trainset_raw_iids, columns=trainset_raw_iids)\n\ndf_all = df_all.reset_index()\ndf_all.index = df_all.id\n\nmovieIdtoindex = df_all['index'].to_dict()\n\ndf_cos_surprise = df_cos_surprise.rename(index=movieIdtoindex, columns=movieIdtoindex)\n\n# Make a pandas dataframe of movie x movie length from df_all\n# Fill in the values from matrix 'algo.sim'\n# Set the diagonal to \"1\"\ndf_blank = pd.DataFrame(np.nan, range(1,len(df_all)), range(1,len(df_all)))\n\ndf_blank = df_cos_surprise.combine_first(df_blank)\n\nnp.fill_diagonal(df_blank.values, 1)\ndf_bank = df_blank.fillna(0)\n\nnp.save('cosine_similarity/cos_ratings_all.npy', df_blank)\n"
},
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.804347813129425,
"avg_line_length": 45,
"blob_id": "a1db4b9b4a59551d2a28c923801abd1dff2f0a37",
"content_id": "6020955cd8371dc45cfdce1b80c705b99597c4e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 1,
"path": "/project-3/Data_NHANES/2011-2012/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "Data from 2011-2012 used in Jupyter notebook.\n"
},
{
"alpha_fraction": 0.7733110189437866,
"alphanum_fraction": 0.7839195728302002,
"avg_line_length": 84.33333587646484,
"blob_id": "bf3abf54b6bd0f40273395f0681ceac7fc5eada3",
"content_id": "b7bb1d2d559d16b450c1e73978ae59e57c019d5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1791,
"license_type": "no_license",
"max_line_length": 531,
"num_lines": 21,
"path": "/project-3/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "# Identifying Depression in Adults\n\nThe goal of this project is to identify self-assessed feelings of depression in adults using the National Health and Nutrition Examination Survey (NHANES) as the data source. The prominent features identified stem from the PHQ-9 survey (*e.g.* issues surrounding appetite, energy levels, and speech pace ) and demographic information.\n\n\n\n## Objective\n\nThe objective of this project is to explore different classification models to identify depression in adults (age 20 and higher). Additionally, there is an explorative component for identifying appropriate features to identify depression. Gaussian Naives Bayes and XGBoost classifier were found to be the best model for this objective; the latter being used for: obtaining feature importance, tunability for higher recall score (relative to other models), and personal interest because of the traction it's gaining in data science.\n\n### Data\n\nThe NHANES data set is used as our source, compiled from a ten year span (2009-2018). The target variable is a self-assessment of feeling down, depressed, or hopeless for nearly all days within the past two weeks (DPQ020, score = 3). Approximately 30 features were initially examined, with 16 features being used for the final model. These features are primarily from the demographic and questionnaire sections of the data set.\n\n### Tools Used\n\n**Jupyter Notebook** was used as the interface to deploy Python code. **Pandas** was used for generating, cleaning, and exploration of the dataframe. **Matplotlib** and **Seaborn** were used for plotting. **Numpy** was used for computation. **Scikit-learn** and **Xgboost** were used for modeling. **Flask** and **Junicorn** were used to deploy an app on Heroku.\n\n### Author\n\nBrian Nguyen (https://github.com/bt-nguyen/)"
},
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.804347813129425,
"avg_line_length": 45,
"blob_id": "a2c300d2fdd4dcc0dc0f3c7827647ed231b7a6d4",
"content_id": "dec81fb0c5cc1e00c6b978f7b5dbb2f3342aef85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 1,
"path": "/project-3/Data_NHANES/2015-2016/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "Data from 2015-2016 used in Jupyter notebook.\n"
},
{
"alpha_fraction": 0.549453616142273,
"alphanum_fraction": 0.553376317024231,
"avg_line_length": 38.21977996826172,
"blob_id": "0a078c2c7433cee663e92bea2dbe078fdeddf72d",
"content_id": "6c680bab3286d62b1d6c0a88e95f23078d241288",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3569,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 91,
"path": "/project-2/steamDataScrape.py",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "'''\nThis python function scrapes detailed information\nfrom the txt file: 'steamGameList.txt', which\nis a list of all/most games from Steam.\nThe final file is a csv titled:\n'steam_dataframe.csv'\n'''\n\n# Imports\nfrom bs4 import BeautifulSoup\nimport requests\nimport pandas as pd\n\n# Initiate a dataframe\ndf = pd.DataFrame()\n\nwith open(\"steamGameList.txt\", \"r\") as file:\n for line in file:\n try:\n url = line.split(\"\\n\")[0]\n\n response = requests.get(url)\n soup = BeautifulSoup(response.content, 'lxml')\n\n # Title\n title = soup.find('div', class_='apphub_AppName').text\n\n # Release Date\n release_date = soup.find('div', class_='date').text\n\n # Price: will collect discounted prices and other text; must be cleaned in dataframe\n price = soup.find(\n 'div', class_='game_purchase_action_bg').text.strip()\n\n # Storage: this will pull storage from Windows (min, then recommend), Mac, and Linux (if compatible)\n storage = []\n\n for requirement in soup.find('div', class_ = 'sysreq_contents').find_all('li'):\n if 'Storage' in requirement.getText():\n storage.append(requirement.getText())\n\n # Make empty genre to append multiple genres\n genre = []\n developer = []\n publisher = []\n\n # Checks for specific keywords in line; then makes a list (in case multiple genres/devs/pubs)\n for detail in soup.find('div', class_='details_block').find_all('a'):\n if 'genre' in detail.get('href'):\n genre.append(detail.getText())\n elif 'developer' in detail.get('href'):\n developer.append(detail.getText())\n elif 'publisher' in detail.get('href'):\n publisher.append(detail.getText())\n\n # Create a PRIMARY genre that's listed at the TOP LEFT of the Game Page for reference (may be needed later)\n primary_genre = soup.find(\n 'div', class_='breadcrumbs').find_all('a')[1].text\n\n # Collects a string for the ratings (recent and all); to be cleaned in dataframe\n for rating in soup.find('div',\n class_='user_reviews').find_all('span', class_='nonresponsive_hidden responsive_reviewdesc'):\n if 'reviews in the last' in rating.text:\n recent_reviews = rating.getText().strip()\n else:\n all_reviews = rating.getText().strip()\n\n # Collect Metacritic score; some games do not have a score and will print 'No Score'\n try:\n metacritic_score = soup.find(\n 'div', class_='score high').text.strip()\n except:\n metacritic_score = \"No Score\"\n\n game_dictionary = {'Title': title, 'Release_Date': release_date, 'Price': price,\n 'Genre': genre, 'Developer': developer, 'Publisher': publisher,\n 'Primary_Genre': primary_genre, 'Recent_Reviews': recent_reviews,\n 'All_Reviews': all_reviews, 'Metacritic': metacritic_score, 'Storage': storage[0]}\n\n df = df.append(game_dictionary, ignore_index=True)\n\n if len(df) % 2500 == 0:\n df.to_csv('steam_dataframe.csv')\n\n if len(df) > 40000:\n break\n\n except:\n continue\n\ndf.to_csv('steam_dataframe.csv')\n"
},
{
"alpha_fraction": 0.689263105392456,
"alphanum_fraction": 0.6957398056983948,
"avg_line_length": 40.35714340209961,
"blob_id": "56b934aede9bdb4344cdcdd58726d24952da5a88",
"content_id": "e49f495c852e1b07f520c2ca0a8a01c50d943ee6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6948,
"license_type": "no_license",
"max_line_length": 146,
"num_lines": 168,
"path": "/project-5/overview_doc2vec.py",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "###############\n### IMPORTS ###\n###############\n\nimport pandas as pd\nimport numpy as np\n\nimport matplotlib as plt\n\n\nimport re\nimport string\n\n\nfrom gensim.models.doc2vec import Doc2Vec, TaggedDocument\nfrom sklearn.model_selection import train_test_split\n\n\nimport nltk\nfrom nltk import word_tokenize\nfrom nltk.corpus import stopwords\nfrom sklearn import svm\nfrom nltk.tag import StanfordNERTagger\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.feature_extraction.text import TfidfVectorizer\nfrom nltk.tokenize.treebank import TreebankWordDetokenizer\nfrom nltk.stem import PorterStemmer\nfrom nltk.stem import LancasterStemmer\nfrom nltk.stem.snowball import SnowballStemmer\nfrom nltk.stem import WordNetLemmatizer\nfrom nltk.corpus import words\nfrom nltk.tag import pos_tag\n\n# Reference: http://zwmiller.com/projects/nlp_pipeline.html\n# Reference: https://github.com/ZWMiller/nlp_pipe_manager/blob/master/nlp_pipeline_manager/nlp_preprocessor.py\n# Reference: https://towardsdatascience.com/a-practitioners-guide-to-natural-language-processing-part-i-processing-understanding-text-9f4abfd13e72\n\n# Reference: http://zwmiller.com/projects/nlp_pipeline.html\n# Reference: https://github.com/ZWMiller/nlp_pipe_manager/blob/master/nlp_pipeline_manager/nlp_preprocessor.py\n# Reference: https://towardsdatascience.com/a-practitioners-guide-to-natural-language-processing-part-i-processing-understanding-text-9f4abfd13e72\n\n# Reference: http://zwmiller.com/projects/nlp_pipeline.html\n# Reference: https://github.com/ZWMiller/nlp_pipe_manager/blob/master/nlp_pipeline_manager/nlp_preprocessor.py\n# Reference: https://towardsdatascience.com/a-practitioners-guide-to-natural-language-processing-part-i-processing-understanding-text-9f4abfd13e72\n\nclass nlp_pipe:\n\n # Initialize the class\n def __init__(self, vectorizer, stemmer, lemmatizer, tokenizer, dataframe, column='Title'):\n self.vectorizer = vectorizer\n self.tokenizer = tokenizer\n self.lemmatizer = lemmatizer\n self.stemmer = stemmer\n self.dataframe = dataframe\n self.column = column\n self.dataframe[self.column] = self.dataframe[self.column].apply(str)\n\n ######################################################################\n\n # Create a cleaning method (aka fit) that will use several functions in order\n def cleaner(self):\n #self.vader_sentiment()\n self.dataframe = self._remove_numbers(self.dataframe, self.column)\n self.dataframe = self._punctuation(self.dataframe, self.column)\n #self.dataframe = self._dropduplicates(self.dataframe, self.column)\n self.real_words() # Check if it's a real word and then remove if not\n self.remove_single_letter() # Remove single letter words\n self.tokenize_words()\n #self.lemmatize_words()\n #self.stem_words()\n self.dataframe = self._join_words(self.dataframe, self.column)\n #self.dataframe[self.column] = self.dataframe[self.column].replace('', np.nan,)\n #self.dataframe.dropna(subset=[self.column], inplace=True)\n\n ########## Functions that 'cleaner' will call ##########\n @staticmethod\n def _remove_numbers(dataframe, column):\n # Removes all words containing numbers\n remove_numbers = lambda x: re.sub('\\w*\\d\\w*', '', x)\n dataframe[column] = dataframe[column].map(remove_numbers)\n return dataframe\n\n @staticmethod\n def _punctuation(dataframe, column):\n # Removes punctuation marks\n punc_lower = lambda x: re.sub('[^A-Za-z0-9]+', ' ', x)\n dataframe[column] = dataframe[column].map(punc_lower)\n return dataframe\n\n @staticmethod\n def _dropduplicates(dataframe, column):\n # Drop rows that have duplicate 'Titles'\n dataframe.drop_duplicates(subset=column, keep='first', inplace=True)\n return dataframe\n\n @staticmethod\n def _join_words(dataframe, column):\n # Joins words together with space (' ')--used after tokenization\n join_words = lambda x: ' '.join(x)\n dataframe[column] = dataframe[column].map(join_words)\n return dataframe\n\n def tokenize_words(self):\n self.dataframe[self.column] = self.dataframe.apply(lambda x: self.tokenizer(x[self.column]), axis=1)\n\n def stem_words(self):\n self.dataframe[self.column] = self.dataframe.apply(lambda x: [self.stemmer.stem(word) for word in x[self.column]], axis=1)\n\n def lemmatize_words(self):\n self.dataframe[self.column] = self.dataframe.apply(lambda x: [self.lemmatizer.lemmatize(word) for word in x[self.column]], axis=1)\n\n def real_words(self):\n # Removes words that are not within the nltk.corpus library\n words = set(nltk.corpus.words.words())\n self.dataframe[self.column] = self.dataframe.apply(lambda x: \\\n \" \".join(w for w in nltk.wordpunct_tokenize(x[self.column]) if w.lower() in words or not w.isalpha()), axis=1)\n\n def remove_single_letter(self):\n # Removes words that are 1 letter\n self.dataframe[self.column] = self.dataframe.apply(lambda x: ' '.join([w for w in x[self.column].split() if len(w)>2]), axis=1)\n\n\ndf = pd.read_csv('data/dataframe_merged_small.csv', usecols=['id', 'title', 'overview', 'tagline'])\n\n# Replace NaN with empty strings\ndf['overview'] = df['overview'].replace(np.nan, '', regex=True)\ndf['tagline'] = df['tagline'].replace(np.nan, '', regex=True)\n\n# Join [overview] and [keywords] together\n# These two columns are synopsis-associated and it's sensible to join them together\ndf['overview_and_tagline'] = df['overview'] + df['tagline']\n\n# Clean the text using nlp_pipelines class\nnlp = nlp_pipe(dataframe = df,\n column = 'overview_and_tagline',\n tokenizer = nltk.word_tokenize,\n vectorizer = TfidfVectorizer(stop_words='english'),\n stemmer = SnowballStemmer(\"english\"),\n lemmatizer = WordNetLemmatizer())\n\nnlp.cleaner()\n\ndf['overview_and_tagline'] = df['overview_and_tagline'].replace('', 'placeholder', regex=True)\n\ndf['tokenize_overview_and_tagline'] = df['overview_and_tagline'].apply(lambda x: x.lower())\ndf['tokenize_overview_and_tagline'] = df['tokenize_overview_and_tagline'].apply(lambda x: x.split())\n\n\ndf = df.reset_index()\n\n# Reference: https://kanoki.org/2019/03/07/sentence-similarity-in-python-using-doc2vec/\ntagged = [TaggedDocument(words=word_tokenize(_d.lower()),\ntags = [str(i)]) for i, _d in enumerate(df['overview_and_tagline'])]\n\nmodel = Doc2Vec.load('data/doc2vec_small.model')\n\ncos_matrix = np.ones((len(df), len(df)))\n\nfrom itertools import permutations\n\narray_idx = np.arange(0, len(df))\n\nfor idx in permutations(array_idx, 2):\n cos_matrix[idx] = model.n_similarity(df['tokenize_overview_and_tagline'][idx[0]], df['tokenize_overview_and_tagline'][idx[1]])\n print(idx)\n\n# # Save cosine_sim array to use in hybrid recommendation system\nnp.save('similarity_matrix/cos_overview_doc2vec_small.npy', cos_matrix)\n"
},
{
"alpha_fraction": 0.7692307829856873,
"alphanum_fraction": 0.7824339866638184,
"avg_line_length": 81.9047622680664,
"blob_id": "e24af41ad1e8062ef6d5e8927ec66bce1af4d126",
"content_id": "7f52c51e0eeae53d0f720ed16010861551e9c54d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1742,
"license_type": "no_license",
"max_line_length": 463,
"num_lines": 21,
"path": "/project-4/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "# Satirical Headines: Recognizing Truth/Lies\n\nThis project used satirical headlines from two subreddits: /r/TheOnion and /r/NotTheOnion, to investigate different topics between both subreddits and attempt to classify the headline's correpsponding subreddit. A total of 6 distinguishable topics were found, being topics centered around: toilet paper, black lives matter, current affairs, police, New York, and politics (in order of headline frequency). Classification resulted in accuracy of a maximum of 57%.\n\n\n\n## Objective\n\nThe goal of this project is to explore different methods to determine true headlines from fake headlines with both being written in a satirical manner. The explorative approach included topic modeling (LSA, LDA, and NMF) and clustering algorithms (e.g. K-means). After topics were determined, the results were inputted into a classifier, along with VADER sentiment results as features, to investigate if real events could be distinguished from fake events.\n\n### Data\n\nThe data used was obtained from two subreddits: /r/TheOnion and /r/NotTheOnion. Data was scraped from January 1, 2020 to August 15, 2020. 1,081 headlines were scraped from /r/TheOnion and 36,262 headlines were from /r/NotTheOnion. Only the headline titles were used in this analysis.\n\n### Tools Used\n\n**Jupyter Notebook** was used as the interface to deploy Python code. **Pandas** was used for generating, cleaning, and exploration of the dataframe. **Matplotlib** and **Seaborn** were used for plotting. **Numpy** was used for computation. **Scikit-learn** was used for topic modeling and clustering. **Xgboost** was used for classification. **t-SNE** was used for dimensionality reduction.\n\n### Author\n\nBrian Nguyen (https://github.com/bt-nguyen/)\n\n"
},
{
"alpha_fraction": 0.7857574224472046,
"alphanum_fraction": 0.7881714105606079,
"avg_line_length": 77.85713958740234,
"blob_id": "513d016c9b2fb92b3c4904ffbd4bfeeabd660736",
"content_id": "8b43f415a06ee0fc9c698bab619b345a49466bb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1657,
"license_type": "no_license",
"max_line_length": 536,
"num_lines": 21,
"path": "/project-2/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "# Features Leading to a Well-Received Video Game\n\nThis project investigates what features lead to a well-received video game using store.steampowered.com as a source. This project was performed in the scope of the Metis data science program.\n\n\n\n## Objective\n\nThe project's objective is to take an exploratory approac to examine which features lead to a well-received video game. Six features are examined initially, but the scope is narrowed to four features after exploratory data analysis. Linear regression was used to predict how these features effect user ratings, but a poor fit was observed. Regardless, we find that minimum storage required (a possible indicator of AAA games versus indie games) and the quantity of labeled genres are the most impactful features from this investigation.\n\n### Data\n\nThe source for our data is store.steampowered.com. Linked were collected using BeautifulSoup and Selenium to collect specific product links and scrape features/data from those links. Collected features are: release date, number of reviews since release, overall rating since release, number of reviews within past 30 days, rating within past 30 days, labeled genres per game, minimum storage required for installation, and price.\n\n### Tools Used\n\n**Jupyter Notebook** was used as the interface to deploy Python code. **Pandas** was used for generating, cleaning, and exploration of the dataframe. **Matplotlib** and **Seaborn** was used for plotting. **Numpy** was used for computation. **BeautifulSoup** and **Selenium** was used for scraping. **Statsmodel** and **sklearn** was used regression.\n\n### Author\n\nBrian Nguyen (https://github.com/bt-nguyen/)\n\n"
},
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.804347813129425,
"avg_line_length": 45,
"blob_id": "6aea35078823563d4defd671e92c7b36119e8405",
"content_id": "7f3464e4c9c64f72218407f25385227fe7ceb17c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 1,
"path": "/project-3/Data_NHANES/2013-2014/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "Data from 2013-2014 used in Jupyter notebook.\n"
},
{
"alpha_fraction": 0.7202295660972595,
"alphanum_fraction": 0.7317073345184326,
"avg_line_length": 26.8799991607666,
"blob_id": "b5f23b0777b3fb28827626f59bafed1657838a6b",
"content_id": "6bcde0a749948b59a1d3c3b6fa8b9e570c8faba3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1394,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 50,
"path": "/project-2/steamGameList.py",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "'''\nThis python function scrolls through the url (Steam website)\nand generates a list of websites per game to scrape\ndetailed data for project 2 titled:\n'steamGameList.txt'\n'''\n\n# Imports\nfrom bs4 import BeautifulSoup\nimport requests\nimport time\nimport os\nfrom selenium import webdriver\nfrom selenium.webdriver.common.keys import Keys\n\n# path to the chromedriver executable\nchromedriver = \"/Applications/chromedriver\"\nos.environ[\"webdriver.chrome.driver\"] = chromedriver\n\n# Designate a URL to pull data from\nurl = 'https://store.steampowered.com/search/?category1=998'\n\n# Use the chromedriver to access the website\ndriver = webdriver.Chrome(chromedriver)\ndriver.get(url)\n\n# Change range limit for differemt amount of entries (40000 entries)\nfor i in range(800):\n # Scroll\n driver.execute_script(\n # Alternatively, document.body.scrollHeight\n \"window.scrollTo(0, document.documentElement.scrollHeight);\"\n )\n\n # Wait for page to load\n time.sleep(1)\n\nsoup = BeautifulSoup(driver.page_source, 'lxml')\n\n# Make a list of sites to go through\nlist_of_links = []\n\n# Retrieve a list of links\nfor link in soup.find('div', id='search_resultsRows').find_all('a', href=True):\n list_of_links.append(link.get('href'))\n\n# Save list_of_links as a txt file 'steamGameList.txt'\nwith open('steamGameList.txt', 'w') as f:\n for item in list_of_links:\n f.write(\"%s\\n\" % item)\n"
},
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.804347813129425,
"avg_line_length": 45,
"blob_id": "95578025e724b46b8fe9e96bd60794abe5779f97",
"content_id": "8aff08495dfa8dd993ce1c65c632ddefc8999c9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 1,
"path": "/project-3/Data_NHANES/2017-2018/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "Data from 2017-2018 used in Jupyter notebook.\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.8199999928474426,
"avg_line_length": 49,
"blob_id": "a6a127b4ab7cb5f8e2b969159dc679a0d263e1fa",
"content_id": "cfb8eadf98b1ae18b48bec8fbaa5908eff6c56c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 50,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 1,
"path": "/project-3/images/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "This folder contains images related to project 3.\n"
},
{
"alpha_fraction": 0.8536585569381714,
"alphanum_fraction": 0.8536585569381714,
"avg_line_length": 40,
"blob_id": "930914eee6cca94ef4ff3dc7803bcc89ae9afae4",
"content_id": "fcefd212b6525b602a0bad42b7d44542239a56d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 41,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 1,
"path": "/project-5/figures/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "Figures generated from Jupyter notebook.\n"
},
{
"alpha_fraction": 0.7906976938247681,
"alphanum_fraction": 0.8139534592628479,
"avg_line_length": 42,
"blob_id": "8d73ab3147ffbfbc02a56fb2712fb38a5c7e348a",
"content_id": "8e35f764cc627bcbb19f55be6e05a01572bfff28",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 1,
"path": "/project-1/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "This folder contains project 1 from Metis.\n"
},
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.804347813129425,
"avg_line_length": 45,
"blob_id": "bf2b4e74fc83fec58b1ddd518aaf46b729f68e86",
"content_id": "4da923c1fb9a3d0db9a54bc6a13e30243ab95913",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 46,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 1,
"path": "/project-3/Data_NHANES/2009-2010/readme.md",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "Data from 2009-2010 used in Jupyter notebook.\n"
},
{
"alpha_fraction": 0.6885311603546143,
"alphanum_fraction": 0.6933601498603821,
"avg_line_length": 35.54411697387695,
"blob_id": "e7f5e194fa2898c12e3021b2ec3eb4d08273a5d8",
"content_id": "f7a5960cef1dc0dd6dfa55972dde3dd306c57ca8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2485,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 68,
"path": "/project-5/generate_jaccard_matrix.py",
"repo_name": "bt-nguyen/metis-projects",
"src_encoding": "UTF-8",
"text": "###############\n### IMPORTS ###\n###############\n\nimport pandas as pd\nimport numpy as np\n\nfrom sklearn.feature_extraction.text import CountVectorizer\nfrom sklearn.metrics.pairwise import cosine_similarity, pairwise_distances\nimport nltk\n\ndf_all = pd.read_csv('data/dataframe_merged.csv')\ndf = pd.read_csv('data/dataframe_merged.csv', usecols=['id', 'title', 'genres', 'cast', 'director'])\n\n# This will join first and last names to a single string (and lowercase) so that they do not\n# become split during the vectorization process\ndef clean_data(x):\n if isinstance(x, list):\n return [str.lower(i.replace(\" \", \"\")) for i in x]\n else:\n #Check if director exists. If not, return empty string\n if isinstance(x, str):\n return str.lower(x.replace(\" \", \"\"))\n else:\n return ''\n\n# Apply clean_data function to your features.\nfeatures = ['cast', 'director']\n\nfor feature in features:\n df[feature] = df[feature].apply(clean_data)\n\n# Clean the text further by only keeping alphanumerics\nimport re\n\ndef create_metasoup(x):\n string = ''.join(x['cast']) + ' ' + x['director']\n return re.sub(r'\\W+', ' ', string)\ndf['metasoup'] = df.apply(create_metasoup, axis=1)\n\n# tokenize dataset\ndf['split_metasoup'] = df['metasoup'].apply(lambda x: set(nltk.ngrams(nltk.word_tokenize(x), n=1)))\n\n# Convert df['split_metasoup'] into a numpy array for faster computation;\n# working in pandas will take ~40 hours\nsplit_metasoup_array = df['split_metasoup'].to_numpy()\n\n# Write a function to calculte jaccard distance\n# Without the try-except loop, an error occurs: 'cannot divide by 0', when creating df_jaccard below\n# https://python.gotrained.com/nltk-edit-distance-jaccard-distance/#Jaccard_Distance\ndef calculate_jaccard_dist(metasoup_A, metasoup_B):\n try:\n jaccard = 1 - nltk.jaccard_distance(metasoup_A, metasoup_B)\n return jaccard\n except:\n return 0\n\n# Initialize a blank array that will be filled\njaccard = np.zeros((len(split_metasoup_array), len(split_metasoup_array)))\n\n# This for loop will create the filled array, which is the jaccard_similarity array\nfor idx in range(0, len(split_metasoup_array)):\n print(idx)\n for idx2 in range(0, len(split_metasoup_array)):\n jaccard[idx, idx2] = calculate_jaccard_dist(split_metasoup_array[idx], split_metasoup_array[idx2])\n\n# Save the numpy array as 'jaccard_metadata.npy' for use in the application\nnp.save('cosine_similarity/jaccard_metadata.npy', jaccard)\n"
}
] | 18 |
naga-naga/dezie-scraping-discordbot | https://github.com/naga-naga/dezie-scraping-discordbot | 5b816ade023849a42c8c3bf998b3a4c6fdecd963 | 26bdf47cc7cbbb220651f1eaadc06f34dd28776e | b7ee0c4d83eebaff17fac4aab2d6e9da605b7850 | refs/heads/master | 2022-12-29T07:17:48.665268 | 2020-08-07T10:45:32 | 2020-08-07T10:45:32 | 300,245,624 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.636801540851593,
"alphanum_fraction": 0.6483622193336487,
"avg_line_length": 26.68000030517578,
"blob_id": "09de3849a33e48ef6fa6d16a9fbc887616676511",
"content_id": "79c810016ef4a30bba96da823790d5b80321e37c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2626,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 75,
"path": "/main.py",
"repo_name": "naga-naga/dezie-scraping-discordbot",
"src_encoding": "UTF-8",
"text": "import discord\nfrom discord.ext import tasks\nfrom datetime import datetime\nimport os\nimport scrape\n\nTOKEN = os.environ[\"DISCORD_BOT_TOKEN\"]\nCHANNEL_ID = int(os.environ[\"DISCORD_CHANNEL_ID\"])\n\n# デヂエのページ\nurls = [\n \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=357\", # お知らせページ\n \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=391\", # 時間割・講義室変更ページ\n \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=361\", # 休講通知ページ\n \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=363\", # 補講通知ページ\n \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=393\", # 学生呼び出しページ\n \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=364\", # 授業調整・期末試験ページ\n]\n\n# 各ページのIDの書き出し先\noutput_ID_path = [\n \"data/rid_info.dat\", # お知らせページ\n \"data/rid_change.dat\", # 時間割・講義室変更ページ\n \"data/rid_cancel.dat\", # 休講通知ページ\n \"data/rid_makeup.dat\", # 補講通知ページ\n \"data/rid_call.dat\", # 学生呼び出しページ\n \"data/rid_exam.dat\", # 授業調整・期末試験ページ\n]\n\nclient = discord.Client()\n\n# メッセージを送る\nasync def send_message(string):\n channel = client.get_channel(CHANNEL_ID)\n await channel.send(string)\n\n# デヂエから情報を拾ってくる\nasync def get_infomation():\n ret_str = \"\"\n for url, path in zip(urls, output_ID_path):\n scr = scrape.Scrape(url, path)\n ret_str += scr.get_elems_string()\n return ret_str\n\n# デヂエから拾ってきた情報を送信する\nasync def send_infomation():\n # デヂエから拾ってきたデータ\n message = await get_infomation()\n if message != \"\":\n # 新着情報がある場合\n # お知らせを一つずつ分ける\n for text in message.split(\"\\n\\n\"):\n if text != \"\":\n # 送信\n await send_message(text)\n\n# BOTの準備ができた時に呼び出される\[email protected]\nasync def on_ready():\n # loopメソッドを動かす\n loop.start()\n print(\"ログインしたよ\")\n # 再起動時にファイル状態が戻るので,一度読み込む\n await get_infomation()\n await send_message(\"BOT起動!\")\n\n# 60秒ごとに繰り返す\[email protected](seconds=60)\nasync def loop():\n # 現在時刻の「分」を取得\n minute = datetime.now().strftime(\"%M\")\n if minute == \"00\":\n await send_infomation()\n\nclient.run(TOKEN)\n"
},
{
"alpha_fraction": 0.468929648399353,
"alphanum_fraction": 0.47841957211494446,
"avg_line_length": 40.82442855834961,
"blob_id": "e3167be407e9fbe3b6de8b14799cadb153294ee2",
"content_id": "0eaa1a916b889d0d90f86934b990f6764be81325",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12859,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 262,
"path": "/scrape.py",
"repo_name": "naga-naga/dezie-scraping-discordbot",
"src_encoding": "UTF-8",
"text": "# デヂエのお知らせページから,各お知らせへのリンクやタイトルを取得\n\nimport requests, bs4, re\n\nclass Scrape:\n # コンストラクタ\n def __init__(self, url, filepath):\n self.url = url # ページのURL\n self.filepath = filepath # IDの書き出し先\n\n # ----- どのページかの判定に用いる -----\n self.info = False # お知らせページ\n self.change = False # 時間割・講義室変更ページ\n self.cancel = False # 休講通知ページ\n self.makeup = False # 補講通知ページ\n self.call = False # 学生呼び出しページ\n self.exam = False # 授業調整・期末試験ページ\n\n # ----- どのページかの判定 -----\n if \"did=357\" in self.url: # お知らせページ\n self.info = True\n elif \"did=391\" in self.url: # 時間割・講義室変更ページ\n self.change = True\n elif \"did=361\" in self.url: # 休講通知ページ\n self.cancel = True\n elif \"did=363\" in self.url: # 補講通知ページ\n self.makeup = True\n elif \"did=393\" in self.url: # 学生呼び出しページ\n self.call = True\n elif \"did=364\" in self.url: # 授業調整・期末試験ページ\n self.exam = True\n\n\n # ファイルにページIDを書き出し\n def write_rid(self, rid):\n with open(self.filepath, \"w\", encoding=\"utf-8\") as f:\n f.write(str(rid))\n\n\n # ページIDの取得\n def get_rid(self):\n with open(self.filepath) as f:\n rid = f.read()\n return rid\n\n\n # リンクやらタイトルやらを取得\n def get_elems(self):\n req = requests.get(self.url) # 接続\n req.raise_for_status() # 接続チェック\n\n soup = bs4.BeautifulSoup(req.text, \"html.parser\")\n\n # 要素を辞書に入れていく\n elements = {}\n\n # ----- 要素の取得 -----\n # リンクを取得\n elements[\"link_elems\"] = soup.select(\".dz_fontSmall > a\")\n\n # タイトルの取得\n if self.info or self.call or self.exam:\n elements[\"title_elems\"] = soup.select(\".record-value-7\")\n elif self.change:\n elements[\"title_elems\"] = soup.select(\".record-value-116\")\n \n # 日付の取得\n elements[\"date_elems\"] = soup.select(\".record-value-4\")\n\n # 時限等の取得\n if self.info:\n elements[\"period_elems\"] = soup.select(\".record-value-221\")\n elif self.change:\n elements[\"period_elems\"] = soup.select(\".record-value-200\")\n elif self.cancel or self.makeup or self.exam:\n elements[\"period_elems\"] = soup.select(\".record-value-94\")\n\n # 学科の取得\n if self.info or self.cancel or self.makeup or self.call or self.exam:\n elements[\"department_elems\"] = soup.select(\".record-value-109\")\n elif self.change:\n elements[\"department_elems\"] = soup.select(\".record-value-6\")\n \n # 学年の取得\n if self.info or self.cancel or self.makeup or self.exam:\n elements[\"year_elems\"] = soup.select(\".record-value-111\")\n elif self.change:\n elements[\"year_elems\"] = soup.select(\".record-value-109\")\n elif self.call:\n elements[\"year_elems\"] = soup.select(\".record-value-119\")\n \n # 科目の取得\n if self.change:\n elements[\"subject_elems\"] = soup.select(\".record-value-203\")\n elif self.cancel or self.makeup:\n elements[\"subject_elems\"] = soup.select(\".record-value-7\")\n \n # 教員の取得\n if self.change:\n elements[\"teacher_elems\"] = soup.select(\".record-value-204\")\n elif self.cancel or self.makeup or self.exam:\n elements[\"teacher_elems\"] = soup.select(\".record-value-8\")\n\n # 種別の取得(時間割・講義室変更)\n if self.change:\n elements[\"type_elems\"] = soup.select(\".record-value-201\")\n \n # 変更前の取得(時間割・講義室変更)\n if self.change:\n elements[\"before_elems\"] = soup.select(\".record-value-205\")\n \n # 変更後の取得(時間割・講義室変更)\n if self.change:\n elements[\"after_elems\"] = soup.select(\".record-value-206\")\n \n # 注記の取得(学生呼び出し)\n if self.call:\n elements[\"note_elems\"] = soup.select(\".record-value-121\")\n \n # ----- 要素の取得ここまで -----\n\n\n # 要素を返す\n return elements\n\n\n # 取得した情報を文字列として返す\n # 引数:url -> デヂエのページのurl, filepath -> IDの書き出し先\n def get_elems_string(self):\n # 返す文字列\n ret_str = \"\"\n\n # 要素を取得\n elements = self.get_elems()\n\n # 各ページのIDを取得するための正規表現\n pattern = r\"rid=\\d+\"\n rid_regex = re.compile(pattern)\n\n # 最大20件表示する\n for i in range(20):\n # 各ページのURL.0番目には詳細検索のリンクが入る\n page_url = \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/\" + elements[\"link_elems\"][i+1].get(\"href\")\n\n # ページのID取得(正規表現使用)\n match_obj = rid_regex.findall(page_url) # マッチした文字列のリストが返る\n \n # ページのID.\"rid=(数字)\"という文字列から数字のみを取り出す\n rid = int(match_obj[0][4:])\n\n # 最新のページIDを記録\n if(i == 0):\n newest_rid = rid\n\n # datファイルからIDを読み取り,読み取ったIDより大きいものを表示\n if(rid > int(self.get_rid())):\n # ----- 取得した情報の表示 -----\n # お知らせページ\n if self.info:\n #ret_str += \"ID : \" + str(rid) + \"\\n\"\n ret_str += \"【お知らせ】\\n\"\n ret_str += \"URL : \" + page_url + \"\\n\" # 各ページのURL\n ret_str += \"タイトル : \" + str(elements[\"title_elems\"][i].text) + \"\\n\" # タイトル\n ret_str += \"日付 : \" + str(elements[\"date_elems\"][i].text) + \"\\n\" # 日付\n ret_str += \"時限等 : \" + str(elements[\"period_elems\"][i].text) + \"\\n\" # 時限\n ret_str += \"対象学科 : \" + str(elements[\"department_elems\"][i].text) + \"\\n\" # 対象学科\n ret_str += \"対象学年 : \" + str(elements[\"year_elems\"][i].text) + \"\\n\\n\" # 対象学年\n\n # 時間割・講義室変更ページ\n elif self.change:\n #ret_str += \"ID : \" + str(rid) + \"\\n\"\n ret_str += \"【時間割・講義室変更】\\n\"\n ret_str += \"URL : \" + page_url + \"\\n\" # 各ページのURL\n ret_str += \"タイトル : \" + str(elements[\"title_elems\"][i].text) + \"\\n\" # タイトル\n ret_str += \"科目名 : \" + str(elements[\"subject_elems\"][i].text) + \"\\n\" # 科目\n ret_str += \"教員 : \" + str(elements[\"teacher_elems\"][i].text) + \"\\n\" # 教員\n ret_str += \"日付 : \" + str(elements[\"date_elems\"][i].text) + \"\\n\" # 日付\n ret_str += \"時限等 : \" + str(elements[\"period_elems\"][i].text) + \"\\n\" # 時限\n ret_str += \"種別 : \" + str(elements[\"type_elems\"][i].text) + \"\\n\" # 種別\n ret_str += \"変更前 : \" + str(elements[\"before_elems\"][i].text) + \"\\n\" # 変更前\n ret_str += \"変更後 : \" + str(elements[\"after_elems\"][i].text) + \"\\n\" # 変更後\n ret_str += \"対象学科 : \" + str(elements[\"department_elems\"][i].text) + \"\\n\" # 対象学科\n ret_str += \"対象学年 : \" + str(elements[\"year_elems\"][i].text) + \"\\n\\n\" # 対象学年\n\n # 休講通知ページ, 補講通知ページ\n elif self.cancel or self.makeup:\n if self.cancel:\n ret_str += \"【休講通知】\\n\"\n else:\n ret_str += \"【補講通知】\\n\"\n #ret_str += \"ID : \" + str(rid) + \"\\n\"\n ret_str += \"URL : \" + page_url + \"\\n\" # 各ページのURL\n ret_str += \"日付 : \" + str(elements[\"date_elems\"][i].text) + \"\\n\" # 日付\n ret_str += \"時限等 : \" + str(elements[\"period_elems\"][i].text) + \"\\n\" # 時限\n ret_str += \"科目名 : \" + str(elements[\"subject_elems\"][i].text) + \"\\n\" # 科目\n ret_str += \"教員名 : \" + str(elements[\"teacher_elems\"][i].text) + \"\\n\" # 教員\n ret_str += \"対象学科 : \" + str(elements[\"department_elems\"][i].text) + \"\\n\" # 対象学科\n ret_str += \"対象学年 : \" + str(elements[\"year_elems\"][i].text) + \"\\n\\n\" # 対象学年\n\n # 学生呼び出しページ\n elif self.call:\n #ret_str += \"ID : \" + str(rid) + \"\\n\"\n ret_str += \"【学生呼び出し】\\n\"\n ret_str += \"URL : \" + page_url + \"\\n\" # 各ページのURL\n ret_str += \"タイトル : \" + str(elements[\"title_elems\"][i].text) + \"\\n\" # タイトル\n ret_str += \"注記 : \" + str(elements[\"note_elems\"][i].text) + \"\\n\" # 注記\n ret_str += \"対象学科 : \" + str(elements[\"department_elems\"][i].text) + \"\\n\" # 対象学科\n ret_str += \"対象学年 : \" + str(elements[\"year_elems\"][i].text) + \"\\n\" # 対象学年\n ret_str += \"日付 : \" + str(elements[\"date_elems\"][i].text) + \"\\n\\n\" # 日付\n\n # 授業調整・期末試験ページ\n elif self.exam:\n #ret_str += \"ID : \" + str(rid) + \"\\n\"\n ret_str += \"【授業調整・期末試験】\\n\"\n ret_str += \"URL : \" + page_url + \"\\n\" # 各ページのURL\n ret_str += \"タイトル : \" + str(elements[\"title_elems\"][i].text) + \"\\n\" # タイトル\n ret_str += \"日付 : \" + str(elements[\"date_elems\"][i].text) + \"\\n\" # 日付\n ret_str += \"時限等 : \" + str(elements[\"period_elems\"][i].text) + \"\\n\" # 時限\n ret_str += \"対象学科 : \" + str(elements[\"department_elems\"][i].text) + \"\\n\" # 対象学科\n ret_str += \"対象学年 : \" + str(elements[\"year_elems\"][i].text) + \"\\n\\n\" # 対象学年\n\n # 最新のページIDをファイルに書き出し\n self.write_rid(newest_rid)\n\n return ret_str\n\n\nif __name__ == \"__main__\":\n # デヂエのページ\n info_url = \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=357\" # お知らせページ\n change_url = \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=391\" # 時間割・講義室変更ページ\n cancel_url = \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=361\" # 休講通知ページ\n makeup_url = \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=363\" # 補講通知ページ\n call_url = \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=393\" # 学生呼び出しページ\n exam_url = \"https://db.jimu.kyutech.ac.jp/cgi-bin/cbdb/db.cgi?page=DBView&did=364\" # 授業調整・期末試験ページ\n\n # 各ページのIDの書き出し先\n path_to_info = \"data/rid_info.dat\"\n path_to_change = \"data/rid_change.dat\"\n path_to_cancel = \"data/rid_cancel.dat\"\n path_to_makeup = \"data/rid_makeup.dat\"\n path_to_call = \"data/rid_call.dat\"\n path_to_exam = \"data/rid_exam.dat\"\n\n # 表示\n scr = Scrape(info_url, path_to_info)\n print(scr.get_elems_string())\n\n scr2 = Scrape(change_url, path_to_change)\n print(scr2.get_elems_string())\n\n scr3 = Scrape(cancel_url, path_to_cancel)\n print(scr3.get_elems_string())\n\n scr4 = Scrape(makeup_url, path_to_makeup)\n print(scr4.get_elems_string())\n\n scr5 = Scrape(call_url, path_to_call)\n print(scr5.get_elems_string())\n\n scr6 = Scrape(exam_url, path_to_exam)\n print(scr6.get_elems_string())\n\n"
}
] | 2 |
dyw984495/Few-shot-transfer | https://github.com/dyw984495/Few-shot-transfer | 345ce0789e4fe13b00e2c89133cc9fb69a785177 | c2bd826bac0d8504ea86cd7bb0e91d59cd5154b0 | e7bbcd53df75c13e6633335c8ad60d8567001267 | refs/heads/main | 2023-02-04T04:48:43.946881 | 2020-12-26T07:07:06 | 2020-12-26T07:07:06 | 316,416,393 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.74210524559021,
"alphanum_fraction": 0.8052631616592407,
"avg_line_length": 26.14285659790039,
"blob_id": "7d0d1d5d403232a72c6aa5a07b63e9c0bb82884f",
"content_id": "631ea3b44de5df39ba6d0ad2eb13e66c58c30c55",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 298,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 7,
"path": "/README.md",
"repo_name": "dyw984495/Few-shot-transfer",
"src_encoding": "UTF-8",
"text": "# Few-shot-transfer\n\nData: new.csv-龙井茶叶数据 multi_brand3000.csv-杂牌茶叶数据\n\nmodel:baseline、Textcnn、LSTM。分为train和迁移,train之后保存模型再在迁移加载\n\n词向量:word.vector-192维词向量 word60.vector-300维词向量 均为维基百科词向量\n"
},
{
"alpha_fraction": 0.5533302426338196,
"alphanum_fraction": 0.5682347416877747,
"avg_line_length": 37.07272720336914,
"blob_id": "5c49655823533fb9eba92244cded61c450e05800",
"content_id": "904199f1c8dc757021f1fd6b62bb53ed72e3ef9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2215,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 55,
"path": "/LSTM_model.py",
"repo_name": "dyw984495/Few-shot-transfer",
"src_encoding": "UTF-8",
"text": "from torch import nn\r\nimport torch\r\nimport torch.nn.functional as F\r\n\r\nclass BiLSTM_Attention(nn.Module):\r\n\r\n def __init__(self, vocab_size, embedding_dim, hidden_dim, n_layers):\r\n\r\n super(BiLSTM_Attention, self).__init__()\r\n\r\n self.hidden_dim = hidden_dim\r\n self.n_layers = n_layers\r\n self.embedding = nn.Embedding(vocab_size, embedding_dim) #单词数,嵌入向量维度\r\n self.rnn = nn.LSTM(embedding_dim, hidden_dim, num_layers=n_layers, bidirectional=True, dropout=0.5)\r\n self.fc = nn.Linear(hidden_dim * 2, 2)\r\n self.dropout = nn.Dropout(0.5)\r\n\r\n # 初始时间步和最终时间步的隐藏状态作为全连接层输入\r\n self.w_omega = nn.Parameter(torch.Tensor(hidden_dim * 2, hidden_dim * 2))\r\n self.u_omega = nn.Parameter(torch.Tensor(hidden_dim * 2, 1))\r\n\r\n nn.init.uniform_(self.w_omega, -0.1, 0.1)\r\n nn.init.uniform_(self.u_omega, -0.1, 0.1)\r\n\r\n\r\n def attention_net(self, x): #x:[batch, seq_len, hidden_dim*2]\r\n\r\n u = torch.tanh(torch.matmul(x, self.w_omega)) #[batch, seq_len, hidden_dim*2]\r\n att = torch.matmul(u, self.u_omega) #[batch, seq_len, 1]\r\n att_score = F.softmax(att, dim=1)\r\n\r\n scored_x = x * att_score #[batch, seq_len, hidden_dim*2]\r\n\r\n context = torch.sum(scored_x, dim=1) #[batch, hidden_dim*2]\r\n return context\r\n\r\n\r\n def forward(self, x):\r\n embedding = self.dropout(self.embedding(x)) #[seq_len, batch, embedding_dim]\r\n # output: [seq_len, batch, hidden_dim*2] hidden/cell: [n_layers*2, batch, hidden_dim]\r\n output, (final_hidden_state, final_cell_state) = self.rnn(embedding)\r\n # output = output.permute(1, 0, 2) #[batch, seq_len, hidden_dim*2]\r\n attn_output = self.attention_net(output)\r\n logit = self.fc(attn_output)\r\n return logit\r\n\r\n\r\nclass next(nn.Module):\r\n def __init__(self, output_size,hidden_dim):\r\n super(next, self).__init__()\r\n self.fc = nn.Linear(hidden_dim*2, output_size)\r\n\r\n def forward(self,x):\r\n logit = self.fc(x)\r\n return logit"
},
{
"alpha_fraction": 0.5624618530273438,
"alphanum_fraction": 0.5741848945617676,
"avg_line_length": 31.280487060546875,
"blob_id": "4059c77d9d5c37018856418bb9535a3f36909caa",
"content_id": "f66c0dc458718955b13a7a53a7ce1298fe7c697f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8315,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 246,
"path": "/TextRCNN_迁移.py",
"repo_name": "dyw984495/Few-shot-transfer",
"src_encoding": "UTF-8",
"text": "import jieba\r\nimport pandas as pd\r\nfrom tqdm import tqdm\r\nimport numpy as np\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.optim as optim\r\nfrom gensim.models import KeyedVectors\r\nfrom sklearn.model_selection import train_test_split\r\n\r\nSENTENCE_LIMIT_SIZE=200\r\nEMBEDDING_SIZE=300\r\nBATCH_SIZE = 128\r\nLEARNING_RATE = 1e-3\r\n\r\nstopwordFile='.\\Data/stopwords.txt'\r\ntrainFile='./Data/multi_brand3000.csv'\r\nwordLabelFile = 'wordLabel.txt'\r\nlengthFile = 'length.txt'\r\n\r\ndef read_stopword(file):\r\n data = open(file, 'r', encoding='utf-8').read().split('\\n')\r\n\r\n return data\r\n\r\ndef loaddata(trainfile,stopwordfile):\r\n a=pd.read_csv(trainfile,encoding='gbk')\r\n stoplist = read_stopword(stopwordfile)\r\n text=a['rateContent']\r\n y=a['price']\r\n x=[]\r\n\r\n for line in text:\r\n line=str(line)\r\n title_seg = jieba.cut(line, cut_all=False)\r\n use_list = []\r\n for w in title_seg:\r\n if w in stoplist:\r\n continue\r\n else:\r\n use_list.append(w)\r\n x.append(use_list)\r\n\r\n return x,y\r\n\r\n\r\ndef dataset(trainfile,stopwordfile):\r\n word_to_idx = {}\r\n idx_to_word = {}\r\n stoplist = read_stopword(stopwordfile)\r\n a = pd.read_csv(trainfile,encoding='gbk')\r\n datas=a['rateContent']\r\n datas = list(filter(None, datas))\r\n try:\r\n for line in datas:\r\n line=str(line)\r\n title_seg = jieba.cut(line, cut_all=False)\r\n length = 2\r\n for w in title_seg:\r\n if w in stoplist:\r\n continue\r\n if w in word_to_idx:\r\n word_to_idx[w] += 1\r\n length+=1\r\n else:\r\n word_to_idx[w] = length\r\n except:\r\n pass\r\n word_to_idx['<unk>'] = 0\r\n word_to_idx['<pad>'] =1\r\n idx_to_word[0] = '<unk>'\r\n idx_to_word[1] = '<pad>'\r\n return word_to_idx\r\n\r\na=dataset(trainFile,stopwordFile)\r\nprint(len(a))\r\nb={v: k for k, v in a.items()}\r\nVOCAB_SIZE = 352217\r\nx,y=loaddata(trainFile,stopwordFile)\r\ndef convert_text_to_token(sentence, word_to_token_map=a, limit_size=SENTENCE_LIMIT_SIZE):\r\n unk_id = word_to_token_map[\"<unk>\"]\r\n pad_id = word_to_token_map[\"<pad>\"]\r\n\r\n # 对句子进行token转换,对于未在词典中出现过的词用unk的token填充\r\n tokens = [word_to_token_map.get(word, unk_id) for word in sentence]\r\n\r\n if len(tokens) < limit_size: #补齐\r\n tokens.extend([0] * (limit_size - len(tokens)))\r\n else: #截断\r\n tokens = tokens[:limit_size]\r\n\r\n return tokens\r\n\r\nx_data=[convert_text_to_token(sentence) for sentence in x]\r\nx_data=np.array(x_data)\r\nwvmodel=KeyedVectors.load_word2vec_format('word60.vector')\r\nstatic_embeddings = np.zeros([VOCAB_SIZE,EMBEDDING_SIZE ])\r\nfor word, token in tqdm(a.items()):\r\n\r\n if word in wvmodel.vocab.keys():\r\n static_embeddings[token, :] = wvmodel[word]\r\n elif word == '<pad>':\r\n static_embeddings[token, :] = np.zeros(EMBEDDING_SIZE)\r\n else:\r\n static_embeddings[token, :] = 0.2 * np.random.random(EMBEDDING_SIZE) - 0.1\r\n\r\nprint(static_embeddings.shape)\r\n\r\nX_train,X_test,y_train,y_test=train_test_split(x_data, y, test_size=0.3)\r\n\r\ndef get_batch(x,y,batch_size=BATCH_SIZE, shuffle=True):\r\n assert x.shape[0] == y.shape[0], print(\"error shape!\")\r\n\r\n\r\n n_batches = int(x.shape[0] / batch_size) #统计共几个完整的batch\r\n\r\n for i in range(n_batches - 1):\r\n x_batch = x[i*batch_size: (i+1)*batch_size]\r\n y_batch = y[i*batch_size: (i+1)*batch_size]\r\n\r\n yield x_batch, y_batch\r\n\r\nimport torch.nn.functional as F\r\n\r\nclass GlobalMaxPool1d(nn.Module):\r\n def __init__(self):\r\n super(GlobalMaxPool1d, self).__init__()\r\n\r\n def forward(self, x):\r\n return torch.max_pool1d(x, kernel_size=x.shape[-1])\r\n\r\n\r\nclass TextRCNN(nn.Module):\r\n def __init__(self, vocab_size, embedding_dim, hidden_size, num_labels=2):\r\n super(TextRCNN, self).__init__()\r\n self.embedding = nn.Embedding(vocab_size, embedding_dim)\r\n self.lstm = nn.LSTM(input_size=embedding_dim, hidden_size=hidden_size,\r\n batch_first=True, bidirectional=True)\r\n self.globalmaxpool = GlobalMaxPool1d()\r\n self.dropout = nn.Dropout(.5)\r\n self.linear1 = nn.Linear(embedding_dim + 2 * hidden_size, 256)\r\n self.linear2 = nn.Linear(256, num_labels)\r\n\r\n def forward(self, x): # x: [batch,L]\r\n x_embed = self.embedding(x) # x_embed: [batch,L,embedding_size]\r\n last_hidden_state, (c, h) = self.lstm(x_embed) # last_hidden_state: [batch,L,hidden_size * num_bidirectional]\r\n out = torch.cat((x_embed, last_hidden_state),\r\n 2) # out: [batch,L,embedding_size + hidden_size * num_bidirectional]\r\n # print(out.shape)\r\n out = F.relu(self.linear1(out))\r\n out = out.permute(dims=[0, 2, 1]) # out: [batch,embedding_size + hidden_size * num_bidirectional,L]\r\n out = self.globalmaxpool(out).squeeze(-1) # out: [batch,embedding_size + hidden_size * num_bidirectional]\r\n # print(out.shape)\r\n out = self.dropout(out) # out: [batch,embedding_size + hidden_size * num_bidirectional]\r\n out = self.linear2(out) # out: [batch,num_labels]\r\n return out\r\n\r\ndef resnet_cifar(net, input_data):\r\n x = net.embedding(input_data)\r\n out1, (final_hidden_state, final_cell_state) = net.lstm(x)\r\n out = torch.cat((x, out1),\r\n 2)\r\n out = F.relu(net.linear1(out))\r\n out = out.permute(dims=[0, 2, 1]) # out: [batch,embedding_size + hidden_size * num_bidirectional,L]\r\n out = net.globalmaxpool(out).squeeze(-1) # out: [batch,embedding_size + hidden_size * num_bidirectional]\r\n # print(out.shape)\r\n out = net.dropout(out)\r\n return out\r\n\r\nclass next(nn.Module):\r\n def __init__(self, output_size ):\r\n super(next, self).__init__()\r\n self.fc = nn.Linear(256, output_size)\r\n\r\n def forward(self,x):\r\n logit = self.fc(x)\r\n return logit\r\n\r\nrnn=TextRCNN(vocab_size=VOCAB_SIZE,embedding_dim=EMBEDDING_SIZE,hidden_size=64)\r\nrnn.load_state_dict(torch.load('./model-TextRCNN3.pkl'))\r\nrnnnext=next(2)\r\noptimizer = optim.Adam(rnnnext.parameters(), lr=LEARNING_RATE)\r\ncriteon = nn.CrossEntropyLoss()\r\n\r\ndef train(rnnnext, optimizer, criteon):\r\n\r\n global loss\r\n avg_acc = []\r\n rnnnext.train() #表示进入训练\r\n\r\n for x_batch, y_batch in get_batch(X_train,y_train):\r\n try:\r\n x_batch = torch.LongTensor(x_batch)\r\n y_batch = torch.LongTensor(y_batch.to_numpy())\r\n\r\n y_batch = y_batch.squeeze()\r\n x_batch = resnet_cifar(rnn, x_batch)\r\n pred = rnnnext(x_batch)\r\n acc = binary_acc(torch.max(pred, dim=1)[1], y_batch)\r\n avg_acc.append(acc)\r\n\r\n loss =criteon(pred, y_batch)\r\n\r\n optimizer.zero_grad()\r\n loss.backward()\r\n optimizer.step()\r\n except:\r\n pass\r\n\r\n avg_acc = np.array(avg_acc).mean()\r\n return avg_acc,loss\r\n\r\ndef evaluate(rnnnext, criteon):\r\n avg_acc = []\r\n rnnnext.eval() #表示进入测试模式\r\n\r\n with torch.no_grad():\r\n for x_batch, y_batch in get_batch(X_test, y_test):\r\n try:\r\n x_batch = torch.LongTensor(x_batch)\r\n y_batch = torch.LongTensor(y_batch.to_numpy())\r\n\r\n y_batch = y_batch.squeeze() #torch.Size([128])\r\n\r\n x_batch = resnet_cifar(rnn, x_batch)\r\n pred = rnnnext(x_batch) #torch.Size([128, 2])\r\n\r\n acc = binary_acc(torch.max(pred, dim=1)[1], y_batch)\r\n avg_acc.append(acc)\r\n except:\r\n pass\r\n\r\n avg_acc = np.array(avg_acc).mean()\r\n return avg_acc\r\n\r\ndef binary_acc(preds, y):\r\n correct = torch.eq(preds, y).float()\r\n acc = correct.sum() / len(correct)\r\n return acc\r\n\r\nfor epoch in range(15):\r\n\r\n train_acc,loss = train(rnnnext, optimizer, criteon)\r\n print('epoch={},训练准确率={},误判率 ={}'.format(epoch, train_acc,loss))\r\n test_acc = evaluate(rnnnext, criteon)\r\n print(\"epoch={},测试准确率={}\".format(epoch, test_acc))\r\n\r\n"
},
{
"alpha_fraction": 0.5477437973022461,
"alphanum_fraction": 0.5582241415977478,
"avg_line_length": 28.26431655883789,
"blob_id": "f49eea3177c2465e57fa224236ef045cac1529df",
"content_id": "2d3230bc360588b9eb143e6278df7c24ac3116fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7106,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 227,
"path": "/LSTM_迁移.py",
"repo_name": "dyw984495/Few-shot-transfer",
"src_encoding": "UTF-8",
"text": "import jieba\r\nimport pandas as pd\r\nfrom tqdm import tqdm\r\nimport torch\r\nimport numpy as np\r\nimport torch.nn as nn\r\nimport torch.optim as optim\r\nimport LSTM_model\r\nfrom gensim.models import KeyedVectors\r\nfrom sklearn.model_selection import train_test_split\r\n\r\nSENTENCE_LIMIT_SIZE=300\r\nEMBEDDING_SIZE=300\r\nBATCH_SIZE = 128\r\nLEARNING_RATE = 1e-3\r\nSEED = 123\r\nhidden_dim=64\r\nn_layers=2\r\n# 设置device\r\ndevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')\r\n\r\n# 为CPU设置随机种子\r\ntorch.manual_seed(123)\r\n\r\n\r\nstopwordFile='.\\Data/stopwords.txt'\r\ntrainFile='.\\Data/multi_brand3000.csv'\r\nwordLabelFile = 'wordLabel.txt'\r\nlengthFile = 'length.txt'\r\n\r\n\r\ndef read_stopword(file):\r\n data = open(file, 'r', encoding='utf-8').read().split('\\n')\r\n\r\n return data\r\n\r\ndef get_batch(x,y,batch_size=BATCH_SIZE, shuffle=True):\r\n assert x.shape[0] == y.shape[0], print(\"error shape!\")\r\n\r\n\r\n n_batches = int(x.shape[0] / batch_size) #统计共几个完整的batch\r\n\r\n for i in range(n_batches - 1):\r\n x_batch = x[i*batch_size: (i+1)*batch_size]\r\n y_batch = y[i*batch_size: (i+1)*batch_size]\r\n\r\n yield x_batch, y_batch\r\n\r\ndef loaddata(trainfile,stopwordfile):\r\n a=pd.read_csv(trainfile,encoding='gbk')\r\n stoplist = read_stopword(stopwordfile)\r\n text=a['rateContent']\r\n y=a['other']\r\n x=[]\r\n\r\n for line in text:\r\n line=str(line)\r\n title_seg = jieba.cut(line, cut_all=False)\r\n use_list = []\r\n for w in title_seg:\r\n if w in stoplist:\r\n continue\r\n else:\r\n use_list.append(w)\r\n x.append(use_list)\r\n\r\n return x,y\r\n\r\n\r\ndef dataset(trainfile,stopwordfile):\r\n word_to_idx = {}\r\n idx_to_word = {}\r\n stoplist = read_stopword(stopwordfile)\r\n a = pd.read_csv(trainfile,encoding='gbk')\r\n datas=a['rateContent']\r\n datas = list(filter(None, datas))\r\n try:\r\n for line in datas:\r\n line=str(line)\r\n title_seg = jieba.cut(line, cut_all=False)\r\n length = 2\r\n for w in title_seg:\r\n if w in stoplist:\r\n continue\r\n if w in word_to_idx:\r\n word_to_idx[w] += 1\r\n length+=1\r\n else:\r\n word_to_idx[w] = length\r\n except:\r\n pass\r\n word_to_idx['<unk>'] = 0\r\n word_to_idx['<pad>'] =1\r\n idx_to_word[0] = '<unk>'\r\n idx_to_word[1] = '<pad>'\r\n return word_to_idx\r\n\r\ndef resnet_cifar(net, input_data):\r\n embedding =net.dropout(net.embedding(input_data)) # [seq_len, batch, embedding_dim]\r\n # output: [seq_len, batch, hidden_dim*2] hidden/cell: [n_layers*2, batch, hidden_dim]\r\n output, (final_hidden_state, final_cell_state) = net.rnn(embedding)\r\n # output = output.permute(1, 0, 2) #[batch, seq_len, hidden_dim*2]\r\n attn_output = net.attention_net(output)\r\n return attn_output\r\n\r\na=dataset(trainFile,stopwordFile)\r\nprint(len(a))\r\nb={v: k for k, v in a.items()}\r\nVOCAB_SIZE = 352217\r\nx,y=loaddata(trainFile,stopwordFile)\r\ndef convert_text_to_token(sentence, word_to_token_map=a, limit_size=SENTENCE_LIMIT_SIZE):\r\n unk_id = word_to_token_map[\"<unk>\"]\r\n pad_id = word_to_token_map[\"<pad>\"]\r\n\r\n # 对句子进行token转换,对于未在词典中出现过的词用unk的token填充\r\n tokens = [word_to_token_map.get(word, unk_id) for word in sentence]\r\n\r\n if len(tokens) < limit_size: #补齐\r\n tokens.extend([0] * (limit_size - len(tokens)))\r\n else: #截断\r\n tokens = tokens[:limit_size]\r\n\r\n return tokens\r\n\r\nx_data=[convert_text_to_token(sentence) for sentence in x]\r\nx_data=np.array(x_data)\r\nx_data_1=torch.LongTensor(x_data)\r\n\r\n\r\nwvmodel=KeyedVectors.load_word2vec_format('word60.vector')\r\nstatic_embeddings = np.zeros([VOCAB_SIZE,EMBEDDING_SIZE ])\r\nfor word, token in tqdm(a.items()):\r\n #用词向量填充\r\n if word in wvmodel.vocab.keys():\r\n static_embeddings[token, :] = wvmodel[word]\r\n elif word == '<pad>': #如果是空白,用零向量填充\r\n static_embeddings[token, :] = np.zeros(EMBEDDING_SIZE)\r\n else: #如果没有对应的词向量,则用随机数填充\r\n static_embeddings[token, :] = 0.2 * np.random.random(EMBEDDING_SIZE) - 0.1\r\n\r\nprint(static_embeddings.shape)\r\nX_train,X_test,y_train,y_test=train_test_split(x_data, y, test_size=0.3)\r\nprint(X_train.shape, y_train.shape)\r\ny=np.reshape(-1,1)\r\n\r\nrnn = LSTM_model.BiLSTM_Attention(\r\n vocab_size=VOCAB_SIZE,\r\n embedding_dim=EMBEDDING_SIZE,\r\n hidden_dim=hidden_dim,\r\n n_layers=n_layers\r\n )\r\n\r\nrnn.load_state_dict(torch.load('./model-LSTM6.pkl'))\r\n\r\nrnnnext=LSTM_model.next(output_size=2,hidden_dim=hidden_dim)\r\n\r\noptimizer = torch.optim.Adam(rnnnext.parameters(), lr=LEARNING_RATE)\r\ncriterion = torch.nn.CrossEntropyLoss()\r\n\r\n\r\n# 计算准确率\r\ndef binary_acc(preds, y):\r\n correct = torch.eq(preds, y).float()\r\n acc = correct.sum() / len(correct)\r\n return acc\r\n\r\n\r\n\r\n# 训练函数\r\ndef train(rnnnext, optimizer, criteon):\r\n avg_loss = []\r\n avg_acc = []\r\n rnnnext.train() # 表示进入训练模式\r\n try:\r\n for x_batch, y_batch in get_batch(X_train,y_train):\r\n x_batch = torch.LongTensor(x_batch)\r\n y_batch = torch.LongTensor(y_batch.to_numpy())\r\n\r\n x_batch=resnet_cifar(rnn,x_batch)\r\n\r\n pred = rnnnext(x_batch) # [batch, 1] -> [batch]\r\n acc = binary_acc(torch.max(pred, dim=1)[1], y_batch)\r\n avg_acc.append(acc)\r\n\r\n loss = criteon(pred, y_batch)\r\n\r\n optimizer.zero_grad()\r\n loss.backward()\r\n optimizer.step()\r\n except:\r\n pass\r\n\r\n avg_acc = np.array(avg_acc).mean()\r\n return avg_acc, loss\r\n\r\n\r\n# 评估函数\r\ndef evaluate(rnnnext, criteon):\r\n avg_loss = []\r\n avg_acc = []\r\n rnnnext.eval() # 进入测试模式\r\n\r\n with torch.no_grad():\r\n try:\r\n for x_batch, y_batch in get_batch(X_test, y_test):\r\n x_batch = torch.LongTensor(x_batch)\r\n y_batch = torch.LongTensor(y_batch.to_numpy())\r\n x_batch = resnet_cifar(rnn, x_batch)\r\n\r\n pred = rnnnext(x_batch)\r\n loss = criteon(pred, y_batch)\r\n acc = binary_acc(torch.max(pred, dim=1)[1], y_batch).item()\r\n\r\n avg_acc.append(acc)\r\n except:\r\n pass\r\n\r\n avg_acc = np.array(avg_acc).mean()\r\n return avg_acc\r\n\r\n\r\nfor epoch in range(10):\r\n\r\n train_acc,loss = train(rnnnext, optimizer, criterion)\r\n print('epoch={},训练准确率={},loss ={}'.format(epoch, train_acc,loss))\r\n test_acc= evaluate(rnnnext, criterion)\r\n print(\"epoch={},测试准确率={}\".format(epoch, test_acc))\r\n"
},
{
"alpha_fraction": 0.6838709712028503,
"alphanum_fraction": 0.7032257914543152,
"avg_line_length": 22.578947067260742,
"blob_id": "d8d6e883e03f6cfdd00a155d8f367b6455617dfa",
"content_id": "c151f60b51a3320ee109689483be282ef20873cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 499,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 19,
"path": "/datahelper.py",
"repo_name": "dyw984495/Few-shot-transfer",
"src_encoding": "UTF-8",
"text": "import jieba\r\nimport pandas as pd\r\nimport re\r\n\r\ntrain_data=pd.read_csv(r\"D:\\小样本迁移\\Data/new.csv\",encoding='gbk')\r\nprint(train_data)\r\ntrain_text = []\r\nfor line in train_data['rateContent']:\r\n line=str(line)\r\n t = jieba.lcut(line)\r\n train_text.append(t)\r\n\r\n\r\nsentence_length = [len(x) for x in train_text] #train_text是train.csv中每一行分词之后的数据\r\n\r\nimport matplotlib.pyplot as plt\r\nplt.hist(sentence_length,100,normed=1,cumulative=True)\r\nplt.xlim(0,1000)\r\nplt.show()"
}
] | 5 |
retroric/Lunatic--SpaceManiac | https://github.com/retroric/Lunatic--SpaceManiac | 41fd8c06736e5d89e7d87a3fe729278c62c0e5ed | 4a1fe850caf8341e0162768f1579458147948d5e | 603993f56780faceda5d1a3ee04c89d9fe68e7e8 | refs/heads/master | 2020-09-03T00:59:52.108799 | 2015-02-20T02:22:43 | 2015-02-20T02:22:43 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5449379086494446,
"alphanum_fraction": 0.570711076259613,
"avg_line_length": 17.865337371826172,
"blob_id": "3db02301f7cf42bf3ce47a97a2b690a5e31e96c9",
"content_id": "a1ecb1f123b4b08a2dfe65e471d71f4977bef137",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7566,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 401,
"path": "/source/jamulfmv.cpp",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#include \"jamulfmv.h\"\n#include \"game.h\" // For HandleCDMusic()\n\n// different kinds of flic chunks\nenum {\n\tFLI_COLOR = 11,\n\tFLI_LC = 12,\n\tFLI_BLACK = 13,\n\tFLI_BRUN = 15,\n\tFLI_COPY = 16,\n\tFLI_DELTA = 7,\n\tFLI_256_COLOR = 4,\n\tFLI_MINI = 18\n};\n\nstruct fliheader\n{\n\tlong size;\n\tword magic;\n\tword frames;\n\tword width, height;\n\tword flags;\n\tword speed;\n\tlong next, frit;\n\tbyte expand[104];\n};\n\nstruct frmheader\n{\n\tlong size;\n\tword magic; /* always $F1FA */\n\tword chunks;\n\tbyte expand[8];\n};\n\n// because of padding, the following 6-byte header is 8 bytes.\n// therefore use this define instead of sizeof() to read from a FLIc\nconst int sizeofchunkheader = 6;\n\nstruct chunkheader\n{\n\tlong size;\n\tword kind;\n};\n\nFILE * FLI_file;\npalette_t FLI_pal[256];\nword fliWidth, fliHeight;\n\n// ------------------------------------------------------------------------------\n\nvoid PlotSolidRun(int x, int y, int len, byte *scrn, byte c)\n{\n\tint i;\n\tint pos;\n\n\tx *= 2;\n\ty *= 2;\n\tpos = x + y * 640;\n\tfor (i = 0; i < len; i++)\n\t{\n\t\tscrn[pos + 640] = c;\n\t\tscrn[pos + 641] = c;\n\t\tscrn[pos++] = c;\n\t\tscrn[pos++] = c;\n\t}\n}\n\nvoid PlotSolidWordRun(int x, int y, int len, byte *scrn, word c)\n{\n\tint i;\n\tint pos;\n\tbyte c2;\n\n\tx *= 2;\n\ty *= 2;\n\tpos = x + y * 640;\n\tc2 = (byte) (c >> 8);\n\tfor (i = 0; i < len; i++)\n\t{\n\t\tscrn[pos + 640] = (byte) c;\n\t\tscrn[pos + 641] = (byte) c;\n\t\tscrn[pos++] = (byte) c;\n\t\tscrn[pos++] = (byte) c;\n\t\tscrn[pos + 640] = c2;\n\t\tscrn[pos + 641] = c2;\n\t\tscrn[pos++] = c2;\n\t\tscrn[pos++] = c2;\n\t}\n}\n\nvoid PlotDataRun(int x, int y, int len, byte *scrn, byte *data)\n{\n\tint i;\n\tint pos;\n\n\tx *= 2;\n\ty *= 2;\n\tpos = x + y * 640;\n\tfor (i = 0; i < len; i++)\n\t{\n\t\tscrn[pos + 640] = *data;\n\t\tscrn[pos + 641] = *data;\n\t\tscrn[pos++] = *data;\n\t\tscrn[pos++] = *data;\n\t\tdata++;\n\t}\n}\n\nvoid FLI_docolor2(byte *p, MGLDraw *mgl)\n{\n\tword numpak;\n\tword pos = 0;\n\tbyte palpos = 0;\n\tbyte numcol;\n\n\tmemcpy(&numpak, p, 2);\n\tpos = 2;\n\twhile (numpak > 0)\n\t{\n\t\tnumpak--;\n\t\tpalpos += p[pos++];\n\t\tnumcol = p[pos++];\n\t\tdo\n\t\t{\n\t\t\tmemcpy(&FLI_pal[palpos], &p[pos], 4);\n\t\t\tFLI_pal[palpos].blue = FLI_pal[palpos].green;\n\t\t\tFLI_pal[palpos].green = FLI_pal[palpos].red;\n\t\t\tFLI_pal[palpos].red = FLI_pal[palpos].alpha;\n\t\t\tpalpos++;\n\t\t\tpos += 3;\n\t\t\t--numcol;\n\t\t}\n\t\twhile (numcol > 0);\n\t}\n\t// apply the palette here\n\tmgl->SetPalette(FLI_pal);\n}\n\nvoid FLI_docolor(byte *p, MGLDraw *mgl)\n{\n\t// docolor2 and docolor are supposed to be different, but they aren't\n\tFLI_docolor2(p, mgl);\n}\n\nvoid FLI_doDelta(byte *scrn, int scrWidth, byte *p)\n{\n\tshort numLines, numPaks;\n\tint pos, x, y;\n\tchar sizeCount;\n\tword v;\n\n\t/*\n\t Bit 15 Bit 14 Description\n\t\t0 0 Packet count for the line, it can be zero\n\t\t0 1 Undefined\n\t\t1 0 Store the opcode's low byte in the last pixel of the line\n\t\t1 1 The absolute value of the opcode is the line skip count\n\t */\n\tmemcpy(&numLines, p, 2);\n\tpos = 2;\n\ty = 0;\n\twhile (numLines > 0)\n\t{\n\t\tx = 0;\n\t\tnumLines--;\n\t\tnumPaks = (word) 65535;\n\t\twhile (numPaks & 0xC000) // while it doesn't have 00 as the top two bits\n\t\t{\n\t\t\tmemcpy(&numPaks, &p[pos], 2);\n\t\t\tpos += 2;\n\t\t\tswitch (numPaks & 0xC000) {\n\t\t\t\tcase 0xC000: // both bits set, this is a skip\n\t\t\t\t\ty -= numPaks;\n\t\t\t\t\tbreak;\n\t\t\t\tcase 0x4000: // bottom bit, undefined\n\t\t\t\t\tnumPaks = numPaks;\n\t\t\t\t\tbreak;\n\t\t\t\tcase 0x8000: // top bit, supposedly last pixel thing\n\t\t\t\t\tnumPaks = numPaks;\n\t\t\t\t\tbreak;\n\t\t\t}\n\t\t}\n\n\t\twhile (numPaks > 0)\n\t\t{\n\t\t\tx += p[pos++];\n\t\t\tsizeCount = (char) p[pos++];\n\t\t\tif (sizeCount > 0) // copy sizeCount words\n\t\t\t{\n\t\t\t\tPlotDataRun(x, y, sizeCount * 2, scrn, &p[pos]);\n\t\t\t\tpos += sizeCount * 2;\n\t\t\t\tx += sizeCount * 2;\n\t\t\t}\n\t\t\telse if (sizeCount < 0) // copy the word value -sizeCount times\n\t\t\t{\n\t\t\t\tmemcpy(&v, &p[pos], 2);\n\t\t\t\tPlotSolidWordRun(x, y, -sizeCount, scrn, v);\n\t\t\t\tx -= 2 * sizeCount;\n\t\t\t\tpos += 2;\n\t\t\t}\n\t\t\tnumPaks--;\n\t\t}\n\t\ty++;\n\t}\n}\n\nvoid FLI_doLC(byte *scrn, int scrWidth, byte *p)\n{\n\tword numln;\n\tword x, y;\n\tbyte packets, skip;\n\tchar size;\n\tword pos = 0;\n\n\tmemcpy(&y, &p[pos++], 2);\n\tpos++;\n\tmemcpy(&numln, &p[pos++], 2);\n\tpos++;\n\twhile (numln > 0)\n\t{\n\t\tnumln--;\n\t\tpackets = p[pos++];\n\t\tx = 0;\n\t\twhile (packets > 0)\n\t\t{\n\t\t\tpackets--;\n\t\t\tskip = p[pos++];\n\t\t\tsize = p[pos++];\n\t\t\tx += skip;\n\t\t\tif (size < 0)\n\t\t\t{\n\t\t\t\tPlotSolidRun(x, y, -size, scrn, p[pos]);\n\t\t\t\tpos++;\n\t\t\t\tx -= size;\n\t\t\t}\n\t\t\tif (size > 0)\n\t\t\t{\n\t\t\t\tPlotDataRun(x, y, size, scrn, &p[pos]);\n\t\t\t\tpos += size;\n\t\t\t\tx += size;\n\t\t\t}\n\t\t}\n\t\ty++;\n\t}\n}\n\nvoid FLI_doBRUN(byte *scrn, int scrWidth, byte *p)\n{\n\tbyte numpak;\n\tword x, y = 0;\n\tchar size;\n\tword pos = 0;\n\n\tdo\n\t{\n\t\tx = 0;\n\t\tnumpak = p[pos++];\n\t\twhile (numpak > 0)\n\t\t{\n\t\t\tnumpak--;\n\t\t\tsize = p[pos++];\n\t\t\tif (size > 0)\n\t\t\t{\n\t\t\t\tPlotSolidRun(x, y, size, scrn, p[pos]);\n\t\t\t\tpos++;\n\t\t\t\tx += size;\n\t\t\t}\n\t\t\tif (size < 0)\n\t\t\t{\n\t\t\t\tPlotDataRun(x, y, -size, scrn, &p[pos]);\n\t\t\t\tpos -= size;\n\t\t\t\tx -= size;\n\t\t\t}\n\t\t}\n\t\t++y;\n\t}\n\twhile (y < fliHeight);\n}\n\nvoid FLI_nextchunk(MGLDraw *mgl, int scrWidth)\n{\n\tint i;\n\tchunkheader chead;\n\tbyte *p;\n\n\tfread(&chead, 1, sizeofchunkheader, FLI_file);\n\tp = (byte *) malloc(chead.size - sizeofchunkheader);\n\tfread(p, 1, chead.size - sizeofchunkheader, FLI_file);\n\tswitch (chead.kind) {\n\t\tcase FLI_COPY: for (i = 0; i < fliHeight; i++)\n\t\t\t\tmemcpy(&mgl->GetScreen()[i * scrWidth], &p[i * fliWidth], fliWidth);\n\t\t\tbreak;\n\t\tcase FLI_BLACK: mgl->ClearScreen();\n\t\t\tbreak;\n\t\tcase FLI_COLOR: FLI_docolor(p, mgl);\n\t\t\tbreak;\n\t\tcase FLI_LC: FLI_doLC(mgl->GetScreen(), scrWidth, p);\n\t\t\tbreak;\n\t\tcase FLI_BRUN: FLI_doBRUN(mgl->GetScreen(), scrWidth, p);\n\t\t\tbreak;\n\t\tcase FLI_MINI: break; // ignore it\n\t\tcase FLI_DELTA: FLI_doDelta(mgl->GetScreen(), scrWidth, p);\n\t\t\tbreak;\n\t\tcase FLI_256_COLOR: FLI_docolor2(p, mgl);\n\t\t\tbreak;\n\t}\n\tfree(p);\n}\n\nvoid FLI_nextfr(MGLDraw *mgl, int scrWidth)\n{\n\tfrmheader fhead;\n\tint i;\n\n\tfread(&fhead, 1, sizeof (frmheader), FLI_file);\n\n\t// check to see if this is a FLC file's special frame... if it is, skip it\n\tif (fhead.magic == 0x00A1)\n\t{\n\t\tfseek(FLI_file, fhead.size, SEEK_CUR);\n\t\treturn;\n\t}\n\n\tfor (i = 0; i < fhead.chunks; i++)\n\t\tFLI_nextchunk(mgl, scrWidth);\n}\n\nvoid FLI_skipfr(void)\n{\n\tfrmheader fhead;\n\n\tfread(&fhead, 1, sizeof (frmheader), FLI_file);\n\n\tfseek(FLI_file, fhead.size - sizeof (frmheader), SEEK_CUR);\n}\n\nvoid FLI_play(const char *name, byte loop, word wait, MGLDraw *mgl)\n{\n\tint frmon = 0;\n\tlong frsize;\n\tfliheader FLI_hdr;\n\tint scrWidth;\n\tchar k;\n\n\tFLI_file = fopen(name, \"rb\");\n\tif (!FLI_file)\n\t\treturn;\n\n\tfread(&FLI_hdr, 1, sizeof (fliheader), FLI_file);\n\tfread(&frsize, 1, 4, FLI_file);\n\tfseek(FLI_file, -4, SEEK_CUR);\n\tfliWidth = FLI_hdr.width;\n\tfliHeight = FLI_hdr.height;\n\n\tmgl->LastKeyPressed(); // clear key buffer\n\n\t// if this is a FLC, skip the first frame\n\tif ((name[strlen(name) - 1] == 'c') ||\n\t\t\t(name[strlen(name) - 1] == 'C'))\n\t{\n\t\tFLI_skipfr();\n\t\tfrmon++;\n\t\tFLI_hdr.frames++; // a confusion issue\n\t}\n\tdo\n\t{\n\t\tfrmon++;\n\t\tscrWidth = mgl->GetWidth();\n\t\tFLI_nextfr(mgl, scrWidth);\n\t\tHandleCDMusic();\n\t\tmgl->Flip();\n\t\tif (wait > 0)\n\t\t\tSleep((dword) wait);\n\t\tif ((loop) && (frmon == FLI_hdr.frames + 1))\n\t\t{\n\t\t\tfrmon = 1;\n\t\t\tfseek(FLI_file, 128 + frsize, SEEK_SET);\n\t\t}\n\t\tif ((!loop) && (frmon == FLI_hdr.frames))\n\t\t\tfrmon = FLI_hdr.frames + 1;\n\t\tk = mgl->LastKeyPressed();\n\t\t// key #27 is escape\n\t}\n\twhile ((frmon < FLI_hdr.frames + 1) && (mgl->Process()) && (k != 27));\n\tfclose(FLI_file);\n}\n\nword FLI_numFrames(char *name)\n{\n\tfliheader FLI_hdr;\n\n\tFLI_file = fopen(name, \"rb\");\n\tfread(&FLI_hdr, 1, sizeof (fliheader), FLI_file);\n\tfclose(FLI_file);\n\tif ((name[strlen(name) - 1] == 'c') ||\n\t\t\t(name[strlen(name) - 1] == 'C'))\n\t\treturn FLI_hdr.frames;\n\telse\n\t\treturn FLI_hdr.frames;\n}\n\n"
},
{
"alpha_fraction": 0.715410590171814,
"alphanum_fraction": 0.7255343198776245,
"avg_line_length": 20.16666603088379,
"blob_id": "69e092365412b40141503ba86d158ada9594e592",
"content_id": "b48f37bc8637207366d609871947935fa057eba3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 889,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 42,
"path": "/tools/formats/common.py",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "# common.py - part of the Loonymod project\n# these structures and adapters are used by various formats.\n\nfrom construct import *\n\n# pretty much everything is little endian\n# dword = ULInt32\n# word = ULInt16\n# byte = ULInt8\n\n# constructs\n\nclass WithContext(Construct):\n\tdef __init__(self, func):\n\t\tConstruct.__init__(self, \"WithContext\")\n\t\tself.func = func\n\tdef _parse(self, stream, context):\n\t\tself.func(context)\n\n# adapters\n\nclass NullTerminateAdapter(Adapter):\n\tdef _encode(self, obj, ctx):\n\t\treturn obj\n\tdef _decode(self, obj, ctx):\n\t\treturn obj[:obj.find('\\x00')]\n\n# utilities\n\ndef echo(x): print x\n\ndef PrintContext():\n\treturn WithContext(echo)\n\ndef PrintContextItem(field):\n\treturn WithContext(lambda ctx: echo(ctx[field]))\n\ndef PackedString(name, len=32):\n\treturn NullTerminateAdapter(String(name, len))\n\ndef CtxRepeater(name, obj):\n\treturn MetaRepeater(lambda ctx: ctx[name], obj)\n"
},
{
"alpha_fraction": 0.7418546080589294,
"alphanum_fraction": 0.7468671798706055,
"avg_line_length": 23.9375,
"blob_id": "47fe84b979d71b614ea68ab15182b89b5d88eac8",
"content_id": "5d38273ef5b0d5a3b1b0457031bf764053c5b170",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 399,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 16,
"path": "/source/winpch.h",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#ifndef WINPCH_H\n#define WINPCH_H\n\n// this header is just meant to be precompiled for compilation speed reasons.\n// mainly for the purposes of making it fast when windows.h is involved.\n#undef UNICODE\n#define WIN32_LEAN_AND_MEAN\n#include \"mgldraw.h\" // for allegro\n#include <windows.h>\n#include \"jamultypes.h\"\n#include <string.h>\n#include <stdio.h>\n#include <stdlib.h>\n#include <mmsystem.h>\n\n#endif\n"
},
{
"alpha_fraction": 0.674492359161377,
"alphanum_fraction": 0.6890863180160522,
"avg_line_length": 23.625,
"blob_id": "8936fe1fa0a8e57453b0db0176c2e1d76f94004f",
"content_id": "c6b0c833dcb3ca54921766018635838ad08fb976",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1576,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 64,
"path": "/tools/formats/jsp.py",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "# jsp.py - part of the Loonymod project\n# import this file and use the jsp construct.\n\nfrom common import *\n\n# Official documentation:\n# Jamul Sprite - JSP\n#\n# header:\n# count\t\t1 word\thow many frames in this sprite\n# data:\n# count structures:\n# \twidth\t1 word\t\twidth of sprite in pixels\n# \theight\t1 word\t\theight of sprite in pixels\n# \tofsX\t1 short\t\tx-coord of hotspot relative to left\n# \tofsY\t1 short\t\ty-coord of hotspot relative to top\n# \tsize\t1 dword\t\thow big the sprite data is in bytes\n# \tdata\tsize bytes\ttransparency RLE'd sprite data\n# \n# \tThe RLE format is as follows:\n# \n# \tcount\t1 byte\tif count is positive, this is considered\n# \t\t\ta run of data, negative is a run of\n# \t\t\ttransparency. If the run is data, it is\n# \t\t\tfollowed by count bytes of data. If\n# \t\t\tit is transparent, the next RLE tag\n# \t\t\tsimply follows it.\n# \t\t\tRuns do not cross line boundaries.\n\n# constructs\n\nclass RleSprite(Construct):\n\tdef _parse(self, stream, context):\n\t\tif \"_curSprite\" in context:\n\t\t\tinfo = context[\"frameInfo\"][context[\"_curSprite\"]]\n\t\t\tcontext[\"_curSprite\"] += 1\n\t\telse:\n\t\t\tinfo = context[\"frameInfo\"][0]\n\t\t\tcontext[\"_curSprite\"] = 1\n\t\t\n\t\treturn stream.read(info.dataSize)\n\t\t\n\tdef _build(self, obj, stream, context):\n\t\treturn obj\n\t\t\n\tdef _sizeof(self, context):\n\t\traise SizeofError\n\n# structures\n\nframeInfo = Struct(\"frameInfo\",\n\tULInt16(\"width\"),\n\tULInt16(\"height\"),\n\tSLInt16(\"offsetX\"),\n\tSLInt16(\"offsetY\"),\n\tULInt32(\"dataSize\"),\n\tField(\"garbage\", 4)\n)\n\njsp = Struct(\"jsp\",\n\tULInt16(\"count\"),\n\tCtxRepeater(\"count\", frameInfo),\n\tCtxRepeater(\"count\", RleSprite(\"frameData\"))\n)\n"
},
{
"alpha_fraction": 0.5040996074676514,
"alphanum_fraction": 0.5178481936454773,
"avg_line_length": 17.71094512939453,
"blob_id": "635bb2da81dd8c51fcbe9e69a30aa593ff8d2e39",
"content_id": "b06498c1b9141b3dc23aa8e0f99e7640e4d1fc97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 20002,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 1069,
"path": "/source/jamulspr.cpp",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#include \"jamulspr.h\"\n\n// the sprites are 12 bytes, not including the data itself\n// note that the value here is 16 - there are four bytes of\n// garbage between each sprite header\nconst int SPRITE_INFO_SIZE = 16;\n\n/*\nJamul Sprite - JSP\n\nheader:\ncount\t\t1 word\thow many frames in this sprite\ndata:\ncount structures:\n\twidth\t1 word\t\twidth of sprite in pixels\n\theight\t1 word\t\theight of sprite in pixels\n\tofsX\t1 short\t\tx-coord of hotspot relative to left\n\tofsY\t1 short\t\ty-coord of hotspot relative to top\n\tsize\t1 dword\t\thow big the sprite data is in bytes\n\ncount data chunks:\n\tdata\tsize bytes\ttransparency RLE'd sprite data\n\n\tThe RLE format is as follows:\n\n\tcount\t1 byte\tif count is positive, this is considered\n\t\t\ta run of data, negative is a run of\n\t\t\ttransparency. If the run is data, it is\n\t\t\tfollowed by count bytes of data. If\n\t\t\tit is transparent, the next RLE tag\n\t\t\tsimply follows it.\n\t\t\tRuns do not cross line boundaries.\n */\n\n// -------------------------------------------------------------------------\n// ****************************** SPRITE_T *********************************\n// -------------------------------------------------------------------------\n\n// Helper shenanigans for C stuff\nstatic const int constrainX = 0, constrainY = 0, constrainX2 = 639, constrainY2 = 479;\n\nbyte SprModifyColor(byte color, byte hue)\n{\n\treturn (hue << 5) | (color & 31);\n}\n\nbyte SprGetColor(byte color)\n{\n\treturn (color >> 5);\n}\n\nbyte SprModifyLight(byte color, char bright)\n{\n\tbyte value = (color & 31) + bright;\n\tif (value > 128) value = 0; // since byte is unsigned...\n\telse if (value > 31) value = 31;\n\treturn (color & ~31) | value;\n}\n\nbyte SprModifyGhost(byte src, byte dst, char bright)\n{\n\tif (src >> 5 == 0)\n\t{\n\t\treturn SprModifyLight(dst, src);\n\t}\n\telse\n\t{\n\t\treturn SprModifyLight(src, bright);\n\t}\n}\n\nbyte SprModifyGlow(byte src, byte dst, char bright)\n{\n\treturn SprModifyLight(src, (dst & 31) + bright);\n}\n\n// CONSTRUCTORS & DESTRUCTORS\n\nsprite_t::sprite_t(void)\n{\n\twidth = 0;\n\theight = 0;\n\tofsx = 0;\n\tofsy = 0;\n\tsize = 0;\n\tdata = NULL;\n}\n\nsprite_t::sprite_t(byte *info)\n{\n\tmemcpy(&width, &info[0], 2);\n\tmemcpy(&height, &info[2], 2);\n\tmemcpy(&ofsx, &info[4], 2);\n\tmemcpy(&ofsy, &info[6], 2);\n\tmemcpy(&size, &info[8], 4);\n}\n\nsprite_t::~sprite_t(void)\n{\n\tif (data)\n\t\tfree(data);\n}\n\n// REGULAR MEMBER FUNCTIONS\n\nbool sprite_t::LoadData(FILE *f)\n{\n\tif (size == 0)\n\t\treturn TRUE;\n\n\tdata = (byte *) malloc(size);\n\tif (!data)\n\t\treturn FALSE;\n\n\tif (fread(data, 1, size, f) != size)\n\t{\n\t\treturn FALSE;\n\t}\n\treturn TRUE;\n}\n\nbool sprite_t::SaveData(FILE *f)\n{\n\tif (size == 0)\n\t\treturn TRUE;\n\n\tif (!data)\n\t\treturn TRUE;\n\n\tif (fwrite(data, 1, size, f) != size)\n\t{\n\t\treturn FALSE;\n\t}\n\treturn TRUE;\n}\n\nvoid sprite_t::GetHeader(byte *buffer)\n{\n\tmemcpy(&buffer[0], &width, 2);\n\tmemcpy(&buffer[2], &height, 2);\n\tmemcpy(&buffer[4], &ofsx, 2);\n\tmemcpy(&buffer[6], &ofsy, 2);\n\tmemcpy(&buffer[8], &size, 4);\n}\n\nvoid sprite_t::GetCoords(int x, int y, int *rx, int *ry, int *rx2, int *ry2)\n{\n\t*rx = x - ofsx;\n\t*ry = y - ofsy;\n\t*rx2 = *rx + width;\n\t*ry2 = *ry + height;\n}\n\nvoid sprite_t::Draw(int x, int y, MGLDraw *mgl)\n{\n\tbyte *src, *dst, b, skip;\n\tdword pitch;\n\tint srcx, srcy;\n\tbyte noDraw;\n\n\tx -= ofsx;\n\ty -= ofsy;\n\tif (x > constrainX2 || y > constrainY2)\n\t\treturn; // whole sprite is offscreen\n\n\tpitch = mgl->GetWidth();\n\tsrc = data;\n\tdst = mgl->GetScreen() + x + y*pitch;\n\n\tsrcx = x;\n\tsrcy = y;\n\tif (srcy < constrainY)\n\t\tnoDraw = 1;\n\telse\n\t\tnoDraw = 0;\n\twhile (srcy < height + y)\n\t{\n\t\tif ((*src)&128) // transparent run\n\t\t{\n\t\t\tb = (*src)&127;\n\t\t\tsrcx += b;\n\t\t\tdst += b;\n\t\t\tsrc++;\n\t\t}\n\t\telse // solid run\n\t\t{\n\t\t\tb = *src;\n\t\t\tsrc++;\n\t\t\tif (srcx < constrainX - b || srcx > constrainX2)\n\t\t\t{\n\t\t\t\t// don't draw this line\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse if (srcx < constrainX)\n\t\t\t{\n\t\t\t\t// skip some of the beginning\n\t\t\t\tskip = (constrainX - srcx);\n\t\t\t\tsrc += skip;\n\t\t\t\tsrcx += skip;\n\t\t\t\tdst += skip;\n\t\t\t\tb -= skip;\n\t\t\t\tif (srcx > constrainX2 - b)\n\t\t\t\t{\n\t\t\t\t\tskip = (b - (constrainX2 - srcx)) - 1;\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tmemcpy(dst, src, b - skip);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tmemcpy(dst, src, b);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (srcx > constrainX2 - b)\n\t\t\t{\n\t\t\t\t// skip some of the end\n\t\t\t\tskip = (srcx - (constrainX2 - b)) - 1;\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tmemcpy(dst, src, b - skip);\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t// do it all!\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tmemcpy(dst, src, b);\n\t\t\t\tsrcx += b;\n\t\t\t\tsrc += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t}\n\t\tif (srcx >= width + x)\n\t\t{\n\t\t\tsrcx = x;\n\t\t\tsrcy++;\n\t\t\tdst += pitch - width;\n\t\t\tif (srcy >= constrainY)\n\t\t\t\tnoDraw = 0;\n\t\t\tif (srcy > constrainY2)\n\t\t\t\treturn;\n\t\t}\n\t}\n}\n\n// bright: how much to darken or lighten the whole thing (-16 to +16 reasonable)\n\nvoid sprite_t::DrawBright(int x, int y, MGLDraw *mgl, char bright)\n{\n\tbyte *src, *dst, b, skip;\n\tdword pitch;\n\tint srcx, srcy;\n\tbyte noDraw;\n\tint i;\n\n\tif (bright == 0)\n\t{ // don't waste time!\n\t\tDraw(x, y, mgl);\n\t\treturn;\n\t}\n\n\tx -= ofsx;\n\ty -= ofsy;\n\tif (x > constrainX2 || y > constrainY2)\n\t\treturn; // whole sprite is offscreen\n\n\tpitch = mgl->GetWidth();\n\tsrc = data;\n\tdst = mgl->GetScreen() + x + y*pitch;\n\n\tsrcx = x;\n\tsrcy = y;\n\tif (srcy < constrainY)\n\t\tnoDraw = 1;\n\telse\n\t\tnoDraw = 0;\n\twhile (srcy < height + y)\n\t{\n\t\tif ((*src)&128) // transparent run\n\t\t{\n\t\t\tb = (*src)&127;\n\t\t\tsrcx += b;\n\t\t\tdst += b;\n\t\t\tsrc++;\n\t\t}\n\t\telse // solid run\n\t\t{\n\t\t\tb = *src;\n\t\t\tsrc++;\n\t\t\tif (srcx < constrainX - b || srcx > constrainX2)\n\t\t\t{\n\t\t\t\t// don't draw this line\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse if (srcx < constrainX)\n\t\t\t{\n\t\t\t\t// skip some of the beginning\n\t\t\t\tskip = (constrainX - srcx);\n\t\t\t\tsrc += skip;\n\t\t\t\tsrcx += skip;\n\t\t\t\tdst += skip;\n\t\t\t\tb -= skip;\n\t\t\t\tif (srcx > constrainX2 - b)\n\t\t\t\t{\n\t\t\t\t\tskip = (b - (constrainX2 - srcx)) - 1;\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyLight(src[i], bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyLight(src[i], bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (srcx > constrainX2 - b)\n\t\t\t{\n\t\t\t\t// skip some of the end\n\t\t\t\tskip = (srcx - (constrainX2 - b)) - 1;\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyLight(src[i], bright);\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t// do it all!\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyLight(src[i], bright);\n\t\t\t\tsrcx += b;\n\t\t\t\tsrc += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t}\n\t\tif (srcx >= width + x)\n\t\t{\n\t\t\tsrcx = x;\n\t\t\tsrcy++;\n\t\t\tdst += pitch - width;\n\t\t\tif (srcy >= constrainY)\n\t\t\t\tnoDraw = 0;\n\t\t\tif (srcy > constrainY2)\n\t\t\t\treturn;\n\t\t}\n\t}\n}\n\n//\t color: which hue (0-7) to use for the entire thing, ignoring its real hue\n// bright: how much to darken or lighten the whole thing (-16 to +16 reasonable)\n\nvoid sprite_t::DrawColored(int x, int y, MGLDraw *mgl, byte color, char bright)\n{\n\tbyte *src, *dst, b, skip;\n\tdword pitch;\n\tint srcx, srcy;\n\tbyte noDraw;\n\tint i;\n\n\tx -= ofsx;\n\ty -= ofsy;\n\tif (x > constrainX2 || y > constrainY2)\n\t\treturn; // whole sprite is offscreen\n\n\tpitch = mgl->GetWidth();\n\tsrc = data;\n\tdst = mgl->GetScreen() + x + y*pitch;\n\n\tsrcx = x;\n\tsrcy = y;\n\tif (srcy < constrainY)\n\t\tnoDraw = 1;\n\telse\n\t\tnoDraw = 0;\n\twhile (srcy < height + y)\n\t{\n\t\tif ((*src)&128) // transparent run\n\t\t{\n\t\t\tb = (*src)&127;\n\t\t\tsrcx += b;\n\t\t\tdst += b;\n\t\t\tsrc++;\n\t\t}\n\t\telse // solid run\n\t\t{\n\t\t\tb = *src;\n\t\t\tsrc++;\n\t\t\tif (srcx < constrainX - b || srcx > constrainX2)\n\t\t\t{\n\t\t\t\t// don't draw this line\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse if (srcx < constrainX)\n\t\t\t{\n\t\t\t\t// skip some of the beginning\n\t\t\t\tskip = (constrainX - srcx);\n\t\t\t\tsrc += skip;\n\t\t\t\tsrcx += skip;\n\t\t\t\tdst += skip;\n\t\t\t\tb -= skip;\n\t\t\t\tif (srcx > constrainX2 - b)\n\t\t\t\t{\n\t\t\t\t\tskip = (b - (constrainX2 - srcx)) - 1;\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyLight(SprModifyColor(src[i], color), bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyLight(SprModifyColor(src[i], color), bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (srcx > constrainX2 - b)\n\t\t\t{\n\t\t\t\t// skip some of the end\n\t\t\t\tskip = (srcx - (constrainX2 - b)) - 1;\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyLight(SprModifyColor(src[i], color), bright);\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t// do it all!\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyLight(SprModifyColor(src[i], color), bright);\n\t\t\t\tsrcx += b;\n\t\t\t\tsrc += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t}\n\t\tif (srcx >= width + x)\n\t\t{\n\t\t\tsrcx = x;\n\t\t\tsrcy++;\n\t\t\tdst += pitch - width;\n\t\t\tif (srcy >= constrainY)\n\t\t\t\tnoDraw = 0;\n\t\t\tif (srcy > constrainY2)\n\t\t\t\treturn;\n\t\t}\n\t}\n}\n\nvoid sprite_t::DrawOffColor(int x, int y, MGLDraw *mgl, byte fromColor, byte toColor, char bright)\n{\n\tbyte *src, *dst, b, skip;\n\tdword pitch;\n\tint srcx, srcy;\n\tbyte noDraw;\n\tint i;\n\n\tx -= ofsx;\n\ty -= ofsy;\n\tif (x > constrainX2 || y > constrainY2)\n\t\treturn; // whole sprite is offscreen\n\n\tpitch = mgl->GetWidth();\n\tsrc = data;\n\tdst = mgl->GetScreen() + x + y*pitch;\n\n\tsrcx = x;\n\tsrcy = y;\n\tif (srcy < constrainY)\n\t\tnoDraw = 1;\n\telse\n\t\tnoDraw = 0;\n\twhile (srcy < height + y)\n\t{\n\t\tif ((*src)&128) // transparent run\n\t\t{\n\t\t\tb = (*src)&127;\n\t\t\tsrcx += b;\n\t\t\tdst += b;\n\t\t\tsrc++;\n\t\t}\n\t\telse // solid run\n\t\t{\n\t\t\tb = *src;\n\t\t\tsrc++;\n\t\t\tif (srcx < constrainX - b || srcx > constrainX2)\n\t\t\t{\n\t\t\t\t// don't draw this line\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse if (srcx < constrainX)\n\t\t\t{\n\t\t\t\t// skip some of the beginning\n\t\t\t\tskip = (constrainX - srcx);\n\t\t\t\tsrc += skip;\n\t\t\t\tsrcx += skip;\n\t\t\t\tdst += skip;\n\t\t\t\tb -= skip;\n\t\t\t\tif (srcx > constrainX2 - b)\n\t\t\t\t{\n\t\t\t\t\tskip = (b - (constrainX2 - srcx)) - 1;\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyLight(SprGetColor(src[i]) == fromColor ? SprModifyColor(src[i], toColor) : src[i], bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyLight(SprGetColor(src[i]) == fromColor ? SprModifyColor(src[i], toColor) : src[i], bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (srcx > constrainX2 - b)\n\t\t\t{\n\t\t\t\t// skip some of the end\n\t\t\t\tskip = (srcx - (constrainX2 - b)) - 1;\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyLight(SprGetColor(src[i]) == fromColor ? SprModifyColor(src[i], toColor) : src[i], bright);\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t// do it all!\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyLight(SprGetColor(src[i]) == fromColor ? SprModifyColor(src[i], toColor) : src[i], bright);\n\t\t\t\tsrcx += b;\n\t\t\t\tsrc += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t}\n\t\tif (srcx >= width + x)\n\t\t{\n\t\t\tsrcx = x;\n\t\t\tsrcy++;\n\t\t\tdst += pitch - width;\n\t\t\tif (srcy >= constrainY)\n\t\t\t\tnoDraw = 0;\n\t\t\tif (srcy > constrainY2)\n\t\t\t\treturn;\n\t\t}\n\t}\n}\n\n// a ghost sprite is rather special. It is drawn normally (except lightened\n// or darkened according to the brightness parameter), except where it is grey\n// (color 1-31). Wherever those colors occur, they are instead used as the\n// degree to which the background should be brightened instead of drawn over.\n// bright: how much to darken or lighten the whole thing (-16 to +16 reasonable)\n\nvoid sprite_t::DrawGhost(int x, int y, MGLDraw *mgl, char bright)\n{\n\tbyte *src, *dst, b, skip;\n\tdword pitch;\n\tint srcx, srcy;\n\tbyte noDraw;\n\tint i;\n\n\tx -= ofsx;\n\ty -= ofsy;\n\tif (x > constrainX2 || y > constrainY2)\n\t\treturn; // whole sprite is offscreen\n\n\tpitch = mgl->GetWidth();\n\tsrc = data;\n\tdst = mgl->GetScreen() + x + y*pitch;\n\n\tsrcx = x;\n\tsrcy = y;\n\tif (srcy < constrainY)\n\t\tnoDraw = 1;\n\telse\n\t\tnoDraw = 0;\n\twhile (srcy < height + y)\n\t{\n\t\tif ((*src)&128) // transparent run\n\t\t{\n\t\t\tb = (*src)&127;\n\t\t\tsrcx += b;\n\t\t\tdst += b;\n\t\t\tsrc++;\n\t\t}\n\t\telse // solid run\n\t\t{\n\t\t\tb = *src;\n\t\t\tsrc++;\n\t\t\tif (srcx < constrainX - b || srcx > constrainX2)\n\t\t\t{\n\t\t\t\t// don't draw this line\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse if (srcx < constrainX)\n\t\t\t{\n\t\t\t\t// skip some of the beginning\n\t\t\t\tskip = (constrainX - srcx);\n\t\t\t\tsrc += skip;\n\t\t\t\tsrcx += skip;\n\t\t\t\tdst += skip;\n\t\t\t\tb -= skip;\n\t\t\t\tif (srcx > constrainX2 - b)\n\t\t\t\t{\n\t\t\t\t\tskip = (b - (constrainX2 - srcx)) - 1;\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyGhost(src[i], dst[i], bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyGhost(src[i], dst[i], bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (srcx > constrainX2 - b)\n\t\t\t{\n\t\t\t\t// skip some of the end\n\t\t\t\tskip = (srcx - (constrainX2 - b)) - 1;\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyGhost(src[i], dst[i], bright);\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t// do it all!\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyGhost(src[i], dst[i], bright);\n\t\t\t\tsrcx += b;\n\t\t\t\tsrc += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t}\n\t\tif (srcx >= width + x)\n\t\t{\n\t\t\tsrcx = x;\n\t\t\tsrcy++;\n\t\t\tdst += pitch - width;\n\t\t\tif (srcy >= constrainY)\n\t\t\t\tnoDraw = 0;\n\t\t\tif (srcy > constrainY2)\n\t\t\t\treturn;\n\t\t}\n\t}\n}\n\nvoid sprite_t::DrawGlow(int x, int y, MGLDraw *mgl, char bright)\n{\n\tbyte *src, *dst, b, skip;\n\tdword pitch;\n\tint srcx, srcy;\n\tbyte noDraw;\n\tint i;\n\n\tx -= ofsx;\n\ty -= ofsy;\n\tif (x > constrainX2 || y > constrainY2)\n\t\treturn; // whole sprite is offscreen\n\n\tpitch = mgl->GetWidth();\n\tsrc = data;\n\tdst = mgl->GetScreen() + x + y*pitch;\n\n\tsrcx = x;\n\tsrcy = y;\n\tif (srcy < constrainY)\n\t\tnoDraw = 1;\n\telse\n\t\tnoDraw = 0;\n\twhile (srcy < height + y)\n\t{\n\t\tif ((*src)&128) // transparent run\n\t\t{\n\t\t\tb = (*src)&127;\n\t\t\tsrcx += b;\n\t\t\tdst += b;\n\t\t\tsrc++;\n\t\t}\n\t\telse // solid run\n\t\t{\n\t\t\tb = *src;\n\t\t\tsrc++;\n\t\t\tif (srcx < constrainX - b || srcx > constrainX2)\n\t\t\t{\n\t\t\t\t// don't draw this line\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse if (srcx < constrainX)\n\t\t\t{\n\t\t\t\t// skip some of the beginning\n\t\t\t\tskip = (constrainX - srcx);\n\t\t\t\tsrc += skip;\n\t\t\t\tsrcx += skip;\n\t\t\t\tdst += skip;\n\t\t\t\tb -= skip;\n\t\t\t\tif (srcx > constrainX2 - b)\n\t\t\t\t{\n\t\t\t\t\tskip = (b - (constrainX2 - srcx)) - 1;\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyGlow(src[i], dst[i], bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tif (!noDraw)\n\t\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyGlow(src[i], dst[i], bright);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (srcx > constrainX2 - b)\n\t\t\t{\n\t\t\t\t// skip some of the end\n\t\t\t\tskip = (srcx - (constrainX2 - b)) - 1;\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyGlow(src[i], dst[i], bright);\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t// do it all!\n\t\t\t\tif (!noDraw)\n\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyGlow(src[i], dst[i], bright);\n\t\t\t\tsrcx += b;\n\t\t\t\tsrc += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t}\n\t\tif (srcx >= width + x)\n\t\t{\n\t\t\tsrcx = x;\n\t\t\tsrcy++;\n\t\t\tdst += pitch - width;\n\t\t\tif (srcy >= constrainY)\n\t\t\t\tnoDraw = 0;\n\t\t\tif (srcy > constrainY2)\n\t\t\t\treturn;\n\t\t}\n\t}\n}\n\nvoid sprite_t::DrawShadow(int x, int y, MGLDraw *mgl)\n{\n\tbyte *src, *dst, b, skip;\n\tdword pitch;\n\tint srcx, srcy, x2;\n\tbyte noDraw;\n\tbyte alternate;\n\tint i;\n\n\tx -= ofsx + height / 2;\n\ty -= ofsy / 2;\n\tif (x > constrainX2 || y > constrainY2)\n\t\treturn; // whole sprite is offscreen\n\n\tpitch = mgl->GetWidth();\n\tsrc = data;\n\tdst = mgl->GetScreen() + x + y*pitch;\n\n\tsrcx = x;\n\tsrcy = y;\n\tif (srcy < constrainY)\n\t\tnoDraw = 1;\n\telse\n\t\tnoDraw = 0;\n\n\talternate = 1;\n\tx2 = x;\n\n\twhile (srcy < height / 2 + y)\n\t{\n\t\tif ((*src)&128) // transparent run\n\t\t{\n\t\t\tb = (*src)&127;\n\t\t\tsrcx += b;\n\t\t\tdst += b;\n\t\t\tsrc++;\n\t\t}\n\t\telse // solid run\n\t\t{\n\t\t\tb = *src;\n\t\t\tsrc++;\n\t\t\tif (srcx < constrainX - b || srcx > constrainX2)\n\t\t\t{\n\t\t\t\t// don't draw this line\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse if (srcx < constrainX)\n\t\t\t{\n\t\t\t\t// skip some of the beginning\n\t\t\t\tskip = (constrainX - srcx);\n\t\t\t\tsrc += skip;\n\t\t\t\tsrcx += skip;\n\t\t\t\tdst += skip;\n\t\t\t\tb -= skip;\n\t\t\t\tif (srcx > constrainX2 - b)\n\t\t\t\t{\n\t\t\t\t\tskip = (b - (constrainX2 - srcx)) - 1;\n\t\t\t\t\tif (!noDraw && alternate)\n\t\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyLight(dst[i], -4);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tif (!noDraw && alternate)\n\t\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\t\tdst[i] = SprModifyLight(dst[i], -4);\n\t\t\t\t\tsrc += b;\n\t\t\t\t\tsrcx += b;\n\t\t\t\t\tdst += b;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (srcx > constrainX2 - b)\n\t\t\t{\n\t\t\t\t// skip some of the end\n\t\t\t\tskip = (srcx - (constrainX2 - b)) - 1;\n\t\t\t\tif (!noDraw && alternate)\n\t\t\t\t\tfor (i = 0; i < b - skip; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyLight(dst[i], -4);\n\t\t\t\tsrc += b;\n\t\t\t\tsrcx += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t\telse\n\t\t\t{\n\t\t\t\t// do it all!\n\t\t\t\tif (!noDraw && alternate)\n\t\t\t\t\tfor (i = 0; i < b; ++i)\n\t\t\t\t\t\tdst[i] = SprModifyLight(dst[i], -4);\n\t\t\t\tsrcx += b;\n\t\t\t\tsrc += b;\n\t\t\t\tdst += b;\n\t\t\t}\n\t\t}\n\t\tif (srcx >= width + x2)\n\t\t{\n\t\t\talternate = 1 - alternate;\n\t\t\tx2 += alternate;\n\t\t\tsrcx -= width - alternate;\n\t\t\tsrcy += alternate;\n\t\t\tdst += (alternate ? pitch : 1) - width;\n\t\t\tif (srcy >= constrainY)\n\t\t\t\tnoDraw = 0;\n\t\t\tif (srcy > constrainY2)\n\t\t\t\treturn;\n\t\t}\n\t}\n}\n\n// -------------------------------------------------------------------------\n// ***************************** SPRITE_SET_T ******************************\n// -------------------------------------------------------------------------\n\n// CONSTRUCTORS & DESTRUCTORS\n\nsprite_set_t::sprite_set_t(void)\n{\n\tcount = 0;\n\tspr = NULL;\n}\n\nsprite_set_t::sprite_set_t(const char *fname)\n{\n\tcount = 0;\n\tspr = NULL;\n\tLoad(fname);\n}\n\nsprite_set_t::~sprite_set_t(void)\n{\n\tFree();\n}\n\n// REGULAR MEMBER FUNCTIONS\n\nbool sprite_set_t::Load(const char *fname)\n{\n\tFILE *f;\n\tint i;\n\tbyte *buffer;\n\n\tif (spr)\n\t\tFree();\n\n\tf = fopen(fname, \"rb\");\n\tif (!f)\n\t\treturn FALSE;\n\t// read the count\n\tfread(&count, 2, 1, f);\n\n#ifndef NDEBUG\n\tprintf(\"loading %s, count = %d\\n\", fname, count);\n#endif\n\n\tspr = (sprite_t **) malloc(sizeof (sprite_t *) * count);\n\tif (!spr)\n\t{\n\t\tfclose(f);\n\t\treturn FALSE;\n\t}\n\n\t// allocate a buffer to load sprites into\n\tbuffer = (byte *) malloc(SPRITE_INFO_SIZE * count);\n\tif (!buffer)\n\t{\n\t\tfclose(f);\n\t\tfree(spr);\n\t\treturn FALSE;\n\t}\n\n\t// read in the sprite headers\n\tif (fread(buffer, SPRITE_INFO_SIZE, count, f) != count)\n\t{\n\t\tfclose(f);\n\t\tfree(spr);\n\t\tfree(buffer);\n\t\treturn FALSE;\n\t}\n\n\t// allocate the sprites and read in the data for them\n\tfor (i = 0; i < count; i++)\n\t{\n\t\tspr[i] = new sprite_t(&buffer[i * SPRITE_INFO_SIZE]);\n\t\tif (!spr[i])\n\t\t{\n\t\t\tfclose(f);\n\t\t\treturn FALSE;\n\t\t}\n\t\tif (!spr[i]->LoadData(f))\n\t\t{\n\t\t\tfclose(f);\n\t\t\treturn FALSE;\n\t\t}\n\t}\n\tfree(buffer);\n\tfclose(f);\n\n\treturn TRUE;\n}\n\nbool sprite_set_t::Save(const char *fname)\n{\n\tFILE *f;\n\tint i;\n\tbyte *buffer;\n\n\tf = fopen(fname, \"wb\");\n\tif (!f)\n\t\treturn FALSE;\n\t// write the count\n\tfwrite(&count, 2, 1, f);\n\n\t// allocate a buffer to copy sprites into\n\tbuffer = (byte *) malloc(SPRITE_INFO_SIZE * count);\n\tif (!buffer)\n\t{\n\t\tfclose(f);\n\t\treturn FALSE;\n\t}\n\n\tfor (i = 0; i < count; i++)\n\t\tspr[i]->GetHeader(&buffer[i * SPRITE_INFO_SIZE]);\n\n\t// write the sprites out\n\tif (fwrite(buffer, SPRITE_INFO_SIZE, count, f) != count)\n\t{\n\t\tfclose(f);\n\t\tfree(buffer);\n\t\treturn FALSE;\n\t}\n\n\t// write the sprite data\n\tfor (i = 0; i < count; i++)\n\t{\n\t\tif (!spr[i]->SaveData(f))\n\t\t{\n\t\t\tfclose(f);\n\t\t\treturn FALSE;\n\t\t}\n\t}\n\tfclose(f);\n\treturn TRUE;\n\n}\n\nvoid sprite_set_t::Free(void)\n{\n\tint i;\n\tfor (i = 0; i < count; i++)\n\t\tdelete spr[i];\n\tfree(spr);\n}\n\nsprite_t *sprite_set_t::GetSprite(int which)\n{\n\tif (spr && which <= count && spr[which])\n\t\treturn spr[which];\n\treturn NULL;\n}\n\nword sprite_set_t::GetCount(void)\n{\n\treturn count;\n}\n"
},
{
"alpha_fraction": 0.5851776599884033,
"alphanum_fraction": 0.6102213263511658,
"avg_line_length": 15.470024108886719,
"blob_id": "be89d3668f8d4eb24cdf1cb3ac0a31d4f7fb7b29",
"content_id": "b2509e213d5311c2f3d3ff91a133ff8ad5e6f056",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6868,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 417,
"path": "/source/mgldraw.cpp",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#include \"mgldraw.h\"\n#include \"winpch.h\"\n#include \"game.h\"\t// for SetGameIdle and GetGameIdle only\n#include \"sound.h\"\n#include \"music.h\"\n#include \"ctype.h\"\n#include \"shlobj.h\" // for SHGetFolderPath\n#include <stdio.h>\n#include <random>\n\n// Appdata shenanigans\n\nFILE* AppdataOpen(const char* file, const char* mode)\n{\n\tchar buffer[MAX_PATH];\n\tSHGetFolderPath(NULL, CSIDL_APPDATA, NULL, 0, buffer);\n\tsprintf(buffer + strlen(buffer), \"\\\\Hamumu\");\n\tmkdir(buffer);\n\tsprintf(buffer + strlen(buffer), \"\\\\DrLunatic\");\n\tmkdir(buffer);\n\tsprintf(buffer + strlen(buffer), \"\\\\%s\", file);\n\treturn fopen(buffer, mode);\n}\n\n// Allegro shenanigans\nstatic char prevKey[KEY_MAX];\nstatic bool closeButtonPressed;\n\nstatic void closeButtonCallback()\n{\n\tcloseButtonPressed = true;\n}\n\nstatic void switchInCallback()\n{\n\tSetGameIdle(0);\n}\n\nstatic void switchOutCallback()\n{\n\tSetGameIdle(1);\n}\n\n// Replacements for missing MGL functions\nstd::mt19937_64 mersenne;\n\nint MGL_random(int max)\n{\n\treturn std::uniform_int_distribution<int>(0, max - 1)(mersenne);\n}\n\nvoid MGL_srand(int seed)\n{\n\tmersenne.seed(seed);\n}\n\nlong MGL_randoml(long max)\n{\n\treturn std::uniform_int_distribution<long>(0, max - 1)(mersenne);\n}\n\nvoid MGL_fatalError(const char* txt)\n{\n\tset_gfx_mode(GFX_TEXT, 0, 0, 0, 0);\n\tallegro_message(txt);\n\texit(0);\n}\n\nMGLDraw::MGLDraw(const char *name, int xRes, int yRes, bool window)\n{\n\tallegro_init();\n\tinstall_keyboard();\n\tinstall_mouse();\n\tinstall_sound(DIGI_AUTODETECT, MIDI_AUTODETECT, \"donotuse.cfg\");\n\tset_color_depth(32);\n\n\tif (set_gfx_mode(window ? GFX_AUTODETECT_WINDOWED : GFX_AUTODETECT_FULLSCREEN, xRes, yRes, 0, 0) != 0)\n\t{\n\t\tchar buf[256];\n\t\tsprintf(buf, \"Unable to set graphics mode: %s\", allegro_error);\n\t\tMGL_fatalError(buf);\n\t}\n\tset_window_title(name);\n\tset_close_button_callback(&closeButtonCallback);\n\tset_display_switch_mode(SWITCH_BACKGROUND);\n\tset_display_switch_callback(SWITCH_IN, switchInCallback);\n\tset_display_switch_callback(SWITCH_OUT, switchOutCallback);\n\n\t// this used to have to be in a very specific place but now it doesn't, hooray!\n\tif (JamulSoundInit(512))\n\t\tSoundSystemExists();\n\n\treadyToQuit = false;\n\n\t// gimme windows colors\n\tthis->xRes = xRes;\n\tthis->yRes = yRes;\n\tthis->pitch = xRes;\n\tscrn.reset(new byte[xRes * yRes]);\n\tbuffer.reset(create_bitmap(xRes, yRes));\n\n\tmouseDown = 0;\n}\n\nMGLDraw::~MGLDraw()\n{\n\tJamulSoundExit();\n}\n\nbool MGLDraw::Process()\n{\n\tblit(buffer.get(), screen, 0, 0, 0, 0, xRes, yRes);\n\n\twhile (keypressed())\n\t{\n\t\tint k = readkey();\n\t\tSetLastKey((char) (k & 0xff));\n\t}\n\n\tfor (int i = 0; i < KEY_MAX; ++i)\n\t{\n\t\tif (key[i] && !prevKey[i])\n\t\t{\n\t\t\tControlKeyDown(i);\n\t\t}\n\t\telse if (!key[i] && prevKey[i])\n\t\t{\n\t\t\tControlKeyUp(i);\n\t\t}\n\t\tprevKey[i] = key[i];\n\t}\n\n\tSetMouse(mouse_x, mouse_y);\n\tSetMouseDown(mouse_b & 3);\n\n\tif (closeButtonPressed)\n\t{\n\t\treadyToQuit = true;\n\t}\n\n\treturn (!readyToQuit);\n}\n\nHWND MGLDraw::GetHWnd()\n{\n\treturn win_get_window();\n}\n\nvoid MGLDraw::Flip()\n{\n\tif (GetGameIdle())\n\t\tGameIdle();\n\n\t// This is nice and fast, thankfully\n\tfor (int i = 0; i < xRes * yRes; ++i)\n\t{\n\t\tpalette_t c = pal[scrn[i]];\n\t\tputpixel(buffer.get(), i % xRes, i / xRes, makecol(c.red, c.green, c.blue));\n\t}\n\tProcess();\n}\n\nvoid MGLDraw::ClearScreen()\n{\n\tmemset(scrn.get(), 0, xRes * yRes);\n}\n\nbyte *MGLDraw::GetScreen()\n{\n\treturn scrn.get();\n}\n\nint MGLDraw::GetWidth()\n{\n\treturn pitch;\n}\n\nint MGLDraw::GetHeight()\n{\n\treturn yRes;\n}\n\nvoid MGLDraw::Quit()\n{\n\treadyToQuit = true;\n}\n\nstruct palfile_t\n{\n\tchar r, g, b;\n};\n\nbool MGLDraw::LoadPalette(const char *name)\n{\n\tFILE *f;\n\tpalfile_t p[256];\n\tint i;\n\n\tf = fopen(name, \"rb\");\n\tif (!f)\n\t\treturn false;\n\n\tif (fread(p, sizeof (palfile_t), 256, f) != 256)\n\t{\n\t\tfclose(f);\n\t\treturn false;\n\t}\n\n\tfor (i = 0; i < 256; i++)\n\t{\n\t\tpal[i].red = p[i].r;\n\t\tpal[i].green = p[i].g;\n\t\tpal[i].blue = p[i].b;\n\t\tpal[i].alpha = 0;\n\t}\n\n\tfclose(f);\n\treturn true;\n}\n\nvoid MGLDraw::SetPalette(const palette_t *pal2)\n{\n\tmemcpy(pal, pal2, sizeof (palette_t)*256);\n}\n\n// 8-bit graphics only\n\nvoid MGLDraw::Box(int x, int y, int x2, int y2, byte c)\n{\n\tint i;\n\n\tif (x < 0)\n\t\tx = 0;\n\tif (x >= xRes)\n\t\tx = xRes - 1;\n\tif (y < 0)\n\t\ty = 0;\n\tif (y >= yRes)\n\t\ty = yRes - 1;\n\tif (x2 < 0)\n\t\treturn;\n\tif (x2 >= xRes)\n\t\tx2 = xRes - 1;\n\tif (y2 < 0)\n\t\treturn;\n\tif (y2 >= yRes)\n\t\ty2 = yRes - 1;\n\tif (x > x2)\n\t{\n\t\ti = x;\n\t\tx = x2;\n\t\tx2 = i;\n\t}\n\tif (y > y2)\n\t{\n\t\ti = y;\n\t\ty = y2;\n\t\ty2 = i;\n\t}\n\tmemset(&scrn[x + y * pitch], c, x2 - x + 1);\n\tmemset(&scrn[x + y2 * pitch], c, x2 - x + 1);\n\tfor (i = y; i <= y2; i++)\n\t{\n\t\tscrn[x + i * pitch] = c;\n\t\tscrn[x2 + i * pitch] = c;\n\t}\n}\n\nvoid MGLDraw::FillBox(int x, int y, int x2, int y2, byte c)\n{\n\tint i;\n\n\tif (y >= yRes)\n\t\treturn;\n\n\tif (x < 0)\n\t\tx = 0;\n\tif (x >= xRes)\n\t\tx = xRes - 1;\n\tif (y < 0)\n\t\ty = 0;\n\tif (y >= yRes)\n\t\ty = yRes - 1;\n\tif (x2 < 0)\n\t\treturn;\n\tif (x2 >= xRes)\n\t\tx2 = xRes - 1;\n\tif (y2 < 0)\n\t\treturn;\n\tif (y2 >= yRes)\n\t\ty2 = yRes - 1;\n\n\tfor (i = y; i <= y2; i++)\n\t{\n\t\tmemset(&scrn[x + i * pitch], c, x2 - x + 1);\n\t}\n}\n\nvoid MGLDraw::SetLastKey(char c)\n{\n\tlastKeyPressed = c;\n}\n\nchar MGLDraw::LastKeyPressed()\n{\n\tchar c = lastKeyPressed;\n\tlastKeyPressed = 0;\n\treturn c;\n}\n\nvoid MGLDraw::SetMouseDown(byte w)\n{\n\tmouseDown = w;\n}\n\nbyte MGLDraw::MouseDown()\n{\n\treturn mouseDown;\n}\n\nvoid MGLDraw::SetMouse(int x, int y)\n{\n\tmousex = x;\n\tmousey = y;\n}\n\nvoid MGLDraw::TeleportMouse(int x, int y)\n{\n\tPOINT pt = {x, y};\n\tClientToScreen(GetHWnd(), &pt);\n\tSetCursorPos(pt.x, pt.y);\n\tSetMouse(x, y);\n}\n\nvoid MGLDraw::GetMouse(int *x, int *y)\n{\n\t*x = mousex;\n\t*y = mousey;\n}\n\nchar MGLDraw::LastKeyPeek()\n{\n\treturn lastKeyPressed;\n}\n\nbool MGLDraw::LoadBMP(const char *name)\n{\n\tFILE *f;\n\tBITMAPFILEHEADER bmpFHead;\n\tBITMAPINFOHEADER bmpIHead;\n\tRGBQUAD pal2[256];\n\n\tint i;\n\tbyte *scr;\n\n\tf = fopen(name, \"rb\");\n\tif (!f)\n\t\treturn FALSE;\n\n\tfread(&bmpFHead, sizeof (BITMAPFILEHEADER), 1, f);\n\tfread(&bmpIHead, sizeof (BITMAPINFOHEADER), 1, f);\n\n\t// 8-bit BMPs only\n\tif (bmpIHead.biBitCount != 8)\n\t\treturn FALSE;\n\n\t// Non-RLE BMPs only\n\tif (bmpIHead.biCompression != 0)\n\t{\n\t\tprintf(\"bitmap %s is compressed (%lu)\\n\", name, bmpIHead.biCompression);\n\t\treturn FALSE;\n\t}\n\n\tfread(pal2, sizeof (pal2), 1, f);\n\tfor (i = 0; i < 256; i++)\n\t{\n\t\tpal[i].red = pal2[i].rgbRed;\n\t\tpal[i].green = pal2[i].rgbGreen;\n\t\tpal[i].blue = pal2[i].rgbBlue;\n\t}\n\n\tfor (i = 0; i < bmpIHead.biHeight; i++)\n\t{\n\t\tscr = &scrn[(bmpIHead.biHeight - 1 - i) * pitch];\n\t\tfread(scr, 1, bmpIHead.biWidth, f);\n\t}\n\tfclose(f);\n\treturn TRUE;\n}\n\nvoid MGLDraw::GammaCorrect(byte gamma)\n{\n\tint i;\n\tint r, g, b;\n\tpalette_t temp[256];\n\n\tmemcpy(temp, pal, sizeof (palette_t)*256);\n\tfor (i = 0; i < 256; i++)\n\t{\n\t\tr = pal[i].red;\n\t\tg = pal[i].green;\n\t\tb = pal[i].blue;\n\t\tr = (r * (gamma + 4)) / 4;\n\t\tg = (g * (gamma + 4)) / 4;\n\t\tb = (b * (gamma + 4)) / 4;\n\t\tif (r > 255)\n\t\t\tr = 255;\n\t\tif (g > 255)\n\t\t\tg = 255;\n\t\tif (b > 255)\n\t\t\tb = 255;\n\t\tpal[i].red = r;\n\t\tpal[i].green = g;\n\t\tpal[i].blue = b;\n\t}\n\tmemcpy(pal, temp, sizeof (palette_t)*256);\n}\n"
},
{
"alpha_fraction": 0.7384615540504456,
"alphanum_fraction": 0.7384615540504456,
"avg_line_length": 12,
"blob_id": "39d1029a2b3eb926a342114e23ea1261376cbc18",
"content_id": "b3dee3a31c7615d2a1f92058ec95ef4de495beae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 10,
"path": "/source/clock.h",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#ifndef CLOCK_H\n#define CLOCK_H\n\n#include \"winpch.h\"\n\nvoid StartClock(void);\nvoid EndClock(void);\ndword TimeLength(void);\n\n#endif\n"
},
{
"alpha_fraction": 0.7237569093704224,
"alphanum_fraction": 0.7237569093704224,
"avg_line_length": 17.100000381469727,
"blob_id": "17d9f82239f895fe7ff820aa6889664488d142c9",
"content_id": "8b58d03e98936d0a4ca987f0d03a6db3625ce093",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 181,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 10,
"path": "/source/jamulfmv.h",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#ifndef JAMULFMV_H\n#define JAMULFMV_H\n\n#include \"jamultypes.h\"\n#include \"mgldraw.h\"\n#include <stdio.h>\n\nvoid FLI_play(const char *name, byte loop, word wait, MGLDraw *mgl);\n\n#endif\n"
},
{
"alpha_fraction": 0.6224116683006287,
"alphanum_fraction": 0.6333739161491394,
"avg_line_length": 20.605262756347656,
"blob_id": "39e3771d71d8621b02b9d1f25241efdd87e4281f",
"content_id": "2971a382e5e024e49ef5773facc8e7ad7b55d664",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 821,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 38,
"path": "/tools/blankline.py",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "# Lunatic blanklines.py\n# Tad Hardesty, aka SpaceManiac, 2011\n# Ensures every file in source has a blank line at the end\n# usage: 'python tools/blankline.py'\n\nimport os\nimport itertools\n\ndef getFileList(dir, ext):\n\tfor dirpath, dirnames, filenames in os.walk(dir):\n\t\tfor name in filenames:\n\t\t\tif 'old/' not in name and name.endswith(ext):\n\t\t\t\tyield os.path.join(dirpath, name)\n\nfiles = itertools.chain(\n\tgetFileList('source', '.cpp'),\n\tgetFileList('source', '.h'),\n\tgetFileList('tools', '.py'))\n\nfor path in files:\n\tf = file(path)\n\tdata = f.read()\n\tf.close()\n\n\tlines = 0\n\twhile len(data) > lines and data[-1 - lines] == '\\n':\n\t\tlines += 1\n\n\tif lines != 1:\n\t\tif lines > 0:\n\t\t\tdata = data[:-lines] + '\\n'\n\t\telse:\n\t\t\tdata = data + '\\n'\n\t\tf = file(path, 'w')\n\t\tf.write(data)\n\t\tf.write('\\n')\n\t\tf.close()\n\t\tprint 'Corrected ' + path\n"
},
{
"alpha_fraction": 0.7215508818626404,
"alphanum_fraction": 0.7240684628486633,
"avg_line_length": 34.46428680419922,
"blob_id": "0b196ff04dc900b40aee7deb04ef25c9106808a7",
"content_id": "9b1265c41eec221ac520238cf031577ce3a0268d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1986,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 56,
"path": "/source/jamulfont.h",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#ifndef JAMULFONT_H\n#define JAMULFONT_H\n\n#include \"winpch.h\"\n#include \"mgldraw.h\"\n\nconst int FONT_MAX_CHARS = 128;\n\nstruct mfont_t\n{\n\tbyte numChars; // # of characters in the font\n\tbyte firstChar; // the first character's ASCII value (they ascend from there)\n\tbyte height; // height in pixels of the font\n\tbyte spaceSize; // # of pixels wide to make spaces\n\tbyte gapSize; // # of pixels between adjacent letters\n\tbyte gapHeight; // # of pixels to descend for a carriage return\n\tlong dataSize; // the size in bytes of the data of the characters themselves\n\tbyte *data; // pointer to the character data\n\tbyte * chars[FONT_MAX_CHARS]; // pointers to each character's data (can't have more than FONT_MAX_CHARS)\n};\n\n// each character in the font is stored as:\n// width 1 byte width of the character in pixels\n// data width*height bytes of actual data\n\n// error codes\nenum {\n\tFONT_OK = 0,\n\tFONT_FILENOTFOUND,\n\tFONT_CANTALLOC,\n\tFONT_INVALIDFILE\n};\n\nvoid FontInit(MGLDraw *mgl);\nvoid FontExit(void);\n\nvoid FontFree(mfont_t *font);\n\n\nint FontLoad(const char *fname, mfont_t *font);\nint FontSave(const char *fname, mfont_t *font);\n\nvoid FontPrintChar(int x, int y, char c, mfont_t *font);\nvoid FontPrintCharSolid(int x, int y, char c, mfont_t *font, byte color);\nvoid FontPrintCharBright(int x, int y, char c, char bright, mfont_t *font);\nvoid FontPrintString(int x, int y, const char *s, mfont_t *font);\nvoid FontPrintStringSolid(int x, int y, const char *s, mfont_t *font, byte color);\nvoid FontPrintStringDropShadow(int x, int y, const char *s, mfont_t *font, byte shadowColor, byte shadowOffset);\nvoid FontPrintStringColor(int x, int y, const char *s, mfont_t *font, byte color);\nvoid FontPrintStringBright(int x, int y, const char *s, mfont_t *font, char bright);\n\nint FontStrLen(const char *s, mfont_t *font);\nvoid FontSetColors(byte first, byte count, byte *data);\nbool FontInputText(char *prompt, char *buffer, int len, void (*renderScrn)(mfont_t *), mfont_t *font);\n\n#endif\n"
},
{
"alpha_fraction": 0.5488898158073425,
"alphanum_fraction": 0.5662667155265808,
"avg_line_length": 19.71714210510254,
"blob_id": "cdae5858fc27fe2205473f3bda01583e255e0949",
"content_id": "2dc2bb2f549d76b79b3c1e6b4983205341ef783b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7251,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 350,
"path": "/source/jamulfont.cpp",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#include \"jamulfont.h\"\n\n\nMGLDraw *fontmgl;\n// this is a sort of palette translation table for the font\nbyte fontPal[256];\n\nvoid FontInit(MGLDraw *mgl)\n{\n\tint i;\n\n\tfontmgl = mgl;\n\t// default translation is none for the font palette\n\tfor (i = 0; i < 256; i++)\n\t\tfontPal[i] = (byte) i;\n}\n\nvoid FontExit(void)\n{\n}\n\nvoid FontFree(mfont_t *font)\n{\n\tif (font->data)\n\t\tfree(font->data);\n}\n\nint FontLoad(const char *fname, mfont_t *font)\n{\n\tFILE *f;\n\tint i;\n\n\tf = fopen(fname, \"rb\");\n\tif (!f)\n\t\treturn FONT_FILENOTFOUND;\n\n\tif (fread(font, sizeof (mfont_t), 1, f) != 1)\n\t\treturn FONT_INVALIDFILE;\n\n\tfont->data = (byte *) malloc(font->dataSize);\n\tif (!font->data)\n\t\treturn FONT_CANTALLOC;\n\n\tif (fread(font->data, font->dataSize, 1, f) != 1)\n\t\treturn FONT_INVALIDFILE;\n\n\tfclose(f);\n\tfont->chars[0] = font->data;\n\tfor (i = 1; i < font->numChars; i++)\n\t\tfont->chars[i] = font->chars[i - 1] + 1 + ((*font->chars[i - 1]) * font->height);\n\n\treturn FONT_OK;\n}\n\nint FontSave(char *fname, mfont_t *font)\n{\n\tFILE *f;\n\n\tf = fopen(fname, \"wb\");\n\tif (!f)\n\t\treturn FONT_FILENOTFOUND;\n\n\tif (fwrite(font, sizeof (mfont_t), 1, f) != 1)\n\t\treturn FONT_INVALIDFILE;\n\n\tif (fwrite(font->data, font->dataSize, 1, f) != 1)\n\t\treturn FONT_INVALIDFILE;\n\n\tfclose(f);\n\treturn FONT_OK;\n}\n\nvoid FontPrintChar(int x, int y, char c, mfont_t *font)\n{\n\tbyte *dst, *src;\n\tint scrWidth, scrHeight, chrWidth;\n\tint i, j;\n\n\tscrWidth = fontmgl->GetWidth();\n\tscrHeight = fontmgl->GetHeight();\n\tdst = fontmgl->GetScreen() + x + y*scrWidth;\n\n\tif (c < font->firstChar || c >= (font->firstChar + font->numChars))\n\t\treturn; // unprintable\n\n\tc -= (char) font->firstChar;\n\n\t// c -> (int)c to prevent warning: array subscript has type 'char'\n\tchrWidth = *(font->chars[(int) c]);\n\tsrc = font->chars[(int) c] + 1;\n\tfor (j = 0; j < font->height; j++)\n\t{\n\t\tfor (i = 0; i < (*font->chars[(int) c]); i++)\n\t\t{\n\t\t\tif (*src && (x > 0) && (x < scrWidth) && (y > 0) && (y < scrHeight))\n\t\t\t\t*dst = fontPal[*src];\n\t\t\tdst++;\n\t\t\tsrc++;\n\t\t\tx++;\n\t\t}\n\t\ty++;\n\t\tx -= chrWidth;\n\t\tdst += (scrWidth - chrWidth);\n\t}\n}\n\nvoid FontPrintCharColor(int x, int y, char c, byte color, mfont_t *font)\n{\n\tbyte *dst, *src;\n\tint scrWidth, scrHeight, chrWidth;\n\tint i, j;\n\n\tscrWidth = fontmgl->GetWidth();\n\tscrHeight = fontmgl->GetHeight();\n\tdst = fontmgl->GetScreen() + x + y*scrWidth;\n\n\tif (c < font->firstChar || c >= (font->firstChar + font->numChars))\n\t\treturn; // unprintable\n\n\tc -= (char) font->firstChar;\n\n\tchrWidth = *(font->chars[(int) c]);\n\tsrc = font->chars[(int) c] + 1;\n\tcolor *= 32;\n\tfor (j = 0; j < font->height; j++)\n\t{\n\t\tfor (i = 0; i < (*font->chars[(int) c]); i++)\n\t\t{\n\t\t\tif (*src && (x > 0) && (x < scrWidth) && (y > 0) && (y < scrHeight))\n\t\t\t{\n\t\t\t\tif ((*src >= 64 && *src < 64 + 32) || (*src >= 128 && *src < 128 + 32))\n\t\t\t\t\t*dst = ((*src)&31) + color;\n\t\t\t\telse\n\t\t\t\t\t*dst = *src;\n\t\t\t}\n\t\t\tdst++;\n\t\t\tsrc++;\n\t\t\tx++;\n\t\t}\n\t\ty++;\n\t\tx -= chrWidth;\n\t\tdst += (scrWidth - chrWidth);\n\t}\n}\n\nvoid FontPrintCharBright(int x, int y, char c, char bright, mfont_t *font)\n{\n\tbyte *dst, *src;\n\tint scrWidth, scrHeight, chrWidth;\n\tint i, j;\n\n\tscrWidth = fontmgl->GetWidth();\n\tscrHeight = fontmgl->GetHeight();\n\tdst = fontmgl->GetScreen() + x + y*scrWidth;\n\n\tif (c < font->firstChar || c >= (font->firstChar + font->numChars))\n\t\treturn; // unprintable\n\n\tc -= (char) font->firstChar;\n\n\tchrWidth = *(font->chars[(int) c]);\n\tsrc = font->chars[(int) c] + 1;\n\n\tfor (j = 0; j < font->height; j++)\n\t{\n\t\tfor (i = 0; i < (*font->chars[(int) c]); i++)\n\t\t{\n\t\t\tif (*src && (x > 0) && (x < scrWidth) && (y > 0) && (y < scrHeight))\n\t\t\t{\n\t\t\t\t*dst = *src + bright;\n\t\t\t\tif (*dst > (*src & (~31)) + 31)\n\t\t\t\t\t*dst = (*src & (~31)) + 31;\n\t\t\t\telse if (*dst < (*src & (~31)))\n\t\t\t\t\t*dst = *src & (~31);\n\t\t\t}\n\t\t\tdst++;\n\t\t\tsrc++;\n\t\t\tx++;\n\t\t}\n\t\ty++;\n\t\tx -= chrWidth;\n\t\tdst += (scrWidth - chrWidth);\n\t}\n}\n\nvoid FontPrintCharSolid(int x, int y, char c, mfont_t *font, byte color)\n{\n\tbyte *dst, *src;\n\tint scrWidth, scrHeight, chrWidth;\n\tint i, j;\n\n\tscrWidth = fontmgl->GetWidth();\n\tscrHeight = fontmgl->GetHeight();\n\tdst = fontmgl->GetScreen() + x + y*scrWidth;\n\n\tif (c < font->firstChar || c >= (font->firstChar + font->numChars))\n\t\treturn; // unprintable\n\n\tc -= (char) font->firstChar;\n\n\tchrWidth = *(font->chars[(int) c]);\n\tsrc = font->chars[(int) c] + 1;\n\tfor (j = 0; j < font->height; j++)\n\t{\n\t\tfor (i = 0; i < (*font->chars[(int) c]); i++)\n\t\t{\n\t\t\tif (*src && (x > 0) && (x < scrWidth) && (y > 0) && (y < scrHeight))\n\t\t\t\t*dst = color;\n\t\t\tdst++;\n\t\t\tsrc++;\n\t\t\tx++;\n\t\t}\n\t\ty++;\n\t\tx -= chrWidth;\n\t\tdst += (scrWidth - chrWidth);\n\t}\n}\n\nbyte CharWidth(char c, mfont_t *font)\n{\n\tif (c < font->firstChar || c >= (font->firstChar + font->numChars))\n\t\treturn font->spaceSize; // unprintable\n\n\tc -= (char) font->firstChar;\n\n\treturn *(font->chars[(int) c]);\n}\n\nvoid FontPrintString(int x, int y, const char *s, mfont_t *font)\n{\n\tint i;\n\n\tfor (i = 0; i < (int) strlen(s); i++)\n\t{\n\t\tFontPrintChar(x, y, s[i], font);\n\t\tx += CharWidth(s[i], font) + font->gapSize;\n\t}\n}\n\nvoid FontPrintStringColor(int x, int y, const char *s, mfont_t *font, byte color)\n{\n\tint i;\n\n\tfor (i = 0; i < (int) strlen(s); i++)\n\t{\n\t\tFontPrintCharColor(x, y, s[i], color, font);\n\t\tx += CharWidth(s[i], font) + font->gapSize;\n\t}\n}\n\nvoid FontPrintStringBright(int x, int y, const char *s, mfont_t *font, char bright)\n{\n\tint i;\n\n\tfor (i = 0; i < (int) strlen(s); i++)\n\t{\n\t\tFontPrintCharBright(x, y, s[i], bright, font);\n\t\tx += CharWidth(s[i], font) + font->gapSize;\n\t}\n}\n\nvoid FontPrintStringSolid(int x, int y, const char *s, mfont_t *font, byte color)\n{\n\tint i;\n\n\tfor (i = 0; i < (int) strlen(s); i++)\n\t{\n\t\tFontPrintCharSolid(x, y, s[i], font, color);\n\t\tx += CharWidth(s[i], font) + font->gapSize;\n\t}\n}\n\nvoid FontPrintStringDropShadow(int x, int y, const char *s, mfont_t *font, byte shadowColor, byte shadowOffset)\n{\n\tint i;\n\n\tfor (i = 0; i < (int) strlen(s); i++)\n\t{\n\t\tFontPrintCharSolid(x + shadowOffset, y + shadowOffset, s[i], font, shadowColor);\n\t\tFontPrintChar(x, y, s[i], font);\n\t\tx += CharWidth(s[i], font) + font->gapSize;\n\t}\n}\n\nvoid FontSetColors(byte first, byte count, byte *data)\n{\n\tmemcpy(&fontPal[first], data, count);\n}\n\nint FontStrLen(const char *s, mfont_t *font)\n{\n\tint i, len = 0;\n\n\tfor (i = 0; i < (int) strlen(s); i++)\n\t{\n\t\tlen += CharWidth(s[i], font) + font->gapSize;\n\t}\n\treturn len;\n}\n\nbool FontInputText(char *prompt, char *buffer, int len, void (*renderScrn)(mfont_t *), mfont_t *font)\n{\n\tint pos = 0;\n\tbool done = 0;\n\tchar c;\n\n\twhile (buffer[pos] && pos < len)\n\t\tpos++;\n\twhile (!done)\n\t{\n\t\trenderScrn(font);\n\t\tfontmgl->FillBox(0, 200, 639, 250, 0);\n\t\tfontmgl->Box(0, 200, 639, 250, 255);\n\t\tFontPrintString(2, 202, prompt, font);\n\t\tbuffer[pos] = '_';\n\t\tbuffer[pos + 1] = '\\0';\n\t\tFontPrintString(2, 202 + font->height + 2, buffer, font);\n\t\tbuffer[pos] = '\\0';\n\t\tfontmgl->Flip();\n\t\tif (!fontmgl->Process())\n\t\t\treturn FALSE;\n\t\tif ((c = fontmgl->LastKeyPressed())) // extra pair of parentheses for a warning about assignment in truth value\n\t\t{\n\t\t\tif (c == 8) // backspace\n\t\t\t{\n\t\t\t\tif (pos > 0)\n\t\t\t\t{\n\t\t\t\t\tpos--;\n\t\t\t\t\tbuffer[pos] = '\\0';\n\t\t\t\t}\n\t\t\t}\n\t\t\telse if (c == 27)\n\t\t\t{\n\t\t\t\tdone = TRUE;\n\t\t\t\tbuffer[0] = '\\0';\n\t\t\t}\n\t\t\telse if (c == 13)\n\t\t\t{\n\t\t\t\tdone = TRUE;\n\t\t\t\tbuffer[pos] = '\\0';\n\t\t\t}\n\t\t\telse if (pos < len)\n\t\t\t{\n\t\t\t\tbuffer[pos++] = c;\n\t\t\t\tbuffer[pos] = '\\0';\n\t\t\t}\n\t\t}\n\t}\n\treturn TRUE;\n}\n"
},
{
"alpha_fraction": 0.557830274105072,
"alphanum_fraction": 0.5895013213157654,
"avg_line_length": 17.92384147644043,
"blob_id": "ada0bffca1e6778d5fc112a73cbb836380406bf8",
"content_id": "fc299cc5cac98d1ca4ef5dc7f517e9222e47f07d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5715,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 302,
"path": "/source/control.cpp",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#include \"control.h\"\n#include \"mgldraw.h\"\n#include \"options.h\"\n\n// text strings corresponding to scan codes 0-88\nchar scanCodeTable[128][16] = {\n\t// 0\n\t\"Null\", \"A\", \"B\", \"C\", \"D\", \"E\", \"F\", \"G\", \"H\", \"I\", \"J\", \"K\", \"L\", \"M\", \"N\", \"O\",\n\t// 16\n\t\"P\", \"Q\", \"R\", \"S\", \"T\", \"U\", \"V\", \"W\", \"X\", \"Y\", \"Z\", \"0\", \"1\", \"2\", \"3\", \"4\",\n\t// 32\n\t\"5\", \"6\", \"7\", \"8\", \"9\", \"Numpad0\", \"Numpad1\", \"Numpad2\", \"Numpad3\", \"Numpad4\", \"Numpad5\", \"Numpad6\", \"Numpad7\", \"Numpad8\", \"Numpad9\", \"F1\",\n\t// 48\n\t\"F2\", \"F3\", \"F4\", \"F5\", \"F6\", \"F7\", \"F8\", \"F9\", \"F10\", \"F11\", \"F12\", \"Escape\", \"~\", \"-\", \"=\", \"Backspace\",\n\t// 64\n\t\"Tab\", \"[\", \"]\", \"Enter\", \":\", \"\\\"\", \"\\\\\", \"\\\\ 2\", \",\", \"Stop\", \"/\", \"Space\", \"Insert\", \"Delete\", \"Home\", \"End\",\n\t// 80\n\t\"PageUp\", \"PageDown\", \"Left\", \"Right\", \"Up\", \"Down\", \"Numpad/\", \"Numpad*\", \"Numpad-\", \"Numpad+\", \"NumpadDel\", \"NumpadEnter\", \"PrintScreen\", \"Pause\", \"ABNT-C1\", \"Yen\",\n\t// 96\n\t\"Kana\", \"Convert\", \"NoConvert\", \"@\", \"Circumflex\", \": 2\", \"Kanji\", \"Numpad=\", \"`\", \";\", \"Command\", \"Unknown1\", \"Unknown2\", \"Unknown3\", \"Unknown4\", \"Unknown5\",\n\t// 112\n\t\"Unknown6\", \"Unknown7\", \"Unknown8\", \"LShift\", \"RShift\", \"LControl\", \"RControl\", \"Alt\", \"AltGr\", \"LWin\", \"RWin\", \"Menu\", \"ScrollLock\", \"NumLock\", \"CapsLock\", \"Maximum\"\n};\n\n\nbyte arrowState;\nbyte keyState;\nbyte keyTap;\nbyte arrowTap;\n\nint joyMinX = 2000000000, joyMinY = 2000000000;\nint joyMaxX = 0, joyMaxY = 0;\nint joyCX, joyCY;\nint joyDeadX, joyDeadY;\n\nbyte joystickOn = 1;\nbyte oldJoy;\n\nbyte lastScanCode;\n\nbyte kb[8][4];\nbyte joyBtn[2];\n\nvoid ControlKeyDown(char k)\n{\n\tint i, j;\n\tbyte bit;\n\n\tlastScanCode = k;\n\n\tfor (i = 0; i < 4; i++)\n\t{\n\t\tbit = 1;\n\t\tfor (j = 0; j < 8; j++)\n\t\t{\n\t\t\tif (k == kb[j][i])\n\t\t\t{\n\t\t\t\tkeyState |= bit;\n\t\t\t\tkeyTap |= bit;\n\t\t\t}\n\t\t\tbit *= 2;\n\t\t}\n\t}\n\t// always track arrows, no matter what the keys are, for menus\n\tif (k == KEY_UP)\n\t{\n\t\tarrowState |= CONTROL_UP;\n\t\tarrowTap |= CONTROL_UP;\n\t}\n\tif (k == 85)\n\t{\n\t\tarrowState |= CONTROL_DN;\n\t\tarrowTap |= CONTROL_DN;\n\t}\n\tif (k == 82)\n\t{\n\t\tarrowState |= CONTROL_LF;\n\t\tarrowTap |= CONTROL_LF;\n\t}\n\tif (k == 83)\n\t{\n\t\tarrowState |= CONTROL_RT;\n\t\tarrowTap |= CONTROL_RT;\n\t}\n\tif (k == 67)\n\t{\n\t\tarrowState |= CONTROL_B1;\n\t\tarrowTap |= CONTROL_B1;\n\n\t}\n}\n\nvoid ControlKeyUp(char k)\n{\n\tint i, j;\n\tbyte bit;\n\n\tfor (i = 0; i < 4; i++)\n\t{\n\t\tbit = 1;\n\t\tfor (j = 0; j < 8; j++)\n\t\t{\n\t\t\tif (k == kb[j][i])\n\t\t\t{\n\t\t\t\tkeyState &= (~bit);\n\t\t\t}\n\t\t\tbit *= 2;\n\t\t}\n\t}\n\n\t// always track arrows, no matter what the keys are, for menus\n\t// keys updated for PixelToaster\n\tif (k == 84)\n\t\tarrowState &= (~CONTROL_UP);\n\telse if (k == 85)\n\t\tarrowState &= (~CONTROL_DN);\n\telse if (k == 82)\n\t\tarrowState &= (~CONTROL_LF);\n\telse if (k == 83)\n\t\tarrowState &= (~CONTROL_RT);\n\telse if (k == 67)\n\t\tarrowState &= (~CONTROL_B1);\n}\n\nvoid InitControls(void)\n{\n\tMMRESULT result;\n\tJOYCAPS joyCaps;\n\n\tlastScanCode = 0;\n\n\tkeyState = 0;\n\tkeyTap = 0;\n\tarrowState = 0;\n\n\tif (joystickOn)\n\t{\n\t\tresult = joyGetDevCaps(JOYSTICKID1, &joyCaps, sizeof (JOYCAPS));\n\t\tif (result != JOYERR_NOERROR)\n\t\t{\n\t\t\tjoystickOn = 0;\n\t\t\treturn;\n\t\t}\n\t\tjoyCX = (joyCaps.wXmax - joyCaps.wXmin) / 2 + joyCaps.wXmin;\n\t\tjoyCY = (joyCaps.wYmax - joyCaps.wYmin) / 2 + joyCaps.wYmin;\n\t\tjoyMinX = joyCaps.wXmin;\n\t\tjoyMinY = joyCaps.wYmin;\n\t\tjoyMaxX = joyCaps.wXmax;\n\t\tjoyMaxY = joyCaps.wYmax;\n\t\toldJoy = 0;\n\t}\n}\n\nbyte GetJoyState(void)\n{\n\tMMRESULT result;\n\tJOYINFOEX joyInfo;\n\tint joyX, joyY;\n\tbyte joyState;\n\n\tmemset(&joyInfo, 0, sizeof (JOYINFOEX));\n\tjoyInfo.dwSize = sizeof (JOYINFOEX);\n\tjoyInfo.dwFlags = JOY_RETURNBUTTONS | JOY_RETURNX | JOY_RETURNY;\n\tresult = joyGetPosEx(JOYSTICKID1, &joyInfo);\n\tif (result != JOYERR_NOERROR)\n\t{\n\t\treturn 0;\n\t}\n\tjoyX = (int) joyInfo.dwXpos;\n\tjoyY = (int) joyInfo.dwYpos;\n\tif (joyX < joyMinX)\n\t{\n\t\tjoyMinX = joyX;\n\t}\n\tif (joyX > joyMaxX)\n\t{\n\t\tjoyMaxX = joyX;\n\t}\n\tif (joyY < joyMinY)\n\t{\n\t\tjoyMinY = joyY;\n\t}\n\tif (joyY > joyMaxY)\n\t{\n\t\tjoyMaxY = joyY;\n\t}\n\tjoyDeadX = (joyMaxX - joyMinX) / 8;\n\tjoyDeadY = (joyMaxY - joyMinY) / 8;\n\tjoyState = 0;\n\tif (joyX - joyCX<-joyDeadX)\n\t\tjoyState |= CONTROL_LF;\n\tif (joyX - joyCX > joyDeadX)\n\t\tjoyState |= CONTROL_RT;\n\tif (joyY - joyCY<-joyDeadY)\n\t\tjoyState |= CONTROL_UP;\n\tif (joyY - joyCY > joyDeadY)\n\t\tjoyState |= CONTROL_DN;\n\tif (joyInfo.dwButtons & (joyBtn[0]))\n\t{\n\t\tif (!(oldJoy & CONTROL_B1))\n\t\t\tkeyTap |= CONTROL_B1;\n\t\tjoyState |= CONTROL_B1;\n\t}\n\tif (joyInfo.dwButtons & (joyBtn[1]))\n\t{\n\t\tif (!(oldJoy & CONTROL_B2))\n\t\t\tkeyTap |= CONTROL_B2;\n\t\tjoyState |= CONTROL_B2;\n\t}\n\toldJoy = joyState;\n\n\treturn joyState;\n}\n\ndword GetJoyButtons(void)\n{\n\tMMRESULT result;\n\tJOYINFOEX joyInfo;\n\n\tif (!joystickOn)\n\t\treturn 0;\n\n\tmemset(&joyInfo, 0, sizeof (JOYINFOEX));\n\tjoyInfo.dwSize = sizeof (JOYINFOEX);\n\tjoyInfo.dwFlags = JOY_RETURNBUTTONS | JOY_RETURNX | JOY_RETURNY;\n\tresult = joyGetPosEx(JOYSTICKID1, &joyInfo);\n\tif (result != JOYERR_NOERROR)\n\t{\n\t\treturn 0;\n\t}\n\treturn joyInfo.dwButtons;\n}\n\nbyte GetControls(void)\n{\n\tif (joystickOn)\n\t\treturn GetJoyState() | (keyState);\n\telse\n\t\treturn keyState;\n}\n\nbyte GetTaps(void)\n{\n\tbyte tapState;\n\n\tif (joystickOn)\n\t\tGetJoyState();\n\n\ttapState = keyTap | arrowTap;\n\n\tkeyTap = 0;\n\tarrowTap = 0;\n\n\treturn tapState;\n}\n\nbyte GetArrows(void)\n{\n\treturn arrowState;\n}\n\nbyte LastScanCode(void)\n{\n\tbyte c;\n\n\tc = lastScanCode;\n\tlastScanCode = 0;\n\treturn c;\n}\n\nbyte JoystickAvailable(void)\n{\n\treturn joystickOn;\n}\n\nvoid SetKeys(byte keys[8])\n{\n\tmemcpy(kb, keys, 8);\n}\n\nchar *ScanCodeText(byte s)\n{\n\tstatic char unknown[16] = \"Unknown\";\n\tchar* r = scanCodeTable[s];\n\tif (r[0] == 0) return unknown; // empty string\n\treturn r;\n}\n\nvoid ApplyControlSettings(void)\n{\n\tint i;\n\n\tfor (i = 0; i < 6; i++)\n\t{\n\t\tkb[i][0] = opt.control[0][i];\n\t\tkb[i][1] = opt.control[1][i];\n\t\tkb[i][2] = 0;\n\t\tkb[i][3] = 0;\n\t}\n\tjoyBtn[0] = (1 << opt.joyCtrl[0]);\n\tjoyBtn[1] = (1 << opt.joyCtrl[1]);\n}\n"
},
{
"alpha_fraction": 0.7082630395889282,
"alphanum_fraction": 0.733558177947998,
"avg_line_length": 25.954545974731445,
"blob_id": "92f92ba327ad3d7fe289c7997d006bfba22477c8",
"content_id": "84e4a8fa86f9aabb5217eb983a7d86c829a839f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 593,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 22,
"path": "/source/jamultypes.h",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "/* these are basic types I just can't live without */\n\n#ifndef JAMTYPES_H\n#define JAMTYPES_H\n\n// I feel horrible doing this, but this is a dumb warning.\n// it warns when the compiler is generating overhead by converting the value to\n// a bool type, which in C++ means it actually forces it to be either 0 or 1, which\n// requires extra code.\n\n#ifndef __MINGW32__ // appears to be a Visual Studio thing\n#pragma warning( disable : 4800 )\n#endif\n\nconst int FIXSHIFT = 16;\nconst int FIXAMT = 65536;\n\ntypedef unsigned char byte;\ntypedef unsigned short word;\ntypedef unsigned long dword;\n\n#endif\n"
},
{
"alpha_fraction": 0.7003567218780518,
"alphanum_fraction": 0.7051129341125488,
"avg_line_length": 19.265060424804688,
"blob_id": "b31006ba62c53f57e6bc253ccf8922f811bd4ca2",
"content_id": "c1e1abef6d84db4b9228ca12501cf882b0976ed0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1682,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 83,
"path": "/source/mgldraw.h",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#ifndef MGLDRAW_H\n#define MGLDRAW_H\n\n#include \"allegro.h\"\n#include <winalleg.h>\n#include \"winpch.h\"\n#include \"jamulsound.h\"\n#include \"control.h\"\n#include <stdio.h>\n#include <memory>\n\n// For appdata storage of stuff\nFILE* AppdataOpen(const char* filename, const char* mode);\n\n// Replacement for missing palette_t\n\nstruct palette_t\n{\n\tbyte alpha, red, green, blue;\n};\n\n// Replacement for missing MGL functions\nint MGL_random(int max);\nvoid MGL_srand(int seed);\nlong MGL_randoml(long max);\nvoid MGL_fatalError(const char* txt);\n\nclass MGLDraw\n{\npublic:\n\tMGLDraw(const char *name, int xRes, int yRes, bool window);\n\t~MGLDraw();\n\n\tbool Process(); // handle windows messages and such\n\n\tHWND GetHWnd();\n\tbyte *GetScreen(); // get a pointer to the screen memory\n\tint GetWidth();\n\tint GetHeight();\n\tvoid ClearScreen();\n\tvoid Flip();\n\tvoid Quit();\n\n\tbool LoadPalette(const char *name);\n\tvoid SetPalette(const palette_t *pal2);\n\n\tbool LoadBMP(const char *name);\n\n\tchar LastKeyPressed();\n\tchar LastKeyPeek();\n\tvoid SetLastKey(char c);\n\n\tvoid GammaCorrect(byte gamma);\n\n\t// handy little drawing routines\n\tvoid Box(int x, int y, int x2, int y2, byte c);\n\tvoid FillBox(int x, int y, int x2, int y2, byte c);\n\n\t// mouse functions\n\tbyte MouseDown();\n\tvoid SetMouseDown(byte w);\n\tvoid SetMouse(int x, int y);\n\tvoid TeleportMouse(int x, int y);\n\tvoid GetMouse(int *x, int *y);\n\nprotected:\n\tstruct bitmap_deleter {\n\t\tvoid operator()(BITMAP* buffer) {\n\t\t\tdestroy_bitmap(buffer);\n\t\t}\n\t};\n\n\tint xRes, yRes, pitch;\n\tint mousex, mousey;\n\tstd::unique_ptr<byte[]> scrn;\n\tstd::unique_ptr<BITMAP, bitmap_deleter> buffer;\n\tpalette_t pal[256];\n\tbool readyToQuit;\n\tchar lastKeyPressed;\n\tbyte mouseDown;\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.63356614112854,
"alphanum_fraction": 0.6401736736297607,
"avg_line_length": 22.334802627563477,
"blob_id": "0346de043374bd45f883bac0673abcfa47233a4d",
"content_id": "704ee0140f0b06b1dab99369201ff3c8c9e4ec60",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5297,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 227,
"path": "/source/jamulsound.cpp",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#include \"jamulsound.h\"\n#include \"mgldraw.h\"\n\nconst int MAX_FEW_SOUNDS = 2;\t// most copies of a SND_FEW sound that can play at once\nconst int MAX_SOUNDS_AT_ONCE = 16;\n\n// internal sound playing flags\nenum {\n\tSOUND_LOOP = 1,\t\t// loop the sound indefinitely (actually does nothing)\n\tSOUND_CUTOFF = 2\t// if the copy of the sound is busy, cut it off and restart\n};\n\n// a loaded sound buffer\nstruct soundbuf_t\n{\n\tSAMPLE *sample;\n};\n\nstatic int soundbufSize = 0;\nstatic soundbuf_t *soundbuf = NULL;\n\n// a sound currently playing\nstruct sound_t\n{\n\tint voice; // allegro handle\n\tint soundNum; // which game sound number\n\tint priority;\n\tlong pan, vol;\n\tbyte flags;\n};\n\nsound_t playBuffer[MAX_SOUNDS_AT_ONCE];\n\nbool JamulSoundInit(int numBuffers)\n{\n\tint i;\n\n\tsoundbufSize = numBuffers;\n\tsoundbuf = new soundbuf_t[numBuffers];\n\tfor (i = 0; i < numBuffers; i++)\n\t{\n\t\tsoundbuf[i].sample = NULL;\n\t}\n\n\tfor (i = 0; i < MAX_SOUNDS_AT_ONCE; i++)\n\t{\n\t\tplayBuffer[i].soundNum = -1;\n\t\tplayBuffer[i].voice = -1;\n\t\tplayBuffer[i].flags = 0;\n\t}\n\treturn TRUE;\n}\n\nvoid JamulSoundDestroyBuffer(int which)\n{\n\tif (soundbuf[which].sample)\n\t{\n\t\tdestroy_sample(soundbuf[which].sample);\n\t\tsoundbuf[which].sample = NULL;\n\t}\n}\n\nvoid JamulSoundExit(void)\n{\n\tint i;\n\n\tif (soundbuf)\n\t{\n\t\tfor (i = 0; i < soundbufSize; i++)\n\t\t\tJamulSoundDestroyBuffer(i);\n\t\tdelete[] soundbuf;\n\t}\n}\n\nbool JamulSoundPlay(int voice, long pan, long vol, byte playFlags)\n{\n\t// if this copy is in use, can't play it\n\tif (voice_get_position(voice) > 0)\n\t{\n\t\tif (playFlags & SOUND_CUTOFF)\n\t\t{\n\t\t\tvoice_set_position(voice, 0);\n\t\t\t// keep going to handle the rest of the stuff\n\t\t}\n\t\telse\n\t\t\treturn FALSE; // can't play if it's playing\n\t}\n\n\t// set the pan and volume and start the voice\n\tvoice_set_volume(voice, vol);\n\tvoice_set_pan(voice, pan);\n\tvoice_start(voice);\n\n\treturn TRUE;\n}\n\n// now here is all the big sound manager stuff, that allows multiple sounds at once\n\nvoid JamulSoundUpdate(void)\n{\n\tint i;\n\n\tfor (i = 0; i < MAX_SOUNDS_AT_ONCE; i++)\n\t{\n\t\tif (playBuffer[i].voice != -1 && playBuffer[i].flags & SND_PLAYING)\n\t\t{\n\t\t\tif (voice_get_position(playBuffer[i].voice) == -1)\n\t\t\t{\n\t\t\t\tplayBuffer[i].flags &= (~SND_PLAYING);\n\t\t\t}\n\t\t}\n\t}\n}\n\nvoid JamulSoundPurge(void)\n{\n\tint i;\n\n\tfor (i = 0; i < soundbufSize; i++)\n\t{\n\t\tJamulSoundDestroyBuffer(i);\n\t}\n}\n\nvoid GoPlaySound(int num, long pan, long vol, byte flags, int priority)\n{\n\tchar txt[32];\n\tint i, best, count;\n\n\t// load the sample if it isn't already\n\tif (soundbuf[num].sample == NULL)\n\t{\n\t\tsprintf(txt, \"sound\\\\snd%03d.wav\", num);\n\t\tsoundbuf[num].sample = load_sample(txt);\n\t\tif (soundbuf[num].sample == NULL)\n\t\t\treturn; // can't play the sound, it won't load for some reason\n\t}\n\n\tpriority += vol; // the quieter a sound, the lower the priority\n\tif (flags & SND_MAXPRIORITY)\n\t\tpriority = MAX_SNDPRIORITY;\n\n\tif (flags & SND_ONE)\n\t{\n\t\tfor (i = 0; i < MAX_SOUNDS_AT_ONCE; i++)\n\t\t\tif (playBuffer[i].soundNum == num)\n\t\t\t{\n\t\t\t\t// if you want to cut it off, or it isn't playing, then start anew\n\t\t\t\tif ((flags & SND_CUTOFF) || (!(playBuffer[i].flags & SND_PLAYING)))\n\t\t\t\t{\n\t\t\t\t\tplayBuffer[i].pan = pan;\n\t\t\t\t\tplayBuffer[i].vol = vol;\n\t\t\t\t\tplayBuffer[i].flags = flags | SND_PLAYING;\n\t\t\t\t\tplayBuffer[i].priority = priority;\n\t\t\t\t\tJamulSoundPlay(playBuffer[i].voice, playBuffer[i].pan, playBuffer[i].vol, SOUND_CUTOFF);\n\t\t\t\t\treturn; // good job\n\t\t\t\t}\n\t\t\t\telse\n\t\t\t\t\treturn; // can't be played because can't cut it off\n\t\t\t}\n\t\t// if you fell through to here, it isn't playing, so go ahead as normal\n\t}\n\tif (flags & SND_FEW)\n\t{\n\t\tcount = 0;\n\t\tfor (i = 0; i < MAX_SOUNDS_AT_ONCE; i++)\n\t\t\tif (playBuffer[i].soundNum == num && (playBuffer[i].flags & SND_PLAYING))\n\t\t\t\tcount++;\n\n\t\tif (count >= MAX_FEW_SOUNDS)\n\t\t{\n\t\t\tfor (i = 0; i < MAX_SOUNDS_AT_ONCE; i++)\n\t\t\t\tif (playBuffer[i].soundNum == num)\n\t\t\t\t{\n\t\t\t\t\tif ((flags & SND_CUTOFF) && (playBuffer[i].flags & SND_PLAYING))\n\t\t\t\t\t{\n\t\t\t\t\t\tplayBuffer[i].pan = pan;\n\t\t\t\t\t\tplayBuffer[i].vol = vol;\n\t\t\t\t\t\tplayBuffer[i].flags = flags | SND_PLAYING;\n\t\t\t\t\t\tplayBuffer[i].priority = priority;\n\t\t\t\t\t\tJamulSoundPlay(playBuffer[i].voice, playBuffer[i].pan, playBuffer[i].vol, SOUND_CUTOFF);\n\t\t\t\t\t\treturn; // good job\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\treturn; // failed for some reason\n\t\t}\n\t}\n\tbest = -1;\n\tfor (i = 0; i < MAX_SOUNDS_AT_ONCE; i++)\n\t{\n\t\tif (playBuffer[i].soundNum == -1 || (!(playBuffer[i].flags & SND_PLAYING)))\n\t\t{\n\t\t\tbest = i;\n\t\t\tbreak; // can't beat that\n\t\t}\n\t\tif ((playBuffer[i].priority < priority) || (playBuffer[i].soundNum == num && (flags & SND_CUTOFF)))\n\t\t{\n\t\t\tif (best == -1 || playBuffer[i].priority < playBuffer[best].priority)\n\t\t\t\tbest = i;\n\t\t}\n\t}\n\tif (best == -1)\n\t\treturn; // sound is not worthy to be played\n\n\tif (playBuffer[best].soundNum != num) // if it was already playing that sound, don't waste time\n\t{\n\t\tplayBuffer[best].soundNum = num;\n\t\tif (playBuffer[best].voice != -1)\n\t\t{\n\t\t\tdeallocate_voice(playBuffer[best].voice); // slash & burn\n\t\t}\n\t\tplayBuffer[best].voice = allocate_voice(soundbuf[num].sample);\n\t}\n\telse\n\t{\n\t\tvoice_set_position(playBuffer[best].voice, 0);\n\t}\n\n\tif (playBuffer[best].voice == -1)\n\t\treturn; // can't play it\n\tplayBuffer[best].priority = priority;\n\tplayBuffer[best].pan = pan;\n\tplayBuffer[best].vol = vol;\n\tplayBuffer[best].flags = flags | SND_PLAYING;\n\n\tJamulSoundPlay(playBuffer[best].voice, playBuffer[best].pan, playBuffer[best].vol, 0);\n}\n"
},
{
"alpha_fraction": 0.6125977039337158,
"alphanum_fraction": 0.6324413418769836,
"avg_line_length": 20.667753219604492,
"blob_id": "8c23ee29e0535e1e0a63c643c3c3cab91b1b0ebd",
"content_id": "8c6438629f3023639ded0cc207b927a0dfa5a932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6652,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 307,
"path": "/tools/formats/supreme_dlw.py",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "# supreme_dlw.py - part of the Loonymod project\n# import this file and use the supreme_dlw construct.\n\nfrom common import *\n\n# constructs and adapters\n\nclass RleBitmap(Construct):\n\tdef isEncoded(self, method, row):\n\t\treturn bool((ord(method[row / 8]) >> (row % 8)) & 1)\n\t\t\n\tdef _parse(self, stream, context):\n\t\trows = []\n\t\tfor row in range(24):\n\t\t\tif self.isEncoded(context[\"method\"], row):\n\t\t\t\tcols = []\n\t\t\t\twhile len(cols) < 32:\n\t\t\t\t\tcols += map(ord, ord(stream.read(1)) * stream.read(1))\n\t\t\t\trows.append(cols)\n\t\t\telse:\n\t\t\t\trows.append(map(ord, stream.read(32)))\n\t\treturn rows\n\t\t\n\tdef _build(self, obj, stream, context):\n\t\tfor row in range(24):\n\t\t\tcols = obj[row]\n\t\t\tif self.isEncoded(context[\"method\"], row):\n\t\t\t\tvalue, run = cols[0], 1\n\t\t\t\tfor pixel in cols[1:]:\n\t\t\t\t\tif pixel == value:\n\t\t\t\t\t\trun += 1\n\t\t\t\t\telse:\n\t\t\t\t\t\tstream.write(chr(run) + value.build())\n\t\t\t\t\t\tvalue, run = pixel, 1\n\t\t\t\tstream.write(chr(run) + value.build())\n\t\t\telse:\n\t\t\t\tstream.write(''.join(map(chr, cols)))\n\t\t\n\tdef _sizeof(self, context):\n\t\traise SizeofError\n\nclass RleLevel(Construct):\n\tdef _parse(self, stream, context):\n\t\twidth, height = context[\"width\"], context[\"height\"]\n\t\trawTiles = []\n\t\twhile len(rawTiles) < width * height:\n\t\t\trun = SLInt8(\"run\").parse(stream.read(1))\n\t\t\tif run < 0:\n\t\t\t\ttile = levelTile.parse(stream.read(levelTile.sizeof()))\n\t\t\t\tfor i in range(-run):\n\t\t\t\t\trawTiles.append(tile)\n\t\t\telse:\n\t\t\t\tfor i in range(run):\n\t\t\t\t\trawTiles.append(levelTile.parse(stream.read(levelTile.sizeof())))\n\t\trows = []\n\t\tfor row in range(height):\n\t\t\tcols = []\n\t\t\tfor col in range(width):\n\t\t\t\tcols.append(rawTiles[row * width + col])\n\t\t\trows.append(cols)\n\t\treturn rows\n\t\t\n\tdef _build(self, obj, stream, context):\n\t\ttiles = []\n\t\tfor row in obj:\n\t\t\tfor col in row:\n\t\t\t\ttiles.append(col)\n\t\tvalue, run = tiles[0], run\n\t\tfor tile in tiles[1:]:\n\t\t\tif tile == value and run < 127:\n\t\t\t\trun += 1\n\t\t\telse:\n\t\t\t\tstream.write(chr(run) + levelTile.build(value))\n\t\t\t\tvalue, run = tile, 1\n\t\tstream.write(chr(run) + levelTile.build(value))\n\t\t\n\tdef _sizeof(self, context):\n\t\traise SizeofError\n\nclass ItemContainer(Construct):\n\tdef _parse(self, stream, context):\n\t\tresult = []\n\t\titemId = 0\n\t\tfor i in range(context[\"itemCount\"]):\n\t\t\tif itemId != 255:\n\t\t\t\titemId = ord(stream.read(1))\n\t\t\t\tdata = item.parse(stream.read(item.sizeof()))\n\t\t\t\tdata.itemId = itemId\n\t\t\t\tresult.append(data)\n\t\t\telse:\n\t\t\t\tdata = item.parse(stream.read(item.sizeof()))\n\t\t\t\tdata.itemId = 255\n\t\t\t\tresult.append(data)\n\t\treturn result\n\t\t\n\tdef _build(self, obj, stream, context):\n\t\tpart = 0\n\t\tfor data in obj:\n\t\t\tif data.itemId == 255:\n\t\t\t\tif part == 0:\n\t\t\t\t\tstream.write(chr(255))\n\t\t\t\t\tpart = 1\n\t\t\t\tstream.write(item.build(data))\n\t\t\telse:\n\t\t\t\tstream.write(chr(data.itemId))\n\t\t\t\tstream.write(item.build(data))\n\t\t\n\tdef _sizeof(self, context):\n\t\traise SizeofError\n\nclass ItemDropAdapter(Adapter):\n\tdef _encode(self, obj, ctx):\n\t\treturn chr(256 * (obj - int(obj))) + chr(obj)\n\tdef _decode(self, obj, ctx):\n\t\treturn ord(obj[1]) + ord(obj[0]) / 256.0\n\n# structures\n\nmonster = Struct(\"monster\",\n\tULInt8(\"x\"),\n\tULInt8(\"y\"),\n\tULInt8(\"type\"),\n\tULInt8(\"item\"),\n)\n\ntrigger = Struct(\"trigger\",\n\tULInt8(\"parameter\"),\n\tULInt8(\"type\"),\n\tULInt8(\"x\"),\n\tULInt8(\"y\"),\n\tULInt32(\"index1\"),\n\tULInt32(\"index2\"),\n)\n\neffect = Struct(\"effect\",\n\tEmbed(trigger),\n\tPackedString(\"text\"),\n)\n\nspecial = Struct(\"special\",\n\tULInt8(\"x\"),\n\tULInt8(\"y\"),\n\tULInt8(\"uses\"),\n\tBitStruct(\"length\",\n\t\tBitField(\"effects\", 5),\n\t\tBitField(\"triggers\", 3)\n\t),\n\tMetaRepeater(lambda ctx: ctx[\"length\"][\"triggers\"], trigger),\n\tMetaRepeater(lambda ctx: ctx[\"length\"][\"effects\"], effect),\n)\n\nlevelTile = Struct(\"levelTile\",\n\tULInt16(\"floor\"),\n\tULInt16(\"wall\"),\n\tULInt8(\"item\"),\n\tSLInt8(\"light\"),\n)\n\nlevel = Struct(\"level\",\n\tULInt8(\"width\"),\n\tULInt8(\"height\"),\n\tPackedString(\"name\"),\n\tPackedString(\"song\"),\n\tULInt8(\"monsterCount\"),\n\tMetaRepeater(lambda ctx: ctx[\"monsterCount\"], monster),\n\tULInt8(\"specialCount\"),\n\tMetaRepeater(lambda ctx: ctx[\"specialCount\"], special),\n\tBitStruct(\"flags\",\n\t\tFlag(\"underwater\"),\n\t\tFlag(\"starry\"),\n\t\tFlag(\"lantern\"),\n\t\tFlag(\"torch\"),\n\t\tFlag(\"secret\"),\n\t\tFlag(\"hub\"),\n\t\tFlag(\"raining\"),\n\t\tFlag(\"snowing\"),\n\t\tFlag(\"reserved5\"),\n\t\tFlag(\"reserved4\"),\n\t\tFlag(\"reserved3\"),\n\t\tFlag(\"reserved2\"),\n\t\tFlag(\"reserved1\"),\n\t\tFlag(\"reserved0\"),\n\t\tFlag(\"stealth\"),\n\t\tFlag(\"underlava\"),\n\t),\n\tULInt16(\"brains\"),\n\tULInt16(\"candles\"),\n\tItemDropAdapter(Bytes(\"itemDrop\", 2)),\n\tRleLevel(\"tiles\"),\n)\n\ntileImage = Struct(\"tileImage\",\n\tBytes(\"method\", 3),\n\tRleBitmap(\"bitmap\"),\n)\n\ntileData = Struct(\"tileData\",\n\tBitStruct(\"flags\",\n\t\tFlag(\"animate\"),\n\t\tFlag(\"canpushon\"),\n\t\tFlag(\"pushable\"),\n\t\tFlag(\"lava\"),\n\t\tFlag(\"water\"),\n\t\tFlag(\"muddy\"),\n\t\tFlag(\"icy\"),\n\t\tFlag(\"impassible\"),\n\t\tFlag(\"bouncy\"),\n\t\tFlag(\"enemyProof\"),\n\t\tFlag(\"ghostProof\"),\n\t\tFlag(\"bunnyPath\"),\n\t\tFlag(\"minecartPath\"),\n\t\tFlag(\"transparentRoof\"),\n\t\tFlag(\"animateHit\"),\n\t\tFlag(\"animateStep\"),\n\t),\n\tULInt16(\"nextTile\"),\n)\n\nitem = Struct(\"item\",\n\tPackedString(\"name\"),\n\tSLInt8(\"offsetX\"),\n\tSLInt8(\"offsetY\"),\n\tULInt16(\"sprite\"),\n\tULInt8(\"fromColor\"),\n\tULInt8(\"toColor\"),\n\tSLInt8(\"light\"),\n\tULInt8(\"rarity\"),\n\tBitStruct(\"flags\",\n\t\tPadding(1),\n\t\tFlag(\"useTileGraphic\"),\n\t\tFlag(\"loonyColor\"),\n\t\tFlag(\"pickup\"),\n\t\tFlag(\"bulletproof\"),\n\t\tFlag(\"impassible\"),\n\t\tFlag(\"glowing\"),\n\t\tFlag(\"shadow\"),\n\t\tPadding(8)\n\t),\n\tBitStruct(\"themes\",\n\t\tFlag(\"crate\"),\n\t\tFlag(\"rock\"),\n\t\tFlag(\"tree\"),\n\t\tFlag(\"door\"),\n\t\tFlag(\"bulletproof\"),\n\t\tFlag(\"obstacle\"),\n\t\tFlag(\"decoration\"),\n\t\tFlag(\"pickup\"),\n\t\tFlag(\"chair\"),\n\t\tFlag(\"entrance\"),\n\t\tFlag(\"food\"),\n\t\tFlag(\"collectible\"),\n\t\tFlag(\"key\"),\n\t\tFlag(\"powerup\"),\n\t\tFlag(\"weapon\"),\n\t\tFlag(\"sign\"),\n\t\tPadding(7),\n\t\tFlag(\"custom\"),\n\t\tPadding(8)\n\t),\n\tBitStruct(\"trigger\",\n\t\tFlag(\"always\"),\n\t\tFlag(\"minecart\"),\n\t\tFlag(\"machete\"),\n\t\tFlag(\"friendbump\"),\n\t\tFlag(\"enemybump\"),\n\t\tFlag(\"playerbump\"),\n\t\tFlag(\"shoot\"),\n\t\tFlag(\"pickup\"),\n\t\tPadding(8)\n\t),\n\tULInt8(\"effect\"),\n\tSLInt16(\"effectData\"),\n\tPackedString(\"message\", 64),\n\tULInt16(\"sound\")\n)\n\nsound = Struct(\"sound\",\n\tULInt16(\"soundId\"),\n\tPackedString(\"name\"),\n\tBitStruct(\"theme\",\n\t\tPadding(2),\n\t\tFlag(\"custom\"),\n\t\tFlag(\"vocal\"),\n\t\tFlag(\"effect\"),\n\t\tFlag(\"monster\"),\n\t\tFlag(\"player\"),\n\t\tFlag(\"intface\")\n\t),\n\tSLInt32(\"dataSize\"),\n\tMetaField(\"data\", lambda ctx: ctx[\"dataSize\"])\n)\n\nsupreme_dlw = Struct(\"world\",\n\tString(\"gameid\", 8),\n\tPackedString(\"author\"),\n\tPackedString(\"name\"),\n\tULInt8(\"levelCount\"),\n\tULInt32(\"totalPoints\"),\n\tULInt16(\"tileCount\"),\n\tMetaRepeater(lambda ctx: ctx[\"tileCount\"], tileImage),\n\tMetaRepeater(lambda ctx: ctx[\"tileCount\"], tileData),\n\tMetaRepeater(lambda ctx: ctx[\"levelCount\"], level),\n\tULInt16(\"itemCount\"),\n\tItemContainer(\"items\"),\n\tSLInt16(\"soundCount\"),\n\tMetaRepeater(lambda ctx: ctx[\"soundCount\"], sound)\n)\n"
},
{
"alpha_fraction": 0.6763485670089722,
"alphanum_fraction": 0.6846473217010498,
"avg_line_length": 11.684210777282715,
"blob_id": "6e232612204a7a9a0886f8aa2d1caff7af496f0f",
"content_id": "81f730db0a4e42e32a30f092b838af3ae9e7431e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 19,
"path": "/source/clock.cpp",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#include \"clock.h\"\n\ndword timeStart = 0, timeEnd = 0;\n\nvoid StartClock(void)\n{\n\ttimeStart = timeGetTime();\n\ttimeEnd = timeStart;\n}\n\nvoid EndClock(void)\n{\n\ttimeEnd = timeGetTime();\n}\n\ndword TimeLength(void)\n{\n\treturn (timeEnd - timeStart);\n}\n"
},
{
"alpha_fraction": 0.6891322731971741,
"alphanum_fraction": 0.6916596293449402,
"avg_line_length": 20.196428298950195,
"blob_id": "571d45ba4feb97b59f462a6229b260622beec704",
"content_id": "7a8ef6b8edb220e89057228f2517b92462a4b7ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1187,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 56,
"path": "/source/jamulspr.h",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "#ifndef JAMULSPR_H\n#define JAMULSPR_H\n\n#include \"winpch.h\"\n#include \"mgldraw.h\"\n\nclass sprite_t\n{\npublic:\n\tsprite_t(void);\n\tsprite_t(byte *info);\n\n\t~sprite_t(void);\n\n\tbool LoadData(FILE *f);\n\tbool SaveData(FILE *f);\n\tvoid GetHeader(byte *buffer);\n\tvoid Draw(int x, int y, MGLDraw *mgl);\n\n\tvoid DrawBright(int x, int y, MGLDraw *mgl, char bright);\n\tvoid DrawColored(int x, int y, MGLDraw *mgl, byte color, char bright);\n\tvoid DrawOffColor(int x, int y, MGLDraw *mgl, byte fromColor, byte toColor, char bright);\n\tvoid DrawGhost(int x, int y, MGLDraw *mgl, char bright);\n\tvoid DrawGlow(int x, int y, MGLDraw *mgl, char bright);\n\n\t// this makes half-height tilted black shadows (they darken by 4)\n\tvoid DrawShadow(int x, int y, MGLDraw *mgl);\n\tvoid GetCoords(int x, int y, int *rx, int *ry, int *rx2, int *ry2);\n\n\tword width;\n\tword height;\n\tshort ofsx;\n\tshort ofsy;\n\tdword size;\n\tbyte *data;\n};\n\nclass sprite_set_t\n{\npublic:\n\tsprite_set_t(void);\n\tsprite_set_t(const char *fname);\n\n\t~sprite_set_t(void);\n\n\tbool Save(const char *fname);\n\tbool Load(const char *fname);\n\tvoid Free(void);\n\tsprite_t *GetSprite(int which);\n\tword GetCount(void);\nprotected:\n\tword count;\n\tsprite_t **spr;\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.6436464190483093,
"alphanum_fraction": 0.650276243686676,
"avg_line_length": 31.321428298950195,
"blob_id": "eead8a143151c4551ca0018f2ea5ed14003c9f63",
"content_id": "8300f6be6ab9d00335513ec4f215a7ae3c446263",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1810,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 56,
"path": "/SConstruct",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "# Dr. Lunatic SCons configuration script\n\nimport os\nimport platform\n\nLIBS = ['winmm', 'alleg44', 'ws2_32', 'logg', 'vorbisfile', 'vorbis', 'ogg', 'vorbisenc']\n\ndef getFileList(dir, ext):\n\tfor dirpath, dirnames, filenames in os.walk(dir):\n\t\tfor name in filenames:\n\t\t\tif 'old/' not in name and name.endswith(ext):\n\t\t\t\tyield os.path.join(dirpath, name)\n\ndef program(output, debug):\n\t# if we're on Windows, force Mingw use\n\tif platform.system() == 'Windows':\n\t\tenv = Environment(ENV = os.environ, tools = ['mingw'])\n\telse:\n\t\tenv = Environment(ENV = os.environ)\n\n\t# compiler\n\tenv.Append(CCFLAGS = ['-Wall', '-Wextra', '-Wno-unused-parameter', '-std=c++0x'])\n\tenv.Append(CPPPATH = ['include'])\n\tenv.Append(CPPDEFINES = ['ALLEGRO_MINGW32', 'EXPANDO'])\n\tif debug:\n\t\tenv.Append(CPPDEFINES = ['_DEBUG', 'LOG'])\n\t\tenv.Append(CCFLAGS = ['-g'])\n\telse:\n\t\tenv.Append(CPPDEFINES = ['NDEBUG'])\n\t\tenv.Append(CCFLAGS = ['-O2', '-s', '-mwindows'])\n\t\tenv.Append(LINKFLAGS = ['-O2', '-s'])\n\n\t# linker\n\tenv.Append(LINKFLAGS = ['-static-libgcc', '-static-libstdc++', '-std=c++11'])\n\tenv.Append(LIBPATH = ['include'])\n\tenv.Append(LIBS = LIBS)\n\n\t# output files\n\tobjects = []\n\tfor source in getFileList('source/', '.cpp'):\n\t\tobject = 'build/' + output + '/' + source.replace('.cpp', '.o')\n\t\tobjects.append(env.Object(target=object, source=source))\n\n\t# resources\n\tfor source in getFileList('source/', '.rc'):\n\t\tobject = 'build/' + output + '/' + source.replace('.rc', '.res')\n\t\tobjects.append(env.Command(object, source, 'windres ' + source + ' -O coff -o ' + object))\n\n\t# finish\n\toutputExe = 'bin/' + output + '.exe'\n\tresult = [env.Program(target=outputExe, source=objects)]\n\tresult.append(env.Install('game/', outputExe))\n\treturn Alias(output, result)\n\nlunatic = program('lunatic', False)\nlunatic_debug = program('lunatic_debug', True)\n"
},
{
"alpha_fraction": 0.6198729276657104,
"alphanum_fraction": 0.6499133706092834,
"avg_line_length": 18.233333587646484,
"blob_id": "c1a99f79e95fcfe6b4964bf178fa8a366511c01f",
"content_id": "0e28a8afffea51e574b69e5192e126c457ae892d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1731,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 90,
"path": "/tools/formats/lunatic_dlw.py",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "# lunatic_dlw.py - part of the Loonymod project\n# import this file and use the lunatic_dlw construct.\n\nfrom common import *\n\n# structures\n\nmonster = Struct(\"monster\",\n\tULInt8(\"x\"),\n\tULInt8(\"y\"),\n\tULInt8(\"type\")\n)\n\nspecial = Struct(\"special\",\n\tBitStruct(\"trigger\",\n\t\tFlag(\"shoot\"),\n\t\tFlag(\"haveBrains\"),\n\t\tFlag(\"killAll\"),\n\t\tFlag(\"haveKeychains\"),\n\t\tFlag(\"passedLevels\"),\n\t\tFlag(\"near\"),\n\t\tFlag(\"enemyStep\"),\n\t\tFlag(\"step\"),\n\t\tFlag(\"floorAt\"),\n\t\tFlag(\"killMonster\"),\n\t\tFlag(\"hasLoonyKey\"),\n\t\tFlag(\"randomChance\"),\n\t\tFlag(\"timer\"),\n\t\tFlag(\"chainAdjacent\"),\n\t\tFlag(\"showMessage\"),\n\t\tFlag(\"canRepeat\")\n\t),\n\tULInt8(\"triggerValue\"),\n\tULInt8(\"effect\"),\n\tULInt8(\"x\"),\n\tULInt8(\"y\"),\n\tULInt8(\"effectX\"),\n\tULInt8(\"effectY\"),\n\tPackedString(\"message\")\n)\n\nlevelTile = Struct(\"levelTile\",\n\tULInt8(\"floor\"),\n\tULInt8(\"wall\"),\n\tULInt8(\"item\"),\n\tSLInt8(\"light\"),\n\tSLInt8(\"tempLight\"),\n\tULInt8(\"opaque\")\n)\n\nlevel = Struct(\"level\",\n\tSLInt16(\"width\"),\n\tSLInt16(\"height\"),\n\tPackedString(\"name\"),\n\tRepeater(128, 128, monster),\n\tRepeater(32, 32, special),\n\tULInt8(\"song\"),\n\tULInt8(\"flags\"),\n\tMetaRepeater(lambda ctx: ctx[\"height\"],\n\t\tMetaRepeater(lambda ctx: ctx[\"width\"], levelTile)\n\t)\n)\n\ntileData = Struct(\"tileData\",\n\tBitStruct(\"flags\",\n\t\tFlag(\"animate\"),\n\t\tFlag(\"canpushon\"),\n\t\tFlag(\"pushable\"),\n\t\tFlag(\"lava\"),\n\t\tFlag(\"water\"),\n\t\tFlag(\"muddy\"),\n\t\tFlag(\"icy\"),\n\t\tFlag(\"impassible\"),\n\t\tPadding(3),\n\t\tFlag(\"bunnyPath\"),\n\t\tFlag(\"minecartPath\"),\n\t\tFlag(\"transparentRoof\"),\n\t\tFlag(\"animateHit\"),\n\t\tFlag(\"animateStep\"),\n\t),\n\tULInt8(\"nextTile\")\n)\n\nlunatic_dlw = Struct(\"world\",\n\tULInt8(\"levelCount\"),\n\tSLInt16(\"totalPoints\"),\n\tRepeater(400, 400, Field(\"tileImage\", 32*24)),\n\tRepeater(200, 200, tileData),\n\tMetaRepeater(lambda ctx: ctx[\"levelCount\"], level)\n)\n"
},
{
"alpha_fraction": 0.6184501647949219,
"alphanum_fraction": 0.6405904293060303,
"avg_line_length": 17.310810089111328,
"blob_id": "cbeed861458d8be24696da5c24ee3cf5437ff2af",
"content_id": "1607763117a5e4e6c382fb2f5311cb0c22dad9ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1355,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 74,
"path": "/source/main.cpp",
"repo_name": "retroric/Lunatic--SpaceManiac",
"src_encoding": "UTF-8",
"text": "/* DR. LUNATIC (working title)\n \n A HamumuSoft Production.\n\n v 0.04\n\n Copyright 1998, Mike Hommel\n */\n\n#include \"winpch.h\"\n#include \"mgldraw.h\"\n#include \"jamulfont.h\"\n#include \"jamulsound.h\"\n#include <shellapi.h>\n\n#include \"game.h\"\n#include \"editor.h\"\n#include \"tile.h\"\n#include \"sound.h\"\n#include \"monster.h\"\n#include \"title.h\"\n\nbool windowedGame = FALSE;\nMGLDraw *mainmgl;\n\nvoid parseCmdLine(char *cmdLine)\n{\n\tchar *token;\n\n\ttoken = strtok(cmdLine, \" \");\n\twhile (token != NULL)\n\t{\n\t\tif (!strcmp(token, \"window\"))\n\t\t\twindowedGame = TRUE;\n\t\ttoken = strtok(NULL, \" \");\n\t}\n}\n\nint PASCAL WinMain(HINSTANCE hInstance, HINSTANCE hPrevInstance, LPSTR cmdLine, int nCmdShow)\n{\n\tparseCmdLine(cmdLine);\n\tmainmgl = new MGLDraw(\"Dr. Lunatic\", 640, 480, windowedGame);\n\tif (!mainmgl)\n\t\treturn 0;\n\n\tLunaticInit(mainmgl);\n\tSplashScreen(mainmgl, \"graphics\\\\hamumu.bmp\", 128, 2);\n\n\twhile (1)\n\t{\n\t\tswitch (MainMenu(mainmgl)) {\n\t\t\tcase 255: // quit\n\t\t\t\tLunaticExit();\n\t\t\t\tdelete mainmgl;\n\t\t\t\treturn 0;\n\t\t\t\tbreak;\n\t\t\tcase 0: // new game\n\t\t\t\tLunaticGame(mainmgl, 0);\n\t\t\t\tbreak;\n\t\t\tcase 1: // continue\n\t\t\t\tLunaticGame(mainmgl, 1);\n\t\t\t\tbreak;\n\t\t\tcase 3: // editor\n\t\t\t\tLunaticEditor(mainmgl);\n\t\t\t\tbreak;\n\t\t\tcase 4: // ordering\n\t\t\t\tLunaticExit();\n\t\t\t\tdelete mainmgl;\n\t\t\t\tShellExecute(NULL, \"open\", \"docs\\\\order.html\", \"\", \"\", SW_SHOWNORMAL);\n\t\t\t\treturn 0;\n\t\t\t\tbreak;\n\t\t}\n\t}\n}\n"
}
] | 21 |
haondt/Echo | https://github.com/haondt/Echo | ffc733e8b8f0b2a6473263844d46eb2f3773ca4d | c92bb5d4dfc86d677a6c6f352568b3ff8c0df813 | 010b6aadd5a1207138bc1a82fda0518ad427f085 | refs/heads/master | 2020-04-09T16:41:39.382892 | 2019-01-03T02:17:30 | 2019-01-03T02:17:30 | 160,460,118 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7106918096542358,
"alphanum_fraction": 0.7704402804374695,
"avg_line_length": 27.909090042114258,
"blob_id": "5ce49c118cd427840b8daec8a0162ea6efa85791",
"content_id": "230f84b8d7b4e0b3cc35ab4d7378f99e23bff1ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 318,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 11,
"path": "/README.md",
"repo_name": "haondt/Echo",
"src_encoding": "UTF-8",
"text": "# Echo\nEcho is a Discord bot, written in Python that provides a variety of functions.\n\nToken should be stored in a single line file in the root directory called \"token.txt\"\n\n\n[Invite link](https://discordapp.com/api/oauth2/authorize?scope=bot&client_id=530116202069098496)\n\n### Requirements\n* discord.py\n* youtube\\_dl\n"
},
{
"alpha_fraction": 0.6926530599594116,
"alphanum_fraction": 0.6951020359992981,
"avg_line_length": 25.630434036254883,
"blob_id": "0a0377a2549ada719ba652bde46822a4a10cf44a",
"content_id": "6c744b8efe1fe55f431dbb751ecaefa3643882b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2450,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 92,
"path": "/main.py",
"repo_name": "haondt/Echo",
"src_encoding": "UTF-8",
"text": "# Echo is a Discord bot\n\nimport discord\n\nwith open('token.txt') as tokenfile:\n\ttoken = tokenfile.read().strip()\n\nclient = discord.Client()\n\n\[email protected]\nasync def on_ready():\n\tprint('Logged in as')\n\tprint(client.user.name)\n\tprint(client.user.id)\n\tprint('-'*10)\n\[email protected]\nasync def on_message(message):\n\n\t# don't let bot reply to itself\n\tif message.author != client.user:\n\t\ttext_channel = message.channel\n\t\tserver = message.server\n\t\tvoice_channel = message.author.voice.voice_channel\n\n\t\tif message.content.startswith('!hello'):\n\t\t\tawait client.send_message(text_channel, 'Moshi moshi')\n\t\t\treturn\n\t\t\n\t\telif message.content.startswith('!play'):\n\t\t\t# get the voice client for this server\n\t\t\tvoice_client = client.voice_client_in(server)\n\n\t\t\t# ensure user is in a voice and text channel\n\t\t\tif server == None or text_channel == None:\n\t\t\t\treturn\n\t\t\telif voice_channel == None:\n\t\t\t\tawait client.send_message(text_channel, 'You must be in a voice channel for me to play music')\n\t\t\t\treturn \n\n\t\t\t# check if client is already in a voice channel\n\t\t\tif client.is_voice_connected(server):\n\n\t\t\t\t# client is in a different voice channel\n\t\t\t\tif voice_client.channel != voice_channel:\n\t\t\t\t\tawait client.send_message(message.channel, 'I\\'m already ~~Tracer~~ in a different voice channel')\n\t\t\t\t\treturn\n\n\t\t\t# join users voice channel if not already in it\n\t\t\telse:\n\t\t\t\tvoice_client = await client.join_voice_channel(voice_channel)\n\t\t\t\n\t\t\t\n\t\t\t# ensure message includes a song title or url is valid\n\t\t\ttitle = message.content.split()\n\t\t\tif len(title) < 2:\n\t\t\t\treturn\n\t\t\ttitle = ' '.join(title[1:])\n\t\t\t\n\t\t\t# start player and/or add song to queue\n\t\t\tplayer = await voice_client.create_ytdl_player(title, after=playnext)\n\t\t\tprint(player.url)\n\t\t\tplayer.start()\n\n\t\t\tawait client.send_message(message.channel, 'Added %s to queue' % title)\n\ndef playnext(player):\n\tpass\n\t#play next song in queue\n\tprint(player.is_done())\n\tprint(player.is_playing())\n\tprint('test1')\n\tprint(player.error)\n\tprint('test')\n\n# leave voice channel if it is in there all by itself\[email protected]\nasync def on_voice_state_update(before, after):\n\tchannel = before.voice.voice_channel\n\tif channel != None:\n\t\tserver = channel.server\n\t\tif channel != None:\n\t\t\tif client.is_voice_connected(server):\n\t\t\t\tvoice_client = client.voice_client_in(server)\n\t\t\t\tif voice_client.channel == channel:\n\t\t\t\t\tif len(channel.voice_members) < 2:\n\t\t\t\t\t\tplayer = None\n\t\t\t\t\t\tawait voice_client.disconnect()\n\t\t\t\t\n\t\t\nclient.run(token)\n"
}
] | 2 |
Uneivi/hello-world | https://github.com/Uneivi/hello-world | 7c3c79f79db45b5ce6adb1d2bef57e1c14a8906f | a9f5038aa16b172c853a53c5c78771e599598d94 | 899c9c53bedeaf013be28a033d6ab980882906a0 | refs/heads/master | 2020-12-30T22:58:04.795021 | 2019-02-08T20:47:03 | 2019-02-08T20:47:03 | 80,650,378 | 0 | 0 | null | 2017-02-01T18:29:35 | 2017-02-01T18:29:35 | 2017-02-01T18:45:02 | null | [
{
"alpha_fraction": 0.6440422534942627,
"alphanum_fraction": 0.6500754356384277,
"avg_line_length": 30.619047164916992,
"blob_id": "097ece872a0d452ccb881232415d6fc1f694cc57",
"content_id": "290121e4dd5803d5e5766f38867d419f3bc94e5c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 668,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 21,
"path": "/indCount.py",
"repo_name": "Uneivi/hello-world",
"src_encoding": "UTF-8",
"text": "\"\"\"Módulo para a contagem do índice\"\"\"\n\ndef contagem(arranjo):\n tamArranjo = len(arranjo)\n for ind in range(tamArranjo):\n print(ind, arranjo[ind])\n\ndef maiorPalavra(listaDePalavras):\n \"\"\"Indendificará a maior palavra em uma lista com várias palavras\"\"\"\n\n maiorPalavra = listaDePalavras[0] #Inicia a primeira palavra da lista\n i = 0\n\n for palavra in listaDePalavras:\n if len(palavra) > len(maiorPalavra): # Compara a palavra atual com a próxima da lista, caso verdadeiro, substitui pela nova palavra\n maiorPalavra = palavra\n i += 1\n else:\n i += 1\n continue\n return maiorPalavra"
},
{
"alpha_fraction": 0.7867867946624756,
"alphanum_fraction": 0.7867867946624756,
"avg_line_length": 54.5,
"blob_id": "2db50db473763132dce071c8f4196933de1a32dd",
"content_id": "dbfb687a7aba4c475d18b41fec56e3e23fd85cdb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 340,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 6,
"path": "/README.md",
"repo_name": "Uneivi/hello-world",
"src_encoding": "UTF-8",
"text": "# hello-world\nPara guardar todas os códigos\nBem, eu sou o Marcelo. Estou 'começando' agora na programaço e pretendo me aprofundar.\nEstou aprendendo Python, apesar de já ter visto um pouco de Ruby e C++. Quero aprender\nbastante para me tornar um excelente programador e trabalhar com isso.\nBom, então vamos lá! Muito esforço pra mim!\n"
},
{
"alpha_fraction": 0.6469780206680298,
"alphanum_fraction": 0.6579670310020447,
"avg_line_length": 41.82352828979492,
"blob_id": "ff64decb29cef8dc457dbb07b22d64d51e1d90ff",
"content_id": "7ffe62722364e547975d368c1512f4df15b55518",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 17,
"path": "/marcacao.py",
"repo_name": "Uneivi/hello-world",
"src_encoding": "UTF-8",
"text": "import indCount\nCRED = '\\x1B[34;1m'\nCEND = '\\x1B[0m'\n\n\ndef destaqueRect(lista_nomes, simbolo_linha='*', simbolo='+'):\n '''Criará destaque sobre os nomes de entrada desenhando um quadrado'''\n\n tamanho_nome = indCount.maiorPalavra(lista_nomes)\n tamanhoLinha = (len(tamanho_nome) + 4) # O tamanho da linha será proporcional a maior palavra encontrada na lista.\n # simbolo_linha = '*'\n # simbolo = '+'\n print(simbolo_linha * tamanhoLinha)\n for nome in lista_nomes: # Ao entrar na lista, cada palavra será mostrada em sua linha, formatada.\n espaco = tamanhoLinha - len(nome) - 3\n print(f\"{simbolo + ' ' + CRED + nome + CEND + (' ' * espaco) + simbolo}\")\n print(simbolo_linha * tamanhoLinha)\n"
},
{
"alpha_fraction": 0.6110236048698425,
"alphanum_fraction": 0.6157480478286743,
"avg_line_length": 18.24242401123047,
"blob_id": "9089f0e9ec2875cfc7ea1df292544a3b06c76336",
"content_id": "a1d4fce1fac878ae1febd9a86450b89c8bbebc05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 635,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 33,
"path": "/nome.py",
"repo_name": "Uneivi/hello-world",
"src_encoding": "UTF-8",
"text": "nome = \"Marcelo augusto\"\n\ndef reverseWord(word):\n storeWord = ''\n for i in word:\n storeWord = i + storeWord\n\n return storeWord\n\nnome_revertido = reverseWord(nome)\nprint(nome_revertido)\n\nrevertido = reverseWord(nome_revertido)\nprint(revertido)\n\n\ntamPhrase = len(nome)\npalavra = ''\nlistaPalavra = []\ncounter = 0\nfor letter in nome:\n if letter != ' ':\n palavra = palavra + letter\n counter += 1\n elif letter == ' ' or counter < tamPhrase:\n print(letter)\n listaPalavra.append(palavra)\n palavra = ''\n counter += 1\n # else:\n # listaPalavra.append(palavra)\n\nprint(listaPalavra)\n"
}
] | 4 |
follow-thetime/arxivHelper | https://github.com/follow-thetime/arxivHelper | 0ea99dd209a624be10ac0a471c61848d81300488 | 44952a2a8820fa2756400d96cb6892385dd0ff2e | 709cf8fc9207251776bcba91af0e717a9f3d1d42 | refs/heads/main | 2023-08-04T06:38:17.953562 | 2021-09-12T20:04:47 | 2021-09-12T20:04:47 | 373,873,634 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5981523990631104,
"alphanum_fraction": 0.5989222526550293,
"avg_line_length": 26.19565200805664,
"blob_id": "b49ee33fe61e59c5e7c4c6db553686ee7a1cadf1",
"content_id": "f15ce1e40765a3bbd1df6ab345e9fb125efac4fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1299,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 46,
"path": "/autopush.py",
"repo_name": "follow-thetime/arxivHelper",
"src_encoding": "UTF-8",
"text": "from watchdog.observers import Observer\r\nfrom watchdog.events import *\r\nimport time\r\nimport os\r\n\r\n\r\ndef auto_push(change):\r\n os.chdir('./arxivPaperPage/')\r\n os.system('git add .')\r\n os.system('git commit -m\\\"auto' + change + '\\\"')\r\n os.system('git push origin gh-pages')\r\n\r\n\r\nclass FileEventHandler(FileSystemEventHandler):\r\n def __init__(self):\r\n FileSystemEventHandler.__init__(self)\r\n\r\n def on_moved(self, event):\r\n if not event.is_directory:\r\n auto_push(f\"file move from {event.src_path} to {event.dest_path}\")\r\n\r\n def on_created(self, event):\r\n if not event.is_directory:\r\n auto_push(f\"create file {event.src_path}\")\r\n\r\n def on_deleted(self, event):\r\n if not event.is_directory:\r\n auto_push(f\"delete file {event.src_path}\")\r\n\r\n def on_modified(self, event):\r\n if not event.is_directory:\r\n auto_push(f\"modify file {event.src_path}\")\r\n\r\n\r\nif __name__ == \"__main__\":\r\n observer = Observer()\r\n event_handler = FileEventHandler()\r\n dest_dir = './arxivPaperPage/_posts/'\r\n observer.schedule(event_handler, dest_dir, True)\r\n observer.start()\r\n try:\r\n while True:\r\n time.sleep(1)\r\n except KeyboardInterrupt:\r\n observer.stop()\r\n observer.join()\r\n\r\n"
},
{
"alpha_fraction": 0.7868852615356445,
"alphanum_fraction": 0.7868852615356445,
"avg_line_length": 29.5,
"blob_id": "cad6cf52fd4ace12497a52e73a8597906cd8139d",
"content_id": "cf5d11066adf2b5950c3cabe1f5ce6129be60c58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 2,
"path": "/README.md",
"repo_name": "follow-thetime/arxivHelper",
"src_encoding": "UTF-8",
"text": "# arxivHelper\na slack bot to help dealing with arxiv papers.\n"
},
{
"alpha_fraction": 0.38598304986953735,
"alphanum_fraction": 0.3903624415397644,
"avg_line_length": 38.9600715637207,
"blob_id": "92b6ebfb28d6029eb0f246fc1750606ac7ac48e9",
"content_id": "a30b5a66533804b92d40e26824c6ef326be7da2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 68731,
"license_type": "no_license",
"max_line_length": 305,
"num_lines": 1678,
"path": "/app.py",
"repo_name": "follow-thetime/arxivHelper",
"src_encoding": "UTF-8",
"text": "import os\r\nimport re\r\nimport time\r\nfrom slack_bolt import App\r\nfrom slack_bolt.oauth.oauth_settings import OAuthSettings\r\nfrom slack_sdk.oauth.installation_store import FileInstallationStore\r\nfrom slack_sdk.oauth.state_store import FileOAuthStateStore\r\nimport urllib.request\r\nimport feedparser\r\nimport pymysql\r\n\r\noauth_settings = OAuthSettings(\r\n client_id=os.environ[\"SLACK_CLIENT_ID\"],\r\n client_secret=os.environ[\"SLACK_CLIENT_SECRET\"],\r\n scopes=[\"app_mentions:read\", \"channels:history\", \"groups:history\", \"chat:write\", \"commands\", \"im:history\", \"im:read\",\r\n \"im:write\", \"incoming-webhook\", \"mpim:history\", \"mpim:read\", \"mpim:write\"],\r\n installation_store=FileInstallationStore(base_dir=\"./data\"),\r\n state_store=FileOAuthStateStore(expiration_seconds=600, base_dir=\"./data\")\r\n)\r\n\r\napp = App(\r\n # token=os.environ['SLACK_BOT_TOKEN'],\r\n signing_secret=os.environ[\"SLACK_SIGNING_SECRET\"],\r\n oauth_settings=oauth_settings\r\n)\r\n\r\nurl_Reg = r\"https://arxiv.org/abs/([\\w.]+)\"\r\nlast_Message = ''\r\n\r\n\r\ndef get_feed(query):\r\n base_url = 'http://export.arxiv.org/api/query?'\r\n feedparser._FeedParserMixin.namespaces['http://a9.com/-/spec/opensearch/1.1/'] = 'opensearch'\r\n feedparser._FeedParserMixin.namespaces['http://arxiv.org/schemas/atom'] = 'arxiv'\r\n response = urllib.request.urlopen(base_url + query).read()\r\n feed = feedparser.parse(response)\r\n return feed\r\n\r\n\r\ndef get_links_from_feed(feed, max_link_num):\r\n papers = []\r\n for entry in feed.entries:\r\n paper_title = entry.title.replace('\\n', '').replace('\\r', '')\r\n paper_title = '['+paper_title+']'\r\n for link in entry.links:\r\n if link.rel == 'alternate':\r\n link = '('+link.href+')'\r\n papers.append(paper_title+link)\r\n papers = papers[0:max_link_num]\r\n return papers\r\n\r\n\r\ndef new_for_user(arxiv_id, user):\r\n connect = pymysql.connect(host='localhost', port=3306, user='root', passwd='mysql1999',\r\n database='arxivurls', charset='utf8')\r\n cursor = connect.cursor()\r\n count = cursor.execute(f\"select users from post where arxivid='{arxiv_id}'\")\r\n if count == 0:\r\n cursor.close()\r\n connect.close()\r\n return 1\r\n else:\r\n users = cursor.fetchone()[0]\r\n if user not in users:\r\n cursor.close()\r\n connect.close()\r\n return 2\r\n cursor.close()\r\n connect.close()\r\n return 0\r\n\r\n\r\ndef no_past_tag(arxiv_id, user, username, tags):\r\n if tags:\r\n connect = pymysql.connect(host='localhost', port=3306, user='root', passwd='mysql1999', database='arxivurls',\r\n charset='utf8')\r\n cursor = connect.cursor()\r\n cursor.execute(f\"select postname from post where arxivid='{arxiv_id}'\")\r\n post_name = cursor.fetchone()[0]\r\n post_path = \"./arxivPaperPage/_posts/\" + post_name\r\n tag_input = tags + f'  -assigned by {username}\\n'\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n tag_tab = re.search('Comments:', content)\r\n tag_position = tag_tab.span()[0]\r\n with open(post_path, 'w') as f:\r\n content = content[:tag_position] + tag_input + content[tag_position:]\r\n f.write(content)\r\n cursor.execute(f\"update userinput set tags='{tags}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n connect.commit()\r\n cursor.close()\r\n connect.close()\r\n\r\n\r\ndef no_past_comment(arxiv_id, user, username, comment):\r\n if comment:\r\n connect = pymysql.connect(host='localhost', port=3306, user='root', passwd='mysql1999', database='arxivurls',\r\n charset='utf8')\r\n cursor = connect.cursor()\r\n cursor.execute(f\"select postname from post where arxivid='{arxiv_id}'\")\r\n post_name = cursor.fetchone()[0]\r\n post_path = \"./arxivPaperPage/_posts/\" + post_name\r\n comment_input = f'comment from {username}:\\n  ' + comment + '\\n'\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n comment_tab = re.search('Title:', content)\r\n comment_pos = comment_tab.span()[0]\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:comment_pos] + comment_input + content[comment_pos:]\r\n f.write(content)\r\n cursor.execute(f\"update userinput set comment='{comment}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n connect.commit()\r\n cursor.close()\r\n connect.close()\r\n\r\n\r\ndef add_new_input(arxiv_id, user, username, tags, comment):\r\n connect = pymysql.connect(host='localhost', port=3306, user='root', passwd='mysql1999', database='arxivurls',\r\n charset='utf8')\r\n cursor = connect.cursor()\r\n cursor.execute(f\"select postname from post where arxivid='{arxiv_id}'\")\r\n post_name = cursor.fetchone()[0]\r\n post_path = \"./arxivPaperPage/_posts/\" + post_name\r\n post_time = time.strftime(\"%Y-%m-%d\", time.localtime())\r\n tag_input = tags + f'  -assigned by {username}\\n'\r\n comment_input = f'comment from {username}:\\n  ' + comment + '\\n'\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n tag_tab = re.search('Comments:', content)\r\n tag_position = tag_tab.span()[0]\r\n comment_tab = re.search('Title:', content)\r\n comment_pos = comment_tab.span()[0]\r\n if tags and comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:tag_position] + tag_input + content[tag_position:comment_pos] + \\\r\n comment_input + content[comment_pos:]\r\n f.write(content)\r\n elif tags and not comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:tag_position] + tag_input + content[tag_position:]\r\n f.write(content)\r\n elif not tags and comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:comment_pos] + comment_input + content[comment_pos:]\r\n f.write(content)\r\n cursor.execute(f\"select users from post where arxivid='{arxiv_id}'\")\r\n users = cursor.fetchone()[0]\r\n cursor.execute(f\"update post set users='{users}, {user}' where arxivid='{arxiv_id}'\")\r\n cursor.execute(f\"insert into userinput values('{arxiv_id}','{user}','{post_time}','{tags}','{comment}')\")\r\n connect.commit()\r\n cursor.close()\r\n connect.close()\r\n\r\n\r\ndef rewrite_past_input(arxiv_id, user, username, tags, comment):\r\n connect = pymysql.connect(host='localhost', port=3306, user='root', passwd='mysql1999', database='arxivurls',\r\n charset='utf8')\r\n cursor = connect.cursor()\r\n cursor.execute(f\"select postname from post where arxivid='{arxiv_id}'\")\r\n post_name = cursor.fetchone()[0]\r\n post_path = \"./arxivPaperPage/_posts/\" + post_name\r\n cursor.execute(f\"select tags from userinput where arxivid='{arxiv_id}' and user='{user}'\")\r\n past_tag = cursor.fetchone()[0]\r\n cursor.execute(f\"select comment from userinput where arxivid='{arxiv_id}' and user='{user}'\")\r\n past_comment = cursor.fetchone()[0]\r\n post_time = time.strftime(\"%Y-%m-%d\", time.localtime())\r\n if not past_tag and not past_comment:\r\n no_past_tag(arxiv_id, user, username, tags)\r\n no_past_comment(arxiv_id, user, username, comment)\r\n elif not past_tag and past_comment:\r\n no_past_tag(arxiv_id, user, username, tags)\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n if comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n temp = re.sub(past_comment, comment, content)\r\n f.write(temp)\r\n cursor.execute(f\"update userinput set comment='{comment}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n elif past_tag and not past_comment:\r\n no_past_comment(arxiv_id, user, username, comment)\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n if tags:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n temp = re.sub(past_tag, tags, content)\r\n f.write(temp)\r\n cursor.execute(f\"update userinput set tags='{tags}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n elif past_tag and past_comment:\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n if tags and comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n temp1 = re.sub(past_tag, tags, content)\r\n temp2 = re.sub(past_comment, comment, temp1)\r\n f.write(temp2)\r\n elif tags and not comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n temp = re.sub(past_tag, tags, content)\r\n f.write(temp)\r\n elif not tags and comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n temp = re.sub(past_comment, comment, content)\r\n f.write(temp)\r\n if tags:\r\n cursor.execute(f\"update userinput set tags='{tags}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n if comment:\r\n cursor.execute(f\"update userinput set comment='{comment}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n cursor.execute(f\"update userinput set posttime='{post_time}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n connect.commit()\r\n cursor.close()\r\n connect.close()\r\n\r\n\r\ndef append_past_input(arxiv_id, user, username, tags, comment):\r\n connect = pymysql.connect(host='localhost', port=3306, user='root', passwd='mysql1999', database='arxivurls',\r\n charset='utf8')\r\n cursor = connect.cursor()\r\n cursor.execute(f\"select postname from post where arxivid='{arxiv_id}'\")\r\n post_name = cursor.fetchone()[0]\r\n post_path = \"./arxivPaperPage/_posts/\" + post_name\r\n cursor.execute(f\"select tags from userinput where arxivid='{arxiv_id}' and user='{user}'\")\r\n past_tag = cursor.fetchone()[0]\r\n new_tag = past_tag + ', ' + tags\r\n cursor.execute(f\"select comment from userinput where arxivid='{arxiv_id}' and user='{user}'\")\r\n past_comment = cursor.fetchone()[0]\r\n post_time = time.strftime(\"%Y-%m-%d\", time.localtime())\r\n comment_input = f'added on {post_time}:\\n  ' + comment\r\n new_comment = past_comment + '\\n' + comment_input\r\n if not past_tag and not past_comment:\r\n no_past_tag(arxiv_id, user, username, tags)\r\n no_past_comment(arxiv_id, user, username, comment)\r\n elif not past_tag and past_comment:\r\n no_past_tag(arxiv_id, user, username, tags)\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n comment_tab = re.search(past_comment + '\\n', content)\r\n comment_pos = comment_tab.span()[1]\r\n if comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:comment_pos] + comment_input + '\\n' + content[comment_pos:]\r\n f.write(content)\r\n cursor.execute(f\"update userinput set comment='{new_comment}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n elif past_tag and not past_comment:\r\n no_past_comment(arxiv_id, user, username, comment)\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n tag_tab = re.search(past_tag, content)\r\n tag_position = tag_tab.span()[1]\r\n if tags:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:tag_position] + ', ' + tags + content[tag_position:]\r\n f.write(content)\r\n cursor.execute(f\"update userinput set tags='{new_tag}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n elif past_tag and past_comment:\r\n with open(post_path, 'r', encoding='utf-8') as fp:\r\n content = fp.read()\r\n tag_tab = re.search(past_tag, content)\r\n tag_position = tag_tab.span()[1]\r\n comment_tab = re.search(past_comment+'\\n', content)\r\n comment_pos = comment_tab.span()[1]\r\n if tags and comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:tag_position] + ', ' + tags + content[tag_position:comment_pos] + \\\r\n comment_input + '\\n' + content[comment_pos:]\r\n f.write(content)\r\n elif tags and not comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:tag_position] + ', ' + tags + content[tag_position:]\r\n f.write(content)\r\n elif not tags and comment:\r\n with open(post_path, 'w', encoding='utf-8') as f:\r\n content = content[:comment_pos] + comment_input + '\\n' + content[comment_pos:]\r\n f.write(content)\r\n if tags:\r\n cursor.execute(f\"update userinput set tags='{new_tag}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n if comment:\r\n cursor.execute(f\"update userinput set comment='{new_comment}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n cursor.execute(f\"update userinput set posttime='{post_time}' where arxivid='{arxiv_id}' and user='{user}'\")\r\n connect.commit()\r\n cursor.close()\r\n connect.close()\r\n\r\n\r\ndef window_filename(name):\r\n name = name.strip().replace('\\n', '').replace('\\r', '')\r\n name = name.replace('\\\\', '')\r\n name = name.replace('/', '')\r\n name = name.replace('<', '')\r\n name = name.replace('>', '')\r\n name = name.replace('?', '')\r\n name = name.replace('*', '')\r\n name = name.replace('\"', '')\r\n name = name.replace(':', '')\r\n name = name.replace('|', '')\r\n return name\r\n\r\n\r\ndef create_post(arxiv_id, user, username, tags, comment):\r\n connect = pymysql.connect(host='localhost', port=3306, user='root', passwd='mysql1999', database='arxivurls', charset='utf8')\r\n cursor = connect.cursor()\r\n post_time = time.strftime(\"%Y-%m-%d\", time.localtime())\r\n post_url = 'https://arxiv.org/abs/' + arxiv_id\r\n query = 'id_list=%s' % arxiv_id\r\n feed = get_feed(query)\r\n entry = feed.entries[0]\r\n title = entry.title\r\n authors = ''\r\n try:\r\n authors = ', '.join(author.name for author in entry.authors)\r\n except AttributeError:\r\n pass\r\n tag_list = [t['term'] for t in entry.tags]\r\n suggested_tag = ', '.join(tag_list)\r\n summary = entry.summary\r\n summary = summary.replace('\\r', '').replace('\\n', '')\r\n title_name = window_filename(title)\r\n post_name = post_time + \"-\" + f'{title_name}.md'\r\n post_path = \"./arxivPaperPage/_posts/\" + post_name\r\n last_author = authors.split(',')[-1].strip().replace(' ', '+')\r\n query1 = f'search_query=au:{last_author}&start=0&max_result=5'\r\n feed = get_feed(query1)\r\n relevant1 = get_links_from_feed(feed, 5)\r\n r1 = '\\n '.join(link for link in relevant1)\r\n r1 = ' ' + r1\r\n r2 = ''\r\n if tags:\r\n relevant2 = []\r\n tag_list = [tag.strip() for tag in tags.split(',')]\r\n each_max = 1 if len(tag_list) > 5 else int(6 / len(tag_list))\r\n try:\r\n for tag in tag_list:\r\n query = f'search_query=cat:{tag}&start=0&max_result={each_max}'\r\n feed = get_feed(query)\r\n relevant2.extend(get_links_from_feed(feed, each_max))\r\n r2 = '\\n '.join(link for link in relevant2)\r\n except:\r\n pass\r\n else:\r\n relevant2 = []\r\n tag_list = [tag.strip() for tag in suggested_tag.split(',')]\r\n each_max = 1 if len(tag_list) > 5 else int(6 / len(tag_list))\r\n for tag in tag_list:\r\n query = f'search_query=cat:{tag}&start=0&max_result={each_max}'\r\n feed = get_feed(query)\r\n relevant2.extend(get_links_from_feed(feed, each_max))\r\n r2 = '\\n '.join(link for link in relevant2)\r\n r2 = ' ' + r2\r\n tag_in_post = ''\r\n comment_in_post = ''\r\n if tags:\r\n tag_in_post = f'{tags}  -assigned by {username}'\r\n if comment:\r\n comment_in_post = f'comment from {username}:\\n  {comment} '\r\n post_data = \\\r\nf'''\r\n---\r\nlayout: post\r\n---\r\nUrl of paper: {post_url}\r\nposted by: {username}\r\nTags:\\n{tag_in_post}\r\nComments:\\n{comment_in_post}\r\nTitle:{title}\r\nAbstract:{summary}\r\nRelevant papers:\r\npapers from the same last author:\r\n{r1}\r\npapers of similar category(tag):\r\n{r2}'''\r\n with open(post_path, 'w', encoding='utf-8') as fp:\r\n fp.write(post_data)\r\n cursor.execute(f\"insert into post values(default,'{arxiv_id}','{post_time}','{user}','{post_name}')\")\r\n cursor.execute(f\"insert into userinput values('{arxiv_id}','{user}','{post_time}','{tags}','{comment}')\")\r\n connect.commit()\r\n cursor.close()\r\n connect.close()\r\n\r\n\r\[email protected](\"app_home_opened\")\r\ndef home_opened(client, event, logger):\r\n try:\r\n client.views_publish(\r\n user_id=event['user'],\r\n view={\r\n \"type\": \"home\",\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"welcome home!\",\r\n \"emoji\": True\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"mrkdwn\",\r\n \"text\": \"Thanks for using arxivHelper, this is a slack bot to help you deal with arXiv urls, and there is a static web site(https://follow-thetime.github.io/arxivPaperPage/) to store interesting urls posted by users during the usage of this bot.\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"You can use this bot by easily typing the url of the arxiv paper that interests you to any channel this bot was added to, then follow the guidance and do what you want. Or you can use slash commands. For more instructions, you can type '@arxivHelper' in the channel.\",\r\n \"emoji\": True\r\n }\r\n },\r\n {\r\n \"type\": \"context\",\r\n \"elements\": [\r\n {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Version: 1.0\",\r\n \"emoji\": True\r\n }\r\n ]\r\n },\r\n {\r\n \"type\": \"context\",\r\n \"elements\": [\r\n {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Author: Sheng Guo\",\r\n \"emoji\": True\r\n }\r\n ]\r\n },\r\n {\r\n \"type\": \"context\",\r\n \"elements\": [\r\n {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Email: [email protected]\",\r\n \"emoji\": True\r\n }\r\n ]\r\n }\r\n ]\r\n }\r\n )\r\n except Exception as e:\r\n logger.error(f\"Error publishing home tab: {e}\")\r\n\r\n\r\[email protected](\"app_mention\")\r\ndef app_mention(ack, body, say):\r\n ack()\r\n say({\"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Hello <@{body['event']['user']}>!\",\r\n \"emoji\": True\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"mrkdwn\",\r\n \"text\": \"This is a slcak bot to help you deal with arXiv urls, and there is a static web site(https://follow-thetime.github.io/arxivPaperPage/) to store interesting urls posted by you during the usage of this bot.\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"You can use this bot by typing an url of arxiv paper, or you can use slash commands:\",\r\n \"emoji\": True\r\n }\r\n },\r\n {\r\n \"type\": \"context\",\r\n \"elements\": [\r\n {\r\n \"type\": \"mrkdwn\",\r\n \"text\": \"By using */post (url you want to post)</font>* you can simply post an url to the web site;\"\r\n }\r\n ]\r\n },\r\n {\r\n \"type\": \"context\",\r\n \"elements\": [\r\n {\r\n \"type\": \"mrkdwn\",\r\n \"text\": \"By using */tag (tags you assign to the paper) (url you want to post)* you can post an url with tags to the web site; if you had assigned tags to it before, it will cover the past tags;\"\r\n }\r\n ]\r\n },\r\n {\r\n \"type\": \"context\",\r\n \"elements\": [\r\n {\r\n \"type\": \"mrkdwn\",\r\n \"text\": \"By using */comment (comments you write for the paper) (url you want to post)* you can post an url with comments to the web site; also you may cover your past comment;\"\r\n }\r\n ]\r\n },\r\n {\r\n \"type\": \"context\",\r\n \"elements\": [\r\n {\r\n \"type\": \"mrkdwn\",\r\n \"text\": \"By using */comtag (tags) (url) (comments)* you can post an url with tags and comments to the web site; also you may cover the past content;\"\r\n }\r\n ]\r\n },\r\n {\r\n \"type\": \"context\",\r\n \"elements\": [\r\n {\r\n \"type\": \"plain_text\",\r\n \"text\": \"If you want to add something to your past input, please type the url in the channel.\",\r\n \"emoji\": True\r\n }\r\n ]\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"For more information, please go to app home page.\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]})\r\n\r\n\r\[email protected](url_Reg)\r\ndef message_url(message, say):\r\n global last_Message\r\n last_Message = message['text']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n user = message['user']\r\n if new_for_user(arxiv_id, user) == 1:\r\n say({\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"It looks like there is a new url that never appears before!\"\r\n \"Click the button to deal with it: \"\r\n },\r\n \"accessory\": {\r\n \"type\": \"button\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"click me\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"click_me_123\",\r\n \"action_id\": \"new_url_dealing\"\r\n }\r\n }\r\n ]\r\n })\r\n elif new_for_user(arxiv_id, user) == 0:\r\n say({\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"It seems that you had dealt with this paper before!\"\r\n \"Click the button to make some changes: \"\r\n },\r\n \"accessory\": {\r\n \"type\": \"button\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"click me\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"click_me_123\",\r\n \"action_id\": \"old_url_dealing\"\r\n }\r\n }\r\n ]\r\n })\r\n else:\r\n say({\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"It looks like someone had dealt with this paper before!\"\r\n \"Click the button to join him(her): \"\r\n },\r\n \"accessory\": {\r\n \"type\": \"button\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"click me\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"click_me_123\",\r\n \"action_id\": \"new_url_dealing\"\r\n }\r\n }\r\n ]\r\n })\r\n\r\n\r\[email protected]('new_url_dealing')\r\ndef deal_item(ack, body, client, say):\r\n ack()\r\n if re.search(url_Reg, last_Message):\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"new_checkbox_view\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"deal with arxiv url\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"block_id\": \"checkbox_block\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Choose what you'd like to do with the url :\"\r\n },\r\n \"accessory\": {\r\n \"type\": \"checkboxes\",\r\n \"action_id\": \"checkBox\",\r\n \"initial_options\": [\r\n {\r\n \"value\": \"value-0\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"post it\"\r\n },\r\n \"description\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"if you do not post it, other behaviors might be meaningless!\",\r\n \"emoji\": True\r\n }\r\n }\r\n ],\r\n \"options\": [\r\n {\r\n \"value\": \"value-0\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"post it\"\r\n },\r\n \"description\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"if you do not post it, other behaviors might be meaningless!\",\r\n \"emoji\": True\r\n }\r\n },\r\n {\r\n \"value\": \"value-1\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"add tags\"\r\n }\r\n },\r\n {\r\n \"value\": \"value-2\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"add comments\"\r\n }\r\n }\r\n ]\r\n }\r\n }\r\n ]\r\n }\r\n )\r\n else:\r\n say('please type an arxiv url you want to deal with to start!')\r\n\r\n\r\[email protected]('old_url_dealing')\r\ndef old_url_dealing(ack, body, client):\r\n ack()\r\n if re.search(url_Reg, last_Message):\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"old_checkbox_view\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Make some changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"block_id\": \"tag_radio_block\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"About tags:\"\r\n },\r\n \"accessory\": {\r\n \"type\": \"radio_buttons\",\r\n \"options\": [\r\n {\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"reassign tags\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"value-0\"\r\n },\r\n {\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"add another tag or several new tags\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"value-1\"\r\n },\r\n {\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"keep the same and don't make changes\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"value-2\"\r\n }\r\n ],\r\n \"action_id\": \"tag_choice\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"block_id\": \"comment_radio_block\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"About comments:\"\r\n },\r\n \"accessory\": {\r\n \"type\": \"radio_buttons\",\r\n \"options\": [\r\n {\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"rewrite your comments\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"value-0\"\r\n },\r\n {\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"add a new comment\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"value-1\"\r\n },\r\n {\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"keep the same and don't make changes\",\r\n \"emoji\": True\r\n },\r\n \"value\": \"value-2\"\r\n }\r\n ],\r\n \"action_id\": \"comment_choice\"\r\n }\r\n }\r\n ]\r\n }\r\n )\r\n\r\n\r\[email protected]('new_checkbox_view')\r\ndef get_user_input(ack, view, body, client):\r\n ack()\r\n print(body)\r\n selected = view[\"state\"][\"values\"][\"checkbox_block\"][\"checkBox\"][\"selected_options\"]\r\n selected_options = [x[\"value\"] for x in selected]\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n query = 'id_list=%s' % arxiv_id\r\n feed = get_feed(query)\r\n entry = feed.entries[0]\r\n title = entry.title.replace('\\r', '').replace('\\n', '')\r\n authors = ''\r\n try:\r\n authors = ', '.join(author.name for author in entry.authors)\r\n except AttributeError:\r\n pass\r\n try:\r\n arxiv_comment = entry.arxiv_comment.replace('\\r', '').replace('\\n', '')\r\n except AttributeError:\r\n arxiv_comment = 'No comment found'\r\n tag_list = [t['term'] for t in entry.tags]\r\n suggested_tag = ', '.join(tag_list)\r\n summary = entry.summary\r\n summary = summary.replace('\\r', '').replace('\\n', '')\r\n if \"value-0\" in selected_options:\r\n if \"value-1\" in selected_options and \"value-2\" in selected_options:\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"both_input_view\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"deal with arxiv url\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Title of the paper:\\n {title}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Authors:\\n {authors}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Arxiv's comment:\\n{arxiv_comment}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Abstract:\\n{summary}\"\r\n }\r\n },\r\n {\r\n \"type\": \"divider\"\r\n },\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_1\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"action_id\": \"tag_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"assign a tag or several tags for it(suggested ones:{suggested_tag}):\",\r\n \"emoji\": True\r\n },\r\n },\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_2\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"multiline\": True,\r\n \"action_id\": \"comment_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"write down your comment about it:\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]\r\n })\r\n elif \"value-1\" in selected_options and \"value-2\" not in selected_options:\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"tag_input_view\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"deal with arxiv url\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Title of the paper:\\n {title}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Authors:\\n {authors}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Arxiv's comment:\\n{arxiv_comment}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Abstract:\\n{summary}\"\r\n }\r\n },\r\n {\r\n \"type\": \"divider\"\r\n },\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_1\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"action_id\": \"tag_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"assign a tag or several tags for it(suggested ones: {suggested_tag}):\",\r\n \"emoji\": True\r\n },\r\n }\r\n ]\r\n })\r\n elif \"value-1\" not in selected_options and \"value-2\" in selected_options:\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"comment_input_view\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"deal with arxiv url\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Title of the paper:\\n {title}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Authors:\\n {authors}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Arxiv's comment:\\n{arxiv_comment}\"\r\n }\r\n },\r\n {\r\n \"type\": \"section\",\r\n \"text\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"Abstract:\\n{summary}\"\r\n }\r\n },\r\n {\r\n \"type\": \"divider\"\r\n },\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_2\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"multiline\": True,\r\n \"action_id\": \"comment_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"write down your comment about it:\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]\r\n })\r\n else:\r\n user = body['user']['id']\r\n if new_for_user(arxiv_id,user) == 1:\r\n username = body['user']['username']\r\n create_post(arxiv_id, user, username, \"\", \"\")\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have posted this url to the web page!\"\r\n )\r\n\r\n\r\[email protected](\"both_input_view\")\r\ndef both_deal(ack, body, view, client):\r\n ack()\r\n print(body)\r\n tags = view['state']['values']['input_block_1'][\"tag_input\"]['value']\r\n comments = view['state']['values']['input_block_2']['comment_input']['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n if new_for_user(arxiv_id, user) == 1:\r\n create_post(arxiv_id, user, tags, username, comments)\r\n elif new_for_user(arxiv_id, user) == 2:\r\n add_new_input(arxiv_id, user, tags, username, comments)\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have posted this url,tags and comments to the web page!\"\r\n )\r\n\r\n\r\[email protected](\"tag_input_view\")\r\ndef tag_deal(ack, body, view, client):\r\n ack()\r\n tags = view['state']['values']['input_block_1'][\"tag_input\"]['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n if new_for_user(arxiv_id, user) == 1:\r\n create_post(arxiv_id, user, username, tags, '')\r\n elif new_for_user(arxiv_id, user) == 2:\r\n add_new_input(arxiv_id, user, username, tags, '')\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have posted this url and tags to the web page!\"\r\n )\r\n\r\n\r\[email protected](\"comment_input_view\")\r\ndef comment_deal(ack, body, view, client):\r\n ack()\r\n comments = view['state']['values']['input_block_2']['comment_input']['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n if new_for_user(arxiv_id, user) == 1:\r\n create_post(arxiv_id, user, username, '', comments)\r\n elif new_for_user(arxiv_id, user) == 2:\r\n add_new_input(arxiv_id, user, username, '', comments)\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have posted this url and your comment to the web page!\"\r\n )\r\n\r\n\r\[email protected]('old_checkbox_view')\r\ndef get_user_input(ack, view, body, client):\r\n ack()\r\n tag_value = view[\"state\"][\"values\"][\"tag_radio_block\"][\"tag_choice\"][\"selected_option\"][\"value\"]\r\n comment_value = view[\"state\"][\"values\"][\"comment_radio_block\"][\"comment_choice\"][\"selected_option\"][\"value\"]\r\n connect = pymysql.connect(host='localhost', port=3306, user='root', passwd='mysql1999', database='arxivurls',\r\n charset='utf8')\r\n cursor = connect.cursor()\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n user = body['user']['id']\r\n cursor.execute(f\"select tags from userinput where arxivid='{arxiv_id}' and user='{user}'\")\r\n past_tags = cursor.fetchone()[0]\r\n if not past_tags:\r\n past_tags = \"you hadn't assigned any tags to this url.\"\r\n else:\r\n past_tags = f\"last time you assigned:{past_tags} to this url.\"\r\n cursor.execute(f\"select comment from userinput where arxivid='{arxiv_id}' and user='{user}'\")\r\n past_comment = cursor.fetchone()[0]\r\n if not past_comment:\r\n past_comment = \"you hadn't writen any comment for this url.\"\r\n else:\r\n past_comment = f\"your comment last time is:{past_comment}\"\r\n if tag_value == 'value-0' and comment_value == 'value-0':\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"view00\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"make changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_1\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"action_id\": \"tag_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"reassign a tag or several tags({past_tags}):\",\r\n \"emoji\": True\r\n },\r\n },\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_2\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"multiline\": True,\r\n \"action_id\": \"comment_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"rewrite your comment({past_comment}):\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]\r\n })\r\n elif tag_value == 'value-0' and comment_value == 'value-1':\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"view01\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"make changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_1\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"action_id\": \"tag_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"reassign a tag or several tags({past_tags}):\",\r\n \"emoji\": True\r\n },\r\n },\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_2\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"multiline\": True,\r\n \"action_id\": \"comment_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"add another comment({past_comment}):\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]\r\n })\r\n elif tag_value == 'value-0' and comment_value == 'value-2':\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"view02\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"make changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_1\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"action_id\": \"tag_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"reassign a tag or several tags({past_tags}):\",\r\n \"emoji\": True\r\n },\r\n }\r\n ]\r\n })\r\n elif tag_value == 'value-1' and comment_value == 'value-0':\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"view10\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"make changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_1\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"action_id\": \"tag_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"add another tag or several tags({past_tags}):\",\r\n \"emoji\": True\r\n },\r\n },\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_2\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"multiline\": True,\r\n \"action_id\": \"comment_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"rewrite your comment({past_comment}):\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]\r\n })\r\n elif tag_value == 'value-1' and comment_value == 'value-1':\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"both_add\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"make changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_1\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"action_id\": \"tag_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"add another tag or several tags({past_tags}):\",\r\n \"emoji\": True\r\n },\r\n },\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_2\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"multiline\": True,\r\n \"action_id\": \"comment_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"add another comment({past_comment}):\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]\r\n })\r\n elif tag_value == 'value-1' and comment_value == 'value-2':\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"view02\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"make changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_1\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"action_id\": \"tag_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"add another tag or several tags({past_tags}):\",\r\n \"emoji\": True\r\n },\r\n }\r\n ]\r\n })\r\n elif tag_value == 'value-2' and comment_value == 'value-0':\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"view20\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"make changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_2\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"multiline\": True,\r\n \"action_id\": \"comment_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"rewrite your comment({past_comment}):\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]\r\n })\r\n elif tag_value == 'value-2' and comment_value == 'value-1':\r\n client.views_open(\r\n trigger_id=body[\"trigger_id\"],\r\n view={\r\n \"type\": \"modal\",\r\n \"callback_id\": \"view21\",\r\n \"title\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"make changes\",\r\n \"emoji\": True\r\n },\r\n \"submit\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Submit\",\r\n \"emoji\": True\r\n },\r\n \"close\": {\r\n \"type\": \"plain_text\",\r\n \"text\": \"Cancel\",\r\n \"emoji\": True\r\n },\r\n \"blocks\": [\r\n {\r\n \"type\": \"input\",\r\n \"block_id\": \"input_block_2\",\r\n \"element\": {\r\n \"type\": \"plain_text_input\",\r\n \"multiline\": True,\r\n \"action_id\": \"comment_input\"\r\n },\r\n \"label\": {\r\n \"type\": \"plain_text\",\r\n \"text\": f\"add another comment({past_comment}):\",\r\n \"emoji\": True\r\n }\r\n }\r\n ]\r\n })\r\n else:\r\n pass\r\n cursor.close()\r\n connect.close()\r\n\r\n\r\[email protected](\"view00\")\r\ndef view00(ack, body, view, client):\r\n ack()\r\n tags = view['state']['values']['input_block_1'][\"tag_input\"]['value']\r\n comment = view['state']['values']['input_block_2']['comment_input']['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n rewrite_past_input(arxiv_id, user, username, tags, comment)\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have successfully reassigned tags and rewriten your comment!\"\r\n )\r\n\r\n\r\[email protected](\"view01\")\r\ndef view00(ack, body, view, client):\r\n ack()\r\n tags = view['state']['values']['input_block_1'][\"tag_input\"]['value']\r\n comment = view['state']['values']['input_block_2']['comment_input']['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n rewrite_past_input(arxiv_id, user, username, tags, '')\r\n append_past_input(arxiv_id, user, username, '', comment)\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have successfully reassigned tags and added a new comment!\"\r\n )\r\n\r\n\r\[email protected](\"view02\")\r\ndef view00(ack, body, view, client):\r\n ack()\r\n tags = view['state']['values']['input_block_1'][\"tag_input\"]['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n rewrite_past_input(arxiv_id, user, username, tags, '')\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have successfully reassigned tags to the url!\"\r\n )\r\n\r\n\r\[email protected](\"view10\")\r\ndef view00(ack, body, view, client):\r\n ack()\r\n tags = view['state']['values']['input_block_1'][\"tag_input\"]['value']\r\n comment = view['state']['values']['input_block_2']['comment_input']['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n append_past_input(arxiv_id, user, username, tags, '')\r\n rewrite_past_input(arxiv_id, user, username, '', comment)\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have successfully added a new tag and rewriten your comment!\"\r\n )\r\n\r\n\r\[email protected](\"view11\")\r\ndef view00(ack, body, view, client):\r\n ack()\r\n tags = view['state']['values']['input_block_1'][\"tag_input\"]['value']\r\n comment = view['state']['values']['input_block_2']['comment_input']['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n append_past_input(arxiv_id, user, username, tags, comment)\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have successfully added a new tag and a new comment!\"\r\n )\r\n\r\n\r\[email protected](\"view12\")\r\ndef view00(ack, body, view, client):\r\n ack()\r\n tags = view['state']['values']['input_block_1'][\"tag_input\"]['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n append_past_input(arxiv_id, user, username, tags, '')\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have successfully added a new tag!\"\r\n )\r\n\r\n\r\[email protected](\"view20\")\r\ndef view00(ack, body, view, client):\r\n ack()\r\n comment = view['state']['values']['input_block_2']['comment_input']['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n rewrite_past_input(arxiv_id, user, username, '', comment)\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have successfully rewriten your comment!\"\r\n )\r\n\r\n\r\[email protected](\"view21\")\r\ndef view00(ack, body, view, client):\r\n ack()\r\n comment = view['state']['values']['input_block_2']['comment_input']['value']\r\n user = body['user']['id']\r\n username = body['user']['username']\r\n arxiv_id = re.search(url_Reg, last_Message).group(1)\r\n append_past_input(arxiv_id, user, username, '', comment)\r\n client.chat_postMessage(\r\n channel=body['user']['id'],\r\n text=\"You have successfully added a new comment!\"\r\n )\r\n\r\n\r\[email protected](\"/post\")\r\ndef post_command(ack, command, say):\r\n ack()\r\n url = command['text']\r\n user = command['user_id']\r\n username = command['user_name']\r\n arxiv_id = re.search(url_Reg, url).group(1)\r\n if new_for_user(arxiv_id, user) == 1:\r\n create_post(arxiv_id, user, username, \"\", \"\")\r\n say(\"You have posted this url to the web page!\")\r\n else:\r\n say('This url had been posted by another user!')\r\n\r\n\r\[email protected](\"/tag\")\r\ndef tag_command(ack, command, say):\r\n ack()\r\n match_obj = re.search(r\"(.+)\\s*(https://arxiv.org/abs/[\\w.]+)\\s*\", command['text'])\r\n tags = match_obj.group(1)\r\n url = match_obj.group(2)\r\n user = command['user_id']\r\n username = command['user_name']\r\n arxiv_id = re.search(url_Reg, url).group(1)\r\n if new_for_user(arxiv_id, user) == 1:\r\n create_post(arxiv_id, user, username, tags, '')\r\n elif new_for_user(arxiv_id, user) == 2:\r\n add_new_input(arxiv_id, user, username, tags, '')\r\n else:\r\n rewrite_past_input(arxiv_id, user, username, tags, '')\r\n say(\"You have posted this url and tags to the web page!\")\r\n\r\n\r\[email protected](\"/comment\")\r\ndef comment_command(ack, command, say):\r\n ack()\r\n match_obj = re.search(r\"(https://arxiv.org/abs/[\\w.]+)\\s*(.+)\", command['text'])\r\n comment = match_obj.group(1)\r\n url = match_obj.group(2)\r\n user = command['user_id']\r\n username = command['user_name']\r\n arxiv_id = re.search(url_Reg, url).group(1)\r\n if new_for_user(arxiv_id, user) == 1:\r\n create_post(arxiv_id, user, username, '', comment)\r\n elif new_for_user(arxiv_id, user) == 2:\r\n add_new_input(arxiv_id, user, username, '', comment)\r\n else:\r\n rewrite_past_input(arxiv_id, user, username, '', comment)\r\n say(\"You have posted this url and your comments to the web page!\")\r\n\r\n\r\[email protected](\"/comtag\")\r\ndef comtag_command(ack, command, say):\r\n ack()\r\n match_obj = re.search(r\"(.+)\\s*(https://arxiv.org/abs/[\\w.]+)\\s*(.+)\", command['text'])\r\n url = match_obj.group(2)\r\n tags = match_obj.group(1)\r\n comment = match_obj.group(3)\r\n user = command['user_id']\r\n username = command['user_name']\r\n arxiv_id = re.search(url_Reg, url).group(1)\r\n if new_for_user(arxiv_id, user) == 1:\r\n create_post(arxiv_id, user, username, tags, comment)\r\n elif new_for_user(arxiv_id, user) == 2:\r\n add_new_input(arxiv_id, user, username, tags, comment)\r\n else:\r\n rewrite_past_input(arxiv_id, user, username, tags, comment)\r\n say(\"You have posted this url,tags and your comments to the web page!\")\r\n\r\n\r\nif __name__ == \"__main__\":\r\n app.start(port=int(os.environ.get(\"PORT\", 3000)))\r\n"
}
] | 3 |
luvwinnie/dialogflow-flask-api | https://github.com/luvwinnie/dialogflow-flask-api | f1e660210c5d2a875329add5e3ee1e61423004cf | 692a41340bbeb72734cb8f0ebe72669187a9d5fa | 20ddbce368f311f34e825066bff2864df72e34fa | refs/heads/master | 2020-03-27T04:28:12.026615 | 2018-08-24T04:59:36 | 2018-08-24T04:59:36 | 145,942,400 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6359620094299316,
"alphanum_fraction": 0.6472277641296387,
"avg_line_length": 31.80434799194336,
"blob_id": "5bba3b9f08a7475e92d96c64bb17c58b8a9a6697",
"content_id": "5af020aa5a8243eb3ea0083f6d3bcbebbb31055b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4741,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 138,
"path": "/webhook.py",
"repo_name": "luvwinnie/dialogflow-flask-api",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom __future__ import print_function\nfrom flask import Flask, request, jsonify\nfrom flask_assistant import Assistant, ask, tell, context_manager\nimport requests\nimport logging\nimport gspread\nfrom oauth2client.service_account import ServiceAccountCredentials\nlogging.getLogger('flask_assistant').setLevel(logging.DEBUG)\nimport os\nfrom settings import APP_STATIC\napp = Flask(__name__)\nassist = Assistant(app, route='/')\n\n\[email protected]('give-employee')\ndef retrieve_position():\n if request.headers['Content-Type'] != \"application/json; charset=UTF-8\":\n print(request.headers['Content-Type'])\n return jsonify(res='error'), 400\n\n name = request.json[\"result\"][\"parameters\"][\"employee\"]\n familyName = name[0:2]\n givenName = name[2:]\n\n # ここにAPIを呼ぶ処理\n baseUrl = \"http://leow.tk\"\n\n apiUrl = baseUrl + \"/\" + familyName + \"/\" + givenName + \"/\" + \"position\"\n result = requests.get(apiUrl)\n if result.status_code != 200:\n return jsonify(res='error'), 400\n\n json = result.json()\n position = json[0][\"position\"]\n speech = familyName + \"さんは\" + position + \"にいます。\"\n print(speech)\n return ask(speech)\n\[email protected]('get-place-employees')\ndef retrieve_employees():\n if request.headers['Content-Type'] != \"application/json; charset=UTF-8\":\n print(request.headers['Content-Type'])\n return jsonify(res='error'), 400\n\n position = request.json[\"result\"][\"parameters\"][\"position\"]\n\n baseUrl = \"http://leow.tk\"\n apiUrl = baseUrl + \"/\" + position + \"/employees\"\n result = requests.get(apiUrl)\n if result.status_code != 200:\n speech = position + \"はどこなのかがわかりません\"\n return ask(speech)\n\n speech = \"エントランスには\"\n employees = result.json()\n for employee in employees:\n speech += employee[\"family_name\"] + \",\"\n number_of_employees = str(len(employees))\n \n speech += \"がいます。\"\n context_manager.add('number-of-employees',lifespan=1)\n context_manager.set('number-of-employees', 'num', number_of_employees)\n context_manager.set('number-of-employees', 'employees', employees)\n return ask(speech)\n\[email protected]('get-employees-places')\ndef retrieve_employees_places():\n if request.headers['Content-Type'] != \"application/json; charset=UTF-8\":\n print(request.headers['Content-Type'])\n return jsonify(res='error'), 400\n\n baseUrl = \"http://leow.tk\"\n apiUrl = baseUrl + \"/\" + \"employees_position\"\n result = requests.get(apiUrl)\n if result.status_code != 200:\n speech = \"職員が一人も見つかりませんでした\"\n return ask(speech)\n\n employees = result.json()\n logging.debug(\"{}\".format(employees))\n places = dict()\n for employee in employees:\n if employee[\"position\"] not in places:\n places[employee[\"position\"]] = [employee[\"family_name\"]]\n continue\n places[employee[\"position\"]].append(employee[\"family_name\"])\n # print(places.keys())\n speech = \"\"\n for place, all_employees in places.items():\n speech += place + \"にいるのは\"\n logging.debug(place, all_employees)\n for employee in all_employees:\n speech += \",\" + employee + \"さん\"\n speech += \". \"\n speech += \"です\"\n\n return ask(speech)\n\[email protected]('get-weekly-study-time')\ndef get_study_time():\n if request.headers['Content-Type'] != \"application/json; charset=UTF-8\":\n print(request.headers['Content-Type'])\n return jsonify(res='error'), 400\n scope = ['https://spreadsheets.google.com/feeds',\n 'https://www.googleapis.com/auth/drive']\n credentials = ServiceAccountCredentials.from_json_keyfile_name(os.path.join(APP_STATIC,'asiaquest-intern-leow-3e0b0d31061a.json'), scope)\n gc = gspread.authorize(credentials)\n worksheet = gc.open('weekly_report').sheet1\n total_study_time = worksheet.acell('E19')\n \n speech = \"\"\n if total_study_time != \"\":\n speech += \"グーグルスプレッドシートに合計勉強時間が記入されていません\"\n \n speech = \"合計勉強時間は\" + total_study_time.value\n return ask(speech)\n\n\[email protected]('number-of-employees')\[email protected]('get-number-employees')\ndef retrieve_employees_number():\n if request.headers['Content-Type'] != \"application/json; charset=UTF-8\":\n print(request.headers['Content-Type'])\n return jsonify(res='error'), 400\n\n num_employees = request.json[\"result\"][\"contexts\"][0][\"parameters\"][\"num\"]\n speech = num_employees + \"人です。\"\n logging.debug(\"number of {}\".format(speech))\n return ask(speech)\n \n\n\n\n\n\nif __name__ == '__main__':\n app.run()\n"
},
{
"alpha_fraction": 0.7287522554397583,
"alphanum_fraction": 0.7540687322616577,
"avg_line_length": 33.5625,
"blob_id": "45d65fd487154e9af9af76cd561961edae4e96ec",
"content_id": "6ddfe741736de8b70d6f6d1f1e1509a88662d383",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 553,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 16,
"path": "/google_spread_test.py",
"repo_name": "luvwinnie/dialogflow-flask-api",
"src_encoding": "UTF-8",
"text": "#! -*- coding:utf-8 -*-\nfrom __future__ import print_function\nimport gspread\nfrom oauth2client.service_account import ServiceAccountCredentials\n\nscope = ['https://spreadsheets.google.com/feeds',\n 'https://www.googleapis.com/auth/drive']\n\ncredentials = ServiceAccountCredentials.from_json_keyfile_name('static/asiaquest-intern-leow-3e0b0d31061a.json', scope)\ngc = gspread.authorize(credentials)\nworksheet = gc.open('weekly_report').sheet1\nprint(worksheet)\ncell = worksheet.acell('E19')\n\n# wks.update_acell('A1', 'Hello World!')\nprint(cell.value)\n"
}
] | 2 |
SajjadPSavoji/sdn_routing | https://github.com/SajjadPSavoji/sdn_routing | e920f20e0c87fb42534373a36e2b448b01f64fe2 | 78f9d98b9b38296b8f3e16b34e054bc7580480a9 | d8d3b9f022bb3d3cd55835800ac2d9e9a9eb451c | refs/heads/master | 2022-12-12T15:27:27.660003 | 2020-08-19T17:42:41 | 2020-08-19T17:42:41 | 292,510,955 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5862507820129395,
"alphanum_fraction": 0.6153193116188049,
"avg_line_length": 23.675392150878906,
"blob_id": "70b869532622d2c8f012b6426e1c8a9a3ef9d4f1",
"content_id": "18b1d077698da40c92f92fdc80bb8d3f67b76eb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4713,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 191,
"path": "/new_dtopo.py",
"repo_name": "SajjadPSavoji/sdn_routing",
"src_encoding": "UTF-8",
"text": "from mininet.net import Mininet\nfrom mininet.topo import Topo\nfrom mininet.link import TCLink # So we can rate limit links\nfrom mininet.cli import CLI # So we can bring up the Mininet CLI\nfrom mininet.node import RemoteController #remote controller\nimport random\nimport time\n\nimport json\nimport numpy as np\nimport os\n\nimport matplotlib\nmatplotlib.use('Agg')\nimport matplotlib.pyplot as plt\n\n# create trace files\nwith open ('flowtable.trace', 'w') as f:\n\tpass\nwith open ('path.trace', 'w') as f:\n\tpass\n\n\nclass DataPacket(dict):\n\tdef __init__(self, host, dest, rtt, time):\n\t\tself.host = host\n\t\tself.dest = dest\n\t\tself.rtt = rtt\n\t\tself.time = time\n\n\ndef MyRandom():\n\treturn np.random.uniform()*4+1\n\ndef save_weights(weights):\n\twith open(\"weights.config\", \"w\") as f:\n\t\tjson.dump(weights,f) \n\ndef draw_plot(history, index):\n\tfig, ax = plt.subplots()\n\tfor i in range(num_hosts):\n\t\ty = []\n\t\tx = []\n\t\tif i != index:\n\t\t\tfor data in history:\n\t\t\t\tif data.dest == i:\n\t\t\t\t\ty.append(data.rtt)\n\t\t\t\t\tx.append(float(data.time))\n\t\t\t\n\t\t\tif y != []:\n\t\t\t\tx, y = zip(*sorted(zip(x, y)))\n\t\t\t\t# ax.scatter(x, y, label=i+1)\n\t\t\t\tax.plot(x, y, label=i+1)\n\n\tplt.title(str(index + 1))\n\tplt.xlabel('time s')\t\n\tplt.ylabel('rtt ms')\n\tax.legend()\n\tplt.savefig(\"./pics/plt\" + str(index + 1) + \".png\")\n\tplt.close() \n\nc0 = RemoteController( 'c0', ip='127.0.0.1', port=6633 )\n\n# 5\nnum_runs = 5\n# 6\nnum_net_up = 6\n# num hosts\nnum_hosts = 7\n\nhistory = [[] for i in range(num_hosts)]\nswitches = ['s1', 's2', 's3', 's4']\nbase_time = time.time()\n\nfor i in range(num_runs):\n\tfor j in range(num_net_up):\n\n\t\t# all possible connections between switches\n\t\tmask = {}\n\t\tfor s1 in switches:\n\t\t\tmask[s1] = {}\n\t\t\tfor s2 in switches:\n\t\t\t\tmask[s1][s2] = False\n\n\t\t# costumize links mask\n\t\tmask['s1']['s2'] = True\n\t\tmask['s2']['s3'] = True\n\t\tmask['s3']['s4'] = True\n\n\t\tweights = {}\n\t\tbws = {}\n\t\tfor i, s in enumerate(switches):\n\t\t\tweights[i+1] = {}\n\t\t\tbws[s] = {}\n\t\tfor i in range(len(switches)):\n\t\t\tfor j in range(i+1, len(switches)):\n\t\t\t\tif not mask[switches[i]][switches[j]]:\n\t\t\t\t\tcontinue\n\t\t\t\trand = MyRandom()\n\t\t\t\tbws[switches[i]][switches[j]] = rand\n\t\t\t\tbws[switches[j]][switches[i]] = rand\n\t\t\t\tweights[i+1][j+1] = 1/rand\n\t\t\t\tweights[j+1][i+1] = 1/rand\n\t\tsave_weights(weights)\n\n\t\ttopo = Topo() # Create an empty topology\n\n\t\t# Add hosts\n\t\th1 = topo.addHost( 'h1' )\n\t\th2 = topo.addHost( 'h2' )\n\t\th3 = topo.addHost( 'h3' )\n\t\th4 = topo.addHost( 'h4' )\n\t\th5 = topo.addHost( 'h5' )\n\t\th6 = topo.addHost( 'h6' )\n\t\th7 = topo.addHost( 'h7' )\n\n\t\t# Add switches\n\t\ts1 = topo.addSwitch( 's1' )\n\t\ts2 = topo.addSwitch( 's2' )\n\t\ts3 = topo.addSwitch( 's3' )\n\t\ts4 = topo.addSwitch( 's4' )\n\n\t\t# Add links\n\t\tbw = MyRandom()\n\t\ttopo.addLink('h1', 's1', bw=bw, use_htb=True, cls=TCLink)\n\t\tbw = MyRandom()\n\t\ttopo.addLink('h2', 's2', bw=bw, use_htb=True, cls=TCLink)\n\t\tbw = MyRandom()\n\t\ttopo.addLink('h3', 's3', bw=bw, use_htb=True, cls=TCLink)\n\t\tbw = MyRandom()\n\t\ttopo.addLink('h4', 's3', bw=bw, use_htb=True, cls=TCLink)\n\t\tbw = MyRandom()\n\t\ttopo.addLink('h5', 's4', bw=bw, use_htb=True, cls=TCLink)\n\t\tbw = MyRandom()\n\t\ttopo.addLink('h6', 's4', bw=bw, use_htb=True, cls=TCLink)\n\t\tbw = MyRandom()\n\t\ttopo.addLink('h7', 's4', bw=bw, use_htb=True, cls=TCLink)\n\n\t\tbw = weights[1][2]\n\t\ttopo.addLink('s1', 's2', bw=bw, use_htb=True, cls=TCLink)\n\t\tbw = weights[2][3]\n\t\ttopo.addLink('s2', 's3', bw=bw, use_htb=True, cls=TCLink)\n\t\t# topo.addLink('s1', 's3')\n\t\tbw = weights[3][4]\n\t\ttopo.addLink('s3', 's4', bw=bw, use_htb=True, cls=TCLink)\n\t\t# topo.addLink('s2', 's4')\n\n\n\t\tnet = Mininet(topo=topo, controller=c0)\n\t\tnet.start()\n\n\t\ttime.sleep(2)\n\t\tnet.pingAll()\n\t\t\n\t\t# Getting hosts from network\n\t\thosts = []\n\t\tfor i in range(num_hosts):\n\t\t\thosts.append(net.get('h'+str(i+1)))\n\t\t# print(hosts)\n\n\t\t# need to change links every 10 secs\n\t\tbegin_time = time.time()\n\t\twhile time.time() - begin_time < 10:\n\n\t\t\t# random destinations for every host\n\t\t\trand_index = [0] * num_hosts\n\t\t\tfor rand_dest in range(num_hosts):\n\t\t\t\trand_index[rand_dest] = random.randint(0, 6)\n\n\t\t\t\n\t\t\t# need to change connections every 100 ms\n\t\t\tstart_time = time.time()\n\t\t\t# seding tcp packets with size 100000 bytes for 100 ms\n\t\t\twhile time.time() - start_time < 0.1:\n\t\t\t\tfor host_num in range(num_hosts):\n\t\t\t\t\tlog = hosts[host_num].cmd('hping3 -d 100000 -c 3', hosts[rand_index[host_num]].IP())\n\t\t\t\t\tlog_split = log.split()\n\t\t\t\t\trtt = log_split[23]\n\t\t\t\t\tif (rtt[0:3] == 'rtt'):\n\t\t\t\t\t\trtt_number = rtt[4:]\n\t\t\t\t\t\thistory[host_num].append(DataPacket(host_num, rand_index[host_num], float(rtt_number)/ 2, float(time.time() - start_time)))\n\t\t\t\t\t\t\n\t\t\t\t\t# else:\n\t\t\t\t\t# \tprint(log_split)\n\n\t\t# CLI(net) # Bring up the mininet CLI\n\t\tnet.stop()\t\n\nfor i in range(num_hosts):\n\tprint('creating plot #' + str(i+1))\n\tdraw_plot(history[i], i)\n"
},
{
"alpha_fraction": 0.6001734733581543,
"alphanum_fraction": 0.6574154496192932,
"avg_line_length": 24.64444351196289,
"blob_id": "ba897e43eb68f4c50a43746c6760e33845728a2f",
"content_id": "fdd0d1b0e06147357ee82a19bc323223fc078fa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1153,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 45,
"path": "/dtopo.py",
"repo_name": "SajjadPSavoji/sdn_routing",
"src_encoding": "UTF-8",
"text": "from mininet.net import Mininet\nfrom mininet.topo import Topo\nfrom mininet.link import TCLink # So we can rate limit links\nfrom mininet.cli import CLI # So we can bring up the Mininet CLI\nfrom mininet.node import RemoteController #remote controller\n\nc0 = RemoteController( 'c0', ip='127.0.0.1', port=6633 )\n\ntopo = Topo() # Create an empty topology\n\n# Add hosts\nh1 = topo.addHost( 'h1' )\nh2 = topo.addHost( 'h2' )\nh3 = topo.addHost( 'h3' )\nh4 = topo.addHost( 'h4' )\nh5 = topo.addHost( 'h5' )\nh6 = topo.addHost( 'h6' )\nh7 = topo.addHost( 'h7' )\n\n# Add switches\ns1 = topo.addSwitch( 's1' )\ns2 = topo.addSwitch( 's2' )\ns3 = topo.addSwitch( 's3' )\ns4 = topo.addSwitch( 's4' )\n\n# Add links\ntopo.addLink('h1', 's1')\ntopo.addLink('h2', 's2')\ntopo.addLink('h3', 's3')\ntopo.addLink('h4', 's3')\ntopo.addLink('h5', 's4')\ntopo.addLink('h6', 's4')\ntopo.addLink('h7', 's4')\n\ntopo.addLink('s1', 's2')\ntopo.addLink('s2', 's3')\ntopo.addLink('s3', 's1')\ntopo.addLink('s3', 's4')\ntopo.addLink('s2', 's4')\n\n# topo.addLink(\"h1\", \"s1\", bw=20.0, delay='10ms', use_htb=True)\nnet = Mininet(topo=topo, controller=c0)\nnet.start()\nCLI(net) # Bring up the mininet CLI\nnet.stop()"
},
{
"alpha_fraction": 0.6498050093650818,
"alphanum_fraction": 0.6587873697280884,
"avg_line_length": 29.548736572265625,
"blob_id": "a4307c569d2b95b6eb808f3a84543b4998661491",
"content_id": "466522c29e5d8120adc6d32c20a3850fc9761c5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8461,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 277,
"path": "/main.py",
"repo_name": "SajjadPSavoji/sdn_routing",
"src_encoding": "UTF-8",
"text": "# Copyright (C) 2011 Nippon Telegraph and Telephone Corporation.\n#\n# Licensed under the Apache License, Version 2.0 (the \"License\");\n# you may not use this file except in compliance with the License.\n# You may obtain a copy of the License at\n#\n# http://www.apache.org/licenses/LICENSE-2.0\n#\n# Unless required by applicable law or agreed to in writing, software\n# distributed under the License is distributed on an \"AS IS\" BASIS,\n# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or\n# implied.\n# See the License for the specific language governing permissions and\n# limitations under the License.\n\n\"\"\"\nAn OpenFlow 1.0 L2 learning switch implementation.\n\"\"\"\n\n\nfrom ryu.base import app_manager\nfrom ryu.controller import ofp_event\nfrom ryu.controller.handler import MAIN_DISPATCHER\nfrom ryu.controller.handler import set_ev_cls\nfrom ryu.ofproto import ofproto_v1_0\nfrom ryu.lib.mac import haddr_to_bin\nfrom ryu.lib.packet import packet\nfrom ryu.lib.packet import ethernet\nfrom ryu.lib.packet import ether_types\n\nfrom ryu.topology.api import get_switch, get_link, get_host\nfrom ryu.app.wsgi import ControllerBase\nfrom ryu.topology import event, switches\n\nimport time\n\nT0 = time.time()\nimport json\ndef load_wights():\n\twith open('weights.config') as f:\n\t\treturn json.load(f)\n\ndef make_flow_trace(ft):\n\t# ft = [datapath.id, src, dst, in_port, out_port, time.time()]\n\tSPACE = \" \"\n\tEQUAL = \"=\"\n\tnames = ['dpid', 'src', 'dst', 'in_port', 'out_port', 'time']\n\tENDL = '\\n'\n\trep = ''\n\tfor i in range(len(names)):\n\t\trep = rep + names[i] + EQUAL + str(ft[i]) + SPACE\n\treturn rep + ENDL\n\n\n\nclass SimpleSwitch(app_manager.RyuApp):\n\tOFP_VERSIONS = [ofproto_v1_0.OFP_VERSION]\n\n\tdef __init__(self, *args, **kwargs):\n\t\tsuper(SimpleSwitch, self).__init__(*args, **kwargs)\n\t\tself.mac_to_port = {}\n\t\tself.topology_api_app = self\n\n\t\tself.datapath_list = []\n\t\tself.switches = []\n\n\t\tself.adjacency = {} #map[sw1][sw2] -> port\n\t\tself.mymac = {} \n\t\tself.weights = {} #map[sw1][sw2] -> w12\n\n\n\tdef get_min(self, distances, remining_nodes):\n\t\tmin = float('inf')\n\t\tmin_node = None\n\n\t\tfor node in remining_nodes:\n\t\t\tif distances[node] < min:\n\t\t\t\tmin = distances[node]\n\t\t\t\tmin_node = node\n\n\t\treturn min_node\n\n\tdef dijkestra(self, src,dst):\n\t\tdistances = {}\n\t\tprev = {}\n\n\t\t#init table\n\t\tfor dpid in self.switches:\n\t\t\tdistances[dpid] = float('inf')\n\t\t\tprev[dpid] = None\t\n\t\tdistances[src] = 0\n\n\t\t# print 'initial distances', distances\n\n\n\t\tremaining_nodes = set(self.switches[::])\n\t\twhile len(remaining_nodes)>0:\n\t\t\t# print 'len remaining nodes ', len(remaining_nodes)\n\t\t\tnode = self.get_min(distances, remaining_nodes)\n\t\t\t# print 'selected node', node\n\t\t\tremaining_nodes.remove(node)\n\t\t\tfor r_node in remaining_nodes:\n\t\t\t\tif r_node in self.adjacency[node]:\n\t\t\t\t\tif distances[node] + self.weights[node][r_node] < distances[r_node]:\n\t\t\t\t\t\tdistances[r_node] = distances[node] + self.weights[node][r_node]\n\t\t\t\t\t\tprev[r_node] = node\n\n\t\t#back track in path\n\t\tpath = []\n\t\t# print 'before loop kiri'\n\t\tx = dst\n\t\tpath.append(x)\n\t\twhile (not prev[x] == src) and (not prev[x] is None):\n\t\t\tx = prev[x]\n\t\t\tpath.append(x)\n\t\t# print 'after loop kiri'\n\t\tpath.append(src)\n\t\t# print 'path= ', path[::-1] \n\n\t\treturn self.adjacency[src][x], path\n\n\tdef add_flow(self, datapath, in_port, dst, src, actions, out_port):\n\t\tflowtabeltrace = [datapath.id, src, dst, in_port, out_port, float(time.time()-T0)]\n\t\twith open('flowtable.trace', 'a') as f:\n\t\t\tf.write(make_flow_trace(flowtabeltrace))\n\n\t\tofproto = datapath.ofproto\n\n\t\tmatch = datapath.ofproto_parser.OFPMatch(\n\t\t\tin_port=in_port,\n\t\t\tdl_dst=haddr_to_bin(dst), dl_src=haddr_to_bin(src))\n\n\t\tmod = datapath.ofproto_parser.OFPFlowMod(\n\t\t\tdatapath=datapath, match=match, cookie=0,\n\t\t\tcommand=ofproto.OFPFC_ADD, idle_timeout=0, hard_timeout=0,\n\t\t\tpriority=ofproto.OFP_DEFAULT_PRIORITY,\n\t\t\tflags=ofproto.OFPFF_SEND_FLOW_REM, actions=actions)\n\t\tdatapath.send_msg(mod)\n\n\t@set_ev_cls(ofp_event.EventOFPPacketIn, MAIN_DISPATCHER)\n\tdef _packet_in_handler(self, ev):\n\t\tmsg = ev.msg\n\t\tdatapath = msg.datapath\n\t\tofproto = datapath.ofproto\n\n\t\tpkt = packet.Packet(msg.data)\n\t\teth = pkt.get_protocol(ethernet.ethernet)\n\n\t\tif eth.ethertype == ether_types.ETH_TYPE_LLDP:\n\t\t\t# ignore lldp packet\n\t\t\treturn\n\t\tdst = eth.dst\n\t\tsrc = eth.src\n\n\t\tdpid = datapath.id\n\t\tself.mac_to_port.setdefault(dpid, {})\n\n\n\t\t# learn a mac address to avoid FLOOD next time.\n\t\tself.mac_to_port[dpid][src] = msg.in_port\n\t\t# print 'mac to port', self.mac_to_port\n\n\t\tif not src in self.mymac:\n\t\t\tself.mymac[src] = (dpid, msg.in_port)\n\n\t\tif dst in self.mymac and self.mymac[dst][0] == dpid:\n\t\t\t# print '_______ONE HUP__________'\n\t\t\t# self.logger.info(\"packet in %s %s %s %s\", dpid, src, dst, msg.in_port)\n\t\t\t# print 'my mac', self.mymac\n\t\t\tout_port = self.mymac[dst][1]\n\t\t\tif self.mymac[src] == (dpid, msg.in_port):\n\t\t\t\twith open('path.trace', 'a') as f:\n\t\t\t\t\tSPACE = \" \"\n\t\t\t\t\trep = \"SEND\" + SPACE + 'time=' +str(time.time()-T0) + SPACE +\"src=\" + src + SPACE + \"dst=\" + dst + SPACE + 'path='+str([dpid]) + '\\n' \n\t\t\t\t\tf.write(rep)\n\n\t\t\twith open('path.trace', 'a') as f:\n\t\t\t\tSPACE = \" \"\n\t\t\t\trep = \"RECV\" + SPACE + 'time=' +str(time.time()-T0) + SPACE +\"src=\" + src + SPACE + \"dst=\" + dst + SPACE+ '\\n' \n\t\t\t\tf.write(rep)\n\n\t\telif dst in self.mymac:\n\t\t\t# print '___________ perform dijkestra ___________'\n\t\t\t# self.logger.info(\"packet in %s %s %s %s\", dpid, src, dst, msg.in_port)\n\t\t\t# print 'my mac', self.mymac\n\t\t\t# sw_src = self.mymac[src][0]\n\t\t\tsw_src = dpid\n\t\t\tsw_dst = self.mymac[dst][0]\n\t\t\t# print 'sw_srd: ', sw_src, 'sw_dst:', sw_dst\n\t\t\t# print '*********befor dij'\n\t\t\tout_port, path = self.dijkestra(sw_src, sw_dst)\n\t\t\tif self.mymac[src] == (dpid, msg.in_port):\n\t\t\t\twith open('path.trace', 'a') as f:\n\t\t\t\t\tSPACE = \" \"\n\t\t\t\t\trep = \"SEND\" + SPACE + 'time=' +str(time.time()-T0) + SPACE +\"src=\" + src + SPACE + \"dst=\" + dst + SPACE + 'path='+str(path) + '\\n' \n\t\t\t\t\tf.write(rep)\n\t\t\t# print '*********after dij'\n\t\t\t# print 'dij out port', out_port\n\n\t\telse:\n\t\t\tout_port = ofproto.OFPP_FLOOD\n\n\t\tactions = [datapath.ofproto_parser.OFPActionOutput(out_port)]\n\n\t\t# install a flow to avoid packet_in next time\n\t\tif out_port != ofproto.OFPP_FLOOD:\n\t\t\tself.add_flow(datapath, msg.in_port, dst, src, actions, out_port)\n\n\t\tdata = None\n\t\tif msg.buffer_id == ofproto.OFP_NO_BUFFER:\n\t\t\tdata = msg.data\n\n\t\tout = datapath.ofproto_parser.OFPPacketOut(\n\t\t\tdatapath=datapath, buffer_id=msg.buffer_id, in_port=msg.in_port,\n\t\t\tactions=actions, data=data)\n\t\tdatapath.send_msg(out)\n\n\t@set_ev_cls(ofp_event.EventOFPPortStatus, MAIN_DISPATCHER)\n\tdef _port_status_handler(self, ev):\n\t\tmsg = ev.msg\n\t\treason = msg.reason\n\t\tport_no = msg.desc.port_no\n\n\t\tofproto = msg.datapath.ofproto\n\t\tif reason == ofproto.OFPPR_ADD:\n\t\t\tself.logger.info(\"port added %s\", port_no)\n\t\telif reason == ofproto.OFPPR_DELETE:\n\t\t\tself.logger.info(\"port deleted %s\", port_no)\n\t\telif reason == ofproto.OFPPR_MODIFY:\n\t\t\tself.logger.info(\"port modified %s\", port_no)\n\t\telse:\n\t\t\tself.logger.info(\"Illeagal port state %s %s\", port_no, reason)\n\n\n\t@set_ev_cls(event.EventSwitchEnter)\n\tdef get_topology_data(self, ev):\n\t\tprint 'entered event.EvnetSwitchEnter'\n\t\ttemp_dict = load_wights()\n\t\t# print 'temp_dict', temp_dict\n\t\tself.weights = {}\n\t\tfor key1 in temp_dict:\n\t\t\tself.weights[int(key1)] = {}\n\t\t\tfor key2 in temp_dict[key1]:\n\t\t\t\tself.weights[int(key1)][int(key2)] = float(temp_dict[key1][key2])\n\t\t\t\n\t\tswitch_list = get_switch(self.topology_api_app, None)\n\t\tswitches=[switch.dp.id for switch in switch_list]\n\t\tself.switches = [switch.dp.id for switch in switch_list]\n\t\tself.datapath_list=[switch.dp for switch in switch_list]\n\t\tlinks_list = get_link(self.topology_api_app, None)\n\t\tsrcs = [link.src for link in links_list]\n\t\tmylinks=[(link.src.dpid,link.dst.dpid,link.src.port_no,link.dst.port_no) for link in links_list]\n\t\tprint 'my links', mylinks\n\t\tfor s1,s2,port1,port2 in mylinks:\n\t\t\t# check if keys(s1 and s2 are valid)\n\t\t\tif not s1 in self.adjacency:\n\t\t\t\tself.adjacency[s1] = {}\n\t\t\tif not s2 in self.adjacency:\n\t\t\t\tself.adjacency[s2] = {}\n\n\t\t\tif not s1 in self.weights:\n\t\t\t\tself.weights[s1] = {}\n\t\t\tif not s2 in self.weights:\n\t\t\t\tself.weights[s2]={}\n\n\t\t\tself.adjacency[s1][s2]=port1\n\t\t\tself.adjacency[s2][s1]=port2\n\n\t\t\t#@TODO add real costs to self.weights\n\t\t\tif (not s1 in self.weights) or (not s2 in self.weights[s1]):\n\t\t\t\tself.weights[s1][s2]=1\n\t\t\tif (not s2 in self.weights) or (not s1 in self.weights[s2]):\n\t\t\t\tself.weights[s2][s1]=1\n\n\t\tprint 'switches = ', self.switches\n\t\tprint 'adjecency = ', self.adjacency\n\t\tprint 'weights = ', self.weights"
},
{
"alpha_fraction": 0.7530364394187927,
"alphanum_fraction": 0.7570850253105164,
"avg_line_length": 26.55555534362793,
"blob_id": "eaf89259f834262176e6e9ff86214475d55d4243",
"content_id": "566566e387ed65f47ec5531f944fde8a09dba5e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 9,
"path": "/run.py",
"repo_name": "SajjadPSavoji/sdn_routing",
"src_encoding": "UTF-8",
"text": "# run the whole project from here\n# clear mn\n'sudo mn -c'\n# run controller\n'sudo ryu-manager --observe-links main.py'\n# run constum ropology\n'sudo python new_dtopo.py'\n# calculate slope of flowtable changes\n'sudo python3 flow_table_update_rate.py'"
},
{
"alpha_fraction": 0.4885803759098053,
"alphanum_fraction": 0.510076105594635,
"avg_line_length": 27.64102554321289,
"blob_id": "8bfdf35206a8b98782dd1b75392ed26d2c91b03b",
"content_id": "4241610902b2c31a811c34e4f79f8f095d7fd48c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2233,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 78,
"path": "/flow_table_update_rate.py",
"repo_name": "SajjadPSavoji/sdn_routing",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\nclass FT():\n def __init__(self, ft_string):\n '''\n dpid=1 src=e6:9a:b3:e3:16:85 dst=ee:0d:33:e9:b8:a7 in_port=1 out_port=2 time=4.8078379631\n '''\n self.dpid = None\n self.src = None\n self.dst = None\n self.in_port = None\n self.out_port = None\n self.time = None\n self.attrs = [self.dpid, self.src, self.dst, self.in_port, self.out_port, self.time]\n\n ft_seperated = ft_string.split()\n for i, part in enumerate(ft_seperated):\n temp = part.split('=')\n if temp[0] == 'time':\n self.attrs[i] = float(temp[1])\n self.time = float(temp[1])\n elif temp[0] == 'dpid':\n self.attrs[i] = temp[1]\n self.dpid = temp[1]\n elif temp[0] == 'src':\n self.attrs[i] = temp[1]\n self.src = temp[1]\n elif temp[0] == 'dst':\n self.attrs[i] = temp[1]\n self.dst = temp[1]\n elif temp[0] == 'in_port':\n self.attrs[i] = temp[1]\n self.in_port = temp[1]\n elif temp[0] == 'out_port':\n self.attrs[i] = temp[1]\n self.out_port = temp[1]\n\n\n def __str__(self):\n return str(self.attrs)\n def __repr__(self):\n return self.__str__()\n\nfts = []\n\nwith open('flowtable.trace', 'r') as f:\n while(True):\n line = f.readline()\n if not line:\n break\n fts.append(FT(line))\n\ndpids = []\nfor ft in fts:\n if not ft.dpid in dpids:\n dpids.append(ft.dpid)\n\ndpid_ft_map = {}\nrates = {}\nfor dpid in dpids:\n dpid_ft_map[dpid] = []\n rates[dpid] = -1\n\nfor ft in fts:\n dpid_ft_map[ft.dpid].append(ft)\n\nfor dpid in dpids:\n data = [x.time for x in dpid_ft_map[dpid]]\n rates[dpid] = len(data)/(max(data) - min(data))\n\nfor dpid in dpids:\n plt.plot([x.time for x in dpid_ft_map[dpid]], [i for i in range(len(dpid_ft_map[dpid]))], label='s'+dpid + \": rate={:.2f}\".format(rates[dpid]))\nplt.grid()\nplt.legend()\nplt.xlabel('time')\nplt.ylabel('updates made')\nplt.title('update frequency of flow tables in switches')\nplt.savefig('res_updates.png')"
}
] | 5 |
cosmozhang1995/music-compose | https://github.com/cosmozhang1995/music-compose | b48ec6202604cbf90ec4d745fb88b9663cdc3541 | c43c2da817e1604baf77cf0d7ba789b4a8b5fcf8 | bc508f1e07eb5c1ce622355fdc9aad14daeb5ec3 | refs/heads/master | 2023-09-03T02:12:49.665370 | 2021-10-21T09:50:00 | 2021-10-21T09:50:00 | 419,666,490 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6035168766975403,
"alphanum_fraction": 0.6246598362922668,
"avg_line_length": 23.4974365234375,
"blob_id": "4362761f00924bbcc8b82b20fb0dde8b370a5d5f",
"content_id": "5e8c14ce878815f91ff96d43662f6200f2212e3b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4777,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 195,
"path": "/main.py",
"repo_name": "cosmozhang1995/music-compose",
"src_encoding": "UTF-8",
"text": "# Usage: python main.py example.music\n\nimport wave\nimport math\nimport collections\nimport re\nimport sys, os\n\nwav_filename = 'my.wav'\nframerate = 11025\ndefault_base_duration = 0.5\n\nfile = wave.open('my.wav', 'wb')\n\nfile.setnchannels(1)\nfile.setsampwidth(1)\nfile.setframerate(framerate)\n\ncenter_c_frequence = 261.6\nbase_octa_scales = {\n\t'C': 0,\n\t'D': 1,\n\t'E': 2,\n\t'F': 2.5,\n\t'G': 3.5,\n\t'A': 4.5,\n\t'B': 5.5\n}\nfor note in 'CDEFGAB':\n\tbase_octa_scales['b' + note] = base_octa_scales[note] - 0.5\n\tbase_octa_scales['#' + note] = base_octa_scales[note] + 0.5\ndef note_frequnce(note):\n\tocta = 0\n\twhile len(note) > 1:\n\t\tif note[-1] == '+':\n\t\t\tocta += 1\n\t\t\tnote = note[:-1]\n\t\telif note[-1] == '-':\n\t\t\tocta -= 1\n\t\t\tnote = note[:-1]\n\t\telse:\n\t\t\tbreak\n\tif note not in base_octa_scales:\n\t\traise ValueError(\"illegal note: {}\".format(note))\n\treturn center_c_frequence * math.pow(2, octa + base_octa_scales[note] / 6)\nnf = note_frequnce\n\nclass SoundSegment:\n\tdef __init__(self, frequence=None, duration=None):\n\t\tself.frequence = frequence\n\t\tself.duration = duration\n\tdef __str__(self):\n\t\treturn \"sound<{}Hz, {}s>\".format(self.frequence, self.duration)\n\ndef parse_music(music_file):\n\tif isinstance(music_file, str):\n\t\twith open(music_file, 'r') as f:\n\t\t\treturn parse_music(f)\n\tbase_duration = default_base_duration\n\tsound = []\n\tstarted = False\n\tline_id = 0\n\twhile True:\n\t\tline = music_file.readline()\n\t\tif line is None or len(line) == 0:\n\t\t\tbreak\n\t\tline_id += 1\n\t\tline = line.strip()\n\t\tif len(line) == 0:\n\t\t\tcontinue\n\t\tpos = line.find('--')\n\t\tif pos >= 0:\n\t\t\tcomment = line[pos+2:].strip()\n\t\t\tline = line[:pos].strip()\n\t\telse:\n\t\t\tcomment = None\n\t\tif not started:\n\t\t\tpos = line.find('=')\n\t\t\tif pos >= 0:\n\t\t\t\targ_key = line[:pos].strip()\n\t\t\t\targ_value = line[pos+1:].strip()\n\t\t\t\tif arg_key == 'speed':\n\t\t\t\t\tbase_duration = default_base_duration / float(arg_value)\n\t\t\t\tcontinue\n\t\t\telse:\n\t\t\t\tstarted = True\n\t\tsegments = []\n\t\tsegment = \"\"\n\t\tfor b in line:\n\t\t\tif b in (' ', '\\t'):\n\t\t\t\tif len(segment) > 0:\n\t\t\t\t\tsegments.append(segment)\n\t\t\t\t\tsegment = \"\"\n\t\t\telse:\n\t\t\t\tsegment += b\n\t\tif len(segment) > 0:\n\t\t\tsegments.append(segment)\n\t\t\tsegment = \"\"\n\t\tsegment_id = 0\n\t\tfor segment in segments:\n\t\t\tsegment_id += 1\n\t\t\tsound.append(parse_music_segment(segment, base_duration=base_duration, line_id=line_id, segment_id=segment_id))\n\treturn sound\n\ndef parse_music_segment(segment, base_duration=1, line_id=None, segment_id=None):\n\tduration = 1\n\tnote = segment\n\twhile len(note) > 1:\n\t\tif note[-1] == '~':\n\t\t\tduration += 1\n\t\t\tnote = note[:-1]\n\t\telif note[-1] == '\\'':\n\t\t\tduration += 0.5\n\t\t\tnote = note[:-1]\n\t\telif note[-1] == '\"':\n\t\t\tduration += 0.25\n\t\t\tnote = note[:-1]\n\t\telse:\n\t\t\tbreak\n\tif duration == 1:\n\t\tduration = 0\n\t\twhile len(note) > 1:\n\t\t\tif note[0] == '\\'':\n\t\t\t\tduration += 0.5\n\t\t\t\tnote = note[1:]\n\t\t\telif note[0] == '\"':\n\t\t\t\tduration += 0.25\n\t\t\t\tnote = note[1:]\n\t\t\telse:\n\t\t\t\tbreak\n\t\tif duration == 0:\n\t\t\tduration = 1\n\tis_stop = False\n\tif note == '.':\n\t\tis_stop = True\n\telif note == ',':\n\t\tis_stop = True\n\t\tduration *= 0.5\n\telif note == ';':\n\t\tis_stop = True\n\t\tduration *= 0.25\n\tduration *= base_duration\n\tif is_stop:\n\t\tfrequence = 0\n\telse:\n\t\ttry:\n\t\t\tfrequence = nf(note)\n\t\texcept ValueError:\n\t\t\traise ValueError(\"illegal segment {} at line:{} segment:{}. note is: {}\".format(segment, line_id, segment_id, segment, note))\n\treturn SoundSegment(frequence = frequence, duration = duration)\n\nclass BaseSound:\n\tdef __init__(self, sound_file):\n\t\tself._sound = BaseSound.load_base_sound(sound_file)\n\t\n\t@staticmethod\n\tdef load_base_sound(sound_file):\n\t\tif isinstance(sound_file, str):\n\t\t\twith open(sound_file, 'rb') as f:\n\t\t\t\treturn BaseSound.load_base_sound(f)\n\t\tsound = []\n\t\twhile True:\n\t\t\tdata = sound_file.read(1)\n\t\t\tif len(data) == 0:\n\t\t\t\tbreak\n\t\t\tsound.append(int.from_bytes(data, byteorder='big', signed=False))\n\t\treturn sound\n\n\tdef make_sound(self, phase):\n\t\t\"\"\"extract a sound amplitude according to phase\n\t\tphase should be in range [0, 1]\"\"\"\n\t\tindex = int(round(phase * (len(self._sound) - 1)))\n\t\tif index < 0 or index >= len(self._sound):\n\t\t\tprint(phase, index, len(self._sound))\n\t\treturn self._sound[index]\n\n\nbase_sound = BaseSound(os.path.join(os.path.realpath(os.path.dirname(__file__)), 'base_sounds', 'default.bin'))\nsound = parse_music(sys.argv[1])\n# print([str(x) for x in sound])\nfor segment in sound:\n\tfrequence = float(segment.frequence)\n\tduration = float(segment.duration)\n\tnum_bits = int(duration * framerate)\n\tba = bytearray(num_bits)\n\tfor i in range(num_bits):\n\t\ttime = i / framerate * frequence\n\t\tphase = time - math.floor(time)\n\t\t# ba[i] = int(((math.sin(i / framerate * frequence * 2 * math.pi)) + 1) / 2 * 255)\n\t\tba[i] = int(round(base_sound.make_sound(phase) * (math.sin(time * 2 * math.pi) + 1) / 2))\n\tfile.writeframes(bytes(ba))\n\nfile.close()\n\nos.system('afplay ' + wav_filename)\n"
},
{
"alpha_fraction": 0.6202020049095154,
"alphanum_fraction": 0.6525252461433411,
"avg_line_length": 29.9375,
"blob_id": "5b926ae6c699e860f6f75f24d6a86bf7454de272",
"content_id": "f56838529bf3bfce9d3f11be9ddc2c5d67790a71",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 495,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 16,
"path": "/generate-simple-base-sound.py",
"repo_name": "cosmozhang1995/music-compose",
"src_encoding": "UTF-8",
"text": "import os\nimport math\n\nnsamples = 50000\ndata = bytearray(nsamples)\nfor i in range(nsamples):\n\tt = float(i) / float(nsamples - 1)\n\ty = (math.sin(t * 2 * math.pi) + 1) / 2 * math.pow(t - 1, 2)\n\ty = math.pow(t - 1, 2)\n\tdata[i] = int(round(y * 255))\n\nbase_sounds_dir = os.path.join(os.path.realpath(os.path.dirname(__file__)), 'base_sounds')\nif not os.path.exists(base_sounds_dir):\n\tos.mkdir(base_sounds_dir)\nwith open(os.path.join(base_sounds_dir, 'default.bin'), 'wb') as f:\n\tf.write(bytes(data))\n"
}
] | 2 |
casanova12345/Projekt-zespolowy | https://github.com/casanova12345/Projekt-zespolowy | fc618161b99e88de816d43eb263e88f9b6540ed3 | 29600727acdfed566c5bfc06a4c848fe3b7e5df5 | 5d6d29ce455474532b5ddc04319c938fbcc4eda5 | refs/heads/master | 2020-04-16T11:40:51.240060 | 2019-01-13T19:53:52 | 2019-01-13T19:53:52 | 165,546,980 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.50719153881073,
"alphanum_fraction": 0.5109765529632568,
"avg_line_length": 24.420000076293945,
"blob_id": "8607054f2bbad25ce7ded488dee7a644a9b670c7",
"content_id": "eeb3495e097e9ee1cffc0aea4e0507c7d09f525a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1321,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 50,
"path": "/Projekt_Zespolowy-master/SRP/forms.py",
"repo_name": "casanova12345/Projekt-zespolowy",
"src_encoding": "UTF-8",
"text": "from django import forms\r\nfrom .models import Praktyki\r\nfrom django.forms import ModelForm\r\n\r\n\r\nclass StworzPraktyke(ModelForm):\r\n DataZakonczenia = forms.DateTimeField(widget=forms.TextInput(\r\n attrs={\r\n 'placeholder': 'YYYY-MM-DD',\r\n 'class': 'form-control'\r\n }\r\n ))\r\n DataRozpoczecia = forms.DateTimeField(widget=forms.TextInput(\r\n attrs={\r\n 'placeholder': 'YYYY-MM-DD',\r\n 'class': 'form-control'\r\n }\r\n ))\r\n opis = forms.CharField(widget=forms.Textarea(\r\n attrs={\r\n 'rows': '10',\r\n 'cols': '100',\r\n 'class': 'form-control'\r\n }\r\n ))\r\n miasto = forms.CharField(widget=forms.TextInput(\r\n attrs={\r\n 'class': 'form-control'\r\n }\r\n ))\r\n stanowisko = forms.CharField(widget=forms.TextInput(\r\n attrs={\r\n 'class': 'form-control'\r\n }\r\n ))\r\n wynagrodzenie = forms.CharField(widget=forms.TextInput(\r\n attrs={\r\n 'class': 'form-control'\r\n }\r\n ))\r\n\r\n class Meta:\r\n model = Praktyki\r\n fields = [\r\n 'DataZakonczenia', 'DataRozpoczecia', 'miasto', 'stanowisko', 'opis', 'wynagrodzenie',\r\n ]\r\n\r\n widgets = {\r\n 'id_Firma': forms.HiddenInput(),\r\n }\r\n"
},
{
"alpha_fraction": 0.7324966788291931,
"alphanum_fraction": 0.7437252402305603,
"avg_line_length": 46.83871078491211,
"blob_id": "19857b0030a5b89fdc85c8fcf91c78e49cd28257",
"content_id": "4d4519a7544b565b7d511261ed0d0f0b8a1b12e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1514,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 31,
"path": "/Projekt_Zespolowy-master/SRP/models.py",
"repo_name": "casanova12345/Projekt-zespolowy",
"src_encoding": "UTF-8",
"text": "from django.db import models\r\nfrom accounts.models import User\r\nfrom django.core.validators import MaxValueValidator, MinValueValidator\r\nfrom django.conf import settings\r\n\r\n\r\nclass Praktyki(models.Model):\r\n id_Praktyki = models.AutoField(primary_key=True)\r\n iloscMiejscMax = models.IntegerField(null=True, blank=True)\r\n iloscMiejscZajetych = models.IntegerField(blank=True, null=True)\r\n dataUtworzenia = models.DateTimeField(auto_now_add=True)\r\n dataRozpoczecia = models.DateTimeField(null=True, blank=True)\r\n dataZakonczenia = models.DateTimeField(null=True, blank=True)\r\n wynagrodzenie = models.CharField(max_length=45, blank=True, null=True)\r\n stanowisko = models.CharField(max_length=45)\r\n opis = models.TextField(max_length=255, blank=True, null=True)\r\n miasto = models.CharField(max_length=45, blank=True, null=True)\r\n id_Firma = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE, blank=True, null=True)\r\n\r\n def __str__(self):\r\n return self.stanowisko\r\n\r\n\r\nclass Grupa(models.Model):\r\n id_Grupy = models.AutoField(primary_key=True)\r\n imieUczestnika = models.CharField(max_length=45)\r\n nazwiskoUczestnika = models.CharField(max_length=45)\r\n imieProwadzacego = models.CharField(max_length=45)\r\n nazwiskoProwadzacego = models.CharField(max_length=45)\r\n id_Praktyki = models.ForeignKey(Praktyki, on_delete=models.CASCADE)\r\n id_Firma = models.ForeignKey(settings.AUTH_USER_MODEL, on_delete=models.CASCADE, null=True, blank=True)\r\n"
},
{
"alpha_fraction": 0.6814371347427368,
"alphanum_fraction": 0.6868263483047485,
"avg_line_length": 27.821428298950195,
"blob_id": "be04ae3524b8feb2ec4915a6931dd0e1559c49d2",
"content_id": "1c75d38365d22f935742044e3242b2de793cd196",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1670,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 56,
"path": "/Projekt_Zespolowy-master/SRP/views.py",
"repo_name": "casanova12345/Projekt-zespolowy",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect, get_object_or_404\r\nfrom django.contrib.auth.decorators import login_required\r\nfrom .forms import StworzPraktyke\r\nfrom .models import Praktyki\r\nfrom accounts.models import User\r\n\r\n\r\ndef main_page(request):\r\n return render(request, 'main.html')\r\n\r\n\r\n@login_required()\r\ndef user_profile(request):\r\n return render(request, 'account/profile.html')\r\n\r\n\r\ndef lista_praktyk(request):\r\n listapraktyk = Praktyki.objects.all()\r\n return render(request, 'practice/praktyki.html', {'listapraktyk': listapraktyk})\r\n\r\n\r\ndef stworz_Praktyke(request):\r\n user = User.objects.get(nazwafirmy=request.user.nazwafirmy)\r\n\r\n form = StworzPraktyke(request.POST or None)\r\n if form.is_valid():\r\n instance = form.save(commit=False)\r\n instance.id_Firma = user\r\n instance.save()\r\n redirect(lista_praktyk)\r\n\r\n return render(request, 'practice/stworz_Praktyke.html', {'form': form}, {'user',user})\r\n\r\n\r\ndef edytuj_praktyke(request, id_Praktyki):\r\n praktyka = get_object_or_404(Praktyki, pk=id_Praktyki)\r\n form_praktyk = StworzPraktyke(request.POST or None, instance=praktyka)\r\n\r\n if form_praktyk.is_valid():\r\n form_praktyk.save()\r\n\r\n return render(request, 'practice/stworz_Praktyke.html', {'form_praktyk': form_praktyk})\r\n\r\n\r\ndef usun_praktyke(request, id_Praktyki):\r\n praktyka = get_object_or_404(Praktyki, pk=id_Praktyki)\r\n\r\n if request.method == 'POST':\r\n praktyka.delete()\r\n return redirect(lista_praktyk)\r\n\r\n return render(request, 'practice/confirm.html', {'praktyka': praktyka})\r\n\r\n\r\ndef CRUD(request):\r\n return render(request, 'practice/CRUD.html')\r\n"
},
{
"alpha_fraction": 0.6899670958518982,
"alphanum_fraction": 0.6899670958518982,
"avg_line_length": 48.66666793823242,
"blob_id": "975e0d20ad3d228058fb3a2d02f70e6210535d1f",
"content_id": "48b1c11230aeca36bc512f2d271aca517255cfc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1216,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 24,
"path": "/Projekt_Zespolowy-master/PZ/urls.py",
"repo_name": "casanova12345/Projekt-zespolowy",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\r\nfrom django.urls import path, include\r\nfrom django.conf import settings\r\nfrom django.conf.urls.static import static\r\n\r\nfrom accounts.views import UserRegisterView, FirmaRegisterView, LoginView, logout_view\r\nfrom SRP.views import lista_praktyk, stworz_Praktyke, edytuj_praktyke, usun_praktyke, CRUD, main_page, user_profile\r\n\r\n\r\nurlpatterns = [\r\n path('admin/', admin.site.urls),\r\n path('', main_page, name='main'),\r\n path('main/', main_page, name='main_page'),\r\n path('login/', LoginView.as_view(), name='login'),\r\n path('logout/', logout_view, name='logout'),\r\n path('signup_firm/', FirmaRegisterView.as_view(), name='signup_firm'),\r\n path('signup/', UserRegisterView.as_view(), name='signup'),\r\n path('user_settings/', user_profile, name='user_settings'),\r\n path('praktyki/', lista_praktyk, name='praktyki'),\r\n path('str_pr/', stworz_Praktyke, name='create_practice'),\r\n path('edytuj_praktyke/<int:id_Praktyki>/', edytuj_praktyke, name=\"edytuj_praktyke\"),\r\n path('usun_praktyke/<int:id_Praktyki>/', usun_praktyke, name=\"usun_praktyke\"),\r\n path('CRUD/', CRUD, name=\"CRUD\"),\r\n] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)\r\n"
},
{
"alpha_fraction": 0.7938144207000732,
"alphanum_fraction": 0.7938144207000732,
"avg_line_length": 22.25,
"blob_id": "9a5d00a15eda07a723b66acd0c6deb92882dfcde",
"content_id": "73a3de88c151e5cbe4a2e497f037d073ca34ac7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 4,
"path": "/Projekt_Zespolowy-master/SRP/admin.py",
"repo_name": "casanova12345/Projekt-zespolowy",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\r\nfrom .models import Praktyki\r\n\r\nadmin.site.register(Praktyki)\r\n"
}
] | 5 |
Anu-1110/SEO_Project_Python | https://github.com/Anu-1110/SEO_Project_Python | 4640a6cbaad621aa0024a6c622d9024f4fffcf28 | d182181e145c1718064a87eaf8a4ad2b1fcd80a4 | df95bf7c32d04f68e93a050df368ddaec4476c21 | refs/heads/master | 2021-04-22T22:42:04.515831 | 2020-03-25T03:34:07 | 2020-03-25T03:34:07 | 249,878,581 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5422382950782776,
"alphanum_fraction": 0.5530685782432556,
"avg_line_length": 27.78494644165039,
"blob_id": "00ef7016b1bd8dae041f4ac6485df836cb073836",
"content_id": "2a9835d0e9ddfe612910910e78165fb6d8ad9bfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2770,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 93,
"path": "/SEO_Tool_Matplot.py",
"repo_name": "Anu-1110/SEO_Project_Python",
"src_encoding": "UTF-8",
"text": "from urllib.request import Request\r\nfrom urllib.request import urlopen\r\nfrom bs4 import BeautifulSoup\r\nimport xlsxwriter\r\nimport re\r\nimport numpy as np\r\nfrom matplotlib import pyplot as mp\r\n\r\ncom_chars = ['more', 'has', 'it', 'in', 'by', 'the', 'ies', 'and', 'be', 'these', 'not', 'such',\r\n 'can', 'then', 'when', 'which', 'one', 'of', 'as', 'from', 'ed', 'ing', 's', 'on',\r\n 'that', '1', '2', '3', '4', '5', '6', '7', '8', '9', '0', 'was', 'a', 'be', 'ly', 'is',\r\n 'with', 'e', 'are', 'for', 'an', 'ia', 'or', 'to','th']\r\nfrequent_words = []\r\nfrequency = []\r\ndensity = []\r\nmass = []\r\ndata = []\r\ndct = {}\r\nheading = ['WORDS', 'FREQUENCY', 'DENSITY']\r\n\r\ntry:\r\n input_file = open(input('Enter your input file name with extension : '))\r\n r_file = input_file.read()\r\nexcept Exception as e:\r\n print(type(e), ':Incorrect')\r\nelse:\r\n print('Input file read successfully')\r\n\r\nurl = r_file.split()\r\nprint('Received URL count is ', len(url))\r\n\r\nxl_file = xlsxwriter.Workbook('SEO_Tool_Matplot_Result.xlsx')\r\nprint('Please wait...')\r\n\r\ncount = 0\r\nwhile count < len(url):\r\n request = Request(url[count], data=None)\r\n page = urlopen(request)\r\n soup = BeautifulSoup(page, 'html.parser')\r\n Heading = [soup.title.string]\r\n for script in soup(['script', 'style']):\r\n script.extract()\r\n text = soup.get_text().lower()\r\n fltr = filter(None, re.split(r'\\W|d', text))\r\n dct.clear()\r\n word_count = len(text)\r\n for word in fltr:\r\n word = word.lower()\r\n if word in com_chars:\r\n continue\r\n if word not in dct:\r\n dct[word] = 1\r\n else:\r\n dct[word] += 1\r\n srt = sorted(dct.items(), key=lambda v: v[1], reverse=True, )[:5]\r\n density.clear()\r\n for sk, sv in srt:\r\n key = len(sk)\r\n den = (key / word_count) * 100\r\n density.append(den)\r\n var = [(k, v) for k, v in srt]\r\n data.clear()\r\n for r in var:\r\n data.append(r)\r\n frequent_words.clear()\r\n frequency.clear()\r\n for k, v in data:\r\n frequent_words.append(k)\r\n frequency.append(v)\r\n mass.clear()\r\n for sv in density:\r\n mass.append(sv)\r\n\r\n xl_sheet = xl_file.add_worksheet()\r\n style = xl_file.add_format({'bold': 1})\r\n column = [frequent_words, frequency, mass]\r\n xl_sheet.write_row('D6', heading, style)\r\n xl_sheet.write_column('D7', column[0])\r\n xl_sheet.write_column('E7', column[1])\r\n xl_sheet.write_column('F7', column[2])\r\n\r\n count += 1\r\n\r\n mp.title(\"Result\")\r\n mp.xlabel(\"Words\")\r\n mp.ylabel(\"Frequency\")\r\n mp.plot(column[0], column[1],'*-r')\r\n\r\n mp.savefig('Output'+str(count)+'.png')\r\n mp.show()\r\n\r\nprint('Result generated successfully and shown in graph')\r\nxl_file.close()\r\n"
}
] | 1 |
dsteed77/coding-challenges-python | https://github.com/dsteed77/coding-challenges-python | 07d8ebb7740818b2d845e3ee1ac742cfce137b81 | 71210d7c3bd54c99a806d7e6d0c8800fb6d7b487 | c6b8c1a8f1a29eb439311369dede1e22d17476e9 | refs/heads/master | 2020-03-27T14:13:34.740868 | 2018-09-27T22:56:23 | 2018-09-27T22:56:23 | 146,650,975 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6292377710342407,
"alphanum_fraction": 0.6348521113395691,
"avg_line_length": 38.24576187133789,
"blob_id": "3babea03fc20b2348e768405448443cedcae18d0",
"content_id": "d5534650a8b5b62326b1ab0f784f842348b29139",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4631,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 118,
"path": "/Hello/menu_functions.py",
"repo_name": "dsteed77/coding-challenges-python",
"src_encoding": "UTF-8",
"text": "import String_Manipulation\nimport Arrays\nimport Linked_Lists\nimport Stack_Queue\nimport Tree\nimport Recursion\nimport Hashing\nimport etc\n\nfunction_cat_list = [\n ['String Manipulation', \"Parenthesis Checker\", \"Reverse Words\", \n \"Permutations Of String\", \"Longest Palindrome String\", \"Recursively Remove Adjacent Duplicates\", \n \"Check if string is rotated by two places\", \"Roman Number to Integer\", \"Anagram\", \"Longest Common Substring\", \n \"Remove Duplicates\", \"Form Palindrome\", \"Longest Distinct Characters String\", \"Implement Atoi\", \n \"Implement strstr\", \"Longest Common Prefix\", \"Subarray With Sum\"], \n\n ['Arrays', \"Finding middle element in a linked list\", \"Reverse a linked list\", \"Rotate a Linked List\", \n \"Reverse a Linked List in groups of given size\", \"Detect Loop in linked list\", \"Remove loop in Linked List\", \n \"nth node from end of linked list\", \"Flattening a Linked List\", \"Merge two sorted linked lists\", \n \"Intersection point of two Linked Lists\", \"Pairwise swap of a linked list\", \"Add two numbers represented by linked lists\", \n \"Check if Linked List is Palindrome\", \"Implement Queue using Linked List\", \"Implement Stack using Linked List\", \n \"Given a linked list of 0s, 1s and 2s, sort it\", \"Delete without head pointer\"], \n\n ['Linked Lists', \"Next larger element\", \"Queue using two Stacks\", \"Stack using two queues\", \"Get minimum element from stack\", \n \"LRU Cache\", \"Circular tour\", \"First non-repeating character in a stream\", \"Rotten Oranges\"],\n \n ['Stack Queue'], \n ['Tree'], \n ['Recursion'],\n ['Hashing'],\n ['etc.']\n ]\n\ndef printMainMenu():\n print('\\nHello, This is a console app I made to help prepare for interviews! \\nMain Menu: \\n ')\n\n i=0\n for cat in function_cat_list:\n print((i+1) , ' ' , function_cat_list[i][0])\n i+=1\n\ndef userSelection():\n invalid_choice = True\n while invalid_choice:\n #print(len(function_cat_list)) #DEBUG\n user_selection = input('\\nPlease select a number from the menu: \\n')\n #print(user_selection)\n val = 0\n try:\n val = int(user_selection)\n except ValueError:\n print(\"That's not a number!\")\n\n if val <= len(function_cat_list) and val > 0:\n invalid_choice = False #meaning that if valid unput is given, it will work!\n else:\n print('Please select a valid input.') \n\n #print(user_selection)#DEBUG - Remove. \n \n print('\\nYou selected - ' + function_cat_list[val-1][0])\n return val\n \ndef printSubMenu(user_selection):\n i=0\n for sub_cat in range(len((function_cat_list[user_selection-1]))-1):\n i+=1\n print((i) , ' ' , function_cat_list[user_selection-1][i]) \n\n invalid_choice = True\n while invalid_choice:\n #print(len(function_cat_list)) #DEBUG\n user_selection_sub = input('\\nPlease select a number from the sub-menu: \\n')\n val = 0\n\n try:\n val = int(user_selection_sub)\n except ValueError:\n print(\"That's not a number!\")\n\n print (len(function_cat_list[user_selection - 2]))\n if val < len(function_cat_list[user_selection - 1]) and val > 0:\n invalid_choice = False #meaning that if valid unput is given, it will work!\n else:\n print('\\nPlease select a valid input.') \n\n #print(user_selection)#DEBUG - Remove. \n print('\\nYou selected - ' + function_cat_list[user_selection - 1][val])\n return val\n\ndef executeFunction(category, function):\n function_name = function_cat_list[category-1][function]\n category_name = function_cat_list[category-1][0]\n\n print('Executing ' + function_name)\n print('From Category: ' + category_name + '\\n')\n\n function_mod = function_name.replace(' ', '_')\n category_name = category_name.replace(' ','_')\n function_available = False\n\n #Assuming module String_Manipulation with method function:\n #String_Manipulation.Reverse_Words()\n if category_name == String_Manipulation: \n function_to_call = getattr(String_Manipulation, function_mod)\n function_to_call()\n function_available = True\n else:\n print('It appears that this function is not available. Please choose a different option.')\n while not function_available:\n val = int(printSubMenu(category))\n print('>>>>>>>>>>>>>')\n print(function_cat_list[category-1][val])\n print(function_name)\n if function_name == function_cat_list[category-1][val]:\n function_available = True\n\n #method_to_call = getattr(foo, 'bar')\n"
},
{
"alpha_fraction": 0.7806451320648193,
"alphanum_fraction": 0.7806451320648193,
"avg_line_length": 18.25,
"blob_id": "31609f0741e11c85a81ef610649c95a0c429df92",
"content_id": "91d04ae1521c7a0d9a55edf4498e51c96ef38954",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 155,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 8,
"path": "/Hello/master_impl.py",
"repo_name": "dsteed77/coding-challenges-python",
"src_encoding": "UTF-8",
"text": "#Coding challenges from \n\nfrom menu_functions import *\n\nprintMainMenu()\ncat = userSelection()\nfunction = printSubMenu(cat)\nexecuteFunction(cat, function)\n\n"
},
{
"alpha_fraction": 0.706256628036499,
"alphanum_fraction": 0.7083775401115417,
"avg_line_length": 27.515151977539062,
"blob_id": "b25c6ad1b41d0c7575bf99765725b430ad7e8881",
"content_id": "4e425773967586ba822b51196d62e9a24b4022ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 943,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 33,
"path": "/Hello/String_Manipulation.py",
"repo_name": "dsteed77/coding-challenges-python",
"src_encoding": "UTF-8",
"text": "###\n# This string manipultation file contains the following fuctions:\n# Parenthesis_Checker\n# Reverse_Words \n# Permutations_Of_String\n# Longest_Palindrome_String\n# Recursively_Remove_Adjacent_Duplicates \n# Check_if_string_is_rotated_by_two_places\n# Roman_Number_to_Integer\n# Anagram Longest_Common_Substring \n# Remove_Duplicates Form_Palindrome\n# Longest_Distinct_Characters_String\n# Implement_Atoi \n# Implement_strstr\n# Longest_Common_Prefix\n# Subarray_With_Sum\n###\n\ndef Reverse_Words(): #this is the function definition so we can break our coding challenges in different modules\n rev_string = input('Enter string to reverse(words):')\n\n print('You entered: ' + rev_string)\n\n string_list = rev_string.split()\n new_string = ''\n i_length = len(string_list) - 1\n\n for string in string_list:\n new_string+=string_list[i_length]\n new_string+=' '\n i_length-=1\n \n print('Reversed String: ' + new_string)\n\n\n"
}
] | 3 |
sleekEagle/hide_emotion | https://github.com/sleekEagle/hide_emotion | dec3f5b7db7616ee1c28461fdec1d87e28cd3d04 | 06da0aa22bca2a3f49a52780244287bc751ed70b | a699b509fbdbdfa0cf153b8662706aa8de6301c8 | refs/heads/master | 2020-11-24T16:35:10.049619 | 2020-01-22T19:56:29 | 2020-01-22T19:56:29 | 228,249,044 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6075678467750549,
"alphanum_fraction": 0.6237505674362183,
"avg_line_length": 30.95437240600586,
"blob_id": "df5beb0523224adf0692ce145095c1f3815e3fd1",
"content_id": "5b31ffcefcc82de12975f5c25c24c683a554ba15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8404,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 263,
"path": "/voice_mod.py",
"repo_name": "sleekEagle/hide_emotion",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Dec 8 19:21:16 2019\n\n@author: sleek_eagle\n\"\"\"\n\nfrom os import listdir\nfrom os.path import isfile, join\nimport librosa\nimport librosa.display\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom random import randint\nimport cnn\nfrom scipy import signal\nimport math\nimport cmath\nfrom numpy import diff\nfrom keras.models import load_model\nimport keras.backend as K\nimport scipy.io.wavfile as wav\nimport os\n\n\n#hop (stride) used in FFT. Time of the recording = hop*length_of_array ms\nfft_hop=10\n#desired length of sample in ms\nsample_len=2000\nframe_len=fft_hop=int(sample_len/fft_hop)\n\n\npath='/home/sleek_eagle/research/security/project/results/11.2_0.14/'\n\nemotions=np.array(['W','L','E','A','F','T','N'])\ndef get_emo_num(file_name):\n emotion=file_name[5]\n emo_num=to_onehot(np.where(emotions==emotion)[0][0])\n return emo_num\n\ndef to_onehot(num):\n num_classes=emotions.shape[0]\n out = np.empty([0,num_classes])\n for x in np.nditer(num):\n onehot = np.zeros(num_classes)\n onehot[int(x)] = 1\n out = np.append(out,[onehot],axis = 0)\n return out\n\ndef get_file_list(file_path,ext):\n with open(file_path) as f:\n lines = f.readlines()\n files=[]\n for line in lines:\n file_name=line[1:-5]+ext\n files.append(file_name)\n return files\n\ndef get_data_list(path,files):\n data=[]\n labels=[]\n for file in files:\n if(len(file)<11):\n continue\n ar=np.load(path+file)\n data.append(ar)\n label=get_emo_num(file)\n labels.append(label)\n return data,labels\n\n\ndef get_spec_voice(voice_list,sr):\n #length of FFT window in ms\n fft_len = 25 \n window_len = int(sr*fft_len*0.001)\n #hop (stride) of FFT in ms\n hop_length = int(sr*fft_hop*0.001)\n #librosa.display.waveplot(voice, sr=sr);\n n_mels = 40\n spec_list=[]\n for voice in voice_list:\n S = librosa.feature.melspectrogram(voice, sr=sr, n_fft=window_len, \n hop_length=hop_length, \n n_mels=n_mels)\n S_DB = librosa.power_to_db(S, ref=np.max)\n spec_list.append(S_DB)\n return spec_list\n\ndef read_voices(files):\n voice_list=[]\n labels=[]\n for file in files:\n y,sr=librosa.load(path+file)\n voice,_=librosa.effects.trim(y)\n voice_list.append(voice)\n label=get_emo_num(file)\n labels.append(label)\n return voice_list,labels,sr\n\ndef get_derivatives(spec,voice):\n resampled=signal.resample(voice, spec.shape[1])\n (n_mels,spec_len)=spec.shape\n max_freq=8196\n freqs=list(range(int(max_freq/n_mels),max_freq,int(max_freq/n_mels)))\n dX_dt=np.zeros((n_mels,spec_len))\n for a in range(n_mels):\n for b in range(spec_len):\n val=-2*math.pi*b*freqs[a]\n v=cmath.exp(-val*1j)*resampled[b]\n dX_dt[a][b]=abs(v)\n \n diff_resampled=diff(resampled)\n diff_resampled=np.append(diff_resampled,values=[0],axis=0)\n return dX_dt,diff_resampled\n\ndef get_norm_data(ar_list):\n data=[]\n for ar in ar_list:\n #standardize data\n m=np.tile(mean_ar,ar.shape[1])\n s=np.tile(std_ar,ar.shape[1])\n norm_ar=(ar-m)/s\n diff=frame_len-ar.shape[1]\n if(ar.shape[1] < frame_len):\n norm_ar=np.pad(norm_ar,pad_width=((0,0),(0,diff)),mode='mean')\n else:\n max_index=-diff\n start=randint(0,max_index)\n norm_ar=norm_ar[:,start:(start+frame_len)]\n data.append(norm_ar)\n data=np.array(data)\n return data\n\nsess = K.get_session()\ndef get_adv(labels,input_data):\n loss = 1*K.categorical_crossentropy(labels, model.output)\n grads = K.gradients(loss, model.input)\n res=sess.run(grads,{model.input:input_data})\n return res\n\n#load saved trained model\nmodel=load_model('/home/sleek_eagle/research/security/project/emodb.h5')\n\ndef save_files(path,files):\n spec_list=[]\n for file in files:\n y, sr = librosa.load(path+file)\n voice,_=librosa.effects.trim(y)\n \n fft_len = 25 \n window_len = int(sr*fft_len*0.001)\n #hop (stride) of FFT in ms\n hop = 10\n hop_length = int(sr*hop*0.001)\n #librosa.display.waveplot(voice, sr=sr);\n n_mels = 40\n S = librosa.feature.melspectrogram(voice, sr=sr, n_fft=window_len, \n hop_length=hop_length, \n n_mels=n_mels)\n S_DB = librosa.power_to_db(S, ref=np.max)\n spec_list.append(S_DB)\n print(file)\n file_name=file.split('.')[0]\n return spec_list\n\ndef spec_from_voice(voice_list):\n spec_list=[]\n for voice in voice_list: \n fft_len = 25 \n window_len = int(sr*fft_len*0.001)\n #hop (stride) of FFT in ms\n hop = 10\n hop_length = int(sr*hop*0.001)\n #librosa.display.waveplot(voice, sr=sr);\n n_mels = 40\n S = librosa.feature.melspectrogram(voice, sr=sr, n_fft=window_len, \n hop_length=hop_length, \n n_mels=n_mels)\n S_DB = librosa.power_to_db(S, ref=np.max)\n spec_list.append(S_DB)\n return spec_list\n\ndef get_voice_data(files):\n global sr\n voice_list=[]\n for file in files:\n y, sr = librosa.load(path+file)\n voice,_=librosa.effects.trim(y)\n voice_list.append(voice)\n return voice_list\n\ndef get_data_from_voice(voice_list):\n spec_list=spec_from_voice(voice_list)\n test_data=get_norm_data(spec_list)\n test_data=np.expand_dims(test_data,axis=-1)\n return test_data\n\n\ndef save_wav_files(voice_list,res): \n for i in range(0,len(voice_list)):\n file_name=test_files[i]\n dir_name=str(res[0])[0:4]+\"_\"+str(res[1])[0:4]\n dir_path='/home/sleek_eagle/research/security/project/results/'+dir_name+'/'\n if not os.path.exists(dir_path):\n os.makedirs(dir_path)\n wav.write(dir_path+file_name,sr,voice_list[i])\n \n \n#get train data for calculating statistics to normalize\ntrain_files=get_file_list('/home/sleek_eagle/research/security/project/train.txt','npy')\ntrain_list,train_labels = get_data_list('/home/sleek_eagle/research/security/project/data/np_arrays/',train_files)\ntest_files=get_file_list('/home/sleek_eagle/research/security/project/test.txt','npy')\n_,test_labels = get_data_list('/home/sleek_eagle/research/security/project/data/emo_db_test_spectro/',test_files)\ntest_files=get_file_list('/home/sleek_eagle/research/security/project/test.txt','wav')\ntest_labels=np.array(test_labels)\ntest_labels=np.squeeze(test_labels)\n\n#get fft coefficiant wise mean and std for normalization\nbig_ar=np.empty(shape=(40,1))\nfor ar in train_list:\n big_ar=np.append(big_ar,ar,axis=1)\nbig_ar=big_ar[:,1:]\nmean_ar=np.mean(big_ar,axis=1)\nstd_ar=np.std(big_ar,axis=1)\nmean_ar=np.reshape(mean_ar,newshape=(mean_ar.shape[0],1))\nstd_ar=np.reshape(std_ar,newshape=(std_ar.shape[0],1))\n\n\n\nvoice_list=get_voice_data(test_files)\ntest_data=get_data_from_voice(voice_list)\nadv_voice_list=voice_list\n\nres=model.evaluate(x=test_data,y=test_labels)\n#use predicted labels as proxy for ground truth labels\ntargets=model.predict(x=test_data)\n#save modified (adversarial) wav files so we can later wun speech-to-text on them\nsave_wav_files(adv_voice_list,res)\n\n#perform multi step FGSM in the raw voice data domain\nfor k in range(0,1000):\n grad=get_adv(targets,test_data)[0]\n der_list=[]\n adv_voice_list_tmp=[]\n epsilon=0.004\n for i in range(0,len(test_data)):\n spec=np.squeeze(test_data[i])\n dX_dt,diff_resampled=get_derivatives(spec,adv_voice_list[i])\n diff_resampled=np.expand_dims(diff_resampled,axis=-1)\n diff_resampled=1/(diff_resampled+0.001)\n m1=np.matmul(dX_dt,diff_resampled)\n g= np.matrix.transpose(np.squeeze(grad[i]))\n mul=np.matmul(g,m1)\n grad_to_add=signal.resample(mul,adv_voice_list[i].shape[0])\n grad_sign=np.sign(grad_to_add)\n adv_voice=adv_voice_list[i]+epsilon*grad_sign[:,0]\n adv_voice_list_tmp.append(adv_voice)\n adv_voice_list=adv_voice_list_tmp\n test_data=get_data_from_voice(adv_voice_list)\n res=model.evaluate(x=test_data,y=test_labels)\n save_wav_files(adv_voice_list,res)\n print(res)\n"
},
{
"alpha_fraction": 0.818443775177002,
"alphanum_fraction": 0.818443775177002,
"avg_line_length": 519.5,
"blob_id": "841affb62326daa56b8670808cabf8044c71f4b4",
"content_id": "1d9d8a1ecce2d656c37e876233afcfaa4d0b9fb9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1041,
"license_type": "no_license",
"max_line_length": 967,
"num_lines": 2,
"path": "/README.md",
"repo_name": "sleekEagle/hide_emotion",
"src_encoding": "UTF-8",
"text": "# Hiding Emotions in plain sight: Adversarial approach to ensure privacy\nWith the prevalence of intelligent personal digital assistance devices like amazon Alexa, Siri andGoogle home, Privacy has become a greater concern. This is because these devices listen to the user(and other people around them) and process these vocal data and make inferences. For example these devices may learn your identity and emotional state. Some researchers are calling for a ban for emotion recognition technologies because they can be biased (e.g racially). Also it may listen to confidential and private conversations you are having. The threat becomes greater since these devices usually send the data (voice recordings) to cloud for further analysis. Some malicious agent may get hold of these data. Therefore it is important to investigate methods to mask certain attributes out from voice. For example, if we can hide the emotional content from voice, and if we can still use other voice functions (such as speech recognition), it would be beneficial\n"
},
{
"alpha_fraction": 0.5628913044929504,
"alphanum_fraction": 0.5916334390640259,
"avg_line_length": 29.284482955932617,
"blob_id": "ef9cd04e1d699e5f8cd681180beda8bde6b7f8f9",
"content_id": "97fa2af41b78c17f71120bf81975d87776b5dbc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3519,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 116,
"path": "/speech_recog.py",
"repo_name": "sleekEagle/hide_emotion",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Dec 11 11:18:20 2019\n\n@author: sleek_eagle\n\"\"\"\n\nimport speech_recognition as sr\nimport scipy.io.wavfile as wav\nfrom os import listdir\nfrom os.path import isfile, join\n\n\n\n\ntext_dict={\"a01\":\"Der Lappen liegt auf dem Eisschrank\",\n \"a02\":\"Das will sie am Mittwoch abgeben\",\n \"a04\":\"Heute abend könnte ich es ihm sagen\",\n \"a05\":\"Das schwarze Stück Papier befindet sich da oben neben dem Holzstück\",\n \"a07\":\"In sieben Stunden wird es soweit sein\",\n \"b01\":\"Was sind denn das für Tüten, die da unter dem Tisch stehen?\",\n \"b02\":\"Sie haben es gerade hochgetragen und jetzt gehen sie wieder runter\",\n \"b03\":\"An den Wochenenden bin ich jetzt immer nach Hause gefahren und habe Agnes besucht\",\n \"b09\":\"Ich will das eben wegbringen und dann mit Karl was trinken gehen\",\n \"b10\":\"Die wird auf dem Platz sein, wo wir sie immer hinlegen\"\n }\n\ndef wer(r, h):\n \"\"\"\n Calculation of WER with Levenshtein distance.\n\n Works only for iterables up to 254 elements (uint8).\n O(nm) time ans space complexity.\n\n Parameters\n ----------\n r : list\n h : list\n\n Returns\n -------\n int\n\n Examples\n --------\n >>> wer(\"who is there\".split(), \"is there\".split())\n 1\n >>> wer(\"who is there\".split(), \"\".split())\n 3\n >>> wer(\"\".split(), \"who is there\".split())\n 3\n \"\"\"\n # initialisation\n import numpy\n d = numpy.zeros((len(r)+1)*(len(h)+1), dtype=numpy.uint8)\n d = d.reshape((len(r)+1, len(h)+1))\n for i in range(len(r)+1):\n for j in range(len(h)+1):\n if i == 0:\n d[0][j] = j\n elif j == 0:\n d[i][0] = i\n\n # computation\n for i in range(1, len(r)+1):\n for j in range(1, len(h)+1):\n if r[i-1] == h[j-1]:\n d[i][j] = d[i-1][j-1]\n else:\n substitution = d[i-1][j-1] + 1\n insertion = d[i][j-1] + 1\n deletion = d[i-1][j] + 1\n d[i][j] = min(substitution, insertion, deletion)\n\n return d[len(r)][len(h)]\n\ndef get_text(file):\n tmp_file='/home/sleek_eagle/research/security/project/results/test.wav'\n data=wav.read(file)\n track=data[1]\n #track_scaled=(track-np.min(track))/(np.max(track)-np.min(track))*255\n track_scaled=2/(np.max(track)-np.min(track))*track + (np.max(track)+np.min(track))/(np.min(track)-np.max(track))\n track_scaled*=32767\n track_scaled=track_scaled.astype('int16')\n data=wav.write(tmp_file,data[0],track_scaled)\n harvard = sr.AudioFile(tmp_file)\n with harvard as source:\n audio = r.record(source)\n text=r.recognize_google(audio,language='de')\n return text\n\ndef get_wer(file):\n idx=file.split('/')[-1][2:5]\n reference=text_dict[idx].lower()\n \n text=get_text(file).lower()\n \n er=wer(reference,text)\n return er\n\n'''\ndo speech recognition and calaulate WER for each resutl\ndo this for all .wav files in the input directoty\n'''\nr = sr.Recognizer()\npath='/home/sleek_eagle/research/security/project/results/12.0_0.14/'\nfiles = [f for f in listdir(path) if isfile(join(path, f))]\nwer_list=[]\nfor i,file in enumerate(files):\n er=get_wer(path+file)\n wer_list.append(er)\n print(i)\n\nnp.save('/home/sleek_eagle/research/security/project/results/wer/12.0_0.14',np.array(wer_list))\nnp.mean(np.load('/home/sleek_eagle/research/security/project/results/wer/12.0_0.14.npy'))\n\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6714975833892822,
"avg_line_length": 27.568965911865234,
"blob_id": "ff6e53180efe8db96e38cb8d4c7475c2a185ac41",
"content_id": "017ae9a37c24a24cd986d567a141ecb5438f4e29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1656,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 58,
"path": "/cnn.py",
"repo_name": "sleekEagle/hide_emotion",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Dec 7 09:52:34 2019\n\n@author: sleek_eagle\n\"\"\"\n\nimport keras\nfrom keras.models import Model\nfrom keras.layers import Input, Dense, Activation, Dropout, Flatten, Conv2D, MaxPooling2D, Flatten\nfrom keras.layers.normalization import BatchNormalization\nimport numpy as np\nnp.random.seed(1000)\nfrom os import listdir\nfrom os.path import isfile, join\nfrom random import randint\nfrom keras import optimizers\nfrom keras import regularizers\nfrom keras.callbacks import ReduceLROnPlateau\nimport keras.backend as K\n\ndef get_cnn():\n inputs = Input(shape=(40,200,1))\n #1st cnn layer\n x = Conv2D(filters=16,kernel_size=(10,10),strides=(2,2))(inputs)\n x = BatchNormalization()(x)\n x = Activation('relu')(x)\n \n #2nd cnn layer\n x = Conv2D(filters=32,kernel_size=(10,10),strides=(2,2))(x)\n x = BatchNormalization()(x)\n x = Activation('relu')(x)\n \n #flatten\n x=Flatten()(x)\n \n #1st FC layer\n x = Dense(716)(x)\n x = BatchNormalization()(x)\n x = Activation('relu')(x)\n x = Dropout(0.6)(x)\n \n #2nd FC layer\n x = Dense(716)(x)\n x = BatchNormalization()(x)\n x = Activation('relu')(x)\n x = Dropout(0.7)(x)\n \n #softmax\n predictions = Dense(7, activation='softmax')(x)\n \n model=Model(inputs=inputs,outputs=predictions)\n sgd = optimizers.SGD(lr=0.001, momentum=0.6, decay=0.0, nesterov=False)\n rms=optimizers.RMSprop(lr=0.001, rho=0.9)\n lrs = ReduceLROnPlateau(monitor='val_loss', factor=0.1, patience=20,verbose=1)\n model.compile(optimizer=rms, loss='categorical_crossentropy',metrics=['accuracy'])\n return model"
},
{
"alpha_fraction": 0.6151805520057678,
"alphanum_fraction": 0.6340456604957581,
"avg_line_length": 26.56910514831543,
"blob_id": "9400038b555620e4585888e5432a0dc1ab22eda5",
"content_id": "5fe09f645f07ff3a5452e92b9f783cafb3bb5edf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6785,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 246,
"path": "/emodb_extract.py",
"repo_name": "sleekEagle/hide_emotion",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Nov 10 10:58:21 2019\n\n@author: sleek_eagle\n\"\"\"\nfrom os import listdir\nfrom os.path import isfile, join\nimport librosa\nimport librosa.display\nimport numpy as np\nimport matplotlib.pyplot as plt\nfrom random import randint\nimport cnn\nfrom scipy import signal\nimport math\nimport cmath\nfrom numpy import diff\n\nemotions=np.array(['W','L','E','A','F','T','N'])\ndef get_emo_num(file_name):\n emotion=file_name[5]\n emo_num=to_onehot(np.where(emotions==emotion)[0][0])\n return emo_num\n\ndef to_onehot(num):\n num_classes=emotions.shape[0]\n out = np.empty([0,num_classes])\n for x in np.nditer(num):\n onehot = np.zeros(num_classes)\n onehot[int(x)] = 1\n out = np.append(out,[onehot],axis = 0)\n return out\n\ndef get_data_list(files):\n path='/home/sleek_eagle/research/security/project/data/np_arrays/'\n data=[]\n labels=[]\n for file in files:\n if(len(file)<11):\n continue\n ar=np.load(path+file)\n data.append(ar)\n label=get_emo_num(file)\n labels.append(label)\n return data,labels\n\ndef get_norm_data(ar_list):\n data=[]\n for ar in ar_list:\n #standardize data\n m=np.tile(mean_ar,ar.shape[1])\n s=np.tile(std_ar,ar.shape[1])\n norm_ar=(ar-m)/s\n diff=frame_len-ar.shape[1]\n if(ar.shape[1] < frame_len):\n norm_ar=np.pad(norm_ar,pad_width=((0,0),(0,diff)),mode='mean')\n else:\n max_index=-diff\n start=randint(0,max_index)\n norm_ar=norm_ar[:,start:(start+frame_len)]\n data.append(norm_ar)\n data=np.array(data)\n return data\n\ndef get_file_list(file_path,ext):\n with open(file_path) as f:\n lines = f.readlines()\n files=[]\n for line in lines:\n file_name=line[1:-5]+ext\n files.append(file_name)\n return files\n\n\n\n'''\ncalculate features\n'''''\n\n\npath='/home/sleek_eagle/research/security/project/results/2.19_0.48/'\ndef get_spec(file):\n y, sr = librosa.load(path+file)\n #length of FFT window in ms\n fft_len = 25 \n window_len = int(sr*fft_len*0.001)\n #hop (stride) of FFT in ms\n hop = 10\n hop_length = int(sr*hop*0.001)\n voice,_=librosa.effects.trim(y)\n #librosa.display.waveplot(voice, sr=sr);\n n_mels = 40\n S = librosa.feature.melspectrogram(voice, sr=sr, n_fft=window_len, \n hop_length=hop_length, \n n_mels=n_mels)\n return S,voice\n\ndef get_spec_voice(voice,sr):\n #length of FFT window in ms\n fft_len = 25 \n window_len = int(sr*fft_len*0.001)\n #hop (stride) of FFT in ms\n hop = 10\n hop_length = int(sr*hop*0.001)\n #librosa.display.waveplot(voice, sr=sr);\n n_mels = 40\n S = librosa.feature.melspectrogram(voice, sr=sr, n_fft=window_len, \n hop_length=hop_length, \n n_mels=n_mels)\n return S\n\n\n'''\n*******************************\ncreate spectrograms from .wav files\n**********************************\n'''\nout_path='/home/sleek_eagle/research/security/project/data/emo_db_test_spectro/'\n\nfiles = [f for f in listdir(path) if isfile(join(path, f))]\n\nfor file in test_files:\n y, sr = librosa.load(path+file)\n voice,_=librosa.effects.trim(y)\n\n fft_len = 25 \n window_len = int(sr*fft_len*0.001)\n #hop (stride) of FFT in ms\n hop = 10\n hop_length = int(sr*hop*0.001)\n #librosa.display.waveplot(voice, sr=sr);\n n_mels = 40\n S = librosa.feature.melspectrogram(voice, sr=sr, n_fft=window_len, \n hop_length=hop_length, \n n_mels=n_mels)\n S_DB = librosa.power_to_db(S, ref=np.max)\n '''\n librosa.display.specshow(S_DB, sr=sr, hop_length=220, \n x_axis='time', y_axis='mel')\n plt.colorbar(format='%+2.0f dB')\n '''\n print(file)\n file_name=file.split('.')[0]\n np.save(out_path+file_name,S_DB)\n \n\n#find files names from text files\ntrain_files=get_file_list('/home/sleek_eagle/research/security/project/train.txt','npy')\nvali_files=get_file_list('/home/sleek_eagle/research/security/project/vali.txt','npy')\ntest_files=get_file_list('/home/sleek_eagle/research/security/project/test.txt','npy')\n \n#hop (stride) used in FFT. Time of the recording = hop*length_of_array ms\nfft_hop=10\n#desired length of sample in ms\nsample_len=2000\nframe_len=fft_hop=int(sample_len/fft_hop)\n\ntrain_list,train_labels = get_data_list(train_files)\ntest_list,test_labels = get_data_list(test_files)\nvali_list,vali_labels = get_data_list(vali_files)\n\n#get fft coefficiant wise mean and std for normalization\nbig_ar=np.empty(shape=(40,1))\nfor ar in train_list:\n big_ar=np.append(big_ar,ar,axis=1)\nbig_ar=big_ar[:,1:]\nmean_ar=np.mean(big_ar,axis=1)\nstd_ar=np.std(big_ar,axis=1)\nmean_ar=np.reshape(mean_ar,newshape=(mean_ar.shape[0],1))\nstd_ar=np.reshape(std_ar,newshape=(std_ar.shape[0],1))\n\n\ntrain_data=get_norm_data(train_list)\ntrain_data=np.expand_dims(train_data,axis=-1)\n\nvali_data=get_norm_data(vali_list)\nvali_data=np.expand_dims(vali_data,axis=-1)\n\ntest_data=get_norm_data(test_list)\ntest_data=np.expand_dims(test_data,axis=-1)\n\ntrain_labels=np.array(train_labels)\ntrain_labels=np.squeeze(train_labels)\n\nvali_labels=np.array(vali_labels)\nvali_labels=np.squeeze(vali_labels)\n\ntest_labels=np.array(test_labels)\ntest_labels=np.squeeze(test_labels)\n \n#load saved model\nfrom keras.models import load_model\nimport keras.backend as K\nmodel=load_model('/home/sleek_eagle/research/security/project/emodb.h5')\n \nmodel.evaluate(test_data,test_labels)\n\nS_DB\n\nepsilon=0.01\n\n#create adversarial spectrograms\nx=test_data\ntarget=model.predict(x=x)\n \ndef get_adv(labels,input_data):\n loss = 1*K.categorical_crossentropy(labels, model.output)\n grads = K.gradients(loss, model.input)\n delta = K.sign(grads[0])\n out = input_data+epsilon*delta\n res=sess.run(out,{model.input:input_data})\n return res\n\nget_adv(test_labels,test_data)\nsess = K.get_session()\n\nloss_list,acc_list=[],[] \n\n#target=test_labels\nx=test_data\n\nres = model.evaluate(x=x,y=test_labels)\nloss_list.append(res[0])\nacc_list.append(res[1]) \n#use prediction as a proxy for ground truth labels\ntarget=model.predict(x=test_data)\n#perform FGSM for all the data at one step\n#range(0,10). So 10 is the number of steps we do FGSM\nfor i in range(0,10):\n x=get_adv(target,x)\n #evaluate model under adversarial samples\n res=model.evaluate(x=x,y=test_labels)\n loss_list.append(res[0])\n acc_list.append(res[1]) \n print(res)\n\n\n#plot results\nplt.plot(acc_list)\nplt.title('Accuracy vs FGSM steps')\nplt.xlabel('FGSM steps')\nplt.ylabel('accuracy')\nr=list(range(0,21))\nplt.xticks(r)\n\n\n\n"
}
] | 5 |
nscharan1/API-s | https://github.com/nscharan1/API-s | 642becb830bb1d5d432f828feb3544e3a04d0e81 | f1dd3fc853040a76b26b061548b359d24f64c5dc | a62c89b5c1f7dab0b0694cb5e0d939945a80b941 | refs/heads/master | 2021-01-02T15:40:29.579476 | 2020-02-11T05:49:59 | 2020-02-11T05:49:59 | 239,686,610 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.70015949010849,
"alphanum_fraction": 0.7320573925971985,
"avg_line_length": 30.399999618530273,
"blob_id": "5f487fc6452f0e0666c2087e9aeade0e36ce7d77",
"content_id": "196fa172f388362c38b855e888cea76468d68afd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 627,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 20,
"path": "/FLIGHTINFO.py",
"repo_name": "nscharan1/API-s",
"src_encoding": "UTF-8",
"text": "import requests\n\nprint(\"Please enter your Origin and Destination ?\")\nuserinput1=input(\"Enter your Origin: \");\nuserinput2=input(\"Enter your Destination: \");\n\nurl = \"https://travelpayouts-travelpayouts-flight-data-v1.p.rapidapi.com/v1/prices/cheap\"\n\nquerystring = {\"destination\":userinput1,\"origin\":userinput2,\"currency\":\"USD\",\"page\":\"None\"}\n\nheaders = {\n 'x-rapidapi-host': \"travelpayouts-travelpayouts-flight-data-v1.p.rapidapi.com\",\n 'x-rapidapi-key': \"83a69214c6msh70b62fd60e4fd1ep1a3f19jsn6b278bdadb79\",\n 'x-access-token': \"a4dd61ae0300a50da722075244ad7089\"\n }\n\nresponse = requests.get(url, headers=headers, params=querystring)\n\n\nprint(response.text)"
},
{
"alpha_fraction": 0.6982758641242981,
"alphanum_fraction": 0.704023003578186,
"avg_line_length": 23.785715103149414,
"blob_id": "fbc4fed96c350878d147672dcf79eead8796cd52",
"content_id": "e25faf94ca1405c6eebcc8f0d9948908fb9b538c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 348,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 14,
"path": "/airport_finder.py",
"repo_name": "nscharan1/API-s",
"src_encoding": "UTF-8",
"text": "import requests\n\nurl = \"https://cometari-airportsfinder-v1.p.rapidapi.com/api/airports/by-text\"\n\nquerystring = {\"text\":\"detroit\"}\n\nheaders = {\n 'x-rapidapi-host': \"cometari-airportsfinder-v1.p.rapidapi.com\",\n 'x-rapidapi-key': \"83a69214c6msh70b62fd60e4fd1ep1a3f19jsn6b278bdadb79\"\n }\n\nresponse = requests.request(\"GET\", url, headers=headers, params=querystring)\n\nprint(response.text)\n\n"
}
] | 2 |
vdimir/captcha-cv-lab | https://github.com/vdimir/captcha-cv-lab | 46d177a2a9bc01418486b6c3f35d755738668dfb | 2ba35d07644ab379208d4bac16c84f50df634283 | 53e7eb9deaa898f0a924aa640ba0512b998148b4 | refs/heads/master | 2021-10-19T06:39:17.649110 | 2019-02-18T20:59:41 | 2019-02-18T20:59:41 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7469505667686462,
"alphanum_fraction": 0.7664670944213867,
"avg_line_length": 27.006210327148438,
"blob_id": "4c384d29b66483bf6f614782fcacfb7ccffbf160",
"content_id": "0c101e797b714efeb001eb2ffefa1380c813cd81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6560,
"license_type": "no_license",
"max_line_length": 246,
"num_lines": 161,
"path": "/README.md",
"repo_name": "vdimir/captcha-cv-lab",
"src_encoding": "UTF-8",
"text": "# Лабораторная работа по курсу «Компьютерное зрение»\n\n[Результаты тестов](https://www.dropbox.com/sh/dk933atpilyqth3/AAD9dOz575Qa6dyTWsQx9WDKa?dl=0)\n\n```python\n%matplotlib inline\nfrom caplib import *\nimport cv2\n```\n\n### Пример работы алгоритма\nОсновной код вынесен в отдельный модуль `caplib`\n\nФункция `break_captcha` рапознает капчу и возвращает результат в виде строки\n\n\n\n```python\n(fname,img) = load_random_img(68)\nprint(break_captcha(img))\nshow(img)\n```\n\n WNB2\n\n\n\n\n### Разбор алгоритма\n\nБуквы имеют однотонный цвет и выделяются на фоне.\n\nДля отделения букв, фона и цветных полос используем кластеризацию.\n\nФункция `clusterize` выполняет кластеризацию на 8 кластеров по цвету, используя алгоритм `KMeans`.\n\n`simple_bin` приводит изображения к бинарным, так как после кластеризации в изображениях хранится информация о цвете, которая болше не понадобится\n\n\n```python\nclusters = list(map(simple_bin, clusterize(img)))\nshow_clusters(clusters)\n\n```\n\n\n\n\n\nТаким образом, мы получили набор изображений, на некоторых из которых содержатся нужные символы, на остальных -- остатки фона и полосы.\n\nСледующим этапом стал выбор характеристих, которые позволили бы из восьми полученных бинарных изображений выбрать те, на которых содержаться символы.\n\nПредварительно к изображениям применялась эрозия и дилатация, чтобы убрать отдельные ненужные пиксели, попавшие в кластер, и залить разрывы на буквах, оставленные полосами.\n\n\n```python\ndef morph(img):\n c_erode = cv2.erode(img, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3)))\n c_erode = cv2.morphologyEx(c_erode, cv2.MORPH_DILATE,\n cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 6)))\n return c_erode\n\nmorph_clusters = list(map(morph, clusters))\nshow_clusters(morph_clusters)\n```\n\n\n\n\n\nДалее убираем изображения с большим количесвом связных комонент, так как символ обычно состоит из 2-3 компонент *(разрывы происходят лишь там, где сверху прошла зашумляющая полоса)*.\n\nНиже приведены изображения и число компонент связности на них:\n\n\n```python\nnumber_connected_components = lambda img: cv2.connectedComponentsWithStats(morph(img))[0]\nshow_clusters(morph_clusters, list(map(number_connected_components, morph_clusters)))\n```\n\n\n\n\n\nОставляем только изображения с числом компонент `1 < c < 10`\n\n\n```python\nstage1_clusters = list(filter(filter_comp_count,morph_clusters))\nshow_clusters(stage1_clusters)\n```\n\n\n\n\n\nДалее рассмотрим каждый столбец изображения и посчитаем количесвто ненулевых точек в нем.\nТаким образом мы получим связность вдоль оси y.\n\nВидно, что буквы имеют определенную ширину в пределах от 10 до 50 пикселей.\nПоэтому выбираем только те изображения, где все интервалы подряд идущих ненулевых столбцов имеют заданную ширину.\n\nРезультаты `find_cont_subsec` и `get_hist`:\n\n\n\n\n\n```python\nstage2_clusters = list(filter(non_zero_seq, stage1_clusters))\nshow_clusters(stage2_clusters)\n```\n\n\n\n\n\nТеперь изображения готовы для распознавания. Используем программу для оптического разпознавания текста `Tesseract`\n\n\n```python\nimport pytesseract\nfrom PIL import Image\n\ndef recog(img):\n pilimg = Image.fromarray(img)\n conf = '-psm 8 -c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890'\n res = pytesseract.image_to_string(pilimg, config=conf)\n return res\n\nshow_clusters(stage2_clusters, list(map(recog, stage2_clusters)))\n```\n\n\n\n\n\nОстлось лишь собрать буквы в правльном порядке на основе расстояния до левого края изображения.\n\nПосмотрим примеры удачных и неудачных попыток распознавания:\n\n\n```python\nfig = plt.figure(figsize = (10,8))\nfor i in range(1,9): \n (_,img) = load_random_img()\n show(img, break_captcha(img))\n```\n\n\n\n\n\nИтоговая точность данного алгоритма составила 50-60%.\n\nОшибки происходят как на этапе кластеризации и отбора \"хороших\" кластеров, так и на этапе распознавания.\n\nДолю ошибок на этапе предобработки можно уменьшить используя более точные критерии отбора кластеров, содержащих символы, или написав специализированный алгоритм кластеризацаии(что, однако, может повлиять на общность и не дать лучшего результата).\n\nСистема распознавания дает неверный результат либо в случае сильной изрезанности буквы перекрывающими полосами, либо из-за особенностей шрифта.\n"
},
{
"alpha_fraction": 0.5591985583305359,
"alphanum_fraction": 0.5794373750686646,
"avg_line_length": 23.22058868408203,
"blob_id": "d4c0abac8f4cbf28d737ac9df17cf92ff0eb83d3",
"content_id": "897d72083acbcf4d483cd99afc21c1b1c8f6b3f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4941,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 204,
"path": "/caplib.py",
"repo_name": "vdimir/captcha-cv-lab",
"src_encoding": "UTF-8",
"text": "import cv2\nfrom matplotlib import pyplot as plt\nimport random\nfrom sklearn.cluster import KMeans\nimport numpy as np\nfrom functools import reduce\nfrom operator import add\n\nimport pytesseract\nfrom PIL import Image\n\n\ndef show(img, **kwargs):\n if isinstance(img, list):\n for i in img:\n show_image(i, **kwargs)\n else:\n show_image(img, **kwargs)\n\n\ndef show_image(img, **kwargs):\n if kwargs.get('cmap') is not None:\n plt.imshow(img, **kwargs)\n if len(img.shape) == 2:\n plt.imshow(img, cmap='gray')\n else:\n plt.imshow(img, cmap='brg')\n plt.show()\n\n\ndef crop(img):\n (x, y, w, h) = cv2.boundingRect(img)\n t = img[y:y + h, x:x + w]\n return t\n\n\ndef crop_erode(img):\n c_erode = cv2.erode(img, cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(3,3)))\n c_erode = cv2.dilate(c_erode, cv2.getStructuringElement(cv2.MORPH_ELLIPSE,(2,2)))\n (x, y, w, h) = cv2.boundingRect(c_erode)\n d=5\n (x, y, w, h) = (max(x-d,0), max(y-d,0), w+d, h+d)\n t = img[y:y + h, x:x + w]\n return (x,t)\n\n\ndef load_random_img(n=None):\n fname = n or round(random.random()*100)\n img = cv2.imread(\"img/4/%d.jpg\" % fname)\n return fname, img\n\n\ndef k_means_cluster_centres(image):\n clt = KMeans(n_clusters=12)\n clt.fit(image)\n return clt.cluster_centers_\n\n\ndef get_cluster(img, cluster):\n d = 20\n res = cv2.inRange(img, cluster-d,cluster+d)\n return res\n\n\ndef get_hist(img):\n arr = np.transpose(img)\n hist = np.zeros(arr.shape[0])\n m = np.max(arr)\n m = max([m, 1])\n for i in range(arr.shape[0]):\n hist[i] = sum(arr[i]/m)\n return hist\n\n\nclass IntervalBuilder:\n def __init__(self):\n self.beg = None\n self.end = None\n self.ints = []\n\n def cont(self, val):\n if self.beg is None:\n self.beg = val\n else:\n self.end = val\n\n def brk(self):\n if self.end is not None:\n self.ints.append((self.beg, self.end))\n self.beg = None\n self.end = None\n\n\ndef find_cont_subsec(arr):\n intervals = IntervalBuilder()\n for i,a in enumerate(arr):\n if a != 0:\n intervals.cont(i)\n else:\n intervals.brk()\n intervals.brk()\n return intervals.ints\n\n\ndef clusterize(img):\n h,w = img.shape[0],img.shape[1]\n\n img = cv2.cvtColor(img, cv2.COLOR_BGR2HSV)\n im = img.reshape((img.shape[0] * img.shape[1], 3))\n\n clt = KMeans(n_clusters=8)\n\n labels = clt.fit_predict(im)\n for x in range(8):\n cluster_cent = clt.cluster_centers_.astype(\"uint8\")\n cluster_cent = np.zeros(cluster_cent.shape)\n cluster_cent[x] = clt.cluster_centers_.astype(\"uint8\")[x]\n quant = cluster_cent[labels]\n quant = quant.reshape((h, w, 3)).astype(\"uint8\")\n yield quant\n\n\ndef iterate_2d_arr(img):\n for row in img:\n for p in row:\n yield p\n\n\ndef simple_bin(img):\n res = np.zeros((img.shape[0], img.shape[1]), np.uint8)\n\n for x in range(img.shape[0]):\n for y in range(img.shape[1]):\n if not np.all(img[x,y] == 0):\n res[x,y] = 1\n\n return res\n\n\ndef non_zero_pixels(img):\n s = 0\n for p in iterate_2d_arr(img):\n if (not np.all(p == 0)):\n s += 1\n return s\n\n\ndef recognize(img):\n pilimg = Image.fromarray(img)\n res = pytesseract.image_to_string(pilimg,\n config='-psm 10 -c tessedit_char_whitelist=abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ1234567890')\n return res\n\n\ndef filter_comp_count(img):\n c2 = cv2.connectedComponentsWithStats(morph(img))[0]\n return 1 < c2 <= 10\n\n\ndef morph(img):\n c_erode = cv2.erode(img, cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 3)))\n c_erode = cv2.morphologyEx(c_erode, cv2.MORPH_DILATE,\n cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (3, 6)))\n return c_erode\n\n\ndef try_collect_letters(img):\n c_m = morph(img)\n return find_cont_subsec(get_hist(c_m))\n\n\ndef non_zero_seq(img):\n int_len = lambda t: t[1] - t[0]\n s = try_collect_letters(img)\n # s = filter(lambda t: int_len(t) >= 10, s)\n # s = list(s)\n # if len(s) == 0:\n # return False\n # if len(s) > 10:\n # return False\n if any(map(lambda t: int_len(t) < 10, s)):\n return False\n if any(map(lambda t: int_len(t) > 50, s)):\n return False\n return True\n\n\ndef get_filtered_clusters(img):\n clusters = map(simple_bin, clusterize(img))\n clusters = filter(filter_comp_count, clusters)\n clusters = filter(non_zero_seq, clusters)\n clusters = list(clusters)\n return clusters\n\n\ndef break_captcha(img):\n res = []\n for c in get_filtered_clusters(img):\n inter = try_collect_letters(c)\n for (b, e) in inter:\n letter = recognize(c[:, b:e])\n res.append((b, letter))\n r = reduce(add, map(lambda x: x[1], sorted(res, key=lambda x: x[0])), '')\n return r\n"
},
{
"alpha_fraction": 0.5938104391098022,
"alphanum_fraction": 0.6028369069099426,
"avg_line_length": 20.845069885253906,
"blob_id": "aa46f65747bebd2a033f20eeb5316cac1b71dfde",
"content_id": "e4ed17a23bca04748d0a760b0f685dbf82253fed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1551,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 71,
"path": "/test.py",
"repo_name": "vdimir/captcha-cv-lab",
"src_encoding": "UTF-8",
"text": "from tkinter import *\nfrom PIL import ImageTk, Image\nimport os\nfrom os.path import isfile, join\n\n\nclass ImgIter:\n def __init__(self):\n self.dirname = \"/mnt/userdata2/cvis/captcha/_out3/\"\n listdir = os.listdir(self.dirname)\n self.fnames = [f for f in listdir if isfile(join(self.dirname, f))]\n self.i = 0\n self.n = len(self.fnames)\n\n def accept(self, good):\n if good:\n subdir = '/goods/'\n else:\n subdir = '/bads/'\n os.rename(self.get_fname(), self.dirname+subdir+self.fnames[self.i])\n\n def get_fname(self):\n return self.dirname+self.fnames[self.i]\n\n def get_name(self):\n return self.fnames[self.i].replace(\".jpg\",\"\")\n\n def get_prog(self):\n return str(self.i) + '/' + str(self.n)\n\n def next(self):\n self.i += 1\n return self.i == self.n\n\n\nit = ImgIter()\n\nroot = Tk()\n\nimg = ImageTk.PhotoImage(Image.open(it.get_fname()))\npanel = Label(root, image=img)\npanel.pack(side=\"bottom\", fill=\"both\", expand=\"yes\")\n\nw = Label(root, text=it.get_prog())\nw.pack()\n\nw2 = Label(root, text=it.get_name())\nw2.pack()\n\n\ndef next_img(good):\n it.accept(good)\n if it.next():\n pass\n img2 = ImageTk.PhotoImage(Image.open(it.get_fname()))\n panel.configure(image=img2)\n panel.image = img2\n w.config(text=str(it.get_prog()))\n w2.config(text=str(it.get_name()))\n\n\ndef callback1(e):\n next_img(False)\n\ndef callback2(e):\n next_img(True)\n\n\nroot.bind('<space>', callback1)\nroot.bind('<Return>', callback2)\nroot.mainloop()\n"
},
{
"alpha_fraction": 0.6151419281959534,
"alphanum_fraction": 0.7003154754638672,
"avg_line_length": 34.22222137451172,
"blob_id": "bf0a616940ba8745d915451c70cf83a64d8a7a0b",
"content_id": "352e609f1cb9f25b5883675b0a6199d7cdc4c4f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 317,
"license_type": "no_license",
"max_line_length": 270,
"num_lines": 9,
"path": "/img/4/get.sh",
"repo_name": "vdimir/captcha-cv-lab",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nfor i in `seq 1 100`;\ndo\n\ncurl -A \"Mozilla/5.0 (iPhone; U; CPU iPhone OS 4_3_3 like Mac OS X; en-us) AppleWebKit/533.17.9 (KHTML, like Gecko) Version/5.0.2 Mobile/8J2 Safari/6533.18.5\" \"http://openvibe.inria.fr/openvibe/wp-content/plugins/si-contact-form/captcha/securimage_show.php\" > \"${i}.jpg\"\n\n\ndone\n"
}
] | 4 |
H-daniel00/Bot-Python | https://github.com/H-daniel00/Bot-Python | 486917f98cc9e2998f149a0e43478ab9ada26624 | 05acabad7f419a050d30df37e9ba884014102abe | d56b2b96f53b31f724c8e26cc5f8e78cffc6d6b0 | refs/heads/master | 2022-01-22T19:42:03.357912 | 2019-07-26T01:30:18 | 2019-07-26T01:30:18 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6481028199195862,
"alphanum_fraction": 0.6676866412162781,
"avg_line_length": 34.31111145019531,
"blob_id": "f93d99f502c4a2a5299b50517ec5113c900dcbc1",
"content_id": "99dbb31b0b84ed4891979e66436f409f49bf6518",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1639,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 45,
"path": "/BOT_VersionF_KM/pdf_miner.py",
"repo_name": "H-daniel00/Bot-Python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Fri Jul 12 14:13:42 2019\r\n\r\n@author: jorellanau\r\n\"\"\"\r\n\r\nimport PyPDF2\r\nimport validador\r\nimport os\r\nimport time\r\nfor pdf in os.listdir(path=validador.val_busqueda):\r\n pdf_file = open('D:/Trasladar/Python/Proyecto/Tarea/'+validador.val_busqueda+'/'+pdf,'rb')\r\n read_pdf = PyPDF2.PdfFileReader(pdf_file)\r\n number_of_pages = read_pdf.getNumPages()\r\n page = read_pdf.getPage(0)\r\n page_content = page.extractText()\r\n cont = 0\r\n for i in range(number_of_pages):\r\n page = read_pdf.getPage(0)\r\n page_content = page.extractText()\r\n #apariciones = page_content.upper().count(validador.val_busqueda.upper())\r\n #cont = cont+apariciones\r\n #print (\"validacion del pdf \"+pdf+\": \\n \"+\"Número de páginas: \"+str(number_of_pages)+\"\\n\"+\"Número de apariciones: \"+str(apariciones))\r\n print (\"validacion del pdf \"+pdf+\": \\n \"+\"Número de páginas: \"+str(number_of_pages))\r\ntime.sleep(100)\r\nwait = input(\"PRESS ENTER TO CONTINUE.\")\r\n#pdf_file2 = open('D:/Trasladar/Python/Proyecto/Tarea/'+validador.val_busqueda+'/getBackgroundReport.pdf','rb')\r\n#read_pdf = PyPDF2.PdfFileReader(pdf_file2)\r\n#page2 = read_pdf.getPage(0)\r\n#page_content = page2.extractText()\r\n#\r\n#\r\n#\r\n#number_of_pages = read_pdf.getNumPages()\r\n#page = read_pdf.getPage(0)\r\n#page_content = page.extractText()\r\n#print (page_content)\r\n#page_content.split()\r\n#File_object = open(r\"File_Name\",\"Access_Mode\")\r\n#File_object.write(str1)\r\n#File_object.writelines(L) for L = [str1, str2, str3]\r\n#file_object.close()\r\n#print(page_content.split().index('JULIO'))\r\n#print(page_content.split().index('JULIOS'))\r\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 35,
"blob_id": "50116aca39fbdee9c2db496ae79f86defa5c9097",
"content_id": "18177696b9b6e1d064716dd60d7682461c533ef4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 1,
"path": "/BOT_VersionF_KM/validador.py",
"repo_name": "H-daniel00/Bot-Python",
"src_encoding": "UTF-8",
"text": "val_busqueda = 'project management'"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 31,
"blob_id": "a2118492397357040234de2a2c49cf24617cbd6f",
"content_id": "7d98bfe3bb7093552ce16885100f55030d534546",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 2,
"path": "/README.md",
"repo_name": "H-daniel00/Bot-Python",
"src_encoding": "UTF-8",
"text": "# Bot-Python\nBot para automatizar búsqueda y descarga de papers\n"
},
{
"alpha_fraction": 0.6746987700462341,
"alphanum_fraction": 0.6746987700462341,
"avg_line_length": 25.66666603088379,
"blob_id": "091b95a10dcbe46543b8b82028f57ca854e5fe87",
"content_id": "8904c54e82d177816335edac0517f2ae31ff55e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 3,
"path": "/BOT_VersionF_KM/busqueda.py",
"repo_name": "H-daniel00/Bot-Python",
"src_encoding": "UTF-8",
"text": "val_busqueda_input = 'knowledge'\r\nval_journal_input = 'km'\r\nval_autor_input = 'N'\r\n"
},
{
"alpha_fraction": 0.5973409414291382,
"alphanum_fraction": 0.632478654384613,
"avg_line_length": 23.0238094329834,
"blob_id": "0c383bd0d0936a2f4ae8fa0c392bc4da3c0b879d",
"content_id": "f56c9f908c18400d7fa8e1c47e928a51e40bedb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1055,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 42,
"path": "/BOT_VersionF_KM/input_busqueda.py",
"repo_name": "H-daniel00/Bot-Python",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Thu Jul 18 01:02:50 2019\r\n\r\n@author: jorellanau\r\n\"\"\"\r\n#administracion del conocimiento\r\n#administracion\r\ndef printtext():\r\n global e\r\n string = e.get()\r\n string2 = f.get()\r\n string3 = g.get()\r\n busqueda_file = open(\"busqueda.py\",\"w+\")\r\n busqueda_file.write(\"val_busqueda_input = '\"+string+'\\''+'\\n')\r\n busqueda_file.write(\"val_journal_input = '\"+string2+'\\''+'\\n')\r\n busqueda_file.write(\"val_autor_input = '\"+string3+'\\''+'\\n')\r\n busqueda_file.close()\r\n print(string)\r\n#Recibe Consulta y Evalúa\r\nfrom tkinter import *\r\nroot = Tk()\r\nroot.geometry(\"310x180\")\r\nf1=Frame(root, height=150, width=200)\r\nroot.title('Buscador de Papers 3000')\r\nLabel1=Label(root,text='Ingrese Búsqueda:').pack()\r\ne = Entry(root)\r\ne.pack()\r\n\r\nLabel2=Label(root,text='Ingrese Libro:').pack()\r\nf = Entry(root)\r\nf.pack()\r\nLabel3=Label(root,text='Ingrese Autor:').pack()\r\ng = Entry(root)\r\ng.pack()\r\n\r\ne.focus_set()\r\n\r\n\r\nb = Button(root,text='Submit',command=printtext)\r\nb.pack(side='bottom')\r\nroot.mainloop()\r\n\r\n"
},
{
"alpha_fraction": 0.6328815817832947,
"alphanum_fraction": 0.6387743353843689,
"avg_line_length": 37.95294189453125,
"blob_id": "3378c05fbf77d32d03775c4085d7e6b11ba5e304",
"content_id": "729abed7e807569074aaaa35f468c14fd3b64cdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3394,
"license_type": "no_license",
"max_line_length": 181,
"num_lines": 85,
"path": "/BOT_VersionF_KM/descargador_papers.py",
"repo_name": "H-daniel00/Bot-Python",
"src_encoding": "UTF-8",
"text": "import requests\r\nfrom bs4 import BeautifulSoup\r\nimport time\r\nfrom selenium import webdriver\r\nfrom selenium.webdriver.common.keys import Keys\r\nimport os\r\nimport busqueda\r\nfrom datetime import datetime, timedelta\r\n\r\nmain_search = busqueda.val_busqueda_input\r\nlibro = ''#busqueda.val_journal_input\r\nautor = busqueda.val_autor_input\r\nmain_search2 = main_search.replace(':','').replace('\\\\','').replace('/','').replace('*','').replace('?','').replace('\"','\\'').replace('<','(').replace('>',')').replace('|','l')\r\n\r\ntry:\r\n os.mkdir(main_search)\r\nexcept FileExistsError:\r\n print(\"creado\")\r\n\r\ndriver = webdriver.Chrome()\r\ndriver.get('https://www.sciencedirect.com/search')\r\ndriver.find_element_by_id('qs-searchbox-input').send_keys(main_search)\r\ndriver.find_element_by_id('authors-searchbox-input').send_keys(autor)\r\ndriver.find_element_by_id('pub-searchbox-input').send_keys(libro)\r\ndriver.find_element_by_id('volume-searchbox-input').send_keys('')\r\ndriver.find_element_by_id('issue-searchbox-input').send_keys('')\r\ndriver.find_element_by_id('page-searchbox-input').send_keys('')\r\n\r\ndriver.find_element_by_id('qs-searchbox-input').send_keys(Keys.RETURN)\r\ntime.sleep(4)\r\n\r\ndriver.find_element_by_css_selector(\"button[class='button modal-close-button button-anchor move-right move-top u-margin-s size-xs']\").click()\r\nli_list = driver.find_elements_by_xpath('//li[@data-doi]')\r\n\r\ndoi_list = []\r\nfor li in li_list:\r\n doi_list.append(li.get_attribute('data-doi'))\r\n\r\na_list = driver.find_elements_by_xpath('//li[@data-doi]//h2/a')\r\nnombres_list = []\r\nfor a in a_list:\r\n nombres_list.append(a.text.replace(':','').replace('\\\\','').replace('/','').replace('*','').replace('?','').replace('\"','\\'').replace('<','(').replace('>',')').replace('|','l'))\r\n\r\ndriver.close()\r\n\r\n\r\nnum=0\r\nnum2=0\r\nflag_descargado = []\r\nfor i, doi in enumerate(doi_list):\r\n r = requests.get('https://sci-hub.tw/'+doi)\r\n html_soup = BeautifulSoup(r.text, 'html.parser')\r\n try:\r\n # if html_body.find()\r\n pdf_link = html_soup.find(id='article').iframe.get('src').split('#view')[0] \r\n if pdf_link[:2] == '//':\r\n pdf_link = 'http:' + pdf_link\r\n with open(main_search+'/'+nombres_list[i]+'.pdf', 'wb') as f:\r\n #print(nose+'/'+nombres_list[i]+'.pdf')\r\n #print(pdf_link)\r\n f.write(requests.get(pdf_link).content)\r\n print('Descargado el paper ',str(i))\r\n flag_descargado.append('downloaded')\r\n num=num+1\r\n except (AttributeError,ConnectionError):\r\n flag_descargado.append('failed')\r\n num2=num2+1\r\n except UnicodeEncodeError:\r\n flag_descargado.append('failed')\r\n num2=num2+1\r\n\r\nhistoric_file = open(\"historico.txt\",\"a\")\r\nhistoric_file.write(main_search2+' LISTA DE PAPERS:'+'\\t'+'STATUS'+'\\t'+'FECHA'+'\\t'+'DOI'+'\\n')\r\nfor i, k in enumerate(nombres_list):\r\n historic_file.write(k+'\\t'+flag_descargado[i]+'\\t'+datetime.now().strftime(\"%Y/%m/%d, %H:%M:%S\")+'\\t'+doi_list[i]+'\\n')\r\n\r\nhistoric_file.write('FIN DE BUSQUEDA '+main_search2+'\\t'+str(num)+' PAPERS DESCARGADOS'+'\\t'+str(num2)+' PAPERS NO DISPONIBLES'+'\\t'+'TEMA: '+main_search+'\\r\\n')\r\nhistoric_file.close()\r\n\r\nvalidation_file = open(\"validador.py\",\"w+\")\r\nvalidation_file.write(\"val_busqueda = '\"+main_search2+'\\'')\r\nvalidation_file.close()\r\n \r\n# si no encuentra el paper en scihub\r\n#si esta siendo usado cerrarlo PermissionError"
}
] | 6 |
Suryavandana123/Python-Programs | https://github.com/Suryavandana123/Python-Programs | d706be28d21b8fdeb39e5e5b6a2e74b82058c406 | acc600c8e89ca5ae517838f3a87773c5c16dec46 | ce59375df47aa610bac67a5e212d72c028b5c5ac | refs/heads/main | 2023-07-17T02:20:01.151770 | 2021-08-26T16:35:43 | 2021-08-26T16:35:43 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5203452706336975,
"alphanum_fraction": 0.5647348761558533,
"avg_line_length": 14.8125,
"blob_id": "9ca222f76bba53244b865b99052ed875a4d1496d",
"content_id": "1bea50ff078c8d37bf924e8a424fdb30fd75c149",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 811,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 48,
"path": "/while_loop.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''a=int(input(\"enter the range\"))\r\nprint(\"fibonacci series\")\r\ni=1\r\np=0\r\nq=1\r\nsum=0\r\nprint(q)\r\nwhile i<a+1:\r\n sum=p+q \r\n print(sum)\r\n p=q=sum \r\n i+=1'''\r\n\r\n'''#list using while loop\r\nlist=[1,2,3,4,5,6,7,8,9,50,60]\r\n#legth of list\r\nlength=len(list)\r\ni=0\r\nsum=0\r\n#iterating over while loop\r\nwhile i<length:\r\n sum=sum+list[i]\r\n i+=1\r\nprint(\"sum of list\",sum)'''\r\n\r\n'''i=1\r\nwhile(i<=10):\r\n print(i)\r\n i=i+1'''\r\n\r\n'''# print numbers in reverse order\r\nprint(\"numbers in reverse order\")\r\ni=10\r\nwhile i>0:\r\n print(i)\r\n i-=1'''\r\n\r\n'''#sum of natural numbers up to 10\r\nn=int(input(\"enter a numbers:\"))\r\nif n<0:\r\n print(\"please enater a positive numbers\")\r\nelse:\r\n sum=0\r\n#use while loop to iterate until zero\r\nwhile(n>0):\r\n sum+=n\r\n n-=1\r\n print(\"the result is\",sum)'''\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.585780143737793,
"alphanum_fraction": 0.636738657951355,
"avg_line_length": 24.8410587310791,
"blob_id": "4e0ca6599ac0b9ab2a296da806a6a82be9d45d14",
"content_id": "1f7bb9a1933a51af515496781da42bc8b6545a83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4121,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 151,
"path": "/Try_Exception.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''a=int(input(\"enter first number\"))\r\nb=int(input(\"enter second number\"))\r\nprint(a/b)'''\r\n\r\n'''a=int(input(\"enter first number\"))\r\nb=int(input(\"enter second number\"))\r\ntry: print(a/b)\r\nexcept:\r\n print(\" you can not divide any number by zero\")'''\r\n\r\n'''a=int(input(\"enter first number\"))\r\nb=int(input(\"enter second number\"))\r\ntry: \r\n print(2/0)\r\nexcept:\r\n print(\"the description of exception:\",message)'''\r\n\r\n'''a=int(input(\"enter any one number a=\"))\r\nb=int(input(\"enter second number b=\"))\r\ntry: \r\n b>a\r\n print(\"b is greater than a\")\r\nexcept:\r\n a==b\r\n print(\"a and b are equal\")'''\r\n\r\n'''a=int(input(\"enter an age\"))\r\nage=18\r\ntry:\r\n a>=18\r\n print(\"you are eligible\")\r\n\r\nexcept:\r\n a<18\r\n print(\"you are not eligible\")'''\r\n\r\n'''#WAP to reverse 3 numbers\r\nnum=int(input(\"enter three number\"))\r\na=num%10 #a=3 123%10\r\nnum=num//10 #num=12 |123//10=12\r\n#print(a)\r\nb=num%10 #12 |123//10=12\r\nc=num%10 #c=1\r\nrev=a*100+b*10+c*1 #(3*100=321)\r\nprint(\"reverse= \",rev)'''\r\n\r\n'''#WAP to reverse 5 numbers\r\nnum=int(input(\"enter five number\"))\r\na=num%10 #a=5 12345%10\r\nnum=num//10 #num=1234 |12345//10=1234\r\n#print(a)\r\nb=num%10 #1234 |12345//10=12\r\nc=num%10 #c=1\r\nrev=a*100+b*10+c #(5*100=54321)\r\nprint(\"reverse= \",rev)'''\r\n\r\n'''#WAP to reverse 7 numbers\r\nnum=int(input(\"enter seven number\"))\r\na=num%10 #a=7 1234567%10\r\nnum=num//10 #num=123456 |1234567//10=123456\r\n#print(a)\r\nb=num%10 #123456 |1234567//10=12345\r\nc=num%10 #c=1\r\nrev=a*100+b*10+c #(7*100=7654321)\r\nprint(\"reverse= \",rev)'''\r\n\r\n'''#armstrong number\r\ndef number(n):\r\n temp=n #153\r\n sum=0 #0 \r\n while(temp!=0):\r\n rm=temp%10\r\n sum=sum+(rm*rm*rm)\r\n temp=temp//10\r\n print(sum)\r\n return (sum==n)\r\nn= int(input(\"enter numbet to check it is armstrong number or not\"))\r\nprint(number(n)) #calling function'''\r\n\r\n#a=int(input(\"enter first integer\"))\r\n#b=int(input(\"enter second integer\"))\r\n#multiple except block\r\n'''try:\r\n a=int(input(\"enter first integer\"))\r\n b=int(input(\"eneter second integer\"))\r\n print(a/b)\r\nexcept ZeroDivisionError as message:\r\n print(\"plz ensure that you can't divide any no by zero:\",ZeroDivisionError)\r\nexcept ValueError as message:\r\n print(\"enter only integer no=>\",message)'''\r\n\r\n'''#Handling multiple diffrent kinds of exception with single except block\r\ntry:\r\n a=int(input(\"enter first number\"))\r\n b=int(input(\"enter second number\"))\r\n print(a/b)\r\nexcept (ValueError,ZeroDivisionError) as messaage:\r\n print(\"enter correct number:\")'''\r\n\r\n'''try:\r\n a=int(input(\"enter first number\"))\r\n b=int(input(\"enter second number\"))\r\n print(a/b)\r\nexcept (ValueError,ZeroDivisionError) as messaage:\r\n print(\"enter correct number:\")\r\nelse:\r\n print(\"Everything is ok\")'''\r\n\r\n'''try:\r\n a=int(input(\"enter first number\"))\r\n b=int(input(\"enter second number\"))\r\n print(a/b)\r\nexcept (ValueError,ZeroDivisionError) as messaage:\r\n print(\"enter correct number:\")\r\nfinally:\r\n print(\"I will always execute\")'''\r\n\r\n#Nested try except block\r\n'''try:\r\n a=int(input(\"enter first number\"))\r\n b=int(input(\"enter second number\"))\r\n try:\r\n print(a/b)\r\n except ZeroDivisionError as msg:\r\n print(msg)\r\nexcept ValueError as msg:\r\n print(msg)'''\r\n\r\n#user defined exception by raise keyword\r\n'''obj=50\r\nif obj>40:\r\n raise Exception(\"value 40 is not greater than 50\")'''\r\n\r\n'''#python logging\r\nimport logging\r\nlogging.basicConfig(filename=\"newfile.txt\",level=logging.DEBUG)\r\nlogging.debug(\"this indicates the debugging information\")\r\nlogging.info(\"this indicates the imortant information\")\r\nlogging.error(\"this indcates error information\")\r\nlogging.warning(\"this indicates the warning information\")\r\nlogging.critical(\"this indicates the critical infrmation\")'''\r\n\r\n'''import logging\r\nlogging.basicConfig(filename=\"newexception.txt\",level=logging.DEBUG)\r\ntry:\r\n a=int(input(\"enter first number\"))\r\n b=int(input(\"enter second number\"))\r\n print(a/b)\r\nexcept(ZeroDivisionError, ValueError) as message:\r\n print(message)\r\n logging.exception(message)'''\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6146789193153381,
"alphanum_fraction": 0.6238532066345215,
"avg_line_length": 23,
"blob_id": "a44b80231562981ece6bb88d977261a7962545bb",
"content_id": "307ac9dc13798899bef242f14117f318104884fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 327,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 13,
"path": "/Module1.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "def welcome(fname,lname): #called function\r\n print(\"First Name =\",fname)\r\n print(\"Second Name=\",lname)\r\n\r\ndef square(n):\r\n print(n*n)\r\npi=3.14\r\n\r\ndef login(username,password):\r\n if username == password:\r\n print(\"you have login successfully\")\r\n else:\r\n print(\"you have enterd wrong credentials\")\r\n\r\n"
},
{
"alpha_fraction": 0.45875096321105957,
"alphanum_fraction": 0.5080956220626831,
"avg_line_length": 16.72058868408203,
"blob_id": "c88450efa2fef98c74e110b87f9a0f9509ba0469",
"content_id": "af634527a413d1ed7fe9f89086b77bc7e890b238",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1297,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 68,
"path": "/range 1.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "#task 1\r\n'''a=input(\"enter the range\")\r\nx=range(a)\r\nfor i in x:\r\n print(i)'''\r\n\r\n'''y=range(10,0,-1)\r\nfor i in y:\r\n print(i)'''\r\n\r\n'''b=int(input(\"tables of\"))\r\nd=int(input(\"enter the range of table\"))\r\nc=range(0,d)\r\nfor i in c:\r\n print(b,'*',i,'=',b*i)'''\r\n\r\n'''a=int(input(\"enter the range of the tables\"))\r\nb=int(input(\"enter the nos tables\"))\r\nprint(\"\\t\\t\\tMULTIPLICATION TABLES OF\",a)\r\n#y=range(1,a)\r\n#x=range(1,b)\r\nfor i in range(1,a):\r\n for j in range(1,b):\r\n print(i,'*',j,i*j)\r\n print(\"\\n\")'''\r\n\r\n\r\n'''asc=str(input(\"enter any value from keyboard\"))\r\nch = int(asc)\r\nif(ch >= 65 and ch <= 90):\r\n\tprint(\"Upper\")\r\nelif(ch >= 97 and ch <= 122):\r\n\tprint(\"Lower\")\r\nelif(ch >= 48 and ch <= 57):\r\n\tprint(\"Number\")\r\nelse:\r\n\tprint(\"Symbol\")'''\r\n\r\n'''r= range(30,10,-2)\r\nprint(r)\r\nfor i in r: #i=\r\n print(i)'''\r\n\r\n'''for i in range (1,11):\r\n print(i*2,\" \",i*3,\" \",i*4,\" \",i*5,\" \",i*6,\" \",i*7,\" \",i*8,\" \",i*9,\" \",i*10)'''\r\n\r\n#reverse number from 1-10\r\n'''for i in range(10,0,-1):\r\n print(i)'''\r\n\r\n'''r=range(10)\r\nprint(r)\r\nfor i in r:#(0,10) i=2\r\n print(i)'''\r\n\r\n'''import time\r\nr= range(10)\r\nprint(r)\r\nfor i in r:\r\ntime.sleep(2)\r\nprint(i)'''\r\n\r\n'''import time\r\nr= range(10)\r\nprint(r)\r\nfor i in r: #(0,10) i=3\r\ntime .sleep(2)\r\nprint(i)'''\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n \r\n"
},
{
"alpha_fraction": 0.5708990097045898,
"alphanum_fraction": 0.634847104549408,
"avg_line_length": 20.89130401611328,
"blob_id": "e3f8995c6c748b6806446512f9d712e2fccf578e",
"content_id": "e483de021c7ad97d9ffeb34f7ca6e0873f6ca1e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1079,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 46,
"path": "/Set.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''myset={1,2,\"sanjay\",5.66,\"rrahul\",\"ayush\",\"ramesh\",\"ankit\",\"rishikesh\"}\r\nprint(myset)'''\r\n\r\n'''myset.add(60)\r\nprint(myset)'''\r\n'''myset.discard(3)\r\nprint(myset)'''\r\n#new set={1,2,3,\"saanjay\",5.66,\"rahul\",\"ayush\"}\r\n#print(type(newset))\r\n#print(newset)\r\n\r\n'''myset={10,20,30,40}\r\nyorset={\"Surya\",\"Vandana\"}\r\nnewset=newset.union\r\nprint(newset)'''\r\n#union()this method will return newset\r\n\r\n#intersection will return common element\r\n'''myset={10,20,30,40}\r\nyorset={10,50,60,30}\r\nprint(myset.intersection(yorset))'''\r\n\r\n#diffrence()method will return the lemenets present in myset but not in yorset\r\n'''myset={10,20,30,40}\r\nyorset={10,50,60,30}\r\nprint(myset.diffrence(yorset))'''\r\n#clear() we can use to clear data\r\n\r\n'''newset={1,2,\"sanjay\",5.66,\"rrahul\",\"ayush\",\"ramesh\",\"ankit\",\"rishikesh\"}\r\nprint(type(newset))\r\n\r\nfs=frozenset(newset)\r\nprint(type(fs))\r\nprint(fs)'''\r\n\r\n'''mydict={\r\n \"name\":\"Vandana\"\r\n \"Student\"\r\n }\r\nprint(mydict)\r\n\r\nmydict[\"Mobile_number\"]=9510879487\r\nprint(mydict)\r\n\r\nmydict[\"department\"]= \"Electronics\"\r\nprint(mydict)'''\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.4465034604072571,
"alphanum_fraction": 0.4792371094226837,
"avg_line_length": 21.912338256835938,
"blob_id": "438cd92d4b2d3044c972c5448572ec471d21944c",
"content_id": "ce70f97eb958667303f9fecc7f11cbd7f4f8fd0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7393,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 308,
"path": "/Nested_for_loop_examples.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1): \r\n print(\"* \"*n)'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \")) #n=5\r\nfor i in range(1,n+1): #i=1 , n=6\r\n for j in range(1,n+1): # j=1\r\n print(i,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \")) #5\r\nfor i in range(1,n+1): #i=1\r\n for j in range(1,n+1): #j=2\r\n print(chr(64+i),end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,n+1):\r\n print(n+1-i,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,1+i): \r\n print(\"*\",end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\"*\"*i)'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,1+i):\r\n print(i,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,1+i):\r\n print(j,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,1+i):\r\n print(chr(64+i),end=\" \")\r\n print()'''\r\n\r\n'''import time\r\nn=int(input(\"Enter the number of rows: \"))\r\nfor i in range(3,n+1):6\r\ntime.sleep(1)\r\nfor j in range(1,n+2-i): 4\r\ntime.sleep(1)\r\nprint(\"*\",end=\" \")\r\nprint()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,n+2-i):\r\n print(chr(64+j),end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,n+2-i):\r\n print(n+1-i,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,n+2-i):\r\n print(n+1-j,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,n+2-i):\r\n print(chr(65+n-i),end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),\"*\"*i,end=\" \")\r\n print() '''\r\n\r\n'''import time\r\nn=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1, i+1):\r\n time.sleep(1)\r\n print(\"*\",end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1, i+1):\r\n print(i,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1, i+1):\r\n print(j,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1, i+1):\r\n print(chr(64+i),end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1, i+1):\r\n print(chr(64+j),end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(i-1),end=\" \")\r\n for j in range(1, n+2-i):\r\n print(i,end=\"\")\r\n print()'''\r\n\r\n''''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(i-1),end=\" \")\r\n for j in range(1, n+2-i):\r\n print(j,end=\"\")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(i-1),end=\" \")\r\n for j in range(1, n+2-i):\r\n print(chr(64+i),end=\"\")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(i-1),end=\" \")\r\n for j in range(1, n+2-i):\r\n print(chr(64+j),end=\"\")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1,i):\r\n print(i-j,end=\" \")\r\n for k in range(0,i):\r\n print(k,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1,i):\r\n print(chr(i-j+65),end=\" \")\r\n for k in range(0,i):\r\n print(chr(k+65),end=\" \")\r\n print()\r\nn=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1,i+1):\r\n print(\"*\",end=\" \")\r\n print()'''\r\n\r\n'''for k in range(1,n+1):\r\n print(\" \"*k,end=\" \")\r\n for l in range(1,n+1-k):\r\n print(\"*\", end=\" \")\r\n print()\r\n\r\nn=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1,i+1):\r\n print(i ,end=\" \")\r\n print()\r\n\r\nfor k in range(1,n+1):\r\n print(\" \"*k,end=\" \")\r\n for l in range(1,n+1-k):\r\n print(k, end=\" \")\r\n print()'''\r\n\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(n-i),end=\" \")\r\n for j in range(1,i+1):\r\n print(chr(64+i) ,end=\" \")\r\n print()\r\n\r\nfor k in range(1,n+1):\r\n print(\" \"*k,end=\" \")\r\n for l in range(1,n+1-k):\r\n print(chr(64+k), end=\" \")\r\n print() '''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,i+1):\r\n print(\"*\",end=\" \")\r\n print()\r\nfor k in range(1,n+1):\r\n for l in range(1,n+2-k):\r\n print(\"*\",end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,i+1):\r\n print(i,end=\" \")\r\n print()\r\nfor k in range(1,n+1):\r\n for l in range(1,n+2-k):\r\n print(k,end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n for j in range(1,i+1):\r\n print(chr(64+i),end=\" \")\r\n print()\r\nfor k in range(1,n+1):\r\n for l in range(1,n+2-k):\r\n print(chr(64+k),end=\" \")\r\n print()'''\r\n\r\n'''n=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(i-1),end=\" \")\r\n for j in range(1,i):\r\n print(\"*\",end=\" \")\r\n print()\r\n\r\nfor k in range(1,n+1):\r\n print(\" \"*(n-k),end=\" \")\r\n for l in range(1,k+1):\r\n print(\"*\",end=\" \")\r\n print()'''\r\n\r\n'''import time\r\nn=int(input(\"Enter the number of rows: \"))\r\nfor i in range(1,n+1):\r\n print(\" \"*(i-1),end=\" \")\r\n time.sleep(1)\r\n for j in range(i,n+2-i):\r\n print(j,end=\" \")\r\n print()\r\n\r\nfor k in range(1,n+1):\r\n print(\" \"*(n-k),end=\" \")\r\n time.sleep(1)\r\n for l in range(1,k+1):\r\n print(k,end=\" \")\r\n print()'''\r\n\r\n\r\n#nterms = int(input(\"How many terms? \"))\r\n\r\n# first two terms\r\n'''n1, n2 = 0, 1\r\ncount = 0\r\n\r\n# check if the number of terms is valid\r\nif nterms <= 0:\r\n print(\"Please enter a positive integer\")\r\nelif nterms == 1:\r\n print(\"Fibonacci sequence upto\",nterms,\":\")\r\n print(n1)\r\nelse:\r\n print(\"Fibonacci sequence:\")\r\n while count < nterms:\r\n print(n1)\r\n nth = n1 + n2\r\n # update values\r\n n1 = n2\r\n n2 = nth\r\n count += 1'''\r\n\r\n'''i=1\r\nwhlie i<6:\r\n print(i)\r\n i+=1'''\r\n\r\n'''n=int(input(\"enter the number of rows:\"))\r\nfor i in range(1,n+1):#i=1\r\n for j in range(1,n+1):#j=2\r\n print(chr(64+i),end=\" \")\r\n print()'''\r\n\r\n '''for.ch.in.'Surya vandana':#ch=0,1...,2,3,4\r\n print(ch)\r\n if ch=='r' or ch=='d':\r\n break\r\n print('current letter:',ch)'''\r\n\r\n\r\n\r\n\r\n\r\n \r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.42034804821014404,
"alphanum_fraction": 0.5140562057495117,
"avg_line_length": 20.696969985961914,
"blob_id": "c38c8a6fa67d269b116d5b1a32dc1c7a5efd92be",
"content_id": "a874d2eca34ee3167d75b150a77e49b0fd78a4ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 747,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 33,
"path": "/Break_function.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''for i in range(1,10): #i=1,2,3,4,5\r\n if i ==5:\r\n break\r\n else:\r\n print(i)'''\r\n\r\n'''name=input(\"enter a name:\")\r\ni=0\r\nfor x in name:#x=1,2,3\r\n #if x=='n':\r\n print(\"the character present at ndex no\",i,\"vale=:=\",x)\r\n #break\r\n i=i+1'''\r\n\r\n#to print sum of numbers present inside list\r\n'''list=[1,2,3,4,5]\r\nsum=0\r\nfor x in list:#x=0\r\n sum=sum+x\r\n print(\"the sum\",sum)'''\r\n\r\n'''for i in range(20): #i=0,1,2,3,4,5,6,7,8,9,10,11,12\r\n if i==12:\r\n print(\"this is the right time to take break\")\r\n continue\r\n print(i)'''\r\n\r\n'''mycart=[10,20,200,300,800,60,700]\r\nfor i in mycart: #i=0,1,2,3,4,5,6,7\r\n if i>400:\r\n #print(\"this is my purchased cart item\")\r\n continue\r\n print(i)'''"
},
{
"alpha_fraction": 0.62848299741745,
"alphanum_fraction": 0.6625387072563171,
"avg_line_length": 15.833333015441895,
"blob_id": "7059864f15b22b787f7da62f9bc7fe7e2684d0e3",
"content_id": "1233d995e5bf31e54ca3ce63fd36517b925588e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 323,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 18,
"path": "/Module2.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''import Module1\r\nModule1.square(8)\r\nprint(Module1.pi)\r\nprint(Module1.login)'''\r\n\r\n'''import Module1 as mod\r\nmod.square(9)\r\nprint(mod.welcome)\r\nprint(mod.pi)'''\r\n\r\n'''from Module1 import pi,square,welcome\r\nprint(pi)\r\nsquare(3)\r\nwelcome(\"Vandana\",\"Vandana\")'''\r\n\r\n'''import math\r\nprint(math.sqrt(20))\r\nprint(math.pi)'''\r\n\r\n"
},
{
"alpha_fraction": 0.5502347350120544,
"alphanum_fraction": 0.6028168797492981,
"avg_line_length": 20.10416603088379,
"blob_id": "22b911ebe10c2b5a5fa742a8e0b1fe6151f090b3",
"content_id": "d53a33c8af463b8ec9ed773f256b608c691ef941",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1065,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 48,
"path": "/List.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''mylist= [\"Vandana\",\"Rahul\",\"Gauri\",\"Astha\",\"Riya\",\"Komal\",\"Ramesh\",\"77\",\"Sonal\",\"60.52\"]\r\n\r\nprint(mylist)\r\nprint(type(mylist))\r\nprint(mylist[0])\r\nprint(mylist[1])\r\nprint(mylist[2])\r\nprint(mylist[-1])\r\nprint(mylist[-2])\r\nprint(mylist[2:5])\r\nprint(mylist[:5])\r\nprint(mylist[1:])'''\r\n\r\n'''mylist[2]=\"Suraj\"\r\nprint(mylist)'''\r\n\r\n'''mylist.append(\"pranay\")\r\nprint(mylist)'''\r\n\r\n#append and extend() both work like same\r\n#to add an item at specified position\r\n'''mylist.insert(3,\"Minal\")\r\nprint(mylist'''\r\n\r\n'''mylist.remove(\"sonal\")\r\nprint(mylist)'''\r\n\r\n'''newlist=mylist.copy() #cloning\r\nprint(mylist)\r\n\r\n'''mytuple=(\"Vandana\",\"Rahul\",\"Gauri\",\"Astha\",\"Riya\",\"Komal\",\"Ramesh\",\"77\",\"Sonal\",\"60.52\")\r\nprint(mytuple)\r\n\r\nmylist=[['Surya','Vandana'],['85,56'],[440022,\"yyy\"]]\r\nprint(mylist[0][0])\r\nprint(mylist[0][1])\r\nprint(mylist[1][0])\r\nprint(mylist[2][0])\r\nprint(mylist[2][1])'''\r\n\r\n'''li=[\"vandana\",\"Riya\",\"Sonakshi\"]\r\nfor i in li:# i=0,1,2,3\r\n print(i)''''\r\n\r\n'''#iterating over a string\r\nname='Vandana'\r\nfor i in name: #i=0,1,2,3,4,5,6,7,8\r\n print(i)'''\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5401517152786255,
"alphanum_fraction": 0.5882814526557922,
"avg_line_length": 22.61688232421875,
"blob_id": "8d8fc45f56f22f526f32b7985e1a038b586e66f6",
"content_id": "79d82e380300ba99e70397f2bd827e28898c5419",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3823,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 154,
"path": "/Control Statements.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''age=18\r\nif age>=18:\r\n print(\"you re eligible\")\r\n\r\nelse:\r\n print(\"you are not eligible\")'''\r\n\r\n''' age=16\r\nif age>=18:\r\n print(\"you re eligible\")\r\n\r\nelse:\r\n print(\"you are not eligible\")'''\r\n\r\n'''a=int(input(\"enter any one number a=\"))\r\nb=int(input(\"enter second number b=\"))\r\nif b>a:\r\n print(\"b is greater than a\")\r\nelif a==b:\r\n print(\"a and b are equal\")'''\r\n\r\n'''brand= input(\"Enter your cold drink name\")\r\nif brand== \"pepsi\" or brand== \"PEPSI\":\r\n print(\"Swag\")\r\nelif brand== \"dew\" or brand==\"DEW\":\r\n print(\"Dar ke aage jeet hain\")\r\nelif brand==\"thumsup\" or brand==\"THUMSUP\":\r\n print(\" Taste the thunder \")\r\nelse:\r\n print(\"Go with your brand\")'''\r\n\r\n'''num=int(input(\"enter a number\"))\r\nfactorial=5\r\nif num<0:\r\n print(\"factorial does not exist for negative number\")\r\nelif num==0:\r\n print(\"factorial of 0 is 1\")\r\nelse:\r\n for i in range(1,num+1):\r\n factorial=factorial*i\r\n print(\"the factorial of\",num,\"is\",factorial)'''\r\n\r\n'''def fibonacci(n):\r\n if n<0:\r\n print(\"incorrect input\")\r\n elif n==0:\r\n return 0\r\n elif n==1 or n==2:\r\n return 1\r\n else:\r\n return fibonacci(n-1)+ fibonacci(n-2)\r\nprint(fibonacci(9))'''\r\n \r\n'''a=int(input(\"enter the value of a\"))\r\nb=int(input(\"enter the value of b\"))\r\nc=int(input(\"enter the value of c\"))\r\nif a>b:\r\n if a>c:\r\n print(\"A is greater\")\r\n else:\r\n print(\"C is greater\")\r\nelse:\r\n if b>c:\r\n print(\"B is greater\")\r\n else:\r\n print(\"C is greater\")'''\r\n\r\n'''#WAP to check if year is a leap year or not\r\nyear=int(input(\"Enter a year:\"))\r\nif(year % 4)==0:\r\n if(year % 400)==0:\r\n print(\"the year is a leap year\")\r\nelse:\r\n print(\"the year is not a leap year\")'''\r\n\r\n'''a=int(input(\"enter the value of a\"))\r\nb=int(input(\"enter the value of b\"))b\r\nc=int(input(\"enter the value of c\"))\r\nif a<b:\r\n print(\"b is greater\")\r\n if a<c:\r\n print(\"C is greater\")\r\nelse:\r\n print(\"C is greater\")\r\n\r\nif b<c:\r\n print(\"C is greater\")\r\n\r\nelse:\r\n print(\"B is greater\")'''\r\n\r\n'''#wap practicle marks\r\n\r\np1=int(input(\"enter the marks of Maths\"))\r\np2=int(input(\"enter the marrks of Eglish\"))\r\np3=int(input(\"enter the marks of science\"))\r\np4=int(input(\"enter the marks of Chemistry\"))\r\np5=int(input(\"enter the marks of Hindi\"))\r\npractical1=int(input(\"enter the mark of physics practical\"))\r\npractical2=int(input(\"enter the marks of Chemistry practical\"))\r\na=p1+p2+p3+p3+p4+p5+practical1+practical2;\r\nb=(a/700.0)*10\r\n#print (b)\r\n#print(a)\r\nprint(\"total marks\",a)\r\nprint(\"total marks\",b)\r\n\r\nif p1>40 and p2>40 and p3>40 and p4<40 and p5>40 and practical1>50 and practical2<50:\r\n print(\"grade D\")\r\n\r\nelif p1>40 and p2>40 and p3>40 and p4>40 and p5>40 and practical1>15 and practical2>20 and b>10 and b<=20:\r\n print(\"grade C\")\r\n \r\nelif P1>40 and P2>40 and P3>40 and P4>40 and P5>40 and practical>15 and practical2>20 and b>40 and b<=60:\r\n print(\"grade B\")\r\n\r\nelif p1>40 and P2>40 and P3>40 and P4>40 and P5>40 and practical1>15 and practical2>20 and b>60 and b<=80:\r\n print(\"grade A\")\r\n\r\nelif p1> 40 and p2>40 and p3> and p4> and p5>40 and practical1>15 and practical2>20:\r\n print(\" Grade= A+\")\r\nelse:\r\n print(\" Fail\")'''\r\n\r\n'''container=[2,1,4,5,5,4,4,1,1]\r\ncount=0\r\neven=0\r\nodd=0\r\nfor i in container:\r\n if i==4:\r\n count+=1\r\n elif i==2:\r\n even+=1\r\n elif i==5:\r\n odd+=1\r\nprint(count-even)\r\nprint(count-odd)'''\r\n\r\n'''name=input(\"Enter name\")\r\nif name== \"Vandana\":\r\n print(\"Hello Iam Vandana and Iam an Engineer\")\r\nelse:\r\n print(\"Did not match the pattern\")'''\r\n\r\n'''no= int(input(\"Enter any single number \"))\r\n\r\nif no>0:\r\n print(\"the number is positive\")\r\n\r\nif no<0:\r\n print(\"the number is negative\")\r\n\r\nif no==0:\r\n print(\"the number is zero\")'''\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n\r\n \r\n \r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6153846383094788,
"alphanum_fraction": 0.6351810097694397,
"avg_line_length": 26.88524627685547,
"blob_id": "decd81acfb89d5f7e056cac1aecfc2d0e561c285",
"content_id": "a7005191c17f98ca0d0645f2255615dd17be56f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1768,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 61,
"path": "/File_Handling_Programs.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''f=open(\"myfile.txt\",\"w\")\r\nprint(\"name of the file\",f.name)\r\nprint(\"filemode\",f.mode)\r\nprint(\"readeable\",f.readable)\r\nf.close'''\r\n\r\n'''f=open(\"covid.txt\",\"w\")\r\nf.write(\"Vandana is the university topper\")\r\nprint(\"written work has done successfully\")\r\nf.close'''\r\n\r\n'''f=open(\"covid.txt\",\"w\")\r\nmylist=[\"Surya\",\"Vandana\",\"pythonclass\"]\r\nf.writelines(mylist)\r\nf.close\r\n\r\nf=open(\"covid.txt\",\"r\")\r\nprint(f.read())\r\nprint(f.read(5))\r\nprint(f.readline())\r\nprint(f.readlines())'''\r\n\r\n'''with open(\"myfile.txt\",\"w\") as f:\r\n f.write(\"amit\\n\")\r\n f.write(\"Vandana\\n\")\r\n print(\"file closed:\",f.closed)\r\nprint(\"file closed:\",f.closed)'''\r\n\r\n'''f=open(\"myfile.txt\",\"r\")\r\nprint(f.tell())\r\n\r\nprint(\"total data\",f.read())\r\nprint(f.tell())\r\nf.seek(5)'''\r\n\r\n'''f1=open(\"flowers.jpg\",\"rb\")\r\nf2=open(\"flowers2.jpg\",\"wb\")\r\ndata=f1.read()\r\nf2.write(data)'''\r\n\r\n'''import csv\r\nf=open(\"student.csv\",\"w\",newline=\"\")\r\na=csv.writer(f)\r\nb=int(input(\"enter the no of student\"))\r\na.writerow([\"rollno\",\"name\",\"mobileno\",\"email\",\"address\",\"paper1\",\"paper2\",\"paper3\",\"paper4\",\"paper5\",\"total\",\"percentage\",\"result\",\"grade\"])\r\nfor i in range(1,b+1):\r\n rollno=int(input(\"enter the roll no\"))\r\n name=input(\"enter the name\")\r\n mobileno=int(input(\"enter the mobileno\"))\r\n email=input(\"enter the email\")\r\n address=input(\"enter the address\")\r\n paper1=int(input(\"enter the marks\"))\r\n paper2=int(input(\"enter the marks\"))\r\n paper3=int(input(\"enter the marks\"))\r\n paper4=int(input(\"enter the marks\"))\r\n paper5=int(input(\"enter the marks\"))\r\n total=paper1+paper2+paper3+paper4+paper5\r\n percentage=(total/500)*100\r\n \r\n a.writerow([rollno,name,mobileno,email,address,paper1,paper2,paper3,paper4,paper5,total,percentage])\r\nprint(\"student record has save\")'''\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.562160074710846,
"alphanum_fraction": 0.5780885815620422,
"avg_line_length": 19.11475372314453,
"blob_id": "c149b2207f2345bf1c40258241d9a26cd5d8e4d5",
"content_id": "8555b8a7ddc0b5f10dd2d08159003bbaf00ab876",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2574,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 122,
"path": "/Function.py",
"repo_name": "Suryavandana123/Python-Programs",
"src_encoding": "UTF-8",
"text": "'''def add(): #called function\r\n a=int(input(\"enter first value\"))\r\n b=int(input(\"enter second value\"))\r\n print(a+b)\r\n add()#calling function'''\r\n\r\n'''import time\r\ndef add(): #called function\r\n a=int(input(\"enter first value\"))\r\n b=int(input(\"enter second value\"))\r\n print(a+b)\r\n time.sleep(2)\r\n\r\nadd()#calling function\r\nprint(\"first time call completed\")\r\nadd()\r\nprint(\"second time call completed\")\r\nadd\r\nprint(\"third time call completed\")'''\r\n\r\n'''def info(first_nam,Last_name): #called function\r\n print(\"first name=\",first_name)\r\n print(\"second name=\",second_name)\r\n info(\"vandana\",\"atreyapurapu\")'''\r\n\r\n'''def addition(val):#called func\r\n print(\"addition of two no=\",val+val)\r\n\r\n addition(5)#calling func\r\n addition(10)'''\r\n\r\n'''#positional argument passing in correct \r\ndef add(num1,num2):\r\n return num1+num2\r\n print(add(2,3))#called function'''\r\n\r\n'''def factorial(n):\r\n if n == 0:\r\n return 1\r\n else:\r\n return n * factorial(n-1)\r\nn=int(input(\"enter a number: \"))\r\nprint(factorial(n))'''\r\n\r\n'''def sum(x,y):\r\n return x+y\r\n\r\na= int(input(\"Enter first number:\"))\r\nb= int(input(\"Enter second number:\"))\r\nprint(\"Sum of the given two numbers is: \", sum(a,b))'''\r\n\r\n'''def diff(x,y):\r\n return x-y\r\n\r\na=int(input(\"enter first number\"))\r\nb=int(input(\"enter second number\"))\r\nprint(\"diff of given two numbers is:\",diff(a,b))'''\r\n\r\n'''def largest(x, y):\r\n if x > y:\r\n return x\r\n else:\r\n return y\r\nx = int(input(\"Enter first number:\"))\r\ny = int(input(\"Enter second number:\"))\r\nresult = largest(x, y)\r\nprint(\"Largest is:\", result)'''\r\n\r\n'''def smallest(x,y):\r\n if x<y:\r\n return x\r\n else:\r\n return y\r\nx=int(input(\"enter first number\"))\r\ny=int(input(\"enter second number\"))\r\nresult=smallest(x,y)\r\nprint(\"smallest is:\",result)'''\r\n\r\n'''# Function for fibonacci\r\n\r\ndef fibonacci(n):\r\n\ta = 0\r\n\tb = 1\r\n\t\r\n\t# Check is n is less\r\n\t# than 0\r\n\tif n < 0:\r\n\t\tprint(\"Incorrect input\")\r\n\t\t\r\n\t# Check is n is equal\r\n\t# to 0\r\n\telif n == 0:\r\n\t\treturn 0\r\n\t\r\n\t# Check if n is equal to 1\r\n\telif n == 1:\r\n\t\treturn b\r\n\telse:\r\n\t\tfor i in range(1, n):\r\n\t\t\tc = a + b\r\n\t\t\ta = b\r\n\t\t\tb = c\r\n\t\treturn b\r\nprint(fibonacci(9))'''\r\n\r\n'''def func(name):# called function [\"Vandana\",\"Garima\",\"Sonal\",\"Rahul\"]\r\n for i in (name): #i=0,1,2,3,4\r\n print(i)\r\n\r\nname_of_p=[\"vandana\",\"Garima\",\"Sonal\",\"Rahul\"]\r\nfunc(name_of_p)#calling function'''\r\n\r\n'''mydict={\r\n 101: \"Vandana\",\r\n 102: \"Garima\",\r\n 103: \"Sonal\",\r\n 104: \"Rahul\"\r\n}\r\nprint(mydict)\r\n\r\nfor x in mydict.values():\r\n print(x)'''"
}
] | 12 |
cuglilong/spac | https://github.com/cuglilong/spac | 0b51d47339224c5f63f6dd385f0724b6c9e15c4d | e58968124b46af69bcb9d9493f9573284732ea6f | 0d49cc3dbf2f5e544b5b7c31e50f5ac3287818ad | refs/heads/master | 2023-06-09T06:22:44.766288 | 2018-01-18T04:16:51 | 2018-01-18T04:16:51 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.36867979168891907,
"alphanum_fraction": 0.3830881416797638,
"avg_line_length": 53.32008361816406,
"blob_id": "46e54b55d145975a1c4b1e32acb25200350a9238",
"content_id": "29ed3830b445ecf40aafa15e060235fb0572c2c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 26443,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 478,
"path": "/SPAC.py",
"repo_name": "cuglilong/spac",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Sun Jan 14 14:38:00 2018\r\n\r\n@author: ainurrofiq\r\n\"\"\"\r\nimport os\r\nimport numpy as np\r\nimport scipy as sp\r\nfrom obspy import read\r\nimport scipy.signal as sg\r\nimport matplotlib.pyplot as plt\r\nimport collections \r\nimport scipy.special\r\nfrom datetime import datetime\r\n\r\nclass Clustering(object):\r\n def __init__ (self, array, deviation=5):\r\n self.array = array\r\n self.deviation = deviation\r\n def __call__ (self):\r\n ValList, IdxList, Cluster, ClusIdx, kepake=[], [], [], [], []\r\n for i in range(len(self.array)):\r\n if self.array[i] not in kepake:\r\n Cluster=[self.array[i]]\r\n ClusIdx=[i]\r\n for j in range(len(self.array)):\r\n if i<j and self.array[j] not in kepake:\r\n if len(Cluster)==1:\r\n if np.std([self.array[i], self.array[j]],0)<= np.abs((self.deviation/100.0)*np.mean([self.array[i], self.array[j]],0)):\r\n Cluster.append(self.array[j])\r\n ClusIdx.append(j)\r\n else:\r\n if np.abs(self.array[j]-np.mean(Cluster,0))<= np.abs((self.deviation/100.0)*np.mean(Cluster,0)):\r\n Cluster.append(self.array[j])\r\n ClusIdx.append(j)\r\n if len(Cluster)>=1:\r\n kepake=Cluster+kepake\r\n ValList.append(np.array(Cluster))\r\n IdxList.append(np.array(ClusIdx))\r\n ClustDict={}\r\n for j in range(len(ValList)):\r\n ClustDict[np.mean(ValList[j])]=[IdxList[j],ValList[j]]\r\n ClustDict=collections.OrderedDict(sorted(ClustDict.items())) \r\n for i in range(len(ClustDict.keys())):\r\n IdxList[i]=ClustDict[ClustDict.keys()[i]][0]\r\n ValList[i]=ClustDict[ClustDict.keys()[i]][1]\r\n return IdxList, ValList\r\n \r\n \r\nclass xcross0(object):\r\n def __init__ (self, xdata, ydata):\r\n self.xdata = xdata\r\n self.ydata = ydata\r\n def __call__ (self):\r\n xnol=[]\r\n for p in range(len(self.ydata)-1):\r\n if (self.ydata[p]<0 and self.ydata[p+1]>0) or (self.ydata[p]>0 and self.ydata[p+1]<0) :\r\n for k in range(len(np.argwhere(self.ydata==self.ydata[p]))):\r\n for l in range(len(np.argwhere(self.ydata==self.ydata[p+1]))):\r\n if np.argwhere(self.ydata==self.ydata[p+1])[l][0]-np.argwhere(self.ydata==self.ydata[p])[k][0]==1:\r\n idx1=np.argwhere(self.ydata==self.ydata[p])[k][0]\r\n idx2=np.argwhere(self.ydata==self.ydata[p+1])[l][0]\r\n x1=self.xdata[idx1]\r\n x2=self.xdata[idx2]\r\n y1=self.ydata[idx1]\r\n y2=self.ydata[idx2]\r\n xnol.append((((x2-x1)/(y2-y1))*(-y1))+x1)\r\n return np.array(xnol)\r\n \r\n \r\nclass SPAC(object):\r\n def __init__(self, fout, unique='', akhir='', filtSignal=None, window=3600, CoordinateFile='coordinate.txt', diststd=5):\r\n \"\"\" \r\n Atributes :\r\n unique = part of input name (string)\r\n akhir = format file(string)\r\n fout = output frequency in output file ([fmin, fmax])\r\n format = input's format (string)\r\n filtSignal = apply bandpass filter to all signal\r\n None - No filter appy\r\n [freqmin, freqmax] - filter from freqmin to freqmax\r\n window = length window in seconds \r\n CoordinateFile = file coordinate (name, x, y, z)(string)\r\n \"\"\"\r\n self.unique = unique\r\n self.akhir = akhir\r\n self.window = window\r\n self.CoordinateFile = CoordinateFile\r\n self.fout = fout\r\n self.diststd = diststd\r\n self.filtSignal = filtSignal\r\n \r\n def __call__(self):\r\n start_time = datetime.now()\r\n \r\n #=============== Zero Order Bessel Function of the First Kind ==================\r\n xo = np.linspace(0,50,500)\r\n Jo = scipy.special.jv(0,xo)\r\n x0 = xcross0(xo, Jo)()\r\n x0 = x0[0:12]\r\n \r\n \r\n if not os.path.exists(os.getcwd()+'\\\\TIME AVERAGE'):\r\n os.makedirs(os.getcwd()+'\\\\TIME AVERAGE')\r\n if not os.path.exists(os.getcwd()+'\\\\SPATIAL_AVERAGE'):\r\n os.makedirs(os.getcwd()+'\\\\SPATIAL_AVERAGE')\r\n \r\n #=============== List of Input Record Files ==================\r\n RecordFiles=[a for a in os.listdir(os.getcwd()) if self.unique in a and a.endswith(self.akhir)]\r\n \r\n #=============== Identify Station Coordinate ==================\r\n floc=open((self.CoordinateFile),'r')\r\n fline=floc.readlines()\r\n LocDict={}\r\n for i in range(len(fline)):\r\n fline[i]=fline[i].split()\r\n LocDict[fline[i][0]]=[float(fline[i][1]),float(fline[i][2]),float(fline[i][3])]\r\n\r\n #=============== Read Input Files ==================\r\n st=read(RecordFiles[0])\r\n for i in range(len(RecordFiles)-1):\r\n st+=read(RecordFiles[i+1])\r\n st.sort(keys=['station']) \r\n if self.filtSignal != None:\r\n st.filter('bandpass', freqmin=self.filtSignal[0], freqmax=self.filtSignal[1])\r\n \r\n #=============== Apply Coordinate to Station ==================\r\n for i in range(len(st)):\r\n if LocDict.has_key(st[i].stats.station)==True:\r\n st[i].stats.location=LocDict[st[i].stats.station]\r\n \r\n #========================= Logfile ===========================\r\n logfile=''\r\n logfile=logfile+'=======================================\\n'\r\n logfile=logfile+'Start Time = '+str(start_time)+'\\n'\r\n logfile=logfile+'=======================================\\n'\r\n logfile=logfile+'=======================================\\n'\r\n logfile=logfile+'Length Window = '+'{:>8.2f}'.format(self.window)+' seconds\\n'\r\n logfile=logfile+('Output Frequency = '+'{:5.2f}'.format(self.fout[0])+\r\n ' Hz to '+'{:5.2f}'.format(self.fout[1])+' Hz\\n')\r\n if self.filtSignal != None:\r\n logfile=logfile+('Filter ( Bandpass ) = '+'{:5.2f}'.format(self.filtSignal[0])+\r\n ' Hz to '+'{:5.2f}'.format(self.filtSignal[1])+' Hz\\n')\r\n else:\r\n logfile=logfile+'Filter ( Bandpass ) = No Filter\\n'\r\n logfile=logfile+'\\n----------- Station List -----------\\n'\r\n logfile=logfile+'Name \\t Easting (m) \\t Northing (m) \\t Elevation(m)\\n'\r\n for i in range(len(st)):\r\n logfile=(logfile+\r\n '{:8.6}'.format(str(st[i].stats.station))+\r\n '{:12.4f}'.format(st[i].stats.location[0])+\r\n '{:17.4f}'.format(st[i].stats.location[1])+\r\n '{:14.4f}'.format(st[i].stats.location[2])+'\\n')\r\n logfile=logfile+'--------------------------------------\\n\\n'\r\n with open(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\LOGFILE.txt','w') as f: \r\n f.write(logfile)\r\n f.close() \r\n \r\n #=========== Smoothing Constant ( Hanning Window ) =============\r\n smooth=(np.hanning(int(0.0005*self.window*st[0].stats.sampling_rate))/\r\n sum(np.hanning(int(0.0005*self.window*st[0].stats.sampling_rate))))\r\n \r\n #=== Iteration to make every station as a center of irregular array ===\r\n for sig in range(len(st)):\r\n #========================= Logfile ===========================\r\n log=open(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\LOGFILE.txt','a')\r\n log.write('{:8.6}'.format(str(st[sig].stats.station))+'( Center of Array )'+'\\n')\r\n \r\n # Amplitude and sampling frequency of centre in time domain \r\n StaPusat=st[sig]\r\n Fs=StaPusat.stats.sampling_rate \r\n \r\n # ================= FFT Parameter =================== \r\n wd=self.window*StaPusat.stats.sampling_rate\r\n nft=self.window*StaPusat.stats.sampling_rate\r\n \r\n # ================= Do FFT at center ================ \r\n freq_pusat, time_pusat, Sxx_pusat_ = sg.spectrogram(StaPusat.data, \r\n nperseg=wd,\r\n noverlap=0,\r\n nfft=nft, \r\n fs=Fs, \r\n scaling='spectrum',\r\n mode='complex')\r\n \r\n # ================= Find Data in range output frequency =================\r\n idx = np.where((freq_pusat >= self.fout[0]) & (freq_pusat <= self.fout[1]))\r\n freq_pusat=freq_pusat[idx]\r\n Sxx_pusat_=Sxx_pusat_[idx]\r\n \r\n # Make directory for 'TIME AVERAGE' and 'SPATIAL AVERAGE' output \r\n if not os.path.exists(os.getcwd()+'\\\\TIME AVERAGE\\\\'+StaPusat.stats.station):\r\n os.makedirs(os.getcwd()+'\\\\TIME AVERAGE\\\\'+StaPusat.stats.station)\r\n if not os.path.exists(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\'+StaPusat.stats.station):\r\n os.makedirs(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\'+StaPusat.stats.station)\r\n \r\n # ================= List of non Center Station =================\r\n irover=[x for x in range(len(st)) if x!=sig]\r\n autocorr=np.zeros((len(Sxx_pusat_[:,0]),len(irover)), dtype=np.complex)\r\n \r\n xnolList=[]\r\n distList=[]\r\n ListDist=[]\r\n \r\n # ================= Iteration of non Center Station =================\r\n for c in range(len(irover)):\r\n # ================= Non center Station Index =================\r\n Atr=st[irover[c]]\r\n \r\n # ================= Do FFT at non center =================\r\n freq_rover, time_rover, Sxx_rover_ = sg.spectrogram(Atr.data ,\r\n nperseg=wd, \r\n noverlap=0,\r\n nfft=nft, \r\n fs=Fs,\r\n scaling='spectrum',\r\n mode='complex')\r\n \r\n # ======== Find Data in range output frequency ===========\r\n Sxx_rover_=Sxx_rover_[idx]\r\n \r\n # ================= Measure AutoCorrelation Ratio ================\r\n rat_autocorr=np.zeros((len(Sxx_pusat_[:,0]),len(Sxx_pusat_[0,:])), dtype=np.complex)\r\n for nwd in range(len(Sxx_pusat_[0,:])):\r\n Abs_Sxx_pusat=(abs(Sxx_pusat_[:,nwd]))\r\n Smooth_Abs_Sxx_pusat=sg.convolve(Abs_Sxx_pusat,smooth,mode='same')\r\n \r\n Abs_Sxx_rover=(abs(Sxx_rover_[:,nwd]))\r\n Smooth_Abs_Sxx_rover=sg.convolve(Abs_Sxx_rover,smooth,mode='same')\r\n \r\n rat_autocorr[:,nwd]=((Sxx_pusat_[:,nwd]*np.conj(Sxx_rover_[:,nwd]))/\r\n (Smooth_Abs_Sxx_pusat*Smooth_Abs_Sxx_rover))\r\n \r\n time_autocorr=np.mean(rat_autocorr,axis=1)\r\n autocorr[:,c]=time_autocorr \r\n \r\n # ======== Save result every pair AutoCorrelation Ratio ======== \r\n with open(os.getcwd()+'\\\\TIME AVERAGE\\\\'+StaPusat.stats.station+'\\\\SPAC_'+\r\n StaPusat.stats.station+'-'+Atr.stats.station+'.txt','w') as f: \r\n datas=np.array([freq_pusat,autocorr[:,c].real])\r\n np.savetxt(f,datas.T,fmt='%8.5f')\r\n f.close()\r\n \r\n # ======== measure distance every possible station pair ======== \r\n distance=((Atr.stats.location[0]-StaPusat.stats.location[0])**2+\r\n (Atr.stats.location[1]-StaPusat.stats.location[1])**2+\r\n (Atr.stats.location[2]-StaPusat.stats.location[2])**2)**0.5\r\n ListDist.append(distance)\r\n \r\n # ======== CLusterting pair based on its distance ======== \r\n ListDist=np.array(ListDist)\r\n [IdxList,AllList]=Clustering(ListDist, self.diststd)()\r\n StaList, IdxListNew = [], []\r\n for k in range(len(IdxList)):\r\n StaList_, IdxListNew_ = '', []\r\n for l in range(len(IdxList[k])):\r\n if IdxList[k][l]>= sig :\r\n IdxListNew_.append(IdxList[k][l]+1)\r\n if l==0:\r\n StaList_+=str(st[IdxList[k][l]+1].stats.station)\r\n else:\r\n StaList_+=' + '+str(st[IdxList[k][l]+1].stats.station)\r\n else:\r\n IdxListNew_.append(IdxList[k][l])\r\n if l==0:\r\n StaList_+=str(st[IdxList[k][l]].stats.station)\r\n else:\r\n StaList_+=' + '+str(st[IdxList[k][l]].stats.station)\r\n StaList.append(StaList_)\r\n IdxListNew.append(np.array(IdxListNew_))\r\n \r\n dispersion, labelplot = [], []\r\n # ========================= smoothing ========================== \r\n for j in range(len(AllList)):\r\n time_mean=np.mean(autocorr[:,IdxList[j]].real,axis=1)\r\n #========================= Logfile ===========================\r\n logfile=('\\t'+StaList[j]+'\\n\\taverage radius '+'{:10.4f}'.format(np.mean(AllList[j]))+\r\n ' Standart Deviation '+'{:6.2f}'.format(np.std(AllList[j]))+\r\n ' ( '+'{:4.2f}'.format(100*(np.std(AllList[j])/np.mean(AllList[j])))+\r\n ' % from average radius )\\n')\r\n log.write(logfile)\r\n \r\n # ========================================================== \r\n # ============== smoothing Correlation Curve =============== \r\n # NEED TO BE FIXED!!!!!\r\n # MUST KNOW RELATION BETWEEN FFT LENGTH WINDOW, RADII, \r\n # FREQUENCY (FIRST CROSS) AND SMOOTHING CONSTANT\r\n # \r\n # NOT A GOOD CHOICE FOR LONG DISTANCE PAIR\r\n # SO, MANUAL !!!!\r\n # ==========================================================\r\n delta=[]\r\n if (np.mean(AllList[j]))<=1000:\r\n wind=np.arange(2001, 10001, 100) \r\n elif (np.mean(AllList[j]))>1000 and (np.mean(AllList[j]))<=4000 :\r\n wind=np.arange(401, 2001, 50) \r\n elif (np.mean(AllList[j]))>4000 and (np.mean(AllList[j]))<=8000 :\r\n wind=np.arange(201, 801, 20) \r\n elif (np.mean(AllList[j]))>8000 and (np.mean(AllList[j]))<=16000 :\r\n wind=np.arange(101, 401, 10) \r\n elif (np.mean(AllList[j]))>16000:\r\n wind=np.arange(5, 201, 2) \r\n \r\n for i in range(len(wind)):\r\n ydata2 = sp.signal.savgol_filter(time_mean,wind[i],3)\r\n delta.append(np.mean(abs(time_mean-ydata2))**2)\r\n gradient=np.gradient(delta)\r\n \r\n if np.argwhere(gradient<0).size!=0:\r\n locgradient=np.argwhere(gradient<0)\r\n window=wind[min(locgradient)[0]]\r\n \r\n if np.argwhere(gradient<0).size==0:\r\n locgradient=np.argmin(gradient)\r\n window=wind[locgradient]\r\n ydata = sp.signal.savgol_filter(time_mean,window,3)\r\n \r\n #---------------------------------------------------------------------\r\n #-----------------------cross at y-axes = 0 --------------------------\r\n #---------------------------------------------------------------------\r\n xnol=xcross0(freq_pusat, ydata)()\r\n if np.gradient(ydata)[max(np.argwhere(freq_pusat<=xnol[0]))]>0:\r\n xnol=xnol[1:len(xnol)]\r\n else:\r\n xnol=xnol[0:len(xnol)]\r\n \r\n #--------------------------------------------------------------------------\r\n #----------------------------Dispersion Curve----------------------\r\n #--------------------------------------------------------------------------\r\n vphase = []\r\n if len(xnol)<len(x0):\r\n for dc in range(len(xnol)):\r\n if ((2*(22/7)*np.mean(AllList[j])*xnol[dc])/x0[dc])<4000:\r\n vphase.append((2*(22/7)*np.mean(AllList[j])*xnol[dc])/x0[dc])\r\n elif len(xnol)>len(x0):\r\n for dc in range(len(x0)):\r\n if ((2*(22/7)*np.mean(AllList[j])*xnol[dc])/x0[dc])<4000:\r\n vphase.append((2*(22/7)*np.mean(AllList[j])*xnol[dc])/x0[dc])\r\n vphase=np.array(vphase)\r\n dispersion.append([xnol[0:len(vphase)],vphase])\r\n labelplot.append('{:.2f}'.format(np.mean(AllList[j])))\r\n #print len(vphase),len(xnol[0:len(vphase)])\r\n \r\n \r\n #--------------------------------------------------------------------------\r\n #--Clustering for crossing y=0 (Avoid double Crossing / x-value to close)--\r\n #--------------------------------------------------------------------------\r\n [IdxList1,AllList1]=Clustering(xnol, 0.05)()\r\n xnol_rev=[] \r\n for s in range((len(AllList1))):\r\n xnol_rev.append(np.mean(AllList1[s]))\r\n xnol_rev=np.array(xnol_rev) \r\n \r\n #---------------------------------------------------------------------\r\n # -------------------------Plot Figure--------------------------------\r\n #---------------------------------------------------------------------\r\n fig1=plt.figure()\r\n plt.plot(freq_pusat,time_mean)\r\n plt.plot(freq_pusat, ydata,'r',lw=3)\r\n plt.xlabel('frequency [Hz]')\r\n plt.ylabel('AutoCorrelation')\r\n plt.ylim(-1,1)\r\n plt.title(StaPusat.stats.station+' - '+str(StaList[j])+' - '+\r\n str(np.mean(AllList[j])))\r\n plt.grid() \r\n if len(xnol_rev)>=25:\r\n plt.xlim(0,xnol_rev[24]) \r\n \r\n fig2=plt.figure()\r\n plt.plot(freq_pusat, ydata,'r')\r\n plt.plot(xnol_rev,np.linspace(0,0,len(xnol_rev)),'bo',ms=4)\r\n plt.xlabel('frequency [Hz]')\r\n plt.ylabel('AutoCorrelation')\r\n plt.ylim(-0.5,0.5)\r\n plt.title(StaPusat.stats.station+' - '+str(StaList[j])+' - '+\r\n str(np.mean(AllList[j])))\r\n plt.grid()\r\n if len(xnol_rev)>=25:\r\n plt.xlim(0,xnol_rev[24]) \r\n \r\n #------------------------------------------------------------- \r\n #----------------------- Save Figure ------------------------- \r\n #------------------------------------------------------------- \r\n fig1.savefig(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\'+StaPusat.stats.station+\r\n '\\\\'+StaPusat.stats.station+'_raw - '+str(np.mean(AllList[j]))+\r\n '.png',dpi=fig1.dpi)\r\n fig2.savefig(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\'+StaPusat.stats.station+\r\n '\\\\'+StaPusat.stats.station+' - '+str(np.mean(AllList[j]))+\r\n '.png',dpi=fig1.dpi)\r\n plt.close(fig1)\r\n plt.close(fig2)\r\n \r\n xnolList.append(xnol_rev)\r\n distList.append(np.mean(AllList[j]))\r\n \r\n #---------------------------------------------------------------------\r\n # ------- Save frequency, Spatial average (raw and smoothing) -------- \r\n #---------------------------------------------------------------------\r\n with open(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\'+StaPusat.stats.station+\r\n '\\\\SPAC_'+str(round(np.mean(AllList[j]/1000),2))+'_RADIUS_'+\r\n str(len(IdxList[j]))+'-STATION(s).txt','w') as f: \r\n datas=np.array([freq_pusat,time_mean, ydata])\r\n np.savetxt(f,datas.T,fmt='%8.5f')\r\n f.close()\r\n \r\n #-------------------------------------------------------------- \r\n #-------------- Dispersion Curve for all pairs ---------------- \r\n #-------------------------------------------------------------- \r\n freqCurve, dispCurve=[], []\r\n for pi in range(len(dispersion)):\r\n for qi in range(len(dispersion[pi][0])):\r\n freqCurve.append(dispersion[pi][0][qi])\r\n dispCurve.append(dispersion[pi][1][qi])\r\n IdxFreq=np.argsort(freqCurve)\r\n dispCurveSort=[]\r\n freqCurveSort=[]\r\n for si in IdxFreq:\r\n freqCurveSort.append(freqCurve[si])\r\n dispCurveSort.append(dispCurve[si])\r\n \r\n fig4=plt.figure() \r\n plt.semilogx(freqCurveSort,dispCurveSort,'k')\r\n plt.semilogx(freqCurveSort,dispCurveSort,'ro')\r\n plt.ylim(ymin=0)\r\n plt.title('Dispersion ('+StaPusat.stats.station+')')\r\n plt.xlabel('Frequency (Hz)')\r\n plt.ylabel('Phase Velocity (m/s)')\r\n plt.grid()\r\n fig4.savefig(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\'+StaPusat.stats.station+\r\n '\\\\CurvDisp_'+StaPusat.stats.station+'.png',\r\n bbox_inches=\"tight\",dpi=fig4.dpi)\r\n \r\n fig3=plt.figure() \r\n for di in range(len(dispersion)):\r\n plt.semilogx(dispersion[di][0],dispersion[di][1],'--',color='gray')\r\n plt.semilogx(dispersion[di][0],dispersion[di][1],'o', label='Ring = '+labelplot[di])\r\n plt.hold(True)\r\n plt.legend(loc='upper left', prop={'size':10}, bbox_to_anchor=(1,1))\r\n plt.ylim(ymin=0)\r\n plt.title('Dispersion ('+StaPusat.stats.station+')')\r\n plt.xlabel('Frequency (Hz)')\r\n plt.ylabel('Phase Velocity (m/s)')\r\n plt.grid()\r\n fig3.savefig(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\'+StaPusat.stats.station+\r\n '\\\\Dispersion_'+StaPusat.stats.station+'.png',\r\n bbox_inches=\"tight\",dpi=fig3.dpi)\r\n \r\n plt.close(fig3)\r\n plt.close(fig4)\r\n #---------------------------------------------------------------------\r\n # -------------------- Save Location Y=0 -----------------------------\r\n #---------------------------------------------------------------------\r\n nxnol=25 \r\n xnolall=np.empty((len(xnolList),nxnol+1),dtype=float)\r\n xnolall[:]=np.nan\r\n for i in range(len(xnolList)+1):\r\n if i==0:\r\n xnolall[:,i]=np.array(distList)\r\n else:\r\n if len(xnolList[i-1])>=nxnol:\r\n xnolall[i-1,1:nxnol+1]=xnolList[i-1][0:nxnol]\r\n else:\r\n xnolall[i-1,1:len(xnolList[i-1])+1]=xnolList[i-1]\r\n with open(os.getcwd()+'\\\\SPATIAL_AVERAGE\\\\'+StaPusat.stats.station+'\\\\Xnol.txt','w') as f: \r\n np.savetxt(f,xnolall.T,fmt='%12.5f')\r\n f.close()\r\n \r\n \r\n #========================= Logfile =========================== \r\n end_time = datetime.now() \r\n logfile='------------------------------------------------\\n'\r\n logfile=logfile+'End Time = '+str(end_time)+'\\n\\n'\r\n logfile=logfile+'Duration = '+str(end_time-start_time)\r\n \r\n log.write(logfile)\r\n log.close() \r\n return\r\n"
}
] | 1 |
rstoddard24/PVtools | https://github.com/rstoddard24/PVtools | 6a4bba4e5ae5549f6ebe9cb3df834400dd86d6eb | fcae41ebe12fbd964b36e4dc2901c92d6ec276e5 | 856552cad3314a8d57da20cb5589337ca7d79185 | refs/heads/master | 2021-05-06T18:14:14.033352 | 2019-03-01T21:28:02 | 2019-03-01T21:28:02 | 111,946,868 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5489186644554138,
"alphanum_fraction": 0.6091657876968384,
"avg_line_length": 25.243244171142578,
"blob_id": "a09508c9fc5494930396aaf1519d79e90bd72d06",
"content_id": "e87e643a10c0aa9016e88b35d33819325be2b303",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1942,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 74,
"path": "/PVtools/UVvis/UVvis_8718.py",
"repo_name": "rstoddard24/PVtools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Oct 10 12:50:47 2018\n\n@author: ryanstoddard\n\"\"\"\n\n#standard imports\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport matplotlib as mpl\nfrom os import listdir\n\n\n#change default plot settings\ndefault_figsize = mpl.rcParamsDefault['figure.figsize']\nmpl.rcParams['figure.figsize'] = [1.5*val for val in default_figsize]\nfont = {'family' : 'DejaVu Sans',\n 'weight' : 'bold',\n 'size' : 24}\n\nmpl.rc('font', **font)\nmpl.rc('axes', linewidth=3)\n\n#Specify Directory\ndirectory = '../../data/UVvis_data/2018_8-7UVvis'\n\n#Get all csv files other than 100%T file\nnames = []\nfor file in listdir(directory):\n if file[-3:]=='csv' and not ('100' in file):\n names.append(file)\n\ndata = [] \nfor name in names:\n a = np.loadtxt(directory + '/' + name,delimiter=',',skiprows=2)\n data.append(a)\n plt.plot(1240/a[:,0],a[:,1],linewidth=3)\nplt.xlabel('$E\\ [eV]$')\nplt.ylabel('$Absorbance$')\n#plt.ylim(-20,5)\n#plt.xlim(0,1.2)\nplt.legend(['FAGACs','1.25 PEAI','2.5 PEAI','3.75 PEAI','5 PEAI']) \n\nplt.figure()\n\n#make Tauc plot\nEgs = []\nfor ii in range(len(names)):\n a = data[ii]\n plt.plot(1240/a[:,0],(a[:,1])**2,linewidth=3)\n \n #choose limits for linear fit\n fit_low = 0.005\n fit_high = 0.05\n if ii == 4:\n fit_high = .015\n low_idx = np.argmin(np.abs(a[:,1]**2-fit_low))\n high_idx = np.argmin(np.abs(a[:,1]**2-fit_high))\n min_idx = min(low_idx,high_idx)\n max_idx = max(low_idx,high_idx)\n #fit and plot fit\n Xs = np.polyfit(1240/a[min_idx:max_idx,0],a[min_idx:max_idx,1]**2,1)\n plt.plot(1240/a[min_idx:max_idx,0],Xs[0]*1240/a[min_idx:max_idx,0]+Xs[1],linestyle='--',linewidth=2,color='0')\n #Calculate Eg\n Eg = -Xs[1]/Xs[0]\n Egs.append(Eg)\nplt.xlabel('$E\\ [eV]$')\nplt.ylabel('$A^2$')\nplt.ylim(0,.1)\n#plt.xlim(0,1.2)\n#plt.legend({'FAGACs','1.25 PEAI','2.5 PEAI','3.75 PEAI','5 PEAI'}) \nprint(Egs)\n"
},
{
"alpha_fraction": 0.44390973448753357,
"alphanum_fraction": 0.46382343769073486,
"avg_line_length": 24.974138259887695,
"blob_id": "059cf566e83ba2fc77218b0a465881942002373c",
"content_id": "c2732f70e5e49b4778ab6f7c0d7b1377b40ef5ca",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6026,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 232,
"path": "/PVtools/PL/PL_2phase_viewer.py",
"repo_name": "rstoddard24/PVtools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Oct 20 12:25:41 2018\n\n@author: ryanstoddard\n\"\"\"\n\nimport dash\nimport dash_core_components as dcc\nimport dash_html_components as html\nimport plotly.graph_objs as go\nfrom plotly import tools\nfrom dash.dependencies import Input, Output, State\nfrom datetime import datetime as dt\nfrom dateutil import parser\nimport pandas as pd\nimport numpy as np\n\nimport sys\nsys.path.append('../../')\nfrom PVtools.PL import PLtools\n\ndef model(theta=1.5,gam=37,Eg1=1.7,Eg2=1.8,x1=.03,QFLS=1.3,T=100):\n \"\"\"\n Model two phase PL\n \"\"\"\n theta = float(theta)\n gam = float(gam)\n Eg1 = float(Eg1)\n Eg2 = float(Eg2)\n x1 = float(x1)\n QFLS = float(QFLS)\n T = float(T)\n Emin = np.mean((Eg1,Eg2))-.15\n Emax = np.mean((Eg1,Eg2))+.15\n E = np.linspace(Emin,Emax,num=100)\n AIPL = PLtools.LSWK_2phase_gfunc(E,theta,gam/1000,Eg1,Eg2,x1,QFLS,T)\n \n return (E, np.exp(AIPL))\n\n\n\n\n\napp = dash.Dash()\ncss_url = \"https://maxcdn.bootstrapcdn.com/bootstrap/4.0.0-beta.2/css/bootstrap.min.css\"\napp.css.append_css({\n \"external_url\": css_url\n})\n\n\napp.layout = html.Div(children=[\n html.H1(children='Photoluminescence of 2-phase nanostructure'),\n\n html.Div(children=[\n html.Div(children=[\n html.Div(children=[\n html.P(\"Eg1 [eV]\")\n ], className='col'),\n html.Div(children=[\n dcc.Input(\n id='Eg1',\n placeholder='Eg1',\n type='float',\n value='1.7'\n ),\n ], className='col'),\n ], className='row'),\n html.Div(children=[\n html.Div(children=[\n html.P(\"Eg2 [eV]\")\n ], className='col'),\n html.Div(children=[\n dcc.Input(\n id='Eg2',\n placeholder='Eg2',\n type='float',\n value='1.8'\n ),\n ], className='col'),\n ], className='row'),\n html.Div(children=[\n html.Div(children=[\n html.P(\"x1\")\n ], className='col'),\n html.Div(children=[\n dcc.Input(\n id='x1',\n placeholder='x1',\n type='float',\n value='.03'\n ),\n ], className='col'),\n ], className='row'),\n html.Div(children=[\n html.Div(children=[\n html.P(\"theta\")\n ], className='col'),\n html.Div(children=[\n dcc.Input(\n id='theta',\n placeholder='theta',\n type='float',\n value='1.5'\n ),\n ], className='col'),\n ], className='row'),\n html.Div(children=[\n html.Div(children=[\n html.P(\"gamma [meV]\")\n ], className='col'),\n html.Div(children=[\n dcc.Input(\n id='gamma',\n placeholder='gamma',\n type='float',\n value='37'\n ),\n ], className='col'),\n ], className='row'),\n html.Div(children=[\n html.Div(children=[\n html.P(\"QFLS [eV]\")\n ], className='col'),\n html.Div(children=[\n dcc.Input(\n id='QFLS',\n placeholder='QFLS',\n type='float',\n value='1.32'\n ),\n ], className='col'),\n ], className='row'),\n html.Div(children=[\n html.Div(children=[\n html.P(\"T [K]\")\n ], className='col'),\n html.Div(children=[\n dcc.Input(\n id='T',\n placeholder='T',\n type='float',\n value='300'\n ),\n ], className='col'),\n ], className='row'), \n html.Div(children=[\n html.Button('Submit', id=\"final-submit-button\", className=\"btn btn-primary btn-lg\"),\n ], className='row', style={'text-align': 'center'}),\n ], className='col'),\n\n\n html.Div(children=[\n html.Div(children=[\n dcc.Graph(id='graph-linear'),\n ], className='col', style={'text-align': 'center'}),\n html.Div(children=[\n dcc.Graph(id='graph-log')\n ], className='col', style={'text-align': 'center'}),\n ], className='row')\n ])\n\[email protected](\n Output('graph-linear', 'figure'),\n [Input('final-submit-button', 'n_clicks')],\n [State('Eg1', 'value'),\n State('Eg2', 'value'),\n State('x1', 'value'),\n State('theta', 'value'),\n State('gamma', 'value'),\n State('QFLS', 'value'),\n State('T', 'value')]\n)\ndef update_graph_linear(_, Eg1, Eg2, x1, theta, gamma, QFLS, T):\n (E, AIPL) = model(theta,gamma,Eg1,Eg2,x1,QFLS,T)\n \n traces = []\n \n traces.append(go.Scatter(\n x=E,\n y=AIPL,\n mode=\"lines\",\n \n ))\n return {\n 'data': traces,\n 'layout': go.Layout(\n xaxis={'title': 'E [eV]'},\n yaxis={'title': 'AIPL [photons/m^2-eV-s]'},\n height=400,\n width=500\n )\n }\n\n\n\[email protected](\n Output('graph-log', 'figure'),\n [Input('final-submit-button', 'n_clicks')],\n [State('Eg1', 'value'),\n State('Eg2', 'value'),\n State('x1', 'value'),\n State('theta', 'value'),\n State('gamma', 'value'),\n State('QFLS', 'value'),\n State('T', 'value')]\n)\ndef update_graph_log(_, Eg1, Eg2, x1, theta, gamma, QFLS, T):\n (E, AIPL) = model(theta,gamma,Eg1,Eg2,x1,QFLS,T)\n \n traces = []\n \n traces.append(go.Scatter(\n x=E,\n y=AIPL,\n mode=\"lines\",\n \n ))\n return {\n 'data': traces,\n 'layout': go.Layout(\n xaxis={'title': 'E [eV]'},\n yaxis={'title': 'AIPL [photons/m^2-eV-s]','type': 'log'},\n height=400,\n width=500\n )\n }\n\n\nif __name__ == '__main__':\n app.run_server()\n"
},
{
"alpha_fraction": 0.5666275024414062,
"alphanum_fraction": 0.6072855591773987,
"avg_line_length": 24.485029220581055,
"blob_id": "bbb2930ae9935901c298b827c0b1144ba811bf81",
"content_id": "de831b84defb261f7455cad9a5e1e39429228847",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4255,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 167,
"path": "/PVtools/JV/JV_DOE_analysis_100118.py",
"repo_name": "rstoddard24/PVtools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Oct 2 12:06:40 2018\n\n@author: ryanstoddard\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\nimport math\nimport scipy\nfrom scipy.interpolate import interp1d\nimport matplotlib.pyplot as plt\nimport matplotlib as mpl\nimport pandas as pd\nfrom os import listdir\n\n#Constants\npi = math.pi\nheV = 4.14e-15 #eV*s\nc = 2.99792e8 #m/s\nkbeV = 8.6173e-5 #eV/K\nkeV = 8.6173e-5 #eV/K\nh = 6.626e-34\nkb = 1.38065e-23\nq = 1.60218e-19\nk = 1.3806488e-23\nT = 300\n\nCellAreacm = 0.0453\nCellArea = CellAreacm*10**-4 #m^2\nPs=100 #mW/cm^2\n\n\ndefault_figsize = mpl.rcParamsDefault['figure.figsize']\nmpl.rcParams['figure.figsize'] = [1.5*val for val in default_figsize]\nfont = {'family' : 'DejaVu Sans',\n 'weight' : 'bold',\n 'size' : 22}\n\nmpl.rc('font', **font)\nmpl.rc('axes', linewidth=3)\n\n\nDirectory = '../../data/JVdata/2018_10-1JV/'\nnames = listdir(Directory)\nnames_fs = []\nnames_rs = []\nnames_hold = []\n\n#%%\ndef is_number(s):\n try:\n float(s)\n return True\n except ValueError:\n return False\n\ndef reject_outliers(data, m):\n if len(data) > 2:\n return data[abs(data - np.mean(data)) < m * np.std(data)]\n else:\n return data\n\n#sort names\nfor name in names:\n if 'liv2' in name:\n names_fs.append(name)\n elif 'liv1' in name:\n names_rs.append(name)\n elif ('hold' in name) and not ('.png' in name):\n names_hold.append(name)\n \ndev_types = np.zeros(len(names_rs))\nPCEs = np.zeros(len(names_rs))\nVocs = np.zeros(len(names_rs))\nJscs = np.zeros(len(names_rs))\nFFs = np.zeros(len(names_rs))\nhyst_idx = np.zeros(len(names_rs))\n\n\nbasename = 'Stoddard_2018_10-2JV_'\n\n#%%\nfor ii in range(len(names_rs)):\n k = 1\n if is_number(names_rs[ii][len(basename)+3]):\n k += 1\n dev_type = float(names_rs[ii][len(basename):len(basename)+k])\n dev_types[ii] = dev_type\n \n Ldata = pd.read_csv(Directory + names_rs[ii], delimiter='\\t', header=None)\n idx_end = Ldata[Ldata.iloc[:,0] == 'Jsc:'].index[0]\n Ldata = Ldata.iloc[:idx_end-1,:]\n Ldata.iloc[:,0] = pd.to_numeric(Ldata.iloc[:,0])\n Ldata.iloc[:,0]\n Ldata = np.array(Ldata)\n\n Ldata = np.insert(Ldata, 2, -Ldata[:,1], axis=1)\n\n JVinterp = interp1d(Ldata[:,0], Ldata[:,2], kind='cubic', bounds_error=False, fill_value='extrapolate')\n\n JscL = -JVinterp(0)\n VocL = scipy.optimize.fsolve(JVinterp,.95*max(Ldata[:,0]))\n PPV = scipy.optimize.fmin(lambda x: x*JVinterp(x),.8*VocL,disp=False)\n PCE = -PPV*JVinterp(PPV)\n FF = PCE/(JscL*VocL)*100\n \n PCEs[ii] = PCE\n Vocs[ii] = VocL\n Jscs[ii] = JscL\n FFs[ii] = FF\n\n#Delete shunted devices / bad data\nk = 0\nwhile k < len(PCEs):\n if (Jscs[k] < 1) or (Vocs[k] < 0.5) or (FFs[k] < 25) or (FFs[k] > 85) or (PCEs[k] < 1):\n PCEs = np.delete(PCEs,k)\n Vocs = np.delete(Vocs,k)\n Jscs = np.delete(Jscs,k)\n FFs = np.delete(FFs,k)\n dev_types = np.delete(dev_types,k)\n names_rs = np.delete(names_rs,k)\n else:\n k += 1\n \n#%% Get stabilized data from hold files\nrun_num = 16\nPCE_stab = np.zeros(run_num)\nddt_PCE = np.zeros(run_num)\n\nfor ii in range(len(names_hold)):\n k = 1\n if is_number(names_hold[ii][len(basename)+3]):\n k += 1\n dev_type_hold = float(names_hold[ii][len(basename):len(basename)+k])\n \n \n hold_data = np.genfromtxt(Directory + names_hold[ii],skip_header=1,skip_footer=4)\n \n PCE_stab[int(dev_type_hold)-1] = hold_data[-1,2]\n ddt_PCE[int(dev_type_hold)-1] = (hold_data[-1,2]-hold_data[6,2])/(hold_data[-1,0]-hold_data[6,0])\n\n#%%\n\nPCE_list = []\nVoc_list = []\nJsc_list = []\nFF_list = []\n\ndata_out = np.zeros([run_num,7])\nfor ii in range(run_num):\n idxs = np.argwhere(dev_types == ii +1)\n PCE_list.append(reject_outliers(PCEs[idxs],2))\n Voc_list.append(reject_outliers(Vocs[idxs],2))\n Jsc_list.append(reject_outliers(Jscs[idxs],2))\n FF_list.append(reject_outliers(FFs[idxs],2))\n data_out[ii,0] = np.mean(PCE_list[ii])\n data_out[ii,1] = np.mean(Voc_list[ii])\n data_out[ii,2] = np.mean(Jsc_list[ii])\n data_out[ii,3] = np.mean(FF_list[ii])\n \ndata_out[:,4] = PCE_stab\ndata_out[:,5] = ddt_PCE\ndata_out[:,6] = np.abs(ddt_PCE)\nnp.savetxt(Directory + 'data_to_DOE.txt',data_out)"
},
{
"alpha_fraction": 0.5046112537384033,
"alphanum_fraction": 0.572204053401947,
"avg_line_length": 37.936363220214844,
"blob_id": "3e9aaf7481d96fb139acca72cd6c04a87d6b5070",
"content_id": "0bb4e86a479a8d85239398f2555faf27ecd7d526",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17132,
"license_type": "permissive",
"max_line_length": 176,
"num_lines": 440,
"path": "/PVtools/PL/PLtools.py",
"repo_name": "rstoddard24/PVtools",
"src_encoding": "UTF-8",
"text": "#%%\nimport numpy as np\nimport math\nimport scipy\nfrom scipy.optimize import curve_fit\nfrom scipy.interpolate import interp1d\nfrom scipy.interpolate import CloughTocher2DInterpolator\nfrom scipy.integrate import quad\nimport sys\nsys.path.append('../')\nimport SQ_calcs\n\n# Constants\npi = math.pi\nheV = 4.14e-15 # eV*s\nc = 2.99792e8 # m/s\nkbeV = 8.6173e-5 # eV/K\nkeV = 8.6173e-5 # eV/K\nh = 6.626e-34\nkb = 1.38065e-23\nq = 1.60218e-19\n\n\n#%%\n# This module contains functions for Photoluminescence data analysis and modeling\n\ndef aipl(data, dark, grating):\n \"\"\"\n This function takes PL data in cts/second units and\n converts to AIPL based on a laser power and grating calibration\n file. Functionality is built in to handle both single and map files\n\n INPUTS:\n data - data matrix containing input wavelength and PL cts/sec data\n if m x 2 matrix, treats as single spectra file\n if m x n matrix, treats as map along m\n if n x m matrix, treats as map along n\n\n dark - can be 0\n\n grating - specifies which grating used, a string either '500nm' or '1200nm'\n or '1200nm-InGaAs'\n \n OUTPUTS:\n aipl_data - data converted to absolute units , [=] photons/m^2-s-eV\n \"\"\"\n \n #Get grating calibration file, then calculate conversion factor\n def BBPhotonFluxPerNM(lam,T):\n a = 2*pi/(h**3*c**2)*((h*c/(lam*1e-9))**2/(np.exp((h*c/(lam*1e-9))/(kb*T))-1))*(h*c/(lam*1e-9)**2)*1e-9\n return a\n if grating == '500nm':\n BB1050 = np.loadtxt('../../data/PLdata/grating_calibration_files/150 500'\n 'blaze BB files/BB 1050 10 um hole 10x SiCCD 532 LP'\n 'F No Duoscan Autoscanning_2.txt')\n\n BB_raw_photon_data = BB1050[:,1]/np.insert(BB1050[1:,0]-BB1050[:-1,0], \n 0,BB1050[1,0]-BB1050[0,0])\n\n \n\n AbsFluxesPerNM = np.zeros(BB1050.shape[0])\n Ts = 1050;\n\n for ii in range(BB1050.shape[0]):\n AbsFluxesPerNM[ii] = BBPhotonFluxPerNM(BB1050[ii,0],Ts+273.15)\n\n AbsPhotonRate = pi*(10/2*1e-6)**2*AbsFluxesPerNM #photons/sec-nm\n Conversion_factor = AbsPhotonRate/BB_raw_photon_data\n\n Ave_conv_factors = np.zeros([BB1050.shape[0],2])\n Ave_conv_factors[:,0] = BB1050[:,0]\n Ave_conv_factors[:,1] = Conversion_factor\n f2 = interp1d(Ave_conv_factors[:,0], Ave_conv_factors[:,1], kind='cubic')\n elif grating == '1200nm': \n BB850 = np.loadtxt('../../data/PLdata/grating_calibration_files/BB 850C 10 um hole D0 10x 150 grating CCD 532 nm NoDS.txt')\n BB950 = np.loadtxt('../../data/PLdata/grating_calibration_files/BB 950C 10 um hole D0 10x 150 grating CCD 532 nm NoDS.txt')\n BB1050 = np.loadtxt('../../data/PLdata/grating_calibration_files/BB 1050C 10 um hole D0 10x 150 grating CCD 532 nm NoDS.txt')\n\n BB_raw_photon_data_1 = BB850[:,1]/np.insert(BB1050[1:,0]-BB1050[:-1,0], \n 0,BB1050[1,0]-BB1050[0,0])\n BB_raw_photon_data_2 = BB950[:,1]/np.insert(BB1050[1:,0]-BB1050[:-1,0], \n 0,BB1050[1,0]-BB1050[0,0])\n BB_raw_photon_data_3 = BB1050[:,1]/np.insert(BB1050[1:,0]-BB1050[:-1,0], \n 0,BB1050[1,0]-BB1050[0,0])\n \n BB_raw_photon_data = np.array([BB_raw_photon_data_1,BB_raw_photon_data_2,BB_raw_photon_data_3])\n \n AbsFluxesPerNM = np.zeros(BB_raw_photon_data.shape)\n for lam in range(len(BB_raw_photon_data_1)):\n tt = 0\n for T in (850,950,1050):\n AbsFluxesPerNM[tt,lam] = BBPhotonFluxPerNM(BB850[lam,0],T+273.15)\n tt += 1\n \n AbsPhotonRate = pi*(10/2*1e-6)**2*AbsFluxesPerNM #photons/sec-nm\n Conversion_factor = AbsPhotonRate/BB_raw_photon_data\n \n Ave_conv_factors = np.zeros([BB850.shape[0],2])\n Ave_conv_factors[:,0] = BB850[:,0]\n Ave_conv_factors[:,1] = np.mean(Conversion_factor,0)\n f2 = interp1d(Ave_conv_factors[:,0], Ave_conv_factors[:,1], kind='cubic')\n elif grating == '1200nm-InGaAs': \n BB850 = np.loadtxt('../../data/PLdata/grating_calibration_files/Response_Synapse CCD2_784_150_Objective_x10_UV_0_Detector_Second_InjRej_Edge 785nm PL.txt')\n\n BB_raw_photon_data = BB850[:,1]/np.insert(BB850[1:,0]-BB850[:-1,0], \n 0,BB850[1,0]-BB850[0,0])\n\n \n\n AbsFluxesPerNM = np.zeros(BB850.shape[0])\n Ts = 850;\n\n for ii in range(BB850.shape[0]):\n AbsFluxesPerNM[ii] = BBPhotonFluxPerNM(BB850[ii,0],Ts+273.15)\n\n AbsPhotonRate = pi*(10/2*1e-6)**2*AbsFluxesPerNM #photons/sec-nm\n Conversion_factor = AbsPhotonRate/BB_raw_photon_data\n\n Ave_conv_factors = np.zeros([BB850.shape[0],2])\n Ave_conv_factors[:,0] = BB850[:,0]\n Ave_conv_factors[:,1] = Conversion_factor\n f2 = interp1d(Ave_conv_factors[:,0], Ave_conv_factors[:,1], kind='cubic')\n if data.shape[1] == 2: #single spectrum\n aipl_data = data \n lam = data[:,0]\n Ipl_raw = data[:,1] #cts/sec\n if dark == []:\n Ipl_raw2 = Ipl_raw\n else:\n Ipl_raw = Ipl_raw - dark[:,1]\n Ipl_raw2 = Ipl_raw/np.insert(lam[1:]-lam[:-1],0,lam[1]-lam[0]) #cts/sec-nm \n Ipl_nm = Ipl_raw2*f2(lam) #photons/sec-nm\n bandwidth_conv = np.insert(lam[1:]-lam[:-1],0,lam[1]-lam[0])/(heV*c/(lam*1e-9)**2*np.insert(lam[1:]-lam[:-1],0,lam[1]-lam[0])*1e-9)\n Ipl = Ipl_nm*bandwidth_conv/(pi*(6.01e-6)**2*2*0.921) #photons/sec-eV-m^2 (divide by factor of 2 since only considering FWHM beam area) (divide by 0.921 for window)\n aipl_data[:,1] = Ipl\n else:\n aipl_data = data\n k = 0\n while np.isnan(data[0,k]):\n k = k + 1\n lam = data[0,k:]\n for ii in range(1,data.shape[0]):\n Ipl_raw = data[ii,k:]\n if dark == []:\n Ipl_raw2 = Ipl_raw\n else:\n Ipl_raw = Ipl_raw - dark[:,1]\n Ipl_raw2 = Ipl_raw/np.insert(lam[1:]-lam[:-1],0,lam[1]-lam[0]) #cts/sec-nm \n Ipl_nm = Ipl_raw2*f2(lam) #photons/sec-nm\n bandwidth_conv = np.insert(lam[1:]-lam[:-1],0,lam[1]-lam[0])/(heV*c/(lam*1e-9)**2*np.insert(lam[1:]-lam[:-1],0,lam[1]-lam[0])*1e-9)\n Ipl = Ipl_nm*bandwidth_conv/(pi*(6.01e-6)**2*2*0.921) #photons/sec-eV-m^2 (divide by factor of 2 since only considering FWHM beam area) (divide by 0.921 for window)\n aipl_data[ii,k:] = Ipl\n return aipl_data\n \n\ndef plqy_ext(aipl_data, laser_power, laser, temperature):\n '''\n This is the simple PLQY method for determining quasi-Fermi level splitting\n from PLQY, using SQ limit as reference. Presently the assumed temperature\n is 350K for SQ calculation and 300K for chi calculation (this avoids\n overestimation of QLFS or chi)\n \n INPUTS:\n aipl_data - PL spectrum matrix in absolute units (output from \n PLtools.aipl function)\n laser_power - laser powermeter reason in SI units (needed for PLQY calc)\n laser - string\n \n OUTPUTs:\n All of the useful PL parameters\n mean_Ipl - mean PL emission E [eV] (also called 1st moment)\n peak_pos - PL peak position [eV]\n FWHM - Full Width Half Max of PL peak [eV]\n PLQY - Photoluminescence Quantuum Yield [fraction]\n dmu_PLQY - Quasi-Fermi Level splitting from PLQY method\n chi_PLQY - QFLS/SQ-max from PLQY method\n dmu_PLQY_Eg - QFLS, PLQY method, using PL integrated above peak_pos only\n chi_PLQY_Eg - QFLS / SQ-Max, from PLQY-Eg method\n '''\n DiodeReadings_1sun = laser_power\n if laser == '532nm': \n DiodeResponse532= 0.2741\n Ep532 = 2.3305 #E per photon @532\n Area785ImageJ = pi*(6.01e-6)**2 #m^2\n elif laser == '785nm':\n DiodeResponse532= 0.4165906265 # for 785\n Ep532 = 1.59236 #E per photon @785\n Area785ImageJ = 1.77e-10 #m^2\n\n #Load data from Mathmatica calcs to determine SQ limits @ 300 K and 350 K for various\n #Egs\n Egs = np.loadtxt('../../data/PLdata/vocmax_data/Egs.txt',delimiter=',')\n VocSQs300 = np.loadtxt('../../data/PLdata/vocmax_data/VocMaxs.txt',delimiter=',') # 300 K\n Jphs = np.loadtxt('../../data/PLdata/vocmax_data/Jphs.txt',delimiter=',') #300 K\n \n VocSQs350 = np.loadtxt('../../data/PLdata/vocmax_data/' + temperature + '/VocMaxs2.txt',delimiter=',') # 350 K\n \n VocSQs350 = np.loadtxt('../../data/PLdata/vocmax_data/VocMaxs2.txt',delimiter=',') # 350 K\n \n VocSQs300_fn = interp1d(Egs, VocSQs300, kind='cubic')\n VocSQs350_fn = interp1d(Egs, VocSQs350, kind='cubic')\n Jphs_fn = interp1d(Egs, Jphs, kind='cubic')\n\n\n DiodeReading = DiodeReadings_1sun\n P532 = DiodeReading/(DiodeResponse532*Area785ImageJ*10) #W/m^2\n Jp532 = DiodeReading*0.925/(DiodeResponse532*Area785ImageJ*1.60218e-19*Ep532*2)\n\n T = float(temperature[:-1])\n if aipl_data.shape[1] == 2: #single spectrum\n lam = aipl_data[:,0]\n E = heV*c/(lam*1e-9)\n Ipl = aipl_data[:,1] \n maxI = np.max(Ipl)\n maxI_idx = np.argmax(Ipl)\n peak_pos = E[maxI_idx]\n HHMax_idx = np.argmin(np.absolute(maxI/2-Ipl[:maxI_idx]))\n LHMax_idx = np.argmin(np.absolute(maxI/2-Ipl[maxI_idx:]))\n LHMax_idx = LHMax_idx+maxI_idx-1\n FWHM = E[HHMax_idx]-E[LHMax_idx]\n try:\n VocSQ300 = VocSQs300_fn(E[maxI_idx])\n VocSQ350 = VocSQs350_fn(E[maxI_idx]) \n JphSQ = Jphs_fn(E[maxI_idx])\n except ValueError:\n VocSQ300 = SQ_calcs.VocSQ(E[maxI_idx],300)\n VocSQ350 = SQ_calcs.VocSQ(E[maxI_idx],315)\n JphSQ = SQ_calcs.JphSQ(E[maxI_idx],300)\n NSuns = Jp532*q/JphSQ;\n VocMax300 = VocSQ300 + kb*300/q*np.log(Jp532*q/JphSQ)\n VocMax350 = VocSQ350 + kb*T/q*np.log(Jp532*q/JphSQ)\n TotalPL = np.mean(-E[1:-1]+E[0:-2])/2*(Ipl[0]+Ipl[-1]+2*np.sum(Ipl[1:-2]))\n TotalPL = np.max([TotalPL, -TotalPL])\n TotalPL_Eg = np.mean(-E[1:maxI_idx]+E[0:maxI_idx-1])/2*(Ipl[0]+Ipl[maxI_idx]+2*np.sum(Ipl[1:maxI_idx-1]))\n TotalPL_Eg = np.max([TotalPL_Eg, -TotalPL_Eg])\n PLQY = TotalPL/Jp532\n dmu_PLQY = VocMax350-kbeV*T*np.log(1/PLQY)\n chi_PLQY = dmu_PLQY/VocMax300 \n chi_PLQY_Eg = (VocMax350-kbeV*T*np.log(1/(TotalPL_Eg/Jp532)))/VocMax300\n PLQY_Eg = TotalPL_Eg/Jp532\n dmu_PLQY_Eg = VocMax350-kbeV*T*np.log(1/(TotalPL_Eg/Jp532))\n mean_Ipl = np.sum(Ipl*E)/np.sum(Ipl)\n else: #maps\n k = 0\n while np.isnan(aipl_data[0,k]):\n k = k + 1\n lam = aipl_data[0,k:]\n E = heV*c/(lam*1e-9)\n mean_Ipl = np.zeros(aipl_data.shape[0]-1)\n peak_pos = np.zeros(aipl_data.shape[0]-1)\n FWHM = np.zeros(aipl_data.shape[0]-1)\n PLQY = np.zeros(aipl_data.shape[0]-1)\n dmu_PLQY = np.zeros(aipl_data.shape[0]-1)\n chi_PLQY = np.zeros(aipl_data.shape[0]-1)\n dmu_PLQY_Eg = np.zeros(aipl_data.shape[0]-1)\n chi_PLQY_Eg = np.zeros(aipl_data.shape[0]-1)\n for ii in range(1,aipl_data.shape[0]):\n Ipl = aipl_data[ii,k:]\n maxI = np.max(Ipl)\n maxI_idx = np.argmax(Ipl)\n peak_pos[ii-1] = E[maxI_idx]\n HHMax_idx = np.argmin(np.absolute(maxI/2-Ipl[:maxI_idx]))\n LHMax_idx = np.argmin(np.absolute(maxI/2-Ipl[maxI_idx:]))\n LHMax_idx = LHMax_idx+maxI_idx-1\n FWHM[ii-1] = E[HHMax_idx]-E[LHMax_idx]\n try:\n VocSQ300 = VocSQs300_fn(E[maxI_idx])\n VocSQ350 = VocSQs350_fn(E[maxI_idx]) \n JphSQ = Jphs_fn(E[maxI_idx])\n except ValueError:\n VocSQ300 = SQ_calcs.VocSQ(E[maxI_idx],300)\n VocSQ350 = SQ_calcs.VocSQ(E[maxI_idx],315)\n JphSQ = SQ_calcs.JphSQ(E[maxI_idx],300)\n NSuns = Jp532*q/JphSQ;\n VocMax300 = VocSQ300 + kb*300/q*np.log(Jp532*q/JphSQ)\n VocMax350 = VocSQ350 + kb*T/q*np.log(Jp532*q/JphSQ)\n TotalPL = np.mean(-E[1:-1]+E[0:-2])/2*(Ipl[0]+Ipl[-1]+2*np.sum(Ipl[1:-2]))\n TotalPL = np.max([TotalPL, -TotalPL])\n TotalPL_Eg = np.mean(-E[1:maxI_idx]+E[0:maxI_idx-1])/2*(Ipl[0]+Ipl[maxI_idx]+2*np.sum(Ipl[1:maxI_idx-1]))\n TotalPL_Eg = np.max([TotalPL_Eg, -TotalPL_Eg])\n PLQY[ii-1] = TotalPL/Jp532\n dmu_PLQY[ii-1] = VocMax350-kbeV*T*np.log(1/PLQY[ii-1])\n chi_PLQY[ii-1] = dmu_PLQY[ii-1]/VocMax300 \n chi_PLQY_Eg[ii-1] = (VocMax350-kbeV*T*np.log(1/(TotalPL_Eg/Jp532)))/VocMax300\n PLQY_Eg = TotalPL_Eg/Jp532\n dmu_PLQY_Eg[ii-1] = VocMax350-kbeV*T*np.log(1/(TotalPL_Eg/Jp532))\n mean_Ipl[ii-1] = np.sum(Ipl*E)/np.sum(Ipl)\n \n return (mean_Ipl,peak_pos,FWHM,PLQY,dmu_PLQY,chi_PLQY,dmu_PLQY_Eg,chi_PLQY_Eg)\n\ndef med_idx(aipl_data):\n '''\n This function finds the index the AIPL spectrum with median PLQY\n '''\n k = 0\n while np.isnan(aipl_data[0,k]):\n k = k + 1\n lam = aipl_data[0,k:]\n E = heV*c/(lam*1e-9)\n TotalPL = np.zeros(aipl_data.shape[0]-1)\n for ii in range(1,aipl_data.shape[0]):\n Ipl = aipl_data[ii,k:]\n TotalPL[ii-1] = np.mean(-E[1:-1]+E[0:-2])/2*(Ipl[0]+Ipl[-1]+2*np.sum(Ipl[1:-2]))\n idx = np.argsort(TotalPL)[len(TotalPL)//2]\n return (idx+1)\n\ndef LSWK(E,theta,gam,Eg,QFLS,T):\n '''\n The Lasher-Stern-Wuerfel-Katahara equation\n '''\n\n '''\n theta = X[0]\n gam = X[1]\n #a0 = X(3)*Xscale(3);\n a0 = X[2]\n Eg = X[3]\n #Eg = Xscale(4);\n QFLS = X[4]\n T = X[5]\n #T = Xscale(6);\n d = 375/(1e7)\n '''\n a0 = 1e5\n d = 375/(1e7)\n ge = np.zeros(E.shape[0])\n\n for ii in range(E.shape[0]):\n ge[ii] = 1/(gam*2*scipy.special.gamma(1+1/theta))*quad(lambda u: np.exp(-np.absolute(u/gam)**theta)*np.sqrt((E[ii]-Eg)-u),-math.inf,E[ii]-Eg)[0]\n\n AIPL = 2*pi*E**2/(heV**3*c**2)*((1-np.exp(-a0*d*ge))/(np.exp((E-QFLS)/(keV*T))-1))*(1-2/(np.exp((E-QFLS)/(2*keV*T))+1))\n\n #AIPL = np.log(AIPL)\n return AIPL\n\n\n#Load GFuncTable and make interpolation function to speed up full peak fit\n#%%\ng_func_table = np.loadtxt('../../data/PLdata/GFuncTables/GFuncTable.csv',delimiter=',')\na = np.array([g_func_table[:,0],g_func_table[:,1]])\ng_interp_func = CloughTocher2DInterpolator(np.transpose(np.array([g_func_table[:,0],g_func_table[:,1]])),g_func_table[:,2])\n#%%\ndef LSWK_gfunc(E,theta,gam,Eg,QFLS,T):\n '''\n The Lasher-Stern-Wuerfel-Katahara equation\n This uses a Table lookup to calculate G (rather than taking integral)\n which saves time during peak fit\n '''\n\n '''\n theta = X[0]\n gam = X[1]\n #a0 = X(3)*Xscale(3);\n a0 = X[2]\n Eg = X[3]\n #Eg = Xscale(4);\n QFLS = X[4]\n T = X[5]\n #T = Xscale(6);\n d = 375/(1e7)\n '''\n a0 = 1e5\n d = 375/(1e7)\n \n \n ge = np.sqrt(np.absolute(gam))*g_interp_func(theta, (E-Eg)/gam)\n \n AIPL = 2*pi*E**2/(heV**3*c**2)*((1-np.exp(-a0*d*ge))/(np.exp((E-QFLS)/(keV*T))-1))*(1-2/(np.exp((E-QFLS)/(2*keV*T))+1))\n\n #AIPL = np.log(AIPL)\n return AIPL\n\ndef LSWK_2phase_gfunc(E,theta,gam,Eg1,Eg2,x1,QFLS,T):\n '''\n The Lasher-Stern-Wuerfel-Katahara equation\n This uses a Table lookup to calculate G (rather than taking integral)\n which saves time during peak fit\n '''\n\n '''\n theta = X[0]\n gam = X[1]\n #a0 = X(3)*Xscale(3);\n a0 = X[2]\n Eg = X[3]\n #Eg = Xscale(4);\n QFLS = X[4]\n T = X[5]\n #T = Xscale(6);\n d = 375/(1e7)\n '''\n a0 = 1e5\n d = 375/(1e7)\n \n \n ge1 = np.sqrt(np.absolute(gam))*g_interp_func(theta, (E-Eg1)/gam)\n ge2 = np.sqrt(np.absolute(gam))*g_interp_func(theta, (E-Eg2)/gam)\n \n ge = x1*ge1 + (1-x1)*ge2\n \n AIPL = 2*pi*E**2/(heV**3*c**2)*((1-np.exp(-a0*d*ge))/(np.exp((E-QFLS)/(keV*T))-1))*(1-2/(np.exp((E-QFLS)/(2*keV*T))+1))\n\n #AIPL = np.log(AIPL)\n return AIPL\n\ndef full_peak_fit(E,Ipl,X0):\n '''\n This is work in progress. Want to add variable number of arguments, and\n add the following functionality\n 1. Ability to set thresh to determine fit ranges\n 2. Ability to override thresh determined fit ranges \n 3. Ability to specify which params to fit and keep constant\n 4. Ability to pass unfit params to function (e.g. a0*d)\n '''\n \n thresh = 1e16\n maxI_idx = np.argmax(Ipl)\n lb_idx = np.argmin(np.absolute(Ipl[:maxI_idx]-thresh))\n rb_idx = np.argmin(np.absolute(Ipl[maxI_idx:]-thresh))+maxI_idx\n \n #ll_idx = np.argmin(np.absolute(E-1.7))\n \n X = np.ones(5);\n Xscale = X0\n X[0] = Xscale[0]\n X[1] = Xscale[1]\n #X[2] = Xscale[2]\n X[2] = Xscale[3]\n X[3] = Xscale[4]\n X[4] = Xscale[5]\n \n \n (Xf, pcov) = curve_fit(LSWK_gfunc, E[lb_idx:rb_idx], Ipl[lb_idx:rb_idx],p0=X)\n #(Xf, pcov) = curve_fit(LSWK_gfunc, E[lb_idx:rb_idx], Ipl[lb_idx:rb_idx],p0=X)\n\n \n aipl_mod = LSWK(E[lb_idx:rb_idx],Xf[0],Xf[1],Xf[2],Xf[3],Xf[4])\n #aipl_mod = LSWK(E[lb_idx:rb_idx],Xf[0],Xf[1],Xf[2],Xf[3],Xf[4])\n return (E[lb_idx:rb_idx], aipl_mod,Xf[0],Xf[1],Xf[2],Xf[3],Xf[4])\n"
},
{
"alpha_fraction": 0.7767857313156128,
"alphanum_fraction": 0.7767857313156128,
"avg_line_length": 27,
"blob_id": "155ed93f0575c444a9daef23488fbb3f2f051cb7",
"content_id": "701b800425345e3c227985a0e4f4247523dd53ad",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 112,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 4,
"path": "/README.md",
"repo_name": "rstoddard24/PVtools",
"src_encoding": "UTF-8",
"text": "\n\n# PVtools\nA collection of useful tools for thin film photovoltaic research\n"
},
{
"alpha_fraction": 0.6303529739379883,
"alphanum_fraction": 0.6590216755867004,
"avg_line_length": 27.911916732788086,
"blob_id": "6897c21ed801953b7f3f01254d61cf134721467f",
"content_id": "deb2bcbfd8694286d8f7c3afdee6221b6ef84b97",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5581,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 193,
"path": "/PVtools/PL/2018_10-19_PL_analysis.py",
"repo_name": "rstoddard24/PVtools",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Oct 19 09:08:27 2018\n\n@author: ryanstoddard\n\"\"\"\n#%%\n#This section is just standard imports, defining default plot settings,\n# and defining constants\n#standard imports\nimport numpy as np\nimport pandas as pd\nimport math\nimport scipy\nfrom scipy.interpolate import interp1d\nimport matplotlib.pyplot as plt\n\nimport time\nimport matplotlib.cm as cm\nimport matplotlib as mpl\nfrom os import listdir\n\nimport sys\nsys.path.append('../../')\nfrom PVtools.PL import PLtools\n\n\n#change default plot settings\ndefault_figsize = mpl.rcParamsDefault['figure.figsize']\nmpl.rcParams['figure.figsize'] = [1.5*val for val in default_figsize]\nfont = {'family' : 'DejaVu Sans',\n 'weight' : 'bold',\n 'size' : 24}\n\nmpl.rc('font', **font)\nmpl.rc('axes', linewidth=3)\n\n#Constants\npi = math.pi\nheV = 4.14e-15 #eV*s\nc = 2.99792e8 #m/s\nkbeV = 8.6173e-5 #eV/K\nkeV = 8.6173e-5 #eV/K\nh = 6.626e-34\nkb = 1.38065e-23\nq = 1.60218e-19\n\n#%%\n#This section we define inputs \n#Inputs Here\ndirectory = '2018_10-12PL'\nlaser_power = 32*1e-9\ngrating = '500nm' # '500nm' or '1200nm'\n#dname = 'Dark.txt' #assumes 1 dark name per folder\n\n#Now lets look into the directory to see what files we have to analyze\n#(this avoids having to copy/paste filenames)\nnames = []\nfor file in listdir(directory):\n if file[-6:] == 'XY.txt':\n names.append(file)\n elif file[-8:] == 'Dark.txt':\n dname = file\n \nprint(names)\nprint(dname)\n'''\n#%%\n#Use Case 1: We want to took at a few PL maps, convert to absolute units,\n#then plot 1 spectrum per map on same plot. \nfor ii in (7, 2, 1, 0):\n #Load data, using pd. Can also use np.loadtxt, but less flexible\n df = pd.read_table(directory + '/' + dname,header=None)\n dark = df.values \n df = pd.read_table(directory + '/' + names[ii],header=None)\n data = df.values\n \n #Convert to aboslute units with single line of code, calling function from\n #PLtools module\n aipl_data = PLtools.aipl(data,dark,grating)\n \n #Lets choose the peak with median PLQY. There is a function in PLtools \n #that returns index to median PLQY spectrum\n idx = PLtools.med_idx(aipl_data)\n \n #Look at map data to see where AIPL info is, and also to find E\n k = 0\n while np.isnan(aipl_data[0,k]):\n k = k + 1\n lam = aipl_data[0,k:]\n E = heV*c/(lam*1e-9)\n spectrum = aipl_data[idx,k:]\n \n #Now prepare plot\n plt.plot(E,spectrum,'-',linewidth=3)\nplt.xlabel('$E\\ [eV]$')\nplt.ylabel('$I_{PL}\\ [photons/m^2*sec*eV]$')\nplt.legend(['FAGACs','+PEAI','+TOPO','+Both'])\n\n#%%\n#Use Case 2: Lets look at maps, calculate QFLS and chi with PLQY method,\n#then plot distributions\n\n#Pre-allocate lists, we will use these to plot\nmeanPL_list = []\nPLQY_list = []\nQFLS_list = []\nchi_list = []\nfor ii in (7, 2, 1, 0):\n #Load data, using pd. Can also use np.loadtxt, but less flexible\n df = pd.read_table(directory + '/' + dname,header=None)\n dark = df.values\n df = pd.read_table(directory + '/' + names[ii],header=None)\n data = df.values\n \n #Convert to aboslute units with single line of code, calling function from\n #PLtools module\n aipl_data = PLtools.aipl(data,dark,grating)\n \n #Determine PL params using PLtools.plqy_ext function\n (mean_Ipl, peak_pos, FWHM, \n PLQY, dmu_PLQY, chi_PLQY,\n dmu_PLQY_Eg, chi_PLQY_Eg) = PLtools.plqy_ext(aipl_data, laser_power)\n \n #We will make a list for each param we want to plot (a list of np arrays)\n #Exclude 0 entries (datapoints that were skipped)\n meanPL_list.append(mean_Ipl[np.where(mean_Ipl>0)])\n PLQY_list.append(PLQY[np.where(PLQY>0)])\n QFLS_list.append(dmu_PLQY[np.where(dmu_PLQY>0)])\n chi_list.append(chi_PLQY[np.where(chi_PLQY>0)])\n \n#Make 4 different boxplots for each parameter\nplt.figure()\nplt.boxplot(meanPL_list)\n#plt.ylim(1.7,1.8)\nplt.ylabel('$<E_{PL}>\\ [eV]$')\nplt.xticks([1, 2, 3, 4], ['FAGACs', '+PEAI', '+TOPO', '+Both'])\n\nplt.figure()\nplt.boxplot(PLQY_list)\n#plt.ylim(1.7,1.8)\nplt.ylabel('$PLQY\\ [\\%]$')\nplt.xticks([1, 2, 3, 4], ['FAGACs', '+PEAI', '+TOPO', '+Both'])\n\nplt.figure()\nplt.boxplot(QFLS_list)\n#plt.ylim(1.7,1.8)\nplt.ylabel('$QFLS\\ [eV]$')\nplt.xticks([1, 2, 3, 4], ['FAGACs', '+PEAI', '+TOPO', '+Both'])\n\nplt.figure()\nplt.boxplot(chi_list)\n#plt.ylim(1.7,1.8)\nplt.ylabel('$\\chi\\ [\\%]$')\nplt.xticks([1, 2, 3, 4], ['FAGACs', '+PEAI', '+TOPO', '+Both'])\n'''\n#%%\n#Use Case 3: Study Full Peak Fit for a single spectrum\n#Lets do + PEAI and choose the peak with median PLQY\nii = 2 #+PEAI filename index\n\n#Load data, using pd. Can also use np.loadtxt, but less flexible\ndf = pd.read_table(directory + '/' + dname,header=None)\ndark = df.values\ndf = pd.read_table(directory + '/' + names[ii],header=None)\ndata = df.values\n\n#Convert to aboslute units with single line of code, calling function from\n#PLtools module\naipl_data = PLtools.aipl(data,dark,grating)\n\n#Lets choose the peak with median PLQY. There is a function in PLtools \n#that returns index to median PLQY spectrum\nidx = PLtools.med_idx(aipl_data)\n\n#Look at map data to see where AIPL info is, and also to find E\nk = 0\nwhile np.isnan(aipl_data[0,k]):\n k = k + 1\nlam = aipl_data[0,k:]\nE = heV*c/(lam*1e-9)\nIpl = aipl_data[idx,k:]\n\n#Use full_peak_fit to make a full peak fit\n(Emod, aipl_mod, theta, gam, Eg, QFLS, T) = PLtools.full_peak_fit(E,Ipl)\n\n#%%\nplt.semilogy(E,Ipl,'.',Emod,aipl_mod)\n#aipl_mod1 = np.exp(PLtools.LSWK(Emod,theta, gam, Eg, QFLS, T))\n#aipl_mod2 = np.exp(PLtools.LSWK_gfunc(Emod,theta, gam, Eg, QFLS, T))\n#plt.semilogy(Emod,aipl_mod2)\n#plt.semilogy(Emod,aipl_mod2)\n\n"
},
{
"alpha_fraction": 0.5669269561767578,
"alphanum_fraction": 0.6282766461372375,
"avg_line_length": 30.89285659790039,
"blob_id": "2b380b39ecfba98b20e526d8b47fd1f0e7f64dea",
"content_id": "88bacdef08b251dde8ee5acf2473a64f5cbb38e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3586,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 112,
"path": "/PVtools/SQ_calcs.py",
"repo_name": "rstoddard24/PVtools",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\nimport math\nimport scipy\nfrom scipy.interpolate import interp1d\nfrom scipy.integrate import trapz\nfrom scipy import signal\n\n\nimport matplotlib.pyplot as plt\n\n#Constants\npi = math.pi\nheV = 4.14e-15 #eV*s\nc = 2.99792e8 #m/s\nkbeV = 8.6173e-5 #eV/K\nkeV = 8.6173e-5 #eV/K\nh = 6.626e-34\nkb = 1.38065e-23\nq = 1.60218e-19\nk = 1.3806488e-23\nJperEV = 1.60218e-19\nT = 293\nFs = 0.0000680024\n\n#Load data\n\ntry:\n am15_nm = np.loadtxt('../../data/PLdata/vocmax_data/am15_nmdata.txt', delimiter = ',')\n am15_energy_pernm = np.loadtxt('../../data/PLdata/vocmax_data/am15_spec_data.txt', delimiter = ',')\nexcept OSError:\n try:\n am15_nm = np.loadtxt('data/PLdata/vocmax_data/am15_nmdata.txt', delimiter = ',')\n am15_energy_pernm = np.loadtxt('data/PLdata/vocmax_data/am15_spec_data.txt', delimiter = ',')\n except OSError:\n am15_nm = np.loadtxt('../data/PLdata/vocmax_data/am15_nmdata.txt', delimiter = ',')\n am15_energy_pernm = np.loadtxt('../data/PLdata/vocmax_data/am15_spec_data.txt', delimiter = ',')\n\n\n \nam15_ev = heV * c/ 1e-9 / am15_nm\n \n#calculate photon flux at one sun for different bandgap\ndef one_sun_photon_flux(bandgap):\n '''\n This function integrates above bandgap photon flux for AM1.5GT Spectrum\n INPUTS:\n bandgap = bandgap [eV]\n \n OUTPUTS:\n above_bandgap_photon_flux = integrated above bandgap photon flux [photons/m^2-s]\n '''\n # This function inputs bandgap [eV] and returns above bandgap photon flux [photons/m^2-s] from AM1.5GT spectrum\n am15_idx = np.argmin(np.abs(am15_ev-bandgap))\n am15_photon_perev = AM15GTPhotonFluxPerEV(am15_ev)\n above_bandgap_photon_flux = -trapz(am15_photon_perev[:am15_idx],am15_ev[:am15_idx]) #photons/m^2-sec\n return above_bandgap_photon_flux\n \ndef AM15GTPhotonFluxPerEV(eV):\n '''\n This function does bandwith conversion for AM1.5GT Spectrum\n INPUTS:\n eV = energy [eV]\n \n OUTPUTS:\n photon_flux = photon flux per eV [photons/m^2-s-eV]\n '''\n AM15GT_fun = interp1d(am15_nm,am15_energy_pernm,'cubic',fill_value=0,bounds_error=False)\n photon_flux = (1/(eV*JperEV))*AM15GT_fun(h*c*1e9/(eV*JperEV))*(h*c/(eV*JperEV)**2)*1e9*JperEV\n return photon_flux\n\ndef JphSQ(Eg, Ta):\n '''\n This functions calculates the Shockley-Quiesser limit short curcuit current\n INPUTS:\n Eg = bandgap [eV]\n Ta = Temperature [K]\n \n OUTPUTS:\n J = short-circuit current [A/m^2]\n '''\n dm = 0 # delta mu\n beEV = (2*pi/(heV**3*c**2)*((am15_ev)**2/(np.exp((am15_ev-dm)/(keV*Ta))-1)))\n Japh = AM15GTPhotonFluxPerEV(am15_ev) - (Fs/pi)*beEV\n am15_idx = np.argmin(np.abs(am15_ev-Eg))\n J = -q*trapz(Japh[:am15_idx], am15_ev[:am15_idx])\n return J\n\ndef VocSQ(Eg, Ta):\n '''\n This functions calculates the Shockley-Quiesser limit open-circuit voltage\n INPUTS:\n Eg = bandgap [eV]\n Ta = Temperature [K]\n \n OUTPUTS:\n V = open-circuit voltage [V]\n '''\n \n dm = 0 # delta mu\n beEV = (2*pi/(h**3*c**2)*((am15_ev*JperEV)**2/(np.exp((am15_ev-dm)/(keV*Ta))-1))*JperEV)\n beEV_dm = np.zeros(am15_ev.shape)\n dm = Eg/2\n for ii in range(am15_ev.shape[0]):\n if am15_ev[ii] > dm:\n beEV_dm[ii] = (2*pi/(h**3*c**2)*((am15_ev[ii]*JperEV)**2/(np.exp((am15_ev[ii]-dm)/(keV*Ta))-1))*JperEV) \n Jeph = (beEV_dm-beEV) \n am15_idx = np.argmin(np.abs(am15_ev-Eg)) \n JdarkSQ = -q*trapz(Jeph[:am15_idx],am15_ev[:am15_idx])\n JoSQ = JdarkSQ/(np.exp(q*Eg/2/(k*Ta))-1) \n V = k*Ta/q * np.log(JphSQ(Eg, Ta)/JoSQ + 1) \n return V\n \n \n "
}
] | 7 |
diwanc/python_basics | https://github.com/diwanc/python_basics | a150e3d9c6b90e10abf50285e95ad5ac86bf2953 | 57a8e822709201cd4c9735cae474940591e007ae | 16d52876f829edd579095f725cf0148b2aa1a596 | refs/heads/master | 2020-06-12T08:27:30.639749 | 2019-06-28T12:16:59 | 2019-06-28T12:16:59 | 194,245,294 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.45679011940956116,
"alphanum_fraction": 0.6604938507080078,
"avg_line_length": 19.375,
"blob_id": "7c532f859cdc020eaebb7e61fcd63eaad3d18bd1",
"content_id": "6d8af8669a98f60e218818f0fff8bb8c86464f20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 8,
"path": "/src/arithmatic.py",
"repo_name": "diwanc/python_basics",
"src_encoding": "UTF-8",
"text": "print(100+10)\nprint(7.0//3.5) #truncate decimal. floor division\nprint(253/32)\nprint(253.0/32)\nprint(3**5) #power\nprint(10+2*7+3) #BODMAS\n\nprint((0.1+0.2) - (0.3))"
},
{
"alpha_fraction": 0.6140350699424744,
"alphanum_fraction": 0.6885964870452881,
"avg_line_length": 13.3125,
"blob_id": "a895c1b601d94a6b7e9d5860579b7a839076f288",
"content_id": "38fb3679c80fe5942d8d4a4806062b4621a68ae2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 228,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 16,
"path": "/src/variables.py",
"repo_name": "diwanc/python_basics",
"src_encoding": "UTF-8",
"text": "_a = 10\nprint(_a)\nmyvar1 = 5.45\nprint(myvar1)\n#print(myVar1) #case sensitive. so error\n\n#dynamic typing\nprint(type(_a))\nprint(type(myvar1))\nmyvar1 = \"Test\"\nprint(type(myvar1))\n\nmyvar1 = [5,7,2.7]\nprint(type(myvar1))\n\nprint(type)"
},
{
"alpha_fraction": 0.5579710006713867,
"alphanum_fraction": 0.5724637508392334,
"avg_line_length": 16.125,
"blob_id": "7d2e48f6600e7ca717269511280dcec0b52be521",
"content_id": "46ba3709189c9a531d4c741eaa86f80c09bb0de2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 138,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 8,
"path": "/src/tuples.py",
"repo_name": "diwanc/python_basics",
"src_encoding": "UTF-8",
"text": "listVar = ['t','y','r']\ntupleVar = ('t','y','r')\n\nlistVar[1] = 's'\n#tupleVar[1] = 's' # error. immutable\n\nprint(listVar)\nprint(tupleVar)\n\n"
},
{
"alpha_fraction": 0.5855855941772461,
"alphanum_fraction": 0.6738739013671875,
"avg_line_length": 11.086956977844238,
"blob_id": "e4df8211d1cecf71f8e4fc6a85e112e38a929e27",
"content_id": "cf6bd5dab8512f6e4e81f0c53c25a759e11139b5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 46,
"path": "/src/lists.py",
"repo_name": "diwanc/python_basics",
"src_encoding": "UTF-8",
"text": "list1 = [3,'rer',9.67]\n\nprint(list1)\n\nprint(type(list1))\n\n#nested lists\n\nlist2 = [1, 4, 6, list1]\nprint(list2)\n\ntup1 = (1,3,'ty')\n\nlist3 = [list2, tup1]\nprint(list3)\n\ntup2 = (tup1,list1)\n\nprint(tup2)\n\nlist1[0] = 'chnaged list element'\n\nprint(list1)\n\nprint(tup2)\n\nprint(list3[1][2]) #access nested list elements\n\n#list concat\nlist4 = list1 + list(tup1)\nprint(list4)\n\n# multuply list\ntup3 = tup2 * 2\nprint(tup3)\n\n# multuply list\ntup3 = tup2 * 0\nprint(tup3)\n\nlist3.append('object')\nprint(list3)\n\nprint(list3.pop(1))\nprint(list3.remove('object'))\nprint(list3)"
},
{
"alpha_fraction": 0.6058394312858582,
"alphanum_fraction": 0.6642335653305054,
"avg_line_length": 11.454545021057129,
"blob_id": "6fa48189a650728c164e7f49dae562466ff898c5",
"content_id": "dd0b5ceb340e7d01bf9c4c14699b9ea08e729a0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 11,
"path": "/src/listcompre.py",
"repo_name": "diwanc/python_basics",
"src_encoding": "UTF-8",
"text": "\nstr1 = \"list-comprehension\"\n\nprint(list(str1))\n\nlist1 = [x for x in str1]\n\nprint(list1)\n\nlist1 = [x.upper() for x in str1]\n\nprint(list1)"
},
{
"alpha_fraction": 0.5925925970077515,
"alphanum_fraction": 0.6702508926391602,
"avg_line_length": 16.82978630065918,
"blob_id": "a9b7859f298623dbdd73e655a00285bca9d76203",
"content_id": "98af5f4700f4844a20408fc1a371198698549ffb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 837,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 47,
"path": "/src/strings.py",
"repo_name": "diwanc/python_basics",
"src_encoding": "UTF-8",
"text": "str1 = \"Test\"\nstr2 = \"Tes't2\"\nint1=143\n\nprint(str(int1)+str1+str2)\nprint(list(str1))\n\nprint(str1[0])\n\nprint(str1[0-len(str1)]) #reverse index\n\n#str1[0]='r' #error. str is immutable\n\n\n#string slicing\nstr3 = \"Hello World\"\nprint(str3[0:5])\nprint(str3[-11:5]) #same result\nprint(str3[-11:-5])\n\n#print(str3[22]) # out of range error\n#print(str3[-12]) # out of range error\n\nprint(str3[7:]) # 7 till last\nprint(str3[:3]) # first to 3-1\n\nprint(str3[0:5:2]) #step 2\n\nprint(str3.upper())\n\nprint(type(print))\nprint(type(str.upper))\n\nsplitstr = str3.split()\nprint(type(splitstr))\nprint(splitstr)\n\nsplitstr = str3.split(None,0)\nprint(splitstr)\n\nsplitstr = str3.split('o',2)\nprint(splitstr)\n\nprint(str3.count('o', 0, 6))\nprint(str3.count('l')) #count of l\nprint(str3.count('l', 0, 3)) # count of l in the first 3 positions\nprint(str3.count('l', 0, 4))"
},
{
"alpha_fraction": 0.4794520437717438,
"alphanum_fraction": 0.5958904027938843,
"avg_line_length": 13.699999809265137,
"blob_id": "301b7c06097b29639aa01ff8e47a311b1ab8f8cb",
"content_id": "d69dc2e7b6b21df039cf5a51f802dd513fdc7ceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 10,
"path": "/src/loop.py",
"repo_name": "diwanc/python_basics",
"src_encoding": "UTF-8",
"text": "for x in range(0,20):\n print(x**2)\n\nlist1 = [x**2 for x in range(20)]\n\nprint(list1)\n\nlist1 = [x for x in range(20) if x**2 < 201]\n\nprint(list1)"
},
{
"alpha_fraction": 0.703125,
"alphanum_fraction": 0.703125,
"avg_line_length": 15.25,
"blob_id": "d7e4d3055e474e6ad7d753e978a1595786ecbd6a",
"content_id": "b58824c973093709a3222908f7c38183a0a265d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 64,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 4,
"path": "/src/helloworld.py",
"repo_name": "diwanc/python_basics",
"src_encoding": "UTF-8",
"text": "print(\"Hello World\")\n\nprint('''Hello World\nin multiple lines''')"
}
] | 8 |
thzlet/Tarefa-009 | https://github.com/thzlet/Tarefa-009 | db7d19db886e739f8fced3448e0726c10b0e395b | 5e5cde0f0d6716ecf731d4c57b87a0169a5b2863 | daeddd516cac482367750f46f6a5f134b655c735 | refs/heads/main | 2023-08-15T04:11:17.447609 | 2021-09-29T02:33:56 | 2021-09-29T02:33:56 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.659217894077301,
"alphanum_fraction": 0.6759776473045349,
"avg_line_length": 18.88888931274414,
"blob_id": "a8a165cfe684eccb888b46a42c3680d81369531a",
"content_id": "58c8ac1fb0ae670655b55a99548d41e3a726f583",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 183,
"license_type": "permissive",
"max_line_length": 31,
"num_lines": 9,
"path": "/README.md",
"repo_name": "thzlet/Tarefa-009",
"src_encoding": "UTF-8",
"text": "# Tarefa-009\n\nABOUT -Matheus ||\nLOGIN - Cristina || \nCADASTRO - Letícia, Cristina ||\nNEWS - Matheus, Letícia ||\nCONTACT - Letícia ||\nSONGS - Letícia, Angela ||\nEXEMPLOS - Angela;\n"
},
{
"alpha_fraction": 0.5873256325721741,
"alphanum_fraction": 0.5894481539726257,
"avg_line_length": 22.32624053955078,
"blob_id": "c813ed9cae661d16ec2e5322542fec086a616fa7",
"content_id": "96be4c28335a4b59d8ab93f8a69d44021d00662d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3301,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 141,
"path": "/site/run.py",
"repo_name": "thzlet/Tarefa-009",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, request, redirect, flash\nfrom werkzeug.exceptions import BadRequestKeyError\n\napp = Flask(__name__)\n\napp.secret_key = '120302'\n\napp.debug = True\n\nusuarios = [\n {'id': '',\n 'nome': '',\n 'email': '',\n 'senha': '',\n 'endereco': '',\n 'estadoC':'',\n 'checkboxedi': '',\n 'checkboxred': '',\n 'curriculo': '',\n 'idade': ''\n }\n]\n\ncontact = [\n {'nome': '',\n 'email': '',\n 'assunto': ''\n }\n]\n\[email protected]('/')\[email protected]('/home')\ndef home_page():\n return render_template('about.html')\n\[email protected]('/news')\ndef news_page():\n return render_template('news.html')\n\[email protected]('/songs')\ndef songs_page():\n return render_template('songs.html')\n\[email protected]('/exemplos')\ndef exemplos_page():\n return render_template('exemplos.html')\n\[email protected]('/projeto')\ndef projeto_page():\n return render_template('projeto.html')\n\[email protected]('/cadastro')\ndef cadastro_page():\n return render_template('cadastro.html', )\n\[email protected]('/novocadastro')\ndef cadastrar_page():\n id_nv = len(usuarios)+1\n nome_nv = request.form['nome']\n email_nv = request.form['email']\n senha_nv = request.form['senha']\n endereco_nv = request.form['endereco']\n\n try:\n estadoC_nv = request.form['estadoC']\n except BadRequestKeyError:\n estadoC_nv = None\n try:\n checkboxedi_nv = request.form['ceckboxedi']\n except BadRequestKeyError:\n checkboxedi_nv = None\n try:\n checkboxred_nv = request.form['checkboxred']\n except BadRequestKeyError:\n checkboxred_nv = None\n try:\n curriculo_nv = request.form['curriculo']\n except BadRequestKeyError:\n curriculo_nv = None\n idade_nv = request.form['idade']\n\n novo_usuario = {\n 'id': id_nv,\n 'nome': nome_nv,\n 'email': email_nv,\n 'senha': senha_nv,\n 'endereco': endereco_nv,\n 'estadoC' : estadoC_nv,\n 'checkboxedi': checkboxedi_nv,\n 'checkboxred': checkboxred_nv,\n 'curriculo': curriculo_nv,\n 'idade': idade_nv\n }\n usuarios.append(novo_usuario)\n\n flash(f'Currículo de {nome_nv} enviado com sucesso! Entraremos em contato assim que possível :)')\n\n return redirect('/home')\n\[email protected]('/contact')\ndef contact_page():\n return render_template('contact.html')\n\[email protected]('/novocontact')\ndef contatar_page():\n nome_nv = request.form['nome']\n email_nv = request.form['email']\n assunto_nv = request.form['assunto']\n\n novo_contact = {\n 'nome': nome_nv,\n 'email': email_nv,\n 'assunto': assunto_nv\n }\n contact.append(novo_contact)\n\n flash(f'Olá, {nome_nv} seu recado foi enviado! :)')\n\n return redirect('/home')\n\[email protected]('/login')\ndef login_page():\n return render_template('login.html')\n\[email protected]('/entrar')\ndef entrar_page():\n email_l = request.form['email']\n senha_l = request.form['senha']\n res = None\n for usuario in usuarios:\n if email_l == usuario['email'] and senha_l == usuario['senha']:\n res = True\n else:\n res = False\n\n if res == True:\n flash('Logado com sucesso!!')\n return redirect('/home')\n else:\n flash('Algo deu errado :( tente novamente!')\n return redirect('/login')\n\n\n\n\n\n\n\n\n\n"
}
] | 2 |
nikita1803/Employee_Wage_Rest_Api | https://github.com/nikita1803/Employee_Wage_Rest_Api | f100c7d6d3e30d12b64426126bf08bdd2420df73 | d01fd0db7b07f685be1b48398049c52e702446bd | 57cdea15133dc629fffdc8611af6628093613769 | refs/heads/main | 2023-07-07T13:23:42.071814 | 2021-08-22T15:08:41 | 2021-08-22T15:08:41 | 398,819,204 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4972568452358246,
"alphanum_fraction": 0.5127182006835938,
"avg_line_length": 26.067567825317383,
"blob_id": "625a23b2d04e40eaf3c8d220649ae31369428c56",
"content_id": "84259b832d8f117b8c72354aa93faf33585a61d3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2005,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 74,
"path": "/employee_wage_Api.py",
"repo_name": "nikita1803/Employee_Wage_Rest_Api",
"src_encoding": "UTF-8",
"text": " \n'''\n@Author: Nikita Rai\n@Date: 2021-08-19 03:10:00\n@Last Modified by: Nikita Rai\n@Last Modified time: 2021-08-19 03:10:00\n@Title : Check Employee is\nPresent or Absent\n- Use ((RANDOM)) for Attendance\nCheck\n'''\nimport random\nfrom flask_restful import Resource, Api\nfrom flask import Flask,request\n\napp = Flask(__name__)\napi = Api(app)\nemp_data = []\n\nclass employee(Resource):\n def get(self,name):\n '''\n Description:\n get function is use to only read the data \n Parameter:\n self and name\n Return:\n the data of index matches with the name\n '''\n for i in emp_data:\n if i['Data'] == name:\n return i\n return {'Data': None}\n\n def post(self,name):\n '''\n Description:\n post function is use to add the data \n Parameter:\n self and name\n Return:\n temprary variable in which i can store the data\n '''\n ISPRESENT = 1\n randomCheck = random.randint(0, 1)\n if ( ISPRESENT == randomCheck ) :\n emp_Status= \"present\" \n Tem_emp_data = {'Data':name,'Attendence' : randomCheck,'Status' : emp_Status\n \n }\n else:\n emp_Status= \"absent\" \n Tem_emp_data = {'Data':name,'Attendence' : randomCheck,'Status' : emp_Status}\n\n emp_data.append(Tem_emp_data)\n return Tem_emp_data\n \n def delete(self,name):\n '''\n Description:\n delete is a function which is use to delete(pop) the value \n Parameter:\n self and name\n Return:\n string value\n '''\n for ind,i in enumerate(emp_data):\n if i['Data'] == name:\n Tem_emp_data = emp_data.pop(ind)\n return {'Note':\"Deleted\"}\n \napi.add_resource(employee,'/Name/<string:name>')\n\nif __name__ == '__main__':\n app.run(debug = True)"
},
{
"alpha_fraction": 0.7857142686843872,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 41,
"blob_id": "a652929a97a8397b309501ac16196d7308a1a838",
"content_id": "f361932cb8420d91698bfe44ecae875110952835",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 1,
"path": "/README.md",
"repo_name": "nikita1803/Employee_Wage_Rest_Api",
"src_encoding": "UTF-8",
"text": "# Welcome in employee wage using Rest Api\n"
},
{
"alpha_fraction": 0.4883960783481598,
"alphanum_fraction": 0.5079938173294067,
"avg_line_length": 32.73043441772461,
"blob_id": "583bc3163567525e0f16ef320c35f7b88ba9cdd3",
"content_id": "9d58357e8f25c795e5ec3fd0a126634849ca1fa0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3878,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 115,
"path": "/employee_wage_uc6.py",
"repo_name": "nikita1803/Employee_Wage_Rest_Api",
"src_encoding": "UTF-8",
"text": "'''\n@Author: Nikita Rai\n@Date: 2021-08-19 08:10:00\n@Last Modified by: Nikita Rai\n@Last Modified time: 2021-08-19 08:10:00\n@Title : Check Employee is\nPresent or Absent\n- Use ((RANDOM)) for Attendance\nCheck and calculate the wage using switcher\n'''\nimport random\nfrom flask_restful import Resource, Api\nfrom flask import Flask,request,jsonify\n\napp = Flask(__name__)\napi = Api(app)\nemp_data = []\nclass employee(Resource):\n '''\n Description:\n employee is a class which is use to get post and delete the data \n Methods: \n get , post , delete\n '''\n def get(self,name):\n '''\n Description:\n get function is use to only read the data \n Parameter:\n self and name\n Return:\n the data of index matches with the name\n '''\n for i in emp_data:\n if i['Name'] == name:\n return i\n return {'Name': None}\n app.route(\"/employee_month/<string:name>\", methods=['POST'])\n def post(self,name):\n '''\n Description:\n post function is use to add the data , if employee is present thr calculate the wage using switch case\n Parameter:\n self and name\n Return:\n temprary variable in which i can store the data\n '''\n EMP_RATE_PER_DAY = 20 \n TOTAL_SALARY = 0\n NUM_OF_WORKING_DAYS = 20\n MAX_HRS_IN_MONTH = 100\n TOTAL_EMP_HR = 0\n TOTAL_WORKING_DAYS = 0\n EMP_RATE_PER_HR = 20\n randomCheck = random.randint(1,3)\n switcher = {\n 1: 8,\n 2: 4,\n 3: 0,\n }\n while ( TOTAL_EMP_HR<100 and TOTAL_WORKING_DAYS < NUM_OF_WORKING_DAYS ) :\n TOTAL_WORKING_DAYS+=1\n empHrs = switcher.get(randomCheck,\"employee wadge\")\n TOTAL_EMP_HR = empHrs + TOTAL_EMP_HR\n TOTAL_SALARY = ( TOTAL_EMP_HR * EMP_RATE_PER_HR)\n Tem_emp_data = {'Name':name,'Attendence' : randomCheck,'Total Employee hours': TOTAL_EMP_HR,'Total Salary': TOTAL_SALARY }\n emp_data.append(Tem_emp_data)\n return jsonify(Tem_emp_data)\n \n def delete(self,name):\n '''\n Description:\n delete is a function which is use to delete(pop) the value \n Parameter:\n self and name\n Return:\n string value\n '''\n for ind,i in enumerate(emp_data):\n if i['Name'] == name:\n Tem_emp_data = emp_data.pop(ind)\n return {'Note':\"Deleted\"}\n\n def patch(self,name):\n for i in emp_data:\n if i['Name'] == name:\n EMP_RATE_PER_DAY = 20 \n TOTAL_SALARY = 0\n NUM_OF_WORKING_DAYS = 20\n MAX_HRS_IN_MONTH = 100\n TOTAL_EMP_HR = 0\n TOTAL_WORKING_DAYS = 0\n EMP_RATE_PER_HR = 20\n randomCheck = random.randint(1,3)\n switcher = {\n 1: 8,\n 2: 4,\n 3: 0,\n }\n while ( TOTAL_EMP_HR<100 and TOTAL_WORKING_DAYS < NUM_OF_WORKING_DAYS ) :\n TOTAL_WORKING_DAYS+=1\n empHrs = switcher.get(randomCheck,\"employee wadge\")\n TOTAL_EMP_HR = empHrs + TOTAL_EMP_HR\n TOTAL_SALARY = ( TOTAL_EMP_HR * EMP_RATE_PER_HR)\n Tem_emp_data = {'Name':name,'Attendence' : randomCheck,'Total Employee hours': TOTAL_EMP_HR,'Total Salary': TOTAL_SALARY }\n emp_data.append(Tem_emp_data)\n return Tem_emp_data\n return {'Name': None}\n\n \napi.add_resource(employee,'/Employee_month/<string:name>')\n\nif __name__ == '__main__':\n app.run(debug = True)\n object = employee()"
},
{
"alpha_fraction": 0.564972996711731,
"alphanum_fraction": 0.5794594883918762,
"avg_line_length": 33.78195571899414,
"blob_id": "481e3720e18fae42408d5c1b4d1f16526eff808e",
"content_id": "060bcd27c53047be20d8a177d4161f6f29a0b0a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4625,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 133,
"path": "/employee_wage.py",
"repo_name": "nikita1803/Employee_Wage_Rest_Api",
"src_encoding": "UTF-8",
"text": "'''\n@Author: Nikita Rai\n@Date: 2021-08-21 08:10:00\n@Last Modified by: Nikita Rai\n@Last Modified time: 2021-08-21 08:10:00\n@Title : Check Employee is\nPresent or Absent\n- Use ((RANDOM)) for Attendance\nand calculate the wage \n'''\nfrom employee_wage_uc4 import employee\nimport random\nfrom flask_restful import Resource, Api, abort , reqparse\nfrom flask import Flask, json,request,jsonify\n\napp = Flask(__name__)\napi = Api(app)\n\nEmp_details = {\n 1: {\"employee_name\": \"Nikita\",\"Attendence\":\"2\",\"Work_hours\":\"20\",\"Total_Salary\": \"800\"},\n}\ntask_post_args = reqparse.RequestParser()\ntask_post_args.add_argument(\"employee_name\" , type=str, help = \"employee_name.\" , required=True)\ntask_post_args.add_argument(\"Attendence\" , type=str, help = \"Attendence.\" )\ntask_post_args.add_argument(\"Work_hours\" , type=str, help = \"Work_hours.\" )\ntask_post_args.add_argument(\"Total_Salary\" , type=str, help = \"employee_salary.\" )\n\ntask_put_args = reqparse.RequestParser()\ntask_put_args.add_argument(\"employee_name\" , type=str, help = \"employee_name.\")\ntask_put_args.add_argument(\"Attendence\" , type=str, help = \"Attendence.\")\ntask_put_args.add_argument(\"Work_hours\" , type=str, help = \"Work_hours.\")\ntask_put_args.add_argument(\"Total_Salary\" , type=str, help = \"employee_salary.\")\n\nclass ToDoList(Resource):\n '''\n Description:\n Todo list is a class which is use to show all the data related to employees.\n Methods: \n get method is used\n '''\n def get(self):\n return Emp_details\n\nclass ToDo(Resource):\n '''\n Description:\n Todo is a class which is use to get , post , put patch and delete the data \n Methods: \n get , post , delete , put\n '''\n def get(self,employee_id):\n '''\n Description:\n get function is use to only read the data \n Parameter:\n self and employee_id\n Return:\n employee details\n '''\n return Emp_details\n\n def post(self,employee_id):\n '''\n Description:\n post function is use to store the value \n Parameter:\n self and employee_id\n Return:\n employee details of employee id\n '''\n args = task_post_args.parse_args()\n if employee_id in Emp_details:\n error = \"Employee already exsists\"\n return jsonify(error)\n EMP_RATE_PER_DAY = 20 \n TOTAL_SALARY = 0\n NUM_OF_WORKING_DAYS = 20\n MAX_HRS_IN_MONTH = 100\n TOTAL_EMP_HR = 0\n TOTAL_WORKING_DAYS = 0\n EMP_RATE_PER_HR = 20\n randomCheck = random.randint(1,3)\n switcher = {\n 1: 8,\n 2: 4,\n 3: 0,\n }\n while ( TOTAL_EMP_HR<100 and TOTAL_WORKING_DAYS < NUM_OF_WORKING_DAYS ) :\n TOTAL_WORKING_DAYS+=1\n empHrs = switcher.get(randomCheck,\"employee wadge\")\n TOTAL_EMP_HR = empHrs + TOTAL_EMP_HR\n salary = ( TOTAL_EMP_HR * EMP_RATE_PER_HR)\n Emp_details[employee_id] = {\"employee_name\": args[\"employee_name\"],\"Attendence\" : randomCheck,\"Work_hours\" : TOTAL_EMP_HR, \"Total_Salary\": salary}\n return Emp_details[employee_id]\n\n def put(self, employee_id):\n '''\n Description:\n put function is use to update the data of employee \n Parameter:\n self and employee_id\n Return:\n employee details of employee id\n '''\n args = task_put_args.parse_args()\n if employee_id not in Emp_details:\n abort(404, message=\"Employee doesn't exist, cannot update\")\n if args['employee_name']:\n Emp_details[employee_id][\"employee_name\"] = args[\"employee_name\"]\n if args['Attendence']:\n Emp_details[employee_id]['Attendence'] = args['Attendence']\n if args['Work_hours']:\n Emp_details[employee_id]['Work_hours'] = args['Work_hours']\n if args[\"Total_Salary\"]:\n Emp_details[employee_id]['Total_Salary'] = args['Total_Salary']\n return Emp_details[employee_id]\n\n def delete(self, employee_id):\n '''\n Description:\n delete function is use to delete the data \n Parameter:\n self and employee_id\n Return:\n employee details of employee id\n '''\n del Emp_details[employee_id]\n return Emp_details\napi.add_resource(ToDo, '/emp/<int:employee_id>')\napi.add_resource(ToDoList , '/Emp_details')\n\nif __name__ == '__main__':\n app.run(port = 5000,debug = True)"
}
] | 4 |
maelp/scikits.image | https://github.com/maelp/scikits.image | 05c347eae419810b41dc1faeb604cfa394ef3122 | c7ff5d510722b59f17e016b54c2aeb6a4cfda27d | 3e2bd03415e16739441152044ff7fd5ea0e96836 | refs/heads/master | 2021-01-16T22:41:59.591409 | 2010-11-08T21:58:09 | 2010-11-08T21:58:09 | 925,158 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.761904776096344,
"alphanum_fraction": 0.761904776096344,
"avg_line_length": 20,
"blob_id": "c65fcc78fc6235f8c09aa058ac22396343d0c9fe",
"content_id": "eee0df76c373e0e4612a7b74b457303e0f5aea69",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21,
"license_type": "permissive",
"max_line_length": 20,
"num_lines": 1,
"path": "/scikits/image/utils/__init__.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from shapes import *\n"
},
{
"alpha_fraction": 0.6009237766265869,
"alphanum_fraction": 0.6023094654083252,
"avg_line_length": 33.91935348510742,
"blob_id": "1f48cb51304bc75bc557bb89c22117a93e0e4fad",
"content_id": "5bde664b307f843d07e955410946cf1aaaaa93ee",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2165,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 62,
"path": "/scikits/image/morphology/tests/test_morphology.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "import os.path\n\nimport numpy as np\nfrom numpy.testing import *\n\nfrom scikits.image import data_dir\nfrom scikits.image.io import imread\nfrom scikits.image import data_dir\nfrom scikits.image.morphology import *\n\nlena = np.load(os.path.join(data_dir, 'lena_GRAY_U8.npy'))\n\nclass TestMorphology():\n\n def morph_worker(self, img, fn, morph_func, strel_func):\n matlab_results = np.load(os.path.join(data_dir, fn))\n k = 0\n for expected_result in matlab_results:\n mask = strel_func(k)\n actual_result = morph_func(lena, mask)\n assert_equal(expected_result, actual_result)\n k = k + 1\n\n def test_erode_diamond(self):\n self.morph_worker(lena, \"diamond-erode-matlab-output.npy\",\n greyscale_erode, diamond)\n\n def test_dilate_diamond(self):\n self.morph_worker(lena, \"diamond-dilate-matlab-output.npy\",\n greyscale_dilate, diamond)\n\n def test_open_diamond(self):\n self.morph_worker(lena, \"diamond-open-matlab-output.npy\",\n greyscale_open, diamond)\n\n def test_close_diamond(self):\n self.morph_worker(lena, \"diamond-close-matlab-output.npy\",\n greyscale_close, diamond)\n\n def test_tophat_diamond(self):\n self.morph_worker(lena, \"diamond-tophat-matlab-output.npy\",\n greyscale_white_top_hat, diamond)\n\n def test_bothat_diamond(self):\n self.morph_worker(lena, \"diamond-bothat-matlab-output.npy\",\n greyscale_black_top_hat, diamond)\n\n def test_erode_disk(self):\n self.morph_worker(lena, \"disk-erode-matlab-output.npy\",\n greyscale_erode, disk)\n\n def test_dilate_disk(self):\n self.morph_worker(lena, \"disk-dilate-matlab-output.npy\",\n greyscale_dilate, disk)\n\n def test_open_disk(self):\n self.morph_worker(lena, \"disk-open-matlab-output.npy\",\n greyscale_open, disk)\n\n def test_close_disk(self):\n self.morph_worker(lena, \"disk-close-matlab-output.npy\",\n greyscale_close, disk)\n"
},
{
"alpha_fraction": 0.6114670038223267,
"alphanum_fraction": 0.6300448179244995,
"avg_line_length": 30.209999084472656,
"blob_id": "b3d60e20b201edc5a1492a6961cb075e0de3031d",
"content_id": "243bda8d12aaeba51cb5071bf3d58de9c819fc94",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3122,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 100,
"path": "/scikits/image/transform/hough_transform.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "## Copyright (C) 2006 Stefan van der Walt <[email protected]>\n##\n## Redistribution and use in source and binary forms, with or without\n## modification, are permitted provided that the following conditions are\n## met:\n##\n## 1. Redistributions of source code must retain the above copyright\n## notice, this list of conditions and the following disclaimer.\n## 2. Redistributions in binary form must reproduce the above copyright\n## notice, this list of conditions and the following disclaimer in\n## the documentation and/or other materials provided with the\n## distribution.\n##\n## THIS SOFTWARE IS PROVIDED BY THE AUTHOR ``AS IS'' AND ANY EXPRESS OR\n## IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED\n## WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE\n## DISCLAIMED. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR ANY DIRECT,\n## INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES\n## (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR\n## SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)\n## HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT,\n## STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING\n## IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE\n## POSSIBILITY OF SUCH DAMAGE.\n\n__all__ = ['hough']\n\nimport numpy as np\n\nitype = np.uint16 # See ticket 225\n\ndef hough(img, angles=None):\n \"\"\"Perform a straight line Hough transform.\n\n Parameters\n ----------\n img : (M, N) bool ndarray\n Thresholded input image.\n angles : ndarray or list\n Angles at which to compute the transform.\n\n Returns\n -------\n H : 2-D ndarray\n Hough transform coefficients.\n distances : ndarray\n Distance values.\n angles : ndarray\n Angle values.\n\n Examples\n --------\n Generate a test image:\n\n >>> img = np.zeros((100, 150), dtype=bool)\n >>> img[30, :] = 1\n >>> img[:, 65] = 1\n >>> img[35:45, 35:50] = 1\n >>> for i in range(90):\n >>> img[i, i] = 1\n >>> img += np.random.random(img.shape) > 0.95\n\n Apply the Hough transform:\n\n >>> out, angles, d = houghtf(img)\n\n Plot the results:\n\n >>> import matplotlib.pyplot as plt\n >>> plt.imshow(out, cmap=plt.cm.bone)\n >>> plt.xlabel('Angle (degree)')\n >>> plt.ylabel('Distance %d (pixel)' % d[0])\n >>> plt.show()\n\n \"\"\"\n if img.ndim != 2:\n raise ValueError(\"Input must be a two-dimensional array\")\n\n img = img.astype(bool)\n\n if not angles:\n angles = np.linspace(-90,90,180)\n\n theta = angles / 180. * np.pi\n d = np.ceil(np.hypot(*img.shape))\n nr_bins = 2*d - 1\n bins = np.linspace(-d, d, nr_bins)\n out = np.zeros((nr_bins, len(theta)), dtype=itype)\n\n rows, cols = img.shape\n x,y = np.mgrid[:rows, :cols]\n\n for i, (cT, sT) in enumerate(zip(np.cos(theta), np.sin(theta))):\n rho = np.round_(cT * x[img] + sT * y[img]) - bins[0] + 1\n rho = rho.astype(itype)\n rho[(rho < 0) | (rho > nr_bins)] = 0\n bc = np.bincount(rho.flat)[1:]\n out[:len(bc), i] = bc\n\n return out, angles, bins\n\n"
},
{
"alpha_fraction": 0.5434871912002563,
"alphanum_fraction": 0.5857436060905457,
"avg_line_length": 30.350482940673828,
"blob_id": "aece28ef389db3596cb1e4117b4cfe496ad60f2b",
"content_id": "f09fbf99e8d32f78e8e36c4eef7a64684f1dba9c",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9750,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 311,
"path": "/scikits/image/opencv/tests/test_opencv_cv.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "# test for the opencv_cv extension module\n\nfrom __future__ import with_statement\n\nimport os\nimport warnings\n\nimport numpy as np\nfrom numpy.testing import *\n\nfrom scikits.image import data_dir\nimport cPickle\n\nwith warnings.catch_warnings():\n warnings.simplefilter(\"ignore\")\n from scikits.image.opencv import *\n\nopencv_skip = dec.skipif(not loaded, 'OpenCV libraries not found')\n\nclass OpenCVTest(object):\n lena_RGB_U8 = np.load(os.path.join(data_dir, 'lena_RGB_U8.npy'))\n lena_GRAY_U8 = np.load(os.path.join(data_dir, 'lena_GRAY_U8.npy'))\n\n\nclass TestSobel(OpenCVTest):\n @opencv_skip\n def test_cvSobel(self):\n cvSobel(self.lena_GRAY_U8)\n\n\nclass TestLaplace(OpenCVTest):\n @opencv_skip\n def test_cvLaplace(self):\n cvLaplace(self.lena_GRAY_U8)\n\n\nclass TestCanny(OpenCVTest):\n @opencv_skip\n def test_cvCanny(self):\n cvCanny(self.lena_GRAY_U8)\n\n\nclass TestPreCornerDetect(OpenCVTest):\n @opencv_skip\n def test_cvPreCornerDetect(self):\n cvPreCornerDetect(self.lena_GRAY_U8)\n\n\nclass TestCornerEigenValsAndVecs(OpenCVTest):\n @opencv_skip\n def test_cvCornerEigenValsAndVecs(self):\n cvCornerEigenValsAndVecs(self.lena_GRAY_U8)\n\n\nclass TestCornerMinEigenVal(OpenCVTest):\n @opencv_skip\n def test_cvCornerMinEigenVal(self):\n cvCornerMinEigenVal(self.lena_GRAY_U8)\n\n\nclass TestCornerHarris(OpenCVTest):\n @opencv_skip\n def test_cvCornerHarris(self):\n cvCornerHarris(self.lena_GRAY_U8)\n\n\nclass TestFindCornerSubPix(object):\n @opencv_skip\n def test_cvFindCornersSubPix(self):\n img = np.array([[1, 1, 1, 0, 0, 0, 1, 1, 1],\n [1, 1, 1, 0, 0, 0, 1, 1, 1],\n [1, 1, 1, 0, 0, 0, 1, 1, 1],\n [0, 0, 0, 1, 1, 1, 0, 0, 0],\n [0, 0, 0, 1, 1, 1, 0, 0, 0],\n [0, 0, 0, 1, 1, 1, 0, 0, 0],\n [1, 1, 1, 0, 0, 0, 1, 1, 1],\n [1, 1, 1, 0, 0, 0, 1, 1, 1],\n [1, 1, 1, 0, 0, 0, 1, 1, 1]], dtype='uint8')\n corners = np.array([[2, 2],\n [2, 5],\n [5, 2],\n [5, 5]], dtype='float32')\n cvFindCornerSubPix(img, corners, (2, 2))\n\n\nclass TestGoodFeaturesToTrack(OpenCVTest):\n @opencv_skip\n def test_cvGoodFeaturesToTrack(self):\n cvGoodFeaturesToTrack(self.lena_GRAY_U8, 100, 0.1, 3)\n\n\nclass TestGetRectSubPix(OpenCVTest):\n @opencv_skip\n def test_cvGetRectSubPix(self):\n cvGetRectSubPix(self.lena_RGB_U8, (20, 20), (48.6, 48.6))\n\n\nclass TestGetQuadrangleSubPix(OpenCVTest):\n @opencv_skip\n def test_cvGetQuadrangleSubPix(self):\n warpmat = np.array([[0.5, 0.3, 0.4],\n [-.4, .23, 0.4]], dtype='float32')\n cvGetQuadrangleSubPix(self.lena_RGB_U8, warpmat)\n\n\nclass TestResize(OpenCVTest):\n @opencv_skip\n def test_cvResize(self):\n cvResize(self.lena_RGB_U8, (50, 50), method=CV_INTER_LINEAR)\n cvResize(self.lena_RGB_U8, (200, 200), method=CV_INTER_CUBIC)\n\n\nclass TestWarpAffine(OpenCVTest):\n @opencv_skip\n def test_cvWarpAffine(self):\n warpmat = np.array([[0.5, 0.3, 0.4],\n [-.4, .23, 0.4]], dtype='float32')\n cvWarpAffine(self.lena_RGB_U8, warpmat)\n\n\nclass TestWarpPerspective(OpenCVTest):\n @opencv_skip\n def test_cvWarpPerspective(self):\n warpmat = np.array([[0.5, 0.3, 0.4],\n [-.4, .23, 0.4],\n [0.0, 1.0, 1.0]], dtype='float32')\n cvWarpPerspective(self.lena_RGB_U8, warpmat)\n\n\nclass TestLogPolar(OpenCVTest):\n @opencv_skip\n def test_cvLogPolar(self):\n img = self.lena_RGB_U8\n width = img.shape[1]\n height = img.shape[0]\n x = width / 2.\n y = height / 2.\n cvLogPolar(img, (x, y), 20)\n\n\nclass TestErode(OpenCVTest):\n @opencv_skip\n def test_cvErode(self):\n kern = np.array([[0, 1, 0],\n [1, 1, 1],\n [0, 1, 0]], dtype='int32')\n cvErode(self.lena_RGB_U8, kern, in_place=True)\n\n\nclass TestDilate(OpenCVTest):\n @opencv_skip\n def test_cvDilate(self):\n kern = np.array([[0, 1, 0],\n [1, 1, 1],\n [0, 1, 0]], dtype='int32')\n cvDilate(self.lena_RGB_U8, kern, in_place=True)\n\n\nclass TestMorphologyEx(OpenCVTest):\n @opencv_skip\n def test_cvMorphologyEx(self):\n kern = np.array([[0, 1, 0],\n [1, 1, 1],\n [0, 1, 0]], dtype='int32')\n cvMorphologyEx(self.lena_RGB_U8, kern, CV_MOP_TOPHAT, in_place=True)\n\n\nclass TestSmooth(OpenCVTest):\n @opencv_skip\n def test_cvSmooth(self):\n for st in (CV_BLUR_NO_SCALE, CV_BLUR, CV_GAUSSIAN, CV_MEDIAN,\n CV_BILATERAL):\n cvSmooth(self.lena_GRAY_U8, st, 3, 0, 0, 0, False)\n\n\nclass TestFilter2D(OpenCVTest):\n @opencv_skip\n def test_cvFilter2D(self):\n kern = np.array([[0, 1.5, 0],\n [1, 1, 2.6],\n [0, .76, 0]], dtype='float32')\n cvFilter2D(self.lena_RGB_U8, kern, in_place=True)\n\n\nclass TestIntegral(OpenCVTest):\n @opencv_skip\n def test_cvIntegral(self):\n cvIntegral(self.lena_RGB_U8, True, True)\n\n\nclass TestCvtColor(OpenCVTest):\n @opencv_skip\n def test_cvCvtColor(self):\n cvCvtColor(self.lena_RGB_U8, CV_RGB2BGR)\n cvCvtColor(self.lena_RGB_U8, CV_RGB2BGRA)\n cvCvtColor(self.lena_RGB_U8, CV_RGB2HSV)\n cvCvtColor(self.lena_RGB_U8, CV_RGB2BGR565)\n cvCvtColor(self.lena_RGB_U8, CV_RGB2BGR555)\n cvCvtColor(self.lena_RGB_U8, CV_RGB2GRAY)\n cvCvtColor(self.lena_GRAY_U8, CV_GRAY2BGR)\n cvCvtColor(self.lena_GRAY_U8, CV_GRAY2BGR565)\n cvCvtColor(self.lena_GRAY_U8, CV_GRAY2BGR555)\n\n\nclass TestThreshold(OpenCVTest):\n @opencv_skip\n def test_cvThreshold(self):\n cvThreshold(self.lena_GRAY_U8, 100, 255, CV_THRESH_BINARY)\n cvThreshold(self.lena_GRAY_U8, 100, 255, CV_THRESH_BINARY_INV)\n cvThreshold(self.lena_GRAY_U8, 100, threshold_type=CV_THRESH_TRUNC)\n cvThreshold(self.lena_GRAY_U8, 100, threshold_type=CV_THRESH_TOZERO)\n cvThreshold(self.lena_GRAY_U8, 100, threshold_type=CV_THRESH_TOZERO_INV)\n cvThreshold(self.lena_GRAY_U8, 100, 1, CV_THRESH_BINARY, use_otsu=True)\n\n\nclass TestAdaptiveThreshold(OpenCVTest):\n @opencv_skip\n def test_cvAdaptiveThreshold(self):\n cvAdaptiveThreshold(self.lena_GRAY_U8, 100)\n\n\nclass TestPyrDown(OpenCVTest):\n @opencv_skip\n def test_cvPyrDown(self):\n cvPyrDown(self.lena_RGB_U8)\n\n\nclass TestPyrUp(OpenCVTest):\n @opencv_skip\n def test_cvPyrUp(self):\n cvPyrUp(self.lena_RGB_U8)\n\n\nclass TestFindChessboardCorners(object):\n @opencv_skip\n def test_cvFindChessboardCorners(self):\n chessboard_GRAY_U8 = np.load(os.path.join(data_dir,\n 'chessboard_GRAY_U8.npy'))\n pts = cvFindChessboardCorners(chessboard_GRAY_U8, (7, 7))\n\n\nclass TestDrawChessboardCorners(object):\n @opencv_skip\n def test_cvDrawChessboardCorners(self):\n chessboard_GRAY_U8 = np.load(os.path.join(data_dir,\n 'chessboard_GRAY_U8.npy'))\n chessboard_RGB_U8 = np.load(os.path.join(data_dir,\n 'chessboard_RGB_U8.npy'))\n corners = cvFindChessboardCorners(chessboard_GRAY_U8, (7, 7))\n cvDrawChessboardCorners(chessboard_RGB_U8, (7, 7), corners)\n\n\nclass TestCalibrateCamera2(object):\n @opencv_skip\n def test_cvCalibrateCamera2_Identity(self):\n ys = xs = range(4)\n\n image_points = np.array( [(4 * x, 4 * y) for x in xs for y in ys ],\n dtype=np.float64)\n object_points = np.array( [(x, y, 0) for x in xs for y in ys ],\n dtype=np.float64)\n\n image_points = np.ascontiguousarray(np.vstack((image_points,) * 3))\n object_points = np.ascontiguousarray(np.vstack((object_points,) * 3))\n\n intrinsics, distortions = cvCalibrateCamera2(\n object_points, image_points,\n np.array([16, 16, 16], dtype=np.int32), (4, 4)\n )\n\n assert_almost_equal(distortions, np.array([0., 0., 0., 0., 0.]))\n # The intrinsics will be strange, but we can at least check\n # for known zeros and ones\n assert_almost_equal( intrinsics[0,1], 0)\n assert_almost_equal( intrinsics[1,0], 0)\n assert_almost_equal( intrinsics[2,0], 0)\n assert_almost_equal( intrinsics[2,1], 0)\n assert_almost_equal( intrinsics[2,2], 1)\n\n @opencv_skip\n @dec.slow\n def test_cvCalibrateCamera2_KnownData(self):\n (object_points,points_count,image_points,intrinsics,distortions) =\\\n cPickle.load(open(os.path.join(\n data_dir, \"cvCalibrateCamera2TestData.pck\"), \"rb\")\n )\n\n intrinsics_test, distortion_test = cvCalibrateCamera2(\n object_points, image_points, points_count, (1024,1280)\n )\n\n\nclass TestUndistort2(OpenCVTest):\n @opencv_skip\n def test_cvUndistort2(self):\n intrinsics = np.array([[1, 0, 0],\n [0, 1, 0],\n [0, 0, 1]], dtype='float64')\n distortions = np.array([0., 0., 0., 0., 0.], dtype='float64')\n\n undist = cvUndistort2(self.lena_RGB_U8, intrinsics, distortions)\n undistg = cvUndistort2(self.lena_GRAY_U8, intrinsics, distortions)\n\n assert_array_almost_equal(undist, self.lena_RGB_U8)\n assert_array_almost_equal(undistg, self.lena_GRAY_U8)\n\n\n\n\nif __name__ == '__main__':\n run_module_suite()\n"
},
{
"alpha_fraction": 0.6269931793212891,
"alphanum_fraction": 0.6355352997779846,
"avg_line_length": 26.873016357421875,
"blob_id": "5da5b44d89f34d9da31fd816d3a989a325b24ef0",
"content_id": "f9e906a390e7f9950400bcea1c64021e4d1a2e78",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1756,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 63,
"path": "/scikits/image/io/_plugins/qt2_plugin.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from util import prepare_for_display, window_manager, GuiLockError\nimport numpy as np\nimport sys\n\n# We try to aquire the gui lock first or else the gui import might\n# trample another GUI's PyOS_InputHook.\nwindow_manager.acquire('qt2')\n\ntry:\n from PyQt4.QtGui import (QApplication, QMainWindow, QImage, QPixmap,\n QLabel, QWidget)\n from PyQt4 import QtCore, QtGui\n from scivi2 import _simple_imshow, _advanced_imshow\n\nexcept ImportError:\n window_manager._release('qt2')\n\n raise ImportError(\"\"\"\\\n PyQt4 libraries not installed. Please refer to\n\n http://www.riverbankcomputing.co.uk/software/pyqt/intro\n\n for more information. PyQt4 is GPL licensed. For an\n LGPL equivalent, see\n\n http://www.pyside.org\n \"\"\")\n\napp = None\n\ndef imshow(im, flip=None, fancy=False):\n global app\n if not app:\n app = QApplication([])\n\n if not fancy:\n iw = _simple_imshow(im, flip=flip, mgr=window_manager)\n else:\n iw = _advanced_imshow(im, flip=flip, mgr=window_manager)\n\n iw.show()\n\ndef _app_show():\n global app\n if app and window_manager.has_windows():\n app.exec_()\n else:\n print 'No images to show. See `imshow`.'\n\n\ndef imsave(filename, img):\n # we can add support for other than 3D uint8 here...\n img = prepare_for_display(img)\n qimg = QImage(img.data, img.shape[1], img.shape[0],\n img.strides[0], QImage.Format_RGB888)\n saved = qimg.save(filename)\n if not saved:\n from textwrap import dedent\n msg = dedent(\n '''The image was not saved. Allowable file formats\n for the QT imsave plugin are:\n BMP, JPG, JPEG, PNG, PPM, TIFF, XBM, XPM''')\n raise RuntimeError(msg)\n"
},
{
"alpha_fraction": 0.5761834383010864,
"alphanum_fraction": 0.5887573957443237,
"avg_line_length": 27.16666603088379,
"blob_id": "22c4a9ac80711a9820bbc38f6d374004badf960f",
"content_id": "7d53db12c6340733fc167e7b1183f0a60de3e2ac",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1352,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 48,
"path": "/scikits/image/io/__init__.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "__doc__ = \"\"\"Utilities to read and write images in various formats.\n\nThe following plug-ins are available:\n\n\"\"\"\n\nfrom _plugins import use as use_plugin\nfrom _plugins import available as plugins\nfrom _plugins import info as plugin_info\n\n# Add this plugin so that we can read images by default\nuse_plugin('null')\nuse_plugin('pil')\n\nfrom sift import *\nfrom collection import *\n\nfrom io import *\n\ndef _update_doc(doc):\n \"\"\"Add a list of plugins to the module docstring, formatted as\n a ReStructuredText table.\n\n \"\"\"\n from textwrap import wrap\n\n info = [(p, plugin_info(p)) for p in plugins() if not p == 'test']\n col_1_len = max([len(n) for (n, _) in info])\n\n wrap_len = 73\n col_2_len = wrap_len - 1 - col_1_len\n\n # Insert table header\n info.insert(0, ('=' * col_1_len, {'description': '=' * col_2_len}))\n info.insert(1, ('Plugin', {'description': 'Description'}))\n info.insert(2, ('-' * col_1_len, {'description': '-' * col_2_len}))\n info.append( ('=' * col_1_len, {'description': '=' * col_2_len}))\n\n for (name, meta_data) in info:\n wrapped_descr = wrap(meta_data.get('description', ''),\n col_2_len)\n doc += \"%s %s\\n\" % (name.ljust(col_1_len),\n '\\n'.join(wrapped_descr))\n doc = doc.strip()\n\n return doc\n\n__doc__ = _update_doc(__doc__)\n"
},
{
"alpha_fraction": 0.7710843086242676,
"alphanum_fraction": 0.7710843086242676,
"avg_line_length": 26.66666603088379,
"blob_id": "463633f4e692945db2b2a951e95db33ca44d276b",
"content_id": "1584882cbc3f410e408d1212572d5cae83c1f9b4",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 83,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 3,
"path": "/scikits/image/io/_plugins/null_plugin.ini",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "[null]\ndescription = Default plugin that does nothing\nprovides = imshow, _app_show\n"
},
{
"alpha_fraction": 0.6031163930892944,
"alphanum_fraction": 0.6040329933166504,
"avg_line_length": 22.212766647338867,
"blob_id": "fd79bf0a6d41d04fceda3a9ba4ea7dfe8eb2635b",
"content_id": "9cc4edc519a5b2c8aa77e48c00f1d8a5dfb1f73c",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1091,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 47,
"path": "/scikits/image/__init__.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "\"\"\"Image Processing SciKit (Toolbox for SciPy)\"\"\"\n\n\nimport os.path as _osp\n\ndata_dir = _osp.join(_osp.dirname(__file__), 'data')\n\nfrom version import version as __version__\n\ndef _setup_test():\n import functools\n\n basedir = _osp.dirname(_osp.join(__file__, '../'))\n args = ['', '--exe', '-w', '%s' % basedir]\n\n try:\n import nose as _nose\n except ImportError:\n print \"Could not load nose. Unit tests not available.\"\n return None\n else:\n return functools.partial(_nose.run, 'scikits.image', argv=args)\n\ntest = _setup_test()\nif test is None:\n del test\n\ndef get_log(name):\n \"\"\"Return a console logger.\n\n Output may be sent to the logger using the `debug`, `info`, `warning`,\n `error` and `critical` methods.\n\n Parameters\n ----------\n name : str\n Name of the log.\n\n References\n ----------\n .. [1] Logging facility for Python,\n http://docs.python.org/library/logging.html\n\n \"\"\"\n import logging, sys\n logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)\n return logging.getLogger(name)\n"
},
{
"alpha_fraction": 0.7714285850524902,
"alphanum_fraction": 0.7714285850524902,
"avg_line_length": 22.33333396911621,
"blob_id": "5e0253abe21df6a9af9122de10ba595229d164ee",
"content_id": "acc8ea3f45f165c734f530b6abc93b7dfc574651",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 70,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 3,
"path": "/scikits/image/filter/__init__.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from lpi_filter import *\nfrom median import *\nfrom tvdenoise import *\n"
},
{
"alpha_fraction": 0.6350710988044739,
"alphanum_fraction": 0.657819926738739,
"avg_line_length": 23.534883499145508,
"blob_id": "ddcf4653ee87267102eeef749e19eddd14fe5d81",
"content_id": "9b173eb08ab57e43d1e7eb9e8348a4fb052bd74f",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1055,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 43,
"path": "/scikits/image/scripts/test_tvdenoise.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\nimport numpy as np\n\nfrom scikits.image import data_dir\nfrom scikits.image.io import *\nfrom scikits.image.filter import tvdenoise\n\nimport sys\nimport os.path\nimport argparse\n\nif len(sys.argv) > 1:\n parser = argparse.ArgumentParser(description='Total-variation denoising')\n parser.add_argument('filename_in', metavar='in', help='the input file')\n parser.add_argument('-W', default=50.0, type=float,\n help='weight on regularization term')\n parser.add_argument('-n', default=10, type=int,\n help='number of iterations')\n args = parser.parse_args()\n \n filename = args.filename_in\n n = args.n\n W = args.W\nelse:\n filename = os.path.join(data_dir, 'lena256.tif')\n n = 10\n W = 50.0\n\nim = imread(filename)\nimshow(im)\nim = np.array(im, dtype=np.float32)\nim2 = tvdenoise(im, n, W)\n\ndef view_float(im):\n m = np.min(im)\n M = np.max(im)\n scale = float(M - m)\n rescaled = np.rint(255.0 * (im - m) / scale)\n imshow(np.array(rescaled, dtype=np.uint8))\n\nview_float(im2)\n"
},
{
"alpha_fraction": 0.536195695400238,
"alphanum_fraction": 0.5491762161254883,
"avg_line_length": 28.880596160888672,
"blob_id": "40139757a987dcc73c78709ad2562f38c1e3dd3d",
"content_id": "6d487eac7b98de92353dc43a51c57f31154497ce",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2003,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 67,
"path": "/scikits/image/_build.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "import os\nimport shutil\nimport hashlib\nimport subprocess\n\ndef cython(pyx_files, working_path=''):\n \"\"\"Use Cython to convert the given files to C.\n\n Parameters\n ----------\n pyx_files : list of str\n The input .pyx files.\n\n \"\"\"\n try:\n import Cython\n except ImportError:\n # If cython is not found, we do nothing -- the build will make use of\n # the distributed .c files\n pass\n else:\n for pyxfile in [os.path.join(working_path, f) for f in pyx_files]:\n # make a backup of the good c files\n c_file = pyxfile[:-4] + '.c'\n c_file_new = c_file + '.new'\n\n # run cython compiler\n cmd = 'cython -o %s %s' % (c_file_new, pyxfile)\n print cmd\n status = subprocess.call(['cython', '-o', c_file_new, pyxfile])\n # if the resulting file is small, cython compilation failed\n if status != 0 or os.path.getsize(c_file_new) < 100:\n print \"Cython compilation of %s failed. Falling back \" \\\n \"on pre-generated file.\" % os.path.basename(pyxfile)\n elif not same_cython(c_file_new, c_file):\n # if the generated .c file differs from the one provided,\n # use that one instead\n shutil.copy(c_file_new, c_file)\n os.remove(c_file_new)\n \n\ndef same_cython(f0, f1):\n '''Compare two Cython generated C-files, based on their md5-sum.\n\n Returns True if the files are identical, False if not. The first\n lines are skipped, due to the timestamp printed there.\n\n '''\n def md5sum(f):\n m = hashlib.new('md5')\n while True:\n d = f.read(8096)\n if not d:\n break\n m.update(d)\n return m.hexdigest()\n\n if not (os.path.isfile(f0) and os.path.isfile(f1)):\n return False\n\n f0 = file(f0)\n f0.readline()\n\n f1 = file(f1)\n f1.readline()\n\n return md5sum(f0) == md5sum(f1)\n\n"
},
{
"alpha_fraction": 0.6319141983985901,
"alphanum_fraction": 0.6523362398147583,
"avg_line_length": 29.3295955657959,
"blob_id": "2ad75d24578aaf2b1e5f55d7b673e0561ba38e0a",
"content_id": "ea1fcb96a3fb64631d88b41b2d1e0b04c751a8fa",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 83835,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 2764,
"path": "/scikits/image/opencv/opencv_cv.pyx",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "# -*- python -*-\n\nimport ctypes\nimport numpy as np\n\ncimport numpy as np\nfrom python cimport *\nfrom stdlib cimport *\nfrom opencv_type cimport *\nfrom opencv_backend import *\nfrom opencv_backend cimport *\nfrom opencv_constants import *\n\nfrom opencv_constants import *\nfrom opencv_cv import *\n\nfrom _libimport import cv\nfrom _utilities import cvdoc\n\nif cv is None:\n raise RuntimeError(\"Could not load libcv\")\n\n# setup numpy tables for this module\nnp.import_array()\n\n#-------------------------------------------------------------------------------\n# Useful global stuff\n#-------------------------------------------------------------------------------\n\n# a dict for cvCvtColor to get the appropriate types and shapes without\n# if statements all over the place (this way is faster, cause the dict is\n# created at import time)\n# the order of list arguments is:\n# [in_channels, out_channels, [input_dtypes]]\n# out type is always the same as in type\n\n_cvtcolor_dict = {CV_BGR2BGRA: [3, 4, [UINT8, UINT16, FLOAT32]],\n CV_RGB2RGBA: [3, 4, [UINT8, UINT16, FLOAT32]],\n CV_BGRA2BGR: [4, 3, [UINT8, UINT16, FLOAT32]],\n CV_RGBA2RGB: [4, 3, [UINT8, UINT16, FLOAT32]],\n CV_BGR2RGBA: [3, 4, [UINT8, UINT16, FLOAT32]],\n CV_RGB2BGRA: [3, 4, [UINT8, UINT16, FLOAT32]],\n CV_RGBA2BGR: [4, 3, [UINT8, UINT16, FLOAT32]],\n CV_BGRA2RGB: [4, 3, [UINT8, UINT16, FLOAT32]],\n CV_BGR2RGB: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_RGB2BGR: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_BGRA2RGBA: [4, 4, [UINT8, UINT16, FLOAT32]],\n CV_RGBA2BGRA: [4, 4, [UINT8, UINT16, FLOAT32]],\n CV_BGR2GRAY: [3, 1, [UINT8, UINT16, FLOAT32]],\n CV_RGB2GRAY: [3, 1, [UINT8, UINT16, FLOAT32]],\n CV_GRAY2BGR: [1, 3, [UINT8, UINT16, FLOAT32]],\n CV_GRAY2RGB: [1, 3, [UINT8, UINT16, FLOAT32]],\n CV_GRAY2BGRA: [1, 4, [UINT8, UINT16, FLOAT32]],\n CV_GRAY2RGBA: [1, 4, [UINT8, UINT16, FLOAT32]],\n CV_BGRA2GRAY: [4, 1, [UINT8, UINT16, FLOAT32]],\n CV_RGBA2GRAY: [4, 1, [UINT8, UINT16, FLOAT32]],\n CV_BGR2BGR565: [3, 2, [UINT8]],\n CV_RGB2BGR565: [3, 2, [UINT8]],\n CV_BGR5652BGR: [2, 3, [UINT8]],\n CV_BGR5652RGB: [2, 3, [UINT8]],\n CV_BGRA2BGR565: [4, 2, [UINT8]],\n CV_RGBA2BGR565: [4, 2, [UINT8]],\n CV_BGR5652BGRA: [2, 4, [UINT8]],\n CV_BGR5652RGBA: [2, 4, [UINT8]],\n CV_GRAY2BGR565: [1, 2, [UINT8]],\n CV_BGR5652GRAY: [2, 1, [UINT8]],\n CV_BGR2BGR555: [3, 2, [UINT8]],\n CV_RGB2BGR555: [3, 2, [UINT8]],\n CV_BGR5552BGR: [2, 3, [UINT8]],\n CV_BGR5552RGB: [2, 3, [UINT8]],\n CV_BGRA2BGR555: [4, 2, [UINT8]],\n CV_RGBA2BGR555: [4, 2, [UINT8]],\n CV_BGR5552BGRA: [2, 4, [UINT8]],\n CV_BGR5552RGBA: [2, 4, [UINT8]],\n CV_GRAY2BGR555: [1, 2, [UINT8]],\n CV_BGR5552GRAY: [2, 1, [UINT8]],\n CV_BGR2XYZ: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_RGB2XYZ: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_XYZ2BGR: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_XYZ2RGB: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_BGR2YCrCb: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_RGB2YCrCb: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_YCrCb2BGR: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_YCrCb2RGB: [3, 3, [UINT8, UINT16, FLOAT32]],\n CV_BGR2HSV: [3, 3, [UINT8, FLOAT32]],\n CV_RGB2HSV: [3, 3, [UINT8, FLOAT32]],\n CV_BGR2Lab: [3, 3, [UINT8, FLOAT32]],\n CV_RGB2Lab: [3, 3, [UINT8, FLOAT32]],\n CV_BayerBG2BGR: [1, 3, [UINT8]],\n CV_BayerGB2BGR: [1, 3, [UINT8]],\n CV_BayerRG2BGR: [1, 3, [UINT8]],\n CV_BayerGR2BGR: [1, 3, [UINT8]],\n CV_BayerBG2RGB: [1, 3, [UINT8]],\n CV_BayerGB2RGB: [1, 3, [UINT8]],\n CV_BayerRG2RGB: [1, 3, [UINT8]],\n CV_BayerGR2RGB: [1, 3, [UINT8]],\n CV_BGR2Luv: [3, 3, [UINT8, FLOAT32]],\n CV_RGB2Luv: [3, 3, [UINT8, FLOAT32]],\n CV_BGR2HLS: [3, 3, [UINT8, FLOAT32]],\n CV_RGB2HLS: [3, 3, [UINT8, FLOAT32]],\n CV_HSV2BGR: [3, 3, [UINT8, FLOAT32]],\n CV_HSV2RGB: [3, 3, [UINT8, FLOAT32]],\n CV_Lab2BGR: [3, 3, [UINT8, FLOAT32]],\n CV_Lab2RGB: [3, 3, [UINT8, FLOAT32]],\n CV_Luv2BGR: [3, 3, [UINT8, FLOAT32]],\n CV_Luv2RGB: [3, 3, [UINT8, FLOAT32]],\n CV_HLS2BGR: [3, 3, [UINT8, FLOAT32]],\n CV_HLS2RGB: [3, 3, [UINT8, FLOAT32]]}\n\n\n###################################\n# opencv function declarations\n###################################\n\n# cvSobel\nctypedef void (*cvSobelPtr)(IplImage*, IplImage*, int, int, int)\ncdef cvSobelPtr c_cvSobel\nc_cvSobel = (<cvSobelPtr*><size_t>ctypes.addressof(cv.cvSobel))[0]\n\n# cvLaplace\nctypedef void (*cvLaplacePtr)(IplImage*, IplImage*, int)\ncdef cvLaplacePtr c_cvLaplace\nc_cvLaplace = (<cvLaplacePtr*><size_t>ctypes.addressof(cv.cvLaplace))[0]\n\n# cvCanny\nctypedef void (*cvCannyPtr)(IplImage*, IplImage*, double, double, int)\ncdef cvCannyPtr c_cvCanny\nc_cvCanny = (<cvCannyPtr*><size_t>ctypes.addressof(cv.cvCanny))[0]\n\n# cvPreCornerDetect\nctypedef void (*cvPreCorneDetectPtr)(IplImage*, IplImage*, int)\ncdef cvPreCorneDetectPtr c_cvPreCornerDetect\nc_cvPreCornerDetect = (<cvPreCorneDetectPtr*><size_t>\n ctypes.addressof(cv.cvPreCornerDetect))[0]\n\n# cvCornerEigenValsAndVecs\nctypedef void (*cvCornerEigenValsAndVecsPtr)(IplImage*, IplImage*, int, int)\ncdef cvCornerEigenValsAndVecsPtr c_cvCornerEigenValsAndVecs\nc_cvCornerEigenValsAndVecs = (<cvCornerEigenValsAndVecsPtr*><size_t>\n ctypes.addressof(cv.cvCornerEigenValsAndVecs))[0]\n\n# cvCornerMinEigenVal\nctypedef void (*cvCornerMinEigenValPtr)(IplImage*, IplImage*, int, int)\ncdef cvCornerMinEigenValPtr c_cvCornerMinEigenVal\nc_cvCornerMinEigenVal = (<cvCornerMinEigenValPtr*><size_t>\n ctypes.addressof(cv.cvCornerMinEigenVal))[0]\n\n# cvCornerHarris\nctypedef void (*cvCornerHarrisPtr)(IplImage*, IplImage*, int, int, double)\ncdef cvCornerHarrisPtr c_cvCornerHarris\nc_cvCornerHarris = (<cvCornerHarrisPtr*><size_t>\n ctypes.addressof(cv.cvCornerHarris))[0]\n\n# cvFindCornerSubPix\nctypedef void (*cvFindCornerSubPixPtr)(IplImage*, CvPoint2D32f*, int,\n CvSize, CvSize, CvTermCriteria)\ncdef cvFindCornerSubPixPtr c_cvFindCornerSubPix\nc_cvFindCornerSubPix = (<cvFindCornerSubPixPtr*>\n <size_t>ctypes.addressof(cv.cvFindCornerSubPix))[0]\n\n# cvGoodFeaturesToTrack\nctypedef void (*cvGoodFeaturesToTrackPtr)(IplImage*, IplImage*, IplImage*,\n CvPoint2D32f*, int*, double, double,\n IplImage*, int, int, double)\ncdef cvGoodFeaturesToTrackPtr c_cvGoodFeaturesToTrack\nc_cvGoodFeaturesToTrack = (<cvGoodFeaturesToTrackPtr*><size_t>\n ctypes.addressof(cv.cvGoodFeaturesToTrack))[0]\n\n# cvGetRectSubPix\nctypedef void (*cvGetRectSubPixPtr)(IplImage*, IplImage*, CvPoint2D32f)\ncdef cvGetRectSubPixPtr c_cvGetRectSubPix\nc_cvGetRectSubPix = (<cvGetRectSubPixPtr*><size_t>\n ctypes.addressof(cv.cvGetRectSubPix))[0]\n\n# cvGetQuadrangleSubPix\nctypedef void (*cvGetQuadrangleSubPixPtr)(IplImage*, IplImage*, CvMat*)\ncdef cvGetQuadrangleSubPixPtr c_cvGetQuadrangleSubPix\nc_cvGetQuadrangleSubPix = (<cvGetQuadrangleSubPixPtr*><size_t>\n ctypes.addressof(cv.cvGetQuadrangleSubPix))[0]\n\n# cvResize\nctypedef void (*cvResizePtr)(IplImage*, IplImage*, int)\ncdef cvResizePtr c_cvResize\nc_cvResize = (<cvResizePtr*><size_t>ctypes.addressof(cv.cvResize))[0]\n\n# cvWarpAffine\nctypedef void (*cvWarpAffinePtr)(IplImage*, IplImage*, CvMat*, int, CvScalar)\ncdef cvWarpAffinePtr c_cvWarpAffine\nc_cvWarpAffine = (<cvWarpAffinePtr*><size_t>\n ctypes.addressof(cv.cvWarpAffine))[0]\n\n# cvWarpPerspective\nctypedef void (*cvWarpPerspectivePtr)(IplImage*, IplImage*, CvMat*, int,\n CvScalar)\ncdef cvWarpPerspectivePtr c_cvWarpPerspective\nc_cvWarpPerspective = (<cvWarpPerspectivePtr*><size_t>\n ctypes.addressof(cv.cvWarpPerspective))[0]\n\n# cvLogPolar\nctypedef void (*cvLogPolarPtr)(IplImage*, IplImage*, CvPoint2D32f, double, int)\ncdef cvLogPolarPtr c_cvLogPolar\nc_cvLogPolar = (<cvLogPolarPtr*><size_t>ctypes.addressof(cv.cvLogPolar))[0]\n\n# cvErode\nctypedef void (*cvErodePtr)(IplImage*, IplImage*, IplConvKernel*, int)\ncdef cvErodePtr c_cvErode\nc_cvErode = (<cvErodePtr*><size_t>ctypes.addressof(cv.cvErode))[0]\n\n# cvDilate\nctypedef void (*cvDilatePtr)(IplImage*, IplImage*, IplConvKernel*, int)\ncdef cvDilatePtr c_cvDilate\nc_cvDilate = (<cvDilatePtr*><size_t>ctypes.addressof(cv.cvDilate))[0]\n\n# cvMorphologyEx\nctypedef void (*cvMorphologyExPtr)(IplImage*, IplImage*, IplImage*,\n IplConvKernel*, int, int)\ncdef cvMorphologyExPtr c_cvMorphologyEx\nc_cvMorphologyEx = (<cvMorphologyExPtr*><size_t>\n ctypes.addressof(cv.cvMorphologyEx))[0]\n\n# cvSmooth\nctypedef void (*cvSmoothPtr)(IplImage*, IplImage*, int, int,\n int, double, double)\ncdef cvSmoothPtr c_cvSmooth\nc_cvSmooth = (<cvSmoothPtr*><size_t>ctypes.addressof(cv.cvSmooth))[0]\n\n# cvFilter2D\nctypedef void (*cvFilter2DPtr)(IplImage*, IplImage*, CvMat*, CvPoint)\ncdef cvFilter2DPtr c_cvFilter2D\nc_cvFilter2D = (<cvFilter2DPtr*><size_t>ctypes.addressof(cv.cvFilter2D))[0]\n\n# cvIntegral\nctypedef void (*cvIntegralPtr)(IplImage*, IplImage*, IplImage*, IplImage*)\ncdef cvIntegralPtr c_cvIntegral\nc_cvIntegral = (<cvIntegralPtr*><size_t>ctypes.addressof(cv.cvIntegral))[0]\n\n# cvCvtColor\nctypedef void (*cvCvtColorPtr)(IplImage*, IplImage*, int)\ncdef cvCvtColorPtr c_cvCvtColor\nc_cvCvtColor = (<cvCvtColorPtr*><size_t>ctypes.addressof(cv.cvCvtColor))[0]\n\n# cvThreshold\nctypedef double (*cvThresholdPtr)(IplImage*, IplImage*, double, double, int)\ncdef cvThresholdPtr c_cvThreshold\nc_cvThreshold = (<cvThresholdPtr*><size_t>ctypes.addressof(cv.cvThreshold))[0]\n\n# cvAdaptiveThreshold\nctypedef void (*cvAdaptiveThresholdPtr)(IplImage*, IplImage*, double, int, int,\n int, double)\ncdef cvAdaptiveThresholdPtr c_cvAdaptiveThreshold\nc_cvAdaptiveThreshold = (<cvAdaptiveThresholdPtr*><size_t>\n ctypes.addressof(cv.cvAdaptiveThreshold))[0]\n\n# cvPyrDown\nctypedef void (*cvPyrDownPtr)(IplImage*, IplImage*, int)\ncdef cvPyrDownPtr c_cvPyrDown\nc_cvPyrDown = (<cvPyrDownPtr*><size_t>ctypes.addressof(cv.cvPyrDown))[0]\n\n# cvPyrUp\nctypedef void (*cvPyrUpPtr)(IplImage*, IplImage*, int)\ncdef cvPyrUpPtr c_cvPyrUp\nc_cvPyrUp = (<cvPyrUpPtr*><size_t>ctypes.addressof(cv.cvPyrUp))[0]\n\n# cvWatershed\nctypedef void (*cvWatershedPtr)(IplImage*, IplImage*)\ncdef cvWatershedPtr c_cvWatershed\nc_cvWatershed = (<cvWatershedPtr*><size_t>ctypes.addressof(cv.cvWatershed))[0]\n\n# cvCalibrateCamera2\nctypedef void (*cvCalibrateCamera2Ptr)(CvMat*, CvMat*, CvMat*,\n CvSize, CvMat*, CvMat*, CvMat*, CvMat*, int)\ncdef cvCalibrateCamera2Ptr c_cvCalibrateCamera2\nc_cvCalibrateCamera2 = (<cvCalibrateCamera2Ptr*>\n <size_t>ctypes.addressof(cv.cvCalibrateCamera2))[0]\n\n# cvUndistort2\nctypedef void (*cvUndistort2Ptr)(IplImage*, IplImage*, CvMat*, CvMat*)\ncdef cvUndistort2Ptr c_cvUndistort2\nc_cvUndistort2 = (<cvUndistort2Ptr*><size_t>ctypes.addressof(cv.cvUndistort2))[0]\n\n# cvFindChessboardCorners\nctypedef void (*cvFindChessboardCornersPtr)(IplImage*, CvSize, CvPoint2D32f*,\n int*, int)\ncdef cvFindChessboardCornersPtr c_cvFindChessboardCorners\nc_cvFindChessboardCorners = (<cvFindChessboardCornersPtr*><size_t>\n ctypes.addressof(cv.cvFindChessboardCorners))[0]\n\n# cvFindExtrinsicCameraParams2\nctypedef void (*cvFindExtrinsicCameraParams2Ptr)(CvMat*, CvMat*, CvMat*, CvMat*,\n CvMat*, CvMat*, int)\ncdef cvFindExtrinsicCameraParams2Ptr c_cvFindExtrinsicCameraParams2\nc_cvFindExtrinsicCameraParams2 = \\\n (<cvFindExtrinsicCameraParams2Ptr*><size_t>\n ctypes.addressof(cv.cvFindExtrinsicCameraParams2))[0]\n\n# cvDrawChessboardCorners\nctypedef void (*cvDrawChessboardCornersPtr)(IplImage*, CvSize, CvPoint2D32f*,\n int, int)\ncdef cvDrawChessboardCornersPtr c_cvDrawChessboardCorners\nc_cvDrawChessboardCorners = (<cvDrawChessboardCornersPtr*><size_t>\n ctypes.addressof(cv.cvDrawChessboardCorners))[0]\n\n# cvFloodFill\nctypedef void (*cvFloodFillPtr)(IplImage*, CvPoint, CvScalar, CvScalar,\n CvScalar, void*, int, IplImage*)\ncdef cvFloodFillPtr c_cvFloodFill\nc_cvFloodFill = (<cvFloodFillPtr*><size_t>ctypes.addressof(cv.cvFloodFill))[0]\n\n# cvMatchTemplate\nctypedef void (*cvMatchTemplatePtr)(IplImage*, IplImage*, IplImage*, int)\ncdef cvMatchTemplatePtr c_cvMatchTemplate\nc_cvMatchTemplate = (<cvMatchTemplatePtr*><size_t>\n ctypes.addressof(cv.cvMatchTemplate))[0]\n\n#-------------------------------------------------------------------------------\n# Function Implementations\n#-------------------------------------------------------------------------------\n\n#--------\n# cvSobel\n#--------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvSobel(src, xorder=1, yorder=0, aperture_size=3)\n\nApply the Sobel operator to the input image.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8, int8, float32]\n The source image.\nxorder : integer\n The x order of the Sobel operator.\nyorder : integer\n The y order of the Sobel operator.\naperture_size : integer=[3, 5, 7]\n The size of the Sobel kernel.\n\nReturns\n-------\nout : ndarray\n A new which is the result of applying the Sobel\n operator to src.''')\ndef cvSobel(np.ndarray src, int xorder=1, int yorder=0,\n int aperture_size=3):\n\n validate_array(src)\n assert_dtype(src, [UINT8, INT8, FLOAT32])\n assert_nchannels(src, [1])\n\n if (aperture_size != 3 and aperture_size != 5 and aperture_size != 7):\n raise ValueError('aperture_size must be 3, 5, or 7')\n\n cdef np.ndarray out\n\n if src.dtype == UINT8 or src.dtype == INT8:\n out = new_array_like_diff_dtype(src, INT16)\n else:\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvSobel(&srcimg, &outimg, xorder, yorder, aperture_size)\n\n return out\n\n\n#----------\n# cvLaplace\n#----------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvLaplace(src, aperture_size=3)\n\nApply the Laplace operator to the input image.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8, int8, float32]\n The source image.\naperture_size : integer=[3, 5, 7]\n The size of the Sobel kernel.\n\nReturns\n-------\nout : ndarray\n A new which is the result of applying the Laplace\n operator to src.''')\ndef cvLaplace(np.ndarray src, int aperture_size=3):\n\n validate_array(src)\n assert_dtype(src, [UINT8, INT8, FLOAT32])\n assert_nchannels(src, [1])\n\n if (aperture_size != 3 and aperture_size != 5 and aperture_size != 7):\n raise ValueError('aperture_size must be 3, 5, or 7')\n\n cdef np.ndarray out\n\n if src.dtype == UINT8 or src.dtype == INT8:\n out = new_array_like_diff_dtype(src, INT16)\n else:\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvLaplace(&srcimg, &outimg, aperture_size)\n\n return out\n\n\n#--------\n# cvCanny\n#--------\n\n@cvdoc(package='cv', group='feature', doc=\\\n'''cvCanny(src, threshold1=10, threshold2=50, aperture_size=3)\n\nApply Canny edge detection to the input image.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8]\n The source image.\nthreshold1 : float\n The lower threshold used for edge linking.\nthreshold2 : float\n The upper threshold used to find strong edges.\naperture_size : integer=[3, 5, 7]\n The size of the Sobel kernel.\n\nReturns\n-------\nout : ndarray\n A new which is the result of applying Canny\n edge detection to src.''')\ndef cvCanny(np.ndarray src, double threshold1=10, double threshold2=50,\n int aperture_size=3):\n\n validate_array(src)\n assert_dtype(src, [UINT8])\n assert_nchannels(src, [1])\n\n if (aperture_size != 3 and aperture_size != 5 and aperture_size != 7):\n raise ValueError('aperture_size must be 3, 5, or 7')\n\n cdef np.ndarray out\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvCanny(&srcimg, &outimg, threshold1, threshold2, aperture_size)\n\n return out\n\n\n#------------------\n# cvPreCornerDetect\n#------------------\n\n@cvdoc(package='cv', group='feature', doc=\\\n'''cvPreCornerDetect(src, aperture_size=3)\n\nCalculate the feature map for corner detection.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8, float32]\n The source image.\naperture_size : integer=[3, 5, 7]\n The size of the Sobel kernel.\n\nReturns\n-------\nout : ndarray\n A new array of the corner candidates.''')\ndef cvPreCornerDetect(np.ndarray src, int aperture_size=3):\n\n validate_array(src)\n assert_dtype(src, [UINT8, FLOAT32])\n assert_nchannels(src, [1])\n\n if (aperture_size != 3 and aperture_size != 5 and aperture_size != 7):\n raise ValueError('aperture_size must be 3, 5, or 7')\n\n cdef np.ndarray out\n out = new_array_like_diff_dtype(src, FLOAT32)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvPreCornerDetect(&srcimg, &outimg, aperture_size)\n\n return out\n\n\n#-------------------------\n# cvCornerEigenValsAndVecs\n#-------------------------\n\n@cvdoc(package='cv', group='feature', doc=\\\n'''cvCornerEigenValsAndVecs(src, block_size=3, aperture_size=3)\n\nCalculates the eigenvalues and eigenvectors of image\nblocks for corner detection.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8, float32]\n The source image.\nblock_size : integer\n The size of the neighborhood in which to calculate\n the eigenvalues and eigenvectors.\naperture_size : integer=[3, 5, 7]\n The size of the Sobel kernel.\n\nReturns\n-------\nout : ndarray\n A new array of the eigenvalues and eigenvectors.\n The shape of this array is (height, width, 6),\n Where height and width are the same as that\n of src.''')\ndef cvCornerEigenValsAndVecs(np.ndarray src, int block_size=3,\n int aperture_size=3):\n\n validate_array(src)\n assert_nchannels(src, [1])\n assert_dtype(src, [UINT8, FLOAT32])\n\n if (aperture_size != 3 and aperture_size != 5 and aperture_size != 7):\n raise ValueError('aperture_size must be 3, 5, or 7')\n\n cdef np.ndarray out\n cdef np.npy_intp outshape[2]\n outshape[0] = src.shape[0]\n outshape[1] = src.shape[1] * 6\n\n out = new_array(2, outshape, FLOAT32)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvCornerEigenValsAndVecs(&srcimg, &outimg, block_size, aperture_size)\n\n return out.reshape(out.shape[0], -1, 6)\n\n\n#--------------------\n# cvCornerMinEigenVal\n#--------------------\n\n@cvdoc(package='cv', group='feature', doc=\\\n'''cvCornerMinEigenVal(src, block_size=3, aperture_size=3)\n\nCalculates the minimum eigenvalues of gradient matrices\nfor corner detection.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8, float32]\n The source image.\nblock_size : integer\n The size of the neighborhood in which to calculate\n the eigenvalues.\naperture_size : integer=[3, 5, 7]\n The size of the Sobel kernel.\n\nReturns\n-------\nout : ndarray\n A new array of the eigenvalues.''')\ndef cvCornerMinEigenVal(np.ndarray src, int block_size=3,\n int aperture_size=3):\n\n validate_array(src)\n assert_nchannels(src, [1])\n assert_dtype(src, [UINT8, FLOAT32])\n\n if (aperture_size != 3 and aperture_size != 5 and aperture_size != 7):\n raise ValueError('aperture_size must be 3, 5, or 7')\n\n cdef np.ndarray out\n out = new_array_like_diff_dtype(src, FLOAT32)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvCornerMinEigenVal(&srcimg, &outimg, block_size, aperture_size)\n\n return out\n\n\n#---------------\n# cvCornerHarris\n#---------------\n\n@cvdoc(package='cv', group='feature', doc=\\\n'''cvCornerHarris(src, block_size=3, aperture_size=3, k=0.04)\n\nApplies the Harris edge detector to the input image.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8, float32]\n The source image.\nblock_size : integer\n The size of the neighborhood in which to apply the detector.\naperture_size : integer=[3, 5, 7]\n The size of the Sobel kernel.\nk : float\n Harris detector free parameter. See Notes.\n\nReturns\n-------\nout : ndarray\n A new array of the Harris corners.\n\nNotes\n-----\nThe function cvCornerHarris() runs the Harris edge\ndetector on the image. Similarly to cvCornerMinEigenVal()\nand cvCornerEigenValsAndVecs(), for each pixel it calculates\na gradient covariation matrix M over a block_size X block_size\nneighborhood. Then, it stores det(M) - k * trace(M)**2\nto the output image. Corners in the image can be found as the\nlocal maxima of the output image.''')\ndef cvCornerHarris(np.ndarray src, int block_size=3, int aperture_size=3,\n double k=0.04):\n\n validate_array(src)\n assert_nchannels(src, [1])\n assert_dtype(src, [UINT8, FLOAT32])\n\n if (aperture_size != 3 and aperture_size != 5 and aperture_size != 7):\n raise ValueError('aperture_size must be 3, 5, or 7')\n\n cdef np.ndarray out\n out = new_array_like_diff_dtype(src, FLOAT32)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvCornerHarris(&srcimg, &outimg, block_size, aperture_size, k)\n\n return out\n\n\n#-------------------\n# cvFindCornerSubPix\n#-------------------\n\n@cvdoc(package='cv', group='feature', doc=\\\n'''cvFindCornerSubPix(src, corners, win, zero_zone=(-1, -1), iterations=0, epsilon=1e-5)\n\nRefines corner locations to sub-pixel accuracy.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8]\n The source image.\ncorners : ndarray, shape=(N x 2)\n An initial approximation of the corners in the image.\n The corners will be refined in-place in this array.\nwin : tuple, (height, width)\n The window within which the function iterates until it\n converges on the real corner. The actual window is twice\n the size of what is declared here. (an OpenCV peculiarity).\nzero_zone : Half of the size of the dead region in the middle\n of the search zone over which the calculations are not\n performed. It is used sometimes to avoid possible\n singularities of the autocorrelation matrix.\n The value of (-1,-1) indicates that there is no such size.\niterations : integer\n The maximum number of iterations to perform. If 0,\n the function iterates until the error is less than epsilon.\nepsilon : float\n The epsilon error, below which the function terminates.\n Can be used in combination with iterations.\n\nReturns\n-------\nNone. The array 'corners' is modified in place.''')\ndef cvFindCornerSubPix(np.ndarray src, np.ndarray corners, win,\n zero_zone=(-1, -1), int iterations=0,\n double epsilon=1e-5):\n\n validate_array(src)\n assert_nchannels(src, [1])\n assert_dtype(src, [UINT8])\n\n validate_array(corners)\n assert_ndims(corners, [2])\n assert_dtype(corners, [FLOAT32])\n\n cdef int count = <int>(corners.shape[0] * corners.shape[1] / 2.)\n cdef CvPoint2D32f* cvcorners = array_as_cvPoint2D32f_ptr(corners)\n\n if len(win) != 2:\n raise ValueError('win must be a 2-tuple')\n cdef CvSize cvwin\n cvwin.height = <int> win[0]\n cvwin.width = <int> win[1]\n\n cdef int imgheight = src.shape[0]\n cdef int imgwidth = src.shape[1]\n if imgwidth < (cvwin.width * 2 + 5) or imgheight < (cvwin.height * 2 + 5):\n raise ValueError('The window is too large.')\n\n cdef CvSize cvzerozone\n cvzerozone.height = <int> zero_zone[0]\n cvzerozone.width = <int> zero_zone[1]\n\n cdef IplImage srcimg\n populate_iplimage(src, &srcimg)\n\n cdef CvTermCriteria crit\n crit = get_cvTermCriteria(iterations, epsilon)\n\n c_cvFindCornerSubPix(&srcimg, cvcorners, count, cvwin, cvzerozone, crit)\n\n return None\n\n\n#----------------------\n# cvGoodFeaturesToTrack\n#----------------------\n\n@cvdoc(package='cv', group='feature', doc=\\\n'''cvGoodFeaturesToTrack(src, corner_count, quality_level, min_distance, block_size=3, use_harris=0, k=0.04)\n\nDetermines strong corners in an image.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8, float32]\n The source image.\ncorner_count : int\n The maximum number of corners to find.\n Only found corners are returned.\nquality_level : float\n Multiplier for the max/min eigenvalue;\n specifies the minimal accepted quality of\n image corners.\nmin_distance : float\n Limit, specifying the minimum possible\n distance between the returned corners;\n Euclidian distance is used.\nblock_size : integer\n The size of the neighborhood in which to apply the detector.\nuse_harris : integer\n If nonzero, Harris operator (cvCornerHarris())\n is used instead of default cvCornerMinEigenVal()\nk : float\n Harris detector free parameter.\n Used only if use_harris != 0.\n\nReturns\n-------\nout : ndarray\n The locations of the found corners in the image.\n\nNotes\n-----\nThis function finds distinct and strong corners\nin an image which can be used as features in a tracking\nalgorithm. It also insures that features are distanced\nfrom one another by at least min_distance.''')\ndef cvGoodFeaturesToTrack(np.ndarray src, int corner_count,\n double quality_level, double min_distance,\n int block_size=3, int use_harris=0, double k=0.04):\n\n validate_array(src)\n assert_dtype(src, [UINT8, FLOAT32])\n assert_nchannels(src, [1])\n\n cdef np.ndarray eig = new_array_like_diff_dtype(src, FLOAT32)\n cdef np.ndarray temp = new_array_like(eig)\n\n cdef np.npy_intp cornershape[2]\n cornershape[0] = <np.npy_intp>corner_count\n cornershape[1] = 2\n\n cdef np.ndarray out = new_array(2, cornershape, FLOAT32)\n cdef CvPoint2D32f* cvcorners = array_as_cvPoint2D32f_ptr(out)\n\n cdef int ncorners_found\n ncorners_found = corner_count\n\n cdef IplImage srcimg\n cdef IplImage eigimg\n cdef IplImage tempimg\n cdef IplImage *maskimg\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(eig, &eigimg)\n populate_iplimage(temp, &tempimg)\n\n # don't need to support ROI. The user can just pass a slice.\n maskimg = NULL\n\n c_cvGoodFeaturesToTrack(&srcimg, &eigimg, &tempimg, cvcorners,\n &ncorners_found, quality_level, min_distance,\n maskimg, block_size,\n use_harris, k)\n\n return out[:ncorners_found]\n\n\n#----------------\n# cvGetRectSubPix\n#----------------\n\n@cvdoc(package='cv', group='geometry', doc=\\\n'''cvGetRectSubPix(src, size, center)\n\nRetrieves the pixel rectangle from an image with\nsub-pixel accuracy.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nsize : two tuple, integers, (height, width)\n The size of the rectangle to extract.\ncenter : two tuple, floats, (x, y)\n The center location of the rectangle.\n The center must lie within the image, but the\n rectangle may extend beyond the bounds of the image.\n\nReturns\n-------\nout : ndarray\n The extracted rectangle of the image.\n\nNotes\n-----\nThe center of the specified rectangle must\nlie within the image, but the bounds of the rectangle\nmay extend beyond the image. Border replication is used\nto fill in missing pixels.''')\ndef cvGetRectSubPix(np.ndarray src, size, center):\n\n validate_array(src)\n\n cdef np.npy_intp* shape = clone_array_shape(src)\n shape[0] = <np.npy_intp>size[0]\n shape[1] = <np.npy_intp>size[1]\n\n cdef CvPoint2D32f cvcenter\n cvcenter.x = <float>center[0]\n cvcenter.y = <float>center[1]\n\n cdef np.ndarray out = new_array(src.ndim, shape, src.dtype)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvGetRectSubPix(&srcimg, &outimg, cvcenter)\n\n PyMem_Free(shape)\n\n return out\n\n\n#----------------------\n# cvGetQuadrangleSubPix\n#----------------------\n\n@cvdoc(package='cv', group='geometry', doc=\\\n'''cvGetQuadrangleSubPix(src, warpmat, float_out=False)\n\nRetrieves the pixel quandrangle from an image with\nsub-pixel accuracy. In english: apply an affine transform to an image.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nwarpmat : ndarray, 2x3\n The affine transformation to apply to the src image.\nfloat_out : bool\n If True, the return array will have dtype np.float32.\n Otherwise, the return array will have the same dtype\n as the src array.\n If True, the src array MUST have dtype np.uint8\n\nReturns\n-------\nout : ndarray\n Warped image of same size as src.\n\nNotes\n-----\nThe values of pixels at non-integer coordinates are retrieved\nusing bilinear interpolation. When the function needs pixels\noutside of the image, it uses replication border mode to\nreconstruct the values. Every channel of multiple-channel\nimages is processed independently.\n\nThis function has less overhead than cvWarpAffine\nand should be used unless specific feature of that\nfunction are required.''')\ndef cvGetQuadrangleSubPix(np.ndarray src, np.ndarray warpmat, float_out=False):\n\n validate_array(src)\n validate_array(warpmat)\n\n assert_nchannels(src, [1, 3])\n\n assert_nchannels(warpmat, [1])\n\n if warpmat.shape[0] != 2 or warpmat.shape[1] != 3:\n raise ValueError('warpmat must be 2x3')\n\n cdef np.ndarray out\n\n if float_out:\n assert_dtype(src, [UINT8])\n out = new_array_like_diff_dtype(src, FLOAT32)\n else:\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n cdef IplImage cvmat\n cdef CvMat* cvmatptr\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n populate_iplimage(warpmat, &cvmat)\n cvmatptr = cvmat_ptr_from_iplimage(&cvmat)\n\n c_cvGetQuadrangleSubPix(&srcimg, &outimg, cvmatptr)\n\n PyMem_Free(cvmatptr)\n\n return out\n\n\n#---------\n# cvResize\n#---------\n\n@cvdoc(package='cv', group='geometry', doc=\\\n'''cvResize(src, size, method=CV_INTER_LINEAR)\n\nResize an to the given size.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nsize : tuple, (height, width)\n The target resize size.\nmethod : integer\n The interpolation method used for resizing.\n Supported methods are:\n CV_INTER_NN\n CV_INTER_LINEAR\n CV_INTER_AREA\n CV_INTER_CUBIC\n\nReturns\n-------\nout : ndarray\n The resized image.''')\ndef cvResize(np.ndarray src, size, int method=CV_INTER_LINEAR):\n\n validate_array(src)\n\n if len(size) != 2:\n raise ValueError('size must be a 2-tuple (height, width)')\n\n if method not in [CV_INTER_NN, CV_INTER_LINEAR, CV_INTER_AREA,\n CV_INTER_CUBIC]:\n raise ValueError('unsupported interpolation type')\n\n cdef int ndim = src.ndim\n cdef np.npy_intp* shape = clone_array_shape(src)\n shape[0] = <np.npy_intp>size[0]\n shape[1] = <np.npy_intp>size[1]\n\n cdef np.ndarray out = new_array(ndim, shape, src.dtype)\n validate_array(out)\n\n PyMem_Free(shape)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvResize(&srcimg, &outimg, method)\n\n return out\n\n\n#-------------\n# cvWarpAffine\n#-------------\n\n@cvdoc(package='cv', group='geometry', doc=\\\n'''cvWarpAffine(src, warpmat, flag=CV_INTER_LINEAR+CV_WARP_FILL_OUTLIERS, fillval=(0., 0., 0., 0.))\n\nApplies an affine transformation to the image.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nwarpmat : ndarray, 2x3\n The affine transformation to apply to the src image.\nflag : integer\n A combination of interpolation and method flags.\n Supported flags are: (see notes)\n Interpolation:\n CV_INTER_NN\n CV_INTER_LINEAR\n CV_INTER_AREA\n CV_INTER_CUBIC\n Method:\n CV_WARP_FILL_OUTLIERS\n CV_WARP_INVERSE_MAP\nfillval : 4-tuple, (R, G, B, A)\n The color to fill in missing pixels. Defaults to black.\n For < 4 channel images, use 0.'s for the value.\n\nReturns\n-------\nout : ndarray\n The warped image of same size and dtype as src.\n\nNotes\n-----\nCV_WARP_FILL_OUTLIERS - fills all of the destination image pixels;\n if some of them correspond to outliers in the source image,\n they are set to fillval.\nCV_WARP_INVERSE_MAP - indicates that warpmat is inversely transformed\n from the destination image to the source and, thus, can be used\n directly for pixel interpolation. Otherwise, the function finds\n the inverse transform from warpmat.\n\nThis function has a larger overhead than cvGetQuadrangleSubPix,\nand that function should be used instead, unless specific\nfeatures of this function are needed.''')\ndef cvWarpAffine(np.ndarray src, np.ndarray warpmat,\n int flag=CV_INTER_LINEAR+CV_WARP_FILL_OUTLIERS,\n fillval=(0., 0., 0., 0.)):\n\n validate_array(src)\n validate_array(warpmat)\n if len(fillval) != 4:\n raise ValueError('fillval must be a 4-tuple')\n assert_nchannels(src, [1, 3])\n assert_nchannels(warpmat, [1])\n\n if warpmat.shape[0] != 2 or warpmat.shape[1] != 3:\n raise ValueError('warpmat must be 2x3')\n\n valid_flags = [0, 1, 2, 3, 8, 16, 9, 17, 11, 19, 10, 18]\n if flag not in valid_flags:\n raise ValueError('unsupported flag combination')\n\n cdef np.ndarray out\n out = new_array_like(src)\n\n cdef CvScalar cvfill\n cdef int i\n for i in range(4):\n cvfill.val[i] = <double>fillval[i]\n\n cdef IplImage srcimg\n cdef IplImage outimg\n cdef IplImage cvmat\n cdef CvMat* cvmatptr\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n populate_iplimage(warpmat, &cvmat)\n cvmatptr = cvmat_ptr_from_iplimage(&cvmat)\n\n c_cvWarpAffine(&srcimg, &outimg, cvmatptr, flag, cvfill)\n\n PyMem_Free(cvmatptr)\n\n return out\n\n\n#------------------\n# cvWarpPerspective\n#------------------\n\n@cvdoc(package='cv', group='geometry', doc=\\\n'''cvWarpPerspective(src, warpmat, flag=CV_INTER_LINEAR+CV_WARP_FILL_OUTLIERS, fillval=(0., 0., 0., 0.))\n\nApplies a perspective transformation to an image.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nwarpmat : ndarray, 3x3\n The affine transformation to apply to the src image.\nflag : integer\n A combination of interpolation and method flags.\n Supported flags are: (see notes)\n Interpolation:\n CV_INTER_NN\n CV_INTER_LINEAR\n CV_INTER_AREA\n CV_INTER_CUBIC\n Method:\n CV_WARP_FILL_OUTLIERS\n CV_WARP_INVERSE_MAP\nfillval : 4-tuple, (R, G, B, A)\n The color to fill in missing pixels. Defaults to black.\n For < 4 channel images, use 0.'s for the value.\n\nReturns\n-------\nout : ndarray\n The warped image of same size and dtype as src.\n\nNotes\n-----\nCV_WARP_FILL_OUTLIERS - fills all of the destination image pixels;\n if some of them correspond to outliers in the source image,\n they are set to fillval.\nCV_WARP_INVERSE_MAP - indicates that warpmat is inversely transformed\n from the destination image to the source and, thus, can be used\n directly for pixel interpolation. Otherwise, the function finds\n the inverse transform from warpmat.''')\ndef cvWarpPerspective(np.ndarray src, np.ndarray warpmat,\n int flag=CV_INTER_LINEAR+CV_WARP_FILL_OUTLIERS,\n fillval=(0., 0., 0., 0.)):\n\n validate_array(src)\n validate_array(warpmat)\n if len(fillval) != 4:\n raise ValueError('fillval must be a 4-tuple')\n assert_nchannels(src, [1, 3])\n assert_nchannels(warpmat, [1])\n if warpmat.shape[0] != 3 or warpmat.shape[1] != 3:\n raise ValueError('warpmat must be 3x3')\n\n valid_flags = [0, 1, 2, 3, 8, 16, 9, 17, 11, 19, 10, 18]\n if flag not in valid_flags:\n raise ValueError('unsupported flag combination')\n\n cdef np.ndarray out\n out = new_array_like(src)\n\n cdef CvScalar cvfill\n cdef int i\n for i in range(4):\n cvfill.val[i] = <double>fillval[i]\n\n cdef IplImage srcimg\n cdef IplImage outimg\n cdef IplImage cvmat\n cdef CvMat* cvmatptr = NULL\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n populate_iplimage(warpmat, &cvmat)\n cvmatptr = cvmat_ptr_from_iplimage(&cvmat)\n c_cvWarpPerspective(&srcimg, &outimg, cvmatptr, flag, cvfill)\n\n PyMem_Free(cvmatptr)\n\n return out\n\n\n#-----------\n# cvLogPolar\n#-----------\n\n@cvdoc(package='cv', group='geometry', doc=\\\n'''cvLogPolar(src, center, M, flag=CV_INTER_LINEAR+CV_WARP_FILL_OUTLIERS)\n\nRemaps and image to Log-Polar space.\n\nParameters\n----------\nsrc : ndarray\n The source image.\ncenter : tuple, (x, y)\n The keypoint for the log polar transform.\nM : float\n The scale factor for the transform.\n (40 is a good starting point for a 256x256 image)\nflag : integer\n A combination of interpolation and method flags.\n Supported flags are: (see notes)\n Interpolation:\n CV_INTER_NN\n CV_INTER_LINEAR\n CV_INTER_AREA\n CV_INTER_CUBIC\n Method:\n CV_WARP_FILL_OUTLIERS\n CV_WARP_INVERSE_MAP\n\nReturns\n-------\nout : ndarray\n A transformed image the same size and dtype as src.\n\nNotes\n-----\nCV_WARP_FILL_OUTLIERS - fills all of the destination image pixels;\n if some of them correspond to outliers in the source image,\n they are set to zero.\nCV_WARP_INVERSE_MAP - assume that the source image is already\n in Log-Polar space, and transform back to cartesian space.\n\nThe function emulates the human “foveal” vision and can be used\nfor fast scale and rotation-invariant template matching,\nfor object tracking and so forth.''')\ndef cvLogPolar(np.ndarray src, center, double M,\n int flag=CV_INTER_LINEAR+CV_WARP_FILL_OUTLIERS):\n\n validate_array(src)\n if len(center) != 2:\n raise ValueError('center must be a 2-tuple')\n\n valid_flags = [0, 16, 8, 24, 1, 17, 9, 25, 2, 18, 10, 26, 3, 19, 11, 27]\n if flag not in valid_flags:\n raise ValueError('unsupported flag combination')\n\n cdef np.ndarray out = new_array_like(src)\n\n cdef CvPoint2D32f cv_center\n cv_center.x = <float>center[0]\n cv_center.y = <float>center[1]\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvLogPolar(&srcimg, &outimg, cv_center, M, flag)\n return out\n\n\n#--------\n# cvErode\n#--------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvErode(src, element=None, iterations=1, anchor=None, in_place=False)\n\nErode the source image with the given element.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nelement : ndarray, 2D\n The structuring element. Must be 2D. Non-zero elements\n indicate which pixels of the underlying image to include\n in the operation as the element is slid over the image.\n If None, a 3x3 block element is used.\niterations : integer\n The number of times to perform the operation.\nanchor: 2-tuple, (x, y)\n The anchor of the structuring element. Must be\n FULLY inside the element. If None, the center of the\n element is used.\nin_place: bool\n If True, perform the operation in place.\n Otherwise, store the results in a new image.\n\nReturns\n-------\nout/None : ndarray or None\n An new array is returned only if in_place=False.\n Otherwise, this function returns None.''')\ndef cvErode(np.ndarray src, np.ndarray element=None, int iterations=1,\n anchor=None, in_place=False):\n\n validate_array(src)\n\n cdef np.ndarray out\n cdef IplConvKernel* iplkernel\n\n if element == None:\n iplkernel = NULL\n else:\n iplkernel = get_IplConvKernel_ptr_from_array(element, anchor)\n\n if in_place:\n out = src\n else:\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvErode(&srcimg, &outimg, iplkernel, iterations)\n\n free_IplConvKernel(iplkernel)\n\n if in_place:\n return None\n else:\n return out\n\n\n#---------\n# cvDilate\n#---------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvDilate(src, element=None, iterations=1, anchor=None, in_place=False)\n\nDilate the source image with the given element.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nelement : ndarray, 2D\n The structuring element. Must be 2D. Non-zero elements\n indicate which pixels of the underlying image to include\n in the operation as the element is slid over the image.\n If None, a 3x3 block element is used.\niterations : integer\n The number of times to perform the operation.\nanchor: 2-tuple, (x, y)\n The anchor of the structuring element. Must be\n FULLY inside the element. If None, the center of the\n element is used.\nin_place: bool\n If True, perform the operation in place.\n Otherwise, store the results in a new image.\n\nReturns\n-------\nout/None : ndarray or None\n An new array is returned only if in_place=False.\n Otherwise, this function returns None.''')\ndef cvDilate(np.ndarray src, np.ndarray element=None, int iterations=1,\n anchor=None, in_place=False):\n\n validate_array(src)\n\n cdef np.ndarray out\n cdef IplConvKernel* iplkernel\n\n if element == None:\n iplkernel = NULL\n else:\n iplkernel = get_IplConvKernel_ptr_from_array(element, anchor)\n\n if in_place:\n out = src\n else:\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvDilate(&srcimg, &outimg, iplkernel, iterations)\n\n free_IplConvKernel(iplkernel)\n\n if in_place:\n return None\n else:\n return out\n\n\n#---------------\n# cvMorphologyEx\n#---------------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvMorphologyEx(src, element, operation, iterations=1, anchor=None, in_place=False)\n\nApply a morphological operation to the image.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nelement : ndarray, 2D\n The structuring element. Must be 2D. Non-zero elements\n indicate which pixels of the underlying image to include\n in the operation as the element is slid over the image.\n Cannot be None.\noperation : flag\n The morphology operation to perform. Must be one of:\n CV_MOP_OPEN\n CV_MOP_CLOSE\n CV_MOP_GRADIENT\n CV_MOP_TOPHAT\n CV_MOP_BLACKHAT\niterations : integer\n The number of times to perform the operation.\nanchor: 2-tuple, (x, y)\n The anchor of the structuring element. Must be\n FULLY inside the element. If None, the center of the\n element is used.\nin_place: bool\n If True, perform the operation in place.\n Otherwise, store the results in a new image.\n\nReturns\n-------\nout/None : ndarray or None\n An new array is returned only if in_place=False.\n Otherwise, this function returns None.''')\ndef cvMorphologyEx(np.ndarray src, np.ndarray element, int operation,\n int iterations=1, anchor=None, in_place=False):\n\n validate_array(src)\n\n cdef np.ndarray out\n cdef np.ndarray temp\n cdef IplConvKernel* iplkernel\n\n iplkernel = get_IplConvKernel_ptr_from_array(element, anchor)\n\n if in_place:\n out = src\n else:\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n cdef IplImage tempimg\n cdef IplImage* tempimgptr = &tempimg\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n # determine if we need the tempimg\n if operation == CV_MOP_OPEN or operation == CV_MOP_CLOSE:\n tempimgptr = NULL\n elif operation == CV_MOP_GRADIENT:\n temp = new_array_like(src)\n populate_iplimage(temp, &tempimg)\n elif operation == CV_MOP_TOPHAT or operation == CV_MOP_BLACKHAT:\n if in_place:\n temp = new_array_like(src)\n populate_iplimage(temp, &tempimg)\n else:\n tempimgptr = NULL\n else:\n raise RuntimeError('operation type not understood')\n\n c_cvMorphologyEx(&srcimg, &outimg, tempimgptr, iplkernel, operation,\n iterations)\n\n free_IplConvKernel(iplkernel)\n\n if in_place:\n return None\n else:\n return out\n\n\n#---------\n# cvSmooth\n#---------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvSmooth(src, smoothtype=CV_GAUSSIAN, param1=3, param2=0, param3=0., param4=0., in_place=False)\n\nSmooth an image with the specified filter.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nsmoothtype : integer\n The flag representing which smoothing operation to perfom.\n See notes on restrictions.\n Must be one of:\n CV_BLUR_NO_SCALE\n CV_BLUR\n CV_GAUSSIAN\n CV_MEDIAN\n CV_BILATERAL\nparam1 : integer\n See notes.\nparam2 : integer\n See notes.\nparam3 : float\n See notes.\nparam4 : float\n See notes.\nin_place : bool\n If True, perform the operation in place.\n This is not supported for every combination of arguments.\n See notes.\n\nReturns\n-------\nout/None : ndarray or None\n If in_place == True the function operates in place and returns None.\n Otherwise, the operation returns a new array that is\n the result of the smoothing operation.\n\nNotes\n-----\nThe following details the restrictions and argument interpretaions\nfor each of the smoothing operations.\n\nCV_BLUR_NO_SCALE:\n Source image must be 2D and have dtype uint8, int8, or float32.\n param1 x param2 define the neighborhood over which the pixels\n are summed. If param2 is zero it is set equal to param1.\n param3 and param4 are ignored.\n in_place operation is not supported.\nCV_BLUR:\n Source image must have dtype uint8, int8, or float32.\n param1 x param2 define the neighborhood over which the pixels\n are summed. If param2 is zero it is set equal to param1.\n param3 and param4 are ignored.\nCV_GAUSSIAN:\n Source image must have dtype uint8, int8, or float32.\n param1 x param2 defines the size of the gaussian kernel.\n If param2 is zero it is set equal to param1.\n param3 is the standard deviation of the kernel.\n If param3 is zero, an optimum stddev is calculated based\n on the kernel size. If both param1 and param2 or zero,\n then an optimum kernel size is calculated based on\n param3.\n in_place operation is supported.\nCV_MEDIAN:\n Source image must have dtype uint8, or int8.\n param1 x param1 define the neigborhood over which\n to find the median.\n param2, param3, and param4 are ignored.\n in_place operation is not supported.\nCV_BILATERAL:\n Source image must have dtype uint8, or int8.\n param1 x param2 define the neighborhood.\n param3 defines the color stddev.\n param4 defines the space stddev.\n in_place operation is not supported.\n\nUsing standard sigma for small kernels (3x3 to 7x7)\ngives better speed.''')\ndef cvSmooth(np.ndarray src, int smoothtype=CV_GAUSSIAN, int param1=3,\n int param2=0, double param3=0, double param4=0,\n bool in_place=False):\n\n validate_array(src)\n\n cdef np.ndarray out\n # there are restrictions that must be placed on the data depending on\n # the smoothing operation requested\n\n # CV_BLUR_NO_SCALE\n if smoothtype == CV_BLUR_NO_SCALE:\n\n if in_place:\n raise RuntimeError('In place operation not supported with this '\n 'filter')\n\n assert_dtype(src, [UINT8, INT8, FLOAT32])\n assert_ndims(src, [2])\n\n if src.dtype == FLOAT32:\n out = new_array_like(src)\n else:\n out = new_array_like_diff_dtype(src, INT16)\n\n # CV_BLUR and CV_GAUSSIAN\n elif smoothtype == CV_BLUR or smoothtype == CV_GAUSSIAN:\n\n assert_dtype(src, [UINT8, INT8, FLOAT32])\n assert_nchannels(src, [1, 3])\n\n if in_place:\n out = src\n else:\n out = new_array_like(src)\n\n # CV_MEDIAN and CV_BILATERAL\n else:\n assert_dtype(src, [UINT8, INT8])\n assert_nchannels(src, [1, 3])\n\n if in_place:\n raise RuntimeError('In place operation not supported with this '\n 'filter')\n\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvSmooth(&srcimg, &outimg, smoothtype, param1, param2, param3, param4)\n\n if in_place:\n return None\n else:\n return out\n\n\n#-----------\n# cvFilter2D\n#-----------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvFilter2D(src, kernel, anchor=None, in_place=False)\n\nConvolve an image with the given kernel.\n\nParameters\n----------\nsrc : ndarray\n The source image.\nkernel : ndarray, 2D, dtype=float32\n The kernel with which to convolve the image.\nanchor : 2-tuple, (x, y)\n The kernel anchor.\nin_place : bool\n If True, perform the operation in_place.\n\nReturns\n-------\nout/None : ndarray or None\n If in_place is True, returns None.\n Otherwise a new array is returned which is the result\n of the convolution.\n\nNotes\n-----\nThis is a high performance function. OpenCV automatically\ndetermines, based on the size of the image and the kernel,\nwhether it will faster to do the convolution in the spatial\nor the frequency domain, and behaves accordingly.''')\ndef cvFilter2D(np.ndarray src, np.ndarray kernel, anchor=None, in_place=False):\n\n validate_array(src)\n validate_array(kernel)\n\n assert_ndims(kernel, [2])\n assert_dtype(kernel, [FLOAT32])\n\n cdef CvPoint cv_anchor\n if anchor is not None:\n assert len(anchor) == 2, 'anchor must be (x, y) tuple'\n cv_anchor.x = <int>anchor[0]\n cv_anchor.y = <int>anchor[1]\n assert (cv_anchor.x < kernel.shape[1]) and (cv_anchor.x >= 0) \\\n and (cv_anchor.y < kernel.shape[0]) and (cv_anchor.y >= 0), \\\n 'anchor point must be inside kernel'\n else:\n cv_anchor.x = <int>(kernel.shape[1] / 2.)\n cv_anchor.y = <int>(kernel.shape[0] / 2.)\n\n cdef np.ndarray out\n\n if in_place:\n out = src\n else:\n out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n cdef IplImage kernelimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n populate_iplimage(kernel, &kernelimg)\n\n cdef CvMat* cv_kernel\n cv_kernel = cvmat_ptr_from_iplimage(&kernelimg)\n\n c_cvFilter2D(&srcimg, &outimg, cv_kernel, cv_anchor)\n\n PyMem_Free(cv_kernel)\n\n if in_place:\n return None\n else:\n return out\n\n\n#-----------\n# cvIntegral\n#-----------\n\n@cvdoc(package='cv', group='transforms', doc=\\\n'''cvIntegral(src, square_sum=False, titled_sum=False)\n\nCalculate the integral of an image.\n\nParameters\n----------\nsrc : ndarray, dtyp=[uint8, float32, float64]\n The source image.\nsquare_sum : bool\n If True, also returns the square sum.\ntilted_sum : bool\n If True, also returns the titled sum (45 degree tilt)\n\nReturns\n-------\n[out1, out2, out3] : list of ndarray's\n Returns a list consisting at least of:\n out1: the integral image, and optionally:\n out2: the square sum image\n out3: the titled sum image,\n or any combination of these two.''')\ndef cvIntegral(np.ndarray src, square_sum=False, tilted_sum=False):\n\n validate_array(src)\n assert_dtype(src, [UINT8, FLOAT32, FLOAT64])\n\n out = []\n\n cdef np.ndarray outsum\n cdef np.ndarray outsqsum\n cdef np.ndarray outtiltsum\n\n cdef IplImage srcimg\n cdef IplImage outsumimg\n cdef IplImage outsqsumimg\n cdef IplImage outtiltsumimg\n cdef IplImage* outsqsumimgptr = &outsqsumimg\n cdef IplImage* outtiltsumimgptr = &outtiltsumimg\n\n populate_iplimage(src, &srcimg)\n\n # out arrays need to be (H + 1) x (W + 1)\n cdef np.npy_intp* out_shape = clone_array_shape(src)\n out_shape[0] = src.shape[0] + 1\n out_shape[1] = src.shape[1] + 1\n cdef int out_dims = src.ndim\n\n if src.dtype == UINT8:\n outsum = new_array(out_dims, out_shape, INT32)\n else:\n outsum = new_array(out_dims, out_shape, FLOAT64)\n\n populate_iplimage(outsum, &outsumimg)\n out.append(outsum)\n\n if square_sum:\n outsqsum = new_array(out_dims, out_shape, FLOAT64)\n populate_iplimage(outsqsum, &outsqsumimg)\n out.append(outsqsum)\n else:\n outsqsumimgptr = NULL\n\n if tilted_sum:\n outtiltsum = new_array(out_dims, out_shape, outsum.dtype)\n populate_iplimage(outtiltsum, &outtiltsumimg)\n out.append(outtiltsum)\n else:\n outtiltsumimgptr = NULL\n\n c_cvIntegral(&srcimg, &outsumimg, outsqsumimgptr, outtiltsumimgptr)\n\n PyMem_Free(out_shape)\n\n return out\n\n\n#-----------\n# cvCvtColor\n#-----------\n\n@cvdoc(package='cv', group='transforms', doc=\\\n'''cvCvtColor(src, code)\n\nConvert an image to another color space.\n\nParameters\n----------\nsrc : ndarray, dtype=[uint8, uint16, float32]\n The source image.\ncode : integer\n A flag representing which color conversion to perform.\n Valid flags are the following:\n CV_BGR2BGRA, CV_RGB2RGBA, CV_BGRA2BGR, CV_RGBA2RGB,\n CV_BGR2RGBA, CV_RGB2BGRA, CV_RGBA2BGR, CV_BGRA2RGB,\n CV_BGR2RGB, CV_RGB2BGR, CV_BGRA2RGBA, CV_RGBA2BGRA,\n CV_BGR2GRAY, CV_RGB2GRAY, CV_GRAY2BGR, CV_GRAY2RGB,\n CV_GRAY2BGRA, CV_GRAY2RGBA, CV_BGRA2GRAY, CV_RGBA2GRAY,\n CV_BGR2BGR565, CV_RGB2BGR565, CV_BGR5652BGR, CV_BGR5652RGB,\n CV_BGRA2BGR565, CV_RGBA2BGR565, CV_BGR5652BGRA, CV_BGR5652RGBA,\n CV_GRAY2BGR565, CV_BGR5652GRAY, CV_BGR2BGR555, CV_RGB2BGR555,\n CV_BGR5552BGR, CV_BGR5552RGB, CV_BGRA2BGR555, CV_RGBA2BGR555,\n CV_BGR5552BGRA, CV_BGR5552RGBA, CV_GRAY2BGR555, CV_BGR5552GRAY,\n CV_BGR2XYZ, CV_RGB2XYZ, CV_XYZ2BGR, CV_XYZ2RGB,\n CV_BGR2YCrCb, CV_RGB2YCrCb, CV_YCrCb2BGR, CV_YCrCb2RGB,\n CV_BGR2HSV, CV_RGB2HSV, CV_BGR2Lab, CV_RGB2Lab,\n CV_BayerBG2BGR, CV_BayerGB2BGR, CV_BayerRG2BGR, CV_BayerGR2BGR,\n CV_BayerBG2RGB, CV_BayerGB2RGB, CV_BayerRG2RGB, CV_BayerGR2RGB,\n CV_BGR2Luv, CV_RGB2Luv, CV_BGR2HLS, CV_RGB2HLS,\n CV_HSV2BGR, CV_HSV2RGB, CV_Lab2BGR, CV_Lab2RGB,\n CV_Luv2BGR, CV_Luv2RGB, CV_HLS2BGR, CV_HLS2RGB\n\nReturns\n-------\nout : ndarray\n A new image in the requested color-space, with\n an appropriate dtype.\n\nNotes\n-----\nNot all conversion types support all dtypes.\nAn exception will be raise if the dtype is not supported.\nSee the OpenCV documentation for more details\nabout the specific color conversions.''')\ndef cvCvtColor(np.ndarray src, int code):\n\n validate_array(src)\n assert_dtype(src, [UINT8, UINT16, FLOAT32])\n\n try:\n conversion_params = _cvtcolor_dict[code]\n except KeyError:\n print 'unknown conversion code'\n raise\n\n cdef int src_channels = <int>conversion_params[0]\n cdef int out_channels = <int>conversion_params[1]\n src_dtypes = conversion_params[2]\n\n assert_nchannels(src, [src_channels])\n assert_dtype(src, src_dtypes)\n\n cdef np.ndarray out\n\n # the out array can be 2, 3, or 4 channels so we need shapes that\n # can handle either\n cdef np.npy_intp out_shape2[2]\n cdef np.npy_intp out_shape3[3]\n out_shape2[0] = src.shape[0]\n out_shape2[1] = src.shape[1]\n out_shape3[0] = src.shape[0]\n out_shape3[1] = src.shape[1]\n\n if out_channels == 1:\n out = new_array(2, out_shape2, src.dtype)\n else:\n out_shape3[2] = <np.npy_intp>out_channels\n out = new_array(3, out_shape3, src.dtype)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvCvtColor(&srcimg, &outimg, code)\n\n return out\n\n\n#------------\n# cvThreshold\n#------------\n\n@cvdoc(package='cv', group='transforms', doc=\\\n'''cvThreshold(src, threshold, max_value=255, threshold_type=CV_THRESH_BINARY, use_otsu=False)\n\nThreshold an image.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=[uint8, float32]\nthreshold : float\n The threshold value. (decision value)\nmax_value : float\n The maximum value.\nthreshold_type : integer\n The flag representing which type of thresholding to apply.\n Valid flags are:\n CV_THRESH_BINARY (max_value if src(x,y) > threshold else 0)\n CV_THRESH_BINARY_INV (0 if src(x,y) > threshold else max_value)\n CV_THRESH_TRUNC (threshold if src(x,y) > threshold else src(x,y))\n CV_THRESH_TOZERO (src(x,y) if src(x,y) > threshold else 0)\n CV_THRESH_TOZERO_INV (0 if src(x,y) > threshold else src(x,y))\nuse_otsu : bool\n If true, the optimum threshold is automatically computed\n and the passed in threshold value is ignored.\n Only implemented for uint8 source images.\n\nReturns\n-------\nout/(out, threshold) : ndarray or (ndarray, float)\n If use_otsu is True, then the computed threshold value is\n returned in addition to the thresholded image. Otherwise\n just the thresholded image is returned.''')\ndef cvThreshold(np.ndarray src, double threshold, double max_value=255,\n int threshold_type=CV_THRESH_BINARY, use_otsu=False):\n\n validate_array(src)\n assert_nchannels(src, [1])\n assert_dtype(src, [UINT8, FLOAT32])\n\n if use_otsu:\n assert_dtype(src, [UINT8])\n threshold_type += 8\n\n cdef np.ndarray out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n threshold = c_cvThreshold(&srcimg, &outimg, threshold, max_value,\n threshold_type)\n\n if use_otsu:\n return (out, threshold)\n else:\n return out\n\n\n#--------------------\n# cvAdaptiveThreshold\n#--------------------\n\n@cvdoc(package='cv', group='transforms', doc=\\\n'''cvAdaptiveThreshold(src, max_value, adaptive_method=CV_ADAPTIVE_THRESH_MEAN_C, threshold_type=CV_THRESH_BINARY, block_size=3, param1=5)\n\nApply an adaptive threshold to an image.\n\nParameters\n----------\nsrc : ndarray, 2D, dtype=uint8\nmax_value : float\n The maximum value.\nadaptive_method : integer\n The flag representing the adaptive method.\n Valid flags are:\n CV_ADAPTIVE_THRESH_MEAN_C (uses mean of the neighborhood)\n CV_ADAPTIVE_THRESH_GAUSSIAN_C (uses gaussian of the neighborhood)\nthreshold_type : integer\n The flag representing which type of thresholding to apply.\n Valid flags are:\n CV_THRESH_BINARY (max_value if src(x,y) > threshold else 0)\n CV_THRESH_BINARY_INV (0 if src(x,y) > threshold else max_value)\nblock_size : integer\n Defines a block_size x block_size neighborhood\nparam1 : float\n The weight to be subtracted from the neighborhood computation.\n\nReturns\n-------\nout : ndarray\n The thresholded image.''')\ndef cvAdaptiveThreshold(np.ndarray src, double max_value,\n int adaptive_method=CV_ADAPTIVE_THRESH_MEAN_C,\n int threshold_type=CV_THRESH_BINARY,\n int block_size=3, double param1=5):\n\n validate_array(src)\n assert_nchannels(src, [1])\n assert_dtype(src, [UINT8])\n\n if (adaptive_method!=CV_ADAPTIVE_THRESH_MEAN_C and\n adaptive_method!=CV_ADAPTIVE_THRESH_GAUSSIAN_C):\n raise ValueError('Invalid adaptive method')\n\n if (threshold_type!=CV_THRESH_BINARY and\n threshold_type!=CV_THRESH_BINARY_INV):\n raise ValueError('Invalid threshold type')\n\n if (block_size % 2 != 1 or block_size <= 1):\n raise ValueError('block size must be and odd number and greater than 1')\n\n cdef np.ndarray out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvAdaptiveThreshold(&srcimg, &outimg, max_value, adaptive_method,\n threshold_type, block_size, param1)\n\n return out\n\n\n#----------\n# cvPyrDown\n#----------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvPyrDown(src)\n\nDownsample an image.\n\nParameters\n----------\nsrc : ndarray, dtype=[uint8, uint16, float32, float64]\n\nReturns\n-------\nout : ndarray\n Downsampled image half the size of the original\n in each dimension.''')\ndef cvPyrDown(np.ndarray src):\n\n validate_array(src)\n assert_dtype(src, [UINT8, UINT16, FLOAT32, FLOAT64])\n\n cdef int outdim = src.ndim\n cdef np.npy_intp* outshape = clone_array_shape(src)\n outshape[0] = <np.npy_intp>(src.shape[0] + 1) / 2\n outshape[1] = <np.npy_intp>(src.shape[1] + 1) / 2\n\n cdef np.ndarray out = new_array(outdim, outshape, src.dtype)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvPyrDown(&srcimg, &outimg, 7)\n\n PyMem_Free(outshape)\n\n return out\n\n\n#--------\n# cvPyrUp\n#--------\n\n@cvdoc(package='cv', group='filter', doc=\\\n'''cvPyrUp(src)\n\nUpsample an image.\n\nParameters\n----------\nsrc : ndarray, dtype=[uint8, uint16, float32, float64]\n\nReturns\n-------\nout : ndarray\n Upsampled image twice the size of the original\n in each dimension.''')\ndef cvPyrUp(np.ndarray src):\n\n validate_array(src)\n assert_dtype(src, [UINT8, UINT16, FLOAT32, FLOAT64])\n\n cdef int outdim = src.ndim\n cdef np.npy_intp* outshape = clone_array_shape(src)\n outshape[0] = <np.npy_intp>(src.shape[0] * 2)\n outshape[1] = <np.npy_intp>(src.shape[1] * 2)\n\n cdef np.ndarray out = new_array(outdim, outshape, src.dtype)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n\n c_cvPyrUp(&srcimg, &outimg, 7)\n\n PyMem_Free(outshape)\n\n return out\n\n\n#------------\n# cvWatershed\n#------------\n\n@cvdoc(package='cv', group='image', doc=\\\n'''cvWatershed(src, markers)\n\nPerforms watershed segmentation.\n\nParameters\n----------\nsrc : ndarray, 3D, dtype=uint8\n The source image.\nmarkers : ndarray, 2D, dtype=int32\n The markers identifying the regions of interest.\n Marker values should be non-zero.\n This array should have the same width and height as src.\n\nReturns\n-------\nNone : None\n The markers array is modified in place. The results of which\n identify the segmented regions of the image.''')\ndef cvWatershed(src, markers):\n\n validate_array(src)\n validate_array(markers)\n\n assert_ndims(src, [3])\n assert_dtype(src, [UINT8])\n\n assert_ndims(markers, [2])\n assert_dtype(markers, [INT32])\n\n #assert src.shape[:2] == markers.shape[:2], \\\n # 'The src and markers array must have same width and height'\n\n cdef IplImage srcimg\n cdef IplImage markersimg\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(markers, &markersimg)\n\n c_cvWatershed(&srcimg, &markersimg)\n\n return None\n\n\n#-------------------\n# cvCalibrateCamera2\n#-------------------\n\n@cvdoc(package='cv', group='calibration', doc=\\\n'''cvCalibrateCamera2(object_points, image_points, point_counts, image_size)\n\nFinds the intrinsic and extrinsic camera parameters\nusing a calibration pattern.\n\nParameters\n----------\nobject_points : ndarray, Nx3\n An array representing the (X, Y, Z) known coordinates of the\n calibration object.\nimage_points : ndarry, Nx2\n An array representing the pixel image coordinate of the\n points in object_points.\npoint_counts : ndarry, 1D, dtype=int32\n Vector containing the number of points in each particular view.\nimage_size : 2-tuple, (height, width)\n The height and width of the images used.\n\nReturns\n-------\n(intrinsics, distortion) : ndarray 3x3, ndarray 5-vector\n Intrinsics is the 3x3 camera instrinsics matrix.\n Distortion is the 5-vector of distortion coefficients.''')\ndef cvCalibrateCamera2(np.ndarray object_points, np.ndarray image_points,\n np.ndarray point_counts, image_size):\n\n # Validate input\n validate_array(object_points)\n assert_ndims(object_points, [2])\n\n validate_array(image_points)\n assert_ndims(image_points, [2])\n\n assert_dtype(point_counts, [INT32])\n assert_ndims(point_counts, [1])\n\n # Allocate a new intrinsics array\n cdef np.npy_intp intrinsics_shape[2]\n intrinsics_shape[0] = <np.npy_intp> 3\n intrinsics_shape[1] = <np.npy_intp> 3\n cdef np.ndarray intrinsics = new_array(2, intrinsics_shape, FLOAT64)\n cdef IplImage ipl_intrinsics\n populate_iplimage(intrinsics, &ipl_intrinsics)\n cdef CvMat* cvmat_intrinsics = cvmat_ptr_from_iplimage(&ipl_intrinsics)\n\n # Allocate a new distortion array\n cdef np.npy_intp distortion_shape[2]\n distortion_shape[0] = <np.npy_intp> 1\n distortion_shape[1] = <np.npy_intp> 5\n cdef np.ndarray distortion = new_array(2, distortion_shape, FLOAT64)\n cdef IplImage ipl_distortion\n populate_iplimage(distortion, &ipl_distortion)\n cdef CvMat* cvmat_distortion = cvmat_ptr_from_iplimage(&ipl_distortion)\n\n # Make the object & image points & npoints accessible for OpenCV\n cdef IplImage ipl_object_points, ipl_image_points, ipl_point_counts\n cdef CvMat* cvmat_object_points, *cvmat_image_points, *cvmat_point_counts\n populate_iplimage(object_points, &ipl_object_points)\n populate_iplimage(image_points, &ipl_image_points)\n populate_iplimage(point_counts, &ipl_point_counts)\n\n cvmat_object_points = cvmat_ptr_from_iplimage(&ipl_object_points)\n cvmat_image_points = cvmat_ptr_from_iplimage(&ipl_image_points)\n cvmat_point_counts = cvmat_ptr_from_iplimage(&ipl_point_counts)\n\n # Set image size\n cdef CvSize cv_image_size\n cv_image_size.height = image_size[0]\n cv_image_size.width = image_size[1]\n\n # Call the function\n c_cvCalibrateCamera2(cvmat_object_points, cvmat_image_points,\n cvmat_point_counts, cv_image_size, cvmat_intrinsics,\n cvmat_distortion, NULL, NULL, 0)\n\n # Convert distortion back into a vector\n distortion = np.PyArray_Squeeze(distortion)\n\n PyMem_Free(cvmat_intrinsics)\n PyMem_Free(cvmat_distortion)\n PyMem_Free(cvmat_object_points)\n PyMem_Free(cvmat_image_points)\n PyMem_Free(cvmat_point_counts)\n\n return intrinsics, distortion\n\n\n#-------------\n# cvUndistort2\n#-------------\n\n@cvdoc(package='cv', group='calibration', doc=\\\n'''cvUndistort2(src, intrinsics, distortions)\n\nUndistorts an image given the camera intrinsics matrix and distortions vector.\nThese values can be calculated using cvCalibrateCamera2.\n\nParameters\n----------\nsrc : ndarray\n The image to undistort\nintrinsics : ndarray, 3x3, dtype=float64\n The camera intrinsics matrix.\ndistortions : ndarray, 5-vector, dtype=float64\n The camera distortion coefficients.\n\nReturns\n-------\nout : ndarray\n The undistorted image the same size and dtype\n as the source image.''')\ndef cvUndistort2(src, intrinsics, distortions):\n validate_array(src)\n assert_dtype(intrinsics, [FLOAT64])\n assert_dtype(distortions, [FLOAT64])\n assert_ndims(intrinsics, [2])\n assert_ndims(distortions, [1])\n\n if intrinsics.shape[0] != 3 or intrinsics.shape[1] != 3:\n raise ValueError('intrinsics must be 3x3')\n if distortions.shape[0] != 5:\n raise ValueError('distortions must be a 5-vector')\n\n cdef np.ndarray out = new_array_like(src)\n\n cdef IplImage srcimg\n cdef IplImage outimg\n cdef IplImage intrimg\n cdef IplImage distimg\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(out, &outimg)\n populate_iplimage(intrinsics, &intrimg)\n populate_iplimage(distortions, &distimg)\n\n cdef CvMat* cvintr = cvmat_ptr_from_iplimage(&intrimg)\n cdef CvMat* cvdist = cvmat_ptr_from_iplimage(&distimg)\n\n c_cvUndistort2(&srcimg, &outimg, cvintr, cvdist)\n\n PyMem_Free(cvintr)\n PyMem_Free(cvdist)\n\n return out\n\n#------------------------\n# cvFindChessboardCorners\n#------------------------\n\n@cvdoc(package='cv', group='calibration', doc=\\\n'''cvFindChessboardCorners(src, pattern_size, flag=CV_CALIB_CB_ADAPTIVE_THRESH)\n\nFinds the position of the internal corners of a chessboard.\n\nParameters\n----------\nsrc : ndarray, dtype=uint8\n Image to search for chessboard corners.\npattern_size : 2-tuple of inner corners (h,w)\nflag : integer\n CV_CALIB_CB_ADAPTIVE_THRESH - use adaptive thresholding\n to convert the image to black and white,\n rather than a fixed threshold level\n (computed from the average image brightness).\n CV_CALIB_CB_NORMALIZE_IMAGE - normalize the image using\n cvNormalizeHist() before applying fixed or adaptive\n thresholding.\n CV_CALIB_CB_FILTER_QUADS - use additional criteria\n (like contour area, perimeter, square-like shape) to\n filter out false quads that are extracted at the contour\n retrieval stage.\n\nReturns\n-------\nout : ndarray Nx2\n An nx2 array of the corners found.''')\ndef cvFindChessboardCorners(np.ndarray src, pattern_size,\n int flag=CV_CALIB_CB_ADAPTIVE_THRESH):\n\n validate_array(src)\n\n assert_nchannels(src, [1, 3])\n assert_dtype(src, [UINT8])\n\n cdef np.npy_intp outshape[2]\n outshape[0] = <np.npy_intp> pattern_size[0] * pattern_size[1]\n outshape[1] = <np.npy_intp> 2\n\n cdef np.ndarray out\n out = new_array(2, outshape, FLOAT32)\n cdef CvPoint2D32f* cvpoints = array_as_cvPoint2D32f_ptr(out)\n\n cdef CvSize cvpattern_size\n cvpattern_size.height = pattern_size[0]\n cvpattern_size.width = pattern_size[1]\n\n cdef IplImage srcimg\n populate_iplimage(src, &srcimg)\n\n cdef int ncorners_found\n c_cvFindChessboardCorners(&srcimg, cvpattern_size, cvpoints,\n &ncorners_found, flag)\n\n return out[:ncorners_found]\n\n\n#-----------------------------\n# cvFindExtrinsicCameraParams2\n#-----------------------------\n\n@cvdoc(package='cv', group='calibration', doc=\\\n'''cvFindExtrinsicCameraParams2(object_points, image_points, intrinsic_matrix,\n distortion_coeffs)\n\nCalculates the extrinsic camera parameters given a set of 3D points, their\n2D locations in the image, and the camera instrinsics matrix and distortion\ncoefficients.\n\ni.e. given this information, it calculates the offset and rotation of the\ncamera from the chessboard origin.\n\nParameters\n----------\nobject_points: ndarray, nx3\n The 3D coordinates of the chessboard corners.\nimage_points: ndarray, nx2\n The 2D image coordinates of the object_points\nintrinsic_matrix: ndarray, 3x3, dtype=float64\n The 2D camera intrinsics matrix that is the result of camera calibration\ndistortion_coeffs: ndarray, 5-vector, dtype=float64\n The 5 distortion coefficients that are the result of camera calibration\n\nReturns\n-------\n(rvec, tvec): ndarray 3-vector dtype=float64, ndarray 3-vector dtype=float64\n rvec - the rotation vector representing the rotation of the camera\n relative to the chessboard. The direction of the vector represents the\n axis of rotation and its magnitude the amount of rotation.\n tvec - the translation vector representing the offset of the camera\n relative to the chessboard origin.''')\ndef cvFindExtrinsicCameraParams2(object_points, image_points, intrinsic_matrix,\n distortion_coeffs):\n\n validate_array(object_points)\n validate_array(image_points)\n validate_array(intrinsic_matrix)\n\n assert_ndims(object_points, [2])\n assert_dtype(object_points, [FLOAT32, FLOAT64])\n assert object_points.shape[1] == 3, 'object_points should be nx3'\n\n assert_ndims(image_points, [2])\n assert_dtype(image_points, [FLOAT32, FLOAT64])\n assert image_points.shape[1] == 2, 'image_points should be nx2'\n\n assert_dtype(intrinsic_matrix, [FLOAT64])\n assert intrinsic_matrix.shape == (3, 3), 'instrinsics should be 3x3'\n\n assert_dtype(distortion_coeffs, [FLOAT64])\n assert distortion_coeffs.shape == (5,), 'distortions should be 5-vector'\n\n # allocate the numpy return arrays\n cdef np.npy_intp shape[1]\n shape[0] = 3\n cdef np.ndarray rvec = new_array(1, shape, FLOAT64)\n cdef np.ndarray tvec = new_array(1, shape, FLOAT64)\n\n # allocate the cv images\n cdef IplImage obj_img\n cdef IplImage img_img\n cdef IplImage intr_img\n cdef IplImage dist_img\n cdef IplImage rot_img\n cdef IplImage tran_img\n populate_iplimage(object_points, &obj_img)\n populate_iplimage(image_points, &img_img)\n populate_iplimage(intrinsic_matrix, &intr_img)\n populate_iplimage(distortion_coeffs, &dist_img)\n populate_iplimage(rvec, &rot_img)\n populate_iplimage(tvec, &tran_img)\n\n # allocate the cv mats\n cdef CvMat* cvobj = cvmat_ptr_from_iplimage(&obj_img)\n cdef CvMat* cvimg = cvmat_ptr_from_iplimage(&img_img)\n cdef CvMat* cvint = cvmat_ptr_from_iplimage(&intr_img)\n cdef CvMat* cvdis = cvmat_ptr_from_iplimage(&dist_img)\n cdef CvMat* cvrot = cvmat_ptr_from_iplimage(&rot_img)\n cdef CvMat* cvtrn = cvmat_ptr_from_iplimage(&tran_img)\n\n # the last argument is new to OpenCV 2.0 and tells it NOT to use\n # an extrinsics guess\n c_cvFindExtrinsicCameraParams2(cvobj, cvimg, cvint, cvdis, cvrot, cvtrn, 0)\n\n PyMem_Free(cvobj)\n PyMem_Free(cvimg)\n PyMem_Free(cvint)\n PyMem_Free(cvdis)\n PyMem_Free(cvrot)\n PyMem_Free(cvtrn)\n\n return (rvec, tvec)\n\n#------------------------\n# cvFindChessboardCorners\n#------------------------\n\n@cvdoc(package='cv', group='calibration', doc=\\\n'''cvDrawChessboardCorners(src, pattern_size, corners, in_place=False)\n\nRenders found chessboard corners into an image.\n\nParameters\n----------\nsrc : ndarray, dim 3, dtype: uint8\n Image to draw into.\npattern_size : 2-tuple, (h, w)\n Number of inner corners (h,w)\ncorners : ndarray, nx2, dtype=float32\n Corners found in the image. See cvFindChessboardCorners and\n cvFindCornerSubPix\nin_place: bool\n If true, perform the drawing on the submitted\n image. If false, a copy of the image will be made and drawn to.\n\nReturns\n-------\nout/None : ndarray or none\n If in_place is True, the function returns None.\n Otherwise, the function returns a new image with\n the corners drawn into it.''')\ndef cvDrawChessboardCorners(np.ndarray src, pattern_size, np.ndarray corners,\n in_place=False):\n\n validate_array(src)\n\n assert_nchannels(src, [3])\n assert_dtype(src, [UINT8])\n\n assert_ndims(corners, [2])\n assert_dtype(corners, [FLOAT32])\n\n cdef np.ndarray out\n\n if not in_place:\n out = src.copy()\n else:\n out = src\n\n cdef CvSize cvpattern_size\n cvpattern_size.height = pattern_size[0]\n cvpattern_size.width = pattern_size[1]\n\n cdef IplImage outimg\n populate_iplimage(out, &outimg)\n\n cdef CvPoint2D32f* cvcorners = array_as_cvPoint2D32f_ptr(corners)\n\n cdef int ncount = pattern_size[0] * pattern_size[1]\n\n cdef int pattern_was_found\n\n if corners.shape[0] == ncount:\n pattern_was_found = 1\n else:\n pattern_was_found = 0\n\n c_cvDrawChessboardCorners(&outimg, cvpattern_size, cvcorners,\n ncount, pattern_was_found)\n\n if in_place:\n return None\n else:\n return out\n\n\n#------------\n# cvFloodFill\n#------------\n\n@cvdoc(package='cv', group='image', doc=\\\n'''cvFloodFill(np.ndarray src, seed_point, new_val, low_diff, high_diff,\n mask=None, connect_diag=False, mask_only=False,\n mask_fillval=None, fixed_range=False)\n\nFills a connected component with the given color.\n\nParameters\n----------\nsrc : ndarray, ndims=[2, 3], dtypes[uint8, float32]\n The source image\nseed_point : (x, y) int tuple\n The starting point of the fill in image pixel coordinates.\nnew_val : scalar double or 3-tuple (R, G, B) doubles\n The color value of the repainted area. If a scalar, the RGB values\n are all set equal to the scalar.\nlow_diff : scalar double or 3-tuple (R, G, B) doubles\n Maximal lower brightness/color difference between the currently\n observed pixel and one of its neighbors belonging to the component,\n or a seed pixel being added to the component. Must be positive.\nhigh_diff : scalar double or 3-tuple (R, G, B) doubles\n Maximal upper brightness/color difference between the currently\n observed pixel and one of its neighbors belonging to the component,\n or a seed pixel being added to the component. Must be positive.\nmask : ndarray 2d, dtype=uint8 or None\n The mask in which to draw the results and/or use as a mask.\n See the opencv documentation for more details.\n If not None, the mask shape must be 2 pixels wider and taller than src.\nconnect_diag : bool\n If True, implies connectivity across the diagonals in addition to\n the standard horizontal and vertical directions.\nmask_only : bool\n If True, fill the mask instead of the image.\n Mask must not be None\nmask_fillval : int 0 - 255 or None\n The value to fill the mask if mask is not None.\n If None, defaults to 1\nfixed_range : bool\n If True, fills relative to seed value, else, fills relative to\n neighbors value.\n\nReturns\n-------\nNone : None\n This is an in-place operation which draws into src and/or image depending\n on the flags set in the input arguments''')\ndef cvFloodFill(np.ndarray src, seed_point, new_val, low_diff, high_diff,\n mask=None, connect_diag=False, mask_only=False,\n mask_fillval=None, fixed_range=False):\n\n validate_array(src)\n assert_ndims(src, [2, 3])\n assert_dtype(src, [UINT8, FLOAT32])\n\n # src\n cdef IplImage srcimg\n populate_iplimage(src, &srcimg)\n\n # seed_point\n if len(seed_point) != 2:\n raise ValueError('seed_point should be an (x, y) tuple of ints')\n cdef CvPoint cv_seed_point\n cdef int x = <int>seed_point[0]\n cdef int y = <int>seed_point[1]\n cdef int xmax = <int>src.shape[1]\n cdef int ymax = <int>src.shape[0]\n if x < 0 or x > xmax or y < 0 or y > ymax:\n raise ValueError('seed_point must be image pixel coordinates')\n cv_seed_point.x = x\n cv_seed_point.y = y\n\n # loop counter\n cdef int i\n cdef double temp\n\n # new_val\n cdef CvScalar cv_new_val\n if hasattr(new_val, '__len__'):\n if len(new_val) != 3:\n raise ValueError('If not a scalar, new_val must be 3 tuple')\n for i in range(3):\n cv_new_val.val[i] = <double>new_val[i]\n else:\n temp = <double>new_val\n for i in range(3):\n cv_new_val.val[i] = temp\n\n # low_diff\n cdef CvScalar cv_low_diff\n if hasattr(low_diff, '__len__'):\n if len(low_diff) != 3:\n raise ValueError('If not a scalar, low_diff must be 3 tuple')\n for i in range(3):\n cv_low_diff.val[i] = <double>low_diff[i]\n else:\n temp = <double>low_diff\n for i in range(3):\n cv_low_diff.val[i] = temp\n\n # high_diff\n cdef CvScalar cv_high_diff\n if hasattr(high_diff, '__len__'):\n if len(high_diff) != 3:\n raise ValueError('If not a scalar, high_diff must be 3 tuple')\n for i in range(3):\n cv_high_diff.val[i] = <double>high_diff[i]\n else:\n temp = <double>high_diff\n for i in range(3):\n cv_high_diff.val[i] = temp\n\n # mask\n cdef IplImage maskimg\n cdef IplImage* maskimgptr = NULL\n if mask is not None:\n validate_array(mask)\n assert_ndims(mask, [2])\n assert_dtype(mask, [UINT8])\n if mask.shape[0] != (src.shape[0] + 2) or \\\n mask.shape[1] != (src.shape[1] + 2):\n raise ValueError('mask must be 2 pixels wider and taller than src.')\n populate_iplimage(mask, &maskimg)\n maskimgptr = &maskimg\n\n # flags\n cdef int flags\n\n # connect_diag\n cdef int cv_connect_diag = 4\n if connect_diag:\n cv_connect_diag = 8\n\n # mask_only\n cdef int cv_mask_only = 0\n if mask_only:\n if mask is None:\n raise ValueError('If mask_only==True, mask must not be None')\n cv_mask_only = (1 << 17)\n\n # mask_fillval\n cdef int cv_mask_fillval = (1 << 8)\n if mask_fillval:\n if mask_fillval < 0 or mask_fillval > 255:\n raise ValueError('mask_fillval must be in range 0-255')\n cv_mask_fillval = ((<int>mask_fillval) << 8)\n\n # fixed_range\n cdef int cv_fixed_range = 0\n if fixed_range:\n cv_fixed_range = (1 << 16)\n\n flags = cv_connect_diag | cv_mask_only | cv_mask_fillval | cv_fixed_range\n\n c_cvFloodFill(&srcimg, cv_seed_point, cv_new_val, cv_low_diff, cv_high_diff,\n NULL, flags, maskimgptr)\n\n return None\n\n\n#----------------\n# cvMatchTemplate\n#----------------\n\n@cvdoc(package='cv', group='image', doc=\\\n'''cvMatchTemplate(src, template, method)\n\nCompares a template against overlapped image regions and returns a match array\ndependent on the match method requested.\n\nParameters\n----------\nsrc : ndarray, ndims=[2, 3], dtype=[uint8, float32]\n The source image.\ntemplate : ndarray, ndim=src.ndim, dtype=src.dtype\n The template to match in the source.\nmethod : int\n The method to use for matching.\n One of:\n CV_TM_SQDIFF\n CV_TM_SQDIFF_NORMED\n CV_TM_CCORR\n CV_TM_CCORR_NORMED\n CV_TM_CCOEFF\n CV_TM_CCOEFF_NORMED\n\nReturns\n-------\nout : ndarray, 2d, dtype=float3d\n The results of the template matching.\n The size of this array (H - h + 1) x (W - w + 1)\n where (H, W) is (Height, Width) of src and (h, w) is\n (height, width) of template.\n\nNotes\n-----\nAfter the function finishes the comparison, the best matches can be found\nas global minimums (CV_TM_SQDIFF) or maximums (CV_TM_CCORR and CV_TM_CCOEFF)\nusing the appropriate numpy functions. In the case of a color image,\ntemplate summation in the numerator and each sum in the denominator\nis done over all of the channels (and separate mean values are used for each\nchannel).''')\ndef cvMatchTemplate(np.ndarray src, np.ndarray template, int method):\n\n validate_array(src)\n validate_array(template)\n\n assert_ndims(src, [2, 3])\n assert_dtype(src, [UINT8, FLOAT32])\n\n assert_ndims(template, [src.ndim])\n assert_dtype(template, [src.dtype])\n\n if method not in [CV_TM_SQDIFF_NORMED, CV_TM_CCORR, CV_TM_CCORR_NORMED,\n CV_TM_CCOEFF, CV_TM_CCOEFF_NORMED]:\n raise ValueError('Unknown method type')\n\n if src.shape[0] <= template.shape[0] or src.shape[1] <= template.shape[1]:\n raise ValueError('template must be smaller than source image')\n\n cdef np.npy_intp outshape[2]\n outshape[0] = <np.npy_intp>(src.shape[0] - template.shape[0] + 1)\n outshape[1] = <np.npy_intp>(src.shape[1] - template.shape[1] + 1)\n cdef np.ndarray out = new_array(2, outshape, FLOAT32)\n\n cdef IplImage srcimg\n cdef IplImage templateimg\n cdef IplImage outimg\n\n populate_iplimage(src, &srcimg)\n populate_iplimage(template, &templateimg)\n populate_iplimage(out, &outimg)\n\n c_cvMatchTemplate(&srcimg, &templateimg, &outimg, method)\n\n return out\n"
},
{
"alpha_fraction": 0.7888888716697693,
"alphanum_fraction": 0.7888888716697693,
"avg_line_length": 28.66666603088379,
"blob_id": "d488bf7a731be347b7915bd30b7206187f708010",
"content_id": "91711c6e80c88fcc7b2a8b37f6f11cdd632296bc",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "permissive",
"max_line_length": 36,
"num_lines": 3,
"path": "/scikits/image/transform/__init__.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from hough_transform import *\nfrom finite_radon_transform import *\nfrom project import *\n\n"
},
{
"alpha_fraction": 0.434225857257843,
"alphanum_fraction": 0.4540162980556488,
"avg_line_length": 18.976743698120117,
"blob_id": "d205991619567683286e7778aefcce0ed6b2405d",
"content_id": "7c46eb5ece1be3b794136021eaf986c6d40a9a17",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 859,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 43,
"path": "/scikits/image/filter/c_src/c_median.c",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n\nstatic int\ncomp(void* i,void* j)\n{ \n return ((int)*((unsigned char *)i)-(int)*((unsigned char *)j));\n}\n\nint c_median_iteration(unsigned char* u, int nx, int ny, unsigned char* v, int* s, int ns)\n{\n int changed;\n register int i,x,y,xx,yy,p;\n unsigned char curr[10000];\n long adr;\n int px,py;\n\n changed = 0;\n for (x=0;x<nx;x++)\n {\n for (y=0;y<ny;y++)\n {\n i=0;\n for (p=0;p<ns;p++)\n {\n px = s[p*2+0];\n py = s[p*2+1];\n xx = x+px;\n yy = y+py;\n if( xx>=0 && xx<nx && yy>=0 && yy<ny )\n {\n curr[i++] = u[yy*nx+xx];\n }\n }\n qsort((char *)curr, i, sizeof(char), comp);\n adr = y*nx+x;\n v[adr] = curr[i/2];\n if( v[adr] != u[adr] ) changed++;\n }\n }\n return changed;\n}\n"
},
{
"alpha_fraction": 0.7435897588729858,
"alphanum_fraction": 0.7435897588729858,
"avg_line_length": 18.5,
"blob_id": "c794a6afb950769775fc48b6476d5f8db9eee69e",
"content_id": "65a36d8883e0a478820fd7c5f2a99d99dd5cc4b9",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 2,
"path": "/scikits/image/morphology/__init__.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from grey import *\nfrom selem import *\n"
},
{
"alpha_fraction": 0.40649673342704773,
"alphanum_fraction": 0.4692082107067108,
"avg_line_length": 21.38888931274414,
"blob_id": "de814445dbba518de32efa9c9a6eb4b03435c56b",
"content_id": "8cadc935ea9ccba2e2a6212d197986ffa5b213cd",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 8866,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 396,
"path": "/scikits/image/transform/c_src/c_zoom.c",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <string.h>\n#include <math.h>\n\n/* extract image value (even outside image domain) */\nstatic inline float\nv(float* in, int w, int h, int x, int y, float bg)\n{\n if (x<0 || x>=w || y<0 || y>=h)\n return(bg); else return(in[y*w+x]);\n}\n\n/* c[] = values of interpolation function at ...,t-2,t-1,t,t+1,... */\n\n/* coefficients for cubic interpolant (Keys' function) */\nstatic void\nkeys(float *c, float t, float a)\n{\n float t2,at;\n\n t2 = t*t;\n at = a*t;\n c[0] = a*t2*(1.0-t);\n c[1] = (2.0*a+3.0 - (a+2.0)*t)*t2 - at;\n c[2] = ((a+2.0)*t - a-3.0)*t2 + 1.0;\n c[3] = a*(t-2.0)*t2 + at;\n}\n\n/* coefficients for cubic spline */\nstatic void\nspline3(float *c, float t)\n{\n float tmp;\n\n tmp = 1.-t;\n c[0] = 0.1666666666*t*t*t;\n c[1] = 0.6666666666-0.5*tmp*tmp*(1.+t);\n c[2] = 0.6666666666-0.5*t*t*(2.-t);\n c[3] = 0.1666666666*tmp*tmp*tmp;\n}\n\nstatic double\ninitcausal(double *c, int n, double z)\n{\n double zk,z2k,iz,sum;\n int k;\n\n zk = z; iz = 1./z;\n z2k = pow(z,(double)n-1.);\n sum = c[0] + z2k * c[n-1];\n z2k = z2k*z2k*iz;\n for (k=1;k<=n-2;k++) {\n sum += (zk+z2k)*c[k];\n zk *= z;\n z2k *= iz;\n }\n return (sum/(1.-zk*zk));\n}\n\nstatic double\ninitanticausal(double *c, int n, double z)\n{\n return((z/(z*z-1.))*(z*c[n-2]+c[n-1]));\n}\n\nstatic void\ninvspline1D(double *c, int size, double *z, int npoles)\n{\n double lambda;\n int n,k;\n\n /* normalization */\n for (k=npoles,lambda=1.;k--;) lambda *= (1.-z[k])*(1.-1./z[k]);\n for (n=size;n--;) c[n] *= lambda;\n\n /*----- Loop on poles -----*/\n for (k=0;k<npoles;k++) {\n\n /* forward recursion */\n c[0] = initcausal(c,size,z[k]);\n for (n=1;n<size;n++) \n c[n] += z[k]*c[n-1];\n\n /* backwards recursion */\n c[size-1] = initanticausal(c,size,z[k]);\n for (n=size-1;n--;) \n c[n] = z[k]*(c[n+1]-c[n]);\n \n }\n}\n\nstatic int\nfinvspline(float *in, int nx, int ny, int order, float *out)\n{\n double *c,*d,z[5];\n int npoles,x,y;\n \n /* initialize poles of associated z-filter */\n switch (order) \n {\n case 2: z[0]=-0.17157288; /* sqrt(8)-3 */\n break;\n\n case 3: z[0]=-0.26794919; /* sqrt(3)-2 */ \n break;\n\n case 4: z[0]=-0.361341; z[1]=-0.0137254;\n break;\n\n case 5: z[0]=-0.430575; z[1]=-0.0430963;\n break;\n \n case 6: z[0]=-0.488295; z[1]=-0.0816793; z[2]=-0.00141415;\n break;\n\n case 7: z[0]=-0.53528; z[1]=-0.122555; z[2]=-0.00914869;\n break;\n \n case 8: z[0]=-0.574687; z[1]=-0.163035; z[2]=-0.0236323; z[3]=-0.000153821;\n break;\n\n case 9: z[0]=-0.607997; z[1]=-0.201751; z[2]=-0.0432226; z[3]=-0.00212131;\n break;\n \n case 10: z[0]=-0.636551; z[1]=-0.238183; z[2]=-0.065727; z[3]=-0.00752819;\n z[4]=-0.0000169828;\n break;\n \n case 11: z[0]=-0.661266; z[1]=-0.27218; z[2]=-0.0897596; z[3]=-0.0166696; \n z[4]=-0.000510558;\n break;\n \n default:\n /* mwerror(FATAL,1,\"finvspline: order should be in 2..11.\\n\"); */\n return -1;\n }\n npoles = order/2;\n\n /* initialize double array containing image */\n c = (double *)malloc(nx*ny*sizeof(double));\n d = (double *)malloc(nx*ny*sizeof(double));\n for (x=nx*ny;x--;) \n c[x] = (double)in[x];\n\n /* apply filter on lines */\n for (y=0;y<ny;y++) \n invspline1D(c+y*nx,nx,z,npoles);\n\n /* transpose */\n for (x=0;x<nx;x++)\n for (y=0;y<ny;y++) \n d[x*ny+y] = c[y*nx+x];\n \n /* apply filter on columns */\n for (x=0;x<nx;x++) \n invspline1D(d+x*ny,ny,z,npoles);\n\n /* transpose directy into image */\n for (x=0;x<nx;x++)\n for (y=0;y<ny;y++) \n out[y*nx+x] = (float)(d[x*ny+y]);\n\n /* free array */\n free(d);\n free(c);\n\n return 0;\n}\n\n/* pre-computation for spline of order >3 */\nstatic void\ninit_splinen(float *a, int n)\n{\n int k;\n\n a[0] = 1.;\n for (k=2;k<=n;k++) a[0]/=(float)k;\n for (k=1;k<=n+1;k++)\n a[k] = - a[k-1] *(float)(n+2-k)/(float)k;\n}\n\n/* fast integral power function */\nstatic inline float\nipow(float x, int n)\n{\n float res;\n\n for (res=1.;n;n>>=1) {\n if (n&1) res*=x;\n x*=x;\n }\n return(res);\n}\n\n/* coefficients for spline of order >3 */\nstatic void\nsplinen(float *c, float t, float *a, int n)\n{\n int i,k;\n float xn;\n \n memset((void *)c,0,(n+1)*sizeof(float));\n for (k=0;k<=n+1;k++) { \n xn = ipow(t+(float)k,n);\n for (i=k;i<=n;i++) \n c[i] += a[i-k]*xn;\n }\n}\n\nstatic int\n_c_zoom(\n float *in, /* Input image */\n int nx, int ny, /* Size of the input image */\n float fx, float fy, /* Coordinates (in the input image) of the sample\n corresponding to the first pixel in the output image */\n float *out, /* Output image */\n int wx, int wy, /* Size of the output image */\n float z, /* Desired zoom */\n float bgcolor, /* Background color */\n int o /* Zoom order */\n)\n{\n int n1,n2,x,y,xi,yi,d;\n float zx,zy,res,xp,yp,u,c[12],ak[13];\n float *ref,*tmp,*coeffs;\n\n if( fabs(z) < 1E-4 ) return -1;\n\n /* We only want homogeneous zooms (for now) */\n zx = z;\n zy = z;\n\n /* Keys parameter for the bicubic zoom, can be in [-1.0, 0.0] */\n float p = -0.5;\n\n /* CHECK ORDER */\n if (o!=0 && o!=1 && o!=-3 && o!=3 && o!=5 && o!=7 && o!=9 && o!=11)\n return -1;\n if (wx<0 || wy<0)\n return -1;\n\n if (o>=3) {\n coeffs = (float*)calloc(nx*ny, sizeof(float));\n if( coeffs == NULL )\n return 1;\n finvspline(in,nx,ny,o,coeffs);\n ref = coeffs;\n if (o>3) init_splinen(ak,o);\n }\n else {\n coeffs = NULL;\n ref = in;\n }\n\n tmp = (float*)calloc(ny*wx, sizeof(float));\n if( tmp == NULL )\n return 1;\n\n /********** FIRST LOOP (x) **********/\n \n for (x=0;x<wx;x++)\n {\n xp = fx+( (float)x + 0.5 )/zx;\n\n if (o==0)\n { /* zero order interpolation (pixel replication) */\n xi = (int)floor((double)xp); \n if (xi<0 || xi>=nx)\n {\n for (y=0;y<ny;y++) tmp[y*wx+x] = bgcolor; \n }\n else\n {\n for (y=0;y<ny;y++) tmp[y*wx+x] = ref[y*nx+xi];\n }\n }\n else { /* higher order interpolations */\n if (xp<0. || xp>(float)nx) \n {\n for (y=0;y<ny;y++) tmp[y*wx+x] = bgcolor; \n }\n else\n {\n xp -= 0.5;\n xi = (int)floor((double)xp); \n u = xp-(float)xi;\n switch (o) \n {\n case 1: /* first order interpolation (bilinear) */\n n2 = 1; c[0]=u; c[1]=1.-u; break;\n \n case -3: /* third order interpolation (bicubic Keys' function) */\n n2 = 2; keys(c,u,p); break;\n \n case 3: /* spline of order 3 */\n n2 = 2; spline3(c,u); break;\n \n default: /* spline of order >3 */\n n2 = (1+o)/2; splinen(c,u,ak,o); break;\n }\n\n n1 = 1-n2;\n /* this test saves computation time */\n if (xi+n1>=0 && xi+n2<nx) {\n for (y=0;y<ny;y++) {\n for (d=n1,res=0.;d<=n2;d++) \n res += c[n2-d]*ref[y*nx+xi+d];\n tmp[y*wx+x] = res;\n }\n }\n else \n {\n for (y=0;y<ny;y++) {\n for (d=n1,res=0.;d<=n2;d++) \n res += c[n2-d]*v(ref,nx,ny,xi+d,y,bgcolor);\n tmp[y*wx+x] = res;\n }\n }\n }\n }\n }\n \n ref = tmp;\n\n /********** SECOND LOOP (y) **********/\n \n for (y=0;y<wy;y++)\n {\n\n yp = fy+( (float)y + 0.5 )/zy;\n\n if (o==0)\n { /* zero order interpolation (pixel replication) */\n yi = (int)floor((double)yp); \n if (yi<0 || yi>=ny)\n {\n for (x=0;x<wx;x++) out[y*wx+x] = bgcolor; \n }\n for (x=0;x<wx;x++) out[y*wx+x] = ref[yi*wx+x];\n }\n else\n { /* higher order interpolations */\n if (yp<0. || yp>(float)ny) \n {\n for (x=0;x<wx;x++) out[y*wx+x] = bgcolor; \n }\n else\n {\n yp -= 0.5;\n yi = (int)floor((double)yp); \n u = yp-(float)yi;\n switch (o) \n {\n case 1: /* first order interpolation (bilinear) */\n n2 = 1; c[0]=u; c[1]=1.-u; break;\n \n case -3: /* third order interpolation (bicubic Keys' function) */\n n2 = 2; keys(c,u,p); break;\n \n case 3: /* spline of order 3 */\n n2 = 2; spline3(c,u); break;\n \n default: /* spline of order >3 */\n n2 = (1+o)/2; splinen(c,u,ak,o); break;\n }\n \n n1 = 1-n2;\n /* this test saves computation time */\n if (yi+n1>=0 && yi+n2<ny)\n {\n for (x=0;x<wx;x++)\n {\n for (d=n1,res=0.;d<=n2;d++) \n res += c[n2-d]*ref[(yi+d)*wx+x];\n out[y*wx+x] = res;\n }\n }\n else\n {\n for (x=0;x<wx;x++)\n {\n for (d=n1,res=0.;d<=n2;d++) \n res += c[n2-d]*v(ref,wx,ny,x,yi+d,bgcolor);\n out[y*wx+x] = res;\n }\n }\n }\n }\n }\n\n free(tmp);\n if (coeffs) free(coeffs);\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.5297536849975586,
"alphanum_fraction": 0.5399637222290039,
"avg_line_length": 34.89072799682617,
"blob_id": "6b3ca65d817745c7237b1da33c5081bc481fd9dd",
"content_id": "aa77a3a56602c56635457c15c167ab925a11e84f",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 32517,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 906,
"path": "/scikits/image/io/_plugins/scivi2.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n# encoding: utf-8\n\nfrom PyQt4.QtGui import *\nfrom PyQt4.QtCore import *\nimport sip\n\nimport numpy as np\n\nfrom scikits.image.transform import zoom\nfrom scikits.image.io._plugins import _scivi2_utils as utils\n\n# TODO\n# HIGH PRIORITY\n# - force translations to be an integer number*zoom, thus we do not have subpixel\n# translations when zooming in or out (this can be annoying when zooming out, often\n# we will zoom back to 1.0X with a +0.5 translation)\n# - we should have fit zoom\n# - multicore if available (use _plugins.util)\n# - ctrl++/- should zoom in/out and resize the window to fit the image (if it is\n# smaller than the screen)\n# - the application should have an F10 shortcut to display zoom/histo/etc controls\n# additional widgets:\n# - choose zoom (eg. Nearest, Bilinear etc)\n# - choose level-lines display parameters\n# - show histograms\n# - save image to stack/file\n# - a panning widget that display the currently viewed area of the complete\n# image (eg. a grey widget that \"represents the complete image\", and a red\n# rectangle inside that displays the currently displayed part of the image)\n# - closing main window / pressing Q should close all windows (even when the\n# controls window is displayed)\n# - if it is too complicated to have a correct widget resizing when displaying the\n# controls we might also display a popup window with the controls\n#\n# LOW PRIORITY\n# - find some better way to tell the ImageRenderer to reset its state when\n# the rendering changes (we change the zoom, the rendering of level-lines, etc)\n# rather than setting image_renderer.state = None\n# - check that the subimages that we extract before we zoom are the minimal\n# subimages that should be extracted for each zoom\n# - reduce copying of image by using the ndarray C interface directly in the\n# zoom code (eg. we don't necessarily have to ensure the image is contiguous)\n# - we should have rectangle zoom (eg. ctrl+click makes it possible to define a\n# rectangle, and the zoom/panning is computed to fit this rectangle in the view)\n# - the application should have an F11 shortcut to display a python interpreter\n# with numpy and scikits.image already loaded\n# - we should perhaps cache the zoomed image that was last rendered, if we want to\n# have fast color rescaling (eg. change hue/contrast, but do not recompute zoom\n# each time)\n# - allow non-uniform zoom (this is easy, we only have to add a zoom_x and zoom_y\n# parameter in the C code, those values are already used inside the code for\n# zooming, we should adapt all python code with scale_x and scale_y rather than\n# scale, but it isn't obvious whether this will really have an use)\n\n# Suggested application design\n#\n# ImageViewer: the control that acts on the view, handles \n# - it should have viewChanged etc signals\n# BasicImageViewer: handles mouse for basic operations (zoom in, zoom out, 1:1,\n# zoom fit, fit rectangle in view), and keys if requested (+, - and directions etc)\n# Application: has some controls that can interact with the ImageViewer\n# - key press can have an action on the ImageViewer, etc\n# - handles flip, etc\n# - histograms, color modes, levels etc\n# - Extending the Viewer should be very easy (either include it in a QGraphicsView,\n# or have some way to easily extend it to permit to input points, etc)\n\n# FEATURES:\n# - any amount of zoom, any subpixel translation (WARNING: when checking if\n# the scale of the zoom is 1.0, as well as when checking for integer\n# translations at a certain scale, we have a floating-point comparison at\n# precision ImageRenderer.EPS, and therefore the zoom/translation has a precision,\n# which should be way below what we request in practice, so this should not be\n# an issue)\n# - only recompute the parts of the images that change\n# - when the image is rendered at scale 1.0 with an integer translation,\n# we do not do any zoom computation\n# - gray/color images\n# - integer/real images\n# - image flip\n# - level lines (one level, several lines, upper/lower sets, range)\n# - configurable ImageRenderer\n\n################################################################################\n# Zoom classes\n################################################################################\n\n# Utility function for zoom windows\ndef _extract_subwindow_with_border(im, x, y, w, h, scale, border=1):\n # If we need p border pixels, we should have the subimage\n # [ ceil(x)-p, floor(x+(w-1)/scale)+p ]\n x1 = max(0, np.ceil(x)-border)\n y1 = max(0, np.ceil(y)-border)\n x2 = min(im.shape[1]-1.0, np.floor(x+(w-1)/scale)+border)\n y2 = min(im.shape[0]-1.0, np.floor(y+(h-1)/scale)+border)\n return (im[y1:y2+1,x1:x2+1], x-x1, y-y1)\n\nclass NearestZoom(object):\n def __str__(self):\n return \"NearestZoom\"\n\n def subwindow(self, im, x, y, w, h, scale):\n \"\"\"\n Extract the minimal subwindow of im required to compute the\n requested (x, y, w, h, scale) zoom\n \"\"\"\n x1 = max(0, np.ceil(x-0.5)-1)\n y1 = max(0, np.ceil(y-0.5)-1)\n x2 = min(im.shape[1]-1.0, np.ceil(x+(w-1)/scale-0.5)+1)\n y2 = min(im.shape[0]-1.0, np.ceil(y+(h-1)/scale-0.5)+1)\n return (im[y1:y2+1,x1:x2+1], x-x1, y-y1)\n\n def render(self, im, x, y, w, h, scale, bgcolor):\n \"\"\"\n Parameters\n ----------\n im: float32 grey image\n x, y: initial point\n w, h: size of zoomed output\n scale: zoom factor\n\n Output\n ------\n out: zoomed image\n \"\"\"\n return zoom.fzoom(im, zoom.Zoom.NEAREST, x, y, w, h, scale, bgcolor)\n\nclass BilinearZoom(object):\n def __str__(self):\n return \"BilinearZoom\"\n\n def subwindow(self, im, x, y, w, h, scale):\n \"\"\"\n Extract the minimal subwindow of im required to compute the\n requested (x, y, w, h, scale) zoom\n \"\"\"\n return _extract_subwindow_with_border(im, x, y, w, h, scale, 2)\n\n def render(self, im, x, y, w, h, scale, bgcolor):\n \"\"\"\n Parameters\n ----------\n im: float32 grey image\n x, y: initial point\n w, h: size of zoomed output\n scale: zoom factor\n\n Output\n ------\n out: zoomed image\n \"\"\"\n return zoom.fzoom(im, zoom.Zoom.BILINEAR, x, y, w, h, scale, bgcolor)\n\nclass BicubicZoom(object):\n def __str__(self):\n return \"CubicZoom\"\n\n def subwindow(self, im, x, y, w, h, scale):\n \"\"\"\n Extract the minimal subwindow of im required to compute the\n requested (x, y, w, h, scale) zoom\n \"\"\"\n return _extract_subwindow_with_border(im, x, y, w, h, scale, 3)\n\n def render(self, im, x, y, w, h, scale, bgcolor):\n \"\"\"\n Parameters\n ----------\n im: float32 grey image\n x, y: initial point\n w, h: size of zoomed output\n scale: zoom factor\n\n Output\n ------\n out: zoomed image\n \"\"\"\n return zoom.fzoom(im, zoom.Zoom.BICUBIC, x, y, w, h, scale, bgcolor)\n\nclass SplineZoom(object):\n def __init__(self, order=3):\n assert order in [3,5,7,9,11]\n self.order = order\n\n def __str__(self):\n return \"SplineZoom(\"+str(self.order)+\")\"\n\n def subwindow(self, im, x, y, w, h, scale):\n \"\"\"\n Extract the minimal subwindow of im required to compute the\n requested (x, y, w, h, scale) zoom\n \"\"\"\n return _extract_subwindow_with_border(im, x, y, w, h, scale, (1+self.order)/2+1)\n\n def render(self, im, x, y, w, h, scale, bgcolor):\n \"\"\"\n Parameters\n ----------\n im: float32 grey image\n x, y: initial point\n w, h: size of zoomed output\n scale: zoom factor\n\n Output\n ------\n out: zoomed image\n \"\"\"\n return zoom.fzoom(im, self.order, x, y, w, h, scale, bgcolor)\n\n################################################################################\n# ImageRenderer\n################################################################################\n\n# Utility function that converts an image to float32 when required\ndef _ensures_float32(im):\n if not np.issubdtype(im.dtype, np.float32):\n return im.astype(np.float32)\n else:\n return im\n\nclass ImageRenderer(object):\n \"\"\"\n Renders a subimage at any floating-point position and zoom scale.\n This is very efficient (uses caching to avoid complete recomputations).\n It is extensible, and you can register postprocessing functions that act on the\n part of the original image that you want to render -- for instance to change\n the gray value scales, processing functions that act on the zoomed subimage\n as a floating-point image and postprocessing functions that act on the zoomed\n subimage after it has been rescaled as a char image. These processing functions\n can request to work on a wider subimage than the one originally requested, when\n processing computations need an \"image border\".\n \"\"\"\n EPS = 1e-5 # precision for floating-point computations for the point coordinates\n\n def __init__(self, zoom=NearestZoom()):\n # Image\n self.planes = None # Image planes, either 1 (gray) or 3 (r, g, b) elements\n self.width, self.height = 0, 0 # Image size\n\n # Caching\n self.state = None # Last requested view\n self.cache = None # Last subimage rendering\n\n self.zoom = zoom # Zoom to use\n\n self.rescale = None # Rescale images\n # TODO\n # Not used right now, should enable to set the desired range\n # to display (particularly for float images)\n\n self.show_level_lines = False # Display level-lines\n\n def set_image(self, image, rescale=None):\n if image is None:\n self.planes = None\n self.width = self.height = 0\n else:\n if image.ndim == 2:\n self.planes = [_ensures_float32(image)]\n elif image.ndim == 3:\n if image.shape[2] == 1:\n self.planes = [_ensures_float32(image[:,:,0])]\n elif image.shape[2] == 3 or image.shape[2] == 4:\n imageR = _ensures_float32(image[:,:,0])\n imageG = _ensures_float32(image[:,:,1])\n imageB = _ensures_float32(image[:,:,2])\n self.planes = [imageR, imageG, imageB]\n else:\n raise ValueError('Invalid number of planes')\n else:\n raise ValueError('The image must be either a 2D or 3D array')\n\n self.height, self.width = image.shape[0], image.shape[1]\n self.rescale = rescale\n def set_zoom(self, zoom):\n self.zoom = zoom\n def set_rescale(self, rescale):\n self.rescale = rescale\n\n def render(self, x, y, w, h, scale=1.0, bgcolor=0.0):\n \"\"\"\n Parameters\n ----------\n x, y: float\n position (in the first image) of the sample corresponding to the\n zoomed image first pixel\n w, h: int\n size of the output zoomed image\n scale: float\n value of the zoom (1.0: no zooming)\n bgcolor: float\n gray value of the background, when interpolating around the border\n\n Output\n ------\n out: QPixmap\n the zoomed and cropped image\n \"\"\"\n def render_all():\n self.state = (x, y, w, h, scale, bgcolor)\n self.cache = self._force_render(x, y, w, h, scale, bgcolor)\n return self.cache\n\n if self.state is None or self.cache is None:\n return render_all()\n\n if self.planes is None or w == 0 or h == 0:\n return render_all()\n\n px, py, pw, ph, pscale, pbgcolor = self.state\n if pscale != scale or pbgcolor != bgcolor:\n return render_all()\n\n if self.state == (x, y, w, h, scale, bgcolor):\n return self.cache\n\n self.state = (x, y, w, h, scale, bgcolor)\n\n # Is the translation (px,py) -> (x,y) an integer amount of the current\n # scale?\n dx = (x-px)*scale\n dy = (y-py)*scale\n if abs(dx-np.rint(dx)) < self.EPS and abs(dy-np.rint(dy)) < self.EPS:\n # convert the floating coords to integer coords\n # we set the origin at (px, py) (ie. i_px = 0, i_py = 0)\n i_px, i_py = 0, 0\n i_x, i_y = int(np.rint(dx)), int(np.rint(dy))\n\n prev = utils.IntBox(i_px, i_py, pw, ph)\n next = utils.IntBox(i_x, i_y, w, h)\n\n intersection = next.intersection(prev)\n\n if intersection.is_empty():\n return render_all()\n else:\n difference_list = next.difference(prev)\n\n # TODO\n #\n # if the common part is really small compared to the whole area\n # to render, perhaps it is more efficient to render the whole picture\n # rather than rendering parts, and the copying\n #\n # eg.\n # if intersection.area()/next.area() < thresh:\n # return render_all()\n # or\n # if intersection.area() < thresh:\n # return render_all()\n\n out = np.empty((h,w,3), dtype=np.uint8)\n\n a, b, s, t = intersection.coords() # in cache coords\n c, d = a-i_x, b-i_y # in out coords\n out[d:d+t, c:c+s, :] = self.cache[b:b+t, a:a+s, :]\n\n for diff in difference_list:\n a, b, s, t = diff.coords() # in cache coords\n c, d = a-i_x, b-i_y # in out coords\n fx = px + float(a)/scale\n fy = py + float(b)/scale\n A = self._force_render(fx, fy, s, t, scale, bgcolor)\n out[d:d+t, c:c+s, :] = A\n\n self.cache = out\n return out\n\n else:\n print \"px=\", px, \"x=\", x, \"dx=\", dx\n print \"py=\", py, \"y=\", y, \"dy=\", dy\n print \"[WARNING] not an integer translation, force rendering!\"\n\n return render_all()\n\n def _force_render(self, x, y, w, h, scale, bgcolor=0):\n\n # Since level_lines can not be computed on last line and col, we should\n # request one line and col more (filled with background color if out of\n # the image)\n if self.show_level_lines:\n w = w+1\n h = h+1\n\n if self.planes is None or w == 0 or h == 0:\n return np.empty((0,0))\n else:\n zoomed_planes = []\n if abs(scale-1.0) < self.EPS and \\\n abs(x-np.rint(x)) < self.EPS and abs(y - np.rint(y)) < self.EPS:\n # integer translation of scale 1.0, we can immediately crop\n # and copy the image planes\n i_x = int(np.rint(x))\n i_y = int(np.rint(y))\n # Compute the intersection between the original image at\n # (0, 0) of size (self.width, self.height) and the desired\n # subimage at (i_x, i_y) of size (w, h)\n i_px, i_py = 0, 0\n pw, ph = self.width, self.height\n prev = utils.IntBox(i_px, i_py, pw, ph)\n next = utils.IntBox(i_x, i_y, w, h)\n\n intersection = next.intersection(prev)\n if intersection.is_empty():\n # empty intersection\n for plane in self.planes:\n new_plane = np.ones((h,w), dtype=np.float32)*bgcolor\n zoomed_planes.append(new_plane)\n else:\n # non-empty intersection\n # dimension of the intersecting rectangle\n a, b, cw, ch = intersection.coords()\n x0, y0 = a-i_x, b-i_y # in new_plane coords\n for plane in self.planes:\n new_plane = np.ones((h,w), dtype=np.float32)*bgcolor\n new_plane[y0:y0+ch, x0:x0+cw] = \\\n plane[b:b+ch, a:a+cw]\n zoomed_planes.append(new_plane)\n else:\n for plane in self.planes:\n # non-integer translation, or scale != 1.0\n im, new_x, new_y = \\\n self.zoom.subwindow(plane, x, y, w, h, scale)\n # If required: preprocess im\n im_zoom = self.zoom.render(im, new_x, new_y, w, h, scale, bgcolor)\n zoomed_planes.append(im_zoom)\n\n res = self.process(zoomed_planes)\n assert len(res) == 1 or len(res) == 3\n\n # Show level-lines and remove extra col\n if self.show_level_lines:\n res = self._display_level_lines(zoomed_planes)\n h = h-1\n w = w-1\n for i in xrange(len(res)):\n res[i] = res[i][0:h, 0:w]\n\n # Clip results, avoiding duplicates of the channels\n for i, im in enumerate(res):\n for j in xrange(i):\n if res[i] is res[j]:\n break\n else:\n # If we haven't processed res[i] before\n res[i] = im.clip(0,255).astype(np.uint8)\n\n if len(res) == 1:\n im=res[0]\n res = [im, im, im]\n\n out = np.empty((h, w, 3), dtype=np.uint8)\n out[:,:,0] = res[0]\n out[:,:,1] = res[1]\n out[:,:,2] = res[2]\n\n return out\n\n def process(self, planes):\n return planes\n\n def _display_level_lines(self, planes):\n if len(planes) == 1:\n if self.show_level_lines:\n im = planes[0]\n level_lines = utils._extract_level_lines(im,ofs=0.0,step=27.0,mode=1)\n imR = im\n imG = im.copy()\n imB = im.copy()\n imR[level_lines]=255.0\n imG[level_lines]=0.0\n imB[level_lines]=0.0\n return [imR, imG, imB]\n else:\n return planes\n #return list(planes)\n elif len(planes) == 3:\n if self.show_level_lines:\n im = (planes[0]+planes[1]+planes[2])/3.0\n level_lines = utils._extract_level_lines(im,ofs=0.0,step=27.0,mode=1)\n planes[0][level_lines]=255.0\n planes[1][level_lines]=0.0\n planes[2][level_lines]=0.0\n return planes\n else:\n return planes\n else:\n raise ValueError(\"Either one or three arguments\")\n\n def reinit_state(self):\n self.state = None\n self.cache = None\n\n################################################################################\n# ImageViewer\n################################################################################\n\nclass ImageViewer(QWidget):\n \"\"\"\n Simple image viewer widget, that uses an ImageRenderer to display its state\n \"\"\"\n def __init__(self, parent=None):\n super(ImageViewer, self).__init__(parent)\n self.setBackgroundColor(QPalette.Window)\n self.setForegroundColor(QPalette.Text)\n self.image_renderer = None\n self.pan_x, self.pan_y = 0.0, 0.0\n self.scale = 1.0\n self.dirty = True\n self.pixmap = None\n\n def setBackgroundColor(self, color):\n self.background_color = color\n self.background_brush = QBrush(self.background_color)\n def setForegroundColor(self, color):\n self.foreground_color = color\n self.foreground_pen = QPen(self.foreground_color)\n def setImageRenderer(self, image_renderer):\n self.image_renderer = image_renderer\n\n def _image_coords_to_widget_coords(self, ix, iy):\n return (int((self.pan_x+ix)*self.scale+0.5), int((self.pan_y+iy)*self.scale+0.5))\n def _widget_coords_to_image_coords(self, wx, wy):\n return (float(wx)/self.scale-self.pan_x, float(wy)/self.scale-self.pan_y)\n\n # This function computes the top-left pixel of the image to draw, as well as\n # the rectangle to render\n def _get_image_representation_coordinates(self):\n image_renderer = self.image_renderer\n im_w, im_h = image_renderer.width, image_renderer.height\n pan_x, pan_y = self.pan_x, self.pan_y\n scale = self.scale\n # Upper-left coords of the image to show, in image coords\n x = max(-pan_x, 0.0)\n y = max(-pan_y, 0.0)\n # In widget coords\n wx = int(max(pan_x*scale, 0.0))\n wy = int(max(pan_y*scale, 0.0))\n # Part of the image that is displayed\n ex = min(self.width(), int((pan_x+im_w)*scale))\n ey = min(self.height(), int((pan_y+im_h)*scale))\n w = max(ex - wx, 0)\n h = max(ey - wy, 0)\n return (x, y, wx, wy, w, h)\n\n def resizeEvent(self, event):\n self.dirty = True\n self.repaint()\n\n def paintEvent(self, event):\n painter = QPainter()\n painter.begin(self)\n painter.setClipRect(event.rect())\n\n # Background\n painter.setPen(self.foreground_pen)\n painter.setBrush(self.background_brush)\n painter.drawRect(self.rect().adjusted(0,0,-1,-1))\n\n # Image\n w, h = self.width(), self.height()\n\n if self.image_renderer is None:\n painter.setPen(self.foreground_pen)\n painter.drawLine(QPoint(0, 0), QPoint(w, h))\n painter.drawLine(QPoint(w, 0), QPoint(0, h))\n else:\n image_renderer = self.image_renderer\n im_w, im_h = image_renderer.width, image_renderer.height\n pan_x, pan_y = self.pan_x, self.pan_y\n scale = self.scale\n\n x, y, wx, wy, w, h = self._get_image_representation_coordinates()\n if self.dirty or self.pixmap is None:\n out = image_renderer.render(x, y, w, h, self.scale)\n self.pixmap = utils._to_pixmap(out)\n self.dirty = False\n\n if w > 0 and h > 0:\n painter.setPen(QPen(Qt.red))\n painter.setBrush(Qt.NoBrush)\n painter.drawRect(wx, wy, w-1, h-1)\n painter.drawPixmap(QPoint(wx, wy), self.pixmap)\n\n painter.end()\n\n def sizeHint(self):\n if self.image_renderer is not None:\n i = self.image_renderer\n width, height = i.width, i.height\n return QSize(width, height)\n else:\n return QSize(100, 100)\n\n################################################################################\n# MouseImageViewer\n################################################################################\n\nclass MouseImageViewer(ImageViewer):\n \"\"\"\n This superclass of ImageViewer handles mouse clicks if required\n \"\"\"\n def mousePressEvent(self, event):\n wx, wy = event.x(), event.y()\n btn = event.button()\n\n ix, iy = self._widget_coords_to_image_coords(wx, wy)\n print \"You clicked on image position ({0:.3g}, {0:.3g})\".format(ix, iy)\n\n if btn == Qt.LeftButton or btn == Qt.RightButton:\n dx = self.pan_x - wx/self.scale\n dy = self.pan_y - wy/self.scale\n if btn == Qt.LeftButton:\n self.scale *= 2.0\n elif btn == Qt.RightButton:\n self.scale /= 2.0\n self.pan_x = dx + wx/self.scale\n self.pan_y = dy + wy/self.scale\n # TODO\n # should signal pan/zoom change\n # eg. emit self.viewChanged(...)\n self.dirty = True\n self.repaint()\n\n################################################################################\n# Controls\n################################################################################\n\nclass ControlWindow(QWidget):\n def __init__(self, controls, parent=None):\n super(ControlWindow, self).__init__(parent)\n self.controls = controls\n\n self.zooms = {\n \"Nearest\": NearestZoom(),\n \"Bilinear\": BilinearZoom(),\n \"Bicubic\": BicubicZoom(),\n }\n for order in [3,5,7,9,11]:\n self.zooms[\"Spline \"+str(order)] = SplineZoom(order)\n\n layout = QVBoxLayout()\n comboZoom = QComboBox()\n\n ordered_zooms = [\"Nearest\", \"Bilinear\", \"Bicubic\"]\n for order in [3,5,7,9,11]:\n ordered_zooms.append(\"Spline \"+str(order))\n comboZoom.addItems(QStringList(ordered_zooms))\n comboZoom.currentIndexChanged[str].connect(self.set_zoom)\n _layout = QHBoxLayout()\n _layout.addWidget(QLabel(\"Zoom:\"))\n _layout.addWidget(comboZoom)\n _widget = QWidget()\n _widget.setLayout(_layout)\n layout.addWidget(_widget)\n\n self.setLayout(layout)\n\n def set_zoom(self, str_zoom):\n zoom = self.zooms[str(str_zoom)]\n self.controls.set_zoom(zoom)\n\n def keyPressEvent(self, event):\n c = event.key()\n if c == Qt.Key_F10:\n self.hide()\n\nclass Controls(QWidget):\n \"\"\"\n Widget that has a viewer, handle some keyboard actions, and is able to\n flip between two images\n \"\"\"\n def __init__(self, parent=None):\n super(Controls, self).__init__(parent)\n self.viewer = None\n self.flip = None\n\n #self.layout_mode = \"image\"\n\n self.control_window = ControlWindow(self)\n\n def setViewer(self, viewer):\n self.viewer = viewer\n #self.setLayoutMode(self.layout_mode)\n layout = QVBoxLayout()\n layout.addWidget(self.viewer)\n self.setLayout(layout)\n\n def setImageRenderer(self, image_renderer, flip=None):\n if self.viewer is not None:\n self.viewer.setImageRenderer(image_renderer)\n self.flip = flip\n\n def showControlWindow(self):\n self.control_window.show()\n\n def toggleControlWindow(self):\n if self.control_window.isVisible():\n self.control_window.hide()\n else:\n self.control_window.show()\n\n def set_zoom(self, zoom):\n viewer = self.viewer\n print str(zoom)\n viewer.image_renderer.zoom = zoom\n viewer.image_renderer.state = None\n if self.flip:\n self.flip.zoom = self.zooms[0]\n self.flip.state = None\n viewer.dirty = True\n viewer.repaint()\n\n def _is_view_fitting(self):\n if self.viewer is not None:\n viewer = self.viewer\n ir = viewer.image_renderer\n if ir is not None:\n w, h = ir.width, ir.height\n scale = viewer.scale\n real_width = int(np.ceil(w*scale))\n real_height = int(np.ceil(h*scale))\n return real_width <= viewer.width() and real_height <= viewer.height()\n else:\n return False\n else:\n return False\n def _fit_view(self):\n if self.viewer is not None:\n viewer = self.viewer\n ir = viewer.image_renderer\n if ir is not None:\n w, h = ir.width, ir.height\n scale = viewer.scale\n real_width = int(np.ceil(w*scale))\n real_height = int(np.ceil(h*scale))\n widget_width = viewer.width()\n widget_height = viewer.height()\n if real_width <= widget_width:\n viewer.pan_x = (widget_width-real_width)/scale/2\n if real_height <= widget_height:\n viewer.pan_y = (widget_height-real_height)/scale/2\n\n def resizeEvent(self, event):\n viewer = self.viewer\n self._fit_view()\n viewer.dirty = True\n\n def pan(self, dx=0.0, dy=0.0):\n viewer = self.viewer\n viewer.pan_x += dx\n viewer.pan_y += dy\n self._fit_view()\n viewer.dirty = True\n\n def zoom(self, scale):\n viewer = self.viewer\n viewer.scale = scale\n self._fit_view()\n viewer.dirty = True\n\n def zoom_fit(self):\n # self.zoom_rect(image_rect())\n pass\n def zoom_rect(self, rect):\n pass\n\n def keyPressEvent(self, event):\n viewer = self.viewer\n\n c = event.key()\n if c == Qt.Key_Left:\n self.pan(dx=50.0/viewer.scale)\n viewer.repaint()\n elif c == Qt.Key_Right:\n self.pan(dx=-50.0/viewer.scale)\n viewer.repaint()\n elif c == Qt.Key_Up:\n self.pan(dy=50.0/viewer.scale)\n viewer.repaint()\n elif c == Qt.Key_Down:\n self.pan(dy=-50.0/viewer.scale)\n viewer.repaint()\n elif c == Qt.Key_Plus:\n self.zoom(viewer.scale*2.0)\n viewer.repaint()\n elif c == Qt.Key_Minus:\n self.zoom(viewer.scale/2.0)\n viewer.repaint()\n elif c == Qt.Key_Space:\n # Flip images\n if self.flip is not None:\n image_renderer = self.flip\n self.flip = viewer.image_renderer\n viewer.setImageRenderer(image_renderer)\n viewer.dirty = True\n viewer.repaint()\n elif c == Qt.Key_F:\n # Force redraw\n viewer.image_renderer.state = None\n viewer.dirty = True\n viewer.repaint()\n elif c == Qt.Key_L:\n # Show level-lines\n # TODO\n # parameters for level-lines should be in extra controls accessible\n # with F10\n viewer.image_renderer.show_level_lines = not viewer.image_renderer.show_level_lines\n viewer.image_renderer.state = None\n if self.flip:\n self.flip.show_level_lines = not self.flip.show_level_lines\n self.flip.state = None\n viewer.dirty = True\n viewer.repaint()\n elif c == Qt.Key_0:\n # Reinit zoom\n self.zoom(1.0)\n viewer.repaint()\n elif c == Qt.Key_F10:\n self.toggleControlWindow()\n\n################################################################################\n# AdvancedImageViewerApp\n################################################################################\n\nclass AdvancedImageViewerApp(QMainWindow):\n \"\"\"\n This is the application that is displayed when using imshow\n \"\"\"\n def __init__(self, im, flip=None, mgr=None):\n super(AdvancedImageViewerApp, self).__init__()\n self.mgr = mgr\n if mgr is not None:\n self.mgr.add_window(self)\n\n # Basic image rendering\n im_renderer = ImageRenderer()\n im_renderer.set_image(im)\n\n if flip is not None:\n # Basic image rendering\n flip_renderer = ImageRenderer()\n flip_renderer.set_image(flip)\n else:\n flip_renderer = None\n\n # Viewer handling mouse\n viewer = MouseImageViewer()\n\n # Advanced controls\n self.controls = controls = Controls()\n controls.setViewer(viewer)\n controls.setImageRenderer(im_renderer, flip=flip_renderer)\n self.setCentralWidget(controls)\n controls.show()\n\n def keyPressEvent(self, event):\n c = event.key()\n\n if c == Qt.Key_Q:\n # Close\n self.close()\n else:\n self.centralWidget().keyPressEvent(event)\n\n def closeEvent(self, event):\n # Allow window to be destroyed by removing any\n # references to it\n if self.mgr is not None:\n self.mgr.remove_window(self)\n \n def sizeHint(self):\n return self.controls.sizeHint()\n\ndef _simple_imshow(im, flip=None, mgr=None):\n # TODO: simpler imshow, without complete GUI\n return _advanced_imshow(im, flip=flip, mgr=mgr)\n\ndef _advanced_imshow(im, flip=None, mgr=None):\n return AdvancedImageViewerApp(im, flip=flip, mgr=mgr)\n\nif __name__ == \"__main__\":\n\n from scikits.image.filter import tvdenoise\n from scikits.image.io import imread, imshow\n import numpy.random as npr\n import os, os.path\n import sys\n\n app = QApplication(sys.argv)\n\n if len(sys.argv) > 1:\n image = imread(sys.argv[1])\n else:\n import scipy\n image = scipy.lena()\n\n flip = None\n if len(sys.argv) > 2:\n flip = imread(sys.argv[2])\n\n viewer = _advanced_imshow(image, flip=flip, mgr=None)\n viewer.show()\n\n sys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.5077319741249084,
"alphanum_fraction": 0.5850515365600586,
"avg_line_length": 20.55555534362793,
"blob_id": "7cb4ffba7a7a124ee5a7ed863f243f244297dfeb",
"content_id": "3bc1e6c90fdf9119259ff5be9f960893f249b0fc",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 388,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 18,
"path": "/scikits/image/transform/tests/test_hough_transform.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom numpy.testing import *\n\nfrom scikits.image.transform import *\n\ndef test_hough():\n # Generate a test image\n img = np.zeros((100, 150), dtype=bool)\n img[30, :] = 1\n img[:, 65] = 1\n img[35:45, 35:50] = 1\n for i in range(90):\n img[i, i] = 1\n\n out, angles, d = hough(img)\n\n assert_equal(out.max(), 100)\n assert_equal(len(angles), 180)\n"
},
{
"alpha_fraction": 0.5964912176132202,
"alphanum_fraction": 0.6140350699424744,
"avg_line_length": 21.600000381469727,
"blob_id": "547cbf603edf754ec1d03a936a881f4d340caebe",
"content_id": "54d2c8d1f5c56a4dd52a582ad9e35383936e103a",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 5,
"path": "/scikits/image/scripts/scivi2",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nif __name__ == \"__main__\":\n from scikits.image.scripts import scivi2\n scivi2.main()\n\n"
},
{
"alpha_fraction": 0.7835051417350769,
"alphanum_fraction": 0.7835051417350769,
"avg_line_length": 31,
"blob_id": "7bbf76fa9f76a1e103dba5e9dda06e5a08e1f81e",
"content_id": "39d78fbb5c07007b88ab51891f33e1f34e051417",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 97,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 3,
"path": "/scikits/image/io/_plugins/matplotlib_plugin.ini",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "[matplotlib]\ndescription = Display or save images using Matplotlib\nprovides = imshow, _app_show\n\n"
},
{
"alpha_fraction": 0.4019733965396881,
"alphanum_fraction": 0.458172470331192,
"avg_line_length": 29.671052932739258,
"blob_id": "ed929686a2513c72499bc84bc63a3a858c353b03",
"content_id": "c5fdacb4551ac44681c9da5a161af680712bb6a7",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2331,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 76,
"path": "/scikits/image/utils/shapes.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "# encoding: utf-8\n\nimport numpy as np\n\n# (0, 0) is the center of the first pixel\n# a pixel is in the disc if its center is in the continuous ball\n\ndef disc(radius):\n assert(radius >= 0)\n c = int(np.floor(radius))\n width = 2*c+1\n mask = np.zeros((width,width), dtype=np.int8)\n rad_sq = radius*radius\n sqrt = np.sqrt\n for x in xrange(c+1):\n y = int(np.floor(sqrt(rad_sq - x*x)))\n mask[c+x,c-y:c+y+1] = 1\n mask[c-x,c-y:c+y+1] = 1\n return mask\n\ndef check_disc():\n assert disc(0) == np.array([[1]], dtype=np.int8)\n assert disc(0.9) == np.array([[1]], dtype=np.int8)\n assert disc(1.0) == np.array([[0, 1, 0],\n [1, 1, 1],\n [0, 1, 0]], dtype=np.int8)\n assert disc(2.8) == np.array([[0, 1, 1, 1, 0],\n [1, 1, 1, 1, 1],\n [1, 1, 1, 1, 1],\n [1, 1, 1, 1, 1],\n [0, 1, 1, 1, 0]], dtype=np.int8)\n\ndef circle(radius):\n assert(radius >= 0)\n c = int(np.floor(radius))\n width = 2*c+1\n mask = np.zeros((width,width), dtype=np.int8)\n rad_sq = radius*radius\n sqrt = np.sqrt\n for x in xrange(c):\n y = int(np.floor(sqrt(rad_sq - x*x)))\n mask[c+x,c+y] = 1\n mask[c+x,c-y] = 1\n mask[c-x,c+y] = 1\n mask[c-x,c-y] = 1\n # Frontiers\n yc = int(np.floor(sqrt(rad_sq - c*c)))\n mask[2*c,c-yc:c+yc+1] = 1\n mask[0,c-yc:c+yc+1] = 1\n return mask\n\ndef check_circle():\n assert circle(0) == np.array([[1]], dtype=np.int8)\n assert circle(0.9) == np.array([[1]], dtype=np.int8)\n assert circle(1.0) == np.array([[0, 1, 0],\n [1, 0, 1],\n [0, 1, 0]], dtype=np.int8)\n assert circle(2.8) == np.array([[0, 1, 1, 1, 0],\n [1, 0, 0, 0, 1],\n [1, 0, 0, 0, 1],\n [1, 0, 0, 0, 1],\n [0, 1, 1, 1, 0]], dtype=np.int8)\n\ndef shape_coords(shape):\n n_coords = (shape>0).sum()\n coords = np.zeros((n_coords,2), dtype=np.int32)\n nx, ny = shape.shape\n cx, cy = nx/2, ny/2\n n_coord = 0\n for x in xrange(nx):\n for y in xrange(ny):\n if shape[x,y] > 0:\n coords[n_coord][0] = x-cx\n coords[n_coord][1] = y-cy\n n_coord += 1\n return coords\n"
},
{
"alpha_fraction": 0.41834861040115356,
"alphanum_fraction": 0.4409785866737366,
"avg_line_length": 21.397260665893555,
"blob_id": "9e127ec3857a78e9fa999f80d9518dd0f96b0bb9",
"content_id": "c1dca04e90af26b53aa030153e8c956cdfb5f094",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1635,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 73,
"path": "/scikits/image/filter/c_src/c_shock.c",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n\nstatic void\n_c_shock_iter(float* u, float* v, int width, int height, float s)\n{\n int i,j,im,i1,jm,j1;\n float new,val;\n float laplacian;\n\n for (i=0;i<width;i++) \n for (j=0;j<height;j++) {\n\n if (j==0) jm=1; else jm=j-1;\n if (j==height-1) j1=height-2; else j1=j+1;\n if (i==0) im=1; else im=i-1;\n if (i==width-1) i1=width-2; else i1=i+1;\n\n laplacian=(\n u[width * j + i1]+\n u[width * j + im]+\n u[width * j1 + i ]+\n u[width * jm + i ]-\n\t 4.0*u[width * j + i]);\n \n new = u[width * j + i];\n\n if (laplacian > 0.0)\n {\n /* erosion */\n val = u[width * j + i1]; if (val<new) new = val;\n val = u[width * j + im]; if (val<new) new = val;\n val = u[width * j1 + i ]; if (val<new) new = val;\n val = u[width * jm + i ]; if (val<new) new = val;\n } else if (laplacian < 0.0)\n {\n /* dilation */\n val = u[width * j + i1]; if (val>new) new = val;\n val = u[width * j + im]; if (val>new) new = val;\n val = u[width * j1 + i ]; if (val>new) new = val;\n val = u[width * jm + i ]; if (val>new) new = val;\n }\n\n v[width*j+i] = s * new + (1.0-s) * u[width*j+i];\n }\n}\n\nint\nc_shock(float* u, float* v, int nx, int ny, int n, float s)\n{\n int i;\n float *old, *new, *tmp;\n\n old = u;\n new = v;\n\n for( i=0 ; i<n ; i++ )\n {\n _c_shock_iter(old,new,nx,ny,s);\n tmp=old; old=new; new=tmp;\n }\n \n if (old == u)\n {\n for( i=0 ; i < nx*ny ; i++ )\n {\n *v++ = *u++ ;\n }\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6371237635612488,
"alphanum_fraction": 0.667224109172821,
"avg_line_length": 41.67856979370117,
"blob_id": "2412aaa3710b6df62b3eb9f746f7404694c9c354",
"content_id": "3539ca81a606d8313ef002e5135aec5a95ce7cf6",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1196,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 28,
"path": "/scikits/image/filter/tests/test_tvdenoise.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom numpy.testing import assert_array_almost_equal\nimport scipy\n\n\nfrom scikits.image.filter.tvdenoise import tvdenoise\n\ndef gradient_magnitude(a):\n grad_mag = np.zeros(tuple(np.array(a.shape) - 1), dtype=a.dtype)\n for dim in range(a.ndim):\n a_roll = np.rollaxis(a, dim, start=0)\n grad_axis = np.rollaxis(np.diff(a, axis=0)[[slice(None, None)] + \\\n (a.ndim -1) * [slice(0, -1)]], 0, start=dim)\n grad_mag += (grad_axis ** 2)\n return np.sqrt(grad_mag)\n\ndef test_tvdenoise():\n lena = scipy.lena().astype(np.float)\n noisy_lena = lena + 0.2 * lena.std()*np.random.randn(*lena.shape)\n denoised_lena_W5 = tvdenoise(lena, niter=10, W=5.0)\n denoised_lena_W50 = tvdenoise(lena, niter=10, W=50.)\n grad_mag_lena = gradient_magnitude(lena).sum()\n grad_mag_noisy = gradient_magnitude(noisy_lena).sum()\n grad_mag_denoised_W5 = gradient_magnitude(denoised_lena_W5).sum()\n grad_mag_denoised_W50 = gradient_magnitude(denoised_lena_W50).sum()\n assert grad_mag_noisy > max(grad_mag_denoised_W5, grad_mag_denoised_W50)\n assert grad_mag_denoised_W5 > grad_mag_denoised_W50\n assert grad_mag_denoised_W5 > 0.5 * grad_mag_lena \n"
},
{
"alpha_fraction": 0.6342902183532715,
"alphanum_fraction": 0.6386157870292664,
"avg_line_length": 26.197860717773438,
"blob_id": "7fd69780d5de6289e984f900a356637f184ff347",
"content_id": "58a93a67d31c5697d2c0934f0e9f7f127cac45da",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5086,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 187,
"path": "/scikits/image/morphology/grey.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "\"\"\"\n:author: Damian Eads, 2009\n:license: modified BSD\n\"\"\"\n\n__docformat__ = 'restructuredtext en'\n\nimport numpy as np\n\neps = np.finfo(float).eps\n\ndef greyscale_erode(image, selem, out=None):\n \"\"\"\n Performs a greyscale morphological erosion on an image given a\n structuring element. The eroded pixel at (i,j) is the minimum\n over all pixels in the neighborhood centered at (i,j).\n \n Parameters\n ----------\n image : ndarray\n The image as an ndarray.\n\n selem : ndarray\n The neighborhood expressed as a 2-D array of 1's and 0's.\n\n out : ndarray\n The array to store the result of the morphology. If None is\n passed, a new array will be allocated.\n\n Returns\n -------\n eroded : ndarray\n The result of the morphological erosion.\n \"\"\"\n if image is out:\n raise NotImplementedError(\"In-place erosion not supported!\")\n try:\n import scikits.image.morphology.cmorph as cmorph\n out = cmorph.erode(image, selem, out=out)\n return out;\n except ImportError:\n raise ImportError(\"cmorph extension not available.\")\n\ndef greyscale_dilate(image, selem, out=None):\n \"\"\"\n Performs a greyscale morphological dilation on an image given a\n structuring element. The dilated pixel at (i,j) is the maximum\n over all pixels in the neighborhood centered at (i,j).\n\n Parameters\n ----------\n \n image : ndarray\n The image as an ndarray.\n\n selem : ndarray\n The neighborhood expressed as a 2-D array of 1's and 0's.\n\n out : ndarray\n The array to store the result of the morphology. If None, is\n passed, a new array will be allocated.\n\n Returns\n -------\n dilated : ndarray\n The result of the morphological dilation.\n \"\"\"\n if image is out:\n raise NotImplementedError(\"In-place dilation not supported!\")\n try:\n import cmorph\n out = cmorph.dilate(image, selem, out=out)\n return out;\n except ImportError:\n raise ImportError(\"cmorph extension not available.\")\n \ndef greyscale_open(image, selem, out=None):\n \"\"\"\n Performs a greyscale morphological opening on an image given a\n structuring element defined as a erosion followed by a dilation.\n\n Parameters\n ----------\n image : ndarray\n The image as an ndarray.\n\n selem : ndarray\n The neighborhood expressed as a 2-D array of 1's and 0's.\n\n out : ndarray\n The array to store the result of the morphology. If None\n is passed, a new array will be allocated.\n\n Returns\n -------\n opening : ndarray\n The result of the morphological opening.\n \"\"\"\n eroded = greyscale_erode(image, selem)\n out = greyscale_dilate(eroded, selem, out=out)\n return out\n\ndef greyscale_close(image, selem, out=None):\n \"\"\"\n Performs a greyscale morphological closing on an image given a\n structuring element defined as a dilation followed by an erosion.\n\n Parameters\n ----------\n image : ndarray\n The image as an ndarray.\n\n selem : ndarray\n The neighborhood expressed as a 2-D array of 1's and 0's.\n\n out : ndarray\n The array to store the result of the morphology. If None,\n is passed, a new array will be allocated.\n\n Returns\n -------\n opening : ndarray\n The result of the morphological opening.\n \"\"\"\n dilated = greyscale_dilate(image, selem)\n out = greyscale_erode(dilated, selem, out=out)\n return out\n\ndef greyscale_white_top_hat(image, selem, out=None):\n \"\"\"\n Applies a white top hat on an image given a structuring element.\n\n Parameters\n ----------\n image : ndarray\n The image as an ndarray.\n\n selem : ndarray\n The neighborhood expressed as a 2-D array of 1's and 0's.\n\n out : ndarray\n The array to store the result of the morphology. If None\n is passed, a new array will be allocated.\n\n Returns\n -------\n opening : ndarray\n The result of the morphological white top hat.\n \"\"\"\n if image is out:\n raise NotImplementedError(\"Cannot perform white top hat in place.\")\n \n eroded = greyscale_erode(image, selem)\n out = greyscale_dilate(eroded, selem, out=out)\n out = image - out\n return out\n\ndef greyscale_black_top_hat(image, selem, out=None):\n \"\"\"\n Applies a black top hat on an image given a structuring element.\n\n Parameters\n ----------\n image : ndarray\n The image as an ndarray.\n\n selem : ndarray\n The neighborhood expressed as a 2-D array of 1's and 0's.\n\n out : ndarray\n The array to store the result of the morphology. If None\n is passed, a new array will be allocated.\n\n Returns\n -------\n opening : ndarray\n The result of the black top filter.\n \"\"\"\n if image is out:\n raise NotImplementedError(\"Cannot perform white top hat in place.\")\n dilated = greyscale_dilate(image, selem)\n out = greyscale_erode(dilated, selem, out=out)\n\n out = out - image\n if image is out:\n raise NotImplementedError(\"Cannot perform black top hat in place.\")\n return out\n"
},
{
"alpha_fraction": 0.6060393452644348,
"alphanum_fraction": 0.6077949404716492,
"avg_line_length": 29.623655319213867,
"blob_id": "9df8c6bfea4f00e2e0ef3656c9c0074d583c6251",
"content_id": "81918bc8104a415ef35dbbccde82dbe9d9744739",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2848,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 93,
"path": "/setup.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\ndescr = \"\"\"Image Processing SciKit\n\nImage processing algorithms for SciPy, including IO, morphology, filtering,\nwarping, color manipulation, object detection, etc.\n\nPlease refer to the online documentation at\nhttp://stefanv.github.com/scikits.image\n\"\"\"\n\nDISTNAME = 'scikits.image'\nDESCRIPTION = 'Image processing routines for SciPy'\nLONG_DESCRIPTION = descr\nMAINTAINER = 'Stefan van der Walt'\nMAINTAINER_EMAIL = '[email protected]'\nURL = 'http://stefanv.github.com/scikits.image'\nLICENSE = 'Modified BSD'\nDOWNLOAD_URL = 'http://github.com/stefanv/scikits.image'\nVERSION = '0.3dev'\n\nimport os\nimport setuptools\nfrom numpy.distutils.core import setup\n\ndef configuration(parent_package='', top_path=None):\n if os.path.exists('MANIFEST'): os.remove('MANIFEST')\n\n from numpy.distutils.misc_util import Configuration\n config = Configuration(None, parent_package, top_path,\n namespace_packages=['scikits'])\n\n config.set_options(\n ignore_setup_xxx_py=True,\n assume_default_configuration=True,\n delegate_options_to_subpackages=True,\n quiet=True)\n\n config.add_subpackage('scikits')\n config.add_subpackage(DISTNAME)\n config.add_data_files('scikits/__init__.py')\n config.add_data_dir('scikits/image/data')\n\n return config\n\ndef write_version_py(filename='scikits/image/version.py'):\n template = \"\"\"# THIS FILE IS GENERATED FROM THE SCIKITS.IMAGE SETUP.PY\nversion='%s'\n\"\"\"\n\n vfile = open(os.path.join(os.path.dirname(__file__),\n filename), 'w')\n\n try:\n vfile.write(template % VERSION)\n finally:\n vfile.close()\n\nif __name__ == \"__main__\":\n write_version_py()\n\n setup(\n name=DISTNAME,\n description=DESCRIPTION,\n long_description=LONG_DESCRIPTION,\n maintainer=MAINTAINER,\n maintainer_email=MAINTAINER_EMAIL,\n url=URL,\n license=LICENSE,\n download_url=DOWNLOAD_URL,\n version=VERSION,\n\n classifiers =\n [ 'Development Status :: 4 - Beta',\n 'Environment :: Console',\n 'Intended Audience :: Developers',\n 'Intended Audience :: Science/Research',\n 'License :: OSI Approved :: BSD License',\n 'Topic :: Scientific/Engineering'],\n\n configuration=configuration,\n install_requires=[],\n namespace_packages=['scikits'],\n packages=setuptools.find_packages(),\n include_package_data=True,\n zip_safe=False, # the package can run out of an .egg file\n\n entry_points={\n 'console_scripts': [\n 'scivi = scikits.image.scripts.scivi:main',\n 'scivi2 = scikits.image.scripts.scivi2:main']\n },\n )\n"
},
{
"alpha_fraction": 0.49607983231544495,
"alphanum_fraction": 0.6096460223197937,
"avg_line_length": 18.928909301757812,
"blob_id": "db7fa0d0dd1ba853dd44f6d809a4296312374b97",
"content_id": "a7bec83da59d55b88be835c295edef4ae93185d3",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4209,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 211,
"path": "/scikits/image/opencv/opencv_constants.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "\n#############################################\n# Image Processing Constants\n############################################\n\nCV_BLUR_NO_SCALE = 0\nCV_BLUR = 1\nCV_GAUSSIAN = 2\nCV_MEDIAN = 3\nCV_BILATERAL = 4\n\nCV_TERMCRIT_NUMBER = 1\nCV_TERMCRIT_ITER = 1\nCV_TERMCRIT_EPS = 2\n\nCV_INTER_NN = 0\nCV_INTER_LINEAR = 1\nCV_INTER_CUBIC = 2\nCV_INTER_AREA = 3\n\nCV_WARP_FILL_OUTLIERS = 8\nCV_WARP_INVERSE_MAP = 16\n\nCV_SHAPE_RECT = 0\nCV_SHAPE_CROSS = 1\nCV_SHAPE_ELLIPSE = 2\nCV_SHAPE_CUSTOM = 100\n\nCV_THRESH_BINARY = 0\nCV_THRESH_BINARY_INV = 1\nCV_THRESH_TRUNC = 2\nCV_THRESH_TOZERO = 3\nCV_THRESH_TOZERO_INV = 4\nCV_THRESH_MASK = 7\nCV_ADAPTIVE_THRESH_MEAN_C = 0\nCV_ADAPTIVE_THRESH_GAUSSIAN_C = 1\n\nCV_MOP_OPEN = 2\nCV_MOP_CLOSE = 3\nCV_MOP_GRADIENT = 4\nCV_MOP_TOPHAT = 5\nCV_MOP_BLACKHAT = 6\n\n#-------------------------------------------------------------------------------\n# Color Conversion\n#-------------------------------------------------------------------------------\nCV_BGR2BGRA = 0\nCV_RGB2RGBA = CV_BGR2BGRA\n\nCV_BGRA2BGR = 1\nCV_RGBA2RGB = CV_BGRA2BGR\n\nCV_BGR2RGBA = 2\nCV_RGB2BGRA = CV_BGR2RGBA\n\nCV_RGBA2BGR = 3\nCV_BGRA2RGB = CV_RGBA2BGR\n\nCV_BGR2RGB = 4\nCV_RGB2BGR = CV_BGR2RGB\n\nCV_BGRA2RGBA = 5\nCV_RGBA2BGRA = CV_BGRA2RGBA\n\nCV_BGR2GRAY = 6\nCV_RGB2GRAY = 7\nCV_GRAY2BGR = 8\nCV_GRAY2RGB = CV_GRAY2BGR\nCV_GRAY2BGRA = 9\nCV_GRAY2RGBA = CV_GRAY2BGRA\nCV_BGRA2GRAY = 10\nCV_RGBA2GRAY = 11\n\nCV_BGR2BGR565 = 12\nCV_RGB2BGR565 = 13\nCV_BGR5652BGR = 14\nCV_BGR5652RGB = 15\nCV_BGRA2BGR565 = 16\nCV_RGBA2BGR565 = 17\nCV_BGR5652BGRA = 18\nCV_BGR5652RGBA = 19\n\nCV_GRAY2BGR565 = 20\nCV_BGR5652GRAY = 21\n\nCV_BGR2BGR555 = 22\nCV_RGB2BGR555 = 23\nCV_BGR5552BGR = 24\nCV_BGR5552RGB = 25\nCV_BGRA2BGR555 = 26\nCV_RGBA2BGR555 = 27\nCV_BGR5552BGRA = 28\nCV_BGR5552RGBA = 29\n\nCV_GRAY2BGR555 = 30\nCV_BGR5552GRAY = 31\n\nCV_BGR2XYZ = 32\nCV_RGB2XYZ = 33\nCV_XYZ2BGR = 34\nCV_XYZ2RGB = 35\n\nCV_BGR2YCrCb = 36\nCV_RGB2YCrCb = 37\nCV_YCrCb2BGR = 38\nCV_YCrCb2RGB = 39\n\nCV_BGR2HSV = 40\nCV_RGB2HSV = 41\n\nCV_BGR2Lab = 44\nCV_RGB2Lab = 45\n\nCV_BayerBG2BGR = 46\nCV_BayerGB2BGR = 47\nCV_BayerRG2BGR = 48\nCV_BayerGR2BGR = 49\n\nCV_BayerBG2RGB = CV_BayerRG2BGR\nCV_BayerGB2RGB = CV_BayerGR2BGR\nCV_BayerRG2RGB = CV_BayerBG2BGR\nCV_BayerGR2RGB = CV_BayerGB2BGR\n\nCV_BGR2Luv = 50\nCV_RGB2Luv = 51\nCV_BGR2HLS = 52\nCV_RGB2HLS = 53\n\nCV_HSV2BGR = 54\nCV_HSV2RGB = 55\n\nCV_Lab2BGR = 56\nCV_Lab2RGB = 57\nCV_Luv2BGR = 58\nCV_Luv2RGB = 59\nCV_HLS2BGR = 60\nCV_HLS2RGB = 61\n\n#########################\n# Calibration Constants #\n#########################\nCV_CALIB_USE_INTRINSIC_GUESS = 1\nCV_CALIB_FIX_ASPECT_RATIO = 2\nCV_CALIB_FIX_PRINCIPAL_POINT = 4\nCV_CALIB_ZERO_TANGENT_DIST = 8\nCV_CALIB_CB_ADAPTIVE_THRESH = 1\nCV_CALIB_CB_NORMALIZE_IMAGE = 2\nCV_CALIB_CB_FILTER_QUADS = 4\n\n####################\n# cvMat TypeValues #\n####################\nCV_CN_MAX = 4\nCV_CN_SHIFT = 3\nCV_DEPTH_MAX = (1 << CV_CN_SHIFT)\n\nCV_8U = 0\nCV_8S = 1\nCV_16U = 2\nCV_16S = 3\nCV_32S = 4\nCV_32F = 5\nCV_64F = 6\nCV_USRTYPE1 = 7\n\ndef _CV_MAKETYPE(depth,cn):\n return ((depth) + (((cn)-1) << CV_CN_SHIFT))\n\nCV_8UC1 = _CV_MAKETYPE(CV_8U,1)\nCV_8UC2 = _CV_MAKETYPE(CV_8U,2)\nCV_8UC3 = _CV_MAKETYPE(CV_8U,3)\nCV_8UC4 = _CV_MAKETYPE(CV_8U,4)\n\nCV_8SC1 = _CV_MAKETYPE(CV_8S,1)\nCV_8SC2 = _CV_MAKETYPE(CV_8S,2)\nCV_8SC3 = _CV_MAKETYPE(CV_8S,3)\nCV_8SC4 = _CV_MAKETYPE(CV_8S,4)\n\nCV_16UC1 = _CV_MAKETYPE(CV_16U,1)\nCV_16UC2 = _CV_MAKETYPE(CV_16U,2)\nCV_16UC3 = _CV_MAKETYPE(CV_16U,3)\nCV_16UC4 = _CV_MAKETYPE(CV_16U,4)\n\nCV_16SC1 = _CV_MAKETYPE(CV_16S,1)\nCV_16SC2 = _CV_MAKETYPE(CV_16S,2)\nCV_16SC3 = _CV_MAKETYPE(CV_16S,3)\nCV_16SC4 = _CV_MAKETYPE(CV_16S,4)\n\nCV_32SC1 = _CV_MAKETYPE(CV_32S,1)\nCV_32SC2 = _CV_MAKETYPE(CV_32S,2)\nCV_32SC3 = _CV_MAKETYPE(CV_32S,3)\nCV_32SC4 = _CV_MAKETYPE(CV_32S,4)\n\nCV_32FC1 = _CV_MAKETYPE(CV_32F,1)\nCV_32FC2 = _CV_MAKETYPE(CV_32F,2)\nCV_32FC3 = _CV_MAKETYPE(CV_32F,3)\nCV_32FC4 = _CV_MAKETYPE(CV_32F,4)\n\nCV_64FC1 = _CV_MAKETYPE(CV_64F,1)\nCV_64FC2 = _CV_MAKETYPE(CV_64F,2)\nCV_64FC3 = _CV_MAKETYPE(CV_64F,3)\nCV_64FC4 = _CV_MAKETYPE(CV_64F,4)\n\n#-------------------------------------------------------------------------------\n# Template Matching\n#-------------------------------------------------------------------------------\nCV_TM_SQDIFF = 0\nCV_TM_SQDIFF_NORMED = 1\nCV_TM_CCORR = 2\nCV_TM_CCORR_NORMED = 3\nCV_TM_CCOEFF = 4\nCV_TM_CCOEFF_NORMED = 5\n\n\n\n"
},
{
"alpha_fraction": 0.7373887300491333,
"alphanum_fraction": 0.7373887300491333,
"avg_line_length": 25.920000076293945,
"blob_id": "aaf588bfed7050ace14a2190a3884c68996ea24f",
"content_id": "c886a88e61083429c916b5d055849a7bd474c611",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 674,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 25,
"path": "/scikits/image/opencv/__init__.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from opencv_constants import *\n\n# Note: users should be able to import this module even if\n# the extensions are uncompiled or the opencv libraries unavailable.\n# In that case, the opencv functionality is simply unavailable.\n\nloaded = False\n\ntry:\n from opencv_cv import *\nexcept ImportError:\n print \"\"\"*** The opencv extension was not compiled. Run\n\npython setup.py build_ext -i\n\nin the source directory to build in-place. Please refer to INSTALL.txt\nfor further detail.\"\"\"\nexcept RuntimeError:\n # Libraries could not be loaded\n print \"*** Skipping import of OpenCV functions.\"\n del (opencv_backend, opencv_cv)\nelse:\n loaded = True\n\ndel opencv_constants\n\n"
},
{
"alpha_fraction": 0.5616883039474487,
"alphanum_fraction": 0.5909090638160706,
"avg_line_length": 24.66666603088379,
"blob_id": "a145e1e8042e5fb6225a8f885512e49d6d8120dc",
"content_id": "975d55d9e33e4ff8867130f037c273731159a449",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 308,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 12,
"path": "/scikits/image/io/_plugins/test_plugin.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "def imread(fname, as_grey=False, dtype=None):\n assert fname == 'test.png'\n assert as_grey == True\n assert dtype == 'i4'\n\ndef imsave(fname, arr):\n assert fname == 'test.png'\n assert arr == [1, 2, 3]\n\ndef imshow(arr, plugin_arg=None):\n assert arr == [1, 2, 3]\n assert plugin_arg == (1, 2)\n"
},
{
"alpha_fraction": 0.5562660098075867,
"alphanum_fraction": 0.5575447678565979,
"avg_line_length": 25.508474349975586,
"blob_id": "d605d0e3fdff9c702764dff4c5100ed144ae7b57",
"content_id": "b5a2d924bcc60e2feab320dd032696be8ed923af",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1564,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 59,
"path": "/scikits/image/opencv/_libimport.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\n\"\"\"\nThis file properly imports the open CV libraries and returns them\nas an object. This function goes a longer way to try to find them\nsince especially on MacOS X Library Paths are not clearly defined.\n\nThis module also removes the code duplication in __init__ and\nopencv_cv\n\"\"\"\n\n__all__ = [\"cv\", \"cxcore\"]\n\nimport ctypes\nimport sys\nimport os.path\nimport warnings\n\ndef _import_opencv_lib(which=\"cv\"):\n \"\"\"\n Try to import a shared library of OpenCV.\n\n which - Which library [\"cv\", \"cxcore\", \"highgui\"]\n \"\"\"\n library_paths = ['',\n '/lib/',\n '/usr/lib/',\n '/usr/local/lib/',\n '/opt/local/lib/', # MacPorts\n '/sw/lib/', # Fink\n ]\n\n if sys.platform.startswith('linux'):\n extensions = ['.so', '.so.1']\n elif sys.platform.startswith(\"darwin\"):\n extensions = ['.dylib']\n else:\n extensions = ['.dll']\n library_paths = []\n\n lib = 'lib' + which\n shared_lib = None\n\n for path in library_paths:\n for ext in extensions:\n try:\n shared_lib = ctypes.CDLL(os.path.join(path, lib + ext))\n except OSError:\n pass\n else:\n return shared_lib\n\n warnings.warn(RuntimeWarning(\n 'The opencv libraries were not found. Please ensure that they '\n 'are installed and available on the system path. '))\n\ncv = _import_opencv_lib(\"cv\")\ncxcore = _import_opencv_lib(\"cxcore\")\n"
},
{
"alpha_fraction": 0.6111438870429993,
"alphanum_fraction": 0.6191037893295288,
"avg_line_length": 27.991453170776367,
"blob_id": "4271fa72b20d4b929367a08c5b1dc4221295b5bb",
"content_id": "731a6cff1cf3d772b12a492673752cb448c7e12b",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3392,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 117,
"path": "/scikits/image/io/_plugins/qt_plugin.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from util import prepare_for_display, window_manager, GuiLockError\nimport numpy as np\nimport sys\n\n# We try to aquire the gui lock first or else the gui import might\n# trample another GUI's PyOS_InputHook.\nwindow_manager.acquire('qt')\n\ntry:\n from PyQt4.QtGui import (QApplication, QMainWindow, QImage, QPixmap,\n QLabel, QWidget)\n from PyQt4 import QtCore, QtGui\n\nexcept ImportError:\n window_manager._release('qt')\n\n raise ImportError(\"\"\"\\\n PyQt4 libraries not installed. Please refer to\n\n http://www.riverbankcomputing.co.uk/software/pyqt/intro\n\n for more information. PyQt4 is GPL licensed. For an\n LGPL equivalent, see\n\n http://www.pyside.org\n \"\"\")\n\napp = None\n\nclass ImageLabel(QLabel):\n def __init__(self, parent, arr):\n QLabel.__init__(self)\n\n # we need to hold a reference to\n # arr because QImage doesn't copy the data\n # and the buffer must be alive as long\n # as the image is alive.\n self.arr = arr\n\n # we also need to pass in the row-stride to\n # the constructor, because we can't guarantee\n # that every row of the numpy data is\n # 4-byte aligned. Which Qt would require\n # if we didnt pass the stride.\n self.img = QImage(arr.data, arr.shape[1], arr.shape[0],\n arr.strides[0], QImage.Format_RGB888)\n self.pm = QPixmap.fromImage(self.img)\n self.setPixmap(self.pm)\n self.setAlignment(QtCore.Qt.AlignTop)\n self.setMinimumSize(100, 100)\n\n def resizeEvent(self, evt):\n width = self.width()\n pm = QPixmap.fromImage(self.img)\n self.pm = pm.scaledToWidth(width)\n self.setPixmap(self.pm)\n\n\nclass ImageWindow(QMainWindow):\n def __init__(self, arr, mgr):\n QMainWindow.__init__(self)\n self.setWindowTitle('scikits.image')\n self.mgr = mgr\n self.mgr.add_window(self)\n\n self.main_widget = QWidget()\n self.layout = QtGui.QGridLayout(self.main_widget)\n self.setCentralWidget(self.main_widget)\n\n self.label = ImageLabel(self, arr)\n self.layout.addWidget(self.label, 0, 0)\n self.layout.addLayout\n self.main_widget.show()\n\n def closeEvent(self, event):\n # Allow window to be destroyed by removing any\n # references to it\n self.mgr.remove_window(self)\n\n\ndef imshow(arr, fancy=False):\n global app\n if not app:\n app = QApplication([])\n\n arr = prepare_for_display(arr)\n\n if not fancy:\n iw = ImageWindow(arr, window_manager)\n else:\n from scivi import SciviImageWindow\n iw = SciviImageWindow(arr, window_manager)\n\n iw.show()\n\n\ndef _app_show():\n global app\n if app and window_manager.has_windows():\n app.exec_()\n else:\n print 'No images to show. See `imshow`.'\n\n\ndef imsave(filename, img):\n # we can add support for other than 3D uint8 here...\n img = prepare_for_display(img)\n qimg = QImage(img.data, img.shape[1], img.shape[0],\n img.strides[0], QImage.Format_RGB888)\n saved = qimg.save(filename)\n if not saved:\n from textwrap import dedent\n msg = dedent(\n '''The image was not saved. Allowable file formats\n for the QT imsave plugin are:\n BMP, JPG, JPEG, PNG, PPM, TIFF, XBM, XPM''')\n raise RuntimeError(msg)\n"
},
{
"alpha_fraction": 0.316118061542511,
"alphanum_fraction": 0.33200907707214355,
"avg_line_length": 26.53125,
"blob_id": "64e6fae869dd640a7e0656299c6b908b48838f86",
"content_id": "f5e706b5d88adbdb1f1e0846ce4a982630d2dbf3",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1762,
"license_type": "permissive",
"max_line_length": 68,
"num_lines": 64,
"path": "/scikits/image/io/_plugins/c_src/c_level_lines.c",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <math.h>\n\nint _c_extract_level_lines(\n float *in, /* Input image */\n int nx, int ny, /* Size of the input image */\n unsigned char *out, /* Output image */\n float ofs, float step,\n int mode\n)\n{\n memset(out, 0, nx*ny);\n\n float v,w;\n int x,y,adr,ok;\n double fv;\n\n for (x=0;x<nx-1;x++)\n for (y=0;y<ny-1;y++) {\n adr = y*nx+x;\n v = in[adr];\n ok = 0;\n\n switch(mode) \n {\n case 1: /* level lines */\n fv = floor((double)((v-ofs)/step));\n w = in[adr+1];\n if (floor((double)((w-ofs)/step)) != fv) ok = 1;\n w = in[adr+nx];\n if (floor((double)((w-ofs)/step)) != fv) ok = 1;\n w = in[adr+nx+1];\n if (floor((double)((w-ofs)/step)) != fv) ok = 1;\n break;\n\n case 2: /* one level line */\n w = in[adr+1];\n if ((w-ofs)*(v-ofs)<=0. && v!=w) ok=1;\n w = in[adr+nx];\n if ((w-ofs)*(v-ofs)<=0. && v!=w) ok=1;\n w = in[adr+nx+1];\n if ((w-ofs)*(v-ofs)<=0. && v!=w) ok=1;\n break;\n\n case 3: /* one lower level set */\n ok = (v<ofs);\n break;\n\n case 4: /* one upper level set */\n ok = (v>=ofs);\n break;\n\n case 5: /* one bi-level set */\n ok = (v>=ofs && v<ofs+step);\n break;\n\n }\n if (ok) {\n out[adr] = 255;\n }\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.7525773048400879,
"alphanum_fraction": 0.7525773048400879,
"avg_line_length": 31,
"blob_id": "4f64627137107b5cc1ce90d56aef4003e6cd3ed0",
"content_id": "9e98ba8138806505bfa435411e01ee267aa19240",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 97,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 3,
"path": "/scikits/image/io/_plugins/qt_plugin.ini",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "[qt]\ndescription = Fast image display using the Qt library\nprovides = imshow, _app_show, imsave\n\n"
},
{
"alpha_fraction": 0.5466321110725403,
"alphanum_fraction": 0.5621761679649353,
"avg_line_length": 23.0625,
"blob_id": "23c0348db368afb89f59f56438fbfd5fac900a44",
"content_id": "d7eea8143e0d5375d456eeceb17a3d11cf3f2762",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 386,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 16,
"path": "/scikits/image/scripts/scivi2.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "\"\"\"scikits.image viewer\"\"\"\ndef main():\n import scikits.image.io as io\n import sys\n\n if len(sys.argv) < 2:\n print \"Usage: scivi <image-file> [<flip-file>]\"\n sys.exit(-1)\n\n io.use_plugin('qt2')\n im = io.imread(sys.argv[1])\n flip = None\n if len(sys.argv) > 2:\n flip = io.imread(sys.argv[2])\n io.imshow(im, flip=flip, fancy=True)\n io.show()\n\n"
},
{
"alpha_fraction": 0.7727272510528564,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 21,
"blob_id": "c4762152fab0929b00f3f3488ecd86f4d4d105da",
"content_id": "4fadcd3a3039042948a92e26fd60d101406b605f",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22,
"license_type": "permissive",
"max_line_length": 21,
"num_lines": 1,
"path": "/scikits/image/version.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "version='unbuilt-dev'\n"
},
{
"alpha_fraction": 0.5213325619697571,
"alphanum_fraction": 0.52308589220047,
"avg_line_length": 30.090909957885742,
"blob_id": "25b4ceee5aa5f65d7d2b3bf02228cea1a5606665",
"content_id": "5f1f3ff43f6482fe4fa218847966d7322ee9e9db",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1711,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 55,
"path": "/scikits/image/opencv/_utilities.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from textwrap import dedent\nimport numpy as np\n# some utility functions for the opencv wrappers\n\n\n# the doc decorator\nclass cvdoc(object):\n '''A doc decorator which adds the docs for the opencv functions.\n It primarily serves to append the appropriate opencv doc url to\n each function.\n '''\n\n base_url = 'http://opencv.willowgarage.com/documentation/'\n branch_urls = {'cv':\n {'filter': 'image_filtering',\n 'feature': 'feature_detection',\n 'geometry': 'geometric_image_transformations',\n 'transforms': 'miscellaneous_image_transformations',\n 'structural': 'structural_analysis',\n 'calibration': 'camera_calibration_and_3d_reconstruction'\n },\n 'cxcore': {},\n 'highgui': {}\n }\n\n def __init__(self, package='', group='', doc=''):\n self.package = str(package)\n self.group = str(group)\n self.doc = str(doc)\n\n def __call__(self, func):\n # if key errors occur, fail silently\n try:\n self._add_url(func)\n np.add_docstring(func, self.doc)\n return func\n\n except KeyError:\n return func\n\n def _add_url(self, func):\n # Remove cv prefix from name\n name = func.__name__.lower()[2:]\n\n full_url = (self.base_url +\n self.branch_urls[self.package][self.group] +\n '.html' + '#' + name)\n message = dedent('''\nReferences\n----------\n.. [1] OpenCV documentation for `%(name)s`, %(url)s.\n''' % {'name': name,\n 'url': full_url})\n\n self.doc += '\\n\\n' + message\n\n"
},
{
"alpha_fraction": 0.6849315166473389,
"alphanum_fraction": 0.6849315166473389,
"avg_line_length": 17,
"blob_id": "acf57451590b123f8eecc7441cf076ca341904de",
"content_id": "7fb70da215f3893febc5c0e1c7dc3f9aca9e0e10",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 73,
"license_type": "permissive",
"max_line_length": 42,
"num_lines": 4,
"path": "/scikits/image/io/_plugins/matplotlib_plugin.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "from matplotlib.pyplot import imshow, show\n\ndef _app_show():\n show()\n\n"
},
{
"alpha_fraction": 0.6111547350883484,
"alphanum_fraction": 0.6127258539199829,
"avg_line_length": 31.64102554321289,
"blob_id": "008d20c1a3216da75646f5b4d9813abc08978b10",
"content_id": "0cab7b3bd5cf5a43eb1a40021d199af9e3e36d59",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1273,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 39,
"path": "/scikits/image/opencv/setup.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom scikits.image._build import cython\n\nimport os.path\n\nbase_path = os.path.abspath(os.path.dirname(__file__))\n\ndef configuration(parent_package='', top_path=None):\n from numpy.distutils.misc_util import Configuration, get_numpy_include_dirs\n\n config = Configuration('opencv', parent_package, top_path)\n\n config.add_data_dir('tests')\n\n cython_files = ['opencv_backend.pyx', 'opencv_cv.pyx']\n\n # This function tries to create C files from the given .pyx files. If\n # it fails, we build the checked-in .c files.\n cython(cython_files, working_path=base_path)\n\n for pyxfile in cython_files:\n c_file = pyxfile[:-4] + '.c'\n config.add_extension(pyxfile[:-4],\n sources=[c_file],\n include_dirs=[get_numpy_include_dirs()])\n\n return config\n\nif __name__ == '__main__':\n from numpy.distutils.core import setup\n setup(maintainer = 'Scikits.Image Developers',\n author = 'Steven C. Colbert',\n maintainer_email = '[email protected]',\n description = 'OpenCV wrapper for NumPy arrays',\n url = 'http://stefanv.github.com/scikits.image/',\n license = 'SciPy License (BSD Style)',\n **(configuration(top_path='').todict())\n )\n"
},
{
"alpha_fraction": 0.4364069998264313,
"alphanum_fraction": 0.45230525732040405,
"avg_line_length": 23.66666603088379,
"blob_id": "919848a1ad45e70e68048ba5859faf183f109291",
"content_id": "f1d6e13530f9c7d11b2f13de7b0c2b659823ca43",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2516,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 102,
"path": "/scikits/image/filter/c_src/c_nlmeans.c",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n\n#define MIN(a,b) ((a)<(b)?(a):(b))\n#define MAX(a,b) ((a)>(b)?(a):(b))\n\nint\nc_nlmeans(\n float* in, float* out, int nx0, int ny0, /* input/output buffers */\n float h, /* regularization parameter */\n int s, /* patch side length (odd integer) */\n float a, /* decay of Euclidean patch distance */\n int d, /* maximum patch distance */\n float c /* weight for self-patch */\n)\n{\n int *dadr=NULL,*dd=NULL,nx,ny,x,y,xp,yp,i,adr,adrp,wsize,ds;\n double *w=NULL,*ww=NULL,dist,new,sum,e,A,*ref=NULL;\n register double v;\n\n if (s<1 || ((s)&1)==0) \n {\n /* Parameter error */\n return -1 ;\n }\n A = 2.*a*a; if (A==0.) A=1.;\n ds = (s-1)/2; /* patch = [-ds,ds]x[-ds,ds] */\n\n nx = nx0+2*ds; \n ny = ny0+2*ds;\n\n ref = (double *)malloc(nx*ny*sizeof(double));\n if (!ref)\n goto err_not_enough_memory;\n\n /* enlarge image to deal properly with borders */\n for (y=0;y<ny;y++) {\n yp = y-ds;\n if (yp<0) yp=-yp;\n if (yp>=ny0) yp=ny0*2-2-yp;\n for (x=0;x<nx;x++) {\n xp = x-ds;\n if (xp<0) xp=-xp;\n if (xp>=nx0) xp=nx0*2-2-xp;\n ref[y*nx+x] = (double)in[yp*nx0+xp];\n }\n }\n\n /* precompute weights */\n wsize = s*s;\n w = (double *)malloc(wsize*sizeof(double));\n dadr = (int *)malloc(wsize*sizeof(int));\n if( !w || !dadr )\n goto err_not_enough_memory;\n\n for(sum=0.,i=0,x=-ds;x<=ds;x++)\n for(y=-ds;y<=ds;y++,i++) {\n dadr[i] = y*nx+x;\n w[i] = exp(-(double)(x*x+y*y)/A);\n sum += w[i];\n }\n for (i=wsize;i--;) w[i] /= sum*2.*h*h;\n\n /* main loop */\n for (x=ds;x<nx-ds;x++)\n {\n /*printf(\"x=%d/%d\\n\",x-ds+1,nx-ds*2);*/\n for (y=ds;y<ny-ds;y++)\n {\n adr = y*nx+x;\n new = sum = 0.;\n /* loop on patches */\n for (xp=MAX(x-d,ds);xp<=MIN(x+d,nx-1-ds);xp++)\n {\n for (yp=MAX(y-d,ds);yp<=MIN(y+d,ny-1-ds);yp++)\n {\n adrp = yp*nx+xp;\n for (i=wsize,dist=0.,ww=w,dd=dadr;i--;ww++,dd++)\n {\n v = ref[adr+*dd]-ref[adrp+*dd];\n dist += *ww*v*v;\n }\n e = (adrp==adr?c:exp(-dist));\n new += e*(double)ref[adrp];\n sum += e;\n }\n }\n out[(y-ds)*nx0+x-ds] = (float)(new/sum);\n }\n }\n free(ref);\n free(dadr);\n free(w);\n return 0;\n\nerr_not_enough_memory:\n free(ref);\n free(dadr);\n free(w);\n return 1;\n}\n"
},
{
"alpha_fraction": 0.6554726362228394,
"alphanum_fraction": 0.6741293668746948,
"avg_line_length": 24.935483932495117,
"blob_id": "10fa00d1896b50eecf30f7441e0eb28979f0180b",
"content_id": "1615a369205972a5b75fa6c1ffad42a42cd7ee97",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 804,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 31,
"path": "/scikits/image/scripts/test_median.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# encoding: utf-8\n\nfrom scikits.image import data_dir\nfrom scikits.image.io import *\nfrom scikits.image.filter import median\n\nimport sys\nimport os.path\nimport argparse\n\nif len(sys.argv) > 1:\n parser = argparse.ArgumentParser(description='Total-variation denoising')\n parser.add_argument('filename_in', metavar='in', help='the input file')\n parser.add_argument('-r', default=1.0, type=float, help='radius of the disk')\n parser.add_argument('-n', default=10, type=int,\n help='number of iterations')\n args = parser.parse_args()\n \n filename = args.filename_in\n n = args.n\n r = args.r\nelse:\n filename = os.path.join(data_dir, 'lena256.tif')\n n = 10\n r = 1.0\n\nim = imread(filename)\nimshow(im)\nim2 = median(im, radius=r, niter=n)\nimshow(im2)\n"
},
{
"alpha_fraction": 0.5321100950241089,
"alphanum_fraction": 0.5657492280006409,
"avg_line_length": 30.14285659790039,
"blob_id": "0a0c806d27d171778d3b3d4a94442ae2cf29d168",
"content_id": "44c0e557433b36a086685c0b51ac1baba41c9088",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 654,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 21,
"path": "/scikits/image/transform/tests/test_project.py",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom numpy.testing import assert_array_almost_equal\n\nfrom scikits.image.transform.project import _stackcopy, homography\n\ndef test_stackcopy():\n layers = 4\n x = np.empty((3, 3, layers))\n y = np.eye(3, 3)\n _stackcopy(x, y)\n for i in range(layers):\n assert_array_almost_equal(x[...,i], y)\n\ndef test_homography():\n x = np.arange(9).reshape((3, 3)) + 1\n theta = -np.pi/2\n M = np.array([[np.cos(theta),-np.sin(theta),0],\n [np.sin(theta), np.cos(theta),2],\n [0, 0, 1]])\n x90 = homography(x, M, order=1)\n assert_array_almost_equal(x90, np.rot90(x))\n"
},
{
"alpha_fraction": 0.3811475336551666,
"alphanum_fraction": 0.40491804480552673,
"avg_line_length": 21.592592239379883,
"blob_id": "00a9a298224d5d85e3860de9f3485512d67fbc90",
"content_id": "b5aefd50335482e3756d4c3b841067ce4546f870",
"detected_licenses": [
"LicenseRef-scancode-warranty-disclaimer",
"BSD-2-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1220,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 54,
"path": "/scikits/image/filter/c_src/c_tvdenoise.c",
"repo_name": "maelp/scikits.image",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <stdlib.h>\n#include <math.h>\n\n#define C_TVDENOISE(_type) \\\nint \\\nc_tvdenoise_ ## _type (_type* A, int nx, int ny, int n, _type weight, _type* u) \\\n{ \\\n _type *px = calloc(nx*ny, sizeof(_type)); \\\n _type *py = calloc(nx*ny, sizeof(_type)); \\\n\\\n int k, x, y, addr; \\\n _type d, gx, gy, norm; \\\n\\\n if( !(px && py) ) \\\n { \\\n if( px ) free(px); \\\n if( py ) free(py); \\\n return -1; \\\n } \\\n\\\n for( k = 0 ; k < n ; k++ ) \\\n { \\\n for( y = 0, addr = 0 ; y < ny ; y++ ) \\\n { \\\n for( x = 0 ; x < nx ; x++, addr++ ) \\\n { \\\n d = -px[addr]-py[addr]; \\\n if( x > 0 ) d += px[addr-1]; \\\n if( y > 0 ) d += py[addr-nx]; \\\n u[addr] = A[addr]+d; \\\n } \\\n } \\\n for( y = 0, addr = 0 ; y < ny ; y++ ) \\\n { \\\n for( x = 0 ; x < nx ; x++, addr++ ) \\\n { \\\n gx = (x < nx-1)? u[addr+1]-u[addr] : 0.0; \\\n gy = (y < ny-1)? u[addr+nx]-u[addr] : 0.0; \\\n norm = sqrt(gx*gx+gy*gy); \\\n norm = 1.0 + 0.5*norm/weight; \\\n px[addr] = (px[addr]-0.25*gx)/norm; \\\n py[addr] = (py[addr]-0.25*gy)/norm; \\\n } \\\n } \\\n } \\\n\\\n free(px); free(py); \\\n\\\n return 0; \\\n}\n\nC_TVDENOISE(float)\nC_TVDENOISE(double)\n"
}
] | 41 |
5l1v3r1/mail-domain-sorter | https://github.com/5l1v3r1/mail-domain-sorter | 68fc6054ba811840f88c674d94674227ffd767e9 | 46db82198b80f23bda48f9ab27ac71147e4d6aff | 2f4ceb6f6f1b9739563c31d3a1eb895db41b77ea | refs/heads/main | 2023-03-28T05:39:12.007874 | 2021-03-26T13:02:00 | 2021-03-26T13:02:00 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.704781711101532,
"alphanum_fraction": 0.7141371965408325,
"avg_line_length": 28.15151596069336,
"blob_id": "71124991e391c3fd11000521fb53fc35b07a070d",
"content_id": "033c33bef81afa77362805e74ea94c482c2f850e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 964,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 33,
"path": "/README.md",
"repo_name": "5l1v3r1/mail-domain-sorter",
"src_encoding": "UTF-8",
"text": "# Mail Domain Sorter and All Word Sorter\n\n[](https://github.com/v-Cx/mail-domain-sorter/releases/tag/0.2)\n\n### What can you do with this software?\n- ✨ You can save the lines belonging to all the words you want from a text file in a separate text file.\n\n>If you want to improve the program, download it to your computer. Make improvements and send them back to the repo.\n```sh\ngit clone https://github.com/v-Cx/mail-domain-sorter.git\n```\n### Screenshots of the program converted to exe\n\n##### Opening Screen\n\n\n##### The word input we want to separate\n\n\n##### And Finish\n\n\n## Installation\n\n```sh\ngit clone https://github.com/v-Cx/mail-domain-sorter.git\n```\n\n## Download Exe\n\n```sh\nhttps://github.com/v-Cx/mail-domain-sorter/releases/tag/0.2\n```\n"
},
{
"alpha_fraction": 0.4279915392398834,
"alphanum_fraction": 0.4311683773994446,
"avg_line_length": 34.10190963745117,
"blob_id": "c5d89d9d1d33a4f41ee34c142c44b4787d0eee0d",
"content_id": "dd489789fbab433a1c9c327e22a4eaf4242859b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5666,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 157,
"path": "/explode.py",
"repo_name": "5l1v3r1/mail-domain-sorter",
"src_encoding": "UTF-8",
"text": "\"\"\"\r\nSellthing.co\r\nStyx\r\nAndwiseb\r\n\r\nversion: 0.2\r\n\"\"\"\r\n\r\n\r\nimport tkinter as tk\r\nfrom tkinter import filedialog\r\nimport os\r\nfrom os import system\r\nimport os.path\r\nimport time\r\nsystem(\"title \" + \"Mail Domain Sorter - Sellthing - Styx\")\r\nfrom datetime import date\r\nfrom datetime import datetime\r\n\r\nroot = tk.Tk()\r\nroot.withdraw()\r\n\r\n\r\nlogTextSellhting = \"\"\"\r\n \r\n _|_|_| _| \r\n _| _|_|_| _|_|_| _| _|_| _|_| _|_|_| \r\n _| _| _| _| _| _|_| _| _| _| _| \r\n _| _| _| _| _| _| _| _| _| _| \r\n _|_|_| _| _| _|_|_| _| _|_| _| _| \r\n \r\n \r\nwww.sellthing.co | Styx\r\n\"\"\"\r\nprint(logTextSellhting)\r\n\r\ndef getStarted():\r\n \r\n print('Please separate each word with a comma (,). Example: test, test1, test2')\r\n getWords = input(\"Enter the words you want to split :\")\r\n replace = getWords.replace(', ', ',').replace(',', ',').replace(' ', '').replace('\\s+ ', '').replace(' ,', '').replace(' \\s+', '')\r\n splitWords = \"\"\r\n\r\n if(getWords == \"\"):\r\n print('Please enter words.')\r\n getStarted();\r\n else:\r\n if(',' in replace):\r\n splitWords = replace.split(',')\r\n else:\r\n splitWords = replace\r\n\r\n splitWord(splitWords)\r\n \r\n\r\n\r\n\r\ndef splitWord(word): \r\n print(\"-------------------------------------------\")\r\n print(\"Select the file\")\r\n print(\"-------------------------------------------\")\r\n \r\n \"\"\" When the file selection panel is opened, we synchronize the uploaded file to file_path. \"\"\"\r\n file_path = filedialog.askopenfile(mode ='r', filetypes =[('Text Files', '*.txt')])\r\n\r\n \"\"\" If the file is not selected, we send it to the beginning.\"\"\"\r\n if(not file_path):\r\n print(\"You haven't selected a file!\")\r\n print(\"-------------------------------------------\")\r\n getStarted()\r\n \r\n if(file_path == None):\r\n print(\"Restart the program.\")\r\n exit()\r\n \r\n \"\"\" If there is no folder named result it will create \"\"\"\r\n if(not os.path.isdir('result')):\r\n os.mkdir('result')\r\n\r\n \"\"\" We have created an empty array so that we will put the words read into it.\"\"\"\r\n findList = []\r\n\r\n\r\n \"\"\"\r\n If the user is scanning more than one word, we check it.\r\n This is due to the following for and if codes.\r\n \"\"\"\r\n\r\n now = datetime.now()\r\n getTime = now.strftime(\"%H-%M-%S\")\r\n\r\n if(isinstance(word, list)):\r\n print(\"Completing the process please wait.\")\r\n system(\"title \" + \"Mail Domain Sorter - Process has started.\")\r\n for words in word:\r\n i = 0\r\n control = False\r\n \"\"\" We have the process of reading each line of the selected file. \"\"\"\r\n for line in open(file_path.name, 'r').readlines():\r\n \"\"\" CPM Left Count \"\"\"\r\n\r\n \"\"\" If the words given by the user are in the file, we check.\"\"\"\r\n if words in line:\r\n control = True\r\n \"\"\"\r\n If there is a word in the file that the user searched for, a file of that word is opened below. Example: test1.txt\r\n \"\"\"\r\n i += 1\r\n open('result/' + os.path.basename(str(words) + \" - \" + getTime + '.txt'), 'w+')\r\n findList.append(line)\r\n if control == True:\r\n \"\"\"\r\n The reason for checking the \"Control\" variable is to prevent creating a new file from each line in the file.\r\n \"\"\"\r\n open(\"result/\" + str(words) + \" - \" + getTime + '.txt', \"w\").writelines(findList)\r\n\r\n \"\"\" After all searches for a word are completed, we reset the records found. \"\"\"\r\n findList = []\r\n print(\"Generate Process is Starting.\")\r\n time.sleep(0.5)\r\n print(\"---------------------------------------------------\")\r\n print(str(len(open('result/' + words + \" - \" + getTime + '.txt').read().splitlines())) + \" \" + str(words) + \" records found.\")\r\n print(\"---------------------------------------------------\")\r\n time.sleep(0.5)\r\n \r\n else:\r\n \"\"\" If the user has entered a single word, the actions will be done here. \"\"\"\r\n print(\"Completing the process please wait.\")\r\n system(\"title \" + \"Mail Domain Sorter - Process has started.\")\r\n control = False\r\n i = 0\r\n for line in open(file_path.name, 'r').readlines():\r\n if word in line:\r\n control = True\r\n i += 1\r\n open('result/' + os.path.basename(str(word) + \" - \" + getTime + '.txt'), 'w+')\r\n findList.append(line)\r\n if control == True:\r\n open(\"result/\" + str(word) + \" - \" + getTime + '.txt', \"w\").writelines(findList)\r\n else:\r\n print(\"No line found about \" + word)\r\n\r\n\r\n print(\"---------------------------------------------------\")\r\n print(str(len(open('result/' + word + \" - \" + getTime + '.txt').read().splitlines())) + \" \" + word + \" records found.\")\r\n print(\"---------------------------------------------------\")\r\n \r\n time.sleep(0.5)\r\n print(\"The program shuts down...\")\r\n time.sleep(0.4)\r\n print(\"Bye\")\r\n time.sleep(3)\r\n \r\n\r\n \r\n\r\ngetStarted()"
}
] | 2 |
ReshmaRegijc/BookStore_flask | https://github.com/ReshmaRegijc/BookStore_flask | e1f4056dcc4cf33b58520d8ffc4fd47227089586 | f4ff69e92c60af17da56c6323197e1a53e2239bf | 7f5a816d8c0edb07a76a18664c2ff8f988b751dc | refs/heads/master | 2023-08-03T19:11:42.714934 | 2021-09-26T17:39:21 | 2021-09-26T17:39:21 | 410,252,140 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6082251071929932,
"alphanum_fraction": 0.6082251071929932,
"avg_line_length": 24.72222137451172,
"blob_id": "48fc60ee66de52050a576d88cb79706ae178ff0e",
"content_id": "7de6ed570bb1cc892082efe9789398cf09597c8a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 462,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 18,
"path": "/myprojects/models.py",
"repo_name": "ReshmaRegijc/BookStore_flask",
"src_encoding": "UTF-8",
"text": "from myprojects import db\n\nclass Book(db.Model):\n\n __tablename__ = \"books\"\n\n id = db.Column(db.Integer,primary_key = True)\n name = db.Column(db.Text)\n author = db.Column(db.Text)\n price = db.Column(db.Integer)\n\n def __init__(self,name,author,price):\n self.name = name\n self.author = author\n self.price = price\n\n def __repr__(self):\n return f\"Book Name: {self.name}\\n\\tAuthor: {self.author}\\n\\tPrice: {self.price}\""
},
{
"alpha_fraction": 0.6446352005004883,
"alphanum_fraction": 0.6446352005004883,
"avg_line_length": 21.365385055541992,
"blob_id": "9a25719ca43b0bd97f697b78e26a26f7ad6bccbf",
"content_id": "ca1a80f180436d78e77ca7a1fdab12cb44e6ad75",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1165,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 52,
"path": "/myprojects/books/views.py",
"repo_name": "ReshmaRegijc/BookStore_flask",
"src_encoding": "UTF-8",
"text": "from flask import Blueprint, render_template,redirect,url_for\n\n\nfrom myprojects import db\nfrom myprojects.models import Book\n\nfrom myprojects.books.forms import *\n\n\nbook_blueprint = Blueprint('books',__name__,template_folder= 'templates/books')\n\n@book_blueprint.route('/add', methods=['GET','POST'])\ndef add():\n\n form = AddForm()\n\n if form.validate_on_submit():\n name = form.name.data\n author = form.author.data\n price = form.price.data\n\n new_book = Book(name,author,price)\n\n db.session.add(new_book)\n db.session.commit()\n\n return redirect(url_for('books.list'))\n \n return render_template('add.html',form=form)\n\n@book_blueprint.route('/delete', methods=['GET','POST'])\ndef delete():\n\n form = DeleteForm()\n\n if form.validate_on_submit():\n id = form.id.data\n\n buy_book = Book.query.getid(id)\n\n db.session.delete(buy_book)\n db.session.commit()\n\n return redirect(url_for('books.list'))\n\n return render_template('delete.html',form=form)\n\n\n@book_blueprint.route('/list')\ndef list():\n books = Book.query.all()\n return render_template('list.html',books=books)\n\n\n"
},
{
"alpha_fraction": 0.7504655718803406,
"alphanum_fraction": 0.7504655718803406,
"avg_line_length": 22.39130401611328,
"blob_id": "572146f3108149b1ae344762c491ba352bcc06e4",
"content_id": "3620aa45de275a4b5190e3ee9e175b808883df50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 537,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 23,
"path": "/myprojects/__init__.py",
"repo_name": "ReshmaRegijc/BookStore_flask",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nimport os\nfrom flask_sqlalchemy import SQLAlchemy\nfrom flask_migrate import Migrate\n\n\napp = Flask(__name__)\n\napp.config['SECRET_KEY'] = 'mykey'\n\nbasedir = os.path.abspath(os.path.dirname(__file__))\napp.config['SQLALCHEMY_DATABASE_URI'] = 'sqlite:///' + os.path.join(basedir,'data.sqlite')\napp.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False\n\ndb = SQLAlchemy(app)\nMigrate(app,db)\n\n\n#Register Blueprints \n\nfrom myprojects.books.views import book_blueprint\n\napp.register_blueprint(book_blueprint,url_prfix='/books')"
}
] | 3 |
GowriShanker98/Final-pro | https://github.com/GowriShanker98/Final-pro | 6143c8162be46fdeeabe87b2f5444a97bc4a7359 | 8ab9012d9561672f5032778b315d36c7fa623529 | b151d8025091cacfca37c2279277bb30022bcb01 | refs/heads/master | 2022-12-18T12:01:58.925863 | 2020-09-28T11:18:06 | 2020-09-28T11:18:06 | 299,283,040 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8235294222831726,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 25.85714340209961,
"blob_id": "9cef1918ea7dcff565fc09379bc8f148565d88a0",
"content_id": "42ebbbfdc6cb76893ea9b59b27f05b13c82a6e81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 7,
"path": "/Vote/admin.py",
"repo_name": "GowriShanker98/Final-pro",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom Vote.models import *\n\n# Register your models here.\nadmin.site.register(Constituency)\nadmin.site.register(Candidate)\nadmin.site.register(VoterDetails)"
}
] | 1 |
FalseSky/CourseProject | https://github.com/FalseSky/CourseProject | 3a56cf4d47bd7f207777ddb3f91dd55faaba3477 | faa3fcad836e3a4f6ec8830c782a2fa105da8406 | 889106ce4491f512e670db80c4293f447f54f04b | refs/heads/master | 2016-09-14T14:33:39.529856 | 2016-04-26T15:15:52 | 2016-04-26T15:15:52 | 57,081,723 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.71089106798172,
"alphanum_fraction": 0.7181518077850342,
"avg_line_length": 29.299999237060547,
"blob_id": "4e1c5165bf7cd5da3c5a755172f99d123e591660",
"content_id": "79bf20f40f0a8d96449c2dec4c23694a1b444704",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3030,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 100,
"path": "/Model/TimerManager.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "from Gui.MessageBox import ShowMessageBox\nfrom Model.Timer import Timer\n\nfrom datetime import time\nimport os.path\nimport sqlite3\n\nfrom Resources.Strings import FailIconPath, ErrorMessageBoxTitle, TimerAlreadyAddedMessage, DatabaseName, \\\n\tCreateTimerTableQuery, RemoveTimerTableQuery, AddTimerQuery, SelectTimersQuery, TrueValue, \\\n\tNoneValue\n\n\nclass TimerManager:\n\tdef __init__( self ):\n\t\t# Dictionary( Map )\n\t\tself._timers = { }\n\n\tdef addTimer( self, _timer ):\n\t\ttimerName = _timer.getName( )\n\t\tif self._timers.get( timerName ) is None:\n\t\t\tself._timers.setdefault( timerName, _timer )\n\t\t\treturn self._timers.get( timerName )\n\n\t\tShowMessageBox( FailIconPath, ErrorMessageBoxTitle, TimerAlreadyAddedMessage )\n\n\tdef getTimer( self, _timerName ):\n\t\treturn self._timers.get( _timerName )\n\n\tdef removeTimer( self, _timerName ):\n\t\ttimer = self.getTimer( _timerName )\n\n\t\tif timer:\n\t\t\ttimer.pause()\n\t\t\tself._timers.pop( _timerName )\n\n\tdef getTimersCount( self ):\n\t\treturn len( self._timers )\n\n\tdef items( self ):\n\t\treturn self._timers.items( )\n\n\tdef save( self ):\n\t\t# Connect to database by name\n\t\tdatabase = sqlite3.connect( DatabaseName )\n\n\t\t# Cursor ( object for work with database )\n\t\tdatabaseCursor = database.cursor( )\n\n\t\tdatabaseCursor.execute( RemoveTimerTableQuery )\n\t\tdatabaseCursor.execute( CreateTimerTableQuery )\n\n\t\t# Add all timers from timers dictionary\n\t\tfor timerName, timerValue in self._timers.items( ):\n\t\t\tdatabaseCursor.execute( AddTimerQuery.format(\n\t\t\t\ttimerName\n\t\t\t\t, timerValue.getFullTime().hour\n\t\t\t\t, timerValue.getFullTime().minute\n\t\t\t\t, timerValue.getFullTime().second\n\t\t\t\t, timerValue.getCurrentTime().hour\n\t\t\t\t, timerValue.getCurrentTime().minute\n\t\t\t\t, timerValue.getCurrentTime().second\n\t\t\t\t, timerValue.isStarted()\n\t\t\t\t, timerValue.getExecEndTimeWindow()\n\t\t\t\t, timerValue.getShellScriptPath()\n\t\t\t\t, timerValue.getPythonScriptPath()\n\t\t\t\t, timerValue.getPerlScriptPath()\n\t\t\t)\n\t\t\t)\n\n\t\t# Close and commit\n\t\tdatabaseCursor.close( )\n\t\tdatabase.commit( )\n\t\tdatabase.close( )\n\t\tpass\n\n\tdef restore( self ):\n\t\t# If database exist - restore\n\t\tif os.path.exists( DatabaseName ):\n\t\t\tdatabase = sqlite3.connect( DatabaseName )\n\t\t\tdatabaseCursor = database.cursor( )\n\t\t\tdatabaseCursor.execute( SelectTimersQuery )\n\n\t\t\t# databaseCursor contain query result\n\t\t\tfor databaseRow in databaseCursor:\n\t\t\t\trestoredTimer = Timer( databaseRow[ 0 ], time( databaseRow[ 1 ], databaseRow[ 2 ], databaseRow[ 3 ] ) )\n\t\t\t\trestoredTimer.setCurrentTime( time( databaseRow[ 4 ], databaseRow[ 5 ], databaseRow[ 6 ] ) )\n\t\t\t\trestoredTimer._execEndTimerWindow = databaseRow[ 8 ] == TrueValue\n\t\t\t\tif databaseRow[ 9 ] != NoneValue:\n\t\t\t\t\trestoredTimer._execShellScript = databaseRow[ 9 ]\n\t\t\t\tif databaseRow[ 10 ] != NoneValue:\n\t\t\t\t\trestoredTimer._execPythonScript = databaseRow[ 10 ]\n\t\t\t\tif databaseRow[ 11 ] != NoneValue:\n\t\t\t\t\trestoredTimer._execPerlScript = databaseRow[ 11 ]\n\n\t\t\t\trestoredTimer = self.addTimer( restoredTimer )\n\t\t\t\tif databaseRow[ 7 ] == TrueValue:\n\t\t\t\t\trestoredTimer.start( )\n\n\t\t\tdatabaseCursor.close( )\n\t\t\tdatabase.close( )\n"
},
{
"alpha_fraction": 0.7388809323310852,
"alphanum_fraction": 0.7417503595352173,
"avg_line_length": 30.68181800842285,
"blob_id": "ba34e411d2d7717633ce64e3af6da382395f187f",
"content_id": "07724d395eaf502d2841e701a816ae1ee88c2820",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 697,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 22,
"path": "/Gui/SystemTrayIcon.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtWidgets import QSystemTrayIcon, QApplication\nfrom PyQt5.QtGui import QIcon\n\nfrom Resources.Strings import IconPath\n\n# TrayIcon class. Contain even than emmited if user click on icon\nclass SystemTrayIcon( QSystemTrayIcon ):\n\tdef __init__( self, _parentWidget = None ):\n\t\tsuper( SystemTrayIcon, self ).__init__( QIcon( IconPath ), _parentWidget )\n\n\t\tself.parentWidget = _parentWidget\n\t\tself.activated.connect( self.onActivated )\n\n\tdef onActivated( self, _reason ):\n\t\tif _reason == QSystemTrayIcon.Trigger:\n\t\t\tif self.parentWidget._isOpened:\n\t\t\t\t# Hide if parentWidget is opened\n\t\t\t\tself.parentWidget._isOpened = False\n\t\t\t\tself.parentWidget.hide()\n\n\t\t\telse:\n\t\t\t\tself.parentWidget.show()\n"
},
{
"alpha_fraction": 0.7292746305465698,
"alphanum_fraction": 0.7347150444984436,
"avg_line_length": 24.739999771118164,
"blob_id": "eed78511093e2978221687adadd524319bf63a94",
"content_id": "542ad85d57e7e08f186786126cf03fdcd420b3bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3860,
"license_type": "no_license",
"max_line_length": 181,
"num_lines": 150,
"path": "/Model/Timer.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "from PyQt5 import QtCore\nfrom Gui.MessageBox import ShowMessageBox\n\nfrom Resources.Strings import SuccessIconPath, EndTimerMessageBoxTitle, EndTimerMessageBoxMessage, MessageIconPath, EndTimerMessageFileMissing, ShellFormat, PythonFormat, PerlFormat\nfrom Resources.Values import oneSecond\n\nfrom datetime import time\nimport os\n\n\nclass Timer:\n\tdef __init__( self, _timerName, _fullTime = time( 0, 0, 0 ) ):\n\t\tself._timerName = _timerName\n\t\tself._fullTime = _fullTime\n\t\tself._currentTime = self._fullTime\n\t\tself._nullTime = time( 0, 0, 0 )\n\n\t\t# Internal 1 second timer\n\t\tself._internalTimer = QtCore.QTimer( )\n\t\tself._internalTimer.timeout.connect( self.onSecondPassed )\n\t\tself._isStarted = False\n\n\t\tself._execEndTimerWindow = True\n\n\t\t# Do nothing if script path is None\n\t\tself._execShellScript = None\n\t\tself._execPythonScript = None\n\t\tself._execPerlScript = None\n\n\t\t# Vector\n\t\tself._connectedListenersArray = []\n\n\t# Getters\n\tdef isStarted( self ):\n\t\treturn self._isStarted\n\n\tdef getName( self ):\n\t\treturn self._timerName\n\n\tdef getFullTime( self ):\n\t\treturn self._fullTime\n\n\tdef getCurrentTime( self ):\n\t\treturn self._currentTime\n\n\tdef getExecEndTimeWindow( self ):\n\t\treturn self._execEndTimerWindow\n\n\tdef getShellScriptPath( self ):\n\t\treturn self._execShellScript\n\n\tdef getPythonScriptPath( self ):\n\t\treturn self._execPythonScript\n\n\tdef getPerlScriptPath( self ):\n\t\treturn self._execPerlScript\n\n\t# Setters\n\tdef setFullTime( self, _fullTime ):\n\t\tself._fullTime = _fullTime\n\t\tself._currentTime = self._fullTime\n\n\t\t# Emit message for listeners\n\t\tfor currentListener in self._connectedListenersArray:\n\t\t\tcurrentListener.onTimeChanged()\n\n\tdef setCurrentTime( self, _currentTime ):\n\t\tself._currentTime = _currentTime\n\n\t\tfor currentListener in self._connectedListenersArray:\n\t\t\tcurrentListener.onTimeChanged()\n\n\tdef start( self ):\n\t\tself._isStarted = True\n\t\t# Start internal 1 second timer\n\t\tself._internalTimer.start( oneSecond )\n\n\t\tfor currentListener in self._connectedListenersArray:\n\t\t\tcurrentListener.onTimerStart()\n\n\tdef pause( self ):\n\t\tself._isStarted = False\n\t\tself._internalTimer.stop()\n\n\t\tfor currentListener in self._connectedListenersArray:\n\t\t\tcurrentListener.onTimerStop()\n\n\tdef reset( self ):\n\t\tself.pause()\n\t\tself.setFullTime( self._fullTime )\n\n\tdef onFinish( self ):\n\t\tself.reset()\n\n\t\t# self._execShellScript != None\n\t\tif self._execShellScript:\n\t\t\tself.executeScript( ShellFormat, self._execShellScript )\n\n\t\tif self._execPythonScript:\n\t\t\tself.executeScript( PythonFormat, self._execPythonScript )\n\n\t\tif self._execPerlScript:\n\t\t\tself.executeScript( PerlFormat, self._execPerlScript )\n\n\t\tif self._execEndTimerWindow:\n\t\t\tShowMessageBox( SuccessIconPath, EndTimerMessageBoxTitle, EndTimerMessageBoxMessage.format( self._timerName ) )\n\n\tdef executeScript( self, _scriptFormatString, _filePath ):\n\t\tif os.path.exists( _filePath ):\n\t\t\t# Call script using standart system shell\n\t\t\t# Answer to application shell\n\t\t\tos.system( _scriptFormatString.format( _filePath ) )\n\n\t\telse:\n\t\t\tShowMessageBox(\n\t\t\t\t\tMessageIconPath\n\t\t\t\t,\tEndTimerMessageBoxTitle\n\t\t\t\t,\tEndTimerMessageFileMissing.format( _filePath, self._timerName )\n\t\t\t)\n\n\t# Event emmited then internalTimer tick\n\tdef onSecondPassed( self ):\n\t\tif self._currentTime == self._nullTime:\n\t\t\tself.onFinish()\n\n\t\telse:\n\t\t\thour = self._currentTime.hour\n\t\t\tminute = self._currentTime.minute\n\t\t\tsecond = self._currentTime.second\n\n\t\t\tif second == 0 and minute == 0:\n\t\t\t\thour -= 1\n\t\t\t\tminute = 59\n\t\t\t\tsecond = 59\n\t\t\telif second == 0:\n\t\t\t\tminute -= 1\n\t\t\t\tsecond = 59\n\t\t\telse:\n\t\t\t\tsecond -= 1\n\n\t\t\tself._currentTime = time( hour, minute, second )\n\n\t\t\tfor currentListener in self._connectedListenersArray:\n\t\t\t\tcurrentListener.onSecondPassed()\n\n\tdef addListener( self, _listener ):\n\t\tself._connectedListenersArray.append( _listener )\n\n\tdef removeListener( self, _listener ):\n\t\tself._connectedListenersArray.remove( _listener )"
},
{
"alpha_fraction": 0.8045375347137451,
"alphanum_fraction": 0.8062826991081238,
"avg_line_length": 26.285715103149414,
"blob_id": "dec2a8f40d57ceb631009cca5535134ddc9d881b",
"content_id": "0220ece3127171e8be767d98b8d5668cee515b30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 21,
"path": "/Main.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "import sys\nfrom PyQt5.QtWidgets import QApplication\n\nfrom Gui.MessageBox import SetTimerManager\nfrom Gui.SystemTrayIcon import SystemTrayIcon\nfrom Gui.TimerManagerWindow import TimerManagerWindow\nfrom Model.TimerManager import TimerManager\n\nif __name__ == '__main__':\n\tapplication = QApplication( sys.argv )\n\n\ttimerManager = TimerManager()\n\ttimerManager.restore()\n\n\ttimerManagerWindow = TimerManagerWindow( timerManager )\n\tSetTimerManager( timerManagerWindow )\n\n\tsystemTrayIcon = SystemTrayIcon( timerManagerWindow )\n\tsystemTrayIcon.show()\n\n\tsys.exit( application.exec() )\n"
},
{
"alpha_fraction": 0.7499653100967407,
"alphanum_fraction": 0.7595340609550476,
"avg_line_length": 35.60913848876953,
"blob_id": "2b267524accc0932961356ec342c7b6fcc0fb0e7",
"content_id": "1ce532ba6762826479e09fe067a9d1c0012dcb05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7211,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 197,
"path": "/Gui/AddTimerDialog.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "from datetime import time\n\nfrom PyQt5.QtGui import QIcon\nfrom PyQt5.QtWidgets import QGridLayout, QDialog, QLabel, QLineEdit, QSpinBox, QCheckBox, QFileDialog, QPushButton, QMessageBox\n\nfrom Gui.MessageBox import ShowMessageBox\nfrom Model.Timer import Timer\n\nimport platform\n\nfrom Resources.Strings import TimerNameDefaultValue, NewTimerDialogTitle, EndTimerMessageValue, EndTimerShellValue, \\\n\tEndTimerPythonValue, EndTimerPerlValue, StartTimerAfterApplyValue, ApplyButtonValue, TimerNameLabelValue, \\\n\tTimeLabelValue, NoneValue, ChoiseShellScript, ChoisePythonScript, ChoisePerlScript, FailIconPath, \\\n\tErrorMessageBoxTitle, EmptyTimerName, TimerAlreadyAddedMessage, IconPath\n\n\n# Dialog for add or change timer\nclass AddTimerDialog( QDialog ):\n\tdef __init__( self, _parentWidget, _timerManager, _timer = None ):\n\t\tsuper().__init__( _parentWidget )\n\n\t\tself.setWindowIcon( QIcon( IconPath ) )\n\t\tself.resultTimer = None\n\t\tself.setWindowTitle( NewTimerDialogTitle )\n\n\t\tself._timer = _timer\n\t\tself._timerManager = _timerManager\n\n\t\tself.name = TimerNameDefaultValue\n\t\tself.hour = 0\n\t\tself.minute = 0\n\t\tself.second = 0\n\t\tself.showTimerEndWindow = True\n\t\tself.shellScriptPath = \"\"\n\t\tself.pythonScriptPath = \"\"\n\t\tself.perlScriptPath = \"\"\n\n\t\t# if timer non not fill timer info\n\t\tif self._timer:\n\t\t\tself.name = self._timer.getName()\n\n\t\t\tself.hour = self._timer.getFullTime().hour\n\t\t\tself.minute = self._timer.getFullTime().minute\n\t\t\tself.second = self._timer.getFullTime().second\n\n\t\t\tself.showTimerEndWindow = self._timer.getExecEndTimeWindow()\n\t\t\tself.shellScriptPath = self._timer.getShellScriptPath()\n\t\t\tself.pythonScriptPath = self._timer.getPythonScriptPath()\n\t\t\tself.perlScriptPath = self._timer.getPerlScriptPath()\n\n\t\t# Create controls\n\t\tself.nameTextEdit = QLineEdit( self.name )\n\n\t\tself.hourSpinBox = QSpinBox()\n\t\tself.hourSpinBox.setMinimum( 0 )\n\t\tself.hourSpinBox.setMaximum( 23 )\n\t\tself.hourSpinBox.setValue( self.hour )\n\n\t\tself.minuteSpinBox = QSpinBox()\n\t\tself.minuteSpinBox.setMinimum( 0 )\n\t\tself.minuteSpinBox.setMaximum( 59 )\n\t\tself.minuteSpinBox.setValue( self.minute )\n\n\t\tself.secondSpinBox = QSpinBox()\n\t\tself.secondSpinBox.setMinimum( 0 )\n\t\tself.secondSpinBox.setMaximum( 59 )\n\t\tself.secondSpinBox.setValue( self.second )\n\n\t\tself.showTimerEndWindowCheckBox = QCheckBox( EndTimerMessageValue )\n\t\tself.showTimerEndWindowCheckBox.setChecked( self.showTimerEndWindow )\n\n\t\tself.execShellScriptCheckBox = QCheckBox( )\n\t\tself.execShellScriptCheckBox.clicked[ bool ].connect( self.onExecShellScriptClicked )\n\t\tif self.shellScriptPath:\n\t\t\tself.execShellScriptCheckBox.setText( self.shellScriptPath )\n\t\t\tself.execShellScriptCheckBox.setChecked( True )\n\t\telse:\n\t\t\tself.execShellScriptCheckBox.setText( EndTimerShellValue )\n\n\t\tself.execPythonScriptCheckBox = QCheckBox( )\n\t\tself.execPythonScriptCheckBox.clicked[ bool ].connect( self.onExecPythonScriptClicked )\n\t\tif self.pythonScriptPath:\n\t\t\tself.execPythonScriptCheckBox.setText( self.pythonScriptPath )\n\t\t\tself.execPythonScriptCheckBox.setChecked( True )\n\t\telse:\n\t\t\tself.execPythonScriptCheckBox.setText( EndTimerPythonValue )\n\n\t\tself.execPerlScriptCheckBox = QCheckBox( )\n\t\tself.execPerlScriptCheckBox.clicked[ bool ].connect( self.onExecPerlScriptClicked )\n\t\tif self.perlScriptPath:\n\t\t\tself.execPerlScriptCheckBox.setText( self.perlScriptPath )\n\t\t\tself.execPerlScriptCheckBox.setChecked( True )\n\t\telse:\n\t\t\tself.execPerlScriptCheckBox.setText( EndTimerPerlValue )\n\n\t\tself.startTimerAfterCreateCheckBox = QCheckBox( StartTimerAfterApplyValue )\n\t\tself.startTimerAfterCreateCheckBox.setChecked( True )\n\n\t\tself.applyPushButton = QPushButton( ApplyButtonValue )\n\t\tself.applyPushButton.clicked[ bool ].connect( self.onApplyPushButtonClicked )\n\n\t\tself.initUI()\n\n\tdef initUI( self ):\n\t\tgridLayout = QGridLayout()\n\n\t\tgridLayout.addWidget( QLabel( TimerNameLabelValue ), 0, 0, 1, 1 )\n\t\tgridLayout.addWidget( self.nameTextEdit, 0, 1, 1, 3 )\n\n\t\tgridLayout.addWidget( QLabel( TimeLabelValue ), 1, 0, 1, 1 )\n\t\tgridLayout.addWidget( self.hourSpinBox, 1, 1, 1, 1 )\n\t\tgridLayout.addWidget( self.minuteSpinBox, 1, 2, 1, 1 )\n\t\tgridLayout.addWidget( self.secondSpinBox, 1, 3, 1, 1 )\n\n\t\tgridLayout.addWidget( self.showTimerEndWindowCheckBox, 2, 1, 1, 3 )\n\t\tgridLayout.addWidget( self.execShellScriptCheckBox, 3, 1, 1, 3 )\n\t\tgridLayout.addWidget( self.execPythonScriptCheckBox, 4, 1, 1, 3 )\n\t\tgridLayout.addWidget( self.execPerlScriptCheckBox, 5, 1, 1, 3 )\n\n\t\tgridLayout.addWidget( self.startTimerAfterCreateCheckBox, 7, 1, 1, 3 )\n\n\t\tgridLayout.addWidget( self.applyPushButton, 8, 1, 1, 4 )\n\n\t\tself.setLayout( gridLayout )\n\n\tdef onExecShellScriptClicked( self ):\n\t\t# Create OpenFileDioalog for choise script\n\t\tif self.execShellScriptCheckBox.isChecked( ):\n\t\t\tscriptFilter = \"\"\n\t\t\tif platform.system() == \"Windows\":\n\t\t\t\tscriptFilter = \"*.bat\"\n\t\t\telif platform.system() == \"Linux\":\n\t\t\t\tscriptFilter = \"*.sh\"\n\n\t\t\tfilePath = QFileDialog().getOpenFileName( self, ChoiseShellScript, \"\", scriptFilter, NoneValue )\n\n\t\t\tif filePath[ 1 ] != NoneValue:\n\t\t\t\tself.execShellScriptCheckBox.setText( filePath[ 0 ] )\n\t\t\telse:\n\t\t\t\tself.execShellScriptCheckBox.setChecked( False )\n\n\t\telse:\n\t\t\tself.execShellScriptCheckBox.setText( EndTimerShellValue )\n\n\tdef onExecPythonScriptClicked( self ):\n\t\tif self.execPythonScriptCheckBox.isChecked( ):\n\t\t\tfilePath = QFileDialog().getOpenFileName( self, ChoisePythonScript, \"\", \"*.py\", NoneValue )\n\n\t\t\tif filePath[ 1 ] != NoneValue:\n\t\t\t\tself.execPythonScriptCheckBox.setText( filePath[ 0 ] )\n\t\t\telse:\n\t\t\t\tself.execPythonScriptCheckBox.setChecked( False )\n\n\t\telse:\n\t\t\tself.execPythonScriptCheckBox.setText( EndTimerPythonValue )\n\n\tdef onExecPerlScriptClicked( self ):\n\t\tif self.execPerlScriptCheckBox.isChecked( ):\n\t\t\tfilePath = QFileDialog().getOpenFileName( self, ChoisePerlScript, \"\", \"*.pl\", NoneValue )\n\n\t\t\tif filePath[ 1 ] != NoneValue:\n\t\t\t\tself.execPerlScriptCheckBox.setText( filePath[ 0 ] )\n\t\t\telse:\n\t\t\t\tself.execPerlScriptCheckBox.setChecked( False )\n\n\t\telse:\n\t\t\tself.execPerlScriptCheckBox.setText( EndTimerPerlValue )\n\n\tdef onApplyPushButtonClicked( self ):\n\t\t# Check nameTextEdit is not empty\n\t\tif len( self.nameTextEdit.text() ) == 0:\n\t\t\tShowMessageBox( FailIconPath, ErrorMessageBoxTitle, EmptyTimerName )\n\n\t\t# Check that timer name is unique\n\t\telif self._timerManager.getTimer( self.nameTextEdit.text() ) and not self._timer:\n\t\t\tShowMessageBox( FailIconPath, ErrorMessageBoxTitle, TimerAlreadyAddedMessage.format( self.nameTextEdit.text() ) )\n\n\t\t# Fill result timer\n\t\telse:\n\t\t\tself.resultTimer = Timer(\n\t\t\t\t\tself.nameTextEdit.text()\n\t\t\t\t,\ttime( self.hourSpinBox.value(), self.minuteSpinBox.value(), self.secondSpinBox.value() )\n\t\t\t)\n\t\t\tself.resultTimer.setCurrentTime( time( self.hourSpinBox.value(), self.minuteSpinBox.value(), self.secondSpinBox.value() ) )\n\n\t\t\tself.resultTimer._execEndTimerWindow = self.showTimerEndWindowCheckBox.isChecked()\n\n\t\t\tif self.execShellScriptCheckBox.isChecked( ):\n\t\t\t\tself.resultTimer._execShellScript = self.execShellScriptCheckBox.text( )\n\n\t\t\tif self.execPerlScriptCheckBox.isChecked( ):\n\t\t\t\tself.resultTimer._execPerlScript = self.execPerlScriptCheckBox.text( )\n\n\t\t\tif self.execPythonScriptCheckBox.isChecked( ):\n\t\t\t\tself.resultTimer._execPythonScript = self.execPythonScriptCheckBox.text( )\n\n\t\t\tself.close()"
},
{
"alpha_fraction": 0.7363505959510803,
"alphanum_fraction": 0.7363505959510803,
"avg_line_length": 38.2253532409668,
"blob_id": "ba002bc2e8f632026abc2d5e555b3ee48871a8e3",
"content_id": "30de27eb9af45eb7547a3aa24b7388c3d64b4e0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3336,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 71,
"path": "/Resources/Strings.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "SuccessIconPath = \"Resources/Images/Success.ico\"\nMessageIconPath = \"Resources/Images/Message.ico\"\nFailIconPath = \"Resources/Images/Fail.ico\"\nIconPath = \"Resources/Images/Icon.ico\"\nStartIconPath = \"Resources/Images/Start.ico\"\nPauseIconPath = \"Resources/Images/Pause.ico\"\nStopIconPath = \"Resources/Images/Stop.ico\"\nAddIconPath = \"Resources/Images/Add.ico\"\nRemoveIconPath = \"Resources/Images/Remove.ico\"\nEditIconPath = \"Resources/Images/Edit.ico\"\nExitIconPath = \"Resources/Images/Exit.ico\"\n\nDatabaseName = \"timer_database.db\"\nRemoveTimerTableQuery = \"DROP TABLE IF EXISTS timers\"\nCreateTimerTableQuery = \"\"\"\nCREATE TABLE timers (\n\tname \tTEXT NOT NULL,\n\ttime_hour \tINTEGER NOT NULL,\n\ttime_minute \tINTEGER NOT NULL,\n\ttime_second \tINTEGER NOT NULL,\n\tcurrent_time_hour \tINTEGER NOT NULL,\n\tcurrent_time_minute \tINTEGER NOT NULL,\n\tcurrent_time_second \tINTEGER NOT NULL,\n\tstarted\t\t\t\t\tTEXT NOT NULL,\n\tshow_timer_end_window\tTEXT NOT NULL,\n\tshell_path\t\t\t\tTEXT NOT NULL,\n\tperl_path\t\t\t\tTEXT NOT NULL,\n\tpython_path\t\t\t\tTEXT NOT NULL,\n\tPRIMARY KEY ( name )\n);\n\"\"\"\nAddTimerQuery = \"INSERT INTO timers VALUES ( \\'{}\\', {}, {}, {}, {}, {}, {}, \\'{}\\', \\'{}\\', \\'{}\\', \\'{}\\', \\'{}\\' );\"\nSelectTimersQuery = \"SELECT * FROM timers\"\nTrueValue = str( True )\nNoneValue = str( None )\n\nTableColumnsNames = [ \"Состояние\", \"Имя\", \"Полное Время\", \"Текущее Время\", \"Окно завершение таймера\", \"Shell Скрипт\", \"Python Скрипт\", \"Perl Скрипт\" ]\nTimerManagerDialogTitle = \"Менеджер таймеров\"\nStartButtonText = \"Активировать\"\nPauseButtonText = \"Остановить\"\nResetButtonText = \"Сбросить\"\nAddButtonText = \"Добавить\"\nRemoveButtonText = \"Удалить\"\nEditButtonText = \"Изменить\"\nExitButtonText = \"Сохранить и выйти\"\n\nNewTimerDialogTitle = \"Новый таймер\"\nTimerNameDefaultValue = \"Новый таймер\"\nEndTimerMessageValue = \"По завершению таймера вывести окно с сообщением\"\nEndTimerShellValue = \"По завершению таймера выполнить shell скрипт\"\nEndTimerPythonValue = \"По завершению таймера выполнить python скрипт\"\nEndTimerPerlValue = \"По завершению таймера выполнить perl скрипт\"\nStartTimerAfterApplyValue = \"Запустить таймер после того, как это окно будет закрыто\"\nApplyButtonValue = \"Применить\"\nTimerNameLabelValue = \"Имя таймера:\"\nTimeLabelValue = \"Время:\"\nChoiseShellScript = \"Выберете Shell Cкрипт\"\nChoisePythonScript = \"Выберете Python Cкрипт\"\nChoisePerlScript = \"Выберете Perl Cкрипт\"\n\nEndTimerMessageBoxTitle = \"Таймер завершен\"\nEndTimerMessageBoxMessage = \"Таймер \\\"{}\\\" завершен\"\nEndTimerMessageFileMissing = \"Файл {} не существует, но таймер \\\"{}\\\" завершен\"\n\nErrorMessageBoxTitle = \"Ошибка!\"\nTimerAlreadyAddedMessage = \"Таймер с именем \\\"{}\\\" уже был добавлен!\"\nEmptyTimerName = \"Имя таймера не может быть пустым\"\n\nPerlFormat = \"perl {}\"\nPythonFormat = \"python {}\"\nShellFormat = \"{}\""
},
{
"alpha_fraction": 0.7495753169059753,
"alphanum_fraction": 0.7573404312133789,
"avg_line_length": 33.63445281982422,
"blob_id": "b2e58d18f1a3379b695c8e8240bedd349f967ff3",
"content_id": "74d89f8805557a216aefa6ed2a4ece26d9257065",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8242,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 238,
"path": "/Gui/TimerManagerWindow.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtWidgets import QWidget, QGridLayout, QTableWidget, QTableWidgetItem, QHeaderView, QPushButton, QAbstractItemView\nfrom PyQt5.QtCore import Qt\nfrom PyQt5.QtGui import QIcon\n\nfrom Gui.TimersManagerListener import TimersManagerListener\nfrom Gui.AddTimerDialog import AddTimerDialog\nfrom Resources.Strings import TableColumnsNames, TimerManagerDialogTitle, StartButtonText, PauseButtonText, \\\n\tResetButtonText, AddButtonText, RemoveButtonText, EditButtonText, ExitButtonText, IconPath, StartIconPath, \\\n\tPauseIconPath, StopIconPath, AddIconPath, RemoveIconPath, EditIconPath, ExitIconPath\nfrom Resources.Values import tableColumnsCount\n\n\nclass TimerManagerWindow( QWidget ):\n\tdef __init__( self, _timerManager ):\n\t\tsuper().__init__()\n\t\tself.setWindowIcon( QIcon( IconPath ) )\n\n\t\tself._isExitInitiatedByUser = False\n\t\t# If true - window if opened\n\t\tself._isOpened = False\n\t\tself._timerManager = _timerManager\n\n\t\tself._tableWidget = QTableWidget( self )\n\t\tself._tableWidget.setColumnCount( tableColumnsCount )\n\t\tself._tableWidget.setHorizontalHeaderLabels( TableColumnsNames )\n\t\tself._tableWidget.horizontalHeader().setSectionResizeMode( QHeaderView.ResizeToContents )\n\t\tself._tableWidget.setSelectionBehavior( QAbstractItemView.SelectRows )\n\n\t\tself._listenersArray = {}\n\n\t\t# Initialize all controll\n\t\tself.initUi()\n\n\tdef initUi( self ):\n\t\tself.setWindowTitle( TimerManagerDialogTitle )\n\n\t\tgridLayout = QGridLayout()\n\n\t\tstartButton = QPushButton( StartButtonText )\n\t\tstartButton.setIcon( QIcon( StartIconPath ) )\n\t\tstartButton.clicked[ bool ].connect( self.onStartButtonClicked )\n\n\t\tpauseButton = QPushButton( PauseButtonText )\n\t\tpauseButton.setIcon( QIcon( PauseIconPath ) )\n\t\tpauseButton.clicked[ bool ].connect( self.onPauseButtonClicked )\n\n\t\tresetButton = QPushButton( ResetButtonText )\n\t\tresetButton.setIcon( QIcon( StopIconPath ) )\n\t\tresetButton.clicked[ bool ].connect( self.onResetButtonClicked )\n\n\t\taddButton = QPushButton( AddButtonText )\n\t\taddButton.setIcon( QIcon( AddIconPath ) )\n\t\taddButton.clicked[ bool ].connect( self.onAddButtonClicked )\n\n\t\tremoveButton = QPushButton( RemoveButtonText )\n\t\tremoveButton.setIcon( QIcon( RemoveIconPath ) )\n\t\tremoveButton.clicked[ bool ].connect( self.onRemoveButtonClicked )\n\n\t\teditButton = QPushButton( EditButtonText )\n\t\teditButton.setIcon( QIcon( EditIconPath ) )\n\t\teditButton.clicked[ bool ].connect( self.onEditButtonClicked )\n\n\t\texitButton = QPushButton( ExitButtonText )\n\t\texitButton.setIcon( QIcon( ExitIconPath ) )\n\t\texitButton.clicked[ bool ].connect( self.onExitButtonClicked )\n\n\t\tgridLayout.addWidget( self._tableWidget,\t0, 0, 1, 3 )\n\t\tgridLayout.addWidget( startButton,\t\t\t1, 0, 1, 1 )\n\t\tgridLayout.addWidget( pauseButton,\t\t\t1, 1, 1, 1 )\n\t\tgridLayout.addWidget( resetButton,\t\t\t1, 2, 1, 1 )\n\t\tgridLayout.addWidget( addButton,\t\t\t2, 0, 1, 1 )\n\t\tgridLayout.addWidget( removeButton,\t\t\t2, 1, 1, 1 )\n\t\tgridLayout.addWidget( editButton,\t\t\t2, 2, 1, 1 )\n\t\tgridLayout.addWidget( exitButton,\t\t\t3, 0, 1, 3 )\n\n\t\tself.setGeometry( 500, 500, 1000, 500 )\n\t\tself.setLayout( gridLayout )\n\n\t# Update timer table before show window\n\tdef show( self ):\n\t\tself.updateTimerTable()\n\t\tself._isOpened = True\n\t\tsuper().show()\n\n\t# Fill timerTable using timers info\n\tdef updateTimerTable( self ):\n\t\tself.detachListeners()\n\t\tself._tableWidget.setRowCount( self._timerManager.getTimersCount() )\n\n\t\trowNumber = 0\n\t\tfor timerName, timer in self._timerManager.items():\n\t\t\trunTimerStateTableWidgetItem = QTableWidgetItem()\n\t\t\tnameTableWidgetItem = QTableWidgetItem()\n\t\t\ttimeTableWidgetItem = QTableWidgetItem()\n\t\t\tcurrentTimeTableWidgetItem = QTableWidgetItem()\n\t\t\twindowTableWidgetItem = QTableWidgetItem()\n\t\t\tshellTableWidgetItem = QTableWidgetItem()\n\t\t\tpythonTableWidgetItem = QTableWidgetItem()\n\t\t\tperlTableWidgetItem = QTableWidgetItem()\n\n\t\t\tif timer.isStarted():\n\t\t\t\trunTimerStateTableWidgetItem.setCheckState( Qt.Checked )\n\t\t\telse:\n\t\t\t\trunTimerStateTableWidgetItem.setCheckState( Qt.Unchecked )\n\n\t\t\tif timer.getExecEndTimeWindow():\n\t\t\t\twindowTableWidgetItem.setCheckState( Qt.Checked )\n\t\t\telse:\n\t\t\t\twindowTableWidgetItem.setCheckState( Qt.Unchecked )\n\n\t\t\tif timer.getShellScriptPath():\n\t\t\t\tshellTableWidgetItem.setCheckState( Qt.Checked )\n\t\t\telse:\n\t\t\t\tshellTableWidgetItem.setCheckState( Qt.Unchecked )\n\n\t\t\tif timer.getPythonScriptPath():\n\t\t\t\tpythonTableWidgetItem.setCheckState( Qt.Checked )\n\t\t\telse:\n\t\t\t\tpythonTableWidgetItem.setCheckState( Qt.Unchecked )\n\n\t\t\tif timer.getPerlScriptPath():\n\t\t\t\tperlTableWidgetItem.setCheckState( Qt.Checked )\n\t\t\telse:\n\t\t\t\tperlTableWidgetItem.setCheckState( Qt.Unchecked )\n\n\t\t\tnameTableWidgetItem.setText( timer.getName() )\n\t\t\ttimeTableWidgetItem.setText( str( timer.getFullTime() ) )\n\t\t\tcurrentTimeTableWidgetItem.setText( str( timer.getCurrentTime() ) )\n\n\t\t\tself._tableWidget.setItem( rowNumber, 0, runTimerStateTableWidgetItem )\n\t\t\tself._tableWidget.setItem( rowNumber, 1, nameTableWidgetItem )\n\t\t\tself._tableWidget.setItem( rowNumber, 2, timeTableWidgetItem )\n\t\t\tself._tableWidget.setItem( rowNumber, 3, currentTimeTableWidgetItem )\n\t\t\tself._tableWidget.setItem( rowNumber, 4, windowTableWidgetItem )\n\t\t\tself._tableWidget.setItem( rowNumber, 5, shellTableWidgetItem )\n\t\t\tself._tableWidget.setItem( rowNumber, 6, pythonTableWidgetItem )\n\t\t\tself._tableWidget.setItem( rowNumber, 7, perlTableWidgetItem )\n\n\t\t\tfor i in range( 0, 8 ):\n\t\t\t\tself._tableWidget.item( rowNumber, i ).setFlags( Qt.ItemIsSelectable | Qt.ItemIsEnabled )\n\n\t\t\tself._listenersArray.setdefault( timer, TimersManagerListener( timer, self._tableWidget, rowNumber ) )\n\t\t\ttimer.addListener( self._listenersArray[ timer ] )\n\n\t\t\trowNumber += 1\n\n\tdef detachListeners( self ):\n\t\tfor timer, listener in self._listenersArray.items():\n\t\t\ttimer.removeListener( listener )\n\n\t\tself._listenersArray = {}\n\n\t# onclicked methods\n\tdef onStartButtonClicked( self ):\n\t\tfor timerName in self.getSelectedTimerNames():\n\t\t\tself._timerManager.getTimer( timerName ).start()\n\n\tdef onResetButtonClicked( self ):\n\t\tfor timerName in self.getSelectedTimerNames():\n\t\t\tself._timerManager.getTimer( timerName ).reset()\n\n\tdef onPauseButtonClicked( self ):\n\t\tfor timerName in self.getSelectedTimerNames():\n\t\t\tself._timerManager.getTimer( timerName ).pause()\n\n\t# Create AddTimerDialog and add new timer if it will be created\n\tdef onAddButtonClicked( self ):\n\t\teditTimerWindow = AddTimerDialog( self, self._timerManager )\n\t\teditTimerWindow.exec()\n\n\t\tif editTimerWindow.resultTimer:\n\t\t\tnewTimer = self._timerManager.addTimer( editTimerWindow.resultTimer )\n\n\t\t\tself.updateTimerTable()\n\n\t\t\tif editTimerWindow.startTimerAfterCreateCheckBox.isChecked():\n\t\t\t\tnewTimer.start()\n\n\tdef onRemoveButtonClicked( self ):\n\t\tfor timerName in self.getSelectedTimerNames():\n\t\t\tself._timerManager.removeTimer( timerName )\n\n\t\tself.updateTimerTable()\n\n\tdef onEditButtonClicked( self ):\n\t\tselectedTimerNames = self.getSelectedTimerNames()\n\n\t\t# only for first selected timer\n\t\tif len( selectedTimerNames ) > 0:\n\t\t\toldTimer = self._timerManager.getTimer( selectedTimerNames[ 0 ] )\n\t\t\tisStarted = oldTimer.isStarted()\n\t\t\toldTimer.pause()\n\n\t\t\teditTimerWindow = AddTimerDialog( self, self._timerManager, oldTimer )\n\t\t\teditTimerWindow.exec()\n\n\t\t\t# If new timer created, remove old and add new. Update table\n\t\t\tif editTimerWindow.resultTimer:\n\t\t\t\tself._timerManager.removeTimer( selectedTimerNames[ 0 ] )\n\n\t\t\t\tnewTimer = self._timerManager.addTimer( editTimerWindow.resultTimer )\n\n\t\t\t\tself.updateTimerTable()\n\n\t\t\t\tif editTimerWindow.startTimerAfterCreateCheckBox.isChecked():\n\t\t\t\t\tnewTimer.start()\n\n\t\t\telif isStarted:\n\t\t\t\toldTimer.start()\n\n\tdef onExitButtonClicked( self ):\n\t\tself._isExitInitiatedByUser = True\n\t\tself.close()\n\n\t# return selected timers name in table\n\tdef getSelectedTimerNames( self ):\n\t\tselectedRows = []\n\t\tfor index in self._tableWidget.selectedIndexes( ):\n\t\t\tif index.row().numerator not in selectedRows:\n\t\t\t\tselectedRows.append( index.row().numerator )\n\n\t\ttimerNames = []\n\t\tfor row in selectedRows:\n\t\t\ttimerNames.append( self._tableWidget.item( row, 1 ).text() )\n\n\t\treturn timerNames\n\n\t# dont close application if user don't click on exit button\n\tdef closeEvent(self, QCloseEvent):\n\t\tself._isOpened = False\n\t\tself.detachListeners()\n\n\t\tif not self._isExitInitiatedByUser:\n\t\t\tself.hide()\n\t\t\tQCloseEvent.ignore()\n\n\t\telse:\n\t\t\tself._timerManager.save()"
},
{
"alpha_fraction": 0.6282051205635071,
"alphanum_fraction": 0.6282051205635071,
"avg_line_length": 25.33333396911621,
"blob_id": "5b51cd664eed70ef5b178003186208a1d043a2e8",
"content_id": "e4fb91f87660c367b8d4841175ec94c66222f108",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 3,
"path": "/EndTimerScripts/PythonFileExample.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "file = open( \"python_result.txt\", \"w\" )\nfile.write( \"It's Work\" )\nfile.close()"
},
{
"alpha_fraction": 0.6822840571403503,
"alphanum_fraction": 0.7042459845542908,
"avg_line_length": 34.02564239501953,
"blob_id": "11467902d5559999d81fb6df7e1ba48cc30890aa",
"content_id": "e187b3653892f70cef083855c9ddf252d098cc7b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1366,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 39,
"path": "/Test/TimerTests.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom datetime import time\n\nfrom Model.Timer import Timer\n\n\nclass TimerTestCase( unittest.TestCase ):\n\tdef test_TimerCurrentTimeEqualFullTimeByDefault( self ):\n\t\ttimer = Timer( \"Test Timer\", time( 0, 0, 5 ) )\n\t\tself.assertEqual( timer.getCurrentTime(), timer.getFullTime() )\n\n\tdef test_TimerNotStartedByDefault( self ):\n\t\ttimer = Timer( \"Test Timer\", time( 0, 0, 5 ) )\n\t\tself.assertEqual( timer.isStarted(), False )\n\n\tdef test_TimerOnlyExecEndTimerWindowByDefault( self ):\n\t\ttimer = Timer( \"Test Timer\", time( 0, 0, 5 ) )\n\t\tself.assertEqual( timer.getExecEndTimeWindow(), True )\n\t\tself.assertEqual( timer.getShellScriptPath(), None )\n\t\tself.assertEqual( timer.getPythonScriptPath(), None )\n\t\tself.assertEqual( timer.getPerlScriptPath(), None )\n\n\tdef test_TimerCorrectSecondPass( self ):\n\t\ttimer = Timer( \"Test Timer\", time( 0, 0, 5 ) )\n\t\ttimer.onSecondPassed()\n\t\tself.assertEqual( timer.getCurrentTime(), time( 0, 0, 4 ) )\n\n\tdef test_TimerCorrectSecondPassOnMinutePass( self ):\n\t\ttimer = Timer( \"Test Timer\", time( 0, 1, 0 ) )\n\t\ttimer.onSecondPassed()\n\t\tself.assertEqual( timer.getCurrentTime(), time( 0, 0, 59 ) )\n\n\tdef test_TimerCorrectSecondPassOnHourPass( self ):\n\t\ttimer = Timer( \"Test Timer\", time( 1, 0, 0 ) )\n\t\ttimer.onSecondPassed()\n\t\tself.assertEqual( timer.getCurrentTime(), time( 0, 59, 59 ) )\n\nif __name__ == '__main__':\n\tunittest.main()\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.6875,
"avg_line_length": 32,
"blob_id": "5d836d34327305961c1efed9fc81a20a3539de81",
"content_id": "927ad252424628efc6e621512e92c38928d5b38e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 32,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 1,
"path": "/EndTimerScripts/ShFileExample.sh",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "echo \"It's Work\" > sh_result.txt"
},
{
"alpha_fraction": 0.7781752943992615,
"alphanum_fraction": 0.7817531228065491,
"avg_line_length": 25.619047164916992,
"blob_id": "a8b65d1952df642bbab830736a5eb60f2ab97336",
"content_id": "e6ef45a69acb0930e0c92ff2223c05b2945ef218",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 559,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 21,
"path": "/Gui/MessageBox.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtWidgets import QMessageBox\nfrom PyQt5.QtGui import QIcon\n\nmessageBox = None\nTimerManager = None\n\ndef SetTimerManager( _timerManager ):\n\tglobal TimerManager\n\tTimerManager = _timerManager\n\n# display message box with icon, title, message and ok button\n# open timer manager if executed\ndef ShowMessageBox( _iconPath, _titleName, _message ):\n\tglobal messageBox\n\tTimerManager.show()\n\n\tmessageBox = QMessageBox()\n\tmessageBox.setWindowIcon( QIcon( _iconPath ) )\n\tmessageBox.setWindowTitle( _titleName )\n\tmessageBox.setText( _message )\n\tmessageBox.exec()\n"
},
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.7002652287483215,
"avg_line_length": 34.904762268066406,
"blob_id": "b111b16aea254990b5ceacab13d21f81d91113ba",
"content_id": "35f9deac1fd4b666318239dcf6dc0dfe48b70629",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 21,
"path": "/Gui/TimersManagerListener.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "from PyQt5.QtCore import Qt\n\n# Listener for change table by timers events\nclass TimersManagerListener:\n\tdef __init__( self, _timer, _tableWidget, _currentRow ):\n\t\tself._table = _tableWidget\n\t\tself._timerRow = _currentRow\n\t\tself._timer = _timer\n\n\tdef onTimerStart( self ):\n\t\tself._table.item( self._timerRow, 0 ).setCheckState( Qt.Checked )\n\n\tdef onTimerStop( self ):\n\t\tself._table.item( self._timerRow, 0 ).setCheckState( Qt.Unchecked )\n\n\tdef onTimeChanged( self ):\n\t\tself._table.item( self._timerRow, 2 ).setText( str( self._timer.getFullTime() ) )\n\t\tself._table.item( self._timerRow, 3 ).setText( str( self._timer.getCurrentTime() ) )\n\n\tdef onSecondPassed( self ):\n\t\tself._table.item( self._timerRow, 3 ).setText( str( self._timer.getCurrentTime() ) )\n"
},
{
"alpha_fraction": 0.6840202212333679,
"alphanum_fraction": 0.7020968794822693,
"avg_line_length": 30.454545974731445,
"blob_id": "6262b821df1642b29698c63395f2e0d761d7a808",
"content_id": "552d6d2dbfa6c91dc3dda342617e6803485167d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1383,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 44,
"path": "/Test/TimerManagerTests.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom datetime import time\n\nfrom Model.TimerManager import TimerManager\nfrom Model.Timer import Timer\n\n\nclass TimerManagerTestCase( unittest.TestCase ):\n\tdef test_AddTimer( self ):\n\t\ttimerManager = TimerManager()\n\t\ttimerManager.addTimer( Timer( \"Timer Name\", time( 0, 0, 0 ) ) )\n\t\tself.assertIsNotNone( timerManager.getTimer( \"Timer Name\" ) )\n\n\tdef test_GetNotExistingTimer( self ):\n\t\ttimerManager = TimerManager()\n\t\tself.assertIsNone( timerManager.getTimer( \"Timer Name\" ) )\n\n\tdef test_RemoveTimer( self ):\n\t\ttimerManager = TimerManager()\n\t\ttimerManager.addTimer( Timer( \"Timer Name\", time( 0, 0, 0 ) ) )\n\t\ttimerManager.removeTimer( \"Timer Name\" )\n\t\tself.assertIsNone( timerManager.getTimer( \"Timer Name\" ) )\n\n\tdef test_GetTimersCount( self ):\n\t\ttimerManager = TimerManager()\n\t\ttimerManager.addTimer( Timer( \"Timer Name\", time( 0, 0, 0 ) ) )\n\t\tself.assertEqual( timerManager.getTimersCount(), 1 )\n\t\ttimerManager.addTimer( Timer( \"Timer Name 2\", time( 0, 0, 0 ) ) )\n\t\tself.assertEqual( timerManager.getTimersCount(), 2 )\n\n\tdef test_Items( self ):\n\t\ttimerManager = TimerManager()\n\t\ttimerManager.addTimer( Timer( \"Timer Name\", time( 0, 0, 0 ) ) )\n\t\ttimerManager.addTimer( Timer( \"Timer Name 2\", time( 0, 0, 0 ) ) )\n\n\t\titemsCount = 0\n\t\tfor item in timerManager.items():\n\t\t\titemsCount += 1\n\n\t\tself.assertEqual( itemsCount, 2 )\n\n\nif __name__ == '__main__':\n\tunittest.main()"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.7948718070983887,
"avg_line_length": 18.5,
"blob_id": "e3eeafabdf178128cea994cc2a06ec8e23513b25",
"content_id": "878cb38db6a1e259d1723f4990b84d0492538b2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/Resources/Values.py",
"repo_name": "FalseSky/CourseProject",
"src_encoding": "UTF-8",
"text": "oneSecond = 1000\ntableColumnsCount = 8\n"
}
] | 14 |
Neltarim/faster-zsh | https://github.com/Neltarim/faster-zsh | b2543c6dd4d94cb9dd8a8c7dd743f3a1771ee907 | 9f1e45145f3852f68d199cb34fdd905b8517f983 | ff8a43e9138f91e5b1716841a62baca74eefed5d | refs/heads/master | 2022-05-05T08:27:52.917908 | 2022-03-26T10:00:34 | 2022-03-26T10:00:34 | 263,608,689 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5859901309013367,
"alphanum_fraction": 0.597665011882782,
"avg_line_length": 25.5238094329834,
"blob_id": "73a5fb384d9dc9a7c2e8066aa1cb736524afde03",
"content_id": "3d43285b42c385356a170ea0030903779f36affb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2227,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 84,
"path": "/lib/ithree.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from lib.profile import WORKSPACES, DISPLAYS\nfrom tools.termup import prompt\n\nfrom os import system as sc\n\ndef workspace_loader():\n \"\"\"Load all saved workspaces\"\"\"\n for workspace in WORKSPACES:\n prompt(\"Restoring workspace {}\".format(workspace))\n sc(\"i3-resurrect restore -w {}\".format(workspace))\n\ndef bright(bright_lvl):\n formatted_lvl = None\n\n if int(bright_lvl) < 10 and int(bright_lvl) > 0:\n formatted_lvl = \"0.\" + bright_lvl\n formatted_lvl = float(formatted_lvl)\n\n elif int(bright_lvl) == 10:\n formatted_lvl = 1\n\n\n if formatted_lvl != None:\n index = 0\n for display in DISPLAYS:\n sc(\"xrandr --output {} --brightness {}\".format(display, formatted_lvl))\n index += 1\n \n prompt(\"Brightness set to {}\".format(bright_lvl))\n\n elif formatted_lvl == None:\n prompt(\"ERROR: Invalid arguments.\")\n\ndef bright_for(screen, bright_lvl):\n\n if screen == \"top\":\n screen = DISPLAYS[1]\n\n elif screen == \"bot\":\n screen = DISPLAYS[0]\n\n formatted_lvl = None\n\n if int(bright_lvl) < 10 and int(bright_lvl) > 0:\n formatted_lvl = \"0.\" + bright_lvl\n formatted_lvl = float(formatted_lvl)\n\n elif int(bright_lvl) == 10:\n formatted_lvl = 1\n\n\n if formatted_lvl != None:\n sc(\"xrandr --output {} --brightness {}\".format(screen, formatted_lvl))\n \n prompt(\"Brightness set to {}\".format(bright_lvl))\n\n elif formatted_lvl == None:\n prompt(\"ERROR: Invalid arguments.\")\n\n\ndef bastion():\n prompt(\"Moving this workspace to bastion screen.\")\n sc(\"xrandr --output {} --auto --right-of {}\".format(DISPLAYS[1], DISPLAYS[0]))\n sc(\"i3-msg move workspace to output right\")\n\ndef scout():\n prompt(\"Moving this workspace to scout screen.\")\n sc(\"i3-msg move workspace to output right\")\n sc(\"xrandr --output {} --off\".format(DISPLAYS[1]))\n\ndef wmove(side):\n\n if side == \"bot\":\n side = \"left\"\n\n elif side == \"top\":\n side = \"right\"\n\n else:\n prompt(\"Wrong argument. Must be \\\"top\\\" or \\\"bot\\\".\", type=\"fail\", plus=\"bold\")\n return 0\n\n sc(\"i3-msg move workspace to output \" + side)\n prompt(\"Workspace moved.\", type=\"okgreen\")"
},
{
"alpha_fraction": 0.5017421841621399,
"alphanum_fraction": 0.5662021040916443,
"avg_line_length": 30.88888931274414,
"blob_id": "f8819e822141c8289f1b4b4ccb119c1e75aad9b7",
"content_id": "69daa45fee38c02d025e06abb5b02a58ea87e556",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 574,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 18,
"path": "/tools/const.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "class bcolors:\n HEADER = '\\033[95m'\n OKBLUE = '\\033[94m'\n OKGREEN = '\\033[92m'\n WARNING = '\\033[93m'\n FAIL = '\\033[91m'\n ENDC = '\\033[0m'\n BOLD = '\\033[1m'\n UNDERLINE = '\\033[4m'\n\n def colortest(self):\n print(self.HEADER + \"HEADER\" +self.ENDC)\n print(self.OKBLUE + \"OKBLUE\" +self.ENDC)\n print(self.OKGREEN + \"OKGREEN\" +self.ENDC)\n print(self.WARNING + \"WARNING\" +self.ENDC)\n print(self.FAIL + \"FAIL\" +self.ENDC)\n print(self.BOLD + \"BOLD\" +self.ENDC)\n print(self.UNDERLINE + \"UNDERLINE\" +self.ENDC)\n"
},
{
"alpha_fraction": 0.5457484722137451,
"alphanum_fraction": 0.5483349561691284,
"avg_line_length": 23.95161247253418,
"blob_id": "e5d96d1d984873926a127e9eef66e7dfc5d1e6bf",
"content_id": "1c8f6b41057892a3ac8f4636206333f73b870222",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3093,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 124,
"path": "/lib/db.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from os import system as sc\nfrom getpass import getpass\nimport mysql.connector\n\nfrom lib.profile import USR_NAME, msql_profile\nfrom lib.zsh_c import prompt\n \n\ndef msqlScript():\n\n default = prompt(\"Use default mysql profile ? (y/N) :\", plus=\"input\")\n db_exist = prompt(\"Database already exist ? (y/N) :\", plus=\"input\")\n\n prof = msql_profile()\n\n if default.lower() != \"y\":\n prof.host = prompt(\"Host adress :\", plus=\"input\")\n prof.usr = prompt(\"User :\", plus=\"input\")\n \n prof.pwd = prompt(\"Password :\", plus=\"password\")\n prof.script = prompt(\"Script to use :\", plus=\"input\")\n prof.db = prompt(\"Database name :\", plus=\"input\")\n\n if db_exist.lower() == \"y\":\n pass\n\n else:\n conn = mysql.connector.connect(\n host=prof.host,\n user=prof.usr,\n password=prof.pwd\n )\n cursor = conn.cursor()\n query = \"CREATE DATABASE {};\".format(prof.db)\n cursor.execute(query)\n conn.close()\n \n sc(\"sudo mysql -h {} -u root -p{} {} < {}\".format(prof.host, prof.pwd, prof.db, prof.script))\n\n\ndef msqlconnect():\n\n host = \"localhost\"\n usr = input(\"user :\")\n pwd = getpass(\"password :\")\n\n charset=\"--default-character-set=utf8\"\n\n sc(\"mysql --host={} --user={} --password={} {}\".format(host, usr, pwd, charset))\n\ndef quick_sql_query(query):\n\n msql_params = msql_profile()\n\n conn = mysql.connector.connect(\n host=msql_params.host,\n user=msql_params.usr,\n password=msql_params.pwd,\n database=msql_params.db\n )\n cursor = conn.cursor()\n cursor.execute(query)\n conn.close()\n\ndef execute_query(query, fetch=False, commit=False, payload=None, no_except=False, no_db=False, msg=None):\n\n msql_params = msql_profile()\n\n conn = mysql.connector.connect(\n host=msql_params.host,\n user=msql_params.usr,\n password=msql_params.pwd,\n database=msql_params.db\n )\n cursor = conn.cursor()\n\n try:\n if payload == None:\n cursor.execute(query)\n\n else:\n cursor.execute(query, payload)\n\n except:\n\n if no_except:\n print(\"WARNING: Exception cancelled.\")\n pass\n\n else:\n print(\"ERROR: while executing this query :\\n\" + query)\n yn = input(\"\\nType \\\"quit\\\" to leave or press ENTER to continue ...\")\n\n if yn == \"quit\":\n quit(0)\n\n else:\n pass\n\n if fetch:\n rows = cursor.fetchall()\n conn.close()\n return rows\n \n if commit:\n conn.commit()\n \n conn.close()\n\ndef kill_process_list():\n\n process_lst = execute_query(\"SHOW PROCESSLIST;\", fetch=True)\n\n params = msql_profile()\n\n i = 0\n for process in process_lst:\n \n if process[7] != \"SHOW PROCESSLIST\":\n i += 1\n print(\"{}:{}\".format(process[7], process[0]))\n sc(\"mysqladmin -u {} -p{} kill {}\".format(params.usr, params.pwd, process[0]))\n\n print(\"{} process killed.\".format(i))"
},
{
"alpha_fraction": 0.7552098631858826,
"alphanum_fraction": 0.7646023035049438,
"avg_line_length": 26.475807189941406,
"blob_id": "ecc3ebddfd7cbf898185e0995a66c8dd78362132",
"content_id": "898dd159104bd0ade5cb34740aeb53fea796640a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3407,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 124,
"path": "/code_aliases.zsh",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "#alias control\nalias aliasedit='vi ~/Documents/faster-zsh/code_aliases.zsh'\nalias src='source ~/.zshrc'\nalias aliasshow='cat ~/.oh-my-zsh/custom/code_aliases.zsh'\nalias aliassave='py ~/Documents/faster-zsh/alias_starter.py aliassave'\n\n#network\nalias wifi='nmcli'\nalias wifisaved='nmcli c'\nalias scanport='sudo netstat -lpn |grep'\nalias wifiscan='sudo arp-scan --interface=wlp1s0 --localnet'\nalias ipscan='sudo nmap -sV -O -T4 '\nalias myip='ip -4 a show dev wlp1s0'\n\n\n#MetaSploit\nalias metasploit='msfconsole'\n\n#python\nalias py='python3'\nalias py2='python2'\nalias supy='sudo python3'\nalias pudb='sudo pudb3'\n\n#virtualenv\nalias envnew='virtualenv -p python3 env'\nalias envstart='source env/bin/activate'\nalias envstop='deactivate'\n\n#shadow\nalias shadow='~/Shadow.AppImage'\n\n#VS code\nalias vs='code .'\nalias vsdir='code ..'\n\n#againPy\nalias again='python3 ~/Documents/againPy/again.py'\n\n#zsh\nalias rm='rm -rf'\nalias rmrf='sudo rm -rf'\nalias mk='mkdir'\nalias doc='cd ~/Documents/ && l'\nalias term='gnome-terminal'\nalias aliasup='py ~/Documents/faster-zsh/alias_starter.py aliasup'\nalias pp='cd ~/Documents/faster-zsh/ && l'\nalias trash='cd ~/Documents/trash/ && l'\n\n#faster zsh\nalias fzsh='py ~/Documents/faster-zsh/alias_starter.py'\nalias gitnew='hub init && hub create'\nalias gitdel='fzsh gitdel'\nalias gitpush='fzsh gitpush'\nalias newdev='fzsh newdevice'\nalias rmpr='fzsh rmpr'\nalias chnpr='fzsh chnpr'\nalias bright='fzsh bright'\nalias gitimport='fzsh gitimport'\nalias gitrez='fzsh gitreload'\nalias hardpush='fzsh hardpush'\nalias apt='fzsh apt'\nalias fcolors='fzsh color'\nalias mysqlscript='fzsh msqlscript'\nalias gitapi='py ~/Documents/python-learning/API/github_API.py'\nalias bastion='fzsh bastion'\nalias scout='fzsh scout'\nalias quicksql='fzsh quicksql'\nalias msqlreset='fzsh msqlreset'\nalias wmove='fzsh wmove'\nalias killport='fzsh killport'\nalias delcache='fzsh delcache'\nalias brightfor='fzsh brightfor'\nalias newflask='fzsh newflask'\nalias exponew='fzsh exponew'\nalias rchmod='fzsh rchmod'\nalias finstaller='fzsh finstaller'\nalias fgitinit=\"fzsh fgitinit\"\nalias hrconsole='fzsh herokuconsole'\nalias djmanager='fzsh djmanager'\n\n#pip\nalias pip='sudo pip3'\nalias pipm='python3 -m pip3'\nalias freeze='pip3 freeze > requirements.txt && cat requirements.txt'\nalias pipreq='pip install -r requirements.txt'\n\n\n#django & flask\nalias dj='python3 manage.py'\nalias djnew='django-admin startproject'\nalias djstart='python3 manage.py runserver'\nalias djmigrate='python3 manage.py migrate'\nalias djnewapp='django-admin startapp'\nalias djtmpl='fzsh djtmpl'\n\nalias flask='FLASK_APP=run.py flask'\n\n#JavaScript\nalias npm='sudo npm'\nalias reactnew='sudo create-react-app'\n\n#mysql\nalias sqleasyscript='mysql -h localhost -u root'\nalias mysqlconsole='sudo mysql -h localhost -u root -p'\nalias mysqlreload='sudo systemctl daemon-reload && sudo systemctl restart mysql'\n\n#postgres\nalias pgstart='sudo -u postgres psql'\nalias pgnew='sudo createdb -O neltarim'\n\n#keyboard control\nalias xin='xinput set-prop 10 \"libinput Tapping Enabled\" 1'\nalias fr='setxkbmap fr'\nalias us='setxkbmap us'\n\n#i3 windows tilling manager\nalias wsave='i3-save-tree --workspace 1 > ~/.i3/workspace-1.json'\nalias isave='i3-resurrect save -w'\nalias iload='i3-resurrect restore -w'\nalias chrome='i3-resurrect restore -w 2'\nalias logout='gnome-session-quit'\nalias autosleep='xset -dpms'\nalias settings='env XDG_CURRENT_DESKTOP=GNOME gnome-control-center'\n"
},
{
"alpha_fraction": 0.6284403800964355,
"alphanum_fraction": 0.6284403800964355,
"avg_line_length": 23.33333396911621,
"blob_id": "33ed4152cabc8f796eea24cd4df86c266b479424",
"content_id": "6ecd01000185f9e0d82793f4be59cfaa54729464",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 218,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 9,
"path": "/lib/js.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from os import system as sc\nfrom os import getcwd, chdir\n\ndef expoNew(name_pr):\n sc(\"sudo expo init \" + name_pr)\n pr_path = getcwd() + \"/\" + name_pr\n chdir(pr_path)\n\n sc(\"sudo n stable && sudo npm install\")"
},
{
"alpha_fraction": 0.5659722089767456,
"alphanum_fraction": 0.5891203880310059,
"avg_line_length": 26.838708877563477,
"blob_id": "9d11df307737e1983f2093537b7777ecd17eabbc",
"content_id": "04b9ab24e204f441e0bccac5f8f859074ad36c34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 864,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 31,
"path": "/lib/profile.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from os import getlogin\n\n\n##### AUTOMATED ########\n## DON'T TOUCH IT ######\n\nUSR_NAME = getlogin()\nDOC_PATH = \"/home/{}/Documents\".format(USR_NAME)\nZSH_CUSTOM_PATH = \"~/.oh-my-zsh/custom/code_aliases.zsh\"\nGIT_ROOT = \"http://github.com/\"\nPERSONAL_GIT_URL = \"{}{}/\".format(GIT_ROOT, USR_NAME)\n\n########################\n\n\n###### MANUAL ##########\n\nFZSH_PATH = DOC_PATH + \"/faster-zsh\"\nDISPLAYS = [\"eDP-1\", \"HDMI-1\"] #append the list with the name of your displays\nWORKSPACES = [2,1] #append the list if you want to save more workspaces\nQWERTY_ON_I3 = True #if you want to setup your keyboard on qwerty with i3\nDEFAULT_BRIGHT = \"8\"\nPROP_9_TAP = [305,304,302, 303]\n\nclass msql_profile():\n def __init__(self):\n self.host = \"localhost\"\n self.usr = \"neltarim\"\n self.pwd = \"usertest\"\n self.db = None\n self.script = None\n\n"
},
{
"alpha_fraction": 0.5816776752471924,
"alphanum_fraction": 0.5816776752471924,
"avg_line_length": 27.0625,
"blob_id": "d619754368a5b7d77bdc083f1cf647fc6468f2e6",
"content_id": "c5736d6f0dbc4f7e6b3be802a45a0713eb7dda3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 906,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 32,
"path": "/lib/py_pr.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from os import system as sc\nfrom os import getcwd\n\nfrom lib.profile import FZSH_PATH\nfrom tools.termup import prompt\n\n\ndef herokuconsole():\n app = prompt(\"Heroku app name:\", plus=\"input\")\n sc(\"heroku run bash --app \" + app)\n\ndef new_flask(name_pr):\n pr_path = getcwd()\n pr_path += \"/\" + name_pr\n sc(\"mkdir \" + name_pr)\n sc(\"touch {}/config.py {}/.gitignore\".format(pr_path, pr_path))\n\n app_name = input(\"app name :\")\n \n app_path = pr_path + \"/{}/\".format(app_name)\n sc(\"mkdir {}\".format(app_path))\n sc(\"touch {}__init__.py\".format(app_path))\n dirs = [\"static\", \"templates\", \"tests\"]\n\n for dr in dirs:\n sc(\"mkdir \" + app_path + dr)\n\n file_to_copy = FZSH_PATH + \"/lib/src/flask_views_tpl.py\"\n sc(\"cp {} {}views.py\".format(file_to_copy, app_path))\n\n with open(pr_path + \"/run.py\", 'w') as file:\n file.write(\"\"\"from {}.views import app\"\"\")\n "
},
{
"alpha_fraction": 0.46703529357910156,
"alphanum_fraction": 0.4691620469093323,
"avg_line_length": 22.989795684814453,
"blob_id": "654a267570a22498a7ffff0fc5e8852967efc948",
"content_id": "e5462d89781225e5f8bdd921cad4660606347602",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2351,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 98,
"path": "/lib/downloader.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from os import system as sc\nimport json\n\nfrom tools.termup import prompt\nfrom lib.profile import FZSH_PATH\n\nclass module():\n def __init__(self, name):\n self.name = name\n self.installed = None\n self.apt = None\n self.pip = None\n self.npm = None\n self.desc = None\n\nclass installer():\n\n def __init__(self):\n self.loop = True\n self.main()\n \n def main(self):\n prompt(\"Welcome to the fzsh installer.\\n\", plus='bold')\n\n mods = self.parser()\n\n i = 1\n for mod in mods:\n if mod.installed != True:\n print(str(i) + \". \" + mod.name)\n print(\" |\")\n tmp = []\n tmp += mod.apt + mod.pip + mod.npm\n\n \n\n for el in tmp:\n print(\" |__\" + el)\n\n i += 1\n print()\n\n choice = input('What module you want to install? :')\n choice = int(choice) - 1\n\n try:\n self.get_module(mods[choice])\n\n except:\n self.main()\n\n \n def parser(self):\n mods_path = FZSH_PATH + '/lib/src/modules.json'\n\n\n with open(mods_path, 'r') as file:\n mods_json = json.load(file)\n\n modules_formatted = []\n\n for mod in mods_json:\n tmp = module(mod)\n tmp.installed = mods_json[mod]['installed']\n\n tmp.apt = mods_json[mod]['apt']\n tmp.pip = mods_json[mod]['pip']\n tmp.npm = mods_json[mod]['npm']\n\n modules_formatted.append(tmp)\n\n return modules_formatted\n\n def get_module(self, mod):\n\n mods_path = FZSH_PATH + '/lib/src/modules.json'\n\n prompt(\"Downloading {} ...\".format(mod.name))\n \n with open(mods_path, 'r') as file:\n mods = json.load(file)\n\n if mod.apt != []:\n for apt in mod.apt:\n sc(\"sudo apt-get install \" + apt)\n\n if mod.pip != []:\n for pip in mod.pip:\n sc(\"sudo python3-pip install \" + pip)\n\n if mod.npm != []:\n for npm in mod.npm:\n sc(\"sudo npm install --global \" + npm)\n \n mods[mod.name]['installed'] = \"True\"\n\n with open(mods_path, 'w') as file:\n json.dump(mods, file, indent=4, separators=(',', ': '))\n"
},
{
"alpha_fraction": 0.5578778386116028,
"alphanum_fraction": 0.5578778386116028,
"avg_line_length": 20.39655113220215,
"blob_id": "06ee3d891e9efc6d30e71dd0ce1f91ceedddc6c2",
"content_id": "0bc5b88b8cca056c7f6d8921f8e84bdde54fab30",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1244,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 58,
"path": "/tools/termup.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from tools.const import bcolors\nfrom getpass import getpass\n\n\ndef color():\n \"\"\" Print all availables colors. \"\"\"\n bc = bcolors()\n bc.colortest()\n\ndef prompt(string, type=\"header\", plus=None, endl='\\n'):\n\n fprompt = \"\"\n\n if plus == \"bold\":\n fprompt = bcolors.BOLD\n\n elif plus == \"underline\":\n fprompt = bcolors.UNDERLINE\n\n else:\n pass\n\n\n if type == \"header\":\n fprompt += bcolors.HEADER + \"{Faster-zsh}\"\n\n elif type == \"okblue\":\n fprompt += bcolors.OKBLUE + \"{Faster-zsh}\"\n\n elif type == \"okgreen\":\n fprompt += bcolors.OKGREEN + \"{Faster-zsh}\"\n\n elif type == \"warning\":\n fprompt += bcolors.WARNING + \"{Faster-zsh}WARNING :\"\n\n elif type == \"fail\":\n fprompt += bcolors.FAIL + \"{Faster-zsh}ERROR :\"\n\n else:\n prompt(\"Basic prompt use case: prompt(string, type=\\\"header\\\", plus=None)\", type=\"fail\", plus=\"bold\")\n exit()\n\n fprompt += bcolors.ENDC\n\n if plus == \"input\":\n print(bcolors.HEADER + string + bcolors.ENDC, end='')\n ans = input()\n\n return ans\n\n elif plus == \"password\":\n str = fprompt + string\n pwd = getpass(str)\n\n return pwd\n\n else:\n print(fprompt + string, end=endl)\n\n\n\n"
},
{
"alpha_fraction": 0.6406460404396057,
"alphanum_fraction": 0.6473755240440369,
"avg_line_length": 22.21875,
"blob_id": "8ebe7392a49111be7fbcdb4b092e3a87e8a251d7",
"content_id": "c71fc48e6eb153f1983ae83c90545f3bb257a9f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 743,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 32,
"path": "/hello.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "#/usr/bin/python3.6\n# -*-coding:Utf-8 -*\nfrom os import system as sc\nimport logging\n\nfrom lib.profile import USR_NAME, QWERTY_ON_I3, DEFAULT_BRIGHT\nfrom lib.zsh_c import forceTapping, prompt\nfrom lib.ithree import workspace_loader, bright\n\n\nlogging.basicConfig(level=logging.INFO)\nlogger = logging.getLogger(__name__)\n\ndef hello():\n \"\"\"Start to work's function\"\"\"\n bright(DEFAULT_BRIGHT)\n prompt(\"Hello {}, have a nice coding day.\".format(USR_NAME))\n\n workspace_loader()\n\n if USR_NAME == \"neltarim\":\n prompt(\"Enabling tapping on trackpad.\")\n forceTapping()\n\n if QWERTY_ON_I3 == True:\n prompt(\"setting keyboard on QWERTY.\")\n sc(\"setxkbmap us\")\n \n \n\nif __name__ == \"__main__\":\n hello()\n"
},
{
"alpha_fraction": 0.5774495601654053,
"alphanum_fraction": 0.579250693321228,
"avg_line_length": 23.79464340209961,
"blob_id": "edbce7f06a89295f98c18fae6ad43a1b4f7139b2",
"content_id": "28425559fa26a59bf2b8b450f48d4e7a46847693",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2776,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 112,
"path": "/lib/zsh_c.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from os import system as sc\nfrom os import getcwd, chdir, listdir, walk\nfrom os.path import isdir\nimport mysql.connector\nimport logging\n\nfrom lib.profile import USR_NAME, ZSH_CUSTOM_PATH, PROP_9_TAP, msql_profile, FZSH_PATH\nfrom tools.termup import prompt\n\nlogging.basicConfig(level=logging.INFO)\nlogger = logging.getLogger(__name__)\n\nLOOP = True\n\ndef aliasup():\n sc(\"rm -rf {}\".format(ZSH_CUSTOM_PATH))\n\n chdir(\"/home/{}/Documents/faster-zsh\".format(USR_NAME))\n sc(\"cp ./code_aliases.zsh {}\".format(ZSH_CUSTOM_PATH))\n prompt(\"New alias saved locally. Please use \\\"src\\\" to update your terminal.\")\n\ndef aliassave():\n aliasup()\n com = input(\"commit :\")\n\n sc(\"git add code_aliases.zsh\")\n sc(\"git commit -m \\\"{}\\\"\".format(com))\n sc(\"git push origin master\")\n\ndef forceTapping():\n # WARNING: Function Deprecated. use only \"xin\" alias.\n for prop in PROP_9_TAP:\n sc(\"xinput set-prop 10 {} 1\".format(prop))\n\ndef apt():\n prompt(\"Welcome to the installer environnement.\", type=\"okblue\")\n\n while LOOP:\n prompt(\"Name the package you need to install now or quit/ENTER to exit.\")\n pkg = input(\">\")\n\n if pkg == \"\" or pkg == \"quit\":\n prompt(\"Have a nice coding day.\", type=\"okblue\", plus=\"bold\")\n exit()\n\n else:\n sc(\"sudo apt-get install {}\".format(pkg))\n\ndef profile_edit():\n sc(\"vs ~/Documents/faster-zsh/lib/profile.py\")\n\ndef kill_port(port):\n sc(\"sudo fuser -k {}/tcp\".format(port))\n\ndef pcache_lister(path, pc_lst=[]):\n \n dirs = listdir(path)\n\n for file in dirs:\n if file == \"__pycache__\":\n pc_lst.append(path + \"/\" + file)\n pass\n\n if isdir(path + \"/\" + file) == True:\n new_path = path + \"/\" + file\n pcache_lister(new_path, pc_lst=pc_lst)\n\n return pc_lst\n\ndef delete_pycache():\n\n root_path = getcwd()\n pc_lst = pcache_lister(root_path)\n\n for cache in pc_lst:\n sc(\"sudo rm -rf \" + cache)\n prompt(\"Deleting {} ...\".format(cache))\n \n\n if pc_lst == []:\n prompt(\"No pycache detected.\", type=\"fail\", plus=\"bold\")\n\n else:\n prompt(\"All pycaches has been deleted.\", type=\"okgreen\")\n\n\ndef parse_files(root, paths=[]):\n\n for file in listdir(root):\n\n if file != \".git\":\n \n file_path = root + \"/\" + file\n paths.append(file_path)\n\n if isdir(file_path):\n parse_files(file_path, paths=paths)\n\n return paths\n\ndef rchmod(mods, dir_name):\n\n path = getcwd() + \"/\" + dir_name\n\n if mods == None:\n prompt(\"Mods invalid or missing.\", type=\"fail\", plus=\"bold\")\n \n paths = parse_files(path)\n\n for path in paths:\n sc(\"sudo chmod {} {}\".format(mods, path))\n print(path)"
},
{
"alpha_fraction": 0.4850597679615021,
"alphanum_fraction": 0.48954182863235474,
"avg_line_length": 26.90277862548828,
"blob_id": "124984bb5d553a9392f418e36f1aa394e4cb9832",
"content_id": "bbe52e2fcc1a34bee5ccc8a042f1e9963759af65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2008,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 72,
"path": "/alias_starter.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from sys import argv\n\nfrom tools.termup import prompt, color\nfrom lib import db\nfrom lib import ithree\nfrom lib import git_c\nfrom lib import zsh_c\nfrom lib import py_pr\nfrom lib import js\nfrom lib import downloader\nfrom lib import django\n\n\nFUNC = [\n {\n \"msqlscript\" : db.msqlScript,\n \"gitpush\" : git_c.gitPush,\n \"gitdel\" : git_c.gitdel,\n \"hardpush\" : git_c.hardpush,\n \"aliassave\" : zsh_c.aliassave,\n \"wload\" : ithree.workspace_loader,\n \"color\" : color,\n \"aliasup\" : zsh_c.aliasup,\n \"apt\" : zsh_c.apt,\n \"profile\" : zsh_c.profile_edit,\n \"bastion\" : ithree.bastion,\n \"scout\" : ithree.scout,\n \"msqlreset\" : db.kill_process_list,\n \"delcache\" : zsh_c.delete_pycache,\n \"finstaller\" : downloader.installer,\n \"fgitinit\" : git_c.fgitinit,\n \"herokuconsole\" : py_pr.herokuconsole,\n \"djmanager\" : django.djmanager,\n },\n\n {\n \"rmpr\" : git_c.rmpr,\n \"gitreload\" : git_c.gitreload,\n \"bright\" : ithree.bright,\n \"quicksql\" : db.quick_sql_query,\n \"wmove\" : ithree.wmove,\n \"killport\" : zsh_c.kill_port,\n \"newflask\" : py_pr.new_flask,\n \"exponew\" : js.expoNew,\n \n },\n\n {\n \"chnpr\" : git_c.chnpr,\n \"gitimport\" : git_c.gitimport,\n \"brightfor\" : ithree.bright_for,\n \"rchmod\" : zsh_c.rchmod,\n }\n]\n\nif __name__ == \"__main__\":\n\n func_name = argv[1]\n argtype = len(argv) - 2\n\n if argtype == 0:\n FUNC[argtype][func_name]()\n\n elif argtype == 1:\n FUNC[argtype][func_name](argv[2])\n\n elif argtype == 2:\n FUNC[argtype][func_name](argv[2], argv[3])\n\n else:\n prompt(\"mmhh .... you're dumb.\", type=\"warning\", plus=\"bold\")\n exit(0)"
},
{
"alpha_fraction": 0.501344621181488,
"alphanum_fraction": 0.5040338039398193,
"avg_line_length": 29.629411697387695,
"blob_id": "239578ad059a31ba449136db0cabd9f8104645a1",
"content_id": "d7300f4c5c32fcf7510faadb0f7cc53ad25f90f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5206,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 170,
"path": "/lib/django.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "import subprocess\n\nfrom os import system as sc\nfrom os import getcwd, chdir, listdir, walk, mkdir, path\nfrom os.path import isdir\nfrom secrets import token_urlsafe\n\nfrom tools.termup import prompt\n\ndef djmanager():\n manager = dj_manager()\n\n\nclass dj_manager():\n \"\"\"Not finished\"\"\"\n def __init__(self):\n self.pr_path = getcwd()\n self.pr_name = path.basename(self.pr_path)\n self.app_name = None\n\n self.events = {\n 'help' : {\n 'desc' : 'List all functions available',\n 'call' : self.list_events\n },\n 'migrate' : {\n 'desc' : 'Make django migrations and migrate.',\n 'call' : self.migrate\n },\n 'mktpl' : {\n 'desc' : 'Create new templates dir for an app.',\n 'call' : self.djtmpl\n },\n 'tree' : {\n 'desc' : 'Display dir tree.',\n 'call' : self.tree\n },\n 'vs' : {\n 'desc' : 'Open VS Code.',\n 'call' : self.vscode\n },\n }\n\n self.check_integrity()\n self.list_events([])\n self.event_loop()\n\n def event_loop(self):\n arg = input('>')\n try:\n args = arg.split()\n\n self.events[args[0]]['call'](args)\n self.event_loop()\n except:\n prompt('Wrong argument. Please try again.', type='fail')\n self.event_loop()\n\n\n def check_integrity(self):\n ok = False\n prompt('Hi. Welcome to the Fzsh django manager.')\n\n for file in listdir(getcwd()):\n if file == 'manage.py':\n ok = True\n\n if not ok:\n prompt('It appear that this directory is not a django project yet.', type='fail')\n print('Do you want to create a new project in {} ? (yes/n)\\n'.format(self.pr_name))\n inp = prompt('>', plus='input')\n\n if inp == 'yes' or inp == 'y':\n self.install([])\n else:\n prompt('Exiting.', type=\"fail\")\n exit()\n\n def rename(self, path):\n\n for file in listdir(path):\n if isdir(file):\n self.rename(path + '/' + file)\n\n else:\n tmp_path = path + '/' + file\n\n with open(tmp_path, 'r') as file :\n filedata = file.read()\n\n filedata = filedata.replace('APP_NAME', self.app_name)\n filedata = filedata.replace('PROJECT_NAME', self.pr_name)\n filedata = filedata.replace('SECRET_REPLACE_KEY', token_urlsafe(26))\n filedata = filedata.replace('UPPER_NAME_APP', self.app_name.capitalize())\n\n with open(tmp_path, 'w') as file:\n file.write(filedata)\n\n\n ############### EVENTS ####################\n\n def list_events(self, args):\n for i in self.events:\n spaces = 14 - len(i)\n print(i + ' :' + ' ' * spaces + self.events[i]['desc'])\n\n print()\n\n def tree(self, args):\n sc('tree')\n\n def vscode(self, args):\n sc('code .')\n\n def serv(self, args):\n print('Not working yet.')\n #https://stackoverflow.com/questions/4322624/how-to-make-django-restart-runserver-on-template-change\n #utiliser Thread\n\n def install(self, args):\n prompt('Welcome to the django-vue project installer.', type='okblue')\n prompt('Installing template ...', type=\"okblue\")\n sc(\"git clone http://github.com/Neltarim/dj_vue_template.git \" + getcwd())\n sc('mv SETTINGS_DIR ' + self.pr_name + '_settings')\n prompt('Template created.', type='okgreen')\n sc('rm -rf .git')\n\n prompt('Name your first app:', type='header')\n self.app_name = prompt('>', plus='input')\n prompt('Formatting template ...', type='header')\n self.rename(self.pr_path)\n\n prompt('Creating {} ...'.format(self.app_name), type='header')\n sc('django-admin startapp ' + self.app_name)\n\n prompt('Creating templates for {} ...'.format(self.app_name), type='header')\n self.djtmpl(auto=True)\n\n sc('hub init && hub create')\n self.migrate([])\n\n\n prompt('Project {} installed successfuly.\\n'.format(self.pr_name), type='okgreen')\n\n def migrate(self, args):\n prompt('Making migrations ...', type='header')\n sc('python3 ./manage.py makemigrations')\n prompt('Migrating ...', type='header')\n sc('python3 ./manage.py migrate')\n\n def djtmpl(self, auto=False):\n if not auto:\n prompt('What app need a new static template ?\\n')\n app_name = prompt('>', plus='input')\n else:\n app_name = self.app_name\n\n path = getcwd() + '/' + app_name + '/'\n\n mkdir(path + 'templates')\n mkdir(path + 'static')\n\n mkdir(path + 'templates/' + app_name)\n mkdir(path + 'static/' + app_name)\n sc('touch ' + path + 'templates/' + app_name + '/index.html')\n\n prompt('templates and static\\'s dirs created.', type='okgreen')\n\n\n ############### EVENTS ####################"
},
{
"alpha_fraction": 0.5474197864532471,
"alphanum_fraction": 0.5474197864532471,
"avg_line_length": 24.91566276550293,
"blob_id": "04b716281d8d64279fb112ff38e5c042c476a8fd",
"content_id": "13ff09024530646d6269b663ff103b6be68238fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4302,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 166,
"path": "/lib/git_c.py",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "from os import system as sc\nfrom os import getcwd, path, chdir, listdir, mkdir\nfrom os.path import isdir, exists\n\nfrom lib.profile import GIT_ROOT, PERSONAL_GIT_URL, USR_NAME\nfrom lib.zsh_c import delete_pycache\nfrom tools.termup import prompt\n\n\ndef gitdel():\n \"\"\"Delete the git repository attached to the active working directory\"\"\"\n pr_path = getcwd()\n pr_name = path.basename(pr_path)\n sc(\"sudo rm -rf .git && hub delete {}\".format(pr_name))\n\ndef gitignore(auto=False):\n \"\"\"Create a .gitignore file to the current directory.\"\"\"\n path = getcwd()\n prompt(\"name the directory you want to avoid (ex: env/).\")\n prompt(\"When you're done, just press \\\"ENTER\\\" to pass ...\")\n\n if exists(path + \"/.gitignore\"):\n prompt(\"Gitignore file already exist.\")\n exit()\n\n else:\n dirs = []\n files = []\n\n loop = True\n while loop == True:\n elem = input(\"Directoy :\")\n if elem == \"\":\n loop = False\n\n else:\n dirs.append(elem)\n\n prompt(\"Now name the files you want to avoid (ex: text.py)...\")\n prompt(\"When you're done, just press \\\"ENTER\\\" to pass ...\")\n loop = True\n while loop == True:\n elem = input(\"File :\")\n if elem == \"\":\n loop = False\n\n else:\n files.append(elem)\n\n with open(path + \"/.gitignore\", \"w\") as file:\n for name in dirs:\n file.write(name)\n\n for name in files:\n file.write(name)\n\n prompt(\"gitignore file created successfuly.\")\n\ndef chnpr(old, new):\n \"\"\"Change the name of the project\"\"\"\n path = getcwd()\n old_path = path + \"/\" + old\n new_path = path + \"/\" + new\n\n chdir(old_path)\n gitdel()\n\n chdir(path)\n sc(\"mv {} {}\".format(old_path, new_path))\n chdir(new_path)\n sc(\"hub init && hub create\")\n gitPush(\"fresh name !\")\n if exists(new_path + \"/.gitignore\"):\n pass\n \n else:\n print('asshole')\n gitignore(auto=True)\n\n\ndef rmpr(pr_name):\n \"\"\"Delete all the project and repository git attached\"\"\"\n yn = input(\"Are you sure to delete {}?(yes/N) :\".format(pr_name))\n yn.lower()\n\n if yn == \"yes\" or yn == \"y\":\n sc(\"hub delete {}\".format(pr_name))\n sc(\"rm -rf ./{}\".format(pr_name))\n\n\ndef gitPush(com=None):\n \"\"\"Push all the files to git with\"\"\"\n\n delete_pycache()\n \n if com == None:\n com = input(\"Commit :\")\n\n formatted = \"\\\"\" + com + \"\\\"\"\n\n sc(\"git add *\")\n sc(\"git commit -m {}\".format(formatted))\n sc(\"git push\")\n\n\ndef gitimport(owner, repo_name):\n \"\"\"Import a personal repository with is name (no url)\"\"\"\n repo_path = GIT_ROOT + \"{}/{}.git\".format(owner, repo_name)\n\n sc(\"git clone {}\".format(repo_path))\n\n\ndef gitreload(repo_name):\n \"\"\"Import a personal repository with is name (no url)\"\"\"\n repo_path = PERSONAL_GIT_URL + \"{}.git\".format(repo_name)\n\n sc(\"git clone {}\".format(repo_path))\n\n\ndef hardpush():\n prompt(\"THIS FUNCTION IS SILLY. DON'T USE IT.\", type=\"warning\", plus=\"bold\")\n a = input('Do it anyway? (y/any key):')\n if a != 'y' or a != 'yes':\n return False\n DOC_PATH = \"/home/{}/Documents\".format(USR_NAME)\n chdir(DOC_PATH)\n dirs = listdir(DOC_PATH)\n\n DOC_PATH += \"/\"\n\n for project in dirs:\n project_path = DOC_PATH + project\n if isdir(project_path):\n project_l = listdir(project_path)\n\n for doc in project_l:\n if doc == \".git\":\n chdir(project_path)\n gitPush(com=\"[auto save]\")\n\n\ndef fgitinit():\n \"\"\" Only use if git won't push with gitpush (not working yet ...)\"\"\"\n\n repo_name = path.basename(getcwd())\n prompt(\"basename: \" + repo_name)\n\n prompt(\"hub create ...\")\n sc(\"hub init && hub create \" + repo_name)\n chdir(\"../\")\n\n prompt(\"creating tmp directory ...\")\n mkdir(\"tmp\")\n prompt(\"copying files in tmp directory ...\")\n sc(\"cp -r {}/* ./tmp && sudo rm -rf {}\".format(repo_name, repo_name))\n\n prompt(\"git reloading ...\")\n gitreload(repo_name)\n\n prompt(\"copying files into new dir ...\")\n sc(\"cp -r ./tmp/* \" + repo_name)\n sc('rm -rf ./tmp')\n chdir(\"./\" + repo_name)\n\n prompt(\"Push ...\")\n gitPush()\n"
},
{
"alpha_fraction": 0.7319148778915405,
"alphanum_fraction": 0.73617023229599,
"avg_line_length": 22.5,
"blob_id": "59d22e13c785c7c3ded778517ee4d8132f1c339a",
"content_id": "f41466d39527d8c1ca633bc48b32045ff24679bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 235,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/README.md",
"repo_name": "Neltarim/faster-zsh",
"src_encoding": "UTF-8",
"text": "# faster-zsh\n\nThis program is meant to be used on linux.\nIt's my personnal configuration of Ubuntu with I3wm, \nif you want to use it, just run :\n>git clone https://github.com/Neltarim/faster-zsh.git\nand :\n>sh faster-zsh/install.sh\n\n:)\n"
}
] | 15 |
subho781/MCA-python-Assignment5 | https://github.com/subho781/MCA-python-Assignment5 | cd8f48e0c6ef6bd071f711ab49e912d40df81ce7 | f84a8fbaf1a67fb0c2c4e4c2bf7ccff6e3e33aee | 206cc4d13937b4217a9f3a737db041cda772c407 | refs/heads/main | 2023-03-23T11:14:29.070786 | 2021-03-21T06:06:18 | 2021-03-21T06:06:18 | 349,907,156 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.510869562625885,
"alphanum_fraction": 0.5942028760910034,
"avg_line_length": 23.272727966308594,
"blob_id": "3e10d05e2f210e56eca7b5c7191a4c2027bded3b",
"content_id": "765d11cf6e88e474236d63e326b5cfb6c18effe7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 276,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 11,
"path": "/Q5.py",
"repo_name": "subho781/MCA-python-Assignment5",
"src_encoding": "UTF-8",
"text": "'''Create one list of five element. Find \r\nthe index of 10 in the list. Insert a \r\nnew element in the 2nd position.'''\r\n\r\nl1 = [20,10,50,12.8]\r\nprint(l1)\r\nfor i in range(len(l1)):\r\n if l1[i] == 10:\r\n print(\"Index of 10 is: \" + str(i))\r\nl1.insert(2, \"abc\")\r\nprint(l1)"
},
{
"alpha_fraction": 0.49162012338638306,
"alphanum_fraction": 0.5921787619590759,
"avg_line_length": 20.625,
"blob_id": "6f0f2b9a05b0038bc1f2705ac50d369d3cff07b5",
"content_id": "73915c022382a5738f6353dc3ada649da62450c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 8,
"path": "/Q3.py",
"repo_name": "subho781/MCA-python-Assignment5",
"src_encoding": "UTF-8",
"text": "'''Write an expression that changes the \r\nfirst item in a tuple. (4, 5, 6) should \r\nbecome (1, 5, 6) in the process.'''\r\n\r\nT1=(4,5,6)\r\nprint('T1=',T1)\r\nT1=(1,5,6)\r\nprint('T1=',T1)"
},
{
"alpha_fraction": 0.4950000047683716,
"alphanum_fraction": 0.5400000214576721,
"avg_line_length": 18.200000762939453,
"blob_id": "09aa2b8a198bc841bcd4c0af44ad6dc46d920caa",
"content_id": "99bc16ad7b9e8371f0d9062ee85fc2e54fbdd4a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 10,
"path": "/Q2.py",
"repo_name": "subho781/MCA-python-Assignment5",
"src_encoding": "UTF-8",
"text": "'''build a dictionary with two keys, 'a' \r\nand 'b', each having an associated \r\nvalue of 0 (using two method)'''\r\n\r\nD1={'a':0,'b':0}\r\nprint(D1)\r\nL = [('a', 0),\r\n ('b', 0)]\r\nD2 = dict(L)\r\nprint(D2)"
},
{
"alpha_fraction": 0.7916666865348816,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 24,
"blob_id": "f86bc855f9f834edbf0a449b66c5bbf056658b9b",
"content_id": "8ceb9fb48d1310e87c67fb2250fb5c04c9151645",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 1,
"path": "/README.md",
"repo_name": "subho781/MCA-python-Assignment5",
"src_encoding": "UTF-8",
"text": "# MCA-python-Assignment5"
},
{
"alpha_fraction": 0.5482233762741089,
"alphanum_fraction": 0.5989847779273987,
"avg_line_length": 19.66666603088379,
"blob_id": "05082dd07d50e06b70609fe50fb44a0aa47058ac",
"content_id": "06854f07fbb0546de115df953ebf084e8c851b45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 9,
"path": "/Q1.py",
"repo_name": "subho781/MCA-python-Assignment5",
"src_encoding": "UTF-8",
"text": "# Build a list containing five integer zeros(using two methods)\r\n\r\ndef L1(number):\r\n return [0] * number\r\nlist = L1(5)\r\nprint('L1=',list)\r\nfor i in range(6):\r\n L2=[0] * i\r\nprint('L2=',L2)\r\n\r\n"
}
] | 5 |
jonathanhanley/StashpediaEbayBot | https://github.com/jonathanhanley/StashpediaEbayBot | d73d8b1f20e2471ce75504279d649c0ee18c2fce | 35b53e855f3846f6a09c3ab2dde46a0a33d81988 | 21263fa71e320940bad59f066b5e487c3637c810 | refs/heads/master | 2020-03-25T12:40:10.926162 | 2019-11-07T22:53:26 | 2019-11-07T22:53:26 | 143,786,922 | 3 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6169819831848145,
"alphanum_fraction": 0.6382095217704773,
"avg_line_length": 32.338462829589844,
"blob_id": "28bdb435335aea7a3f7c77c7dea3c8827c291cef",
"content_id": "09bcf2e300db60511db71bcaffd564473f420004",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2167,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 65,
"path": "/run_bot.py",
"repo_name": "jonathanhanley/StashpediaEbayBot",
"src_encoding": "UTF-8",
"text": "import re\nimport requests\nimport discord\nfrom discord.ext import commands\n\nTOKEN = 'TOKEN HERE'\ndescription = ''''''\nbot = commands.Bot(command_prefix='?', description=description)\n\n\ndef stash(name):\n name = name.replace(' ', '+')\n search_page = requests.get('https://stashpedia.com/search?terms=%s' % name)\n search_page = search_page.text\n link = re.findall('<a class=\"fill-height\" href=\"(.*?)\"', search_page)[0]\n link = 'https://stashpedia.com' + link\n main_page = requests.get(link)\n main_page = main_page.text\n number = '#'+str(re.findall('<H5>#(.*?)<', main_page)[0])\n stash_price = re.findall('<span class=\"gridValue\">(.*?)<', search_page)[0]\n title = re.findall('<H4 class=\"toUpperCase\">(.*?)<', search_page)[0]\n image_link = 'https://stashpedia.com'+re.findall('img-responsive gridImage\" src=\"(.*?)\"', search_page)[0]\n return stash_price, title, number, image_link, link\n\n\ndef ebay(search):\n link = 'https://www.ebay.com/sch/i.html?_from=R40&_trksid=p2334524.m570.l1313.TR12.TRC2.A0.H0.XTEST.TRS0&_nkw=%s' \\\n '&_sacat=0&LH_TitleDesc=0&_osacat=0&_odkw=%%23101' % search\n search_page = requests.get(link)\n search_page = search_page.text\n price = re.findall('<span class=\"s-item__price\">(.*?)<', search_page)[0]\n return price\n\n\ndef main(name):\n stash_price, title, number, image_link, link = stash(name)\n ebay_search = (title+' '+number).replace(' ', '+').replace('#', '%23')\n ebay_price = ebay(ebay_search)\n\n embed = discord.Embed(title=title, url=link, description=\"\", color=0x00ff00)\n embed.add_field(name=\"Ebay Price\", value=ebay_price, inline=False)\n embed.add_field(name=\"Stashpedia Price\", value=stash_price, inline=False)\n embed.set_image(url=image_link)\n\n return embed\n\n\[email protected]\nasync def on_ready():\n print('Logged in as')\n print(bot.user.name)\n print(bot.user.id)\n print('------')\n\n\[email protected]\nasync def on_message(message):\n if message.content.startswith('!funko'):\n name = message.content.split(' ')[1:]\n name = ' '.join(name)\n embed = main(name)\n await bot.send_message(message.channel, embed=embed)\n\n\nbot.run(TOKEN)\n"
},
{
"alpha_fraction": 0.7279411554336548,
"alphanum_fraction": 0.7426470518112183,
"avg_line_length": 26.299999237060547,
"blob_id": "ac811e7486f5c69a625a18bfb948d48de8df4e2c",
"content_id": "78b97c20cc482d42ff1ee13f28c498caadd64205",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 10,
"path": "/README.md",
"repo_name": "jonathanhanley/StashpediaEbayBot",
"src_encoding": "UTF-8",
"text": "# StashpediaEbayBot\nA Discord bot that returns the Stashpedia price and the current Ebay price<br>\n\n**Requirements**<br>\ndiscord.py<br>\nrequests<br>\n\n**Usage**\n1) Insert your own bot token\n2) `python3 run_bot.py` OR `python3 run_bot.py > logs.txt &` to abandon the process"
}
] | 2 |
noa99kee/ZEncode | https://github.com/noa99kee/ZEncode | 25dd9f84a5a1690cfcca3730ba979ca07d132ca3 | 591a7343d7f38773d96d0fca6e15a998045716ab | 7cd9d2f769a99462890052904128e191ef9e9bbe | refs/heads/master | 2020-06-30T20:44:20.596217 | 2012-04-05T22:50:25 | 2012-04-05T22:50:25 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7576197385787964,
"alphanum_fraction": 0.7663280367851257,
"avg_line_length": 22.758621215820312,
"blob_id": "910f89e1e1a6fe1cd09a69e2d9a39e50db8c9410",
"content_id": "748b4bdfb900b04ac2b6300c009c1e1460a5686a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 689,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 29,
"path": "/uninstall_homebrew.sh",
"repo_name": "noa99kee/ZEncode",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n# Just copy and paste the lines below\n# MAKE SURE YOU ARE HAPPY WITH WHAT IT DOES FIRST! THERE IS NO WARRANTY!\n\nbrew remove yasm\nbrew remove xvid\nbrew remove x264\nbrew remove theora\nbrew remove pkg-config\nbrew remove libvpx\nbrew remove libvorbis\nbrew remove libogg\nbrew remove lame\nbrew remove faac\nbrew remove ffmpeg\n\ncd `brew --prefix`\ngit ls-files -z | pbcopy\nrm -rf Cellar\nbin/brew prune\npbpaste | xargs -0 rm\nrm -r Library/Homebrew Library/Aliases Library/Formula Library/Contributions \ntest -d Library/LinkedKegs && rm -r Library/LinkedKegs\nrmdir -p bin Library share/man/man1 2> /dev/null\nrm -rf .git\nrm -rf ~/Library/Caches/Homebrew\ncd /usr/local/\nrm .gitignore\nrm -rf *\n"
},
{
"alpha_fraction": 0.66576087474823,
"alphanum_fraction": 0.679347813129425,
"avg_line_length": 27.30769157409668,
"blob_id": "0ecf6130eea7f1c9a2a3b45acf2ee6df97ac667a",
"content_id": "32f49d9bd4808952b571b0a439666c43c02d02da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 368,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 13,
"path": "/get_video_info.py",
"repo_name": "noa99kee/ZEncode",
"src_encoding": "UTF-8",
"text": "import sys, getopt, re\nfrom subprocess import Popen, PIPE, STDOUT\n\nopts = getopt.getopt( sys.argv[1:], 'f', ['file'] )\ntry: \n\tfile = opts[1][0]\nexcept: \n\tprint '-f (--file) must be specified with a valid file path'\n\tsys.exit( 2 )\n\nstdout = Popen( '/usr/local/bin/ffmpeg -i '+file, shell=True, stdout=PIPE, stderr=STDOUT )\nresult = stdout.communicate()\nprint result[0]\n"
},
{
"alpha_fraction": 0.6689497828483582,
"alphanum_fraction": 0.689497709274292,
"avg_line_length": 28.200000762939453,
"blob_id": "c809a67bc2157387762dea4cbc2214aec93c2860",
"content_id": "c93f5f4f410127ff2e096275418caae37ae29201",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 15,
"path": "/encode_ffmpeg.py",
"repo_name": "noa99kee/ZEncode",
"src_encoding": "UTF-8",
"text": "import sys, getopt, re\nfrom subprocess import Popen, PIPE, STDOUT\n\nopts = getopt.getopt( sys.argv[1:], 'f', ['ffmpegcmd'] )\ntry:\n\tcmd = opts[1][0]\nexcept:\n\tprint '-f (--ffmpegcmd) must be specified with a valid ffmpeg command' \n\tsys.exit( 2 )\n\nprint 'encode_ffmpeg.py -f '\nprint cmd[1:-1] + '\\n'\nffmpeg_stdout = Popen( cmd[1:-1], shell=True, stdout=PIPE, stderr=STDOUT )\nffmpeg_result = ffmpeg_stdout.communicate()[0]\nprint ffmpeg_result\n"
},
{
"alpha_fraction": 0.74301677942276,
"alphanum_fraction": 0.748603343963623,
"avg_line_length": 34.79999923706055,
"blob_id": "2e9f3c604c5e495b978df1a99ea7ada4cccd8d8c",
"content_id": "adc3d30c663193113051fa32d1310598cd4d4577",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 5,
"path": "/confirm_ffmpeg.py",
"repo_name": "noa99kee/ZEncode",
"src_encoding": "UTF-8",
"text": "from subprocess import Popen, PIPE, STDOUT\n\nstdout = Popen( 'cd /usr/local/Cellar/ffmpeg/', shell=True, stdout=PIPE, stderr=STDOUT )\nresult = stdout.communicate()\nprint result[0]\n"
}
] | 4 |
pombredanne/python-assorted-algorithms-101-material | https://github.com/pombredanne/python-assorted-algorithms-101-material | bd85d29d22f4551d704f44215a5f2c405c803b0e | dd47b3f3b221d079f5ecf51c60c660870dce44eb | 05e23e3f1856684a9cdbdb432b921560a9f94ba8 | refs/heads/master | 2017-05-03T04:05:16.438213 | 2010-11-16T20:08:08 | 2010-11-16T20:08:45 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5738984942436218,
"alphanum_fraction": 0.5772448182106018,
"avg_line_length": 28.883333206176758,
"blob_id": "6ee2d59e143426f0fd8c237ecf69a34ac3a9c635",
"content_id": "d7ef9d865b47f223efc1f31195dbcf0b07381347",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1793,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 60,
"path": "/lzw.py",
"repo_name": "pombredanne/python-assorted-algorithms-101-material",
"src_encoding": "UTF-8",
"text": "import struct\n\nfrom itertools import count\n\ndef compress(string):\n \"\"\"\n The last yielded value will be the dict of keycodes.\n \"\"\"\n symbol_count = count(1)\n words = {symbol : symbol_count.next() for symbol in set(string)}\n\n w = \"\"\n for letter in string:\n if w + letter in words:\n w += letter\n else:\n words[w + letter] = symbol_count.next()\n yield words[w]\n w = letter\n yield words\n\ndef decompress(compressed_file, keycodes):\n keycodes = {v : k for k, v in keycodes.iteritems()}\n\n output = []\n while True:\n next_key = compressed_file.read(4)\n if not next_key:\n return \"\".join(output)\n output.append(keycodes[struct.unpack(\"<I\", next_key)[0]])\n\nif __name__ == \"__main__\":\n import os\n import json\n\n output, keycodes = \"output.bin\", \"keycodes.json\"\n print (\"Outputting the compressed data to \\n\\t{0}\\nand the corresponding \"\n \"keycodes to \\n\\t{1}\".format(os.path.join(os.getcwd(), output),\n os.path.join(os.getcwd(), keycodes)))\n\n with open(output, \"wb\") as op, open(keycodes, \"w\") as json_op:\n compressed = compress(\"aaaavvabbabasdfbwbabababadfnbbbasdfwbbbbasdfawn\"\n \"ekrjnzxcvzxcvzbxcvbababdfbbbbabaaaabbababababa\")\n # or try: compress(open(\"/path/to/huckleberry/finn/.txt/\").read())\n for i in compressed:\n try:\n op.write(struct.pack(\"<I\", i))\n except struct.error:\n json_op.write(json.dumps(i, sort_keys=True, indent=4))\n\n\"\"\"\nTo decode:\n output = open(\"output.bin\")\n json_keycodes = open(\"keycodes.json\")\n\n import json\n keycodes = json.load(json_keycodes)\n\n decompress(output, keycodes)\n\"\"\"\n"
}
] | 1 |
mihaimt/Computational_Science_II | https://github.com/mihaimt/Computational_Science_II | d14ae963865614ffc5095f4632e41f6a98974e20 | 97fc83de77f22d686e91e48261e0b62a0d9cfbcd | 011314819fa3e5b2154f84e9ced30f26ef485568 | refs/heads/master | 2021-01-23T18:52:22.737287 | 2015-06-09T16:25:16 | 2015-06-09T16:25:16 | 31,419,839 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5609264969825745,
"alphanum_fraction": 0.6193353533744812,
"avg_line_length": 25.810810089111328,
"blob_id": "28f361b03a43cce0de6d5eb42ab05907519a726e",
"content_id": "5743ee0b265d49cde01a30508e1c49d6819a3196",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 37,
"path": "/mihai/time_plot.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\n\nfig = plt.figure()\nax = fig.add_subplot(111)\n\n## the data\nN = 9\ntime = [409.2, 235, 249, 242, 22.8, 22.1, 19.3, 18.3, 16.8]\n\n\n## necessary variables\nind = np.arange(N) # the x locations for the groups\nwidth = 0.35 # the width of the bars\n\n## the bars\nrects1 = ax.bar(ind, time, width,color='black')\n\n\n\n# axes and labels\nax.set_xlim(-width,len(ind)+width)\n#ax.set_ylim(0,450)\nax.set_ylabel('cpu time [s]', fontsize = 20)\nxTickMarks = [\"raw\", \"precalc 1\", \"reduct\", \"precalc 2\", \"optimiz 1\", \"symmetry\", \"precalc 3\", \"optimiz 2\", \"memory\" ]\nax.set_xticks(ind+width)\nxtickNames = ax.set_xticklabels(xTickMarks)\nplt.setp(xtickNames, rotation=45, fontsize=10)\nplt.yscale('log')\ni = 0\nfor t in time:\n \n ax.text(ind[i]+0.2, 1.05*t, '%d'%int(t)+' s',\n ha='center', va='bottom')\n\ti = i+1\n## add a legend\nplt.savefig(\"/home/ics/mihai/git/Computational_Science_II_Open/time_plot.png\")\n\n"
},
{
"alpha_fraction": 0.507635772228241,
"alphanum_fraction": 0.5718151926994324,
"avg_line_length": 25.253807067871094,
"blob_id": "5cded8d637a13100925507eea48ae5bbb2bad35d",
"content_id": "f5f2e04194428891cdea05f53b95a4793e4c039d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5173,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 197,
"path": "/DanielStuder/plot.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nSpyder Editor\n\nThis temporary script file is located here:\n/home/omer/.spyder2/.temp.py\n\"\"\"\n\nfrom pylab import*\n\nforce0=loadtxt(\"Results/force0_project.data\")\nforcel=loadtxt(\"Results/forcel_project.data\")\nforcelosc=loadtxt(\"Results/forcelosc_project.data\")\ndensity=loadtxt(\"../Data/density_project.data\")\nf_r0=force0[:,0]\nf_theta0=force0[:,1]\n\nf_rl=forcel[:,0]\nf_thetal=forcel[:,1]\n\nf_rl=forcelosc[:,0]\nf_thetal=forcelosc[:,1]\nr=loadtxt(\"../Data/r_project.data\")\ntheta=loadtxt(\"../Data/theta_project.data\") \n\ndr=r[1]-r[0]\nr=r-dr/2 \n\ndtheta=theta[1]-theta[0]\ntheta=theta-dtheta/2 \n\nfr0=zeros((256,128))\nfrl=zeros((256,128))\nfrlosc=zeros((256,128))\nftheta0=zeros((256,128))\nfthetal=zeros((256,128))\nfthetalosc=zeros((256,128))\ndfrl=zeros((256,128))\ndfthetal=zeros((256,128))\ndfrlosc=zeros((256,128))\ndfthetalosc=zeros((256,128))\ndens=zeros((256,128))\nF0=zeros((256,128))\nFl=zeros((256,128))\ndFl=zeros((256,128))\nfor i in arange(0,128):\n for j in arange(0,256):\n ftheta0[j][i]=f_theta0[i*256+j]\n fr0[j][i]=f_r0[i*256+j]\n F0[j][i]=sqrt(ftheta0[j][i]**2+fr0[j][i]**2)\n dens[j][i]=density[i*256+j]\n\nfor i in arange(0,128):\n for j in arange(0,256):\n fthetal[j][i]=f_thetal[i*256+j]\n frl[j][i]=f_rl[i*256+j]\n Fl[j][i]=sqrt(fthetal[j][i]**2+frl[j][i]**2)\n\n\n \n\ndfrl=frl-fr0\ndfthetal=fthetal-ftheta0\n\ndFl=Fl-F0\n\n#plot(r,dfl[256/2,:])\n#plot(r,dfl[0,:])\n#plot(r,dfl[255,:])\n#plot(r,dfl[255/4,:])\n#plot(r,dfl[3*255/4,:])\n#xlim([r[0],r[127]])\n#title('Level 1 Oscillations')\n#xlabel('$r$')\n#ylabel('$\\Delta F_{\\Theta}(r)$')\n#legend([\"$\\Theta = \\pi$\",\"$\\Theta = 0$\",\"$\\Theta = 2\\pi$\",\"$\\Theta = \\pi/2$\",\"$\\Theta = 3\\pi/2$\"])\n\n## make dF(theta) for each r\n#for i in range(128):\n# hold(False)\n# plot(theta,dFl[:,i])\n# xlim([theta[0],theta[255]])\n# ylim([-1.3,1.3])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$\\Theta [rad]$')\n# ylabel('$\\Delta F(\\Theta)$')\n# name=(\"$r =$%f\" %r[i])\n# legend([name])\n# if i<10:\n# savefig(\"Animation/Level1/DF_theta/dfr00%i.png\" %i)\n# elif i<100:\n# savefig(\"Animation/Level1/DF_theta/dfr0%i.png\" %i)\n# else:\n# savefig(\"Animation/Level1/DF_theta/dfr%i.png\" %i)\n#\n## make dF(r) for each theta\n#for i in range(256):\n# hold(False)\n# plot(r,dFl[i,:])\n# xlim([r[0],r[127]])\n# ylim([-1.3,1.3])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$r [r_0]$')\n# ylabel('$\\Delta F(r)$')\n# name=(\"$\\Theta =$%f\" %theta[i])\n# legend([name])\n# if i<10:\n# savefig(\"Animation/Level1/DF_r/dfr00%i.png\" %i)\n# elif i<100:\n# savefig(\"Animation/Level1/DF_r/dfr0%i.png\" %i)\n# else:\n# savefig(\"Animation/Level1/DF_r/dfr%i.png\" %i)\n#\n## make dFr(theta) for each r\n#for i in range(128):\n# hold(False)\n# plot(theta,dfrl[:,i])\n# xlim([theta[0],theta[255]])\n# ylim([-1.3,1.3])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$\\Theta [rad]$')\n# ylabel('$\\Delta F_{r}(\\Theta)$')\n# name=(\"$r =$%f\" %r[i])\n# legend([name])\n# if i<10:\n# savefig(\"Animation/Level1/DFr_theta/dfr00%i.png\" %i)\n# elif i<100:\n# savefig(\"Animation/Level1/DFr_theta/dfr0%i.png\" %i)\n# else:\n# savefig(\"Animation/Level1/DFr_theta/dfr%i.png\" %i)\n# \n# \n## make dFtheta(theta) for each r\n#for i in range(128):\n# hold(False)\n# plot(theta,dfthetal[:,i])\n# xlim([theta[0],theta[255]])\n# ylim([-0.1,0.1])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$\\Theta [rad]$')\n# ylabel('$\\Delta F_{\\Theta}(\\Theta)$')\n# name=(\"$r =$%f\" %r[i])\n# legend([name])\n# if i<10:\n# savefig(\"Animation/Level1/DFtheta_theta/dftheta00%i.png\" %i)\n# elif i<100:\n# savefig(\"Animation/Level1/DFtheta_theta/dftheta0%i.png\" %i)\n# else:\n# savefig(\"Animation/Level1/DFtheta_theta/dftheta%i.png\" %i)\n#\n## make dFr(r) for each theta\n#for i in range(256):\n# hold(False)\n# plot(r,dfrl[i,:])\n# xlim([r[0],r[127]])\n# ylim([-1.3,1.3])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$r [r_0]$')\n# ylabel('$\\Delta F_{r}(r)$')\n# name=(\"$\\Theta =$%f\" %theta[i])\n# legend([name])\n# if i<10:\n# savefig(\"Animation/Level1/DFr_r/dfr00%i.png\" %i)\n# elif i<100:\n# savefig(\"Animation/Level1/DFr_r/dfr0%i.png\" %i)\n# else:\n# savefig(\"Animation/Level1/DFr_r/dfr%i.png\" %i)\n## make dFtheta(r) for each theta\n#for i in range(256):\n# hold(False)\n# plot(r,dfthetal[i,:])\n# xlim([r[0],r[127]])\n# ylim([-0.1,0.1])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$r [r_0]$')\n# ylabel('$\\Delta F_{\\Theta}(r)$')\n# name=(\"$\\Theta =$%f\" %theta[i])\n# legend([name])\n# if i<10:\n# savefig(\"Animation/Level1/DFtheta_r/dftheta00%i.png\" %i)\n# elif i<100:\n# savefig(\"Animation/Level1/DFtheta_r/dftheta0%i.png\" %i)\n# else:\n# savefig(\"Animation/Level1/DFtheta_r/dftheta%i.png\" %i)\n\n#fig, ax = plt.subplots(subplot_kw=dict(projection='polar'))\n#ax.contourf(theta, r, dens.T)\n#ylim([0,2])\n\n\npcolormesh(r,theta,frl)\ntitle('$\\Delta F$ $Level0$')\nxlabel('Radius $r$ [$r_0$]')\nylabel('Azimuth $\\Theta$ [$rad$]')\nxlim([r[0],r[127]])\nylim([theta[0],theta[255]])\ncolorbar()\n\n"
},
{
"alpha_fraction": 0.7674418687820435,
"alphanum_fraction": 0.8139534592628479,
"avg_line_length": 42,
"blob_id": "9cf7c0a6f22ef7ae52c4406e8b57919286f59d0b",
"content_id": "a3f596b3d9e8b1f5da8a5ed5770dd787f12a6a37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 1,
"path": "/jonrue/Level_i/README.txt",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "The Main Function is forcegrid_level_i.f90\n"
},
{
"alpha_fraction": 0.542242705821991,
"alphanum_fraction": 0.6251919865608215,
"avg_line_length": 15.48717975616455,
"blob_id": "a5ea1f456670e094755f62a25c177ec37ed7703e",
"content_id": "4e6ff9081470d7fece1faf084f3db573a689b101",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 651,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 39,
"path": "/jonrue/Level_i/forcegrid_level_i.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 11 15:40:49 2015\n\n@author: jonas\n\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\na0=[]\nb0=[]\na=np.zeros((256,128))\n\n\n\ndata=open(\"../output/forcegrid_rcomponent_level1.txt\")\nfor line in data:\n a0.append(float(line))\ndata2=open(\"../output/forcegrid_rcomponent.txt\")\nfor line in data2:\n b0.append(float(line))\n \n\nindex=0 \nfor j in range(256):\n for i in range(128):\n a[j,i]=a0[index]-b0[index]\n index=index+1\nsubplot(1,2,1) \nimshow(a,origin='lower')\ncolorbar()\n\nsubplot(1,2,2)\nindex2=19\nhold(True)\nfor i in range(1):\n plot(a[30:100,index2])\n index2+=2\n \n\n\n\n"
},
{
"alpha_fraction": 0.552598774433136,
"alphanum_fraction": 0.587110161781311,
"avg_line_length": 29.43037986755371,
"blob_id": "f21c1d01a474d265e65d2f70c8240de77c690ec9",
"content_id": "dc3deb1ff62052134522f9b5117f183e057c714c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2405,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 79,
"path": "/mihai/Codes_Final/gravity_plots.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "import numpy\nfrom matplotlib import pyplot\nimport time\n#nr = 128+4\n#nt = 256\n\nnr = 128 #128\nnt = 256# 256\n\ndef reading_data(nr,nt):\n\n r_file = open(\"/home/ics/mihai/git/Computational_Science_II/Data/r_project.data\", 'r')\n t_file = open(\"/home/ics/mihai/git/Computational_Science_II/Data/theta_project.data\", 'r')\n d_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/acc_r_lvl0_new.data\", 'r')\n#\td_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/acc_r_project.data\", 'r')\n#\td_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/acc_r_lvl0_new.data\", 'r')\n\n# r_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/New_attempt/radius_l.data\", 'r')\n# t_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/New_attempt/theta_l.data\", 'r')\n# d_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/New_attempt/mass_l.data\", 'r')\n\n r = []\n\n for line in r_file.readlines():\n r = r + [float(line[0:-1])]\n\n r = numpy.array(r)\n r_file.close()\n dr = r[1]-r[0]\n t = []\n\n for line in t_file.readlines():\n t = t + [float(line[0:-1])]\n\n t = numpy.array(t)\n t_file.close()\n dt = t[1]-t[0]\n\n d = numpy.zeros((nr,nt))\n m = numpy.zeros((nr,nt))\n\n i = 0\n for line in d_file.readlines():\n\t\t\n d[i/nt, i%nt] = float(line[0:-1])\n# m[i/nt, i%nt] = float(line[0:-1])*r[i/nt]*dr*dt\n i = i + 1\n\n d_file.close()\n\n\n return r, t, d\n\n\ndef linear_plot(x,y, data):\n pyplot.imshow(data, interpolation='none', aspect = 'auto')#extent=[min(x),max(x),min(y), max(y)], aspect = 'auto')\n\tpyplot.colorbar(label = r\"radial acceleration [AU]\")\n\tpyplot.title(\"Level 0\")\n# pyplot.colorbar(label = \"density [DU]\")\n\tpyplot.clim(-1.25,1.25)\n\tpyplot.xlabel(r\"$\\theta$ array\")\n\tpyplot.ylabel(r\"r array\")\n# pyplot.show()\n\tpyplot.savefig(\"/home/ics/mihai/Desktop/Presentations/Computational_Science_II_June/level0_radial.png\")\n\n\nr, t, d = reading_data(nr, nt)\n#print d[1::2,1::2].shape\n#dbig = d[1::2,1::2]+d[0::2,0::2]+d[0::2,1::2]+d[1::2,0::2]\n\n#pyplot.imshow(dbig*10**5, interpolation = 'none', aspect = 'auto')\n#pyplot.colorbar()\n#pyplot.show()\n\n#for element in d:\n#\tprint element\n\n\nlinear_plot(r, t, d)\n\n"
},
{
"alpha_fraction": 0.6280777454376221,
"alphanum_fraction": 0.6431965231895447,
"avg_line_length": 27.231706619262695,
"blob_id": "9ee90789b53260bd4567bf39faca02a33ffe2476",
"content_id": "fef88a56459b4c2d8750ec019615b1cd1c1294a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 2315,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 82,
"path": "/dephil/Makefile",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# Makefile\n########## in 'make all', grav_force, grav_force_lvl1 and grav_force_lvl2 are exculded, since grav_force_lvlx takes over their function\n\n# Definitions\n\nCC = gcc\nFC = gfortran\nOPT = -O2\nDEBUG = -g -Wall\nFFLAGS = -funderscoring -fno-range-check -fmessage-length=0\nCFLAGS = -fno-leading-underscore \nDEPS = module_grav_IO.o module_grav_precalcs.o module_grav_mass.o module_grav_parameters.o\nIDIR =\nLIBS = \nFOBJ_LEVEL_0 = archive/grav_force.o\nFOBJ_LEVEL_1 = archive/grav_force_lvl1.o\nFOBJ_LEVEL_2 = archive/grav_force_lvl2.o\nFOBJ_LEVEL_X = archive/grav_force_lvlx.o\nFOBJ_OSC_F = archive/oscillation_force.o\nFOBJ_PURE = grav_pure_lvlx.o\nFOBJ_REFINED = grav_refined.o\nCOBJ = bin/c_invsqrt64.o\nEXE_LEVEL_0 = grav_force\nEXE_LEVEL_1 = grav_force_lvl1\nEXE_LEVEL_2 = grav_force_lvl2\nEXE_LEVEL_X = grav_force_lvlx\nEXE_OSC_F = oscillation_force\nEXE_PURE = grav_pure_lvlx\nEXE_REFINED = grav_refined\n\n\n%.o: %.c\n\t$(CC) -c $(DEBUG) $(OPT) -o $@ $< $(CFLAGS)\n\n%.o: %.f90\n\t$(FC) -c $(DEBUG) $(OPT) -o $@ $< $(FFLAGS)\n\ndefault: $(EXE_PURE) $(EXE_REFINED)\n\nall: $(EXE_LEVEL_X) $(EXE_OSC_F) $(EXE_PURE) $(EXE_REFINED)\n\n$(EXE_LEVEL_0): $(FOBJ_LEVEL_0) $(COBJ)\n\t$(FC) -o $@ $^ $(LIBS)\n\n$(EXE_LEVEL_1): $(FOBJ_LEVEL_1) $(COBJ)\n\t$(FC) -o $@ $^ $(LIBS)\n\n$(EXE_LEVEL_2): $(FOBJ_LEVEL_2) $(COBJ)\n\t$(FC) -o $@ $^ $(LIBS)\n\n$(EXE_LEVEL_X): $(FOBJ_LEVEL_X) $(DEPS) $(COBJ)\n\t$(FC) -o $@ $^ $(LIBS)\n\n$(EXE_OSC_F): $(FOBJ_OSC_F) $(DEPS)\n\t$(FC) -o $@ $^ $(LIBS)\n\n$(EXE_PURE): $(FOBJ_PURE) $(DEPS)\n\t$(FC) -o $@ $^ $(LIBS)\n\n$(EXE_REFINED): $(FOBJ_REFINED) $(DEPS)\n\t$(FC) -o $@ $^ $(LIBS)\n\n.PHONY: clean\n\nclean:\n\trm -f *.o *.mod *~ core\n\tcd archive/; rm -f *.o *.mod *~ core\n\tcd bin/; rm -f *.o *.mod *~ core\n\ncleanall: clean\n\trm -f $(EXE_LEVEL_0) $(EXE_LEVEL_1) $(EXE_LEVEL_2) $(EXE_LEVEL_X) $(EXE_OSC_F) $(EXE_PURE) $(EXE_REFINED)\n\n\n# Dependencies\n\n$(FOBJ_LEVEL_X) : archive/$(EXE_LEVEL_X).f90 module_grav_IO.o module_grav_precalcs.o module_grav_mass.o module_grav_parameters.o\n\n$(FOBJ_OSC_F) : archive/$(EXE_OSC_F).f90 module_grav_IO.o module_grav_precalcs.o module_grav_mass.o module_grav_parameters.o\n\n$(FOBJ_PURE) : $(EXE_PURE).f90 module_grav_IO.o module_grav_precalcs.o module_grav_mass.o module_grav_parameters.o\n\n$(FOBJ_REFINED) : $(EXE_REFINED).f90 module_grav_IO.o module_grav_precalcs.o module_grav_mass.o module_grav_parameters.o\n"
},
{
"alpha_fraction": 0.6280566453933716,
"alphanum_fraction": 0.6602316498756409,
"avg_line_length": 24.899999618530273,
"blob_id": "c13187b723a79902d20db8d06284911c326c03d0",
"content_id": "b678aaa436ee5f0eb5ed300bc9e78936d83aa691",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 777,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 30,
"path": "/Sara/testinput/totxt.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# Overwrite density_project.data with any of the image files.\n# From one directory below:\n# python testinput/totext.py testinput/planet.png > density_project.data\n\nimport subprocess\nimport sys\n\nfrom string import maketrans\n\n#print sys.argv\n\ncommand = ['convert', sys.argv[1], 'txt:-']\n#print ' '.join(command)\nconversion = subprocess.Popen(command, stdout=subprocess.PIPE)\n\n(output, error) = conversion.communicate()\n\nlines = output.split('\\n')\n\nempty_trans = maketrans(\"\", \"\")\nfor line in lines:\n if line.startswith('#') or not line:\n continue\n\n rgb = line.split(\"(\")[1].split(\")\")[0]\n colors = rgb.split(',')\n color = (float(colors[0]) / 255.0 + float(colors[1]) / 255.0 +\n float(colors[2]) / 255.0) / 3.0\n color = 0.03 * (1.0 - color)\n print ' %e ' % color\n"
},
{
"alpha_fraction": 0.6592643857002258,
"alphanum_fraction": 0.6717557311058044,
"avg_line_length": 24.73214340209961,
"blob_id": "2194ee98278e1bed5100c8911c994ca812461b82",
"content_id": "d361b4894cbdd02c1d5b69bb305705eaaa87513f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1441,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 56,
"path": "/Sara/Makefile",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# Tuning parameters.\nMASS_DIFF_P=\"0.2\"\nCOM_CORR=\"\" # turn on with 'com', wasn't working\n\n# All test files\ntestinput := $(shell find 'testinput' -name '*.png')\ntestnames = $(testinput:testinput/%.png=%)\n\n# The default file and all test files.\nallexperiments = default $(testnames)\n\nall: run/default.plots\n\nall_base: $(allexperiments:%=run/%.run0)\n\nall_expt: $(allexperiments:%=run/%.plots)\n\n# Don't delete my intermediate files!\n.SECONDARY:\n\nadaptive: adaptive.f95\n\tmkdir -p bin\n\tgfortran -O5 adaptive.f95 -o adaptive\n\n# Always run, even if there is a file called 'clean'\n.PHONY: clean\nclean:\n\trm -f bin/*\n\trm -f testinput/*.data\n\trm -f run/*.run*\n\nclean_expt:\n\trm -f run/*.run run/*.plots run/*/*.data\n\nrun/default/density_project.data:\n\tmkdir -p run/default\n\tcp -f density_project.data run/default/\n\nrun/%/density_project.data: testinput/%.png\n\tmkdir -p run/$*\n\tpython testinput/totxt.py testinput/$*.png > $@\n\nrun/%.run: adaptive run/%/density_project.data\n\t./adaptive 6 0 $(MASS_DIFF_P) $(COM_CORR) run/$*/density_project.data run/$*/ | tee $@\n\nrun/%.run0: adaptive run/%/density_project.data\n\tmkdir -p run/$*/level0\n\t./adaptive 0 0 0.0 \"\" run/$*/density_project.data run/$*/level0/ | tee $@\n\nrun/%.plots: run/%.run\n\tpython graphing.py --prefix \"run/$*\" --save --all | tee $@\n\tpython graphing.py --prefix \"run/$*\" --save --all --polar | tee $@\n\n# Only used for development.\nrun/%.test: run/%.run\n\tpython graphing.py --prefix \"run/$*\" -d2\n"
},
{
"alpha_fraction": 0.5946374535560608,
"alphanum_fraction": 0.6066022515296936,
"avg_line_length": 36.9071044921875,
"blob_id": "a5990415b84a4208ce1726bbb7a90a9a8bbbb50f",
"content_id": "e1211f3623ea5e149d57c22b4e76a235229fb250",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6937,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 183,
"path": "/dephil/bin/residual_plot.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun May 17 14:51:52 2015\n\n@author: dephil\n\"\"\"\n\nimport matplotlib.pyplot as plt\nfrom numpy import zeros\nimport os.path\n\nmax_level = 4\ncounter_files = 0\ncounter_plots = 0\n\n\ndef read_path(path):\n \"\"\"\n Reads data and stores it in a 1-D list/array as floats\n \"\"\"\n # open data\n d_data = open(path, 'r')\n d_ = list()\n # first line read\n aline = d_data.readline()\n while aline:\n items = aline.split() # in case there are spaces\n d_.append(float(items[0])) # have python floats double precision ???\n aline = d_data.readline() # next line\n d_data.close()\n return d_\n\n \ndef to_matrix(ilist, N_r, N_theta):\n \"\"\"\n Rearranges the olist 1-D to 2-D array\n \"\"\"\n surface = zeros((N_theta,N_r))\n for i in range(N_r):\n for j in range(N_theta):\n surface[j][i] = ilist[j+N_theta*i]\n return surface\n\n\ndef plot_density(density, r, theta, name):\n \"\"\"\n Plots the density on a r vs. theta plot\n \"\"\"\n # rearrange density 1-D array to 2-D array\n N_r = len(r)\n N_theta = len(theta)\n surface = to_matrix(density, N_r, N_theta)\n # start figure\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(\"density map\")\n ax.set_xlabel(r'radius [$r_{0}$]')\n ax.set_ylabel('azimuth')\n # plot the 2-D array\n cax = ax.imshow(surface, aspect='auto', origin='lower',\n extent=[min(r), max(r), min(theta), max(theta)],\n cmap=plt.get_cmap('jet'),# interpolation='hamming', # change interpolation to None, if not wanted\n vmin=min(density), vmax=max(density))\n fig.colorbar(cax)\n fig.savefig(name)\n plt.close()\n\n\ndef plot_force_radial(force, r, theta, name):\n \"\"\"\n Plots the force on a r vs. theta plot\n \"\"\"\n # rearrange force 1-D array to 2-D array\n N_r = len(r)\n N_theta = len(theta)\n surface = to_matrix(force, N_r, N_theta)\n # start figure\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(\"force map (radial component)\")\n ax.set_xlabel('radius [r]')\n ax.set_ylabel('azimuth')\n # plot the 2-D array\n cax = ax.imshow(surface, aspect='auto', origin='lower',\n extent=[min(r)-.5*(r[1]-r[0]), max(r)-.5*(r[-1]-r[-2]), min(theta)-.5*(theta[1]-theta[0]), max(theta)-.5*(theta[-1]-theta[-2])],\n cmap=plt.get_cmap('jet'),# interpolation='hamming', # change interpolation to None, if not wanted\n vmin=min(force), vmax=max(force))\n fig.colorbar(cax)\n fig.savefig(name)\n plt.close()\n\n\ndef plot_force_angular(force, r, theta, name):\n \"\"\"\n Plots the force on a r vs. theta plot\n \"\"\"\n # rearrange force 1-D array to 2-D array\n N_r = len(r)\n N_theta = len(theta)\n surface = to_matrix(force, N_r, N_theta)\n # start figure\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(\"force map (angular component)\")\n ax.set_xlabel('radius [r]')\n ax.set_ylabel('azimuth')\n # plot the 2-D array\n cax = ax.imshow(surface, aspect='auto', origin='lower',\n extent=[min(r)-.5*(r[1]-r[0]), max(r)-.5*(r[-1]-r[-2]), min(theta)-.5*(theta[1]-theta[0]), max(theta)-.5*(theta[-1]-theta[-2])],\n cmap=plt.get_cmap('jet'),# interpolation='hamming', # change interpolation to None, if not wanted\n vmin=min(force), vmax=max(force))\n fig.colorbar(cax)\n fig.savefig(name)\n plt.close()\n\n\nif __name__ == \"__main__\":\n\n# define paths to files in ./diff/\n r_path = \"../data/r_project.data\"\n theta_path = \"../data/theta_project.data\" \n\n diff_radial_paths = list()\n diff_angular_paths = list()\n\n for i in range(1, max_level+1):\n r = \"../data/diff/radial_pure_diff\"+str(i)+\".data\"\n t = \"../data/diff/angular_pure_diff\"+str(i)+\".data\"\n diff_radial_paths.append(r)\n diff_angular_paths.append(t)\n \n for i in range(1, max_level+1):\n r = \"../data/diff/radial_refined_diff\"+str(i)+\".data\"\n t = \"../data/diff/angular_refined_diff\"+str(i)+\".data\"\n diff_radial_paths.append(r)\n diff_angular_paths.append(t)\n \n\n# read and plot data\n r = read_path(r_path)\n theta = read_path(theta_path)\n \n diff_radial = list()\n diff_angular = list()\n \n r_files_exist = [os.path.isfile(i) for i in diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]]\n t_files_exist = [os.path.isfile(i) for i in diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]]\n if (all(r_files_exist)) and (all(t_files_exist)):\n print diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]\n print diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]\n for s in diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]:\n diff_radial.append(read_path(s))\n for d in range(1, max_level+1):\n rstring = \"../pictures/radial_pure_diff\"+str(d)+\".png\"\n plot_force_radial(diff_radial[counter_plots*(max_level)+d-1], r, theta, rstring)\n for s in diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]:\n diff_angular.append(read_path(s))\n for d in range(1, max_level+1):\n tstring = \"../pictures/angular_pure_diff\"+str(d)+\".png\"\n plot_force_angular(diff_angular[counter_plots*(max_level)+d-1], r, theta, tstring)\n counter_plots = counter_plots + 1\n print \"pure residuals plotted\"\n counter_files = counter_files + 1\n \n r_files_exist = [os.path.isfile(i) for i in diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]]\n t_files_exist = [os.path.isfile(i) for i in diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]]\n if (all(r_files_exist)) and (all(t_files_exist)):\n print diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]\n print diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]\n for s in diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]:\n diff_radial.append(read_path(s))\n for d in range(1, max_level+1):\n rstring = \"../pictures/radial_refined_diff\"+str(d)+\".png\"\n plot_force_radial(diff_radial[counter_plots*(max_level)+d-1], r, theta, rstring)\n for s in diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]:\n diff_angular.append(read_path(s))\n for d in range(1, max_level+1):\n tstring = \"../pictures/angular_refined_diff\"+str(d)+\".png\"\n plot_force_angular(diff_angular[counter_plots*(max_level)+d-1], r, theta, tstring)\n counter_plots = counter_plots + 1\n print \"refined residuals plotted\"\n counter_files = counter_files + 1\n"
},
{
"alpha_fraction": 0.6436132788658142,
"alphanum_fraction": 0.6637262105941772,
"avg_line_length": 20.587785720825195,
"blob_id": "35bdb2d84d4865356bfe1c684169d057e8bc52c2",
"content_id": "19d35f3946c5958804765f8f5b94b2337216525c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2834,
"license_type": "no_license",
"max_line_length": 225,
"num_lines": 131,
"path": "/mihai/visualize.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot\nimport numpy\nfrom sys import argv\n\ndef reading_1D(filename):\n\tfileb = open(str(filename), 'r')\n\traw = fileb.readlines()\n\ta = numpy.zeros(len(raw))\n\ti = 0\n\twhile i < len(raw):\n\t\ta[i] = float(raw[i][0:-1])\n\t\ti = i + 1\n\n\tfileb.close()\n\treturn a\n\ndef colorbar(data, outpath, title):\n\n#\tfigure(num=None, figsize=(8, 2), dpi=80, facecolor='w', edgecolor='k')\n\n\tax1 = pyplot.subplot(111)\n\n#\tpyplot.figure(num=None, figsize=(8, 2), dpi=80, facecolor='w', edgecolor='k')\n\n\n\timport matplotlib as mpl\n\tcmap = mpl.cm.jet\n\tnorm = mpl.colors.Normalize(vmin=min(data), vmax = max(data))\n\n\tcb1 = mpl.colorbar.ColorbarBase(ax1, cmap=cmap, norm=norm,orientation='vertical')\n\n\tpyplot.savefig(outpath + \"colorbar_\"+title+\".png\")\n\n\tpyplot.cla()\n\tpyplot.clf()\n\n\n\n\n\n\n\n\n\ndef polar_plot(x, y, data, title, outpath):\n\tfrom matplotlib import pyplot\n\n\tax = pyplot.subplot( projection=\"polar\")\n\tax.pcolormesh(y,x ,data_2D)\n#\tax.set_rmax(max(x))\n\tax.grid(True)\n\n\tax.set_title(title, va='bottom')\n\tpyplot.savefig(outpath + title + \"_polar.png\")\n\ndef linear_plot(x, y, data, title, outpath):\n\tfrom matplotlib import pyplot\n\n\timport matplotlib.pyplot as plt\n\tfrom mpl_toolkits.axes_grid1 import make_axes_locatable\n\timport numpy as np\n\n\tplt.figure()\n\tax = plt.gca()\n\t\n\n# create an axes on the right side of ax. The width of cax will be 5%\n# of ax and the padding between cax and ax will be fixed at 0.05 inch.\n\n\n ax = pyplot.subplot()\n\tim = ax.pcolormesh(y,x ,data_2D)\n# ax.set_rmax(max(x))\n\n\n\n\tax.set_title(title, va='bottom', fontsize = 20)\n pyplot.ylabel(\"Radius [$r_0$]\", fontsize = 20)\n pyplot.xlabel(r\"$\\theta$\", fontsize = 20)\n\n ax.grid(True)\n\n\tdivider = make_axes_locatable(ax)\n\tcax = divider.append_axes(\"right\", size=\"5%\", pad=0.05)\n\n\tplt.colorbar(im, cax=cax)\n\n\n \n pyplot.savefig(outpath + title + \"_linear.png\")\n\n\n\n# python visualize /home/ics/mihai/git/Computational_Science_II/Data/r_project.data /home/ics/mihai/git/Computational_Science_II/Data/theta_project.data /home/ics/mihai/git/Computational_Science_II_Closed/force_r.data Force_r\n\n\n#script, x, y, map, outpath, title = argv\n\nscript, param = argv\nparam_f = open(str(param), 'r')\nnr = int(param_f.readline()[0:-1])\nprint nr\nnt = int(param_f.readline()[0:-1])\nprint nt\nr_path = str(param_f.readline()[0:-1])\nprint r_path\nt_path = str(param_f.readline()[0:-1])\nprint t_path\nm_path = str(param_f.readline()[0:-1])\nprint m_path\no_path = str(param_f.readline()[0:-1])\nprint o_path\ntitle = str(param_f.readline()[0:-1])\nprint title\n\n\nparam_f.close()\n\n\nx = reading_1D(r_path)\ny = reading_1D(t_path)\ndata = reading_1D(m_path)\ndata_2D = data.reshape(nr, nt)\n\nr = x\ntheta = y\n\n\ncolorbar(data, str(o_path), str(title))\npolar_plot(x,y, data_2D, str(title), o_path)\nlinear_plot(x,y, data_2D, str(title), o_path)\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7177006006240845,
"alphanum_fraction": 0.7359135150909424,
"avg_line_length": 72.20833587646484,
"blob_id": "b65f829c3fd4bc590bf337241b151e10d492d792",
"content_id": "2d5ee08d2a5a5b08e26daa67fc890d51cfcdf3c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1757,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 24,
"path": "/dephil/bin/residuals.sh",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n./diff_gridlvl ../data/f_radial.data ../data/radial_pure_lvl1.data ../data/diff/radial_pure_diff1.data\n./diff_gridlvl ../data/f_radial.data ../data/radial_pure_lvl2.data ../data/diff/radial_pure_diff2.data\n./diff_gridlvl ../data/f_radial.data ../data/radial_pure_lvl3.data ../data/diff/radial_pure_diff3.data\n./diff_gridlvl ../data/f_radial.data ../data/radial_pure_lvl4.data ../data/diff/radial_pure_diff4.data\n\n./diff_gridlvl ../data/f_angular.data ../data/angular_pure_lvl1.data ../data/diff/angular_pure_diff1.data\n./diff_gridlvl ../data/f_angular.data ../data/angular_pure_lvl2.data ../data/diff/angular_pure_diff2.data\n./diff_gridlvl ../data/f_angular.data ../data/angular_pure_lvl3.data ../data/diff/angular_pure_diff3.data\n./diff_gridlvl ../data/f_angular.data ../data/angular_pure_lvl4.data ../data/diff/angular_pure_diff4.data\n\n\n./diff_gridlvl ../data/f_radial.data ../data/radial_refined_lvl1.data ../data/diff/radial_refined_diff1.data\n./diff_gridlvl ../data/f_radial.data ../data/radial_refined_lvl2.data ../data/diff/radial_refined_diff2.data\n./diff_gridlvl ../data/f_radial.data ../data/radial_refined_lvl3.data ../data/diff/radial_refined_diff3.data\n./diff_gridlvl ../data/f_radial.data ../data/radial_refined_lvl4.data ../data/diff/radial_refined_diff4.data\n\n./diff_gridlvl ../data/f_angular.data ../data/angular_refined_lvl1.data ../data/diff/angular_refined_diff1.data\n./diff_gridlvl ../data/f_angular.data ../data/angular_refined_lvl2.data ../data/diff/angular_refined_diff2.data\n./diff_gridlvl ../data/f_angular.data ../data/angular_refined_lvl3.data ../data/diff/angular_refined_diff3.data\n./diff_gridlvl ../data/f_angular.data ../data/angular_refined_lvl4.data ../data/diff/angular_refined_diff4.data\n\n./residual_plot.py\n"
},
{
"alpha_fraction": 0.7048917412757874,
"alphanum_fraction": 0.7113071084022522,
"avg_line_length": 31.8157901763916,
"blob_id": "99a9769e5598fe922b059b58f8f8ee83219a1d23",
"content_id": "1d01304194808396144ad16125448e8bc27d96a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1247,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 38,
"path": "/Setup.md",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "### Steps to complete before being able to contribute to the repository\n1. Create your GitHub account at: \n <https://github.com/>;\n2. Set up git on your machine by following the instructions at: \n\n <https://help.github.com/articles/set-up-git/>\n (all instructions before the \"Celebrate\" section); \n \n3. Send me via mail your GitHub username so that I can add you to the contributors list; \n \n4. As soon as I send you a confirmation you can modify/add files in the current repository via your browser; \n\n5. Make a directory on your machine where you want to clone the repository;\n\n6. Change directory to the respective folder; \n\n7. Clone the repository with: \n\n **git clone [email protected]:mihaimt/Computational_Science_II**.\n\n Now you should be able to modify/add files in the repository from your terminal. \n \n### Essential commands that you will use from your terminal\n* **git pull** \n\n* **git add *filename*** \n\n* **git commit -am \"*description*\"** \n\n* **git push** \n\n For tests on modifying/creating files use the **Computational_Science_II/Testing_git** directory. \n \n### Succint description:\n<https://training.github.com/kit/downloads/github-git-cheat-sheet.pdf> \n\n### A book about git:\n<http://git-scm.com/book/en/v2>\n"
},
{
"alpha_fraction": 0.5934877991676331,
"alphanum_fraction": 0.6087194681167603,
"avg_line_length": 43.544715881347656,
"blob_id": "2ed8cca4b71e06f62ca0da647da1df2f7507a248",
"content_id": "f559d791427f108b1eb9ffc4dab957ba3a7f9cf6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10964,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 246,
"path": "/dephil/bin/force_plot.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Mar 5 15:32:47 2015\n\n@author: dephil\n\"\"\"\nimport matplotlib.pyplot as plt\nfrom numpy import zeros\nimport os.path\n\nmax_level = 4\ncounter_files = 0\ncounter_plots = 0\n\n\ndef read_path(path):\n \"\"\"\n Reads data and stores it in a 1-D list/array as floats\n \"\"\"\n # open data\n d_data = open(path, 'r')\n d_ = list()\n # first line read\n aline = d_data.readline()\n while aline:\n items = aline.split() # in case there are spaces\n d_.append(float(items[0])) # have python floats double precision ???\n aline = d_data.readline() # next line\n d_data.close()\n return d_\n\n \ndef to_matrix(ilist, N_r, N_theta):\n \"\"\"\n Rearranges the olist 1-D to 2-D array\n \"\"\"\n surface = zeros((N_theta,N_r))\n for i in range(N_r):\n for j in range(N_theta):\n surface[j][i] = ilist[j+N_theta*i]\n return surface\n\n\ndef plot_density(density, r, theta, name):\n \"\"\"\n Plots the density on a r vs. theta plot\n \"\"\"\n # rearrange density 1-D array to 2-D array\n N_r = len(r)\n N_theta = len(theta)\n surface = to_matrix(density, N_r, N_theta)\n # start figure\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(\"density map\")\n ax.set_xlabel(r'radius [$r_{0}$]')\n ax.set_ylabel('azimuth')\n # plot the 2-D array\n cax = ax.imshow(surface, aspect='auto', origin='lower',\n extent=[min(r), max(r), min(theta), max(theta)],\n cmap=plt.get_cmap('jet'),# interpolation='hamming', # change interpolation to None, if not wanted\n vmin=min(density), vmax=max(density))\n fig.colorbar(cax)\n fig.savefig(name)\n plt.close()\n\n\ndef plot_force_radial(force, r, theta, name):\n \"\"\"\n Plots the force on a r vs. theta plot\n \"\"\"\n # rearrange force 1-D array to 2-D array\n N_r = len(r)\n N_theta = len(theta)\n surface = to_matrix(force, N_r, N_theta)\n # start figure\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(\"force map (radial component)\")\n ax.set_xlabel('radius [r]')\n ax.set_ylabel('azimuth')\n # plot the 2-D array\n cax = ax.imshow(surface, aspect='auto', origin='lower',\n extent=[min(r)-.5*(r[1]-r[0]), max(r)-.5*(r[-1]-r[-2]), min(theta)-.5*(theta[1]-theta[0]), max(theta)-.5*(theta[-1]-theta[-2])],\n cmap=plt.get_cmap('jet'),# interpolation='hamming', # change interpolation to None, if not wanted\n vmin=min(force), vmax=max(force))\n fig.colorbar(cax)\n fig.savefig(name)\n plt.close()\n\n\ndef plot_force_angular(force, r, theta, name):\n \"\"\"\n Plots the force on a r vs. theta plot\n \"\"\"\n # rearrange force 1-D array to 2-D array\n N_r = len(r)\n N_theta = len(theta)\n surface = to_matrix(force, N_r, N_theta)\n # start figure\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(\"force map (angular component)\")\n ax.set_xlabel('radius [r]')\n ax.set_ylabel('azimuth')\n # plot the 2-D array\n cax = ax.imshow(surface, aspect='auto', origin='lower',\n extent=[min(r)-.5*(r[1]-r[0]), max(r)-.5*(r[-1]-r[-2]), min(theta)-.5*(theta[1]-theta[0]), max(theta)-.5*(theta[-1]-theta[-2])],\n cmap=plt.get_cmap('jet'),# interpolation='hamming', # change interpolation to None, if not wanted\n vmin=min(force), vmax=max(force))\n fig.colorbar(cax)\n fig.savefig(name)\n plt.close()\n\n\nif __name__ == \"__main__\":\n\n# define the paths to the files\n r_path = \"../data/r_project.data\"\n theta_path = \"../data/theta_project.data\"\n density_path = \"../data/density_project.data\"\n \n force_r_path = \"../data/f_radial.data\"\n force_theta_path = \"../data/f_angular.data\"\n\n force_lvl_r_paths = list()\n force_lvl_theta_paths = list()\n\n for i in range(max_level+1):\n r = \"../data/f_radial_lvl\"+str(i)+\".data\"\n t = \"../data/f_angular_lvl\"+str(i)+\".data\"\n force_lvl_r_paths.append(r)\n force_lvl_theta_paths.append(t)\n \n for i in range(max_level+1):\n r = \"../data/radial_pure_lvl\"+str(i)+\".data\"\n t = \"../data/angular_pure_lvl\"+str(i)+\".data\"\n force_lvl_r_paths.append(r)\n force_lvl_theta_paths.append(t)\n \n for i in range(max_level+1):\n r = \"../data/radial_osc_force_lvl\"+str(i)+\".data\"\n t = \"../data/angular_osc_force_lvl\"+str(i)+\".data\"\n force_lvl_r_paths.append(r)\n force_lvl_theta_paths.append(t)\n\n for i in range(1, max_level+2):\n r = \"../data/radial_refined_lvl\"+str(i)+\".data\"\n t = \"../data/angular_refined_lvl\"+str(i)+\".data\"\n force_lvl_r_paths.append(r)\n force_lvl_theta_paths.append(t)\n\n\n# read and plot data\n r = read_path(r_path)\n theta = read_path(theta_path)\n density = read_path(density_path)\n plot_density(density, r, theta, '../pictures/density.png')\n print \"density plotted\"\n \n if (os.path.isfile(force_r_path) and os.path.isfile(force_theta_path)):\n force_r = read_path(force_r_path)\n plot_force_radial(force_r, r, theta, '../pictures/radial_force.png')\n force_theta = read_path(force_theta_path)\n plot_force_angular(force_theta, r, theta, '../pictures/angular_force.png')\n print \"grav_force output plotted\"\n\n force_lvl_r = list()\n force_lvl_theta = list()\n \n r_files_exist = [os.path.isfile(i) for i in force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]]\n t_files_exist = [os.path.isfile(i) for i in force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]]\n if (all(r_files_exist)) and (all(t_files_exist)):\n print force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]\n print force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]\n for s in force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]:\n force_lvl_r.append(read_path(s))\n for d in range(max_level+1):\n rstring = \"../pictures/radial_force_lvl\"+str(d)+\".png\"\n plot_force_radial(force_lvl_r[counter_plots*(max_level+1)+d], r, theta, rstring)\n for s in force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]:\n force_lvl_theta.append(read_path(s))\n for d in range(max_level+1):\n tstring = \"../pictures/angular_force_lvl\"+str(d)+\".png\"\n plot_force_angular(force_lvl_theta[counter_plots*(max_level+1)+d], r, theta, tstring)\n counter_plots = counter_plots + 1\n print \"grav_force_lvlx output plotted\"\n counter_files = counter_files + 1\n \n r_files_exist = [os.path.isfile(i) for i in force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]]\n t_files_exist = [os.path.isfile(i) for i in force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]]\n if (all(r_files_exist) and all(t_files_exist)):\n print force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]\n print force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]\n for s in force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]:\n force_lvl_r.append(read_path(s))\n for d in range(max_level+1):\n rstring = \"../pictures/radial_pure_lvl\"+str(d)+\".png\"\n plot_force_radial(force_lvl_r[counter_plots*(max_level+1)+d], r, theta, rstring)\n for s in force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]:\n force_lvl_theta.append(read_path(s))\n for d in range(max_level+1):\n tstring = \"../pictures/angular_pure_lvl\"+str(d)+\".png\"\n plot_force_angular(force_lvl_theta[counter_plots*(max_level+1)+d], r, theta, tstring)\n counter_plots = counter_plots + 1\n print \"grav_pure_lvlx output plotted\"\n counter_files = counter_files + 1\n \n r_files_exist = [os.path.isfile(i) for i in force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]]\n t_files_exist = [os.path.isfile(i) for i in force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]]\n if (all(r_files_exist) and all(t_files_exist)):\n print force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]\n print force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]\n for s in force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]:\n force_lvl_r.append(read_path(s))\n for d in range(max_level+1):\n rstring = \"../pictures/osc_force_radial_lvl\"+str(d)+\".png\"\n plot_force_radial(force_lvl_r[counter_plots*(max_level+1)+d], r, theta, rstring)\n for s in force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]:\n force_lvl_theta.append(read_path(s))\n for d in range(max_level+1):\n tstring = \"../pictures/osc_force_angular_lvl\"+str(d)+\".png\"\n plot_force_angular(force_lvl_theta[counter_plots*(max_level+1)+d], r, theta, tstring)\n counter_plots = counter_plots + 1\n print \"oscillation_force output plotted\"\n counter_files = counter_files + 1\n\n r_files_exist = [os.path.isfile(i) for i in force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]]\n t_files_exist = [os.path.isfile(i) for i in force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]]\n if (all(r_files_exist) and all(t_files_exist)):\n print force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]\n print force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]\n for s in force_lvl_r_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]:\n force_lvl_r.append(read_path(s))\n for d in range(1, max_level+2):\n rstring = \"../pictures/radial_refined_lvl\"+str(d)+\".png\"\n plot_force_radial(force_lvl_r[counter_plots*(max_level+1)+d-1], r, theta, rstring)\n for s in force_lvl_theta_paths[counter_files*(max_level+1):(counter_files*(max_level+1)+(max_level+1))]:\n force_lvl_theta.append(read_path(s))\n for d in range(1, max_level+2):\n tstring = \"../pictures/angular_refined_lvl\"+str(d)+\".png\"\n plot_force_angular(force_lvl_theta[counter_plots*(max_level+1)+d-1], r, theta, tstring)\n counter_plots = counter_plots + 1\n print \"grav_refined output plotted\"\n counter_files = counter_files + 1\n\n \n"
},
{
"alpha_fraction": 0.5625,
"alphanum_fraction": 0.629807710647583,
"avg_line_length": 26.733333587646484,
"blob_id": "fff12585962afec2ef214824ed45d0d07137f59c",
"content_id": "1a160f2061cf42626eb1269ca70e9514962a15f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 416,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 15,
"path": "/README.md",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "### Computational Science Project:\n- Course: Computational Science II \n- Place: University of Zurich \n- Semester: Spring 2015 \n\n### Project Members:\n- Participants: Tino Valentin Baechtold, Philipp Denzel, Valère Lambert, Jonas Rüegsegger, Daniel Studer, Sara Vossoughi, Mihai Tomozeiu\n- Lecturers: Clement Surville, Prasenjit Saha, George Lake\n- Teaching Assistant: Mihai Tomozeiu\n\n### Meetings:\n- Days: Thursdays \n- Time: 10:00 am\n- Room: 11 G 40\n- Valid: 26.02.2015 - 28.05.2015\n"
},
{
"alpha_fraction": 0.5815085172653198,
"alphanum_fraction": 0.6070559620857239,
"avg_line_length": 15.755102157592773,
"blob_id": "95734fe4870625e6a827f9ef33fb80c346ff33a7",
"content_id": "f41366e8b0ec67552b4860478cfe107116743bb4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 822,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 49,
"path": "/dephil/update.sh",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# execute in main folder with ./update.sh\n\nif [ -x grav_refined ]; then\n ./grav_refined 1\n ./grav_refined 2\n ./grav_refined 3\n ./grav_refined 4\n ./grav_refined 5\nfi \n\nif [ -x grav_pure_lvlx ]; then\n ./grav_pure_lvlx 1\n ./grav_pure_lvlx 2\n ./grav_pure_lvlx 3\n ./grav_pure_lvlx 4\nfi\n\nif [ -x grav_force_lvlx ]; then\n ./grav_force_lvlx 1\n ./grav_force_lvlx 2\n ./grav_force_lvlx 3\n ./grav_force_lvlx 4\nfi\n\nif [ -x grav_force ]; then\n ./grav_force\nfi\n\nif [ -x oscillation_force ]; then\n ./oscillation_force 1\n ./oscillation_force 2\n ./oscillation_force 3\n ./oscillation_force 4\nfi\n\nif [ -x grav_force_lvl1 ]; then\n ./grav_force_lvl1\nfi\n\nif [ -x grav_force_lvl2 ]; then\n ./grav_force_lvl2\nfi\n\ncd bin/\n./force_plot.py\n./residuals.sh\n./error_plot.py\ncd ../\n\n"
},
{
"alpha_fraction": 0.5620555877685547,
"alphanum_fraction": 0.6144149899482727,
"avg_line_length": 30.56122398376465,
"blob_id": "68f9c71e33ab07ac01e73f0f9cb490fc0ee43e42",
"content_id": "f9a3d40099c95a0b062e97eefe5334a2fb08247e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3094,
"license_type": "no_license",
"max_line_length": 233,
"num_lines": 98,
"path": "/mihai/Codes_Final/gravity_1d_plots.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "import numpy\nfrom matplotlib import pyplot\nimport time\n#nr = 128+4\n#nt = 256\n\nnr = 132 #128\nnt = 256# 256\n\nname = \"/home/ics/mihai/git/Computational_Science_II_Open/acc_r_lvl0_new.data\"\n \n\ndef reading_data(nr,nt, name):\n\n r_file = open(\"/home/ics/mihai/git/Computational_Science_II/Data/r_project.data\", 'r')\n t_file = open(\"/home/ics/mihai/git/Computational_Science_II/Data/theta_project.data\", 'r')\n #d_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/density_project.data\", 'r')\n#\td_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/acc_r_project.data\", 'r')\n\td_file = open(name, 'r')\n\n# r_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/New_attempt/radius_l.data\", 'r')\n# t_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/New_attempt/theta_l.data\", 'r')\n# d_file = open(\"/home/ics/mihai/git/Computational_Science_II_Open/New_attempt/mass_l.data\", 'r')\n\n r = []\n\n for line in r_file.readlines():\n r = r + [float(line[0:-1])]\n\n r = numpy.array(r)\n r_file.close()\n dr = r[1]-r[0]\n t = []\n\n for line in t_file.readlines():\n t = t + [float(line[0:-1])]\n\n t = numpy.array(t)\n t_file.close()\n dt = t[1]-t[0]\n\n d = numpy.zeros((nr,nt))\n m = numpy.zeros((nr,nt))\n\n i = 0\n for line in d_file.readlines():\n\t\t\n d[i/nt, i%nt] = float(line[0:-1])\n# m[i/nt, i%nt] = float(line[0:-1])*r[i/nt]*dr*dt\n i = i + 1\n\n d_file.close()\n\n\n return r, t, d\n\n\ndef linear_plot(x,y, data):\n\ti = 0\n\tmax_line, index_l = [], []\n\tfor line in data:\n\t\tmax_line = max_line + [max(line)]\n\t\tindex_l = index_l + [i]\n\t\ti = i +1\n\n\tmax_line, index_l = numpy.array(max_line), numpy.array(index_l)\n\tpyplot.plot(index_l, max_line, 'r.')\n\n# pyplot.imshow(data, interpolation='none', aspect = 'auto')#extent=[min(x),max(x),min(y), max(y)], aspect = 'auto')\n#\tpyplot.colorbar(label = r\"relative radial acceleration difference\")\n\tpyplot.title(\"LEVEL0 - REFINED radial\")\n# pyplot.colorbar(label = \"density [DU]\")\n#\tpyplot.clim(-.1,.1)\n\tpyplot.xlabel(r\"$\\theta$ array\")\n\tpyplot.ylabel(r\"maximum difference in a row\")\n\tpyplot.xlim(0,256)\n# pyplot.show()\n\tpyplot.savefig(\"/home/ics/mihai/Desktop/Presentations/Computational_Science_II_June/1D_diff_radial.png\")\n\n\n\nname = \"/home/ics/mihai/git/Computational_Science_II_Open/acc_r_lvl0_new.data\"\nr, t, d = reading_data(nr, nt, name)\n\nname1 = \"/home/ics/mihai/git/Computational_Science_II_Open/acc_r_ref.data\"\nr1, t1, d1 = reading_data(nr,nt, name1)\n\n#print d[1::2,1::2].shape\n#dbig = d[1::2,1::2]+d[0::2,0::2]+d[0::2,1::2]+d[1::2,0::2]\n\n#pyplot.imshow(dbig*10**5, interpolation = 'none', aspect = 'auto')\n#pyplot.colorbar()\n#pyplot.show()\n\n#for element in d:\n#\tprint element\n\nlinear_plot(r, t, numpy.transpose(d-d1)/2.5)\n\n"
},
{
"alpha_fraction": 0.5472496747970581,
"alphanum_fraction": 0.6248236894607544,
"avg_line_length": 21.90322494506836,
"blob_id": "38cff3c18121dcaad9e9cfeb33992e10742b7f8c",
"content_id": "398489bf8c0dc9e2fa3f3b2485c8fded28057f6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 709,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 31,
"path": "/DanielStuder/densmass.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Apr 21 11:40:46 2015\n\n@author: omer\n\"\"\"\nfrom pylab import*\ndensity=loadtxt(\"../Data/density_project.data\")\nmass=loadtxt(\"Results/massl_project.data\")\nr=loadtxt(\"../Data/r_project.data\")\ntheta=loadtxt(\"../Data/theta_project.data\") \ndr=r[1]-r[0]\nr=r-dr/2 \ndtheta=theta[1]-theta[0]\ntheta=theta-dtheta/2 \nd=zeros((256,128))\nm=zeros((256,128))\n\nfor i in arange(0,128):\n for j in arange(0,256):\n d[j][i]=density[i*256+j]*dr*dtheta\n m[j][i]=mass[i*256+j]\n\nprint(mean(d-m))\npcolormesh(r,theta,d-m)\ntitle('$\\Delta F$ $Level0$')\nxlabel('Radius $r$ [$r_0$]')\nylabel('Azimuth $\\Theta$ [$rad$]')\nxlim([r[0],r[127]])\nylim([theta[0],theta[255]])\ncolorbar()"
},
{
"alpha_fraction": 0.6479189991950989,
"alphanum_fraction": 0.6805399060249329,
"avg_line_length": 24.428571701049805,
"blob_id": "85497e8fd6f56e448db248414895d119fc774bc4",
"content_id": "2e28dcbfc144b3c9ce62a7fc6d2befef19cd5d91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 889,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 35,
"path": "/DanielStuder/gif.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Apr 15 21:16:03 2015\n\n@author: omer\n\"\"\"\n\nfrom pylab import *\nimport os\n# set the interactive mode of pylab to ON\nion()\n# opens a new figure to plot into\nfig_hndl = figure()\n# make an empty list into which we'll append\n# the filenames of the PNGs that compose each\n# frame.\nfiles=[] \n# filename for the name of the resulting movie\nfilename = 'animation'\nnumber_of_frames = 10\nfor t in range(number_of_frames):\n # draw the frame\n imshow(rand(1000,1000))\n # form a filename\n fname = 'Animation/Level1/DFr_theta/DFrtheta%03d.png'%t\n # save the frame\n savefig(fname)\n # append the filename to the list\n files.append(fname)\n# call mencoder\nos.system(\"mencoder 'mf://_tmp*.png' -mf type=png:fps=10 -ovc lavc -lavcopts vcodec=wmv2 -oac copy -o \" + filename + \".mpg\")\n# cleanup\nfor fname in files: os.remove(fname):\n \nffmpeg()"
},
{
"alpha_fraction": 0.6103249192237854,
"alphanum_fraction": 0.6200916767120361,
"avg_line_length": 35.882354736328125,
"blob_id": "f3631e40b45a93d4beff39989f2f9f087f291600",
"content_id": "10eef9b89ddca172f34b951bae1de870e4a635ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5017,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 136,
"path": "/dephil/bin/error_plot.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun May 18 10:23:15 2015\n\n@author: dephil\n\"\"\"\n\nimport matplotlib.pyplot as plt\nfrom numpy import zeros, max\nimport os.path\n\nmax_level = 4\ncounter_files = 0\ncounter_plots = 0\n\n\ndef read_path(path):\n \"\"\"\n Reads data and stores it in a 1-D list/array as floats\n \"\"\"\n # open data\n d_data = open(path, 'r')\n d_ = list()\n # first line read\n aline = d_data.readline()\n while aline:\n items = aline.split() # in case there are spaces\n d_.append(float(items[0])) # have python floats double precision ???\n aline = d_data.readline() # next line\n d_data.close()\n return d_\n\n\ndef to_matrix(ilist, N_r, N_theta):\n \"\"\"\n Rearranges the olist 1-D to 2-D array\n \"\"\"\n surface = zeros((N_theta,N_r))\n for i in range(N_r):\n for j in range(N_theta):\n surface[j][i] = ilist[j+N_theta*i]\n return surface\n\n\ndef plot_maxerror(diff_force, r, theta, name):\n \"\"\"\n Plots the density on a r vs. theta plot\n \"\"\"\n # rearrange density 1-D array to 2-D array\n N_r = len(r)\n N_theta = len(theta)\n diffs = to_matrix(diff_force, N_r, N_theta)\n maxerrors = list()\n for j in range(N_theta):\n maxerrors.append(max(diffs[j][:]))\n # start figure\n fig = plt.figure()\n ax = fig.add_subplot(111)\n ax.set_title(\"maximal error\")\n ax.set_xlabel('azimuth')\n ax.set_ylabel('maximal difference')\n my_blue = '#39b3e6'\n ax.plot(theta, maxerrors, color=my_blue, ls='-')\n ax.grid()\n plt.savefig(name)\n plt.close()\n\n\n\nif __name__ == \"__main__\":\n\n# define paths to files in ./diff/\n r_path = \"../data/r_project.data\"\n theta_path = \"../data/theta_project.data\"\n\n diff_radial_paths = list()\n diff_angular_paths = list()\n\n for i in range(1, max_level+1):\n r = \"../data/diff/radial_pure_diff\"+str(i)+\".data\"\n t = \"../data/diff/angular_pure_diff\"+str(i)+\".data\"\n diff_radial_paths.append(r)\n diff_angular_paths.append(t)\n\n for i in range(1, max_level+1):\n r = \"../data/diff/radial_refined_diff\"+str(i)+\".data\"\n t = \"../data/diff/angular_refined_diff\"+str(i)+\".data\"\n diff_radial_paths.append(r)\n diff_angular_paths.append(t)\n\n\n# read and plot data\n r = read_path(r_path)\n theta = read_path(theta_path)\n\n diff_radial = list()\n diff_angular = list()\n\n r_files_exist = [os.path.isfile(i) for i in diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]]\n t_files_exist = [os.path.isfile(i) for i in diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]]\n if (all(r_files_exist)) and (all(t_files_exist)):\n print diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]\n print diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]\n for s in diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]:\n diff_radial.append(read_path(s))\n for d in range(1, max_level+1):\n rstring = \"../pictures/radial_pure_error\"+str(d)+\".png\"\n plot_maxerror(diff_radial[counter_plots*(max_level)+d-1], r, theta, rstring)\n for s in diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]:\n diff_angular.append(read_path(s))\n for d in range(1, max_level+1):\n tstring = \"../pictures/angular_pure_error\"+str(d)+\".png\"\n plot_maxerror(diff_angular[counter_plots*(max_level)+d-1], r, theta, tstring)\n counter_plots = counter_plots + 1\n print \"pure errors plotted\"\n counter_files = counter_files + 1\n\n r_files_exist = [os.path.isfile(i) for i in diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]]\n t_files_exist = [os.path.isfile(i) for i in diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]]\n if (all(r_files_exist)) and (all(t_files_exist)):\n print diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]\n print diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]\n for s in diff_radial_paths[counter_files*max_level:((counter_files*max_level)+max_level)]:\n diff_radial.append(read_path(s))\n for d in range(1, max_level+1):\n rstring = \"../pictures/radial_refined_error\"+str(d)+\".png\"\n plot_maxerror(diff_radial[counter_plots*(max_level)+d-1], r, theta, rstring)\n for s in diff_angular_paths[counter_files*max_level:((counter_files*max_level)+max_level)]:\n diff_angular.append(read_path(s))\n for d in range(1, max_level+1):\n tstring = \"../pictures/angular_refined_error\"+str(d)+\".png\"\n plot_maxerror(diff_angular[counter_plots*(max_level)+d-1], r, theta, tstring)\n counter_plots = counter_plots + 1\n print \"refined errors plotted\"\n counter_files = counter_files + 1\n\n"
},
{
"alpha_fraction": 0.5212264060974121,
"alphanum_fraction": 0.5966981053352356,
"avg_line_length": 15.470588684082031,
"blob_id": "6e6d1dcc2207c94b7c919fa166125aafb60ab684",
"content_id": "7b36a7353df31800059d901aff5d99bbb7f69b8d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 848,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 51,
"path": "/Tino_jonrue/levelPatching.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 11 15:40:49 2015\n\n@author: \n\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\na0=[]\nb0=[]\na=np.zeros((256,128))\n\n\n\ndata=open(\"output/forcegrid_rcomponent.txt\")\nfor line in data:\n a0.append(float(line))\ndata2=open(\"output/force_r.txt\")\nfor line in data2:\n b0.append(float(line))\n \n\nindex=0 \nfor j in range(256):\n for i in range(128):\n a[j][i]=a0[index]-b0[index]\n index=index+1\n#subplot(1,1,1) \nimshow(a,origin='lower')\ncolorbar()\ntitle(\"std=0.08 ohne Verschiebung des Grids\")\n\n\n#index=0 \n#for j in range(256):\n# for i in range(128):\n# a[j][i]=b0[index]\n# index=index+1\n#subplot(1,2,2) \n#imshow(a,origin='lower')\n#colorbar()\n\n\n#subplot(1,2,2)\n#index2=250\n#hold(True)\n#for i in range(1):\n# plot(a[:][index2],'o')\n# index2+=1\n \n\n\n\n"
},
{
"alpha_fraction": 0.5439208745956421,
"alphanum_fraction": 0.58086097240448,
"avg_line_length": 23.9818172454834,
"blob_id": "3af6a17da603195c9c2c96deb761c6fbea144b35",
"content_id": "c4b5760508aa50be01dea59ea16754609b14a711",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6876,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 275,
"path": "/Daniel,Tino,Jonas/Src/plot.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nSpyder Editor\n\nThis temporary script file is located here:\n/home/omer/.spyder2/.temp.py\n\"\"\"\n\nfrom pylab import*\nhold(False)\n\"\"\"\nMake plot of density\n\"\"\"\ndensity=loadtxt(\"../Data/density_project.data\")\nr=loadtxt(\"../Data/r_project.data\")\ntheta=loadtxt(\"../Data/theta_project.data\")\ndim_r=len(r)\ndim_theta=len(theta)\ndens=zeros((dim_r,dim_theta))\n\nfor j in arange(0,dim_theta):\n for i in arange(0,dim_r):\n dens[i][j]=density[i*256+j]\n \npcolormesh(theta,r,dens)\ntitle('$Density$')\nylabel('Radius $r$ [$r_0$]')\nxlabel('Azimuth $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/Density.png\")\nclose() \n\"\"\"\nMake plots of force level 0 \n\"\"\"\nforce0=loadtxt(\"Res/force0_project.data\")\n\ndr=r[1]-r[0]\nr=r-dr/2\ndtheta=theta[1]-theta[0]\ntheta=theta-dtheta/2 \n\nftheta0=zeros((dim_r,dim_theta))\nfr0=zeros((dim_r,dim_theta))\n\nfor j in arange(0,dim_theta):\n for i in arange(0,dim_r):\n fr0[i][j]=force0[i*256+j,0]\n ftheta0[i][j]=force0[i*256+j,1]\n \nF0=sqrt(ftheta0**2+fr0**2)\n\npcolormesh(theta,r,F0)\ntitle('$Force$ $Level$ $0$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/Force_0.png\")\nclose()\npcolormesh(theta,r,fr0)\ntitle('$Force_r$ $Level$ $0$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/Force_r_0.png\")\nclose()\npcolormesh(theta,r,ftheta0)\ntitle('$Force_theta$ $Level$ $0$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/Force_theta_0.png\")\nclose()\n\"\"\"\nMake plots of force level l \n\"\"\"\nforcel=loadtxt(\"Res/force_project.data\")\n\nfthetal=zeros((dim_r,dim_theta))\nfrl=zeros((dim_r,dim_theta))\n\nfor j in arange(0,dim_theta):\n for i in arange(0,dim_r):\n frl[i][j]=forcel[i*256+j,0]\n fthetal[i][j]=forcel[i*256+j,1]\n \nFl=sqrt(fthetal**2+frl**2)\n\npcolormesh(theta,r,Fl)\ntitle('$Force$ $Level$ $l$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/Force_l.png\")\nclose()\npcolormesh(theta,r,frl)\ntitle('$Force_r$ $Level$ $l$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/Force_r_l.png\")\nclose()\npcolormesh(theta,r,fthetal)\ntitle('$Force_theta$ $Level$ $l$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/Force_theta_l.png\")\nclose()\n\"\"\"\nMake plots of force level l-0 differences \n\"\"\"\ndfthetal=fthetal-ftheta0\ndfrl=frl-fr0\ndFl=Fl-F0\n\n\npcolormesh(theta,r,dFl)\ntitle('$\\Delta F$ $Level$ $l$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/dForce_l.png\")\nclose()\n\npcolormesh(theta,r,dfrl)\ntitle('$\\Delta F_r$ $Level$ $l$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/dForce_r_l.png\")\nclose()\n\npcolormesh(theta,r,fthetal)\ntitle('$\\Delta F_\\Theta$ $Level$ $l$')\nylabel('$Radius$ $r$ [$r_0$]')\nxlabel('$Azimuth$ $\\Theta$ [$rad$]')\nylim([r[0],r[dim_r-1]])\nxlim([theta[0],theta[dim_theta-1]])\ncolorbar()\nsavefig(\"Res/dForce_theta_l.png\")\nclose()\n\n\n\"\"\"\nMake frames of force level l-0 differences \n\"\"\"\n## make dF(theta) for each r\n#for i in range(128):\n# hold(False)\n# plot(theta,dFl[i,:])\n# xlim([theta[0],theta[255]])\n# ylim([-1.3,1.3])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$\\Theta [rad]$')\n# ylabel('$\\Delta F(\\Theta)$')\n# name=(\"$r =$%f\" %r[i])\n# legend([name])\n# if i<10:\n# savefig(\"../Res/Anim/Level1/DF_theta/dfr00%i.png\" %i)\n# elif i<100:\n# savefig(\"../Res/Anim/Level1/DF_theta/dfr0%i.png\" %i)\n# else:\n# savefig(\"../Res/Anim/Level1/DF_theta/dfr%i.png\" %i)\n\n\n## make dF(r) for each theta\n#for i in range(256):\n# hold(False)\n# plot(r,dFl[:,i])\n# xlim([r[0],r[127]])\n# ylim([-1.3,1.3])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$r [r_0]$')\n# ylabel('$\\Delta F(r)$')\n# name=(\"$\\Theta =$%f\" %theta[i])\n# legend([name])\n# if i<10:\n# savefig(\"../Res/Anim/Level1/DF_r/dfr00%i.png\" %i)\n# elif i<100:\n# savefig(\"../Res/Anim/Level1/DF_r/dfr0%i.png\" %i)\n# else:\n# savefig(\"../Res/Anim/Level1/DF_r/dfr%i.png\" %i)\n\n\n## make dFr(theta) for each r\n#for i in range(128):\n# hold(False)\n# plot(theta,dfrl[i,:])\n# xlim([theta[0],theta[255]])\n# ylim([-1.3,1.3])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$\\Theta [rad]$')\n# ylabel('$\\Delta F_{r}(\\Theta)$')\n# name=(\"$r =$%f\" %r[i])\n# legend([name])\n# if i<10:\n# savefig(\"../Res/Anim/Level1/DFr_theta/dfr00%i.png\" %i)\n# elif i<100:\n# savefig(\"../Res/Anim/Level1/DFr_theta/dfr0%i.png\" %i)\n# else:\n# savefig(\"../Res/Anim/Level1/DFr_theta/dfr%i.png\" %i)\n\n \n## make dFtheta(theta) for each r\n#for i in range(128):\n# hold(False)\n# plot(theta,dfthetal[:,i])\n# xlim([theta[0],theta[255]])\n# ylim([-0.1,0.1])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$\\Theta [rad]$')\n# ylabel('$\\Delta F_{\\Theta}(\\Theta)$')\n# name=(\"$r =$%f\" %r[i])\n# legend([name])\n# if i<10:\n# savefig(\"../Res/Anim/Level1/DFtheta_theta/dftheta00%i.png\" %i)\n# elif i<100:\n# savefig(\"../Res/Anim/Level1/DFtheta_theta/dftheta0%i.png\" %i)\n# else:\n# savefig(\"../Res/Anim/Level1/DFtheta_theta/dftheta%i.png\" %i)\n\n\n## make dFr(r) for each theta\n#for i in range(256):\n# hold(False)\n# plot(r,dfrl[i,:])\n# xlim([r[0],r[127]])\n# ylim([-1.3,1.3])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$r [r_0]$')\n# ylabel('$\\Delta F_{r}(r)$')\n# name=(\"$\\Theta =$%f\" %theta[i])\n# legend([name])\n# if i<10:\n# savefig(\"Animation/Level1/DFr_r/dfr00%i.png\" %i)\n# elif i<100:\n# savefig(\"Animation/Level1/DFr_r/dfr0%i.png\" %i)\n# else:\n# savefig(\"Animation/Level1/DFr_r/dfr%i.png\" %i)\n\n## make dFtheta(r) for each theta\n#for i in range(256):\n# hold(False)\n# plot(r,dfthetal[i,:])\n# xlim([r[0],r[127]])\n# ylim([-0.1,0.1])\n# title('$Level 1$ $Oscillations$')\n# xlabel('$r [r_0]$')\n# ylabel('$\\Delta F_{\\Theta}(r)$')\n# name=(\"$\\Theta =$%f\" %theta[i])\n# legend([name])\n# if i<10:\n# savefig(\"Animation/Level1/DFtheta_r/dftheta00%i.png\" %i)\n# elif i<100:\n# savefig(\"Animation/Level1/DFtheta_r/dftheta0%i.png\" %i)\n# else:\n# savefig(\"Animation/Level1/DFtheta_r/dftheta%i.png\" %i)\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.6297500133514404,
"alphanum_fraction": 0.6588947176933289,
"avg_line_length": 37.283260345458984,
"blob_id": "b7cfd2f6dc12bd6daa8bba4f8b67ce8565eb4e5c",
"content_id": "ffd1bdd3a2e54e92effd8ef50a6cea27b1ce4635",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8923,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 233,
"path": "/Sara/graphing.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport argparse\nimport math\nimport matplotlib.colors as colors\nimport matplotlib.pyplot as plt\nimport matplotlib.ticker as mtick\nimport numpy as np\nimport os\nimport sys\nimport time\n\npiformat = mtick.FormatStrFormatter(u'%.1fπ')\n\n# A bunch of command line flags to define which graphs to generate.\nparser = argparse.ArgumentParser(description=\"Various plots.\")\nparser.add_argument(\"--prefix\", help=\"Prefix for input files\", default=\"run/default\")\nparser.add_argument(\"--polar\", action=\"store_true\", help=\"Make polar plots instead.\")\nparser.add_argument(\"-a\", \"--all\", action=\"store_true\", help=\"Plot all graphs\")\nparser.add_argument(\"-b\", \"--base\", action=\"store_true\", help=\"Plot the level0 graph\")\nparser.add_argument(\"-e\", \"--expt\", action=\"store_true\", help=\"Plot the higher level graph\")\nparser.add_argument(\"-d\", \"--diff\", action=\"store_true\", help=\"Plot the diff between level 0 and higher\")\nparser.add_argument(\"-d2\", \"--diff2D\", action=\"store_true\", help=\"Plot the 2d diff between level 0 and higher\")\nparser.add_argument(\"-d1\", \"--diff1D\", action=\"store_true\", help=\"Plot the 1d diff between level 0 and higher\")\nparser.add_argument(\"-l\", \"--levels\", action=\"store_true\", help=\"Debug plot the lookup distribution for one sample\")\nparser.add_argument(\"-m\", \"--masses\", action=\"store_true\", help=\"Debug plot all the masses.\")\nparser.add_argument(\"--summary\", action=\"store_true\", help=\"Plot the summary of density and forces.\")\nparser.add_argument(\"-s\",\"--save\", action=\"store_true\", help=\"Save plots instead of displaying them\")\n\nFLAGS = parser.parse_args(sys.argv[1:])\nprint FLAGS\n\n# 2 graphs from two files, next to each other (horizontally)\ndef plot2(a, name_a, b, name_b):\n fig = plt.figure()\n ax1 = fig.add_axes([0.05, 0.1, 0.35, 0.8], polar=FLAGS.polar)\n ax2 = fig.add_axes([0.55, 0.1, 0.35, 0.8], polar=FLAGS.polar)\n ax1_cbar = fig.add_axes([0.41, 0.1, 0.03, 0.8])\n ax2_cbar = fig.add_axes([0.91, 0.1, 0.03, 0.8])\n plotFile(a, name_a, fig, ax1, ax1_cbar)\n plotFile(b, name_b, fig, ax2, ax2_cbar)\n\n# 2 graphs of the difference of 4 files\ndef plotDiff2(a1, a2, b1, b2):\n fig = plt.figure()\n ax1 = fig.add_axes([0.05, 0.1, 0.35, 0.8], polar=FLAGS.polar)\n ax2 = fig.add_axes([0.55, 0.1, 0.35, 0.8], polar=FLAGS.polar)\n ax1_cbar = fig.add_axes([0.41, 0.1, 0.03, 0.8])\n ax2_cbar = fig.add_axes([0.91, 0.1, 0.03, 0.8])\n plotDiff(a1, a2, 'Radial Force (%)', fig, ax1, ax1_cbar)\n plotDiff(b1, b2, 'Tangential Force (%)', fig, ax2, ax2_cbar)\n\n# the 1D max value of the differences, 4 graphs.\ndef plotDiff2_1D(a1, a2, b1, b2):\n fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, sharex='col', sharey='row')\n plotDiff_1D(a1, a2, ax1, ax2, 'radial')\n plotDiff_1D(b1, b2, ax3, ax4, 'tangential')\n\n\n# Read a file, plot it to ax.\ndef plotFile(filename, name, fig, ax, ax_cbar):\n print \"plotFile\", filename\n fp = open(os.path.join(FLAGS.prefix, filename), 'r')\n values = [float(line) for line in fp]\n fp.close()\n plotArray(values, name, fig, ax, ax_cbar, FLAGS.polar)\n\n# Read two files, plot the percent difference to ax.\ndef plotDiff(file_a, file_b, name, fig, ax, ax_cbar):\n print \"plotDiff\", file_a, file_b\n fp = open(os.path.join(FLAGS.prefix, file_a), 'r')\n values_a = [float(line) for line in fp]\n fp.close()\n fp = open(os.path.join(FLAGS.prefix, file_b), 'r')\n values_b = [float(line) for line in fp]\n fp.close()\n spread = max(values_b) - min(values_b)\n # assumption, file_b is baseline\n diff = np.array([b_i - a_i for a_i, b_i in zip(values_a, values_b)])\n diff_percent = abs(diff) * 100.0 / spread\n mean_squared_error = (diff ** 2).mean()\n name = name + '\\nMean Squared Error: %f' % mean_squared_error\n plotArray(diff_percent, name, fig, ax, ax_cbar, FLAGS.polar)\n\n# Read two files, plot the max percent difference in both dimensions separately.\ndef plotDiff_1D(file_a, file_b, plt1, plt2, title_prefix):\n print \"plotDiff_1D\", file_a, file_b\n fp = open(os.path.join(FLAGS.prefix, file_a), 'r')\n values_a = [float(line) for line in fp]\n fp.close()\n fp = open(os.path.join(FLAGS.prefix, file_b), 'r')\n values_b = [float(line) for line in fp]\n fp.close()\n spread = max(values_b) - min(values_b)\n # assumption, file_b is baseline\n diff = [abs(b_i - a_i) * 100.0 / spread for a_i, b_i in zip(values_a, values_b)]\n\n npvalues = np.array(diff).reshape(len(radii),len(angles))\n # max values per row\n err_radial = map(max, npvalues)\n # max values per column\n err_tangential = map(max, npvalues.T)\n\n my_blue = '#39b3e6'\n\n plt1.set_title(\"Relative \" + title_prefix + \" error\")\n plt1.set_xlim([-0.1, 2.1])\n plt1.set_xlabel('azimuth')\n plt1.set_ylabel('maximal difference')\n plt1.xaxis.set_major_formatter(piformat)\n plt1.yaxis.set_major_formatter(mtick.FormatStrFormatter('%.2f%%'))\n plt1.plot(angles_no_pi, err_tangential, color=my_blue, ls='-')\n plt1.grid()\n\n\n plt2.set_title(\"Relative \" + title_prefix + \" error\")\n plt2.set_xlabel('radius')\n plt2.set_xlim([radii[0] - 0.03, radii[-1] + 0.03])\n plt2.set_ylabel('maximal difference')\n plt2.plot(radii, err_radial, color=my_blue, ls='-')\n plt2.grid()\n\n# Read a mass file and plot it in a single chart.\ndef plotMass(level, fig, ax, ax_cbar, polar):\n fp = open(os.path.join(FLAGS.prefix, 'mass_%.2d.txt' % level), 'r')\n # Masses are negative (from -sigma term)\n masses = [-float(line) for line in fp]\n fp.close()\n\n plotArray(masses, 'Mass Level %d' % (level), fig, ax, ax_cbar, polar)\n\n# Generalized plotting method. Autodetects higher levels, can switch to polar rendering if requested.\ndef plotArray(values, name, fig, ax, ax_cbar, polar):\n size = int(math.sqrt(len(values)/2))\n value_min = min(values)\n value_max = max(values)\n npvalues = np.array(values).reshape(size, size*2)\n\n level_mult = len(radii) / size\n dr_level = dr * level_mult\n dt_level = dtheta * level_mult\n\n if polar:\n t, r = np.mgrid[slice(min(angles),max(angles)+dt_level, dt_level),\n slice(min(radii), max(radii)+dr_level, dr_level) ]\n cax = ax.pcolor(t, r, npvalues.T, cmap=plt.get_cmap('jet'), vmin=value_min, vmax=value_max)\n ax.set_xlim([t.min(), t.max()])\n ax.set_ylim([0, r.max()]);\n ax.get_yaxis().set_visible(False)\n else:\n dt_level = dt_level / np.pi\n r, t = np.mgrid[slice(min(radii),max(radii)+dr_level, dr_level),\n slice(min(angles_no_pi), max(angles_no_pi)+dt_level, dt_level) ]\n cax = ax.pcolor(r, t, npvalues, cmap=plt.get_cmap('jet'), vmin=value_min, vmax=value_max)\n ax.set_xlim([r.min(), r.max()])\n ax.set_ylim([t.min(), t.max()]);\n ax.set_xlabel(\"r\")\n ax.set_ylabel(u\"θ\")\n ax.yaxis.set_major_formatter(piformat)\n ax.set_title(name)\n\n if ax_cbar:\n fig.colorbar(cax, cax=ax_cbar)\n\n# Always read the radii and angles.\nfp = open('r_project.data', 'r')\nradii = [float(line) for line in fp]\nfp.close()\ndr = radii[1]-radii[0]\n\nfp = open('theta_project.data', 'r')\nangles = [float(line) for line in fp]\nfp.close()\n\n# Divide the angles by pi so that the numbers are in interval [0, 2)\nangles_no_pi = np.array(angles) / np.pi\n\ndtheta = angles[1]-angles[0]\n\n# Save to a file.\ndef save(filename, is2d=True):\n if is2d:\n suffix = '-polar' if FLAGS.polar else '-euclid'\n filename = filename.replace('.png', suffix + '.png')\n plt.savefig(os.path.join(FLAGS.prefix, filename))\n print \"saved \" + filename\n\n# Save to a file if --save is set on the commandline, otherwise show the plot.\ndef saveOrShow(filename, is2d=True):\n if FLAGS.save:\n save(filename, is2d)\n else:\n plt.show()\n plt.close()\n\nif (FLAGS.all or FLAGS.levels):\n fig = plt.figure()\n ax = fig.add_axes([0.05, 0.05, 0.9, 0.9], polar=FLAGS.polar)\n plotFile('level.data', 'Lookup level', fig, ax, ax_cbar=None)\n saveOrShow(\"debug_level.png\")\n\n\nif (FLAGS.all or FLAGS.expt):\n plot2('force_r.data', 'Radial force', 'force_theta.data', 'Tangential Force')\n saveOrShow(\"forcesA.png\")\n\nif (FLAGS.all or FLAGS.base):\n plot2('level0/force_r.data', 'Radial force (L0)', 'level0/force_theta.data', 'Tangential Force (L0)')\n saveOrShow(\"forces0.png\")\n\nif FLAGS.all or FLAGS.diff or FLAGS.diff2D:\n plotDiff2('force_r.data', 'level0/force_r.data',\n 'force_theta.data', 'level0/force_theta.data')\n saveOrShow(\"diff_2D.png\")\n\nif FLAGS.all or FLAGS.diff or FLAGS.diff1D:\n plotDiff2_1D('force_r.data', 'level0/force_r.data',\n 'force_theta.data', 'level0/force_theta.data')\n saveOrShow(\"diff_1D.png\", is2d=False)\n\nif (FLAGS.all or FLAGS.masses):\n for i in range(0,100):\n fig = plt.figure()\n ax = fig.add_axes([0.05, 0.1, 0.75, 0.8], polar=FLAGS.polar)\n ax_cbar = fig.add_axes([0.83, 0.1, 0.03, 0.8])\n if not os.path.isfile(os.path.join(FLAGS.prefix, 'mass_%.2d.txt' % i)):\n break\n plotMass(i, fig, ax, ax_cbar, FLAGS.polar)\n save(\"mass_%.2d.png\" % i)\n\nif (FLAGS.all or FLAGS.summary):\n plot2('density_project.data', 'Density (input)', 'force_mag.data', 'Force magnitude')\n saveOrShow(\"summary.png\")\n\n"
},
{
"alpha_fraction": 0.5219594836235046,
"alphanum_fraction": 0.5971283912658691,
"avg_line_length": 17.13846206665039,
"blob_id": "4fc260a2a9f1e32b0ab5a186b8d9f2637abd1ccf",
"content_id": "0bc8cc7619bca7e8ba68a3e10acfcce6af21f7de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1184,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 65,
"path": "/jonrue/Level0/forcegrid_level_0.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 11 15:40:49 2015\n\n@author: jonas\n\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\na0=[]\nb0=[]\na=np.zeros((256,128))\nc=np.zeros((256,128))\nd=np.zeros((256,128))\n\n\ndata=open(\"../output/forcegrid_rcomponent.txt\")\nfor line in data:\n a0.append(float(line))\ndata2=open(\"../output/forcegrid_thetacomponent.txt\")\nfor line in data2:\n b0.append(float(line))\n \n\nindex=0 \nfor j in range(256):\n for i in range(128):\n a[j][i]=a0[index]\n index=index+1\nimshow(a,origin='lower')\ncolorbar()\n#\n#index=0 \n#for j in range(257):\n# for i in range(129):\n# c[j][i]=b0[index]\n# index=index+1\n#imshow(c,origin='lower')\n#colorbar()\n\n#index=0 \n#for j in range(257):\n# for i in range(129):\n# d[j][i]=sqrt(a0[index]*a0[index]+b0[index]*b0[index])\n# index=index+1\n#imshow(d,origin='lower')\n#colorbar()\n\n\n# \n#data3=open(\"density_project.data\")\n#c0=[]\n#for line in data3:\n# c0.append(float(line))\n#\n#b=np.zeros((256,128))\n#index=0 \n#for j in range(128):\n# for i in range(256):\n# b[i][j]=c0[index]\n# index=index+1\n#subplot(1,2,2)\n#imshow(b,origin='lower')\n#colorbar()\n \n"
},
{
"alpha_fraction": 0.5424208045005798,
"alphanum_fraction": 0.6119909286499023,
"avg_line_length": 15.49532699584961,
"blob_id": "c7ff3a665bddd728467445ca229fb079f799a710",
"content_id": "c827f1ff4b6b60d186cfd001beaac9c52c8d279f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1768,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 107,
"path": "/jonrue/Level_i_shifted/forcegrid_level_i_shifted.py",
"repo_name": "mihaimt/Computational_Science_II",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Mar 11 15:40:49 2015\n\n@author: jonas\n\"\"\"\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\na0=[]\nb0=[]\na=np.zeros((256,128))\nb=np.zeros((256,128))\n\n\n\ndata=open(\"level0.txt\")\nfor line in data:\n a0.append(float(line))\ndata2=open(\"forcegrid_rcomponent.txt\")\nfor line in data2:\n b0.append(float(line))\n \n\nindex=0 \nfor j in range(256):\n for i in range(128):\n a[j,i]=a0[index]-b0[index]\n b[j,i]=b0[index]\n index=index+1\n\n \nsubplot(2,2,1)\nimshow(b,origin='lower')\ncolorbar()\n\n \n\nsubplot(2,2,2) \nimshow(a,origin='lower')\ncolorbar()\n\nmean_theta=np.zeros(256)\nfor i in range(256):\n mean_theta[i]=mean(abs(a[i,:]))\n\n\nmean_r=np.zeros(128)\nfor i in range(128):\n mean_r[i]=mean(abs(a[:,i]))\n\nsubplot(2,2,3)\nplot(mean_theta)\n\nsubplot(2,2,4)\nplot(mean_r)\n\nindex=0\nmean_odd_odd=0\nfor i in range(0,256,2):\n for j in range(0,128,2):\n mean_odd_odd+=abs(a[i,j])\n index+=1\nmean_odd_odd=mean_odd_odd/index\nprint \"mean_odd_odd:\"\nprint mean_odd_odd\n\n\nindex=0\nmean_even_even=0\nfor i in range(1,256,2):\n for j in range(1,128,2):\n mean_even_even+=abs(a[i,j])\n index+=1\nmean_even_even=mean_even_even/index\nprint \"mean_even_even:\"\nprint mean_even_even\n \nindex=0\nmean_even_odd=0\nfor i in range(1,256,2):\n for j in range(0,128,2):\n mean_even_odd+=abs(a[i,j])\n index+=1\nmean_even_odd=mean_even_odd/index\nprint \"mean_even_odd:\"\nprint mean_even_odd \n\nindex=0\nmean_odd_even=0\nfor i in range(0,256,2):\n for j in range(1,128,2):\n mean_odd_even+=abs(a[i,j])\n index+=1\nmean_odd_even=mean_odd_even/index\nprint \"mean_odd_even:\"\nprint mean_odd_even \n\n\n\n\n \n#index=1\n#for i in range(50):\n# print a[index,index]\n# index+=2\n\n\n\n"
}
] | 24 |
ivanfeli/pypcpp | https://github.com/ivanfeli/pypcpp | 353676fd008b76a251c765c23a32f1b058b21cf7 | 07ccd24079c1729a3804cfe40a66a8889ed15040 | 98f0b56854f371b73f84250f3cb45a7e2fb9a796 | refs/heads/master | 2021-05-29T15:31:56.435028 | 2015-07-10T20:20:21 | 2015-07-10T20:20:21 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5176151990890503,
"alphanum_fraction": 0.5284552574157715,
"avg_line_length": 20.764705657958984,
"blob_id": "852531556a77b12f2c4ef4a1042197d59caa5aea",
"content_id": "3f4f630b7e18cc081885937053c1f208aae8c95d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 369,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 17,
"path": "/pypcpp/parts/case.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from pypcpp.parts.common import Part\n\nclass Case(Part):\n _arg = '--tower'\n _fetch = 'case'\n \n @staticmethod\n def generateFields():\n from collections import OrderedDict\n \n fields = OrderedDict()\n fields['case'] = 1\n fields['type'] = 2\n #fields['psu'] = 5\n fields['price'] = 8\n \n return fields"
},
{
"alpha_fraction": 0.750507116317749,
"alphanum_fraction": 0.750507116317749,
"avg_line_length": 28,
"blob_id": "e47175d900c70b74cf99ec41e4863a2d3ccc911a",
"content_id": "bda8fd8bdf2f3a0e03b1f7c58799df66aca1111e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 17,
"path": "/pypcpp/parts/__init__.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from pypcpp.parts.common import Part\nfrom pypcpp.parts.case import Case\nfrom pypcpp.parts.cpu import CPU\nfrom pypcpp.parts.motherboard import Motherboard\nfrom pypcpp.parts.psu import PSU\nfrom pypcpp.parts.ram import RAM\nfrom pypcpp.parts.storage import Storage\nfrom pypcpp.parts.videocard import VideoCard\n\n_parts_list = [\n klass for name, klass in locals().items()\n if issubclass(type(klass), Part.__class__)\n and klass.__name__ != 'Part'\n]\n\ndef list_parts():\n return _parts_list\n"
},
{
"alpha_fraction": 0.5773993730545044,
"alphanum_fraction": 0.5781733989715576,
"avg_line_length": 27.406593322753906,
"blob_id": "b33951ac0488abd6d9af22766a2aed4fcb75fdde",
"content_id": "4fc5b6186e84a81e41f512cc838fdbc5e31d138a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2584,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 91,
"path": "/pypcpp/tools.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "import os\nfrom configparser import SafeConfigParser\nimport pypcpp.parts as parts\n\nclass PartType:\n def __init__(self, name):\n self.name = name\n self.pclass = self.__gen_part()\n self.fields = self.pclass.generateFields()\n self.fetch = self.pclass._fetch\n \n def __gen_part(self):\n for p in parts.list_parts():\n if p.isName(self.name):\n return p\n\n # returns a8, d8, depending on the column and order\n # will default to price in ascending order\n def sortString(self, sortby, order):\n return '{}{}'.format(order, self.fields.get(sortby, 'price'))\n\n def newPart(self):\n return self.pclass()\n\n @staticmethod\n def typeFromArgs(arg):\n typestring = None\n for p in parts.list_parts():\n if arg[p._arg] == True:\n typestring = p.name()\n \n return PartType(typestring)\n\ndef extractRows(type, rows):\n def __workRow(row):\n tds = row.findAll('td')\n \n part = type.newPart()\n \n for c, n in type.fields.items():\n if not tds[n].a:\n part.fields[c] = tds[n].text\n else:\n part.fields[c] = tds[n].a.text\n \n part.beautifyFields()\n \n return part if part.fields['price'] else None #Only return Part if price is available\n\n result = []\n\n for a in rows:\n rowresult = __workRow(a)\n if rowresult is not None:\n result.append(rowresult)\n\n return result\n\ndef getLoginInfo():\n FILEPATH = os.path.join(currentDir(), 'pypcpp.conf')\n if not os.path.isfile(FILEPATH):\n open(FILEPATH, 'a').close()\n writeLoginInfo('', '', True)\n \n parser = SafeConfigParser()\n parser.read(FILEPATH)\n result = {\n 'username': parser.get('Login Info', 'username'),\n 'password': parser.get('Login Info', 'password')\n }\n return result\n\ndef writeLoginInfo(username, password, acceptNone=False):\n parser = SafeConfigParser()\n parser.add_section('Login Info')\n if username or acceptNone:\n parser.set('Login Info', 'username', username)\n if password or acceptNone:\n parser.set('Login Info', 'password', password)\n \n cfg = os.path.join(currentDir(), 'pypcpp.conf')\n with open(cfg, 'w') as fh:\n parser.write(fh) \n \n # delete session file\n sess_file = os.path.join(currentDir(), 'sess.pkl')\n if os.path.isfile(sess_file):\n os.remove(sess_file)\n \ndef currentDir():\n return os.path.dirname(os.path.abspath(__file__))"
},
{
"alpha_fraction": 0.5474163889884949,
"alphanum_fraction": 0.5480242967605591,
"avg_line_length": 31.899999618530273,
"blob_id": "111cf3dad44b42f3f3e1dad89c60fe028383b436",
"content_id": "636c7f7b348cb15c9af67a17b61a5d8dde2398e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3290,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 100,
"path": "/pypcpp/search.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "import os\nimport pickle\nimport requests\nfrom bs4 import BeautifulSoup, SoupStrainer\nimport pypcpp.tools as tools\n\ndef search(search, opts):\n ptype = opts['type']\n cback = opts.get('callback', print)\n sess_file = os.path.join(tools.currentDir(), 'sess.pkl')\n \n def _load_session():\n if os.path.isfile(sess_file) and opts.get('login', False):\n return pickle.load(open(sess_file, 'rb')), False\n \n return requests.Session(), True\n\n session, new_s = _load_session()\n\n def _dump_session():\n if opts.get('login', False):\n pickle.dump(session, open(sess_file, 'w+b'))\n \n def login():\n if not new_s:\n cback('Automatic log in (from the previous session).')\n return\n \n LOGININFO = tools.getLoginInfo()\n if not LOGININFO['username'] or not LOGININFO['password']:\n cback('Credentials not found! Will perform search without logging in.')\n cback('run \\'pypcpp logininfo\\' for more information\\n')\n return\n\n cback('Logging in...')\n LOGIN_URL = \"https://pcpartpicker.com/accounts/login/\"\n session.headers.update({'referer':LOGIN_URL})\n session.headers.update({'User-Agent':'Python PCPartPicker (github.com/drivfe/pypcpp)'})\n\n r = session.get(LOGIN_URL)\n toparse = SoupStrainer('input', attrs={'name':'csrfmiddlewaretoken'})\n token = BeautifulSoup(r.text, 'html.parser', parse_only=toparse).find('input')['value']\n \n data = {\n 'checkbox':'on',\n 'csrfmiddlewaretoken':token,\n 'next':''\n }\n data.update(LOGININFO)\n \n r = session.post(LOGIN_URL, data=data)\n if 'pad-block login-error' in r.text:\n cback('LOGIN FAILED: Please check your credentials, run \\'pypcpp logininfo\\' for more information')\n cback('Will perform the search without logging in\\n')\n else:\n cback('Login successful!\\n')\n \n URL = \"http://pcpartpicker.com/parts/{}/fetch/\".format(ptype.fetch)\n CACHE = os.path.join(tools.currentDir(), 'cachejson.html')\n \n payload = {\n 'mode': 'list',\n 'xslug': '',\n 'search': search,\n 'page': opts.get('page', 1),\n 'sort': ptype.sortString(\n opts['sortby'],\n opts['order']\n )\n }\n \n if True: # debug if statement :p\n if opts['login']:\n login()\n\n r = session.get(URL, params=payload)\n with open(CACHE, 'w+') as fh:\n try:\n rjson = r.json()['result']['html']\n fh.write(rjson)\n except ValueError:\n import sys\n cback(\"ERROR: No JSON returned. The website might be down. Exiting\")\n sys.exit()\n \n # save session to file for later\n _dump_session()\n \n cback(\"Searching '{}' of '{}' sorted by {} in {} order.\\n\".format(\n search,\n ptype.name,\n opts['sortby'],\n 'ascending' if opts['order'] == 'a' else 'descending'\n )\n )\n \n soup = BeautifulSoup(open(CACHE), 'html.parser')\n rows = soup.findAll('tr')\n extracted = tools.extractRows(ptype, rows)\n return extracted\n"
},
{
"alpha_fraction": 0.5941354036331177,
"alphanum_fraction": 0.6423677802085876,
"avg_line_length": 37.02083206176758,
"blob_id": "8dde43ff829496d0a92bf8f0435dc546c85284fd",
"content_id": "f334d17e3635117a0fd2f8311cc2c710e0010b52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3649,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 96,
"path": "/README.md",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "# PYPCPP\n(Unofficial) Command line interface for searching parts on [pcpartpicker](https://pcpartpicker.com).\n\nPython 3.x only.\n\n## Installation\n```\ngit clone https://github.com/drivfe/pypcpp.git\ncd pypcpp\npython setup.py install\npypcpp -h # assuming the Scripts/ directory is in your PATH\n```\n**Requirements** (All via pip):\n* requests\n* BeautifulSoup4\n* PrettyTable\n\n## Usage\n```sh\n pypcpp (-c | -v | -r | -m | -t | -p | -s) <search>... [--sort=<sort> [-a | -d]] [-l]\n pypcpp logininfo --user=<username> --pass=<password>\n pypcpp logininfo\n pypcpp (-h | --help)\n```\n#### Options\n```sh\n -c, --cpu CPU search\n -v, --videocard Video Card search\n -r, --ram RAM search\n -m, --motherboard Motherboard search\n -t, --tower Tower/Case search\n -p, --psu Power Supply search\n -s, --storage Storage search (HDD/SSD)\n \n --sort=<sort> Sort by. [default: price]\n -a, --ascending Ascending order\n -d, --descending Descending order\n \n -h, --help Show help\n -l, --login Login before doing search\n --user=<username> Save username to config file\n --pass=<password> Save password to config file\n ```\n\n## Examples\nBasic examples:\n```sh\npypcpp -v r9 280\npypcpp -s 128gb ssd samsung\npypcpp -r corsair vengeance --sort=speed -d # print the fastest RAMs\n```\n\nTo log in you have to set up your username and password. (This is needed if you want your settings such as 'include mail-in rebates' to affect the output):\n```sh\npypcpp logininfo --user=USERHERE --pass=PASSHERE # set credentials\npypcpp logininfo # will output your credentials\n```\n\nAfter you have set up your login info you can use the '-l/--login' switch and the program will log you in before performing a search:\n```sh\npypcpp --cpu fx 6300 -l\npypcpp --storage western digital 1tb --sort=type -a -l # check the notes for more info on what to pass to --sort\npypcpp -v r9 280 --sort=coreclock -d --login # This will list all r9 280s sorted by their coreclock speed in descending order after logging in on your account.\n```\n\nHere is the ouput of the last example:\n```sh\nLogging in...\nLogin successful!\n\nSearching 'r9 280' of 'VideoCard' sorted by coreclock in descending order.\n\n VIDEOCARD SERIES CHIPSET MEMORY CORECLOCK PRICE\n XFX Double Dissipation R9 280X 3GB 1.08Ghz $259.50\n XFX Double Dissipation R9 280 3GB 1.0GHz $169.99\n Gigabyte WINDFORCE R9 280 3GB 950MHz $212.98\n PowerColor TurboDuo R9 280X 3GB 880MHz $242.99\n PowerColor TurboDuo R9 280 3GB 855MHz $188.99\n Sapphire DUAL-X R9 280 3GB 850MHz $202.98\n XFX Double Dissipation R9 280X 3GB 850MHz $237.50\n VisionTek R9 280X 3GB 850MHz $271.98\n Sapphire Dual-X R9 280 3GB 850MHz $182.98\n XFX Double Dissipation R9 280 3GB 827MHz $199.99\n Club royalKing R9 280 3GB N/A $299.99\n Sapphire Dual-X R9 280X 3GB N/A $229.99\n```\n\n### Notes:\n* Will sort by speed by default \n* Will sort in ascending order by default.\n* Some info (such as price/gb for HDD/SSDs) are omitted because they are too long to fit the command line interface.\n* To know what to pass to the --sort argument, check the table header on pcpartpicker.com\n\t* Go to: http://pcpartpicker.com/parts/power-supply/\n\t* Say you want to sort by watts, you use --sort=watts or --sort=modular to sort by the 'modular' column\n\t\t* If the header has a space in it, remove it. (e.g. core clock -> coreclock)\n* Python 3.x"
},
{
"alpha_fraction": 0.5051020383834839,
"alphanum_fraction": 0.5178571343421936,
"avg_line_length": 20.83333396911621,
"blob_id": "8701519c26e747b9c917308f70eb29af8d51683b",
"content_id": "d82c6306135beff187de38af8b26497a0530496d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 18,
"path": "/pypcpp/parts/cpu.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from pypcpp.parts.common import Part\n\nclass CPU(Part):\n _arg = '--cpu'\n _fetch = 'cpu'\n \n @staticmethod\n def generateFields():\n from collections import OrderedDict\n \n fields = OrderedDict()\n fields['cpu'] = 1\n fields['speed'] = 2\n fields['cores'] = 3\n fields['tdp'] = 4\n fields['price'] = 7\n \n return fields"
},
{
"alpha_fraction": 0.5457025766372681,
"alphanum_fraction": 0.5579808950424194,
"avg_line_length": 27.230770111083984,
"blob_id": "8d81ff5ac284971fd622eb1cf0cc441716a6b845",
"content_id": "8974ff8aabd8ac6814ce8203688ce9e845df3fc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 733,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 26,
"path": "/pypcpp/parts/storage.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from pypcpp.parts.common import Part\n\nclass Storage(Part):\n _arg = '--storage'\n _fetch = 'internal-hard-drive'\n \n def beautifyFields(self):\n #Only brand, Western Digital fails\n self.fields['storage'] = self.fields['storage'].split(' ')[0]\n if 'Western' in self.fields['storage']:\n self.fields['storage'] = 'Western Digital'\n\n @staticmethod\n def generateFields():\n from collections import OrderedDict\n \n fields = OrderedDict()\n fields['storage'] = 1\n fields['series'] = 2\n fields['type'] = 4\n fields['capacity'] = 5\n fields['cache'] = 6\n #fields['price/gb'] = 7\n fields['price'] = 10\n \n return fields"
},
{
"alpha_fraction": 0.5614035129547119,
"alphanum_fraction": 0.7368420958518982,
"avg_line_length": 18,
"blob_id": "4437d9cfd2ed2d09806278a45fdb84f0c6968e6f",
"content_id": "34ce6eae06b5b8babceeb2d66d9963a5d3ff2052",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 57,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "beautifulsoup4>=4.3.2\nprettytable>=0.7.2\nrequests>=2.7.0\n"
},
{
"alpha_fraction": 0.5621301531791687,
"alphanum_fraction": 0.5661982297897339,
"avg_line_length": 27.776596069335938,
"blob_id": "11e6e8d8a5efd5cd81625336ca549b7fb82b5986",
"content_id": "be60dd084a281ecade0cee96c07201a7453cd355",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2704,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 94,
"path": "/pypcpp/__main__.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "\"\"\"Python PCPartPicker\nUsage:\n pypcpp.py (-c | -v | -r | -m | -t | -p | -s) <search>... [--sort=<sort> [-a | -d]] [-l]\n pypcpp.py logininfo --user=<username> --pass=<password>\n pypcpp.py logininfo\n pypcpp.py (-h | --help)\n\nOptions:\n -c, --cpu CPU search\n -v, --videocard Video Card search\n -r, --ram RAM search\n -m, --motherboard Motherboard search\n -t, --tower Tower/Case search\n -p, --psu Power Supply search\n -s, --storage Storage search (HDD/SSD)\n \n --sort=<sort> Sort by. [default: price]\n -a, --ascending Ascending order\n -d, --descending Descending order\n \n -h, --help Show help\n -l, --login Log in before doing search\n --user=<username> Save username to config file\n --pass=<password> Save password to config file\n\"\"\"\n\nimport os\nimport sys\nfrom prettytable import PrettyTable\n\ncDir = lambda: os.path.dirname(os.path.realpath(os.path.abspath(__file__)))\nsys.path.append(os.path.dirname(cDir()))\n\nimport pypcpp as pcp\n\nfrom pypcpp.docopt import docopt\n\ndef tableOutput(result):\n if len(result) < 1:\n print('No results found!')\n return\n \n tbl = PrettyTable(list(result[0].fields))\n tbl.align = 'l'\n tbl.border = False\n tbl.header_style = 'upper'\n\n for r in result:\n tbl.add_row(shrinkText(r.fields.values()))\n\n print(tbl)\n\ndef shrinkText(values):\n MAX_LENGTH = 100\n newList = list(values)\n limit = int(MAX_LENGTH / len(newList))\n shrink = lambda text: text if len(text) < limit else text[0:limit]+'...'\n \n length = len(newList[0])\n if length > limit:\n newList[0] = shrink(newList[0])\n \n return newList\n\ndef main(args=None):\n args = docopt(__doc__, version='Python PCPartPicker 0.1')\n if args['logininfo']: \n if args['--user'] or args['--pass']:\n pcp.tools.writeLoginInfo(args['--user'], args['--pass'])\n \n linfo = pcp.tools.getLoginInfo()\n if not linfo['username'] or not linfo['password']:\n print('Your info is not yet saved, Use \\'--user=<user>\\' and \\'--pass=<password>\\' to save your info')\n else:\n print('Here is your login info: {}'.format(linfo))\n print('The config file is saved in:', cDir())\n \n else:\n sterm = ' '.join(args['<search>'])\n \n type = pcp.tools.PartType.typeFromArgs(args)\n options = {\n 'type' : type,\n 'sortby' : args['--sort'],\n 'order' : 'd' if args['--descending'] else 'a',\n 'login' : args['--login']\n }\n\n result = pcp.search(sterm, options)\n \n tableOutput(result)\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.5621621608734131,
"alphanum_fraction": 0.569729745388031,
"avg_line_length": 30.931034088134766,
"blob_id": "b13f7f57fbad2e2bdbb68c9dcabcb1cc102ace09",
"content_id": "8be6f108a4ba7ec8c03f5aa841fd139f033833b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 925,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 29,
"path": "/pypcpp/parts/videocard.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from pypcpp.parts.common import Part\n\nclass VideoCard(Part):\n _arg = '--videocard'\n _fetch = 'video-card'\n \n def beautifyFields(self):\n #Only brand name of the Videocard\n self.fields['videocard'] = self.fields['videocard'].split(' ')[0]\n \n #Remove 'Radeon' and 'Geforce' from chipset\n self.fields['chipset'] = self.fields['chipset'].replace('Radeon ', '').replace('GeForce ', '')\n \n #Remove 'black edition' from series (string too long)\n self.fields['series'] = self.fields['series'].replace('Black Edition ', '')\n \n @staticmethod\n def generateFields():\n from collections import OrderedDict\n \n fields = OrderedDict()\n fields['videocard'] = 1\n fields['series'] = 2\n fields['chipset'] = 3\n fields['memory'] = 4\n fields['coreclock'] = 5\n fields['price'] = 8\n \n return fields"
},
{
"alpha_fraction": 0.5710014700889587,
"alphanum_fraction": 0.5754858255386353,
"avg_line_length": 22.928571701049805,
"blob_id": "f5b6b68f316d9d767181f4731b0ed239288d294d",
"content_id": "99c93d0073877df29d71468915a1b2a7f2f7a57d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 669,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 28,
"path": "/setup.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "import os\nfrom setuptools import setup\n\ndef read(fname):\n return open(os.path.join(os.path.dirname(__file__), fname)).read()\n\nsetup(\n name = \"pypcpp\",\n version = \"0.1\",\n author = \"drivfe\",\n description = (\n \"Unofficial command line interface for https://pcpartpicker.com/\"\n ),\n keywords = \"pcpartpicker\",\n url = \"https://github.com/drivfe/pypcpp\",\n packages=['pypcpp', 'pypcpp.parts'],\n entry_points={\n 'console_scripts': [\n 'pypcpp = pypcpp.__main__:main',\n ]\n },\n install_requires=[\n \"beautifulsoup4\",\n \"requests\",\n \"PrettyTable\"\n ],\n long_description=read('README.md'),\n)"
},
{
"alpha_fraction": 0.5458422303199768,
"alphanum_fraction": 0.558635413646698,
"avg_line_length": 23.736841201782227,
"blob_id": "72ad778f9e7e0d69ff809d2c19ac259088689ede",
"content_id": "50661764d43799b5adba4139352985cf3243380f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 19,
"path": "/pypcpp/parts/motherboard.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from pypcpp.parts.common import Part\n\nclass Motherboard(Part):\n _arg = '--motherboard'\n _fetch = 'motherboard'\n \n @staticmethod\n def generateFields():\n from collections import OrderedDict\n \n fields = OrderedDict()\n fields['motherboard'] = 1\n fields['socket/cpu'] = 2\n fields['formfactor'] = 3\n fields['ramslots'] = 4\n #fields['maxram'] = 5\n fields['price'] = 8\n \n return fields"
},
{
"alpha_fraction": 0.8653846383094788,
"alphanum_fraction": 0.8653846383094788,
"avg_line_length": 25.5,
"blob_id": "cc62d9488763d1a37cf310c0a3532f9883f3aec6",
"content_id": "5699716cced8ffaf64c7e758babd8d8e3d855299",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 2,
"path": "/pypcpp/__init__.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from pypcpp.search import search\nimport pypcpp.tools"
},
{
"alpha_fraction": 0.49239543080329895,
"alphanum_fraction": 0.49239543080329895,
"avg_line_length": 18.923076629638672,
"blob_id": "4f1c64bf734424f5676f7b092e001b87403c1d24",
"content_id": "0ab50e4f8f015873987e2563e18706b0209f3681",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 26,
"path": "/pypcpp/parts/common.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from collections import OrderedDict\n\nclass Part:\n def __init__(self):\n self.fields = OrderedDict()\n \n @classmethod\n def name(cls):\n return cls.__name__\n \n @classmethod\n def isName(cls, name):\n return name == cls.name()\n \n def __repr__(self):\n ret = []\n for k, v in self.fields.items():\n ret.append(v)\n \n return ' '.join(ret)\n \n def __str__(self):\n return repr(self)\n \n def beautifyFields(self):\n pass\n "
},
{
"alpha_fraction": 0.4945533871650696,
"alphanum_fraction": 0.5119825601577759,
"avg_line_length": 22,
"blob_id": "7e05cbe26deeebf9b71656326276185fd64ed984",
"content_id": "822c93733f0e9de286be872bc08c630b011d136e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 459,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 20,
"path": "/pypcpp/parts/ram.py",
"repo_name": "ivanfeli/pypcpp",
"src_encoding": "UTF-8",
"text": "from pypcpp.parts.common import Part\n\nclass RAM(Part):\n _arg = '--ram'\n _fetch = 'memory'\n \n @staticmethod\n def generateFields():\n from collections import OrderedDict\n \n fields = OrderedDict()\n fields['ram'] = 1\n fields['speed'] = 2\n #fields['type'] = 3\n fields['modules'] = 5\n #fields['size'] = 6\n fields['price/gb'] = 7\n fields['price'] = 10\n \n return fields"
}
] | 15 |
jackpolentes/getsst | https://github.com/jackpolentes/getsst | 829aef4beba3ec3e152630f89b3079a697d12bc3 | 03031fb78b68ff7fe45f3e8ba92ed7438a8bf90f | c99783a88d4aaf0ac4917146f0def283ae561dd6 | refs/heads/master | 2022-11-08T18:35:09.649756 | 2020-06-29T20:37:45 | 2020-06-29T20:37:45 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.609716534614563,
"alphanum_fraction": 0.6545119881629944,
"avg_line_length": 45.44221115112305,
"blob_id": "8b2641a759e83253764bb522373d177a42136bd6",
"content_id": "b1649dc740495dd05faeaade523ae86c9af04c7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9242,
"license_type": "no_license",
"max_line_length": 241,
"num_lines": 199,
"path": "/getsst.py",
"repo_name": "jackpolentes/getsst",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Nov 15 14:02:40 2017\nSimple version of Sat SST plot with one panel\n@author: huimin\nModifications by JiM in June 2019 to work on laptop at home\nModifications by JiM in mid-June 2020 to update both the URL, add netCDF4 method, cont_lev, and miniboat overlay\nModifications by JiM in late-June 2020 to add another sat image option\n\"\"\"\n\nimport datetime as dt\nimport matplotlib.pyplot as plt\nfrom netCDF4 import Dataset\nimport pandas as pd\nimport numpy as np\nfrom numpy import ma\nimport time\n#NOTE: JiM NEEDED THE FOLLOWING LINE TO POINT TO his PROJ LIBRARY\nimport os,imageio\nimport glob\n#os.environ['PROJ_LIB'] = 'c:\\\\Users\\\\Joann\\\\anaconda3\\\\pkgs\\\\proj4-5.2.0-ha925a31_1\\\\Library\\share'\nfrom mpl_toolkits.basemap import Basemap\n\n#HARDCODES\nsat_option='MARACOOS' #'MARACOOS' or 'UDEL', the two options for imagery available in mid-2020\ndatetime_wanted=dt.datetime(2020,6,25,8,0,0,0)\nndays=4\npng_dir='c:\\\\Users\\\\Joann\\\\Downloads\\\\getsst\\\\pngs\\\\'\narea='WNERR' # geographic box (see gbox function below)\ncont_lev=[17.6,21.6,.2]# min, max, and interval in either degC or degF of temp contours wanted\nagg=\"3\" # number of days of satellite image aggragation done by UDEL\ncluster='wnerr_2020_1' # batch of drifter\ngif_name=cluster+'.gif'\n#cluster='ep_2020_1' #leave blank if none\n#ID=206430702 # drifter ID to overlay\nID=203400681\n\n#FUNCTIONS\ndef make_gif(gif_name,png_dir,start_time=False,end_time=False,frame_length = 2,end_pause = 4 ):\n '''use images to make the gif\n frame_length: seconds between frames\n end_pause: seconds to stay on last frame\n the format of start_time and end time is string, for example: %Y-%m-%d(YYYY-MM-DD)'''\n \n if not os.path.exists(os.path.dirname(gif_name)):\n os.makedirs(os.path.dirname(gif_name))\n allfile_list = glob.glob(os.path.join(png_dir,'*.png')) # Get all the pngs in the current directory\n print(allfile_list)\n file_list=[]\n '''if start_time: \n for file in allfile_list:\n if start_time<=os.path.basename(file).split('.')[0]<=end_time:\n file_list.append(file)\n else:'''\n file_list=allfile_list\n #list.sort(file_list, key=lambda x: x.split('/')[-1].split('t')[0]) # Sort the images by time, this may need to be tweaked for your use case\n images=[]\n # loop through files, join them to image array, and write to GIF called 'wind_turbine_dist.gif'\n for ii in range(0,len(file_list)): \n file_path = os.path.join(png_dir, file_list[ii])\n if ii==len(file_list)-1:\n for jj in range(0,int(end_pause/frame_length)):\n images.append(imageio.imread(file_path))\n else:\n images.append(imageio.imread(file_path))\n # the duration is the time spent on each image (1/duration is frame rate)\n imageio.mimsave(gif_name, images,'GIF',duration=frame_length)\n\ndef getgbox(area):\n # gets geographic box based on area\n if area=='SNE':\n gbox=[-71.,-66.,39.,42.] # for SNE\n elif area=='OOI':\n gbox=[-72.,-69.5,39.5,41.5] # for OOI\n elif area=='GBANK':\n gbox=[-70.,-64.,39.,42.] # for GBANK\n elif area=='GS': \n gbox=[-71.,-63.,38.,42.5] # for Gulf Stream\n elif area=='NorthShore':\n gbox=[-71.,-69.5,41.5,43.] # for north shore\n elif area=='WNERR':\n gbox=[-71.,-70.,42.5,43.3] # for WNERR deployment\n elif area=='DESPASEATO':\n gbox=[-71.,-69.5,42.6,43.25] # for miniboat Despaseato deployment\n elif area=='CCBAY':\n gbox=[-70.75,-69.8,41.5,42.23] # CCBAY\n elif area=='inside_CCBAY':\n gbox=[-70.75,-70.,41.7,42.23] # inside_CCBAY\n elif area=='NEC':\n gbox=[-69.,-64.,39.,43.5] # NE Channel\n elif area=='NE':\n gbox=[-76.,-66.,35.,44.5] # NE Shelf \n return gbox\n\ndef getsst(m,datetime_wanted,gbox,sat_option):\n # gets and contours satellite SST\n second=time.mktime(datetime_wanted.timetuple())\n if sat_option=='UDEL':\n #url1='http://basin.ceoe.udel.edu/thredds/dodsC/Aqua3DayAggregate.nc' # new address found in Nov 2017\n url1='http://thredds.demac.udel.edu/thredds/dodsC/Aqua'+agg+'DayAggregate.nc'\n dataset=Dataset(url1)\n #times=list(nc.variables['time']) # this took way too much time\n times=ma.getdata(dataset.variables['time'])\n print('finding the nearest image index over times')\n index_second=int(round(np.interp(second,times,range(len(times)))))# finds the closest time index\n url='http://thredds.demac.udel.edu/thredds/dodsC/Aqua'+agg+'DayAggregate.nc?lat[0:1:4499],lon[0:1:4999],'+'sst['+str(index_second)+':1:'+str(index_second)+'][0:1:4499][0:1:4999]'+',time['+str(index_second)+':1:'+str(index_second)+']'\n dataset=Dataset(url)\n print('converting the masked array sst to an array') \n sst=ma.getdata(list(dataset['sst']))\n else: #sat_option='MARACOOS'\n url1='http://tds.maracoos.org/thredds/dodsC/AVHRR'+agg+'.nc'\n dataset=Dataset(url1)\n times=ma.getdata(dataset.variables['time'])\n inds=int(round(np.interp(second,times,range(len(times)))))# finds the closest time index\n #url='http://tds.maracoos.org/thredds/dodsC/AVHRR7.nc?lon[0:1:4499],lat[0:1:3660],mcsst['+str(inds)+':1:'+str(inds)+'][0:1:4499][0:1:3660],time['+str(inds)+':1:'+str(inds)+']'\n url='http://tds.maracoos.org/thredds/dodsC/AVHRR7.nc?lon[0:1:4499],lat[0:1:3660],time['+str(inds)+':1:'+str(inds)+'],mcsst['+str(inds)+':1:'+str(inds)+'][0:1:3660][0:1:4499]'\n dataset=Dataset(url)\n print('converting the masked array sst to an array') \n sst=ma.getdata(list(dataset['mcsst']))\n print('got the sst')\n lat=ma.getdata(dataset['lat'][:])\n lon=ma.getdata(dataset['lon'][:])\n print('got the lat & lon')\n # find the index for the gbox\n index_lon1=int(round(np.interp(gbox[0],lon,range(len(lon)))))\n index_lon2=int(round(np.interp(gbox[1],lon,range(len(lon)))))\n index_lat1=int(round(np.interp(gbox[2],lat,range(len(lat)))))\n index_lat2=int(round(np.interp(gbox[3],lat,range(len(lat)))))\n # get part of the sst\n sst_part=sst[0,index_lat1:index_lat2,index_lon1:index_lon2]#*1.8+32\n print('got the subsampled sst')\n sst_part[(sst_part==-999)]=np.NaN# if sst_part=-999, convert to NaN\n if cont_lev[0]>30: # use degF\n sst_part=sst_part*1.8+32 # conver to degF\n labelT='deg F'\n else:\n labelT='deg C'\n print('temp range is '+str(np.nanmin(sst_part))+' to '+str(np.nanmax(sst_part))+' deg')\n #X,Y=np.meshgrid(lon[index_lon1:index_lon2],lat[index_lat1:index_lat2])\n X,Y=m.makegrid(len(lon[index_lon1:index_lon2]),len(lat[index_lat1:index_lat2]))#lon[index_lon1:index_lon2],lat[index_lat1:index_lat2])\n print('ready to contour')\n X,Y=m(X,Y)\n cmap = plt.cm.jet\n m.contourf(X,Y,sst_part,np.arange(cont_lev[0],cont_lev[1],cont_lev[2]),cmap=cmap,zorder=0)\n cb=plt.colorbar(cmap=cmap)\n cb.set_ticks(np.linspace(cont_lev[0],cont_lev[1],int(cont_lev[1]-cont_lev[0])+1))#/(cont_lev[2]*2.))))\n cb.set_label(labelT)\n\n#MAINCODE -- MAKE BASEMAP and overlay tracks\ngbox=getgbox(area) # uses the getgbox function to define lat/lon boundary\nlatsize=[gbox[2],gbox[3]]\nlonsize=[gbox[0],gbox[1]]\ntick_int=(gbox[3]-gbox[2])/4. # allow for 3-4 tick axis label intervals\nif tick_int>2:\n tick_int=int(tick_int) # make the tick_interval integer increments\nif tick_int<=2:\n tick_int=.3\nfor jj in range(-1,ndays-1):\n datetime_wanted=datetime_wanted+dt.timedelta(days=1)\n fig,ax=plt.subplots()\n m = Basemap(projection='merc',llcrnrlat=min(latsize),urcrnrlat=max(latsize),\\\n llcrnrlon=min(lonsize),urcrnrlon=max(lonsize),resolution='f')\n m.fillcontinents(color='gray')\n #GET SST & PLOT\n getsst(m,datetime_wanted,gbox,sat_option)\n #GET TRACK & PLOT\n if len(cluster)!=0:\n if cluster[0:2]=='ep': # case of educational passages miniboats\n df=pd.read_csv('http://nefsc.noaa.gov/drifter/drift_'+str(ID)+'_sensor.csv')\n df=df[0:24*3] # end it 3 days in\n #df=df[df['id']==ID]\n xx=df.yearday.values #bad header makes lon yearday and lat lon\n yy=df.lon.values\n x,y=m(xx,yy)\n m.plot(x,y,'m-')\n for k in np.arange(5,len(xx),5):\n if cont_lev[0]>30:\n t=df['mean_sst'][k]*1.8+32 # actually getting mean_sst\n else:\n t=df['mean_sst'][k]\n ax.annotate('%.1f' % t,(x[k],y[k]),color='k',fontweight='bold',fontsize=12,zorder=10)#xytext=(-500,500),textcoords='offset points'\n else: # case of multiple drifters\n df=pd.read_csv('http://nefsc.noaa.gov/drifter/drift_'+cluster+'.csv')\n ids=np.unique(df['ID'])\n for k in ids:\n df1=df[df['ID']==k]\n df1=df1[df1['DAY']==datetime_wanted.day]\n x,y=m(df1['LON'].values,df1['LAT'].values)\n m.plot(x,y,'k')\n \n m.drawparallels(np.arange(min(latsize),max(latsize)+1,tick_int),labels=[1,0,0,0])\n m.drawmeridians(np.arange(min(lonsize),max(lonsize)+1,tick_int),labels=[0,0,0,1])\n #m.drawcoastlines()\n m.drawmapboundary()\n plt.title(str(datetime_wanted.strftime(\"%d-%b-%Y\"))+' '+agg+'-day '+sat_option+' composite')#+cluster)\n plt.savefig(png_dir+sat_option+'_'+area+'_'+datetime_wanted.strftime('%Y-%m-%d')+'_'+agg+'.png')\n plt.show()\ngif_name=png_dir+gif_name\nmake_gif(gif_name,png_dir,start_time=datetime_wanted-dt.timedelta(days=ndays),end_time=datetime_wanted)\n"
}
] | 1 |
etalab/datagouvfr-pages | https://github.com/etalab/datagouvfr-pages | daadc286688b36357d3dd584a339d03bd86f9b69 | a7904aa35602bcdef0baadd6bb9bc12f0c90dd59 | a40af978b1399d9a4a0cc68a396b6a2a0adbede5 | refs/heads/master | 2023-08-19T02:46:27.931538 | 2023-08-10T08:16:44 | 2023-08-10T08:16:44 | 274,710,303 | 7 | 30 | NOASSERTION | 2020-06-24T15:57:46 | 2023-03-11T19:24:35 | 2023-09-14T15:24:16 | HTML | [
{
"alpha_fraction": 0.7701537609100342,
"alphanum_fraction": 0.7842497825622559,
"avg_line_length": 80.75238037109375,
"blob_id": "b84fefa2c19ecf3e8db0701cc460beceb5ae2fc7",
"content_id": "987bfb234d4b9aac9f233a11e0312dc5904dfd76",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8607,
"license_type": "permissive",
"max_line_length": 585,
"num_lines": 105,
"path": "/pages/udata/4/introducing-udata-4.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Introducing udata 4\nkeywords:\n - udata\ndescription: Introducing udata 4\npublished: 2022-04-07\nauthor: abulte\n---\n\n# Introducing udata 4\n\n**Introducing udata 4**, codename: _cockroach_ — you'll see why in a bit!\n\nThis a follow up on the latest [major release (udata 3) roadmap post](https://www.data.gouv.fr/fr/pages/udata/3/the-road-to-udata-3).\n\nOur goal here is to highlight the major coming with udata 4 and what we think can be built with it.\n\nIt's intended for anyone looking at udata for their needs or already using it. Please be aware, it can get quite technical.\n\nWe'll also talk about the community around udata and how we hope to share and communicate in the future.\n\n## Architectural changes\n\nSince the release of udata 3, aka _snowpiercer_, we mainly focused on the development of [our new frontend](https://github.com/etalab/udata-front), which was necessary for the graphical overhaul of data.gouv.fr.\n\nWe believe this new system is now stable and brought us closer to our ultimate goal, as previously stated: `udata` should be focused on bringing an API and business logic around an open data catalog. By removing (almost) anything frontend-related to `udata-front`, we made a big step toward this. As planned, we [iterated _a lot_](https://github.com/etalab/udata-front/blob/master/CHANGELOG.md) around this graphical redesign and we did so in a swift manner.\n\nNow that the frontend architecture is out of the way, we can focus on new components, following the same approach: services around `udata` rather than a fat monolith. Thoses services are (so far):\n- the search engine — done! :white_check_mark:\n- resources analysis — doing 👷♀️\n- and some perspectives!\n\nIf you're a udata user, you should know that, moving forward, you'll either:\n- need to keep up with the new services we're adding to be feature-par with data.gouv.fr,\n- live without those features,\n- or plug in your own services.\n\n### Search engine\n\nOur search engine has long been a frustrating part for the users of data.gouv.fr. Searching through 40k+ datasets with often poor metadata can be a daunting experience and is a true technical challenge.\n\nThat's why we decided to rebuild our search engine from the ground up. We relied on an old version of ElasticSearch, tightly coupled to a lot of udata code. Our goals were to:\n- regain control of the search engine by whacking through technical debt\n- improve our search results relevance\n- uncouple the search service from `udata`\n\nIn order to do that, we built [udata-search-service](https://github.com/opendatateam/udata-search-service). It's responsible for managing the search index: (de)indexing search metadata for every object and sending back search results given a query.\n\n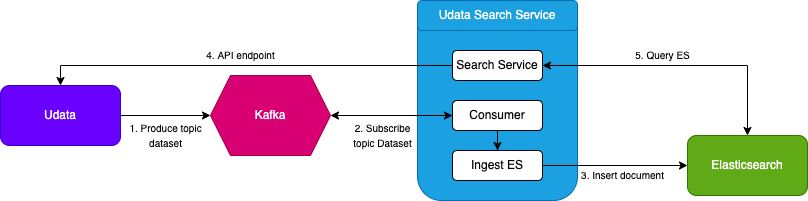\n\nYou'll notice [Apache Kafka](https://kafka.apache.org) has been introduced in this architecture. It acts as a broker between `udata` and `udata-search-service` for indexation purposes.\n\n**While the usage Apache Kafka is largely overkill for this scenario, we believe that moving towards an event based model, through Kafka, will allow us to build powerful services around udata**. You should also know why this release has been dubbed _cockroach_ now :-)\n\n#### API changes\nWe made a difference between list endpoints and smart full-text search endpoints. Existing list endpoints in API v1 (`/api/1/datasets`) still exists but is based on Mongo lists. It is the case for organizations, datasets, reuses and users. Some parameters have been dropped, but a `q` parameter is still supported.\n\nThe smart full-text search is now optional and is enabled by setting the SEARCH_SERVICE_API_URL setting. It is now defined in API v2 with the following url pattern: `/{object}/search` (ex: `/datasets/search`). This endpoint makes an HTTP request to a remote server with the query and parameters. You can easily plug your own full text search engine API here or use our own [udata-search-service](https://github.com/opendatateam/udata-search-service)!\n\nFinally, the suggest endpoints now use mongo `contains` instead of a smart full-text search. The user suggest endpoint has been dropped.\n\n### Resources analysis\n\nOne possibility we're very excited about with this new architecture is being able to analyze what's going on _in_ the data we host or link to. Up until now, we almost exclusively focused on metadata and we believed it's time to dig deeper!\n\nWe're still brainstorming and experimenting around this, but the architecture could look something like below. As you can see, Kafka becomes a primary citizen and distributes events to and from multiples services:\n- udata itself, obviously — udata shall remain the core of the catalog and the primary source of truth on everyting it is responsible for ;\n- a datalake that will store all or part of the data we link to — useful for analysis, caching, history... ;\n- analyzer tool(s) — we currently focus on [csv-detective](https://github.com/etalab/csv-detective) for guessing the types of columns in a CSV ;\n- a remote metadata crawler for detecting changes and errors in remote links — we're currently experimenting with [decapode](https://github.com/etalab/decapode).\n\n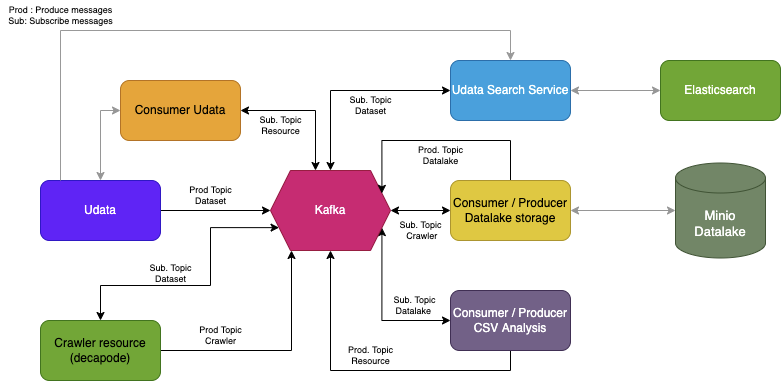\n\nAll those services shall communicate through Kafka and enrich whichever service is interested. We're also thinking about communicating with external systems (i.e. services outside our architecture) through a REST gateway.\n\n### And more to come!\n\nAs stated, we think of the new event-driven architecture as an enabler for future services and features. Thinking long term, it might even be a way to integrate external systems more seamlessly with udata or data.gouv.fr.\n\n## The community\n\nThe last time we wrote on [udata, regarding the v3 release](https://www.data.gouv.fr/fr/pages/udata/3/the-road-to-udata-3), we highlighted the fact that Etalab was pretty much alone in maintaining udata.\n\n> An overwhelming majority of commits on udata have been made by members of Etalab, the French government agency responsible for data.gouv.fr.\n>\n> The technical team dedicated at Etalab responsible not only for development but also for operating the platform and handling user support has always been relatively small: between one and three people.\n\nWe also had lost touch with the main platforms reusing udata for their needs, leading us to focus on our needs first and not so much on the community's.\n\nSince then, we are happy to have had renewed contacts with some udata users, mainly the governments of Serbia and Luxembourg. We felt an increasing need for help and documentation, mainly for dealing with a migration to the latest version of udata.\n\nWe heard this and we will try to produce more documentation and give more visibility on our technical choices, hence this post. We also [revamped our main documentation](https://udata.readthedocs.io/en/stable/) quite a bit. A much needed [focus on the new metrics (Matomo) collection system](https://www.data.gouv.fr/fr/pages/udata/3/udata-3-usage-metrics-explained) has been written too.\n\n If you're interested in udata 4, you can join the community to discuss architectural changes or get started with udata 4 at https://github.com/opendatateam/udata/discussions/2724.\n\n**We believe we need a vibrant and responsive community in order for those efforts to be successful.** It can be pretty frustrating producing those efforts in the dark.\n\n**That's why we need your help!** Our first step is opening Github discussions on the udata project. If you're using or are interested in udata, **[please come and comment on this discussion](https://github.com/opendatateam/udata/discussions/2721)**. Tell us how you're using it, what you're expecting from the community and are willing to give back... Also feel free to [open a new discussion](https://github.com/opendatateam/udata/discussions/new) if you want to reach out for something broader than a specific udata technical issue (plugins, governance, migration, installation...).\n\n## udata releases history\n\n- udata 1 aka _uData_, our original version\n- udata 2 aka _lazysnake_, which mainly introduced a switch to Python 3\n- udata 3 aka _snowpiercer_, which introduced `udata-front` and a cleaner separation of concern between front and back\n- udata 4 aka _cockroach_, which brings a service orientend architecture a step further\n"
},
{
"alpha_fraction": 0.740005373954773,
"alphanum_fraction": 0.742956817150116,
"avg_line_length": 70.67308044433594,
"blob_id": "0a07b220fc63b8401f6f9dcd738c438d11c827fb",
"content_id": "3d31ad8694080599df60336e61a220de0991ba2c",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3836,
"license_type": "permissive",
"max_line_length": 277,
"num_lines": 52,
"path": "/pages/about/ressources.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "# **En savoir plus sur [data.gouv.fr](http://data.gouv.fr/)**\n\n- **[Qu’est-ce que data.gouv.fr ?](https://www.data.gouv.fr/fr/pages/about/a-propos/)**\n Découvrez à qui s’adresse [data.gouv.fr](http://data.gouv.fr/) et qui est derrière la plateforme.\n\n- **[À quoi sert l’open data ?](https://www.data.gouv.fr/fr/pages/about/opendata/)**\n En savoir plus sur les bénéfices de l’open data à travers des exemples emblématiques.\n\n# **Publier des données**\n- **[Utiliser la plateforme data.gouv.fr](https://doc.data.gouv.fr/)**\n Consulter la documentation pour vous aider dans votre parcours d’utilisation de la plateforme.\n\n- **[Apprendre les bonnes pratiques de l’open data](https://guides.etalab.gouv.fr/)**\n Les guides d’Etalab sont là pour vous accompagner dans votre démarche d’ouverture et d’exploitation des données publiques.\n - **[Comment préparer des données à l'ouverture / la circulation ?](https://guides.etalab.gouv.fr/qualite/)**\n - **[Quelles données doivent être publiées en open data ?](https://guides.etalab.gouv.fr/juridique/)**\n - **[Comment publier des données sur data.gouv.fr ?](https://guides.etalab.gouv.fr/data.gouv.fr/)**\n - **[Comment publier des réutilisations sur data.gouv.fr ?](https://guides.etalab.gouv.fr/reutilisation/)**\n\n- **[Publier des données structurées](https://publier.etalab.studio/)**\n Découvrez notre outil pour vous permettre de saisir, valider et publier des données structurées.\n\n- **[Découvrir les schémas de données](http://schema.data.gouv.fr/)**\n La plateforme [schema.data.gouv.fr](http://schema.data.gouv.fr/) référence l’ensemble des schémas de données et permet de consulter les jeux de données conformes.\n\n# **Réutiliser des données**\n\n- **[Consulter et utiliser les API publiques](https://api.gouv.fr/)**\n La plateforme [api.gouv.fr](http://api.gouv.fr/) référence et permet de consulter et d’utiliser les API publiques.\n\n- **[Accéder aux données des transports](https://transport.data.gouv.fr/)**\n Le site [transport.data.gouv.fr](http://transport.data.gouv.fr/) permet de consulter et télécharger les données de mobilité.\n\n- **[Consulter et télécharger les données des adresses](https://adresse.data.gouv.fr/)**\n [adresse.data.gouv.fr](https://adresse.data.gouv.fr/) référence l’intégralité des adresses du territoire pour les rendre utilisables par toutes et tous.\n\n- **[Consulter, télécharger et intégrer facilement les données cadastrales](https://cadastre.data.gouv.fr/)**\n [cadastre.data.gouv.fr](https://cadastre.data.gouv.fr/) permet de consulter, télécharger et intégrer facilement les données cadastrales.\n\n- **[Identifier et utiliser les jeux de données open data pour le Machine Learning](https://datascience.etalab.studio/dgml/)**\n Découvrez une sélection de jeux de données de [data.gouv.fr](http://data.gouv.fr/) qui se prêtent particulièrement bien à l’apprentissage automatique.\n\n# **Suivre l’actualité de l’open data**\n\n- **[Suivre les ouvertures de données](https://ouverture.data.gouv.fr/)**\n [ouverture.data.gouv.fr](http://ouverture.data.gouv.fr/) permet de suivre les ouvertures programmées des données, codes sources et API publics.\n\n- **[Retrouvez un avis de la CADA](https://cada.data.gouv.fr/)**\n [cada.data.gouv.fr](https://cada.data.gouv.fr/) permet d’explorer les avis rendus par la Commission d’Accès aux documents administratifs (CADA).\n\n- **[Consulter les statistiques de data.gouv.fr et des produits satellites](https://stats.data.gouv.fr/index.php?module=CoreHome&action=index&idSite=109&period=range&date=previous30#?idSite=109&period=range&date=previous30&segment=&category=Dashboard_Dashboard&subcategory=1)**\n Consulter les statistiques de fréquentations des sites en [data.gouv.fr](http://data.gouv.fr/).\n"
},
{
"alpha_fraction": 0.76752769947052,
"alphanum_fraction": 0.7693727016448975,
"avg_line_length": 40.69230651855469,
"blob_id": "8f179da68d14490d172245979895f1ba6a99dd4f",
"content_id": "7b3e43766d4713cb3b906b4af4897c37e6634662",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1116,
"license_type": "permissive",
"max_line_length": 109,
"num_lines": 26,
"path": "/pages/donnees-cles-par-sujet.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Thématiques à la une\nkeywords:\n - données\n - inventaire\n - opendata\n - datagouv\ndescription: Sommaire des pages inventaires proposées sur data.gouv.fr\nmenu:\n - footer\nreuses:\ndatasets:\n---\n## Thématiques à la une\n\nRetrouvez ici une sélection de jeux de données clés regroupés par sujet :\n- [Les données de référence (Service public de la donnée)](/pages/spd/reference/)\n- [Les données relatives au COVID-19](/pages/donnees-coronavirus)\n- [Les données relatives au logement et à l'urbanisme](/pages/donnees-logement-urbanisme)\n- [Les données relatives à l'emploi](/pages/donnees-emploi/)\n- [Les données relatives à la santé](/pages/donnees-sante/)\n- [Les données des élections](/pages/donnees-des-elections)\n- [Les données relatives aux associations et aux fondations](/pages/donnees-associations-fondations)\n- [Les données relatives aux comptes publics](/pages/donnees-comptes-publics)\n- [Les données ouvertes pour l’apprentissage automatique (Machine Learning)](/pages/donnees-machine-learning)\n- [Les données à composante géographique](/pages/donnees-geographiques)\n"
},
{
"alpha_fraction": 0.7921177744865417,
"alphanum_fraction": 0.7971705198287964,
"avg_line_length": 114.44999694824219,
"blob_id": "1e9d633840ac1325a8702d60c155bfa8f8a12902",
"content_id": "055f3936015c922e84ceef707efa158911dd518d",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7030,
"license_type": "permissive",
"max_line_length": 810,
"num_lines": 60,
"path": "/pages/about/opendata.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "# A quoi sert l'open data ?\n> Les données ouvertes (ou open data) constituent une ressource essentielle pour de nombreux acteurs. \nCe sont des données numériques produites par les acteurs publics et privés, diffusées de manière structurée selon une licence ouverte garantissant leur libre accès et leur réutilisation par tous, sans restriction technique, juridique ou financière.\nDécouvrez ici quelques exemples d'usages des données ouvertes qui illustrent la diversité des impacts potentiels. \n\n## L'open data nous aide à nous déplacer\n\nLes [données ouvertes relatives aux transports](https://transport.data.gouv.fr/) comme les [horaires des transports en commun](https://transport.data.gouv.fr/datasets?type=public-transit) permettent aux collectivités comme le [département de l’Isère avec Citiway](https://blog.transport.data.gouv.fr/billets/city-way/) et aux calculateurs d'itinéraires comme Google Maps, City Mapper ou [MyBus](https://www.data.gouv.fr/fr/reuses/mybus/) de nous accompagner dans nos déplacements, même en dehors des grandes métropoles.\n\n\n\n## L'open data est un outil de transparence démocratique\n\nDe nombreuses données sur la vie publique et politique sont mises à disposition par l'administration. Citons par exemple l'activité parlementaire, les [données essentielles des marchés publics](https://www.data.gouv.fr/fr/datasets/fichiers-consolides-des-donnees-essentielles-de-la-commande-publique/), [les subventions aux associations](https://www.data.gouv.fr/fr/datasets/projet-de-loi-de-finances-pour-2020-plf-2020-donnees-de-lannexe-jaune-effort-financier-de-letat-en-faveur-des-associations/) ou encore les [balances comptables des communes](https://www.data.gouv.fr/fr/datasets/balances-comptables-des-communes/). \n\nLa société civile s'empare de ces données pour les rendre plus intelligibles et faciliter l'accès au fonctionnement des institutions. C'est le cas, par exemple, du collectif [Regards Citoyens](https://www.regardscitoyens.org/qui-sommes-nous/) grâce à [nosdéputés.fr](https://www.nosdeputes.fr/). \n\n\n\n## L'open data permet un suivi transparent de l'épidémie de Covid-19\n\nLes données publiques sont un [outil essentiel au service de la gestion de crise et du pilotage des politiques publiques](https://www.etalab.gouv.fr/les-donnees-publiques-au-service-de-la-gestion-de-crise-et-du-pilotage-des-politiques-publiques). \n\nLa mise à disposition et la visualisation de très nombreuses [données relatives au coronavirus](https://www.data.gouv.fr/pages/donnees-coronavirus) permettent d’assurer la juste information du public et de faire acte de transparence sur les informations fondant les décisions du gouvernement.\n\nCes données sont exploitées par l'[administration](https://www.gouvernement.fr/info-coronavirus/carte-et-donnees) mais également [largement réutilisée](https://www.data.gouv.fr/fr/posts/retour-sur-les-activites-de-data-gouv-fr-en-2020/) par la société civile comme en atteste le succès de [CovidTracker](https://covidtracker.fr/). \n\n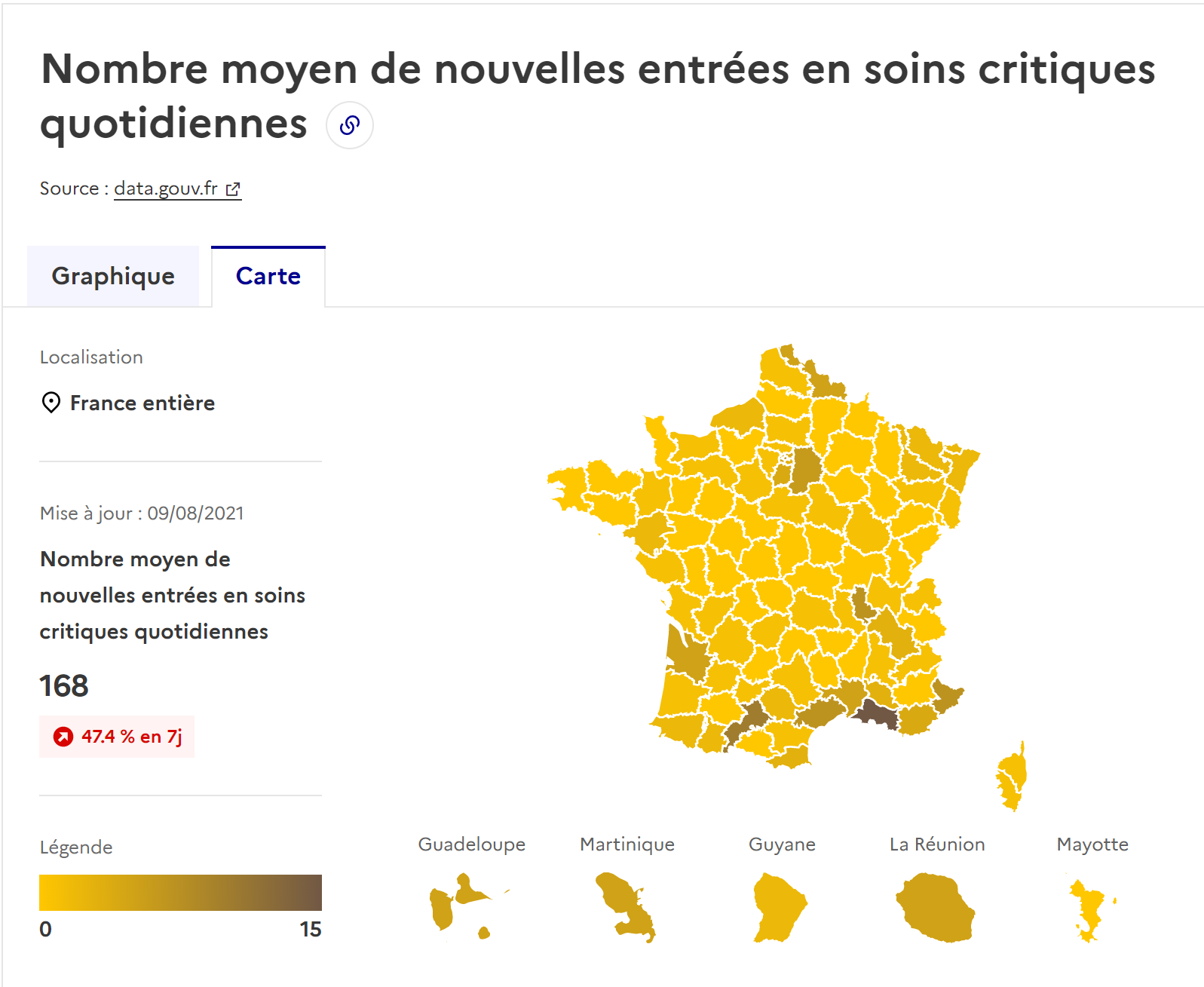\n\n## L'open data permet de connaître le prix des biens immobiliers\n\nLes données de vente des biens immobiliers permettent d'avoir une indication sur les prix en vigueur. Elles sont rendues accessibles au grand public grâce à l'[explorateur DVF développé par Etalab](https://www.data.gouv.fr/fr/reuses/explorateur-de-donnees-de-valeur-fonciere-dvf/) ou par des acteurs privés tels que [Meilleurs Agents](https://www.meilleursagents.com/prix-immobilier/dvf/) qui enrichit notamment ces données d'estimations de prix actualisées.\n\n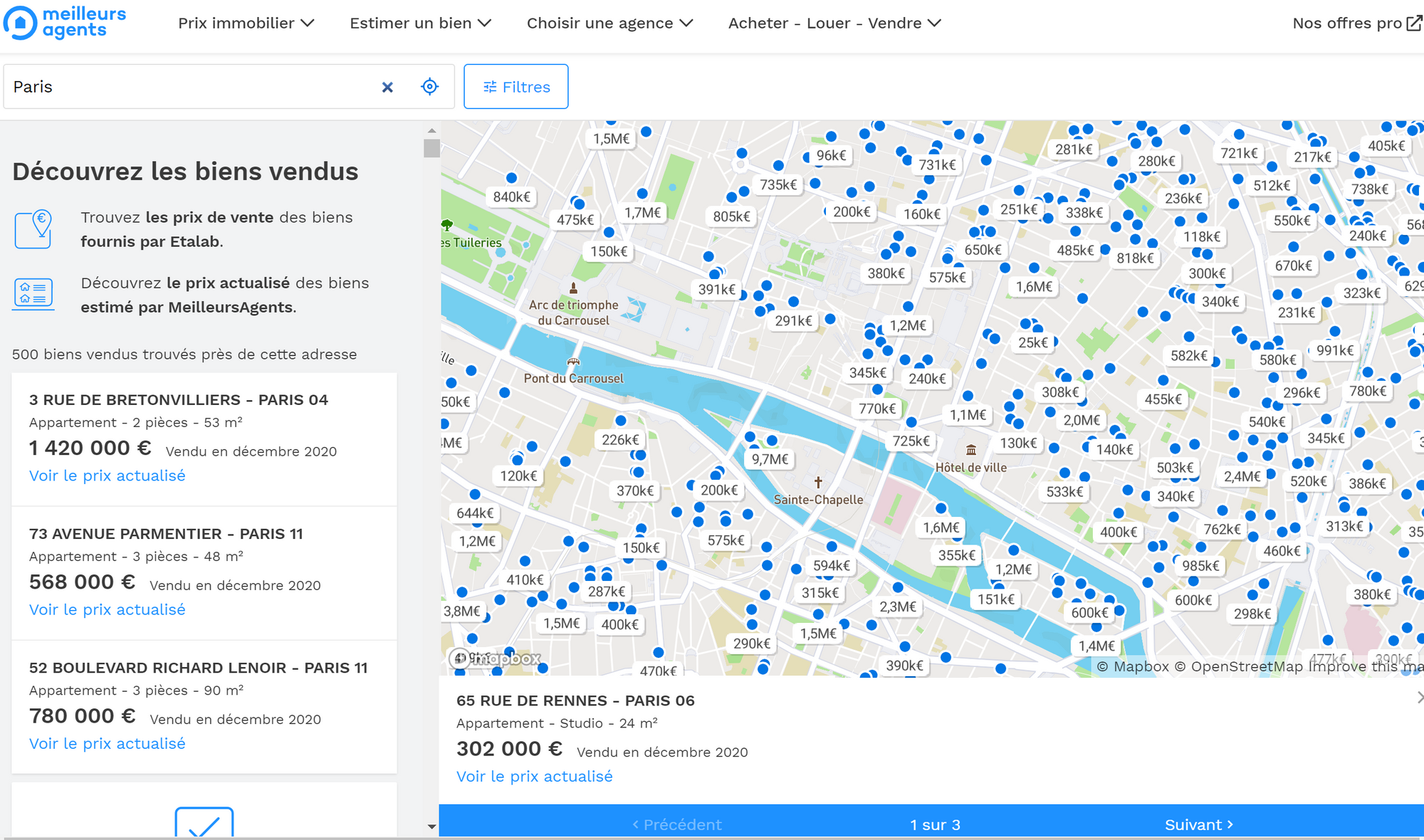\n\n## L'open data facilite les recherches généalogiques\n\n[L'INSEE](https://www.data.gouv.fr/fr/organizations/institut-national-de-la-statistique-et-des-etudes-economiques-insee/) met à disposition de nombreuses données démographiques, dont un [fichier des personnes décédées](https://www.data.gouv.fr/fr/datasets/fichier-des-personnes-decedees/) depuis 1970. A partir de ces données, le site [MatchID](https://www.data.gouv.fr/fr/reuses/moteur-de-recherche-des-personnes-decedees-matchid/) permet, entre autre, d'effectuer une recherche parmi plus de 25 millions de décès depuis 1970. \n\nLes recherches généalogiques sont, bien sûr, un des nombreux usages de ces données essentielles.\n\n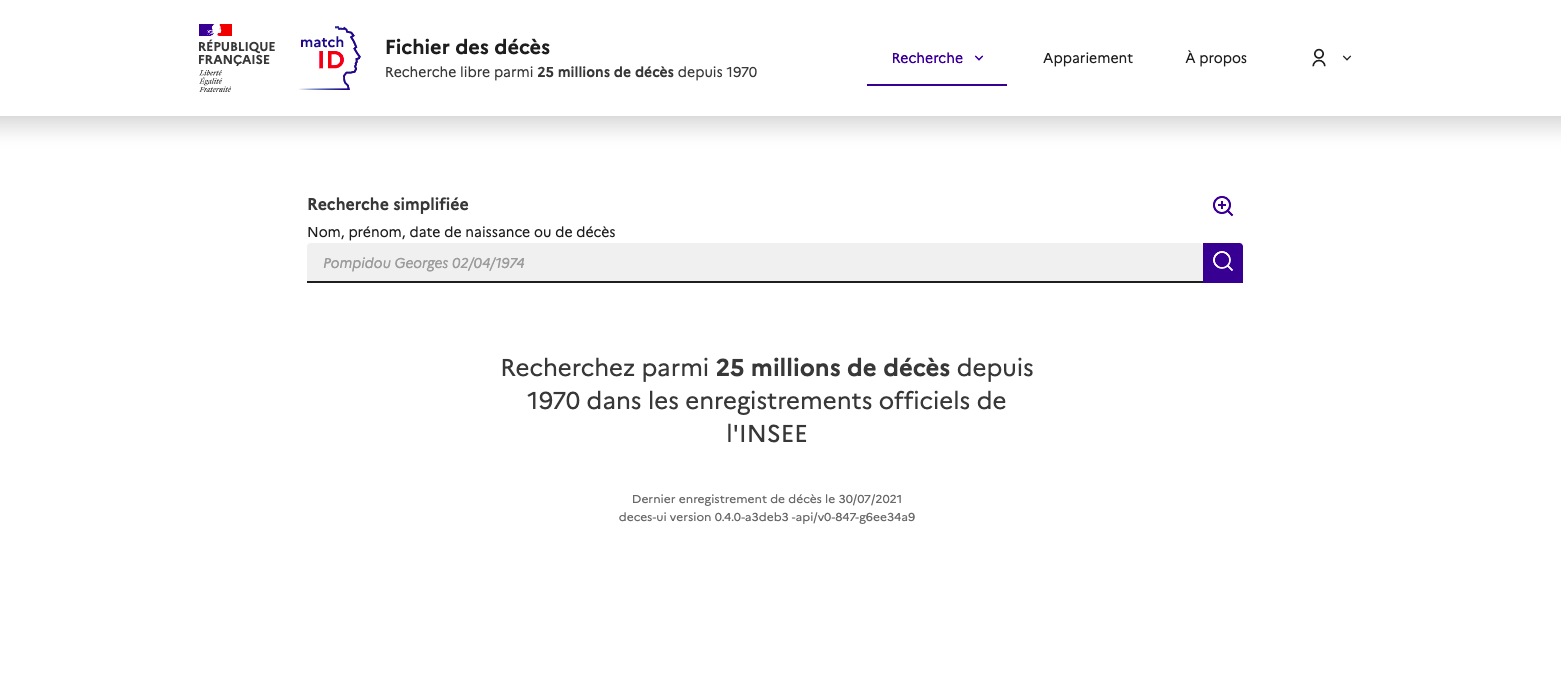\n\n## L'open data nous aide à mieux manger\n\nLes données environnementales, notamment celles produites par [l'ADEME](https://www.data.gouv.fr/fr/organizations/ademe/), ou les données sur l['alimentation](https://www.data.gouv.fr/fr/datasets/open-food-facts-produits-alimentaires-ingredients-nutrition-labels/) produites par l'association [OpenFoodFacts](https://fr.openfoodfacts.org/) constituent une ressource essentielle pour nous aider à choisir des produits bons pour notre santé et pour l'environnement.\n\nLa [startup d'Etat](https://beta.gouv.fr/approche/) [Datagir](https://datagir.ademe.fr/) permet par exemple de [trouver les fruits de saison](https://www.data.gouv.fr/fr/reuses/mes-fruits-legumes-de-saison-votre-moteur-de-recherche-pour-retrouver-les-fruits-legumes-du-mois/) ou de calculer l'[impact environnemental de son alimentation](https://www.data.gouv.fr/fr/reuses/explorer-la-base-agribalyse-pour-decouvrir-limpact-environnemental-de-lalimentation/) . Ces données ont aussi permis à l'association [OpenFoodFacts](https://www.data.gouv.fr/fr/organizations/open-food-facts/) de calculer un [Eco-Score](https://www.data.gouv.fr/fr/reuses/eco-score-limpact-environnemental-des-produits-alimentaires-1/) sur les produits, qui sera visible sur de nombreuses applications telles que [Yuka](https://yuka.io/).\n\n*Quelques exemples des réutilisateurs des données de l'ADEME :* \n\n\n\n## Faites savoir vos usages des données publiques !\n\nCes exemples ne représentent qu'une infime partie de ce qu'il est possible de faire avec les données ouvertes. \n\nPour découvrir d'autres exemples vous pouvez consulter les [réutilisations publiées sur data.gouv.fr](https://www.data.gouv.fr/fr/reuses/) ainsi que suivre les [actualités de data.gouv.fr](https://www.data.gouv.fr/fr/posts/). \n\nNous vous invitons par ailleurs à [référencer votre usage des données ouvertes sur data.gouv.fr](https://guides.etalab.gouv.fr/reutilisation/#pourquoi-referencer-une-reutilisation). Mieux connaître ces usages nous aide à valoriser et développer l'open data !\n"
},
{
"alpha_fraction": 0.4076082706451416,
"alphanum_fraction": 0.4255729615688324,
"avg_line_length": 81.12633514404297,
"blob_id": "23d78a5f937cbfa0c839dd6ca153e69801c84986",
"content_id": "432526cdb44b6be2b1d0b0e7eb376fc166923c31",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 38679,
"license_type": "permissive",
"max_line_length": 222,
"num_lines": 467,
"path": "/pages/donnees_comptes-publics.html",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Données relatives aux comptes publics\nkeywords:\n - comptes publics\n - donnees\n - inventaire\ndescription: Page inventaire des données relatives aux comptes publics.\ncontent_type: html\n---\n\n <section class=\"section-blue section-main\">\n <div class=\"fr-container\">\n <div>\n <h1>Les données relatives aux comptes publics</h1>\n <div class=\"fr-col-12\">\n <div class=\"fr-highlight fr-my-6w\">\n <p>Cette page a pour vocation de référencer les principaux jeux de données relatifs aux comptes\n publics disponibles sur data.gouv.fr. Celle-ci n'est pas exhaustive et <a\n href=\"https://github.com/etalab/datagouvfr-pages/blob/master/pages/donnees_comptes-publics.html\">est\n ouverte aux\n contributions</a>.</p>\n </div>\n\n <div class=\"fr-grid-row\">\n <div class=\"fr-col-12 fr-col-md-4\">\n <nav aria-label=\"Menu latéral\" class=\"fr-sidemenu fr-sidemenu--sticky-full-height\"\n style=\"max-width:350px;\">\n <div class=\"fr-sidemenu__inner\">\n <button aria-controls=\"fr-sidemenu-wrapper\" aria-expanded=\"false\"\n class=\"fr-sidemenu__btn\" hidden=\"\">\n Dans cette rubrique\n </button>\n <img class=\"fr-responsive-img fr-hidden fr-displayed-lg fr-mb-4w\"\n src=\"https://user-images.githubusercontent.com/72090652/199032798-c9b17525-3d4e-4aea-9c83-6de1db81648f.svg\"\n alt=\"\">\n <div class=\"fr-collapse\" id=\"fr-sidemenu-wrapper\">\n <ul class=\"fr-sidemenu__list\">\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#balances\" target=\"_self\">\n 1. Les balances comptables\n </a>\n </li>\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#agregats\" target=\"_self\">\n 2. Les agrégats comptables\n </a>\n </li>\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#comptes-individuels\" target=\"_self\">\n 3. Les comptes individuels\n </a>\n </li>\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#dotations\" target=\"_self\">\n 4. Les critères de répartition des dotations\n </a>\n </li>\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#intercommunalites\" target=\"_self\">\n 5. Le fonctionnement des intercommunalités\n </a>\n </li>\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#REI\" target=\"_self\">\n 6. Le fichier de recensement des élements d'imposition à la\n fiscalité locale (REI)\n </a>\n </li>\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#commande-publique\" target=\"_self\">\n 7. La commande publique\n\n </a>\n </li>\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#plf\" target=\"_self\">\n 8. Le projet de loi Finance (PLF)\n </a>\n </li>\n <li class=\"fr-sidemenu__item\">\n <a class=\"fr-sidemenu__link\" href=\"#rapport\" target=\"_self\">\n 9. Les rapports relatifs aux comptes publics\n </a>\n </li>\n </ul>\n </div>\n </div>\n </nav>\n </div>\n <div class=\"fr-col-12 fr-col-md-8 markdown\">\n <h2 id=\"balances\">Les balances comptables</h2>\n <p>La balance comptable est un document comptable qui reprend tous les comptes d’un\n organisme. Elle fait apparaître les soldes créditeurs et débiteurs sur la période de\n l'exercice.</p>\n <p>La balance comptable reproduit l'état de l'exercice à partir du grand livre (recueil de\n l'ensemble des comptes d'une structure qui tient sa comptabilité en partie double) en\n regroupant tous les totaux sur les soldes créditeurs et débiteurs.</p>\n <p>Le Ministère de l'Economie et des Finances publie en open data les données des balances\n comptables de différentes structures administratives :</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/donnees-de-comptabilite-generale-de-letat/\">Données\n de comptabilité générale de l'État</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-regions-depuis-2010/\">Balances\n comptables des régions depuis 2010</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-departements-depuis-2010/\">Balances\n comptables des départements depuis 2010</a></li>\n <li>Balances\n comptables des communes <a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-communes/\">2010\n - 2017</a>, <a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-communes-en-2018/\">\n 2018</a>, <a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-communes-en-2019/\">\n 2019</a>, <a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-communes-en-2020/\">\n 2020</a> et <a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-communes-en-2021/\">\n 2021</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-collectivites-et-des-etablissements-publics-locaux-avec-la-presentation-croisee-nature-fonction-2019/\">Balances\n comptables des collectivités et des établissements publics locaux avec la\n présentation croisée nature-fonction 2019</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-groupements-a-fiscalite-propre-depuis-2010/\">Balances\n comptables des groupements à fiscalité propre depuis 2010</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-etablissements-publics-locaux-depuis-2010/\">Balances\n comptables des établissements publics locaux depuis 2010</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/balances-comptables-des-syndicats-depuis-2010/\">Balances\n comptables des syndicats depuis 2010</a></li>\n </ul>\n </div>\n\n <h2 id=\"agregats\">Les agrégats comptables</h2>\n <p>Les agrégats comptables sont produits en complément des balances comptables.Ce sont des\n instruments d'information destinés à faciliter l'analyse financière. Ils présentent des\n éléments chiffrés du bilan, des charges et produits de fonctionnement, des dépenses et\n recettes d'investissement, à un niveau plus ou moins fin.</p>\n <p>Les agrégats publiés sont ceux des budgets principaux et des budgets annexes des\n collectivités locales et de leurs établissements publics locaux (groupements à fiscalité\n propre, syndicats, caisses des écoles, caisses communales d'action sociale etc.).</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/agregats-comptables-des-collectivites-et-des-etablissements-publics-locaux-2017/\">Agrégats\n comptables des collectivités et des établissements publics locaux 2017</a>\n </li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/agregats-comptables-des-collectivites-et-des-etablissements-publics-locaux-2018/\">Agrégats\n comptables des collectivités et des établissements publics locaux 2018</a>\n </li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/agregats-comptables-des-collectivites-et-des-etablissements-publics-locaux-2019/\">Agrégats\n comptables des collectivités et des établissements publics locaux 2019</a>\n </li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/agregats-comptables-des-collectivites-et-des-etablissements-publics-locaux-2020/\">Agrégats\n comptables des collectivités et des établissements publics locaux 2020</a>\n </li>\n </ul>\n </div>\n\n <h2 id=\"comptes-individuels\">Les comptes individuels</h2>\n <p>Les comptes individuels permettent une analyse des équilibres financiers fondamentaux des\n budgets exécutés des communes, régions, départements et groupement à fiscalité propre.\n </p>\n <p>Les comptes individuels permettent d’analyser :</p>\n <div class=\"markdown\">\n <ul>\n <li>Les équilibres financiers fondamentaux : opérations de fonctionnement,\n opérations d’investissement, autofinancement, endettement.</li>\n <li>Les éléments de fiscalité directe locale : les bases imposées et les réductions\n (exonérations, abattements) accordées sur délibérations, les taux et les\n produits de la fiscalité directe lo.</li>\n </ul>\n </div>\n <p>Le Ministère de l'Economie et des Finances met à disposition en open data les données des\n comptes individuelles des différentes structures administratives :</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-individuels-des-communes-fichier-global-a-compter-de-2000/\">Comptes\n individuels des communes (fichier global) à compter de 2000</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-individuels-des-groupements-a-fiscalite-propre-fichier-global-a-compter-de-2007/\">Comptes\n individuels des groupements à fiscalité propre (fichier global) à compter de\n 2007</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-individuels-des-departements-et-des-collectivites-territoriales-uniques-fichier-global-a-compter-de-2008/\">Comptes\n individuels des départements et des collectivités territoriales uniques\n (fichier global) à compter de 2008</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-individuels-des-regions-fichier-global-a-compter-de-2008/\">Comptes\n individuels des régions (fichier global) à compter de 2008</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-individuels-des-collectivites/\">Comptes\n individuels des collectivités</a></li>\n </ul>\n </div>\n <p>Pour plus d’informations, vous pouvez <a\n href=\"https://www.impots.gouv.fr/cll/application/pdf/methodo_commune.pdf\">télécharger\n la note méthodologique</a>.</p>\n <p>Par ailleurs, l'<a\n href=\"https://www.data.gouv.fr/fr/organizations/observatoire-des-finances-et-de-la-gestion-publique-locales/\">observatoire\n des finances et de la gestion publique locales (OFGL)</a> utiliser les données\n publiées par le Ministère de l'Economie et des Finances afin de proposer des comptes\n consolidés :</p>\n <div class=\"markdown\">\n <ul>\n <li><a href=\"https://www.data.gouv.fr/fr/datasets/comptes-des-regions-2012-2020/\">Comptes\n des régions 2012-2021</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-consolides-des-groupements-a-fiscalite-propre-2012-2020/\">Comptes\n consolidés des groupements à fiscalité propre 2012-2021</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-consolides-des-communes-2012-2020/\">Comptes\n consolidés des communes 2012-2021</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-des-departements-2012-2020/\">Comptes\n des départements 2012-2021</a></li>\n <li><a href=\"https://www.data.gouv.fr/fr/datasets/comptes-des-communes-2012-2020/\">Comptes\n des communes 2012-2021</a></li>\n <li><a href=\"https://www.data.gouv.fr/fr/datasets/comptes-des-sdis-2012-2020/\">Comptes\n des SDIS 2012-2021</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-consolides-des-regions-2012-2020/\">Comptes\n consolidés des régions 2012-2021</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-consolides-des-departements-2012-2020/\">Comptes\n consolidés des départements 2012-2021</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/comptes-des-groupements-a-fiscalite-propre-2012-2020/\">Comptes\n des groupements à fiscalité propre 2012-2021</a></li>\n </ul>\n </div>\n\n <h2 id=\"dotations\">Les critères de répartition des dotations</h2>\n <p>La péréquation est un mécanisme de redistribution qui vise à réduire les écarts de\n richesse et les inégalités. Dans le secteur public, il s'agit un système de\n redistribution des ressources financières entre plusieurs personnes publiques.</p>\n <p>La <a\n href=\"https://www.data.gouv.fr/fr/organizations/direction-generale-des-collectivites-locales/\">Direction\n générale des collectivités locales (DGCL)</a> publie en open data les principaux\n critères physiques et financiers utilisés pour la répartition des fonds nationaux de\n péréquation et pour la répartition des dotations de l’État aux collectivités\n territoriales.</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/criteres-de-repartition-des-dotations-versees-par-letat-aux-collectivites-territoriales/\">Critères\n de répartition des dotations versées par l’Etat aux collectivités\n territoriales</a></li>\n </ul>\n </div>\n\n <h2 id=\"intercommunalites\">Le fonctionnement des intercommunalités</h2>\n <p>L'expression \"intercommunalité\" désigne les différentes formes de coopérations existantes\n entre les communes.</p>\n <p>La DGCL met à disposition des donneés qui contient de nombreuses informations sur les\n intercommunalités :</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/base-nationale-sur-les-intercommunalites/\">Les\n données relatives à la liste, les coordonnées et le périmètre des\n groupements</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/les-donnees-contextuelles-des-intercommunalites-et-autres-structures-territoriales/\">Les\n données relatives aux ressources financières et fiscales et à la situation\n socio-démographique des intercommunalités et autres structures\n territoriales</a></li>\n </ul>\n </div>\n\n <h2 id=\"REI\">Le fichier de recensement des élements d'imposition à la fiscalité locale (REI)\n </h2>\n <p>Le fichier de recensement des éléments d’imposition à la fiscalité directe locale est un\n fichier agrégé au niveau communal. Il détaille l'ensemble des données de fiscalité\n directe locale par taxe et par collectivité bénéficiaire (commune, syndicats et\n assimilés, intercommunalité, département, région).</p>\n <p>Ces données concernent exclusivement les impositions primitives, c’est-à-dire qu’elles ne\n tiennent pas compte des impositions supplémentaires consécutives à des omissions ou\n insuffisances de l'imposition initiale.</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/impots-locaux-fichier-de-recensement-des-elements-dimposition-a-la-fiscalite-directe-locale-rei-3/\">Impôts\n locaux : fichier de recensement des éléments d'imposition à la fiscalité\n directe locale (REI)</a></li>\n </ul>\n </div>\n <p>Pour en savoir plus vous pouvez consultez les notices explicatives du REI <a\n href=\"https://www.impots.gouv.fr/sites/default/files/media/stats/notice_explicative_rei_2018.pdf\">ici</a>.\n Vous pouvez trouver la liste des variables et leur signification dans le tracé du\n fichier <a\n href=\"https://www.impots.gouv.fr/portail/files/media/stats/trace_rei_complet_2018.xlsx\">ici</a>.\n </p>\n\n <h2 id=\"commande-publique\">La commande publique</h2>\n <p>Les acheteurs publics sont tenus de publier les données essentielles de leurs marchés\n publics dépassant 40.000€ HT. Ces données essentielles correspondent aux données\n d'attribution de marchés publics, c’est-à-dire la phase qui se conclut par l’annonce de\n la ou les entreprises qui ont remporté le marché.</p>\n <p>Les acheteurs publics disposent de plusieurs modes de publication. Afin d'apporter une\n vision complète des données essentielles de la commande publique, Etalab publie une\n consolidation des données publiées sur différentes plateformes :</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/donnees-essentielles-de-la-commande-publique-fichiers-consolides/\">Fichiers\n consolidés des données essentielles de la commande publique (DECP)</a></li>\n </ul>\n </div>\n <p>Il est également possible de consulter les données publiées via le PES Marché :</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/donnees-essentielles-de-la-commande-publique-transmises-via-le-pes-marche/\">Données\n essentielles de la commande publique transmises via le PES Marché</a></li>\n </ul>\n </div>\n\n <h2 id=\"plf\">Le projet de loi Finance (PLF)</h2>\n <p>Le projet de loi de finances est un document unique qui rassemble l’ensemble des recettes\n et des dépenses de l’État pour l’année à venir. Il propose le montant, la nature et\n l’affectation des ressources et des charges de l’État selon un équilibre économique et\n financier déterminé.</p>\n <p>Le <a\n href=\"https://www.data.gouv.fr/fr/organizations/ministere-de-leconomie-des-finances-et-de-la-relance/\">ministère\n de l'Economie et des Finances</a> met disposition les données sous-jacentes au\n projet de loi de finances et de ses annexes :</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/projet-de-loi-de-finances-pour-2022-plf-2022-donnees-du-plf-et-des-annexes-projet-annuel-de-performance-pap/\">Projet\n de loi de finances pour 2022 (PLF 2022), données du PLF et des annexes\n projet annuel de performance (PAP)</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/projet-de-loi-de-finances-pour-2022-plf-2022-donnees-de-lannexe-jaune-effort-financier-de-letat-en-faveur-des-associations/\">Projet\n de loi de finances pour 2022 (PLF 2022), données de l'annexe Jaune « Effort\n financier de l’État en faveur des associations »</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/projet-de-loi-de-finances-pour-2021-plf-2021-donnees-du-plf-et-des-annexes-projet-annuel-de-performance-pap/\">Projet\n de loi de finances pour 2021 (PLF 2021), données du PLF et des annexes\n projet annuel de performance (PAP)</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/projet-de-loi-de-finances-pour-2021-plf-2021-donnees-de-lannexe-jaune-effort-financier-de-letat-en-faveur-des-associations/\">Projet\n de loi de finances pour 2021 (PLF 2021), données de l'annexe Jaune « Effort\n financier de l’État en faveur des associations »</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/projet-de-loi-de-finances-pour-2020-plf-2020-donnees-du-plf-et-des-annexes-projet-annuel-de-performance-pap/\">Projet\n de loi de finances pour 2020 (PLF 2020), données du PLF et des annexes\n projet annuel de performance (PAP)</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/projet-de-loi-de-finances-pour-2020-plf-2020-donnees-de-lannexe-jaune-effort-financier-de-letat-en-faveur-des-associations/\">Projet\n de loi de finances pour 2020 (PLF 2020), données de l'annexe Jaune « Effort\n financier de l’État en faveur des associations »</a></li>\n </ul>\n </div>\n <p>Par la suite, l'Assemblée Nationale publie les amendements déposés sur le projet de loi\n proposé :</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/amendements-deposes-a-lassemblee-nationale-lies-aux-plf-et-plfss-2018-2019-2020/\">Amendements\n déposés à l'Assemblée nationale liés aux PLF et PLFSS 2018, 2019, 2020</a>\n </li>\n </ul>\n </div>\n <p>Enfin, le Sénat publie en open data :</p>\n <div class=\"markdown\">\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/projets-de-loi-de-finances-redaction-de-1ere-lecture-au-senat-resultant-des-travaux-de-lassemblee-nationale/\">Projets\n de loi de finances - Rédaction de 1ère lecture au Sénat résultant des\n travaux de l’Assemblée nationale</a></li>\n <li><a href=\"https://www.data.gouv.fr/fr/datasets/amendements-deposes-au-senat/\">Amendements\n déposés au Sénat</a></li>\n </ul>\n </div>\n\n <h2 id=\"rapport\">Les rapports relatifs aux comptes publics</h2>\n <p>La <a href=\"https://www.data.gouv.fr/fr/organizations/cour-des-comptes/\">Cour des\n comptes</a> publie différents rapports relatifs aux comptes publics :</p>\n <div class=\"markdown\">\n <ul>\n <li>Budget de l'État</li>\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/budget-de-letat-exercice-2012/\">Exercice\n 2012</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/budget-de-letat-exercice-2013-1/\">Exercice\n 2013</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/budget-de-letat-exercice-2014/\">Exercice\n 2014</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/budget-de-letat-exercice-2015-resultats-et-gestion/\">Exercice\n 2015 (résultats et gestion)</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/le-budget-de-letat-en-2016-resultats-et-gestion/\">Exercice\n 2016 (résultats et gestion)</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/le-budget-de-letat-en-2017-resultats-et-gestion/\">Exercice\n 2017 (résultats et gestion)</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/le-budget-de-letat-en-2018-resultats-et-gestion-1/\">Exercice\n 2018 (résultats et gestion)</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/le-budget-de-letat-en-2019-resultats-et-gestion/\">Exercice\n 2019 (résultats et gestion)</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/le-budget-de-letat-en-2020-resultats-et-gestion/\">Exercice\n 2020 (résultats et gestion)</a></li>\n </ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/compte-general-de-letat-2006-2014/\">Compte\n général de l’État (2006-2014)</a></li>\n <li>Certification des comptes de l'État</li>\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-de-letat-pour-lexercice-2015/\">Exercice\n 2015</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-de-letat-pour-lexercice-2016/\">Exercice\n 2016</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-2017-de-letat/\">Exercice\n 2017</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-2019-de-letat/\">Exercice\n 2019</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-2020-de-letat/\">Exercice\n 2020</a></li>\n </ul>\n <li>Certification des comptes du régime général de sécurité sociale</li>\n <ul>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-du-regime-general-de-securite-sociale-2015-1/\">Exercice\n 2015</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-du-regime-general-de-securite-sociale-exercice-2016/\">Exercice\n 2016</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-2017-du-regime-general-de-securite-sociale/\">Exercice\n 2017</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-2019-du-regime-general-de-securite-sociale/\">Exercice\n 2019</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-2020-du-regime-general-de-securite-sociale-et-du-cpsti/\">Exercice\n 2020</a></li>\n <li><a\n href=\"https://www.data.gouv.fr/fr/datasets/certification-des-comptes-2021-du-regime-general-de-securite-sociale-et-du-cpsti/\">Exercice\n 2021</a></li>\n </ul>\n </ul>\n </div>\n </div>\n </div>\n"
},
{
"alpha_fraction": 0.7762060761451721,
"alphanum_fraction": 0.7858298420906067,
"avg_line_length": 86.02887725830078,
"blob_id": "2083791ca1b1b4aa9a3b286f165ac2fcd01b0548",
"content_id": "7826ab5c1cfa139e6c78414e3ea16ad32431d4f0",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24696,
"license_type": "permissive",
"max_line_length": 526,
"num_lines": 277,
"path": "/pages/donnees-logement-urbanisme.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Les données relatives au logement et à l'urbanisme\nkeywords:\n - inventaire\n - logement\n - urbanisme\ndescription: Les jeux de données relatifs au logement et à l'urbanisme en France référencés sur data.gouv.fr\nmenu:\n - footer\nreuses:\n - \ndatasets:\n - inventaire-des-bases-de-donnees-relatives-au-logement-et-a-lurbanisme\n - energie-et-patrimoine-communal-5-batiments\n - diagnostics-de-performance-energetique-pour-les-logements-par-habitation\n - population\n - adresses-locales\n - observatoire-des-performances-energetiques\n - valeurs-immobilieres-economiques-et-financieres-de-1800-a-2015\n - cadastre\n - annuaire-des-diagnostiqueurs-immobiliers\n - resultats-nationaux-des-observatoires-locaux-des-loyers\n - carte-des-loyers-indicateurs-de-loyers-dannonce-par-commune-en-2018\n - couts-et-surfaces-moyennes-des-logements-sociaux\n - base-de-donnees-eco-ptz-eco-pret-a-taux-zero\n - base-de-donnees-ptz-prets-a-taux-zero\n - base-de-donnee-pas-pret-a-laccession-sociale\n - simulaideurs-dispositifs\n - plans-de-financement-ressources-des-logements-sociaux-par-departement-2016-2018\n - financement-et-cout-des-logements-sociaux-construits\n - financement-et-cout-des-logements-sociaux-rehabilites\n - compte-satellite-du-logement\n - base-des-ecoquartiers\n - communes-de-la-loi-littoral-au-code-officiel-geographique-cog-2020\n - communes-de-la-loi-montagne-au-code-officiel-geographique-cog-2020\n - programme-action-coeur-de-ville\n - zones-urbaines-sensibles-zus\n - quartiers-prioritaires-de-la-polit\n - contrats-urbains-de-cohesion-sociale-cucs\n - quartiers-de-veille-active\n - programme-petites-villes-de-demain\n - structures-dinnovation-sur-le-territoire-non-exhaustif-1\n - logements-sociaux-et-bailleurs-par-region\n - logements-sociaux-et-bailleurs-par-departement\n - lagence-nationale-pour-la-renovation-urbaine-anru-et-la-mise-en-oeuvre-des-programmes-de-renouvellement-urbain\n - referentiel-a-grande-echelle-rge\n - corine-land-cover-occupation-des-sols-en-france\n - immeubles-proteges-au-titre-des-monuments-historiques-2\n - base-des-permis-de-construire-et-autres-autorisations-durbanisme-sitadel\n - enquete-tremi-2017\n - couts-des-travaux-de-renovation-ecs\n - espaces-conseil-faire\n - base-de-donnee-nationale-des-batiments-version-0-6\n---\n\n# Les données relatives au logement et à l'urbanisme\n\nDans le cadre de ses missions, le département Etalab a réalisé un travail de recensement le plus complet possible des bases et jeux de données publiques existantes dans le domaine du logement et de l'urbanisme, et [publie cet inventaire en open data](/datasets/inventaire-des-bases-de-donnees-relatives-au-logement-et-a-lurbanisme/). 136 bases de données de 44 gestionnaires ont été recensés.\nPour faciliter la découverte des données, cette page présente une sélection des principales bases qui sont disponibles en format ouvert sur le portail national data.gouv.fr. La liste n'est pas exhaustive et est ouverte aux contributions.\n\nCes jeux de données sont présentés en 6 catégories :\n\n-\t**Situation, caractéristiques et performances du logement** : jeux de données présentant une photographie du logement, sur plusieurs thèmes : cadastre, performances énergétiques, valeur, etc. \n-\t**Coût du logement** : informations sur les loyers sur l’ensemble du territoire national\n-\t**Financement du logement** : données sur les aides disponibles, sur les aides accordées, sur le budget des politiques de logements, etc.\n-\t**Aménagement du territoire** : projets d'aménagement urbains, politiques d’aménagement du territoire, …\n-\t**Urbanisme au sens large** : informations descriptives sur l’occupation des sols.\n-\t**Travaux, gestes de rénovation et construction** : Permis de construire, travaux de Rénovation, …\n\nChaque base listée ci-dessous fait l’objet d’une page dédiée sur data.gouv.fr, présentant de manière plus détaillée les données téléchargeables.\n\nSont ensuite listés les noms des principales organisations gestionnaires des données relatives au logement et à l’urbanisme. La plupart de ces gestionnaires proposent sur leurs portails ou sites web des informations ou publications construites sur la base des jeux de données listés ci-dessous. \n\n## Situation, caractéristiques et performances du logement\n\n- **[Registre national d'Immatriculation des Copropriétés](/datasets/registre-national-dimmatriculation-des-coproprietes/)**\n - Le registre vise à recenser les copropriétés à usage d’habitat. Il permet de procéder en ligne à l’immatriculation et à la mise à jour des données d’une copropriété par son représentant légal ou par un notaire, et d’accéder à un annuaire et à des données statistiques. Les données collectées contribuent aux politiques publiques à destination des copropriétés.\n\n- **[Enquête « Énergie et patrimoine communal » (2012-2017)](/datasets/energie-et-patrimoine-communal-5-batiments/)**\n - Enquête portant sur les consommations, les émissions de CO2 et les dépenses énergétiques des communes, et de leurs Groupements à Fiscalité Propre pour leur patrimoine.\n\n- **[Diagnostics de performance énergétique (DPE) pour les logements par habitation](/datasets/diagnostics-de-performance-energetique-pour-les-logements-par-habitation/)**\n - Le DPE décrit le bâtiment ou le logement (surface, orientation, murs, fenêtres, matériaux, etc), ainsi que ses équipements de chauffage, de production d'eau chaude sanitaire, de refroidissement et de ventilation. Renseigne sur la performance énergétique d'un logement ou d'un bâtiment, en évaluant sa consommation d'énergie et son impact en termes d'émissions de gaz à effet de serre.\n\n- **[Recensement de la population (INSEE)](/datasets/population/)**\n - Le recensement de la population permet de connaître la diversité et l'évolution de la population de la France. L'Insee fournit ainsi des statistiques sur les habitants et les logements, leur nombre et leurs caractéristiques : répartition par sexe et âge, professions, diplômes-formation, conditions de logement, modes de transport, déplacements domicile-travail, etc.\n\n- **[Bases adresses locales](/datasets/adresses-locales/)**\n - Regroupe toutes les adresses d'une ou plusieurs communes et est publiée sous leur responsabilité.\n\n- **[Données de l'observatoire des performances énergétiques OPE)](/datasets/observatoire-des-performances-energetiques/)**\n - Les données disponibles sont un résumé de ce que contiennent les RSET. Elles sont anonymisées avant leur intégration dans l'observatoire.\n\n- **[Valeurs immobilières, économiques et financières de 1800 à 2015](/datasets/valeurs-immobilieres-economiques-et-financieres-de-1800-a-2015/)**\n - Statistiques historiques sur le marché immobilier (indices de prix de vente et de loyer des maisons et des appartements, nombre et valeur des ventes, crédit immobilier etc.) et sur son environnement (revenu par ménage, taux d'intérêt, inflation, valeur des autres investissements (actions, obligations, or), nombre de ménages, etc.)\n\n- **[Données du plan cadastral](/datasets/cadastre/)** disponibles également sur [cadastre.data.gouv.fr](https://cadastre.data.gouv.fr/)\n - Plans et fichiers administratifs qui recensent toutes les propriétés immobilières situées dans chaque commune française, et qui en consigne la valeur afin de servir de base de calcul à certains impôts.\n\n- **[Annuaire des diagnostiqueurs immobiliers (ADI)](/datasets/annuaire-des-diagnostiqueurs-immobiliers/)**\n - Met à disposition du grand public la liste des personnes habilitées pour établir des diagnostics immobiliers (diagnostiqueurs immobiliers). Cet annuaire est alimenté par les organismes de certification qui fournissent la liste des diagnostiqueurs qu'ils ont certifiés.\n\n- **[Base de donnée nationale des bâtiments (BDNB)](/datasets/base-de-donnee-nationale-des-batiments-version-0-6/)**\n - Cartographie du parc de bâtiments existants, construite par croisement géospatial d’une vingtaine de base de données issues d’organismes publics. Structurée à la maille « bâtiment », elle contient une carte d’identité pour chacun des 20 millions de bâtiments, résidentiels ou tertiaires.\n\n## Coût du logement\n\n- **[Observatoires locaux des loyers](/datasets/resultats-nationaux-des-observatoires-locaux-des-loyers/)**\n - Données relatives aux loyers créées par les observatoires. Le parc de référence est l'ensemble des locaux à usage d'habitation ou à usage mixte, à l'exception de certains cas précis.\n\n- **[\"Carte des loyers\" - Indicateurs de loyers d'annonce par commune en 2018](/datasets/carte-des-loyers-indicateurs-de-loyers-dannonce-par-commune-en-2018/)**\n - Indicateurs de loyers, à l'échelle de la commune, produits sur la base de données d'annonces parues sur leboncoin, SeLoger et PAP sur la période 2015-2019.\n\n- **[Coûts et surfaces moyennes des logements sociaux](/datasets/couts-et-surfaces-moyennes-des-logements-sociaux/)**\n - Présente les surfaces moyennes des logements sociaux financés, leur coût moyen au m² et le coût moyen du logement. Ces informations sont présentées selon l'année de financement (à partir de 2016), par région et avec distinction entre construction et réhabilitation.\n\n## Financement du logement\n\n- **[Enquête national DGALN « Eco-PTZ »](/datasets/base-de-donnees-eco-ptz-eco-pret-a-taux-zero/)**\n - Enquête DGALN sur les logements locatifs sociaux éligibles à l'éco-prêt logement social, permettant d'étudier les types de travaux et les gains de performance énergétique induits par un dispositif incitatif tel que l'éco-PLS.\n\n- **[Enquête national DGALN « PTZ »](/datasets/base-de-donnees-ptz-prets-a-taux-zero/)**\n - Recense depuis 1995 les données relatives aux opérations financées par des prêts à taux zéro. Liste en particulier l'année d'émission du prêt, le type d'opération, la localisation géographique, le prix au mètre carré de l'opération, les durées, montants et taux du PTZ de l'ensemble des prêts de l'opération, ou le revenu par unité de consommation du ménage.\n\n- **[Base de données PAS (prêt à l'accession sociale)](/datasets/base-de-donnee-pas-pret-a-laccession-sociale/)**\n - Recense depuis 1993 les données relatives aux opérations financées par le biais des prêts PAS. Liste en particulier l'année d'émission de l'opération, le type de logement financé, ou sa localisation géographique.\n\n- **[Dispositifs Simul'Aid€s](/datasets/simulaideurs-dispositifs/)**\n - L'outil Simul'Aid€s est un calculateur d'aides financières pour la rénovation énergétique de l'habitat privée. Ce jeu de données met à disposition du grand public la liste des dispositifs d'aides financières, identifiée par les conseillers du réseau FAIRE. Cette liste contient l'ensemble des règles de calcul des dispositifs.\n\n- **[Plans de financement (ressources) des logements sociaux par département 2016-2018](/datasets/plans-de-financement-ressources-des-logements-sociaux-par-departement-2016-2018/)**\n - Présente, par département, la répartition des ressources dans les plans de financement de construction/acquisition de logements sociaux familiaux en moyenne sur la période 2016-2018. Les prix de revient moyen par département sur la même période et pour les mêmes opérations sont également indiqués (en euros).\n\n- **[Financement et coût des logements sociaux construits](/datasets/financement-et-cout-des-logements-sociaux-construits/)**\n - Le fichier présente, par région, les surfaces moyennes des logements sociaux construits, leur prix de revient moyen ainsi que la structure du financement (poids des fonds propres, prêts CDC, autres prêts et subvention) et du coût de ces logements sociaux (poids du coût du terrain, de la construction et autres coûts).\n\n- **[Financement et coût des logements sociaux réhabilités](/datasets/financement-et-cout-des-logements-sociaux-rehabilites/)**\n - Le fichier présente, par région, les surfaces moyennes des logements sociaux réhabilités, leur prix de revient moyen ainsi que la structure du financement (poids des fonds propres, prêts CDC, autres prêts, subventions) et du coût de ces logement sociaux (poids du coût des travaux et autres coûts).\n\n- **[Compte satellite du logement CSL](/datasets/compte-satellite-du-logement/)**\n - Synthétise un grand nombre de sources de données afin de dresser un bilan comptable complet et structuré des dépenses de logement de l'ensemble des acteurs.\n \n- **[Logements sociaux et bailleurs par région](/datasets/logements-sociaux-et-bailleurs-par-region/)**\n - Le jeu de données présente, par région, le nombre de logements sociaux et le nombre de bailleurs gérant ces logements dans le département. Il indique également la répartition des logements sociaux par type d'opérateurs (OPH, ESH, SEM, autres).\n \n- **[Logements sociaux et bailleurs par département](https://www.data.gouv.fr/fr/datasets/logements-sociaux-et-bailleurs-par-departement/)**\n - Le jeu de données présente, par département, le nombre de logements sociaux et le nombre de bailleurs gérant ces logements dans le département. Il indique également la répartition des logements sociaux par type d'opérateurs (OPH, ESH, SEM, autres).\n\n## Aménagement du territoire\n\n- **[Base de données nationale des bâtiments](datasets/base-de-donnees-nationale-des-batiments-version-0-6/)**\n - La BDNB (Base de Données Nationale des Bâtiments) est une cartographie du parc de bâtiments existants, construite par croisement géospatial d’une vingtaine de base de données issues d’organismes publics. Structurée à la maille « bâtiment », elle contient une carte d’identité pour chacun des 20 millions de bâtiments, résidentiels ou tertiaires.\n\n- **[Base des ÉcoQuartiers](/datasets/base-des-ecoquartiers/)**\n - Offre une lecture exhaustive de tous les projets d'aménagement urbains durables rentrés dans la démarche ÉcoQuartier entre 2009 et 2016. (2 appels à projets en 2009 et 2011, 4 campagnes annuelles de labelisation entre 2013 et 2016)\n\n- **[Communes de la loi littoral au Code Officiel Géographique (COG) 2020](/datasets/communes-de-la-loi-littoral-au-code-officiel-geographique-cog-2020/)**\n - Liste les communes concernées par l'application de la \"loi Littoral\"\n\n- **[Communes de la loi Montagne au Code Officiel Géographique (COG) 2020](/datasets/communes-de-la-loi-montagne-au-code-officiel-geographique-cog-2020/)**\n - Liste les communes concernées par l'application de la \"loi Montagne\" de 1985\n\n- **[Programme Action cœur de ville ACV](/datasets/programme-action-coeur-de-ville/)**\n - Contient la liste des communes sélectionnées pour le programme Action cœur de ville\n\n- **[Zones urbaines sensibles (ZUS)](/datasets/zones-urbaines-sensibles-zus/)**\n - Contient la liste et le périmètre des 750+ quartiers classés zone urbaine sensible\n\n- **[Quartiers prioritaires de la politique de la ville - Habitat ancien dégradé](/datasets/quartiers-prioritaires-de-la-polit)**\n - Liste et qualifie les quartiers prioritaires de la politique de la ville présentant une concentration élevée d'habitat ancien dégradé et faisant l'objet d'une convention pluriannuelle\n\n- **[Contrats urbains de cohésion sociale (Cucs)](/datasets/contrats-urbains-de-cohesion-sociale-cucs/)**\n - Liste les 2500 quartiers qui soient sont classés Zones urbaines sensibles (Zus) et bénéficiant de la part de l'État d'avantages particuliers, soit sont classé non-Zus mais repérés comme quartiers prioritaires.\n\n- **[Quartiers de veille active QVA](/datasets/quartiers-de-veille-active/)**\n - Liste et qualifie les zones urbaines sensibles (ZUS) et quartiers en contrats urbains de cohésion sociale (CUCS) qui ne sont pas remplacés par les quartiers prioritaires de la politique de la ville (QPV)\n\n- **[Communes sélectionnées pour le programme Petites villes de demain](/datasets/programme-petites-villes-de-demain/#_)**\n - Contient la liste des communes sélectionnées pour le programme Petites villes de demain.\n\n- **[Structures d'innovation sur le territoire (non exhaustif)](/datasets/structures-dinnovation-sur-le-territoire-non-exhaustif-1/)**\n - Recensement des structures d'innovation ouverte sur l'ensemble du territoire français, travaillant sur des thématiques ayant un impact territorial fort et dans les secteurs stratégiques de la Banque des Territoires.\n\n- **[Données sur mise en œuvre des PNRU](/datasets/lagence-nationale-pour-la-renovation-urbaine-anru-et-la-mise-en-oeuvre-des-programmes-de-renouvellement-urbain/#_)**\n - Jeux de données sur les caractéristiques et déroulements des politiques nationales de renouvellement urbain\n\n## Urbanisme au sens large\n\n- **[Référentiel à grande échelle (RGE)](/datasets/referentiel-a-grande-echelle-rge/)**\n - Le RGE est constitué des composantes orthophotographique (BD ORTHO®), topographique et adresse (BD TOPO), parcellaire (BD Parcellaire) et altimétrique (RGE ALTI® for ArcGIS : modèle numérique de terrain (MNT) au pas de un mètre.).\n\n- **[CORINE Land Cover - Occupation des sols en France](/datasets/corine-land-cover-occupation-des-sols-en-france/)**\n\n - Inventaire biophysique de l'occupation des terres produit dans le cadre du programme européen d'observation de la terre Copernicus (39 États européens)\n\n- **[Mérimée](/datasets/immeubles-proteges-au-titre-des-monuments-historiques-2/)**\n - Base de données du patrimoine monumental français de la Préhistoire à nos jours\n\n## Travaux, gestes de rénovation et construction\n\n- **[Base de données des permis de construire (Sitadel)](/datasets/base-des-permis-de-construire-et-autres-autorisations-durbanisme-sitadel/)**\n - Jeu de données offrant une large partie de la base de données Sitadel. Liste en particulier les permis de construire (PC), permis de déclarations préalables (DP), ou encore de permis de démolir (PD), délivrés depuis 2017.\n\n- **[Enquête TREMI (Travaux de Rénovation Énergétique des Maisons Individuelles)](/datasets/enquete-tremi-2017/)**\n - Données à grande échelle sur les travaux réalisés, sur les motivations et freins, sur les accompagnements proposés, et sur les aspects financiers des travaux.\n\n- **[Enquête 2017-2018 : Coûts des travaux de rénovation](/datasets/couts-des-travaux-de-renovation-ecs/)**\n - Enquête menée auprès du réseau FAIRE afin de faire remonter les données de nature économique que les structures ont pu capitaliser au cours des années de conseils auprès des particuliers. Travaux concernés : Isolation Chauffage Menuiseries ECS (Eau chaude sanitaire) Ventilation Photovoltaïque\n\n- **[Annuaire des espaces Conseil FAIRE](/datasets/espaces-conseil-faire/)**\n - Jeu de données composé des coordonnées des espaces conseil FAIRE points d'entrées pour les particuliers. Jeu complété par un jeu de données proposant la couverture territoriale de ces espaces conseil FAIRE (à la maille de la commune)\n\n# Liste des organisations qui publient des données relatives au logement et à l'urbanisme\n\n## Principaux producteurs et gestionnaires des données publiées sur data.gouv.fr\n\n- [**Le Ministère de la Transition écologique**](/organizations/ministere-de-la-transition-ecologique/), et notamment :\n - [**Direction générale de l'aménagement, du logement et de la nature (DGALN)** ](https://www.ecologie.gouv.fr/direction-generale-lamenagement-du-logement-et-nature-dgaln):\n élabore, anime et évalue les politiques :\n - de l'urbanisme, de la construction, du logement (via la DHUP)\n - des paysages, de la biodiversité, de l'eau et des substances minérales non énergétiques (via le DEB)\n - [**Direction de l'habitat, de l'urbanisme et des paysages (DHUP)**](https://immobilier-etat.gouv.fr/pages/direction-lhabitat-lurbanisme-paysages-dhup): principal gestionnaire de bases de données sur la thématique du logement. La DHUP doit répondre aux besoins en logement et en hébergement des citoyens et notamment contribuer à programmer la production de logements à la bonne échelle du territoire national. Elle vise aussi à améliorer la gestion de l'offre de logements existante. Principales bases gérées par la DHUP :\n - Enquête nationale DGALN - Ecoprêts logements à taux zéro - Eco-PTZ\n - Base de données PAS (prêt à l'accession sociale)\n - Annuaire des diagnostiqueurs immobiliers (ADI)\n - Enquête nationale DGALN - prêts logement à taux zéro - PTZ\n - Base des ÉcoQuartiers (LOAD)\n\n- [**Agence de la transition écologique (ADEME)**](/organizations/ademe/): suscite, anime, coordonne, facilite ou réalise des opérations de protection de l'environnement et la maîtrise de l'énergie. L'Ademe réalise un important travail systématique d'ouverture de ses données. Il s'agit donc d'un des principaux fournisseurs de jeux de données à destination de data.gouv.fr. Principales bases gérées par l'ADEME :\n - Enquête TREMI 2017\n - Liste des espaces conseils FAIRE\n - Enquête «Énergie et patrimoine communal»\n - Simul'Aid€s\n - Enquête 2017-2018 : Coûts des travaux de rénovation : Isolation Chauffage Menuiseries ECS (Eau chaude sanitaire) Ventilation Photovoltaïque\n - Diagnostics de performance énergétique pour les logements par habitation\n\n- [**Agence nationale de la cohésion des territoires (ANCT)** ](/organizations/agence-nationale-de-la-cohesion-des-territoires/): Son action cible prioritairement, d'une part, les territoires caractérisés par des contraintes géographiques, des difficultés en matière démographique, économique, sociale, environnementale ou d'accès aux services publics. Principales bases gérées par l'ANCT :\n - Bases Adresses Locales\n - Zones urbaines sensibles (ZUS)\n - Quartiers prioritaires de la politique de la ville - Habitat ancien dégradé\n - Programme Action cœur de ville ACV\n - Quartiers de veille active QVA\n - Contrats urbains de cohésion sociale (Cucs)\n - Communes sélectionnées pour le programme Petites villes de demain.\n\n- [**Caisse des dépôts et consignations (CDC)**](/organizations/caisse-des-depots-1/): institution financière publique qui exerce des activités d'intérêt général comme la gestion d'une partie de l'épargne (Livrets A, LDDS) et le financement de projets publics et privés. Elle est notamment composée d'une branche CDC Habitat ayant un rôle de bailleur. Toutes les données ouvrables gérées par la CDC sont déjà publiées en Open Data. Principales bases gérées par la CDC :\n - Structures d'innovation sur le territoire (non exhaustif)\n - Plans de financement (ressources) des logements sociaux par département 2016-2018\n - Plan de financement (emplois) des logements sociaux par région 2017-2019\n - Coûts et surfaces moyennes des logements sociaux\n - Financement et coût des logements sociaux construits\n - Financement et coût des logements sociaux réhabilités\n - Logements sociaux et bailleurs par région\n - Logements sociaux et bailleurs par département\n\n## Autres producteurs et gestionnaires de données sur le thème logement et urbanisme\n\n- Au sein du [Ministère de la Transiton écologique](/organizations/ministere-de-la-transition-ecologique/) :\n - [Services des données et études statistiques (SDES) du Ministère de la Transiton écologique](https://www.statistiques.developpement-durable.gouv.fr/qui-sommes-nous)\n - [Département de l'eau et de la biodiversité (DEB)](https://www.ecologie.gouv.fr/direction-generale-lamenagement-du-logement-et-nature-dgaln)\n - [Conseil général de l'environnement et du développement (CGEDD)](http://www.cgedd.developpement-durable.gouv.fr/)\n\n- [Institut National de la Statistique et des Etudes Economiques (INSEE)](/organizations/institut-national-de-la-statistique-et-des-etudes-economiques-insee/)\n\n- [Centre d'études et d'expertise sur les risques, l'environnement, la mobilité et l'aménagement (CEREMA)](/organizations/cerema/)\n\n- [Institut national de l'information géographique et forestière (IGN)](/organizations/institut-national-de-l-information-geographique-et-forestiere/)\n\n- [Observatoire des performances énergétiques (OPE)](https://www.observatoire-dpe.fr/)\n\n- [Agence Nationale pour la Renovation Urbaine (ANRU)](/organizations/agence-nationale-pour-la-renovation-urbaine/)\n\n- [Agence Nationale de l'habitat (ANAH)](https://www.anah.fr/)\n\n- [Bureau de recherches géologiques et minières (BRGM)](https://www.brgm.fr/fr)\n\n- [Centre Scientifique et Technique du Batiment (CSTB)](https://www.cstb.fr)\n"
},
{
"alpha_fraction": 0.7772563695907593,
"alphanum_fraction": 0.7991553544998169,
"avg_line_length": 84.39189147949219,
"blob_id": "2e24c071458361190582983b945ebc65e7c450e2",
"content_id": "c0b2ec921f3bedaa8f43ec80ad0e1330a3c2520f",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6576,
"license_type": "permissive",
"max_line_length": 812,
"num_lines": 74,
"path": "/pages/spd/reference.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: Service Public de la Donnée\r\nkeywords:\r\n - service public de la donnée\r\n - données reference\r\ndescription: Service Public de la donnée de référence, des données sur lesquelles vous pouvez compter.\r\nmenu:\r\n - footer\r\n\r\ndatasets:\r\n - base-adresse-nationale\r\n - base-sirene-des-entreprises-et-de-leurs-etablissements-siren-siret\r\n - code-officiel-geographique-cog\r\n - plan-cadastral-informatise\r\n - registre-parcellaire-graphique-rpg-contours-des-parcelles-et-ilots-culturaux-et-leur-groupe-de-cultures-majoritaire\r\n - referentiel-de-lorganisation-administrative-de-letat\r\n - referentiel-a-grande-echelle-rge\r\n - repertoire-national-des-associations\r\n - repertoire-operationnel-des-metiers-et-des-emplois-rome\r\n---\r\n\r\n# Service public de la donnée : des données sur lesquelles vous pouvez compter\r\nLe service public de la donnée créé par [l’Article 14 de la loi pour une République numérique](https://www.legifrance.gouv.fr/affichTexteArticle.do?cidTexte=JORFTEXT000033202746&idArticle=JORFARTI000033203033&categorieLien=cid) vise à mettre à disposition, en vue de faciliter leur réutilisation, les jeux de données de référence qui présentent le plus fort impact économique et social. Il s’adresse principalement aux entreprises et aux administrations pour qui la disponibilité d’une donnée de qualité est critique. Les producteurs et les diffuseurs prennent des engagements auprès de ces utilisateurs. Le département Etalab de la Direction interministérielle du numérique est chargé de la mise en oeuvre et de la gouvernance de ce service public. Il référence l’ensemble des données concernées sur cette page.\r\n\r\n## Les données de référence\r\nÀ ce jour, neuf jeux de données, qui couvrent un large champ thématique ont été identifiés comme des données de référence.\r\n\r\n- [Base Adresse Nationale (BAN)](/datasets/base-adresse-nationale/)\r\n- [Base Sirene des entreprises et de leurs établissements (SIREN, SIRET)](/datasets/base-sirene-des-entreprises-et-de-leurs-etablissements-siren-siret/)\r\n- [Code Officiel Géographique (COG)](/datasets/code-officiel-geographique-cog/)\r\n- [Plan Cadastral Informatisé](/datasets/plan-cadastral-informatise/)\r\n- [Registre parcellaire graphique (RPG) : contours des parcelles et îlots culturaux et leur groupe de cultures majoritaire](/datasets/registre-parcellaire-graphique-rpg-contours-des-parcelles-et-ilots-culturaux-et-leur-groupe-de-cultures-majoritaire/)\r\n- [Référentiel de l'organisation administrative de l'Etat](/datasets/referentiel-de-lorganisation-administrative-de-letat/)\r\n- [Référentiel à grande échelle (RGE)](/datasets/referentiel-a-grande-echelle-rge/)\r\n- [Répertoire National des Associations (RNA)](/datasets/repertoire-national-des-associations/)\r\n- [Répertoire Opérationnel des Métiers et des Emplois (ROME)](/datasets/repertoire-operationnel-des-metiers-et-des-emplois-rome/)\r\n\r\n## L’organisation du service public de la donnée\r\nElle est déterminée par le décret d’application [2017-331](https://www.legifrance.gouv.fr/affichTexte.do?cidTexte=JORFTEXT000034194946&categorieLien=id) du 14 mars 2017 relatif au service public de mise à disposition des données de référence.\r\n\r\n**Les producteurs** produisent la donnée de référence et documentent les métadonnées.\r\nIls traitent les remontées des utilisateurs ou le cas échéant, orientent les utilisateurs vers le service compétent pour traiter ces demandes.\r\nIls prennent des engagements sur la mise à jour des données.\r\nIls désignent les diffuseurs pour chacun des jeux de données de référence.\r\n\r\n**Les diffuseurs** mettent à disposition les données avec un haut niveau de qualité.\r\nIls s’engagent sur des niveaux de performance et de disponibilité.\r\n\r\n**Les utilisateurs** utilisent les données de référence pour produire de nouveaux services et créer de la valeur économique et sociale.\r\nIls participent à la montée en qualité des données de référence (signalement des erreurs, propositions d’amélioration).\r\n\r\n**Le département Etalab**, recense l’ensemble des jeux de données de référence.\r\nIl gère le service public de la donnée en lien avec les producteurs.\r\nIl anime le dispositif et en assure la promotion auprès des utilisateurs.\r\nIl développe des outils mutualisables, notamment sur la montée en qualité des données.\r\n\r\nPar ailleurs, en cas de défaillance des diffuseurs, ou de non-respect des engagements notamment en matière de performance et de disponibilité, le département Etalab est habilité à se substituer au diffuseur désigné par le producteur.\r\n\r\n## Les prochaines étapes\r\nLe service public de la donnée se construit progressivement, dans un mode itératif avec les producteurs et les utilisateurs. Chaque producteur doit publier ses engagements sur les conditions de la mise à disposition (documentation des données, fréquence de mise à jour, performance et disponibilité de la mise à disposition).\r\n\r\nLe département Etalab publiera sur ce site les indicateurs de disponibilité des données, et assurera plus généralement le suivi du respect de ces engagements.\r\n\r\n## Découvrez des exemples d'utilisation du SPD\r\n\r\nLes données du Service public de la donnée sont des données de références indispensables à de nombreuses applications qu'elles soient publiques ou privées. \r\nVous trouverez sur [ce jeu de donnée](https://www.data.gouv.fr/fr/datasets/exemples-dexploitation-des-donnees-de-reference-du-service-public-de-la-donnee-spd/) une liste d'exemples d'exploitation non exhaustive qui vise à illustrer une partie de la diversité des cas d'usages. \r\n\r\n\r\n## Références\r\n- [L’article L321-4 du Code des relations entre le public et les administrations](https://www.legifrance.gouv.fr/affichCodeArticle.do?cidTexte=LEGITEXT000031366350&idArticle=LEGIARTI000033205649&dateTexte=29990101&categorieLien=cid)\r\n- [Le décret d’application 2017-331 du 14 mars 2017 relatif au service public de mise à disposition des données de référence](https://www.legifrance.gouv.fr/affichTexte.do?cidTexte=JORFTEXT000034194946&categorieLien=id)\r\n- [L'arrêté du 14 juin 2017 relatif aux règles techniques et d'organisation de mise à disposition des données de référence prévues à l'article L. 321-4 du code des relations entre le public et l'administration](https://www.legifrance.gouv.fr/eli/arrete/2017/6/14/PRMJ1713859A/jo/texte)\r\n- [La synthèse de la consultation publique organisée par Etalab en octobre 2016](http://www.etalab.gouv.fr/consultation-spd)\r\n"
},
{
"alpha_fraction": 0.8067227005958557,
"alphanum_fraction": 0.8067227005958557,
"avg_line_length": 117,
"blob_id": "2f86ad7a1e761430899b8b58c74077096975c4e3",
"content_id": "03a7b6bc840e72affb708e22652cef3a15c30466",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 119,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 1,
"path": "/pages/about/readme.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "\nCe dossier rassemble les pages statitiques ayant pour vocation de donner du contexte sur data.gouv.fr et l'open data.\n"
},
{
"alpha_fraction": 0.7773741483688354,
"alphanum_fraction": 0.7861961722373962,
"avg_line_length": 71.2125015258789,
"blob_id": "2dfc9de81f239217061871994704b8ed4422ecd1",
"content_id": "3f99a8820b2bbec20b7c3d8c45b94567dc68fb08",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5887,
"license_type": "permissive",
"max_line_length": 301,
"num_lines": 80,
"path": "/pages/donnees-renovation-logements-et-batiments.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Les données relatives à la rénovation des logements et des bâtiments\nkeywords:\n - rénovation\n - rénovation énergétique\n - DPE\ndescription: Les jeux de données relatifs à la rénovation des logements et des bâtiments référencés sur data.gouv.fr\nreuses:\ndatasets:\n - diagnostics-de-performance-energetique-pour-les-logements-par-habitation\n - diagnostics-de-performance-energetique-pour-les-batiments-publics\n - dispositifs-daides-financieres-a-la-renovation-energetique\n - nombre-de-dispositifs-daides-financieres-a-la-renovation-energetique-par-region\n - donnees-de-letude-individualisation-des-frais-de-chauffage\n - couts-des-travaux-de-renovation-energetique\n - couts-des-travaux-de-renovation-isolation\n - couts-des-travaux-de-renovation-ecs\n - couts-des-travaux-de-renovation-chauffage\n - couts-des-travaux-de-renovation-menuiseries\n - couts-des-travaux-de-renovation-photovoltaique\n - couts-des-travaux-de-renovation-ventilation\n - energie-et-patrimoine-communal-1-description\n - energie-et-patrimoine-communal-2-energie\n - energie-et-patrimoine-communal-3-divers\n - energie-et-patrimoine-communal-4-depenses-et-consommation\n - energie-et-patrimoine-communal-5-batiments\n - marches-et-emploi-de-lefficacite-energetique-et-des-enr-enr-2019\n - marches-et-emploi-de-lefficacite-energetique-et-des-enr-transport-2019\n - marches-et-emploi-de-lefficacite-energetique-et-des-enr-batiment-2019\n---\n# Les données relatives à la rénovation énergétique des logements et bâtiments\n\n## Données de [l'ADEME](https://www.data.gouv.fr/fr/organizations/ademe/)\n\n### Diagnostics de performance énergétique\n\n- [Les diagnostics de performance énergétique pour les logements par habitation](https://www.data.gouv.fr/fr/datasets/diagnostics-de-performance-energetique-pour-les-logements-par-habitation/)\n- [Les diagnostics de performance énergétique pour les bâtiments publics](https://www.data.gouv.fr/fr/datasets/diagnostics-de-performance-energetique-pour-les-batiments-publics/)\n\nCes données sont également accessibles via les API correspondantes sur le site api.gouv.fr :\n\n- [Accéder à l'API DPE pour les logements](https://api.gouv.fr/les-api/api_dpe_logements)\n- [Accéder à l'API DPE pour les bâtiments publics](https://api.gouv.fr/les-api/api_dpe_batiments_publics)\n\nPour plus d'informations sur la base DPE et ses usages possibles, [voir aussi l'article de blog \"La base des diagnostics de performance énergétique DPE : quelles données, pour quels usages ?\"](https://www.data.gouv.fr/fr/posts/la-base-des-diagnostics-de-performance-energetique-dpe/) sur data.gouv.fr.\n\n### Aides financières à la rénovation énergétique \n\n- [Nombre de dispositifs d’aides financières à la rénovation énergétique, par région](https://www.data.gouv.fr/fr/datasets/nombre-de-dispositifs-daides-financieres-a-la-renovation-energetique-par-region/)\n- [Dispositifs d’aides financières à la rénovation énergétique](https://www.data.gouv.fr/fr/datasets/dispositifs-daides-financieres-a-la-renovation-energetique/)\n\n### Estimation des coûts de rénovation énergétique\n\n- [Données de l'étude \"Individualisation des frais de chauffage\"](https://www.data.gouv.fr/fr/datasets/donnees-de-letude-individualisation-des-frais-de-chauffage/)\n- [Coûts des travaux de rénovation énergétique](https://www.data.gouv.fr/fr/datasets/couts-des-travaux-de-renovation-energetique/)\n- [Coûts des travaux de rénovation - Isolation](https://www.data.gouv.fr/fr/datasets/couts-des-travaux-de-renovation-isolation/)\n- [Coûts des travaux de rénovation - ECS](https://www.data.gouv.fr/fr/datasets/couts-des-travaux-de-renovation-ecs/)\n- [Coûts des travaux de rénovation - Chauffage](https://www.data.gouv.fr/fr/datasets/couts-des-travaux-de-renovation-chauffage/)\n- [Coûts des travaux de rénovation - Menuiseries](https://www.data.gouv.fr/fr/datasets/couts-des-travaux-de-renovation-menuiseries/)\n- [Coûts des travaux de rénovation - Photovoltaïque](https://www.data.gouv.fr/fr/datasets/couts-des-travaux-de-renovation-photovoltaique/)\n- [Coûts des travaux de rénovation - Ventilation](https://www.data.gouv.fr/fr/datasets/couts-des-travaux-de-renovation-ventilation/)\n\n### Energie et patrimoine communal\n\n- [Energie et patrimoine communal -1- Description](https://www.data.gouv.fr/fr/datasets/energie-et-patrimoine-communal-1-description/)\n- [Energie et patrimoine communal -2- Energie](https://www.data.gouv.fr/fr/datasets/energie-et-patrimoine-communal-2-energie/)\n- [Energie et patrimoine communal -3- Divers](https://www.data.gouv.fr/fr/datasets/energie-et-patrimoine-communal-3-divers/)\n- [Energie et patrimoine communal -4- Dépenses et consommation](https://www.data.gouv.fr/fr/datasets/energie-et-patrimoine-communal-4-depenses-et-consommation/)\n- [Energie et patrimoine communal -5- Bâtiments](https://www.data.gouv.fr/fr/datasets/energie-et-patrimoine-communal-5-batiments/)\n\n### Marchés et emplois de l'efficacité énergétique\n\n- [Marchés et emploi de l'efficacité énergétique et des EnR - EnR (2019)](https://www.data.gouv.fr/fr/datasets/marches-et-emploi-de-lefficacite-energetique-et-des-enr-enr-2019/)\n- [Marchés et emploi de l'efficacité énergétique et des EnR - Transport (2019)](https://www.data.gouv.fr/fr/datasets/marches-et-emploi-de-lefficacite-energetique-et-des-enr-transport-2019/)\n- [Marchés et emploi de l'efficacité énergétique et des EnR - Bâtiment (2019)](https://www.data.gouv.fr/fr/datasets/marches-et-emploi-de-lefficacite-energetique-et-des-enr-batiment-2019/)\n\n## Données du Ministère de la Cohésion des Territoires\n\n- [Observatoire des performances énergétiques OPE](https://www.data.gouv.fr/fr/datasets/observatoire-des-performances-energetiques/)\n- [Base des permis de construire (Sitadel)](https://www.data.gouv.fr/fr/datasets/base-des-permis-de-construire-sitadel/)\n\n\n\n\n"
},
{
"alpha_fraction": 0.773934543132782,
"alphanum_fraction": 0.7770228385925293,
"avg_line_length": 66.45833587646484,
"blob_id": "93953219d87b9d643d4eba0f2f2e8e591a6d0fa5",
"content_id": "8e07f6ec94a7e59189035c2eb3a3a43426705c01",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1650,
"license_type": "permissive",
"max_line_length": 172,
"num_lines": 24,
"path": "/README.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "# datagouvfr-pages\n\nCe dépôt contient les fichiers qui alimentent [les pages inventaire du portail data.gouv.fr](https://www.data.gouv.fr/fr/pages/thematiques-a-la-une).\n\nLes pages sont écrites en [GitHub Flavored Markdown](https://github.github.com/gfm/), avec un en-tête spécifique pour ajouter des jeux de données et des réutilisations.\nPour plus d'informations techniques sur les pages inventaire, consulter [cette pull request dans le dépôt de udata-gouvfr](https://github.com/etalab/udata-gouvfr/pull/483).\n\n## Pages inventaire actuellement publiées\n- [Les données de référence (Service public de la donnée)](/pages/spd/reference.md)\n- [Les données relatives au COVID-19](/pages/donnees-coronavirus.md)\n- [Les données relatives au logement et à l'urbanisme](/pages/donnees-logement-urbanisme.md)\n- [Les données relatives à l'emploi](/pages/donnees-emploi.md)\n- [Les données des élections](/pages/donnees-des-elections.md)\n- [Les données relatives aux associations et aux fondations](/pages/donnees-associations-fondations.md)\n- [Les données relatives aux comptes publics](/pages/donnees-comptes-publics.md)\n- [Les données ouvertes pour l’apprentissage automatique (Machine Learning)](/pages/donnees-machine-learning.md)\n\n## Autres pages statiques\n- [Accessibilité](https://www.data.gouv.fr/fr/pages/legal/accessibility/)\n- [Conditions d’utilisation](https://www.data.gouv.fr/fr/terms/)\n- [Licences de réutilisation](https://www.data.gouv.fr/fr/pages/legal/licences/)\n- [Redevances](https://www.data.gouv.fr/fr/pages/legal/redevances/)\n\n:warning: ne pas publier de pages dans un sous-dossier nommé `pages/static`.\n"
},
{
"alpha_fraction": 0.7652014493942261,
"alphanum_fraction": 0.7985348105430603,
"avg_line_length": 79.29412078857422,
"blob_id": "16bd2249fbecc8d0fb1f0c3c4aade8533add45ed",
"content_id": "e0407da412adbbd42b6dadce531c3992cc20e426",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2730,
"license_type": "permissive",
"max_line_length": 504,
"num_lines": 34,
"path": "/pages/udata/3/udata-3-usage-metrics-explained.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: udata 3 usage metrics explained\nkeywords:\n - udata\ndescription: udata 3 usage metrics explained\npublished: 2022-04-07\nauthor: abulte\n---\n\n# udata 3 usage metrics explained\n\nUsage metrics are basically download counts and views counts for various objects (datasets, resources...). In udata 3 we heavily refactored the way it works.\n\n## Current architecture\n\nIn udata 3, we introduced InfluxDB to act as an aggregator between Matomo (`udata-piwik`) and `udata`. This interface is handled by [udata-metrics](https://github.com/opendatateam/udata-metrics). The process is two stepped:\n1. udata periodically requests Matomo stats for a given time period for datasets, reuses, resources... ; tries to map it to database objects and then send a count for this time period to InfluxDB\n2. udata periodically requests InfluxDB for an aggregated stats count overtime for each object in the database and enriches the `metrics` attributes with it\n\nThis refactoring allowed us to be more precise on our stats count, making the connection with Matomo less brittle and getting rid of the `metrics` collection that was growing huge in our database. Plus we got rid of some technical debt. We also had in mind to use the InfluxDB database for more features: time-based statistics on udata, external dashboard...\n\n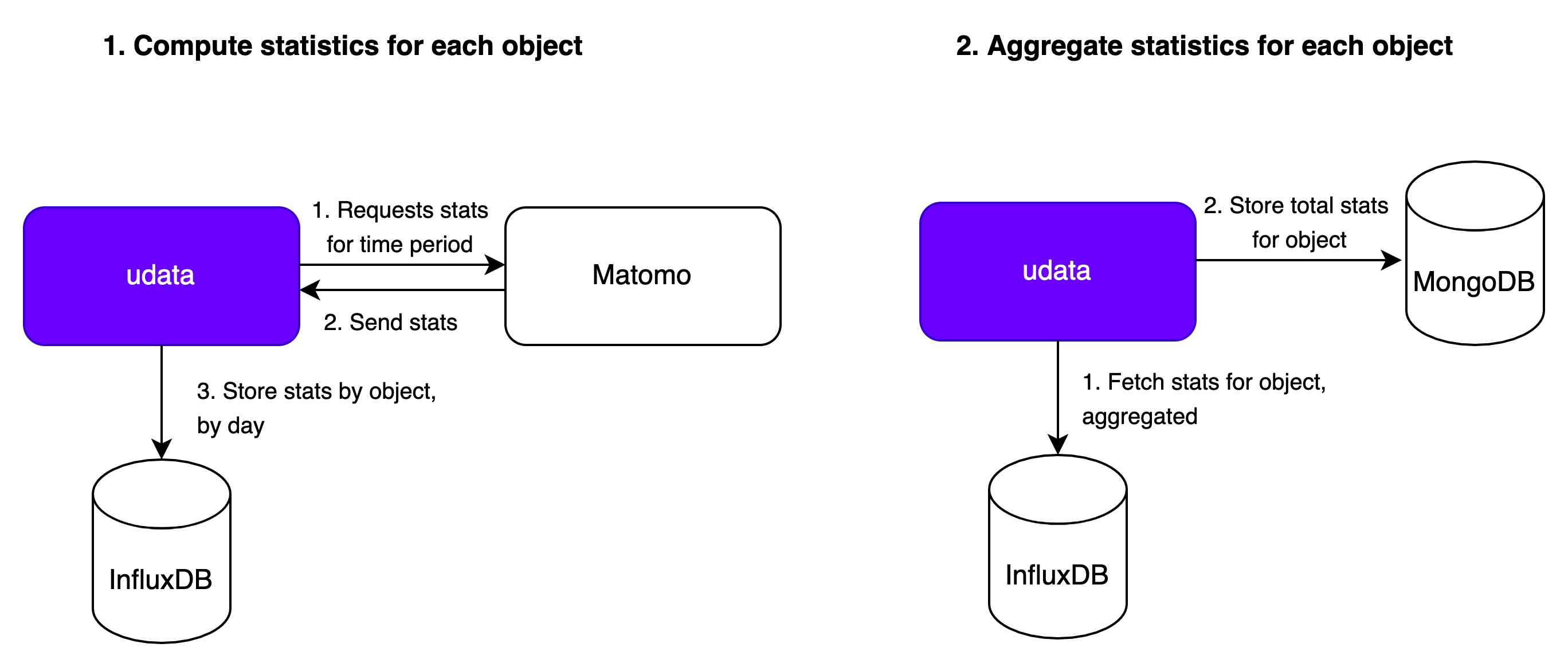\n\nUnfortunately, it did not go quite as planned. We got bit by the release of InfluxDB v2 right after we launched with v1 in production, which would have forced us to rewrite most of our logic to migrate. We also did not take the time to leverage the capabilities of InfluxDB for more features. In the current state, InfluxDB is only used as an aggregator for Matomo stats, which is clearly overkill and still not very satisfactory in terms of stats precision, due to the sheer size of our Matomo instance.\n\nStill, this is what is used in production at the time of writing.\n\n## Future\n\nWe're currently investigating other ways to gather some broader and more precise statistics. It will probably involve ingesting server logs (haproxy and/or nginx in our case).\n\n## Do It Yourself\n\nFollowing our architecture principles, the metrics collection is actually pretty distinct from the way it's stored in udata. If you want to gather statistics from some other sources and compute them differently, all you have to do is fill the `(dataset|resource|reuse|...).metrics` dictionnary with your own value, [like we do here for Matomo-through-InfluxDB values](https://github.com/opendatateam/udata-piwik/blob/06a4738ca672519217259c431c4a84d65d733e39/udata_piwik/metrics.py#L43).\n"
},
{
"alpha_fraction": 0.7832401394844055,
"alphanum_fraction": 0.7878085374832153,
"avg_line_length": 86.82035827636719,
"blob_id": "cdd6f0323de444aac0961d72b0e2ce4f6d0d1064",
"content_id": "e027201a4fea98e25110f5af66d432c0bfc63692",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 15004,
"license_type": "permissive",
"max_line_length": 609,
"num_lines": 167,
"path": "/pages/donnees-emploi.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Les données relatives à l'emploi\nkeywords:\n - inventaire\n - emploi\n - travail\ndescription: Les jeux de données relatifs à l'emploi en France référencés sur data.gouv.fr\nmenu:\n - footer\nreuses:\ndatasets:\n - inventaire-des-bases-de-donnees-relatives-a-lemploi\n - declarations-prealables-a-lembauche-mensuelles-de-plus-dun-mois-france-entiere\n - nombre-dactifs-cotisant-a-la-cnracl-selon-les-employeurs\n - effectifs-de-cotisants-a-lircantec-par-employeurs\n - enquete-besoins-en-main-doeuvre-bmo\n - offres-demploi-diffusees-a-pole-emploi\n - particuliers-employeurs-en-2019\n - marche-du-travail\n - repertoire-operationnel-des-metiers-et-des-emplois-rome\n - masse-salariale-et-assiette-chomage-partiel-mensuelles-du-secteur-prive\n - taux-dimpayes-mensuels-entreprises-de-10-salaries-ou-plus-metropole\n - les-adresses-des-centres-apec\n - numero-de-telephone-des-services-usagers\n - repertoire-national-des-certifications-professionnelles-et-repertoire-specifique\n - liste-publique-des-organismes-de-formation-l-6351-7-1-du-code-du-travail\n - entrees-en-formation-des-demandeurs-demploi\n - sortants-de-formation-et-retour-a-lemploi\n---\n\n# Les données relatives à l'emploi\n\nDans le cadre de ses missions, le département Etalab a réalisé un travail de recensement le plus complet possible des bases et jeux de données publiques existantes dans le domaine de l'emploi, et [publie cet inventaire en open data](/datasets/inventaire-des-bases-de-donnees-relatives-a-lemploi/). 161 bases de données de 26 gestionnaires ont été recensés.\nPour faciliter la découverte des données, cette page présente une sélection des principales bases qui sont disponibles en format ouvert sur le portail national data.gouv.fr. La liste n'est pas exhaustive et est ouverte aux contributions.\n\nCes jeux de données sont présentés en 3 catégories :\n\n- **Données sur le marché du travail** : jeux de données présentant une photographie du marché du travail, sur plusieurs thèmes : chômage et demandeurs d'emploi, retraite, activité, etc.\n- **Données sur les caractéristiques de l'emploi du travailleur** : informations sur le régime du travailleur, les secteurs d'activités, les contrats, les régimes, les salaires, etc.\n- **Données sur les droits et les aides liés à l'emploi :** données sur les services proposés, sur les formations et certifications, etc.\n\nChaque base listée ci-dessous fait l’objet d’une page dédiée sur data.gouv.fr, présentant de manière plus détaillée les données téléchargeables.\n\nSont ensuite listés les noms des principales organisations gestionnaires des données relatives à l'emploi. La plupart de ces gestionnaires proposent sur leurs portails ou sites web des informations ou publications construites sur la base des jeux de données listés ci-dessous. \n\n## Données sur le marché du travail\n\n### Données sur le chômage et les demandeurs d'emploi\n\n- **[Déclarations préalables à l'embauche mensuelles de plus d'un mois (URSSAF)](/datasets/declarations-prealables-a-lembauche-mensuelles-de-plus-dun-mois-france-entiere/)**\n - Série mensuelle des déclarations préalables à l'embauche (DPAE) de plus d'un mois au niveau France entière\n\n### Données sur les retraites\n\n- **[Nombre d'actifs cotisant à la CNRACL selon les employeurs (CDC) :](/datasets/nombre-dactifs-cotisant-a-la-cnracl-selon-les-employeurs/)**\n - La CNRACL est La Caisse nationale de retraites des agents des collectivités locales. Cette caisse couvre le risque vieillesse et invalidité des fonctionnaires territoriaux et des fonctionnaires hospitaliers. Elle est gérée par la Caisse des dépôts.\n\n- **[Effectifs de cotisants à l'IRCANTEC, par employeurs (CDC) :](/datasets/effectifs-de-cotisants-a-lircantec-par-employeurs/)**\n - L'IRCANTEC est l'Institution de Retraite Complémentaire des Agents Non Titulaires de l'Etat et des Collectivités publiques. Le régime de l'Ircantec s'applique aux salariés de la fonction publique d'État, des collectivités territoriales et hospitalières ainsi que des autres employeurs publics (EPIC, sociétés de droit privé, Pôle Emploi, Banque de France, OPH, ...). Le jeu de données présente les effectifs des cotisants l'IRCANTEC, par familles d'employeurs, depuis 2014.\n\n### Données sur les offres d'emploi et de recrutement\n\n- **[Enquête Besoins en Main d'Œuvre (BMO) (Pôle Emploi) :](/datasets/enquete-besoins-en-main-doeuvre-bmo/)**\n - Chaque année, Pôle emploi adresse un questionnaire à 1,9 million d'établissements afin de connaître leurs besoins en recrutement par secteur d'activité et par bassin d'emploi.\n - Cette enquête permet entre autres : d'anticiper les difficultés de recrutement ; d'améliorer l'orientation des demandeurs d'emploi vers des formations ou des métiers en adéquation avec les besoins du marché du travail ; d'informer les demandeurs d'emploi sur l'évolution de leur marché du travail et les métiers porteurs.\n\n- **[Offres d'emploi diffusées à Pôle emploi (Pôle Emploi) :](/datasets/offres-demploi-diffusees-a-pole-emploi/)**\n - Le nombre d'offres publiées ici correspond à l'ensemble des offres accessibles par les demandeurs d'emploi sur le site pole-emploi.fr\n\n- **[Particuliers employeurs en 2019 (URSSAF) :](/datasets/particuliers-employeurs-en-2019/)**\n - Données sur les particuliers employeurs en 2019 issues des dispositifs Cesu, Pajemploi et DNS.\n\n### Données sur le niveau d'activité\n\n- **[Marché du travail (INSEE) :](/datasets/marche-du-travail/)**\n - Ce jeu de données provient de la Banque de Données Macro-économiques de l'INSEE. La BDM est la principale base de données de séries et indices sur l'ensemble des domaines économiques et sociaux. Elle met à disposition toutes les informations nécessaires au diagnostic conjoncturel, et plus généralement à l'analyse des fluctuations de l'activité économique, aux niveaux global et sectoriel, dans une présentation harmonisée, pour un ensemble de séries en provenance de sources multiples.\n\n### Secteurs d'activités et branches professionnelles\n\n- **[Répertoire Opérationnel des Métiers et des Emplois (ROME) (Pôle Emploi) :](/datasets/repertoire-operationnel-des-metiers-et-des-emplois-rome/)**\n - Le ROME a été construit par les équipes de Pôle emploi avec la contribution d'un large réseau de partenaires (entreprises, branches et syndicats professionnels, AFPA...), en s'appuyant sur une démarche pragmatique : inventaire des dénominations d'emplois/métiers les plus courantes, analyse des activités et compétences, regroupement des emplois selon un principe d'équivalence ou de proximité.\n\n## Données sur les caractéristiques de l'emploi du travailleur\n\n### Régime du travailleur\n\n- **[Masse salariale et assiette chômage partiel mensuelles du secteur privé (URSSAF) :](/datasets/masse-salariale-et-assiette-chomage-partiel-mensuelles-du-secteur-prive/)**\n\n### Secteurs d'activités et branches professionnelles\n\n- **[Taux d'impayés mensuels - entreprises de 10 salariés ou plus, métropole (URSSAF) :](/datasets/taux-dimpayes-mensuels-entreprises-de-10-salaries-ou-plus-metropole/)**\n - Séries mensuelles des taux d'impayés (restes à recouvrer : RAR) des entreprises de 10 salariés ou plus hors taxations d'office\n\n## Données sur les droits et les aides liés à l'emploi\n\n### Services proposés\n\n- **[Les adresses des centres Apec (APEC) :](/datasets/les-adresses-des-centres-apec/)**\n - L'Apec est présente sur l'ensemble du territoire avec une cinquantaine de centres, en France métropolitaine et en Outre-mer. Les 500 consultantes et consultants peuvent ainsi accompagner les entreprises, les cadres et les jeunes diplômés au plus près de leurs besoins et de leurs attentes. L'Apec propose à ses clients un accompagnement ciblé.\n\n- **[Numéro de téléphone des services usagers (URSSAF) :](/datasets/numero-de-telephone-des-services-usagers/)**\n\n### Formations et certifications\n\n- **[Répertoire National des Certifications Professionnelles et Répertoire Spécifique (France compétences) :](/datasets/repertoire-national-des-certifications-professionnelles-et-repertoire-specifique/)**\n - Les certifications enregistrées au RNCP (classées par niveau de qualification et domaine d'activité) permettent de valider des compétences et des connaissances acquises, nécessaires à l'exercice d'activités professionnelles. Elles sont constituées de blocs de compétences : ensembles homogènes et cohérents de compétences, pouvant être évaluées et validées, qui doivent permettre l'exercice autonome d'une activité professionnelle. Les certifications enregistrées au RS correspondent à des compétences complémentaires : habilitations sécurité, certification professionnalisante, compétences transversales.\n\n- **[Liste Publique des Organismes de Formation (DARES) :](/datasets/liste-publique-des-organismes-de-formation-l-6351-7-1-du-code-du-travail/)**\n - Conformément à l'article L.6351-7-1 du Code du Travail, la liste des organismes déclarés auprès du Préfet de Région territorialement compétent et à jour de leur obligation de transmission du Bilan Pédagogique et Financier est rendue publique.\n\n- **[Entrées en formation des demandeurs d'emploi (Pôle Emploi) :](/datasets/entrees-en-formation-des-demandeurs-demploi/)**\n - Ce fichier présente des données sur les entrées en formation des demandeurs d'emploi.\n\n- **[Sortants de formation et retour à l'emploi (Pôle Emploi) :](/datasets/sortants-de-formation-et-retour-a-lemploi/)**\n - Ce fichier présente des données sur les taux d'accès à l'emploi des demandeurs d'emploi qui sortent de formation.\n\n# Liste des organisations qui publient des données relatives à l'emploi\n\n## Principaux producteurs et gestionnaires des données publiées sur data.gouv.fr\n\n- [**Union de recouvrement des cotisations de sécurité sociale et d'allocations familiales (URSSAF)**](/organizations/unions-de-recouvrement-des-cotisations-de-securite-sociale-et-dallocations-familiales/) : Le réseau des Urssaf est le moteur de notre système de protection sociale avec pour mission principale la collecte des cotisations et contributions sociales, sources du financement du régime général de la Sécurité sociale. Principales bases gérées par l'URSSAF :\n - Déclarations préalables à l'embauche mensuelles de plus d'un mois\n - Particuliers employeurs\n - Masse salariale et assiette chômage partiel mensuelles du secteur privé\n - Taux d'impayés mensuels\n\n- [**Caisse des dépôts et consignations (CDC)**](/organizations/caisse-des-depots-1/) : institution financière publique qui exerce des activités d'intérêt général comme la gestion d'une partie de l'épargne (Livrets A, LDDS) et le financement de projets publics et privés. Elle publie des bases relatives aux politiques publique et aux retraites. Toutes les données ouvrables gérées par la CDC sont déjà publiées en Open Data. Principales bases gérées par la CDC :\n - Nombre d'actifs cotisant à la CNRACL selon les employeurs\n - Effectifs de cotisants à l'IRCANTEC, par employeurs\n\n- [**Pôle emploi (PE)**](/organizations/pole-emploi/) : Pôle emploi a choisi de s'associer à la démarche globale d'ouverture des données publiques (Open Data), initiée par l'Etat en collaboration avec la mission Etalab, en rendant accessibles des données sur cette page. Principales bases gérées par Pôle emploi :\n - Offres d'emploi diffusées à Pôle emploi\n - Répertoire Opérationnel des Métiers et des Emplois (ROME)\n - Entrées en formation des demandeurs d'emploi\n - Sortants de formation et retour à l'emploi\n\n- [**Association pour l'emploi des cadres (APEC)**](/organizations/apec-association-pour-lemploi-des-cadres/) : L'Apec a pour principale mission d'aider les cadres à (re)trouver un emploi en lien avec les entreprises qui recrutent. L'association fournit également des études sur le marché de l'emploi des cadres permettant ainsi de mieux répondre à leurs attentes et besoins futurs. Principales bases gérées par l'APEC :\n - Prévisions APEC\n - Baromètre des intentions de recrutement et de mobilité des cadres\n - Baromètre de la rémunération des cadres\n\n- [**Direction de l'Animation de la recherche, des Études et des Statistiques (DARES) **](/organizations/ministere-du-travail-de-l-emploi-et-du-dialogue-social/): La Dares est la direction du ministère du Travail qui produit des analyses, des études et des statistiques sur les thèmes du travail, de l'emploi, de la formation professionnelle et du dialogue social Principales bases gérées par la Dares :\n - Portraits statistiques des métiers\n - L'emploi intérimaire\n - La durée individuelle du travail\n\n## Autres producteurs et gestionnaires de données sur le thème emploi\n\n- [France Compétences](/organizations/france-competences/)\n- [Institut National de la Statistique et des Etudes Economiques (INSEE)](/organizations/institut-national-de-la-statistique-et-des-etudes-economiques-insee/)\n- [Agence Nationale pour l'Amélioration des Conditions de Travail (ANACT)](/organizations/agence-nationale-pour-l-amelioration-des-conditions-de-travail-anact/)\n- [Agence du numérique en santé](https://esante.gouv.fr/) (ANS)\n- [Agence nationale de sécurité sanitaire, de l'alimentation, de l'environnement et du travail (ANSES)](/organizations/agence-nationale-de-securite-sanitaire-de-l-alimentation-de-l-environnement-et-du-travail-anses/)\n- [Agence de services et de paiement (ASP)](/organizations/agence-de-services-et-de-paiement-asp/)\n- [Business France](https://www.businessfrance.fr/)\n- [Centre d'études de l'emploi et du travail (CEET)](https://ceet.cnam.fr/ceet/centre-d-etudes-de-l-emploi-et-du-travail-accueil-947519.kjsp)\n- [Centre pour le développement de l'information sur la formation permanente (CentreINFFO)](https://www.centre-inffo.fr/)\n- [Centre d'études et de recherche sur les qualifications (CEREQ)](https://www.cereq.fr/)\n- [Caisse Nationale d'Assurance Maladie (CNAM)](/organizations/caisse-nationale-de-l-assurance-maladie-des-travailleurs-salaries/)\n- [Caisse Nationale d'Assurance Vieillesse (CNAV)](https://www.lassuranceretraite.fr/)\n- [France Compétences](/organizations/france-competences/)\n- [Groupement d'intérêt scientifique Evrest (ANSES, ANACT, CEE...)](http://evrest.istnf.fr/page-0-0-0.html)\n- [Institut National de Recherche et de Sécurité (INRS)](https://www.inrs.fr/)\n- [Institut de recherche et documentation en économie de la santé (IRDES)](/organizations/irdes-ecosante-fr-institut-de-recherche-et-documentation-en-economie-de-la-sante/)\n- [Ministère de l'économie des finances et de la relance](/organizations/ministere-de-leconomie-des-finances-et-de-la-relance/)\n- [Ministère du travail, de l'emploi et de l'insertion](/organizations/ministere-du-travail-de-l-emploi-et-du-dialogue-social/)\n- [Santé Publique France (SPF)](/organizations/sante-publique-france/)\n"
},
{
"alpha_fraction": 0.5564415454864502,
"alphanum_fraction": 0.564895749092102,
"avg_line_length": 56.82777786254883,
"blob_id": "cd715d587c8c53a38ccd02445ad09a91c6787fd2",
"content_id": "98d0b40bfd7ff556804b8491bf0004f1b9b1d24f",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 21238,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 360,
"path": "/pages/nouveautes.html",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Nouveautés de data.gouv.fr\nkeywords:\n - Open data\n - Plateforme\n - Fonctionalité\ndescription: Les nouveautés de la plateforme data.gouv.fr\ncontent_type: html\n---\n\n\n <h1 class=\"fr-display--sm fr-mb-2w\"> Nouveautés de data.gouv.fr</h1>\n\n <div class=\"fr-callout\">\n <p class=\"fr-callout__text\">\n Nous améliorons la plateforme en continu à partir de vos retours. <br />\n Vous avez une fonctionalité en tête ou un retour à nous faire ?\n <a href=\"https://support.data.gouv.fr/particulier/retour-plateforme\">Écrivez-nous</a> ou\n <a href=\"https://github.com/etalab/data.gouv.fr/issues/new/choose\">envoyez-nous une <i>issue</i></a>.<br />\n Vous pouvez également <a href=\"https://tally.so/r/mOalMA\">vous inscrire comme beta testeur</a>.\n </p>\n </div>\n\n\n <h2 class=\"fr-mt-4w\">Développements à venir</h2>\n <p>Parmi les grandes nouveautés à venir dans les prochains mois :\n <div class=\"markdown\">\n <ul>\n <li>Amélioration de l'affichage et de la qualité des dates sur la plateforme</li>\n <li>Amélioration de la pertinence et de l'affichage des métriques sur la plateforme</li>\n <li>Meilleure valorisation des schémas de données sur la plateforme</li>\n </ul>\n </div>\n </p>\n <p>Pour suivre les développements de data.gouv.fr vous pouvez vous rendre sur <a\n href=\"https://github.com/orgs/etalab/projects/6\">notre Github</a>.</p>\n\n <h2>Découvrez les dernières nouveautés</h2>\n\n <section class=\"fr-accordion\">\n <h3 class=\"fr-accordion__title\">\n <button class=\"fr-accordion__btn\" aria-expanded=\"false\" aria-controls=\"accordion-98\">Janvier, Février, Mars\n 2023</button>\n </h3>\n <div class=\"fr-collapse\" id=\"accordion-98\">\n <div class=\"fr-callout fr-fi-information-line\">\n <p class=\"fr-callout__title\">En bref</p>\n <p class=\"fr-callout__text\">\n <div class=\"markdown\">\n <ul>\n <li>Refonte de la page jeux de données</li>\n <li>Refonte de la page réutilisation</li>\n <li>Amélioration du moissonage DCAT</li>\n <li>Travaux sur l'amélioration de la qualité des dates</li>\n </ul>\n </div>\n </p>\n </div>\n <h3>Refonte de la page jeux de données</h3>\n <div class=\"markdown\">\n <p>A la lumière des retours collectés, nous avons entrepris une refonte des pages de jeux de données,\n nouvellement pensées pour faciliter la navigation et l’accès rapide aux informations importantes.\n Trouvez en un coup d’oeil description, fichiers, réutilisations, discussions, métadonnées ou encore\n score de qualité des métadonnées.\n Cette nouvelle page intègre aussi la prévisualisation, disponible pour tous les jeux de données\n tabulaires. Au niveau des fichiers, vous pouvez ainsi visualiser les cinq premières lignes du\n fichier (avec la possibilité de trier) et accéder directement à une exploration plus poussée des\n données sur l’application explore.data.gouv.fr </p>\n </div>\n <h3>Refonte de la page réutilisation</h3>\n <div class=\"markdown\">\n <p>Les pages de réutilisation ont également été repensées pour faciliter la navigation et inciter au\n référencement.</p>\n </div>\n </div>\n <h3 class=\"fr-accordion__title\">\n <button class=\"fr-accordion__btn\" aria-expanded=\"false\" aria-controls=\"accordion-99\">Novembre, Décembre\n 2022</button>\n </h3>\n <div class=\"fr-collapse\" id=\"accordion-99\">\n <div class=\"fr-callout fr-fi-information-line\">\n <p class=\"fr-callout__title\">En bref</p>\n <p class=\"fr-callout__text\">\n <div class=\"markdown\">\n <ul>\n <li>Refonte de la prévisualisation</li>\n <li>Amélioration du score qualité</li>\n <li>Possibilité de changer son adresse mail</li>\n <li>Ajout du score de qualité à l’export des catalogues</li>\n </ul>\n </div>\n </p>\n </div>\n <h3>Refonte de la prévisualisation </h3>\n <div class=\"markdown\">\n <p>L’affichage des fichiers et la prévisualisation des données ont été repensé. L’explorateur de\n données est désormais disponible directement depuis data.gouv.fr. </p>\n </div>\n <h3>Amélioration du score qualité</h3>\n <div class=\"markdown\">\n <p>Notamment par l’amélioration du moissonnage de certaines métadonnées. Des travaux sont encore en\n cours sur ce sujet. </p>\n </div>\n <h3>Possibilité de changer son adresse mail</h3>\n <div class=\"markdown\">\n <p>Il est désormais possible pour un usager de changer son adresse mail si besoin.</p>\n </div>\n <h3>Ajout du score de qualité à l’export des catalogues</h3>\n <div class=\"markdown\">\n <p>Comme il nous l’a été demandé, les organisations disposent désormais du score de chacun de leurs\n jeux de données dans l’export de leur catalogue. </p>\n </div>\n\n </div>\n <h3 class=\"fr-accordion__title\">\n <button class=\"fr-accordion__btn\" aria-expanded=\"false\" aria-controls=\"accordion-100\">Septembre, Octobre\n 2022</button>\n </h3>\n <div class=\"fr-collapse\" id=\"accordion-100\">\n <div class=\"fr-callout fr-fi-information-line\">\n <p class=\"fr-callout__title\">En bref</p>\n <p class=\"fr-callout__text\">\n <div class=\"markdown\">\n <ul>\n <li>Mise en place d'explore.data.gouv.fr</li>\n <li>Mise en place d'explore.data.gouv.fr/prix-carburants</li>\n <li>Publication d'une nouvelle page inventaire sur les données relative à l'énergie</li>\n <li>Lancement de l'Open Data University</li>\n <li>Mise en place d'un Captcha souverain</li>\n\n\n\n </ul>\n </div>\n </p>\n </div>\n <h3>Mise en place d'explore.data.gouv.fr </h3>\n <div class=\"markdown\">\n <p>Pour faciliter l’exploitation des données, nous avons profondément revu la prévisualisation et\n l’exploration de données sur la plateforme. Nous attendons vos retours avec impatience !</p>\n </div>\n <h3>Mise en place d'explore.data.gouv.fr/prix-carburants </h3>\n <div class=\"markdown\">\n <p>Nous disposons de nombreuses briques techniques ouvertes, mutualisables et réutilisables qu’il\n est possible de mobiliser pour proposer des visualisations de données sur une diversité de\n thématiques comme le logement, l’aménagement du territoire, l’éducation ou encore l’énergie.\n En guise de démonstration, nous les avons appliquées à un exemple d’actualité en les utilisant\n sur les données des prix des carburants</p>\n </div>\n <h3>Publication d'une nouvelle page inventaire sur les données relatives à l'énergie</h3>\n <div class=\"markdown\">\n <p><a href=\"https://www.data.gouv.fr/fr/pages/donnees-energie/\">Cette page</a> a pour vocation de\n référencer les principaux jeux de données relatifs à la thématique “énergie” disponibles sur\n data.gouv.fr. Nous avons également publié une série d'articles sur le sujet.</p>\n </div>\n <h3>Lancement de l'Open Data University</h3>\n <div class=\"markdown\">\n <p>L’Open Data University est un dispositif imaginé par l’association Latitudes et soutenu par la\n DINUM\n pour une année d’expérimentation sur l’année scolaire 2022/2023.\n <a href=\"https://www.data.gouv.fr/fr/pages/odu/home/\">Découvrez l’Open Data University.</a>\n </p>\n </div>\n <h3>Mise en place d'un Captcha souverain </h3>\n <div class=\"markdown\">\n <p>Pour lutter contre la création de faux comptes utilisateur nous avons déployé <a\n href=\"https://api.gouv.fr/les-api/api-captchetat\">CaptchEtat</a>.</p>\n </div>\n </div>\n <h3 class=\"fr-accordion__title\">\n <button class=\"fr-accordion__btn\" aria-expanded=\"false\" aria-controls=\"accordion-109\">Août 2022</button>\n </h3>\n <div class=\"fr-collapse\" id=\"accordion-109\">\n <div class=\"fr-callout fr-fi-information-line\">\n <p class=\"fr-callout__title\">En bref</p>\n <p class=\"fr-callout__text\">\n <div class=\"markdown\">\n <ul>\n <li>Mise en place du score de qualité des métadonnées </li>\n <li>Mettre en avant des publications selon l’actualité </li>\n </ul>\n </div>\n </p>\n </div>\n <h3>Mise en place du score de qualité des métadonnées </h3>\n <div class=\"markdown\">\n <p>Pour vous permettre d'identifier plus facilement les jeux de données de qualité et vous\n accompagner dans la documentation de vos données, nous avons mis en place un score de qualité\n des métadonnées en version bêta.\n Ce score a vocation à être amélioré et <a\n href=\"https://app.evalandgo.com/form/372035/s/?id=JTk5cSU5NWwlOUMlQTk%3D&a=JTk3cCU5M2glOTklQUU%3D\">vos\n retours</a> sont bienvenus.</p>\n </div>\n <h3>Mettre en avant des publications selon l’actualité </h3>\n <div class=\"markdown\">\n <p>Afin de vous faire découvrir certains jeux de données et réutilisations, nous avons mis en place\n un calendrier éditorial. Selon l’actualité nous partagerons sur twitter certains jeux de données\n et réutilisations.\n Ces publications ont été introduites à l’occasion de la rentrée des classes. </p>\n </div>\n </div>\n <h3 class=\"fr-accordion__title\">\n <button class=\"fr-accordion__btn\" aria-expanded=\"false\" aria-controls=\"accordion-108\">Juillet\n 2022</button>\n </h3>\n <div class=\"fr-collapse\" id=\"accordion-108\">\n <div class=\"fr-callout fr-fi-information-line\">\n <p class=\"fr-callout__title\">En bref</p>\n <p class=\"fr-callout__text\">\n <div class=\"markdown\">\n <ul>\n <li>Refonte des cartes des objets </li>\n <li>Un nouvel inventaire de données </li>\n </ul>\n </div>\n </p>\n </div>\n <h3>Refonte des cartes des objets </h3>\n <div class=\"markdown\">\n <p>PLes cartes de jeux de données, de réutilisations et d’organisations ont été refondues. Cette\n modification était notamment motivée par le fait d’afficher les informations les plus\n importantes sur les cartes de différencier davantage les objets entre eux et mieux correspondre\n au contenu publié en ce qui concerne les réutilisations.\n Pour constater la différence vous pouvez <a\n href=\"https://web.archive.org/web/20220628080841/https://www.data.gouv.fr/fr/datasets/\">faire\n un tour sur la wayback machine</a>.</p>\n </div>\n <h3>Un nouvel inventaire de données </h3>\n <div class=\"markdown\">\n <p>Nous avons publié un <a href=\"https://www.data.gouv.fr/fr/pages/donnees-securite/)\">nouvel\n inventaire</a> ayant pour vocation de référencer les principaux jeux de données relatifs à\n la thématique “sécurité” disponibles sur data.gouv.fr. Merci aux équipes du ministère de\n l’Intérieur pour leur aide dans l’identification des données pertinentes. Cet inventaire est\n ouvert aux contributions. </p>\n </div>\n </div>\n <h3 class=\"fr-accordion__title\">\n <button class=\"fr-accordion__btn\" aria-expanded=\"false\" aria-controls=\"accordion-107\">Juin 2022</button>\n </h3>\n <div class=\"fr-collapse\" id=\"accordion-107\">\n <div class=\"fr-callout fr-fi-information-line\">\n <p class=\"fr-callout__title\">En bref</p>\n <p class=\"fr-callout__text\">\n <div class=\"markdown\">\n <ul>\n <li>Le retour des articles mensuels</li>\n <li>Mise à jour du système de design de l’État </li>\n <li>Progrès sur l’accessibilité</li>\n </ul>\n </div>\n </p>\n </div>\n <p>Le mois de juin a été largement consacré aux travaux sur le score de qualité des métadonnées\n et la prévisualisation des données. Ces deux fonctionnalités sont désormais en phase de tests.</p>\n <h3>Le retour des articles mensuels</h3>\n <div class=\"markdown\">\n <p>Les <a href=\"https://www.data.gouv.fr/fr/posts/suivi-des-sorties-mai-2022/\">suivis des\n sorties</a>,\n articles dans lesquels nous partageons les publications qui ont retenu notre attention qu’il\n s’agisse de jeux de données, de réutilisations ont connu une petite période d’hibernation.\n Ils sont désormais de retour et accompagnés de la notion de tendance :\n il s'agit des jeux de données et des réutilisations créés récemment les plus consultés sur le\n mois.\n Le retour du suivi des sorties est aussi l’occasion de partager notre <a\n href=\"http://activites-datagouv.app.etalab.studio/\">prototype de tableau de bord de\n data.gouv.fr</a>.</p>\n </div>\n <h3>Mise à jour du système de design de l’État </h3>\n <div class=\"markdown\">\n <p>Les utilisatrices et utilisateurs les plus attentifs d’entre vous ont pu remarquer de nombreux\n petits ajustements graphiques sur la plateforme comme la taille des conteneurs ou l’aspect des\n tags sur cliquable.\n Il s’agit de la mise en conformité progressive de data.gouv.fr avec le <a\n href=\"https://www.systeme-de-design.gouv.fr/\">système de design de l’État</a> qui est en\n amélioration continue.</p>\n </div>\n <h3>Progrès sur l’accessibilité</h3>\n <div class=\"markdown\">\n <p>Parmi nos chantiers, <a href=\"https://www.data.gouv.fr/fr/pages/legal/accessibility/\">l’accessibilité\n de la\n plateforme</a> occupe une place de choix.\n Au mois de juin, nous sommes passés au-dessus des 50% de respect des critères du référentiel\n général d’amélioration de l’accessibilité (RGAA).\n Nous espérons pouvoir bientôt vous annoncer que nous sommes totalement conformes.</p>\n </div>\n </div>\n <h3 class=\"fr-accordion__title\">\n <button class=\"fr-accordion__btn\" aria-expanded=\"false\" aria-controls=\"accordion-106\">Mai 2022</button>\n </h3>\n <div class=\"fr-collapse\" id=\"accordion-106\">\n <div class=\"fr-callout fr-fi-information-line\">\n <p class=\"fr-callout__title\">En bref</p>\n <p class=\"fr-callout__text\">\n <div class=\"markdown\">\n <ul>\n <li>Nouvelle pages pour accompagner les producteurs et les réutilisateurs de données</li>\n <li>Refonte des filtres de recherches </li>\n <li>Une campagne d'articles sur les usages des données ouvertes</li>\n <li>Une page pour référencer les données géographiques essentielles</li>\n <li>Le retour des articles mensuels</li>\n <li>Un chantier de fond sur la qualité des métadonnées</li>\n </ul>\n </div>\n </p>\n </div>\n <h3>Nouvelle pages pour accompagner les producteurs et réutilisateurs de données</h3>\n <div class=\"markdown\">\n Pour faciliter la prise en main de la plateforme et orienter vers les ressources pertinentes, nous\n proposons désormais trois nouvelles pages qui ont vocation à guider, pas à pas, producteurs et\n réutilisateurs de données dans leur parcours d’utilisation.\n <ul>\n <li><a href=\"https://www.data.gouv.fr/fr/pages/onboarding/about_test/\">Une page à propos</a>\n </li>\n <li><a href=\"https://www.data.gouv.fr/fr/pages/onboarding/producteurs/\">Une page dédiée aux\n producteurs de données</a></li>\n <li><a href=\"https://www.data.gouv.fr/fr/pages/onboarding/reutilisateurs/\">Une page dédiée aux\n réutilisateurs de données</a></li>\n </ul>\n </div>\n <h3>Refonte des filtres de recherches</h3>\n <div class=\"markdown\">\n Nous avons fait évoluer les filtres de recherche pour vous permettre de trouver le bon jeu de\n données plus facilement. Parmi les changements :\n <ul>\n <li>Un nouveau filtre “Schéma de données”</li>\n <li>Des tris de résultats de recherche pour les données mais également les réutilisations et les\n organisations</li>\n </ul>\n </div>\n <h3>Une campagne sur les usages des données ouvertes</h3>\n <div class=\"markdown\">\n Ces dernières semaines, nous vous avons proposé une immersion dans l’univers des réutilisations de\n données ouvertes. Vous avez ainsi pu découvrir :\n <ul>\n <li><a href=\"https://www.data.gouv.fr/fr/posts/quel-suivi-des-usages-des-donnees-ouvertes/\">Les\n enjeux autour de la connaissance de ces usages</a></li>\n <li><a href=\"https://www.data.gouv.fr/fr/posts/quel-suivi-des-usages-des-donnees-ouvertes/\">Des\n usages développés dans les administrations</a></li>\n <li><a href=\"https://www.data.gouv.fr/fr/posts/quel-suivi-des-usages-des-donnees-ouvertes/\">Des\n types d’exploitation des données de transport</a></li>\n </ul>\n <p>Nous avons également entrepris d’exposer sur data.gouv.fr <a\n href=\"https://www.data.gouv.fr/fr/pages/onboarding/liste_cas_usage/\">une sélection\n d’exemples d’utilisation</a> qui met en lumière la diversité des sujets traités,\n des impacts possibles et des personnes qui se saisissent de l’open data.</p>\n </div>\n <h3>Une page pour référencer les données géographiques essentielles</h3>\n <p>Les données à composantes géographiques sont souvent indispensables pour réaliser des analyses.<br />\n Pour vous aider à vous y retrouver nous avons référencé sur <a\n href=\"https://www.data.gouv.fr/fr/pages/donnees-geographiques/\">une page</a>\n les principaux jeux de données disponibles sur data.gouv.fr.</p>\n\n <h3>Un chantier de fond sur la qualité des métadonnées</h3>\n <p>Nous avons également beaucoup travaillé ces derniers temps sur l’amélioration de la qualité des\n métadonnées\n des données disponibles sur la plateforme en particulier des données moissonées.\n Ces travaux préliminaires nous permettrons bientôt de vous proposer de nouveaux services.</p>\n\n </div>\n </section>\n"
},
{
"alpha_fraction": 0.7791455984115601,
"alphanum_fraction": 0.7835648059844971,
"avg_line_length": 83.86161041259766,
"blob_id": "9af712582bee42d72cedfa823753e5bf4239606a",
"content_id": "405c878b16dacc2a7a7e85baf6410f4bcf455c28",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 19481,
"license_type": "permissive",
"max_line_length": 567,
"num_lines": 224,
"path": "/pages/donnees-sante.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Les données relatives à la santé\nkeywords:\n - inventaire\n - santé\ndescription: Les jeux de données relatifs à la santé en France référencés sur data.gouv.fr\nmenu:\n - footer\nreuses:\ndatasets:\n - inventaire-des-bases-de-donnees-relatives-a-la-sante\n - la-sante-des-enfants-en-grande-section-de-maternelle-et-en-cm2-00000000\n - resultats-du-controle-sanitaire-de-leau-distribuee-commune-par-commune\n - transparence-sante-1\n - la-statistique-annuelle-des-etablissements-sae\n - personnes-en-affection-de-longue-duree-ald\n - base-de-donnees-publique-des-medicaments-base-officielle\n - evaluation-des-medicaments-2021\n - prix-hebergement-et-tarifs-dependance-des-ehpad\n - les-subventions-de-la-caisse-nationale-de-solidarite-pour-lautonomie-cnsa\n - medicaments-rembourses-par-lassurance-maladie\n - open-bio-base-complete-sur-les-depenses-de-biologie-medicale-interregimes\n - open-damir-base-complete-sur-les-depenses-dassurance-maladie-inter-regimes\n - open-medic-base-complete-sur-les-depenses-de-medicaments-interregimes\n - open-phmev-bases-sur-les-prescriptions-hospitalieres-de-medicaments-delivrees-en-ville\n - tableau-des-donnees-essentielles-des-conventions-de-subventions-accordees-par-le-siege-de-letablissement-francais-du-sang-efs\n - donnees-essentielles-marches-publics-inca\n - hospi-diag\n - logiciels-daide-a-la-prescription-certifies\n - indicateurs-de-satisfaction-et-de-performance-de-lefs\n---\n\n# Les données relatives à la santé\n\n> Un inventaire spécifique sur **les données relatives à la COVID-19** **[est disponible ici](/pages/donnees-coronavirus/)**.\n\nDans le cadre de ses missions, le département Etalab a réalisé un travail de recensement le plus complet possible des bases et jeux de données publiques existantes dans le domaine de la santé, et [publie cet inventaire en open data](/datasets/inventaire-des-bases-de-donnees-relatives-a-la-sante/). 172 bases de données de 79 gestionnaires ont été recensés.\nPour faciliter la découverte des données, cette page présente une sélection des principales bases qui sont disponibles en format ouvert sur le portail national data.gouv.fr. La liste n'est pas exhaustive et est ouverte aux contributions.\n\nCes jeux de données sont présentés en 3 catégories :\n\n- **Données de santé publique et épidémiologie** : données sur les habitudes de vie, les inégalités de santé, l'épidémiologie, etc.\n- **Données sur les offres de soins** : informations sur les infrastructures, les services proposés, le personnel, les honoraires, etc.\n- **Données sur les consommations de soins et dépenses :** données sur les activités des établissements de santé, les consultations, les médicaments et dispositifs, etc.\n- **Données sur les performances et opérations :** informations sur les performances financières, les performances opérationnelles, etc.\n\nChaque base listée ci-dessous fait l’objet d’une page dédiée sur data.gouv.fr, présentant de manière plus détaillée les données téléchargeables.\n\nSont ensuite listés les noms des principales organisations gestionnaires des données relatives à la santé. La plupart de ces gestionnaires proposent sur leurs portails ou sites web des informations ou publications construites sur la base des jeux de données listés ci-dessous. \n\n## Données de santé publique et épidémiologie\n\n### Etat de santé\n\n- **[La santé des enfants en grande section de maternelle et en CM2 (Ministère de l'Education Nationale)](/datasets/la-sante-des-enfants-en-grande-section-de-maternelle-et-en-cm2-00000000/)**\n - Tableaux statistiques : état de santé des enfants de 5 et 6 ans scolarisés en grande section de maternelle ; état de santé des enfants scolarisés en CM2\n\n### Environnement\n\n- **[Base nationale SISE-Eaux d'alimentation (Ministère des Solidarités et de la Santé)](/datasets/resultats-du-controle-sanitaire-de-leau-distribuee-commune-par-commune/)**\n - Données sur les paramètres microbiologiques, physico-chimiques ou radiologiques, afin de s'assurer que les eaux sont conformes aux exigences de qualité réglementaires et ne présentent pas de risque pour la santé des consommateurs.\n\n### Autres\n\n- **[Base de données publique Transparence Santé (Direction Générale de la Santé)](/datasets/transparence-sante-1/)**\n - La base de données publique « Transparence - Santé » précise, pour chaque type de lien d'intérêts, les informations suivantes :\n - Pour les conventions : l'identité des parties concernées, la date de la convention, son objet précis, le montant et l'organisateur, le nom, la date et le lieu de la manifestation le cas échéant ;\n - Pour les avantages en nature et en espèce, directs ou indirects : l'identité des parties concernées, le montant, la nature et la date de chaque avantage dès lors que le montant de chaque avantage est supérieur ou égal à 10 euros TTC.\n - Pour les rémunérations : l'identité des parties, la date du versement, le montant dès lors qu'il est supérieur ou égal à 10 euros. Le cas échéant, le bénéficiaire final de la rémunération ou de l'avantage est renseigné par l'entreprise.\n\n## Données sur les offres de soins\n\n### Infrastructures\n\n- **[Base Statistique Annuelle des Etablissements de Santé (SAE) (DREES)](/datasets/la-statistique-annuelle-des-etablissements-sae/)**\n - Statistiques nationales, locales et par établissements sur :\n - Capacités d'accueil en établissements de santé (lits et places, nombre de structures)\n - Activité hospitalière (séjours, journées, nombre d'actes ou de consultations)\n - Équipements (salles de chirurgie, équipements médicaux lourds, pharmacie, biologie)\n - Personnels hospitaliers au 31 décembre et en ET, pour 2 concepts : rémunérés par les établissements ou contribuant à l'activité d'un service, déclinés par spécialités pour les personnels médicaux, et par catégories de professions pour les personnels médicaux, avec une ventilation par statut et type de contrat de travail\n\n### Services proposés\n\n- **[Données relatives à l'ensemble des bénéficiaires du dispositif des ALD une année donnée (prévalence) (CNAM)](/datasets/personnes-en-affection-de-longue-duree-ald/)**\n - Données relatives à l'ensemble des bénéficiaires du dispositif des ALD une année donnée.\n\n## Données sur les consommations de soins et dépenses\n\n### Médicaments et dispositifs\n\n- **[Base de données publique des médicaments (ANSM)](/datasets/base-de-donnees-publique-des-medicaments-base-officielle/)**\n - Données et documents de référence sur les médicaments commercialisés ou ayant été commercialisés durant les cinq dernières années en France.\n\n- **[Evaluation des médicaments (HAS)](/datasets/evaluation-des-medicaments-2021/)**\n\n- **[Evaluation du dispositif médical (HAS)](/datasets/evaluation-des-dispositifs-medicaux-2021/)**\n - En vue de leur prise en charge par l'assurance maladie, la Commission Nationale d'Évaluation des Dispositifs Médicaux et des Technologies de Santé (CNEDiMTS), commission spécialisée de la Haute Autorité de santé, évalue les dispositifs médicaux à usage individuel ou d'autres produits à visée diagnostique, thérapeutique ou de compensation du handicap (à l'exclusion des médicaments) et des prestations associées.\n\n### Activité des établissements médicaux-sociaux\n\n- **[Prix hébergement et tarifs dépendance des EHPAD (CNSA)](/datasets/prix-hebergement-et-tarifs-dependance-des-ehpad/)**\n\n- **[Subventions de la Caisse nationale de solidarité pour l'autonomie (CNSA)](/datasets/les-subventions-de-la-caisse-nationale-de-solidarite-pour-lautonomie-cnsa/)**\n - Il contient les données de subventions de l'ensemble de la CNSA :\n - Les subventions attribuées dans le cadre de la Section IV du budget de la CNSA, relatives à la modernisation et à la professionnalisation du secteur de l'aide et de l'accompagnement à domicile, la formation des professionnels notamment des accueillants familiaux, le soutien aux bénévoles ainsi qu'à l'accompagnement des proches aidants.\n - Les subventions attribuées au titre de la Section V du budget de la CNSA dans le cadre de ses partenariats et de son soutien aux actions innovantes.\n - Les subventions attribuées aux Conseils Départementaux et/ou Maisons Départementales des Personnes Handicapées dans le cadre de l'harmonisation de leurs Systèmes d'Informations.\n - Les subventions attribuées à divers organismes (ASIP Santé, ANCREAI, ODAS, etc.) dans le cadre d'un partenariat avec la CNSA.\n - Les subventions attribuées à divers établissements et services d'aide à domicile pour l'accompagnement de l'expérimentation de dérogations aux durées légales de travail dans le cadre de la mise en œuvre des prestations de suppléance de l'aidant à domicile.\".\n\n### Dépenses\n\n- **[Base Medic'AM (CNAM)](/datasets/medicaments-rembourses-par-lassurance-maladie/)**\n - Données sur les médicaments délivrés par les pharmacies de ville et remboursés par l'Assurance Maladie, par type de prescripteur ; Pour chaque médicament (code CIP13) ou classe de médicaments (classes ATC1 à ATC5) : la base de remboursement ; le montant remboursé ; le nombre de boites remboursées.\n\n- **[Base Open Bio (CNAM)](/datasets/open-bio-base-complete-sur-les-depenses-de-biologie-medicale-interregimes/)**\n - Base complète sur les dépenses de biologie médicale interrégimes ; l'offre de données Open Bio est constituée d'un ensemble de bases annuelles, portant sur les remboursements et le nombre de bénéficiaires d'actes de biologie médicale de 2014 à 2019.\n\n- **[Base Open DAMIR (CNAM)](/datasets/open-damir-base-complete-sur-les-depenses-dassurance-maladie-inter-regimes/)**\n - Base complète sur les dépenses d'assurance maladie interrégimes ; extraction du système national interrégimes de l'Assurance Maladie (Sniiram) portant sur l'ensemble des remboursements de l'Assurance Maladie tous régimes confondus.\n\n\n- **[Base Open Medic (CNAM)](/datasets/open-medic-base-complete-sur-les-depenses-de-medicaments-interregimes/)**\n - Base complète sur les dépenses de médicaments interrégimes, offre articulée autour de 2 jeux de données (une complète et une complémentaire enrichie des dénombrements des consommants).\n\n- **[Base Open PHMEV (CNAM)](/datasets/open-phmev-bases-sur-les-prescriptions-hospitalieres-de-medicaments-delivrees-en-ville/)**\n - Bases sur les prescriptions hospitalières de médicaments délivrées en ville ; constituée d'un ensemble de bases annuelles interrégimes (une complète et une régionale) portant sur les remboursements de médicaments prescrits par les établissements publics et ESPIC (établissements de santé privés d'intérêt collectif) et délivrés en officine de ville de 2014 à 2019.\n\n## Données sur les performances et opérations\n\n### Performance financière\n\n- **[Tableau des données essentielles des conventions de subventions accordées par le siège de l'Etablissement français du sang (EFS)](/datasets/tableau-des-donnees-essentielles-des-conventions-de-subventions-accordees-par-le-siege-de-letablissement-francais-du-sang-efs/)**\n - Données essentielles des conventions accordant des subventions conclues depuis le 1er août 2017 par le siège de l'EFS.\n\n\n- **[Données essentielles marchés publics INCa (INCA)](/datasets/donnees-essentielles-marches-publics-inca/)**\n - L'Institut national du cancer met à disposition les données essentielles de ses marchés publics passés depuis le 1er octobre 2018.\n\n### Performance opérationnelle\n\n- **[Indicateurs Hospi Diag (ANAP)](/datasets/hospi-diag/)**\n - Hospi Diag est un outil d'aide à la décision permettant de mesurer la performance d'un établissement de santé qui pratique de la médecine, de la chirurgie ou de l'obstétrique, en comparaison avec d'autres établissements de santé. Il permet d'identifier ses forces et ses faiblesses et donc ses gisements de performance dans 5 composantes : qualité des soins, pratiques professionnelles, organisation des soins, ressources humaines et finances.\n\n- **[Logiciels d'aide à la prescription certifiés (HAS)](/datasets/logiciels-daide-a-la-prescription-certifies/)**\n - Liste des logiciels d'aide à la prescription certifiés par l'HAS : Editeur, logiciel, version, date de certification, base de données médicaments.\n\n### Qualité\n\n- **[Indicateurs de satisfaction et de performance de l'EFS (EFS)](/datasets/indicateurs-de-satisfaction-et-de-performance-de-lefs/)**\n - Indicateurs de satisfaction et de performance de l'EFS.\n\n# Liste des organisations qui publient des données relatives à la santé\n\n## Principaux producteurs et gestionnaires des données publiées sur data.gouv.fr (citées ci-dessus) :\n\n- [**Agence nationale de sécurité du médicament et des produits de santé (ANSM)**](/organizations/agence-nationale-de-securite-du-medicament-et-des-produits-de-sante-ansm/) : L'Agence nationale de sécurité du médicament et des produits de santé est l'acteur public qui permet, au nom de l'État, l'accès aux produits de santé en France et qui assure leur sécurité tout au long de leur cycle de vie.\n - Principale base gérée par l'ANSM :\n - Base de données publique des médicaments\n\n- [**Caisse nationale de l'assurance maladie (CNAM)**](/organizations/caisse-nationale-de-l-assurance-maladie-des-travailleurs-salaries/) : La CNAM des travailleurs salariés est un établissement public à caractère administratif ayant la mission d'assureur solidaire en santé définissant au niveau national, la politique de l'assurance maladie en France. Son rôle est de piloter, coordonner et conseiller l'action des organismes locaux qui composent son réseau, notamment les caisses primaires d'assurance maladie (CPAM) et les 5 caisses générales de sécurité sociale.\n - Principales bases gérées par la CNAM :\n - Base Medic'AM\n - Base Open Bio\n - Base Open DAMIR\n - Base Open Medic\n - Base Open PHMEV\n - Données relatives à l'ensemble des bénéficiaires du dispositif des ALD une année donnée (prévalence)\n\n- [**Caisse nationale de solidarité pour l'autonomie (CNSA)**](/organizations/caisse-nationale-de-solidarite-pour-lautonomie-cnsa/) : la CNSA contribue au financement de l'aide à l'autonomie des personnes âgées et des personnes handicapées en versant aux conseils départementaux un concours au financement de l'allocation personnalisée d'autonomie et de la prestation de compensation du handicap.\n - Principales bases gérées par la CNSA :\n - Prix hébergement et tarifs dépendance des EHPAD\n - Subventions de la Caisse nationale de solidarité pour l'autonomie\n\n- [**Direction générale de la Santé (DGS)**](/organizations/ministere-des-solidarites-et-de-la-sante/) : Ses missions sont fixées par le code de la santé publique. Elle est chargée de préparer la politique de santé publique et de contribuer à sa mise en œuvre.\n - Principale base gérée par la DGS :\n - Base de données publique Transparence Santé\n\n- [**Direction de la recherche, des études, de l'évaluation et des statistiques (Drees)**](/organizations/ministere-des-solidarites-et-de-la-sante/) : La Drees est une direction de l'administration publique centrale française produisant des travaux de statistiques et d'études socio-économiques.\n - Principale base gérée par la Drees :\n - Base Statistique Annuelle des Etablissements de Santé (SAE)\n\n- [**Etablissement Français du Sang (EFS)**](/organizations/etablissement-francais-du-sang/) : L'EFS est un établissement public administratif avec des prérogatives d'établissement public à caractère industriel et commercial chargé de collecter, préparer, qualifier et distribuer les produits sanguins labiles (sang, plasma, plaquettes) en France, en vue de leur transfusion.\n - Principales bases gérées par l'EFS :\n - Indicateurs de satisfaction et de performance de l'EFS\n - Tableau des données essentielles des conventions de subventions accordées par le siège de l'EFS\n\n- [**Haute Autorité de Santé (HAS)**](/organizations/haute-autorite-de-sante-has/) : La HAS est une autorité publique indépendante qui contribue à la régulation du système de santé par la qualité. Elle exerce ses missions dans les champs de l'évaluation des produits de santé, des pratiques professionnelles, de l'organisation des soins et de la santé publique.\n - Principales bases gérées par la HAS :\n - Evaluation des médicaments\n - Evaluation du dispositif médical\n - Logiciels d'aide à la prescription certifiés\n\n## Autres producteurs et gestionnaires de données sur le thème santé\n\n- [Agence de la biomédecine](https://www.agence-biomedecine.fr)\n- [Agence Nationale d'Appui à la Performance (ANAP)](/organizations/agence-nationale-d-appui-a-la-performance-des-etablissements-de-sante-et-medico-sociaux-anap/)\n- [Maladies infectieuses émergentes (ANRS)](https://www.anrs.fr/fr)\n- [Agence du numérique en santé (ANS)](https://esante.gouv.fr)\n- [Assistance Publique - Hopitaux de Paris (AP-HP)](https://www.aphp.fr)\n- [Agence Régionale de Santé (ARS)](https://www.ars.sante.fr)\n- [Agence Technique de l'Information sur l'Hospitalisation (ATIH)](/organizations/agence-technique-de-l-information-sur-l-hospitalisation-atih/)\n- [Cegedim](https://www.cegedim.fr/Pages/default.aspx)\n- [Comité Economique des Produits de Santé (CEPS)](https://solidarites-sante.gouv.fr/ministere/acteurs/instances-rattachees/article/ceps-comite-economique-des-produits-de-sante)\n- [Centre National Hospitalier d'Information sur le Médicament (CNHIM)](https://www.theriaque.org)\n- [Centre d'Appui pour la Prévention des Infections associées aux soins en Ile de France](http://www.cpias-ile-de-france.fr)\n- [Direction de l'Animation de la Recherche, des Etudes et des Statistiques (DARES)](https://dares.travail-emploi.gouv.fr)\n- [Ecole des Hautes Etudes en Santé Publique (EHESP)](https://www.ehess.fr/fr)\n- [European Patent Office (EPO)](https://www.epo.org/searching-for-patents/technical/espacenet_fr.html)\n- [Fédération Hospitalière de France (FHF)](https://www.fhf.fr)\n- [Institut National du Cancer (INCA)](/organizations/institut-national-du-cancer/)\n- [Institut National de la Statistique et des Etudes Economiques (INSEE)](/organizations/institut-national-de-la-statistique-et-des-etudes-economiques-insee/)\n- [Institut National de Santé et de Recherche Médicale (INSERM)](https://www.inserm.fr)\n- [Institut Pasteur](https://www.pasteur.fr/fr)\n- [Institut de Recherche et de Documentation en Economie de la Santé (IRDES)](/organizations/irdes-ecosante-fr-institut-de-recherche-et-documentation-en-economie-de-la-sante/)\n- [Ministère de l'Education Nationale](/organizations/education-nationale/)\n- [Ministère des Solidarités et de la Santé](/organizations/ministere-des-solidarites-et-de-la-sante/)\n- [Observatoire Français des Drogues et des Toxicomanies (OFDT)](/organizations/observatoire-francais-des-drogues-et-des-toxicomanies/)\n- [Office National Public et de Communication (ONPC)](https://www.onpc.fr)\n- [Ordre national des pharmaciens](http://www.ordre.pharmacien.fr)\n- [Réseau France Coag](https://francecoag.org)\n- [Société Française de Cardiologie](https://sfcardio.fr/)\n- [SOS médecins](https://www.sosmedecins.fr/)\n- [Santé publique France (SpF)](/organizations/sante-publique-france/)"
},
{
"alpha_fraction": 0.5685064792633057,
"alphanum_fraction": 0.5836039185523987,
"avg_line_length": 34.606937408447266,
"blob_id": "1d72c9b948f5dea5b2cdc76a31b8b69bf2c43e0c",
"content_id": "54ee18cedf36c77b71cc1ebc07735677c75f0892",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6185,
"license_type": "permissive",
"max_line_length": 222,
"num_lines": 173,
"path": "/pages/generate_geo_html.py",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "import re\nimport unidecode\n\nfrom bs4 import BeautifulSoup\nimport mistune\nfrom mistune.directives import DirectiveToc\nfrom mistune.directives.toc import extract_toc_items\n\nr = re.compile(r'^(\\s*)', re.MULTILINE)\n\n# Code borrowed and adapted from https://github.com/lepture/mistune/blob/master/mistune/directives/toc.py#L138\ndef render_toc_ul(toc):\n \"\"\"Render a <ul> table of content HTML. The param \"toc\" should\n be formatted into this structure::\n [\n (toc_id, text, level),\n ]\n For example::\n [\n ('toc-intro', 'Introduction', 1),\n ('toc-install', 'Install', 2),\n ('toc-upgrade', 'Upgrade', 2),\n ('toc-license', 'License', 1),\n ]\n \"\"\"\n if not toc:\n return ''\n\n s = '<ul class=\"fr-sidemenu__list\">\\n'\n levels = []\n for k, text, level in toc:\n item = '<a href=\"#{}\" class=\"fr-sidemenu__link\" target=\"_self\">{}</a>'.format(k, text)\n if not levels:\n s += '<li class=\"fr-sidemenu__item\">' + item\n levels.append(level)\n elif level == levels[-1]:\n s += '</li>\\n<li class=\"fr-sidemenu__item\">' + item\n elif level > levels[-1]:\n s += '\\n<ul class=\"fr-sidemenu__list\">\\n<li class=\"fr-sidemenu__item\">' + item\n levels.append(level)\n else:\n last_level = levels.pop()\n while levels:\n last_level = levels.pop()\n if level == last_level:\n s += '</li>\\n</ul>\\n</li>\\n<li class=\"fr-sidemenu__item\">' + item\n levels.append(level)\n break\n elif level > last_level:\n s += '</li>\\n<li class=\"fr-sidemenu__item\">' + item\n levels.append(last_level)\n levels.append(level)\n break\n else:\n s += '</li>\\n</ul>\\n'\n else:\n levels.append(level)\n s += '</li>\\n<li class=\"fr-sidemenu__item\">' + item\n\n while len(levels) > 1:\n s += '</li>\\n</ul>\\n'\n levels.pop()\n\n return s + '</li>\\n</ul>\\n'\n\ndirToc = DirectiveToc()\nmarkdown_renderer_with_toc_directive = mistune.create_markdown(escape=False,\n plugins=[DirectiveToc()])\n\nwith open('donnees-geo.md', 'r') as input_file:\n content = input_file.read()\n\nhtml_tree = markdown_renderer_with_toc_directive(content)\ncontent_resulting = []\n\ndirectives_tags = \"\"\"---\ntitle: Données géographiques\nkeywords:\n - geo\n - adresses\n - SIG\n - geomatique\n - geographie\n - cartographie\ndescription: Page inventaire des données géographiques essentielles.\ncontent_type: html\n---\n\"\"\"\n\ncontent_resulting.append(directives_tags)\n\ntitle = \"Les données à composante géographique\"\nillustration_url = \"https://user-images.githubusercontent.com/72090652/201092205-31a8911c-844c-4f59-b652-8b27cda0c217.svg\"\nbasic_description = \"\"\"<p>\n Les données à composantes géographiques sont souvent indispensables pour réaliser des analyses. Sont référencées ici les principaux jeux de données disponibles sur <a href=\"http://data.gouv.fr/\">data.gouv.fr</a>.\n Celle-ci n'est pas exhaustive et est\n <a href=\"https://github.com/etalab/datagouvfr-pages/blob/master/pages/donnees-geo.md\" target=\"_blank\">\n ouverte aux contributions\n </a>\n .\n </p>\n <p>\n Un certains nombre de ces données font office de référentiel qui servent de pivot avec d'autres jeux de données. Elles font parties\n <a href=\"https://www.data.gouv.fr/fr/pages/spd/reference/\">\n du SPD (Service Public de la Donnée)\n </a>\n . Voir aussi\n <a href=\"https://guides.etalab.gouv.fr/qualite/lier-les-donnees-a-un-referentiel/\" target=\"_blank\">\n cet article sur comment lier des données à un référentiel\n </a>\n </p>\"\"\"\n\nlevels_to_inf_3 = [i for i in extract_toc_items(markdown_renderer_with_toc_directive, content) if i[2] < 3]\nleft_menu = render_toc_ul(levels_to_inf_3)\n\nmain_content_template = \"\"\"<section class=\"section-blue section-main\">\n <div class=\"fr-container\">\n <div class=\"fr-grid-row fr-grid-row--gutters\">\n <div class=\"fr-col\">\n <h1>{}</h1>\n </div>\n <div class=\"fr-col-12\">\n <div class=\"fr-highlight\">\n <p>{}\n </p>\n </div>\n </div>\n <div class=\"fr-col-12 fr-col-md-4\">\n <nav class=\"fr-sidemenu fr-sidemenu--sticky-full-height\" aria-label=\"Menu latéral\" style=\"min-width:230px;\">\n <div class=\"fr-sidemenu__inner\">\n <button class=\"fr-sidemenu__btn\" hidden aria-controls=\"fr-sidemenu-wrapper\" aria-expanded=\"false\">Dans cette rubrique</button>\n <img class=\"fr-responsive-img fr-hidden fr-displayed-lg fr-mb-4w\" src=\"{}\" alt=\"\">\n <div class=\"fr-collapse\" id=\"fr-sidemenu-wrapper\">{}</div>\n </div>\n </nav>\n </div>\n <div class=\"fr-col-12 fr-col-md-8 markdown\">{}</div>\n </div>\n </div>\n</section>\n\"\"\".format(title, basic_description, illustration_url, left_menu, html_tree)\n\n'''\nmain_content_template = \"\"\"<section class=\"section-blue section-main\">\n <div class=\"fr-container\">\n <div class=\"fr-grid-row fr-grid-row--gutters\">\n <div class=\"fr-col\">\n <h1>{}</h1>\n </div>\n <div class=\"fr-col-12\">\n <div class=\"fr-highlight\">\n <p>{}\n </p>\n </div>\n </div>\n <div class=\"fr-col-12 fr-col-md-4\">\n </div>\n <div class=\"fr-col-12 fr-col-md-8 markdown\">{}</div>\n </div>\n </div>\n</section>\n\"\"\".format(title, basic_description, left_menu, html_tree)\n'''\n\n# <h1 class=\"fr-h1\"> pour surcharger\nmain_content_template = main_content_template.replace(\"<h1 \", '<h1 class=\"fr-h1 fr-mt-4w\"').replace('<h1 class=\"fr-h1 fr-mt-4w\"id=\"toc_1\">', '<h1 class=\"fr-h1\" id=\"toc_1\">')\nsoup = BeautifulSoup(main_content_template, 'html.parser')\nmain_content_template = r.sub(r'\\1\\1', soup.prettify())\ncontent_resulting.append(main_content_template)\n\nhtml = '\\n'.join(content_resulting)\nwith open('donnees-geographiques.html', 'w') as input_file:\n input_file.write(html)\n"
},
{
"alpha_fraction": 0.7506426572799683,
"alphanum_fraction": 0.7647814750671387,
"avg_line_length": 32.826087951660156,
"blob_id": "17f136af35c6e48d8ea5a2f449bbd64f075c29df",
"content_id": "b2cf58aedff110817b0decb0515849f834473972",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 778,
"license_type": "permissive",
"max_line_length": 170,
"num_lines": 23,
"path": "/pages/udata/summary.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: udata technical posts summary\nkeywords:\n - udata\ndescription: Technicals posts about udata\n---\n\n# udata technical posts\n\nThis page acts as a table of content for various udata related technical blog posts.\n\n[udata](https://github.com/opendatateam/udata) is data.gouv.fr's underlying software. It's available as a free software and can be reused by anyone interested.\n\nThose blog posts aim at giving an overview on technical subjects regarding udata. The detailed documentation [is available here](https://udata.readthedocs.io/en/stable/).\n\n## udata 4\n\n- [Introducing udata 4](pages/udata/4/introducing-udata-4)\n\n## udata 3\n\n- [The Road to udata 3](pages/udata/3/the-road-to-udata-3)\n- [udata 3 usage metrics explained](pages/udata/3/udata-3-usage-metrics-explained)\n"
},
{
"alpha_fraction": 0.7610319256782532,
"alphanum_fraction": 0.7637474536895752,
"avg_line_length": 94.03225708007812,
"blob_id": "4a3f56a0cba256420fdb01660475da4444b85f3c",
"content_id": "1b042b1b06e0cfc97e47bbd698b749255977fe51",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3041,
"license_type": "permissive",
"max_line_length": 415,
"num_lines": 31,
"path": "/pages/about/a-propos.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "# À propos de data.gouv.fr\n\n## **Qu’est-ce que l’open data ?**\n\nLes données ouvertes, ou open data sont des données numériques produites par les acteurs publics (ministère, collectivité ou établissement public, etc.), mais aussi par des acteurs privés (entreprise, association, citoyen, etc.).\n\nCes données sont diffusées de manière structurée selon une licence ouverte garantissant leur libre accès et leur réutilisation par tous, sans restriction technique, juridique ou financière.\n\nLes données ouvertes portent sur des sujets très divers. Il peut s’agir, par exemple, de données géographiques, financières, de transport, de santé publique ou encore d’environnement.\n\n[En savoir plus sur les bénéfices de l'open data.](/pages/about/opendata/)\n\n## **Qu’est-ce que [data.gouv.fr](http://data.gouv.fr/) ?**\n\n[data.gouv.fr](http://data.gouv.fr/) est la plateforme ouverte des données publiques françaises. C'est une plateforme **ouverte et [communautaire](https://guides.etalab.gouv.fr/data.gouv.fr/animer-communaute-reutilisateurs/#repondre-aux-questions-posees-a-propos-d-un-jeu-de-donnees) sur laquelle tout le monde a la possibilité de publier !** Celle-ci s’adresse :\n\n- aux **producteurs de données** qui souhaitent [les publier dans des formats ouverts et réutilisables](https://guides.etalab.gouv.fr/qualite/) ;\n- aux **réutilisateurs** qui téléchargent les données et [référencent leurs réalisations](https://guides.etalab.gouv.fr/reutilisation/) ;\n- mais aussi à **tout citoyen**, association ou entreprise, qui peuvent ainsi découvrir et utiliser des données ouvertes.\n\n## **Qui est derrière [data.gouv.fr](http://data.gouv.fr/) ?**\n\nLancée en 2011 par la mission [Etalab](https://www.etalab.gouv.fr/), la plateforme [data.gouv.fr](http://data.gouv.fr/) est [développée et opérée](https://github.com/etalab/data.gouv.fr) par le département Opérateur des Produits Interministériels de la Direction interministérielle du numérique (**[DINUM](https://numerique.gouv.fr/)**).\n\n## **Vous avez une question ?**\n\n- Si vous avez des interrogations sur la plateforme, nous vous invitons à consulter **[la documentation](https://doc.data.gouv.fr/)** de celle-ci ;\n- Si vous êtes à la recherche de ressources pour être accompagné dans votre démarche d'ouverture de données, **les [guides d’Etalab](https://guides.etalab.gouv.fr/)** sont faits pour vous ;\n- Si vous souhaitez suggérer un nouveau jeu de données à publier, nous signaler un problème ou simplement nous écrire, rendez-vous **[ici](https://support.data.gouv.fr/).**\n\nNous vous invitons par ailleurs à suivre les comptes Twitter [@datagouvfr](https://twitter.com/datagouvfr) (actualité de la plateforme, annonce des nouveaux jeux de données) et [@etalab](https://twitter.com/etalab) (actualité du département Etalab et de l’ouverture des données publiques) ainsi qu’à vous [abonner à notre infolettre](https://f.info.data.gouv.fr/f/lp/infolettre-data-gouv-fr-landing-page/lk3q01y6) !\n"
},
{
"alpha_fraction": 0.7595529556274414,
"alphanum_fraction": 0.775223970413208,
"avg_line_length": 109.05923461914062,
"blob_id": "f5d076a1c4726cd5256303d2cb71ae1b84406324",
"content_id": "0bf36a1a0bec981a2722a43892d1261449f7ec5e",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 32047,
"license_type": "permissive",
"max_line_length": 562,
"num_lines": 287,
"path": "/pages/donnees-geo.md",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "# Données limites administratives\n\n## **Données communales**\n\nLe Code Officiel Géographique (COG). C’est une donnée pivot qui permet de rattacher les données à d’autres jeux de données, à des données géographiques ou de faire des calculs à des niveaux administratifs issus d’une combinaison de communes.\n\n- [Code officiel géographique](https://www.data.gouv.fr/fr/datasets/code-officiel-geographique-cog/) avec les données sous forme JSON dans le cadre de <a href=\"https://github.com/etalab/decoupage-administratif#via-des-urls\" target=\"_blank\">l’API Découpage Administratif</a> (**SPD**)\n\n### *Données IGN*\n\n- [Admin Express](https://www.data.gouv.fr/fr/datasets/admin-express/): données communales à partir de 2017 jusqu’à nos jours. Les versions récentes intègrent les EPCI\n- [Geofla](https://www.data.gouv.fr/fr/datasets/geofla-r/): données communales, cantonales et départementales en 1997, 2002 puis régulièrement de 2010 à 2016 régulièrement \n\nLa précision géométrique de ces limites a changé au fil du temps. Lors du passage Geofla vers Admin Express puis avec le passage de Admin Express en version 3. Voir <a href=\"https://geoservices.ign.fr/admin-express-passe-la-grande-echelle\" target=\"_blank\">cet article pour faire la distinction</a>\n\nCes données font partie du SPD via le RGE (Référentiel à Grande Échelle)\n\n*Il faut noter que les Collectivités d’Outre-Mer (COM) ne sont pas présentes. Si vous voulez une version avec les COM, Etalab produit une version avec Admin Express pour métropole et DOM avec les géométries venant d’OpenStreetMap pour les COM. Voir les <a href=\"http://etalab-datasets.geo.data.gouv.fr/contours-administratifs/\" target=\"_blank\">données générées par Etalab</a> (avec le <a href=\"https://github.com/etalab/contours-administratifs\" target=\"_blank\">dépôt associé pour générer</a>)*\n\nPour ne pas avoir à gérer les DOM/TOM du fait de l’éloignement, lorsqu'on produit des cartes France entière, il existe une [version de données avec les Contours des communes de France simplifié, avec régions et département d'outre-mer rapprochés](https://www.data.gouv.fr/fr/datasets/contours-des-communes-de-france-simplifie-avec-regions-et-departement-doutre-mer-rapproches/)\n\n### *Données OpenStreetMap*\n\nPour les données communales, celle-ci ont tracées depuis un fond raster communal de la direction générale des Finances publiques (DGFiP) comme cet article <a href=\"http://prev.openstreetmap.fr/36680-communes\" target=\"_blank\">\"Achèvement du tracé collaboratif des limites communales françaises dans OpenStreetMap\"</a> le retrace.\n\n- [Extractions de OpenStreetMap France](https://www.data.gouv.fr/fr/datasets/decoupage-administratif-communal-francais-issu-d-openstreetmap/) sur [data.gouv.fr](http://data.gouv.fr)\n\n## **Données postales**\n\n- [Base officielle des codes postaux](https://www.data.gouv.fr/fr/datasets/base-officielle-des-codes-postaux/) de La Poste. Comme la donnée n'est qu'à date courante, il est possible d'avoir <a href=\"http://files.opendatarchives.fr/datanova.laposte.fr/archives/laposte_hexasmal/\" target=\"_blank\">les mêmes données archivées plus anciennes sur OpenDatarchives</a>\n- Fond de carte des codes postaux [https://www.data.gouv.fr/fr/datasets/fond-de-carte-des-codes-postaux/](https://www.data.gouv.fr/fr/datasets/fond-de-carte-des-codes-postaux/)\n\n## **Données dérivées ou dérivables des données communales générales**\n\nGénéralement des zonages sont dérivés de zonage communaux. Voici une liste ci-dessous. Vous pouvez pour certains zonages passer par la <a href=\"https://www.insee.fr/fr/information/2028028\" target=\"_blank\">\"Table d’appartenance géographique des communes et tables de passage\" de l'INSEE</a>\n\n- Militaires:\n - [zone de défense et de sécurité](https://www.data.gouv.fr/fr/datasets/zones-de-defense-et-de-securite-2016/)\n- Écoles: académie et zones de vacances\n - [Contours géographiques des académies](https://www.data.gouv.fr/fr/datasets/contours-geographiques-des-academies/)\n- Zonages liés à des actions, principalement ANCT (Agence Nationale de Cohésion des Territoires)\n - [Zones de revitalisation rurale (ZRR)](https://www.data.gouv.fr/fr/datasets/zone-de-revitalisation-rurale-zrr-30382904/)\n - [Aides à finalité régionale (AFR)](https://www.data.gouv.fr/fr/datasets/zones-daide-a-finalite-regionale-afr/)\n - [Communes classées en zone de montagne](https://www.data.gouv.fr/fr/datasets/communes-de-la-loi-montagne-au-code-officiel-geographique-cog-2020-2022/)\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/kiosque/zonage-les-zones-de-perimetre-de-massifs\" target=\"_blank\">Communes classées en Périmètre de massif</a>\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/perimetre-des-territoires-dindustrie-0\" target=\"_blank\">Programme Territoires d'industrie</a>\n - [Communes bénéficiant du plan Action Cœur de Ville (ACV)](https://www.data.gouv.fr/fr/datasets/programme-action-coeur-de-ville/)\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/classement-des-communes-en-loi-littoral\" target=\"_blank\">Communes classées en Loi Littoral</a>\n - Communes classées en Périmètres des parcs naturels régionaux (PNR): voir <a href=\"https://inpn.mnhn.fr/telechargement/cartes-et-information-geographique/ep/pnr\" target=\"_blank\">les zonages des PNR</a>\n - Communes classées en Parcs Nationaux: voir <a href=\"https://inpn.mnhn.fr/telechargement/cartes-et-information-geographique/ep/pn\" target=\"_blank\">les zonages des PN</a>\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/classement-des-communes-en-zone-de-revitalisation-des-commerces-en-milieu-rural-zorcomir\" target=\"_blank\">zones de revitalisation des commerces en milieu rural (ZORCOMIR)</a>\n - [Zones urbaines sensibles (ZUS)](https://www.data.gouv.fr/fr/datasets/zones-urbaines-sensibles-zus/)\n - Établissements Publics de Coopération Intercommunale (EPCI) Voir [Admin Express](https://www.data.gouv.fr/fr/datasets/admin-express/) pour les données récentes. Pour reconstituer les données EPCI, utiliser les données DGCL qui donnent la <a href=\"https://www.collectivites-locales.gouv.fr/institutions/liste-et-composition-des-epci-fiscalite-propre\" target=\"_blank\">composition communale des EPCI depuis 1999</a> ou bien [la BANATIC (Base nationale sur les intercommunalités)](https://www.data.gouv.fr/fr/datasets/base-nationale-sur-les-intercommunalites/)\n - Établissements publics territoriaux (EPT). Ils composent la Métropole du Grand Paris et sont disponibles sur <a href=\"https://opendata.apur.org/datasets/Apur::etablissements-publics-territoriaux-metropole-du-grand-paris/explore?location=48.828504%2C2.379750%2C10.99\" target=\"_blank\">le portail de l'APUR</a>\n - Pays et Pôles d'Équilibre Territoriaux et Ruraux (PETR). Ils sont renseignés dans [la BANATIC (Base nationale sur les intercommunalités)](https://www.data.gouv.fr/fr/datasets/base-nationale-sur-les-intercommunalites/)\n - Départements: disponibles dans [Admin Express](https://www.data.gouv.fr/fr/datasets/admin-express/)\n - Régions: disponibles dans [Admin Express](https://www.data.gouv.fr/fr/datasets/admin-express/)\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/perimetre-des-anciennes-regions-1972\" target=\"_blank\">Anciennes Régions</a>\n - <a href=\"https://www.insee.fr/fr/information/4652957\" target=\"_blank\">Zone d'emploi (2020)</a>\n - <a href=\"https://www.insee.fr/fr/information/2115016\" target=\"_blank\">Bassin de vie (2012)</a>\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/perimetre-des-pseudo-cantons\" target=\"_blank\">Canton-ou-ville (appelé pseudo-canton)</a>\n - Arrondissement: disponibles dans [Admin Express](https://www.data.gouv.fr/fr/datasets/admin-express/)\n - <a href=\"https://www.insee.fr/fr/information/4802589\" target=\"_blank\">Unité urbaine (2020)</a>\n - <a href=\"https://www.insee.fr/fr/information/4803954\" target=\"_blank\">Aire d'attraction des villes (2020)</a>\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/typologie-du-zonage-en-aires-dattraction-des-villes-aav-2020-0\" target=\"_blank\">Pôle / couronne des AAV (2020)</a>\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/perimetre-des-ressorts-des-cours-dappel\" target=\"_blank\">Périmètre des cours d'appel</a>\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/perimetre-des-ressorts-des-tribunaux-judiciaires\" target=\"_blank\">Périmètre des tribunaux judiciaires</a>\n - <a href=\"https://www.observatoire-des-territoires.gouv.fr/perimetre-des-ressorts-des-tribunaux-de-proximite-ou-poles-de-proximite-de-tribunaux-judiciaires\" target=\"_blank\">Périmètre des tribunaux de proximité</a>\n - [Programme Petites villes de demain](https://www.data.gouv.fr/fr/datasets/programme-petites-villes-de-demain/)\n - [CRTE (Contrat de Relance et de Transition Ecologique)](https://www.data.gouv.fr/fr/datasets/contrat-de-relance-et-de-transition-ecologique/)\n - [Quartiers prioritaires politique de la ville (QPV)](https://www.data.gouv.fr/fr/datasets/quartiers-prioritaires-de-la-politique-de-la-ville-qpv/)\n\n\n**Données intracommunales et carroyées haute-résolution**\n\n- IRIS: Il existe deux produits\n - [Contour IRIS](https://www.data.gouv.fr/fr/datasets/contours-iris/) adapté pour représenter sur une carte car simplifiée\n - <a href=\"https://geoservices.ign.fr/irisge\" target=\"_blank\">IRIS GE comme Grande Échelle</a> adapté pour dénombrer dans quel IRIS un habitation est par exemple car la donnée a une plus grande précision\n- Bureaux de vote: pas de renseignement national. Au cas par cas, mis à disposition par la commune. Repris dans OpenStreetMap\n- Quartiers (cas par cas): soit disponible sur des portails OpenData soit sur OpenStreetMap\n- <a href=\"https://www.insee.fr/fr/statistiques/6215138?sommaire=6215217\" target=\"_blank\">Données carroyées 200m</a>\n\n**Données statistiques à associer aux communes ou aux iris (ne contient pas de géographie)**\n\n- <a href=\"https://www.insee.fr/fr/statistiques/5359146\" target=\"_blank\">Base du dossier complet</a> (INSEE, niveau communal, 1900 indicateurs)\n- IRIS (source INSEE)\n - <a href=\"https://www.insee.fr/fr/statistiques/5650708\" target=\"_blank\">Activité des résidents en 2018</a>\n - <a href=\"https://www.insee.fr/fr/statistiques/5650712\" target=\"_blank\">Diplômes - Formation en 2018</a>\n - <a href=\"https://www.insee.fr/fr/statistiques/5650714\" target=\"_blank\">Couples - Familles - Ménages en 2018</a>\n - <a href=\"https://www.insee.fr/fr/statistiques/5650749\" target=\"_blank\">Logement en 2018</a>\n - <a href=\"https://www.insee.fr/fr/statistiques/5650720\" target=\"_blank\">Population en 2018</a>\n- [1526 variables regroupées en 19 classes sur les 49461 IRIS de France](https://www.data.gouv.fr/fr/datasets/1526-variables-regroupees-en-19-classes-sur-les-49461-iris-de-france/)\n\n# **Transports/mobilités**\n\n- Le Point d'Accès National (PAN) aux données ouvertes de transport <a href=\"https://transport.data.gouv.fr/\" target=\"_blank\">transport.data.gouv.fr</a>. Il concerne tous les types de transports ainsi que certains aspects de mobilité comme le covoiturage.\n\n## Voiture/transport routier\n\n- <a href=\"https://transport.data.gouv.fr/datasets/base-nationale-des-lieux-de-covoiturage/\" target=\"_blank\">Aires de covoiturage en France</a>\n- <a href=\"https://transport.data.gouv.fr/datasets?type=low-emission-zones\" target=\"_blank\">Zones à faibles émissions</a>\n- [Base Nationale des Lieux de Stationnement](https://www.data.gouv.fr/fr/datasets/base-nationale-des-lieux-de-stationnement/)\n- [Bases de données annuelles des accidents corporels de la circulation routière - Années de 2005 à 2020](https://www.data.gouv.fr/fr/datasets/bases-de-donnees-annuelles-des-accidents-corporels-de-la-circulation-routiere-annees-de-2005-a-2020/)\n- [Accidents de vélo](https://www.data.gouv.fr/fr/datasets/accidents-de-velo/) (dérivée des bases de données annuelles des accidents corporels de la circulation routière ci-dessus)\n- [Trafic moyen journalier annuel sur le réseau routier national](https://www.data.gouv.fr/fr/datasets/trafic-moyen-journalier-annuel-sur-le-reseau-routier-national/)\n- [ROUTE 500, base de données des principales routes en France](https://www.data.gouv.fr/fr/datasets/route-500/). Initialement, elle était gérée à part. Maintenant, il s’agit d’un produit dérivé de la BD TOPO\n- [Paris Respire - Secteurs](https://www.data.gouv.fr/fr/datasets/paris-respire-secteurs/)\n- [Prix des carburants en France](https://www.data.gouv.fr/fr/datasets/prix-des-carburants-en-france/)\n- [Prix des contrôles techniques](https://www.data.gouv.fr/fr/datasets/prix-des-controles-techniques/)\n- [Fichier consolidé des Bornes de Recharge pour Véhicules Électriques](https://www.data.gouv.fr/fr/datasets/fichier-consolide-des-bornes-de-recharge-pour-vehicules-electriques/)\n- [Radars automatiques](https://www.data.gouv.fr/fr/datasets/radars-automatiques/)\n- [Gestionnaires du réseau routier national](https://www.data.gouv.fr/fr/datasets/gestionnaires-du-reseau-routier-national/)\n- [Registre public des gares routières et des aménagements routiers](https://www.data.gouv.fr/fr/datasets/registre-public-des-gares-routieres/) Il contient des coordonnées géographiques</a>\n\n## Transport ferroviaire\n\n- [Liste des gares](https://www.data.gouv.fr/fr/datasets/liste-des-gares/)\n- [Gares ferroviaires de tous types, exploitées ou non](https://www.data.gouv.fr/fr/datasets/gares-ferroviaires-de-tous-types-exploitees-ou-non/)\n- [Positions géographiques des stations du réseau RATP](https://www.data.gouv.fr/fr/datasets/positions-geographiques-des-stations-du-reseau-ratp-ratp/) (voir aussi <a href=\"https://data.iledefrance-mobilites.fr/explore/dataset/emplacement-des-gares-idf-data-generalisee/\" target=\"_blank\">ce jeu de données</a>).\n\n## Transport aérien\n\n- [Aéroports français](https://www.data.gouv.fr/fr/datasets/aeroports-francais-coordonnees-geographiques/)\n- [Données d'espace aérien de la base aéronautique du SIA](https://www.data.gouv.fr/fr/datasets/donnees-despace-aerien-de-la-base-aeronautique-du-sia/)\n\n## Mobilité\n\n- <a href=\"https://www.insee.fr/fr/information/2383370\" target=\"_blank\">INSEE Base des flux de mobilité</a>\n - <a href=\"https://www.insee.fr/fr/information/2383337\" target=\"_blank\">Mobilités professionnelles</a> : déplacements domicile-travail\n - <a href=\"https://www.insee.fr/fr/information/2383343\" target=\"_blank\">Mobilités scolaires</a> : déplacements domicile-études\n - <a href=\"https://www.insee.fr/fr/information/2383331\" target=\"_blank\">Migrations résidentielles</a> : commune de résidence / commune de résidence antérieure\n\n# **Annuaires/référentiels**\n\n- [Service-Public.fr](https://www.data.gouv.fr/fr/datasets/service-public-fr-annuaire-de-l-administration-base-de-donnees-locales/)\n- [Base Sirene des entreprises et de leurs établissements (SIREN, SIRET)](https://www.data.gouv.fr/fr/datasets/base-sirene-des-entreprises-et-de-leurs-etablissements-siren-siret/) dont versions géolocalisées ci-dessous\n - [Sirene INSEE](https://www.data.gouv.fr/fr/datasets/geolocalisation-des-etablissements-du-repertoire-sirene-pour-les-etudes-statistiques/)\n - <a href=\"https://data.cquest.org/geo_sirene/v2019/\" target=\"_blank\">Sirene géolocalisée (Christian Quest)</a> (dans les ressources communautaires de [ce jeu de données](https://www.data.gouv.fr/fr/datasets/base-sirene-des-entreprises-et-de-leurs-etablissements-siren-siret/))\n- [Base Adresse Nationale (BAN)](https://www.data.gouv.fr/fr/datasets/base-adresse-nationale/) (**SPD**)\n- [Adresses extraites du cadastre](https://www.data.gouv.fr/fr/datasets/adresses-extraites-du-cadastre/)\n- [Base d'Adresses Nationale Ouverte - BANO](https://www.data.gouv.fr/fr/datasets/base-d-adresses-nationale-ouverte-bano/) (en complément de la BAN)\n- [Cadastre](https://www.data.gouv.fr/fr/datasets/cadastre/) (**SPD**)\n- [COG (Code officiel géographique)](https://www.data.gouv.fr/fr/datasets/code-officiel-geographique-cog/) (**SPD**)\n- [Référentiel à grande échelle (RGE)](https://www.data.gouv.fr/fr/datasets/referentiel-a-grande-echelle-rge/) (**SPD**) Le RGE est constitué des composantes orthophotographique, topographique et adresse, parcellaire et altimétrique.\n- [Services Publics Plus](https://www.data.gouv.fr/fr/datasets/referentiel-structure-de-la-plateforme-services-publics-plus-de-la-ditp/) (référentiel structure)\n\n# Risques\n\n- [Connaître le potentiel radon de ma commune](https://www.data.gouv.fr/fr/datasets/connaitre-le-potentiel-radon-de-ma-commune/)\n- <a href=\"https://www.georisques.gouv.fr/donnees/bases-de-donnees\" target=\"_blank\">Géorisques</a>,\n - <a href=\"https://www.georisques.gouv.fr/risques/installations/donnees\" target=\"_blank\">ICPE</a>\n- InfoTerre dont les <a href=\"https://infoterre.brgm.fr/page/geoservices-ogc\" target=\"_blank\">flux OGC</a>\n- [Base nationale de Gestion Assistée des Procédures Administratives relatives aux Risques (GASPAR)](https://www.data.gouv.fr/fr/datasets/base-nationale-de-gestion-assistee-des-procedures-administratives-relatives-aux-risques-gaspar/) (attention, CSV à joindre à des informations communales par le code INSEE, pas d’information géographique directe).\n\n# Environnement (géologie, eau, autres)\n\n- [Cartes géologiques départementales à 1/50 000 (BD Charm)](https://www.data.gouv.fr/fr/datasets/cartes-geologiques-departementales-a-1-50-000-bd-charm-50/)\n- InfoTerre dont les <a href=\"https://infoterre.brgm.fr/page/geoservices-ogc\" target=\"_blank\">flux OGC</a>\n- Vigicrues\n - [Hauteurs d’eau et débits des cours d’eau observés en temps réel aux stations du réseau Vigicrues](https://www.data.gouv.fr/fr/datasets/hauteurs-deau-et-debits-des-cours-deau-observes-en-temps-reel-aux-stations-du-reseau-vigicrues/)\n - [Tronçons de cours d'eau Vigicrues, simplifiés avec niveau de vigilance crues](https://www.data.gouv.fr/fr/datasets/troncons-de-cours-deau-vigicrues-simplifies-avec-niveau-de-vigilance-crues-2/)\n- <a href=\"https://www.sandre.eaufrance.fr/atlas/\" target=\"_blank\">Sandre (Service d'administration nationale des données et référentiels sur l'eau)</a>\n- <a href=\"https://hubeau.eaufrance.fr\" target=\"_blank\">Hubeau (API)</a>\n- <a href=\"http://www.naiades.eaufrance.fr/acces-donnees\" target=\"_blank\">Naiades</a>\n- [Corine Land Cover](https://www.data.gouv.fr/fr/datasets/corine-land-cover-occupation-des-sols-en-france/)\n- [Données d'observation des principales stations météorologiques](https://www.data.gouv.fr/fr/datasets/donnees-d-observation-des-principales-stations-meteorologiques/)\n- [Température quotidienne régionale (depuis janvier 2016)](https://www.data.gouv.fr/fr/datasets/temperature-quotidienne-regionale-depuis-janvier-2016/)\n- [Données « temps réel » de mesure des concentrations de polluants atmosphériques réglementés](https://www.data.gouv.fr/fr/datasets/donnees-temps-reel-de-mesure-des-concentrations-de-polluants-atmospheriques-reglementes-1/)\n- [Pesticides dans les eaux souterraines](https://www.data.gouv.fr/fr/datasets/pesticides-dans-les-eaux-souterraines/)\n- [Carroyage DFCI](https://www.data.gouv.fr/fr/datasets/carroyage-dfci-2-km/) (Défense des Forêts Contre les Incendies) 2 km\n\n# Urbanisme (cadastre, données vente, logement)\n\n- [Plan cadastral informatisé](https://www.data.gouv.fr/fr/datasets/plan-cadastral-informatise/) (**SPD**)\n- [Base de donnée nationale des bâtiments](https://www.data.gouv.fr/fr/datasets/base-de-donnee-nationale-des-batiments-version-0-6/)\n- <a href=\"https://www.geoportail-urbanisme.gouv.fr\" target=\"_blank\">Géoportail de l’Urbanisme (PLU et SUP)</a>\n- [Liste des PLU disponibles sur le Géoportail de l'Urbanisme](https://www.data.gouv.fr/fr/datasets/liste-des-plu-disponibles-sur-le-geoportail-de-lurbanisme-1/)\n- [Demandes de valeurs foncières géolocalisées](https://www.data.gouv.fr/fr/datasets/demandes-de-valeurs-foncieres-geolocalisees/)\n- [DVF+ open-data (version géolocalisée produite par le Cerema)](https://www.data.gouv.fr/fr/datasets/dvf-open-data/)\n- [\"Carte des loyers\" - Indicateurs de loyers d'annonce par commune en 2018](https://www.data.gouv.fr/fr/datasets/carte-des-loyers-indicateurs-de-loyers-dannonce-par-commune-en-2018/)\n- [Sitadel](https://www.data.gouv.fr/fr/datasets/base-des-permis-de-construire-et-autres-autorisations-durbanisme-sitadel/)\n- [Logements vacants du parc privé par ancienneté de vacance, par commune et par EPCI](https://www.data.gouv.fr/fr/datasets/logements-vacants-du-parc-prive-par-anciennete-de-vacance-par-commune-et-par-epci/)\n- [Prix moyen au m² des ventes de maisons et d'appartements par commune en 2017](https://www.data.gouv.fr/fr/datasets/prix-moyen-au-m2-des-ventes-de-maisons-et-dappartements-par-commune-en-2017/)\n- [Répertoire des logements locatifs des bailleurs sociaux](https://www.data.gouv.fr/fr/datasets/repertoire-des-logements-locatifs-des-bailleurs-sociaux/) (rapportable à la commune)\n- [Annuaire des diagnostiqueurs immobiliers](https://www.data.gouv.fr/fr/datasets/annuaire-des-diagnostiqueurs-immobiliers/) (via géocodage)\n- [Zonage des Plan d'Exposition au Bruit](https://www.data.gouv.fr/fr/datasets/zonage-des-plan-dexposition-au-bruit-peb/) (PEB) Voir les <a href=\"https://geoservices.ign.fr/services-web-experts-transports#2314\" target=\"_blank\">services WFS de l’IGN</a> pour une version à jour.\n- [Sites référencés dans Cartofriches](https://www.data.gouv.fr/fr/datasets/sites-references-dans-cartofriches/)\n- [Corine Land Cover](https://www.data.gouv.fr/fr/datasets/corine-land-cover-occupation-des-sols-en-france/)\n- [Fiches signalétiques des points géodésiques et des repères de nivellement](https://www.data.gouv.fr/fr/datasets/fiches-signaletiques-des-points-geodesiques-et-des-reperes-de-nivellement/). Voir aussi <a href=\"https://geoservices.ign.fr/services-web-experts-geodesie#3390\" target=\"_blank\">les services de l’IGN</a>.\n\n# Télécommunications (antennes, réseaux)\n\n- [Arcep couverture mobile](https://www.data.gouv.fr/fr/datasets/mon-reseau-mobile/)\n- [Données ADSL et fibre](https://www.data.gouv.fr/fr/datasets/ma-connexion-internet/)\n- [Déploiement haut et très haut débit fixe](https://www.data.gouv.fr/fr/datasets/le-marche-du-haut-et-tres-haut-debit-fixe-deploiements/)\n- <a href=\"https://data.anfr.fr/anfr/visualisation/information/?id=dd11fac6-4531-4a27-9c8c-a3a9e4ec2107\" target=\"_blank\">Données sur les réseaux mobiles</a>\n- [Données sur les installations radioélectriques de plus de 5 watts](https://www.data.gouv.fr/fr/datasets/donnees-sur-les-installations-radioelectriques-de-plus-de-5-watts-1/)\n\n# Éducation\n\n- Académies\n - [Contours géographiques des académies](https://www.data.gouv.fr/fr/datasets/contours-geographiques-des-academies/)\n- Zones de vacances\n- Emplacement écoles\n - [Adresse et géolocalisation des établissements d'enseignement du premier et second degrés](https://www.data.gouv.fr/fr/datasets/adresse-et-geolocalisation-des-etablissements-denseignement-du-premier-et-second-degres-1/)\n\n# Élections\n\n- [Contours des circonscriptions des législatives](https://www.data.gouv.fr/fr/datasets/countours-des-circonscriptions-des-legislatives-nd/)\n- [Carte des circonscriptions législatives françaises (2012+)](https://www.data.gouv.fr/fr/datasets/carte-des-circonscriptions-legislatives-francaises-2012-nd/)\n- [Découpage des cantons pour les élections départementales de mars 2015](https://www.data.gouv.fr/fr/datasets/decoupage-des-cantons-pour-les-elections-departementales-de-mars-2015/)\n- [Contours détaillés des circonscriptions des législatives](https://www.data.gouv.fr/fr/datasets/contours-detailles-des-circonscriptions-des-legislatives/)\n- [Panneaux d'affichage électoral](https://www.data.gouv.fr/fr/datasets/panneaux-daffichage-electoral/)\n\n# Police, sécurité publique, sécurité civile, justice\n\nDispatcher entre droits/justice et sécurité\n\n- [Opérations coordonnées par les CROSS](https://www.data.gouv.fr/fr/datasets/operations-coordonnees-par-les-cross/) (Centres régionaux opérationnels de surveillance et de sauvetage)\n- [Liste et localisation des Secrétariats Généraux pour l'Administration du Ministère de l'Intérieur (SGAMI) en métropole](https://www.data.gouv.fr/fr/datasets/liste-et-localisation-des-sgami/)\n- [Liste des services de police accueillant du public avec géolocalisation](https://www.data.gouv.fr/fr/datasets/liste-des-services-de-police-accueillant-du-public-avec-geolocalisation/)\n- [Liste des unités de gendarmerie accueillant du public, comprenant leur géolocalisation et leurs horaires d'ouverture](https://www.data.gouv.fr/fr/datasets/liste-des-unites-de-gendarmerie-accueillant-du-public-comprenant-leur-geolocalisation-et-leurs-horaires-douverture/)\n- [Compétence territoriale gendarmerie et police nationales](https://www.data.gouv.fr/fr/datasets/competence-territoriale-gendarmerie-et-police-nationales/)\n- [Découpage des zones de sécurité prioritaires (ZSP)](https://www.data.gouv.fr/fr/datasets/decoupage-des-zones-de-securite-prioritaires-zsp-1/)\n- [Base de données des barreaux d'avocats de France](https://www.data.gouv.fr/fr/datasets/base-de-donnees-des-barreaux-davocats-de-france/)\n\n# Santé\n\n- [Don du sang](https://www.data.gouv.fr/fr/datasets/dates-et-lieux-des-collectes-de-don-du-sang/)\n- [FINESS Extraction du Fichier des établissements](https://www.data.gouv.fr/fr/datasets/finess-extraction-du-fichier-des-etablissements/)\n- [Lieux de vaccination Covid-19 (pharmacies)](https://www.data.gouv.fr/fr/datasets/lieux-de-vaccination-covid-19-pharmacies-sante-fr/)\n- [Lieux de vaccination contre la Covid-19](https://www.data.gouv.fr/fr/datasets/lieux-de-vaccination-contre-la-covid-19/)\n- [Géo'DAE - Base Nationale des Défibrillateurs](https://www.data.gouv.fr/fr/datasets/geodae-base-nationale-des-defibrillateurs/)\n- [Résultats des contrôles officiels sanitaires : dispositif d'information « Alim’confiance »](https://www.data.gouv.fr/fr/datasets/resultats-des-controles-officiels-sanitaires-dispositif-dinformation-alimconfiance/) (API sans archivage). Voir [ce jeu de données](https://www.data.gouv.fr/fr/datasets/resultats-des-controles-officiels-sanitaires-dispositif-dinformation-alimconfiance/#resource-6c6484fe-7024-452a-a156-b2effbaad598-title) pour une version avec historique et coordonnées.\n\n# Agriculture\n\n- [Registre parcellaire graphique (RPG)](https://www.data.gouv.fr/fr/datasets/registre-parcellaire-graphique-rpg-contours-des-parcelles-et-ilots-culturaux-et-leur-groupe-de-cultures-majoritaire/) : contours des parcelles et îlots culturaux et leur groupe de cultures majoritaire (**SPD**)\n- [Parcelles en Agriculture Biologique (AB) déclarées à la PAC](https://www.data.gouv.fr/fr/datasets/parcelles-en-agriculture-biologique-ab-declarees-a-la-pac/)\n- [Agriculture biologique 2008-2011 - nombre d'opérateurs engagés en agriculture biologique](https://www.data.gouv.fr/fr/datasets/agriculture-biologique-2008-2011-nombre-d-operateurs-engages-en-agriculture-biologique-30378896/) (information rapportable à une région ou un département)\n- [Délimitation Parcellaire des AOC Viticoles de l'INAO](https://www.data.gouv.fr/fr/datasets/delimitation-parcellaire-des-aoc-viticoles-de-linao/)\n\n# Patrimoine/culture/tourisme/sports\n\n- [Immeubles protégés au titre des Monuments Historiques](https://www.data.gouv.fr/fr/datasets/immeubles-proteges-au-titre-des-monuments-historiques-2/)\n- [Liste et localisation des Musées de France](https://www.data.gouv.fr/fr/datasets/liste-et-localisation-des-musees-de-france/)\n- [Liste des objets mobiliers propriété publique classés au titre des Monuments Historiques](https://www.data.gouv.fr/fr/datasets/liste-des-objets-mobiliers-propriete-publique-classes-au-titre-des-monuments-historiques/) (information rapportable à la commune via le code INSEE)\n- [Fréquentation des musées de France](https://www.data.gouv.fr/fr/datasets/frequentation-des-musees-de-france/) (à lier géographiquement avec <a href=\"https://data.culture.gouv.fr/explore/dataset/liste-et-localisation-des-musees-de-france/information/\" target=\"_blank\">ce jeu de données</a>)\n- [Liste des festivals en France](https://www.data.gouv.fr/fr/datasets/liste-des-festivals-en-france/)\n- [DATAtourisme, la base nationale des données du tourisme en Open Data](https://www.data.gouv.fr/fr/datasets/datatourisme-la-base-nationale-des-donnees-du-tourisme-en-open-data/)\n- [Données touristiques de la base DATAtourisme](https://www.data.gouv.fr/fr/datasets/donnees-touristiques-de-la-base-datatourisme/)\n- [Zones Touristiques Internationales](https://www.data.gouv.fr/fr/datasets/zones-touristiques-internationales/)\n- [Localisation des sites de fouille archéologiques de l'Inrap](https://www.data.gouv.fr/fr/datasets/localisation-des-sites-de-fouille-archeologiques-de-l-inrap-576210/)\n- [Données géocodées issues du recensement des licences et clubs auprès des fédérations sportives agréées par le ministère chargé des sports](https://www.data.gouv.fr/fr/datasets/donnees-geocodees-issues-du-recensement-des-licences-et-clubs-aupres-des-federations-sportives-agreees-par-le-ministere-charge-des-sports/)\n- [Base des lieux et équipements culturels (Basilic)](https://www.data.gouv.fr/fr/datasets/base-des-lieux-et-equipements-culturels-basilic/)\n\n# POIs\n\n- [Recensement des équipements sportifs, espaces et sites de pratiques](https://www.data.gouv.fr/fr/datasets/recensement-des-equipements-sportifs-espaces-et-sites-de-pratiques/) (soit à géocoder soit pour avoir les informations à la commune)\n- [Base permanente des équipements](https://www.data.gouv.fr/fr/datasets/base-permanente-des-equipements-1/)\n- [Liste des boîtes aux lettres de rue France métropolitaine et DOM avec heure limite de dépôt](https://www.data.gouv.fr/fr/datasets/liste-des-boites-aux-lettres-de-rue-france-metropolitaine-et-dom-avec-heure-limite-de-depot-1/)\n- [Adresses des débits de tabac](https://www.data.gouv.fr/fr/datasets/adresses-des-debits-de-tabac/)\n- [Liste des structures France services](https://www.data.gouv.fr/fr/datasets/62503e25bc0f6370f4a651ce/)\n\n# Fonds de plan\n\n## Niveau France\n\n- [Données OpenStreetMap intégrales de France Métropolitaine](https://www.data.gouv.fr/fr/datasets/donnees-openstreetmap-integrales-de-france-metropolitaine/)\n- [Fonds de carte IGN France et régions](https://www.data.gouv.fr/fr/datasets/fonds-de-carte-ign-france-et-regions-571459/) (rare cas où la donnée est en fait des PDF à réutiliser sous forme papier)\n- [BD TOPO®](https://www.data.gouv.fr/fr/datasets/bd-topo-r/) (description vectorielle 3D des éléments du territoire et de ses infrastructures)\n- [BD ORTHO®](https://www.data.gouv.fr/fr/datasets/bd-ortho-r/) (images aériennes raster)\n- [Métadonnée des photos aériennes anciennes de l'IGN](https://www.data.gouv.fr/fr/datasets/metadonnee-des-photos-aeriennes-anciennes-de-lign/)\n\n## Niveau Europe\n\n- [EuroGlobalMap - données topographiques au 1/1 000 000 couvrant 45 pays et territoires en Europe](https://www.data.gouv.fr/fr/datasets/euroglobalmap-donnees-topographiques-au-1-1-000-000-couvrant-45-pays-et-territoires-en-europe/)\n\n## Niveau Monde\n\n- [COPERNICUS - Satellite Sentinel 1A](https://www.data.gouv.fr/fr/datasets/copernicus-satellite-sentinel-1a/)\n\n## Données Monde génériques (hors [data.gouv.fr](http://data.gouv.fr/))\n\n- <a href=\"https://www.naturalearthdata.com/downloads/\" target=\"_blank\">Natural Earth Data</a>(pays, principales villes, rivières, lacs, fond de plan raster altimétrie/bathymétrie)\n- <a href=\"https://www.gebco.net/data_and_products/gridded_bathymetry_data/\" target=\"_blank\">Données bathymétriques</a>\n- <a href=\"https://registry.opendata.aws/speedtest-global-performance/\" target=\"_blank\">Speedtest by Ookla Global Fixed and Mobile Network Performance Maps</a>\n"
},
{
"alpha_fraction": 0.6511849761009216,
"alphanum_fraction": 0.6597657203674316,
"avg_line_length": 53.38518524169922,
"blob_id": "fbaecb63d1e7922d62e6f584df058ab545754283",
"content_id": "d310f7fb2df553207b00a59fcce3c0a495aea9c2",
"detected_licenses": [
"CC-BY-3.0",
"CC-BY-4.0",
"etalab-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 7493,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 135,
"path": "/pages/odu/defi_carte-scolaire.html",
"repo_name": "etalab/datagouvfr-pages",
"src_encoding": "UTF-8",
"text": "---\ntitle: Projet Carte scolaire\nkeywords:\n- university\n- open data\n- defi\n- projet\ndescription: Fiche descriptive du projet Carte scolaire\ncontent_type: html\n---\n\n <script data-udata=\"https://www.data.gouv.fr/\" src=\"https://static.data.gouv.fr/static/oembed.js\" async\n defer></script>\n <div class=\"fr-grid-row fr-grid-row--gutters fr-pt-6w\">\n <div class=\"fr-col fr-col-12 fr-col-md-6\">\n <h1>Projet : Carte scolaire</h1>\n </div>\n </div>\n\n <h2 class=\"fr-h3\">Contexte du projet</h2>\n <p><i>Description rapide des utilisateurs, de la problématique, de l'état de l'art et des besoins.</i>\n </p>\n <p>Chaque élève d’école élémentaire, de collège et de lycée général ou technologique est <b>affecté à un\n établissement\n scolaire selon son lieu de résidence</b> : il s’agit de la carte scolaire.</p>\n <p>Il est encore <b>difficile pour les parents de connaître la zone de rattachement de leur enfant</b>, ne disposant\n souvent que de listes par noms de rue. Malgré la sémantique, il existe aujourd’hui peu de représentations\n cartographiques de cette carte scolaire, et les rares exemples demeurent partiels et/ou très locaux.</p>\n <p><b>La problématique</b></p>\n <p>Ce projet portera sur deux enjeux :</p>\n <div class=\"markdown\">\n <ul>\n <li><b>Comment permettre aux parents de savoir facilement dans quel collège inscrire leur enfant ?</b></li>\n <li><b>Comment permettre à l’administration de mieux piloter l’offre en collèges sur le territoire ?</b>\n </li>\n </ul>\n </div>\n\n <h2 class=\"fr-h3\">Objectifs du projet</h2>\n <p><i>L'objectif général du projet et les impacts recherchés.</i></p>\n <p>Les travaux réalisés dans le cadre de ce projet permettront :</p>\n <div class=\"markdown\">\n <ul>\n <li>aux parents <b>d’avoir une information claire pour prendre des décisions éclairées quant à la\n scolarisation\n de leur enfant</b> ;</li>\n <li>à l’administration de <b>mieux évaluer l’offre en collège</b> (proximité, diversité, équité, qualité,\n etc.) et\n ainsi mieux piloter sa politique scolaire.\n </li>\n </ul>\n </div>\n\n <h2 class=\"fr-h3\">Réalisations possibles</h2>\n <p><i>Les types de production qui peuvent être attendus des élèves.</i></p>\n <p>Ce projet s’inscrit dans le cadre de l’Open Data University, vous êtes libres de choisir les livrables que vous\n jugerez les plus pertinents pour répondre au mieux à la problématique proposée. Voilà quelques exemples de\n réalisations possibles pour vous aider dans votre démarche, pouvant être réalisés à l’échelon territorial de\n votre choix :</p>\n <div class=\"markdown\">\n <ul>\n <li><b>Analyse de données</b> - Une analyse de l’offre en collèges. Quelques pistes : densité de collèges à\n proximité d’une adresse/dans une commune, distance des collèges à proximité, zone de chalandise d’un\n collège, inégalités dans le rattachement à un collège, corrélation avec les mobilités scolaires, etc.\n </li>\n <li><b>Edito / Traitement de données</b> - Un état des lieux des limites concernant les données (données non\n disponibles, problématiques de qualité) : zones géographiques non couvertes, etc ainsi que des\n recommandations associées.</li>\n </ul>\n </div>\n <p>Quelques cartographies en guise d’inspiration de livrables :</p>\n <div class=\"markdown\">\n <ul>\n <li><a href=\"https://cartescolaire.netlify.app/\">Carte scolaire pour Paris</a></li>\n <li><a href=\"https://capgeo.sig.paris.fr/Apps/SecteursScolaires/\">Carte scolaire pour Paris</a></li>\n <li><a\n href=\"https://loire-atlantique.maps.arcgis.com/apps/webappviewer/index.html?id=80cec632eeff426a9d5cc22c64dc9983\">Carte\n scolaire pour la Loire Atlantique</a></li>\n </ul>\n </div>\n\n <h2 class=\"fr-h3\">Aspects techniques</h2>\n <p><i>Les contraintes techniques du projet : environnement matériel et logiciel, outils de développement,\n méthodologies, ressources de calcul, etc.</i></p>\n <p>De nombreuses données ouvertes sont mises à votre disposition par l’équipe de l’Open Data University pour vous\n aider à\n répondre au projet proposé. Cette liste constitue une première base à exploiter dans le cadre du projet, elle\n est\n non exhaustive et nous vous encourageons à explorer davantage de données ouvertes :</p>\n <div class=\"udata-oembed--border-bottom\" data-udata-dataset=\"annuaire-de-leducation\"></div>\n <div class=\"udata-oembed--border-bottom\" data-udata-dataset=\"carte-scolaire-des-colleges-publics\"></div>\n <div class=\"udata-oembed--border-bottom\"\n data-udata-dataset=\"adresse-et-geolocalisation-des-etablissements-denseignement-du-premier-et-second-degres-1\">\n </div>\n <div class=\"udata-oembed--border-bottom\" data-udata-dataset=\"diplome-national-du-brevet-par-etablissement\"></div>\n <div class=\"udata-oembed--border-bottom\"\n data-udata-dataset=\"indices-de-position-sociale-dans-les-colleges-de-france-metropolitaine-et-drom\"></div>\n <div class=\"udata-oembed--border-bottom\" data-udata-dataset=\"base-adresse-nationale\"></div>\n <div class=\"udata-oembed--border-bottom\" data-udata-dataset=\"admin-express\"></div>\n\n <p>Ces <a href=\"https://www.insee.fr/fr/information/2383343\">données sur les mobilités scolaires (domicile-lieu\n d'études)</a> pourront également être utiles.</p>\n\n <h2 class=\"fr-h3 fr-mb-1w\">Les travaux déjà réalisés par des étudiants et étudiantes</h2>\n <div class=\"fr-my-2w fr-grid-row fr-grid-row--gutters\">\n <div class=\"udata-oembed--border-bottom fr-col-lg-3 fr-col-sm-6 fr-col-12\"\n data-udata-reuse=\"bordeaux-une-inegalitaire-sectorisation-des-colleges\">\n </div>\n </div>\n\n\n <h2 class=\"fr-h3\">Moyens mis à disposition par l'Open Data University</h2>\n <p>Ce projet s'inscrit dans le cadre de l'Open Data University, un dispositif imaginé par <a\n href=\"https://www.latitudes.cc/\">l'association Latitudes</a> et soutenu par <a\n href=\"https://www.numerique.gouv.fr/\">la Direction Interministérielle du numérique</a>.</p>\n <p>En tant que participante ou participant à l'Open Data University, seront mis à disposition :</p>\n <div class=\"markdown\">\n <ul>\n <li>des webinaires sur l'open data ;</li>\n <li>des mentors open data de la communauté Latitudes ;</li>\n <li>une plateforme d'échange avec les autres équipes de l'Open Data University ;</li>\n <li>un concours inter-établissements.</li>\n </ul>\n </div>\n\n <h2 class=\"fr-h3\">Contacts et informations</h2>\n <p>Pour toute question sur Latitudes, le programme Open Data University ou ce projet, vous pouvez <a\n href=\"mailto:[email protected]\">contacter l'équipe</a>.</p>\n\n <div class=\"fr-col-12 fr-mb-4w\" style=\"text-align:center\">\n <a class=\"fr-btn fr-btn--primary fr-mt-4w\" href=\"https://www.data.gouv.fr/fr/pages/odu/home/\">Revenir sur la\n page\n d'accueil de l'Open Data University</a>\n </div>\n </div>\n"
}
] | 19 |
beimingmaster/CarND-Behavioral-Cloning-P3 | https://github.com/beimingmaster/CarND-Behavioral-Cloning-P3 | ab38d0c4a2c73b43fe899f00e4dfeeb374a1c25c | 7140ff2db36c7f1d5be0b18d9dd52aaca6beaf5a | 6767b8802c4a12c4b18494c9962537c2e08cd800 | refs/heads/master | 2021-09-21T18:02:32.963134 | 2018-02-26T10:44:55 | 2018-02-26T10:44:55 | 112,448,698 | 0 | 0 | null | 2017-11-29T08:35:50 | 2017-11-27T16:09:31 | 2017-11-19T03:15:54 | null | [
{
"alpha_fraction": 0.6411416530609131,
"alphanum_fraction": 0.6761225461959839,
"avg_line_length": 31.647727966308594,
"blob_id": "cae92b1639d3e558eaec419f8aba99faf35d1ea7",
"content_id": "4be30f2e0ea0496ef7ee7a0b725e9ebbf5829e94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5746,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 176,
"path": "/model.py",
"repo_name": "beimingmaster/CarND-Behavioral-Cloning-P3",
"src_encoding": "UTF-8",
"text": "import os\nimport csv\nimport cv2\nimport numpy as np \n\nfrom keras.models import Sequential\nfrom keras.layers import Flatten, Dense, MaxPool2D, Conv2D, Dropout, Lambda, Cropping2D\nfrom keras.callbacks import ModelCheckpoint\nfrom keras.utils import plot_model\n\ndef create_nvidia_model(input_shape, output_shape, drop_out=1.0):\n\tprint('creating nvidia model ...')\n\tmodel = Sequential()\n\n\tmodel.add(Cropping2D(cropping=((50, 20), (0, 0)), input_shape=input_shape))\n\n\tmodel.add(Lambda(lambda x: (x / 255.0) - 0.5, input_shape=input_shape))\t\n\n\tmodel.add(Conv2D(filters=24, kernel_size=(5, 5), padding='valid', strides=(2, 2), activation='relu'))\n\t#model.add(MaxPool2D(pool_size=(2, 2)))\n\tmodel.add(Dropout(drop_out))\n\t\n\tmodel.add(Conv2D(filters=36, kernel_size=(5, 5), padding='valid', strides=(2, 2), activation='relu'))\n\t#model.add(MaxPool2D(pool_size=(2, 2)))\n\tmodel.add(Dropout(drop_out))\n\n\tmodel.add(Conv2D(filters=48, kernel_size=(5, 5), padding='valid', strides=(2, 2), activation='relu'))\n\t#model.add(MaxPool2D(pool_size=(2, 2)))\n\tmodel.add(Dropout(drop_out))\n\n\tmodel.add(Conv2D(filters=64, kernel_size=(3, 3), padding='valid', strides=(1, 1), activation='relu'))\n\t#model.add(MaxPool2D(pool_size=(2, 2)))\n\tmodel.add(Dropout(drop_out))\n\n\tmodel.add(Conv2D(filters=64, kernel_size=(3, 3), padding='valid', strides=(1, 1), activation='relu'))\n\t#model.add(MaxPool2D(pool_size=(2, 2)))\n\tmodel.add(Dropout(drop_out))\n\n\tmodel.add(Flatten())\n\n\tmodel.add(Dense(100, activation='relu'))\n\t#model.add(Dropout(drop_out))\n\n\tmodel.add(Dense(50, activation='relu'))\n\t#model.add(Dropout(drop_out))\n\n\tmodel.add(Dense(10, activation='relu'))\n\t#model.add(Dropout(drop_out))\n\n\t#model.add(Dense(10, activation='relu'))\n\n\tmodel.add(Dense(1))\n\t\n\tprint('model summary: ', model.summary())\n\t\n\treturn model\n\ndef create_vgg_model(input_shape, output_shape):\n\tprint('creating vgg model ...')\n\ndef create_lenet_model(input_shape, output_shape):\n\tprint('creating letnet model ...')\n\t\ndef train_model(model, X_train, y_train, batch_size, split_rate, shuffle, epochs, model_path=None):\n\tprint('training model ...')\n\tmodel.compile(loss = 'mse', optimizer = 'adam')\n\tif model_path:\n\t\tcheckpointer = ModelCheckpoint(filepath=model_path, verbose=1, save_best_only=True)\n\t\tmodel.fit(X_train, y_train, batch_size=batch_size, validation_split=split_rate, shuffle=shuffle, epochs=epochs, callbacks=[checkpointer])\n\telse:\n\t\tmodel.fit(X_train, y_train, batch_size=batch_size, validation_split=split_rate, shuffle=shuffle, epochs=epochs)\n\ndef load_data(data_path):\n\tprint('loading data ...')\n\t\n\tlines = []\n\timages = []\n\tmeasurements = []\n\n\t#reading csv file\n\twith open('%s/%s' % (data_path, 'driving_log.csv')) as f:\n\t\treader = csv.reader(f)\n\t\tfor line in reader:\n\t\t\t#print('line: ', line)\n\t\t\tlines.append(line)\n\n\t#parsing data\n\tfor line in lines:\n\t\t#print('line: ', line)\n\t\tcenter_image_path = line[0].strip().split('/')[-1]\n\t\tleft_image_path = line[1].strip().split('/')[-1]\n\t\tright_image_path = line[2].strip().split('/')[-1]\n\n\t\t#print('center image path: %s' % center_image_path)\n\t\t#print('left image path: %s' % left_image_path)\n\t\t#print('right image path: %s' % right_image_path)\n\n\t\tcenter_image = cv2.imread('%s/IMG/%s' % (data_path, center_image_path))\n\t\tleft_image = cv2.imread('%s/IMG/%s' % (data_path, left_image_path))\n\t\tright_image = cv2.imread('%s/IMG/%s' % (data_path, center_image_path))\n\t\t\n\t\t#scale\n\t\t#print('center image size: ', center_image.shape)\n\t\t#print('left image size: ', left_image.shape)\n\t\t#print('right image size: ', right_image.shape)\n\n\t\t#center_image = cv2.resize(center_image, (0, 0), fx = 0.5, fy = 0.5)\n\t\t#left_image = cv2.resize(left_image, (0, 0), fx = 0.5, fy = 0.5)\n\t\t#right_image = cv2.resize(right_image, (0, 0), fx = 0.5, fy = 0.5)\n\n\t\timages.append(center_image)\n\t\timages.append(left_image)\n\t\timages.append(right_image)\n\n\t\tcenter_measurement = float(line[3])\n\t\tleft_measurement = center_measurement + 0.2\n\t\tright_measurement = center_measurement - 0.2\n\t\t\n\t\t#if left_measurement > 1.0:\n\t\t#\tleft_measurement = 1.0\n\t\t\n\t\t#if right_measurement < -1.0:\n\t\t#\tright_measurement = -1.0\n\n\t\tmeasurements.append(center_measurement)\n\t\tmeasurements.append(left_measurement)\n\t\tmeasurements.append(right_measurement)\n\t\n\tprint('count of images: ', len(images))\t\n\tprint('count of measurements: ', len(measurements))\n\t\n\treturn images, measurements\n\ndef main():\n\timages, measurements = load_data('./my_data/20171205/left2center')\n\t#images, measurements = load_data('./data')\n\n\tX_train = np.array(images)\n\ty_train = np.array(measurements)\n\n\t#data augmentation\n\taug_x = []\n\taug_y = []\n\tsize = len(X_train)\n\tfor i in range(size):\n\t\tx = X_train[i]\n\t\ty = y_train[i]\n\t\taug_x.append(np.fliplr(x))\n\t\taug_y.append(-y)\t\n\t\n\tX_train = np.vstack((X_train, np.array(aug_x)))\n\ty_train = np.hstack((y_train, np.array(aug_y)))\n\n\t#cv2.imwrite('./output_images/source_100.jpg', X_train[100])\n\t#cv2.imwrite('./output_images/flip_100.jpg', aug_x[100])\n\t#cv2.imwrite('./output_images/source_1000.jpg', X_train[1000])\n\t#cv2.imwrite('./output_images/flip_1000.jpg', aug_x[1000])\n\t#cv2.imwrite('./output_images/source_10000.jpg', X_train[10000])\n\t#cv2.imwrite('./output_images/flip_10000.jpg', aug_x[10000])\n\n\tprint('mean: %.3f, min: %.3f, max: %.3f' % (np.mean(y_train), np.min(y_train), np.max(y_train)))\n\tprint('size of X_train: %d, size of y_train: %d' % (len(X_train), len(y_train)))\n\tinput_shape = X_train.shape[1:]\n\toutput_shape = 1\n\tprint('image shape: ', input_shape)\n\tmodel = create_nvidia_model(input_shape, output_shape, 0.5)\n\n\t#plot_model(model, to_file='model.png', show_shapes=True)\n\n\tmodel_path = 'model.h5'\n\tif os.path.isfile(model_path):\n\t\tmodel.load_weights(model_path)\n\ttrain_model(model, X_train, y_train, 128, 0.2, True, 20, model_path)\n\nif __name__ == '__main__':\n\tmain()\n"
}
] | 1 |
YihanKim/cifar10-knn | https://github.com/YihanKim/cifar10-knn | e7c55965ad2eac951a9cd2c3cf4340520a5984b6 | 3e9fa5432cad1692c11b2945e08d00db8394b3d0 | f9263f5be8fda06eb08ca9ffafaa7733ea191a82 | refs/heads/master | 2020-03-28T20:31:56.542955 | 2018-09-19T03:30:50 | 2018-09-19T03:53:20 | 149,079,353 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6111999750137329,
"alphanum_fraction": 0.6424000263214111,
"avg_line_length": 27.712644577026367,
"blob_id": "bba7b9c26775fb219ac066594329f69fa20dfcbe",
"content_id": "057d6df506af3b13ebb1d98cdabe11fb158e1e66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2500,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 87,
"path": "/main.py",
"repo_name": "YihanKim/cifar10-knn",
"src_encoding": "UTF-8",
"text": "\nimport math\nimport numpy as np\n\n# import knn model from \"model.py\"\nfrom model import KNearestNeighbor\n\n\n### 1. Data reading\n\n# Data truncation constant\n\n# DATA_TRAIN TOTAL_READ\n# | DATA_USE |\n# 0 | | |\n# --------------------------------\n# | TRAIN | VAL | .. |\n# --------------------------------\n\nDATA_USE = 50000 \t\t\t# max 50000\nDATA_VALIDATE = 100\t\t\t# should be greater than 0, less than DATA_USE\nDATA_TRAIN = DATA_USE - DATA_VALIDATE\n\nDATA_BATCH_SIZE = 10000\t\t# unit batch size\n\n# CIFAR-10 Data reader\n# (from https://www.cs.toronto.edu/~kriz/cifar.html)\n\ndef unpickle(file):\n\t'''\n\tThe archive contains the files data_batch_1, ..., data_batch_5, as well as test_batch. \n\tEach of these files is a Python \"pickled\" object produced with cPickle.\n\t'''\n\timport pickle\n\twith open(file, 'rb') as fo:\n\t\tdict = pickle.load(fo, encoding='bytes')\n\treturn dict\n\n# Each data batch has 10,000 images recorded as 3,072(= 32 * 32 * 3) integers.\n# Read data as much as we need (<= 50000, determined by value of DATA_USE),\n# and save it(data and labels) to the X_rows and Y respectively.\n\nX_rows = []\nY = []\n\nfor i in range(1, 1 + math.ceil(DATA_USE / DATA_BATCH_SIZE)):\n\tdata = unpickle(\"data/data_batch_%s\" % str(i))\n\tX_rows += list(data[b'data'])\n\tY += list(data[b'labels'])\n\nX_rows = np.asarray(X_rows)\t\nY = np.asarray(Y)\n\n# Each row vector in X contains 3,072 integer belongs to 0 to 255.\n# Y contains integer from 0 to 9, which indicates 10 classes in CIFAR-10.\n# if Y[i] == Y[j] for i != j, \n# X[i] and X[j] represents the different object in same class(such as car).\n\n\n### 2. Data splitting\n\n# Now, split the data and the labels into training set and validation set.\n# CIFAR-10 batch data has mixed order of class, so we don't need to shuffle it. \n\nXtr_rows = X_rows[:DATA_TRAIN]\nYtr = Y[:DATA_TRAIN]\n\nXval_rows = X_rows[DATA_TRAIN:DATA_USE]\nYval = Y[DATA_TRAIN:DATA_USE]\n\n\n### 3. Running k-NN model\n\n# Use k-NN classifier for CIFAR-10\n\ncifar_knn = KNearestNeighbor() # kNN model defined in \"model.py\"\ncifar_knn.train(Xtr_rows, Ytr) # give training data into model\nvalidation_accuracies = []\n\nfor k in [1, 3, 5, 10, 20, 50, 100]:\n\tYval_predict = cifar_knn.predict(Xval_rows, k = k)\n\tacc = np.mean(Yval_predict == Yval)\n\tprint ('accuracy for k = %s: %f' % (k, acc))\n\t# use a particular value of k and evaluation on validation data\n\tvalidation_accuracies.append((k, acc))\n\nprint(\"running results: \", end=\"\")\nprint(validation_accuracies)\n\n"
},
{
"alpha_fraction": 0.6359270215034485,
"alphanum_fraction": 0.6469740867614746,
"avg_line_length": 31.015384674072266,
"blob_id": "81ce055b15519c16fe89bf09757ff8ed13fd1d7c",
"content_id": "1ccfd87ee49324a58fc375acfe2525cf2c69ed50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2082,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 65,
"path": "/model.py",
"repo_name": "YihanKim/cifar10-knn",
"src_encoding": "UTF-8",
"text": "\nimport numpy as np\n\n# K-Nearest Neighbor Class\n# (from http://cs231n.github.io/classification/, modified slightly)\n\nclass KNearestNeighbor(object):\n\t'''\n\tK-nearest Neighbor class\n\t\n\ttrain : Saves training data(lists of data and its labels). That's it.\n\tpredict : Consumes data list and parameter k, return list of predicted class number\n\t'''\n\tdef __init__(self):\n\t\t# do nothing\n\t\tpass\n\n\tdef train(self, X, y):\n\t\t\"\"\" \n\t\tX is N x D where each row is an example. \n\t\tY is 1-dimension of size N \n\t\treturn None\n\t\t\"\"\"\n\t\t# the nearest neighbor classifier simply remembers all the training data\n\t\tself.Xtr = X\n\t\tself.ytr = y\n\t\treturn\n\n\tdef predict(self, X, k = 1):\n\t\t\"\"\" \n\t\tX is N x D where each row is an example we wish to predict label for.\n\t\tk is hyperparameter; the number of neighbors that use to predict.\n\t\treturn list of class indices with length N.\n\t\t\"\"\"\n\t\tnum_test = X.shape[0]\n\t\t# lets make sure that the output type matches the input type\n\t\tYpred = np.zeros(num_test, dtype = self.ytr.dtype)\n\n\t\t# loop over all test rows\n\t\tfor i in range(num_test):\n\t\t\t# find the nearest training image to the i'th test image\n\t\t\t# using the L1 distance (sum of absolute value differences)\n\t\t\t# You can change distance function as you need.\n\t\t\t# -----------------------\n\t\t\tdistances = np.sum(np.abs(self.Xtr - X[i,:]), axis = 1)\n\t\t\t# distances = np.sum(np.square(self.Xtr - X[i, :]), axis = 1)\n\t\t\t# -----------------------\n\t\t\t\n\t\t\tnearest_indices = distances.argsort()[:k]\n\t\t\tnearest_distances = distances[nearest_indices]\n\t\t\t\n\t\t\t# List \"nearest_label\" have form [3, 4, 8, 3, 1] (when k = 5), \n\t\t\t# and function should return 3 in that case.\n\t\t\tnearest_labels = self.ytr[nearest_indices]\n\t\t\t\n\t\t\t# You have to implement strategy in case of nearest_label have multiple majority.\n\t\t\t# (ex. top 5 nearest neighbors are [3, 3, 4, 9, 4])\n\t\t\t# select predictions from prediction list \n\n\t\t\t# implement kNN using nearest_indices and nearest_distances below.\n\t\t\t# ----------------------\n\t\t\t# it only returns first nearest element.\n\t\t\tYpred[i] = nearest_labels[0]\n\t\t\t# ----------------------\n\n\t\treturn Ypred\n"
}
] | 2 |
Playfish/youbot | https://github.com/Playfish/youbot | 394e51e2a50958d7647210f91f13a2b6b61f0286 | 1e8f3956e094c27c14821e8b6b870bacce3ced3c | 01d9de825888af55700f24128897dc269e5b4f56 | refs/heads/master | 2020-07-15T00:38:16.991636 | 2017-06-14T07:20:29 | 2017-06-14T07:20:29 | 94,300,959 | 0 | 0 | null | 2017-06-14T07:11:12 | 2017-05-17T03:09:56 | 2015-08-06T21:53:40 | null | [
{
"alpha_fraction": 0.5754386186599731,
"alphanum_fraction": 0.5777778029441833,
"avg_line_length": 31.80769157409668,
"blob_id": "4b345faf301fde788014d6f8fa42737f230a5e0a",
"content_id": "4cd856ba81efff8b8e3f063c19c2178848760741",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 855,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 26,
"path": "/youbot_apps/src/robotproxy/test/test.py",
"repo_name": "Playfish/youbot",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n\nimport robotproxy\nimport sys\nimport rospy\n\nif __name__ == \"__main__\":\n# try:\n #print \"Running unit tests\"\n #print \"Joint position definition test +++++++++++++++++\"\n #robotproxy.test_joint_pose_defs()\n #print \"Command list test +++++++++++++++++\"\n #robotproxy.test_commands_list()\n #print \"Youbot Gazebo load config files +++++++++++++++++\"\n #robotproxy.test_load_control_plan()\n #print \"Youbot Gazebo proxy test load +++++++++++++++++\"\n #robotproxy.test_youbot_gazebo_proxy_move()\n print \"Youbot Gazebo proxy test exec +++++++++++++++++\"\n robotproxy.test_youbot_gazebo_proxy_exec() \n print \"Done +++++++++++++++++\"\n robotproxy.moveit_commander.os._exit(0)\n# except Exception as e:\n# rospy.logerr(str(e))\n# robotproxy.moveit_commander.os._exit(0)\n# sys.exit()\n\n\n"
},
{
"alpha_fraction": 0.7666666507720947,
"alphanum_fraction": 0.7666666507720947,
"avg_line_length": 30,
"blob_id": "4e0c17de9e2c5f1ea4a61f02520185de8d6ac2fc",
"content_id": "e657197d7d3c36b7ee2979f8ff9e037bd6e78e53",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30,
"license_type": "permissive",
"max_line_length": 30,
"num_lines": 1,
"path": "/youbot_apps/test/test.py",
"repo_name": "Playfish/youbot",
"src_encoding": "UTF-8",
"text": "../src/robotproxy/test/test.py"
},
{
"alpha_fraction": 0.7734928131103516,
"alphanum_fraction": 0.7773981094360352,
"avg_line_length": 37.990474700927734,
"blob_id": "52a4ea454c502957fb8f79722cc1277cab26b733",
"content_id": "17f8e8be35cd0944a3e2941884d1c88babc770d7",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4097,
"license_type": "permissive",
"max_line_length": 419,
"num_lines": 105,
"path": "/README.md",
"repo_name": "Playfish/youbot",
"src_encoding": "UTF-8",
"text": "Package: youbot\n================\nAuthor: Rick Candell <br>\nContact: [email protected] <br>\nLicense: Public Domain\n\n# Overview\nThis repository contains many different ROS packages required to run the youbot in simulation and with the actual robot.\n\n# Package Contents\n\n- **youbot_description**\nThis package contains all of the URDF and XACRO files that describe the build and kinematics of the robot. Some minor changes have been made from the original debian release.\n\n- **youbot_moveit**\nThis package was created using the MoveIt! Setup Assistant. \n\n- **youbot_msgs**\nThis package contains custom message definitions used by the youbot applications.\n\n- **youbot_apps**\nThis package contains scripts and launch files to run the robot under gazebo or with the hardware. This package also contains a core python package for controlling multiple youbots using modules in the *robot_proxy* package. \n\n- **twoarm_cage**\nThis package contains all scripts, launch files, and configuration required to run a two arm collaborative experimental platform in the NIST security lab. Robots under this configuraiton are controlled using independent PC's with a remote ROS master. Three computers are typically required under this configuration; although, with minor modifications, a single computer with a two-arm driver could be used.\n\n# Installation\n- Install Ubuntu 12.04 [http://releases.ubuntu.com/12.04/](http://releases.ubuntu.com/12.04/)\n\n- Install ROS Hydro [http://wiki.ros.org/hydro/Installation/Ubuntu](http://wiki.ros.org/hydro/Installation/Ubuntu)\n\n- Install ROS dependencies: This list is an attempt to cover all of the dependencies required to run the python scripts and launch files included in this package. If a package has been overlooked, please notify me through email.\n\n```\nsudo apt-get update\nsudo apt-get upgrade\nsudo apt-get install ros-hydro-youbot* ros-hydro-controller-* ros-hydro-ros-control* ros-hydro-gazebo-* ros-hydro-joint-state-* ros-hydro-joint-trajectory-* ros-hydro-moveit-full\n```\n\n- Create and configure your catkin workspace. [http://wiki.ros.org/catkin/Tutorials](http://wiki.ros.org/catkin/Tutorials)\n- Install this package under your Catkin workspace. \n\n```\ncd ~/catkin_ws/src\ngit clone [this-repository-url]\n```\n\n# Running the Apps\n\n## Using Gazebo\nOpen a terminal and execute the following command. This will launch gazebo and moveit. \n\n```\nroslaunch youbot_apps gazebo.launch\n```\n\nOpen a new terminal and run:\n\n```\nroslaunch youbot_apps moveit.launch\n```\n\nOpen a new terminal and run:\n\n```\nrosrun youbot_apps youbot_gazebo_exec.py\n```\n\nThis will execute a series of poses specified in the python code. This script will only work with Gazebo. Some modification is required for interoperabililty with the Youbot hardware.\n\n## Youbot Robot (not Gazebo)\nThis is similar to the Gazebo configuration, but the internal messages are very different. The major difference between the gazebo implementation and the youbot implementation is that the Gazebo configuration uses the action server which employs a torque controller behind the scenes. Accurate trajectory following is possible with the gazebo model. Accuracy of the model to the real-world has yet to be ascertained.\n\nThe youbot-based controller uses the brics_actuator messages and a position/velocity controller hardware module in the youbot base link. A torque controller has not been developed by Kuka as of October 2014. Accuracy or repeatability testing would require a torque controller.\n\nTo run the demonstrations in the youbot apps, follow these instructions.\n\n```\nsudo bash\nroslaunch youbot_apps youbot_one_arm.launch\n```\n\nor if using two arms\n\n```\nsudo\nroslaunch youbot_apps youbot_two_arm.launch\n```\n\nThen in another terminal\n\n```\nroslaunch youbot_apps moveit.launch\n```\n\nThen in yet another terminal\n\n```\nrosrun youbot_apps selpose.py\nrosrun youbot_apps two_arm_collab_demo.py\nroslaunch youbot_apps circle_tap.launch\n```\n\n##Running the Two Arm Cage\nThis is a little more complex and requires careful configuration of the user environment. Look for the README file under the twoarm_cage package.\n\n\n\n"
},
{
"alpha_fraction": 0.7684210538864136,
"alphanum_fraction": 0.7684210538864136,
"avg_line_length": 93,
"blob_id": "cf4868a92a81a6cdb515997e8bc625a2c758e662",
"content_id": "8adada4ff35c465ad716b72cdd5d7ebf72535a9b",
"detected_licenses": [
"LicenseRef-scancode-public-domain"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 95,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 1,
"path": "/bare_repo_instructions.md",
"repo_name": "Playfish/youbot",
"src_encoding": "UTF-8",
"text": "[Refer to here](https://github.com/usnistgov/ics_general_info/blob/master/using_bare_repo.md)\n\n"
}
] | 4 |
mazlo/lodcc | https://github.com/mazlo/lodcc | 5faa31b05921b8a5175a4c0121078165d1df793a | dcc3403fe7785c9dc73f09154f397c0ff42f1920 | 97c2d9919370686a80f3a4b19b8599a89fc60f46 | refs/heads/master | 2022-03-08T06:45:16.441163 | 2021-02-12T12:36:55 | 2021-02-12T12:36:55 | 128,509,275 | 4 | 1 | null | 2018-04-07T08:13:40 | 2018-12-09T21:52:59 | 2018-12-11T13:06:51 | PLSQL | [
{
"alpha_fraction": 0.5856269001960754,
"alphanum_fraction": 0.6009174585342407,
"avg_line_length": 32.53845977783203,
"blob_id": "bce6627f84966129ff5a217d28897987f8c39329",
"content_id": "fd4d32272a0a4eed3bf55876ef6e30294280b045",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1308,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 39,
"path": "/graph/measures/fernandez_et_al/tests/test_subject_out_degrees.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import unittest\nimport unitgraphs\nimport graph.measures.fernandez_et_al.subject_out_degrees as sod\n\nclass MetricsTestCase( unittest.TestCase ):\n \"\"\"\"\"\"\n\n def setUp( self ):\n \"\"\"\"\"\"\n self.G = unitgraphs.basic_graph()\n self.stats = dict()\n\n def test_out_degree( self ):\n \"\"\"\"\"\"\n sod.out_degree( self.G, None, self.stats )\n\n self.assertEqual( self.stats['max_out_degree'], 4 )\n self.assertEqual( round( self.stats['mean_out_degree'], 2 ), 1.75 )\n\n def test_partial_out_degree( self ):\n \"\"\"\"\"\"\n sod.partial_out_degree( self.G, None, self.stats )\n\n self.assertEqual( self.stats['max_partial_out_degree'], 2 )\n self.assertEqual( round( self.stats['mean_partial_out_degree'], 2 ), 1.17 )\n\n def test_labelled_out_degree( self ):\n \"\"\"\"\"\"\n sod.labelled_out_degree( self.G, None, self.stats )\n\n self.assertEqual( self.stats['max_labelled_out_degree'], 3 )\n self.assertEqual( round( self.stats['mean_labelled_out_degree'], 2 ), 1.50 )\n\n def test_direct_out_degree( self ):\n \"\"\"\"\"\"\n sod.direct_out_degree( self.G, None, self.stats )\n\n self.assertEqual( self.stats['max_direct_out_degree'], 4 )\n self.assertEqual( round( self.stats['mean_direct_out_degree'], 2 ), 1.75 )\n"
},
{
"alpha_fraction": 0.7056229114532471,
"alphanum_fraction": 0.7056229114532471,
"avg_line_length": 42.19047546386719,
"blob_id": "64f6549b5471a24d00d4e5d65e152e9af8f4b3e1",
"content_id": "1573bea273c0d16075087a6ec8a3d7b691b9d8f5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 907,
"license_type": "permissive",
"max_line_length": 274,
"num_lines": 21,
"path": "/graph/tasks/edgelists/merge.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging\nimport os\nimport re\n\nfrom graph.building.edgelist import merge_edgelists\n\nlog = logging.getLogger( __name__ )\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description = 'lodcc task - Merges edgelists created by individual RDF dataset files into a combined data.edgelist.csv file. This is an internal helper function. If you do not know what you are doing, use graph.tasks.prepare instead.' )\n parser.add_argument( '--from-file', '-ffl', nargs='+', required = True, help = '' )\n parser.add_argument( '--rm-edgelists', '-re', action = \"store_true\", help = 'Remove intermediate edgelists, obtained from individual files, after creating a combined data.edgelist.csv file. Default False.' )\n\n args = vars( parser.parse_args() )\n dataset_names = args['from_file']\n\n merge_edgelists( dataset_names, args['rm_edgelists'] )\n\n log.info( 'done' )\n"
},
{
"alpha_fraction": 0.6480262875556946,
"alphanum_fraction": 0.6480262875556946,
"avg_line_length": 42.42856979370117,
"blob_id": "364f7df1f26e4d46360cc96a5a9238e9ca110005",
"content_id": "f64dc532be990458eb0f8ea18271050bfcfaccdd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 304,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 7,
"path": "/constants/edgelist.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "FORMAT_EDGELIST_FILE_ENDING_REGEX = '.edgelist.csv$'\nFORMAT_CSV_FILE_ENDING_REGEX = '.csv$'\nFORMAT_NT_FILE_ENDING_REGEX = '.nt$'\n\nSUPPORTED_FORMATS = { 'edgelist' : FORMAT_EDGELIST_FILE_ENDING_REGEX, \\\n 'csv' : FORMAT_CSV_FILE_ENDING_REGEX, \\\n 'nt' : FORMAT_NT_FILE_ENDING_REGEX }\n"
},
{
"alpha_fraction": 0.6688181757926941,
"alphanum_fraction": 0.6701535582542419,
"avg_line_length": 43.48514938354492,
"blob_id": "49f3fe06bf097a25c7b6b55dfea3e7d910d7514b",
"content_id": "c99714f3ac657f0828ffe2e3bb7a171f6e33212c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4493,
"license_type": "permissive",
"max_line_length": 283,
"num_lines": 101,
"path": "/graph/tasks/README.md",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "## `graph.tasks`\n\nThis package contains executable code for *preparing* a graph-based analysis on the graph topology of RDF datasets. \n\n---\n\n**Note that**, although it is possible and a reasonable use case to use code without preliminary preparation with the framework, it is still advisable. It facilitates a lot of things, especially when using a database to perform a large-scale analysis on several datasets in parallel.\n\n---\n\n### RDF Dataset Preparation\n\n#### Preparation _without_ a database\n\nTo prepare a small bunch of RDF datasets for graph analysis you do not need a database. However, a database enables our framework to look up and store required information, such as the URL and available media types of the RDF dataset that you want to prepare.\n\n---\n\n**Note:** When using the framework without a database, you have to downloaded the RDF dataset beforehand, as the framework does not have the information about where to download it from.\n\n---\n\nTo start the preparation use the following command:\n\n```sh\n$ python3 -m graph.tasks.prepare --from-file lexvo lexvo_latest.rdf.gz rdfxml\n```\n\n**Convention:** The framework will use the `ROOT/dumps/<dataset name>`-folder to read and write corresponding files during execution. \n\n---\n\nAlong with the dataset name you have to pass the name of the main source file of the RDF dump and the correspong format. See `--help` below for details.\n\nAfter this step the framework will have created a combined and concise *edgelist*, a file that contains per line one labelled edge in the graph structure, of all RDF data related files found in the source file.\n\n---\n\n**Convention:** The framework will name the combined file `data.edgelist.csv`. \n\n---\n\n#### Preparation _with_ a database\n\nWhen working with a large set of datasets it is advisable to use a database to persist some required data for graph instantiation and graph analysis. You can use the `--from-db` command-line parameter for that. For example,\n\n```sh\n$ python3 -m graph.tasks.prepare --from-db webisalod ecd-linked-data asn-us\n```\n\nDatabase configuration will be read from `ROOT/constants/db.py` file.\n\n---\n\n**Convention:** The framework will use the `ROOT/dumps/<dataset name>`-folder to read and write corresponding files during execution. \n\n---\n \n\n#### `prepare.py`\n\n`--help` gives you an explanation about the available options.\n\n```sh\n$ python3 -m graph.tasks.prepare --help\nusage: prepare.py [-h]\n (--from-file FROM_FILE [FROM_FILE ...] | --from-db FROM_DB [FROM_DB ...])\n [--overwrite-dl] [--overwrite-nt] [--rm-original]\n [--keep-edgelists] [--log-debug] [--log-info] [--log-file]\n [--threads THREADS]\n\nlodcc - A software framework to prepare and perform a large-scale graph-based analysis on the graph topology of RDF datasets.\n\noptional arguments:\n -h, --help Show this help message and exit\n --from-file FROM_FILE [FROM_FILE ...], -ffl FROM_FILE [FROM_FILE ...]\n Pass a list of dataset names to prepare. Please pass\n the filename and media type too. Leave empty to get\n further details about this parameter.\n --from-db FROM_DB [FROM_DB ...], -fdb FROM_DB [FROM_DB ...]\n Pass a list of dataset names. Filenames and media\n types are loaded from database. Specify details in\n constants/db.py and db.sqlite.properties.\n --overwrite-dl, -ddl Overwrite RDF dataset dump if already downloaded.\n Default False.\n --overwrite-nt, -dnt Overwrite transformed files used to build the graph\n from. Default False.\n --rm-original, -dro Remove the initially downloaded RDF dataset dump file.\n Default False.\n --keep-edgelists, -dke\n Remove intermediate edgelists, obtained from\n individual files. A combined data.edgelist.csv file\n will be generated nevertheless. Default False.\n --log-debug, -ld Show logging.DEBUG state messages. Default False.\n --log-info, -li Show logging.INFO state messages. Default True.\n --log-file, -lf Log into a file named \"lodcc.log\".\n --threads THREADS, -pt THREADS\n Number of CPU cores/datasets to use in parallel for\n preparation. Handy when working with multiple\n datasets. Default 1. Max 20.\n```\n"
},
{
"alpha_fraction": 0.8107666969299316,
"alphanum_fraction": 0.8107666969299316,
"avg_line_length": 67.11111450195312,
"blob_id": "9f447e4ee0269e0f7d243fe6cea17ff73cff3017",
"content_id": "19e3c5fd9513d629ff59d17fd8a9b0a616b21e5c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1226,
"license_type": "permissive",
"max_line_length": 168,
"num_lines": 18,
"path": "/graph/measures/fernandez_et_al/all.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import graph.measures.fernandez_et_al.subject_out_degrees as subject_out_degrees\nfrom graph.measures.fernandez_et_al.subject_out_degrees import *\nimport graph.measures.fernandez_et_al.object_in_degrees as object_in_degrees\nimport graph.measures.fernandez_et_al.predicate_degrees as predicate_degrees\nimport graph.measures.fernandez_et_al.common_ratios as ratios\nimport graph.measures.fernandez_et_al.predicate_lists as predicate_lists\nfrom graph.measures.fernandez_et_al.predicate_lists import *\nimport graph.measures.fernandez_et_al.typed_subjects_objects as typed_subjects_objects\nfrom graph.measures.fernandez_et_al.typed_subjects_objects import *\n\nall = subject_out_degrees.METRICS + object_in_degrees.METRICS + predicate_degrees.METRICS + ratios.METRICS + predicate_lists.METRICS + typed_subjects_objects.METRICS\nLABELS = subject_out_degrees.LABELS + object_in_degrees.LABELS + predicate_degrees.LABELS + ratios.LABELS + predicate_lists.LABELS + typed_subjects_objects.LABELS\nSETS = {}\nSETS.update( subject_out_degrees.METRICS_SET )\nSETS.update( object_in_degrees.METRICS_SET )\nSETS.update( predicate_degrees.METRICS_SET )\nSETS.update( predicate_lists.METRICS_SET )\nSETS.update( typed_subjects_objects.METRICS_SET )\n"
},
{
"alpha_fraction": 0.6653143763542175,
"alphanum_fraction": 0.6673427820205688,
"avg_line_length": 36.92307662963867,
"blob_id": "f11d7a6033d2603e41fb9a92269fbd3c84d0fafb",
"content_id": "3fb39f89318967de1c96bc2650783441d4fee813",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 986,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 26,
"path": "/graph/measures/core/clustering.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging \n\nfrom graph_tool.clustering import global_clustering, local_clustering\nfrom graph_tool.stats import vertex_average\n\nlog = logging.getLogger( __name__ )\n\ndef f_global_clustering( U, stats, options={ 'features': [], 'skip_features': [] } ):\n \"\"\"\"\"\"\n\n if not 'global_clustering' in options['features'] or ('skip_features' in options and 'global_clustering' in options['skip_features']):\n log.debug( 'Skipping global_clustering' )\n return\n\n stats['global_clustering']=global_clustering(U)[0]\n log.debug( 'done global_clustering' )\n\ndef f_local_clustering( D, stats, options={ 'features': [], 'skip_features': [] } ):\n \"\"\"\"\"\"\n \n if not 'local_clustering' in options['features'] or ('skip_features' in options and 'local_clustering' in options['skip_features']):\n log.debug( 'Skipping local_clustering' )\n return\n\n stats['local_clustering']=vertex_average(D, local_clustering(D))[0]\n log.debug( 'done local_clustering' )\n"
},
{
"alpha_fraction": 0.6229656338691711,
"alphanum_fraction": 0.6265822649002075,
"avg_line_length": 33.5625,
"blob_id": "1cb17bbd3d43752af4c848bdf7826c5ccdb75e5d",
"content_id": "0599058c61373022c61e25e8e27299d0be79f9ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1106,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 32,
"path": "/graph/measures/core/edge_based.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\n\nfrom graph_tool import GraphView\nfrom graph_tool.topology import edge_reciprocity, label_largest_component, pseudo_diameter\n\nlog = logging.getLogger( __name__ )\n\ndef f_reciprocity( D, stats, options={ 'features': [] } ):\n \"\"\"\"\"\"\n\n if 'reciprocity' in options['features']:\n stats['reciprocity']=edge_reciprocity(D)\n log.debug( 'done reciprocity' )\n\ndef f_pseudo_diameter( D, stats, options={ 'features': [] } ):\n \"\"\"\"\"\"\n\n LC = label_largest_component(D)\n LCD = GraphView( D, vfilt=LC )\n\n if 'diameter' in options['features']:\n if LCD.num_vertices() == 0 or LCD.num_vertices() == 1:\n # if largest component does practically not exist, use the whole graph\n dist, ends = pseudo_diameter(D)\n else:\n dist, ends = pseudo_diameter(LCD)\n\n stats['pseudo_diameter']=dist\n # D may be used in both cases\n stats['pseudo_diameter_src_vertex']=D.vertex_properties['name'][ends[0]]\n stats['pseudo_diameter_trg_vertex']=D.vertex_properties['name'][ends[1]]\n log.debug( 'done pseudo_diameter' )\n"
},
{
"alpha_fraction": 0.5793163776397705,
"alphanum_fraction": 0.5836985111236572,
"avg_line_length": 25.534883499145508,
"blob_id": "eb7a33928d7efc5e40ae374138d81a446fd6e3eb",
"content_id": "1b397f54ab74442ccd0255a58f13388d3a69ebcb",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1141,
"license_type": "permissive",
"max_line_length": 107,
"num_lines": 43,
"path": "/bin/merge_edgelists.sh",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nFOLDER_ROOT=${1:-\"dumps/\"}\nRM_EDGELISTS=${2:-true}\n\n# remove backslash from FOLDER if present\nif [[ \"${FOLDER_ROOT%/}\" != \"$FOLDER_ROOT\" ]]; then\n FOLDER_ROOT=${FOLDER_ROOT%/}\nfi\n\nFILES_COUNT=`find \"$FOLDER_ROOT\" -name \"*.edgelist.csv\" -type f | wc -l`\n\n# remove data.edgelist, if present\nif [ $FILES_COUNT -gt 1 ]; then\n rm \"$FOLDER_ROOT/data.edgelist.csv\" &> /dev/null # ignore errors when file does not exist, for instance\nelse\n # if data.edgelist is the only file, we're fine\n if [ -f \"$FOLDER_ROOT/data.edgelist.csv\" ]; then\n exit 0\n else\n # else take that one edgelist file and rename it\n FILE=`ls $FOLDER_ROOT/*.edgelist.csv`\n FOLDER=${FILE%/*}\n mv \"$FILE\" \"$FOLDER/data.edgelist.csv\"\n exit 0\n fi\nfi\n\nFILES=`find \"$FOLDER_ROOT\" -name \"*.edgelist.csv\" -type f`\n\nfor file in $FILES; do\n \n # ignore data.edgelist, if present\n if [[ \"${file%*/data.edgelist.csv}\" == \"$file\" ]]; then\n FOLDER=${file%/*}\n cat $file >> \"$FOLDER/data.edgelist.csv\"\n \n if [[ $RM_EDGELISTS = true ]]; then\n rm $file\n fi\n fi\n\ndone\n"
},
{
"alpha_fraction": 0.5877636075019836,
"alphanum_fraction": 0.5966736078262329,
"avg_line_length": 37.701148986816406,
"blob_id": "16d8cafca8ea4a85c94518405f7223fcb09537de",
"content_id": "75331412e6444c1e2cc891a86776cfe789db8b8e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3367,
"license_type": "permissive",
"max_line_length": 204,
"num_lines": 87,
"path": "/graph/measures/fernandez_et_al/object_in_degrees.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\n\ndef in_degree( D, edge_labels=None, stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n # the number of triples in G in which o occurs as object\n l = D.get_in_degrees( D.get_vertices() ) + 0.0\n l[l == 0] = np.nan\n\n if print_stats:\n print( \"(Eq.5) in-degree deg^{+}(o). max: %s, mean: %f\" % ( np.nanmax(l), np.nanmean(l) ) )\n\n stats['max_in_degree'], stats['mean_in_degree'] = np.nanmax(l), np.nanmean(l)\n\n return l\n\ndef partial_in_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = [ D.ep.c0[p] for p in D.get_edges() ]\n\n # the number of triples of G, in which o occurs as object and p as predicate\n ## e.g. l = ['foaf:[email protected]', 'foaf:[email protected]', 'rdf:type_/Researcher', 'ex:areaOfWork_/Rome', 'ex:areaOfWork_/Rome', 'ex:birthPlace_/Rome', 'foaf:name_\"Roma\"@it']\n l = list( zip( D.get_edges()[:,1], edge_labels ) )\n _, l = np.unique( l, return_counts=True, axis=0 )\n\n if print_stats:\n print( \"(Eq.6) partial in-degree deg^{++}(o,p). max: %s, mean: %f\" % ( np.max( l ), np.mean( l ) ) )\n\n stats['max_partial_in_degree'], stats['mean_partial_in_degree'] = np.max( l ), np.mean( l )\n\n return l\n\ndef labelled_in_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = [ D.ep.c0[p] for p in D.get_edges() ]\n\n # the number of different predicates (labels) of G with which o is related as a object\n df = pd.DataFrame( \n data=list( zip( D.get_edges()[:,1], edge_labels ) ), \n index=np.arange( 0, D.get_edges().shape[0] ), \n columns=np.arange( 0, D.get_edges().shape[1] ) )\n\n df = df.groupby(0).nunique()[1]\n\n if print_stats:\n print( \"(Eq.7) labelled in-degree deg^{+}_L(s). max: %s, mean: %f\" % ( df.max(), df.mean() ) )\n\n stats['max_labelled_in_degree'], stats['mean_labelled_in_degree'] = df.max(), df.mean()\n\n return df\n\ndef direct_in_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n # the number of different subjects of G with which o is related as a object\n df = pd.DataFrame( \n data=D.get_edges(), \n index=np.arange( 0, D.get_edges().shape[0] ), \n columns=np.arange( 0, D.get_edges().shape[1] ) )\n\n df = df.groupby(1).nunique()[0]\n\n if print_stats:\n print( \"(Eq.8) direct in-degree deg^{+}_D(o). max: %s, mean: %f\" % ( df.max(), df.mean() ) )\n\n stats['max_direct_in_degree'], stats['mean_direct_in_degree'] = df.max(), df.mean()\n\n return df\n\ndef collect_metric( feature, O_G_s, edge_labels, vals, stats, print_stats ):\n \"\"\"\"\"\"\n if vals is None:\n vals = np.empty(0)\n\n return np.append( vals, feature( O_G_s, edge_labels, stats, print_stats ) )\n\ndef reduce_metric( vals, stats, max_metric, mean_metric ):\n \"\"\"\"\"\"\n stats[max_metric], stats[mean_metric] = np.nanmax(vals), np.nanmean(vals)\n\nMETRICS = [ in_degree, partial_in_degree, labelled_in_degree, direct_in_degree ]\nMETRICS_SET = { 'OBJECT_IN_DEGREES': METRICS }\nLABELS = [ 'max_in_degree', 'mean_in_degree', 'max_partial_in_degree', 'mean_partial_in_degree', 'max_labelled_in_degree', 'mean_labelled_in_degree', 'max_direct_in_degree', 'mean_direct_in_degree' ]\n"
},
{
"alpha_fraction": 0.8717948794364929,
"alphanum_fraction": 0.8717948794364929,
"avg_line_length": 6.800000190734863,
"blob_id": "6c591a9a897aa06ddba6f6493373e30849b8704e",
"content_id": "6aa5dbc515a8935e74df6c5e157c9de65abe531a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 39,
"license_type": "permissive",
"max_line_length": 8,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "argparse\nlogging\nnumpy\npowerlaw\nxxhash\n"
},
{
"alpha_fraction": 0.6678851246833801,
"alphanum_fraction": 0.7039164304733276,
"avg_line_length": 28.921875,
"blob_id": "6ef4944d4e44d2b4594fd685f081be3443764ff1",
"content_id": "c77437e93d48f7775f88eb484f1ae79b1285e90a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1915,
"license_type": "permissive",
"max_line_length": 63,
"num_lines": 64,
"path": "/resources/db/01-create-table-postgresql.sql",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "CREATE TABLE stats_2017_08 ( \n id int DEFAULT nextval('stats_id_seq'::regclass) NOT NULL, \n name varchar(128), \n title varchar(255), \n domain varchar(255), \n url varchar(255) );\n\nCREATE TABLE stats_graph_2017_08\n(\n id int PRIMARY KEY NOT NULL,\n name varchar(128),\n n bigint,\n m bigint,\n mean_degree float(19),\n mean_degree_centrality float(19),\n mean_in_degree_centrality float(19),\n mean_out_degree_centrality float(19),\n max_degree bigint,\n max_in_degree bigint,\n max_out_degree bigint,\n h_index_d int,\n h_index_u int,\n fill float(19),\n reciprocity float(19),\n local_clustering float(19),\n global_clustering float(19),\n max_degree_vertex text,\n max_pagerank_vertex text,\n max_eigenvector_vertex text,\n pseudo_diameter real,\n pseudo_diameter_src_vertex text,\n pseudo_diameter_trg_vertex text,\n fill_overall float(19),\n parallel_edges bigint,\n m_unique bigint,\n lines_match_edgelist bool,\n max_pagerank float(19),\n max_in_degree_centrality float(19),\n max_out_degree_centrality float(19),\n max_degree_centrality float(19),\n powerlaw_exponent_degree text,\n powerlaw_exponent_degree_dmin text,\n powerlaw_exponent_in_degree text,\n powerlaw_exponent_in_degree_dmin text,\n max_in_degree_vertex text,\n max_out_degree_vertex text,\n stddev_in_degree float(19),\n stddev_out_degree float(19),\n coefficient_variation_in_degree real,\n coefficient_variation_out_degree real,\n path_edgelist text,\n path_graph_gt text,\n var_in_degree float(19),\n var_out_degree float(19),\n centralization_in_degree float(19),\n centralization_out_degree float(19),\n max_degree_vertex_uri text,\n max_pagerank_vertex_uri text,\n max_in_degree_vertex_uri text,\n max_out_degree_vertex_uri text,\n pseudo_diameter_src_vertex_uri text,\n pseudo_diameter_trg_vertex_uri text,\n centralization_degree float(19),\n domain varchar(64) );\n"
},
{
"alpha_fraction": 0.6357868313789368,
"alphanum_fraction": 0.6375997066497803,
"avg_line_length": 47.81415939331055,
"blob_id": "d386b8cb2b620e3e675637d9c69fac66dab4225e",
"content_id": "48e9015241f3caf159c9746091de9c2c198c31b4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5516,
"license_type": "permissive",
"max_line_length": 266,
"num_lines": 113,
"path": "/graph/tasks/analysis/README.md",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "## `graph.tasks.analysis`\n\nThis package contains executable code for performing a graph-based analysis on RDF datasets. \n\n---\n\n**Note:** You need to have an *edgelist* or binary materialization of a *graph-object* at hand, to be able to do the analysis. The framework uses both to create the graph-object in memory and to compute the measures on that object. \n\n---\n\n**Note:** Although it is possible and a reasonable use case to use code without preliminary preparation with the framework, it is still advisable, as it facilitates a lot of things. See [this README](../README.md) on how to prepare an RDF dataset for graph analysis.\n\n---\n\n#### Analysis of single RDF graphs\n\nTo start an analysis on, say 3 datasets, you do not need a database. You can use the `--from-file` command-line parameter like in the following command: \n\n```sh\n$ python3 -m graph.tasks.analysis.core_measures --from-file webisalod ecd-linked-data asn-us --features fill reciprocity\n```\n\n**Convention:** The framework will use the `ROOT/dumps/<dataset name>`-folder to read and write corresponding files during execution. \n\n---\n\nFor graph instantiation, e.g. of the dataset with name `ecd-linked-data`, it expects either of the two files to be located in `ROOT/dumps/ecd-linked-data/`: \n\n1. `data.edgelist.csv`, a source-vertex target-vertex mapping file, representing a graph edge per line, or\n2. `data.graph.gt.gz`, a binary materialized graph-object previously obtained from graph-tool.\n\nAfter graph instantiation the framework will compute the requested measures. It will print the values to STDOUT, if you add the `--print-stats` parameter.\n\n#### Analysis of a large sets of RDF graphs\n\nFor a large set of datasets it is advisable to use a database to persist the requested measure values. You can use the `--from-db` command-line parameter for that. For example,\n\n```sh\n$ python3 -m graph.tasks.analysis.core_measures --from-db webisalod ecd-linked-data asn-us --features fill reciprocity\n```\n\nDatabase configuration will be read from `ROOT/constants/db.py` file.\n\nFor graph instantiation, the framework gets the path to the corresponding files from either of the two columns `path_edgelist` or `path_graph_gt`.\n\nHowever, it will use the `ROOT/dumps/<dataset name>/` folder for writing plots etc.\n \n### Measures\n\nThere are two sets of measures to choose from.\n\n#### `core_measures.py`\n\n`--help` gives you an explanation about the available options.\n\n```sh\n$ python3 -m graph.tasks.analysis.core_measures --help\nusage: core_measures.py [-h]\n (--from-file FROM_FILE [FROM_FILE ...] | --from-db FROM_DB [FROM_DB ...])\n [--print-stats] [--threads THREADS]\n [--sample-vertices] [--sample-size SAMPLE_SIZE]\n [--openmp-disabled] [--threads-openmp THREADS_OPENMP]\n [--do-heavy-analysis]\n [--features [FEATURES [FEATURES ...]]]\n [--skip-features [SKIP_FEATURES [SKIP_FEATURES ...]]]\n\nlodcc - A software framework to prepare and perform a large-scale graph-based analysis on the graph topology of RDF datasets.\n\noptional arguments:\n -h, --help Show this help message and exit\n --from-file FROM_FILE [FROM_FILE ...], -ffl FROM_FILE [FROM_FILE ...]\n Pass a list of dataset names. Indicates that measure\n values will be written to a file called\n \"measures.<dataset name>.csv\".\n --from-db FROM_DB [FROM_DB ...], -fdb FROM_DB [FROM_DB ...]\n Pass a list of dataset names. Indicates that further\n details and measure values are written to database.\n Specify details in constants/db.py and\n db.sqlite.properties.\n --print-stats, -lp Prints measure values to STDOUT instead of writing to\n db or file. Default False.\n --threads THREADS, -pt THREADS\n Number of CPU cores/datasets to use in parallel for\n graph analysis. Handy when working with multiple\n datasets. Default 1. Max 20.\n --sample-vertices, -gsv\n not yet supported\n --sample-size SAMPLE_SIZE, -gss SAMPLE_SIZE\n not yet supported\n --openmp-disabled, -gto\n Pass if you did not have OpenMP enabled during\n compilation of graph-tool. Default False.\n --threads-openmp THREADS_OPENMP, -gth THREADS_OPENMP\n Number of CPU cores used by the core graph-tool\n library. See also --openmp-disabled. Default 8.\n --do-heavy-analysis, -gfsh\n Obsolete. See --skip-features.\n --features [FEATURES [FEATURES ...]], -gfs [FEATURES [FEATURES ...]]\n Give a list of graph measures to compute, e.g., \"-gfs\n degree diameter\" for all degree-related measures and\n the diameter. Default is the full list of less\n computation intensive graph measures. See also\n constants/measures.py.\n --skip-features [SKIP_FEATURES [SKIP_FEATURES ...]], -gsfs [SKIP_FEATURES [SKIP_FEATURES ...]]\n When --features not given, specify the list of graph\n measures to skip. Default [].\n```\n\n### `rdf_measures.py`\n\n`--help` gives you an explanation about the available options.\n\ntbc\n"
},
{
"alpha_fraction": 0.5212026238441467,
"alphanum_fraction": 0.5279805064201355,
"avg_line_length": 31.8799991607666,
"blob_id": "3f09b2c597181eca0e2a279a687349b820895933",
"content_id": "77daca2145113650e331b89fb3aefece00af48dc",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5754,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 175,
"path": "/graph/building/edgelist.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\nimport re\nimport threading\nimport xxhash as xh\n\nlog = logging.getLogger( __name__ )\n\nfrom constants.edgelist import SUPPORTED_FORMATS\n\ndef parse_spo( line, format_='nt' ):\n \"\"\"\"\"\"\n if format_ == 'nt':\n spo = re.split( ' ', line )\n return spo[0], spo[1], ' '.join( spo[2:-1] )\n\n # from here is legacy code, merged from refactoring. \n # used in the context of bfv and integer vertex label encoding.\n if format_ == 'edgelist':\n sop=re.split( ' ', line )\n return sop[0], sop[1]\n\n if format_ == 'csv':\n sp=re.split( '{\\'edge\\':\\'', line )\n so=re.split( ' ', sp[0] )\n p=sp[1]\n return so[0], p[0:-3], ' '.join( so[1:-1] )\n\ndef xxhash_line( line, format_='nt' ):\n \"\"\"Splits the line into the individual parts (S,P,O) of an RDF statement\n and returns the hashed values for the individuals.\"\"\"\n\n spo = parse_spo( line, format_ )\n return ( xh.xxh64( spo[0] ).hexdigest(), xh.xxh64( spo[1] ).hexdigest(), xh.xxh64( spo[2] ).hexdigest() )\n\ndef create_edgelist( path, format_='nt', hashed=True ):\n \"\"\"Reads the file given by the first parameter 'path' (expected to be in ntriples-format) \n and writes an <path>.edgelist.csv counterpart file.\"\"\"\n\n dirname=os.path.dirname( path )\n filename=os.path.basename( path )\n\n # expect file with .nt ending\n if not re.search( '\\.nt$', path ):\n path += '.nt'\n\n if os.path.getsize( path ) == 0:\n return\n\n # read first line and check the format first\n with open( path, 'r' ) as file:\n first_line = file.readline()\n\n while first_line.strip() == '':\n first_line = file.readline()\n\n spo = re.split( ' ', first_line )\n\n if not len(spo) >= 4:\n if log:\n log.error( 'File has wrong format, no n-triples found in \\'%s\\'. Could not transform into xxhash-ed triples', path )\n else:\n print( 'File has wrong format, no n-triples found in \\'%s\\'. Could not transform into xxhash-ed triples' % path )\n\n return\n\n # now open and transform all lines\n with open( path, 'r' ) as file:\n # write the hashed output into a file with ending edgelist.csv,\n # e.g. lod.rdf.nt becomes written into lod.rdf.edglist.csv\n fh = open( dirname + '/'+ re.sub('.nt$', '', filename) + '.edgelist.csv', 'w' )\n\n for line in file:\n # ignore empty lines and comments\n if line.strip() == '' or re.search( '^# ', line ):\n continue\n \n # get the hashed values for S,P,O per line\n hashed_s, hashed_p, hashed_o = xxhash_line( line )\n # one line in the edgelist is build as: \n # source vertex (S), target vertex (O), edge label (P)\n fh.write( '%s %s %s\\n' % ( hashed_s, hashed_o, hashed_p ) )\n fh.close()\n\ndef merge_edgelists( dataset_names, rm_edgelists=False ):\n \"\"\"\"\"\"\n\n # ensure it is a list\n if not type( dataset_names ) is list:\n dataset_names = [dataset_names]\n\n for dataset in dataset_names:\n dataset = 'dumps/'+ dataset\n\n if not os.path.isdir( dataset ):\n log.error( '%s is not a directory', dataset )\n\n continue\n\n if re.search( '/$', dataset ):\n dataset = dataset[0:-1]\n\n log.info( 'Merging edgelists..' )\n\n # TODO extract to constants.py\n os.popen( './bin/merge_edgelists.sh %s %s' % (dataset,rm_edgelists) )\n\ndef iedgelist_edgelist( path, format_='nt' ):\n \"\"\"\"\"\"\n\n dirname = os.path.dirname( path )\n filename = os.path.basename( path )\n ending = SUPPORTED_FORMATS[format_]\n prefix = re.sub( ending, '', filename )\n\n with open( path ) as edgelist:\n idx = 1\n spo_dict = {}\n \n\n with open( '%s/%s.%s' % (dirname,prefix,'iedgelist.csv'), 'w' ) as iedgelist:\n log.info( 'handling %s', iedgelist.name )\n\n for line in edgelist:\n s,_,o = parse_spo( line, format_ )\n\n if s not in spo_dict:\n spo_dict[s] = idx\n idx += 1\n if o not in spo_dict:\n spo_dict[o] = idx\n idx += 1\n\n if idx % 10000000 == 0:\n log.info( idx )\n\n s = spo_dict[s]\n o = spo_dict[o]\n\n iedgelist.write( '%s %s\\n' % (s,o) )\n\n if args['pickle']:\n rev_spo_dict = { v: k for k, v in spo_dict.items() }\n\n pkl_filename = '%s/%s.%s' % (dirname,prefix,'iedgelist.pkl')\n with open( pkl_filename, 'w' ) as pkl:\n log.info( 'dumping pickle %s', pkl_filename )\n pickle.dump( rev_spo_dict, pkl )\n\ndef xxhash_csv( path, sem=threading.Semaphore(1) ):\n \"\"\"Obsolete. Creates a hashed version of an edgelist not in ntriples format, but in csv.\n Use <i>create_edgelist</i> instead.\"\"\"\n\n # can I?\n with sem:\n dirname=os.path.dirname( path )\n filename=os.path.basename( path )\n\n with open( path, 'r' ) as file:\n fh = open( dirname +'/'+ re.sub('.csv$', '', filename) +'.edgelist.csv','w' )\n\n for line in file:\n # ignore empty lines and comments\n if line.strip() == '' or re.search( '^# ', line ):\n continue\n \n # get the hashed values per line\n hashed_s, hashed_p, hashed_o = xxhash_line( line, format='csv' )\n # one line in the edgelist is build as: \n # source vertex, target vertex, edge label\n fh.write( '%s %s %s\\n' % ( hashed_s, hashed_o, hashed_p ) )\n\n fh.close()\n\n os.remove( path )\n"
},
{
"alpha_fraction": 0.6028469800949097,
"alphanum_fraction": 0.6080664396286011,
"avg_line_length": 33.54917907714844,
"blob_id": "d45acb6c5a6125fd623bfb67a1a2d0def842287d",
"content_id": "bc58d0b668c53e3241a009e38f69324c5b797f77",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4215,
"license_type": "permissive",
"max_line_length": 144,
"num_lines": 122,
"path": "/graph/measures/core/centrality.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nfrom functools import reduce\nimport os\nimport threading\n\nimport collections\n\ntry:\n mlog = logging.getLogger( 'matplotlib' )\n mlog.setLevel( logging.WARN )\n import matplotlib.pyplot as plt\nexcept:\n print( 'matplotlib.pyplot module could not be imported' )\n \nfrom graph_tool.centrality import eigenvector, pagerank\nfrom graph_tool.stats import remove_parallel_edges\n\nlog = logging.getLogger( __name__ )\nlock = threading.Lock()\n\ndef f_centralization( D, stats, options={ 'features': [] } ):\n \"\"\"\"\"\"\n\n if not 'centralization' in options['features']:\n return\n\n D_copied = D.copy()\n D = None\n\n remove_parallel_edges( D_copied )\n\n degree_list = D_copied.degree_property_map( 'total' ).a\n max_degree = degree_list.max()\n\n stats['centralization_degree'] = float((max_degree-degree_list).sum()) / ( ( degree_list.size-1 )*(degree_list.size-2))\n \n # stats['centralization_in_degree'] = (v_max_in[0]-(D.get_in_degrees( D.get_vertices() ))).sum() / ( ( num_vertices-1 )*(num_vertices-2))\n # stats['centralization_out_degree'] = (v_max_out[0]-(D.get_out_degrees( D.get_vertices() ))).sum() / ( ( num_vertices-1 )*(num_vertices-2))\n\n log.debug( 'done centrality measures' )\n\ndef f_eigenvector_centrality( D, stats, options={ 'features': [], 'skip_features': [] } ):\n \"\"\"\"\"\"\n\n if 'eigenvector_centrality' not in options['features']:\n log.debug( 'Skipping eigenvector_centrality' )\n return\n\n eigenvector_list = eigenvector(D)[1].get_array()\n \n # info: vertex with largest eigenvector value\n ev_list_idx=zip( eigenvector_list, D.vertex_index )\n largest_ev_vertex=reduce( (lambda new_tpl, last_tpl: new_tpl if new_tpl[0] >= last_tpl[0] else last_tpl), ev_list_idx )\n stats['max_eigenvector_vertex']=D.vertex_properties['name'][largest_ev_vertex[1]]\n log.debug( 'done max_eigenvector_vertex' )\n\n # plot degree distribution\n if 'plots' in options['features'] and (not 'skip_features' in options or not 'plots' in options['skip_features']):\n eigenvector_list[::-1].sort()\n\n values_counted = collections.Counter( eigenvector_list )\n values, counted = zip( *values_counted.items() )\n \n with lock:\n fig, ax = plt.subplots()\n plt.plot( values, counted )\n\n plt.title( 'Eigenvector-Centrality Histogram' )\n plt.ylabel( 'Frequency' )\n plt.xlabel( 'Eigenvector-Centrality Value' )\n\n ax.set_xticklabels( values )\n\n ax.set_xscale( 'log' )\n ax.set_yscale( 'log' )\n\n plt.tight_layout()\n plt.savefig( '/'.join( [os.path.dirname( stats['path_edgelist'] ), 'distribution_eigenvector-centrality.pdf'] ) )\n log.debug( 'done plotting eigenvector_centrality' )\n \ndef f_pagerank( D, stats, options={ 'features': [], 'skip_features': [] } ):\n \"\"\"\"\"\"\n\n if 'pagerank' not in options['features']:\n log.debug( 'Skipping pagerank' )\n return\n\n pagerank_list = pagerank(D).get_array()\n\n pr_max = (0.0, 0)\n idx = 0\n\n # iterate and collect max value and idx\n for pr_val in pagerank_list:\n pr_max = ( pr_val, idx ) if pr_val >= pr_max[0] else pr_max\n idx += 1\n\n stats['max_pagerank'], stats['max_pagerank_vertex'] = pr_max[0], str( D.vertex_properties['name'][pr_max[1]] )\n\n # plot degree distribution\n if 'plots' in options['features'] and (not 'skip_features' in options or not 'plots' in options['skip_features']):\n pagerank_list[::-1].sort()\n\n values_counted = collections.Counter( pagerank_list )\n values, counted = zip( *values_counted.items() )\n \n with lock:\n fig, ax = plt.subplots()\n plt.plot( values, counted )\n\n plt.title( 'PageRank Histogram' )\n plt.ylabel( 'Frequency' )\n plt.xlabel( 'PageRank Value' )\n\n ax.set_xticklabels( values )\n\n ax.set_xscale( 'log' )\n ax.set_yscale( 'log' )\n\n plt.tight_layout()\n plt.savefig( '/'.join( [os.path.dirname( stats['path_edgelist'] ), 'distribution_pagerank.pdf'] ) )\n log.debug( 'done plotting pagerank distribution' )\n"
},
{
"alpha_fraction": 0.48139795660972595,
"alphanum_fraction": 0.49605411291122437,
"avg_line_length": 22.945945739746094,
"blob_id": "5c7d10121345257ca818808fe1d879eb6afa594f",
"content_id": "d3148bd291bcd5dc461133d371c27779cc829018",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 887,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 37,
"path": "/bin/bfv_vertice.sh",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# this script finds a matching uri to a given hashed vertice value\n#\n# ATTENTION\n# Be sure that your files have the exact same number of lines \n# with the exact same ordering and corresponding values.\n# \n\nVERTICE=$1\nEDGELIST=$2\nNT=$3\n\nMATCHED_LINE=`egrep -n $VERTICE -m 1 $EDGELIST`\nLNUMBER=`echo \"$MATCHED_LINE\" | cut -d ':' -f1 `\nRES=`sed -n \"$LNUMBER\"p $NT`\n\ncorresponding_uri()\n{\n idx=1\n for m in `echo $MATCHED_LINE | cut -d ':' -f2 -f3`; do\n if [[ $VERTICE == $m ]]; then\n echo $RES | while read -r s p o; do\n if [[ $idx == 1 ]]; then \n echo $s | cut -d ' ' -f1\n return\n elif [[ $idx == 2 ]]; then\n echo $o | cut -d ' ' -f1\n return\n fi\n done\n fi\n let \"idx += 1\"\n done \n}\n\ncorresponding_uri\n\n"
},
{
"alpha_fraction": 0.6093327403068542,
"alphanum_fraction": 0.6178990006446838,
"avg_line_length": 45.19791793823242,
"blob_id": "c78032f1fbb7a9f3c2169dffc9ed7633b922c568",
"content_id": "d980de2fabbbe56166ce7c48f2d2cd492d7d34aa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4436,
"license_type": "permissive",
"max_line_length": 198,
"num_lines": 96,
"path": "/tests/test_lodcc.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import unittest\nimport lodcc\nimport logging\nimport os\n\nlogger = logging.getLogger()\nlogger.level = logging.INFO\n\nclass LodccTestCase( unittest.TestCase ):\n\n def setUp( self ):\n\n lodcc.args = { 'no_cache' : False, 'rm_extracted' : False }\n os.popen( 'mkdir -p dumps/foo-lod' )\n\n def tearDown( self ):\n\n os.popen( 'rm -rf dumps/foo-lod' )\n os.popen( 'rm tests/data/tests/data/dump-extracted.txt' )\n\n def test_download_prepare( self ):\n\n # test single valued\n\n ## n_triples\n urls = lodcc.download_prepare( ['id', 'name', 'https://example.org/dataset.nt'] )\n self.assertEqual( urls[0], ( 'https://example.org/dataset.nt', 'application_n_triples' ) )\n urls = lodcc.download_prepare( ['id', 'name', 'https://example.org/dataset.nt', 'https://example.org/dataset.rdf'] )\n self.assertEqual( urls[0], ( 'https://example.org/dataset.nt', 'application_n_triples' ) )\n\n ## rdf_xml\n urls = lodcc.download_prepare( ['id', 'name', None, 'https://example.org/dataset.rdf'] )\n self.assertEqual( urls[0], ( 'https://example.org/dataset.rdf', 'application_rdf_xml' ) )\n\n ## turtle\n urls = lodcc.download_prepare( ['id', 'name', None, None, 'https://example.org/dataset.ttl'] )\n self.assertEqual( urls[0], ( 'https://example.org/dataset.ttl', 'text_turtle' ) )\n\n ## notation3\n urls = lodcc.download_prepare( ['id', 'name', None, None, None, 'https://example.org/dataset.n3'] )\n self.assertEqual( urls[0], ( 'https://example.org/dataset.n3', 'text_n3' ) )\n\n ## nquads\n urls = lodcc.download_prepare( ['id', 'name', None, None, None, None, 'https://example.org/dataset.nq'] )\n self.assertEqual( urls[0], ( 'https://example.org/dataset.nq', 'application_n_quads' ) )\n\n # test multi valued\n ## n_triples and notation3\n urls = lodcc.download_prepare( ['id', 'name', 'https://example.org/dataset.nt', None, None, 'https://example.org/dataset.n3'] )\n self.assertEqual( urls[0], ( 'https://example.org/dataset.nt', 'application_n_triples' ) )\n self.assertEqual( urls[1], ( 'https://example.org/dataset.n3', 'text_n3' ) )\n\n\n def test_download_prepare__None( self ):\n\n # returns a tuple\n self.assertIsNotNone( lodcc.download_prepare( None ) )\n # returns None and APPLICATION_UNKNOWN when None passed as dataset\n self.assertEqual( (None, 'unknown'), lodcc.download_prepare( None )[0] )\n # returns None if fields are None\n self.assertEqual( (None, 'unknown'), lodcc.download_prepare( ['id', 'name', None, None, None, None, None] )[0] )\n\n def test_download_data__Fails_first( self ):\n\n # ntriples fails, n3 is ok\n file = lodcc.download_data( [None,'foo-lod'], [('http://www.gesis.org/missy/metadata/MZ/2020', 'application_n_triples'), ('http://www.gesis.org/missy/metadata/MZ/2012', 'text_n3')] )\n self.assertEqual( 'dumps/foo-lod', file['folder'] )\n self.assertEqual( 'foo-lod.n3', file['filename'] )\n self.assertEqual( 'text_n3', file['format'] )\n\n def test_download_data( self ):\n\n # no filename in url, suppose filename is taken from dataset name\n file = lodcc.download_data( [None,'foo-lod'], [('http://www.gesis.org/missy/metadata/MZ/2012', 'application_rdf_xml')] )\n self.assertEqual( 'dumps/foo-lod', file['folder'] )\n self.assertEqual( 'foo-lod.rdf', file['filename'] )\n self.assertEqual( 'application_rdf_xml', file['format'] )\n\n # \n lodcc.args['no_cache'] = True\n file = lodcc.download_data( [None,'foo-lod'], [('http://www.gesis.org/missy/metadata/MZ/2012', 'application_rdf_xml')] )\n self.assertEqual( 'dumps/foo-lod', file['folder'] )\n self.assertEqual( 'foo-lod.rdf', file['filename'] )\n self.assertEqual( 'application_rdf_xml', file['format'] )\n\n def test_build_graph_prepare__x_and_nt( self ):\n\n lodcc.build_graph_prepare( [None, 'dump-compressed'], { 'path': 'tests/data/dump-compressed.tar.gz', 'filename': 'dump-compressed.tar.gz', 'folder': 'tests/data', 'format': 'text_turtle' } )\n # check if file was extracted\n self.assertTrue( os.path.isfile( 'tests/data/dump-extracted.txt' ) )\n\n #def test_build_graph_prepare__x_and_not_nt( self ):\n\n #def test_build_graph_prepare__not_x_and_nt( self ):\n\n #def test_build_graph_prepare__not_x_and_not_nt( self ):\n\n"
},
{
"alpha_fraction": 0.5669937133789062,
"alphanum_fraction": 0.5686022043228149,
"avg_line_length": 35.145347595214844,
"blob_id": "6599b556e1e00ada61ca5b430cfbe78aca1135b4",
"content_id": "fefd1145a4bfd679b542b164b6b56bea155123e2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6217,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 172,
"path": "/db/SqliteHelper.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\nimport re\nimport sqlite3\n\nfrom constants.db import DB_PROPERTIES_FILE\nfrom constants.preparation import SHORT_FORMAT_MAP\n\nlog = logging.getLogger( __name__ )\n\nclass SqliteHelper:\n \"\"\"This is a helper class for Sqlite database connections.\"\"\"\n\n def __init__( self, init_db=False, tbl_datasets='stats', tbl_measures='stats_graph' ):\n \"\"\"\"\"\"\n\n if not os.path.isfile( DB_PROPERTIES_FILE ):\n log.error( 'No %s file found. could not create sqlite connection.' % DB_PROPERTIES_FILE )\n return\n\n with open( DB_PROPERTIES_FILE, 'rt' ) as f:\n # read all db properties into self.conf variable\n self.conf = dict( ( key.replace( '.', '_' ), value ) for key, value in ( re.split( \"=\", option ) for option in ( line.strip() for line in f ) ) )\n log.debug( self.conf )\n\n # create connection\n self.conn = sqlite3.connect( self.conf['db_url'] )\n self.conn.row_factory = sqlite3.Row\n\n # \n self.tbl_datasets = self.conf['db_schema_datasets_table_name']\n self.tbl_measures = self.conf['db_schema_measures_table_name']\n\n if init_db:\n self.init_schema()\n self.init_datasets()\n\n def init_schema( self, drop=False ):\n \"\"\"\"\"\"\n\n # TODO implement drop before creating\n\n log.info( 'Initializing schema' )\n\n cur = self.conn.cursor()\n with open( self.conf['db_import_schema_file'] ) as sql:\n cur.executescript( sql.read() )\n\n def init_datasets( self, truncate=False ):\n \"\"\"\"\"\"\n\n # TODO implement truncate before importing\n\n log.info( 'Initializing data' )\n\n cur = self.conn.cursor()\n with open( self.conf['db_import_datasets_file'] ) as sql:\n cur.executescript( sql.read() )\n\n def get_datasets( self, columns=['id','url','name'], limit=-1 ):\n \"\"\"\"\"\"\n\n cur = self.conn.cursor()\n return cur.execute( 'SELECT %s FROM %s LIMIT %s' % (','.join(columns),self.tbl_datasets,limit) ).fetchall()\n\n def get_datasets_and_formats( self, dataset_names=None ):\n \"\"\"\"\"\"\n\n # gives us the long version of the formats supported (they are columns in the table)\n formats = ','.join( SHORT_FORMAT_MAP.values() )\n # gives us a list of disjunctive conditions for the WHERE-clause, e.g., application_rdf_xml IS NOT NULL [OR ...]\n formats_not_null = ' OR '.join( f + ' IS NOT NULL' for f in SHORT_FORMAT_MAP.values() )\n \n if dataset_names:\n # prepare the WHERE-clause for the requested datasets\n names_query = '( ' + ' OR '.join( 'name = ?' for ds in dataset_names ) + ' )'\n\n # prepare the whole query\n sql = 'SELECT id, name, %s FROM %s WHERE %s AND (%s) ORDER BY id' % (formats,self.tbl_datasets,names_query,formats_not_null)\n else:\n # prepare the whole query\n sql = 'SELECT id, name, %s FROM %s WHERE %s ORDER BY id' % (formats,self.tbl_datasets,formats_not_null)\n\n cur = self.conn.cursor()\n cur.execute( sql, tuple( dataset_names ) )\n \n return cur.fetchall()\n\n def get_datasets_and_paths( self, dataset_names=None ):\n \"\"\"\"\"\"\n\n paths_not_null = '(path_edgelist IS NOT NULL OR path_graph_gt IS NOT NULL)'\n \n if dataset_names:\n # prepare the WHERE-clause for the requested datasets\n names_query = '( ' + ' OR '.join( 'name = ?' for ds in dataset_names ) + ' )'\n\n # prepare the whole query\n sql = 'SELECT id, name, path_edgelist, path_graph_gt FROM %s WHERE %s AND (%s) ORDER BY id' % (self.tbl_measures,names_query,paths_not_null)\n else:\n # prepare the whole query\n sql = 'SELECT id, name, path_edgelist, path_graph_gt FROM %s WHERE %s ORDER BY id' % (self.tbl_measures,paths_not_null)\n\n cur = self.conn.cursor()\n cur.execute( sql, tuple( dataset_names ) )\n \n return cur.fetchall()\n\n def ensure_schema_completeness( self, attrs, table=None ):\n \"\"\"\"\"\"\n\n if not table:\n table = self.tbl_datasets\n\n cur = self.conn.cursor()\n \n if type(attrs) == str:\n attrs = [attrs]\n\n for attr in attrs:\n # this is invoked for every attribute to ensure multi-threading is respected\n table_attrs = cur.execute( 'PRAGMA table_info(%s)' % table ).fetchall()\n table_attrs = list( map( lambda c: c[1], table_attrs ) )\n \n if not attr in table_attrs:\n log.info( 'Couldn''t find attribute %s in table, creating..', attr )\n cur.execute( 'ALTER TABLE %s ADD COLUMN %s varchar' % (table,attr) )\n \n self.conn.commit()\n cur.close()\n\n # -----------------\n\n def save_attribute( self, dataset ):\n \"\"\"\n This function saves the given dataset in the database.\n It ensures that the attribute exists.\n The passed dataset-parameter is expected to be of this shape: (id,name,attribute,value).\"\"\"\n\n # make sure these attributes exist\n self.ensure_schema_completeness( [dataset[2]] )\n\n # TODO check if it exists and INSERT if not\n \n sql='UPDATE %s SET %s=? WHERE id=?' % (self.tbl_datasets,dataset[2])\n\n cur = self.conn.cursor()\n cur.execute( sql, (dataset[3],dataset[0],) )\n self.conn.commit()\n\n log.debug( 'done saving attribute value' )\n\n def save_stats( self, dataset, stats ):\n \"\"\"\"\"\"\n\n # make sure these attributes exist\n self.ensure_schema_completeness( sorted( stats.keys() ), self.tbl_measures )\n\n # e.g. mean_degree=%(mean_degree)s, max_degree=%(max_degree)s, ..\n cols = ', '.join( map( lambda d: d +'=:'+ d, stats ) )\n \n # TODO check if it exists and INSERT if not\n # TODO check if id exists in stats\n \n sql=( 'UPDATE %s SET ' % self.tbl_measures ) + cols +' WHERE id=:id'\n stats['id']=dataset[0]\n\n cur = self.conn.cursor()\n cur.execute( sql, stats )\n self.conn.commit()\n\n log.debug( 'done saving results' )\n"
},
{
"alpha_fraction": 0.6053560376167297,
"alphanum_fraction": 0.6121029853820801,
"avg_line_length": 34.422794342041016,
"blob_id": "9466d1fcc9bf99e4ce1e5d381d551d983fb24d0d",
"content_id": "6b585dc435f40b9e178efc13768de209a488a476",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9634,
"license_type": "permissive",
"max_line_length": 175,
"num_lines": 272,
"path": "/graph/building/preparation.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\nimport re\nimport sqlite3\nimport subprocess as proc\nimport sys\nimport threading\nfrom urllib import parse as urlparse\n\n# lodcc module imports\nfrom constants.preparation import *\nfrom graph.building.edgelist import create_edgelist, merge_edgelists\n\nlog = logging.getLogger( __name__ )\n\ndef download_prepare( dataset, from_file ):\n \"\"\"download_prepare\n\n returns a tuple of url and application media type, if it can be discovered from the given dataset. For instance,\n returns ( 'http://example.org/foo.nt', APPLICATION_N_TRIPLES ) if { _, _, http://example.org/foo.nt, ... } was passed.\"\"\"\n\n if not dataset:\n log.error( 'dataset is None' )\n return [( None, APPLICATION_UNKNOWN )]\n\n if not dataset[1]:\n log.error( 'dataset name is None' )\n return [( None, APPLICATION_UNKNOWN )]\n\n log.debug( 'Download folder will be %s', 'dumps/'+ dataset[1] )\n os.popen( 'mkdir -p dumps/'+ dataset[1] )\n\n # id, name, application_n_triples, application_rdf_xml, text_turtle, text_n3, application_n_quads\n\n urls = list()\n \n if from_file:\n # if run --from-file, the format is given on cli not from db column\n log.debug( 'Using format passed as third parameter with --from-file' )\n \n if len( dataset ) != 4:\n log.error( 'Missing third format argument in --from-file. Please specify' )\n return [( None, APPLICATION_UNKNOWN )]\n\n if not dataset[3] in SHORT_FORMAT_MAP:\n log.error( 'Wrong format \"%s\". Please specify one of %s', dataset[3], ','.join( SHORT_FORMAT_MAP.keys()) )\n return [( None , APPLICATION_UNKNOWN )]\n \n urls.append( ( dataset[2], SHORT_FORMAT_MAP[dataset[3]] ) )\n return urls\n\n log.debug( 'Determining available formats..' )\n # this list of if-else's also respects db column priority\n\n # n-triples\n if len( dataset ) >= 3 and dataset[2]:\n log.debug( 'Found format APPLICATION_N_TRIPLES with url %s', dataset[2] )\n urls.append( ( dataset[2], APPLICATION_N_TRIPLES ) )\n\n # rdf+xml\n if len( dataset ) >= 4 and dataset[3]:\n log.debug( 'Found format APPLICATION_RDF_XML with url: %s', dataset[3] )\n urls.append( ( dataset[3], APPLICATION_RDF_XML ) )\n\n # turtle\n if len( dataset ) >= 5 and dataset[4]:\n log.debug( 'Found format TEXT_TURTLE with url: %s', dataset[4] )\n urls.append( ( dataset[4], TEXT_TURTLE ) )\n\n # notation3\n if len( dataset ) >= 6 and dataset[5]:\n log.debug( 'Found format TEXT_N3 with url: %s', dataset[5] )\n urls.append( ( dataset[5], TEXT_N3 ) )\n\n # nquads\n if len( dataset ) >= 7 and dataset[6]:\n log.debug( 'Found format APPLICATION_N_QUADS with url: %s', dataset[6] )\n urls.append( ( dataset[6], APPLICATION_N_QUADS ) )\n\n # more to follow?\n\n if len( urls ) == 0:\n log.warn( 'Could not determine format. returning APPLICATION_UNKNOWN instead' )\n return [( None, APPLICATION_UNKNOWN )]\n \n return urls\n \ndef ensure_valid_filename_from_url( dataset, url, format_ ):\n \"\"\"ensure_valid_filename_from_url\n\n returns 'foo-bar.tar.gz' for url 'http://some-domain.com/foo-bar.tar.gz (filename is obtained from url), if invoked with ( [_], _, _ )'\n returns 'foo-dump.rdf' for url 'http://some-domain.com/strange-url (filename is NOT obtained from url), if invoked with ( [_, 'foo-dump.rdf', _], _, APPLICATION_RDF_XML )'\n \"\"\"\n\n if not url:\n log.warn( 'No url given for %s. Cannot determine filename.', dataset[1] )\n return None\n\n log.debug( 'Parsing filename from %s', url )\n # transforms e.g. \"https://drive.google.com/file/d/0B8VUbXki5Q0ibEIzbkUxSnQ5Ulk/dump.tar.gz?usp=sharing\" \n # into \"dump.tar.gz\"\n url = urlparse.urlparse( url )\n basename = os.path.basename( url.path )\n\n if not '.' in basename:\n filename = '%s_%s%s' % (dataset[1], dataset[0], MEDIATYPES[format_]['extension'])\n log.debug( 'Cannot determine filename from remaining url path: %s', url.path )\n log.debug( 'Using composed valid filename %s', filename )\n \n return filename\n\n log.debug( 'Found valid filename %s', basename )\n return basename\n\ndef ensure_valid_download_data( path ):\n \"\"\"ensure_valid_download_data\"\"\"\n\n if not os.path.isfile( path ):\n # TODO save error in db\n log.warn( 'Download not valid: file does not exist (%s)', path )\n return False\n\n if os.path.getsize( path ) < 1000:\n # TODO save error in db\n log.warn( 'Download not valid: file is < 1000 byte (%s)', path )\n return False\n\n if 'void' in os.path.basename( path ) or 'metadata' in os.path.basename( path ):\n # TODO save error in db\n log.warn( 'Download not valid: file contains probably void or metadata descriptions, not data (%s)', path )\n return False\n\n return True\n\ndef download_data( dataset, urls, options=[] ):\n \"\"\"download_data\"\"\"\n\n for url, format_ in urls:\n\n if format_ == APPLICATION_UNKNOWN:\n log.error( 'Could not continue due to unknown format. ignoring this one..' )\n continue\n\n filename = ensure_valid_filename_from_url( dataset, url, format_ )\n folder = '/'.join( ['dumps', dataset[1]] )\n path = '/'.join( [ folder, filename ] )\n\n # reuse dump if exists\n valid = ensure_valid_download_data( path )\n if not options['overwrite_dl'] and valid:\n log.debug( 'Overwrite dl? %s. Reusing local dump', options['overwrite_dl'] )\n return dict( { 'path': path, 'filename': filename, 'folder': folder, 'format': format_ } )\n\n # download anew otherwise\n # thread waits until this is finished\n log.info( 'Downloading dump (from %s) ...', url )\n proc.call( 'wget --quiet --output-document %s %s' % (path,url), shell=True )\n\n valid = ensure_valid_download_data( path )\n if not valid:\n log.warn( 'Skipping format %s. Trying with other format if available.', format_ )\n continue\n else:\n return dict( { 'path': path, 'filename': filename, 'folder': folder, 'format': format_ } )\n\n return dict()\n\ndef build_graph_prepare( dataset, file, options=[] ):\n \"\"\"build_graph_prepare\"\"\"\n\n if not file:\n log.error( 'Cannot continue due to error in downloading data. returning.' )\n return\n\n if not 'filename' in file:\n log.error( 'Cannot prepare graph for %s, aborting', dataset[1] )\n return\n\n format_ = file['format']\n path = file['path']\n\n overwrite_nt = 'true' if options['overwrite_nt'] else 'false'\n rm_original = 'true' if options['rm_original'] else 'false'\n\n # transform into ntriples if necessary\n # TODO do not transform if file has ntriples format\n # TODO check content of file\n # TODO check if file ends with .nt\n log.info( 'Transforming to ntriples..' )\n log.debug( 'Overwrite nt? %s', overwrite_nt )\n log.debug( 'Remove original file? %s', rm_original )\n log.debug( 'Calling command %s', MEDIATYPES[format_]['cmd_to_ntriples'] % (path,overwrite_nt,rm_original) )\n \n proc.call( MEDIATYPES[format_]['cmd_to_ntriples'] % (path,overwrite_nt,rm_original), shell=True )\n\n # TODO check correct mediatype if not compressed\n\n # transform into hashed edgelist\n log.info( 'Preparing edgelist graph structure..' )\n log.debug( 'Calling function create_edgelist( %s )', path )\n \n types = [ type_ for type_ in MEDIATYPES_COMPRESSED if re.search( '.%s$' % type_, path ) ]\n if len( types ) == 0:\n # file it not compressed\n create_edgelist( path )\n else:\n # file is compressed, strip the type\n create_edgelist( re.sub( '.%s' % types[0], '', path ) )\n\n# real job\ndef job_start_download_and_prepare( dataset, sem, from_file, options=[] ):\n \"\"\"job_start_download_and_prepare\"\"\"\n\n # let's go\n with sem:\n log.info( 'Let''s go' )\n \n # - download_prepare\n urls = download_prepare( dataset, from_file )\n\n # - download_data\n file = download_data( dataset, urls, options )\n\n # - build_graph_prepare\n build_graph_prepare( dataset, file, options )\n\n log.info( 'Done' ) \n\ndef job_cleanup_intermediate( dataset, rm_edgelists, sem ):\n \"\"\"\"\"\"\n\n # can I?\n with sem:\n merge_edgelists( dataset, rm_edgelists )\n \ndef prepare_graph( datasets, no_of_threads=1, from_file=False, options=[] ):\n \"\"\"prepare_graph\"\"\"\n\n if len( datasets ) == 0:\n log.error( 'No datasets to parse. exiting' )\n return None\n\n sem = threading.Semaphore( int( 1 if no_of_threads <= 0 else ( 20 if no_of_threads > 20 else no_of_threads ) ) )\n threads = []\n\n for dataset in datasets:\n \n # create a thread for each dataset. work load is limited by the semaphore\n t = threading.Thread( target = job_start_download_and_prepare, name = '%s[%s]' % (dataset[1],dataset[0]), args = ( dataset, sem, from_file, options ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n\n # after all processing, merge edgelists\n dataset_names = set( [ ds[1] for ds in datasets] )\n rm_edgelists = 'false' if options['keep_edgelists'] else 'true'\n threads = []\n\n for dataset in dataset_names:\n \n t = threading.Thread( target = job_cleanup_intermediate, name = '%s' % dataset, args = ( dataset, rm_edgelists, sem ) )\n t.start()\n\n threads.append(t)\n \n # wait for all threads to finish\n for t in threads:\n t.join()"
},
{
"alpha_fraction": 0.6055703163146973,
"alphanum_fraction": 0.6121236681938171,
"avg_line_length": 38.379032135009766,
"blob_id": "0a73636326216aa9369d87c6e5cbed0e0fb4e1b7",
"content_id": "1ee7af1b71e306da71f144c2c4dae2568ea5db22",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4883,
"license_type": "permissive",
"max_line_length": 212,
"num_lines": 124,
"path": "/graph/measures/fernandez_et_al/subject_out_degrees.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\n\n# SUBJECT OUT-DEGREES\n\ndef out_degree( D, edge_labels=None, stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n # the number of triples in G in which s occurs as subject\n l = D.get_out_degrees( D.get_vertices() ) + 0.0\n l[l == 0] = np.nan\n\n if print_stats:\n print( \"(Eq.1) out-degree deg^{-}(s). max: %s, mean: %f\" % ( np.nanmax(l), np.nanmean(l) ) )\n\n stats['max_out_degree'], stats['mean_out_degree'] = np.nanmax(l), np.nanmean(l)\n\n return l\n\ndef partial_out_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = [ D.ep.c0[p] for p in D.get_edges() ]\n\n # the number of triples of G, in which s occurs as subject and p as predicate\n ## e.g. l = [ ['/John','foaf:mbox'], ['/John','foaf:mbox'], ['/John','rdf:type'], ['/John','ex:birthPlace'], ['/Rome', 'foaf:name'], ['/Giacomo', 'ex:areaOfWork'], ['/Piero', 'ex:areaOfWork'] ]\n l = list( zip( D.get_edges()[:,0], edge_labels ) )\n _, l = np.unique( l, return_counts=True, axis=0 )\n\n if print_stats:\n print( \"(Eq.2) partial out-degree deg^{--}(s,p). max: %s, mean: %f\" % ( np.max( l ), np.mean( l ) ) )\n\n stats['max_partial_out_degree'], stats['mean_partial_out_degree'] = np.max( l ), np.mean( l )\n\n return l\n\ndef labelled_out_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = [ D.ep.c0[p] for p in D.get_edges() ]\n\n # the number of different predicates (labels) of G with which s is related as a subject\n df = pd.DataFrame( \n data=list( zip( D.get_edges()[:,0], edge_labels ) ), \n index=np.arange( 0, D.get_edges().shape[0] ), \n columns=np.arange( 0, D.get_edges().shape[1] ) )\n\n df = df.groupby(0).nunique()[1]\n\n if print_stats:\n print( \"(Eq.3) labelled out-degree deg^{-}_L(s). max: %s, mean: %f\" % ( df.max(), df.mean() ) )\n\n stats['max_labelled_out_degree'], stats['mean_labelled_out_degree'] = df.max(), df.mean()\n\n return df\n\ndef direct_out_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n # the number of different objects of G with which s is related as a subject\n df = pd.DataFrame( \n data=D.get_edges(), \n index=np.arange( 0, D.get_edges().shape[0] ), \n columns=np.arange( 0, D.get_edges().shape[1] ) )\n\n df = df.groupby(0).nunique()[1]\n\n if print_stats:\n print( \"(Eq.4) direct out-degree deg^{-}_D(s). max: %s, mean: %f\" % ( df.max(), df.mean() ) )\n\n stats['max_direct_out_degree'], stats['mean_direct_out_degree'] = df.max(), df.mean()\n\n return df\n\ndef collect_metric( feature, S_G_s, edge_labels, vals, stats, print_stats ):\n \"\"\"\"\"\"\n if vals is None:\n vals = np.empty(0)\n\n return np.append( vals, feature( S_G_s, edge_labels, stats, print_stats ) )\n\ndef reduce_metric( vals, stats, max_metric, mean_metric ):\n \"\"\"\"\"\"\n stats[max_metric], stats[mean_metric] = np.nanmax(vals), np.nanmean(vals)\n\n###\n\ndef collect_out_degree( S_G_s, edge_labels, vals=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n return collect_metric( out_degree, S_G_s, edge_labels, vals, stats, print_stats )\n\ndef collect_partial_out_degree( S_G_s, edge_labels, vals=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n return collect_metric( partial_out_degree, S_G_s, edge_labels, vals, stats, print_stats )\n\ndef collect_labelled_out_degree( S_G_s, edge_labels, vals=pd.DataFrame(), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n return collect_metric( labelled_out_degree, S_G_s, edge_labels, vals, stats, print_stats )\n\ndef collect_direct_out_degree( S_G_s, edge_labels, vals=pd.DataFrame(), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n return collect_metric( direct_out_degree, S_G_s, edge_labels, vals, stats, print_stats )\n\ndef reduce_out_degree( vals, D, S_G, stats ):\n \"\"\"\"\"\"\n reduce_metric( vals, stats, 'max_out_degree', 'mean_out_degree' )\n\ndef reduce_partial_out_degree( vals, D, S_G, stats ):\n \"\"\"\"\"\"\n reduce_metric( vals, stats, 'max_partial_out_degree', 'mean_partial_out_degree' )\n\ndef reduce_labelled_out_degree( vals, D, S_G, stats ):\n \"\"\"\"\"\"\n reduce_metric( vals, stats, 'max_labelled_out_degree', 'mean_labelled_out_degree' )\n\ndef reduce_direct_out_degree( vals, D, S_G, stats ):\n \"\"\"\"\"\"\n reduce_metric( vals, stats, 'max_direct_out_degree', 'mean_direct_out_degree' )\n\nMETRICS = [ out_degree, partial_out_degree, labelled_out_degree, direct_out_degree ]\nMETRICS_SET = { 'SUBJECT_OUT_DEGREES' : METRICS }\nLABELS = [ 'max_out_degree', 'mean_out_degree', 'max_partial_out_degree', 'mean_partial_out_degree', 'max_labelled_out_degree', 'mean_labelled_out_degree', 'max_direct_out_degree', 'mean_direct_out_degree' ]\n"
},
{
"alpha_fraction": 0.6133333444595337,
"alphanum_fraction": 0.6133333444595337,
"avg_line_length": 37,
"blob_id": "3fd4eb90c3f240f561d66ba5e27a52b57d047bdf",
"content_id": "8fb4b04be4b75a59fffcec2181c43cd91151284e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 75,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 2,
"path": "/constants/db.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "DB_TYPE = 'sqlite'\nDB_PROPERTIES_FILE = 'db.sqlite.properties'"
},
{
"alpha_fraction": 0.596906304359436,
"alphanum_fraction": 0.6132848262786865,
"avg_line_length": 36.89655303955078,
"blob_id": "d9116331e6538415d402e9320ea89f269dc3fcf0",
"content_id": "c3a908c11535ff2f40f997a7e2f232a15ac92933",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1099,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 29,
"path": "/graph/measures/fernandez_et_al/tests/test_predicate_degrees.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import unittest\nimport unitgraphs\nimport graph.measures.fernandez_et_al.predicate_degrees as pd\n\nclass MetricsTestCase( unittest.TestCase ):\n \"\"\"\"\"\"\n\n def setUp( self ):\n \"\"\"\"\"\"\n self.G = unitgraphs.basic_graph()\n self.stats = dict()\n\n def test_predicate_degree( self ):\n \"\"\"\"\"\"\n pd.predicate_degree( self.G, None, self.stats )\n self.assertEqual( round( self.stats['max_predicate_degree'], 2 ), 2 )\n self.assertEqual( round( self.stats['mean_predicate_degree'], 2), 1.40 )\n\n def test_predicate_in_degree( self ):\n \"\"\"\"\"\"\n pd.predicate_in_degree( self.G, None, self.stats )\n self.assertEqual( round( self.stats['max_predicate_in_degree'], 2 ), 2 )\n self.assertEqual( round( self.stats['mean_predicate_in_degree'], 2), 1.20 )\n\n def test_predicate_out_degree( self ):\n \"\"\"\"\"\"\n pd.predicate_out_degree( self.G, None, self.stats )\n self.assertEqual( round( self.stats['max_predicate_out_degree'], 2 ), 2 )\n self.assertEqual( round( self.stats['mean_predicate_out_degree'], 2), 1.20 )\n"
},
{
"alpha_fraction": 0.5423627495765686,
"alphanum_fraction": 0.5590692162513733,
"avg_line_length": 36.10700988769531,
"blob_id": "a31bd76eb9010e4492e3e588fad06663454afddd",
"content_id": "af364350c85fc4277ba6467837396eb7229efe91",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10056,
"license_type": "permissive",
"max_line_length": 232,
"num_lines": 271,
"path": "/query/generator.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "from graph_tool.all import *\nimport argparse\nfrom importlib import import_module\nimport logging as log\nimport os\nimport pystache\nimport re\nimport sys\nimport xxhash as xh\n\nfrom util.bfv_from_file import job_find_vertices\n\nhmap_global = dict()\n\ndef slice_url( e, prefixes={} ):\n \"\"\"\"\"\"\n # '<http://purl.org/asit/terms/hasTown>' becomes\n # ( 'http://purl.org/asit/terms/', 'hasTown' )\n \n # because e is a dictionary entry\n h, url = e\n # extracts the property from a url, e.g. \"hasTown\" from <http://purl.org/asit/terms/hasTown>\n m = re.search( '<.*(/|#)(.*)>$', url )\n \n if not m:\n return e\n \n cut_idx = url.index( m.group(2) )\n\n prefix = url[1:cut_idx] # e.g. http://purl.org/asit/terms/\n m = re.search( '.*/(.*)(/|#)$', prefix ) # extracts the last part of the url as prefix, e.g. \"terms\" from http://purl.org/asit/terms/\n hprefix = re.sub( '[^a-z]', '', m.group(1) )\n hprefix = re.sub( 'rdfsyntaxns', 'rdf', hprefix )\n hprefix = re.sub( 'rdfschema', 'rdfs', hprefix )\n prop = url[cut_idx:-1] # e.g. hasTown\n \n # a map of hashed urls to their url\n # e.g. { 'e123': 'http://../', 'abc1': 'http://..#' }\n prefixes[hprefix] = prefix\n \n return ( h , '%s:%s' % ( hprefix, prop ) )\n \ndef prefix_it( hmap ):\n \"\"\"\"\"\"\n # input: hmap = { 'e0: '<http://...', 'e1': '<http://...', ... }\n \n # supposed to be a map of hashed urls to their url\n # e.g. { 'e123': 'http://../', 'abc1': 'http://..#' }\n hprefixes = {}\n \n # after: hmap = { 'e0': 'prefix:property1', 'e1': 'prefix:property2', ... }\n hmap = dict( map( lambda e: slice_url( e, hprefixes ), hmap.items() ) )\n \n # after: prefixes = [ { 'prefix': 'PREFIX prefix1: <http://...> .' }, { 'prefix': 'PREFIX prefix2: <..> .' }, ... ]\n prefixes = list( map( lambda e: { 'prefix': 'PREFIX %s: <%s>' % (e[0], e[1]) }, hprefixes.items() ) )\n \n # add to the dictionary\n hmap['prefixes'] = prefixes\n\n return hmap\n\ndef instantiate_query( D, QG, template, dataset, max_n=3 ):\n \"\"\"instantiates the query given by the template\"\"\"\n \n log.debug( 'finding subgraph isomorphism' )\n I=subgraph_isomorphism( QG, D, max_n=max_n )\n\n queries = []\n \n if len(I) == 0:\n log.warn( 'No isomorphisms found' )\n return queries\n \n global hmap_global\n\n for i in range(len(I)):\n pmap = I[i]\n \n log.debug( 'creating edge hash-map' )\n \n # after: [ [ 0,src_vertex,trg_vertex ], [ 1,src_vertex,trg_vertex ], ... ]\n D_edges = list( map( lambda e: [ QG.edge_index[e], pmap.fa[int( e.source() )], pmap.fa[int( e.target() )] ], QG.edges() ) )\n log.debug( D_edges )\n \n log.debug( 'creating vertices hash-map' )\n \n # after: {'e0': 'ae98476863dc6ec5', 'e0_subj': 'b3101bcc997b3d96', 'e0_obj': '80c23150a161b2d1', ... }\n mmap = {}\n \n for e in D_edges:\n # e.g. { 'e0': 'ae98476863dc6ec5', 'e1': '00c4ee7beb8097f0', .. }\n mmap['e%s' % e[0]] = D.ep.c0[ (e[1],e[2]) ]\n # e.g. { 'e0_subj': 'b3101bcc997b3d96' }, the source of the edge e0\n mmap['e%s_subj' % e[0]] = D.vp.name[ e[1] ]\n # e.g. { 'e0_obj': '80c23150a161b2d1' }, the target of the edge e0\n mmap['e%s_obj' % e[0]] = D.vp.name[ e[2] ]\n \n log.debug( mmap )\n \n log.info( 'Resolving hashes ..' )\n log.debug( 'resolving hashes to URIs from nt-files in folder %s' % dataset )\n \n # returned by this function is a map of hashes to urls, \n # e.g. { 'ae984768': 'ae984768', '63dc6ec5': 'http://', ... }\n # remember for later use\n hmap_global = hmap = job_find_vertices( dataset, list(mmap.values()), hmap_global )\n\n # after: { 'e0: '<http://...', 'e1': '<http://...', ... }\n hmap = dict( map( lambda t: (t[0], hmap[t[1]]) if t[1] in hmap else t, mmap.items() ) )\n \n log.debug( hmap )\n log.debug( 'Resolving prefixes ..' )\n \n # after: { 'e0': 'prefix1:prop1', 'e1': 'prefix2:prop2', ... }\n hmap = prefix_it( hmap )\n\n # the real query\n query = pystache.render( template, hmap )\n queries.append( query )\n \n return queries\n\ndef generate_queries( D, queries, dataset, no=1 ):\n \"\"\"\"\"\"\n\n log.debug( 'Entering generate_queries' )\n\n if type(queries) == int:\n queries = range( queries, queries+1 )\n \n log.info( 'Rendering queries ..' )\n for query_name in queries:\n\n query_template = '%s/%s.tpl' % (args['query_templates_folder'],query_name)\n query_graph = 'query_graph_%s' % query_name\n \n log.debug( query_name )\n log.debug( query_template )\n log.debug( query_graph )\n \n if not os.path.isfile( query_template ):\n log.error( 'no query template found for query %s', query_name )\n continue\n \n if not hasattr( _module, query_graph ):\n log.error( 'no query graph found for query %s', query_name )\n continue\n \n QG = getattr( _module, query_graph )() # the query-graph, represented as Graph-object\n QT = open( query_template, 'r' ).read() # the query-template, as mustache template\n\n if args['log_debug']:\n graph_draw( QG, output_size=(200,200) )\n \n log.debug( 'Rendering query %s' % query_name.upper() )\n instances = instantiate_query( D, QG, QT, dataset['folder'], no )\n \n if len( instances ) == 0:\n log.warn( 'Could not instantiate query' )\n continue\n \n for idx,q in enumerate( instances ):\n with open( '%s/queries_%s/%s%s.sparql' % ( args['output_folder'], dataset['name'], query_name, '' if len( instances ) == 1 else '_%s' % idx+1 ), 'w' ) as qf:\n qf.write( q )\n\ndef load_graph_from_edgelist( dataset ):\n \"\"\"\"\"\"\n\n log.debug( 'Entering load_graph_from_edgelist' )\n edgelist, graph_gt = dataset['path_edgelist'], dataset['path_graph_gt']\n\n D=None\n\n # prefer graph_gt file\n if graph_gt and os.path.isfile( graph_gt ):\n log.info( 'Constructing DiGraph from gt.xz' )\n D=load_graph( graph_gt )\n \n elif edgelist and os.path.isfile( edgelist ):\n log.info( 'Constructing DiGraph from edgelist' )\n\n D=load_graph_from_csv( edgelist, directed=True, string_vals=True, skip_first=False, csv_options={'delimiter': ' ', 'quotechar': '\"'} )\n \n else:\n log.error( 'edgelist or graph_gt file to read graph from does not exist' )\n return None\n\n return D\n\nif __name__ == '__main__':\n\n # configure args parser\n parser = argparse.ArgumentParser( description = 'generator - instantiate common queries from a given dataset' )\n parser.add_argument( '--datasets', '-d', action = \"append\", required = True, help = '', nargs = '*')\n parser.add_argument( '--queries', '-q', action = \"append\", help = '', nargs = '*', type=str )\n \n parser.add_argument( '--query-graphs', '-qg', required = False, type=str, default = 'query.watdiv.query_graphs', help = 'The python module to import the graph graphs from. Example parameter value: \"query.watdiv.query_graphs\".' )\n parser.add_argument( '--query-templates-folder', '-qf', required = False, type=str, default = 'query/watdiv/templates', help = 'The folder where to find the query templates. Example parameter value: \"query/watdiv/templates\".' )\n \n parser.add_argument( '--output-folder', '-o', required = False, type = str, default = 'target' )\n # TODO ZL add param --instances-per-query\n # TODO ZL add param --instances-choose\n\n parser.add_argument( '--log-debug', action='store_true', help = '' )\n\n args = vars( parser.parse_args() )\n\n if args['log_debug']:\n level = log.DEBUG\n else:\n level = log.INFO\n\n # configure log\n log.basicConfig( level = level, format = '[%(asctime)s] - %(levelname)-8s : %(threadName)s: %(message)s', )\n\n z = vars( parser.parse_args() ).copy()\n z.update( args )\n args = z\n\n # import query graph methods\n _module = args['query_graphs']\n\n try:\n _module = import_module( _module )\n except:\n log.debug( 'Query graphs module: %s', _module )\n log.error( 'Could not find module with query graphs, which is required.' )\n sys.exit(0)\n\n # check query templates folder\n if not os.path.isdir( args['query_templates_folder'] ):\n log.debug( 'Query templates folder: %s', args['query_templates_folder'] )\n log.error( 'Could not find folder with query templates, which is required.' )\n sys.exit(0)\n\n # \n datasets = args['datasets'] # argparse returns [[..], [..]]\n datasets = list( map( lambda ds: { # to be compatible with existing build_graph function we transform the array to a dict\n 'name': ds[0], \n 'folder': 'dumps/%s' % ds[0],\n 'path_edgelist': 'dumps/%s/data.edgelist.csv' % ds[0], \n 'path_graph_gt': 'dumps/%s/data.graph.gt.gz' % ds[0] }, datasets ) )\n \n names = ', '.join( map( lambda d: d['name'], datasets ) )\n log.debug( 'Configured datasets: %s', names )\n\n queries = args['queries']\n if not queries or len( queries ) == 0:\n queries = range(1,21) # we got 20 queries\n else:\n queries = queries[0]\n\n log.debug( 'Configured queries: %s', queries)\n\n if not os.path.isdir( args['output_folder'] ):\n os.mkdir( args['output_folder'] ) # e.g. target\n for dataset in datasets:\n target_folder = '%s/queries_%s' % (args['output_folder'], dataset['name'])\n if not os.path.isdir( target_folder ):\n os.mkdir( target_folder ) # e.g. target/queries_lexvo\n\n for dataset in datasets:\n D = load_graph_from_edgelist( dataset )\n\n if not D:\n log.error( 'Could not instantiate graph for dataset %s', dataset['name'] )\n continue\n\n generate_queries( D, queries, dataset )\n\n log.info( 'Done' )\n"
},
{
"alpha_fraction": 0.6039084792137146,
"alphanum_fraction": 0.6153479218482971,
"avg_line_length": 39.346153259277344,
"blob_id": "30631eb8ea19b08e79eec371e9c37e71349ba071",
"content_id": "7ed19fa0420ea1e4f0a66f5e2b8ee30d63fa148c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2098,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 52,
"path": "/graph/measures/fernandez_et_al/predicate_lists.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "from graph_tool import GraphView\nimport numpy as np\nimport pandas as pd\n\ndef repeated_predicate_lists( D, edge_labels=np.empty(0), stats=dict(), print_stats=False, return_collected=True ):\n \"\"\"\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = [ D.ep.c0[p] for p in D.get_edges() ]\n\n # filter those vertices v | out-degree(v) > 0\n S = GraphView( D, vfilt=D.get_out_degrees( D.get_vertices() ) )\n\n # .. is defined as the ratio of repeated predicate lists from the total lists in the graph G\n df = pd.DataFrame( \n data=list( zip( D.get_edges()[:,0], edge_labels ) ), \n index=np.arange( 0, D.get_edges().shape[0] ), \n columns=np.arange( 0, D.get_edges().shape[1] ) )\n\n df = df.groupby(0)[1].apply(tuple).apply(hash).to_frame().reset_index()\n\n if return_collected:\n df = df.groupby(1).count()[0]\n\n if print_stats:\n print( \"(Eq.17) ratio of repeated predicate lists r_L(G): %f\" % (1 - ( df.size / S.num_vertices() )) )\n print( \"(Eq.18/19) predicate list degree deg_{PL}(G). max: %f, mean: %f\" % ( df.max(), df.mean() ) )\n\n stats['repeated_predicate_lists'] = 1 - ( df.size / S.num_vertices() )\n stats['max_predicate_list_degree'], stats['mean_predicate_list_degree'] = df.max(), df.mean()\n\n return df\n\ndef collect_repeated_predicate_lists( S_G_s, edge_labels, df=pd.DataFrame(), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n if df is None:\n df = pd.DataFrame()\n\n df = df.append( repeated_predicate_lists( S_G_s, edge_labels, stats, print_stats, False ), ignore_index=True )\n\n return df\n\ndef reduce_repeated_predicate_lists( df, G, S_G, stats={} ):\n \"\"\"\"\"\"\n df = df.groupby(1).count()[0]\n\n stats['repeated_predicate_lists'] = 1 - ( df.size / S_G.num_vertices() )\n stats['max_predicate_list_degree'], stats['mean_predicate_list_degree'] = df.max(), df.mean()\n\nMETRICS = [ repeated_predicate_lists ]\nMETRICS_SET = { 'PREDICATE_LISTS': METRICS }\nLABELS = [ 'repeated_predicate_lists', 'max_predicate_list_degree', 'mean_predicate_list_degree' ]\n"
},
{
"alpha_fraction": 0.612500011920929,
"alphanum_fraction": 0.6178571581840515,
"avg_line_length": 23.39130401611328,
"blob_id": "8357e3f0e1a19107ffc7c1511810f77d40a89ad2",
"content_id": "9215d855b34aacebbb540f321da7950cd217bbc9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 560,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 23,
"path": "/graph/tasks/dbpedia/download_files.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\nimport sys\n\nfrom constants.dbpedia import LINKS_FILE\nfrom extras.dbpedia.loader import start_crawling\n\nlog = logging.getLogger( __name__ )\n\nif __name__ == '__main__':\n\n if not os.path.isfile( LINKS_FILE ):\n log.error( 'File with links to DBpedia-related files not found. nothing to do' )\n sys.exit() \n\n with open( LINKS_FILE, 'rt' ) as f:\n urls = [ line.strip() for line in f ]\n\n if len( urls ) == 0:\n log.error( 'File empty' )\n sys.exit()\n\n start_crawling( urls, 'dumps/dbpedia-en', 12 )"
},
{
"alpha_fraction": 0.6533292531967163,
"alphanum_fraction": 0.7167074084281921,
"avg_line_length": 61.35238265991211,
"blob_id": "95433804415f3155c62ece53e6d4efa33d58f478",
"content_id": "1e425587f611d595d725ec69afb37ec04685e690",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6550,
"license_type": "permissive",
"max_line_length": 463,
"num_lines": 105,
"path": "/README.md",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "[](https://doi.org/10.5281/zenodo.2109469)\n\n\n# A Software Framework for the graph-based Analysis on RDF Graphs\n\nThis framework enables to prepare and perform a graph-based analysis on the graph topology of RDF datasets. One of the main goals were to do that on large-scale and with focus on performance, i.e., with large state-of-the-art RDF graphs (hundreds of millions of edges) and in parallel, with many datasets at once. \n\n[A recent analysis](https://arxiv.org/abs/1907.01885) on 280 datasets from the [LOD Cloud](https://lod-cloud.net/) 2017 has been conducted with this framework. Please find here [the results](https://github.com/mazlo/lod-graph-analysis) on 28 graph measures as [a browsable version](http://data.gesis.org/lodcc/2017-08) of the study. Also, the results are available as [a citable resource](https://doi.org/10.5281/zenodo.1214433) at [Zenodo](https://zenodo.org/). \n\n| __Domain__ | __Datasets analyzed__ | __Max. # of Vertices__ | __Max. # of Edges__ | __Avg. # of Vertices__ | __Avg. # of Edges__ | \n| ---------- | ------------------: | ----------------------: | -------------------: | ----------------------: | -------------------: | \n| Cross Domain | 15 | 614,448,283 | 2,656,226,986 | 57,827,358 | 218,930,066 |\n| Geography | 11 | 47,541,174 | 340,880,391 | 9,763,721 | 61,049,429 |\n| Government | 37 | 131,634,287 | 1,489,689,235 | 7,491,531 | 71,263,878 |\n| Life Sciences | 32 | 356,837,444 | 722,889,087 | 25,550,646 | 85,262,882 |\n| Linguistics | 122 | 120,683,397 | 291,314,466 | 1,260,455 | 3,347,268 |\n| Media | 6 | 48,318,259 | 161,749,815 | 9,504,622 | 31,100,859 |\n| Publications | 50 | 218,757,266 | 720,668,819 | 9,036,204 | 28,017,502 |\n| Social Networking | 3 | 331,647 | 1,600,499 | 237,003 | 1,062,986 |\n| User Generated | 4 | 2,961,628 | 4,932,352 | 967,798 | 1,992,069 |\n\n### Goodies\n\nRDF data dumps are preferred (so far). The framework is capable of dealing with the following:\n\n* Automatic downloading of the RDF data dumps before preparation.\n* Packed data dumps. Various formats are supported, like bz2, 7zip, tar.gz, etc. This is achieved by employing the unix-tool [dtrx](https://brettcsmith.org/2007/dtrx/).\n* Archives, which contain a hierarchy of files and folders, will get scanned for files containing RDF data. Files which are not associated with RDF data will be ignored, e.g. Excel-, HTML-, or text-files.\n* The list of supported [RDF media types](https://www.w3.org/2008/01/rdf-media-types) is currently limited to the most common ones for RDF data, which are N-Triples, RDF/XML, Turtle, N-Quads, and Notation3. Any files containing these formats are transformed into N-Triples while graph creation. The transformation is achieved by employing the cli-tool [rapper](http://librdf.org/raptor/). \n\nFurther:\n\n+ The framework is implemented in Python. The list of supported graph measures is extendable.\n+ There is a ready-to-go docker-image available, with all third-party libraries pre-installed.\n\nCurrently ongoing and work in progress:\n\n+ Query instantiation from graph representation, and\n+ Edge- and vertex-based graph sampling.\n\n## Documentation\n\n### Installation\n\nInstallation instructions can be found in [`INSTALL`](INSTALL).\n\n### Project Structure\n\nIn each of the subpackages you will find a detailed README file. The following table gives you an overview of the most important subpackages.\n\n| Package | Description |\n| :------ | :---------- |\n| `constants` | Contains files which hold some static values. Some of them are configurable, e.g., `datapackage.py` and `db.py` | \n| `datapackages` | Contains code for (optional) pre-processing of datahub.io related datapackage.json files. |\n| `db` | Contains code to connect to a (optional) local database. A local database stores detailed information about dataset names, URLs, available RDF media types, etc. This is parsed by the `datapackage.parser`-module. | \n| `graph` | This is the main package which contains code for RDF data transformation, edgelist creation for graph building, graph measure computation, etc. | \n| `query` | Contains code for query generation from query templates. |\n| `util` | Utility subpackage with helper modules, used by various other modules. |\n\n\n### Usage\n\nExecutable code can be found in each of the corresponding `*.tasks.*` subpackages, i.e., \n\n| Tasks Package | Task Description |\n| ------- | ----------- |\n| [`datapackage/tasks/*`](datapackage/tasks/README.md) | for an optional preliminary step to acquire metadata for datasets from [datahub.io](http://old.datahub.io). |\n| [`graph/tasks/*`](graph/tasks/README.md) | for a preliminary preparation process which turns your RDF dataset into an edgelist. |\n| [`graph/tasks/analysis/*`](graph/tasks/analysis/README.md) | for graph-based measure computation of your graph instances. |\n\nPlease find more detailed instructions in the README files of the corresponding packages. \n\n#### Example commands\n\nThe software is suppossed to be run from command-line on a unix-based system.\n\n##### 1. Prepare RDF datasets for graph-analysis\n\n```\n$ python3 -m graph.tasks.prepare --from-db core education-data-gov-uk webisalod --threads 3\n```\n\nThis command will (1) download (if not present), (2) transform (if necessary), and (3) prepare an RDF dataset as an edgelist, ready to be instantiated as graph-object. \n\n- `--from-db` used to load dataset URLs and available formats from an sqlite-database configured in `db.sqlite.properties`.\n- `--threads` indicates the number of datasets that are handled in parallel.\n\n##### 2. Run an analysis on the prepared RDF datasets in parallel\n\n```\n$ python3 -m graph.tasks.analysis.core_measures --from-file core education-data-gov-uk webisalod --threads 2 --threads-openmp 8 --features diameter --print-stats\n```\n\nThis command instantiates the graph-objects, by loading the edgelists or the binary graph-objects, if available. After that, the graph measure `diameter` will be computed in the graphs. \n\n- `--from-file` used here, so measure values will be printed to STDOUT. \n- `--threads` indicates the number of datasets that are handled in parallel.\n\n## License\n\nThis package is licensed under the MIT License.\n\n## How to Cite\n\nPlease refer to the DOI for citation. You can cite all versions of this project by using the canonical DOI [10.5281/zenodo.2109469](https://doi.org/10.5281/zenodo.2109469). This DOI represents all versions, and will always resolve to the latest one.\n\n"
},
{
"alpha_fraction": 0.5728476643562317,
"alphanum_fraction": 0.5774834156036377,
"avg_line_length": 34.11627960205078,
"blob_id": "f4d23b172b8ce559aaf84c2a15cec93aa911b72f",
"content_id": "18424ef12d1cdbbe5d68be44ec3faa5a4394cb4a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1510,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 43,
"path": "/constants/preparation.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "APPLICATION_N_QUADS = 'application_n_quads'\nAPPLICATION_N_TRIPLES = 'application_n_triples'\nAPPLICATION_RDF_XML = 'application_rdf_xml'\nAPPLICATION_UNKNOWN = 'unknown'\nTEXT_TURTLE = 'text_turtle'\nTEXT_N3 = 'text_n3'\n\nSHORT_FORMAT_MAP = {\n 'ntriples': APPLICATION_N_TRIPLES,\n 'rdfxml': APPLICATION_RDF_XML,\n 'turtle': TEXT_TURTLE,\n 'n3': TEXT_N3,\n 'nquads': APPLICATION_N_QUADS\n}\n\nMEDIATYPES = { \n APPLICATION_RDF_XML: { \n 'cmd_to_ntriples': './bin/to_ntriples.sh rdfxml %s %s %s', \n 'cmd_merge_edgelists': './bin/merge_edgelists.sh %s %s',\n 'extension': '.rdf' \n },\n APPLICATION_N_QUADS: {\n 'cmd_to_ntriples': './bin/to_ntriples.sh nquads %s %s %s',\n 'cmd_merge_edgelists': './bin/merge_edgelists.sh %s %s',\n 'extension': '.nq'\n },\n APPLICATION_N_TRIPLES: {\n 'cmd_to_ntriples': './bin/to_ntriples.sh ntriples %s %s %s',\n 'cmd_merge_edgelists': './bin/merge_edgelists.sh %s %s',\n 'extension': '.nt'\n },\n TEXT_TURTLE: {\n 'cmd_to_ntriples': './bin/to_ntriples.sh turtle %s %s %s', \n 'cmd_merge_edgelists': './bin/merge_edgelists.sh %s %s',\n 'extension': '.ttl'\n },\n TEXT_N3: {\n 'cmd_to_ntriples': './bin/to_ntriples.sh turtle %s %s %s', \n 'cmd_merge_edgelists': './bin/merge_edgelists.sh %s %s',\n 'extension': '.n3'\n }\n}\nMEDIATYPES_COMPRESSED = [ 'tar.gz', 'tar.xz', 'tgz', 'gz', 'zip', 'bz2', 'tar' ] # do not add 'xy.z' types at the end, they have privilege\n"
},
{
"alpha_fraction": 0.5830535888671875,
"alphanum_fraction": 0.588897168636322,
"avg_line_length": 39.11471176147461,
"blob_id": "31766c58b89fbe86ccd60403e9b889131aa5382c",
"content_id": "3f1e1c917388b1c925de107c36e4c60579ffe551",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16086,
"license_type": "permissive",
"max_line_length": 190,
"num_lines": 401,
"path": "/graph/measures/fernandez_et_al/main.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import re\nimport os\nimport argparse\nimport gc\nimport json\nimport logging as log\nimport pandas as pd\nimport multiprocessing\nimport threading\nimport sys\n\ntry:\n from graph_tool.all import *\nexcept:\n print( 'graph_tool module could not be imported' )\nimport numpy as np\nimport powerlaw\nnp.warnings.filterwarnings('ignore')\n\nimport db.helpers as db\nimport graph.measures.fernandez_et_al.all as measures\nfrom graph.building import builder\n\nlock = multiprocessing.Lock()\n\nROOT_DIR = os.path.abspath( os.curdir )\nDEFAULT_DATAFRAME_INDEX = [ 'time_overall' ]\n\ndef job_on_partition_out_degrees( sem, feature, G, edge_labels, data ):\n \"\"\"\"\"\"\n # can I?\n with sem:\n data[feature] = getattr( measures, 'collect_'+ feature.__name__ )( G, edge_labels, data[feature], {}, args['print_stats'] )\n\ndef job_on_partition_in_degrees( sem, feature, G, edge_labels, data ):\n \"\"\"\"\"\"\n # can I?\n with sem:\n data[feature] = measures.object_in_degrees.collect_metric( feature, G, edge_labels, data[feature], {}, args['print_stats'] )\n\ndef job_on_partition_predicate_lists( sem, feature, G, edge_labels, data ):\n \"\"\"\"\"\"\n # can I?\n with sem:\n data[feature] = measures.predicate_degrees.collect_metric( feature, G, edge_labels, data[feature], {}, args['print_stats'] )\n\ndef graph_analyze_on_partitions( dataset, D, features, stats ):\n \"\"\"\"\"\"\n\n NO_PARTITIONS = args['partitions']\n\n # collect features that require out-degree filtering\n feature_subset = [ ftr for ftr in features if ftr in measures.SETS['SUBJECT_OUT_DEGREES'] \\\n or ftr in measures.SETS['PREDICATE_LISTS'] \\\n or ftr in measures.SETS['TYPED_SUBJECTS_OBJECTS'] ]\n\n if len( feature_subset ) > 0:\n log.info( 'Computing features %s on %s partitions of the DiGraph' % ( ', '.join( [ f.__name__ for f in feature_subset ] ), NO_PARTITIONS ) )\n gc.collect()\n \n # filter the graph for subjects, vertices with out-degree > 0\n S_G = GraphView( D, vfilt=lambda v:v.out_degree() > 0 )\n\n # we split up all subjects into X partitions. For example, 10 fragments of ~7600 vertices \n # will result in this: [ [0,..,759], [760,.., 1519], .., [6840,7599] ]\n partitions = np.array_split( S_G.get_vertices(), NO_PARTITIONS )\n\n # init data dictionary\n data = dict( [ (feature,None) for feature in feature_subset ] )\n for s_idx in np.arange( NO_PARTITIONS ):\n log.info( 'Lets go with partition %s', (s_idx+1) )\n \n # now, we filter out those edges with source vertices from the current partition\n S_G_s = GraphView( D, efilt=np.isin( D.get_edges()[:,0], partitions[s_idx] ) )\n\n hash_func = np.vectorize( lambda e: hash(e) )\n edge_labels = hash_func( [ S_G_s.ep.c0[p] for p in S_G_s.edges() ] )\n\n sem = threading.Semaphore( min( 10, len( feature_subset ) ) )\n threads = []\n\n for feature in feature_subset:\n # this should add up all the values we need later when computing the metric\n t = threading.Thread( target = job_on_partition_out_degrees, name = feature.__name__, args = ( sem, feature, S_G_s, edge_labels, data ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n\n gc.collect()\n\n for feature in feature_subset:\n # compute metric from individual partitions\n getattr( measures, 'reduce_'+ feature.__name__ )( data[feature], D, S_G, stats )\n\n if args['from_db']:\n db.save_stats( dataset, stats )\n\n # collect features that require in-degree filtering\n feature_subset = [ ftr for ftr in features if ftr in measures.SETS['OBJECT_IN_DEGREES'] ]\n\n if len( feature_subset ) > 0:\n log.info( 'Computing features %s on %s partitions of the DiGraph' % ( ', '.join( [ f.__name__ for f in feature_subset ] ), NO_PARTITIONS ) )\n gc.collect()\n\n # filter the graph for objects, vertices with in-degree > 0\n O_G = GraphView( D, vfilt=lambda v:v.in_degree() > 0 )\n\n # we split up all subjects into X partitions. For example, 10 fragments of ~7600 vertices \n # will result in this: [ [0,..,759], [760,.., 1519], .., [6840,7599] ]\n partitions = np.array_split( O_G.get_vertices(), NO_PARTITIONS )\n\n # init data dictionary\n data = dict( [ (feature,None) for feature in feature_subset ] )\n for o_idx in np.arange( NO_PARTITIONS ):\n log.info( 'Lets go with partition %s', (o_idx+1) )\n \n # now, we filter out those edges with source vertices from the current partition\n O_G_s = GraphView( D, efilt=np.isin( D.get_edges()[:,1], partitions[o_idx] ) )\n\n hash_func = np.vectorize( lambda e: hash(e) )\n edge_labels = hash_func( [ O_G_s.ep.c0[p] for p in O_G_s.edges() ] )\n\n sem = threading.Semaphore( min( 10, len( feature_subset ) ) )\n threads = []\n\n for feature in feature_subset:\n # this should add up all the values we need later when computing the metric\n t = threading.Thread( target = job_on_partition_in_degrees, name = feature.__name__, args = ( sem, feature, O_G_s, edge_labels, data ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n\n gc.collect()\n\n for feature in feature_subset:\n # compute metric from individual partitions\n measures.object_in_degrees.reduce_metric( data[feature], stats, 'max_'+ feature.__name__, 'mean_'+ feature.__name__ )\n \n if args['from_db']:\n db.save_stats( dataset, stats )\n\n # collect features that require in-degree filtering\n feature_subset = [ ftr for ftr in features if ftr in measures.SETS['PREDICATE_DEGREES'] ]\n\n if len( feature_subset ) > 0:\n log.info( 'Computing features %s on %s partitions of the DiGraph' % ( ', '.join( [ f.__name__ for f in feature_subset ] ), NO_PARTITIONS ) )\n gc.collect()\n \n # we first compute a unique set of predicates\n edge_labels = np.array( [D.ep.c0[p] for p in D.edges() ] )\n # and split up all predicates into X partitions. \n partitions = np.array_split( np.unique( edge_labels ), NO_PARTITIONS )\n\n # init data dictionary\n data = dict( [ (feature,None) for feature in feature_subset ] )\n for p_idx in np.arange( NO_PARTITIONS ):\n \n log.info( 'Lets go with partition %s', (p_idx+1) )\n # now, we filter all edges with labels from the corresponding partition \n P_G_s = GraphView( D, efilt=np.isin( edge_labels, partitions[p_idx] ) )\n \n # and use the edge labels from the current GraphView for the computation of the feature\n hash_func = np.vectorize( lambda e: hash(e) )\n edge_labels_subgraph = hash_func( [ P_G_s.ep.c0[p] for p in P_G_s.edges() ] )\n\n sem = threading.Semaphore( min( 10, len( feature_subset ) ) )\n threads = []\n\n for feature in feature_subset:\n # this should add up all the values we need later when computing the metric\n t = threading.Thread( target = job_on_partition_predicate_lists, name = feature.__name__, args = ( sem, feature, P_G_s, edge_labels_subgraph, data ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n\n gc.collect()\n\n for feature in feature_subset:\n # compute metric from individual partitions\n measures.predicate_degrees.reduce_metric( data[feature], stats, 'max_'+ feature.__name__, 'mean_'+ feature.__name__ )\n\n if args['from_db']:\n db.save_stats( dataset, stats )\n\ndef graph_analyze( dataset, D, stats ):\n \"\"\"\n CAUTION\n please keep in mind that YOU CANNOT work with the vertice's and edge's index, 'cause it's a unique integer.\n you have to work with the vertice's and edge's label in all operations\n \"\"\"\n\n # final set of features is the intersection of both sets\n features = [ ftr_func for ftr_func in np.array( measures.all ).flatten() if ftr_func.__name__ in args['features'] ]\n\n if len( features ) == 0:\n log.warn( 'Set of features to be computed is empty :/' )\n return\n\n NO_PARTITIONS = args['partitions']\n\n if NO_PARTITIONS <= 1:\n # compute the feature on the whole graph\n # one-time computation of edge-labels\n log.info( 'Preparing edge-label structure' )\n # we unfortunately need to iterate over all edges once, since the order of appearance of\n # edge labels together with subjects and objects is important\n hash_func = np.vectorize( lambda e: hash(e) )\n edge_labels = hash_func( [ D.ep.c0[p] for p in D.edges() ] )\n\n log.info( 'Computing features' )\n for ftr in features:\n ftr( D, edge_labels, stats )\n\n if args['from_db']:\n db.save_stats( dataset, stats )\n else:\n # requested to partition the graph\n graph_analyze_on_partitions( dataset, D, features, stats )\n\ndef build_graph_analyse( dataset, D, stats, threads_openmp=7 ):\n \"\"\"\"\"\"\n\n # before starting off: limit the number of threads a graph_tool job may acquire\n # TODO graph_tool.openmp_set_num_threads( threads_openmp )\n \n graph_analyze( dataset, D, stats )\n\n if args['print_stats']:\n print( ', '.join( [ key for key in stats.keys() ] ) )\n print( ', '.join( [ str(stats[key]) for key in stats.keys() ] ) )\n\ndef build_graph_prepare( dataset, stats ):\n \"\"\"build_graph_prepare\"\"\"\n\n D = builder.load_graph_from_edgelist( dataset )\n\n if not D:\n log.error( 'Could not instantiate graph, None' )\n return None\n\n return D\n\nimport datetime\n\n# real job\ndef job_start_build_graph( dataset, dataframe, sem, threads_openmp=7 ):\n \"\"\"job_start_build_graph\"\"\"\n\n # let's go\n with sem:\n log.info( 'Let''s go' )\n log.debug( dataset )\n\n # - build_graph_prepare\n stats = dict()\n D = build_graph_prepare( dataset, stats )\n\n if not D:\n log.error( 'Exiting due to graph None' )\n return\n\n # start timer\n start = datetime.datetime.now()\n\n # - build_graph_analyse\n build_graph_analyse( dataset, D, stats, threads_openmp )\n\n # save results\n stats['time_overall'] = datetime.datetime.now() - start\n dataframe[dataset['name']] = pd.Series( stats )\n\n if 'stats_file' in args:\n dataframe = dataframe.T.reset_index().rename( columns={ 'index': 'name' } )\n dataframe.to_csv( '%s/%s' % (ROOT_DIR, args['stats_file']), index_label='id' )\n\n # - job_cleanup\n\n log.info( 'Done' ) \n\ndef build_graph( datasets, no_of_threads=1, threads_openmp=7 ):\n \"\"\"\"\"\"\n\n if len( datasets ) == 0:\n log.error( 'No datasets to parse. exiting' )\n return None\n\n # init dataframe with index being all measures + some defaults.\n # the transposed DataFrame is written to csv-file a results.\n dataframe = pd.DataFrame( index=measures.LABELS + DEFAULT_DATAFRAME_INDEX )\n\n sem = multiprocessing.Semaphore( int( 1 if no_of_threads <= 0 else ( 20 if no_of_threads > 20 else no_of_threads ) ) )\n threads = []\n\n for dataset in datasets:\n \n # create a thread for each dataset. work load is limited by the semaphore\n t = multiprocessing.Process( target = job_start_build_graph, name = dataset['name'], args = ( dataset, dataframe, sem, threads_openmp ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n\n# ----------------\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description = 'lodcc' )\n actions = parser.add_mutually_exclusive_group( required = True )\n\n actions.add_argument( '--build-graph', '-b', action = \"store_true\", help = '' )\n\n group = parser.add_mutually_exclusive_group( required = True )\n group.add_argument( '--from-db', '-fdb', action = \"store_true\", help = '' )\n group.add_argument( '--from-file', '-ffl', action = \"store_true\", help = '' )\n\n parser.add_argument( '--use-datasets', '-d', nargs='*', required = True, help = '' )\n parser.add_argument( '--print-stats', '-dp', action= \"store_true\", help = '' )\n parser.add_argument( '--stats-file', '-df', required = False, type = str, help = 'Specify the name of the file to save the statistics to.' ) \n \n parser.add_argument( '--log-debug', '-ld', action = \"store_true\", help = '' )\n parser.add_argument( '--log-info', '-li', action = \"store_true\", help = '' )\n parser.add_argument( '--threads', '-t', required = False, type = int, default = 1, help = 'Specify how many threads will be used for downloading and parsing' )\n\n # RE graph or feature computation\n parser.add_argument( '--threads-openmp', '-th', required = False, type = int, default = 7, help = 'Specify how many threads will be used for the graph analysis' )\n parser.add_argument( '--features', '-f', nargs='*', required = False, default = list(), help = '' )\n parser.add_argument( '--skip-features', '-fs', nargs='*', required = False, default = list(), help = '' )\n parser.add_argument( '--partitions', '-p', required = False, type = int, default = 1, help = 'If > 1, features will be computed on this number of partitions separately.' ) \n \n # args is available globaly\n args = vars( parser.parse_args() ).copy()\n\n # configure logging\n if args['log_debug']:\n level = log.DEBUG\n else:\n level = log.INFO\n\n log.basicConfig( level = level, format = '[%(asctime)s] - %(levelname)-8s : %(processName)s: %(message)s', )\n\n # configure datasets\n datasets = args['use_datasets'] # argparse returns [[..], [..]]\n log.debug( 'Configured datasets: '+ ', '.join( datasets ) )\n\n # either from db\n if args['from_db']:\n log.debug( 'Requested to read data from db' )\n\n try:\n # connects, checks connection, and loads datasets\n db.init( args )\n db.connect()\n except:\n log.error( 'Database not ready for query execution. Check db.properties.\\n Raised error: %s', sys.exc_info() )\n sys.exit(0)\n\n # read datasets\n names_query = '( ' + ' OR '.join( 'name = %s' for ds in datasets ) + ' )'\n \n if 'names_query' in locals():\n sql = ('SELECT id,name,path_edgelist,path_graph_gt FROM %s WHERE ' % args['db_tbname']) + names_query +' AND (path_edgelist IS NOT NULL OR path_graph_gt IS NOT NULL) ORDER BY id'\n else:\n sql = 'SELECT id,name,path_edgelist,path_graph_gt FROM %s WHERE (path_edgelist IS NOT NULL OR path_graph_gt IS NOT NULL) ORDER BY id' % args['db_tbname']\n \n datasets = db.run( sql, tuple( datasets ) )\n\n # or passed by cli arg\n elif args['from_file']:\n log.debug( 'Requested to read data from file' )\n\n # transform the cli arg list into object structure.\n # this format is compatible with the format that is returned by the database\n datasets = list( map( lambda ds: {\n 'name': ds, \n 'path_edgelist': '%s/dumps/%s/data.edgelist.csv' % (ROOT_DIR, ds), \n 'path_graph_gt': '%s/dumps/%s/data.graph.gt.gz' % (ROOT_DIR, ds) }, datasets ) )\n\n # option 3\n if args['build_graph']:\n\n # init feature list\n if len( args['features'] ) == 0:\n #\n args['features'] = [ ftr.__name__ for ftr in np.array( measures.all ).flatten() ]\n\n build_graph( datasets, args['threads'], args['threads_openmp'] )\n"
},
{
"alpha_fraction": 0.611869752407074,
"alphanum_fraction": 0.6129201650619507,
"avg_line_length": 32.403507232666016,
"blob_id": "6a1c89a63a025f2acb8caf011abc97523448f6ff",
"content_id": "4e64fb07cf63ed6cf404f60bf0b1d3731e3aa4f6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1904,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 57,
"path": "/graph/building/builder.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nimport numpy as np\nnp.warnings.filterwarnings('ignore')\nimport os\nimport re\n\ntry:\n from graph_tool import Graph, GraphView, load_graph, load_graph_from_csv\nexcept:\n print( 'graph_tool module could not be imported' )\n\nlog = logging.getLogger( __name__ )\n\ndef dump_graph( D, edgelist_path, options={} ):\n \"\"\"\"\"\"\n\n # dump graph after reading if required\n if D and 'dump_graph' in options and options['dump_graph']:\n log.info( 'Dumping graph..' )\n\n prefix = re.split( '.edgelist.csv', os.path.basename( edgelist_path ) )\n if prefix[0] != 'data':\n prefix = prefix[0]\n else:\n prefix = 'data'\n\n graph_gt_path = '/'.join( [os.path.dirname( edgelist_path ), '%s.graph.gt.gz' % prefix] )\n D.save( graph_gt_path )\n \ndef load_graph_from_edgelist( dataset, options={} ):\n \"\"\"\"\"\"\n\n edgelist, graph_gt = dataset['path_edgelist'], dataset['path_graph_gt']\n\n D=None\n\n # prefer graph_gt file\n if (not 'reconstruct_graph' in options or not options['reconstruct_graph']) and \\\n (graph_gt and os.path.isfile( graph_gt )):\n log.info( 'Constructing DiGraph from gt.xz' )\n D=load_graph( graph_gt )\n \n elif edgelist and os.path.isfile( edgelist ):\n log.info( 'Constructing DiGraph from edgelist' )\n\n if 'dict_hashed' in options and options['dict_hashed']:\n D=load_graph_from_csv( edgelist, directed=True, hashed=False, skip_first=False, csv_options={'delimiter': ' ', 'quotechar': '\"'} )\n else:\n D=load_graph_from_csv( edgelist, directed=True, hashed=True, skip_first=False, csv_options={'delimiter': ' ', 'quotechar': '\"'} )\n \n # check if graph should be dumped\n dump_graph( D, edgelist, options )\n else:\n log.error( 'edgelist or graph_gt file to read graph from does not exist' )\n return None\n\n return D\n"
},
{
"alpha_fraction": 0.7106382846832275,
"alphanum_fraction": 0.714893639087677,
"avg_line_length": 32.57143020629883,
"blob_id": "88facd27765a73bd26b284cea5ac1217ba0324dd",
"content_id": "f84acba28403b04538702dd9bc2ae059b157683a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 235,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 7,
"path": "/graph/__init__.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\n\nmpl_logger = logging.getLogger( 'matplotlib' )\nmpl_logger.setLevel( logging.WARNING )\n\n# configure logging\nlogging.basicConfig( level = logging.DEBUG, format = '[%(asctime)s] %(levelname)-6s - %(name)s: %(message)s', )\n"
},
{
"alpha_fraction": 0.6224489808082581,
"alphanum_fraction": 0.6292517185211182,
"avg_line_length": 19.928571701049805,
"blob_id": "8caf48c70e56a09cbef33e78bc702af026465263",
"content_id": "4b39a2dbe921b6f0cec9c57a3461b8ac1569251c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 294,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 14,
"path": "/bin/zip-data-edgelists.sh",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# this is to zip all data edgelists (csv files) to save space\n#\n\nset -e\n\nfind dumps/* -name \"data.edgelist.csv\" -type f -print0 | while read -d $'\\0' file \ndo\n FILE=$file\n echo \"Doing $FILE\"\n FOLDER=`echo ${FILE%/*}`\n tar -czf $FOLDER/data.edgelist.tar.gz $FILE\ndone\n\n"
},
{
"alpha_fraction": 0.6268817186355591,
"alphanum_fraction": 0.6354838609695435,
"avg_line_length": 34.80769348144531,
"blob_id": "7c78ca7d68d2af5f951d04c5ad33ecba2b9a2cb8",
"content_id": "386b1c73a8a2f9466c857a6321a537b03de5dfab",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 930,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 26,
"path": "/graph/measures/fernandez_et_al/common_ratios.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\ndef subject_object_ratio( D, edge_labels=None, stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n # the number of elements acting both as subject and objects among all subjects and objects\n nom_intersection = set( D.get_edges()[:,0] ) & set( D.get_edges()[:,1] )\n denom_union = set( D.get_edges()[:,0] ) | set( D.get_edges()[:,1] )\n\n if print_stats:\n print( \"(Eq.12) subject-object ratio \\\\alpha_{s-o}(G): %f\" % ( float(len(nom_intersection)) / len(denom_union) ) )\n \n stats['subject_object_ratio'] = float(len(nom_intersection)) / len(denom_union)\n\ndef subject_predicate_ratio( D, edge_labels=np.empty(0), stats=dict() ):\n \"\"\"\"\"\"\n\n # TODO because this is a costly computation\n\ndef predicate_object_ratio( D, edge_labels=np.empty(0), stats=dict() ):\n \"\"\"\"\"\"\n\n # TODO because this is a costly computation\n\nMETRICS = [ subject_object_ratio ]\nLABELS = [ 'subject_object_ratio' ]"
},
{
"alpha_fraction": 0.7525773048400879,
"alphanum_fraction": 0.7525773048400879,
"avg_line_length": 48,
"blob_id": "54187e5d131dcd7ff12ddd5bf9b96c4bf929e320",
"content_id": "4e5092bfc22e26d0429ec95987096d4d54f63622",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 97,
"license_type": "permissive",
"max_line_length": 50,
"num_lines": 2,
"path": "/constants/datapackage.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "DATAPACKAGE_FOLDER = 'resources/datapackages'\nFORMAT_MAPPINGS_FILE = 'formats.properties'"
},
{
"alpha_fraction": 0.5423255562782288,
"alphanum_fraction": 0.5469767451286316,
"avg_line_length": 27.289474487304688,
"blob_id": "dbfcd0fbf71cd390496210b9102cec4259bb9942",
"content_id": "6ea8a9094e656e119b9392d52abd4d923a5235e9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1075,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 38,
"path": "/bin/lodcc_qa.sh",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nFOLDER=${1:-\"dumps/\"}\nFILE=$2\nFILES_LIST=`find $FOLDER* -name \"*.edgelist.csv\" -type f`\n\nfor f in $FILES_LIST; do\n echo -n \"Analyzing $f..\"\n\n ORIG_FILEPATH=$f\n\n # if $2 is present, respect that. otherwise use corresponding .nt file derived from .edgelist.csv\n # e.g. xyz.edgelist.csv -> xyz.nt\n if [ -z $FILE ]; then\n NT_FILEPATH=\"${f%*.edgelist.csv}.nt\"\n else\n NT_FILEPATH=\"$FOLDER/$FILE\"\n fi\n\n if [ -f $NT_FILEPATH ]; then\n ORIG_LINES=`wc -l $ORIG_FILEPATH | cut -d ' ' -f1 &` \n NT_LINES=`wc -l $NT_FILEPATH | cut -d ' ' -f1 &` \n wait\n\n if [[ $ORIG_LINES = '' || $NT_LINES = '' ]]; then\n printf \"\\n!! Couldn't obtain line numbers\\n\"\n fi\n\n if [[ $ORIG_LINES != $NT_LINES ]]; then\n printf \"\\n!! Number of lines is not the same:\\n\\tEdgelist: $ORIG_LINES\\n\\tntriple-file: $NT_LINES\\n\"\n else\n echo \" $NT_LINES lines both. done\"\n fi\n else\n echo \"Could not find ntriple-file for $f (I was looking for $NT_FILEPATH)\"\n fi\n\ndone\n"
},
{
"alpha_fraction": 0.623505175113678,
"alphanum_fraction": 0.6247422695159912,
"avg_line_length": 33.16197204589844,
"blob_id": "607ac1a071b80974b6c243ec478632ff1aed62f2",
"content_id": "f83586c346aa87216b4b04a6490308708188f595",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4850,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 142,
"path": "/datapackage/parser.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import json\nimport logging as log\nimport os\nimport re\nimport subprocess as proc\n\nfrom constants.datapackage import DATAPACKAGE_FOLDER\nfrom datapackage import mediatype_mappings\n\ndef ensure_format_in_dictionary( format_ ):\n \"\"\"\n Maps the given format according to the provided format mapping file.\"\"\"\n\n if format_ in mediatype_mappings:\n log.info( 'Format %s will be mapped to %s', format_, mediatype_mappings[format_] )\n return mediatype_mappings[format_]\n\n return format_\n\ndef ensure_format_is_valid( r, dataset_name ):\n \"\"\"\n This extracts the format from the given resource\n and maps it according to the formats mapping, if provided.\"\"\"\n\n if not 'format' in r:\n log.error( '%s resources-object is missing format-property. Cannot save this value', dataset_name )\n # TODO create error message and exit\n return None\n\n format_ = r['format'].strip().lower()\n format_ = re.sub( r'[^a-zA-Z0-9]', '_', format_ ) # replace special character in format-attribute with _\n format_ = re.sub( r'^_+', '', format_ ) # replace leading _\n format_ = re.sub( r'_+$', '', format_ ) # replace trailing _\n format_ = re.sub( r'__*', '_', format_ ) # replace double __\n\n if not format_:\n log.error( 'Format is not valid after cleanup, original: %s. Will continue with next resource', r['format'] )\n return None\n\n format_ = ensure_format_in_dictionary( format_ )\n\n log.info( 'Found valid format \"%s\"', format_ )\n\n return format_\n\ndef curl_datapackage( datahub_url, dataset_name ):\n \"\"\"\n cURLs the datapackage from the given url.\n\n Returns the full path to the json file, to be read by subsequent method.\"\"\"\n\n # prepare target directory\n os.makedirs( DATAPACKAGE_FOLDER, exist_ok=True )\n\n datapackage = '%s/datapackage_%s.json' % ( DATAPACKAGE_FOLDER, dataset_name )\n if not os.path.isfile( datapackage ):\n log.info( 'cURLing datapackage.json for %s', dataset_name )\n proc.call( 'curl -s -L \"%s/datapackage.json\" -o %s' % ( datahub_url,datapackage ), shell=True )\n # TODO ensure the process succeeds\n else:\n log.info( 'Using local datapackage.json for %s', dataset_name )\n\n return datapackage\n\ndef parse_resources( dataset_id, dataset_name, datapackage ):\n \"\"\"\n Parses the resources-attribute in the json structure. \n Performs format mapping, if provided.\n\n Returns a list of urls and formats found.\n \"\"\"\n\n ret = []\n log.debug( 'Found resources-object. reading' )\n for r in datapackage['resources']:\n\n format_ = ensure_format_is_valid( r, dataset_name )\n\n if not format_:\n continue\n\n # depending on the version of the datapackage\n attr = 'url'\n attr = 'path' if attr not in r else attr\n\n # we save the format as own column and the url as its value\n ret.append( (dataset_id, dataset_name, format_, r[attr]) )\n\n return ret\n\ndef get_parse_datapackage( dataset_id, datahub_url, dataset_name, dry_run=False ):\n \"\"\"\n This function has two goals:\n 1. cURLing the json datapackage for the given url, and\n 2. parsing the package for resources.\n\n Returns a list of resources and formats found in the json file.\n The formats are already mapped according to the formats mapping, if provided.\"\"\"\n\n log.info( 'Getting and parsing %s datapackage' % dataset_name )\n \n dp = None\n datapackage = curl_datapackage( datahub_url, dataset_name )\n\n with open( datapackage, 'r' ) as file:\n \n try:\n log.debug( 'Parsing datapackage.json' )\n dp = json.load( file )\n\n if not 'resources' in dp:\n log.error( '\"resources\" does not exist for %s', dataset_name )\n # TODO create error message and exit\n return []\n\n ret = parse_resources( dataset_id, dataset_name, dp )\n\n # now save some basic information from the package to be at hand later\n if 'name' in dp:\n dataset_name = dp['name']\n ret.append( (dataset_id, dataset_name, 'name', dataset_name) )\n else:\n log.warn( 'No name-property given. File will be saved in datapackage.json' )\n\n # save whole datapackage.json in column\n ret.append( (dataset_id, dataset_name, 'datapackage_content', str( json.dumps( dp ) )) )\n\n except:\n # TODO create error message and exit\n raise\n return []\n\n return ret\n\nif __name__ == '__main__':\n\n log.basicConfig( level = log.DEBUG, format = '[%(asctime)s] - %(levelname)-8s : %(threadName)s: %(message)s', )\n\n log.info( 'Started' )\n # dataset_id, datahub_url, dataset_name\n ret = get_parse_datapackage( 1, 'https://old.datahub.io/dataset/bis-linked-data', 'bis-linked-data' )\n print( ret )"
},
{
"alpha_fraction": 0.6162246465682983,
"alphanum_fraction": 0.6318252682685852,
"avg_line_length": 34.61111068725586,
"blob_id": "6af1c3a7d83c72b86e5c7e1bd905b3aa9af955bd",
"content_id": "3b87e2efaf26dfeab82184c96efcf0e5c08a5c4c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 641,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 18,
"path": "/graph/measures/fernandez_et_al/tests/test_predicate_lists.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import unittest\nimport unitgraphs\nimport graph.measures.fernandez_et_al.predicate_lists as pl\n\nclass MetricsTestCase( unittest.TestCase ):\n \"\"\"\"\"\"\n\n def setUp( self ):\n \"\"\"\"\"\"\n self.G = unitgraphs.basic_graph()\n self.stats = dict()\n\n def test_repeated_predicate_lists( self ):\n \"\"\"\"\"\"\n pl.repeated_predicate_lists( self.G, None, self.stats )\n self.assertEqual( round( self.stats['repeated_predicate_lists'], 2 ), 0.25 )\n self.assertEqual( round( self.stats['max_predicate_list_degree'], 2 ), 2 )\n self.assertEqual( round( self.stats['mean_predicate_list_degree'], 2 ), 1.33 )\n"
},
{
"alpha_fraction": 0.5873731970787048,
"alphanum_fraction": 0.5930101275444031,
"avg_line_length": 31.86419677734375,
"blob_id": "b433c11f84a9694bb2ae3a9a2815daf0bea7be22",
"content_id": "fb5bf55574d4eab445478c246182e399c0e8ed78",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2661,
"license_type": "permissive",
"max_line_length": 287,
"num_lines": 81,
"path": "/graph/extras/chead_urls.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "# THIS IS LEGACY CODE AND NEEDS TO BE UPDATED\n#\nimport os\nimport psycopg2\nimport psycopg2.extras\nimport re\nimport requests\n\ndef save_stats( cur, dataset, urls ):\n \"\"\"\"\"\"\n\n # e.g. mean_degree=%(mean_degree)s, max_degree=%(max_degree)s, ..\n cols = ', '.join( map( lambda d: d +'=%('+ d +')s', urls ) )\n\n sql='UPDATE stats_urls SET '+ cols +' WHERE id=%(id)s'\n urls['id']=dataset['id']\n\n print sql % urls\n cur.execute( sql, urls )\n conn.commit()\n\ndef head_curl_urls( cur ):\n \"\"\"\"\"\"\n\n datasets = cur.fetchall()\n cols = ['application_n_triples', 'application_rdf_xml', 'text_turtle', 'application_n_quads', 'text_n3']\n\n for dataset in datasets:\n stats = {}\n for idx,format_ in enumerate(cols):\n\n if not dataset[format_]:\n continue\n\n try:\n res = requests.head( dataset[format_], timeout=10 )\n\n stats[format_] = res.status_code\n stats['content_type'] = res.headers['content-type'] if 'content-type' in res.headers else None\n stats['content_length'] = res.headers['content-length'] if 'content-length' in res.headers else None\n except:\n stats[format_] = 400\n\n break\n\n if len(stats) > 0:\n save_stats( cur, dataset, stats )\n\nif __name__ == '__main__':\n\n # read all properties in file into args-dict\n if os.path.isfile( 'db.properties' ):\n with open( 'db.properties', 'rt' ) as f:\n args = dict( ( key.replace( '.', '-' ), value ) for key, value in ( re.split( \"=\", option ) for option in ( line.strip() for line in f ) ) )\n else:\n print 'Please verify your settings in db.properties (file exists?)'\n sys.exit()\n\n # connect to an existing database\n conn = psycopg2.connect( host=args['db-host'], dbname=args['db-dbname'], user=args['db-user'], password=args['db-password'] )\n conn.set_session( autocommit=True )\n\n try:\n cur = conn.cursor()\n cur.execute( \"SELECT 1;\" )\n result = cur.fetchall()\n cur.close()\n\n print 'Database ready to query execution' \n except:\n print 'Database not ready for query execution. %s', sys.exc_info()[0]\n raise \n\n #\n sql = 'SELECT id, name, application_rdf_xml, application_n_triples, application_n_quads, text_turtle, text_n3 FROM stats s WHERE application_rdf_xml IS NOT NULL OR application_n_triples IS NOT NULL OR application_n_quads IS NOT NULL OR text_turtle IS NOT NULL OR text_n3 IS NOT NULL'\n\n cur = conn.cursor( cursor_factory=psycopg2.extras.DictCursor )\n cur.execute( sql )\n\n head_curl_urls( cur )\n cur.close()"
},
{
"alpha_fraction": 0.5981651544570923,
"alphanum_fraction": 0.5993883609771729,
"avg_line_length": 31.058822631835938,
"blob_id": "265310ba1510e7292f97c3671893f73f4a195fc5",
"content_id": "ce96a004ab759a8ebdffc0c040565b0457963eb7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1635,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 51,
"path": "/graph/measures/core/basic_measures.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\n\nfrom graph_tool import GraphView\nfrom graph_tool.stats import label_parallel_edges\n\nlog = logging.getLogger( __name__ )\n\ndef fs_digraph_using_basic_properties( D, stats, options={ 'features': [] } ):\n \"\"\"\"\"\"\n\n # at least one of these features needed to continue\n if len([f for f in ['degree','parallel_edges','fill'] if f in options['features']]) == 0:\n return\n\n # feature: order\n num_vertices = D.num_vertices()\n log.debug( 'done order' )\n\n # feature: size\n num_edges = D.num_edges()\n log.debug( 'done size' )\n\n stats['n']=num_vertices\n stats['m']=num_edges\n\n # feature: mean_degree\n if 'degree' in options['features']:\n stats['mean_degree']=float( 2*num_edges ) / num_vertices\n log.debug( 'done mean_degree' )\n \n # feature: fill_overall\n if 'fill' in options['features']:\n stats['fill_overall']=float( num_edges ) / ( num_vertices * num_vertices )\n log.debug( 'done fill_overall' )\n\n if 'parallel_edges' in options['features'] or 'fill' in options['features']:\n eprop = label_parallel_edges( D, mark_only=True )\n PE = GraphView( D, efilt=eprop )\n num_edges_PE = PE.num_edges()\n\n stats['m_unique']=num_edges - num_edges_PE\n\n # feature: parallel_edges\n if 'parallel_edges' in options['features']:\n stats['parallel_edges']=num_edges_PE\n log.debug( 'done parallel_edges' )\n\n # feature: fill\n if 'fill' in options['features']:\n stats['fill']=float( num_edges - num_edges_PE ) / ( num_vertices * num_vertices )\n log.debug( 'done fill' )\n"
},
{
"alpha_fraction": 0.6899999976158142,
"alphanum_fraction": 0.6899999976158142,
"avg_line_length": 66,
"blob_id": "a292800b4a9eb46082e972b0714ab06b6a4878e7",
"content_id": "c1aff5a4513173a2317a88813fe7738475064abd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 3,
"path": "/constants/measures.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "BASIC = ['degree','parallel_edges','fill','h_index','reciprocity','centralization','diameter']\nADVANCED = ['gini','powerlaw','pagerank']\nMORE_ADVANCED = ['global_clustering','local_clustering']"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 32,
"blob_id": "c19e2fdd07c270a7243ed361ce138bdd749928b0",
"content_id": "8a7a24dd64e54f61c976e3a8b894bc0133d41420",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 32,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 1,
"path": "/constants/dbpedia.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "LINKS_FILE = 'dbpedia-links.txt'"
},
{
"alpha_fraction": 0.6650398373603821,
"alphanum_fraction": 0.6688928604125977,
"avg_line_length": 62.819671630859375,
"blob_id": "7ddf6b26b717f3c2e71b28dd6cd23d0756424903",
"content_id": "4b244b31d380506773cadc218a7893bd4022e911",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3893,
"license_type": "permissive",
"max_line_length": 426,
"num_lines": 61,
"path": "/graph/tasks/prepare.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging\nimport sys\nimport xxhash as xh\n\nfrom constants.preparation import SHORT_FORMAT_MAP\nfrom db.SqliteHelper import SqliteHelper\nfrom graph.building import preparation\n\nlog = logging.getLogger( __name__ )\n\n# ----------------\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description='lodcc - A software framework to prepare and perform a large-scale graph-based analysis on the graph topology of RDF datasets.' )\n\n group = parser.add_mutually_exclusive_group( required=True )\n group.add_argument( '--from-file', '-ffl', nargs='*', action=\"append\", help='Pass a list of dataset names to prepare. Please pass the filename and media type too. Leave empty to get further details about this parameter.' )\n group.add_argument( '--from-db', '-fdb', nargs='+', type=str, help='Pass a list of dataset names. Filenames and media types are loaded from database. Specify details in constants/db.py and db.sqlite.properties.' )\n\n parser.add_argument( '--overwrite-dl', '-ddl', action=\"store_true\", help='Overwrite RDF dataset dump if already downloaded. Default False.' )\n parser.add_argument( '--overwrite-nt', '-dnt', action=\"store_true\", help='Overwrite transformed files used to build the graph from. Default False.' )\n parser.add_argument( '--rm-original', '-dro', action=\"store_true\", help='Remove the initially downloaded RDF dataset dump file. Default False.' )\n parser.add_argument( '--keep-edgelists', '-dke', action=\"store_true\", help='Keep intermediate edgelists, obtained from individual files. A combined data.edgelist.csv file will be generated nevertheless. Default False.' )\n \n parser.add_argument( '--log-debug', '-ld', action=\"store_true\", help='Show logging.DEBUG state messages. Default False.' )\n parser.add_argument( '--log-info', '-li', action=\"store_true\", help='Show logging.INFO state messages. Default True.' )\n parser.add_argument( '--log-file', '-lf', action=\"store_true\", help='Log into a file named \"lodcc.log\".' )\n parser.add_argument( '--threads', '-pt', required=False, type=int, default=1, help='Number of CPU cores/datasets to use in parallel for preparation. Handy when working with multiple datasets. Default 1. Max 20.' )\n\n # args is available globaly\n args = vars( parser.parse_args() ).copy()\n\n log.info( 'graph.tasks.prepare: Welcome' )\n\n # option 2\n if args['from_db']:\n log.info( 'Requested to prepare graph from db' )\n db = SqliteHelper()\n\n # respect --use-datasets argument\n log.debug( 'Configured datasets: ' + ', '.join( args['from_db'] ) )\n datasets = db.get_datasets_and_formats( args['from_db'] )\n else:\n log.info( 'Requested to prepare graph from file' )\n datasets = args['from_file'] # argparse returns [[..], [..],..]\n\n # flattens the 2-d array and checks length\n datasets_flat = [ nested for dataset in datasets for nested in dataset ]\n if len( datasets_flat ) == 0 \\\n or len( datasets_flat ) < 3:\n log.error( 'No datasets specified or wrong parameter format, exiting. \\n\\n\\tPlease specify exactly as follows: --from-file <name> <filename> <format> [--from-file ...]\\n\\n\\tname\\t: name of the dataset, i.e., corresponding folder in dumps/, e.g. worldbank-linked-data\\n\\tfilename: the name of the file in the corresponding folder (may be an archive)\\n\\tformat\\t: one of %s\\n' % ','.join( SHORT_FORMAT_MAP.keys() ) )\n sys.exit(1)\n\n # add an artificial id from hash. array now becomes [[id, ..],[id,..],..]\n datasets = list( map( lambda d: [xh.xxh64( d[0] ).hexdigest()[0:4]] + d, datasets ) )\n names = ', '.join( map( lambda d: d[1], datasets ) )\n log.debug( 'Configured datasets: %s', names )\n\n preparation.prepare_graph( datasets, None if 'threads' not in args else args['threads'], args['from_file'], args )\n"
},
{
"alpha_fraction": 0.6009190678596497,
"alphanum_fraction": 0.6111700534820557,
"avg_line_length": 36.720001220703125,
"blob_id": "3a0b68b375db101eb4f03268922e68787eaeff32",
"content_id": "7e42777978928e45e010afb3146a00a14a09b06b",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2829,
"license_type": "permissive",
"max_line_length": 177,
"num_lines": 75,
"path": "/graph/measures/fernandez_et_al/predicate_degrees.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pandas as pd\n\ndef predicate_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = [ D.ep.c0[p] for p in D.get_edges() ]\n\n # number of triples of graph G, in which p occurs as predicate\n _, l = np.unique( edge_labels, return_counts=True )\n\n if print_stats:\n print( \"(Eq.9) predicate degree deg_P(p). max: %s, mean: %f\" % ( np.max(l), np.mean(l) ) )\n\n stats['max_predicate_degree'], stats['mean_predicate_degree'] = np.max(l), np.mean(l)\n\n return l\n\ndef predicate_in_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = [ D.ep.c0[p] for p in D.get_edges() ]\n\n # the number of different subjects of G with which p is related as a predicate\n df = pd.DataFrame( \n data=list( zip ( edge_labels, D.get_edges()[:,0] ) ), \n index=np.arange( 0, D.get_edges().shape[0] ), \n columns=np.arange( 0, D.get_edges().shape[1] ) )\n\n df = df.groupby(0).nunique()[1]\n\n if print_stats:\n print( \"(Eq.10) predicate in-degree deg^{+}_P(p). max: %s, mean: %f\" % ( df.max(), df.mean() ) )\n\n stats['max_predicate_in_degree'], stats['mean_predicate_in_degree'] = df.max(), df.mean()\n\n return df\n\ndef predicate_out_degree( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = [ D.ep.c0[p] for p in D.get_edges() ]\n\n # the number of different objects of G with which p is related as a predicate\n df = pd.DataFrame( \n data=list( zip ( edge_labels, D.get_edges()[:,1] ) ), \n index=np.arange( 0, D.get_edges().shape[0] ), \n columns=np.arange( 0, D.get_edges().shape[1] ) )\n\n df = df.groupby(0).nunique()[1]\n\n if print_stats:\n print( \"(Eq.11) predicate out-degree deg^{-}_P(p). max: %s, mean: %f\" % ( df.max(), df.mean() ) )\n\n stats['max_predicate_out_degree'], stats['mean_predicate_out_degree'] = df.max(), df.mean()\n\n return df\n\ndef collect_metric( feature, P_G, edge_labels, vals, stats, print_stats ):\n \"\"\"\"\"\"\n if vals is None:\n vals = np.empty(0)\n\n return np.append( vals, feature( P_G, edge_labels, stats, print_stats ) )\n\ndef reduce_metric( vals, stats, max_metric_name, mean_metric_name ):\n \"\"\"\"\"\"\n stats[max_metric_name], stats[mean_metric_name] = np.nanmax(vals), np.nanmean(vals)\n\nMETRICS = [ predicate_degree, predicate_in_degree, predicate_out_degree ]\nMETRICS_SET = { 'PREDICATE_DEGREES': METRICS }\nLABELS = [ 'max_predicate_degree', 'mean_predicate_degree', 'max_predicate_in_degree', 'mean_predicate_in_degree', 'max_predicate_out_degree', 'mean_predicate_out_degree' ]\n"
},
{
"alpha_fraction": 0.5812865495681763,
"alphanum_fraction": 0.5859649181365967,
"avg_line_length": 28.517240524291992,
"blob_id": "289598fce57b12e9745f96f8592f01de7514e11c",
"content_id": "0b2e2613f73c458411cd8b2d3dbc5a9ea58451f1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 855,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 29,
"path": "/datapackage/tasks/parse.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging\nfrom datapackage.parser import get_parse_datapackage\n\nfrom db.SqliteHelper import SqliteHelper\n\nlog = logging.getLogger( __name__ )\n\n# ----------------\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description = 'lodcc' )\n\n parser.add_argument( '--init-db', '-dbi', action = \"store_true\", help = '' )\n parser.add_argument( '--limit', '-l', type = int, required = False, default = -1, help = '' )\n \n args = vars( parser.parse_args() ).copy()\n db = SqliteHelper( init_db=args['init_db'] )\n\n # \n datasets = db.get_datasets( columns=['id', 'url', 'name'], limit=args['limit'] )\n \n for ds in datasets:\n res = get_parse_datapackage( ds[0], ds[1], ds[2] )\n\n for r in res:\n # r is a tuple of shape (id,name,attribute,value)\n db.save_attribute( r )"
},
{
"alpha_fraction": 0.5685427784919739,
"alphanum_fraction": 0.5746726393699646,
"avg_line_length": 35.81025695800781,
"blob_id": "b0f82987a170dfdbd3a7f01a92b7fdd2c9ee822d",
"content_id": "57722ca631b97056e44952ded3a3912321fa4063",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7178,
"license_type": "permissive",
"max_line_length": 148,
"num_lines": 195,
"path": "/graph/measures/core/degree_based.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\nimport threading\n\nimport collections\nimport numpy as n\nimport powerlaw\n\ntry:\n mlog = logging.getLogger( 'matplotlib' )\n mlog.setLevel( logging.WARN )\n import matplotlib.pyplot as plt\nexcept:\n print( 'matplotlib.pyplot module could not be imported' )\n\nfrom graph.measures.core.gini import gini\n\nlog = logging.getLogger( __name__ )\nlock = threading.Lock()\nn.warnings.filterwarnings('ignore')\n\ndef fs_digraph_using_degree( D, stats, options={ 'features': [], 'skip_features': [] } ):\n \"\"\"\"\"\"\n\n # compute once\n degree_list = D.degree_property_map( 'total' ).a\n\n # feature: max_(in|out)degree\n # feature: (in|out)_degree_centrality\n if 'degree' in options['features']:\n\n v_max = (0, None)\n v_max_in = (0, None)\n v_max_out = (0, None)\n\n sum_degrees = 0.0\n sum_in_degrees = 0.0\n sum_out_degrees = 0.0\n\n # max_(in|out)degree are computed that way because we want also the node's name\n for v in D.vertices():\n v_in_degree = v.in_degree()\n v_out_degree = v.out_degree()\n\n v_degree = v_in_degree + v_out_degree\n # for max_degree, max_degree_vertex\n v_max = ( v_degree,v ) if v_degree >= v_max[0] else v_max\n # for max_in_degree, max_in_degree_vertex\n v_max_in = ( v_in_degree,v ) if v_in_degree >= v_max_in[0] else v_max_in\n # for max_out_degree, max_out_degree_vertex\n v_max_out = ( v_out_degree,v ) if v_out_degree >= v_max_out[0] else v_max_out\n\n sum_degrees += v_degree\n sum_in_degrees += v_in_degree\n sum_out_degrees += v_out_degree\n\n stats['max_degree'], stats['max_degree_vertex'] = v_max[0], str( D.vertex_properties['name'][v_max[1]] )\n stats['max_in_degree'], stats['max_in_degree_vertex'] = v_max_in[0], str( D.vertex_properties['name'][v_max_in[1]] )\n stats['max_out_degree'], stats['max_out_degree_vertex'] = v_max_out[0], str( D.vertex_properties['name'][v_max_out[1]] )\n\n log.debug( 'done degree' )\n\n # feature: degree_centrality\n num_vertices = stats['n']\n s = 1.0 / ( num_vertices - 1 )\n\n stats['mean_degree_centrality']=(sum_degrees*s) / num_vertices\n stats['mean_in_degree_centrality']=(sum_in_degrees*s) / num_vertices\n stats['mean_out_degree_centrality']=(sum_out_degrees*s) / num_vertices\n\n stats['max_degree_centrality']=v_max[0]*s\n stats['max_in_degree_centrality']=v_max_in[0]*s\n stats['max_out_degree_centrality']=v_max_out[0]*s\n\n # stats['centralization_in_degree'] = (v_max_in[0]-(D.get_in_degrees( D.get_vertices() ))).sum() / ( ( num_vertices-1 )*(num_vertices-2))\n # stats['centralization_out_degree'] = (v_max_out[0]-(D.get_out_degrees( D.get_vertices() ))).sum() / ( ( num_vertices-1 )*(num_vertices-2))\n\n\n # feature: standard deviation\n stddev_in_degree = D.get_in_degrees( D.get_vertices() ).std()\n stats['stddev_in_degree'] = stddev_in_degree\n stats['coefficient_variation_in_degree'] = ( stddev_in_degree / ( sum_in_degrees / num_vertices ) ) * 100\n stddev_out_degree = D.get_out_degrees( D.get_vertices() ).std()\n stats['stddev_out_degree'] = stddev_out_degree\n stats['coefficient_variation_out_degree'] = ( stddev_out_degree / ( sum_out_degrees / num_vertices ) ) * 100\n\n stats['var_in_degree'] = D.get_in_degrees( D.get_vertices() ).var()\n stats['var_out_degree'] = D.get_out_degrees( D.get_vertices() ).var()\n\n log.debug( 'done standard deviation and variance' )\n\n if 'gini' in options['features']:\n gini_coeff = gini( degree_list )\n stats['gini_coefficient'] = float( gini_coeff )\n\n gini_coeff_in_degree = gini( D.get_in_degrees( D.get_vertices() ) )\n stats['gini_coefficient_in_degree'] = float( gini_coeff_in_degree )\n \n gini_coeff_out_degree = gini( D.get_out_degrees( D.get_vertices() ) )\n stats['gini_coefficient_out_degree'] = float( gini_coeff_out_degree )\n\n # feature: h_index_u\n if 'h_index' in options['features']:\n degree_list[::-1].sort()\n \n h = 0\n for x in degree_list:\n if x >= h + 1:\n h += 1\n else:\n break\n\n stats['h_index_u']=h\n log.debug( 'done h_index_u' )\n\n # feature: p_law_exponent\n if 'powerlaw' in options['features']:\n fit = powerlaw.Fit( degree_list )\n \n stats['powerlaw_exponent_degree'] = float( fit.power_law.alpha )\n stats['powerlaw_exponent_degree_dmin'] = float( fit.power_law.xmin )\n log.debug( 'done powerlaw_exponent' )\n\n # plot degree distribution\n if 'plots' in options['features'] and (not 'skip_features' in options or not 'plots' in options['skip_features']):\n degree_counted = collections.Counter( degree_list )\n degree, counted = zip( *degree_counted.items() )\n\n with lock:\n fig, ax = plt.subplots()\n plt.plot( degree, counted )\n\n plt.title( 'Degree Histogram' )\n plt.ylabel( 'Frequency' )\n plt.xlabel( 'Degree' )\n\n ax.set_xticklabels( degree )\n\n ax.set_xscale( 'log' )\n ax.set_yscale( 'log' )\n\n plt.tight_layout()\n plt.savefig( '/'.join( [os.path.dirname( stats['path_edgelist'] ), 'distribution_degree.pdf'] ) )\n degree_counted = collections.Counter( degree_list )\n log.debug( 'done plotting degree distribution' )\n\ndef fs_digraph_using_indegree( D, stats, options={ 'features': [], 'skip_features': [] } ):\n \"\"\"\"\"\"\n\n # compute once\n degree_list = D.get_in_degrees( D.get_vertices() )\n\n # feature: h_index_d\n if 'h_index' in options['features']:\n degree_list[::-1].sort()\n \n h = 0\n for x in degree_list:\n if x >= h + 1:\n h += 1\n else:\n break\n \n stats['h_index_d']=h\n log.debug( 'done h_index_d' )\n\n # feature: p_law_exponent\n if 'powerlaw' in options['features']:\n fit = powerlaw.Fit( degree_list )\n \n stats['powerlaw_exponent_in_degree'] = float( fit.power_law.alpha )\n stats['powerlaw_exponent_in_degree_dmin'] = float( fit.power_law.xmin )\n log.debug( 'done powerlaw_exponent' )\n\n # plot degree distribution\n if 'plots' in options['features'] and (not 'skip_features' in options or not 'plots' in options['skip_features']):\n degree_counted = collections.Counter( degree_list )\n degree, counted = zip( *degree_counted.items() )\n\n with lock:\n fig, ax = plt.subplots()\n plt.plot( degree, counted )\n\n plt.title( 'In-Degree Histogram' )\n plt.ylabel( 'Frequency' )\n plt.xlabel( 'In-Degree' )\n\n ax.set_xticklabels( degree )\n\n ax.set_xscale( 'log' )\n ax.set_yscale( 'log' )\n\n plt.tight_layout()\n plt.savefig( '/'.join( [os.path.dirname( stats['path_edgelist'] ), 'distribution_in-degree.pdf'] ) )\n log.debug( 'done plotting in-degree distribution' )\n"
},
{
"alpha_fraction": 0.6087701320648193,
"alphanum_fraction": 0.6169921159744263,
"avg_line_length": 27.900989532470703,
"blob_id": "0feb441ee842673038b77e0420cb4045e8e32474",
"content_id": "7d5750c4fc019d3f039c34ff6e5409ecb315802c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2919,
"license_type": "permissive",
"max_line_length": 156,
"num_lines": 101,
"path": "/db/helpers.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "# 2020-05-20, matthaeus\n# This is legacy code using a Postgresql database. It is currently still in use\n# in package graph.metric.fernandez_et_al, and needs to be refactored/removed/\n# replaced with the implementation in db.SqliteHelper.\n\nimport logging as log\nimport numpy as np\nimport os\nimport re\ntry:\n import psycopg2\n import psycopg2.extras\n\n from psycopg2.extensions import register_adapter, AsIs\n psycopg2.extensions.register_adapter( np.int64, psycopg2._psycopg.AsIs )\n psycopg2.extensions.register_adapter( np.float64, psycopg2._psycopg.AsIs )\nexcept:\n print( 'psycopg2 could not be found' )\n\n# remember\nconn = None\ndb = None\n\ndef init( args ):\n \"\"\"\"\"\"\n\n if not os.path.isfile( 'db.properties' ):\n log.error( 'no db.properties file found. please specify.' )\n return none\n\n with open( 'db.properties', 'rt' ) as f:\n args.update( dict( ( key.replace( '.', '_' ), value ) for key, value in ( re.split( \"=\", option ) for option in ( line.strip() for line in f ) ) ) )\n\n global db\n db = args\n\n return args\n\ndef connect():\n \"\"\"\"\"\"\n\n # connect to an existing database\n global conn\n conn = psycopg2.connect( host=db['db_host'], dbname=db['db_dbname'], user=db['db_user'], password=db['db_password'] )\n conn.set_session( autocommit=True )\n\n cur = conn.cursor()\n cur.execute( 'SELECT * FROM information_schema.tables AS t WHERE t.table_name=%s AND t.table_schema=%s', (db['db_tbname'],'public') )\n \n if cur.rowcount == 0:\n raise Exception( 'Table %s could not be found in database.' % db['db_tbname'] )\n\ndef ensure_schema_completeness( stats ):\n \"\"\"\"\"\"\n\n cur = conn.cursor()\n \n for attr in stats:\n cur.execute( \"SELECT column_name FROM information_schema.columns WHERE table_name = %s AND column_name = %s\", (db['db_tbname'], attr) )\n\n if cur.rowcount == 0:\n log.debug( 'Creating missing attribute %s', attr )\n ctype = 'BIGINT' if 'max' in attr else 'DOUBLE PRECISION'\n cur.execute( 'ALTER TABLE %s.%s ADD COLUMN %s %s' % ('public',db['db_tbname'],attr,ctype) )\n \n cur.close()\n\ndef save_stats( dataset, stats ):\n \"\"\"\"\"\"\n\n if 'id' in stats:\n del stats['id']\n\n ensure_schema_completeness( stats )\n\n # e.g. mean_degree=%(mean_degree)s, max_degree=%(max_degree)s, ..\n cols = ', '.join( map( lambda d: d +'=%('+ d +')s', stats ) )\n\n sql=('UPDATE %s SET ' % db['db_tbname']) + cols +' WHERE id=%(id)s'\n stats['id']=dataset['id']\n\n log.debug( 'Saving: %s' % stats )\n log.debug( sql )\n\n cur = conn.cursor()\n cur.execute( sql, stats )\n conn.commit()\n cur.close()\n\n log.debug( 'done saving results' )\n\ndef run( sql, arguments=None ):\n \"\"\"\"\"\"\n\n cur = conn.cursor( cursor_factory=psycopg2.extras.DictCursor )\n cur.execute( sql, arguments )\n\n fetched = cur.fetchall()\n cur.close()\n\n return fetched\n"
},
{
"alpha_fraction": 0.7158671617507935,
"alphanum_fraction": 0.8191881775856018,
"avg_line_length": 53.400001525878906,
"blob_id": "b9fee9ac1e64951c262d383ade165171221549ea",
"content_id": "e5383c533d2ec9768cbf2ae68bf95571e4c8a89a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 271,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 5,
"path": "/db.sqlite.properties",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "db.url=resources/test/stats.db\ndb.import.schema.file=resources/db/sqlite/2017-08/01-create-tables.sql\ndb.import.datasets.file=resources/db/sqlite/2017-08/02-init-table-stats.sql\ndb.schema.datasets.table_name=stats_2017_08\ndb.schema.measures.table_name=stats_graph_2017_08"
},
{
"alpha_fraction": 0.5174129605293274,
"alphanum_fraction": 0.5254496932029724,
"avg_line_length": 27.714284896850586,
"blob_id": "2c5c2827e4b8e5916f90cfe932c3ff3442b75dc7",
"content_id": "27d47ed5ae77f48c4b2f46cebe8282bd72dc5754",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2613,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 91,
"path": "/graph/tasks/sampling/sample_vertices_data.graph.gt.gz.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging as log\nimport numpy as np\nfrom graph_tool import *\nimport os\nimport threading\n\ndef sample_vertices_job( dataset, k, sem ):\n \"\"\"creates a sampled sub graph from dataset with k vertices and corresponding edges\"\"\"\n\n with sem:\n if log:\n log.info( 'Reconstructing graph ...')\n\n # dataset e.g. 'dumps/education-data-gov-uk/data.graph.gt.gz'\n D = load_graph( dataset )\n \n vfilt = D.new_vertex_property( 'bool' )\n v = D.get_vertices()\n\n if log:\n log.info( 'Sampling vertices ...')\n\n v_rand = np.random.choice( v, size=int( len(v)*k ), replace=False )\n \n for e in v_rand:\n vfilt[e] = True\n \n if log:\n log.info( 'Saving subgraph ...' )\n\n D_sub = GraphView( D, vfilt=vfilt )\n \n # e.g. 'dumps/education-data-gov-uk/data.graph.0.25.gt.gz'\n graph_gt = '/'.join( [os.path.dirname( dataset ), 'data.graph.%s.gt.gz' % k] )\n D_sub.save( graph_gt )\n\ndef sample_vertices( paths, log=None ):\n \"\"\"\"\"\"\n\n # ensure it is a list\n if not type(paths) is list:\n paths = [paths]\n\n for dataset in paths:\n if not os.path.isfile( dataset ):\n dataset = 'dumps/'+ dataset\n\n if not os.path.isdir( dataset ):\n if log:\n log.error( '%s is not a directory', dataset )\n continue\n\n dataset = dataset + '/data.graph.gt.gz'\n\n if not os.path.isfile( dataset ):\n if log:\n log.error( 'graph file does not exit (was looking in %s). this is a requirement', dataset )\n continue\n\n # prepare\n sem = threading.Semaphore( 10 )\n threads = []\n\n for k in np.linspace(0.05, 0.5, num=10): # e.g. [ 0.25, 0.5, 0.75 ]\n\n t = threading.Thread( target = sample_vertices_job, name = '%s[%s]' % ( os.path.dirname(dataset), k ), args = ( dataset, k, sem ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n\n#\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description = 'lodcc - sample vertices' )\n parser.add_argument( '--paths', '-p', nargs='*', required = True, help = '' )\n\n log.basicConfig(\n level = log.INFO, \n format = '[%(asctime)s] - %(levelname)-8s : %(threadName)s: %(message)s', )\n\n args = vars( parser.parse_args() )\n paths = args['paths']\n\n sample_vertices( paths, log )\n\n log.info( 'done' )\n"
},
{
"alpha_fraction": 0.565571129322052,
"alphanum_fraction": 0.5684428811073303,
"avg_line_length": 29.42718505859375,
"blob_id": "2481ba6c636c9bb33dd40cd3cc4d706917afadd8",
"content_id": "efa660ca80df5072d1784ccd0e901312159b1017",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6268,
"license_type": "permissive",
"max_line_length": 313,
"num_lines": 206,
"path": "/graph/extras/bfv.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging as log\nimport os\nimport pickle\ntry:\n import psycopg2\n import psycopg2.extras\nexcept:\n print 'psycogp2 could not be found'\nimport re\nimport threading\nimport xxhash as xh\n\nfrom graph.building.edgelist import parse_spo\n\ndef find_path( dataset ):\n \"\"\"\"\"\"\n\n if dataset['path_edgelist']:\n return os.path.dirname( dataset['path_edgelist'] )\n elif dataset['path_graph_gt']:\n return os.path.dirname( dataset['path_graph_gt'] )\n\n return None\n\ndef find_nt_files( path ):\n \"\"\"\"\"\"\n\n return [ nt for nt in os.listdir( path ) if re.search( '\\.nt$', nt ) ]\n\ndef save_hash( dataset, column, uri ):\n \"\"\"\"\"\"\n\n sql = 'UPDATE stats_graph SET '+ column +'_uri=%(uri)s WHERE id=%(id)s'\n val_dict = { 'uri': uri, 'id': dataset['id'] }\n\n cur = conn.cursor()\n cur.execute( sql, val_dict )\n conn.commit()\n cur.close()\n \n log.debug( sql % val_dict )\n\ndef get_hashes_to_find( dataset, col_names ):\n \"\"\"\"\"\"\n\n hashes_to_find = {} \n for name in col_names:\n hashv = dataset[name]\n if not hashv:\n continue\n\n if hashv in hashes_to_find:\n hashes_to_find[hashv].append( name )\n else:\n hashes_to_find[hashv] = [name]\n\n return hashes_to_find\n\ndef find_vertices( in_file, dataset, hashes_to_find ):\n \"\"\"\"\"\"\n\n if not in_file:\n log.error( 'Exiting because of previrous errors' )\n return\n\n with open( in_file, 'r' ) as openedfile:\n for line in openedfile:\n\n s,_,o = parse_spo( line, 'nt' )\n\n sh = xh.xxh64( s ).hexdigest()\n oh = xh.xxh64( o ).hexdigest()\n \n if sh in hashes_to_find:\n cols = hashes_to_find[sh]\n for col in cols:\n save_hash( dataset, col, s )\n \n del hashes_to_find[sh]\n\n if oh in hashes_to_find:\n cols = hashes_to_find[oh]\n for col in cols:\n save_hash( dataset, col, o )\n \n del hashes_to_find[oh]\n\n # checked, over?\n if len( hashes_to_find ) == 0:\n break # done\n\ndef job_find_vertices( dataset, sem ):\n \"\"\"\"\"\"\n\n # can I?\n with sem:\n path = find_path( dataset )\n files = find_nt_files( path )\n\n if len( files ) == 0:\n log.warning( 'No nt-file found for dataset %s', dataset['name'] )\n return\n\n col_names = ['max_degree_vertex', 'max_pagerank_vertex', 'max_in_degree_vertex', 'max_out_degree_vertex'] #,'pseudo_diameter_src_vertex', 'pseudo_diameter_trg_vertex']\n hashes_to_find = get_hashes_to_find( dataset, col_names )\n\n for file in files:\n find_vertices( '/'.join( [path,file] ), dataset, hashes_to_find )\n\n # checked, over?\n if len( hashes_to_find ) == 0:\n break # done\n\n log.info( 'Done' )\n\nif __name__ == '__main__':\n\n # configure args parser\n parser = argparse.ArgumentParser( description = 'lodcc - find xxhash from original data' )\n parser.add_argument( '--use-datasets', '-du', nargs='*', required=True, help = '' )\n parser.add_argument( '--processes', '-dp', type=int, required=False, default=1, help = '' )\n parser.add_argument( '--vertices', '-n', nargs='*', required=False, help = '' )\n\n parser.add_argument( '--log-debug', action='store_true', help = '' )\n\n args = vars( parser.parse_args() )\n\n if args['log_debug']:\n level = log.DEBUG\n else:\n level = log.INFO\n\n # configure log\n log.basicConfig( level = level, format = '[%(asctime)s] - %(levelname)-8s : %(threadName)s: %(message)s', )\n\n # read all properties in file into args-dict\n if os.path.isfile( 'db.properties' ):\n with open( 'db.properties', 'rt' ) as f:\n args = dict( ( key.replace( '.', '-' ), value ) for key, value in ( re.split( \"=\", option ) for option in ( line.strip() for line in f ) ) )\n else:\n log.error( 'Please verify your settings in db.properties (file exists?)' )\n sys.exit()\n\n z = vars( parser.parse_args() ).copy()\n z.update( args )\n args = z\n\n # connect to an existing database\n conn = psycopg2.connect( host=args['db-host'], dbname=args['db-dbname'], user=args['db-user'], password=args['db-password'] )\n conn.set_session( autocommit=True )\n\n # check database connection\n try:\n cur = conn.cursor()\n cur.execute( \"SELECT 1;\" )\n result = cur.fetchall()\n cur.close()\n\n log.debug( 'Database ready to query execution' )\n except:\n log.error( 'Database not ready for query execution. %s', sys.exc_info()[0] )\n raise \n\n # respect --use-datasets argument\n if not args['use_datasets'] or len( args['use_datasets'] ) == 0:\n log.error( '--use-datasets not provided' )\n sys.exit()\n\n names_query = '( ' + ' OR '.join( 'name = %s' for ds in args['use_datasets'] ) + ' )'\n names = tuple( args['use_datasets'] )\n\n sql = 'SELECT id,name,max_degree_vertex,max_pagerank_vertex,max_in_degree_vertex,max_out_degree_vertex,pseudo_diameter_src_vertex,pseudo_diameter_trg_vertex,path_edgelist,path_graph_gt FROM stats_graph WHERE '+ names_query +' AND (max_degree_vertex IS NOT NULL OR max_pagerank_vertex IS NOT NULL) ORDER BY id'\n\n # get datasets from database\n cur = conn.cursor( cursor_factory=psycopg2.extras.DictCursor )\n cur.execute( sql, names )\n\n if cur.rowcount == 0:\n log.warning( '--use-datasets specified but empty result set' )\n sys.exit()\n\n datasets = cur.fetchall()\n\n if os.path.isfile( 'found_hashes.pkl' ):\n # load already found hashes\n pkl_file = open( 'found_hashes.pkl', 'rb')\n global_hashes = pickle.load( pkl_file )\n else:\n global_hashes = {}\n\n # setup threading\n sem = threading.Semaphore( args['processes'] )\n threads = []\n\n for dataset in datasets:\n\n t = threading.Thread( target = job_find_vertices, name = dataset['name'], args = ( dataset, sem ) )\n t.start()\n threads.append(t)\n\n for t in threads:\n t.join()\n \n pkl_file = open( 'found_hashes.pkl', 'wb')\n pickle.dump( global_hashes, pkl_file )\n"
},
{
"alpha_fraction": 0.5329431891441345,
"alphanum_fraction": 0.5609015822410583,
"avg_line_length": 33.43283462524414,
"blob_id": "170cfdf442094f637f740b6c0497e95ba1994aa3",
"content_id": "494c791bff15baff0eec3dc36e8703e23efc94c6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4614,
"license_type": "permissive",
"max_line_length": 125,
"num_lines": 134,
"path": "/graph/extras/bfv_from_file.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging as log\nimport os\nimport pickle\nimport re\nimport xxhash as xh\n\nfrom graph.building.edgelist import parse_spo\n\ndef find_nt_files( path ):\n \"\"\"\"\"\"\n\n return [ nt for nt in os.listdir( path ) if re.search( '\\.nt$', nt ) ]\n\ndef bf_necessary( vertices_map ):\n \"\"\"Argument is expected to contain items like { 'v1': ( 'value', False ) }, \n i.e. the hash as key and a tuple ('value', False) as value.\n This method iterates vertices_map and returns in turn a dictionary \n with those items where the value-tuple contains False.\"\"\"\n\n if len( vertices_map ) == 0:\n return {}\n\n # vertices_map = { 'v1': ( 'value', False ) }\n # False, in case the value still has to be dereferenced\n\n return dict( { v[0]:v for k,v in vertices_map.items() if type(v) == tuple and not v[1] } )\n\ndef find_vertices( in_file, dataset, vertices_map ):\n \"\"\"\"\"\"\n\n if not in_file:\n log.error( 'Exiting because of previrous errors' )\n return vertices_map\n\n left_to_bf = bf_necessary( vertices_map )\n if len( left_to_bf ) == 0:\n return vertices_map\n\n with open( in_file, 'r' ) as openedfile:\n for line in openedfile:\n\n s,p,o = parse_spo( line, 'nt' )\n\n sh = xh.xxh64( s ).hexdigest()\n ph = xh.xxh64( p ).hexdigest()\n oh = xh.xxh64( o ).hexdigest()\n\n if sh in left_to_bf:\n vertices_map[sh] = (s,True)\n\n if ph in left_to_bf:\n vertices_map[ph] = (p,True)\n\n if oh in left_to_bf:\n vertices_map[oh] = (o,True)\n\n # over?\n left_to_bf = bf_necessary( vertices_map )\n if len( left_to_bf ) == 0:\n break # done\n\n return vertices_map\n\ndef job_find_vertices( dataset, vertices, vertices_map={} ):\n \"\"\"\n dataset: a path to a directory where the original ntriple files reside.\n vertices: a list of all hashes to find, e.g. [ 'ae984768', '63dc6ec5', ... ]\n \"\"\"\n\n if not os.path.isdir( dataset ):\n log.error( 'Dataset %s is not a directory.' % ( dataset ) )\n return\n\n files = find_nt_files( dataset )\n\n if len( files ) == 0:\n log.warning( 'No nt-file found for dataset %s', dataset )\n return\n\n if type( vertices ) == list:\n # initialize the dictionary required for processing.\n # before: vertices = [ 'ae984768', '63dc6ec5', ... ]\n # after: vertices = { 'ae984768': ('ae984768', False), '63dc6ec5': ('63dc6ec5', False), ... }\n vertices = dict( { v:(v,False) for v in vertices } )\n\n if len( vertices_map ) != 0:\n # reuse already resolved hashes\n # before: vertices = { 'ae984768': ('ae984768', False), '63dc6ec5': ('63dc6ec5', False), ... }\n # after: vertices = { 'ae984768': ('http://..', True), '63dc6ec5': ('63dc6ec5', False), ... }\n vertices = dict( map( lambda e: (e[0],(vertices_map[e[0]],True)) if e[0] in vertices_map else e, vertices.items() ) )\n\n log.debug( 'Scanning %s files (in %s)' % ( len(files), files ) )\n for file in files:\n vertices = find_vertices( '/'.join( [dataset,file] ), dataset, vertices )\n\n # over?\n left_to_bf = bf_necessary( vertices )\n if len( left_to_bf ) == 0:\n break # done\n\n # before: vertices = { 'ae984768': ('ae984768', False), '63dc6ec5': ('http://', True), ... }\n # after: vertices = { 'ae984768': 'ae984768', '63dc6ec5': 'http://', ... }\n return dict( { k:v[0] for k,v in vertices.items() } )\n\nif __name__ == '__main__':\n\n # configure args parser\n parser = argparse.ArgumentParser( description = 'lodcc - find xxhash from original data' )\n parser.add_argument( '--from-file', '-ffl', action = \"append\", help = '', nargs = '*')\n parser.add_argument( '--processes', '-dp', type=int, required=False, default=1, help = '' )\n parser.add_argument( '--vertices', '-n', nargs='*', required=True, help = '' )\n\n parser.add_argument( '--log-debug', action='store_true', help = '' )\n\n args = vars( parser.parse_args() )\n\n if args['log_debug']:\n level = log.DEBUG\n else:\n level = log.INFO\n\n # configure log\n log.basicConfig( level = level, format = '[%(asctime)s] - %(levelname)-8s : %(threadName)s: %(message)s', )\n\n z = vars( parser.parse_args() ).copy()\n z.update( args )\n args = z\n\n datasets = args['from_file'] # argparse returns [[..], [..],..]\n datasets = map( lambda d: 'dumps/%s' % d[0], datasets )\n\n for dataset in datasets:\n print( job_find_vertices( dataset, args['vertices'] ) )\n"
},
{
"alpha_fraction": 0.6368367671966553,
"alphanum_fraction": 0.6392485499382019,
"avg_line_length": 40.03125,
"blob_id": "3efed20bc7845699407b6c289f1d641406c1ff26",
"content_id": "5a7b6b92e13c9683a93aa6ada5fedb94e7d53d3d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7878,
"license_type": "permissive",
"max_line_length": 322,
"num_lines": 192,
"path": "/graph/tasks/analysis/core_measures.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging\nimport threading\n\nfrom db.SqliteHelper import SqliteHelper\n\nfrom graph.building import builder\nfrom graph.measures.core.basic_measures import fs_digraph_using_basic_properties\nfrom graph.measures.core.degree_based import fs_digraph_using_degree, fs_digraph_using_indegree\nfrom graph.measures.core.edge_based import f_reciprocity, f_pseudo_diameter\nfrom graph.measures.core.centrality import f_centralization, f_eigenvector_centrality, f_pagerank\nfrom graph.measures.core.clustering import f_global_clustering, f_local_clustering\n\nlog = logging.getLogger( __name__ )\n\nimport graph_tool\n\ndef fs_digraph_start_job( dataset, D, stats, options ):\n \"\"\"\"\"\"\n\n features = [ \n # fs = feature set\n fs_digraph_using_basic_properties,\n fs_digraph_using_degree, fs_digraph_using_indegree,\n f_centralization,\n f_reciprocity,\n f_pseudo_diameter,\n f_local_clustering,\n f_pagerank, \n f_eigenvector_centrality,\n ]\n\n if not args['from_file']:\n db = SqliteHelper()\n\n for ftr in features:\n ftr( D, stats, options )\n\n if not args['print_stats'] and not args['from_file']:\n db.save_stats( dataset, stats )\n\ndef fs_ugraph_start_job( dataset, U, stats, options ):\n \"\"\"\"\"\"\n\n features = [ \n # fs = feature set\n f_global_clustering, #f_local_clustering, \n # f_avg_shortest_path, \n ]\n\n if not args['from_file']:\n db = SqliteHelper()\n\n for ftr in features:\n ftr( U, stats, options )\n\n if not args['print_stats'] and not args['from_file']:\n db.save_stats( dataset, stats )\n\ndef graph_analyze( dataset, stats, options ):\n \"\"\"\"\"\"\n \n D = builder.load_graph_from_edgelist( dataset, options )\n\n if not D:\n log.error( 'Could not instantiate graph, None' )\n return\n\n log.info( 'Computing feature set DiGraph' )\n log.debug( 'Feature set to compute: %s' % options['features'] )\n log.debug( 'Feature set to skip: %s' % options['skip_features'] )\n fs_digraph_start_job( dataset, D, stats, options )\n \n D.set_directed(False)\n log.info( 'Computing feature set UGraph' )\n fs_ugraph_start_job( dataset, D, stats, options )\n \n # slow\n #stats['k_core(U)']=nx.k_core(U)\n #stats['radius(U)']=nx.radius(U)\n \n return stats\n\ndef build_graph_analyse( dataset, options ):\n \"\"\"\"\"\"\n\n # before starting off: limit the number of threads a graph_tool job may acquire\n if not args['openmp_disabled']:\n graph_tool.openmp_set_num_threads( options['threads_openmp'] )\n\n # init stats\n stats = dict( (attr, dataset[attr]) for attr in ['path_edgelist','path_graph_gt'] )\n\n graph_analyze( dataset, stats, options )\n\n if args['print_stats']:\n if args['from_file']:\n print( ', '.join( [ key for key in stats.keys() ] ) )\n print( ', '.join( [ str(stats[key]) for key in stats.keys() ] ) )\n else:\n print( stats )\n\n# real job\ndef job_start_build_graph( dataset, sem, options ):\n \"\"\"job_start_build_graph\"\"\"\n\n # let's go\n with sem:\n log.info( 'Let''s go' )\n log.debug( dataset )\n\n # - build_graph_analyse\n build_graph_analyse( dataset, options )\n\n # - job_cleanup\n\n log.info( 'Done' ) \n\ndef build_graph( datasets, options ):\n \"\"\"\"\"\"\n\n if len( datasets ) == 0:\n log.error( 'No datasets to parse. exiting' )\n return None\n\n sem = threading.Semaphore( int( 1 if options['threads'] <= 0 else ( 20 if options['threads'] > 20 else options['threads'] ) ) )\n threads = []\n\n for dataset in datasets:\n \n # create a thread for each dataset. work load is limited by the semaphore\n t = threading.Thread( target = job_start_build_graph, name = dataset['name'], args = ( dataset, sem, options ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n\n# ----------------\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description='lodcc - A software framework to prepare and perform a large-scale graph-based analysis on the graph topology of RDF datasets.' )\n\n group = parser.add_mutually_exclusive_group( required = True )\n group.add_argument( '--from-file', '-ffl', nargs='+', action=\"append\", help='Pass a list of dataset names. Indicates that measure values will be written to a file called \"measures.<dataset name>.csv\".' )\n group.add_argument( '--from-db', '-fdb', nargs='+', type=str, help='Pass a list of dataset names. Indicates that further details and measure values are written to database. Specify details in constants/db.py and db.sqlite.properties.' )\n\n parser.add_argument( '--print-stats', '-lp', action=\"store_true\", help='Prints measure values to STDOUT instead of writing to db or file. Default False.' )\n parser.add_argument( '--threads', '-pt', required=False, type=int, default=1, help='Number of CPU cores/datasets to use in parallel for graph analysis. Handy when working with multiple datasets. Default 1. Max 20.' )\n\n # TODO add --sample-edges\n parser.add_argument( '--sample-size', '-gss', required=False, type=float, default=0.2, help='not yet supported' )\n parser.add_argument( '--sample-vertices', '-gsv', action=\"store_true\", help='not yet supported' )\n\n # RE graph or feature computation\n parser.add_argument( '--openmp-disabled', '-gto', action=\"store_true\", help='Pass if you did not have OpenMP enabled during compilation of graph-tool. Default False.' )\n parser.add_argument( '--threads-openmp', '-gth', required=False, type=int, default=8, help='Number of CPU cores used by the core graph-tool library. See also --openmp-disabled. Default 8.' )\n parser.add_argument( '--do-heavy-analysis', '-gfsh', action=\"store_true\", help='Obsolete. See --skip-features.' )\n parser.add_argument( '--features', '-gfs', nargs='*', required=False, default=list(), help='Give a list of graph measures to compute, e.g., \"-gfs degree diameter\" for all degree-related measures and the diameter. Default is the full list of less computation intensive graph measures. See also constants/measures.py.' )\n parser.add_argument( '--skip-features', '-gsfs', nargs='*', required=False, default=list(), help='When --features is not passed, specify here the list of graph measures not to compute. Default [].' )\n \n parser.add_argument( '--dump-graph', '-gd', required=False, type=bool, default=True, help='Dumps the instantiated graph from the edgelist (csv) as a optimized binary archive that is preferred in future analyses. Defaut True.' )\n \n # args is available globaly\n args = vars( parser.parse_args() ).copy()\n\n if args['from_db']:\n log.info( 'Requested to prepare graph from db' )\n db = SqliteHelper()\n\n # respect --use-datasets argument\n log.debug( 'Configured datasets: ' + ', '.join( args['from_db'] ) )\n datasets = db.get_datasets_and_paths( args['from_db'] )\n else:\n datasets = args['from_file'] # argparse returns [[..], [..]]\n datasets = list( map( lambda ds: { # to be compatible with existing build_graph function we transform the array to a dict\n 'name': ds[0], \n 'path_edgelist': 'dumps/%s/data.edgelist.csv' % ds[0], \n 'path_graph_gt': 'dumps/%s/data.graph.gt.gz' % ds[0] }, datasets ) )\n \n names = ', '.join( map( lambda d: d['name'], datasets ) )\n log.debug( 'Configured datasets: %s', names )\n\n # init feature list\n if len( args['features'] ) == 0:\n # eigenvector_centrality, global_clustering and local_clustering left out due to runtime\n args['features'] = ['degree', 'plots', 'diameter', 'fill', 'h_index', 'pagerank', 'parallel_edges', 'powerlaw', 'reciprocity']\n\n build_graph( datasets, args )\n"
},
{
"alpha_fraction": 0.625668466091156,
"alphanum_fraction": 0.6456003785133362,
"avg_line_length": 54.5945930480957,
"blob_id": "f2542dc31a77decb8732332df3ab708a20ca6331",
"content_id": "35a947c5150bdb270f1b4ed6335f3fd670a509e5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2057,
"license_type": "permissive",
"max_line_length": 171,
"num_lines": 37,
"path": "/tests/test_lodcchelpers.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import unittest\nimport lodcc\n\nclass LodccHelperTestCase( unittest.TestCase ):\n\n def test_ensure_valid_filename_from_url( self ):\n \n basenames = [ \n # column1: url, column2: expected filename\n # easy: filename exists\n { 'url': 'https://ckannet-storage.commondatastorage.googleapis.com/2014-11-27T14:31:27.350Z/apertium-es-ast-rdf.zip', 'basename': 'apertium-es-ast-rdf.zip' },\n { 'url': 'https://drive.google.com/file/d/0B8VUbXki5Q0ibEIzbkUxSnQ5Ulk/dump.tar.gz?usp=sharing', 'basename': 'dump.tar.gz' },\n { 'url': 'http://gilmere.upf.edu/corpus_data/ParoleSimpleOntology/ParoleEntries.owl', 'basename': 'ParoleEntries.owl' },\n # hard: set own filename\n { 'url': 'http://dump.linkedopendata.it/musei', 'basename': 'testfile.rdf' },\n { 'url': 'http://n-lex.publicdata.eu/resource/export/f/rdfxml?r=http%3A%2F%2Fn-lex.publicdata.eu%2Fgermany%2Fid%2FBJNR036900005', 'basename': 'testfile.rdf' },\n { 'url': 'http://data.nobelprize.org', 'basename': 'testfile.rdf' },\n { 'url': 'http://spatial.ucd.ie/lod/osn/data/term/k:waterway/v:river', 'basename': 'testfile.rdf' },\n ]\n\n for test in basenames:\n basename_is = lodcc.ensure_valid_filename_from_url( [None,'testfile'], test['url'], 'application_rdf_xml' )\n self.assertEqual( basename_is, test['basename'] )\n \n def test_ensure_valid_filename_from_url_None( self ):\n\n self.assertIsNone( lodcc.ensure_valid_filename_from_url( [None,'testfile'], None, None ) )\n\n def test_ensure_valid_download_data__True( self ):\n\n self.assertTrue( lodcc.ensure_valid_download_data( 'tests/data/more-than-1kb.txt' ) )\n\n def test_ensure_valid_download_data__False( self ):\n\n self.assertFalse( lodcc.ensure_valid_download_data( 'tests/data' ) )\n self.assertFalse( lodcc.ensure_valid_download_data( 'tests/data/less-than-1kb.txt' ) )\n self.assertFalse( lodcc.ensure_valid_download_data( 'tests/data/void-descriptions.rdf' ) )\n"
},
{
"alpha_fraction": 0.5503197312355042,
"alphanum_fraction": 0.5523392558097839,
"avg_line_length": 22.76799964904785,
"blob_id": "ea03cd8c2681c5627a0287e58ceab068fde71c62",
"content_id": "f8bfe12e81a1c62d45ec258236e4de02a079c272",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2971,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 125,
"path": "/extras/dbpedia/loader.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\nimport sys\nimport threading\n\nlog = logging.getLogger( __name__ )\n\ndef download_prepare( directory ):\n \"\"\"\"\"\"\n log.info( 'Creating dumps directory' )\n os.popen( 'mkdir -p %s' % directory )\n\ndef dump_download( url, directory ):\n \"\"\"\"\"\"\n # extract filename from url\n filename = url[url.rfind( '/' )+1:]\n path = '/'.join( [directory, filename] )\n\n if os.path.isfile( path ):\n log.info( 'File already downloaded. see %s', path )\n return path\n\n # download anew\n log.info( 'Downloading %s ..', filename )\n os.popen( 'wget --quiet %s ' % url )\n log.info( 'Moving to dumps-directory ..' )\n os.popen( 'mv %s %s' % ( filename, directory ) )\n\n return path\n\ndef dump_extract( file ):\n \"\"\"\"\"\"\n if not file:\n return None\n\n if not os.path.isfile( file ):\n log.error( 'File not found, %s', file )\n return None\n\n xfile = file[0:file.rfind( '.bz2' )]\n if os.path.isfile(xfile + '.csv'):\n log.info( 'File already converted. see %s', xfile + '.csv' )\n return xfile\n\n log.info( 'Extracting %s', file )\n os.popen( './to_one-liner.sh %s %s %s' % ( os.path.dirname( file ), os.path.basename( file ), '.bz2' ) )\n\n return xfile\n\ndef dump_convert( file ):\n \"\"\"\"\"\"\n if not file:\n return None\n\n if not os.path.isfile( file ):\n log.error( 'File to extract not found, %s', file )\n return None\n \n log.info( 'Converting %s', file )\n os.popen( './to_csv.sh %s %s %s' % ( file, 'true', '.ttl' ) )\n\n return file\n\ndef dump_append( file, output_file ):\n \"\"\"\"\"\"\n file = file + '.csv'\n if not file:\n return None\n\n if not os.path.isfile( file ):\n log.error( 'File to append not found, %s', file )\n return None\n\n os.popen( 'cat %s >> %s' % ( file, output_file ) )\n\ndef dump_cleanup( file ):\n \"\"\"\"\"\"\n if not file:\n return None\n\n os.remove( file )\n\ndef handle_url( sem, url, directory ):\n \"\"\"\"\"\"\n with sem:\n\n log.info( 'Handling %s', url )\n\n # returns downloaded file\n file = dump_download( url, directory )\n\n # returns extracted file\n file = dump_extract( file )\n\n # returns extracted file\n file = dump_convert( file )\n\n # rm xf\n dump_cleanup( file )\n\n # append\n # dump_append( file, directory + '/dbpedia-all-en.ttl.csv' )\n\n log.info( 'Done' )\n\ndef start_crawling( urls, directory, no_of_threads=1 ):\n \"\"\"\"\"\"\n download_prepare( directory )\n\n threads = []\n\n sem = threading.Semaphore( no_of_threads )\n\n for url in urls:\n \n filename = url[url.rfind( '/' )+1:]\n # create a thread for each url. work load is limited by the semaphore\n t = threading.Thread( target = handle_url, name = filename, args = ( sem, url, directory ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n"
},
{
"alpha_fraction": 0.5573448538780212,
"alphanum_fraction": 0.5616653561592102,
"avg_line_length": 31.433120727539062,
"blob_id": "6c916cac05b49cb7bc7fa79d6d14c7543b2b4ec0",
"content_id": "abeef61a496078cdf3d2842008ea42b053ee5cb0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 5092,
"license_type": "permissive",
"max_line_length": 367,
"num_lines": 157,
"path": "/bin/to_ntriples.sh",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n# \n# This script takes an rdf format and a file as input. It converts the file\n# from the given format into ntriples, while it also extracts the file if\n# necessary. If the compressed file is an archive containing more than one\n# file, all files will be converted and merged.\n# \n# Given a file with name 'foo.bar' or 'foo.bar.tar.gz', this process will \n# write the data into a file named: 'foo.bar.nt'.\n#\n\nFILE_FORMAT=\"${1:-rdfxml}\"\nFPATH=\"$2\" # e.g. dumps/foo/bar.gz\nOVERWRITE_NT=${3:-false}\nRM_ORIGINAL=${4:-false}\n\nif [[ $OVERWRITE_NT = false ]]; then\n USE_CACHE=true\nelse\n USE_CACHE=false\nfi\n\n# from PATH\nFILENAME=`echo ${FPATH##*/}`\nFOLDER_DEST=`echo ${FPATH%/*}`\n\nfpath_output()\n{\n if [[ \"${FPATH_STRIPPED%*.nt}\" != \"$FPATH_STRIPPED\" ]]; then\n echo \"$FPATH_STRIPPED\"\n return\n fi\n\n echo \"$FPATH_STRIPPED.nt\"\n}\n\ndo_respect_existing_file()\n{\n # returns false, \n # if FPATH_OUTPUT does not exist or\n # if USE_CACHE is true\n # returns false otherwise\n \n if [ ! -f \"$FPATH_OUTPUT\" ]; then\n return 1 # exit failure\n fi\n\n SIZE=`ls -s \"$FPATH_OUTPUT\" | cut -d ' ' -f1`\n if [[ $USE_CACHE = true && $SIZE > 1000 ]]; then\n return 0 # exit success\n fi\n \n return 1 # exit failure\n}\n\nget_xmtype()\n{\n for mtype in 'tar.gz' 'tar.xz' 'tgz' 'gz' 'zip' 'bz2' 'tar'; do\n # ${\"foo.bar.tar.gz\"%*.tar.gz} returns \"foo.bar\"\n # ${\"foo.bar.bz2\"%*.gz} returns \"foo.bar.bz2\"\n if [[ \"${FILENAME%*.$mtype}\" != \"$FILENAME\" ]]; then\n echo $mtype\n return\n fi\n done\n}\n\ndo_extract()\n{\n # 'tar.gz', 'tar.xz', 'tgz', 'gz', 'zip', 'bz2', 'tar'\n if [[ $XMTYPE == 'tar.gz' ]] || \n [[ $XMTYPE == 'tar.xz' ]] || \n [[ $XMTYPE == 'tgz' ]] || \n [[ $XMTYPE == 'gz' ]] || \n [[ $XMTYPE == 'zip' ]] ||\n [[ $XMTYPE == 'bz2' ]] || \n [[ $XMTYPE == 'tar' ]]; then\n\n # ensure to remove existing before\n rm -rf \"$FPATH_STRIPPED\" &> /dev/null # file may not exit, so ignore this error\n\n FOLDER_SRC=`pwd`\n cd $FOLDER_DEST\n dtrx --one rename --overwrite $FILENAME\n cd $FOLDER_SRC\n fi\n}\n\ndo_convert()\n{\n # convert all files in directory\n if [[ -d \"$FPATH_STRIPPED\" ]]; then\n #echo \"Converting all files in folder $FPATH_STRIPPED\"\n for f in `find \"$FPATH_STRIPPED\" -type f \\( ! -name \"*.bib\" ! -name \"*.csv\" ! -name \"*.log\" ! -name \"*.py\" ! -name \"*.pl\" ! -name \"*.sh\" ! -name \"*.tsv\" ! -name \"*.txt\" ! -name \"*.md\" ! -name \"*.sparql\" ! -name \"*.tab\" ! -name \"*.xls\" ! -name \"*.xlsx\" ! -name \"*.xsl\" ! -name \"LICENSE\" ! -name \"log\" ! -name \"README\" ! -name \"Readme\" ! -name \"readme\" \\) `; do\n # if the given format is ntriples and the file DOES NOT end with .nt\n if [[ $FILE_FORMAT == 'ntriples' && \"${FPATH_STRIPPED%*.nt}\" == \"$FPATH_STRIPPED\" ]]; then\n mv \"$f\" \"$f.nt\"\n # if the given format is ntriples and the file DOES end with .nt -> do nothing\n elif [[ $FILE_FORMAT == 'ntriples' && \"${FPATH_STRIPPED%*.nt}\" != \"$FPATH_STRIPPED\" ]]; then\n continue\n # else convert the file and leave with .nt ending\n else\n rapper --ignore-errors --input $FILE_FORMAT --output \"ntriples\" \"$f\" > \"$f.nt\"\n fi\n done\n fi\n\n # convert file\n if [[ -f \"$FPATH_STRIPPED\" ]]; then\n # if the given format is ntriples and the file DOES end with .nt -> do nothing\n if [[ $FILE_FORMAT == 'ntriples' && \"${FPATH_STRIPPED%*.nt}\" != \"$FPATH_STRIPPED\" ]]; then\n return 0 # return success\n else\n #echo \"Converting $FPATH_STRIPPED\"\n rapper --ignore-errors --input $FILE_FORMAT --output \"ntriples\" \"$FPATH_STRIPPED\" > \"$FPATH_OUTPUT\"\n fi\n fi\n}\n\ndo_oneliner()\n{\n # check if extracted file is directory\n # if so, create one file from all the files there\n if [ -d \"$FPATH_STRIPPED\" ]; then\n find \"$FPATH_STRIPPED\" -name \"*.nt\" -type f -exec cat {} >> \"$FPATH_STRIPPED.tmp\" \\; \\\n && rm -rf \"$FPATH_STRIPPED\" \\\n && mv \"$FPATH_STRIPPED.tmp\" \"$FPATH_OUTPUT\"\n fi\n\n # if the given format is ntriples and the file DOES end with .nt -> do nothing\n if [[ $FILE_FORMAT == 'ntriples' && \"${FPATH_STRIPPED%*.nt}\" != \"$FPATH_STRIPPED\" ]]; then\n return 0 # exit success\n # otherwise respect RM_ORIGINAL paramter\n elif [[ $RM_ORIGINAL = true ]]; then\n rm -rf \"$FPATH_STRIPPED\"\n fi\n}\n\n# 1. dumps/foo/bar.nt.tgz -> dumps/foo/bar.nt\n# 2. dumps/foo/bar.tar.gz -> dumps/foo/bar\n# this will be the directory or filename\nXMTYPE=`get_xmtype`\n# this is the file with stripped ending if it is a compressed media type\nFPATH_STRIPPED=`echo ${FPATH%*.$XMTYPE}`\n# this is the file that we use as final filename\nFPATH_OUTPUT=`fpath_output`\n\nif do_respect_existing_file; then\n if [[ $RM_ORIGINAL = true ]]; then\n rm -rf \"$FPATH_STRIPPED\" &> /dev/null # file may not exit, so ignore this error\n fi\n exit 0 # exit success\nfi\n\ndo_extract\ndo_convert\ndo_oneliner\n"
},
{
"alpha_fraction": 0.509616494178772,
"alphanum_fraction": 0.5623664259910583,
"avg_line_length": 22.27748680114746,
"blob_id": "4e63ec546775215f7546a2a1cb079299177820c2",
"content_id": "fcbb1d5d49103585ab961f52ce6905a86bf3f70c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8891,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 382,
"path": "/query/watdiv/query_graphs.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "from graph_tool import Graph\n\ndef query_graph_l1():\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n \n G.add_edge(v0,v1) # e0\n G.add_edge(v0,v2) # e1\n G.add_edge(v2,v3) # e2\n \n return G\n\ndef query_graph_l2():\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n \n G.add_edge(v2,v3) # e0, wsdbm:likes\n G.add_edge(v2,v1) # e1, sorg:nationality\n G.add_edge(v0,v1) # e2, gn:parentCountry, switched directions\n \n return G\n\ndef query_graph_l3():\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, wsdbm:likes\n G.add_edge(v0,v2) # e1, wsdbm:subscribes\n \n return G\n\ndef query_graph_l4():\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, og:tag\n G.add_edge(v0,v2) # e1, sorg:caption\n \n return G\n\ndef query_graph_l5():\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, sorg:jobTitle\n G.add_edge(v0,v3) # e1, sorg:nationality\n G.add_edge(v2,v3) # e2, gn:parentCountry\n \n return G\n\ndef query_graph_s1():\n \"\"\"query s1\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex() \n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n v7=G.add_vertex()\n v8=G.add_vertex()\n v9=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, gr:includes\n G.add_edge(v2,v0) # e1, gr:offers\n G.add_edge(v0,v3) # e2, gr:price\n G.add_edge(v0,v4) # e3, gr:serial_number\n G.add_edge(v0,v5) # e4, gr:validFrom\n G.add_edge(v0,v6) # e5, gr:validThrough\n G.add_edge(v0,v7) # e6, sorg:eligible_Region\n G.add_edge(v0,v8) # e7, sorg:eligible_Region\n G.add_edge(v0,v9) # e8, gr:priceValidUntil\n \n return G\n\ndef query_graph_s2():\n \"\"\"query s2\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex() \n v4=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, dc:Location\n G.add_edge(v0,v2) # e1, sorg:nationality\n G.add_edge(v0,v3) # e2, wsdbm:gender\n G.add_edge(v0,v4) # e3, rdf:type\n \n return G\n\ndef query_graph_s3():\n \"\"\"query s3\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex() \n v4=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, rdf:type\n G.add_edge(v0,v2) # e1, sorg:caption\n G.add_edge(v0,v3) # e2, wsdbm:hasGenre\n G.add_edge(v0,v4) # e3, sorg:publisher\n \n return G\n\ndef query_graph_s4():\n \"\"\"query s4\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex() \n v4=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, foaf:age\n G.add_edge(v0,v2) # e1, foaf:familyName\n G.add_edge(v3,v0) # e2, mo:artist\n G.add_edge(v0,v4) # e3, sorg:nationality\n \n return G\n\ndef query_graph_s5():\n \"\"\"query s5\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex() \n v4=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, dc:Location\n G.add_edge(v0,v2) # e1, sorg:nationality\n G.add_edge(v0,v3) # e2, wsdbm:gender\n G.add_edge(v0,v4) # e3, rdf:type\n \n return G\n\ndef query_graph_s6():\n \"\"\"query s6\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex() \n \n G.add_edge(v0,v1) # e0, mo:conductor\n G.add_edge(v0,v2) # e1, rdf:type\n G.add_edge(v0,v3) # e2, wsdbm:hasGenre\n \n return G\n\ndef query_graph_s7():\n \"\"\"query s7\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex() \n \n G.add_edge(v0,v1) # e0, rdf:type\n G.add_edge(v0,v2) # e1, sorg:text\n G.add_edge(v3,v0) # e2, wsdbm:likes\n \n return G\n\ndef query_graph_f1():\n \"\"\"query f1\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, og:tag\n G.add_edge(v0,v2) # e1, rdf:type\n G.add_edge(v3,v0) # e2, wsdbm:hasGenre\n G.add_edge(v3,v4) # e3, sorg:trailer\n G.add_edge(v3,v5) # e4, rdf:type\n G.add_edge(v3,v6) # e5, sorg:keywords\n \n return G\n\ndef query_graph_f2():\n \"\"\"query f2\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n v7=G.add_vertex()\n v8=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, foaf:homepage\n G.add_edge(v0,v2) # e1, og:title\n G.add_edge(v0,v3) # e2, rdf:type\n G.add_edge(v0,v4) # e3, sorg:caption\n G.add_edge(v0,v5) # e4, sorg:description\n G.add_edge(v1,v6) # e5, sorg:url\n G.add_edge(v1,v7) # e6, wsdbm:hits\n G.add_edge(v0,v8) # e7, wsdbm:hasGenre\n \n return G\n\ndef query_graph_f3():\n \"\"\"query f3\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, sorg:contentRating\n G.add_edge(v0,v2) # e1, sorg:contentSize\n G.add_edge(v0,v3) # e2, wsdbm:HasGenre\n G.add_edge(v5,v0) # e3, wsdbm:purchaseFor\n G.add_edge(v4,v5) # e4, wsdbm:makesPurchase\n G.add_edge(v5,v6) # e5, wsdbm:purchaseDate\n \n return G\n\ndef query_graph_f4():\n \"\"\"query f4\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n v7=G.add_vertex()\n v8=G.add_vertex()\n v9=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, foaf:homepage\n G.add_edge(v2,v0) # e1, gr:includes\n G.add_edge(v0,v3) # e2, og:title\n G.add_edge(v0,v4) # e3, sorg:description\n G.add_edge(v0,v8) # e4, sorg:contentSize\n G.add_edge(v1,v5) # e5, sorg:url\n G.add_edge(v1,v6) # e6, wsdbm:hits\n G.add_edge(v7,v1) # e7, wsdbm:likes\n G.add_edge(v1,v9) # e8, sorg:language\n \n return G\n \ndef query_graph_f5():\n \"\"\"query f5\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, gr:includes\n G.add_edge(v2,v0) # e1, gr:offers\n G.add_edge(v0,v3) # e2, gr:price\n G.add_edge(v0,v4) # e3, gr:validThrough\n G.add_edge(v1,v5) # e4, og:title\n G.add_edge(v1,v6) # e5, rdf:type\n \n return G\n\ndef query_graph_c1():\n \"\"\"query c1\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n v7=G.add_vertex()\n v8=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, sorg:caption\n G.add_edge(v0,v2) # e1, sorg:text\n G.add_edge(v0,v3) # e2, sorg:contentRating\n G.add_edge(v0,v4) # e3, rev:hasReview\n G.add_edge(v4,v5) # e4, rev:title\n G.add_edge(v4,v6) # e5, rev:reviewer\n G.add_edge(v7,v6) # e6, sorg:actor\n G.add_edge(v7,v8) # e7, sorg:language\n \n return G\n\ndef query_graph_c2():\n \"\"\"query c2\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n v7=G.add_vertex()\n v8=G.add_vertex()\n v9=G.add_vertex()\n v10=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, sorg:legalName\n G.add_edge(v0,v2) # e1, gr:offers\n G.add_edge(v2,v3) # e2, gr:includes\n G.add_edge(v2,v5) # e3, sorg:eligibleRegion\n G.add_edge(v3,v8) # e4, sorg:actor\n G.add_edge(v8,v9) # e5, rev:totalVotes\n G.add_edge(v7,v3) # e6, wsdbm:purchaseFor\n G.add_edge(v4,v7) # e7, wsdbm:makesPurchase\n G.add_edge(v4,v10) # e8, sorg:jobTitle\n G.add_edge(v4,v6) # e9, foaf:homepage\n \n return G\n\ndef query_graph_c3():\n \"\"\"query c3\"\"\"\n G=Graph( directed=True )\n \n v0=G.add_vertex()\n v1=G.add_vertex()\n v2=G.add_vertex()\n v3=G.add_vertex()\n v4=G.add_vertex()\n v5=G.add_vertex()\n v6=G.add_vertex()\n \n G.add_edge(v0,v1) # e0, wsdbm:likes\n G.add_edge(v0,v2) # e1, wsdbm:friendOf\n G.add_edge(v0,v3) # e2, dc:Location\n G.add_edge(v0,v4) # e3, foaf:age\n G.add_edge(v0,v5) # e4, wsdbm:gender\n G.add_edge(v0,v6) # e5, foaf:givenName\n \n return G"
},
{
"alpha_fraction": 0.608315110206604,
"alphanum_fraction": 0.617067813873291,
"avg_line_length": 27.5625,
"blob_id": "7d3c4cc6d0ad8641e10e27bbcb166e01730a0998",
"content_id": "237557cc02abe2aac07b1e1e6024385790fcc6af",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 457,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 16,
"path": "/graph/measures/fernandez_et_al/tests/test_common_ratios.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import unittest\nimport unitgraphs\nimport graph.measures.fernandez_et_al.common_ratios as cr\n\nclass MetricsTestCase( unittest.TestCase ):\n \"\"\"\"\"\"\n\n def setUp( self ):\n \"\"\"\"\"\"\n self.G = unitgraphs.basic_graph()\n self.stats = dict()\n\n def test_subject_object_ratio( self ):\n \"\"\"\"\"\"\n cr.subject_object_ratio( self.G, None, self.stats )\n self.assertEqual( round( self.stats['subject_object_ratio'], 2 ), 0.12 )\n"
},
{
"alpha_fraction": 0.4702166020870209,
"alphanum_fraction": 0.5108303427696228,
"avg_line_length": 22.10416603088379,
"blob_id": "cbae74fde5e2a689c57713472ec671bf89877d31",
"content_id": "78493dc081bc6897b92a653322b035af1dd063ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1108,
"license_type": "permissive",
"max_line_length": 46,
"num_lines": 48,
"path": "/graph/measures/fernandez_et_al/tests/unitgraphs.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "from graph_tool import Graph\n\ndef basic_graph():\n \"\"\"\"\"\"\n\n G = Graph()\n \n v0 = G.add_vertex()\n v1 = G.add_vertex()\n v2 = G.add_vertex()\n v3 = G.add_vertex()\n v4 = G.add_vertex()\n v5 = G.add_vertex()\n v6 = G.add_vertex()\n v7 = G.add_vertex()\n\n e0 = G.add_edge( v0, v1 )\n e1 = G.add_edge( v0, v2 )\n e2 = G.add_edge( v0, v3 )\n e3 = G.add_edge( v0, v4 )\n e4 = G.add_edge( v5, v4 )\n e5 = G.add_edge( v6, v4 )\n e6 = G.add_edge( v4, v7 )\n\n prop_v = G.new_vertex_property( 'string' )\n prop_e = G.new_edge_property( 'string' )\n\n G.vertex_properties['name'] = prop_v\n G.edge_properties['c0'] = prop_e\n\n prop_v[v0] = '/John'\n prop_v[v1] = '[email protected]'\n prop_v[v2] = '[email protected]'\n prop_v[v3] = '/Researcher'\n prop_v[v4] = '/Rome'\n prop_v[v5] = '/Giacomo'\n prop_v[v6] = '/Piero'\n prop_v[v7] = '\"Roma\"@it'\n\n prop_e[e0] = 'foaf:mbox'\n prop_e[e1] = 'foaf:mbox'\n prop_e[e2] = 'rdf:type'\n prop_e[e3] = 'ex:birthPlace'\n prop_e[e4] = 'ex:areaOfWork'\n prop_e[e5] = 'ex:areaOfWork'\n prop_e[e6] = 'foaf:name'\n\n return G"
},
{
"alpha_fraction": 0.5039311051368713,
"alphanum_fraction": 0.512167751789093,
"avg_line_length": 26.82291603088379,
"blob_id": "4168c50b2a6eb156e0535abc7724b6274bbcb46d",
"content_id": "5743cba2223869f35df1e30e35c0e23721324a3e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2671,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 96,
"path": "/graph/tasks/sampling/sample_edgelist_weighted.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport pandas as pd\nimport logging as log\nimport numpy as np\nimport os\nimport re\nimport threading\n\ndef sample_edgelist_job( dataset, df, n, k, sem ):\n \"\"\"\"\"\"\n\n with sem:\n v_filt = np.array( [False]*n )\n \n if log:\n log.info( 'Sampling edges ...' )\n\n v_rand = np.random.choice( np.arange( n ), size=int( n*k ), replace=False )\n \n for e in v_rand:\n v_filt[e] = True\n\n sample_dir = os.path.dirname( dataset ) + '-sampled-%s' % k\n\n # e.g. dumps/core-sampled-0.25 gets creted if not present\n if not os.path.isdir( sample_dir ):\n if log:\n log.info( 'Creating directory ..' )\n\n os.mkdir( sample_dir )\n \n df.iloc[v_filt].to_csv( '%s/data.edgelist.csv' % sample_dir, sep=' ', header=False, index=False )\n\n if log:\n log.info( 'Done' )\n \ndef sample_edgelist( paths, log=None ):\n \"\"\"\"\"\"\n\n # ensure it is a list\n if not type(paths) is list:\n paths = [paths]\n\n for dataset in paths:\n if not os.path.isfile( dataset ):\n dataset = 'dumps/'+ dataset\n\n if not os.path.isdir( dataset ):\n if log:\n log.error( '%s is not a directory', dataset )\n continue\n\n dataset = dataset + '/data.edgelist.csv'\n\n if not os.path.isfile( dataset ):\n if log:\n log.error( 'Edgelist file does not exit (was looking in %s). this is a requirement', dataset )\n continue\n\n if log:\n log.info( 'Reading lines ..' )\n \n df = pd.read_csv( dataset, delim_whitespace=True, header=None )\n n = df.shape[0]\n\n # prepare\n sem = threading.Semaphore( 10 )\n threads = []\n\n for k in np.linspace(0.05, 0.5, num=10): # e.g. [ 0.25, 0.5, 0.75 ]\n\n t = threading.Thread( target = sample_edgelist_job, name = '%s[%s]' % ( os.path.dirname(dataset), k ), args = ( dataset, df, n, k, sem ) )\n t.start()\n\n threads.append( t )\n\n # wait for all threads to finish\n for t in threads:\n t.join()\n\n#\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description = 'lodcc - sample edgelist' )\n parser.add_argument( '--paths', '-p', nargs='*', required = True, help = '' )\n\n log.basicConfig(\n level = log.INFO, \n format = '[%(asctime)s] - %(levelname)-8s : %(threadName)s: %(message)s', )\n\n args = vars( parser.parse_args() )\n paths = args['paths']\n\n sample_edgelist( paths, log )\n\n log.info( 'done' )\n"
},
{
"alpha_fraction": 0.6820128560066223,
"alphanum_fraction": 0.6852248311042786,
"avg_line_length": 37.95833206176758,
"blob_id": "c9c85e9a31c25125fad745e9210be2ef66bd8c27",
"content_id": "5cd13ce40d4f5d27707d90e0c5bfad28b7de3728",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 934,
"license_type": "permissive",
"max_line_length": 139,
"num_lines": 24,
"path": "/datapackage/__init__.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import logging\nimport os\nimport re\n\nfrom constants.datapackage import FORMAT_MAPPINGS_FILE\n\n# configure logging\nlogging.basicConfig( level = logging.DEBUG, format = '[%(asctime)s] %(levelname)-6s - %(name)s: %(message)s', )\n\n# this variable will be read by other modules\nmediatype_mappings = {}\n\n# read all format mappings\nif os.path.isfile( FORMAT_MAPPINGS_FILE ):\n logging.info( 'Reading %s' % FORMAT_MAPPINGS_FILE )\n \n with open( FORMAT_MAPPINGS_FILE, 'rt' ) as f:\n # reads all lines and splits it so that we got a list of lists\n parts = list( re.split( \"[=, ]+\", option ) for option in ( line.strip() for line in f ) if option and not option.startswith( '#' ))\n # creates a hashmap from each multimappings\n mediatype_mappings = dict( ( format, mappings[0] ) for mappings in parts for format in mappings[1:] )\n\nelse:\n logging.warn( 'Mapping file for formats \"formats.properties\" not found' )"
},
{
"alpha_fraction": 0.5165562629699707,
"alphanum_fraction": 0.5178807973861694,
"avg_line_length": 20.571428298950195,
"blob_id": "03d885bfc22d458bcda86702eb121661f614ec3e",
"content_id": "75a18550467bfb799f155e5268b79b4fcf9d1ca0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 755,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 35,
"path": "/bin/dbpedia/dbpedia-links-curl.sh",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nlinename='dbpedia-links.txt'\n\nwhile read line; do\n echo \"$line\"\n FILE=`echo $line | sed 's#^.*/##'`\n EXT_FILE=${FILE%.bz2}\n OUTPUT_FILE=dbpedia-all-en.ttl.nt\n \n # curl and extract if FILE does not exist\n if [ ! -f $FILE ]\n then\n echo \"cURLing\"\n curl --silent -L $line -O\n\n # extract if necessary\n if [ ! -f $EXT_FILE ]\n then\n echo \"dtrx'ing\"\n dtrx $FILE\n fi\n fi\n \n # append to file if exists\n if [ -f $EXT_FILE ]\n then\n echo \"appending\"\n cat $EXT_FILE >> $OUTPUT_FILE\n \n echo \"removing extracted file\"\n rm $EXT_FILE\n else\n echo \"ERROR: Extracted line $EXT_FILE not found\"\n fi\ndone < $linename\n"
},
{
"alpha_fraction": 0.6134831309318542,
"alphanum_fraction": 0.617977499961853,
"avg_line_length": 23.66666603088379,
"blob_id": "b2c06359afaf7d56529d922311aee07a4db05aa0",
"content_id": "1c3d3a8a78e3cd2e3c7b323323c3c5e3916f7457",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 445,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 18,
"path": "/bin/cp-to-folder.sh",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#\n# this is to cp all data.graph.gt.gz in dumps/* (final graphs) to a folder called \"datasets\".\n# this folder may than be published, e.g.\n\nset -e\n\nfind dumps/* -name \"data.graph.gt.gz\" -type f -print0 | while read -d $'\\0' file \ndo\n FILE=$file\n echo \"Doing $FILE\"\n FOLDER=`echo ${FILE%/*}`\n DATASET=`echo ${FOLDER##*/}`\n FOLDER_DEST=\"datasets/$DATASET\"\n\n mkdir \"$FOLDER_DEST\"\n cp -p $FILE \"$FOLDER_DEST/.\"\ndone\n\n"
},
{
"alpha_fraction": 0.5744525790214539,
"alphanum_fraction": 0.5751824975013733,
"avg_line_length": 30.136363983154297,
"blob_id": "14705bbaf44880f50c5525c9775e5458561d6299",
"content_id": "2c0dce1a9f9c26f12579b090fc7836cf471467d7",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1370,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 44,
"path": "/graph/tasks/edgelists/dict_based.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging as log\nimport os\nimport pickle\nimport re\nimport sys\n\nfrom constants.edgelist import SUPPORTED_FORMATS\nfrom graph.building.edgelist import iedgelist_edgelist\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description = 'lodcc iedgelist' )\n parser.add_argument( '--paths', '-p', nargs='*', required = True, help = '' )\n parser.add_argument( '--format', '-f', required = False, type = str, default = 'nt', help = '' )\n parser.add_argument( '--pickle', '-d', action = 'store_true', help = '' )\n \n log.basicConfig( level = log.INFO, \n format = '[%(asctime)s] - %(levelname)-8s : %(message)s', )\n\n args = vars( parser.parse_args() )\n paths = args['paths']\n format_ = args['format']\n\n if not format_ in SUPPORTED_FORMATS:\n sys.exit()\n\n for path in paths:\n\n if os.path.isdir( path ):\n # if given path is directory get the .nt file there and transform\n\n if not re.search( '/$', path ):\n path = path+'/'\n\n for filename in os.listdir( path ):\n\n if not re.search( SUPPORTED_FORMATS[format_], filename ):\n continue\n\n iedgelist_edgelist( path + filename, format_ )\n else:\n # if given path is a file, use it\n iedgelist_edgelist( path, format_ )\n"
},
{
"alpha_fraction": 0.589657723903656,
"alphanum_fraction": 0.6149553656578064,
"avg_line_length": 35.32432556152344,
"blob_id": "7b699eab518068d2b394037a4223495025318dd0",
"content_id": "b2fd8fa96d6bf1638ad8dca2c904a6440cbdb97c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2688,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 74,
"path": "/graph/measures/fernandez_et_al/typed_subjects_objects.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "from graph_tool import GraphView\nimport numpy as np\n\ndef number_of_classes( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"counts the number of different classes\"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = np.array( [ D.ep.c0[p] for p in D.get_edges() ] )\n\n # ae98476863dc6ec5 = http://www.w3.org/1999/02/22-rdf-syntax-ns#type\n rdf_type = hash( 'ae98476863dc6ec5' )\n C_G = GraphView( D, efilt=edge_labels == rdf_type )\n C_G = np.unique( C_G.get_edges()[:,1] )\n\n if print_stats:\n print( \"number of different classes C_G: %s\" % C_G.size )\n\n stats['distinct_classes'] = C_G.size\n\n return C_G\n\ndef ratio_of_typed_subjects( D, edge_labels=np.empty(0), stats=dict(), print_stats=False ):\n \"\"\"\n (1) number of all different typed subjects\n (2) ratio of typed subjects\n \"\"\"\n\n if edge_labels is None or edge_labels.size == 0:\n edge_labels = np.array( [ D.ep.c0[p] for p in D.get_edges() ] )\n\n # ae98476863dc6ec5 = http://www.w3.org/1999/02/22-rdf-syntax-ns#type\n rdf_type = hash( 'ae98476863dc6ec5' )\n S_C_G = GraphView( D, efilt=edge_labels == rdf_type )\n S_C_G = np.unique( S_C_G.get_edges()[:,0] )\n\n if print_stats:\n print( \"number of different typed subjects S^{C}_G: %s\" % S_C_G.size )\n\n S_G = GraphView( D, vfilt=D.get_out_degrees( D.get_vertices() ) )\n\n if print_stats:\n print( \"ratio of typed subjects r_T(G): %s\" % ( float(S_C_G.size)/S_G.num_vertices() ) )\n\n stats['typed_subjects'], stats['ratio_of_typed_subjects'] = S_C_G.size, ( float(S_C_G.size)/S_G.num_vertices() )\n\n return S_C_G\n\ndef collect_number_of_classes( D, edge_labels, vals=set(), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n if vals is None:\n vals = set()\n\n return vals | set( number_of_classes( D, edge_labels, stats, print_stats ) )\n\ndef reduce_number_of_classes( vals, D, C_G, stats={} ):\n \"\"\"\"\"\"\n stats['distinct_classes'] = len( vals )\n\ndef collect_ratio_of_typed_subjects( D, edge_labels, vals=set(), stats=dict(), print_stats=False ):\n \"\"\"\"\"\"\n if vals is None:\n vals = set()\n\n return vals | set( ratio_of_typed_subjects( D, edge_labels, stats, print_stats ) )\n\ndef reduce_ratio_of_typed_subjects( vals, D, S_G, stats={} ):\n \"\"\"\"\"\"\n S_G = GraphView( D, vfilt=D.get_out_degrees( D.get_vertices() ) )\n\n stats['typed_subjects'], stats['ratio_of_typed_subjects'] = len( vals ), ( float(len( vals ))/S_G.num_vertices() )\n\nMETRICS = [ number_of_classes, ratio_of_typed_subjects ]\nMETRICS_SET = { 'TYPED_SUBJECTS_OBJECTS': METRICS }\nLABELS = [ 'distinct_classes', 'typed_subjects', 'ratio_of_typed_subjects' ]\n"
},
{
"alpha_fraction": 0.574853777885437,
"alphanum_fraction": 0.5754386186599731,
"avg_line_length": 34.625,
"blob_id": "75b1c6c46fca25b10cd36eec9795aefddd1eefb0",
"content_id": "942753a3de94401553d418702a3f7859048c136d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1710,
"license_type": "permissive",
"max_line_length": 258,
"num_lines": 48,
"path": "/graph/tasks/edgelists/create.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import argparse\nimport logging\nimport xxhash as xh\nimport os\nimport re\nimport threading\n\nfrom graph.building.edgelist import create_edgelist, xxhash_csv\n\nlog = logging.getLogger( __name__ )\n\nif __name__ == '__main__':\n\n parser = argparse.ArgumentParser( description = 'lodcc task - Creates edgelists for graph instantiation from RDF datasets of N-Triples format. This is an internal helper function. If you do not know what you are doing, use graph.tasks.prepare instead.' )\n parser.add_argument( '--from-file', '-ffl', nargs='+', required = True, help = 'List of directory names where to find the RDF dataset. Example value: dumps/oecd-linked-data/' )\n parser.add_argument( '--format', '-f', required=False, type=str, default='nt', help='Obsolete parameter. Possible values are csv or nt. Default: nt.' )\n\n args = vars( parser.parse_args() )\n paths = args['from_file']\n sem = threading.Semaphore( 8 )\n threads = []\n\n if args['format'] == 'nt':\n method = create_edgelist\n else:\n method = xxhash_csv\n \n for path in paths:\n if os.path.isdir( path ):\n if not re.search( '/$', path ):\n path = path+'/'\n\n for filename in os.listdir( path ):\n if args['format'] == 'csv':\n if not re.search( '.csv$', filename ):\n continue\n if 'edgelist' in filename:\n continue\n\n t = threading.Thread( target = method, name = filename, args = ( path + filename, sem ) )\n t.start()\n\n threads.append( t )\n\n for t in threads:\n t.join()\n else:\n method( path )\n"
},
{
"alpha_fraction": 0.6510171890258789,
"alphanum_fraction": 0.6557120680809021,
"avg_line_length": 22.66666603088379,
"blob_id": "31ae52b44b651c06ffcf8b961369576063d0caf0",
"content_id": "e227c9f8d726b8de3eafe02cd0e372887fce469e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 639,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 27,
"path": "/bin/to_one-liner.sh",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nFOLDER_SRC=`pwd`\n# arg: folder, e.g. dumps/foo-ds\nFOLDER_DEST=$1\n# arg: filename, e.g. bar.nt.tgz\nFILENAME=$2\n# arg: extension, e.g. .tgz\nMTYPE=$3\n\n# cd and extract\ncd $FOLDER_DEST\ndtrx --one rename --overwrite $FILENAME\n\n# e.g. bar.nt.tgz becomes bar.nt\nFILE_STRIPPED=`echo \"$FILENAME\" | sed \"s/$MTYPE//\"`\n\n# check if extracted file is directory\n# if so, create one file from all the files there\nif [ -d \"$FILE_STRIPPED\" ]; then\n find \"$FILE_STRIPPED\" -type f -exec cat {} >> \"$FILE_STRIPPED.tmp\" \\; \\\n && rm -rf \"$FILE_STRIPPED\" \\\n && mv \"$FILE_STRIPPED.tmp\" \"$FILE_STRIPPED\"\nfi\n\n# cd back to root folder\ncd $FOLDER_SRC\n"
},
{
"alpha_fraction": 0.5798449516296387,
"alphanum_fraction": 0.5953488349914551,
"avg_line_length": 32.07692337036133,
"blob_id": "ad74f22b77f17eef36cc395213353ae2f086e3a4",
"content_id": "89d44f701c2ebaee601cb704821a6198a9e8cf9a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1290,
"license_type": "permissive",
"max_line_length": 83,
"num_lines": 39,
"path": "/graph/measures/fernandez_et_al/tests/test_object_in_degrees.py",
"repo_name": "mazlo/lodcc",
"src_encoding": "UTF-8",
"text": "import unittest\nimport unitgraphs\nimport graph.measures.fernandez_et_al.object_in_degrees as oid\n\nclass MetricsTestCase( unittest.TestCase ):\n \"\"\"\"\"\"\n\n def setUp( self ):\n \"\"\"\"\"\"\n self.G = unitgraphs.basic_graph()\n self.stats = dict()\n\n def test_in_degree( self ):\n \"\"\"\"\"\"\n oid.in_degree( self.G, None, self.stats )\n\n self.assertEqual( self.stats['max_in_degree'], 3 )\n self.assertEqual( round( self.stats['mean_in_degree'], 2 ), 1.40 )\n\n def test_partial_in_degree( self ):\n \"\"\"\"\"\"\n oid.partial_in_degree( self.G, None, self.stats )\n\n self.assertEqual( self.stats['max_partial_in_degree'], 2 )\n self.assertEqual( round( self.stats['mean_partial_in_degree'], 2 ), 1.17 )\n\n def test_labelled_in_degree( self ):\n \"\"\"\"\"\"\n oid.labelled_in_degree( self.G, None, self.stats )\n\n self.assertEqual( self.stats['max_labelled_in_degree'], 2 )\n self.assertEqual( round( self.stats['mean_labelled_in_degree'], 2 ), 1.20 )\n\n def test_direct_in_degree( self ):\n \"\"\"\"\"\"\n oid.direct_in_degree( self.G, None, self.stats )\n\n self.assertEqual( self.stats['max_direct_in_degree'], 3 )\n self.assertEqual( round( self.stats['mean_direct_in_degree'], 2 ), 1.40 )\n"
}
] | 64 |
Anuja1994/DeepVideos | https://github.com/Anuja1994/DeepVideos | 3a9b928cd862bc166f419db72152d934a883f2df | 2b0d123eff58af36a6c6f11c64fa78c7a5c30678 | fa621c98bb428fe83ac6fae5633e5e18d6275883 | refs/heads/master | 2021-07-22T19:42:21.482628 | 2017-10-31T19:12:38 | 2017-10-31T19:12:38 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5622665286064148,
"alphanum_fraction": 0.5655874013900757,
"avg_line_length": 37.238094329833984,
"blob_id": "94175c48c3010d2b470e417fd7452898c3b3e690",
"content_id": "42a0a4f2b03c4ac1cc6ff5bfb73699b5aeecfe23",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4818,
"license_type": "permissive",
"max_line_length": 154,
"num_lines": 126,
"path": "/datasets/batch_generator.py",
"repo_name": "Anuja1994/DeepVideos",
"src_encoding": "UTF-8",
"text": "import os\nimport random\nfrom frame_extraction import frame_extractor\nimport cPickle\n\nclass datasets(object):\n def __init__(self, batch_size=64, val_split=0.005, test_split=0.005, heigth=64, width=64, DIR='../../data', output_filename='../../all_videos.txt', ):\n self.file_path = os.path.abspath(os.path.dirname(__file__))\n self.DIR = os.path.join(self.file_path,DIR)\n self.output_filename = os.path.join(self.file_path,output_filename)\n self.batch_size = batch_size\n self.flagged_activities = ['PlayingDaf', 'BodyWeightSquats', 'Nunchucks', 'ShavingBeard', 'SkyDiving']\n self.data = None\n self.frame_ext = frame_extractor(heigth=heigth,width=width)\n self.videos_to_text_file()\n self.load_problematic_videos()\n self.train_test_split(val_split,test_split)\n\n def load_problematic_videos(self):\n _frames_file = os.path.join(self.file_path, 'frames.pickle')\n _problem_videos_file = os.path.join(self.file_path, 'problematic_videos.pickle')\n with open(_frames_file, 'rb') as fp:\n short_frames = cPickle.load(fp)\n with open(_problem_videos_file, 'rb') as fp:\n problematic_videos = cPickle.load(fp)\n\n self.blacklist = set(short_frames + problematic_videos)\n\n def videos_to_text_file(self):\n with open(self.output_filename, \"w\") as a:\n for path, subdirs, files in os.walk(self.DIR):\n for filename in files:\n f = os.path.join(path, filename)\n a.write(str(f) + os.linesep)\n\n\n def train_test_split(self, split_test_data, split_validation_data):\n \"\"\"\n split_test_data : '%' of test data to split between 0 to 1\n \"\"\"\n data = {}\n unseen = []\n seen = []\n for line in open(self.output_filename):\n line = line.rstrip('\\n')\n if line in self.blacklist:\n continue\n if any(substring in line for substring in self.flagged_activities):\n unseen.append(line)\n else:\n seen.append(line)\n\n datasize = len(seen)\n\n #Random Shuffle\n random.shuffle(seen)\n\n validation_index = int(datasize * split_validation_data)\n data['validation'] = seen[:validation_index]\n\n seen = seen[validation_index:]\n test_index = int(datasize * split_test_data)\n data['train'] = seen[test_index:]\n data['test'] = seen[:test_index]\n data['unseen'] = unseen\n\n self.data = data\n\n def train_next_batch(self,):\n \"\"\"Returns lists of length batch_size.\n This is a generator function, and it returns lists of the\n entries from the supplied iterator. Each list will have\n batch_size entries, although the final list may be shorter.\n \"\"\"\n train_iter = iter(self.data['train'])\n while True:\n curr_batch = []\n while len(curr_batch) < self.batch_size:\n entry = None\n try:\n entry = train_iter.next()\n except StopIteration:\n # Shuffle data for next rollover ...\n random.shuffle(self.data['train'])\n train_iter = iter(self.data['train'])\n if entry != None:\n curr_batch.append(entry)\n if curr_batch:\n yield self.frame_ext.get_frames(curr_batch)\n\n def fixed_next_batch(self,data_iter):\n is_done = False\n while True:\n curr_batch = []\n while len(curr_batch) < self.batch_size:\n entry = None\n try:\n entry = data_iter.next()\n except StopIteration:\n is_done = True\n break\n if entry != None:\n curr_batch.append(entry)\n if len(curr_batch)==self.batch_size:\n yield self.frame_ext.get_frames(curr_batch)\n if is_done:\n break\n\n def val_next_batch(self,):\n \"\"\"\n Returns lists of length batch_size.\n This is a generator function, and it returns lists of the\n entries from the supplied iterator. Each list will have\n batch_size entries, although the final list may be shorter.\n \"\"\"\n val_iter = iter(self.data['validation'])\n return self.fixed_next_batch(val_iter)\n\n def test_next_batch(self,):\n \"\"\"Returns lists of length batch_size.\n This is a generator function, and it returns lists of the\n entries from the supplied iterator. Each list will have\n batch_size entries, although the final list may be shorter.\n \"\"\"\n val_iter = iter(self.data['test'])\n return self.fixed_next_batch(val_iter)\n"
},
{
"alpha_fraction": 0.6467065811157227,
"alphanum_fraction": 0.6646706461906433,
"avg_line_length": 32.375,
"blob_id": "81bd51a92aac0023305ebacd5bef831ac22cd23b",
"content_id": "2ce30662c8a4d90044fa9bae36f56e172ef9607e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2672,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 80,
"path": "/datasets/frame_extraction.py",
"repo_name": "Anuja1994/DeepVideos",
"src_encoding": "UTF-8",
"text": "import random\nimport skvideo.io\nimport cv2\nimport numpy as np\nimport os\n\nclass frame_extractor():\n\tdef __init__(self,heigth=64, width=64, time_frame=32, dir_to_save=os.path.join(os.path.abspath(os.path.dirname(__file__)), \"../../output/\")):\n\t\tself.heigth = heigth\n\t\tself.width = width\n\t\tself.time_frame = time_frame\n\t\t#self.count = 0\n\t\tself.dir_to_save = dir_to_save\n\n\tdef image_processing(self,X):\n\t\tX = (X - 127.5) / 127.5\n\t\treturn X\n\n\tdef image_postprocessing(self,X):\n\t\tX = (X * 127.5) + 127.5\n\t\treturn X\n\n\tdef get_frames(self, list_video_filenames):\n\t\ttrain_X = []\n\t\ttrain_y = []\n\t\tfor each_filename in list_video_filenames:\n\t\t\tvideo_data = skvideo.io.vread(each_filename)\n\t\t\tN, H, W, C = video_data.shape\n\t\t\tmax_frame_number = N - (self.time_frame+1)\n\t\t\tframe_index = 0 \n\t\t\tif max_frame_number>=1:\n\t\t\t\tframe_index = random.randint(0,max_frame_number)\n\t\t\tdata = video_data[frame_index : frame_index+self.time_frame+1]\n\t\t\tframes = []\n\t\t\tfor each_frame in data:\n\t\t\t\tresized_image = cv2.resize(each_frame, (self.heigth,self.width))\n\t\t\t\tframes.append(resized_image)\n\t\t\tframes = np.array(frames)\n\t\t\tX = frames[ 0 : self.time_frame]\n\t\t\ty = frames[ 1 : self.time_frame+1]\n\t\t\ttrain_X.append(X)\n\t\t\ttrain_y.append(y)\n\t\ttrain_X = self.image_processing(np.array(train_X))\n\t\ttrain_y = self.image_processing(np.array(train_y))\n\t\treturn train_X, train_y, list_video_filenames\n\n\tdef get_frames_with_interval_x(self, list_video_filenames, x=2):\n\t\ttrain_X = []\n\t\ttrain_y = []\n\t\tfor each_filename in list_video_filenames:\n\t\t\tvideo_data = skvideo.io.vread(each_filename)\n\t\t\tN, H, W, C = video_data.shape\n\t\t\tmax_frame_number = N - ((self.time_frame + 1) * x)\n\t\t\tframe_index = 0 \n\t\t\tif max_frame_number>=1:\n\t\t\t\tframe_index = random.randint(0,max_frame_number)\n\t\t\tdata = video_data[frame_index : frame_index+(self.time_frame + 1) * x : x]\n\t\t\tframes = []\n\t\t\tfor each_frame in data:\n\t\t\t\tresized_image = cv2.resize(each_frame, (self.heigth,self.width))\n\t\t\t\tframes.append(resized_image)\n\t\t\tframes = np.array(frames)\n\t\t\tX = frames[ 0 : self.time_frame]\n\t\t\ty = frames[ 1 : self.time_frame+(1*x)]\n\t\t\ttrain_X.append(X)\n\t\t\ttrain_y.append(y)\n\t\ttrain_X = self.image_processing(np.array(train_X))\n\t\ttrain_y = self.image_processing(np.array(train_y))\n\t\treturn train_X, train_y\n\n\tdef generate_output_video(self, frames, filenames):\n\n\t\tframes = self.image_postprocessing(frames)\n\t\tno_videos = frames.shape[0]\n\t\tno_frames = frames.shape[1]\n\t\tfor i in range(no_videos):\n\t\t\tcur_video = np.array([frames[i][j] for j in range(no_frames)])\n\t\t\tfilename = os.path.splitext(os.path.basename(filenames[i]))[0]\n\t\t\tskvideo.io.vwrite(os.path.join(self.dir_to_save, filename + '.mp4'), cur_video)\n\t\t\t#self.count += 1\n\t\t"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 20,
"blob_id": "ba4bde9a9f68e33b99cf8f6d46e88f6a1cc3d277",
"content_id": "d114c6702a6d8d504e9698ae674123b027ad9f39",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 42,
"license_type": "permissive",
"max_line_length": 28,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Anuja1994/DeepVideos",
"src_encoding": "UTF-8",
"text": "# DeepVideos\nVideo Generation from Images\n"
},
{
"alpha_fraction": 0.737500011920929,
"alphanum_fraction": 0.765625,
"avg_line_length": 30.899999618530273,
"blob_id": "e01286ddeb9792e049476a0eff3beb2ea89ee213",
"content_id": "adaf5a65a2410a6b18e2314179243708b8dcfc71",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 320,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 10,
"path": "/datasets/extract_data.sh",
"repo_name": "Anuja1994/DeepVideos",
"src_encoding": "UTF-8",
"text": "mkdir data\ncd data\nwget -r http://crcv.ucf.edu/data/UCF101/UCF101.rar\nsudo apt-get update\nsudo apt-get install unrar\nunrar e UCF101.rar\n#wget http://www.cslab.openu.ac.il/personal/Hassner/aslan/Data/ASLAN_AVI.zip --user=aslan --password=aslan789\n#sudo apt-get install unzip\n#mkdir ASLAN\n#unzip ASLAN_AVI.zip -d ASLAN\n\n"
}
] | 4 |
shyshach/flask-starter | https://github.com/shyshach/flask-starter | af84758066da14364e4b3858594fd7d32e87423a | 075158755fb98fdf6fbc8c098e461e786f1f3bd5 | d32dd3a84c7dbe617afa4cbeeb0821637f876dec | refs/heads/main | 2023-01-13T21:21:58.509974 | 2020-11-19T13:19:56 | 2020-11-19T13:19:56 | 312,242,699 | 0 | 0 | null | 2020-11-12T10:30:03 | 2020-11-19T13:19:00 | 2020-11-19T13:19:56 | Python | [
{
"alpha_fraction": 0.6767485737800598,
"alphanum_fraction": 0.695652186870575,
"avg_line_length": 13.297297477722168,
"blob_id": "5673ad6e1a82c4b3e2f72163a9f66b35389f9613",
"content_id": "2b6a2062bdda7426dfd5a8cebb3e0a38a23a1d39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 37,
"path": "/README.md",
"repo_name": "shyshach/flask-starter",
"src_encoding": "UTF-8",
"text": "# {{cookiecutter.project_name}}\n\n\n## Run locally with docker\n\nUse docker-compose\n```\ndocker-compose up\n```\n\n\n## Initialise environment variables. \n\nSave `.env.example` as a `.env` file.\nExample content:\n\n```\nexport FLASK_APP=\"src/main.py\"\nexport POSTGRES_URL=\"127.0.0.1:5432\"\nexport POSTGRES_DB=\"mydb\"\nexport POSTGRES_USER=\"postgres\"\nexport POSTGRES_PASSWORD=\"example\"\nexport JWT_SECRET_KEY=\"super-secret\"\n```\n\n## Run migrations\n\n```\nfab migrate\n```\n\n\n## Run with gunicorn\nFor production.\n```\ncd src && gunicorn main:app\n```\n"
},
{
"alpha_fraction": 0.5826486945152283,
"alphanum_fraction": 0.5915215015411377,
"avg_line_length": 31.720430374145508,
"blob_id": "f0699f4452c043f32f13b79e6535744e53787938",
"content_id": "5415b11a5cdd8154fa20f8e6c8d04dbbfe6c948d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3043,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 93,
"path": "/src/resources/user.py",
"repo_name": "shyshach/flask-starter",
"src_encoding": "UTF-8",
"text": "from flask import request\nfrom flask_restful import Resource\nfrom flask_jwt_extended import (\n create_access_token,\n create_refresh_token,\n jwt_required,\n jwt_refresh_token_required,\n get_jwt_identity,\n get_raw_jwt,\n)\nfrom repositories import UserRepository\nfrom models.revoked_token_model import RevokedTokenModel\nfrom sqlalchemy.exc import IntegrityError\n\n\nclass User(Resource):\n def get(self, username: str):\n user = UserRepository.get(username)\n return user, 200\n\n\nclass UserList(Resource):\n def get(self):\n \"\"\" Get users list.\"\"\"\n users_query = UserRepository.all()\n if len(users_query):\n users = []\n for user in users_query:\n users.append(\n {\n \"username\": user.username,\n \"avatar\": user.avatar_url,\n \"created\": str(user.date_created),\n }\n )\n else:\n users = {}\n return users, 200\n\n\nclass UserLogin(Resource):\n def post(self):\n request_json = request.get_json(silent=True)\n username: str = request_json[\"username\"]\n password: str = request_json.get(\"password\")\n # lookup by username\n if UserRepository.get(username):\n current_user = UserRepository.get(username)\n else:\n return {\"message\": \"User {} doesn't exist\".format(username)}, 404\n\n if UserRepository.verify_hash(password, current_user[\"password\"]):\n access_token = create_access_token(identity=username)\n refresh_token = create_refresh_token(identity=username)\n return {\n \"message\": \"Logged in as {}\".format(current_user[\"username\"]),\n \"access_token\": access_token,\n \"refresh_token\": refresh_token,\n }, 200\n else:\n return {\"message\": \"Wrong password\"}, 401\n\n\nclass UserLogoutAccess(Resource):\n @jwt_required\n def post(self):\n jti = get_raw_jwt()[\"jti\"]\n try:\n revoked_token = RevokedTokenModel(jti=jti)\n revoked_token.add()\n return {\"message\": \"Access token has been revoked\"}, 200\n except IntegrityError:\n return {\"message\": \"Something went wrong while revoking token\"}, 500\n\n\nclass UserLogoutRefresh(Resource):\n @jwt_refresh_token_required\n def post(self):\n jti = get_raw_jwt()[\"jti\"] # id of a jwt accessing this post method\n try:\n revoked_token = RevokedTokenModel(jti=jti)\n revoked_token.add()\n return {\"message\": \"Refresh token has been revoked\"}, 200\n except IntegrityError:\n return {\"message\": \"Something went wrong while revoking token\"}, 500\n\n\nclass TokenRefresh(Resource):\n @jwt_refresh_token_required\n def post(self):\n current_user_identity = get_jwt_identity()\n access_token = create_access_token(identity=current_user_identity)\n return {\"access_token\": access_token}\n"
},
{
"alpha_fraction": 0.7349693179130554,
"alphanum_fraction": 0.7349693179130554,
"avg_line_length": 22.97058868408203,
"blob_id": "1f9feac3ca71c588f45459bf58de39faddc8b660",
"content_id": "220910a2d077165f2363460444c1ecb659a1198e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 34,
"path": "/src/main.py",
"repo_name": "shyshach/flask-starter",
"src_encoding": "UTF-8",
"text": "from flask_restful import Api\nfrom resources import (\n HealthCheck,\n UserList,\n User,\n UserLogin,\n UserLogoutAccess,\n UserLogoutRefresh,\n TokenRefresh,\n)\nfrom models import User as UserModel, db\nfrom flask_migrate import Migrate\nfrom app import create_app\n\n\napp = create_app()\nmigrate = Migrate(app, db)\n\n\n# API\napi = Api(app)\napi.add_resource(HealthCheck, \"/healthcheck\")\napi.add_resource(User, \"/api/users/<username>\")\napi.add_resource(UserList, \"/api/users/\")\napi.add_resource(UserLogin, \"/api/login\")\napi.add_resource(UserLogoutAccess, \"/api/logout_access\")\napi.add_resource(UserLogoutRefresh, \"/api/logout_refresh\")\napi.add_resource(TokenRefresh, \"/api/refresh\")\n\n\n# CLI for migrations\[email protected]_context_processor\ndef make_shell_context():\n return dict(app=app, db=db, User=UserModel)\n"
},
{
"alpha_fraction": 0.645348846912384,
"alphanum_fraction": 0.6773256063461304,
"avg_line_length": 17.105262756347656,
"blob_id": "c26a3947d42f0c50b0d6921a4fbbed9bfe9ae8ab",
"content_id": "0bb5b99453c4c8737f6d5f3e9e66f686c3ad0864",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 344,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 19,
"path": "/Dockerfile",
"repo_name": "shyshach/flask-starter",
"src_encoding": "UTF-8",
"text": "FROM python:3.9\n\nRUN mkdir -p /app\nWORKDIR /app\n\n# Copy files\nCOPY ./requirements.txt ./\nCOPY ./setup.py ./\n\n# Copy folders\nADD ./src ./src\n\n# Install packages\nRUN pip install -U pip && pip install -r requirements.txt\n\n# Run flask app\nEXPOSE 5000\nENV FLASK_APP=\"src/main.py\" FLASK_DEBUG=1 FLASK_ENV=docker\nCMD [\"flask\", \"run\", \"-h\", \"0.0.0.0\"]\n"
},
{
"alpha_fraction": 0.47704917192459106,
"alphanum_fraction": 0.519672155380249,
"avg_line_length": 14.666666984558105,
"blob_id": "5bb950aebef55ce7761192935e63ae5cd2c08032",
"content_id": "d97f34713ff61b7b69235196e511d18c0bf6ff25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 39,
"path": "/docker-compose.yml",
"repo_name": "shyshach/flask-starter",
"src_encoding": "UTF-8",
"text": "version: '3.7'\nservices:\n db:\n image: postgres:12\n restart: always\n env_file:\n - ./.env\n volumes:\n - ./data/postgres/data:/var/lib/postgresql/data\n\n networks:\n - local\n app:\n build: .\n restart: on-failure\n env_file:\n - ./.env\n volumes:\n - ./src:/app/src\n - ./scripts:/app/scripts\n ports:\n - \"5000:5000\"\n depends_on: \n - db\n networks:\n - local\n adminer:\n image: adminer\n restart: always\n ports:\n - \"127.0.0.1:8080:8080\"\n depends_on:\n - db\n networks:\n - local\n\nnetworks:\n local:\n driver: bridge"
},
{
"alpha_fraction": 0.5625,
"alphanum_fraction": 0.5706967115402222,
"avg_line_length": 30.483871459960938,
"blob_id": "2005600ca45a1dbf687471a32e665307c653c4de",
"content_id": "b27df337ef2af32e58b25ac02afd7399e6b671b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1952,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 62,
"path": "/src/repositories/user.py",
"repo_name": "shyshach/flask-starter",
"src_encoding": "UTF-8",
"text": "from sqlalchemy.exc import IntegrityError\nfrom exceptions import ResourceExists\nfrom models import User\nfrom flask_jwt_extended import create_access_token, create_refresh_token\nfrom passlib.hash import pbkdf2_sha256 as sha256\n\n\nclass UserRepository:\n @staticmethod\n def create(username: str, avatar_url: str, password: str) -> dict:\n \"\"\" Create user \"\"\"\n result: dict = {}\n try:\n user = User(\n username=username,\n avatar_url=avatar_url,\n password=UserRepository.generate_hash(password),\n )\n user.save()\n access_token = create_access_token(identity=username)\n refresh_token = create_refresh_token(identity=username)\n result = {\n \"username\": user.username,\n \"avatar_url\": user.avatar_url,\n \"date_created\": str(user.date_created),\n \"message\": \"User {} was created\".format(user.username),\n \"access_token\": access_token,\n \"refresh_token\": refresh_token,\n }\n\n except IntegrityError:\n User.rollback()\n raise ResourceExists(\"user already exists\")\n\n return result\n\n @staticmethod\n def get(username: str) -> dict:\n \"\"\" Query a user by username \"\"\"\n user: dict = {}\n user = User.query.filter_by(username=username).first_or_404()\n user = {\n \"username\": user.username,\n \"date_created\": str(user.date_created),\n \"avatar_url\": str(user.avatar_url),\n \"password\": str(user.password),\n }\n return user\n\n @staticmethod\n def all() -> list:\n users = []\n users = User.query.all()\n return users\n\n @staticmethod\n def generate_hash(password):\n return sha256.hash(password)\n\n @staticmethod\n def verify_hash(password, hash):\n return sha256.verify(password, hash)\n"
},
{
"alpha_fraction": 0.6842684149742126,
"alphanum_fraction": 0.6842684149742126,
"avg_line_length": 25.735294342041016,
"blob_id": "6ebc4d57b4f583698eebe1c221f09591bd0c3451",
"content_id": "d37958ddf34bb87aee3dec0c1d2264c202e83a01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 909,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 34,
"path": "/src/app.py",
"repo_name": "shyshach/flask-starter",
"src_encoding": "UTF-8",
"text": "from flask import Flask\nfrom flask_sqlalchemy import SQLAlchemy\nfrom config import get_config\nfrom flask_jwt_extended import JWTManager\nimport os\n\n\ndb = SQLAlchemy()\n\n\ndef setup_jwt(app):\n if os.environ.get(\"JWT_SECRET_KEY\"):\n app.config[\"JWT_SECRET_KEY\"] = os.environ.get(\"JWT_SECRET_KEY\")\n else:\n app.config[\"JWT_SECRET_KEY\"] = \"jwt-secret-key\"\n jwt = JWTManager(app)\n\n app.config[\"JWT_BLACKLIST_ENABLED\"] = True\n app.config[\"JWT_BLACKLIST_TOKEN_CHECKS\"] = [\"access\", \"refresh\"]\n\n from models.revoked_token_model import RevokedTokenModel\n\n @jwt.token_in_blacklist_loader\n def check_if_token_in_blacklist(decrypted_token):\n jti = decrypted_token[\"jti\"]\n return RevokedTokenModel.is_jti_blacklisted(jti)\n\n\ndef create_app(env=None):\n app = Flask(__name__)\n app.config.from_object(get_config(env))\n db.init_app(app)\n setup_jwt(app)\n return app\n"
},
{
"alpha_fraction": 0.6327608823776245,
"alphanum_fraction": 0.6380448937416077,
"avg_line_length": 26.035715103149414,
"blob_id": "d98c9f3d803021da5cde02d657b471d76bfdae29",
"content_id": "3772fe2f7a4c032c4de9d2b186886c82e27bd128",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 757,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 28,
"path": "/src/models/revoked_token_model.py",
"repo_name": "shyshach/flask-starter",
"src_encoding": "UTF-8",
"text": "from . import db\nimport datetime\nfrom sqlalchemy.exc import IntegrityError\n\nTABLE_ID = db.Sequence(\"autoid\", start=1)\n\n\nclass RevokedTokenModel(db.Model):\n __tablename__ = \"revoked_tokens\"\n\n id = db.Column(\n db.Integer, TABLE_ID, primary_key=True, server_default=TABLE_ID.next_value()\n )\n jti = db.Column(db.String(120))\n blacklisted_on = db.Column(db.DateTime, default=datetime.datetime.utcnow)\n\n def add(self):\n try:\n db.session.add(self)\n return db.session.commit()\n except IntegrityError:\n db.session.rollback()\n raise IntegrityError\n\n @classmethod\n def is_jti_blacklisted(cls, jti):\n query = cls.query.filter_by(jti=jti).first()\n return bool(query)\n"
}
] | 8 |
jayednahain/Push-notification-coro-update | https://github.com/jayednahain/Push-notification-coro-update | 275b1170015cf0b60f786b84bcd3a8dfbf55fac0 | 1ff46adccf8f9580cb7620fae37ab5b8645a32e6 | 6aad2460b0ab2f2e55fa6101cb1c9427bbd88369 | refs/heads/main | 2023-03-15T01:29:59.692436 | 2021-03-06T05:58:36 | 2021-03-06T05:58:36 | 345,016,901 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6490166187286377,
"alphanum_fraction": 0.6580938100814819,
"avg_line_length": 19.53125,
"blob_id": "31713ab79266901094287dfa9c86742bbd6fc95e",
"content_id": "7f5fd03364ac70ed2d41abf19626ef836fef9d25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 661,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 32,
"path": "/main_file.py",
"repo_name": "jayednahain/Push-notification-coro-update",
"src_encoding": "UTF-8",
"text": "from plyer import notification\nfrom bs4 import BeautifulSoup\nimport requests\n\n\nurl = \"https://www.worldometers.info/coronavirus/\"\n\n\n\ndef notify(title,message):\n notification.notify(\n title = title,\n message = message,\n app_icon = \"coronavirus_gi2_icon.ico\",\n timeout = 2,\n app_name = \"jayed\"\n )\n\nr = requests.get(url)\ns = BeautifulSoup(r.text,\"html.parser\")\n \n\ndata = s.find_all(\"div\",class_=\"maincounter-number\")\nprint(data)\ncase = data[0].text.strip()\ndeath = data[1].text.strip()\nrecovered = data[2].text.strip()\n\n \nnotify(\"Total case\",case)\nnotify(\"Total death\",death)\nnotify(\"Total recovered\",recovered)\n "
},
{
"alpha_fraction": 0.7698412537574768,
"alphanum_fraction": 0.7698412537574768,
"avg_line_length": 30.5,
"blob_id": "6700f8e8ca4ee6a27a19ec0747097ce60b1a227f",
"content_id": "9229e94d3e824c48cc5285c21e092b1653958ead",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 4,
"path": "/README.md",
"repo_name": "jayednahain/Push-notification-coro-update",
"src_encoding": "UTF-8",
"text": "# Push-notification-coro-update\n\n# BeautifulSoup to scarp web data\n## web source \"https://www.worldometers.info/coronavirus/\"\n"
}
] | 2 |
guillaumemen/Pong-Guillaume- | https://github.com/guillaumemen/Pong-Guillaume- | bd57d3caf251044da8cd5b2e556d3907f7da4344 | 6216ebaf47c401975ceb2580c85381130119efd0 | 716024d5f66866da107373d0bce147d6a5624dac | refs/heads/master | 2020-04-15T02:49:13.856415 | 2019-01-06T16:52:52 | 2019-01-06T16:52:52 | 164,325,608 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5760916471481323,
"alphanum_fraction": 0.6057068705558777,
"avg_line_length": 20.13397216796875,
"blob_id": "01111742558a9b03090a8a9f397a6e9766696fe3",
"content_id": "3b633f156829fca14b5771d16ed11e8e520e032c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4626,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 209,
"path": "/pong.py",
"repo_name": "guillaumemen/Pong-Guillaume-",
"src_encoding": "UTF-8",
"text": "import random\r\nfrom tkinter import *\r\n\r\n\r\ndef move(direction):\r\n global player\r\n global canvas\r\n global PADDLE_MOVEMENT\r\n global HEIGHT\r\n\r\n coords = canvas.coords(player)\r\n\r\n if (direction == 'up' and coords[1] <= 10) or \\\r\n (direction == 'down' and coords[3] >= HEIGHT):\r\n return False\r\n\r\n if direction == 'up':\r\n movement = -PADDLE_MOVEMENT\r\n else:\r\n movement = PADDLE_MOVEMENT\r\n\r\n canvas.move(player, 0, movement)\r\n\r\ndef move2(direction):\r\n global player2\r\n global canvas\r\n global PADDLE_MOVEMENT\r\n global HEIGHT\r\n\r\n coords = canvas.coords(player)\r\n\r\n if (direction == 'up' and coords[1] <= 10) or \\\r\n (direction == 'down' and coords[3] >= HEIGHT):\r\n return False\r\n\r\n if direction == 'up':\r\n movement = -PADDLE_MOVEMENT\r\n else:\r\n movement = PADDLE_MOVEMENT\r\n\r\n canvas.move(player2, 0, movement)\r\n\r\ndef move_up(event):\r\n move('up')\r\n\r\ndef move_up2(event):\r\n move2('up')\r\n\r\ndef move_down(event):\r\n move('down')\r\n \r\ndef move_down2(event):\r\n move2('down')\r\n\r\n\r\ndef move_ball():\r\n global ball\r\n global canvas\r\n global dx\r\n global dy\r\n\r\n canvas.move(ball, dx, dy)\r\n\r\n'''def move_computer():\r\n global computer\r\n global ball\r\n global canvas\r\n global HEIGHT\r\n global PADDLE_MOVEMENT\r\n\r\n ball_pos = canvas.coords(ball)\r\n comp_pos = canvas.coords(computer)\r\n\r\n if ball_pos[1] > comp_pos[1] and comp_pos[3] < HEIGHT:\r\n canvas.move(computer, 0, PADDLE_MOVEMENT)\r\n elif ball_pos[1] < comp_pos[1] and comp_pos[1] > 10:\r\n canvas.move(computer, 0, -PADDLE_MOVEMENT)\r\n '''\r\n\r\ndef show_scores():\r\n global canvas\r\n global player_score\r\n global player2_score\r\n global player_score_label\r\n global player2_score_label\r\n\r\n canvas.delete(player_score_label)\r\n canvas.delete(player2_score_label)\r\n\r\n player_score_label = canvas.create_text(190, 15, text=player2_score, fill='white', font=('Arial', 15))\r\n player2_score_label = canvas.create_text(210, 15, text=player_score, fill='white', font=('Arial', 15))\r\n\r\n\r\ndef bounce_ball():\r\n global dx\r\n global dy\r\n\r\n dx = -dx\r\n dy = random.randint(1, 3)\r\n flip_y = random.randint(0, 1) * 1\r\n\r\n if flip_y:\r\n dy = -dy\r\n\r\n\r\ndef reset_ball():\r\n global canvas\r\n global ball\r\n global dx\r\n global dy\r\n\r\n flip_x = random.randint(0, 1) * 1\r\n dx = random.randint(2, 3)\r\n dy = random.randint(1, 3)\r\n\r\n if flip_x == 1:\r\n dx = -dx\r\n\r\n canvas.delete(ball)\r\n ball = canvas.create_rectangle((190, 190, 210, 210), fill=\"white\")\r\n\r\n\r\ndef refresh():\r\n \"\"\"\r\n This is the method which updates all elements in the game.\r\n \"\"\"\r\n global canvas\r\n global ball\r\n global player\r\n global player2\r\n global player_score\r\n global player2_score\r\n global WIDTH\r\n global HEIGHT\r\n global dx\r\n global dy\r\n global master\r\n global REFRESH_TIME\r\n\r\n show_scores()\r\n move_ball()\r\n ball_coords = canvas.coords(ball)\r\n\r\n if ball_coords[0] < 0:\r\n player_score = player_score + 1\r\n reset_ball()\r\n elif ball_coords[0] > WIDTH:\r\n player2_score = player2_score + 1\r\n reset_ball()\r\n\r\n if ball_coords[1] < 0 or ball_coords[3] > HEIGHT:\r\n dy = -dy\r\n\r\n overlapping = canvas.find_overlapping(*ball_coords)\r\n\r\n if len(overlapping) > 1:\r\n collided_item = overlapping[0]\r\n\r\n if collided_item == player or collided_item == player2:\r\n bounce_ball()\r\n\r\n master.after(REFRESH_TIME, refresh)\r\n\r\n\r\n\r\n\r\n# Window dimensions and other constants\r\nWIDTH = 400\r\nHEIGHT = 400\r\nPADDLE_MOVEMENT = 10\r\nREFRESH_TIME = 20 # milliseconds\r\n\r\n# Game variables\r\nplayer_score = 0\r\nplayer2_score = 0\r\n\r\n# The Tk labels to show the score\r\nplayer_score_label = None\r\nplayer2_score_label = None\r\n\r\n# Set up the GUI window via Tk\r\nmaster = Tk()\r\nmaster.title(\"Pong\")\r\n\r\ncanvas = Canvas(master, background=\"black\", width=WIDTH, height=HEIGHT)\r\ncanvas.create_line((200, 0, 200, 400), fill=\"red\")\r\n\r\n# Keep a reference for the GUI elements\r\nplayer = canvas.create_rectangle((10, 150, 30, 250), fill=\"white\")\r\nplayer2 = canvas.create_rectangle((370, 150, 390, 250), fill=\"white\")\r\nball = None # Set this variable up for reset_ball()\r\n\r\n# Ball acceleration (set in reset_ball())\r\ndx = 0\r\ndy = 0\r\n\r\ncanvas.pack()\r\n\r\n# Bind the keyboard events to our functions\r\nmaster.bind(\"w\", move_up)\r\nmaster.bind(\"s\", move_down)\r\nmaster.bind(\"<KeyPress-Up>\", move_up2)\r\nmaster.bind(\"<KeyPress-Down>\", move_down2)\r\n\r\n\r\n# Let's play!\r\nreset_ball()\r\nmaster.after(REFRESH_TIME, refresh)\r\nmaster.mainloop()\r\n"
}
] | 1 |
nategri/heaterbot | https://github.com/nategri/heaterbot | 078aa9ce1e9785444cc82c140d92531e166a6476 | fc3a0876bbc22887a02f6a546546984c0096ba4d | f1369e19edcf61d1ceb592383c58bc00dc9c89de | refs/heads/master | 2018-01-06T09:41:41.218067 | 2016-10-10T04:38:41 | 2016-10-10T04:38:41 | 70,425,963 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8541666865348816,
"alphanum_fraction": 0.8541666865348816,
"avg_line_length": 47,
"blob_id": "c8927313d801642d394cabdad06d9f1db4952696",
"content_id": "cb211b89c732692f1f729590ad8717f66de4c64f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 1,
"path": "/README.md",
"repo_name": "nategri/heaterbot",
"src_encoding": "UTF-8",
"text": "Script for the Heaterbot space heater automator\n"
},
{
"alpha_fraction": 0.6756159067153931,
"alphanum_fraction": 0.6882501840591431,
"avg_line_length": 24.327999114990234,
"blob_id": "76f73aef7d6ccc5117f033e6407dc96048dcd487",
"content_id": "519dae2e5c07067e7c08b530aa8583e0b2f05c04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3166,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 125,
"path": "/heaterbot.py",
"repo_name": "nategri/heaterbot",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom ouimeaux.environment import Environment\nfrom sense_hat import SenseHat\n\nfrom flask import Flask\nfrom flask_restful import reqparse, abort, Api, Resource, request\n\nimport datetime\nimport time\nimport threading\n\n# Initialize REST API components\napp = Flask(__name__)\napi = Api(app)\n\n# THERMOSTAT FUNCTIONS AND CLASSES\n\ndef tempCalFunction(t):\n # Sense Hat calibration function\n # Thanks to AndersM\n # https://www.raspberrypi.org/forums/viewtopic.php?f=104&t=111457\n return 0.0071*t*t + 0.86*t - 10.0\n\ndef toF(t):\n return 1.8*t + 32\n\ndef senseTemp():\n return toF(tempCalFunction(sense.get_temperature()))\n\ndef getEpochTime(d):\n s = (d - datetime.datetime(1970,1,1)).total_seconds()\n return s\n\nclass SchedInfo:\n def __init__(self, startSetting, durationSetting, startTime, endTime, tempSetting):\n self.startSetting = startSetting\n self.durationSetting = durationSetting\n self.startTime = startTime\n self.endTime = endTime\n self.tempSetting = tempSetting\n\nclass Scheduler:\n def __init__(self):\n self.schedInfoList = []\n self.needsUpdate = True\n\n def readSchedule(self):\n self.schedInfoList = []\n\n scheduleFile = open('schedule.conf','r')\n \n for line in scheduleFile:\n lineSplit = line.split()\n \n rawTime = lineSplit[0]\n hr = int(rawTime.split(\":\")[0])\n mn = int(rawTime.split(\":\")[1])\n \n duration = float(lineSplit[1])\n tempSetting = float(lineSplit[2])\n \n currTime = datetime.datetime.now()\n schedTime = currTime.replace(hour=hr,minute=mn)\n \n startTime = (getEpochTime(schedTime))\n endTime = (getEpochTime(schedTime)) + (duration*60)\n \n self.schedInfoList.append(SchedInfo(rawTime, duration, startTime, endTime, tempSetting))\n \n scheduleFile.close()\n self.needsUpdate = False\n\ndef thermostat():\n while 1:\n if sched.needsUpdate:\n sched.readSchedule()\n\n runHeater = False\n\n currTime = getEpochTime(datetime.datetime.now())\n\n for item in sched.schedInfoList:\n if senseTemp() < item.tempSetting and currTime > item.startTime and currTime < item.endTime:\n runHeater = (True or runHeater)\n\n if runHeater:\n heater.on()\n else:\n heater.off()\n\n time.sleep(5)\n\n# Initialize necessary variables for thermostat\nsense = SenseHat()\nenv = Environment()\nenv.start()\nenv.discover(seconds=5)\nheater = env.get_switch('heaterbot')\nsched = Scheduler()\n\n# REST API FUNCTIONS AND CLASSES\nclass Settings(Resource):\n def get(self):\n data = []\n for item in sched.schedInfoList:\n data.append({'startTime': item.startSetting, 'duration': item.durationSetting, 'tempSetting': item.tempSetting})\n return data\n\n def post(self):\n jsonData = request.get_json()\n schedFile = open('schedule.conf','w')\n for item in jsonData:\n schedFile.write(item['startTime'] + \" \" + str(item['duration']) + \" \" + str(item['tempSetting']) + '\\n')\n schedFile.close()\n sched.needUpdate = True\n return jsonData\n\n# Create and start thermostat/schedule thread\nthermostatThread = threading.Thread(target=thermostat)\nthermostatThread.start()\n\n# Start REST API\napi.add_resource(Settings, '/api')\napp.run()\n"
}
] | 2 |
thhapke/tmxconverter | https://github.com/thhapke/tmxconverter | f972b9839a5f7e84faec3bb573096c091c193880 | 842ff6d7a1cc1fa7fed29437e26b57bf104785a4 | 31332052a9022e4baf572ea337526de7d5805b84 | refs/heads/master | 2023-02-20T14:58:40.750862 | 2021-01-20T08:35:54 | 2021-01-20T08:35:54 | 329,595,791 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6020100712776184,
"alphanum_fraction": 0.6110552549362183,
"avg_line_length": 28.235294342041016,
"blob_id": "2e9d5de1613d54ea374a21a114424c1c917a5e2c",
"content_id": "05408d73e04f0bb5fadde805e4cb9391f7ae868e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 995,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 34,
"path": "/setup.py",
"repo_name": "thhapke/tmxconverter",
"src_encoding": "UTF-8",
"text": "import setuptools\n\nwith open(\"README.md\", \"r\") as fh:\n long_description = fh.read()\n\nsetuptools.setup(\n name=\"Lxconverter\",\n version=\"0.0.6\",\n author=\"Thorsten Hapke\",\n author_email=\"[email protected]\",\n description=\"Converts TMX files to CSV-files and/or stores to HANA table\",\n long_description=long_description,\n long_description_content_type=\"text/markdown\",\n url=\"https://github.com/thhapke/tmxconverter\",\n keywords = ['tmx'],\n #packages=setuptools.find_packages(),\n packages=[\"Lxconverter\"],\n install_requires=[\n 'pandas','pyyaml','hdbcli'\n ],\n include_package_data=True,\n entry_points={\n 'console_scripts': [\n \"Lxconverter = Lxconverter.convert:main\"\n ]\n },\n classifiers=[\n \t'Programming Language :: Python :: 3.6',\n \t'Programming Language :: Python :: 3.7',\n 'Programming Language :: Python :: 3.8',\n \"License :: OSI Approved :: MIT License\",\n \"Operating System :: OS Independent\",\n ],\n)\n\n"
},
{
"alpha_fraction": 0.5430916547775269,
"alphanum_fraction": 0.5458276271820068,
"avg_line_length": 25.071428298950195,
"blob_id": "4ed7f07ab443ecddf6efc2ecbb4e512122e6b757",
"content_id": "729cde1ea5b98b28a9a421d98a0a5b24d9148566",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "permissive",
"max_line_length": 47,
"num_lines": 28,
"path": "/Lxconverter/readfiles.py",
"repo_name": "thhapke/tmxconverter",
"src_encoding": "UTF-8",
"text": "\nimport csv\nimport re\n\ndef read_regex(filename,outputfile) :\n regex_pattern = list()\n with open(filename) as file:\n while True :\n line = file.readline().rstrip('\\n')\n if line :\n if not re.match('\\s*#', line) :\n regex_pattern.append(line)\n else :\n break\n file.close()\n # clean log file\n with open(outputfile, 'w') as file:\n csvwriter = csv.writer(file)\n file.close()\n return regex_pattern\n\n\ndef read_code_mapping(filename) :\n # language mapping file\n mapcodes = dict()\n with open(filename) as file :\n for line in csv.reader(file):\n mapcodes[line[0]] = line[1]\n return mapcodes\n"
},
{
"alpha_fraction": 0.6306122541427612,
"alphanum_fraction": 0.6306122541427612,
"avg_line_length": 43.6363639831543,
"blob_id": "b6decc027a567b3bc9a8b84a8d6b23defead06ee",
"content_id": "5ab266ac9003fe45482cc26cd1cbcb3e698c9a8c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 490,
"license_type": "permissive",
"max_line_length": 103,
"num_lines": 11,
"path": "/Lxconverter/save2files.py",
"repo_name": "thhapke/tmxconverter",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\n### Output routines\ndef save_file(records,filename) :\n df = pd.DataFrame(records)\n #remove newlines\n df.source_text = df.source_text.apply(lambda x : x.replace('\\n',' '))\n df.target_text = df.target_text.apply(lambda x: x.replace('\\n', ''))\n df = df[['source_lang', 'source_text', 'target_lang', 'target_text', 'domain', 'origin', 'created',\n 'changed', 'last_usage', 'usage_count']]\n df.to_csv(filename, index=False, line_terminator='\\n')"
},
{
"alpha_fraction": 0.6957831382751465,
"alphanum_fraction": 0.7051957845687866,
"avg_line_length": 27.869565963745117,
"blob_id": "06d17c682dd2603b9c0b62b6df63b7ac555d5b96",
"content_id": "37b7659871ba1014407361b7d921b3471f9cbda5",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2656,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 92,
"path": "/README.md",
"repo_name": "thhapke/tmxconverter",
"src_encoding": "UTF-8",
"text": "# TMX Converter\n\ntmxconverter reads tmx-files from an input folder and saves the outcome either\n* as csv-files to an output folder or\n* stores them into a database table\n\n\nThe language code is mapped to the 2-character code based on the given file 'language_code_mapping.csv' (specified in 'config.yaml')\n\nThe application is using a yaml-configuration file **config.yaml** to control the behaviour read from the working directory. \n\n## Command line options\n``tmxconverter -log [loglevel]``` with 'warning','info' and 'debug'\n\n\n## Mapping\n\n* ```<tmx><header srclang=\"en-US\"> ```: source_lang\n* ```<body><tu creationdate``` : created\n* ```<body><tu creationid``` : creation_id\n* ```<body><tu changeid``` : change_id\n* ```<body><tu changedate``` : changed\n* ```<body><tu lastusagedate``` : lastusage\n* From filename substring until '_' : domain\n* Filename : origin\n* ```<body><tu><tuv xml:lang``` : target_lang if different from source_lang using the language mapping\n* ```<body><tu><tuv><seg>```: source_text or target_text depending lang-attribute`\n\n## Regular Expression\nAs a first basic filter a list of regular expressions separated by a 'line separator' can be passed that are stored\nin a text-file. \n\nExamples: \n* ```\\s*$```\n* ```\\s*\\d+\\s*$```\n* ```\\s*\\d*\\.\\d+\\s*$```\n\n\n## Files Output\n\nIf the parameter FILES_OUTPUT is ```true all``` tmx-files are written to the OUTPUT_FOLDER taking the same filename but replacing the suffix. \nThe output is using a comma-separator and double quotes strings (pandas.to_csv used)\n\n## Database Output\n\nIf the parameter HDB_OUTPUT is ````True```` then the data is stored to the HANA Database for which the details are given in the \nconfig.yaml-file.\n\nThe current table structure: \n\n```\nCREATE COLUMN TABLE \"TMX\".\"DATA\"(\n\t\"SOURCE_LANG\" NVARCHAR(2),\n\t\"SOURCE_TEXT\" NVARCHAR(5000),\n\t\"TARGET_LANG\" NVARCHAR(2),\n\t\"TARGET_TEXT\" NVARCHAR(5000),\n\t\"DOMAIN\" NVARCHAR(15),\n\t\"ORIGIN\" NVARCHAR(30),\n\t\"CREATION_ID\" NVARCHAR(30),\n\t\"CREATED\" LONGDATE,\n\t\"CHANGE_ID\" NVARCHAR(30),\n\t\"CHANGED\" LONGDATE,\n\t\"LAST_USAGE\" LONGDATE,\n\t\"USAGE_COUNT\" INTEGER\n)\n```\n\n## Example Config.YAML\n```\n# input folder\ninput_folder : /Users/Shared/data/tmx/input\n\n#language coding map\nlang_map_file : language_code_mapping.csv\n\n# output files\nOUTPUT_FILES : true # save to output folder\nOUTPUT_FOLDER : /Users/Shared/data/tmx/output\n\n# HANA DB\nOUTPUT_HDB : false # Save to db\nHDB_HOST : 'xxx.com'\nHDB_USER : 'TMXUSER'\nHDB_PWD : 'PassWord'\nHDB_PORT : 111\n\n# Test Parameter\nTEST : true\nMAX_NUMBER_FILES : 100 # max number of files processed. NOT used when EXCLUSIVE_FILE given\nEXCLUSIVE_FILE : reviews.tmx # If not used leave empty\n#EXCLUSIVE_FILE :\n```\n"
},
{
"alpha_fraction": 0.5928338766098022,
"alphanum_fraction": 0.5946952104568481,
"avg_line_length": 55.55263137817383,
"blob_id": "1c68d3d7b398b6d1fb10a680e00757bd5a183100",
"content_id": "06195ae336ffc8e9ea5d80c39273771c8ddf77b9",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2149,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 38,
"path": "/Lxconverter/save2hdb.py",
"repo_name": "thhapke/tmxconverter",
"src_encoding": "UTF-8",
"text": "\nfrom hdbcli import dbapi\nimport logging\nimport pandas as pd\n\ndef save_db(source, records,db,batchsize = 0 ) :\n conn = dbapi.connect(address=db['host'], port=db['port'], user=db['user'], password=db['pwd'], encrypt=True,\n sslValidateCertificate=False)\n\n\n if source == 'TMX' :\n data = [\n (r['source'], r['source_lang'], r['source_text'], r['target_lang'], r['target_text'], r['domain'], r['origin'],\n r['created'], r['changed'], r['last_usage'], r['usage_count']) for r in records]\n sql = 'UPSERT TMX.DATA (SOURCE,SOURCE_LANG, SOURCE_TEXT, TARGET_LANG, TARGET_TEXT, DOMAIN, ORIGIN, ' \\\n 'CREATED,CHANGED, LAST_USAGE,USAGE_COUNT) VALUES (?,?,?,?,?,?,?,?,?,?,?) WITH PRIMARY KEY;'\n elif source == 'ABAP' :\n data = records[['source','source_lang','source_text','target_lang','target_text','domain','origin','exported','changed',\n 'last_usage','transl_system','abap_package','central_system','objtype','objname','max_length','ach_comp',\n 'sw_comp','sw_comp_version','pp_type','pp_qstatus','orig_lang']].to_records(index= False).tolist()\n sql ='UPSERT TMX.DATA (SOURCE,SOURCE_LANG, SOURCE_TEXT, TARGET_LANG, TARGET_TEXT, DOMAIN, ORIGIN, EXPORTED, ' \\\n 'CHANGED,LAST_USAGE,USAGE_COUNT,TRANSL_SYSTEM,ABAP_PACKAGE,CENTRAL_SYSTEM,OBJTYPE,OBJNAME,MAX_LENGTH,ACH_COMP, '\\\n 'SW_COMP,SW_COMP_VERSION,PP_TYPE,PP_QSTATUS,ORIG_LANG) VALUES (?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?,?) WITH PRIMARY KEY;'\n else:\n raise ValueError('Unknown source: {}',format(source))\n\n cursor = conn.cursor()\n\n if batchsize == 0 :\n logging.debug('Uploading: {}'.format(len(data)))\n cursor.executemany(sql, data)\n else:\n logging.debug('Uploading in batches: {} of batch size: {} (#{})'.format(len(data),batchsize,int(len(data)/batchsize)+1))\n for i in range(0,len(data),batchsize) :\n logging.debug('Uploaded: {}/{} - Uploading: {}'.format(i,len(data),len(data[i:i+batchsize])))\n cursor.executemany(sql, data[i:i+batchsize])\n\n cursor.close()\n conn.close()"
},
{
"alpha_fraction": 0.6965944170951843,
"alphanum_fraction": 0.7012383937835693,
"avg_line_length": 21.275861740112305,
"blob_id": "11239117feb0b4d177b9696901595fa7278280ab",
"content_id": "8f55e1d3d3594793af6add686ae98a19115f7baa",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 646,
"license_type": "permissive",
"max_line_length": 66,
"num_lines": 29,
"path": "/Lxconverter/test_domain_filenames.py",
"repo_name": "thhapke/tmxconverter",
"src_encoding": "UTF-8",
"text": "\nimport logging\nfrom os import path, listdir\nimport re\n\nimport yaml\n\nfrom Lxconverter.readfiles import read_regex, read_code_mapping\n\n###\n# configuration\n###\nlogging.info('Open configuraion file {}'.format('config.yaml'))\nwith open('config.yaml') as yamls:\n params = yaml.safe_load(yamls)\n\n# directories\ninput_folder = params['TMX_INPUT_FOLDER']\n\ntmxfiles = listdir(input_folder)\ndomains = list()\n\nfor f in tmxfiles :\n domains.append(re.search(\"(.+)_\\w{4}_\\w{4}\\.tmx$\",f).group(1))\n\n# domain mapping file\ndomainmapcodes = read_code_mapping(params['DOMAIN_CODE_MAPPING'])\n\nfor d in domains :\n print('{} -> {}'.format(d,domainmapcodes[d]))"
},
{
"alpha_fraction": 0.5242671370506287,
"alphanum_fraction": 0.527064859867096,
"avg_line_length": 37.58685302734375,
"blob_id": "b3b261becb5661040c0904ccfff1c4e876dd76c9",
"content_id": "adfa135038ca7caa68cc4e6793dc5bd368802ca8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8221,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 213,
"path": "/Lxconverter/TMXconvert.py",
"repo_name": "thhapke/tmxconverter",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET\nfrom os import path, listdir\nfrom _datetime import datetime\nimport csv\nimport re\nimport logging\nfrom datetime import datetime, timedelta\nfrom argparse import ArgumentParser\n\nimport yaml\n\nfrom Lxconverter.save2files import save_file\nfrom Lxconverter.save2hdb import save_db\nfrom Lxconverter.readfiles import read_regex, read_code_mapping\n\n\n\ndef main() : # encapsulated into main otherwise entrypoint is not working\n ### Command line\n parser = ArgumentParser(description='Converts tmx-files')\n parser.add_argument('--log','-l',help='Setting logging level \\'warning\\' (default), \\'info\\', \\'debug\\'')\n args = parser.parse_args()\n loglevelmap = {'warning':logging.WARNING,'debug':logging.DEBUG,'info':logging.INFO}\n loglevel = logging.WARNING if args.log == None else loglevelmap[args.log]\n\n ### Logging\n logging.basicConfig(format='%(levelname)s: %(asctime)s %(message)s',level=loglevel)\n\n start_timestamp = datetime.now()\n logging.info('Conversion started: {}'.format(start_timestamp.strftime('%H:%M:%S%f')))\n\n ###\n # configuration\n ###\n logging.info('Open configuraion file {}'.format('config.yaml'))\n with open('config.yaml') as yamls :\n params = yaml.safe_load(yamls)\n\n # directories\n input_folder = params['TMX_INPUT_FOLDER']\n if params['TMX_OUTPUT_FILES'] :\n logging.info('CSV Files stored to: {}'.format(params['TMX_OUTPUT_FOLDER']))\n output_folder = params['TMX_OUTPUT_FOLDER']\n\n # language mapping file\n langmapcodes = read_code_mapping(params['LANGUAGE_CODE_MAPPING'])\n\n # domain mapping file\n domainmapcodes = read_code_mapping(params['DOMAIN_CODE_MAPPING'])\n\n # db config\n if params['OUTPUT_HDB'] :\n logging.info('Setting DB connection parameter.')\n db = {'host':params['HDB_HOST'],\n 'user':params['HDB_USER'],\n 'pwd':params['HDB_PWD'],\n 'port':params['HDB_PORT']}\n batchsize = int(params['BATCHSIZE'])\n text_max_len = 100000 if params['MAX_LEN'] == 0 else params['MAX_LEN']\n\n # regex\n regex_pattern = list()\n regex_dropouts = list()\n if params['REGEX'] :\n logging.info('Reading regex pattern file {}'.format(params['INPUT_REGEX']))\n regex_pattern = read_regex(params['INPUT_REGEX'],params['OUTPUT_REGEX_LOG'])\n\n # files to be processed\n tmxfiles = listdir(input_folder)\n\n\n # test parameters\n max_number_files = 0\n if params['TEST'] :\n logging.info('Run in TEST-mode')\n exclusive_file = params['EXCLUSIVE_FILE']\n #exclusive_filename = None\n max_number_files = params['MAX_NUMBER_FILES']\n if exclusive_file :\n max_number_files = 0\n max_number_files = len(tmxfiles) if max_number_files == 0 or max_number_files > len(tmxfiles) else max_number_files\n\n all_records = 0\n for i, filename in enumerate(tmxfiles):\n\n if params['TEST'] :\n # for development only\n if exclusive_file and not filename == exclusive_file:\n continue\n if i > max_number_files :\n break\n\n ###\n # tmx parsing\n ###\n # check suffix\n if not filename.endswith('.tmx') :\n continue\n\n logging.info('{}/{}: {}'.format(i+1,max_number_files, filename))\n\n\n\n # variables for each filename context\n tu_elements = []\n drop = False\n src_lang = ''\n lang = ''\n rec = dict()\n tu_count = 0\n tu_count_drop = 0\n seg_branch = False\n domain_file = re.search(\"(.+)_\\w{4}_\\w{4}\\.tmx$\",filename).group(1)\n try :\n domain = domainmapcodes[domain_file]\n except KeyError:\n logging.warning('Domain not in mapping code list: {} ({}'.format(domain_file,filename))\n domain = 'XX'\n\n context = iter(ET.iterparse(path.join(input_folder, filename), events=(\"start\", \"end\")))\n event, elem = next(context)\n while not elem == None:\n if event == 'start':\n if elem.tag == 'tuv' :\n lang = langmapcodes[list(elem.attrib.values())[0]]\n elif elem.tag == 'tu':\n drop = False\n rec = dict() # new dict\n elif elem.tag == 'header':\n src_lang = langmapcodes[elem.attrib['srclang']]\n elif elem.tag == 'seg':\n seg_branch = True\n text = elem.text if elem.text else ''\n\n elif event == 'end' :\n if elem.tag == 'tu' :\n tu_count += 1\n if not drop : # If sth went wrong do not save elem\n rec['source'] = 'TMX'\n uc = elem.attrib.get('usagecount')\n rec['usage_count'] = None if uc == None else int(uc)\n created = elem.attrib.get('creationdate')\n rec['created'] = None if not created else datetime.strptime(created, '%Y%m%dT%H%M%SZ')\n changed = elem.attrib.get('changedate')\n rec['changed'] = None if not changed else datetime.strptime(changed, '%Y%m%dT%H%M%SZ')\n lastusage = elem.attrib.get('lastusagedate')\n rec['last_usage'] = None if not lastusage else datetime.strptime(lastusage, '%Y%m%dT%H%M%SZ')\n rec['origin'] = filename.split('.')[0]\n rec['domain'] = domain\n tu_elements.append(rec)\n drop = False\n else :\n drop = False\n tu_count_drop += 1\n elif elem.tag == 'seg':\n if elem.text:\n seg_branch = False\n if params['REGEX']:\n for r in regex_pattern:\n if re.match(r, text):\n drop = True\n dropout = (filename, r, text)\n regex_dropouts.append(dropout)\n if lang == src_lang:\n rec['source_lang'] = lang\n rec['source_text'] = text[:text_max_len]\n else:\n rec['target_text'] = text[:text_max_len]\n rec['target_lang'] = lang\n else :\n drop = True\n elif seg_branch :\n if elem.text :\n text += elem.text\n if elem.tail :\n text += elem.tail\n try:\n event, elem = next(context)\n except ET.ParseError as e:\n logging.warning('XML ParseError in file {} #records: {}\\n{}'.format(filename,len(tu_elements), e))\n drop = True\n except StopIteration :\n break\n\n logging.info('Number of Records: processed: {} - saved: {} - dropped: {}'.format(len(tu_elements),tu_count,tu_count_drop))\n all_records += len(tu_elements)\n if params['TMX_OUTPUT_FILES'] :\n csvfilename = filename.replace('.tmx', '.csv')\n outfile = path.join(output_folder,csvfilename)\n save_file(tu_elements,outfile)\n logging.info('TMX data save as csv-file: {}'.format(csvfilename))\n\n if params['OUTPUT_HDB'] :\n save_db(source = 'TMX',records=tu_elements,db=db,batchsize=batchsize)\n logging.info('TMX data saved in DB: {}'.format(filename))\n\n if params['REGEX'] :\n with open(params['OUTPUT_REGEX_LOG'],'a') as file :\n csvwriter = csv.writer(file)\n for line in regex_dropouts :\n csvwriter.writerow(line)\n\n\n # time calculation\n end_timestamp = datetime.now()\n duration = end_timestamp - start_timestamp\n\n logging.info('Number of all records: {}'.format(all_records))\n logging.info('Conversion ended: {} (Time: {})'.format(end_timestamp,str(duration)))\n\n\nif __name__ == '__main__':\n main()\n\n\n"
},
{
"alpha_fraction": 0.6194078326225281,
"alphanum_fraction": 0.6226496696472168,
"avg_line_length": 35.41732406616211,
"blob_id": "1ff9076fe58254802cadeb6ae4ab861ad4635095",
"content_id": "330f81c5862820ec320a025a0cbfcc7243dfc8c6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4627,
"license_type": "permissive",
"max_line_length": 132,
"num_lines": 127,
"path": "/Lxconverter/ABAPconvert.py",
"repo_name": "thhapke/tmxconverter",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET\nfrom os import path, listdir\nfrom _datetime import datetime\nimport csv\nimport re\nimport logging\nfrom datetime import datetime, timedelta\nfrom argparse import ArgumentParser\nimport pandas as pd\n\nimport yaml\n\nfrom Lxconverter.save2files import save_file\nfrom Lxconverter.save2hdb import save_db\nfrom Lxconverter.readfiles import read_regex, read_code_mapping\n\n\n\ndef main() : # encapsulated into main otherwise entrypoint is not working\n ### Command line\n parser = ArgumentParser(description='Converts tmx-files')\n parser.add_argument('--log','-l',help='Setting logging level \\'warning\\' (default), \\'info\\', \\'debug\\'')\n parser.add_argument('--exportdate', '-e', help='Provide the export date of the ABAP files with format: \\'YYYY-MM-DD\\'')\n args = parser.parse_args()\n loglevelmap = {'warning':logging.WARNING,'debug':logging.DEBUG,'info':logging.INFO}\n loglevel = logging.WARNING if args.log == None else loglevelmap[args.log]\n\n if not args.exportdate :\n exportdate = datetime.now()\n logging.warning('No Export date given. For default taking todays date: {}'.format(datetime.strftime(exportdate,'%Y-%m-%d')))\n else :\n exportdate = datetime.strptime(args.exportdate,'%Y-%m-%d')\n\n\n ### Logging\n logging.basicConfig(format='%(levelname)s: %(asctime)s %(message)s',level=loglevel)\n\n start_timestamp = datetime.now()\n logging.info('Conversion started: {}'.format(start_timestamp.strftime('%H:%M:%S%f')))\n\n ###\n # configuration\n ###\n logging.info('Open configuraion file {}'.format('config.yaml'))\n with open('config.yaml') as yamls :\n params = yaml.safe_load(yamls)\n\n\n # language mapping file\n langmapcodes = read_code_mapping(params['LANGUAGE_CODE_MAPPING'])\n\n # db config\n if params['OUTPUT_HDB'] :\n logging.info('Setting DB connection parameter.')\n db = {'host':params['HDB_HOST'],\n 'user':params['HDB_USER'],\n 'pwd':params['HDB_PWD'],\n 'port':params['HDB_PORT']}\n batchsize = int(params['BATCHSIZE'])\n text_max_len = 100000 if params['MAX_LEN'] == 0 else params['MAX_LEN']\n\n # regex\n regex_pattern = list()\n regex_dropouts = list()\n if params['REGEX'] :\n logging.info('Reading regex pattern file {}'.format(params['INPUT_REGEX']))\n regex_pattern = read_regex(params['INPUT_REGEX'],params['OUTPUT_REGEX_LOG'])\n\n # files to be processed\n files = listdir(params['ABAP_INPUT_FOLDER'])\n\n # ABAP CSV header\n headers = ['transl_system','abap_package','central_system','objtype','objname','orig_lang','domain','max_length',\n 'ach_comp','sw_comp','sw_comp_version','source_text','source_lang','target_text','target_lang','pp_type',\n 'pp_qstatus','last_usage','changed']\n\n # test parameters\n max_number_files = 0\n if params['TEST'] :\n logging.info('Run in TEST-mode')\n exclusive_file = params['EXCLUSIVE_FILE']\n #exclusive_filename = None\n max_number_files = params['MAX_NUMBER_FILES']\n if exclusive_file :\n max_number_files = 0\n max_number_files = len(files) if max_number_files == 0 or max_number_files > len(files) else max_number_files\n\n all_records = 0\n for i, filename in enumerate(files):\n\n b = re.match('.+\\.zip$', filename)\n if not (re.match('.+\\.zip$',filename) or re.match('.+\\.csv$',filename) ):\n continue\n\n if params['TEST'] :\n # for development only\n if exclusive_file and not filename == exclusive_file:\n continue\n if i > max_number_files :\n break\n\n df = pd.read_csv(path.join(params['ABAP_INPUT_FOLDER'],filename),names = headers,escapechar='\\\\', encoding='utf-8')\n df['origin'] = filename.split('.')[0]\n df['source'] = 'ABAP'\n df['exported'] = exportdate\n\n if params['OUTPUT_HDB'] :\n save_db(source = 'ABAP',records=df,db=db,batchsize=batchsize)\n logging.info('ABAP data saved in DB: {}'.format(filename))\n\n if params['REGEX'] :\n with open(params['OUTPUT_REGEX_LOG'],'a') as file :\n csvwriter = csv.writer(file)\n for line in regex_dropouts :\n csvwriter.writerow(line)\n\n\n # time calculation\n end_timestamp = datetime.now()\n duration = end_timestamp - start_timestamp\n\n logging.info('Number of all records: {}'.format(all_records))\n logging.info('Conversion ended: {} (Time: {})'.format(end_timestamp,str(duration)))\n\n\nif __name__ == '__main__':\n main()\n\n\n"
}
] | 8 |
Billtholomew/Fractals | https://github.com/Billtholomew/Fractals | b7666eab5669ae2c13ce23c130681568a71aeace | 8b92fb252ee21a812eefac46ffa2d8dcd06ae989 | d13425c14c7297552387497393d56e5768b876ed | refs/heads/master | 2021-01-13T00:59:13.458067 | 2016-11-05T03:07:56 | 2016-11-05T03:07:56 | 48,406,626 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5656682252883911,
"alphanum_fraction": 0.6267281174659729,
"avg_line_length": 22.45945930480957,
"blob_id": "804baa279fe9ef5f7c57832caa7ca2c132bfb16d",
"content_id": "25911a0006aa77edce33fa7987e0996af57ec169",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 868,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 37,
"path": "/sierpinski.py",
"repo_name": "Billtholomew/Fractals",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\n\n\ndef spawn(triangle):\n def mid_point(p1, p2):\n return (p1[0] + p2[0]) / 2, (p1[1] + p2[1]) / 2\n a, b, c = triangle\n left = mid_point(a, b)\n right = mid_point(a, c)\n bottom = mid_point(b, c)\n yield [a, left, right]\n yield [left, b, bottom]\n yield [right, bottom, c]\n\n\ndef fractal(triangles, func):\n shapes2 = []\n map(lambda triangle: map(lambda t: shapes2.append(t), func(triangle)), triangles)\n return shapes2\n\n\ndef draw_triangles(triangles):\n im = np.zeros((1000, 1000))\n map(lambda triangle: cv2.fillConvexPoly(im, np.array(triangle), 255), triangles)\n cv2.imshow('Sierpinski', im)\n cv2.waitKey(100)\n\n\ntriangles = [[(500, 10), (10, 990), (990, 990)]]\n\nfor a in xrange(10):\n draw_triangles(triangles)\n triangles = fractal(triangles,spawn)\n\ncv2.waitKey()\ncv2.destroyAllWindows()\n"
},
{
"alpha_fraction": 0.4794520437717438,
"alphanum_fraction": 0.5593607425689697,
"avg_line_length": 24.02857208251953,
"blob_id": "6e7b28f1b88cf3b1f046c338364315b41cfe984a",
"content_id": "02b4e81b07f89797fb15754a7c0429535cd3e03c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 876,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 35,
"path": "/dragon.py",
"repo_name": "Billtholomew/Fractals",
"src_encoding": "UTF-8",
"text": "import cv2\nimport numpy as np\n\n\ndef fold_line(i, line):\n x1, y1, x2, y2 = line\n dx, dy = (x2 - x1, y2 - y1)\n angle = np.arctan2(dy, dx) + (-1) ** i * np.pi / 4\n leg = np.cos(np.pi / 4) * np.sqrt(dx ** 2 + dy ** 2)\n x3 = x1 + np.cos(angle) * leg\n y3 = y1 + np.sin(angle) * leg\n line1 = [x1, y1, x3, y3]\n line2 = [x3, y3, x2, y2]\n return map(int, line1), map(int, line2)\n\n\ndef fold_lines(lines):\n for i, line in enumerate(lines):\n line1, line2 = fold_line(i, line)\n yield line1\n yield line2\n\n\ndef draw_lines(lines):\n im = np.zeros((1000, 1000))\n map(lambda line: cv2.line(im, (line[0], line[1]), (line[2], line[3]), 255), lines)\n cv2.imshow('Dragon', im)\n cv2.waitKey(100)\n\nlines = [[250, 500, 750, 500]]\nfor a in xrange(16):\n draw_lines(lines)\n lines = [line for line in fold_lines(lines)]\n\nprint 'Complete'\n"
},
{
"alpha_fraction": 0.7931034564971924,
"alphanum_fraction": 0.8017241358757019,
"avg_line_length": 18.33333396911621,
"blob_id": "ffa7beef324c618141a87ee200dae6bb8c490d57",
"content_id": "9188a018696cc2c1a23ad84779756906a152ea75",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 116,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 6,
"path": "/README.md",
"repo_name": "Billtholomew/Fractals",
"src_encoding": "UTF-8",
"text": "# Fractals\nsmall programs for creating fractal patterns\n\nRequires Numpy and CV2.\n\nRuns with no arguments or inputs.\n"
}
] | 3 |
ugurduzel/Machine-Learning-Algorithms | https://github.com/ugurduzel/Machine-Learning-Algorithms | 0b82f2542e5741421f03336986c015188e8b3a39 | 7f3669ac17d00c2bcf787440d34ffa30c3e7ed70 | 52ed14fff5e2af1660fd4746e5ed7075b7f35ddc | refs/heads/master | 2020-04-03T02:04:18.282032 | 2018-12-05T12:06:13 | 2018-12-05T12:06:13 | 154,881,647 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5990371108055115,
"alphanum_fraction": 0.6334250569343567,
"avg_line_length": 26.923076629638672,
"blob_id": "2e8e5f9d06444a79a7b3bc09a9bd0d0f12aae0ae",
"content_id": "c4f059526fcb23a113a8828da54f36ccf8020ba4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2908,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 104,
"path": "/algorithms/perceptron.py",
"repo_name": "ugurduzel/Machine-Learning-Algorithms",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n###\n#\tBinary Classification\n#\tThe most primitive version\t\n#\tStep Function is used\n#\tLabels are : 1 and -1\n# \tUpdate Rule : W(t+1) <- W(t) + (True Label) * (Predicted Label)\n###\nclass Perceptron:\n\t\n\tdef __init__(self, max_iter = 300, verbose = False):\n\t\tself.max_iter = max_iter\n\t\tself.verbose = verbose\n\n\t\tself.loss = 0\n\t\tself.weights = None\n\n\t\tself.vectorized_step_func = np.vectorize(lambda x: -1 if x < 0 else 1)\n\t\tself.vectorized_equal_func = np.vectorize(lambda x, y: 1 if x != y else 0)\n\n\t###\n\t#\tdata = [ [--X1--],\tlabels = [Y1, Y2, ... , Ym]\n\t#\t\t\t [--X2--],\n\t#\t\t\t ...\t ,\n\t#\t\t\t [--Xm--] ]\n\t###\n\tdef fit(self, data, labels):\n\t\tself.X = np.insert(arr = data, obj = 0, values = 1, axis = 1)\n\t\tself.Y = labels\n\t\tself.weights = np.zeros([1, data.shape[1]+1]) \n\t\tloss_history = np.zeros(self.max_iter)\n\t\tprint(\"\\n\")\n\t\tfor iter in range(self.max_iter):\n\t\t\ttotal = self.X.dot(self.weights.T)\n\t\t\thypothesis = self.vectorized_step_func(total.T)\n\t\t\tlabel_comparison = self.vectorized_equal_func(hypothesis, self.Y)\n\t\t\tupdate = (self.Y * label_comparison).dot(self.X)\n\t\t\tself.weights += update \n\t\t\tself.loss = label_comparison.sum()\n\t\t\tloss_history[iter] = self.loss\n\t\t\tprint(\"Iter {} Loss : {}\".format(iter, self.loss))\n\t\t\tif self.loss == 0:\n\t\t\t\tbreak\n\t\t\tif self.verbose == True:\n\t\t\t\tprint(\"Weights : \\n{}\".format(self.weights))\n\t\t\t\tprint(\"Predictions : {}\".format(hypothesis))\n\t\t\t\tprint(\"Labels : {}\".format(label_comparison))\n\t\t\t\tprint(\"Update : \\n{}\".format(update))\n\n\n\tdef predict(self, data):\n\t\ttotal = np.insert(arr = data, obj = 0, values = 1).dot(self.weights.T)\n\t\treturn -1 if total < 0 else 1\n\n\t###\t\n\t# \tReturns the mean accuracy given the training set in data and labels\n\t###\n\tdef score(self, data, labels):\n\t\ttotal = np.insert(arr = data, obj = 0, values = 1, axis = 1).dot(self.weights.T)\n\t\thypothesis = self.vectorized_step_func(total.T)\n\t\tlabel_comparison = self.vectorized_equal_func(hypothesis, labels)\n\t\treturn 1 - label_comparison.sum() / label_comparison.shape[1]\n\n\nimport random\nimport matplotlib.pyplot as plt\nimport sklearn.linear_model \n\nif __name__ == \"__main__\":\n\tp = Perceptron(verbose = False)\n\tm = 700\n\tX = []\n\tY = []\n\tfor i in range(0,m):\n\t\tX.append([random.randint(-500,100),random.randint(-500,100)])\n\t\tY.append(-1)\n\t\tX.append([random.randint(-100,500),random.randint(-100,500)])\n\t\tY.append(1)\n\n\tX = np.array(X)\n\tY = np.array(Y)\n\n\t#plt.scatter(X[:,0], X[:,1])\n\t#plt.show()\n\tp.fit(X, Y)\n\n\tmtest = 300\n\ttestX = []\n\ttestY = []\n\tfor i in range(0,mtest):\n\t\ttestX.append([random.randint(-500,100),random.randint(-500,100)])\n\t\ttestY.append(-1)\n\t\ttestX.append([random.randint(-100,500),random.randint(-100,500)])\n\t\ttestY.append(1)\n\n\ttestX = np.array(testX)\n\ttestY = np.array(testY)\n\n\tprint(\"Score : \", p.score(testX, testY))\n\n\tp2 = sklearn.linear_model.Perceptron(max_iter = p.max_iter, tol=1e-3)\n\tp2.fit(X,Y.T)\n\tprint(\"Score Scikit : \", p2.score(testX, testY.T))\n\n\n\n\n"
},
{
"alpha_fraction": 0.8251366019248962,
"alphanum_fraction": 0.8251366019248962,
"avg_line_length": 60,
"blob_id": "2f8f0d30c3e3bd4be32067c31cdb284c81609c6c",
"content_id": "daec7341d1d5696994bcd874b3197ac3ce71f398",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 3,
"path": "/README.md",
"repo_name": "ugurduzel/Machine-Learning-Algorithms",
"src_encoding": "UTF-8",
"text": "# Machine-Learning-Algorithms\n\nThese are some of my implementations of the machine learning algorithm from scratch. They were tested with scikit-learn methods, before uploading here.\n"
},
{
"alpha_fraction": 0.6054826974868774,
"alphanum_fraction": 0.633293628692627,
"avg_line_length": 26.34782600402832,
"blob_id": "a8e7c5a311fb8fe1e8ca0115855ec1c7e15843f6",
"content_id": "b6438c4e683493753802d9d904387e1d9a1adfb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2517,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 92,
"path": "/algorithms/ridge.py",
"repo_name": "ugurduzel/Machine-Learning-Algorithms",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport matplotlib.pyplot as plt\n\n###\n#\tMultivariate Ridge regression or Tikhonov Regularization\n#\tLoss function is the least squares function\n#\tand regularization is given by the L2-norm\n###\nclass Ridge:\n\n\tdef __init__(self, alpha = 1.0, learning_rate = 0.001, max_epochs = 300, verbose = False):\n\t\tself.verbose = verbose\n\t\tself.max_epochs = max_epochs\n\t\tself.lr = learning_rate\n\t\tself.alpha = alpha\n\n\t\tself.loss = 0\n\t\tself.weights = None\n\n\tdef gradientDescent(self):\n\t cost_history = np.zeros(self.max_epochs)\n\t for iter in range(self.max_epochs):\n\t hypothesis = self.X.dot(self.weights.T)\n\t update = ( (self.lr/self.m) * self.X.T.dot((hypothesis - self.Y))).reshape(1,self.X.shape[1])\n\t self.weights = self.weights * (1 - self.lr*self.alpha/self.m) - ((self.lr/self.m) * self.X.T.dot((hypothesis - self.Y))).reshape(1,self.X.shape[1])\n\t self.loss = np.sum(np.square(hypothesis - self.Y)) / (2*self.m) + (self.alpha / (2*self.m)) * np.sum(np.square(self.weights)) \n\t if self.verbose == True:\n\t \tprint(\"Iter {} Loss : {}\".format(iter, self.loss))\n\t cost_history[iter] = self.loss \n\t return cost_history\n\n\t###\n\t#\tdata = [ [--X1--],\tlabels = [Y1, Y2, ... , Ym]\n\t#\t\t\t [--X2--],\n\t#\t\t\t ...\t ,\n\t#\t\t\t [--Xm--] ]\n\t###\n\tdef fit(self, data, labels):\n\t\tself.X = np.array(data)\n\t\tself.m = self.X.shape[0]\n\t\tself.Y = labels.reshape(self.m, 1)\n\t\tself.weights = np.zeros([1,data.shape[1]]) \n\t\tcosts = self.gradientDescent()\n\t\tif self.verbose == True:\n\t\t\tplt.plot(np.arange(self.max_epochs), costs)\n\t\t\tplt.show()\n\t\n\t\n\tdef predict(self, data):\n\t\treturn np.array(data).dot(self.weights.T)\n\n\n\n\n\nimport random\nimport sklearn.preprocessing\nimport sklearn.linear_model \nimport sklearn.metrics\n\nif __name__ == \"__main__\":\n\tmodel = Ridge(alpha = 0.5, learning_rate = 0.0001, max_epochs = 300, verbose = True)\n\tm = 10000\n\tX = []\n\tY = []\n\tfor i in range(0,m):\n\t\tX.append([random.randint(10,20)])\n\t\tY.append(random.randint(10,20))\n\t\n\tX = np.array(X)\n\tY = np.array(Y)\n\n\t#plt.scatter(X,Y)\n\t#plt.show()\n\tmodel.fit(X, Y)\n\n\tmtest = 3000\n\ttestX = []\n\ttestY = []\n\tfor i in range(0,mtest):\n\t\ttestX.append([random.randint(30,60)])\n\t\ttestY.append(random.randint(30,60))\n\n\n\ttestX = np.array(testX)\n\ttestY = np.array(testY)\n\n\tprint(\"Score : \", sklearn.metrics.r2_score(testY.T, model.predict(testX)))\n\n\tmodel2 = sklearn.linear_model.Ridge(alpha = 0.5, fit_intercept=False)\n\tmodel2.fit(X,Y.T)\n\tprint(\"Score Scikit : \", sklearn.metrics.r2_score(testY.T, model2.predict(testX)))\n\n"
}
] | 3 |
geekchick/todo_project | https://github.com/geekchick/todo_project | 06c3f761046dbe56fa52f647d82996e2f47dfad8 | 00744ef231e7818093a5f0c12b32578e8364736f | c84418b6fd3cca1e5932188661800a5fce8e3e9f | refs/heads/master | 2022-12-14T08:43:01.154070 | 2020-09-19T19:07:24 | 2020-09-19T19:07:24 | 296,931,567 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 24.600000381469727,
"blob_id": "7220aa2dde578f552fb5c6e0809a5ba553c2f91d",
"content_id": "abe11df9ac06cd6e645a7a0148b1fa80194ab97d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 255,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 10,
"path": "/task/todo/forms.py",
"repo_name": "geekchick/todo_project",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom django.forms import ModelForm\n\nfrom .models import ToDo\n\nclass ToDoForm(forms.ModelForm):\n\n class Meta:\n model = ToDo # the model we create the form\n fields = ['todo_name'] # which fields to allow in the form"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 31,
"blob_id": "8792027dc9d680c6df5d3cf255e0951f6da522cc",
"content_id": "2a9d17f5bffb3aaf7314518fa75f16007f9ea0f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 96,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 3,
"path": "/README.md",
"repo_name": "geekchick/todo_project",
"src_encoding": "UTF-8",
"text": "# Todo Project in Python & Django\n\nThis project allows you to add, edit and delete a todo item.\n"
},
{
"alpha_fraction": 0.6431717872619629,
"alphanum_fraction": 0.6431717872619629,
"avg_line_length": 27.5,
"blob_id": "d9511e9341f2592cb208ce3827e8a69716c77266",
"content_id": "4e4d92f05b4cd7c74b0449da670e9e0eac4fd9eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 8,
"path": "/task/todo/urls.py",
"repo_name": "geekchick/todo_project",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\nurlpatterns = [\n path('', views.index, name=\"home\"),\n path('item/<int:pk>', views.edit, name=\"edit_todo\"),\n path('delete/<int:pk>', views.delete, name=\"delete_todo\"),\n]"
},
{
"alpha_fraction": 0.6246764659881592,
"alphanum_fraction": 0.6246764659881592,
"avg_line_length": 25.930233001708984,
"blob_id": "67f5134910ee8973d709c04b688627f13962a958",
"content_id": "21324bf71d31ddf13ca2cec70e666ee3746f421d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1159,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 43,
"path": "/task/todo/views.py",
"repo_name": "geekchick/todo_project",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom django.http import HttpResponse\nfrom .forms import ToDoForm\nfrom .models import ToDo\n\n# Create your views here.\ndef index(request):\n todos = ToDo.objects.all()\n form = ToDoForm()\n \n\n if request.method == \"POST\":\n form = ToDoForm(request.POST) \n if form.is_valid():\n form.save()\n return redirect(\"/\")\n \n context = {'todos':todos, 'form':form}\n return render(request, 'todo/index.html', context)\n\ndef edit(request, pk):\n get_todo_item = ToDo.objects.get(id=pk)\n edit_form = ToDoForm(instance=get_todo_item)\n\n if request.method == \"POST\":\n edit_form = ToDoForm(request.POST, instance=get_todo_item)\n if edit_form.is_valid():\n edit_form.save()\n return redirect(\"/\")\n\n context = {'form':edit_form}\n return render(request, \"todo/item.html\", context)\n\ndef delete(request, pk):\n get_todo_item = ToDo.objects.get(id=pk)\n\n if request.method == \"POST\":\n get_todo_item.delete()\n return redirect(\"/\")\n\n context = {'item': get_todo_item}\n\n return render(request, \"todo/delete.html\", context)\n\n"
}
] | 4 |
ethan-massey/Surfing-Data-HTML-Parser | https://github.com/ethan-massey/Surfing-Data-HTML-Parser | b4602e3188d09981102f77f72d04bcd6fb068ec1 | bde2985b3326e8452580b8fa37474decbe46bfb2 | f67dfac1de18661d6c8255013ec6de1ac005ac3b | refs/heads/master | 2020-09-22T17:20:00.689732 | 2019-12-02T17:35:50 | 2019-12-02T17:35:50 | 225,284,236 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5726928114891052,
"alphanum_fraction": 0.5837547183036804,
"avg_line_length": 24.72357749938965,
"blob_id": "2fc74644f6b1f0798dc1e6adb415947eec01ddf7",
"content_id": "6a5514ed9dee9aab3546897a2a5f37b4410e45de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6328,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 246,
"path": "/url.py",
"repo_name": "ethan-massey/Surfing-Data-HTML-Parser",
"src_encoding": "UTF-8",
"text": "# Written by Jim Cohoon, University of Virginia, 2017\n\n''' Module url: provide function(s) in support of getting web-based data\n into the needed information structures.\n\n version 2: added csv access\n version 3: added dictionary access\n version 4: added image access\n version 5: added coloring book access\n'''\n\n# need help to get web data\nimport urllib.request\n\ndef get_contents( link ) :\n ''' returns the contents of the web resource indicated by parameter link\n '''\n\n stream = urllib.request.urlopen( link ) # connect to resource stream\n\n bytes = stream.read() # read stream to gets its contents\n\n content = bytes.decode( 'UTF-8' ) # decode contents to get text\n\n return content\n\ndef get_lines( link ) :\n ''' returns the lines of text stored at the web resource indicated by\n parameter link\n '''\n\n # get the contents of the page\n data = get_contents( link )\n\n # strip the data of surrounding whitespace\n data = data.strip()\n\n # split data into lines\n lines = data.split( '\\n' )\n\n # return what they asked for\n return lines\n\ndef get_strings( link ) :\n ''' returns the strings stored at the web resource indicated by\n parameter link\n '''\n\n # get the contents of the page\n data = get_contents( link )\n\n # split data into strings\n strings = data.split( )\n\n # return what they asked for\n return strings\n\ndef get_dataset( link, separator=',' ) :\n ''' returns the contents of the web resource indicated by parameter\n link as a list of lists of strings\n '''\n\n contents = get_contents( link )\n\n # get contents into dataset form\n dataset = contents.strip()\n dataset = dataset.split( '\\n' )\n\n nbr_rows = len( dataset )\n\n for r in range( 0, nbr_rows ) :\n row = dataset[ r ]\n row = row.strip()\n row = row.split( separator )\n nbr_columns = len( row )\n for c in range( 0, nbr_columns) :\n cell = row[ c ]\n cell = cell.strip()\n row[ c ] = cell\n dataset[ r ] = row\n\n return dataset\n\n### Version 2 addition\n\ndef get_and_parse_dataset( link ) :\n ''' the contents of the web resource indicated by parameter link as a\n list of lists. The elements of the lists will be converted to int,\n float, or bool as appropriate\n '''\n\n dataset = get_dataset( link )\n\n # get element contents into proper form\n nbr_rows = len( dataset )\n\n for r in range( 0, nbr_rows ) :\n row = dataset[ r ]\n nbr_columns = len( row )\n for c in range( 0, nbr_columns) :\n cell = row[ c ]\n if ( cell.isnumeric() ) :\n cell = int( cell )\n elif ( cell.capitalize() == 'True' ) :\n cell = True\n elif ( cell.capitalize() == 'False' ) :\n cell = False\n else: \n try :\n cell = float( cell )\n except :\n pass\n row[ c ] = cell\n dataset[ r ] = row\n return dataset\n\n### Version 3 added get_dictionary()\n\ndef get_dictionary( link ) :\n ''' return the contents of the page indicated by parameter link as\n a dictionary\n '''\n\n dataset = get_dataset( link )\n\n # initialize the dictionary\n dictionary = {}\n\n # accumulate the dictionary entries from the sheet\n for entry in dataset :\n key, value = entry\n dictionary[ key ] = value\n\n # return what they asked for\n return dictionary\n\n\n\n### Version 4 added get images\n\nfrom PIL import Image\n\n# needed for web support\nimport urllib.request, io\n\n# process image acquistion and display\n\n''' Function get_web_image() return image at web resource indicated by link\n'''\ndef get_web_image( link ) :\n\n # get access to module Image\n from PIL import Image\n ''' Returns a pil image of the image named by link '''\n\n # get a connection to the web resource name by link\n stream = urllib.request.urlopen( link )\n\n # get the conents of the web resource\n data = stream.read()\n\n # convert the data to bytes\n bytes = io.BytesIO( data )\n\n # get the image represented by the bytes\n image = Image.open( bytes )\n\n # convert the image to RGB format\n image = image.convert('RGB')\n\n # hand back the image\n return image\n\n''' Function get_selfie() returns a selfie of the indicated id\n'''\ndef get_selfie( email_id ) :\n\n REPOSITORY = 'http://www.cs.virginia.edu/~cs1112/people/'\n\n link = REPOSITORY + email_id + '/selfie.jpg'\n\n return get_web_image( link )\n\n\ndef get_image( source ) :\n ''' returns a image from online or local source or an existing Image\n '''\n\n try :\n if ( str( type( source ) ) == \"<class 'PIL.Image.Image'>\" ) :\n # check to if source is an existing Image\n image = source\n elif ( 'http://' == source[ 0 : 7 ].lower() ) :\n # look at the initial characters of source to see if its on the web\n # initial characters indicate the image is out on the web\n image = get_web_image( source )\n else :\n # initial characters indicate the image is a local file\n image = Image.open( source )\n except :\n image = None\n\n return image.copy()\n\n### Version 5\n\ndef get_coloring_page( source, bg=(255,255,255), fg=(0,0,0) ) :\n ''' returns a cleaned up coloring book page from the indicated image\n source\n '''\n\n im = get_image( source )\n page = scrub( im, bg, fg )\n\n return page\n\n\ndef get_selfie_page( email_id, bg=(255,255,255), fg=(0,0,0) ) :\n ''' returns a cleaned up coloring book page from the indicated image\n source\n '''\n\n REPOSITORY = 'http://www.cs.virginia.edu/~cs1112/people/'\n\n link = REPOSITORY + email_id + '/coloring_page.jpg'\n\n page = get_coloring_page( link, bg, fg )\n\n return page\n\ndef scrub( im, bg=(255,255,255), fg=(0,0,0) ) :\n ''' returns a cleaned up coloring book page from the source image\n '''\n\n w, h = im.size\n\n for y in range( 0, h ) :\n for x in range( 0, w ) :\n spot = ( x, y )\n r, g, b = im.getpixel( spot )\n if ( ( r + g + b ) < 2.5 * 255 ) :\n im.putpixel( spot, fg )\n else :\n im.putpixel( spot, bg )\n\n return im\n"
},
{
"alpha_fraction": 0.6739966869354248,
"alphanum_fraction": 0.7042331099510193,
"avg_line_length": 28.338708877563477,
"blob_id": "25b3d7fa726da44fde3545e54c8cc7d1a5cf7d23",
"content_id": "ecb8edfaa1d13ea72e6d72405f7742fbdc3424da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1819,
"license_type": "no_license",
"max_line_length": 197,
"num_lines": 62,
"path": "/surfline.py",
"repo_name": "ethan-massey/Surfing-Data-HTML-Parser",
"src_encoding": "UTF-8",
"text": "import url\nimport tkinter as tk\nfrom PIL import Image, ImageTk\nimport general\n\n\n'''\nThis is using a known user-agent to extract the data. \nhttps://stackoverflow.com/questions/16627227/http-error-403-in-python-3-web-scraping\n'''\ntry:\n from urllib.request import Request, urlopen\n req = Request('https://www.surfline.com/surf-report/duck-pier/5842041f4e65fad6a7708a45', headers={'User-Agent': 'Mozilla/5.0'})\n webpage = urlopen(req).read()\n page = webpage.decode( 'UTF-8' )\n\nexcept:\n print( 'Problem parsing web data.' )\n quit()\n\n\n# Handles whether opening delimiter uses AM or PM\ntry:\n\n OPENING_DELIM = 'Northern Outer Banks PM Report:</strong><br>'\n CLOSING_DELIM = '</p>' # check this. changes from time to time\n\n start_index = page.index(OPENING_DELIM) + len(OPENING_DELIM)\n\nexcept:\n\n OPENING_DELIM = 'Northern Outer Banks AM Report:</strong><br>'\n CLOSING_DELIM = '</p>' # check this. changes from time to time\n\n start_index = page.index( OPENING_DELIM ) + len( OPENING_DELIM )\n\nend_index = page.index( CLOSING_DELIM, start_index )\n\nconditions = page[ start_index : end_index ]\n\n# gets rid of ' ' left over in HTML code\nconditions = general.remove( conditions, ' ' )\n\n# formats text for the GUI\nconditions = general.guiformat( conditions )\n\nwindow = tk.Tk()\nwindow.title( 'SURF CONDITIONS' )\nwindow.geometry( '990x550')\n\n\nim = ImageTk.PhotoImage(url.get_web_image( 'https://s3-us-west-1.amazonaws.com/sl-coldfusion-static-prod/surfnews/images/2010/09_september/earl_south/full/JesseHines_AvalonPier_OBX_Earl-Lusk.jpg'))\npanel = tk.Label( window, image = im, height=0, width=0 )\npanel.grid()\n\n\nupdate_label = tk.Label( text= 'TODAY\\'S CONDITIONS: \\n\\n' + conditions, font=('Times New Roman',15), bg= '#D9C3D3' )\nupdate_label.grid( column=0, row=0 )\n\n\n\nwindow.mainloop()\n"
},
{
"alpha_fraction": 0.537800669670105,
"alphanum_fraction": 0.5446735620498657,
"avg_line_length": 25.363636016845703,
"blob_id": "27a5943dc2a29344b0eecf63114554a8807c6404",
"content_id": "079a67828fb550dfee6b2fd575db6689a21388fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 22,
"path": "/general.py",
"repo_name": "ethan-massey/Surfing-Data-HTML-Parser",
"src_encoding": "UTF-8",
"text": "\n'''Finds and removes an unwanted string from another string'''\ndef remove( original, trash ):\n if trash in original:\n splitted = original.split( trash )\n new_text = ''\n for i in splitted:\n new_text += i\n return new_text\n\n'''Formats text to have lines of 50 characters'''\ndef guiformat( text ):\n final_text = ''\n current_line = ''\n for i in text:\n\n final_text += i\n current_line += i\n\n if len(current_line) > 50 and i == ' ':\n final_text += '\\n'\n current_line = ''\n return final_text\n\n"
}
] | 3 |
DavidCPorter/CS502_final_project | https://github.com/DavidCPorter/CS502_final_project | bc022a248a2ac3389401eda7004c6caa4336f5e1 | c4c94841e2fc4616b8f23875ab9cc4086d650fd7 | dec3007c026859d119f530926786faea96907c19 | refs/heads/master | 2020-04-14T18:06:33.091007 | 2018-12-12T01:36:53 | 2018-12-12T01:36:53 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.579071581363678,
"alphanum_fraction": 0.625491738319397,
"avg_line_length": 30.024391174316406,
"blob_id": "a896de85eae475eed12e7db8c902d272dd0244f9",
"content_id": "39b5b1bfbd11c9dad14bfaed5536c5b342898e56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1271,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 41,
"path": "/src/rna_dfs.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Dec 1 10:11:52 2018\n\n@author: Erik\n\"\"\"\n\nfrom DFS import DFS\nimport pandas as pd\nfrom sklearn.preprocessing import LabelEncoder\nfrom keras.utils import to_categorical\nfrom sklearn.model_selection import train_test_split\n\nX = pd.read_csv('../data/rna/data.csv')\ny_str = pd.read_csv('../data/rna/labels.csv')\n\n#they come through with a string\nX = X.drop('Unnamed: 0', axis = 1)\ny_str = y_str.drop('Unnamed: 0', axis = 1)\n\n#forgot about this little guy, get dummies one hot encodes from strings!\ny = pd.get_dummies(y_str)\n\nX = X.fillna(0)\nX = (X - X.min()) / (X.max() - X.min())\nX = X.fillna(0)\n\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)\n\n\nlambdas = [0, 0.000001, 0.00005, 0.00001, 0.0001]\nfor lda in lambdas:\n model = DFS(in_dim = len(X_train.columns), \n num_classes = len(y_train.columns),\n alpha1 = 0.00001, \n lambda1 = lda,\n learning_rate = 0.5)\n \n model.fit(X_train, y_train, batch_size = 10, epochs = 50, validation_data = [X_test, y_test])\n model.write_features('../results/rna_featurs_' + str(lda) + \".csv\", X_train.columns)\n model.write_predictions('../results/rna_predictions' + str(lda) + \".csv\", X_test, y_test)"
},
{
"alpha_fraction": 0.686855673789978,
"alphanum_fraction": 0.7117697596549988,
"avg_line_length": 34.272727966308594,
"blob_id": "6aa1fa50f80b76d2adfab44e6d1ce6b8b747a6bf",
"content_id": "42705da1ca4df4007df71b6641343a8fc1462448",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2328,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 66,
"path": "/template_code/feedforward_nn.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Oct 24 18:32:35 2018\n\n@author: Erik\n\"\"\"\n#pandas dataframes make csv reading really easy.\nimport pandas as pd\n#types of layers and the function to convert to categorical\nfrom keras.models import Sequential\nfrom keras.layers import Dense, Activation, Input, LocallyConnected1D\nfrom keras.utils import to_categorical\nfrom keras.regularizers import l2, l1\nimport keras\nimport numpy as np\nnp.random.seed(8)\n#used to split data\nfrom sklearn.model_selection import train_test_split\n\n#get data\ndata = pd.read_csv('template_code/iris.csv')\nprint(data.columns)\n#get only the left two columns\nX_data = data.drop(['type'], axis = 1)\n#get only the label column, type\ny_data = data[['type']]\n\n#transfer from 1, 2, 3 to [0,1,0,0], [0, 0, 1, 0], and [0,0,0,1] respectively\ny_data = to_categorical(y_data)\n\n#split into test and train, 30% test, 70% train\nX_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size = 0.3, random_state = 8)\n\n#no need validation set and test set, can't train network on data it will predict on\n#this is seriously manditory. If you use the test set direclty for validation then you are training on the test set!\nX_validation, X_test, y_validation, y_test = train_test_split(X_test, y_test, test_size = 0.5, random_state = 8)\n\n#type of neural network is sequential\nmodel = Sequential()\n#l1 regularized\nmodel.add(Dense(4, input_shape = (3, ), activation = 'softmax', name = 'dense_one', kernel_regularizer = l1(0.2)))\n\n#generate the model\nmodel.compile(optimizer = keras.optimizers.SGD(lr = 0.1),\n loss = 'categorical_crossentropy',\n metrics = ['accuracy'],\n )\n\n#actually do training\nhistory = model.fit(x = X_train, y = y_train, epochs = 100, batch_size = 50,\n validation_data = [X_validation, y_validation])\n\n\n\n#now report accuracy with train and totally withheld test set\nprint(\"Train accuracy: \")\nprint(model.evaluate(X_train, y_train)[1]) #returns both loss and accuracy, so this is getting the accuracy\n\nprint(\"Test accuracy: \")\nprint(model.evaluate(X_test, y_test)[1]) #returns both loss and accuracy, so this is getting the accuracy\n\n#the weights of the model with regularization. So close! Just need that one-to-one layer\nprint(\"\\nWeights:\")\nprint(model.get_layer('dense_one').get_weights())\n\n#\n"
},
{
"alpha_fraction": 0.7250000238418579,
"alphanum_fraction": 0.7785714268684387,
"avg_line_length": 68.75,
"blob_id": "d5363382f09af9ad1a5ef9670eced57fd58d5683",
"content_id": "d2943779d2787ee5b72ef12cfbd18feec6074780",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 280,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 4,
"path": "/hmp_utils/curlbio.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "\nbashCommand = \"curl -k --user dcpchi:deepfeature --ftp-ssl ftp://downloads.hmpdacc.org/data/HMR16S/HMDEMO/SRP002422/SRR052230.sff.bz2 > ./results.txt\"\nimport subprocess\nprocess = subprocess.Popen(bashCommand.split(), stdout=subprocess.PIPE)\noutput, error = process.communicate()\n"
},
{
"alpha_fraction": 0.48543688654899597,
"alphanum_fraction": 0.6116504669189453,
"avg_line_length": 12,
"blob_id": "92c2039dbf12a7517a363a554804cfd1ff81ada9",
"content_id": "ae30eb483d3c2588bebef924ac4dfef48043ddb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 103,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/template_code/pandas_test.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Thu Oct 25 14:35:09 2018\n\n@author: Erik\n\"\"\"\n\nimport pandas as pd"
},
{
"alpha_fraction": 0.6687306761741638,
"alphanum_fraction": 0.7120742797851562,
"avg_line_length": 29.809524536132812,
"blob_id": "68e4a5a55c565ed40058ccfe654f019ed7e01398",
"content_id": "a0f57df5f24851e526539ce149b1431da605a4ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 646,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 21,
"path": "/src/example_for_writeup.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "from keras.models import Sequential\nfrom keras.layers.core import Dense, Dropout, Activation\nfrom OneToOne import OneToOne\nfrom keras.optimizers import SGD\nfrom keras.utils import to_categorical\nimport numpy as np \n\nX = np.array([[0,0],[0,10],[1,0],[1,10]])\ny = np.array([[0],[1],[1],[0]])\ny = to_categorical(y)\n\nmodel = Sequential()\n#model.add(OneToOne(2, input_dim = 2, use_bias = False))\nmodel.add(Dense(2, input_dim = 2, activation = 'sigmoid'))\nmodel.add(Dense(2, activation = 'softmax'))\n\nsgd = SGD(lr=0.05)\nmodel.compile(loss='categorical_crossentropy', optimizer=sgd)\n\nmodel.fit(X, y, batch_size=4, epochs = 10000)\nprint(model.predict(X))"
},
{
"alpha_fraction": 0.8130564093589783,
"alphanum_fraction": 0.8308605551719666,
"avg_line_length": 55.16666793823242,
"blob_id": "03c84dbba52de96c85efbe82ae79737f959675db",
"content_id": "9662e66e6c488d097b4c5530a4c3f6b7858df0a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 203,
"num_lines": 6,
"path": "/hmp_utils/ascp-commans.sh",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nexport ASCP=/Users/Dporter1/Applications/AsperaCLI/bin/ascp\nexport ASPERA_USER=dcpchi\nexport ASPERA_SCP_PASS=deepfeature\n\n/Users/Dporter1/Applications/AsperaCLI/bin/ascp -d [email protected]:ibd/metatranscriptome/microbiome/analysis/CSM5FZ4C_P_genefamilies.biom ./ibd/metatranscriptome/microbiome/analysis/CSM5FZ4C_P_genefamilies.biom\n"
},
{
"alpha_fraction": 0.6943191885948181,
"alphanum_fraction": 0.7243763208389282,
"avg_line_length": 36.382022857666016,
"blob_id": "84bffeb384ef5ec24595160498a30b2e88583a7a",
"content_id": "c06795fa7fba4032c7c7df25789d87e24e993c7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3327,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 89,
"path": "/src/keras_dfs_with_custom_layer.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Nov 10 16:59:42 2018\n\n@author: Erik\n\"\"\"\n\nfrom keras import Sequential\nfrom keras.layers import Dense\nfrom OneToOne import OneToOne\nfrom keras.regularizers import l2, l1, l1_l2\nfrom keras.optimizers import SGD\nimport numpy as np\nfrom keras.utils import to_categorical\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.preprocessing import LabelEncoder\nfrom keras.constraints import max_norm\n\n\n'''\nThis is the main thing we're working with. Increasing the regularization on the input layer with DECREASE the number of features\nselected. Setting it to 0 allows the neural network to just grab everything because it can. We can definitely just increase this\nuntil the quality of the model starts to erode. Just before that point we will have a minimal feature set and a high quality model which\nis what we are going for I think.\n'''\nFEATURE_REG =1 #discourage features from being selected\n\n'''This is also necessary, otherwise the neural net could just ramp up the rest of the weights to compinsate for the\nsurpression on the input layer.\n'''\nMODEL_REG = 0.0001 #discourage complex model\n\ndata_dir= 'C:/Working/UIC/Fall2018/CS502/CS502_final_project/DECRES/data/'\n\n# Get data\nfilename=data_dir + \"GM12878_200bp_Data.txt\";\nX = np.loadtxt(filename,delimiter='\\t',dtype='float32')\n\nfilename=data_dir + \"GM12878_200bp_Classes.txt\";\ny_str = np.loadtxt(filename,delimiter='\\t',dtype=object)\n\n#do one hot encoding=====================\n#transform to int\nle = LabelEncoder()\ny_int = le.fit_transform(y_str)\n#and transform to encoded\ny_enc = to_categorical(y_int)\n#done one hot encoding===================\n\n\nX_train, X_test, y_train, y_test = train_test_split(X, y_enc, test_size = 0.2)\nX_val, X_test, y_val, y_test = train_test_split(X_test, y_test, test_size = 0.5)\n\n\n\nffnn = Sequential()\n\n# this model definitely will break if number of nodes and input shape differ. They are one to one and I haven't figured out how to \n# fully automate their connection\nffnn.add(OneToOne(102, name = 'input', input_shape = (102, ), use_bias = False, activation = 'linear', kernel_regularizer = l2(FEATURE_REG)))\n\n\nffnn.add(Dense(128, name = 'layer1', activation = 'sigmoid', kernel_regularizer = l1(MODEL_REG)))\nffnn.add(Dense(64, name = 'layer2', activation = 'sigmoid', kernel_regularizer = l1(MODEL_REG)))\nffnn.add(Dense(7, name = 'output', activation = 'softmax'))\nffnn.compile(optimizer = SGD(lr = 0.01),\n loss = 'categorical_crossentropy',\n metrics = ['accuracy'])\n\n#really fast run of the model, just 15 epochs and 100 batch size. We can improve with more epochs and smaller batch sizes\n#but the model slows down then.\nffnn.fit(x = X_train, y = y_train, epochs = 100, batch_size = 100, validation_data = [X_val, y_val])\n\n#get accuracy\nprint(ffnn.evaluate(X_test, y_test))\n\n#retrieve feature weights\nfeature_weights = ffnn.get_layer('input').get_weights()[0]\n\n#get the ones that exceed a certain threshold in magnitude\nselected = abs(feature_weights) > 0.0001 #may need to figure out better threshold, study was using 1/1000 of max in the vector\n\n#print weight and selection status\nfor i in range(20):\n print(feature_weights[i], end = \"--\")\n print(selected[i])\n\n#report total number selected\nprint(\"Total features selected: \" + str(sum(selected)))\n"
},
{
"alpha_fraction": 0.5741626620292664,
"alphanum_fraction": 0.6092504262924194,
"avg_line_length": 35.764705657958984,
"blob_id": "20878cbb24b621d73c18081c084e06ee3477e9d1",
"content_id": "f7d0adfb3ab774dc973330cb15d8cf09f84d5e06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1881,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 51,
"path": "/src/housing_dfs.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Nov 30 13:08:00 2018\n\n@author: Erik\n\"\"\"\nimport pandas as pd\nimport housing_normalize as hn\nimport housing_outliers as ho\nfrom DFS import DFS\nfrom sklearn.model_selection import train_test_split\n\n#all the preprocessing from my cs412 project\ndata = pd.read_csv('../data/housing/data.csv')\ndata = hn.fill_in_missing_values(data)\ndata = ho.remove_outliers(data)\ndata = hn.normalize(data)\nX = data.drop('log_SalePrice', 1)\ny = data['log_SalePrice']\n\n#do the 0-1 normalization\nX = (X - X.min()) / (X.max() - X.min())\n\n#80/20 split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)\n\n\n# custom R2-score metrics for keras backend, borrowed from the interwebs\nfrom keras import backend as K\ndef r2_keras(y_true, y_pred):\n SS_res = K.sum(K.square(y_true - y_pred)) \n SS_tot = K.sum(K.square(y_true - K.mean(y_true))) \n return ( 1 - SS_res/(SS_tot + K.epsilon()) )\n\n#rachet down on features, starting with no regularization and going to relatively harsh regularization\nlambdas = [0, 0.0001, 0.001, 0.01, 0.1]\nfor lda in lambdas:\n reg_model = DFS(in_dim = len(X_train.columns), \n num_classes = 1, \n lambda1 = lda, \n alpha1 = 0.0001,\n hidden_layers = [128, 32],\n hidden_layer_activation = 'relu', \n output_layer_activation = 'linear', \n loss_function = 'mean_squared_error', \n learning_rate = 0.005,\n addl_metrics = [r2_keras])\n \n reg_model.fit(x = X_train, y = y_train, batch_size = 10, epochs = 100, validation_data = [X_test, y_test])\n reg_model.write_features('../results/housing_weights_'+ str(lda) + '.csv', X.columns)\n reg_model.write_predictions('../results/housing_predictions_' + str(lda) + '.csv', X_test, y_test)\n \n\n"
},
{
"alpha_fraction": 0.7464503049850464,
"alphanum_fraction": 0.7606490850448608,
"avg_line_length": 53.77777862548828,
"blob_id": "f297bad3baf87540f05dd0ecb1ce3e4c3f302353",
"content_id": "61a940fbdaae62e07d6d053dcb58c028c57a7db9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 493,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 9,
"path": "/README.md",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "NODEjs Framework setup for our app:\nOverview: I'm using virtualenv for python and also a virtual env for nodejs -> nodeenv:\n\n1) Load your python env then \"pip install nodeenv\".\n2) then type \"nodeenv .env\" to create a new environment named \".env\"\n3) Then in the root of the directory of this project type \". .env/bin/activate\" in your shell to activate the virtual env for node-> \nThen load the nodejs dependencies with \"npm install\"\nto run the app type: \"npm start\"\nnavigate to localhost:3000\n"
},
{
"alpha_fraction": 0.6755319237709045,
"alphanum_fraction": 0.7154255509376526,
"avg_line_length": 22.5625,
"blob_id": "1d1b05b3e66eec7c2cf3fe2e83588d91edf8ec36",
"content_id": "de9208c0ed54a8269f4e34b15a70856465be513f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 376,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 16,
"path": "/template_code/ngram_example.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Oct 24 13:19:39 2018\n\n@author: Erik\n\"\"\"\nimport nltk\nfrom itertools import chain\nsentence = \"At eight o'clock on Thursday morning Arthur didn't feel very good.\"\ntokens = nltk.word_tokenize(sentence)\n\nunigrams = nltk.ngrams(tokens,1) \nbigrams = nltk.ngrams(tokens, 2)\ngrams = chain(unigrams, bigrams)\nfor gram in grams:\n print(gram)"
},
{
"alpha_fraction": 0.5596774220466614,
"alphanum_fraction": 0.5717741847038269,
"avg_line_length": 24.85416603088379,
"blob_id": "777016dba4141e4d1e45c20a361c3bac89ec2da3",
"content_id": "fb2d25a80297a5e237909a31d883a9ff040805bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1241,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 48,
"path": "/template_code/pos_translation.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Oct 24 16:30:05 2018\n\n@author: Erik\n\"\"\"\n\npos_dict = {\n \"CC\":\"Coordinating conjunction\",\n \"CD\":\"Cardinal number\",\n \"DT\":\"Determiner\",\n \"EX\":\"Existential there\",\n \"FW\":\"Foreign word\",\n \"IN\":\"Preposition or subordinating conjunction\",\n \"JJ\":\"Adjective\",\n \"JJR\":\"Adjective, comparative\",\n \"JJS\":\"Adjective, superlative\",\n \"LS\":\"List item marker\",\n \"MD\":\"Modal\",\n \"NN\":\"Noun, singular or mass\",\n \"NNS\":\"Noun, plural\",\n \"NNP\":\"Proper noun, singular\",\n \"NNPS\":\"Proper noun, plural\",\n \"PDT\":\"Predeterminer\",\n \"POS\":\"Possessive ending\",\n \"PRP\":\"Personal pronoun\",\n \"PRP$\":\"Possessive pronoun\",\n \"RB\":\"Adverb\",\n \"RBR\":\"Adverb, comparative\",\n \"RBS\":\"Adverb, superlative\",\n \"RP\":\"Particle\",\n \"SYM\":\"Symbol\",\n \"TO\":\"to\",\n \"UH\":\"Interjection\",\n \"VB\":\"Verb, base form\",\n \"VBD\":\"Verb, past tense\",\n \"VBG\":\"Verb, gerund or present participle\",\n \"VBN\":\"Verb, past participle\",\n \"VBP\":\"Verb, non-3rd person singular present\",\n \"VBZ\":\"Verb, 3rd person singular present\",\n \"WDT\":\"Wh-determiner\",\n \"WP\":\"Wh-pronoun\",\n \"WP$\":\"Possessive wh-pronoun\",\n \"WRB\":\"Wh-adverb\",\n \".\" : \".\"\n }\n\nprint(pos_dict[\"VB\"])"
},
{
"alpha_fraction": 0.702674925327301,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 29.375,
"blob_id": "fc9da2eb4a4190e5ad0266d84fe03a8906cfc275",
"content_id": "f0119ab1dc0689950ed1d13a2c90223f255fc37d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1944,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 64,
"path": "/template_code/em_algo.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "from sklearn.naive_bayes import MultinomialNB\nfrom get_data import get_data_tfidf\nfrom sklearn.model_selection import train_test_split\nimport numpy as np\n\n#get features\ndef get_params(mnb):\n model_params = mnb.class_log_prior_\n for elt in mnb.feature_log_prob_:\n model_params = np.concatenate((model_params, elt))\n return model_params\n\n#get same data from the project, if you want to test just replace this line of code\nX, y = get_data_tfidf('data-1_train.csv')\n\n#set 80% of it to unlabelled\nX_labelled, X_unlabelled, y_labelled, y_unlabelled = train_test_split(X, y, test_size = 0.8) #never use y_unlabelled, that's cheating\n\n#train on labelled data only\nmnb = MultinomialNB()\nmnb.fit(X_labelled, y_labelled)\ny_pred = mnb.predict(X_labelled)\nprint(np.sum(y_pred == y_labelled)/len(y_pred))\n\n\n#now predict on unlabelled data, overwrites the original true labels\ny_unlabelled = mnb.predict(X_unlabelled)\n\n#make sure that order is unchanged so set X to the concatenation of labelled an unlabelled, same with y\nX = np.concatenate((X_labelled, X_unlabelled))\ny = np.concatenate((y_labelled, y_unlabelled))\n\n#now do initial fitting on labelled and unlabelled data\nmnb.fit(X, y)\nparams = get_params(mnb)\n\ni = 1\nwhile True:\n print(i)\n\n i += 1\n\n #reset label for the unlabelled data\n y_unlabelled = mnb.predict(X_unlabelled)\n\n #re concatenate for y, no need to do this again for X\n y = np.concatenate((y_labelled, y_unlabelled))\n\n #re fit\n mnb = MultinomialNB()\n mnb.fit(X, y)\n\n #get new param set\n new_params = get_params(mnb)\n\n #get the sum of absolute differences of the model parameters\n diff = np.sum(abs(new_params - params))\n print(diff) #print it for fun\n params = new_params #set the current model params to the new model params\n if diff < 0.001: #and break if gap is small enough\n break\n\ny_pred = mnb.predict(X_labelled)\nprint(np.sum(y_pred == y_labelled)/len(y_pred))\n"
},
{
"alpha_fraction": 0.7851851582527161,
"alphanum_fraction": 0.7925925850868225,
"avg_line_length": 32.5,
"blob_id": "d8ed722d957b5e7c39a48951aa799f35fddd501c",
"content_id": "32a112c8d7d2047c3b13590e6991cc81d43e7bd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 135,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 4,
"path": "/hmp_utils/ascp-commands.sh",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nexport ASCP=/Users/Dporter1/Applications/Aspera CLI/bin/ascp\nexport ASPERA_USER=dcp_chi\nexport ASPERA_SCP_PASS=deepfeature\n\n"
},
{
"alpha_fraction": 0.6566866040229797,
"alphanum_fraction": 0.6756486892700195,
"avg_line_length": 28.895523071289062,
"blob_id": "40d6178a4f29af9657f35cf808cec05258c69113",
"content_id": "3a60c331fb28d7ba400180f9ed60675beecdc1e9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2004,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 67,
"path": "/template_code/neural_network.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Jan 31 09:35:35 2018\n\n@author: Erik\n\"\"\"\n\nimport tensorflow as tf\nimport pandas as pd\nimport numpy as np\nfrom sklearn.model_selection import train_test_split\n\n\ndef train_input_fn(features, labels, batch_size):\n \"\"\"An input function for training\"\"\"\n # Convert the inputs to a Dataset.\n dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))\n\n # Shuffle, repeat, and batch the examples.\n dataset = dataset.shuffle(1000).repeat().batch(batch_size)\n\n # Return the read end of the pipeline.\n return dataset.make_one_shot_iterator().get_next()\n\ndef eval_input_fn(features, labels, batch_size):\n \"\"\"An input function for evaluation or prediction\"\"\"\n features=dict(features)\n if labels is None:\n # No labels, use only features.\n inputs = features\n else:\n inputs = (features, labels)\n\n # Convert the inputs to a Dataset.\n dataset = tf.data.Dataset.from_tensor_slices(inputs)\n\n # Batch the examples\n assert batch_size is not None, \"batch_size must not be None\"\n dataset = dataset.batch(batch_size)\n\n # Return the read end of the pipeline.\n return dataset.make_one_shot_iterator().get_next()\n\nCSV_COLUMN_NAMES = ['len', 'width', 'type']\n\nprint(tf.__version__)\n\ndata = pd.read_csv('iris.csv', names=CSV_COLUMN_NAMES, header=0)\nX_data = data.iloc[:, :2]\ny_data = data[['type']]\nprint(type(X_data))\n\nX_train, X_test, y_train, y_test = train_test_split(X_data, y_data, test_size = 0.2)\n\nfeature_cols = []\nfor col in X_train.keys():\n feature_cols.append(tf.feature_column.numeric_column(key=col))\n\nclassifier = tf.estimator.DNNClassifier(feature_columns = feature_cols, hidden_units = [10, 10], n_classes = 2)\n\nclassifier.train(input_fn = lambda:train_input_fn(X_train, y_train, 100)\n , steps = 1000)\n\neval_result = classifier.evaluate(\n input_fn=lambda:eval_input_fn(X_test, y_test, 100))\n\nprint('\\nTest set accuracy: {accuracy:0.3f}\\n'.format(**eval_result))\n\n"
},
{
"alpha_fraction": 0.512922465801239,
"alphanum_fraction": 0.622266411781311,
"avg_line_length": 24.200000762939453,
"blob_id": "00176ad9768a5651a0259f68a2f10ec264654f8a",
"content_id": "296b988062dfbabefea30ef1a784dd2f34afe471",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 503,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 20,
"path": "/src/xor_example.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Nov 26 16:57:45 2018\n\n@author: Erik\n\"\"\"\n\nfrom DFS import DFS\nfrom keras.utils import to_categorical\nimport numpy as np\n\n#de normalizing\nX = np.array([[0, 0], [0, 10], [1, 0], [1, 10]])\ny = np.array([0, 1, 1, 0])\ny = to_categorical(y)\n\nmodel = DFS(2, 2, hidden_layers = [200], learning_rate = 0.05, lambda1 = 0.001, lambda2 = 0.5, alpha1 = 0.01, alpha2 = 0.5)\nmodel.fit(x = X, y = y, batch_size = 1, epochs = 5000)\nprint(model.predict(X))\nmodel.show_bar_chart()"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7843137383460999,
"avg_line_length": 75.5,
"blob_id": "98cac12a3e2539f89fc12587aebde3719091e47f",
"content_id": "4880c6c328bc32aa8eb07818aaae3981894dfe93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 306,
"license_type": "no_license",
"max_line_length": 177,
"num_lines": 4,
"path": "/hmp_utils/getbiomedata.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "bashCommand = \"./manifest2ascp.py --manifest=manifesttsv.tsv --user=dcp_chi --password=deepfeature --ascp_path=/Users/Dporter1/Applications/AsperaCLI/bin/ascp > ascp-commands.sh\"\nimport subprocess\nprocess = subprocess.Popen(bashCommand.split(), stdout=subprocess.PIPE)\noutput, error = process.communicate()\n"
},
{
"alpha_fraction": 0.6263065934181213,
"alphanum_fraction": 0.650696873664856,
"avg_line_length": 29.210525512695312,
"blob_id": "32c1bd6e164e95772e03aafd2580c7c87c3a25a0",
"content_id": "c0dfd5aabbeef1e8ee106d5fe300105420b03bfd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2296,
"license_type": "no_license",
"max_line_length": 220,
"num_lines": 76,
"path": "/src/baboon_dfs.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Nov 28 17:18:16 2018\n\n@author: Erik\n\"\"\"\n\nimport pandas as pd\nfrom DFS import DFS\nfrom keras.utils import to_categorical\nfrom os import listdir\nfrom sklearn.model_selection import train_test_split\n\n#get rid of correlated features\nbad_cols =['LAT_mean', 'LAT_mean_n', 'LAT_std', 'LON_std', 'LON_mean', 'LON_mean_n', 'BABOON_NODE_n', 'speed_imputed', 'TIME_S_mean', 'ID_mean_n','ID_mean', 'TIME_mean', 'TIME_S_mean_n','TIME_mean_n', 'NEIGH', 'NEIGH_n']\n\ndata_dir = \"../data/baboon/\"\n\n\ndata = None\nfor i, file in enumerate(listdir(data_dir)):\n if i != 9: #9 is a problem child, I have absolutely no idea why but it is. So, BYE FELICIA!\n print(\"importing file \" + str(i))\n if data is None:\n data = pd.read_csv(data_dir + file)\n else:\n data = data.append(pd.read_csv(data_dir + file), sort = False)\n\nfor col in bad_cols:\n if col in data.columns:\n data = data.drop(col, axis = 1)\n\n#get rid of labels with -2\ndata = data[data.LABEL_O_majority >= 0]\n\n\ny = data['LABEL_O_majority']\n\nprint(set(y))\ny = y.replace(4, 1) #set running and walking to the same thing\ny = y.replace(3, 2) #set standing at rest and sitting to the same thing\n\n\n#get class count, necessary for nueral network input\n\n\ny = to_categorical(y)\nprint(len(data.columns))\nlabel_cols = ['NEIGH_O_n','LABEL_O_majority_n', 'LABEL_F_values', 'LABEL_O_values', 'NEIGH_F_n','LABEL_F_majority_n', 'LABEL_O_majority', 'LABEL_F_majority']\nfor col in label_cols:\n data = data.drop(col, axis = 1) #get rid of labels\n\n\n\n\n\n#now handle NaN's\ndata = data.fillna(0)\n#do dataframe normalization to 0-1 range\nX = (data - data.min())/(data.max() - data.min())\n#NaN's can creep back if data.max() - data.min() = 0\nX = X.fillna(0)\n\n#do test train split\nX_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2)\nnum_classes = len(y[0])\ninput_dim = len(X.columns)\n#actually do neural net training\n\nlambda1s = [1, 10]\nmodels = []\nfor lmda in lambda1s:\n print(\"Training on lambda = \" + str(lmda))\n model = DFS(input_dim, num_classes, hidden_layers = [1024, 256], lambda1 = lmda, alpha1 = 0.001, learning_rate = 0.01)\n model.fit(X_train, y_train, batch_size = 100, epochs = 5, validation_data = [X_test, y_test])\n models.append(model)\n"
},
{
"alpha_fraction": 0.6370370388031006,
"alphanum_fraction": 0.6740740537643433,
"avg_line_length": 26.066667556762695,
"blob_id": "8325a0fd7959bd6dd6a2c19d01913d10cc6daf4d",
"content_id": "4154ec2146c635dd0170c5ba6280679e15d2efbd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 15,
"path": "/template_code/part_of_speech_tag.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Wed Oct 24 13:19:39 2018\n\n@author: Erik\n\"\"\"\nimport nltk\nfrom pos_translation import pos_dict\nsentence = \"At eight o'clock on Thursday morning Arthur didn't feel very good.\"\ntokens = nltk.word_tokenize(sentence)\ntagged = nltk.pos_tag(tokens)\n\nfor tag in tagged:\n print(tag) # print raw tag\n print(\" \" + tag[1] + \": \" + pos_dict[tag[1]]) #print tag translation"
},
{
"alpha_fraction": 0.637509822845459,
"alphanum_fraction": 0.6422379612922668,
"avg_line_length": 25.4375,
"blob_id": "882e0c0bdabe06aa4c33f4b8f9a8bcdabb145ea0",
"content_id": "5429d6912965ea31014c5203b24cd707b87c4a04",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1269,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 48,
"path": "/routes/index.js",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "var express = require('express');\nvar ps = require('python-shell');\n\nvar router = express.Router();\n\n\n\n/* GET home page. */\nrouter.get('/', function(req, res, next) {\n res.render('index', { title: 'Express' });\n});\nrouter.get('/project1', function(req, res, next) {\n res.render('project1.ejs', { title: 'Project1' });\n});\nrouter.get('/paper_review', function(req, res, next) {\n res.render('paper_review.ejs', { title: 'paper review' });\n});\nrouter.get('/final_project', function(req, res, next) {\n res.render('final_project.ejs', { title: 'FINAL PROJECT' });\n});\nrouter.get('/dfs_app', function(req, res, next) {\n var data_uploaded = 'false';\n res.render('dfs_app.ejs', { data_uploaded: data_uploaded, title: 'DFS APP' });\n});\n//file handler\nrouter.post('/upload', function(req, res) {\n console.log(req.files.filedata); // the uploaded file object\n\n var filedata = req.files.filedata;\n\n filedata.mv('uploads/datafile.txt', function(err) {\n if (err)\n return res.status(500).send(err);\n });\n var data_uploaded = 'true';\n res.render('dfs_app.ejs', { data_uploaded: data_uploaded });\n\n ps.PythonShell.run('template_code/feedforward_nn.py', null, function (err, res) {\n if (err) throw err;\n console.log(res);\n });\n\n\n\n});\n\n\nmodule.exports = router;\n"
},
{
"alpha_fraction": 0.6291698813438416,
"alphanum_fraction": 0.678820788860321,
"avg_line_length": 28.953489303588867,
"blob_id": "5622e9ad62984aac98ae05ab0d2619d1189e8d61",
"content_id": "4b4cc1b2f540562c8fd88661f5b2e0aef21727da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1289,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 43,
"path": "/src/cis_non_encoding_dna_example.py",
"repo_name": "DavidCPorter/CS502_final_project",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Nov 26 13:27:50 2018\n\n@author: Erik\n\"\"\"\n\nfrom DFS import DFS\nfrom sklearn.model_selection import train_test_split\nimport numpy as np\nfrom sklearn.preprocessing import LabelEncoder\nfrom keras.utils import to_categorical\nfrom sklearn.linear_model import LogisticRegression\n\n\ndata_dir= 'C:/Working/UIC/Fall2018/CS502/CS502_final_project/DECRES/data/'\n\n# Get data\nfilename=data_dir + \"GM12878_200bp_Data.txt\";\nX = np.loadtxt(filename,delimiter='\\t',dtype='float32')\n#X = (X - np.min(X, axis =0))/(np.max(X, axis = 0) - np.min(X, axis = 0))\n\n\nfilename=data_dir + \"GM12878_200bp_Classes.txt\";\ny_str = np.loadtxt(filename,delimiter='\\t',dtype=object)\n\n#do one hot encoding=====================\n#transform to int\nle = LabelEncoder()\ny_int = le.fit_transform(y_str)\n#and transform to encoded\ny_enc = to_categorical(y_int)\n#done one hot encoding===================\n\n\nX_train, X_test, y_train, y_test = train_test_split(X, y_enc, test_size = 0.2)\nX_val, X_test, y_val, y_test = train_test_split(X_test, y_test, test_size = 0.5)\n\n\nmodel = DFS(in_dim = 102, num_classes = 7, lambda1 = 0.0001) #\nmodel.fit(x = X_train, y = y_train, epochs = 100, batch_size = 100, validation_data = [X_val, y_val])\nprint(model.accuracy(X_test, y_test))\nmodel.show_bar_chart()\n\n"
}
] | 20 |
rhasspy/rhasspy-snips-nlu | https://github.com/rhasspy/rhasspy-snips-nlu | d0c824dbd95f232822469d010a9588ae8365fd7e | c46857fe5f3acf84b812853d4f5f280c534196f0 | e092cef5093a196a1e1ad9b8ce685c666946ba75 | refs/heads/master | 2023-02-07T07:55:56.519622 | 2020-07-17T19:08:34 | 2020-07-17T19:08:34 | 258,616,926 | 0 | 2 | MIT | 2020-04-24T20:27:23 | 2020-07-17T20:21:45 | 2020-07-17T20:21:42 | Python | [
{
"alpha_fraction": 0.5147058963775635,
"alphanum_fraction": 0.6911764740943909,
"avg_line_length": 16,
"blob_id": "1f3145e34b834e153060b22eb3ba076a29e645ba",
"content_id": "505a48d2327ba721d79d5a5a49db80a5fd80ef77",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 68,
"license_type": "permissive",
"max_line_length": 18,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "rhasspy/rhasspy-snips-nlu",
"src_encoding": "UTF-8",
"text": "jsonlines==1.2.0\nnetworkx==2.4\nrhasspy-nlu~=0.3.0\nsnips-nlu==0.20.2\n"
},
{
"alpha_fraction": 0.5647512078285217,
"alphanum_fraction": 0.5655888915061951,
"avg_line_length": 28.54950523376465,
"blob_id": "ae44e04dd62dc7ac3cd3db0203d8a00d196986ae",
"content_id": "3affb659e5248eb465b588d4ff544fb992cd7525",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5969,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 202,
"path": "/rhasspysnips_nlu/__main__.py",
"repo_name": "rhasspy/rhasspy-snips-nlu",
"src_encoding": "UTF-8",
"text": "\"\"\"Command-line interface to rhasspysnips_nlu.\"\"\"\nimport argparse\nimport dataclasses\nimport json\nimport logging\nimport os\nimport sys\nimport time\nimport typing\nfrom pathlib import Path\n\nimport jsonlines\nimport networkx as nx\nimport rhasspynlu\nfrom snips_nlu import SnipsNLUEngine\n\nfrom . import recognize, train\n\n_LOGGER = logging.getLogger(\"rhasspysnips_nlu\")\n\n\ndef main():\n \"\"\"Main entry point.\"\"\"\n parser = argparse.ArgumentParser(prog=\"rhasspysnips_nlu\")\n parser.add_argument(\n \"--debug\", action=\"store_true\", help=\"Print DEBUG messages to console\"\n )\n\n sub_parsers = parser.add_subparsers()\n sub_parsers.required = True\n sub_parsers.dest = \"command\"\n\n # -----\n # Train\n # -----\n train_parser = sub_parsers.add_parser(\n \"train\", help=\"Train Snips engine from sentences/slots\"\n )\n train_parser.set_defaults(func=do_train)\n\n train_parser.add_argument(\n \"--language\",\n required=True,\n help=\"Snips language (de, en, es, fr, it, ja, ko, pt_br, pt_pt, zh)\",\n )\n train_parser.add_argument(\n \"--sentences\",\n required=True,\n action=\"append\",\n default=[],\n help=\"Path to sentences.ini\",\n )\n train_parser.add_argument(\n \"--engine-path\", required=True, help=\"Path to save Snips NLU engine\"\n )\n train_parser.add_argument(\"--slots-dir\", help=\"Path to slots directory\")\n train_parser.add_argument(\"--dataset-path\", help=\"Path to save Snips NLU dataset\")\n train_parser.add_argument(\n \"--debug\", action=\"store_true\", help=\"Print DEBUG messages to console\"\n )\n\n # ---------\n # Recognize\n # ---------\n recognize_parser = sub_parsers.add_parser(\n \"recognize\", help=\"Recognize intent from text\"\n )\n recognize_parser.set_defaults(func=do_recognize)\n recognize_parser.add_argument(\n \"sentence\", nargs=\"*\", default=[], help=\"Sentences to recognize\"\n )\n recognize_parser.add_argument(\n \"--engine-path\", required=True, help=\"Path to load Snips NLU engine\"\n )\n recognize_parser.add_argument(\"--slots-dir\", help=\"Path to slots directory\")\n recognize_parser.add_argument(\n \"--json-input\", action=\"store_true\", help=\"Input is JSON instead of plain text\"\n )\n\n # -------------------------------------------------------------------------\n\n args = parser.parse_args()\n\n if args.debug:\n logging.basicConfig(level=logging.DEBUG)\n else:\n logging.basicConfig(level=logging.INFO)\n\n _LOGGER.debug(args)\n\n args.func(args)\n\n\n# -----------------------------------------------------------------------------\n\n\ndef do_train(args: argparse.Namespace):\n \"\"\"Train Snips engine from sentences/slots.\"\"\"\n\n # Load sentences and slots\n _LOGGER.debug(\"Loading sentences from %s\", args.sentences)\n sentences_dict: typing.Dict[str, str] = {\n sentences_path: open(sentences_path, \"r\").read()\n for sentences_path in args.sentences\n }\n\n slots_dict: typing.Dict[str, typing.List[str]] = {}\n\n if args.slots_dir:\n slots_dir = Path(args.slots_dir)\n if slots_dir.is_dir():\n _LOGGER.debug(\"Loading slots from %s\", args.slots_dir)\n slots_dict = {\n slot_path.name: slot_path.read_text().splitlines()\n for slot_path in slots_dir.glob(\"*\")\n if slot_path.is_file()\n }\n\n train(\n sentences_dict,\n args.language,\n slots_dict=slots_dict,\n engine_path=args.engine_path,\n dataset_path=args.dataset_path,\n )\n\n\n# -----------------------------------------------------------------------------\n\n\ndef do_recognize(args: argparse.Namespace):\n \"\"\"Recognize intent from text.\"\"\"\n _LOGGER.debug(\"Loading Snips engine from %s\", args.engine_path)\n engine = SnipsNLUEngine.from_path(args.engine_path)\n\n slots_dict: typing.Dict[str, typing.List[str]] = {}\n\n if args.slots_dir:\n slots_dir = Path(args.slots_dir)\n if slots_dir.is_dir():\n _LOGGER.debug(\"Loading slots from %s\", args.slots_dir)\n slots_dict = {\n slot_path.name: slot_path.read_text().splitlines()\n for slot_path in slots_dir.glob(\"*\")\n if slot_path.is_file()\n }\n\n if args.sentence:\n sentences = args.sentence\n else:\n if os.isatty(sys.stdin.fileno()):\n print(\"Reading sentences from stdin\", file=sys.stderr)\n\n sentences = sys.stdin\n\n # Process sentences\n slot_graphs: typing.Dict[str, nx.DiGraph] = {}\n try:\n for sentence in sentences:\n if args.json_input:\n sentence_object = json.loads(sentence)\n else:\n sentence_object = {\"text\": sentence}\n\n text = sentence_object[\"text\"]\n\n start_time = time.perf_counter()\n recognitions = recognize(\n text, engine, slots_dict=slots_dict, slot_graphs=slot_graphs,\n )\n end_time = time.perf_counter()\n\n if recognitions:\n recognition = recognitions[0]\n else:\n recognition = rhasspynlu.fsticuffs.Recognition.empty()\n\n recognition.recognize_seconds = end_time - start_time\n\n recognition.tokens = text.split()\n\n recognition.raw_text = text\n recognition.raw_tokens = list(recognition.tokens)\n\n recognition_dict = dataclasses.asdict(recognition)\n for key, value in recognition_dict.items():\n if (key not in sentence_object) or (value is not None):\n sentence_object[key] = value\n\n with jsonlines.Writer(sys.stdout) as out:\n # pylint: disable=E1101\n out.write(sentence_object)\n\n sys.stdout.flush()\n except KeyboardInterrupt:\n pass\n\n\n# -----------------------------------------------------------------------------\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5095113515853882,
"alphanum_fraction": 0.5103839635848999,
"avg_line_length": 35.61341857910156,
"blob_id": "21acdd14137a44286d248319823bdab93b75c121",
"content_id": "ce1a820e27792eeb7a84014a516d182cd3d7e308",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11460,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 313,
"path": "/rhasspysnips_nlu/__init__.py",
"repo_name": "rhasspy/rhasspy-snips-nlu",
"src_encoding": "UTF-8",
"text": "\"\"\"Snips NLU training/recognize methods for Rhasspy.\"\"\"\nimport io\nimport logging\nimport shutil\nimport tempfile\nimport typing\nfrom pathlib import Path\n\nimport networkx as nx\nimport rhasspynlu\nfrom rhasspynlu.intent import Entity, Intent, Recognition\nfrom snips_nlu import SnipsNLUEngine\nfrom snips_nlu.dataset import Dataset\nfrom snips_nlu.default_configs import DEFAULT_CONFIGS\n\n_LOGGER = logging.getLogger(\"rhasspysnips_nlu\")\n\n# -----------------------------------------------------------------------------\n\n\ndef train(\n sentences_dict: typing.Dict[str, str],\n language: str,\n slots_dict: typing.Optional[typing.Dict[str, typing.List[str]]] = None,\n engine_path: typing.Optional[typing.Union[str, Path]] = None,\n dataset_path: typing.Optional[typing.Union[str, Path]] = None,\n) -> SnipsNLUEngine:\n \"\"\"Generate Snips YAML dataset from Rhasspy sentences/slots.\"\"\"\n slots_dict = slots_dict or {}\n\n _LOGGER.debug(\"Creating Snips engine for language %s\", language)\n engine = SnipsNLUEngine(config=DEFAULT_CONFIGS[language])\n\n # Parse JSGF sentences\n _LOGGER.debug(\"Parsing sentences\")\n with io.StringIO() as ini_file:\n # Join as single ini file\n for lines in sentences_dict.values():\n print(lines, file=ini_file)\n print(\"\", file=ini_file)\n\n intents = rhasspynlu.parse_ini(ini_file.getvalue())\n\n # Split into sentences and rule/slot replacements\n sentences, replacements = rhasspynlu.ini_jsgf.split_rules(intents)\n\n for intent_sentences in sentences.values():\n for sentence in intent_sentences:\n rhasspynlu.jsgf.walk_expression(\n sentence, rhasspynlu.number_range_transform, replacements\n )\n\n # Convert to directed graph *without* expanding slots\n # (e.g., $rhasspy/number)\n _LOGGER.debug(\"Converting to intent graph\")\n intent_graph = rhasspynlu.sentences_to_graph(\n sentences, replacements=replacements, expand_slots=False\n )\n\n # Get start/end nodes for graph\n start_node, end_node = rhasspynlu.jsgf_graph.get_start_end_nodes(intent_graph)\n assert (start_node is not None) and (\n end_node is not None\n ), \"Missing start/end node(s)\"\n\n if dataset_path:\n # Use user file\n dataset_file = open(dataset_path, \"w+\")\n else:\n # Use temporary file\n dataset_file = typing.cast(\n typing.TextIO, tempfile.NamedTemporaryFile(suffix=\".yml\", mode=\"w+\")\n )\n dataset_path = dataset_file.name\n\n with dataset_file:\n _LOGGER.debug(\"Writing YAML dataset to %s\", dataset_path)\n\n # Walk first layer of edges with intents\n for _, intent_node, edge_data in intent_graph.edges(start_node, data=True):\n intent_name: str = edge_data[\"olabel\"][9:]\n\n # New intent\n print(\"---\", file=dataset_file)\n print(\"type: intent\", file=dataset_file)\n print(\"name:\", quote(intent_name), file=dataset_file)\n print(\"utterances:\", file=dataset_file)\n\n # Get all paths through the graph (utterances)\n used_utterances: typing.Set[str] = set()\n paths = nx.all_simple_paths(intent_graph, intent_node, end_node)\n for path in paths:\n utterance = []\n entity_name = None\n slot_name = None\n slot_value = None\n\n # Walk utterance edges\n for from_node, to_node in rhasspynlu.utils.pairwise(path):\n edge_data = intent_graph.edges[(from_node, to_node)]\n ilabel = edge_data.get(\"ilabel\")\n olabel = edge_data.get(\"olabel\")\n if olabel:\n if olabel.startswith(\"__begin__\"):\n slot_name = olabel[9:]\n entity_name = None\n slot_value = \"\"\n elif olabel.startswith(\"__end__\"):\n if entity_name == \"rhasspy/number\":\n # Transform to Snips number\n entity_name = \"snips/number\"\n elif not entity_name:\n # Collect actual value\n assert (\n slot_name and slot_value\n ), f\"No slot name or value (name={slot_name}, value={slot_value})\"\n\n entity_name = slot_name\n slot_values = slots_dict.get(slot_name)\n if not slot_values:\n slot_values = []\n slots_dict[slot_name] = slot_values\n\n slot_values.append(slot_value.strip())\n\n # Reference slot/entity (values will be added later)\n utterance.append(f\"[{slot_name}:{entity_name}]\")\n\n # Reset current slot/entity\n entity_name = None\n slot_name = None\n slot_value = None\n elif olabel.startswith(\"__source__\"):\n # Use Rhasspy slot name as entity\n entity_name = olabel[10:]\n\n if ilabel:\n # Add to current slot/entity value\n if slot_name and (not entity_name):\n slot_value += ilabel + \" \"\n else:\n # Add directly to utterance\n utterance.append(ilabel)\n elif (\n olabel\n and (not olabel.startswith(\"__\"))\n and slot_name\n and (not slot_value)\n and (not entity_name)\n ):\n slot_value += olabel + \" \"\n\n if utterance:\n utterance_str = \" \".join(utterance)\n if utterance_str not in used_utterances:\n # Write utterance\n print(\" -\", quote(utterance_str), file=dataset_file)\n used_utterances.add(utterance_str)\n\n print(\"\", file=dataset_file)\n\n # Write entities\n for slot_name, values in slots_dict.items():\n if slot_name.startswith(\"$\"):\n # Remove arguments and $\n slot_name = slot_name.split(\",\")[0][1:]\n\n # Skip numbers\n if slot_name in {\"rhasspy/number\"}:\n # Should have been converted already to snips/number\n continue\n\n # Keep only unique values\n values_set = set(values)\n\n print(\"---\", file=dataset_file)\n print(\"type: entity\", file=dataset_file)\n print(\"name:\", quote(slot_name), file=dataset_file)\n print(\"values:\", file=dataset_file)\n\n slot_graph = rhasspynlu.sentences_to_graph(\n {\n slot_name: [\n rhasspynlu.jsgf.Sentence.parse(value) for value in values_set\n ]\n }\n )\n\n start_node, end_node = rhasspynlu.jsgf_graph.get_start_end_nodes(slot_graph)\n n_data = slot_graph.nodes(data=True)\n for path in nx.all_simple_paths(slot_graph, start_node, end_node):\n words = []\n for node in path:\n node_data = n_data[node]\n word = node_data.get(\"word\")\n if word:\n words.append(word)\n\n if words:\n print(\" -\", quote(\" \".join(words)), file=dataset_file)\n\n print(\"\", file=dataset_file)\n\n # ------------\n # Train engine\n # ------------\n\n if engine_path:\n # Delete existing engine\n engine_path = Path(engine_path)\n engine_path.parent.mkdir(exist_ok=True)\n\n if engine_path.is_dir():\n # Snips will fail it the directory exists\n _LOGGER.debug(\"Removing existing engine at %s\", engine_path)\n shutil.rmtree(engine_path)\n elif engine_path.is_file():\n _LOGGER.debug(\"Removing unexpected file at %s\", engine_path)\n engine_path.unlink()\n\n _LOGGER.debug(\"Training engine\")\n dataset_file.seek(0)\n dataset = Dataset.from_yaml_files(language, [dataset_file])\n engine = engine.fit(dataset)\n\n if engine_path:\n # Save engine\n engine.persist(engine_path)\n _LOGGER.debug(\"Engine saved to %s\", engine_path)\n\n return engine\n\n\n# -----------------------------------------------------------------------------\n\n\ndef recognize(\n text: str,\n engine: SnipsNLUEngine,\n slots_dict: typing.Optional[typing.Dict[str, typing.List[str]]] = None,\n slot_graphs: typing.Optional[typing.Dict[str, nx.DiGraph]] = None,\n **parse_args,\n) -> typing.List[Recognition]:\n \"\"\"Recognize intent using Snips NLU.\"\"\"\n result = engine.parse(text, **parse_args)\n intent_name = result.get(\"intent\", {}).get(\"intentName\")\n\n if not intent_name:\n # Recognition failure\n return []\n\n slots_dict = slots_dict or {}\n slot_graphs = slot_graphs or {}\n\n recognition = Recognition(\n text=text, raw_text=text, intent=Intent(name=intent_name, confidence=1.0)\n )\n\n # Replace Snips slot values with Rhasspy slot values (substituted)\n for slot in result.get(\"slots\", []):\n slot_name = slot.get(\"slotName\")\n slot_value_dict = slot.get(\"value\", {})\n slot_value = slot_value_dict.get(\"value\")\n\n entity = Entity(\n entity=slot_name,\n source=slot.get(\"entity\", \"\"),\n value=slot_value,\n raw_value=slot.get(\"rawValue\", slot_value),\n start=slot[\"range\"][\"start\"],\n end=slot[\"range\"][\"end\"],\n )\n recognition.entities.append(entity)\n\n if (not slot_name) or (not slot_value):\n continue\n\n slot_graph = slot_graphs.get(slot_name)\n if not slot_graph and (slot_name in slots_dict):\n # Convert slot values to graph\n slot_graph = rhasspynlu.sentences_to_graph(\n {\n slot_name: [\n rhasspynlu.jsgf.Sentence.parse(slot_line)\n for slot_line in slots_dict[slot_name]\n if slot_line.strip()\n ]\n }\n )\n\n slot_graphs[slot_name] = slot_graph\n\n entity.tokens = slot_value.split()\n entity.raw_tokens = list(entity.tokens)\n\n if slot_graph:\n # Pass Snips value through graph\n slot_recognitions = rhasspynlu.recognize(entity.tokens, slot_graph)\n if slot_recognitions:\n # Pull out substituted value and replace in Rhasspy entitiy\n new_slot_value = slot_recognitions[0].text\n entity.value = new_slot_value\n entity.tokens = new_slot_value.split()\n\n return [recognition]\n\n\n# -----------------------------------------------------------------------------\n\n\ndef quote(s):\n \"\"\"Surround with quotes for YAML.\"\"\"\n return f'\"{s}\"'\n"
},
{
"alpha_fraction": 0.729468584060669,
"alphanum_fraction": 0.729468584060669,
"avg_line_length": 14.923076629638672,
"blob_id": "0079708cd35f1f3f31d7523795c80c2beb7e14eb",
"content_id": "1704418762f30875485fc69130ca6a5663440c03",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 207,
"license_type": "permissive",
"max_line_length": 29,
"num_lines": 13,
"path": "/mypy.ini",
"repo_name": "rhasspy/rhasspy-snips-nlu",
"src_encoding": "UTF-8",
"text": "[mypy]\n\n[mypy-jsonlines.*]\nignore_missing_imports = True\n\n[mypy-networkx.*]\nignore_missing_imports = True\n\n[mypy-setuptools.*]\nignore_missing_imports = True\n\n[mypy-snips_nlu.*]\nignore_missing_imports = True\n"
},
{
"alpha_fraction": 0.6854220032691956,
"alphanum_fraction": 0.6905370950698853,
"avg_line_length": 15.291666984558105,
"blob_id": "56ab940dd553a2006c098b62fa98caa40dbccb0a",
"content_id": "6eb3bd6653211f01cfd125d98640bda56b707689",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 391,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 24,
"path": "/README.md",
"repo_name": "rhasspy/rhasspy-snips-nlu",
"src_encoding": "UTF-8",
"text": "# Rhasspy Snips NLU\n\nRhasspy wrapper for [Snips NLU](https://snips-nlu.readthedocs.io/en/latest/).\n\n## Requirements\n\n* Python 3.7\n* [Snips NLU](https://snips-nlu.readthedocs.io/en/latest/)\n\n## Installation\n\n```bash\n$ git clone https://github.com/rhasspy/rhasspy-snips-nlu\n$ cd rhasspy-snips-nlu\n$ ./configure\n$ make\n$ make install\n```\n\n## Running\n\n```bash\n$ bin/rhasspy-snips-nlu <ARGS>\n```\n"
}
] | 5 |
ndickey/docsend_scraper | https://github.com/ndickey/docsend_scraper | 4fe9e672775dacb110162ce0d57b7270c9fa9f8d | b8baada4019bea1b4c9581ae8f4183b2cda76c5b | 26e1ce338f474e505ae3fc54834d4191817ffc52 | refs/heads/master | 2020-03-26T04:19:24.581469 | 2018-08-15T01:29:56 | 2018-08-15T01:29:56 | 144,497,904 | 0 | 1 | null | 2018-08-12T20:17:02 | 2018-08-12T20:17:04 | 2018-08-15T01:29:57 | Python | [
{
"alpha_fraction": 0.5381679534912109,
"alphanum_fraction": 0.5687022805213928,
"avg_line_length": 15.375,
"blob_id": "1ecbea92ddbe80a356f236b18a52f132980333dd",
"content_id": "20bb39695a88f8274bcec9418b54bd2f1f3f1e63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "YAML",
"length_bytes": 262,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 16,
"path": "/docker-compose.yml",
"repo_name": "ndickey/docsend_scraper",
"src_encoding": "UTF-8",
"text": "version: \"2\"\n\nservices:\n\n api:\n build:\n context: .\n dockerfile: Dockerfile\n command: \"python application.py\"\n volumes:\n - ./api:/api\n environment:\n - PYTHONPATH=/api\n - PYTHONDONTWRITEBYTECODE=0\n ports:\n - \"80:5000\"\n"
},
{
"alpha_fraction": 0.5293659567832947,
"alphanum_fraction": 0.5371553301811218,
"avg_line_length": 40.14743423461914,
"blob_id": "513ff2c0ed2fff0d0a13b3102b8b395807ca1868",
"content_id": "ebe8d195121fd39b1ab5864f738c7a4c9ea06dad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6419,
"license_type": "no_license",
"max_line_length": 215,
"num_lines": 156,
"path": "/api/application.py",
"repo_name": "ndickey/docsend_scraper",
"src_encoding": "UTF-8",
"text": "import json\nimport re\n\nimport http.cookiejar\nfrom urllib.request import Request, build_opener\nimport urllib\nfrom urllib import parse\nfrom http.cookiejar import CookieJar\n\nfrom flask import Flask, render_template, request, make_response, jsonify, send_from_directory\n\nfrom fpdf import FPDF\nfrom PIL import Image, ImageChops\n\nimport os\n\napplication = Flask(__name__)\n\nagentheaders={'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.47 Safari/537.36'}\n\[email protected]('/')\ndef render_index():\n return render_template('index.html')\n\ndef convert_images_to_pdf(image_array, opener_ref, init_h):\n h = init_h.copy()\n pdf_set = False\n pdf = None\n for index, r in enumerate(image_array):\n img_req = Request(r, data=None, headers=h)\n img_resp = opener_ref.open(img_req)\n if img_resp:\n file_type = img_resp.headers['Content-Type'].split(';')[0].lower().split(\"/\")[1]\n file_path = '/tmp/' + str(index) + '.' + file_type\n with open(file_path, 'wb') as f:\n f.write(img_resp.read())\n f.close()\n try:\n im = Image.open(file_path)\n if not pdf_set:\n pdf = FPDF(\"L\",\"pt\",[im.size[1],im.size[0]])\n pdf.set_margins(0,0,0)\n pdf_set = True\n pdf.add_page()\n pdf.image(file_path, 0, 0)\n except:\n pass\n if os.path.isfile(file_path):\n os.remove(file_path)\n resp_file = pdf.output('/tmp/pdf_output.pdf', 'F')\n return resp_file\n\ndef update_cookie(header, cookie_jar):\n header_copy = header.copy()\n cookie_refs = []\n for c in cookie_jar:\n cookie_name, cookie_val = str(c.__dict__.get('name')), str(c.__dict__.get('value'))\n cookie_refs.append( cookie_name + \"=\" + cookie_val )\n if cookie_refs:\n header_copy['Cookie'] = \"; \".join(cookie_refs)\n return header_copy\n \n\[email protected]('/now/<file_id>', methods=['GET', 'POST'])\ndef download_pdf(file_id):\n # retrieve email and password\n content = request.get_json(force=True) or {}\n email = content.get('email') or '[email protected]'\n password = content.get('password') or 'notvalidpassword'\n\n error_msg = \"unknown error\"\n\n try:\n # set basic cookies\n cookie_request = Request(\"https://docsend.com/view/\" + file_id, data=None, headers=agentheaders)\n cj = CookieJar()\n op = build_opener(urllib.request.HTTPCookieProcessor(cj))\n cookie_resp = op.open(cookie_request)\n image_array_body = \"\"\n if cookie_resp:\n auth_result = cookie_resp.read()\n\n decoded = auth_result.decode()\n\n auth_matches = re.search(r'link_auth_form\\[passcode\\]', decoded)\n auth_matches_email = re.search(r'link_auth_form\\[email\\]', decoded)\n if auth_matches:\n auth_token_match = re.search(r'authenticity_token\\\"\\s*value\\=\\\"(.*)\\\"', decoded)\n if auth_token_match:\n auth_token = auth_token_match[1]\n # password required\n # try given password\n if password:\n data_send = parse.urlencode({\"_method\": \"patch\", \"authenticity_token\": auth_token, 'commit': \"Continue\", \"link_auth_form[email]\": email, \"link_auth_form[passcode]\": password}).encode(\"ascii\")\n auth_request = Request(\"https://docsend.com/view/\" + file_id, data=data_send, headers=agentheaders)\n h = agentheaders.copy()\n h = update_cookie(h, cj)\n \n auth_request = Request(\"https://docsend.com/view/\" + file_id, data=data_send, headers=h)\n auth_result = op.open(auth_request)\n if auth_result:\n auth_body = auth_result.read()\n incorrect_email = re.search(r'class\\=\\\"error\\\"\\>Passcode', auth_body.decode())\n if incorrect_email:\n return jsonify({\"error\": 'password invalid'}), 401\n image_array_body = auth_body\n\n elif auth_matches_email:\n auth_token_match = re.search(r'authenticity_token\\\"\\s*value\\=\\\"(.*)\\\"', decoded)\n if auth_token_match:\n auth_token = auth_token_match[1]\n data_send = parse.urlencode({\"_method\": \"patch\", \"authenticity_token\": auth_token, 'commit': \"Continue\", \"link_auth_form[email]\": email}).encode(\"ascii\")\n auth_request = Request(\"https://docsend.com/view/\" + file_id, data=data_send, headers=agentheaders)\n h = agentheaders.copy()\n h = update_cookie(h, cj)\n\n auth_request = Request(\"https://docsend.com/view/\" + file_id, data=data_send, headers=h)\n auth_result = op.open(auth_request)\n if auth_result:\n image_array_body = auth_result.read()\n else:\n image_array_body = cookie_resp.read()\n\n data_matches = re.findall(r'data\\-url\\=\\'(https\\:\\/\\/docsend.com\\/view\\/.*\\/thumb\\/\\d+)\\'', image_array_body.decode())\n if data_matches:\n data_matches = [thumb.replace('thumb', 'page_data') for thumb in data_matches]\n\n results = []\n\n h = None\n for index, d in enumerate(data_matches):\n if index >= 0:\n h = agentheaders.copy()\n h = update_cookie(h, cj)\n\n req = Request(d, data=None, headers=h)\n try:\n req_resp = op.open(req)\n except Exception as e:\n return jsonify({\"error\": 'password invalid'}), 401\n if req_resp:\n tada = req_resp.read()\n tada_json = json.loads(tada)\n results.append(tada_json.get('imageUrl'))\n\n if results:\n pdf_file = convert_images_to_pdf(results, op, h)\n return send_from_directory('/tmp/', 'pdf_output.pdf')\n\n except Exception as e:\n error_msg = str(e)\n\n return jsonify({\"error\": error_msg}), 401\n\nif __name__ == \"__main__\":\n application.run(host='0.0.0.0', debug=True, threaded=True)\n"
},
{
"alpha_fraction": 0.37735849618911743,
"alphanum_fraction": 0.6226415038108826,
"avg_line_length": 12.25,
"blob_id": "9d542bbc5b52aefa13d03b41b66a7f5f5dde84b5",
"content_id": "e6066e4f7b7cc9f2d81100651f5ebfbaf9b157ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 4,
"path": "/api/requirements.txt",
"repo_name": "ndickey/docsend_scraper",
"src_encoding": "UTF-8",
"text": "Flask==1.0.2\nfpdf==1.7.2\nimage==1.5.24\nPillow==5.1.0\n"
},
{
"alpha_fraction": 0.5080849528312683,
"alphanum_fraction": 0.5112555623054504,
"avg_line_length": 33.850830078125,
"blob_id": "f47c4699371e4fb677490024b57e2a5f3cef3847",
"content_id": "649bba9688d410f13181c2d1b1039edef89e5cdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6308,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 181,
"path": "/api/static/js/app.js",
"repo_name": "ndickey/docsend_scraper",
"src_encoding": "UTF-8",
"text": "'use strict';\n\nconst react_render = React.createElement\n\n// requires downloadjs\nfunction downloadFileNow(url, callbackfunc, file_data) {\n var data = new FormData();\n data.append( \"json\", JSON.stringify( file_data ) );\n \n return fetch(url, {method: \"POST\", body: data})\n .then(\n (resp) => {\n if (!resp.ok) {\n return undefined\n } else {\n callbackfunc()\n return resp.blob()\n }\n }\n ).then(function(blob) {\n if (blob)\n download(blob, file_data.file_id + \".pdf\")\n })\n}\n\n\n// requires downloadjs\nfunction downloadFile(url, file_data, callbackfunc = () => {}, error_handler = () => {}) {\n if (url && file_data) {\n \n return fetch(`/now/${file_data.file_id}`, {method: \"POST\", body: JSON.stringify( file_data )}).then(\n (resp) => {\n if (!resp.ok)\n throw resp\n\n callbackfunc()\n return resp.blob()\n }).then(\n (blob) => {\n if (blob)\n download(blob, file_data.file_id + \".pdf\")\n }).catch(\n (err) => {\n console.log(err)\n return err.json()\n .then(\n (json_error) => {\n error_handler(json_error.error, err)\n }\n ).catch(() => {\n error_handler(\"unknown error\", {})})\n })\n }\n}\n\nclass FormGroup extends React.Component {\n\n render() {\n var children = []\n if (this.props.labeltext)\n children = [react_render('label', {className: \"control-label col-sm-2\", key: \"cc_\" + this.props.labeltext, htmlFor: this.props.for}, this.props.labeltext)]\n children.push(\n react_render('div', {key: \"c_\" + this.props.labeltext, className: this.props.className || \"col-sm-10\"}, this.props.children)\n )\n\n return react_render('div', {className: 'form-group has-feedback', key: this.props.labeltext}, children)\n }\n}\n\n\nconst createFormElement = (inputElement, formGroupData) => {\n return react_render(FormGroup, formGroupData, inputElement)\n}\n\nconst createScrapeButton = (onClickFunction) => {\n return createFormElement(\n react_render('button',\n { onClick: onClickFunction, type: \"submit\", id:\"submit\", className: \"btn btn-primary btn-med\" },\n 'Scrape'\n ),\n {key: \"submit_btn\", className: \"col-sm-offset-2 col-sm-10\"}\n )\n}\n\nclass SinglePageForm extends React.Component {\n\n constructor(props) {\n super(props)\n this.state = { download_msg: \"\" }\n this.form_ref = React.createRef()\n }\n\n updateMsg(url, buttonRef, loading = true, msg = null) {\n let msg_txt = msg || `Downloading from url: ${url} ...`;\n\n if (url && !loading) {\n msg_txt = msg || \"Download complete.\"\n } else if (!url) {\n msg_txt = msg || \"Invalid data\"\n }\n\n this.setState((prevState) => {\n return {download_msg: msg_txt}\n })\n\n buttonRef.disabled = loading\n }\n\n onInputChange(term) {\n this.setState({ term });\n }\n onclick2(event) {\n return false;\n }\n onclick(event) {\n if (this.form_ref.current.checkValidity()) {\n event.preventDefault()\n event.persist()\n\n let formdata = this.form_ref.current\n if (formdata && formdata.url && formdata.url.value && formdata.emailad && formdata.emailpass) {\n let file_id = null\n var re = /https\\:\\/\\/docsend.com\\/view\\/([A-Za-z0-9]+)/\n let matches = re.exec(formdata.url.value)\n if (matches.length >= 1) {\n file_id = matches[1]\n }\n\n let download_data = {\n url: formdata.url.value,\n email: formdata.emailad.value,\n password: formdata.emailpass.value,\n file_id: file_id\n }\n // console.log(\"sending\", download_data)\n\n this.updateMsg(formdata.url.value, event.target)\n let callback = () => this.updateMsg(formdata.url.value, event.target, false)\n let on_error = (msg, response) => {\n // console.log(response)\n this.updateMsg(null, event.target, false, msg || \"unknown error\")\n }\n downloadFile('/now', download_data, callback, on_error)\n\n } else {\n this.updateMsg(null, event.target, false)\n }\n }\n return false;\n }\n\n render() {\n let input_defaults = {type: \"text\", className:\"form-control\"}\n\n let msg_box = react_render('div', null, this.state.download_msg)\n\n let link_pattern = \"^https\\:\\/\\/docsend\\.com\\/view\\/[A-Za-z0-9]+$\"\n\n let input1 = react_render('input', {...input_defaults, pattern: link_pattern, type: \"url\", id: \"url\", name: \"url\", placeholder: \"enter link, i.e. https://docsend.com/view/p8jxsqr\", required: true})\n let input2 = react_render('input', {...input_defaults, type: \"email\", id: \"emailad\", name: \"emailad\", placeholder: \"enter email if needed ...\"})\n let input3 = react_render('input', {...input_defaults, id: \"emailpass\", name: \"emailpass\", placeholder: \"enter password if needed ...\"})\n\n return react_render('form', {ref: this.form_ref, role: \"form\", className: \"needs-validation form-horizontal\" },\n [\n createFormElement(input1, {key: \"url\", for: \"url\", labeltext: \"Link:\"}),\n createFormElement(input2, {key: \"emailad\", for: \"emailad\", labeltext: \"Email Address:\"}),\n createFormElement(input3, {key: \"pwd\", for: \"pwd\", labeltext: \"Docsend Password:\"}),\n createFormElement(msg_box, {key: \"txt\", for: \"txt\", labeltext: \" \"}),\n createScrapeButton(this.onclick.bind(this)),\n ]\n )\n }\n }\n\nclass ScraperApp extends React.Component {\n\n render() {\n return react_render(SinglePageForm)\n }\n\n }\n"
},
{
"alpha_fraction": 0.7197231650352478,
"alphanum_fraction": 0.7301037907600403,
"avg_line_length": 29.964284896850586,
"blob_id": "67b6996b3f27ab768813aa4d69fe005f2ff46782",
"content_id": "26ec915b2b0acced9e452f6cd36ef6555bb850a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 867,
"license_type": "no_license",
"max_line_length": 137,
"num_lines": 28,
"path": "/Dockerfile",
"repo_name": "ndickey/docsend_scraper",
"src_encoding": "UTF-8",
"text": "FROM python:3.6.0\n\n# RUN apt-get update -y\n# RUN apt-get install -y wget xvfb unzip\n# RUN wget -q -O - https://dl-ssl.google.com/linux/linux_signing_key.pub | apt-key add -\n# RUN echo \"deb http://dl.google.com/linux/chrome/deb/ stable main\" >> /etc/apt/sources.list.d/google.list\n# RUN apt-get update -y\n# RUN apt-get install -f\n# RUN apt-get install -y google-chrome-stable\n#\n# ENV CHROMEDRIVER_VERSION 2.41\n# ENV CHROMEDRIVER_DIR /chromedriver\n# RUN mkdir $CHROMEDRIVER_DIR\n#\n# RUN wget -q --continue -P $CHROMEDRIVER_DIR \"http://chromedriver.storage.googleapis.com/$CHROMEDRIVER_VERSION/chromedriver_linux64.zip\"\n# RUN unzip $CHROMEDRIVER_DIR/chromedriver* -d $CHROMEDRIVER_DIR\n#\n# # Put Chromedriver into the PATH\n# ENV PATH $CHROMEDRIVER_DIR:$PATH\n\nRUN mkdir -p /api\n\nADD ./api/requirements.txt /\nRUN pip3 install -r /requirements.txt\n\nWORKDIR /api\n\nADD ./api .\n"
}
] | 5 |
siddhesh-vartak98/Count-color-ball-python-game | https://github.com/siddhesh-vartak98/Count-color-ball-python-game | e24efe7ba35f8d54e684de791acea5d028535948 | 794635905bcb24a62581116e0ba3beaeecb880b5 | 3ac4ed6526c3b7adb0d299a386b3b336bf3a6838 | refs/heads/master | 2022-11-11T04:06:06.428842 | 2020-06-27T11:18:06 | 2020-06-27T11:18:06 | 275,346,092 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7681159377098083,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 102,
"blob_id": "926ff07128e659f98e1326b7343a78f734b824a3",
"content_id": "75fdf903b7a6b5adeead122973bcdf988f9ee71e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 207,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 2,
"path": "/README.md",
"repo_name": "siddhesh-vartak98/Count-color-ball-python-game",
"src_encoding": "UTF-8",
"text": "# Count-color-ball-python-game\nThis program has three basic levels. We have to select one level. This program we have 10 sec to count the RGB colour ball. And then write down in text box of respective one. \n"
},
{
"alpha_fraction": 0.497964084148407,
"alphanum_fraction": 0.5585628747940063,
"avg_line_length": 27.195804595947266,
"blob_id": "fb86cb67ae92b26db87f26b50dfb14cbaaeb6f35",
"content_id": "d881d1d9be8b75c76eaeef964aa481cf4215f63a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4175,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 143,
"path": "/frameGameCountColor.py",
"repo_name": "siddhesh-vartak98/Count-color-ball-python-game",
"src_encoding": "UTF-8",
"text": "from tkinter import *\r\nfrom tkinter import messagebox\r\nfrom tkinter import ttk\r\nimport random\r\nimport time\r\nimport pygame\r\npygame.font.init()\r\n\r\ncolorset=['blue','red','yellow','pink','green','black','red','pink','green','black']\r\nglobal i\r\ni=0\r\nglobal redcount\r\nredcount=0\r\nglobal greencount\r\ngreencount=0 \r\nglobal canvas \r\nglobal canvas1 \r\nglobal canvas2\r\nglobal var\r\n\r\ndef startgame():\r\n global canvas \r\n s=startclick()\r\n if s==1:\r\n time.sleep(5)\r\n messagebox.showinfo(\"answer\",\"number of red ball:\"+str(redcount)+\"number of grren ball:\"+str(greencount))\r\n t=txt1.get()\r\n t1=txt2.get()\r\n if (t==redcount and t1==greencount):\r\n messagebox.showinfo(\"your answer\",\"your answer match\")\r\n else:\r\n messagebox.showinfo(\"your answer\",\"your answer not match\")\r\n \r\n\r\ndef countDown():\r\n '''start countdown 10 seconds before new year starts'''\r\n\r\n lbl1.config(height=3, font=('times', 20, 'bold'))\r\n for k in range(10, 0, -1):\r\n lbl1[\"text\"] = k\r\n root.update()\r\n time.sleep(1)\r\n lbl1.config(bg='red')\r\n lbl1.config(fg='white')\r\n lbl1[\"text\"] = \"Happy new year!\"\r\n return mat\r\n \r\ndef startclick():\r\n global i \r\n global canvas\r\n global canvas2\r\n global canvas3\r\n global var\r\n global redcount \r\n global greencount\r\n v=var.get()\r\n if v==1:\r\n for j in range(1,26):\r\n for i in range(1,26):\r\n m=random.randint(0,10)\r\n if m==1 or m==6:\r\n redcount=redcount+1\r\n if m==4 or m==8:\r\n greencount=greencount+1\r\n try:\r\n a=random.randint(50,250)\r\n b=random.randint(50,300)\r\n canvas.create_oval(a,b,a+50,b+50,outline=\"white\",fill=colorset[m])\r\n canvas.update()\r\n except:\r\n print()\r\n elif v==2:\r\n for j in range(1,35):\r\n for i in range(1,35):\r\n m=random.randint(0,10)\r\n if m==1 or m==6:\r\n redcount=redcount+1\r\n if m==4 or m==8:\r\n greencount=greencount+1\r\n try:\r\n a=random.randint(50,250)\r\n b=random.randint(50,300)\r\n canvas.create_oval(a,b,a+50,b+50,outline=\"white\",fill=colorset[m])\r\n canvas.update()\r\n except:\r\n print()\r\n elif v==3:\r\n for j in range(1,50):\r\n for i in range(1,50):\r\n m=random.randint(0,10)\r\n if m==1 or m==6:\r\n redcount=redcount+1\r\n if m==4 or m==8:\r\n greencount=greencount+1\r\n try:\r\n a=random.randint(50,250)\r\n b=random.randint(50,300)\r\n canvas.create_oval(a,b,a+50,b+50,outline=\"white\",fill=colorset[m])\r\n canvas.update()\r\n except:\r\n print()\r\n return(1)\r\n \r\nroot=Tk()\r\n\r\nroot.title(\"count the color \")\r\nroot.geometry(\"800x650+20+20\")\r\ncanvas=Canvas(width=500,height=500,bg='#89ceeb')\r\ncanvas.place(x=20,y=20)\r\nprint(time)\r\nw=Label(root,text=\"can you count the color ball ?\",bg=\"black\",fg=\"yellow\")\r\nw.place(x=20,y=500)\r\ny=Label(root,text=\"you have 10 sec to answer the quiz\",bg=\"black\",fg=\"red\")\r\ny.place(x=20,y=550)\r\n\r\n\r\n\r\nb=Button(root,text=\"LOGIN\",bg='#e79700',width=15,height=1,font=(\"Open Sans\",13,'bold'),fg='white',command=startgame)\r\nb.place(x=20,y=600)\r\n\r\ncanvas1=Canvas(width=300,height=300,bg='#ee7600')\r\ncanvas1.place(x=540,y=299)\r\n\r\nd=Label(root,text=\"enter the red ball count:\",bg=\"red\",fg=\"black\")\r\nd.place(x=600,y=300)\r\ntxt1=Entry(root,width=8)\r\ntxt1.place(x=600,y=325)\r\n\r\nd=Label(root,text=\"enter the green ball count:\",bg=\"green\",fg=\"black\")\r\nd.place(x=601,y=350)\r\ntxt2=Entry(root,width=8)\r\ntxt2.place(x=600,y=375)\r\n\r\n\r\ncanvas2=Canvas(width=300,height=200,bg='#e70066')\r\ncanvas2.place(x=540,y=30)\r\nvar = IntVar() \r\nvar.set(\"Radio\")\r\nRadiobutton(root, text='Easy', variable=var, value=1).place(x=548,y=50)\r\nRadiobutton(root, text='Mediam', variable=var, value=2).place(x=548,y=85)\r\nRadiobutton(root, text='Hard', variable=var, value=3).place(x=548,y=120)\r\n\r\nroot.mainloop()\r\n"
}
] | 2 |
SPawson/python-TTD-challenges | https://github.com/SPawson/python-TTD-challenges | 9c94e31ed0cd23312e5a646b3660ef8465310024 | ccd02431499aafa4a15263f21fae76c39e268caf | 92a44261410dc36965ec5bd3345e15f7af186356 | refs/heads/master | 2020-06-10T00:47:35.240339 | 2019-06-27T17:43:15 | 2019-06-27T17:43:15 | 193,538,599 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5182926654815674,
"alphanum_fraction": 0.5541158318519592,
"avg_line_length": 33.55263137817383,
"blob_id": "e7030b48dea1325ac240e83e5b3975317b43b7bd",
"content_id": "dc2a68ef6adbb98e5f65db5502d19c7a901d6b1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1312,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 38,
"path": "/evens-challenge.py",
"repo_name": "SPawson/python-TTD-challenges",
"src_encoding": "UTF-8",
"text": "def even_number_of_evens(numbers):\n length = len(numbers)\n \n if length == 0:\n return False\n elif length== 1:\n if numbers[0] % 2 == 0:\n return False\n else:\n return False\n else:\n even_count = 0\n for num in numbers:\n if num%2 == 0:\n even_count += 1\n\n if length == 2 and even_count == 2:\n return True\n elif length == 2 and even_count == 1:\n return False\n elif length > 2 and even_count == 3:\n return False \n elif length > 2 and even_count == 4:\n return True \n else:\n return False\n \n \nassert even_number_of_evens([]) == False, \"No numbers\"\nassert even_number_of_evens([1]) == False, \"One number\"\nassert even_number_of_evens([2]) == False, \"One even number\"\nassert even_number_of_evens([2, 4]) == True, \"Two even numbers\"\nassert even_number_of_evens([2, 3]) == False, \"Two numbers, only one even\"\nassert even_number_of_evens([2, 3, 9, 10, 13, 7, 8]) == False, \"Multiple numbers, three are even\"\nassert even_number_of_evens([2, 3, 9, 10, 13, 7, 8, 5, 12]) == True, \"Multiple numbers, four are even\"\nassert even_number_of_evens([1, 3, 9]) == False, \"No even numbers\"\n\nprint(\"All tests completed successfully\")"
},
{
"alpha_fraction": 0.6385542154312134,
"alphanum_fraction": 0.6532797813415527,
"avg_line_length": 36.349998474121094,
"blob_id": "7130575280c1dff23a54bd946df687f7880b1ef9",
"content_id": "3707e9347d9238b9720ac1ffda5dc276ba965b76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 747,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 20,
"path": "/byotest.py",
"repo_name": "SPawson/python-TTD-challenges",
"src_encoding": "UTF-8",
"text": "def test_are_equal(actual,expected):\n assert expected == actual,\"Expected {0}, instead got {1}\".format(expected,actual)\n \ndef test_not_equal(a,b):\n assert a != b, \"Did not expect {0}, but got {1}\".format(a,b)\n \ndef test_is_in(collection,item):\n assert item in collection, \"{0} does not contain the item {1}\".format(collection,item)\n \ndef test_isnt_in(collection,item):\n assert item not in collection, \"{0} does contain the item {1}\".format(collection,item)\n\ndef between(min,max,value):\n if value >= min and value <= max:\n return True\n else:\n return False\n \ndef test_between(min,max,value):\n assert between(min,max,value) == True, \"The number {0} is not between {1} and {2}\".format(value,min,max)\n"
},
{
"alpha_fraction": 0.6708661317825317,
"alphanum_fraction": 0.6803149580955505,
"avg_line_length": 29.285715103149414,
"blob_id": "c1222e2a5de0800f262998b25e3891a2f3eb14a5",
"content_id": "98969c553e78cf651d22d412cce62542c2d9b278",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 635,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 21,
"path": "/counter.py",
"repo_name": "SPawson/python-TTD-challenges",
"src_encoding": "UTF-8",
"text": "def capital_counter(message):\n count = 0\n \n for c in message:\n if c.isupper():\n count+= 1\n return count\n \nvar = capital_counter(\"Hello My Name Is Sam\")\n\ntestMessage = \"Hello My Name Is Samuel J Pawson\"\ntestMessageAmount = capital_counter(testMessage)\n\n\nassert capital_counter(\"\") == 0, \"Empty message\"\nassert capital_counter(\"AD\") == 2, \"Counting more than one upper\"\nassert capital_counter(\"ad\") == 0, \"counting upper when there is none\"\nassert capital_counter(\"@$%^\") == 0, \"Special chars counted\"\nassert capital_counter(testMessage) == testMessageAmount, \"Not all uppers counted\"\n\nprint(\"All tests complete\")"
},
{
"alpha_fraction": 0.5726587772369385,
"alphanum_fraction": 0.6426264643669128,
"avg_line_length": 30,
"blob_id": "afc77e047d8feadeafa4ae1205d906b1401a7c28",
"content_id": "14989266c0e9c4bab675abe7b9058992e5ac0ab0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 929,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 30,
"path": "/vending-machine.py",
"repo_name": "SPawson/python-TTD-challenges",
"src_encoding": "UTF-8",
"text": "from byotest import*\n\nusd_coins = [100,50,25,10,5,2,1]\neur_coins = [100,50,20,10,5,2,1]\n\n#Get change function\ndef get_change(amount,coin_list=eur_coins):\n change = []\n for coin in coin_list:\n while coin <= amount:\n amount -= coin\n change.append(coin)\n return change \n \n \n#Tests\ntest_are_equal(get_change(0,eur_coins),[])\ntest_are_equal(get_change(1,eur_coins),[1])\ntest_are_equal(get_change(2,eur_coins),[2])\ntest_are_equal(get_change(5,eur_coins),[5])\ntest_are_equal(get_change(10,eur_coins),[10])\ntest_are_equal(get_change(20,eur_coins),[20])\ntest_are_equal(get_change(50,eur_coins),[50])\ntest_are_equal(get_change(100,eur_coins),[100])\ntest_are_equal(get_change(3,eur_coins),[2,1])\ntest_are_equal(get_change(7,eur_coins),[5,2])\ntest_are_equal(get_change(9,eur_coins),[5,2,2])\ntest_are_equal(get_change(75,usd_coins),[50,25])\n\nprint(\"All tests passed!\")"
}
] | 4 |
MarioProjects/ensemble_analysis | https://github.com/MarioProjects/ensemble_analysis | cbae4361f26dad015b7cdf938a6dd216743fcd42 | 65a9daa0165ec0302d681208db2c1c4b4cfe1206 | 1c69a8a92ac6e5e1278ff6060e7be784d8a1d294 | refs/heads/main | 2023-03-01T18:44:38.475392 | 2021-01-22T12:32:07 | 2021-01-22T12:32:07 | 316,925,270 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6237331032752991,
"alphanum_fraction": 0.6364020109176636,
"avg_line_length": 37.819671630859375,
"blob_id": "456e0ad62240f28898912de88aca41de0be0ccfd",
"content_id": "37d83c916bc6af4c9d72974e2abe119f304a4458",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2368,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 61,
"path": "/utils/dataloaders/__init__.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "from torch.utils.data import DataLoader\n\nfrom utils.dataloaders.cifar10 import CIFAR10Dataset\nfrom utils.dataloaders.cifar100 import CIFAR100Dataset\n\n\ndef dataset_selector(train_aug, val_aug, args, is_test=False, data_prefix=\"\"):\n if args.dataset == \"CIFAR10\":\n if is_test:\n test_dataset = CIFAR10Dataset(\n mode=\"test\", transform=val_aug, normalization=args.normalization, data_prefix=data_prefix\n )\n\n return DataLoader(\n test_dataset, batch_size=args.batch_size, shuffle=False, pin_memory=True, drop_last=False\n )\n\n train_dataset = CIFAR10Dataset(\n mode=\"train\", transform=train_aug, normalization=args.normalization, data_prefix=data_prefix\n )\n train_loader = DataLoader(\n train_dataset, batch_size=args.batch_size, pin_memory=True, shuffle=True\n )\n\n val_dataset = CIFAR10Dataset(\n mode=\"validation\", transform=val_aug, normalization=args.normalization, data_prefix=data_prefix\n )\n val_loader = DataLoader(\n val_dataset, batch_size=args.batch_size, pin_memory=True, shuffle=False, drop_last=False\n )\n\n elif args.dataset == \"CIFAR100\":\n if is_test:\n test_dataset = CIFAR100Dataset(\n mode=\"test\", transform=val_aug, normalization=args.normalization, data_prefix=data_prefix\n )\n\n return DataLoader(\n test_dataset, batch_size=args.batch_size, shuffle=False, pin_memory=True, drop_last=False\n )\n\n train_dataset = CIFAR100Dataset(\n mode=\"train\", transform=train_aug, normalization=args.normalization, data_prefix=data_prefix\n )\n train_loader = DataLoader(\n train_dataset, batch_size=args.batch_size, pin_memory=True, shuffle=True\n )\n\n val_dataset = CIFAR100Dataset(\n mode=\"validation\", transform=val_aug, normalization=args.normalization, data_prefix=data_prefix\n )\n val_loader = DataLoader(\n val_dataset, batch_size=args.batch_size, pin_memory=True, shuffle=False, drop_last=False\n )\n\n else:\n assert False, f\"Unknown dataset '{args.dataset}'\"\n\n print(f\"Train dataset len: {len(train_dataset)}\")\n print(f\"Validation dataset len: {len(val_dataset)}\")\n return train_loader, val_loader\n"
},
{
"alpha_fraction": 0.8613861203193665,
"alphanum_fraction": 0.8613861203193665,
"avg_line_length": 10.941176414489746,
"blob_id": "24c262095ede4a79761a2112583ed90a3b32d577",
"content_id": "1cd9d95bcd4c3c9199289d7a8e604d1a93a84932",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 17,
"path": "/requirements.txt",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "numpy\nscipy\npandas\nnibabel\nalbumentations\nsklearn\nscikit-learn\npytorchcv\nmatplotlib\nopencv-python\nPillow\ntqdm\nscikit-image\npydicom\npretty_errors\ntorch\ngit+https://github.com/ildoonet/pytorch-randaugment"
},
{
"alpha_fraction": 0.5670859813690186,
"alphanum_fraction": 0.579402506351471,
"avg_line_length": 34.33333206176758,
"blob_id": "838470aaeb9649a399d74e9d30ccc89f28009f9f",
"content_id": "4ae363bfc9ecc8c622c4bda658ed5c947f344b3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3816,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 108,
"path": "/utils/metrics.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "import os\nfrom utils.general import dict2df\nimport numpy as np\nimport torch\n\nAVAILABLE_METRICS = (\"accuracy\")\n\n\nclass MetricsAccumulator:\n \"\"\"\n Tendremos una lista de metricas que seran un dicccionario\n al hacer el print mostrara el promedio para cada metrica\n Ejemplo metrics 2 epochs con 2 clases:\n {\"iou\": [[0.8, 0.3], [0.9, 0.7]], \"dice\": [[0.76, 0.27], [0.88, 0.66]]}\n \"\"\"\n\n def __init__(self, problem_type, metric_list):\n \"\"\"\n\n Args:\n problem_type:\n metric_list:\n \"\"\"\n if problem_type not in [\"classification\"]:\n assert False, f\"Unknown problem type: '{problem_type}', please specify a valid one!\"\n self.problem_type = problem_type\n\n if metric_list is None or not isinstance(metric_list, list):\n assert False, \"Please, you need to specify a metric [list]\"\n\n diffmetrics = np.setdiff1d(metric_list, AVAILABLE_METRICS)\n if len(diffmetrics):\n assert False, f\"'{diffmetrics}' metric(s) not implemented.\"\n\n self.metric_list = metric_list\n self.metric_methods_args = {}\n self.metrics_helpers = {}\n self.metric_methods = self.__metrics_init__()\n self.metrics = {metric_name: [] for metric_name in metric_list}\n self.is_updated = True\n\n def __metrics_init__(self):\n metric_methods = []\n for metric_str in self.metric_list:\n if metric_str in [\"accuracy\"]:\n self.metric_methods_args[metric_str] = {}\n metric_methods.append(compute_accuracy)\n self.metrics_helpers[\"accuracy_best_method\"] = \"max\"\n self.metrics_helpers[\"accuracy_best_value\"] = -1\n\n return metric_methods\n\n def record(self, prediction, target):\n\n if self.is_updated:\n for key in self.metrics:\n self.metrics[key].append([])\n self.is_updated = False\n\n for indx, metric in enumerate(self.metric_methods):\n self.metrics[self.metric_list[indx]][-1] += [\n metric(target, prediction, **self.metric_methods_args[self.metric_list[indx]])]\n\n def update(self):\n \"\"\"\n CALL THIS METHOD AFTER RECORD ALL SAMPLES / AFTER EACH EPOCH\n We have accumulated metrics along different samples/batches and want to average accross that same epoch samples:\n {'accuracy': [[[0.8, 0.6, 0.3, 0.5]]]} -> {'accuracy': [[0.55]]}\n \"\"\"\n for key in self.metrics:\n\n self.metrics[key][-1] = np.mean(self.metrics[key][-1])\n mean_metric_value = self.metrics[key][-1]\n\n if self.metrics_helpers[f\"{key}_best_value\"] < mean_metric_value:\n self.metrics_helpers[f\"{key}_best_value\"] = mean_metric_value\n self.metrics_helpers[f\"{key}_is_best\"] = True\n else:\n self.metrics_helpers[f\"{key}_is_best\"] = False\n\n self.is_updated = True\n\n def report_best(self):\n for key in self.metrics:\n print(\"\\t- {}: {}\".format(key, self.metrics_helpers[f\"{key}_best_value\"]))\n\n def mean_value(self, metric_name):\n return self.metrics[metric_name][-1][-1]\n\n def __str__(self, precision=3):\n output_str = \"\"\n for metric_key in self.metric_list:\n output_str += '{:{align}{width}.{prec}f} | '.format(\n self.metrics[metric_key][-1], align='^', width=len(metric_key), prec=3\n )\n\n if self.metrics_helpers[f\"{metric_key}_is_best\"]:\n output_str += \"*\"\n\n return output_str\n\n\ndef compute_accuracy(y_true, y_pred):\n # Standard accuracy metric computed over all classes\n _, predicted = torch.max(y_pred.data, 1)\n total = y_true.size(0)\n correct = (predicted == y_true).sum().item()\n return correct / total\n"
},
{
"alpha_fraction": 0.49604639410972595,
"alphanum_fraction": 0.5513969659805298,
"avg_line_length": 46.42499923706055,
"blob_id": "3b72714af136dd8cb6afc77cfa40509746029b68",
"content_id": "aa731d9e9c2ebcf8648766bf9be7765a5c3e0fee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3794,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 80,
"path": "/utils/dataloaders/cifar100.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "import torch\nimport os\nimport numpy as np\nfrom torch.utils.data import Dataset\nimport albumentations\n\nimport utils.dataloaders.utils as d\n\n\nclass CIFAR100Dataset(Dataset):\n \"\"\"\n Dataset CIFAR100.\n https://www.cs.toronto.edu/~kriz/cifar.html\n \"\"\"\n\n def __init__(self, mode, transform, normalization=\"statistics\", data_prefix=\"\"):\n \"\"\"\n :param mode: (string) Dataset mode in [\"train\", \"validation\"]\n :param transform: (list) List of transforms applied to image and mask\n :param normalization: (str) Normalization mode. One of 'reescale', 'standardize', 'statistics'\n \"\"\"\n\n if mode not in [\"train\", \"validation\", \"test\"]:\n assert False, \"Unknown mode '{}'\".format(mode)\n\n if normalization not in ['reescale', 'standardize', 'statistics']:\n assert False, \"Unknown normalization '{}'\".format(normalization)\n\n self.base_dir = os.path.join(data_prefix, \"data\", \"CIFAR100\")\n self.include_background = False\n self.img_channels = 3\n self.class_to_cat = {\n 0: 'apple', 1: 'aquarium_fish', 2: 'baby', 3: 'bear', 4: 'beaver', 6: 'bee', 7: 'beetle', 8: 'bicycle',\n 9: 'bottle', 10: 'bowl', 11: 'boy', 12: 'bridge', 13: 'bus', 14: 'butterfly', 15: 'camel', 16: 'can',\n 17: 'castle', 18: 'caterpillar', 19: 'cattle', 20: 'chair', 21: 'chimpanzee', 22: 'clock', 23: 'cloud',\n 24: 'cockroach', 25: 'couch', 26: 'crab', 27: 'crocodile', 28: 'cup', 29: 'dinosaur', 30: 'dolphin',\n 31: 'elephant', 32: 'flatfish', 33: 'forest', 34: 'fox', 35: 'girl', 36: 'hamster', 37: 'house',\n 38: 'kangaroo', 39: 'keyboard', 40: 'lamp', 41: 'lawn_mower', 42: 'leopard', 43: 'lion', 44: 'lizard',\n 45: 'lobster', 46: 'man', 47: 'maple_tree', 48: 'motorcycle', 49: 'mountain', 50: 'mouse', 51: 'mushroom',\n 52: 'oak_tree', 53: 'orange', 54: 'orchid', 55: 'otter', 56: 'palm_tree', 57: 'pear', 58: 'pickup_truck',\n 59: 'pine_tree', 60: 'plain', 61: 'plate', 62: 'poppy', 63: 'porcupine', 64: 'possum', 65: 'rabbit',\n 66: 'raccoon', 67: 'ray', 68: 'road', 69: 'rocket', 70: 'rose', 71: 'sea', 72: 'seal', 73: 'shark',\n 74: 'shrew', 75: 'skunk', 76: 'skyscraper', 77: 'snail', 78: 'snake', 79: 'spider', 80: 'squirrel',\n 81: 'streetcar', 82: 'sunflower', 83: 'sweet_pepper', 84: 'table', 85: 'tank', 86: 'telephone',\n 87: 'television', 88: 'tiger', 89: 'tractor', 90: 'train', 91: 'trout', 92: 'tulip', 93: 'turtle',\n 94: 'wardrobe', 95: 'whale', 96: 'willow_tree', 97: 'wolf', 98: 'woman', 99: 'worm'\n }\n self.num_classes = 100\n\n if mode == \"train\":\n data = np.load(os.path.join(self.base_dir, \"x_train.npy\"))\n labels = np.load(os.path.join(self.base_dir, \"y_train.npy\"))\n data = data[:int(len(data) * .90)]\n labels = labels[:int(len(labels) * .90)]\n elif mode == \"validation\":\n data = np.load(os.path.join(self.base_dir, \"x_train.npy\"))\n labels = np.load(os.path.join(self.base_dir, \"y_train.npy\"))\n data = data[int(len(data) * .90):]\n labels = labels[int(len(labels) * .90):]\n else: # mode == test\n data = np.load(os.path.join(self.base_dir, \"x_test.npy\"))\n labels = np.load(os.path.join(self.base_dir, \"y_test.npy\"))\n\n self.labels = labels\n self.data = data\n self.mode = mode\n self.normalization = normalization\n\n self.transform = transform\n\n def __len__(self):\n return len(self.data)\n\n def __getitem__(self, idx):\n\n image = self.data[idx]\n label = self.labels[idx]\n image = self.transform(image)\n\n return {\"image\": image, \"label\": label}\n"
},
{
"alpha_fraction": 0.5305416584014893,
"alphanum_fraction": 0.555897057056427,
"avg_line_length": 33.7066650390625,
"blob_id": "3547737ea8085638cddf5145809924f0b35e8edf",
"content_id": "8e053dbeeff76832396b26cabbad94df2292e2ef",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2603,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 75,
"path": "/utils/data_augmentation.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "\"\"\" --- DATA AUGMENTATION METHODS --- \"\"\"\n\nfrom RandAugment.augmentations import RandAugment, CutoutDefault\nfrom torchvision.transforms import transforms\n\n\ndef data_augmentation_selector(da_policy, cutout_size=0, randaugment=False, n=0, m=0):\n \"\"\"\n\n Args:\n da_policy:\n cutout_size: (int) If > 0 then apply cutout technique\n randaugment: (bool) Whether apply RandAugment or not [https://arxiv.org/pdf/1909.13719.pdf]\n n: (int) Number of augmentation transformations to apply sequentially.\n m: (int) Magnitude for all the transformations.\n\n Returns:\n\n \"\"\"\n if da_policy == \"cifar\":\n return cifar_da(cutout_size, randaugment, n, m)\n\n assert False, \"Unknown Data Augmentation Policy: {}\".format(da_policy)\n\n\n# ----------------------------------------------------------------------------------------- #\n# ----------------------------------------------------------------------------------------- #\n# ----------------------------------------------------------------------------------------- #\n\n\n###########################################\n# --- DATA AUGMENTATION COMBINATIONS --- #\n###########################################\n\ndef cifar_da(cutout_size=0, randaugment=False, n=0, m=0):\n \"\"\"\n\n Args:\n cutout_size: (int) If > 0 then apply cutout technique\n randaugment: (bool) Whether apply RandAugment or not [https://arxiv.org/pdf/1909.13719.pdf]\n n: (int) Number of augmentation transformations to apply sequentially.\n m: (int) Magnitude for all the transformations.\n\n Returns:\n\n \"\"\"\n print(\"Using CIFAR Data Augmentation Combinations\")\n\n _CIFAR_MEAN, _CIFAR_STD = (0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010)\n\n train_aug = transforms.Compose([\n transforms.ToPILImage(),\n transforms.RandomCrop(32, padding=4),\n transforms.RandomHorizontalFlip(),\n transforms.ToTensor(),\n transforms.Normalize(_CIFAR_MEAN, _CIFAR_STD),\n ])\n val_aug = transforms.Compose([\n transforms.ToPILImage(),\n transforms.ToTensor(),\n transforms.Normalize(_CIFAR_MEAN, _CIFAR_STD),\n ])\n\n if randaugment:\n if n == 0 or m == 0:\n assert False, f\"(RandAugment) Please, N and M should be greater than 0!\"\n print(\"Applying RandAugment!\")\n train_aug.transforms.insert(1, RandAugment(n, m))\n elif n != 0 or m != 0:\n assert False, f\"You specified RandAugment arguments but do not use RandAugment flag!\"\n\n if cutout_size > 0:\n train_aug.transforms.append(CutoutDefault(cutout_size))\n\n return train_aug, val_aug\n"
},
{
"alpha_fraction": 0.6351686120033264,
"alphanum_fraction": 0.6439321637153625,
"avg_line_length": 40.33070755004883,
"blob_id": "574cf3cd280da61efdb54f75450af46e8f9e4558",
"content_id": "8f58ef258945a5f4bea33873dda270f98960502b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10498,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 254,
"path": "/matrix_scaling.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# Usage: python matrix_scaling.py --epochs 250 --scheduler_steps 70 125 180 220 --logits_dir logits_res18_cifar10\n\nimport pretty_errors\n\n# ---- My utils ----\nfrom utils.logits import *\nfrom utils.neural import *\nfrom utils.metrics import compute_accuracy\nfrom utils.calibration import compute_calibration_metrics\nfrom torch.optim import SGD\nfrom torch.optim.lr_scheduler import MultiStepLR\n\nimport argparse\n\n\nclass SmartFormatter(argparse.HelpFormatter):\n\n def _split_lines(self, text, width):\n if text.startswith('R|'):\n return text[2:].splitlines()\n # this is the RawTextHelpFormatter._split_lines\n return argparse.HelpFormatter._split_lines(self, text, width)\n\n\nparser = argparse.ArgumentParser(description='Matrix Scaling Analysis', formatter_class=SmartFormatter)\n\nparser.add_argument('--verbose', action='store_true', help='Display or not matrix learning process')\nparser.add_argument('--epochs', type=int, default=100, help='Total number epochs for training')\nparser.add_argument('--batch_size', type=int, default=128, help='Batch Size for training')\nparser.add_argument('--learning_rate', type=float, default=0.1, help='Learning rate')\nparser.add_argument('--logits_dir', type=str, default=\"logits\", help='Logits directory')\nparser.add_argument('--scheduler_steps', '--arg', nargs='+', type=int, help='Steps for learning rate decay')\nargs = parser.parse_args()\n\npretty_errors.mono()\nverbose = args.verbose # Display or not matrix learning process\n\n# ---- Load logits ----\nlogits_dir = args.logits_dir\n\n# -> Validation Logits\nprefix = \"val_logits\"\nval_logits_paths = get_logits_paths(logits_dir, prefix)\nval_logits_list, val_labels_list, val_logits_names, _ = load_logits(val_logits_paths, get_accuracy=False)\nval_labels = val_labels_list[0]\n\n# -> Validation Avg Ensemble\nprefix = \"val_avg_ensemble\"\nval_avg_ensemble_logits_paths = get_logits_paths(logits_dir, prefix)\nval_avg_ensemble_logits_list, val_avg_ensemble_labels_list, val_avg_ensemble_logits_names, _ = load_logits(\n val_avg_ensemble_logits_paths, get_accuracy=False\n)\nval_avg_ensemble_labels = val_avg_ensemble_labels_list[0]\n\nif not (val_avg_ensemble_labels == val_labels).all():\n assert False, \"Validation logits and Validation ensemble logits should be equal!\"\n\n# -> Test Logits\nprefix = \"test_logits\"\ntest_logits_paths = get_logits_paths(logits_dir, prefix)\ntest_logits_list, test_labels_list, test_logits_names, _ = load_logits(test_logits_paths, get_accuracy=False)\ntest_labels = test_labels_list[0]\n\n# -> Test Avg Ensemble\nprefix = \"test_avg_ensemble\"\ntest_avg_ensemble_logits_paths = get_logits_paths(logits_dir, prefix)\ntest_avg_ensemble_logits_list, test_avg_ensemble_labels_list, test_avg_ensemble_logits_names, _ = load_logits(\n test_avg_ensemble_logits_paths, get_accuracy=False\n)\ntest_avg_ensemble_labels = test_avg_ensemble_labels_list[0]\n\n\n# ---- matrix SCALING ----\n# https://github.com/gpleiss/matrix_scaling/blob/master/matrix_scaling.py\nclass MatrixScaling(nn.Module):\n \"\"\"\n A thin decorator, which wraps a model with matrix scaling\n model (nn.Module):\n A classification neural network\n NB: Output of the neural network should be the classification logits, NOT the softmax (or log softmax)!\n \"\"\"\n\n def __init__(self, logits_size):\n super(MatrixScaling, self).__init__()\n self.matrix = nn.Parameter(torch.ones(logits_size))\n\n def forward(self, model_logits):\n return self.matrix * model_logits\n\n\ndef chunks(lst, n):\n \"\"\"Yield successive n-sized chunks from lst.\"\"\"\n for i in range(0, len(lst), n):\n yield lst[i:i + n]\n\n\ndef learn_matrix(model_logits, model_labels):\n # Training parameters\n criterion = nn.CrossEntropyLoss().cuda()\n if args.scheduler_steps is None:\n scheduler_steps = np.arange(0, args.epochs, args.epochs // 5)\n\n # Create 1 matrix parameter per model / val logits\n matrix = MatrixScaling(model_logits.shape[1])\n optimizer = SGD(matrix.parameters(), lr=args.learning_rate, momentum=0.9, weight_decay=5e-4)\n scheduler = MultiStepLR(optimizer, milestones=args.scheduler_steps, gamma=0.1)\n\n if verbose:\n header = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthA}} | {:{align}{widthLL}} | {:{align}{widthA}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} |\".format(\n \"Epoch\", \"LR\", \"Loss\", \"Temp Param\", \"Accuracy\", \"ECE\", \"MCE\", \"BRIER\", \"NNL\",\n align='^', widthL=8, widthLL=10, widthA=8, widthM=6,\n )\n\n print(\"\".join([\"_\"] * len(header)))\n print(header)\n print(\"\".join([\"_\"] * len(header)))\n\n for epoch in range(args.epochs):\n\n matrix.train()\n train_loss, correct, total = [], 0, 0\n c_ece, c_mce, c_brier, c_nnl = [], [], [], []\n\n for c_logits, c_labels in zip(chunks(model_logits, args.batch_size), chunks(model_labels, args.batch_size)):\n # Train\n optimizer.zero_grad()\n new_logits = matrix(c_logits)\n loss = criterion(new_logits, c_labels)\n loss.backward()\n optimizer.step()\n\n # Metrics\n train_loss.append(loss.item())\n _, predicted = new_logits.max(1)\n total += len(c_labels)\n correct += predicted.eq(c_labels).sum().item()\n\n softmax = nn.Softmax(dim=1)\n new_probs_list = softmax(new_logits)\n ece, mce, brier, nnl = compute_calibration_metrics(new_probs_list, c_labels, apply_softmax=False, bins=15)\n c_ece.append(ece)\n c_mce.append(mce)\n c_brier.append(brier.item())\n c_nnl.append(nnl.item())\n\n c_train_loss = np.array(train_loss).mean()\n c_accuracy = correct / total\n c_ece = np.array(c_ece).mean()\n c_mce = np.array(c_mce).mean()\n c_brier = np.array(c_brier).mean()\n c_nnl = np.array(c_nnl).mean()\n current_lr = get_current_lr(optimizer)\n\n if verbose:\n line = \"| {:{align}{widthL}} | {:{align}{widthA}.6f} | {:{align}{widthA}.4f} | {:{align}{widthLL}.4f} | {:{align}{widthA}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} |\".format(\n epoch + 1, current_lr, c_train_loss, matrix.matrix.item(), c_accuracy, c_ece, c_mce,\n c_brier,\n c_nnl,\n align='^', widthL=8, widthA=8, widthM=6, widthLL=10\n )\n print(line)\n\n scheduler.step()\n\n return matrix\n\n\nmatrices_val = []\nprint(f\"Validation Logits -> Calculating matrix for {len(val_logits_list)} models...\")\nfor indx, val_model_logits in enumerate(val_logits_list):\n matrices_val.append(learn_matrix(val_model_logits, val_labels))\n print(f\"Model {indx} done!\")\nprint(\"-- Finished --\\n\")\n\nmatrices_avg_ensemble = []\nprint(f\"Validation Logits Ensemble Avg -> Calculating matrix for {len(val_avg_ensemble_logits_list)} models...\")\nfor indx, val_model_logits in enumerate(val_avg_ensemble_logits_list):\n matrices_avg_ensemble.append(learn_matrix(val_model_logits, val_labels))\n print(f\"Ensemble Avg {indx} done!\")\nprint(\"-- Finished --\\n\")\n\n\n# ---- Display Results ----\ndef display_results(logits_names, logits_list, labels, matrices, avg=True, get_logits=False):\n softmax = nn.Softmax(dim=1)\n width_methods = max(len(\"Avg probs ensemble\"), max([len(x) for x in logits_names]))\n\n header = \"\\n| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} |\".format(\n \"Method\", \"Accuracy\", \"ECE\", \"MCE\", \"BRIER\", \"NNL\", align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(\"\".join([\"_\"] * len(header)))\n print(header)\n print(\"\".join([\"_\"] * len(header)))\n probs_list, t_logits = [], []\n for indx, logit_name in enumerate(logits_names):\n # Scale with learned matrix parameter the logits\n matrices[indx].eval()\n logits = matrices[indx](logits_list[indx])\n t_logits.append(logits)\n # Compute metrics\n accuracy = compute_accuracy(labels, logits)\n probs = softmax(logits)\n probs_list.append(probs)\n ece, mce, brier, nnl = compute_calibration_metrics(probs, labels, apply_softmax=False, bins=15)\n # Display\n line = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} |\".format(\n logit_name, accuracy, ece, mce, brier, nnl, align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(line)\n\n # ---- Ensemble Strategies: Average ----\n if avg:\n probs_list = torch.stack(probs_list)\n probs_avg = probs_list.sum(dim=0) / len(probs_list)\n probs_avg_accuracy = compute_accuracy(labels, probs_avg)\n ece, mce, brier, nnl = compute_calibration_metrics(probs_avg, labels, apply_softmax=False, bins=15)\n line = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} |\".format(\n \"Avg probs ensemble\", probs_avg_accuracy, ece, mce, brier, nnl,\n align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(line)\n if get_logits:\n return torch.stack(t_logits)\n\n\n# --- Avg ensemble\nval_cal_logits = display_results(val_logits_names, val_logits_list, val_labels, matrices_val, get_logits=True)\nval_cal_logits_ensemble = val_cal_logits.detach().sum(dim=0)\ntest_cal_logits = display_results(test_logits_names, test_logits_list, test_labels, matrices_val, get_logits=True)\ntest_cal_logits_ensemble = test_cal_logits.detach().sum(dim=0)\n\n# --- Avg ensemble T\nprint(\"\\n\\n--- Avg ensemble T ---\")\ndisplay_results(\n val_avg_ensemble_logits_names, val_avg_ensemble_logits_list, val_labels, matrices_avg_ensemble, avg=False\n)\ndisplay_results(\n test_avg_ensemble_logits_names, test_avg_ensemble_logits_list, test_labels, matrices_avg_ensemble, avg=False\n)\n\n# --- Avg ensemble CT\nprint(\"\\n\\n--- Avg ensemble CT ---\")\nmatrices_avg_ensemble = []\nval_ct_temp = [learn_matrix(val_cal_logits_ensemble, val_labels)]\n\ndisplay_results(\n [\"val_ct_avg_ensemble_logits\"], val_cal_logits_ensemble.unsqueeze(0), val_labels, val_ct_temp, avg=False\n)\ndisplay_results(\n [\"test_ct_avg_ensemble_logits\"], test_cal_logits_ensemble.unsqueeze(0), test_labels, val_ct_temp, avg=False\n)\n"
},
{
"alpha_fraction": 0.6048480868339539,
"alphanum_fraction": 0.6207376718521118,
"avg_line_length": 30.81549835205078,
"blob_id": "abc53efa5ee0370481658de06b717de7d2171706",
"content_id": "f2e6137094e93b63d3671d1a91e0b16462d3dcf7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8622,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 271,
"path": "/utils/calibration.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nimport numpy\n\nimport torch\nfrom torch.nn.functional import softmax\n\n\n# Compute Calibration Metrics\ndef compute_calibration_metrics(predictions: torch.tensor, true_labels: torch.tensor, apply_softmax: bool,\n bins: int) -> list:\n predictions = softmax(predictions, 1) if apply_softmax else predictions\n\n # ECE and MCE\n acc_bin, prob, samples_per_bin = accuracy_per_bin(predictions, true_labels, n_bins=bins, apply_softmax=False)\n conf_bin, prob, samples_per_bin = average_confidence_per_bin(predictions, n_bins=bins, apply_softmax=False)\n ece, _ = compute_ece(acc_bin, conf_bin, samples_per_bin)\n mce, _ = compute_mce(acc_bin, conf_bin, samples_per_bin)\n\n # Brier Score\n max_val = predictions.size(1)\n t_one_hot = categorical_to_one_hot(true_labels, max_val)\n brier = compute_brier(predictions, t_one_hot)\n\n # NNL\n # NNL=((t_one_hot*(-1*torch.log(predictions))).sum(1)).mean()\n nnl = -1 * torch.log(predictions[t_one_hot.bool()]).mean()\n\n return [ece * 100, mce * 100, brier, nnl]\n\n\n# Compute average confidence\ndef average_confidence(predicted, apply_softmax=True):\n predicted = check_type_float(predicted)\n\n if apply_softmax:\n predicted_prob = softmax(predicted, dim=1).data\n else:\n predicted_prob = predicted.data\n\n predicted_prob, index = torch.max(predicted_prob, 1)\n\n return predicted_prob.sum().float() / float(predicted_prob.shape[0])\n\n\ndef accuracy(predicted, real_tag, apply_softmax=True):\n predicted = check_type_float(predicted)\n real_tag = check_type_int(real_tag)\n\n if apply_softmax:\n predicted_prob = softmax(predicted, dim=1).data\n else:\n predicted_prob = predicted.data\n\n accuracy, index = torch.max(predicted_prob, 1)\n selected_label = index == real_tag\n\n return selected_label.sum().float() / float(selected_label.shape[0])\n\n\ndef accuracy_per_bin(predicted, real_tag, n_bins=10, apply_softmax=True):\n predicted = check_type_float(predicted)\n real_tag = check_type_int(real_tag)\n\n if apply_softmax:\n predicted_prob = softmax(predicted, dim=1).data\n else:\n predicted_prob = predicted.data\n\n accuracy, index = torch.max(predicted_prob, 1)\n selected_label = index.long() == real_tag\n\n prob = numpy.linspace(0, 1, n_bins + 1)\n acc = numpy.linspace(0, 1, n_bins + 1)\n total_data = len(accuracy)\n samples_per_bin = []\n for p in range(len(prob) - 1):\n # find elements with probability in between p and p+1\n min_ = prob[p]\n max_ = prob[p + 1]\n boolean_upper = accuracy <= max_\n\n if p == 0: # we include the first element in bin\n boolean_down = accuracy >= min_\n else: # after that we included in the previous bin\n boolean_down = accuracy > min_\n\n index_range = boolean_down & boolean_upper\n label_sel = selected_label[index_range]\n\n if len(label_sel) == 0:\n acc[p] = 0.0\n else:\n acc[p] = label_sel.sum().float() / float(len(label_sel))\n\n samples_per_bin.append(len(label_sel))\n\n samples_per_bin = numpy.array(samples_per_bin)\n acc = acc[0:-1]\n prob = prob[0:-1]\n return acc, prob, samples_per_bin\n\n\ndef average_confidence_per_bin(predicted, n_bins=10, apply_softmax=True):\n predicted = check_type_float(predicted)\n\n if apply_softmax:\n predicted_prob = softmax(predicted, dim=1).data\n else:\n predicted_prob = predicted.data\n\n prob = numpy.linspace(0, 1, n_bins + 1)\n conf = numpy.linspace(0, 1, n_bins + 1)\n max_confidence, index = torch.max(predicted_prob, 1)\n\n samples_per_bin = []\n\n for p in range(len(prob) - 1):\n # find elements with probability in between p and p+1\n min_ = prob[p]\n max_ = prob[p + 1]\n boolean_upper = max_confidence <= max_\n\n if p == 0: # we include the first element in bin\n boolean_down = max_confidence >= min_\n else: # after that we included in the previous bin\n boolean_down = max_confidence > min_\n\n index_range = boolean_down & boolean_upper\n prob_sel = max_confidence[index_range]\n\n if len(prob_sel) == 0:\n conf[p] = 0.0\n else:\n conf[p] = prob_sel.sum().float() / float(len(prob_sel))\n\n samples_per_bin.append(len(prob_sel))\n\n samples_per_bin = numpy.array(samples_per_bin)\n conf = conf[0:-1]\n prob = prob[0:-1]\n\n return conf, prob, samples_per_bin\n\n\ndef confidence_per_bin(predicted, n_bins=10, apply_softmax=True):\n predicted = check_type_float(predicted)\n\n if apply_softmax:\n predicted_prob = softmax(predicted, dim=1).data\n else:\n predicted_prob = predicted.data\n\n prob = numpy.linspace(0, 1, n_bins + 1)\n conf = numpy.linspace(0, 1, n_bins + 1)\n max_confidence, index = torch.max(predicted_prob, 1)\n\n samples_per_bin = []\n conf_values_per_bin = []\n\n for p in range(len(prob) - 1):\n # find elements with probability in between p and p+1\n min_ = prob[p]\n max_ = prob[p + 1]\n\n boolean_upper = max_confidence <= max_\n\n if p == 0: # we include the first element in bin\n boolean_down = max_confidence >= min_\n else: # after that we included in the previous bin\n boolean_down = max_confidence > min_\n\n index_range = boolean_down & boolean_upper\n prob_sel = max_confidence[index_range]\n\n if len(prob_sel) == 0:\n conf_values_per_bin.append([0.0])\n else:\n conf_values_per_bin.append(prob_sel)\n\n samples_per_bin.append(len(prob_sel))\n\n samples_per_bin = numpy.array(samples_per_bin)\n conf = conf[0:-1]\n prob = prob[0:-1]\n\n return conf_values_per_bin, prob, samples_per_bin\n\n\ndef compute_ece(acc_bin, conf_bin, samples_per_bin):\n assert len(acc_bin) == len(conf_bin)\n ece = 0.0\n total_samples = float(samples_per_bin.sum())\n\n ece_list = []\n for samples, acc, conf in zip(samples_per_bin, acc_bin, conf_bin):\n ece_list.append(samples / total_samples * numpy.abs(acc - conf))\n ece += samples / total_samples * numpy.abs(acc - conf)\n return ece, ece_list\n\n\ndef reliability_histogram(prob, acc, show=0, save=None, ece=None):\n assert len(prob) == len(acc)\n n_bins = len(prob)\n aux = numpy.linspace(0, 1, n_bins + 1)\n plt.bar(prob, acc, 1 / float(n_bins), align='edge', label='calibration', edgecolor=[0, 0, 0])\n plt.plot(aux, aux, 'r', label='perfect calibration')\n plt.ylim((0, 1))\n plt.xlim((0, 1))\n plt.legend(fontsize=12)\n plt.xlabel('Confidence', fontsize=14, weight='bold')\n plt.ylabel('Accuracy', fontsize=14, weight='bold')\n\n props = dict(boxstyle='square', facecolor='lightblue', alpha=0.9)\n # place a text box in upper left in axes coords\n textstr = '$ECE=%.3f$' % (ece * 100)\n plt.text(0.65, 0.05, textstr, weight='bold', fontsize=20,\n verticalalignment='bottom', bbox=props)\n plt.tick_params(axis='both', labelsize=12)\n if show:\n plt.show()\n else:\n if save is not None and type(save) == str:\n plt.savefig(save + '_' + str(n_bins) + '.png')\n plt.close()\n\n\ndef compute_mce(acc_bin, conf_bin, samples_per_bin):\n assert len(acc_bin) == len(conf_bin)\n mce = 0.0\n sample = 0\n total_samples = float(samples_per_bin.sum())\n for i in range(len(samples_per_bin)):\n a = samples_per_bin[i] / total_samples * numpy.abs(acc_bin[i] - conf_bin[i])\n if a > mce:\n mce = a\n sample = i\n\n return mce, sample\n\n\ndef compute_brier(prob, acc):\n prob = prob.cpu()\n acc = acc.cpu()\n return torch.pow(prob - acc, 2).mean()\n\n\ndef categorical_to_one_hot(t, max_val):\n one_hot = torch.zeros(t.size(0), max_val, device=t.device)\n one_hot.scatter_(1, t.view(-1, 1), 1)\n return one_hot\n\n\ndef check_type_float(tensor):\n if type(tensor) is numpy.ndarray and tensor.dtype == numpy.float32:\n tensor = torch.from_numpy(tensor)\n elif type(tensor) is torch.Tensor and tensor.dtype is torch.float32:\n pass\n else:\n raise Exception(\n \"Either torch.FloatTensor or numpy.ndarray type float32 expected, got {}\".format(tensor.type()))\n return tensor\n\n\ndef check_type_int(tensor):\n if type(tensor) is numpy.ndarray and tensor.dtype == numpy.int64:\n tensor = torch.from_numpy(tensor)\n elif type(tensor) is torch.Tensor and tensor.dtype is torch.int64:\n pass\n else:\n raise Exception(\"Either torch.LongTensor or numpy.ndarray type int64 expected\")\n return tensor\n"
},
{
"alpha_fraction": 0.6347992420196533,
"alphanum_fraction": 0.6386232972145081,
"avg_line_length": 21.7391300201416,
"blob_id": "f1dc3cdcf7433ec67ab6281007905e0ef046b7f6",
"content_id": "1bcc3a53a4a682fd9a9ab63a608ee31961e5ac67",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 23,
"path": "/models/classification/__init__.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "from .osmrbag import *\nfrom .cifar import *\n\n\ndef model_selector_classification(model_name, num_classes=2, in_channels=3):\n \"\"\"\n\n :param model_name:\n :param num_classes:\n :param in_channels:\n :return:\n \"\"\"\n\n if \"osmr\" in model_name:\n model = osmr_selector(model_name, num_classes, in_channels)\n\n elif \"cifar\" in model_name:\n model = cifar_selector(model_name, in_channels, num_classes)\n\n else:\n assert False, \"Unknown model selected: {}\".format(model_name)\n\n return model\n"
},
{
"alpha_fraction": 0.7189939022064209,
"alphanum_fraction": 0.7207285165786743,
"avg_line_length": 28.564102172851562,
"blob_id": "6e8b9f2daffe8b1f754b7d089961a9c1984cc1c9",
"content_id": "8fa41bd170e4eba9eaffd15b62c7d8d49f68c85e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1153,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 39,
"path": "/evaluate.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# ---- My utils ----\nfrom models import model_selector\nfrom utils.arguments import *\nfrom utils.data_augmentation import data_augmentation_selector\nfrom utils.dataloaders import dataset_selector\nfrom utils.neural import *\n\n_, val_aug = data_augmentation_selector(args.data_augmentation)\ntest_loader = dataset_selector(None, val_aug, args, is_test=True)\n\nmodel = model_selector(\n args.problem_type, args.model_name, test_loader.dataset.num_classes, from_swa=args.swa_checkpoint,\n in_channels=test_loader.dataset.img_channels, checkpoint=args.model_checkpoint\n)\n\ntest_metrics = MetricsAccumulator(\n args.problem_type, args.metrics\n)\n\ntest_metrics, test_logits, test_labels = val_step(\n test_loader, model, test_metrics,\n)\n\ntorch.save(\n {\"logits\": test_logits, \"labels\": test_labels, \"config\": args},\n args.output_dir + f\"/test_logits_{args.model_checkpoint.split('/')[-1]}\"\n)\n\nprint(\"\\nResults:\")\ntest_metrics.report_best()\n\nif args.notify:\n slack_message(\n message=f\"(Seed {args.seed}) {args.dataset.upper()} evaluation experiments finished!\",\n channel=\"ensembles_analysis\"\n )\n"
},
{
"alpha_fraction": 0.6821808218955994,
"alphanum_fraction": 0.7240691781044006,
"avg_line_length": 37.56410217285156,
"blob_id": "b227e0457768fc9f2ad3ae0b3ced9e6bb93b52d3",
"content_id": "5a36c94e827da955c91c7fd9ecad895480b8c355",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 3008,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 78,
"path": "/tests/classification/cifar10.sh",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# Only download the data argument ./tests/classification/cifar10.sh only_data\n\n# Check if CIFAR10 data is available, if not download\nif [ ! -d \"data/CIFAR10\" ]\nthen\n echo \"CIFAR10 data not found at 'data' directory. Downloading...\"\n curl -O -J https://nextcloud.maparla.duckdns.org/s/N8eW6MkyQyLEfRz/download\n mkdir -p data/CIFAR10\n tar -zxf cifar10.tar.gz -C data/CIFAR10/\n rm cifar10.tar.gz\n echo \"Done!\"\nelse\n echo \"CIFAR10 data found at 'data' directory!\"\nfi\n\nif [[ $1 == \"only_data\" ]]\nthen\n exit\nfi\n\nseed=301220201\ngpu=\"0\"\ndataset=\"CIFAR10\"\nproblem_type=\"classification\"\n\n# Available models:\n# -> cifar_resnet[18-34-50-101-152] - osmr_resnet18 - osmr_resnet18_pretrained\n# -> cifar_densenet[121-161] - cifar_densenet - cifar_wresnet28_10 - cifar_shakeshake26_2x96d\nmodel=\"cifar_wresnet28_10\"\n\nimg_size=32\ncrop_size=32\nbatch_size=128\n\nepochs=350\nswa_start=999\ndefrost_epoch=-1\nscheduler=\"steps\"\nlr=0.1\nswa_lr=0.256\n# Available schedulers:\n# constant - steps - plateau - one_cycle_lr (max_lr) - cyclic (min_lr, max_lr, scheduler_steps)\n# Available optimizers:\n# adam - sgd - over9000\noptimizer=\"sgd\"\n\n# Available data augmentation policies:\n# \"none\" - \"random_crops\" - \"rotations\" - \"vflips\" - \"hflips\" - \"elastic_transform\" - \"grid_distortion\" - \"shift\"\n# \"scale\" - \"optical_distortion\" - \"coarse_dropout\" or \"cutout\" - \"downscale\"\ndata_augmentation=\"cifar\"\nnormalization=\"statistics\" # reescale - standardize - statistics\n\n# Available criterions for classification:\n# ce\ncriterion=\"ce\"\nweights_criterion=\"1.0\"\n\n# RandAugment Parameters (Dont forget to add --randaugment flag to train.py arguments)\nrandaugment_N=3 # shakeshake26_2x96d->3 / wresnet28_10->3\nrandaugment_M=9 # shakeshake26_2x96d->9 / wresnet28_10->5\n\noutput_dir=\"results/$dataset/$model/seed_$seed/$optimizer/${scheduler}_lr${lr}/${criterion}_weights${weights_criterion}\"\noutput_dir=\"$output_dir/normalization_${normalization}/da${data_augmentation}\"\n\npython3 -u train.py --gpu $gpu --dataset $dataset --model_name $model --img_size $img_size --crop_size $crop_size \\\n--epochs $epochs --swa_start $swa_start --batch_size $batch_size --defrost_epoch $defrost_epoch \\\n--scheduler $scheduler --learning_rate $lr --swa_lr $swa_lr --optimizer $optimizer --criterion $criterion \\\n--normalization $normalization --weights_criterion \"$weights_criterion\" --data_augmentation $data_augmentation \\\n--output_dir \"$output_dir\" --metrics accuracy --problem_type $problem_type --scheduler_steps 150 250 --seed $seed \\\n--randaugment_N $randaugment_N --randaugment_M $randaugment_M --randaugment\n\nmodel_checkpoint=\"$output_dir/model_${model}_best_accuracy.pt\"\npython3 -u evaluate.py --gpu $gpu --dataset $dataset --model_name $model --img_size $img_size --crop_size $crop_size \\\n--batch_size $batch_size --normalization $normalization --output_dir \"$output_dir\" \\\n--metrics accuracy --problem_type $problem_type --model_checkpoint \"$model_checkpoint\" --seed $seed \\\n--data_augmentation $data_augmentation --notify\n"
},
{
"alpha_fraction": 0.6402082443237305,
"alphanum_fraction": 0.6488856673240662,
"avg_line_length": 40.786258697509766,
"blob_id": "610f8713296e1927537375e26608c872305fcf4e",
"content_id": "af230df4a88ed1b4bf47878af8036387b8ed69ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10948,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 262,
"path": "/temperature_scaling.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# # Usage: python temperature_scaling.py --epochs 250 --scheduler_steps 70 125 180 220 --logits_dir logits_res18_cifar10\n\nimport pretty_errors\n\n# ---- My utils ----\nfrom utils.logits import *\nfrom utils.neural import *\nfrom utils.metrics import compute_accuracy\nfrom utils.calibration import compute_calibration_metrics\nfrom torch.optim import SGD\nfrom torch.optim.lr_scheduler import MultiStepLR\n\nimport argparse\n\n\nclass SmartFormatter(argparse.HelpFormatter):\n\n def _split_lines(self, text, width):\n if text.startswith('R|'):\n return text[2:].splitlines()\n # this is the RawTextHelpFormatter._split_lines\n return argparse.HelpFormatter._split_lines(self, text, width)\n\n\nparser = argparse.ArgumentParser(description='Temperature Scaling Analysis', formatter_class=SmartFormatter)\n\nparser.add_argument('--verbose', action='store_true', help='Display or not temperature learning process')\nparser.add_argument('--epochs', type=int, default=100, help='Total number epochs for training')\nparser.add_argument('--batch_size', type=int, default=128, help='Batch Size for training')\nparser.add_argument('--learning_rate', type=float, default=0.1, help='Learning rate')\nparser.add_argument('--logits_dir', type=str, default=\"logits\", help='Logits directory')\nparser.add_argument('--scheduler_steps', '--arg', nargs='+', type=int, help='Steps for learning rate decay')\nargs = parser.parse_args()\n\npretty_errors.mono()\nverbose = args.verbose # Display or not temperature learning process\n\n# ---- Load logits ----\nlogits_dir = args.logits_dir\n\n# -> Validation Logits\nprefix = \"val_logits\"\nval_logits_paths = get_logits_paths(logits_dir, prefix)\nval_logits_list, val_labels_list, val_logits_names, _ = load_logits(val_logits_paths, get_accuracy=False)\nval_labels = val_labels_list[0]\n\n# -> Validation Avg Ensemble\nprefix = \"val_avg_ensemble\"\nval_avg_ensemble_logits_paths = get_logits_paths(logits_dir, prefix)\nval_avg_ensemble_logits_list, val_avg_ensemble_labels_list, val_avg_ensemble_logits_names, _ = load_logits(\n val_avg_ensemble_logits_paths, get_accuracy=False\n)\nval_avg_ensemble_labels = val_avg_ensemble_labels_list[0]\n\nif not (val_avg_ensemble_labels == val_labels).all():\n assert False, \"Validation logits and Validation ensemble logits should be equal!\"\n\n# -> Test Logits\nprefix = \"test_logits\"\ntest_logits_paths = get_logits_paths(logits_dir, prefix)\ntest_logits_list, test_labels_list, test_logits_names, _ = load_logits(test_logits_paths, get_accuracy=False)\ntest_labels = test_labels_list[0]\n\n# -> Test Avg Ensemble\nprefix = \"test_avg_ensemble\"\ntest_avg_ensemble_logits_paths = get_logits_paths(logits_dir, prefix)\ntest_avg_ensemble_logits_list, test_avg_ensemble_labels_list, test_avg_ensemble_logits_names, _ = load_logits(\n test_avg_ensemble_logits_paths, get_accuracy=False\n)\ntest_avg_ensemble_labels = test_avg_ensemble_labels_list[0]\n\n\n# ---- TEMPERATURE SCALING ----\n# https://github.com/gpleiss/temperature_scaling/blob/master/temperature_scaling.py\nclass TempScaling(nn.Module):\n \"\"\"\n A thin decorator, which wraps a model with temperature scaling\n model (nn.Module):\n A classification neural network\n NB: Output of the neural network should be the classification logits, NOT the softmax (or log softmax)!\n \"\"\"\n\n def __init__(self):\n super(TempScaling, self).__init__()\n self.temperature = nn.Parameter(torch.ones(1))\n\n def forward(self, model_logits):\n return self.temperature_scale(model_logits)\n\n def temperature_scale(self, model_logits):\n \"\"\"\n Perform temperature scaling on logits\n \"\"\"\n # Expand temperature to match the size of logits\n temperature = self.temperature.unsqueeze(1).expand(model_logits.size(0), model_logits.size(1))\n return model_logits * temperature\n\n\ndef chunks(lst, n):\n \"\"\"Yield successive n-sized chunks from lst.\"\"\"\n for i in range(0, len(lst), n):\n yield lst[i:i + n]\n\n\ndef learn_temperature(model_logits, model_labels):\n # Training parameters\n criterion = nn.CrossEntropyLoss().cuda()\n if args.scheduler_steps is None:\n scheduler_steps = np.arange(0, args.epochs, args.epochs // 5)\n\n # Create 1 temperature parameter per model / val logits\n temperature = TempScaling()\n optimizer = SGD(temperature.parameters(), lr=args.learning_rate, momentum=0.9, weight_decay=5e-4)\n scheduler = MultiStepLR(optimizer, milestones=args.scheduler_steps, gamma=0.1)\n\n if verbose:\n header = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthA}} | {:{align}{widthLL}} | {:{align}{widthA}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} |\".format(\n \"Epoch\", \"LR\", \"Loss\", \"Temp Param\", \"Accuracy\", \"ECE\", \"MCE\", \"BRIER\", \"NNL\",\n align='^', widthL=8, widthLL=10, widthA=8, widthM=6,\n )\n\n print(\"\".join([\"_\"] * len(header)))\n print(header)\n print(\"\".join([\"_\"] * len(header)))\n\n for epoch in range(args.epochs):\n\n temperature.train()\n train_loss, correct, total = [], 0, 0\n c_ece, c_mce, c_brier, c_nnl = [], [], [], []\n\n for c_logits, c_labels in zip(chunks(model_logits, args.batch_size), chunks(model_labels, args.batch_size)):\n # Train\n optimizer.zero_grad()\n new_logits = temperature(c_logits)\n loss = criterion(new_logits, c_labels)\n loss.backward()\n optimizer.step()\n\n # Metrics\n train_loss.append(loss.item())\n _, predicted = new_logits.max(1)\n total += len(c_labels)\n correct += predicted.eq(c_labels).sum().item()\n\n softmax = nn.Softmax(dim=1)\n new_probs_list = softmax(new_logits)\n ece, mce, brier, nnl = compute_calibration_metrics(new_probs_list, c_labels, apply_softmax=False, bins=15)\n c_ece.append(ece)\n c_mce.append(mce)\n c_brier.append(brier.item())\n c_nnl.append(nnl.item())\n\n c_train_loss = np.array(train_loss).mean()\n c_accuracy = correct / total\n c_ece = np.array(c_ece).mean()\n c_mce = np.array(c_mce).mean()\n c_brier = np.array(c_brier).mean()\n c_nnl = np.array(c_nnl).mean()\n current_lr = get_current_lr(optimizer)\n\n if verbose:\n line = \"| {:{align}{widthL}} | {:{align}{widthA}.6f} | {:{align}{widthA}.4f} | {:{align}{widthLL}.4f} | {:{align}{widthA}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} |\".format(\n epoch + 1, current_lr, c_train_loss, temperature.temperature.item(), c_accuracy, c_ece, c_mce,\n c_brier,\n c_nnl,\n align='^', widthL=8, widthA=8, widthM=6, widthLL=10\n )\n print(line)\n\n scheduler.step()\n\n return temperature\n\n\ntemperatures_val = []\nprint(f\"Validation Logits -> Calculating temperature for {len(val_logits_list)} models...\")\nfor indx, val_model_logits in enumerate(val_logits_list):\n temperatures_val.append(learn_temperature(val_model_logits, val_labels))\n print(f\"Model {indx} done!\")\nprint(\"-- Finished --\\n\")\n\ntemperatures_avg_ensemble = []\nprint(f\"Validation Logits Ensemble Avg -> Calculating temperature for {len(val_avg_ensemble_logits_list)} models...\")\nfor indx, val_model_logits in enumerate(val_avg_ensemble_logits_list):\n temperatures_avg_ensemble.append(learn_temperature(val_model_logits, val_labels))\n print(f\"Ensemble Avg {indx} done!\")\nprint(\"-- Finished --\\n\")\n\n\n# ---- Display Results ----\ndef display_results(logits_names, logits_list, labels, temperatures, avg=True, get_logits=False):\n softmax = nn.Softmax(dim=1)\n width_methods = max(len(\"Avg probs ensemble\"), max([len(x) for x in logits_names]))\n\n header = \"\\n| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} |\".format(\n \"Method\", \"Accuracy\", \"ECE\", \"MCE\", \"BRIER\", \"NNL\", align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(\"\".join([\"_\"] * len(header)))\n print(header)\n print(\"\".join([\"_\"] * len(header)))\n probs_list, t_logits = [], []\n for indx, logit_name in enumerate(logits_names):\n # Scale with learned temperature parameter the logits\n temperatures[indx].eval()\n logits = temperatures[indx](logits_list[indx])\n t_logits.append(logits)\n # Compute metrics\n accuracy = compute_accuracy(labels, logits)\n probs = softmax(logits)\n probs_list.append(probs)\n ece, mce, brier, nnl = compute_calibration_metrics(probs, labels, apply_softmax=False, bins=15)\n # Display\n line = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} |\".format(\n logit_name, accuracy, ece, mce, brier, nnl, align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(line)\n\n # ---- Ensemble Strategies: Average ----\n if avg:\n probs_list = torch.stack(probs_list)\n probs_avg = probs_list.sum(dim=0) / len(probs_list)\n probs_avg_accuracy = compute_accuracy(labels, probs_avg)\n ece, mce, brier, nnl = compute_calibration_metrics(probs_avg, labels, apply_softmax=False, bins=15)\n line = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} |\".format(\n \"Avg probs ensemble\", probs_avg_accuracy, ece, mce, brier, nnl,\n align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(line)\n if get_logits:\n return torch.stack(t_logits)\n\n\n# --- Avg ensemble\nval_cal_logits = display_results(val_logits_names, val_logits_list, val_labels, temperatures_val, get_logits=True)\nval_cal_logits_ensemble = val_cal_logits.detach().sum(dim=0)\ntest_cal_logits = display_results(test_logits_names, test_logits_list, test_labels, temperatures_val, get_logits=True)\ntest_cal_logits_ensemble = test_cal_logits.detach().sum(dim=0)\n\n# --- Avg ensemble T\nprint(\"\\n\\n--- Avg ensemble T ---\")\ndisplay_results(\n val_avg_ensemble_logits_names, val_avg_ensemble_logits_list, val_labels, temperatures_avg_ensemble, avg=False\n)\ndisplay_results(\n test_avg_ensemble_logits_names, test_avg_ensemble_logits_list, test_labels, temperatures_avg_ensemble, avg=False\n)\n\n# --- Avg ensemble CT\nprint(\"\\n\\n--- Avg ensemble CT ---\")\ntemperatures_avg_ensemble = []\nval_ct_temp = [learn_temperature(val_cal_logits_ensemble, val_labels)]\n\ndisplay_results(\n [\"val_ct_avg_ensemble_logits\"], val_cal_logits_ensemble.unsqueeze(0), val_labels, val_ct_temp, avg=False\n)\ndisplay_results(\n [\"test_ct_avg_ensemble_logits\"], test_cal_logits_ensemble.unsqueeze(0), test_labels, val_ct_temp, avg=False\n)\n"
},
{
"alpha_fraction": 0.7150084376335144,
"alphanum_fraction": 0.728499174118042,
"avg_line_length": 41.35714340209961,
"blob_id": "59f55924da94b8e5357691d26436fb74404df076",
"content_id": "ba1ed03ae0d668f63235d1d5b9eb8ca3d0965de1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 593,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 14,
"path": "/models/classification/osmrbag.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "# https://github.com/osmr/imgclsmob/tree/master/pytorch\n# https://github.com/osmr/imgclsmob/blob/master/pytorch/pytorchcv/model_provider.py\n# pip install pytorchcv\nfrom torch import nn\nfrom pytorchcv.model_provider import get_model as ptcv_get_model\n\n\ndef osmr_selector(model_name, num_classes, in_channels):\n if \"resnet18\" in model_name:\n model = ptcv_get_model(\"resnet18\", pretrained=True if \"pretrained\" in model_name else False)\n model.last_fc = nn.Linear(2048, num_classes)\n else:\n assert False, \"Unknown model selected: {}\".format(model_name)\n return model\n"
},
{
"alpha_fraction": 0.6431398391723633,
"alphanum_fraction": 0.6807388067245483,
"avg_line_length": 29.31999969482422,
"blob_id": "7defb8c16e44e948d38258839ea07ba7ff1ebfc9",
"content_id": "aafd6fdee067350d58c1144a1f3147142752817f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1516,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 50,
"path": "/models/classification/cifar/__init__.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "from .shake_resnet import ShakeResNet\nfrom .vgg import *\nfrom .dpn import *\nfrom .lenet import *\nfrom .senet import *\nfrom .pnasnet import *\nfrom .densenet import *\nfrom .googlenet import *\nfrom .shufflenet import *\nfrom .shufflenetv2 import *\nfrom .resnet import *\nfrom .resnext import *\nfrom .preact_resnet import *\nfrom .mobilenet import *\nfrom .mobilenetv2 import *\nfrom .efficientnet import *\nfrom .regnet import *\nfrom .dla_simple import *\nfrom .dla import *\nfrom .wideresnet import WideResNet\n\n\ndef cifar_selector(model_name, in_channels, num_classes):\n \n if \"resnet18\" in model_name:\n model = ResNet18(in_channels, num_classes)\n elif \"resnet34\" in model_name:\n model = ResNet34(in_channels, num_classes)\n elif \"resnet50\" in model_name:\n model = ResNet50(in_channels, num_classes)\n elif \"resnet101\" in model_name:\n model = ResNet101(in_channels, num_classes)\n elif \"resnet152\" in model_name:\n model = ResNet152(in_channels, num_classes)\n\n elif \"densenet121\" in model_name:\n model = DenseNet121()\n elif \"densenet161\" in model_name:\n model = DenseNet161()\n elif \"densenet\" in model_name:\n model = densenet_cifar()\n\n elif 'wresnet28_10' in model_name:\n model = WideResNet(28, 10, dropout_rate=0.0, num_classes=num_classes)\n elif 'shakeshake26_2x96d' in model_name:\n model = ShakeResNet(26, 96, num_classes)\n \n else:\n assert False, \"Unknown model selected: {}\".format(model_name)\n return model\n"
},
{
"alpha_fraction": 0.6224109530448914,
"alphanum_fraction": 0.628624677658081,
"avg_line_length": 42.890907287597656,
"blob_id": "abd5c6a3da81cc90cb4353b7ecad358fa28494c9",
"content_id": "1b6569e9b3d89736701da42e178034f7ded17a1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4828,
"license_type": "no_license",
"max_line_length": 164,
"num_lines": 110,
"path": "/ensemble.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\nimport pretty_errors\n\n# ---- My utils ----\nfrom utils.logits import *\nfrom utils.neural import *\nfrom utils.metrics import compute_accuracy\nfrom utils.calibration import compute_calibration_metrics\nimport argparse\n\n\nclass SmartFormatter(argparse.HelpFormatter):\n\n def _split_lines(self, text, width):\n if text.startswith('R|'):\n return text[2:].splitlines()\n # this is the RawTextHelpFormatter._split_lines\n return argparse.HelpFormatter._split_lines(self, text, width)\n\n\nparser = argparse.ArgumentParser(description='Ensemble Analysis', formatter_class=SmartFormatter)\nparser.add_argument('--logits_dir', type=str, default=\"logits\", help='Logits directory')\nargs = parser.parse_args()\n\npretty_errors.mono()\n\nlogits_dir = args.logits_dir\n\n\ndef ensemble_evaluation(logits_directory, prefix, ensemble_strategy=None, ensemble_name=\"\"):\n # Check ensemble strategies are fine\n available_strategies = [\"avg\", \"vote\"]\n if ensemble_strategy is None or len(ensemble_strategy) == 0:\n assert False, \"Please specify a ensemble strategy\"\n ensemble_strategy = [ensemble_strategy] if isinstance(ensemble_strategy, str) else ensemble_strategy\n for strategy in ensemble_strategy:\n if strategy not in available_strategies:\n assert False, f\"Unknown strategy {strategy}\"\n\n # Get logits paths\n logits_paths = get_logits_paths(logits_directory, prefix)\n\n # Get logits and labels\n logits_list, labels_list, logits_names, logits_accuracy = load_logits(logits_paths, get_accuracy=True)\n labels = labels_list[0]\n\n # Compute calibration metrics\n softmax = nn.Softmax(dim=2)\n probs_list = softmax(logits_list)\n\n logits_calibration_metrics = []\n for prob_list in probs_list:\n ece, mce, brier, nnl = compute_calibration_metrics(prob_list, labels, apply_softmax=False, bins=15)\n logits_calibration_metrics.append({\"ece\": ece, \"mce\": mce, \"brier\": brier, \"nnl\": nnl})\n\n # -- Display Results --\n width_methods = max(len(\"Avg probs ensemble\"), max([len(x) for x in logits_names]))\n\n header = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} |\".format(\n \"Method\", \"Accuracy\", \"ECE\", \"MCE\", \"BRIER\", \"NNL\", align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(\"\".join([\"_\"] * len(header)))\n print(header)\n print(\"\".join([\"_\"] * len(header)))\n for indx, logit_name in enumerate(logits_names):\n line = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} |\".format(\n logit_name, logits_accuracy[indx],\n logits_calibration_metrics[indx][\"ece\"], logits_calibration_metrics[indx][\"mce\"],\n logits_calibration_metrics[indx][\"brier\"], logits_calibration_metrics[indx][\"nnl\"],\n align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(line)\n\n # -- Ensemble Strategies --\n if \"avg\" in ensemble_strategy:\n probs_avg = probs_list.sum(dim=0) / len(probs_list)\n probs_avg_accuracy = compute_accuracy(labels, probs_avg)\n ece, mce, brier, nnl = compute_calibration_metrics(probs_avg, labels, apply_softmax=False, bins=15)\n line = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} | {:{align}{widthM}.4f} |\".format(\n \"Avg probs ensemble\", probs_avg_accuracy, ece, mce, brier, nnl,\n align='^', widthL=width_methods, widthA=8, widthM=6,\n )\n print(line)\n torch.save(\n {\"logits\": logits_list.sum(dim=0), \"labels\": labels},\n os.path.join(logits_directory, f\"{ensemble_name}_avg_ensemble_logits.pt\")\n )\n\n if \"vote\" in ensemble_strategy:\n _, vote_list = torch.max(logits_list.data, dim=2)\n vote_list = torch.nn.functional.one_hot(vote_list)\n vote_list = vote_list.sum(dim=0)\n _, vote_list = torch.max(vote_list.data, dim=1)\n vote_accuracy = (vote_list == labels).sum().item() / len(labels)\n line = \"| {:{align}{widthL}} | {:{align}{widthA}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} | {:{align}{widthM}} |\".format(\n \"Vote ensemble\", vote_accuracy, \"----\", \"----\", \"----\", \"----\",\n align='', widthL=width_methods, widthA=8, widthM=6,\n )\n print(line)\n\n print(\"\".join([\"_\"] * len(header)))\n\n\nprint(\"\\n---- Validation evaluation ----\\n\")\nensemble_evaluation(logits_dir, prefix=\"val_logits\", ensemble_strategy=[\"avg\"], ensemble_name=\"val\")\n\nprint(\"\\n---- Test evaluation ----\\n\")\nensemble_evaluation(logits_dir, prefix=\"test_logits\", ensemble_strategy=[\"avg\"], ensemble_name=\"test\")\n"
},
{
"alpha_fraction": 0.5495885610580444,
"alphanum_fraction": 0.5621480941772461,
"avg_line_length": 35.078125,
"blob_id": "00e690ac48e52a8322469f6cd852cf5b79b83e80",
"content_id": "663715df8d08e80dc2f5e47138ba5c387449b197",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2309,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 64,
"path": "/utils/dataloaders/cifar10.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "import os\nimport numpy as np\nfrom torch.utils.data import Dataset\n\n\nclass CIFAR10Dataset(Dataset):\n \"\"\"\n Dataset CIFAR10.\n https://www.cs.toronto.edu/~kriz/cifar.html\n \"\"\"\n\n def __init__(self, mode, transform, normalization=\"statistics\", data_prefix=\"\"):\n \"\"\"\n :param mode: (string) Dataset mode in [\"train\", \"validation\"]\n :param transform: (list) List of pytorch transforms applied to image and mask\n :param normalization: (str) Normalization mode. One of 'reescale', 'standardize', 'statistics'\n \"\"\"\n\n if mode not in [\"train\", \"validation\", \"test\"]:\n assert False, \"Unknown mode '{}'\".format(mode)\n\n if normalization not in ['reescale', 'standardize', 'statistics']:\n assert False, \"Unknown normalization '{}'\".format(normalization)\n\n self.base_dir = os.path.join(data_prefix, \"data\", \"CIFAR10\")\n self.include_background = False\n self.img_channels = 3\n self.class_to_cat = {\n 0: \"airplane\", 1: \"automobile\", 2: \"bird\", 3: \"cat\", 4: \"deer\",\n 5: \"dog\", 6: \"frog\", 7: \"horse\", 8: \"ship\", 9: \"truck\", 10: \"Mean\"\n }\n self.num_classes = 10\n\n if mode == \"train\":\n data = np.load(os.path.join(self.base_dir, \"x_train.npy\"))\n labels = np.load(os.path.join(self.base_dir, \"y_train.npy\"))\n data = data[:int(len(data) * .90)]\n labels = labels[:int(len(labels) * .90)]\n elif mode == \"validation\":\n data = np.load(os.path.join(self.base_dir, \"x_train.npy\"))\n labels = np.load(os.path.join(self.base_dir, \"y_train.npy\"))\n data = data[int(len(data) * .90):]\n labels = labels[int(len(labels) * .90):]\n else: # mode == test\n data = np.load(os.path.join(self.base_dir, \"x_test.npy\"))\n labels = np.load(os.path.join(self.base_dir, \"y_test.npy\"))\n\n self.labels = labels\n self.data = data\n self.mode = mode\n self.normalization = normalization\n\n self.transform = transform\n\n def __len__(self):\n return len(self.data)\n\n def __getitem__(self, idx):\n\n image = self.data[idx]\n label = self.labels[idx]\n image = self.transform(image)\n\n return {\"image\": image, \"label\": label}\n"
},
{
"alpha_fraction": 0.6194968819618225,
"alphanum_fraction": 0.6270440220832825,
"avg_line_length": 32.808509826660156,
"blob_id": "e08765b1fa4e1960d097c4fc59351d8310163d32",
"content_id": "dc8899ff8e901d557de2ddfeb232bb9778057893",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1590,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 47,
"path": "/utils/logits.py",
"repo_name": "MarioProjects/ensemble_analysis",
"src_encoding": "UTF-8",
"text": "import os\nimport torch\n\nfrom utils.metrics import compute_accuracy\n\n\ndef get_logits_paths(logits_dir, prefix):\n paths = []\n for subdir, dirs, files in os.walk(logits_dir):\n for file in files:\n file_path = os.path.join(subdir, file)\n if f\"{prefix}\" in file_path:\n paths.append(file_path)\n\n if not len(paths):\n assert False, f\"Could not find any file at subdirectories of '{logits_dir}' with prefix '{prefix}'\"\n\n return paths\n\n\ndef load_logits(logits_paths, get_accuracy=False):\n logits_list, labels_list, logits_names, logits_accuracy = [], [], [], []\n for lp in logits_paths:\n logits_name = \"/\".join(lp.split(\"/\")[-2:])\n info = torch.load(lp, map_location=torch.device('cpu'))\n logits = info[\"logits\"].cpu()\n labels = info[\"labels\"].cpu()\n\n logits_list.append(logits)\n labels_list.append(labels)\n logits_names.append(logits_name)\n\n if get_accuracy:\n accuracy = compute_accuracy(labels, logits)\n logits_accuracy.append(accuracy)\n\n # logits_list shape: torch.Size([N, 10000, 10]) (CIFAR10 example)\n logits_list = torch.stack(logits_list)\n\n # -- Check if al labels has the same order for all logits --\n labels = labels_list[0]\n for indx, label_list in enumerate(labels_list[1:]):\n # Si alguno difiere del primero es que no es igual al resto tampoco\n if not torch.all(labels.eq(label_list)):\n assert False, f\"Labels list does not match!\"\n\n return logits_list, labels_list, logits_names, logits_accuracy\n\n"
}
] | 16 |
CompletelyGeneric/Pixiv-Fave-Downloader | https://github.com/CompletelyGeneric/Pixiv-Fave-Downloader | 70528fe7c8615ce7d830088a0eaca21753fea0bb | 2adbc9e0c8f596cd53c4d202b2a718bac450b0ba | 4735df8c17683753e02295cef9e77f7edfb5071a | refs/heads/master | 2021-01-11T03:08:10.259918 | 2017-06-01T14:39:16 | 2017-06-01T14:39:16 | 71,087,427 | 0 | 0 | null | 2016-10-17T00:57:29 | 2016-10-10T07:47:35 | 2016-10-14T02:28:55 | null | [
{
"alpha_fraction": 0.5542813539505005,
"alphanum_fraction": 0.5818042755126953,
"avg_line_length": 35.33333206176758,
"blob_id": "c87cdf3fc6b42d91f46da2122eadab5c68358858",
"content_id": "15791d8dfab3cfa47616f402f5ab914f889a9a37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1308,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 36,
"path": "/pixiv-fave-dl.py",
"repo_name": "CompletelyGeneric/Pixiv-Fave-Downloader",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nfrom pixivpy3 import *\nimport json\nimport os\nfrom datetime import datetime\n\napi = PixivAPI()\nwith open('config.json', 'r') as f: # config file location\n config = json.load(f)\n\ndownload_path = config['download_path']\n\n\nfor user in range(len(config[\"username\"])):\n api.login(config['username'][user], config['password'][user])\n last_fave_id = int(config['last_fave_id'][user])\n\n json_result = api.me_favorite_works()\n my_ids = json_result.response\n for my_id in my_ids:\n if (my_id.work.favorite_id <= last_fave_id):\n break\n url = my_id.work.image_urls['large']\n for p in range(my_id.work.page_count):\n page_url = url[:-5] + str(p) + url[-4:]\n api.download(page_url, path=download_path)\n print('[' + datetime.now().strftime('%d/%m/%Y %H:%M:%S') + '] \\033[1;32;40m::\\033[0;37;40m ' + 'Downloaded [ Fave ID: ' +\n str(my_id.work.favorite_id) + ' ID: ' + str(my_id.work.id) + ' Page: ' + str(p) + ' ] for user ' + config['username'][user])\n\n config['last_fave_id'][user] = str(my_ids[0].work.favorite_id)\n\nprint('[' + datetime.now().strftime('%d/%m/%Y %H:%M:%S') +\n '] \\033[1;32;40m::\\033[0;37;40m ' + 'End of new faves')\nwith open('config.json', 'w') as f:\n json.dump(config, f)\n"
}
] | 1 |
Vulfpeck/InstaAutoAccept | https://github.com/Vulfpeck/InstaAutoAccept | 3f1168d6f6e3bcc15b2c25bc7216b84f1dcbd3cd | b62820b4f88bfea4848c7cef61a6e1e6ad028c1d | 85c9147202d632a85ec396ecf7102f682ad271e6 | refs/heads/master | 2020-08-03T04:38:52.815897 | 2019-09-29T08:02:28 | 2019-09-29T08:02:28 | 211,626,846 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.691946804523468,
"alphanum_fraction": 0.7154026627540588,
"avg_line_length": 26.212766647338867,
"blob_id": "37c46c7cae0262e7d06d48de969a3ef4abceedf2",
"content_id": "9bab7dc2271f1d9d45910ac8b49a54e86fc770dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 1279,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 47,
"path": "/server_scrips/docker/Dockerfile",
"repo_name": "Vulfpeck/InstaAutoAccept",
"src_encoding": "UTF-8",
"text": "FROM google/dart\n\nFROM ubuntu:bionic\n\nRUN apt-get update && apt-get install -y \\\n python3 python3-pip \\\n fonts-liberation libappindicator3-1 libasound2 libatk-bridge2.0-0 \\\n libnspr4 libnss3 lsb-release xdg-utils libxss1 libdbus-glib-1-2 \\\n curl unzip wget \\\n xvfb\n\n# install chromedriver and google-chrome\n\nRUN CHROMEDRIVER_VERSION=`curl -sS chromedriver.storage.googleapis.com/LATEST_RELEASE` && \\\n wget https://chromedriver.storage.googleapis.com/$CHROMEDRIVER_VERSION/chromedriver_linux64.zip && \\\n unzip chromedriver_linux64.zip -d /usr/bin && \\\n chmod +x /usr/bin/chromedriver && \\\n rm chromedriver_linux64.zip\n\nRUN CHROME_SETUP=google-chrome.deb && \\\n wget -O $CHROME_SETUP \"https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb\" && \\\n dpkg -i $CHROME_SETUP && \\\n apt-get install -y -f && \\\n rm $CHROME_SETUP\n\nRUN pip3 install selenium\n\nWORKDIR /app\nADD pubspec.* /app/\n\nRUN groupadd -r aqueduct\nRUN useradd -m -r -g aqueduct aqueduct\nRUN chown -R aqueduct:aqueduct /app\n\nUSER aqueduct\nRUN pub get --no-precompile\n\nUSER root\nADD . /app\nRUN chown -R aqueduct:aqueduct /app\n\nUSER aqueduct\nRUN pub get --offline --no-precompile\n\nEXPOSE 8082\n\nENTRYPOINT [\"pub\", \"run\", \"aqueduct:aqueduct\", \"serve\", \"--port\", \"8082\"]\n"
},
{
"alpha_fraction": 0.7190635204315186,
"alphanum_fraction": 0.7265886068344116,
"avg_line_length": 25,
"blob_id": "9a0eb89ed854822e225cec69e80004c88c6c06de",
"content_id": "a59e0680ebc387580a56523f5d292f4667cce8bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2392,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 92,
"path": "/server_scrips/login_complex.py",
"repo_name": "Vulfpeck/InstaAutoAccept",
"src_encoding": "UTF-8",
"text": "import time\nimport sys\nimport os\n\nfrom selenium import webdriver\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.webdriver.common.action_chains import ActionChains\nfrom selenium.common.exceptions import NoSuchElementException\nimport shutil\n\nusername = sys.argv[1]\npasswd = sys.argv[2]\n\n\n# For security reasons, this script will remove the directory of the user every time he logs in\nif username in os.listdir('./profiles'):\n shutil.rmtree(f'./profiles/{username}')\n\n# and then create it again\nos.mkdir(f'./profiles/{username}')\nos.chdir(f'./profiles/{username}/')\n\noptions = webdriver.ChromeOptions()\noptions.add_argument('--disable-gpu')\noptions.headless = True\noptions.add_argument(f'user-data-dir=./profile')\ndriver = webdriver.Chrome(executable_path = \"/home/abhishek_nexus26/chromedriver\", options = options)\nactions = ActionChains(driver)\n\nlogin_url = \"https://www.instagram.com/accounts/login/\"\n\ndriver.get(login_url)\ntime.sleep(2)\n\nuname_field = driver.find_element_by_name(\"username\")\npwd_field = driver.find_element_by_name(\"password\")\n\n# this will return a list of web elements instead of a web element, as we search with regex\nsubmit_button = driver.find_elements_by_xpath(\n \"//*[contains(text(), 'Log In')]\")\n\nuname_field.send_keys(username)\npwd_field.send_keys(passwd)\n\ntime.sleep(1)\nsubmit_button[0].click()\n\ntime.sleep(2)\n\nif driver.current_url != \"https://www.instagram.com/accounts/login/two_factor\":\n print(\"error\")\n driver.close()\n quit()\n\n\notp_filename = username + \"_otp.txt\"\nfile_list = os.listdir()\n\n# Wait for the file to be created\nwhile otp_filename not in file_list:\n time.sleep(1)\n file_list = os.listdir()\n\ntime.sleep(2)\notp_file = open(otp_filename, \"r\")\notp = otp_file.readline().split(\"\\n\")[0]\nprint(otp)\n\notp_file.close()\n\nverification_code_field = driver.find_element_by_name(\"verificationCode\")\nverification_code_field.click()\nsubmit_otp_button = driver.find_elements_by_xpath(\n \"//*[contains(text(), 'Confirm')]\")\n\n\n#driver.execute_script(f\"document.getElementsByName('verificationCode')[0].setAttribute('value', {otp})\")\nfor x in otp:\n verification_code_field.send_keys(x)\n time.sleep(0.1)\n\ntime.sleep(1)\nsubmit_otp_button[0].click()\n\ntime.sleep(30)\n\nif driver.current_url == \"https://www.instagram.com/accounts/login/two_factor\":\n print(\"error\")\nelse:\n print(\"done\")\n\ndriver.close()\n"
},
{
"alpha_fraction": 0.6726190447807312,
"alphanum_fraction": 0.6785714030265808,
"avg_line_length": 14.318181991577148,
"blob_id": "3c236ea17fc72f82cd53757f58644647efd0bc1d",
"content_id": "eef9b8b84acc80e0527b4dfa0102e1febc5753e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 22,
"path": "/server_scrips/proxy_otp_result_check.py",
"repo_name": "Vulfpeck/InstaAutoAccept",
"src_encoding": "UTF-8",
"text": "import time\nimport os\nimport sys\n\n\nusername = sys.argv[1]\n\n\nos.chdir(f'./profiles/{username}')\n\notp_filename = username + \"_otp_result.txt\"\nfile_list = os.listdir()\n\nwhile otp_filename not in file_list:\n time.sleep(1)\n file_list = os.listdir()\n\n\notp_file = open(otp_filename, \"r\")\notp = otp_file.read()\notp_file.close()\nprint(otp)"
},
{
"alpha_fraction": 0.7507598996162415,
"alphanum_fraction": 0.7568389177322388,
"avg_line_length": 28.909090042114258,
"blob_id": "ab0c6c3e161456bff463451aaca9fa511d5c99be",
"content_id": "e945a75f2f54a816a87f5dcf54fac34848ae5e4b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1645,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 55,
"path": "/server_scrips/login_simple.py",
"repo_name": "Vulfpeck/InstaAutoAccept",
"src_encoding": "UTF-8",
"text": "import time \nimport sys\nimport os\nimport subprocess\n\nfrom selenium import webdriver\nfrom selenium.webdriver.support.ui import WebDriverWait\nfrom selenium.webdriver.common.action_chains import ActionChains\nfrom selenium.common.exceptions import NoSuchElementException\nimport shutil\n\nusername = sys.argv[1]\npasswd = sys.argv[2]\n\n# For security reasons, this script will remove the directory of the user every time he logs in\nif username in os.listdir('./profiles'):\n shutil.rmtree(f'./profiles/{username}')\n\n# and then create it again\nos.mkdir(f'./profiles/{username}')\nos.chdir(f'./profiles/{username}/')\noptions = webdriver.ChromeOptions()\noptions.add_argument('--disable-gpu')\noptions.add_argument('--disable-dev-shm-usage')\noptions.headless = True\noptions.add_argument(f'user-data-dir=./profile')\ndriver = webdriver.Chrome(executable_path = \"/home/abhishek_nexus26/chromedriver\", options = options)\nactions = ActionChains(driver)\nprint(driver.desired_capabilities)\nlogin_url = \"https://www.instagram.com/accounts/login/\"\ndriver.get(login_url)\ntime.sleep(2)\nuname_field = driver.find_element_by_name(\"username\")\npwd_field = driver.find_element_by_name(\"password\")\n\n# this will return a list of web elements instead of a web element, as we search with regex\nsubmit_button = driver.find_elements_by_xpath(\"//*[contains(text(), 'Log In')]\")\n\nuname_field.send_keys(username)\npwd_field.send_keys(passwd)\n\ntime.sleep(1)\nsubmit_button[0].click()\ntime.sleep(3)\nif driver.current_url == login_url:\n print(\"error\")\n driver.close()\n quit() \n\n\ntime.sleep(25)\n# check redirect url to see what flow to follow\nprint('login done')\n\ndriver.close()\n"
},
{
"alpha_fraction": 0.7162162065505981,
"alphanum_fraction": 0.7364864945411682,
"avg_line_length": 20.285715103149414,
"blob_id": "80e1addece059c4fb6cd0cf07ade0a49d9272025",
"content_id": "4c47ed8373341b97ee5f3b297d41fa191f0799dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 148,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 7,
"path": "/server_scrips/proxy_accept.py",
"repo_name": "Vulfpeck/InstaAutoAccept",
"src_encoding": "UTF-8",
"text": "import subprocess\nimport sys\n\nusername = sys.argv[1]\nstatus = sys.argv[2]\n\nsubprocess.Popen([\"python3\", \"accept.py\", username, status], shell=False)"
},
{
"alpha_fraction": 0.5678966641426086,
"alphanum_fraction": 0.5760147571563721,
"avg_line_length": 30.650602340698242,
"blob_id": "b951a1ff481e11d50132349bc707b87feecef14a",
"content_id": "7e1374bb4e9181b2dae9b9afe975926fa4cee8af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2710,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 83,
"path": "/server_scrips/accept.py",
"repo_name": "Vulfpeck/InstaAutoAccept",
"src_encoding": "UTF-8",
"text": "import time \r\nimport sys\r\nimport os\r\n\r\nfrom selenium import webdriver\r\nfrom selenium.webdriver.common.action_chains import ActionChains\r\nfrom selenium.common.exceptions import NoSuchElementException\r\n\r\n\r\naccepted_count = 0\r\n\r\ndef acceptRequests(accept_limit):\r\n global accepted_count\r\n\r\n options = webdriver.ChromeOptions()\r\n options.add_argument('--disable-gpu')\r\n options.headless = True\r\n options.add_argument(f'user-data-dir=./profile')\r\n options.add_argument('--disable-dev-shm-usage')\r\n driver = webdriver.Chrome(executable_path = \"/home/abhishek_nexus26/chromedriver\", options = options)\r\n print (driver.desired_capabilities)\r\n driver.get('https://www.instagram.com/accounts/activity/?followRequests=1')\r\n time.sleep(10)\r\n confirm_request_button_list = driver.find_elements_by_xpath(\"//*[contains(text(), 'Confirm')]\")\r\n print(confirm_request_button_list)\r\n print(driver.title)\r\n for confirm_button in confirm_request_button_list:\r\n try: \r\n confirm_button.click()\r\n accepted_count += 1\r\n accept_limit -= 1\r\n except:\r\n print(\"button no found\")\r\n break\r\n\r\n if accept_limit <= 0:\r\n time.sleep(2)\r\n driver.close()\r\n break\r\n time.sleep(2)\r\n driver.close()\r\n\r\nif __name__ == \"__main__\":\r\n \r\n username = sys.argv[1]\r\n mode = sys.argv[2]\r\n\r\n os.chdir(f\"./profiles/{username}/\")\r\n hourly_accept_limit = 9500\r\n status_filename = username + \"_status.txt\"\r\n try: \r\n count_file = open(f\"./{username}_count.txt\", \"r\")\r\n curr_count = count_file.read()\r\n print(curr_count)\r\n if curr_count== '':\r\n accepted_count = 0\r\n else:\r\n accepted_count = int(curr_count)\r\n \r\n print(\"Input from file\" + count_file.readline())\r\n print(\"parse: \" + str(accepted_count))\r\n count_file.close()\r\n except:\r\n print(\"failed to read file, assuming new user\")\r\n accepted_count = 0\r\n pass\r\n # count_file = open(f\"./{username}_count.txt\", \"w\")\r\n # count_file.write(\"str(accepted_count)\")\r\n # count_file.close()\r\n while True:\r\n \r\n with open(f\"./{status_filename}\", \"r\") as status_file:\r\n status = status_file.read().split('\\n')[0]\r\n print(status)\r\n if status == \"on\":\r\n print(\"status turned on\")\r\n acceptRequests(hourly_accept_limit)\r\n print(\"Accepted count:\" + str(accepted_count))\r\n with open(f\"./{username}_count.txt\", \"w\") as count_file:\r\n count_file.write(str(accepted_count))\r\n time.sleep(10)\r\n else:\r\n quit()\r\n"
}
] | 6 |
nonolemono/libpompomgali-base | https://github.com/nonolemono/libpompomgali-base | 28219de2c264e9285dca650723d26b74c2df413a | 84ce6f292ce8221a0eeef9c59ec9136ecb3abd91 | 347d91d74658435b90289dcd26aa868f3dc764bc | refs/heads/master | 2016-09-11T04:33:51.280903 | 2011-05-24T23:24:45 | 2011-05-24T23:24:45 | 773,645 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6949055790901184,
"alphanum_fraction": 0.7008585929870605,
"avg_line_length": 32.024574279785156,
"blob_id": "69d977e9b7dd0d1cafd18cf8d21d9a0bd23fa040",
"content_id": "5949423d50de4e451f24d8a241934c3d1060a907",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17484,
"license_type": "no_license",
"max_line_length": 273,
"num_lines": 529,
"path": "/libpompomgali/Base.py",
"repo_name": "nonolemono/libpompomgali-base",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport logging,os,sys,smtplib,commands,socket,shutil,time,md5,tarfile,mimetypes,logging.handlers,ConfigParser,urlparse\nlog = logging.getLogger(\"main.Base\")\n\nfrom email.Utils import COMMASPACE, formatdate\nfrom email import Encoders\nfrom email.Message import Message\nfrom email.MIMEAudio import MIMEAudio\nfrom email.MIMEBase import MIMEBase\nfrom email.MIMEImage import MIMEImage\nfrom email.MIMEMultipart import MIMEMultipart\nfrom email.MIMEText import MIMEText\n\nmimetypes.add_type('text/plain',\".log\")\nyes_answers = [\"y\",\"yes\"]\n\ndef sortDictKeys(dict):\n\tkeys = dict.keys()\n\tkeys.sort()\n\treturn keys\n\ndef sortDictValue(dict):\n\tkeys = dict.keys()\n\tkeys.sort()\n\treturn [dict[key] for key in keys]\n\ndef decodeString(string):\n\t'''Convert a string to unicode using utf-8 or latin-1 codecs'''\n\ttry:\n\t\tstring_unicode = string.decode('utf-8')\n\t\tlog.debug(\"Unicode from utf-8: %s\"%string)\n\texcept:\n\t\ttry:\n\t\t\tstring_unicode = string.decode('latin-1')\n\t\t\tlog.debug(\"Unicode from latin-1: %s\"%string)\n\t\texcept:\n\t\t\traise\n\t\t\tlog.error(\"Unable to decode this string using utf8/latin1 codecs.\")\n\t\t\tsys.exit(1)\n\treturn string_unicode\n\ndef convertToUtf8(folder):\n\t'''Convert filenames and foldernames to utf-8 encoding. Same as convm but native python. Returns folder name in unicode.'''\n\ttry:\n\t\tif not os.path.isdir(folder):\n\t\t\tlog.error(\"This folder does not exist\")\n\t\t\treturn False\n\texcept:\n\t\traise\n\tfoldercomefrom = os.getcwd()\n\tos.chdir(folder)\n\tif not isinstance(folder,unicode):\n\t\tfolder_unicode = decodeString(folder)\n\t\tos.rename(folder,folder_unicode)\n\t\tfolder = folder_unicode\n\n\tfor name in os.listdir(folder):\n\t\tif not isinstance(name,unicode):\n\t\t\tname_unicode = decodeString(name)\n\t\t\tos.rename(name,name_unicode)\n\t\t\tname = name_unicode\n\n\t\tif os.path.isdir(name):\n\t\t\tconvertToUtf8(os.path.join(folder,name))\n\n\tos.chdir(foldercomefrom) #Places us back in the folder we were in when this function was called\n\treturn folder\n\ndef sudoMe(command,comment=\"\"):\n\t'''Run a command as superuser. Exit program if sudo command is not available on host'''\n\tif os.path.isfile(\"/usr/bin/kdesudo\"):\n\t\ttry:\n\t\t\tcommands.getstatusoutput(\"/usr/bin/kdesudo -c \\\"\"+command+\"\\\" --comment \\\"\"+comment+\"\\\"\")\n\t\t\treturn True\n\t\texcept:\n\t\t\traise\n\telif os.path.isfile(\"/usr/bin/sudo\"):\n\t\ttry:\n\t\t\tstatus, output = commands.getstatusoutput(\"/usr/bin/sudo \"+command)\n\t\t\tif status: #This means an error occured\n\t\t\t\treturn False\n\t\t\treturn True\n\t\texcept:\n\t\t\traise\n\telse:\n\t\ttry:\n\t\t\t\tlog.error(\"Unable to find sudo command on this system\")\n\t\t\t\tsys.exit(1)\n\t\texcept:\n\t\t\t\tprint \"Unable to find sudo command on this system\"\n\t\t\t\tsys.exit(1)\n\ndef initLog(logger,log_file=\"python.log\",log_stdout=False,log_level=\"WARNING\",log_dir=\"/var/log\", format='%(asctime)s - %(name)-15s - %(funcName)s - %(levelname)-8s %(message)s',format_stdout = '%(name)-15s - %(funcName)s - %(levelname)-8s %(message)s',do_rollover = True):\n\t'''Initialize a logger object'''\n\tif log_level == \"DEBUG\":\n\t\tlogger.setLevel(logging.DEBUG)\n\telif log_level == \"WARNING\":\n\t\tlogger.setLevel(logging.WARNING)\n\telif log_level == \"ERROR\":\n\t\tlogger.setLevel(logging.ERROR)\n\telif log_level == \"CRITICAL\":\n\t\tlogger.setLevel(logging.CRITICAL)\n\telif log_level == \"INFO\":\n\t\tlogger.setLevel(logging.INFO)\n\n\t# Log to this file\n\tif log_dir != \"/var/log\":\n\t\tlog_folder = os.path.join(\"/var/log\",log_dir)\n\telse:\n\t\tlog_folder = log_dir\n\n\tif not os.path.isdir(log_folder):\n\t\tcommand = \"mkdir -p --mode=777 \"+log_folder\n\t\tcomment = \"Please enter sudo password to create log folder\"\n\t\tif not sudoMe(command,comment):\n\t\t\tsys.exit(\"Unable to create log folder\")\n\n\tlogfile = logging.handlers.RotatingFileHandler(filename = os.path.join(log_folder,log_file), maxBytes = 10000000, backupCount = 10)\n\n\tif do_rollover:\n\t\tlogfile.doRollover() #We want to have a new log file for each time the script is called\n\n\tformatter = logging.Formatter(format)\n\tlogfile.setFormatter(formatter)\n\tlogger.addHandler(logfile)\n\n\tif log_stdout:\n\t\tlogstderr = logging.StreamHandler()\n\t\tformatter = logging.Formatter(format_stdout)\n\t\tlogstderr.setFormatter(formatter)\n\t\tlogger.addHandler(logstderr)\n\treturn log_folder\n\ndef addDefaultOptions(parser,script,config=True,report=False,create_config=False):\n\t'''Add common options to scripts menu'''\n\tif config:\n\t\tparser.add_option(\"--config_file\",action=\"store\",help=\"Set configuration file [%default]\",default = os.path.join(os.environ[\"HOME\"],\".pompomgali\",os.path.splitext(script)[0].split(\"/\")[-1],os.path.splitext(script)[0].split(\"/\")[-1]+\".conf\"))\n\tif report:\n\t\tparser.add_option(\"-r\",\"--report\",action=\"store_true\",help=\"Send a report to root\")\n\tif create_config:\n\t\tparser.add_option(\"--create_config\",action=\"store_true\",help=\"Create a configuration file\")\n\tparser.add_option(\"-v\",\"--verbose\",action=\"store_true\",help=\"Display execution on stdout\")\n\tparser.add_option(\"-l\",\"--log_level\",action=\"store\",help=\"Set log level [default: WARNING]\")\n\ndef getAnswer(question,default_value=\"\",required=True):\n\t'''Ask a user to answer a question'''\n\tif required and default_value==\"\":\n\t\tanswer = \"\"\n\t\twhile answer == \"\":\n\t\t\tanswer = raw_input(question+\" [\"+default_value+\"] \")\n\t\t\tif answer != \"\":\n\t\t\t\treturn answer\n\t\t\telse:\n\t\t\t\tprint \"This question needs an answer, you must provide a value!\"\n\telse:\n\t\tanswer = raw_input(question+\" [\"+default_value+\"] \")\n\t\tif answer != \"\":\n\t\t\treturn answer\n\t\telse:\n\t\t\treturn default_value\n\ndef getFolderFileCount(folder):\n\t'''Return the number of files in a folder'''\n\tfile_count = 0\n\tif not isinstance(folder,unicode):\n\t\tfolder = folder.decode('utf-8')\n\tfor root, dirs, files in os.walk(folder.decode('utf-8'), topdown=False):\n\t\tfile_count += len(files)\n\treturn file_count\n\ndef getFolderPartFromPath(path):\n\t'''Return the folder component of a path. Return the parameter if it is already a folder.'''\n\tif os.path.isdir(path):\n\t\treturn path\n\telse:\n\t\tthepath = \"/\"\n\t\tfor folder in path.split(\"/\")[1:-1]:\n\t\t\tthepath = os.path.join(thepath,folder)\n\t\treturn thepath\n\ndef createConfigFile(file_param_path,sections_list,parameters_dic_list):\n\t'''Create a configuration file'''\n\tconf = ConfigParser.ConfigParser()\n\tif os.path.isfile(file_param_path): #Read existing params if any\n\t\tlog.info(\"Reading existing parameters from configuration file: %s\"%file_param_path)\n\t\tconf.readfp(open(file_param_path))\n\telse:\n\t\tlog.info(\"Configuration file \\\"%s\\\" does not exist. Creating one.\"%file_param_path)\n\n\tif not os.path.isdir(getFolderPartFromPath(file_param_path)):\n\t\tos.makedirs(getFolderPartFromPath(file_param_path))\n\tf = open(file_param_path,\"w\")\n\tfor i in range(len(sections_list)):\n\t\tif not conf.has_section(sections_list[i]):\n\t\t\tconf.add_section(sections_list[i])\n\n\t\t#print sortDictKeys(parameters_dic_list[i])\n\t\tfor param in sortDictKeys(parameters_dic_list[i]):\n\t\t\tparam_value = getParamForConfig(conf,sections_list[i],parameters_dic_list[i],param)\n\t\t\tif param == \"gallery_url\":\n\t\t\t\tparam_value = urlparse.urljoin(param_value,\"main.php\")\n\t\t\tconf.set(sections_list[i],param,param_value)\n\tconf.write(f)\n\tf.close()\n\ndef getSectionConfig_old(file_param_path,section,parameters_dic):\n\t'''Return a dictionnary of all parameters in section of file_param_path'''\n\tconf = ConfigParser.ConfigParser()\n\tif os.path.isfile(file_param_path): #Read existing params if any\n\t\tlog.debug(\"Reading existing parameters from configuration file: %s\"%file_param_path)\n\t\tconf.readfp(open(file_param_path))\n\t\tif section == \"list\":\n\t\t\tprint \"The following gallery instance are declared:\",getSectionsList(file_param_path,prefix=\"GALLERY\")\n\t\t\tsys.exit()\n\t\tif not conf.has_section(section):\n\t\t\tsys.exit(\"There is no such gallery declared in this config file.\")\n\telse:\n\t\tsys.exit(\"Config file \\\"%s\\\" does not exist, please create one using --create_config\"%file_param_path)\n\n\tparam_dic = {}\n\tfor param in parameters_dic.iterkeys():\n\t\ttry:\n\t\t\tvalue = conf.get(section,param)\n\t\t\tif value[0] == \"[\":\n\t\t\t\tparam_dic[param] = eval(value)\n\t\t\telse:\n\t\t\t\tparam_dic[param] = value.decode('utf-8')\n\t\texcept:\n\t\t\tsys.exit(\"Missing mandatory parameter \\\"%s\\\" in config file\"%param)\n\treturn param_dic\n\ndef getSectionConfig(config_object, section, parameters_dic=None):\n\t'''Return a dictionnary of all parameters in section of file_param_path'''\n\tparam_dic = {}\n\tif parameters_dic == None:\n\t\tfor value in config_object.items(section):\n\t\t\tif len(value[1]) == 0:\n\t\t\t\tparam_dic[value[0].decode('utf-8')] = value[1].decode('utf-8')\n\t\t\telse:\n\t\t\t\tif value[1][0] == \"[\":\n\t\t\t\t\tparam_dic[value[0].decode('utf-8')] = [x.decode('utf-8') for x in eval(value[1])] #Turns the list recognised as a string to a real list\n\t\t\t\telse:\n\t\t\t\t\tparam_dic[value[0].decode('utf-8')] = value[1].decode('utf-8')\n\telse:\n\t\tfor param in parameters_dic.iterkeys():\n\t\t\ttry:\n\t\t\t\tvalue = config_object.get(section,param)\n\t\t\t\tif value[0] == \"[\":\n\t\t\t\t\tparam_dic[param.decode('utf-8')] = eval(value[1])\n\t\t\t\telse:\n\t\t\t\t\tparam_dic[param.decode('utf-8')] = value.decode('utf-8')\n\t\t\texcept:\n\t\t\t\tsys.exit(\"Missing mandatory parameter \\\"%s\\\" in config file\"%param)\n\tlog.debug(param_dic)\n\treturn param_dic\n\ndef getSectionsList(config_object,prefix=\"\"):\n\t'''Get sections of a config file, optionaly returning only those with a given prefix'''\n\tsections = [ x for x in config_object.sections() if x[0:len(prefix)] == prefix ]\n\treturn sections\n\ndef checkConfigItemValue(config_object,section,item,value):\n\tif section not in getSectionsList(config_object):\n\t\tlog.error(\"Missing section ==> %s\"%(section))\n\t\treturn False\n\tif not getSectionConfig(config_object,section).has_key(item):\n\t\tlog.error(\"Missing item ==> %s\"%(item))\n\t\treturn False\n\tif getSectionConfig(config_object,section)[item] != value:\n\t\tlog.error(\"Wrong item value ==> %s\"%(value))\n\t\treturn False\n\treturn True\n\ndef setConfigItemValue(config_object,section,item,value):\n\tif section not in getSectionsList(config_object):\n\t\tconfig_object.add_section(section)\n\tif not checkConfigItemValue(config_object,section,item,value):\n\t\tconfig_object.set(section,item,value)\n\t\treturn True\n\treturn False\n\ndef delConfigItem(config_object,section,item):\n\tif section not in getSectionsList(config_object):\n\t\treturn False\n\tif not getSectionConfig(config_object,section).has_key(item):\n\t\treturn False\n\telse:\n\t\tconfig_object.remove_option(section,item)\n\t\treturn True\n\ndef removeConfigFileItemsSpace(file_path):\n\tlignes = readFileToList(file_path)\n\tf = open(file_path,'w')\n\tfor ligne in lignes:\n\t\tligne = ligne.replace(\" = \", \"=\")\n\t\tf.write(ligne)\n\tf.close()\n\ndef writeConfigToFile(file_path,config_object,removespace = False):\n\tconfig_file = open(file_path,'w')\n\tconfig_object.write(config_file)\n\tconfig_file.close()\n\tif removespace == True:\n\t\tremoveConfigFileItemsSpace(file_path)\n\ndef getConfigObject(file_param_path,create_if_needed=True):\n\tconfig = ConfigParser.ConfigParser()\n\tconfig.optionxform=str #Preserve item case\n\tif os.path.isfile(file_param_path):\n\t\tlog.debug(\"Reading existing parameters from configuration file: %s\"%file_param_path)\n\t\tconfig.read(file_param_path)\n\telse:\n\t\tif not create_if_needed:\n\t\t\tlog.error(\"Configuration file \\\"%s\\\" does not exist.\"%file_param_path)\n\t\t\tsys.exit(1)\n\treturn config\n\n#TODO: add a parameter to force users to enter a value if it is mandatory to have one\ndef getParamForConfig(conf,section,parameters_dic,param):\n\t'''Get a parameter - ask a user to type in a value or try to get it from an existing config file'''\n\ttry:\n\t\tvalue = conf.get(section,param)\n\texcept:\n\t\tlog.info(\"Unable to get \\\"%s\\\" in section \\\"%s\\\"\"%(param,section))\n\t\tif isinstance(parameters_dic[param],list): #this mean there is a default value at declaration\n\t\t\tvalue = parameters_dic[param][1]\n\t\telse:\n\t\t\tvalue=None\n\tif isinstance(parameters_dic[param],list): #this mean there is a default value at declaration\n\t\tquestion = parameters_dic[param][0]\n\telse:\n\t\tquestion = parameters_dic[param]\n\tif value:\n\t\tresult = raw_input(question+\"[%s]:\"%value)\n\telse:\n\t\tresult = raw_input(question+\"[No default value]:\")\n\tif not result:\n\t\tresult = value\n\treturn result\n\ndef folderGetSize(folder):\n\t'''Return the size of a folder in bytes'''\n\tsize = os.stat(folder)[6]\n\tfor root, dirs, files in os.walk(folder, topdown=True):\n\t\tfor name in dirs:\n\t\t\tsize = size+os.stat(os.path.join(root,name))[6]\n\t\tfor name in files:\n\t\t\tsize = size+os.stat(os.path.join(root,name))[6]\n\treturn size\n\ndef removeAccents(name): #Not used at the moment - may be removed\n\t'''Removes accents from a string'''\n\tarray = {}\n\tarray[\"e\"] = [\"é\",\"è\",\"ê\",\"ë\"]\n\tarray[\"a\"] = [\"à\",\"â\",\"ä\"]\n\tarray[\"i\"] = [\"î\",\"ï\"]\n\tarray[\"o\"] = [\"ô\",\"ö\"]\n\tarray[\"u\"] = [\"û\",\"ü\"]\n\tarray[\"c\"] = [\"ç\"]\n\n\tfor key in array.iterkeys():\n\t\tfor char in array[key]:\n\t\t\tname = name.replace(char,key)\n\treturn name\n\ndef readFileToList(file):\n\t'''Read a file and return a list of lignes in the file'''\n\tlignes = []\n\tif os.path.isfile(file):\n\t\tf = open(file,\"r\")\n\t\tlignes = f.readlines()\n\t\tf.close()\n\telse:\n\t\tlog.debug(\"File \\\"%s\\\" does not exist\"%file)\n\treturn lignes\n\ndef renameInCycle(root,name,new_name):\n\t'''Rename a file/folder and add an increment if dest name already exists'''\n\tdone = False\n\ti = 1\n\twhile not done:\n\t\tif not os.path.exists(os.path.join(root,new_name)):\n\t\t\tlog.debug(\"new_name: %s\"%os.path.join(root,new_name).encode('utf-8'))\n\t\t\tos.rename(os.path.join(root,name),os.path.join(root,new_name))\n\t\t\tdone = True\n\t\telse:\n\t\t\tnew_name = os.path.splitext(new_name)[0]+\"_\"+str(i)+os.path.splitext(new_name)[-1]\n\t\t\ti = i+1\n\ndef fileCalculateMD5(fileName, excludeLine=\"\", includeLine=\"\", purejpeg=True):\n\t\"\"\"Compute md5 hash of the specified file\"\"\"\n\ttmp_file = \"/tmp/md5_tmp\"\n\tif os.path.splitext(name)[-1].lower() == \".jpg\" and purejpeg:\n\t\tshutil.copy(name,tmp_file)\n\t\t#Add a check for this at import time\n\t\tcommands.getoutput(\"jhead -purejpg \"+tmp_file)\n\t\tfilename = tmp_file\n\n\tm = hashlib.md5()\n\ttry:\n\t\tfd = open(fileName,\"rb\")\n\texcept IOError:\n\t\tprint \"Unable to open the file in readmode:\", filename\n\t\treturn\n\tcontent = fd.readlines()\n\tfd.close()\n\tfor eachLine in content:\n\t\tif excludeLine and eachLine.startswith(excludeLine):\n\t\t\tcontinue\n\t\tm.update(eachLine)\n\tm.update(includeLine)\n\tif os.path.isfile(tmp_file):\n\t\tos.remove(tmp_file)\n\treturn m.hexdigest()\n\ndef fileCalculateMD5_old(name,purejpeg=True):\n\t'''Return the md5 hexadecimal encoded hash of a file. Can remove non jpeg data from jpeg file (on by default)'''\n\ttmp_file = \"/tmp/md5_tmp\"\n\tif os.path.splitext(name)[-1].lower() == \".jpg\":\n\t\tif purejpeg:\n\t\t\tshutil.copy(name,tmp_file)\n\t\t\t#Add a check for this at import time\n\t\t\tcommands.getoutput(\"jhead -purejpg \"+tmp_file)\n\t\t\tname = tmp_file\n\n\tf = open(name,'rb')\n\thash_value = md5.new(f.read()).hexdigest()\n\tf.close()\n\tif os.path.isfile(tmp_file):\n\t\tos.remove(tmp_file)\n\treturn hash_value\n\ndef sendMail(mfrom,mto,subject,content,files=[],add_server_name=False,smtp_server=\"localhost\"):\n\t'''Send and email and also deals with attachments'''\n\tassert type(mto)==list\n\tassert type(files)==list\n\n\touter = MIMEMultipart()\n\touter['From'] = mfrom\n\touter['To'] = COMMASPACE.join(mto)\n\touter['Date'] = formatdate(localtime=True)\n\touter['Subject'] = subject\n\tif add_server_name:\n\t\touter['Subject'] = subject+\" @ \"+socket.gethostname()\n\touter.attach(MIMEText(content,_charset='utf-8'))\n\n\tfor name in files:\n\t\tif os.path.isfile(name):\n\t\t\tctype, encoding = mimetypes.guess_type(name,False)\n\t\t\tif ctype is None or encoding is not None:\n\t\t\t\t# No guess could be made, or the file is encoded (compressed), so\n\t\t\t\t# use a generic bag-of-bits type.\n\t\t\t\tctype = 'application/octet-stream'\n\t\t\tmaintype, subtype = ctype.split('/', 1)\n\t\t\tif maintype == 'text':\n\t\t\t\tfp = open(name)\n\t\t\t\t# Note: we should handle calculating the charset\n\t\t\t\tmsg = MIMEText(fp.read(), _subtype=subtype)\n\t\t\t\tfp.close()\n\t\t\telif maintype == 'image':\n\t\t\t\tfp = open(name, 'rb')\n\t\t\t\tmsg = MIMEImage(fp.read(), _subtype=subtype)\n\t\t\t\tfp.close()\n\t\t\telif maintype == 'audio':\n\t\t\t\tfp = open(name, 'rb')\n\t\t\t\tmsg = MIMEAudio(fp.read(), _subtype=subtype)\n\t\t\t\tfp.close()\n\t\t\telse:\n\t\t\t\tfp = open(name, 'rb')\n\t\t\t\tmsg = MIMEBase(maintype, subtype)\n\t\t\t\tmsg.set_payload(fp.read())\n\t\t\t\tfp.close()\n\t\t\t\t#Encode the payload using Base64\n\t\t\t\tEncoders.encode_base64(msg)\n\n\t\t\t# Set the filename parameter\n\t\t\tmsg.add_header('Content-Disposition', 'attachment', name=name)\n\t\t\touter.attach(msg)\n\n\tsmtp = smtplib.SMTP(smtp_server)\n\tsmtp.sendmail(mfrom,mto,outer.as_string())\n\tsmtp.close()\n\ndef tar_element(element,dst_filename,add_time=False,format=\"gz\"):\n\t'''Tar a file or a folder. The tar of a folder is very slow in comparison to the direct system call'''\n\textension=\"\"\n\n\tif add_time:\n\t\textension=\"_\"+time.strftime(\"%Y-%m-%d_%H-%M-%S\")\n\tif format==\"gz\":\n\t\ttar_format=\"w:gz\"\n\t\textension=extension+\".tar.gz\"\n\telif format==\"bz2\":\n\t\ttar_format=\"w:bz2\"\n\t\textension=extension+\".tar.bz2\"\n\telse:\n\t\tlog.error(\"Unknown archive format %s\"%format)\n\t\tsys.exit(1)\n\n\tif dst_filename!= \"\":\n\t\tbase_archive_name=dst_filename\n\telse:\n\t\tbase_archive_name=element\n\n\tif os.path.isfile(element):\n\t\ttar = tarfile.open(base_archive_name+extension, tar_format)\n\t\ttar.add(element.encode('utf-8')) #This function does not seem to like unicode string, so we force it to utf-8\n\t\ttar.close()\n\t\treturn 0\n\telif os.path.isdir(element):\n\t\ttar = tarfile.open(base_archive_name+extension,tar_format)\n\t\tfor root, dirs, files in os.walk(element, topdown=False):\n\t\t\tfor name in files:\n\t\t\t\ttar.add(os.path.join(root, name))\n\t\ttar.close()\n\t\treturn 0\n\telse:\n\t\tprint \"Unsupported element type\"\n\t\treturn 1\n\t\ndef checkLimit(options, root, name):\n\tstatus = False\n\tif options.limit:\n\t\tfor element in options.limit:\n\t\t\tif element in os.path.join(root, name):\n\t\t\t\tstatus = True\n\treturn status\n"
}
] | 1 |
MelvynnHadia/107 | https://github.com/MelvynnHadia/107 | e1b2cc64452323966f7c84cb45b64e4ff99ddac9 | fd3aa604a3b79fa65893a16ed408e3b9590a1d72 | ee44c1bb48c51ffd2e1a61b7c988d0067344a10e | refs/heads/main | 2023-05-09T02:19:00.540573 | 2021-05-29T09:10:38 | 2021-05-29T09:10:38 | 371,928,393 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6470588445663452,
"avg_line_length": 32,
"blob_id": "47322d833bed3131aa7981b169db845a33a297cb",
"content_id": "514accedf89e7a4db447470203dc98140c552a3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 238,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 7,
"path": "/main.py",
"repo_name": "MelvynnHadia/107",
"src_encoding": "UTF-8",
"text": "import pandas as pd\r\nimport plotly.express as px\r\n\r\ndf = pd.read_csv(\"data.csv\")\r\nmean = df.groupby(\"level\"), [\"attempt\"].mean()\r\nfigure = px.scatter(mean, x = \"student_id\", y = \"level\", size = \"attempt\", color=\"attempt\")\r\nfigure.show()\r\n"
}
] | 1 |
yizhou-wang/dict-deep | https://github.com/yizhou-wang/dict-deep | f84213489cd35b7073921740182ecc7ee41947a7 | cd19b9205c1c08703e6fd22cea06fff499d775af | 763b159cf465466455d2575489a7ef93dd6e5c16 | refs/heads/master | 2021-06-17T15:46:31.165838 | 2017-05-23T15:11:48 | 2017-05-23T15:11:48 | 90,563,780 | 1 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.6357254385948181,
"alphanum_fraction": 0.66458660364151,
"avg_line_length": 31.871795654296875,
"blob_id": "69a19317e79a0c2423003e4755173da5ce2a0a24",
"content_id": "1b44ae86480628a052be5d6628c926c08562d230",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1282,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 39,
"path": "/mlp_utils.py",
"repo_name": "yizhou-wang/dict-deep",
"src_encoding": "UTF-8",
"text": "from keras.models import Sequential\nfrom keras.layers.core import Dense, Dropout, Flatten\nfrom keras.layers.convolutional import Convolution3D, MaxPooling3D, ZeroPadding3D\nfrom keras.layers.normalization import BatchNormalization\nfrom keras.optimizers import SGD\n\n'''\ndim_ordering issue:\n- 'th'-style dim_ordering: [batch, channels, depth, height, width]\n- 'tf'-style dim_ordering: [batch, depth, height, width, channels]\n'''\n\ndef get_model(summary=False, backend='tf', class_num=10):\n \"\"\" Return the Keras model of the network\n \"\"\"\n model = Sequential()\n if backend == 'tf':\n input_shape=(256 * 2,) # l, h, w, c\n else:\n input_shape=(256 * 2,) # c, l, h, w\n\n # FC layers group\n model.add(BatchNormalization(input_shape=input_shape, axis=-1, momentum=0.99, epsilon=0.001, center=True))\n model.add(Dense(4096, activation='relu', name='fc1'))\n model.add(Dropout(.3))\n # model.add(Dense(512, activation='relu', name='fc2'))\n # model.add(Dropout(.3))\n # model.add(Dense(256, activation='relu', name='fc3'))\n # model.add(Dropout(.3))\n model.add(Dense(class_num, activation='softmax', name='softmax'))\n\n if summary:\n print(model.summary())\n\n return model\n\n\nif __name__ == '__main__':\n model = get_model(summary=True)\n"
},
{
"alpha_fraction": 0.6109510064125061,
"alphanum_fraction": 0.6302593946456909,
"avg_line_length": 27.442623138427734,
"blob_id": "e44e3fdeba308acae0e32efa1e375f84daf42f3e",
"content_id": "40ce8f68b8739e0b608a817d6e71be5fc83bf79d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3470,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 122,
"path": "/deep_net.py",
"repo_name": "yizhou-wang/dict-deep",
"src_encoding": "UTF-8",
"text": "import os\nfrom os import listdir\nfrom os.path import isfile, join\n\nimport numpy as np\nimport scipy.io\nfrom sklearn.utils import shuffle\n\nimport keras\nimport mlp_utils\nimport c3d_utils\nfrom keras import callbacks\n\nimport time\n\nstart_time = time.time()\n\n\nremote = callbacks.RemoteMonitor(root='http://localhost:9000')\n\n\ndataset_name = 'weizmann'\n# dataset_name = 'kth'\nlabel_dic = [ 'bend', 'jack', 'jump', 'pjump', 'run', 'side', 'skip', 'walk', 'wave1', 'wave2' ]\nlabel_dic_num = len(label_dic)\n# label_dic = [ 'boxing', 'handclapping', 'handwaving', 'jogging', 'running', 'walking' ]\n# label_dic_num = len(label_dic)\ntransform_n_nonzero_coefs = 20\n\n## Load Dic Results ##\nprint('Loading Dic Results ...')\nroot_dir = '../results/' + dataset_name + '_dic_' + str(transform_n_nonzero_coefs) + '/'\nfiles = []\nlabels_name = []\nfor file in sorted(os.listdir(root_dir)):\n if file.endswith(\".mat\"):\n files.append(os.path.join(root_dir, file))\n labels_name.append(file.split('.')[0])\n\n\nfor file, label in zip(files, labels_name): # NUM of loops: 10\n \n print(file)\n print(label)\n\n X1 = scipy.io.loadmat(file)['X_train']\n X2 = scipy.io.loadmat(file)['X_test']\n try:\n X_train = np.concatenate((X_train, X1), axis=0)\n except:\n X_train = X1\n try:\n X_test = np.concatenate((X_test, X2), axis=0)\n except:\n X_test = X2\n \n try:\n label_num = label_dic.index(label)\n except:\n label_num = label_dic.index(label[0:-1])\n\n tr_num = X1.shape[0]\n te_num = X2.shape[0]\n Y1 = np.full((tr_num, 1), label_num, dtype=int)\n Y2 = np.full((te_num, 1), label_num, dtype=int)\n try:\n Y_train = np.concatenate((Y_train, Y1), axis=0)\n except:\n Y_train = Y1\n try:\n Y_test = np.concatenate((Y_test, Y2), axis=0)\n except:\n Y_test = Y2\n\nprint('* ----------------------------- *')\nprint('X_train.shape:', X_train.shape)\nprint('Y_train.shape:', Y_train.shape)\nprint('X_test.shape:', X_test.shape)\nprint('Y_test.shape:', Y_test.shape)\nprint('* ----------------------------- *')\n\n\n## Put sparse features into simple neural networks ##\n\nX_train, Y_train = shuffle(X_train, Y_train, random_state=0)\nX_test, Y_test = shuffle(X_test, Y_test, random_state=0)\n# print('X.shape:', X.shape)\n# print('Y.shape:', Y.shape)\n\nmodel_mlp = mlp_utils.get_model(summary=True, class_num=label_dic_num)\nmodel_mlp.compile(optimizer='rmsprop',\n loss='categorical_crossentropy',\n metrics=['accuracy'])\n\n# # Generate dummy data\n# data = np.random.random((1000, 100))\n# labels = np.random.randint(10, size=(1000, 1))\n\n# Convert labels to categorical one-hot encoding\ntr_labels = keras.utils.to_categorical(Y_train, num_classes=label_dic_num)\nte_labels = keras.utils.to_categorical(Y_test, num_classes=label_dic_num)\n\n# Train the model, iterating on the data in batches of 32 samples\nprint('Training Model ...')\nmodel_mlp.fit(X_train, tr_labels, epochs=50, batch_size=256, validation_data=(X_test, te_labels), callbacks=[remote])\n\n# model_mlp.evaluate(X_test, te_labels, batch_size=32)\n\npre = model_mlp.predict(X_test)\nscore = model_mlp.evaluate(X_test, te_labels, batch_size=32)\nprint('\\nTest Score:', score[1])\n\nprint(\"--- %s seconds ---\" % (time.time() - start_time))\n\nscipy.io.savemat('../results/pre.mat', {'te_labels': te_labels, 'pre': pre})\n\n## Put original video into C3D networks ##\n# model_c3d = c3d_utils.get_model(summary=True)\n\n\n\n## Evaluation ##\n"
},
{
"alpha_fraction": 0.7457627058029175,
"alphanum_fraction": 0.7796609997749329,
"avg_line_length": 19,
"blob_id": "aeca754ec456bf553c7b49194d09ab9a05c5e7b6",
"content_id": "350ec94b0700bffa8a8c9f7b913d6d905975ac4c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 3,
"path": "/run_demo.py",
"repo_name": "yizhou-wang/dict-deep",
"src_encoding": "UTF-8",
"text": "import c3d_utils\n\nmodel = c3d_utils.get_model(summary=True)"
},
{
"alpha_fraction": 0.61588054895401,
"alphanum_fraction": 0.6318289637565613,
"avg_line_length": 24.105113983154297,
"blob_id": "be62d1aadd5cf608af7589164edd8f612d8d5055",
"content_id": "f4248adc5d52e3076aab0f7d0375b7cf7ed59cc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8841,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 352,
"path": "/feature_extract.py",
"repo_name": "yizhou-wang/dict-deep",
"src_encoding": "UTF-8",
"text": "# Spare action recognition\n# Lingyu & Yizhou\n# Loading videos\n# Extract keypoints\n# Compute local motion pattern\n\n\nimport numpy as np\nfrom matplotlib import pyplot as plt\nimport scipy.io\nfrom scipy import stats\n\nimport os\nfrom os import listdir\nfrom os.path import isfile, join\n\nimport cv2\n\nnfeatures = 100\n\ndef readvideo(source):\n\tcam = cv2.VideoCapture(source)\n\timglist=[]\n\t# If Camera Device is not opened, exit the program\n\tif not cam.isOpened():\n\t\tprint \"Video device or file couldn't be opened\"\n\t\texit()\n\n\t# retval, img = cam.read()\n\t# print type(img)\n\t# print \"frame\"\n\t# imglist.append(img)\n\ti = 0\n\twhile True:\n\t\t# Retrieve an image and Display it.\n\t\tretval, img = cam.read()\n\t\t \n\t\t#print type(retval)\n\t\ti = i + 1\n\t\t\n\t\t\n\t\t\n\t\tif not retval:\n\t\t\t# print \"Cannot capture frame device\"\n\t\t\tbreak\n\t\t\n\t\t#print type(img)\n\t\t#image = rgb2gray(img)\n\t\timglist.append(img)\n\t\t# print '%s %s %s'%(i,'th','frame')\n\t\t\n\t\t\n\n\treturn imglist\n\ndef subseq(imglist, N_sq):\n\t# N_sq is the number of subsequences.\n\t#N_frame = len(imglist)/N_sq\n\n\tchunks = [imglist[x:x+N_sq] for x in range(0, len(imglist), N_sq)]\n\t#print len(chunks[0]) # number of subsequences\n\t#print imglist[0].shape\n\t#print chunks[0][1].shape # the second subsequence\n\t#print type(chunks[0])\n\treturn chunks\n\n\ndef orbkeypoint(img_frame):\n\n\torb = cv2.ORB(edgeThreshold=12, nfeatures=nfeatures)\n\n\tcurrent_image = img_frame\n\t# print '%s %s %s'%('original','dimension',current_image.shape)\n\tkp1, des1 = orb.detectAndCompute(current_image,None)\n\t# kp1 is list\n\t\n\treturn kp1\n\n\n# def matching(imglist):\n# \torb = cv2.ORB_create()\n# \timg1 = imglist[0]\n# \timg2 = imglist[1]\n# \t# find the keypoints and descriptors with SIFT\n# \tkp1, des1 = orb.detectAndCompute(img1,None)\n# \tkp2, des2 = orb.detectAndCompute(img2,None)\n\n# \t# print des1\n# \t# print des2\n# \t# des1, des2 are the feature descriptors of keypoint\n\n# \t# point keypoint location.\n# \tprint kp1[0].pt\n\n# \tprint '%s %s %s'%('has',len(kp1),'keypoints')\n# \tprint '%s %s %s'%('has',len(kp2),'keypoints')\n\t\n# \t#print type(kp1)\n\n# \t# create BFMatcher object\n# \tbf = cv2.BFMatcher(cv2.NORM_HAMMING, crossCheck=True)\n\n# \t# Match descriptors.\n# \tmatches = bf.match(des1,des2)\n\n# \t# Sort them in the order of their distance.\n# \t#matches = sorted(matches, key = lambda x:x.distance)\n\n# \t# Draw first 10 matches.\n# \timg3 = cv2.drawMatches(img1,kp1,img2,kp2,matches[:50], None,flags=2)\n\n# \tplt.imshow(img3),plt.show()\n\t\n\n\ndef kplocation(kp_frame):\n\t\n\tkploc_frame = []\n\t# for each point in one frame\n\tfor i in range(0, len(kp_frame)):\n\t\tkp = kp_frame[i]\n\t\tkp_xy = kp.pt\n\t\t# tuple list\n\t\tkploc_frame.append(kp_xy)\n\t\n\treturn kploc_frame\n\ndef kppatchfuc(kploc_frame, sub_video_seq):\n\t# get patch around the keypoint.\n\tkppatch = []\n\tfor i in range(0,len(kploc_frame)):\n\t\tkploc_pt = kploc_frame[i]\n\t\tpatch_center = kploc_pt\n\t\tpatch_size = 24 # Note by Lingyu, increasing patch size will increasing accuracy\n\t\tpatch_x = patch_center[0] - patch_size/2\n\t\tpatch_y = patch_center[1] - patch_size/2\n\n\t\tsub_patch = []\n\t\tfor f in range(0, len(sub_video_seq)):\n\t\t\tframe = rgb2gray(sub_video_seq[f])\n\t\t\t#print frame.shape\n\t\t\tpatch_pt = frame[int(patch_y):int(patch_y+patch_size), int(patch_x):int(patch_x+patch_size)]\n\t\t\tsub_patch.append(patch_pt)\n\n\t\t\t# if patch_pt.shape == (0,24):\n\t\t\t# \tprint patch_center, patch_x,patch_y\n\t\t\t# \texit()\n\t\t\t#print patch_pt.shape\n\n\t\tkppatch.append(sub_patch)\n\n\t\n\n\treturn kppatch\n\ndef motionpattern(kppatch,N_sq):\n\n\tk = len(kppatch)\n\tpatch_array = np.zeros(shape=[24,24,N_sq])\n\tfeature = np.zeros(shape=[k,24,24,3])\n\tfor i in range(0,len(kppatch)):\n\t\t# for ith keypoint\n\t\tpatch = kppatch[i]\n\t\t# for ith keypoint, we have N_sq frames, so the dimentsion of patch is 24*24*N_sq\n\t\t# We need to calculate central moments for this N_sq data which is 24*24\n\t\t#print patch[0].shape\n\t\t\n\t\tfor m in range(0,N_sq):\n\t\t\t#print patch[m].shape\n\t\t\tpatch_array[:,:,m] = patch[m]\n\t\t#print patch_array.shape\n\t\t\n\t\tfeature[i,:,:,0] = stats.moment(patch_array,moment=2,axis=2)\n\t\tfeature[i,:,:,1] = stats.moment(patch_array,moment=3,axis=2)\n\t\tfeature[i,:,:,2] = stats.moment(patch_array,moment=4,axis=2)\n\n\tfeature = np.reshape(feature,(k,1728))\n\t# print 'shape'\n\t# print feature.shape\n\t\n\treturn feature\n\n\ndef rgb2gray(rgb):\n return np.dot(rgb[...,:3], [0.299, 0.587, 0.114])\n\n# def centralmoment(imglist):\n# \timg = imglist[0]\n\n# \timage = rgb2gray(img) \n# \tfeature = cv2.moments(image)\n# \tprint feature.shape\n\n\n\n\nif __name__ == '__main__':\n\n\tdataset_name = 'weizmann'\n\t# dataset_name = 'kth'\n\troot_dir = '../dataset/' + dataset_name + '/'\n\tN_sq = 16\n\n\tcat_folders = [f for f in listdir(root_dir) if not isfile(join(root_dir, f))]\n\tprint cat_folders\n\n\tfor cat in cat_folders:\n\t\t\n\t\tcat_dir = root_dir + cat + '/'\n\t\tprint cat_dir\n\n\t\tvideo_dirs = []\n\t\tname_list = sorted(os.listdir(cat_dir))\n\t\tvideo_name_list = []\n\t\tfor video in name_list:\n\t\t\tif video.endswith(\".avi\"):\n\t\t\t\tvideo_name_list.append(video)\n\n\t\tif dataset_name == 'weizmann':\n\t\t\t# For training videos\n\t\t\tfor video in video_name_list[:-1]:\n\t\t\t\tprint 'Working on', video, '...'\n\t\t\t\tvideo_name = video.split('.')[0]\n\t\t\t\tcur_video_dir = os.path.join(cat_dir, video)\n\t\t\t\tvideo_dirs.append(cur_video_dir)\n\n\t\t\t\timglist = readvideo(cur_video_dir)\n\t\t\t\t# print video, 'Read!'\n\t\t\t\t#matching(imglist)\n\n\n\t\t\t\tN = len(imglist)\n\t\t\t\tvideo_seq = subseq(imglist, N_sq)\n\t\t\t\tprint '%s %s %s'%(' Total',N,'frames')\n\t\t\t\tprint '%s %s %s'%(' videoseq',len(video_seq[0]),'frames')\n\t\t\t\tprint '%s %s %s'%(' Total',len(video_seq),'segments')\n\n\n\t\t\t\t# Extract patch for all the subsequence\n\t\t\t\tpatch = []\n\t\t\t\tfeature = ['EMPTY']\n\t\t\t\tfor i in range(0, N / N_sq):\n\t\t\t\t\tsub_video_seq = video_seq[i]\n\t\t\t\t\tkp_frame = orbkeypoint(sub_video_seq[0])\n\t\t\t\t\tkploc_frame = kplocation(kp_frame)\n\t\t\t\t\tkppatch = kppatchfuc(kploc_frame, sub_video_seq)\n\t\t\t\t\tf = motionpattern(kppatch,N_sq)\n\t\t\t\t\t# print 'test!!!'\n\t\t\t\t\ttry:\n\t\t\t\t\t\tfeature = np.concatenate((feature, f), axis=0)\n\t\t\t\t\texcept:\n\t\t\t\t\t\tfeature = f\n\n\t\t\t\tmat_dir = '../results/' + dataset_name + '_features/'\n\t\t\t\tif not os.path.exists(mat_dir):\n\t\t\t\t\tos.makedirs(mat_dir)\n\t\t\t\tmat_name = mat_dir + video_name + '_train.mat'\n\t\t\t\tscipy.io.savemat(mat_name, {\"feature\": feature})\n\n\t\t\t\tprint 'feature.shape:', feature.shape\n\t\t\t\tprint 'MAT:', mat_name, 'saved!'\n\t\t\t\n\t\t\t# For test video\n\t\t\tvideo = video_name_list[-1]\n\t\t\tprint 'Working on', video, '...'\n\t\t\tvideo_name = video.split('.')[0]\n\t\t\tcur_video_dir = os.path.join(cat_dir, video)\n\t\t\tvideo_dirs.append(cur_video_dir)\n\n\t\t\timglist = readvideo(cur_video_dir)\n\t\t\tprint video, 'Read!'\n\t\t\t#matching(imglist)\n\n\n\t\t\tN = len(imglist)\n\t\t\tvideo_seq = subseq(imglist, N_sq)\n\t\t\tprint '%s %s %s'%(' Total',N,'frames')\n\t\t\tprint '%s %s %s'%(' videoseq',len(video_seq[0]),'frames')\n\t\t\tprint '%s %s %s'%(' Total',len(video_seq),'segments')\n\n\n\t\t\t# Extract patch for all the subsequence\n\t\t\tpatch = []\n\t\t\tfeature = ['EMPTY']\n\t\t\tfor i in range(0, N / N_sq):\n\t\t\t\tsub_video_seq = video_seq[i]\n\t\t\t\tkp_frame = orbkeypoint(sub_video_seq[0])\n\t\t\t\tkploc_frame = kplocation(kp_frame)\n\t\t\t\tkppatch = kppatchfuc(kploc_frame, sub_video_seq)\n\t\t\t\tf = motionpattern(kppatch,N_sq)\n\n\t\t\t\ttry:\n\t\t\t\t\tfeature = np.concatenate((feature, f), axis=0)\n\t\t\t\texcept:\n\t\t\t\t\tfeature = f\n\n\n\t\t\tmat_dir = '../results/' + dataset_name + '_features/'\n\t\t\tif not os.path.exists(mat_dir):\n\t\t\t\tos.makedirs(mat_dir)\n\t\t\tmat_name = mat_dir + video_name + '_test.mat'\n\t\t\tscipy.io.savemat(mat_name, {\"feature\": feature})\n\t\t\tprint 'feature.shape:', feature.shape\n\t\t\tprint 'MAT:', mat_name, 'saved!'\n\n\t\tif dataset_name == 'kth':\n\t\t\t# For training videos\n\t\t\tfor video in video_name_list:\n\t\t\t\tprint 'Working on', video, '...'\n\t\t\t\tvideo_name = video.split('.')[0]\n\t\t\t\tnum = video_name.split('_')[2]\n\t\t\t\tcur_video_dir = os.path.join(cat_dir, video)\n\t\t\t\tvideo_dirs.append(cur_video_dir)\n\n\t\t\t\timglist = readvideo(cur_video_dir)\n\t\t\t\tprint video, 'Read!'\n\t\t\t\t#matching(imglist)\n\n\t\t\t\tN = len(imglist)\n\t\t\t\tvideo_seq = subseq(imglist, N_sq)\n\t\t\t\tprint '%s %s %s'%(' Total',N,'frames')\n\t\t\t\tprint '%s %s %s'%(' videoseq',len(video_seq[0]),'frames')\n\t\t\t\tprint '%s %s %s'%(' Total',len(video_seq),'segments')\n\n\n\t\t\t\t# Extract patch for all the subsequence\n\t\t\t\tpatch = []\n\t\t\t\tfeature = ['EMPTY']\n\t\t\t\tfor i in range(0, N / N_sq):\n\t\t\t\t\tsub_video_seq = video_seq[i]\n\t\t\t\t\tkp_frame = orbkeypoint(sub_video_seq[0])\n\t\t\t\t\tkploc_frame = kplocation(kp_frame)\n\t\t\t\t\tkppatch = kppatchfuc(kploc_frame, sub_video_seq)\n\t\t\t\t\tf = motionpattern(kppatch,N_sq)\n\n\t\t\t\t\ttry:\n\t\t\t\t\t\tfeature = np.concatenate((feature, f), axis=0)\n\t\t\t\t\texcept:\n\t\t\t\t\t\tfeature = f\n\n\t\t\t\tmat_dir = '../results/' + dataset_name + '_features/'\n\t\t\t\tif not os.path.exists(mat_dir):\n\t\t\t\t\tos.makedirs(mat_dir)\n\n\t\t\t\tif num != 'd4':\t\n\t\t\t\t\tmat_name = mat_dir + video_name + '_train.mat'\n\t\t\t\telse:\n\t\t\t\t\tmat_name = mat_dir + video_name + '_test.mat'\n\n\t\t\t\tscipy.io.savemat(mat_name, {\"feature\": feature})\n\t\t\t\tprint 'feature.shape:', feature.shape\n\t\t\t\tprint 'MAT:', mat_name, 'saved!'\n\n\n\n\n"
},
{
"alpha_fraction": 0.8005908131599426,
"alphanum_fraction": 0.8109305500984192,
"avg_line_length": 168,
"blob_id": "54b8a73d716d13e1d8de436dea3ca39d8805a853",
"content_id": "c9f3cfa5c361d93bd6e90d273d0a3dc21886d529",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 685,
"license_type": "no_license",
"max_line_length": 556,
"num_lines": 4,
"path": "/README.md",
"repo_name": "yizhou-wang/dict-deep",
"src_encoding": "UTF-8",
"text": "# Dict-Deep: An Architecture for Action Detection in Videos using Over-Complete Dictionary Learning\nYizhou Wang and Lingyu Zhang\n\nThis project explores the traditional as well as novel approaches solving action detection problems. It is common to use neural networks which always cost a lot of time for training and testing. To solve this bottleneck of action detection, “Dict-Deep” and “Faster-C3D” architectures are proposed. Dict-Deep architecture adds feature extraction and over-complete dictionary learning steps before neural network. Then, Dict-Deep algorithm is implemented and tested on Weizmann and KTH human action dataset, which obtained 99.2% on Weizmann and 80.4% on KTH.\n\n"
},
{
"alpha_fraction": 0.5629303455352783,
"alphanum_fraction": 0.5797300934791565,
"avg_line_length": 26.454545974731445,
"blob_id": "5ff17c26ee7084a43aee00c2e2f6e355d2582666",
"content_id": "87e59421ed0e176f35e23ce8f31b8777533df3b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3631,
"license_type": "no_license",
"max_line_length": 107,
"num_lines": 132,
"path": "/dic_learn.py",
"repo_name": "yizhou-wang/dict-deep",
"src_encoding": "UTF-8",
"text": "import os\nfrom os import listdir\nfrom os.path import isfile, join\n\nimport numpy as np\nimport scipy.io\n\nimport ksvd\nfrom ksvd import ApproximateKSVD\n\n\ndataset_name = 'weizmann'\n# dataset_name = 'kth'\nroot_dir = '../results/' + dataset_name + '_features/'\nlabel_dic = [ 'bend', 'jack', 'jump', 'pjump', 'run', 'side', 'skip', 'walk', 'wave1', 'wave2' ]\nlabel_dic_num = len(label_dic)\n# label_dic = [ 'boxing', 'handclapping', 'handwaving', 'jogging', 'running', 'walking' ]\n# label_dic_num = len(label_dic)\n\n\n## Reading Features ##\n\nprint('Reading Features ...')\ntrain_files = []\ntrain_labels = []\ntest_files = []\ntest_labels = []\nfor file in os.listdir(root_dir):\n if file.endswith(\".mat\"):\n video_name = file.split('.')[0]\n if video_name.split('_')[-1] == 'train':\n train_files.append(os.path.join(root_dir, file))\n train_labels.append(video_name.split('_')[1])\n else:\n test_files.append(os.path.join(root_dir, file))\n test_labels.append(video_name.split('_')[1])\n\n# print(test_files)\n# print(test_labels)\n\nprint('Loading Training Data ...')\nDescr = ['EMPTY'] * label_dic_num\n# print(Descr)\nfor file, label in zip(train_files, train_labels):\n # print(file, label)\n try:\n label_num = label_dic.index(label)\n except:\n label_num = label_dic.index(label[0:-1])\n # print(label_num)\n\n descr = scipy.io.loadmat(file)['feature']\n # print(descr.shape)\n\n try:\n Descr[label_num] = np.concatenate((Descr[label_num], descr), axis=0)\n except:\n Descr[label_num] = descr\n\nprint('Loading Test Data ...')\ntest_Descr = ['EMPTY'] * label_dic_num\nprint(test_Descr)\nfor file, label in zip(test_files, test_labels):\n # print(file, label)\n try:\n label_num = label_dic.index(label)\n except:\n label_num = label_dic.index(label[0:-1])\n # print(label_num)\n\n descr = scipy.io.loadmat(file)['feature']\n # print(descr.shape)\n\n try:\n test_Descr[label_num] = np.concatenate((test_Descr[label_num], descr), axis=0)\n except:\n test_Descr[label_num] = descr\n\n\nprint('Number of Classes:', len(Descr))\nprint('* ----------------------------- *')\nfor d in Descr:\n print('Descr.shape', d.shape)\nprint('* ----------------------------- *')\nfor d in test_Descr:\n print('test_Descr.shape', d.shape)\nprint('* ----------------------------- *')\n\n\n## Dictionary Learning:\n\nprint('Dictionary Learning ...')\nR = np.random.randn(1728, 256)\nn_components = 256 * 2 # Over complete factor = 2\ntransform_n_nonzero_coefs = 20\n\nmat_dir = '../results/' + dataset_name + '_dic_' + str(transform_n_nonzero_coefs) + '/'\nif not os.path.exists(mat_dir):\n os.makedirs(mat_dir)\n\n\nfor label, Y1, Y2 in zip(label_dic, Descr, test_Descr):\n\n print('Learning', label, '...')\n\n # Y subtract mean \n mean = Y1.mean(axis=1)\n Y1 = Y1 - mean[:, np.newaxis]\n Y1 = np.dot(Y1, R) # Y: k x 128\n\n mean = Y2.mean(axis=1)\n Y2 = Y2 - mean[:, np.newaxis]\n Y2 = np.dot(Y2, R) # Y: k x 128\n \n\n aksvd = ApproximateKSVD(n_components=n_components, transform_n_nonzero_coefs=transform_n_nonzero_coefs)\n D = aksvd.fit(Y1).components_\n X1 = aksvd.transform(Y1)\n X2 = aksvd.transform(Y2)\n\n print('* ----------------------------- *')\n print('D.shape:', D.shape)\n print('Y1.shape:', Y1.shape)\n print('X1.shape:', X1.shape)\n print('Y2.shape:', Y2.shape)\n print('X2.shape:', X2.shape)\n print('* ----------------------------- *')\n\n mat_name = mat_dir + label + '.mat'\n scipy.io.savemat(mat_name, {'dic': D, 'X_train': X1, 'X_test': X2})\n\n print('MAT:', mat_name, 'saved!')\n\n\n\n\n\n\n\n"
}
] | 6 |
eliranta02/RubidiumProfile | https://github.com/eliranta02/RubidiumProfile | 045136d97646cf6866170dd6d7c8967d8d065488 | 9f6725f262efca0aa545c1609c287e3ae12b4b52 | eb46642a0b9ea6da7c02d2c091a4b575f3ab7db6 | refs/heads/main | 2023-07-09T20:57:48.853459 | 2021-08-19T20:35:26 | 2021-08-19T20:35:26 | 375,756,292 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5661764740943909,
"alphanum_fraction": 0.5970588326454163,
"avg_line_length": 24.230770111083984,
"blob_id": "8bf00f8d06f36085d2efbf12a24f2503ecbcd013",
"content_id": "e9db4d0e089ba7b4f0f77fc6f6970e88910b108d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 680,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 26,
"path": "/Main/Operators/utils.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom numpy import pi\r\nimport numpy as np\r\nfrom scipy import interpolate\r\n\r\n\r\ndef intensity_calc(p, radi):\r\n '''\r\n calculate the beam intensity\r\n :param p: beam power [mW]\r\n :param radi: beam radius 1/e^2 [mm]\r\n :return: peak intensity mW/cm^2\r\n '''\r\n ret_val = 0.1 * (2 *p * 1e-3)/(pi * (radi * 1e-3)**2)\r\n return ret_val\r\n\r\ndef half_max_roots(x, y):\r\n half_max = np.max(y) / 2\r\n spline = interpolate.UnivariateSpline(x, y - half_max, s=0)\r\n r1, r2 = spline.roots()\r\n return half_max, r1, r2\r\n\r\n\r\ndef full_width_at_half_max(x, y):\r\n half_max, r1, r2 = half_max_roots(x, y)\r\n return r2 - r1"
},
{
"alpha_fraction": 0.5214953422546387,
"alphanum_fraction": 0.590654194355011,
"avg_line_length": 16.517240524291992,
"blob_id": "3d549b5a34dc9c8041f1c4c374ef05e8e7c92899",
"content_id": "fd1e2c1a103779b34356e12db821148eef218714",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 535,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 29,
"path": "/Main/Breit Rabi Diagram/F_matrix.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nfrom numpy import *\r\nfrom J_matrix import getJ\r\nfrom I_matrix import *\r\n\r\n\r\n\r\nI=3/2\r\nJ=1/2\r\n'''\r\nFx=kron(Jx,eye(2*I+1))+kron(eye(2*J+1),Ix)\r\nFy=kron(Jy,eye(2*I+1))+kron(eye(2*J+1),Iy)\r\nFz=kron(Jz,eye(2*I+1))+kron(eye(2*J+1),Iz)\r\n'''\r\n\r\n\r\nJvals=getJ(0)\r\nJx=Jvals[0]\r\nJy=Jvals[1]\r\nJz=Jvals[2]\r\n\r\nFx=kron(Jx,eye(2*I+1))+kron(eye(2*J+1),Ix)\r\nFy=kron(Jy,eye(2*I+1))+kron(eye(2*J+1),Iy)\r\nFz=kron(Jz,eye(2*I+1))+kron(eye(2*J+1),Iz)\r\n\r\nF_2=Fx.dot(Fx)+Fy.dot(Fy)+Fz.dot(Fz)\r\nF_2=F_2/(hbar**2)\r\n\r\nprint(F_2/hbar)"
},
{
"alpha_fraction": 0.5280373692512512,
"alphanum_fraction": 0.5327102541923523,
"avg_line_length": 19.46666717529297,
"blob_id": "7f413e93c60219b27ffd7d64fe81bd7cceeadf47",
"content_id": "d9f4e35ba22490f921176233ed25a7278022fdc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 642,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 30,
"path": "/Main/Quantum_states_and_operators/build_bloch_equation_matrix.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom numpy import kron, eye, transpose\r\n\r\n\r\ndef buildGammaMatrix(g_matrix, N):\r\n '''\r\n Lp = {L, p}\r\n :param g_matrix:\r\n :param N:\r\n :return:\r\n '''\r\n LR = kron(g_matrix, eye(N))\r\n RL = kron(eye(N), transpose(g_matrix))\r\n ret_val = -1/2 * (LR + RL)\r\n return ret_val\r\n\r\ndef buildRhoMatrix(H, N):\r\n '''\r\n [H, p]\r\n :param H: hamiltonian\r\n :param N: number of levels\r\n :param L: decay matrix\r\n :return:\r\n '''\r\n Hrho = kron(H, eye(N))\r\n rhoH = kron(eye(N), transpose(H))\r\n ret_val = -1j * (Hrho - rhoH)\r\n return ret_val\r\n\r\n#def build"
},
{
"alpha_fraction": 0.509392261505127,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 16.100000381469727,
"blob_id": "38769fc114ce13b2a06b8901eb90279364937e4e",
"content_id": "b36c7d4c71baea125b8e4f431f98030fb4dd858d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 905,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 50,
"path": "/Main/Constants/Rb_constants.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom scipy.constants import atomic_mass, c\r\n#from Global_constants import S\r\nfrom numpy import pi\r\n\r\nS = 1/2\r\n\r\nD_line = 'D2'\r\n\r\n# pressure atomic vapor constants\r\npa = -94.04826\r\npb = 1961.258\r\npc = -0.03771687\r\npd = 42.57526\r\n\r\n#mass of the rubidium\r\n#Rubidium 85\r\nmRb85 = 85 * atomic_mass\r\nI_85 = 5/2\r\n\r\n#Rubidium 87\r\nmRb85 = 87 * atomic_mass\r\nI_87 = 3/2\r\n\r\n#mass uses for the entire simulation\r\nm = mRb85\r\nI = I_85\r\n#ground state angular momentum\r\nL = 0\r\njg = L + S\r\n\r\n\r\n# wavelength and wavevector\r\n# D2 line\r\n\r\nif D_line == 'D2':\r\n #excited state angular momentum\r\n L = 1\r\n wavelen = 780e-9\r\n gamma = 2 * pi * 6.06e6 # [MHz]\r\n je = L + S\r\nelif D_line == 'D1':\r\n #excited state angular momentum\r\n L = 1\r\n wavelen = 795e-9\r\n gamma = 2 * pi * 5.75e6 # [MHz]\r\n je = L - S\r\n\r\nk_num = 2 * pi / wavelen\r\nfrequency = k_num/ c\r\n"
},
{
"alpha_fraction": 0.5969372987747192,
"alphanum_fraction": 0.6535683274269104,
"avg_line_length": 30.189189910888672,
"blob_id": "34e9dc71243367f4aa15542913aee03a88537462",
"content_id": "3d29bdfa2531f2df5e091f1472cf64f72b56720e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3461,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 111,
"path": "/Main/Breit Rabi Diagram/EigenSystem.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from scipy.linalg import eig, eigh\nfrom numpy import pi, append, transpose, identity\n\nimport AtomicConstants as AC\nfrom FundamentalConstants import *\n\nfrom sz_lsi import sz, lz, Iz\nfrom fs_hfs import Hfs,Hhfs,Bbhfs\n\nimport pylab as plt\n\ndef groundStateManifold(A_hyp_coeff,IsotopeShift,Bfield):\n \"\"\"Function to produce the ground state manifold\"\"\"\n ds = int((2*S+1)*(2*I+1)) # total dimension of matrix\n #print 'Matrix dim:', ds\n As = A_hyp_coeff\n # Add the S-term hyperfine interaction\n S_StateHamiltonian = As*Hhfs(0.0,S,I)+IsotopeShift*identity(ds)\n Ez = muB*Bfield*1.e-4/(hbar*2.0*pi*1.0e6)\n S_StateHamiltonian += Ez*(gs*sz(0.0,S,I)+gI*Iz(0.0,S,I)) # Add Zeeman\n EigenSystem = eigh(S_StateHamiltonian)\n EigenValues = EigenSystem[0].real\n EigenVectors = EigenSystem[1]\n stateManifold = append([EigenValues],EigenVectors,axis=0)\n sortedManifold = sorted(transpose(stateManifold),key=(lambda i:i[0]))\n return sortedManifold, EigenValues\n\ndef excitedStateManifold(gL,A_hyp_coeff,B_hyp_coeff,Bfield):\n \"\"\"Function to produce the excited state manifold\"\"\"\n dp = int(3*(2*S+1)*(2*I+1)) # total dimension of matrix\n # The actual value of FS is unimportant.\n FS = 7.123e6 # Fine structure splitting (of Rb - careful when using other elements at high B fields)\n Ap = A_hyp_coeff\n Bp = B_hyp_coeff\n # Add P-term fine and hyperfine interactions\n if Bp==0.0:\n P_StateHamiltonian=FS*Hfs(1.0,S,I)+FS*identity(dp)+Ap*Hhfs(1.0,S,I)\n if Bp!=0.0:\n P_StateHamiltonian=FS*Hfs(1.0,S,I)-(FS/2.0)*identity(dp)+Ap*Hhfs(1.0,S,I)\n P_StateHamiltonian+=Bp*Bbhfs(1.0,S,I) # add p state quadrupole\n E=muB*(Bfield*1.0e-4)/(hbar*2.0*pi*1.0e6)\n # Add magnetic interaction\n P_StateHamiltonian+=E*(gL*lz(1.0,S,I)+gs*sz(1.0,S,I)+gI*Iz(1.0,S,I))\n ep=eigh(P_StateHamiltonian)\n EigenValues=ep[0].real\n EigenVectors=ep[1]\n stateManifold=append([EigenValues],EigenVectors,axis=0)\n sortedManifold=sorted(transpose(stateManifold),key=(lambda i:i[0]))\n return sortedManifold, EigenValues\n\n\nI = AC.I #Nuclear spin\nA_hyp_coeff = AC.As #Ground state hyperfine constant in units of MHz\ngI = AC.gI #nuclear spin g-factor\nIsotopeShift=21.734\n#Bfield=10\n\nfrom pylab import *\nB =linspace(1e-7,0.1e5,1000)\nval=[]\nval1=[]\nval2=[]\nval3=[]\nval4=[]\nval5=[]\nval6=[]\nval7=[]\nval8=[]\nval9=[]\nval10=[]\nval11=[]\nfor Bfield in B:\n x=groundStateManifold(A_hyp_coeff,IsotopeShift,Bfield)[1]\n val.append(x[0]/1e3)\n val1.append(x[1]/1e3)\n val2.append(x[2]/1e3)\n val3.append(x[3]/1e3)\n val4.append(x[4]/1e3)\n val5.append(x[5]/1e3)\n val6.append(x[6]/1e3)\n val7.append(x[7]/1e3)\n #val8.append(x[8])\n #val9.append(x[9])\n #val10.append(x[10])\n #val11.append(x[11])\n\n'''\n#Example\nplt.figure(1,facecolor='w',figsize=(5, 4))\n\nB = 0.0001 * B\nplt.plot(B,val,label='$F_{1,-1}$',lw=2)\nplt.plot(B,val1,label='$F_{1,0}$',lw=2)\nplt.plot(B,val2,label='$F_{1,1}$',lw=2)\nplt.plot(B,val3,label='$F_{2,-2}$',lw=2)\nplt.plot(B,val4,label='$F_{2,-1}$',lw=2)\nplt.plot(B,val5,label='$F_{2,0}$',lw=2)\nplt.plot(B,val6,label='$F_{2,1}$',lw=2)\nplt.plot(B,val7,label='$F_{2,2}$',lw=2)\n#plot(B,val8,label='$F_{3,0}$',lw=2)\n#plot(B,val9,label='$F_{3,1}$',lw=2)\n#plot(B,val10,label='$F_{3,2}$',lw=2)\n#plot(B,val11,label='$F_{3,3}$',lw=2)\nplt.grid()\nplt.legend(loc=0)\nplt.xlabel('B [Tesla]')\nplt.ylabel('E/h [GHz]')\nplt.tight_layout()\n#plt.savefig('magnetic_sublevel.png')\nplt.show()\n'''"
},
{
"alpha_fraction": 0.6705882549285889,
"alphanum_fraction": 0.6941176652908325,
"avg_line_length": 19.25,
"blob_id": "3ff017f3693f3c62fe9709e10f241a832855fc6c",
"content_id": "6dccf740a29c9b5f7105d5108acbcc3150540a05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 4,
"path": "/Main/Constants/Global_constants.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\n\r\n# spin angular momentum\r\nS = 1/2\r\n"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 25.66666603088379,
"blob_id": "556950ce6413bb818151ccf0295d8d3351f21e1f",
"content_id": "48e52c5fa65c778ed0b549cb60298919ca56d1ba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 3,
"path": "/README.md",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "# RubidiumProfile\n## Introduction\nThis folder contain all the data for rubidium\n"
},
{
"alpha_fraction": 0.4796863794326782,
"alphanum_fraction": 0.5463293194770813,
"avg_line_length": 27.55789566040039,
"blob_id": "9e28aa9968345c5b6495a17ae683f97cfc410cfc",
"content_id": "19187b957ed5210e2e4733e642c66a2f50a051f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2806,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 95,
"path": "/Main/Quantum_states_and_operators/frequency_strength_calc.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom Main.Operators.Wigner_Calc import *\r\nfrom numpy import sqrt, pi\r\nfrom Main.Constants.Rb_constants import *\r\nfrom scipy.constants import c, hbar, h\r\nfrom Main.Constants.Rb_constants import I\r\n#from Main.Operators.utils import intensity_calc\r\n\r\ndef i_sat(wavelen, gamma):\r\n '''\r\n calculate the saturation intensity\r\n :param wavelen: wave length [m]\r\n :param gamma: relaxation rate [1/sec]\r\n :return: saturation intensity [mW/cm^2]\r\n '''\r\n\r\n tau_lt = 1/gamma\r\n ret_val = (pi * h * c)/(3 * wavelen**3 * tau_lt)\r\n return 0.1 * ret_val\r\n\r\n#calculate the Rabi frequency of define transition. the calculation is based on aritcle \"On the consistency of Rabi frequency calculations\"\r\ndef rabi_freq(inten,state1,state2):\r\n '''\r\n rabi frequency calculation of the transition from s1 --> s2\r\n :param I: intensity\r\n :param state1: state 1\r\n :param state2: state 2\r\n :return: rabi frequency [Hz]\r\n '''\r\n\r\n s1 = state1\r\n f1 = s1.get_F()\r\n m_f1 = s1.get_mF()\r\n j_f1= s1.get_J()\r\n l_f1 = s1.get_L()\r\n\r\n s2 = state2\r\n f2 = s2.get_F()\r\n m_f2 = s2.get_mF()\r\n j_f2 = s2.get_J()\r\n l_f2 = s2.get_L()\r\n\r\n q = m_f1 - m_f2\r\n\r\n a1 = -1**(1/2 * q * (q+1) + 1 + 2 * f1 - m_f1 + I + j_f2 + S + l_f2 + j_f1)\r\n a2 = sqrt((2 * f1 + 1) * (2 * f2 + 1) * (2 * j_f1 + 1)* (2 * j_f2 + 1)* (2 * l_f1 + 1))\r\n a3 = Wigner3j(f2, 1, f1, m_f2, q, -m_f1) \\\r\n * Wigner6j(j_f1, j_f2, 1, f2, f1, I) *\\\r\n Wigner6j(l_f1, l_f2, 1, j_f2, j_f1, S)\r\n\r\n ret_val = a1 * a2 * a3 * sqrt(3 * wavelen**3 * gamma * inten/(4 * pi**2 * c * hbar))\r\n return ret_val\r\n\r\ndef transition_strength(state1,state2):\r\n '''\r\n calcualte the transition strength between state1 to state2\r\n :param state1: state 1\r\n :param state2: state 2\r\n :return: transition strength\r\n '''\r\n s1 = state1\r\n f1 = s1.get_F()\r\n m_f1 = s1.get_mF()\r\n j_f1 = s1.get_J()\r\n l_f1 = s1.get_L()\r\n\r\n s2 = state2\r\n f2 = s2.get_F()\r\n m_f2 = s2.get_mF()\r\n j_f2 = s2.get_J()\r\n l_f2 = s2.get_L()\r\n\r\n q = m_f1 - m_f2\r\n\r\n a = sqrt((2 * f1 + 1) * (2 * f2 + 1) * (2 * j_f1 + 1) * (2 * j_f2 + 1) * (2 * l_f1 + 1))\r\n b = Wigner3j(f2, 1, f1, m_f2, q, -m_f1) * Wigner6j(j_f1, j_f2, 1, f2, f1, I) * Wigner6j(l_f1, l_f2, 1, j_f2, j_f1, S)\r\n ret_val = (-1) ** (2 * f2 + I + j_f1 + j_f2 + l_f1 + S + m_f1 + 1) * a * b\r\n ret_val = ret_val ** 2\r\n return ret_val\r\n\r\n\r\n'''\r\n#Example\r\nfrom Main.Operators.utils import *\r\nf1 = State(2,1,3,3,0,0,True)\r\nf1.set_S(S)\r\nf2 = State(2,1,4,4,1,0,False)\r\nf2.set_S(S)\r\n#print(i_sat(wavelen,gamma))\r\n#inten = intensity_calc(2,2)\r\n#print(inten)\r\n#print('Rabi frequency : {} MHz'.format(rabi_freq(inten,f1,f2) * 1e-6))\r\na = transition_strength(f1, f2)\r\nprint(a)\r\n'''"
},
{
"alpha_fraction": 0.45725592970848083,
"alphanum_fraction": 0.5171504020690918,
"avg_line_length": 28.4417667388916,
"blob_id": "4ba5470ec2d92fa500f9e274b4539a9567f811d1",
"content_id": "245fbaabe1aa0649f7ac5cc64537d6b4c1827915",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7580,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 249,
"path": "/Main/Examples/Ob_Three_level_system.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom Main.Quantum_states_and_operators import q_state, qunatum_states_dictionary\r\nfrom Main.Quantum_states_and_operators.build_bloch_equation_matrix import *\r\nfrom Main.Quantum_states_and_operators.Linblad_master_equation_solver import *\r\n\r\nfrom Main.Constants.Rb_constants import *\r\n\r\nimport pylab as plt\r\n\r\nVEE_TYPE = 1\r\nLAMBDA_TYPE = 2\r\nLADDER_TYPE = 3\r\n\r\nDIAGRAM_LEVEL_TYPE = LAMBDA_TYPE\r\nstates = None\r\nN = 0\r\n\r\n\r\ndef init_states():\r\n state1 = q_state.State(3,0,1)\r\n state2 = q_state.State(3,1,2)\r\n state3 = q_state.State(3,2,3)\r\n return state1, state2, state3\r\n\r\ndef init():\r\n global states, N\r\n states = init_states()\r\n N = 3\r\n return 1\r\n#----------------------VEE TYPE EIT -------------------------------------------------#\r\n\r\ndef H_vee(delta_pr, delta_pu, omega_pr, omega_pu):\r\n '''\r\n |2> ----- |3> -----\r\n || ||\r\n || ||\r\n |1> -----\r\n\r\n :param delta_pr:\r\n :param delta_pu:\r\n :param omega_pr:\r\n :param omega_pu:\r\n :return:\r\n '''\r\n global states\r\n a1, a2, a3 = states\r\n\r\n rho22 = a2 *a2\r\n rho12 = a1 * a2\r\n rho21 = a2 * a1\r\n\r\n rho33 = a3 * a3\r\n rho13 = a1 * a3\r\n rho31 = a3 * a1\r\n\r\n H = (delta_pr) * rho22 + (delta_pu) * rho33 + 0.5 * omega_pr * rho12 + 0.5 * omega_pr * rho21+ \\\r\n 0.5 * omega_pu * rho13 + 0.5 * omega_pu * rho31\r\n\r\n return H\r\n\r\ndef decay_martrix_vee(gamma2, gamma3):\r\n\r\n a1, a2, a3 = states\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n L = gamma2 * rho22 + gamma3 * rho33\r\n return L\r\n\r\ndef repopulation_decay_matrix_vee(gamma2, gamma3):\r\n a1, a2, a3 = states\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n ret_val = gamma3 * outer(rho11, rho33) + gamma2 * outer(rho11, rho22)\r\n return ret_val\r\n\r\n#-----------------------------LAMBDA TYPE EIT --------------------------------------#\r\ndef H_Lambda(delta_pr, delta_pu, omega_pr, omega_pu):\r\n '''\r\n |3> -----\r\n || ||\r\n || ||\r\n |1> ----- |2> -----\r\n\r\n :param delta_pr:\r\n :param delta_pu:\r\n :param omega_pr:\r\n :param omega_pu:\r\n :return:\r\n '''\r\n global states\r\n\r\n a1, a2, a3 = states\r\n\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n rho13 = a1 * a3\r\n rho31 = a3 * a1\r\n\r\n rho23 = a2 * a3\r\n rho32 = a3 * a2\r\n\r\n H = (delta_pr) * rho33 + (delta_pr - delta_pu) * rho22 + 0.5 * omega_pr * rho13 + 0.5 * omega_pr * rho31 + \\\r\n 0.5 * omega_pu * rho23 + 0.5 * omega_pu * rho32\r\n return H\r\n\r\ndef decay_martrix_Lambda(gamma3):\r\n\r\n a1, a2, a3 = states\r\n rho33 = a3 * a3\r\n L = gamma3 * rho33\r\n return L\r\n\r\ndef repopulation_decay_matrix_Lambda(gamma3):\r\n a1, a2, a3 = states\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n ret_val = 0.5 * gamma3 * outer(rho11, rho33) + 0.5 * gamma3 * outer(rho22, rho33)\r\n return ret_val\r\n\r\n#-----------------------------------------------------------------------#\r\ndef H_Ladder(delta_pr, delta_pu, omega_pr, omega_pu):\r\n global states\r\n\r\n a1, a2, a3 = states\r\n\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n\r\n rho12 = a1 * a2\r\n rho21 = a2 * a1\r\n\r\n rho23 = a2 * a3\r\n rho32 = a3 * a2\r\n\r\n H = (delta_pu) * rho22 + (delta_pr + delta_pu) * rho33 + 0.5 * omega_pr * rho23 + 0.5 * omega_pr * rho32 + \\\r\n 0.5 * omega_pu * rho12 + 0.5 * omega_pu * rho21\r\n\r\n return H\r\n\r\ndef decay_martrix_Ladder(gamma2, gamma3):\r\n\r\n a1, a2, a3 = states\r\n rho33 = a3 * a3\r\n rho22 = a2 * a2\r\n L = gamma3 * rho33 + gamma2 * rho22\r\n return L\r\n\r\ndef repopulation_decay_matrix_Ladder(gamma2, gamma3):\r\n a1, a2, a3 = states\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n ret_val = gamma2 * outer(rho11, rho22) + gamma3 * outer(rho22, rho33)\r\n return ret_val\r\n\r\n#-----------------------------------------------------------------------#\r\n\r\ndef callback(param):\r\n k_pump = 2 * pi / (795e-9)\r\n k_probe = 2 * pi / (780e-9)\r\n omegaProbe = 2 * pi * 1e6\r\n omegaPump = 2 * pi * 20e6\r\n delta_pu = 0\r\n (del_val, velocity) = param\r\n\r\n if DIAGRAM_LEVEL_TYPE == VEE_TYPE:\r\n gamma2, gamma3 = 2 * pi * 6.06e6, 2 * pi * 5.75e6\r\n ret_val = buildRhoMatrix(H_vee(del_val-k_probe * velocity, delta_pu + k_pump * velocity, omegaProbe, omegaPump), N) + buildGammaMatrix(decay_martrix_vee(gamma2, gamma3), N) + \\\r\n repopulation_decay_matrix_vee(gamma2, gamma3)\r\n\r\n\r\n if DIAGRAM_LEVEL_TYPE == LAMBDA_TYPE:\r\n gamma3 = 2 * pi * 6.06e6\r\n ret_val = buildRhoMatrix(H_Lambda(del_val-k_probe * velocity, delta_pu - k_probe * velocity, omegaProbe, omegaPump), N) + buildGammaMatrix(\r\n decay_martrix_Lambda(gamma3), N) + repopulation_decay_matrix_Lambda(gamma3)\r\n\r\n if DIAGRAM_LEVEL_TYPE == LADDER_TYPE:\r\n gamma2 = 2 * pi * 6.06e6\r\n gamma3 = 2 * pi * 1.8e6\r\n ret_val = buildRhoMatrix(H_Ladder(param, delta_pu, omegaProbe, omegaPump), N) + buildGammaMatrix(\r\n decay_martrix_Ladder(gamma2, gamma3), N) + repopulation_decay_matrix_Ladder(gamma2, gamma3)\r\n\r\n\r\n return ret_val\r\n\r\n\r\nif __name__ == \"__main__\":\r\n # init all states\r\n init()\r\n\r\n states_name = qunatum_states_dictionary.rhoMatrixNames(N)\r\n rho11 = states_name.getLocationByName('rho11')\r\n rho12 = states_name.getLocationByName('rho12')\r\n rho13 = states_name.getLocationByName('rho13')\r\n rho22 = states_name.getLocationByName('rho22')\r\n print(states_name)\r\n\r\n if DIAGRAM_LEVEL_TYPE == VEE_TYPE:\r\n\r\n y0 = zeros((N * N, 1))\r\n y0[rho11] = 1\r\n\r\n lmes = Linblad_master_equation_solver(False)\r\n\r\n returnDic = [rho12, rho22]\r\n\r\n running_param = linspace(-2 * pi * 0.2e9, 2 * pi * 0.2e9, 2000) # (frequency scaning) detuning array\r\n v_param = linspace(-800, 800, 600) # atomic velocities array\r\n time_val = 1\r\n Tc = 50\r\n #results = lmes.solve_master_equation_with_Doppler_effect(callback, running_param, v_param, y0, time_val,\r\n # Tc, returnDic)\r\n\r\n results = lmes.solve_master_equation_steady_state_with_Doppler_effect(callback, running_param, v_param, N, Tc,\r\n returnDic)\r\n\r\n solution = [exp(-res.imag) for res in results[rho12]]\r\n plt.plot(running_param / (2 * pi), solution)\r\n plt.show()\r\n\r\n\r\n if DIAGRAM_LEVEL_TYPE == LAMBDA_TYPE:\r\n\r\n y0 = zeros((N * N, 1))\r\n y0[rho11] = 0.5\r\n y0[rho22] = 0.5\r\n\r\n lmes = Linblad_master_equation_solver(False)\r\n\r\n returnDic = [rho13, rho22]\r\n\r\n running_param = linspace(-2 * pi * 1e9, 2 * pi * 1e9, 1000) # (frequency scaning) detuning array\r\n v_param = linspace(-800, 800, 600) # atomic velocities array\r\n time_val = 1\r\n Tc = 50\r\n # results = lmes.solve_master_equation_with_Doppler_effect(callback, running_param, v_param, y0, time_val,\r\n # Tc, returnDic)\r\n\r\n results = lmes.solve_master_equation_steady_state_with_Doppler_effect(callback, running_param, v_param, N, Tc,\r\n returnDic)\r\n\r\n solution = [exp(-res.imag) for res in results[rho13]]\r\n plt.plot(running_param / (2 * pi), solution)\r\n plt.show()\r\n\r\n if DIAGRAM_LEVEL_TYPE == LADDER_TYPE:\r\n pass\r\n"
},
{
"alpha_fraction": 0.582456111907959,
"alphanum_fraction": 0.6043859720230103,
"avg_line_length": 22.7391300201416,
"blob_id": "8b518f5abed271f5988a7bfc7d7f4cef9d51738d",
"content_id": "6f81be5d6110848418e159d2df8e7b6b00e2ebe0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1140,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 46,
"path": "/Main/Unit_converters/Rb_unit_converter.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom Main.Constants.Rb_constants import *\r\nfrom numpy import *\r\nfrom scipy.constants import k\r\n\r\ndef p(T):\r\n '''\r\n calculate the pressure in the atomic media\r\n :param T: temperature [k]\r\n :return: the pressure of atomic media\r\n '''\r\n ret_val = 10**(pa - pb/T + pc*T + pd*log10(T))\r\n return ret_val\r\n\r\ndef temp2den(T):\r\n '''\r\n calculate the atomic density of rubidium atoms\r\n :param T: temperature (K)\r\n :return: atomic density (1/m^3)\r\n '''\r\n ret_val = p(T)*133.3/(k * T)\r\n return ret_val\r\n\r\ndef temp2den_cm(T):\r\n '''\r\n calculate the atomic density of rubidium atoms\r\n :param T: temperature (K)\r\n :return: atomic density (1/cm^3)\r\n '''\r\n ret_val = temp2den(T)/(100**3)\r\n return ret_val\r\n\r\ndef temp2velocity(T):\r\n '''\r\n calculate the most probable velocity for a specific temperature\r\n :param T: temperature (K)\r\n :return: most probable velocity (m/s)\r\n '''\r\n ret_val = sqrt(2 * k * T / m)\r\n return ret_val\r\n\r\n'''\r\nfrom Global_unit_converter import *\r\nT = celsius2kelvin(25)\r\nprint(temp2velocity(T))\r\n'''\r\n\r\n"
},
{
"alpha_fraction": 0.5085039138793945,
"alphanum_fraction": 0.5727875232696533,
"avg_line_length": 27.398305892944336,
"blob_id": "49d5646d4f92f1be807017083d1f48aba930ce39",
"content_id": "195d38c69111f47fa6d8e6df27b42df9a2d6f4a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3469,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 118,
"path": "/Main/Examples/Four_wave_mixing.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom __future__ import division, print_function\r\nfrom Main.Quantum_states_and_operators import q_state, qunatum_states_dictionary\r\nfrom Main.Quantum_states_and_operators.build_bloch_equation_matrix import *\r\nfrom Main.Quantum_states_and_operators.frequency_strength_calc import *\r\nfrom Main.Quantum_states_and_operators.Linblad_master_equation_solver import *\r\nfrom Main.Constants.Rb_constants import *\r\nimport pylab as plt\r\n\r\nstates = None\r\nN = 4\r\n\r\ndef init_states():\r\n state1 = q_state.State(N,0,2, is_Ground = True)\r\n state2 = q_state.State(N,1,3, is_Ground = True)\r\n state3 = q_state.State(N,2,2)\r\n state4 = q_state.State(N,3,3)\r\n return state1, state2, state3, state4\r\n\r\ndef init():\r\n global states\r\n states = init_states()\r\n return True\r\n\r\n#--------------------------------------------------------------------------------------------------------#\r\n\r\n# All the calculation is based on\r\n\r\ndef H(delta, Delta_1, Delta_2, omega_c, omega_p, omega_1, omega_2):\r\n global states\r\n a1, a2, a3, a4 = states\r\n\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n\r\n rho13 = a1 * a3\r\n rho14 = a1 * a4\r\n\r\n rho23 = a2 * a3\r\n rho24 = a2 * a4\r\n\r\n\r\n H0 = (delta) * rho22 + (Delta_1) * rho33 + (Delta_2) * rho44\r\n\r\n V = (omega_1) * rho13 + (omega_c) * rho14 + (omega_p) * rho23 + (omega_2) * rho24\r\n V += transpose(V)\r\n return H0 + V\r\n\r\ndef decay_martrix(gamma1, gamma2):\r\n\r\n a1, a2, a3, a4 = states\r\n\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n\r\n L = gamma1 * rho33 + gamma2 * rho44\r\n\r\n return L\r\n\r\ndef repopulation_decay_matrix(gamma1, gamma2):\r\n a1, a2, a3, a4 = states\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n ret_val = 0.5 * gamma1 * outer(rho11, rho33) + 0.5 * gamma1 * outer(rho22, rho44) + \\\r\n 0.5 * gamma2 * outer(rho22, rho33) + 0.5 * gamma2 * outer(rho22, rho44)\r\n return ret_val\r\n\r\n#--------------------------------------------------------------------------------------------------------#\r\n\r\ndef callback(param):\r\n (del_val, velocity) = param\r\n delta = param[0]\r\n gamma1 = gamma2 = 2\r\n Delta_1 = 6\r\n Delta_2 = 6\r\n omega_c = 0\r\n omega_p = 0\r\n omega_1 = 10 * gamma1\r\n omega_2 = 10 * gamma1\r\n\r\n\r\n ret_val = buildRhoMatrix(H(delta, Delta_1, Delta_2, omega_c, omega_p, omega_1, omega_2), N) + buildGammaMatrix(\r\n decay_martrix(gamma1, gamma2), N) + repopulation_decay_matrix(gamma1, gamma2)\r\n\r\n return ret_val\r\n\r\n\r\nif __name__ == \"__main__\":\r\n init()\r\n\r\n states_name = qunatum_states_dictionary.rhoMatrixNames(N)\r\n rho11 = states_name.getLocationByName('rho11')\r\n rho22 = states_name.getLocationByName('rho22')\r\n rho24 = states_name.getLocationByName('rho24')\r\n\r\n y0 = zeros((N * N, 1))\r\n y0[rho11] = 0.5\r\n y0[rho22] = 0.5\r\n\r\n lmes = Linblad_master_equation_solver(False)\r\n\r\n returnDic = [rho24]\r\n\r\n running_param = linspace(-300, 300, 2000) # (frequency scaning) detuning array\r\n #v_param = linspace(-800, 800, 600) # atomic velocities array\r\n #time_val = 1\r\n #Tc = 50\r\n\r\n results = lmes.solve_master_equation_steady_state_without_Doppler_effect(callback, running_param, N, returnDic)\r\n\r\n solution = [res.imag for res in results[rho24]]\r\n solution1 = [res.real for res in results[rho24]]\r\n plt.plot(running_param , solution)\r\n #plt.plot(running_param , solution1)\r\n plt.show()\r\n"
},
{
"alpha_fraction": 0.5748640894889832,
"alphanum_fraction": 0.6233793497085571,
"avg_line_length": 29.655628204345703,
"blob_id": "e919a380a6156ab883b27ff284907bc0a54615c7",
"content_id": "e0119f0064f2aa9176d635bfd9c83e9e95eb0f63",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4782,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 151,
"path": "/Main/Examples/Ob_two_level_system.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom Main.Quantum_states_and_operators import q_state, qunatum_states_dictionary\r\nfrom Main.Quantum_states_and_operators.build_bloch_equation_matrix import *\r\nfrom Main.Quantum_states_and_operators.Linblad_master_equation_solver import *\r\n\r\nfrom Main.Constants.Rb_constants import *\r\n\r\nfrom Main.Tools.PlottingTemplate import *\r\n\r\n\r\nstates = None\r\nN = 2\r\n\r\ndef init_states():\r\n state1 = q_state.State(2,0,1)\r\n state2 = q_state.State(2,1,2)\r\n return state1, state2\r\n\r\n\r\ndef H(delta,omega):\r\n #global states\r\n #if states == None:\r\n # states = init_states()\r\n\r\n a1, a2 = states\r\n\r\n rho22 = a2 *a2\r\n rho12 = a1 * a2\r\n rho21 = a2 * a1\r\n H = (delta) * rho22 + 0.5 * omega * rho12 + 0.5 * omega * rho21\r\n return H\r\n\r\ndef decay_martrix(gamma):\r\n #global states\r\n #if states == None:\r\n # states = init_states()\r\n\r\n a1, a2 = states\r\n rho22 = a2 * a2\r\n L = gamma * rho22\r\n return L\r\n\r\n\r\ndef callback(param):\r\n omegaProbe = 2 * pi * 0.5e5\r\n (del_val, velocity) = param\r\n\r\n global states\r\n if states == None:\r\n states = init_states()\r\n\r\n a1, a2 = states\r\n rho11 = a1*a1\r\n rho22 = a2*a2\r\n k_wave = k_num\r\n ret_val = buildRhoMatrix(H(del_val-k_wave * velocity, omegaProbe), N) + buildGammaMatrix(decay_martrix(gamma), N) + gamma * outer(rho11 ,rho22)\r\n return ret_val\r\n\r\ndef time_dependent_TLS():\r\n\r\n global states\r\n if states == None:\r\n states = init_states()\r\n\r\n lmes = Linblad_master_equation_solver(False)\r\n\r\n states_name = qunatum_states_dictionary.rhoMatrixNames(N)\r\n\r\n rho11_num = states_name.getLocationByName('rho11')\r\n rho12_num = states_name.getLocationByName('rho12')\r\n rho22_num = states_name.getLocationByName('rho22')\r\n\r\n y0 = zeros((N * N, 1))\r\n y0[rho11_num] = 1\r\n\r\n a1, a2 = states\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n\r\n returnDic = [rho12_num, rho22_num,rho11_num]\r\n\r\n time_arr = linspace(0,0.2e-6,1000)\r\n omegaProbe = 2 * pi * 50e6\r\n g = gamma + 2 * pi * 10e6\r\n matrix_val = buildRhoMatrix(H(0, omegaProbe), N) + buildGammaMatrix(decay_martrix(g), N) + g * outer(rho11 ,rho22)\r\n\r\n ret_val = lmes.solve_density_matrix_evolution(matrix_val, y0, time_arr, returnDic)\r\n solution = [res.imag for res in ret_val[rho12_num]]\r\n solution1 = [res.real for res in ret_val[rho22_num]]\r\n #plt.plot(time_arr, solution)\r\n plt.figure(1,figsize=(10, 8))\r\n plt.subplot(121)\r\n plt.plot(time_arr*200e6, solution1,lw=2,color=d_red)\r\n plt.xlim([0,35])\r\n plt.xlabel('L ($\\mu m$)')\r\n plt.ylabel(r'Population ($\\rho_{22}$)')\r\n plt.subplot(122)\r\n plt.plot(time_arr * 200e6, solution, lw=2, color=d_blue)\r\n plt.xlim([0, 35])\r\n plt.xlabel('L ($\\mu m$)')\r\n plt.ylabel(r'Population ($\\rho_{12}$)')\r\n\r\n g = gamma\r\n matrix_val = buildRhoMatrix(H(0, omegaProbe), N) + buildGammaMatrix(decay_martrix(g), N) + g * outer(rho11, rho22)\r\n\r\n ret_val = lmes.solve_density_matrix_evolution(matrix_val, y0, time_arr, returnDic)\r\n solution = [res.real for res in ret_val[rho11_num]]\r\n solution1 = [res.real for res in ret_val[rho22_num]]\r\n #plt.plot(time_arr, solution)\r\n #plt.plot(time_arr*1e5, solution1,color=d_blue,lw=2)\r\n plt.savefig('TLS.png')\r\n plt.show()\r\n\r\ndef run():\r\n states_name = qunatum_states_dictionary.rhoMatrixNames(N)\r\n\r\n rho11 = states_name.getLocationByName('rho11')\r\n rho12 = states_name.getLocationByName('rho12')\r\n rho22 = states_name.getLocationByName('rho22')\r\n\r\n y0 = zeros((N * N, 1))\r\n y0[rho11] = 1\r\n\r\n lmes = Linblad_master_equation_solver(False)\r\n\r\n returnDic = [rho12, rho22]\r\n\r\n running_param = linspace(-2 * pi * 2.5e9, 2 * pi * 2.5e9, 3000) #(frequency scaning) detuning array\r\n v_param = linspace(-600, 600, 500) #atomic velocities array\r\n time_val = 0.1\r\n k_wave = k_num\r\n Tc = 50\r\n #results = lmes.solve_master_equation_with_Doppler_effect(callback, running_param, v_param, y0, time_val, Tc, returnDic)\r\n #results = lmes.solve_master_equation_steady_state_without_Doppler_effect(callback, running_param, N, returnDic)\r\n results = lmes.solve_master_equation_steady_state_with_Doppler_effect(callback, running_param, v_param, N, Tc, returnDic)\r\n plt.figure(1,figsize=(5,4))\r\n solution = [res.real for res in results[rho12]]\r\n plt.plot(running_param/(2 * pi*1e9), solution,color=d_blue,lw=2,label=r'$\\chi_R$')\r\n\r\n solution = [res.imag for res in results[rho12]]\r\n plt.plot(running_param / (2 * pi*1e9), solution,color=d_red,lw=2,label=r'$\\chi_I$')\r\n\r\n plt.xlabel('Detunning (GHz)')\r\n plt.yticks([])\r\n plt.legend(loc=0)\r\n plt.tight_layout()\r\n plt.savefig('abs.png')\r\n plt.show()\r\n\r\nif __name__ == \"__main__\":\r\n run()\r\n\r\n"
},
{
"alpha_fraction": 0.4689655303955078,
"alphanum_fraction": 0.5034482479095459,
"avg_line_length": 19.64285659790039,
"blob_id": "50fdf27438683f1fa9cebe43ca3faf0438abd88d",
"content_id": "aa3b256d781553f8626d53d7e6985ed2ba3ba024",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 290,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 14,
"path": "/Main/Breit Rabi Diagram/ang_mon_p.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nfrom numpy import zeros,sqrt,arange\n\ndef jp(jj):\n b = 0\n dim = int(2*jj+1)\n jp = zeros((dim,dim))\n z = arange(dim)\n m = jj-z\n while b<dim-1.0:\n mm = m[b+1]\n jp[b,b+1] = sqrt(jj*(jj+1)-mm*(mm+1))\n b = b+1\n return jp\n\n"
},
{
"alpha_fraction": 0.7906976938247681,
"alphanum_fraction": 0.7906976938247681,
"avg_line_length": 41,
"blob_id": "d5cb83735e7e8cbb2f04c59e3e789bb376450f82",
"content_id": "5616ea26c0f2fc0374188db0796ba6b5d651b9bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 1,
"path": "/Main/test.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from Main.Constants.Rb_constants import *\r\n"
},
{
"alpha_fraction": 0.457337886095047,
"alphanum_fraction": 0.5665528774261475,
"avg_line_length": 24.454545974731445,
"blob_id": "41599b3fc57a6077333195c4416904cd88e6d62b",
"content_id": "d3b86d9f8fdb99d7c7d7fbe0f9bb55ca98ce0b26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 293,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 11,
"path": "/Main/Breit Rabi Diagram/L_matrix.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nfrom scipy.constants import hbar\r\nfrom numpy import *\r\n\r\n\r\nLx=(sqrt(0.5)*hbar)*array([[0,1,0],[1,0,1],[0,1,0]])\r\nLy=(sqrt(0.5)*hbar)*array([[0,-1j,0],[1j,0,-1j],[0,1j,0]])\r\nLz=hbar*array([[1,0,0],[0,0,0],[0,0,-1]])\r\n\r\n\r\nL_2=Lx.dot(Lx)+Ly.dot(Ly)+Lz.dot(Lz)\r\n\r\n"
},
{
"alpha_fraction": 0.5941422581672668,
"alphanum_fraction": 0.6443514823913574,
"avg_line_length": 17.75,
"blob_id": "ffb98487902554da044028ce77c3205cd5df080d",
"content_id": "44fe093200d9bda037a92a9398929ae8aae4e076",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/Main/Breit Rabi Diagram/multiplication.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nfrom numpy import linalg as LA\r\nfrom J_matrix import *\r\nfrom S_matrix import *\r\nfrom L_matrix import *\r\n\r\nS=0.5\r\nL=1\r\n\r\nLS=0.5*(J_2-kron(L_2,eye(2*S+1))-kron(S_2,eye(2*L+1)))\r\n\r\neigVal,eigVec=LA.eig(LS)\r\n\r\n"
},
{
"alpha_fraction": 0.608428418636322,
"alphanum_fraction": 0.62423175573349,
"avg_line_length": 18.98245620727539,
"blob_id": "48f2beb80b4dabd55bcc612c1e16d87f2a859f70",
"content_id": "940299577b6c2226b0a6f9280a03577b12eaca9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1139,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 57,
"path": "/Main/Breit Rabi Diagram/sz_lsi.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "\"\"\"\nFunctions to calculate the z-projection matrices.\n\nCalculates the full size matrices for the projection on the quantization\naxis for electron spin, orbital angular momentum, nuclear spin, and the\ncoupled angular momentum F. Essentially takes results from jz and puts\nthem in the full Hilbert space.\n\nCalls jz from ang_mom.\n\"\"\"\n\nfrom numpy import identity\nfrom scipy.linalg import kron\nfrom ang_mon import jz\n\ndef sz(L,S,I):\n Sz=jz(S)\n gL=int(2*L+1)\n Li=identity(gL)\n gI=int(2*I+1)\n Ii=identity(gI)\n sz=kron(kron(Li,Sz),Ii)\n return sz\n\ndef lz(L,S,I):\n gS=int(2*S+1)\n Si=identity(gS)\n Lz=jz(L)\n gI=int(2*I+1)\n Ii=identity(gI)\n lz=kron(kron(Lz,Si),Ii)\n return lz\n\ndef Iz(L,S,I):\n gS=int(2*S+1)\n gL=int(2*L+1)\n Si=identity(gS)\n Li=identity(gL)\n Iz_num=jz(I)\n Iz=kron(kron(Li,Si),Iz_num)\n return Iz\n\ndef fz(L,S,I):\n gS=int(2*S+1)\n Sz=jz(S)\n Si=identity(gS)\n gL=int(2*L+1)\n Lz=jz(L)\n Li=identity(gL)\n gJ=gL*gS\n Jz=kron(Lz,Si)+kron(Li,Sz)\n Ji=identity(gJ)\n gI=int(2*I+1)\n Iz=jz(I)\n Ii=identity(gI)\n Fz=kron(Jz,Ii)+kron(Ji,Iz)\n return Fz\n"
},
{
"alpha_fraction": 0.468873530626297,
"alphanum_fraction": 0.5594120621681213,
"avg_line_length": 30.90243911743164,
"blob_id": "bd1a6ea8c6bd1e5c30f6e17ad9ad6ebcfe12c7a6",
"content_id": "e384d2ea917490d1b121894047aa91c6ca6c14e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8096,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 246,
"path": "/Main/Examples/SAS_spectra.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom __future__ import division, print_function\r\nfrom Main.Quantum_states_and_operators import q_state, qunatum_states_dictionary\r\nfrom Main.Quantum_states_and_operators.build_bloch_equation_matrix import *\r\nfrom Main.Quantum_states_and_operators.frequency_strength_calc import *\r\nfrom Main.Quantum_states_and_operators.Linblad_master_equation_solver import *\r\nfrom Main.Constants.Rb_constants import *\r\nimport pylab as plt\r\n\r\n#Constants\r\nDELTA_1 = -2 * pi * 1.770e9\r\nDELTA_2 = 2 * pi * 1.264e9\r\nDELTA_3 = -2 * pi * 113.208e6\r\nDELTA_4 = -2 * pi * 83.835e6\r\nDELTA_5 = -2 * pi * 20.435e6\r\nDELTA_6 = 2 * pi * 100.205e6\r\n\r\n\r\n\r\nstates = None\r\nN = 11\r\n\r\ndef init_states():\r\n state1 = q_state.State(N,0,2, is_Ground = True)\r\n state1.set_S(0.5)\r\n state2 = q_state.State(N,1,3, is_Ground = True)\r\n\r\n #probe\r\n state2.set_S(0.5)\r\n state3 = q_state.State(N,2,1)\r\n state3.set_L(1)\r\n state3.set_S(0.5)\r\n state4 = q_state.State(N,3,2)\r\n state4.set_L(1)\r\n state4.set_S(0.5)\r\n state5 = q_state.State(N,4,3)\r\n state5.set_L(1)\r\n state5.set_S(0.5)\r\n state6 = q_state.State(N,5,4)\r\n state6.set_L(1)\r\n state6.set_S(0.5)\r\n\r\n # pump\r\n\r\n state7 = q_state.State(N,2,1)\r\n state7.set_L(1)\r\n state7.set_S(0.5)\r\n state8 = q_state.State(N,3,2)\r\n state8.set_L(1)\r\n state8.set_S(0.5)\r\n state9 = q_state.State(N,4,3)\r\n state9.set_L(1)\r\n state9.set_S(0.5)\r\n state10 = q_state.State(N,5,4)\r\n state10.set_L(1)\r\n state10.set_S(0.5)\r\n\r\n return state1, state2, state3, state4, state5, state6, state7, state8, state9, state10\r\n\r\ndef init():\r\n global states\r\n states = init_states()\r\n return True\r\n\r\n#--------------------------------------------------------------------------------------------------------#\r\n\r\ndef H(delta_pr, delta_pu, omega_pr, omega_pu):\r\n global states\r\n a1, a2, a3, a4, a5, a6, a7, a8, a9, a10 = states\r\n\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n rho55 = a5 * a5\r\n rho66 = a6 * a6\r\n rho77 = a7 * a7\r\n rho88 = a8 * a8\r\n rho99 = a9 * a9\r\n rho1010 = a10 * a10\r\n\r\n #probe\r\n rho13 = a1 * a3\r\n rho14 = a1 * a4\r\n rho15 = a1 * a5\r\n\r\n rho24 = a2 * a4\r\n rho25 = a2 * a5\r\n rho26 = a2 * a6\r\n\r\n # pump\r\n rho17 = a1 * a7\r\n rho18 = a1 * a8\r\n rho19 = a1 * a9\r\n\r\n rho28 = a2 * a8\r\n rho29 = a2 * a9\r\n rho210 = a2 * a10\r\n\r\n # probe\r\n H0 = (DELTA_1) * rho11 + (DELTA_2) * rho22 + (delta_pr + DELTA_3) * rho33 + (delta_pr + DELTA_4) * rho44\\\r\n + (delta_pr + DELTA_5) * rho55 + (delta_pr + DELTA_5) * rho66\r\n\r\n # pump\r\n H0 = (delta_pu + DELTA_3) * rho77 + (delta_pu + DELTA_4) * rho88 \\\r\n + (delta_pu + DELTA_5) * rho99 + (delta_pu + DELTA_5) * rho1010\r\n\r\n #probe\r\n omega_pr_13 = transition_strength(a1,a3) * omega_pr\r\n omega_pr_14 = transition_strength(a1,a4) * omega_pr\r\n omega_pr_15 = transition_strength(a1,a5) * omega_pr\r\n\r\n omega_pr_24 = transition_strength(a2, a4) * omega_pr\r\n omega_pr_25 = transition_strength(a2, a5) * omega_pr\r\n omega_pr_26 = transition_strength(a2, a6) * omega_pr\r\n\r\n # pump\r\n omega_pu_17 = transition_strength(a1, a7) * omega_pu\r\n omega_pu_18 = transition_strength(a1, a8) * omega_pu\r\n omega_pu_19 = transition_strength(a1, a9) * omega_pu\r\n\r\n omega_pu_28 = transition_strength(a2, a8) * omega_pu\r\n omega_pu_29 = transition_strength(a2, a9) * omega_pu\r\n omega_pu_210 = transition_strength(a2, a10) * omega_pu\r\n\r\n #probe\r\n V = (omega_pr_13) * rho13 + (omega_pr_14) * rho14 + (omega_pr_15) * rho15 + (omega_pr_24) * rho24 + (omega_pr_25) * rho25 \\\r\n + (omega_pr_26) * rho26\r\n V += transpose(V)\r\n\r\n #pump\r\n V = (omega_pu_17) * rho17 + (omega_pu_18) * rho18 + (omega_pu_19) * rho19 + (omega_pu_28) * rho28 + (\r\n omega_pu_29) * rho29 + (omega_pu_210) * rho210\r\n V += transpose(V)\r\n return H0 + V\r\n\r\ndef decay_martrix(gamma_val):\r\n a1, a2, a3, a4, a5, a6, a7, a8, a9, a10 = states\r\n\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n rho55 = a5 * a5\r\n rho66 = a6 * a6\r\n rho77 = a7 * a7\r\n rho88 = a8 * a8\r\n rho99 = a9 * a9\r\n rho1010 = a10 * a10\r\n\r\n L = gamma_val * (rho33 + rho44 + rho55 + rho66 + rho77 + rho88 + rho99 + rho1010)\r\n\r\n return L\r\n\r\ndef repopulation_decay_matrix_vee(gamma_val):\r\n a1, a2, a3, a4, a5, a6, a7, a8, a9, a10 = states\r\n\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n rho55 = a5 * a5\r\n rho66 = a6 * a6\r\n rho77 = a7 * a7\r\n rho88 = a8 * a8\r\n rho99 = a9 * a9\r\n rho1010 = a10 * a10\r\n\r\n gamma_val_13 = transition_strength(a1,a3) * gamma_val\r\n gamma_val_14 = transition_strength(a1,a4) * gamma_val\r\n gamma_val_15 = transition_strength(a1,a5) * gamma_val\r\n gamma_val_24 = transition_strength(a2, a4) *gamma_val\r\n gamma_val_25 = transition_strength(a2, a5) *gamma_val\r\n gamma_val_26 = transition_strength(a2, a6) *gamma_val\r\n\r\n gamma_val_17 = transition_strength(a1, a7) * gamma_val\r\n gamma_val_18 = transition_strength(a1, a8) * gamma_val\r\n gamma_val_19 = transition_strength(a1, a9) * gamma_val\r\n gamma_val_28 = transition_strength(a2, a8) * gamma_val\r\n gamma_val_29 = transition_strength(a2, a9) * gamma_val\r\n gamma_val_210 = transition_strength(a2, a10) * gamma_val\r\n\r\n ret_val = gamma_val_13 * outer(rho11, rho33) + gamma_val_14 * outer(rho11, rho44) + gamma_val_15 * outer(rho11, rho55) + \\\r\n gamma_val_24 * outer(rho22, rho44) + gamma_val_25 * outer(rho22, rho55) + gamma_val_26 * outer(rho22,rho66)\r\n\r\n ret_val += gamma_val_17 * outer(rho11, rho77) + gamma_val_18 * outer(rho11, rho88) + gamma_val_19 * outer(rho11,\r\n rho99) + \\\r\n gamma_val_28 * outer(rho22, rho88) + gamma_val_29 * outer(rho22, rho99) + gamma_val_210* outer(rho22,\r\n rho1010)\r\n\r\n return ret_val\r\n#--------------------------------------------------------------------------------------------------------#\r\n\r\n\r\ndef callback(param):\r\n k_probe = 2 * pi /(780e-9)\r\n (del_val, velocity) = param\r\n omega_pr = 2 * pi * 0.5e5\r\n gamma_val = 2 * pi * 6.06e6\r\n delta_pr = del_val\r\n delta_pu = delta_pr\r\n omega_pu = 2 * pi * 5e6\r\n\r\n ret_val = buildRhoMatrix(H(delta_pr - k_probe * velocity, delta_pu + k_probe * velocity, omega_pr, omega_pu),N) + buildGammaMatrix(decay_martrix(gamma_val), N)\r\n ret_val += repopulation_decay_matrix_vee(gamma_val)\r\n\r\n return ret_val\r\n\r\nif __name__ == \"__main__\":\r\n # init all states\r\n init()\r\n\r\n states_name = qunatum_states_dictionary.rhoMatrixNames(N)\r\n\r\n rho11 = states_name.getLocationByName('rho11')\r\n rho22 = states_name.getLocationByName('rho22')\r\n\r\n rho13 = states_name.getLocationByName('rho13')\r\n rho14 = states_name.getLocationByName('rho14')\r\n rho15 = states_name.getLocationByName('rho15')\r\n\r\n rho24 = states_name.getLocationByName('rho24')\r\n rho25 = states_name.getLocationByName('rho25')\r\n rho26 = states_name.getLocationByName('rho26')\r\n\r\n y0 = zeros((N * N, 1))\r\n y0[rho11] = 0.5\r\n y0[rho22] = 0.5\r\n\r\n lmes = Linblad_master_equation_solver(False)\r\n\r\n returnDic = [rho13, rho14, rho15, rho24, rho25, rho26]\r\n\r\n running_param = linspace(-2 * pi * 4e9, 2 * pi * 4e9, 500) # (frequency scaning) detuning array\r\n v_param = linspace(-600, 600, 200) # atomic velocities array\r\n time_val = 1\r\n Tc = 25\r\n results = lmes.solve_master_equation_with_Doppler_effect(callback, running_param,v_param, y0, time_val, Tc, returnDic)\r\n\r\n\r\n absor = []\r\n\r\n for idx, _ in enumerate(running_param):\r\n absor.append(results[rho13][idx].imag + results[rho14][idx].imag + results[rho15][idx].imag + results[rho24][idx].imag + results[rho25][idx].imag + \\\r\n results[rho26][idx].imag)\r\n\r\n plt.plot(running_param / (2 * pi), absor)\r\n plt.show()\r\n\r\n"
},
{
"alpha_fraction": 0.5822102427482605,
"alphanum_fraction": 0.5983827710151672,
"avg_line_length": 16.66666603088379,
"blob_id": "67bf7876c52261edf350bdf733fe7437629fd348",
"content_id": "6916515050c0875a2817128d9bc174b435a29571",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 371,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 21,
"path": "/Main/Breit Rabi Diagram/ang_mon.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nfrom numpy import transpose,dot\nimport ang_mon_p\n\ndef jx(jj):\n jp=ang_mon_p.jp(jj)\n jm=transpose(jp)\n jx=0.5*(jp+jm)\n return jx\n\ndef jy(jj):\n jp=ang_mon_p.jp(jj)\n jm=transpose(jp)\n jy=0.5j*(jm-jp)\n return jy\n\ndef jz(jj):\n jp=ang_mon_p.jp(jj)\n jm=transpose(jp)\n jz=0.5*(dot(jp,jm)-dot(jm,jp))\n return jz\n"
},
{
"alpha_fraction": 0.5003971457481384,
"alphanum_fraction": 0.5702939033508301,
"avg_line_length": 20.122806549072266,
"blob_id": "39ce0ae978c37158bc34dab7fa0edbf13d49af12",
"content_id": "b6837e541708f0e4659667cf0d36212405bffcc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1259,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 57,
"path": "/Main/Relaxation Time Calculation/T1_T2_calculation.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division,print_function\r\nfrom numpy import *\r\nfrom Buffer_gas_constants import *\r\nfrom Relaxation_Mechanisim import *\r\nfrom pylab import *\r\n\r\nN2 = N2()\r\nAr = Ar()\r\n\r\npressures = linspace(0.1,100,1000)\r\nT2 = []\r\nT1 = []\r\ns_ds = []\r\n\r\n\r\nrubidium_num = 87\r\nT = celsius2kelvin(90)\r\n\r\nfor pressure in pressures:\r\n param = [0.06, 3.48/2]\r\n D0 = N2.get_D0()\r\n N2.set_pressure(pressure)\r\n N2.set_density(T,pressure)\r\n #Ar.set_pressure(30)\r\n #Ar.set_density(T,30)\r\n y1 = wall_relaxation(T, pressure, 'cylind', param, D0)\r\n y2 = spin_exchange_relaxation(rubidium_num,T)\r\n y3 = spin_destruction_relaxation(rubidium_num,T,[N2])\r\n T2.append(1e3/(y1+y2+y3))\r\n T1.append(1e3/(y1+y3))\r\n s_ds.append(y3)\r\n\r\ndef wall_collision(L,r,T):\r\n V = pi * r **2 * L\r\n A = 2 * pi * r **2 + 2 * pi * r * L\r\n m = 87 / N_A # [gram]\r\n m = 0.001 * m # convert to Kg\r\n M = m / 2\r\n v = sqrt(8 * k * T/ (pi * M))\r\n\r\n return 1e3 * 4 * V / (v * A)\r\n\r\n\r\n\r\n\r\n#print (wall_collision(0.6e-3, 1.5e-3,T))\r\n#print (wall_collision(2e-3, 1.5e-3,T))\r\n\r\nplot(pressures,T1,label='T1')\r\nplot(pressures,T2,label='T2')\r\n#plot(pressures,s_ds,label='T2')\r\nlegend()\r\n#yscale(\"log\")\r\nylabel('sec [ms]')\r\n#ylim([10**-2,10**3])\r\n\r\nshow()"
},
{
"alpha_fraction": 0.5274038314819336,
"alphanum_fraction": 0.550000011920929,
"avg_line_length": 18.62264060974121,
"blob_id": "8315dcafaba630e74a80bd3e12ec26783c848998",
"content_id": "5c27ef52ba70885a4540cc800001442df2991956",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2080,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 106,
"path": "/Main/Breit Rabi Diagram/fs_hfs.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from numpy import identity,dot\nfrom scipy.linalg import kron\nfrom ang_mon import jx,jy,jz\n\n\ndef Hfs(L,S,I):\n \"\"\"Provides the L dot S matrix (fine structure)\"\"\"\n gS=int(2*S+1) #number of mS values\n Sx=jx(S)\n Sy=jy(S)\n Sz=jz(S)\n Si=identity(gS)\n\n gL=int(2*L+1)\n Lx=jx(L)\n Ly=jy(L)\n Lz=jz(L)\n Li=identity(gL)\n\n gJ=gL*gS\n Jx=kron(Lx,Si)+kron(Li,Sx)\n Jy=kron(Ly,Si)+kron(Li,Sy)\n Jz=kron(Lz,Si)+kron(Li,Sz)\n J2=dot(Jx,Jx)+dot(Jy,Jy)+dot(Jz,Jz)\n\n gI=int(2*I+1)\n Ii=identity(gI)\n gF=gJ*gI\n Fi=identity(gF)\n Hfs=0.5*(kron(J2,Ii)-L*(L+1)*Fi-S*(S+1)*Fi) # fine structure in m_L,m_S,m_I basis\n return Hfs\n\ndef Hhfs(L,S,I):\n \"\"\"Provides the I dot J matrix (hyperfine structure interaction)\"\"\"\n gS=int(2*S+1)\n Sx=jx(S)\n Sy=jy(S)\n Sz=jz(S)\n Si=identity(gS)\n\n gL=int(2*L+1)\n Lx=jx(L)\n Ly=jy(L)\n Lz=jz(L)\n Li=identity(gL)\n\n gJ=gL*gS\n Jx=kron(Lx,Si)+kron(Li,Sx)\n Jy=kron(Ly,Si)+kron(Li,Sy)\n Jz=kron(Lz,Si)+kron(Li,Sz)\n Ji=identity(gJ)\n J2=dot(Jx,Jx)+dot(Jy,Jy)+dot(Jz,Jz)\n\n gI=int(2*I+1)\n gF=gJ*gI\n Ix=jx(I)\n Iy=jy(I)\n Iz=jz(I)\n Ii=identity(gI)\n Fx=kron(Jx,Ii)+kron(Ji,Ix)\n Fy=kron(Jy,Ii)+kron(Ji,Iy)\n Fz=kron(Jz,Ii)+kron(Ji,Iz)\n Fi=identity(gF)\n F2=dot(Fx,Fx)+dot(Fy,Fy)+dot(Fz,Fz)\n Hhfs=0.5*(F2-I*(I+1)*Fi-kron(J2,Ii))\n return Hhfs\n\ndef Bbhfs(L,S,I):\n \"\"\"Calculates electric quadrupole matrix.\n\n Calculates the part in square brakets from\n equation (8) in manual\n \"\"\"\n gS=int(2*S+1)\n Sx=jx(S)\n Sy=jy(S)\n Sz=jz(S)\n Si=identity(gS)\n\n gL=int(2*L+1)\n Lx=jx(L)\n Ly=jy(L)\n Lz=jz(L)\n Li=identity(gL)\n\n gJ=gL*gS\n Jx=kron(Lx,Si)+kron(Li,Sx)\n Jy=kron(Ly,Si)+kron(Li,Sy)\n Jz=kron(Lz,Si)+kron(Li,Sz)\n\n gI=int(2*I+1)\n gF=gJ*gI\n Ix=jx(I)\n Iy=jy(I)\n Iz=jz(I)\n\n Fi=identity(gF)\n\n IdotJ=kron(Jx,Ix)+kron(Jy,Iy)+kron(Jz,Iz)\n IdotJ2=dot(IdotJ,IdotJ)\n\n if I != 0:\n Bbhfs=1./(6*I*(2*I-1))*(3*IdotJ2+3./2*IdotJ-I*(I+1)*15./4*Fi)\n else:\n Bbhfs = 0\n return Bbhfs\n"
},
{
"alpha_fraction": 0.4735576808452606,
"alphanum_fraction": 0.5028846263885498,
"avg_line_length": 22.761905670166016,
"blob_id": "1ea7bcb310f4fe47aad410a19fdb3801a5f6c1ea",
"content_id": "990a79cc2d36a169485684c3e1c5d9fc6ba99bc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2080,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 84,
"path": "/Main/Relaxation Time Calculation/Buffer_gas_constants.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division,print_function\r\nfrom scipy.constants import k,N_A\r\nfrom numpy import sqrt, pi\r\n\r\nclass GAS:\r\n\r\n def set_pressure(self,pressure):\r\n '''\r\n\r\n :param pressure: set pressure in torr\r\n :return:\r\n '''\r\n self.__pressure = pressure\r\n\r\n def get_pressure(self):\r\n '''\r\n\r\n :return: pressure [Torr]\r\n '''\r\n return self.__pressure\r\n\r\n def set_D0(self,D0):\r\n self.__Do = D0\r\n\r\n def get_D0(self):\r\n return self.__Do\r\n\r\n def set_sigma(self, sigma):\r\n '''\r\n\r\n :param sigma: collisional cross section [cm^2]\r\n :return:\r\n '''\r\n self.__sigma_sd = sigma\r\n\r\n def get_sigma(self):\r\n return self.__sigma_sd\r\n\r\n def set_mass(self,mass):\r\n '''\r\n :param mas: mas in atomic mass unit[u] (basically taken from the periodic table)\r\n '''\r\n retVal = mass/N_A #[gram]\r\n retVal = 0.001 * retVal #convert to Kg\r\n self.__mass = retVal\r\n\r\n def get_mass(self):\r\n '''\r\n :return:Mass in Kg\r\n '''\r\n return self.__mass\r\n\r\n def set_density(self,temp,pressure=0):\r\n '''\r\n :param temp: cell temperatuer [K]\r\n :param pressure: buffer gas pressure [Torr]\r\n :return: density of the buffer gas [cm^-3]\r\n '''\r\n pressure = pressure/760 #convert Torr to atmosphere\r\n R = 82.06 #[cm^3 * atm * mol^-1 * K^-1]\r\n self.__density = pressure * N_A / (R * temp)\r\n\r\n def get_density(self):\r\n return self.__density\r\n\r\n def get_relative_velocity(self,T,m):\r\n # k = 1.380649e-23 [m^2 * kg * s^-2 * K^-1]\r\n M = (self.__mass * m) / (self.__mass + m)\r\n ret_Val = sqrt(8 * k * T/ (pi * M))\r\n return ret_Val\r\n\r\n\r\n\r\nclass Ar(GAS):\r\n def __init__(self):\r\n GAS.set_D0(self,0.22)\r\n GAS.set_sigma(self,3.7e-22)\r\n GAS.set_mass(self,39.948)\r\n\r\nclass N2(GAS):\r\n def __init__(self):\r\n GAS.set_D0(self,0.23)\r\n GAS.set_sigma(self,1e-22)\r\n GAS.set_mass(self,2*14.007)\r\n"
},
{
"alpha_fraction": 0.4059167504310608,
"alphanum_fraction": 0.48950809240341187,
"avg_line_length": 24.651376724243164,
"blob_id": "3cc7737806813cb0805eaba5bb9755c5f2fb23c6",
"content_id": "d0b6c70985a7587671593c16a6833e2417f09d70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2907,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 109,
"path": "/Main/Relaxation Time Calculation/Relaxation_Mechanisim.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom numpy import pi,sqrt,log10\r\nfrom scipy.constants import k,N_A\r\nfrom Buffer_gas_constants import *\r\n\r\npa = -94.04826\r\npb =1961.258\r\npc = -0.03771687\r\npd =42.57526\r\n\r\ndef p(T):\r\n ret_val = 10**(pa - pb/T + pc*T + pd*log10(T))\r\n return ret_val\r\n\r\ndef celsius2kelvin(Tc):\r\n ret_val = Tc + 273.15\r\n return ret_val\r\n\r\ndef n(T):\r\n ret_val = p(T)*133.3/(k * T)\r\n return ret_val\r\n\r\ndef n_cm(T):\r\n ret_val = n(T)/(100**3)\r\n return ret_val\r\n\r\ndef n_zeltser(T):\r\n A = 4.312\r\n B = 4040\r\n ret_val = (1/T) * 10**(21.866 + A -B/T)\r\n return ret_val * (1/((0.01)**3))\r\n\r\ndef wall_relaxation(T,P,cell_shape,param,D0):\r\n '''\r\n :param T: cell temperature [K]\r\n :param P: pressure [Torr]\r\n :param cell_shape: 'rect' / 'circ' / 'cylind'\r\n :param param: param of the cell dimensions in cm\r\n :return:\r\n '''\r\n k = 0\r\n if cell_shape == 'rect':\r\n k = pi**2 * (1/(param[0])**2 + 1/(param[1])**2 + 1/(param[2])**2)\r\n if cell_shape == 'circ':\r\n # param[0] cell radius\r\n k = (pi / param[0]) **2\r\n if cell_shape == 'cylind':\r\n #param[0] cell length\r\n #param[1] cell radius\r\n k = (pi/param[0])**2 + (2.405/param[1])**2\r\n\r\n P0 = 760 # [Torr]\r\n T0 = celsius2kelvin(100) #[C]\r\n\r\n D = D0 * (P0/P) * (T/T0)**(3/2)\r\n ret_val = k * D\r\n return ret_val\r\n\r\ndef spin_exchange_relaxation(rubidium_num,T):\r\n if rubidium_num == 85:\r\n I = 5/2\r\n elif rubidium_num == 87:\r\n I = 3/2\r\n\r\n qse = (3 * (2 * I + 1)**2)/(2 * I * (2 * I - 1))\r\n\r\n sigma_se = 1.9e-14 #[cm^2]\r\n sigma_se = sigma_se*(0.01*0.01) #[m^2]\r\n mass = 86.909184\r\n if rubidium_num == 85:\r\n mass = 84.911\r\n elif rubidium_num == 87:\r\n mass = 86.909184\r\n m = mass/N_A #[gram]\r\n m = 0.001 * m #convert to Kg\r\n M = m/2\r\n den = n(T)#n_zeltser(T)\r\n vrel = sqrt(8 * k * T/ (pi * M))\r\n ret_val = den * sigma_se * vrel\r\n return (1/qse)*ret_val\r\n\r\ndef spin_destruction_relaxation(rubidium_num,T,buffer_gas_list):\r\n P = 0.5\r\n if rubidium_num == 85:\r\n q = (38 + 52 * P ** 2 + 6 * P**4) / (3 + 10 * P ** 2 + 3 * P**4)\r\n elif rubidium_num == 87:\r\n q = (6 + 2 * P**2)/(1 + P**2)\r\n\r\n sigma_d = 1.6e-17 #[cm^2]\r\n sigma_d = sigma_d * (0.01 * 0.01) #[m^2]\r\n mass = 86.909184\r\n if rubidium_num == 85:\r\n mass = 85.4678\r\n elif rubidium_num == 87:\r\n mass = 86.909184\r\n m = mass / N_A # [gram]\r\n m = 0.001 * m # -> convert to Kg\r\n M = m / 2\r\n den = n(T)\r\n vrel = sqrt(8 * k * T / (pi * M))\r\n rb_sd = den * sigma_d * vrel\r\n bg_sd = 0\r\n for bg in buffer_gas_list:\r\n sigma_bg_d = bg.get_sigma()\r\n vrel_bg = bg.get_relative_velocity(T,m) * 100 #\r\n den_bg = bg.get_density() #cm^-3\r\n bg_sd += den_bg * sigma_bg_d * vrel_bg\r\n\r\n return (1/q) * (rb_sd + bg_sd)\r\n\r\n"
},
{
"alpha_fraction": 0.4628751873970032,
"alphanum_fraction": 0.519747257232666,
"avg_line_length": 18.700000762939453,
"blob_id": "5fc5951b973970608f537b6bfce52af2eacc7597",
"content_id": "fe8339dca5afcbf85b46d0061a7965e38f0ee618",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 633,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 30,
"path": "/Main/Breit Rabi Diagram/J_matrix.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nfrom numpy import *\r\nfrom L_matrix import *\r\nfrom S_matrix import *\r\n\r\nS=0.5\r\nL=1\r\n\r\n\r\n\r\nJx=kron(Lx,eye(2*S+1))+kron(eye(2*L+1),Sx)\r\nJy=kron(Ly,eye(2*S+1))+kron(eye(2*L+1),Sy)\r\nJz=kron(Lz,eye(2*S+1))+kron(eye(2*L+1),Sz)\r\n\r\nJ_2=Jx.dot(Jx)+Jy.dot(Jy)+Jz.dot(Jz)\r\n\r\n\r\n\r\n\r\ndef getJ(L):\r\n if L==0:\r\n Jx=kron(eye(2*L+1),Sx)\r\n Jy=kron(eye(2*L+1),Sy)\r\n Jz=kron(eye(2*L+1),Sz)\r\n elif L==1:\r\n Jx=kron(Lx,eye(2*S+1))+kron(eye(2*L+1),Sx)\r\n Jy=kron(Ly,eye(2*S+1))+kron(eye(2*L+1),Sy)\r\n Jz=kron(Lz,eye(2*S+1))+kron(eye(2*L+1),Sz)\r\n\r\n return Jx,Jy,Jz\r\n\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5967926979064941,
"alphanum_fraction": 0.6048110127449036,
"avg_line_length": 21.37837791442871,
"blob_id": "d19f2b432e846441ae5bb4cb2a754387bde3ed15",
"content_id": "ad662071153e3cd4f7735bcb71818d960769e646",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 37,
"path": "/Main/Operators/tools.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division,print_function\r\nimport numpy as np\r\nimport scipy.sparse as sp\r\n\r\n\r\n\r\n\r\ndef mat2vec(mat):\r\n \"\"\"\r\n Private function reshaping matrix to vector.\r\n \"\"\"\r\n return mat.T.reshape(np.prod(np.shape(mat)), 1)\r\n\r\n\r\ndef vec2mat(vec):\r\n \"\"\"\r\n Private function reshaping vector to matrix.\r\n \"\"\"\r\n n = int(np.sqrt(len(vec)))\r\n return vec.reshape((n, n)).T\r\n\r\ndef vec2mat_index(N, I):\r\n \"\"\"\r\n Convert a vector index to a matrix index pair that is compatible with the\r\n vector to matrix rearrangement done by the vec2mat function.\r\n \"\"\"\r\n j = int(I / N)\r\n i = I - N * j\r\n return i, j\r\n\r\n\r\ndef mat2vec_index(N, i, j):\r\n \"\"\"\r\n Convert a matrix index pair to a vector index that is compatible with the\r\n matrix to vector rearrangement done by the mat2vec function.\r\n \"\"\"\r\n return i + N * j\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5166666507720947,
"alphanum_fraction": 0.5833333134651184,
"avg_line_length": 21.799999237060547,
"blob_id": "2fd740467122a0db5f1f2567ed20c9d121cebda4",
"content_id": "22293b7a841f306e7263e12950979b760d806feb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 10,
"path": "/Main/Breit Rabi Diagram/S_matrix.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nfrom scipy.constants import hbar\r\nfrom numpy import *\r\n\r\n\r\nSx=(hbar/2)*array([[0,1],[1,0]])\r\nSy=(hbar/2)*array([[0,-1j],[1j,0]])\r\nSz=(hbar/2)*array([[1,0],[0,-1]])\r\n\r\nS_2=Sx.dot(Sx)+Sy.dot(Sy)+Sz.dot(Sz)\r\n\r\n"
},
{
"alpha_fraction": 0.4792804419994354,
"alphanum_fraction": 0.6135560274124146,
"avg_line_length": 33,
"blob_id": "48c01b408f0cb32ac4039cb079c30b0a8053088c",
"content_id": "94d242e83c3e7697baa47781e0b29d77c7577e97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3113,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 89,
"path": "/Main/Tools/PlottingTemplate.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\n\r\nimport numpy as np\r\nimport matplotlib.pyplot as plt\r\nimport matplotlib.colors as mcolors\r\nfrom matplotlib.patches import Polygon\r\n\r\n\r\n\r\n## HUJI Colour Palette ##\r\nd_black = [35./255,31./255,32./255]\t\t\t #\tBlack\t\t\t\tBlackC\r\nd_olive\t= [159.0/255.0,161.0/255.0,97.0/255.0] \t# \tOlive Green\t5835C\r\nd_blue\t= [0,99.0/255.0,136.0/255.0] \t\t\t# \tBlue\t\t\t634C\r\nd_red\t= [170.0/255.0,43.0/255.0,74.0/255.0] \t# Red\t\t\t201C\r\nd_midblue = [145./255,184.0/255.0,189.0/255.0]\t# Mid Blue\t\t5493C\r\nd_pinck=[227.0/255.0, 37.0/255.0, 132.0/255.0] # Pinck\r\nd_green=[84.0/255.0, 207.0/255.0, 146.0/255.0] # Green\r\nd_orange=[248.0/255.0, 69.0/255.0, 123.0/255.0] #Orange\r\ndd_blue=[64.0/255.0, 210.0/255.0, 254.0/255.0]\r\nd_green=[94.0/255.0, 184.0/255.0, 122.0/255.0] #green\r\n\r\n#Pastel colors\r\npastel_green=[201.0/255.0,255.0/255.0,178.0/255.0]\r\npastel_blue=[194.0/255.0,178.0/255.0,255.0/255.0]\r\npastel_yellow=[255.0/255.0,242.0/255.0,178.0/255.0]\r\npastel_light_blue=[178.0/255.0,225.0/255.0,255.0/255.0]\r\npastel_red=[255.0/255.0,178.0/255.0,185.0/255.0]\r\npastel_torqize=[178.0/255.0,255.0/255.0,218.0/255.0]\r\npastel_purpule=[255.0/255.0,178.0/255.0,249.0/255.0]\r\n\r\n\r\n\r\n\r\n\r\n# update matplotlib fonts etc\r\nplt.rc('font',**{'family':'Serif','serif':['Times New Roman']})\r\nparams={'axes.labelsize':16,'xtick.labelsize':16,'ytick.labelsize':16,'legend.fontsize': 16,'axes.linewidth':2}\r\nplt.rcParams.update(params)\r\n\r\n\r\ndef gradient_fill(x, y, fill_color=None, ax=None, **kwargs):\r\n \"\"\"\r\n Plot a line with a linear alpha gradient filled beneath it.\r\n\r\n Parameters\r\n ----------\r\n x, y : array-like\r\n The data values of the line.\r\n fill_color : a matplotlib color specifier (string, tuple) or None\r\n The color for the fill. If None, the color of the line will be used.\r\n ax : a matplotlib Axes instance\r\n The axes to plot on. If None, the current pyplot axes will be used.\r\n Additional arguments are passed on to matplotlib's ``plot`` function.\r\n\r\n Returns\r\n -------\r\n line : a Line2D instance\r\n The line plotted.\r\n im : an AxesImage instance\r\n The transparent gradient clipped to just the area beneath the curve.\r\n \"\"\"\r\n if ax is None:\r\n ax = plt.gca()\r\n\r\n line, = ax.plot(x, y, **kwargs)\r\n if fill_color is None:\r\n fill_color = line.get_color()\r\n\r\n zorder = line.get_zorder()\r\n alpha = line.get_alpha()\r\n alpha = 1.0 if alpha is None else alpha\r\n\r\n z = np.empty((100, 1, 4), dtype=float)\r\n rgb = mcolors.colorConverter.to_rgb(fill_color)\r\n z[:,:,:3] = rgb\r\n z[:,:,-1] = np.linspace(0, alpha, 100)[:,None]\r\n\r\n xmin, xmax, ymin, ymax = x.min(), x.max(), y.min(), y.max()\r\n im = ax.imshow(z, aspect='auto', extent=[xmin, xmax, ymin, ymax],\r\n origin='lower', zorder=zorder)\r\n\r\n xy = np.column_stack([x, y])\r\n xy = np.vstack([[xmin, ymin], xy, [xmax, ymin], [xmin, ymin]])\r\n clip_path = Polygon(xy, facecolor='none', edgecolor='none', closed=True)\r\n ax.add_patch(clip_path)\r\n im.set_clip_path(clip_path)\r\n\r\n ax.autoscale(True)\r\n return line, im"
},
{
"alpha_fraction": 0.5133748650550842,
"alphanum_fraction": 0.5218028426170349,
"avg_line_length": 23.745283126831055,
"blob_id": "b7d211963f3cb4782176abd699acf8d84c0faf89",
"content_id": "ad7ec53af855c0f20cd15eba6d496e0e2266047b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2729,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 106,
"path": "/Main/Quantum_states_and_operators/q_state.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division,print_function\r\nfrom numpy import zeros,transpose,tensordot\r\nfrom Main.Constants.Rb_constants import S\r\n\r\nclass State:\r\n def __init__(self,total_levels_number,key,F=0,mF=0,L=0,gF=0,is_Ground = False):\r\n '''\r\n Parameters\r\n ----------\r\n total_levels_number : how many levels total in your system in order to define the vector size\r\n key - unique value of the state (default the state number)\r\n F - F number of the state\r\n mF - qunatum number of F\r\n L - angular momentum number\r\n gF -\r\n is_Ground - boolean if it is the ground state or not\r\n '''\r\n self.level = zeros((total_levels_number, 1 ))\r\n self.L = L\r\n self.F = F\r\n self.mF = mF\r\n self.gF = gF\r\n self.is_Ground = is_Ground\r\n if 0 <= key < total_levels_number:\r\n self.level[key] = 1\r\n\r\n def set_S(self,S):\r\n self.S = S\r\n\r\n def set_L(self,L):\r\n self.L = L\r\n\r\n def set_gF(self,gF):\r\n self.gF = gF\r\n\r\n\r\n def set_F(self,F):\r\n self.F = F\r\n\r\n def set_mF(self, mF):\r\n self.mF = mF\r\n\r\n def set_isGround(self,is_Ground):\r\n self.is_Ground = is_Ground\r\n\r\n def set_key(self,key):\r\n self.key = key\r\n\r\n\r\n def get_L(self):\r\n return self.L\r\n\r\n def get_J(self):\r\n J = self.L + self.S\r\n return J\r\n\r\n def get_gF(self):\r\n return self.gF\r\n\r\n def get_F(self):\r\n return (self.F)\r\n\r\n def get_mF(self):\r\n return (self.mF)\r\n\r\n def get_isGround(self):\r\n return (self.is_Ground)\r\n\r\n def get_key(self):\r\n return (self.key)\r\n\r\n def get_level(self):\r\n return self.level\r\n\r\n def outer_product(self,state):\r\n lhs = state.get_level()\r\n ret_val = tensordot(self.get_level(),lhs,axes=0)\r\n ret_val = ret_val.reshape(len(self.get_level())*len(lhs),1)\r\n return ret_val\r\n\r\n def __str__(self):\r\n if self.is_Ground:\r\n ret_val = '|Fg:{},mFg:{}>'.format(self.F,self.mF)\r\n else:\r\n ret_val = '|Fe:{},mFe:{}>'.format(self.F, self.mF)\r\n return ret_val\r\n\r\n def __mul__(self, other):\r\n ret_val = None\r\n if isinstance(other, State):\r\n ret_val = self.level * transpose(other.level)\r\n else:\r\n print ('Multiply must be between to states')\r\n return ret_val\r\n\r\n def __rmul__(self, other):\r\n ret_val = None\r\n if isinstance(other, State):\r\n ret_val = other.level * transpose(self.level)\r\n else:\r\n print('Multiply must be between to states')\r\n return ret_val\r\n\r\n\r\na1 = State(2,0,1,0,0,0,True)\r\na2 = State(2,1,2,0,0,0,True)\r\n"
},
{
"alpha_fraction": 0.5310676693916321,
"alphanum_fraction": 0.5412017703056335,
"avg_line_length": 33.394927978515625,
"blob_id": "575028c66e30f56272873f69733dc6006c0361f4",
"content_id": "c7afb8114ea2346d06414adf0663f045d8ec1d92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9769,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 276,
"path": "/Main/Quantum_states_and_operators/Linblad_master_equation_solver.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\n\r\nfrom numpy import zeros, transpose, kron, sqrt, dot, array, linspace\r\nfrom numpy.linalg import solve, lstsq, pinv\r\nfrom pylab import eig,mat,inv,exp,diag\r\nfrom scipy.integrate import ode, simps\r\n\r\nimport concurrent.futures\r\nimport functools\r\n\r\nfrom Main.Constants.Velocities_distribution import *\r\n\r\nfrom Main.Unit_converters.Rb_unit_converter import *\r\nfrom Main.Unit_converters.Global_unit_converter import *\r\nfrom tqdm import tqdm\r\n\r\n\r\nclass Ode_time_dependent_solver(object):\r\n\r\n def timeDependentSolver(self,matrix_val,y0,time_val,keys):\r\n\r\n eval, evec = eig(matrix_val)\r\n solT = evec * mat(diag(exp(eval * time_val))) * inv(evec) * y0\r\n ret_val = {}\r\n for key in keys:\r\n ret_val[key] = solT[key].item()\r\n\r\n return ret_val\r\n\r\n def solveSteadyState(self, matrix, N, keys):\r\n vec = zeros((N * N,))\r\n for i in range(N):\r\n psi = zeros((N,))\r\n psi[i] = 1.0\r\n vec += transpose(kron(psi, psi))\r\n\r\n matrix[- 1, :] = vec\r\n inverse_matrix = pinv(matrix)\r\n equality = zeros((N * N, ))\r\n equality[-1] = 1.0\r\n solT = dot(inverse_matrix, equality)\r\n\r\n retval = {}\r\n for key in keys:\r\n retval[key] = solT[key]\r\n\r\n return retval\r\n\r\n def timeDependentSolverWithParam(self,jac, userSupply, param):\r\n # initate state\r\n t0 = 0\r\n points = param[0]\r\n t_scan = param[1]\r\n y0 = param[2]\r\n\r\n H = t_scan / points\r\n r = ode(userSupply, jac).set_integrator('zvode', method='bdf', with_jacobian=True, rtol=1e-6, order=5)\r\n tm = param\r\n r.set_initial_value(y0, t0).set_f_params(tm).set_jac_params(tm)\r\n x = []\r\n y = []\r\n\r\n loc = 0\r\n while r.successful() and r.t < t_scan:\r\n if (t_scan - r.t) < H:\r\n H = t_scan - r.t\r\n r.integrate(r.t + H)\r\n x.append(r.t)\r\n a = (r.y).reshape(1, len(r.y))\r\n y.append(a[0])\r\n loc += 1\r\n\r\n return x, y\r\n\r\n def odeSolver(self,matrix,y0,time_val,keys):\r\n\r\n '''\r\n Parameters\r\n ----------\r\n y0 : y0 = zeros((N,1)) ; y0[1] = 1\r\n time_val: runing integration parameters (e.g. time parameter)\r\n keys : all the return values\r\n\r\n Returns\r\n -------\r\n returnDic\r\n '''\r\n eval, evec = eig(matrix)\r\n solT = evec * mat(diag(exp(eval * time_val))) * inv(evec) * y0\r\n retval = {}\r\n for key in keys:\r\n retval[key]= solT[key].item()\r\n\r\n return retval\r\n\r\n @staticmethod\r\n def print_info():\r\n print('This class is used in order to solve differential equations.')\r\n\r\n def __str__(self):\r\n N = len(self.matrix)\r\n return 'The number of levels : {} \\nThe '.format(int(sqrt(N)))\r\n\r\nclass Linblad_master_equation_solver(Ode_time_dependent_solver):\r\n\r\n def __init__(self, enable_multiprocessing):\r\n self.is_multi_processing_enabled = enable_multiprocessing\r\n\r\n '''def test_solve(self,callback, delta_array,v_array, y0):\r\n time_val = 3\r\n k_wave = 1\r\n rho22 = zeros((4 ,1))\r\n rho22[3] = 1\r\n rho22_del = []\r\n\r\n for idx, delt in enumerate(delta_array):\r\n returnDic = {3: []}\r\n rho22_vel = []\r\n for v in v_array:\r\n delta = delt - k_wave * v\r\n matrix = callback(delta)\r\n #eval, evec = eig(matrix)\r\n #solT = evec * mat(diag(exp(eval * time_val))) * inv(evec) * y0\r\n #sol_with_doppler = ((transpose(rho22) * solT)).item()\r\n #rho22_vel.append(sol_with_doppler)\r\n sol_with_doppler = self.odeSolver(matrix,y0,time_val,returnDic)\r\n\r\n velocity_dist = [maxwell(param, 300) for param in v_array]\r\n #product = [a * b for a, b in zip(rho22_vel, velocity_dist)]\r\n product1 = [a * b for a, b in zip(returnDic[3], velocity_dist)]\r\n\r\n #rho22_del.append(simps(product,v_array))\r\n rho22_del.append(simps(product1,v_array))\r\n return rho22_del'''\r\n def solve_master_equation_without_Doppler_effect(self, callback, detuning_param, y0, time_val, keys):\r\n '''\r\n :param callback:\r\n :param detuning_param:\r\n :param y0: initial vector y0 = zeros((N,)) ; y0[1] = 1\r\n :param returnDic:\r\n :return:\r\n '''\r\n\r\n ret_val = {}\r\n for key in keys:\r\n ret_val[key] = []\r\n\r\n mat_solver = [callback((param, 0)) for param in detuning_param]\r\n\r\n if self.is_multi_processing_enabled == True:\r\n with concurrent.futures.ProcessPoolExecutor() as executor:\r\n results = executor.map(functools.partial(self.odeSolver, y0 = y0, time_val = time_val, keys = keys), mat_solver)\r\n temp_list = list(results)\r\n else:\r\n results = map(functools.partial(self.odeSolver, y0=y0, time_val = time_val, keys = keys), mat_solver)\r\n temp_list = list(results)\r\n\r\n for key in keys:\r\n ret_val[key] = [item[key] for item in temp_list]\r\n\r\n return ret_val\r\n\r\n def solve_master_equation_with_Doppler_effect(self, callback, detuning_param, velocity_param, y0, time_val, Tc, keys):\r\n ret_val = {}\r\n for key in keys:\r\n ret_val[key] = []\r\n\r\n velocity_dist = [maxwell(param, temp2velocity(celsius2kelvin(Tc))) for param in velocity_param]\r\n\r\n for del_val in tqdm(detuning_param):\r\n #mat_solver = [callback(param) for param in (del_val-k_wave * velocity_param)]\r\n mat_solver = [callback((del_val, velocity)) for velocity in velocity_param]\r\n if self.is_multi_processing_enabled == True:\r\n with concurrent.futures.ProcessPoolExecutor() as executor:\r\n results = executor.map(functools.partial(self.odeSolver, y0=y0, time_val=time_val, keys=keys),\r\n mat_solver)\r\n temp_list = list(results)\r\n else:\r\n results = map(functools.partial(self.odeSolver, y0=y0, time_val=time_val, keys = keys), mat_solver)\r\n temp_list = list(results)\r\n\r\n vell = {}\r\n for key in keys:\r\n rho = [item[key] for item in temp_list]\r\n vell[key] = [a * b for a, b in zip(rho, velocity_dist)]\r\n\r\n for key in keys:\r\n ret_val[key].append(simps(vell[key],velocity_param))\r\n\r\n return ret_val\r\n\r\n def solve_master_equation_steady_state_without_Doppler_effect(self, callback, detuning_param, N, keys):\r\n ret_val = {}\r\n for key in keys:\r\n ret_val[key] = []\r\n\r\n mat_solver = [callback((param, 0)) for param in detuning_param]\r\n\r\n if self.is_multi_processing_enabled == True:\r\n with concurrent.futures.ProcessPoolExecutor() as executor:\r\n results = executor.map(functools.partial(self.solveSteadyState, N = N, keys = keys), mat_solver)\r\n temp_list = list(results)\r\n else:\r\n results = map(functools.partial(self.solveSteadyState, N = N, keys = keys), mat_solver)\r\n temp_list = list(results)\r\n\r\n for key in keys:\r\n ret_val[key] = [item[key] for item in temp_list]\r\n\r\n return ret_val\r\n\r\n def solve_master_equation_steady_state_with_Doppler_effect(self, callback, detuning_param, velocity_param, N, Tc, keys):\r\n ret_val = {}\r\n for key in keys:\r\n ret_val[key] = []\r\n\r\n velocity_dist = [maxwell(param, temp2velocity(celsius2kelvin(Tc))) for param in velocity_param]\r\n\r\n for del_val in tqdm(detuning_param):\r\n #mat_solver = [callback(param) for param in (del_val-k_wave * velocity_param)]\r\n mat_solver = [callback((del_val, velocity)) for velocity in velocity_param]\r\n if self.is_multi_processing_enabled == True:\r\n with concurrent.futures.ProcessPoolExecutor() as executor:\r\n results = executor.map(functools.partial(self.solveSteadyState, N = N, keys = keys), mat_solver)\r\n temp_list = list(results)\r\n else:\r\n\r\n results = map(functools.partial(self.solveSteadyState, N = N, keys = keys), mat_solver)\r\n temp_list = list(results)\r\n\r\n vell = {}\r\n for key in keys:\r\n rho = [item[key] for item in temp_list]\r\n vell[key] = [a * b for a, b in zip(rho, velocity_dist)]\r\n\r\n for key in keys:\r\n ret_val[key].append(simps(vell[key],velocity_param))\r\n\r\n return ret_val\r\n\r\n def solve_density_matrix_evolution(self, matrix_val, y0, time_arr, keys):\r\n '''\r\n :param callback:\r\n :param detuning_param:\r\n :param y0: initial vector y0 = zeros((N,)) ; y0[1] = 1\r\n :param returnDic:\r\n :return:\r\n '''\r\n ret_val = {}\r\n for key in keys:\r\n ret_val[key] = []\r\n\r\n for time_val in time_arr:\r\n result = self.timeDependentSolver(matrix_val,y0,time_val,keys)\r\n for key in keys:\r\n ret_val[key].append(result[key])\r\n return ret_val\r\n'''\r\ndef jac(t,y,param):\r\n delta = param[0] * t\r\n retVal=buildRhoMatrix(delta)\r\n return retVal\r\n\r\n\r\ndef userSupply(t,y,param):\r\n delta = param[0] * t\r\n rhoDot = buildRhoMatrix(delta)\r\n N = len(rhoDot[0])\r\n retVal=zeros((N,), dtype=complex)\r\n for i in range(N):\r\n sumVal=0\r\n for j in range(N):\r\n sumVal+=rhoDot[i][j]*y[j]\r\n retVal[i]=sumVal\r\n return retVal\r\n'''\r\n"
},
{
"alpha_fraction": 0.4989067018032074,
"alphanum_fraction": 0.5801749229431152,
"avg_line_length": 30.081871032714844,
"blob_id": "cc56beaf2fb9221a1503c61e600860970277aaef",
"content_id": "37b001fdb5bc2c72b43f7e24dd7bd31de22eb9de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5488,
"license_type": "no_license",
"max_line_length": 157,
"num_lines": 171,
"path": "/Main/Examples/D2_line.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom __future__ import division, print_function\r\nfrom Main.Quantum_states_and_operators import q_state, qunatum_states_dictionary\r\nfrom Main.Quantum_states_and_operators.build_bloch_equation_matrix import *\r\nfrom Main.Quantum_states_and_operators.frequency_strength_calc import *\r\nfrom Main.Quantum_states_and_operators.Linblad_master_equation_solver import *\r\nfrom Main.Constants.Rb_constants import *\r\nimport pylab as plt\r\n\r\n#Constants\r\nDELTA_1 = -2 * pi * 1.770e9\r\nDELTA_2 = 2 * pi * 1.264e9\r\nDELTA_3 = -2 * pi * 113.208e6\r\nDELTA_4 = -2 * pi * 83.835e6\r\nDELTA_5 = -2 * pi * 20.435e6\r\nDELTA_6 = 2 * pi * 100.205e6\r\n\r\n\r\n\r\nstates = None\r\nN = 6\r\n\r\ndef init_states():\r\n state1 = q_state.State(N,0,2, is_Ground = True)\r\n state1.set_S(0.5)\r\n state2 = q_state.State(N,1,3, is_Ground = True)\r\n state2.set_S(0.5)\r\n state3 = q_state.State(N,2,1)\r\n state3.set_L(1)\r\n state3.set_S(0.5)\r\n state4 = q_state.State(N,3,2)\r\n state4.set_L(1)\r\n state4.set_S(0.5)\r\n state5 = q_state.State(N,4,3)\r\n state5.set_L(1)\r\n state5.set_S(0.5)\r\n state6 = q_state.State(N,5,4)\r\n state6.set_L(1)\r\n state6.set_S(0.5)\r\n return state1, state2, state3, state4, state5, state6\r\n\r\ndef init():\r\n global states\r\n states = init_states()\r\n return True\r\n\r\n#--------------------------------------------------------------------------------------------------------#\r\n\r\ndef H(delta_pr, omega_pr):\r\n global states\r\n a1, a2, a3, a4, a5, a6 = states\r\n\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n rho55 = a5 * a5\r\n rho66 = a6 * a6\r\n\r\n rho13 = a1 * a3\r\n rho14 = a1 * a4\r\n rho15 = a1 * a5\r\n\r\n rho24 = a2 * a4\r\n rho25 = a2 * a5\r\n rho26 = a2 * a6\r\n\r\n H0 = (DELTA_1) * rho11 + (DELTA_2) * rho22 + (delta_pr + DELTA_3) * rho33 + (delta_pr + DELTA_4) * rho44\\\r\n + (delta_pr + DELTA_5) * rho55 + (delta_pr + DELTA_5) * rho66\r\n\r\n omega_pr_13 = transition_strength(a1,a3) * omega_pr\r\n omega_pr_14 = transition_strength(a1,a4) * omega_pr\r\n omega_pr_15 = transition_strength(a1,a5) * omega_pr\r\n\r\n omega_pr_24 = transition_strength(a2, a4) * omega_pr\r\n omega_pr_25 = transition_strength(a2, a5) * omega_pr\r\n omega_pr_26 = transition_strength(a2, a6) * omega_pr\r\n\r\n V = (omega_pr_13) * rho13 + (omega_pr_14) * rho14 + (omega_pr_15) * rho15 + (omega_pr_24) * rho24 + (omega_pr_25) * rho25 \\\r\n + (omega_pr_26) * rho26\r\n V += transpose(V)\r\n return H0 + V\r\n\r\ndef decay_martrix(gamma_val):\r\n\r\n a1, a2, a3, a4, a5, a6 = states\r\n\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n rho55 = a5 * a5\r\n rho66 = a6 * a6\r\n\r\n L = gamma_val * (rho33 + rho44 + rho55 + rho66)\r\n\r\n return L\r\n\r\ndef repopulation_decay_matrix_vee(gamma_val):\r\n a1, a2, a3, a4, a5, a6 = states\r\n\r\n rho11 = a1 * a1\r\n rho22 = a2 * a2\r\n rho33 = a3 * a3\r\n rho44 = a4 * a4\r\n rho55 = a5 * a5\r\n rho66 = a6 * a6\r\n\r\n gamma_val_13 = transition_strength(a1,a3) * gamma_val\r\n gamma_val_14 = transition_strength(a1,a4) * gamma_val\r\n gamma_val_15 = transition_strength(a1,a5) * gamma_val\r\n gamma_val_24 = transition_strength(a2, a4) *gamma_val\r\n gamma_val_25 = transition_strength(a2, a5) *gamma_val\r\n gamma_val_26 = transition_strength(a2, a6) *gamma_val\r\n\r\n ret_val = gamma_val_13 * outer(rho11, rho33) + gamma_val_14 * outer(rho11, rho44) + gamma_val_15 * outer(rho11, rho55) + \\\r\n gamma_val_24 * outer(rho22, rho44) + gamma_val_25 * outer(rho22, rho55) + gamma_val_26 * outer(rho22,rho66)\r\n\r\n return ret_val\r\n#--------------------------------------------------------------------------------------------------------#\r\n\r\n\r\ndef callback(param):\r\n k_probe = 2 * pi /(780e-9)\r\n (del_val, velocity) = param\r\n omega_pr = 2 * pi * 0.5e5\r\n gamma_val = 2 * pi * 6.06e6\r\n delta_pr = del_val\r\n ret_val = buildRhoMatrix(H(delta_pr - k_probe * velocity, omega_pr),N) + buildGammaMatrix(decay_martrix(gamma_val), N)\r\n ret_val += repopulation_decay_matrix_vee(gamma_val)\r\n\r\n return ret_val\r\n\r\nif __name__ == \"__main__\":\r\n # init all states\r\n init()\r\n\r\n states_name = qunatum_states_dictionary.rhoMatrixNames(N)\r\n\r\n rho11 = states_name.getLocationByName('rho11')\r\n rho22 = states_name.getLocationByName('rho22')\r\n\r\n rho13 = states_name.getLocationByName('rho13')\r\n rho14 = states_name.getLocationByName('rho14')\r\n rho15 = states_name.getLocationByName('rho15')\r\n\r\n rho24 = states_name.getLocationByName('rho24')\r\n rho25 = states_name.getLocationByName('rho25')\r\n rho26 = states_name.getLocationByName('rho26')\r\n\r\n y0 = zeros((N * N, 1))\r\n y0[rho11] = 0.5\r\n y0[rho22] = 0.5\r\n\r\n lmes = Linblad_master_equation_solver(False)\r\n\r\n returnDic = [rho13, rho14, rho15, rho24, rho25, rho26]\r\n\r\n running_param = linspace(-2 * pi * 4e9, 2 * pi * 4e9, 500) # (frequency scaning) detuning array\r\n v_param = linspace(-600, 600, 200) # atomic velocities array\r\n time_val = 1\r\n Tc = 25\r\n results = lmes.solve_master_equation_with_Doppler_effect(callback, running_param,v_param, y0, time_val, Tc, returnDic)\r\n\r\n\r\n absor = []\r\n\r\n for idx, _ in enumerate(running_param):\r\n absor.append(results[rho13][idx].imag + results[rho14][idx].imag + results[rho15][idx].imag + results[rho24][idx].imag + results[rho25][idx].imag + \\\r\n results[rho26][idx].imag)\r\n\r\n plt.plot(running_param / (2 * pi), absor)\r\n plt.show()\r\n\r\n"
},
{
"alpha_fraction": 0.7368420958518982,
"alphanum_fraction": 0.7631579041481018,
"avg_line_length": 40.900001525878906,
"blob_id": "839f0307ab513264eeb1bbfecf0df9e6c921f0c2",
"content_id": "dab195bca43572036319ff1357a86c3d348e5f76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 10,
"path": "/Main/Breit Rabi Diagram/FundamentalConstants.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from numpy import pi, sqrt\nfrom scipy.constants import physical_constants, epsilon_0, hbar, c, e, h\n\nS=0.5 #Electron spin\ngs = -physical_constants['electron g factor'][0]\nmuB=physical_constants['Bohr magneton'][0]\nkB=physical_constants['Boltzmann constant'][0]\namu=physical_constants['atomic mass constant'][0] #An atomic mass unit in kg\ne0=epsilon_0 #Permittivity of free space\na0=physical_constants['Bohr radius'][0]"
},
{
"alpha_fraction": 0.4075867533683777,
"alphanum_fraction": 0.4196932911872864,
"avg_line_length": 24.89130401611328,
"blob_id": "1db86d7177a5bf82e8e9769668e4570d9a65545f",
"content_id": "b4ea76c63e724688e71bf9a6cd19ad34e9b43251",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1239,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 46,
"path": "/Main/Quantum_states_and_operators/qunatum_states_dictionary.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "\"Bulid all the density matrix states\"\r\n\r\nclass rhoMatrixNames:\r\n\r\n def __init__(self,N):\r\n self.N = N\r\n self.rho = {}\r\n counter = 0\r\n for i in range(N):\r\n for j in range(N):\r\n state = 'rho' + str(i + 1) + str(j + 1)\r\n self.rho.update({state: counter})\r\n counter += 1\r\n\r\n def getLocationByName(self,rho_name):\r\n return self.rho[rho_name]\r\n\r\n @staticmethod\r\n def getStatesNames(N):\r\n rho={}\r\n counter=0\r\n for i in range(N):\r\n for j in range(N):\r\n state='rho'+str(i+1)+str(j+1)\r\n rho.update({state:counter})\r\n counter+=1\r\n return rho\r\n\r\n @staticmethod\r\n def buildRhoName(row,col):\r\n ret_val = 'rho'+str(row)+str(col)\r\n return ret_val\r\n\r\n\r\n def __str__(self):\r\n txt = 'rho = \\n'\r\n for i in range(self.N):\r\n txt += '\\t'\r\n for idx, j in enumerate(range(self.N-1)):\r\n txt +='rho'+str(i+1)+str(j+1)+'| '\r\n txt += 'rho' + str(i + 1) + str(j + 2)\r\n txt += '\\n\\t'\r\n txt += 20 * '-'\r\n txt += '\\t'\r\n txt += '\\n' \r\n return txt\r\n\r\n"
},
{
"alpha_fraction": 0.6118143200874329,
"alphanum_fraction": 0.7436708807945251,
"avg_line_length": 36.959999084472656,
"blob_id": "a702061382be7a0d7347d870eb062a2540df4849",
"content_id": "9a1168df466d372115c807f59cf04824220a26a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 948,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 25,
"path": "/Main/Breit Rabi Diagram/AtomicConstants.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\nfrom numpy import pi, sqrt\nfrom FundamentalConstants import *\n\n'''\n\"\"\"Constants relating to the rubidium-85 atom\"\"\"\nI = 2.5 #Nuclear spin\nAs = 1011.910813 #Ground state hyperfine constant in units of MHz\ngI = -0.00029364 #nuclear spin g-factor\nmass = 84.911789732*amu\n'''\n\n\"\"\"Constants relating to the rubidium-87 atom\"\"\"\nI = 3/2 #Nuclear spin\nAs = 3417.341305452145 #Ground state hyperfine constant in units of MHz\ngI = -0.0009951414 #nuclear spin g-factor\nmass = 86.909180520*amu\n\n\n\"\"\"Constants relating to the rubidium D1 transition\"\"\"\nwavelength=794.978969380e-9 #The weighted linecentre of the rubidium D1 line in m\nwavevectorMagnitude=2.0*pi/wavelength #Magnitude of the wavevector\nNatGamma=5.746 #Rubidium D1 natural linewidth in MHz\ndipoleStrength=3.0*sqrt(e0*hbar*(2.0*NatGamma*(10.0**6))*(wavelength**3)/(8.0*pi))\nv0=377107407.299e6 #The weighted linecentre of the rubidium D1 line in Hz"
},
{
"alpha_fraction": 0.654411792755127,
"alphanum_fraction": 0.6642156839370728,
"avg_line_length": 35.272727966308594,
"blob_id": "5e4e07e122258ed8d45963a0fec7c85289d390f5",
"content_id": "6728519443a75f9942a1fd99ff09e73812f73cf2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 11,
"path": "/Main/Constants/Velocities_distribution.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\nfrom numpy import sqrt, exp, pi\r\n\r\ndef maxwell(v,vp):\r\n '''\r\n Maxwell-Boltzmann Velocity Distribution\r\n :param v: velocity [m/s]\r\n :param vp: most probable velocity [m/s] (you can use the temp2velocity() function to calculate the most probable velocity)\r\n :return: velocity distribution\r\n '''\r\n return (1/(sqrt(pi)*vp))*exp(-v**2 / vp**2)"
},
{
"alpha_fraction": 0.40506330132484436,
"alphanum_fraction": 0.554430365562439,
"avg_line_length": 37.099998474121094,
"blob_id": "88dd1c44a4fc52e7b5b5251d1f3621a0969add82",
"content_id": "fbc5d0efd2ea19d0df491a838e8799c3a7441f17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 10,
"path": "/Main/Breit Rabi Diagram/I_matrix.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division\r\nfrom scipy.constants import hbar\r\nfrom numpy import *\r\n\r\n\r\nIx=(0.5*hbar)*array([[0,sqrt(3),0,0],[sqrt(3),0,2,0],[0,2,0,sqrt(3)],[0,0,sqrt(3),0]])\r\nIy=(0.5*hbar)*array([[0,-sqrt(3)*1j,0,0],[sqrt(3)*1j,0,-2j,0],[0,2j,0,-sqrt(3)*1j],[0,0,sqrt(3)*1j,0]])\r\nIz=(0.5*hbar)*array([[3,0,0,0],[0,1,0,0],[0,0,-1,0],[0,0,0,-3]])\r\n\r\nI_2=Ix.dot(Ix)+Iy.dot(Iy)+Iz.dot(Iz)\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6072874665260315,
"alphanum_fraction": 0.6315789222717285,
"avg_line_length": 22.899999618530273,
"blob_id": "834d1d9374d9c4c0f8591d591b60077dced34ac8",
"content_id": "87f63549aedf7479e56642dfd3c74976a1815f96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 10,
"path": "/Main/Unit_converters/Global_unit_converter.py",
"repo_name": "eliranta02/RubidiumProfile",
"src_encoding": "UTF-8",
"text": "from __future__ import division, print_function\r\n\r\ndef celsius2kelvin(T):\r\n '''\r\n convert from celsius to kelvin\r\n :param T: temperature in celsius\r\n :return: temperature in kelvin\r\n '''\r\n ret_val = T + 273.15\r\n return ret_val"
}
] | 36 |
Enderych/places365 | https://github.com/Enderych/places365 | aa766702151dfc5a972c6eae0a898eab125f1d61 | 701361813dd9e6115e9723b95d650f293f8e28f9 | 879c0030556d2ff84482b6bcf7f68cdb30a7671d | refs/heads/master | 2020-04-26T04:51:36.495488 | 2019-03-07T09:40:44 | 2019-03-07T09:40:44 | 173,315,985 | 0 | 0 | MIT | 2019-03-01T14:31:04 | 2019-03-01T14:30:59 | 2018-05-22T22:23:30 | null | [
{
"alpha_fraction": 0.4402795433998108,
"alphanum_fraction": 0.46696314215660095,
"avg_line_length": 38.375,
"blob_id": "a1a7e4f5a5ebe7a3a9788c28f2ee92ffc7c5738a",
"content_id": "55c8684939e933f9dfea71e2e52fcb4aa7c01256",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1574,
"license_type": "permissive",
"max_line_length": 130,
"num_lines": 40,
"path": "/cvusa_py/filter_top1.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Mar 1 20:00:06 2019\n\n@author: yang\n\"\"\"\n\n\n\nwith open('air_semantic_raw.txt', 'r') as fa:\n with open('ground_semantic.txt', 'r') as fb:\n with open('result_top1.txt', 'w') as fc:\n top1count = 0\n indoor_count_air = 0\n indoor_count_ground = 0\n for line in fa:\n lineA = line.strip().split(',')\n lineB = fb.readline().strip().split(',')\n img_name = lineA[0]\n classA = lineA[1]\n classB = lineB[1]\n topA1 = lineA[2]\n topA1 = topA1[:-7]\n fc.write(img_name[-11:] + ',' + classA + ',' + classB + ',' + topA1 + ',')\n topB1 = lineB[2]\n topB1 = topB1[:-7]\n fc.write(topB1 +'\\n')\n if (topA1 == topB1):\n# print(img_name)\n top1count += 1\n if (classA == ' indoor'):\n indoor_count_air += 1\n if (classB == ' indoor'):\n indoor_count_ground += 1\n# c = str(count)\n# t = str(len(fb.readline())\n length = len(open('air_semantic_raw.txt').readlines())\n print('The number of same top1 label for air and ground without training is ' + str(top1count) + ' in ' + str(length))\n print('Number of air image was wrong classified to indoor: ' + str(indoor_count_air))\n print('Number of ground image was wrong classified to indoor: ' + str(indoor_count_ground))"
},
{
"alpha_fraction": 0.5463297367095947,
"alphanum_fraction": 0.5812274217605591,
"avg_line_length": 22.514286041259766,
"blob_id": "39d4ae8a8dc66efee0acb08d6145ae4fb48623ea",
"content_id": "2271154c153d664927ebbcb2d2eb59330c730c7b",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 851,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 35,
"path": "/cvusa_py/split_val.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Mar 1 12:44:07 2019\n\n@author: yang\n\"\"\"\n\nimport cv2\nimport csv\n\n\n'''\npath = ('/home/yang/cross_view/Data/CVUSA/cvusa_places/air_val' + '/') \n\nfilename = '/home/yang/cross_view/Data/CVUSA/splits/val-19zl.csv'\nwith open(filename) as f:\n reader = csv.reader(f)\n for row in reader:\n # 行号从1开始\n img_name = (row[0])\n img = cv2.imread(img_name)\n cv2.imwrite(path + img_name[-11:], img)\n''' \n \npath = ('/home/yang/cross_view/Data/CVUSA/cvusa_places/ground_val' + '/') \n\n\nfilename = '/home/yang/cross_view/Data/CVUSA/splits/val-19zl.csv'\nwith open(filename) as f:\n reader = csv.reader(f)\n for row in reader:\n # 行号从1开始\n img_name = (row[1])\n img = cv2.imread(img_name)\n cv2.imwrite(path + img_name[-11:], img)\n "
},
{
"alpha_fraction": 0.38610827922821045,
"alphanum_fraction": 0.409601628780365,
"avg_line_length": 30.53333282470703,
"blob_id": "4bf1ae6645883e78f5de214e1c95a2162cf3d078",
"content_id": "0cb0b962fa4196f0aa65557a18b0b16b37fff8c5",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 979,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 30,
"path": "/cvusa_py/3val_extract.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Mar 2 23:04:24 2019\n\n@author: yang\n\"\"\"\n\nimport os\nimport cv2\n\n\npath = ('/home/yang/cross_view/Data/CVUSA' + '/')\nwith open('class_sorted.txt', 'r') as fa:\n with open('train.txt', 'w') as fb:\n with open('val.txt', 'w') as fc:\n count = 0\n \n for (num, line) in enumerate(fa):\n if (num%5 == 0):\n line=line.strip('\\n')\n img = cv2.imread(path + line)\n class_name = line[6:-12]\n img_name = line[-11:]\n if not os.path.exists('val/' + class_name):\n os.mkdir('val/' + class_name)\n cv2.imwrite(path + 'val/' + class_name + '/' + img_name, img)\n fc.write('val/' + class_name + '/' + img_name + '\\n')\n os.remove(path + line)\n else:\n fb.write(line)\n \n "
},
{
"alpha_fraction": 0.49754902720451355,
"alphanum_fraction": 0.5269607901573181,
"avg_line_length": 20.526315689086914,
"blob_id": "d3fcce6d90f6ba666fbe19f9b915930750aa72a3",
"content_id": "1871bda696557ca2d08f5889f40989edc91bcdc9",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 19,
"path": "/cvusa_py/2sort.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Mar 2 23:13:16 2019\n\n@author: yang\n\"\"\"\n\nwith open('class.txt', 'r') as fa:\n with open('class_sorted.txt', 'w') as fb:\n\n#with open('val_unsorted.txt', 'r') as fa:\n# with open('val.txt', 'w') as fb:\n result = []\n for line in fa:\n result.append(line)\n fa.close\n result.sort()\n fb.writelines(result)\n fb.close"
},
{
"alpha_fraction": 0.49845677614212036,
"alphanum_fraction": 0.529321014881134,
"avg_line_length": 23.961538314819336,
"blob_id": "2f0b816693a8837663516c4d0bc95a16ec2727a7",
"content_id": "4a3fd45fae72cc82ac74e8eb4cf93f2ff22a50c0",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 648,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 26,
"path": "/cvusa_py/compare_top1.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Mar 1 22:00:59 2019\n\n@author: yang\n\"\"\"\n\n\n\n\nwith open('result_top1.txt', 'r') as f:\n top1count = 0\n \n for line in f:\n lineA = line.strip().split(',')\n img_name = lineA[0]\n classA = lineA[1]\n classA = str(classA)\n indoor = 'indoor'\n if (classA == indoor):\n print(img_name)\n top1count += 1\n# c = str(count)\n# t = str(len(fb.readline())\n length = len(open('air_semantic_raw.txt').readlines())\n print('The number of same label for air and ground without training is ' + str(top1count) + ' in ' + str(length))"
},
{
"alpha_fraction": 0.4006352126598358,
"alphanum_fraction": 0.43738657236099243,
"avg_line_length": 41.403846740722656,
"blob_id": "97d241460a8a253553a5350c363880451ae1a130",
"content_id": "035aff8489e70545cbcabf6d114c563bd0274e85",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2204,
"license_type": "permissive",
"max_line_length": 146,
"num_lines": 52,
"path": "/cvusa_py/filter_top5.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Mar 1 22:36:59 2019\n\n@author: yang\n\"\"\"\n\n\n\n\nwith open('air_semantic_raw.txt', 'r') as fa:\n with open('ground_semantic.txt', 'r') as fb:\n with open('result_top5.txt', 'w') as fc:\n top1count = 0\n indoor_count_air = 0\n indoor_count_ground = 0\n for line in fa:\n lineA = line.strip().split(',')\n lineB = fb.readline().strip().split(',')\n img_name = lineA[0]\n classA = lineA[1]\n classB = lineB[1]\n topA1 = lineA[2][:-7]\n topA2 = lineA[3][:-7]\n topA3 = lineA[4][:-7]\n topA4 = lineA[5][:-7]\n topA5 = lineA[6][:-7]\n list_a = [topA1, topA2, topA3, topA4, topA5]\n fc.write(img_name[-11:] + ',' + classA + ',' + classB + ',' + topA1 + ',' + topA2 + ',' + topA3 + ',' + topA4 + ',' + topA5 + ',')\n topB1 = lineB[2][:-7]\n topB2 = lineB[3][:-7]\n topB3 = lineB[4][:-7]\n topB4 = lineB[5][:-7]\n topB5 = lineB[6][:-7]\n list_b = [topB1, topB2, topB3, topB4, topB5]\n set_c = set(list_a) & set(list_b)\n list_c = list(set_c)\n fc.write(topB1 + ',' + topB2 + ',' + topB3 + ',' + topB4 + ',' + topB5 + '\\n')\n if (list_c):\n# print(img_name)\n top1count += 1\n if (classA == ' indoor'):\n indoor_count_air += 1\n if (classB == ' indoor'):\n print(img_name[-11:] + ',' + classB + ',' + topB1)\n indoor_count_ground += 1\n# c = str(count)\n# t = str(len(fb.readline())\n length = len(open('air_semantic_raw.txt').readlines())\n print('The number of same top5 label for air and ground without training is ' + str(top1count) + ' in ' + str(length))\n print('Number of air image was wrong classified to indoor: ' + str(indoor_count_air))\n print('Number of ground image was wrong classified to indoor: ' + str(indoor_count_ground))"
},
{
"alpha_fraction": 0.6527777910232544,
"alphanum_fraction": 0.6972222328186035,
"avg_line_length": 19.05555534362793,
"blob_id": "93e30a100936368648b67bb53e7ca6dd48eea31b",
"content_id": "af46361e3c5f6f750ce833a0ff998129ef24a388",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 360,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 18,
"path": "/cvusa_py/txt2csv.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Mar 1 20:35:49 2019\n\n@author: yang\n\"\"\"\n\n\nimport numpy as np\nimport pandas as pd\n \ntxt = np.loadtxt('ground_semantic.txt')\ntxtDF = pd.DataFrame(txt)\ntxtDF.to_csv('ground_semantic.csv',index=False)\n\ntxt2 = np.loadtxt('air_semantic_raw.txt')\ntxtDF2 = pd.DataFrame(txt2)\ntxtDF2.to_csv('air_semantic_raw.csv',index=False)"
},
{
"alpha_fraction": 0.4022698700428009,
"alphanum_fraction": 0.43757882714271545,
"avg_line_length": 30.739999771118164,
"blob_id": "06122de75ff20ad6f7272466e62a45544f9f3dff",
"content_id": "40a2da423ec21923b8160b728aa44133fba29bf3",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1586,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 50,
"path": "/cvusa_py/1class2split.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat Mar 2 22:48:37 2019\n\n@author: yang\n\"\"\"\n\nimport os\nimport cv2\n\n\npath = ('/home/yang/cross_view/Data/CVUSA/bingmap/19' + '/')\nwith open('ground_semantic.txt', 'r') as fa:\n with open('class.txt', 'w') as fb:\n \n\n#path = ('/home/yang/cross_view/Data/CVUSA/cvusa_places/air_train' + '/')\n#with open('ground_train.txt', 'r') as fa:\n# with open('train_unsorted.txt', 'w') as fb: \n \n count = 0\n for line in fa:\n lineA = line.strip().split(',')\n img_name = lineA[0][-11:]\n topA1 = lineA[2][1:-7]\n# topA2 = lineA[3][1:-7]\n# topA3 = lineA[4][1:-7]\n# topA4 = lineA[5][1:-7]\n# topA5 = lineA[6][1:-7]\n if topA1.count('/'):\n count += 1\n print (img_name + ',' + topA1)\n topA1 = topA1.replace('/','-')\n if not os.path.exists('train/' + topA1):\n os.mkdir('train/' + topA1)\n img = cv2.imread(path + img_name)\n if not(img is None):\n cv2.imwrite('train/' + topA1 + '/' + img_name, img)\n fb.write('train/' + topA1 + '/' + img_name + '\\n')\n \n \n \n \"\"\"\n if not os.path.exists('train/' + topA1):\n os.mkdir('train/' + topA1)\n img = cv2.imread(path + '/' + img_name)\n cv2.imwrite('train/' + topA1 + '/' + img_name, img)\n fb.write('train/' + topA1 + '/' + img_name + '\\n') \n \"\"\"\n print(count)"
},
{
"alpha_fraction": 0.5372093319892883,
"alphanum_fraction": 0.5709302425384521,
"avg_line_length": 22.742856979370117,
"blob_id": "f0c52222f3a32fb17e7e4e38a30e78403fef697d",
"content_id": "3b61f7885c698e3ac46375389c6b57da567d9931",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 880,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 35,
"path": "/cvusa_py/split_train.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Mar 1 10:46:02 2019\n\n@author: yang\n\"\"\"\nimport cv2\nimport csv\n\n\n\npath = ('/home/yang/cross_view/Data/CVUSA/cvusa_places/air_train' + '/') \n\nfilename = '/home/yang/cross_view/Data/CVUSA/splits/train-19zl.csv'\nwith open(filename) as f:\n reader = csv.reader(f)\n for row in reader:\n # 行号从1开始\n img_name = (row[0])\n img = cv2.imread(img_name)\n cv2.imwrite(path + img_name[-11:], img)\n''' \n \npath = ('/home/yang/cross_view/Data/CVUSA/cvusa_places/ground_train' + '/') \n\n\nfilename = '/home/yang/cross_view/Data/CVUSA/splits/train-19zl.csv'\nwith open(filename) as f:\n reader = csv.reader(f)\n for row in reader:\n # 行号从1开始\n img_name = (row[1])\n img = cv2.imread(img_name)\n cv2.imwrite(path + img_name[-11:], img)\n''' \n \n \n\n\n "
},
{
"alpha_fraction": 0.5779221057891846,
"alphanum_fraction": 0.6298701167106628,
"avg_line_length": 19.600000381469727,
"blob_id": "82d94182912ea83a003f70e692b56273f8ad3df0",
"content_id": "3b2bc577f50f0809d40df232bcdaa8514734f416",
"detected_licenses": [
"MIT",
"CC-BY-4.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 308,
"license_type": "permissive",
"max_line_length": 37,
"num_lines": 15,
"path": "/cvusa_py/process.py",
"repo_name": "Enderych/places365",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Mar 3 04:57:04 2019\n\n@author: yang\n\"\"\"\n\nimport os\nif not os.path.exists('val/'):\n os.mkdir('val/')\nif not os.path.exists('train/'):\n os.mkdir('train/')\nos.system(\"python ./1class2split.py\")\nos.system(\"python ./2sort.py\")\nos.system(\"python ./3val_extract.py\")"
}
] | 10 |
ODM-Caradryan/CS385-Course-Project-2 | https://github.com/ODM-Caradryan/CS385-Course-Project-2 | 710f2b3b98717634ae61ce3e04e203990de34685 | fa0e6c5e69022fe440cd4594a15845a5fdda8a4f | 947c6008c51c1e701d8bb1f808c735dd826f067c | refs/heads/main | 2023-06-02T04:30:47.844084 | 2021-06-23T15:22:02 | 2021-06-23T15:22:02 | 373,182,826 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.7895569801330566,
"avg_line_length": 27.727272033691406,
"blob_id": "bfd74e62124b13c062d61140d7f09ac88d9345c9",
"content_id": "4fee1c45adcb17b5cf595d93c77d9597060c720b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 632,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 22,
"path": "/README.md",
"repo_name": "ODM-Caradryan/CS385-Course-Project-2",
"src_encoding": "UTF-8",
"text": "# CS385-Course-Project-2\nChumeng Liang 518030910015\n\n## Structure\n\nResnet18 is implemented in models/resnet.py\n\nGrad-Cam is implemented in models/grad_cam.py\n\n## Schedule\n\nResnet18 for cifar10 is now being trained on 26422 in tmux 114\nResnet18 for fmnist is now being trained on 26422 in tmux 115(finished)\nVGG16 for cifar10 is now being trained on 26422 in tmux 116\nVGG16 for fmnist is now being trained on 26422 in tmux 126(finished)\nAlexNet for cifar10 is now being trained on 26422 in tmux 115\nAlexNet for fmnist is now being trained on 26422 in tmux 126\n\nvgg16_v1 fmnist 114\nvgg16_v1 cifar 116\nvgg16_v2 cifar 123\nvgg16_v2 fmnist 128\n"
},
{
"alpha_fraction": 0.5922039151191711,
"alphanum_fraction": 0.6112996339797974,
"avg_line_length": 36.164222717285156,
"blob_id": "30a4edbdeb26c338b6b9961ff2e25395fe1b523d",
"content_id": "b10fc7a36c0d2cfd9160dd313687ecf604525885",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12673,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 341,
"path": "/sample.py",
"repo_name": "ODM-Caradryan/CS385-Course-Project-2",
"src_encoding": "UTF-8",
"text": "import torch\nimport argparse\nimport cv2\nimport numpy as np\nimport torch\nfrom torch.autograd import Function\nfrom torchvision import models\nimport os\nimport sys\nfrom mpl_toolkits.mplot3d import Axes3D \nsys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\nsys.path.insert( 0, '/slstore/liangchumeng/DPR/')\nfrom models.imagenet.resnet import ResNetDCT_Upscaled_Static\nimport datasets.cvtransforms as transforms\nimport torchvision.transforms as nntransforms\nfrom datasets import train_y_mean, train_y_std, train_cb_mean, train_cb_std, \\\n train_cr_mean, train_cr_std\nfrom datasets import train_y_mean_upscaled, train_y_std_upscaled, train_cb_mean_upscaled, train_cb_std_upscaled, \\\n train_cr_mean_upscaled, train_cr_std_upscaled\nfrom datasets import train_dct_subset_mean, train_dct_subset_std\nfrom datasets import train_upscaled_static_mean, train_upscaled_static_std\nfrom datasets import train_upscaled_static_dct_direct_mean, train_upscaled_static_dct_direct_std\nfrom datasets import train_upscaled_static_dct_direct_mean_interp, train_upscaled_static_dct_direct_std_interp\nclass FeatureExtractor():\n \"\"\" Class for extracting activations and\n registering gradients from targetted intermediate layers \"\"\"\n\n def __init__(self, model, target_layers):\n self.model = model\n self.target_layers = target_layers\n self.gradients = []\n\n def save_gradient(self, grad):\n self.gradients.append(grad)\n\n def __call__(self, x):\n outputs = []\n self.gradients = []\n # for each layer, fetch the gradient\n for name, module in self.model._modules.items():\n x = module(x)\n if name in self.target_layers:\n x.register_hook(self.save_gradient)\n # x has been replaced by grad_x\n outputs += [x]\n return outputs, x\n\nclass ModelOutputs():\n \"\"\" Class for making a forward pass, and getting:\n 1. The network output.\n 2. Activations from intermeddiate targetted layers.\n 3. Gradients from intermeddiate targetted layers. \"\"\"\n\n def __init__(self, model, feature_module, target_layers):\n self.model = model\n self.feature_module = feature_module\n self.feature_extractor = FeatureExtractor(self.feature_module, target_layers)\n\n def get_gradients(self):\n return self.feature_extractor.gradients\n\n def __call__(self, x):\n target_activations = []\n for name, module in self.model._modules.items():\n print(name)\n if module == self.feature_module:\n target_activations, x = self.feature_extractor(x)\n elif \"avgpool\" in name.lower():\n x = module(x)\n x = x.view(x.size(0),-1)\n else:\n if (len(x.shape) == 4):\n if x.shape[2] ==1 & x.shape[3] ==1:\n print('reshaping')\n x = x.squeeze()\n print(x.shape)\n x = module(x)\n\n return target_activations, x\n\ndef preprocess_image(args,img):\n if args.model == 'resnet50':\n normalize = nntransforms.Normalize(mean=[0.485, 0.456, 0.406],\n std=[0.229, 0.224, 0.225])\n preprocessing = nntransforms.Compose([\n nntransforms.ToTensor(),\n normalize,\n ])\n return preprocessing(img.copy()).unsqueeze(0)\n elif args.model == 'dct':\n input_size1 = 512\n input_size2 = 448\n preprocessing = transforms.Compose([\n transforms.Resize(input_size1),\n transforms.CenterCrop(input_size2),\n transforms.Upscale(upscale_factor=2),\n transforms.TransformUpscaledDCT(),\n transforms.ToTensorDCT(),\n #transforms.SubsetDCT(channels=args.subset, pattern=args.pattern),\n transforms.SubsetDCT(channels=192),\n transforms.Aggregate(),\n transforms.NormalizeDCT(\n train_upscaled_static_mean,\n train_upscaled_static_std,\n channels=192#,\n #pattern=args.pattern\n )\n ])\n return preprocessing(img.copy())[0].unsqueeze(0).cuda()\ndef show_cam_on_image(img, mask):\n heatmap = cv2.applyColorMap(np.uint8(255 * mask), cv2.COLORMAP_JET)\n heatmap = np.float32(heatmap) / 255\n cam = heatmap + np.float32(img)\n cam = cam / np.max(cam)\n return np.uint8(255 * cam)\n\nclass GradCam:\n def __init__(self, model, feature_module, target_layer_names, use_cuda):\n self.model = model\n self.feature_module = feature_module\n self.model.eval()\n self.cuda = use_cuda\n if self.cuda:\n self.model = model.cuda()\n\n self.extractor = ModelOutputs(self.model, self.feature_module, target_layer_names)\n\n def forward(self, input_img):\n return self.model(input_img)\n\n def __call__(self, input_img, target_category=None):\n if self.cuda:\n input_img = input_img.cuda()\n\n features, output = self.extractor(input_img)\n\n if target_category == None:\n target_category = np.argmax(output.cpu().data.numpy())\n\n one_hot = np.zeros((1, output.size()[-1]), dtype=np.float32)\n one_hot[0][target_category] = 1\n one_hot = torch.from_numpy(one_hot).requires_grad_(True)\n if self.cuda:\n one_hot = one_hot.cuda()\n \n one_hot = torch.sum(one_hot * output)\n\n self.feature_module.zero_grad()\n self.model.zero_grad()\n one_hot.backward(retain_graph=True)\n\n grads_val = self.extractor.get_gradients()[-1].cpu().data.numpy()\n\n target = features[-1]\n target = target.cpu().data.numpy()[0, :]\n\n weights = np.mean(grads_val, axis=(2, 3))[0, :]\n cam = np.zeros(target.shape[1:], dtype=np.float32)\n\n for i, w in enumerate(weights):\n cam += w * target[i, :, :]\n\n cam = np.maximum(cam, 0)\n cam = cv2.resize(cam, input_img.shape[2:])\n cam = cam - np.min(cam)\n cam = cam / np.max(cam)\n return cam\n\n\nclass GuidedBackpropReLU(Function):\n @staticmethod\n def forward(self, input_img):\n positive_mask = (input_img > 0).type_as(input_img)\n output = torch.addcmul(torch.zeros(input_img.size()).type_as(input_img), input_img, positive_mask)\n self.save_for_backward(input_img, output)\n return output\n\n @staticmethod\n def backward(self, grad_output):\n input_img, output = self.saved_tensors\n grad_input = None\n\n positive_mask_1 = (input_img > 0).type_as(grad_output)\n positive_mask_2 = (grad_output > 0).type_as(grad_output)\n grad_input = torch.addcmul(torch.zeros(input_img.size()).type_as(input_img),\n torch.addcmul(torch.zeros(input_img.size()).type_as(input_img), grad_output,\n positive_mask_1), positive_mask_2)\n return grad_input\n\n\nclass GuidedBackpropReLUModel:\n def __init__(self, model, use_cuda):\n self.model = model\n self.model.eval()\n self.cuda = use_cuda\n if self.cuda:\n self.model = model.cuda()\n\n def recursive_relu_apply(module_top):\n for idx, module in module_top._modules.items():\n recursive_relu_apply(module)\n if module.__class__.__name__ == 'ReLU':\n module_top._modules[idx] = GuidedBackpropReLU.apply\n\n # replace ReLU with GuidedBackpropReLU\n recursive_relu_apply(self.model)\n\n def forward(self, input_img):\n return self.model(input_img)\n\n def __call__(self, input_img, target_category=None):\n if self.cuda:\n input_img = input_img.cuda()\n\n input_img = input_img.requires_grad_(True)\n\n output = self.forward(input_img)\n\n if target_category == None:\n if isinstance(output,tuple):\n output = output[0]\n target_category = np.argmax(output.cpu().data.numpy())\n\n one_hot = np.zeros((1, output.size()[-1]), dtype=np.float32)\n one_hot[0][target_category] = 1\n one_hot = torch.from_numpy(one_hot).requires_grad_(True)\n if self.cuda:\n one_hot = one_hot.cuda()\n\n one_hot = torch.sum(one_hot * output)\n one_hot.backward(retain_graph=True)\n\n output = input_img.grad.cpu().data.numpy()\n output = output[0, :, :, :]\n\n return output\n\ndef get_args():\n parser = argparse.ArgumentParser()\n parser.add_argument('--use-cuda', action='store_true', default=True,\n help='Use NVIDIA GPU acceleration')\n parser.add_argument('--image-path', type=str, default='/slstore/liangchumeng/datasets/New_ImagenetSubset_100/train/n01440764/n01440764_10026.JPEG', help='Input image path')\n parser.add_argument('--adv-path', type=str, default='/slstore/liangchumeng/datasets/fgsm_New_ImagenetSubset_100/train/n01440764/n01440764_10026.JPEG', help='Input image path')\n parser.add_argument('--mpath', type=str, default='all_no_adv_dct.pth.tar', help='Input image path')\n parser.add_argument('-M', '--model', type = str, default = 'resnet50', help = 'Model name')\n parser.add_argument('--fc', type = int, default = 100, help = 'number of fc')\n args = parser.parse_args()\n args.use_cuda = args.use_cuda and torch.cuda.is_available()\n if args.use_cuda:\n print(\"Using GPU for acceleration\")\n else:\n print(\"Using CPU for computation\")\n\n return args\n\ndef deprocess_image(img):\n \"\"\" see https://github.com/jacobgil/keras-grad-cam/blob/master/grad-cam.py#L65 \"\"\"\n img = img - np.mean(img)\n img = img / (np.std(img) + 1e-5)\n img = img * 0.1\n img = img + 0.5\n img = np.clip(img, 0, 1)\n return np.uint8(img*255)\n\nif __name__ == '__main__':\n \"\"\" python grad_cam.py <path_to_image>\n 1. Loads an image with opencv.\n 2. Preprocesses it for ResNet50 and converts to a pytorch variable.\n 3. Makes a forward pass to find the category index with the highest score,\n and computes intermediate activations.\n Makes the visualization. \"\"\"\n\n args = get_args()\n model = models.resnet50(pretrained=True)\n grad_cam = GradCam(model=model, feature_module=model.layer4, \\\n target_layer_names=[\"2\"], use_cuda=args.use_cuda)\n\n\n\n img = cv2.imread(args.image_path, 1)\n img = np.float32(img) / 255\n # Opencv loads as BGR:\n img = img[:, :, ::-1]\n input_img = preprocess_image(args, img)\n\n # If None, returns the map for the highest scoring category.\n # Otherwise, targets the requested category.\n target_category = None\n grayscale_cam = grad_cam(input_img, target_category)\n print('####alert',grayscale_cam.shape)\n grayscale_cam = cv2.resize(grayscale_cam, (img.shape[1], img.shape[0]))\n cam = show_cam_on_image(img, grayscale_cam)\n\n gb_model = GuidedBackpropReLUModel(model=model, use_cuda=args.use_cuda)\n gb = gb_model(input_img, target_category=target_category)\n gb = gb.transpose((1, 2, 0))\n\n cam_mask = cv2.merge([grayscale_cam, grayscale_cam, grayscale_cam])\n cam_gb = deprocess_image(cam_mask*gb)\n gb = deprocess_image(gb)\n name2 = 'gb' + args.model + '.jpg'\n name3 = 'cam_gb' + args.model + '.jpg'\n cv2.imwrite(name2, gb)\n cv2.imwrite(name3, cam_gb)\n name1 = \"cam\" + args.model + '.jpg'\n\n cv2.imwrite(name1, cam)\n \n model = models.resnet50(pretrained=True)\n grad_cam = GradCam(model=model, feature_module=model.layer4, \\\n target_layer_names=[\"2\"], use_cuda=args.use_cuda)\n\n img = cv2.imread(args.adv_path, 1)\n print(img.shape)\n img = np.float32(img) / 255\n # Opencv loads as BGR:\n img = img[:, :, ::-1]\n input_img = preprocess_image(args,img)\n\n # If None, returns the map for the highest scoring category.\n # Otherwise, targets the requested category.\n target_category = None\n grayscale_cam = grad_cam(input_img, target_category)\n\n grayscale_cam = cv2.resize(grayscale_cam, (img.shape[1], img.shape[0]))\n cam = show_cam_on_image(img, grayscale_cam)\n\n gb_model = GuidedBackpropReLUModel(model=model, use_cuda=args.use_cuda)\n gb = gb_model(input_img, target_category=target_category)\n gb = gb.transpose((1, 2, 0))\n\n cam_mask = cv2.merge([grayscale_cam, grayscale_cam, grayscale_cam])\n cam_gb = deprocess_image(cam_mask*gb)\n gb = deprocess_image(gb)\n name2 = 'adv_' + name2\n name3 = 'adv_' + name3\n cv2.imwrite(name2, gb)\n cv2.imwrite(name3, cam_gb)\n name1 = 'adv_' + name1\n\n cv2.imwrite(name1, cam)\n"
},
{
"alpha_fraction": 0.5140537023544312,
"alphanum_fraction": 0.6030606031417847,
"avg_line_length": 52.38333511352539,
"blob_id": "3ae0a389ef3138aeaafafbde989e24e1d3bed038",
"content_id": "f4176579b1cc21632f10ad33cc52421db1292850",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3202,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 60,
"path": "/demo.py",
"repo_name": "ODM-Caradryan/CS385-Course-Project-2",
"src_encoding": "UTF-8",
"text": "import torch\nfrom models.resnet import ResNet18\nfrom models.grad_cam import GradCam\n\ndef main():\n model = ResNet18()\n for name, module in model._modules.items():\n print(\"Name:{}, Module:{}\".format(name, module))\n return\n\nif __name__ == '__main__':\n main()\n\n'''\n Structure of ResNet18:\n Name:conv1, Module:Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3))\n Name:maxpool, Module:MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)\n Name:layer1, Module:BasicBlock(\n (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu): ReLU(inplace=True)\n (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n )\n Name:layer2, Module:BasicBlock(\n (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu): ReLU(inplace=True)\n (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (downsample): Sequential(\n (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)\n (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n Name:layer3, Module:BasicBlock(\n (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu): ReLU(inplace=True)\n (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (downsample): Sequential(\n (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)\n (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n Name:layer4, Module:BasicBlock(\n (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)\n (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (relu): ReLU(inplace=True)\n (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)\n (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n (downsample): Sequential(\n (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)\n (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)\n )\n )\n Name:avgpool, Module:AvgPool2d(kernel_size=1, stride=1, padding=0)\n Name:fc, Module:Linear(in_features=512, out_features=10, bias=True)\n'''"
},
{
"alpha_fraction": 0.5856370329856873,
"alphanum_fraction": 0.6237980723381042,
"avg_line_length": 33.67708206176758,
"blob_id": "36b846f0f183482a442f6565e61695b533057a23",
"content_id": "5ad3bb13922008c48ed91dff0a0d0e5f25a12754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3328,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 96,
"path": "/main/visualize.py",
"repo_name": "ODM-Caradryan/CS385-Course-Project-2",
"src_encoding": "UTF-8",
"text": "import os\nimport argparse\nimport cv2\nimport sys\nimport numpy as np\nsys.path.insert(0, os.path.dirname(os.path.dirname(os.path.abspath(__file__))))\n\nimport torch\nimport torch.nn as nn\nimport torchvision.transforms as transforms\n\nfrom models.resnet import ResNet18\nfrom models.vgg16 import VGG16\nfrom models.alexnet import AlexNet\nfrom models.grad_cam import FeatureExtractor, GradCam\n\nparser = argparse.ArgumentParser()\nparser.add_argument('--arch', default='vgg', type=str)\nparser.add_argument('--dataset', default='cifar10', type=str)\nparser.add_argument('--checkpoint', default='./checkpoints/', type=str)\nparser.add_argument('--gpu-id', default='1', type=str)\nparser.add_argument('--inputdir', default='./grad_cam/input/', type=str)\nparser.add_argument('--outputdir', default='./grad_cam/output/', type=str)\nargs = parser.parse_args()\nstate = {k: v for k, v in args._get_kwargs()}\nos.environ['CUDA_VISIBLE_DEVICES'] = args.gpu_id\n\ndef main(): \n # Raise Model\n if args.arch == 'resnet':\n model = ResNet18()\n solver = GradCam(model, model.layer2, \"3\")\n elif args.arch == 'alexnet':\n model = AlexNet()\n solver = GradCam(model, model.layer2, \"3\")\n elif args.arch == 'vgg':\n model = VGG16()\n solver = GradCam(model, model.model, \"18\")\n else:\n raise NotImplementedError(\"Arch {} is not implemented.\".format(args.arch))\n model = nn.DataParallel(model).cuda()\n model.eval()\n checkpoint_path = os.path.join(args.checkpoint, args.dataset+'/', args.arch+'/model_best.pth.tar')\n print(\"=> loading model: '{}'\".format(checkpoint_path))\n checkpoint = torch.load(checkpoint_path)\n model.load_state_dict(checkpoint['state_dict'])\n '''\n model_dict = model.module.state_dict()\n checkpoint = checkpoint['state_dict']\n model_dict.update(chec)\n model.module.load_state_dict(model_dict)\n '''\n\n # Dataset\n if args.dataset == 'cifar10':\n transform = transforms.Compose([\n transforms.ToTensor(),\n transforms.Normalize(mean=[0.4912393, 0.4820985, 0.44652376], std=[0.24508634, 0.24272567, 0.26051667])\n ])\n elif args.dataset == 'fmnist':\n transform = transforms.Compose([\n transforms.Resize(32),\n transforms.ToTensor(),\n transforms.Normalize(mean=[0.2888097,], std=[0.3549146,])\n ])\n else:\n raise NotImplementedError(\"Dataset {} is not implemented.\".format(args.dataset))\n\n for img_path in os.listdir(args.inputdir):\n # load the image\n img_path_abs = os.path.join(args.inputdir, img_path)\n img = cv2.imread(img_path_abs)\n img = np.float32(img) / 255 # 0-255 to 0-1\n img = img[:, :, ::-1] #BGR to RGB\n # img = img.transpose((2, 0, 1)) # [32, 32, 3] to [3, 32, 32]\n\n # generate heatmap\n #print(x.shape)\n x = transform(img.copy())\n x = x.unsqueeze(0)\n gray_cam = solver(x)\n heatmap = solver.heatmap(img, gray_cam)\n\n # save the heatmap\n name = 'GradCam_' + args.arch + '_' + args.dataset + '_' + img_path + '.jpg'\n heatmap = np.clip(heatmap, 0, 1)\n heatmap = np.uint8(heatmap * 255)\n\n print(heatmap.shape)\n\n cv2.imwrite(os.path.join(args.outputdir, name), heatmap)\n \n return\n\nif __name__ == '__main__':\n main()"
}
] | 4 |
sk-ip/bank-note-authentication | https://github.com/sk-ip/bank-note-authentication | 1aacd36729a7908629383c26da26eb5735c8029d | 27e256474b84457b555a66048cd65741446ac6f9 | 05ee29a12f1655bb49714b570820f47d10098179 | refs/heads/master | 2021-01-25T14:39:27.879188 | 2018-04-06T11:02:02 | 2018-04-06T11:02:02 | 123,720,541 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8059071898460388,
"alphanum_fraction": 0.8059071898460388,
"avg_line_length": 117,
"blob_id": "f43770268ab5c518b454fc3c90eb40dacbba803f",
"content_id": "467f335bfeecc1a7d27ec5463e0e39faa19423f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 237,
"license_type": "no_license",
"max_line_length": 208,
"num_lines": 2,
"path": "/README.md",
"repo_name": "sk-ip/bank-note-authentication",
"src_encoding": "UTF-8",
"text": "# bank-note-authentication\na program which uses logistic regression model to classify whether the parameters of a note belongs to a real note or not. data set is from uic https://archive.ics.uci.edu/ml/datasets/banknote+authentication. \n"
},
{
"alpha_fraction": 0.61548912525177,
"alphanum_fraction": 0.63722825050354,
"avg_line_length": 25.600000381469727,
"blob_id": "17388847b7911b33ec32776a9edb37247eff844c",
"content_id": "4a4ce853fdf58f7b735d5c12eb13e19d2755ca88",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2208,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 80,
"path": "/code.py",
"repo_name": "sk-ip/bank-note-authentication",
"src_encoding": "UTF-8",
"text": "# importing dependencies.\r\nimport numpy as np\r\nimport tensorflow as tf\r\nimport matplotlib.pyplot as plt\r\n\r\n# reading the data from the csv file.\r\nraw_data = []\r\nraw_labels = []\r\n\r\nfile = open('dataset.csv')\r\nread_file = file.readline().rstrip(\"\\n\")\r\n\r\nwhile read_file:\r\n\tvalues = read_file.split(\",\")\r\n\tvalues = [float(i) for i in values]\r\n\traw_data.append(values[0:-1])\r\n\t\r\n\tlabel = int(values[-1])\r\n\tif label == 0:\r\n\t\traw_labels.append([float(0)])\r\n\telse:\r\n\t\traw_labels.append([float(1)])\r\n\t\r\n\tread_file = file.readline().rstrip(\"\\n\")\r\n \r\nfile.close()\r\n\r\n# splitting the data into training and testing data.\r\n# training and testing data.\r\n\r\ntrain_data = raw_data[0:500]\r\ntest_data = raw_data[501:]\r\ntrain_label = raw_labels[0:500]\r\ntest_label = raw_labels[501:]\r\n\r\n# defining variables and placeholders.\r\nw = tf.Variable(tf.random_uniform([4, 1], -1.0,1.0), tf.float32)\r\nb = tf.Variable(tf.constant(0.5), tf.float32)\r\n\r\nx = tf.placeholder(name = \"data\", dtype = tf.float32, shape = [None, 4])\r\ny = tf.placeholder(name = \"label\", dtype = tf.float32, shape = [None, 1])\r\n\r\n# creating the computation graph.\r\n\r\n# logistic model.\r\nz = tf.matmul(x, w) + b\r\npred = tf.sigmoid(-z) \r\n\r\n# cost function.\r\ncost = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels = y, logits = pred))\r\n\r\n#optimizer.\r\noptimizer = tf.train.GradientDescentOptimizer(1e-3)\r\n\r\n# training the model or minimizing the cost.\r\ntrain = optimizer.minimize(cost)\r\n\r\n# running/training the model under a session.\r\n\r\nwith tf.Session() as sess:\r\n sess.run(tf.global_variables_initializer())\r\n loss_trace = []\r\n for step in range(10):\r\n for _ in range(1000):\r\n _ ,c = sess.run([train, cost], feed_dict = {x:train_data, y:train_label})\r\n loss_trace.append(c)\r\n print('step',step,'weights',sess.run(w),'cost',c)\r\n \r\n correct = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))\r\n accuracy = tf.reduce_mean(tf.cast(correct, 'float'))\r\n print('accuracy:',accuracy.eval({x: test_data, y: test_label}))\r\n \r\n \r\n\r\n# to visualize the loss with the no of epochs.\r\nplt.plot(loss_trace)\r\nplt.title('Cross Entropy Loss')\r\nplt.xlabel('epoch')\r\nplt.ylabel('loss')\r\nplt.show()\r\n"
}
] | 2 |
soulquiz/JavaWebServiceApp | https://github.com/soulquiz/JavaWebServiceApp | 8cdd587847c579340a1ad63f8974e9690d5a6b06 | a17b70a617bdb740ca90ba04bfd0f76f030e23ef | 4067f1dd546dc12e9865a381e8b41863c671f58c | refs/heads/master | 2021-05-16T04:47:50.525176 | 2017-10-13T14:55:56 | 2017-10-13T14:55:56 | 106,200,297 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8382353186607361,
"alphanum_fraction": 0.8382353186607361,
"avg_line_length": 33,
"blob_id": "4d1af6966e557a2bc288daaacaf710f17430f94e",
"content_id": "639ef2a1863111db836485f7980d7b77dd278885",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 68,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 2,
"path": "/README.md",
"repo_name": "soulquiz/JavaWebServiceApp",
"src_encoding": "UTF-8",
"text": "# JavaWebServiceApp\nJava WebService Application (Server&Client)\n"
},
{
"alpha_fraction": 0.5640686750411987,
"alphanum_fraction": 0.5970938205718994,
"avg_line_length": 32.40909194946289,
"blob_id": "f8b871038bfe643bc7ed56b7be23ec19dc15b9e2",
"content_id": "695ff7b54efb0eea21c4ced965bd5ea299f7fae3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Ruby",
"length_bytes": 757,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 22,
"path": "/savon_client.rb",
"repo_name": "soulquiz/JavaWebServiceApp",
"src_encoding": "UTF-8",
"text": "require 'savon'\r\nclient = Savon.client(wsdl: \"http://localhost:8080/CalculatorWS/CalculatorWS?wsdl\")\r\n\r\ni = 10\r\nj = 2\r\nmessage = {i: i, j: j}\r\n\r\nresponse = client.call(:add, message: message).to_hash[:add_response][:return]\r\nprint i , \" + \" , j , \" = \" , response # 10 + 2 = 12\r\nputs \"\"\r\n\r\nresponse = client.call(:subtraction, message: message).to_hash[:subtraction_response][:return]\r\nprint i , \" - \" , j , \" = \" , response # 10 - 2 = 8\r\nputs \"\"\r\n\r\nresponse = client.call(:multiply, message: message).to_hash[:multiply_response][:return]\r\nprint i , \" * \" , j , \" = \" , response # 10 * 2 = 20\r\nputs \"\"\r\n\r\nresponse = client.call(:divide, message: message).to_hash[:divide_response][:return]\r\nprint i , \" / \" , j , \" = \" , response # 10 / 2 = 5\r\nputs \"\"\r\n"
},
{
"alpha_fraction": 0.5114068388938904,
"alphanum_fraction": 0.5589353442192078,
"avg_line_length": 25.6842098236084,
"blob_id": "7b9113b6dc89a62a9cd2baa608ab8210e9dc5b82",
"content_id": "0415d88011e58f9219cdf049438ec1a8f5a2bbbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 19,
"path": "/zeep_client.py",
"repo_name": "soulquiz/JavaWebServiceApp",
"src_encoding": "UTF-8",
"text": "import zeep\r\n\r\nwsdl = 'http://localhost:8080/CalculatorWS/CalculatorWS?wsdl'\r\nclient = zeep.Client(wsdl=wsdl)\r\n\r\ni = 10\r\nj = 2\r\n\r\nresult = client.service.add(i, j) # 10 + 2 = 12\r\nprint(\"{} + {} = {}\".format(i, j, result))\r\n\r\nresult = client.service.subtraction(i, j) # 10 - 2 = 8\r\nprint(\"{} - {} = {}\".format(i, j, result))\r\n\r\nresult = client.service.multiply(i, j) # 10 * 2 = 20\r\nprint(\"{} * {} = {}\".format(i, j, result))\r\n\r\nresult = client.service.divide(i, j) # 10 / 2 = 5\r\nprint(\"{} / {} = {}\".format(i, j, result))\r\n"
}
] | 3 |
Schwartz210/Database-software | https://github.com/Schwartz210/Database-software | 116c90a35476abcac43099aaedbc528ce66d1bbd | bd41397edd2184b17fa60f8a2a355a44db39102d | 3d6d8e8a561e17ac08dd2a876309c1ef47b2ce2e | refs/heads/master | 2021-01-24T08:42:04.729267 | 2016-09-30T20:37:05 | 2016-09-30T20:37:05 | 69,061,503 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5970630645751953,
"alphanum_fraction": 0.6069722771644592,
"avg_line_length": 37.5080451965332,
"blob_id": "1912c3702029bbdf2fb8757e07a466da36f5bf85",
"content_id": "fa46d8fe0e625f72d0adfda4f88b66d2138f39cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16752,
"license_type": "no_license",
"max_line_length": 228,
"num_lines": 435,
"path": "/gui.py",
"repo_name": "Schwartz210/Database-software",
"src_encoding": "UTF-8",
"text": "__author__ = 'aschwartz - [email protected]'\nfrom db_interface import add_record, pull_data, update_record, select, select_where, field_name, query_sum, fields_type_mapping, delete_where\nfrom excel import export\nfrom tkinter import *\nfrom functools import partial\nfrom PIL import Image, ImageTk\n\ntype_to_fields = {'contacts': ['ID', 'First_name', 'Last_name','Address1', 'Address2','City','State','Zip','Phone'],\n 'sales' : ['Order_num', 'Customer_ID', 'Amount', 'Order_date']}\n\nspecial_id = {'contacts' : 'ID',\n 'sales' : 'Order_num'}\n\ndef null_entry_handler(entry):\n if len(entry.get()) == 0:\n return ''\n else:\n return entry.get()\n\nclass HomeScreen(object):\n def __init__(self):\n self.master = Tk()\n self.build_canvas()\n self.menubar()\n self.master.mainloop()\n\n def build_canvas(self):\n self.master.title('Avi Enterprise Pro')\n self.master.wm_geometry(\"600x600\")\n self.photo_contact = ImageTk.PhotoImage(Image.open('image/contact.png'))\n self.photo_record = ImageTk.PhotoImage(Image.open('image/record.png'))\n self.photo_sales = ImageTk.PhotoImage(Image.open('image/sales.png'))\n self.button_new_contact = Button(self.master, image=self.photo_contact, borderwidth=0, command=self.new_contact)\n self.button_new_contact.grid(sticky=W, column=0, row=0)\n self.button_record = Button(image=self.photo_record, borderwidth=0, command=self.contacts)\n self.button_record.grid(sticky=W, column=0, row=1)\n self.button_sales = Button(image=self.photo_sales, borderwidth=0, command=self.sales)\n self.button_sales.grid(sticky=W, column=0, row=2)\n\n def menubar(self):\n self.menu = Menu(self.master)\n #File menu\n filemenu = Menu(self.menu, tearoff=0)\n filemenu.add_command(label=\"Open\", command=self.hello)\n filemenu.add_command(label=\"Save\", command=self.hello)\n filemenu.add_separator()\n filemenu.add_command(label=\"Exit\", command=self.master.destroy)\n self.menu.add_cascade(label=\"File\", menu=filemenu)\n #Record menu\n recordmenu = Menu(self.menu, tearoff=0)\n recordmenu.add_command(label=\"New Contact\", command=self.new_contact)\n recordmenu.add_command(label=\"New Sales Order\", command=self.new_sales_order)\n recordmenu.add_command(label=\"Customer Center\", command=self.customer_center)\n self.menu.add_cascade(label=\"Records\", menu=recordmenu)\n #Reporting menu\n reportingmenu = Menu(self.menu, tearoff=0)\n reportingmenu.add_command(label=\"Customer List\", command=self.contacts)\n reportingmenu.add_command(label=\"Sales Orders\", command=self.sales)\n reportingmenu.add_command(label=\"Customer Sales Total\", command=self.customer_sales_total)\n self.menu.add_cascade(label=\"Reporting\", menu=reportingmenu)\n self.master.config(menu=self.menu)\n\n def hello(self):\n pass\n\n def new_contact(self):\n CreateRecordWindow('contacts')\n\n def new_sales_order(self):\n CreateRecordWindow('sales')\n\n def contacts(self):\n fields = list(type_to_fields['contacts'])\n Report('contacts', fields)\n\n def sales(self):\n fields = list(type_to_fields['sales'])\n Report('sales', fields)\n\n def customer_center(self):\n fields = ['Last_name', 'First_name']\n CustomerCenter('contacts', fields)\n\n def customer_sales_total(self):\n fields = ['Last_name', 'First_name', 'Amount']\n Report('contacts', fields, True)\n\n\nclass CreateRecordWindow(object):\n def __init__(self, report_type):\n self.report_type = report_type\n self.master = Tk()\n icon = 'image/%s.ico' % (report_type)\n self.master.iconbitmap(icon)\n self.entries = []\n self.build_canvas()\n\n def build_canvas(self):\n fields = list(type_to_fields[self.report_type])\n spec_id = special_id[self.report_type]\n fields.remove(spec_id)\n titles = {'contacts' : 'New Contact', 'sales' : 'New Sales Order'}\n self.master.title(titles[self.report_type])\n entry_width = 30\n row_num = 1\n for field in fields:\n text = field.replace('_', ' ')\n Label(self.master, text=text).grid(column=1, row=row_num, sticky=W)\n entry = Entry(self.master, width=entry_width)\n entry.grid(row=row_num, column=2)\n self.entries.append(entry)\n row_num += 1\n Button(self.master, text='OK', command=self.entry_handler, width=10).grid(row=9, column=1, sticky=S)\n Button(self.master, text='Cancel', command=self.master.destroy, width=10).grid(row=9, column=2, sticky=S)\n\n def entry_handler(self):\n record = [null_entry_handler(entry) for entry in self.entries if entry]\n add_record(self.report_type, record)\n self.master.destroy()\n\n\nclass Report(object):\n def __init__(self, report_type, fields, total_amount=False):\n self.report_type = report_type\n self.total_amount = total_amount\n self.sp_field = special_id[self.report_type]\n self.set_fields(fields)\n self.sorted_by_field = 0\n self.rightmost_column = len(self.display_fields) - 1\n self.width = 600\n self.height = 800\n self.master = Toplevel()\n self.master.title('Reporting')\n self.master.iconbitmap('image/record.ico')\n self.prepare_images()\n self.canvas1 = Canvas(self.master)\n self.canvas2 = Canvas(self.master)\n self.refresh_report()\n mainloop()\n\n def set_fields(self, fields):\n if self.sp_field not in fields:\n self.display_fields = list(fields)\n fields.insert(0,self.sp_field)\n self.fields = fields\n else:\n self.fields = list(fields)\n self.display_fields = list(fields)\n\n def field_name_modifier(self, fields):\n '''\n Used only for 'mixed' reports\n '''\n out = []\n for field in fields:\n new_name = field_name(field)\n out.append(new_name)\n return out\n\n def get_sql_data(self):\n field_query = ''\n if self.report_type == 'mixed':\n fields = self.field_name_modifier(self.fields)\n else:\n fields = self.fields\n\n for field in fields:\n if fields_type_mapping[field] == self.report_type:\n field_query += field + ','\n sql_request = select(field_query[:-1], self.report_type)\n self.data = pull_data(sql_request)\n if self.total_amount:\n self.aggregation_handler()\n\n def aggregation_handler(self):\n ind = self.fields.index('Customer_ID')\n if self.total_amount:\n for record in self.data:\n total = query_sum('Amount', 'Customer_ID', record[ind])\n record.append(total)\n\n def canvas_master_processs(self):\n self.canvas1.destroy()\n self.canvas2.destroy()\n self.canvas1 = Canvas(self.master)\n self.canvas2 = Canvas(self.master)\n self.determine_button_width()\n self.layout_headers()\n self.layout_buttons()\n self.canvas1.grid()\n self.canvas2.grid()\n\n def layout_headers(self):\n Button(self.canvas1,\n borderwidth=0,\n image=self.photo_custom,\n command=self.customize_report).grid(column=0, row=0)\n\n Button(self.canvas1,\n borderwidth=0,\n image=self.photo_refresh,\n command=self.refresh_report).grid(column=1, row=0)\n Button(self.canvas1,\n borderwidth=0,\n image=self.photo_excel,\n command=lambda: export(self.data)).grid(column=2, row=0)\n\n iterator_column = 0\n for field in self.display_fields:\n text = field.replace('_',' ')\n text = text.replace('Address',' Address ')\n Button(self.canvas2,\n text=text,\n width=self.button_width[iterator_column],\n height=1,\n borderwidth=1,\n font=('Corbel',10,'bold'),\n anchor=W,\n command=partial(self.custom_sort,iterator_column)).grid(row=1, column=iterator_column)\n iterator_column += 1\n\n def layout_buttons(self):\n iterator_row = 2\n for record in self.data:\n iterator_field = 0\n if self.sp_field in self.display_fields:\n for field in record:\n Button(self.canvas2,text=field,width=self.button_width[iterator_field],height=1,borderwidth=0,command=partial(self.open_record_window,record[0]),anchor=W).grid(row=iterator_row,column=iterator_field,sticky=S)\n iterator_field += 1\n else:\n for field in record[1:]:\n Button(self.canvas2,text=field,width=self.button_width[iterator_field],height=1,borderwidth=0,command=partial(self.open_record_window,record[0]),anchor=W).grid(row=iterator_row,column=iterator_field,sticky=S)\n iterator_field += 1\n iterator_row += 1\n\n def refresh_report(self):\n self.get_sql_data()\n self.canvas_master_processs()\n\n def customize_report(self):\n CustomizeReportWindow()\n\n def open_record_window(self, ID):\n RecordWindow(self.report_type, ID)\n\n def custom_sort(self, field):\n if self.sp_field not in self.display_fields:\n field += 1\n self.data.sort(key=lambda x: x[field])\n if field == self.sorted_by_field:\n self.data.reverse()\n self.sorted_by_field = ''\n else:\n self.sorted_by_field = field\n self.canvas_master_processs()\n\n def determine_button_width(self):\n self.button_width = []\n for field in self.display_fields:\n ind = self.fields.index(field)\n max_value = self.list_of_list_column_len(self.data, ind, field)\n self.button_width.append(max_value)\n\n def list_of_list_column_len(self, list_of_lists, column, header):\n max_value = len(header)\n for lst in list_of_lists:\n if len(str(lst[column])) > max_value:\n max_value = len(str(lst[column]))\n return max_value\n\n def prepare_images(self):\n self.photo_custom = ImageTk.PhotoImage(Image.open('image/custom.png'))\n self.photo_refresh = ImageTk.PhotoImage(Image.open('image/refresh_report.png'))\n self.photo_excel = ImageTk.PhotoImage(Image.open('image/excel.png'))\n\n\nclass CustomerCenter(Report):\n def __init__(self, report_type, fields):\n self.report_type = report_type\n self.sp_field = special_id[self.report_type]\n self.set_fields(fields)\n self.sorted_by_field = 0\n self.rightmost_column = len(self.display_fields) - 1\n self.width = 600\n self.height = 800\n self.master = Toplevel()\n self.master.title('Reporting')\n self.master.iconbitmap('image/record.ico')\n self.prepare_images()\n self.canvas1 = Canvas(self.master)\n self.canvas2 = Canvas(self.master)\n self.canvas3 = Canvas(self.master)\n self.refresh_report()\n mainloop()\n\n def canvas_master_processs(self):\n self.canvas1.destroy()\n self.canvas2.destroy()\n self.canvas3.destroy()\n self.canvas1 = Canvas(self.master)\n self.canvas2 = Canvas(self.master)\n self.canvas3 = Canvas(self.master, bg='blue')\n self.determine_button_width()\n self.layout_headers()\n self.layout_buttons()\n self.canvas1.grid(row=0)\n self.canvas2.grid(column=0, row=1)\n self.canvas3.grid(column=1, row=1)\n\n\nclass RecordWindow(object):\n def __init__(self, report_type, ID):\n self.report_type = report_type\n self.sp_field = special_id[self.report_type]\n self.ID = ID\n self.fields = list(type_to_fields[report_type])\n self.width = 200\n self.height = 200\n self.entries = []\n self.master = Toplevel()\n self.master.iconbitmap('image/record.ico')\n self.get_data()\n self.build_canvas()\n\n def get_data(self):\n sql_request = select_where(self.report_type, self.sp_field, self.ID)\n try:\n self.data = pull_data(sql_request)[0]\n except:\n self.data = pull_data(sql_request)\n\n def build_canvas(self):\n self.canvas = Canvas(self.master, width=self.width, height=self.height)\n self.photo_edit = ImageTk.PhotoImage(Image.open('image/edit.png'))\n self.photo_exit = ImageTk.PhotoImage(Image.open('image/exit.png'))\n self.photo_delete = ImageTk.PhotoImage(Image.open('image/delete.png'))\n fields = list(self.fields)\n iterator = 0\n for field in fields:\n Label(self.canvas, text=field).grid(row=iterator, column=0, sticky=W)\n Label(self.canvas, text=self.data[iterator]).grid(row=iterator, column=1, sticky=W)\n iterator += 1\n Button(self.canvas, image=self.photo_edit, command=self.edit_record, borderwidth=0).grid(row=iterator, column=0)\n Button(self.canvas, image=self.photo_exit, command=self.master.destroy, borderwidth=0).grid(row=iterator, column=1)\n Button(self.canvas, image=self.photo_delete, command=self.delete_record, borderwidth=0).grid(row=iterator, column=2)\n self.canvas.grid()\n\n def edit_record(self):\n self.canvas.destroy()\n self.canvas = Canvas(self.master, width=self.width, height=self.height)\n iterator = 0\n display_fields = list(self.fields)\n display_fields.remove('ID')\n for field in display_fields:\n Label(self.canvas, text=field).grid(row=iterator, column=0, sticky=W)\n iterator += 1\n iterator = 0\n Label(self.canvas, text=self.data[0]).grid(row=iterator, column=1, sticky=W)\n\n for field in self.data[1:]:\n a = StringVar()\n a.set(field)\n entry = Entry(self.canvas, width=15,textvariable=a)\n entry.grid(row=iterator, column=1)\n self.entries.append(entry)\n iterator += 1\n Button(self.canvas, text='Save', width=10, command=self.save_record).grid(row=iterator, column=0)\n Button(self.canvas, text='Cancel', width=10, command=self.master.destroy).grid(row=iterator, column=1)\n self.canvas.grid()\n\n def save_record(self):\n record = [null_entry_handler(entry) for entry in self.entries if entry]\n record.append(self.ID)\n update_record(self.report_type, record)\n self.master.destroy()\n self.__init__(self.report_type, self.ID)\n\n def delete_record(self):\n delete_parameters = (self.report_type, self.sp_field, self.ID)\n DeleteRecordWindow(delete_parameters)\n self.master.destroy()\n\n\nclass CustomizeReportWindow(object):\n def __init__(self):\n self.master = Toplevel()\n self.check_dict = {}\n self.create_canvas()\n self.master.mainloop()\n\n def create_canvas(self):\n self.width = 100\n self.height = 100\n self.canvas = Canvas(self.master, width=self.width, height=self.height)\n fields = ['ID', 'First name', 'Last name','Address1', 'Address2','City','State','Zip','Phone']\n iterator = 1\n self.results = []\n for field in fields:\n self.check_dict[field] = IntVar()\n Checkbutton(self.master, text=field, variable=self.check_dict[field],onvalue = 1, offvalue = 0).grid(row=iterator, sticky=W)\n iterator += 1\n\n Button(self.master, text='Run Report', command=self.call_report, width=15).grid(row=iterator)\n self.canvas.grid()\n\n def clean_dict(self):\n for key in self.check_dict.keys():\n self.check_dict[key] = self.check_dict[key].get()\n\n def call_report(self):\n self.clean_dict()\n fields = [field.replace(' ','_') for field in self.check_dict.keys() if self.check_dict[field] == 1]\n self.master.destroy()\n Report('contacts',fields)\n\n\nclass DeleteRecordWindow(object):\n def __init__(self, parameters):\n self.parameters = parameters\n self.master = Toplevel()\n self.master.title('Delete Record')\n Label(self.master, text='Are you sure you want to DELETE this record?').grid()\n Button(self.master,text='Ok', width=15, command=self.ok).grid()\n Button(self.master,text='Cancel', width=15, command=self.master.destroy).grid()\n\n def ok(self):\n table, field, criteria = self.parameters\n self.master.destroy()\n delete_where(table, field, criteria)\n\n\n\n\ndef run():\n HomeScreen()\n\n"
},
{
"alpha_fraction": 0.6485623121261597,
"alphanum_fraction": 0.6549520492553711,
"avg_line_length": 23.153846740722656,
"blob_id": "03365cddd0b5c606a5cf4458016b7c90ce7f9a19",
"content_id": "9b2cb830f44f9e1228775e95bae6247eb27afd24",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 313,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 13,
"path": "/scrap.py",
"repo_name": "Schwartz210/Database-software",
"src_encoding": "UTF-8",
"text": "import Tkinter\nimport tkMessageBox\n\ntop = Tkinter.Tk()\ndef deleteme():\n tkMessageBox.askquestion(\"Delete\", \"Are You Sure?\", icon='warning')\n if 'yes':\n print \"Deleted\"\n else:\n print \"I'm Not Deleted Yet\"\nB1 = Tkinter.Button(top, text = \"Delete\", command = deleteme)\nB1.pack()\ntop.mainloop()"
},
{
"alpha_fraction": 0.43619489669799805,
"alphanum_fraction": 0.4974121153354645,
"avg_line_length": 34.910255432128906,
"blob_id": "fbbddcd63ad6914912948d72808f490905e0747b",
"content_id": "3918f79c7f754665b8e5349bd4cbfa1f83f58d93",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5603,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 156,
"path": "/db_interface.py",
"repo_name": "Schwartz210/Database-software",
"src_encoding": "UTF-8",
"text": "__author__ = 'aschwartz - [email protected]'\nfrom sqlite3 import connect\nDATABASE = 'test.db'\ntables = {'contacts' :'test_table4',\n 'sales' : 'sales5'}\n\nfields_type_mapping = {'ID' : 'contacts',\n 'First_name' : 'contacts',\n 'Last_name' : 'contacts',\n 'Address1' : 'contacts',\n 'Address2' : 'contacts',\n 'City' : 'contacts',\n 'State' : 'contacts',\n 'Zip' : 'contacts',\n 'Phone' : 'contacts',\n 'Order_num' : 'sales',\n 'Customer_ID' : 'sales',\n 'Amount' : 'sales',\n 'Order_date' : 'sales'}\n\ndef select(field, table):\n return 'SELECT %s FROM %s' % (field, tables[table])\n\ndef select_where(table, field, criteria):\n return 'SELECT * FROM %s WHERE %s=\"%s\"' % (tables[table], field, criteria)\n\ndef delete_where(table, field, criteria):\n sql_request = 'DELETE FROM %s WHERE %s=\"%s\"' % (tables[table], field, criteria)\n execute_sql(sql_request)\n\ndef query_sum(total_by, field, criteria):\n table = fields_type_mapping[total_by]\n try:\n sql_request = 'SELECT SUM(%s) FROM %s WHERE %s=\"%s\"' % (total_by, tables[table], field, criteria)\n total = pull_data(sql_request)[0][0]\n return total\n except:\n return 0.00\n\ndef create_table(table):\n if table == 'contacts':\n sql_request = 'CREATE TABLE %s(ID INTEGER PRIMARY KEY AUTOINCREMENT, First_name, Last_name, Address1, Address2, City, State, Zip, Phone)' % (tables[table])\n elif table == 'sales':\n sql_request = 'CREATE TABLE %s (Order_num INTEGER PRIMARY KEY AUTOINCREMENT, Customer_ID, Amount Decimal(19,2), Order_date DATE)' % (tables[table])\n else:\n raise Exception('Unknown table')\n execute_sql(sql_request)\n\ndef execute_sql(SQL_request):\n '''\n Alter database. Does not query data.\n '''\n conn = connect(DATABASE)\n c = conn.cursor()\n c.execute(SQL_request)\n conn.commit()\n conn.close()\n\ndef execute_multiple_sql(SQL_requests):\n conn = connect(DATABASE)\n c = conn.cursor()\n for SQL_request in SQL_requests:\n c.execute(SQL_request)\n conn.commit()\n conn.close()\n\ndef exists(sql_request):\n '''\n Evualuate if record exists. Returns boolean.\n '''\n conn = connect(DATABASE)\n c = conn.cursor()\n count = len(list(c.execute(sql_request)))\n if count > 0:\n out = True\n else:\n out = False\n conn.commit()\n conn.close()\n return out\n\ndef pull_data(SQL_request):\n conn = connect(DATABASE)\n c = conn.cursor()\n try:\n list_of_tuples = list(c.execute(SQL_request))\n list_of_lists = [list(elem) for elem in list_of_tuples]\n conn.commit()\n conn.close()\n return list_of_lists\n except:\n raise Exception('Not able to fulfill request')\n\ndef add_record(table, record):\n if table == 'contacts':\n sql_request = 'INSERT INTO %s VALUES(NULL, \"%s\", \"%s\", \"%s\", \"%s\", \"%s\", \"%s\", \"%s\", \"%s\")' % (tables[table], record[0], record[1], record[2], record[3], record[4], record[5], record[6], record[7])\n elif table == 'sales':\n sql_request = 'INSERT INTO %s VALUES(NULL, \"%s\", %s, \"%s\")' % (tables[table], record[0], record[1], record[2])\n else:\n raise Exception()\n execute_sql(sql_request)\n\ndef update_record(table, values):\n if table == 'contacts':\n sql_request = 'UPDATE %s SET First_name=\"%s\", Last_name=\"%s\", Address1=\"%s\", Address2=\"%s\", City=\"%s\", ' \\\n 'State=\"%s\", Zip=\"%s\", Phone=\"%s\" WHERE ID=\"%s\"' % (tables[table],\n values[0],\n values[1],\n values[2],\n values[3],\n values[4],\n values[5],\n values[6],\n values[7],\n values[8])\n elif table == 'sales':\n sql_request = 'UPDATE %s SET Customer_ID=\"%s\", Amount=%s, Order_date=\"%s\" WHERE ID=\"%s\"' % (tables[table], values[0], values[1], values[2],values[3])\n else:\n raise Exception()\n execute_sql(sql_request)\n\ndef field_name(field):\n table = fields_type_mapping[field]\n sql_table_name = tables[table]\n name = sql_table_name + '.' + field\n return name\n\n\n\n\n\nsales_report1 = 'SELECT test_table4.First_name, test_table4.Address1, sales2.Amount FROM sales2 INNER JOIN test_table4 ON sales2.Customer_ID=test_table4.ID'\n\nsales_sample_data = [\n [12,12.16,'20160928'],\n [10,13.16,'20160822'],\n [2,12.66,'20160823'],\n [4,48.16,'20160707'],\n [6,52.17,'20160628'],\n [5,9.16,'20160228'],\n [11,11.16,'20160815'],\n [9,58.16,'20160928'],\n [3,149.16,'20160905'],\n [12,153.16,'20160928'],\n [4,77.58,'20160427'],\n [6,22.58,'20160428'],\n [8,155.58,'20160429'],\n [10,77.22,'20160401'],\n [12,98.63,'20160402'],\n [14,172.54,'20160403'],\n [16,180.45,'20160404'],\n [15,190.10,'20160405'],\n [13,117.45,'20160406'],\n [11,111.23,'20160407'],\n [9,145.96,'20160408']\n]\n\n"
}
] | 3 |
novking/AWS_Lambda_DynamoDB_RDS | https://github.com/novking/AWS_Lambda_DynamoDB_RDS | 433a493ffd3ee4397b3ce8b43c579fbc81d4a7bc | 075eaa4494c69ca14890fa608d04ad3865d05ce5 | 93e5f5e6fb8d80de31f79686e1d8ea73be054350 | refs/heads/master | 2020-09-15T19:47:42.158314 | 2016-08-24T20:30:09 | 2016-08-24T20:30:09 | 66,231,610 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6482412219047546,
"alphanum_fraction": 0.6683416962623596,
"avg_line_length": 35.181819915771484,
"blob_id": "76465bb919bb3dac243f534b539f1eb3a76de5de",
"content_id": "0a01f63f4022524ea01141d374ff629f88795af7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 398,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/kinesis_lambda.py",
"repo_name": "novking/AWS_Lambda_DynamoDB_RDS",
"src_encoding": "UTF-8",
"text": "import base64\nimport json\n\ndef lambda_handler(event, context):\n print(\"Received event:\"+json.dumps(event))\n for record in event['Records']:\n #Kinesis is base64 encoded.\n #we need to decode the data\n payload = base64.b64decode(record['kinesis']['data'])\n print(\"Decoded payload: \"+payload)\n return 'Successfully process {} records'.format(len(event['Records']))\n"
},
{
"alpha_fraction": 0.38346341252326965,
"alphanum_fraction": 0.3857835829257965,
"avg_line_length": 40.596492767333984,
"blob_id": "d66d2916a63cb1ce9469d4f26c6061fcd8ca5e07",
"content_id": "19aaaf8cb4e4541289a47bd82886578c1109da27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4741,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 114,
"path": "/GetStatus/index.js",
"repo_name": "novking/AWS_Lambda_DynamoDB_RDS",
"src_encoding": "UTF-8",
"text": "console.log('Loading function');\nvar doc = require('dynamobd-doc');\nvar dynamo = new doc.DynamoDB();\nvar fs = require('fs');\nvar mysql = require('mysql');\n\nfunction readModuleFile(path, callback){\n try{\n var filename = require.resolve(path);\n fs.readFile(filename, 'utf8', callback);\n }catch(e){\n callback(e);\n }\n}\n\nexports.handler(event, context){\n console.log('Recieved event: ', JSON.stringify(event, null, 2));\n var username = event.name;\n var password = event.password;\n var conn = mysql.createConnection({\n host: \"RDS_endpoint\",\n user: \"user\",\n ssl: \"Amazon RDS\",\n password: \"password\",\n database: \"the_databas\",\n });\n conn.connect(function(err){\n if(err){\n console.error('error connecting'+err.stack);\n return;\n }\n console.log('connected as id'+conn.threadId);\n });\n \n var sql = 'SELECT * FROM login WHERE name =\"'+username+'\"';\n var result = conn.query(sql, function(error, rows, fields){\n if (error){\n console.log(error.message);\n console.log(\"The user does't exit\");\n console.succeed(\"The user does't exit.. please create an account\");\n throw error;\n }\n else{\n if(typeof rows[0]!='undefined'){\n console.log(\"Found the userdata\");\n if(event.password!=rows[0].password){\n console.log('incorrect password');\n readModuleFile('./incorrect.html', function(err, incorrect){\n var resp = incorrect;\n context.succeed({\"respon\":incorrect});\n });\n }\n var row_id = rows[0].id;\n var name = rows[0].name;\n var sql = \"SELECT * FROM login\";\n var result = conn.query( sql, function(error, rows, fields){\n if(error){\n console.log(error.message);\n throw error;\n }\n else{\n console.log(\"row details\", rows);\n details = [];\n name_detail = [];\n tail = \"\";\n rows.forEach(function(row){\n console.log(\"my Id:\"+row.id);\n var i = 0;\n var rowID = row.id;\n var params = {\n \"TableName\":\"status\",\n \"Key\":{\n \"UserId\":row.id\n }\n };\n dynamo.getItem(params, function(err, data){\n if (err){\n console.log(err);\n context.succeed(err);\n }\n else{\n console.log(\"the data is :\", data);\n i++;\n console.log(\"value of i:\", i);\n details[rowID]=data.Item.status;\n name_detail[rowID]=data.Item.name;\n console.log(\"the status to be printed\",details[rowID]);\n console.log(\"The length of details array is:\",details.length);\n tail=tail+\"<tr><td><h4>\"+name_detail[rowID]+\"</h4></td><td><h4>\"+details[rowID]+\"</h4></td></tr>\";\t\n console.log(\"the raw length =\",rows.length);\n console.log(\"the current raw \",row.length);\n if(i>=rows.length){\n readModuleFile('./success.html', function(err, success){\n var res = success;\n lastres=res+tail+\"</tbody></table></div></body></html>\"; \n context.succeed({\"respon\":lastres});\n });\n }\n }\n });\n });\n }\n });\n }\n else{\n console.log(\"The user doesn't exit here\");\n readModuleFile('./notexist.html', function(err, not){\n var rest = not:\n context.succeed({\"respon\":rest});\n });\n }\n }\n });\n};"
},
{
"alpha_fraction": 0.5846112370491028,
"alphanum_fraction": 0.5924132466316223,
"avg_line_length": 35.27450942993164,
"blob_id": "eadb9c988babb5d54324b908d5fc4d286559674e",
"content_id": "d309128bcc07e87f9cd95163e39eed03e4d162a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3717,
"license_type": "no_license",
"max_line_length": 189,
"num_lines": 102,
"path": "/kinesis_IAM_creation.py",
"repo_name": "novking/AWS_Lambda_DynamoDB_RDS",
"src_encoding": "UTF-8",
"text": "import time\nimport json\nimport boto3\n\nkinesis = boto3.client('kinesis')\niam = boto3.client('iam')\nl = boto3.client('lambda')\n\ndef create_stream(name):\n if name not in [f for f in kinesis.list_streams()['StreamNames']]:\n print 'Creating Kinesis stream %s'%(name)\n kinesis.create_stream(StreamName=name, ShardCount=1)\n else:\n print \"Kinesis stream %s exists\" % (name)\n \n while kinesis.describe_stream(StreamName=name)['StreamDescription']['StreamStatus']=='CREATING':\n time.sleep(2)\n return kinesis.describe_stream(StreamName=name)['StreamDescription']\n\n\n\ndef create_role(name, policies=None): #policies here is actually the policies's ARN\n '''this function is to create a role that can allow Lambda have some access'''\n policydoc ={\n \"Version\":\"2012-10-17\",\n \"Statement\":[\n {\n \"Effect\":\"Allow\",\n \"Principal\":{\n \"Service\":[\"lambda.amazonaws.com\"]\n },\n \"Action\":[\"sts:AssumeRole\"]\n },\n ]\n }\n \n roles = [r['RoleName'] for r in iam.list_roles()['Roles']]\n if name in roles:\n print 'IAM role %s exists'%(name)\n role = iam.get_role(RoleName = name)['Role']\n else:\n print 'Creating IAM role %s' %(name)\n role = iam.create_role(RoleName=name, AssumeRolePolicyDocument=json.dumps(policydoc))['Role']\n \n if policies is not None:\n for p in policies:\n iam.attach_role_policy(RoleName=role['RoleName'], PolicyArn = p)\n return role\n\ndef create_function(name, zfile, lsize=512, timeout=10, update=False):\n '''this is for creating or updating lambda function'''\n role = create_role(name+'_lambda', policies=['arn:aws:iam::aws:policy/service-role/AWSLambdaKinesisExecutionRole']) #note that i attached Kinesis Role in order to run kinesis in lambda\n with open(zfile, 'rb') as zipfile:\n if name in [f['FunctionName'] for f in l.list_functions()['Functions']]:\n if update:\n print 'Updating %s lambda function code' % (name)\n return l.update_function_code(FunctionName=name, ZipFile=zipfile.read())\n else:\n print 'Lambda function %s exists' % (name)\n # do something\n else:\n print 'Creating {} lambda function'.format((name))\n lfunc = l.create_fucntion(\n FunctionName=name,\n Runtime='python2.7',\n Role=role['Arn'],#????hmm im not sure\n Handler='lambda.lambda_handler',\n Description='Example lambda function to ingest a Kinesis stream',\n Timeout=timeout,\n MemorySize=lsize,\n Publish=True,\n Code = {'ZipFile': zipfile.read()}\n )\n lfunc['Role']=role\n return lfunc\n \ndef create_mapping(name, stream):\n '''map to stream'''\n sources= l.list_event_source_mappings(FunctionName=name, EventSourceArn=stream['StreamARN'])['EventSourceMappings']\n if stream['StreamARN'] not in [s['EventSourceArn'] for s in sources]:\n source = l.create_event_source_mapping(FunctionName=name, EventSourceArn=stream['StreamARN'],StartingPosition='TRIM_HORIZON')\n else:\n for s in sources:\n source = s\n return source\n\nif __name__=='__main__':\n name= 'aaron'\n \n #create stream\n stream = create_stream(name)\n \n #create lambda function\n lfunc = create_function(name, 'lambda.zip', update=True)\n \n #mapping\n create_mapping(name, stream)\n \n \n \n# reference:\n# https://developmentseed.org/blog/2016/03/08/aws-lambda-functions/\n \n "
},
{
"alpha_fraction": 0.5373704433441162,
"alphanum_fraction": 0.551554799079895,
"avg_line_length": 33.59434127807617,
"blob_id": "aaf5812985ed26fc6f2315b8e9af1be0669a6b75",
"content_id": "fc7e3ccd967ad3b3ba6b3caa38b8de2e40e85070",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3668,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 106,
"path": "/waiter_lambda.py",
"repo_name": "novking/AWS_Lambda_DynamoDB_RDS",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\nimport json\nimport boto3\nimport time\nimport urllib\nprint ('Loading function')\n\ns3 = boto3.client('s3')\n\ndef lambda_handle(event, context):\n bucket = event['Records'][0]['s3']['bucket']['name']\n key = urllib.unquote_plus(event['Records'][0]['s3']['object']['key'])\n try:\n print(\"Using waiter to waiting for oject to persist on s3\")\n #waiter can suspend lambda runtime until object is completely uploaded to s3. \n #Document: \n '''Waiters use a client's service operations to poll the status of an AWS resource and suspend execution until the AWS resource reaches the state that the waiter is polling for or a failure occurs while polling.'''\n #http://boto3.readthedocs.io/en/latest/guide/clients.html\n \n waiter = s3.get_waiter('object_exists')\n # Retrieve waiter instance that will wait till a specified S3 bucket exists\n \n \n '''Then to actually start waiting, you must call the waiter's wait() method with the method's appropriate parameters passed in:'''\n waiter.wait(Bucket = bucket, Key = key)\n \n response = s3.head_object(Bucket=bucket, Key=key)\n \n #some output\n print(\"CONTENT TYPE: \" + response['ContentType'])\n print(\"ETag: \" + response['ETag'])\n print(\"Content-Length: \", response['ContentLength'])\n print(\"Keyname: \" + key)\n print(\"Deleting object…\" + key)\n \n #start to delete the object\n s3.delete_object(Bucket=bucket, Key=key)\n return response['ContentType']\n except Exception as e:\n print(e)\n print('Error getting object {} from bucket {}. Make sure they exist and your bucket is in the same region as this lambda function'.format(key, bucket))\n raise e\n \n \n \n \n#IAM\n'''\n{\n \"Effect\": \"Allow\",\n \"Action\": [\n \"s3:GetObject\",\n \"s3:DeleteObject\"\n ],\n \"Resource\": [\n \"arn:aws:s3:::*\"\n ]\n}\n'''\n\n#s3 structure\n\"\"\"\n{ \n \"Records\":[ \n { \n \"eventVersion\":\"2.0\",\n \"eventSource\":\"aws:s3\",\n \"awsRegion\":\"us-east-1\",\n \"eventTime\":The time, in ISO-8601 format, for example, 1970-01-01T00:00:00.000Z, when S3 finished processing the request,\n \"eventName\":\"event-type\",\n \"userIdentity\":{ \n \"principalId\":\"Amazon-customer-ID-of-the-user-who-caused-the-event\"\n },\n \"requestParameters\":{ \n \"sourceIPAddress\":\"ip-address-where-request-came-from\"\n },\n \"responseElements\":{ \n \"x-amz-request-id\":\"Amazon S3 generated request ID\",\n \"x-amz-id-2\":\"Amazon S3 host that processed the request\"\n },\n \"s3\":{ \n \"s3SchemaVersion\":\"1.0\",\n \"configurationId\":\"ID found in the bucket notification configuration\",\n \"bucket\":{ \n \"name\":\"bucket-name\",\n \"ownerIdentity\":{ \n \"principalId\":\"Amazon-customer-ID-of-the-bucket-owner\"\n },\n \"arn\":\"bucket-ARN\"\n },\n \"object\":{ \n \"key\":\"object-key\",\n \"size\":object-size,\n \"eTag\":\"object eTag\",\n \"versionId\":\"object version if bucket is versioning-enabled, otherwise null\",\n \"sequencer\": \"a string representation of a hexadecimal value used to determine event sequence, \n only used with PUTs and DELETEs\" \n }\n }\n },\n {\n // Additional events\n }\n ]\n} \n\"\"\""
},
{
"alpha_fraction": 0.4789755344390869,
"alphanum_fraction": 0.48126912117004395,
"avg_line_length": 30.914634704589844,
"blob_id": "26de0d54572ef5f00cb15049f767e2fa8f3797b3",
"content_id": "1d7fb0e3062760b64570a66d5a209c2195aef0d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2616,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 82,
"path": "/CreateAccount/index.js",
"repo_name": "novking/AWS_Lambda_DynamoDB_RDS",
"src_encoding": "UTF-8",
"text": "console.log('Loading function');\n\nvar doc = require('dynamodb-doc');\nvar dynamo = new doc.DynamoDB();\nvar fs = require('fs');\nvar mysql = require('mysql');\n\nfunction readModuleFile(path, callback){\n try{\n var filename = require.resolve(path);\n fs.readFile(filename, 'utf8', callback);\n }\n catch(e){\n callback(e);\n }\n}\n\nexports.handler = function(event, context){\n console.log('Received event:', JSON.stringify(event, null, 2));\n var username = event.name;\n var password = event.password;\n var conn = mysql.createConnection({\n host:'AWS RDS endpoint',//im using windows, don't want to install CLI\n user: 'user',\n ssl: 'Amazon RDS',\n password:'mypassword',\n database:'the_data_base_name'\n });\n \n conn.connect(function(err){\n if (err){\n console.error('error connecting: '+ err.stack);\n return;\n }\n console.log('connected as id' + conn.threadId);\n });\n \n var sql = 'INSERT INTO login (name, password) VALUES(\"'+username+'\",\"'+password+'\")';\n var result = conn.query(sql, function(error, info){\n if (error){\n console.log(error.message);\n if(error.errno==1062){\n console.log(\"already exists\");\n };\n readModuleFile('./unsuccessful.txt', function(err, alreadyexit){\n var resp = alreadyexit;\n context.succeed({\"respon\":resp});\n });\n }\n else{\n console.log(\"trying to add the no status\");\n var row_id = info.insertId;\n console.log(\"the info contains:\", info);\n console.log(\"the row_id:\", info.insertId);\n var name = event.name;\n var status = \"No Status\";\n dynamo.putItem({\n \"TableName\":\"status\",\n \"Item\":{\n \"UserId\":row_id,\n \"name\": name,\n \"status\":status,\n }\n },\n function(err, data){\n if(err){\n console.log(err);\n }\n else{\n console.log(data);\n console.log(\"Status updated\");\n readModuleFile('./successful.txt', function(err, added){\n var res = added;\n console.log('success');\n console.log(\"insert values in to database:\", result.sql);\n context.succeed({\"respon\":res});\n });\n }\n });\n }\n });\n}"
}
] | 5 |
brittanymareeott/LOQ_Compliance_FDA | https://github.com/brittanymareeott/LOQ_Compliance_FDA | a733c2116f1ab504636f4c037dcdf1d4bdeac98c | d3e3e7de6f4ae496980bd64e69e3cf0f1857fe0b | cbd524b017d748850716ac60a0cbfa54a172ccf9 | refs/heads/master | 2020-09-26T05:09:04.627341 | 2019-12-12T18:15:53 | 2019-12-12T18:15:53 | 225,947,789 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5654600858688354,
"alphanum_fraction": 0.5687016248703003,
"avg_line_length": 46.879310607910156,
"blob_id": "feffb5353c34fdddff1b4c7a64dc1cccaed737b8",
"content_id": "eef1ba79bb19251c4982b80ac29d9f6c51b324cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5553,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 116,
"path": "/loq_compliance/test_csv6.py",
"repo_name": "brittanymareeott/LOQ_Compliance_FDA",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n############################# Documentation #############################\n# test_csv6.py #\n# #\n# Author: Brittany M. Ott #\n# #\n# This script allows the user to parse down a .tsv file produced #\n# by the Total Diet Study at the FDA. It produces two files: #\n# 1) An output `.txt` file that contains all samples where the #\n# concentration of the analyte of interest is greater than the #\n# sample's LOQ (limit of quantitation); and 2) An output `.txt` #\n# file containing all samples where the analyte requested is not #\n# detected. #\n# #\n# For documentation used to generate this script, please visit: #\n# * Python's argparse page: #\n# https://docs.python.org/dev/library/argparse.html#argparse.Namespace #\n# * Pandas's API reference page: #\n# https://pandas.pydata.org/pandas-docs/stable/reference/index.html #\n# * PyPi's chardet page: #\n# https://chardet.readthedocs.io/en/latest/ #\n# #\n# The script takes 3 required arguments: #\n# 1) --file | The Total Diet Study file that is to be analyzed (`.txt`) #\n# 2) --analyte | The analyte to be extracted (e.g. Arsenic), this is #\n# case sensitive #\n# 3) --type | The type of analyte that the Total Diet study is #\n# examining (e.g. Element), this is case sensitive #\n# #\n# This script currently also takes two arguments that are optional: #\n# 1) --cutoff | This allows the user to specify a new cutoff #\n# concentration; default=None #\n# 2) --filename | This allows the user to specify a file name for the #\n# output files; default=outfile.txt and nodetect.txt, output as TSV #\n# #\n# usage: python test_csv6.py [-h] --file FILE --analyte ANALYTE # \n# --type TYPE [--cutoff CUTOFF] [--filename FILENAME] #\n#########################################################################\n\n\n# import the necessary packages\nimport csv\nimport pandas as pd\nimport numpy as np\nfrom pandas import DataFrame\nimport argparse\nimport sys\nimport chardet\n\n#### Importing the data ####\n\n# Parsing arguments with argparse\nparser = argparse.ArgumentParser(description = 'This script allows data selection for various requested analytes from Total Diet Studies at the FDA.')\nparser.add_argument('--file', required=True, help='The Total Diet Study file to be analyzed.')\nparser.add_argument('--analyte', required=True, help='The analyte that is to be extracted, e.g. Arsenic. CASE SENSITIVE.')\nparser.add_argument('--type', required=True, help='The type of analyte that the Total Diet Study input file is measuring, e.g. Element. CASE SENSITIVE.')\n# parser.add_argument('--number', required=False, help='optional: The Food Number associated with a specific food.')\nparser.add_argument('--cutoff', required=False, type=float, help='optional: Specifiy a new cut-off concentration, default=None.')\nparser.add_argument('--filename', required=False, default='outfile', help='optional: name of the file, default=outfile.txt and nodetect.txt, output as TSV')\nargs = parser.parse_args()\n\n#### Cleaning up the data ####\n\n# determining the file encoding for reading by pandas\nrawdata = open(args.file, 'rb').read()\nresult = chardet.detect(rawdata)\ncharenc = result['encoding']\n\n### Processing the Data ###\n\n# reading in the file\nfile = pd.read_csv(args.file, sep='\\t', encoding=charenc)\n\n# obtaining the rows that contain the desired analyte\ndf1 = file[file[args.type].str.contains(args.analyte)]\n\n#incorporating food number; currently sorting this out\n#df2 = df1[df1['Food No.'].str.contains(args.number))]\n\n# removes rows containing RAP\ndf_remove = df1[df1['Sample Qualifier'].str.contains('UAP', '', na=True, regex=False)]\n\n#### LOQ compliance ####\n\n# generating a dataframe that compares the concentration detected to a cut off\n# *note*: currently working on a way to compare the new cutoff with the LOQ column\nif args.cutoff == None:\n\tLOQ_compliant = df_remove[df_remove['Conc'] > df_remove['LOQ']] # if no cutoff is provided\nelse:\n\tLOQ_compliant = df_remove[df_remove['Conc'] > args.cutoff] # if a cutoff is provided\n\nNo_detect = df_remove[df_remove['Conc'] == 0]\n\n#### Generating the output file ####\n\n# Code for printing LOQ compliant to a file \nif args.filename == None:\n\toutput_LOQ = open('outfile.txt', 'w')\nelse:\n\toutput_LOQ = open(args.filename + '_outfile.txt', 'w')\n\nLOQ_compliant.to_csv(output_LOQ, sep='\\t')\n\noutput_LOQ.close()\n\n# Code for printing the No Detect to a file\nif args.filename == None:\n\toutput_nodetect = open('No_detect.txt', 'w')\nelse:\n\toutput_nodetect = open(args.filename + '_nodetect.txt', 'w')\n\nNo_detect.to_csv(output_nodetect, sep='\\t')\n\noutput_nodetect.close()"
},
{
"alpha_fraction": 0.7347062230110168,
"alphanum_fraction": 0.7359176278114319,
"avg_line_length": 41.33333206176758,
"blob_id": "d4d865918a6ee25668c56ebbe2c2a75132b57ad2",
"content_id": "876d077ba6c209d0a3edbffe704302b9c61e95ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1651,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 39,
"path": "/tests/test_csv2.py",
"repo_name": "brittanymareeott/LOQ_Compliance_FDA",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# import the necessary packages\nimport csv\nimport pandas as pd\nfrom pandas import DataFrame\nimport argparse\nimport sys\nimport chardet\n\n# Parsing arguments with argparse\nparser = argparse.ArgumentParser(description = 'This script allows data selection for various requested analytes from Total Diet Studies at the FDA.')\nparser.add_argument('--file', required=True, help='The Total Diet Study file to be analyzed.')\nparser.add_argument('--analyte', required=True, help='The analyte that is to be extracted, e.g. Arsenic.')\nparser.add_argument('--type', required=True, help='The type of analyte that the Total Diet Study input file is measuring, e.g. Element.')\nparser.add_argument('--out', required=True, help='The directory where you want output files written.')\nparser.add_argument('--number', required=False, help='optional: The Food Number associated with a specific food.')\nparser.add_argument('--cutoff', required=False, help='optional: Specifiy a new cut-off concentration, default=0.')\nargs = parser.parse_args()\n\nrawdata = open(args.file, 'rb').read()\nresult = chardet.detect(rawdata)\ncharenc = result['encoding']\n\nwith open(args.file, newline='', encoding=charenc) as csvfile:\n csvreader = csv.reader(csvfile, delimiter='\\t')\n rows = [r for r in csvreader]\n# check consistency of rows\nprint(len(rows))\nprint(set((len(r) for r in rows)))\nprint(tuple(((i, r) for i, r in enumerate(rows) if len(r) == bougus_nbr)))\n# find bougus lines and modify in memory, or change csv and re-read it.\n\n# Code for printing to a file \noutput = open('Results.txt', 'w') \n \nprint(file, file = output) \noutput.close()\n"
},
{
"alpha_fraction": 0.7614411115646362,
"alphanum_fraction": 0.7633885145187378,
"avg_line_length": 38.5,
"blob_id": "e806c3ce7ae5dbb06729a3a7fa457465d279d243",
"content_id": "a02ffca709d987acbe2c444ad588b9473451d64a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1027,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 26,
"path": "/tests/test_argparse.py",
"repo_name": "brittanymareeott/LOQ_Compliance_FDA",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# import the necessary packages\nimport csv\nfrom pandas import DataFrame\nimport argparse\nimport sys\nimport chardet\n\n# Parsing arguments with argparse\nparser = argparse.ArgumentParser(description = 'This script allows data selection for various requested analytes from Total Diet Studies at the FDA.')\nparser.add_argument('--file', required=True, help='The Total Diet Study file to be analyzed.')\nparser.add_argument('--analyte', required=True, help='The analyte that is to be extracted, e.g. Arsenic.')\nparser.add_argument('--type', required=True, help='The type of analyte that the Total Diet Study input file is measuring, e.g. Element.')\nparser.add_argument('--number', required=False, help='optional: The Food Number associated with a specific food.')\nparser.add_argument('--cutoff', required=False, type=float, help='optional: Specifiy a new cut-off concentration, default=0.')\nargs = parser.parse_args()\n\nfloat(args.cutoff)\n\nprint(type(args.cutoff))\n\nprint(args.cutoff)\n\nprint(args)\n"
},
{
"alpha_fraction": 0.7211855053901672,
"alphanum_fraction": 0.7241126894950867,
"avg_line_length": 34.0512809753418,
"blob_id": "269e8f4722f0f99b99e821f229a4b5c2d4d466c1",
"content_id": "9ce588dd3840632ff5f030f13560e39cf9b0f1dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2733,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 78,
"path": "/tests/test_csv6.py",
"repo_name": "brittanymareeott/LOQ_Compliance_FDA",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# import the necessary packages\nimport csv\nimport pandas as pd\nimport numpy as np\nfrom pandas import DataFrame\nimport argparse\nimport sys\nimport chardet\n\n#### Importing the data ####\n\n# Parsing arguments with argparse\nparser = argparse.ArgumentParser(description = 'This script allows data selection for various requested analytes from Total Diet Studies at the FDA.')\nparser.add_argument('--file', required=True, help='The Total Diet Study file to be analyzed.')\nparser.add_argument('--analyte', required=True, help='The analyte that is to be extracted, e.g. Arsenic. CASE SENSITIVE.')\nparser.add_argument('--type', required=True, help='The type of analyte that the Total Diet Study input file is measuring, e.g. Element. CASE SENSITIVE.')\nparser.add_argument('--number', required=False, help='optional: The Food Number associated with a specific food.')\nparser.add_argument('--cutoff', required=False, type=float, help='optional: Specifiy a new cut-off concentration, default=None.')\nparser.add_argument('--filename', required=False, default='outfile', help='optional: name of the file, default=outfile.txt, output as TSV')\nargs = parser.parse_args()\n\n#### Cleaning up the data ####\n\n# determining the file encoding for reading by pandas\nrawdata = open(args.file, 'rb').read()\nresult = chardet.detect(rawdata)\ncharenc = result['encoding']\n\n##### Processing the Data #####\n\n# reading in the file\nfile = pd.read_csv(args.file, sep='\\t', encoding=charenc)\n\n# obtaining the rows that contain the desired analyte\ndf1 = file[file[args.type].str.contains(args.analyte)]\n\n#incorporating food number; currently sorting this out\n#df2 = df1[df1['Food No.'].str.contains(args.number))]\n\n# removes rows containing RAP\ndf_remove = df1[df1['Sample Qualifier'].str.contains('UAP', '', na=True, regex=False)]\n\n#### LOQ compliance ####\n\n# generating a dataframe that compares the concentration detected to a cut off\nif args.cutoff == None:\n\tLOQ_compliant = df_remove[df_remove['Conc'] > df_remove['LOQ']] # if no cutoff is provided\nelse:\n\tLOQ_compliant = df_remove[df_remove['Conc'] > args.cutoff] # if a cutoff is provided\n\nNo_detect = df_remove[df_remove['Conc'] == 0]\n\n# tests \n\n#### Generating the output file ####\n\n# Code for printing LOQ compliant to a file \nif args.filename == None:\n\toutput_LOQ = open('outfile.txt', 'w')\nelse:\n\toutput_LOQ = open(args.filename + '_outfile.txt', 'w')\n\nLOQ_compliant.to_csv(output_LOQ, sep='\\t')\n\noutput_LOQ.close()\n\n# Code for printing the No Detect to a file\nif args.filename == None:\n\toutput_nodetect = open('No_detect.txt', 'w')\nelse:\n\toutput_nodetect = open(args.filename + '_nodetect.txt', 'w')\n\nNo_detect.to_csv(output_nodetect, sep='\\t')\n\noutput_nodetect.close()"
},
{
"alpha_fraction": 0.7916434407234192,
"alphanum_fraction": 0.7961002588272095,
"avg_line_length": 162.18182373046875,
"blob_id": "08505ec26f656e60a82837dd564cddb449de11fe",
"content_id": "bba10800158241f229bcf98ce2dd2862f98078bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1795,
"license_type": "no_license",
"max_line_length": 845,
"num_lines": 11,
"path": "/README.md",
"repo_name": "brittanymareeott/LOQ_Compliance_FDA",
"src_encoding": "UTF-8",
"text": "# LOQ_Compliance_FDA\n\nIn the FDA, a number of studies result in file upon file of datasheets, and many times, these sheets are hard to process in programs such as Microsoft's excel. As a result, small scripts such as these can really speed up analysis. Also, when reporting or studying a certain analyte, such as Arsenic, Cesium-137, or various pesticides, you don't want to wade through line upon line of data that is unnecessary.\n\nAdditionally, detection of these analytes usually has a limit depending on what you are looking at, and in what kind of food you are looking at it in. Therefore, Total Diet Studies contain what is call the LOQ, or limit of quantitation. If the concentration of the analyte is below the LOQ, the results are not necessarily reliable, so that anything that registers as \"detected\", the concentration must be above the LOQ to be considered a valid reading. Therefore, this script will output a file where the LOQ has been considered. As an added parameter, the user has the option of introducing another cutoff score beyond the LOQ (_note: this script will soon backcheck the new cutoff score with the LOQ to ensure that any new cutoff requested is above the LOQ as well and warns the user if their new cutoff is above or below the designated LOQ).\n\nFinally, an additional file is output where all samples that meet the analyte criteria where there was no detection of the analyte (concentration = 0), as this information is just as important.\n\nThis script will hopefully speed up data analysis in regards to Total Diet Studies.\n\nPlease refer to the [LOQ Compliance Folder](https://github.com/brittanymareeott/LOQ_Compliance_FDA/tree/master/loq_compliance) for the latest version of the working script as well as an example file to work with (`Elements_2003.txt`).\n"
},
{
"alpha_fraction": 0.7461140155792236,
"alphanum_fraction": 0.7475943565368652,
"avg_line_length": 39.93939208984375,
"blob_id": "4a4588dfb1d43bc1317af26bbb68d2de780f2f42",
"content_id": "2f5148eed3082c74794e202a3ab8da65346f2c72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1351,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 33,
"path": "/tests/test_csv.py",
"repo_name": "brittanymareeott/LOQ_Compliance_FDA",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding: utf-8\n\n# import the necessary packages\nimport csv\nimport pandas as pd\nfrom pandas import DataFrame\nimport argparse\nimport sys\nimport chardet\n\n# Parsing arguments with argparse\nparser = argparse.ArgumentParser(description = 'This script allows data selection for various requested analytes from Total Diet Studies at the FDA.')\nparser.add_argument('--file', required=True, help='The Total Diet Study file to be analyzed.')\nparser.add_argument('--analyte', required=True, help='The analyte that is to be extracted, e.g. Arsenic.')\nparser.add_argument('--type', required=True, help='The type of analyte that the Total Diet Study input file is measuring, e.g. Element.')\nparser.add_argument('--out', required=True, help='The directory where you want output files written.')\nparser.add_argument('--number', required=False, help='optional: The Food Number associated with a specific food.')\nparser.add_argument('--cutoff', required=False, help='optional: Specifiy a new cut-off concentration, default=0.')\nargs = parser.parse_args()\n\nrawdata = open(args.file, 'rb').read()\nresult = chardet.detect(rawdata)\ncharenc = result['encoding']\n\n#CSV file loading\nfile = pd.read_csv(args.file, sep='\\t', encoding=charenc)\n\n# Code for printing to a file \noutput = open('Results.txt', 'w') \n \nprint(file, file = output) \noutput.close()\n"
}
] | 6 |
coinlab/bitcoin-docs | https://github.com/coinlab/bitcoin-docs | 34ff10c5d50d693bb082e617c0179b7d27ce35b7 | 172b745e12a2a13d6d59f97d5038cd704522c1cb | 98055cb039fba0f6a2750c18847ca5b892e5e3b5 | refs/heads/master | 2021-01-19T07:13:31.251700 | 2012-01-08T22:43:39 | 2012-01-08T22:43:39 | 3,081,473 | 4 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.4539363384246826,
"alphanum_fraction": 0.4974874258041382,
"avg_line_length": 20.321428298950195,
"blob_id": "c2021bb43c023251237f56752fe6fde021c97a30",
"content_id": "6b44671fb34c69abb1719ea77de9e1cfa368448b",
"detected_licenses": [
"CC-BY-3.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 597,
"license_type": "permissive",
"max_line_length": 53,
"num_lines": 28,
"path": "/bin/strip-unicode.py",
"repo_name": "coinlab/bitcoin-docs",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport sys\nimport codecs\n\ntranslations = {0x2018: u\"'\",\n 0x2019: u\"'\",\n 0x201C: u'\"',\n 0x201D: u'\"',\n 0x2013: u'-',\n }\n\ndef main():\n for file_name in sys.argv[1:]:\n print file_name\n strip_file(file_name)\n\ndef strip_file(file_name):\n f = codecs.open(file_name, encoding='utf-8')\n t = f.read()\n t = t.translate(translations).encode('ascii')\n f.close()\n f = codecs.open(file_name, 'w', encoding='utf-8')\n f.write(t)\n f.close()\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5970588326454163,
"alphanum_fraction": 0.6264705657958984,
"avg_line_length": 27.33333396911621,
"blob_id": "58c11a34c3073211763ab03387b7af9c6c338ab9",
"content_id": "a1356b435b797934d3eaeec65fe9266361c60443",
"detected_licenses": [
"CC-BY-3.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 340,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 12,
"path": "/bin/make-pdf.sh",
"repo_name": "coinlab/bitcoin-docs",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nBINDIR=$(cd `dirname $0` && pwd)\n\nif [ \"$1\" == \"\" ]; then\n echo \"Usage: $0 base-name\"\n echo \"Produces base-name.html and base-name.pdf from base-name.md.\"\n exit 1\nfi\n\n$BINDIR/Markdown.pl $1.md > $1.html\npisa -s --encoding=utf8 --css=default.css $1.html\n# htmldoc --links --webpage --footer format=pdf -f $1.pdf $1.html\n"
},
{
"alpha_fraction": 0.6218181848526001,
"alphanum_fraction": 0.6527272462844849,
"avg_line_length": 33.375,
"blob_id": "36dac328c11a9378a2a29befa580d5d72a621516",
"content_id": "dab1c8bbfaea49c8b6f072316c65f2d18b199e60",
"detected_licenses": [
"CC-BY-3.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 550,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 16,
"path": "/bin/make-tex-pdf.sh",
"repo_name": "coinlab/bitcoin-docs",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nBINDIR=$(cd `dirname $0` && pwd)\n\nif [ \"$1\" == \"\" ]; then\n echo \"Usage: $0 base-name\"\n echo \"Produces base-name.tex, base-name.pdf, and base-name.epub from base-name.md.\"\n exit 1\nfi\n\npandoc -f markdown -t latex --template=template.tex $1.md -o $1.tex\npandoc -f markdown -t epub --template=template.tex $1.md -o $1.epub\nmarkdown2pdf $1.md --template=template.tex -o $1.pdf\n\n# $BINDIR/Markdown.pl $1.md > $1.html\n# pisa -s --encoding=utf8 --css=default.css $1.html\n# htmldoc --links --webpage --footer format=pdf -f $1.pdf $1.html\n"
},
{
"alpha_fraction": 0.7400530576705933,
"alphanum_fraction": 0.7559681534767151,
"avg_line_length": 46.125,
"blob_id": "5839cedd59dea700c167b002fd0bdcb82c5df904",
"content_id": "36e9aef2fd599ff1f0040424ddc76ecf3deee544",
"detected_licenses": [
"CC-BY-3.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1131,
"license_type": "permissive",
"max_line_length": 345,
"num_lines": 24,
"path": "/readme.md",
"repo_name": "coinlab/bitcoin-docs",
"src_encoding": "UTF-8",
"text": "# Bitcoin-related documentation files.\n\n- [A Bitcoin Primer](https://github.com/coinlab/bitcoin-docs/blob/master/a-bitcoin-primer.md)\n\n## License\n\n<a rel=\"license\" href=\"http://creativecommons.org/licenses/by/3.0/\"><img alt=\"Creative Commons License\" style=\"border-width:0\" src=\"http://i.creativecommons.org/l/by/3.0/88x31.png\" /></a><br />This work is licensed under a <a rel=\"license\" href=\"http://creativecommons.org/licenses/by/3.0/\">Creative Commons Attribution 3.0 Unported License</a>.\n\n## Building\n\nDocuments are written in [Markdown] format and designed to be easy to edit and repurpose. This\ndirection contains generated HTML and PDF version as well. We use the [XHTML2PDF] converter for\ngenerating PDF documents.\n\n pip install reportlab xhtml2pdf\n\n*Note: I had errors installing xhtml2pdf from pip - using the current github repo and running setup.py fixed it.*\n\nFor example, to generate HTML and PDF versions type:\n\n bin/make-pdf.sh a-bitcoin-primer\n\n [Markdown]: http://daringfireball.net/projects/markdown/ \"Markdown\"\n [XHTML2PDF]: https://github.com/chrisglass/xhtml2pdf \"HTML/CSS to PDF converter - Python\"\n"
},
{
"alpha_fraction": 0.787345290184021,
"alphanum_fraction": 0.7971079349517822,
"avg_line_length": 56.1985969543457,
"blob_id": "b2890403479441e72552dc4785427e4e58e5d195",
"content_id": "f4489cc6fb6f1ff9e14e6ce9c2b4c662a85783db",
"detected_licenses": [
"CC-BY-3.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 24481,
"license_type": "permissive",
"max_line_length": 196,
"num_lines": 428,
"path": "/a-bitcoin-primer.md",
"repo_name": "coinlab/bitcoin-docs",
"src_encoding": "UTF-8",
"text": "# A Bitcoin Primer\n\n<div id=\"footer\">\n<table><tr>\n <td>A Bitcoin Primer</td>\n <td style=\"text-align: center;\">- <pdf:pagenumber/> -</td>\n <td style=\"text-align: right;\">Jan-01-2012</td>\n</tr></table>\n</div>\n\n<p class=\"author\">\n<i>\nby CoinLab.com\n<br/>Authors: Chris Koss, Mike Koss\n<br/>January 1, 2012\n</i>\n<pdf:nexttemplate name=\"two-column\"/>\n</p>\n\nWhat if you could store and transfer money safely, securely, cheaply and quickly\nanywhere in the world yourself, without relying on anyone else?\n\nBitcoin is a new technology that has the potential of supplanting many of our\ncontemporary banking and money transfer services (at least in the online\neconomy).\n\n## What is Bitcoin?\n\nThe term *Bitcoin* refers to both the digital unit of stored value and the\npeer-to-peer network of computers transmitting and validating transactions of\nthese units. The project was publicly [launched in January 2009][Nakamoto], by a\nmysterious inventor using the pseudonym \"Satoshi Nakamoto,\" whose identity is\nstill a mystery. For the first couple of years, it was mostly just a novelty for\ncomputer geeks, hackers, and idealistic anarchists.\n\nIn April 2011, Forbes Magazine's Andy Greenberg wrote an [article][Greenberg]\ndescribing the qualities of Bitcoin: it cannot be forged or double-spent,\ncontrolled or inflated by any government, it is not impeded by international\nboundaries, has a geek-friendly economy of $30,000 per day, and some digital\ndrug-dealers have started accepting it.\n\nThe price of a Bitcoin surged from less than a dollar to over $30 as a new\ndemographic became interested: speculators. Geeks who had casually collected\nBitcoin as a curiosity in 2009 found themselves sitting on tens, or even\nhundreds, of thousands of dollars. Over the next several months, Bitcoin prices\nwere extremely volatile, dropping suddenly after each of a half dozen high\nprofile incidents. Exchanges were hacked, Bitcoins were lost from carelessness,\nviruses popped up which stole any Bitcoin it could find, and some services\nclosed without warning, disappearing with their customers' money.\n\nAs users learned better and safer practices for handling their Bitcoin, price\nvolatility decreased, and the price of a Bitcoin has climbed to over $5.\nMany new services popped up including margin trading and short selling, digital\ndownloads, banking and escrow services, a World-of-Warcraft-style MMORPG where\nyou can gamble on everything with Bitcoin, web hosting, domain name\nregistration, web design, and currency exchanges.\n\n## How does Bitcoin work?\n\nA Bitcoin *address* is like a bank account, into which a user can receive,\nstore, and send Bitcoins. Instead of being physically secured in a vault,\nBitcoins are secured with public-key cryptography. Each address consists of a\npublic key, which is published, and a private key, which you must keep secret.\nAnyone can send Bitcoins to any public key, but only the person with the private\nkey can spend them. While addresses are public, nobody knows which addresses\nbelong to which people; Bitcoin addresses are pseudonymous.\n\nThe Bitcoin protocol uses [the strongest algorithms][Yang] used by the NSA for\nencrypting Secret level documents. Anyone can generate as many addresses as they\nwant for free. There are approximately as many possible Bitcoin addresses as\nthere are atoms in the Earth, so generating duplicate addresses (and thus having\naccess to someone else's funds) is practically impossible. Most Bitcoin users\nmaintain a number of addresses, stored in a digital wallet.\n\nWhen someone wants to send money to another user, they use software which\ncreates a transaction containing the receiver's address and an amount, and\ncryptographically signs it with their private key. This is published on a\npeer-to-peer network which validates it against the sender's public key, checks\nthat the sending address's balance is sufficient, and propagates it to all the\nother nodes on the network.\n\nA transaction does not become certified until it is included in a Block in the\nBitcoin Block Chain.\n\nToday, there are thousands of computers *mining* on the Bitcoin network. Each\ncomputer collects transactions broadcast by other nodes and tries to guess a\nnumber which solves an unpredictable cryptographic problem. A powerful home\ncomputer can try 100's of millions of numbers every second. The more computers\nthat mine, the more difficult finding a solution becomes; the difficulty is\nself-adjusting so that, on average, a new block is found every 10 minutes. The\nlucky computer that is the first to find each block earns 50 Bitcoins for its\nowner.\n\nAs each Block is found, it is added to an ever-growing *Block Chain* (now\nstanding at over [150,000 Blocks][Bitcoin Difficulty]). Any transaction listed\nin the Block Chain is deemed to be valid, and eliminates the possibility that\nBitcoins can be doubly-spent. Since the only way to re-write history in the\nBlock Chain is to use more computing power than is available in the rest of the\nBitcoin network, it is generally deemed too costly for any single party to cheat\n(the raw computing power of the Bitcoin network is 10 times that of the world's\nlargest supercomputing center).\n\nThe Block Chain allows every Bitcoin client to examine the complete historical\ntransaction record to determine the current account balance of every public\naddress in the system.\n\nSince newly created Bitcoins are constantly issued to miners, one would think\nthat the currency is inherently inflationary (with an ever expanding money\nsupply). While that is true in the short-term, the rate of issuing coins is\nscheduled to be cut in half every four years. So, while 2.6M Bitcoins are\ncreated each year (until January 2013), there will never be more that [21M total\nBitcoins created][BitcoinGraph]. And since Bitcoins are almost infinitely\ndivisible (up to 8 decimal places), there is no fear that we won't have enough\nBitcoins to deal with an ever expanding economic base of Bitcoin-denominated\ntransactions.\n\n## What are the benefits of Bitcoin?\n\n### Financial Self-Determinism and Control\n\nThe Bitcoin system is unique because it is the first digital store of value\nwhich can be safely and securely saved and transacted by individuals, without\nhaving to rely on a trusted third party. Once acquired and properly secured,\nBitcoins can't be taken from their owner, by a thief, a bank, or a government.\nNeither can any entity freeze any account, nor prevent the owner from performing\n(essentially free) transactions on the Bitcoin network.\n\n### Irrevocable Transactions\n\nChargebacks are a big problem for many merchants. Virtually all current payment\nsystems (credit card, inter-bank transfer, PayPal, etc.) allow the consumer to\nrefute a transaction, and have their funds returned to them. Merchants have to\nfollow an expensive dispute process to receive their money and sometimes pay\nfees of $10-$50 per chargeback. Merchants can be charged additional penalties\n[up to $25,000][Visa Chargebacks] if they have an unusually high rate of\nchargebacks.\n\nOnline merchants have chosen to live with a certain amount of fraudulent\nchargebacks while expending company resources on various anti-fraud detection\nmeasures. In an effort to minimize chargebacks, merchants typically ask their\ncustomers to reveal personal information about themselves beyond what is necessary to\ndeliver their product or service, leading to a loss of personal privacy for the\nconsumer.\n\nBitcoin transactions reverse the role of trust by being inherently irrevocable.\nOnce certified in the Block Chain, a transaction cannot be (practically)\nreversed. It is incumbent on the consumer to trust each merchant they are\nordering from. Since there are many ways to establish the credibility of a\nmerchant (e.g., online ratings and word-of-mouth reputation), the Bitcoin trust system is\na good match for Internet commerce (verifying the trustworthiness of\nmerchants is much easier than verifying the trustworthiness of all consumers).\n\nBecause Bitcoin payments cannot be reversed (without the consent of the\nmerchant), merchants can offer their products to a wider audience and require\nless personal information from their customers.\n\n### No Need for Middlemen\n\nThe policies of payment processors are sometimes not well aligned with those\nreceiving money; e.g., people who take donations.\n\nIn December 2011, [Regretsy][Regretsy Cats], a humorous snarky craft blog,\nraised donations to buy Christmas presents for children in families undergoing\nfinancial hardship. After raising thousands of dollars, Regretsy's PayPal\naccount was frozen.\n\nWhen Regretsy's writer, Helen Killer, contacted PayPal support, she was told\nthat her account was frozen because PayPal's \"Donate\" button can only be used by\nnon-profit organizations. PayPal later admitted this is false: any company can\nuse a \"Donate\" button. But PayPal support told her \"it's not a worthy cause, it's\ncharity,\" and that she would need to make a new website if she wanted to keep\nraising money, and that gifts couldn't be shipped to a different address from\nthe customer who paid for them (which was odd during the holiday gift-giving\nseason).\n\nBy publicizing her frustrating experience on her blog, she\neventually got an apology from PayPal, and they unfroze her account. But there\nare many similar stories from other PayPal users who have had accounts closed or\nfunds frozen. Without an audience to create a public outcry, many still haven't\nhad their situations remedied.\n\n[Alex King][King] is an open source software developer who stopped accepting\ndonations when some of them started costing him money. In 2009, after an\nanonymous user donated $1 ($0.67 after PayPal's fees), they charged back their\ndonation. PayPal then passed a $10 chargeback fee onto King, without any prior\nwarning. He says, \"I was never able to issue a refund to avoid this charge - the\nrefund link was unavailable as the payment was listed as in dispute.\"\n\nPayPal exposes sellers to the risks of frozen accounts and chargeback fees. The\nbenefit of PayPal, giving customers the ability to get their money back if they\ndon't receive what they paid for, does not apply in the donation scenario.\nBitcoin transactions are irreversible and can be accepted without a middle man.\nAs a result, Bitcoin donations can be accepted without worrying about these\nrisks.\n\n### Low Cost Transactions\n\nIn addition to the unanticipated risks of using payment processors (e.g., frozen\naccounts and chargebacks), the known per-transaction costs of these services can\nsignificantly cut into the profits of some businesses.\n[PayPal](https://cms.paypal.com/cgi-bin/marketingweb?cmd=_render-content&content_ID=merchant/merchant_fees),\n[Google Checkout](https://checkout.google.com/seller/fees.html) and [Amazon\nCheckout's](https://payments.amazon.com/sdui/sdui/business/cba#pricing) rates\nall start at 2.9% + $0.30 per transaction, decreasing to 1.9% for merchants with\nover $30,000 of transactions per month. Otherwise viable businesses with low profit\nmargins or requiring many small transactions may not be profitable due to these\nfees.\n\nBitcoin transaction fees are voluntary and payments can be accepted directly by\nmerchants. Assuming a gross profit margin of 20%, eliminating processing fees\nwould increase a merchant's profit by 10%, as these expenses would come directly\noff the bottom line.\n\n<!-- Hack - Widow control not working -->\n<pdf:nextframe>\n### A World-Wide System\n\nUnlike current payment processing systems, Bitcoins are inherently world-wide\nand multi-national. There are no artificial barriers for making payments across\nnational boundaries; in fact, it's impossible to verify a transaction's country\nof origin. A merchant accepting Bitcoins immediately has access to a world-wide\nmarket, without any risk of non-payment from those outside his own country's\nlegal enforcement system.\n\n### An Inflation Hedge for Long-term Savings\n\nBecause the lifetime creation limit is 21M Bitcoins, it may be that they will\nbe a good way to store long-term value as a hedge against inflation. This may be\nespecially true for citizens of countries that are experiencing run-away\ninflation. If they can transfer their earnings to Bitcoins, they can be isolated\nfrom the rapid inflation of their native currency, and only convert back when\nneeded to purchase goods or services using their native currency.\n\nWhile this strategy is premature due to Bitcoin's very volatile valuation today,\nit may become common as Bitcoin becomes more widely adopted and develops a\nhistory of value stability.\n\n## What are the Inherent Risks of Bitcoins?\n\n### Irrevocable Transactions\n\nMerchants do not have to trust their customers to verify payments, but customers\nhave to now trust merchants to deliver the goods or services they have paid for.\nThere are methods to alleviate this problem; for example, use of third-party\ntrusted escrow services which require merchants to post a performance bond and\nenter into binding arbitration of disputes.\n\n### Underlying Value and Volatility in Prices\n\nWhat is a Bitcoin worth? The underlying value is a function of the demand of the\ncurrency by consumers, and their ability to use it to exchange it for other\ngoods and services. Just as fiat currencies no longer are tied to the value of\nan underlying commodity, like gold, Bitcoins are only valuable in as much as\npeople want them and use them.\n\nNumerous public exchanges exist for people to buy and sell Bitcoin in exchange\nfor dollars or other currencies. This helps establish an underlying comparative\nvalue and allows merchants to cash out of their Bitcoin holdings on a regular\n(e.g., daily) basis, minimizing their exposure to any currency volatility of\nBitcoins. While Bitcoins have fluctuated in value between $1 and $30 in 2011\nalone, there are mechanisms for merchants to quote prices in dollar-equivalents\n(or other currency), and to exchange the Bitcoins they receive for other\ncurrencies immediately upon receipt.\n\nAn additional concern with the price volatility of Bitcoin is that the total\nvalue of all Bitcoins mined so far is just over [$30 million][Bitcoin Stats].\nThis relatively small market cap, in conjunction with a lack of regulatory\noversight, exposes Bitcoin prices to market manipulation.\n\nThere is already significant speculation in online forums about who may be\nmanipulating prices and to what end. When Bitcoin speculators talk about\nsurprising market movements, they discuss \"The Manipulator,\" a shadowy\nindividual or group who is manipulating the price of Bitcoin with their great\nwealth. Whether they have actually recognized a wealthy market manipulator or\nare anthropomorphizing the Invisible Hand of the market remains unclear.\n\n### Anti-Inflationary\n\nNoted economist Paul Krugman wrote an [article in the New York Times][Krugman]\ncriticizing Bitcoin's anti-inflationary provision (due to the 21M Bitcoin\ncreation limit). His argument is that Bitcoins will cause people to hoard the\ncurrency rather than spend it. But we feel his argument ignores the near\ninfinite divisibility of the currency. If Bitcoin values go up, people will\nstill desire to spend some of their gains from the currency by using a fraction\nof what they own. While fiat currencies are artificially inflated by expanding\ngovernment debts, Bitcoin will remain relatively stable in value over time.\n\nAs a creditor, I would be happy to loan Bitcoins as I can be assured that they\nwon't be artificially inflated before they are returned to me (with interest).\n\nContrary to his argument, we also have examples where deflationary prices in\nsome markets (consumer electronics and computers) would seem to predict\nconsumers refraining from purchases (why spend $2,000 on a computer today when I\ncan wait 2 years and get the same computer for $500). Rather, we see a healthy\nmarket providing ever-increasing value to consumers.\n\n### Computational Attack\n\nThe Bitcoin network recognizes the longest Block Chain as the current valid\nledger of all transactions. Block chains can only be extended with\ncomputation-intensive cryptographic hashing. Anyone wanting to maliciously\nre-write the history of the Block Chain must have available greater\ncomputational power than the entire remainder of the Bitcoin network.\n\nCreating this \"alternate history\" does not allow transactions to be created\nwithout a private key, but it has the ability to erase transactions in the past.\nTheoretically, a scammer could buy a product with Bitcoin, and once they receive\nit, release an alternate block chain, of greater length than the current one,\nthat does not contain the scammer's transaction. Because this new block chain is\nlonger, and thus demonstrates greater past computation, the network will accept\nit as the current, most-up-to date block chain. This allows the scammer to spend\nBitcoin to receive a good, then reverse his transaction to keep both the good\nand the Bitcoin (i.e., double-spending).\n\nA computational attack would be very difficult to carry out today. The total\ncomputational power of the Bitcoin network is the equivalent of [over 100\nPetaFLOPs][BitcoinWatch] (the number of computations it can perform per second).\nBy comparison, this is about 10 times the speed of the world's greatest\nsupercomputer, [Japan's K computer][K Computer], at 10.51 PetaFLOPs. The expense\nof creating a large supercomputer outweighs any potential gains that could come\nfrom the ability to double spend a portion of Bitcoins.\n\nBecause of the risk of double spending, it has become common practice in the\nBitcoin community to wait for six confirmations (six ten-minute blocks to be\nadded to the block chain after your transaction) before treating a payment as\nreceived. While a scammer might get lucky and reverse one or two blocks with an\nalternate chain and a great amount of computation, each additional block is\nexponentially more unlikely.\n\n### Regulatory Uncertainty\n\nThe legal classification of Bitcoin is still unclear: it could be considered a\ncommodity, a currency, a financial product, or legally equivalent to World of\nWarcraft gold. It remains to be seen what licenses and financial regulations\nBitcoin businesses will be required to obtain. The largest currency exchange\nmarket, MtGox, reportedly has experienced some [difficulties wiring\nmoney](https://bitcointalk.org/index.php?topic=52846.msg635859#msg635859)\nbecause of money laundering investigations.\n\nBitcoin is inherently hard to regulate as there is no central authority. Because\ntransactions are semi-anonymous and accounts cannot be frozen, it could become a\nmedium of choice for money laundering, tax evasion, and illicit trade. Using the\nTOR anonymizing network, any internet user with some technical savvy can access\na service called the Silk Road, a marketplace for illegal drugs denominated in\nBitcoin.\n\nIn the above respects, Bitcoin has very similar characteristics to governmental\npaper currency, like US dollar bills (i.e., cash). They can both be transacted\nnearly anonymously without an easily auditable paper trail. However, Bitcoin's\ntechnological complexity may cause regulators to view it as a threat to the rule\nof law. The regulatory classification and legality of direct party-to-party\nbusiness transactions are still uncertain.\n\n### Risk of Loss\n\nUsers of Bitcoin today have to ensure that they secure their digital wallets\nfrom both loss and theft. This can be challenging, requiring use of secure\nencryption, password management, and information backup methods. There have been\nsome high-profile cases where people made mistakes and lost hundreds of dollars'\nworth of Bitcoin. With no central authority to appeal to, these funds are truly\nunrecoverable.\n\nIt is important for Bitcoin adopters to employ best practices and use methods\ncommensurate with the potential for loss of their Bitcoin holdings.\n\n### Is Bitcoin \"The One\"?\n\nThe Bitcoin system is very young, barely 3 years old. While it has an engaged\ncommunity of early adopters, many of whom have done a deep technical analysis of\nthe security of the Bitcoin protocol, there may be inherent flaws in the design\nleading people to abandon the currency in favor of some other design (or to lose\nfaith in the concept of a distributed anonymous currency altogether).\n\nSome competing digital currencies have been proposed, but with much more limited\nadoption than Bitcoin has seen. It seems likely to us, that Bitcoin, or\nsomething very much like it, will be a viable option for many types of\ntransactions and exchanges in the online world.\n\n## Applications Well-suited to Bitcoin\n\n1. **Online sales of digital goods**. Customers can receive delivery\n immediately and the merchant gets a guaranteed irrevocable payment.\n2. **Online donations**. Payments can optionally be publicly visible to\n demonstrate social proof of support for a charitable cause.\n3. **Super Vault**. A Bitcoin wallet can be created from a passphrase or stored\n on one or more USB-keys. Bitcoins can be deposited to the generated public\n addresses even when the wallet is offline. So there is no risk of loss through\n online hacking; money can flow in, but is impossible to flow out without\n retrieving the offline wallet from storage (or the memory of the wallet\n creator).\n4. **[Remittances](http://en.wikipedia.org/wiki/Remittance)**. Inexpensive\n money transfer system across national boundaries. Agents could accept cash in a\n developed country, and transfer Bitcoins to an agent in the home country of a\n foreign worker, to be picked up by the family of the worker.\n\n<pdf:nexttemplate name=\"one-column\">\n<pdf:nextpage/>\n\n## References and Links\n\n1. [Bitcoin: A Peer-to-Peer Electronic Cash System][Nakamoto] - by Satoshi Nakamoto (original paper)\n2. [Bitcoin](http://en.wikipedia.org/wiki/Bitcoin) on Wikipedia\n3. [We Use Coins](http://www.weusecoins.com/) - An Excellent introductory video.\n4. [Bitcoin Forum](https://bitcointalk.org/) - Online discussions of Bitcoin by early adopters and enthusiasts.\n5. [Bitcoin Wiki](https://en.bitcoin.it/wiki/Main_Page) - Technical information on the Bitcoin protocol, software, and services.\n6. [Bitcoin.org](http://bitcoin.org/) - Primary download site for the \"official\" Bitcoin client\n [(source code)][Bitcoin Client]\n7. [BlockChain](http://blockchain.info/) and [Block Explorer](http://blockexplorer.com/) - Online browsers of Bitcoin published transactions\n8. [MtGox](https://mtgox.com/) - The largest Bitcoin exchange (Dollars exchanged with Bitcoin) - live price and order book chart at [MtGoxLive](http://mtgoxlive.com/orders).\n9. [Bitcoinica](https://bitcoinica.com/trading) - The 2nd most popular Bitcoin trading site, offers margin and short-selling not offered on MyGox.\n10. [TradeHill](https://www.tradehill.com/) - Another popular (international) Bitcoin exchange.\n10. [StrongCoin](https://strongcoin.com/) - An easy-to-use online digital wallet.\n11. [InstaWallet](https://www.instawallet.org/) - On-demand online wallet with no account needed - creates a private URL per address.\n12. [DeepBit](https://deepbit.net/) - One of the largest mining pools for Bitcoin with a combined compute power of 3,000 Giga-hashes per second (3 x 10^12 hashes/sec)\n\n [Nakamoto]: http://bitcoin.org/bitcoin.pdf \"Bitcoin: A Peer-to-Peer Electronic Cash System\"\n [Greenberg]: http://www.forbes.com/forbes/2011/0509/technology-psilocybin-bitcoins-gavin-andresen-crypto-currency.html \"Crypto Currency\"\n [Yang]: http://blog.ezyang.com/2011/06/the-cryptography-of-bitcoin/ \"The Cryptography of Bitcoin\"\n [BitcoinGraph]: https://en.bitcoin.it/wiki/File:Total_bitcoins_over_time_graph.png \"Total Bitcoins over Time\"\n [Visa Chargebacks]: http://www.internetretailer.com/2003/09/04/visa-to-lower-fee-inducing-chargeback-ratio-to-1-of-transaction \"Visa to lower fee-inducing chargeback ratio to 1% of transactions\"\n [Regretsy Cats]: http://www.regretsy.com/2011/12/05/cats-1-kids-0/ \"Cats 1, Kids 0\"\n [King]: http://alexking.org/blog/2009/03/23/beware-of-paypal-donation-chargebacks \"Beware of PayPal Donation Chargebacks\"\n [Bitcoin Stats]: http://blockchain.info/stats \"Bitcoin Stats\"\n [Krugman]: http://krugman.blogs.nytimes.com/2011/09/07/golden-cyberfetters/ \"Golden Cyberfetters\"\n [BitcoinWatch]: http://www.bitcoinwatch.com/ \"Network Hashrate\"\n [K Computer]: http://www.top500.org/lists/2011/11/press-release \"Japan's K Computer Tops 10 Petaflop/s to Stay Atop TOP500 List\"\n [Bitcoin Difficulty]: http://btcserv.net/bitcoin/history/ \"Bitcoin History\"\n [Bitcoin Client]: https://github.com/bitcoin/bitcoin \"Bitcoin Client Source Code\"\n"
}
] | 5 |
Leonardo767/Abmarl | https://github.com/Leonardo767/Abmarl | 032b16a20238be9be9088c71583cb31b1344a8ef | 9fada5447b09174c6a70b6032b4a8d08b66c4589 | a25a653e619bd8eb0ab15e836ab9a7f77a715c42 | refs/heads/main | 2023-06-21T06:57:03.181057 | 2021-07-30T05:42:44 | 2021-07-30T05:42:44 | 393,420,126 | 0 | 0 | NOASSERTION | 2021-08-06T15:31:10 | 2021-07-30T05:42:47 | 2021-08-05T23:19:40 | null | [
{
"alpha_fraction": 0.644571840763092,
"alphanum_fraction": 0.6497671008110046,
"avg_line_length": 36.46308898925781,
"blob_id": "77715f46443a309eaf7f69154a24d19844b68f25",
"content_id": "7d54c195d6a6044e791d1b79907ef10c220b1dac",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5582,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 149,
"path": "/abmarl/sim/components/examples/fighting_for_resources.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport numpy as np\nimport seaborn as sns\n\nfrom abmarl.sim.components.state import GridPositionState, GridResourceState, LifeState\nfrom abmarl.sim.components.observer import PositionObserver, GridResourceObserver, \\\n HealthObserver, LifeObserver\nfrom abmarl.sim.components.actor import GridMovementActor, GridResourcesActor, AttackActor\nfrom abmarl.sim.components.done import DeadDone\nfrom abmarl.sim.components.agent import PositionObservingAgent, ResourceObservingAgent, \\\n HealthObservingAgent, LifeObservingAgent, GridMovementAgent, HarvestingAgent, AttackingAgent\nfrom abmarl.sim import AgentBasedSimulation\nfrom abmarl.tools.matplotlib_utils import mscatter\n\n\nclass FightForResourcesAgent(\n PositionObservingAgent, ResourceObservingAgent, HealthObservingAgent, LifeObservingAgent,\n GridMovementAgent, HarvestingAgent, AttackingAgent\n): pass\n\n\nclass FightForResourcesSim(AgentBasedSimulation):\n def __init__(self, **kwargs):\n self.agents = kwargs['agents']\n\n # State components\n self.position_state = GridPositionState(**kwargs)\n self.life_state = LifeState(**kwargs)\n self.resource_state = GridResourceState(**kwargs)\n\n # Observer components\n self.position_observer = PositionObserver(position_state=self.position_state, **kwargs)\n self.resource_observer = GridResourceObserver(resource_state=self.resource_state, **kwargs)\n self.health_observer = HealthObserver(**kwargs)\n self.life_observer = LifeObserver(**kwargs)\n\n # Actor components\n self.move_actor = GridMovementActor(position_state=self.position_state, **kwargs)\n self.resource_actor = GridResourcesActor(resource_state=self.resource_state, **kwargs)\n self.attack_actor = AttackActor(**kwargs)\n\n # Done components\n self.done = DeadDone(**kwargs)\n\n self.finalize()\n\n def reset(self, **kwargs):\n self.position_state.reset(**kwargs)\n self.life_state.reset(**kwargs)\n self.resource_state.reset(**kwargs)\n\n def step(self, action_dict, **kwargs):\n # Process harvesting\n for agent_id, action in action_dict.items():\n agent = self.agents[agent_id]\n harvested_amount = self.resource_actor.process_action(agent, action, **kwargs)\n if harvested_amount is not None:\n self.life_state.modify_health(agent, harvested_amount)\n\n # Process attacking\n for agent_id, action in action_dict.items():\n attacking_agent = self.agents[agent_id]\n attacked_agent = self.attack_actor.process_action(agent, action, **kwargs)\n if attacked_agent is not None:\n self.life_state.modify_health(attacked_agent, -attacking_agent.attack_strength)\n\n # Process movement\n for agent_id, action in action_dict.items():\n self.move_actor.process_action(self.agents[agent_id], action, **kwargs)\n\n # Apply entropy to all agents\n for agent_id in action_dict:\n self.life_state.apply_entropy(self.agents[agent_id])\n\n # Regrow the resources\n self.resource_state.regrow()\n\n def render(self, fig=None, **kwargs):\n fig.clear()\n\n # Draw the resources\n ax = fig.gca()\n ax = sns.heatmap(np.flipud(self.resource_state.resources), ax=ax, cmap='Greens')\n\n # Draw the agents\n render_condition = {agent.id: agent.is_alive for agent in self.agents.values()}\n ax.set(xlim=(0, self.position_state.region), ylim=(0, self.position_state.region))\n ax.set_xticks(np.arange(0, self.position_state.region, 1))\n ax.set_yticks(np.arange(0, self.position_state.region, 1))\n ax.grid()\n\n agents_x = [\n agent.position[1] + 0.5 for agent in self.agents.values() if render_condition[agent.id]\n ]\n agents_y = [\n self.position_state.region - 0.5 - agent.position[0] for agent in self.agents.values()\n if render_condition[agent.id]\n ]\n mscatter(agents_x, agents_y, ax=ax, m='o', s=200, edgecolor='black', facecolor='gray')\n\n plt.plot()\n plt.pause(1e-6)\n\n def get_obs(self, agent_id, **kwargs):\n agent = self.agents[agent_id]\n return {\n **self.position_observer.get_obs(agent),\n **self.resource_observer.get_obs(agent),\n **self.health_observer.get_obs(agent, **kwargs),\n **self.life_observer.get_obs(agent, **kwargs),\n }\n\n def get_reward(self, agent_id, **kwargs):\n pass\n\n def get_done(self, agent_id, **kwargs):\n return self.done.get_done(self.agents[agent_id])\n\n def get_all_done(self, **kwargs):\n return self.done.get_all_done(**kwargs)\n\n def get_info(self, **kwargs):\n return {}\n\n\nif __name__ == '__main__':\n agents = {f'agent{i}': FightForResourcesAgent(\n id=f'agent{i}', attack_range=1, attack_strength=0.4, move_range=1, max_harvest=1.0,\n resource_view=3\n ) for i in range(6)}\n sim = FightForResourcesSim(\n region=10,\n agents=agents\n )\n sim.reset()\n print({agent_id: sim.get_obs(agent_id) for agent_id in sim.agents})\n fig = plt.gcf()\n sim.render(fig=fig)\n\n for _ in range(50):\n action_dict = {\n agent.id: agent.action_space.sample() for agent in sim.agents.values()\n if agent.is_alive\n }\n sim.step(action_dict)\n sim.render(fig=fig)\n print({agent_id: sim.get_done(agent_id) for agent_id in sim.agents})\n\n print(sim.get_all_done())\n"
},
{
"alpha_fraction": 0.5118989944458008,
"alphanum_fraction": 0.5721223950386047,
"avg_line_length": 26.453332901000977,
"blob_id": "53cab3d169e60ce1bbe6b69fedbd5d790059991d",
"content_id": "def583b62437e338966bfdf85881e4adea59ad5c",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2059,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 75,
"path": "/tests/test_grid_resources.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.modules import GridResources\n\n\ndef test_builder():\n sim = GridResources.build()\n assert sim.region == 10\n assert sim.max_value == 1.\n assert sim.min_value == 0.1\n assert sim.revive_rate == 0.04\n assert sim.coverage == 0.75\n\n\ndef test_builder_custom():\n sim = GridResources.build({\n 'region': 5,\n 'max_value': 2.,\n 'min_value': 0.01,\n 'revive_rate': 0.5,\n 'coverage': 0.4\n })\n assert sim.region == 5\n assert sim.max_value == 2.\n assert sim.min_value == 0.01\n assert sim.revive_rate == 0.5\n assert sim.coverage == 0.4\n\n\ndef test_reset():\n np.random.seed(24)\n sim = GridResources.build({'region': 5})\n sim.reset()\n assert ((sim.resources <= sim.max_value) & (sim.resources >= 0.)).all()\n\n\ndef test_harvest_and_regrow():\n np.random.seed(24)\n sim = GridResources.build()\n sim.reset()\n\n # Normal action with harvest and replenish\n value_before = {\n (4,5) : sim.resources[(4,5)],\n (3,3) : sim.resources[(3,3)]\n }\n assert sim.harvest((4,5), 0.7) == 0.7\n assert sim.harvest((3,3), 0.1) == 0.1\n sim.regrow()\n assert sim.resources[(4,5)] == value_before[(4,5)] - 0.7 + 0.04\n assert sim.resources[(3,3)] == value_before[(3,3)] - 0.1 + 0.04\n\n # action that has depleted one of the resources\n value_before = {\n (4,5) : sim.resources[(4,5)],\n (2,1) : sim.resources[(2,1)]\n }\n assert sim.harvest((4,5), 0.7) == value_before[(4,5)]\n assert sim.harvest((2,1), 0.15) == 0.15\n sim.regrow()\n assert sim.resources[(4,5)] == 0.\n assert sim.resources[(2,1)] == value_before[(2,1)] - 0.15 + 0.04\n\n # Check that the depleted resources do not restore\n value_before = {\n (2,1) : sim.resources[(2,1)]\n }\n sim.regrow()\n assert sim.resources[(4,5)] == 0.\n assert sim.resources[(2,1)] == value_before[(2,1)] + 0.04\n\n # Check that nothing is above maximum value\n for _ in range(25):\n sim.regrow()\n assert (sim.resources <= sim.max_value).all()\n"
},
{
"alpha_fraction": 0.6537421345710754,
"alphanum_fraction": 0.6537421345710754,
"avg_line_length": 14.619718551635742,
"blob_id": "1cb838b1925da8f8d35d5f2d1e6831e739ebf317",
"content_id": "c432a6798859187e1932164ccd7f0e2deb1fdd7f",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1109,
"license_type": "permissive",
"max_line_length": 48,
"num_lines": 71,
"path": "/docs/src/api.rst",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": ".. Abmarl documentation API.\n\nAbmarl API Specification\n=========================\n\n\nAbmarl Simulations\n--------------------\n\n.. _api_agent:\n\n.. autoclass:: abmarl.sim.PrincipleAgent\n\t:members:\n\t:undoc-members:\n\n.. autoclass:: abmarl.sim.ObservingAgent\n\t:members:\n\t:undoc-members:\n\n.. autoclass:: abmarl.sim.ActingAgent\n\t:members:\n\t:undoc-members:\n\n.. autoclass:: abmarl.sim.Agent\n\t:members:\n\t:undoc-members:\n\t:show-inheritance:\n\n.. _api_abs:\n\n.. autoclass:: abmarl.sim.AgentBasedSimulation\n\t:members:\n\t:undoc-members:\n\n\n.. _api_sim:\n\nAbmarl Simulation Managers\n---------------------------\n\n.. autoclass:: abmarl.managers.SimulationManager\n\t:members:\n\t:undoc-members:\n\n.. _api_turn_based:\n\n.. autoclass:: abmarl.managers.TurnBasedManager\n\t:members:\n\t:undoc-members:\n\n.. _api_all_step:\n\n.. autoclass:: abmarl.managers.AllStepManager\n\t:members:\n\t:undoc-members:\n\n\n.. _api_gym_wrapper:\n\nAbmarl External Integration\n----------------------------\n\n.. autoclass:: abmarl.external.GymWrapper\n\t:members:\n\t:undoc-members:\n\n.. _api_ma_wrapper:\n\n.. autoclass:: abmarl.external.MultiAgentWrapper\n\t:members:\n\t:undoc-members:\n"
},
{
"alpha_fraction": 0.6939195394515991,
"alphanum_fraction": 0.6991397738456726,
"avg_line_length": 38.98823547363281,
"blob_id": "e20dd7f2338e8a9b69a03e3587d3e4ac57d17e88",
"content_id": "bd48f4a45f79c14a83e82ca42bfb499223517502",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 13601,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 340,
"path": "/docs/src/overview.rst",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": ".. Abmarl documentation overview.\n\nDesign\n======\n\nA reinforcement learning experiment in Abmarl contains two interacting components:\na Simulation and a Trainer.\n\nThe Simulation contains agent(s) who can observe the state (or a substate) of the\nSimulation and whose actions affect the state of the simulation. The simulation is\ndiscrete in time, and at each time step agents can provide actions. The simulation\nalso produces rewards for each agent that the Trainer can use to train optimal behaviors.\nThe Agent-Simulation interaction produces state-action-reward tuples (SARs), which\ncan be collected in *rollout fragments* and used to optimize agent behaviors. \n\nThe Trainer contains policies that map agents' observations to actions. Policies\nare one-to-many with agents, meaning that there can be multiple agents using\nthe same policy. Policies may be heuristic (i.e. coded by the researcher) or trainable\nby the RL algorithm.\n\nIn Abmarl, the Simulation and Trainer are specified in a single Python configuration\nfile. Once these components are set up, they are passed as parameters to\nRLlib's tune command, which will launch the RLlib application and begin the training\nprocess. The training process will save checkpoints to an output directory,\nfrom which the user can visualize and analyze results. The following diagram\ndemonstrates this workflow.\n\n.. figure:: .images/workflow.png\n :width: 100 %\n :alt: Abmarl usage workflow\n\n Abmarl's usage workflow. An experiment configuration is used to train agents'\n behaviors. The policies and simulation are saved to an output directory. Behaviors can then\n be analyzed or visualized from the output directory.\n\n\nCreating Agents and Simulations\n-------------------------------\n\nAbmarl provides three interfaces for setting up an agent-based simulations.\n\n.. _overview_agent:\n\nAgent\n`````\n\nFirst, we have :ref:`Agents <api_agent>`. An agent is an object with an observation and\naction space. Many practitioners may be accustomed to gym.Env's interface, which\ndefines the observation and action space for the *simulation*. However, in heterogeneous\nmultiagent settings, each *agent* can have different spaces; thus we assign these\nspaces to the agents and not the simulation.\n\nAn agent can be created like so:\n\n.. code-block:: python\n\n from gym.spaces import Discrete, Box\n from abmarl.sim import Agent\n agent = Agent(\n id='agent0',\n observation_space=Box(-1, 1, (2,)),\n action_space=Discrete(3)\n )\n\nAt this level, the Agent is basically a dataclass. We have left it open for our\nusers to extend its features as they see fit.\n\n.. _abs:\n\nAgent Based Simulation\n``````````````````````\nNext, we define an :ref:`Agent Based Simulation <api_abs>`, or ABS for short, with the\nususal ``reset`` and ``step``\nfunctions that we are used to seeing in RL simulations. These functions, however, do\nnot return anything; the state information must be obtained from the getters:\n``get_obs``, ``get_reward``, ``get_done``, ``get_all_done``, and ``get_info``. The getters\ntake an agent's id as input and return the respective information from the simulation's\nstate. The ABS also contains a dictionary of agents that \"live\" in the simulation.\n\nAn Agent Based Simulation can be created and used like so:\n\n.. code-block:: python\n\n from abmarl.sim import Agent, AgentBasedSimulation \n class MySim(AgentBasedSimulation):\n def __init__(self, agents=None, **kwargs):\n self.agents = agents\n ... # Implement the ABS interface\n\n # Create a dictionary of agents\n agents = {f'agent{i}': Agent(id=f'agent{i}', ...) for i in range(10)}\n # Create the ABS with the agents\n sim = MySim(agents=agents)\n sim.reset()\n # Get the observations\n obs = {agent.id: sim.get_obs(agent.id) for agent in agents.values()}\n # Take some random actions\n sim.step({agent.id: agent.action_space.sample() for agent in agents.values()})\n # See the reward for agent3\n print(sim.get_reward('agent3'))\n\n.. WARNING::\n Implementations of AgentBasedSimulation should call ``finalize`` at the\n end of its ``__init__``. Finalize ensures that all agents are configured and\n ready to be used for training.\n\n.. NOTE::\n Instead of treating agents as dataclasses, we could have included the relevant\n information in the Agent Based Simulation with various dictionaries. For example,\n we could have ``action_spaces`` and ``observation_spaces`` that\n maps agents' ids to their action spaces and observation spaces, respectively.\n In Abmarl, we favor the dataclass approach and use it throughout the package\n and documentation.\n\n.. _sim-man:\n\nSimulation Managers\n```````````````````\n\nThe Agent Based Simulation interface does not specify an ordering for agents' interactions\nwith the simulation. This is left open to give our users maximal flexibility. However,\nin order to interace with RLlib's learning library, we provide a :ref:`Simulation Manager <api_sim>`\nwhich specifies the output from ``reset`` and ``step`` as RLlib expects it. Specifically,\n\n1. Agents that appear in the output dictionary will provide actions at the next step.\n2. Agents that are done on this step will not provide actions on the next step.\n\nSimulation managers are open-ended requiring only ``reset`` and ``step`` with output\ndescribed above. For convenience, we have provided two managers: :ref:`Turn Based <api_turn_based>`,\nwhich implements turn-based games; and :ref:`All Step <api_all_step>`, which has every non-done\nagent provide actions at each step.\n\nSimluation Managers \"wrap\" simulations, and they can be used like so:\n\n.. code-block:: python\n\n from abmarl.managers import AllStepManager\n from abmarl.sim import AgentBasedSimulation, Agent\n class MySim(AgentBasedSimulation):\n ... # Define some simulation\n\n # Instatiate the simulation\n sim = MySim(agents=...)\n # Wrap the simulation with the simulation manager\n sim = AllStepManager(sim)\n # Get the observations for all agents\n obs = sim.reset()\n # Get simulation state for all non-done agents, regardless of which agents\n # actually contribute an action.\n obs, rewards, dones, infos = sim.step({'agent0': 4, 'agent2': [-1, 1]})\n\n\n.. _external:\n\nExternal Integration\n````````````````````\n\nIn order to train agents in a Simulation Manager using RLlib, we must wrap the simulation\nwith either a :ref:`GymWrapper <api_gym_wrapper>` for single-agent simulations\n(i.e. only a single entry in the `agents` dict) or a\n:ref:`MultiAgentWrapper <api_ma_wrapper>` for multiagent simulations.\n\n\n\nTraining with an Experiment Configuration\n-----------------------------------------\nIn order to run experiments, we must define a configuration file that\nspecifies Simulation and Trainer parameters. Here is the configuration file\nfrom the :ref:`Corridor tutorial<tutorial_multi_corridor>` that demonstrates a\nsimple corridor simulation with multiple agents. \n\n.. code-block:: python\n\n # Import the MultiCorridor ABS, a simulation manager, and the multiagent\n # wrapper needed to connect to RLlib's trainers\n from abmarl.sim.corridor import MultiCorridor\n from abmarl.managers import TurnBasedManager\n from abmarl.external import MultiAgentWrapper\n \n # Create and wrap the simulation\n # NOTE: The agents in `MultiCorridor` are all homogeneous, so this simulation\n # just creates and stores the agents itself.\n sim = MultiAgentWrapper(TurnBasedManager(MultiCorridor()))\n \n # Register the simulation with RLlib\n sim_name = \"MultiCorridor\"\n from ray.tune.registry import register_env\n register_env(sim_name, lambda sim_config: sim)\n \n # Set up the policies. In this experiment, all agents are homogeneous,\n # so we just use a single shared policy.\n ref_agent = sim.unwrapped.agents['agent0']\n policies = {\n 'corridor': (None, ref_agent.observation_space, ref_agent.action_space, {})\n }\n def policy_mapping_fn(agent_id):\n return 'corridor'\n \n # Experiment parameters\n params = {\n 'experiment': {\n 'title': f'{sim_name}',\n 'sim_creator': lambda config=None: sim,\n },\n 'ray_tune': {\n 'run_or_experiment': 'PG',\n 'checkpoint_freq': 50,\n 'checkpoint_at_end': True,\n 'stop': {\n 'episodes_total': 2000,\n },\n 'verbose': 2,\n 'config': {\n # --- simulation ---\n 'env': sim_name,\n 'horizon': 200,\n 'env_config': {},\n # --- Multiagent ---\n 'multiagent': {\n 'policies': policies,\n 'policy_mapping_fn': policy_mapping_fn,\n },\n # --- Parallelism ---\n \"num_workers\": 7,\n \"num_envs_per_worker\": 1,\n },\n }\n }\n \n.. WARNING::\n The simulation must be a :ref:`Simulation Manager <sim-man>` or an\n :ref:`External Wrapper <external>` as described above.\n \n.. NOTE::\n This example has ``num_workers`` set to 7 for a computer with 8 CPU's.\n You may need to adjust this for your computer to be `<cpu count> - 1`.\n\nExperiment Parameters\n`````````````````````\nThe strucutre of the parameters dictionary is very important. It *must* have an\n`experiment` key which contains both the `title` of the experiment and the `sim_creator`\nfunction. This function should receive a config and, if appropriate, pass it to\nthe simulation constructor. In the example configuration above, we just retrun the\nalready-configured simulation. Without the title and simulation creator, Abmarl\nmay not behave as expected.\n\nThe experiment parameters also contains information that will be passed directly\nto RLlib via the `ray_tune` parameter. See RLlib's documentation for a\n`list of common configuration parameters <https://docs.ray.io/en/releases-1.2.0/rllib-training.html#common-parameters>`_.\n\nCommand Line\n````````````\nWith the configuration file complete, we can utilize the command line interface\nto train our agents. We simply type ``abmarl train multi_corridor_example.py``,\nwhere `multi_corridor_example.py` is the name of our configuration file. This will launch\nAbmarl, which will process the file and launch RLlib according to the\nspecified parameters. This particular example should take 1-10 minutes to\ntrain, depending on your compute capabilities. You can view the performance\nin real time in tensorboard with ``tensorboard --logdir ~/abmarl_results``.\n\n.. NOTE::\n\n By default, the \"base\" of the output directory is the home directory, and Abmarl will\n create the `abmarl_results` directory there. The base directory can by configured\n in the `params` under `ray_tune` using the `local_dir` parameter. This value\n should be a full path. For example, ``'local_dir': '/usr/local/scratch'``.\n\n\nVisualizing\n-----------\nWe can visualize the agents' learned behavior with the ``visualize`` command, which\ntakes as argument the output directory from the training session stored in\n``~/abmarl_results``. For example, the command\n\n.. code-block::\n\n abmarl visualize ~/abmarl_results/MultiCorridor-2020-08-25_09-30/ -n 5 --record\n\nwill load the experiment (notice that the directory name is the experiment\ntitle from the configuration file appended with a timestamp) and display an animation\nof 5 episodes. The ``--record`` flag will save the animations as `.mp4` videos in\nthe training directory.\n\n\n\nAnalyzing\n---------\n\nThe simulation and trainer can also be loaded into an analysis script for post-processing via the\n``analyze`` command. The analysis script must implement the following `run` function.\nBelow is an example that can serve as a starting point.\n\n.. code-block:: python\n\n # Load the simulation and the trainer from the experiment as objects\n def run(sim, trainer):\n \"\"\"\n Analyze the behavior of your trained policies using the simulation and trainer\n from your RL experiment.\n\n Args:\n sim:\n Simulation Manager object from the experiment.\n trainer:\n Trainer that computes actions using the trained policies.\n \"\"\"\n # Run the simulation with actions chosen from the trained policies\n policy_agent_mapping = trainer.config['multiagent']['policy_mapping_fn']\n for episode in range(100):\n print('Episode: {}'.format(episode))\n obs = sim.reset()\n done = {agent: False for agent in obs}\n while True: # Run until the episode ends\n # Get actions from policies\n joint_action = {}\n for agent_id, agent_obs in obs.items():\n if done[agent_id]: continue # Don't get actions for done agents\n policy_id = policy_agent_mapping(agent_id)\n action = trainer.compute_action(agent_obs, policy_id=policy_id)\n joint_action[agent_id] = action\n # Step the simulation\n obs, reward, done, info = sim.step(joint_action)\n if done['__all__']:\n break\n\nAnalysis can then be performed using the command line interface:\n\n.. code-block::\n\n abmarl analyze ~/abmarl_results/MultiCorridor-2020-08-25_09-30/ my_analysis_script.py\n\nSee the :ref:`Predator Prey tutorial <tutorial_predator_prey>` for an example of\nanalyzing trained agent behavior.\n\nRunning at scale with HPC\n-------------------------\n\nAbmarl also supports some functionality for training at scale. See the\n:ref:`magpie tutorial <tutorial_magpie>`, which provides a walkthrough\nfor launching a training experiment on multiple compute nodes with slurm.\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.8586956262588501,
"alphanum_fraction": 0.8586956262588501,
"avg_line_length": 33.5,
"blob_id": "5c563d3cee35818a7e7299f76c3d20e67dafe133",
"content_id": "d42a29541009fd8f4b55b1676c0fa7081a7576b3",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 276,
"license_type": "permissive",
"max_line_length": 65,
"num_lines": 8,
"path": "/abmarl/sim/wrappers/__init__.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .wrapper import Wrapper\n\n# SAR-based wrappers\nfrom .sar_wrapper import SARWrapper\nfrom .flatten_wrapper import FlattenActionWrapper, FlattenWrapper\nfrom .ravel_discrete_wrapper import RavelDiscreteWrapper\n\nfrom .communication_wrapper import CommunicationHandshakeWrapper\n"
},
{
"alpha_fraction": 0.5824081897735596,
"alphanum_fraction": 0.6376316547393799,
"avg_line_length": 38.03333282470703,
"blob_id": "75658d9a9420bf98dba149695b4b72565cac0481",
"content_id": "e0f4bb6f4c00530197463e2a03a135eb2f58c00e",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3513,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 90,
"path": "/tests/test_health_component.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abmarl.sim.components.agent import ComponentAgent as Agent\nfrom abmarl.sim.components.state import LifeState\n\n\ndef test_health_agents():\n agents = {\n 'agent0': Agent(id='agent0', min_health=0.0, max_health=5.0, initial_health=3.4),\n 'agent1': Agent(id='agent1', min_health=0.0, max_health=5.0, initial_health=2.4),\n 'agent2': Agent(id='agent2', min_health=0.0, max_health=5.0),\n 'agent3': Agent(id='agent3', min_health=0.0, max_health=5.0),\n }\n\n assert agents['agent0'].min_health == 0.0\n assert agents['agent0'].max_health == 5.0\n assert agents['agent0'].initial_health == 3.4\n assert agents['agent0'].is_alive\n assert agents['agent1'].min_health == 0.0\n assert agents['agent1'].max_health == 5.0\n assert agents['agent1'].initial_health == 2.4\n assert agents['agent1'].is_alive\n assert agents['agent2'].min_health == 0.0\n assert agents['agent2'].max_health == 5.0\n assert agents['agent2'].is_alive\n assert agents['agent3'].min_health == 0.0\n assert agents['agent3'].max_health == 5.0\n assert agents['agent3'].is_alive\n\n\ndef test_life_state():\n agents = {\n 'agent0': Agent(id='agent0', min_health=0.0, max_health=5.0, initial_health=3.4),\n 'agent1': Agent(id='agent1', min_health=0.0, max_health=5.0, initial_health=2.4),\n 'agent2': Agent(id='agent2', min_health=0.0, max_health=5.0),\n 'agent3': Agent(id='agent3', min_health=0.0, max_health=5.0),\n }\n\n assert agents['agent0'].min_health == 0.0\n assert agents['agent0'].max_health == 5.0\n assert agents['agent0'].initial_health == 3.4\n assert agents['agent0'].is_alive\n assert agents['agent1'].min_health == 0.0\n assert agents['agent1'].max_health == 5.0\n assert agents['agent1'].initial_health == 2.4\n assert agents['agent1'].is_alive\n assert agents['agent2'].min_health == 0.0\n assert agents['agent2'].max_health == 5.0\n assert agents['agent2'].is_alive\n assert agents['agent3'].min_health == 0.0\n assert agents['agent3'].max_health == 5.0\n assert agents['agent3'].is_alive\n\n state = LifeState(agents=agents, entropy=0.5)\n state.reset()\n\n assert agents['agent0'].health == 3.4\n assert agents['agent1'].health == 2.4\n assert 0.0 <= agents['agent2'].health <= 5.0\n assert 0.0 <= agents['agent3'].health <= 5.0\n\n state.apply_entropy(agents['agent0'])\n state.apply_entropy(agents['agent1'])\n assert agents['agent0'].health == 2.9\n assert agents['agent1'].health == 1.9\n\n for _ in range(10):\n state.apply_entropy(agents['agent0'])\n state.apply_entropy(agents['agent1'])\n state.apply_entropy(agents['agent2'])\n state.apply_entropy(agents['agent3'])\n\n assert not agents['agent0'].is_alive\n assert not agents['agent1'].is_alive\n assert not agents['agent2'].is_alive\n assert not agents['agent3'].is_alive\n\n state.reset()\n assert agents['agent0'].min_health == 0.0\n assert agents['agent0'].max_health == 5.0\n assert agents['agent0'].initial_health == 3.4\n assert agents['agent0'].is_alive\n assert agents['agent1'].min_health == 0.0\n assert agents['agent1'].max_health == 5.0\n assert agents['agent1'].initial_health == 2.4\n assert agents['agent1'].is_alive\n assert agents['agent2'].min_health == 0.0\n assert agents['agent2'].max_health == 5.0\n assert agents['agent2'].is_alive\n assert agents['agent3'].min_health == 0.0\n assert agents['agent3'].max_health == 5.0\n assert agents['agent3'].is_alive\n"
},
{
"alpha_fraction": 0.6256320476531982,
"alphanum_fraction": 0.6332166194915771,
"avg_line_length": 34.46207046508789,
"blob_id": "8cc5f2f630eadc98ca717bc796d448e6ec0101c7",
"content_id": "08112eb0bbcfd94aea9c8f44469e0b7aa6d4a20c",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5142,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 145,
"path": "/abmarl/sim/components/examples/bird_fighting.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport numpy as np\n\nfrom abmarl.sim.components.state import ContinuousPositionState, SpeedAngleState, LifeState\nfrom abmarl.sim.components.actor import SpeedAngleMovementActor, AttackActor\nfrom abmarl.sim.components.observer import SpeedObserver, AngleObserver, PositionObserver, \\\n LifeObserver, HealthObserver\nfrom abmarl.sim.components.done import DeadDone\nfrom abmarl.sim.components.agent import SpeedAngleAgent, SpeedAngleActingAgent, AttackingAgent, \\\n SpeedAngleObservingAgent, PositionObservingAgent, LifeObservingAgent, HealthObservingAgent\nfrom abmarl.sim import AgentBasedSimulation\nfrom abmarl.tools.matplotlib_utils import mscatter\n\n\nclass FightingBirdAgent(\n SpeedAngleAgent, SpeedAngleActingAgent, AttackingAgent, SpeedAngleObservingAgent,\n PositionObservingAgent, LifeObservingAgent, HealthObservingAgent\n): pass\n\n\nclass FightingBirdsSim(AgentBasedSimulation):\n def __init__(self, **kwargs):\n self.agents = kwargs['agents']\n\n # State\n self.position_state = ContinuousPositionState(**kwargs)\n self.speed_angle_state = SpeedAngleState(**kwargs)\n self.life_state = LifeState(**kwargs)\n\n # Actor\n self.move_actor = SpeedAngleMovementActor(\n position_state=self.position_state, speed_angle_state=self.speed_angle_state, **kwargs\n )\n self.attack_actor = AttackActor(**kwargs)\n\n # Observer\n self.position_observer = PositionObserver(position_state=self.position_state, **kwargs)\n self.speed_observer = SpeedObserver(**kwargs)\n self.angle_observer = AngleObserver(**kwargs)\n self.health_observer = HealthObserver(**kwargs)\n self.life_observer = LifeObserver(**kwargs)\n\n # Done\n self.done = DeadDone(**kwargs)\n\n self.finalize()\n\n def reset(self, **kwargs):\n self.position_state.reset(**kwargs)\n self.speed_angle_state.reset(**kwargs)\n self.life_state.reset(**kwargs)\n\n def step(self, action_dict, **kwargs):\n # Process attacking\n for agent_id, action in action_dict.items():\n attacking_agent = self.agents[agent_id]\n attacked_agent = self.attack_actor.process_action(attacking_agent, action, **kwargs)\n if attacked_agent is not None:\n self.life_state.modify_health(attacked_agent, -attacking_agent.attack_strength)\n\n # Process movement\n for agent_id, action in action_dict.items():\n self.move_actor.process_move(\n self.agents[agent_id], action.get('accelerate', np.zeros(1)),\n action.get('bank', np.zeros(1)), **kwargs\n )\n\n def render(self, fig=None, **kwargs):\n fig.clear()\n render_condition = {agent.id: agent.is_alive for agent in self.agents.values()}\n\n # Draw the resources\n ax = fig.gca()\n\n # Draw the agents\n ax.set(xlim=(0, self.position_state.region), ylim=(0, self.position_state.region))\n ax.set_xticks(np.arange(0, self.position_state.region, 1))\n ax.set_yticks(np.arange(0, self.position_state.region, 1))\n\n agents_x = [\n agent.position[0] for agent in self.agents.values() if render_condition[agent.id]\n ]\n agents_y = [\n agent.position[1] for agent in self.agents.values() if render_condition[agent.id]\n ]\n mscatter(agents_x, agents_y, ax=ax, m='o', s=100, edgecolor='black', facecolor='gray')\n\n plt.plot()\n plt.pause(1e-6)\n\n def get_obs(self, agent_id, **kwargs):\n agent = self.agents[agent_id]\n return {\n **self.position_observer.get_obs(agent, **kwargs),\n **self.speed_observer.get_obs(agent, **kwargs),\n **self.angle_observer.get_obs(agent, **kwargs),\n **self.health_observer.get_obs(agent, **kwargs),\n **self.life_observer.get_obs(agent, **kwargs),\n }\n\n def get_reward(self, agent_id, **kwargs):\n pass\n\n def get_done(self, agent_id, **kwargs):\n return self.done.get_done(self.agents[agent_id], **kwargs)\n\n def get_all_done(self, **kwargs):\n return self.done.get_all_done(**kwargs)\n\n def get_info(self, agent_id, **kwargs):\n pass\n\n\nif __name__ == \"__main__\":\n agents = {\n f'bird{i}': FightingBirdAgent(\n id=f'bird{i}', min_speed=0.5, max_speed=1.0, max_acceleration=0.1,\n max_banking_angle=90, max_banking_angle_change=90,\n initial_banking_angle=45, attack_range=1.0, attack_strength=0.5\n ) for i in range(24)\n }\n\n sim = FightingBirdsSim(\n region=20,\n agents=agents,\n attack_norm=2,\n )\n fig = plt.figure()\n sim.reset()\n sim.render(fig=fig)\n\n print(sim.get_obs('bird0'))\n\n for i in range(50):\n action_dict = {\n agent.id: agent.action_space.sample() for agent in sim.agents.values()\n if agent.is_alive\n }\n sim.step(action_dict)\n sim.render(fig=fig)\n for agent in agents:\n print(agent, ': ', sim.get_done(agent))\n print('\\n')\n\n print(sim.get_all_done())\n"
},
{
"alpha_fraction": 0.5917728543281555,
"alphanum_fraction": 0.6249720454216003,
"avg_line_length": 43.50746154785156,
"blob_id": "f6a00074ba9c4abcabf3c8049bea34901a29a8dc",
"content_id": "a09452dd500cf9290c2f29f4b63d1ab802c82b85",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8946,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 201,
"path": "/tests/test_attacking_component.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.components.agent import AttackingAgent\nfrom abmarl.sim.components.actor import AttackActor\n\n\ndef test_position_based_attack_actor():\n agents = {\n 'agent0': AttackingAgent(\n id='agent0', attack_range=1, initial_position=np.array([1, 1]), attack_strength=0.6\n ),\n 'agent1': AttackingAgent(\n id='agent1', attack_range=1, initial_position=np.array([0, 1]), attack_strength=0.6\n ),\n 'agent2': AttackingAgent(\n id='agent2', attack_range=1, initial_position=np.array([4, 2]), attack_strength=0.6\n ),\n 'agent3': AttackingAgent(\n id='agent3', attack_range=1, initial_position=np.array([4, 3]), attack_strength=0.6\n ),\n 'agent4': AttackingAgent(\n id='agent4', attack_range=0, initial_position=np.array([3, 2]), attack_strength=0.6\n ),\n 'agent5': AttackingAgent(\n id='agent5', attack_range=2, initial_position=np.array([4, 0]), attack_strength=0.6\n ),\n }\n\n assert agents['agent0'].attack_range == 1\n np.testing.assert_array_equal(agents['agent0'].initial_position, np.array([1, 1]))\n assert agents['agent1'].attack_range == 1\n np.testing.assert_array_equal(agents['agent1'].initial_position, np.array([0, 1]))\n assert agents['agent2'].attack_range == 1\n np.testing.assert_array_equal(agents['agent2'].initial_position, np.array([4, 2]))\n assert agents['agent3'].attack_range == 1\n np.testing.assert_array_equal(agents['agent3'].initial_position, np.array([4, 3]))\n assert agents['agent4'].attack_range == 0\n np.testing.assert_array_equal(agents['agent4'].initial_position, np.array([3, 2]))\n assert agents['agent5'].attack_range == 2\n np.testing.assert_array_equal(agents['agent5'].initial_position, np.array([4, 0]))\n\n actor = AttackActor(agents=agents)\n for agent in agents.values():\n agent.position = agent.initial_position\n\n assert actor.process_action(agents['agent0'], {'attack': True}).id == 'agent1'\n assert actor.process_action(agents['agent1'], {'attack': True}).id == 'agent0'\n assert actor.process_action(agents['agent2'], {'attack': True}).id == 'agent3'\n assert actor.process_action(agents['agent3'], {'attack': True}).id == 'agent2'\n assert actor.process_action(agents['agent4'], {'attack': True}) is None\n assert actor.process_action(agents['agent5'], {'attack': True}).id == 'agent2'\n\n agents['agent0'].is_alive = False\n agents['agent2'].is_alive = False\n\n assert actor.process_action(agents['agent1'], {'attack': True}) is None\n assert actor.process_action(agents['agent3'], {'attack': True}).id == 'agent4'\n assert actor.process_action(agents['agent4'], {'attack': True}) is None\n assert actor.process_action(agents['agent5'], {'attack': True}).id == 'agent4'\n\n\ndef test_position_team_based_attack_actor():\n agents = {\n 'agent0': AttackingAgent(\n id='agent0', attack_range=1, initial_position=np.array([1, 1]), attack_strength=0.6,\n team=1\n ),\n 'agent1': AttackingAgent(\n id='agent1', attack_range=1, initial_position=np.array([0, 1]), attack_strength=0.6,\n team=2\n ),\n 'agent2': AttackingAgent(\n id='agent2', attack_range=1, initial_position=np.array([4, 2]), attack_strength=0.6,\n team=1\n ),\n 'agent3': AttackingAgent(\n id='agent3', attack_range=1, initial_position=np.array([4, 3]), attack_strength=0.6,\n team=1\n ),\n 'agent4': AttackingAgent(\n id='agent4', attack_range=0, initial_position=np.array([3, 2]), attack_strength=0.6,\n team=3\n ),\n 'agent5': AttackingAgent(\n id='agent5', attack_range=2, initial_position=np.array([4, 0]), attack_strength=0.6,\n team=1\n ),\n }\n\n assert agents['agent0'].attack_range == 1\n assert agents['agent0'].team == 1\n np.testing.assert_array_equal(agents['agent0'].initial_position, np.array([1, 1]))\n assert agents['agent1'].attack_range == 1\n assert agents['agent1'].team == 2\n np.testing.assert_array_equal(agents['agent1'].initial_position, np.array([0, 1]))\n assert agents['agent2'].attack_range == 1\n assert agents['agent2'].team == 1\n np.testing.assert_array_equal(agents['agent2'].initial_position, np.array([4, 2]))\n assert agents['agent3'].attack_range == 1\n assert agents['agent3'].team == 1\n np.testing.assert_array_equal(agents['agent3'].initial_position, np.array([4, 3]))\n assert agents['agent4'].attack_range == 0\n assert agents['agent4'].team == 3\n np.testing.assert_array_equal(agents['agent4'].initial_position, np.array([3, 2]))\n assert agents['agent5'].attack_range == 2\n assert agents['agent5'].team == 1\n np.testing.assert_array_equal(agents['agent5'].initial_position, np.array([4, 0]))\n\n for agent in agents.values():\n agent.position = agent.initial_position\n actor = AttackActor(agents=agents, number_of_teams=3)\n\n assert actor.process_action(agents['agent0'], {'attack': True}).id == 'agent1'\n assert actor.process_action(agents['agent1'], {'attack': True}).id == 'agent0'\n assert actor.process_action(agents['agent2'], {'attack': True}).id == 'agent4'\n assert actor.process_action(agents['agent3'], {'attack': True}).id == 'agent4'\n assert actor.process_action(agents['agent4'], {'attack': True}) is None\n assert actor.process_action(agents['agent5'], {'attack': True}).id == 'agent4'\n\n agents['agent4'].is_alive = False\n agents['agent0'].is_alive = False\n\n assert actor.process_action(agents['agent1'], {'attack': True}) is None\n assert actor.process_action(agents['agent2'], {'attack': True}) is None\n assert actor.process_action(agents['agent3'], {'attack': True}) is None\n assert actor.process_action(agents['agent5'], {'attack': True}) is None\n\n\ndef test_attack_accuracy():\n np.random.seed(24)\n agents = {\n 'agent0': AttackingAgent(\n id='agent0', attack_range=1, attack_strength=0, attack_accuracy=0,\n initial_position=np.array([1,1])\n ),\n 'agent1': AttackingAgent(\n id='agent1', attack_range=0, attack_strength=0, initial_position=np.array([0,0])\n )\n }\n\n assert agents['agent0'].attack_accuracy == 0\n assert agents['agent1'].attack_accuracy == 1\n\n for agent in agents.values():\n agent.position = agent.initial_position\n\n actor = AttackActor(agents=agents)\n # Action failed because low accuracy\n assert actor.process_action(agents['agent0'], {'attack': True}) is None\n\n agents['agent0'].attack_accuracy = 0.5\n assert actor.process_action(agents['agent0'], {'attack': True}) is None\n assert actor.process_action(agents['agent0'], {'attack': True}) is None\n assert actor.process_action(agents['agent0'], {'attack': True}).id == 'agent1'\n assert actor.process_action(agents['agent0'], {'attack': True}).id == 'agent1'\n assert actor.process_action(agents['agent0'], {'attack': True}) is None\n assert actor.process_action(agents['agent0'], {'attack': True}) is None\n\n\ndef test_team_matrix():\n agents = {\n 'agent0': AttackingAgent(\n id='agent0', attack_range=1, initial_position=np.array([1, 1]), attack_strength=0.6,\n team=1\n ),\n 'agent1': AttackingAgent(\n id='agent1', attack_range=4, initial_position=np.array([0, 1]), attack_strength=0.6,\n team=2\n ),\n 'agent2': AttackingAgent(\n id='agent2', attack_range=1, initial_position=np.array([4, 2]), attack_strength=0.6,\n team=1\n ),\n 'agent3': AttackingAgent(\n id='agent3', attack_range=1, initial_position=np.array([4, 3]), attack_strength=0.6\n ),\n 'agent4': AttackingAgent(\n id='agent4', attack_range=1, initial_position=np.array([3, 2]), attack_strength=0.6,\n team=3\n ),\n 'agent5': AttackingAgent(\n id='agent5', attack_range=1, initial_position=np.array([4, 0]), attack_strength=0.6,\n team=1\n ),\n }\n\n for agent in agents.values():\n agent.position = agent.initial_position\n\n team_attack_matrix = np.zeros((4,4))\n team_attack_matrix[0, :] = 1\n team_attack_matrix[1, 0] = 1\n team_attack_matrix[2, 3] = 1\n\n actor = AttackActor(agents=agents, number_of_teams=3, team_attack_matrix=team_attack_matrix)\n assert actor.process_action(agents['agent0'], {'attack': True}) is None\n assert actor.process_action(agents['agent1'], {'attack': True}).id == 'agent4'\n assert actor.process_action(agents['agent2'], {'attack': True}).id == 'agent3'\n assert actor.process_action(agents['agent3'], {'attack': True}).id == 'agent2'\n assert actor.process_action(agents['agent4'], {'attack': True}) is None\n assert actor.process_action(agents['agent5'], {'attack': True}) is None\n"
},
{
"alpha_fraction": 0.6042216420173645,
"alphanum_fraction": 0.6055408716201782,
"avg_line_length": 40.724769592285156,
"blob_id": "1f1da351293d63cc0bdd7c704a3ce6567a30ceb9",
"content_id": "b037ad6f1a9382f3587a8dd4d9e3c5109f0bd8e4",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4548,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 109,
"path": "/abmarl/make_runnable.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import os\nimport shutil\n\nmain_if_block_begin = \"\"\"\nif __name__ == \"__main__\":\n # Create output directory and save to params\n import os\n import time\n home = os.path.expanduser(\"~\")\n output_dir = os.path.join(\n home, 'abmarl_results/{}_{}'.format(\n params['experiment']['title'], time.strftime('%Y-%m-%d_%H-%M')\n )\n )\n params['ray_tune']['local_dir'] = output_dir\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n\n # Copy this configuration file to the output directory\n import shutil\n shutil.copy(os.path.join(os.getcwd(), __file__), output_dir)\n\n # Initialize and run ray\n import ray\n from ray import tune\n\"\"\"\n\nmain_if_block_end = \"\"\"\n tune.run(**params['ray_tune'])\n ray.shutdown()\n\"\"\"\n\n\ndef _process_magpie_sbatch(config, full_runnable_config_path):\n with open(\n '/usr/tce/packages/magpie/magpie2/submission-scripts/script-sbatch-srun/'\n 'magpie.sbatch-srun-ray', 'r'\n ) as file_reader:\n magpie_script = file_reader.readlines()\n for ndx, line in enumerate(magpie_script):\n if line.startswith(\"#SBATCH --nodes\"):\n magpie_script[ndx] = \"#SBATCH --nodes={}\\n\".format(config['nodes'])\n elif line.startswith(\"#SBATCH --time\"):\n magpie_script[ndx] = \"#SBATCH --time={}:00:00\\n\".format(config['time_limit'])\n elif line.startswith(\"#SBATCH --job-name\"):\n magpie_script[ndx] = \"#SBATCH --job-name={}\\n\".format(config['title'])\n elif line.startswith(\"#SBATCH --partition\"):\n magpie_script[ndx] = \"#SBATCH --partition=pbatch\\n\"\n elif line.startswith('export MAGPIE_PYTHON'):\n magpie_script[ndx] = 'export MAGPIE_PYTHON=\"{}\"\\n'.format(shutil.which('python'))\n elif line.startswith('export RAY_PATH'):\n magpie_script[ndx] = 'export RAY_PATH=\"{}\"\\n'.format(shutil.which('ray'))\n elif line.startswith('export RAY_LOCAL_DIR=\"/tmp/${USER}/ray\"'):\n pass\n # I cannot specify the output directory becasue it doesn't exist\n # until the script is actually run!\n elif line.startswith('export RAY_JOB'):\n magpie_script[ndx] = 'export RAY_JOB=\"script\"\\n'\n elif line.startswith('# export RAY_SCRIPT_PATH'):\n magpie_script[ndx] = 'export RAY_SCRIPT_PATH=\"{}\"\\n'.format(full_runnable_config_path)\n with open(\n os.path.join(\n os.path.dirname(full_runnable_config_path),\n f\"{config['title']}_magpie.sbatch-srun-ray\"), 'w'\n ) as file_writer:\n file_writer.writelines(magpie_script)\n return \" ray.init(address=os.environ['MAGPIE_RAY_ADDRESS'])\"\n\n\ndef run(full_config_path, parameters):\n \"\"\"Convert a configuration file to a runnable script, outputting additional\n scripts as requested.\"\"\"\n # Copy the configuration script\n import os\n import shutil\n full_runnable_config_path = os.path.join(\n os.path.dirname(full_config_path),\n 'runnable_' + os.path.basename(full_config_path)\n )\n shutil.copy(full_config_path, full_runnable_config_path)\n\n ray_init_line = \" ray.init()\"\n if parameters.magpie:\n # We need to get two parameters from the experiment configuration. We don't want to load the\n # entire thing because that is overkill and its costly, so we just read the file and store\n # a few pieces.\n with open(full_config_path, 'r') as file_reader:\n config_items_needed = {\n 'nodes': parameters.nodes,\n 'time_limit': parameters.time_limit,\n }\n for line in file_reader.readlines():\n if line.strip().strip(\"'\").strip('\"').startswith('title'):\n title = line.split(':')[1].strip().strip(',')\n exec(\"config_items_needed['title'] = {}\".format(title))\n break\n # I'm not worried about executing here becuase the entire module will be\n # executed when the script is run.\n try:\n ray_init_line = _process_magpie_sbatch(config_items_needed, full_runnable_config_path)\n except FileNotFoundError:\n print('Could not find magpie. Is it installed on your HPC system?')\n\n # Open the runnable file and write parts to enable runnable\n with open(full_runnable_config_path, 'a') as file_writer:\n file_writer.write('\\n')\n file_writer.write(main_if_block_begin)\n file_writer.write(ray_init_line)\n file_writer.write(main_if_block_end)\n"
},
{
"alpha_fraction": 0.49400922656059265,
"alphanum_fraction": 0.5093702077865601,
"avg_line_length": 27.805309295654297,
"blob_id": "efa8bb998be2b8718ae1ca55e33300346d0449c9",
"content_id": "eb7f425097dacb0ed327edc38f8c991c4f7cc561",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3255,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 113,
"path": "/tests/helpers.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abmarl.sim import AgentBasedSimulation\nfrom abmarl.sim import Agent\n\nfrom gym.spaces import Discrete, MultiBinary, MultiDiscrete, Box, Dict, Tuple\nimport numpy as np\n\n\nclass FillInHelper(AgentBasedSimulation):\n def reset(self):\n pass\n\n def step(self, action):\n pass\n\n def render(self):\n pass\n\n def get_obs(self, agent_id, **kwargs):\n pass\n\n def get_reward(self, agent_id, **kwargs):\n pass\n\n def get_done(self, agent_id, **kwargs):\n pass\n\n def get_all_done(self, **kwargs):\n pass\n\n def get_info(self, agent_id, **kwargs):\n pass\n\n\nclass MultiAgentSim(FillInHelper):\n def __init__(self, num_agents=3):\n self.agents = {\n 'agent' + str(i): Agent(\n id='agent'+str(i), observation_space=Discrete(2), action_space=Discrete(2)\n ) for i in range(num_agents)\n }\n\n def reset(self):\n self.action = {agent.id: None for agent in self.agents.values()}\n\n def step(self, action_dict):\n for agent_id, action in action_dict.items():\n self.action[agent_id] = action\n\n def get_obs(self, agent_id, **kwargs):\n return \"Obs from \" + agent_id\n\n def get_reward(self, agent_id, **kwargs):\n return \"Reward from \" + agent_id\n\n def get_done(self, agent_id, **kwargs):\n return \"Done from \" + agent_id\n\n def get_all_done(self, **kwargs):\n return \"Done from all agents and/or simulation.\"\n\n def get_info(self, agent_id, **kwargs):\n return {'Action from ' + agent_id: self.action[agent_id]}\n\n\nclass MultiAgentGymSpacesSim(MultiAgentSim):\n def __init__(self):\n self.params = {'params': \"there are none\"}\n self.agents = {\n 'agent0': Agent(\n id='agent0',\n observation_space=MultiBinary(4),\n action_space=Tuple((\n Dict({\n 'first': Discrete(4),\n 'second': Box(low=-1, high=3, shape=(2,), dtype=np.int)\n }),\n MultiBinary(3)\n ))\n ),\n 'agent1': Agent(\n id='agent1',\n observation_space=Box(low=0, high=1, shape=(1,), dtype=np.int),\n action_space=MultiDiscrete([4, 6, 2])\n ),\n 'agent2': Agent(\n id='agent2',\n observation_space=MultiDiscrete([2, 2]),\n action_space=Dict({'alpha': MultiBinary(3)})\n ),\n 'agent3': Agent(\n id='agent3',\n observation_space=Dict({\n 'first': Discrete(4),\n 'second': Box(low=-1, high=3, shape=(2,), dtype=np.int)\n }),\n action_space=Tuple((Discrete(3), MultiDiscrete([10, 10]), Discrete(2)))\n )\n }\n\n\n def get_obs(self, agent_id, **kwargs):\n if agent_id == 'agent0':\n return [0, 0, 0, 1]\n elif agent_id == 'agent1':\n return 0\n elif agent_id == 'agent2':\n return [1, 0]\n elif agent_id == 'agent3':\n return {'first': 1, 'second': [3, 1]}\n\n\n def get_info(self, agent_id, **kwargs):\n return self.action[agent_id]\n"
},
{
"alpha_fraction": 0.8571428656578064,
"alphanum_fraction": 0.8571428656578064,
"avg_line_length": 41,
"blob_id": "9086475c93e2a944aef17fadacf3132551701281",
"content_id": "3b4d54e2206e2244eee104f5b7b3c7d512ddadaf",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 42,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 1,
"path": "/abmarl/sim/modules/__init__.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .grid_resources import GridResources\n"
},
{
"alpha_fraction": 0.5745700001716614,
"alphanum_fraction": 0.635423481464386,
"avg_line_length": 42.535545349121094,
"blob_id": "694ba84aa7fb89badf81248795886f24dc9bf564",
"content_id": "555d507646760f5a9290ba71169193d546a597fa",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9186,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 211,
"path": "/tests/test_movement_component.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.components.state import GridPositionState, ContinuousPositionState, \\\n SpeedAngleState, VelocityState\nfrom abmarl.sim.components.actor import GridMovementActor, SpeedAngleMovementActor, \\\n AccelerationMovementActor\nfrom abmarl.sim.components.agent import SpeedAngleAgent, SpeedAngleActingAgent, VelocityAgent, \\\n GridMovementAgent, AcceleratingAgent\n\n\nclass GridMovementTestAgent(GridMovementAgent): pass\n\n\ndef test_grid_movement_component():\n agents = {\n 'agent0': GridMovementTestAgent(\n id='agent0', initial_position=np.array([6, 4]), move_range=2\n ),\n 'agent1': GridMovementTestAgent(\n id='agent1', initial_position=np.array([3, 3]), move_range=3\n ),\n 'agent2': GridMovementTestAgent(\n id='agent2', initial_position=np.array([0, 1]), move_range=1\n ),\n 'agent3': GridMovementTestAgent(\n id='agent3', initial_position=np.array([8, 4]), move_range=1\n ),\n }\n state = GridPositionState(region=10, agents=agents)\n actor = GridMovementActor(position_state=state, agents=agents)\n\n for agent in agents.values():\n assert 'move' in agent.action_space\n\n state.reset()\n\n np.testing.assert_array_equal(\n actor.process_action(agents['agent0'], {'move': np.array([-1, 1])}), np.array([-1, 1])\n )\n np.testing.assert_array_equal(\n actor.process_action(agents['agent1'], {'move': np.array([0, 1])}), np.array([0, 1])\n )\n np.testing.assert_array_equal(\n actor.process_action(agents['agent2'], {'move': np.array([0, -1])}), np.array([0, -1])\n )\n np.testing.assert_array_equal(\n actor.process_action(agents['agent3'], {'move': np.array([1, 0])}), np.array([1, 0])\n )\n np.testing.assert_array_equal(agents['agent0'].position, np.array([5, 5]))\n np.testing.assert_array_equal(agents['agent1'].position, np.array([3, 4]))\n np.testing.assert_array_equal(agents['agent2'].position, np.array([0, 0]))\n np.testing.assert_array_equal(agents['agent3'].position, np.array([9, 4]))\n\n np.testing.assert_array_equal(\n actor.process_action(agents['agent0'], {'move': np.array([2, -2])}), np.array([2, -2])\n )\n np.testing.assert_array_equal(\n actor.process_action(agents['agent1'], {'move': np.array([-3, 0])}), np.array([-3, 0])\n )\n np.testing.assert_array_equal(\n actor.process_action(agents['agent2'], {'move': np.array([-1, 0])}), np.array([0, 0])\n )\n np.testing.assert_array_equal(\n actor.process_action(agents['agent3'], {'move': np.array([1, 1])}), np.array([0, 0])\n )\n np.testing.assert_array_equal(agents['agent0'].position, np.array([7, 3]))\n np.testing.assert_array_equal(agents['agent1'].position, np.array([0, 4]))\n np.testing.assert_array_equal(agents['agent2'].position, np.array([0, 0]))\n np.testing.assert_array_equal(agents['agent3'].position, np.array([9, 4]))\n\n\nclass SpeedAngleMovementTestAgent(SpeedAngleAgent, SpeedAngleActingAgent): pass\n\n\ndef test_speed_angle_movement_component():\n agents = {\n 'agent0': SpeedAngleMovementTestAgent(\n id='agent0', initial_position=np.array([6.2, 3.3 ]), initial_speed=1.0,\n min_speed=0.0, max_speed=1.0, max_acceleration=0.35, initial_banking_angle=-30,\n max_banking_angle=45, max_banking_angle_change=30, initial_ground_angle=300\n ),\n 'agent1': SpeedAngleMovementTestAgent(\n id='agent1', initial_position=np.array([2.1, 3.15 ]), initial_speed=0.5,\n min_speed=0.0, max_speed=1.0, max_acceleration=0.35, initial_banking_angle=10,\n max_banking_angle=45, max_banking_angle_change=30, initial_ground_angle=100\n ),\n 'agent2': SpeedAngleMovementTestAgent(\n id='agent2', initial_position=np.array([0.5, 1.313]), initial_speed=0.24,\n min_speed=0.0, max_speed=1.0, max_acceleration=0.35, initial_banking_angle=0.0,\n max_banking_angle=45, max_banking_angle_change=30, initial_ground_angle=45\n ),\n 'agent3': SpeedAngleMovementTestAgent(\n id='agent3', initial_position=np.array([8.24, 4.4 ]), initial_speed=0.6,\n min_speed=0.0, max_speed=1.0, max_acceleration=0.35, initial_banking_angle=24,\n max_banking_angle=45, max_banking_angle_change=30, initial_ground_angle=180\n ),\n }\n position_state = ContinuousPositionState(region=10, agents=agents)\n speed_angle_state = SpeedAngleState(agents=agents)\n actor = SpeedAngleMovementActor(\n position_state=position_state, speed_angle_state=speed_angle_state, agents=agents\n )\n\n for agent in agents.values():\n assert 'accelerate' in agent.action_space\n assert 'bank' in agent.action_space\n\n position_state.reset()\n speed_angle_state.reset()\n for agent in agents.values():\n np.testing.assert_array_equal(agent.position, agent.initial_position)\n assert agent.speed == agent.initial_speed\n assert agent.banking_angle == agent.initial_banking_angle\n assert agent.ground_angle == agent.initial_ground_angle\n\n assert np.allclose(\n actor.process_move(agents['agent0'], np.array([0.0]), np.array([0.0])), np.array([0., -1.])\n )\n assert np.allclose(agents['agent0'].position, np.array([6.2, 2.3]))\n assert np.allclose(\n actor.process_move(agents['agent1'], np.array([0.0]), np.array([0.0])),\n np.array([-0.17101007, 0.46984631])\n )\n assert np.allclose(agents['agent1'].position, np.array([1.92898993, 3.61984631]))\n assert np.allclose(\n actor.process_move(agents['agent2'], np.array([0.0]), np.array([0.0])),\n np.array([0.16970563, 0.16970563])\n )\n assert np.allclose(agents['agent2'].position, np.array([0.66970563, 1.48270563]))\n assert np.allclose(\n actor.process_move(agents['agent3'], np.array([0.0]), np.array([0.0])),\n np.array([-0.54812727, -0.24404199])\n )\n assert np.allclose(agents['agent3'].position, np.array([7.69187273, 4.15595801]))\n\n assert np.allclose(\n actor.process_move(agents['agent0'], np.array([-0.35]), np.array([30])),\n np.array([0, -0.65])\n )\n assert np.allclose(agents['agent0'].position, np.array([6.2, 1.65]))\n assert np.allclose(\n actor.process_move(agents['agent1'], np.array([-0.1]), np.array([-30])),\n np.array([0, 0.4])\n )\n assert np.allclose(agents['agent1'].position, np.array([1.92898993, 4.01984631]))\n assert np.allclose(\n actor.process_move(agents['agent2'], np.array([-0.24]), np.array([30])),\n np.array([0, 0.0])\n )\n assert np.allclose(agents['agent2'].position, np.array([0.66970563, 1.48270563]))\n assert np.allclose(\n actor.process_move(agents['agent3'], np.array([0.0]), np.array([-24])),\n np.array([-0.54812727, -0.24404199])\n )\n assert np.allclose(agents['agent3'].position, np.array([7.14374545, 3.91191603]))\n\n\nclass ParticleAgent(VelocityAgent, AcceleratingAgent): pass\n\n\ndef test_acceleration_movement_component():\n agents = {\n 'agent0': ParticleAgent(\n id='agent0', initial_position=np.array([2.3, 4.5]), initial_velocity=np.array([1, 0]),\n max_speed=1.0, max_acceleration=0.5\n ),\n 'agent1': ParticleAgent(\n id='agent1', initial_position=np.array([8.5, 1.0]), initial_velocity=np.array([0, 0]),\n max_speed=1.0, max_acceleration=0.5\n ),\n 'agent2': ParticleAgent(\n id='agent2', initial_position=np.array([5.0, 5.0]),\n initial_velocity=np.array([-1, -1]), max_speed=2.0, max_acceleration=0.5\n ),\n }\n\n position_state = ContinuousPositionState(region=10, agents=agents)\n velocity_state = VelocityState(agents=agents, friction=0.1)\n actor = AccelerationMovementActor(\n position_state=position_state, velocity_state=velocity_state, agents=agents\n )\n\n for agent in agents.values():\n assert 'accelerate' in agent.action_space\n\n position_state.reset()\n velocity_state.reset()\n for agent in agents.values():\n np.testing.assert_array_equal(agent.position, agent.initial_position)\n np.testing.assert_array_equal(agent.velocity, agent.initial_velocity)\n\n assert np.allclose(\n actor.process_action(agents['agent0'], {'accelerate': np.array([-1, 0])}),\n np.array([0., 0.])\n )\n assert np.allclose(agents['agent0'].position, np.array([2.3, 4.5]))\n assert np.allclose(\n actor.process_action(agents['agent1'], {'accelerate': np.array([-1, 1])}),\n np.array([-0.70710678, 0.70710678])\n )\n assert np.allclose(agents['agent1'].position, np.array([7.79289322, 1.70710678]))\n assert np.allclose(\n actor.process_action(agents['agent2'], {'accelerate': np.array([0, 0])}),\n np.array([-1, -1])\n )\n assert np.allclose(agents['agent2'].position, np.array([4, 4]))\n\n velocity_state.apply_friction(agents['agent0'])\n assert np.allclose(agents['agent0'].velocity, np.array([0, 0]))\n velocity_state.apply_friction(agents['agent1'])\n assert np.allclose(agents['agent1'].velocity, np.array([-0.6363961, 0.6363961]))\n"
},
{
"alpha_fraction": 0.711810290813446,
"alphanum_fraction": 0.7222982048988342,
"avg_line_length": 34.95082092285156,
"blob_id": "cc5e092ef99fb756bec4ce697fb5572854a7275b",
"content_id": "03e5b2aeb2e93a525e412bf8a15ec5289c3c4023",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2193,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 61,
"path": "/tests/test_monte_carlo.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abmarl.algs.monte_carlo import exploring_starts, epsilon_soft, off_policy\nfrom abmarl.sim.corridor import MultiCorridor as Corridor\nfrom abmarl.managers import AllStepManager\nfrom abmarl.sim.wrappers import RavelDiscreteWrapper\nfrom abmarl.external import GymWrapper\nfrom abmarl.pols import RandomFirstActionPolicy, EpsilonSoftPolicy, GreedyPolicy\n\n\ndef test_exploring_starts_corridor():\n sim = AllStepManager(RavelDiscreteWrapper(Corridor(num_agents=1)))\n sim, q_table, policy = exploring_starts(sim, iteration=100, horizon=10)\n\n assert isinstance(sim, GymWrapper)\n assert isinstance(sim.sim, AllStepManager)\n assert isinstance(sim.sim.sim, RavelDiscreteWrapper)\n assert isinstance(sim.sim.sim.sim, Corridor)\n\n assert q_table.shape == (sim.observation_space.n, sim.action_space.n)\n assert isinstance(policy, RandomFirstActionPolicy)\n\n\ndef test_epsilon_soft():\n sim = AllStepManager(RavelDiscreteWrapper(Corridor(num_agents=1)))\n sim, q_table, policy = epsilon_soft(sim, iteration=1000, horizon=20)\n\n assert isinstance(sim, GymWrapper)\n assert isinstance(sim.sim, AllStepManager)\n assert isinstance(sim.sim.sim, RavelDiscreteWrapper)\n assert isinstance(sim.sim.sim.sim, Corridor)\n\n assert q_table.shape == (sim.observation_space.n, sim.action_space.n)\n assert isinstance(policy, EpsilonSoftPolicy)\n\n obs = sim.reset()\n for _ in range(10):\n action = policy.act(obs)\n obs, reward, done, info = sim.step(action)\n if done:\n break\n assert done\n\n\ndef test_off_policy():\n sim = AllStepManager(RavelDiscreteWrapper(Corridor(num_agents=1)))\n sim, q_table, policy = off_policy(sim, iteration=100, horizon=10)\n\n assert isinstance(sim, GymWrapper)\n assert isinstance(sim.sim, AllStepManager)\n assert isinstance(sim.sim.sim, RavelDiscreteWrapper)\n assert isinstance(sim.sim.sim.sim, Corridor)\n\n assert q_table.shape == (sim.observation_space.n, sim.action_space.n)\n assert isinstance(policy, GreedyPolicy)\n\n obs = sim.reset()\n for _ in range(10):\n action = policy.act(obs)\n obs, reward, done, info = sim.step(action)\n if done:\n break\n assert done\n"
},
{
"alpha_fraction": 0.6165199875831604,
"alphanum_fraction": 0.6291512846946716,
"avg_line_length": 35.128204345703125,
"blob_id": "c2141c46078e191da86074c57981649aae89428f",
"content_id": "425e2bde9d67e850ce67c829b3558d35c9c03c00",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7046,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 195,
"path": "/examples/hunting_foraging_demo.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "\n# ----------------------------- #\n# --- Setup the environment --- #\n# ----------------------------- #\n\n# --- Create the agents and the environment --- #\n\n# Import the simulation environment and agents\nfrom abmarl.sim.components.examples.hunting_and_foraging import HuntingForagingEnv, \\\n HuntingForagingAgent, FoodAgent\n\n# Instatiate the agents that will operate in this environment. All possible agent\n# attributes are listed below.\n\n# Food agents are not really agents in the RL sense. They're just entites for the\n# foragers to eat.\nfood = {f'food{i}': FoodAgent(id=f'food{i}', team=1) for i in range(12)}\n\n# Foragers try to eat all the food agents before they die\nforagers = {f'forager{i}': HuntingForagingAgent(\n id=f'forager{i}',\n agent_view=3, # Partial Observation Mask: how far away this agent can see other agents.\n team=2, # Which team this agent is on\n move_range=1, # How far the agent can move within a single step.\n min_health=0.0, # If the agent's health falls below this value, it will die.\n max_health=1.0, # Agent's health cannot grow above this value.\n attack_range=1, # How far this agent's attack will reach.\n attack_strength=1.0, # How powerful the agent's attack is.\n attack_accuracy=1.0, # Probability of successful attack\n initial_position=None # Episode-starting position. If None, then random within the region.\n) for i in range(5)}\n\n# # Hunters try to eat all the foraging agents before all the food disappears.\nhunters = {f'hunter{i}': HuntingForagingAgent(\n id=f'hunter{i}',\n agent_view=2, # Partial Observation Mask: how far away this agent can see other agents.\n team=3, # Which team this agent is on\n move_range=1, # How far the agent can move within a single step.\n min_health=0.0, # If the agent's health falls below this value, it will die.\n max_health=1.0, # Agent's health cannot grow above this value.\n attack_range=1, # How far this agent's attack will reach.\n attack_strength=1.0, # How powerful the agent's attack is.\n attack_accuracy=1.0, # Probability of successful attack\n initial_position=None # Episode-starting position. If None, then random within the region.\n) for i in range(2)}\n\nagents = {**food, **foragers, **hunters}\n\n# Instantiate the environment\n\n# Set the size of the map\nregion = 20\n\n# Determine which teams can \"attack\" each other. In this scenario, team 2 is the\n# foragers, and they can attack the food, which is team 1. Team 3 is the hunters\n# and they can attack the foragers. So we setup a matrix that represents this.\nimport numpy as np\nteam_attack_matrix = np.zeros((4, 4))\nteam_attack_matrix[2, 1] = 1 # Foragers can attack food\nteam_attack_matrix[3, 2] = 1 # Hunters can attack foragers\nenv = HuntingForagingEnv(\n region=region, # The size of the region, both x and y\n number_of_teams=3, # The number of teams\n agents=agents, # Give the environment the dictionary of agents we created above\n team_attack_matrix=team_attack_matrix,\n # attack_norm=np.inf, # The norm to use. Default is np.inf, which means that\n # the attack radius is square box around the agent\n)\n\n# --- Prepare the environment for use with RLlib --- #\n\n# Now that you've created the environment, you must wrap it with a simulation manager,\n# which controls the timing of the simulation step.\nfrom abmarl.managers import AllStepManager # All agents take the step at the same time\nenv = AllStepManager(env)\n\n# We must wrap the environment with the MultiAgentWrapper so that it\n# works with RLlib\nfrom abmarl.external.rllib_multiagentenv_wrapper import MultiAgentWrapper\nenv = MultiAgentWrapper(env)\n\n# Finally we must register the environment with RLlib\nfrom ray.tune.registry import register_env\nenv_name = \"HuntingForaging\"\nregister_env(env_name, lambda env_config: env)\n\n\n# -------------------------- #\n# --- Setup the policies --- #\n# -------------------------- #\n\n# Here we have it setup so that every agent on a team trains the same policy.\n# Because every agent on the team has the same observation and action space, we can just use\n# the specs from one of the agent to define the policies' inputs and outputs.\npolicies = {\n 'foragers': (None, agents['forager0'].observation_space, agents['forager0'].action_space, {}),\n 'hunters': (None, agents['hunter0'].observation_space, agents['hunter0'].action_space, {}),\n}\n\n\ndef policy_mapping_fn(agent_id):\n if agents[agent_id].team == 2:\n return 'foragers'\n else:\n return 'hunters'\n\n# USE FOR DEBUGGING\n# print(agents['forager0'].action_space)\n# print(agents['forager0'].observation_space)\n# print(agents['hunter0'].action_space)\n# print(agents['hunter0'].observation_space)\n# # for agent in agents:\n# # print(policy_mapping_fn(agent))\n# import sys; sys.exit()\n\n\n# --------------------------- #\n# --- Setup the algorithm --- #\n# --------------------------- #\n\n# Full list of supported algorithms here:\n# https://docs.ray.io/en/releases-0.8.5/rllib-algorithms.html\nalgo_name = 'A2C'\n\n\n# ------------------ #\n# --- Parameters --- #\n# ------------------ #\n\n# List of common ray_tune parameters here:\n# https://docs.ray.io/en/latest/rllib-training.html#common-parameters\nparams = {\n 'experiment': {\n 'title': '{}'.format('ManyForager_5-ManySmartPredator_2-GridTeamObs-View_3-PenalizeDeath'),\n 'sim_creator': lambda config=None: env,\n },\n 'ray_tune': {\n 'run_or_experiment': algo_name,\n 'checkpoint_freq': 10,\n 'checkpoint_at_end': True,\n 'stop': {\n 'episodes_total': 2000,\n },\n 'verbose': 2,\n 'config': {\n # --- Environment ---\n 'env': \"HuntingForaging\",\n 'horizon': 200,\n 'env_config': {},\n # --- Multiagent ---\n 'multiagent': {\n 'policies': policies,\n 'policy_mapping_fn': policy_mapping_fn,\n },\n \"num_workers\": 7,\n \"num_envs_per_worker\": 1, # This must be 1 because we are not \"threadsafe\"\n \"rollout_fragment_length\": 200,\n \"batch_mode\": \"complete_episodes\",\n \"train_batch_size\": 1000,\n },\n }\n}\n\n\n# ---------------------------- #\n# --- Random demonstration --- #\n# ---------------------------- #\n\nif __name__ == \"__main__\":\n from matplotlib import pyplot as plt\n fig = plt.gcf()\n shape_dict = {\n 1: 's',\n 2: 'o',\n 3: 'd'\n }\n\n obs = env.reset()\n import pprint\n pprint.pprint(obs)\n env.render(fig=fig, shape_dict=shape_dict)\n\n for _ in range(100):\n action_dict = {\n agent.id: agent.action_space.sample()\n for agent in agents.values()\n if agent.is_alive and isinstance(agent, HuntingForagingAgent)\n }\n obs, _, done, _ = env.step(action_dict)\n env.render(fig=fig, shape_dict=shape_dict)\n if done['__all__']:\n break\n # if action_dict['forager0'] == 9:\n # print('Attack occured!')\n # print(obs['forager0']['life'])\n # plt.pause(1)\n"
},
{
"alpha_fraction": 0.6556451320648193,
"alphanum_fraction": 0.6572580933570862,
"avg_line_length": 36.57575607299805,
"blob_id": "1887c47be6187773e31f5404db496019791dc140",
"content_id": "6916ef3618a8c6f23e6d1b7353bdfc44faca3936",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1240,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 33,
"path": "/abmarl/scripts/make_runnable_script.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "def create_parser(subparsers):\n \"\"\"Parse the arguments for the make_runnable command.\n\n Returns\n -------\n parser : ArgumentParser\n \"\"\"\n runnable_parser = subparsers.add_parser(\n 'make-runnable',\n help='Convert a configuration + script to be runnable from the commandline. Save the '\n 'coverted script in the same directory as the original script. This option is useful for '\n 'running batch jobs from the command line and/or integration with magpie.'\n )\n runnable_parser.add_argument(\n 'configuration', type=str, help='Path to python config file. Include the .py extension.'\n )\n runnable_parser.add_argument(\n '--magpie', action='store_true', help='Output a magpie script as well.'\n )\n runnable_parser.add_argument(\n '-n', '--nodes', type=int,\n help='Specify the number of compute nodes (not rollout workers) you want.', default=2\n )\n runnable_parser.add_argument(\n '-t', '--time-limit', type=str, help='The maximum runtime for this job in hours',\n default='2'\n )\n return runnable_parser\n\n\ndef run(full_config_path, parameters):\n from abmarl import make_runnable\n make_runnable.run(full_config_path, parameters)\n"
},
{
"alpha_fraction": 0.6405919790267944,
"alphanum_fraction": 0.6405919790267944,
"avg_line_length": 29.516128540039062,
"blob_id": "0f6a153997b3a5b00c72763655d9e9cfc9c07417",
"content_id": "a390e2d39270cffbc230e6889bf035df03006ffa",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 946,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 31,
"path": "/abmarl/train.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abmarl.tools import utils as adu\n\n\ndef run(full_config_path):\n \"\"\"Train MARL policies using the config_file.\"\"\"\n\n # Load the experiment as a module\n experiment_mod = adu.custom_import_module(full_config_path)\n title = experiment_mod.params['experiment']['title']\n\n # Copy the configuration module to the output directory\n import os\n import shutil\n import time\n base = experiment_mod.params['ray_tune'].get('local_dir', os.path.expanduser(\"~\"))\n output_dir = os.path.join(\n base, 'abmarl_results/{}_{}'.format(\n title, time.strftime('%Y-%m-%d_%H-%M')\n )\n )\n experiment_mod.params['ray_tune']['local_dir'] = output_dir\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n shutil.copy(full_config_path, output_dir)\n\n # Train with ray\n import ray\n from ray import tune\n ray.init()\n tune.run(**experiment_mod.params['ray_tune'])\n ray.shutdown()\n"
},
{
"alpha_fraction": 0.6623134613037109,
"alphanum_fraction": 0.6623134613037109,
"avg_line_length": 35.965518951416016,
"blob_id": "b264ef85a5b1eff8b4e0f7c56c42120a6d1e6f0e",
"content_id": "debd10c127fb4382a02c3b6b538e924e73a2f1f4",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2144,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 58,
"path": "/abmarl/sim/wrappers/sar_wrapper.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .wrapper import Wrapper\n\n\nclass SARWrapper(Wrapper):\n \"\"\"\n Wraps the actions and observations for all the agents at reset and step.\n To create your own wrapper, inherit from this class and override the wrap\n and unwrap functions.\n\n Note: wrapping the action \"goes the other way\" than the reward and observation, like this:\n obs: sim agent -> wrapper -> trainer\n reward: sim agent -> wrapper -> trainer\n action: sim agent <- wrapper <- trainer\n\n If you wrap an action, be aware that the wrapper must return what the simulation\n agents expect; whereas if you wrap an observation or reward, the wrapper must return\n what the trainer expects. The expectations are defined by the observation and\n action spaces of the wrapped simulation agents at initialization.\n \"\"\"\n def step(self, action_dict, **kwargs):\n \"\"\"\n Wrap each of the agent's actions from the policies before passing them\n to sim.step.\n \"\"\"\n self.sim.step(\n {\n agent_id: self.wrap_action(self.sim.agents[agent_id], action)\n for agent_id, action in action_dict.items()\n },\n **kwargs\n )\n\n def get_obs(self, agent_id, **kwargs):\n return self.wrap_observation(self.sim.agents[agent_id], self.sim.get_obs(agent_id))\n\n def get_reward(self, agent_id, **kwargs):\n return self.wrap_reward(self.sim.get_reward(agent_id))\n\n # Default wrapping and unwrapping behavior. Override these in your custom wrapper.\n # Developer note: we have to have separate wrappers for each because we don't\n # want to force the observation and action space to map to the same wrapped space.\n def wrap_observation(self, from_agent, observation):\n return observation\n\n def unwrap_observation(self, from_agent, observation):\n return observation\n\n def wrap_action(self, from_agent, action):\n return action\n\n def unwrap_action(self, from_agent, action):\n return action\n\n def wrap_reward(self, reward):\n return reward\n\n def unwrap_reward(self, reward):\n return reward\n"
},
{
"alpha_fraction": 0.6315456032752991,
"alphanum_fraction": 0.6383023858070374,
"avg_line_length": 35.152671813964844,
"blob_id": "d6877d72c52e06ff71f2f5eee9c955424e04446e",
"content_id": "b03160a1399f14d61a665ff7ab0baa94903f272f",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4736,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 131,
"path": "/abmarl/sim/components/examples/fighting_teams.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport numpy as np\n\nfrom abmarl.sim.components.state import GridPositionState, LifeState\nfrom abmarl.sim.components.observer import TeamObserver, PositionObserver, HealthObserver, \\\n LifeObserver\nfrom abmarl.sim.components.actor import GridMovementActor, AttackActor\nfrom abmarl.sim.components.done import TeamDeadDone\nfrom abmarl.sim.components.agent import TeamObservingAgent, PositionObservingAgent, \\\n HealthObservingAgent, LifeObservingAgent, GridMovementAgent, AttackingAgent\nfrom abmarl.sim import AgentBasedSimulation\nfrom abmarl.tools.matplotlib_utils import mscatter\n\n\nclass FightingTeamsAgent(\n TeamObservingAgent, PositionObservingAgent, HealthObservingAgent,\n LifeObservingAgent, GridMovementAgent, AttackingAgent\n): pass\n\n\nclass FightingTeamsSim(AgentBasedSimulation):\n def __init__(self, **kwargs):\n self.agents = kwargs['agents']\n\n # State Components\n self.position_state = GridPositionState(**kwargs)\n self.life_state = LifeState(**kwargs)\n\n # Observer Components\n self.position_observer = PositionObserver(position_state=self.position_state, **kwargs)\n self.health_observer = HealthObserver(**kwargs)\n self.life_observer = LifeObserver(**kwargs)\n self.team_observer = TeamObserver(**kwargs)\n\n # Actor Components\n self.move_actor = GridMovementActor(position_state=self.position_state, **kwargs)\n self.attack_actor = AttackActor(**kwargs)\n\n # Done components\n self.done = TeamDeadDone(**kwargs)\n\n self.finalize()\n\n def reset(self, **kwargs):\n self.position_state.reset(**kwargs)\n self.life_state.reset(**kwargs)\n\n def step(self, action_dict, **kwargs):\n # Process attacking\n for agent_id, action in action_dict.items():\n attacking_agent = self.agents[agent_id]\n attacked_agent = self.attack_actor.process_action(attacking_agent, action, **kwargs)\n if attacked_agent is not None:\n self.life_state.modify_health(attacked_agent, -attacking_agent.attack_strength)\n\n # Process movement\n for agent_id, action in action_dict.items():\n self.move_actor.process_action(self.agents[agent_id], action, **kwargs)\n\n def render(self, fig=None, **kwargs):\n fig.clear()\n render_condition = {agent.id: agent.is_alive for agent in self.agents.values()}\n shape_dict = {agent.id: 'o' if agent.team == 1 else 's' for agent in self.agents.values()}\n\n ax = fig.gca()\n ax.set(xlim=(0, self.position_state.region), ylim=(0, self.position_state.region))\n ax.set_xticks(np.arange(0, self.position_state.region, 1))\n ax.set_yticks(np.arange(0, self.position_state.region, 1))\n ax.grid()\n\n agents_x = [\n agent.position[1] + 0.5 for agent in self.agents.values() if render_condition[agent.id]\n ]\n agents_y = [\n self.position_state.region - 0.5 - agent.position[0] for agent in self.agents.values()\n if render_condition[agent.id]\n ]\n\n if shape_dict:\n shape = [shape_dict[agent_id] for agent_id in shape_dict if render_condition[agent_id]]\n else:\n shape = 'o'\n mscatter(agents_x, agents_y, ax=ax, m=shape, s=200, edgecolor='black', facecolor='gray')\n\n plt.plot()\n plt.pause(1e-6)\n\n def get_obs(self, agent_id, **kwargs):\n agent = self.agents[agent_id]\n return {\n **self.position_observer.get_obs(agent, **kwargs),\n **self.health_observer.get_obs(agent, **kwargs),\n **self.life_observer.get_obs(agent, **kwargs),\n **self.team_observer.get_obs(agent, **kwargs),\n }\n\n def get_reward(self, agent_id, **kwargs):\n pass\n\n def get_done(self, agent_id, **kwargs):\n return self.done.get_done(agent_id)\n\n def get_all_done(self, **kwargs):\n return self.done.get_all_done(**kwargs)\n\n def get_info(self, **kwargs):\n return {}\n\n\nif __name__ == '__main__':\n agents = {f'agent{i}': FightingTeamsAgent(\n id=f'agent{i}', attack_range=1, attack_strength=0.4, team=i % 2 + 1, move_range=1\n ) for i in range(24)}\n sim = FightingTeamsSim(\n region=12,\n agents=agents,\n number_of_teams=2\n )\n sim.reset()\n print({agent_id: sim.get_obs(agent_id) for agent_id in sim.agents})\n fig = plt.gcf()\n sim.render(fig=fig)\n\n for _ in range(100):\n action_dict = {\n agent.id: agent.action_space.sample() for agent in sim.agents.values()\n if agent.is_alive\n }\n sim.step(action_dict)\n sim.render(fig=fig)\n print(sim.get_all_done())\n"
},
{
"alpha_fraction": 0.8529411554336548,
"alphanum_fraction": 0.8529411554336548,
"avg_line_length": 33,
"blob_id": "14f52b3a84e2a1c6a1ee02d3475120c8690730cb",
"content_id": "59aefabba6d4b66eee98cade917960b486a8945c",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 34,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 1,
"path": "/abmarl/sim/components/__init__.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .agent import ComponentAgent\n"
},
{
"alpha_fraction": 0.5516244769096375,
"alphanum_fraction": 0.5925717353820801,
"avg_line_length": 37.04021453857422,
"blob_id": "b23e67b0bbeed61fbbd751698df36efd805abefd",
"content_id": "42a12aca01826791b2a3115ee24b4611785e6a20",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14189,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 373,
"path": "/tests/test_component_observer_wrapper.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.components.agent import SpeedAngleAgent, VelocityAgent, BroadcastingAgent\nfrom abmarl.sim.components.state import GridPositionState, LifeState, SpeedAngleState, \\\n VelocityState, BroadcastState\nfrom abmarl.sim.components.observer import HealthObserver, LifeObserver, PositionObserver, \\\n RelativePositionObserver, SpeedObserver, AngleObserver, VelocityObserver, TeamObserver\nfrom abmarl.sim.components.wrappers.observer_wrapper import \\\n PositionRestrictedObservationWrapper, TeamBasedCommunicationWrapper\nfrom abmarl.sim.components.actor import BroadcastActor\n\nfrom abmarl.sim.components.agent import AgentObservingAgent, VelocityObservingAgent, \\\n PositionObservingAgent, SpeedAngleObservingAgent, TeamObservingAgent, LifeObservingAgent, \\\n HealthObservingAgent\n\n\nclass AllObservingAgent(\n AgentObservingAgent, VelocityObservingAgent, PositionObservingAgent, SpeedAngleObservingAgent,\n TeamObservingAgent, LifeObservingAgent, HealthObservingAgent\n): pass\n\n\nclass NonViewAgent(\n VelocityObservingAgent, PositionObservingAgent, SpeedAngleObservingAgent, TeamObservingAgent,\n LifeObservingAgent, HealthObservingAgent\n): pass\n\n\nclass AllAgent( AllObservingAgent, SpeedAngleAgent, VelocityAgent): pass\nclass SpeedAnglelessAgent(AllObservingAgent, VelocityAgent): pass\nclass VelocitylessAgent( AllObservingAgent, SpeedAngleAgent ): pass\n\n\ndef test_position_restricted_observer_wrapper():\n agents = {\n 'agent0': AllAgent(\n id='agent0', agent_view=2, initial_position=np.array([2, 2]), initial_health=0.67,\n team=1, max_speed=1, initial_speed=0.30, initial_banking_angle=7,\n initial_ground_angle=123, initial_velocity=np.array([-0.3, 0.8])\n ),\n 'agent1': AllAgent(\n id='agent1', agent_view=1, initial_position=np.array([4, 4]), initial_health=0.54,\n team=2, max_speed=2, initial_speed=0.00, initial_banking_angle=0,\n initial_ground_angle=126, initial_velocity=np.array([-0.2, 0.7])\n ),\n 'agent2': AllAgent(\n id='agent2', agent_view=1, initial_position=np.array([4, 3]), initial_health=0.36,\n team=2, max_speed=1, initial_speed=0.12, initial_banking_angle=30,\n initial_ground_angle=180, initial_velocity=np.array([-0.1, 0.6])\n ),\n 'agent3': AllAgent(\n id='agent3', agent_view=1, initial_position=np.array([4, 2]), initial_health=0.24,\n team=2, max_speed=4, initial_speed=0.05, initial_banking_angle=13,\n initial_ground_angle=46, initial_velocity=np.array([0.0, 0.5])\n ),\n 'agent6': SpeedAnglelessAgent(\n id='agent6', agent_view=0, initial_position=np.array([1, 1]), initial_health=0.53,\n team=1, max_speed=1, initial_velocity=np.array([0.3, 0.2])\n ),\n 'agent7': VelocitylessAgent(\n id='agent7', agent_view=5, initial_position=np.array([0, 4]), initial_health=0.50,\n team=2, max_speed=1, initial_speed=0.36, initial_banking_angle=24,\n initial_ground_angle=0\n ),\n }\n\n def linear_drop_off(distance, view):\n return 1. - 1. / (view+1) * distance\n\n np.random.seed(12)\n position_state = GridPositionState(agents=agents, region=5)\n life_state = LifeState(agents=agents)\n speed_state = SpeedAngleState(agents=agents)\n angle_state = SpeedAngleState(agents=agents)\n velocity_state = VelocityState(agents=agents)\n\n position_observer = PositionObserver(position_state=position_state, agents=agents)\n relative_position_observer = RelativePositionObserver(\n position_state=position_state, agents=agents\n )\n health_observer = HealthObserver(agents=agents)\n life_observer = LifeObserver(agents=agents)\n team_observer = TeamObserver(number_of_teams=3, agents=agents)\n speed_observer = SpeedObserver(agents=agents)\n angle_observer = AngleObserver(agents=agents)\n velocity_observer = VelocityObserver(agents=agents)\n\n position_state.reset()\n life_state.reset()\n speed_state.reset()\n angle_state.reset()\n velocity_state.reset()\n\n wrapped_observer = PositionRestrictedObservationWrapper(\n [\n position_observer,\n relative_position_observer,\n health_observer,\n life_observer,\n team_observer,\n speed_observer,\n angle_observer,\n velocity_observer\n ],\n obs_filter=linear_drop_off,\n agents=agents\n )\n\n obs = wrapped_observer.get_obs(agents['agent0'])\n assert obs['health'] == {\n 'agent0': 0.67,\n 'agent1': -1,\n 'agent2': 0.36,\n 'agent3': -1,\n 'agent6': 0.53,\n 'agent7': -1,\n }\n assert obs['life'] == {\n 'agent0': True,\n 'agent1': -1,\n 'agent2': True,\n 'agent3': -1,\n 'agent6': 1,\n 'agent7': -1,\n }\n assert obs['team'] == {\n 'agent0': 1,\n 'agent1': -1,\n 'agent2': 2,\n 'agent3': -1,\n 'agent6': 1,\n 'agent7': -1,\n }\n np.testing.assert_array_equal(obs['position']['agent0'], np.array([2, 2]))\n np.testing.assert_array_equal(obs['position']['agent1'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent2'], np.array([4, 3]))\n np.testing.assert_array_equal(obs['position']['agent3'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent6'], np.array([1, 1]))\n np.testing.assert_array_equal(obs['position']['agent7'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['relative_position']['agent0'], np.array([0, 0]))\n np.testing.assert_array_equal(obs['relative_position']['agent1'], np.array([-5, -5]))\n np.testing.assert_array_equal(obs['relative_position']['agent2'], np.array([2, 1]))\n np.testing.assert_array_equal(obs['relative_position']['agent3'], np.array([-5, -5]))\n np.testing.assert_array_equal(obs['relative_position']['agent6'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['relative_position']['agent7'], np.array([-5, -5]))\n assert obs['mask'] == {\n 'agent0': 1,\n 'agent1': 0,\n 'agent2': 1,\n 'agent3': 0,\n 'agent6': 1,\n 'agent7': 0,\n }\n assert obs['speed'] == {\n 'agent0': 0.3,\n 'agent1': -1,\n 'agent2': 0.12,\n 'agent3': -1,\n 'agent6': -1,\n 'agent7': -1,\n }\n assert obs['ground_angle'] == {\n 'agent0': 123,\n 'agent1': -1,\n 'agent2': 180,\n 'agent3': -1,\n 'agent6': -1,\n 'agent7': -1,\n }\n np.testing.assert_array_equal(obs['velocity']['agent0'], np.array([-0.3, 0.8]))\n np.testing.assert_array_equal(obs['velocity']['agent1'], np.array([0.0, 0.0]))\n np.testing.assert_array_equal(obs['velocity']['agent2'], np.array([-0.1, 0.6]))\n np.testing.assert_array_equal(obs['velocity']['agent3'], np.array([0.0, 0.0]))\n np.testing.assert_array_equal(obs['velocity']['agent6'], np.array([0.3, 0.2]))\n np.testing.assert_array_equal(obs['velocity']['agent7'], np.array([0.0, 0.0]))\n\n\n obs = wrapped_observer.get_obs(agents['agent1'])\n assert obs['health'] == {\n 'agent0': -1,\n 'agent1': 0.54,\n 'agent2': -1,\n 'agent3': -1,\n 'agent6': -1,\n 'agent7': -1,\n }\n assert obs['life'] == {\n 'agent0': -1,\n 'agent1': True,\n 'agent2': -1,\n 'agent3': -1,\n 'agent6': -1,\n 'agent7': -1,\n }\n assert obs['team'] == {\n 'agent0': -1,\n 'agent1': 2,\n 'agent2': -1,\n 'agent3': -1,\n 'agent6': -1,\n 'agent7': -1,\n }\n np.testing.assert_array_equal(obs['position']['agent0'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent1'], np.array([4, 4]))\n np.testing.assert_array_equal(obs['position']['agent2'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent3'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent6'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent7'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['relative_position']['agent0'], np.array([-5, -5]))\n np.testing.assert_array_equal(obs['relative_position']['agent1'], np.array([0, 0]))\n np.testing.assert_array_equal(obs['relative_position']['agent2'], np.array([-5, -5]))\n np.testing.assert_array_equal(obs['relative_position']['agent3'], np.array([-5, -5]))\n np.testing.assert_array_equal(obs['relative_position']['agent6'], np.array([-5, -5]))\n np.testing.assert_array_equal(obs['relative_position']['agent7'], np.array([-5, -5]))\n assert obs['mask'] == {\n 'agent0': 0,\n 'agent1': 1,\n 'agent2': 0,\n 'agent3': 0,\n 'agent6': 0,\n 'agent7': 0,\n }\n assert obs['speed'] == {\n 'agent0': -1,\n 'agent1': 0.0,\n 'agent2': -1,\n 'agent3': -1,\n 'agent6': -1,\n 'agent7': -1,\n }\n assert obs['ground_angle'] == {\n 'agent0': -1,\n 'agent1': 126,\n 'agent2': -1,\n 'agent3': -1,\n 'agent6': -1,\n 'agent7': -1,\n }\n np.testing.assert_array_equal(obs['velocity']['agent0'], np.array([0.0, 0.0]))\n np.testing.assert_array_equal(obs['velocity']['agent1'], np.array([-0.2, 0.7]))\n np.testing.assert_array_equal(obs['velocity']['agent2'], np.array([0.0, 0.0]))\n np.testing.assert_array_equal(obs['velocity']['agent3'], np.array([0.0, 0.0]))\n np.testing.assert_array_equal(obs['velocity']['agent6'], np.array([0.0, 0.0]))\n np.testing.assert_array_equal(obs['velocity']['agent7'], np.array([0.0, 0.0]))\n\n\nclass CommunicatingAgent(\n BroadcastingAgent, PositionObservingAgent, TeamObservingAgent, AgentObservingAgent\n): pass\n\n\ndef test_broadcast_communication_observer_wrapper():\n agents = {\n 'agent0': CommunicatingAgent(\n id='agent0', initial_position=np.array([1, 7]), team=1, broadcast_range=0,\n agent_view=0\n ),\n 'agent1': CommunicatingAgent(\n id='agent1', initial_position=np.array([3, 3]), team=1, broadcast_range=4,\n agent_view=3\n ),\n 'agent2': CommunicatingAgent(\n id='agent2', initial_position=np.array([5, 0]), team=2, broadcast_range=4,\n agent_view=2\n ),\n 'agent3': CommunicatingAgent(\n id='agent3', initial_position=np.array([6, 9]), team=2, broadcast_range=4,\n agent_view=2\n ),\n 'agent4': CommunicatingAgent(\n id='agent4', initial_position=np.array([4, 7]), team=2, broadcast_range=4,\n agent_view=3\n ),\n }\n\n position_state = GridPositionState(region=10, agents=agents)\n broadcast_state = BroadcastState(agents=agents)\n\n position_observer = PositionObserver(position_state=position_state, agents=agents)\n team_observer = TeamObserver(number_of_teams=2, agents=agents)\n partial_observer = PositionRestrictedObservationWrapper(\n [position_observer, team_observer], agents=agents\n )\n comms_observer = TeamBasedCommunicationWrapper([partial_observer], agents=agents)\n\n broadcast_actor = BroadcastActor(broadcast_state=broadcast_state, agents=agents)\n\n position_state.reset()\n broadcast_state.reset()\n\n action_dict = {\n 'agent0': {'broadcast': 0},\n 'agent1': {'broadcast': 1},\n 'agent2': {'broadcast': 0},\n 'agent3': {'broadcast': 0},\n 'agent4': {'broadcast': 1},\n }\n for agent_id, action in action_dict.items():\n broadcast_actor.process_action(agents[agent_id], action)\n\n obs = partial_observer.get_obs(agents['agent0'])\n assert obs['mask'] == {\n 'agent0': 1,\n 'agent1': 0,\n 'agent2': 0,\n 'agent3': 0,\n 'agent4': 0,\n }\n assert obs['team'] == {\n 'agent0': 1,\n 'agent1': -1,\n 'agent2': -1,\n 'agent3': -1,\n 'agent4': -1,\n }\n np.testing.assert_array_equal(obs['position']['agent0'], np.array([1, 7]))\n np.testing.assert_array_equal(obs['position']['agent1'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent2'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent3'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent4'], np.array([-1, -1]))\n\n obs = comms_observer.get_obs(agents['agent0'])\n assert obs['mask'] == {\n 'agent0': 1,\n 'agent1': 1,\n 'agent2': 1,\n 'agent3': 0,\n 'agent4': 1,\n }\n assert obs['team'] == {\n 'agent0': 1,\n 'agent1': 1,\n 'agent2': 2,\n 'agent3': -1,\n 'agent4': 2,\n }\n np.testing.assert_array_equal(obs['position']['agent0'], np.array([1, 7]))\n np.testing.assert_array_equal(obs['position']['agent1'], np.array([3, 3]))\n np.testing.assert_array_equal(obs['position']['agent2'], np.array([5, 0]))\n np.testing.assert_array_equal(obs['position']['agent3'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent4'], np.array([4, 7]))\n\n\n action_dict = {\n 'agent0': {'broadcast': 0},\n 'agent1': {'broadcast': 0},\n 'agent2': {'broadcast': 1},\n 'agent3': {'broadcast': 1},\n 'agent4': {'broadcast': 0},\n }\n for agent_id, action in action_dict.items():\n broadcast_actor.process_action(agents[agent_id], action)\n\n obs = comms_observer.get_obs(agents['agent0'])\n assert obs['mask'] == {\n 'agent0': 1,\n 'agent1': 0,\n 'agent2': 0,\n 'agent3': 0,\n 'agent4': 0,\n }\n assert obs['team'] == {\n 'agent0': 1,\n 'agent1': -1,\n 'agent2': -1,\n 'agent3': -1,\n 'agent4': -1,\n }\n np.testing.assert_array_equal(obs['position']['agent0'], np.array([1, 7]))\n np.testing.assert_array_equal(obs['position']['agent1'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent2'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent3'], np.array([-1, -1]))\n np.testing.assert_array_equal(obs['position']['agent4'], np.array([-1, -1]))\n"
},
{
"alpha_fraction": 0.5087694525718689,
"alphanum_fraction": 0.5663931965827942,
"avg_line_length": 48.509803771972656,
"blob_id": "4af052e3abc3d4b5a7541c6356b170a80681429a",
"content_id": "1589fa21cf6bf20ff3bdb8c933f5a4a5b7255471",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35350,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 714,
"path": "/tests/test_all_step_predator_prey.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pytest\n\nfrom abmarl.sim.predator_prey import PredatorPreySimulation, Predator, Prey\nfrom abmarl.managers import AllStepManager\n\n\ndef test_turn_based_predator_prey_distance():\n np.random.seed(24)\n predators = [Predator(id=f'predator{i}', attack=1) for i in range(2)]\n prey = [Prey(id=f'prey{i}') for i in range(7)]\n agents = predators + prey\n sim_config = {\n 'region': 6,\n 'observation_mode': PredatorPreySimulation.ObservationMode.DISTANCE,\n 'agents': agents,\n }\n sim = PredatorPreySimulation.build(sim_config)\n sim = AllStepManager(sim)\n\n # Little hackish here because I have to explicitly set their values\n obs = sim.reset()\n sim.agents['predator0'].position = np.array([2, 3])\n sim.agents['predator1'].position = np.array([0, 1])\n sim.agents['prey0'].position = np.array([1, 1])\n sim.agents['prey1'].position = np.array([4, 3])\n sim.agents['prey2'].position = np.array([4, 3])\n sim.agents['prey3'].position = np.array([2, 3])\n sim.agents['prey4'].position = np.array([3, 3])\n sim.agents['prey5'].position = np.array([3, 1])\n sim.agents['prey6'].position = np.array([2, 1])\n obs = {agent_id: sim.sim.get_obs(agent_id) for agent_id in sim.agents}\n\n np.testing.assert_array_equal(obs['predator0']['predator1'], np.array([-2, -2, 2]))\n np.testing.assert_array_equal(obs['predator0']['prey0'], np.array([-1, -2, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey1'], np.array([2, 0, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey2'], np.array([2, 0, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey3'], np.array([0, 0, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey4'], np.array([1, 0, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey5'], np.array([1, -2, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey6'], np.array([0, -2, 1]))\n\n np.testing.assert_array_equal(obs['predator1']['predator0'], np.array([2, 2, 2]))\n np.testing.assert_array_equal(obs['predator1']['prey0'], np.array([1, 0, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey1'], np.array([4, 2, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey2'], np.array([4, 2, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey3'], np.array([2, 2, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey4'], np.array([3, 2, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey5'], np.array([3, 0, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey6'], np.array([2, 0, 1]))\n\n np.testing.assert_array_equal(obs['prey0']['predator0'], np.array([1, 2, 2]))\n np.testing.assert_array_equal(obs['prey0']['predator1'], np.array([-1, 0, 2]))\n np.testing.assert_array_equal(obs['prey0']['prey1'], np.array([3, 2, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey2'], np.array([3, 2, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey3'], np.array([1, 2, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey4'], np.array([2, 2, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey5'], np.array([2, 0, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey6'], np.array([1, 0, 1]))\n\n np.testing.assert_array_equal(obs['prey1']['predator0'], np.array([-2, 0, 2]))\n np.testing.assert_array_equal(obs['prey1']['predator1'], np.array([-4, -2, 2]))\n np.testing.assert_array_equal(obs['prey1']['prey0'], np.array([-3, -2, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey2'], np.array([0, 0, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey3'], np.array([-2, 0, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey4'], np.array([-1, 0, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey5'], np.array([-1, -2, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey6'], np.array([-2, -2, 1]))\n\n np.testing.assert_array_equal(obs['prey2']['predator0'], np.array([-2, 0, 2]))\n np.testing.assert_array_equal(obs['prey2']['predator1'], np.array([-4, -2, 2]))\n np.testing.assert_array_equal(obs['prey2']['prey0'], np.array([-3, -2, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey1'], np.array([0, 0, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey3'], np.array([-2, 0, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey4'], np.array([-1, 0, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey5'], np.array([-1, -2, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey6'], np.array([-2, -2, 1]))\n\n np.testing.assert_array_equal(obs['prey3']['predator0'], np.array([0, 0, 2]))\n np.testing.assert_array_equal(obs['prey3']['predator1'], np.array([-2, -2, 2]))\n np.testing.assert_array_equal(obs['prey3']['prey0'], np.array([-1, -2, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey1'], np.array([2, 0, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey2'], np.array([2, 0, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey4'], np.array([1, 0, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey5'], np.array([1, -2, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey6'], np.array([0, -2, 1]))\n\n np.testing.assert_array_equal(obs['prey4']['predator0'], np.array([-1, 0, 2]))\n np.testing.assert_array_equal(obs['prey4']['predator1'], np.array([-3, -2, 2]))\n np.testing.assert_array_equal(obs['prey4']['prey0'], np.array([-2, -2, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey1'], np.array([1, 0, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey2'], np.array([1, 0, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey3'], np.array([-1, 0, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey5'], np.array([0, -2, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey6'], np.array([-1, -2, 1]))\n\n np.testing.assert_array_equal(obs['prey5']['predator0'], np.array([-1, 2, 2]))\n np.testing.assert_array_equal(obs['prey5']['predator1'], np.array([-3, 0, 2]))\n np.testing.assert_array_equal(obs['prey5']['prey0'], np.array([-2, 0, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey1'], np.array([1, 2, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey2'], np.array([1, 2, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey3'], np.array([-1, 2, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey4'], np.array([0, 2, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey6'], np.array([-1, 0, 1]))\n\n np.testing.assert_array_equal(obs['prey6']['predator0'], np.array([0, 2, 2]))\n np.testing.assert_array_equal(obs['prey6']['predator1'], np.array([-2, 0, 2]))\n np.testing.assert_array_equal(obs['prey6']['prey0'], np.array([-1, 0, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey1'], np.array([2, 2, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey2'], np.array([2, 2, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey3'], np.array([0, 2, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey4'], np.array([1, 2, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey5'], np.array([1, 0, 1]))\n\n\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey0': np.array([-1, 1]),\n 'prey1': np.array([0, -1]),\n 'prey2': np.array([1, 1]),\n 'prey3': np.array([1, -1]),\n 'prey4': np.array([-1, 1]),\n 'prey5': np.array([1, 1]),\n 'prey6': np.array([0, 0]),\n })\n\n np.testing.assert_array_equal(obs['predator0']['predator1'], np.array([-2, -2, 2]))\n np.testing.assert_array_equal(obs['predator0']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey1'], np.array([2, -1, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey2'], np.array([3, 1, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey4'], np.array([0, 1, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey5'], np.array([2, -1, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey6'], np.array([0, -2, 1]))\n\n np.testing.assert_array_equal(obs['predator1']['predator0'], np.array([2, 2, 2]))\n np.testing.assert_array_equal(obs['predator1']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey1'], np.array([4, 1, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey2'], np.array([5, 3, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey4'], np.array([2, 3, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey5'], np.array([4, 1, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey6'], np.array([2, 0, 1]))\n\n np.testing.assert_array_equal(obs['prey0']['predator0'], np.array([1, 2, 2]))\n np.testing.assert_array_equal(obs['prey0']['predator1'], np.array([-1, 0, 2]))\n np.testing.assert_array_equal(obs['prey0']['prey1'], np.array([3, 1, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey2'], np.array([4, 3, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey0']['prey4'], np.array([1, 3, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey5'], np.array([3, 1, 1]))\n np.testing.assert_array_equal(obs['prey0']['prey6'], np.array([1, 0, 1]))\n\n np.testing.assert_array_equal(obs['prey1']['predator0'], np.array([-2, 1, 2]))\n np.testing.assert_array_equal(obs['prey1']['predator1'], np.array([-4, -1, 2]))\n np.testing.assert_array_equal(obs['prey1']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey2'], np.array([1, 2, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey4'], np.array([-2, 2, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey5'], np.array([0, 0, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey6'], np.array([-2, -1, 1]))\n\n np.testing.assert_array_equal(obs['prey2']['predator0'], np.array([-3, -1, 2]))\n np.testing.assert_array_equal(obs['prey2']['predator1'], np.array([-5, -3, 2]))\n np.testing.assert_array_equal(obs['prey2']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey1'], np.array([-1, -2, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey4'], np.array([-3, 0, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey5'], np.array([-1, -2, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey6'], np.array([-3, -3, 1]))\n\n np.testing.assert_array_equal(obs['prey3']['predator0'], np.array([0, 0, 2]))\n np.testing.assert_array_equal(obs['prey3']['predator1'], np.array([-2, -2, 2]))\n np.testing.assert_array_equal(obs['prey3']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey3']['prey1'], np.array([2, -1, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey2'], np.array([3, 1, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey4'], np.array([0, 1, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey5'], np.array([2, -1, 1]))\n np.testing.assert_array_equal(obs['prey3']['prey6'], np.array([0, -2, 1]))\n\n np.testing.assert_array_equal(obs['prey4']['predator0'], np.array([0, -1, 2]))\n np.testing.assert_array_equal(obs['prey4']['predator1'], np.array([-2, -3, 2]))\n np.testing.assert_array_equal(obs['prey4']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey4']['prey1'], np.array([2, -2, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey2'], np.array([3, 0, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey4']['prey5'], np.array([2, -2, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey6'], np.array([0, -3, 1]))\n\n np.testing.assert_array_equal(obs['prey5']['predator0'], np.array([-2, 1, 2]))\n np.testing.assert_array_equal(obs['prey5']['predator1'], np.array([-4, -1, 2]))\n np.testing.assert_array_equal(obs['prey5']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey5']['prey1'], np.array([0, 0, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey2'], np.array([1, 2, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey5']['prey4'], np.array([-2, 2, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey6'], np.array([-2, -1, 1]))\n\n np.testing.assert_array_equal(obs['prey6']['predator0'], np.array([0, 2, 2]))\n np.testing.assert_array_equal(obs['prey6']['predator1'], np.array([-2, 0, 2]))\n np.testing.assert_array_equal(obs['prey6']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey6']['prey1'], np.array([2, 1, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey2'], np.array([3, 3, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey6']['prey4'], np.array([0, 3, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey5'], np.array([2, 1, 1]))\n\n assert reward == {\n 'predator0': 36,\n 'predator1': 36,\n 'prey0': -36,\n 'prey1': -1,\n 'prey2': -1,\n 'prey3': -36,\n 'prey4': -1,\n 'prey5': -1,\n 'prey6': 0,\n }\n\n assert done == {\n 'predator0': False,\n 'predator1': False,\n 'prey0': True,\n 'prey1': False,\n 'prey2': False,\n 'prey3': True,\n 'prey4': False,\n 'prey5': False,\n 'prey6': False,\n '__all__': False}\n\n with pytest.raises(AssertionError):\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey0': np.array([-1, 1]),\n 'prey1': np.array([0, -1]),\n 'prey2': np.array([1, 1]),\n 'prey3': np.array([1, -1]),\n 'prey4': np.array([-1, 1]),\n 'prey5': np.array([1, 1]),\n 'prey6': np.array([0, 0]),\n })\n\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 0, 'move': np.array([1, 0])},\n 'prey1': np.array([-1, -1]),\n 'prey2': np.array([-1, 0]),\n 'prey4': np.array([-1, 0]),\n 'prey5': np.array([-1, 0]),\n 'prey6': np.array([0, -1]),\n })\n\n np.testing.assert_array_equal(obs['predator0']['predator1'], np.array([-1, -2, 2]))\n np.testing.assert_array_equal(obs['predator0']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey1'], np.array([1, -2, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey2'], np.array([2, 1, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey5'], np.array([1, -1, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey6'], np.array([0, -3, 1]))\n\n np.testing.assert_array_equal(obs['predator1']['predator0'], np.array([1, 2, 2]))\n np.testing.assert_array_equal(obs['predator1']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey1'], np.array([2, 0, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey2'], np.array([3, 3, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey5'], np.array([2, 1, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey6'], np.array([1, -1, 1]))\n\n np.testing.assert_array_equal(obs['prey1']['predator0'], np.array([-1, 2, 2]))\n np.testing.assert_array_equal(obs['prey1']['predator1'], np.array([-2, 0, 2]))\n np.testing.assert_array_equal(obs['prey1']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey2'], np.array([1, 3, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey5'], np.array([0, 1, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey6'], np.array([-1, -1, 1]))\n\n np.testing.assert_array_equal(obs['prey2']['predator0'], np.array([-2, -1, 2]))\n np.testing.assert_array_equal(obs['prey2']['predator1'], np.array([-3, -3, 2]))\n np.testing.assert_array_equal(obs['prey2']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey1'], np.array([-1, -3, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey5'], np.array([-1, -2, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey6'], np.array([-2, -4, 1]))\n\n np.testing.assert_array_equal(obs['prey4']['predator0'], np.array([0, -1, 2]))\n np.testing.assert_array_equal(obs['prey4']['predator1'], np.array([-1, -3, 2]))\n np.testing.assert_array_equal(obs['prey4']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey4']['prey1'], np.array([1, -3, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey2'], np.array([2, 0, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey4']['prey5'], np.array([1, -2, 1]))\n np.testing.assert_array_equal(obs['prey4']['prey6'], np.array([0, -4, 1]))\n\n np.testing.assert_array_equal(obs['prey5']['predator0'], np.array([-1, 1, 2]))\n np.testing.assert_array_equal(obs['prey5']['predator1'], np.array([-2, -1, 2]))\n np.testing.assert_array_equal(obs['prey5']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey5']['prey1'], np.array([0, -1, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey2'], np.array([1, 2, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey5']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey5']['prey6'], np.array([-1, -2, 1]))\n\n np.testing.assert_array_equal(obs['prey6']['predator0'], np.array([0, 3, 2]))\n np.testing.assert_array_equal(obs['prey6']['predator1'], np.array([-1, 1, 2]))\n np.testing.assert_array_equal(obs['prey6']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey6']['prey1'], np.array([1, 1, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey2'], np.array([2, 4, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey6']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey6']['prey5'], np.array([1, 2, 1]))\n\n assert reward == {\n 'predator0': 36,\n 'predator1': -1,\n 'prey1': -1,\n 'prey2': -1,\n 'prey4': -36,\n 'prey5': -1,\n 'prey6': -1,\n }\n\n assert done == {\n 'predator0': False,\n 'predator1': False,\n 'prey1': False,\n 'prey2': False,\n 'prey4': True,\n 'prey5': False,\n 'prey6': False,\n '__all__': False}\n\n with pytest.raises(AssertionError):\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey1': np.array([0, -1]),\n 'prey2': np.array([1, 1]),\n 'prey4': np.array([-1, 1]),\n 'prey5': np.array([1, 1]),\n 'prey6': np.array([0, 0]),\n })\n\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey1': np.array([-1, 0]),\n 'prey2': np.array([-1, 0]),\n 'prey5': np.array([0, 1]),\n 'prey6': np.array([-1, 0]),\n })\n\n np.testing.assert_array_equal(obs['predator0']['predator1'], np.array([-1, -2, 2]))\n np.testing.assert_array_equal(obs['predator0']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey1'], np.array([0, -2, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey2'], np.array([1, 1, 1]))\n np.testing.assert_array_equal(obs['predator0']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey5'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey6'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(obs['predator1']['predator0'], np.array([1, 2, 2]))\n np.testing.assert_array_equal(obs['predator1']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey1'], np.array([1, 0, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey2'], np.array([2, 3, 1]))\n np.testing.assert_array_equal(obs['predator1']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey5'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey6'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(obs['prey1']['predator0'], np.array([0, 2, 2]))\n np.testing.assert_array_equal(obs['prey1']['predator1'], np.array([-1, 0, 2]))\n np.testing.assert_array_equal(obs['prey1']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey2'], np.array([1, 3, 1]))\n np.testing.assert_array_equal(obs['prey1']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey5'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey6'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(obs['prey2']['predator0'], np.array([-1, -1, 2]))\n np.testing.assert_array_equal(obs['prey2']['predator1'], np.array([-2, -3, 2]))\n np.testing.assert_array_equal(obs['prey2']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey1'], np.array([-1, -3, 1]))\n np.testing.assert_array_equal(obs['prey2']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey5'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey6'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(obs['prey5']['predator0'], np.array([-1, 1, 2]))\n np.testing.assert_array_equal(obs['prey5']['predator1'], np.array([-2, -1, 2]))\n np.testing.assert_array_equal(obs['prey5']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey5']['prey1'], np.array([-1, -1, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey2'], np.array([0, 2, 1]))\n np.testing.assert_array_equal(obs['prey5']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey5']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey5']['prey6'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(obs['prey6']['predator0'], np.array([0, 3, 2]))\n np.testing.assert_array_equal(obs['prey6']['predator1'], np.array([-1, 1, 2]))\n np.testing.assert_array_equal(obs['prey6']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey6']['prey1'], np.array([0, 1, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey2'], np.array([1, 4, 1]))\n np.testing.assert_array_equal(obs['prey6']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey6']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey6']['prey5'], np.array([0, 0, 0]))\n\n assert reward == {\n 'predator0': 36,\n 'predator1': 36,\n 'prey1': -1,\n 'prey2': -1,\n 'prey5': -36,\n 'prey6': -36\n }\n\n assert done == {\n 'predator0': False,\n 'predator1': False,\n 'prey1': False,\n 'prey2': False,\n 'prey5': True,\n 'prey6': True,\n '__all__': False}\n\n with pytest.raises(AssertionError):\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey1': np.array([0, -1]),\n 'prey2': np.array([1, 1]),\n 'prey5': np.array([1, 1]),\n 'prey6': np.array([0, 0]),\n })\n\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey1': np.array([-1, 0]),\n 'prey2': np.array([-1, 0]),\n })\n\n np.testing.assert_array_equal(obs['predator0']['predator1'], np.array([-1, -2, 2]))\n np.testing.assert_array_equal(obs['predator0']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey1'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey2'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey5'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator0']['prey6'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(obs['predator1']['predator0'], np.array([1, 2, 2]))\n np.testing.assert_array_equal(obs['predator1']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey1'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey2'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey5'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['predator1']['prey6'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(obs['prey1']['predator0'], np.array([0, 2, 2]))\n np.testing.assert_array_equal(obs['prey1']['predator1'], np.array([-1, 0, 2]))\n np.testing.assert_array_equal(obs['prey1']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey2'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey5'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey1']['prey6'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(obs['prey2']['predator0'], np.array([-1, -1, 2]))\n np.testing.assert_array_equal(obs['prey2']['predator1'], np.array([-2, -3, 2]))\n np.testing.assert_array_equal(obs['prey2']['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey1'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey5'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(obs['prey2']['prey6'], np.array([0, 0, 0]))\n\n assert reward == {\n 'predator0': 36,\n 'predator1': 36,\n 'prey1': -36,\n 'prey2': -36,\n }\n\n assert done == {\n 'predator0': False,\n 'predator1': False,\n 'prey1': True,\n 'prey2': True,\n '__all__': True}\n\n\ndef test_turn_based_predator_prey_grid():\n np.random.seed(24)\n predators = [Predator(id=f'predator{i}', attack=1, view=0) for i in range(2)]\n prey = [Prey(id=f'prey{i}', view=0) for i in range(7)]\n agents = predators + prey\n sim_config = {\n 'region': 6,\n 'observation_mode': PredatorPreySimulation.ObservationMode.GRID,\n 'agents': agents,\n }\n sim = PredatorPreySimulation.build(sim_config)\n sim = AllStepManager(sim)\n\n # Little hackish here because I have to explicitly set their values\n obs = sim.reset()\n sim.agents['predator0'].position = np.array([2, 3])\n sim.agents['predator1'].position = np.array([0, 1])\n sim.agents['prey0'].position = np.array([1, 1])\n sim.agents['prey1'].position = np.array([4, 3])\n sim.agents['prey2'].position = np.array([4, 3])\n sim.agents['prey3'].position = np.array([2, 3])\n sim.agents['prey4'].position = np.array([3, 3])\n sim.agents['prey5'].position = np.array([3, 1])\n sim.agents['prey6'].position = np.array([2, 1])\n obs = {agent_id: sim.sim.get_obs(agent_id) for agent_id in sim.agents}\n\n assert 'predator0' in obs\n assert 'predator0' in obs\n assert 'prey0' in obs\n assert 'prey1' in obs\n assert 'prey2' in obs\n assert 'prey3' in obs\n assert 'prey4' in obs\n assert 'prey5' in obs\n assert 'prey6' in obs\n\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey0': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey1': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey2': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey3': {'move': np.array([0, 0]), 'harvest': 0},\n 'prey4': {'move': np.array([-1, 1]), 'harvest': 0},\n 'prey5': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey6': {'move': np.array([0, 0]), 'harvest': 0},\n })\n\n assert 'predator0' in obs\n assert 'predator0' in obs\n assert 'prey0' in obs\n assert 'prey1' in obs\n assert 'prey2' in obs\n assert 'prey3' in obs\n assert 'prey4' in obs\n assert 'prey5' in obs\n assert 'prey6' in obs\n\n assert reward == {\n 'predator0': 36,\n 'predator1': 36,\n 'prey0': -36,\n 'prey1': -1,\n 'prey2': -1,\n 'prey3': -36,\n 'prey4': -1,\n 'prey5': -1,\n 'prey6': 0,\n }\n\n assert done == {\n 'predator0': False,\n 'predator1': False,\n 'prey0': True,\n 'prey1': False,\n 'prey2': False,\n 'prey3': True,\n 'prey4': False,\n 'prey5': False,\n 'prey6': False,\n '__all__': False}\n\n\n with pytest.raises(AssertionError):\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey0': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey1': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey2': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey3': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey4': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey5': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey6': {'move': np.array([0, 0]), 'harvest': 0},\n })\n\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 0, 'move': np.array([1, 0])},\n 'prey1': {'move': np.array([-1, -1]), 'harvest': 0},\n 'prey2': {'move': np.array([-1, 0]), 'harvest': 0},\n 'prey4': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey5': {'move': np.array([-1, 0]), 'harvest': 0},\n 'prey6': {'move': np.array([0, -1]), 'harvest': 0},\n })\n\n assert 'predator0' in obs\n assert 'predator0' in obs\n assert 'prey1' in obs\n assert 'prey2' in obs\n assert 'prey4' in obs\n assert 'prey5' in obs\n assert 'prey6' in obs\n\n assert reward == {\n 'predator0': 36,\n 'predator1': -1,\n 'prey1': -1,\n 'prey2': -1,\n 'prey4': -36,\n 'prey5': -1,\n 'prey6': -1,\n }\n\n assert done == {\n 'predator0': False,\n 'predator1': False,\n 'prey1': False,\n 'prey2': False,\n 'prey4': True,\n 'prey5': False,\n 'prey6': False,\n '__all__': False}\n\n\n with pytest.raises(AssertionError):\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey1': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey2': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey4': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey5': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey6': {'move': np.array([0, 0]), 'harvest': 0},\n })\n\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey1': {'move': np.array([-1, 0]), 'harvest': 0},\n 'prey2': {'move': np.array([-1, 0]), 'harvest': 0},\n 'prey5': {'move': np.array([-1, 0]), 'harvest': 0},\n 'prey6': {'move': np.array([1, -1]), 'harvest': 0},\n })\n\n assert 'predator0' in obs\n assert 'predator0' in obs\n assert 'prey1' in obs\n assert 'prey2' in obs\n assert 'prey5' in obs\n assert 'prey6' in obs\n\n assert reward == {\n 'predator0': 36,\n 'predator1': 36,\n 'prey1': -1,\n 'prey2': -1,\n 'prey5': -36,\n 'prey6': -36,\n }\n\n assert done == {\n 'predator0': False,\n 'predator1': False,\n 'prey1': False,\n 'prey2': False,\n 'prey5': True,\n 'prey6': True,\n '__all__': False}\n\n\n with pytest.raises(AssertionError):\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey1': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey2': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey5': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey6': {'move': np.array([0, 0]), 'harvest': 0},\n })\n\n obs, reward, done, info = sim.step({\n 'predator0': {'attack': 1, 'move': np.array([0, 0])},\n 'predator1': {'attack': 1, 'move': np.array([0, 0])},\n 'prey1': {'move': np.array([-1, 0]), 'harvest': 0},\n 'prey2': {'move': np.array([-1, 0]), 'harvest': 0},\n })\n\n assert 'predator0' in obs\n assert 'predator0' in obs\n assert 'prey1' in obs\n assert 'prey2' in obs\n\n assert reward == {\n 'predator0': 36,\n 'predator1': 36,\n 'prey1': -36,\n 'prey2': -36,\n }\n\n assert done == {\n 'predator0': False,\n 'predator1': False,\n 'prey1': True,\n 'prey2': True,\n '__all__': True}\n"
},
{
"alpha_fraction": 0.6524999737739563,
"alphanum_fraction": 0.6524999737739563,
"avg_line_length": 20.052631378173828,
"blob_id": "abb01c2a46a943ec105fe63fb968490a4ec9b217",
"content_id": "79f56d714b01ae89e3de7ca21b3a57930028f85b",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 400,
"license_type": "permissive",
"max_line_length": 56,
"num_lines": 19,
"path": "/abmarl/pols/abstract_policy.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\nfrom ray.rllib.policy.policy import Policy\n\n\nclass HeuristicPolicy(Policy, ABC):\n \"\"\"Abstract class for policies that do not learn.\"\"\"\n @abstractmethod\n def compute_actions(self, *args, **kwargs):\n pass\n\n def learn_on_batch(self, samples):\n pass\n\n def get_weights(self):\n pass\n\n def set_weights(self, weights):\n pass\n"
},
{
"alpha_fraction": 0.6678981781005859,
"alphanum_fraction": 0.6880131363868713,
"avg_line_length": 36.476924896240234,
"blob_id": "ed63402ed072d66a20af48b6a1804a670a7cc094",
"content_id": "0febf9a37ba38edfa7e9941b37ec34c9988f1318",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2436,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 65,
"path": "/tests/sim/simulation_components/test_agent.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pytest\n\nfrom abmarl.sim.components import ComponentAgent\n\n\ndef test_component_agent_defaults():\n agent = ComponentAgent(id='agent')\n assert agent.initial_position is None\n np.testing.assert_array_equal(agent._min_max_health, np.array([0., 1.]))\n assert agent.min_health == 0\n assert agent.max_health == 1\n assert agent.initial_health is None\n assert agent.team == 0\n assert agent.is_alive\n assert agent.configured\n\n\ndef test_component_agent_initial_position():\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', initial_position=[2, 4])\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', initial_position=np.array([[2, 4]]))\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', initial_position=np.array(['2', '4']))\n agent = ComponentAgent(id='agent', initial_position=np.array([2, 4]))\n np.testing.assert_array_equal(agent.initial_position, np.array([2, 4]))\n\n\ndef test_component_agent_min_max_health():\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', min_health='3', max_health=30)\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', min_health=3, max_health='30')\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', min_health=4, max_health=2)\n agent = ComponentAgent(id='agent', min_health=2, max_health=4)\n np.testing.assert_array_equal(agent._min_max_health, np.array([2, 4]))\n assert agent.min_health == 2\n assert agent.max_health == 4\n\n with pytest.raises(AttributeError):\n agent.min_health = 0\n with pytest.raises(AttributeError):\n agent.max_health = 10\n\n\ndef test_component_agent_initial_health():\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', min_max_health=np.array([0, 10]), initial_health='3')\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', initial_health=2)\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', initial_health=-2)\n agent = ComponentAgent(id='agent', initial_health=0.78)\n assert agent.initial_health == 0.78\n\n\ndef test_component_agent_team():\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', team=2.0)\n with pytest.raises(AssertionError):\n ComponentAgent(id='agent', team=0)\n agent = ComponentAgent(id='agent', team=2)\n assert agent.team == 2\n"
},
{
"alpha_fraction": 0.6657963395118713,
"alphanum_fraction": 0.6710183024406433,
"avg_line_length": 35.47618865966797,
"blob_id": "9ef032c2e49fe91e7d22d72ea8088b4a42c43591",
"content_id": "440e2d55b093360db9914d524fd170fc0a63f55c",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 766,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 21,
"path": "/abmarl/tools/numpy_utils.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\ndef array_in_array(search_element, elements, axis=0):\n \"\"\"\n Exact check for a a search element within a collection of elements. Te search element is a\n numpy array, and hte elements is a numpy ndarray. We treat the search element as a single\n entity, so the match has to be across the entire array, not just on the elements within the\n array.\n\n Args:\n search_element: numpy array that we want to match\n elements: numpy ndarray that we search for a match\n axis: which axis we want to search along. Support 0 and 1.\n \"\"\"\n if axis == 1:\n elements = elements.transpose()\n for test_element in elements:\n if np.all(search_element == test_element):\n return True\n return False\n"
},
{
"alpha_fraction": 0.5705045461654663,
"alphanum_fraction": 0.5827943086624146,
"avg_line_length": 36.70731735229492,
"blob_id": "2c7376985745a5b4ba0ef78395c5237bf2b68ea3",
"content_id": "2b91cf18dbf1590ae63b79ee39d33c395eced0a6",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1546,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 41,
"path": "/examples/predator_prey/movement_map.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "def run(sim, trainer):\n import numpy as np\n import seaborn as sns\n import matplotlib.pyplot as plt\n\n # Create a grid\n grid = np.zeros((sim.sim.region, sim.sim.region))\n attack = np.zeros((sim.sim.region, sim.sim.region))\n\n # Run the trained policy\n policy_agent_mapping = trainer.config['multiagent']['policy_mapping_fn']\n for episode in range(100): # Run 100 trajectories\n print('Episode: {}'.format(episode))\n obs = sim.reset()\n done = {agent: False for agent in obs}\n pox, poy = sim.agents['predator0'].position\n grid[pox, poy] += 1\n while True:\n joint_action = {}\n for agent_id, agent_obs in obs.items():\n if done[agent_id]: continue # Don't get actions for dead agents\n policy_id = policy_agent_mapping(agent_id)\n action = trainer.compute_action(agent_obs, policy_id=policy_id)\n joint_action[agent_id] = action\n obs, _, done, _ = sim.step(joint_action)\n pox, poy = sim.agents['predator0'].position\n grid[pox, poy] += 1\n if joint_action['predator0']['attack'] == 1: # This is the attack action\n attack[pox, poy] += 1\n if done['__all__']:\n break\n\n plt.figure(1)\n plt.title(\"Position concentration\")\n sns.heatmap(np.flipud(np.transpose(grid)), linewidth=0.5)\n\n plt.figure(2)\n plt.title(\"Attack action frequency\")\n sns.heatmap(np.flipud(np.transpose(attack)), linewidth=0.5)\n\n plt.show()\n"
},
{
"alpha_fraction": 0.5660660862922668,
"alphanum_fraction": 0.5660660862922668,
"avg_line_length": 34.05263137817383,
"blob_id": "de2c1b74f62aec506f7175c12e92c720fd77d832",
"content_id": "7c263fe6a4f3a965cb35de4145a8a8c7a48489f5",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 666,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 19,
"path": "/abmarl/tools/matplotlib_utils.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "def mscatter(x, y, ax=None, m=None, **kw):\n \"\"\"\n Scatter plot with markers m assigned to each element.\n \"\"\"\n import matplotlib.pyplot as plt\n import matplotlib.markers as mmarkers\n ax = ax or plt.gca()\n sc = ax.scatter(x, y, **kw)\n if (m is not None) and (len(m) == len(x)):\n paths = []\n for marker in m:\n if isinstance(marker, mmarkers.MarkerStyle):\n marker_obj = marker\n else:\n marker_obj = mmarkers.MarkerStyle(marker)\n path = marker_obj.get_path().transformed(marker_obj.get_transform())\n paths.append(path)\n sc.set_paths(paths)\n return sc\n"
},
{
"alpha_fraction": 0.6010199785232544,
"alphanum_fraction": 0.6010199785232544,
"avg_line_length": 37.621212005615234,
"blob_id": "9572d1bb8698eafcc37464730971fbd83ea420ca",
"content_id": "dfaf2d654f0934cd9d8a85533e2260a4f0160ade",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2549,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 66,
"path": "/abmarl/managers/all_step_manager.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abmarl.sim import ObservingAgent, ActingAgent\n\nfrom .simulation_manager import SimulationManager\n\n\nclass AllStepManager(SimulationManager):\n \"\"\"\n The AllStepManager gets the observations of all agents at reset. At step, it gets\n the observations of all the agents that are not done. Once all the agents\n are done, the manager returns all done.\n \"\"\"\n def reset(self, **kwargs):\n \"\"\"\n Reset the simulation and return the observation of all the agents.\n \"\"\"\n self.done_agents = set(\n agent.id for agent in self.agents.values()\n if not (isinstance(agent, ActingAgent) and isinstance(agent, ObservingAgent))\n )\n self.sim.reset(**kwargs)\n return {\n agent.id: self.sim.get_obs(agent.id)\n for agent in self.agents.values() if agent.id not in self.done_agents\n }\n\n def step(self, action_dict, **kwargs):\n \"\"\"\n Assert that the incoming action does not come from an agent who is recorded\n as done. Step the simulation forward and return the observation, reward,\n done, and info of all the non-done agents, including the agents that were\n done in this step. If all agents are done in this turn, then the manager\n returns all done.\n \"\"\"\n for agent_id in action_dict:\n assert agent_id not in self.done_agents, \\\n \"Received an action for an agent that is already done.\"\n self.sim.step(action_dict, **kwargs)\n\n obs = {\n agent.id: self.sim.get_obs(agent.id) for agent in self.agents.values()\n if agent.id not in self.done_agents\n }\n rewards = {\n agent.id: self.sim.get_reward(agent.id) for agent in self.agents.values()\n if agent.id not in self.done_agents\n }\n dones = {\n agent.id: self.sim.get_done(agent.id) for agent in self.agents.values()\n if agent.id not in self.done_agents\n }\n infos = {\n agent.id: self.sim.get_info(agent.id) for agent in self.agents.values()\n if agent.id not in self.done_agents\n }\n\n for agent, done in dones.items():\n if done:\n self.done_agents.add(agent)\n\n # if all agents are done or the simulation is done, then return done\n if self.sim.get_all_done() or not (self.agents.keys() - self.done_agents):\n dones['__all__'] = True\n else:\n dones['__all__'] = False\n\n return obs, rewards, dones, infos\n"
},
{
"alpha_fraction": 0.589211642742157,
"alphanum_fraction": 0.5917012691497803,
"avg_line_length": 40.55172348022461,
"blob_id": "6cd74e5dbe86493f9c7ebb98e63a9a299af637e8",
"content_id": "bf6b339d8793e1ceb86f048c96aa44e814e3c719",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1205,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 29,
"path": "/examples/analysis_prototype.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "def run(sim, trainer):\n \"\"\"\n Analyze the behavior of your trained policies using the simulation and trainer\n from your RL experiment.\n\n Args:\n sim:\n Simulation Manager object from the experiment.\n trainer:\n Trainer that computes actions using the trained policies.\n \"\"\"\n # Run the simulation with actions chosen from the trained policies\n policy_agent_mapping = trainer.config['multiagent']['policy_mapping_fn']\n for episode in range(100):\n print('Episode: {}'.format(episode))\n obs = sim.reset()\n done = {agent: False for agent in obs}\n while True: # Run until the episode ends\n # Get actions from policies\n joint_action = {}\n for agent_id, agent_obs in obs.items():\n if done[agent_id]: continue # Don't get actions for done agents\n policy_id = policy_agent_mapping(agent_id)\n action = trainer.compute_action(agent_obs, policy_id=policy_id)\n joint_action[agent_id] = action\n # Step the simulation\n obs, reward, done, info = sim.step(joint_action)\n if done['__all__']:\n break\n"
},
{
"alpha_fraction": 0.6208333373069763,
"alphanum_fraction": 0.6505208611488342,
"avg_line_length": 35.92307662963867,
"blob_id": "469233c05a86c0d51ab8cfe083ccf2286ea93f9a",
"content_id": "0f4075c964adeccf3c24c9b1df99714c31b46018",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3840,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 104,
"path": "/tests/test_done_component.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.components.agent import ComponentAgent as Agent\nfrom abmarl.sim.components.state import LifeState, ContinuousPositionState\nfrom abmarl.sim.components.done import DeadDone, TeamDeadDone, TooCloseDone\n\n\ndef test_dead_done_condition():\n agents = {\n 'agent0': Agent(id='agent0'),\n 'agent1': Agent(id='agent1'),\n 'agent2': Agent(id='agent2'),\n 'agent3': Agent(id='agent3'),\n }\n state = LifeState(agents=agents)\n done = DeadDone(agents=agents)\n state.reset()\n\n assert not done.get_done(agents['agent0'])\n assert not done.get_done(agents['agent1'])\n assert not done.get_done(agents['agent2'])\n assert not done.get_done(agents['agent3'])\n assert not done.get_all_done()\n\n agents['agent0'].is_alive = False\n agents['agent1'].is_alive = False\n assert done.get_done(agents['agent0'])\n assert done.get_done(agents['agent1'])\n assert not done.get_done(agents['agent2'])\n assert not done.get_done(agents['agent3'])\n assert not done.get_all_done()\n\n agents['agent2'].is_alive = False\n agents['agent3'].is_alive = False\n assert done.get_done(agents['agent0'])\n assert done.get_done(agents['agent1'])\n assert done.get_done(agents['agent2'])\n assert done.get_done(agents['agent3'])\n assert done.get_all_done()\n\n\ndef test_team_dead_done_condition():\n agents = {\n 'agent0': Agent(id='agent0', team=1),\n 'agent1': Agent(id='agent1', team=2),\n 'agent2': Agent(id='agent2', team=1),\n 'agent3': Agent(id='agent3', team=2),\n 'agent4': Agent(id='agent4', team=1),\n 'agent5': Agent(id='agent5', team=3),\n }\n state = LifeState(agents=agents)\n done = TeamDeadDone(agents=agents, number_of_teams=3)\n state.reset()\n\n assert not done.get_done(agents['agent0'])\n assert not done.get_done(agents['agent1'])\n assert not done.get_done(agents['agent2'])\n assert not done.get_done(agents['agent3'])\n assert not done.get_done(agents['agent4'])\n assert not done.get_done(agents['agent5'])\n assert not done.get_all_done()\n\n agents['agent5'].is_alive = False\n agents['agent4'].is_alive = False\n assert not done.get_done(agents['agent0'])\n assert not done.get_done(agents['agent1'])\n assert not done.get_done(agents['agent2'])\n assert not done.get_done(agents['agent3'])\n assert done.get_done(agents['agent4'])\n assert done.get_done(agents['agent5'])\n assert not done.get_all_done()\n\n agents['agent1'].is_alive = False\n agents['agent3'].is_alive = False\n assert not done.get_done(agents['agent0'])\n assert done.get_done(agents['agent1'])\n assert not done.get_done(agents['agent2'])\n assert done.get_done(agents['agent3'])\n assert done.get_done(agents['agent4'])\n assert done.get_done(agents['agent5'])\n assert done.get_all_done()\n\n\ndef test_too_close_done_with_continuous():\n agents = {\n 'agent0': Agent(id='agent0', initial_position=np.array([0.1, 0.1])),\n 'agent1': Agent(id='agent1', initial_position=np.array([0.24, 0.5])),\n 'agent2': Agent(id='agent2', initial_position=np.array([0.3, 0.5])),\n 'agent3': Agent(id='agent3', initial_position=np.array([3.76, 3.5])),\n 'agent4': Agent(id='agent4', initial_position=np.array([3.75, 3.6])),\n 'agent5': Agent(id='agent5', initial_position=np.array([2.5, 3.0])),\n }\n\n state = ContinuousPositionState(region=4, agents=agents)\n done = TooCloseDone(position=state, agents=agents, collision_distance=0.25)\n state.reset()\n\n assert done.get_done(agents['agent0'])\n assert done.get_done(agents['agent1'])\n assert done.get_done(agents['agent2'])\n assert done.get_done(agents['agent3'])\n assert done.get_done(agents['agent4'])\n assert not done.get_done(agents['agent5'])\n assert done.get_all_done()\n"
},
{
"alpha_fraction": 0.5140665173530579,
"alphanum_fraction": 0.5140665173530579,
"avg_line_length": 29.076923370361328,
"blob_id": "675d2c345c15924514164f2ed49c25976b4bcbd0",
"content_id": "4af775ae1c2b600086e2c0a3501ab4407a499428",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 782,
"license_type": "permissive",
"max_line_length": 70,
"num_lines": 26,
"path": "/abmarl/pols/random_policy.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from . import HeuristicPolicy\n\n\nclass RandomAction(HeuristicPolicy):\n \"\"\"A policy to take random actions.\"\"\"\n def __init__(self, observation_space, action_space, config={}):\n super().__init__(observation_space, action_space, config)\n\n def compute_actions(self,\n obs_batch,\n state_batches=None,\n prev_action_batch=None,\n prev_reward_batch=None,\n info_batch=None,\n episodes=None,\n **kwargs):\n return [self.action_space.sample() for _ in obs_batch], [], {}\n\n def learn_on_batch(self, samples):\n pass\n\n def get_weights(self):\n pass\n\n def set_weights(self, weights):\n pass\n"
},
{
"alpha_fraction": 0.7764706015586853,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 9.75,
"blob_id": "cd61bf94392e2e5803ade3fc67de472e06c0dfdd",
"content_id": "add6e512cc81bff6fda8f5be4ed104a924109b1f",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 85,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "tensorflow\nray[rllib]==1.4.0\nmatplotlib\nseaborn\nsphinx\nsphinx-rtd-theme\nflake8\npytest"
},
{
"alpha_fraction": 0.8606964945793152,
"alphanum_fraction": 0.8606964945793152,
"avg_line_length": 32.5,
"blob_id": "44de2527bbd843ee23f6aad3fe17e989e3a4063c",
"content_id": "8c374c289c498d77021f4ba74421169e4595ab8b",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 201,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 6,
"path": "/abmarl/pols/__init__.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .abstract_policy import HeuristicPolicy\nfrom .random_policy import RandomAction\n\nfrom .policy import GreedyPolicy\nfrom .policy import EpsilonSoftPolicy\nfrom .policy import RandomFirstActionPolicy\n"
},
{
"alpha_fraction": 0.5767490267753601,
"alphanum_fraction": 0.587191104888916,
"avg_line_length": 27.729999542236328,
"blob_id": "77123c7321405b768f8d33c94eb89ff6d6aeaf1e",
"content_id": "896bbec37fe9a1beb86408c48ab54c4824f30136",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2873,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 100,
"path": "/examples/predator_prey/runnable_predator_prey_training.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "# Setup the simulation\nfrom abmarl.sim.predator_prey import PredatorPreySimulation, Predator, Prey\nfrom abmarl.managers import AllStepManager\n\nregion = 6\npredators = [Predator(id=f'predator{i}', attack=1) for i in range(2)]\nprey = [Prey(id=f'prey{i}') for i in range(7)]\nagents = predators + prey\n\nsim_config = {\n 'region': region,\n 'max_steps': 200,\n 'agents': agents,\n}\nsim_name = 'PredatorPrey'\n\nfrom abmarl.external.rllib_multiagentenv_wrapper import MultiAgentWrapper\nfrom ray.tune.registry import register_env\nsim = MultiAgentWrapper(AllStepManager(PredatorPreySimulation.build(sim_config)))\nagents = sim.unwrapped.agents\nregister_env(sim_name, lambda sim_config: sim)\n\n# Set up heuristic policies\npolicies = {\n 'predator': (None, agents['predator0'].observation_space, agents['predator0'].action_space, {}),\n 'prey': (None, agents['prey0'].observation_space, agents['prey0'].action_space, {})\n}\n\n\ndef policy_mapping_fn(agent_id):\n if agent_id.startswith('prey'):\n return 'prey'\n else:\n return 'predator'\n\n\n# Algorithm\nalgo_name = 'PG'\n\n# Experiment parameters\nparams = {\n 'experiment': {\n 'title': '{}'.format('PredatorPrey'),\n 'sim_creator': lambda config=None: sim,\n },\n 'ray_tune': {\n 'run_or_experiment': algo_name,\n 'checkpoint_freq': 50,\n 'checkpoint_at_end': True,\n 'stop': {\n 'episodes_total': 20_000,\n },\n 'verbose': 2,\n 'config': {\n # --- Simulation ---\n 'env': sim_name,\n 'env_config': sim_config,\n 'horizon': 200,\n # --- Multiagent ---\n 'multiagent': {\n 'policies': policies,\n 'policy_mapping_fn': policy_mapping_fn,\n },\n # \"lr\": 0.0001,\n # --- Parallelism ---\n # Number of workers per experiment: int\n \"num_workers\": 7,\n # Number of simulations that each worker starts: int\n \"num_envs_per_worker\": 1, # This must be 1 because we are not \"threadsafe\"\n # 'simple_optimizer': True,\n # \"postprocess_inputs\": True\n },\n }\n}\n\n\nif __name__ == \"__main__\":\n # Create output directory and save to params\n import os\n import time\n home = os.path.expanduser(\"~\")\n output_dir = os.path.join(\n home, 'abmarl_results/{}_{}'.format(\n params['experiment']['title'], time.strftime('%Y-%m-%d_%H-%M')\n )\n )\n params['ray_tune']['local_dir'] = output_dir\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n\n # Copy this configuration file to the output directory\n import shutil\n shutil.copy(os.path.join(os.getcwd(), __file__), output_dir)\n\n # Initialize and run ray\n import ray\n from ray import tune\n ray.init()\n tune.run(**params['ray_tune'])\n ray.shutdown()\n"
},
{
"alpha_fraction": 0.6335012316703796,
"alphanum_fraction": 0.6372795701026917,
"avg_line_length": 32.08333206176758,
"blob_id": "df95fd062b1197f4d2c1e3940139ff1a29e169de",
"content_id": "e1012e6166359d34da89dcb89e621c1e0f00a2d9",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 794,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 24,
"path": "/abmarl/algs/generate_episode.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "# This probably shouldn't go in algs, but we'll move it later after we've figured out the\n# architecture a bit more.\n\ndef generate_episode(sim, policy, horizon=200):\n \"\"\"\n Generate an episode from a policy acting on an simulation.\n\n Returns: sequence of state, action, reward.\n \"\"\"\n obs = sim.reset()\n policy.reset() # Reset the policy too so that it knows its the beginning of the episode.\n states, actions, rewards = [], [], []\n states.append(obs)\n for _ in range(horizon):\n action = policy.act(obs)\n obs, reward, done, _ = sim.step(action)\n states.append(obs)\n actions.append(action)\n rewards.append(reward)\n if done:\n break\n\n states.pop() # Pop off the terminating state\n return states, actions, rewards\n"
},
{
"alpha_fraction": 0.5524299144744873,
"alphanum_fraction": 0.5612064599990845,
"avg_line_length": 41.118621826171875,
"blob_id": "f3b31d45d1f42d697ba0fd57b2211d93147cf161",
"content_id": "d90efaf7cc831607d07ac192c68ff9e14a83d972",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30536,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 725,
"path": "/abmarl/sim/predator_prey/predator_prey.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\nfrom enum import IntEnum\n\nfrom gym.spaces import Box, Discrete, Dict\nimport numpy as np\n\nfrom abmarl.sim import Agent, AgentBasedSimulation\n\n\nclass PredatorPreyAgent(Agent, ABC):\n \"\"\"\n In addition to their own agent-type-specific parameters, every Agent in the\n Predator Prey simulation will have the following parameters:\n\n move: int\n The maximum movement range. 0 means the agent can only stay, 1 means the agent\n can move one square away (including diagonals), 2 means two, and so on.\n Default 1.\n\n view: int\n How much of the region the agent can observe.\n Default whole region.\n \"\"\"\n @abstractmethod\n def __init__(self, move=None, view=None, **kwargs):\n super().__init__(**kwargs)\n self.move = move\n self.view = view\n\n @property\n def configured(self):\n \"\"\"\n Determine if the agent has been successfully configured.\n \"\"\"\n return super().configured and self.move is not None and self.view is not None\n\n\nclass Prey(PredatorPreyAgent):\n \"\"\"\n In addition to the shared parameters, Prey must have the following property:\n harvest_amount: float\n How much of the resource the prey will try to harvest if it chooses the\n harvest action. Default 0.4\n \"\"\"\n def __init__(self, harvest_amount=None, **kwargs):\n super().__init__(**kwargs)\n self.harvest_amount = harvest_amount\n\n @property\n def configured(self):\n \"\"\"\n Determine if the agent has been successfully configured.\n \"\"\"\n return super().configured and self.harvest_amount is not None\n\n @property\n def value(self):\n \"\"\"\n The enumerated value of this agent is 1.\n \"\"\"\n return 1\n\n\nclass Predator(PredatorPreyAgent):\n \"\"\"\n In addition to the shared parameters, Predators must have the following property:\n\n attack: int\n The effective range of the attack. 0 means only effective on the same square, 1\n means effective at range 1, 2 at range 2, and so on.\n Default 0.\n \"\"\"\n def __init__(self, attack=None, **kwargs):\n super().__init__(**kwargs)\n self.attack = attack\n\n @property\n def configured(self):\n \"\"\"\n Determine if the agent has been successfully configured.\n \"\"\"\n return super().configured and self.attack is not None\n\n @property\n def value(self):\n \"\"\"\n The enumerated value of this agent is 1.\n \"\"\"\n return 2\n\n\nclass PredatorPreySimulation(AgentBasedSimulation):\n \"\"\"\n Each agent observes other agents around its own location. Both predators and\n prey agents can move around. Predators' goal is to approach prey and attack\n it. Preys' goal is to stay alive for as long as possible.\n\n Note: we recommend that you use the class build function to instantiate the simulation because\n it has smart config checking for the simulation and will create agents that are configured to\n work with the simulation.\n \"\"\"\n\n class ObservationMode(IntEnum):\n GRID = 0\n DISTANCE = 1\n\n class ActionStatus(IntEnum):\n BAD_MOVE = 0\n GOOD_MOVE = 1\n NO_MOVE = 2\n BAD_ATTACK = 3\n GOOD_ATTACK = 4\n EATEN = 5\n BAD_HARVEST = 6\n GOOD_HARVEST = 7\n\n def __init__(self, config):\n self.region = config['region']\n self.max_steps = config['max_steps']\n self.agents = config['agents']\n self.reward_map = config['rewards']\n\n def reset(self, **kwargs):\n \"\"\"\n Randomly pick positions for each of the agents.\n \"\"\"\n self.step_count = 0\n\n # Randomly assign agent positions, using row-column indexing\n for agent in self.agents.values():\n agent.position = np.random.randint(0, self.region, 2)\n\n # Holding for all agents that have died. Agents\n # in the cememtery are effectively removed from the simulation. They don't\n # appear in other agents' observations and they don't have observations\n # of their own, except for the one step in which they died.\n self.cemetery = set()\n\n # Track the agents' rewards over multiple steps.\n self.rewards = {agent_id: 0 for agent_id in self.agents}\n\n def step(self, joint_actions, **kwargs):\n \"\"\"\n The simulation will update its state with the joint actions from all\n the agents. All agents can choose to move up to the amount of squares\n enabled in their move configuration. In addition, predators can choose\n to ATTACK.\n \"\"\"\n self.step_count += 1\n\n # We want to make sure that only agents that are still alive have sent us actions\n for agent_id in joint_actions:\n assert agent_id not in self.cemetery\n\n # Initial setup\n for agent_id in joint_actions:\n self.rewards[agent_id] = 0 # Reset the reward of the acting agent(s).\n\n # Process the predators first\n for predator_id, action in joint_actions.items():\n predator = self.agents[predator_id]\n if type(predator) == Prey: continue # Process the predators first\n # Attack takes precedent over move\n if action['attack'] == 1:\n action_status = self._process_attack_action(predator)\n else:\n action_status = self._process_move_action(predator, action['move'])\n self.rewards[predator_id] = self.reward_map['predator'][action_status]\n\n # The prey are processed differently for Grid and Distance modes because\n # grid mode supports resources on the grid.\n\n def get_reward(self, agent_id, **kwargs):\n return self.rewards[agent_id]\n\n def get_done(self, agent_id, **kwargs):\n \"\"\"\n Agent is done if it is not alive or in the morgue.\n \"\"\"\n if agent_id in self.cemetery:\n return True\n else:\n return False\n\n def get_all_done(self, **kwargs):\n \"\"\"\n If there are no prey left, the simulation is done.\n \"\"\"\n if self.step_count >= self.max_steps:\n return True\n for agent in self.agents.values():\n if type(agent) == Prey and agent.id not in self.cemetery:\n return False\n return True\n\n def get_info(self, agent_id, **kwargs):\n \"\"\"\n Just return an empty dictionary becuase this simulation does not track\n any info.\n \"\"\"\n return {}\n\n def _process_move_action(self, agent, action):\n \"\"\"\n The simulation will attempt to move the agent according to its action.\n If that move is successful, the agent will move and we will return GOOD_MOVE.\n If that move is unsuccessful, the agent will not move and we will return\n BAD_MOVE. Moves can be unsuccessful if the agent moves against a wall.\n If the agent chooses to stay, then we do not move the agent and return NO_MOVE.\n\n This should only be called if the agent has chosen to move or stay still.\n \"\"\"\n action = np.rint(action)\n if all(action == [0, 0]):\n return self.ActionStatus.NO_MOVE\n elif 0 <= agent.position[0] + action[0] < self.region and \\\n 0 <= agent.position[1] + action[1] < self.region:\n # Still inside the boundary, good move\n agent.position[0] += action[0]\n agent.position[1] += action[1]\n return self.ActionStatus.GOOD_MOVE\n else:\n return self.ActionStatus.BAD_MOVE\n\n def _process_attack_action(self, predator):\n \"\"\"\n The simulation will process the predator's attack action. If that attack\n is successful, the prey will be added to the morgue and we will return\n GOOD_ATTACK. If the attack is unsuccessful, then we will return BAD_ATTACK.\n\n This should only be called if the agent chooses to attack. Only predators\n can choose to attack.\n \"\"\"\n for prey in self.agents.values():\n if type(prey) == Predator: continue # Not a prey\n if prey.id in self.cemetery: continue # Ignore already dead agents\n if abs(predator.position[0] - prey.position[0]) <= predator.attack \\\n and abs(predator.position[1] - prey.position[1]) <= predator.attack:\n # Good attack, prey is eaten:\n self.cemetery.add(prey.id)\n self.rewards[prey.id] += self.reward_map['prey'][self.ActionStatus.EATEN]\n return self.ActionStatus.GOOD_ATTACK\n return self.ActionStatus.BAD_ATTACK\n\n def _process_harvest_action(self, prey):\n \"\"\"\n The simulation will process the prey's harvest action by calling the resources\n harvest api. If the amount harvested is the same as the amount attempted\n to harvest, then it was a good harvest. Otherwise, the agent over-harvested,\n or harvested a resource that wasn't ready yet, and so it was a bad harvest.\n\n This should only be called if the agent chooses to harvest. Only prey\n can choose to harvest.\n \"\"\"\n harvested_amount = self.resources.harvest(tuple(prey.position), prey.harvest_amount)\n if harvested_amount == prey.harvest_amount:\n return self.ActionStatus.GOOD_HARVEST\n else:\n return self.ActionStatus.BAD_HARVEST\n\n @classmethod\n def build(cls, sim_config={}):\n \"\"\"\n Args:\n region: int\n The size of the discrete space.\n Region must be >= 2.\n Default 10.\n max_steps: int\n The maximum number of steps per episode.\n Must be >= 1.\n Default 200.\n observation_mode: ObservationMode enum\n Either GRID or DISTANCE. In GRID, the agents see a grid of values around them as\n large as their view. In DISTANCE, the agents see the distance between themselves and\n other agents that they can see. Note: communication only works with\n DISTANCE observation mode.\n Default GRID.\n rewards: dict\n A dictionary that maps the various action status to a reward per each\n agent type. Any agent type that you create must have mappings for all\n possible action statuses for that agent type. The default is {\n 'predator': {\n BAD_MOVE: -region,\n GOOD_MOVE: -1,\n NO_MOVE: 0,\n BAD_ATTACK: -region,\n GOOD_ATTACK: region**2\n },\n 'prey': {\n BAD_MOVE: -2,\n GOOD_MOVE: region,\n NO_MOVE: region,\n EATEN: -region**2\n },\n }\n resources: dictionary of resource-related parameters.\n See GridResources documentation for more information.\n agents: list of PredatorPreyAgent objects.\n You can set the parameters for each of the agent that will override\n the default parameters. For example,\n agents = [\n Prey(id='prey0', view=7, move=2),\n Predator(id='predator1', view=3, attack=2),\n Prey(id='prey2', view=5, move=3),\n Predator(id='predator3', view=2, move=2, attack=1),\n Predator(id='predator4', view=0, attack=3)\n ]\n\n Returns:\n Configured instance of PredatorPreySimulation with configured PredatorPreyAgents.\n \"\"\"\n config = { # default config\n 'region': 10,\n 'max_steps': 200,\n 'observation_mode': cls.ObservationMode.GRID,\n 'resources': {} # Use the defaults in GridResources\n # 'rewards': # Determined based on the size of the region. See below.\n # 'agents': # Determine based on the size of the region. See below.\n }\n\n # --- region --- #\n if 'region' in sim_config:\n region = sim_config['region']\n if type(region) is not int or region < 2:\n raise TypeError(\"region must be an integer greater than 2.\")\n else:\n config['region'] = region\n\n # Assign this here because we must use the right size of the region.\n config['agents'] = [\n Prey(id='prey0', view=config['region']-1, move=1, harvest_amount=0.1),\n Predator(id='predator0', view=config['region']-1, move=1, attack=0)\n ]\n # Assign this here so that we can coordinate rewards with region size.\n config['rewards'] = {\n 'predator': {\n cls.ActionStatus.BAD_MOVE: -config['region'],\n cls.ActionStatus.GOOD_MOVE: -1,\n cls.ActionStatus.NO_MOVE: 0,\n cls.ActionStatus.BAD_ATTACK: -config['region'],\n cls.ActionStatus.GOOD_ATTACK: config['region']**2,\n },\n 'prey': {\n cls.ActionStatus.BAD_MOVE: -config['region'],\n cls.ActionStatus.GOOD_MOVE: -1,\n cls.ActionStatus.NO_MOVE: 0,\n cls.ActionStatus.EATEN: -config['region']**2,\n cls.ActionStatus.BAD_HARVEST: -config['region'],\n cls.ActionStatus.GOOD_HARVEST: config['region'],\n },\n }\n\n # --- max_steps --- #\n if 'max_steps' in sim_config:\n max_steps = sim_config['max_steps']\n if type(max_steps) is not int or max_steps < 1:\n raise TypeError(\"max_steps must be an integer at least 1.\")\n else:\n config['max_steps'] = max_steps\n\n # --- observation_mode --- #\n if 'observation_mode' in sim_config:\n observation_mode = sim_config['observation_mode']\n if observation_mode not in cls.ObservationMode:\n raise TypeError(\"observation_mode must be either GRID or DISTANCE.\")\n else:\n config['observation_mode'] = observation_mode\n\n # --- rewards --- #\n if 'rewards' in sim_config:\n rewards = sim_config['rewards']\n if type(rewards) is not dict:\n raise TypeError(\"rewards must be a dict (see docstring).\")\n else:\n config['rewards'] = rewards\n\n # --- resources --- #\n from abmarl.sim.modules import GridResources\n if 'resources' not in sim_config:\n sim_config['resources'] = {}\n sim_config['resources']['region'] = config['region']\n config['resources'] = GridResources.build(sim_config['resources'])\n\n # --- agents --- #\n if 'agents' in sim_config:\n agents = sim_config['agents']\n if type(agents) is not list:\n raise TypeError(\n \"agents must be a list of PredatorPreyAgent objects. \"\n \"Each element in the list is an agent's configuration. See \"\n \"PredatorPreyAgent docstring for more information.\"\n )\n else:\n for agent in agents:\n if not isinstance(agent, PredatorPreyAgent):\n raise TypeError(\"Every agent must be an instance of PredatorPreyAgent.\")\n\n if agent.view is None:\n agent.view = config['region'] - 1\n elif type(agent.view) is not int or agent.view < 0 or \\\n agent.view > config['region'] - 1:\n raise TypeError(\n f\"{agent['id']} must have a view that is an integer \"\n f\"between 0 and {config['region'] - 1}\"\n )\n\n if agent.move is None:\n agent.move = 1\n elif type(agent.move) is not int or agent.move < 0 or \\\n agent.move > config['region'] - 1:\n raise TypeError(\n f\"{agent['id']} must have a move that is an integer \"\n f\"between 0 and {config['region'] - 1}\"\n )\n\n if type(agent) is Predator:\n if agent.attack is None:\n agent.attack = 0\n elif type(agent.attack) is not int or agent.attack < 0 or \\\n agent.attack > config['region']:\n raise TypeError(\n f\"{agent['id']} must have an attack that is an integer \"\n f\"between 0 and {config['region']}\"\n )\n\n if type(agent) is Prey:\n if agent.harvest_amount is None:\n agent.harvest_amount = 0.4\n elif type(agent.harvest_amount) is not float or agent.harvest_amount < 0:\n raise TypeError(\n f\"{agent['id']} must have a harvest amount that is a float \"\n \"greater than 0.\"\n )\n\n config['agents'] = agents\n\n if config['observation_mode'] == cls.ObservationMode.GRID:\n obs_space_builder = lambda agent: Dict({\n 'agents': Box(-1, 2, (2*agent.view+1, 2*agent.view+1), np.int),\n 'resources': Box(\n -1., config['resources'].max_value, (2*agent.view+1, 2*agent.view+1), np.float\n )\n })\n prey_action_space_builder = lambda agent: Dict({\n 'harvest': Discrete(2),\n 'move': Box(-agent.move-0.5, agent.move+0.5, (2,))\n })\n else:\n obs_space_builder = lambda agent: Dict({\n other_agent.id: Box(-config['region']+1, config['region']-1, (3,), np.int)\n for other_agent in config['agents'] if other_agent.id != agent.id\n })\n prey_action_space_builder = lambda agent: Box(-agent.move-0.5, agent.move+0.5, (2,))\n\n for agent in config['agents']:\n if type(agent) is Prey:\n agent.observation_space = obs_space_builder(agent)\n agent.action_space = prey_action_space_builder(agent)\n else:\n agent.observation_space = obs_space_builder(agent)\n agent.action_space = Dict({\n 'attack': Discrete(2),\n 'move': Box(-agent.move-0.5, agent.move+0.5, (2,)),\n })\n config['agents'] = {agent.id: agent for agent in config['agents']}\n\n if config['observation_mode'] == cls.ObservationMode.GRID:\n return PredatorPreySimGridObs(config)\n else:\n return PredatorPreySimDistanceObs(config)\n\n\nclass PredatorPreySimGridObs(PredatorPreySimulation):\n \"\"\"\n PredatorPreySimulation where observations are of the grid and the items/agents on\n that grid up to the view.\n \"\"\"\n def __init__(self, config):\n super().__init__(config)\n self.resources = config['resources']\n\n def reset(self, **kwargs):\n super().reset(**kwargs)\n self.resources.reset(**kwargs)\n\n def step(self, joint_actions, **kwargs):\n super().step(joint_actions, **kwargs)\n\n for prey_id, action in joint_actions.items():\n prey = self.agents[prey_id]\n if type(prey) == Predator: continue # Process the prey now\n if prey_id in self.cemetery: # This prey was eaten by a predator in this time step.\n continue\n if action['harvest'] == 1:\n action_status = self._process_harvest_action(prey)\n else:\n action_status = self._process_move_action(prey, action['move'])\n self.rewards[prey_id] = self.reward_map['prey'][action_status]\n\n # Now process the other pieces of the simulation\n self.resources.regrow()\n\n def render(self, *args, fig=None, **kwargs):\n \"\"\"\n Visualize the state of the simulation. If a figure is received, then we\n will draw but not actually plot because we assume the caller will do the\n work (e.g. with an Animation object). If there is no figure received, then\n we will draw and plot the simulation. Call the resources render function\n too to plot the resources heatmap.\n \"\"\"\n draw_now = fig is None\n if draw_now:\n from matplotlib import pyplot as plt\n fig = plt.gcf()\n\n fig.clear()\n ax = self.resources.render(fig=fig)\n\n prey_x = [\n agent.position[1] + 0.5 for agent in self.agents.values()\n if type(agent) == Prey and agent.id not in self.cemetery\n ]\n prey_y = [\n self.region - 0.5 - agent.position[0] for agent in self.agents.values()\n if type(agent) == Prey and agent.id not in self.cemetery\n ]\n ax.scatter(prey_x, prey_y, marker='s', s=200, edgecolor='black', facecolor='gray')\n\n predator_x = [\n agent.position[1] + 0.5 for agent in self.agents.values()\n if type(agent) == Predator and agent.id not in self.cemetery\n ]\n predator_y = [\n self.region - 0.5 - agent.position[0] for agent in self.agents.values()\n if type(agent) == Predator and agent.id not in self.cemetery\n ]\n ax.scatter(predator_x, predator_y, s=200, marker='o', edgecolor='black', facecolor='gray')\n\n if draw_now:\n plt.plot()\n plt.pause(1e-17)\n\n return ax\n\n def get_obs(self, my_id, **kwargs):\n \"\"\"\n Each agent observes a grid of values surrounding its location, whose size\n is determiend by the agent's view. There are two channels in this grid:\n an agents channel and a resources channel.\n \"\"\"\n return {\n 'agents': self._observe_other_agents(my_id, **kwargs),\n 'resources': self._observe_resources(my_id, **kwargs),\n }\n\n def _observe_other_agents(self, my_id, **kwargs):\n \"\"\"\n These cells are filled with the value of the agent's type, including -1\n for out of bounds and 0 for empty square. If there are multiple agents\n on the same cell, then we prioritize the agent that is of a different\n type. For example, a prey will only see a predator on a cell that a predator\n and another prey both occupy.\n \"\"\"\n my_agent = self.agents[my_id]\n signal = np.zeros((my_agent.view*2+1, my_agent.view*2+1))\n\n # --- Determine the boundaries of the agents' grids --- #\n # For left and top, we just do: view - x,y >= 0\n # For the right and bottom, we just do region - x,y - 1 - view > 0\n if my_agent.view - my_agent.position[0] >= 0: # Top end\n signal[0:my_agent.view - my_agent.position[0], :] = -1\n if my_agent.view - my_agent.position[1] >= 0: # Left end\n signal[:, 0:my_agent.view - my_agent.position[1]] = -1\n if self.region - my_agent.position[0] - my_agent.view - 1 < 0: # Bottom end\n signal[self.region - my_agent.position[0] - my_agent.view - 1:, :] = -1\n if self.region - my_agent.position[1] - my_agent.view - 1 < 0: # Right end\n signal[:, self.region - my_agent.position[1] - my_agent.view - 1:] = -1\n\n # --- Determine the positions of all the other alive agents --- #\n for other_id, other_agent in self.agents.items():\n if other_id == my_id or other_id in self.cemetery: continue\n r_diff = other_agent.position[0] - my_agent.position[0]\n c_diff = other_agent.position[1] - my_agent.position[1]\n if -my_agent.view <= r_diff <= my_agent.view and \\\n -my_agent.view <= c_diff <= my_agent.view:\n r_diff += my_agent.view\n c_diff += my_agent.view\n if signal[r_diff, c_diff] != 0: # Already another agent here\n if type(my_agent) != type(other_agent):\n signal[r_diff, c_diff] = other_agent.value\n else:\n signal[r_diff, c_diff] = other_agent.value\n\n return signal\n\n def _observe_resources(self, agent_id, **kwargs):\n \"\"\"\n These cells are filled with the values of the resources surrounding the\n agent.\n \"\"\"\n agent = self.agents[agent_id]\n signal = -np.ones((agent.view*2+1, agent.view*2+1))\n\n # Derived by considering each square in the resources as an \"agent\" and\n # then applied the agent diff logic from above. The resulting for-loop\n # can be written in the below vectorized form.\n (r, c) = agent.position\n r_lower = max([0, r-agent.view])\n r_upper = min([self.region-1, r+agent.view])+1\n c_lower = max([0, c-agent.view])\n c_upper = min([self.region-1, c+agent.view])+1\n signal[\n (r_lower+agent.view-r):(r_upper+agent.view-r),\n (c_lower+agent.view-c):(c_upper+agent.view-c)\n ] = self.resources.resources[r_lower:r_upper, c_lower:c_upper]\n return signal\n\n\nclass PredatorPreySimDistanceObs(PredatorPreySimulation):\n \"\"\"\n PredatorPrey simulation where observations are of the distance from each\n other agent within the view.\n \"\"\"\n def step(self, joint_actions, **kwargs):\n super().step(joint_actions, **kwargs)\n for prey_id, action in joint_actions.items():\n prey = self.agents[prey_id]\n if type(prey) == Predator: continue # Process the prey now\n if prey_id in self.cemetery: # This prey was eaten by a predator in this time step.\n continue\n action_status = self._process_move_action(prey, action)\n self.rewards[prey_id] = self.reward_map['prey'][action_status]\n\n def render(self, *args, fig=None, **kwargs):\n \"\"\"\n Visualize the state of the simulation. If a figure is received, then we\n will draw but not actually plot because we assume the caller will do the\n work (e.g. with an Animation object). If there is no figure received, then\n we will draw and plot the simulation.\n \"\"\"\n draw_now = fig is None\n if draw_now:\n from matplotlib import pyplot as plt\n fig = plt.gcf()\n\n fig.clear()\n ax = fig.gca()\n ax.set(xlim=(-0.5, self.region - 0.5), ylim=(-0.5, self.region - 0.5))\n ax.set_xticks(np.arange(-0.5, self.region - 0.5, 1.))\n ax.set_yticks(np.arange(-0.5, self.region - 0.5, 1.))\n ax.grid(linewidth=5)\n\n prey_x = [\n agent.position[1] for agent in self.agents.values()\n if type(agent) == Prey and agent.id not in self.cemetery\n ]\n prey_y = [\n self.region - 1 - agent.position[0] for agent in self.agents.values()\n if type(agent) == Prey and agent.id not in self.cemetery\n ]\n ax.scatter(prey_x, prey_y, marker='s', s=200, edgecolor='black', facecolor='gray')\n\n predator_x = [\n agent.position[1] for agent in self.agents.values()\n if type(agent) == Predator and agent.id not in self.cemetery\n ]\n predator_y = [\n self.region - 1 - agent.position[0] for agent in self.agents.values()\n if type(agent) == Predator and agent.id not in self.cemetery\n ]\n ax.scatter(predator_x, predator_y, s=200, marker='o', edgecolor='black', facecolor='gray')\n\n if draw_now:\n plt.plot()\n plt.pause(1e-17)\n\n return ax\n\n def get_obs(self, my_id, fusion_matrix={}, **kwargs):\n \"\"\"\n Agents observe a distance from itself to other agents only if the other\n agents are visible (i.e. within the agent's view). If agents are not visible,\n then the observation \"slot\" is empty.\n\n Via communication an agent's observations can be combined with other agents.\n The fusion_matrix dictates which observations to share.\n \"\"\"\n my_agent = self.agents[my_id]\n my_obs = {}\n\n # --- Determine the positions of all the other alive agents --- #\n for other_id in self.agents:\n if my_id == other_id: continue\n my_obs[other_id] = np.zeros(3, dtype=np.int)\n # Fill values for agents that are still alive\n for other_id, other_agent in self.agents.items():\n if other_id == my_id or other_id in self.cemetery: continue\n r_diff = other_agent.position[0] - my_agent.position[0]\n c_diff = other_agent.position[1] - my_agent.position[1]\n if -my_agent.view <= c_diff <= my_agent.view and \\\n -my_agent.view <= r_diff <= my_agent.view:\n my_obs[other_id] = np.array((r_diff, c_diff, other_agent.value))\n\n # --- Get the observations from other agents --- #\n for sending_agent_id, message in fusion_matrix.items():\n # Only receive messages from alive agents\n if sending_agent_id not in self.cemetery and message:\n for spied_agent_id, distance_type in self.get_obs(sending_agent_id).items():\n # Don't receive a message about yourself or other agents\n # that you already see\n if spied_agent_id != my_id and \\\n my_obs[spied_agent_id][2] == 0 and \\\n distance_type[2] != 0: # We actually see an agent here\n spied_agent = self.agents[spied_agent_id]\n r_diff = spied_agent.position[0] - my_agent.position[0]\n c_diff = spied_agent.position[1] - my_agent.position[1]\n my_obs[spied_agent_id] = np.array([r_diff, c_diff, spied_agent.value])\n # Also see the relative location of the sending agent itself\n sending_agent = self.agents[sending_agent_id]\n c_diff = sending_agent.position[1] - my_agent.position[1]\n r_diff = sending_agent.position[0] - my_agent.position[0]\n my_obs[sending_agent_id] = np.array([r_diff, c_diff, sending_agent.value])\n\n return my_obs\n"
},
{
"alpha_fraction": 0.5474956631660461,
"alphanum_fraction": 0.5545001029968262,
"avg_line_length": 33.05882263183594,
"blob_id": "29f8e791d034600770f6d8ce18cd9a3531343d97",
"content_id": "2037ccdcc086b344ceed4f6ff5437c6de8ec1e7e",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20844,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 612,
"path": "/abmarl/sim/components/observer.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod, abstractproperty\n\nfrom gym.spaces import Box, Dict\nimport numpy as np\n\nfrom abmarl.sim.components.agent import HealthObservingAgent, LifeObservingAgent, \\\n AgentObservingAgent, PositionObservingAgent, SpeedAngleObservingAgent, \\\n VelocityObservingAgent, ResourceObservingAgent, TeamObservingAgent, BroadcastObservingAgent, \\\n SpeedAngleAgent, VelocityAgent, BroadcastingAgent, ComponentAgent\n\n\nclass Observer(ABC):\n \"\"\"\n Base observer class provides the interface required of all observers. Setup\n the agents' observation space according to the Observer's channel.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, agents=None, **kwargs):\n self.agents = agents\n\n def _set_obs_space_simple(self, instance, space_func, **kwargs):\n \"\"\"\n Observers that don't depend on the type of the other agents can use this\n method.\n\n instance (Agent):\n An Agent class. This is used in the isinstance check to determine if\n the agent will receive the observation channel.\n\n space_func (function):\n A function that takes the other agent as input and outputs the\n observation space.\n \"\"\"\n for agent in self.agents.values():\n if isinstance(agent, instance):\n agent.observation_space[self.channel] = Dict({\n other.id: space_func(other) for other in self.agents.values()\n })\n\n def _set_obs_space(self, instance, other_instance, space_func, alt_space_func, **kwargs):\n \"\"\"\n Observers that depend on the type of the other agents must use this method.\n\n instance (Agent):\n An Agent class. This is used in the isinstance check to determine if\n the agent will receive the observation channel.\n\n other_instance (Agent):\n An Agent class. This is used in the isinstance check on the other agents\n to determine whether to use the space_func or the alt_space_func.\n\n space_func (function):\n A function that takes the other agent as input and outputs the\n observation space.\n\n alt_space_func (function):\n Use this function for cases when the isinstance check fails on the\n other agent. Function does not have inputs and outputs observation space.\n \"\"\"\n for agent in self.agents.values():\n if isinstance(agent, instance):\n obs_space = {}\n for other in self.agents.values():\n if isinstance(other, other_instance):\n obs_space[other.id] = space_func(other)\n else:\n obs_space[other.id] = alt_space_func()\n agent.observation_space[self.channel] = Dict(obs_space)\n\n def _get_obs(self, agent, instance=None, other_instance=ComponentAgent, attr=None, **kwargs):\n \"\"\"\n Many observers just directly query the corresponding state field from the\n agent. This function does exactly that, checking the instance of the observing\n agent and the other agents and setting the observation value accordingly.\n \"\"\"\n if isinstance(agent, instance):\n obs = {}\n for other in self.agents.values():\n if isinstance(other, other_instance):\n attr_obs = getattr(other, attr)\n if not isinstance(attr_obs, np.ndarray):\n attr_obs = np.array([attr_obs])\n obs[other.id] = attr_obs\n else:\n obs[other.id] = self.null_value\n return {self.channel: obs}\n else:\n return {}\n\n @abstractmethod\n def get_obs(self, agent, **kwargs):\n pass\n\n @abstractproperty\n def channel(self):\n pass\n\n @abstractproperty\n def null_value(self):\n pass\n\n\n# --------------------- #\n# --- Communication --- #\n# --------------------- #\n\nclass BroadcastObserver(Observer):\n \"\"\"\n Observe the broadcast state of broadcasting agents.\n \"\"\"\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self._set_obs_space_simple(\n BroadcastObservingAgent, lambda *args: Box(-1, 1, (1,)), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n return self._get_obs(\n agent,\n instance=BroadcastObservingAgent,\n other_instance=BroadcastingAgent,\n attr='broadcasting',\n **kwargs\n )\n\n @property\n def channel(self):\n return 'broadcast'\n\n @property\n def null_value(self):\n return np.array([-1])\n\n\n# ----------------------- #\n# --- Health and Life --- #\n# ----------------------- #\n\nclass HealthObserver(Observer):\n \"\"\"\n Observe the health state of all the agents in the simulator.\n \"\"\"\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self._set_obs_space_simple(\n HealthObservingAgent, lambda other: Box(-1, other.max_health, (1,)), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the health state of all the agents in the simulator.\n\n agent (HealthObservingAgent):\n The agent making the observation.\n \"\"\"\n return self._get_obs(\n agent,\n instance=HealthObservingAgent,\n attr='health',\n **kwargs\n )\n\n @property\n def channel(self):\n return 'health'\n\n @property\n def null_value(self):\n return np.array([-1])\n\n\nclass LifeObserver(Observer):\n \"\"\"\n Observe the life state of all the agents in the simulator.\n \"\"\"\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self._set_obs_space_simple(\n LifeObservingAgent, lambda *args: Box(-1, 1, (1,), np.int), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the life state of all the agents in the simulator.\n\n agent (LifeObservingAgent):\n The agent making the observation.\n \"\"\"\n return self._get_obs(\n agent,\n instance=LifeObservingAgent,\n attr='is_alive',\n **kwargs\n )\n\n @property\n def channel(self):\n return 'life'\n\n @property\n def null_value(self):\n return np.array([-1])\n\n\n# ----------------------------- #\n# --- Position and Movement --- #\n# ----------------------------- #\n\nclass PositionObserver(Observer):\n \"\"\"\n Observe the positions of all the agents in the simulator.\n \"\"\"\n def __init__(self, position_state=None, **kwargs):\n super().__init__(**kwargs)\n self.position_state = position_state\n self._set_obs_space_simple(\n PositionObservingAgent,\n lambda *args: Box(-1, self.position_state.region, (2,), np.int), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the positions of all the agents in the simulator.\n \"\"\"\n return self._get_obs(agent, instance=PositionObservingAgent, attr='position')\n\n @property\n def channel(self):\n return 'position'\n\n @property\n def null_value(self):\n return np.array([-1, -1])\n\n\nclass RelativePositionObserver(Observer):\n \"\"\"\n Observe the relative positions of agents in the simulator.\n \"\"\"\n def __init__(self, position_state=None, **kwargs):\n super().__init__(**kwargs)\n self.position_state = position_state\n self._set_obs_space_simple(\n PositionObservingAgent,\n lambda *args: Box(\n -self.position_state.region, self.position_state.region, (2,), np.int\n ), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the relative positions of all the agents in the simulator.\n \"\"\"\n if isinstance(agent, PositionObservingAgent):\n obs = {}\n for other in self.agents.values():\n r_diff = other.position[0] - agent.position[0]\n c_diff = other.position[1] - agent.position[1]\n obs[other.id] = np.array([r_diff, c_diff])\n return {self.channel: obs}\n else:\n return {}\n\n @property\n def channel(self):\n return 'relative_position'\n\n @property\n def null_value(self):\n return np.array([-self.position_state.region, -self.position_state.region])\n\n\nclass GridPositionBasedObserver:\n \"\"\"\n Agents observe a grid of size agent_view centered on their\n position. The values of the cells are as such:\n Out of bounds : -1\n Empty : 0\n Agent occupied : 1\n\n position (PositionState):\n The position state handler, which contains the region.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, position_state=None, agents=None, **kwargs):\n self.position_state = position_state\n self.agents = agents\n\n for agent in agents.values():\n if isinstance(agent, AgentObservingAgent) and \\\n isinstance(agent, PositionObservingAgent):\n agent.observation_space['position'] = Box(\n -1, 1, (agent.agent_view*2+1, agent.agent_view*2+1), np.int\n )\n\n def get_obs(self, my_agent, **kwargs):\n \"\"\"\n Generate an observation of other agents in the grid surrounding this agent's\n position.\n \"\"\"\n if isinstance(my_agent, AgentObservingAgent) and \\\n isinstance(my_agent, PositionObservingAgent):\n signal = np.zeros((my_agent.agent_view*2+1, my_agent.agent_view*2+1))\n\n # --- Determine the boundaries of the agents' grids --- #\n # For left and top, we just do: view - x,y >= 0\n # For the right and bottom, we just do region - x,y - 1 - view > 0\n if my_agent.agent_view - my_agent.position[0] >= 0: # Top end\n signal[0:my_agent.agent_view - my_agent.position[0], :] = -1\n if my_agent.agent_view - my_agent.position[1] >= 0: # Left end\n signal[:, 0:my_agent.agent_view - my_agent.position[1]] = -1\n if self.position_state.region - my_agent.position[0] - my_agent.agent_view - 1 < 0:\n # Bottom end\n signal[\n self.position_state.region - my_agent.position[0] - my_agent.agent_view - 1:,\n :\n ] = -1\n if self.position_state.region - my_agent.position[1] - my_agent.agent_view - 1 < 0:\n # Right end\n signal[\n :, self.position_state.region - my_agent.position[1] - my_agent.agent_view - 1:\n ] = -1\n\n # --- Determine the positions of all the other alive agents --- #\n for other_id, other_agent in self.agents.items():\n if other_id == my_agent.id: continue # Don't observe yourself\n if not other_agent.is_alive: continue # Can only observe alive agents\n r_diff = other_agent.position[0] - my_agent.position[0]\n c_diff = other_agent.position[1] - my_agent.position[1]\n if -my_agent.agent_view <= r_diff <= my_agent.agent_view and \\\n -my_agent.agent_view <= c_diff <= my_agent.agent_view:\n r_diff += my_agent.agent_view\n c_diff += my_agent.agent_view\n signal[r_diff, c_diff] = 1 # There is an agent at this location.\n\n return {'position': signal}\n else:\n return {}\n\n\nclass GridPositionTeamBasedObserver:\n \"\"\"\n Agents observe a grid of size agent_view centered on their\n position. The observation contains one channel per team, where the value of\n the cell is the number of agents on that team that occupy that square. -1\n indicates out of bounds.\n\n position (PositionState):\n The position state handler, which contains the region.\n\n number_of_teams (int):\n The number of teams in this simuation.\n Default 0.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, position_state=None, number_of_teams=0, agents=None, **kwargs):\n self.position_state = position_state\n self.number_of_teams = number_of_teams + 1\n self.agents = agents\n\n for agent in self.agents.values():\n if isinstance(agent, AgentObservingAgent) and \\\n isinstance(agent, PositionObservingAgent):\n agent.observation_space['position'] = Box(\n -1,\n len(self.agents),\n (agent.agent_view*2+1, agent.agent_view*2+1, self.number_of_teams),\n np.int\n )\n\n def get_obs(self, my_agent, **kwargs):\n \"\"\"\n Generate an observation of other agents in the grid surrounding this agent's\n position. Each team has its own channel and the value represents the number\n of agents of that team occupying the same square.\n \"\"\"\n if isinstance(my_agent, AgentObservingAgent) and \\\n isinstance(my_agent, PositionObservingAgent):\n signal = np.zeros((my_agent.agent_view*2+1, my_agent.agent_view*2+1))\n\n # --- Determine the boundaries of the agents' grids --- #\n # For left and top, we just do: view - x,y >= 0\n # For the right and bottom, we just do region - x,y - 1 - view > 0\n if my_agent.agent_view - my_agent.position[0] >= 0: # Top end\n signal[0:my_agent.agent_view - my_agent.position[0], :] = -1\n if my_agent.agent_view - my_agent.position[1] >= 0: # Left end\n signal[:, 0:my_agent.agent_view - my_agent.position[1]] = -1\n if self.position_state.region - my_agent.position[0] - my_agent.agent_view - 1 < 0:\n # Bottom end\n signal[\n self.position_state.region - my_agent.position[0] - my_agent.agent_view - 1:,\n :\n ] = -1\n if self.position_state.region - my_agent.position[1] - my_agent.agent_view - 1 < 0:\n # Right end\n signal[\n :,\n self.position_state.region - my_agent.position[1] - my_agent.agent_view - 1:\n ] = -1\n\n # Repeat the boundaries signal for all teams\n signal = np.repeat(signal[:, :, np.newaxis], self.number_of_teams, axis=2)\n\n # --- Determine the positions of all the other alive agents --- #\n for other_id, other_agent in self.agents.items():\n if other_id == my_agent.id: continue # Don't observe yourself\n if not other_agent.is_alive: continue # Can only observe alive agents\n r_diff = other_agent.position[0] - my_agent.position[0]\n c_diff = other_agent.position[1] - my_agent.position[1]\n if -my_agent.agent_view <= r_diff <= my_agent.agent_view and \\\n -my_agent.agent_view <= c_diff <= my_agent.agent_view:\n r_diff += my_agent.agent_view\n c_diff += my_agent.agent_view\n signal[r_diff, c_diff, other_agent.team] += 1\n\n return {'position': signal}\n else:\n return {}\n\n\nclass SpeedObserver(Observer):\n \"\"\"\n Observe the speed of all the agents in the simulator.\n \"\"\"\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self._set_obs_space(\n SpeedAngleObservingAgent,\n SpeedAngleAgent,\n lambda other: Box(-1, other.max_speed, (1,)),\n lambda: Box(-1, -1, (1,)), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the speed of all the agents in the simulator.\n \"\"\"\n return self._get_obs(\n agent,\n instance=SpeedAngleObservingAgent,\n other_instance=SpeedAngleAgent,\n attr='speed',\n **kwargs\n )\n\n @property\n def channel(self):\n return 'speed'\n\n @property\n def null_value(self):\n return np.array([-1])\n\n\nclass AngleObserver(Observer):\n \"\"\"\n Observe the angle of all the agents in the simulator.\n \"\"\"\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self._set_obs_space(\n SpeedAngleObservingAgent,\n SpeedAngleAgent,\n lambda *args: Box(-1, 360, (1,)),\n lambda *args: Box(-1, -1, (1,)), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the angle of all the agents in the simulator.\n \"\"\"\n return self._get_obs(\n agent,\n instance=SpeedAngleObservingAgent,\n other_instance=SpeedAngleAgent,\n attr='ground_angle',\n **kwargs\n )\n\n @property\n def channel(self):\n return 'ground_angle'\n\n @property\n def null_value(self):\n return np.array([-1])\n\n\nclass VelocityObserver(Observer):\n \"\"\"\n Observe the velocity of all the agents in the simulator.\n \"\"\"\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self._set_obs_space(\n VelocityObservingAgent, VelocityAgent,\n lambda other: Box(-other.max_speed, other.max_speed, (2,)),\n lambda: Box(0, 0, (2,)), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the velocity of all the agents in the simulator.\n \"\"\"\n return self._get_obs(\n agent,\n instance=VelocityObservingAgent,\n other_instance=VelocityAgent,\n attr='velocity',\n **kwargs\n )\n\n @property\n def channel(self):\n return 'velocity'\n\n @property\n def null_value(self):\n return np.zeros(2)\n\n\n# -------------------------------- #\n# --- Resources and Harvesting --- #\n# -------------------------------- #\n\nclass GridResourceObserver:\n \"\"\"\n Agents observe a grid of size resource_view centered on their\n position. The values in the grid are the values of the resources in that\n area.\n\n resources (ResourceState):\n The resource state handler.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, resource_state=None, agents=None, **kwargs):\n self.resource_state = resource_state\n self.agents = agents\n\n for agent in agents.values():\n if isinstance(agent, ResourceObservingAgent):\n agent.observation_space['resources'] = Box(\n -1, self.resource_state.max_value,\n (agent.resource_view*2+1, agent.resource_view*2+1)\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n These cells are filled with the values of the resources surrounding the\n agent's position.\n \"\"\"\n if isinstance(agent, ResourceObservingAgent):\n signal = -np.ones((agent.resource_view*2+1, agent.resource_view*2+1))\n\n # Derived by considering each square in the resources as an \"agent\" and\n # then applied the agent diff logic from above. The resulting for-loop\n # can be written in the below vectorized form.\n (r, c) = agent.position\n r_lower = max([0, r-agent.resource_view])\n r_upper = min([self.resource_state.region-1, r+agent.resource_view])+1\n c_lower = max([0, c-agent.resource_view])\n c_upper = min([self.resource_state.region-1, c+agent.resource_view])+1\n signal[\n (r_lower+agent.resource_view-r):(r_upper+agent.resource_view-r),\n (c_lower+agent.resource_view-c):(c_upper+agent.resource_view-c)\n ] = self.resource_state.resources[r_lower:r_upper, c_lower:c_upper]\n return {'resources': signal}\n else:\n return {}\n\n\n# ------------ #\n# --- Team --- #\n# ------------ #\n\nclass TeamObserver(Observer):\n \"\"\"\n Observe the team of each agent in the simulator.\n \"\"\"\n def __init__(self, number_of_teams=0, **kwargs):\n super().__init__(**kwargs)\n self.number_of_teams = number_of_teams\n self._set_obs_space_simple(\n TeamObservingAgent, lambda *args: Box(-1, self.number_of_teams, (1,), np.int), **kwargs\n )\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the team of each agent in the simulator.\n \"\"\"\n return self._get_obs(\n agent,\n instance=TeamObservingAgent,\n attr='team',\n **kwargs\n )\n\n @property\n def channel(self):\n return 'team'\n\n @property\n def null_value(self):\n return np.array([-1])\n"
},
{
"alpha_fraction": 0.8387096524238586,
"alphanum_fraction": 0.8387096524238586,
"avg_line_length": 61,
"blob_id": "57bdd486ae13ae0d8f4d0ff5eb88b9935d877563",
"content_id": "bd6b2a7279e80ea9dc7d2afd44eef584f806b0f0",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 2,
"path": "/abmarl/sim/predator_prey/__init__.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .predator_prey import PredatorPreySimulation, PredatorPreySimGridObs, \\\n PredatorPreySimDistanceObs, Predator, Prey\n"
},
{
"alpha_fraction": 0.6187891364097595,
"alphanum_fraction": 0.6273486614227295,
"avg_line_length": 31.364864349365234,
"blob_id": "d942c220a0db733a92cd5da4d96936fd73590e48",
"content_id": "436c9052a651ced8a4962fe5d93218420b98cf05",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4790,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 148,
"path": "/abmarl/sim/components/examples/simple_particle.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport numpy as np\n\nfrom abmarl.sim.components.state import VelocityState, ContinuousPositionState\nfrom abmarl.sim.components.actor import AccelerationMovementActor, ContinuousCollisionActor\nfrom abmarl.sim.components.observer import VelocityObserver, PositionObserver\nfrom abmarl.sim.components.agent import VelocityAgent, AcceleratingAgent, \\\n VelocityObservingAgent, PositionObservingAgent, ActingAgent, CollisionAgent, ComponentAgent\nfrom abmarl.sim import AgentBasedSimulation\nfrom abmarl.tools.matplotlib_utils import mscatter\n\n\nclass ParticleAgent(\n VelocityAgent, AcceleratingAgent, VelocityObservingAgent, PositionObservingAgent,\n CollisionAgent\n): pass\nclass FixedLandmark(ComponentAgent): pass\nclass MovingLandmark(VelocityAgent): pass\n\n\nclass ParticleSim(AgentBasedSimulation):\n def __init__(self, **kwargs):\n self.agents = kwargs['agents']\n\n # State\n self.position_state = ContinuousPositionState(**kwargs)\n self.velocity_state = VelocityState(**kwargs)\n\n # Actor\n self.move_actor = AccelerationMovementActor(\n position_state=self.position_state,\n velocity_state=self.velocity_state, **kwargs\n )\n self.collision_actor = ContinuousCollisionActor(\n position_state=self.position_state,\n velocity_state=self.velocity_state, **kwargs\n )\n\n # Observer\n self.velocity_observer = VelocityObserver(**kwargs)\n self.position_observer = PositionObserver(position_state=self.position_state, **kwargs)\n\n self.finalize()\n\n def reset(self, **kwargs):\n self.position_state.reset(**kwargs)\n self.velocity_state.reset(**kwargs)\n\n def step(self, action_dict, **kwargs):\n for agent, action in action_dict.items():\n self.move_actor.process_action(self.agents[agent], action, **kwargs)\n self.velocity_state.apply_friction(self.agents[agent], **kwargs)\n\n self.collision_actor.detect_collisions_and_modify_states(**kwargs)\n\n if 'moving_landmark0' in self.agents:\n self.move_actor.process_action(self.agents['moving_landmark0'], {}, **kwargs)\n\n def render(self, fig=None, **kwargs):\n fig.clear()\n\n # Draw the resources\n ax = fig.gca()\n\n # Draw the agents\n ax.set(xlim=(0, self.position_state.region), ylim=(0, self.position_state.region))\n ax.set_xticks(np.arange(0, self.position_state.region, 1))\n ax.set_yticks(np.arange(0, self.position_state.region, 1))\n\n landmark_x = [\n agent.position[0] for agent in self.agents.values()\n if isinstance(agent, (FixedLandmark, MovingLandmark))\n ]\n landmark_y = [\n agent.position[1] for agent in self.agents.values()\n if isinstance(agent, (FixedLandmark, MovingLandmark))\n ]\n mscatter(\n landmark_x, landmark_y, ax=ax, m='o', s=3000, edgecolor='black', facecolor='black'\n )\n\n agents_x = [\n agent.position[0] for agent in self.agents.values() if isinstance(agent, ParticleAgent)\n ]\n agents_y = [\n agent.position[1] for agent in self.agents.values() if isinstance(agent, ParticleAgent)\n ]\n agents_size = [\n 3000*agent.size for agent in self.agents.values() if isinstance(agent, ParticleAgent)\n ]\n mscatter(\n agents_x, agents_y, ax=ax, m='o', s=agents_size, edgecolor='black', facecolor='gray'\n )\n\n plt.plot()\n plt.pause(1e-6)\n\n def get_obs(self, agent_id, **kwargs):\n agent = self.agents[agent_id]\n return {\n **self.position_observer.get_obs(agent),\n **self.velocity_observer.get_obs(agent),\n }\n\n def get_reward(self, agent_id, **kwargs):\n pass\n\n def get_done(self, agent_id, **kwargs):\n pass\n\n def get_all_done(self, **kwargs):\n pass\n\n def get_info(self, agent_id, **kwargs):\n pass\n\n\nif __name__ == \"__main__\":\n agents = {f'agent{i}': ParticleAgent(\n id=f'agent{i}',\n max_speed=.25,\n max_acceleration=0.1,\n mass=1,\n size=1,\n ) for i in range(10)}\n\n agents = {\n **agents,\n 'fixed_landmark0': FixedLandmark(id='fixed_landmark0'),\n 'moving_landmark0': MovingLandmark(id='moving_landmark0', max_speed=1),\n }\n\n sim = ParticleSim(\n agents=agents,\n region=10,\n friction=0.0\n )\n fig = plt.figure()\n sim.reset()\n sim.render(fig=fig)\n\n for _ in range(50):\n action = {\n agent.id: agent.action_space.sample() for agent in agents.values()\n if isinstance(agent, ActingAgent)\n }\n sim.step(action)\n sim.render(fig=fig)\n"
},
{
"alpha_fraction": 0.6419516205787659,
"alphanum_fraction": 0.6688436269760132,
"avg_line_length": 40.98387145996094,
"blob_id": "a2e205fecd0b80933d62e1f5bbc27d0cbf9aa695",
"content_id": "a801c531a251d707a9e60738305f9625d0877255",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2603,
"license_type": "permissive",
"max_line_length": 91,
"num_lines": 62,
"path": "/tests/test_collision_component.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.components.state import VelocityState, ContinuousPositionState\nfrom abmarl.sim.components.actor import AccelerationMovementActor, ContinuousCollisionActor\nfrom abmarl.sim.components.actor import VelocityAgent, AcceleratingAgent, CollisionAgent\n\n\nclass ParticleAgent(VelocityAgent, AcceleratingAgent, CollisionAgent): pass\n\n\ndef test_collision():\n\n agents = {\n 'agent0': ParticleAgent(\n id='agent0', max_acceleration=0, max_speed=10, size=1, mass=1,\n initial_velocity=np.array([1, 1]), initial_position=np.array([1,1])\n ),\n 'agent1': ParticleAgent(\n id='agent1', max_acceleration=0, max_speed=10, size=1, mass=1,\n initial_velocity=np.array([-1, 1]), initial_position=np.array([4, 1])\n )\n }\n\n position_state = ContinuousPositionState(region=10, agents=agents)\n velocity_state = VelocityState(agents=agents, friction=0.0)\n position_state.reset()\n velocity_state.reset()\n\n movement_actor = AccelerationMovementActor(\n position_state=position_state, velocity_state=velocity_state, agents=agents\n )\n collision_actor = ContinuousCollisionActor(\n position_state=position_state, velocity_state=velocity_state, agents=agents\n )\n\n np.testing.assert_array_equal(\n movement_actor.process_action(agents['agent0'], {'accelerate': np.zeros(2)}),\n np.array([1., 1.])\n )\n np.testing.assert_array_equal(agents['agent0'].position, np.array([2., 2.]))\n np.testing.assert_array_equal(agents['agent0'].velocity, np.array([1., 1.]))\n np.testing.assert_array_equal(\n movement_actor.process_action(agents['agent1'], {'accelerate': np.zeros(2)}),\n np.array([-1., 1.])\n )\n np.testing.assert_array_equal(agents['agent1'].position, np.array([3., 2.]))\n np.testing.assert_array_equal(agents['agent1'].velocity, np.array([-1., 1.]))\n\n collision_actor.detect_collisions_and_modify_states()\n np.testing.assert_array_equal(agents['agent0'].position, np.array([1.5, 1.5]))\n np.testing.assert_array_equal(agents['agent1'].position, np.array([3.5, 1.5]))\n np.testing.assert_array_equal(agents['agent0'].velocity, np.array([-1., 1.]))\n np.testing.assert_array_equal(agents['agent1'].velocity, np.array([1., 1.]))\n\n np.testing.assert_array_equal(\n movement_actor.process_action(agents['agent0'], {'accelerate': np.zeros(2)}),\n np.array([-1., 1.])\n )\n np.testing.assert_array_equal(\n movement_actor.process_action(agents['agent1'], {'accelerate': np.zeros(2)}),\n np.array([1., 1.])\n )\n"
},
{
"alpha_fraction": 0.5838223695755005,
"alphanum_fraction": 0.5870288610458374,
"avg_line_length": 34.77705764770508,
"blob_id": "d7ad947d999817ac8893b3ccc92f01fe98fb6d9d",
"content_id": "a23b2cad1cae927702f15b7eed1ad0d0aa81873b",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16529,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 462,
"path": "/abmarl/sim/components/state.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\nimport numpy as np\n\nfrom abmarl.sim.components.agent import SpeedAngleAgent, VelocityAgent, CollisionAgent, \\\n BroadcastingAgent\n\n\n# --------------------- #\n# --- Communication --- #\n# --------------------- #\n\nclass BroadcastState:\n \"\"\"\n Tracks which agents have broadcasted in this step.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, agents=None, **kwargs):\n self.agents = agents\n\n def reset(self, **kwargs):\n \"\"\"\n Reset the broadcasting state of all applicable agents.\n \"\"\"\n for agent in self.agents.values():\n if isinstance(agent, BroadcastingAgent):\n agent.broadcasting = False\n\n def set_broadcast(self, agent, _broadcast):\n \"\"\"\n Set the broadcasting state of the agent.\n \"\"\"\n if isinstance(agent, BroadcastingAgent):\n agent.broadcasting = _broadcast\n\n def modify_broadcast(self, agent, value):\n \"\"\"\n Set the broadcasting state of the agent.\n \"\"\"\n self.set_broadcast(agent, value)\n\n\n# ----------------------- #\n# --- Health and Life --- #\n# ----------------------- #\n\nclass LifeState:\n \"\"\"\n Agents can die if their health falls below their minimal health value. Health\n can decrease in a number of interactions. This simulation provides an entropy\n that indicates how much health an agent loses when apply_entropy is called.\n This is a generic entropy for the step. If you want to specify health changes\n for specific actions, such as being attacked or harvesting, you must write\n it in the simulation.\n\n agents (dict):\n Dictionary of agents.\n\n entropy (float):\n The amount of health that is depleted from an agent whenever apply_entropy\n is called.\n \"\"\"\n def __init__(self, agents=None, entropy=0.1, **kwargs):\n assert type(agents) is dict, \"Agents must be a dict\"\n self.agents = agents\n self.entropy = entropy\n\n def reset(self, **kwargs):\n \"\"\"\n Reset the health and life state of all applicable agents.\n \"\"\"\n for agent in self.agents.values():\n if agent.initial_health is not None:\n agent.health = agent.initial_health\n else:\n agent.health = np.random.uniform(agent.min_health, agent.max_health)\n agent.is_alive = True\n\n def set_health(self, agent, _health):\n \"\"\"\n Set the health of an agent to a specific value, bounded by the agent's\n min and max health-value. If that value is less than the agent's health,\n then the agent dies.\n \"\"\"\n if _health <= agent.min_health:\n agent.health = 0\n agent.is_alive = False\n elif _health >= agent.max_health:\n agent.health = agent.max_health\n else:\n agent.health = _health\n\n def modify_health(self, agent, value):\n \"\"\"\n Add some value to the health of the agent.\n \"\"\"\n self.set_health(agent, agent.health + value)\n\n def apply_entropy(self, agent, **kwargs):\n \"\"\"\n Apply entropy to the agent, decreasing its health by a small amount.\n \"\"\"\n self.modify_health(agent, -self.entropy, **kwargs)\n\n\n# ----------------------------- #\n# --- Position and Movement --- #\n# ----------------------------- #\n\nclass PositionState(ABC):\n \"\"\"\n Manages the agents' positions.\n\n region (int):\n The size of the simulation map.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, region=None, agents=None, **kwargs):\n assert type(region) is int, \"Region must be an integer.\"\n self.region = region\n assert type(agents) is dict, \"agents must be a dict\"\n self.agents = agents\n\n def reset(self, **kwargs):\n \"\"\"\n Reset the agents' positions. If the agents were created with a starting\n position, then use that. Otherwise, randomly assign a position in the region.\n \"\"\"\n # Invalidate all the agents' positions from last episode\n for agent in self.agents.values():\n agent.position = None\n\n for agent in self.agents.values():\n if agent.initial_position is not None:\n agent.position = agent.initial_position\n else:\n self.random_reset(agent)\n\n @abstractmethod\n def random_reset(self, agent, **kwargs):\n \"\"\"\n Reset the agents' positions. Child classes implement this according to their\n specs. For example, GridPositionState assigns random integers as the position,\n whereas ContinuousPositionState assigns random numbers.\n \"\"\"\n pass\n\n @abstractmethod\n def set_position(self, agent, position, **kwargs):\n \"\"\"\n Set the position of the agents. Child classes implement.\n \"\"\"\n pass\n\n def modify_position(self, agent, value, **kwargs):\n \"\"\"\n Add some value to the position of the agent.\n \"\"\"\n self.set_position(agent, agent.position + value)\n\n\nclass GridPositionState(PositionState):\n \"\"\"\n Agents are positioned in a grid and cannot go outside of the region. Positions\n are a 2-element numpy array, where the first element is the grid-row from top\n to bottom and the second is the grid-column from left to right.\n \"\"\"\n def set_position(self, agent, _position, **kwargs):\n \"\"\"\n Set the agent's position to the incoming value only if the new position\n is within the region.\n \"\"\"\n if 0 <= _position[0] < self.region and 0 <= _position[1] < self.region:\n agent.position = _position\n\n def random_reset(self, agent, **kwargs):\n \"\"\"\n Set the agents' random positions as integers within the region.\n \"\"\"\n agent.position = np.random.randint(0, self.region, 2)\n\n\nclass ContinuousPositionState(PositionState):\n \"\"\"\n Agents are positioned in a continuous space and can go outside the bounds\n of the region. Positions are a 2-element array, where the first element is\n the x-location and the second is the y-location.\n \"\"\"\n def __init__(self, reset_attempts=100, **kwargs):\n super().__init__(**kwargs)\n self.reset_attempts = reset_attempts\n\n def set_position(self, agent, _position, **kwargs):\n \"\"\"\n Set the agent's position to the incoming value.\n \"\"\"\n agent.position = _position\n\n def random_reset(self, agent, **kwargs):\n \"\"\"\n Set the agents' random positions as numbers within the region.\n \"\"\"\n if isinstance(agent, CollisionAgent):\n for _ in range(self.reset_attempts):\n potential_position = np.random.uniform(0, self.region, 2)\n collision = False\n for other in self.agents.values():\n if other.id != agent.id and \\\n isinstance(other, CollisionAgent) and \\\n other.position is not None and \\\n np.linalg.norm(other.position - potential_position) < \\\n (other.size + agent.size):\n collision = True\n break\n if not collision:\n agent.position = potential_position\n return\n raise Exception(\"Could not fit all the agents in the region without collisions\")\n else:\n agent.position = np.random.uniform(0, self.region, 2)\n\n\nclass SpeedAngleState:\n \"\"\"\n Manages the agents' speed, banking angles, and ground angles.\n \"\"\"\n def __init__(self, agents=None, **kwargs):\n self.agents = agents\n\n def reset(self, **kwargs):\n \"\"\"\n Reset the agents' speeds and ground angles.\n \"\"\"\n for agent in self.agents.values():\n if isinstance(agent, SpeedAngleAgent):\n # Reset agent speed\n if agent.initial_speed is not None:\n agent.speed = agent.initial_speed\n else:\n agent.speed = np.random.uniform(agent.min_speed, agent.max_speed)\n\n # Reset agent banking angle\n if agent.initial_banking_angle is not None:\n agent.banking_angle = agent.initial_banking_angle\n else:\n agent.banking_angle = np.random.uniform(\n -agent.max_banking_angle, agent.max_banking_angle\n )\n\n # Reset agent ground angle\n if agent.initial_ground_angle is not None:\n agent.ground_angle = agent.initial_ground_angle\n else:\n agent.ground_angle = np.random.uniform(0, 360)\n\n def set_speed(self, agent, _speed, **kwargs):\n \"\"\"\n Set the agent's speed if it is between its min and max speed.\n \"\"\"\n if isinstance(agent, SpeedAngleAgent):\n if agent.min_speed <= _speed <= agent.max_speed:\n agent.speed = _speed\n\n def modify_speed(self, agent, value, **kwargs):\n \"\"\"\n Modify the agent's speed.\n \"\"\"\n if isinstance(agent, SpeedAngleAgent):\n self.set_speed(agent, agent.speed + value)\n\n def set_banking_angle(self, agent, _banking_angle, **kwargs):\n \"\"\"\n Set the agent's banking angle if it is between its min and max angle.\n \"\"\"\n if isinstance(agent, SpeedAngleAgent):\n if abs(_banking_angle) <= agent.max_banking_angle:\n agent.banking_angle = _banking_angle\n self.modify_ground_angle(agent, agent.banking_angle)\n\n def modify_banking_angle(self, agent, value, **kwargs):\n \"\"\"\n Modify the agent's banking angle.\n \"\"\"\n if isinstance(agent, SpeedAngleAgent):\n self.set_banking_angle(agent, agent.banking_angle + value)\n\n def set_ground_angle(self, agent, _ground_angle, **kwargs):\n \"\"\"\n Set the agent's ground angle, which will be modded to fall between 0 and\n 360.\n \"\"\"\n if isinstance(agent, SpeedAngleAgent):\n agent.ground_angle = _ground_angle % 360\n\n def modify_ground_angle(self, agent, value, **kwargs):\n \"\"\"\n Modify the agent's ground angle.\n \"\"\"\n if isinstance(agent, SpeedAngleAgent):\n self.set_ground_angle(agent, agent.ground_angle + value)\n\n\nclass VelocityState:\n \"\"\"\n Manages the agents' velocities.\n \"\"\"\n def __init__(self, agents=None, friction=0.05, **kwargs):\n self.agents = agents\n self.friction = friction\n\n def reset(self, **kwargs):\n \"\"\"\n Reset the agents' velocities.\n \"\"\"\n for agent in self.agents.values():\n if isinstance(agent, VelocityAgent):\n # Reset the agent's velocity\n if agent.initial_velocity is not None:\n agent.velocity = agent.initial_velocity\n else:\n agent.velocity = np.random.uniform(-agent.max_speed, agent.max_speed, (2,))\n\n def set_velocity(self, agent, _velocity, **kwargs):\n \"\"\"\n Set the agent's velocity if it is within its max speed.\n \"\"\"\n if isinstance(agent, VelocityAgent):\n vel_norm = np.linalg.norm(_velocity)\n if vel_norm < agent.max_speed:\n agent.velocity = _velocity\n else:\n agent.velocity = _velocity / vel_norm * agent.max_speed\n\n def modify_velocity(self, agent, value, **kwargs):\n \"\"\"\n Modify the agent's velocity.\n \"\"\"\n if isinstance(agent, VelocityAgent):\n self.set_velocity(agent, agent.velocity + value, **kwargs)\n\n def apply_friction(self, agent, **kwargs):\n \"\"\"\n Apply friction to the agent's movement, decreasing its speed by a small amount.\n \"\"\"\n if isinstance(agent, VelocityAgent):\n old_speed = np.linalg.norm(agent.velocity)\n new_speed = old_speed - self.friction\n if new_speed <= 0:\n agent.velocity = np.zeros(2)\n else:\n agent.velocity *= new_speed / old_speed\n\n\n# -------------------------------- #\n# --- Resources and Harvesting --- #\n# -------------------------------- #\n\nclass GridResourceState:\n \"\"\"\n Resources exist in the cells of the grid. The grid is populated with resources\n between the min and max value on some coverage of the region at reset time.\n If original resources is specified, then reset will set the resources back\n to that original value. This component supports resource depletion: if a resource falls below\n the minimum value, it will not regrow. Agents can harvest resources from the cell they occupy.\n Agents can observe the resources in a grid-like observation surrounding their positions.\n\n An agent can harvest up to its max harvest value on the cell it occupies. It\n can observe the resources in a grid surrounding its position, up to its view\n distance.\n\n agents (dict):\n The dictionary of agents.\n\n region (int):\n The size of the region\n\n coverage (float):\n The ratio of the region that should start with resources.\n\n min_value (float):\n The minimum value a resource can have before it cannot grow back. This is\n different from the absolute minimum value, 0, which indicates that there\n are no resources in the cell.\n\n max_value (float):\n The maximum value a resource can have.\n\n regrow_rate (float):\n The rate at which resources regrow.\n\n initial_resources (np.array):\n Instead of specifying the above resource-related parameters, we can provide\n an initial state of the resources. At reset time, the resources will be\n set to these original resources. Otherwise, the resources will be set\n to random values between the min and max value up to some coverage of the\n region.\n \"\"\"\n def __init__(self, agents=None, region=None, coverage=0.75, min_value=0.1, max_value=1.0,\n regrow_rate=0.04, initial_resources=None, **kwargs):\n self.initial_resources = initial_resources\n if self.initial_resources is None:\n assert type(region) is int, \"Region must be an integer.\"\n self.region = region\n else:\n self.region = self.initial_resources.shape[0]\n self.min_value = min_value\n self.max_value = max_value\n self.regrow_rate = regrow_rate\n self.coverage = coverage\n\n assert type(agents) is dict, \"agents must be a dict\"\n self.agents = agents\n\n def reset(self, **kwargs):\n \"\"\"\n Reset the resources. If original resources is specified, then the resources\n will be reset back to this original value. Otherwise, the resources will\n be randomly generated values between the min and max value up to some coverage\n of the region.\n \"\"\"\n if self.initial_resources is not None:\n self.resources = self.initial_resources\n else:\n coverage_filter = np.zeros((self.region, self.region))\n coverage_filter[\n np.random.uniform(0, 1, (self.region, self.region)) < self.coverage\n ] = 1.\n self.resources = np.multiply(\n np.random.uniform(self.min_value, self.max_value, (self.region, self.region)),\n coverage_filter\n )\n\n def set_resources(self, location, value, **kwargs):\n \"\"\"\n Set the resource at a certain location to a value, bounded between 0 and\n the maximum resource value.\n \"\"\"\n assert type(location) is tuple\n if value <= 0:\n self.resources[location] = 0\n elif value >= self.max_value:\n self.resources[location] = self.max_value\n else:\n self.resources[location] = value\n\n def modify_resources(self, location, value, **kwargs):\n \"\"\"\n Add some value to the resource at a certain location.\n \"\"\"\n assert type(location) is tuple\n self.set_resources(location, self.resources[location] + value, **kwargs)\n\n def regrow(self, **kwargs):\n \"\"\"\n Regrow the resources according to the regrow_rate.\n \"\"\"\n self.resources[self.resources >= self.min_value] += self.regrow_rate\n self.resources[self.resources >= self.max_value] = self.max_value\n"
},
{
"alpha_fraction": 0.6249021291732788,
"alphanum_fraction": 0.6288175582885742,
"avg_line_length": 35.141510009765625,
"blob_id": "58420a930ec419cc7555f3e1a101209d60354df8",
"content_id": "f119fea079009b9fa1c28cb09d3331b7b04bfdd7",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7662,
"license_type": "permissive",
"max_line_length": 90,
"num_lines": 212,
"path": "/abmarl/sim/wrappers/flatten_wrapper.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import copy\n\nfrom gym.spaces import Box, Discrete, Tuple, Dict, MultiDiscrete, MultiBinary\nimport numpy as np\n\nfrom .sar_wrapper import SARWrapper\n\n\ndef flatdim(space):\n \"\"\"Return the number of dimensions a flattened equivalent of this space\n would have.\n\n Accepts a space and returns an integer. Raises TypeError if\n the space is not defined in gym.spaces.\n \"\"\"\n if isinstance(space, Box):\n return int(np.prod(space.shape))\n elif isinstance(space, Discrete):\n return int(space.n)\n elif isinstance(space, Tuple):\n return int(sum([flatdim(s) for s in space.spaces]))\n elif isinstance(space, Dict):\n return int(sum([flatdim(s) for s in space.spaces.values()]))\n elif isinstance(space, MultiBinary):\n return int(space.n)\n elif isinstance(space, MultiDiscrete):\n return int(np.prod(space.shape))\n else:\n raise TypeError\n\n\ndef flatten(space, x):\n \"\"\"Flatten a data point from a space.\n\n This is useful when e.g. points from spaces must be passed to a neural\n network, which only understands flat arrays of floats.\n\n Accepts a space and a point from that space. Always returns a 1D array.\n Raises TypeError if the space is not a gym space.\n \"\"\"\n if isinstance(space, Box):\n return np.asarray(x, dtype=space.dtype).flatten()\n elif isinstance(space, Discrete):\n onehot = np.zeros(space.n, dtype=np.int)\n onehot[x] = 1\n return onehot\n elif isinstance(space, Tuple):\n return np.concatenate([flatten(s, x_part) for x_part, s in zip(x, space.spaces)])\n elif isinstance(space, Dict):\n return np.concatenate(\n [flatten(s, x[key]) for key, s in space.spaces.items()])\n elif isinstance(space, MultiBinary):\n return np.asarray(x, dtype=np.int).flatten()\n elif isinstance(space, MultiDiscrete):\n return np.asarray(x, dtype=np.int).flatten()\n else:\n raise TypeError('space must be instance of gym.spaces')\n\n\ndef unflatten(space, x):\n \"\"\"Unflatten a data point from a space.\n\n This reverses the transformation applied by flatten(). You must ensure\n that the space argument is the same as for the flatten() call.\n\n Accepts a space and a flattened point. Returns a point with a structure\n that matches the space. Raises TypeError if the space is not\n defined in gym.spaces.\n \"\"\"\n if isinstance(space, Box):\n return np.asarray(x, dtype=space.dtype).reshape(space.shape)\n elif isinstance(space, Discrete):\n return int(np.nonzero(x)[0][0])\n elif isinstance(space, Tuple):\n dims = [flatdim(s) for s in space.spaces]\n list_flattened = np.split(x, np.cumsum(dims)[:-1])\n list_unflattened = [\n unflatten(s, flattened)\n for flattened, s in zip(list_flattened, space.spaces)\n ]\n return tuple(list_unflattened)\n elif isinstance(space, Dict):\n dims = [flatdim(s) for s in space.spaces.values()]\n list_flattened = np.split(x, np.cumsum(dims)[:-1])\n list_unflattened = [\n (key, unflatten(s, flattened))\n for flattened, (key,\n s) in zip(list_flattened, space.spaces.items())\n ]\n from collections import OrderedDict\n return OrderedDict(list_unflattened)\n elif isinstance(space, MultiBinary):\n return np.asarray(x, dtype=np.int).reshape(space.shape)\n elif isinstance(space, MultiDiscrete):\n return np.asarray(x, dtype=np.int).reshape(space.shape)\n else:\n raise TypeError\n\n\ndef flatten_space(space):\n \"\"\"Flatten a space into a single Box.\n\n This is equivalent to flatten(), but operates on the space itself. The\n result always is a Box with flat boundaries. The box has exactly\n flatdim(space) dimensions. Flattening a sample of the original space\n has the same effect as taking a sample of the flattenend space.\n\n Raises TypeError if the space is not defined in gym.spaces.\n\n Example::\n\n >>> box = Box(0.0, 1.0, shape=(3, 4, 5))\n >>> box\n Box(3, 4, 5)\n >>> flatten_space(box)\n Box(60,)\n >>> flatten(box, box.sample()) in flatten_space(box)\n True\n\n Example that flattens a discrete space::\n\n >>> discrete = Discrete(5)\n >>> flatten_space(discrete)\n Box(5,)\n >>> flatten(box, box.sample()) in flatten_space(box)\n True\n\n Example that recursively flattens a dict::\n\n >>> space = Dict({\"position\": Discrete(2),\n ... \"velocity\": Box(0, 1, shape=(2, 2))})\n >>> flatten_space(space)\n Box(6,)\n >>> flatten(space, space.sample()) in flatten_space(space)\n True\n \"\"\"\n if isinstance(space, Box):\n return Box(space.low.flatten(), space.high.flatten(), dtype=space.dtype)\n if isinstance(space, Discrete):\n return Box(low=0, high=1, shape=(space.n, ), dtype=np.int)\n if isinstance(space, Tuple):\n space = [flatten_space(s) for s in space.spaces]\n encapsulating_type = np.int \\\n if all([this_space.dtype == np.int for this_space in space]) \\\n else np.float\n return Box(\n low=np.concatenate([s.low for s in space]),\n high=np.concatenate([s.high for s in space]),\n dtype=encapsulating_type\n )\n if isinstance(space, Dict):\n space = [flatten_space(s) for s in space.spaces.values()]\n encapsulating_type = np.int \\\n if all([this_space.dtype == np.int for this_space in space]) \\\n else np.float\n return Box(\n low=np.concatenate([s.low for s in space]),\n high=np.concatenate([s.high for s in space]),\n dtype=encapsulating_type\n )\n if isinstance(space, MultiBinary):\n return Box(low=0, high=1, shape=(space.n, ), dtype=np.int)\n if isinstance(space, MultiDiscrete):\n return Box(\n low=np.zeros_like(space.nvec),\n high=space.nvec,\n dtype=np.int\n )\n raise TypeError\n\n\nclass FlattenWrapper(SARWrapper):\n \"\"\"\n Flattens all agents' action and observation spaces into continuous Boxes.\n \"\"\"\n def __init__(self, sim):\n super().__init__(sim)\n for agent_id, wrapped_agent in self.sim.agents.items(): # Wrap the agents' spaces\n self.agents[agent_id].action_space = flatten_space(wrapped_agent.action_space)\n self.agents[agent_id].observation_space = flatten_space(\n wrapped_agent.observation_space\n )\n\n def wrap_observation(self, from_agent, observation):\n return flatten(from_agent.observation_space, observation)\n\n def unwrap_observation(self, from_agent, observation):\n return unflatten(from_agent.observation_space, observation)\n\n def wrap_action(self, from_agent, action):\n return unflatten(from_agent.action_space, action)\n\n def unwrap_action(self, from_agent, action):\n return flatten(from_agent.action_space, action)\n\n\nclass FlattenActionWrapper(SARWrapper):\n \"\"\"\n Flattens all agents' action spaces into continuous Boxes.\n \"\"\"\n def __init__(self, sim):\n super().__init__(sim)\n self.agents = copy.deepcopy(self.sim.agents)\n for agent_id, wrapped_agent in self.sim.agents.items():\n # Wrap the action spaces of the agents\n self.agents[agent_id].action_space = flatten_space(wrapped_agent.action_space)\n\n def wrap_action(self, from_agent, action):\n return unflatten(from_agent.action_space, action)\n\n def unwrap_action(self, from_agent, action):\n return flatten(from_agent.action_space, action)\n"
},
{
"alpha_fraction": 0.6185778379440308,
"alphanum_fraction": 0.6216134428977966,
"avg_line_length": 30.448686599731445,
"blob_id": "5f5504f9c01d97df03e213a2b48b946523868e00",
"content_id": "5cbbda805353101f4f16f912c01c69d30cd1db74",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13177,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 419,
"path": "/abmarl/sim/components/agent.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim import PrincipleAgent, ActingAgent, ObservingAgent\n\n\n# ------------------ #\n# --- Base Agent --- #\n# ------------------ #\n\nclass ComponentAgent(PrincipleAgent):\n \"\"\"\n Component Agents have a position, life, and team.\n\n initial_position (np.array or None):\n The desired starting position for this agent.\n\n min_health (float):\n The minimum health the agent can reach before it dies.\n Default 0.0.\n\n max_health (float):\n The maximum health the agent can reach.\n Default 1.0.\n\n initial_health (float or None):\n The initial health of the agent. The health will be set to this initial\n option at reset time.\n\n team (int or None):\n The agent's team. Teams are indexed starting from 1, with team 0 reserved\n for agents that are not on a team (None).\n \"\"\"\n def __init__(self, initial_position=None, min_health=0.0, max_health=1.0, initial_health=None,\n team=None, **kwargs):\n super().__init__(**kwargs)\n self.initial_position = initial_position\n assert type(min_health) in [float, int] and type(max_health) in [float, int], \\\n \"Min and max health must be numerical.\"\n assert min_health <= max_health, \\\n \"The min health must be less than or equal to the max_health.\"\n self._min_max_health = np.array([min_health, max_health])\n self.initial_health = initial_health\n self.is_alive = True\n self.team = team\n\n @property\n def initial_position(self):\n return self._initial_position\n\n @initial_position.setter\n def initial_position(self, value):\n if value is not None:\n assert type(value) is np.ndarray, \"Initial position must be a numpy array.\"\n assert value.shape == (2,), \"Initial position must be a 2-dimensional array.\"\n assert value.dtype in [np.int, np.float], \"Initial position must be numerical.\"\n self._initial_position = value\n\n @property\n def min_health(self):\n return self._min_max_health[0]\n\n @property\n def max_health(self):\n return self._min_max_health[1]\n\n @property\n def initial_health(self):\n return self._initial_health\n\n @initial_health.setter\n def initial_health(self, value):\n if value is not None:\n assert type(value) in [float, int], \"Initial health must be a float.\"\n assert self.min_health <= value <= self.max_health, \\\n \"Initial health must be between the min and max health.\"\n self._initial_health = value\n\n @property\n def team(self):\n return self._team\n\n @team.setter\n def team(self, value):\n if value is not None:\n assert type(value) is int, \"Team must be an int.\"\n assert value != 0, \"Team 0 is reserved for agents who do not have a team. \" + \\\n \"Use a team number greater than 0.\"\n self._team = value\n else:\n self._team = 0\n\n @property\n def configured(self):\n \"\"\"\n Determine if the agent has been successfully configured.\n \"\"\"\n return super().configured and \\\n self._min_max_health is not None and \\\n self.is_alive is not None and \\\n self.team is not None\n\n\n# ----------------- #\n# --- Attacking --- #\n# ----------------- #\n\nclass AttackingAgent(ActingAgent, ComponentAgent):\n \"\"\"\n Agents that can attack other agents.\n\n attack_range (int):\n The effective range of the attack. Can be used to determine if an attack\n is successful based on distance between agents.\n\n attack_strength (float):\n How effective the agent's attack is. This is applicable in situations where\n the agents' health is affected by attacks.\n\n attack_accuracy (float):\n The effective accuracy of the agent's attack. Should be between 0 and 1.\n To make deterministic attacks, use 1. Default is 1.\n \"\"\"\n def __init__(self, attack_range=None, attack_strength=None, attack_accuracy=1, **kwargs):\n super().__init__(**kwargs)\n assert attack_range is not None, \"attack_range must be a nonnegative integer\"\n self.attack_range = attack_range\n assert attack_strength is not None, \"attack_strength must be a nonnegative number\"\n self.attack_strength = attack_strength\n self.attack_accuracy = attack_accuracy\n\n @property\n def configured(self):\n \"\"\"\n The agent is successfully configured if the attack range and strength is\n specified.\n \"\"\"\n return super().configured and self.attack_range is not None and \\\n self.attack_strength is not None\n\n\n# --------------------- #\n# --- Communication --- #\n# --------------------- #\n\nclass BroadcastingAgent(ActingAgent, ComponentAgent):\n \"\"\"\n BroadcastingAgents can broadcast their observation within some range of their\n position.\n\n braodcast_range (int):\n The agent's broadcasting range.\n \"\"\"\n def __init__(self, broadcast_range=None, **kwargs):\n super().__init__(**kwargs)\n self.broadcast_range = broadcast_range\n self.broadcasting = False\n\n @property\n def configured(self):\n \"\"\"\n The agent is successfully configured if the broadcast range is specified.\n \"\"\"\n return super().configured and self.broadcast_range is not None\n\n\nclass BroadcastObservingAgent(ObservingAgent, ComponentAgent): pass\n\n\n# ----------------------- #\n# --- Health and Life --- #\n# ----------------------- #\n\nclass LifeObservingAgent(ObservingAgent, ComponentAgent): pass\nclass HealthObservingAgent(ObservingAgent, ComponentAgent): pass\n\n\n# ----------------- #\n# --- Observing --- #\n# ----------------- #\n\n# TODO: move this to a more specific location\nclass AgentObservingAgent(ObservingAgent, ComponentAgent):\n \"\"\"\n Agents can observe other agents.\n\n agent_view (int):\n Any agent within this many spaces will be fully observed.\n \"\"\"\n def __init__(self, agent_view=None, **kwargs):\n \"\"\"\n Agents can see other agents up to some maximal distance away, indicated\n by the view.\n \"\"\"\n super().__init__(**kwargs)\n assert agent_view is not None, \"agent_view must be nonnegative integer\"\n self.agent_view = agent_view\n\n @property\n def configured(self):\n \"\"\"\n Agents are configured if the agent_view parameter is set.\n \"\"\"\n return super().configured and self.agent_view is not None\n\n\n# ----------------------------- #\n# --- Position and Movement --- #\n# ----------------------------- #\n\n\nclass PositionObservingAgent(ObservingAgent, ComponentAgent): pass\n\n\nclass GridMovementAgent(ActingAgent, ComponentAgent):\n \"\"\"\n Agents can move up to some number of spaces away.\n\n move_range (int):\n The maximum number of cells away that the agent can move.\n \"\"\"\n def __init__(self, move_range=None, **kwargs):\n super().__init__(**kwargs)\n assert move_range is not None, \"move_range must be an integer\"\n self.move_range = move_range\n\n @property\n def configured(self):\n \"\"\"\n Agents are configured if the move_range parameter is set.\n \"\"\"\n return super().configured and self.move_range is not None\n\n\nclass SpeedAngleAgent(ComponentAgent):\n \"\"\"\n Agents have a speed and a banking angle which are used to determine how the\n agent moves around a continuous field.\n\n min_speed (float):\n The minimum speed this agent can travel.\n\n max_speed (float):\n The maximum speed this agent can travel.\n\n max_banking_angle (float):\n The maximum banking angle the agent can endure.\n\n initial_speed (float):\n The agent's initial speed.\n\n initial_banking_angle (float):\n The agent's initial banking angle.\n\n initial_ground_angle (float):\n The agent's initial ground angle.\n \"\"\"\n def __init__(self, min_speed=0.25, max_speed=1.0, max_banking_angle=45, initial_speed=None,\n initial_banking_angle=None, initial_ground_angle=None, **kwargs):\n super().__init__(**kwargs)\n self.min_speed = min_speed\n self.max_speed = max_speed\n self.initial_speed = initial_speed\n self.speed = None # Should be set by the state handler\n\n self.max_banking_angle = max_banking_angle\n self.initial_banking_angle = initial_banking_angle\n self.initial_ground_angle = initial_ground_angle\n self.banking_angle = None # Should be set by the state handler\n\n @property\n def configured(self):\n return super().configured and self.min_speed is not None and self.max_speed is not None \\\n and self.max_banking_angle is not None\n\n\nclass SpeedAngleActingAgent(ActingAgent, ComponentAgent):\n \"\"\"\n Agents can change their speed and banking angles.\n\n max_acceleration (float):\n The maximum amount by which an agent can change its speed in a single time\n step.\n\n max_banking_angle_change (float):\n The maximum amount by which an agent can change its banking angle in a\n single time step.\n \"\"\"\n def __init__(self, max_acceleration=0.25, max_banking_angle_change=30, **kwargs):\n super().__init__(**kwargs)\n self.max_acceleration = max_acceleration\n self.max_banking_angle_change = max_banking_angle_change\n\n @property\n def configured(self):\n return super().configured and self.max_acceleration is not None and \\\n self.max_banking_angle_change is not None\n\n\nclass SpeedAngleObservingAgent(ObservingAgent, ComponentAgent): pass\n\n\nclass VelocityAgent(ComponentAgent):\n \"\"\"\n Agents have a velocity which determines how it moves around in a continuous\n field. Agents can accelerate to modify their velocities.\n\n initial_velocity (np.array):\n Two-element float array that is the agent's initial velocity.\n\n max_speed (float):\n The maximum speed the agent can travel.\n\n max_acceleration (float):\n The maximum amount by which an agent can change its velocity in a single\n time step.\n \"\"\"\n def __init__(self, initial_velocity=None, max_speed=None, **kwargs):\n super().__init__(**kwargs)\n self.initial_velocity = initial_velocity\n self.max_speed = max_speed\n\n @property\n def configured(self):\n return super().configured and self.max_speed is not None\n\n\nclass AcceleratingAgent(ActingAgent, ComponentAgent):\n \"\"\"\n Agents can accelerate to modify their velocities.\n\n max_acceleration (float):\n The maximum amount by which an agent can change its velocity in a single\n time step.\n \"\"\"\n def __init__(self, max_acceleration=None, **kwargs):\n super().__init__(**kwargs)\n self.max_acceleration = max_acceleration\n\n @property\n def configured(self):\n return super().configured and self.max_acceleration is not None\n\n\nclass VelocityObservingAgent(ObservingAgent, ComponentAgent): pass\n\n\nclass CollisionAgent(PrincipleAgent):\n \"\"\"\n Agents that have physical size and mass and can be used in collisions.\n\n size (float):\n The size of the agent.\n Default 1.\n\n mass (float):\n The mass of the agent.\n Default 1.\n \"\"\"\n def __init__(self, size=1, mass=1, **kwargs):\n super().__init__(**kwargs)\n self.size = size\n self.mass = mass\n\n @property\n def configured(self):\n return super().configured and self.size is not None and self.mass is not None\n\n\n# -------------------------------- #\n# --- Resources and Harvesting --- #\n# -------------------------------- #\n\nclass HarvestingAgent(ActingAgent, ComponentAgent):\n \"\"\"\n Agents can harvest resources.\n\n max_harvest (double):\n The maximum amount of resources the agent can harvest from the cell it\n occupies.\n \"\"\"\n def __init__(self, min_harvest=0, max_harvest=None, **kwargs):\n super().__init__(**kwargs)\n assert max_harvest is not None, \"max_harvest must be nonnegative number\"\n self.min_harvest = min_harvest\n self.max_harvest = max_harvest\n\n @property\n def configured(self):\n \"\"\"\n Agents are configured if max_harvest is set.\n \"\"\"\n return super().configured and self.max_harvest is not None and self.min_harvest is not None\n\n\nclass ResourceObservingAgent(ObservingAgent, ComponentAgent):\n \"\"\"\n Agents can observe the resources in the simulation.\n\n resource_view (int):\n Any resources within this range of the agent's position will be fully observed.\n \"\"\"\n def __init__(self, resource_view=None, **kwargs):\n super().__init__(**kwargs)\n assert resource_view is not None, \"resource_view must be nonnegative integer\"\n self.resource_view = resource_view\n\n @property\n def configured(self):\n \"\"\"\n Agents are configured if the resource_view parameter is set.\n \"\"\"\n return super().configured and self.resource_view is not None\n\n\n# ------------ #\n# --- Team --- #\n# ------------ #\n\nclass TeamObservingAgent(ObservingAgent, ComponentAgent): pass\n"
},
{
"alpha_fraction": 0.6163108944892883,
"alphanum_fraction": 0.626163125038147,
"avg_line_length": 30.77391242980957,
"blob_id": "02cd95cc8715fabef582612e0e7d333f055a9d87",
"content_id": "6cfa862dca105473145c2dbebedcb876daddbae7",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3654,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 115,
"path": "/abmarl/sim/components/examples/bird_flight.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport numpy as np\n\nfrom abmarl.sim.components.state import ContinuousPositionState, SpeedAngleState\nfrom abmarl.sim.components.actor import SpeedAngleMovementActor\nfrom abmarl.sim.components.observer import SpeedObserver, AngleObserver\nfrom abmarl.sim.components.done import TooCloseDone\nfrom abmarl.sim.components.agent import SpeedAngleAgent, SpeedAngleActingAgent, \\\n SpeedAngleObservingAgent\nfrom abmarl.sim import AgentBasedSimulation\nfrom abmarl.tools.matplotlib_utils import mscatter\n\n\nclass BirdAgent(SpeedAngleAgent, SpeedAngleActingAgent, SpeedAngleObservingAgent): pass\n\n\nclass Flight(AgentBasedSimulation):\n def __init__(self, **kwargs):\n self.agents = kwargs['agents']\n\n # State\n self.position_state = ContinuousPositionState(**kwargs)\n self.speed_angle_state = SpeedAngleState(**kwargs)\n\n # Actor\n self.move_actor = SpeedAngleMovementActor(\n position_state=self.position_state, speed_angle_state=self.speed_angle_state, **kwargs\n )\n\n # Observer\n self.speed_observer = SpeedObserver(**kwargs)\n self.angle_observer = AngleObserver(**kwargs)\n\n # Done\n self.done = TooCloseDone(position=self.position_state, **kwargs)\n\n self.finalize()\n\n def reset(self, **kwargs):\n self.position_state.reset(**kwargs)\n self.speed_angle_state.reset(**kwargs)\n\n def step(self, action_dict, **kwargs):\n for agent, action in action_dict.items():\n self.move_actor.process_move(\n self.agents[agent], action.get('accelerate', np.zeros(1)),\n action.get('bank', np.zeros(1)), **kwargs\n )\n\n def render(self, fig=None, **kwargs):\n fig.clear()\n\n # Draw the resources\n ax = fig.gca()\n\n # Draw the agents\n ax.set(xlim=(0, self.position_state.region), ylim=(0, self.position_state.region))\n ax.set_xticks(np.arange(0, self.position_state.region, 1))\n ax.set_yticks(np.arange(0, self.position_state.region, 1))\n\n agents_x = [agent.position[0] for agent in self.agents.values()]\n agents_y = [agent.position[1] for agent in self.agents.values()]\n mscatter(agents_x, agents_y, ax=ax, m='o', s=100, edgecolor='black', facecolor='gray')\n\n plt.plot()\n plt.pause(1e-6)\n\n def get_obs(self, agent_id, **kwargs):\n agent = self.agents[agent_id]\n return {\n **self.speed_observer.get_obs(agent, **kwargs),\n **self.angle_observer.get_obs(agent, **kwargs),\n }\n\n def get_reward(self, agent_id, **kwargs):\n pass\n\n def get_done(self, agent_id, **kwargs):\n return self.done.get_done(self.agents[agent_id], **kwargs)\n\n def get_all_done(self, **kwargs):\n return self.done.get_all_done(**kwargs)\n\n def get_info(self, agent_id, **kwargs):\n pass\n\n\nif __name__ == \"__main__\":\n agents = {\n f'bird{i}': BirdAgent(\n id=f'bird{i}', min_speed=0.5, max_speed=1.0, max_acceleration=0.1,\n max_banking_angle=90, max_banking_angle_change=90,\n initial_banking_angle=30\n ) for i in range(24)\n }\n\n sim = Flight(\n region=20,\n agents=agents,\n collision_distance=1.0,\n )\n fig = plt.figure()\n sim.reset()\n sim.render(fig=fig)\n\n print(sim.get_obs('bird0'))\n\n for i in range(50):\n sim.step({agent.id: agent.action_space.sample() for agent in agents.values()})\n sim.render(fig=fig)\n for agent in agents:\n print(agent, ': ', sim.get_done(agent))\n print('\\n')\n\n print(sim.get_all_done())\n"
},
{
"alpha_fraction": 0.26834776997566223,
"alphanum_fraction": 0.3097478449344635,
"avg_line_length": 19.9212589263916,
"blob_id": "fb4fb10e4e96ed45de179cc22107bcf3bb5991d4",
"content_id": "1001ca6ad9173af758c49f672e3ce8f0409e4bb2",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2657,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 127,
"path": "/tests/tools/test_gym_utils.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from gym.spaces import Discrete, Dict\nimport pytest\n\nfrom abmarl.tools import gym_utils as gu\n\n\ndef test_check_space():\n space = {\n 1: Discrete(1),\n 2: {\n 1: {},\n 2: Discrete(2),\n },\n 3: {\n 1: Dict({\n 1: Discrete(1),\n }),\n 2: {\n 1: Discrete(2),\n 2: Discrete(2),\n },\n 3: Dict({\n 1: Discrete(3),\n 2: Discrete(3),\n 3: Discrete(3),\n })\n }\n }\n assert gu.check_space(space)\n assert not gu.check_space(space, True)\n\n space = {\n 1: Discrete(1),\n 2: {\n 1: {},\n 2: Discrete(2),\n },\n 3: {\n 1: Dict({\n 1: Discrete(1),\n }),\n 2: {\n 1: 2, # This is not gym space or dict\n 2: Discrete(2),\n },\n 3: Dict({\n 1: Discrete(3),\n 2: Discrete(3),\n 3: Discrete(3),\n })\n }\n }\n assert not gu.check_space(space)\n\n\ndef test_make_dict():\n space = {\n 1: Discrete(1),\n 2: {\n 1: {},\n 2: Discrete(2),\n },\n 3: {\n 1: Dict({\n 1: Discrete(1),\n }),\n 2: {\n 1: Discrete(2),\n 2: Discrete(2),\n },\n 3: Dict({\n 1: Discrete(3),\n 2: Discrete(3),\n 3: Discrete(3),\n })\n }\n }\n\n space = gu.make_dict(space)\n\n assert space == Dict({\n 1: Discrete(1),\n 2: Dict({\n 1: Dict(),\n 2: Discrete(2),\n }),\n 3: Dict({\n 1: Dict({\n 1: Discrete(1),\n }),\n 2: Dict({\n 1: Discrete(2),\n 2: Discrete(2),\n }),\n 3: Dict({\n 1: Discrete(3),\n 2: Discrete(3),\n 3: Discrete(3),\n })\n })\n })\n\n\ndef test_make_dict_fail():\n space = {\n 1: Discrete(1),\n 2: {\n 1: Discrete(2),\n 2: {},\n },\n 3: {\n 1: Dict({\n 1: Discrete(1),\n }),\n 2: {\n 1: 2, # This is not a gym space or dict\n 2: Discrete(2),\n },\n 3: Dict({\n 1: Discrete(3),\n 2: Discrete(3),\n 3: Discrete(3),\n })\n }\n }\n with pytest.raises(AssertionError):\n gu.make_dict(space)\n"
},
{
"alpha_fraction": 0.600629448890686,
"alphanum_fraction": 0.604604959487915,
"avg_line_length": 32.35359191894531,
"blob_id": "c5c14b36027aa7e7d0d776ad1d75ac7a7120c3b6",
"content_id": "95a702ba1ce08c2ece1522c0df25fa0006302aed",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6037,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 181,
"path": "/abmarl/sim/components/done.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nclass ResourcesDepletedDone:\n \"\"\"\n Simulation ends when all the resources are depleted.\n\n resource_state (GridResourceState):\n The state of the resources\n \"\"\"\n def __init__(self, resource_state=None, **kwargs):\n self.resource_state = resource_state\n\n def get_done(self, *args, **kwargs):\n \"\"\"\n Return true if all the resources are depleted.\n \"\"\"\n return self.get_all_done(**kwargs)\n\n def get_all_done(self, **kwargs):\n \"\"\"\n Return True if all the resources are depleted.\n \"\"\"\n return np.all(self.resource_state.resources == 0)\n\n\nclass DeadDone:\n \"\"\"\n Dead agents are indicated as done. Additionally, the simulation is over when\n all the agents are dead.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, agents=None, **kwargs):\n self.agents = agents\n\n def get_done(self, agent, **kwargs):\n \"\"\"\n Return True if the agent is dead. Otherwise, return False.\n \"\"\"\n return not agent.is_alive\n\n def get_all_done(self, **kwargs):\n \"\"\"\n Return True if all agents are dead. Otherwise, return False.\n \"\"\"\n for agent in self.agents.values():\n if agent.is_alive:\n return False\n return True\n\n\nclass TeamDeadDone:\n \"\"\"\n Dead agents are indicated as done. Additionally, the simulation is over when\n the only agents remaining are on the same team.\n\n agents (dict):\n The dictionary of agents.\n\n number_of_teams (int):\n The fixed number of teams in this simulation.\n Default 0.\n \"\"\"\n def __init__(self, agents=None, number_of_teams=0, **kwargs):\n self.agents = agents\n assert type(number_of_teams) is int, \"number_of_teams must be a positive integer.\"\n # +1 because team 0 is default team and not counted.\n self.number_of_teams = number_of_teams + 1\n\n def get_done(self, agent, **kwargs):\n \"\"\"\n Return True if the agent is dead. Otherwise, return False.\n \"\"\"\n return not agent.is_alive\n\n def get_all_done(self, **kwargs):\n \"\"\"\n Return true if the only agent left alive are all on the same team. Otherwise,\n return false.\n \"\"\"\n team = np.zeros(self.number_of_teams)\n for agent in self.agents.values():\n if agent.is_alive:\n team[agent.team] += 1\n return sum(team != 0) <= 1\n\n\nclass AnyTeamDeadDone:\n \"\"\"\n Dead agents are indicated as done. Additionally, the simulation ends if any\n team, except for team 0 because it's not a real team, completely dies.\n agents (dict):\n The dictionary of agents. Because the done condition is determined by the\n agent's life status, all agents must be LifeAgents; and because the done\n condition is determined by the agents' teams, all agents must be TeamAgents.\n number_of_teams (int):\n The fixed number of teams in this simulation.\n Default 0.\n \"\"\"\n def __init__(self, agents=None, number_of_teams=0, **kwargs):\n self.agents = agents\n assert type(number_of_teams) is int, \"number_of_teams must be a positive integer.\"\n self.number_of_teams = number_of_teams\n\n def get_done(self, agent, **kwargs):\n \"\"\"\n Return True if the agent is dead. Otherwise, return False.\n \"\"\"\n return not agent.is_alive\n\n def get_all_done(self, **kwargs):\n \"\"\"\n Return true if any team is wiped out, except for team 0 because it's not\n a real team. Otherwise, return false.\n \"\"\"\n team = np.zeros(self.number_of_teams)\n for agent in self.agents.values():\n if agent.is_alive:\n team[agent.team-1] += 1\n return any(team == 0)\n\n\nclass TooCloseDone:\n \"\"\"\n Agents that are too close to each other or too close to the edge of the region\n are indicated as done. If any agent is done, the entire simulation is done.\n\n position (PositionState):\n The position state handler.\n\n agents (dict):\n Dictionay of agent objects.\n\n collision_distance (float):\n The threshold for calculating if a collision has occured.\n\n collision_norm (int):\n The norm to use when calculating the collision. For example, you would\n probably want to use 1 in the Grid space but 2 in a Continuous space.\n Default is 2.\n \"\"\"\n def __init__(self, position=None, agents=None, collision_distance=None, collision_norm=2,\n **kwargs):\n assert position is not None\n self.position = position\n self.agents = agents\n assert collision_distance is not None\n self.collision_distance = collision_distance\n self.collision_norm = collision_norm\n\n def get_done(self, agent, **kwargs):\n \"\"\"\n Return true if the agent is too close to another agent or too close to\n the edge of the region.\n \"\"\"\n # Collision with region edge\n if np.any(agent.position[0] < self.collision_distance) \\\n or np.any(agent.position[0] > self.position.region - self.collision_distance) \\\n or np.any(agent.position[1] < self.collision_distance) \\\n or np.any(agent.position[1] > self.position.region - self.collision_distance):\n return True\n\n # Collision with other birds\n for other in self.agents.values():\n if other.id == agent.id: continue # Cannot collide with yourself\n if np.linalg.norm(other.position - agent.position, self.collision_norm) < \\\n self.collision_distance:\n return True\n return False\n\n def get_all_done(self, **kwargs):\n \"\"\"\n Return true if any agent is too close to another agent or too close to\n the edge of the region.\n \"\"\"\n for agent in self.agents.values():\n if self.get_done(agent):\n return True\n return False\n"
},
{
"alpha_fraction": 0.6829268336296082,
"alphanum_fraction": 0.7560975551605225,
"avg_line_length": 13,
"blob_id": "404b79d1b05dd6a3aa7a7f35efc2845b5b9ff165",
"content_id": "f70c66ee66b2ecb22e2cfdec3e8c7f60ccc31289",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 41,
"license_type": "permissive",
"max_line_length": 17,
"num_lines": 3,
"path": "/docs/requirements.txt",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "sphinx\nsphinx-rtd-theme\nray[rllib]==1.2.0"
},
{
"alpha_fraction": 0.5010636448860168,
"alphanum_fraction": 0.5416415929794312,
"avg_line_length": 37.15467071533203,
"blob_id": "2d7293870b7713e730a48c973a2a2f4786860a7a",
"content_id": "2e6cbf3ee9e5e6dfa9c02c2c8cbd4c9dc6832bd3",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24915,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 653,
"path": "/tests/test_predator_prey_communication.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.predator_prey import PredatorPreySimulation, Predator, Prey\nfrom abmarl.sim.wrappers import CommunicationHandshakeWrapper\n\n\ndef test_communication():\n np.random.seed(24)\n agents = [\n Predator(id='predator0', view=1, attack=1),\n Predator(id='predator1', view=8, attack=0),\n Prey(id='prey1', view=4),\n Prey(id='prey2', view=5)\n ]\n sim = PredatorPreySimulation.build(\n {'agents': agents, 'observation_mode': PredatorPreySimulation.ObservationMode.DISTANCE}\n )\n sim = CommunicationHandshakeWrapper(sim)\n\n\n sim.reset()\n sim.sim.agents['prey1'].position = np.array([1, 1])\n sim.sim.agents['prey2'].position = np.array([1, 4])\n sim.sim.agents['predator0'].position = np.array([2, 3])\n sim.sim.agents['predator1'].position = np.array([0, 7])\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([-1, 1, 1])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': False, 'prey1': False, 'prey2': False}\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([2, -4, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([1, -6, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([1, -3, 1])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': False, 'prey1': False, 'prey2': False}\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([1, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 3, 1])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n\n np.testing.assert_array_equal(\n sim.get_obs('prey2')['obs']['predator0'], np.array([1, -1, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey2')['obs']['predator1'], np.array([-1, 3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey2')['obs']['prey1'], np.array([0, -3, 1])\n )\n assert sim.get_obs('prey2')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey1': False}\n\n\n action1 = {\n 'predator0': {\n 'action': {'move': np.zeros(2), 'attack': 1},\n 'send': {'predator1': False, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': False, 'prey1': False, 'prey2': True},\n },\n 'predator1': {\n 'action': {'move': np.zeros(2), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator0': True, 'prey1': True, 'prey2': True},\n },\n 'prey1': {\n 'action': np.array([-1, 0]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': False},\n 'receive': {'predator0': False, 'predator1': False, 'prey2': False},\n },\n 'prey2': {\n 'action': np.array([0, 1]),\n 'send': {'predator0': False, 'predator1': False, 'prey1': True},\n 'receive': {'predator0': True, 'predator1': True, 'prey1': True},\n }\n }\n sim.step(action1)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == 100\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([2, -4, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([0, -6, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': False, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == 0\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([2, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': True}\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey2')['obs']['predator0'], np.array([1, -1, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey2')['obs']['predator1'], np.array([-1, 3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey2')['obs']['prey1'], np.array([-1, -3, 1])\n )\n assert sim.get_obs('prey2')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey1': False}\n assert sim.get_reward('prey2') == -100\n assert sim.get_done('prey2')\n\n assert not sim.get_all_done()\n\n\n action2 = {\n 'predator0': {\n 'action': {'move': np.array([-1, 0]), 'attack': 0},\n 'send': {'predator1': False, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': False, 'prey1': False, 'prey2': False}\n },\n 'predator1': {\n 'action': {'move': np.array([1, -1]), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator0': True, 'prey1': True, 'prey2': False}\n },\n 'prey1': {\n 'action': np.array([1, -1]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': True},\n 'receive': {'predator0': False, 'predator1': False, 'prey2': True}\n },\n }\n sim.step(action2)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([0, -3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([0, -6, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': False, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == -1\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([0, 3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n\n action3 = {\n 'predator0': {\n 'action': {'move': np.array([0, -1]), 'attack': 0},\n 'send': {'predator1': False, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': False, 'prey1': False, 'prey2': False},\n },\n 'predator1': {\n 'action': {'move': np.array([1, -1]), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receieve': {'predator0': True, 'prey1': True, 'prey2': False}\n },\n 'prey1': {\n 'action': np.array([1, 0]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': True},\n 'receive': {'predator0': False, 'predator1': False, 'prey2': True}\n }\n }\n sim.step(action3)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([-1, -3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([0, -5, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': False, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == -1\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([-1, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n\n action4 = {\n 'predator0': {\n 'action': {'move': np.array([0, 0]), 'attack': 1},\n 'send': {'predator1': False, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': False, 'prey1': True, 'prey2': False},\n },\n 'predator1': {\n 'action': {'move': np.array([1, -1]), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator0': True, 'prey1': True, 'prey2': False}\n },\n 'prey1': {\n 'action': np.array([1, 0]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': False},\n 'receive': {'predator0': True, 'predator1': True, 'prey2': True}\n },\n }\n sim.step(action4)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == -10\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([-2, -2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([0, -4, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': False, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == -1\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([-2, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([0, 4, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n\n action5 = {\n 'predator0': {\n 'action': {'move': np.zeros(2), 'attack': 0},\n 'send': {'predator1': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': True, 'prey1': False, 'prey2': False},\n },\n 'predator1': {\n 'action': {'move': np.array([1, 0]), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator0': True, 'prey1': True, 'prey2': False},\n },\n 'prey1': {\n 'action': np.array([0, -1]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': False},\n 'receive': {'predator0': False, 'predator1': False, 'prey2': False},\n },\n }\n sim.step(action5)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([3, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([2, -2, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == 0\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([-3, -2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([-1, -4, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == -1\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([-2, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([1, 4, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n assert sim.get_reward('prey1') == -10\n assert not sim.get_done('prey1')\n\n action6 = {\n 'predator0': {\n 'action': {'move': np.array([1, 0]), 'attack': 0},\n 'send': {'predator1': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': True, 'prey1': False, 'prey2': False}\n },\n 'predator1': {\n 'action': {'move': np.array([1, 0]), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator0': True, 'prey1': True, 'prey2': False}\n },\n 'prey1': {\n 'action': np.array([1, 1]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': False},\n 'receive': {'predator0': False, 'predator1': False, 'prey2': False},\n }\n }\n sim.step(action6)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([3, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([2, -1, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([-3, -2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([-1, -3, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == -1\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([-2, 1, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([1, 3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n\n action7 = {\n 'predator0': {\n 'action': {'move': np.array([1, 0]), 'attack': 0},\n 'send': {'predator1': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': True, 'prey1': False, 'prey2': False}\n },\n 'predator1': {\n 'action': {'move': np.array([1, 1]), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator0': True, 'prey1': True, 'prey2': False}\n },\n 'prey1': {\n 'action': np.array([1, 1]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': False},\n 'receive': {'predator0': False, 'predator1': False, 'prey2': False},\n }\n }\n sim.step(action7)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([3, 3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([2, 0, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([-3, -3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([-1, -3, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == -1\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([-2, 0, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([1, 3, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n\n action8 = {\n 'predator0': {\n 'action': {'move': np.array([1, 0]), 'attack': 0},\n 'send': {'predator1': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': True, 'prey1': False, 'prey2': False}\n },\n 'predator1': {\n 'action': {'move': np.array([-1, -1]), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator0': True, 'prey1': True, 'prey2': False}\n },\n 'prey1': {\n 'action': np.array([0, 1]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': False},\n 'receive': {'predator0': False, 'predator1': False, 'prey2': False},\n }\n }\n sim.step(action8)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([1, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([1, 1, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([-1, -2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([0, -1, 1])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == -1\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([-1, -1, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([0, 1, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n\n action9 = {\n 'predator0': {\n 'action': {'move': np.array([0, 0]), 'attack': 1},\n 'send': {'predator1': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator1': True, 'prey1': False, 'prey2': False}\n },\n 'predator1': {\n 'action': {'move': np.array([0, 0]), 'attack': 0},\n 'send': {'predator0': True, 'prey1': False, 'prey2': False},\n 'receive': {'predator0': True, 'prey1': True, 'prey2': False}\n },\n 'prey1': {\n 'action': np.array([-1, 1]),\n 'send': {'predator0': False, 'predator1': False, 'prey2': False},\n 'receive': {'predator0': False, 'predator1': False, 'prey2': False},\n }\n }\n sim.step(action9)\n\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['predator1'], np.array([1, 2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator0')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator0')['message_buffer'] == \\\n {'predator1': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator0') == 100\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['predator0'], np.array([-1, -2, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey1'], np.array([0, 0, 0])\n )\n np.testing.assert_array_equal(\n sim.get_obs('predator1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('predator1')['message_buffer'] == \\\n {'predator0': True, 'prey1': False, 'prey2': False}\n assert sim.get_reward('predator1') == 0\n assert not sim.get_done('predator1')\n\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator0'], np.array([-1, -1, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['predator1'], np.array([0, 1, 2])\n )\n np.testing.assert_array_equal(\n sim.get_obs('prey1')['obs']['prey2'], np.array([0, 0, 0])\n )\n assert sim.get_obs('prey1')['message_buffer'] == \\\n {'predator0': False, 'predator1': False, 'prey2': False}\n assert sim.get_reward('prey1') == -100\n assert sim.get_done('prey1')\n\n assert sim.get_all_done()\n"
},
{
"alpha_fraction": 0.6243420839309692,
"alphanum_fraction": 0.6243420839309692,
"avg_line_length": 28.230770111083984,
"blob_id": "5d87b04b463e7f2f91ccd38eaea562dd7a217091",
"content_id": "89f544f6ed36c7740a51c226608cc5c439164c2a",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1520,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 52,
"path": "/abmarl/sim/wrappers/wrapper.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abmarl.sim import AgentBasedSimulation\n\n\nclass Wrapper(AgentBasedSimulation):\n \"\"\"\n Abstract Wrapper class implements the AgentBasedSimulation interface. The simulation\n is stored and the simulation agents are deep-copied. The interface functions\n calls are forwarded to the simulation.\n \"\"\"\n def __init__(self, sim):\n \"\"\"\n Wrap the simulation and copy the agents.\n \"\"\"\n assert isinstance(sim, AgentBasedSimulation)\n self.sim = sim\n\n import copy\n self.agents = copy.deepcopy(sim.agents)\n\n def reset(self, **kwargs):\n self.sim.reset(**kwargs)\n\n def step(self, action, **kwargs):\n self.sim.step(action, **kwargs)\n\n def render(self, **kwargs):\n self.sim.render(**kwargs)\n\n def get_obs(self, agent_id, **kwargs):\n return self.sim.get_obs(agent_id, **kwargs)\n\n def get_reward(self, agent_id, **kwargs):\n return self.sim.get_reward(agent_id, **kwargs)\n\n def get_done(self, agent_id, **kwargs):\n return self.sim.get_done(agent_id, **kwargs)\n\n def get_all_done(self, **kwargs):\n return self.sim.get_all_done(**kwargs)\n\n def get_info(self, agent_id, **kwargs):\n return self.sim.get_info(agent_id, **kwargs)\n\n @property\n def unwrapped(self):\n \"\"\"\n Fall through all the wrappers and obtain the original, completely unwrapped simulation.\n \"\"\"\n try:\n return self.sim.unwrapped\n except AttributeError:\n return self.sim\n"
},
{
"alpha_fraction": 0.6636971235275269,
"alphanum_fraction": 0.6703786253929138,
"avg_line_length": 37.36392593383789,
"blob_id": "615f2984988dfdfde795588a521c90299042913f",
"content_id": "ac9184eda8a05dacd158f301264af1e49757528f",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 12123,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 316,
"path": "/docs/src/tutorials/predator_prey.rst",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": ".. Abmarl documentation PredatorPrey tutorial.\n\n.. _tutorial_predator_prey:\n\nPredatorPrey\n============\n\nPredatorPrey is a multiagent simulation useful for exploring competitve behaviors\nbetween groups of agents. Resources \"grow\" in a two-dimensional grid. Prey agents\nmove around the grid harvesting resources, and predator agents move around the\ngrid hunting the prey agents.\n \n.. figure:: /.images/predatorprey.*\n :width: 80 %\n :alt: Animation of predator and prey agents in a two-dimensional grid.\n\n Animation of predator and prey agents in a two-dimensional grid.\n\nThis tutorial uses the `PredatorPrey simulation <https://github.com/LLNL/Abmarl/blob/main/abmarl/sim/predator_prey/predator_prey.py>`_,\nand the `PredatorPrey configuration <https://github.com/LLNL/Abmarl/blob/main/examples/predator_prey/predator_prey_training.py>`_.\n\n.. ATTENTION::\n This tutorial requires seaborn for visualizing the resources. This can be easily\n added to your virtual environment with ``pip install seaborn``.\n\nCreating the PredatorPrey Simulation\n------------------------------------\n\nThe Agents in the Simulation\n````````````````````````````\nIn this tutorial, we will train predators to hunt prey by moving around the grid\nand attacking them when they are nearby. In order to learn this, they must be able\nto see a subset of the grid around their position, and they must be able to distinguish\nbetween other predators and prey. We will reward the predators as follows:\n\n* The predator should be rewarded for successfully killing a prey.\n* The predator should be penalized for trying to move off the edge of the grid.\n* The predator should be penalized for taking too long.\n\nConcurrently, we will train prey agents to harvest resources while attempting to\navoid predators. To learn this, prey must be able to see a subset off the\ngrid around them, both the resources available and any other agents. We will reward\nthe prey as follows:\n\n* The prey should be rewarded for harvesting resources.\n* The prey should be penalized for trying to move off the edge of the grid.\n* The prey should be penalized for getting eaten by a predator.\n* The prey should be penalized for taking too long.\n\nIn order to accomodate this, we will create two types of Agents, one for Predators\nand one for Prey. Notice that all agents can move around and view a subset of the\ngrid, so we'll capture this in a parent class and encode the distinction in the\nagents' respective child classes.\n\n.. code-block:: python\n\n from abc import ABC, abstractmethod\n \n from gym.spaces import Box, Discrete, Dict\n import numpy as np\n \n from abmarl.sim import PrincipleAgent, AgentBasedSimulation\n\n class PredatorPreyAgent(PrincipleAgent, ABC):\n @abstractmethod\n def __init__(self, move=None, view=None, **kwargs):\n super().__init__(**kwargs)\n self.move = move\n self.view = view\n \n @property\n def configured(self):\n return super().configured and self.move is not None and self.view is not None\n\n class Prey(PredatorPreyAgent):\n def __init__(self, harvest_amount=None, **kwargs):\n super().__init__(**kwargs)\n self.harvest_amount = harvest_amount\n \n @property\n def configured(self):\n return super().configured and self.harvest_amount is not None\n \n @property\n def value(self):\n return 1\n\n class Predator(PredatorPreyAgent):\n def __init__(self, attack=None, **kwargs):\n super().__init__(**kwargs)\n self.attack = attack\n \n @property\n def configured(self)\n return super().configured and self.attack is not None\n \n @property\n def value(self):\n return 2\n\nThe PredatorPrey Simulation\n```````````````````````````\nThe PredatorPrey Simulation needs much detailed explanation, which we believe will\ndistract from this tutorial. Suffice it to say that we have created a simulation\nthat works with the above agents and captures our desired features. This simulation\ncan be found in full `in our repo <https://github.com/LLNL/Abmarl/blob/main/abmarl/sim/predator_prey/predator_prey.py>`_.\n\nTraining the Predator Prey Simulation\n-------------------------------------\n\nWith the PredatorPrey simulation and agents at hand, we can create a configuration\nfile for training.\n\nSimulation Setup\n````````````````\nSetting up the PredatorPrey simulation requires us to explicity make agents and\npass those to the simulation builder. Once we've done that, we can choose which\n`SimulationManager` to use. In this tutorial, we'll use the `AllStepManager`. Then,\nwe'll wrap the simulation with our `MultiAgentWrapper`, which enables us to connect\nwith RLlib. Finally, we'll register the simulation with RLlib.\n\n\nPolicy Setup\n````````````\n\nNext, we will create the policies and the policy mapping function. Because predators\nand prey are competitve, they must train separate polices from one another. Furthermore,\nsince each prey is homogeneous with other prey and each predator with other predators,\nwe can have them train the same policy. Thus, we will have two policies: one for\npredators and one for prey.\n\nExperiment Parameters\n`````````````````````\nThe last thing is to wrap all the parameters together into a\nsingle `params` dictionary. Below is the full configuration file:\n\n.. code-block:: python\n\n # Setup the simulation\n from abmarl.sim.predator_prey import PredatorPreySimulation, Predator, Prey\n from abmarl.managers import AllStepManager\n \n region = 6\n predators = [Predator(id=f'predator{i}', attack=1) for i in range(2)]\n prey = [Prey(id=f'prey{i}') for i in range(7)]\n agents = predators + prey\n \n sim_config = {\n 'region': region,\n 'max_steps': 200,\n 'agents': agents,\n }\n sim_name = 'PredatorPrey'\n \n from abmarl.external.rllib_multiagentenv_wrapper import MultiAgentWrapper\n from ray.tune.registry import register_env\n sim = MultiAgentWrapper(AllStepManager(PredatorPreySimulation.build(sim_config)))\n agents = sim.unwrapped.agents\n register_env(sim_name, lambda sim_config: sim)\n \n # Set up policies\n policies = {\n 'predator': (None, agents['predator0'].observation_space, agents['predator0'].action_space, {}),\n 'prey': (None, agents['prey0'].observation_space, agents['prey0'].action_space, {})\n }\n def policy_mapping_fn(agent_id):\n if agent_id.startswith('prey'):\n return 'prey'\n else:\n return 'predator'\n \n # Experiment parameters\n params = {\n 'experiment': {\n 'title': '{}'.format('PredatorPrey'),\n 'sim_creator': lambda config=None: sim,\n },\n 'ray_tune': {\n 'run_or_experiment': \"PG\",\n 'checkpoint_freq': 50,\n 'checkpoint_at_end': True,\n 'stop': {\n 'episodes_total': 20_000,\n },\n 'verbose': 2,\n 'config': {\n # --- Simulation ---\n 'env': sim_name,\n 'env_config': sim_config,\n 'horizon': 200,\n # --- Multiagent ---\n 'multiagent': {\n 'policies': policies,\n 'policy_mapping_fn': policy_mapping_fn,\n },\n # \"lr\": 0.0001,\n # --- Parallelism ---\n # Number of workers per experiment: int\n \"num_workers\": 7,\n # Number of simulations that each worker starts: int\n \"num_envs_per_worker\": 1, # This must be 1 because we are not \"threadsafe\"\n # 'simple_optimizer': True,\n # \"postprocess_inputs\": True\n },\n }\n }\n\nUsing the Command Line\n``````````````````````\n\nTraining\n''''''''\nWith the configuration script complete, we can utilize the command line interface\nto train our predator. We simply type ``abmarl train predator_prey_training.py``,\nwhere `predator_prey_training.py` is our configuration file. This will launch Abmarl,\nwhich will process the script and launch RLlib according to the\nspecified parameters. This particular example should take about 10 minutes to\ntrain, depending on your compute capabilities. You can view the performance in\nreal time in tensorboard with ``tensorboard --logdir ~/abmarl_results``.\nWe can find the rewards associated with the policies on the second page of tensorboard.\n\n\nVisualizing\n'''''''''''\nHaving successfully trained predators to attack prey, we can vizualize the agents'\nlearned behavior with the `visualize` command,\nwhich takes as argument the output directory from the training session stored\nin `~/abmarl_results`. For example, the command\n\n.. code-block:: python\n\n abmarl visualize ~/abmarl_results/PredatorPrey-2020-08-25_09-30/ -n 5 --record\n\n\nwill load the training session (notice that the\ndirectory name is the experiment title from the configuration script appended with a\ntimestamp) and display an animation of 5 episodes. The `--record` flag will\nsave the animations as `.mp4` videos in the training directory.\n\nAnalyzing\n'''''''''\nWe can further investigate the learned behaviors using the `analyze` command along\nwith an analysis script. Analysis scripts implement a `run` command which takes\nthe Simulation and the Trainer as input arguments. We can define any\nscript to further investigate the agents' behavior. In this\nexample, we will craft a script that records how\noften a predator attacks from each grid square.\n\n.. code-block:: python\n\n def run(sim, trainer):\n import numpy as np\n import seaborn as sns\n import matplotlib.pyplot as plt\n \n # Create a grid\n grid = np.zeros((sim.sim.region, sim.sim.region))\n attack = np.zeros((sim.sim.region, sim.sim.region))\n \n # Run the trained policy\n policy_agent_mapping = trainer.config['multiagent']['policy_mapping_fn']\n for episode in range(100): # Run 100 trajectories\n print('Episode: {}'.format(episode))\n obs = sim.reset()\n done = {agent: False for agent in obs}\n pox, poy = sim.agents['predator0'].position\n grid[pox, poy] += 1\n while True:\n joint_action = {}\n for agent_id, agent_obs in obs.items():\n if done[agent_id]: continue # Don't get actions for dead agents\n policy_id = policy_agent_mapping(agent_id)\n action = trainer.compute_action(agent_obs, policy_id=policy_id)\n joint_action[agent_id] = action\n obs, _, done, _ = sim.step(joint_action)\n pox, poy = sim.agents['predator0'].position\n grid[pox, poy] += 1\n if joint_action['predator0']['attack'] == 1: # This is the attack action\n attack[pox, poy] += 1\n if done['__all__']:\n break\n \n plt.figure(2)\n plt.title(\"Attack action frequency\")\n ax = sns.heatmap(np.flipud(np.transpose(attack)), linewidth=0.5)\n\n plt.show()\n\nWe can run this analysis with\n\n.. code-block:: python\n\n abmarl analyze ~/abmarl_results/PredatorPrey-2020-08-25_09-30/ movement_map.py\n\nwhich renders the following image for us\n\n.. image:: /.images/attack_freq.png\n :width: 80 %\n :alt: Animation of agents moving back and forth in a corridor until they reach the end.\n\nThe heatmap figures indicate that the predators spend most of their time attacking\nprey from the center of the map and rarely ventures to the corners.\n\n.. NOTE::\n Creating the analysis script required some in-depth knowledge about\n the inner workings of the PredatorPrey Simulation. This will likely be needed\n when analyzing most simulation you work with.\n\n\nExtra Challenges\n----------------\nHaving successfully trained the predators to attack prey experiment, we can further\nexplore the agents' behaviors and the training process. For example, you may have\nnoticed that the prey agents didn't seem to learn anything. We may need to improve\nour reward schema for the prey or modify the way agents interact in the simulation.\nThis is left open to exploration.\n"
},
{
"alpha_fraction": 0.6596194505691528,
"alphanum_fraction": 0.6596194505691528,
"avg_line_length": 26.823530197143555,
"blob_id": "f0d70eeb41712396b556dfa54112b5c8f851ef7d",
"content_id": "daf4f40a56847530790ae05492d5a1fadd112fc4",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 473,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 17,
"path": "/abmarl/scripts/train_script.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "def create_parser(subparsers):\n \"\"\"Parse the arguments for the train command.\n\n Returns\n -------\n parser : ArgumentParser\n \"\"\"\n train_parser = subparsers.add_parser('train', help='Train MARL policies ')\n train_parser.add_argument(\n 'configuration', type=str, help='Path to python config file. Include the .py extension.'\n )\n return train_parser\n\n\ndef run(full_config_path):\n from abmarl import train\n train.run(full_config_path)\n"
},
{
"alpha_fraction": 0.6597001552581787,
"alphanum_fraction": 0.6619718074798584,
"avg_line_length": 32.34848403930664,
"blob_id": "adad07c62ed98b5d206e2a98a6543c112e07dd67",
"content_id": "7df705981bd4f013ce2613d37e88dd70fbf3d653",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2201,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 66,
"path": "/abmarl/tools/utils.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import fnmatch\nimport os\n\n\ndef custom_import_module(full_config_path):\n \"\"\"\n Import and execute a python file as a module. Useful for import the experiment module and the\n analysis module.\n\n Args:\n full_config_path: Full path to the python file.\n\n Returns: The python file as a module\n \"\"\"\n import importlib.util\n spec = importlib.util.spec_from_file_location(\"mod\", full_config_path)\n mod = importlib.util.module_from_spec(spec)\n spec.loader.exec_module(mod)\n return mod\n\n\ndef checkpoint_from_trained_directory(full_trained_directory, checkpoint_desired):\n \"\"\"\n Return the checkpoint directory to load the policy. If checkpoint_desired is specified and\n found, then return that policy. Otherwise, return the last policy.\n \"\"\"\n checkpoint_dirs = find_dirs_in_dir('checkpoint*', full_trained_directory)\n\n # Try to load the desired checkpoint\n if checkpoint_desired is not None: # checkpoint specified\n for checkpoint in checkpoint_dirs:\n if checkpoint_desired == int(checkpoint.split('/')[-1].split('_')[-1]):\n return checkpoint, checkpoint_desired\n import warnings\n warnings.warn(\n f'Could not find checkpoint_{checkpoint_desired}. Attempting to load the last '\n 'checkpoint.'\n )\n\n # Load the last checkpoint\n max_checkpoint = None\n max_checkpoint_value = 0\n for checkpoint in checkpoint_dirs:\n checkpoint_value = int(checkpoint.split('/')[-1].split('_')[-1])\n if checkpoint_value > max_checkpoint_value:\n max_checkpoint_value = checkpoint_value\n max_checkpoint = checkpoint\n\n if max_checkpoint is None:\n raise FileNotFoundError(\"Did not find a checkpoint file in the given directory.\")\n\n return max_checkpoint, max_checkpoint_value\n\n\ndef find_dirs_in_dir(pattern, path):\n \"\"\"\n Traverse the path looking for directories that match the pattern.\n\n Return: list of paths that match\n \"\"\"\n result = []\n for root, dirs, files in os.walk(path):\n for name in dirs:\n if fnmatch.fnmatch(name, pattern):\n result.append(os.path.join(root, name))\n return result\n"
},
{
"alpha_fraction": 0.8585858345031738,
"alphanum_fraction": 0.8585858345031738,
"avg_line_length": 48.5,
"blob_id": "9315fcd70484e13d83e26b0a84327e00fe262eb5",
"content_id": "91b2fc73338a83a5556d3aa4a26c0aaf803dae69",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": true,
"language": "Python",
"length_bytes": 99,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 2,
"path": "/abmarl/external/__init__.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .gym_env_wrapper import GymWrapper\nfrom .rllib_multiagentenv_wrapper import MultiAgentWrapper\n"
},
{
"alpha_fraction": 0.659326434135437,
"alphanum_fraction": 0.6709844470024109,
"avg_line_length": 16.953489303588867,
"blob_id": "739693a955265c0c6021bcd80550a010f632437b",
"content_id": "1eccae4ae955b8a00a2c353c008e068811281ca4",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 772,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 43,
"path": "/docs/src/install.rst",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": ".. Abmarl documentation installation instructions.\n\n.. _installation:\n\nInstallation\n============\n\nUser Installation\n-----------------\nYou can install abmarl via `pip`:\n\n.. code-block::\n\n pip install abmarl\n\n\nDeveloper Installation\n----------------------\nTo install Abmarl for development, first clone the repository and then install\nvia pip's development mode.\n\n.. code-block::\n\n git clone [email protected]:LLNL/Abmarl.git\n cd abmarl\n pip install -r requirements.txt\n pip install -e . --no-deps\n\n\n.. WARNING::\n If you are using `conda` to manage your virtual environment, then you must also\n install ffmpeg.\n\n\nDependency Note\n---------------\nAbmarl has the following dependencies\n\n* Python 3.7 or Python3.8\n* Tensorflow 2.4+\n* Ray 1.2.0\n* matplotlib\n* seaborn\n"
},
{
"alpha_fraction": 0.6430601477622986,
"alphanum_fraction": 0.6497669816017151,
"avg_line_length": 39.34862518310547,
"blob_id": "69a7a5dccd787ed493dfa35833f310857500a072",
"content_id": "48cf4e154ac2b8c32eb696776f2358b4ee1e2a0d",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8797,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 218,
"path": "/abmarl/sim/components/examples/hunting_and_foraging.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "\nfrom matplotlib import pyplot as plt\nimport numpy as np\n\n# Import all the features that we need from the simulation components\nfrom abmarl.sim.components.state import GridPositionState, LifeState\nfrom abmarl.sim.components.observer import PositionObserver, LifeObserver, TeamObserver\nfrom abmarl.sim.components.wrappers.observer_wrapper import PositionRestrictedObservationWrapper\nfrom abmarl.sim.components.actor import GridMovementActor, AttackActor\nfrom abmarl.sim.components.done import AnyTeamDeadDone\n\n# Environment needs a corresponding agent component\nfrom abmarl.sim.components.agent import ComponentAgent, AttackingAgent, GridMovementAgent, \\\n AgentObservingAgent, PositionObservingAgent, TeamObservingAgent, LifeObservingAgent\n\n# Import the interface\nfrom abmarl.sim import AgentBasedSimulation\n\n# Import extra tools\nfrom abmarl.tools.matplotlib_utils import mscatter\n\n\n# All HuntingForagingAgents\n# have a position, team, and life/death state\n# can observe positions, teams, and life state of other agents\n# can move around the grid and attack other agents\nclass HuntingForagingAgent(\n AttackingAgent, GridMovementAgent, AgentObservingAgent, PositionObservingAgent,\n TeamObservingAgent, LifeObservingAgent\n): pass\n\n\n# All FoodAgents\n# have a tema, position, and life\n# They are not really \"agents\" in the RL sense, they're just entities in the\n# simulation for the foragers to gather.\nclass FoodAgent(ComponentAgent): pass\n\n\n# Create the simulation environment from the components\nclass HuntingForagingEnv(AgentBasedSimulation):\n def __init__(self, **kwargs):\n # Explicitly pull out the the dictionary of agents. This makes the env\n # easier to work with.\n self.agents = kwargs['agents']\n\n # State components\n # These components track the state of the agents. This environment supports\n # agents with positions, life, and team.\n self.position_state = GridPositionState(**kwargs)\n self.life_state = LifeState(**kwargs)\n\n # Observer components\n # These components handle the observations that the agents receive whenever\n # get_obs is called. In this environment supports agents that can observe\n # the position, health, and team of other agents and itself.\n position_observer = PositionObserver(position_state=self.position_state, **kwargs)\n team_observer = TeamObserver(**kwargs)\n life_observer = LifeObserver(**kwargs)\n self.partial_observer = PositionRestrictedObservationWrapper(\n [position_observer, team_observer, life_observer], **kwargs\n )\n\n # Actor components\n # These components handle the actions in the step function. This environment\n # supports agents that can move around and attack agents from other teams.\n self.move_actor = GridMovementActor(position_state=self.position_state, **kwargs)\n self.attack_actor = AttackActor(**kwargs)\n\n # Done components\n # This component tracks when the simulation is done. This environment is\n # done when either:\n # (1) All the hunter have killed all the foragers.\n # (2) All the foragers have killed all the resources.\n self.done = AnyTeamDeadDone(**kwargs)\n\n # This is needed at the end of init in every environment. It ensures that\n # agents have been configured correctly.\n self.finalize()\n\n def reset(self, **kwargs):\n # The state handlers need to reset. Since the agents' teams do not change\n # throughout the episode, the team state does not need to reset.\n self.position_state.reset(**kwargs)\n self.life_state.reset(**kwargs)\n\n # We haven't designed the rewards handling yet, so we'll do it manually for now.\n # An important principle to follow in MARL: track the rewards of all the agents\n # and report them when get_reward is called. Once the reward is reported,\n # reset it to zero.\n self.rewards = {agent: 0 for agent in self.agents}\n\n def step(self, action_dict, **kwargs):\n # Process attacking\n for agent_id, action in action_dict.items():\n attacking_agent = self.agents[agent_id]\n # The actor processes the agents' attack action.\n attacked_agent = self.attack_actor.process_action(attacking_agent, action, **kwargs)\n # The attacked agent loses health depending on the strength of the attack.\n # If the agent loses all its health, it dies.\n if attacked_agent is not None:\n self.life_state.modify_health(attacked_agent, -attacking_agent.attack_strength)\n # Reward the attacking agent for its successful attack\n self.rewards[attacking_agent.id] += 1\n\n # Process movement\n for agent_id, action in action_dict.items():\n # The actor processes the agents' movement action. The agents can move\n # within their max move radius, and they can occupy the same cells.\n # If an agent attempts to move out of bounds, the move is invalid,\n # and it will not move at all.\n proposed_amount_move = action.get('move', np.zeros(2))\n amount_moved = self.move_actor.process_action(self.agents[agent_id], action, **kwargs)\n if np.any(proposed_amount_move != amount_moved):\n # This was a rejected move, so we penalize a bit for it\n self.rewards[agent_id] -= 0.1\n\n # Small penalty for every agent that acted in this time step to incentive rapid actions\n for agent_id in action_dict:\n self.rewards[agent_id] -= 0.01\n\n def render(self, fig=None, shape_dict=None, **kwargs):\n fig.clear()\n render_condition = {agent.id: agent.is_alive for agent in self.agents.values()}\n\n ax = fig.gca()\n ax.set(xlim=(0, self.position_state.region), ylim=(0, self.position_state.region))\n ax.set_xticks(np.arange(0, self.position_state.region, 1))\n ax.set_yticks(np.arange(0, self.position_state.region, 1))\n ax.grid()\n\n agents_x = [\n agent.position[1] + 0.5 for agent in self.agents.values() if render_condition[agent.id]\n ]\n agents_y = [\n self.position_state.region - 0.5 - agent.position[0]\n for agent in self.agents.values() if render_condition[agent.id]\n ]\n\n if shape_dict:\n shape = [\n shape_dict[agent.team]\n for agent in self.agents.values() if render_condition[agent.id]\n ]\n else:\n shape = 'o'\n mscatter(agents_x, agents_y, ax=ax, m=shape, s=100, edgecolor='black', facecolor='gray')\n\n plt.plot()\n plt.pause(1e-6)\n\n def get_obs(self, agent_id, **kwargs):\n agent = self.agents[agent_id]\n return self.partial_observer.get_obs(agent, **kwargs)\n\n def get_reward(self, agent_id, **kwargs):\n \"\"\"\n Return the agents reward and reset it to zero.\n \"\"\"\n reward_out = self.rewards[agent_id]\n self.rewards[agent_id] = 0\n return reward_out\n\n def get_done(self, agent_id, **kwargs):\n return self.done.get_done(self.agents[agent_id], **kwargs)\n\n def get_all_done(self, **kwargs):\n return self.done.get_all_done(**kwargs)\n\n def get_info(self, *args, **kwargs):\n return {}\n\n\nif __name__ == '__main__':\n food = {f'food{i}': FoodAgent(id=f'food{i}', team=1) for i in range(12)}\n foragers = {\n f'forager{i}': HuntingForagingAgent(\n id=f'forager{i}', agent_view=5, team=2, move_range=1, attack_range=1, attack_strength=1\n ) for i in range(7)\n }\n hunters = {\n f'hunter{i}': HuntingForagingAgent(\n id=f'hunter{i}', agent_view=2, team=3, move_range=1, attack_range=1, attack_strength=1\n ) for i in range(2)\n }\n agents = {**food, **foragers, **hunters}\n\n region = 20\n team_attack_matrix = np.zeros((4, 4))\n team_attack_matrix[2, 1] = 1\n team_attack_matrix[3, 2] = 1\n env = HuntingForagingEnv(\n region=region,\n agents=agents,\n team_attack_matrix=team_attack_matrix,\n number_of_teams=3,\n )\n env.reset()\n\n shape_dict = {\n 1: 's',\n 2: 'o',\n 3: 'd'\n }\n\n import pprint\n pprint.pprint({agent_id: env.get_obs(agent_id) for agent_id in env.agents})\n fig = plt.gcf()\n env.render(fig=fig, shape_dict=shape_dict)\n\n for _ in range(50):\n action_dict = {\n agent.id: agent.action_space.sample()\n for agent in env.agents.values()\n if agent.is_alive and isinstance(agent, HuntingForagingAgent)\n }\n env.step(action_dict)\n env.render(fig=fig, shape_dict=shape_dict)\n print(env.get_all_done())\n"
},
{
"alpha_fraction": 0.5484169721603394,
"alphanum_fraction": 0.5737451910972595,
"avg_line_length": 32.72395706176758,
"blob_id": "42b0c725316b048dc3c32d0d5de4f1324b3e95a6",
"content_id": "08bfacb2299ac6308bdc5a250f8013ddc393dd63",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6475,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 192,
"path": "/abmarl/sim/components/examples/observing_agent_example.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from matplotlib import pyplot as plt\nimport numpy as np\n\nfrom abmarl.sim.components.state import GridPositionState, LifeState\nfrom abmarl.sim.components.observer import GridPositionTeamBasedObserver\nfrom abmarl.sim.components.actor import GridMovementActor\nfrom abmarl.sim.components.agent import PositionObservingAgent, AgentObservingAgent, \\\n GridMovementAgent\nfrom abmarl.sim import AgentBasedSimulation\nfrom abmarl.tools.matplotlib_utils import mscatter\n\n\nclass ObservingTeamMovementAgent(PositionObservingAgent, AgentObservingAgent, GridMovementAgent):\n pass\n\n\nclass SimpleGridObservations(AgentBasedSimulation):\n def __init__(self, **kwargs):\n self.agents = kwargs['agents']\n\n # State components\n self.position_state = GridPositionState(**kwargs)\n self.life_state = LifeState(**kwargs)\n\n # Actor components\n self.move_actor = GridMovementActor(position_state=self.position_state, **kwargs)\n\n # Observers\n self.observer = GridPositionTeamBasedObserver(position_state=self.position_state, **kwargs)\n\n self.finalize()\n\n def reset(self, **kwargs):\n self.position_state.reset(**kwargs)\n self.life_state.reset(**kwargs)\n\n return {'agent0': self.get_obs('agent0')}\n\n def step(self, action_dict, **kwargs):\n\n # Process movement\n for agent_id, action in action_dict.items():\n self.move_actor.process_action(self.agents[agent_id], action, **kwargs)\n\n return {'agent0': self.get_obs('agent0')}\n\n def render(self, fig=None, **kwargs):\n fig.clear()\n\n # Draw the agents\n team_shapes = {\n 1: 'o',\n 2: 's',\n 3: 'd'\n }\n\n ax = fig.gca()\n shape_dict = {agent.id: team_shapes[agent.team] for agent in self.agents.values()}\n ax.set(xlim=(0, self.position_state.region), ylim=(0, self.position_state.region))\n ax.set_xticks(np.arange(0, self.position_state.region, 1))\n ax.set_yticks(np.arange(0, self.position_state.region, 1))\n ax.grid()\n\n agents_x = [agent.position[1] + 0.5 for agent in self.agents.values()]\n agents_y = [\n self.position_state.region - 0.5 - agent.position[0] for agent in self.agents.values()\n ]\n shape = [shape_dict[agent_id] for agent_id in shape_dict]\n mscatter(agents_x, agents_y, ax=ax, m=shape, s=200, edgecolor='black', facecolor='gray')\n\n plt.plot()\n plt.pause(1e-6)\n\n def get_obs(self, agent_id, **kwargs):\n agent = self.agents[agent_id]\n return {\n **self.observer.get_obs(agent, **kwargs),\n }\n\n def get_reward(self, agent_id, **kwargs):\n pass\n\n def get_done(self, agent_id, **kwargs):\n pass\n\n def get_all_done(self, agent_id, **kwargs):\n pass\n\n def get_info(self, agent_id, **kwargs):\n return {}\n\n\nif __name__ == '__main__':\n agents = {\n 'agent0': ObservingTeamMovementAgent(\n id='agent0', team=1, agent_view=1, move_range=1, initial_position=np.array([2, 1])\n ),\n 'agent1': ObservingTeamMovementAgent(\n id='agent1', team=1, agent_view=1, move_range=0, initial_position=np.array([2, 2])\n ),\n 'agent2': ObservingTeamMovementAgent(\n id='agent2', team=2, agent_view=1, move_range=0, initial_position=np.array([0, 4])\n ),\n 'agent3': ObservingTeamMovementAgent(\n id='agent3', team=2, agent_view=1, move_range=0, initial_position=np.array([0, 0])\n ),\n 'agent4': ObservingTeamMovementAgent(\n id='agent4', team=3, agent_view=1, move_range=0, initial_position=np.array([4, 0])\n ),\n 'agent5': ObservingTeamMovementAgent(\n id='agent5', team=3, agent_view=1, move_range=0, initial_position=np.array([4, 4])\n ),\n }\n sim = SimpleGridObservations(\n region=5,\n agents=agents,\n number_of_teams=3\n )\n obs = sim.reset()\n fig = plt.gcf()\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n obs = sim.step({'agent0': {'move': np.array([-1, 0])}})\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n obs = sim.step({'agent0': {'move': np.array([0, 1])}})\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n obs = sim.step({'agent0': {'move': np.array([0, 1])}})\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n obs = sim.step({'agent0': {'move': np.array([1, 0])}})\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n obs = sim.step({'agent0': {'move': np.array([1, 0])}})\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n obs = sim.step({'agent0': {'move': np.array([0, -1])}})\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n obs = sim.step({'agent0': {'move': np.array([0, -1])}})\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n obs = sim.step({'agent0': {'move': np.array([-1, 0])}})\n sim.render(fig=fig)\n print(obs['agent0']['position'][:, :, 0])\n print(obs['agent0']['position'][:, :, 1])\n print(obs['agent0']['position'][:, :, 2])\n print(obs['agent0']['position'][:, :, 3])\n print()\n\n plt.show()\n"
},
{
"alpha_fraction": 0.6081531047821045,
"alphanum_fraction": 0.6148086786270142,
"avg_line_length": 29.43037986755371,
"blob_id": "df2716ea98ef113f8f608cdf2d3c40c161f5a7b8",
"content_id": "753e34b298390a3773e8e17b521b06ca1314d6da",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2404,
"license_type": "permissive",
"max_line_length": 92,
"num_lines": 79,
"path": "/docs/src/tutorials/gym.rst",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": ".. Abmarl documentation Gym tutorial.\n\n.. _tutorial_gym:\n\nGym Environment\n===============\n\nAbmarl can be used with OpenAI Gym environments. In this tutorial, we'll create\na training configuration file that trains a gym environment. This tutorial uses\nthe `gym configuration <https://github.com/LLNL/Abmarl/blob/main/examples/gym_example.py>`_.\n\n\nTraining a Gym Environment\n--------------------------\n\nSimulation Setup\n````````````````\n\nWe'll start by creating gym's built-in guessing game.\n\n.. code-block:: python\n\n import gym\n from ray.tune.registry import register_env\n\n sim = gym.make('GuessingGame-v0')\n sim_name = \"GuessingGame\"\n register_env(sim_name, lambda sim_config: sim)\n\n.. NOTE::\n\n Even gym's built-in environments need to be registered with RLlib.\n\nExperiment Parameters\n`````````````````````\n\nAll training configuration parameters are stored in a dictionary called `params`.\nHaving setup the simualtion, we can now create the `params` dictionary that will\nbe read by Abmarl and used to launch RLlib.\n\n.. code-block:: python\n\n params = {\n 'experiment': {\n 'title': f'{sim_name}',\n 'sim_creator': lambda config=None: sim,\n },\n 'ray_tune': {\n 'run_or_experiment': 'A2C',\n 'checkpoint_freq': 1,\n 'checkpoint_at_end': True,\n 'stop': {\n 'episodes_total': 2000,\n },\n 'verbose': 2,\n 'config': {\n # --- Simulation ---\n 'env': sim_name,\n 'horizon': 200,\n 'env_config': {},\n # --- Parallelism ---\n # Number of workers per experiment: int\n \"num_workers\": 6,\n # Number of simulations that each worker starts: int\n \"num_envs_per_worker\": 1,\n },\n }\n }\n\n\nCommand Line interface\n``````````````````````\nWith the configuration file complete, we can utilize the command line interface\nto train our agents. We simply type ``abmarl train gym_example.py``,\nwhere `gym_example.py` is the name of our configuration file. This will launch\nAbmarl, which will process the file and launch RLlib according to the\nspecified parameters. This particular example should take 1-10 minutes to\ntrain, depending on your compute capabilities. You can view the performance\nin real time in tensorboard with ``tensorboard --logdir ~/abmarl_results``.\n"
},
{
"alpha_fraction": 0.6352841258049011,
"alphanum_fraction": 0.6352841258049011,
"avg_line_length": 26.418603897094727,
"blob_id": "0942c9a26b2d35437e3f6f4bf4435258c36852e4",
"content_id": "30534893d4f8261e9dc7562bb23ba27ecc4da629",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": true,
"language": "Python",
"length_bytes": 1179,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 43,
"path": "/abmarl/external/rllib_multiagentenv_wrapper.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from ray.rllib import MultiAgentEnv\n\n\nclass MultiAgentWrapper(MultiAgentEnv):\n \"\"\"\n Enable connection between SimulationManager and RLlib Trainer.\n\n Wraps a SimulationManager and forwards all calls to the manager. This class\n is boilerplate and needed because RLlib checks that the simulation is an instance\n of MultiAgentEnv.\n\n Attributes:\n sim: The SimulationManager.\n \"\"\"\n def __init__(self, sim):\n from abmarl.managers import SimulationManager\n assert isinstance(sim, SimulationManager)\n self.sim = sim\n\n def reset(self):\n \"\"\"See SimulationManager.\"\"\"\n return self.sim.reset()\n\n def step(self, actions):\n \"\"\"See SimulationManager.\"\"\"\n return self.sim.step(actions)\n\n def render(self, *args, **kwargs):\n \"\"\"See SimulationManager.\"\"\"\n return self.sim.render(*args, **kwargs)\n\n @property\n def unwrapped(self):\n \"\"\"\n Fall through all the wrappers to the SimulationManager.\n\n Returns:\n The wrapped SimulationManager.\n \"\"\"\n try:\n return self.sim.unwrapped\n except AttributeError:\n return self.sim\n"
},
{
"alpha_fraction": 0.8611111044883728,
"alphanum_fraction": 0.8611111044883728,
"avg_line_length": 47,
"blob_id": "4cb6d1d014940953335930798193fa68a76d566a",
"content_id": "241c3cee3d77d75f34326665fa7a9d5eedc08393",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 144,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 3,
"path": "/abmarl/managers/__init__.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .simulation_manager import SimulationManager\nfrom .turn_based_manager import TurnBasedManager\nfrom .all_step_manager import AllStepManager\n"
},
{
"alpha_fraction": 0.6690607666969299,
"alphanum_fraction": 0.6690607666969299,
"avg_line_length": 41.093021392822266,
"blob_id": "067064ed68f0467c6d1fe88492fc27d87ac1737f",
"content_id": "ba23a45e2b490a24a9f15cde61ae5797f7883d16",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1810,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 43,
"path": "/abmarl/tools/gym_utils.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from gym.spaces import Space, Discrete, MultiBinary, MultiDiscrete, Box, Dict, Tuple\n\n\ndef check_space(space, strict=False):\n \"\"\"\n Ensure that the space is a gym Space, including all nested spaces.\n\n strict (bool), default False:\n If strict is True, then the recursion rule is that every subspace must be\n a gym space. If strict is False, then the recursion rule is that every subspace\n must be a gym space OR a dict or tuple. In this way, we allow the space\n to be iteratively built and assume that the final wrapping to Dict or Tuple\n has yet to occur.\n \"\"\"\n if isinstance(space, (Discrete, MultiDiscrete, MultiBinary, Box)):\n return True\n elif isinstance(space, Dict):\n return all([check_space(sub_space) for sub_space in space.spaces.values()])\n elif isinstance(space, Tuple):\n return all([check_space(sub_space) for sub_space in space.spaces])\n elif not strict:\n if isinstance(space, dict):\n return all([check_space(sub_space) for sub_space in space.values()])\n elif isinstance(space, tuple):\n return all([check_space(sub_space) for sub_space in space])\n else:\n return False\n\n\ndef make_dict(space):\n \"\"\"\n Convert a hierarchical space into a gym space by recursively moving through\n the layers and converting the subspaces to gym spaces. Unsafe, modifies the\n items of the input as it moves through them.\n \"\"\"\n assert isinstance(space, (dict, Space)), \"Cannot convert this to a Dict.\"\n for key, subspace in space.items():\n if isinstance(subspace, dict):\n space[key] = make_dict(subspace)\n else:\n assert isinstance(subspace, Space), \"Cannot convert this to a Dict.\"\n\n return Dict(space) if type(space) is dict else space\n"
},
{
"alpha_fraction": 0.3953578770160675,
"alphanum_fraction": 0.4722869098186493,
"avg_line_length": 46.18681335449219,
"blob_id": "5a5176316cf57235b7c62931a7f15e1243a7db14",
"content_id": "b45ca9591c34aa6a8e36e317ec2807ba30d0aa72",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12882,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 273,
"path": "/tests/test_position_component.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.components.state import GridPositionState, LifeState\nfrom abmarl.sim.components.observer import GridPositionBasedObserver, \\\n GridPositionTeamBasedObserver, RelativePositionObserver\nfrom abmarl.sim.components.agent import PositionObservingAgent, AgentObservingAgent, \\\n ComponentAgent\n\n\nclass PositionTestAgent(PositionObservingAgent, AgentObservingAgent): pass\nclass PositionTeamTestAgent(PositionObservingAgent, AgentObservingAgent): pass\nclass PositionTeamNoViewTestAgent(ComponentAgent): pass\n\n\ndef test_grid_position_observer():\n agents = {\n 'agent0': PositionTestAgent(id='agent0', initial_position=np.array([0, 0]), agent_view=1),\n 'agent1': PositionTestAgent(id='agent1', initial_position=np.array([2, 2]), agent_view=2),\n 'agent2': PositionTestAgent(id='agent2', initial_position=np.array([3, 2]), agent_view=3),\n 'agent3': PositionTestAgent(id='agent3', initial_position=np.array([1, 4]), agent_view=4),\n 'agent4': ComponentAgent(id='agent4', initial_position=np.array([1, 4])),\n }\n\n state = GridPositionState(agents=agents, region=5)\n life = LifeState(agents=agents)\n observer = GridPositionBasedObserver(position_state=state, agents=agents)\n state.reset()\n life.reset()\n\n np.testing.assert_array_equal(observer.get_obs(agents['agent0'])['position'], np.array([\n [-1., -1., -1.],\n [-1., 0., 0.],\n [-1., 0., 0.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent1'])['position'], np.array([\n [1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0.],\n [0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 0.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent2'])['position'], np.array([\n [-1., 1., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 1., -1.],\n [-1., 0., 0., 1., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent3'])['position'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 1., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 1., -1., -1., -1., -1.],\n [ 0., 0., 1., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 1., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n ]))\n assert observer.get_obs(agents['agent4']) == {}\n\n\ndef test_grid_team_position_observer():\n agents = {\n 'agent0': PositionTeamTestAgent(\n id='agent0', team=1, initial_position=np.array([0, 0]), agent_view=1\n ),\n 'agent1': PositionTeamNoViewTestAgent(\n id='agent1', team=1, initial_position=np.array([0, 0])\n ),\n 'agent2': PositionTeamTestAgent(\n id='agent2', team=1, initial_position=np.array([2, 2]), agent_view=2\n ),\n 'agent3': PositionTeamTestAgent(\n id='agent3', team=2, initial_position=np.array([3, 2]), agent_view=3\n ),\n 'agent4': PositionTeamTestAgent(\n id='agent4', team=2, initial_position=np.array([1, 4]), agent_view=4\n ),\n 'agent5': PositionTeamNoViewTestAgent(\n id='agent5', team=2, initial_position=np.array([1, 4])\n ),\n 'agent6': PositionTeamNoViewTestAgent(\n id='agent6', team=2, initial_position=np.array([1, 4])\n ),\n 'agent7': PositionTeamTestAgent(\n id='agent7', team=3, initial_position=np.array([1, 4]), agent_view=2\n ),\n }\n for agent in agents.values():\n agent.position = agent.initial_position\n\n state = GridPositionState(agents=agents, region=5)\n life = LifeState(agents=agents)\n observer = GridPositionTeamBasedObserver(\n position_state=state, number_of_teams=3, agents=agents\n )\n state.reset()\n life.reset()\n\n np.testing.assert_array_equal(observer.get_obs(agents['agent0'])['position'][:,:,1], np.array([\n [-1., -1., -1.],\n [-1., 1., 0.],\n [-1., 0., 0.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent0'])['position'][:,:,2], np.array([\n [-1., -1., -1.],\n [-1., 0., 0.],\n [-1., 0., 0.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent0'])['position'][:,:,3], np.array([\n [-1., -1., -1.],\n [-1., 0., 0.],\n [-1., 0., 0.],\n ]))\n\n np.testing.assert_array_equal(observer.get_obs(agents['agent2'])['position'][:,:,1], np.array([\n [2., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent2'])['position'][:,:,2], np.array([\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 3.],\n [0., 0., 0., 0., 0.],\n [0., 0., 1., 0., 0.],\n [0., 0., 0., 0., 0.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent2'])['position'][:,:,3], np.array([\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 1.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n ]))\n\n np.testing.assert_array_equal(observer.get_obs(agents['agent3'])['position'][:,:,1], np.array([\n [-1., 2., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 1., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent3'])['position'][:,:,2], np.array([\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 3., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent3'])['position'][:,:,3], np.array([\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 1., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., 0., 0., 0., 0., 0., -1.],\n [-1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1.],\n ]))\n\n np.testing.assert_array_equal(observer.get_obs(agents['agent4'])['position'][:,:,1], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 2., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 1., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent4'])['position'][:,:,2], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 2., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 1., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent4'])['position'][:,:,3], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n ]))\n\n np.testing.assert_array_equal(observer.get_obs(agents['agent7'])['position'][:,:,1], np.array([\n [-1., -1., -1., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n [ 1., 0., 0., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent7'])['position'][:,:,2], np.array([\n [-1., -1., -1., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n [ 0., 0., 3., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n [ 1., 0., 0., -1., -1.],\n ]))\n np.testing.assert_array_equal(observer.get_obs(agents['agent7'])['position'][:,:,3], np.array([\n [-1., -1., -1., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n [ 0., 0., 0., -1., -1.],\n ]))\n\n\ndef test_relative_position_observer():\n agents = {\n 'agent0': PositionTestAgent(id='agent0', initial_position=np.array([0, 0]), agent_view=1),\n 'agent1': PositionTestAgent(id='agent1', initial_position=np.array([2, 2]), agent_view=2),\n 'agent2': PositionTestAgent(id='agent2', initial_position=np.array([3, 2]), agent_view=3),\n 'agent3': PositionTestAgent(id='agent3', initial_position=np.array([1, 4]), agent_view=4),\n 'agent4': ComponentAgent(id='agent4', initial_position=np.array([1, 4])),\n }\n\n state = GridPositionState(agents=agents, region=5)\n observer = RelativePositionObserver(position_state=state, agents=agents)\n state.reset()\n\n assert observer.get_obs(agents['agent0'])['relative_position']['agent1'][0] == 2\n assert observer.get_obs(agents['agent0'])['relative_position']['agent1'][1] == 2\n assert observer.get_obs(agents['agent0'])['relative_position']['agent2'][0] == 3\n assert observer.get_obs(agents['agent0'])['relative_position']['agent2'][1] == 2\n assert observer.get_obs(agents['agent0'])['relative_position']['agent3'][0] == 1\n assert observer.get_obs(agents['agent0'])['relative_position']['agent3'][1] == 4\n assert observer.get_obs(agents['agent0'])['relative_position']['agent4'][0] == 1\n assert observer.get_obs(agents['agent0'])['relative_position']['agent4'][1] == 4\n\n assert observer.get_obs(agents['agent1'])['relative_position']['agent0'][0] == -2\n assert observer.get_obs(agents['agent1'])['relative_position']['agent0'][1] == -2\n assert observer.get_obs(agents['agent1'])['relative_position']['agent2'][0] == 1\n assert observer.get_obs(agents['agent1'])['relative_position']['agent2'][1] == 0\n assert observer.get_obs(agents['agent1'])['relative_position']['agent3'][0] == -1\n assert observer.get_obs(agents['agent1'])['relative_position']['agent3'][1] == 2\n assert observer.get_obs(agents['agent1'])['relative_position']['agent4'][0] == -1\n assert observer.get_obs(agents['agent1'])['relative_position']['agent4'][1] == 2\n\n assert observer.get_obs(agents['agent2'])['relative_position']['agent0'][0] == -3\n assert observer.get_obs(agents['agent2'])['relative_position']['agent0'][1] == -2\n assert observer.get_obs(agents['agent2'])['relative_position']['agent1'][0] == -1\n assert observer.get_obs(agents['agent2'])['relative_position']['agent1'][1] == 0\n assert observer.get_obs(agents['agent2'])['relative_position']['agent3'][0] == -2\n assert observer.get_obs(agents['agent2'])['relative_position']['agent3'][1] == 2\n assert observer.get_obs(agents['agent2'])['relative_position']['agent4'][0] == -2\n assert observer.get_obs(agents['agent2'])['relative_position']['agent4'][1] == 2\n\n assert observer.get_obs(agents['agent3'])['relative_position']['agent0'][0] == -1\n assert observer.get_obs(agents['agent3'])['relative_position']['agent0'][1] == -4\n assert observer.get_obs(agents['agent3'])['relative_position']['agent1'][0] == 1\n assert observer.get_obs(agents['agent3'])['relative_position']['agent1'][1] == -2\n assert observer.get_obs(agents['agent3'])['relative_position']['agent2'][0] == 2\n assert observer.get_obs(agents['agent3'])['relative_position']['agent2'][1] == -2\n assert observer.get_obs(agents['agent3'])['relative_position']['agent4'][0] == 0\n assert observer.get_obs(agents['agent3'])['relative_position']['agent4'][1] == 0\n"
},
{
"alpha_fraction": 0.6241103410720825,
"alphanum_fraction": 0.6376779079437256,
"avg_line_length": 26.248485565185547,
"blob_id": "eb9aa368d7e5524daa2ef25c517f2e21f432e5b7",
"content_id": "31f60ce09f48f899068d545d558c5fe281628e9f",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4496,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 165,
"path": "/tests/sim/test_agent_based_simulation.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import pytest\n\nfrom abmarl.sim import AgentBasedSimulation, PrincipleAgent, ActingAgent, ObservingAgent, Agent\n\n\ndef test_principle_agent_id():\n with pytest.raises(AssertionError):\n PrincipleAgent()\n\n with pytest.raises(AssertionError):\n PrincipleAgent(id=1)\n\n agent = PrincipleAgent(id='my_id')\n assert agent.id == 'my_id'\n assert agent.seed is None\n assert agent.configured\n\n with pytest.raises(AssertionError):\n agent.id = 4\n\n\ndef test_principle_agent_seed():\n with pytest.raises(AssertionError):\n PrincipleAgent(id='my_id', seed=13.5)\n agent = PrincipleAgent(id='my_id', seed=12)\n assert agent.seed == 12\n\n with pytest.raises(AssertionError):\n agent.seed = '12'\n\n\ndef test_principle_agents_equal():\n agent_1 = PrincipleAgent(id='1', seed=13)\n agent_2 = PrincipleAgent(id='1', seed=13)\n assert agent_1 == agent_2\n\n agent_2.id = '2'\n assert agent_1 != agent_2\n\n agent_2.id = '1'\n agent_2.seed = 12\n assert agent_1 != agent_2\n\n\ndef test_acting_agent_action_space():\n with pytest.raises(AssertionError):\n ActingAgent(id='agent', action_space=13)\n\n with pytest.raises(AssertionError):\n agent = ActingAgent(id='agent', action_space={'key': 'value'})\n\n agent = ActingAgent(id='agent')\n assert not agent.configured\n\n from gym.spaces import Discrete\n agent = ActingAgent(id='agent', action_space={'key': Discrete(12)})\n assert not agent.configured\n agent.finalize()\n assert agent.configured\n\n\ndef test_acting_agent_seed():\n from gym.spaces import Discrete\n agent = ActingAgent(id='agent', seed=24, action_space={\n 1: Discrete(12),\n 2: Discrete(3),\n })\n agent.finalize()\n assert agent.configured\n assert agent.action_space.sample() == {1: 6, 2: 2}\n\n\ndef test_observing_agent_observation_space():\n with pytest.raises(AssertionError):\n ObservingAgent(id='agent', observation_space=13)\n\n with pytest.raises(AssertionError):\n agent = ObservingAgent(id='agent', observation_space={'key': 'value'})\n\n agent = ObservingAgent(id='agent')\n assert not agent.configured\n\n from gym.spaces import Discrete\n agent = ObservingAgent(id='agent', observation_space={'key': Discrete(12)})\n assert not agent.configured\n agent.finalize()\n assert agent.configured\n\n\ndef test_agent():\n from gym.spaces import Discrete\n agent = Agent(\n id='agent', seed=7, observation_space={'obs': Discrete(2)},\n action_space={'act': Discrete(5)}\n )\n assert not agent.configured\n agent.finalize()\n assert agent.configured\n\n assert agent.action_space.sample() == {'act': 0}\n assert agent.observation_space.sample() == {'obs': 0}\n\n\ndef test_agent_based_simulation_agents():\n class ABS(AgentBasedSimulation):\n def __init__(self, agents):\n self.agents = agents\n\n def reset(self, **kwargs):\n pass\n\n def step(self, action, **kwargs):\n pass\n\n def render(self, **kwargs):\n pass\n\n def get_obs(self, agent_id, **kwargs):\n pass\n\n def get_reward(self, agent_id, **kwargs):\n pass\n\n def get_done(self, agent_id, **kwargs):\n pass\n\n def get_all_done(self, **kwargs):\n pass\n\n def get_info(self, agent_id, **kwargs):\n pass\n\n agents_single_object = PrincipleAgent(id='just_a_simple_agent')\n agents_list = [PrincipleAgent(id=f'{i}') for i in range(3)]\n agents_dict_key_id_no_match = {f'{i-1}': PrincipleAgent(id=f'{i}') for i in range(3)}\n agents_dict_bad_values = {f'{i}': 'PrincipleAgent(id=f\"i\")' for i in range(3)}\n agents_dict = {f'{i}': PrincipleAgent(id=f'{i}') for i in range(3)}\n\n with pytest.raises(AssertionError):\n ABS(agents=agents_single_object)\n\n with pytest.raises(AssertionError):\n ABS(agents=agents_list)\n\n with pytest.raises(AssertionError):\n ABS(agents=agents_dict_key_id_no_match)\n\n with pytest.raises(AssertionError):\n ABS(agents=agents_dict_bad_values)\n\n sim = ABS(agents=agents_dict)\n assert sim.agents == agents_dict\n sim.finalize()\n\n with pytest.raises(AssertionError):\n sim.agents = agents_single_object\n\n with pytest.raises(AssertionError):\n sim.agents = agents_list\n\n with pytest.raises(AssertionError):\n sim.agents = agents_dict_key_id_no_match\n\n with pytest.raises(AssertionError):\n ABS(agents=agents_dict_bad_values)\n"
},
{
"alpha_fraction": 0.632929265499115,
"alphanum_fraction": 0.6667606234550476,
"avg_line_length": 28.07377052307129,
"blob_id": "0998faed2a96921c66d71f7e60b861a620ac97ea",
"content_id": "0cb6478b7901f65ae4017afe541f51e4ca893555",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3547,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 122,
"path": "/tests/test_policy.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pytest\n\nfrom abmarl.pols import GreedyPolicy, EpsilonSoftPolicy, RandomFirstActionPolicy\n\n\ndef test_abstract_policy():\n from abmarl.pols.policy import Policy\n with pytest.raises(TypeError):\n Policy(np.zeros((2,3)))\n\n\ndef test_greedy_policy_init():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = GreedyPolicy(table)\n np.testing.assert_array_equal(table, policy.q_table)\n\n\ndef test_greedy_policy_act():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = GreedyPolicy(table)\n action = policy.act(0)\n assert action == np.argmax(policy.q_table[0])\n\n\ndef test_greedy_policy_probability():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = GreedyPolicy(table)\n prob = policy.probability(4, 2)\n assert prob == (1 if 2 == np.argmax(policy.q_table[4]) else 0)\n\n\ndef test_epsilon_soft_policy_init():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = EpsilonSoftPolicy(table)\n np.testing.assert_array_equal(table, policy.q_table)\n assert policy.epsilon == 0.1\n\n\ndef test_epsilon_soft_policy_init_epsilon():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n with pytest.raises(AssertionError):\n EpsilonSoftPolicy(table, epsilon=-0.2)\n with pytest.raises(AssertionError):\n EpsilonSoftPolicy(table, epsilon=1.4)\n EpsilonSoftPolicy(table, epsilon=0.5)\n\n\ndef test_epsilon_soft_policy_act():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,20))\n policy = EpsilonSoftPolicy(table, epsilon=0.)\n action = policy.act(3)\n assert action == np.argmax(policy.q_table[3])\n\n\ndef test_epsilon_soft_policy_probability():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = EpsilonSoftPolicy(table, epsilon=0.5)\n prob = policy.probability(4, 2)\n assert prob == (\n 1 - policy.epsilon + policy.epsilon / policy.q_table[4].size\n if 2 == np.argmax(policy.q_table[4])\n else policy.epsilon / policy.q_table[4].size\n )\n\n\ndef test_random_first_action_policy_init():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = RandomFirstActionPolicy(table)\n np.testing.assert_array_equal(table, policy.q_table)\n\n\ndef test_random_first_action_policy_reset():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = RandomFirstActionPolicy(table)\n policy.reset()\n assert policy.take_random_action\n\n\ndef test_random_first_action_policy_no_reset():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = RandomFirstActionPolicy(table)\n with pytest.raises(AttributeError):\n policy.act(5)\n with pytest.raises(AttributeError):\n policy.probability(1, 2)\n\n\ndef test_random_first_action_policy_act():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = RandomFirstActionPolicy(table)\n\n policy.reset()\n policy.act(1)\n assert not policy.take_random_action\n action = policy.act(2)\n assert action == np.argmax(policy.q_table[2])\n\n\ndef test_random_first_action_policy_probability():\n np.random.seed(24)\n table = np.random.normal(0, 1, size=(6,3))\n policy = RandomFirstActionPolicy(table)\n\n policy.reset()\n prob = policy.probability(1, 1)\n assert prob == 1. / policy.q_table[1].size\n\n policy.act(2)\n prob = policy.probability(0, 2)\n assert prob == (1 if 2 == np.argmax(policy.q_table[4]) else 0)\n"
},
{
"alpha_fraction": 0.771500825881958,
"alphanum_fraction": 0.7723439931869507,
"avg_line_length": 41.35714340209961,
"blob_id": "77cf44631fe2419db5199307d2d622fe1e9750e4",
"content_id": "8c4437cb62ebfa3b824c803688a83c4343276e9c",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1186,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 28,
"path": "/docs/src/index.rst",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": ".. Abmarl documentation index\n\nWelcome to Abmarl's documentation!\n===================================\n\nAbmarl is a package for developing Agent-Based Simulations and training them\nwith MultiAgent Reinforcement Learning (MARL). We provide an intuitive command line\ninterface for engaging with the full workflow of MARL experimentation: training,\nvisualizing, and analyzing agent behavior. We define an\n:ref:`Agent-Based Simulation Interface <abs>` and :ref:`Simulation Manager <sim-man>`,\nwhich control which agents interact with the simulation at each step. We support\n:ref:`integration <external>` with popular reinforcement learning simulation interfaces, including\n:ref:`gym.Env <api_gym_wrapper>` and :ref:`MultiAgentEnv <api_ma_wrapper>`.\n\nAbmarl leverages RLlib's framework for reinforcement learning and extends it to more easily\nsupport custom simulations, algorithms, and policies. We enable researchers to\nrapidly prototype MARL experiments and simulation design and lower the barrier\nfor pre-existing projects to prototype RL as a potential solution.\n\n.. toctree::\n :maxdepth: 2\n :caption: Contents\n\n overview\n featured_usage\n install\n tutorials/tutorials\n api\n"
},
{
"alpha_fraction": 0.6888567209243774,
"alphanum_fraction": 0.6888567209243774,
"avg_line_length": 33.54999923706055,
"blob_id": "1c2f0bf1eb777ef0b9d732b4137a77736a20b5a6",
"content_id": "da26826054c0da42287893808232284fdff3ee71",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 691,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 20,
"path": "/docs/Makefile",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "# Minimal makefile for Sphinx documentation\n#\n\n# -W and --keep-going will treat warning like errors and capture all warnings.\n# -n will raise warning about missing references in the docs.\nSPHINXOPTS ?= -W --keep-going -n\nSPHINXBUILD ?= sphinx-build\nSOURCEDIR = src\nBUILDDIR = build\n\n# Put it first so that \"make\" without argument is like \"make help\".\nhelp:\n\t@$(SPHINXBUILD) -M help \"$(SOURCEDIR)\" \"$(BUILDDIR)\" $(SPHINXOPTS) $(O)\n\n.PHONY: help Makefile\n\n# Catch-all target: route all unknown targets to Sphinx using the new\n# \"make mode\" option. $(O) is meant as a shortcut for $(SPHINXOPTS).\n%: Makefile\n\t@$(SPHINXBUILD) -M $@ \"$(SOURCEDIR)\" \"$(BUILDDIR)\" $(SPHINXOPTS) $(O)\n"
},
{
"alpha_fraction": 0.6658735275268555,
"alphanum_fraction": 0.6712270379066467,
"avg_line_length": 36.47770690917969,
"blob_id": "6df358b910d0ae94612da6387bc7bdd7c0d193d8",
"content_id": "d63bfddac66364529bfb62499b7d8afab05a83d3",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 11768,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 314,
"path": "/examples/predator_prey/PredatorPrey_magpie.sbatch-srun-ray",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n#############################################################################\n# Copyright (C) 2013-2015 Lawrence Livermore National Security, LLC.\n# Produced at Lawrence Livermore National Laboratory (cf, DISCLAIMER).\n# Written by Albert Chu <[email protected]>\n# LLNL-CODE-644248\n#\n# This file is part of Magpie, scripts for running Hadoop on\n# traditional HPC systems. For details, see https://github.com/llnl/magpie.\n#\n# Magpie is free software; you can redistribute it and/or modify it\n# under the terms of the GNU General Public License as published by\n# the Free Software Foundation; either version 2 of the License, or\n# (at your option) any later version.\n#\n# Magpie is distributed in the hope that it will be useful, but\n# WITHOUT ANY WARRANTY; without even the implied warranty of\n# MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU\n# General Public License for more details.\n#\n# You should have received a copy of the GNU General Public License\n# along with Magpie. If not, see <http://www.gnu.org/licenses/>.\n#############################################################################\n\n############################################################################\n# SLURM Customizations\n############################################################################\n\n#SBATCH --nodes=2\n#SBATCH --output=\"slurm-%j.out\"\n\n# Note defaults of MAGPIE_STARTUP_TIME & MAGPIE_SHUTDOWN_TIME, this\n# timelimit should be a fair amount larger than them combined.\n#SBATCH --time=2:00:00\n\n# Job name. This will be used in naming directories for the job.\n#SBATCH --job-name=PredatorPrey\n\n# Partition to launch job in, usually pbatch\n#SBATCH --partition=pbatch\n\n## SLURM Values\n# Generally speaking, don't touch the following, misc other configuration\n\n#SBATCH --ntasks-per-node=1\n#SBATCH --exclusive\n#SBATCH --no-kill\n\n# Need to tell Magpie how you are submitting this job\nexport MAGPIE_SUBMISSION_TYPE=\"sbatchsrun\"\n\n\n############################################################################\n# Magpie Configurations\n############################################################################\n\n# Directory your launching scripts/files are stored\n#\n# Normally an NFS mount, someplace magpie can be reached on all nodes.\nexport MAGPIE_SCRIPTS_HOME=\"/usr/tce/packages/magpie/magpie2\"\n\n# Path to store data local to each cluster node, typically something\n# in /tmp. This will store local conf files and log files for your\n# job. If local scratch space is not available, consider using the\n# MAGPIE_NO_LOCAL_DIR option. See README for more details.\n#\nexport MAGPIE_LOCAL_DIR=\"/tmp/${USER}/magpie\"\n\n# Magpie job type\n#\n# \"ray\" - Run a job according to the settings of RAY_JOB.\n#\n# \"testall\" - Run a job that runs all basic sanity tests for all\n# software that is configured to be setup. This is a good\n# way to sanity check that everything has been setup\n# correctly and the way you like.\n#\n# For Ray, testall will run rayips\n#\n# \"script\" - Run arbitraty script, as specified by MAGPIE_JOB_SCRIPT.\n# You can find example job scripts in examples/.\n#\n# \"setuponly\" - do not launch any daemons or services, only setup\n# configuration files. Useful for debugging or\n# development.\n#\nexport MAGPIE_JOB_TYPE=\"ray\"\n\n# Specify script and arguments to execute for \"script\" mode in\n# MAGPIE_JOB_TYPE\n#\n# export MAGPIE_JOB_SCRIPT=\"${HOME}/my-job-script\"\n\n# Specify script startup / shutdown time window\n#\n# Specifies the amount of time to give startup / shutdown activities a\n# chance to succeed before Magpie will give up (or in the case of\n# shutdown, when the resource manager/scheduler may kill the running\n# job). Defaults to 30 minutes for startup, 30 minutes for shutdown.\n#\n# The startup time in particular may need to be increased if you have\n# a large amount of data. As an example, HDFS may need to spend a\n# significant amount of time determine all of the blocks in HDFS\n# before leaving safemode.\n#\n# The stop time in particular may need to be increased if you have a\n# large amount of cleanup to be done. HDFS will save its NameSpace\n# before shutting down. Hbase will do a compaction before shutting\n# down.\n#\n# The startup & shutdown window must together be smaller than the\n# timelimit specified for the job.\n#\n# MAGPIE_STARTUP_TIME and MAGPIE_SHUTDOWN_TIME at minimum must be 5\n# minutes. If MAGPIE_POST_JOB_RUN is specified below,\n# MAGPIE_SHUTDOWN_TIME must be at minimum 10 minutes.\n#\n# export MAGPIE_STARTUP_TIME=30\n# export MAGPIE_SHUTDOWN_TIME=30\n\n# Magpie One Time Run\n#\n# Normally, Magpie assumes that when a user runs a job, data created\n# and stored within that job will be desired to be accessed again. For\n# example, data created and stored within HDFS will be accessed again.\n#\n# Under a number of scenarios, this may not be desired. For example\n# during testing.\n#\n# To improve useability and performance, setting MAGPIE_ONE_TIME_RUN\n# below to yes will have two effects on the Magpie job.\n#\n# 1) A number of data paths (such as for HDFS) will be put into unique\n# paths for this job. Therefore, no other job should be able to\n# access the data again. This is particularly useful if you wish\n# to run performance tests with this job script over and over\n# again.\n#\n# Magpie will not remove data that was written, so be sure to clean up\n# your directories later.\n#\n# 2) In order to improve job throughout, Magpie will take shortcuts by\n# not properly tearing down the job. As data corruption should not be\n# a concern on job teardown, the job can complete more quickly.\n#\n# export MAGPIE_ONE_TIME_RUN=yes\n\n# Convenience Scripts\n#\n# Specify script to be executed to before / after your job. It is run\n# on all nodes.\n#\n# Typically the pre-job script is used to set something up or get\n# debugging info. It can also be used to determine if system\n# conditions meet the expectations of your job. The primary job\n# running script (magpie-run) will not be executed if the\n# MAGPIE_PRE_JOB_RUN exits with a non-zero exit code.\n#\n# The post-job script is typically used for cleaning up something or\n# gathering info (such as logs) for post-debugging/analysis. If it is\n# set, MAGPIE_SHUTDOWN_TIME above must be > 5.\n#\n# See example magpie-example-pre-job-script and\n# magpie-example-post-job-script for ideas of what you can do w/ these\n# scripts\n#\n# Multiple scripts can be specified separated by comma. Arguments can\n# be passed to scripts as well.\n#\n# A number of convenient scripts are available in the\n# ${MAGPIE_SCRIPTS_HOME}/scripts directory.\n#\n# export MAGPIE_PRE_JOB_RUN=\"${MAGPIE_SCRIPTS_HOME}/scripts/pre-job-run-scripts/my-pre-job-script\"\n# export MAGPIE_POST_JOB_RUN=\"${MAGPIE_SCRIPTS_HOME}/scripts/post-job-run-scripts/my-post-job-script\"\n#\n# Similar to the MAGPIE_PRE_JOB_RUN and MAGPIE_POST_JOB_RUN, scripts can be\n# run after the stack is setup but prior to the script or interactive mode \n# begins. This enables frontends and other processes that depend on the stack\n# to be started up and torn down. In similar fashion the cleanup will be done \n# immediatly after the script or interactive mode exits before the stack is \n# shutdown.\n#\n# export MAGPIE_PRE_EXECUTE_RUN=\"${MAGPIE_SCRIPTS_HOME}/scripts/pre-job-run-scripts/my-pre-job-script\"\n# export MAGPIE_POST_EXECUTE_RUN=\"${MAGPIE_SCRIPTS_HOME}/scripts/post-job-run-scripts/my-post-job-script\"\n\n# Environment Variable Script\n#\n# When working with Magpie interactively by logging into the master\n# node of your job allocation, many environment variables may need to\n# be set. For example, environment variables for config file\n# directories (e.g. HADOOP_CONF_DIR, HBASE_CONF_DIR, etc.) and home\n# directories (e.g. HADOOP_HOME, HBASE_HOME, etc.) and more general\n# environment variables (e.g. JAVA_HOME) may need to be set before you\n# begin interacting with your big data setup.\n#\n# The standard job output from Magpie provides instructions on all the\n# environment variables typically needed to interact with your job.\n# However, this can be tedious if done by hand.\n#\n# If the environment variable specified below is set, Magpie will\n# create the file and put into it every environment variable that\n# would be useful when running your job interactively. That way, it\n# can be sourced easily if you will be running your job interactively.\n# It can also be loaded or used by other job scripts.\n#\n# export MAGPIE_ENVIRONMENT_VARIABLE_SCRIPT=\"${HOME}/my-job-env\"\n\n# Environment Variable Shell Type\n#\n# Magpie outputs environment variables in help output and\n# MAGPIE_ENVIRONMENT_VARIABLE_SCRIPT based on your SHELL environment\n# variable.\n#\n# If you would like to output in a different shell type (perhaps you\n# have programmed scripts in a different shell), specify that shell\n# here.\n#\n# export MAGPIE_ENVIRONMENT_VARIABLE_SCRIPT_SHELL=\"/bin/bash\"\n\n# Remote Shell\n#\nexport MAGPIE_REMOTE_CMD=\"mrsh\"\nexport MAGPIE_REMOTE_CMD_OPTS=\"\"\n\n############################################################################\n# General Configuration\n############################################################################\n\n# MAGPIE_PYTHON path used for:\n# - Spark PySpark path\n# - Launching tensorflow tasks\nexport MAGPIE_PYTHON=\"/g/g13/rusu1/.conda/envs/abmarl/bin/python\"\n\n############################################################################\n# Ray Core Configurations\n############################################################################\n\n# Should Ray be run\n#\n# Specify yes or no. Defaults to no.\n#\nexport RAY_SETUP=yes\n\n# Path to ray command\n#\n# This should be accessible on all nodes in your allocation. Typically\n# this is in an NFS mount.\n#\nexport RAY_PATH=\"/g/g13/rusu1/.conda/envs/abmarl/bin/ray\"\n\n# Path to store data local to each cluster node, typically something\n# in /tmp. This will store local conf files and log files for your\n# job. If local scratch space is not available, consider using the\n# MAGPIE_NO_LOCAL_DIR_DIR option. See README for more details.\n#\nexport RAY_LOCAL_DIR=\"/tmp/${USER}/ray\"\n\n############################################################################\n# Ray Job/Run Configurations\n############################################################################\n\n# Set ray job for MAGPIE_JOB_TYPE = ray\n#\n# \"rayips\" - run Ray IP example. Useful for making sure things are\n# setup correctly.\n#\n# \"script\" - execute the python script indicated by RAY_SCRIPT_PATH.\n# See RAY_SCRIPT_PATH below for more information.\n#\nexport RAY_JOB=\"script\"\n\n# Specify script to execute for \"script\" mode in RAY_JOB.\n#\n# This python script will be executed on the master node via the\n# default python path or the python specified in MAGPIE_PYTHON if it\n# is set.\n#\n# It is assumed that ray libraries are already in your python\n# path. If it is not, it should be added.\n#\nexport RAY_SCRIPT_PATH=\"/usr/WS1/rusu1/abmarl/examples/predator_prey/runnable_predator_prey_training.py\"\n\n############################################################################\n# Run Job\n############################################################################\n\nsrun --no-kill -W 0 $MAGPIE_SCRIPTS_HOME/magpie-check-inputs\nif [ $? -ne 0 ]\nthen\n exit 1\nfi\nsrun --no-kill -W 0 $MAGPIE_SCRIPTS_HOME/magpie-setup-core\nif [ $? -ne 0 ]\nthen\n exit 1\nfi\nsrun --no-kill -W 0 $MAGPIE_SCRIPTS_HOME/magpie-setup-projects\nif [ $? -ne 0 ]\nthen\n exit 1\nfi\nsrun --no-kill -W 0 $MAGPIE_SCRIPTS_HOME/magpie-setup-post\nif [ $? -ne 0 ]\nthen\n exit 1\nfi\nsrun --no-kill -W 0 $MAGPIE_SCRIPTS_HOME/magpie-pre-run\nif [ $? -ne 0 ]\nthen\n exit 1\nfi\nsrun --no-kill -W 0 $MAGPIE_SCRIPTS_HOME/magpie-run\nsrun --no-kill -W 0 $MAGPIE_SCRIPTS_HOME/magpie-cleanup\nsrun --no-kill -W 0 $MAGPIE_SCRIPTS_HOME/magpie-post-run\n"
},
{
"alpha_fraction": 0.5962591767311096,
"alphanum_fraction": 0.5972925424575806,
"avg_line_length": 45.52404022216797,
"blob_id": "6984981260fa188acfca444771257f8445194821",
"content_id": "b05a4f10c1cd97c9434b5c277ad4575260d3360b",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9677,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 208,
"path": "/abmarl/sim/components/wrappers/observer_wrapper.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from gym.spaces import Dict, Discrete\nimport numpy as np\n\nfrom abmarl.sim.components.agent import AgentObservingAgent, ObservingAgent, BroadcastingAgent\n\n\ndef obs_filter_step(distance, view):\n \"\"\"\n Perfectly observe the agent if it is within the observing agent's view. If\n it is not within the view, then don't observe it at all.\n \"\"\"\n return 0 if distance > view else 1\n\n\nclass PositionRestrictedObservationWrapper:\n \"\"\"\n Partial observation based on position distance. If the observing agent is an\n AgentObservingAgent, then we will filter the observation based on agent's view\n and the distance between the agents according to the given obs_filter function.\n We will also append that agent's observation with a \"mask\" channel that shows\n which agents have been observed and which have been filtered.\n\n We wrap multiple observers in one because you probably want to apply the same\n observation filter to many observers in the same step. For example, suppose\n your agent can observe the health and position of other agents. Suppose based\n on its position and view, another agent gets filtered out of the observation.\n We want that agent to be filtered out from both the position and health channels\n consistently, so we wrap both of those observers with a single wrapper.\n\n observers (list of Observers):\n All the observers to which you want to apply the same partial observation\n filter.\n\n obs_filter (function):\n A function with inputs distance and observing agent's view and outputs\n the probabilty of observing that agent.\n Default is obs_filter_step.\n\n obs_norm (int):\n The norm to use in calculating the distance.\n Default is np.inf.\n\n agents (dict):\n Dictionary of agents.\n \"\"\"\n def __init__(self, observers, obs_filter=obs_filter_step, obs_norm=np.inf, agents=None,\n **kwargs):\n assert type(observers) is list, \"observers must be in a list.\"\n self.observers = observers\n self._channel_observer_map = {observer.channel: observer for observer in self.observers}\n\n assert callable(obs_filter), \"obs_filter must be a function.\"\n self.obs_filter = obs_filter\n\n self.obs_norm = obs_norm\n\n assert type(agents) is dict, \"agents must be the dictionary of agents.\"\n self.agents = agents\n\n # Append a \"mask\" observation to the observing agents\n for agent in agents.values():\n if isinstance(agent, ObservingAgent):\n agent.observation_space['mask'] = Dict({\n other: Discrete(2) for other in agents\n })\n\n def get_obs(self, agent, **kwargs):\n \"\"\"\n Get the observation for this agent from the observers and filter based\n on the obs_filter.\n\n agent (ObservingAgent):\n An agent that can observe. If the agent does not have a position, then\n we cannot do position-based filtering, so we just return the observations\n without a filter and with a mask that is all 1's for all agents.\n\n return (dict):\n A dictionary composed of the channels from the observers and a \"mask\"\n channel that is 1 if the agent was observed, otherwise 0.\n \"\"\"\n if isinstance(agent, ObservingAgent):\n all_obs = {}\n\n # If the observing agent does not have a position and view, then we cannot filter\n # it here, so we just return the observations from the wrapped observers.\n if not isinstance(agent, AgentObservingAgent):\n mask = {other: 1 for other in self.agents}\n all_obs['mask'] = mask\n for observer in self.observers:\n all_obs.update(observer.get_obs(agent, **kwargs))\n return all_obs\n\n # Determine which other agents the observing agent sees. Add the observation mask.\n mask = {}\n for other in self.agents.values():\n if np.random.uniform() <= self.obs_filter(\n np.linalg.norm(agent.position - other.position, self.obs_norm),\n agent.agent_view\n ):\n mask[other.id] = 1 # We perfectly observed this agent\n else:\n mask[other.id] = 0 # We did not observe this agent\n all_obs['mask'] = mask\n\n # Go through each observer and filter out the observations.\n for observer in self.observers:\n obs = observer.get_obs(agent, **kwargs)\n for obs_content in obs.values():\n for other, masked in mask.items():\n if not masked:\n obs_content[other] = observer.null_value\n\n all_obs.update(obs)\n\n return all_obs\n else:\n return {}\n\n def null_value(self, channel):\n if channel == 'mask':\n return np.array([0])\n else:\n return self._channel_observer_map[channel].null_value\n\n\nclass TeamBasedCommunicationWrapper:\n \"\"\"\n Agents can broadcast their observations for other agents to see. Other agents\n that are on the same team will receive the observation, and it will be fused\n in with their own observations. Other agents that are on a different team will\n not receive the message contents but will receive information about the broadcasting\n agent, such as its location.\n\n Note: This wrapper only works with channel observers that are keyed off the\n agents' ids.\n\n observers (list of PositionRestrictedObservationWrapper):\n The PositionRestrictedObservationWrapper masks agents from one another,\n making it necessary for communications to occur in order to reveal observations.\n\n agents (dict):\n The dictionary of agents.\n\n obs_norm (int):\n The norm to use for measuring the distance between agents.\n Default np.inf.\n \"\"\"\n def __init__(self, observers, agents=None, obs_norm=np.inf, **kwargs):\n self.observers = observers\n self.agents = agents\n self.obs_norm = obs_norm\n\n def get_obs(self, receiving_agent, **kwargs):\n \"\"\"\n If the receiving agent is within range of a broadcasting agent, it will receive\n a message. If they're on the same team, then the receiving agent will augment\n its observation with the observation of the broadcasting agent. If they\n are not different teams, then the receiving agent will not receive the\n observation of the broadcasting agent but will receive information about\n that agent itself.\n \"\"\"\n if isinstance(receiving_agent, ObservingAgent):\n # Generate my normal observation\n my_obs = {}\n for observer in self.observers:\n my_obs.update(observer.get_obs(receiving_agent, **kwargs))\n\n # Fuse my observation with information from the broadcasting agent.\n # If I'm on the same team, then I will see its observation.\n # If I'm not on the same team, then I will not see its observation,\n # but I will still see its own attributes.\n for broadcasting_agent in self.agents.values():\n if isinstance(broadcasting_agent, BroadcastingAgent) and \\\n broadcasting_agent.broadcasting:\n distance = np.linalg.norm(\n broadcasting_agent.position - receiving_agent.position, self.obs_norm\n )\n if distance > broadcasting_agent.broadcast_range:\n # Too far from this broadcasting agent\n continue\n elif receiving_agent.team == broadcasting_agent.team:\n # Broadcasting and receiving agent are on the same team,\n # so the receiving agent receives the observation\n for observer in self.observers:\n tmp_obs = observer.get_obs(broadcasting_agent, **kwargs)\n for obs_type, obs_content in tmp_obs.items():\n for agent_id, obs_value in obs_content.items():\n if np.all(my_obs[obs_type][agent_id] ==\n observer.null_value(obs_type)):\n my_obs[obs_type][agent_id] = obs_value\n else:\n # I received a message, but we're not on the same team,\n # so I only observe the broadcasting agent's information.\n # Since I don't have a state, I have to go through the\n # agent's observation of itself.\n # NOTE: This is a bit of a hack. It's not fullproof because\n # the broadcasting agent might not have information about\n # itself. This is the best we can do right now without a re-design.\n for observer in self.observers:\n tmp_obs = observer.get_obs(broadcasting_agent, **kwargs)\n for obs_type, obs_content in tmp_obs.items():\n if np.all(my_obs[obs_type][broadcasting_agent.id] ==\n observer.null_value(obs_type)):\n my_obs[obs_type][broadcasting_agent.id] = \\\n obs_content[broadcasting_agent.id]\n return my_obs\n else:\n return {}\n"
},
{
"alpha_fraction": 0.5878357291221619,
"alphanum_fraction": 0.5967891216278076,
"avg_line_length": 34.988887786865234,
"blob_id": "44226239df5893602077742613ae944fdb66b77d",
"content_id": "8ef884620ee9faf406573075f73f96b321c89f9c",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3239,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 90,
"path": "/abmarl/sim/modules/grid_resources.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nclass GridResources:\n \"\"\"\n GridResources provides resources that exist on the grid and can be consumed\n by agents in the simulation via their \"harvest\" action. The resources will\n replenish over time. The grid is covered up to some coverage percentage, and\n the initial value of the resources on each cell are random between the minimum\n and maximum values.\n\n max_value: double\n The maximum value that a resource can reach. Default 1.0\n min_value: double\n The minimum value that a resource can reach and still be able\n to regenerate itself over time. If the resource value falls below the\n min_value, then the resource will not revive itself. Default 0.1\n revive_rate: double\n The rate of revival for each of the resources. Default 0.04\n coverage: double\n The ratio of the map that is covered with a resource. Default 0.75.\n \"\"\"\n def __init__(self, config):\n self.region = config['region']\n self.coverage = config['coverage']\n self.min_value = config['min_value']\n self.max_value = config['max_value']\n self.revive_rate = config['revive_rate']\n\n def reset(self, **kwargs):\n \"\"\"\n Reset the grid and cover with resources.\n \"\"\"\n coverage_filter = np.zeros((self.region, self.region))\n coverage_filter[np.random.uniform(0, 1, (self.region, self.region)) < self.coverage] = 1.\n self.resources = np.multiply(\n np.random.uniform(self.min_value, self.max_value, (self.region, self.region)),\n coverage_filter\n )\n\n def harvest(self, location, amount, **kwargs):\n \"\"\"\n Process harvesting a certain amount at a certain location. Return the amount\n that was actually harvested here.\n \"\"\"\n # Process all the harvesting\n if self.resources[location] - amount >= 0.:\n actual_amount_harvested = amount\n else:\n actual_amount_harvested = self.resources[location]\n self.resources[location] = max([0., self.resources[location] - amount])\n\n return actual_amount_harvested\n\n def regrow(self, **kwargs):\n \"\"\"\n Process the regrowth, which is done according to the revival rate.\n \"\"\"\n self.resources[self.resources >= self.min_value] += self.revive_rate\n self.resources[self.resources >= self.max_value] = self.max_value\n\n def render(self, *args, fig=None, **kwargs):\n draw_now = fig is None\n if draw_now:\n from matplotlib import pyplot as plt\n fig = plt.gcf()\n import seaborn as sns\n\n fig.clear()\n ax = fig.gca()\n ax = sns.heatmap(np.flipud(self.resources), ax=ax, cmap='Greens')\n\n if draw_now:\n plt.plot()\n plt.pause(1e-17)\n\n return ax\n\n @classmethod\n def build(cls, sim_config={}):\n config = {\n 'region': 10,\n 'max_value': 1.,\n 'min_value': 0.1,\n 'revive_rate': 0.04,\n 'coverage': 0.75\n }\n for key, value in config.items():\n config[key] = sim_config.get(key, value)\n return cls(config)\n"
},
{
"alpha_fraction": 0.6017506718635559,
"alphanum_fraction": 0.6071857810020447,
"avg_line_length": 34.891170501708984,
"blob_id": "f449f73a4063a0e2711b8d752ca5bf8968263e9f",
"content_id": "5f357a1063dd0d8fe94980c06bd8af476d91ce43",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17479,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 487,
"path": "/abmarl/sim/components/actor.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod, abstractproperty\n\nfrom gym.spaces import Discrete, Box\nimport numpy as np\n\nfrom abmarl.sim.components.agent import AttackingAgent, GridMovementAgent, HarvestingAgent, \\\n SpeedAngleAgent, AcceleratingAgent, VelocityAgent, \\\n CollisionAgent, BroadcastingAgent\n\n\nclass Actor(ABC):\n \"\"\"\n Base actor class provides the interface required of all actors. Setup the agents'\n action space according to the Actor's channel.\n\n agents (dict):\n The dictionary of agents.\n\n instance (Agent):\n An Agent class. This is used in the isinstance check to determine if\n the agent will receive the action channel.\n\n space_func (function):\n A function that takes the agent as input and outputs the action space.\n \"\"\"\n def __init__(self, agents=None, instance=None, space_func=None, **kwargs):\n self.agents = agents\n for agent in self.agents.values():\n if isinstance(agent, instance):\n agent.action_space[self.channel] = space_func(agent)\n\n def _get_action_from_dict(self, action_dict, **kwargs):\n \"\"\"\n The action dict passed to an AgentBasedSimulation will be keyed off the\n agent id's. This action dict, however, is just the specific agent's actions,\n which is a dictionary keyed off the action channels. This function extracts\n that action if available, otherwise returning the Actor's null_value.\n \"\"\"\n return action_dict.get(self.channel, self.null_value)\n\n @abstractmethod\n def process_action(self, agent, action_dict, **kwargs):\n pass\n\n @abstractproperty\n def channel(self):\n pass\n\n @abstractproperty\n def null_value(self):\n pass\n\n\n# ----------------- #\n# --- Attacking --- #\n# ----------------- #\n\nclass AttackActor(Actor):\n \"\"\"\n Agents can attack other agents within their attack radius. If there are multiple\n attackable agents in the radius, then one will be randomly chosen. Attackable\n agents are determiend by the team_matrix.\n\n agents (dict of Agents):\n The dictionary of agents.\n\n attack_norm (int):\n Norm used to measure the distance between agents. For example, you might\n use a norm of 1 or np.inf in a Gird space, while 2 might be used in a Continuous\n space. Default is np.inf.\n\n team_attack_matrix (np.ndarray):\n A matrix that indicates which teams can attack which other team using the\n value at the index, like so:\n team_matrix[attacking_team, attacked_team] = 0 or 1.\n 0 indicates it cannot attack, 1 indicates that it can.\n Default None, meaning that any team can attack any other team, and no team\n can attack itself.\n\n number_of_teams (int):\n Specify the number of teams in the simulation for building the team_attack_matrix\n if that is not specified here.\n Default 0, indicating that there are no teams and its a free-for-all battle.\n \"\"\"\n def __init__(self, attack_norm=np.inf, team_attack_matrix=None, number_of_teams=0, **kwargs):\n super().__init__(\n instance=AttackingAgent,\n space_func=lambda agent: Discrete(2),\n **kwargs\n )\n if team_attack_matrix is None:\n # Default: teams can attack all other teams but not themselves. Agents\n # that are \"on team 0\" are actually teamless, so they can be attacked\n # by and can attack agents from any other team, including \"team 0\"\n # agents.\n self.team_attack_matrix = -np.diag(np.ones(number_of_teams+1)) + 1\n self.team_attack_matrix[0, 0] = 1\n else:\n self.team_attack_matrix = team_attack_matrix\n self.attack_norm = attack_norm\n\n def process_action(self, attacking_agent, action_dict, **kwargs):\n \"\"\"\n If the agent has chosen to attack, then determine which agent got attacked.\n\n return (Agent):\n Return the attacked agent object. This can be None if no agent was\n attacked.\n \"\"\"\n if self._get_action_from_dict(action_dict):\n for attacked_agent in self.agents.values():\n if attacked_agent.id == attacking_agent.id:\n # Cannot attack yourself\n continue\n elif not attacked_agent.is_alive:\n # Cannot attack a dead agent\n continue\n elif np.linalg.norm(attacking_agent.position - attacked_agent.position,\n self.attack_norm) > attacking_agent.attack_range:\n # Agent is too far away\n continue\n elif not self.team_attack_matrix[attacking_agent.team, attacked_agent.team]:\n # Attacking agent cannot attack this agent\n continue\n elif np.random.uniform() > attacking_agent.attack_accuracy:\n # Attempted attack, but it failed\n continue\n else:\n # The agent was successfully attacked!\n return attacked_agent\n\n @property\n def channel(self):\n return 'attack'\n\n @property\n def null_value(self):\n return False\n\n\n# --------------------- #\n# --- Communication --- #\n# --------------------- #\n\nclass BroadcastActor(Actor):\n \"\"\"\n BroadcastingAgents can choose to broadcast in this step or not.\n\n broadcast_state (BroadcastState):\n The broadcast state handler. Needed to modifying the agents' broadcasting state.\n\n agents (dict):\n Dictionary of agents.\n \"\"\"\n def __init__(self, broadcast_state=None, **kwargs):\n super().__init__(\n instance=BroadcastingAgent,\n space_func=lambda agent: Discrete(2),\n **kwargs\n )\n self.broadcast_state = broadcast_state\n\n def process_action(self, agent, action_dict, **kwargs):\n \"\"\"\n Determine the agents new broadcasting state based on its action.\n\n return: bool\n The agent's broadcasting state.\n \"\"\"\n broadcasting = self._get_action_from_dict(action_dict)\n self.broadcast_state.modify_broadcast(agent, broadcasting)\n\n @property\n def channel(self):\n return 'broadcast'\n\n @property\n def null_value(self):\n return False\n\n\n# ----------------------------- #\n# --- Position and Movement --- #\n# ----------------------------- #\n\nclass GridMovementActor(Actor):\n \"\"\"\n Provides the necessary action space for agents who can move and processes such\n movements.\n\n position (GridPositionState):\n The position state handler. Needed to modify the agents' positions.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, position_state=None, **kwargs):\n super().__init__(\n instance=GridMovementAgent,\n space_func=lambda agent: Box(-agent.move_range, agent.move_range, (2,), np.int),\n **kwargs\n )\n self.position_state = position_state\n\n def process_action(self, agent, action_dict, **kwargs):\n \"\"\"\n Determine the agent's new position based on its move action.\n\n return (np.array):\n How much the agent has moved in row and column. This can be different\n from the desired move if the position update was invalid.\n \"\"\"\n move = self._get_action_from_dict(action_dict)\n position_before = agent.position\n self.position_state.modify_position(agent, move, **kwargs)\n return agent.position - position_before\n\n @property\n def channel(self):\n return 'move'\n\n @property\n def null_value(self):\n return np.zeros(2)\n\n\nclass SpeedAngleMovementActor:\n \"\"\"\n Process acceleration and angle changes for SpeedAngleAgents. Update the agents'\n positions based on their new speed and direction.\n\n position (ContinuousPositionState):\n The position state handler. Needed to modify agent positions.\n\n speed_angle (SpeedAngleState):\n The speed and angle state handler.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, position_state=None, speed_angle_state=None, agents=None, **kwargs):\n self.position_state = position_state\n self.speed_angle_state = speed_angle_state\n self.agents = agents\n\n for agent in agents.values():\n if isinstance(agent, SpeedAngleAgent):\n agent.action_space['accelerate'] = Box(\n -agent.max_acceleration, agent.max_acceleration, (1,)\n )\n agent.action_space['bank'] = Box(\n -agent.max_banking_angle_change, agent.max_banking_angle_change, (1,)\n )\n\n def process_move(self, agent, acceleration, angle, **kwargs):\n \"\"\"\n Update the agent's speed by applying the acceleration and the agent's banking\n angle by applying the change. Then use the updated speed and ground angle\n to determine the agent's next position.\n\n agent (SpeedAngleAgent):\n Agent that is attempting to move.\n\n acceleration (np.array):\n A one-element float array that changes the agent's speed. New speed\n must be within the agent's min and max speed.\n\n angle (np.array):\n A one-element float array that changes the agent's banking angle. New\n banking angle must be within the agent's min and max banking angles.\n\n return (np.array):\n Return the change in position.\n \"\"\"\n if isinstance(agent, SpeedAngleAgent):\n self.speed_angle_state.modify_speed(agent, acceleration[0])\n self.speed_angle_state.modify_banking_angle(agent, angle[0])\n\n x_position = agent.speed*np.cos(np.deg2rad(agent.ground_angle))\n y_position = agent.speed*np.sin(np.deg2rad(agent.ground_angle))\n\n position_before = agent.position\n self.position_state.modify_position(agent, np.array([x_position, y_position]))\n return agent.position - position_before\n\n\nclass AccelerationMovementActor(Actor):\n \"\"\"\n Process x,y accelerations for AcceleratingAgents, which are given an 'accelerate'\n action. Update the agents' positions based on their new velocity.\n\n position_state (ContinuousPositionState):\n The position state handler. Needed to modify agent positions.\n\n velocity_state (VelocityState):\n The velocity state handler. Needed to modify agent velocities.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, position_state=None, velocity_state=None, **kwargs):\n super().__init__(\n instance=AcceleratingAgent,\n space_func=lambda agent: Box(-agent.max_acceleration, agent.max_acceleration, (2,)),\n **kwargs\n )\n self.position_state = position_state\n self.velocity_state = velocity_state\n\n def process_action(self, agent, action_dict, **kwargs):\n \"\"\"\n Update the agent's velocity by applying the acceleration. Then use the\n updated velocity to determine the agent's next position.\n\n return (np.array):\n Return the change in position.\n \"\"\"\n acceleration = self._get_action_from_dict(action_dict)\n self.velocity_state.modify_velocity(agent, acceleration)\n position_before = agent.position\n self.position_state.modify_position(agent, agent.velocity, **kwargs)\n return agent.position - position_before\n\n @property\n def channel(self):\n return 'accelerate'\n\n @property\n def null_value(self):\n return np.zeros(2)\n\n\n# -------------------------------- #\n# --- Resources and Harvesting --- #\n# -------------------------------- #\n\nclass GridResourcesActor(Actor):\n \"\"\"\n Provides the necessary action space for agents who can harvest resources and\n processes the harvesting action.\n\n resources (ResourceState):\n The resource state handler.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, resource_state=None, **kwargs):\n super().__init__(\n instance=HarvestingAgent,\n space_func=lambda agent: Box(agent.min_harvest, agent.max_harvest, (1,)),\n **kwargs\n )\n self.resource_state = resource_state\n\n def process_action(self, agent, action_dict, **kwargs):\n \"\"\"\n Harvest some amount of resources at the agent's position.\n\n return (float):\n Return the amount of resources that was actually harvested. This can\n be less than the desired amount if the cell does not have enough resources.\n \"\"\"\n amount = self._get_action_from_dict(action_dict)\n location = tuple(agent.position)\n resource_before = self.resource_state.resources[location]\n self.resource_state.modify_resources(location, -amount)\n return resource_before - self.resource_state.resources[location]\n\n @property\n def channel(self):\n return 'harvest'\n\n @property\n def null_value(self):\n return 0\n\n\n# --------------------------------------------- #\n# --- Actors that don't receive agent input --- #\n# --------------------------------------------- #\n\nclass ContinuousCollisionActor:\n \"\"\"\n Identify collisions among agents and update positions and velocities according to\n elastic collision physics.\n\n position_state (PositionState):\n The PositionState handler.\n\n velocity_state (VelocityState):\n The VelocityState handler.\n\n agents (dict):\n The dictionary of agents.\n \"\"\"\n def __init__(self, position_state=None, velocity_state=None, agents=None, **kwargs):\n self.position_state = position_state\n self.velocity_state = velocity_state\n self.agents = agents\n\n def detect_collisions_and_modify_states(self, **kwargs):\n \"\"\"\n Detect collisions between agents and update position and velocities.\n \"\"\"\n checked_agents = set()\n for agent1 in self.agents.values():\n if not (isinstance(agent1, CollisionAgent) and isinstance(agent1, VelocityAgent)):\n continue\n checked_agents.add(agent1.id)\n for agent2 in self.agents.values():\n if not (isinstance(agent1, VelocityAgent) and isinstance(agent2, CollisionAgent)):\n continue\n if agent1.id == agent2.id: continue # Cannot collide with yourself\n if agent2.id in checked_agents: continue # Already checked this agent\n dist = np.linalg.norm(agent1.position - agent2.position)\n combined_sizes = agent1.size + agent2.size\n if dist < combined_sizes:\n self._undo_overlap(agent1, agent2, dist, combined_sizes)\n self._update_velocities(agent1, agent2)\n\n def _undo_overlap(self, agent1, agent2, dist, combined_sizes, **kwargs):\n \"\"\"\n Colliding agents can overlap within a timestep. So we need to move the\n colliding agents \"backwards\" through their path in order to capture the\n positions they were in when they actually collided.\n\n agent1 (CollisionAgent):\n One of the colliding agents.\n\n agent2 (CollisionAgent):\n The other colliding agent.\n\n dist (float):\n The collision distance threshold.\n\n combined_size (float):\n The combined size of the two agents\n \"\"\"\n overlap = (combined_sizes - dist) / combined_sizes\n self.position_state.modify_position(agent1, -agent1.velocity * overlap)\n self.position_state.modify_position(agent2, -agent2.velocity * overlap)\n\n def _update_velocities(self, agent1, agent2, **kwargs):\n \"\"\"\n Updates the velocities of two agents when they collide based on an\n elastic collision assumption.\n\n agent1 (CollisionAgent):\n One of the colliding agents.\n\n agent2 (CollisionAgent):\n The other colliding agent.\n \"\"\"\n # calculate vector between centers\n rel_position = [\n agent2.position - agent1.position,\n agent1.position - agent2.position\n ]\n # Calculate relative velocities\n rel_velocities = [\n agent1.velocity - agent2.velocity,\n agent2.velocity - agent1.velocity\n ]\n # Calculate mass factor\n mass_factor = [\n 2 * agent2.mass / (agent2.mass + agent1.mass),\n 2 * agent1.mass / (agent2.mass + agent1.mass)\n ]\n # norm\n norm = [\n np.square(np.linalg.norm(rel_position[0])),\n np.square(np.linalg.norm(rel_position[1]))\n ]\n # Dot product of relative velocity and relative distcance\n dot = [\n np.dot(rel_velocities[0], rel_position[0]),\n np.dot(rel_velocities[1], rel_position[1])\n ]\n # bringing it all together\n vel_new = [\n agent1.velocity - (mass_factor[0] * (dot[0]/norm[0]) * rel_position[0]),\n agent2.velocity - (mass_factor[1] * (dot[1]/norm[1]) * rel_position[1])\n ]\n # Only update the velocity if not stationary\n self.velocity_state.set_velocity(agent1, vel_new[0])\n self.velocity_state.set_velocity(agent2, vel_new[1])\n"
},
{
"alpha_fraction": 0.2881297469139099,
"alphanum_fraction": 0.5267425775527954,
"avg_line_length": 48.53845977783203,
"blob_id": "fa855d66f37132071de1643a118a10932cdbbca0",
"content_id": "f6c44a02818cd2ff55ff9c8d3ea30a2cc16c7288",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5796,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 117,
"path": "/tests/test_resources_component.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\nfrom abmarl.sim.components.agent import HarvestingAgent, ResourceObservingAgent\nfrom abmarl.sim.components.state import GridResourceState\nfrom abmarl.sim.components.observer import GridResourceObserver\nfrom abmarl.sim.components.actor import GridResourcesActor\n\n\nclass ResourcesTestAgent(ResourceObservingAgent, HarvestingAgent): pass\n\n\ndef test_grid_resources_components():\n agents = {\n 'agent0': ResourcesTestAgent(\n id='agent0', max_harvest=0.5, resource_view=1, initial_position=np.array([0, 0])\n ),\n 'agent1': ResourcesTestAgent(\n id='agent1', max_harvest=0.5, resource_view=2, initial_position=np.array([2, 2])\n ),\n 'agent2': ResourcesTestAgent(\n id='agent2', max_harvest=0.5, resource_view=3, initial_position=np.array([3, 1])\n ),\n 'agent3': ResourcesTestAgent(\n id='agent3', max_harvest=0.5, resource_view=4, initial_position=np.array([1, 4])\n ),\n }\n initial_resources = np.array([\n [0.84727271, 0.47440489, 0.29693299, 0.5311798, 0.25446477],\n [0.58155565, 0.79666705, 0.53135774, 0.51300926, 0.90118474],\n [0.7125912, 0.86805178, 0., 0., 0.38538807],\n [0.48882905, 0.36891643, 0.76354359, 0., 0.71936923],\n [0.55379678, 0.32311497, 0.46094834, 0.12981774, 0. ],\n ])\n\n state = GridResourceState(agents=agents, initial_resources=initial_resources, regrow_rate=0.4)\n actor = GridResourcesActor(resource_state=state, agents=agents)\n observer = GridResourceObserver(resource_state=state, agents=agents)\n\n state.reset()\n for agent in agents.values():\n agent.position = agent.initial_position\n np.testing.assert_array_equal(state.resources, initial_resources)\n\n assert np.allclose(observer.get_obs(agents['agent0'])['resources'], np.array([\n [-1., -1., -1. ],\n [-1., 0.84727271, 0.47440489],\n [-1., 0.58155565, 0.79666705],\n ]))\n assert np.allclose(observer.get_obs(agents['agent1'])['resources'], np.array([\n [0.84727271, 0.47440489, 0.29693299, 0.5311798, 0.25446477],\n [0.58155565, 0.79666705, 0.53135774, 0.51300926, 0.90118474],\n [0.7125912, 0.86805178, 0., 0., 0.38538807],\n [0.48882905, 0.36891643, 0.76354359, 0., 0.71936923],\n [0.55379678, 0.32311497, 0.46094834, 0.12981774, 0. ],\n ]))\n assert np.allclose(observer.get_obs(agents['agent2'])['resources'], np.array([\n [-1., -1., 0.84727271, 0.47440489, 0.29693299, 0.5311798, 0.25446477],\n [-1., -1., 0.58155565, 0.79666705, 0.53135774, 0.51300926, 0.90118474],\n [-1., -1., 0.7125912, 0.86805178, 0., 0., 0.38538807],\n [-1., -1., 0.48882905, 0.36891643, 0.76354359, 0., 0.71936923],\n [-1., -1., 0.55379678, 0.32311497, 0.46094834, 0.12981774, 0. ],\n [-1., -1., -1., -1., -1., -1., -1. ],\n [-1., -1., -1., -1., -1., -1., -1. ],\n ]))\n assert np.allclose(observer.get_obs(agents['agent3'])['resources'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0.84727271, 0.47440489, 0.29693299, 0.5311798, 0.25446477, -1., -1., -1., -1.],\n [ 0.58155565, 0.79666705, 0.53135774, 0.51300926, 0.90118474, -1., -1., -1., -1.],\n [ 0.7125912, 0.86805178, 0., 0., 0.38538807, -1., -1., -1., -1.],\n [ 0.48882905, 0.36891643, 0.76354359, 0., 0.71936923, -1., -1., -1., -1.],\n [ 0.55379678, 0.32311497, 0.46094834, 0.12981774, 0., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n ]))\n\n state.regrow()\n assert np.allclose(state.resources, np.array([\n [1., 0.87440489, 0.69693299, 0.9311798, 0.65446477],\n [0.98155565, 1., 0.93135774, 0.91300926, 1.],\n [1., 1., 0., 0., 0.78538807],\n [0.88882905, 0.76891643, 1., 0., 1.],\n [0.95379678, 0.72311497, 0.86094834, 0.52981774, 0.],\n ]))\n\n amount = {'harvest': 0.5}\n assert actor.process_action(agents['agent0'], amount) == 0.5\n assert actor.process_action(agents['agent1'], amount) == 0.\n assert actor.process_action(agents['agent2'], amount) == 0.5\n assert actor.process_action(agents['agent3'], amount) == 0.5\n assert np.allclose(state.resources, np.array([\n [0.5, 0.87440489, 0.69693299, 0.9311798, 0.65446477],\n [0.98155565, 1., 0.93135774, 0.91300926, 0.5],\n [1., 1., 0., 0., 0.78538807],\n [0.88882905, 0.26891643, 1., 0., 1.],\n [0.95379678, 0.72311497, 0.86094834, 0.52981774, 0.],\n ]))\n\n assert actor.process_action(agents['agent0'], amount) == 0.5\n assert actor.process_action(agents['agent2'], amount) == 0.26891643\n assert actor.process_action(agents['agent3'], amount) == 0.5\n assert np.allclose(state.resources, np.array([\n [0., 0.87440489, 0.69693299, 0.9311798, 0.65446477],\n [0.98155565, 1., 0.93135774, 0.91300926, 0.],\n [1., 1., 0.,0., 0.78538807],\n [0.88882905, 0., 1., 0., 1.],\n [0.95379678, 0.72311497, 0.86094834, 0.52981774, 0.],\n ]))\n\n state.regrow()\n assert np.allclose(state.resources, np.array([\n [0., 1., 1., 1., 1.],\n [1., 1., 1., 1., 0.],\n [1., 1., 0., 0., 1.],\n [1., 0., 1., 0., 1.],\n [1., 1., 1., 0.92981774, 0.],\n ]))\n"
},
{
"alpha_fraction": 0.6955413818359375,
"alphanum_fraction": 0.6955413818359375,
"avg_line_length": 40.31578826904297,
"blob_id": "91ccc029a40a84dbb211ada0139625d6de59d3ae",
"content_id": "3c507a80fba9a69a81a347cf02a24e1cca03c6dc",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 785,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 19,
"path": "/abmarl/scripts/analyze_script.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "def create_parser(subparsers):\n analyze_parser = subparsers.add_parser('analyze', help='Analyze MARL policies')\n analyze_parser.add_argument(\n 'configuration', type=str, help='Path to saved policy directory.'\n )\n analyze_parser.add_argument(\n 'subscript', type=str, help='Path to subscript to run.'\n )\n analyze_parser.add_argument(\n '-c', '--checkpoint', type=int,\n help='Specify which checkpoint to load. Default is the last timestep in the directory.'\n )\n analyze_parser.add_argument('--seed', type=int, help='Seed for reproducibility.')\n return analyze_parser\n\n\ndef run(full_trained_directory, full_subscript, parameters):\n from abmarl import stage\n stage.run_analysis(full_trained_directory, full_subscript, parameters)\n"
},
{
"alpha_fraction": 0.7683494687080383,
"alphanum_fraction": 0.7769423723220825,
"avg_line_length": 33.06097412109375,
"blob_id": "433e7adfbece6f5a3922807800b2821963ac5056",
"content_id": "75bd347bb3948e38177826b1b5a3c2fb1dcdafe4",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2795,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 82,
"path": "/README.md",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "# Abmarl\n\nAbmarl is a package for developing Agent-Based Simulations and training them with\nMultiAgent Reinforcement Learning (MARL). We provide an intuitive command line\ninterface for engaging with the full workflow of MARL experimentation: training,\nvisualizing, and analyzing agent behavior. We define an Agent-Based\nSimulation Interface and Simulation Manager, which control which agents interact\nwith the simulation at each step. We support integration with popular reinforcement\nlearning simulation interfaces, including gym.Env and MultiAgentEnv.\n\nAbmarl leverages RLlib’s framework for reinforcement learning and extends it to\nmore easily support custom simulations, algorithms, and policies. We enable researchers to rapidly\nprototype MARL experiments and simulation design and lower the barrier for pre-existing\nprojects to prototype RL as a potential solution.\n\n<p align=\"center\">\n <img src=\"https://github.com/LLNL/Abmarl/actions/workflows/build-and-test.yml/badge.svg\" alt=\"Build and Test Badge\" />\n <img src=\"https://github.com/LLNL/Abmarl/actions/workflows/build-docs.yml/badge.svg\" alt=\"Sphinx docs Badge\" />\n <img src=\"https://github.com/LLNL/Abmarl/actions/workflows/lint.yml/badge.svg\" alt=\"Lint Badge\" />\n</p>\n\n\n## Quickstart\n\nTo use Abmarl, install via pip: `pip install abmarl`\n\nTo develop Abmarl, clone the repository and install via pip's development mode.\nNote: Abmarl requires `python3.7` or `python3.8`.\n\n```\ngit clone [email protected]:LLNL/Abmarl.git\ncd abmarl\npip install -r requirements.txt\npip install -e . --no-deps\n```\n\nTrain agents in a multicorridor simulation:\n```\nabmarl train examples/multi_corridor_example.py\n```\n\nVisualize trained behavior:\n```\nabmarl visualize ~/abmarl_results/MultiCorridor-2020-08-25_09-30/ -n 5 --record\n```\n\nNote: If you install with `conda,` then you must also include `ffmpeg` in your\nvirtual environment.\n\n## Documentation\n\nYou can find the latest Abmarl documentation, on\n[our ReadTheDocs page](https://abmarl.readthedocs.io/en/latest/index.html).\n\n[](https://abmarl.readthedocs.io/en/latest/?badge=latest)\n\n\n## Community\n\n### Reporting Issues\n\nPlease use our issue tracker to report any bugs or submit feature requests. Great\nbug reports tend to have:\n- A quick summary and/or background\n- Steps to reproduce, sample code is best.\n- What you expected would happen\n- What actually happens\n\n### Contributing\n\nPlease submit contributions via pull requests from a forked repository. Find out\nmore about this process [here](https://guides.github.com/introduction/flow/index.html).\nAll contributions are under the BSD 3 License that covers the project.\n\n### Additional support\n\n* Edward Rusu, [email protected]\n* Ruben Glatt, [email protected]\n\n## Release\n\nLLNL-CODE-815883\n"
},
{
"alpha_fraction": 0.4876404404640198,
"alphanum_fraction": 0.5022472143173218,
"avg_line_length": 24.428571701049805,
"blob_id": "2db3083d190db1f110ed61bea1102ab632bfb4d4",
"content_id": "19146be0196665ac08ac50971289844b8ae79077",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 890,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 35,
"path": "/examples/gym_example.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import gym\nfrom ray.tune.registry import register_env\n\nsim = gym.make('GuessingGame-v0')\nsim_name = \"GuessingGame\"\nregister_env(sim_name, lambda sim_config: sim)\n\n\n# Experiment parameters\nparams = {\n 'experiment': {\n 'title': f'{sim_name}',\n 'sim_creator': lambda config=None: sim,\n },\n 'ray_tune': {\n 'run_or_experiment': 'A2C',\n 'checkpoint_freq': 1,\n 'checkpoint_at_end': True,\n 'stop': {\n 'episodes_total': 2000,\n },\n 'verbose': 2,\n 'config': {\n # --- Simulation ---\n 'env': sim_name,\n 'horizon': 200,\n 'env_config': {},\n # --- Parallelism ---\n # Number of workers per experiment: int\n \"num_workers\": 6,\n # Number of simulations that each worker starts: int\n \"num_envs_per_worker\": 1,\n },\n }\n}\n"
},
{
"alpha_fraction": 0.6318513751029968,
"alphanum_fraction": 0.6364189982414246,
"avg_line_length": 32.85567092895508,
"blob_id": "ab327a060602dd24bcacf91adbd3336da96b828b",
"content_id": "359907940083a83382a44dcf39d8500da297cc46",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3284,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 97,
"path": "/abmarl/pols/policy.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from abc import ABC, abstractmethod\n\nimport numpy as np\n\n\nclass Policy(ABC):\n \"\"\"\n A policy maps a observation to an action. The relationship between the observations and the\n available actions is stored in a q_table. The act function chooses an action given a state.\n The probability function returns the probability of choosing an action given a state.\n \"\"\"\n def __init__(self, q_table):\n \"\"\"Store a q_table, which maps (state, action) to a value.\"\"\"\n self.q_table = q_table\n\n @abstractmethod\n def act(self, state, *args, **kwargs):\n \"\"\"Choose an action given a state.\"\"\"\n pass\n\n @abstractmethod\n def probability(self, state, action):\n \"\"\"Calculate the probability of choosing this action given this state.\"\"\"\n pass\n\n def reset(self):\n \"\"\"\n Some policies behave differently at the beginning of an episode or as an episode\n progresses. The reset function allows them to reset their parameters accordingly.\n \"\"\"\n pass\n\n\nclass GreedyPolicy(Policy):\n \"\"\"\n The GreedyPolicy will always choose the optimal action.\n \"\"\"\n def act(self, state):\n return np.argmax(self.q_table[state])\n\n def probability(self, state, action):\n return 1 if action == np.argmax(self.q_table[state]) else 0\n\n\nclass EpsilonSoftPolicy(GreedyPolicy):\n \"\"\"\n The EpsilonSoftPolicy will sample a uniform distribution between 0 and 1. If the sampled\n value is less than epsilon, then the policy will randomly choose an action. Otherwise, it\n will return the optimal action.\n \"\"\"\n def __init__(self, *args, epsilon=0.1):\n super().__init__(*args)\n assert 0 <= epsilon <= 1.0\n self.epsilon = epsilon\n\n def act(self, state):\n if np.random.uniform(0, 1) < self.epsilon:\n return np.random.randint(0, self.q_table[state].size)\n else:\n return super().act(state)\n\n def probability(self, state, action):\n if action == np.argmax(self.q_table[state]): # Optimal action\n return 1 - self.epsilon + self.epsilon / self.q_table[state].size\n else: # Nonoptimal action\n return self.epsilon / self.q_table[state].size\n\n\nclass RandomFirstActionPolicy(GreedyPolicy):\n \"\"\"\n The RandomFirstActionPolicy will choose a random action at the beginning of the episode.\n Afterwards, it will behave like a GreedyPolicy. Make sure you call the reset function at the\n beginning of every episode so that the policy knows to reset its parameters.\n \"\"\"\n def __init__(self, *args, **kwargs):\n super().__init__(*args, **kwargs)\n\n def reset(self):\n \"\"\"\n Set take_random_action to True so that the policy takes a random action at the beginning\n of an episode.\n \"\"\"\n self.take_random_action = True\n\n def act(self, state):\n if self.take_random_action:\n action = np.random.randint(0, self.q_table[state].size)\n else:\n action = super().act(state)\n self.take_random_action = False\n return action\n\n def probability(self, state, action):\n if self.take_random_action:\n return 1. / self.q_table[state].size\n else:\n return super().probability(state, action)\n"
},
{
"alpha_fraction": 0.41657328605651855,
"alphanum_fraction": 0.4951972961425781,
"avg_line_length": 42.64366912841797,
"blob_id": "1294b16b0ebfb2f22320bce4636846c47f33515a",
"content_id": "18394707162ecdf5e609e1b5e72080b43c8901ce",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49972,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 1145,
"path": "/tests/test_predator_prey.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from gym.spaces import Dict, Discrete, Box\nimport numpy as np\nimport pytest\n\nfrom abmarl.sim.predator_prey import PredatorPreySimulation, PredatorPreySimDistanceObs, \\\n PredatorPreySimGridObs\nfrom abmarl.sim.predator_prey import Predator, Prey\nfrom abmarl.sim.modules import GridResources\n\n\ndef test_build_fails():\n with pytest.raises(TypeError): # Abstract class error\n PredatorPreySimulation()\n with pytest.raises(TypeError): # Missing argument\n PredatorPreySimDistanceObs()\n with pytest.raises(TypeError): # Missing argument\n PredatorPreySimGridObs()\n with pytest.raises(TypeError): # Abstract class error\n PredatorPreySimulation({\n 'region': None,\n 'max_steps': None,\n 'agents': None,\n 'reward_map': None,\n })\n\n\ndef test_class_attributes():\n assert PredatorPreySimulation.ActionStatus.BAD_MOVE == 0\n assert PredatorPreySimulation.ActionStatus.GOOD_MOVE == 1\n assert PredatorPreySimulation.ActionStatus.NO_MOVE == 2\n assert PredatorPreySimulation.ActionStatus.BAD_ATTACK == 3\n assert PredatorPreySimulation.ActionStatus.GOOD_ATTACK == 4\n assert PredatorPreySimulation.ActionStatus.EATEN == 5\n\n assert PredatorPreySimulation.ObservationMode.GRID == 0\n assert PredatorPreySimulation.ObservationMode.DISTANCE == 1\n\n\ndef test_builder():\n sim = PredatorPreySimulation.build()\n assert isinstance(sim, PredatorPreySimGridObs)\n assert sim.region == 10\n assert sim.max_steps == 200\n assert sim.reward_map == {\n 'predator': {\n PredatorPreySimulation.ActionStatus.BAD_MOVE: -10,\n PredatorPreySimulation.ActionStatus.GOOD_MOVE: -1,\n PredatorPreySimulation.ActionStatus.NO_MOVE: 0,\n PredatorPreySimulation.ActionStatus.BAD_ATTACK: -10,\n PredatorPreySimulation.ActionStatus.GOOD_ATTACK: 100,\n },\n 'prey': {\n PredatorPreySimulation.ActionStatus.BAD_MOVE: -10,\n PredatorPreySimulation.ActionStatus.GOOD_MOVE: -1,\n PredatorPreySimulation.ActionStatus.NO_MOVE: 0,\n PredatorPreySimulation.ActionStatus.EATEN: -100,\n PredatorPreySimulation.ActionStatus.BAD_HARVEST: -10,\n PredatorPreySimulation.ActionStatus.GOOD_HARVEST: 10,\n }\n }\n grid_resources = GridResources.build({'region': sim.region})\n assert sim.resources.region == grid_resources.region\n assert sim.resources.coverage == grid_resources.coverage\n assert sim.resources.min_value == grid_resources.min_value\n assert sim.resources.max_value == grid_resources.max_value\n assert sim.resources.revive_rate == grid_resources.revive_rate\n\n agents = sim.agents\n assert type(agents) == dict\n assert len(agents) == 2\n assert agents['prey0'].id == 'prey0'\n assert type(agents['prey0']) == Prey\n assert agents['prey0'].view == 9\n assert agents['prey0'].harvest_amount == 0.1\n assert agents['prey0'].observation_space == Dict({\n 'agents': Box(low=-1, high=2, shape=(19,19), dtype=np.int),\n 'resources': Box(-1, sim.resources.max_value, (19,19), np.float),\n })\n assert agents['prey0'].action_space == Dict({\n 'move': Box(low=-1.5, high=1.5, shape=(2,)),\n 'harvest': Discrete(2)\n })\n assert agents['predator0'].id == 'predator0'\n assert type(agents['predator0']) == Predator\n assert agents['predator0'].view == 9\n assert agents['predator0'].attack == 0\n assert agents['predator0'].observation_space == Dict({\n 'agents': Box(low=-1, high=2, shape=(19,19), dtype=np.int),\n 'resources': Box(-1, sim.resources.max_value, (19,19), np.float),\n })\n assert agents['predator0'].action_space == Dict({\n 'move': Box(low=-1.5, high=1.5, shape=(2,)),\n 'attack': Discrete(2)\n })\n\n\ndef test_builder_region():\n sim = PredatorPreySimulation.build({'region': 20})\n assert sim.region == 20\n assert sim.resources.region == 20\n with pytest.raises(TypeError):\n PredatorPreySimulation.build({'region': '12'})\n with pytest.raises(TypeError):\n PredatorPreySimulation.build({'region': -2})\n\n agents = sim.agents\n assert len(agents) == 2\n assert agents['prey0'].id == 'prey0'\n assert type(agents['prey0']) == Prey\n assert agents['prey0'].view == 19\n assert agents['prey0'].observation_space == Dict({\n 'agents': Box(low=-1, high=2, shape=(39,39), dtype=np.int),\n 'resources': Box(-1, sim.resources.max_value, (39,39), np.float),\n })\n assert agents['predator0'].id == 'predator0'\n assert type(agents['predator0']) == Predator\n assert agents['predator0'].view == 19\n assert agents['predator0'].attack == 0\n assert agents['predator0'].observation_space == Dict({\n 'agents': Box(low=-1, high=2, shape=(39,39), dtype=np.int),\n 'resources': Box(-1, sim.resources.max_value, (39,39), np.float),\n })\n\n\ndef test_build_max_steps():\n sim = PredatorPreySimulation.build({'max_steps': 100})\n assert sim.max_steps == 100\n with pytest.raises(TypeError):\n PredatorPreySimulation.build({'max_steps': 12.5})\n with pytest.raises(TypeError):\n PredatorPreySimulation.build({'max_steps': -8})\n\n\ndef test_builder_observation_mode():\n sim = PredatorPreySimulation.build(\n {'observation_mode': PredatorPreySimulation.ObservationMode.DISTANCE}\n )\n assert isinstance(sim, PredatorPreySimDistanceObs)\n\n agents = sim.agents\n assert type(agents) == dict\n assert len(agents) == 2\n assert agents['prey0'].id == 'prey0'\n assert type(agents['prey0']) == Prey\n assert agents['prey0'].view == 9\n assert agents['prey0'].observation_space == Dict({\n 'predator0': Box(-9, 9, (3,), np.int)\n })\n assert agents['predator0'].id == 'predator0'\n assert type(agents['predator0']) == Predator\n assert agents['predator0'].view == 9\n assert agents['predator0'].attack == 0\n assert agents['predator0'].observation_space == Dict({\n 'prey0': Box(low=-9, high=9, shape=(3,), dtype=np.int)\n })\n\n\ndef test_builder_rewards():\n rewards = {\n 'predator': {\n PredatorPreySimulation.ActionStatus.BAD_MOVE: -2,\n PredatorPreySimulation.ActionStatus.GOOD_MOVE: -1,\n PredatorPreySimulation.ActionStatus.NO_MOVE: 0,\n PredatorPreySimulation.ActionStatus.BAD_ATTACK: -5,\n PredatorPreySimulation.ActionStatus.GOOD_ATTACK: 10,\n },\n 'prey': {\n PredatorPreySimulation.ActionStatus.BAD_MOVE: -2,\n PredatorPreySimulation.ActionStatus.GOOD_MOVE: 2,\n PredatorPreySimulation.ActionStatus.NO_MOVE: 1,\n PredatorPreySimulation.ActionStatus.EATEN: -10,\n }\n }\n sim = PredatorPreySimulation.build({'rewards': rewards})\n assert sim.reward_map == rewards\n with pytest.raises(TypeError):\n PredatorPreySimulation.build({'rewards': 12})\n\n\ndef test_builder_resources():\n resources = {\n 'coverage': 0.5,\n 'min_value': 0.3,\n 'max_value': 1.2,\n 'revive_rate': 0.1,\n }\n sim = PredatorPreySimulation.build({'resources': resources})\n assert sim.resources.region == sim.region\n assert sim.resources.coverage == resources['coverage']\n assert sim.resources.min_value == resources['min_value']\n assert sim.resources.max_value == resources['max_value']\n assert sim.resources.revive_rate == resources['revive_rate']\n\n\ndef test_builder_agents():\n np.random.seed(24)\n # Create some good agents\n agents = [\n Prey(id='prey0', view=7, move=2),\n Predator(id='predator1', view=3, attack=2),\n Prey(id='prey2', view=5, move=3),\n Predator(id='predator3', view=2, move=2, attack=1),\n Predator(id='predator4', view=0, attack=3)\n ]\n sim = PredatorPreySimulation.build({'agents': agents})\n\n agents = sim.agents\n for agent in agents.values():\n assert agent.configured\n\n assert agents['prey0'].observation_space == Dict({\n 'agents': Box(-1, 2, (15,15), np.int),\n 'resources': Box(-1, sim.resources.max_value, (15,15), np.float),\n })\n assert agents['predator1'].observation_space == Dict({\n 'agents': Box(-1, 2, (7, 7), np.int),\n 'resources': Box(-1, sim.resources.max_value, (7,7), np.float),\n })\n assert agents['prey2'].observation_space == Dict({\n 'agents': Box(-1, 2, (11, 11), np.int),\n 'resources': Box(-1, sim.resources.max_value, (11,11), np.float),\n })\n assert agents['predator3'].observation_space == Dict({\n 'agents': Box(-1, 2, (5, 5), np.int),\n 'resources': Box(-1, sim.resources.max_value, (5,5), np.float),\n })\n assert agents['predator4'].observation_space == Dict({\n 'agents': Box(-1, 2, (1, 1), np.int),\n 'resources': Box(-1, sim.resources.max_value, (1,1), np.float),\n })\n\n assert agents['prey0'].action_space == Dict({\n 'move': Box(-2.5, 2.5, (2,)),\n 'harvest': Discrete(2),\n })\n assert agents['predator1'].action_space == Dict({\n 'attack': Discrete(2),\n 'move': Box(-1.5, 1.5, (2,)),\n })\n assert agents['prey2'].action_space == Dict({\n 'move': Box(-3.5, 3.5, (2,)),\n 'harvest': Discrete(2),\n })\n assert agents['predator3'].action_space == Dict({\n 'attack': Discrete(2),\n 'move': Box(-2.5, 2.5, (2,)),\n })\n assert agents['predator4'].action_space == Dict({\n 'attack': Discrete(2),\n 'move': Box(-1.5, 1.5, (2,)),\n })\n\n\ndef test_reset_grid_obs():\n np.random.seed(24)\n agents = [\n Prey(id='prey0', view=2),\n Predator(id='predator1', view=4),\n Prey(id='prey2', view=2),\n Predator(id='predator3', view=4),\n Predator(id='predator4', view=4),\n ]\n sim = PredatorPreySimulation.build({'agents': agents})\n sim.reset()\n\n # Explicitly place the agents\n sim.agents['predator1'].position = np.array([4,4])\n sim.agents['predator3'].position = np.array([3,3])\n sim.agents['predator4'].position = np.array([7,9])\n sim.agents['prey0'].position = np.array([1,1])\n sim.agents['prey2'].position = np.array([3,2])\n\n assert sim.step_count == 0\n np.testing.assert_array_equal(sim.get_obs('predator1')['agents'], np.array([\n [0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 1., 2., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0., 0., 0., 0., 0.]]\n ))\n np.testing.assert_array_equal(sim.get_obs('predator3')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., 0., 1., 0., 0., 0., 0., 0., 0.],\n [-1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., 0., 0., 1., 0., 0., 0., 0., 0.],\n [-1., 0., 0., 0., 0., 2., 0., 0., 0.],\n [-1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., 0., 0., 0., 0., 0., 0., 0., 0.]]\n ))\n np.testing.assert_array_equal(sim.get_obs('predator4')['agents'], np.array(\n [[ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.]]\n ))\n np.testing.assert_array_equal(sim.get_obs('prey0')['agents'], np.array(\n [[-1., -1., -1., -1., -1.],\n [-1., 0., 0., 0., 0.],\n [-1., 0., 0., 0., 0.],\n [-1., 0., 0., 0., 0.],\n [-1., 0., 0., 1., 2.]]\n ))\n np.testing.assert_array_equal(sim.get_obs('prey2')['agents'], np.array([\n [0., 1., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 2., 0.],\n [0., 0., 0., 0., 2.],\n [0., 0., 0., 0., 0.]]\n ))\n\n\ndef test_reset_distance_obs():\n np.random.seed(24)\n agents = [\n Prey(id='prey0', view=2),\n Predator(id='predator1', view=4),\n Prey(id='prey2', view=2),\n Predator(id='predator3', view=4),\n Predator(id='predator4', view=4),\n ]\n sim = PredatorPreySimulation.build(\n {'agents': agents, 'observation_mode': PredatorPreySimulation.ObservationMode.DISTANCE}\n )\n sim.reset()\n\n # Explicitly place the agents\n sim.agents['predator1'].position = np.array([4,4])\n sim.agents['predator3'].position = np.array([3,3])\n sim.agents['predator4'].position = np.array([7,9])\n sim.agents['prey0'].position = np.array([1,1])\n sim.agents['prey2'].position = np.array([3,2])\n\n assert sim.step_count == 0\n\n np.testing.assert_array_equal(sim.get_obs('predator1')['predator3'], np.array([-1, -1, 2]))\n np.testing.assert_array_equal(sim.get_obs('predator1')['predator4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator1')['prey0'], np.array([-3, -3, 1]))\n np.testing.assert_array_equal(sim.get_obs('predator1')['prey2'], np.array([-1, -2, 1]))\n\n np.testing.assert_array_equal(sim.get_obs('predator3')['predator1'], np.array([1, 1, 2]))\n np.testing.assert_array_equal(sim.get_obs('predator3')['predator4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator3')['prey0'], np.array([-2, -2, 1]))\n np.testing.assert_array_equal(sim.get_obs('predator3')['prey2'], np.array([0, -1, 1]))\n\n np.testing.assert_array_equal(sim.get_obs('predator4')['predator1'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator4')['predator3'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator4')['prey0'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator4')['prey2'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(sim.get_obs('prey0')['predator1'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('prey0')['predator3'], np.array([2, 2, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey0')['predator4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('prey0')['prey2'], np.array([2, 1, 1]))\n\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator1'], np.array([1, 2, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator3'], np.array([0, 1, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator4'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['prey0'], np.array([-2, -1, 1]))\n\n\ndef test_step_grid_obs():\n np.random.seed(24)\n agents = [\n Predator(id='predator0', view=2, attack=1),\n Prey(id='prey1', view=4),\n Prey(id='prey2', view=5)\n ]\n sim = PredatorPreySimulation.build({'agents': agents})\n sim.reset()\n sim.agents['predator0'].position = np.array([2, 3])\n sim.agents['prey1'].position = np.array([0, 7])\n sim.agents['prey2'].position = np.array([1, 1])\n np.testing.assert_array_equal(sim.get_obs('predator0')['agents'], np.array([\n [0., 0., 0., 0., 0.],\n [1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.]\n ]))\n np.testing.assert_array_equal(sim.get_obs('prey1')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., -1., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., -1., -1.],\n [ 2., 0., 0., 0., 0., 0., 0., -1., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., -1., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., -1., -1.]\n ]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 2., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.]\n ]))\n\n action = {\n 'predator0': {'move': np.zeros(2), 'attack': 1},\n 'prey1': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey2': {'move': np.array([-1, 0]), 'harvest': 0},\n }\n sim.step(action)\n np.testing.assert_array_equal(sim.get_obs('predator0')['agents'], np.array([\n [1., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.],\n [0., 0., 0., 0., 0.]\n ]))\n assert sim.get_reward('predator0') == -10\n assert not sim.get_done('predator0')\n np.testing.assert_array_equal(sim.get_obs('prey1')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 2., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.]\n ]))\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n np.testing.assert_array_equal(sim.get_obs('prey2')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 1.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 2., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.]\n ]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n action = {\n 'predator0': {'move': np.array([-1, 0]), 'attack': 0},\n 'prey1': {'move': np.array([1, 0]), 'harvest': 0},\n 'prey2': {'move': np.array([-1, 0]), 'harvest': 0},\n }\n sim.step(action)\n np.testing.assert_array_equal(sim.get_obs('predator0')['agents'], np.array([\n [-1., -1., -1., -1., -1.],\n [ 1., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n np.testing.assert_array_equal(sim.get_obs('prey1')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 2., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., -1.]]))\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n np.testing.assert_array_equal(sim.get_obs('prey2')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 2., 0., 0., 1.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., -1., 0., 0., 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('prey2') == -10\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n action = {\n 'predator0': {'move': np.array([0,0]), 'attack': 0},\n 'prey1': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey2': {'move': np.array([0, 1]), 'harvest': 0},\n }\n sim.step(action)\n np.testing.assert_array_equal(sim.get_obs('predator0')['agents'], np.array([\n [-1., -1., -1., -1., -1.],\n [ 0., 1., 0., 0., 0.],\n [ 0., 0., 0., 0., 1.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('predator0') == 0\n assert not sim.get_done('predator0')\n np.testing.assert_array_equal(sim.get_obs('prey1')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0., 1., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 2., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n np.testing.assert_array_equal(sim.get_obs('prey2')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., 0., 0., 0., 2., 0., 1., 0., 0.],\n [-1., -1., -1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., -1., 0., 0., 0., 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n action = {\n 'predator0': {'move': np.array([0, 1]), 'attack': 0},\n 'prey1': {'move': np.array([1, 0]), 'harvest': 0},\n 'prey2': {'move': np.array([0, 1]), 'harvest': 0},\n }\n sim.step(action)\n np.testing.assert_array_equal(sim.get_obs('predator0')['agents'], np.array([\n [-1., -1., -1., -1., -1.],\n [ 0., 1., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 1., 0.],\n [ 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n np.testing.assert_array_equal(sim.get_obs('prey1')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0., 0., 1., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 2., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n np.testing.assert_array_equal(sim.get_obs('prey2')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 2., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 1., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n action = {\n 'predator0': {'move': np.zeros(2), 'attack': 1},\n 'prey1': {'move': np.array([1, 0]), 'harvest': 0},\n 'prey2': {'move': np.array([1, 0]), 'harvest': 0},\n }\n sim.step(action)\n np.testing.assert_array_equal(sim.get_obs('predator0')['agents'], np.array([\n [-1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 1., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('predator0') == 100\n assert not sim.get_done('predator0')\n np.testing.assert_array_equal(sim.get_obs('prey1')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 1., 2., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('prey1') == -100\n assert sim.get_done('prey1')\n np.testing.assert_array_equal(sim.get_obs('prey2')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 2., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n action = {\n 'predator0': {'move': np.zeros(2), 'attack': 1},\n 'prey2': {'move': np.array([0, 1]), 'harvest': 0},\n }\n sim.step(action)\n np.testing.assert_array_equal(sim.get_obs('predator0')['agents'], np.array([\n [-1., -1., -1., -1., -1.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.],\n [ 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('predator0') == 100\n assert not sim.get_done('predator0')\n np.testing.assert_array_equal(sim.get_obs('prey2')['agents'], np.array([\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., -1., -1., -1., -1., -1., -1., -1., -1., -1.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 2., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],\n [-1., -1., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]))\n assert sim.get_reward('prey2') == -100\n assert sim.get_done('prey2')\n assert sim.get_all_done()\n\n\ndef test_step_distance_obs():\n np.random.seed(24)\n agents = [\n Predator(id='predator0', view=2, attack=1),\n Prey(id='prey1', view=4),\n Prey(id='prey2', view=5)\n ]\n sim = PredatorPreySimulation.build(\n {'agents': agents, 'observation_mode': PredatorPreySimulation.ObservationMode.DISTANCE}\n )\n sim.reset()\n sim.agents['predator0'].position = np.array([2, 3])\n sim.agents['prey1'].position = np.array([0, 7])\n sim.agents['prey2'].position = np.array([1, 1])\n\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey1'], np.array([ 0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey2'], np.array([-1, -2, 1]))\n\n np.testing.assert_array_equal(sim.get_obs('prey1')['predator0'], np.array([ 2, -4, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey1')['prey2'], np.array([0, 0, 0]))\n\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator0'], np.array([ 1, 2, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['prey1'], np.array([0, 0, 0]))\n\n\n action = {\n 'predator0': {'move': np.zeros(2), 'attack': 1},\n 'prey1': np.array([-1, 0]),\n 'prey2': np.array([0, 1]),\n }\n sim.step(action)\n\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey1'], np.array([ 0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey2'], np.array([-1, -1, 1]))\n assert sim.get_reward('predator0') == -10\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(sim.get_obs('prey1')['predator0'], np.array([ 2, -4, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey1')['prey2'], np.array([0, 0, 0]))\n assert sim.get_reward('prey1') == -10\n assert not sim.get_done('prey1')\n\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator0'], np.array([ 1, 1, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['prey1'], np.array([-1, 5, 1]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n\n action = {\n 'predator0': {'move': np.array([-1, 0]), 'attack': 0},\n 'prey1': np.array([0, -1]),\n 'prey2': np.array([0, 1]),\n }\n sim.step(action)\n\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey1'], np.array([ 0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey2'], np.array([0, 0, 1]))\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(sim.get_obs('prey1')['predator0'], np.array([ 1, -3, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey1')['prey2'], np.array([1, -3, 1]))\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator0'], np.array([ 0, 0, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['prey1'], np.array([-1, 3, 1]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n\n action = {\n 'predator0': {'move': np.array([0,0]), 'attack': 0},\n 'prey1': np.array([0, -1]),\n 'prey2': np.array([0, 1]),\n }\n sim.step(action)\n\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey1'], np.array([-1, 2, 1]))\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey2'], np.array([0, 1, 1]))\n assert sim.get_reward('predator0') == 0\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(sim.get_obs('prey1')['predator0'], np.array([ 1, -2, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey1')['prey2'], np.array([1, -1, 1]))\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator0'], np.array([ 0, -1, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['prey1'], np.array([-1, 1, 1]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n\n action = {\n 'predator0': {'move': np.array([0, 1]), 'attack': 0},\n 'prey1': np.array([0, -1]),\n 'prey2': np.array([-1, 0]),\n }\n sim.step(action)\n\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey1'], np.array([-1, 0, 1]))\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey2'], np.array([-1, 0, 1]))\n assert sim.get_reward('predator0') == -1\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(sim.get_obs('prey1')['predator0'], np.array([ 1, 0, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey1')['prey2'], np.array([0, 0, 1]))\n assert sim.get_reward('prey1') == -1\n assert not sim.get_done('prey1')\n\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator0'], np.array([1, 0, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['prey1'], np.array([0,0,1]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n\n action = {\n 'predator0': {'move': np.zeros(2), 'attack': 1},\n 'prey1': np.array([0, 1]),\n 'prey2': np.array([0, -1]),\n }\n sim.step(action)\n\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey1'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey2'], np.array([-1, -1, 1]))\n assert sim.get_reward('predator0') == 100\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(sim.get_obs('prey1')['predator0'], np.array([ 1, 0, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey1')['prey2'], np.array([0, -1, 1]))\n assert sim.get_reward('prey1') == -100\n assert sim.get_done('prey1')\n\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator0'], np.array([1, 1, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['prey1'], np.array([0,0,0]))\n assert sim.get_reward('prey2') == -1\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n\n action = {\n 'predator0': {'move': np.zeros(2), 'attack': 1},\n 'prey2': np.array([1, 0]),\n }\n sim.step(action)\n\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey1'], np.array([0, 0, 0]))\n np.testing.assert_array_equal(sim.get_obs('predator0')['prey2'], np.array([0, 0, 0]))\n assert sim.get_reward('predator0') == 100\n assert not sim.get_done('predator0')\n\n np.testing.assert_array_equal(sim.get_obs('prey2')['predator0'], np.array([1, 1, 2]))\n np.testing.assert_array_equal(sim.get_obs('prey2')['prey1'], np.array([0,0,0]))\n assert sim.get_reward('prey2') == -100\n assert sim.get_done('prey2')\n assert sim.get_all_done()\n\n\ndef test_attack_distances():\n region = 5\n predators = [Predator(id='predator0')]\n # predators = [{'id': 'predator0', 'view': region-1, 'move': 1, 'attack': 0}]\n prey = [Prey(id='prey{}'.format(i)) for i in range(3)]\n # prey = [{'id': 'prey' + str(i), 'view': region-1, 'move': 1} for i in range(3)]\n agents = predators + prey\n config = {'region': region, 'agents': agents}\n sim = PredatorPreySimulation.build(config)\n sim.reset()\n sim.agents['predator0'].position = np.array([2, 2])\n sim.agents['prey0'].position = np.array([2, 2])\n sim.agents['prey1'].position = np.array([1, 1])\n sim.agents['prey2'].position = np.array([0, 0])\n assert sim.agents['predator0'].attack == 0\n action_dict = {\n 'predator0': {'move': np.zeros([0, 0]), 'attack': 1},\n 'prey0': {'move': np.zeros(2), 'harvest': 0},\n 'prey1': {'move': np.zeros(2), 'harvest': 0},\n 'prey2': {'move': np.zeros(2), 'harvest': 0},\n }\n\n\n sim.step(action_dict)\n assert sim.get_reward('predator0') == \\\n sim.reward_map['predator'][PredatorPreySimulation.ActionStatus.GOOD_ATTACK]\n assert sim.get_reward('prey0') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.EATEN\n ]\n assert sim.get_reward('prey1') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.NO_MOVE\n ]\n assert sim.get_reward('prey2') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.NO_MOVE\n ]\n assert not sim.get_done('predator0')\n assert sim.get_done('prey0')\n assert not sim.get_done('prey1')\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n del action_dict['prey0']\n sim.step(action_dict)\n assert sim.get_reward('predator0') == \\\n sim.reward_map['predator'][PredatorPreySimulation.ActionStatus.BAD_ATTACK]\n assert sim.get_reward('prey1') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.NO_MOVE\n ]\n assert sim.get_reward('prey2') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.NO_MOVE\n ]\n assert not sim.get_done('predator0')\n assert not sim.get_done('prey1')\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n\n sim.agents['predator0'].attack = 1\n\n sim.step(action_dict)\n assert sim.get_reward('predator0') == \\\n sim.reward_map['predator'][PredatorPreySimulation.ActionStatus.GOOD_ATTACK]\n assert sim.get_reward('prey1') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.EATEN\n ]\n assert sim.get_reward('prey2') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.NO_MOVE\n ]\n assert not sim.get_done('predator0')\n assert sim.get_done('prey1')\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n del action_dict['prey1']\n sim.step(action_dict)\n assert sim.get_reward('predator0') == \\\n sim.reward_map['predator'][PredatorPreySimulation.ActionStatus.BAD_ATTACK]\n assert sim.get_reward('prey2') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.NO_MOVE\n ]\n assert not sim.get_done('predator0')\n assert not sim.get_done('prey2')\n assert not sim.get_all_done()\n\n\n sim.agents['predator0'].attack = 2\n sim.step(action_dict)\n assert sim.get_reward('predator0') == \\\n sim.reward_map['predator'][PredatorPreySimulation.ActionStatus.GOOD_ATTACK]\n assert sim.get_reward('prey2') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.EATEN]\n assert not sim.get_done('predator0')\n assert sim.get_done('prey2')\n assert sim.get_all_done()\n\n\ndef test_diagonal_moves():\n np.random.seed(24)\n region = 3\n prey = [Prey(id='prey{}'.format(i)) for i in range(12)]\n sim = PredatorPreySimulation.build({'agents': prey, 'region': region})\n sim.reset()\n for prey in sim.agents.values():\n prey.position = np.array([1,1])\n\n\n action = {\n 'prey0': {'move': np.array([0, 1]), 'harvest': 0},\n 'prey1': {'move': np.array([0, 1]), 'harvest': 0},\n 'prey2': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey3': {'move': np.array([0, -1]), 'harvest': 0},\n 'prey4': {'move': np.array([-1, 0]), 'harvest': 0},\n 'prey5': {'move': np.array([-1, 0]), 'harvest': 0},\n 'prey6': {'move': np.array([1, 0]), 'harvest': 0},\n 'prey7': {'move': np.array([1, 0]), 'harvest': 0},\n 'prey8': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey9': {'move': np.array([1, -1]), 'harvest': 0},\n 'prey10': {'move': np.array([-1, -1]), 'harvest': 0},\n 'prey11': {'move': np.array([-1, 1]), 'harvest': 0},\n }\n sim.step(action)\n assert sim.get_reward('prey0') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey1') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey2') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey3') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey4') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey5') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey6') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey7') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey8') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey9') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey10') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n assert sim.get_reward('prey11') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.GOOD_MOVE]\n\n np.testing.assert_array_equal([agent.position for agent in sim.agents.values()], [\n np.array([1, 2]),\n np.array([1, 2]),\n np.array([1, 0]),\n np.array([1, 0]),\n np.array([0, 1]),\n np.array([0, 1]),\n np.array([2, 1]),\n np.array([2, 1]),\n np.array([2, 2]),\n np.array([2, 0]),\n np.array([0, 0]),\n np.array([0, 2]),\n ])\n\n\n action = {\n 'prey0': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey1': {'move': np.array([-1, 1]), 'harvest': 0},\n 'prey2': {'move': np.array([1, -1]), 'harvest': 0},\n 'prey3': {'move': np.array([-1, -1]), 'harvest': 0},\n 'prey4': {'move': np.array([-1, 1]), 'harvest': 0},\n 'prey5': {'move': np.array([-1, -1]), 'harvest': 0},\n 'prey6': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey7': {'move': np.array([1, -1]), 'harvest': 0},\n 'prey8': {'move': np.array([1, 1]), 'harvest': 0},\n 'prey9': {'move': np.array([1, -1]), 'harvest': 0},\n 'prey10': {'move': np.array([-1, -1]), 'harvest': 0},\n 'prey11': {'move': np.array([-1, 1]), 'harvest': 0},\n }\n sim.step(action)\n assert sim.get_reward('prey0') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey1') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey2') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey3') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey4') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey5') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey6') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey7') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey8') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey9') == sim.reward_map['prey'][\n PredatorPreySimulation.ActionStatus.BAD_MOVE\n ]\n assert sim.get_reward('prey10') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.BAD_MOVE]\n assert sim.get_reward('prey11') == \\\n sim.reward_map['prey'][PredatorPreySimulation.ActionStatus.BAD_MOVE]\n\n np.testing.assert_array_equal([agent.position for agent in sim.agents.values()], [\n np.array([1, 2]),\n np.array([1, 2]),\n np.array([1, 0]),\n np.array([1, 0]),\n np.array([0, 1]),\n np.array([0, 1]),\n np.array([2, 1]),\n np.array([2, 1]),\n np.array([2, 2]),\n np.array([2, 0]),\n np.array([0, 0]),\n np.array([0, 2]),\n ])\n\n\ndef test_multi_move():\n np.random.seed(24)\n region = 8\n prey = [Prey(id='prey{}'.format(i), move=4) for i in range(4)]\n sim = PredatorPreySimulation.build({'agents': prey, 'region': region})\n sim.reset()\n sim.agents['prey0'].position = np.array([2, 3])\n sim.agents['prey1'].position = np.array([0, 7])\n sim.agents['prey2'].position = np.array([1, 1])\n sim.agents['prey3'].position = np.array([1, 4])\n\n action = {agent_id: agent.action_space.sample() for agent_id, agent in sim.agents.items()}\n action = {\n 'prey0': {'move': np.array([-2, 3]), 'harvest': 0},\n 'prey1': {'move': np.array([4, 0]), 'harvest': 0},\n 'prey2': {'move': np.array([2, 1]), 'harvest': 0},\n 'prey3': {'move': np.array([3, -2]), 'harvest': 0},\n }\n sim.step(action)\n\n np.testing.assert_array_equal(sim.agents['prey0'].position, [0,6])\n np.testing.assert_array_equal(sim.agents['prey1'].position, [4,7])\n np.testing.assert_array_equal(sim.agents['prey2'].position, [3,2])\n np.testing.assert_array_equal(sim.agents['prey3'].position, [4,2])\n\n\ndef test_done_on_max_steps():\n agents = [Prey(id=f'prey{i}') for i in range(2)]\n sim = PredatorPreySimulation.build({'max_steps': 4, 'agents': agents})\n sim.reset()\n for i in range(4):\n sim.step({agent_id: agent.action_space.sample() for agent_id, agent in sim.agents.items()})\n assert sim.get_all_done()\n\n\ndef test_with_resources():\n np.random.seed(24)\n agents = [\n Prey(id='prey0', view=2, harvest_amount=0.3),\n Prey(id='prey1'),\n Predator(id='predator0', view=1)\n ]\n sim = PredatorPreySimulation.build({'region': 5, 'agents': agents})\n sim.reset()\n\n np.allclose(sim.get_obs('predator0')['resources'], np.array([\n [0. , 0.19804811, 0. ],\n [0.16341112, 0.58086431, 0.4482749 ],\n [0. , 0.38637824, 0.78831386]\n ]))\n np.allclose(sim.get_obs('prey0')['resources'], np.array([\n [ 0.19804811, 0. , 0.42549817, 0.9438245 , -1. ],\n [ 0.58086431, 0.4482749 , 0.40239527, 0.31349653, -1. ],\n [ 0.38637824, 0.78831386, 0.33666274, 0.71590738, -1. ],\n [ 0.6264872 , 0.65159097, 0.84080142, 0.24749604, -1. ],\n [ 0.86455522, 0. , 0. , 0. , -1. ]]))\n np.allclose(sim.get_obs('prey1')['resources'], np.array([\n [-1., -1., -1., -1. , -1. , -1. , -1. , -1. , -1.],\n [-1., -1., -1., -1. , -1. , -1. , -1. , -1. , -1.],\n [-1., -1., -1., -1. , -1. , -1. , -1. , -1. , -1.],\n [-1., -1., -1., -1. , -1. , -1. , -1. , -1. , -1.],\n [-1., -1., -1., 0. , 0.19804811, 0. , 0.42549817, 0.9438245 , -1.],\n [-1., -1., -1., 0.16341112, 0.58086431, 0.4482749 , 0.40239527, 0.31349653, -1.],\n [-1., -1., -1., 0. , 0.38637824, 0.78831386, 0.33666274, 0.71590738, -1.],\n [-1., -1., -1., 0. , 0.6264872 , 0.65159097, 0.84080142, 0.24749604, -1.],\n [-1., -1., -1., 0.67319672, 0.86455522, 0. , 0. , 0. , -1.]\n ]))\n sim.step({\n 'prey0': {'move': np.zeros, 'harvest': 1},\n 'prey1': {'move': np.zeros, 'harvest': 1},\n })\n\n np.allclose(sim.get_obs('predator0')['resources'], np.array([\n [0. , 0.19804811, 0. ],\n [0.16341112, 0.58086431, 0.4482749 ],\n [0. , 0.38637824, 0.78831386]\n ]))\n np.allclose(sim.get_obs('prey0')['resources'], np.array([\n [ 0.19804811, 0. , 0.42549817, 0.9438245 , -1. ],\n [ 0.58086431, 0.4482749 , 0.40239527, 0.31349653, -1. ],\n [ 0.38637824, 0.78831386, 0.07666274, 0.71590738, -1. ],\n [ 0.6264872 , 0.65159097, 0.84080142, 0.24749604, -1. ],\n [ 0.86455522, 0. , 0. , 0. , -1. ]]))\n np.allclose(sim.get_obs('prey1')['resources'], np.array([\n [-1., -1., -1., -1. , -1. , -1. , -1. , -1. , -1.],\n [-1., -1., -1., -1. , -1. , -1. , -1. , -1. , -1.],\n [-1., -1., -1., -1. , -1. , -1. , -1. , -1. , -1.],\n [-1., -1., -1., -1. , -1. , -1. , -1. , -1. , -1.],\n [-1., -1., -1., 0. , 0.19804811, 0. , 0.42549817 , 0.9438245 , -1.],\n [-1., -1., -1., 0.16341112, 0.58086431, 0.4482749 , 0.40239527 , 0.31349653, -1.],\n [-1., -1., -1., 0. , 0.38637824, 0.78831386 , 0.07666274 , 0.71590738, -1.],\n [-1., -1., -1., 0. , 0.6264872 , 0.65159097 , 0.84080142 , 0.24749604, -1.],\n [-1., -1., -1., 0.67319672, 0.86455522, 0. , 0. , 0. , -1.]\n ]))\n assert sim.get_reward('prey0') == sim.reward_map['prey'][sim.ActionStatus.GOOD_HARVEST]\n assert sim.get_reward('prey1') == sim.reward_map['prey'][sim.ActionStatus.BAD_HARVEST]\n"
},
{
"alpha_fraction": 0.631447434425354,
"alphanum_fraction": 0.639835774898529,
"avg_line_length": 39.60144805908203,
"blob_id": "c82273b91113f677fa7f183777aa1cddb9280dc0",
"content_id": "0d17d38e9ba3d310ceb5cdf96a9a7c853fe15c53",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5603,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 138,
"path": "/abmarl/algs/monte_carlo.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "# 5.1 Monte Carlo prediction p92.\nfrom gym.spaces import Discrete\nimport numpy as np\n\nfrom abmarl.managers import SimulationManager\nfrom abmarl.external import GymWrapper\nfrom abmarl.pols import GreedyPolicy, EpsilonSoftPolicy, RandomFirstActionPolicy\nfrom abmarl.tools import numpy_utils as npu\n\nfrom .generate_episode import generate_episode\n\n\ndef exploring_starts(sim, iteration=10_000, gamma=0.9, horizon=200):\n \"\"\"\n Estimate an optimal policy over an simulation using monte carlo policy estimation.\n\n Args:\n sim: The simulation, obviously.\n iteration: The number of times to iterate the learning algorithm.\n gamma: The discount factor\n horizon: the time horizon for the trajectory.\n\n Returns:\n sim: The simulation. Algorithms may wrap simulations before training in them, so this\n simulation may be wrapped.\n q_table: The Q values\n policy: The policy that is learned.\n \"\"\"\n assert isinstance(sim, SimulationManager)\n sim = GymWrapper(sim)\n assert isinstance(sim.observation_space, Discrete)\n assert isinstance(sim.action_space, Discrete)\n q_table = np.random.normal(0, 1, size=(sim.observation_space.n, sim.action_space.n))\n policy = RandomFirstActionPolicy(q_table)\n state_action_returns = {}\n\n for i in range(iteration):\n states, actions, rewards = generate_episode(sim, policy, horizon)\n states = np.stack(states)\n actions = np.stack(actions)\n G = 0\n for i in reversed(range(len(states))):\n state, action, reward = states[i], actions[i], rewards[i]\n G = gamma * G + reward\n if not (npu.array_in_array(state, states[:i]) and\n npu.array_in_array(action, actions[:i])):\n if (state, action) not in state_action_returns:\n state_action_returns[(state, action)] = [G]\n else:\n state_action_returns[(state, action)].append(G)\n q_table[state, action] = np.mean(state_action_returns[(state, action)])\n\n return sim, q_table, policy\n\n\ndef epsilon_soft(sim, iteration=10_000, gamma=0.9, epsilon=0.1, horizon=200):\n \"\"\"\n Estimate an optimal policy over a simulation using monte carlo policy estimation. The policy\n is technically non-optimal because it is epsilon-soft.\n\n Args:\n sim: The simulation, obviously.\n iteration: The number of times to iterate the learning algorithm.\n gamme: The discount factor\n epsilon: The exploration probability.\n\n Returns:\n sim: The simulation. Algorithms may wrap simulations before training in them, so this\n simulation may be wrapped.\n q_table: The Q values\n policy: The policy that is learned.\n \"\"\"\n assert isinstance(sim, SimulationManager)\n sim = GymWrapper(sim)\n assert isinstance(sim.observation_space, Discrete)\n assert isinstance(sim.action_space, Discrete)\n q_table = np.random.normal(0, 1, size=(sim.observation_space.n, sim.action_space.n))\n policy = EpsilonSoftPolicy(q_table, epsilon=epsilon)\n state_action_returns = {}\n\n for i in range(iteration):\n states, actions, rewards = generate_episode(sim, policy, horizon)\n states = np.stack(states)\n actions = np.stack(actions)\n G = 0\n for i in reversed(range(len(states))):\n state, action, reward = states[i], actions[i], rewards[i]\n G = gamma * G + reward\n if not (npu.array_in_array(state, states[:i]) and\n npu.array_in_array(action, actions[:i])):\n if (state, action) not in state_action_returns:\n state_action_returns[(state, action)] = [G]\n else:\n state_action_returns[(state, action)].append(G)\n q_table[state, action] = np.mean(state_action_returns[(state, action)])\n\n return sim, q_table, policy\n\n\ndef off_policy(sim, iteration=10_000, gamma=0.9, horizon=200):\n \"\"\"\n Off-policy Monte Carlo control estimates an optimal policy in a simulation. Trains a greedy\n policy be generating trajectories from an epsilon-soft behavior policy.\n\n Args:\n sim: The simulation, obviously.\n iteration: The number of times to iterate the learning algorithm.\n gamme: The discount factor\n\n Returns:\n sim: The simulation. Algorithms may wrap simulations before training in them, so this\n simulation may be wrapped.\n q_table: The Q values\n policy: The policy that is learned.\n \"\"\"\n assert isinstance(sim, SimulationManager)\n sim = GymWrapper(sim)\n assert isinstance(sim.observation_space, Discrete)\n assert isinstance(sim.action_space, Discrete)\n q_table = np.random.normal(0, 1, size=(sim.observation_space.n, sim.action_space.n))\n c_table = 0 * q_table\n policy = GreedyPolicy(q_table)\n for i in range(iteration):\n behavior_policy = EpsilonSoftPolicy(q_table)\n states, actions, rewards, = generate_episode(sim, behavior_policy, horizon)\n G = 0\n W = 1\n for i in reversed(range(len(states))):\n state, action, reward = states[i], actions[i], rewards[i]\n G = gamma * G + reward\n c_table[state, action] += W\n q_table[state, action] = q_table[state, action] + W/(c_table[state, action]) * \\\n (G - q_table[state, action])\n if action != policy.act(state): # Nonoptimal action\n break\n W /= behavior_policy.probability(state, action)\n\n return sim, q_table, policy\n"
},
{
"alpha_fraction": 0.5812564492225647,
"alphanum_fraction": 0.5899850726127625,
"avg_line_length": 32.10646438598633,
"blob_id": "86c1492e2282a343de7e8462db0aa88950f64dbb",
"content_id": "90c9adc1d09ba8bf18f2993d392ff9dfd2edc7d0",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8707,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 263,
"path": "/abmarl/sim/components/hackathon_prototype_components.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "import copy\n\nfrom gym.spaces import Dict, Box\nfrom matplotlib import pyplot as plt\nimport numpy as np\n\nfrom abmarl.sim import PrincipleAgent\n\n\nclass World:\n def __init__(self, region=None, agents=None, **kwargs):\n assert type(region) is int, \"Region must be an integer.\"\n self.region = region\n self.agents = agents if agents is not None else {}\n\n\nclass ContinuousWorld(World):\n def reset(self, **kwargs):\n for agent in self.agents.values():\n agent.position = np.random.uniform(0, self.region, 2)\n\n\nclass GridWorld(World):\n def reset(self, **kwargs):\n for agent in self.agents.values():\n agent.position = np.random.randint(0, self.region, 2)\n\n def render(self, fig=None, render_condition=None, **kwargs):\n draw_now = fig is None\n if draw_now:\n fig = plt.gcf()\n\n ax = fig.gca()\n if render_condition is None:\n agents_x = [agent.position[1] + 0.5 for agent in self.agents.values()]\n agents_y = [self.region - 0.5 - agent.position[0] for agent in self.agents.values()]\n else:\n agents_x = [\n agent.position[1] + 0.5 for agent in self.agents.values()\n if render_condition[agent.id]\n ]\n agents_y = [\n self.region - 0.5 - agent.position[0] for agent in self.agents.values()\n if render_condition[agent.id]\n ]\n\n ax.scatter(agents_x, agents_y, marker='o', s=200, edgecolor='black', facecolor='gray')\n\n if draw_now:\n plt.plot()\n plt.pause(1e-17)\n\n return ax\n\n\nclass Movement:\n def __init__(self, region=None, agents=None, **kwargs):\n assert type(region) is int, \"Region must be an integer.\"\n self.region = region\n self.agents = agents if agents is not None else {}\n\n\nclass GridMovement(Movement):\n def process_move(self, agent, direction, **kwargs):\n if 0 <= agent.position[0] + direction[0] < self.region and \\\n 0 <= agent.position[1] + direction[1] < self.region:\n # Still inside the boundary, good move\n agent.position += direction\n return True\n else:\n return False\n\n\nclass Resources:\n def __init__(self, region=None, agents=None, coverage=0.75, min_value=0.1, max_value=1.0,\n regrow_rate=0.04, **kwargs):\n assert type(region) is int, \"Region must be an integer.\"\n self.agents = agents if agents is not None else {}\n self.region = region\n self.min_value = min_value\n self.max_value = max_value\n self.regrow_rate = regrow_rate\n self.coverage = coverage\n\n\nclass GridResources(Resources):\n def reset(self, **kwargs):\n coverage_filter = np.zeros((self.region, self.region))\n coverage_filter[np.random.uniform(0, 1, (self.region, self.region)) < self.coverage] = 1.\n self.resources = np.multiply(\n np.random.uniform(self.min_value, self.max_value, (self.region, self.region)),\n coverage_filter\n )\n\n def process_harvest(self, location, amount, **kwargs):\n \"\"\"\n Process harvesting a certain amount at a certain location. Return the amount\n that was actually harvested here.\n \"\"\"\n # Process all the harvesting\n if self.resources[location] - amount >= 0.:\n actual_amount_harvested = amount\n else:\n actual_amount_harvested = self.resources[location]\n self.resources[location] = max([0., self.resources[location] - amount])\n\n return actual_amount_harvested\n\n def regrow(self, **kwargs):\n \"\"\"\n Process the regrowth, which is done according to the revival rate.\n \"\"\"\n self.resources[self.resources >= self.min_value] += self.regrow_rate\n self.resources[self.resources >= self.max_value] = self.max_value\n\n def render(self, fig=None, **kwargs):\n draw_now = fig is None\n if draw_now:\n from matplotlib import pyplot as plt\n fig = plt.gcf()\n import seaborn as sns\n\n ax = fig.gca()\n ax = sns.heatmap(np.flipud(self.resources), ax=ax, cmap='Greens')\n\n if draw_now:\n plt.plot()\n plt.pause(1e-17)\n\n return ax\n\n\nclass DeathLifeAgent(PrincipleAgent):\n count = 0\n\n def __init__(self, death=None, life=None, **kwargs):\n super().__init__(**kwargs)\n self.death = death\n self.life = life\n\n DeathLifeAgent.count += 1\n\n @classmethod\n def copy(cls, original):\n new_agent = copy.deepcopy(original)\n new_agent.id = f'agent{DeathLifeAgent.count}'\n DeathLifeAgent.count += 1\n return new_agent\n\n @property\n def configured(self):\n return super().configured and self.death is not None and self.life is not None\n\n\nclass LifeAndDeath:\n def __init__(self, agents=None, **kwargs):\n assert type(agents) is dict, \"Agents must be a dict.\"\n for agent in agents.values():\n assert isinstance(agent, DeathLifeAgent), \"Agents must have health in this simulation.\"\n self.agents = agents\n for agent in self.agents.values():\n agent.is_original = True\n\n def reset(self, **kwargs):\n for agent_id, agent in list(self.agents.items()):\n if not agent.is_original:\n del self.agents[agent_id]\n DeathLifeAgent.count = len(self.agents)\n for agent in self.agents.values():\n agent.health = np.random.uniform(0.5, 1.0)\n agent.is_alive = True\n\n def process_health_effects(self, agent, **kwargs):\n if agent.health >= agent.life: # Reproduce\n agent.health /= 2.\n new_agent = DeathLifeAgent.copy(agent)\n new_agent.is_original = False\n self.agents[new_agent.id] = new_agent\n elif agent.health <= agent.death:\n agent.is_alive = False\n\n def render(self, **kwargs):\n for agent in self.agents.values():\n print(f'{agent.id}: {agent.health}, {agent.is_alive}')\n\n\nclass CompositeSim:\n def __init__(self, agents=None, **kwargs):\n assert type(agents) is dict, \"Agents must be a dict.\"\n for agent in agents.values():\n assert isinstance(agent, DeathLifeAgent), \"Agents must have health in this simulation.\"\n self.agents = agents\n self.life_and_death = LifeAndDeath(agents=agents, **kwargs)\n self.world = GridWorld(agents=agents, **kwargs)\n self.resources = GridResources(**kwargs)\n self.movement = GridMovement(agents=agents, **kwargs)\n\n def reset(self, **kwargs):\n self.life_and_death.reset(**kwargs)\n self.world.reset(**kwargs)\n self.resources.reset(**kwargs)\n\n def step(self, action_dict, **kwargs):\n for agent_id, action in action_dict.items():\n agent = self.agents[agent_id]\n if agent.is_alive:\n if 'harvest' in action:\n amount_harvested = self.resources.process_harvest(\n tuple(agent.position), action['harvest']\n )\n agent.health += amount_harvested\n if 'move' in action:\n good_move = self.movement.process_move(agent, action['move'])\n agent.health -= 0.1*sum(action['move']) if good_move else 0.5\n\n self.life_and_death.process_health_effects(agent)\n self.resources.regrow()\n\n def render(self, **kwargs):\n fig = plt.gcf()\n fig.clear()\n self.resources.render(fig=fig, **kwargs)\n render_condition = {agent.id: agent.is_alive for agent in self.agents.values()}\n self.world.render(fig=fig, render_condition=render_condition, **kwargs)\n plt.plot()\n plt.pause(1e-6)\n\n self.life_and_death.render(**kwargs)\n\n\n# --- Use case --- #\nregion = 10\nmax_value = 2.0\nagents = {f'agent{i}': DeathLifeAgent(\n id=f'agent{i}',\n action_space=Dict({\n 'move': Box(-1, 1, (2,), np.int),\n 'harvest': Box(0, max_value, (1,), np.float),\n }),\n death=0.,\n life=1.0,\n) for i in range(5)}\n\nsim = CompositeSim(\n region=region,\n agents=agents,\n max_value=max_value\n)\n\n# TODO: Why do parents and children take EXACT SAME action?\n# ANSWER: because the child is a copy of the parent, and that means it copies\n# the random number generator, so the actions will be the same.\nfor ep in range(3):\n print(f'Episode is {ep}')\n sim.reset()\n sim.render()\n\n for i in range(24):\n print(i)\n sim.step({agent.id: agent.action_space.sample() for agent in agents.values()})\n sim.render()\n\nplt.show()\n"
},
{
"alpha_fraction": 0.7455501556396484,
"alphanum_fraction": 0.7455501556396484,
"avg_line_length": 33.33333206176758,
"blob_id": "8eb29df590928c7a322a7f8da6b85461c01d9ddb",
"content_id": "f0d1efe1bb807b1e735f18899f3123b864c8d7ae",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 2472,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 72,
"path": "/docs/src/tutorials/magpie.rst",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": ".. Abmarl documentation Magpie tutorial.\n\n.. _tutorial_magpie:\n\nMagpie\n======\n\nThe prospect of applying MuliAgent Reinforcement Learning algorithms on HPC\nsystems is very attractive. As a first step, we demonstrate that\nabmarl can be used with `magpie <https://github.com/LLNL/magpie>`_ to create batch\njobs for running on multiple compute nodes.\n\n\nInstalling Abmarl on HPC systems\n---------------------------------\n\nHere we'll use conda to install on an HPC system:\n\n* Create the conda virtual environment: `conda create --name abmarl`\n* Activate it: `conda activate abmarl`\n* Install pip installer: `conda install --name abmarl pip`\n* Follow :ref:`installation instructions <installation>`\n\nUsage\n-----\n\nWe demonstrate running the :ref:`PredatorPrey tutorial <tutorial_predator_prey>`\nusing Mapgie.\n\nmake-runnable\n`````````````\nAbmarl's command line interface provides the `make-runnable`\nsubcommand that converts the configuration script into a runnable script and saves it\nto the same directory.\n\n.. code-block::\n\n abmarl make-runnable predator_prey_training.py\n\nThis will create a file called `runnable_predator_prey_training.py`.\n\nMagpie flag\n```````````\nThe full use of `make-runnable` is seen when it is run with the ``--magpie`` flag.\nThis will create a custom magpie script using\n`magpie's ray default script <https://github.com/LLNL/magpie/blob/master/submission-scripts/script-sbatch-srun/magpie.sbatch-srun-ray>`_\nas a starting point. This also adds the correct initialization parameters to\n`ray.init()` in the `runnable_` script. For example,\n\n.. code-block::\n\n abmarl make-runnable predator_prey_training.py --magpie\n\n\nwill create the `runnable_` script with ``ray.init(address=os.environ['MAGPIE_RAY_ADDRESS'])``\nand will create a\n`magpie batch script <https://github.com/LLNL/Abmarl/blob/main/examples/predator_prey/PredatorPrey_magpie.sbatch-srun-ray>`_\nthat is setup to run this example. To launch the batch job, we simply run it from\nthe command line:\n\n.. code-block::\n\n sbatch -k --ip-isolate=yes PredatorPrey_magpie.sbatch-srun-ray\n\nThe script can be modified to adjust the job parameters, such as the number of\ncompute nodes, the time limit for the job, etc. This can also be done through\nabmarl via the ``-n`` and ``-t`` options.\n\n.. ATTENTION::\n the `num_workers` parameter in the tune configuration is the number of processors\n to utilize per compute node, which is the different from the number of compute\n nodes you are requesting.\n"
},
{
"alpha_fraction": 0.6058520078659058,
"alphanum_fraction": 0.6064257025718689,
"avg_line_length": 32.519229888916016,
"blob_id": "39a7d690fc382fcea99165311583beb5aac41480",
"content_id": "b51408e3a2d02bb2d9907b82c367f7a406d43df5",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": true,
"language": "Python",
"length_bytes": 1743,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 52,
"path": "/abmarl/external/gym_env_wrapper.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from gym import Env as GymEnv\n\n\nclass GymWrapper(GymEnv):\n \"\"\"\n Wrap an AgentBasedSimulation object with only a single agent to the gym.Env interface.\n This wrapper exposes the single agent's observation and action space directly\n in the simulation.\n \"\"\"\n def __init__(self, sim):\n from abmarl.managers import SimulationManager\n assert isinstance(sim, SimulationManager)\n assert len(sim.agents) == 1 # Can only work with single agents\n self.sim = sim\n self.agent_id, agent = next(iter(sim.agents.items()))\n self.observation_space = agent.observation_space\n self.action_space = agent.action_space\n\n def reset(self, **kwargs):\n \"\"\"\n Return the observation from the single agent.\n \"\"\"\n obs = self.sim.reset(**kwargs)\n return obs[self.agent_id]\n\n def step(self, action, **kwargs):\n \"\"\"\n Wrap the action by storing it in a dict that maps the agent's id to the\n action. Pass to sim.step. Return the observation, reward, done, and\n info from the single agent.\n \"\"\"\n obs, reward, done, info = self.sim.step({self.agent_id: action}, **kwargs)\n return obs[self.agent_id], \\\n reward[self.agent_id], \\\n done[self.agent_id], \\\n info[self.agent_id]\n\n def render(self, **kwargs):\n \"\"\"\n Forward render calls to the composed simulation.\n \"\"\"\n self.sim.render(**kwargs)\n\n @property\n def unwrapped(self):\n \"\"\"\n Fall through all the wrappers and obtain the original, completely unwrapped simulation.\n \"\"\"\n try:\n return self.sim.unwrapped\n except AttributeError:\n return self.sim\n"
},
{
"alpha_fraction": 0.7662253975868225,
"alphanum_fraction": 0.7692121267318726,
"avg_line_length": 49.97942352294922,
"blob_id": "cf1717625d690dfb757a1e3ecd15706da8943ae4",
"content_id": "ce54ba181d26a745f745671db7f4b61d133b5003",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 12392,
"license_type": "permissive",
"max_line_length": 100,
"num_lines": 243,
"path": "/docs/src/featured_usage.rst",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": ".. Abmarl documentation highlights.\n\nFeatured Use Cases\n==================\n\n\nEmergent Collaborative and Competitive Behavior\n-----------------------------------------------\n\nIn this experiment, we study how collaborative and competitive behaviors emerge\namong agents in a partially observable stochastic game. In our simulation, each\nagent occupies a square and can move around the map. Each agent can \"attack\"\nagents that are on a different \"team\"; the attacked agent loses its life and\nis removed from the simulation. Each agent can observe the state of the map in\na region surrounding its location. It can see other agents and what team they're\non as well as the edges of the map. The diagram below visuially depicts the agents'\nobservation and action spaces.\n\n.. figure:: .images/grid_agent_diagram.png\n :width: 100 %\n :alt: Diagram visually depicting agents' observation and action spaces.\n\n Each agent has a partial observation of the map centered around its\n location. The green box shows the orange agent’s observation of the map,\n and the matrix below it shows the actual observation. Each agent can choose\n to move or to \"attack\" another agent in one of the nearby squares. The policy is just a simple\n 2-layer MLP, each layer having 64 units. We don’t apply any kind of specialized\n architecture that encourages collaboration or competition. Each agent is simple: they do not\n have a model of the simulation; they do not have a global view of the simulation; their\n actions are only local in both space and in agent interaction (they can only\n interact with one agent at a time). Yet, we will see efficient and complex\n strategies emerge, collaboration and competition from the common or conflicting\n interest among agents.\n\n\nIn the various examples below, each policy is a two-layer MLP, with 64 units in\neach layer. We use RLlib's A2C Trainer with default parameters and train for\ntwo million episodes on a compute node with 72 CPUs.\n\n.. ATTENTION::\n This page makes heavy use of animated graphics. It is best to read this content\n on our html site instead of our pdf manual.\n\nSingle Agent Foraging\n`````````````````````\nWe start by considering a single foraging agent whose objective is to move around\nthe map collecting resource agents. The single forager\ncan see up to three squares away, move up to one square away, and forage (\"attack\") resources up\nto one square away. The forager is rewarded for every resource it collects and given a small penalty\nfor attempting to move off the map and an even smaller \"entropy\" penalty every time-step to\nencourage it to act quickly. At the beginning of every episode, the agents spawn\nat random locations in the map. Below is a video showing a typical full episode\nof the learned behavior and a brief analysis.\n\n.. NOTE::\n From an Agent Based Modeling perspective, the resources are technically agents\n themselves. However, since they don't do or see anything, we tend not to call\n them agents in the text that follows.\n\n.. figure:: .images/single_agent_full.*\n :width: 100 %\n :alt: Video showing an episode with the trained behavior.\n\n A full episode showing the forager's learned strategy. The forager is the blue circle\n and the resources are the green squares. Notice how the forager bounces among\n resource clusters, greedily collecting all local resources before exploring the map for\n more.\n\nWhen it can see resources\n'''''''''''''''''''''''''\nThe forager moves toward the closest resource that it observes and collects it. Note\nthat the foraging range is 1 square: the forager rarely\nwaits until it is directly over a resource; it usually forages\nas soon as it is within range. In some cases, the forager intelligently places itself\nin the middle of 2-3 resources in order to forage within the least number of moves.\nWhen the resources are near the edge of the map, it behaves with some inefficiency,\nlikely due to the small penalty we give it for moving off the map, which results\nin an aversion towards the map edges. Below is a series of short video\nclips showing the foraging strategy.\n\n.. figure:: .images/single_agent_exploit.*\n :width: 100 %\n :alt: Video showing the forager's behavior when it observes resources.\n\n The forager learns an effective foraging strategy, moving towards and collecting\n the nearest resources that it observes.\n\nWhen it cannot see resources\n'''''''''''''''''''''''''''''\nThe forager's behavior when it is near resources is not surprising. But how does\nit behave when it cannot see any resources? The forager only sees that\nwhich is near it and does not have any information distinguishing one \"deserted\"\narea of the map from another. Recall, however, that it observes the edges\nof the map, and it uses this information to learn an effecive exploration strategy.\nIn the video below, we can see that the forager learns to explore the map by moving\nalong its edges in a clockwise direction, occasionally making random moves towards\nthe middle of the map.\n\n.. figure:: .images/single_agent_explore.*\n :width: 100 %\n :alt: Video showing the forager's behavior when it does not observe resources.\n\n The forager learns an effective exploration strategy, moving along the edge\n of the map in a clockwise direction.\n\n.. IMPORTANT::\n We do not use any kind of heuristic or mixed policy. The exporation strategy\n *emerges* entirely from reinforcement learning.\n\nMultiple Agents Foraging\n````````````````````````\nHaving experimented with a single forager, let us now turn our attention\nto the strategies learned by multiple foragers interacting in the map at the same\ntime. Each forager is homogeneous with each other as described above: they can\nall move up to one square away, observe up to three squares away, and are rewarded\nthe same way. The observations include other foragers in addition to the resources\nand map edges. All agents share a single policy. Below is a brief analysis of the\nlearned behaviors.\n\nCover and explore\n'''''''''''''''''\nOur reward schema implicitly encourages the foragers to collaborate because we give\na small penalty to each one for taking too long. Thus, the faster they\ncan collect all the resources, the less they are penalized. Furthermore, because each\nagent trains the same policy, there is no incentive for competitive behavior. An\nagent can afford to say, \"I don't need to get the resource first. As long as one\nof us gets it quickly, then we all benefit\". Therefore, the foragers learn to spread\nout to *cover* the map, maximizing the amount of squares that are observed. \n\nIn the video clips below, we see that the foragers avoid being within observation\ndistance of one another. Typically, when two foragers get too close, they repel\neach other, each moving in opposite directions, ensuring that the space is *covered*.\nFurthermore, notice the dance-like exploration strategy.\nSimilar to the single-agent case above, they learn to *explore* along the\nedges of the map in a clockwise direction. However, they're not as efficient as\nthe single agent because they \"repel\" each other.\n\n.. figure:: .images/multi_agent_spread.*\n :width: 100 %\n :alt: Video showing how the foragers spread out.\n\n The foragers cover the map by spreading out and explore it by traveling in a\n clockwise direction.\n\n.. IMPORTANT::\n We do not directly incentivize agents to keep their distance. No part of the\n reward schema directly deals with the agents' distances from each other. These\n strategies are *emergent*.\n\nBreaking the pattern\n''''''''''''''''''''\nWhen a forager observes a resource, it breaks its \"cover and explore\" strategy and\nmoves directly for the resource. Even multiple foragers move towards the same resource.\nThey have no reason to coordinate who will get it because, as we stated above,\nthere is no incentive for competition, so no need to negotiate. If another forager\ngets there first, everyone benefits. The foragers learn to prioritize collecting\nthe resources over keeping their distance from each other.\n\n.. figure:: .images/multi_agent_forage.*\n :width: 100 %\n :alt: Video showing how the foragers move towards resources.\n\n The foragers move towards resources to forage, even when there are other foragers\n nearby.\n\n.. Tip::\n We should expect to see both of these strategies occuring at\n the same time within a simulation because while some agents are \"covering and\n exploring\", others are moving towards resources.\n\nIntroducing Hunters\n```````````````````\nSo far, we have seen intelligent behaviors emerge in both single- and multi-forager\nscenarios; we even saw the emergence of collaborative\nbehavior. In the following experiments, we explore competitive emergence by introducing\nhunters into the simulation. Like foragers, hunters can move up to one square away\nand observe other agents and map edges up to three squares away. Hunters, however,\nare more effective killers and can attack a forager up to two squares away. They are\nrewarded for successful kills, they are and penalized for bad moves and for taking\ntoo long, exactly the same way as foragers.\n\nHowever, the hunters and foragers have completely different objectives:\na forager tries to clear the map of all *resources*, but a hunter tries to clear\nthe map of all *foragers*. Therefore, we set up two policies. All the hunters\nwill train the same policy, and all the foragers will train the same policy, and\nthese policies will be distinct. \n\nThe learned behaviors among the two groups in this mixed collaborate-competitive\nsimulation are tightly integrated, with multiple strategies appearing at the same\ntime within a simulation. Therefore, in contrast to above, we will not show video\nclips that capture a single strategy; instead, we will show video clips that\ncapture multiple strategies and attempt to describe them in detail.\n\nFirst Scenario\n''''''''''''''\n\n.. image:: .images/teams_scenario_1.*\n :width: 100 %\n :alt: Video showing the first scenario with hunters and foragers.\n\nTwo of the foragers spawn next to hunters and are killed immediately. Afterwards,\nthe two hunters on the left do not observe any foragers for some time. They seem to have\nlearned the *cover* strategy by spreading out, but they don't seem to have\nlearned an effecient *explore* strategy since they mostly occupy the same region\nof the map for the duration of the simulation.\n\nThree foragers remain at the bottom of the map. These foragers\nwork together to collect all nearby resources. Just as they finish the resource cluster,\na hunter moves within range and begins to chase them towards the bottom of the\nmap. When they hit the edge, they split in two directions. The hunter kills\none of them and then waits for one step, unsure about which forager to persue next.\nAfter one step, we see that it decides to persue the forager to the right.\n\nMeanwhile, the forager to the left continues to run away, straight into the path\nof another hunter but also another resource. The forager could get away by running\nto the right, but it decides to collect the resource at the cost of its own life.\n\nThe last remaining forager has escaped the hunter and has conveniently found another\ncluster of resources, which it collects. A few frames later, it encounters the\nsame hunter, and this time it is chased all the way across the map. It manages\nto evade the hunter and collect one final resource before encountering yet another\nhunter. At the end, we see both hunters chasing the forager to the top of the map,\nboxing it in and killing it.\n\nSecond scenario\n'''''''''''''''\n\n.. image:: .images/teams_scenario_2.*\n :width: 100 %\n :alt: Video showing the second scenario with hunters and foragers.\n\nNone of the foragers are under threat at the beginning of this scenario. They clear\na cluster of resources before one of them wanders into the path of a hunter. The\nhunter gives chase, and the forager actually leads the hunter back to the group.\nThis works to its benefit, however, as the hunter is repeatedly confused by the\nforagers exercising the *splitting* strategy. Meanwhile the second hunter has spotted\na forager and joins the hunt. The two hunters together are able to split up the pack\nof foragers and systematically hunt them down. The last forager is chased into the\ncorner and killed.\n\n.. NOTE::\n Humorously, the first forager that was spotted is the one who manages to stay\n alive the longest.\n"
},
{
"alpha_fraction": 0.8571428656578064,
"alphanum_fraction": 0.8571428656578064,
"avg_line_length": 41,
"blob_id": "17d85df7874b5677ce980b7cce7a631cafaee919",
"content_id": "367e37dfaf97fce86ea7ebbb4d8f613070e7b7f1",
"detected_licenses": [
"BSD-3-Clause",
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 42,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 1,
"path": "/abmarl/sim/corridor/__init__.py",
"repo_name": "Leonardo767/Abmarl",
"src_encoding": "UTF-8",
"text": "from .multi_corridor import MultiCorridor\n"
}
] | 80 |
snehakhanna/Emotion-Recognition | https://github.com/snehakhanna/Emotion-Recognition | a7c2eb9411a1b1b00376789eab8181ec989e6a5b | 4effccc93061dbd6176d89ceaca9e360ac4c4e98 | 5749818981b718588f7a6c4531798083c4e3aa9c | refs/heads/master | 2020-04-28T06:00:30.478827 | 2019-03-11T16:37:57 | 2019-03-11T16:37:57 | 175,040,421 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5927306413650513,
"alphanum_fraction": 0.6272134184837341,
"avg_line_length": 43,
"blob_id": "0f34b70811cb468e26a436a164a617297e4681df",
"content_id": "1cc9c8163390bcfb5214aee0eb9c00b758993fab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2146,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 47,
"path": "/src/emotion_recognizer.py",
"repo_name": "snehakhanna/Emotion-Recognition",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nTo Dectect Face in Emotion Recognition\nCreated on 4/02/2018 \nBy Jainam Gala\n\"\"\"\nimport cv2\nfrom keras.models import load_model\nimport numpy\n\nface_models_path=\"../trained_models/face_detection_models/haarcascade_frontalface_default.xml\"\nemotion_models_path=\"../trained_models/emotion_models/emotion_recog_1_0.346562721495.model\"\nemotion_labels =[\"Angry\",\"Fear\",\"Happy\",\"Sad\",\"Surprise\",\"Neutral\"]#[] ka matter nhi krta () ka does\n\n\nface_detection=cv2.CascadeClassifier(face_models_path)\nemotion_models =load_model(emotion_models_path)\nemotion_model_input_size =emotion_models.input_shape[1:3]\n\ncap=cv2.VideoCapture(0)\nwhile (True):\n ret_val,frame=cap.read()\n if ret_val==True:\n gray=cv2.cvtColor(frame,cv2.COLOR_BGR2GRAY)\n \n faces=face_detection.detectMultiScale(gray,1.3,5)\n for x,y,w,h in faces:\n gray_face =gray[y:y+h,x:x+w]\n gray_face =cv2.resize(gray_face,emotion_model_input_size)\n pre_processed_img=gray_face.astype(\"float32\")#32 bit representatn hoga 4r normalizatn & array operation etc***float mai convert ..coz divide by 255 toh division ho sake so\n pre_processed_img/=255\n expanded_dimen_img=numpy.expand_dims(pre_processed_img,0)#1st index\n expanded_dimen_img= numpy.expand_dims(expanded_dimen_img,-1)#last index\n emotion_probabilities=emotion_models.predict(expanded_dimen_img)\n emotion_max_prob=numpy.max(emotion_probabilities)# Not necessary argmax does the required function..arg gives index..other gives value\n emotion_label =numpy.argmax(emotion_probabilities)\n \n cv2.rectangle(frame,(x,y),(x+w,y+h),(0,0,255),3)\n cv2.putText(frame,emotion_labels[emotion_label],(x,y),\n cv2.FONT_HERSHEY_COMPLEX, 2, (0,255,0),5) \n \n cv2.imshow(\"Emotion_recognition\",frame)\n# time.sleep(0.05)\n if cv2.waitKey(1)==27:\n break\ncv2.destroyAllWindows()\ncap.release() \n \n \n \n \n \n"
},
{
"alpha_fraction": 0.7339449524879456,
"alphanum_fraction": 0.7394495606422424,
"avg_line_length": 59.44444274902344,
"blob_id": "4732a1df335bfca909b2be280164d3467ee0821e",
"content_id": "d8d9e950fe27238e200d4f96b3e26600aeba2b52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 545,
"license_type": "no_license",
"max_line_length": 400,
"num_lines": 9,
"path": "/.spyproject/workspace.ini",
"repo_name": "snehakhanna/Emotion-Recognition",
"src_encoding": "UTF-8",
"text": "[workspace]\nrestore_data_on_startup = True\nsave_history = True\nsave_data_on_exit = True\nsave_non_project_files = False\n\n[main]\nversion = 0.1.0\nrecent_files = ['C:\\\\Users\\\\SNEHA\\\\Desktop\\\\AI Wrkshop\\\\Projects\\\\emotionrRecognition\\\\src\\\\train_emotion_recog.py', 'C:\\\\Users\\\\SNEHA\\\\Desktop\\\\AI Wrkshop\\\\Projects\\\\emotionrRecognition\\\\src\\\\cnn_model.py', 'C:\\\\Users\\\\SNEHA\\\\Desktop\\\\AI Wrkshop\\\\Projects\\\\emotionrRecognition\\\\src\\\\emotion_recognizer.py', 'C:\\\\Users\\\\SNEHA\\\\Desktop\\\\AI Wrkshop\\\\Projects\\\\faceRecognition\\\\src\\\\create_database.py']\n\n"
},
{
"alpha_fraction": 0.6298317313194275,
"alphanum_fraction": 0.648703932762146,
"avg_line_length": 36.70175552368164,
"blob_id": "fbe7c803aa331beaa21192e51370c3e34b08f2f0",
"content_id": "09a60eeea9249d6c10d09c928530c028b24fe51d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4398,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 114,
"path": "/src/train_emotion_recog.py",
"repo_name": "snehakhanna/Emotion-Recognition",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n#step1: is to check your dataset properly coz it may cause errors\n\"\"\"if tensflow not downloading or something..backend change to theano\n\nfrom keras import backend as K\nimport importlib\nimport os \n\ndef set_keras_backend(backend):\n if K.backend() !=backend:\n os.environ[\"KERAS_BACKEND\"]=backend\n importlib.reload(K)\n assert K.backend()==backend\n \nset_keras_backend(\"theano\") \n \nin c drive-keras.json...mai tensorflow ko theano change backend\n\"\"\"\n\n#import keras\n#from keras import backend as K \nimport os\nimport cv2\nimport numpy\n#from os.path import join\n#import random\nfrom itertools import repeat\nfrom cnn_model import buildCNNModel\nnum_classes=6\n\ndef listAllFilesPath(path,formats=[\"png\",\"jpg\",\"jpeg\",\"tif\"]):#folder se file lena hai in that format only which is \n results=[]\n for root,subFolders,files in os.walk(path):\n for file in files:\n if file.split(\".\")[-1] in formats:#last ka extentn batayega..jpg etc coz of -1\n results.append(\"/\".join([root,file]))#join karega file name ..\n return results\n\ndef preProcessImage(path,img_width,img_height):\n img=cv2.imread(path,0)#grayscale mai convert karna hai\n img=cv2.resize(img,(img_width,img_height),\n interpolation=cv2.INTER_CUBIC)#pading karega taki extenstn mai problem na ho usko\n img=img.astype(\"float32\")#32 bit representatn hoga 4r normalizatn & array operation etc***float mai convert ..coz divide by 255 toh division ho sake so\n img/=255\n return img\n\n#return karega 2 value array mai\ndef prepareData(size):\n input_samples=[]\n output_labels=[]\n for _class in range(0,num_classes):\n path=\"../dataset/ferDataset/%d\" %(_class)#class ka value append karega eg :0\n length=len(os.listdir(path))#folder mai images ka milega length\n samples=numpy.array(list(map(preProcessImage,listAllFilesPath(path),repeat(size[0],length),repeat(size[1],length))))\n input_samples.append(samples)\n output_labels.append(numpy.array([_class]*len(samples)))\n \n #comments ka bhi indentation matter krta hai uppar wale statement jese hi hona chahiye\n \"\"\"numpy.array([0]*10)\n Out[2]: array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0]) \n \n \n inputs=[]\n \n inputs.append(numpy.array([0]*10))\n \n inputs.append(numpy.array([1]*10))\n \n \n F5 se autosave n run \n \"\"\" \n \n inputs=numpy.concatenate(input_samples,axis=0)\n outputs=numpy.concatenate(output_labels,axis=0)\n \n #koi bhi functn ka op chahiye toh console mai put that .. \n \n #convert to hot vectors \n output_hot_vectors=numpy.zeros((len(outputs),num_classes))\n output_hot_vectors[numpy.arange(len(outputs)),outputs]=1\n outputs=output_hot_vectors\n \n #shuffle the inputs and outputs same way\n p=numpy.random.permutation(len(inputs))#p=numpy.random.permutation(10)\n inputs=inputs[p]\n outputs=outputs[p]\n \n return inputs,outputs\n\nif __name__==\"__main__\": #main loop\n no_of_epochs=1\n emotion_models_path=\"../trained_models/emotion_models/\"\n size=[64,64] #256 etc..kaam so kaam time lagega \n inputs,outputs=prepareData(size)\n inputs=inputs.reshape(inputs.shape[0],inputs.shape[1],inputs.shape[2],1)#face to single detect among all the samples given\n \n num_of_samples=len(inputs)\n train_data_length=int(num_of_samples*0.80)#no of samples giving for training data\n x_train,x_test=inputs[0:train_data_length],inputs[train_data_length:]#x inputs.. y outputs\n y_train,y_test=outputs[0:train_data_length],outputs[train_data_length:]\n \n #architecture defined\n model=buildCNNModel(inputs.shape[1:],num_classes,32,(3,3),0.05,(2,2),1)\n print(model.summary())\n \n #training model\n model.compile(loss=\"categorical_crossentropy\",optimizer=\"adam\",metrics=[\"accuracy\"])\n history=model.fit(x_train,y_train,batch_size=16,epochs=no_of_epochs,validation_data=(x_test,y_test))#batch_size kaam or else CPU heated\n \n \n if not os.path.exists(emotion_models_path):\n os.makedirs(emotion_models_path) \n model.save(emotion_models_path + 'emotion_recog_%d_%s.model' %(no_of_epochs,history.history[\"val_acc\"][0]))\n \n \n \n \n \n \n \n \n \n \n \n \n "
},
{
"alpha_fraction": 0.6839972734451294,
"alphanum_fraction": 0.7022282481193542,
"avg_line_length": 35.849998474121094,
"blob_id": "f74eeb060e2081eef6242e57fb0ac925b15d078d",
"content_id": "b27741144e5c24e2304b7c44967501d740765103",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1481,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 40,
"path": "/src/cnn_model.py",
"repo_name": "snehakhanna/Emotion-Recognition",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom keras.models import Sequential\nfrom keras.layers.core import Dense,Dropout,Activation,Flatten\nfrom keras.layers.convolutional import Conv2D, MaxPooling2D #Conv2D for grayscale and for RGB use Conv3D\n\ndef buildCNNModel(input_shape, num_classes, num_channels,kernel_size,dropout,pool_size,stride):#channel means number of features kitne chahye\n model = Sequential()\n model.add(Conv2D(num_channels,kernel_size,padding='valid',strides=stride,input_shape=input_shape))\n \n \n #convolutions adding\n convout1 = Activation('relu')#rectified linear unit\n model.add(convout1)\n model.add(Conv2D(num_channels,kernel_size))\n convout2 = Activation('relu')\n model.add(convout2)\n \n# convout3 = Activation('relu')\n# model.add(convout3)\n# model.add(Conv2D(num_channels,kernel_size))\n# convout4 = Activation('relu')\n# model.add(convout4)\n# model.add(Conv2D(num_channels,kernel_size))\n# convout5 = Activation('relu')\n# model.add(convout5)\n# model.add(Conv2D(num_channels,kernel_size))\n# convout6 = Activation('relu')\n# model.add(convout6)\n# model.add(Conv2D(num_channels,kernel_size))\n# convout7 = Activation('relu')\n# model.add(convout7)\n# model.add(Conv2D(num_channels,kernel_size))\n \n \n model.add(MaxPooling2D(pool_size=pool_size))\n model.add(Dropout(dropout))\n model.add(Flatten())\n model.add(Dense(num_classes))\n model.add(Activation(\"softmax\"))\n return model\n\n\n \n"
}
] | 4 |
sapcc/swift-sentry | https://github.com/sapcc/swift-sentry | 65f0b4c017ea86bd381322fb36819da4e9155849 | 30b999edfa3e78411b54d0ff75451c5568b6e380 | 2e5f64dbf9e34fd13293e13fca9ba4e9efd19c5d | refs/heads/master | 2022-07-10T08:32:56.056335 | 2022-06-08T12:40:45 | 2022-06-08T12:40:45 | 169,219,900 | 0 | 0 | Apache-2.0 | 2019-02-05T10:00:42 | 2020-05-28T08:30:18 | 2022-04-22T12:28:48 | Python | [
{
"alpha_fraction": 0.7052238583564758,
"alphanum_fraction": 0.7059701681137085,
"avg_line_length": 38.411766052246094,
"blob_id": "e02d29e082196fd8f9243ad7997e1a3624512474",
"content_id": "b431923f10409ebe64ca23ce72f1f57e7f3ecbaf",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1342,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 34,
"path": "/swift_sentry/__init__.py",
"repo_name": "sapcc/swift-sentry",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom sentry_sdk import init\nfrom sentry_sdk.integrations.logging import ignore_logger\n\n\n# init initializes the Sentry SDK with the default integrations (logging,\n# etc.). Data is captured automatically from within the application's runtime.\ninit()\n\n\ndef sentry_logger(conf, name, log_to_console, log_route, fmt, logger, adapted_logger):\n \"\"\"\n sentry_logger sets up a custom log handler hook for Swift. Its parameters\n are the same as Swift’s get_logger function (as well as the getLogger and\n LogAdapter object).\n\n The log handler hook is essenitially a no-op, it is called in order to\n initialise Sentry using the init() at the module level.\n\n We could, of course, set things up by manually adding the Handlers to the\n specific logger (as stated in the Swift docs) but that would result in code\n duplication from the SDK.\n This approach is better since it allows Sentry to capture all events\n instead of just capturing the events from the loggers that Swift gives us\n control over.\n \"\"\"\n\n sentry_ignore_loggers = conf.get(\"sentry_ignore_loggers\", None)\n if sentry_ignore_loggers:\n ignore_loggers_list = [\n s.strip() for s in sentry_ignore_loggers.split(\",\") if s.strip()\n ]\n for lgr in ignore_loggers_list:\n ignore_logger(lgr)\n"
},
{
"alpha_fraction": 0.7468706369400024,
"alphanum_fraction": 0.7468706369400024,
"avg_line_length": 34.95000076293945,
"blob_id": "5be3e70d08a7d74d3dd9fc4bcb7945d83c0cc62c",
"content_id": "3e285f1bac91ee5d8f791647aa4aefdc5ed68633",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1438,
"license_type": "permissive",
"max_line_length": 250,
"num_lines": 40,
"path": "/README.md",
"repo_name": "sapcc/swift-sentry",
"src_encoding": "UTF-8",
"text": "# Archived project. No maintenance.\n\nThis project is not maintained anymore and is archived.\n\n# Swift Sentry\n\nThis repo provides Sentry integration for Openstack [Swift](https://github.com/openstack/swift)\nthrough a [custom log handler](https://docs.openstack.org/swift/latest/admin_guide.html#custom-log-handlers).\n\n## Installation\n\n```\npip install git+https://github.com/sapcc/swift-sentry\n```\n\n## Usage\n\nConfigure the Sentry DSN through the `SENTRY_DSN` environment variable:\n\n```sh\nexport SENTRY_DSN='https://<key>@sentry.io/<project>'\n```\n\nAdd the Swift Sentry configuration options under the `[Default]` section of the\nspecific service's config file for which you want to integrate Sentry. e.g.\n`proxy-server.conf`, `object-expirer.conf`, `account-server.conf`, etc.\n\nA minimal complete configuration looks like this:\n\n```\nlog_custom_handlers = swift_sentry.sentry_logger\nsentry_ignore_loggers = ignore_this_logger, and_this_logger\n```\n\n### Configuration Options\n\n| Option | Required | Description |\n| --- | --- | --- |\n| `log_custom_handlers` | yes | Add `swift_sentry.sentry_logger` to this config option. Refer to Swift's [documentation](https://docs.openstack.org/swift/latest/admin_guide.html#custom-log-handlers) for more info regarding custom log handler hooks. |\n| `sentry_ignore_loggers` | no | A comma-separated list of loggers for Sentry to [ignore](https://docs.sentry.io/platforms/python/logging/#ignoring-a-logger). |\n"
},
{
"alpha_fraction": 0.5928646326065063,
"alphanum_fraction": 0.6117523312568665,
"avg_line_length": 35.653846740722656,
"blob_id": "26c208e645274e6040a5e4f4d582df98d3283681",
"content_id": "e38f4a017556a09946f0fa8f55f1a54f3ad17d8d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 953,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 26,
"path": "/setup.py",
"repo_name": "sapcc/swift-sentry",
"src_encoding": "UTF-8",
"text": "from setuptools import setup, find_packages\n\nsetup(\n name=\"sapcc-swift-sentry\",\n version=\"0.1.0\",\n license=\"Apache License 2.0\",\n description=\"Openstack Swift Custom Log Handler for Sentry\",\n author=\"Muhammad Talal Anwar\",\n url=\"https://github.com/sapcc/swift-sentry\",\n packages=find_packages(),\n classifiers=[\n \"Development Status :: 4 - Beta\",\n \"Environment :: OpenStack\",\n \"Intended Audience :: Information Technology\",\n \"Intended Audience :: System Administrators\",\n \"License :: OSI Approved :: Apache Software License\",\n \"Operating System :: POSIX :: Linux\",\n \"Programming Language :: Python\",\n \"Programming Language :: Python :: 2\",\n \"Programming Language :: Python :: 2.7\",\n \"Programming Language :: Python :: 3\",\n \"Programming Language :: Python :: 3.7\",\n \"Programming Language :: Python :: 3.8\",\n ],\n install_requires=[\"sentry-sdk==0.14.4\"],\n)\n"
}
] | 3 |
MathiasDarr/spring-kafka-microservices | https://github.com/MathiasDarr/spring-kafka-microservices | 4681d808af9f15566d959a7270d702a385a541ad | be595378b70dd9b3b77db863f915777b65078264 | 941f7868518662fd6bc50c03a1cd0925e5170cde | refs/heads/master | 2023-02-02T17:52:15.598679 | 2020-12-09T10:13:00 | 2020-12-09T10:13:00 | 316,635,572 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8260869383811951,
"alphanum_fraction": 0.8550724387168884,
"avg_line_length": 22,
"blob_id": "c499b161fb6eaf692b0ff224b0eb8560ce0919f4",
"content_id": "11c03899f119f23bcdd69cbe6591ebae7ba45484",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 69,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 3,
"path": "/microservices/service-utilities/target/maven-archiver/pom.properties",
"repo_name": "MathiasDarr/spring-kafka-microservices",
"src_encoding": "UTF-8",
"text": "artifactId=service-utilities\ngroupId=org.mddarr\nversion=1.0-SNAPSHOT\n"
},
{
"alpha_fraction": 0.7432506680488586,
"alphanum_fraction": 0.7454545497894287,
"avg_line_length": 28.225807189941406,
"blob_id": "2e70fd37b5521358ccec0e71bf767b36877bfc65",
"content_id": "0c10bf94a33bd1c8807849ac0403743a83219d51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1815,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 62,
"path": "/README.md",
"repo_name": "MathiasDarr/spring-kafka-microservices",
"src_encoding": "UTF-8",
"text": "### ECommerce MicroServices ###\n\n##### This directory contains a Spring Boot microservices project. #####\n## The microservices are implemented using the following technologies ##\n* Spring Boot\n* Kafka, spring cloud Kafka binder, avro serialization\n* DynamoDB & Java AWS SDK\n* Ehcache\n* Jmeter for performance testing \n\n### Microservices ###\n\n* producers \n - This module contains classes with main methods that populate the Kafka-topics.\n* orders-service\n - expose endpoints for placing orders\n* inventory-service\n - expose endpoints for querying the product catalog\n* DynamoDB backend\n\n\n### Project Dependencies ###\n* a local dynamoDB environment or AWS account\n* Java 11 & maven (if compiling & running natively instead of through Docker)\n* docker-compose\n\n### How to run the project ###\n* Ensure that the DynamoDB products table has been populated. This can be done following the instructions in the data_model/products directory. \n* Launch zookeeper, kafka broker & schema registry in docker\n * docker-compose -f kafka-compose.yaml up \n* Compile \n * mvn clean packge\n* Run the products service\n - \n\n* Populate the products kafka topic\n * java -jar producers/target/producers-1.0-SNAPSHOT.jar\n\n\n\n# Spring Microservices #\n\n### This repository contains ###\n* Product Scraping\n\n* Inventory Service\n * Spring Boot API with endpoints for querying product database\n\n* Orders Service\n * Spring boot microservice for viewing & creating orders\n\n* Cloud Formation templates for deploying the following resources\n\n\n\n* Integration tests\n - test suite utilizes the python requests module to invoke the Lambda function via the API Gateway resouce & method\n - use requests to upload file file using the presigned post url returned by the lambda function \n\n\n\n### Run the integration tests ###\n\n\n\n"
},
{
"alpha_fraction": 0.737500011920929,
"alphanum_fraction": 0.8374999761581421,
"avg_line_length": 26,
"blob_id": "476e32265dd625a606ef2c2169048500a9c2ade0",
"content_id": "d8ed159530cc5eac5e649d1e1cee781b00f35c0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 3,
"path": "/data_model/products/README.md",
"repo_name": "MathiasDarr/spring-kafka-microservices",
"src_encoding": "UTF-8",
"text": "AWSTemplateFormatVersion: \"2010-09-09\"\nDescription: A sample template\nResources:"
},
{
"alpha_fraction": 0.44955751299858093,
"alphanum_fraction": 0.45781710743904114,
"avg_line_length": 24.298507690429688,
"blob_id": "42110ea11a6d83ccfbbad2c3a5ba71d3f6c69fc6",
"content_id": "cbadb5b635733d3a36e661b53ce2a2ade8a89b32",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1695,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 67,
"path": "/data_model/orders/populate_orders_table.py",
"repo_name": "MathiasDarr/spring-kafka-microservices",
"src_encoding": "UTF-8",
"text": "import boto3\nimport csv\nimport os\nfrom time import sleep\n\n\ndef insert_order(order):\n return table.put_item(\n Item={\n 'orderID': order['orderID'],\n 'customerID': order['customerID'],\n 'vendors': order['vendors'],\n 'products': order['products'],\n 'order_status': order['order_status']\n }\n )\n\n\ndef create_orders_table():\n try:\n resp = dynamodb.create_table(\n\n TableName=\"Orders\",\n\n AttributeDefinitions=[\n {\n \"AttributeName\": \"customerID\",\n \"AttributeType\": \"S\"\n },\n {\n \"AttributeName\": \"orderID\",\n \"AttributeType\": \"S\"\n },\n\n ],\n\n KeySchema=[\n {\n \"AttributeName\": \"customerID\",\n \"KeyType\": \"HASH\"\n },\n {\n \"AttributeName\": \"orderID\",\n \"KeyType\": \"RANGE\"\n }\n ],\n ProvisionedThroughput={\n \"ReadCapacityUnits\": 1,\n \"WriteCapacityUnits\": 1\n },\n )\n return resp\n except Exception as e:\n print(e)\n\n\nif __name__ == '__main__':\n # dynamodb = boto3.resource('dynamodb',endpoint_url=\"http://localhost:4566\")\n dynamodb = boto3.resource('dynamodb', endpoint_url=\"http://localhost:8000\")\n # create_orders_table()\n # sleep(5)\n table = dynamodb.Table('Orders')\n\n with open('orders.csv', newline='') as csvfile:\n reader = csv.DictReader(csvfile)\n for row in reader:\n insert_order(row)\n"
},
{
"alpha_fraction": 0.39068323373794556,
"alphanum_fraction": 0.3981366455554962,
"avg_line_length": 24.539682388305664,
"blob_id": "58669fc5f9ff31bb3bfe48361fe984f94d77849f",
"content_id": "2eb24b985a9ff8ee4cabe9d606e3812ec928e419",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1610,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 63,
"path": "/data_model/products/create_products_table.py",
"repo_name": "MathiasDarr/spring-kafka-microservices",
"src_encoding": "UTF-8",
"text": "\"\"\"\nThis script creates the dynamoDB products table\n\n\"\"\"\n# !/usr/bin/env python3\n\n\nimport boto3\ndynamodb = boto3.resource('dynamodb', region_name='us-west-2', endpoint_url='http://localhost:8000')\ntry:\n resp = dynamodb.create_table(\n AttributeDefinitions=[\n {\n \"AttributeName\": \"vendor\",\n \"AttributeType\": \"S\"\n },\n {\n \"AttributeName\": \"productName\",\n \"AttributeType\": \"S\"\n },\n {\n \"AttributeName\": \"category\",\n \"AttributeType\": \"S\"\n },\n ],\n TableName=\"Products\",\n KeySchema=[\n {\n \"AttributeName\": \"vendor\",\n \"KeyType\": \"HASH\"\n },\n {\n \"AttributeName\": \"productName\",\n \"KeyType\": \"RANGE\"\n }\n ],\n ProvisionedThroughput={\n \"ReadCapacityUnits\": 1,\n \"WriteCapacityUnits\": 1\n },\n GlobalSecondaryIndexes=[\n {\n 'IndexName': 'categoryGSI',\n 'KeySchema': [\n {\n 'AttributeName': 'category',\n 'KeyType': 'HASH',\n },\n ],\n 'Projection': {\n 'ProjectionType': 'KEYS_ONLY',\n },\n 'ProvisionedThroughput': {\n 'ReadCapacityUnits': 1,\n 'WriteCapacityUnits': 1,\n }\n },\n ],\n\n )\n\nexcept Exception as e:\n print(e)\n\n"
}
] | 5 |
LuckyMcLucks/Physics | https://github.com/LuckyMcLucks/Physics | fa946220dd4e4d11277ab9a4a47dd5d972f15184 | 568b90c779408df93cc8f96958364dc69d2ef64d | bf1595172d0cc08367e24b12be088afbfda01fc1 | refs/heads/main | 2023-03-22T14:10:01.662533 | 2021-03-15T05:21:29 | 2021-03-15T05:21:29 | 347,611,778 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5434929132461548,
"alphanum_fraction": 0.5434929132461548,
"avg_line_length": 28.77083396911621,
"blob_id": "aebee997018ab3ee93850f6d63386a08e5fdbafc",
"content_id": "0babb11cefb94d84c95e8f80adbc4ae10c010f08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1483,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 48,
"path": "/Dictionary.py",
"repo_name": "LuckyMcLucks/Physics",
"src_encoding": "UTF-8",
"text": "import pymongo\r\n\r\n\r\n#------------input-------------\r\n\r\n\r\n#-----------class-----------\r\n\r\nclass Dictionary:\r\n def __init__(self,db,collection):\r\n self.client = pymongo.MongoClient()\r\n self.Database = self.client[db]\r\n self.collection =self.Database[collection]\r\n \r\n def change_db(self,db,collection):\r\n self.Database =self.client[db]\r\n self.collection =self.Database[collection]\r\n \r\n def Add_word(self,Word,details):\r\n meaning,catagory,command,synom = details # detila =meaning,catagory,command,Synom\r\n self.collection.insert_one({'Word':Word,'Meaning':meaning,'Catagory':catagory,'Command':command,'Synom':synom})\r\n #cataagory = verb,noun,pronoun command = (module,function name)\r\n def Find(self,Word):\r\n \r\n result = self.collection.find_one({'Word':Word})\r\n if result ==None:\r\n self.New_word(Word)\r\n else:\r\n return result\r\n def Exist(self,word):\r\n result =self.collection.find_one({'Word':word})\r\n if result != None:\r\n return True\r\n else: \r\n return False\r\n\r\n def Update(self,query,item):\r\n self.collection.update_one(query,{\"$set\": item})\r\n def display(self):\r\n for i in self.collection.find({}):\r\n print(i)\r\n\r\n\r\n\r\n\r\nif __name__ == '__main__':\r\n Dictionary = Dictionary('Dictionary','Words')\r\n Dictionary.display()\r\n \r\n"
},
{
"alpha_fraction": 0.5114496350288391,
"alphanum_fraction": 0.5173900723457336,
"avg_line_length": 34.886924743652344,
"blob_id": "4a313aa0b3f37df20e784a539edd4a0b117b2111",
"content_id": "f91a10b11bac54a9ef2bac616032a87fa812a3d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10439,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 283,
"path": "/Question.py",
"repo_name": "LuckyMcLucks/Physics",
"src_encoding": "UTF-8",
"text": "import Dictionary\r\nimport numpy as np\r\nclass DNA:\r\n def __init__(self,data,Value):\r\n self.data = data\r\n self.data['Value'] =Value\r\n def step_up(self):\r\n return self.data['Step up']\r\n def step_down(self):\r\n return self.data['Step down']\r\n def get_up(self):\r\n return self.data['Up']\r\n def get_down(self):\r\n return self.data['Down']\r\n def get_value(self):\r\n return float(self.data['Value'])\r\n def get_units(self):\r\n return self.data['Word']\r\n\r\n def display(self):\r\n print(self.data['Value'])\r\n print(self.data['Units'])\r\n print(self.data['Measures'])\r\n print(self.data['Step up'])\r\nclass Physic_Dic(Dictionary.Dictionary):\r\n\r\n def __int__(self):\r\n super().__init__()\r\n \r\n \r\n def delete_collection(self):\r\n self.collection.drop()\r\n def restart(self):\r\n self.delete_collection()\r\n file = open('C:/Users/Chua Wei Yang/Desktop/Project/Ouroborus/unitss.txt','r')\r\n for line in file:\r\n if line !='\\n':\r\n line = line.strip()\r\n line = line.split(',')\r\n add ={}\r\n for i in line:\r\n field, data = i.split(':')\r\n try: \r\n add[field] = float(data)\r\n except:\r\n add[field] = data\r\n \r\n self.collection.insert_one(add)\r\nclass Classic_mechanics:\r\n def __init__(self):\r\n self.gravity = -9.80665\r\n self.Variables = {}\r\n self.Dictionary = Physic_Dic('Dictionary','Physics')\r\n def read(self,text):\r\n sentence = text.split(' ')\r\n flag = False\r\n for index,word in enumerate(sentence):\r\n \r\n \r\n temp = self.Dictionary.collection.find_one({'Word':word},{'Catagory':1,'Query':1})\r\n if temp ==None:\r\n pass\r\n elif temp['Catagory'] == 'term' and flag ==True:\r\n \r\n print(self.query(temp['Query']))\r\n elif temp['Catagory'] == 'unit':\r\n self.add_data(sentence[index - 1] + ' ' + word)\r\n elif temp['Catagory'] == 'query':\r\n flag =True \r\n def display(self):\r\n for i in self.Variables:\r\n print(i,':',self.Variables[i].get_value(),self.Variables[i].get_units()) \r\n def create_obj(self,data):\r\n \r\n value , unit = data.split(' ')\r\n\r\n if self.Dictionary.Exist(unit):\r\n doc = self.Dictionary.collection.find_one({'Word':unit},{'_id':0})\r\n\r\n d = DNA(doc,value)\r\n else:\r\n print('obj error')\r\n return d \r\n def add_data(self,data,special=None): # data = e.g 10 m,100 cm,0.1 km, \r\n obj = self.create_obj(data)\r\n key = obj.data['Measures']\r\n \r\n while key in self.Variables:\r\n key +='I'\r\n if special != None:\r\n self.Variables[special] =obj\r\n else:\r\n self.Variables[key] = obj\r\n \r\n\r\n def query(self,key):\r\n func = getattr(self,'get_'+key)\r\n return func()\r\n def check(self,func):\r\n test = getattr(self,'get_'+func)()\r\n print(test)\r\n test = float(test.split(' ')[0])\r\n if self.Variables['time'].get_value() == test:\r\n return True\r\n else:\r\n return False\r\n def get_area(self):\r\n \r\n try:\r\n result = str(self.Variables['length'].get_value()*self.Variables['lengthI'].get_value())+' '+self.Variables['length'].get_units()+'^2'\r\n return result\r\n except:\r\n print('Area Erreor')\r\n def STEP_UP(self,obj):\r\n new = obj.get_value()/ obj.step_up()\r\n new_obj = self.create_obj(str(new) +' '+obj.get_up())\r\n return new_obj\r\n\r\n def STEP_DOWN(self,obj):\r\n new = obj.get_value() * obj.step_down()\r\n new_obj = self.create_obj(str(new)+' '+obj.get_down())\r\n return new_obj\r\n def get_pressure(self):\r\n if 'area' not in self.Variables:\r\n self.add_data(self.get_area())\r\n \r\n if 'force' not in self.Variables:\r\n self.add_data(self.get_force())\r\n \r\n area = self.Variables['area']\r\n force = self.Variables['force']\r\n while area.get_units() != 'm^2':\r\n area = self.STEP_UP(area)\r\n \r\n try:\r\n result = str(force.get_value() / area.get_value()) +' '+'Pa'\r\n return result\r\n except:\r\n print(' pressure Error')\r\n def get_mass(self): \r\n if 'volume' not in self.Variables:\r\n self.add_data(self.get_volume) \r\n volume = self.Variables['volume'] \r\n density = self.Variables['density']\r\n\r\n try:\r\n return str(volume.get_value() * density.get_value()) + ' g'\r\n except:\r\n print('Get_mass error')\r\n \r\n def get_velocity(self):\r\n time = self.Variables['time']\r\n distance = self.Variables['length']\r\n while time.get_units() !='s':\r\n time = self.STEP_DOWN(time)\r\n try:\r\n return str(distance.get_value()/ time.get_value())+' m/s'\r\n except:\r\n print('velocity area')\r\n def get_power(self):\r\n energy = self.Variables['energy']\r\n time = self.Variables['time']\r\n while time.get_units() != 's':\r\n time = self.STEP_DOWN(time)\r\n try:\r\n return str(energy.get_value()/time.get_value()) + ' W'\r\n except:\r\n print('power erroe')\r\n def get_accleration(self):\r\n if 'velocity' not in self.Variables:\r\n self.add_data(self.get_velocity)\r\n \r\n time = self.Variables['time']\r\n velocity_1 = self.Variables['Velocity']\r\n velocity_2 = self.Variables['VelocityI']\r\n try :\r\n \r\n average_v = velocity_2.get_value() - velocity_1.get_value()\r\n return str(average_v/time.get_value()) + ' m/s^2'\r\n except:\r\n print('Accelration error')\r\n def get_force(self):\r\n if 'mass' not in self.Variables:\r\n self.add_data(self.get_mass())\r\n \r\n if 'accleration' not in self.Variables:\r\n self.add_data(self.get_accleration())\r\n \r\n mass = self.Variables['mass']\r\n accel = self.Variables['accleration']\r\n try:\r\n return str(mass.get_value() * accel.get_value()) + ' N'\r\n except:\r\n print('Force error')\r\n def get_heat_capacity(self):\r\n if 'power' not in self.Variables:\r\n self.add_data(self.get_power())\r\n power = self.Variables['power']\r\n time = self.Variables['time']\r\n mass = self.Variables['mass']\r\n temp_1 = self.Variables['temperature']\r\n temp_2 = self.Variables['temperatureI']\r\n while time.get_units() !='s':\r\n time = self.STEP_DOWN(time) \r\n while mass.get_units() != 'g':\r\n mass = self.STEP_DOWN(mass)\r\n temp_change = temp_2.get_value() - temp_1.get_value()\r\n return str((power.get_value()*time.get_value())/(mass.get_value()*temp_change)) +' J/C'\r\n def get_trajectory_distance(self):\r\n if 'time' not in self.Variables:\r\n self.add_data(self.get_time_trajectory())\r\n if 'x_velocity' not in self.Variables:\r\n self.get_xy_velocity()\r\n time = self.Variables['time']\r\n x_velocity = self.Variables['x_velocity']\r\n \r\n try:\r\n return str(time.get_value()*x_velocity.get_value()) +' m'\r\n except:\r\n print('trajectory error')\r\n def get_xy_velocity(self):\r\n if 'velocity' not in self.Variables:\r\n self.add_data(self.get_velocity())\r\n velocity =self.Variables['velocity']\r\n angle = self.Variables['angle']\r\n try :\r\n self.add_data(str(velocity.get_value()*np.cos(angle.get_value()*np.pi/180))+' m/s','x_velocity')\r\n self.add_data(str(velocity.get_value()*np.sin(angle.get_value()*np.pi/180))+' m/s','y_velocity')\r\n except:\r\n print('xy error')\r\n def get_trajectory_time(self):\r\n if 'y_velocity' not in self.Variables:\r\n self.get_xy_velocity()\r\n velocity = self.Variables['y_velocity']\r\n \r\n try:\r\n return str(2*(velocity.get_value())/(-self.gravity)) +' s' \r\n except:\r\n print('time trajectory')\r\n def get_trajectory_angle(self):\r\n distance= self.Variables['length']\r\n velocity = self.Variables['velocity']\r\n temp = (-self.gravity)*distance.get_value()/velocity.get_value()**2\r\n \r\n try:\r\n return str(0.5*(np.arcsin(temp)*180/np.pi)) + ' degree'\r\n except:\r\n print('angle error')\r\n def get_trajectory_velocity(self):\r\n if 'time' not in self.Variables:\r\n self.add_data(self.get_trajectory_time())\r\n if 'anlge' not in self.Variables:\r\n self.add_data(self.get_trajectory_angle())\r\n angle = self.Variables['angle']\r\n time = self.Variables['time']\r\n\r\n try:\r\n \r\n return str(0.5*(-self.gravity)*time.get_value()**2/time.get_value()/np.sin(angle.get_value()*np.pi/180)) +' m/s'\r\n\r\n\r\n except:\r\n print('tra velocity ')\r\n def get_trajectory_height(self):\r\n if 'time' not in self.Variables:\r\n self.add_data(self.get_trajectory_time())\r\n if 'y_velocity' not in self.Variables:\r\n self.get_xy_velocity()\r\n time = self.Variables['time']\r\n y_velocity = self.Variables['y_velocity']\r\n\r\n while time.get_units() != 's':\r\n time = self.STEP_DOWN(time)\r\n try:\r\n return str(y_velocity.get_value()*(time.get_value()/2) + 0.5*self.gravity*(time.get_value()/2)**2) +' m'\r\n except:\r\n print('trajectory height error')\r\n\r\nif __name__ == '__main__': \r\n Sim = Classic_mechanics()\r\n Sim.Dictionary.restart()\r\n #Sim.read('An object is launched at a velocity of 20 m/s in a direction making an angle of 25 degree upward with the horizontal. What is the maximum height reached by the object?')\r\n Sim.read('A ball kicked from ground level at an initial velocity of 60 m/s and an angle θ with ground reaches a horizontal distance of 200 m . What is the size of angle θ?')"
}
] | 2 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.